
id
int64 2.05k
16.6k
| title
stringlengths 5
75
| fromurl
stringlengths 19
185
| date
timestamp[s] | tags
sequencelengths 0
11
| permalink
stringlengths 20
37
| content
stringlengths 342
82.2k
| fromurl_status
int64 200
526
⌀ | status_msg
stringclasses 339
values | from_content
stringlengths 0
229k
⌀ |
|---|---|---|---|---|---|---|---|---|---|
7,580 | 如何在 Linux 上永久挂载一个 Windows 共享 | http://www.techrepublic.com/article/how-to-permanently-mount-a-windows-share-on-linux/ | 2016-07-15T20:19:40 | [
"文件系统",
"共享",
"samba"
] | https://linux.cn/article-7580-1.html |
>
> 如果你已经厌倦了每次重启 Linux 就得重新挂载 Windows 共享,读读这个让共享永久挂载的简单方法。
>
>
>

*图片: Jack Wallen*
在 Linux 上和一个 Windows 网络进行交互从来就不是件轻松的事情。想想多少企业正在采用 Linux,需要在这两个平台上彼此协作。幸运的是,有了一些工具的帮助,你可以轻松地将 Windows 网络驱动器映射到一台 Linux 机器上,甚至可以确保在重启 Linux 机器之后共享还在。
### 在我们开始之前
要实现这个,你需要用到命令行。过程十分简单,但你需要编辑 /etc/fstab 文件,所以小心操作。还有,我假设你已经让 Samba 正常工作了,可以手动从 Windows 网络挂载共享到你的 Linux 机器,还知道这个共享的主机 IP 地址。
准备好了吗?那就开始吧。
### 创建你的挂载点
我们要做的第一件事是创建一个文件夹,他将作为共享的挂载点。为了简单起见,我们将这个文件夹命名为 share,放在 /media 之下。打开你的终端执行以下命令:
```
sudo mkdir /media/share
```
### 安装一些软件
现在我们得安装允许跨平台文件共享的系统;这个系统是 cifs-utils。在终端窗口输入:
```
sudo apt-get install cifs-utils
```
这个命令同时还会安装 cifs-utils 所有的依赖。
安装完成之后,打开文件 /etc/nsswitch.conf 并找到这一行:
```
hosts: files mdns4_minimal [NOTFOUND=return] dns
```
编辑这一行,让它看起来像这样:
```
hosts: files mdns4_minimal [NOTFOUND=return] wins dns
```
现在你需要安装 windbind 让你的 Linux 机器可以在 DHCP 网络中解析 Windows 机器名。在终端里执行:
```
sudo apt-get install libnss-windbind windbind
```
用这个命令重启网络服务:
```
sudo service networking restart
```
### 挂载网络驱动器
现在我们要映射网络驱动器。这里我们必须编辑 /etc/fstab 文件。在你做第一次编辑之前,用这个命令备份以下这个文件:
```
sudo cp /etc/fstab /etc/fstab.old
```
如果你需要恢复这个文件,执行以下命令:
```
sudo mv /etc/fstab.old /etc/fstab
```
在你的主目录创建一个认证信息文件 .smbcredentials。在这个文件里添加你的用户名和密码,就像这样(USER 和 PASSWORD 替换为实际的用户名和密码):
```
username=USER
password=PASSWORD
```
你需要知道挂载这个驱动器的用户的组 ID(GID)和用户 ID(UID)。执行命令:
```
id USER
```
USER 是你的实际用户名,你应该会看到类似这样的信息:
```
uid=1000(USER) gid=1000(GROUP)
```
USER 是实际的用户名,GROUP 是组名。在(USER)和(GROUP)之前的数字将会被用在 /etc/fstab 文件之中。
是时候编辑 /etc/fstab 文件了。在你的编辑器中打开那个文件并添加下面这行到文件末尾(替换以下全大写字段以及远程机器的 IP 地址):
```
//192.168.1.10/SHARE /media/share cifs credentials=/home/USER/.smbcredentials,iocharset=uft8,gid=GID,udi=UID,file_mode=0777,dir_mode=0777 0 0
```
**注意**:上面这些内容应该在同一行上。
保存并关闭那个文件。执行 `sudo mount -a` 命令,共享就会挂载上。看看一下 /media/share,你应该能看到那个网络共享上的文件和文件夹了。
### 共享很简单
有了 cifs-utils 和 Samba,映射网络共享在一台 Linux 机器上简单得让人难以置信。现在,你再也不用在每次机器启动的时候手动重新挂载那些共享了。
---
via: <http://www.techrepublic.com/article/how-to-permanently-mount-a-windows-share-on-linux/>
作者:[Jack Wallen](http://www.techrepublic.com/search/?a=jack+wallen) 译者:[alim0x](https://github.com/alim0x) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,581 | Linux 下的最佳云存储服务 | http://itsfoss.com/cloud-services-linux/ | 2016-07-16T08:14:00 | [
"云存储"
] | https://linux.cn/article-7581-1.html | 
什么样的云服务才适合作为 Linux 下的存储服务?让我们猜猜:
* 大量的免费空间。毕竟,个人用户无法支付每月的巨额款项。
* 原生的 Linux 客户端。以便你能够方便的在服务器之间同步文件,而不用做一些特殊的调整或者定时执行脚本。
* 其他桌面系统的客户端,比如 Windows 和 OS X。移动性是必要的,并且同步设备间的文件也很有必要。
* 基于 Android 和 iOS 的移动应用程序。在今天的现代世界里,你需要连接所有设备。
我不将自托管的云服务计算在内,比如 OwnCloud 或 [Seafile](https://www.seafile.com/en/home/) ,因为它们需要自己建立和运行一个服务器。
让我们看看可以用于 Linux 下 云存储服务有什么。
### [Mega](https://mega.nz/)

如果你是一个 It’s FOSS 的普通读者,你可能已经看过我之前的一篇有关 [Mega on Linux](http://itsfoss.com/install-mega-cloud-storage-linux/)的文章。这种云服务由 [Megaupload scandal](https://en.wikipedia.org/wiki/Megaupload) 公司下臭名昭著的 [Kim Dotcom](https://en.wikipedia.org/wiki/Kim_Dotcom) 提供。这也使一些用户怀疑它,因为 Kim Dotcom 已经很长一段时间成为美国当局的目标。
Mega 拥有方便免费云服务下你所期望的一切。它给每个个人用户提供 50 GB 的免费存储空间。提供Linux 和其他平台下的原生客户端,并带有端到端的加密。原生的 Linux 客户端运行良好,可以无缝地跨平台同步。你也能在浏览器上查看操作你的文件。
#### 优点:
* 50 GB 的免费存储空间
* 端到端的加密
* Linux 和其他平台下的原生客户端,例如 Windows,Mac OS X,Android,iOS
#### 缺点:
* Mega 拥有者见不得人的过去
### [Hubic](https://hubic.com/)

Hubic 是一个来自法国公司的云服务。Hubic 在注册时也提供了 25 GB 免费存储空间。你可以通过推荐Hubic给朋友将空间扩大至 50 GB (对免费用户来说)。
Hubic 提供 Linux 客户端,其还是 beta 版本(至今已经两年了)。Hubic 拥有官方的 Linux 客户端,但是它局限在命令行。我没有去测试移动版本。
Hubic 拥有一些不错的功能。除了简单的用户界面、文件共享等等,它还有备份的功能,你可以定期地归档你的重要文件。
#### 优点:
* 25 GB 免费存储空间,可扩大至 50 GB
* 支持多个平台
* 备份功能
#### 缺点:
* beta 版本的 Linux 客户端,只支持命令行
### [pCloud](https://www.pcloud.com/)

pCloud 是另一款欧洲的发行软件,但这一次跨过了法国边境,它来自瑞士。专注于加密和安全,pCloud 为每一个注册者提供 10 GB 的免费存储空间。你可以通过邀请好友、在社交媒体上分享链接等方式将空间增加至 20 GB。
它拥有云服务的所有标准特性,例如文件共享、同步、选择性同步等等。pCloud 也有跨平台原生客户端,当然包括 Linux。
Linux 客户端 容易使用,并在 Linux Mint 17.3 下的有限测试中表现良好。
#### 优点:
* 10 GB 免费存储空间,可扩大至 20 GB
* 运行良好的带有 GUI 的 Linux 客户端
#### 缺点:
* 加密是一个付费功能
### [Yandex Disk](https://disk.yandex.com/)

俄罗斯互联网巨人 Yandex 拥有 Google 所拥有的一切东西。搜索引擎、分析学、网站管理工具、邮箱、网页浏览器和云存储服务。
Yandex Disk 在注册时提供了 10 GB 的免费云存储空间。它有多平台的原生客户端,包括 Linux。然而,官方的 Linux 客户端只是命令行而已。你可以获取[非官方的 GUI 版本的 Yandex Disk 客户端](https://mintguide.org/tools/265-yd-tools-gui-indicator-for-yandexdisk-free-cloud-storage-in-linux-mint.html)。Yandex Disk 支持文件共享链接,同时带有其他标准的云存储特性。
#### 优点:
* 10 GB 的免费存储空间,可通过推荐的方式扩大至 20 GB
#### 缺点:
* 只有命令行客户端
### 公正而深思熟虑的删节
我从列表中删减了[Dropbox](https://www.dropbox.com/)、[SpiderOak](https://spideroak.com/)。Dropbox 对 Linux 来说非常优秀,但是它的免费存储空间限制在 2 GB。在过去的几年里,我已设法将其扩大超过 21 GB,但那又是另一件事了。
SpiderOak 也仅提供了 2 GB 的免费存储空间,你无法在网页浏览器上操作文件。
OwnCloud 需要属于自己的服务器包括建立,因此它并非人见人爱。并且它确切不符合一个典型云服务的标准。
### 结论
如果你问我应该选择哪个,我的答案是 Mega。它带有大量的免费云存储空间和优秀的 Linux 客户端。在 Linux 下最佳云存储服务的列表中,你的选择是什么?你更喜欢哪一个呢?
---
via: <http://itsfoss.com/cloud-services-linux/>
作者:[ABHISHEK](http://itsfoss.com/author/abhishek/) 译者:[cposture](https://github.com/cposture) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,582 | 在 Linux 上安装使用 VirtualBox 的命令行管理界面 VBoxManage | http://linuxpitstop.com/install-and-use-command-line-tool-vboxmanage-on-ubuntu-16-04/ | 2016-07-16T10:01:00 | [
"VirtualBox",
"VBoxManage"
] | https://linux.cn/article-7582-1.html | VirtualBox 拥有一套命令行工具,你可以使用 VirtualBox 的命令行界面 (CLI) 对远程无界面的服务器上的虚拟机进行管理操作。在这篇教程中,你将会学到如何在没有 GUI 的情况下使用 VBoxManage 创建、启动一个虚拟机。VBoxManage 是 VirtualBox 的命令行界面,你可以在你的主机操作系统的命令行中用它来实现对 VirtualBox 的所有操作。VBoxManage 拥有图形化用户界面所支持的全部功能,而且它支持的功能远不止这些。它提供虚拟引擎的所有功能,甚至包含 GUI 还不能实现的那些功能。如果你想尝试下不同的用户界面而不仅仅是 GUI,或者更改虚拟机更多高级和实验性的配置,那么你就需要用到命令行。

当你想要在 VirtualBox 上创建或运行虚拟机时,你会发现 VBoxManage 非常有用,你只需要使用远程主机的终端就够了。这对于需要远程管理虚拟机的服务器来说是一种常见的情形。
### 准备工作
在开始使用 VBoxManage 的命令行工具前,确保在运行着 Ubuntu 16.04 的服务器上,你拥有超级用户的权限或者你能够使用 sudo 命令,而且你已经在服务器上安装了 Oracle Virtual Box。 然后你需要安装 VirtualBox 扩展包,这是运行 VRDE 远程桌面环境,访问无界面虚拟机所必须的。
### 安装 VBoxManage
通过 [Virtual Box 下载页](https://www.virtualbox.org/wiki/Downloads) 这个链接,你能够获取你所需要的软件扩展包的最新版本,扩展包的版本和你安装的 VirtualBox 版本需要一致!

也可以用下面这条命令来获取 VBoxManage 扩展。
```
$ wget http://download.virtualbox.org/virtualbox/5.0.20/Oracle_VM_VirtualBox_Extension_Pack-5.0.20-106931.vbox-extpack
```

运行下面这条命令,确认 VBoxManage 已经成功安装在你的机器上。
```
$ VBoxManage list extpacks
```

### 在 Ubuntu 16.04 上使用 VBoxManage
接下来我们将要使用 VBoxManage 向你展现通过命令行终端工具来新建和管理虚拟机是多么的简单。
运行下面的命令,新建一个将用来安装 Ubuntu 系统的虚拟机。
```
# VBoxManage createvm --name Ubuntu16.04 --register
```
在运行了这条命令之后,VBoxMnage 将会新建一个叫 做“Ubuntu16.vbox” 的虚拟机,这个虚拟机的位置是家目录路径下的 “VirtualBox VMs/Ubuntu16/Ubuntu16.04.vbox”。在上面这条命令中,“createvm” 是用来新建虚拟机,“--name” 定义了虚拟机的名字,而 “registervm” 命令是用来注册虚拟机的。
现在,使用下面这条命令为虚拟机创建一个硬盘镜像。
```
$ VBoxManage createhd --filename Ubuntu16.04 --size 5124
```
这里,“createhd” 用来创建硬盘镜像,“--filename” 用来指定虚拟机的名称,也就是创建的硬盘镜像名称。“--size” 表示硬盘镜像的空间容量,空间容量的单位总是 MB。我们指定了 5Gb,也就是 5124 MB。
接下来我们需要设置操作系统类型,如果要安装 Linux 系的系统,那么用下面这条命令指定系统类型为 Linux 或者 Ubuntu 或者 Fedora 之类的。
```
$ VBoxManage modifyvm Ubuntu16.04 --ostype Ubuntu
```
用下面这条命令来设置虚拟系统的内存大小,也就是从主机中分配到虚拟机系统的内存。
```
$ VBoxManage modifyvm Ubuntu10.10 --memory 512
```

现在用下面这个命令为虚拟机创建一个存储控制器。
```
$ VBoxManage storagectl Ubuntu16.04 --name IDE --add ide --controller PIIX4 --bootable on
```
这里的 “storagect1” 是给虚拟机创建存储控制器的,“--name” 指定了虚拟机里需要创建、更改或者移除的存储控制器的名称。“--add” 选项指明存储控制器所需要连接到的系统总线类型,可选的选项有 ide / sata / scsi / floppy。“--controller” 选择主板的类型,主板需要根据需要的存储控制器选择,可选的选项有 LsiLogic / LSILogicSAS / BusLogic / IntelAhci / PIIX3 / PIIX4 / ICH6 / I82078。最后的 “--bootable” 表示控制器是否可以引导系统。
上面的命令创建了叫做 IDE 的存储控制器。之后虚拟介质就能通过 “storageattach” 命令连接到该控制器。
然后运行下面这个命令来创建一个叫做 SATA 的存储控制器,它将会连接到之后的硬盘镜像上。
```
$ VBoxManage storagectl Ubuntu16.04 --name SATA --add sata --controller IntelAhci --bootable on
```
将之前创建的硬盘镜像和 CD/DVD 驱动器加载到 IDE 控制器。将 Ubuntu 的安装光盘插到 CD/DVD 驱动器上。然后用 “storageattach” 命令连接存储控制器和虚拟机。
```
$ VBoxManage storageattach Ubuntu16.04 --storagectl SATA --port 0 --device 0 --type hdd --medium "your_iso_filepath"
```
这将把 SATA 存储控制器及介质(比如之前创建的虚拟磁盘镜像)连接到 Ubuntu16.04 虚拟机中。
运行下面的命令添加像网络连接,音频之类的功能。
```
$ VBoxManage modifyvm Ubuntu10.10 --nic1 nat --nictype1 82540EM --cableconnected1 on
$ VBoxManage modifyvm Ubuntu10.10 --vram 128 --accelerate3d on --audio alsa --audiocontroller ac97
```
通过指定你想要启动虚拟机的名称,用下面这个命令启动虚拟机。
```
$ VBoxManage startvm Ubuntu16.04
```
然后会打开一个新窗口,新窗口里虚拟机通过关联文件中引导。

你可以用接下来的命令来关掉虚拟机。
```
$ VBoxManage controlvm Ubuntu16.04 poweroff
```
“controlvm” 命令用来控制虚拟机的状态,可选的选项有 pause / resume / reset / poweroff / savestate / acpipowerbutton / acpisleepbutton。controlvm 有很多选项,用下面这个命令来查看它支持的所有选项。
```
$VBoxManage controlvm
```

### 完结
从这篇文章中,我们了解了 Oracle Virtual Box 中一个十分实用的工具 VBoxManage,文章包含了 VBoxManage 的安装和在 Ubuntu 16.04 系统上的使用,包括通过 VBoxManage 中实用的命令来创建和管理虚拟机。希望这篇文章对你有帮助,另外别忘了分享你的评论或者建议。
---
via: <http://linuxpitstop.com/install-and-use-command-line-tool-vboxmanage-on-ubuntu-16-04/>
作者:[Kashif](http://linuxpitstop.com/author/kashif/) 译者:[GitFuture](https://github.com/GitFuture) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
7,584 | 用 Python、 RabbitMQ 和 Nameko 实现微服务 | http://brunorocha.org/python/microservices-with-python-rabbitmq-and-nameko.html | 2016-07-17T16:45:30 | [
"微服务",
"Nameko"
] | https://linux.cn/article-7584-1.html | 
>
> "微服务是一股新浪潮" - 现如今,将项目拆分成多个独立的、可扩展的服务是保障代码演变的最好选择。在 Python 的世界里,有个叫做 “Nameko” 的框架,它将微服务的实现变得简单并且强大。
>
>
>
### 微服务
>
> 在最近的几年里,“微服务架构”如雨后春笋般涌现。它用于描述一种特定的软件应用设计方式,这种方式使得应用可以由多个独立部署的服务以服务套件的形式组成。 - M. Fowler
>
>
>
推荐各位读一下 [Fowler 的文章](http://martinfowler.com/articles/microservices.html) 以理解它背后的原理。
#### 好吧,那它究竟意味着什么呢?
简单来说,**微服务架构**可以将你的系统拆分成多个负责不同任务的小的(单一上下文内)<ruby> 功能块 <rp> ( </rp> <rt> responsibilities blocks </rt> <rp> ) </rp></ruby>,它们彼此互无感知,各自只提供用于通讯的<ruby> 通用指向 <rp> ( </rp> <rt> common point </rt> <rp> ) </rp></ruby>。这个指向通常是已经将通讯协议和接口定义好的消息队列。
#### 这里给大家提供一个真实案例
>
> 案例的代码可以通过 github: <http://github.com/rochacbruno/nameko-example> 访问,查看 service 和 api 文件夹可以获取更多信息。
>
>
>
想象一下,你有一个 REST API ,这个 API 有一个端点(LCTT 译注:REST 风格的 API 可以有多个端点用于处理对同一资源的不同类型的请求)用来接受数据,并且你需要将接收到的数据进行一些运算工作。那么相比阻塞接口调用者的请求来说,异步实现此接口是一个更好的选择。你可以先给用户返回一个 "OK - 你的请求稍后会处理" 的状态,然后在后台任务中完成运算。
同样,如果你想要在不阻塞主进程的前提下,在计算完成后发送一封提醒邮件,那么将“邮件发送”委托给其他服务去做会更好一些。
#### 场景描述

### 用代码说话
让我们将系统创建起来,在实践中理解它:
#### 环境
我们需要的环境:
* 运行良好的 RabbitMQ(LCTT 译注:[RabbitMQ](http://rabbitmq.mr-ping.com/description.html) 是一个流行的消息队列实现)
* 由 VirtualEnv 提供的 Services 虚拟环境
* 由 VirtualEnv 提供的 API 虚拟环境
#### Rabbit
在开发环境中使用 RabbitMQ 最简单的方式就是运行其官方的 docker 容器。在你已经拥有 Docker 的情况下,运行:
```
docker run -d --hostname my-rabbit --name some-rabbit -p 15672:15672 -p 5672:5672 rabbitmq:3-management
```
在浏览器中访问 <http://localhost:15672> ,如果能够使用 guest:guest 验证信息登录 RabbitMQ 的控制面板,说明它已经在你的开发环境中运行起来了。

#### 服务环境
现在让我们创建微服务来满足我们的任务需要。其中一个服务用来执行计算任务,另一个用来发送邮件。按以下步骤执行:
在 Shell 中创建项目的根目录
```
$ mkdir myproject
$ cd myproject
```
用 virtualenv 工具创建并且激活一个虚拟环境(你也可以使用 virtualenv-wrapper)
```
$ virtualenv service_env
$ source service_env/bin/activate
```
安装 nameko 框架和 yagmail
```
(service_env)$ pip install nameko
(service_env)$ pip install yagmail
```
#### 服务的代码
现在我们已经准备好了 virtualenv 所提供的虚拟环境(可以想象成我们的服务是运行在一个独立服务器上的,而我们的 API 运行在另一个服务器上),接下来让我们编码,实现 nameko 的 RPC 服务。
我们会将这两个服务放在同一个 python 模块中,当然如果你乐意,也可以把它们放在单独的模块里并且当成不同的服务运行:
在名为 `service.py` 的文件中
```
import yagmail
from nameko.rpc import rpc, RpcProxy
class Mail(object):
name = "mail"
@rpc
def send(self, to, subject, contents):
yag = yagmail.SMTP('[email protected]', 'mypassword')
# 以上的验证信息请从安全的地方进行读取
# 贴士: 可以去看看 Dynaconf 设置模块
yag.send(to=to.encode('utf-8),
subject=subject.encode('utf-8),
contents=[contents.encode('utf-8)])
class Compute(object):
name = "compute"
mail = RpcProxy('mail')
@rpc
def compute(self, operation, value, other, email):
operations = {'sum': lambda x, y: int(x) + int(y),
'mul': lambda x, y: int(x) * int(y),
'div': lambda x, y: int(x) / int(y),
'sub': lambda x, y: int(x) - int(y)}
try:
result = operations[operation](value, other)
except Exception as e:
self.mail.send.async(email, "An error occurred", str(e))
raise
else:
self.mail.send.async(
email,
"Your operation is complete!",
"The result is: %s" % result
)
return result
```
现在我们已经用以上代码定义好了两个服务,下面让我们将 Nameko RPC service 运行起来。
>
> 注意:我们会在控制台中启动并运行它。但在生产环境中,建议大家使用 supervisord 替代控制台命令。
>
>
>
在 Shell 中启动并运行服务
```
(service_env)$ nameko run service --broker amqp://guest:guest@localhost
starting services: mail, compute
Connected to amqp://guest:**@127.0.0.1:5672//
Connected to amqp://guest:**@127.0.0.1:5672//
```
#### 测试
在另外一个 Shell 中(使用相同的虚拟环境),用 nameko shell 进行测试:
```
(service_env)$ nameko shell --broker amqp://guest:guest@localhost
Nameko Python 2.7.9 (default, Apr 2 2015, 15:33:21)
[GCC 4.9.2] shell on linux2
Broker: amqp://guest:guest@localhost
>>>
```
现在你已经处在 RPC 客户端中了,Shell 的测试工作是通过 n.rpc 对象来进行的,它的使用方法如下:
```
>>> n.rpc.mail.send("[email protected]", "testing", "Just testing")
```
上边的代码会发送一封邮件,我们同样可以调用计算服务对其进行测试。需要注意的是,此测试还会附带进行异步的邮件发送。
```
>>> n.rpc.compute.compute('sum', 30, 10, "[email protected]")
40
>>> n.rpc.compute.compute('sub', 30, 10, "[email protected]")
20
>>> n.rpc.compute.compute('mul', 30, 10, "[email protected]")
300
>>> n.rpc.compute.compute('div', 30, 10, "[email protected]")
3
```
### 在 API 中调用微服务
在另外一个 Shell 中(甚至可以是另外一台服务器上),准备好 API 环境。
用 virtualenv 工具创建并且激活一个虚拟环境(你也可以使用 virtualenv-wrapper)
```
$ virtualenv api_env
$ source api_env/bin/activate
```
安装 Nameko、 Flask 和 Flasgger
```
(api_env)$ pip install nameko
(api_env)$ pip install flask
(api_env)$ pip install flasgger
```
>
> 注意: 在 API 中并不需要 yagmail ,因为在这里,处理邮件是服务的职责
>
>
>
创建含有以下内容的 `api.py` 文件:
```
from flask import Flask, request
from flasgger import Swagger
from nameko.standalone.rpc import ClusterRpcProxy
app = Flask(__name__)
Swagger(app)
CONFIG = {'AMQP_URI': "amqp://guest:guest@localhost"}
@app.route('/compute', methods=['POST'])
def compute():
"""
Micro Service Based Compute and Mail API
This API is made with Flask, Flasgger and Nameko
---
parameters:
- name: body
in: body
required: true
schema:
id: data
properties:
operation:
type: string
enum:
- sum
- mul
- sub
- div
email:
type: string
value:
type: integer
other:
type: integer
responses:
200:
description: Please wait the calculation, you'll receive an email with results
"""
operation = request.json.get('operation')
value = request.json.get('value')
other = request.json.get('other')
email = request.json.get('email')
msg = "Please wait the calculation, you'll receive an email with results"
subject = "API Notification"
with ClusterRpcProxy(CONFIG) as rpc:
# asynchronously spawning and email notification
rpc.mail.send.async(email, subject, msg)
# asynchronously spawning the compute task
result = rpc.compute.compute.async(operation, value, other, email)
return msg, 200
app.run(debug=True)
```
在其他的 shell 或者服务器上运行此文件
```
(api_env) $ python api.py
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
```
然后访问 <http://localhost:5000/apidocs/index.html> 这个 url,就可以看到 Flasgger 的界面了,利用它可以进行 API 的交互并可以发布任务到队列以供服务进行消费。

>
> 注意: 你可以在 shell 中查看到服务的运行日志,打印信息和错误信息。也可以访问 RabbitMQ 控制面板来查看消息在队列中的处理情况。
>
>
>
Nameko 框架还为我们提供了很多高级特性,你可以从 <https://nameko.readthedocs.org/en/stable/> 获取更多的信息。
别光看了,撸起袖子来,实现微服务!
---
via: <http://brunorocha.org/python/microservices-with-python-rabbitmq-and-nameko.html>
作者: [Bruno Rocha](http://facebook.com/rochacbruno) 译者: [mr-ping](http://www.mr-ping.com) 校对: [wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 302 | Moved Temporarily | null |
7,585 | Cassandra 和 Spark 数据处理一窥 | https://opensource.com/life/16/5/basics-cassandra-and-spark-data-processing | 2016-07-17T17:35:16 | [
"Cassandra",
"Spark",
"大数据"
] | https://linux.cn/article-7585-1.html | 
Apache Cassandra 数据库近来引起了很多的兴趣,这主要源于现代云端软件对于可用性及性能方面的要求。
那么,Apache Cassandra 是什么?它是一种为高可用性及线性可扩展性优化的分布式的联机交易处理 (OLTP) 数据库。具体说到 Cassandra 的用途时,可以想想你希望贴近用户的系统,比如说让我们的用户进行交互的系统、需要保证实时可用的程序等等,如:产品目录,物联网,医疗系统,以及移动应用。对这些程序而言,下线时间意味着利润降低甚至导致其他更坏的结果。Netfilix 是这个在 2008 年开源的项目的早期使用者,他们对此项目的贡献以及带来的成功让这个项目名声大噪。
Cassandra 于2010年成为了 Apache 软件基金会的顶级项目,并从此之后就流行起来。现在,只要你有 Cassadra 的相关知识,找工作时就能轻松不少。想想看,NoSQL 语言和开源技术能达到企业级 SQL 技术的高度,真让人觉得十分疯狂而又不可思议的。这引出了一个问题。是什么让它如此的流行?
由于采用了[亚马逊发表的 Dynamo 论文](http://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf)中率先提出的设计,Cassandra 有能力在大规模的硬件及网络故障时保持实时在线。由于采用了点对点模式,在没有单点故障的情况下,我们能幸免于机架故障甚至全网中断。我们能在不影响用户体验的前提下处理数据中心故障。一个能考虑到故障的分布式系统才是一个没有后顾之忧的分布式系统,因为老实说,故障是迟早会发生的。有了 Cassandra, 我们可以直面残酷的生活并将之融入数据库的结构和功能中。
我们能猜到你现在在想什么,“但我只有关系数据库相关背景,难道这样的转变不会很困难吗?”这问题的答案介于是和不是之间。使用 Cassandra 建立数据模型对有关系数据库背景的开发者而言是轻车熟路。我们使用表格来建立数据模型,并使用 CQL ( Cassandra 查询语言)来查询数据库。然而,与 SQL 不同的是,Cassandra 支持更加复杂的数据结构,例如嵌套和用户自定义类型。举个例子,当要储存对一个小猫照片的点赞数目时,我们可以将整个数据储存在一个包含照片本身的集合之中从而获得更快的顺序查找而不是建立一个独立的表。这样的表述在 CQL 中十分的自然。在我们照片表中,我们需要记录名字,URL以及给此照片点赞过的人。

在一个高性能系统中,毫秒级处理都能对用户体验和客户维系产生影响。昂贵的 JOIN 操作制约了我们通过增加不可预见的网络调用而扩容的能力。当我们将数据反范式化使其能通过尽可能少的请求就可获取时,我们即可从磁盘空间成本的降低中获益并获得可预期的、高性能应用。我们将反范式化同 Cassandra 一同介绍是因为它提供了很有吸引力的的折衷方案。
很明显,我们不会局限于对于小猫照片的点赞数量。Canssandra 是一款为高并发写入优化的方案。这使其成为需要时常吞吐数据的大数据应用的理想解决方案。实时应用和物联网方面的应用正在稳步增长,无论是需求还是市场表现,我们也会不断的利用我们收集到的数据来寻求改进技术应用的方式。
这就引出了我们的下一步,我们已经提到了如何以一种现代的、性价比高的方式储存数据,但我们应该如何获得更多的动力呢?具体而言,当我们收集到了所需的数据,我们应该怎样处理呢?如何才能有效的分析几百 TB 的数据呢?如何才能实时的对我们所收集到的信息进行反馈,并在几秒而不是几小时的时间利作出决策呢?Apache Spark 将给我们答案。
Spark 是大数据变革中的下一步。 Hadoop 和 MapReduce 都是革命性的产品,它们让大数据界获得了分析所有我们所取得的数据的机会。Spark 对性能的大幅提升及对代码复杂度的大幅降低则将大数据分析提升到了另一个高度。通过 Spark,我们能大批量的处理计算,对流处理进行快速反应,通过机器学习作出决策,并通过图遍历来理解复杂的递归关系。这并非只是为你的客户提供与快捷可靠的应用程序连接(Cassandra 已经提供了这样的功能),这更是能洞悉 Canssandra 所储存的数据,作出更加合理的商业决策并同时更好地满足客户需求。
你可以看看 [Spark-Cassandra Connector](https://github.com/datastax/spark-cassandra-connector) (开源) 并动手试试。若想了解更多关于这两种技术的信息,我们强烈推荐名为 [DataStax Academy](https://academy.datastax.com/) 的自学课程
---
via: <https://opensource.com/life/16/5/basics-cassandra-and-spark-data-processing>
作者:[Jon Haddad](https://twitter.com/rustyrazorblade),[Dani Traphagen](https://opensource.com/users/dtrapezoid) 译者:[KevinSJ](https://github.com/KevinSJ) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **This article is co-authored by Jon Haddad.**
There's been a huge surge of interest around the Apache Cassandra database due to the increasing uptime and performance demands of modern cloud applications.
So, what is Apache Cassandra? A distributed OLTP database built for high availability and linear scalability. When people ask what Cassandra is used for, think about the type of system you want close to the customer. This is ultimately the system that our users interact with. Applications that must always be available: product catalogs, IoT, medical systems, and mobile applications. In these categories downtime can mean loss of revenue or even more dire outcomes depending on your specific use case. Netflix was one of the earliest adopters of this project, which was open sourced in 2008, and their contributions, along with successes, put it on the radar of the masses.
Cassandra became a top level Apache Software Foundation project in 2010 and has been riding the wave in popularity since then. Now even knowledge in Cassandra gets you serious returns in the job market. It's both crazy and awesome to consider a NoSQL and open source technology could perform this sort of disruption next to the giants of enterprise SQL. This begs the question, what makes it so popular?
Cassandra has the ability to be always on in spite of massive hardware and network failures by utilizing a design first widely discussed in [the Dynamo paper from Amazon](http://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf). By using a peer to peer model, with no single point of failure, we can survive rack failure and even complete network partitions. We can deal with an entire data center failure without impacting our customer's experience. A distributed system that plans for failure is a properly planned distributed system, because frankly, failures are just going to happen. With Cassandra, we accept that cruel fact of life, and bake it into the database's architecture and functionality.
We know what you’re thinking, "But, I’m coming from a relational background, isn't this going to be a daunting transition?" The answer is somewhat yes and no. Data modeling with Cassandra will feel familiar to developers coming from the relational world. We use tables to model our data, and CQL, the Cassandra Query Language, to query the database. However, unlike SQL, Cassandra supports more complex data structures such as nested and user defined types. For instance, instead of creating a dedicated table to store likes on a cat photo, we can store that data in a collection with the photo itself enabling faster, sequential lookups. That's expressed very naturally in CQL. In our photo table we may want to track the name, URL, and the people that liked the photo.
In a high performance system milliseconds matter for both user experience and for customer retention. Expensive JOIN operations limit our ability to scale out by adding unpredictable network calls. By denormalizing our data so it can be fetched in as few requests as possible, we profit from the trend of decreasing costs in disk space and in return get predictable, high performance applications. We embrace the concept of denormalization with Cassandra because it offers a pretty appealing tradeoff.
We're obviously not just limited to storing likes on cat photos. Cassandra is a optimized for high write throughput. This makes it the perfect solution for big data applications where we’re constantly ingesting data. Time series and IoT use cases are growing at a steady rate in both demand and appearance in the market, and we're continuously finding ways to utilize the data we collect to improve our technological application.
This brings us to the next step, we've talked about storing our data in a modern, cost-effective fashion, but how do we get even more horsepower? Meaning, once we've collected all that data, what do we do with it? How can we analyze hundreds of terabytes efficiently? How can we react to information we're receiving in real-time, making decisions in seconds rather than hours? Enter Apache Spark.
Spark is the next step in the evolution of big data processing. Hadoop and MapReduce were revolutionary projects, giving the big data world an opportunity to crunch all the data we've collected. Spark takes our big data analysis to the next level by drastically improving performance and massively decreasing code complexity. Through Spark, we can perform massive batch processing calculations, react quickly to stream processing, make smart decisions through machine learning, and understand complex, recursive relationships through graph traversals. It’s not just about offering your customers a fast and reliable connection to their application (which is what Cassandra offers), it's also about being able to leverage insights from the data Cassandra stores to make more intelligent business decisions and better cater to customer needs.
You can check out the [Spark-Cassandra Connector](https://github.com/datastax/spark-cassandra-connector) (open source) and give it a shot. To learn more about both technologies, we highly recommend the free self-paced courses on [DataStax Academy](https://academy.datastax.com/).
Have fun digging in and learning some killer new technology! If you want to learn more, check out our [OSCON tutorial](http://conferences.oreilly.com/oscon/open-source-us/public/schedule/detail/49162), with a hands on exploration into the worlds of both Cassandra and Spark.
We also love taking questions on Twitter, so give us a shout and we’ll try to help: [Dani](https://twitter.com/dtrapezoid) and [Jon](https://twitter.com/rustyrazorblade).
## Comments are closed. |
7,586 | awk 系列:如何使用 awk 和正则表达式过滤文本或文件中的字符串 | http://www.tecmint.com/use-linux-awk-command-to-filter-text-string-in-files/ | 2016-07-18T08:15:00 | [
"awk"
] | https://linux.cn/article-7586-1.html | 
当我们在 Unix/Linux 下使用特定的命令从字符串或文件中读取或编辑文本时,我们经常需要过滤输出以得到感兴趣的部分。这时正则表达式就派上用场了。
### 什么是正则表达式?
正则表达式可以定义为代表若干个字符序列的字符串。它最重要的功能之一就是它允许你过滤一条命令或一个文件的输出、编辑文本或配置文件的一部分等等。
### 正则表达式的特点
正则表达式由以下内容组合而成:
* **普通字符**,例如空格、下划线、A-Z、a-z、0-9。
* 可以扩展为普通字符的**元字符**,它们包括:
+ `(.)` 它匹配除了换行符外的任何单个字符。
+ `(*)` 它匹配零个或多个在其之前紧挨着的字符。
+ `[ character(s) ]` 它匹配任何由其中的字符/字符集指定的字符,你可以使用连字符(-)代表字符区间,例如 [a-f]、[1-5]等。
+ `^` 它匹配文件中一行的开头。
+ `$` 它匹配文件中一行的结尾。
+ `\` 这是一个转义字符。
你必须使用类似 awk 这样的文本过滤工具来过滤文本。你还可以把 awk 自身当作一个编程语言。但由于这个指南的适用范围是关于使用 awk 的,我会按照一个简单的命令行过滤工具来介绍它。
awk 的一般语法如下:
```
# awk 'script' filename
```
此处 `'script'` 是一个由 awk 可以理解并应用于 filename 的命令集合。
它通过读取文件中的给定行,复制该行的内容并在该行上执行脚本的方式工作。这个过程会在该文件中的所有行上重复。
该脚本 `'script'` 中内容的格式是 `'/pattern/ action'`,其中 `pattern` 是一个正则表达式,而 `action` 是当 awk 在该行中找到此模式时应当执行的动作。
### 如何在 Linux 中使用 awk 过滤工具
在下面的例子中,我们将聚焦于之前讨论过的元字符。
#### 一个使用 awk 的简单示例:
下面的例子打印文件 /etc/hosts 中的所有行,因为没有指定任何的模式。
```
# awk '//{print}' /etc/hosts
```

*awk 打印文件中的所有行*
#### 结合模式使用 awk
在下面的示例中,指定了模式 `localhost`,因此 awk 将匹配文件 `/etc/hosts` 中有 `localhost` 的那些行。
```
# awk '/localhost/{print}' /etc/hosts
```

*awk 打印文件中匹配模式的行*
#### 在 awk 模式中使用通配符 (.)
在下面的例子中,符号 `(.)` 将匹配包含 loc、localhost、localnet 的字符串。
这里的正则表达式的意思是匹配 **l一个字符c**。
```
# awk '/l.c/{print}' /etc/hosts
```

*使用 awk 打印文件中匹配模式的字符串*
#### 在 awk 模式中使用字符 (\*)
(LCTT 译者注:此处原文作者理解有误,感谢微信读者“止此而已”的提醒,`*` 在此处表示其前一个字符重复零次或多次,所以实际上相当于 `*` 及前面的字符是无用的。)
在下面的例子中,将匹配包含 localhost、localnet、lines, capable 的字符串。将匹配带有 `c` 字符的字符串。
```
# awk '/l*c/{print}' /etc/localhost
```

*使用 awk 匹配文件中的字符串*
你可能也意识到 `(*)` 将会尝试匹配它可能检测到的最长的匹配。
让我们看一看可以证明这一点的例子,正则表达式 `t*t` 的意思是在下面的行中匹配以 `t` 开始和 `t` 结束的字符串:将匹配带有 t 字符的字符串:
```
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint.
```
当你使用模式 `/t*t/` 时,会得到如下可能的结果:以下字符串只是有 t 字符而已:
```
this is t
this is tecmint
this is tecmint, where you get t
this is tecmint, where you get the best good t
this is tecmint, where you get the best good tutorials, how t
this is tecmint, where you get the best good tutorials, how tos, guides, t
this is tecmint, where you get the best good tutorials, how tos, guides, tecmint
```
在 `/t*t/` 中的通配符 `(*)` 将使得 awk 选择匹配的最后一项:以下字符串只是有 t 字符而已:
```
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint
```
#### 结合集合 [ character(s) ] 使用 awk
以集合 [al1] 为例,awk 将匹配文件 /etc/hosts 中所有包含字符 a 或 l 或 1 的字符串。
```
# awk '/[al1]/{print}' /etc/hosts
```

*使用 awk 打印文件中匹配的字符*
下一个例子匹配以 `K` 或 `k` 开始(非指行首是该字母),后面跟着一个 `T` 的字符串:
```
# awk '/[Kk]T/{print}' /etc/hosts
```

*使用 awk 打印文件中匹配的字符*
#### 以范围的方式指定字符
awk 所能理解的字符:
* `[0-9]` 代表一个单独的数字
* `[a-z]` 代表一个单独的小写字母
* `[A-Z]` 代表一个单独的大写字母
* `[a-zA-Z]` 代表一个单独的字母
* `[a-zA-Z 0-9]` 代表一个单独的字母或数字
让我们看看下面的例子:
```
# awk '/[0-9]/{print}' /etc/hosts
```

*使用 awk 打印文件中匹配的数字*
在上面的例子中,文件 /etc/hosts 中的所有行都至少包含一个单独的数字 [0-9]。
#### 结合元字符 (^) 使用 awk
在下面的例子中,它匹配所有以给定模式开头的行:
```
# awk '/^fe/{print}' /etc/hosts
# awk '/^ff/{print}' /etc/hosts
```

*使用 awk 打印与模式匹配的行*
#### 结合元字符 ($) 使用 awk
它将匹配所有以给定模式结尾的行:
```
# awk '/ab$/{print}' /etc/hosts
# awk '/ost$/{print}' /etc/hosts
# awk '/rs$/{print}' /etc/hosts
```

*使用 awk 打印与模式匹配的字符串*
#### 结合转义字符 (\) 使用 awk
它允许你将该转义字符后面的字符作为文字,即理解为其字面的意思。
在下面的例子中,第一个命令打印出文件中的所有行,第二个命令中我想匹配具有 $25.00 的一行,但我并未使用转义字符,因而没有打印出任何内容。
第三个命令是正确的,因为一个这里使用了一个转义字符以转义 $,以将其识别为 '$'(而非元字符)。
```
# awk '//{print}' deals.txt
# awk '/$25.00/{print}' deals.txt
# awk '/\$25.00/{print}' deals.txt
```

*结合转义字符使用 awk*
### 总结
以上内容并不是 awk 命令用做过滤工具的全部,上述的示例均是 awk 的基础操作。在下面的章节中,我将进一步介绍如何使用 awk 的高级功能。感谢您的阅读,请在评论区贴出您的评论。
---
via: <http://www.tecmint.com/use-linux-awk-command-to-filter-text-string-in-files/>
作者:[Aaron Kili](http://www.tecmint.com/author/aaronkili/) 译者:[wwy-hust](https://github.com/wwy-hust) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,587 | awk 系列:如何使用 awk 输出文本中的字段和列 | http://www.tecmint.com/awk-print-fields-columns-with-space-separator/ | 2016-07-19T09:26:00 | [
"awk"
] | https://linux.cn/article-7587-1.html | 在 Awk 系列的这一节中,我们将看到 awk 最重要的特性之一,字段编辑。
首先我们要知道,Awk 能够自动将输入的行,分隔为若干字段。每一个字段就是一组字符,它们和其他的字段由一个内部字段分隔符分隔开来。

*Awk 输出字段和列*
如果你熟悉 Unix/Linux 或者懂得 [bash shell 编程](http://www.tecmint.com/category/bash-shell/),那么你应该知道什么是内部字段分隔符(IFS)变量。awk 中默认的 IFS 是制表符和空格。
awk 中的字段分隔符的工作原理如下:当读到一行输入时,将它按照指定的 IFS 分割为不同字段,第一组字符就是字段一,可以通过 $1 来访问,第二组字符就是字段二,可以通过 $2 来访问,第三组字符就是字段三,可以通过 $3 来访问,以此类推,直到最后一组字符。
为了更好地理解 awk 的字段编辑,让我们看一个下面的例子:
**例 1**:我创建了一个名为 tecmintinfo.txt 的文本文件。
```
# vi tecmintinfo.txt
# cat tecmintinfo.txt
```

*在 Linux 上创建一个文件*
然后在命令行中,我试着使用下面的命令从文本 tecmintinfo.txt 中输出第一个,第二个,以及第三个字段。
```
$ awk '//{print $1 $2 $3 }' tecmintinfo.txt
TecMint.comisthe
```
从上面的输出中你可以看到,前三个字段的字符是以空格为分隔符输出的:
* 字段一是 “TecMint.com”,可以通过 `$1` 来访问。
* 字段二是 “is”,可以通过 `$2` 来访问。
* 字段三是 “the”,可以通过 `$3` 来访问。
如果你注意观察输出的话可以发现,输出的字段值并没有被分隔开,这是 print 函数默认的行为。
为了使输出看得更清楚,输出的字段值之间使用空格分开,你需要添加 (,) 操作符。
```
$ awk '//{print $1, $2, $3; }' tecmintinfo.txt
TecMint.com is the
```
需要记住而且非常重要的是,`($)` 在 awk 和在 shell 脚本中的使用是截然不同的!
在 shell 脚本中,`($)` 被用来获取变量的值。而在 awk 中,`($)` 只有在获取字段的值时才会用到,不能用于获取变量的值。
**例 2**:让我们再看一个例子,用到了一个名为 my\_shoping.list 的包含多行的文件。
```
No Item_Name Unit_Price Quantity Price
1 Mouse #20,000 1 #20,000
2 Monitor #500,000 1 #500,000
3 RAM_Chips #150,000 2 #300,000
4 Ethernet_Cables #30,000 4 #120,000
```
如果你只想输出购物清单上每一个物品的`单价`,你只需运行下面的命令:
```
$ awk '//{print $2, $3 }' my_shopping.txt
Item_Name Unit_Price
Mouse #20,000
Monitor #500,000
RAM_Chips #150,000
Ethernet_Cables #30,000
```
可以看到上面的输出不够清晰,awk 还有一个 `printf` 的命令,可以帮助你将输出格式化。
使用 `printf` 来格式化 Item\_Name 和 Unit\_Price 的输出:
```
$ awk '//{printf "%-10s %s\n",$2, $3 }' my_shopping.txt
Item_Name Unit_Price
Mouse #20,000
Monitor #500,000
RAM_Chips #150,000
Ethernet_Cables #30,000
```
### 总结
使用 awk 过滤文本或字符串时,字段编辑的功能是非常重要的。它能够帮助你从一个表的数据中得到特定的列。一定要记住的是,awk 中 `($)` 操作符的用法与其在 shell 脚本中的用法是不同的!
希望这篇文章对您有所帮助。如有任何疑问,可以在评论区域发表评论。
---
via: <http://www.tecmint.com/awk-print-fields-columns-with-space-separator/>
作者:[Aaron Kili](http://www.tecmint.com/author/aaronkili/) 译者:[Cathon](https://github.com/Cathon),[ictlyh](https://github.com/ictlyh) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,588 | Linus Torvalds 是一个糟糕的老板吗? | http://www.computerworld.com/article/3004387/it-management/how-bad-a-boss-is-linus-torvalds.html | 2016-07-18T10:48:00 | [
"Linus Torvalds"
] | https://linux.cn/article-7588-1.html | 
*1999 年 8 月 10 日,加利福尼亚州圣何塞市,在 LinuxWorld Show 上 Linus Torvalds 在一个坐满 Linux 爱好者的礼堂中发表了一篇演讲。图片来自:James Niccolai*
>
> **这取决于所处的领域。在软件开发的世界中,他也是个普通人。问题是,这种情况是否应该继续下去?**
>
>
>
我认识 Linux 的发明人 Linus Torvalds 已经超过 20 年了。我们不是密友,但是我们欣赏彼此。
最近,因为 Linus Torvalds 的管理风格,他正遭到严厉的炮轰。Linus 无法忍受胡来的人。“代码的质量有多好?”这是他在 Linux 内核的开发过程中评判人的一种方式。
没有什么比这个更重要了。正如 Linus 今年(2015年)早些时候在 Linux.conf.au 会议上说的那样,“我不是一个友好的人,我也不在意你。对我重要的是‘[我所关心的技术和内核](http://www.computerworld.com/article/2874475/linus-torvalds-diversity-gaffe-brings-out-the-best-and-worst-of-the-open-source-world.html)’。”
现在我也可以和这种只关心技术的人打交道了。如果你不能,你应当避免参加 Linux 内核会议,因为在那里你会遇到许多有这种精英思想的人。这不代表我认为在 Linux 领域所有东西都是极好的,并且不应该受到其他影响而带来改变。我能够和一个精英相处;而在一个男性做主导的大城堡中遇到的问题是,女性经常受到蔑视和无礼的对待。
这就是我看到的最近关于 Linus 管理风格所引发争论的原因 —— 或者更准确的说,他对于个人管理方面是完全冷漠的 —— 就像是在软件开发世界的标准操作流程一样。与此同时,我看到揭示了这个事情需要改变的另外一个证据。
第一次是在 [Linux 4.3 发布](http://www.zdnet.com/article/linux-4-3-released-after-linus-torvalds-scraps-brain-damage-code/)的时候出现的这个情况,Linus 使用 Linux 内核邮件列表狠狠的数落了一个插入了一些网络方面的代码的开发者——这些代码很“烂”、“[生成了如此烂的代码](http://lkml.iu.edu/hypermail/linux/kernel/1510.3/02866.html)。这看起来太糟糕了,并且完全没有理由这样做。”他继续地咆哮了半天。这里使用“烂”这个词,相对他早期使用的“愚蠢的”这个同义词来说还算好的。
但是,事情就是这样。Linus 是对的。我读了代码后,发现代码确实很烂,并且开发者只是为了用新“overflow\_usub()” 函数而用。
现在,一些人把 Linus 的这种谩骂的行为看作他脾气不好而且恃强凌弱的证据。我也见过一个完美主义者,在他的领域中,他无法忍受这种糟糕。
许多人告诉我,这不是一个专业的程序员应当有的行为。群众们,你曾经和最优秀的开发者一起工作过吗?据我所知道的,在 Apple,Microsoft,Oracle ,这就是他们的行为。
我曾经听过 Steve Jobs 攻击一个开发者,就像要把他撕成碎片那样。我也被一个 Oracle 的高级开发者责骂一屋子的新开发者吓到过,就像食人鱼穿过一群金鱼那样。
在 Robert X. Cringely 关于 PC 崛起的经典书籍《<ruby> <a href="https://www.amazon.cn/Accidental-Empires-Cringely-Robert-X/dp/0887308554/479-5308016-9671450?ie=UTF8&qid=1447101469&ref_=sr_1_1&tag=geo-23"> 意外帝国 </a> <rp> ( </rp> <rt> Accidental Empires </rt> <rp> ) </rp></ruby>》,中,他这样描述了微软的软件管理风格,比尔·盖茨像计算机系统一样管理他们,“比尔·盖茨是最高等级,从他开始每一个等级依次递减,上级会向下级叫嚷,刺激他们,甚至羞辱他们。”
Linus 和所有大型的商业软件公司的领导人不同的是,Linus 说在这里所有的东西都是向全世界公开的。而其他人是在自己的会议室中做东西的。我听有人说 Linus 在那种公司中可能会被开除。这是不可能的。他会处于他现在所处的地位,他在编程世界的最顶端。
但是,这里有另外一个不同。如果 Larry Ellison (Oracle 的首席执行官)向你发火,你就别想在这里干了。如果 Linus 向你发火,你会在邮件中收到他的责骂。这就是差别。
你知道的,Linus 不是任何人的老板。他完全没有雇佣和解聘的权利,他只是负责着有着 10000 个贡献者的一个项目而已。他仅仅能做的就是从心理上伤害你。
这说明,在开源软件开发圈和商业软件开发圈中同时存在一个非常严重的问题。不管你是一个多么好的编程者,如果你是一个女性,你的这个身份就是对你不利的。
这种情况并没有在 Sarah Sharp 的身上有任何好转,她现在是一个 Intel 的开发者,以前是一个顶尖的 Linux 程序员。[在她博客上10月份的一个帖子中](http://sarah.thesharps.us/2015/10/05/closing-a-door/),她解释道:“我最终发现,我不能够再为 Linux 社区做出贡献了。因为在那里,我虽然能够得到技术上的尊重,却得不到个人的尊重……我不想专职于同那些有着点性别歧视或开同性恋玩笑的人一起工作。”
谁会责怪她呢?我不会。很抱歉,我必须说,Linus 就像所有我见过的软件经理一样,是他造成了这种不利的工作环境。
他可能会说,确保 Linux 的贡献者都表现出专业精神和相互尊重不应该是他的工作。除了代码以外,他不关心任何其他事情。
就像 Sarah Sharp 写的那样:
>
> 我对于 Linux 内核社区做出的技术努力表示最大的尊重。他们在那维护一些最高标准的代码,以此来平衡并且发展一个项目。他们专注于优秀的技术,以及超过负荷的维护人员,他们有不同的文化背景和社会规范,这意味着这些 Linux 内核维护者说话非常直率、粗鲁,或者为了完成他们的任务而不讲道理。顶尖的 Linux 内核开发者经常为了使别人改正行为而向他们大喊大叫。
>
>
> 这种事情发生在我身上,但它不是一种有效的沟通方式。
>
>
> 许多高级的 Linux 内核开发者支持那些技术上和人性上不讲道理的维护者的权利,即使他们自己是非常友好的一个人,他们不想看到 Linux 内核交流方式改变。
>
>
>
她是对的。
我和其他观察者不同的是,我不认为这个问题对于 Linux 或开源社区在任何方面有特殊之处。作为一个从事技术商业工作超过五年和有着 25 年技术工作经历的记者,我见多了这种不成熟的小孩子行为。
这不是 Linus 的错误。他不是一个经理,他是一个有想象力的技术领导者。看起来真正的问题是,在软件开发领域没有人能够以一种支持的语气来对待团队和社区。
展望未来,我希望像 Linux 基金会这样的公司和组织,能够找到一种方式去授权社区经理或其他经理来鼓励并且强制实施民主的行为。
非常遗憾的是,我们不能够在我们这种纯技术或纯商业的领导人中找到这种管理策略。它不存在于这些人的基因中。
---
via: <http://www.computerworld.com/article/3004387/it-management/how-bad-a-boss-is-linus-torvalds.html>
作者:[Steven J. Vaughan-Nichols](http://www.computerworld.com/author/Steven-J.-Vaughan_Nichols/) 译者:[FrankXinqi](https://github.com/FrankXinqi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,589 | IT 运行在云端,而云运行在 Linux 上 | http://www.zdnet.com/article/it-runs-on-the-cloud-and-the-cloud-runs-on-linux-any-questions/ | 2016-07-18T13:40:00 | [
"Linux",
"云"
] | https://linux.cn/article-7589-1.html |
>
> IT 正在逐渐迁移到云端。那又是什么驱动了云呢?答案是 Linux。 当连微软的 Azure 都开始拥抱 Linux 时,你就应该知道这一切都已经改变了。
>
>
>

*图片: ZDNet*
不管你接不接受, 云正在接管 IT 已经成为现实。 我们这几年见证了 [云在内部 IT 的崛起](http://www.zdnet.com/article/2014-the-year-the-cloud-killed-the-datacenter/) 。 那又是什么驱动了云呢? 答案是 Linux 。
[Uptime Institute](https://uptimeinstitute.com/) 最近对 1000 个 IT 决策者进行了调查,发现约 50% 左右的资深企业 IT 决策者认为在将来[大部分的 IT 工作应该放在云上](http://www.zdnet.com/article/move-to-cloud-accelerating-faster-than-thought-survey-finds/) 或托管网站上。在这个调查中,23% 的人认为这种改变即将发生在明年,有 70% 的人则认为这种情况会在四年内出现。
这一点都不奇怪。 我们中的许多人仍热衷于我们的物理服务器和机架, 但一般运营一个自己的数据中心并不会产生任何的经济效益。
很简单, 只需要对比你[运行在你自己的硬件上的资本费用(CAPEX)和使用云的业务费用(OPEX)](http://www.zdnet.com/article/rethinking-capex-and-opex-in-a-cloud-centric-world/)即可。 但这并不是说你应该把所有的东西都一股脑外包出去,而是说在大多数情况下你应该把许多工作都迁移到云端。
相应地,如果你想充分地利用云,你就得了解 Linux 。
[亚马逊的 AWS](https://aws.amazon.com/)、 [Apache CloudStack](https://cloudstack.apache.org/)、 [Rackspace](https://www.rackspace.com/en-us)、[谷歌的 GCP](https://cloud.google.com/) 以及 [OpenStack](http://www.openstack.org/) 的核心都是运行在 Linux 上的。那么结果如何?截至到 2014 年, [在 Linux 服务器上部署的应用达到所有企业的 79%](http://www.zdnet.com/article/linux-foundation-finds-enterprise-linux-growing-at-windows-expense/) ,而 在 Windows 服务器上部署的则跌到 36%。从那时起, Linux 就获得了更多的发展动力。
即便是微软自身也明白这一点。
Azure 的技术主管 Mark Russinovich 曾说,仅仅在过去的几年内微软就从[四分之一的 Azure 虚拟机运行在 Linux 上](http://news.microsoft.com/bythenumbers/azure-virtual) 变为[将近三分之一的 Azure 虚拟机运行在 Linux 上](http://www.zdnet.com/article/microsoft-nearly-one-in-three-azure-virtual-machines-now-are-running-linux/)。
试想一下。微软,一家正逐渐将[云变为自身财政收入的主要来源](http://www.zdnet.com/article/microsofts-q3-azure-commercial-cloud-strong-but-earnings-revenue-light/) 的公司,其三分之一的云产业依靠于 Linux 。
即使是到目前为止, 这些不论喜欢或者不喜欢微软的人都很难想象得到[微软会从一家以商业软件为基础的软件公司转变为一家开源的、基于云服务的企业](http://www.zdnet.com/article/why-microsoft-is-turning-into-an-open-source-company/) 。
Linux 对于这些专用服务器机房的渗透甚至比它刚开始的时候更深了。 举个例子, [Docker 最近发行了其在 Windows 10 和 Mac OS X 上的公测版本](http://www.zdnet.com/article/new-docker-betas-for-azure-windows-10-now-available/) 。 这难道是意味着 [Docker](http://www.docker.com/) 将会把其同名的容器服务移植到 Windows 10 和 Mac 上吗? 并不是的。
在这两个平台上, Docker 只是运行在一个 Linux 虚拟机内部。 在 Mac OS 上是 HyperKit ,在 Windows 上则是 Hyper-V 。 在图形界面上可能看起来就像另一个 Mac 或 Windows 上的应用, 但在其内部的容器仍然是运行在 Linux 上的。
所以,就像大量的安卓手机和 Chromebook 的用户压根就不知道他们所运行的是 Linux 系统一样。这些 IT 用户也会随之悄然地迁移到 Linux 和云上。
---
via: <http://www.zdnet.com/article/it-runs-on-the-cloud-and-the-cloud-runs-on-linux-any-questions/>
作者:[Steven J. Vaughan-Nichols](http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/) 译者:[chenxinlong](https://github.com/chenxinlong) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,593 | PHP 、Python 等网站应用惊爆远程代理漏洞:httpoxy | https://httpoxy.org/ | 2016-07-19T21:26:00 | [
"httpoxy",
"HTTP",
"安全"
] | https://linux.cn/article-7593-1.html | 
>
> 这是一个针对 PHP、Go、Python 等语言的 CGI 应用的漏洞。
>
>
>
httpoxy 是一系列影响到以 CGI 或类 CGI 方式运行的应用的漏洞名称。简单的来说,它就是一个名字空间的冲突问题。
* RFC 3875 (CGI)中定义了从 HTTP 请求的 `Proxy` 头部直接填充到环境变量 `HTTP_PROXY` 的方式
* `HTTP_PROXY` 是一个常用于配置外发代理的环境变量
这个缺陷会导致远程攻击。**如果你正在运行着 PHP 或 CGI 程序,你应该马上封挡 Proxy 头部!马上!** 具体做法参见下面。httpoxy 是一个服务器端 web 应用漏洞,如果你没有在服务器端部署这些代码,则不用担心。
### 如果我的 Web 应用存在这种漏洞会怎么样?
当一个利用了此漏洞的 HTTP 客户端发起请求时,它可以做到:
* 通过你的 Web 应用去代理请求别的 URL
* 直接让你的服务器打开指定的远程地址及端口
* 浪费服务器的资源,替攻击者访问指定的资源
httpoxy 漏洞非常容易利用。希望安全人员尽快扫描该漏洞并快速修复。
### 哪些受到影响?
以下情况会存在安全漏洞:
* 代码运行在 CGI 上下文中,这样 `HTTP_PROXY` 就会变成一个真实的或模拟的环境变量
* 一个信任 `HTTP_PROXY`的 HTTP 客户端,并且支持代理功能
* 该客户端会在请求内部发起一个 HTTP(或 HTTPS)请求
下列情形是已经发现存在该缺陷的环境:
| 语言 | 环境 | HTTP 客户端 |
| --- | --- | --- |
| PHP | php-fpm mod\_php | Guzzle 4+ Artax |
| Python | wsgiref.handlers.CGIHandler twisted.web.twcgi.CGIScript | requests |
| Go | net/http/cgi | net/http |
肯定还有很多我们没有确定是否存在缺陷的语言和环境。
#### PHP
* 是否存在缺陷依赖于你的应用代码和 PHP 库,但是影响面看起来似乎非常广泛
* 只要在处理用户请求的过程中使用了一个带有该缺陷的库,就可能被利用
* 如果你使用了有该缺陷的库,该缺陷会影响任意 PHP 版本
+ 甚至会影响到替代的 PHP 运行环境,比如部署在 FastCGI 模式下的 HHVM
* 确认影响 Guzzle、Artax 等库,可能还有很多很多的库也受影响
+ Guzzle 4.0.0rc2 及其以后版本受影响,Guzzle 3 及更低版本不受影响
+ 其它的例子还有 Composer 的 StreamContextBuilder 工具类
举个例子说,如果你在 Drupal 中使用 Guzzle 6 模块发起外发请求(比如请求一个天气 API),该模块发起的请求就存在这个 httpoxy 缺陷。
#### Python
* Python 代码只有部署在 CGI 模式下才存在缺陷,一般来说,存在缺陷的代码会使用类似 `wsgiref.handlers.CGIHandler` 的 CGI 控制器
+ 正常方式部署的 Python web 应用不受影响(大多数人使用 WSGI 或 FastCGI,这两个不受影响),所以受到影响的 Python 应用要比 PHP 少得多
+ wsgi 不受影响,因为 os.environ 不会受到 CGI 数据污染
* 存在缺陷的 requests 库必须信任和使用 `os.environ['HTTP_PROXY']`,并且不做内容检查
#### Go
* Go 代码必须部署在 CGI 下才受影响。一般来说受到影响的代码会使用 `net/http/cgi` 包
+ 像 Python 一样,这并不是部署 Go 为一个 Web 应用的通常方式。所以受到影响的情形很少
+ 相较而言,Go 的 `net/http/fcgi` 包并不设置实际的环境变量,所以不受影响
* 存在缺陷的 `net/http` 版本需要在外发请求中信任并使用 `HTTP_PROXY` ,并不做内容检查
### 马上修复
最好的修复方式是在他们攻击你的应用之前尽早封挡 `Proxy` 请求头部。这很简单,也很安全。
* 说它安全是因为 IETF 没有定义 `Proxy` 请求头部,也没有列在 [IANA 的消息头部注册](http://www.iana.org/assignments/message-headers/message-headers.xhtml)中。这表明对该头部的使用是非标准的,甚至也不会临时用到
* 符合标准的 HTTP 客户端和服务器绝不应该读取和发送这个头部
* 你可以从请求中去掉这个头部或者干脆整个封挡使用它的请求
* 你可以在上游没有发布补丁时自己来解决这个问题
+ 当 HTTP 请求进来时就检查它,这样可以一次性修复好许多存在缺陷的应用
+ 在反向代理和应用防火墙之后的应用剔除 `Proxy` 请求头部是安全的
如何封挡 `Proxy` 请求头部依赖于你的配置。最容易的办法是在你的 Web 应用防火墙上封挡该头部,或者直接在 Apache 和 Nginx 上做也行。以下是一些如何做的指导:
#### Nginx/FastCGI
使用如下语句封挡传递给 PHP-FPM、PHP-PM 的请求头,这个语句可以放在 fastcgi.conf 或 fastcgi\_param 中(视你使用了哪个配置文件):
```
fastcgi_param HTTP_PROXY "";
```
在 FastCGI 模式下,PHP 存在缺陷(但是大多数使用 Nginx FastCGI 的其它语言则不受影响)。
#### Apache
对于 Apache 受影响的具体程度,以及其它的 Apache 软件项目,比如 Tomcat ,推荐参考 [Apache 软件基金会的官方公告](https://www.apache.org/security/asf-httpoxy-response.txt)。 以下是一些主要信息:
如果你在 Apache HTTP 服务器中使用 `mod_cgi`来运行 Go 或 Python 写的脚本,那么它们会受到影响(这里 `HTTP_PROXY` 环境变量是“真实的”)。而 `mod_php` 由于用于 PHP 脚本,也存在该缺陷。
如果你使用 **mod\_headers** 模块,你可以通过下述配置在进一步处理请求前就 unset 掉 `Proxy` 请求头部:
```
RequestHeader unset Proxy early
```
如果你使用 **mod\_security** 模块,你可以使用一个 `SecRule` 规则来拒绝带有 `Proxy` 请求头部的请求。下面是一个例子,要确保 `SecRuleEngine` 打开了。你可以根据自己的情况调整。
```
SecRule &REQUEST_HEADERS:Proxy "@gt 0" "id:1000005,log,deny,msg:'httpoxy denied'"
```
最后,如果你使用 Apache Traffic Server 的话,它本身不受影响。不过你可以用它来剔除掉 Proxy 请求头部,以保护其后面的其它服务。具体可以参考 [ASF 指导](https://www.apache.org/security/asf-httpoxy-response.txt)。
#### HAProxy
通过下述配置剔除该请求头部:
```
http-request del-header Proxy
```
#### Varnish
通过下述语句取消该头部,请将它放到已有的 vcl\_recv 小节里面:
```
sub vcl_recv {
[...]
unset req.http.proxy;
[...]
}
```
#### OpenBSD relayd
使用如下语句移除该头部。把它放到已有的过滤器里面:
```
http protocol httpfilter {
match request header remove "Proxy"
}
```
#### lighttpd (<= 1.4.40)
弹回包含 `Proxy` 头部的请求。
* 创建一个 `/path/to/deny-proxy.lua`文件,让它对于 lighttpd 只读,内容如下:
```
if (lighty.request["Proxy"] == nil) then return 0 else return 403 end
```
* 修改 `lighttpd.conf` 以加载 `mod_magnet` 模块,并运行如上 lua 代码:
```
server.modules += ( "mod_magnet" )
magnet.attract-raw-url-to = ( "/path/to/deny-proxy.lua" )
```
#### lighttpd2 (开发中)
从请求中剔除 `Proxy` 头部。加入如下语句到 `lighttpd.conf`中:
```
req_header.remove "Proxy";
```
### 用户端的 PHP 修复没有作用
用户端的修复不能解决该缺陷,所以不必费劲:
* 使用 `unset($_SERVER['HTTP_PROXY'])` 并不会影响到 `getenv()` 返回的值,所以无用
* 使用 `putenv('HTTP_PROXY=')` 也没效果(putenv 只能影响到来自实际环境变量的值,而不是来自请求头部的)
### httpoxy 的历史
该漏洞首次发现与15年前。
2001 年 3 月
Randal L. Schwartz 在 libwww-perl 发现该缺陷并修复。
2001 年 4 月
Cris Bailiff 在 curl 中发现该缺陷并修复。
2012 年 7 月
在`Net::HTTP` 的 `HTTP_PROXY` 实现中, Ruby 团队的 Akira Tanaka 发现了该缺陷
2013 年 11 月
在 nginx 邮件列表中提到了该缺陷。发现者 Jonathan Matthews 对此不太有把握,不过事实证明他是对的。
2015 年 2 月
Stefan Fritsch 在 Apache httpd-dev 邮件列表中提到了它。
2016 年 7 月
Vend 安全团队的 Scott Geary 发现了对该缺陷,并且它影响到了 PHP 等许多现代的编程语言和库。
所以,这个缺陷已经潜伏了许多年,许多人都在不同方面发现了它的存在,但是没有考虑到它对其它语言和库的影响。安全研究人员为此专门建立了一个网站: <https://httpoxy.org/> ,可以在此发现更多内容。
| 200 | OK | *httpoxy* is a set of vulnerabilities that affect application code running in CGI, or CGI-like environments. It comes
down to a simple namespace conflict:
`Proxy`
header from a request into the environment variables as `HTTP_PROXY`
`HTTP_PROXY`
is a popular environment variable used to configure an outgoing proxyThis leads to a remotely exploitable vulnerability. If you’re running PHP or CGI, you should block the `Proxy`
header.
[Here’s how.](#fix-now)
httpoxy is a vulnerability for server-side web applications. If you’re not deploying code, you don’t need to worry.
If a vulnerable HTTP client makes an outgoing HTTP connection, while running in a server-side CGI application, an attacker may be able to:
httpoxy is extremely easy to exploit in basic form. And we expect security
researchers to be able to scan for it quickly. Luckily, if you read on and
find you are affected, [easy mitigations](#fix-now) are available.
httpoxy **was disclosed in mid-2016**. If you’re reading about it now for the first time, you can *probably* relax and
take your time reading about this quaint historical bug that *hopefully* no longer affects any of the applications you
maintain. But you should verify that to your own satisfaction.
The content below this point reflects the original disclosure, and I’ll be leaving the site up and mostly unchanged, other than noting fix versions where I can. I guess I’m just saying: the time for urgency was last year.
A few things are necessary to be vulnerable:
`HTTP_PROXY`
becomes a real or emulated environment variable`HTTP_PROXY`
, and configures it as the proxyFor example, the confirmed cases we’ve found so far:
Language | Environment | HTTP client |
---|---|---|
PHP | php-fpm mod_php |
Guzzle 4+ Artax |
Python | wsgiref.handlers.CGIHandler twisted.web.twcgi.CGIScript |
requests |
Go | net/http/cgi | net/http |
But obviously there may be languages we haven’t considered yet. CGI is a common standard, and
`HTTP_PROXY`
seems to be becoming more popular over time. Take the below as a sample of the most
commonly affected scenarios:
`>=4.0.0rc2,<6.2.1`
are vulnerable, Guzzle 3 and below is not.So, for example, if you are using a Drupal module that uses Guzzle `6.2.0`
and makes an outgoing HTTP request (for example,
to check a weather API), you are vulnerable to the request that plugin makes being “httpoxied”.
`wsgiref.handlers.CGIHandler`
`os.environ['HTTP_PROXY']`
, without checking if CGI is in use`2.7.13`
, `3.4.6`
, `3.5.3`
, `3.6.0`
(see `net/http/cgi`
package.
`net/http/fcgi`
package, by comparison, does not set actual environment variables, so it is `net/http`
will trust and use `HTTP_PROXY`
for outgoing requests, without checking if CGI is in use`1.7rc3`
, all stable versions of `>=1.7`
The best immediate mitigation is to block `Proxy`
request headers as early as possible, and before they hit your
application. This is easy and safe.
`Proxy`
header is undefined by the IETF, and isn’t listed on the
`Proxy`
header is safe!How you block a `Proxy`
header depends on the specifics of your setup. The earliest convenient place to block the header
might be at a web application firewall device, or directly on the webserver running Apache or NGINX. Here are a few of
the more common mitigations:
Use this to block the header from being passed on to PHP-FPM, PHP-PM etc.
```
fastcgi_param HTTP_PROXY "";
```
In FastCGI configurations, PHP is vulnerable (but many other languages that use NGINX FastCGI are not).
For specific NGINX coverage, we recommend that you read the official [NGINX blog post](https://www.nginx.com/blog/mitigating-the-httpoxy-vulnerability-with-nginx)
on this vulnerability. The blog post provides a graphic depiction of how
httpoxy works and more extensive mitigation information for NGINX.
For specific Apache coverage (and details for other Apache software projects like Tomcat), we strongly recommend
you read the [Apache Software Foundation’s official advisory](https://www.apache.org/security/asf-httpoxy-response.txt) on
the matter. The very basic mitigation information you’ll find below is covered in much greater depth there.
If you’re using Apache HTTP Server with `mod_cgi`
, languages like Go and Python may be vulnerable (the `HTTP_PROXY`
env var
is “real”). And `mod_php`
is affected due to the nature of PHP. If you are using **mod_headers**, you can unset the
`Proxy`
header before further processing with this directive:
```
RequestHeader unset Proxy early
```
Example for using this in `.htaccess`
files:
```
<IfModule mod_headers.c>
RequestHeader unset Proxy
</IfModule>
```
If you are using **mod_security**, you can use a `SecRule`
to deny traffic with a `Proxy`
header. Here’s an example,
vary the action to taste, and make sure `SecRuleEngine`
is on. The 1000005 ID has been assigned to this issue.
```
SecRule &REQUEST_HEADERS:Proxy "@gt 0" "id:1000005,log,deny,msg:'httpoxy denied'"
```
Finally, if you’re using Apache Traffic Server, it’s not itself affected, but you can use it to strip the `Proxy`
header; very helpful
for any services sitting behind it. Again, see the [ASF’s guidance](https://www.apache.org/security/asf-httpoxy-response.txt),
but one possible configuration is:
Within `plugin.config`
, inside the configuration directory (e.g. `/usr/local/etc/trafficserver`
or `/etc/trafficserver`
),
add the following directive:
```
header_rewrite.so strip_proxy.conf
```
Add the following to a new file named `strip_proxy.conf`
in the same directory:
```
cond %{READ_REQUEST_HDR_HOOK}
rm-header Proxy
```
This will strip the header off requests:
```
http-request del-header Proxy
```
If your version of HAProxy is old (i.e. `1.4`
or earlier), you may not have the `http-request del-header`
directive.
If so, you must also take care that headers are stripped from requests served after the first one over an HTTP 1.1
keep-alive connection. (i.e. take special note of the limitation described in the first paragraph of [the 1.4 “header
manipulation” documentation](https://cbonte.github.io/haproxy-dconv/1.4/configuration.html#6))
For Varnish, the following should unset the header. Add it to the pre-existing vcl_recv section:
```
sub vcl_recv {
[...]
unset req.http.proxy;
[...]
}
```
For relayd, the following should remove the header. Add it to a pre-existing filter:
```
http protocol httpfilter {
match request header remove "Proxy"
}
```
To reject requests containing a `Proxy`
header
Create `/path/to/deny-proxy.lua`
, read-only to lighttpd, with the content:
```
if (lighty.request["Proxy"] == nil) then return 0 else return 403 end
```
Modify `lighttpd.conf`
to load `mod_magnet`
and run the above lua code:
```
server.modules += ( "mod_magnet" )
magnet.attract-raw-url-to = ( "/path/to/deny-proxy.lua" )
```
To strip the `Proxy`
header from the request, add the following to `lighttpd.conf`
:
```
req_header.remove "Proxy";
```
For detailed information about mitigating httpoxy on IIS, you should
head to the official [Microsoft article KB3179800](https://support.microsoft.com/en-us/kb/3179800), which covers
the below mitigations in greater detail.
Also important to know: httpoxy does not affect any Microsoft Web Frameworks, e.g. not ASP.NET nor Active Server Pages.
But if you have installed PHP or any other third party framework on top of IIS, we recommend applying mitigation steps
to protect from httpoxy attacks. You can either block requests containing a `Proxy`
header, or clear the header. (The header
is safe to block, because browsers will not generally send it at all).
To *block* requests that contain a `Proxy`
header (the preferred solution), run the following command line.
```
appcmd set config /section:requestfiltering /+requestlimits.headerLimits.[header='proxy',sizelimit='0']
```
**Note:** `appcmd.exe`
is not typically in the path and can be found in the `%systemroot%\system32\inetsrv`
directory
To *clear* the value of the header, use the following URL Rewrite rule:
```
<system.webServer>
<rewrite>
<rules>
<rule name="Erase HTTP_PROXY" patternSyntax="Wildcard">
<match url="*.*" />
<serverVariables>
<set name="HTTP_PROXY" value="" />
</serverVariables>
<action type="None" />
</rule>
</rules>
</rewrite>
</system.webServer>
```
**Note:** URL Rewrite is a downloadable add-in for IIS and is not included in a default IIS installation.
You can block any request containing a `Proxy`
header (or ban the sending client) via the UrlToolkit:
```
UrlToolkit {
ToolkitID = block_httpoxy
Header Proxy .* DenyAccess
}
```
See more information at the [hiawatha blog](https://www.hiawatha-webserver.org/weblog/115)
Upgrade to `>= 5.0.19`
or `>= 5.1.7`
to mitigate. You can do this manually with one of these commands, or you’ll get
an upgrade notification soon.
```
/usr/local/lsws/admin/misc/lsup.sh -v 5.0.19 # or
/usr/local/lsws/admin/misc/lsup.sh -v 5.1.7
```
See more information at the [litespeed blog](http://blog.litespeedtech.com/2016/07/18/the-httpoxy-vulnerability-has-been-taken-care-of-by-litespeed-automatically/)
Upgrade to `>= 2.0.2`
and add this to your configuration:
```
setenv:
HTTP_PROXY: ""
```
More information can be found in this [GitHub pull request](https://github.com/h2o/h2o/pull/996).
Please let us know of other places where httpoxy is found. We’d be happy to help you communicate fixes for your platform,
server or library if you are affected. Contact [[email protected]](mailto:[email protected]?subject=Fix) to let us
know. Or create a PR or issue against the [httpoxy-org repo](https://github.com/httpoxy/httpoxy-org) in GitHub.
Userland PHP fixes don’t work. Don’t bother:
`unset($_SERVER['HTTP_PROXY'])`
does not affect the value returned from `getenv()`
, so is not an effective
mitigation`putenv('HTTP_PROXY=')`
does not work either (to be precise: it only works if that value is coming from an
actual environment variable rather than a header – so, it cannot be used for mitigation)`CGI_HTTP_PROXY`
to set the proxy for a CGI application’s internal requests, if necessary
`HTTP_PROXY`
, but you must assert that CGI is not in use`PHP_SAPI == 'cli'`
Otherwise, a simple check is to not trust `HTTP_PROXY`
if `REQUEST_METHOD`
is also set. RFC 3875 seems to require
this meta-variable:
The
`REQUEST_METHOD`
meta-variable MUST be set to the method which should be used by the script to process the request
`HTTP_PROXY`
Under CGITo put it plainly: there is no way to trust the value of an `HTTP_`
env var in a CGI environment. They cannot be
distinguished from request headers according to the specification. So, *any* usage of `HTTP_PROXY`
in a CGI context is
suspicious.
If you need to configure the proxy of a CGI application via an environment variable, use a variable name that will
never conflict with request headers. That is: one that does not begin with `HTTP_`
. We strongly recommend you go for
`CGI_HTTP_PROXY`
. (As seen in Ruby and libwww-perl’s mitigations for this issue.)
CLI-only code may safely trust `$_SERVER['HTTP_PROXY']`
or `getenv('HTTP_PROXY')`
. But bear in mind that code written
for the CLI context often ends up running in a SAPI eventually, particularly utility or library code. And, with open
source code, that might not even be your doing. So, if you are going to rely on `HTTP_PROXY`
at all, you should guard
that code with a check of the `PHP_SAPI`
constant.
A defense-in-depth strategy that can combat httpoxy (and entire classes of other security problems) is to severely restrict
the outgoing requests your web application can make to an absolute minimum. For example, if a web application is
firewalled in such a way that it *cannot* make outgoing HTTP requests, an attacker will not be able to receive
the “misproxied” requests (because the web application is prevented from connecting to the attacker).
And, of course, another defense-in-depth strategy that works is to use HTTPS for internal requests, not just for
securing your site’s connections to the outside world. HTTPS requests aren’t affected by `HTTP_PROXY`
.
Using PHP as an example, because it is illustrative. PHP has a method called `getenv()`
1.
There is a common vulnerability in many PHP libraries and applications, introduced by confusing
`getenv`
for a method that only returns environment variables. In fact, getenv() is closer to the
`$_SERVER`
superglobal: it contains both environment variables and user-controlled data.
Specifically, when PHP is running under a CGI-like server, the HTTP request headers (data supplied
by the client) are merged into the `$_SERVER`
superglobal under keys beginning with `HTTP_`
. This is
the same information that `getenv`
reads from.
When a user sends a request with a `Proxy`
header, the header appears to the PHP application as `getenv('HTTP_PROXY')`
.
Some common PHP libraries have been trusting this value, even when run in a CGI/SAPI environment.
Reading and trusting `$_SERVER['HTTP_PROXY']`
is exactly the same vulnerability, but tends to happen much less often
(perhaps because of getenv’s name, perhaps because the semantics of the `$_SERVER`
superglobal are better understood among
the community).
Note that these examples require deployment into a vulnerable environment before there is actually a vulnerability
(e.g. php-fpm, or Apache’s `ScriptAlias`
)
```
$client = new GuzzleHttp\Client();
$client->get('http://api.internal/?secret=foo')
```
```
from wsgiref.handlers import CGIHandler
def application(environ, start_response):
requests.get("http://api.internal/?secret=foo")
CGIHandler().run(application)
```
```
cgi.Serve(
http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
res, _ := http.Get("http://api.internal/?secret=foo")
// [...]
```
More complete PoC repos (using Docker, and testing with an actual listener for the proxied request) have been prepared
under the [httpoxy Github organization](https://github.com/httpoxy).
Under the CGI spec, headers are provided mixed into the environment variables. (These are formally known as
“Protocol-Specific Meta-Variables” 2). That’s just the way the spec works, not a failure or bug.
The goal of the code, in most of the vulnerabilities, is to find the correct proxy to use, when auto-configuring a
client for the internal HTTP request made shortly after. This task in Ruby could be completed by
the `find_proxy`
method of `URI::Generic`
, which notes:
`http_proxy`
and`HTTP_PROXY`
are treated specially under the CGI environment, because`HTTP_PROXY`
may be set by Proxy: header. So`HTTP_PROXY`
is not used.`http_proxy`
is not used too if the variable is case insensitive.`CGI_HTTP_PROXY`
can be used instead.
Other instances of the same vulnerability are present in other languages. For example, when
using Go’s `net/http/cgi`
module, and deploying as a CGI application. This indicates the vulnerability
is a standard danger in CGI environments.
This bug was first discovered over 15 years ago. The timeline goes something like:
The issue is discovered in libwww-perl and fixed. Reported by Randal L. Schwartz. [3](#fn:perl-bug)
The issue is discovered in curl, and fixed there too (albeit probably not for Windows). Reported by Cris Bailiff. [4](#fn:curl-bug)
In implementing `HTTP_PROXY`
for `Net::HTTP`
, the Ruby team notice and avoid the potential issue. Nice work Akira Tanaka! [5](#fn:ruby-ref)
The issue is mentioned on the NGINX mailing list. The user humbly points out the issue: “unless
I’m missing something, which is very possible”. No, Jonathan Matthews, you were exactly right! [6](#fn:nginx-ref)
The issue is mentioned on the Apache httpd-dev mailing list. Spotted by Stefan Fritsch. [7](#fn:apache-ref)
Scott Geary, an engineer at Vend, found an instance of the bug in the wild. The Vend security team found the vulnerability was still exploitable in PHP, and present in many modern languages and libraries. We started to disclose to security response teams.
So, the bug was lying dormant for years, like a latent infection: pox. We imagine that many people may have found the issue over
the years, but never investigated its scope in other languages and libraries. If you’ve found a historical discussion
of interest that we’ve missed, let us know. You can contact [[email protected]](mailto:[email protected]?subject=History)
or create an issue against the [httpoxy-org repo](https://github.com/httpoxy/httpoxy-org).
httpoxy has a number of CVEs assigned. These cover the cases where
`Proxy`
header available in such a way that the application cannot tell whether
it is a real environment variable, or`HTTP_PROXY`
environment variable by default in a CGI environment (but only where that application should have been
able to tell it came from a request)The assigned CVEs so far:
We suspect there may be more CVEs coming for httpoxy, as less common software is checked over. If you want to get a CVE assigned for an httpoxy issue, there are a couple of options:
We’ll be linking to official announcements from affected teams here, as they become available.
Over the past two weeks, the Vend security team worked to disclose the issue responsibly to as many affected parties as we could. We’d like to thank the members of:
There’s an [extra](extra.html) page with some meta-discussion on the whole named disclosure thing and contact details.
The content on this page is licensed as [CC0](http://creativecommons.org/publicdomain/zero/1.0/) (TL;DR: use what you
like, no permission/attribution necessary).
I’ve put together some more opinionated notes on httpoxy on [my Medium account](https://medium.com/@nzdominic).
Regards,
Dominic Scheirlinck and the httpoxy disclosure team
July 2016
You can email [[email protected]](mailto:[email protected]?subject=Fix), or, for corrections or suggestions,
feel free to open an issue on the [httpoxy-org repo](https://github.com/httpoxy/httpoxy-org).
Page updated at 2017-06-23 14:17 UTC
The fix applied correctly handles cases with case-insensitive environment variables.
[libwww-perl-5.51 announcement](http://www.nntp.perl.org/group/perl.libwww/2001/03/msg2249.html) [↩](#fnref:perl-bug)
The [fix applied to Curl](https://sourceforge.net/p/curl/bugs/66/) does not
correctly handle cases with case-insensitive environment variables - it specifically mentions the fix would not
be enough for “NT” (Windows). The commit itself carries the prescient message “[since it might become
a security problem](https://github.com/curl/curl/commit/18f044f19d26f2b6dcd41796966f488a62a1bdca).” [↩](#fnref:curl-bug)
The [mitigation in Ruby](https://bugs.ruby-lang.org/issues/6546), like that for libwww-perl, correctly handles
case-insensitive environment variables. [↩](#fnref:ruby-ref)
The [NGINX mailing list](https://forum.nginx.org/read.php?2,244407,244485#msg-244485) even had a PHP-specific
explanation. [↩](#fnref:nginx-ref) |
7,594 | 带有已知安全漏洞的开源组件仍被广泛使用 | http://news.softpedia.com/news/as-open-source-code-spreads-so-do-components-with-security-flaws-506389.shtml | 2016-07-20T08:38:00 | [
"开源",
"缺陷"
] | https://linux.cn/article-7594-1.html | 
提供 Maven 中央仓库托管服务的 Sonatype 公司说, Java 组件下载中,有 1/16 的下载组件中包含了已知的安全问题。
Sonatype 声称,开发者们每年要下载超过 310 亿个/次 Java 组件,每天也会新增超过 1 千个新组件以及超过 1 万个的组件新版本。
现在企业都采用托管式的中央组件仓库来存储他们的代码。这些代码中有一些来自私有项目,而更多的则来自于开源代码,在多数情况下,他们只是下载开源代码并导入到其项目中,而不做必要的安全审计。
Sonatype 发现现在企业中的百分之八、九十的代码都是由开源组件构成的,它们直接来自公开的代码导入。
由于这些安全缺陷都是公开的,而且 Sonatype 能够访问到其托管服务的服务器统计数据,相比其他人来说他们得到的数据会更多,因此他们警告开发者们要注意在他们的代码中使用不安全的或过期的组件所带来的风险。
这个警告对于公司来说更加严重,因为如果攻击者对采用有缺陷的组件创建的应用进行攻击,结果就可能导致更多的经济损失。
### 更老的组件的缺陷率高达三倍
在分析了来自几个不同行业的三千家机构的两万五千个以上的企业应用之后,Sonatype 发现平均每年每个企业都会下载大约五千个不同的组件。
组件越老,就越有可能包含安全缺陷。甚至更糟糕的是, 其中 97% 的下载的组件不能很方便的跟踪和审计。而如果公司仅仅是要修复两千个应用中的 10% 的安全漏洞,就大约需要 742 万美金的巨额投入。
这些问题说明企业需要对软件供应链进行管理,以避免将来出现的缺陷问题。花费在组件安全审计上的时间,将在该项目的以后出现安全漏洞后得到回报。
从这种托管的中央代码仓库中移除有缺陷的组件也应该成为这些项目背后的社区的最高优先级的工作。
[软件供应链报告](http://www.sonatype.com/hubfs/SSC/2016_State_of_the_Software_Supply_Chain_Report.pdf)中包含了当今软件供应链的更多信息。

| 301 | Moved Permanently | null |
7,595 | 国产开源 Web shell 威胁到了网络世界的安全 | http://news.softpedia.com/news/new-made-in-china-web-shell-threatens-the-security-of-web-servers-worldwide-506448.shtml | 2016-07-20T10:42:00 | [
"Webshell",
"木马",
"C刀"
] | https://linux.cn/article-7595-1.html | 两名中国的安全研究人员开发了一个新的 Web shell,并把它开源到 [GitHub](https://github.com/Chora10/Cknife) 上了,任何人都可以使用它,或基于它改造成自己的黑客工具。
这个 Web Shell 的名字是 “<ruby> C刀 <rp> ( </rp> <rt> Cknife </rt> <rp> ) </rp></ruby>”——中国小刀的意思。它首次出现在 2015 年底,以 Java 开发,包括一个可以让它连接到 Java、PHP、ASP 和 ASP.NET 等服务器的服务器端组件。

两位作者是来自 MS509Team 的 Chora 和 MelodyZX,其中 MelodyZX 曾向阿里安全应急响应提交过漏洞,并应邀参加过2016 网络安全年会专题演讲。
### “<ruby> 中国菜刀 <rp> ( </rp> <rt> China Copper </rt> <rp> ) </rp></ruby>”之后的复刻版
据 [Recorded Future 的调查](https://www.recordedfuture.com/web-shell-analysis-part-2/)显示,这两位作者想要创造一个“中国菜刀”的复刻版。“中国菜刀”是一个非常有效的,但是已经过时的 Web Shell,它发布于 2013 年,曾经是中国红客的首选工具。
在“C刀”和“中国菜刀”之间有一些相同的地方,比如图标和发起 HTTP 请求的行为,但是两个工具也有根本性的不同,“C刀”采用 Java 编写,而“中国菜刀”则以 C++ 编写。此外,“C刀”在 Web Shell 的客户端和被入侵的服务器之间的通讯使用 HTTP,而“中国菜刀”则使用的是 HTTPS。Recorded Future 说“C刀”的作者承诺或在未来几个月内增加 HTTPS 支持。

### Recorded Future:“C刀”是 Web 服务器的远程管理木马(RAT)
目前,“C刀”允许使用者同时连接多台服务器,比如同时连接到 Web 服务器和数据库,以及运行一个远程命令行。
由于其大量的功能和甚至支持替换显示样式的漂亮界面,Recorded Future 认为它更像是一个“Web 服务器的远程管理木马(RAT)”而不是传统的 Web Shell。
尽管两位作者作为安全人员的职业很成功,但是这种开源了 Web Shell 的行为似乎跨越了白帽子和黑帽子之间的界限,相对于网络安全从业人员而言,这种工具对于网络攻击者更有用处。
| 301 | Moved Permanently | null |
7,599 | awk 系列:如何使用 awk 按模式筛选文本或字符串 | http://www.tecmint.com/awk-filter-text-or-string-using-patterns/ | 2016-07-21T08:02:00 | [
"awk"
] | https://linux.cn/article-7599-1.html | 
作为 awk 命令系列的第三部分,这次我们将看一看如何基于用户定义的特定模式来筛选文本或字符串。
在筛选文本时,有时你可能想根据某个给定的条件或使用一个可被匹配的特定模式,去标记某个文件或数行字符串中的某几行。使用 awk 来完成这个任务是非常容易的,这也正是 awk 中可能对你有所帮助的几个功能之一。
让我们看一看下面这个例子,比方说你有一个写有你想要购买的食物的购物清单,其名称为 food\_prices.list,它所含有的食物名称及相应的价格如下所示:
```
$ cat food_prices.list
No Item_Name Quantity Price
1 Mangoes 10 $2.45
2 Apples 20 $1.50
3 Bananas 5 $0.90
4 Pineapples 10 $3.46
5 Oranges 10 $0.78
6 Tomatoes 5 $0.55
7 Onions 5 $0.45
```
然后,你想使用一个 `(*)` 符号去标记那些单价大于 $2 的食物,那么你可以通过运行下面的命令来达到此目的:
```
$ awk '/ *\$[2-9]\.[0-9][0-9] */ { print $1, $2, $3, $4, "*" ; } / *\$[0-1]\.[0-9][0-9] */ { print ; }' food_prices.list
```

*打印出单价大于 $2 的项目*
从上面的输出你可以看到在含有<ruby> 芒果 <rp> ( </rp> <rt> mangoes </rt> <rp> ) </rp></ruby>和<ruby> 菠萝 <rp> ( </rp> <rt> pineapples </rt> <rp> ) </rp></ruby>的那行末尾都已经有了一个 `(*)` 标记。假如你检查它们的单价,你可以看到它们的单价的确超过了 $2 。
在这个例子中,我们已经使用了两个模式:
* 第一个模式: `/ *\$[2-9]\.[0-9][0-9] */` 将会得到那些含有食物单价大于 $2 的行,
* 第二个模式: `/*\$[0-1]\.[0-9][0-9] */` 将查找那些食物单价小于 $2 的那些行。
上面的命令具体做了什么呢?这个文件有四个字段,当模式一匹配到含有食物单价大于 $2 的行时,它便会输出所有的四个字段并在该行末尾加上一个 `(*)` 符号来作为标记。
第二个模式只是简单地输出其他含有食物单价小于 $2 的行,按照它们出现在输入文件 food\_prices.list 中的样子。
这样你就可以使用模式来筛选出那些价格超过 $2 的食物项目,尽管上面的输出还有些问题,带有 `(*)` 符号的那些行并没有像其他行那样被格式化输出,这使得输出显得不够清晰。
我们在 awk 系列的第二部分中也看到了同样的问题,但我们可以使用下面的两种方式来解决:
1、可以像下面这样使用 printf 命令,但这样使用又长又无聊:
```
$ awk '/ *\$[2-9]\.[0-9][0-9] */ { printf "%-10s %-10s %-10s %-10s\n", $1, $2, $3, $4 "*" ; } / *\$[0-1]\.[0-9][0-9] */ { printf "%-10s %-10s %-10s %-10s\n", $1, $2, $3, $4; }' food_prices.list
```

*使用 Awk 和 Printf 来筛选和输出项目*
2、 使用 `$0` 字段。Awk 使用变量 **0** 来存储整个输入行。对于上面的问题,这种方式非常方便,并且它还简单、快速:
```
$ awk '/ *\$[2-9]\.[0-9][0-9] */ { print $0 "*" ; } / *\$[0-1]\.[0-9][0-9] */ { print ; }' food_prices.list
```

*使用 Awk 和变量来筛选和输出项目*
### 结论
这就是全部内容了,使用 awk 命令你便可以通过几种简单的方法去利用模式匹配来筛选文本,帮助你在一个文件中对文本或字符串的某些行做标记。
希望这篇文章对你有所帮助。记得阅读这个系列的下一部分,我们将关注在 awk 工具中使用比较运算符。
---
via: <http://www.tecmint.com/awk-filter-text-or-string-using-patterns/>
作者:[Aaron Kili](http://www.tecmint.com/author/aaronkili/) 译者:[FSSlc](https://github.com/FSSlc) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,600 | LFCS 系列第十一讲:如何使用命令 vgcreate、lvcreate 和 lvextend 管理和创建 LVM | http://www.tecmint.com/manage-and-create-lvm-parition-using-vgcreate-lvcreate-and-lvextend/ | 2016-07-21T10:21:00 | [
"LFCS",
"LVM"
] | https://linux.cn/article-7600-1.html | 由于 LFCS 考试中的一些改变已在 2016 年 2 月 2 日生效,我们添加了一些必要的专题到 [LFCS 系列](/article-7161-1.html)。我们也非常推荐备考的同学,同时阅读 [LFCE 系列](http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/)。

*LFCS:管理 LVM 和创建 LVM 分区*
在安装 Linux 系统的时候要做的最重要的决定之一便是给系统文件、home 目录等分配空间。在这个地方犯了错,再要扩大空间不足的分区,那样既麻烦又有风险。
**逻辑卷管理** (**LVM**)相较于传统的分区管理有许多优点,已经成为大多数(如果不能说全部的话) Linux 发行版安装时的默认选择。LVM 最大的优点应该是能方便的按照你的意愿调整(减小或增大)逻辑分区的大小。
LVM 的组成结构:
* 把一块或多块硬盘或者一个或多个分区配置成物理卷(PV)。
* 一个用一个或多个物理卷创建出的卷组(**VG**)。可以把一个卷组想象成一个单独的存储单元。
* 在一个卷组上可以创建多个逻辑卷。每个逻辑卷相当于一个传统意义上的分区 —— 优点是它的大小可以根据需求重新调整大小,正如之前提到的那样。
本文,我们将使用三块 **8 GB** 的磁盘(**/dev/sdb**、**/dev/sdc** 和 **/dev/sdd**)分别创建三个物理卷。你既可以直接在整个设备上创建 PV,也可以先分区在创建。
在这里我们选择第一种方式,如果你决定使用第二种(可以参考本系列[第四讲:创建分区和文件系统](/article-7187-1.html))确保每个分区的类型都是 `8e`。
### 创建物理卷,卷组和逻辑卷
要在 **/dev/sdb**、**/dev/sdc** 和 **/dev/sdd**上创建物理卷,运行:
```
# pvcreate /dev/sdb /dev/sdc /dev/sdd
```
你可以列出新创建的 PV ,通过:
```
# pvs
```
并得到每个 PV 的详细信息,通过:
```
# pvdisplay /dev/sdX
```
(**X** 即 b、c 或 d)
如果没有输入 `/dev/sdX` ,那么你将得到所有 PV 的信息。
使用 /dev/sdb`和`/dev/sdc`创建卷组 ,命名为`vg00`(在需要时是可以通过添加其他设备来扩展空间的,我们等到说明这点的时候再用,所以暂时先保留`/dev/sdd`):
```
# vgcreate vg00 /dev/sdb /dev/sdc
```
就像物理卷那样,你也可以查看卷组的信息,通过:
```
# vgdisplay vg00
```
由于 `vg00` 是由两个 **8 GB** 的磁盘组成的,所以它将会显示成一个 **16 GB** 的硬盘:

*LVM 卷组列表*
当谈到创建逻辑卷,空间的分配必须考虑到当下和以后的需求。根据每个逻辑卷的用途来命名是一个好的做法。
举个例子,让我们创建两个 LV,命名为 `vol_projects` (**10 GB**) 和 `vol_backups` (剩下的空间), 在日后分别用于部署项目文件和系统备份。
参数 `-n` 用于为 LV 指定名称,而 `-L` 用于设定固定的大小,还有 `-l` (小写的 L)在 VG 的预留空间中用于指定百分比大小的空间。
```
# lvcreate -n vol_projects -L 10G vg00
# lvcreate -n vol_backups -l 100%FREE vg00
```
和之前一样,你可以查看 LV 的列表和基础信息,通过:
```
# lvs
```
或是查看详细信息,通过:
```
# lvdisplay
```
若要查看单个 **LV** 的信息,使用 **lvdisplay** 加上 **VG** 和 **LV** 作为参数,如下:
```
# lvdisplay vg00/vol_projects
```

*逻辑卷列表*
如上图,我们看到 LV 已经被创建成存储设备了(参考 LV Path 那一行)。在使用每个逻辑卷之前,需要先在上面创建文件系统。
这里我们拿 ext4 来做举例,因为对于每个 LV 的大小, ext4 既可以增大又可以减小(相对的 xfs 就只允许增大):
```
# mkfs.ext4 /dev/vg00/vol_projects
# mkfs.ext4 /dev/vg00/vol_backups
```
我们将在下一节向大家说明,如何调整逻辑卷的大小并在需要的时候添加额外的外部存储空间。
### 调整逻辑卷大小和扩充卷组
现在设想以下场景。`vol_backups` 中的空间即将用完,而 `vol_projects` 中还有富余的空间。由于 LVM 的特性,我们可以轻易的减小后者的大小(比方说 **2.5 GB**),并将其分配给前者,与此同时调整每个文件系统的大小。
幸运的是这很简单,只需:
```
# lvreduce -L -2.5G -r /dev/vg00/vol_projects
# lvextend -l +100%FREE -r /dev/vg00/vol_backups
```

*减小逻辑卷和卷组*
在调整逻辑卷的时候,其中包含的减号 `(-)` 或加号 `(+)` 是十分重要的。否则 LV 将会被设置成指定的大小,而非调整指定大小。
有些时候,你可能会遭遇那种无法仅靠调整逻辑卷的大小就可以解决的问题,那时你就需要购置额外的存储设备了,你可能需要再加一块硬盘。这里我们将通过添加之前配置时预留的 PV (`/dev/sdd`),用以模拟这种情况。
想把 `/dev/sdd` 加到 `vg00`,执行:
```
# vgextend vg00 /dev/sdd
```
如果你在运行上条命令的前后执行 vgdisplay `vg00` ,你就会看出 VG 的大小增加了。
```
# vgdisplay vg00
```

*查看卷组磁盘大小*
现在,你可以使用新加的空间,按照你的需求调整现有 LV 的大小,或者创建一个新的 LV。
### 在启动和需求时挂载逻辑卷
当然,如果我们不打算实际的使用逻辑卷,那么创建它们就变得毫无意义了。为了更好的识别逻辑卷,我们需要找出它的 `UUID` (用于识别一个格式化存储设备的唯一且不变的属性)。
要做到这点,可使用 blkid 加每个设备的路径来实现:
```
# blkid /dev/vg00/vol_projects
# blkid /dev/vg00/vol_backups
```

*寻找逻辑卷的 UUID*
为每个 LV 创建挂载点:
```
# mkdir /home/projects
# mkdir /home/backups
```
并在 `/etc/fstab` 插入相应的条目(确保使用之前获得的UUID):
```
UUID=b85df913-580f-461c-844f-546d8cde4646 /home/projects ext4 defaults 0 0
UUID=e1929239-5087-44b1-9396-53e09db6eb9e /home/backups ext4 defaults 0 0
```
保存并挂载 LV:
```
# mount -a
# mount | grep home
```

*挂载逻辑卷*
在涉及到 LV 的实际使用时,你还需要按照曾在本系列[第八讲:管理用户和用户组](/article-7418-1.html)中讲解的那样,为其设置合适的 `ugo+rwx`。
### 总结
本文介绍了 [逻辑卷管理](/article-3965-1.html),一个用于管理可扩展存储设备的多功能工具。与 RAID(曾在本系列讲解过的 [第六讲:组装分区为RAID设备——创建和管理系统备份](/article-7229-1.html))结合使用,你将同时体验到(LVM 带来的)可扩展性和(RAID 提供的)冗余。
在这类的部署中,你通常会在 `RAID` 上发现 `LVM`,这就是说,要先配置好 RAID 然后它在上面配置 LVM。
如果你对本问有任何的疑问和建议,可以直接在下方的评论区告诉我们。
---
via: <http://www.tecmint.com/manage-and-create-lvm-parition-using-vgcreate-lvcreate-and-lvextend/>
作者:[Gabriel Cánepa](http://www.tecmint.com/author/gacanepa/) 译者:[martin2011qi](https://github.com/martin2011qi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,601 | 使用 OpenCV 识别图片中的猫咪 | http://www.pyimagesearch.com/2016/06/20/detecting-cats-in-images-with-opencv/ | 2016-07-21T10:38:00 | [
"OpenCV",
"计算机视觉"
] | https://linux.cn/article-7601-1.html | 
你知道 OpenCV 可以识别在图片中小猫的脸吗?而且是拿来就能用,不需要其它的库之类的。
之前我也不知道。
但是在 [Kendrick Tan 曝出这个功能](http://kendricktan.github.io/find-cats-in-photos-using-computer-vision.html)后,我需要亲自体验一下……去看看到 OpenCV 是如何在我没有察觉到的情况下,将这一个功能添加进了他的软件库(就像一只悄悄溜进空盒子的猫咪一样,等待别人发觉)。
下面,我将会展示如何使用 OpenCV 的猫咪检测器在图片中识别小猫的脸。同样的,该技术也可以用在视频流中。
### 使用 OpenCV 在图片中检测猫咪
如果你查找过 [OpenCV 的代码仓库](https://github.com/Itseez/opencv),尤其是在 [haarcascades 目录](https://github.com/Itseez/opencv/tree/master/data/haarcascades)里(OpenCV 在这里保存处理它预先训练好的 Haar 分类器,以检测各种物体、身体部位等), 你会看到这两个文件:
* haarcascade\_frontalcatface.xml
* haarcascade\_frontalcatface\_extended.xml
这两个 Haar Cascade 文件都将被用来在图片中检测小猫的脸。实际上,我使用了相同的 cascades 分类器来生成这篇博文顶端的图片。
在做了一些调查工作之后,我发现这些 cascades 分类器是由鼎鼎大名的 [Joseph Howse](http://nummist.com/) 训练和贡献给 OpenCV 仓库的,他写了很多很棒的教程和书籍,在计算机视觉领域有着很高的声望。
下面,我将会展示给你如何使用 Howse 的 Haar cascades 分类器来检测图片中的小猫。
### 猫咪检测代码
让我们开始使用 OpenCV 来检测图片中的猫咪。新建一个叫 cat\_detector.py 的文件,并且输入如下的代码:
```
# import the necessary packages
import argparse
import cv2
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to the input image")
ap.add_argument("-c", "--cascade",
default="haarcascade_frontalcatface.xml",
help="path to cat detector haar cascade")
args = vars(ap.parse_args())
```
第 2 和第 3 行主要是导入了必要的 python 包。6-12 行用于解析我们的命令行参数。我们仅要求一个必需的参数 `--image` ,它是我们要使用 OpenCV 检测猫咪的图片。
我们也可以(可选的)通过 `--cascade` 参数指定我们的 Haar cascade 分类器的路径。默认使用 `haarcascades_frontalcatface.xml`,假定这个文件和你的 `cat_detector.py` 在同一目录下。
注意:我已经打包了猫咪的检测代码,还有在这个教程里的样本图片。你可以在博文原文的 “下载” 部分下载到。如果你是刚刚接触 Python+OpenCV(或者 Haar cascade),我建议你下载这个 zip 压缩包,这个会方便你跟着教程学习。
接下来,就是检测猫的时刻了:
```
# load the input image and convert it to grayscale
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# load the cat detector Haar cascade, then detect cat faces
# in the input image
detector = cv2.CascadeClassifier(args["cascade"])
rects = detector.detectMultiScale(gray, scaleFactor=1.3,
minNeighbors=10, minSize=(75, 75))
```
在 15、16 行,我们从硬盘上读取了图片,并且进行灰度化(这是一个在将图片传给 Haar cascade 分类器之前的常用的图片预处理步骤,尽管不是必须的)
20 行,从硬盘加载 Haar casacade 分类器,即猫咪检测器,并且实例化 `cv2.CascadeClassifier` 对象。
在 21、22 行通过调用 `detector` 的 `detectMultiScale` 方法使用 OpenCV 完成猫脸检测。我们给 `detectMultiScale` 方法传递了四个参数。包括:
1. 图片 `gray`,我们要在该图片中检测猫脸。
2. 检测猫脸时的[图片金字塔](http://www.pyimagesearch.com/2015/03/16/image-pyramids-with-python-and-opencv/) 的检测粒度 `scaleFactor` 。更大的粒度将会加快检测的速度,但是会对检测<ruby> 准确性 <rp> ( </rp> <rt> true-positive </rt> <rp> ) </rp></ruby>产生影响。相反的,一个更小的粒度将会影响检测的时间,但是会增加<ruby> 准确性 <rp> ( </rp> <rt> true-positive </rt> <rp> ) </rp></ruby>。但是,细粒度也会增加<ruby> 误报率 <rp> ( </rp> <rt> false-positive </rt> <rp> ) </rp></ruby>。你可以看这篇博文的“ Haar cascades 注意事项”部分来获得更多的信息。
3. `minNeighbors` 参数控制了检定框的最少数量,即在给定区域内被判断为猫脸的最少数量。这个参数可以很好的排除<ruby> 误报 <rp> ( </rp> <rt> false-positive </rt> <rp> ) </rp></ruby>结果。
4. 最后,`minSize` 参数不言自明。这个值描述每个检定框的最小宽高尺寸(单位是像素),这个例子中就是 75\*75
`detectMultiScale` 函数会返回 `rects`,这是一个 4 元组列表。这些元组包含了每个检测到的猫脸的 (x,y) 坐标值,还有宽度、高度。
最后,让我们在图片上画下这些矩形来标识猫脸:
```
# loop over the cat faces and draw a rectangle surrounding each
for (i, (x, y, w, h)) in enumerate(rects):
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2)
cv2.putText(image, "Cat #{}".format(i + 1), (x, y - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.55, (0, 0, 255), 2)
# show the detected cat faces
cv2.imshow("Cat Faces", image)
cv2.waitKey(0)
```
给我们这些框(比如,rects)的数据,我们在 25 行依次遍历它。
在 26 行,我们在每张猫脸的周围画上一个矩形。27、28 行展示了一个整数,即图片中猫咪的数量。
最后,31,32 行在屏幕上展示了输出的图片。
### 猫咪检测结果
为了测试我们的 OpenCV 猫咪检测器,可以在原文的最后,下载教程的源码。
然后,在你解压缩之后,你将会得到如下的三个文件/目录:
1. cat\_detector.py:我们的主程序
2. haarcascade\_frontalcatface.xml: 猫咪检测器 Haar cascade
3. images:我们将会使用的检测图片目录。
到这一步,执行以下的命令:
```
$ python cat_detector.py --image images/cat_01.jpg
```

*图 1. 在图片中检测猫脸,甚至是猫咪部分被遮挡了。*
注意,我们已经可以检测猫脸了,即使它的其余部分是被遮挡的。
试下另外的一张图片:
```
python cat_detector.py --image images/cat_02.jpg
```

*图 2. 使用 OpenCV 检测猫脸的第二个例子,这次猫脸稍有不同。*
这次的猫脸和第一次的明显不同,因为它正在发出“喵呜”叫声的当中。这种情况下,我们依旧能检测到正确的猫脸。
在下面这张图片的结果也是正确的:
```
$ python cat_detector.py --image images/cat_03.jpg
```

*图 3. 使用 OpenCV 和 python 检测猫脸*
我们最后的一个样例就是在一张图中检测多张猫脸:
```
$ python cat_detector.py --image images/cat_04.jpg
```

*图 4. 在同一张图片中使用 OpenCV 检测多只猫*
注意,Haar cascade 返回的检定框不一定是以你预期的顺序。这种情况下,中间的那只猫会被标记成第三只。你可以通过判断他们的 (x, y) 坐标来自己排序这些检定框。
#### 关于精度的说明
在这个 xml 文件中的注释非常重要,Joseph Hower 提到了这个猫脸检测器有可能会将人脸识别成猫脸。
这种情况下,他推荐使用两种检测器(人脸 & 猫脸),然后将出现在人脸识别结果中的结果剔除掉。
#### Haar cascades 注意事项
这个方法首先出现在 Paul Viola 和 Michael Jones 2001 年出版的 [Rapid Object Detection using a Boosted Cascade of Simple Features](https://www.cs.cmu.edu/~efros/courses/LBMV07/Papers/viola-cvpr-01.pdf) 论文中。现在它已经成为了计算机识别领域引用最多的论文之一。
这个算法能够识别图片中的对象,无论它们的位置和比例。而且最令人感兴趣的或许是它能在现有的硬件条件下实现实时检测。
在他们的论文中,Viola 和 Jones 关注在训练人脸检测器;但是,这个框架也能用来检测各类事物,如汽车、香蕉、路标等等。
#### 问题是?
Haar cascades 最大的问题就是如何确定 `detectMultiScale` 方法的参数正确。特别是 `scaleFactor` 和 `minNeighbors` 参数。你很容易陷入一张一张图片调参数的坑,这个就是该对象检测器很难被实用化的原因。
这个 `scaleFactor` 变量控制了用来检测对象的图片的各种比例的[图像金字塔](http://www.pyimagesearch.com/2015/03/16/image-pyramids-with-python-and-opencv/)。如果 `scaleFactor` 参数过大,你就只需要检测图像金字塔中较少的层,这可能会导致你丢失一些在图像金字塔层之间缩放时少了的对象。
换句话说,如果 `scaleFactor` 参数过低,你会检测过多的金字塔图层。这虽然可以能帮助你检测到更多的对象。但是他会造成计算速度的降低,还会**明显**提高误报率。Haar cascades 分类器就是这样。
为了避免这个,我们通常使用 [Histogram of Oriented Gradients + 线性 SVM 检测](http://www.pyimagesearch.com/2014/11/10/histogram-oriented-gradients-object-detection/) 替代。
上述的 HOG + 线性 SVM 框架的参数更容易调优。而且更好的误报率也更低,但是唯一不好的地方是无法实时运算。
### 对对象识别感兴趣?并且希望了解更多?

*图 5. 在 PyImageSearch Gurus 课程中学习如何构建自定义的对象识别器。*
如果你对学习如何训练自己的自定义对象识别器感兴趣,请务必要去了解下 PyImageSearch Gurus 课程。
在这个课程中,我提供了 15 节课,覆盖了超过 168 页的教程,来教你如何从 0 开始构建自定义的对象识别器。你会掌握如何应用 HOG + 线性 SVM 框架来构建自己的对象识别器来识别路标、面孔、汽车(以及附近的其它东西)。
要学习 PyImageSearch Gurus 课程(有 10 节示例免费课程),点此: <https://www.pyimagesearch.com/pyimagesearch-gurus/?src=post-cat-detection>
### 总结
在这篇博文里,我们学习了如何使用 OpenCV 默认就有的 Haar cascades 分类器来识别图片中的猫脸。这些 Haar casacades 是由 [Joseph Howse](http://www.pyimagesearch.com/2014/11/10/histogram-oriented-gradients-object-detection/) 训练兵贡献给 OpenCV 项目的。我是在 Kendrick Tan 的[这篇文章](http://kendricktan.github.io/find-cats-in-photos-using-computer-vision.html)中开始注意到这个。
尽管 Haar cascades 相当有用,但是我们也经常用 HOG + 线性 SVM 替代。因为后者相对而言更容易使用,并且可以有效地降低误报率。
我也会[在 PyImageSearch Gurus 课程中](https://www.pyimagesearch.com/pyimagesearch-gurus/)详细的讲述如何构建定制的 HOG + 线性 SVM 对象识别器,来识别包括汽车、路标在内的各种事物。
不管怎样,我希望你喜欢这篇博文。
---
via: <http://www.pyimagesearch.com/2016/06/20/detecting-cats-in-images-with-opencv/>
作者:[Adrian Rosebrock](http://www.pyimagesearch.com/author/adrian/) 译者:[MikeCoder](https://github.com/MikeCoder) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,602 | awk 系列:如何使用 awk 比较操作符 | http://www.tecmint.com/comparison-operators-in-awk/ | 2016-07-22T13:59:00 | [
"awk"
] | https://linux.cn/article-7602-1.html | 
对于 使用 awk 命令的用户来说,处理一行文本中的数字或者字符串时,使用比较运算符来过滤文本和字符串是十分方便的。
在 awk 系列的此部分中,我们将探讨一下如何使用比较运算符来过滤文本或者字符串。如果你是程序员,那么你应该已经熟悉了比较运算符;对于其它人,下面的部分将介绍比较运算符。
### awk 中的比较运算符是什么?
awk 中的比较运算符用于比较字符串和或者数值,包括以下类型:
* `>` – 大于
* `<` – 小于
* `>=` – 大于等于
* `<=` – 小于等于
* `==` – 等于
* `!=` – 不等于
* `some_value ~ / pattern/` – 如果 some\_value 匹配模式 pattern,则返回 true
* `some_value !~ / pattern/` – 如果 some\_value 不匹配模式 pattern,则返回 true
现在我们通过例子来熟悉 awk 中各种不同的比较运算符。
在这个例子中,我们有一个文件名为 food\_list.txt 的文件,里面包括不同食物的购买列表。我想给食物数量小于或等于 30 的物品所在行的后面加上`(**)`
```
File – food_list.txt
No Item_Name Quantity Price
1 Mangoes 45 $3.45
2 Apples 25 $2.45
3 Pineapples 5 $4.45
4 Tomatoes 25 $3.45
5 Onions 15 $1.45
6 Bananas 30 $3.45
```
Awk 中使用比较运算符的通用语法如下:
```
# 表达式 { 动作; }
```
为了实现刚才的目的,执行下面的命令:
```
# awk '$3 <= 30 { printf "%s\t%s\n", $0,"**" ; } $3 > 30 { print $0 ;}' food_list.txt
No Item_Name` Quantity Price
1 Mangoes 45 $3.45
2 Apples 25 $2.45 **
3 Pineapples 5 $4.45 **
4 Tomatoes 25 $3.45 **
5 Onions 15 $1.45 **
6 Bananas 30 $3.45 **
```
在刚才的例子中,发生如下两件重要的事情:
* 第一个“表达式 {动作;}”组合中, `$3 <= 30 { printf “%s\t%s\n”, $0,”**” ; }` 打印出数量小于等于30的行,并且在后面增加`(**)`。物品的数量是通过 `$3` 这个域变量获得的。
* 第二个“表达式 {动作;}”组合中, `$3 > 30 { print $0 ;}` 原样输出数量小于等于 `30` 的行。
再举一个例子:
```
# awk '$3 <= 20 { printf "%s\t%s\n", $0,"TRUE" ; } $3 > 20 { print $0 ;} ' food_list.txt
No Item_Name Quantity Price
1 Mangoes 45 $3.45
2 Apples 25 $2.45
3 Pineapples 5 $4.45 TRUE
4 Tomatoes 25 $3.45
5 Onions 15 $1.45 TRUE
6 Bananas 30 $3.45
```
在这个例子中,我们想通过在行的末尾增加 (TRUE) 来标记数量小于等于20的行。
### 总结
这是一篇对 awk 中的比较运算符介绍性的指引,因此你需要尝试其他选项,发现更多使用方法。
如果你遇到或者想到任何问题,请在下面评论区留下评论。请记得阅读 awk 系列下一部分的文章,那里我将介绍组合表达式。
---
via: <http://www.tecmint.com/comparison-operators-in-awk/>
作者:[Aaron Kili](http://www.tecmint.com/author/aaronkili/) 译者:[chunyang-wen](https://github.com/chunyang-wen) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,603 | awk 系列:如何使用 awk 复合表达式 | http://www.tecmint.com/combine-multiple-expressions-in-awk/ | 2016-07-23T09:12:00 | [
"awk"
] | https://linux.cn/article-7603-1.html | 
一直以来在查对条件是否匹配时,我们使用的都是简单的表达式。那如果你想用超过一个表达式来查对特定的条件呢?
本文中,我们将看看如何在过滤文本和字符串时,结合多个表达式,即复合表达式,用以查对条件。
awk 的复合表达式可由表示“与”的组合操作符 `&&` 和表示“或”的 `||` 构成。
复合表达式的常规写法如下:
```
( 第一个表达式 ) && ( 第二个表达式 )
```
这里只有当“第一个表达式” 和“第二个表达式”都是真值时整个表达式才为真。
```
( 第一个表达式 ) || ( 第二个表达式)
```
这里只要“第一个表达式” 为真或“第二个表达式”为真,整个表达式就为真。
**注意**:切记要加括号。
表达式可以由比较操作符构成,具体可查看 [awk 系列的第四节](/article-7602-1.html)。
现在让我们通过一个例子来加深理解:
此例中,有一个文本文件 `tecmint_deals.txt`,文本中包含着一张随机的 Tecmint 交易清单,其中包含了名称、价格和种类。
```
TecMint Deal List
No Name Price Type
1 Mac_OS_X_Cleanup_Suite $9.99 Software
2 Basics_Notebook $14.99 Lifestyle
3 Tactical_Pen $25.99 Lifestyle
4 Scapple $19.00 Unknown
5 Nano_Tool_Pack $11.99 Unknown
6 Ditto_Bluetooth_Altering_Device $33.00 Tech
7 Nano_Prowler_Mini_Drone $36.99 Tech
```
我们只想打印出价格超过 $20 且其种类为 “Tech” 的物品,在其行末用 (\*) 打上标记。
我们将要执行以下命令。
```
# awk '($3 ~ /^\$[2-9][0-9]*\.[0-9][0-9]$/) && ($4=="Tech") { printf "%s\t%s\n",$0,"*"; } ' tecmint_deals.txt
6 Ditto_Bluetooth_Altering_Device $33.00 Tech *
7 Nano_Prowler_Mini_Drone $36.99 Tech *
```
此例,在复合表达式中我们使用了两个表达式:
* 表达式 1:`($3 ~ /^\$[2-9][0-9]*\.[0-9][0-9]$/)` ;查找交易价格超过 `$20` 的行,即只有当 `$3` 也就是价格满足 `/^\$[2-9][0-9]*\.[0-9][0-9]$/` 时值才为真值。
* 表达式 2:`($4 == “Tech”)` ;查找是否有种类为 “`Tech`”的交易,即只有当 `$4` 等于 “`Tech`” 时值才为真值。 切记,只有当 `&&` 操作符的两端状态,也就是两个表达式都是真值的情况下,这一行才会被打上 `(*)` 标志。
### 总结
有些时候为了真正符合你的需求,就不得不用到复合表达式。当你掌握了比较和复合表达式操作符的用法之后,复杂的文本或字符串过滤条件也能轻松解决。
希望本向导对你有所帮助,如果你有任何问题或者补充,可以在下方发表评论,你的问题将会得到相应的解释。
---
via: <http://www.tecmint.com/combine-multiple-expressions-in-awk/>
作者:[Aaron Kili](http://www.tecmint.com/author/aaronkili/) 译者:[martin2011qi](https://github.com/martin2011qi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,604 | 教你用 google-drive-ocamlfuse 在 Linux 上挂载 Google Drive | http://www.techrepublic.com/article/how-to-mount-your-google-drive-on-linux-with-google-drive-ocamlfuse/ | 2016-07-22T14:36:00 | [
"FUSE",
"文件洗个头"
] | https://linux.cn/article-7604-1.html |
>
> 如果你在找一个方便的方式在 Linux 机器上挂载你的 Google Drive 文件夹, Jack Wallen 将教你怎么使用 google-drive-ocamlfuse 来挂载 Google Drive。
>
>
>

*图片来源: Jack Wallen*
Google 还没有发行 Linux 版本的 Google Drive 应用,尽管现在有很多方法从 Linux 中访问你的 Drive 文件。
如果你喜欢界面化的工具,你可以选择 Insync。如果你喜欢用命令行,有很多像 Grive2 这样的工具,以及更容易使用的以 Ocaml 语言编写的基于 FUSE 的文件系统。我将会用后面这种方式演示如何在 Linux 桌面上挂载你的 Google Drive。尽管这是通过命令行完成的,但是它的用法会简单到让你吃惊。它太简单了以至于谁都能做到。
这个系统的特点:
* 对普通文件/文件夹有完全的读写权限
* 对于 Google Docs,sheets,slides 这三个应用只读
* 能够访问 Drive 回收站(.trash)
* 处理重复文件功能
* 支持多个帐号
让我们接下来完成 google-drive-ocamlfuse 在 Ubuntu 16.04 桌面的安装,然后你就能够访问云盘上的文件了。
### 安装
1. 打开终端。
2. 用 `sudo add-apt-repository ppa:alessandro-strada/ppa` 命令添加必要的 PPA
3. 出现提示的时候,输入你的 root 密码并按下回车。
4. 用 `sudo apt-get update` 命令更新应用。
5. 输入 `sudo apt-get install google-drive-ocamlfuse` 命令安装软件。
### 授权
接下来就是授权 google-drive-ocamlfuse,让它有权限访问你的 Google 账户。先回到终端窗口敲下命令 `google-drive-ocamlfuse`,这个命令将会打开一个浏览器窗口,它会提示你登陆你的 Google 帐号或者如果你已经登陆了 Google 帐号,它会询问是否允许 google-drive-ocamlfuse 访问 Google 账户。如果你还没有登录,先登录然后点击“允许”。接下来的窗口(在 Ubuntu 16.04 桌面上会出现,但不会出现在 Elementary OS Freya 桌面上)将会询问你是否授给 gdfuse 和 OAuth2 Endpoint 访问你的 Google 账户的权限,再次点击“允许”。然后出现的窗口就会告诉你等待授权令牌下载完成,这个时候就能最小化浏览器了。当你的终端提示如下图一样的内容,你就能知道令牌下载完了,并且你已经可以挂载 Google Drive 了。

*应用已经得到授权,你可以进行后面的工作。*
### 挂载 Google Drive
在挂载 Google Drive 之前,你得先创建一个文件夹,作为挂载点。在终端里,敲下`mkdir ~/google-drive`命令在你的家目录下创建一个新的文件夹。最后敲下命令`google-drive-ocamlfuse ~/google-drive`将你的 Google Drive 挂载到 google-drive 文件夹中。
这时你可以查看本地 google-drive 文件夹中包含的 Google Drive 文件/文件夹。你可以把 Google Drive 当作本地文件系统来进行工作。
当你想卸载 google-drive 文件夹,输入命令 `fusermount -u ~/google-drive`。
### 没有 GUI,但它特别好用
我发现这个特别的系统非常容易使用,在同步 Google Drive 时它出奇的快,并且这可以作为一种本地备份你的 Google Drive 账户的巧妙方式。(LCTT 译注:然而首先你得能使用……)
试试 google-drive-ocamlfuse,看看你能用它做出什么有趣的事。
---
via: <http://www.techrepublic.com/article/how-to-mount-your-google-drive-on-linux-with-google-drive-ocamlfuse/>
作者:[Jack Wallen](http://www.techrepublic.com/search/?a=jack+wallen) 译者:[GitFuture](https://github.com/GitFuture) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,605 | 如何在 Ubuntu 上搭建网桥 | http://www.cyberciti.biz/faq/how-to-create-bridge-interface-ubuntu-linux/ | 2016-07-22T14:51:00 | [
"网桥"
] | https://linux.cn/article-7605-1.html |
>
> 作为一个 Ubuntu 16.04 LTS 的初学者。如何在 Ubuntu 14.04 和 16.04 的主机上搭建网桥呢?
>
>
>

顾名思义,网桥的作用是通过物理接口连接内部和外部网络。对于虚拟端口或者 LXC/KVM/Xen/容器来说,这非常有用。网桥虚拟端口看起来是网络上的一个常规设备。在这个教程中,我将会介绍如何在 Ubuntu 服务器上通过 bridge-utils (brctl) 命令行来配置 Linux 网桥。
### 网桥化的网络示例

*图 01: Kvm/Xen/LXC 容器网桥示例 (br0)*
在这个例子中,eth0 和 eth1 是物理网络接口。eth0 连接着局域网,eth1 连接着上游路由器和互联网。
### 安装 bridge-utils
使用 [apt-get 命令](%E3%80%80http://www.cyberciti.biz/tips/linux-debian-package-management-cheat-sheet.html) 安装 bridge-utils:
```
$ sudo apt-get install bridge-utils
```
或者
```
$ sudo apt install bridge-utils
```
样例输出:

*图 02: Ubuntu 安装 bridge-utils 包*
### 在 Ubuntu 服务器上创建网桥
使用你熟悉的文本编辑器修改 `/etc/network/interfaces` ,例如 vi 或者 nano :
```
$ sudo cp /etc/network/interfaces /etc/network/interfaces.bakup-1-july-2016
$ sudo vi /etc/network/interfaces
```
接下来设置 eth1 并且将它映射到 br1 ,输入如下(删除或者注释所有 eth1 相关配置):
```
### br1 使用静态公网 IP 地址,并以 ISP 的路由器作为网关
auto br1
iface br1 inet static
address 208.43.222.51
network 255.255.255.248
netmask 255.255.255.0
broadcast 208.43.222.55
gateway 208.43.222.49
bridge_ports eth1
bridge_stp off
bridge_fd 0
bridge_maxwait 0
```
接下来设置 eth0 并将它映射到 br0,输入如下(删除或者注释所有 eth0 相关配置):
```
auto br0
iface br0 inet static
address 10.18.44.26
netmask 255.255.255.192
broadcast 10.18.44.63
dns-nameservers 10.0.80.11 10.0.80.12
# set static route for LAN
post-up route add -net 10.0.0.0 netmask 255.0.0.0 gw 10.18.44.1
post-up route add -net 161.26.0.0 netmask 255.255.0.0 gw 10.18.44.1
bridge_ports eth0
bridge_stp off
bridge_fd 0
bridge_maxwait 0
```
### 关于 br0 和 DHCP 的一点说明
如果使用 DHCP ,配置选项是这样的:
```
auto br0
iface br0 inet dhcp
bridge_ports eth0
bridge_stp off
bridge_fd 0
bridge_maxwait 0
```
保存并且关闭文件。
### 重启服务器或者网络服务
你需要重启服务器或者输入下列命令来重启网络服务(在 SSH 登录的会话中这可能不管用):
```
$ sudo systemctl restart networking
```
如果你证使用 Ubuntu 14.04 LTS 或者更老的没有 systemd 的系统,输入:
```
$ sudo /etc/init.d/restart networking
```
### 验证网络配置成功
使用 ping/ip 命令来验证 LAN 和 WAN 网络接口运行正常:
```
### 查看 br0 和 br1
ip a show
### 查看路由信息
ip r
### ping 外部站点
ping -c 2 cyberciti.biz
### ping 局域网服务器
ping -c 2 10.0.80.12
```
样例输出:

*图 03: 验证网桥的以太网连接*
现在,你就可以配置 br0 和 br1 来让 XEN/KVM/LXC 容器访问因特网或者私有局域网了。再也没有必要去设置特定路由或者 iptables 的 SNAT 规则了。
---
via: <http://www.cyberciti.biz/faq/how-to-create-bridge-interface-ubuntu-linux/>
作者:[VIVEK GITE](https://twitter.com/nixcraft) 译者:[MikeCoder](https://github.com/MikeCoder) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,606 | 微软要干掉点对点 Skype,Linux 和 Mac 原生客户端将消亡 | http://www.theregister.co.uk/2016/07/21/cloud_upgrade_for_skype_will_kill_os_x_linux_clients/ | 2016-07-23T12:08:00 | [
"Skype"
] | https://linux.cn/article-7606-1.html | 前两天我们报道过,[微软为 Linux 带来了全新的 Skype 客户端](/article-7574-1.html),功能与 Windows 下的最新客户端保持看齐。但是,这个新的 Linux 客户端是基于 WebRTC 的,其事实上宣告了在 Linux 和 OS X 下的原生客户端的终结——虽然它们相对于 Windows 下的客户端比较老旧了,无论是界面和功能。
这是因为,Skype 整个重构了,用以云为中心的代码架构替代了之前的点对点架构。现在的 Windows、iOS、Android 和 Web 浏览器下的 Skype 客户端都已经是基于新的云架构,因此,这次发布的 Linux 客户端也采用了同样的架构。
微软并没有向 Mac 和 Linux 用户宣布原生客户端终结的日期,你现在仍然可以下载到这些应用。但是很显然,微软将不会再为这些臃肿的 OS X 和 Linux 原生客户端投入更多金钱和精力。

在 Skype 博客上的[一篇博文](http://blogs.skype.com/2016/07/20/skype-the-journey-weve-been-on/)中,微软提到了它将更关注于“核心平台”,换言之,就是“更新的发布、更轻、更快的在 Windows 10、iPhone、iPad 和 Android 下的应用。”Linux、OS X 下的客户端 (以及旧式 Windows 版本)最终将会被“基于 Web 的原生版本 Skype ”所取代,“得益于最新的 ORTC / WebRTC 技术”,它会运行在浏览器里。
发布于 2003 年的 Skype 原本由于其可以穿透防火墙的 VoIP 技术而得到了快速发展,从而先后被 eBay 和微软收购。然而当微软完成了向云迈进的转型之后,它就只剩下一个牌子和外壳了,它之前的点对点网络、各种特色的服务,终将消逝。
微软认为他们需要重构 Skype 以改进其通话品质:当语音数据传送到微软的云端时,他们可以对进出的数据进行处理,也就是说,可以控制语音质量。当然,用户的体验仍然与其带宽、ISP 等有关。那些特色服务也会有新的解决方案,现在已经是一个轻量、移动优先的时代了,这些功能都可以放到云端,而不是每个客户端里面。因此,微软可以向这些用户提供新的、增强的功能,比如更好的文件共享服务、视频通话、群聊、翻译以及机器人等等。
没有理由认为微软会取消 Skype 的加密通讯机制,但是离开了点对点模式,显然会增加用户在隐私方面的忧虑。
如今,其点对点 IM 使用的是 AES 256 加密,而通过云传输时则使用的是 TLS。当通话双方都是在网络上时,他们都是通过 TLS 传输的,而拨到电话时则仍旧采用 AES 256。
然而,并不清楚是否是端到端加密,由客户端之间进行加密协商,这一点上微软并没有给出明确的答案。如果加密只是在微软和客户端之间协商建立,用户肯定会面临着其传输的数据被协助司法调查。这一点不像 WhatsApp,微软将有能力做到监听。
| 301 | Moved Permanently | null |
7,608 | 共享的未来:Pydio 与 ownCloud 的联合 | https://opensource.com/business/16/5/sharing-files-pydio-owncloud | 2016-07-24T15:02:00 | [
"共享",
"联合共享",
"ownCloud",
"Pydio"
] | https://linux.cn/article-7608-1.html | 
*图片来源 : opensource.com*
开源共享生态圈内容纳了许多各异的项目,它们每一个都给出了自己的解决方案,且每一个都不按套路来。有很多原因导致你选择开源的解决方案,而非 Dropbox、Google Drive、iCloud 或 OneDrive 这些商业的解决方案。这些商业的解决方案虽然能让你不必为如何管理数据担心,但也理所应当的带着种种限制,其中就包括对于原有基础结构的控制和整合不足。
对于用户而言仍有相当一部分可供选择的文件分享和同步的替代品,其中就包括了 Pydio 和 ownCloud。
### Pydio
Pydio (<ruby> 把你的数据放上轨道 <rp> ( </rp> <rt> Put your data in orbit </rt> <rp> ) </rp></ruby>) 项目由一位作曲家 Charles du Jeu 发起,起初他只是需要一种与乐队成员分享大型音频文件的方法。[Pydio](https://pydio.com/) 是一种文件分享与同步的解决方案,综合了多存储后端,设计时还同时考虑了开发者和系统管理员两方面。在世界各地有逾百万的下载量,已被翻译成 27 种语言。

项目在刚开始的时候便开源了,先是在 [SourceForge](https://sourceforge.net/projects/ajaxplorer/) 上茁壮的成长,现在已在 [GitHub](https://github.com/pydio/) 上安了家。
用户界面基于 Google 的 [Material 设计风格](https://www.google.com/design/spec/material-design/introduction.html)。用户可以使用现有的传统文件基础结构或是根据预估的需求部署 Pydio,并通过 web、桌面和移动端应用随时随地地管理自己的东西。对于管理员来说,细粒度的访问权限绝对是配置访问时的利器。
在 [Pydio 社区](https://pydio.com/en/community),你可以找到许多让你增速的资源。Pydio 网站 [对于如何为 Pydio GitHub 仓库贡献](https://pydio.com/en/community/contribute) 给出了明确的指导方案。[论坛](https://pydio.com/forum/f)中也包含了开发者板块和社区。
### ownCloud
[ownCloud](https://owncloud.org/) 在世界各地拥有逾 8 百万的用户,它是一个开源、自行管理的文件同步共享技术。同步客户端支持所有主流平台并支持 WebDAV 通过 web 界面实现。ownCloud 拥有简单的使用界面,强大的管理工具,和大规模的共享及协作功能——以满足用户管理数据时的需求。

ownCloud 的开放式架构是通过 API 和为应用提供平台来实现可扩展性的。迄今已有逾 300 款应用,功能包括处理像日历、联系人、邮件、音乐、密码、笔记等诸多数据类型。ownCloud 由一个数百位贡献者的国际化的社区开发,安全,并且能做到为小到一个树莓派大到好几百万用户的 PB 级存储集群量身定制。
### <ruby> 联合共享 <rp> ( </rp> <rt> Federated sharing </rt> <rp> ) </rp></ruby>
文件共享开始转向团队合作时代,而标准化为合作提供了坚实的土壤。

<ruby> 联合共享 <rp> ( </rp> <rt> Federated sharing </rt> <rp> ) </rp></ruby>——一个由 [OpenCloudMesh](https://wiki.geant.org/display/OCM/Open+Cloud+Mesh) 项目提供的新的开放标准,就是在这个方向迈出的一步。先不说别的,在支持该标准的服务器之间分享文件和文件夹,比如说 Pydio 和 ownCloud。
ownCloud 7 率先引入该标准,这种服务器到服务器的分享方式可以让你挂载远程服务器上共享的文件,实际上就是创建你自己的云上之云。你可以直接为其它支持联合共享的服务器上的用户创建共享链接。
实现这个新的 API 允许存储解决方案之间更深层次的集成,同时保留了原有平台的安全,控制和特性。
“交换和共享文件是当下和未来不可或缺的东西。”ownCloud 的创始人 Frank Karlitschek 说道:“正因如此,采用联合和分布的方式而非集中的数据孤岛就显得至关重要。联合共享的设计初衷便是在保证安全和用户隐私的同时追求分享的无缝、至简之道。”
### 下一步是什么呢?
正如 OpenCloudMesh 做的那样,将会通过像 Pydio 和 ownCloud 这样的机构和公司,合作推广这一文件共享的新开放标准。ownCloud 9 已经引入联合的服务器之间交换用户列表的功能,让你的用户们在你的服务器上享有和你同样的无缝体验。将来,一个中央地址簿服务(联合的)集合,用以检索其他联合云 ID 的构想可能会把云间合作推向一个新的高度。
这一举措无疑有助于日益开放的技术社区中的那些成员方便地讨论,开发,并推动“OCM 分享 API”作为一个厂商中立协议。所有领导 OCM 项目的合作伙伴都全心致力于开放 API 的设计原则,并欢迎其他开源的文件分享和同步社区参与并加入其中。
---
via: <https://opensource.com/business/16/5/sharing-files-pydio-owncloud>
作者:[ben van 't ende](https://opensource.com/users/benvantende) 译者:[martin2011qi](https://github.com/martin2011qi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The open source file sharing ecosystem accommodates a large variety of projects, each supplying their own solution, and each with a different approach. There are a lot of reasons to choose an open source solution rather than commercial solutions like Dropbox, Google Drive, iCloud, or OneDrive. These solutions offer to take away worries about managing your data but come with certain limitations, including a lack of control and integration into existing infrastructure.
There are quite a few file sharing and sync alternatives available to users, including ownCloud and Pydio.
## Pydio
The Pydio (Put your data in orbit) project was founded by musician Charles du Jeu, who needed a way to share large audio files with his bandmates. [Pydio](https://pydio.com/) is a file sharing and sync solution, with multiple storage backends, designed with developers and system administrators in mind. It has over one million downloads worldwide and has been translated into 27 languages.
Open source from the very start, the project grew organically on [SourceForge](https://sourceforge.net/projects/ajaxplorer/) and now finds its home on [GitHub](https://github.com/pydio/).
The user interface is based on Google's [Material Design](https://www.google.com/design/spec/material-design/introduction.html). Users can use an existing legacy file infrastructure or set up Pydio with an on-premise approach, and use web, desktop, and mobile applications to manage their assets everywhere. For administrators, the fine-grained access rights are a powerful tool for configuring access to assets.
On the [Pydio community page](https://pydio.com/en/community), you will find several resources to get you up to speed quickly. The Pydio website gives some clear guidelines on [how to contribute](https://pydio.com/en/community/contribute) to the Pydio repositories on GitHub. The [forum](https://pydio.com/forum/f) includes sections for developers and community.
## ownCloud
[ownCloud](https://owncloud.org/) has over 8 million users worldwide and is an open source, self-hosted file sync and sharing technology. There are sync clients for all major platforms as well as WebDAV through a web interface. ownCloud has an easy to use interface, powerful administrator tools, and extensive sharing and collaboration features—designed to give users control over their data.
ownCloud's open architecture is extensible via an API and offers a platform for apps. Over 300 applications have been written, featuring capabilities like handling calendar, contacts, mail, music, passwords, notes, and many other types of data. ownCloud provides security, scales from a Raspberry Pi to a cluster with petabytes of storage and millions of users, and is developed by an international community of hundreds of contributors.
## Federated sharing
File sharing is starting to shift toward teamwork, and standardization provides a solid basis for such collaboration.
Federated sharing, a new open standard supported by the [OpenCloudMesh](https://wiki.geant.org/display/OCM/Open+Cloud+Mesh) project, is a step in that direction. Among other things, it allows for the sharing of files and folders between servers that support this, like Pydio and ownCloud instances.
First introduced in ownCloud 7, this server-to-server sharing allows you to mount file shares from remote servers, in effect creating your own cloud of clouds. You can create direct share links with users on other servers that support federated cloud sharing.
Implementing this new API allows for deeper integration between storage solutions while maintaining the security, control, and attributes of the original platforms.
"Exchanging and sharing files is something that is essential today and tomorrow," ownCloud founder Frank Karlitschek said. "Because of that, it is important to do this in a federated and distributed way without centralized data silos. The number one design goal [of federated sharing] is to enable sharing in the most seamless and easiest way while protecting the security and privacy of the users."
## What's next?
An initiative like OpenCloudMesh will extend this new open standard of file sharing through cooperation of institutions and companies like Pydio and ownCloud. ownCloud 9 has already introduced the ability for federated servers to exchange user lists, enabling the same seamless auto-complete experience you have with users on your own server. In the future, the idea of having a (federated!) set of central address book servers that can be used to search for others' federated cloud IDs might bring inter-cloud collaboration to an even higher level.
The initiative will undoubtedly contribute to already growing open technical community within which members can easily discuss, develop, and contribute to the "OCM sharing API" as a vendor-neutral protocol. All leading partners of the OCM project are fully committed to the open API design principle and welcome other open source file share and sync communities to participate and join the connected cloud.
## 2 Comments |
7,609 | awk 系列:如何使用 awk 的 ‘next’ 命令 | http://www.tecmint.com/use-next-command-with-awk-in-linux/ | 2016-07-24T18:26:53 | [
"awk"
] | https://linux.cn/article-7609-1.html | 
在 awk 系列的第六节,我们来看一下`next`命令 ,它告诉 awk 跳过你所提供的所有剩下的模式和表达式,直接处理下一个输入行。
`next` 命令帮助你阻止运行命令执行过程中多余的步骤。
要明白它是如何工作的, 让我们来分析一下 food\_list.txt 它看起来像这样:
```
Food List Items
No Item_Name Price Quantity
1 Mangoes $3.45 5
2 Apples $2.45 25
3 Pineapples $4.45 55
4 Tomatoes $3.45 25
5 Onions $1.45 15
6 Bananas $3.45 30
```
运行下面的命令,它将在每个食物数量小于或者等于 20 的行后面标一个星号:
```
# awk '$4 <= 20 { printf "%s\t%s\n", $0,"*" ; } $4 > 20 { print $0 ;} ' food_list.txt
No Item_Name Price Quantity
1 Mangoes $3.45 5 *
2 Apples $2.45 25
3 Pineapples $4.45 55
4 Tomatoes $3.45 25
5 Onions $1.45 15 *
6 Bananas $3.45 30
```
上面的命令实际运行如下:
* 首先,它用`$4 <= 20`表达式检查每个输入行的第四列(数量(Quantity))是否小于或者等于 20,如果满足条件,它将在末尾打一个星号 `(*)`。
* 接着,它用`$4 > 20`表达式检查每个输入行的第四列是否大于20,如果满足条件,显示出来。
但是这里有一个问题, 当第一个表达式用`{ printf "%s\t%s\n", $0,"**" ; }`命令进行标注的时候在同样的步骤第二个表达式也进行了判断这样就浪费了时间.
因此当我们已经用第一个表达式打印标志行的时候就不再需要用第二个表达式`$4 > 20`再次打印。
要处理这个问题, 我们需要用到`next` 命令:
```
# awk '$4 <= 20 { printf "%s\t%s\n", $0,"*" ; next; } $4 > 20 { print $0 ;} ' food_list.txt
No Item_Name Price Quantity
1 Mangoes $3.45 5 *
2 Apples $2.45 25
3 Pineapples $4.45 55
4 Tomatoes $3.45 25
5 Onions $1.45 15 *
6 Bananas $3.45 30
```
当输入行用`$4 <= 20` `{ printf "%s\t%s\n", $0,"*" ; next ; }`命令打印以后,`next`命令将跳过第二个`$4 > 20` `{ print $0 ;}`表达式,继续判断下一个输入行,而不是浪费时间继续判断一下是不是当前输入行还大于 20。
`next`命令在编写高效的命令脚本时候是非常重要的,它可以提高脚本速度。本系列的下一部分我们将来学习如何使用 awk 来处理标准输入(STDIN)。
希望这篇文章对你有帮助,你可以给我们留言。
---
via: <http://www.tecmint.com/use-next-command-with-awk-in-linux/>
作者:[Aaron Kili](http://www.tecmint.com/author/aaronkili/) 译者:[kokialoves](https://github.com/kokialoves) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,610 | awk 系列:awk 怎么读取标准输入(STDIN) | http://www.tecmint.com/read-awk-input-from-stdin-in-linux/ | 2016-07-25T10:28:00 | [
"awk"
] | https://linux.cn/article-7610-1.html | 
在 awk 系列的前几节,我们看到大多数操作都是从一个文件或多个文件读取输入,或者你想要把标准输入作为 awk 的输入。
在 awk 系列的第七节中,我们将会看到几个例子,你可以筛选其他命令的输出代替从一个文件读取输入作为 awk 的输入。
我们首先从使用 [dir 命令](http://www.tecmint.com/linux-dir-command-usage-with-examples/)开始,它类似于 [ls 命令](http://www.tecmint.com/15-basic-ls-command-examples-in-linux/),在第一个例子下面,我们使用 `dir -l` 命令的输出作为 awk 命令的输入,这样就可以打印出文件拥有者的用户名,所属组组名以及在当前路径下他/她拥有的文件。
```
# dir -l | awk '{print $3, $4, $9;}'
```

*列出当前路径下的用户文件*
再来看另一个例子,我们[使用 awk 表达式](/article-7599-1.html) ,在这里,我们想要在 awk 命令里使用一个表达式筛选出字符串来打印出属于 root 用户的文件。命令如下:
```
# dir -l | awk '$3=="root" {print $1,$3,$4, $9;} '
```

*列出 root 用户的文件*
上面的命令包含了 `(==)` 来进行比较操作,这帮助我们在当前路径下筛选出 root 用户的文件。这是通过使用 `$3=="root"` 表达式实现的。
让我们再看另一个例子,我们使用一个 [awk 比较运算符](/article-7602-1.html) 来匹配一个确定的字符串。
这里,我们使用了 [cat 命令](http://www.tecmint.com/13-basic-cat-command-examples-in-linux/) 来浏览文件名为 tecmint\_deals.txt 的文件内容,并且我们想要仅仅查看有字符串 Tech 的部分,所以我们会运行下列命令:
```
# cat tecmint_deals.txt
# cat tecmint_deals.txt | awk '$4 ~ /tech/{print}'
# cat tecmint_deals.txt | awk '$4 ~ /Tech/{print}'
```

*用 Awk 比较运算符匹配字符串*
在上面的例子中,我们已经用了参数为 `~ /匹配字符/` 的比较操作,但是上面的两个命令给我们展示了一些很重要的问题。
当你运行带有 tech 字符串的命令时终端没有输出,因为在文件中没有 tech 这种字符串,但是运行带有 Tech 字符串的命令,你却会得到包含 Tech 的输出。
所以你应该在进行这种比较操作的时候时刻注意这种问题,正如我们在上面看到的那样,awk 对大小写很敏感。
你总是可以使用另一个命令的输出作为 awk 命令的输入来代替从一个文件中读取输入,这就像我们在上面看到的那样简单。
希望这些例子足够简单到可以使你理解 awk 的用法,如果你有任何问题,你可以在下面的评论区提问,记得查看 awk 系列接下来的章节内容,我们将关注 awk 的一些功能,比如变量,数字表达式以及赋值运算符。
---
via: <http://www.tecmint.com/read-awk-input-from-stdin-in-linux/>
作者:[Aaron Kili](http://www.tecmint.com/author/aaronkili/) 译者:[vim-kakali](https://github.com/vim-kakali) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,611 | Terminix:一个很赞的基于 GTK3 的平铺式 Linux 终端模拟器 | http://www.tecmint.com/terminix-tiling-terminal-emulator-for-linux/ | 2016-07-24T19:02:49 | [
"Terminix",
"终端"
] | https://linux.cn/article-7611-1.html | 现在,你可以很容易的找到[大量的 Linux 终端模拟器](http://www.tecmint.com/linux-terminal-emulators/),每一个都可以给用户留下深刻的印象。
但是,很多时候,我们会很难根据我们的喜好来找到一款心仪的日常使用的终端模拟器。这篇文章中,我们将会推荐一款叫做 Terminix 的令人激动的终端模拟机。

*Terminix Linux 终端模拟器*
Terminix 是一个使用 VTE GTK+ 3 组件的平铺式终端模拟器。使用 GTK 3 开发的原因主要是为了符合 GNOME HIG(<ruby> 人机接口 <rp> ( </rp> <rt> Human Interface Guidelines </rt> <rp> ) </rp></ruby>) 标准。另外,Terminix 已经在 GNOME 和 Unity 桌面环境下测试过了,也有用户在其他的 Linux 桌面环境下测试成功。
和其他的终端模拟器一样,Terminix 有着很多知名的特征,列表如下:
* 允许用户进行任意的垂直或者水平分屏
* 支持拖拽功能来进行重新排布终端
* 支持使用拖拽的方式终端从窗口中将脱离出来
* 支持终端之间的输入同步,因此,可以在一个终端输入命令,而在另一个终端同步复现
* 终端的分组配置可以保存在硬盘,并再次加载
* 支持透明背景
* 允许使用背景图片
* 基于主机和目录来自动切换配置
* 支持进程完成的通知信息
* 配色方案采用文件存储,同时支持自定义配色方案
### 如何在 Linux 系统上安装 Terminix
现在来详细说明一下在不同的 Linux 发行版本上安装 Terminix 的步骤。首先,在此列出 Terminix 在 Linux 所需要的环境需求。
#### 依赖组件
为了正常运行,该应用需要使用如下库:
* GTK 3.14 或者以上版本
* GTK VTE 0.42 或者以上版本
* Dconf
* GSettings
* Nautilus 的 iNautilus-Python 插件
如果你已经满足了如上的系统要求,接下来就是安装 Terminix 的步骤。
#### 在 RHEL/CentOS 7 或者 Fedora 22-24 上
首先,你需要通过新建文件 `/etc/yum.repos.d/terminix.repo` 来增加软件仓库,使用你最喜欢的文本编辑器来进行编辑:
```
# vi /etc/yum.repos.d/terminix.repo
```
然后拷贝如下的文字到我们刚新建的文件中:
```
[heikoada-terminix]
name=Copr repo for terminix owned by heikoada
baseurl=https://copr-be.cloud.fedoraproject.org/results/heikoada/terminix/fedora-$releasever-$basearch/
skip_if_unavailable=True
gpgcheck=1
gpgkey=https://copr-be.cloud.fedoraproject.org/results/heikoada/terminix/pubkey.gpg
enabled=1
enabled_metadata=1
```
保存文件并退出。
然后更新你的系统,并且安装 Terminix,步骤如下:
```
---------------- On RHEL/CentOS 7 ----------------
# yum update
# yum install terminix
---------------- On Fedora 22-24 ----------------
# dnf update
# dnf install terminix
```
#### 在 Ubuntu 16.04-14.04 和 Linux Mint 18-17
虽然没有基于 Debian/Ubuntu 发行版本的官方的软件包,但是你依旧可以通过如下的命令手动安装。
```
$ wget -c https://github.com/gnunn1/terminix/releases/download/1.1.1/terminix.zip
$ sudo unzip terminix.zip -d /
$ sudo glib-compile-schemas /usr/share/glib-2.0/schemas/
```
#### 其它 Linux 发行版
OpenSUSE 用户可以从默认仓库中安装 Terminix,Arch Linux 用户也可以安装 [AUR Terminix 软件包](https://aur.archlinux.org/packages/terminix)。
### Terminix 截图教程

*Terminix 终端*

*Terminix 终端设置*

*Terminix 多终端界面*
### 如何卸载删除 Terminix
如果你是手动安装的 Terminix 并且想要删除它,那么你可以参照如下的步骤来卸载它。从 [Github 仓库](https://github.com/gnunn1/terminix)上下载 uninstall.sh,并且给它可执行权限并且执行它:
```
$ wget -c https://github.com/gnunn1/terminix/blob/master/uninstall.sh
$ chmod +x uninstall.sh
$ sudo sh uninstall.sh
```
但是如果你是通过包管理器安装的 Terminix,你可以使用包管理器来卸载它。
在这篇介绍中,我们在众多优秀的终端模拟器中发现了一个重要的 Linux 终端模拟器。你可以尝试着去体验下它的新特性,并且可以将它和你现在使用的终端进行比较。
重要的一点,如果你想得到更多信息或者有疑问,请使用评论区,而且不要忘了,给我一个关于你使用体验的反馈。
---
via: <http://www.tecmint.com/terminix-tiling-terminal-emulator-for-linux/>
作者:[Aaron Kili](http://www.tecmint.com/author/aaronkili/) 译者:[MikeCoder](https://github.com/MikeCoder) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,612 | LFCS 系列第十二讲:如何使用 Linux 的帮助文档和工具 | http://www.tecmint.com/explore-linux-installed-help-documentation-and-tools/ | 2016-07-25T09:55:38 | [
"LFCS"
] | https://linux.cn/article-7612-1.html | 由于 2016 年 2 月 2 号开始启用了新的 LFCS 考试要求, 我们在 [LFCS 系列](/article-7161-1.html)系列添加了一些必要的内容。为了考试的需要,我们强烈建议你看一下[LFCE 系列](http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/)。

*LFCS: 了解 Linux 的帮助文档和工具*
当你习惯了在命令行下进行工作,你会发现 Linux 已经有了许多使用和配置 Linux 系统所需要的文档。
另一个你必须熟悉命令行帮助工具的理由是,在[LFCS](/article-7161-1.html) 和 [LFCE](http://www.tecmint.com/installing-network-services-and-configuring-services-at-system-boot/) 考试中,它们是你唯一能够使用的信息来源,没有互联网也没有百度。你只能依靠你自己和命令行。
基于上面的理由,在这一章里我们将给你一些建议来可以让你有效的使用这些安装的文档和工具,以帮助你通过**Linux 基金会认证**考试。
### Linux <ruby> 帮助手册 <rp> ( </rp> <rt> man </rt> <rp> ) </rp></ruby>
man 手册是 manual 手册的缩写,就是其名字所揭示的那样:一个给定工具的帮助手册。它包含了命令所支持的选项列表(以及解释),有些工具甚至还提供一些使用范例。
我们用 **man 命令** 跟上你想要了解的工具名称来打开一个帮助手册。例如:
```
# man diff
```
这将打开`diff`的手册页,这个工具将逐行对比文本文件(如你想退出只需要轻轻的点一下 q 键)。
下面我来比较两个文本文件 `file1` 和 `file2`。这两个文本文件包含了使用同一个 Linux 发行版相同版本安装的两台机器上的的安装包列表。
输入`diff` 命令它将告诉我们 `file1` 和`file2` 有什么不同:
```
# diff file1 file2
```

*在Linux中比较两个文本文件*
`<` 这个符号是说`file2`缺失的行。如果是 `file1`缺失,我们将用 `>` 符号来替代指示。
另外,**7d6** 意思是说`file1`的第**7**行要删除了才能和`file2`一致(**24d22** 和 **41d38** 也是同样的意思) **65,67d61** 告诉需要删除从第 **65** 行到 **67** 行。我们完成了以上步骤,那么这两个文件将完全一致。
此外,根据 man 手册说明,你还可以通过 `-y` 选项来以两路的方式显示文件。你可以发现这对于你找到两个文件间的不同根据方便容易。
```
# diff -y file1 file2
```

*比较并列出两个文件的不同*
此外,你也可以用`diff`来比较两个二进制文件。如果它们完全一样,`diff` 将什么也不会输出。否则,它将会返回如下信息:“**Binary files X and Y differ**”。
### –help 选项
`--help`选项,大多数命令都支持它(并不是所有), 它可以理解为一个命令的简短帮助手册。尽管它没有提供工具的详细介绍,但是确实是一个能够快速列出程序的所支持的选项的不错的方法。
例如,
```
# sed --help
```
将显示 sed (流编辑器)的每个支持的选项。
`sed`命令的一个典型用法是替换文件中的字符。用 `-i` 选项(意思是 “**原地编辑编辑文件**”),你可以编辑一个文件而且并不需要打开它。 如果你想要同时备份一个原始文件,用 `-i` 选项加后缀来创建一个原始文件的副本。
例如,替换 `lorem.txt` 中的`Lorem` 为 `Tecmint`(忽略大小写),并且创建一个原文件的备份副本,命令如下:
```
# less lorem.txt | grep -i lorem
# sed -i.orig 's/Lorem/Tecmint/gI' lorem.txt
# less lorem.txt | grep -i lorem
# less lorem.txt.orig | grep -i lorem
```
请注意`lorem.txt`文件中`Lorem` 都已经替换为 `Tecmint`,并且原文件 `lorem.txt` 被保存为`lorem.txt.orig`。

*替换文件中的文本*
### /usr/share/doc 内的文档
这可能是我最喜欢的方法。如果你进入 `/usr/share/doc` 目录,并列出该目录,你可以看到许多以安装在你的 Linux 上的工具为名称的文件夹。
根据 [文件系统层级标准](/article-6132-1.html),这些文件夹包含了许多帮助手册没有的信息,还有一些可以使配置更方便的模板和配置文件。
例如,让我们来看一下 `squid-3.3.8` (不同发行版的版本可能会不同),这还是一个非常受欢迎的 HTTP 代理和 [squid 缓存服务器](http://www.tecmint.com/configure-squid-server-in-linux/)。
让我们用`cd`命令进入目录:
```
# cd /usr/share/doc/squid-3.3.8
```
列出当前文件夹列表:
```
# ls
```

*使用 ls 列出目录*
你应该特别注意 `QUICKSTART` 和 `squid.conf.documented`。这些文件分别包含了 Squid 详细文档及其经过详细备注的配置文件。对于别的安装包来说,具体的名字可能不同(有可能是 **QuickRef** 或者**00QUICKSTART**),但意思是一样的。
对于另外一些安装包,比如 Apache web 服务器,在`/usr/share/doc`目录提供了配置模板,当你配置独立服务器或者虚拟主机的时候会非常有用。
### GNU 信息文档
你可以把它看做帮助手册的“开挂版”。它不仅仅提供工具的帮助信息,而且还是超级链接的形式(没错,在命令行中的超级链接),你可以通过箭头按钮从一个章节导航到另外章节,并按下回车按钮来确认。
一个典型的例子是:
```
# info coreutils
```
因为 coreutils 包含了每个系统中都有的基本文件、shell 和文本处理工具,你自然可以从 coreutils 的 info 文档中得到它们的详细介绍。

*Info Coreutils*
和帮助手册一样,你可以按 q 键退出。
此外,GNU info 还可以显示标准的帮助手册。 例如:
```
# info tune2fs
```
它将显示 **tune2fs**的帮助手册, 这是一个 ext2/3/4 文件系统管理工具。
我们现在看到了,让我们来试试怎么用**tune2fs**:
显示 **/dev/mapper/vg00-vol\_backups** 文件系统信息:
```
# tune2fs -l /dev/mapper/vg00-vol_backups
```
修改文件系统标签(修改为 Backups):
```
# tune2fs -L Backups /dev/mapper/vg00-vol_backups
```
设置文件系统的自检间隔及挂载计数(用`-c` 选项设置挂载计数间隔, 用 `-i` 选项设置自检时间间隔,这里 **d 表示天,w 表示周,m 表示月**)。
```
# tune2fs -c 150 /dev/mapper/vg00-vol_backups # 每 150 次挂载检查一次
# tune2fs -i 6w /dev/mapper/vg00-vol_backups # 每 6 周检查一次
```
以上这些内容也可以通过 `--help` 选项找到,或者查看帮助手册。
### 摘要
不管你选择哪种方法,知道并且会使用它们在考试中对你是非常有用的。你知道其它的一些方法吗? 欢迎给我们留言。
---
via: <http://www.tecmint.com/explore-linux-installed-help-documentation-and-tools/>
作者:[Gabriel Cánepa](http://www.tecmint.com/author/gacanepa/) 译者:[kokialoves](https://github.com/kokialoves) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,613 | 玩转 Windows 10 中的 Linux 子系统 | https://blogs.windows.com/buildingapps/2016/07/22/fun-with-the-windows-subsystem-for-linux/ | 2016-07-25T14:08:00 | [
"WSL"
] | https://linux.cn/article-7613-1.html | 在今年的 Build 2016 上,微软向全世界[介绍了](/article-7177-1.html)他们还处于 Beta 阶段的 <ruby> Windows 下的 Linux 子系统 <rp> ( </rp> <rt> Windows Subsystem for Linux </rt> <rp> ) </rp></ruby>(WSL),它可以让开发者们在 Windows 10 下通过 Bash shell 运行原生的 Ubuntu 用户态二进制程序。如果你参与了 Windows Insider 计划,你就可以在最新的 Windows 10 年度升级版的 Insider 构建版中体验这个功能了。
Web 开发人员们不用再苦恼所用的 Windows 开发平台上没有合适的 Linux 工具和库了。WSL 是由 Windows 内核团队与 Canonical 合作设计和开发的,可以让 Windows 10 下的开发者们在拥有 Windows 中那些强力支持之外,还能使用 Linux 下丰富的开发环境与工具,而不用启动到另外的操作系统或者使用虚拟机。这绝对是一个“来自开发者,服务开发者”的 Windows 10 特色,它的目的是让开发者们每天的开发工作都变得顺畅而便捷。

在本文中,我会展示给你一些我认为非常有趣的功能,以及告诉你一些可以让你找到更多信息的资源。首先,我会展示 WSL 所集成的那些主要命令(比如 ssh)是如何操作服务器和设备的。其次,我会演示使用 Bash 脚本是如何以简明的方式来自动化执行任务的。其三,我会利用极棒的命令行编译器、一些其它工具以及对 \*nix 兼容的能力来玩一个轻量级的古典黑客级游戏: NetHack。最后,我会展示如何使用已有的 Python 脚本和其它来自网上的脚本。
>
> 从我的第一台 286 上运行的 Windows 3.0 开始,Windows 就一直是我的主要操作系统和开发环境。不过,我身边也有很多 Linux 服务器和设备。从树莓派和路由器/网关设备这样的物联网设备,到 Minecraft 服务器,它们堆满了我的办公室的每个角落。而我经常要从我的主工作站中去管理和配置这些 Linux 计算机。
>
>
>
### 管理服务器和设备
我在我的家中运行着一台无显示器的 Ubuntu Minecraft 服务器,这是我去年给我十岁大的儿子的圣诞礼物,但是它已经变成了我的玩具而不是他的(好吧,主要是我的玩具)。我以前在我的 Windows 10 电脑上使用几个客户端来管理它,不过我现在想使用 Windows 中的 Bash 里面的 ssh 命令行来管理它。使用类似 PuTTY 或来自 Cygwin 的 Tera Term 这样的应用当然也可以,但是我想试试真正原生而自然的体验也是一种不错的选择。Cygwin 就像是在披萨店订购的披萨一样,好吃,但是没有那种氛围。
我已经使用 WSL 中的 `ssh-keygen` 和 `ssh-copy-id` 设置好了公私密钥对,所以使用 ssh 只需要如下简单输入即可:
```
$ ssh <username>@<server>
```
我还为此创建了一个别名,以便更快一些。这是一个标准的 Linux/Bash 功能:
```
$ alias mc='ssh <user>@<server>'
```
现在,我要访问我的 Minecraft 服务器只需要在 Windows 10 下的 Bash 中输入“mc”即可。

当然,同样的方法你也可以用于任何 Linux 上的 Web 或数据库服务器上,甚至树莓派或其它的物联网设备也可以。
>
> 在终端里面进行 ssh 只是为了方便而已,不过当你在 shell 中工作时,如果还有类似 apt、node、Ruby、Python 等等工具时,你就有了自动化各种工作的可能。
>
>
>
### 远程脚本
假如说你有一大堆 Linux 服务器和设备,而你要在它们上面执行一个远程命令的话,如果已经配置好公私密钥对,你就可以在 Bash 中直接远程执行命令。
举个例子说,想知道远程服务器自从上次重启后已经运行了多长时间了,你只需要输入:
```
$ ssh <user>@<server> 'last -x|grep reboot'
```
ssh 会连接到该服务器并执行 `last -x` 命令,然后搜索包含“reboot”的一行。我在我的 Ubuntu Minecraft 服务器上运行的结果如下:
```
reboot system boot 4.4.0-28-generic Thu Jul 7 08:14 still running
```
这只是一台服务器,如果你有许多服务器的话,你可以自动化这个过程。我在 WSL 里我的主目录下创建了一个名为 servers.txt 的文件,它包含了一系列 Linux 服务器/设备的名称,每个一行。然后我就可以创建一个脚本来读取这个文件。
在使用了很多年像树莓派这样的设备之后,我已经变成了一个 nano 人(在 VMS 上我是一个 LSEdit 人),下面是我用我喜爱的 nano 编辑器打开的脚本。

当然,你也可以使用 vim 、 emacs 或者其它可以用在 Ubuntu 终端上的编辑器。
该脚本是 Bash 脚本,要执行该脚本,输入:
```
$ ./foreachserver.sh 'last -x|grep reboot'
```
它将迭代输出文件中的每个服务器/设备,然后通过 ssh 远程执行该命令。当然,这个例子非常简单,但是你可以像这样把你的本地脚本或其它命令变成远程的。Bash 脚本语言足够丰富,所以你可以使用它来完成你的大多数远程管理任务。你可以用你下载到 WSL 或远程系统中的其它应用来扩展它的使用。
>
> 你是否需要在工作中把本地的 Windows 文件或资源用于其它的 Linux 计算机吗?或者,你根本不使用 Linux ?Bash 可以操作本地的 Windows 文件或资源,还是说它就是一个完全独立的环境?
>
>
>
### 使用 Windows 文件
WSL 系统可以通过 `/mnt/<盘号>/` 目录(挂载点)来访问你计算机上的文件系统。举个例子,你的 Windows 上的 C:\ 和 D:\ 根目录可以在 WSL 中相应地通过 /mnt/c 和 /mnt/d 访问。当你要把你的 Windows 下的项目文件、下载的内容和其它文件用到 Linux/Bash 之中时这很有用。

上图显示的两个目录分别对应于我的计算机上的 SSD 和硬盘:

这是逻辑挂载,所以当你在 shell 中使用类似 `mount` 这样的命令时它们不会显示。但是它们可以如你预期的那样工作。举个例子,在 Windows 中,我在我的 C 盘根目录下放了一个名为 test.txt 的文件,我可以在 WSL 中如下访问它:

在 Build Tour 大会期间,我们要确保所有的演示都可以在没有互联网时也能正常工作(你绝不会知道会场的网络是什么样子的) ,所以为了让 Bash/WSL 可以演示 Git 操作,该演示访问的是本地计算机上的 Windows 文件,我在 Windows 上的 C:\git\NetHack 下设置一个本地仓库。 要在 WSL 中进行 clone 操作,我执行了如下命令:
```
$ git –clone file:///mnt/c/git/NetHack
```
该命令告诉 git 使用 `file://` 协议,并 clone 了位于 /mnt/c/git/NetHack 下的仓库。你可以以类似的方式来访问你的 Windows 下的所有文件。
警示:就像在其它终端中一样,如果你不小心的话,你可以在 Bash 中修改/删除 Windows 文件系统中的文件。举个例子,你可以像下面这样来干掉你的 Windows ,假如你有合适的权限的话。
```
$ rm -rf /mnt/c/ [千万别试!][千万别试!][千万别试!]
```
我之所以郑重提醒是因为我们很多人都是刚刚接触 Linux 命令,它们不是 Windows 命令。
这种可以让文件系统集成到一起的魔法来自 DrvFs。如果你希望了解该文件系统的更多细节,以及它是如何工作在 WSL 中的,WSL 团队为此写了一篇[详细的文章](https://blogs.msdn.microsoft.com/wsl/2016/06/15/wsl-file-system-support/)。
>
> 当然, 文件系统访问只是 WSL 其中的一部分功能而已,许多开发任务还需要通过 HTTP 或其它网络协议访问远程资源。
>
>
>
### 发起 HTTP 请求
从脚本或命令行而不是从一个编译好的程序或 Web 页面上发起 REST 或其它 HTTP(或 FTP)请求是很有用的。就像在大多数 Linux 发行版一样,WSL 也包括了类似 curl 或 wget 获取资源这样的标准功能,它们可以用来发起 HTTP 或者其它网络请求。举个例子,下面是使用 curl 对 Github 发起 REST 请求来获取我个人的属性信息:
```
$ curl -i https://api.github.com/users/Psychlist1972
HTTP/1.1 200 OK
Server: GitHub.com
Date: Wed, 13 Jul 2016 02:38:08 GMT
Content-Type: application/json; charset=utf-8
Content-Length: 1319
Status: 200 OK
...
{
"login": "Psychlist1972",
"avatar_url": "https://avatars.githubusercontent.com/u/1421146?v=3",
"url": "https://api.github.com/users/Psychlist1972",
"name": "Pete Brown",
"company": "Microsoft",
...
}
$
```
你可以用它和 Bash 脚本来创建一个 REST API 的快速测试客户端,也可以用来探测一个 Web 页面或服务器并报告其返回的状态。它用来从网上下载文件也很棒,你可以简单地重定向输出到一个文件而不是在屏幕上显示它:
```
$ curl -i https://api.github.com/users/Psychlist1972 > pete.json
```
我也是一个 PowerShell 用户,甚至还使用 [Windows 10 MIDI in PowerShell](https://github.com/Psychlist1972/Windows-10-PowerShell-MIDI) 创建了一些有趣的扩展,也[修复](https://github.com/Psychlist1972/Fix-SoundDevices-File-Corruption)过出现在特定的录音硬件设备上的一些文件问题。作为长时间的 .NET 开发者和爱好者,我经常使用和扩展 PowerShell 以满足我的项目需求。但是 PowerShell 并不是一个可以运行所有的那些 Bash 脚本和针对 Linux 的开源工具的地方。我希望以一种最简单、最舒服的方式来完成这些任务,在某种意义上,这意味着我们需要在 Bash 中完成它们。
>
> 我已经一掠而过的介绍了 Bash、Bash 脚本以及你可以在 shell 中完成的任务。到目前为止,我谈论的都是有助于开发工作的那些功能。但是在 WSL 中实际的开发和编译工作是怎样的?我在 Build Tour 大会上演示了下面这个部分。
>
>
>
### Build Tour 大会上的演示:NetHack
这个夏初,来自微软的讲演者们向大家演示了一些来自 Windows 和微软云上的很酷的开发者新功能。作为其中的一部分,我以一种好玩的方式来演示了 WSL,而且这是一种和开发者们相关的方式。
我个人想要展示使用 git 和一些传统的终端开发工具,我已经写好了 Bash 的演示程序,包括了这些基础的东西(用 Python 和 Ruby 写的“Hello World”),不过我还是想要更有冲击力一些。
我回想起我在大学的时光,那时我们在 Unix(DEC Ultrix 及 SunOS)和 VAX/VMS 之间折腾,Unix 几乎全是命令行环境。在我们学校,绝大多数使用图形工作站的用户只是为了在不同的窗口打开多个终端会话而已,当然,会在桌面背景放上一张超酷的月相图。大部分学生都是使用 VT-220 终端来打开他们的会话(学校离波士顿不远,所以我们有很多 DEC 设备)。
那时,计算机系的学生们主要玩两大游戏:MUD (主要是 lpMUD 和当时刚出的 DikuMUD)和 [NetHack](https://en.wikipedia.org/wiki/NetHack)。NetHack 和其它的 [Roguelikes](https://en.wikipedia.org/wiki/Roguelike) 类游戏被视为历史上最有影响力的游戏之一,它们是许多现在流行的地牢冒险和角色扮演类游戏的鼻祖。
NetHack 有很长的历史,现在的它包含了来自几十年前的几十万行 \*nix 代码,以及后来补充的一些代码。该游戏使用 [curses](https://en.wikipedia.org/wiki/Curses_(programming_library)) (及其替代品)作为终端交互方式,需要通过 lex、 yacc(或 flex 和 bison)和 cc(或 gcc),以及一堆其它的开发工具构建。
它是由 C 语言编写的,并包括了一些用 [Bourne shell](https://en.wikipedia.org/wiki/Bourne_shell) 编写的复杂的脚本配置功能。我觉得它是一个体现 WSL 和 Bash on Windows 10 的开发者能力的不错而有趣的方式。由于使用了 curses(在 Linux 和 WSL 中是 libncurses 库),它也可以用来展示 Windows 10 中命令行窗口中的终端模拟能力。
以前,在我们的分时 Ultrix 服务器上从源代码构建 NetHack 要花费掉我们很多时间,而现在我的个人计算机上只需要几分钟就可以搞定。我喜欢这种技术进步。在 Linux 或 WSL 上配置和编译 NetHack 有容易和复杂两种方式。为了节省时间,我们会以容易的方式来进行。
#### 前置需求
首先,更新你的 WSL 环境,确保你的软件是最新的。在安装新的软件包之前,这是一个好的做法。
```
$ sudo apt update
$ sudo apt upgrade
```
然后,安装必须的开发工具。最简单的办法就是使用 build-essential 软件包,它包括了 Linux 开发者构建以 C/C++ 开发的软件时所需的绝大部分程序。
```
$ sudo apt install build-essential
```
这要花几分钟。如果你想更加深入地了解,你可以分别安装 gcc、gdb、make、flex、bison 以及 NetHack 文档中提到的其它工具。不过如果你是一位开发者,有时候你可能还需要一些其它工具。 build-essential 基本上提供了你所需的工具集。
然后,安装 git。如你所想,很容易:
```
$ sudo apt install git
```
就像在 Linux 中一样,你可以添加一个 git 的 PPA 来获取较新的版本,不过这里我们有一个就行了。
最后,我们需要安装 curses(实际上是 ncurses)来进行终端屏幕交互。
```
$ sudo apt install libncurses-dev
```
当我们完成这些步骤之后,就可以开始构建 NetHack 了。
#### 构建 NetHack
官方的 NetHack 仓库放在 [GitHub](https://github.com/NetHack/NetHack) 上,首先我们需要把它抓取下来放到我们的主目录里面。
```
$ cd ~$ git clone http://github.com/NetHack/NetHack
```

因为 NetHack 支持很多种操作系统,所以我们需要做一些基础配置来告诉它我们使用的是 Linux,并且用开源的 gcc 代替了了 Unix 上 cc 的作用。
如我所提到的,这有好几种办法可以实现。有些人想很周到,将这些配置信息放到了 hints 文件中。相信我,使用 hints 文件会避免遇到该 GitHub 仓库中提到的很多麻烦。在 README 文件和其它文档中并没有着重提到如何使用 hints 文件,我们可以这样做:
```
$ cd NetHack/sys/unix
$ ./setup.sh hints/linux
```
这将会设置 Makefile 正确的使用 Linux 下的工具、库及其路径。这个设置脚本很强大,它做了大量的配置工作,很高兴它在 WSL 中工作的也很好。如果你很好奇这个脚本是如何写的,你可以使用你的编辑器打开它一窥究竟。
然后,开始最终的构建:
```
$ cd ~/NetHack
$ make all
```
构建完成之后,你需要安装它。这其实就是将可执行文件复制到目标位置:
```
$ make install
```
它会安装到你的 ~/nh 文件夹下, NetHack 放在 ~/nh/install/games 目录,名为 nethack。要运行它,切换到该目录(或输入完整路径)并输入:
```
$ cd ~/nh/install/games
$ nethack
```
然后,屏幕会清屏并显示你可以玩 NetHack 了。注意,所有的东西都是在这个 Ubuntu Linux 环境中完成的,根本不需要任何 Windows 特有的东西。
#### 玩 NetHack
由于终端游戏的局限性和 NetHack 的复杂性,这里只能一带而过。对于初次接触它的人来说,还有一些神秘的地方,不过我觉得我们程序员们从来不怕挑战未知。
方向键和 vi(vim)中的一样,HJKL 是左、下、上、右。要退出游戏,你可以在地下城顶层找到楼梯出口然后使用它就可以,或者直接按下 CTRL-C 强制退出。
在 NetHack 中, @ 符号代表你自己,每一层都由房间、走廊、门,和向上及向下的楼梯组成。[怪物](https://nethackwiki.com/wiki/Monster)、[宝箱和物品](https://nethackwiki.com/wiki/Item)以各种 ASCII 字符组成,你慢慢就会熟悉它们。为了符合 Roguelikes 游戏规范,并没有存盘功能,你只有一条命。如果你死了就只能重玩,地下城环境是随机生成的,各种物品也是打乱放置的。
NetHack 游戏的目的是在地下城生存,收集金子和物品,尽可能的干掉各种怪物。除了这些目的之外,你就是不断在其中玩来找它们。规则大致遵循“龙与地下城(DnD)”的武器、技能等规则。
下面的 NetHack 截屏上可以看到有三个房间和两个走廊。向上的楼梯在左上角的房间里,我现在在右上角的房间,还有一些宝箱和其它物品。

如果在你的游戏中没有显示颜色,可以创建一个名为 ~/.nethackrc 的文件,并放入如下内容:
```
OPTIONS=color:true,dark_room:true,menucolors:true
```
注:如果 ASCII 字符图形不是你的菜,但是你喜欢这种类型的游戏,你可以在微软商店搜索“roguelike”来找到视觉上更好看的这种游戏。
当然,NetHack 很古老了,可能只有特定年龄段的人们喜欢它。不过,构建它用到了大量重要的开发工具和 \*nix 操作系统功能,也包括终端模拟功能。从这里可以看到,从 gcc、gdb、make、bison 和 flex 到更现代一些的 git,都在 WSL 里面工作的很好。
如果你想看看 Build Tour 大会上的演示,你可以在 Build Tour 加拿大大会上看到这个讲演。WSL 的这部分演示在 6:20 开始。
希望你能喜欢在 NetHack 地下城中的探险。
>
> C 和 C++ 都很伟大,就像其他的那些经典的开发工具一样。你甚至还可以用普通的 Bash 脚本做到很多。不过,也有很多开发者喜欢用 Python 做为他们的脚本语言。
>
>
>
### Python
你可以在网上找到很多 Python 脚本的例子,这意味着 Python 越来越流行,也越来越有用了。当然,大多数情况下这些例子都是运行在 Linux 下的。在过去,这就需要我们有另外一台安装着 Linux 的机器来运行它们,或者使用虚拟机和多引导,否则就需要修改一些东西才能让他们运行在 Windows 下的 Python 环境中。
这是都不是无法解决的问题,但是它会日渐消磨开发人员每天的生活。通过 WSL,不用折腾你就拥有了一个兼容的、具有 Python 功能和 shell 变量的子系统。
要安装最新的 Python 开发版本和 Python 包安装器 pip,在 Bash 中执行如下命令:
```
$ sudo apt install python-pip python-dev
$ sudo pip install --upgrade pip
```
现在 Python 安装好了,我要展示给你如何从网上获取一个典型的 Linux 下的 Python 例子并让它直接工作起来。我去 [Activestate Python 菜谱站](http://code.activestate.com/recipes/langs/python/?query_start=1)找一个排名第一的 Python 例子。好吧,我走眼了,排名第一的是打印出整数名称的脚本,这看起来没啥意思,所以我选择了第二名:俄罗斯方块。我们每天都能看到 Python 出现在各种地方,所以这次让我们去玩另外一个游戏。

我打开了 nano 编辑器,从 Windows 上的浏览器中打开的页面上复制了这 275 行 Python 代码,然后粘贴到我的 WSL 终端窗口终端中的 nano 中,并保存为 tetris.py ,然后执行它:
```
$ python tetris.py
```
它马上就清屏并出现了俄罗斯方块的游戏。同 NetHack 一样,你可以使用同样的 vi 标准的方向键来移动(以前是使用鼠标和 WSAD 键来移动,而右手使用 HJKL 键更方便)。

如我所提到的,你当然可以不用 WSL 就在 Windows 中运行 Python。然而,要想快速简便,不用修改 Linux 下的 Python 代码,只需要简单的复制粘贴代码即可运行,则可以极大的提高开发者的效率。
这是真的。这并不是要替代 Windows 原生的工具,比如 Python、PowerShell、C# 等等,而是当你需要在现代的开发工作流程中快速而有效地完成一些事情时,可以避免种种折腾。
包括 Bash、Python 以及其它所有的 Linux 原生的命令行开发工具,WSL 为我的开发工作提供了所有需要的工具。这不是一个 Linux 服务器,甚至也不是一个完整的客户端,相反,它就是一个可以让我避免每天折腾,让我在 Windows 上开发更有效率、更有快感的一个东西!
---
### 重置你的 WSL 环境
随便去试吧,如果你搞坏了你的 WSL 环境,它很容易重新安装。在进行之前,请确保做好了任何重要内容的备份。
```
C:\> lxrun.exe /uninstall /full
C:\> lxrun.exe /install
```
### 你使用 Bash 和 WSL 的感觉如何?
我们希望 WSL ,特别是 Bash 可以在 Windows 10 中帮你带来更高的效率,减少每天的开发中的折腾。
你对 Windows 10 上的 WSL 怎么看?你喜欢使用它吗?
开发团队做了大量的工作希望让 WSL 成为一个为开发者提供的强大的终端工具。如果你有任何反馈或运行出现问题,我们推荐你查看一下 [GitHub 反馈页面](https://github.com/Microsoft/BashOnWindows/issues),以及 [用户之声的反馈和投票站点](https://wpdev.uservoice.com/forums/266908-command-prompt-console-bash-on-ubuntu-on-windo)。我们真的希望听到你的声音。
### 更多参考与延伸阅读
Linux shell 编程是一个庞大的话题,在网上有很多这方面的内容。如果你还不够熟悉它们,想要了解更多,可以看看各种 Bash 教程。[可以从这一份开始](https://help.ubuntu.com/community/Beginners/BashScripting)。
还有一些其他的参考资料也许对你有用:
* [Build Tour videos](https://channel9.msdn.com/Events/Build/Build-Tour-2016-Toronto)
* [Bash Scripting 101](https://help.ubuntu.com/community/Beginners/BashScripting)
* [WSL Home](https://msdn.microsoft.com/commandline/wsl/)
* [WSL Overview](https://blogs.msdn.microsoft.com/commandline/2016/06/02/learn-more-about-bash-on-ubuntu-on-windows-and-the-windows-subsystem-for-linux/)
* [WSL FAQ](https://msdn.microsoft.com/en-us/commandline/wsl/faq#how-do-i-update-bash-on-ubuntu-on-windows-)
* [WSL System Calls](https://blogs.msdn.microsoft.com/wsl/2016/06/08/wsl-system-calls/)
* [Scott Hanselman’s video on how to run WSL](http://www.hanselman.com/blog/VIDEOHowToRunLinuxAndBashOnWindows10AnniversaryUpdate.aspx)
哦,当然,要更多的了解 NetHack,请访问 [NetHack 主站](http://www.nethack.org/)。
| 403 | Forbidden | null |
7,617 | 出版商统计出最受欢迎的编程语言:Python 居首 | http://webscripts.softpedia.com/blog/today-s-top-3-programming-languages-javascript-python-java-506596.shtml | 2016-07-26T08:08:00 | [
"编程语言"
] | /article-7617-1.html | 世界上编程方面的最大的出版商 Packt Publishing 最近对 11000 名访客进行了调查,根据调查结果,Python 和 JavaScript 是当今最流行的编程语言,而 Java 紧随其后,排名第三。

调查内容包括开发者使用的编程语言、喜欢的框架、薪酬信息等。调查显示,如果就编程人员每天都要使用的语言来看,当今前10名的编程语言排名是 Python、JavaScript、Java、PHP、HTML(虽然不算编程语言)、 C#、SQL、CSS(也不算) 、C++ 和 R。

从之前的类似调查中可以发现,所有的调查均显示 Python 和 JavaScript 得到了极大流行。
Packt Publishing 的调查发现,编程人员薪水和以上排名完全不同,诸如 bash、Perl 和 Scala 语言编程人员获得的年薪平均超过了 8 万美元,甚至 Bash 编程语言人员的薪酬达到了 10 万美元,而 PHP 和 C 语言编程人员年薪几乎没有到达 4 万美元。

而在 Web 开发人员使用的工具方面,AngularJS 取得了第一,其次是 Facebook 的 React.js 框架、Node.js、Docker、Laravel、 Bootstrap、WordPress 和 AWS。

过去几年最流行的新编程语言排行榜当中,毫无疑问 Swift 高居榜首,其次是 C#、Go、Rust 和 Elixir。

新的框架方面, Docker 也如预期的那样得到第一,Apache Spark 和 AWS 分列二、三名。

更多的调查结果,可以看看 Packt Publishing 的[报告](https://www.packtpub.com/skill-up-2016)(需注册)。
| null | HTTPConnectionPool(host='webscripts.softpedia.com', port=80): Max retries exceeded with url: /blog/today-s-top-3-programming-languages-javascript-python-java-506596.shtml (Caused by NameResolutionError("<urllib3.connection.HTTPConnection object at 0x7b83275818a0>: Failed to resolve 'webscripts.softpedia.com' ([Errno -2] Name or service not known)")) | null |
7,618 | LXD 2.0 系列(一):LXD 入门 | https://www.stgraber.org/2016/03/11/lxd-2-0-introduction-to-lxd-112/ | 2016-07-26T08:59:00 | [
"容器",
"LXC",
"LXD",
"Docker"
] | https://linux.cn/article-7618-1.html | 
这是 LXD 2.0 系列介绍文章的第一篇。
1. [LXD 入门](/article-7618-1.html)
2. [安装与配置](/article-7687-1.html)
3. [你的第一个 LXD 容器](/article-7706-1.html)
4. [资源控制](/article-8072-1.html)
5. [镜像管理](/article-8107-1.html)
6. [远程主机及容器迁移](/article-8169-1.html)
7. [LXD 中的 Docker](/article-8235-1.html)
8. [LXD 中的 LXD](/article-8257-1.html)
9. [实时迁移](/article-8263-1.html)
10. [LXD 和 Juju](/article-8273-1.html)
11. [LXD 和 OpenStack](/article-8274-1.html)
12. [调试,及给 LXD 做贡献](/article-8282-1.html)
### 关于 LXD 几个常见问题
#### 什么是 LXD ?
简单地说, LXD 就是一个提供了 REST API 的 LXC 容器管理器。
LXD 最主要的目标就是使用 Linux 容器而不是硬件虚拟化向用户提供一种接近虚拟机的使用体验。
#### LXD 和 Docker/Rkt 又有什么关系呢 ?
这是一个最常被问起的问题,现在就让我们直接指出其中的不同吧。
LXD 聚焦于系统容器,通常也被称为架构容器。这就是说 LXD 容器实际上如在裸机或虚拟机上运行一般运行了一个完整的 Linux 操作系统。
这些容器一般基于一个干净的发布镜像并会长时间运行。传统的配置管理工具和部署工具可以如在虚拟机、云实例和物理机器上一样与 LXD 一起使用。
相对的, Docker 关注于短期的、无状态的、最小化的容器,这些容器通常并不会升级或者重新配置,而是作为一个整体被替换掉。这就使得 Docker 及类似项目更像是一种软件发布机制,而不是一个机器管理工具。
这两种模型并不是完全互斥的。你完全可以使用 LXD 为你的用户提供一个完整的 Linux 系统,然后他们可以在 LXD 内安装 Docker 来运行他们想要的软件。
#### 为什么要用 LXD?
我们已经持续开发并改进 LXC 好几年了。 LXC 成功的实现了它的目标,它提供了一系列很棒的用于创建和管理容器的底层工具和库。
然而这些底层工具的使用界面对用户并不是很友好。使用它们需要用户有很多的基础知识以理解它们的工作方式和目的。同时,向后兼容旧的容器和部署策略也使得 LXC 无法默认使用一些安全特性,这导致用户需要进行更多人工操作来实现本可以自动完成的工作。
我们把 LXD 作为解决这些缺陷的一个很好的机会。作为一个长时间运行的守护进程, LXD 可以绕开 LXC 的许多限制,比如动态资源限制、无法进行容器迁移和高效的在线迁移;同时,它也为创造新的默认体验提供了机会:默认开启安全特性,对用户更加友好。
### LXD 的主要组件
LXD 是由几个主要组件构成的,这些组件都出现在 LXD 目录结构、命令行客户端和 API 结构体里。
#### 容器
LXD 中的容器包括以下及部分:
* 根文件系统(rootfs)
* 配置选项列表,包括资源限制、环境、安全选项等等
* 设备:包括磁盘、unix 字符/块设备、网络接口
* 一组继承而来的容器配置文件
* 属性(容器架构、暂时的还是持久的、容器名)
* 运行时状态(当用 CRIU 来中断/恢复时)
#### 快照
容器快照和容器是一回事,只不过快照是不可修改的,只能被重命名,销毁或者用来恢复系统,但是无论如何都不能被修改。
值得注意的是,因为我们允许用户保存容器的运行时状态,这就有效的为我们提供了“有状态”的快照的功能。这就是说我们可以使用快照回滚容器的状态,包括快照当时的 CPU 和内存状态。
#### 镜像
LXD 是基于镜像实现的,所有的 LXD 容器都是来自于镜像。容器镜像通常是一些纯净的 Linux 发行版的镜像,类似于你们在虚拟机和云实例上使用的镜像。
所以可以「发布」一个容器:使用容器制作一个镜像并在本地或者远程 LXD 主机上使用。
镜像通常使用全部或部分 sha256 哈希码来区分。因为输入长长的哈希码对用户来说不方便,所以镜像可以使用几个自身的属性来区分,这就使得用户在镜像商店里方便搜索镜像。也可以使用别名来一对一地将一个用户好记的名字映射到某个镜像的哈希码上。
LXD 安装时已经配置好了三个远程镜像服务器(参见下面的远程一节):
* “ubuntu”:提供稳定版的 Ubuntu 镜像
* “ubuntu-daily”:提供 Ubuntu 的每日构建镜像
* “images”: 社区维护的镜像服务器,提供一系列的其它 Linux 发布版,使用的是上游 LXC 的模板
LXD 守护进程会从镜像上次被使用开始自动缓存远程镜像一段时间(默认是 10 天),超过时限后这些镜像才会失效。
此外, LXD 还会自动更新远程镜像(除非指明不更新),所以本地的镜像会一直是最新版的。
#### 配置
配置文件是一种在一个地方定义容器配置和容器设备,然后将其应用到一系列容器的方法。
一个容器可以被应用多个配置文件。当构建最终容器配置时(即通常的扩展配置),这些配置文件都会按照他们定义顺序被应用到容器上,当有重名的配置键或设备时,新的会覆盖掉旧的。然后本地容器设置会在这些基础上应用,覆盖所有来自配置文件的选项。
LXD 自带两种预配置的配置文件:
* “default”配置是自动应用在所有容器之上,除非用户提供了一系列替代的配置文件。目前这个配置文件只做一件事,为容器定义 eth0 网络设备。
* “docker”配置是一个允许你在容器里运行 Docker 容器的配置文件。它会要求 LXD 加载一些需要的内核模块以支持容器嵌套并创建一些设备。
#### 远程
如我之前提到的, LXD 是一个基于网络的守护进程。附带的命令行客户端可以与多个远程 LXD 服务器、镜像服务器通信。
默认情况下,我们的命令行客户端会与下面几个预定义的远程服务器通信:
* local:默认的远程服务器,使用 UNIX socket 和本地的 LXD 守护进程通信
* ubuntu:Ubuntu 镜像服务器,提供稳定版的 Ubuntu 镜像
* ubuntu-daily:Ubuntu 镜像服务器,提供 Ubuntu 的每日构建版
* images:images.linuxcontainers.org 的镜像服务器
所有这些远程服务器的组合都可以在命令行客户端里使用。
你也可以添加任意数量的远程 LXD 主机,并配置它们监听网络。匿名的开放镜像服务器,或者通过认证可以管理远程容器的镜像服务器,都可以添加进来。
正是这种远程机制使得与远程镜像服务器交互及在主机间复制、移动容器成为可能。
### 安全性
我们设计 LXD 时的一个核心要求,就是在不修改现代 Linux 发行版的前提下,使容器尽可能的安全。
LXD 通过使用 LXC 库实现的主要安全特性有:
* 内核名字空间。尤其是用户名字空间,它让容器和系统剩余部分完全分离。LXD 默认使用用户名字空间(和 LXC 相反),并允许用户在需要的时候以容器为单位关闭(将容器标为“特权的”)。
* Seccomp 系统调用。用来隔离潜在危险的系统调用。
* AppArmor。对 mount、socket、ptrace 和文件访问提供额外的限制。特别是限制跨容器通信。
* Capabilities。阻止容器加载内核模块,修改主机系统时间,等等。
* CGroups。限制资源使用,防止针对主机的 DoS 攻击。
为了对用户友好,LXD 构建了一个新的配置语言把大部分的这些特性都抽象封装起来,而不是如 LXC 一般直接将这些特性暴露出来。举了例子,一个用户可以告诉 LXD 把主机设备放进容器而不需要手动检查他们的主/次设备号来手动更新 CGroup 策略。
和 LXD 本身通信是基于使用 TLS 1.2 保护的链路,只允许使用有限的几个被允许的密钥算法。当和那些经过系统证书认证之外的主机通信时, LXD 会提示用户验证主机的远程指纹(SSH 方式),然后把指纹缓存起来以供以后使用。
### REST 接口
LXD 的工作都是通过 REST 接口实现的。在客户端和守护进程之间并没有其他的通讯渠道。
REST 接口可以通过本地的 unix socket 访问,这只需要经过用户组认证,或者经过 HTTP 套接字使用客户端认证进行通信。
REST 接口的结构能够和上文所说的不同的组件匹配,是一种简单、直观的使用方法。
当需要一种复杂的通信机制时, LXD 将会进行 websocket 协商完成剩余的通信工作。这主要用于交互式终端会话、容器迁移和事件通知。
LXD 2.0 附带了 1.0 版的稳定 API。虽然我们在 1.0 版 API 添加了额外的特性,但是这不会在 1.0 版 API 端点里破坏向后兼容性,因为我们会声明额外的 API 扩展使得客户端可以找到新的接口。
### 容器规模化
虽然 LXD 提供了一个很好的命令行客户端,但是这个客户端并不能管理多个主机上大量的容器。在这种使用情况下,我们可以使用 OpenStack 的 nova-lxd 插件,它可以使 OpenStack 像使用虚拟机一样使用 LXD 容器。
这就允许在大量的主机上部署大量的 LXD 容器,然后使用 OpenStack 的 API 来管理网络、存储以及负载均衡。
### 额外信息
LXD 的主站在: <https://linuxcontainers.org/lxd>
LXD 的 GitHub 仓库: <https://github.com/lxc/lxd>
LXD 的邮件列表: <https://lists.linuxcontainers.org>
LXD 的 IRC 频道: #lxcontainers on irc.freenode.net
如果你不想或者不能在你的机器上安装 LXD ,你可以在 web 上[试试在线版的 LXD](https://linuxcontainers.org/lxd/try-it) 。
---
作者简介:我是 Stéphane Graber。我是 LXC 和 LXD 项目的领导者,目前在加拿大魁北克蒙特利尔的家所在的Canonical 有限公司担任 LXD 的技术主管。
---
via: <https://www.stgraber.org/2016/03/11/lxd-2-0-introduction-to-lxd-112/>
作者:[Stéphane Graber](https://www.stgraber.org/author/stgraber/) 译者:[ezio](https://github.com/oska874) 校对:[PurlingNayuki](https://github.com/PurlingNayuki)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,620 | 《数字身份验证指南》草案中提议禁用基于短信的双因子认证 | http://news.softpedia.com/news/nist-prepares-to-ban-sms-based-two-factor-authentication-506617.shtml | 2016-07-27T17:07:00 | [
"验证",
"双因子",
"2FA"
] | https://linux.cn/article-7620-1.html | 美国<ruby> 国家标准和技术协会 <rp> ( </rp> <rt> National Institute of Standards and Technology </rt> <rp> ) </rp></ruby>(NIST)发布了《<ruby> <a href="https://pages.nist.gov/800-63-3/sp800-63b.html"> 数字身份验证指南 </a> <rp> ( </rp> <rt> Digital Authentication Guideline </rt> <rp> ) </rp></ruby>(DAG)》的最新草案,其中暗示将来会禁用基于短信的<ruby> 双因子认证方案 <rp> ( </rp> <rt> Two-Factor Authentication </rt> <rp> ) </rp></ruby>(2FA)。
《<ruby> 数字身份验证指南 <rt> Digital Authentication Guideline </rt></ruby>(DAG)》是一系列用于软件商构建安全服务的规则,也被政府和私人机构用于评估其服务和软件的安全性。

NIST 的专家们一直不断地更新该指南,以便应对 IT 领域的快速变化。
### 基于短信的双因子认证仍然可以用,但是不会太久了
据[最新的《数字身份验证指南》草案](https://pages.nist.gov/800-63-3/sp800-63b.html),NIST 正式地不建议公司继续使用基于短信的认证,甚至说将来考虑在该指南中将基于短信的双因子认证视作不安全的。NIST 在该草案中说:
“如果使用基于公共移动电话网络的短信作为带外验证,验证者必须**验证其**预注册的手机号码是基于移动网络的,而非 VoIP(或者其它基于软件的),然后才能发送短信到预注册手机号码。修改预注册手机号码时如果没有双因子验证是不能进行的。不推荐使用短信进行带外验证,本指南的将来版本中将不再允许这种方式。”
NIST 的指南当中认为基于短信的双因子认证是不安全的,因为用户不会总是带着电话。
在该指南中,推荐软件应用应该使用令牌和软件加密验证器,这可能是手机应用或硬件设备的形式,但是就像手机一样,也可能被偷走或“临时借走”。但该指南认为这种风险是可接受的,而不像令牌或软件加密验证器那样,短信在 VoIP 服务之下是一个影响到了联合信任因子的缺陷。
### 短信是不安全的,特别是在 VoIP 连接下
因为一些 VoIP 服务允许劫持短信,所以 NIST 建议厂商在基于短信的双因子系统在发送短信验证码之前,对使用 VoIP 连接的访问进行特别检查。
短信是一个广泛使用的不安全协议,仅在上周,Context Information Security 的安全研究人员就[披露](http://www.contextis.com/resources/blog/binary-sms-old-backdoor-your-new-thing/)了又一起依赖于短信协议而危及到了其用户和设备的攻击。随着对这种攻击类型的越来越多的研究,软件厂商、公司以及用户会逐渐认识到应该换到更安全的验证方式上。
当前的 NIST 指南仍在讨论之中,但是基本上可以确定,该指南的将来版本不会再将使用基于短信的认证方式推荐为带外验证的安全方式。
### 生物识别技术是一个新兴发展方向
在该指南草案中,也提到了生物特征识别技术在特定条件下是可以作为一个验证方式的:
“因此,对生物识别技术的验证是支持的,只需要遵循如下准则:生物识别技术**应该**与其他(你知道的或你拥有的)认证因子配合使用。”
| 301 | Moved Permanently | null |
7,621 | Linux 安全性被鄙视,OpenBSD 6.0 为了安全而抛弃了 Linux 兼容层 | http://www.infoworld.com/article/3099038/open-source-tools/openbsd-60-tightens-security-by-losing-linux-compatibility.html | 2016-07-27T17:59:22 | [
"OpenBSD",
"Linux",
"安全"
] | https://linux.cn/article-7621-1.html |
>
> 最新版本的 OpenBSD 6.0 将关闭潜在的安全漏洞——比如其 Linux 兼容层。
>
>
>
OpenBSD,这个 BSD 家族里面最重要的变种之一将在今年九月份[发布](https://www.openbsd.org/60.html)新的 6.0 版本。它通常被视作 Linux 的一个替代品,以没有专有软件而闻名,并由于其默认情况下比其它的操作系统更安全,以及对[用户安全](http://www.infoworld.com/article/2624916/government/openbsd-chief-believes-contractor-tried-to-write-back-doors.html)的[高度警惕](http://www.infoworld.com/article/2617852/open-source-software/openbsd-founder-calls-red-hat-and-canonical--traitors--to-open-source.html)而广泛受到赞誉。由于其在开发过程中的安全理念,许多软件路由器和防火墙项目都是基于 OpenBSD 而开发的。

在这次 OpenBSD 新版本中安全相关的最大变化是其移除了对 Linux 模拟的支持。在之前的 OpenBSD 版本中,Linux 应用可以通过一个[兼容层](https://www.openbsd.org/papers/slack2k11-on_compat_linux.pdf)直接运行在 BSD 中,但是在最新的 OpenBSD 6.0 的[发布公告](https://www.openbsd.org/60.html)中称,由于“安全改进”而移走了该子系统。
OpenBSD 中有一些软件是以附加的二进制软件包方式提供的,OpenBSD 的维护者们会尽量提供对这些软件的支持,但是他们不会像对待其操作系统一样对这些软件的安全性进行筛选。由于现在很多流行应用的最新版本都可以直接运行在 OpenBSD 中,比如说 Chromium 和 Firefox 浏览器,这意味没有 Linux 兼容层也不要紧。
出于安全考虑,OpenBSD 还抛弃了 [systrace](http://man.openbsd.org/OpenBSD-5.9/systrace) 系统安全实施策略工具。之前版本的 OpenBSD 包括它,但是并没有用它来管理任何重要的东西。[systrace](http://man.openbsd.org/OpenBSD-5.9/systrace) 被[视为不安全已经有段时间](https://www.lightbluetouchpaper.org/2007/08/06/usenix-woot07-exploiting-concurrency-vulnerabilities-in-system-call-wrappers-and-the-evil-genius/)了,所以在这次的 OpenBSD 发行版中它也将被抛弃。
作为安全增强的一部分,还[移除了“usermount”选项](http://undeadly.org/cgi?action=article&sid=20160715125022),它允许非特权用户挂载文件系统。OpenBSD 项目负责人 Theo de Raadt 说 usermount “允许任何不当的程序调用 mount/umount 系统调用”,这意味着“在提供该功能的前提下,任何用户都没有办法保持其系统的安全性和可靠性的预期。”
在发布于今年三月份的 OpenBSD 的前一个版本 5.9 中,它提供了一些自己的安全改进。比如以特权用户身份运行程序的 sudo 被替换成 [doas](http://www.openbsd.org/faq/faq10.html#doas),这个新的程序使用了更简化和潜在问题更少的配置机制。这种为了安全而做的改变在 Linux 世界会更难见到,而 OpenBSD 则通过让其[代码不断采用新的技术](http://www.openbsd.org/papers/pruning.html)而展示了其在安全方面的努力和进步。
| 301 | Moved Permanently | null |
7,622 | 怎样在 Ubuntu 中修改默认程序 | https://itsfoss.com/change-default-applications-ubuntu/ | 2016-07-28T08:25:00 | [
"Ubuntu",
"默认程序"
] | https://linux.cn/article-7622-1.html | 
>
> 简介: 这个新手指南会向你展示如何在 Ubuntu Linux 中修改默认程序
>
>
>
对于我来说,安装 [VLC 多媒体播放器](http://www.videolan.org/vlc/index.html)是[安装完 Ubuntu 16.04 该做的事](/article-7453-1.html)中最先做的几件事之一。为了能够使我双击一个视频就用 VLC 打开,在我安装完 VLC 之后我会设置它为默认程序。
作为一个新手,你需要知道如何在 Ubuntu 中修改任何默认程序,这也是我今天在这篇指南中所要讲的。
### 在 Ubuntu 中修改默认程序
这里提及的方法适用于所有的 Ubuntu 12.04,Ubuntu 14.04 和Ubuntu 16.04。在 Ubuntu 中,这里有两种基本的方法可以修改默认程序:
* 通过系统设置
* 通过右键菜单
#### 1.通过系统设置修改 Ubuntu 的默认程序
进入 Unity 面板并且搜索<ruby> 系统设置 <rp> ( </rp> <rt> System Settings </rt> <rp> ) </rp></ruby>:

在<ruby> 系统设置 <rp> ( </rp> <rt> System Settings </rt> <rp> ) </rp></ruby>中,选择<ruby> 详细选项 <rp> ( </rp> <rt> Details </rt> <rp> ) </rp></ruby>:

在左边的面板中选择<ruby> 默认程序 <rp> ( </rp> <rt> Default Applications </rt> <rp> ) </rp></ruby>,你会发现在右边的面板中可以修改默认程序。

正如看到的那样,这里只有少数几类的默认程序可以被改变。你可以在这里改变浏览器、邮箱客户端、日历、音乐、视频和相册的默认程序。那其他类型的默认程序怎么修改?
不要担心,为了修改其他类型的默认程序,我们会用到右键菜单。
#### 2.通过右键菜单修改默认程序
如果你使用过 Windows 系统,你应该看见过右键菜单的“打开方式”,可以通过这个来修改默认程序。我们在 Ubuntu 中也有相似的方法。
右键一个还没有设置默认打开程序的文件,选择“<ruby> 属性 <rp> ( </rp> <rt> properties </rt> <rp> ) </rp></ruby>”

*从右键菜单中选择属性*
在这里,你可以选择使用什么程序打开,并且设置为默认程序。

*在 Ubuntu 中设置打开 WebP 图片的默认程序为 gThumb*
小菜一碟不是么?一旦你做完这些,所有同样类型的文件都会用你选择的默认程序打开。
我很希望这个新手指南对你在修改 Ubuntu 的默认程序时有帮助。如果你有任何的疑问或者建议,可以随时在下面评论。
---
via: <https://itsfoss.com/change-default-applications-ubuntu/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 译者:[Locez](https://github.com/locez) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | **Brief**: This beginner’s guide shows you **how to change the default applications in Ubuntu** Linux.
Installing [VLC media player](http://www.videolan.org/vlc/index.html) is one of the first few [things to do after installing Ubuntu 18.04/19.10](https://itsfoss.com/things-to-do-after-installing-ubuntu-18-04/) for me. One thing I do after installing VLC is to make it the default application so that I can open a video file with VLC when I double click it.
As a beginner, you may need to know how to change any default application in [Ubuntu](http://www.ubuntu.com/) and this is what I am going to show you in this tutorial.
But before we do that, I recommend that you also read my guide on [how to install/remove software in Ubuntu](https://itsfoss.com/remove-install-software-ubuntu/) – in case you’re still confused about that.
## Changing default applications in Ubuntu
There are basically two ways you can change the default applications in Ubuntu:
- via system settings (valid for changing the default web browser, email client, calendar, music application, video player and image viewer)
- via right-click menu (valid for applications other than the above mentioned ones)
If you prefer videos, you can watch the video below:
### 1. Change default applications in Ubuntu from System Settings
Simply head to the System **Settings**:
In the System Settings, click on the **Details** option:
Now, click on the “**Default Applications**” option as highlighted in the screenshot below:
As you can see, there are only a few kinds of default applications that can be changed here. You can change the default applications for web browsers, email clients, calendar apps, music, videos and photo here. What about other kinds of applications?
Don’t worry. To change the default applications not listed here (for instance – text editor), we’ll use the option in the right-click menu.
### 2. Change default applications in Ubuntu from right-click menu
Let’s say you have a [markdown](https://itsfoss.com/best-markdown-editors-linux/) file (.md) which opens in Gedit text editor by default. But you want to use some other applications to open markdown files. Here’s what you need to do.
Right click on the file and then select **Open with Other Application**:
If you don’t see your choice of application, click on the **View All Applications**:
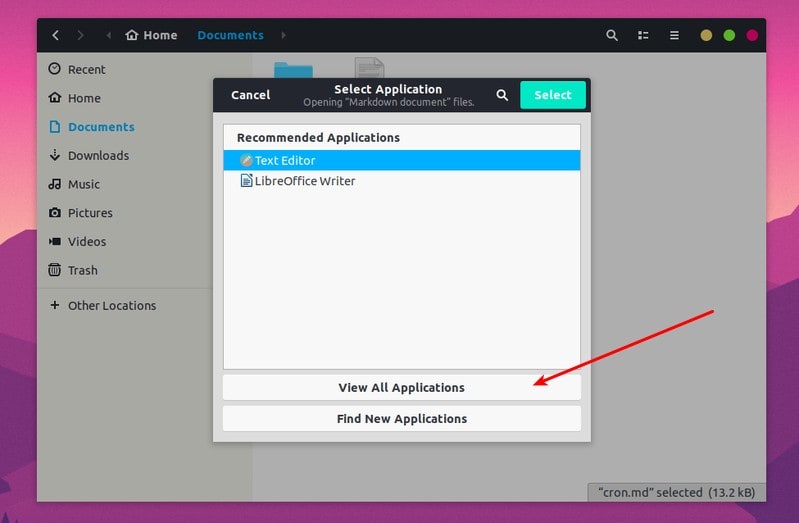
Locate the desire application and select it:
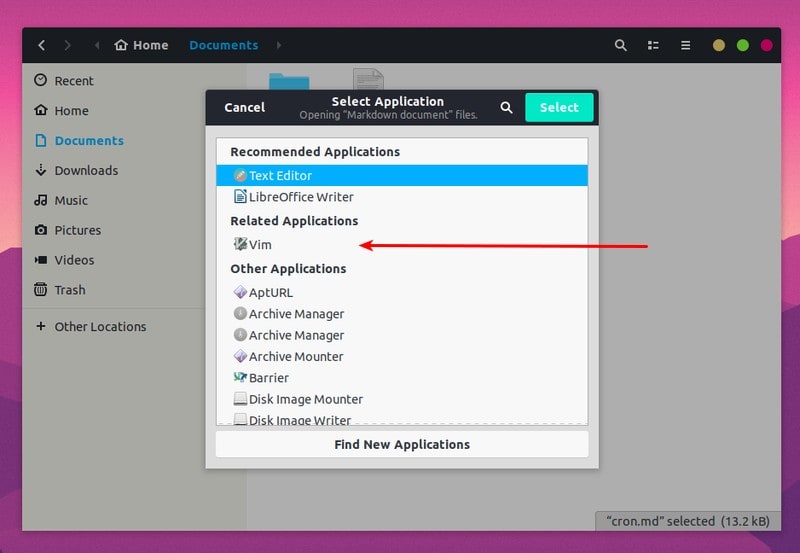
This will open the file in your chosen application.
The thing here is that the file manager automatically recognizes your choice and the next time you double click on the file to open it, it will open it with the application you last chose.
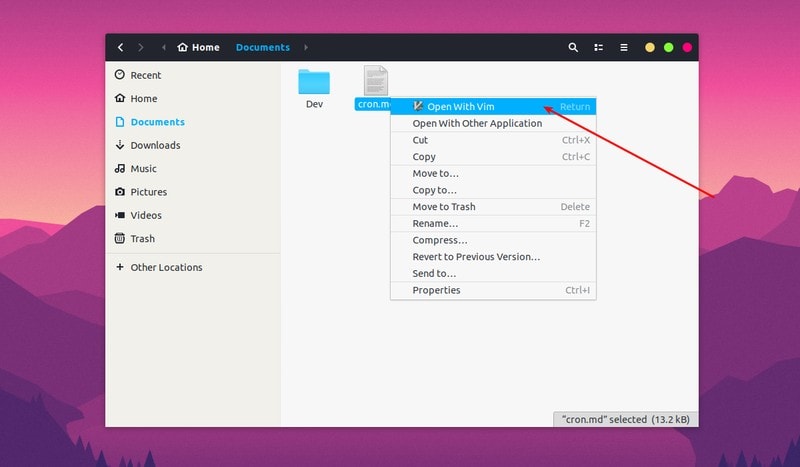
Keep in mind that this behavior is not applicable to web browsers, music players, video players, email clients, calendars and photo viewer. For that you need to use the first method described here.
If you want to [change the default terminal emulator, the steps are entirely different](https://itsfoss.com/change-default-terminal-ubuntu/).
## Troubleshoot: Application not available in ‘open with’ list
In some rare cases, the application may not even be available in the list of open with applications.
I encountered this issue with Pinta a few years back and here’s what I did to fix it.
To add any program in the list of the open with applications, open a terminal and use the following command:
`sudo gedit /usr/share/applications/XXX.desktop`
Please note two things. In XXX.desktop, XXX is the name of your application. And then use of gedit. You can use any other editor. I used Vim. If you use Gedit, it will dispaly some warning messages in the terminal but will open the file in a GUI.
In this desktop file, look for a line that looks like this:
`Exec=XXX`
If you have something like this, replace this line with:
`Exec=XXX %F`
Save it and exit/close the desktop file. No need to restart or anything. It should be working instantly.
### Explanation
Now to explain what this %F means. %F is actually an [Exec Key](https://standards.freedesktop.org/desktop-entry-spec/latest/ar01s06.html). It means the program will be supplied with multiple file inputs at the same time ([arguments](https://en.wikipedia.org/wiki/Parameter_(computer_programming))). So if I have this %F set in Pinta, I can open multiple images in the same instance of Pinta (think it like tabs in a web browser). But the program must support this feature.
The question which you might be wondering why it was not showing in the list of applications before and why after adding %F, it is working. The reason is that when there is no such Exec Key, the program will not accept any argument, which means you can not “open with” a file with this application as “open with” supplies the file as the argument.
You can read more about Exec Key [here](https://standards.freedesktop.org/desktop-entry-spec/latest/ar01s06.html).
I hope you found this beginner’s tutorial to change default applications in Ubuntu helpful. If you have any questions or suggestions, feel free to drop a comment below. |
7,623 | Linux 上 10 个最好的 Markdown 编辑器 | http://www.tecmint.com/best-markdown-editors-for-linux/ | 2016-07-29T09:19:00 | [
"Markdown",
"编辑器"
] | https://linux.cn/article-7623-1.html | 在这篇文章中,我们会点评一些可以在 Linux 上安装使用的最好的 Markdown 编辑器。 你可以在 Linux 平台上找到非常多的 的 Markdown 编辑器,但是在这里我们将尽可能地为您推荐那些最好的。

*Best Linux Markdown Editors*
对于不了解 Markdown 的人做个简单介绍,Markdown 是由著名的 Aaron Swartz 和 John Gruber 发明的标记语言,其最初的解析器是一个用 Perl 写的简单、轻量的[同名工具](https://daringfireball.net/projects/markdown/)。它可以将用户写的纯文本转为可用的 HTML(或 XHTML)。它实际上是一门易读,易写的纯文本语言,以及一个用于将文本转为 HTML 的转换工具。
希望你先对 Markdown 有一个稍微的了解,接下来让我们逐一列出这些编辑器。
### 1. Atom
Atom 是一个现代的、跨平台、开源且强大的文本编辑器,它可以运行在 Linux、Windows 和 MAC OS X 等操作系统上。用户可以在它的基础上进行定制,删减修改任何配置文件。
它包含了一些非常杰出的特性:
* 内置软件包管理器
* 智能自动补全功能
* 提供多窗口操作
* 支持查找替换功能
* 包含一个文件系统浏览器
* 轻松自定义主题
* 开源、高度扩展性的软件包等

*Atom Markdown Editor for Linux*
访问主页: <https://atom.io/>
### 2. GNU Emacs
Emacs 是 Linux 平台上一款的流行文本编辑器。它是一个非常棒的、具备高扩展性和定制性的 Markdown 语言编辑器。
它综合了以下这些神奇的特性:
* 带有丰富的内置文档,包括适合初学者的教程
* 有完整的 Unicode 支持,可显示所有的人类符号
* 支持内容识别的文本编辑模式
* 包括多种文件类型的语法高亮
* 可用 Emacs Lisp 或 GUI 对其进行高度定制
* 提供了一个包系统可用来下载安装各种扩展等

*Emacs Markdown Editor for Linux*
访问主页: <https://www.gnu.org/software/emacs/>
### 3. Remarkable
Remarkable 可能是 Linux 上最好的 Markdown 编辑器了,它也适用于 Windows 操作系统。它的确是是一个卓越且功能齐全的 Markdown 编辑器,为用户提供了一些令人激动的特性。
一些卓越的特性:
* 支持实时预览
* 支持导出 PDF 和 HTML
* 支持 Github Markdown 语法
* 支持定制 CSS
* 支持语法高亮
* 提供键盘快捷键
* 高可定制性和其他

*Remarkable Markdown Editor for Linux*
访问主页: <https://remarkableapp.github.io>
### 4. Haroopad
Haroopad 是为 Linux,Windows 和 Mac OS X 构建的跨平台 Markdown 文档处理程序。用户可以用它来书写许多专家级格式的文档,包括电子邮件、报告、博客、演示文稿和博客文章等等。
功能齐全且具备以下的亮点:
* 轻松导入内容
* 支持导出多种格式
* 广泛支持博客和邮件
* 支持许多数学表达式
* 支持 Github Markdown 扩展
* 为用户提供了一些令人兴奋的主题、皮肤和 UI 组件等等

*Haroopad Markdown Editor for Linux*
访问主页: <http://pad.haroopress.com/>
### 5. ReText
ReText 是为 Linux 和其它几个 POSIX 兼容操作系统提供的简单、轻量、强大的 Markdown 编辑器。它还可以作为一个 reStructuredText 编辑器,并且具有以下的特性:
* 简单直观的 GUI
* 具备高定制性,用户可以自定义语法文件和配置选项
* 支持多种配色方案
* 支持使用多种数学公式
* 启用导出扩展等等

*ReText Markdown Editor for Linux*
访问主页: <https://github.com/retext-project/retext>
### 6. UberWriter
UberWriter 是一个简单、易用的 Linux Markdown 编辑器。它的开发受 Mac OS X 上的 iA writer 影响很大,同样它也具备这些卓越的特性:
* 使用 pandoc 进行所有的文本到 HTML 的转换
* 提供了一个简洁的 UI 界面
* 提供了一种<ruby> 专心 <rp> ( </rp> <rt> distraction free </rt> <rp> ) </rp></ruby>模式,高亮用户最后的句子
* 支持拼写检查
* 支持全屏模式
* 支持用 pandoc 导出 PDF、HTML 和 RTF
* 启用语法高亮和数学函数等等

*UberWriter Markdown Editor for Linux*
访问主页: <http://uberwriter.wolfvollprecht.de/>
### 7. Mark My Words
Mark My Words 同样也是一个轻量、强大的 Markdown 编辑器。它是一个相对比较新的编辑器,因此提供了包含语法高亮在内的大量的功能,简单和直观的 UI。
下面是一些棒极了,但还未捆绑到应用中的功能:
* 实时预览
* Markdown 解析和文件 IO
* 状态管理
* 支持导出 PDF 和 HTML
* 监测文件的修改
* 支持首选项设置

*MarkMyWords Markdown Editor for-Linux*
访问主页: <https://github.com/voldyman/MarkMyWords>
### 8. Vim-Instant-Markdown 插件
Vim 是 Linux 上的一个久经考验的强大、流行而开源的文本编辑器。它用于编程极棒。它也高度支持插件功能,可以让用户为其增加一些其它功能,包括 Markdown 预览。
有好几种 Vim 的 Markdown 预览插件,但是 [Vim-Instant-Markdown](https://github.com/suan/vim-instant-markdown) 的表现最佳。
### 9. Bracket-MarkdownPreview 插件
Brackets 是一个现代、轻量、开源且跨平台的文本编辑器。它特别为 Web 设计和开发而构建。它的一些重要功能包括:支持内联编辑器、实时预览、预处理支持及更多。
它也是通过插件高度可扩展的,你可以使用 [Bracket-MarkdownPreview](https://github.com/gruehle/MarkdownPreview) 插件来编写和预览 Markdown 文档。

*Brackets Markdown Plugin Preview*
### 10. SublimeText-Markdown 插件
Sublime Text 是一个精心打造的、流行的、跨平台文本编辑器,用于代码、markdown 和普通文本。它的表现极佳,包括如下令人兴奋的功能:
* 简洁而美观的 GUI
* 支持多重选择
* 提供专心模式
* 支持窗体分割编辑
* 通过 Python 插件 API 支持高度插件化
* 完全可定制化,提供命令查找模式
[SublimeText-Markdown](https://github.com/SublimeText-Markdown/MarkdownEditing) 插件是一个支持格式高亮的软件包,带有一些漂亮的颜色方案。

*SublimeText Markdown Plugin Preview*
### 结论
通过上面的列表,你大概已经知道要为你的 Linux 桌面下载、安装什么样的 Markdown 编辑器和文档处理程序了。
请注意,这里提到的最好的 Markdown 编辑器可能对你来说并不是最好的选择。因此你可以通过下面的反馈部分,为我们展示你认为列表中未提及的,并且具备足够的资格的,令人兴奋的 Markdown 编辑器。
---
via: <http://www.tecmint.com/best-markdown-editors-for-linux/>
作者:[Aaron Kili](http://www.tecmint.com/author/aaronkili/) 译者:[Locez](https://github.com/locez) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,624 | 使用 Python 创建你自己的 Shell (上) | https://hackercollider.com/articles/2016/07/05/create-your-own-shell-in-python-part-1/ | 2016-07-28T11:11:00 | [
"shell",
"python"
] | /article-7624-1.html | 我很想知道一个 shell (像 bash,csh 等)内部是如何工作的。于是为了满足自己的好奇心,我使用 Python 实现了一个名为 **yosh** (Your Own Shell)的 Shell。本文章所介绍的概念也可以应用于其他编程语言。

(提示:你可以在[这里](https://github.com/supasate/yosh)查找本博文使用的源代码,代码以 MIT 许可证发布。在 Mac OS X 10.11.5 上,我使用 Python 2.7.10 和 3.4.3 进行了测试。它应该可以运行在其他类 Unix 环境,比如 Linux 和 Windows 上的 Cygwin。)
让我们开始吧。
### 步骤 0:项目结构
对于此项目,我使用了以下的项目结构。
```
yosh_project
|-- yosh
|-- __init__.py
|-- shell.py
```
`yosh_project` 为项目根目录(你也可以把它简单命名为 `yosh`)。
`yosh` 为包目录,且 `__init__.py` 可以使它成为与包的目录名字相同的包(如果你不用 Python 编写的话,可以忽略它。)
`shell.py` 是我们主要的脚本文件。
### 步骤 1:Shell 循环
当启动一个 shell,它会显示一个命令提示符并等待你的命令输入。在接收了输入的命令并执行它之后(稍后文章会进行详细解释),你的 shell 会重新回到这里,并循环等待下一条指令。
在 `shell.py` 中,我们会以一个简单的 main 函数开始,该函数调用了 shell\_loop() 函数,如下:
```
def shell_loop():
# Start the loop here
def main():
shell_loop()
if __name__ == "__main__":
main()
```
接着,在 `shell_loop()` 中,为了指示循环是否继续或停止,我们使用了一个状态标志。在循环的开始,我们的 shell 将显示一个命令提示符,并等待读取命令输入。
```
import sys
SHELL_STATUS_RUN = 1
SHELL_STATUS_STOP = 0
def shell_loop():
status = SHELL_STATUS_RUN
while status == SHELL_STATUS_RUN:
### 显示命令提示符
sys.stdout.write('> ')
sys.stdout.flush()
### 读取命令输入
cmd = sys.stdin.readline()
```
之后,我们<ruby> 切分命令 <rp> ( </rp> <rt> tokenize </rt> <rp> ) </rp></ruby>输入并进行<ruby> 执行 <rp> ( </rp> <rt> execute </rt> <rp> ) </rp></ruby>(我们即将实现 `tokenize` 和 `execute` 函数)。
因此,我们的 shell\_loop() 会是如下这样:
```
import sys
SHELL_STATUS_RUN = 1
SHELL_STATUS_STOP = 0
def shell_loop():
status = SHELL_STATUS_RUN
while status == SHELL_STATUS_RUN:
### 显示命令提示符
sys.stdout.write('> ')
sys.stdout.flush()
### 读取命令输入
cmd = sys.stdin.readline()
### 切分命令输入
cmd_tokens = tokenize(cmd)
### 执行该命令并获取新的状态
status = execute(cmd_tokens)
```
这就是我们整个 shell 循环。如果我们使用 `python shell.py` 启动我们的 shell,它会显示命令提示符。然而如果我们输入命令并按回车,它会抛出错误,因为我们还没定义 `tokenize` 函数。
为了退出 shell,可以尝试输入 ctrl-c。稍后我将解释如何以优雅的形式退出 shell。
### 步骤 2:<ruby> 命令切分 <rp> ( </rp> <rt> tokenize </rt> <rp> ) </rp></ruby>
当用户在我们的 shell 中输入命令并按下回车键,该命令将会是一个包含命令名称及其参数的长字符串。因此,我们必须切分该字符串(分割一个字符串为多个元组)。
咋一看似乎很简单。我们或许可以使用 `cmd.split()`,以空格分割输入。它对类似 `ls -a my_folder` 的命令起作用,因为它能够将命令分割为一个列表 `['ls', '-a', 'my_folder']`,这样我们便能轻易处理它们了。
然而,也有一些类似 `echo "Hello World"` 或 `echo 'Hello World'` 以单引号或双引号引用参数的情况。如果我们使用 cmd.spilt,我们将会得到一个存有 3 个标记的列表 `['echo', '"Hello', 'World"']` 而不是 2 个标记的列表 `['echo', 'Hello World']`。
幸运的是,Python 提供了一个名为 `shlex` 的库,它能够帮助我们如魔法般地分割命令。(提示:我们也可以使用正则表达式,但它不是本文的重点。)
```
import sys
import shlex
...
def tokenize(string):
return shlex.split(string)
...
```
然后我们将这些元组发送到执行进程。
### 步骤 3:执行
这是 shell 中核心而有趣的一部分。当 shell 执行 `mkdir test_dir` 时,到底发生了什么?(提示: `mkdir` 是一个带有 `test_dir` 参数的执行程序,用于创建一个名为 `test_dir` 的目录。)
`execvp` 是这一步的首先需要的函数。在我们解释 `execvp` 所做的事之前,让我们看看它的实际效果。
```
import os
...
def execute(cmd_tokens):
### 执行命令
os.execvp(cmd_tokens[0], cmd_tokens)
### 返回状态以告知在 shell_loop 中等待下一个命令
return SHELL_STATUS_RUN
...
```
再次尝试运行我们的 shell,并输入 `mkdir test_dir` 命令,接着按下回车键。
在我们敲下回车键之后,问题是我们的 shell 会直接退出而不是等待下一个命令。然而,目录正确地创建了。
因此,`execvp` 实际上做了什么?
`execvp` 是系统调用 `exec` 的一个变体。第一个参数是程序名字。`v` 表示第二个参数是一个程序参数列表(参数数量可变)。`p` 表示将会使用环境变量 `PATH` 搜索给定的程序名字。在我们上一次的尝试中,它将会基于我们的 `PATH` 环境变量查找`mkdir` 程序。
(还有其他 `exec` 变体,比如 execv、execvpe、execl、execlp、execlpe;你可以 google 它们获取更多的信息。)
`exec` 会用即将运行的新进程替换调用进程的当前内存。在我们的例子中,我们的 shell 进程内存会被替换为 `mkdir` 程序。接着,`mkdir` 成为主进程并创建 `test_dir` 目录。最后该进程退出。
这里的重点在于**我们的 shell 进程已经被 `mkdir` 进程所替换**。这就是我们的 shell 消失且不会等待下一条命令的原因。
因此,我们需要其他的系统调用来解决问题:`fork`。
`fork` 会分配新的内存并拷贝当前进程到一个新的进程。我们称这个新的进程为**子进程**,调用者进程为**父进程**。然后,子进程内存会被替换为被执行的程序。因此,我们的 shell,也就是父进程,可以免受内存替换的危险。
让我们看看修改的代码。
```
...
def execute(cmd_tokens):
### 分叉一个子 shell 进程
### 如果当前进程是子进程,其 `pid` 被设置为 `0`
### 否则当前进程是父进程的话,`pid` 的值
### 是其子进程的进程 ID。
pid = os.fork()
if pid == 0:
### 子进程
### 用被 exec 调用的程序替换该子进程
os.execvp(cmd_tokens[0], cmd_tokens)
elif pid > 0:
### 父进程
while True:
### 等待其子进程的响应状态(以进程 ID 来查找)
wpid, status = os.waitpid(pid, 0)
### 当其子进程正常退出时
### 或者其被信号中断时,结束等待状态
if os.WIFEXITED(status) or os.WIFSIGNALED(status):
break
### 返回状态以告知在 shell_loop 中等待下一个命令
return SHELL_STATUS_RUN
...
```
当我们的父进程调用 `os.fork()` 时,你可以想象所有的源代码被拷贝到了新的子进程。此时此刻,父进程和子进程看到的是相同的代码,且并行运行着。
如果运行的代码属于子进程,`pid` 将为 `0`。否则,如果运行的代码属于父进程,`pid` 将会是子进程的进程 id。
当 `os.execvp` 在子进程中被调用时,你可以想象子进程的所有源代码被替换为正被调用程序的代码。然而父进程的代码不会被改变。
当父进程完成等待子进程退出或终止时,它会返回一个状态,指示继续 shell 循环。
### 运行
现在,你可以尝试运行我们的 shell 并输入 `mkdir test_dir2`。它应该可以正确执行。我们的主 shell 进程仍然存在并等待下一条命令。尝试执行 `ls`,你可以看到已创建的目录。
但是,这里仍有一些问题。
第一,尝试执行 `cd test_dir2`,接着执行 `ls`。它应该会进入到一个空的 `test_dir2` 目录。然而,你将会看到目录并没有变为 `test_dir2`。
第二,我们仍然没有办法优雅地退出我们的 shell。
我们将会在[下篇](https://hackercollider.com/articles/2016/07/06/create-your-own-shell-in-python-part-2/)解决诸如此类的问题。
---
via: <https://hackercollider.com/articles/2016/07/05/create-your-own-shell-in-python-part-1/>
作者:[Supasate Choochaisri](https://disqus.com/by/supasate_choochaisri/) 译者:[cposture](https://github.com/cposture) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='hackercollider.com', port=443): Max retries exceeded with url: /articles/2016/07/05/create-your-own-shell-in-python-part-1/ (Caused by NameResolutionError("<urllib3.connection.HTTPSConnection object at 0x7b83275819c0>: Failed to resolve 'hackercollider.com' ([Errno -2] Name or service not known)")) | null |
7,625 | 使用 Python 创建你自己的 Shell(下) | https://hackercollider.com/articles/2016/07/06/create-your-own-shell-in-python-part-2/ | 2016-07-29T10:36:00 | [
"Python",
"shell"
] | /article-7625-1.html | 在[上篇](/article-7624-1.html)中,我们已经创建了一个 shell 主循环、切分了命令输入,以及通过 `fork` 和 `exec` 执行命令。在这部分,我们将会解决剩下的问题。首先,`cd test_dir2` 命令无法修改我们的当前目录。其次,我们仍无法优雅地从 shell 中退出。

### 步骤 4:内置命令
“`cd test_dir2` 无法修改我们的当前目录” 这句话是对的,但在某种意义上也是错的。在执行完该命令之后,我们仍然处在同一目录,从这个意义上讲,它是对的。然而,目录实际上已经被修改,只不过它是在子进程中被修改。
还记得我们分叉(fork)了一个子进程,然后执行命令,执行命令的过程没有发生在父进程上。结果是我们只是改变了子进程的当前目录,而不是父进程的目录。
然后子进程退出,而父进程在原封不动的目录下继续运行。
因此,这类与 shell 自己相关的命令必须是内置命令。它必须在 shell 进程中执行而不是在分叉中(forking)。
#### cd
让我们从 `cd` 命令开始。
我们首先创建一个 `builtins` 目录。每一个内置命令都会被放进这个目录中。
```
yosh_project
|-- yosh
|-- builtins
| |-- __init__.py
| |-- cd.py
|-- __init__.py
|-- shell.py
```
在 `cd.py` 中,我们通过使用系统调用 `os.chdir` 实现自己的 `cd` 命令。
```
import os
from yosh.constants import *
def cd(args):
os.chdir(args[0])
return SHELL_STATUS_RUN
```
注意,我们会从内置函数返回 shell 的运行状态。所以,为了能够在项目中继续使用常量,我们将它们移至 `yosh/constants.py`。
```
yosh_project
|-- yosh
|-- builtins
| |-- __init__.py
| |-- cd.py
|-- __init__.py
|-- constants.py
|-- shell.py
```
在 `constants.py` 中,我们将状态常量都放在这里。
```
SHELL_STATUS_STOP = 0
SHELL_STATUS_RUN = 1
```
现在,我们的内置 `cd` 已经准备好了。让我们修改 `shell.py` 来处理这些内置函数。
```
...
### 导入常量
from yosh.constants import *
### 使用哈希映射来存储内建的函数名及其引用
built_in_cmds = {}
def tokenize(string):
return shlex.split(string)
def execute(cmd_tokens):
### 从元组中分拆命令名称与参数
cmd_name = cmd_tokens[0]
cmd_args = cmd_tokens[1:]
### 如果该命令是一个内建命令,使用参数调用该函数
if cmd_name in built_in_cmds:
return built_in_cmds[cmd_name](cmd_args)
...
```
我们使用一个 python 字典变量 `built_in_cmds` 作为<ruby> 哈希映射 <rp> ( </rp> <rt> hash map </rt> <rp> ) </rp></ruby>,以存储我们的内置函数。我们在 `execute` 函数中提取命令的名字和参数。如果该命令在我们的哈希映射中,则调用对应的内置函数。
(提示:`built_in_cmds[cmd_name]` 返回能直接使用参数调用的函数引用。)
我们差不多准备好使用内置的 `cd` 函数了。最后一步是将 `cd` 函数添加到 `built_in_cmds` 映射中。
```
...
### 导入所有内建函数引用
from yosh.builtins import *
...
### 注册内建函数到内建命令的哈希映射中
def register_command(name, func):
built_in_cmds[name] = func
### 在此注册所有的内建命令
def init():
register_command("cd", cd)
def main():
###在开始主循环之前初始化 shell
init()
shell_loop()
```
我们定义了 `register_command` 函数,以添加一个内置函数到我们内置的命令哈希映射。接着,我们定义 `init` 函数并且在这里注册内置的 `cd` 函数。
注意这行 `register_command("cd", cd)` 。第一个参数为命令的名字。第二个参数为一个函数引用。为了能够让第二个参数 `cd` 引用到 `yosh/builtins/cd.py` 中的 `cd` 函数引用,我们必须将以下这行代码放在 `yosh/builtins/__init__.py` 文件中。
```
from yosh.builtins.cd import *
```
因此,在 `yosh/shell.py` 中,当我们从 `yosh.builtins` 导入 `*` 时,我们可以得到已经通过 `yosh.builtins` 导入的 `cd` 函数引用。
我们已经准备好了代码。让我们尝试在 `yosh` 同级目录下以模块形式运行我们的 shell,`python -m yosh.shell`。
现在,`cd` 命令可以正确修改我们的 shell 目录了,同时非内置命令仍然可以工作。非常好!
#### exit
最后一块终于来了:优雅地退出。
我们需要一个可以修改 shell 状态为 `SHELL_STATUS_STOP` 的函数。这样,shell 循环可以自然地结束,shell 将到达终点而退出。
和 `cd` 一样,如果我们在子进程中分叉并执行 `exit` 函数,其对父进程是不起作用的。因此,`exit` 函数需要成为一个 shell 内置函数。
让我们从这开始:在 `builtins` 目录下创建一个名为 `exit.py` 的新文件。
```
yosh_project
|-- yosh
|-- builtins
| |-- __init__.py
| |-- cd.py
| |-- exit.py
|-- __init__.py
|-- constants.py
|-- shell.py
```
`exit.py` 定义了一个 `exit` 函数,该函数仅仅返回一个可以退出主循环的状态。
```
from yosh.constants import *
def exit(args):
return SHELL_STATUS_STOP
```
然后,我们导入位于 `yosh/builtins/__init__.py` 文件的 `exit` 函数引用。
```
from yosh.builtins.cd import *
from yosh.builtins.exit import *
```
最后,我们在 `shell.py` 中的 `init()` 函数注册 `exit` 命令。
```
...
### 在此注册所有的内建命令
def init():
register_command("cd", cd)
register_command("exit", exit)
...
```
到此为止!
尝试执行 `python -m yosh.shell`。现在你可以输入 `exit` 优雅地退出程序了。
### 最后的想法
我希望你能像我一样享受创建 `yosh` (**y**our **o**wn **sh**ell)的过程。但我的 `yosh` 版本仍处于早期阶段。我没有处理一些会使 shell 崩溃的极端状况。还有很多我没有覆盖的内置命令。为了提高性能,一些非内置命令也可以实现为内置命令(避免新进程创建时间)。同时,大量的功能还没有实现(请看 [公共特性](http://tldp.org/LDP/Bash-Beginners-Guide/html/x7243.html) 和 [不同特性](http://www.tldp.org/LDP/intro-linux/html/x12249.html))。
我已经在 <https://github.com/supasate/yosh> 中提供了源代码。请随意 fork 和尝试。
现在该是创建你真正自己拥有的 Shell 的时候了。
Happy Coding!
---
via: <https://hackercollider.com/articles/2016/07/06/create-your-own-shell-in-python-part-2/>
作者:[Supasate Choochaisri](https://disqus.com/by/supasate_choochaisri/) 译者:[cposture](https://github.com/cposture) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| null | HTTPSConnectionPool(host='hackercollider.com', port=443): Max retries exceeded with url: /articles/2016/07/06/create-your-own-shell-in-python-part-2/ (Caused by NameResolutionError("<urllib3.connection.HTTPSConnection object at 0x7b8327582710>: Failed to resolve 'hackercollider.com' ([Errno -2] Name or service not known)")) | null |
7,626 | Fedora 中的容器技术:systemd-nspawn | https://fedoramagazine.org/container-technologies-fedora-systemd-nspawn/ | 2016-07-28T16:54:00 | [
"容器",
"systemd"
] | https://linux.cn/article-7626-1.html | 欢迎来到“Fedora 中的容器技术”系列!本文是该系列文章中的第一篇,它将说明你可以怎样使用 Fedora 中各种可用的容器技术。本文将学习 `systemd-nspawn` 的相关知识。

### 容器是什么?
一个容器就是一个用户空间实例,它能够在与托管容器的系统(叫做宿主系统)相隔离的环境中运行一个程序或者一个操作系统。这和 `chroot` 或 [虚拟机](https://en.wikipedia.org/wiki/Virtual_machine) 的思想非常类似。运行在容器中的进程是由与宿主操作系统相同的内核来管理的,但它们是与宿主文件系统以及其它进程隔离开的。
### 什么是 systemd-nspawn?
systemd 项目认为应当将容器技术变成桌面的基础部分,并且应当和用户的其余系统集成在一起。为此,systemd 提供了 `systemd-nspawn`,这款工具能够使用多种 Linux 技术创建容器。它也提供了一些容器管理工具。
`systemd-nspawn` 和 `chroot` 在许多方面都是类似的,但是前者更加强大。它虚拟化了文件系统、进程树以及客户系统中的进程间通信。它的吸引力在于它提供了很多用于管理容器的工具,例如用来管理容器的 `machinectl`。由 `systemd-nspawn` 运行的容器将会与 systemd 组件一同运行在宿主系统上。举例来说,一个容器的日志可以输出到宿主系统的日志中。
在 Fedora 24 上,`systemd-nspawn` 已经从 systemd 软件包分离出来了,所以你需要安装 `systemd-container` 软件包。一如往常,你可以使用 `dnf install systemd-container` 进行安装。
### 创建容器
使用 `systemd-nspawn` 创建一个容器是很容易的。假设你有一个专门为 Debian 创造的应用,并且无法在其它发行版中正常运行。那并不是一个问题,我们可以创造一个容器!为了设置容器使用最新版本的 Debian(现在是 Jessie),你需要挑选一个目录来放置你的系统。我暂时将使用目录 `~/DebianJessie`。
一旦你创建完目录,你需要运行 `debootstrap`,你可以从 Fedora 仓库中安装它。对于 Debian Jessie,你运行下面的命令来初始化一个 Debian 文件系统。
```
$ debootstrap --arch=amd64 stable ~/DebianJessie
```
以上默认你的架构是 x86\_64。如果不是的话,你必须将架构的名称改为 `amd64`。你可以使用 `uname -m` 得知你的机器架构。
一旦设置好你的根目录,你就可以使用下面的命令来启动你的容器。
```
$ systemd-nspawn -bD ~/DebianJessie
```
容器将会在数秒后准备好并运行,当你试图登录时就会注意到:你无法使用你的系统上任何账户。这是因为 `systemd-nspawn` 虚拟化了用户。修复的方法很简单:将之前的命令中的 `-b` 移除即可。你将直接进入容器的 root 用户的 shell。此时,你只能使用 `passwd` 命令为 root 设置密码,或者使用 `adduser` 命令添加一个新用户。一旦设置好密码或添加好用户,你就可以把 `-b` 标志添加回去然后继续了。你会进入到熟悉的登录控制台,然后你使用设置好的认证信息登录进去。
以上对于任意你想在容器中运行的发行版都适用,但前提是你需要使用正确的包管理器创建系统。对于 Fedora,你应使用 DNF 而非 `debootstrap`。想要设置一个最小化的 Fedora 系统,你可以运行下面的命令,要将“/absolute/path/”替换成任何你希望容器存放的位置。
```
$ sudo dnf --releasever=24 --installroot=/absolute/path/ install systemd passwd dnf fedora-release
```

### 设置网络
如果你尝试启动一个服务,但它绑定了你宿主机正在使用的端口,你将会注意到这个问题:你的容器正在使用和宿主机相同的网络接口。幸运的是,`systemd-nspawn` 提供了几种可以将网络从宿主机分开的方法。
#### 本地网络
第一种方法是使用 `--private-network` 标志,它默认仅创建一个回环设备。这对于你不需要使用网络的环境是非常理想的,例如构建系统和其它持续集成系统。
#### 多个网络接口
如果你有多个网络接口设备,你可以使用 `--network-interface` 标志给容器分配一个接口。想要给我的容器分配 `eno1`,我会添加选项 `--network-interface=eno1`。当某个接口分配给一个容器后,宿主机就不能同时使用那个接口了。只有当容器彻底关闭后,宿主机才可以使用那个接口。
#### 共享网络接口
对于我们中那些并没有额外的网络设备的人来说,还有其它方法可以访问容器。一种就是使用 `--port` 选项。这会将容器中的一个端口定向到宿主机。使用格式是 `协议:宿主机端口:容器端口`,这里的协议可以是 `tcp` 或者 `udp`,`宿主机端口` 是宿主机的一个合法端口,`容器端口` 则是容器中的一个合法端口。你可以省略协议,只指定 `宿主机端口:容器端口`。我通常的用法类似 `--port=2222:22`。
你可以使用 `--network-veth` 启用完全的、仅宿主机模式的网络,这会在宿主机和容器之间创建一个虚拟的网络接口。你也可以使用 `--network-bridge` 桥接二者的连接。
### 使用 systemd 组件
如果你容器中的系统含有 D-Bus,你可以使用 systemd 提供的实用工具来控制并监视你的容器。基础安装的 Debian 并不包含 `dbus`。如果你想在 Debian Jessie 中使用 `dbus`,你需要运行命令 `apt install dbus`。
#### machinectl
为了能够轻松地管理容器,systemd 提供了 `machinectl` 实用工具。使用 `machinectl`,你可以使用 `machinectl login name` 登录到一个容器中、使用 `machinectl status name`检查状态、使用 `machinectl reboot name` 启动容器或者使用 `machinectl poweroff name` 关闭容器。
### 其它 systemd 命令
多数 systemd 命令,例如 `journalctl`, `systemd-analyze` 和 `systemctl`,都支持使用 `--machine` 选项来指定容器。例如,如果你想查看一个名为 “foobar” 的容器的日志,你可以使用 `journalctl --machine=foobar`。你也可以使用 `systemctl --machine=foobar status service` 来查看运行在这个容器中的服务状态。

### 和 SELinux 一起工作
如果你要使用 SELinux 强制模式(Fedora 默认模式),你需要为你的容器设置 SELinux 环境。想要那样的话,你需要在宿主系统上运行下面两行命令。
```
$ semanage fcontext -a -t svirt_sandbox_file_t "/path/to/container(/.*)?"
$ restorecon -R /path/to/container/
```
确保使用你的容器路径替换 “/path/to/container”。对于我的容器 "DebianJessie",我会运行下面的命令:
```
$ semanage fcontext -a -t svirt_sandbox_file_t "/home/johnmh/DebianJessie(/.*)?"
$ restorecon -R /home/johnmh/DebianJessie/
```
---
via: <https://fedoramagazine.org/container-technologies-fedora-systemd-nspawn/>
作者:[John M. Harris, Jr.](https://fedoramagazine.org/container-technologies-fedora-systemd-nspawn/) 译者:[ChrisLeeGit](https://github.com/chrisleegit) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Welcome to the “Container technologies in Fedora” series! This is the first article in a series of articles that will explain how you can use the various container technologies available in Fedora. This first article will deal with* systemd-nspawn*.*
## What is a container?
A container is a user-space instance which can be used to run a program or an operating system in isolation from the system hosting the container (called the **host system**). The idea is very similar to a chroot or a [virtual machine](https://en.wikipedia.org/wiki/Virtual_machine). The processes running in a container are managed by the same kernel as the host operating system, but they are isolated from the host file system, and from the other processes.
## What is systemd-nspawn?
The systemd project considers container technologies as something that should fundamentally be part of the desktop and that should integrate with the rest of the user’s systems. To this end, systemd provides *systemd-nspawn*, a tool which is able to create containers using various Linux technologies. It also provides some container management tools.
In many ways, *systemd-nspawn* is similar to *chroot*, but is much more powerful. It virtualizes the file system, process tree, and inter-process communication of the guest system. Much of its appeal lies in the fact that it provides a number of tools, such as *machinectl*, for managing containers. Containers run by *systemd-nspawn* will integrate with the systemd components running on the host system. As an example, journal entries can be logged from a container in the host system’s journal.
In Fedora 24, *systemd-nspawn* has been split out from the systemd package, so you’ll need to install the *systemd-container* package. As usual, you can do that with a *dnf install systemd-container*.
## Creating the container
Creating a container with *systemd-nspawn* is easy. Let’s say you have an application made for Debian, and it doesn’t run well anywhere else. That’s not a problem, we can make a container! To set up a container with the latest version of Debian (at this point in time, Jessie), you need to pick a directory to set up your system in. I’ll be using *~/DebianJessie* for now.
Once the directory has been created, you need to run *debootstrap*, which you can install from the Fedora repositories. For Debian Jessie, you run the following command to initialize a Debian file system.
$ debootstrap --arch=amd64 stable ~/DebianJessie
This assumes your architecture is x86_64. If it isn’t, you must change *amd64* to the name of your architecture. You can find your machine’s architecture with *uname -m*.
Once your root directory is set up, you will start your container with the following command.
$ systemd-nspawn -bD ~/DebianJessie
You’ll be up and running within seconds. You’ll notice something as soon as you try to log in: you can’t use any accounts on your system. This is because *systemd-nspawn* virtualizes users. The fix is simple: remove *-b* from the previous command. You’ll boot directly to the root shell in the container. From there, you can just use *passwd* to set a password for root, or you can use *adduser* to add a new user. As soon as you’re done with that, go ahead and put the *-b* flag back. You’ll boot to the familiar login console and you log in with the credentials you set.
All of this applies for any distribution you would want to run in the container, but you need to create the system using the correct package manager. For Fedora, you would use DNF instead of *debootstrap*. To set up a minimal Fedora system, you can run the following command, replacing the absolute path with wherever you want the container to be.
$ sudo dnf --releasever=24 --installroot=/absolute/path/ install systemd passwd dnf fedora-release
## Setting up the network
You’ll notice an issue if you attempt to start a service that binds to a port currently in use on your host system. Your container is using the same network interface. Luckily, *systemd-nspawn* provides several ways to achieve separate networking from the host machine.
#### Local networking
The first method uses the *–private-network* flag, which only creates a loopback device by default. This is ideal for environments where you don’t need networking, such as build systems and other continuous integration systems.
#### Multiple networking interfaces
If you have multiple network devices, you can give one to the container with the *–network-interface* flag. To give *eno1* to my container, I would add the flag *–network-interface=eno1*. While an interface is assigned to a container, the host can’t use it at the same time. When the container is completely shut down, it will be available to the host again.
#### Sharing network interfaces
For those of us who don’t have spare network devices, there are other options for providing access to the container. One of those is the *–port* flag. This forwards a port on the container to the host. The format is *protocol:host:container*, where protocol is either *tcp* or *udp*, *host* is a valid port number on the host, and *container* is a valid port on the container. You can omit the protocol and specify only *host:container*. I often use something similar to *–port=2222:22*.
You can enable complete, host-only networking with the *–network-veth* flag, which creates a virtual Ethernet interface between the host and the container. You can also bridge two connections with *–network-bridge*.
## Using systemd components
If the system in your container has D-Bus, you can use systemd’s provided utilities to control and monitor your container. Debian doesn’t include *dbus* in the base install. If you want to use it with Debian Jessie, you’ll want to run *apt install dbus*.
#### machinectl
To easily manage containers, systemd provides the *machinectl* utility. Using *machinectl*, you can log in to a container with *machinectl login name*, check the status with
*machinectl status*, reboot with
`name`*machinectl reboot*, or power it off with
`name`*machinectl poweroff*.
`name`## Other systemd commands
Most systemd commands, such as *journalctl*, *systemd-analyze*, and *systemctl*, support containers with the *–machine* option. For example, if you want to see the journals of a container named “foobar”, you can use *journalctl –machine=foobar*. You can also see the status of a service running in this container with *systemctl –machine=foobar status service*.
## Working with SELinux
If you’re running with SELinux enforcing (the default in Fedora), you’ll need to set the SELinux context for your container. To do that, you need to run the following two commands on the host system.
$ semanage fcontext -a -t svirt_sandbox_file_t "/path/to/container(/.*)?" $ restorecon -R /path/to/container/
Make sure you replace “/path/to/container” with the path to your container. For my container, “DebianJessie”, I would run the following:
$ semanage fcontext -a -t svirt_sandbox_file_t "/home/johnmh/DebianJessie(/.*)?" $ restorecon -R /home/johnmh/DebianJessie/
## biji
can I run xwindow app from inside container?
## John M. Harris, Jr.
If you’re sharing host networking, I can confirm that you can. If you aren’t, you may run into issues I don’t know about. Just make sure to set the DISPLAY variable.
## Anass Ahmed
Can you elaborate more?
I started debian with that command:
. What should I do to make it run specifc X app in my current X session?
## Anass Ahmed
After some muddling through searches and topics, I was able to do it 😀
This Guide was great: http://fabiorehm.com/blog/2014/09/11/running-gui-apps-with-docker/
I can now see the differences between the spotify version I’ve here in Fedora and the one that natively work under Debian 😀
## Oleg Pykhalov
I did it in docker and lxc, so pretty sure you can, check info about X11 socket and xhost
## baoboa
look there https://wiki.archlinux.org/index.php/Systemd-nspawn#X_environment for nspawn specific
“–bind=/tmp/.X11-unix:/tmp/.X11-unix” option is needed in addition of setting up the DISPLAY variable inside the container
## Pierre
Interesting. I wonder if there are advantages of using this instead of docker.
Regards, Pierre
## Robert Smol
I think the main advantage is running multiple processes inside the container (e.g. postgresql+uwsgi+nginx) + I guess it also hes better separation then docker. Now I am also guessing, but it looks like you do have direct access to the container filesystem.
## Robert Smol
The commands for SELinux should be run under root user (from $ I was guessing normal user and got :SELinux policy is not managed or store cannot be accessed.)
## Steven Snow
Would you also be able to use this for ARM based OS builds (on X86-64 hardware)? Or does the native architecture dictate the usage?
## Oleg Pykhalov
As i know you can use only x86 on x86 with containers. For others architectures you need a hypervisor like qemu.
## lahcen
can i run gui apps with container?
## Paul Stevensen
Is it possible for a running process (or thread) to enter the container? And is it possible for this process to exit the container to continue in the outside context?
## Wadiyo
Thank for sharing.
I can’t run container in window 7 not yet?
Thank
## baoboa
your are using the same kernel as the host so only linux OS are possible as container.
## biji
I’m trying to nylas sync engine using systemd-nspawn, but failed when installing mysql. would you please shed some light 😀
https://github.com/nylas/sync-engine/wiki/Running-under-systemd-nspawn |
7,628 | Fedora 内核是由什么构成的? | https://fedoramagazine.org/makes-fedora-kernel/ | 2016-07-29T14:40:34 | [
"内核",
"Fedora"
] | https://linux.cn/article-7628-1.html | 
每个 Fedora 系统都运行着一个内核。许多代码片段组合在一起使之成为现实。
每个 Fedora 内核都起始于一个来自于[上游社区](http://www.kernel.org/)的基线版本——通常称之为 vanilla 内核。上游内核就是标准。(Fedora 的)目标是包含尽可能多的上游代码,这样使得 bug 修复和 API 更新更加容易,同时也会有更多的人审查代码。理想情况下,Fedora 能够直接获取 kernel.org 的内核,然后发送给所有用户。
现实情况是,使用 vanilla 内核并不能完全满足 Fedora。Vanilla 内核可能并不支持一些 Fedora 用户希望拥有的功能。用户接收的 [Fedora 内核] 是在 vanilla 内核之上打了很多补丁的内核。这些补丁被认为“<ruby> 不在树上 <rp> ( </rp> <rt> out of tree </rt> <rp> ) </rp></ruby>”。许多这些位于补丁树之外的补丁都不会存在太久。如果某补丁能够修复一个问题,那么该补丁可能会被合并到 Fedora 树,以便用户能够更快地收到修复。当内核变基到一个新版本时,在新版本中的补丁都将被清除。
一些补丁会在 Fedora 内核树上存在很长时间。一个很好的例子是,安全启动补丁就是这类补丁。这些补丁提供了 Fedora 希望支持的功能,即使上游社区还没有接受它们。保持这些补丁更新是需要付出很多努力的,所以 Fedora 尝试减少不被上游内核维护者接受的补丁数量。
通常来说,想要在 Fedora 内核中获得一个补丁的最佳方法是先给 [Linux 内核邮件列表(LKML)](http://www.labbott.name/blog/2015/10/02/the-art-of-communicating-with-lkml/) 发送补丁,然后请求将该补丁包含到 Fedora 中。如果某个维护者接受了补丁,就意味着 Fedora 内核树中将来很有可能会包含该补丁。一些来自于 GitHub 等地方的还没有提交给 LKML 的补丁是不可能进入内核树的。首先向 LKML 发送补丁是非常重要的,它能确保 Fedora 内核树中携带的补丁是功能正常的。如果没有社区审查,Fedora 最终携带的补丁将会充满 bug 并会导致问题。
Fedora 内核中包含的代码来自许多地方。一切都需要提供最佳的体验。
---
via: <https://fedoramagazine.org/makes-fedora-kernel/>
作者:[Laura Abbott](https://fedoramagazine.org/makes-fedora-kernel/) 译者:[ChrisLeeGit](https://github.com/chrisleegit) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Every Fedora system runs a kernel. Many pieces of code come together to make this a reality.
Each release of the Fedora kernel starts with a baseline release from the [upstream community](http://www.kernel.org). This is often called a ‘vanilla’ kernel. The upstream kernel is the standard. The goal is to have as much code upstream as possible. This makes it easier for bug fixes and API updates to happen as well as having more people review the code. In an ideal world, Fedora would be able to to take the kernel straight from kernel.org and send that out to all users.
Realistically, using the vanilla kernel isn’t complete enough for Fedora. Some features Fedora users want may not be available. The [Fedora kernel](http://pkgs.fedoraproject.org/cgit/rpms/kernel.git/) that users actually receive contains a number of patches on top of the vanilla kernel. These patches are considered “out of tree.” Many of these patches will not exist out of tree patches very long. If patches are available to fix an issue, the patches may be pulled in to the Fedora tree so the fix can go out to users faster. When the kernel is rebased to a new version, the patches will be removed if they are in the new version.
Some patches remain in the Fedora kernel tree for an extended period of time. A good example of patches that fall into this category are the secure boot patches. These patches provide a feature Fedora wants to support even though the upstream community has not yet accepted them. It takes effort to keep these patches up to date so Fedora tries to minimize the number of patches that are carried without being accepted by an upstream kernel maintainer.
Generally, the best way to get a patch included in the Fedora kernel is to [send it to the Linux Kernel Mailing List (LKML)](http://www.labbott.name/blog/2015/10/02/the-art-of-communicating-with-lkml/) first and then ask for it to be included in Fedora. If a patch has been accepted by a maintainer it stands a very high chance of being included in the Fedora kernel tree. Patches that come from places like github which have not been submitted to LKML are unlikely to be taken into the tree. It’s important to send the patches to LKML first to ensure Fedora is carrying the correct patches in its tree. Without the community review, Fedora could end up carrying patches which are buggy and cause problems.
The Fedora kernel contains code from many places. All of it is necessary to give the best experience possible.
## Lukes®
Is it True that Kernel race is true master race.
## Gary
A good view of what Fedora kernel is all about. Also, this just goes to show how great the open source community is. Fedora finds a bug fix on their version of the kernel, and submit it upstream. If it’s accepted the kernel includes the bug fix and all the other distros benefit, and indeed everyone using the kernel. Same goes if someone else contributes, the Fedora team benefits, with less bugs, and less maintenance work on the kernel itself.
## Leslie Satenstein
Hi Laura,
A well written summary but your article was too short. What is “rebaseing ” and what about multilanguage support? French/English/Russian/Spanish etc. I am interested in what a rebase means versus an update.
## David
Read something about how git works 😉
## Onyeibo Oku
Something to do with version control management– think CVS/Surbversion/Git/Mercurial etc.
This might help –> https://dotdev.co/git-rebase-for-reasonable-developers-26dc8776dc25#.da3gofmpo
https://git-scm.com/book/en/v2/Git-Branching-Rebasing
https://www.sbf5.com/~cduan/technical/git/git-5.shtml
## Slartibartfas
It’s part of git.
For extensive information type “man git” or “man git-rebase” in a Terminal or look at git’s Wikipedia page.
## Ryan Lerch
As a concept, rebasing is close to what people do think when you say “update”, however the term is slighty more nuanced than that.
Typically, when doing a rebase, you are pulling down the newest version from upstream, and then checking if the patches you are holding in your version still work or are still needed.
For example, say we have Fedora kernel version 4.4.13, and it has 3 patches that are not in the upstream (vanilla) kernel. Rebasing is typically referred to the process of pulling down a newer version of the Kernel from upstream, say 4.6.1, then checking to see if the 3 patches we had applied to 4.4.13 still function as expected on the newer 4.6.1 kernel. Additionally, some of these 3 patches might also not be needed anymore if they were merged upstream, so they would be removed.
## Onyeibo Oku
I like this explanation. Really simple and illustrative
## Robin
A rebase is simply that the kernel version jumps from lets say 4.5 to 4.7 or in directly to 6.** version.
Someone please correct me if im wrong
## Curtis nelson
Timely update for new F24 users. Link to the cgit pkgs site is pure gold. Thanks!
## Wilman Zen
Is latest kernel in F24 already support my Bumblebee card? because before, F24 got hang after install Bumblebee driver.
## Andrew Jamison
Coming from a Linux Ethusiast but someone still very much stuck in Windows for 90% of my tasks can someone explain how the Linux Kernel works differently then the Windows Kernel without going to much into Windows Vs Linux wars? I am just currious on a code level what is really different about the two and how they handle resources/hardware requests.
## Wally Kramer
You are not stuck in Windows. You can leave it behind at any time, though there will be a learning curve.
Many of the differences you can rejoice about. For example, you don’t actually like the complexity of Outlook, right? And how about all those useless system notification messages?
There is a Fedora alternative to every Windows application. In many cases, you can run proprietary Windows applications directly on Fedora! Just type “wine my_windows_app.exe”. Wine is a Windows environment emulator which works well on properly written (follows Microsofts rules for application design) Windows applications. Amusingly, wine does not work well on Microsoft’s flagship applications like Word, Powerpoint, Excel, Outlook, IE, etc., because they did not follow the rules they require of non-MS developers. For some Windows applications, there is no need for a Fedora replacement: Linux is naturally virus resistant. Its security model and open source philosophy do not provide a thriving virus laboratory. Who really wanted to hassle with virus protection in the first place?
LibreOffice is more than a match for Microsoft’s Office suite. For example, LibreOffice Writer is more compatible with Word files than Word is! Writer can easily open and edit ancient Word files which Office 2013 chokes on. And LibreOffice Calc does not (by default) provide all the “corrections” that Excel does when entering data and formulas.
As for the system differences, it largely has to do with clear delineation between privileged and non-privileged operations. Windows is a muddle of patches upon patches. Linux derives from a clear system vs. application functionality derived from Unix’s 1975 architecture. |
7,631 | 如何在 Ubuntu Linux 16.04上安装开源的 Discourse 论坛 | http://linuxpitstop.com/install-discourse-on-ubuntu-linux-16-04/ | 2016-07-30T08:57:00 | [
"Discourse",
"论坛"
] | https://linux.cn/article-7631-1.html | Discourse 是一个开源的论坛,它可以以邮件列表、聊天室或者论坛等多种形式工作。它是一个广受欢迎的现代的论坛工具。在服务端,它使用 Ruby on Rails 和 Postgres 搭建, 并且使用 Redis 缓存来减少读取时间 , 在客户端,它使用支持 Java Script 的浏览器。它非常容易定制,结构良好,并且它提供了转换插件,可以对你现存的论坛、公告板进行转换,例如: vBulletin、phpBB、Drupal、SMF 等等。在这篇文章中,我们将学习在 Ubuntu 操作系统下安装 Discourse。

它以安全作为设计思想,所以发垃圾信息的人和黑客们不能轻易的实现其企图。它能很好的支持各种现代设备,并可以相应的调整以手机和平板的显示。
### 在 Ubuntu 16.04 上安装 Discourse
让我们开始吧 ! 最少需要 1G 的内存,并且官方支持的安装过程需要已经安装了 docker。 说到 docker,它还需要安装Git。要满足以上的两点要求我们只需要运行下面的命令:
```
wget -qO- https://get.docker.com/ | sh
```

用不了多久就安装好了 docker 和 Git,安装结束以后,在你的系统上的 /var 分区创建一个 Discourse 文件夹(当然你也可以选择其他的分区)。
```
mkdir /var/discourse
```
现在我们来克隆 Discourse 的 Github 仓库到这个新建的文件夹。
```
git clone https://github.com/discourse/discourse_docker.git /var/discourse
```
进入这个克隆的文件夹。
```
cd /var/discourse
```

你将看到“discourse-setup” 脚本文件,运行这个脚本文件进行 Discourse 的初始化。
```
./discourse-setup
```
**备注: 在安装 discourse 之前请确保你已经安装好了邮件服务器。**
安装向导将会问你以下六个问题:
```
Hostname for your Discourse?
Email address for admin account?
SMTP server address?
SMTP user name?
SMTP port [587]:
SMTP password? []:
```

当你提交了以上信息以后, 它会让你提交确认, 如果一切都很正常,点击回车以后安装开始。

现在“坐等放宽”,需要花费一些时间来完成安装,倒杯咖啡,看看有什么错误信息没有。

安装成功以后看起来应该像这样。

现在打开浏览器,如果已经做了域名解析,你可以使用你的域名来连接 Discourse 页面 ,否则你只能使用IP地址了。你将看到如下信息:

就是这个,点击 “Sign Up” 选项创建一个新的账户,然后进行你的 Discourse 设置。

### 结论
它安装简便,运行完美。 它拥有现代论坛所有必备功能。它以 GPL 发布,是完全开源的产品。简单、易用、以及特性丰富是它的最大特点。希望你喜欢这篇文章,如果有问题,你可以给我们留言。
---
via: <http://linuxpitstop.com/install-discourse-on-ubuntu-linux-16-04/>
作者:[Aun](http://linuxpitstop.com/author/aun/) 译者:[kokialoves](https://github.com/kokialoves) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
7,633 | JStock:Linux 上不错的股票投资组合管理软件 | http://xmodulo.com/stock-portfolio-management-software-Linux.html | 2016-07-31T15:22:26 | [
"股票",
"Jstock"
] | https://linux.cn/article-7633-1.html | 如果你在股票市场做投资,那么你可能非常清楚投资组合管理计划有多重要。管理投资组合的目标是依据你能承受的风险,时间层面的长短和资金盈利的目标去为你量身打造的一种投资计划。鉴于这类软件的重要性,因此从来不会缺乏商业性的 app 和股票行情检测软件,每一个都可以兜售复杂的投资组合以及跟踪报告功能。

对于我们这些 Linux 爱好者们,我也找到了一些**好用的开源投资组合管理工具**,用来在 Linux 上管理和跟踪股票的投资组合,这里高度推荐一个基于 java 编写的管理软件 [JStock](http://jstock.org/)。如果你不是一个 java 粉,也许你会放弃它,JStock 需要运行在沉重的 JVM 环境上。但同时,在每一个安装了 JRE 的环境中它都可以马上运行起来,在你的 Linux 环境中它会运行的很顺畅。
“开源”就意味着免费或标准低下的时代已经过去了。鉴于 JStock 只是一个个人完成的产物,作为一个投资组合管理软件它最令人印象深刻的是包含了非常多实用的功能,以上所有的荣誉属于它的作者 Yan Cheng Cheok!例如,JStock 支持通过监视列表去监控价格,多种投资组合,自选/内置的股票指标与相关监测,支持27个不同的股票市场和跨平台的云端备份/还原。JStock 支持多平台部署(Linux, OS X, Android 和 Windows),你可以通过云端保存你的 JStock 投资组合,并通过云平台无缝的备份/还原到其他的不同平台上面。
现在我将向你展示如何安装以及使用过程的一些具体细节。
### 在 Linux 上安装 JStock
因为 JStock 使用Java编写,所以必须[安装 JRE](http://ask.xmodulo.com/install-java-runtime-Linux.html)才能让它运行起来。小提示,JStock 需要 JRE1.7 或更高版本。如你的 JRE 版本不能满足这个需求,JStock 将会运行失败然后出现下面的报错。
```
Exception in thread "main" java.lang.UnsupportedClassVersionError: org/yccheok/jstock/gui/JStock : Unsupported major.minor version 51.0
```
在你的 Linux 上安装好了 JRE 之后,从其官网下载最新的发布的 JStock,然后加载启动它。
```
$ wget https://github.com/yccheok/jstock/releases/download/release_1-0-7-13/jstock-1.0.7.13-bin.zip
$ unzip jstock-1.0.7.13-bin.zip
$ cd jstock
$ chmod +x jstock.sh
$ ./jstock.sh
```
教程的其他部分,让我来给大家展示一些 JStock 的实用功能
### 监视监控列表中股票价格的波动
使用 JStock 你可以创建一个或多个监视列表,它可以自动的监视股票价格的波动并给你提供相应的通知。在每一个监视列表里面你可以添加多个感兴趣的股票进去。之后在“Fall Below”和“Rise Above”的表格里添加你的警戒值,分别设定该股票的最低价格和最高价格。

例如你设置了 AAPL 股票的最低/最高价格分别是 $102 和 $115.50,只要在价格低于 $102 或高于 $115.50 时你就得到桌面通知。
你也可以设置邮件通知,这样你将收到一些价格信息的邮件通知。设置邮件通知在“Options”菜单里,在“Alert”标签中国,打开“Send message to email(s)”,填入你的 Gmail 账户。一旦完成 Gmail 认证步骤,JStock 就会开始发送邮件通知到你的 Gmail 账户(也可以设置其他的第三方邮件地址)。

### 管理多个投资组合
JStock 允许你管理多个投资组合。这个功能对于你使用多个股票经纪人时是非常实用的。你可以为每个经纪人创建一个投资组合去管理你的“买入/卖出/红利”用来了解每一个经纪人的业务情况。你也可以在“Portfolio”菜单里面选择特定的投资组合来切换不同的组合项目。下面是一张截图用来展示一个假设的投资组合。

你也可以设置付给中介费,你可以为每个买卖交易设置中介费、印花税以及结算费。如果你比较懒,你也可以在选项菜单里面启用自动费用计算,并提前为每一家经济事务所设置费用方案。当你为你的投资组合增加交易之后,JStock 将自动的计算并计入费用。

### 使用内置/自选股票指标来监控
如果你要做一些股票的技术分析,你可能需要基于各种不同的标准来监控股票(这里叫做“股票指标”)。对于股票的跟踪,JStock提供多个[预设的技术指示器](http://jstock.org/ma_indicator.html) 去获得股票上涨/下跌/逆转指数的趋势。下面的列表里面是一些可用的指标。
* 平滑异同移动平均线(MACD)
* 相对强弱指标 (RSI)
* 资金流向指标 (MFI)
* 顺势指标 (CCI)
* 十字线
* 黄金交叉线,死亡交叉线
* 涨幅/跌幅
开启预设指示器能需要在 JStock 中点击“Stock Indicator Editor”标签。之后点击右侧面板中的安装按钮。选择“Install from JStock server”选项,之后安装你想要的指示器。

一旦安装了一个或多个指示器,你可以用他们来扫描股票。选择“Stock Indicator Scanner”标签,点击底部的“Scan”按钮,选择需要的指示器。

当你选择完需要扫描的股票(例如, NYSE, NASDAQ)以后,JStock 将执行该扫描,并将该指示器捕获的结果通过列表展现。

除了预设指示器以外,你也可以使用一个图形化的工具来定义自己的指示器。下面这张图例用于监控当前价格小于或等于60天平均价格的股票。

### 通过云在 Linux 和 Android JStock 之间备份/恢复
另一个非常棒的功能是 JStock 支持云备份恢复。Jstock 可以通过 Google Drive 把你的投资组合/监视列表在云上备份和恢复,这个功能可以实现在不同平台上无缝穿梭。如果你在两个不同的平台之间来回切换使用 Jstock,这种跨平台备份和还原非常有用。我在 Linux 桌面和 Android 手机上测试过我的 Jstock 投资组合,工作的非常漂亮。我在 Android 上将 Jstock 投资组合信息保存到 Google Drive 上,然后我可以在我的 Linux 版的 Jstock 上恢复它。如果能够自动同步到云上,而不用我手动地触发云备份/恢复就更好了,十分期望这个功能出现。


如果你在从 Google Drive 还原之后不能看到你的投资信息以及监视列表,请确认你的国家信息与“Country”菜单里面设置的保持一致。
JStock 的安卓免费版可以从 [Google Play Store](https://play.google.com/store/apps/details?id=org.yccheok.jstock.gui) 获取到。如果你需要完整的功能(比如云备份,通知,图表等),你需要一次性支付费用升级到高级版。我认为高级版物有所值。

写在最后,我应该说一下它的作者,Yan Cheng Cheok,他是一个十分活跃的开发者,有bug及时反馈给他。这一切都要感谢他!!!
关于 JStock 这个投资组合跟踪软件你有什么想法呢?
---
via: <http://xmodulo.com/stock-portfolio-management-software-Linux.html>
作者:[Dan Nanni](http://xmodulo.com/author/nanni) 译者:[ivo-wang](https://github.com/ivo-wang) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://Linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,634 | 在浏览器中体验 Ubuntu | https://itsfoss.com/ubuntu-online-demo/ | 2016-07-31T18:05:00 | [
"Ubuntu"
] | https://linux.cn/article-7634-1.html | [Ubuntu](http://www.ubuntu.com/) 的背后的公司 [Canonical](http://www.canonical.com/) 为 Linux 推广做了很多努力。无论你有多么不喜欢 Ubuntu,你必须承认它对 “Linux 易用性”的影响。Ubuntu 以及其衍生是使用最多的 Linux 版本。
为了进一步推广 Ubuntu Linux,Canonical 把它放到了浏览器里,你可以在任何地方使用这个 [Ubuntu 演示版](http://tour.ubuntu.com/en/)。 它将帮你更好的体验 Ubuntu,以便让新人更容易决定是否使用它。
你可能争辩说 USB 版的 Linux 更好。我同意,但是你要知道你要下载 ISO,创建 USB 启动盘,修改配置文件,然后才能使用这个 USB 启动盘来体验。这么乏味并不是每个人都乐意这么干的。 在线体验是一个更好的选择。
那么,你能在 Ubuntu 在线看到什么。实际上并不多。
你可以浏览文件,你可以使用 Unity Dash,浏览 Ubuntu 软件中心,甚至装几个应用(当然它们不会真的安装),看一看文件浏览器和其它一些东西。以上就是全部了。但是在我看来,这已经做的很好了,让你知道它是个什么,对这个流行的操作系统有个直接感受。



如果你的朋友或者家人对试试 Linux 抱有兴趣,但是想在安装前想体验一下 Linux 。你可以给他们以下链接:[Ubuntu 在线导览](http://tour.ubuntu.com/en/) 。
---
via: <https://itsfoss.com/ubuntu-online-demo/>
作者:[Abhishek Prakash](https://itsfoss.com/author/abhishek/) 译者:[kokialoves](https://github.com/kokialoves) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,635 | GNU KHATA:开源的会计管理软件 | https://itsfoss.com/using-gnu-khata/ | 2016-08-01T10:35:00 | [
"Khata",
"财务"
] | https://linux.cn/article-7635-1.html | 作为一个活跃的 Linux 爱好者,我经常向我的朋友们介绍 Linux,帮助他们选择最适合他们的发行版本,同时也会帮助他们安装一些适用于他们工作的开源软件。
但是在这一次,我就变得很无奈。我的叔叔,他是一个自由职业的会计师。他会有一系列的为了会计工作的漂亮而成熟的付费软件。我不那么确定我能在在开源软件中找到这么一款可以替代的软件——直到昨天。

Abhishek 给我推荐了一些[很酷的软件](https://itsfoss.com/category/apps/),而其中 GNU Khata 脱颖而出。
[GNU Khata](http://www.gnukhata.in/) 是一个会计工具。 或者,我应该说成是一系列的会计工具集合?它就像经济管理方面的 [Evernote](https://evernote.com/) 一样。它的应用是如此之广,以至于它不但可以用于个人的财务管理,也可以用于大型公司的管理,从店铺存货管理到税率计算,都可以有效处理。
有个有趣的地方,Khata 这个词在印度或者是其他的印度语国家中意味着账户,所以这个会计软件叫做 GNU Khata。
### 安装
互联网上有很多关于旧的 Web 版本的 Khata 安装介绍。现在,GNU Khata 只能用在 Debian/Ubuntu 和它们的衍生版本中。我建议你按照 GNU Khata 官网给出的如下步骤来安装。我们来快速过一下。
* 从[这里](https://cloud.openmailbox.org/index.php/s/L8ppsxtsFq1345E/download)下载安装器。
* 在下载目录打开终端。
* 粘贴复制以下的代码到终端,并且执行。
```
sudo chmod 755 GNUKhatasetup.run
sudo ./GNUKhatasetup.run
```
这就结束了,从你的 Dash 或者是应用菜单中启动 GNU Khata 吧。
### 第一次启动
GNU Khata 在浏览器中打开,并且展现以下的画面。

填写组织的名字、组织形式,财务年度并且点击 proceed 按钮进入管理设置页面。

仔细填写你的用户名、密码、安全问题及其答案,并且点击“create and login”。

你已经全部设置完成了。使用菜单栏来开始使用 GNU Khata 来管理你的财务吧。这很容易。
### 移除 GNU KHATA
如果你不想使用 GNU Khata 了,你可以执行如下命令移除:
```
sudo apt-get remove --auto-remove gnukhata-core-engine
```
你也可以通过新立得软件管理来删除它。
### GNU KHATA 真的是市面上付费会计应用的竞争对手吗?
首先,GNU Khata 以简化为设计原则。顶部的菜单栏组织的很方便,可以帮助你有效的进行工作。你可以选择管理不同的账户和项目,并且切换非常容易。[它们的官网](http://www.gnukhata.in/)表明,GNU Khata 可以“像说印度语一样方便”(LCTT 译注:原谅我,这个软件作者和本文作者是印度人……)。同时,你知道 GNU Khata 也可以在云端使用吗?
所有的主流的账户管理工具,比如分类账簿、项目报表、财务报表等等都用专业的方式整理,并且支持自定义格式和即时展示。这让会计和仓储管理看起来如此的简单。
这个项目正在积极的发展,正在寻求实操中的反馈以帮助这个软件更加进步。考虑到软件的成熟性、使用的便利性还有免费的情况,GNU Khata 可能会成为你最好的账簿助手。
请在评论框里留言吧,让我们知道你是如何看待 GNU Khata 的。
---
via: <https://itsfoss.com/using-gnu-khata/>
作者:[Aquil Roshan](https://itsfoss.com/author/aquil/) 译者:[MikeCoder](https://github.com/MikeCoder) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Looking for a free and open source accounting software? GNU Khata is one such software that is being actively developed.*
Being an active Linux enthusiast, I usually introduce my friends to Linux, help them choose the best distro to suit their needs, and finally get them set with open source alternative software for their work.
But in one case, I was pretty helpless. My uncle, who is a freelance accountant, uses a set of some pretty sophisticated *paid* software for work. And I wasn’t sure if I’d find anything under FOSS for him, until Yesterday.
Abhishek suggested me some [open source accounting software](https://itsfoss.com/open-source-accounting-software/) to check out and this particular one, GNU Khata stuck out.
[GNU Khata](http://www.gnukhata.in/) is an accounting tool. Or shall I say a collection of accounting tools? It is like the [Evernote](https://evernote.com/) of economy management. It is so versatile that it can be used from personal Finance management to large scale business management, from store inventory management to corporate tax works.
One interesting fact for you. ‘Khata’ in Hindi and other Indian languages means ‘account’ and hence this accounting software is called GNU Khata.
## Install and use GNU Khata open source accounting software
There are many installation instructions floating around the internet which actually install the older web app version of GNU Khata. Currently, GNU Khata is available only for Debian/Ubuntu and their derivatives. I suggest you follow the steps given in [GNU Khata](http://www.gnukhata.in/#download) official Website to install the updated standalone. Let me give them out real quick.
- Download the installer here.
- Open the terminal in download location.
- Copy and paste the below code in terminal and run.
`sudo chmod 755 GNUKhatasetup.run`
`sudo ./GNUKhatasetup.run`
- That’s it. Open the GNU Khata from the dash or the application menu.
### First launch
GNU Khata opens up in the browser and displays the following page.
Fill in the Organization name, case and organization type, financial year and click on proceed to go to the admin setup page.
Carefully feed in your name, password, security question and the answer and click on “create and login”.
You’re all set now. Use the Menu bar to start using GNU Khata to manage your finances. It’s that easy.
### Remove GNU Khata
If you don’t want to use GNU Khata, here is what you need to do in order to remove GNU Khata:
sudo apt-get remove --auto-remove gnukhata-core-engine
You can also use Snyaptic to uninstall it.
### Does GNU Khata really rival the paid accounting software in the market?** **
To begin with, GNU Khata keeps it all simple. The menu bar up top is very conveniently organized to help you work faster and better. You can choose to manage different accounts and projects and access them easily. [Their Website](http://www.gnukhata.in/) states that GNU Khata can be “easily transformed into Indian languages”. Also, did you know that GNU Khata can be used on the cloud too?
All the major accounting tools like ledgers, project statements, statement of affairs etc are formatted in a professional manner and are made available in both instantly presentable as well as customizable formats. It makes accounting and inventory management look so easy.
The Project is very actively evolving, seeks feedback and guidance from practicing accountants to make improvements in the software. Considering the maturity, ease of use and the absence of a price tag, GNU Khata can be the perfect assistant in bookkeeping.
Let us know what you think about GNU Khata in the comments below. |
7,636 | 为你的 Linux 桌面设置一张实时的地球照片 | http://www.omgubuntu.co.uk/2016/07/set-real-time-earth-wallpaper-ubuntu-desktop | 2016-08-02T09:03:00 | [
"Himawaripy",
"桌面",
"背景"
] | https://linux.cn/article-7636-1.html | 
厌倦了看同样的桌面背景了么?这里有一个(可能是)世界上最棒的东西。
‘[Himawaripy](https://github.com/boramalper/himawaripy)’ 是一个 Python 3 小脚本,它会抓取由[日本 Himawari 8 气象卫星](https://en.wikipedia.org/wiki/Himawari_8)拍摄的接近实时的地球照片,并将它设置成你的桌面背景。
安装完成后,你可以将它设置成每 10 分钟运行的定时任务(自然,它要在后台运行),这样它就可以实时地取回地球的照片并设置成背景了。
因为 Himawari-8 是一颗同步轨道卫星,你只能看到澳大利亚上空的地球的图片——但是它实时的天气形态、云团和光线仍使它很壮丽,对我而言要是看到英国上方的就更好了!
高级设置允许你配置从卫星取回的图片质量,但是要记住增加图片质量会增加文件大小及更长的下载等待!
最后,虽然这个脚本与其他我们提到过的其他脚本类似,它还仍保持更新及可用。
### 获取 Himawaripy
Himawaripy 已经在一系列的桌面环境中都测试过了,包括 Unity、LXDE、i3、MATE 和其他桌面环境。它是自由开源软件,但是整体来说安装及配置不太简单。
在该项目的 [Github 主页](https://github.com/boramalper/himawaripy)上可以找到安装和设置该应用程序的所有指导(提示:没有一键安装功能)。
* [实时地球壁纸脚本的 GitHub 主页](https://github.com/boramalper/himawaripy)
### 安装及使用
一些读者请我在本文中补充一下一步步安装该应用的步骤。以下所有步骤都在其 GitHub 主页上,这里再贴一遍。
1、下载及解压 Himawaripy
这是最容易的步骤。点击下面的下载链接,然后下载最新版本,并解压到你的下载目录里面。
* [下载 Himawaripy 主干文件(.zip 格式)](https://github.com/boramalper/himawaripy/archive/master.zip)
2、安装 python3-setuptools
你需要手工来安装主干软件包,Ubuntu 里面默认没有安装它:
```
sudo apt install python3-setuptools
```
3、安装 Himawaripy
在终端中,你需要切换到之前解压的目录中,并运行如下安装命令:
```
cd ~/Downloads/himawaripy-master
sudo python3 setup.py install
```
4、 看看它是否可以运行并下载最新的实时图片:
```
himawaripy
```

5、 设置定时任务
如果你希望该脚本可以在后台自动运行并更新(如果你需要手动更新,只需要运行 ‘himarwaripy’ 即可)
在终端中运行:
```
crontab -e
```
在其中新加一行(默认每10分钟运行一次)
```
*/10 * * * * /usr/local/bin/himawaripy
```
关于[配置定时任务](https://help.ubuntu.com/community/CronHowto)可以在 Ubuntu Wiki 上找到更多信息。
该脚本安装后你不需要不断运行它,它会自动的每十分钟在后台运行一次。
---
via: <http://www.omgubuntu.co.uk/2016/07/set-real-time-earth-wallpaper-ubuntu-desktop>
作者:[JOEY-ELIJAH SNEDDON](https://plus.google.com/117485690627814051450/?rel=author) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,639 | Git 系列(一):什么是 Git | https://opensource.com/resources/what-is-git | 2016-08-01T11:12:00 | [
"Git",
"版本控制系统"
] | https://linux.cn/article-7639-1.html | 欢迎阅读本系列关于如何使用 Git 版本控制系统的教程!通过本文的介绍,你将会了解到 Git 的用途及谁该使用 Git。
如果你刚步入开源的世界,你很有可能会遇到一些在 Git 上托管代码或者发布使用版本的开源软件。事实上,不管你知道与否,你都在使用基于 Git 进行版本管理的软件:Linux 内核(就算你没有在手机或者电脑上使用 Linux,你正在访问的网站也是运行在 Linux 系统上的),Firefox、Chrome 等其他很多项目都通过 Git 代码库和世界各地开发者共享他们的代码。
换个角度来说,你是否仅仅通过 Git 就可以和其他人共享你的代码?你是否可以在家里或者企业里私有化的使用 Git?你必须要通过一个 GitHub 账号来使用 Git 吗?为什么要使用 Git 呢?Git 的优势又是什么?Git 是我唯一的选择吗?这对 Git 所有的疑问都会把我们搞的一脑浆糊。
因此,忘记你以前所知的 Git,让我们重新走进 Git 世界的大门。

### 什么是版本控制系统?
Git 首先是一个版本控制系统。现在市面上有很多不同的版本控制系统:CVS、SVN、Mercurial、Fossil 当然还有 Git。
很多像 GitHub 和 GitLab 这样的服务是以 Git 为基础的,但是你也可以只使用 Git 而无需使用其他额外的服务。这意味着你可以以私有或者公有的方式来使用 Git。
如果你曾经和其他人有过任何电子文件方面的合作,你就会知道传统版本管理的工作流程。开始是很简单的:你有一个原始的版本,你把这个版本发送给你的同事,他们在接收到的版本上做了些修改,现在你们有两个版本了,然后他们把他们手上修改过的版本发回来给你。你把他们的修改合并到你手上的版本中,现在两个版本又合并成一个最新的版本了。
然后,你修改了你手上最新的版本,同时,你的同事也修改了他们手上合并前的版本。现在你们有 3 个不同的版本了,分别是合并后最新的版本,你修改后的版本,你同事手上继续修改过的版本。至此,你们的版本管理工作开始变得越来越混乱了。
正如 Jason van Gumster 在他的文章中指出 [即使是艺术家也需要版本控制](https://opensource.com/life/16/2/version-control-isnt-just-programmers),而且已经在个别人那里发现了这种趋势变化。无论是艺术家还是科学家,开发一个某种实验版本是并不鲜见的;在你的项目中,可能有某个版本大获成功,把项目推向一个新的高度,也可能有某个版本惨遭失败。因此,最终你不可避免的会创建出一堆名为project\_justTesting.kdenlive、project\_betterVersion.kdenlive、project\_best\_FINAL.kdenlive、project\_FINAL-alternateVersion.kdenlive 等类似名称的文件。
不管你是修改一个 for 循环,还是一些简单的文本编辑,一个好的版本控制系统都会让我们的生活更加的轻松。
### Git 快照
Git 可以为项目创建快照,并且存储这些快照为唯一的版本。
如果你将项目带领到了一个错误的方向上,你可以回退到上一个正确的版本,并且开始尝试另一个可行的方向。
如果你是和别人合作开发,当有人向你发送他们的修改时,你可以将这些修改合并到你的工作分支中,然后你的同事就可以获取到合并后的最新版本,并在此基础上继续工作。
Git 并不是魔法,因此冲突还是会发生的(“你修改了某文件的最后一行,但是我把这行整行都删除了;我们怎样处理这些冲突呢?”),但是总体而言,Git 会为你保留了所有更改的历史版本,甚至允许并行版本。这为你保留了以任何方式处理冲突的能力。
### 分布式 Git
在不同的机器上为同一个项目工作是一件复杂的事情。因为在你开始工作时,你想要获得项目的最新版本,然后此基础上进行修改,最后向你的同事共享这些改动。传统的方法是通过笨重的在线文件共享服务或者老旧的电邮附件,但是这两种方式都是效率低下且容易出错。
Git 天生是为分布式工作设计的。如果你要参与到某个项目中,你可以<ruby> 克隆 <rp> ( </rp> <rt> clone </rt> <rp> ) </rp></ruby>该项目的 Git 仓库,然后就像这个项目只有你本地一个版本一样对项目进行修改。最后使用一些简单的命令你就可以<ruby> 拉取 <rp> ( </rp> <rt> pull </rt> <rp> ) </rp></ruby>其他开发者的修改,或者你可以把你的修改<ruby> 推送 <rp> ( </rp> <rt> push </rt> <rp> ) </rp></ruby>给别人。现在不用担心谁手上的是最新的版本,或者谁的版本又存放在哪里等这些问题了。全部人都是在本地进行开发,然后向共同的目标推送或者拉取更新。(或者不是共同的目标,这取决于项目的开发方式)。
### Git 界面
最原始的 Git 是运行在 Linux 终端上的应用软件。然而,得益于 Git 是开源的,并且拥有良好的设计,世界各地的开发者都可以为 Git 设计不同的访问界面。
Git 完全是免费的,并且已经打包在 Linux,BSD,Illumos 和其他类 Unix 系统中,Git 命令看起来像这样:
```
$ git --version
git version 2.5.3
```
可能最著名的 Git 访问界面是基于网页的,像 GitHub、开源的 GitLab、Savannah、BitBucket 和 SourceForge 这些网站都是基于网页端的 Git 界面。这些站点为面向公众和面向社会的开源软件提供了最大限度的代码托管服务。在一定程度上,基于浏览器的图形界面(GUI)可以尽量的减缓 Git 的学习曲线。下面的 GitLab 界面的截图:

再者,第三方 Git 服务提供商或者独立开发者甚至可以在 Git 的基础上开发出不是基于 HTML 的定制化前端界面。此类界面让你可以不用打开浏览器就可以方便的使用 Git 进行版本管理。其中对用户最透明的方式是直接集成到文件管理器中。KDE 文件管理器 Dolphin 可以直接在目录中显示 Git 状态,甚至支持提交,推送和拉取更新操作。

[Sparkleshare](http://sparkleshare.org/) 使用 Git 作为其 Dropbox 式的文件共享界面的基础。

想了解更多的内容,可以查看 [Git wiki](https://git.wiki.kernel.org/index.php/InterfacesFrontendsAndTools#Graphical_Interfaces),这个(长长的)页面中展示了很多 Git 的图形界面项目。
### 谁应该使用 Git?
就是你!我们更应该关心的问题是什么时候使用 Git?和用 Git 来干嘛?
### 我应该在什么时候使用 Git 呢?我要用 Git 来干嘛呢?
想更深入的学习 Git,我们必须比平常考虑更多关于文件格式的问题。
Git 是为了管理源代码而设计的,在大多数编程语言中,源代码就意味者一行行的文本。当然,Git 并不知道你把这些文本当成是源代码还是下一部伟大的美式小说。因此,只要文件内容是以文本构成的,使用 Git 来跟踪和管理其版本就是一个很好的选择了。
但是什么是文本呢?如果你在像 Libre Office 这类办公软件中编辑一些内容,通常并不会产生纯文本内容。因为通常复杂的应用软件都会对原始的文本内容进行一层封装,就如把原始文本内容用 XML 标记语言包装起来,然后封装在 Zip 包中。这种对原始文本内容进行一层封装的做法可以保证当你把文件发送给其他人时,他们可以看到你在办公软件中编辑的内容及特定的文本效果。奇怪的是,虽然,通常你的需求可能会很复杂,就像保存 [Kdenlive](https://opensource.com/life/11/11/introduction-kdenlive) 项目文件,或者保存从 [Inkscape](http://inkscape.org/) 导出的SVG文件,但是,事实上使用 Git 管理像 XML 文本这样的纯文本类容是最简单的。
如果你在使用 Unix 系统,你可以使用 `file` 命令来查看文件内容构成:
```
$ file ~/path/to/my-file.blah
my-file.blah: ASCII text
$ file ~/path/to/different-file.kra: Zip data (MIME type "application/x-krita")
```
如果还是不确定,你可以使用 `head` 命令来查看文件内容:
```
$ head ~/path/to/my-file.blah
```
如果输出的文本你基本能看懂,这个文件就很有可能是文本文件。如果你仅仅在一堆乱码中偶尔看到几个熟悉的字符,那么这个文件就可能不是文本文件了。
准确的说:Git 可以管理其他格式的文件,但是它会把这些文件当成二进制大对象(blob)。两者的区别是,在文本文件中,Git 可以明确的告诉你在这两个快照(或者说提交)间有 3 行是修改过的。但是如果你在两个<ruby> 提交 <rp> ( </rp> <rt> commit </rt> <rp> ) </rp></ruby>之间对一张图片进行的编辑操作,Git 会怎么指出这种修改呢?实际上,因为图片并不是以某种可以增加或删除的有意义的文本构成,因此 Git 并不能明确的描述这种变化。当然我个人是非常希望图片的编辑可以像把文本“<sky>丑陋的蓝绿色</sky>”修改成“<sky>漂浮着蓬松白云的天蓝色</sky>”一样的简单,但是事实上图片的编辑并没有这么简单。
经常有人在 Git 上放入 png 图标、电子表格或者流程图这类二进制大型对象(blob)。尽管,我们知道在 Git 上管理此类大型文件并不直观,但是,如果你需要使用 Git 来管理此类文件,你也并不需要过多的担心。如果你参与的项目同时生成文本文件和二进制大文件对象(如视频游戏中常见的场景,这些和源代码同样重要的图像和音频材料),那么你有两条路可以走:要么开发出你自己的解决方案,就如使用指向共享网络驱动器的引用;要么使用 Git 插件,如 Joey Hess 开发的 [git annex](https://git-annex.branchable.com/),以及 [Git-Media](https://github.com/alebedev/git-media) 项目。
你看,Git 真的是一个任何人都可以使用的工具。它是你进行文件版本管理的一个强大而且好用工具,同时它并没有你开始认为的那么可怕。
---
via: <https://opensource.com/resources/what-is-git>
作者:[Seth Kenlon](https://opensource.com/users/seth) 译者:[cvsher](https://github.com/cvsher) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Welcome to my series on learning how to use the Git version control system! In this introduction to the series, you will learn what Git is for and who should use it.
*Read:*
*Part 1: What is Git?**Part 2: Getting started with Git*[Part 3: Creating your first Git repository](https://opensource.com/life/16/7/creating-your-first-git-repository)*Part 4: How to restore older file versions in Git**Part 5: 3 graphical tools for Git**Part 6: How to build your own Git server**Part 7: How to manage binary blobs with Git*
On the other hand, all the excitement and hype over Git tends to make things a little muddy. Can you only use Git to share your code with others, or can you use Git in the privacy of your own home or business? Do you have to have a GitHub account to use Git? Why use Git at all? What are the benefits of Git? Is Git the only option?
So forget what you know or what you think you know about Git, and let's take it from the beginning.
## What is version control?
Git is, first and foremost, a **version control system** (VCS). There are many version control systems out there: CVS, SVN, Mercurial, Fossil, and, of course, Git.
Git serves as the foundation for many services, like GitHub and GitLab, but you can use Git without using any other service. This means that you can use Git privately or publicly.
If you have ever collaborated on anything digital with anyone, then you know how it goes. It starts out simple: you have your version, and you send it to your partner. They make some changes, so now there are two versions, and send the suggestions back to you. You integrate their changes into your version, and now there is one version again.
Then it gets worse: while you change your version further, your partner makes *more* changes to their version. Now you have *three* versions; the merged copy that you both worked on, the version you changed, and the version your partner has changed.
As Jason van Gumster points out in his article, * Even artists need version control*, this syndrome tends to happen in individual settings as well. In both art and science, it's not uncommon to develop a
*trial version*of something; a version of your project that might make it a lot better, or that might fail miserably. So you create file names like
**project_justTesting.kdenlive**and
**project_betterVersion.kdenlive**, and then
**project_best_FINAL.kdenlive**, but with the inevitable allowance for
**project_FINAL-alternateVersion.kdenlive**, and so on.
Whether it's a change to a for loop or an editing change, it happens to the best of us. That is where a good version control system makes life easier.
## Git snapshots
Git takes *snapshots* of a project, and stores those snapshots as unique versions.
If you go off in a direction with your project that you decide was the wrong direction, you can just roll back to the last *good* version and continue along an alternate path.
**[Download our Git cheat sheet]**
If you're collaborating, then when someone sends you changes, you can merge those changes into your working branch, and then your collaborator can grab the merged version of the project and continue working from the new current version.
Git isn't magic, so conflicts do occur ("You changed the last line of the book, but I deleted that line entirely; how do we resolve that?"), but on the whole, Git enables you to manage the many potential variants of a single work, retaining the history of all the changes, and even allows for parallel versions.
## Git distributes
Working on a project on separate machines is complex, because you want to have the latest version of a project while you work, makes your own changes, and share your changes with your collaborators. The default method of doing this tends to be clunky online file sharing services, or old school email attachments, both of which are inefficient and error-prone.
Git is designed for distributed development. If you're involved with a project you can clone the project's Git repository, and then work on it as if it was the only copy in existence. Then, with a few simple commands, you can pull in any changes from other contributors, and you can also push your changes over to someone else. Now there is no confusion about who has what version of a project, or whose changes exist where. It is all locally developed, and pushed and pulled toward a common target (or not, depending on how the project chooses to develop).
## Git interfaces
In its natural state, Git is an application that runs in the Linux terminal. However, as it is well-designed and open source, developers all over the world have designed other ways to access it.
It is free, available to anyone for $0, and comes in packages on Linux, BSD, Illumos, and other Unix-like operating systems. It looks like this:
```
``````
$ git --version
git version 2.5.3
```
Probably the most well-known Git interfaces are web-based: sites like [GitHub](https://github.com/), the open source [GitLab](https://about.gitlab.com/), [Savannah](http://nongnu.org), [BitBucket](https://bitbucket.org/), and [SourceForge](https://sourceforge.net/) all offer online code hosting to maximise the public and social aspect of open source along with, in varying degrees, browser-based GUIs to minimise the learning curve of using Git. This is what the GitLab interface looks like:
Additionally, it is possible that a Git service or independent developer may even have a custom Git frontend that is not HTML-based, which is particularly handy if you don't live with a browser eternally open. The most transparent integration comes in the form of file manager support. The KDE file manager, [Dolphin](https://userbase.kde.org/Dolphin), can show the Git status of a directory, and even generate commits, pushes, and pulls.
[Sparkleshare](http://sparkleshare.org/) uses Git as a foundation for its own Dropbox-style file sharing interface.
For more, see the (long) page on the official [Git wiki](https://git.wiki.kernel.org/index.php/InterfacesFrontendsAndTools#Graphical_Interfaces) listing projects with graphical interfaces to Git.
## Who should use Git?
You should! The real question is *when?* And *what for?*
## When should I use Git, and what should I use it for?
To get the most out of Git, you need to think a little bit more than usual about file formats.
Git is designed to manage source code, which in most languages consists of lines of text. Of course, Git doesn't know if you're feeding it source code or the next Great American Novel, so as long as it breaks down to text, Git is a great option for managing and tracking versions.
But what is text? If you write something in an office application like [Libre Office](http://libreoffice.org), then you're probably not generating raw text. There is usually a wrapper around complex applications like that which encapsulate the raw text in XML markup and then in a zip container, as a way to ensure that all of the assets for your office file are available when you send that file to someone else. Strangely, though, something that you might expect to be very complex, like the save files for a [Kdenlive](https://opensource.com/life/11/11/introduction-kdenlive) project, or an SVG from [Inkscape](http://inkscape.org), are actually raw XML files that can easily be managed by Git.
If you use Unix, you can check to see what a file is made of with the `file`
command:
```
``````
$ file ~/path/to/my-file.blah
my-file.blah: ASCII text
$ file ~/path/to/different-file.kra: Zip data (MIME type "application/x-krita")
```
If unsure, you can view the contents of a file with the `head`
command:
```
``````
$ head ~/path/to/my-file.blah
```
If you see text that is mostly readable by you, then it is probably a file made of text. If you see garbage with some familiar text characters here and there, it is probably not made of text.
Make no mistake: Git *can* manage other formats of files, but it treats them as blobs. The difference is that in a text file, two Git snapshots (or *commits*, as we call them) might be, say, three lines different from each other. If you have a photo that has been altered between two different commits, how can Git express that change? It can't, really, because photographs are not made of any kind of sensible text that can just be inserted or removed. I wish photo editing were as easy as just changing some text from "<sky>ugly greenish-blue</sky>" to "<sky>blue-with-fluffy-clouds</sky>" but it truly is not.
People check in blobs, like PNG icons or a speadsheet or a flowchart, to Git all the time, so if you're working in Git then don't be afraid to do that. Know that it's not sensible to do that with huge files, though. If you are working on a project that does generate both text files and large blobs (a common scenario with video games, which have equal parts source code to graphical and audio assets), then you can do one of two things: either invent your own solution, such as pointers to a shared network drive, or use a Git add-on like Joey Hess's excellent [git annex](https://git-annex.branchable.com/), or the [Git-Media](https://github.com/alebedev/git-media) project.
So you see, Git really is for everyone. It is a great way to manage versions of your files, it is a powerful tool, and it is not as scary as it first seems.
## 12 Comments |
7,640 | 用 VeraCrypt 加密闪存盘 | http://www.esecurityplanet.com/open-source-security/how-to-encrypt-flash-drive-using-veracrypt.html | 2016-08-02T09:34:00 | [
"VeraCrypt",
"加密",
"USB"
] | https://linux.cn/article-7640-1.html | 很多安全专家偏好像 VeraCrypt 这类能够用来加密闪存盘的开源软件,是因为可以获取到它的源代码。
保护 USB 闪存盘里的数据,加密是一个聪明的方法,正如我们在使用 Microsoft 的 BitLocker [加密闪存盘](http://www.esecurityplanet.com/views/article.php/3880616/How-to-Encrypt-a-USB-Flash-Drive.htm) 一文中提到的。
但是如果你不想用 BitLocker 呢?
你可能有顾虑,因为你不能够查看 Microsoft 的程序源码,那么它容易被植入用于政府或其它用途的“后门”。而由于开源软件的源码是公开的,很多安全专家认为开源软件很少藏有后门。
还好,有几个开源加密软件能作为 BitLocker 的替代。

要是你需要在 Windows 系统,苹果的 OS X 系统或者 Linux 系统上加密以及访问文件,开源软件 [VeraCrypt](http://www.esecurityplanet.com/open-source-security/veracrypt-a-worthy-truecrypt-alternative.html) 提供绝佳的选择。
VeraCrypt 源于 TrueCrypt。TrueCrypt 是一个备受好评的开源加密软件,尽管它现在已经停止维护了。但是 TrueCrypt 的代码通过了审核,没有发现什么重要的安全漏洞。另外,在 VeraCrypt 中对它进行了改善。
Windows,OS X 和 Linux 系统的版本都有。
用 VeraCrypt 加密 USB 闪存盘不像用 BitLocker 那么简单,但是它也只要几分钟就好了。
### 用 VeraCrypt 加密闪存盘的 8 个步骤
对应你的操作系统 [下载 VeraCrypt](https://veracrypt.codeplex.com/releases/view/619351) 之后:
打开 VeraCrypt,点击 Create Volume,进入 VeraCrypt 的<ruby> 创建卷向导程序 <rp> ( </rp> <rt> Volume Creation Wizard </rt> <rp> ) </rp></ruby>。

VeraCrypt <ruby> 创建卷向导 <rp> ( </rp> <rt> Volume Creation Wizard </rt> <rp> ) </rp></ruby>允许你在闪存盘里新建一个加密文件容器,这与其它未加密文件是独立的。或者你也可以选择加密整个闪存盘。这个时候你就选加密整个闪存盘就行。

然后选择<ruby> 标准模式 <rp> ( </rp> <rt> Standard VeraCrypt Volume </rt> <rp> ) </rp></ruby>。

选择你想加密的闪存盘的驱动器卷标(这里是 O:)。

选择<ruby> 创建卷模式 <rp> ( </rp> <rt> Volume Creation Mode </rt> <rp> ) </rp></ruby>。如果你的闪存盘是空的,或者你想要删除它里面的所有东西,选第一个。要么你想保持所有现存的文件,选第二个就好了。

这一步允许你选择加密选项。要是你不确定选哪个,就用默认的 AES 和 SHA-512 设置。

确定了卷容量后,输入并确认你想要用来加密数据密码。

要有效工作,VeraCrypt 要从一个熵或者“随机数”池中取出一个随机数。要初始化这个池,你将被要求随机地移动鼠标一分钟。一旦进度条变绿了,或者更方便的是等到进度条到了屏幕右边足够远的时候,点击 “<ruby> 格式化 <rp> ( </rp> <rt> Format </rt> <rp> ) </rp></ruby>” 来结束创建加密盘。

### 用 VeraCrypt 使用加密过的闪存盘
当你想要使用一个加密了的闪存盘,先插入闪存盘到电脑上,启动 VeraCrypt。
然后选择一个没有用过的卷标(比如 Z:),点击<ruby> 自动挂载设备 <rp> ( </rp> <rt> Auto-Mount Devices </rt> <rp> ) </rp></ruby>。

输入密码,点击确定。

挂载过程需要几分钟,这之后你的解密盘就能通过你先前选择的盘符进行访问了。
### VeraCrypt 移动硬盘安装步骤
如果你设置闪存盘的时候,选择的是加密过的容器而不是加密整个盘,你可以选择创建 VeraCrypt 称为<ruby> 移动硬盘 <rp> ( </rp> <rt> Traveler Disk </rt> <rp> ) </rp></ruby>的设备。这会复制安装一个 VeraCrypt 到 USB 闪存盘。当你在别的 Windows 电脑上插入 U 盘时,就能从 U 盘自动运行 VeraCrypt;也就是说没必要在新电脑上安装 VeraCrypt。
你可以设置闪存盘作为一个<ruby> 移动硬盘 <rp> ( </rp> <rt> Traveler Disk </rt> <rp> ) </rp></ruby>,在 VeraCrypt 的<ruby> 工具栏 <rp> ( </rp> <rt> Tools </rt> <rp> ) </rp></ruby>菜单里选择<ruby> 移动硬盘设置 <rp> ( </rp> <rt> Traveler Disk SetUp </rt> <rp> ) </rp></ruby>就行了。

要从<ruby> 移动硬盘 <rp> ( </rp> <rt> Traveler Disk </rt> <rp> ) </rp></ruby>上运行 VeraCrypt,你必须要有那台电脑的管理员权限,这不足为奇。尽管这看起来是个限制,机密文件无法在不受控制的电脑上安全打开,比如在一个商务中心的电脑上。
>
> 本文作者 Paul Rubens 从事技术行业已经超过 20 年。这期间他为英国和国际主要的出版社,包括 《The Economist》《The Times》《Financial Times》《The BBC》《Computing》和《ServerWatch》等出版社写过文章,
>
>
>
---
via: <http://www.esecurityplanet.com/open-source-security/how-to-encrypt-flash-drive-using-veracrypt.html>
作者:[Paul Rubens](http://www.esecurityplanet.com/author/3700/Paul-Rubens) 译者:[GitFuture](https://github.com/GitFuture) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,643 | Vim 起步的五个技巧 | https://opensource.com/life/16/7/tips-getting-started-vim | 2016-08-03T10:36:00 | [
"vim",
"vi",
"Vimtutor",
"Vimium"
] | https://linux.cn/article-7643-1.html | 多年来,我一直想学 Vim。如今 Vim 是我最喜欢的 Linux 文本编辑器,也是开发者和系统管理者最喜爱的开源工具。我说的学习,指的是真正意义上的学习。想要精通确实很难,所以我只想要达到熟练的水平。我使用了这么多年的 Linux ,我会的也仅仅只是打开一个文件,使用上下左右箭头按键来移动光标,切换到插入模式,更改一些文本,保存,然后退出。

但那只是 Vim 的最最基本的操作。我的技能水平只能让我在终端使用 Vim 修改文本,但是它并没有任何一个我想象中强大的文本处理功能。这样我完全无法用 Vim 发挥出胜出 Pico 和 Nano 的能力。
所以到底为什么要学习 Vim?因为我花费了相当多的时间用于编辑文本,而且我知道还有很大的效率提升空间。为什么不选择 Emacs,或者是更为现代化的编辑器例如 Atom?因为 Vim 适合我,至少我有一丁点的使用经验。而且,很重要的一点就是,在我需要处理的系统上很少碰见没有装 Vim 或者它的弱化版(Vi)。如果你有强烈的欲望想学习对你来说更给力的 Emacs,我希望这些对于 Emacs 同类编辑器的建议能对你有所帮助。
花了几周的时间专注提高我的 Vim 使用技巧之后,我想分享的第一个建议就是必须使用它。虽然这看起来就是明知故问的回答,但事实上它比我所预想的计划要困难一些。我的大多数工作是在网页浏览器上进行的,而且每次我需要在浏览器之外打开并编辑一段文本时,就需要避免下意识地打开 Gedit。Gedit 已经放在了我的快速启动栏中,所以第一步就是移除这个快捷方式,然后替换成 Vim 的。
为了更好的学习 Vim,我尝试了很多。如果你也正想学习,以下列举了一些作为推荐。
### Vimtutor
通常如何开始学习最好就是使用应用本身。我找到一个小的应用叫 Vimtutor,当你在学习编辑一个文本时它能辅导你一些基础知识,它向我展示了很多我这些年都忽视的基础命令。Vimtutor 一般在有 Vim 的地方都能找到它,如果你的系统上没有 Vimtutor,Vimtutor 可以很容易从你的包管理器上安装。
### GVim
我知道并不是每个人都认同这个,但就是它让我从使用终端中的 Vim 转战到使用 GVim 来满足我基本编辑需求。反对者表示 GVim 鼓励使用鼠标,而 Vim 主要是为键盘党设计的。但是我能通过 GVim 的下拉菜单快速找到想找的指令,并且 GVim 可以提醒我正确的指令然后通过敲键盘执行它。努力学习一个新的编辑器然后陷入无法解决的困境,这种感觉并不好受。每隔几分钟读一下 man 出来的文字或者使用搜索引擎来提醒你该用的按键序列也并不是最好的学习新事物的方法。
### 键盘表
当我转战 GVim,我发现有一个键盘的“速查表”来提醒我最基础的按键很是便利。网上有很多这种可用的表,你可以下载、打印,然后贴在你身边的某一处地方。但是为了我的笔记本键盘,我选择买一沓便签纸。这些便签纸在美国不到 10 美元,当我使用键盘编辑文本,尝试新的命令的时候,可以随时提醒我。

### Vimium
上文提到,我工作都在浏览器上进行。其中一条我觉得很有帮助的建议就是,使用 [Vimium](https://github.com/philc/vimium) 来用增强使用 Vim 的体验。Vimium 是 Chrome 浏览器上的一个开源插件,能用 Vim 的指令快捷操作 Chrome。我发现我只用了几次使用快捷键切换上下文,就好像比之前更熟悉这些快捷键了。同样的扩展 Firefox 上也有,例如 [Vimerator](http://www.vimperator.org/)。

### 其它人
毫无疑问,最好的学习方法就是求助于在你之前探索过的人,让他给你建议、反馈和解决方法。
如果你住在一个大城市,那么附近可能会有一个 Vim meetup 小组,或者还有 Freenode IRC 上的 #vim 频道。#vim 频道是 Freenode 上最活跃的频道之一,那上面可以针对你个人的问题来提供帮助。听上面的人发发牢骚或者看看别人尝试解决自己没有遇到过的问题,仅仅是这样我都觉得很有趣。
---
那么,现在怎么样了?到现在为止还不错。为它所花的时间是否值得就在于之后它为你节省了多少时间。但是当我发现一个新的按键序列可以来跳过词,或者一些相似的小技巧,我经常会收获意外的惊喜与快乐。每天我至少可以看见,一点点的回报,正在逐渐配得上当初的付出。

学习 Vim 并不仅仅只有这些建议,还有很多。我很喜欢指引别人去 [Vim Advantures](http://vim-adventures.com/),它是一种使用 Vim 按键方式进行移动的在线游戏。而在另外一天我在 [Vimgifts.com](http://vimgifs.com/) 发现了一个非常神奇的虚拟学习工具,那可能就是你真正想要的:用一个小小的 gif 动图来描述 Vim 操作。
你有花时间学习 Vim 吗?或者是任何需要大量键盘操作的程序?那些经过你努力后掌握的工具,你认为这些努力值得吗?效率的提高有没有达到你的预期?分享你们的故事在下面的评论区吧。
---
via: <https://opensource.com/life/16/7/tips-getting-started-vim>
作者:[Jason Baker](https://opensource.com/users/jason-baker) 译者:[maywanting](https://github.com/maywanting) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | For years, I've wanted to learn [Vim](https://en.wikipedia.org/wiki/Vim_(text_editor)), now my preferred Linux text editor and a favorite open source tool among developers and system administrators. And when I say learn, I mean *really* learn. *Master* is probably too strong a word, but I'd settle for advanced proficiency. For most of my years using Linux, my skillset included the ability to open a file, use the arrow keys to navigate up and down, switch into insert mode, change some text, save, and exit.
But that's like minimum-viable-Vim. My skill level enabled me edit text documents from the terminal, but hasn't actually empowered me with any of the text-editing super powers I've always imagined were possible. And it didn't justify using Vim over the totally capable Pico or Nano.
So why learn Vim at all? Because I do spend an awful lot of time editing text, and I know I could be more efficient at it. And why not Emacs, or a more modern editor like Atom? Because Vim works for me, and at least I have *some* minimal experience in it. And perhaps, importantly, because it's rare that I encounter a system that I'm working on which doesn't have Vim or it's less-improved cousin (vi) available on it already. If you've always had a desire to learn Emacs, more power to you—I hope the Emacs-analog of these tips will prove useful to you, too.
A few weeks in to this concentrated effort to up my Vim-use ability, the number one tip I have to share is that you actually must use the tool. While it seems like a piece of advice straight from Captain Obvious, I actually found it considerably harder than I expected to stay in the program. Most of my work happens inside of a web browser, and I had to untrain my trigger-like opening of Gedit every time I needed to edit a block of text outside of a browser. Gedit had made its way to my quick launcher, and so step one was removing this shortcut and putting Vim there instead.
I've tried a number of things that have helped me learn. Here's a few of them I would recommend if you're looking to learn as well.
## Vimtutor
Sometimes the best place to get started isn't far from the application itself. I found Vimtutor, a tiny application that is basically a tutorial in a text file that you edit as you learn, to be as helpful as anything else in showing me the basics of the commands I had skipped learning through the years. Vimtutor is typically found everywhere Vim is, and is an easy install from your package manager if it's not already on your system.
## GVim
I know not everyone will agree with this one, but I found it useful to stop using the version of Vim that lives in my terminal and start using GVim for my basic editing needs. Naysayers will argue that it encourages using the mouse in an environment designed for keyboards, but I found it helpful to be able to quickly find the command I was looking for in a drop-down menu, reminding myself of the correct command, and then executing it with a keyboard. The alternative was often frustration at the inability to figure out how to do something, which is not a good feeling to be under constantly as you struggle to learn a new editor. No, stopping every few minutes to read a man page or use a search engine to remind you of a key sequence is not the best way to learn something new.
## Keyboard maps
Along with switching to GVim, I also found it handy to have a keyboard "cheat sheet" handy to remind me of the basic keystrokes. There are many available on the web that you can download, print, and set beside your station, but I opted for buying a set of stickers for my laptop keyboard. They were less than ten dollars US and had the added bonus of being a subtle reminder every time I used the laptop to at least try out one new thing as I edited.
## Vimium
As I mentioned, I live in the web browser most of the day. One of the tricks I've found helpful to reinforce the Vim way of navigation is to use [Vimium](https://github.com/philc/vimium), an open source extension for Chrome that makes Chrome mimick the shortcuts used by Vim. I've found the fewer times I switch contexts for the keyboard shortcuts I'm using, the more likely I am to actually use them. Similar extensions, like [Vimerator](http://www.vimperator.org/), exist for Firefox.
## Other human beings
Without a doubt, there's no better way to get help learning something new than to get advice, feedback, and solutions from other people who have gone down a path before you.
If you live in a larger urban area, there might be a Vim meetup group near you. Otherwise, the place to be is the #vim channel on Freenode IRC. One of the more popular channels on Freenode, the #vim channel is always full of helpful individuals willing to offer help with your problems. I find it interesting just to listen to the chatter and see what sorts of problems others are trying to solve to see what I'm missing out on.
And so what to make of this effort? So far, so good. The time spent has probably yet to pay for itself in terms of time saved, but I'm always mildly surprised and amused when I find myself with a new reflex, jumping words with the right keypress sequence, or some similarly small feat. I can at least see that every day, the investment is bringing itself a little closer to payoff.
These aren't the only tricks for learning Vim, by far. I also like to point people towards [Vim Adventures](http://vim-adventures.com/), an online game in which you navigate using the Vim keystrokes. And just the other day I came across a marvelous visual learning tool at [Vimgifs.com](http://vimgifs.com/), which is exactly what you might expect it to be: illustrated examples with Vim so small they fit nicely in a gif.
Have you invested the time to learn Vim, or really, any program with a keyboard-heavy interface? What worked for you, and, did you think the effort was worth it? Has your productivity changed as much as you thought it would? Let's share stories in the comments below.
## 6 Comments |
7,647 | Git 系列(三):建立你的第一个 Git 仓库 | https://opensource.com/life/16/7/creating-your-first-git-repository | 2016-08-04T16:05:00 | [
"Git"
] | https://linux.cn/article-7647-1.html | 现在是时候学习怎样创建你自己的 Git 仓库了,还有怎样增加文件和完成提交。
在本系列[前面的文章](/article-7641-1.html)中,你已经学习了怎样作为一个最终用户与 Git 进行交互;你就像一个漫无目的的流浪者一样偶然发现了一个开源项目网站,克隆了仓库,然后你就可以继续钻研它了。你知道了和 Git 进行交互并不像你想的那样困难,或许你只是需要被说服现在去使用 Git 完成你的工作罢了。
虽然 Git 确实是被许多重要软件选作版本控制工具,但是并不是仅能用于这些重要软件;它也能管理你购物清单(如果它们对你来说很重要的话,当然可以了!)、你的配置文件、周报或日记、项目进展日志、甚至源代码!
使用 Git 是很有必要的,毕竟,你肯定有过因为一个备份文件不能够辨认出版本信息而抓狂的时候。

Git 无法帮助你,除非你开始使用它,而现在就是开始学习和使用它的最好时机。或者,用 Git 的话来说,“没有其他的 `push` 能像 `origin HEAD` 一样有帮助了”(千里之行始于足下的意思)。我保证,你很快就会理解这一点的。
### 类比于录音
我们经常用名词“快照”来指代计算机上的镜像,因为很多人都能够对插满了不同时光的照片的相册充满了感受。这很有用,不过,我认为 Git 更像是进行一场录音。
也许你不太熟悉传统的录音棚卡座式录音机,它包括几个部件:一个可以正转或反转的转轴、保存声音波形的磁带,可以通过拾音头在磁带上记录声音波形,或者检测到磁带上的声音波形并播放给听众。
除了往前播放磁带,你也可以把磁带倒回到之前的部分,或快进跳过后面的部分。
想象一下上世纪 70 年代乐队录制磁带的情形。你可以想象到他们一遍遍地练习歌曲,直到所有部分都非常完美,然后记录到音轨上。起初,你会录下鼓声,然后是低音,再然后是吉他声,最后是主唱。每次你录音时,录音棚工作人员都会把磁带倒带,然后进入循环模式,这样它就会播放你之前录制的部分。比如说如果你正在录制低音,你就会在背景音乐里听到鼓声,就像你自己在击鼓一样,然后吉他手在录制时会听到鼓声、低音(和牛铃声)等等。在每个循环中,你都会录制一部分,在接下来的循环中,工作人员就会按下录音按钮将其合并记录到磁带中。
你也可以拷贝或换下整个磁带,如果你要对你的作品重新混音的话。
现在我希望对于上述的上世纪 70 年代的录音工作的描述足够生动,这样我们就可以把 Git 的工作想象成一个录音工作了。
### 新建一个 Git 仓库
首先得为我们的虚拟的录音机买一些磁带。用 Git 的话说,这些磁带就是*仓库*;它是完成所有工作的基础,也就是说这里是存放 Git 文件的地方(即 Git 工作区)。
任何目录都可以成为一个 Git 仓库,但是让我们从一个新目录开始。这需要下面三个命令:
* 创建目录(如果你喜欢的话,你可以在你的图形化的文件管理器里面完成。)
* 在终端里切换到目录。
* 将其初始化成一个 Git 管理的目录。
也就是运行如下代码:
```
$ mkdir ~/jupiter # 创建目录
$ cd ~/jupiter # 进入目录
$ git init . # 初始化你的新 Git 工作区
```
在这个例子中,文件夹 jupiter 是一个空的但是合法的 Git 仓库。
有了仓库接下来的事情就可以按部就班进行了。你可以克隆该仓库,你可以在一个历史点前后来回穿梭(前提是你有一个历史点),创建交替的时间线,以及做 Git 能做的其它任何事情。
在 Git 仓库里面工作和在任何目录里面工作都是一样的,可以在仓库中新建文件、复制文件、保存文件。你可以像平常一样做各种事情;Git 并不复杂,除非你把它想复杂了。
在本地的 Git 仓库中,一个文件可以有以下这三种状态:
* <ruby> 未跟踪文件 <rp> ( </rp> <rt> Untracked </rt> <rp> ) </rp></ruby>:你在仓库里新建了一个文件,但是你没有把文件加入到 Git 的管理之中。
* <ruby> 已跟踪文件 <rp> ( </rp> <rt> Tracked </rt> <rp> ) </rp></ruby>:已经加入到 Git 管理的文件。
* <ruby> 暂存区文件 <rp> ( </rp> <rt> Staged </rt> <rp> ) </rp></ruby>:被修改了的已跟踪文件,并加入到 Git 的提交队列中。
任何你新加入到 Git 仓库中的文件都是未跟踪文件。这些文件保存在你的电脑硬盘上,但是你没有告诉 Git 这是需要管理的文件,用我们的录音机来类比,就是录音机还没打开;乐队就开始在录音棚里忙碌了,但是录音机并没有准备录音。
不用担心,Git 会在出现这种情况时告诉你:
```
$ echo "hello world" > foo
$ git status
On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
foo
nothing added but untracked files present (use "git add" to track)
```
你看到了,Git 会提醒你怎样把文件加入到提交任务中。
### 不使用 Git 命令进行 Git 操作
在 GitHub 或 GitLab 上创建一个仓库只需要用鼠标点几下即可。这并不难,你单击“New Repository”这个按钮然后跟着提示做就可以了。
在仓库中包括一个“README”文件是一个好习惯,这样人们在浏览你的仓库的时候就可以知道你的仓库是干什么的,更有用的是可以让你在克隆一个有东西的仓库前知道它有些什么。
克隆仓库通常很简单,但是在 GitHub 上获取仓库改动权限就稍微复杂一些,为了通过 GitHub 验证你必须有一个 SSH 密钥。如果你使用 Linux 系统,可以通过下面的命令生成:
```
$ ssh-keygen
```
然后复制你的新密钥的内容,它是纯文本文件,你可以使用一个文本编辑器打开它,也可以使用如下 cat 命令查看:
```
$ cat ~/.ssh/id_rsa.pub
```
现在把你的密钥粘贴到 [GitHub SSH 配置文件](https://github.com/settings/keys) 中,或者 [GitLab 配置文件](https://gitlab.com/profile/keys)。
如果你通过使用 SSH 模式克隆了你的项目,你就可以将修改写回到你的仓库了。
另外,如果你的系统上没有安装 Git 的话也可以使用 GitHub 的文件上传接口来添加文件。

### 跟踪文件
正如命令 `git status` 的输出告诉你的那样,如果你想让 git 跟踪一个文件,你必须使用命令 `git add` 把它加入到提交任务中。这个命令把文件存在了暂存区,这里存放的都是等待提交的文件,或者也可以用在快照中。在将文件包括到快照中,和添加要 Git 管理的新的或临时文件时,`git add` 命令的目的是不同的,不过至少现在,你不用为它们之间的不同之处而费神。
类比录音机,这个动作就像打开录音机开始准备录音一样。你可以想象为对已经在录音的录音机按下暂停按钮,或者倒回开头等着记录下个音轨。
当你把文件添加到 Git 管理中,它会标识其为已跟踪文件:
```
$ git add foo
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: foo
```
加入文件到提交任务中并不是“准备录音”。这仅仅是将该文件置于准备录音的状态。在你添加文件后,你仍然可以修改该文件;它只是被标记为**已跟踪**和**处于暂存区**,所以在它被写到“磁带”前你可以将它撤出或修改它(当然你也可以再次将它加入来做些修改)。但是请注意:你还没有在磁带中记录该文件,所以如果弄坏了一个之前还是好的文件,你是没有办法恢复的,因为你没有在“磁带”中记下那个文件还是好着的时刻。
如果你最后决定不把文件记录到 Git 历史列表中,那么你可以撤销提交任务,在 Git 中是这样做的:
```
$ git reset HEAD foo
```
这实际上就是解除了录音机的准备录音状态,你只是在录音棚中转了一圈而已。
### 大型提交
有时候,你想要提交一些内容到仓库;我们以录音机类比,这就好比按下录音键然后记录到磁带中一样。
在一个项目所经历的不同阶段中,你会按下这个“记录键”无数次。比如,如果你尝试了一个新的 Python 工具包并且最终实现了窗口呈现功能,然后你肯定要进行提交,以便你在实验新的显示选项时搞砸了可以回退到这个阶段。但是如果你在 Inkscape 中画了一些图形草样,在提交前你可能需要等到已经有了一些要开发的内容。尽管你可能提交了很多次,但是 Git 并不会浪费很多,也不会占用太多磁盘空间,所以在我看来,提交的越多越好。
`commit` 命令会“记录”仓库中所有的暂存区文件。Git 只“记录”已跟踪的文件,即,在过去某个时间点你使用 `git add` 命令加入到暂存区的所有文件,以及从上次提交后被改动的文件。如果之前没有过提交,那么所有跟踪的文件都包含在这次提交中,以 Git 的角度来看,这是一次非常重要的修改,因为它们从没放到仓库中变成了放进去。
完成一次提交需要运行下面的命令:
```
$ git commit -m 'My great project, first commit.'
```
这就保存了所有提交的文件,之后可以用于其它操作(或者,用英国电视剧《神秘博士》中时间领主所讲的 Gallifreyan 语说,它们成为了“固定的时间点” )。这不仅是一个提交事件,也是一个你在 Git 日志中找到该提交的引用指针:
```
$ git log --oneline
55df4c2 My great project, first commit.
```
如果想浏览更多信息,只需要使用不带 `--oneline` 选项的 `git log` 命令。
在这个例子中提交时的引用号码是 55df4c2。它被叫做“<ruby> 提交哈希 <rp> ( </rp> <rt> commit hash </rt> <rp> ) </rp></ruby>”(LCTT 译注:这是一个 SHA-1 算法生成的哈希码,用于表示一个 git 提交对象),它代表着刚才你的提交所包含的所有新改动,覆盖到了先前的记录上。如果你想要“倒回”到你的提交历史点上,就可以用这个哈希作为依据。
你可以把这个哈希想象成一个声音磁带上的 [SMPTE 时间码](http://slackermedia.ml/handbook/doku.php?id=timecode),或者再形象一点,这就是好比一个黑胶唱片上两首不同的歌之间的空隙,或是一个 CD 上的音轨编号。
当你改动了文件之后并且把它们加入到提交任务中,最终完成提交,这就会生成新的提交哈希,它们每一个所标示的历史点都代表着你的产品不同的版本。
这就是 Charlie Brown 这样的音乐家们为什么用 Git 作为版本控制系统的原因。
在接下来的文章中,我们将会讨论关于 Git HEAD 的各个方面,我们会真正地向你揭示时间旅行的秘密。不用担心,你只需要继续读下去就行了(或许你已经在读了?)。
---
via: <https://opensource.com/life/16/7/creating-your-first-git-repository>
作者:[Seth Kenlon](https://opensource.com/users/seth) 译者:[vim-kakali](https://github.com/vim-kakali) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Read:*
[Part 1: What is Git?](https://opensource.com/resources/what-is-git)*Part 2: Getting started with Git**Part 3: Creating your first Git repository**Part 4: How to restore older file versions in Git**Part 5: 3 graphical tools for Git**Part 6: How to build your own Git server**Part 7: How to manage binary blobs with Git*
Now it is time to learn how to create your own Git repository, and how to add files and make commits.
In the [previous installments](https://opensource.com/tags/git-series) in this series, you learned how to interact with Git as an end user; you were the aimless wanderer who stumbled upon an open source project's website, cloned a repository, and moved on with your life. You learned that interacting with Git wasn't as confusing as you may have thought it would be, and maybe you've been convinced that it's time to start leveraging Git for your own work.
While Git is definitely the tool of choice for major software projects, it doesn't *only* work with major software projects. It can manage your grocery lists (if they're that important to you, and they may be!), your configuration files, a journal or diary, a novel in progress, and even source code!
And it is well worth doing; after all, when have you ever been angry that you have a backup copy of something that you've just mangled beyond recognition?
Git can't work for you unless you use it, and there's no time like the present. Or, translated to Git, "There is no `push`
like `origin HEAD`
". You'll understand that later, I promise.
## The audio recording analogy
We tend to speak of computer imaging in terms of *snapshots* because most of us can identify with the idea of having a photo album filled with particular moments in time. It may be more useful, however, to think of Git more like an analogue audio recording.
A traditional studio tape deck, in case you're unfamiliar, has a few components: it contains the reels that turn either forward or in reverse, tape to preserve sound waves, and a playhead to record or detect sound waves on tape and present them to the listener.
In addition to playing a tape forward, you can rewind it to get back to a previous point in the tape, or fast-forward to skip ahead to a later point.
Imagine a band in the 1970s recording to tape. You can imagine practising a song over and over until all the parts are perfect, and then laying down a track. First, you record the drums, and then the bass, and then the guitar, and then the vocals. Each time you record, the studio engineer rewinds the tape and puts it into loop mode so that it plays the previous part as you play yours; that is, if you're on bass, you get to hear the drums in the background as you play, and then the guitarist hears the drums and bass (and cowbell) and so on. On each loop, you play over the part, and then on the following loop, the engineer hits the **record** button and lays the performance down on tape.
You can also copy and swap out a reel of tape entirely, should you decide to do a re-mix of something you're working on.
Now that I've hopefully painted a vivid Roger Dean-quality image of studio life in the 70s, let's translate that into Git.
## Create a Git repository
The first step is to go out and buy some tape for our virtual tape deck. In Git terms, that's the *repository* ; it's the medium or domain where all the work is going to live.
Any directory can become a Git repository, but to begin with let's start a fresh one. It takes three commands:
- Create the directory (you can do that in your GUI file manager, if you prefer).
- Visit that directory in a terminal.
- Initialise it as a directory managed by Git.
Specifically, run these commands:
```
$ mkdir ~/jupiter # make directory
$ cd ~/jupiter # change into the new directory
$ git init . # initialise your new Git repo
```
Is this example, the folder *jupiter* is now an empty but valid Git repository.
That's all it takes. You can clone the repository, you can go backward and forward in history (once it *has* a history), create alternate timelines, and everything else Git can normally do.
Working inside the Git repository is the same as working in any directory; create files, copy files into the directory, save files into it. You can do everything as normal; Git doesn't get involved until *you* involve it.
In a local Git repository, a file can have one of three states:
- Untracked: a file you create in a repository, but not yet added to Git.
- Tracked: a file that has been added to Git.
- Staged: a
*tracked*file that has been changed and added to Git's commit queue.
Any file that you add to a Git repository starts life out as an *untracked* file. The file exists on your computer, but you have not told Git about it yet. In our tape deck analogy, the tape deck isn't even turned on yet; the band is just noodling around in the studio, nowhere near ready to record yet.
That is perfectly acceptable, and Git will let you know when it happens:
```
$ echo "hello world" > foo
$ git status
On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
foo
nothing added but untracked files present (use "git add" to track)
```
As you can see, Git also tells you how to start tracking files.
### Git without Git
Creating a repository in GitHub or GitLab is a lot more clicky and pointy. It isn't difficult; you click the **New Repository** button and follow the prompts.
It is a good practice to include a README file so that people wandering by have some notion of what your repository is for, and it is a little more satisfying to clone a non-empty repository.
Cloning the repository is no different than usual, but obtaining permission to write back into that repository on GitHub is slightly more complex, because in order to authenticate to GitHub you must have an SSH key. If you're on Linux, create one with this command:
`$ ssh-keygen`
Then copy your new key, which is plain text. You can open it in a plain text editor, or use the `cat`
command:
`$ cat ~/.ssh/id_rsa.pub`
Now paste your key into [GitHub's SSH configuration](https://github.com/settings/keys), or your [GitLab configuration](https://Gitlab.com/profile/keys).
As long as you clone your GitHub project via SSH, you'll be able to write back to your repository.
Alternately, you can use GitHub's file uploader interface to add files without even having Git on your system.
https://opensource.com/sites/default/files/2_githubupload.jpg" title="GitHub file uploader." typeof="foaf:Image" width="520" height="148">
## Tracking files
As the output of `git status`
tells you, if you want Git to start tracking a file, you must `git add`
it. The `git add`
action places a file in a special *staging area*, where files wait to be *committed*, or preserved for posterity in a snapshot. The point of a `git add`
is to differentiate between files that you want to have included in a snapshot, and the new or temporary files you want Git to, at least for now, ignore.
In our tape deck analogy, this action turns the tape deck on and arms it for recording. You can picture the tape deck with the **record** and **pause** button pushed, or in a playback loop awaiting the next track to be laid down.
Once you add a file, Git will identify it as a tracked file:
```
$ git add foo
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: foo
```
Adding a file to Git's tracking system is *not* making a recording. It just puts a file on the stage in preparation for recording. You can still change a file after you've added it; it's being tracked and remains staged, so you can continue to refine it or change it (and then add it again to pick up those changes) before committing it to "tape." *But be warned: You're NOT recording yet, so if you break something in a file that was perfect, there's no going back in time yet, because you never got that perfect moment on tape.*
If you decide that the file isn't really ready to be recorded in the annals of Git history, then you can unstage something, just as the Git message described:
`$ git reset HEAD foo`
This, in effect, disarms the tape deck from being ready to record, and you're back to just noodling around in the studio.
## The big commit
At some point, you're going to want to commit something; in our tape deck analogy, that means finally pressing **record** and laying a track down on tape.
At different stages of a project's life, how often you press that **record** button varies. For example, if you're hacking your way through a new Python toolkit and finally manage to get a window to appear, then you'll certainly want to commit so you have something to fall back on when you inevitably break it later as you try out new display options. But if you're working on a rough draft of some new graphics in Inkscape, you might wait until you have something you want to develop from before committing. Ultimately, though, it's up to you how often you commit; Git doesn't "cost" that much and hard drives these days are big, so in my view, the more the better.
A *commit* records all staged files in a repository. Git only records files that are *tracked*, that is, any file that you did a `git add`
on at some point in the past. and that have been modified since the previous commit. If no previous commit exists, then all tracked files are included in the commit because they went from not existing to existing, which is a pretty major modification from Git's point-of-view.
To make a commit, run this command:
`$ git commit -m 'My great project, first commit.'`
This preserves all files committed for posterity (or, if you speak Gallifreyan, they become "fixed points in time"). You can see not only the commit event, but also the reference pointer back to that commit in your Git log:
```
$ git log --oneline
55df4c2 My great project, first commit.
```
For a more detailed report, just use `git log`
without the `--oneline`
option.
The reference number for the commit in this example is `55df4c2`
. It's called a *commit hash* and it represents all of the new material you just recorded, overlaid onto previous recordings. If you need to "rewind" back to that point in history, you can use that hash as a reference.
You can think of a commit hash as [SMPTE timecode](http://slackermedia.ml/handbook/doku.php?id=timecode) on an audio tape, or if we bend the analogy a little, one of those big gaps between songs on a vinyl record, or track numbers on a CD.
As you change files further and add them to the stage, and ultimately commit them, you accrue new commit hashes, each of which serve as pointers to different versions of your production.
And that's why they call Git a version control system, Charlie Brown.
In the next article, we'll explore everything you need to know about the Git HEAD, and we'll nonchalantly reveal the secret of time travel. No big deal, but you'll want to read it (or maybe you already have?).
## 4 Comments |
7,650 | awk 系列:怎样使用 awk 变量、数值表达式以及赋值运算符 | http://www.tecmint.com/learn-awk-variables-numeric-expressions-and-assignment-operators/ | 2016-08-05T09:14:43 | [
"awk"
] | https://linux.cn/article-7650-1.html | 我觉得 [awk 系列](/article-7586-1.html) 将会越来越好,在本系列的前七节我们讨论了在 Linux 中处理文件和筛选字符串所需要的一些 awk 命令基础。
在这一部分,我们将会进入 awk 更高级的部分,使用 awk 处理更复杂的文本和进行字符串过滤操作。因此,我们将会讲到 Awk 的一些特性,诸如变量、数值表达式和赋值运算符。

*学习 Awk 变量,数值表达式和赋值运算符*
你可能已经在很多编程语言中接触过它们,比如 shell,C,Python 等;这些概念在理解上和这些语言没有什么不同,所以在这一小节中你不用担心很难理解,我们将会简短的提及常用的一些 awk 特性。
这一小节可能是 awk 命令里最容易理解的部分,所以放松点,我们开始吧。
### 1. Awk 变量
在很多编程语言中,变量就是一个存储了值的占位符,当你在程序中新建一个变量的时候,程序一运行就会在内存中创建一些空间,你为变量赋的值会存储在这些内存空间上。
你可以像下面这样定义 shell 变量一样定义 awk 变量:
```
variable_name=value
```
上面的语法:
* `variable_name`: 为定义的变量的名字
* `value`: 为变量赋的值
再看下面的一些例子:
```
computer_name=”tecmint.com”
port_no=”22”
email=”[email protected]”
server=computer_name
```
观察上面的简单的例子,在定义第一个变量的时候,值 'tecmint.com' 被赋给了 'computer\_name' 变量。
此外,值 22 也被赋给了 port\_no 变量,把一个变量的值赋给另一个变量也是可以的,在最后的例子中我们把变量 computer\_name 的值赋给了变量 server。
你可以看看[本系列的第 2 节](/article-7587-1.html)中提到的字段编辑,我们讨论了 awk 怎样将输入的行分隔为若干字段并且使用标准字段访问操作符 `$` 来访问拆分出来的不同字段。我们也可以像下面这样使用变量为字段赋值。
```
first_name=$2
second_name=$3
```
在上面的例子中,变量 first\_name 的值设置为第二个字段,second\_name 的值设置为第三个字段。
再举个例子,有一个名为 names.txt 的文件,这个文件包含了一个应用程序的用户列表,这个用户列表包含了用户的名和姓以及性别。可以使用 [cat 命令](http://www.tecmint.com/13-basic-cat-command-examples-in-linux/) 查看文件内容:
```
$ cat names.txt
```

*使用 cat 命令查看列表文件内容*
然后,我们也可以使用下面的 awk 命令把列表中第一个用户的第一个和第二个名字分别存储到变量 first\_name 和 second\_name 上:
```
$ awk '/Aaron/{ first_name=$2 ; second_name=$3 ; print first_name, second_name ; }' names.txt
```

*使用 Awk 命令为变量赋值*
再看一个例子,当你在终端运行 'uname -a' 时,它可以打印出所有的系统信息。
第二个字段包含了你的主机名,因此,我们可以像下面这样把它赋给一个叫做 hostname 的变量并且用 awk 打印出来。
```
$ uname -a
$ uname -a | awk '{hostname=$2 ; print hostname ; }'
```

*使用 Awk 把命令的输出赋给变量*
### 2. 数值表达式
在 Awk 中,数值表达式使用下面的数值运算符组成:
* `*` : 乘法运算符
* `+` : 加法运算符
* `/` : 除法运算符
* `-` : 减法运算符
* `%` : 取模运算符
* `^` : 指数运算符
数值表达式的语法是:
```
$ operand1 operator operand2
```
上面的 operand1 和 operand2 可以是数值和变量,运算符可以是上面列出的任意一种。
下面是一些展示怎样使用数值表达式的例子:
```
counter=0
num1=5
num2=10
num3=num2-num1
counter=counter+1
```
要理解 Awk 中数值表达式的用法,我们可以看看下面的例子,文件 domians.txt 里包括了所有属于 Tecmint 的域名。
```
news.tecmint.com
tecmint.com
linuxsay.com
windows.tecmint.com
tecmint.com
news.tecmint.com
tecmint.com
linuxsay.com
tecmint.com
news.tecmint.com
tecmint.com
linuxsay.com
windows.tecmint.com
tecmint.com
```
可以使用下面的命令查看文件的内容:
```
$ cat domains.txt
```

*查看文件内容*
如果想要计算出域名 tecmint.com 在文件中出现的次数,我们就可以通过写一个简单的脚本实现这个功能:
```
#!/bin/bash
for file in $@; do
if [ -f $file ] ; then
#print out filename
echo "File is: $file"
#print a number incrementally for every line containing tecmint.com
awk '/^tecmint.com/ { counter=counter+1 ; printf "%s\n", counter ; }' $file
else
#print error info incase input is not a file
echo "$file is not a file, please specify a file." >&2 && exit 1
fi
done
#terminate script with exit code 0 in case of successful execution
exit 0
```

*计算一个字符串或文本在文件中出现次数的 shell 脚本*
写完脚本后保存并赋予执行权限,当我们使用文件运行脚本的时候,文件 domains.txt 作为脚本的输入,我们会得到下面的输出:
```
$ ./script.sh ~/domains.txt
```

*计算字符串或文本出现次数的脚本*
从脚本执行后的输出中,可以看到在文件 domains.txt 中包含域名 tecmint.com 的地方有 6 行,你可以自己计算进行验证。
### 3. 赋值操作符
我们要说的最后的 Awk 特性是赋值操作符,下面列出的只是 awk 中的部分赋值运算符:
* `*=` : 乘法赋值操作符
* `+=` : 加法赋值操作符
* `/=` : 除法赋值操作符
* `-=` : 减法赋值操作符
* `%=` : 取模赋值操作符
* `^=` : 指数赋值操作符
下面是 Awk 中最简单的一个赋值操作的语法:
```
$ variable_name=variable_name operator operand
```
例子:
```
counter=0
counter=counter+1
num=20
num=num-1
```
你可以使用在 awk 中使用上面的赋值操作符使命令更简短,从先前的例子中,我们可以使用下面这种格式进行赋值操作:
```
variable_name operator=operand
counter=0
counter+=1
num=20
num-=1
```
因此,我们可以在 shell 脚本中改变 awk 命令,使用上面提到的 += 操作符:
```
#!/bin/bash
for file in $@; do
if [ -f $file ] ; then
#print out filename
echo "File is: $file"
#print a number incrementally for every line containing tecmint.com
awk '/^tecmint.com/ { counter+=1 ; printf "%s\n", counter ; }' $file
else
#print error info incase input is not a file
echo "$file is not a file, please specify a file." >&2 && exit 1
fi
done
#terminate script with exit code 0 in case of successful execution
exit 0
```

*修改了的 shell 脚本*
在 [awk 系列](/article-7586-1.html) 的这一部分,我们讨论了一些有用的 awk 特性,有变量,使用数值表达式和赋值运算符,还有一些使用它们的实例。
这些概念和其他的编程语言没有任何不同,但是可能在 awk 中有一些意义上的区别。
在本系列的第 9 节,我们会学习更多的 awk 特性,比如特殊格式: BEGIN 和 END。请继续关注。
---
via: <http://www.tecmint.com/learn-awk-variables-numeric-expressions-and-assignment-operators/>
作者:[Aaron Kili](http://www.tecmint.com/author/aaronkili/) 译者:[vim-kakali](https://github.com/vim-kakali) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,651 | 伴随 Linux 成长的职业生涯 | https://opensource.com/life/16/3/my-linux-story-michael-perry | 2016-08-05T14:52:00 | [
"Linux"
] | /article-7651-1.html | 
我与 Linux 的故事开始于 1998 年,一直延续到今天。 当时我在 Gap 公司工作,管理着成千台运行着 [OS/2](https://en.wikipedia.org/wiki/OS/2) 系统的台式机 ( 在随后的几年里变成了 [Warp 3.0](https://archive.org/details/IBMOS2Warp3Collection))。 作为一个 OS/2 的粉丝,那时我非常喜欢那个时候。 随着这些台式机的嗡鸣,我们使用 Gap 开发的工具轻而易举地就能支撑起对成千的用户的服务支持。 然而,一切都将改变了。
在 1998 年的 11 月, 我收到邀请加入一个新成立的公司,这家公司将专注于企业级 Linux 上。 这就是后来非常出名的 [Linuxcare](https://archive.org/details/IBMOS2Warp3Collection)。
### 我在 Linuxcare 的时光
我曾经接触过一些 Linux , 但我从未想过要把它提供给企业客户。仅仅几个月后 ( 从这里开始成为了空间和时间上的转折点 ), 我就在管理一整条线的业务,让企业获得他们的软件,硬件,甚至是证书认证等各种在当时非常盛行的 Linux 服务。
我支持的客户包括像 IBM ,Dell ,HP 这样的厂商以确保他们的硬件能够成功的运行 Linux 。 今天你们应该都听过许多关于在硬件上预装 Linux 的事, 但当时 Dell 邀请我去讨论为即将到来的贸易展上将 Linux 运行在认证的笔记本电脑上。 这是多么激动人心的时刻 !同时我们在之后几年内也支持了 IBM 和 HP 等多项认证工作。
Linux 变化得非常快,并且它总是这样。 它也获得了更多的关键设备的支持,比如声音,网络和图形。在这段时间, 我把个人使用的系统从基于 RPM 的系统换成了 [Debian](https://en.wikipedia.org/wiki/Linuxcare) 。
### 使用 Linux 的这些年
几年前我在一些做 Linux 硬件设备、Linux 定制软件以及 Linux 数据中心的公司工作。而在二十一世纪第一个十年的中期的时候,那时我正在忙为那些在雷蒙德附近(微软公司所在地)的大一些的软件公司做咨询工作,为他们对比 Linux 解决方案及其自己的解决方案做分析和验证。 我个人使用的系统一直没有改变,我仍会在尽可能的情况下运行 Debian 测试系统。
我真的非常欣赏发行版的灵活性和永久更新状态。 Debian 是我所使用过的最有趣且拥有良好支持的发行版,并且它拥有最好的社区,而我是社区的一份子。
当我回首我使用 Linux 的这几年,我仍记得大约在二十一世纪第一个十年的前中期的时候在圣何塞,旧金山,波士顿和纽约召开的那些 Linux Expo 大会。在 Linuxcare 时我们总是会摆一些有趣而且时髦的展位,在那边逛的时候总会碰到一些老朋友。这一切工作都是需要付出代价的,所有的这一切都是在努力地强调使用 Linux 的乐趣。
随着虚拟化和云的崛起也让 Linux 变得更加有趣。 当我在 Linuxcare 的时候, 我们常和斯坦福大学附近的帕洛阿尔托的一个约 30 人左右的小公司在一块。我们会开车到他们的办公处,然后帮他们准备和我们一起参加展览的东西。 谁会想得到这个小小的初创公司会成就后来的 VMware ?
我还有许多的故事,能认识这些人并和他们一起工作我感到很幸运。 Linux 在各方面都不断发展且变得尤为重要。 并且甚至随着它重要性的提升,它使用起来仍然非常有趣。 我认为它的开放性和可定制能力给它带来了大量的新用户,这也是让我感到非常震惊的一点。
### 现在
在过去的五年里我的工作重心逐渐离开 Linux。 我所管理的大规模基础设施项目中包含着许多不同的操作系统 ( 包括非开源的和开源的 ), 但我的心一直以来都是和 Linux 在一起的。
在使用 Linux 过程中的乐趣和不断进步是在过去的 18 年里一直驱动我的动力。我从 Linux 2.0 内核开始看着它变成现在的这样。 Linux 是一个卓越的、生机勃勃的且非常酷的东西。
---
via: <https://opensource.com/life/16/3/my-linux-story-michael-perry>
作者:[Michael Perry](https://opensource.com/users/mpmilestogo) 译者:[chenxinlong](https://github.com/chenxinlong) 校对:[wxy](https://github.com/wxy)
| null | HTTPSConnectionPool(host='opensource.com', port=443): Read timed out. (read timeout=10) | null |
7,652 | 在用户空间做我们会在内核空间做的事情 | https://www.linuxjournal.com/content/doing-user-space-what-we-did-kernel-space | 2016-08-05T20:39:36 | [
"身份"
] | https://linux.cn/article-7652-1.html | 我相信,Linux 最好也是最坏的事情,就是<ruby> 内核空间 <rp> ( </rp> <rt> kernel space </rt> <rp> ) </rp></ruby>和<ruby> 用户空间 <rp> ( </rp> <rt> user space </rt> <rp> ) </rp></ruby>之间的巨大差别。

如果没有这个区别,Linux 可能也不会成为世界上影响力最大的操作系统。如今,Linux 的使用范围在世界上是最大的,而这些应用又有着世界上最大的用户群——尽管大多数用户并不知道,当他们进行谷歌搜索或者触摸安卓手机的时候,他们其实正在使用 Linux。如果不是 Linux 的巨大成功,Apple 公司也可能并不会成为现在这样(即在他们的电脑产品中使用 BSD 的技术)(LCTT 译注:Linux 获得成功后,Apple 曾与 Linus 协商使用 Linux 核心作为 Apple 电脑的操作系统并帮助开发的事宜,但遭到拒绝。因此,Apple 转向使用许可证更为宽松的 BSD 。)。
不(需要)关注用户空间是 Linux 内核开发中的一个特点而非缺陷。正如 Linus 在 2003 年的<ruby> <a href="http://www.linuxjournal.com/article/6427"> 极客巡航 </a> <rp> ( </rp> <rt> Geek Cruise </rt> <rp> ) </rp></ruby>中提到的那样,“我只做内核相关的东西……我并不知道内核之外发生的事情,而且我也并不关心。我只关注内核部分发生的事情。” 多年之后的[另一次极客巡航](http://www.linuxjournal.com/article/8664)上, Andrew Morton 给我上了另外的一课,这之后我写道:
>
> 内核空间是Linux 所在的地方,而用户空间是 Linux 与其它的“自然材料”一起使用的地方。内核空间和用户空间的区别,和自然材料与人类用其生产的人造材料的区别很类似。
>
>
>
这个区别是自然而然的结果,就是尽管外面的世界一刻也离不开 Linux, 但是 Linux 社区还是保持相对较小。所以,为了增加哪怕一点我们社区团体的规模,我希望指出两件事情。第一件已经非常火了,另外一件可能会火起来。
第一件事情就是<ruby> <a href="https://en.wikipedia.org/wiki/Block_chain_%28database%29"> 区块链 </a> <rp> ( </rp> <rt> blockchain </rt> <rp> ) </rp></ruby>,出自著名的分布式货币——比特币之手。当你正在阅读这篇文章的同时,人们对区块链的[关注度正在直线上升](https://www.google.com/trends/explore#q=blockchain)。

*图1. 区块链的谷歌搜索趋势*
第二件事就是<ruby> 自主身份 <rp> ( </rp> <rt> self-sovereign identity </rt> <rp> ) </rp></ruby>。为了解释这个概念,让我先来问你:你是谁,你来自哪里?
如果你从你的老板、你的医生或者车管所,Facebook、Twitter 或者谷歌上得到答案,你就会发现它们都是<ruby> 行政身份 <rp> ( </rp> <rt> administrative identifiers </rt> <rp> ) </rp></ruby>——这些机构完全以自己的便利为原因设置这些身份和职位。正如一家区块链技术公司 [Evernym](http://evernym.com/) 的 Timothy Ruff 所说,“你并不因组织而存在,但你的身份却因此存在。”身份是个因变量。自变量——即控制着身份的变量——是(你所在的)组织。
如果你的答案出自你自己,我们就有一个广大空间来发展一个新的领域,在这个领域中,我们完全自由。
据我所知,第一个解释这个的人是 [Devon Loffreto](https://twitter.com/nzn)。在 2012 年 2 月,他在博客 [Moxy Tongue](http://www.moxytongue.com/2012/02/what-is-sovereign-source-authority.html) 中写道:“什么是 'Sovereign Source Authority'?”。在发表于 2016 年 2 月的 “[Self-Sovereign Identity](http://www.moxytongue.com/2016/02/self-sovereign-identity.html)” 一文中,他写道:
>
> 自主身份必须是独立个人提出的,并且不包含社会因素……自主身份源于每个个体对其自身本源的认识。 一个自主身份可以为个体带来新的社会面貌。每个个体都可能为自己生成一个自主身份,并且这并不会改变固有的人权。使用自主身份机制是所有参与者参与的基石,并且依旧可以同各种形式的人类社会保持联系。
>
>
>
将这个概念放在 Linux 领域中,只有个人才能为他或她设定一个自己的开源社区身份。这在现实实践中,这只是一个非常正常的事件。举个例子,我自己的身份包括:
* David Allen Searls,我父母会这样叫我。
* David Searls,正式场合下我会这么称呼自己。
* Dave,我的亲戚和好朋友会这么叫我。
* Doc,大多数人会这么叫我。
作为承认以上称呼的自主身份来源,我可以在不同的情景中轻易的转换。但是,这只是在现实世界中。在虚拟世界中,这就变得非常困难。除了上述的身份之外,我还可以是 @dsearls (我的 twitter 账号) 和 dsearls (其他的网络账号)。然而为了记住成百上千的不同账号的登录名和密码,我已经不堪重负。
你可以在你的浏览器上感受到这个糟糕的体验。在火狐上,我有成百上千个用户名密码。很多已经废弃(很多都是从 Netscape 时代遗留下来的),但是我想会有大量的工作账号需要处理。对于这些,我只是被动接受者。没有其他的解决方法。甚至一些安全较低的用户认证,已经成为了现实世界中不可缺少的一环。
现在,最简单的方式来联系账号,就是通过 “Log in with Facebook” 或者 “Login in with Twitter” 来进行身份认证。在这种情况下,我们中的每一个甚至并不是真正意义上的自己,甚至(如果我们希望被其他人认识的话)缺乏对其他实体如何认识我们的控制。
我们从一开始就需要的是一个可以实体化我们的自主身份和交流时选择如何保护和展示自身的个人系统。因为缺少这个能力,我们现在陷入混乱。Shoshana Zuboff 称之为 “监视资本主义”,她如此说道:
>
> ...难以想象,在见证了互联网和获得了的巨大成功的谷歌背后。世界因 Apple 和 FBI 的对决而紧密联系在一起。讲道理,热衷于监视的资本家开发的监视系统是每一个国家安全机构都渴望的。
>
>
>
然后,她问道,”我们怎样才能保护自己远离他人的影响?“
我建议使用自主身份。我相信这是我们唯一的既可以保证我们从监视中逃脱、又可以使我们有一个有序的世界的办法。以此为基础,我们才可以完全无顾忌地和社会,政治,商业上的人交流。
我在五月联合国举行的 [ID2020](http://www.id2020.org/) 会议中总结了这个临时的结论。很高兴,Devon Loffreto 也在那,他于 2013 年推动了自主身份的创立。这是[我那时写的一些文章](http://blogs.harvard.edu/doc/2013/10/14/iiw-challenge-1-sovereign-identity-in-the-great-silo-forest),引用了 Devon 的早期博客(比如上面的原文)。
这有三篇这个领域的准则:
* "[Self-Sovereign Identity](http://www.moxytongue.com/2016/02/self-sovereign-identity.html)" - Devon Loffreto.
* "[System or Human First](http://www.moxytongue.com/2016/05/system-or-human.html)" - Devon Loffreto.
* "[The Path to Self-Sovereign Identity](http://www.lifewithalacrity.com/2016/04/the-path-to-self-soverereign-identity.html)" - Christopher Allen.
从 Evernym 的简要说明中,[digi.me](https://get.digi.me/)、 [iRespond](http://irespond.com/) 和 [Respect Network](https://www.respectnetwork.com/) 也被包括在内。自主身份和社会身份 (也被称为“<ruby> 当前模式 <rp> ( </rp> <rt> current model </rt> <rp> ) </rp></ruby>”) 的对比结果,显示在图二中。

*图 2. 当前模式身份 vs. 自主身份*
Sovrin 就是为此而生的[平台](http://evernym.com/technology),它阐述自己为一个“依托于先进、专用、经授权、分布式平台的,完全开源、基于标识的身份声明图平台”。同时,这也有一本[白皮书](http://evernym.com/assets/doc/Identity-System-Essentials.pdf?v=167284fd65)。它的代码名为 [plenum](https://github.com/evernym/plenum),并且公开在 Github 上。
在这里——或者其他类似的地方——我们就可以在用户空间中重现我们在过去 25 年中在内核空间做过的事情。
---
via: <https://www.linuxjournal.com/content/doing-user-space-what-we-did-kernel-space>
作者:[Doc Searls](https://www.linuxjournal.com/users/doc-searls) 译者:[MikeCoder](https://github.com/MikeCoder) 校对:[PurlingNayuki](https://github.com/PurlingNayuki)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | ## Doing for User Space What We Did for Kernel Space
I believe the best and worst thing about Linux is its hard distinction
between *kernel space* and *user
space*.
Without that distinction, Linux never would have become the most leveraged operating system in the world. Today, Linux has the largest range of uses for the largest number of users—most of whom have no idea they are using Linux when they search for something on Google or poke at their Android phones. Even Apple stuff wouldn't be what it is (for example, using BSD in its computers) were it not for Linux's success.
Not caring about user space is a feature of Linux kernel
development, not a bug. As Linus put it on our [2003 Geek Cruise](http://www.linuxjournal.com/article/6427),
"I only do kernel stuff...I
don't know what happens outside the kernel, and I don't much care. What
happens inside the kernel I care about."
After Andrew Morton gave me additional schooling on
the topic a couple years later on [another Geek Cruise](http://www.linuxjournal.com/article/8664),
I wrote:
Kernel space is where the Linux species lives. User space is where Linux gets put to use, along with a lot of other natural building materials. The division between kernel space and user space is similar to the division between natural materials and stuff humans make out of those materials.
A natural outcome of this distinction, however, is for Linux folks to stay relatively small as a community while the world outside depends more on Linux every second. So, in hope that we can enlarge our number a bit, I want to point us toward two new things. One is already hot, and the other could be.
The first is [blockchain](https://en.wikipedia.org/wiki/Block_chain_%28database%29),
made famous
as the distributed ledger used by Bitcoin, but useful for countless other
purposes as well. At the time of this writing, interest in blockchain is [trending
toward the vertical](https://www.google.com/trends/explore#q=blockchain).

Figure 1. Google Trends for Blockchain
The second is **self-sovereign identity**. To
explain that, let me ask who and what you are.
If your answers come from your employer, your doctor, the Department
of Motor Vehicles, Facebook, Twitter or Google, they are each
**administrative identifiers**: entries in
namespaces each of those organizations control, entirely for their own
convenience. As Timothy Ruff of [Evernym](http://evernym.com)
explains,
"You don't exist for them. Only your identifier does." It's the
dependent variable. The independent variable—the one controlling the
identifier—is the organization.
If your answer comes from your self, we have a wide-open area for a new development category—one where, finally, we can be set fully free in the connected world.
The first person to explain this, as far as I know, was [Devon Loffreto](https://twitter.com/nzn)
He wrote "What is 'Sovereign Source
Authority'?" in February 2012, on his blog, [The
Moxy Tongue](http://www.moxytongue.com/2012/02/what-is-sovereign-source-authority.html).
In ["Self-Sovereign
Identity"](http://www.moxytongue.com/2016/02/self-sovereign-identity.html),
published in February 2016, he writes:
Self-Sovereign Identity must emit directly from an individual human life, and not from within an administrative mechanism...self-Sovereign Identity references every individual human identity as the origin of source authority. A self-Sovereign identity produces an administrative trail of data relations that begin and resolve to individual humans. Every individual human may possess a self-Sovereign identity, and no person or abstraction of any type created may alter this innate human Right. A self-Sovereign identity is the root of all participation as a valued social being within human societies of any type.
To put this in Linux terms, *only the individual has root for
his or her own source identity*.
In the physical world, this is a casual thing. For example, my own
portfolio of identifiers includes:
- David Allen Searls, which my parents named me.
- David Searls, the name I tend to use when I suspect official records are involved.
- Dave, which is what most of my relatives and old friends call me.
- Doc, which is what most people call me.
As the sovereign source authority over the use of those, I can jump from one to another in different contexts and get along pretty well. But, that's in the physical world. In the virtual one, it gets much more complicated. In addition to all the above, I am @dsearls (my Twitter handle) and dsearls (my handle in many other net-based services). I am also burdened by having my ability to relate contained within hundreds of different silos, each with their own logins and passwords.
You can get a sense of how bad this is by checking the list of logins and passwords on your browser. On Firefox alone, I have hundreds of them. Many are defunct (since my collection dates back to Netscape days), but I would guess that I still have working logins to hundreds of companies I need to deal with from time to time. For all of them, I'm the dependent variable. It's not the other way around. Even the term "user" testifies to the subordinate dependency that has become a primary fact of life in the connected world.
Today, the only easy way to bridge namespaces is via the compromised convenience of "Log in with Facebook" or "Log in with Twitter". In both of those cases, each of us is even less ourselves or in any kind of personal control over how we are known (if we wish to be knowable at all) to other entities in the connected world.
What we have needed from the start are personal systems for
instantiating our sovereign selves and choosing how to reveal
and protect ourselves when dealing with others in the connected
world. For lack of that ability, we are deep in a metastasized
mess that Shoshana Zuboff calls ["surveillance
capitalism"](http://www.faz.net/aktuell/feuilleton/debatten/the-digital-debate/shoshana-zuboff-secrets-of-surveillance-capitalism-14103616.html?printPagedArticle=true#pageIndex_2),
which she says is:
...unimaginable outside the inscrutable high velocity circuits of Google's digital universe, whose signature feature is the Internet and its successors. While the world is riveted by the showdown between Apple and the FBI, the real truth is that the surveillance capabilities being developed by surveillance capitalists are the envy of every state security agency.
Then she asks, "How can we protect ourselves from its invasive power?"
I suggest self-sovereign identity. I believe it is only there that we have both safety from unwelcome surveillance and an Archimedean place to stand in the world. From that place, we can assert full agency in our dealings with others in society, politics and business.
I came to this provisional conclusion during [ID2020](http://www.id2020.org),
a gathering at the UN on May. It was
gratifying to see Devon Loffreto there, since he's the guy who got the
sovereign ball rolling in 2013. Here's [what
I wrote about it at the time](http://blogs.harvard.edu/doc/2013/10/14/iiw-challenge-1-sovereign-identity-in-the-great-silo-forest),
with pointers to Devon's earlier posts (such as one sourced above).
Here are three for the field's canon:
-
["Self-Sovereign Identity"](http://www.moxytongue.com/2016/02/self-sovereign-identity.html)by Devon Loffreto. -
["System or Human First"](http://www.moxytongue.com/2016/05/system-or-human.html)by Devon Loffreto. -
["The Path to Self-Sovereign Identity"](http://www.lifewithalacrity.com/2016/04/the-path-to-self-soverereign-identity.html)by Christopher Allen.
A one-pager from [Evernym](http://evernym.com), [digi.me](https://get.digi.me), [iRespond](http://irespond.org)
and [Respect Network](https://www.respectnetwork.com)
also was circulated
there, contrasting administrative identity (which it calls the "current
model") with the
self-sovereign one. In it is the graphic shown in Figure 2.

Figure 2. Current Model of Identity vs. Self-Sovereign Identity
The [platform](http://evernym.com/technology) for this is Sovrin, explained as a "Fully
open-source, attribute-based, sovereign identity graph platform
on an advanced, dedicated, permissioned, distributed ledger"
There's a [white
paper](http://evernym.com/assets/doc/Identity-System-Essentials.pdf?v=167284fd65) too.
The code is called [plenum](https://github.com/evernym/plenum),
and it's
at GitHub.
Here—and places like it—we can do for user space what we've done for the last quarter century for kernel space.
[Load Disqus comments](https://www.linuxjournal.com/content/doing-user-space-what-we-did-kernel-space#disqus_thread) |
7,653 | bc : 一个命令行计算器 | https://fedoramagazine.org/bc-command-line-calculator/ | 2016-08-06T18:22:57 | [
"bc",
"命令",
"计算器"
] | https://linux.cn/article-7653-1.html | 
假如你在一个图形桌面环境中需要一个计算器时,你可能只需要一路进行点击便可以找到一个计算器。例如,Fedora 工作站中就已经包含了一个名为 `Calculator` 的工具。它有着几种不同的操作模式,例如,你可以进行复杂的数学运算或者金融运算。但是,你知道吗,命令行也提供了一个与之相似的名为 `bc` 的工具?
`bc` 工具可以为你提供的功能可以满足你对科学计算器、金融计算器或者是简单计算器的期望。另外,假如需要的话,它还可以从命令行中被脚本化。这使得当你需要做复杂的数学运算时,你可以在 shell 脚本中使用它。
因为 bc 也被用于其他的系统软件,例如 CUPS 打印服务,所以它可能已经在你的 Fedora 系统中被安装了。你可以使用下面这个命令来进行检查:
```
dnf list installed bc
```
假如因为某些原因你没有在上面命令的输出中看到它,你可以使用下面的这个命令来安装它:
```
sudo dnf install bc
```
### 用 bc 做一些简单的数学运算
使用 bc 的一种方式是进入它自己的 shell。在那里你可以按行进行许多次计算。当你键入 bc 后,首先出现的是有关这个程序的警告:
```
$ bc
bc 1.06.95
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006 Free Software Foundation, Inc.
This is free software with ABSOLUTELY NO WARRANTY.
For details type `warranty'.
```
现在你可以按照每行一个输入运算式或者命令了:
```
1+1
```
bc 会回答上面计算式的答案是:
```
2
```
在这里你还可以执行其他的命令。你可以使用 加(+)、减(-)、乘(\*)、除(/)、圆括号、指数符号(^) 等等。请注意 bc 同样也遵循所有约定俗成的运算规则,例如运算的先后顺序。你可以试试下面的例子:
```
(4+7)*2
4+7*2
```
若要退出 bc 可以通过按键组合 `Ctrl+D` 来发送 “输入结束”信号给 bc 。
使用 bc 的另一种方式是使用 `echo` 命令来传递运算式或命令。下面这个示例就是计算器中的 “Hello, world” 例子,使用 shell 的管道函数(|) 来将 `echo` 的输出传入 `bc` 中:
```
echo '1+1' | bc
```
使用 shell 的管道,你可以发送不止一个运算操作,你需要使用分号来分隔不同的运算。结果将在不同的行中返回。
```
echo '1+1; 2+2' | bc
```
### 精度
在某些计算中,bc 会使用精度的概念,即小数点后面的数字位数。默认的精度是 0。除法操作总是使用精度的设定。所以,如果你没有设置精度,有可能会带来意想不到的答案:
```
echo '3/2' | bc
echo 'scale=3; 3/2' | bc
```
乘法使用一个更复杂的精度选择机制:
```
echo '3*2' | bc
echo '3*2.0' | bc
```
同时,加法和减法的相关运算则与之相似:
```
echo '7-4.15' | bc
```
### 其他进制系统
bc 的另一个有用的功能是可以使用除了十进制以外的其他计数系统。例如,你可以轻松地做十六进制或二进制的数学运算。可以使用 `ibase` 和 `obase` 命令来分别设定输入和输出的进制系统。需要记住的是一旦你使用了 `ibase`,之后你输入的任何数字都将被认为是在新定义的进制系统中。
要做十六进制数到十进制数的转换或运算,你可以使用类似下面的命令。请注意大于 9 的十六进制数必须是大写的(A-F):
```
echo 'ibase=16; A42F' | bc
echo 'ibase=16; 5F72+C39B' | bc
```
若要使得结果是十六进制数,则需要设定 `obase` :
```
echo 'obase=16; ibase=16; 5F72+C39B' | bc
```
下面是一个小技巧。假如你在 shell 中做这些十六进制运算,怎样才能使得输入重新为十进制数呢?答案是使用 `ibase` 命令,但你必须设定它为在当前进制中与十进制中的 10 等价的值。例如,假如 `ibase` 被设定为十六进制,你需要输入:
```
ibase=A
```
一旦你执行了上面的命令,所有输入的数字都将是十进制的了,接着你便可以输入 `obase=10` 来重置输出的进制系统。
### 结论
上面所提到的只是 bc 所能做到的基础。它还允许你为某些复杂的运算和程序定义函数、变量和循环结构。你可以在你的系统中将这些程序保存为文本文件以便你在需要的时候使用。你还可以在网上找到更多的资源,它们提供了更多的例子以及额外的函数库。快乐地计算吧!
---
via: <https://fedoramagazine.org/bc-command-line-calculator/>
作者:[Paul W. Frields](https://fedoramagazine.org/author/pfrields/) 译者:[FSSlc](https://github.com/FSSlc) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | If you run a graphical desktop environment, you probably point and click your way to a calculator when you need one. The [Fedora Workstation](http://getfedora.org/workstation), for example, includes the [Calculator](https://wiki.gnome.org/Apps/Calculator) tool. It features several different operating modes that allow you to do, for example, complex math or financial calculations. But did you know the command line also offers a similar calculator called *bc*?
The *bc* utility gives you everything you expect from a scientific, financial, or even simple calculator. What’s more, it can be scripted from the command line if needed. This allows you to use it in shell scripts, in case you need to do more complex math.
Because *bc* is used by some other system software, like CUPS printing services, it’s probably installed on your Fedora system already. You can check with this command:
dnf list installed bc
If you don’t see it for some reason, you can install the package with this command:
sudo dnf install bc
## Doing simple math with bc
One way to use *bc* is to enter the calculator’s own shell. There you can run many calculations in a row. When you enter, the first thing that appears is a notice about the program:
$ bc bc 1.06.95 Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006 Free Software Foundation, Inc. This is free software with ABSOLUTELY NO WARRANTY. For details type `warranty'.
Now you can type in calculations or commands, one per line:
1+1
The calculator helpfully answers:
2
You can perform other commands here. You can use addition (+), subtraction (-), multiplication (*), division (/), parentheses, exponents (^), and so forth. Note that the calculator respects all expected conventions such as order of operations. Try these examples:
(4+7)*2 4+7*2
To exit, send the “end of input” signal with the key combination *Ctrl+D*.
Another way is to use the echo command to send calculations or commands. Here’s the calculator equivalent of “Hello, world,” using the shell’s pipe function (|) to send output from *echo* into *bc*:
echo '1+1' | bc
You can send more than one calculation using the shell pipe, with a semicolon to separate entries. The results are returned on separate lines.
echo '1+1; 2+2' | bc
## Scale
The *bc* calculator uses the concept of *scale*, or the number of digits after a decimal point, in some calculations. The default scale is 0. Division operations always use the scale setting. So if you don’t set scale, you may get unexpected answers:
echo '3/2' | bc echo 'scale=3; 3/2' | bc
Multiplication uses a more complex decision for scale:
echo '3*2' | bc echo '3*2.0' | bc
Meanwhile, addition and subtraction are more as expected:
echo '7-4.15' | bc
## Other base number systems
Another useful function is the ability to use number systems other than base-10 (decimal). For instance, you can easily do hexadecimal or binary math. Use the *ibase* and *obase* commands to set input and output base systems between base-2 and base-16. Remember that once you use *ibase*, any number you enter is expected to be in the new declared base.
To do hexadecimal to decimal conversions or math, you can use a command like this. Note the hexadecimal digits above 9 must be in uppercase (A-F):
echo 'ibase=16; A42F' | bc echo 'ibase=16; 5F72+C39B' | bc
To get results in hexadecimal, set the *obase* as well:
echo 'obase=16; ibase=16; 5F72+C39B' | bc
Here’s a trick, though. If you’re doing these calculations in the shell, how do you switch back to input in base-10? The answer is to use *ibase*, but you must set it to the equivalent of decimal number 10 in the **current** input base. For instance, if *ibase* was set to hexadecimal, enter:
ibase=A
Once you do this, all input numbers are now decimal again, so you can enter *obase=10* to reset the output base system.
## Conclusion
This is only the beginning of what *bc* can do. It also allows you to define functions, variables, and loops for complex calculations and programs. You can save these programs as text files on your system to run whenever you need. You can find numerous [resources on the web](http://phodd.net/gnu-bc/) that offer examples and additional function libraries. Happy calculating!
## Roberto
Why publicize a command line calculator in a time when the computer should read the mind of people and execute the operation ( i’m exceeding, I know ).
There are already, formidable and computational complex online tools that allow to do this, see wolfram.
Or very complex software like matlab even if not free.
What I perceive is that linux doesn’t have innovation to offer than a calculator and this is quite sad
Cit “Is this (is) the end my only friend”
## Sebastiaan Franken
Linux has more to offer than a GUI. Some people use it to work on and some of those people (I am one of those) have automated a great number of tasks, some of which include math. I don’t want my scripts to halfway stop and tell me “Hey, can you open the fancy calculator app you have and do some math for me? I’ll wait.”. No, I want my script to be able to do said math and just carry on and only tell me something when it’s done or when there’s an error. I use bc in a few scripts to calculate averages and do conversions from base-16 to base-10.
That way I can get more work done (in the same amount of time). Linux is all about choice and the freedom to choose the tool that works for you. Like I said, bc is a lifesaver to some of us
## Xose
Shorter:
bc <<< 1+1
## bluebat
A Command-line Calculator in pure BASH
http://www.slideshare.net/bluebat/a-commandlinecalculatorinpurebash
https://gist.github.com/bluebat/9760449
## Hiisi
Great and very useful post. Will apply in my work-flow. Thanks!
## Cătălin George Feștilă
new users can try more if you follow https://docs.fedoraproject.org/en-US/index.html
also the dnf is a great tool like yum the repo is the same …
## dhanvi
This is a very good article about bc 🙂
There is also a -l flag for bc which says to define the math lib, which also gives the answer in the decimal points
echo ‘ 3 / 5 ‘ | bc -l
## Elliot
An easier way to avoid issues with scale is to invoke bc with the -l (–mathlib) option.
## djf
Damn – that’s a great tip – thanks
bc -l <<< 5/450
instead of
bc <<< ‘scale=3;5/450’
## Paul W. Frields
@Elliot: Great tip, thanks!
## Brett
I love bc and use bc every day.
I have bc aliased to “bc -lq”. Sets a reasonable scale and drops the startup banner.
## Saman
Thank you so much. I’ve noticed “scale” doesn’t do the rounding. for example If I want to get the result of 3 / 4 using scale=1, the result is 0.7 instead of 0.8.
## Cătălin George Feștilă
! need time to follow the all docs …
## Brett
One thing I like to do when demonstrating bc is this:
2^4096
🙂
Brett
## Stan
Great info, I wasn’t aware of bc, learning something every day! Many thanks for the posting. I use the cli frequently and now don’t need to switch back to a gui for quick calculations ….. many thanks!
## hyhy123
Really great! I find this useful in some cases, especially when I am writing a shell script and find there are some simple math calculations. The bc can get things done perfectly!
## c4ifford
why not just use python?
## rpndude
Being a rpn person, I usually use ‘dc’; but ‘bc’ is great to, especially in scripts.
## Tad Marko
I’d recommend dc.
## Dale Raby
I never knew about this. I’ve been using an actual slide rule to do quick estimates for an “out the door price” for customers as it takes a few seconds to bring the GUI calculator up. As I always have a shell up, I can open bc and type 299.99+13+1.05(enter) and get $314.04. Yeah, I know I could invest a dollar and get a pocket calculator to replace the one that broke a couple months ago, but I always seem to “lose” those when they are on the counter and yeah, I know I could multiply by 10% and divide by two using my actual organic brain… but this is way cooler!
## Dale Raby
Hmmm… a problem manifests itself. You have to remember to hit the correct keys! 299.99+13*1.05
313.64
## Dale Raby
As I said, the CORRECT keys:
(299.99+13)*1.05
328.63
customers would probably prefer I forget about the brackets…
## Dale Raby
Ooops…
(299.99+13)*1.05
328.63
customers would probably prefer I forget about the brackets… |
7,654 | awk 系列:如何使用 awk 的特殊模式 BEGIN 和 END | http://www.tecmint.com/learn-use-awk-special-patterns-begin-and-end/ | 2016-08-06T18:41:00 | [
"awk"
] | https://linux.cn/article-7654-1.html | 在 awk 系列的第八节,我们介绍了一些强大的 awk 命令功能,它们是变量、数字表达式和赋值运算符。
本节我们将学习更多的 awk 功能,即 awk 的特殊模式:`BEGIN` 和 `END`。

*学习 awk 的模式 BEGIN 和 END*
随着我们逐渐展开,并探索出更多构建复杂 awk 操作的方法,将会证明 awk 的这些特殊功能的是多么强大。
开始前,先让我们回顾一下 awk 系列的介绍,记得当我们开始这个系列时,我就指出 awk 指令的通用语法是这样的:
```
# awk 'script' filenames
```
在上述语法中,awk 脚本拥有这样的形式:
```
/pattern/ { actions }
```
你通常会发现脚本中的模式(`/pattern/`)是一个正则表达式,此外,你也可以在这里用特殊模式 `BEGIN` 和 `END`。因此,我们也能按照下面的形式编写一条 awk 命令:
```
awk '
BEGIN { actions }
/pattern/ { actions }
/pattern/ { actions }
……….
END { actions }
' filenames
```
假如你在 awk 脚本中使用了特殊模式:`BEGIN` 和 `END`,以下则是它们对应的含义:
* `BEGIN` 模式:是指 awk 将在读取任何输入行之前立即执行 `BEGIN` 中指定的动作。
* `END` 模式:是指 awk 将在它正式退出前执行 `END` 中指定的动作。
含有这些特殊模式的 awk 命令脚本的执行流程如下:
1. 当在脚本中使用了 `BEGIN` 模式,则 `BEGIN` 中所有的动作都会在读取任何输入行之前执行。
2. 然后,读入一个输入行并解析成不同的段。
3. 接下来,每一条指定的非特殊模式都会和输入行进行比较匹配,当匹配成功后,就会执行模式对应的动作。对所有你指定的模式重复此执行该步骤。
4. 再接下来,对于所有输入行重复执行步骤 2 和 步骤 3。
5. 当读取并处理完所有输入行后,假如你指定了 `END` 模式,那么将会执行相应的动作。
当你使用特殊模式时,想要在 awk 操作中获得最好的结果,你应当记住上面的执行顺序。
为了便于理解,让我们使用第八节的例子进行演示,那个例子是关于 Tecmint 拥有的域名列表,并保存在一个叫做 domains.txt 的文件中。
```
news.tecmint.com
tecmint.com
linuxsay.com
windows.tecmint.com
tecmint.com
news.tecmint.com
tecmint.com
linuxsay.com
tecmint.com
news.tecmint.com
tecmint.com
linuxsay.com
windows.tecmint.com
tecmint.com
```
```
$ cat ~/domains.txt
```

*查看文件内容*
在这个例子中,我们希望统计出 domains.txt 文件中域名 `tecmint.com` 出现的次数。所以,我们编写了一个简单的 shell 脚本帮助我们完成任务,它使用了变量、数学表达式和赋值运算符的思想,脚本内容如下:
```
#!/bin/bash
for file in $@; do
if [ -f $file ] ; then
### 输出文件名
echo "File is: $file"
### 输出一个递增的数字记录包含 tecmint.com 的行数
awk '/^tecmint.com/ { counter+=1 ; printf "%s\n", counter ; }' $file
else
### 若输入不是文件,则输出错误信息
echo "$file 不是一个文件,请指定一个文件。" >&2 && exit 1
fi
done
### 成功执行后使用退出代码 0 终止脚本
exit 0
```
现在让我们像下面这样在上述脚本的 awk 命令中应用这两个特殊模式:`BEGIN` 和 `END`:
我们应当把脚本:
```
awk '/^tecmint.com/ { counter+=1 ; printf "%s\n", counter ; }' $file
```
改成:
```
awk ' BEGIN { print "文件中出现 tecmint.com 的次数是:" ; }
/^tecmint.com/ { counter+=1 ; }
END { printf "%s\n", counter ; }
' $file
```
在修改了 awk 命令之后,现在完整的 shell 脚本就像下面这样:
```
#!/bin/bash
for file in $@; do
if [ -f $file ] ; then
### 输出文件名
echo "File is: $file"
### 输出文件中 tecmint.com 出现的总次数
awk ' BEGIN { print "文件中出现 tecmint.com 的次数是:" ; }
/^tecmint.com/ { counter+=1 ; }
END { printf "%s\n", counter ; }
' $file
else
### 若输入不是文件,则输出错误信息
echo "$file 不是一个文件,请指定一个文件。" >&2 && exit 1
fi
done
### 成功执行后使用退出代码 0 终止脚本
exit 0
```

*awk 模式 BEGIN 和 END*
当我们运行上面的脚本时,它会首先输出 domains.txt 文件的位置,然后执行 awk 命令脚本,该命令脚本中的特殊模式 `BEGIN` 将会在从文件读取任何行之前帮助我们输出这样的消息“`文件中出现 tecmint.com 的次数是:`”。
接下来,我们的模式 `/^tecmint.com/` 会在每个输入行中进行比较,对应的动作 `{ counter+=1 ; }` 会在每个匹配成功的行上执行,它会统计出 `tecmint.com` 在文件中出现的次数。
最终,`END` 模式将会输出域名 `tecmint.com` 在文件中出现的总次数。
```
$ ./script.sh ~/domains.txt
```

*用于统计字符串出现次数的脚本*
最后总结一下,我们在本节中演示了更多的 awk 功能,并学习了特殊模式 `BEGIN` 和 `END` 的概念。
正如我之前所言,这些 awk 功能将会帮助我们构建出更复杂的文本过滤操作。第十节将会给出更多的 awk 功能,我们将会学习 awk 内置变量的思想,所以,请继续保持关注。
---
via: <http://www.tecmint.com/learn-use-awk-special-patterns-begin-and-end/>
作者:[Aaron Kili](http://www.tecmint.com/author/aaronkili/) 译者:[ChrisLeeGit](https://github.com/chrisleegit) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,655 | 如何在 Ubuntu Linux 16.04 LTS 中使用多个连接加速 apt-get/apt | http://www.cyberciti.biz/faq/how-to-speed-up-apt-get-apt-command-ubuntu-linux/ | 2016-08-06T19:16:07 | [
"apt",
"apt-get",
"apt-fast"
] | https://linux.cn/article-7655-1.html | 我该如何加速在 Ubuntu Linux 16.04 或者 14.04 LTS 上从多个仓库中下载包的 apt-get 或者 apt 命令?
你需要使用到 apt-fast 这个 shell 封装器。它会通过多个连接同时下载一个包来加速 apt-get/apt 和 aptitude 命令。所有的包都会同时下载。它使用 aria2c 作为默认的下载加速器。

### 安装 apt-fast 工具
在 Ubuntu Linux 14.04 或者之后的版本尝试下面的命令:
```
$ sudo add-apt-repository ppa:saiarcot895/myppa
```
示例输出:

更新你的仓库:
```
$ sudo apt-get update
```
或者
```
$ sudo apt update
```

安装 apt-fast:
```
$ sudo apt-get -y install apt-fast
```
或者
```
$ sudo apt -y install apt-fast
```
示例输出:
```
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following additional packages will be installed:
aria2 libc-ares2 libssh2-1
Suggested packages:
aptitude
The following NEW packages will be installed:
apt-fast aria2 libc-ares2 libssh2-1
0 upgraded, 4 newly installed, 0 to remove and 0 not upgraded.
Need to get 1,282 kB of archives.
After this operation, 4,786 kB of additional disk space will be used.
Do you want to continue? [Y/n] y
Get:1 http://01.archive.ubuntu.com/ubuntu xenial/universe amd64 libssh2-1 amd64 1.5.0-2 [70.3 kB]
Get:2 http://ppa.launchpad.net/saiarcot895/myppa/ubuntu xenial/main amd64 apt-fast all 1.8.3~137+git7b72bb7-0ubuntu1~ppa3~xenial1 [34.4 kB]
Get:3 http://01.archive.ubuntu.com/ubuntu xenial/main amd64 libc-ares2 amd64 1.10.0-3 [33.9 kB]
Get:4 http://01.archive.ubuntu.com/ubuntu xenial/universe amd64 aria2 amd64 1.19.0-1build1 [1,143 kB]
54% [4 aria2 486 kB/1,143 kB 42%] 20.4 kB/s 32s
```
### 配置 apt-fast
你将会得到下面的提示(必须输入一个5到16的数值):

并且

你也可以直接编辑设置:
```
$ sudo vi /etc/apt-fast.conf
```
>
> **请注意这个工具并不是给慢速网络连接的,它是给快速网络连接的。如果你的网速慢,那么你将无法从这个工具中得到好处。**
>
>
>
### 我该怎么使用 apt-fast 命令?
语法是:
```
apt-fast command
apt-fast [options] command
```
#### 使用 apt-fast 取回新的包列表
```
sudo apt-fast update
```
#### 使用 apt-fast 执行升级
```
sudo apt-fast upgrade
```
#### 执行发行版升级(发布或者强制内核升级),输入:
```
$ sudo apt-fast dist-upgrade
```
#### 安装新的包
语法是:
```
sudo apt-fast install pkg
```
比如要安装 nginx,输入:
```
$ sudo apt-fast install nginx
```
示例输出:

#### 删除包
```
$ sudo apt-fast remove pkg
$ sudo apt-fast remove nginx
```
#### 删除包和它的配置文件
```
$ sudo apt-fast purge pkg
$ sudo apt-fast purge nginx
```
#### 删除所有未使用的包
```
$ sudo apt-fast autoremove
```
#### 下载源码包
```
$ sudo apt-fast source pkgNameHere
```
#### 清理下载的文件
```
$ sudo apt-fast clean
```
#### 清理旧的下载文件
```
$ sudo apt-fast autoclean
```
#### 验证没有破坏的依赖
```
$ sudo apt-fast check
```
#### 下载二进制包到当前目录
```
$ sudo apt-fast download pkgNameHere
$ sudo apt-fast download nginx
```
示例输出:
```
[#7bee0c 0B/0B CN:1 DL:0B]
07/26 15:35:42 [NOTICE] Verification finished successfully. file=/home/vivek/nginx_1.10.0-0ubuntu0.16.04.2_all.deb
07/26 15:35:42 [NOTICE] Download complete: /home/vivek/nginx_1.10.0-0ubuntu0.16.04.2_all.deb
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
7bee0c|OK | n/a|/home/vivek/nginx_1.10.0-0ubuntu0.16.04.2_all.deb
Status Legend:
(OK):download completed.
```
#### 下载并显示指定包的 changelog
```
$ sudo apt-fast changelog pkgNameHere
$ sudo apt-fast changelog nginx
```
---
via: <http://www.cyberciti.biz/faq/how-to-speed-up-apt-get-apt-command-ubuntu-linux/>
作者:[VIVEK GITE](http://www.cyberciti.biz/tips/about-us) 译者:[geekpi](https://github.com/geekpi) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,656 | Linus Torvalds 谈及物联网、智能设备、安全连接等问题 | https://www.linux.com/news/linus-torvalds-talks-iot-smart-devices-security-concerns-and-more-video | 2016-08-06T20:46:09 | [
"物联网",
"IoT",
"Linus Torvalds"
] | https://linux.cn/article-7656-1.html | 
*Dirk Hohndel 在嵌入式大会上采访 Linus Torvalds 。*
4 月 4 日到 6 日,在圣迭戈召开的[嵌入式 Linux 大会(Embedded Linux Conference)](http://events.linuxfoundation.org/events/embedded-linux-conference)(ELC) 从首次举办到现在已经有 11 年了,该会议包括了与 Linus Torvalds 的主题讨论。作为 Linux 内核的缔造者和最高决策者——用采访他的英特尔 Linux 和开源技术总监 Dirk Hohndel 的话说,“(他是)我们聚在一起的理由”——他对 Linux 在嵌入式和物联网应用程序领域的发展表示乐观。Torvalds 很明确地力挺了嵌入式 Linux,它被 Linux 桌面、服务器和云技术这些掩去光芒已经很多年了。

*Linus Torvalds 在嵌入式 Linux 大会上的演讲。*
物联网是嵌入式大会的主题,在 OpenIoT 峰会讲演中谈到了,在 Torvalds 的访谈中也是主要话题。
Torvalds 对 Hohndel 说到,“或许你不会在物联网末端设备上看到 Linux 的影子,但是在你有一个中心设备的时候,你就会需要它。尤其是物联网标准都有 23 个的时候,你就更需要智能设备了。如果你全部使用的是低级设备,它们没必要一定运行 Linux;如果它们采用的标准稍有差异,你就需要很多的智能设备。我们将来也不会有一个完全开放的标准来将这些物联网设备统一到一起,但是我们会有 3/4 的主要协议是一样的,然后那些智能的中心设备就可以对它们进行互相转换。”
当 Hohndel 问及在物联网的巨大安全漏洞的时候,Torvalds 神情如常。他说:“我不担心安全问题因为我们能做的不是很多,物联网(设备)是不能更新的,这是我们面对的事实。"
Linux 缔造者看起来更关心的是一次性嵌入式项目缺少对上游的及时贡献,尽管他注意到近年来这些有了一些显著改善,特别是在硬件整合方面。
“嵌入式领域历来就很难与开源开发者有所联系,但是我认为这些都在发生改变。”Torvalds 说:“ARM 社区变得越来越好了。内核维护者实际上现在也能跟上了一些硬件的更新换代。一切都在变好,但是还不够。”
Torvalds 承认他在家经常使用桌面系统而不是嵌入式系统,并且对硬件不是很熟悉。
“我已经用电烙铁弄坏了很多东西。”他说到。“我真的不适合搞硬件开发。”另一方面,Torvalds 设想如果他现在是个年轻人,他可能也在摆弄 Raspberry Pi 和 BeagleBone。“最棒的是你不需要精通焊接,你只需要买个新的板子就行。”
同时,Torvalds 也承诺他要为 Linux 桌面再奋斗一个 25 年。他笑着说:“我要为它工作一生。”
请看完整[视频](https://youtu.be/tQKUWkR-wtM)。
要获取关于嵌入式 Linux 和物联网的最新信息,请访问 2016 年嵌入式 Linux 大会 150+ 分钟的会议全程。[现在观看](http://go.linuxfoundation.org/elc-openiot-summit-2016-videos?utm_source=lf&utm_medium=blog&utm_campaign=linuxcom)。
---
via: <https://www.linux.com/news/linus-torvalds-talks-iot-smart-devices-security-concerns-and-more-video>
作者:[ERIC BROWN](https://www.linux.com/users/ericstephenbrown) 译者:[vim-kakali](https://github.com/vim-kakali) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,657 | Drupal、IoT 和开源硬件之间的交集 | https://opensource.com/business/16/5/drupalcon-interview-amber-matz | 2016-08-07T10:00:12 | [
"IoT",
"Drupal"
] | https://linux.cn/article-7657-1.html | 
来认识一下 [Amber Matz](https://www.drupal.org/u/amber-himes-matz),她是来自 Lullabot Education 旗下的 [Drupalize.Me](https://events.drupal.org/neworleans2016/) 的产品经理以及培训师。当她没有倒腾 Arduino、Raspberry Pi 以及电子穿戴设备时,通常会在波特兰 Drupal 用户组里担任辩论主持人。
在即将举行的 [DrupalCon NOLA](https://events.drupal.org/neworleans2016/) 大会上,Amber 将主持一个关于 Drupal 和 IoT 的主题。如果你会去参加,也想了解下开源硬件,IoT 和 Drupal 之间的交集,那这个将很合适。如果你去不了新奥尔良的现场也没关系,Amber 还分享了许多很酷的事情。在这次采访中,她讲述了自己参与 Drupal 的原因,一些她自己喜欢的开源硬件项目,以及 IoT 和 Drupal 的未来。

**你是怎么加入 Drupal 社区的?**
在这之前,我在一家大型非盈利性机构市场部的“网站管理部”工作,飞快地批量生产出各种定制 PHP/MySQL 表单。最终我厌烦了这一切,并开始在网上寻找更好的方式。然后我找到了 Drupal 6 并开始沉迷进去。过了几年,在一次跳槽之后,我发现了波特兰 Drupal 用户组,然后在里面找了一份全职的 Drupal 开发者工作。我一直经常参加在波特兰的聚会,在那里我找到了大量的社区、朋友和专业方面的发展。一个偶然的机会,我在 Lullabot 找了一份培训师的工作,为 Drupalize.Me 提供内容。现在,我管理着 Drupalize.Me 的内容输出,负责编撰 Drupal 8 相关的内容,还很大程度地参与到波特兰 Drupal 社区中。我是今年的协调员,寻找并安排演讲者们。
**我们想知道:什么是 Arduino 原型,你是怎么找到它的,以及你用 Arduino 做过的最酷的事是什么?**
Arduino,Raspberry Pi,以及可穿戴电子设备,这些年到处都能听到这些术语。我在几年前通过 Becky Stern 的 YouTube 秀(最近由 Becky 继续主持,每周三播出)发现了 [Adafruit 的可穿戴电子设备](https://www.adafruit.com/beckystern)。我被那些可穿戴设备迷住了,还订了一套 LED 缝制工具,不过没做出任何东西。我不太适合它。我没有任何电子相关的背景,而且在我被那些项目吸引的时候,我根本不知道怎么做出那样的东西,它似乎看上去太遥远了。
后来,我在 Coursera 上找到了一个“物联网”专题。(很时髦,对吧?)我很快就喜欢上了。我最终找到了 Arduino 是什么的解释,以及所有这些其他的重要术语和概念。我订了一套推荐的 Arduino 初学者套件,还附带了一本如何上手的小册子。当我第一次让 LED 闪烁的时候,开心极了。我在圣诞节以及之后有两个星期的假期,然而我什么都没干,就一直根据初学者小册子给 Arduino 电路编程。很奇怪我觉得很放松!我太喜欢了。
在一月份的时候,我开始构思我自己的原型设备。在知道我需要主持公司培训的开场白时,我用五个 LED 灯和 Arduino 搭建了一个开场白视觉计时器的原型。

这是一次巨大的成功。我还做了我的第一个可穿戴项目,一件会发光的连帽衫,使用了和 Arduino IDE 兼容的 Gemma 微控制器,一个小的圆形可缝制部件,然后用可导电的线缝起来,将一个滑动可变电阻和衣服帽口的收缩绳连在一起,用来控制缝到帽子里的五个 NeoPixel 灯的颜色。这就是我对原型设计的看法:做一些很好玩也可能会有点实际用途的疯狂项目。
**Drupal 和 IoT 带来的最大机遇是什么??**
IoT 与 Web Service 以及 Drupal 分层趋势实际并没有太大差别。就是将数据从一个东西传送到另一个东西,然后将数据转换成一些有用的东西。但数据是如何送达?能用来做点什么?你觉得现在就有一大堆现成的解决方案、应用、中间层,以及 API 吗?采用 IoT,这只会继续成几何指数级的增长。我觉得,给我任何一个设备或“东西”,总有办法来将它连接到互联网上,有很多办法。而且有大量现成的代码库来帮助创客们将他们的数据从一个东西传到另一个东西。
那么 Drupal 在这里处于什么位置?首先,Web services 将是第一个明显的地方。但作为一个创客,我不希望将时间花在编写 Drupal 的订制模块上。我想要的是即插即用!所以我很高兴出现这样的模块能连接 IoT 云端 API 和服务,比如 ThingSpeak,Adafruit.io,IFTTT,以及其他的。我觉得也有一个很好的商业机会,在 Drupal 里构建一套 IoT 云服务,允许用户发送和存储他们的传感器数据,并可以制成表格和图像,还可以写一些插件可以响应特定数据或阙值。每一个 IoT 云 API 服务都是一个细分的机会,所以能留下很大空间给其他人。
**这次 DrupalCon 你有哪些期待?**
我喜欢与 Drupal 上的朋友重逢,认识一些新的人,还能见到 Lullabot 和 Drupalize.Me 的同事(我们是分布式的公司)!Drupal 8 有太多东西可以去探索了,我们给我们的客户们提供了海量的培训资料。所以,我很期待参与一些 Drupal 8 相关的主题,以及跟上最新的开发进度。最后,我对新奥尔良也很感兴趣!我曾经在 2004 年去过,很期待将这次将看到哪些改变。
**谈一谈你这次 DrupalCon 上的演讲:“超越闪烁:将 Drupal 加到你的 IoT 游乐场中”。别人为什么要参加?他们最重要的收获会是什么?**
我的主题的标题是,“超越闪烁:将 Drupal 加到你的 IoT 游乐场中”,假设我们所有人都处在同一进度和层次,你不需要了解任何关于 Arduino、物联网、甚至是 Drupal,都能跟上。我将从用 Arduino 让 LED 灯闪烁开始,然后我会谈一下我自己在这里面的最大收获:玩、学、教和做。我会列出一些曾经激励过我的例子,它们也很有希望能激发和鼓励其他听众去尝试一下。然后,就是展示时间!
首先,第一个东西。它是一个建筑提醒信号灯。在这个展示里,我会说明如何将信号灯连到互联网上,以及如何响应从云 API 服务收到的数据。然后,第二个东西。它是一个蒸汽朋克风格 iPhone 外壳形式的“天气手表”。有一个小型 LED 矩阵用来显示我的天气的图标,一个气压和温度传感器,一个 GPS 模块,以及一个 Bluetooth LE 模块,都连接到一个 Adafruit Flora 微控制器上。第二个东西能通过蓝牙连接到我的 iPhone 上的一个应用,并将天气和位置数据通过 MQTT 协议发到 Adafruit.io 的服务器!然后,在 Drupal 这边,我会从云端下载这些数据,更新天气信息,然后更新地图。所以大家也能体验一下通过web service、地图和 Drupal 8 的功能块所能做的事情。
学习和制作这些展示原型是一次烧脑的探险,我也希望有人能参与这个主题并感染一点我对这种技术交叉的传染性热情!我很兴奋能分享一些我的发现。
---
via: <https://opensource.com/business/16/5/drupalcon-interview-amber-matz>
作者:[Jason Hibbets](https://opensource.com/users/jhibbets) 译者:[zpl1025](https://github.com/zpl1025) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Meet [Amber Matz](https://www.drupal.org/u/amber-himes-matz), a Production Manager and Trainer at [Drupalize.Me](https://drupalize.me/), a service of Lullabot Education. When she's not tinkering around with Arduinos, Raspberry Pis, and electronic wearables, you can find her wrangling presenters for the Portland Drupal User Group.
Coming up at [DrupalCon NOLA](https://events.drupal.org/neworleans2016/), Amber will host a session about Drupal and IoT. If you're attending and want to learn about the intersection of open hardware, IoT, and Drupal, this session is for you. If you're not able to join us in New Orleans, Amber has some pretty cool things to share. In this interview, she tells us how she got involved with Drupal, a few of her favorite open hardware projects, and what the future holds for IoT and Drupal.
### How did you get involved with the Drupal community?
Back in the day, I was working at a large nonprofit in the "webmaster's office" of the marketing department and was churning out custom PHP/MySQL forms like nobody's business. I finally got weary of that and starting hunting around the web for a better way. I found Drupal 6 and starting diving in on my own. Years later, after a career shift and a move, I discovered the Portland Drupal User Group and landed a job as a full-time Drupal developer. I continued to regularly attend the meetups in Portland, which I found to be a great source of community, friendships, and professional development. Eventually, I landed a job with Lullabot as a trainer creating content for Drupalize.Me. Now, I'm managing the Drupalize.Me content pipeline, creating Drupal 8 content, and am very much involved in the Portland Drupal community. I'm this year's coordinator, finding and scheduling speakers.
### We have to know: What is Arduino prototyping, how did you discover it, and what's the coolest thing you've done with an Arduino?
Arduino, Raspberry Pi, and wearable electronics have been these terms that I've heard thrown around for years. I found Adafruit's [ Wearable Electronics with Becky Stern](https://www.adafruit.com/beckystern) YouTube show years ago (which, up until recently, when Becky moved on, aired every Wednesday). I was fascinated by wearables and even ordered an LED sewing kit but never did anything with it. I just didn't get it. I had no background in electronics whatsoever, and while I was fascinated by the projects I was finding, I didn't see how I could ever make anything like that. It seemed so out of reach.
Finally, I found a Coursera "Internet of Things" specialization. (So trendy, right?) But I was immediately hooked! I finally got an explanation of what an Arduino was, along with all these other important terms and concepts. I ordered the recommended Arduino starter kit, which came with a getting started booklet. When I made that first LED blink, it was pure delight. I had two weeks' vacation over the holidays and after Christmas, and I did nothing but make and program Arduino circuits from the getting started booklet. It was oddly so relaxing! I enjoyed it so much.
In January, I started creating my own prototypes. When I found out I was emceeing our company retreat's lightning talks, I created a Lightning Talk Visual Timer prototype with five LEDs and an Arduino.

It was a huge hit. I also made my first wearable project, a glowing hoodie, using the Arduino IDE compatible Gemma microcontroller, a tiny round sewable component, to which I sewed using conductive thread, a conductive slider connected to a hoodie's drawstring, which controlled the colors of five NeoPixels sewn around the inside of the hood. So that's what I mean by prototyping: Making crazy projects that are fun and maybe even a little practical.
### What are the biggest opportunities for Drupal and IoT?
IoT isn't that much different than the web services and decoupling Drupal trends. It's the movement of data from thing one to thing two and the rendering of that data into something useful. But how does it get there? And what do you do with it? You think there are a lot of solutions, and apps, and frameworks, and APIs out there now? With IoT, that's only going to continue to increase—exponentially. What I've found is that given any device or any "thing", there is a way to connect it to the Internet—many ways. And there are plenty of code libraries out there to help makers get their data from thing one to thing two.
So where does Drupal fit in? Web services, for one, is going to be the first obvious place. But as a maker, I don't want to spend my time coding custom modules in Drupal. I want to plug and play! So I would love to see modules emerge that connect with IoT Cloud APIs and services like ThingSpeak and Adafruit.io and IFTTT and others. I think there's an opportunity, too, for a business to build an IoT cloud service in Drupal that allows people to send and store their sensor data, visualize it charts and graphs, and build widgets that react to certain values or thresholds. Each of these IoT Cloud API services fill a slightly different niche, and there's plenty of room for others.
### What are a few things you're looking forward to at DrupalCon?
I love reconnecting with Drupal friends, meeting new people, and also seeing Lullabot and Drupalize.Me co-workers (we're distributed companies)! There's so much to learn with Drupal 8 and it's been overwhelming at times to put together training materials for our customers. So, I'm looking forward to attending Drupal 8-related sessions and getting up-to-speed on the latest developments. Finally, I'm really curious about New Orleans! I haven't been there since 2004 and I'm excited to see what's changed.
### Tell us about your DrupalCon talk *Beyond the blink: Add Drupal to your IoT playground*. Why should someone attend? What are the major takeaways?
My session title, *Beyond the blink: Add Drupal to your IoT playground*, in itself is so full of assumptions that first off I'm going to get everyone up to speed and on the same page. You don't need to know anything about Arduino, the Internet of Things, or even Drupal to follow along. We'll start with making an LED blink with an Arduino, and then I want to talk about what the main takeaways have been for me: Play, learn, teach, and make. I'll show examples that have inspired me and that will hopefully inspire and encourage others in the audience to give it a try. Then, it's demo time!
First, thing one. Thing one is a Build Notifier Tower Light. In this demo, I'll show how I connected the Tower Light to the Internet and how I got it to respond to data received from a Cloud API service. Next, Thing two. Thing two is a "weather watch" in the form of a steampunk iPhone case. It's got small LED matrix that displays an icon of the local-to-me weather, a barometric pressure and temperature sensor, a GPS module, and a Bluetooth LE module, all connected and controlled with an Adafruit Flora microcontroller. Thing two sends weather and location data to Adafruit.io by connecting to an app on my iPhone over Bluetooth and sends it up to the cloud using an MQTT protocol! Then, on the Drupal side, I'm pulling down that data from the cloud, updating a block with the weather, and updating a map. So folks will get a taste of what you can do with web services, maps, and blocks in Drupal 8, too.
It's been a brain-melting adventure learning and making these demo prototypes, and I hope others will come to the session and catch a little of this contagious enthusiasm I have for this intersection of technologies! I'm very excited to share what I've discovered.
## 3 Comments |
7,658 | Linux 下的密码管理器:Keeweb | http://www.linuxandubuntu.com/home/keeweb-a-linux-password-manager | 2016-08-07T21:18:06 | [
"密码",
"Keeweb",
"Keepass"
] | https://linux.cn/article-7658-1.html | 
如今,我们依赖于越来越多的线上服务。我们每注册一个线上服务,就要设置一个密码;如此,我们就不得不记住数以百计的密码。这样对于每个人来说,都很容易忘记密码。我将在本文中介绍 Keeweb,它是一款 Linux 密码管理器,可以为你离线或在线地安全存储所有的密码。
当谈及 Linux 密码管理器时,我们会发现有很多这样的软件。我们已经在 LinuxAndUbuntu 上讨论过像 [Keepass](http://www.linuxandubuntu.com/home/keepass-password-management-tool-creates-strong-passwords-and-keeps-them-secure) 和 [Encryptr,一个基于零知识系统的密码管理器](http://www.linuxandubuntu.com/home/encryptr-zero-knowledge-system-based-password-manager-for-linux) 这样的密码管理器。Keeweb 则是另外一款我们将在本文讲解的 Linux 密码管理器。
### Keeweb 可以离线或在线存储密码
Keeweb 是一款跨平台的密码管理器。它可以离线存储你所有的密码,并且能够同步到你自己的云存储服务上,例如 OneDrive、Google Drive、Dropbox 等。Keeweb 并没有它提供它自己的在线数据库来的同步你的密码。
要使用 Keeweb 连接你的线上存储服务,只需要点击界面中的“more”,然后再点击你想要使用的服务即可。

现在,Keeweb 会提示你登录到你的云盘。登录成功后,给 Keeweb 授权使用你的账户。

### 使用 Keeweb 存储密码
使用 Keeweb 存储你的密码是非常容易的。你可以使用一个复杂的密码加密你的密码文件。Keeweb 也允许你使用一个秘钥文件来锁定密码文件,但是我并不推荐这种方式。如果某个家伙拿到了你的秘钥文件,他只需要简单点击一下就可以解锁你的密码文件。
#### 创建密码
想要创建一个新的密码,你只需要简单地点击 `+` 号,然后你就会看到所有需要填充的输入框。根据你的需要创建更多的密码记录。
#### 搜索密码

Keeweb 拥有一个图标库,这样你就可以轻松地找到各种特定的密码记录。你可以改变图标的颜色、下载更多的图标,甚至可以直接从你的电脑中导入图标。这对于密码搜索来说,异常好使。
相似的服务的密码可以分组,这样你就可以在一个文件夹里找到它们。你也可以给密码打上标签并把它们存放在不同分类中。

### 主题

如果你喜欢类似于白色或者高对比度的亮色主题,你可以在“设置 > 通用 > 主题”中修改。(Keeweb)有四款可供选择的主题,其中两款为暗色,另外两款为亮色。
### 不喜欢 Linux 密码管理器?没问题!
我已经发表过文章介绍了另外两款 Linux 密码管理器,它们分别是 Keepass 和 Encryptr,在 Reddit 和其它社交媒体上有些关于它们的争论。有些人反对使用任何密码管理器,也有人持相反意见。在本文中,我想要澄清的是,存放密码文件是我们自己的责任。我认为像 keepass 和 Keeweb 这样的密码管理器是非常好用的,因为它们并没有自己的云来存放你的密码。这些密码管理器会创建一个文件,然后你可以将它存放在你的硬盘上,或者使用像 VeraCrypt 这样的应用给它加密。我个人不使用也不推荐使用那些将密码存储在它们自己数据库的服务。
---
via: <http://www.linuxandubuntu.com/home/keeweb-a-linux-password-manager>
译者:[ChrisLeeGit](https://github.com/chrisleegit) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,661 | awk 系列:如何使用 awk 内置变量 | http://www.tecmint.com/awk-built-in-variables-examples/ | 2016-08-08T19:15:19 | [
"awk"
] | https://linux.cn/article-7661-1.html | 我们将逐渐揭开 awk 功能的神秘面纱,在本节中,我们将介绍 awk <ruby> 内置 <rp> ( </rp> <rt> built-in </rt> <rp> ) </rp></ruby>变量的概念。你可以在 awk 中使用两种类型的变量,它们是:<ruby> 用户自定义 <rp> ( </rp> <rt> user-defined </rt> <rp> ) </rp></ruby>变量(我们在[第八节](/article-7650-1.html)中已经介绍了)和内置变量。

*awk 内置变量示例*
awk 内置变量已经有预先定义的值了,但我们也可以谨慎地修改这些值,awk 内置变量包括:
* `FILENAME` : 当前输入文件名称
* `NR` : 当前输入行编号(是指输入行 1,2,3……等)
* `NF` : 当前输入行的字段编号
* `OFS` : 输出字段分隔符
* `FS` : 输入字段分隔符
* `ORS` : 输出记录分隔符
* `RS` : 输入记录分隔符
让我们继续演示一些使用上述 awk 内置变量的方法:
想要读取当前输入文件的名称,你可以使用 `FILENAME` 内置变量,如下:
```
$ awk ' { print FILENAME } ' ~/domains.txt
```

*awk FILENAME 变量*
你会看到,每一行都会对应输出一次文件名,那是你使用 `FILENAME` 内置变量时 awk 默认的行为。
我们可以使用 `NR` 来统计一个输入文件的行数(记录),谨记,它也会计算空行,正如我们将要在下面的例子中看到的那样。
当我们使用 cat 命令查看文件 domains.txt 时,会发现它有 14 行文本和 2 个空行:
```
$ cat ~/domains.txt
```

*输出文件内容*
```
$ awk ' END { print "Number of records in file is: ", NR } ' ~/domains.txt
```

*awk 统计行数*
想要统计一条记录或一行中的字段数,我们可以像下面那样使用 NR 内置变量:
```
$ cat ~/names.txt
```

*列出文件内容*
```
$ awk '{ "Record:",NR,"has",NF,"fields" ; }' ~/names.txt
```

*awk 统计文件中的字段数*
接下来,你也可以使用 FS 内置变量指定一个输入文件分隔符,它会定义 awk 如何将输入行划分成字段。
FS 默认值为“空格”和“制表符”,但我们也能将 FS 值修改为任何字符来让 awk 根据情况切分输入行。
有两种方法可以达到目的:
* 第一种方法是使用 FS 内置变量
* 第二种方法是使用 awk 的 -F 选项
来看 Linux 系统上的 `/etc/passwd` 文件,该文件中的各字段是使用 `:` 分隔的,因此,当我们想要过滤出某些字段时,可以将 `:` 指定为新的输入字段分隔符,示例如下:
我们可以使用 `-F` 选项,如下:
```
$ awk -F':' '{ print $1, $4 ;}' /etc/passwd
```

*awk 过滤密码文件中的各字段*
此外,我们也可以利用 FS 内置变量,如下:
```
$ awk ' BEGIN { FS=“:” ; } { print $1, $4 ; } ' /etc/passwd
```

*使用 awk 过滤文件中的各字段*
使用 OFS 内置变量来指定一个用于输出的字段分隔符,它会定义如何使用指定的字符分隔输出字段,示例如下:
```
$ awk -F':' ' BEGIN { OFS="==>" ;} { print $1, $4 ;}' /etc/passwd
```

*向文件中的字段添加分隔符*
在本节中,我们已经学习了使用含有预定义值的 awk 内置变量的理念。但我们也能够修改这些值,虽然并不推荐这样做,除非你明白自己在做什么,并且充分理解(这些变量值)。
此后,我们将继续学习如何在 awk 命令操作中使用 shell 变量,所以,请继续关注我们。
---
via: <http://www.tecmint.com/awk-built-in-variables-examples/>
作者:[Aaron Kili](http://www.tecmint.com/author/aaronkili/) 译者:[ChrisLeeGit](https://github.com/chrisleegit) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,662 | 搭个 Web 服务器(一) | https://ruslanspivak.com/lsbaws-part1/ | 2016-08-08T20:51:00 | [
"Web",
"服务器"
] | https://linux.cn/article-7662-1.html | 
一天,有一个正在散步的妇人恰好路过一个建筑工地,看到三个正在工作的工人。她问第一个人:“你在做什么?”第一个人没好气地喊道:“你没看到我在砌砖吗?”妇人对这个答案不满意,于是问第二个人:“你在做什么?”第二个人回答说:“我在建一堵砖墙。”说完,他转向第一个人,跟他说:“嗨,你把墙砌过头了。去把刚刚那块砖弄下来!”然而,妇人对这个答案依然不满意,于是又问了第三个人相同的问题。第三个人仰头看着天,对她说:“我在建造世界上最大的教堂。”当他回答时,第一个人和第二个人在为刚刚砌错的砖而争吵。他转向那两个人,说:“不用管那块砖了。这堵墙在室内,它会被水泥填平,没人会看见它的。去砌下一层吧。”
这个故事告诉我们:如果你能够理解整个系统的构造,了解系统的各个部件如何相互结合(如砖、墙还有整个教堂),你就能够更快地定位及修复问题(那块砌错的砖)。
如果你想从头开始创造一个 Web 服务器,那么你需要做些什么呢?
我相信,如果你想成为一个更好的开发者,你**必须**对日常使用的软件系统的内部结构有更深的理解,包括编程语言、编译器与解释器、数据库及操作系统、Web 服务器及 Web 框架。而且,为了更好更深入地理解这些系统,你**必须**从头开始,用一砖一瓦来重新构建这个系统。
荀子曾经用这几句话来表达这种思想:
>
> “<ruby> 不闻不若闻之。 <rp> ( </rp> <rt> I hear and I forget. </rt> <rp> ) </rp></ruby>”
>
>
>

>
> “<ruby> 闻之不若见之。 <rp> ( </rp> <rt> I see and I remember. </rt> <rp> ) </rp></ruby>”
>
>
>

>
> “<ruby> 知之不若行之。 <rp> ( </rp> <rt> I do and I understand. </rt> <rp> ) </rp></ruby>”
>
>
>

我希望你现在能够意识到,重新建造一个软件系统来了解它的工作方式是一个好主意。
在这个由三篇文章组成的系列中,我将会教你构建你自己的 Web 服务器。我们开始吧~
先说首要问题:Web 服务器是什么?

简而言之,它是一个运行在一个物理服务器上的网络服务器(啊呀,服务器套服务器),等待客户端向其发送请求。当它接收请求后,会生成一个响应,并回送至客户端。客户端和服务端之间通过 HTTP 协议来实现相互交流。客户端可以是你的浏览器,也可以是使用 HTTP 协议的其它任何软件。
最简单的 Web 服务器实现应该是什么样的呢?这里我给出我的实现。这个例子由 Python 写成,即使你没听说过 Python(它是一门超级容易上手的语言,快去试试看!),你也应该能够从代码及注释中理解其中的理念:
```
import socket
HOST, PORT = '', 8888
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
listen_socket.bind((HOST, PORT))
listen_socket.listen(1)
print 'Serving HTTP on port %s ...' % PORT
while True:
client_connection, client_address = listen_socket.accept()
request = client_connection.recv(1024)
print request
http_response = """\
HTTP/1.1 200 OK
Hello, World!
"""
client_connection.sendall(http_response)
client_connection.close()
```
将以上代码保存为 webserver1.py,或者直接从 [GitHub](https://github.com/rspivak/lsbaws/blob/master/part1/webserver1.py) 上下载这个文件。然后,在命令行中运行这个程序。像这样:
```
$ python webserver1.py
Serving HTTP on port 8888 …
```
现在,在你的网页浏览器的地址栏中输入 URL:http://localhost:8888/hello ,敲一下回车,然后来见证奇迹。你应该看到“Hello, World!”显示在你的浏览器中,就像下图那样:

说真的,快去试一试。你做实验的时候,我会等着你的。
完成了?不错!现在我们来讨论一下它实际上是怎么工作的。
首先我们从你刚刚输入的 Web 地址开始。它叫 [URL](http://en.wikipedia.org/wiki/Uniform_resource_locator),这是它的基本结构:

URL 是一个 Web 服务器的地址,浏览器用这个地址来寻找并连接 Web 服务器,并将上面的内容返回给你。在你的浏览器能够发送 HTTP 请求之前,它需要与 Web 服务器建立一个 TCP 连接。然后会在 TCP 连接中发送 HTTP 请求,并等待服务器返回 HTTP 响应。当你的浏览器收到响应后,就会显示其内容,在上面的例子中,它显示了“Hello, World!”。
我们来进一步探索在发送 HTTP 请求之前,客户端与服务器建立 TCP 连接的过程。为了建立链接,它们使用了所谓“<ruby> 套接字 <rp> ( </rp> <rt> socket </rt> <rp> ) </rp></ruby>”。我们现在不直接使用浏览器发送请求,而在命令行中使用 `telnet` 来人工模拟这个过程。
在你运行 Web 服务器的电脑上,在命令行中建立一个 telnet 会话,指定一个本地域名,使用端口 8888,然后按下回车:
```
$ telnet localhost 8888
Trying 127.0.0.1 …
Connected to localhost.
```
这个时候,你已经与运行在你本地主机的服务器建立了一个 TCP 连接。在下图中,你可以看到一个服务器从头开始,到能够建立 TCP 连接的基本过程。

在同一个 telnet 会话中,输入 `GET /hello HTTP/1.1`,然后输入回车:
```
$ telnet localhost 8888
Trying 127.0.0.1 …
Connected to localhost.
GET /hello HTTP/1.1
HTTP/1.1 200 OK
Hello, World!
```
你刚刚手动模拟了你的浏览器(的工作)!你发送了 HTTP 请求,并且收到了一个 HTTP 应答。下面是一个 HTTP 请求的基本结构:

HTTP 请求的第一行由三部分组成:HTTP 方法(`GET`,因为我们想让我们的服务器返回一些内容),以及标明所需页面的路径 `/hello`,还有协议版本。
为了简单一些,我们刚刚构建的 Web 服务器完全忽略了上面的请求内容。你也可以试着输入一些无用内容而不是“GET /hello HTTP/1.1”,但你仍然会收到一个“Hello, World!”响应。
一旦你输入了请求行并敲了回车,客户端就会将请求发送至服务器;服务器读取请求行,就会返回相应的 HTTP 响应。
下面是服务器返回客户端(在上面的例子里是 telnet)的响应内容:

我们来解析它。这个响应由三部分组成:一个状态行 `HTTP/1.1 200 OK`,后面跟着一个空行,再下面是响应正文。
HTTP 响应的状态行 HTTP/1.1 200 OK 包含了 HTTP 版本号,HTTP 状态码以及 HTTP 状态短语“OK”。当浏览器收到响应后,它会将响应正文显示出来,这也就是为什么你会在浏览器中看到“Hello, World!”。
以上就是 Web 服务器的基本工作模型。总结一下:Web 服务器创建一个处于监听状态的套接字,循环接收新的连接。客户端建立 TCP 连接成功后,会向服务器发送 HTTP 请求,然后服务器会以一个 HTTP 响应做应答,客户端会将 HTTP 的响应内容显示给用户。为了建立 TCP 连接,客户端和服务端均会使用套接字。
现在,你应该了解了 Web 服务器的基本工作方式,你可以使用浏览器或其它 HTTP 客户端进行试验。如果你尝试过、观察过,你应该也能够使用 telnet,人工编写 HTTP 请求,成为一个“人形” HTTP 客户端。
现在留一个小问题:“你要如何在不对程序做任何改动的情况下,在你刚刚搭建起来的 Web 服务器上适配 Django, Flask 或 Pyramid 应用呢?”
我会在本系列的第二部分中来详细讲解。敬请期待。
顺便,我在撰写一本名为《搭个 Web 服务器:从头开始》的书。这本书讲解了如何从头开始编写一个基本的 Web 服务器,里面包含本文中没有的更多细节。订阅邮件列表,你就可以获取到这本书的最新进展,以及发布日期。
---
via: <https://ruslanspivak.com/lsbaws-part1/>
作者:[Ruslan](https://linkedin.com/in/ruslanspivak/) 译者:[StdioA](https://github.com/StdioA) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Out for a walk one day, a woman came across a construction site and saw three men working. She asked the first man, “What are you doing?” Annoyed by the question, the first man barked, “Can’t you see that I’m laying bricks?” Not satisfied with the answer, she asked the second man what he was doing. The second man answered, “I’m building a brick wall.” Then, turning his attention to the first man, he said, “Hey, you just passed the end of the wall. You need to take off that last brick.” Again not satisfied with the answer, she asked the third man what he was doing. And the man said to her while looking up in the sky, “I am building the biggest cathedral this world has ever known.” While he was standing there and looking up in the sky the other two men started arguing about the errant brick. The man turned to the first two men and said, “Hey guys, don’t worry about that brick. It’s an inside wall, it will get plastered over and no one will ever see that brick. Just move on to another layer.”
The moral of the story is that when you know the whole system and understand how different pieces fit together (bricks, walls, cathedral), you can identify and fix problems faster (errant brick).
What does it have to do with creating your own Web server from scratch?
**I believe to become a better developer you MUST get a better understanding of the underlying software systems you use on a daily basis and that includes programming languages, compilers and interpreters, databases and operating systems, web servers and web frameworks. And, to get a better and deeper understanding of those systems you MUST re-build them from scratch, brick by brick, wall by wall.**
Confucius put it this way:
“I hear and I forget.”
“I see and I remember.”
“I do and I understand.”
I hope at this point you’re convinced that it’s a good idea to start re-building different software systems to learn how they work.
In this three-part series I will show you how to build your own basic Web server. Let’s get started.
First things first, what is a Web server?
In a nutshell it’s a networking server that sits on a physical server (oops, a server on a server) and waits for a client to send a request. When it receives a request, it generates a response and sends it back to the client. The communication between a client and a server happens using HTTP protocol. A client can be your browser or any other software that speaks HTTP.
What would a very simple implementation of a Web server look like? Here is my take on it. The example is in Python (tested on Python3.7+) but even if you don’t know Python (it’s a very easy language to pick up, try it!) you still should be able to understand concepts from the code and explanations below:
```
# Python3.7+
import socket
HOST, PORT = '', 8888
listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
listen_socket.bind((HOST, PORT))
listen_socket.listen(1)
print(f'Serving HTTP on port {PORT} ...')
while True:
client_connection, client_address = listen_socket.accept()
request_data = client_connection.recv(1024)
print(request_data.decode('utf-8'))
http_response = b"""\
HTTP/1.1 200 OK
Hello, World!
"""
client_connection.sendall(http_response)
client_connection.close()
```
Save the above code as *webserver1.py* or download it directly from [GitHub](https://github.com/rspivak/lsbaws/blob/master/part1/webserver1.py) and run it on the command line like this
```
$ python webserver1.py
Serving HTTP on port 8888 …
```
Now type in the following URL in your Web browser’s address bar [http://localhost:8888/hello](http://localhost:8888/hello), hit Enter, and see magic in action. You should see *“Hello, World!”* displayed in your browser like this:
Just do it, seriously. I will wait for you while you’re testing it.
Done? Great. Now let’s discuss how it all actually works.
First let’s start with the Web address you’ve entered. It’s called an [URL](http://en.wikipedia.org/wiki/Uniform_resource_locator) and here is its basic structure:
This is how you tell your browser the address of the Web server it needs to find and connect to and the page (path) on the server to fetch for you. Before your browser can send a HTTP request though, it first needs to establish a TCP connection with the Web server. Then it sends an HTTP request over the TCP connection to the server and waits for the server to send an HTTP response back. And when your browser receives the response it displays it, in this case it displays “Hello, World!”
Let’s explore in more detail how the client and the server establish a TCP connection before sending HTTP requests and responses. To do that they both use so-called *sockets*. Instead of using a browser directly you are going to simulate your browser manually by using *telnet* on the command line.
On the same computer you’re running the Web server fire up a telnet session on the command line specifying a host to connect to *localhost* and the port to connect to *8888* and then press Enter:
```
$ telnet localhost 8888
Trying 127.0.0.1 …
Connected to localhost.
```
At this point you’ve established a TCP connection with the server running on your local host and ready to send and receive HTTP messages. In the picture below you can see a standard procedure a server has to go through to be able to accept new TCP connections.
In the same telnet session type ** GET /hello HTTP/1.1** and hit Enter:
```
$ telnet localhost 8888
Trying 127.0.0.1 …
Connected to localhost.
GET /hello HTTP/1.1
HTTP/1.1 200 OK
Hello, World!
```
You’ve just manually simulated your browser! You sent an HTTP request and got an HTTP response back. This is the basic structure of an HTTP request:
The HTTP request consists of the line indicating the HTTP method (** GET**, because we are asking our server to return us something), the path
*/hello*that indicates a
*“page”*on the server we want and the protocol version.
For simplicity’s sake our Web server at this point completely ignores the above request line. You could just as well type in any garbage instead of *“GET /hello HTTP/1.1”* and you would still get back a *“Hello, World!”* response.
Once you’ve typed the request line and hit Enter the client sends the request to the server, the server reads the request line, prints it and returns the proper HTTP response.
Here is the HTTP response that the server sends back to your client (*telnet* in this case):
Let’s dissect it. The response consists of a status line *HTTP/1.1 200 OK*, followed by a required empty line, and then the HTTP response body.
The response status line *HTTP/1.1 200 OK* consists of the *HTTP Version*, the *HTTP status code* and the *HTTP status code reason* phrase *OK*. When the browser gets the response, it displays the body of the response and that’s why you see *“Hello, World!”* in your browser.
And that’s the basic model of how a Web server works. To sum it up: The Web server creates a listening socket and starts accepting new connections in a loop. The client initiates a TCP connection and, after successfully establishing it, the client sends an HTTP request to the server and the server responds with an HTTP response that gets displayed to the user. To establish a TCP connection both clients and servers use *sockets*.
Now you have a very basic working Web server that you can test with your browser or some other HTTP client. As you’ve seen and hopefully tried, you can also be a human HTTP client too, by using *telnet* and typing HTTP requests manually.
Here’s a question for you: “How do you run a Django application, Flask application, and Pyramid application under your freshly minted Web server without making a single change to the server to accommodate all those different Web frameworks?”
I will show you exactly how in [Part 2](https://ruslanspivak.com/lsbaws-part2/) of the series. Stay tuned.
*Resources used in preparation for this article (links are affiliate links):*
-
[Unix Network Programming, Volume 1: The Sockets Networking API (3rd Edition)](http://www.amazon.com/gp/product/0131411551/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=0131411551&linkCode=as2&tag=russblo0b-20&linkId=2F4NYRBND566JJQL) -
[The Linux Programming Interface: A Linux and UNIX System Programming Handbook](http://www.amazon.com/gp/product/1593272200/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=1593272200&linkCode=as2&tag=russblo0b-20&linkId=CHFOMNYXN35I2MON)
UPDATE: Sat, July 13, 2019
Updated the server code to run under Python 3.7+
Added resources used in preparation for the article
Get the edge and stay sharp. Subscribe to Beyond Basics for free and get new posts without missing a beat!
**All articles in this series:**
## Comments
comments powered by Disqus |
7,664 | Python 学习:urllib 简介 | http://www.blog.pythonlibrary.org/2016/06/28/python-101-an-intro-to-urllib/ | 2016-08-09T08:20:00 | [
"python",
"urllib",
"爬虫"
] | https://linux.cn/article-7664-1.html | Python 3 的 urllib 模块是一堆可以处理 URL 的组件集合。如果你有 Python 2 的知识,那么你就会注意到 Python 2 中有 urllib 和 urllib2 两个版本的模块。这些现在都是 Python 3 的 urllib 包的一部分。当前版本的 urllib 包括下面几部分:
* urllib.request
* urllib.error
* urllib.parse
* urllib.rebotparser

接下来我们会分开讨论除了 urllib.error 以外的几部分。官方文档实际推荐你尝试第三方库, requests,一个高级的 HTTP 客户端接口。然而我依然认为知道如何不依赖第三方库打开 URL 并与之进行交互是很有用的,而且这也可以帮助你理解为什么 requests 包是如此的流行。
### urllib.request
urllib.request 模块期初是用来打开和获取 URL 的。让我们看看你可以用函数 urlopen 可以做的事:
```
>>> import urllib.request
>>> url = urllib.request.urlopen('https://www.google.com/')
>>> url.geturl()
'https://www.google.com/'
>>> url.info()
<http.client.HTTPMessage object at 0x7fddc2de04e0>
>>> header = url.info()
>>> header.as_string()
('Date: Fri, 24 Jun 2016 18:21:19 GMT\n'
'Expires: -1\n'
'Cache-Control: private, max-age=0\n'
'Content-Type: text/html; charset=ISO-8859-1\n'
'P3P: CP="This is not a P3P policy! See '
'https://www.google.com/support/accounts/answer/151657?hl=en for more info."\n'
'Server: gws\n'
'X-XSS-Protection: 1; mode=block\n'
'X-Frame-Options: SAMEORIGIN\n'
'Set-Cookie: '
'NID=80=tYjmy0JY6flsSVj7DPSSZNOuqdvqKfKHDcHsPIGu3xFv41LvH_Jg6LrUsDgkPrtM2hmZ3j9V76pS4K_cBg7pdwueMQfr0DFzw33SwpGex5qzLkXUvUVPfe9g699Qz4cx9ipcbU3HKwrRYA; '
'expires=Sat, 24-Dec-2016 18:21:19 GMT; path=/; domain=.google.com; HttpOnly\n'
'Alternate-Protocol: 443:quic\n'
'Alt-Svc: quic=":443"; ma=2592000; v="34,33,32,31,30,29,28,27,26,25"\n'
'Accept-Ranges: none\n'
'Vary: Accept-Encoding\n'
'Connection: close\n'
'\n')
>>> url.getcode()
200
```
在这里我们包含了需要的模块,然后告诉它打开 Google 的 URL。现在我们就有了一个可以交互的 HTTPResponse 对象。我们要做的第一件事是调用方法 geturl ,它会返回根据 URL 获取的资源。这可以让我们发现 URL 是否进行了重定向。
接下来调用 info ,它会返回网页的元数据,比如请求头信息。因此,我们可以将结果赋给我们的 headers 变量,然后调用它的方法 as\_string 。就可以打印出我们从 Google 收到的头信息。你也可以通过 getcode 得到网页的 HTTP 响应码,当前情况下就是 200,意思是正常工作。
如果你想看看网页的 HTML 代码,你可以调用变量 url 的方法 read。我不准备再现这个过程,因为输出结果太长了。
请注意 request 对象默认发起 GET 请求,除非你指定了它的 data 参数。如果你给它传递了 data 参数,这样 request 对象将会变成 POST 请求。
---
### 下载文件
urllib 一个典型的应用场景是下载文件。让我们看看几种可以完成这个任务的方法:
```
>>> import urllib.request
>>> url = 'http://www.blog.pythonlibrary.org/wp-content/uploads/2012/06/wxDbViewer.zip'
>>> response = urllib.request.urlopen(url)
>>> data = response.read()
>>> with open('/home/mike/Desktop/test.zip', 'wb') as fobj:
... fobj.write(data)
...
```
这个例子中我们打开一个保存在我的博客上的 zip 压缩文件的 URL。然后我们读出数据并将数据写到磁盘。一个替代此操作的方案是使用 urlretrieve :
```
>>> import urllib.request
>>> url = 'http://www.blog.pythonlibrary.org/wp-content/uploads/2012/06/wxDbViewer.zip'
>>> tmp_file, header = urllib.request.urlretrieve(url)
>>> with open('/home/mike/Desktop/test.zip', 'wb') as fobj:
... with open(tmp_file, 'rb') as tmp:
... fobj.write(tmp.read())
```
方法 urlretrieve 会把网络对象拷贝到本地文件。除非你在使用 urlretrieve 的第二个参数指定你要保存文件的路径,否则这个文件将被拷贝到临时文件夹的随机命名的一个文件中。这个可以为你节省一步操作,并且使代码看起来更简单:
```
>>> import urllib.request
>>> url = 'http://www.blog.pythonlibrary.org/wp-content/uploads/2012/06/wxDbViewer.zip'
>>> urllib.request.urlretrieve(url, '/home/mike/Desktop/blog.zip')
('/home/mike/Desktop/blog.zip',
<http.client.HTTPMessage object at 0x7fddc21c2470>)
```
如你所见,它返回了文件保存的路径,以及从请求得来的头信息。
### 设置你的用户代理
当你使用浏览器访问网页时,浏览器会告诉网站它是谁。这就是所谓的 user-agent (用户代理)字段。Python 的 urllib 会表示它自己为 Python-urllib/x.y , 其中 x 和 y 是你使用的 Python 的主、次版本号。有一些网站不认识这个用户代理字段,然后网站可能会有奇怪的表现或者根本不能正常工作。辛运的是你可以很轻松的设置你自己的 user-agent 字段。
```
>>> import urllib.request
>>> user_agent = ' Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0'
>>> url = 'http://www.whatsmyua.com/'
>>> headers = {'User-Agent': user_agent}
>>> request = urllib.request.Request(url, headers=headers)
>>> with urllib.request.urlopen(request) as response:
... with open('/home/mdriscoll/Desktop/user_agent.html', 'wb') as out:
... out.write(response.read())
```
这里设置我们的用户代理为 Mozilla FireFox ,然后我们访问 <http://www.whatsmyua.com/> , 它会告诉我们它识别出的我们的 user-agent 字段。之后我们将 url 和我们的头信息传给 urlopen 创建一个 Request 实例。最后我们保存这个结果。如果你打开这个结果,你会看到我们成功的修改了自己的 user-agent 字段。使用这段代码尽情的尝试不同的值来看看它是如何改变的。
---
### urllib.parse
urllib.parse 库是用来拆分和组合 URL 字符串的标准接口。比如,你可以使用它来转换一个相对的 URL 为绝对的 URL。让我们试试用它来转换一个包含查询的 URL :
```
>>> from urllib.parse import urlparse
>>> result = urlparse('https://duckduckgo.com/?q=python+stubbing&t=canonical&ia=qa')
>>> result
ParseResult(scheme='https', netloc='duckduckgo.com', path='/', params='', query='q=python+stubbing&t=canonical&ia=qa', fragment='')
>>> result.netloc
'duckduckgo.com'
>>> result.geturl()
'https://duckduckgo.com/?q=python+stubbing&t=canonical&ia=qa'
>>> result.port
None
```
这里我们导入了函数 urlparse , 并且把一个包含搜索查询字串的 duckduckgo 的 URL 作为参数传给它。我的查询字串是搜索关于 “python stubbing” 的文章。如你所见,它返回了一个 ParseResult 对象,你可以用这个对象了解更多关于 URL 的信息。举个例子,你可以获取到端口信息(本例中没有端口信息)、网络位置、路径和很多其它东西。
### 提交一个 Web 表单
这个模块还有一个方法 urlencode 可以向 URL 传输数据。 urllib.parse 的一个典型使用场景是提交 Web 表单。让我们通过搜索引擎 duckduckgo 搜索 Python 来看看这个功能是怎么工作的。
```
>>> import urllib.request
>>> import urllib.parse
>>> data = urllib.parse.urlencode({'q': 'Python'})
>>> data
'q=Python'
>>> url = 'http://duckduckgo.com/html/'
>>> full_url = url + '?' + data
>>> response = urllib.request.urlopen(full_url)
>>> with open('/home/mike/Desktop/results.html', 'wb') as f:
... f.write(response.read())
```
这个例子很直接。基本上我们是使用 Python 而不是浏览器向 duckduckgo 提交了一个查询。要完成这个我们需要使用 urlencode 构建我们的查询字符串。然后我们把这个字符串和网址拼接成一个完整的正确 URL ,然后使用 urllib.request 提交这个表单。最后我们就获取到了结果然后保存到磁盘上。
### urllib.robotparser
robotparser 模块是由一个单独的类 RobotFileParser 构成的。这个类会回答诸如一个特定的用户代理是否获取已经设置了 robot.txt 的网站的 URL。 robot.txt 文件会告诉网络爬虫或者机器人当前网站的那些部分是不允许被访问的。让我们看一个简单的例子:
```
>>> import urllib.robotparser
>>> robot = urllib.robotparser.RobotFileParser()
>>> robot.set_url('http://arstechnica.com/robots.txt')
None
>>> robot.read()
None
>>> robot.can_fetch('*', 'http://arstechnica.com/')
True
>>> robot.can_fetch('*', 'http://arstechnica.com/cgi-bin/')
False
```
这里我们导入了 robot 分析器类,然后创建一个实例。然后我们给它传递一个表明网站 robots.txt 位置的 URL 。接下来我们告诉分析器来读取这个文件。完成后,我们给它了一组不同的 URL 让它找出那些我们可以爬取而那些不能爬取。我们很快就看到我们可以访问主站但是不能访问 cgi-bin 路径。
### 总结一下
现在你就有能力使用 Python 的 urllib 包了。在这一节里,我们学习了如何下载文件、提交 Web 表单、修改自己的用户代理以及访问 robots.txt。 urllib 还有一大堆附加功能没有在这里提及,比如网站身份认证。你可能会考虑在使用 urllib 进行身份认证之前切换到 requests 库,因为 requests 已经以更易用和易调试的方式实现了这些功能。我同时也希望提醒你 Python 已经通过 http.cookies 模块支持 Cookies 了,虽然在 request 包里也很好的封装了这个功能。你应该可能考虑同时试试两个来决定那个最适合你。
---
via: <http://www.blog.pythonlibrary.org/2016/06/28/python-101-an-intro-to-urllib/>
作者:[Mike](http://www.blog.pythonlibrary.org/author/mld/) 译者:[Ezio](https://github.com/oska874) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,667 | 一位女军官的 Linux 探索之路 | http://fossforce.com/2016/05/anatomy-linux-user/ | 2016-08-10T09:23:00 | [
"Linux"
] | https://linux.cn/article-7667-1.html | **一些新的 GNU/Linux 用户很清楚 Linux 不是 Windows,但其他人对此则不甚了解,而最好的发行版设计者们则会谨记着这两种人的存在。**

### Linux 的核心
不管怎么说,Nicky 看起来都不太引人注目。她已经三十岁了,却决定在离开学校多年后回到学校学习。她在海军待了六年,后来接受了一份老友给她的新工作,想试试这份工作会不会比她在军队的工作更有前途。这种换工作的事情在战后的军事后勤处非常常见。我正是因此而认识的她。她那时是一个八个州的货车运输业中介组织的区域经理,而那会我在达拉斯跑肉品包装工具的运输。

Nicky 和我在 2006 年成为了好朋友。她很外向,几乎每一个途经她负责的线路上的人她都乐于接触。我们经常星期五晚上相约去一家室内激光枪战中心打真人 CS。像这样一次就打三个的半小时战役对我们来说并不鲜见。或许这并不像彩弹游戏(LCTT 译注:一种军事游戏,双方以汽枪互射彩色染料弹丸,对方被击中后衣服上会留下彩色印渍即表示“被消灭”——必应词典)一样便宜,但是它很有临场感,还稍微有点恐怖游戏的感觉。某次活动的时候,她问我能否帮她维修电脑。
她知道我在为了让一些贫穷的孩子能拥有他们自己的电脑而奔走,当她抱怨她的电脑很慢的时候,我开玩笑地说她可以给比尔盖茨的 401k 计划交钱了(LCTT 译注:401k 计划始于20世纪80年代初,是一种由雇员、雇主共同缴费建立起来的完全基金式的养老保险制度。此处隐喻需要购买新电脑而向比尔盖茨的微软公司付费软件费用。)。Nicky 却说这是了解 Linux 的最佳时间。
她的电脑是品牌机,是个带有 Dell 19'' 显示器的 2005 年年中款的华硕电脑。不幸的是,这台电脑没有好好照料,上面充斥着所能找到的各种关都关不掉的工具栏和弹窗软件。我们把电脑上的文件都做了备份之后就开始安装 Linux 了。我们一起完成了安装,并且确信她知道了如何分区。不到一个小时,她的电脑上就有了一个“金闪闪”的 PCLinuxOS 桌面。
在她操作新系统时,她经常评论这个系统看起来多么漂亮。她并非随口一说;她为眼前光鲜亮丽的桌面着了魔。她说她的桌面漂亮的就像化了“彩妆”一样。这是我在安装系统期间特意设置的,我每次安装 Linux 的时候都会把它打扮的漂漂亮亮的。我希望这些桌面让每个人看起来都觉得漂亮。
大概第一周左右,她通过电话和邮件问了我一些常规问题,而最主要的问题还是她想知道如何保存她 OpenOffice 文件才可以让她的同事也可以打开这些文件。教一个人使用 Linux 或者 Open/LibreOffice 的时候最重要的就是教她保存文件。大多数用户在弹出的对话框中直接点了保存,结果就用默认的<ruby> 开放文档格式 <rp> ( </rp> <rt> Open Document Format </rt> <rp> ) </rp></ruby>(ODF)保存了,这让他们吃了不少苦头。
曾经有过这么一件事,大约一年前或者更久,一个高中生说他没有通过期末考试,因为教授不能打开包含他的论文的文件。这引来了一些读者的激烈评论,大家都不知道这件事该怪谁,这孩子没错,而他的教授,似乎也没错。
我认识的一些大学教授他们每一个人都知道怎么打开 ODF 文件。另外,那个该死的微软在这方面做得真 XX 的不错,我觉得微软 Office 现在已经能打开 ODT 或者 ODF 文件了。不过我也不确定,毕竟我从 2005 年就没用过 Microsoft Office 了。
甚至在过去糟糕的日子里,微软公开而悍然地通过产品绑架的方式来在企业桌面领域推行他们的软件时,我和一些微软 Office 的用户在开展业务和洽谈合作时从来没有出现过问题,因为我会提前想到可能出现的问题并且不会有侥幸心理。我会发邮件给他们询问他们正在使用的 Office 版本。这样,我就可以确保以他们能够读写的格式保存文件。
说回 Nicky ,她花了很多时间学习她的 Linux 系统。我很惊奇于她的热情。
当人们意识到需要抛弃所有的 Windows 的使用习惯和工具的时候,学习 Linux 系统就会很容易。甚至在告诉那些淘气的孩子们如何使用之后,再次回来检查的时候,他们都不会试图把 .exe 文件下载到桌面上或某个下载文件夹。
在我们通常讨论这些文件的时候,我们也会提及关于更新的问题。长久以来我一直反对在一台机器上有多个软件安装系统和更新管理软件。以 Mint 来说,它完全禁用了 Synaptic 中的更新功能,这让我失去兴趣。但是即便对于我们这些仍然在使用 dpkg 和 apt 的老家伙们来说,睿智的脑袋也已经开始意识到命令行对新用户来说并不那么温馨而友好。
我曾严正抗议并强烈谴责 Synaptic 功能上的削弱,直到它说服了我。你记得什么时候第一次使用的新打造的 Linux 发行版,并拥有了最高管理权限吗? 你记得什么时候对 Synaptic 中列出的大量软件进行过梳理吗?你记得怎样开始安装每个你发现的很酷的程序吗?你记得有多少这样的程序都是以字母"lib"开头的吗?
我也曾做过那样的事。我安装又弄坏了好几次 Linux,后来我才发现那些库(lib)文件是应用程序的螺母和螺栓,而不是应用程序本身。这就是 Linux Mint 和 Ubuntu 幕后那些聪明的开发者创造了智能、漂亮和易用的应用安装器的原因。Synaptic 仍然是我们这些老玩家爱用的工具,但是对于那些在我们之后才来的新手来说,有太多的方式可以让他们安装库文件和其他类似的包。在新的安装程序中,这些文件的显示会被折叠起来,不会展示给用户。真的,这才是它应该做的。
除非你要准备好了打很多支持电话。
现在的 Linux 发行版中藏了很多智慧的结晶,我也很感谢这些开发者们,因为他们,我的工作变得更容易。不是每一个 Linux 新用户都像 Nicky 这样富有学习能力和热情。她对我来说就是一个“装好就行”的项目,只需要为她解答一些问题,其它的她会自己研究解决。像她这样极具学习能力和热情的用户的毕竟是少数。这样的 Linux 新人任何时候都是珍稀物种。
很不错,他们都是要教自己的孩子使用 Linux 的人。
---
via: <http://fossforce.com/2016/05/anatomy-linux-user/>
作者:[Ken Starks](http://linuxlock.blogspot.com/) 译者:[vim-kakali](https://github.com/vim-kakali) 校对:[PurlingNayuki](https://github.com/PurlingNayuki), [wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,668 | awk 系列:如何让 awk 使用 Shell 变量 | http://www.tecmint.com/use-shell-script-variable-in-awk/ | 2016-08-10T09:38:10 | [
"awk"
] | https://linux.cn/article-7668-1.html | 当我们编写 shell 脚本时,我们通常会在脚本中包含其它小程序或命令,例如 awk 操作。对于 awk 而言,我们需要找一些将某些值从 shell 传递到 awk 操作中的方法。
我们可以通过在 awk 命令中使用 shell 变量达到目的,在 awk 系列的这一节中,我们将学习如何让 awk 使用 shell 变量,这些变量可能包含我们希望传递给 awk 命令的值。

有两种可能的方法可以让 awk 使用 shell 变量:
### 1. 使用 Shell 引用
让我们用一个示例来演示如何在一条 awk 命令中使用 shell 引用来替代一个 shell 变量。在该示例中,我们希望在文件 /etc/passwd 中搜索一个用户名,过滤并输出用户的账户信息。
因此,我们可以编写一个 `test.sh` 脚本,内容如下:
```
#!/bin/bash
### 读取用户名
read -p "请输入用户名:" username
### 在 /etc/passwd 中搜索用户名,然后在屏幕上输出详细信息
cat /etc/passwd | awk "/$username/ "' { print $0 }'
```
然后,保存文件并退出。
上述 `test.sh` 脚本中 awk 命令的说明:
```
cat /etc/passwd | awk "/$username/ "' { print $0 }'
```
`"/$username/ "`:该 shell 引用用于在 awk 命令中替换 shell 变量 `username` 的值。`username` 的值就是要在文件 /etc/passwd 中搜索的模式。
注意,双引号位于 awk 脚本 `'{ print $0 }'` 之外。
接下来给脚本添加可执行权限并运行它,操作如下:
```
$ chmod +x test.sh
$ ./text.sh
```
运行脚本后,它会提示你输入一个用户名,然后你输入一个合法的用户名并回车。你将会看到来自 /etc/passwd 文件中详细的用户账户信息,如下图所示:

*在 Password 文件中查找用户名的 shell 脚本*
### 2. 使用 awk 进行变量赋值
和上面介绍的方法相比,该方法更加单,并且更好。考虑上面的示例,我们可以运行一条简单的命令来完成同样的任务。 在该方法中,我们使用 `-v` 选项将一个 shell 变量的值赋给一个 awk 变量。
首先,创建一个 shell 变量 `username`,然后给它赋予一个我们希望在 /etc/passwd 文件中搜索的名称。
```
username="aaronkilik"
```
然后输入下面的命令并回车:
```
# cat /etc/passwd | awk -v name="$username" ' $0 ~ name {print $0}'
```

*使用 awk 在 Password 文件中查找用户名*
上述命令的说明:
* `-v`:awk 选项之一,用于声明一个变量
* `username`:是 shell 变量
* `name`:是 awk 变量
让我们仔细瞧瞧 awk 脚本 `' $0 ~ name {print $0}'` 中的 `$0 ~ name`。还记得么,当我们在 awk 系列第四节中介绍 awk 比较运算符时,`value ~ pattern` 便是比较运算符之一,它是指:如果 `value` 匹配了 `pattern` 则返回 `true`。
cat 命令通过管道传给 awk 的 `output($0)` 与模式 `(aaronkilik)` 匹配,该模式即为我们在 /etc/passwd 中搜索的名称,最后,比较操作返回 `true`。接下来会在屏幕上输出包含用户账户信息的行。
### 结论
我们已经介绍了 awk 功能的一个重要部分,它能帮助我们在 awk 命令中使用 shell 变量。很多时候,你都会在 shell 脚本中编写小的 awk 程序或命令,因此,你需要清晰地理解如何在 awk 命令中使用 shell 变量。
在 awk 系列的下一个部分,我们将会深入学习 awk 功能的另外一个关键部分,即流程控制语句。所以请继续保持关注,并让我们坚持学习与分享。
---
via: <http://www.tecmint.com/use-shell-script-variable-in-awk/>
作者:[Aaron Kili](http://www.tecmint.com/author/aaronkili/) 译者:[ChrisLeeGit](https://github.com/chrisleegit) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,669 | 诠释 Linux 中“一切都是文件”概念和相应的文件类型 | http://www.tecmint.com/explanation-of-everything-is-a-file-and-types-of-files-in-linux/ | 2016-08-10T10:30:00 | [
"文件"
] | https://linux.cn/article-7669-1.html | 
*Linux 系统中一切都是文件并有相应的文件类型*
在 Unix 和它衍生的比如 Linux 系统中,一切都可以看做文件。虽然它仅仅只是一个泛泛的概念,但这是事实。如果有不是文件的,那它一定是正运行的进程。
要理解这点,可以举个例子,您的根目录(/)的空间充斥着不同类型的 Linux 文件。当您创建一个文件或向系统传输一个文件时,它会在物理磁盘上占据的一些空间,而且是一个特定的格式(文件类型)。
虽然 Linux 系统中文件和目录没有什么不同,但目录还有一个重要的功能,那就是有结构性的分组存储其它文件,以方便查找访问。所有的硬件组件都表示为文件,系统使用这些文件来与硬件通信。
这些思想是对 Linux 中的各种事物的重要阐述,因此像文档、目录(Mac OS X 和 Windows 系统下称之为文件夹)、键盘、监视器、硬盘、可移动媒体设备、打印机、调制解调器、虚拟终端,还有进程间通信(IPC)和网络通信等输入/输出资源都是定义在文件系统空间下的字节流。
一切都可看作是文件,其最显著的好处是对于上面所列出的输入/输出资源,只需要相同的一套 Linux 工具、实用程序和 API。
虽然在 Linux 中一切都可看作是文件,但也有一些特殊的文件,比如[套接字和命令管道](http://www.tecmint.com/manage-file-types-and-set-system-time-in-linux/)。
### Linux 文件类型的不同之处?
Linux 系统中有三种基本的文件类型:
* 普通/常规文件
* 特殊文件
* 目录文件
#### 普通/常规文件
它们是包含文本、数据、程序指令等数据的文件,其在 Linux 系统中是最常见的一种。包括如下:
* 可读文件
* 二进制文件
* 图像文件
* 压缩文件等等
#### 特殊文件
特殊文件包括以下几种:
<ruby> 块文件 <rp> ( </rp> <rt> block </rt> <rp> ) </rp></ruby>:设备文件,对访问系统硬件部件提供了缓存接口。它们提供了一种通过文件系统与设备驱动通信的方法。
有关于块文件一个重要的性能就是它们能在指定时间内传输大块的数据和信息。
列出某目录下的块文件:
```
# ls -l /dev | grep "^b"
```
输出例子
```
brw-rw---- 1 root disk 7, 0 May 18 10:26 loop0
brw-rw---- 1 root disk 7, 1 May 18 10:26 loop1
brw-rw---- 1 root disk 7, 2 May 18 10:26 loop2
brw-rw---- 1 root disk 7, 3 May 18 10:26 loop3
brw-rw---- 1 root disk 7, 4 May 18 10:26 loop4
brw-rw---- 1 root disk 7, 5 May 18 10:26 loop5
brw-rw---- 1 root disk 7, 6 May 18 10:26 loop6
brw-rw---- 1 root disk 7, 7 May 18 10:26 loop7
brw-rw---- 1 root disk 1, 0 May 18 10:26 ram0
brw-rw---- 1 root disk 1, 1 May 18 10:26 ram1
brw-rw---- 1 root disk 1, 10 May 18 10:26 ram10
brw-rw---- 1 root disk 1, 11 May 18 10:26 ram11
brw-rw---- 1 root disk 1, 12 May 18 10:26 ram12
brw-rw---- 1 root disk 1, 13 May 18 10:26 ram13
brw-rw---- 1 root disk 1, 14 May 18 10:26 ram14
brw-rw---- 1 root disk 1, 15 May 18 10:26 ram15
brw-rw---- 1 root disk 1, 2 May 18 10:26 ram2
brw-rw---- 1 root disk 1, 3 May 18 10:26 ram3
brw-rw---- 1 root disk 1, 4 May 18 10:26 ram4
brw-rw---- 1 root disk 1, 5 May 18 10:26 ram5
...
```
<ruby> 字符文件 <rp> ( </rp> <rt> Character </rt> <rp> ) </rp></ruby>: 也是设备文件,对访问系统硬件组件提供了非缓冲串行接口。它们与设备的通信工作方式是一次只传输一个字符的数据。
列出某目录下的字符文件:
```
# ls -l /dev | grep "^c"
```
输出例子
```
crw------- 1 root root 10, 235 May 18 15:54 autofs
crw------- 1 root root 10, 234 May 18 15:54 btrfs-control
crw------- 1 root root 5, 1 May 18 10:26 console
crw------- 1 root root 10, 60 May 18 10:26 cpu_dma_latency
crw------- 1 root root 10, 203 May 18 15:54 cuse
crw------- 1 root root 10, 61 May 18 10:26 ecryptfs
crw-rw---- 1 root video 29, 0 May 18 10:26 fb0
crw-rw-rw- 1 root root 1, 7 May 18 10:26 full
crw-rw-rw- 1 root root 10, 229 May 18 10:26 fuse
crw------- 1 root root 251, 0 May 18 10:27 hidraw0
crw------- 1 root root 10, 228 May 18 10:26 hpet
crw-r--r-- 1 root root 1, 11 May 18 10:26 kmsg
crw-rw----+ 1 root root 10, 232 May 18 10:26 kvm
crw------- 1 root root 10, 237 May 18 10:26 loop-control
crw------- 1 root root 10, 227 May 18 10:26 mcelog
crw------- 1 root root 249, 0 May 18 10:27 media0
crw------- 1 root root 250, 0 May 18 10:26 mei0
crw-r----- 1 root kmem 1, 1 May 18 10:26 mem
crw------- 1 root root 10, 57 May 18 10:26 memory_bandwidth
crw------- 1 root root 10, 59 May 18 10:26 network_latency
crw------- 1 root root 10, 58 May 18 10:26 network_throughput
crw-rw-rw- 1 root root 1, 3 May 18 10:26 null
crw-r----- 1 root kmem 1, 4 May 18 10:26 port
crw------- 1 root root 108, 0 May 18 10:26 ppp
crw------- 1 root root 10, 1 May 18 10:26 psaux
crw-rw-rw- 1 root tty 5, 2 May 18 17:40 ptmx
crw-rw-rw- 1 root root 1, 8 May 18 10:26 random
```
<ruby> 符号链接文件 <rp> ( </rp> <rt> Symbolic link </rt> <rp> ) </rp></ruby> : 符号链接是指向系统上其他文件的引用。因此,符号链接文件是指向其它文件的文件,那些文件可以是目录或常规文件。
列出某目录下的符号链接文件:
```
# ls -l /dev/ | grep "^l"
```
输出例子
```
lrwxrwxrwx 1 root root 3 May 18 10:26 cdrom -> sr0
lrwxrwxrwx 1 root root 11 May 18 15:54 core -> /proc/kcore
lrwxrwxrwx 1 root root 13 May 18 15:54 fd -> /proc/self/fd
lrwxrwxrwx 1 root root 4 May 18 10:26 rtc -> rtc0
lrwxrwxrwx 1 root root 8 May 18 10:26 shm -> /run/shm
lrwxrwxrwx 1 root root 15 May 18 15:54 stderr -> /proc/self/fd/2
lrwxrwxrwx 1 root root 15 May 18 15:54 stdin -> /proc/self/fd/0
lrwxrwxrwx 1 root root 15 May 18 15:54 stdout -> /proc/self/fd/1
```
Linux 中使用 `ln` 工具就可以创建一个符号链接文件,如下所示:
```
# touch file1.txt
# ln -s file1.txt /home/tecmint/file1.txt [创建符号链接文件]
# ls -l /home/tecmint/ | grep "^l" [列出符号链接文件]
```
在上面的例子中,首先我们在 `/tmp` 目录创建了一个名叫 `file1.txt` 的文件,然后创建符号链接文件,将 `/home/tecmint/file1.txt` 指向 `/tmp/file1.txt` 文件。
<ruby> 管道 <rp> ( </rp> <rt> Pipe </rt> <rp> ) </rp></ruby>和<ruby> 命令管道 <rp> ( </rp> <rt> Named pipe </rt> <rp> ) </rp></ruby> : 将一个进程的输出连接到另一个进程的输入,从而允许进程间通信(IPC)的文件。
命名管道实际上是一个文件,用来使两个进程彼此通信,就像一个 Linux 管道一样。
列出某目录下的管道文件:
```
# ls -l | grep "^p"
```
输出例子:
```
prw-rw-r-- 1 tecmint tecmint 0 May 18 17:47 pipe1
prw-rw-r-- 1 tecmint tecmint 0 May 18 17:47 pipe2
prw-rw-r-- 1 tecmint tecmint 0 May 18 17:47 pipe3
prw-rw-r-- 1 tecmint tecmint 0 May 18 17:47 pipe4
prw-rw-r-- 1 tecmint tecmint 0 May 18 17:47 pipe5
```
在 Linux 中可以使用 `mkfifo` 工具来创建一个命名管道,如下所示:
```
# mkfifo pipe1
# echo "This is named pipe1" > pipe1
```
在上的例子中,我们创建了一个名叫 `pipe1` 的命名管道,然后使用 [echo 命令](http://www.tecmint.com/echo-command-in-linux/) 加入一些数据,这之后在处理输入的数据时 shell 就变成非交互式的了(LCTT 译注:被管道占住了)。
然后,我们打开另外一个 shell 终端,运行另外的命令来打印出刚加入管道的数据。
```
# while read line ;do echo "This was passed-'$line' "; done<pipe1
```
<ruby> 套接字文件 <rp> ( </rp> <rt> socket </rt> <rp> ) </rp></ruby> : 提供进程间通信方法的文件,它们能在运行在不同环境中的进程之间传输数据和信息。
这就是说,套接字可以为运行网络上不同机器中的进程提供数据和信息传输。
一个 socket 运行的例子就是网页浏览器连接到网站服务器的过程。
```
# ls -l /dev/ | grep "^s"
```
输出例子:
```
srw-rw-rw- 1 root root 0 May 18 10:26 log
```
下面是使用 C 语言编写的调用 `socket()` 系统调用的例子。
```
int socket_desc= socket(AF_INET, SOCK_STREAM, 0 );
```
上例中:
* `AF_INET` 指的是地址域(IPv4)
* `SOCK_STREAM` 指的是类型(默认使用 TCP 协议连接)
* `0` 指协议(IP 协议)
使用 `socket_desc` 来引用管道文件,它跟文件描述符是一样的,然后再使用系统函数 `read()` 和 `write()` 来分别从这个管道文件读写数据。
#### 目录文件
这是一些特殊的文件,既可以包含普通文件又可包含其它的特殊文件,它们在 Linux 文件系统中是以根(/)目录为起点分层组织存在的。
列出某目录下的目录文件:
```
# ls -l / | grep "^d"
```
输出例子:
```
drwxr-xr-x 2 root root 4096 May 5 15:49 bin
drwxr-xr-x 4 root root 4096 May 5 15:58 boot
drwxr-xr-x 2 root root 4096 Apr 11 2015 cdrom
drwxr-xr-x 17 root root 4400 May 18 10:27 dev
drwxr-xr-x 168 root root 12288 May 18 10:28 etc
drwxr-xr-x 3 root root 4096 Apr 11 2015 home
drwxr-xr-x 25 root root 4096 May 5 15:44 lib
drwxr-xr-x 2 root root 4096 May 5 15:44 lib64
drwx------ 2 root root 16384 Apr 11 2015 lost+found
drwxr-xr-x 3 root root 4096 Apr 10 2015 media
drwxr-xr-x 3 root root 4096 Feb 23 17:54 mnt
drwxr-xr-x 16 root root 4096 Apr 30 16:01 opt
dr-xr-xr-x 223 root root 0 May 18 15:54 proc
drwx------ 19 root root 4096 Apr 9 11:12 root
drwxr-xr-x 27 root root 920 May 18 10:54 run
drwxr-xr-x 2 root root 12288 May 5 15:57 sbin
drwxr-xr-x 2 root root 4096 Dec 1 2014 srv
dr-xr-xr-x 13 root root 0 May 18 15:54 sys
drwxrwxrwt 13 root root 4096 May 18 17:55 tmp
drwxr-xr-x 11 root root 4096 Mar 31 16:00 usr
drwxr-xr-x 12 root root 4096 Nov 12 2015 var
```
您可以使用 mkdir 命令来创建一个目录。
```
# mkdir -m 1666 tecmint.com
# mkdir -m 1666 news.tecmint.com
# mkdir -m 1775 linuxsay.com
```
### 结论
现在应该对为什么 Linux 系统中一切都是文件以及 Linux 系统中可以存在哪些类型的文件有一个清楚的认识了。
您可以通过阅读更多有关各个文件类型的文章和对应的创建过程等来增加更多知识。我希望这篇教程对您有所帮助。有任何疑问或有补充的知识,请留下评论,一起来讨论。
---
via: <http://www.tecmint.com/explanation-of-everything-is-a-file-and-types-of-files-in-linux/>
作者:[Aaron Kili](http://www.tecmint.com/author/aaronkili/) 译者:[runningwater](https://github.com/runningwater) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,672 | Linux 命令行下的最佳文本编辑器 | https://itsfoss.com/command-line-text-editors-linux/ | 2016-08-11T13:54:00 | [
"编辑器",
"vi",
"emacs",
"vim"
] | https://linux.cn/article-7672-1.html | 
文本编辑软件在任何操作系统上都是必备的软件。我们在 Linux 上不缺乏[非常现代化的编辑软件](/article-7468-1.html),但是它们都是基于 GUI(图形界面)的编辑软件。
正如你所了解的,Linux 真正的魅力在于命令行。当你正在用命令行工作时,你就需要一个可以在控制台窗口运行的文本编辑器。
正因为这个目的,我们准备了一个基于 Linux 命令行的文本编辑器清单。
### [VIM](http://www.vim.org/)
如果你已经使用 Linux 有一段时间,那么你肯定听到过 Vim 。Vim 是一个高度可配置的、跨平台的、高效率的文本编辑器。
几乎所有的 Linux 发行版本都已经内置了 Vim ,由于其特性之丰富,它已经变得非常流行了。

*Vim 用户界面*
Vim 可能会让第一次使用它的人感到非常痛苦。我记得我第一次尝试使用 Vim 编辑一个文本文件时,我是非常困惑的。我不能用 Vim 输入一个字母,更有趣的是,我甚至不知道该怎么关闭它。如果你准备使用 Vim ,你需要有决心跨过一个陡峭的学习路线。
但是一旦你经历过了那些,通过梳理一些文档,记住它的命令和快捷键,你会发现这段学习经历是非常值得的。你可以将 Vim 按照你的意愿进行改造:配置一个让你看起来舒服的界面,通过使用脚本或者插件等来提高工作效率。Vim 支持格式高亮,宏记录和操作记录。
在Vim官网上,它是这样介绍的:
>
> **Vim: The power tool for everyone!**
>
>
>
如何使用它完全取决于你。你可以仅仅使用它作为文本编辑器,或者你可以将它打造成一个完善的IDE(<ruby> 集成开发环境 <rp> ( </rp> <rt> Integrated Development Environment </rt> <rp> ) </rp></ruby>)。
### [GNU EMACS](https://www.gnu.org/software/emacs/)
GNU Emacs 毫无疑问是非常强大的文本编辑器之一。如果你听说过 Vim 和 Emacs ,你应该知道这两个编辑器都拥有非常忠诚的粉丝基础,并且他们对于文本编辑器的选择非常看重。你也可以在互联网上找到大量关于他们的段子:

*Vim vs Emacs*
Emacs 是一个跨平台的、既有有图形界面也有命令行界面的软件。它也拥有非常多的特性,更重要的是,可扩展!

*Emacs 用户界面*
像 Vim一样,Emacs 也需要经历一个陡峭的学习路线。但是一旦你掌握了它,你就能完全体会到它的强大。Emacs 可以处理几乎所有类型文本文件。它的界面可以定制以适应你的工作流。它也支持宏记录和快捷键。
Emacs 独特的特性是它可以“变形”成和文本编辑器完全不同的的东西。有大量的模块可使它在不同的场景下成为不同的应用,例如:计算器、新闻阅读器、文字处理器等。你甚至都可以在 Emacs 里面玩游戏。
### [NANO](http://www.nano-editor.org/)
如果说到简易方便的软件,Nano 就是一个。不像 Vim 和 Emacs,nano 的学习曲线是平滑的。
如果你仅仅是想创建和编辑一个文本文件,不想给自己找太多挑战,Nano 估计是最适合你的了。

*Nano 用户界面*
Nano 可用的快捷键都在用户界面的下方展示出来了。Nano 仅仅拥有最基础的文本编辑软件的功能。
它是非常小巧的,非常适合编辑系统配置文件。对于那些不需要复杂的命令行编辑功能的人来说,Nano 是完美配备。
### 其它
这里还有一些我想要提及其它编辑器:
[The Nice Editor (ne)](http://ne.di.unimi.it/): 官网是这样介绍的:
>
> 如果你有足够的资料,也有使用 Emacs 的耐心或使用 Vim 的良好心态,那么 ne 可能不适合你。
>
>
>
基本上 ne 拥有像 Vim 和 Emacs 一样多的高级功能,包括:脚本和宏记录。但是它有更为直观的操作方式和平滑的学习路线。
### 你认为呢?
我知道,如果你是一个熟练的 Linux 用户,你可以会说还有很多应该被列入 “Linux 最好的命令行编辑器”清单上。因此我想跟你说,如果你还知道其他的 Linux 命令行文本编辑器,你是否愿意跟我们一同分享?
---
via: <https://itsfoss.com/command-line-text-editors-linux/>
作者:[Munif Tanjim](https://itsfoss.com/author/munif/) 译者:[chenzhijun](https://github.com/chenzhijun) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | 

A text editor is a must-have application for any operating system. We have no dearth of [good text editors on Linux](https://itsfoss.com/best-modern-open-source-code-editors-for-linux/). There is Gedit for quick text note down, there is VS Code for writing codes and more.
But those are all GUI-based editors. What if you need to [edit files in the terminal](https://learnubuntu.com/edit-files-command-line/?ref=itsfoss.com)?
Linux sysadmins need to do that on a daily basis. The average desktop Linux user may also need to edit files in the command line from time to time.
Your distribution has a terminal-based text editor installed by default. But don’t restrict yourself to just that.
Here, I have compiled a list of the **best command line text editors for Linux**. Feel free to experiment.
Please note that this is not a ranking list.
## 1. Neovim
Neovim is a fork of Vim that aims to add more extensibility while simplifying it. If you’re comfortable with Vim, you will be good to go using Neovim.
The project is being actively maintained and the progress is promising so far. Of course, unless you’re acquainted with how Vim works, you may not notice the striking difference between the two.
But, overall, Neovim tries to take Vim up a notch.
**How to install it?**
For Ubuntu-based distros, you can simply install it by typing:
`sudo apt install neovim`
For other Linux distributions or platforms, you may refer to its [official installation instructions](https://github.com/neovim/neovim/wiki/Installing-Neovim?ref=itsfoss.com) to get started.
To give you a head start, I must mention that when using the terminal, you will have to type the following to launch it (instead of neovim):
`nvim`
## 2. ne – The Nice Editor
When compared to the classic and popular text editors, ne (the nice editor) is a good alternative that tries to offer advanced functionalities and make it easier to use them.
In other words, it’s a simpler alternative to Vim/Emacs offering you powerful features. It is being actively maintained. I tried it installing on [U](https://itsfoss.com/ubuntu-22-04-release-features/)buntu 22.04 and it worked just fine. You can explore more about it on their [GitHub page](https://github.com/vigna/ne?ref=itsfoss.com).
Of course, unless you test it extensively, you should take it with a pinch of salt.
**How to install it?**
You should find it available in the official repositories of your Linux distribution. For Ubuntu-based distros, you can install it using the command:
`sudo apt install ne`
You can also check out their [official download page](http://ne.di.unimi.it/?ref=itsfoss.com#downloads) for more information on other Linux distributions.
## 3. Vim
If you’ve been on Linux for quite some time, you must have heard about [Vim](https://www.vim.org/?ref=itsfoss.com). Vim is an extensively configurable, cross-platform, and highly efficient text editor.
It may not be suitable for newbies but it’s something every aspiring Linux System administrator should get comfortable with. You will probably find it pre-installed in your Linux distribution. It is extremely popular for its wide range of advanced features.
Vim can be quite agonizing for first-time users. I remember the first time I tried to edit a text file with Vim, I was completely puzzled. I couldn’t type a single letter on it and the funny part is, I couldn’t even figure out how to close this thing. If you are going to use Vim, you must be determined to climb up a very steep learning curve.
But after you have gone through all that, combed through its [official documentation](https://www.vim.org/docs.php?ref=itsfoss.com), and practice the commands/operations, you’ll find it worth all the time spent. Not to forget, you can use it for basic text editing or leverage its support for hundreds of programming languages, extensions, and file formats.
**How to install it?**
If you don’t have it installed already, you can just try typing in the command (on Debian-based systems) to install it:
`sudo apt install vim`
You can also find it listed in your software center of the Linux distribution you use. In either case, just head on to its [official download page](https://www.vim.org/download.php?ref=itsfoss.com) to get more details.
[Mastering Vim Quickly - Jovica IlicExiting Mastering Vim Quickly From WTF to OMG in no time](https://gumroad.com/a/322499699?ref=linuxhandbook.com)

## 4. GNU Emacs
GNU Emacs is undoubtedly one of the oldest and versatile text editors out there. In case you didn’t know, it was created by GNU Project founder [Richard Stallman](https://en.wikipedia.org/wiki/Richard_Stallman?ref=itsfoss.com).
Emacs is cross-platform and has both command line and a graphical user interface. It is also very rich with various features and, most importantly, extensible.
Just as Vim, Emacs too comes with a steep learning curve. But once you master it, you can completely leverage its power. Emacs can handle just about any type of text file. The interface is customizable to suit your workflow. It supports macro recording and shortcuts as well.
The unique power of Emacs is that it can be transformed into something completely different from a text editor. There is a large collection of modules that can transform the application for use in completely different scenarios, like — calendar, news reader, word processor, etc. You can even play games in Emacs!
**How to install it?**
You should find it in your software center, or if you prefer using the terminal on Ubuntu-based distros, you can type in:
`sudo apt install emacs`
You can find more information on it on their [official download page](https://www.gnu.org/software/emacs/download.html?ref=itsfoss.com#gnu-linux). Once you’re done installing, you need to type in a specific command to launch emacs in your terminal, which is:
`emacs -nw`
Basically, this command instructs not to include any window to launch the program but the terminal itself.
## 5. MCEDIT
Midnight Commander is a fairly popular command line file manager and mcedit is an internal file editor of GNU Midnight Commander. It’s possible that many of us forget about this text editor, which is embedded inside the midnight commander utility.
What this editor does, is open the files specified on the command line. The editor is based on the terminal version of cooledit – a standalone editor for X Window System.
**How to install it?**
mcedit comes with the Midnight Commander package. In Ubuntu, you can install it by:
`sudo apt install mc`
Once installed, you can open files by executing:
`mcedit <file name>`
For more information, you can check out their [GitHub page.](https://github.com/MidnightCommander/mc?ref=itsfoss.com)
## 6. Nano
When it comes to simplicity, Nano is the one. Unlike Vim or Emacs, it is suitable for beginners to get used to quickly.
If you want to simply create & edit a text file, look no further.
The shortcuts available on Nano are displayed at the bottom of the user interface. It is minimal and perfectly suitable for editing system & configuration files. For those who don’t need advanced features from a command-line text editor, Nano is the perfect pick.
If interested, you can learn [how to use Nano text editor](https://itsfoss.com/nano-editor-guide/) in our beginner’s guide.
**How to install it?**
For the most part, Nano editor should come in pre-installed on Ubuntu-based distributions. If it isn’t there, you can simply visit the [official download page](https://www.nano-editor.org/download.php?ref=itsfoss.com) to get the binaries for the distribution you want.
[How to Use Nano Text Editor in Linux [With Cheat Sheet]Though Nano is less complicated to use than Vim and Emacs, it doesn’t mean Nano cannot be overwhelming. Learn how to use the Nano text editor.](https://itsfoss.com/nano-editor-guide/)

## 7. Tilde
Tilde is a terminal-based text editor tailored for users who are normally used to GUI applications.
Unlike other options mentioned in this list — this may not be a power tool. But, for basic text editing operations, this is very easy to use. You do have some advanced functionality – but that’s not something to compare with Vim/Emacs.
If you wanted to try something easy-to-use and different, this is the one I’d recommend you to try.
**How to install it?**
For Ubuntu-based distros, you can simply type the following command in the terminal:
`sudo apt install tilde`
For information on other Linux distributions, you may refer to their [GitHub page](https://github.com/gphalkes/tilde?ref=itsfoss.com) or the [download page](https://os.ghalkes.nl/tilde/download.html?ref=itsfoss.com) to explore more about it.
## 8. Micro
Micro is an easy-to-use and highly customizable text editor. It also implements the universal copy/paste/save shortcuts (CTRL + C/V/S), which is rare in Linux terminal editors. Another cool offering from this text editor is its plugin system and internal command mode.
Though it’s not feature-rich like Vim or other mature text editors, it can easily replace tools like Nano for occasional file editing in the terminal.
**How to install it?**
Micro is available in the repositories of all major distributions. In Ubuntu, you can install it with:
`sudo apt install micro`
For other Linux systems, you can check out their [GitHub page](https://github.com/zyedidia/micro/releases?ref=itsfoss.com). We have an article on [Micro text editor with a free cheat sheet for beginners](https://itsfoss.com/micro-editor-linux/) if you are interested.
## 9. Helix
Helix editor is a rust-based terminal text editor, which is both fast and efficient in resources. It uses Tree-Sitter for syntax highlighting, which helps boost the speed. The built-in language server support provides context-aware completion, diagnostics, and code actions.
Helix editor offers several powerful tools, that can make it work like other editors like Vim and Emacs. On their website, they call themselves, a post-modern text editor, if Neovim is the modern Vim, then Helix is post-modern.
For those who are interested, you can check out a [dedicated Helix article](https://itsfoss.com/helix-editor/)
**How to install it?**
For Arch and its derivatives, there is a package available in the Community repository. Also, an [AUR package](https://aur.archlinux.org/packages/helix-git?ref=itsfoss.com) is also available, which builds the master branch.
For other Linux distributions, you have to use Cargo, the Rust Package Manager.
You should be able to install Cargo using your distribution package manager Also, you need to make sure that Git is installed. On Ubuntu-based distributions, install both like this:
`sudo apt install git cargo`
Next, you should use the below commands one by one.
```
git clone https://github.com/helix-editor/helix
cd helix
cargo install --path helix-term
```
Helix also needs its runtime files so make sure to copy/symlink the `runtime/`
directory into the config directory. This location can be overridden via the `HELIX_RUNTIME`
environment variable.
`ln -s $PWD/runtime ~/.config/helix/runtime`
Now you should add the installed bin directory to your PATH.
`export PATH=$PATH:/home/team/.cargo/bin`
You can [check out their official page](https://docs.helix-editor.com/install.html?ref=itsfoss.com) for more information.
## Wrapping Up
If you are an experienced Linux user, you must have heard of most of the options mentioned in this list, if not all.
For most users, going with Nano, Vim or Emacs should be good enough. The seasoned terminal dwellers could experiment with the likes of Micro, Helix or some other terminal text editors.
That’s just my recommendation. And I would like to know yours. Which text editor do you prefer in the command line? Did you find a new, interesting one on this list? Share it in the comments. |
7,673 | Flatpak 为 Linux 带来了独立应用 | https://fedoramagazine.org/introducing-flatpak/ | 2016-08-11T16:03:17 | [
"Flatpak"
] | https://linux.cn/article-7673-1.html | 
[Flatpak](http://flatpak.org/) 的开发团队[宣布了](http://flatpak.org/press/2016-06-21-flatpak-released.html) Flatpak 桌面应用框架已经可用了。 Flatpak (以前在开发时名为 xdg-app)为应用提供了捆绑为一个 Flatpak 软件包的能力,可以让应用在很多 Linux 发行版上都以轻松而一致的体验来安装和运行。将应用程序捆绑成 Flatpak 为其提供了沙盒安全环境,可以将它们与操作系统和彼此之间相互隔离。查看 [Flatpak 网站](http://flatpak.org/)上的[发布公告](http://flatpak.org/press/2016-06-21-flatpak-released.html)来了解关于 Flatpak 框架技术的更多信息。
### 在 Fedora 中安装 Flatpak
如果用户想要运行以 Flatpak 格式打包的应用,在 Fedora 上安装是很容易的,Flatpak 格式已经可以在官方的 Fedora 23 和 Fedora 24 仓库中获得。Flatpak 网站上有[在 Fedora 上安装的完整细节](http://flatpak.org/getting.html),同时也有如何在 Arch、 Debian、Mageia 和 Ubuntu 中安装的方法。[许多的应用](http://flatpak.org/apps.html)已经使用 Flatpak 打包构建了,这包括 LibreOffice、Inkscape 和 GIMP。
### 对应用开发者
如果你是一个应用开发者,Flatpak 网站也包含许多有关于[使用 Flatpak 打包和分发应用程序](http://flatpak.org/developer.html)的重要资料。这些资料中包括了使用 Flakpak SDK 构建独立的、沙盒化的 Flakpak 应用程序的信息。
---
via: <https://fedoramagazine.org/introducing-flatpak/>
作者:[Ryan Lerch](https://fedoramagazine.org/introducing-flatpak/) 译者:[zky001](https://github.com/zky001) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | The development team behind [Flatpak](http://flatpak.org/) has [just announced the general availability](http://flatpak.org/press/2016-06-21-flatpak-released.html) of the Flatpak desktop application framework. Flatpak (which was also known during development as xdg-app) provides the ability for an application — bundled as a Flatpak — to be installed and run easily and consistently on many different Linux distributions. Applications bundled as Flatpaks also have the ability to be sandboxed for security, isolating them from your operating system, and other applications. Check out the [Flatpak website](http://flatpak.org/), and [the press release](http://flatpak.org/press/2016-06-21-flatpak-released.html) for more information on the tech that makes up the Flatpak framework.
### Installing Flatpak on Fedora
For users wanting to run applications bundled as Flatpaks, installation on Fedora is easy, with Flatpak already available in the official Fedora 23 and Fedora 24 repositories. The Flatpak website has [full details on installation on Fedora](http://flatpak.org/getting.html), as well as how to install on Arch, Debian, Mageia, and Ubuntu. [Many applications](http://flatpak.org/apps.html) have builds already bundled with Flatpak — including LibreOffice, and nightly builds of popular graphics applications Inkscape and GIMP.
### For Application Developers
If you are an application developer, the Flatpak website also contains some great resources on getting started [bundling and distributing your applications with Flatpak](http://flatpak.org/developer.html). These resources contain information on using Flakpak SDKs to build standalone, sandboxed Flatpak applications.
## Sudhir Khanger
How different is Flatpak packaging compared to RPM packaging? Do they share same spec file syntax or are they different?
If anyone is looking to get into packaging should one learn Flatpak or RPM?
## Michal Srb
There are no spec files in Flatpak. This hello world tutorial should give you an insight on how the Flatpak packaging workflow looks like: http://flatpak.org/index.html#developers
As for your second question, it probably depends on what the person is trying to achieve. IMO, Flatpak is much better choice for ISVs who simply want their software to be available for various Linux distributions. But if the goal is to distribute your application for a specific RPM-based distro, then RPM would be more natural (at least nowadays).
## PP
Flatpak is the future, no need for sudo, apps are sandboxed, meaning apps can’t destroy your PC.
## Volodymyr M. Lisivka
Flatpack is the n-th reincarnation of idea of “static binary”: binary with all dependencies compiled-in. Static binaries were supported in version 0.0.1 of Linux. It is not a future.
## Jeremy
Nice article. I am going to be interested to see how Flatpak does in what will surely be a fight with Canonical based Snappy packages, now that those are available on non-Ubuntu based distributions.
## Naheem
Will flatpak packages be available via COPR?
## Kieron
Flatpak > Snappy
😀
## toñog
I prefer Snap,sorry
## Frederico Lima
Why? |
7,674 | ownCloud 的六大神奇用法 | https://opensource.com/life/15/12/6-creative-ways-use-owncloud | 2016-08-11T21:09:00 | [
"ownCloud"
] | https://linux.cn/article-7674-1.html | 
[ownCloud](https://owncloud.com/) 是一个自行托管的开源文件同步和共享服务器。就像“行业老大” Dropbox、Google Drive、Box 和其他的同类服务一样,ownCloud 也可以让你访问自己的文件、日历、联系人和其他数据。你可以在自己设备之间同步任意数据(或部分数据)并分享给其他人。然而,ownCloud 要比其它的商业解决方案更棒,可以[将 ownCloud 运行在自己的服务器](https://blogs.fsfe.org/mk/new-stickers-and-leaflets-no-cloud-and-e-mail-self-defense/)而不是其它人的服务器上。
现在,让我们一起来看看在 ownCloud 上的六个创造性的应用方式。其中一些是由于 ownCloud 的开源才得以完成,而另外的则是 ownCloud 自身特有的功能。
### 1. 可扩展的 ownCloud “派”集群
由于 ownCloud 是开源的,你可以选择将它运行在自己的服务器中,或者从你信任的服务商那里获取空间——没必要将你的文件存储在那些大公司的服务器中,谁知他们将你的文件存储到哪里去。[点击此处查看部分 ownCloud 服务商](https://owncloud.org/providers),或者下载该服务软件到你的虚拟主机中[搭建自己的服务器](https://owncloud.org/install/#instructions-server).

*拍摄: Jörn Friedrich Dreyer. [CC BY-SA 4.0.](https://creativecommons.org/licenses/by-sa/4.0/)*
我们见过最具创意的事情就是架设[香蕉派集群](http://www.owncluster.de/)和[树莓派集群](https://christopherjcoleman.wordpress.com/2013/01/05/host-your-owncloud-on-a-raspberry-pi-cluster/)。ownCloud 的扩展性通常用于支持成千上万的用户,但有些人则将它往不同方向发展,通过将多个微型系统集群在一起,就可以创建出运行速度超快的 ownCloud。酷毙了!
### 2. 密码同步
为了让 ownCloud 更容易扩展,我们将它变得超级的模块化,甚至还有一个 [ownCloud 应用商店](https://apps.owncloud.com/)。你可以在里边找到音乐和视频播放器、日历、联系人、生产力应用、游戏、<ruby> 应用模板 <rp> ( </rp> <rt> sketching app </rt> <rp> ) </rp></ruby>等等。
从近 200 多个应用中仅挑选一个是一件非常困难的事,但密码管理则是一个很独特的功能。只有不超过三个应用提供这个功能:[Passwords](https://apps.owncloud.com/content/show.php/Passwords?content=170480)、[Secure Container](https://apps.owncloud.com/content/show.php/Secure+Container?content=167268) 和 [Passman](https://apps.owncloud.com/content/show.php/Passman?content=166285)。

### 3. 随心所欲地存储文件
外部存储可以让你将现有数据挂载到 ownCloud 上,让你通过一个界面来访问存储在 FTP、WebDAV、Amazon S3,甚至 Dropbox 和 Google Drive 的文件。
行业老大们喜欢创建自己的 “藩篱花园”,Box 的用户只能和其它的 Box 用户协作;假如你想从 Google Drive 分享你的文件,你的同伴也必须要有一个 Google 账号才可以访问的分享。通过 ownCloud 的外部存储功能,你可以轻松打破这些。
最有创意的就是把 Google Drive 和 Dropbox 添加为外部存储。这样你就可以无缝连接它们,通过一个简单的链接即可分享给其它人——并不需要账户。
### 4. 获取上传的文件
由于 ownCloud 是开源的,人们可以不受公司需求的制约而向它贡献感兴趣的功能。我们的贡献者总是很在意安全和隐私,所以 ownCloud 引入的通过密码保护公共链接并[设置失效期限](https://owncloud.com/owncloud45-community/)的功能要比其它人早很多。
现在,ownCloud 可以配置分享链接的读写权限了,这就是说链接的访问者可以无缝的编辑你分享给他们的文件(可以有密码保护,也可以没有),或者将文件上传到服务器前不用强制他们提供私人信息来注册服务。
对于有人想给你分享大体积的文件时,这个特性就非常有用了。相比于上传到第三方站点、然后给你发送一个连接、你再去下载文件(通常需要登录),ownCloud 仅需要上传文件到你提供的分享文件夹,你就可以马上获取到文件了。
### 5. 免费却又安全的存储空间
之前就强调过,我们的代码贡献者最关注的就是安全和隐私,这就是 ownCloud 中有用于加密和解密存储数据的应用的原因。
通过使用 ownCloud 将你的文件存储到 Dropbox 或者 Google Drive,则会违背夺回数据的控制权并保持数据隐私的初衷。但是加密应用则可以改变这个状况。在发送数据给这些提供商前进行数据加密,并在取回数据的时候进行解密,你的数据就会变得很安全。
### 6. 在你的可控范围内分享文件
作为开源项目,ownCloud 没有必要自建 “藩篱花园”。通过“<ruby> 联邦云共享 <rp> ( </rp> <rt> Federated Cloud Sharing </rt> <rp> ) </rp></ruby>”:这个[由 ownCloud 开发和发布的](http://karlitschek.de/2015/08/announcing-the-draft-federated-cloud-sharing-api/)协议使不同的文件同步和共享服务器可以彼此之间进行通信,并能够安全地传输文件。联邦云共享本身来自一个有趣的事情:有 [22 所德国大学](https://owncloud.com/customer/sciebo/) 想要为自身的 50 万名学生建立一个庞大的云服务,但是每个大学都想控制自己学生的数据。于是乎,我们需要一个创造性的解决方案:也就是联邦云服务。该解决方案可以连接全部的大学,使得学生们可以无缝的协同工作。同时,每个大学的系统管理员保持着对自己学生创建的文件的控制权,并可采用自己的策略,如限制限额,或者限制什么人、什么文件以及如何共享。
并且,这项神奇的技术并没有限制于德国的大学之间,每个 ownCloud 用户都能在自己的用户设置中找到自己的[联邦云 ID](https://owncloud.org/federation/),并将之分享给同伴。
现在你明白了吧。通过这六个方式,ownCloud 就能让人们做一些特殊而独特的事。而使这一切成为可能的,就是 ownCloud 是开源的,其设计目标就是让你的数据自由。
你有其它的 ownCloud 的创意用法吗?请发表评论让我们知道。
---
via: <https://opensource.com/life/15/12/6-creative-ways-use-owncloud>
作者:[Jos Poortvliet](https://opensource.com/users/jospoortvliet) 译者:[GHLandy](https://github.com/GHLandy) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | [ownCloud](https://owncloud.com/) is a self-hosted open source file sync and share server. Like "big boys" Dropbox, Google Drive, Box, and others, ownCloud lets you access your files, calendar, contacts, and other data. You can synchronize everything (or part of it) between your devices and share files with others. But ownCloud can do much more than its proprietary, [hosted-on-somebody-else's-computer](https://blogs.fsfe.org/mk/new-stickers-and-leaflets-no-cloud-and-e-mail-self-defense/) competitors.
Let's look at six creative things ownCloud can do. Some of these are possible because ownCloud is open source, whereas others are just unique features it offers.
## 1. A scalable ownCloud Pi cluster
Because ownCloud is open source, you can choose between self-hosting on your own server or renting space from a provider you trust—no need to put your files at a big company that stores it who knows where. [Find some ownCloud providers here](https://owncloud.org/providers) or grab packages or a virtual machine for [your own server here](https://owncloud.org/install/#instructions-server).
Photo by Jörn Friedrich Dreyer.
[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/).The most creative things we've seen are a [Banana Pi cluster](http://www.owncluster.de/) and a [Raspberry Pi cluster](https://christopherjcoleman.wordpress.com/2013/01/05/host-your-owncloud-on-a-raspberry-pi-cluster/). Although ownCloud's scalability is often used to deploy to hundreds of thousands of users, some folks out there take it in a different direction, bringing multiple tiny systems together to make a super-fast ownCloud. Kudos!
## 2. Keep your passwords synced
To make ownCloud easier to extend, we have made it extremely modular and have an [ownCloud app store](https://apps.owncloud.com). There you can find things like music and video players, calendars, contacts, productivity apps, games, a sketching app, and much more.
Picking only one app from the almost 200 available is hard, but managing passwords is certainly a unique feature. There are no less than three apps providing this functionality: [Passwords](https://apps.owncloud.com/content/show.php/Passwords?content=170480), [Secure Container](https://apps.owncloud.com/content/show.php/Secure+Container?content=167268), and [Passman](https://apps.owncloud.com/content/show.php/Passman?content=166285).
## 3. Store your files where you want
External storage allows you to hook your existing data storage into ownCloud, letting you to access files stored on FTP, WebDAV, Amazon S3, and even Dropbox and Google Drive through one interface.
The "big boys" like to create their own little walled gardens—Box user can only collaborate with other Box users; and if you want to share your files from Google Drive, your mate needs a Google account or they can't do much. With ownCloud's external storage, you can break these barriers.
A very creative solution is adding Google Drive and Dropbox as external storage. You can work with files on both seamlessly and share them with others through a simple link—no account needed to work with you!
## 4. Get files uploaded
Because ownCloud is open source, people contribute interesting features without being limited by corporate requirements. Our contributors have always cared about security and privacy, so ownCloud introduced features such as protecting a public link with a password and setting an expire date [years before anybody else did](https://owncloud.com/owncloud45-community/).
Today, ownCloud has the ability to configure a shared link as read-write, which means visitors can seamlessly edit the files you share with them (protected with a password or not) or upload new files to your server without being forced to sign up to another web service that wants their private data.
This is great for when people want to share a large file with you. Rather than having to upload it to a third-party site, send you a link, and make you go there and download it (often requiring a login), they can just upload it to a shared folder you provide, and you can get to work right away.
## 5. Get free secure storage
We already talked about how many of our contributors care about security and privacy. That's why ownCloud has an app that can encrypt and decrypt stored data.
Using ownCloud to store your files on Dropbox or Google Drive defeats the whole idea of retaking control of your data and keeping it private. The Encryption app changes that. By encrypting data before sending it to these providers and decrypting it upon retrieval, your data is safe as kittens.
## 6. Share your files **and** stay in control
As an open source project, ownCloud has no stake in building walled gardens. Enter Federated Cloud Sharing: a protocol [developed and published by ownCloud](http://karlitschek.de/2015/08/announcing-the-draft-federated-cloud-sharing-api/) that enables different file sync and share servers to talk to one another and exchange files securely. Federated Cloud Sharing has an interesting history. [Twenty-two German universities](https://owncloud.com/customer/sciebo/) decided to build a **huge** cloud for their 500,000 students. But as each university wanted to stay in control of the data of their own students, a creative solution was needed: Federated Cloud Sharing. The solution now connects all these universities so the students can seamlessly work together. At the same time, the system administrators at each university stay in control of the files their students have created and can apply policies, such as storage restrictions, or limitations on what, with whom, and how files can be shared.
And this awesome technology isn't limited to German universities: Every ownCloud user can find their [Federated Cloud ID](https://owncloud.org/federation/) in their user settings and share it with others.
So there you have it. Six ways ownCloud enables people to do special and unique things, all made possible because it is open source and designed to help you liberate your data.
*Do you have other creative uses for ownCloud? Let us know about them in the comments, or submit an article proposal.*
## 12 Comments |
7,676 | Python 3: 加密简介 | http://www.blog.pythonlibrary.org/2016/05/18/python-3-an-intro-to-encryption/ | 2016-08-12T08:56:00 | [
"Python",
"加密",
"解密",
"哈希"
] | https://linux.cn/article-7676-1.html | Python 3 的标准库中没多少用来解决加密的,不过却有用于处理哈希的库。在这里我们会对其进行一个简单的介绍,但重点会放在两个第三方的软件包:PyCrypto 和 cryptography 上。我们将学习如何使用这两个库,来加密和解密字符串。

### 哈希
如果需要用到安全哈希算法或是消息摘要算法,那么你可以使用标准库中的 **hashlib** 模块。这个模块包含了符合 FIPS(美国联邦信息处理标准)的安全哈希算法,包括 SHA1,SHA224,SHA256,SHA384,SHA512 以及 RSA 的 MD5 算法。Python 也支持 adler32 以及 crc32 哈希函数,不过它们在 **zlib** 模块中。
哈希的一个最常见的用法是,存储密码的哈希值而非密码本身。当然了,使用的哈希函数需要稳健一点,否则容易被破解。另一个常见的用法是,计算一个文件的哈希值,然后将这个文件和它的哈希值分别发送。接收到文件的人可以计算文件的哈希值,检验是否与接受到的哈希值相符。如果两者相符,就说明文件在传送的过程中未经篡改。
让我们试着创建一个 md5 哈希:
```
>>> import hashlib
>>> md5 = hashlib.md5()
>>> md5.update('Python rocks!')
Traceback (most recent call last):
File "<pyshell#5>", line 1, in <module>
md5.update('Python rocks!')
TypeError: Unicode-objects must be encoded before hashing
>>> md5.update(b'Python rocks!')
>>> md5.digest()
b'\x14\x82\xec\x1b#d\xf6N}\x16*+[\x16\xf4w'
```
让我们花点时间一行一行来讲解。首先,我们导入 **hashlib** ,然后创建一个 md5 哈希对象的实例。接着,我们向这个实例中添加一个字符串后,却得到了报错信息。原来,计算 md5 哈希时,需要使用字节形式的字符串而非普通字符串。正确添加字符串后,我们调用它的 **digest** 函数来得到哈希值。如果你想要十六进制的哈希值,也可以用以下方法:
```
>>> md5.hexdigest()
'1482ec1b2364f64e7d162a2b5b16f477'
```
实际上,有一种精简的方法来创建哈希,下面我们看一下用这种方法创建一个 sha1 哈希:
```
>>> sha = hashlib.sha1(b'Hello Python').hexdigest()
>>> sha
'422fbfbc67fe17c86642c5eaaa48f8b670cbed1b'
```
可以看到,我们可以同时创建一个哈希实例并且调用其 digest 函数。然后,我们打印出这个哈希值看一下。这里我使用 sha1 哈希函数作为例子,但它不是特别安全,读者可以随意尝试其他的哈希函数。
### 密钥导出
Python 的标准库对密钥导出支持较弱。实际上,hashlib 函数库提供的唯一方法就是 **pbkdf2\_hmac** 函数。它是 PKCS#5 的基于口令的第二个密钥导出函数,并使用 HMAC 作为伪随机函数。因为它支持“<ruby> 加盐 <rp> ( </rp> <rt> salt </rt> <rp> ) </rp></ruby>”和迭代操作,你可以使用类似的方法来哈希你的密码。例如,如果你打算使用 SHA-256 加密方法,你将需要至少 16 个字节的“盐”,以及最少 100000 次的迭代操作。
简单来说,“盐”就是随机的数据,被用来加入到哈希的过程中,以加大破解的难度。这基本可以保护你的密码免受字典和<ruby> 彩虹表 <rp> ( </rp> <rt> rainbow table </rt> <rp> ) </rp></ruby>的攻击。
让我们看一个简单的例子:
```
>>> import binascii
>>> dk = hashlib.pbkdf2_hmac(hash_name='sha256',
password=b'bad_password34',
salt=b'bad_salt',
iterations=100000)
>>> binascii.hexlify(dk)
b'6e97bad21f6200f9087036a71e7ca9fa01a59e1d697f7e0284cd7f9b897d7c02'
```
这里,我们用 SHA256 对一个密码进行哈希,使用了一个糟糕的盐,但经过了 100000 次迭代操作。当然,SHA 实际上并不被推荐用来创建密码的密钥。你应该使用类似 **scrypt** 的算法来替代。另一个不错的选择是使用一个叫 **bcrypt** 的第三方库,它是被专门设计出来哈希密码的。
### PyCryptodome
PyCrypto 可能是 Python 中密码学方面最有名的第三方软件包。可惜的是,它的开发工作于 2012 年就已停止。其他人还在继续发布最新版本的 PyCrypto,如果你不介意使用第三方的二进制包,仍可以取得 Python 3.5 的相应版本。比如,我在 Github (<https://github.com/sfbahr/PyCrypto-Wheels>) 上找到了对应 Python 3.5 的 PyCrypto 二进制包。
幸运的是,有一个该项目的分支 PyCrytodome 取代了 PyCrypto 。为了在 Linux 上安装它,你可以使用以下 pip 命令:
```
pip install pycryptodome
```
在 Windows 系统上安装则稍有不同:
```
pip install pycryptodomex
```
如果你遇到了问题,可能是因为你没有安装正确的依赖包(LCTT 译注:如 python-devel),或者你的 Windows 系统需要一个编译器。如果你需要安装上的帮助或技术支持,可以访问 PyCryptodome 的[网站](http://pycryptodome.readthedocs.io/en/latest/)。
还值得注意的是,PyCryptodome 在 PyCrypto 最后版本的基础上有很多改进。非常值得去访问它们的主页,看看有什么新的特性。
#### 加密字符串
访问了他们的主页之后,我们可以看一些例子。在第一个例子中,我们将使用 DES 算法来加密一个字符串:
```
>>> from Crypto.Cipher import DES
>>> key = 'abcdefgh'
>>> def pad(text):
while len(text) % 8 != 0:
text += ' '
return text
>>> des = DES.new(key, DES.MODE_ECB)
>>> text = 'Python rocks!'
>>> padded_text = pad(text)
>>> encrypted_text = des.encrypt(text)
Traceback (most recent call last):
File "<pyshell#35>", line 1, in <module>
encrypted_text = des.encrypt(text)
File "C:\Programs\Python\Python35-32\lib\site-packages\Crypto\Cipher\blockalgo.py", line 244, in encrypt
return self._cipher.encrypt(plaintext)
ValueError: Input strings must be a multiple of 8 in length
>>> encrypted_text = des.encrypt(padded_text)
>>> encrypted_text
b'>\xfc\x1f\x16x\x87\xb2\x93\x0e\xfcH\x02\xd59VQ'
```
这段代码稍有些复杂,让我们一点点来看。首先需要注意的是,DES 加密使用的密钥长度为 8 个字节,这也是我们将密钥变量设置为 8 个字符的原因。而我们需要加密的字符串的长度必须是 8 的倍数,所以我们创建了一个名为 **pad** 的函数,来给一个字符串末尾填充空格,直到它的长度是 8 的倍数。然后,我们创建了一个 DES 的实例,以及我们需要加密的文本。我们还创建了一个经过填充处理的文本。我们尝试着对未经填充处理的文本进行加密,啊欧,报了一个 ValueError 错误!我们需要对经过填充处理的文本进行加密,然后得到加密的字符串。(LCTT 译注:encrypt 函数的参数应为 byte 类型字符串,代码为:`encrypted_text = des.encrypt(padded_text.encode('utf-8'))`)
知道了如何加密,还要知道如何解密:
```
>>> des.decrypt(encrypted_text)
b'Python rocks! '
```
幸运的是,解密非常容易,我们只需要调用 des 对象的 **decrypt** 方法就可以得到我们原来的 byte 类型字符串了。下一个任务是学习如何用 RSA 算法加密和解密一个文件。首先,我们需要创建一些 RSA 密钥。
#### 创建 RSA 密钥
如果你希望使用 RSA 算法加密数据,那么你需要拥有访问 RAS 公钥和私钥的权限,否则你需要生成一组自己的密钥对。在这个例子中,我们将生成自己的密钥对。创建 RSA 密钥非常容易,所以我们将在 Python 解释器中完成。
```
>>> from Crypto.PublicKey import RSA
>>> code = 'nooneknows'
>>> key = RSA.generate(2048)
>>> encrypted_key = key.exportKey(passphrase=code, pkcs=8,
protection="scryptAndAES128-CBC")
>>> with open('/path_to_private_key/my_private_rsa_key.bin', 'wb') as f:
f.write(encrypted_key)
>>> with open('/path_to_public_key/my_rsa_public.pem', 'wb') as f:
f.write(key.publickey().exportKey())
```
首先我们从 **Crypto.PublicKey** 包中导入 **RSA**,然后创建一个傻傻的密码。接着我们生成 2048 位的 RSA 密钥。现在我们到了关键的部分。为了生成私钥,我们需要调用 RSA 密钥实例的 **exportKey** 方法,然后传入密码,使用的 PKCS 标准,以及加密方案这三个参数。之后,我们把私钥写入磁盘的文件中。
接下来,我们通过 RSA 密钥实例的 **publickey** 方法创建我们的公钥。我们使用方法链调用 publickey 和 exportKey 方法生成公钥,同样将它写入磁盘上的文件。
#### 加密文件
有了私钥和公钥之后,我们就可以加密一些数据,并写入文件了。这里有个比较标准的例子:
```
from Crypto.PublicKey import RSA
from Crypto.Random import get_random_bytes
from Crypto.Cipher import AES, PKCS1_OAEP
with open('/path/to/encrypted_data.bin', 'wb') as out_file:
recipient_key = RSA.import_key(
open('/path_to_public_key/my_rsa_public.pem').read())
session_key = get_random_bytes(16)
cipher_rsa = PKCS1_OAEP.new(recipient_key)
out_file.write(cipher_rsa.encrypt(session_key))
cipher_aes = AES.new(session_key, AES.MODE_EAX)
data = b'blah blah blah Python blah blah'
ciphertext, tag = cipher_aes.encrypt_and_digest(data)
out_file.write(cipher_aes.nonce)
out_file.write(tag)
out_file.write(ciphertext)
```
代码的前三行导入 PyCryptodome 包。然后我们打开一个文件用于写入数据。接着我们导入公钥赋给一个变量,创建一个 16 字节的会话密钥。在这个例子中,我们将使用混合加密方法,即 PKCS#1 OAEP ,也就是最优非对称加密填充。这允许我们向文件中写入任意长度的数据。接着我们创建 AES 加密,要加密的数据,然后加密数据。我们将得到加密的文本和消息认证码。最后,我们将随机数,消息认证码和加密的文本写入文件。
顺便提一下,随机数通常是真随机或伪随机数,只是用来进行密码通信的。对于 AES 加密,其密钥长度最少是 16 个字节。随意用一个你喜欢的编辑器试着打开这个被加密的文件,你应该只能看到乱码。
现在让我们学习如何解密我们的数据。
```
from Crypto.PublicKey import RSA
from Crypto.Cipher import AES, PKCS1_OAEP
code = 'nooneknows'
with open('/path/to/encrypted_data.bin', 'rb') as fobj:
private_key = RSA.import_key(
open('/path_to_private_key/my_rsa_key.pem').read(),
passphrase=code)
enc_session_key, nonce, tag, ciphertext = [ fobj.read(x)
for x in (private_key.size_in_bytes(),
16, 16, -1) ]
cipher_rsa = PKCS1_OAEP.new(private_key)
session_key = cipher_rsa.decrypt(enc_session_key)
cipher_aes = AES.new(session_key, AES.MODE_EAX, nonce)
data = cipher_aes.decrypt_and_verify(ciphertext, tag)
print(data)
```
如果你认真看了上一个例子,这段代码应该很容易解析。在这里,我们先以二进制模式读取我们的加密文件,然后导入私钥。注意,当你导入私钥时,需要提供一个密码,否则会出现错误。然后,我们文件中读取数据,首先是加密的会话密钥,然后是 16 字节的随机数和 16 字节的消息认证码,最后是剩下的加密的数据。
接下来我们需要解密出会话密钥,重新创建 AES 密钥,然后解密出数据。
你还可以用 PyCryptodome 库做更多的事。不过我们要接着讨论在 Python 中还可以用什么来满足我们加密解密的需求。
### cryptography 包
**cryptography** 的目标是成为“<ruby> 人类易于使用的密码学包 <rp> ( </rp> <rt> cryptography for humans </rt> <rp> ) </rp></ruby>”,就像 **requests** 是“<ruby> 人类易于使用的 HTTP 库 <rp> ( </rp> <rt> HTTP for Humans </rt> <rp> ) </rp></ruby>”一样。这个想法使你能够创建简单安全、易于使用的加密方案。如果有需要的话,你也可以使用一些底层的密码学基元,但这也需要你知道更多的细节,否则创建的东西将是不安全的。
如果你使用的 Python 版本是 3.5, 你可以使用 pip 安装,如下:
```
pip install cryptography
```
你会看到 cryptography 包还安装了一些依赖包(LCTT 译注:如 libopenssl-devel)。如果安装都顺利,我们就可以试着加密一些文本了。让我们使用 **Fernet** 对称加密算法,它保证了你加密的任何信息在不知道密码的情况下不能被篡改或读取。Fernet 还通过 **MultiFernet** 支持密钥轮换。下面让我们看一个简单的例子:
```
>>> from cryptography.fernet import Fernet
>>> cipher_key = Fernet.generate_key()
>>> cipher_key
b'APM1JDVgT8WDGOWBgQv6EIhvxl4vDYvUnVdg-Vjdt0o='
>>> cipher = Fernet(cipher_key)
>>> text = b'My super secret message'
>>> encrypted_text = cipher.encrypt(text)
>>> encrypted_text
(b'gAAAAABXOnV86aeUGADA6mTe9xEL92y_m0_TlC9vcqaF6NzHqRKkjEqh4d21PInEP3C9HuiUkS9f'
b'6bdHsSlRiCNWbSkPuRd_62zfEv3eaZjJvLAm3omnya8=')
>>> decrypted_text = cipher.decrypt(encrypted_text)
>>> decrypted_text
b'My super secret message'
```
首先我们需要导入 Fernet,然后生成一个密钥。我们输出密钥看看它是什么样儿。如你所见,它是一个随机的字节串。如果你愿意的话,可以试着多运行 **generate\_key** 方法几次,生成的密钥会是不同的。然后我们使用这个密钥生成 Fernet 密码实例。
现在我们有了用来加密和解密消息的密码。下一步是创建一个需要加密的消息,然后使用 **encrypt** 方法对它加密。我打印出加密的文本,然后你可以看到你再也读不懂它了。为了解密出我们的秘密消息,我们只需调用 **decrypt** 方法,并传入加密的文本作为参数。结果就是我们得到了消息字节串形式的纯文本。
### 小结
这一章仅仅浅显地介绍了 PyCryptodome 和 cryptography 这两个包的使用。不过这也确实给了你一个关于如何加密解密字符串和文件的简述。请务必阅读文档,做做实验,看看还能做些什么!
---
### 相关阅读
* [Github](https://github.com/sfbahr/PyCrypto-Wheels) 上 Python 3 的 PyCrypto Wheels
* PyCryptodome 的 [文档](http://pycryptodome.readthedocs.io/en/latest/src/introduction.html)
* Python’s 加密 [服务](https://docs.python.org/3/library/crypto.html)
* Cryptography 包的 [官网](https://cryptography.io/en/latest/)
---
via: <http://www.blog.pythonlibrary.org/2016/05/18/python-3-an-intro-to-encryption/>
作者:[Mike](http://www.blog.pythonlibrary.org/author/mld/) 译者:[Cathon](https://github.com/Cathon) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,677 | Git 系列(四):在 Git 中进行版本回退 | https://opensource.com/life/16/7/how-restore-older-file-versions-git | 2016-08-12T13:06:00 | [
"Git"
] | https://linux.cn/article-7677-1.html | 
在这篇文章中,你将学到如何查看项目中的历史版本,如何进行版本回退,以及如何创建 Git 分支以便你可以大胆尝试而不会出现问题。
在你的 Git 项目的历史中,你的位置就像是摇滚专辑中的一个片段,由一个被称为 HEAD 的 标记来确定(如磁带录音机或录音播放器的播放头)。要在你的 Git 时间线上前后移动 HEAD ,需要使用 `git checkout` 命令。
`git checkout` 命令的使用方式有两种。最常见的用途是从一个以前的提交中恢复文件,你也可以整个倒回磁带,切换到另一个分支。
### 恢复一个文件
当你意识到一个本来很好文件被你完全改乱了。我们都这么干过:我们把文件放到一个地方,添加并提交,然后我们发现它还需要做点最后的调整,最后这个文件被搞得面目全非了。
要把它恢复到最后的完好状态,使用 `git checkout` 从最后的提交(即 HEAD)中恢复:
```
$ git checkout HEAD filename
```
如果你碰巧提交了一个错误的版本,你需要找回更早的版本,使用 git log 查看你更早的提交,然后从合适的提交中找回它:
```
$ git log --oneline
79a4e5f bad take
f449007 The second commit
55df4c2 My great project, first commit.
$ git checkout 55df4c2 filename
```
现在,以前的文件恢复到了你当前的位置。(任何时候你都可以用 `git status` 命令查看你的当前状态)因为这个文件改变了,你需要添加这个文件,再进行提交:
```
$ git add filename
$ git commit -m 'restoring filename from first commit.'
```
使用 `git log` 验证你所提交的:
```
$ git log --oneline
d512580 restoring filename from first commit
79a4e5f bad take
f449007 The second commit
55df4c2 My great project, first commit.
```
从本质上讲,你已经倒好了磁带并修复了坏的地方,所以你需要重新录制正确的。
### 回退时间线
恢复文件的另一种方式是回退整个 Git 项目。这里使用了分支的思想,这是另一种替代方法。
如果你要回到历史提交,你要将 Git HEAD 回退到以前的版本才行。这个例子将回到最初的提交处:
```
$ git log --oneline
d512580 restoring filename from first commit
79a4e5f bad take
f449007 The second commit
55df4c2 My great project, first commit.
$ git checkout 55df4c2
```
当你以这种方式倒回磁带,如果你按下录音键再次开始,就会丢失以前的工作。Git 默认假定你不想这样做,所以将 HEAD 从项目中分离出来,可以让你如所需的那样工作,而不会因为偶尔的记录而影响之后的工作。
如果你想看看以前的版本,想要重新做或者尝试不同的方法,那么安全一点的方式就是创建一个新的分支。可以将这个过程想象为尝试同一首歌曲的不同版本,或者创建一个混音的。原始的依然存在,关闭那个分支做你想做的版本吧。
就像记录到一个空白磁带一样,把你的 Git HEAD 指到一个新的分支处:
```
$ git checkout -b remix
Switched to a new branch 'remix'
```
现在你已经切换到了另一个分支,在你面前的是一个替代的干净工作区,准备开始工作吧。
也可以不用改变时间线来做同样的事情。也许你很想这么做,但切换到一个临时的工作区只是为了尝试一些疯狂的想法。这在工作中完全是可以接受的,请看:
```
$ git status
On branch master
nothing to commit, working directory clean
$ git checkout -b crazy_idea
Switched to a new branch 'crazy_idea'
```
现在你有一个干净的工作空间,在这里你可以完成一些奇怪的想法。一旦你完成了,可以保留你的改变,或者丢弃他们,并切换回你的主分支。
若要放弃你的想法,切换到你的主分支,假装新分支不存在:
```
$ git checkout master
```
想要继续使用你的疯狂的想法,需要把它们拉回到主分支,切换到主分支然后合并新分支到主分支:
```
$ git checkout master
$ git merge crazy_idea
```
git 的分支功能很强大,开发人员在克隆仓库后马上创建一个新分支是很常见的做法;这样,他们所有的工作都在自己的分支上,可以提交并合并到主分支。Git 是很灵活的,所以没有“正确”或“错误”的方式(甚至一个主分支也可以与其所属的远程仓库分离),但分支易于分离任务和提交贡献。不要太激动,你可以如你所愿的有很多的 Git 分支。完全自由。
### 远程协作
到目前为止你已经在自己舒适而私密的家中维护着一个 Git 仓库,但如何与其他人协同工作呢?
有好几种不同的方式来设置 Git 以便让多人可以同时在一个项目上工作,所以首先我们要克隆仓库,你可能已经从某人的 Git 服务器或 GitHub 主页,或在局域网中的共享存储上克隆了一个仓库。
工作在私人仓库下和共享仓库下唯一不同的是你需要把你的改变 `push` 到别人的仓库。我们把工作的仓库称之为<ruby> 本地 <rp> ( </rp> <rt> local </rt> <rp> ) </rp></ruby>仓库,其他仓库称为<ruby> 远程 <rp> ( </rp> <rt> remote </rt> <rp> ) </rp></ruby>仓库。
当你以读写的方式克隆一个仓库时,克隆的仓库会继承自被称为 origin 的远程库。你可以看看你的克隆仓库的远程仓库:
```
$ git remote --verbose
origin [email protected]:~/myproject.Git (fetch)
origin [email protected]:~/myproject.Git (push)
```
有一个 origin 远程库非常有用,因为它有异地备份的功能,并允许其他人在该项目上工作。
如果克隆没有继承 origin 远程库,或者如果你选择以后再添加,可以使用 `git remote` 命令:
```
$ git remote add [email protected]:~/myproject.Git
```
如果你修改了文件,想把它们发到有读写权限的 origin 远程库,使用 `git push`。第一次推送改变,必须也发送分支信息。不直接在主分支上工作是一个很好的做法,除非你被要求这样做:
```
$ git checkout -b seth-dev
$ git add exciting-new-file.txt
$ git commit -m 'first push to remote'
$ git push -u origin HEAD
```
它会推送你当前的位置(HEAD)及其存在的分支到远程。当推送过一次后,以后每次推送可以不使用 -u 选项:
```
$ git add another-file.txt
$ git commit -m 'another push to remote'
$ git push origin HEAD
```
### 合并分支
当你工作在一个 Git 仓库时,你可以合并任意测试分支到主分支。当团队协作时,你可能想在将它们合并到主分支之前检查他们的改变:
```
$ git checkout contributor
$ git pull
$ less blah.txt ### 检查改变的文件
$ git checkout master
$ git merge contributor
```
如果你正在使用 GitHub 或 GitLab 以及类似的东西,这个过程是不同的。但克隆项目并把它作为你自己的仓库都是相似的。你可以在本地工作,将改变提交到你的 GitHub 或 GitLab 帐户,而不用其它人的许可,因为这些库是你自己的。
如果你想要让你克隆的仓库接受你的改变,需要创建了一个<ruby> 拉取请求 <rp> ( </rp> <rt> pull request </rt> <rp> ) </rp></ruby>,它使用 Web 服务的后端发送补丁到真正的拥有者,并允许他们审查和拉取你的改变。
克隆一个项目通常是在 Web 服务端完成的,它和使用 Git 命令来管理项目是类似的,甚至推送的过程也是。然后它返回到 Web 服务打开一个拉取请求,工作就完成了。
下一部分我们将整合一些有用的插件到 Git 中来帮你轻松的完成日常工作。
---
via: <https://opensource.com/life/16/7/how-restore-older-file-versions-git>
作者:[Seth Kenlon](https://opensource.com/users/seth) 译者:[strugglingyouth](https://github.com/strugglingyouth) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Read:*
[Part 1: What is Git?](https://opensource.com/resources/what-is-git)*Part 2: Getting started with Git*[Part 3: Creating your first Git repository](https://opensource.com/life/16/7/creating-your-first-git-repository)*Part 4: How to restore older file versions in Git**Part 5: 3 graphical tools for Git**Part 6: How to build your own Git server**Part 7: How to manage binary blobs with Git*
In today's article you will learn how to find out where you are in the history of your project, how to restore older file versions, and how to make Git branches so you can safely conduct wild experiments.
Where you are in the history of your Git project, much like your location in the span of a rock album, is determined by a marker called HEAD (like the playhead of a tape recorder or record player). To move HEAD around in your own Git timeline, use the `git checkout`
command.
There are two ways to use the `git checkout`
command. A common use is to restore a file from a previous commit, and you can also rewind your entire tape reel and go in an entirely different direction.
## Restore a file
This happens when you realize you've utterly destroyed an otherwise good file. We all do it; we get a file to a great place, we add and commit it, and then we decide that what it really needs is *one last adjustment*, and the file ends up completely unrecognizable.
To restore it to its former glory, use `git checkout`
from the last known commit, which is `HEAD`
:
```
$ git checkout HEAD filename
```
If you accidentally committed a bad version of a file and need to yank a version from even further back in time, look in your Git log to see your previous commits, and then check it out from the appropriate commit:
```
$ git log --oneline
79a4e5f bad take
f449007 The second commit
55df4c2 My great project, first commit.
$ git checkout 55df4c2 filename
```
Now the older version of the file is restored into your current position. (You can see your current status at any time with the `git status`
command.) You need to add the file because it has changed, and then commit it:
```
$ git add filename
$ git commit -m 'restoring filename from first commit.'
```
Look in your Git log to verify what you did:
```
$ git log --oneline
d512580 restoring filename from first commit
79a4e5f bad take
f449007 The second commit
55df4c2 My great project, first commit.
```
Essentially, you have rewound the tape and are taping over a bad take. So you need to re-record the good take.
## Rewind the timeline
The other way to check out a file is to rewind the entire Git project. This introduces the idea of branches, which are, in a way, alternate takes of the same song.
When you go back in history, you rewind your Git HEAD to a previous version of your project. This example rewinds all the way back to your original commit:
```
$ git log --oneline
d512580 restoring filename from first commit
79a4e5f bad take
f449007 The second commit
55df4c2 My great project, first commit.
$ git checkout 55df4c2
```
When you rewind the tape in this way, if you hit the record button and go forward, you are destroying your future work. By default, Git assumes you do not want to do this, so it detaches HEAD from the project and lets you work as needed without accidentally recording over something you have recorded later.
If you look at your previous version and realise suddenly that you want to re-do everything, or at least try a different approach, then the safe way to do that is to create a new branch. You can think of this process as trying out a different version of the same song, or creating a remix. The original material exists, but you're branching off and doing your own version for fun.
To get your Git HEAD back down on blank tape, make a new branch:
```
$ git checkout -b remix
Switched to a new branch 'remix'
```
Now you've moved back in time, with an alternate and clean workspace in front of you, ready for whatever changes you want to make.
You can do the same thing without moving in time. Maybe you're perfectly happy with how your progress is going, but would like to switch to a temporary workspace just to try some crazy ideas out. That's a perfectly acceptable workflow, as well:
```
$ git status
On branch master
nothing to commit, working directory clean
$ git checkout -b crazy_idea
Switched to a new branch 'crazy_idea'
```
Now you have a clean workspace where you can sandbox some crazy new ideas. Once you're done, you can either keep your changes, or you can forget they ever existed and switch back to your master branch.
To forget your ideas in shame, change back to your master branch and pretend your new branch doesn't exist:
`$ git checkout master`
To keep your crazy ideas and pull them back into your master branch, change back to your master branch and merge your new branch:
```
$ git checkout master
$ git merge crazy_idea
```
Branches are powerful aspects of git, and it's common for developers to create a new branch immediately after cloning a repository; that way, all of their work is contained on their own branch, which they can submit for merging to the master branch. Git is pretty flexible, so there's no "right" or "wrong" way (even a master branch can be distinguished from what remote it belongs to), but branching makes it easy to separate tasks and contributions. Don't get too carried away, but between you and me, you can have as many Git branches as you please. They're free!
## Working with remotes
So far you've maintained a Git repository in the comfort and privacy of your own home, but what about when you're working with other people?
There are several different ways to set Git up so that many people can work on a project at once, so for now we'll focus on working on a clone, whether you got that clone from someone's personal Git server or their GitHub page, or from a shared drive on the same network.
The only difference between working on your own private Git repository and working on something you want to share with others is that at some point, you need to `push`
your changes to someone else's repository. We call the repository you are working in a *local* repository, and any other repository a *remote*.
When you clone a repository with read and write permissions from another source, your clone inherits the remote from whence it came as its *origin*. You can see a clone's remote:
```
$ git remote --verbose
origin [email protected]:~/myproject.Git (fetch)
origin [email protected]:~/myproject.Git (push)
```
Having a remote origin is handy because it is functionally an offsite backup, and it also allows someone else to be working on the project.
If your clone didn't inherit a remote origin, or if you choose to add one later, use the `git remote`
command:
`$ git remote add [email protected]:~/myproject.Git`
If you have changed files and want to send them to your remote `origin`
, and have read and write permissions to the repository, use `git push`
. The first time you push changes, you must also send your branch information. It is a good practice to not work on master, unless you've been told to do so:
```
$ git checkout -b seth-dev
$ git add exciting-new-file.txt
$ git commit -m 'first push to remote'
$ git push -u origin HEAD
```
This pushes your current location (HEAD, naturally) *and the branch it exists on* to the remote. After you've pushed your branch once, you can drop the `-u`
option:
```
$ git add another-file.txt
$ git commit -m 'another push to remote'
$ git push origin HEAD
```
## Merging branches
When you're working alone in a Git repository you can merge test branches into your master branch whenever you want. When working in tandem with a contributor, you'll probably want to review their changes before merging them into your master branch:
```
$ git checkout contributor
$ git pull
$ less blah.txt # review the changed files
$ git checkout master
$ git merge contributor
```
If you are using GitHub or GitLab or something similar, the process is different. There, it is traditional to fork the project and treat it as though it is your own repository. You can work in the repository and send changes to your GitHub or GitLab account without getting permission from anyone, because it's *your* repository.
If you want the person you forked it from to receive your changes, you create a *pull request*, which uses the web service's backend to send patches to the real owner, and allows them to review and pull in your changes.
Forking a project is usually done on the web service, but the Git commands to manage your copy of the project are the same, even the `push`
process. Then it's back to the web service to open a pull request, and the job is done.
In our next installment we'll look at some convenience add-ons to help you integrate Git comfortably into your everyday workflow.
## 5 Comments |
7,679 | 5 个最受人喜爱的开源 Django 包 | https://opensource.com/business/15/12/5-favorite-open-source-django-packages | 2016-08-13T20:35:00 | [
"Python",
"Django"
] | https://linux.cn/article-7679-1.html | 
Django 围绕“[可重用应用](https://docs.djangoproject.com/en/1.8/intro/reusable-apps/)”的思想建立:自包含的包提供了可重复使用的特性。你可以将这些可重用应用组装起来,在加上适用于你的网站的特定代码,来搭建你自己的网站。Django 具有一个丰富多样的、由可供你使用的可重用应用组建起来的生态系统——PyPI 列出了[超过 8000个 Django 应用](https://pypi.python.org/pypi?:action=browse&c=523)——可你该如何知道哪些是最好的呢?
为了节省你的时间,我们总结了五个最受喜爱的 Django 应用。它们是:
* [Cookiecutter](https://github.com/audreyr/cookiecutter): 建立 Django 网站的最佳方式。
* [Whitenoise](http://whitenoise.evans.io/en/latest/base.html): 最棒的静态资源服务器。
* [Django Rest Framework](http://www.django-rest-framework.org/): 使用 Django 开发 REST API 的最佳方式。
* [Wagtail](https://wagtail.io/): 基于 Django 的最佳内容管理系统(CMS)。
* [django-allauth](http://www.intenct.nl/projects/django-allauth/): 提供社交账户登录的最佳应用(如 Twitter, Facebook, GitHub 等)。
我们同样推荐你看看 [Django Packages](https://www.djangopackages.com/),这是一个可重用 Django 应用的目录。Django Packages 将 Django 应用组织成“表格”,你可以在功能相似的不同应用之间进行比较并做出选择。你可以查看每个包中提供的特性和使用统计情况。(比如:这是 [REST 工具的表格](https://www.djangopackages.com/grids/g/rest/),也许可以帮助你理解我们为何推荐 Django REST Framework。
### 为什么你应该相信我们?
我们使用 Django 的时间几乎比任何人都长。在 Django 发布之前,我们当中的两个人(Frank 和 Jacob)就在 [Lawrence Journal-World](http://www2.ljworld.com/news/2015/jul/09/happy-birthday-django/) (Django 的发源地)工作(事实上,是他们两人推动了 Django 开源发布的进程)。我们在过去的八年当中运行着一个咨询公司,来建议公司怎样最好地应用 Django。
所以,我们见证了 Django 项目和社群的完整历史,我们见证了那些流行的软件包的兴起和没落。在我们三个之中,我们个人可能试用了 8000 个应用中至少一半以上,或者我们知道谁试用过这些。我们对如何使应用变得坚实可靠有着深刻的理解,并且我们对给予这些应用持久力量的来源也有着深入的了解。
### 建立 Django 网站的最佳方式:[Cookiecutter](https://github.com/audreyr/cookiecutter)
建立一个新项目或应用总是有些痛苦。你可以用 Django 内建的 `startproject`。不过,如果你像我们一样,对如何做事比较挑剔。Cookiecutter 为你提供了一个快捷简单的方式来构建项目或易于重用的应用模板,从而解决了这个问题。一个简单的例子:键入 `pip install cookiecutter`,然后在命令行中运行以下命令:
```
$ cookiecutter https://github.com/marcofucci/cookiecutter-simple-django
```
接下来你需要回答几个简单的问题,比如你的项目名称、<ruby> 目录 <rp> ( </rp> <rt> repo </rt> <rp> ) </rp></ruby>、作者名字、E-Mail 和其他几个关于配置的小问题。这些能够帮你补充项目相关的细节。我们使用最最原始的 “*foo*” 作为我们的目录名称。所以 cokkiecutter 在子目录 “*foo*” 下建立了一个简单的 Django 项目。
如果你在 “*foo*” 项目中闲逛,你会看见你刚刚选择的其它设置已通过模板,连同所需的子目录一同嵌入到文件当中。这个“模板”在我们刚刚在执行 `cookiecutter` 命令时输入的唯一一个参数 Github 仓库 URL 中定义。这个样例工程使用了一个 Github 远程仓库作为模板;不过你也可以使用本地的模板,这在建立非重用项目时非常有用。
我们认为 cookiecutter 是一个极棒的 Django 包,但是,事实上其实它在面对纯 Python 甚至非 Python 相关需求时也极为有用。你能够将所有文件以一种可重复的方式精确地摆放在任何位置上,使得 cookiecutter 成为了一个简化(DRY)工作流程的极佳工具。
### 最棒的静态资源服务器:[Whitenoise](http://whitenoise.evans.io/en/latest/base.html)
多年来,托管网站的静态资源——图片、Javascript、CSS——都是一件很痛苦的事情。Django 内建的 [django.views.static.serve](https://docs.djangoproject.com/en/1.8/ref/views/#django.views.static.serve) 视图,就像 Django 文章所述的那样,“在生产环境中不可靠,所以只应为开发环境的提供辅助功能。”但使用一个“真正的” Web 服务器,如 NGINX 或者借助 CDN 来托管媒体资源,配置起来会比较困难。
Whitenoice 很简洁地解决了这个问题。它可以像在开发环境那样轻易地在生产环境中设置静态服务器,并且针对生产环境进行了加固和优化。它的设置方法极为简单:
1. 确保你在使用 Django 的 [contrib.staticfiles](https://docs.djangoproject.com/en/1.8/ref/contrib/staticfiles/) 应用,并确认你在配置文件中正确设置了 `STATIC_ROOT` 变量。
2. 在 `wsgi.py` 文件中启用 Whitenoise:
```
from django.core.wsgi import get_wsgi_application
from whitenoise.django import DjangoWhiteNoise
application = get_wsgi_application()
application = DjangoWhiteNoise(application)
```
配置它真的就这么简单!对于大型应用,你可能想要使用一个专用的媒体服务器和/或一个 CDN,但对于大多数小型或中型 Django 网站,Whitenoise 已经足够强大。
如需查看更多关于 Whitenoise 的信息,[请查看文档](http://whitenoise.evans.io/en/latest/index.html)。
### 开发 REST API 的最佳工具:[Django REST Framework](http://www.django-rest-framework.org/)
REST API 正在迅速成为现代 Web 应用的标准功能。 API 就是简单的使用 JSON 对话而不是 HTML,当然你可以只用 Django 做到这些。你可以制作自己的视图,设置合适的 `Content-Type`,然后返回 JSON 而不是渲染后的 HTML 响应。这是在像 [Django Rest Framework](http://www.django-rest-framework.org/)(下称 DRF)这样的 API 框架发布之前,大多数人所做的。
如果你对 Django 的视图类很熟悉,你会觉得使用 DRF 构建 REST API 与使用它们很相似,不过 DRF 只针对特定 API 使用场景而设计。一般的 API 设置只需要一点代码,所以我们没有提供一份让你兴奋的示例代码,而是强调了一些可以让你生活的更舒适的 DRF 特性:
* 可自动预览的 API 可以使你的开发和人工测试轻而易举。你可以查看 DRF 的[示例代码](http://restframework.herokuapp.com/)。你可以查看 API 响应,并且不需要你做任何事就可以支持 POST/PUT/DELETE 类型的操作。
* 便于集成各种认证方式,如 OAuth, Basic Auth, 或API Tokens。
* 内建请求速率限制。
* 当与 [django-rest-swagger](http://django-rest-swagger.readthedocs.org/en/latest/index.html) 组合使用时,API 文档几乎可以自动生成。
* 广泛的第三方库生态。
当然,你可以不依赖 DRF 来构建 API,但我们无法想象你不去使用 DRF 的原因。就算你不使用 DRF 的全部特性,使用一个成熟的视图库来构建你自己的 API 也会使你的 API 更加一致、完全,更能提高你的开发速度。如果你还没有开始使用 DRF, 你应该找点时间去体验一下。
### 基于 Django 的最佳 CMS:[Wagtail](https://wagtail.io/)
Wagtail 是当下 Django CMS(内容管理系统)世界中最受人青睐的应用,并且它的热门有足够的理由。就像大多数的 CMS 一样,它具有极佳的灵活性,可以通过简单的 Django 模型来定义不同类型的页面及其内容。使用它,你可以从零开始在几个小时而不是几天之内来和建造一个基本可以运行的内容管理系统。举一个小例子,为你公司的员工定义一个员工页面类型可以像下面一样简单:
```
from wagtail.wagtailcore.models import Page
from wagtail.wagtailcore.fields import RichTextField
from wagtail.wagtailadmin.edit_handlers import FieldPanel, MultiFieldPanel
from wagtail.wagtailimages.edit_handlers import ImageChooserPanel
class StaffPage(Page):
name = models.CharField(max_length=100)
hire_date = models.DateField()
bio = models.RichTextField()
email = models.EmailField()
headshot = models.ForeignKey('wagtailimages.Image', null=True, blank=True)
content_panels = Page.content_panels + [
FieldPanel('name'),
FieldPanel('hire_date'),
FieldPanel('email'),
FieldPanel('bio',classname="full"),
ImageChoosePanel('headshot'),
]
```
然而,Wagtail 真正出彩的地方在于它的灵活性及其易于使用的现代化管理页面。你可以控制不同类型的页面在哪网站的哪些区域可以访问,为页面添加复杂的附加逻辑,还天生就支持标准的适应/审批工作流。在大多数 CMS 系统中,你会在开发时在某些点上遇到困难。而使用 Wagtail 时,我们经过不懈努力找到了一个突破口,使得让我们轻易地开发出一套简洁稳定的系统,使得程序完全依照我们的想法运行。如果你对此感兴趣,我们写了一篇[深入理解 Wagtail][17。
### 提供社交账户登录的最佳工具:[django-allauth](http://www.intenct.nl/projects/django-allauth/)
django-allauth 是一个能够解决你的注册和认证需求的、可重用的 Django 应用。无论你需要构建本地注册系统还是社交账户注册系统,django-allauth 都能够帮你做到。
这个应用支持多种认证体系,比如用户名或电子邮件。一旦用户注册成功,它还可以提供从无需认证到电子邮件认证的多种账户验证的策略。同时,它也支持多种社交账户和电子邮件账户。它还支持插拔式注册表单,可让用户在注册时回答一些附加问题。
django-allauth 支持多于 20 种认证提供者,包括 Facebook、Github、Google 和 Twitter。如果你发现了一个它不支持的社交网站,很有可能通过第三方插件提供该网站的接入支持。这个项目还支持自定义后端,可以支持自定义的认证方式,对每个有定制认证需求的人来说这都很棒。
django-allauth 易于配置,且有[完善的文档](http://django-allauth.readthedocs.org/en/latest/)。该项目通过了很多测试,所以你可以相信它的所有部件都会正常运作。
你有最喜爱的 Django 包吗?请在评论中告诉我们。
### 关于作者

Jeff Triplett 劳伦斯,堪萨斯州 <http://www.jefftriplett.com/>
我在 2007 年搬到了堪萨斯州的劳伦斯,在 Django 的发源地—— Lawrence Journal-World 工作。我现在在劳伦斯市的 [Revolution Systems (Revsys)](http://www.revsys.com/) 工作,做一位开发者兼顾问。
我是[北美 Django 运动基金会(DEFNA)](http://defna.org/)的联合创始人,2015 和 2016 年 [DjangoCon US](https://2015.djangocon.us/) 的会议主席,而且我在 Django 的发源地劳伦斯参与组织了 [Django Birthday](https://djangobirthday.com/) 来庆祝 Django 的 10 岁生日。
我是当地越野跑小组的成员,我喜欢篮球,我还喜欢梦见自己随着一道气流游遍美国。
*Jacob Kaplan-Moss 和 Frank Wiles 也参与了本文的写作。*
---
via: <https://opensource.com/business/15/12/5-favorite-open-source-django-packages>
作者:[Jeff Triplett](https://opensource.com/users/jefftriplett) 译者:[StdioA](https://github.com/StdioA) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Jacob Kaplan-Moss and Frank Wiles also contributed to this article.*
Django is built around the concept of [reusable apps](https://docs.djangoproject.com/en/1.8/intro/reusable-apps/): self-contained packages that provide re-usable features. You can build your site by composing these reusable apps, together with your own site-specific code. There's a rich and varied ecosystem of reusable apps available for your use—PyPI lists more than [8,000 Django apps](https://pypi.python.org/pypi?:action=browse&c=523)—but how do you know which ones are best?
To help focus your app search, we've put together this list of our five favorites. They are:
[Cookiecutter](https://github.com/audreyr/cookiecutter): the best way to start a new Django site.[Whitenoise](http://whitenoise.evans.io/en/latest/base.html): the best static asset server.[Django Rest Framework](http://www.django-rest-framework.org/): the best way to write REST APIs with Django.[Wagtail](https://wagtail.io/): the best Django-based content-management system.[django-allauth](http://www.intenct.nl/projects/django-allauth/): the best way to provide "social login" (e.g., Twitter, Facebook, GitHub, etc).
We also recommend you check out [Django Packages](https://www.djangopackages.com/), a directory of reusable Django apps. Django Packages organizes Django apps into "grids" that allow you to compare similar packages and chose between them. You can see which features are offered by each package, as well as usage statistics. (For example: here's the [grid for REST tools](https://www.djangopackages.com/grids/g/rest/), which might help you understand why we recommend Django REST Framework.)
## Why you should trust us?
We've been using Django for longer than almost anyone. Two of us (Frank and Jacob) worked at the [Lawrence Journal-World](http://www2.ljworld.com/news/2015/jul/09/happy-birthday-django/) (birthplace of Django) before Django was released (and in fact helped make the open source release happen). We've all spent the past eight years running a consultancy that advises companies on how best to use Django.
So, we've seen the entire history of the Django project and community, and we've seen popular packages come and go. Between the three of us, we've probably tried at least half of these 8,000 apps personally, or we know someone who has. We have a strong understanding of what makes an app solid and reliable, and we have a good understanding of what gives these things staying power.
## Best way to start a new Django site: [Cookiecutter](https://github.com/audreyr/cookiecutter)
Starting off a new project or app is always a bit of a pain. You can use Django's built in **`startproject`** but if you're like us, you're particular in how you do things. Cookiecutter solves this by giving you a quick and easy way to define project or app templates that can be easily reused. A quick example, just **`pip install cookiecutter`** and then run this from the command line:
```
````$ cookiecutter https://github.com/marcofucci/cookiecutter-simple-django`
You'll immediately start getting prompted for quick answers, such as the name of your project, repo, author name, email, and a few other bits of configuration. These are used to help fill out the project details. We picked the ever so original **'foo'** to be our repo name. So cookiecutter created a simple Django project in the subdirectory **'foo'**.
If you poke around in the **'foo'** project a bit, you'll see the other bits of configuration you were prompted for have been templated into the files themselves along with sub-directories as necessary. This "template" is all defined at the GitHub repo URL we used as the only argument when we called **`cookiecutter`**. This example used a remote GitHub repo as the template; however, note that you can use local file system directories as well, which is perfect for non-reusable scenarios.
We mention cookiecutter as a great Django package, but honestly it's useful for plain Python or even non-Python-related purposes. Being able to lay things out exactly as you like in an easily repeatable way makes cookiecutter a great tool for keeping your workflow DRY.
## Best static asset server: [Whitenoise](http://whitenoise.evans.io/en/latest/base.html)
For many years, serving your site's static assets—images, JavaScript, CSS—was a pain. The built-in [django.views.static.serve](https://docs.djangoproject.com/en/1.8/ref/views/#django.views.static.serve) view is, as the documentation states, "not hardened for production use and should be used only as a development aid." But serving media from a "real" web server, such as NGINX or out of a CDN, can be difficult to set up.
Whitenoise cleanly solves this problem. It's as easy to set up as the development-only static server, and is hardened and optimized for production. Setup is simple:
- Make sure you're using Django's
[contrib.staticfiles](https://docs.djangoproject.com/en/1.8/ref/contrib/staticfiles/)app, and that you've correctly set**`STATIC_ROOT`**in your settings file. - Enable Whitenoise in your
**`wsgi.py`**file:
```
``````
from django.core.wsgi import get_wsgi_application
from whitenoise.django import DjangoWhiteNoise
application = get_wsgi_application()
application = DjangoWhiteNoise(application)
```
That's really all it takes! For large applications, you'll likely want to use a dedicated media server and/or a CDN, but for most small- or medium-sized Django sites, Whitenoise is more than powerful enough.
For more information on Whitenoise, [check out the documentation](http://whitenoise.evans.io/en/latest/index.html).
## Best Tool for REST APIs: [Django REST Framework](http://www.django-rest-framework.org/)
REST APIs are quickly becoming a standard feature of modern web applications. An API is really simply talking in JSON rather than HTML, and of course you can do this with just Django. You can craft your own views that set the proper content types and return data in JSON rather than templated HTML responses. This is exactly what many people did before API frameworks such as [Django Rest Framework](http://www.django-rest-framework.org/) (a.k.a., DRF) were released.
Building a REST API with DRF is similar to working with Django's Class Based Views if you're familiar with them, except these are specifically designed and targeted around an API use case. Quite a bit of code is involved in your average API setup, so instead of a code sample to get you excited, we'll highlight some of DRF's features that make your life easier:
- Automatic browseable API which makes development and manual testing a breeze. Click around in the DRF
[demo example](http://restframework.herokuapp.com/). You can view API responses and support POST/PUT/DELETE type operations without having to do anything yourself. - Easy integration of authentication styles, such as OAuth, Basic Auth, or API Tokens.
- Simple permission system for fine-grained control of which users can use which API endpoints and/or actions.
- Built in rate limiting.
- Nearly automatic API documentation when combined with
[django-rest-swagger](http://django-rest-swagger.readthedocs.org/en/latest/index.html). - Extensive ecosystem of third-party libraries.
Although you could certainly build an API without DRF, we can't fathom a reason why you would start off down that path. Even if you don't use all of DRF's features, building up your own API views from their solid base view classes is a huge win in terms of safety, consistency of your API, and development velocity. If you aren't using DRF already, you should set aside some time to check it out.
## Best Django-based CMS: [Wagtail](https://wagtail.io/)
Wagtail is the current darling of the Django CMS world and with good reason. Like most CMS systems, it gives you flexibility to define different types of pages and their content via simple Django models. This takes you from zero to a basically working system in hours, not days. To give you a quick example, to define a Staff page type for people at your company can be as simple as:
```
``````
from wagtail.wagtailcore.models import Page
from wagtail.wagtailcore.fields import RichTextField
from wagtail.wagtailadmin.edit_handlers import FieldPanel, MultiFieldPanel
from wagtail.wagtailimages.edit_handlers import ImageChooserPanel
class StaffPage(Page):
name = models.CharField(max_length=100)
hire_date = models.DateField()
bio = models.RichTextField()
email = models.EmailField()
headshot = models.ForeignKey('wagtailimages.Image', null=True, blank=True)
content_panels = Page.content_panels + [
FieldPanel('name'),
FieldPanel('hire_date'),
FieldPanel('email'),
FieldPanel('bio', classname="full"),
ImageChoosePanel('headshot'),
]
```
The real appeal of Wagtail, however, is in its easy-to-use modern admin interface and flexibility. You can control which types of pages are allowed in different areas of the site, add additional complex logic to your pages, and get standard moderation/approval workflows right out of the box. With most CMS systems, at some point you run into a wall you can work around. With Wagtail, we have yet to find a wall we couldn't easy find a door through to make it do exactly what we want in an easy and maintainable way. If you're interested, we wrote up a [deeper dive into Wagtail](https://opensource.com/business/15/5/wagtail-cms).
## Best Social Login Tool: [django-allauth](http://www.intenct.nl/projects/django-allauth/)
django-allauth is a reusable Django application that solves your registration and authentication needs. Whether you need a local or social registration system, django-allauth has you covered.
The project supports multiple authentication schemes, such as user name or email address. Once a user has signed up, multiple strategies are supported for account verification ranging from none to email verification. Multiple social and email accounts are also supported. Pluggable signup forms are also supports which allows asking additional questions during registration.
django-allauth supports more than 20 authentication providers, including Facebook, GitHub, Google, and Twitter. If you have an account on a social website that's not supported, then it's most supported through a third-party add-on. The project supports writing custom backends, which allows custom authentication systems to work, too. This is nice for anyone with custom authentication needs.
django-allauth is easy to setup and has [extensive documentation](http://django-allauth.readthedocs.org/en/latest/). The project is also well tested so you know that everything actually works.
Do you have a favorite Django package? Let us know about it in the comments.
## 1 Comment |
7,680 | Python 高级图像处理 | http://www.cuelogic.com/blog/advanced-image-processing-with-python/ | 2016-08-14T09:46:00 | [
"Python",
"图像处理"
] | https://linux.cn/article-7680-1.html | 
构建图像搜索引擎并不是一件容易的任务。这里有几个概念、工具、想法和技术需要实现。主要的图像处理概念之一是<ruby> 逆图像查询 <rp> ( </rp> <rt> reverse image querying </rt> <rp> ) </rp></ruby>(RIQ)。Google、Cloudera、Sumo Logic 和 Birst 等公司在使用逆图像搜索中名列前茅。通过分析图像和使用数据挖掘 RIQ 提供了很好的洞察分析能力。
### 顶级公司与逆图像搜索
有很多顶级的技术公司使用 RIQ 来取得了不错的收益。例如:在 2014 年 Pinterest 第一次带来了视觉搜索。随后在 2015 年发布了一份白皮书,披露了其架构。逆图像搜索让 Pinterest 获得了时尚品的视觉特征,并可以显示相似产品的推荐。
众所周知,谷歌图片使用逆图像搜索允许用户上传一张图片然后搜索相关联的图片。通过使用先进的算法对提交的图片进行分析和数学建模,然后和谷歌数据库中无数的其他图片进行比较得到相似的结果。
**这是 OpenCV 2.4.9 特征比较报告一个图表:**

### 算法 & Python库
在我们使用它工作之前,让我们过一遍构建图像搜索引擎的 Python 库的主要元素:
### 专利算法
#### <ruby> 尺度不变特征变换 <rp> ( </rp> <rt> Scale-Invariant Feature Transform </rt> <rp> ) </rp></ruby>(SIFT)算法
1. 带有非自由功能的一个专利技术,利用图像识别符,以识别相似图像,甚至那些来自不同的角度,大小,深度和尺度的图片,也会被包括在搜索结果中。[点击这里](https://www.youtube.com/watch?v=NPcMS49V5hg)查看 SIFT 详细视频。
2. SIFT 能与从许多图片中提取了特征的大型数据库正确地匹配搜索条件。
3. 能匹配不同视角的相同图像和匹配不变特征来获得搜索结果是 SIFT 的另一个特征。了解更多关于尺度不变[关键点](https://www.cs.ubc.ca/%7Elowe/papers/ijcv04.pdf)。
#### <ruby> 加速鲁棒特征 <rp> ( </rp> <rt> Speeded Up Robust Features </rt> <rp> ) </rp></ruby>(SURF)算法
1. [SURF](http://docs.opencv.org/3.0-beta/doc/py_tutorials/py_feature2d/py_surf_intro/py_surf_intro.html) 也是一种带有非自由功能的专利技术,而且还是一种“加速”的 SIFT 版本。不像 SIFT,SURF 接近于带有<ruby> 箱式过滤器 <rp> ( </rp> <rt> Box Filter </rt> <rp> ) </rp></ruby>的<ruby> 高斯拉普拉斯算子 <rp> ( </rp> <rt> Laplacian of Gaussian </rt> <rp> ) </rp></ruby>。
2. SURF 依赖于<ruby> 黑塞矩阵 <rp> ( </rp> <rt> Hessian Matrix </rt> <rp> ) </rp></ruby>的位置和尺度。
3. 在许多应用中,旋转不变性不是一个必要条件,所以不按这个方向查找加速了处理。
4. SURF 包括了几种特性,提升了每一步的速度。SIFT 在旋转和模糊化方面做的很好,比 SIFT 的速度快三倍。然而它不擅长处理照明和变换视角。
5. OpenCV 程序功能库提供了 SURF 功能,SURF.compute() 和 SURF.Detect() 可以用来找到描述符和要点。阅读更多关于SURF[点击这里](http://www.vision.ee.ethz.ch/%7Esurf/eccv06.pdf)
### 开源算法
#### KAZE 算法
1. KAZE是一个开源的非线性尺度空间的二维多尺度和新的特征检测和描述算法。在<ruby> 加性算子分裂 <rp> ( </rp> <rt> Additive Operator Splitting </rt> <rp> ) </rp></ruby>(AOS)和可变电导扩散中的有效技术被用来建立非线性尺度空间。
2. 多尺度图像处理的基本原理很简单:创建一个图像的尺度空间,同时用正确的函数过滤原始图像,以提高时间或尺度。
#### <ruby> 加速的 KAZE <rp> ( </rp> <rt> Accelerated-KAZE </rt> <rp> ) </rp></ruby>(AKAZE) 算法
1. 顾名思义,这是一个更快的图像搜索方式,它会在两幅图像之间找到匹配的关键点。AKAZE 使用二进制描述符和非线性尺度空间来平衡精度和速度。
#### <ruby> 二进制鲁棒性不变尺度可变关键点 <rp> ( </rp> <rt> Binary Robust Invariant Scalable Keypoints </rt> <rp> ) </rp></ruby>(BRISK)算法
1. BRISK 非常适合关键点的描述、检测与匹配。
2. 是一种高度自适应的算法,基于尺度空间 FAST 的快速检测器和一个位字符串描述符,有助于显著加快搜索。
3. 尺度空间关键点检测与关键点描述帮助优化当前相关任务的性能。
#### <ruby> 快速视网膜关键点 <rp> ( </rp> <rt> Fast Retina Keypoint </rt> <rp> ) </rp></ruby>(FREAK)
1. 这个新的关键点描述的灵感来自人的眼睛。通过图像强度比能有效地计算一个二进制串级联。FREAK 算法相比 BRISK、SURF 和 SIFT 算法可以更快的计算与内存负载较低。
#### <ruby> 定向 FAST 和旋转 BRIEF <rp> ( </rp> <rt> Oriented FAST and Rotated BRIEF </rt> <rp> ) </rp></ruby>(ORB)
1. 快速的二进制描述符,ORB 具有抗噪声和旋转不变性。ORB 建立在 FAST 关键点检测器和 BRIEF 描述符之上,有成本低、性能好的元素属性。
2. 除了快速和精确的定位元件,有效地计算定向的 BRIEF,分析变动和面向 BRIEF 特点相关,是另一个 ORB 的特征。
### Python库
#### OpenCV
1. OpenCV 支持学术和商业用途,它是一个开源的机器学习和计算机视觉库,OpenCV 便于组织利用和修改代码。
2. 超过 2500 个优化的算法,包括当前最先进的机器学习和计算机视觉算法服务与各种图像搜索--人脸检测、目标识别、摄像机目标跟踪,从图像数据库中寻找类似图像、眼球运动跟随、风景识别等。
3. 像谷歌,IBM,雅虎,索尼,本田,微软和英特尔这样的大公司广泛的使用 OpenCV。
4. OpenCV 拥有 python,java,C,C++ 和 MATLAB 接口,同时支持 Windows,Linux,Mac OS 和 Android。
#### Python 图像库 (PIL)
1. Python 图像库(PIL)支持多种文件格式,同时提供图像处理和图形解决方案。开源的 PIL 为你的 Python解释器添加了图像处理能力。
2. 标准的图像处理能力包括图像增强、透明和遮罩处理、图像过滤、像素操作等。
详细的数据和图表,请看[这里](https://docs.google.com/spreadsheets/d/1gYJsy2ROtqvIVvOKretfxQG_0OsaiFvb7uFRDu5P8hw/edit#gid=10)的 OpenCV 2.4.9 特征比较报告。
### 构建图像搜索引擎
图像搜索引擎可以从预置的图像库选择相似的图像。其中最受欢迎的是谷歌的著名的图像搜索引擎。对于初学者来说,有不同的方法来建立这样的系统。提几个如下:
1. 采用图像提取、图像描述提取、元数据提取和搜索结果提取,建立图像搜索引擎。
2. 定义你的图像描述符,数据集索引,定义你的相似性度量,然后进行搜索和排名。
3. 选择要搜索的图像,选择用于进行搜索的目录,搜索所有图片的目录,创建图片特征索引,评估搜索图片的相同特征,匹配搜索的图片并获得匹配的图片。
我们的方法基本上从比较灰度版本的图像,逐渐演变到复杂的特征匹配算法如 SIFT 和 SURF,最后采用的是开源的解决方案 BRISK 。所有这些算法都提供了有效的结果,但在性能和延迟有细微变化。建立在这些算法上的引擎有许多应用,如分析流行统计的图形数据,在图形内容中识别对象,等等。
**举例**:一个 IT 公司为其客户建立了一个图像搜索引擎。因此,如果如果搜索一个品牌的标志图像,所有相关的品牌形象也应该显示在搜索结果。所得到的结果也能够被客户用于分析,使他们能够根据地理位置估计品牌知名度。但它还比较年轻,RIQ(反向图像搜索)的潜力尚未被完全挖掘利用。
这就结束了我们的文章,使用 Python 构建图像搜索引擎。浏览我们的博客部分来查看最新的编程技术。
数据来源:OpenCV 2.4.9 特征比较报告(computer-vision-talks.com)
(感谢 Ananthu Nair 的指导与补充)
---
via: <http://www.cuelogic.com/blog/advanced-image-processing-with-python/>
作者:[Snehith Kumbla](http://www.cuelogic.com/blog/author/snehith-kumbla/) 译者:[Johnny-Liao](https://github.com/Johnny-Liao) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 302 | Found | null |
7,681 | smem – Linux 下基于进程和用户的内存占用报告 | http://www.tecmint.com/smem-linux-memory-usage-per-process-per-user/ | 2016-08-14T09:33:00 | [
"smem",
"内存",
"监控"
] | https://linux.cn/article-7681-1.html | Linux 系统的内存管理工作中,内存使用情况的监控是十分重要的,在各种 Linux 发行版上你会找到许多这种工具。它们的工作方式多种多样,在这里,我们将会介绍如何安装和使用这样的一个名为 smem 的工具软件。
Smem 是一款命令行下的内存使用情况报告工具,它能够给用户提供 Linux 系统下的内存使用的多种报告。和其它传统的内存报告工具不同的是,它有个独特的功能,可以报告 PSS(<ruby> 按比例占用大小 <rp> ( </rp> <rt> Proportional Set Size </rt> <rp> ) </rp></ruby>),这种内存使用量表示方法对于那些在虚拟内存中的应用和库更有意义。

已有的传统工具会将目光主要集中于读取 RSS(<ruby> 实际占用大小 <rp> ( </rp> <rt> Resident Set Size </rt> <rp> ) </rp></ruby>),这种方法是以物理内存方案来衡量使用情况的标准方法,但是往往高估了应用程序的内存的使用情况。
PSS 从另一个侧面,通过判定在虚拟内存中的应用和库所使用的“合理分享”的内存,来给出更可信的衡量结果。
你可以阅读此[指南 (关于内存的 RSS 和 PSS)](https://emilics.com/notebook/enblog/p871.html)了解 Linux 系统中的内存占用,不过现在让我们继续看看 smem 的特点。
### Smem 这一工具的特点
* 系统概览列表
* 以进程、映射和用户来显示或者是过滤
* 从 /proc 文件系统中得到数据
* 从多个数据源配置显示的条目
* 可配置输出单位和百分比
* 易于配置列表表头和汇总
* 从镜像文件夹或者是压缩的 tar 文件中获得数据快照
* 内置的图表生成机制
* 轻量级的捕获工具,可用于嵌入式系统
### 如何安装 Smem - Linux 下的内存使用情况报告工具
安装之前,需要确保满足以下的条件:
* 现代内核 (版本号高于 2.6.27)
* 较新的 Python 版本 (2.4 及以后版本)
* 可选的 [matplotlib](http://matplotlib.org/index.html) 库用于生成图表
对于当今的大多数的 Linux 发行版而言,内核版本和 Python 的版本都能够满足需要,所以仅需要为生成良好的图表安装 matplotlib 库。
#### RHEL, CentOS 和 Fedora
首先启用 [EPEL (Extra Packages for Enterprise Linux)](/article-2324-1.html) 软件源,然后按照下列步骤操作:
```
# yum install smem python-matplotlib python-tk
```
#### Debian 和 Ubuntu
```
$ sudo apt-get install smem
```
#### Linux Mint
```
$ sudo apt-get install smem python-matplotlib python-tk
```
#### Arch Linux
使用此 [AUR 仓库](https://www.archlinux.org/packages/community/i686/smem/)。
### 如何使用 Smem – Linux 下的内存使用情况报告工具
为了查看整个系统所有用户的内存使用情况,运行以下的命令:
```
$ sudo smem
```
*监视 Linux 系统中的内存使用情况*
```
PID User Command Swap USS PSS RSS
6367 tecmint cat 0 100 145 1784
6368 tecmint cat 0 100 147 1676
2864 tecmint /usr/bin/ck-launch-session 0 144 165 1780
7656 tecmint gnome-pty-helper 0 156 178 1832
5758 tecmint gnome-pty-helper 0 156 179 1916
1441 root /sbin/getty -8 38400 tty2 0 152 184 2052
1434 root /sbin/getty -8 38400 tty5 0 156 187 2060
1444 root /sbin/getty -8 38400 tty3 0 156 187 2060
1432 root /sbin/getty -8 38400 tty4 0 156 188 2124
1452 root /sbin/getty -8 38400 tty6 0 164 196 2064
2619 root /sbin/getty -8 38400 tty1 0 164 196 2136
3544 tecmint sh -c /usr/lib/linuxmint/mi 0 212 224 1540
1504 root acpid -c /etc/acpi/events - 0 220 236 1604
3311 tecmint syndaemon -i 0.5 -K -R 0 252 292 2556
3143 rtkit /usr/lib/rtkit/rtkit-daemon 0 300 326 2548
1588 root cron 0 292 333 2344
1589 avahi avahi-daemon: chroot helpe 0 124 334 1632
1523 root /usr/sbin/irqbalance 0 316 343 2096
585 root upstart-socket-bridge --dae 0 328 351 1820
3033 tecmint /usr/bin/dbus-launch --exit 0 328 360 2160
1346 root upstart-file-bridge --daemo 0 348 371 1776
2607 root /usr/bin/xdm 0 188 378 2368
1635 kernoops /usr/sbin/kerneloops 0 352 386 2684
344 root upstart-udev-bridge --daemo 0 400 427 2132
2960 tecmint /usr/bin/ssh-agent /usr/bin 0 480 485 992
3468 tecmint /bin/dbus-daemon --config-f 0 344 515 3284
1559 avahi avahi-daemon: running [tecm 0 284 517 3108
7289 postfix pickup -l -t unix -u -c 0 288 534 2808
2135 root /usr/lib/postfix/master 0 352 576 2872
2436 postfix qmgr -l -t unix -u 0 360 606 2884
1521 root /lib/systemd/systemd-logind 0 600 650 3276
2222 nobody /usr/sbin/dnsmasq --no-reso 0 604 669 3288
....
```
当普通用户运行 smem,将会显示由该用户启用的进程的占用情况,其中进程按照 PSS 的值升序排列。
下面的输出为用户 “aaronkilik” 启用的进程的使用情况:
```
$ smem
```
*监视 Linux 系统中的内存使用情况*
```
PID User Command Swap USS PSS RSS
6367 tecmint cat 0 100 145 1784
6368 tecmint cat 0 100 147 1676
2864 tecmint /usr/bin/ck-launch-session 0 144 166 1780
3544 tecmint sh -c /usr/lib/linuxmint/mi 0 212 224 1540
3311 tecmint syndaemon -i 0.5 -K -R 0 252 292 2556
3033 tecmint /usr/bin/dbus-launch --exit 0 328 360 2160
3468 tecmint /bin/dbus-daemon --config-f 0 344 515 3284
3122 tecmint /usr/lib/gvfs/gvfsd 0 656 801 5552
3471 tecmint /usr/lib/at-spi2-core/at-sp 0 708 864 5992
3396 tecmint /usr/lib/gvfs/gvfs-mtp-volu 0 804 914 6204
3208 tecmint /usr/lib/x86_64-linux-gnu/i 0 892 1012 6188
3380 tecmint /usr/lib/gvfs/gvfs-afc-volu 0 820 1024 6396
3034 tecmint //bin/dbus-daemon --fork -- 0 920 1081 3040
3365 tecmint /usr/lib/gvfs/gvfs-gphoto2- 0 972 1099 6052
3228 tecmint /usr/lib/gvfs/gvfsd-trash - 0 980 1153 6648
3107 tecmint /usr/lib/dconf/dconf-servic 0 1212 1283 5376
6399 tecmint /opt/google/chrome/chrome - 0 144 1409 10732
3478 tecmint /usr/lib/x86_64-linux-gnu/g 0 1724 1820 6320
7365 tecmint /usr/lib/gvfs/gvfsd-http -- 0 1352 1884 8704
6937 tecmint /opt/libreoffice5.0/program 0 1140 2328 5040
3194 tecmint /usr/lib/x86_64-linux-gnu/p 0 1956 2405 14228
6373 tecmint /opt/google/chrome/nacl_hel 0 2324 2541 8908
3313 tecmint /usr/lib/gvfs/gvfs-udisks2- 0 2460 2754 8736
3464 tecmint /usr/lib/at-spi2-core/at-sp 0 2684 2823 7920
5771 tecmint ssh -p 4521 [email protected] 0 2544 2864 6540
5759 tecmint /bin/bash 0 2416 2923 5640
3541 tecmint /usr/bin/python /usr/bin/mi 0 2584 3008 7248
7657 tecmint bash 0 2516 3055 6028
3127 tecmint /usr/lib/gvfs/gvfsd-fuse /r 0 3024 3126 8032
3205 tecmint mate-screensaver 0 2520 3331 18072
3171 tecmint /usr/lib/mate-panel/notific 0 2860 3495 17140
3030 tecmint x-session-manager 0 4400 4879 17500
3197 tecmint mate-volume-control-applet 0 3860 5226 23736
...
```
使用 smem 时还有一些参数可以选用,例如当查看整个系统的内存占用情况,运行以下的命令:
```
$ sudo smem -w
```
*监视 Linux 系统中的内存使用情况*
```
Area Used Cache Noncache
firmware/hardware 0 0 0
kernel image 0 0 0
kernel dynamic memory 1425320 1291412 133908
userspace memory 2215368 451608 1763760
free memory 4424936 4424936 0
```
如果想要查看每一个用户的内存使用情况,运行以下的命令:
```
$ sudo smem -u
```
*Linux 下以用户为单位监控内存占用情况*
```
User Count Swap USS PSS RSS
rtkit 1 0 300 326 2548
kernoops 1 0 352 385 2684
avahi 2 0 408 851 4740
postfix 2 0 648 1140 5692
messagebus 1 0 1012 1173 3320
syslog 1 0 1396 1419 3232
www-data 2 0 5100 6572 13580
mpd 1 0 7416 8302 12896
nobody 2 0 4024 11305 24728
root 39 0 323876 353418 496520
tecmint 64 0 1652888 1815699 2763112
```
你也可以按照映射显示内存使用情况:
```
$ sudo smem -m
```
*Linux 下以映射为单位监控内存占用情况*
```
Map PIDs AVGPSS PSS
/dev/fb0 1 0 0
/home/tecmint/.cache/fontconfig/7ef2298f 18 0 0
/home/tecmint/.cache/fontconfig/c57959a1 18 0 0
/home/tecmint/.local/share/mime/mime.cac 15 0 0
/opt/google/chrome/chrome_material_100_p 9 0 0
/opt/google/chrome/chrome_material_200_p 9 0 0
/usr/lib/x86_64-linux-gnu/gconv/gconv-mo 41 0 0
/usr/share/icons/Mint-X-Teal/icon-theme. 15 0 0
/var/cache/fontconfig/0c9eb80ebd1c36541e 20 0 0
/var/cache/fontconfig/0d8c3b2ac0904cb8a5 20 0 0
/var/cache/fontconfig/1ac9eb803944fde146 20 0 0
/var/cache/fontconfig/3830d5c3ddfd5cd38a 20 0 0
/var/cache/fontconfig/385c0604a188198f04 20 0 0
/var/cache/fontconfig/4794a0821666d79190 20 0 0
/var/cache/fontconfig/56cf4f4769d0f4abc8 20 0 0
/var/cache/fontconfig/767a8244fc0220cfb5 20 0 0
/var/cache/fontconfig/8801497958630a81b7 20 0 0
/var/cache/fontconfig/99e8ed0e538f840c56 20 0 0
/var/cache/fontconfig/b9d506c9ac06c20b43 20 0 0
/var/cache/fontconfig/c05880de57d1f5e948 20 0 0
/var/cache/fontconfig/dc05db6664285cc2f1 20 0 0
/var/cache/fontconfig/e13b20fdb08344e0e6 20 0 0
/var/cache/fontconfig/e7071f4a29fa870f43 20 0 0
....
```
还有其它的选项可以筛选 smem 的输出,下面将会举两个例子。
要按照用户名筛选输出的信息,使用 `-u` 或者是 `--userfilter="regex"` 选项,就像下面的命令这样:
```
$ sudo smem -u
```
*按照用户报告内存使用情况*
```
User Count Swap USS PSS RSS
rtkit 1 0 300 326 2548
kernoops 1 0 352 385 2684
avahi 2 0 408 851 4740
postfix 2 0 648 1140 5692
messagebus 1 0 1012 1173 3320
syslog 1 0 1400 1423 3236
www-data 2 0 5100 6572 13580
mpd 1 0 7416 8302 12896
nobody 2 0 4024 11305 24728
root 39 0 323804 353374 496552
tecmint 64 0 1708900 1871766 2819212
```
要按照进程名称筛选输出信息,使用 `-P` 或者是 `--processfilter="regex"` 选项,就像下面的命令这样:
```
$ sudo smem --processfilter="firefox"
```
*按照进程名称报告内存使用情况*
```
PID User Command Swap USS PSS RSS
9212 root sudo smem --processfilter=f 0 1172 1434 4856
9213 root /usr/bin/python /usr/bin/sm 0 7368 7793 11984
4424 tecmint /usr/lib/firefox/firefox 0 931732 937590 961504
```
输出的格式有时候也很重要,smem 提供了一些帮助您格式化内存使用报告的参数,我们将举出几个例子。
设置哪些列在报告中,使用 -c 或者是 --columns 选项,就像下面的命令这样:
```
$ sudo smem -c "name user pss rss"
```
*按列报告内存使用情况*
```
Name User PSS RSS
cat tecmint 145 1784
cat tecmint 147 1676
ck-launch-sessi tecmint 165 1780
gnome-pty-helpe tecmint 178 1832
gnome-pty-helpe tecmint 179 1916
getty root 184 2052
getty root 187 2060
getty root 187 2060
getty root 188 2124
getty root 196 2064
getty root 196 2136
sh tecmint 224 1540
acpid root 236 1604
syndaemon tecmint 296 2560
rtkit-daemon rtkit 326 2548
cron root 333 2344
avahi-daemon avahi 334 1632
irqbalance root 343 2096
upstart-socket- root 351 1820
dbus-launch tecmint 360 2160
upstart-file-br root 371 1776
xdm root 378 2368
kerneloops kernoops 386 2684
upstart-udev-br root 427 2132
ssh-agent tecmint 485 992
...
```
也可以调用 `-p` 选项以百分比的形式报告内存使用情况,就像下面的命令这样:
```
$ sudo smem -p
```
*按百分比报告内存使用情况*
```
PID User Command Swap USS PSS RSS
6367 tecmint cat 0.00% 0.00% 0.00% 0.02%
6368 tecmint cat 0.00% 0.00% 0.00% 0.02%
9307 tecmint sh -c { sudo /usr/lib/linux 0.00% 0.00% 0.00% 0.02%
2864 tecmint /usr/bin/ck-launch-session 0.00% 0.00% 0.00% 0.02%
3544 tecmint sh -c /usr/lib/linuxmint/mi 0.00% 0.00% 0.00% 0.02%
5758 tecmint gnome-pty-helper 0.00% 0.00% 0.00% 0.02%
7656 tecmint gnome-pty-helper 0.00% 0.00% 0.00% 0.02%
1441 root /sbin/getty -8 38400 tty2 0.00% 0.00% 0.00% 0.03%
1434 root /sbin/getty -8 38400 tty5 0.00% 0.00% 0.00% 0.03%
1444 root /sbin/getty -8 38400 tty3 0.00% 0.00% 0.00% 0.03%
1432 root /sbin/getty -8 38400 tty4 0.00% 0.00% 0.00% 0.03%
1452 root /sbin/getty -8 38400 tty6 0.00% 0.00% 0.00% 0.03%
2619 root /sbin/getty -8 38400 tty1 0.00% 0.00% 0.00% 0.03%
1504 root acpid -c /etc/acpi/events - 0.00% 0.00% 0.00% 0.02%
3311 tecmint syndaemon -i 0.5 -K -R 0.00% 0.00% 0.00% 0.03%
3143 rtkit /usr/lib/rtkit/rtkit-daemon 0.00% 0.00% 0.00% 0.03%
1588 root cron 0.00% 0.00% 0.00% 0.03%
1589 avahi avahi-daemon: chroot helpe 0.00% 0.00% 0.00% 0.02%
1523 root /usr/sbin/irqbalance 0.00% 0.00% 0.00% 0.03%
585 root upstart-socket-bridge --dae 0.00% 0.00% 0.00% 0.02%
3033 tecmint /usr/bin/dbus-launch --exit 0.00% 0.00% 0.00% 0.03%
....
```
下面的命令将会在输出的最后输出一行汇总信息:
```
$ sudo smem -t
```
*报告内存占用合计*
```
PID User Command Swap USS PSS RSS
6367 tecmint cat 0 100 139 1784
6368 tecmint cat 0 100 141 1676
9307 tecmint sh -c { sudo /usr/lib/linux 0 96 158 1508
2864 tecmint /usr/bin/ck-launch-session 0 144 163 1780
3544 tecmint sh -c /usr/lib/linuxmint/mi 0 108 170 1540
5758 tecmint gnome-pty-helper 0 156 176 1916
7656 tecmint gnome-pty-helper 0 156 176 1832
1441 root /sbin/getty -8 38400 tty2 0 152 181 2052
1434 root /sbin/getty -8 38400 tty5 0 156 184 2060
1444 root /sbin/getty -8 38400 tty3 0 156 184 2060
1432 root /sbin/getty -8 38400 tty4 0 156 185 2124
1452 root /sbin/getty -8 38400 tty6 0 164 193 2064
2619 root /sbin/getty -8 38400 tty1 0 164 193 2136
1504 root acpid -c /etc/acpi/events - 0 220 232 1604
3311 tecmint syndaemon -i 0.5 -K -R 0 260 298 2564
3143 rtkit /usr/lib/rtkit/rtkit-daemon 0 300 324 2548
1588 root cron 0 292 326 2344
1589 avahi avahi-daemon: chroot helpe 0 124 332 1632
1523 root /usr/sbin/irqbalance 0 316 340 2096
585 root upstart-socket-bridge --dae 0 328 349 1820
3033 tecmint /usr/bin/dbus-launch --exit 0 328 359 2160
1346 root upstart-file-bridge --daemo 0 348 370 1776
2607 root /usr/bin/xdm 0 188 375 2368
1635 kernoops /usr/sbin/kerneloops 0 352 384 2684
344 root upstart-udev-bridge --daemo 0 400 426 2132
.....
-------------------------------------------------------------------------------
134 11 0 2171428 2376266 3587972
```
另外,smem 也提供了选项以图形的形式报告内存的使用情况,我们将会在下一小节深入介绍。
比如,你可以生成一张进程的 PSS 和 RSS 值的条状图。在下面的例子中,我们会生成属于 root 用户的进程的内存占用图。
纵坐标为每一个进程的 PSS 和 RSS 值,横坐标为 root 用户的所有进程(的 ID):
```
$ sudo smem --userfilter="root" --bar pid -c"pss rss"
```

*Linux Memory Usage in PSS and RSS Values*
也可以生成进程及其 PSS 和 RSS 占用量的饼状图。以下的命令将会输出一张 root 用户的所有进程的饼状图。
`--pie` name 意思为以各个进程名字为标签,`-s` 选项用来以 PSS 的值排序。
```
$ sudo smem --userfilter="root" --pie name -s pss
```

*Linux Memory Consumption by Processes*
除了 PSS 和 RSS ,其它的字段也可以用于图表的标签:
假如需要获得帮助,非常简单,仅需要输入 `smem -h` 或者是浏览帮助页面。
关于 smem 的介绍到此为止,不过想要更好的了解它,可以通过 man 手册获得更多的选项,然后一一实践。有什么想法或者疑惑,都可以跟帖评价。
参考链接: <https://www.selenic.com/smem/>
---
via: <http://www.tecmint.com/smem-linux-memory-usage-per-process-per-user/>
作者:[Aaron Kili](http://www.tecmint.com/author/aaronkili/) 译者:[dongfengweixiao](https://github.com/dongfengweixiao) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,683 | 五条强化 SSH 安全的建议 | https://www.linux.com/learn/5-ssh-hardening-tips | 2016-08-15T08:27:00 | [
"ssh"
] | https://linux.cn/article-7683-1.html | 
*采用这些简单的建议,使你的 OpenSSH 会话更加安全。*
当你查看你的 SSH 服务日志,可能你会发现充斥着一些不怀好意的尝试性登录。这里有 5 条常规建议(和一些个别特殊策略)可以让你的 OpenSSH 会话更加安全。
### 1. 强化密码登录
密码登录很方便,因为你可以从任何地方的任何机器上登录。但是它们在暴力攻击面前也是脆弱的。尝试以下策略来强化你的密码登录。
* 使用一个密码生成工具,例如 pwgen。pwgen 有几个选项,最有用的就是密码长度的选项(例如,`pwgen 12` 产生一个12位字符的密码)
* 不要重复使用密码。忽略所有那些不要写下你的密码的建议,然后将你的所有登录信息都记在一个本子上。如果你不相信我的建议,那总可以相信安全权威 [Bruce Schneier](https://www.schneier.com/blog/archives/2005/06/write_down_your.html) 吧。如果你足够细心,没有人能够发现你的笔记本,那么这样能够不受到网络上的那些攻击。
* 你可以为你的登录记事本增加一些额外的保护措施,例如用字符替换或者增加新的字符来掩盖笔记本上的登录密码。使用一个简单而且好记的规则,比如说给你的密码增加两个额外的随机字符,或者使用单个简单的字符替换,例如 `#` 替换成 `*`。
* 为你的 SSH 服务开启一个非默认的监听端口。是的,这是很老套的建议,但是它确实很有效。检查你的登录;很有可能 22 端口是被普遍攻击的端口,其他端口则很少被攻击。
* 使用 [Fail2ban](http://www.fail2ban.org/wiki/index.php/Main_Page) 来动态保护你的服务器,是服务器免于被暴力攻击。
* 使用不常用的用户名。绝不能让 root 可以远程登录,并避免用户名为“admin”。
### 2. 解决 `Too Many Authentication Failures` 报错
当我的 ssh 登录失败,并显示“Too many authentication failures for carla”的报错信息时,我很难过。我知道我应该不介意,但是这报错确实很碍眼。而且,正如我聪慧的奶奶曾经说过,伤痛之感并不能解决问题。解决办法就是在你的(客户端的) `~/.ssh/config` 文件设置强制密码登录。如果这个文件不存在,首先创个 `~/.ssh/` 目录。
```
$ mkdir ~/.ssh
$ chmod 700 ~/.ssh
```
然后在一个文本编辑器创建 `~/.ssh/confg` 文件,输入以下行,使用你自己的远程域名替换 HostName。
```
HostName remote.site.com
PubkeyAuthentication=no
```
(LCTT 译注:这种错误发生在你使用一台 Linux 机器使用 ssh 登录另外一台服务器时,你的 .ssh 目录中存储了过多的私钥文件,而 ssh 客户端在你没有指定 -i 选项时,会默认逐一尝试使用这些私钥来登录远程服务器后才会提示密码登录,如果这些私钥并不能匹配远程主机,显然会触发这样的报错,甚至拒绝连接。因此本条是通过禁用本地私钥的方式来强制使用密码登录——显然这并不可取,如果你确实要避免用私钥登录,那你应该用 `-o PubkeyAuthentication=no` 选项登录。显然这条和下两条是互相矛盾的,所以请无视本条即可。)
### 3. 使用公钥认证
公钥认证比密码登录安全多了,因为它不受暴力密码攻击的影响,但是并不方便因为它依赖于 RSA 密钥对。首先,你要创建一个公钥/私钥对。下一步,私钥放于你的客户端电脑,并且复制公钥到你想登录的远程服务器。你只能从拥有私钥的电脑登录才能登录到远程服务器。你的私钥就和你的家门钥匙一样敏感;任何人获取到了私钥就可以获取你的账号。你可以给你的私钥加上密码来增加一些强化保护规则。
使用 RSA 密钥对管理多个用户是一种好的方法。当一个用户离开了,只要从服务器删了他的公钥就能取消他的登录。
以下例子创建一个新的 3072 位长度的密钥对,它比默认的 2048 位更安全,而且为它起一个独一无二的名字,这样你就可以知道它属于哪个服务器。
```
$ ssh-keygen -t rsa -b 3072 -f id_mailserver
```
以下创建两个新的密钥, `id_mailserver` 和 `id_mailserver.pub`,`id_mailserver` 是你的私钥--不要传播它!现在用 `ssh-copy-id` 命令安全地复制你的公钥到你的远程服务器。你必须确保在远程服务器上有可用的 SSH 登录方式。
```
$ ssh-copy-id -i id_rsa.pub user@remoteserver
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
user@remoteserver's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'user@remoteserver'"
and check to make sure that only the key(s) you wanted were added.
```
`ssh-copy-id` 会确保你不会无意间复制了你的私钥。从上述输出中复制登录命令,记得带上其中的单引号,以测试你的新的密钥登录。
```
$ ssh 'user@remoteserver'
```
它将用你的新密钥登录,如果你为你的私钥设置了密码,它会提示你输入。
### 4. 取消密码登录
一旦你已经测试并且验证了你的公钥可以登录,就可以取消密码登录,这样你的远程服务器就不会被暴力密码攻击。如下设置**你的远程服务器**的 `/etc/sshd_config` 文件。
```
PasswordAuthentication no
```
然后重启服务器上的 SSH 守护进程。
### 5. 设置别名 -- 这很快捷而且很酷
你可以为你的远程登录设置常用的别名,来替代登录时输入的命令,例如 `ssh -u username -p 2222 remote.site.with.long-name`。你可以使用 `ssh remote1`。你的客户端机器上的 `~/.ssh/config` 文件可以参照如下设置
```
Host remote1
HostName remote.site.with.long-name
Port 2222
User username
PubkeyAuthentication no
```
如果你正在使用公钥登录,可以参照这个:
```
Host remote1
HostName remote.site.with.long-name
Port 2222
User username
IdentityFile ~/.ssh/id_remoteserver
```
[OpenSSH 文档](http://www.openssh.com/) 很长而且详细,但是当你掌握了基础的 SSH 使用规则之后,你会发现它非常的有用,而且包含很多可以通过 OpenSSH 来实现的炫酷效果。
---
via: <https://www.linux.com/learn/5-ssh-hardening-tips>
作者:[CARLA SCHRODER](https://www.linux.com/users/cschroder) 译者:[maywanting](https://github.com/maywanting) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,685 | 搭个 Web 服务器(二) | https://ruslanspivak.com/lsbaws-part2/ | 2016-08-16T09:33:00 | [
"Web",
"服务器",
"Python"
] | https://linux.cn/article-7685-1.html | 在[第一部分](/article-7662-1.html)中,我提出了一个问题:“如何在你刚刚搭建起来的 Web 服务器上适配 Django, Flask 或 Pyramid 应用,而不用单独对 Web 服务器做做出改动以适应各种不同的 Web 框架呢?”我们可以从这一篇中找到答案。

曾几何时,你所选择的 Python Web 框架会限制你所可选择的 Web 服务器,反之亦然。如果某个框架及服务器设计用来协同工作的,那么一切正常:

但你可能正面对着(或者曾经面对过)尝试将一对无法适配的框架和服务器搭配在一起的问题:

基本上,你需要选择那些能够一起工作的框架和服务器,而不能选择你想用的那些。
所以,你该如何确保在不对 Web 服务器或框架的代码做任何更改的情况下,让你的 Web 服务器和多个不同的 Web 框架一同工作呢?这个问题的答案,就是 Python <ruby> <a href="https://www.python.org/dev/peps/pep-0333/"> Web 服务器网关接口 </a> <rp> ( </rp> <rt> Web Server Gateway Interface </rt> <rp> ) </rp></ruby>(缩写为 [WSGI](https://www.python.org/dev/peps/pep-0333/),念做“wizgy”)。

WSGI 允许开发者互不干扰地选择 Web 框架及 Web 服务器的类型。现在,你可以真正将 Web 服务器及框架任意搭配,然后选出你最中意的那对组合。比如,你可以使用 [Django](https://www.djangoproject.com/),[Flask](http://flask.pocoo.org/) 或者 [Pyramid](http://trypyramid.com/),与 [Gunicorn](http://gunicorn.org/),[Nginx/uWSGI](http://uwsgi-docs.readthedocs.org/) 或 [Waitress](http://waitress.readthedocs.org/) 进行结合。感谢 WSGI 同时对服务器与框架的支持,我们可以真正随意选择它们的搭配了。

所以,WSGI 就是我在第一部分中提出,又在本文开头重复了一遍的那个问题的答案。你的 Web 服务器必须实现 WSGI 接口的服务器部分,而现代的 Python Web 框架均已实现了 WSGI 接口的框架部分,这使得你可以直接在 Web 服务器中使用任意框架,而不需要更改任何服务器代码,以对特定的 Web 框架实现兼容。
现在,你已经知道 Web 服务器及 Web 框架对 WSGI 的支持使得你可以选择最合适的一对来使用,而且它也有利于服务器和框架的开发者,这样他们只需专注于其擅长的部分来进行开发,而不需要触及另一部分的代码。其它语言也拥有类似的接口,比如:Java 拥有 Servlet API,而 Ruby 拥有 Rack。
这些理论都不错,但是我打赌你在说:“Show me the code!” 那好,我们来看看下面这个很小的 WSGI 服务器实现:
```
### 使用 Python 2.7.9,在 Linux 及 Mac OS X 下测试通过
import socket
import StringIO
import sys
class WSGIServer(object):
address_family = socket.AF_INET
socket_type = socket.SOCK_STREAM
request_queue_size = 1
def __init__(self, server_address):
### 创建一个监听的套接字
self.listen_socket = listen_socket = socket.socket(
self.address_family,
self.socket_type
)
### 允许复用同一地址
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
### 绑定地址
listen_socket.bind(server_address)
### 激活套接字
listen_socket.listen(self.request_queue_size)
### 获取主机的名称及端口
host, port = self.listen_socket.getsockname()[:2]
self.server_name = socket.getfqdn(host)
self.server_port = port
### 返回由 Web 框架/应用设定的响应头部字段
self.headers_set = []
def set_app(self, application):
self.application = application
def serve_forever(self):
listen_socket = self.listen_socket
while True:
### 获取新的客户端连接
self.client_connection, client_address = listen_socket.accept()
### 处理一条请求后关闭连接,然后循环等待另一个连接建立
self.handle_one_request()
def handle_one_request(self):
self.request_data = request_data = self.client_connection.recv(1024)
### 以 'curl -v' 的风格输出格式化请求数据
print(''.join(
'< {line}\n'.format(line=line)
for line in request_data.splitlines()
))
self.parse_request(request_data)
### 根据请求数据构建环境变量字典
env = self.get_environ()
### 此时需要调用 Web 应用来获取结果,
### 取回的结果将成为 HTTP 响应体
result = self.application(env, self.start_response)
### 构造一个响应,回送至客户端
self.finish_response(result)
def parse_request(self, text):
request_line = text.splitlines()[0]
request_line = request_line.rstrip('\r\n')
### 将请求行分成几个部分
(self.request_method, # GET
self.path, # /hello
self.request_version # HTTP/1.1
) = request_line.split()
def get_environ(self):
env = {}
### 以下代码段没有遵循 PEP8 规则,但这样排版,是为了通过强调
### 所需变量及它们的值,来达到其展示目的。
###
### WSGI 必需变量
env['wsgi.version'] = (1, 0)
env['wsgi.url_scheme'] = 'http'
env['wsgi.input'] = StringIO.StringIO(self.request_data)
env['wsgi.errors'] = sys.stderr
env['wsgi.multithread'] = False
env['wsgi.multiprocess'] = False
env['wsgi.run_once'] = False
### CGI 必需变量
env['REQUEST_METHOD'] = self.request_method # GET
env['PATH_INFO'] = self.path # /hello
env['SERVER_NAME'] = self.server_name # localhost
env['SERVER_PORT'] = str(self.server_port) # 8888
return env
def start_response(self, status, response_headers, exc_info=None):
### 添加必要的服务器头部字段
server_headers = [
('Date', 'Tue, 31 Mar 2015 12:54:48 GMT'),
('Server', 'WSGIServer 0.2'),
]
self.headers_set = [status, response_headers + server_headers]
### 为了遵循 WSGI 协议,start_response 函数必须返回一个 'write'
### 可调用对象(返回值.write 可以作为函数调用)。为了简便,我们
### 在这里无视这个细节。
### return self.finish_response
def finish_response(self, result):
try:
status, response_headers = self.headers_set
response = 'HTTP/1.1 {status}\r\n'.format(status=status)
for header in response_headers:
response += '{0}: {1}\r\n'.format(*header)
response += '\r\n'
for data in result:
response += data
### 以 'curl -v' 的风格输出格式化请求数据
print(''.join(
'> {line}\n'.format(line=line)
for line in response.splitlines()
))
self.client_connection.sendall(response)
finally:
self.client_connection.close()
SERVER_ADDRESS = (HOST, PORT) = '', 8888
def make_server(server_address, application):
server = WSGIServer(server_address)
server.set_app(application)
return server
if __name__ == '__main__':
if len(sys.argv) < 2:
sys.exit('Provide a WSGI application object as module:callable')
app_path = sys.argv[1]
module, application = app_path.split(':')
module = __import__(module)
application = getattr(module, application)
httpd = make_server(SERVER_ADDRESS, application)
print('WSGIServer: Serving HTTP on port {port} ...\n'.format(port=PORT))
httpd.serve_forever()
```
当然,这段代码要比第一部分的服务器代码长不少,但它仍然很短(只有不到 150 行),你可以轻松理解它,而不需要深究细节。上面的服务器代码还可以做更多——它可以用来运行一些你喜欢的框架写出的 Web 应用,可以是 Pyramid,Flask,Django 或其它 Python WSGI 框架。
不相信吗?自己来试试看吧。把以上的代码保存为 `webserver2.py`,或直接从 [Github](https://github.com/rspivak/lsbaws/blob/master/part2/webserver2.py) 上下载它。如果你打算不加任何参数而直接运行它,它会抱怨一句,然后退出。
```
$ python webserver2.py
Provide a WSGI application object as module:callable
```
它想做的其实是为你的 Web 应用服务,而这才是重头戏。为了运行这个服务器,你唯一需要的就是安装好 Python。不过,如果你希望运行 Pyramid,Flask 或 Django 应用,你还需要先安装那些框架。那我们把这三个都装上吧。我推荐的安装方式是通过 `virtualenv` 安装。按照以下几步来做,你就可以创建并激活一个虚拟环境,并在其中安装以上三个 Web 框架。
```
$ [sudo] pip install virtualenv
$ mkdir ~/envs
$ virtualenv ~/envs/lsbaws/
$ cd ~/envs/lsbaws/
$ ls
bin include lib
$ source bin/activate
(lsbaws) $ pip install pyramid
(lsbaws) $ pip install flask
(lsbaws) $ pip install django
```
现在,你需要创建一个 Web 应用。我们先从 Pyramid 开始吧。把以下代码保存为 `pyramidapp.py`,并与刚刚的 `webserver2.py` 放置在同一目录,或直接从 [Github](https://github.com/rspivak/lsbaws/blob/master/part2/pyramidapp.py) 下载该文件:
```
from pyramid.config import Configurator
from pyramid.response import Response
def hello_world(request):
return Response(
'Hello world from Pyramid!\n',
content_type='text/plain',
)
config = Configurator()
config.add_route('hello', '/hello')
config.add_view(hello_world, route_name='hello')
app = config.make_wsgi_app()
```
现在,你可以用你自己的 Web 服务器来运行你的 Pyramid 应用了:
```
(lsbaws) $ python webserver2.py pyramidapp:app
WSGIServer: Serving HTTP on port 8888 ...
```
你刚刚让你的服务器去加载 Python 模块 `pyramidapp` 中的可执行对象 `app`。现在你的服务器可以接收请求,并将它们转发到你的 Pyramid 应用中了。在浏览器中输入 http://localhost:8888/hello ,敲一下回车,然后看看结果:

你也可以使用命令行工具 `curl` 来测试服务器:
```
$ curl -v http://localhost:8888/hello
...
```
看看服务器和 `curl` 向标准输出流打印的内容吧。
现在来试试 `Flask`。运行步骤跟上面的一样。
```
from flask import Flask
from flask import Response
flask_app = Flask('flaskapp')
@flask_app.route('/hello')
def hello_world():
return Response(
'Hello world from Flask!\n',
mimetype='text/plain'
)
app = flask_app.wsgi_app
```
将以上代码保存为 `flaskapp.py`,或者直接从 [Github](https://github.com/rspivak/lsbaws/blob/master/part2/flaskapp.py) 下载,然后输入以下命令运行服务器:
```
(lsbaws) $ python webserver2.py flaskapp:app
WSGIServer: Serving HTTP on port 8888 ...
```
现在在浏览器中输入 http://localhost:8888/hello ,敲一下回车:

同样,尝试一下 `curl`,然后你会看到服务器返回了一条 `Flask` 应用生成的信息:
```
$ curl -v http://localhost:8888/hello
...
```
这个服务器能处理 Django 应用吗?试试看吧!不过这个任务可能有点复杂,所以我建议你将整个仓库克隆下来,然后使用 [Github](https://github.com/rspivak/lsbaws/) 仓库中的 [djangoapp.py](https://github.com/rspivak/lsbaws/blob/master/part2/flaskapp.py) 来完成这个实验。这里的源代码主要是将 Django 的 helloworld 工程(已使用 `Django` 的 `django-admin.py startproject` 命令创建完毕)添加到了当前的 Python 路径中,然后导入了这个工程的 WSGI 应用。(LCTT 译注:除了这里展示的代码,还需要一个配合的 helloworld 工程才能工作,代码可以参见 [Github](https://github.com/rspivak/lsbaws/) 仓库。)
```
import sys
sys.path.insert(0, './helloworld')
from helloworld import wsgi
app = wsgi.application
```
将以上代码保存为 `djangoapp.py`,然后用你的 Web 服务器运行这个 Django 应用:
```
(lsbaws) $ python webserver2.py djangoapp:app
WSGIServer: Serving HTTP on port 8888 ...
```
输入以下链接,敲回车:

你这次也可以在命令行中测试——你之前应该已经做过两次了——来确认 Django 应用处理了你的请求:
```
$ curl -v http://localhost:8888/hello
...
```
你试过了吗?你确定这个服务器可以与那三个框架搭配工作吗?如果没试,请去试一下。阅读固然重要,但这个系列的内容是**重新搭建**,这意味着你需要亲自动手干点活。去试一下吧。别担心,我等着你呢。不开玩笑,你真的需要试一下,亲自尝试每一步,并确保它像预期的那样工作。
好,你已经体验到了 WSGI 的威力:它可以使 Web 服务器及 Web 框架随意搭配。WSGI 在 Python Web 服务器及框架之间提供了一个微型接口。它非常简单,而且在服务器和框架端均可以轻易实现。下面的代码片段展示了 WSGI 接口的服务器及框架端实现:
```
def run_application(application):
"""服务器端代码。"""
### Web 应用/框架在这里存储 HTTP 状态码以及 HTTP 响应头部,
### 服务器会将这些信息传递给客户端
headers_set = []
### 用于存储 WSGI/CGI 环境变量的字典
environ = {}
def start_response(status, response_headers, exc_info=None):
headers_set[:] = [status, response_headers]
### 服务器唤醒可执行变量“application”,获得响应头部
result = application(environ, start_response)
### 服务器组装一个 HTTP 响应,将其传送至客户端
…
def app(environ, start_response):
"""一个空的 WSGI 应用"""
start_response('200 OK', [('Content-Type', 'text/plain')])
return ['Hello world!']
run_application(app)
```
这是它的工作原理:
1. Web 框架提供一个可调用对象 `application` (WSGI 规范没有规定它的实现方式)。
2. Web 服务器每次收到来自客户端的 HTTP 请求后,会唤醒可调用对象 `applition`。它会向该对象传递一个包含 WSGI/CGI 变量的环境变量字典 `environ`,以及一个可调用对象 `start_response`。
3. Web 框架或应用生成 HTTP 状态码和 HTTP 响应头部,然后将它传给 `start_response` 函数,服务器会将其存储起来。同时,Web 框架或应用也会返回 HTTP 响应正文。
4. 服务器将状态码、响应头部及响应正文组装成一个 HTTP 响应,然后将其传送至客户端(这一步并不在 WSGI 规范中,但从逻辑上讲,这一步应该包含在工作流程之中。所以为了明确这个过程,我把它写了出来)
这是这个接口规范的图形化表达:

到现在为止,你已经看过了用 Pyramid、Flask 和 Django 写出的 Web 应用的代码,你也看到了一个 Web 服务器如何用代码来实现另一半(服务器端的) WSGI 规范。你甚至还看到了我们如何在不使用任何框架的情况下,使用一段代码来实现一个最简单的 WSGI Web 应用。
其实,当你使用上面的框架编写一个 Web 应用时,你只是在较高的层面工作,而不需要直接与 WSGI 打交道。但是我知道你一定也对 WSGI 接口的框架部分感兴趣,因为你在看这篇文章呀。所以,我们不用 Pyramid、Flask 或 Django,而是自己动手来创造一个最朴素的 WSGI Web 应用(或 Web 框架),然后将它和你的服务器一起运行:
```
def app(environ, start_response):
"""一个最简单的 WSGI 应用。
这是你自己的 Web 框架的起点 ^_^
"""
status = '200 OK'
response_headers = [('Content-Type', 'text/plain')]
start_response(status, response_headers)
return ['Hello world from a simple WSGI application!\n']
```
同样,将上面的代码保存为 `wsgiapp.py` 或直接从 [Github](https://github.com/rspivak/lsbaws/blob/master/part2/wsgiapp.py) 上下载该文件,然后在 Web 服务器上运行这个应用,像这样:
```
(lsbaws) $ python webserver2.py wsgiapp:app
WSGIServer: Serving HTTP on port 8888 ...
```
在浏览器中输入下面的地址,然后按下回车。这是你应该看到的结果:

你刚刚在学习如何创建一个 Web 服务器的过程中自己编写了一个最朴素的 WSGI Web 框架!棒极了!
现在,我们再回来看看服务器传给客户端的那些东西。这是在使用 HTTP 客户端调用你的 Pyramid 应用时,服务器生成的 HTTP 响应内容:

这个响应和你在本系列第一部分中看到的 HTTP 响应有一部分共同点,但它还多出来了一些内容。比如说,它拥有四个你曾经没见过的 [HTTP 头部](http://en.wikipedia.org/wiki/List_of_HTTP_header_fields):`Content-Type`, `Content-Length`, `Date` 以及 `Server`。这些头部内容基本上在每个 Web 服务器返回的响应中都会出现。不过,它们都不是被严格要求出现的。这些 HTTP 请求/响应头部字段的目的在于它可以向你传递一些关于 HTTP 请求/响应的额外信息。
既然你对 WSGI 接口了解的更深了一些,那我再来展示一下上面那个 HTTP 响应中的各个部分的信息来源:

我现在还没有对上面那个 `environ` 字典做任何解释,不过基本上这个字典必须包含那些被 WSGI 规范事先定义好的 WSGI 及 CGI 变量值。服务器在解析 HTTP 请求时,会从请求中获取这些变量的值。这是 `environ` 字典应该有的样子:

Web 框架会利用以上字典中包含的信息,通过字典中的请求路径、请求动作等等来决定使用哪个视图来处理响应、在哪里读取请求正文、在哪里输出错误信息(如果有的话)。
现在,你已经创造了属于你自己的 WSGI Web 服务器,你也使用不同 Web 框架做了几个 Web 应用。而且,你在这个过程中也自己创造出了一个朴素的 Web 应用及框架。这个过程真是累人。现在我们来回顾一下,你的 WSGI Web 服务器在服务请求时,需要针对 WSGI 应用做些什么:
* 首先,服务器开始工作,然后会加载一个可调用对象 `application`,这个对象由你的 Web 框架或应用提供
* 然后,服务器读取一个请求
* 然后,服务器会解析这个请求
* 然后,服务器会使用请求数据来构建一个 `environ` 字典
* 然后,它会用 `environ` 字典及一个可调用对象 `start_response` 作为参数,来调用 `application`,并获取响应体内容。
* 然后,服务器会使用 `application` 返回的响应体,和 `start_response` 函数设置的状态码及响应头部内容,来构建一个 HTTP 响应。
* 最终,服务器将 HTTP 响应回送给客户端。

这基本上是服务器要做的全部内容了。你现在有了一个可以正常工作的 WSGI 服务器,它可以为使用任何遵循 WSGI 规范的 Web 框架(如 Django、Flask、Pyramid,还有你刚刚自己写的那个框架)构建出的 Web 应用服务。最棒的部分在于,它可以在不用更改任何服务器代码的情况下,与多个不同的 Web 框架一起工作。真不错。
在结束之前,你可以想想这个问题:“你该如何让你的服务器在同一时间处理多个请求呢?”
敬请期待,我会在第三部分向你展示一种解决这个问题的方法。干杯!
顺便,我在撰写一本名为《搭个 Web 服务器:从头开始》的书。这本书讲解了如何从头开始编写一个基本的 Web 服务器,里面包含本文中没有的更多细节。[订阅邮件列表](https://ruslanspivak.com/lsbaws-part2/),你就可以获取到这本书的最新进展,以及发布日期。
---
via: <https://ruslanspivak.com/lsbaws-part2/>
作者:[Ruslan](https://github.com/rspivak/) 译者:[StdioA](https://github.com/StdioA) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Remember, in [Part 1](http://ruslanspivak.com/lsbaws-part1/) I asked you a question: “How do you run a Django application, Flask application, and Pyramid application under your freshly minted Web server without making a single change to the server to accommodate all those different Web frameworks?” Read on to find out the answer.
In the past, your choice of a Python Web framework would limit your choice of usable Web servers, and vice versa. If the framework and the server were designed to work together, then you were okay:
But you could have been faced (and maybe you were) with the following problem when trying to combine a server and a framework that weren’t designed to work together:
Basically you had to use what worked together and not what you might have wanted to use.
So, how do you then make sure that you can run your Web server with multiple Web frameworks without making code changes either to the Web server or to the Web frameworks?
And the answer to that problem became the **Python Web Server Gateway Interface** (or [WSGI](https://www.python.org/dev/peps/pep-0333/) for short, pronounced *“wizgy”*).
[WSGI](https://www.python.org/dev/peps/pep-0333/) allowed developers to separate choice of a Web framework from choice of a Web server. Now you can actually mix and match Web servers and Web frameworks and choose a pairing that suits your needs. You can run [Django](https://www.djangoproject.com/), [Flask](http://flask.pocoo.org/), or [Pyramid](http://trypyramid.com/), for example, with [Gunicorn](http://gunicorn.org/) or [Nginx/uWSGI](http://uwsgi-docs.readthedocs.org) or [Waitress](http://waitress.readthedocs.org). Real mix and match, thanks to the WSGI support in both servers and frameworks:
So, [WSGI](https://www.python.org/dev/peps/pep-0333/) is the answer to the question I asked you in [Part 1](http://ruslanspivak.com/lsbaws-part1/) and repeated at the beginning of this article. Your Web server must implement the server portion of a WSGI interface and all modern Python Web Frameworks already implement the framework side of the WSGI interface, which allows you to use them with your Web server without ever modifying your server’s code to accommodate a particular Web framework.
Now you know that WSGI support by Web servers and Web frameworks allows you to choose a pairing that suits you, but it is also beneficial to server and framework developers because they can focus on their preferred area of specialization and not step on each other’s toes. Other languages have similar interfaces too: Java, for example, has [Servlet API](http://en.wikipedia.org/wiki/Java_servlet) and Ruby has [Rack](http://en.wikipedia.org/wiki/Rack_%28web_server_interface%29).
It’s all good, but I bet you are saying: “Show me the code!” Okay, take a look at this pretty minimalistic WSGI server implementation:
```
# Tested with Python 3.7+ (Mac OS X)
import io
import socket
import sys
class WSGIServer(object):
address_family = socket.AF_INET
socket_type = socket.SOCK_STREAM
request_queue_size = 1
def __init__(self, server_address):
# Create a listening socket
self.listen_socket = listen_socket = socket.socket(
self.address_family,
self.socket_type
)
# Allow to reuse the same address
listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# Bind
listen_socket.bind(server_address)
# Activate
listen_socket.listen(self.request_queue_size)
# Get server host name and port
host, port = self.listen_socket.getsockname()[:2]
self.server_name = socket.getfqdn(host)
self.server_port = port
# Return headers set by Web framework/Web application
self.headers_set = []
def set_app(self, application):
self.application = application
def serve_forever(self):
listen_socket = self.listen_socket
while True:
# New client connection
self.client_connection, client_address = listen_socket.accept()
# Handle one request and close the client connection. Then
# loop over to wait for another client connection
self.handle_one_request()
def handle_one_request(self):
request_data = self.client_connection.recv(1024)
self.request_data = request_data = request_data.decode('utf-8')
# Print formatted request data a la 'curl -v'
print(''.join(
f'< {line}\n' for line in request_data.splitlines()
))
self.parse_request(request_data)
# Construct environment dictionary using request data
env = self.get_environ()
# It's time to call our application callable and get
# back a result that will become HTTP response body
result = self.application(env, self.start_response)
# Construct a response and send it back to the client
self.finish_response(result)
def parse_request(self, text):
request_line = text.splitlines()[0]
request_line = request_line.rstrip('\r\n')
# Break down the request line into components
(self.request_method, # GET
self.path, # /hello
self.request_version # HTTP/1.1
) = request_line.split()
def get_environ(self):
env = {}
# The following code snippet does not follow PEP8 conventions
# but it's formatted the way it is for demonstration purposes
# to emphasize the required variables and their values
#
# Required WSGI variables
env['wsgi.version'] = (1, 0)
env['wsgi.url_scheme'] = 'http'
env['wsgi.input'] = io.StringIO(self.request_data)
env['wsgi.errors'] = sys.stderr
env['wsgi.multithread'] = False
env['wsgi.multiprocess'] = False
env['wsgi.run_once'] = False
# Required CGI variables
env['REQUEST_METHOD'] = self.request_method # GET
env['PATH_INFO'] = self.path # /hello
env['SERVER_NAME'] = self.server_name # localhost
env['SERVER_PORT'] = str(self.server_port) # 8888
return env
def start_response(self, status, response_headers, exc_info=None):
# Add necessary server headers
server_headers = [
('Date', 'Mon, 15 Jul 2019 5:54:48 GMT'),
('Server', 'WSGIServer 0.2'),
]
self.headers_set = [status, response_headers + server_headers]
# To adhere to WSGI specification the start_response must return
# a 'write' callable. We simplicity's sake we'll ignore that detail
# for now.
# return self.finish_response
def finish_response(self, result):
try:
status, response_headers = self.headers_set
response = f'HTTP/1.1 {status}\r\n'
for header in response_headers:
response += '{0}: {1}\r\n'.format(*header)
response += '\r\n'
for data in result:
response += data.decode('utf-8')
# Print formatted response data a la 'curl -v'
print(''.join(
f'> {line}\n' for line in response.splitlines()
))
response_bytes = response.encode()
self.client_connection.sendall(response_bytes)
finally:
self.client_connection.close()
SERVER_ADDRESS = (HOST, PORT) = '', 8888
def make_server(server_address, application):
server = WSGIServer(server_address)
server.set_app(application)
return server
if __name__ == '__main__':
if len(sys.argv) < 2:
sys.exit('Provide a WSGI application object as module:callable')
app_path = sys.argv[1]
module, application = app_path.split(':')
module = __import__(module)
application = getattr(module, application)
httpd = make_server(SERVER_ADDRESS, application)
print(f'WSGIServer: Serving HTTP on port {PORT} ...\n')
httpd.serve_forever()
```
It’s definitely bigger than the server code in [Part 1](http://ruslanspivak.com/lsbaws-part1/), but it’s also small enough (just under 150 lines) for you to understand without getting bogged down in details. The above server also does more - it can run your basic Web application written with your beloved Web framework, be it Pyramid, Flask, Django, or some other Python WSGI framework.
Don’t believe me? Try it and see for yourself. Save the above code as *webserver2.py* or download it directly from [GitHub](https://github.com/rspivak/lsbaws/blob/master/part2/webserver2.py). If you try to run it without any parameters it’s going to complain and exit.
```
$ python webserver2.py
Provide a WSGI application object as module:callable
```
It really wants to serve your Web application and that’s where the fun begins. To run the server the only thing you need installed is Python (Python 3.7+, to be exact). But to run applications written with Pyramid, Flask, and Django you need to install those frameworks first. Let’s install all three of them. My preferred method is by using [venv](https://packaging.python.org/tutorials/installing-packages/#creating-virtual-environments) (it is available by default in Python 3.3 and later). Just follow the steps below to create and activate a virtual environment and then install all three Web frameworks.
```
$ python3 -m venv lsbaws
$ ls lsbaws
bin include lib pyvenv.cfg
$ source lsbaws/bin/activate
(lsbaws) $ pip install -U pip
(lsbaws) $ pip install pyramid
(lsbaws) $ pip install flask
(lsbaws) $ pip install django
```
At this point you need to create a Web application.
Let’s start with [Pyramid](http://trypyramid.com/) first.
Save the following code as *pyramidapp.py* to the same directory where you saved *webserver2.py* or download the file directly from [GitHub](https://github.com/rspivak/lsbaws/blob/master/part2/pyramidapp.py):
```
from pyramid.config import Configurator
from pyramid.response import Response
def hello_world(request):
return Response(
'Hello world from Pyramid!\n',
content_type='text/plain',
)
config = Configurator()
config.add_route('hello', '/hello')
config.add_view(hello_world, route_name='hello')
app = config.make_wsgi_app()
```
Now you’re ready to serve your Pyramid application with your very own Web server:
```
(lsbaws) $ python webserver2.py pyramidapp:app
WSGIServer: Serving HTTP on port 8888 ...
```
You just told your server to load the *‘app’* callable from the python module *‘pyramidapp’* Your server is now ready to take requests and forward them to your Pyramid application. The application only handles one route now: the */hello* route.
Type [http://localhost:8888/hello](http://localhost:8888/hello) address into your browser, press Enter, and observe the result:
You can also test the server on the command line using the *‘curl’* utility:
```
$ curl -v http://localhost:8888/hello
...
```
Check what the server and *curl* prints to standard output.
Now onto [Flask](http://flask.pocoo.org/). Let’s follow the same steps.
```
from flask import Flask
from flask import Response
flask_app = Flask('flaskapp')
@flask_app.route('/hello')
def hello_world():
return Response(
'Hello world from Flask!\n',
mimetype='text/plain'
)
app = flask_app.wsgi_app
```
Save the above code as *flaskapp.py* or download it from [GitHub](https://github.com/rspivak/lsbaws/blob/master/part2/flaskapp.py) and run the server as:
```
(lsbaws) $ python webserver2.py flaskapp:app
WSGIServer: Serving HTTP on port 8888 ...
```
Now type in the [http://localhost:8888/hello](http://localhost:8888/hello) into your browser and press Enter:
Again, try *‘curl’* and see for yourself that the server returns a message generated by the Flask application:
```
$ curl -v http://localhost:8888/hello
...
```
Can the server also handle a [Django](https://www.djangoproject.com/) application? Try it out!
It’s a little bit more involved, though, and I would recommend cloning the whole repo and use [djangoapp.py](https://github.com/rspivak/lsbaws/blob/master/part2/djangoapp.py), which is part of the [GitHub repository](https://github.com/rspivak/lsbaws/).
Here is the source code which basically adds the Django *‘helloworld’* project (pre-created using Django’s *django-admin.py startproject* command) to the current Python path and then imports the project’s WSGI application.
```
import sys
sys.path.insert(0, './helloworld')
from helloworld import wsgi
app = wsgi.application
```
Save the above code as *djangoapp.py* and run the Django application with your Web server:
```
(lsbaws) $ python webserver2.py djangoapp:app
WSGIServer: Serving HTTP on port 8888 ...
```
Type in the following address and press Enter:
And as you’ve already done a couple of times before, you can test it on the command line, too, and confirm that it’s the Django application that handles your requests this time around:
```
$ curl -v http://localhost:8888/hello
...
```
Did you try it? Did you make sure the server works with those three frameworks? If not, then please do so. Reading is important, but this series is about rebuilding and that means you need to get your hands dirty. Go and try it. I will wait for you, don’t worry. No seriously, you must try it and, better yet, retype everything yourself and make sure that it works as expected.
Okay, you’ve experienced the power of WSGI: it allows you to mix and match your Web servers and Web frameworks. WSGI provides a minimal interface between Python Web servers and Python Web Frameworks. It’s very simple and it’s easy to implement on both the server and the framework side. The following code snippet shows the server and the framework side of the interface:
```
def run_application(application):
"""Server code."""
# This is where an application/framework stores
# an HTTP status and HTTP response headers for the server
# to transmit to the client
headers_set = []
# Environment dictionary with WSGI/CGI variables
environ = {}
def start_response(status, response_headers, exc_info=None):
headers_set[:] = [status, response_headers]
# Server invokes the ‘application' callable and gets back the
# response body
result = application(environ, start_response)
# Server builds an HTTP response and transmits it to the client
...
def app(environ, start_response):
"""A barebones WSGI app."""
start_response('200 OK', [('Content-Type', 'text/plain')])
return [b'Hello world!']
run_application(app)
```
Here is how it works:
- The framework provides an
*‘application’*callable (The WSGI specification doesn’t prescribe how that should be implemented) - The server invokes the
*‘application’*callable for each request it receives from an HTTP client. It passes a dictionary*‘environ’*containing WSGI/CGI variables and a*‘start_response’*callable as arguments to the*‘application’*callable. - The framework/application generates an HTTP status and HTTP response headers and passes them to the
*‘start_response’*callable for the server to store them. The framework/application also returns a response body. - The server combines the status, the response headers, and the response body into an HTTP response and transmits it to the client (This step is not part of the specification but it’s the next logical step in the flow and I added it for clarity)
And here is a visual representation of the interface:
So far, you’ve seen the Pyramid, Flask, and Django Web applications and you’ve seen the server code that implements the server side of the WSGI specification. You’ve even seen the barebones WSGI application code snippet that doesn’t use any framework.
The thing is that when you write a Web application using one of those frameworks you work at a higher level and don’t work with WSGI directly, but I know you’re curious about the framework side of the WSGI interface, too because you’re reading this article. So, let’s create a minimalistic WSGI Web application/Web framework without using Pyramid, Flask, or Django and run it with your server:
```
def app(environ, start_response):
"""A barebones WSGI application.
This is a starting point for your own Web framework :)
"""
status = '200 OK'
response_headers = [('Content-Type', 'text/plain')]
start_response(status, response_headers)
return [b'Hello world from a simple WSGI application!\n']
```
Again, save the above code in *wsgiapp.py* file or download it from [GitHub](https://github.com/rspivak/lsbaws/blob/master/part2/wsgiapp.py) directly and run the application under your Web server as:
```
(lsbaws) $ python webserver2.py wsgiapp:app
WSGIServer: Serving HTTP on port 8888 ...
```
Type in the following address and press Enter. This is the result you should see:
You just wrote your very own minimalistic WSGI Web framework while learning about how to create a Web server! Outrageous.
Now, let’s get back to what the server transmits to the client. Here is the HTTP response the server generates when you call your Pyramid application using an HTTP client:
The response has some familiar parts that you saw in [Part 1](http://ruslanspivak.com/lsbaws-part1/) but it also has something new. It has, for example, four [HTTP headers](http://en.wikipedia.org/wiki/List_of_HTTP_header_fields) that you haven’t seen before: *Content-Type*, *Content-Length*, *Date*, and *Server*. Those are the headers that a response from a Web server generally should have. None of them are strictly required, though. The purpose of the headers is to transmit additional information about the HTTP request/response.
Now that you know more about the WSGI interface, here is the same HTTP response with some more information about what parts produced it:
I haven’t said anything about the **‘environ’** dictionary yet, but basically it’s a Python dictionary that must contain certain WSGI and CGI variables prescribed by the WSGI specification.
The server takes the values for the dictionary from the HTTP request after parsing the request.
This is what the contents of the dictionary look like:
A Web framework uses the information from that dictionary to decide which view to use based on the specified route, request method etc., where to read the request body from and where to write errors, if any.
By now you’ve created your own WSGI Web server and you’ve made Web applications written with different Web frameworks. And, you’ve also created your barebones Web application/Web framework along the way. It’s been a heck of a journey. Let’s recap what your WSGI Web server has to do to serve requests aimed at a WSGI application:
- First, the server starts and loads an
*‘application’*callable provided by your Web framework/application - Then, the server reads a request
- Then, the server parses it
- Then, it builds an
*‘environ’*dictionary using the request data - Then, it calls the
*‘application’*callable with the*‘environ’*dictionary and a*‘start_response’*callable as parameters and gets back a response body. - Then, the server constructs an HTTP response using the data returned by the call to the
*‘application’*object and the status and response headers set by the*‘start_response’*callable. - And finally, the server transmits the HTTP response back to the client
That’s about all there is to it. You now have a working WSGI server that can serve basic Web applications written with WSGI compliant Web frameworks like [Django](https://www.djangoproject.com/), [Flask](http://flask.pocoo.org/), [Pyramid](http://trypyramid.com/), or your very own WSGI framework. The best part is that the server can be used with multiple Web frameworks without any changes to the server code base. Not bad at all.
Before you go, here is another question for you to think about, *“How do you make your server handle more than one request at a time?”*
Stay tuned and I will show you a way to do that in [Part 3](https://ruslanspivak.com/lsbaws-part3/). Cheers!
*Resources used in preparation for this article (some links are affiliate links):*
-
[Unix Network Programming, Volume 1: The Sockets Networking API (3rd Edition)](http://www.amazon.com/gp/product/0131411551/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=0131411551&linkCode=as2&tag=russblo0b-20&linkId=2F4NYRBND566JJQL) -
[The Linux Programming Interface: A Linux and UNIX System Programming Handbook](http://www.amazon.com/gp/product/1593272200/ref=as_li_tl?ie=UTF8&camp=1789&creative=9325&creativeASIN=1593272200&linkCode=as2&tag=russblo0b-20&linkId=CHFOMNYXN35I2MON)
UPDATE: Mon, July 15, 2019
Updated the server code to run under Python 3.7+
Added resources used in preparation for the article
Get the edge and stay sharp. Subscribe to Beyond Basics for free and get new posts without missing a beat!
**All articles in this series:**
## Comments
comments powered by Disqus |
7,687 | LXD 2.0 系列(二):安装与配置 | https://www.stgraber.org/2016/03/15/lxd-2-0-installing-and-configuring-lxd-212/ | 2016-08-16T10:56:00 | [
"容器",
"LXC",
"LXD"
] | https://linux.cn/article-7687-1.html | 
这是 LXD 2.0 系列介绍文章的第二篇。
1. [LXD 入门](/article-7618-1.html)
2. [安装与配置](/article-7687-1.html)
3. [你的第一个 LXD 容器](/article-7706-1.html)
4. [资源控制](/article-8072-1.html)
5. [镜像管理](/article-8107-1.html)
6. [远程主机及容器迁移](/article-8169-1.html)
7. [LXD 中的 Docker](/article-8235-1.html)
8. [LXD 中的 LXD](/article-8257-1.html)
9. [实时迁移](/article-8263-1.html)
10. [LXD 和 Juju](/article-8273-1.html)
11. [LXD 和 OpenStack](/article-8274-1.html)
12. [调试,及给 LXD 做贡献](/article-8282-1.html)
### 安装篇
有很多种办法可以获得 LXD。我们推荐你配合最新版的 LXC 和 Linux 内核使用 LXD,这样就可以享受到它的全部特性。需要注意的是,我们现在也在慢慢的降低对旧版本 Linux 发布版的支持。
#### Ubuntu 标准版
所有新发布的 LXD 都会在发布几分钟后上传到 Ubuntu 开发版的安装源里。这个安装包然后就会作为 Ubuntu 用户的其他安装包源的种子。
如果使用 Ubuntu 16.04,可以直接安装:
```
sudo apt install lxd
```
如果运行的是 Ubuntu 14.04,则可以这样安装:
```
sudo apt -t trusty-backports install lxd
```
#### Ubuntu Core
使用 Ubuntu Core 稳定版的用户可以使用下面的命令安装 LXD:
```
sudo snappy install lxd.stgraber
```
#### Ubuntu 官方 PPA
使用其他 Ubuntu 发布版 —— 比如 Ubuntu 15.10 —— 的用户可以添加下面的 PPA(Personal Package Archive)来安装:
```
sudo apt-add-repository ppa:ubuntu-lxc/stable
sudo apt update
sudo apt dist-upgrade
sudo apt install lxd
```
#### Gentoo
Gentoo 已经有了最新的 LXD 包,你可以直接安装:
```
sudo emerge --ask lxd
```
#### 使用源代码安装
如果你曾经编译过 Go 语言的项目,那么从源代码编译 LXD 并不是十分困难。然而注意,你需要 LXC 的开发头文件。为了运行 LXD, 你的发布版需也要使用比较新的内核(最起码是 3.13)、比较新的 LXC (1.1.4 或更高版本)、LXCFS 以及支持用户子 uid/gid 分配的 shadow 文件。
从源代码编译 LXD 的最新教程可以在[上游 README](https://github.com/lxc/lxd/blob/master/README.md)里找到。
### Ubuntu 上的网络配置
Ubuntu 的安装包会很方便的给你提供一个“lxdbr0”网桥。这个网桥默认是没有配置过的,只提供通过 HTTP 代理的 IPv6 的本地连接。
要配置这个网桥并添加 IPv4 、 IPv6 子网,你可以运行下面的命令:
```
sudo dpkg-reconfigure -p medium lxd
```
或者直接通过 LXD 初始化命令一步一步的配置:
```
sudo lxd init
```
### 存储后端
LXD 提供了几种存储后端。在开始使用 LXD 之前,你应该决定将要使用的后端,因为我们不支持在后端之间迁移已经生成的容器。
各个[后端特性比较表](https://github.com/lxc/lxd/blob/master/doc/storage-backends.md)可以在[这里](https://github.com/lxc/lxd/blob/master/doc/storage-backends.md)找到。
#### ZFS
我们的推荐是 ZFS, 因为它能支持 LXD 的全部特性,同时提供最快和最可靠的容器体验。它包括了以容器为单位的磁盘配额、即时快照和恢复、优化后的迁移(发送/接收),以及快速从镜像创建容器的能力。它同时也被认为要比 btrfs 更成熟。
要和 LXD 一起使用 ZFS ,你需要首先在你的系统上安装 ZFS。
如果你是用的是 Ubuntu 16.04 , 你只需要简单的使用命令安装:
```
sudo apt install zfsutils-linux
```
在 Ubuntu 15.10 上你可以这样安装:
```
sudo apt install zfsutils-linux zfs-dkms
```
如果是更旧的版本,你需要从 zfsonlinux PPA 安装:
```
sudo apt-add-repository ppa:zfs-native/stable
sudo apt update
sudo apt install ubuntu-zfs
```
配置 LXD 只需要执行下面的命令:
```
sudo lxd init
```
这条命令接下来会向你提问一些 ZFS 的配置细节,然后为你配置好 ZFS。
#### btrfs
如果 ZFS 不可用,那么 btrfs 可以提供相同级别的集成,但不能正确地报告容器内的磁盘使用情况(虽然配额仍然可用)。
btrfs 同时拥有很好的嵌套属性,而这是 ZFS 所不具有的。也就是说如果你计划在 LXD 中再使用 LXD,那么 btrfs 就很值得你考虑。
使用 btrfs 的话,LXD 不需要进行任何的配置,你只需要保证 `/var/lib/lxd` 保存在 btrfs 文件系统中,然后 LXD 就会自动为你使用 btrfs 了。
#### LVM
如果 ZFS 和 btrfs 都不是你想要的,你还可以考虑使用 LVM 以获得部分特性。 LXD 会以自动精简配置的方式使用 LVM,为每个镜像和容器创建 LV,如果需要的话也会使用 LVM 的快照功能。
要配置 LXD 使用 LVM,需要创建一个 LVM 卷组,然后运行:
```
lxc config set storage.lvm_vg_name "THE-NAME-OF-YOUR-VG"
```
默认情况下 LXD 使用 ext4 作为全部逻辑卷的文件系统。如果你喜欢的话可以改成 XFS:
```
lxc config set storage.lvm_fstype xfs
```
#### 简单目录
如果上面全部方案你都不打算使用,LXD 依然能在不使用任何高级特性情况下工作。它会为每个容器创建一个目录,然后在创建每个容器时解压缩镜像的压缩包,并在容器拷贝和快照时进行一次完整的文件系统拷贝。
除了磁盘配额以外的特性都是支持的,但是很浪费磁盘空间,并且非常慢。如果你没有其他选择,这还是可以工作的,但是你还是需要认真的考虑一下上面的几个替代方案。
### 配置篇
LXD 守护进程的完整配置项列表可以在[这里找到](https://github.com/lxc/lxd/blob/master/doc/configuration.md)。
#### 网络配置
默认情况下 LXD 不会监听网络。和它通信的唯一办法是通过 `/var/lib/lxd/unix.socket` 使用本地 unix 套接字进行通信。
要让 LXD 监听网络,下面有两个有用的命令:
```
lxc config set core.https_address [::]
lxc config set core.trust_password some-secret-string
```
第一条命令将 LXD 绑定到 IPv6 地址 “::”,也就是监听机器的所有 IPv6 地址。你可以显式的使用一个特定的 IPv4 或者 IPv6 地址替代默认地址,如果你想绑定某个 TCP 端口(默认是 8443)的话可以在地址后面添加端口号即可。
第二条命令设置了密码,用于让远程客户端把自己添加到 LXD 可信证书中心。如果已经给主机设置了密码,当添加 LXD 主机时会提示输入密码,LXD 守护进程会保存他们的客户端证书以确保客户端是可信的,这样就不需要再次输入密码(可以随时设置和取消)。
你也可以选择不设置密码,而是人工验证每个新客户端是否可信——让每个客户端发送“client.crt”(来自于 `~/.config/lxc`)文件,然后把它添加到你自己的可信证书中心:
```
lxc config trust add client.crt
```
#### 代理配置
大多数情况下,你会想让 LXD 守护进程从远程服务器上获取镜像。
如果你处在一个必须通过 HTTP(s) 代理链接外网的环境下,你需要对 LXD 做一些配置,或保证已在守护进程的环境中设置正确的 PROXY 环境变量。
```
lxc config set core.proxy_http http://squid01.internal:3128
lxc config set core.proxy_https http://squid01.internal:3128
lxc config set core.proxy_ignore_hosts image-server.local
```
以上代码使所有 LXD 发起的数据传输都使用 squid01.internal HTTP 代理,但与在 image-server.local 的服务器的数据传输则是例外。
#### 镜像管理
LXD 使用动态镜像缓存。当从远程镜像创建容器的时候,它会自动把镜像下载到本地镜像商店,同时标志为已缓存并记录来源。几天后(默认 10 天)如果某个镜像没有被使用过,那么它就会自动地被删除。每隔几小时(默认是 6 小时)LXD 还会检查一下这个镜像是否有新版本,然后更新镜像的本地拷贝。
所有这些都可以通过下面的配置选项进行配置:
```
lxc config set images.remote_cache_expiry 5
lxc config set images.auto_update_interval 24
lxc config set images.auto_update_cached false
```
这些命令让 LXD 修改了它的默认属性,缓存期替换为 5 天,更新间隔为 24 小时,而且只更新那些标记为自动更新(–auto-update)的镜像(lxc 镜像拷贝被标记为 `–auto-update`)而不是 LXD 自动缓存的镜像。
### 总结
到这里为止,你就应该有了一个可以工作的、最新版的 LXD,现在你可以开始用 LXD 了,或者等待我们的下一篇博文,我们会在其中介绍如何创建第一个容器以及使用 LXD 命令行工具操作容器。
### 额外信息
* LXD 的主站在: <https://linuxcontainers.org/lxd>
* LXD 的 GitHub 仓库: <https://github.com/lxc/lxd>
* LXD 的邮件列表: <https://lists.linuxcontainers.org>
* LXD 的 IRC 频道: #lxcontainers on irc.freenode.net
如果你不想或者不能在你的机器上安装 LXD ,你可以[试试在线版的 LXD](https://linuxcontainers.org/lxd/try-it)。
---
作者简介:我是 Stéphane Graber。我是 LXC 和 LXD 项目的领导者,目前在加拿大魁北克蒙特利尔的家所在的Canonical 有限公司担任 LXD 的技术主管。
---
via: <https://www.stgraber.org/2016/03/15/lxd-2-0-installing-and-configuring-lxd-212/>
作者:[Stéphane Graber](https://www.stgraber.org/author/stgraber/) 译者:[ezio](https://github.com/oska874) 校对:[PurlingNayuki](https://github.com/PurlingNayuki)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,688 | GCC 内联汇编 HOWTO | http://www.ibiblio.org/gferg/ldp/GCC-Inline-Assembly-HOWTO.html | 2016-08-16T17:43:00 | [
"汇编",
"GCC"
] | https://linux.cn/article-7688-1.html | 
v0.1, 01 March 2003.
*本 HOWTO 文档将讲解 GCC 提供的内联汇编特性的用途和用法。对于阅读这篇文章,这里只有两个前提要求,很明显,就是 x86 汇编语言和 C 语言的基本认识。*
### 1. 简介
#### 1.1 版权许可
Copyright (C) 2003 Sandeep S.
本文档自由共享;你可以重新发布它,并且/或者在遵循自由软件基金会发布的 GNU 通用公共许可证下修改它;也可以是该许可证的版本 2 或者(按照你的需求)更晚的版本。
发布这篇文档是希望它能够帮助别人,但是没有任何担保;甚至不包括可售性和适用于任何特定目的的担保。关于更详细的信息,可以查看 GNU 通用许可证。
#### 1.2 反馈校正
请将反馈和批评一起提交给 [Sandeep.S](mailto:[email protected]) 。我将感谢任何一个指出本文档中错误和不准确之处的人;一被告知,我会马上改正它们。
#### 1.3 致谢
我对提供如此棒的特性的 GNU 人们表示真诚的感谢。感谢 Mr.Pramode C E 所做的所有帮助。感谢在 Govt Engineering College 和 Trichur 的朋友们的精神支持和合作,尤其是 Nisha Kurur 和 Sakeeb S 。 感谢在 Gvot Engineering College 和 Trichur 的老师们的合作。
另外,感谢 Phillip , Brennan Underwood 和 [[email protected]](mailto:[email protected]) ;这里的许多东西都厚颜地直接取自他们的工作成果。
### 2. 概览
在这里,我们将学习 GCC 内联汇编。这里<ruby> 内联 <rp> ( </rp> <rt> inline </rt> <rp> ) </rp></ruby>表示的是什么呢?
我们可以要求编译器将一个函数的代码插入到调用者代码中函数被实际调用的地方。这样的函数就是内联函数。这听起来和宏差不多?这两者确实有相似之处。
内联函数的优点是什么呢?
这种内联方法可以减少函数调用开销。同时如果所有实参的值为常量,它们的已知值可以在编译期允许简化,因此并非所有的内联函数代码都需要被包含进去。代码大小的影响是不可预测的,这取决于特定的情况。为了声明一个内联函数,我们必须在函数声明中使用 `inline` 关键字。
现在我们正处于一个猜测内联汇编到底是什么的点上。它只不过是一些写为内联函数的汇编程序。在系统编程上,它们方便、快速并且极其有用。我们主要集中学习(GCC)内联汇编函数的基本格式和用法。为了声明内联汇编函数,我们使用 `asm` 关键词。
内联汇编之所以重要,主要是因为它可以操作并且使其输出通过 C 变量显示出来。正是因为此能力, "asm" 可以用作汇编指令和包含它的 C 程序之间的接口。
### 3. GCC 汇编语法
Linux上的 GNU C 编译器 GCC ,使用 **AT&T** / **UNIX** 汇编语法。在这里,我们将使用 AT&T 语法 进行汇编编码。如果你对 AT&T 语法不熟悉的话,请不要紧张,我会教你的。AT&T 语法和 Intel 语法的差别很大。我会给出主要的区别。
1. 源操作数和目的操作数顺序
AT&T 语法的操作数方向和 Intel 语法的刚好相反。在Intel 语法中,第一操作数为目的操作数,第二操作数为源操作数,然而在 AT&T 语法中,第一操作数为源操作数,第二操作数为目的操作数。也就是说,
Intel 语法中的 `Op-code dst src` 变为 AT&T 语法中的 `Op-code src dst`。
2. 寄存器命名
寄存器名称有 `%` 前缀,即如果必须使用 `eax`,它应该用作 `%eax`。
3. 立即数
AT&T 立即数以 `$` 为前缀。静态 "C" 变量也使用 `$` 前缀。在 Intel 语法中,十六进制常量以 `h` 为后缀,然而 AT&T 不使用这种语法,这里我们给常量添加前缀 `0x`。所以,对于十六进制,我们首先看到一个 `$`,然后是 `0x`,最后才是常量。
4. 操作数大小
在 AT&T 语法中,存储器操作数的大小取决于操作码名字的最后一个字符。操作码后缀 ’b’ 、’w’、’l’ 分别指明了<ruby> 字节 <rp> ( </rp> <rt> byte </rt> <rp> ) </rp></ruby>(8位)、<ruby> 字 <rp> ( </rp> <rt> word </rt> <rp> ) </rp></ruby>(16位)、<ruby> 长型 <rp> ( </rp> <rt> long </rt> <rp> ) </rp></ruby>(32位)存储器引用。Intel 语法通过给存储器操作数添加 `byte ptr`、 `word ptr` 和 `dword ptr` 前缀来实现这一功能。
因此,Intel的 `mov al, byte ptr foo` 在 AT&T 语法中为 `movb foo, %al`。
5. 存储器操作数
在 Intel 语法中,基址寄存器包含在 `[` 和 `]` 中,然而在 AT&T 中,它们变为 `(` 和 `)`。另外,在 Intel 语法中, 间接内存引用为
`section:[base + index*scale + disp]`,在 AT&T中变为 `section:disp(base, index, scale)`。
需要牢记的一点是,当一个常量用于 disp 或 scale,不能添加 `$` 前缀。
现在我们看到了 Intel 语法和 AT&T 语法之间的一些主要差别。我仅仅写了它们差别的一部分而已。关于更完整的信息,请参考 GNU 汇编文档。现在为了更好地理解,我们可以看一些示例。
```
+------------------------------+------------------------------------+
| Intel Code | AT&T Code |
+------------------------------+------------------------------------+
| mov eax,1 | movl $1,%eax |
| mov ebx,0ffh | movl $0xff,%ebx |
| int 80h | int $0x80 |
| mov ebx, eax | movl %eax, %ebx |
| mov eax,[ecx] | movl (%ecx),%eax |
| mov eax,[ebx+3] | movl 3(%ebx),%eax |
| mov eax,[ebx+20h] | movl 0x20(%ebx),%eax |
| add eax,[ebx+ecx*2h] | addl (%ebx,%ecx,0x2),%eax |
| lea eax,[ebx+ecx] | leal (%ebx,%ecx),%eax |
| sub eax,[ebx+ecx*4h-20h] | subl -0x20(%ebx,%ecx,0x4),%eax |
+------------------------------+------------------------------------+
```
### 4. 基本内联
基本内联汇编的格式非常直接了当。它的基本格式为
`asm("汇编代码");`
示例
```
asm("movl %ecx %eax"); /* 将 ecx 寄存器的内容移至 eax */
__asm__("movb %bh (%eax)"); /* 将 bh 的一个字节数据 移至 eax 寄存器指向的内存 */
```
你可能注意到了这里我使用了 `asm` 和 `__asm__`。这两者都是有效的。如果关键词 `asm` 和我们程序的一些标识符冲突了,我们可以使用 `__asm__`。如果我们的指令多于一条,我们可以每个一行,并用双引号圈起,同时为每条指令添加 ’\n’ 和 ’\t’ 后缀。这是因为 gcc 将每一条当作字符串发送给 **as**(GAS)(LCTT 译注: GAS 即 GNU 汇编器),并且通过使用换行符/制表符发送正确格式化后的行给汇编器。
示例
```
__asm__ ("movl %eax, %ebx\n\t"
"movl $56, %esi\n\t"
"movl %ecx, $label(%edx,%ebx,$4)\n\t"
"movb %ah, (%ebx)");
```
如果在代码中,我们涉及到一些寄存器(即改变其内容),但在没有恢复这些变化的情况下从汇编中返回,这将会导致一些意想不到的事情。这是因为 GCC 并不知道寄存器内容的变化,这会导致问题,特别是当编译器做了某些优化。在没有告知 GCC 的情况下,它将会假设一些寄存器存储了一些值——而我们可能已经改变却没有告知 GCC——它会像什么事都没发生一样继续运行(LCTT 译注:什么事都没发生一样是指GCC不会假设寄存器装入的值是有效的,当退出改变了寄存器值的内联汇编后,寄存器的值不会保存到相应的变量或内存空间)。我们所可以做的是使用那些没有副作用的指令,或者当我们退出时恢复这些寄存器,要不就等着程序崩溃吧。这是为什么我们需要一些扩展功能,扩展汇编给我们提供了那些功能。
### 5. 扩展汇编
在基本内联汇编中,我们只有指令。然而在扩展汇编中,我们可以同时指定操作数。它允许我们指定输入寄存器、输出寄存器以及修饰寄存器列表。GCC 不强制用户必须指定使用的寄存器。我们可以把头疼的事留给 GCC ,这可能可以更好地适应 GCC 的优化。不管怎么说,基本格式为:
```
asm ( 汇编程序模板
: 输出操作数 /* 可选的 */
: 输入操作数 /* 可选的 */
: 修饰寄存器列表 /* 可选的 */
);
```
汇编程序模板由汇编指令组成。每一个操作数由一个操作数约束字符串所描述,其后紧接一个括弧括起的 C 表达式。冒号用于将汇编程序模板和第一个输出操作数分开,另一个(冒号)用于将最后一个输出操作数和第一个输入操作数分开(如果存在的话)。逗号用于分离每一个组内的操作数。总操作数的数目限制在 10 个,或者机器描述中的任何指令格式中的最大操作数数目,以较大者为准。
如果没有输出操作数但存在输入操作数,你必须将两个连续的冒号放置于输出操作数原本会放置的地方周围。
示例:
```
asm ("cld\n\t"
"rep\n\t"
"stosl"
: /* 无输出寄存器 */
: "c" (count), "a" (fill_value), "D" (dest)
: "%ecx", "%edi"
);
```
现在来看看这段代码是干什么的?以上的内联汇编是将 `fill_value` 值连续 `count` 次拷贝到寄存器 `edi` 所指位置(LCTT 译注:每执行 stosl 一次,寄存器 edi 的值会递增或递减,这取决于是否设置了 direction 标志,因此以上代码实则初始化一个内存块)。 它也告诉 gcc 寄存器 `ecx` 和 `edi` 一直无效(LCTT 译注:原文为 eax ,但代码修饰寄存器列表中为 ecx,因此这可能为作者的纰漏。)。为了更加清晰地说明,让我们再看一个示例。
```
int a=10, b;
asm ("movl %1, %%eax;
movl %%eax, %0;"
:"=r"(b) /* 输出 */
:"r"(a) /* 输入 */
:"%eax" /* 修饰寄存器 */
);
```
这里我们所做的是使用汇编指令使 ’b’ 变量的值等于 ’a’ 变量的值。一些有意思的地方是:
* "b" 为输出操作数,用 %0 引用,并且 "a" 为输入操作数,用 %1 引用。
* "r" 为操作数约束。之后我们会更详细地了解约束(字符串)。目前,"r" 告诉 GCC 可以使用任一寄存器存储操作数。输出操作数约束应该有一个约束修饰符 "=" 。这修饰符表明它是一个只读的输出操作数。
* 寄存器名字以两个 % 为前缀。这有利于 GCC 区分操作数和寄存器。操作数以一个 % 为前缀。
* 第三个冒号之后的修饰寄存器 %eax 用于告诉 GCC %eax 的值将会在 "asm" 内部被修改,所以 GCC 将不会使用此寄存器存储任何其他值。
当 “asm” 执行完毕, "b" 变量会映射到更新的值,因为它被指定为输出操作数。换句话说, “asm” 内 "b" 变量的修改应该会被映射到 “asm” 外部。
现在,我们可以更详细地看看每一个域。
#### 5.1 汇编程序模板
汇编程序模板包含了被插入到 C 程序的汇编指令集。其格式为:每条指令用双引号圈起,或者整个指令组用双引号圈起。同时每条指令应以分界符结尾。有效的分界符有换行符(`\n`)和分号(`;`)。`\n` 可以紧随一个制表符(`\t`)。我们应该都明白使用换行符或制表符的原因了吧(LCTT 译注:就是为了排版和分隔)?和 C 表达式对应的操作数使用 %0、%1 ... 等等表示。
#### 5.2 操作数
C 表达式用作 “asm” 内的汇编指令操作数。每个操作数前面是以双引号圈起的操作数约束。对于输出操作数,在引号内还有一个约束修饰符,其后紧随一个用于表示操作数的 C 表达式。即,“操作数约束”(C 表达式)是一个通用格式。对于输出操作数,还有一个额外的修饰符。约束字符串主要用于决定操作数的寻址方式,同时也用于指定使用的寄存器。
如果我们使用的操作数多于一个,那么每一个操作数用逗号隔开。
在汇编程序模板中,每个操作数用数字引用。编号方式如下。如果总共有 n 个操作数(包括输入和输出操作数),那么第一个输出操作数编号为 0 ,逐项递增,并且最后一个输入操作数编号为 n - 1 。操作数的最大数目在前一节我们讲过。
输出操作数表达式必须为左值。输入操作数的要求不像这样严格。它们可以为表达式。扩展汇编特性常常用于编译器所不知道的机器指令 ;-)。如果输出表达式无法直接寻址(即,它是一个位域),我们的约束字符串必须给定一个寄存器。在这种情况下,GCC 将会使用该寄存器作为汇编的输出,然后存储该寄存器的内容到输出。
正如前面所陈述的一样,普通的输出操作数必须为只写的; GCC 将会假设指令前的操作数值是死的,并且不需要被(提前)生成。扩展汇编也支持输入-输出或者读-写操作数。
所以现在我们来关注一些示例。我们想要求一个数的5次方结果。为了计算该值,我们使用 `lea` 指令。
```
asm ("leal (%1,%1,4), %0"
: "=r" (five_times_x)
: "r" (x)
);
```
这里我们的输入为 x。我们不指定使用的寄存器。 GCC 将会选择一些输入寄存器,一个输出寄存器,来做我们预期的工作。如果我们想要输入和输出放在同一个寄存器里,我们也可以要求 GCC 这样做。这里我们使用那些读-写操作数类型。这里我们通过指定合适的约束来实现它。
```
asm ("leal (%0,%0,4), %0"
: "=r" (five_times_x)
: "0" (x)
);
```
现在输出和输出操作数位于同一个寄存器。但是我们无法得知是哪一个寄存器。现在假如我们也想要指定操作数所在的寄存器,这里有一种方法。
```
asm ("leal (%%ecx,%%ecx,4), %%ecx"
: "=c" (x)
: "c" (x)
);
```
在以上三个示例中,我们并没有在修饰寄存器列表里添加任何寄存器,为什么?在头两个示例, GCC 决定了寄存器并且它知道发生了什么改变。在最后一个示例,我们不必将 'ecx' 添加到修饰寄存器列表(LCTT 译注: 原文修饰寄存器列表这个单词拼写有错,这里已修正),gcc 知道它表示 x。因此,因为它可以知道 `ecx` 的值,它就不被当作修饰的(寄存器)了。
#### 5.3 修饰寄存器列表
一些指令会破坏一些硬件寄存器内容。我们不得不在修饰寄存器中列出这些寄存器,即汇编函数内第三个 ’**:**’ 之后的域。这可以通知 gcc 我们将会自己使用和修改这些寄存器,这样 gcc 就不会假设存入这些寄存器的值是有效的。我们不用在这个列表里列出输入、输出寄存器。因为 gcc 知道 “asm” 使用了它们(因为它们被显式地指定为约束了)。如果指令隐式或显式地使用了任何其他寄存器,(并且寄存器没有出现在输出或者输出约束列表里),那么就需要在修饰寄存器列表中指定这些寄存器。
如果我们的指令可以修改条件码寄存器(cc),我们必须将 "cc" 添加进修饰寄存器列表。
如果我们的指令以不可预测的方式修改了内存,那么需要将 "memory" 添加进修饰寄存器列表。这可以使 GCC 不会在汇编指令间保持缓存于寄存器的内存值。如果被影响的内存不在汇编的输入或输出列表中,我们也必须添加 **volatile** 关键词。
我们可以按我们的需求多次读写修饰寄存器。参考一下模板内的多指令示例;它假设子例程 \_foo 接受寄存器 `eax` 和 `ecx` 里的参数。
```
asm ("movl %0,%%eax;
movl %1,%%ecx;
call _foo"
: /* no outputs */
: "g" (from), "g" (to)
: "eax", "ecx"
);
```
#### 5.4 Volatile ...?
如果你熟悉内核源码或者类似漂亮的代码,你一定见过许多声明为 `volatile` 或者 `__volatile__`的函数,其跟着一个 `asm` 或者 `__asm__`。我之前提到过关键词 `asm` 和 `__asm__`。那么什么是 `volatile` 呢?
如果我们的汇编语句必须在我们放置它的地方执行(例如,不能为了优化而被移出循环语句),将关键词 `volatile` 放置在 asm 后面、()的前面。以防止它被移动、删除或者其他操作,我们将其声明为 `asm volatile ( ... : ... : ... : ...);`
如果担心发生冲突,请使用 `__volatile__`。
如果我们的汇编只是用于一些计算并且没有任何副作用,不使用 `volatile` 关键词会更好。不使用 `volatile` 可以帮助 gcc 优化代码并使代码更漂亮。
在“一些实用的诀窍”一节中,我提供了多个内联汇编函数的例子。那里我们可以了解到修饰寄存器列表的细节。
### 6. 更多关于约束
到这个时候,你可能已经了解到约束和内联汇编有很大的关联。但我们对约束讲的还不多。约束用于表明一个操作数是否可以位于寄存器和位于哪种寄存器;操作数是否可以为一个内存引用和哪种地址;操作数是否可以为一个立即数和它可能的取值范围(即值的范围),等等。
#### 6.1 常用约束
在许多约束中,只有小部分是常用的。我们来看看这些约束。
1. **寄存器操作数约束(r)**
当使用这种约束指定操作数时,它们存储在通用寄存器(GPR)中。请看下面示例:
`asm ("movl %%eax, %0\n" :"=r"(myval));`
这里,变量 myval 保存在寄存器中,寄存器 eax 的值被复制到该寄存器中,并且 myval 的值从寄存器更新到了内存。当指定 "r" 约束时, gcc 可以将变量保存在任何可用的 GPR 中。要指定寄存器,你必须使用特定寄存器约束直接地指定寄存器的名字。它们为:
```
+---+--------------------+
| r | Register(s) |
+---+--------------------+
| a | %eax, %ax, %al |
| b | %ebx, %bx, %bl |
| c | %ecx, %cx, %cl |
| d | %edx, %dx, %dl |
| S | %esi, %si |
| D | %edi, %di |
+---+--------------------+
```
2. **内存操作数约束(m)**
当操作数位于内存时,任何对它们的操作将直接发生在内存位置,这与寄存器约束相反,后者首先将值存储在要修改的寄存器中,然后将它写回到内存位置。但寄存器约束通常用于一个指令必须使用它们或者它们可以大大提高处理速度的地方。当需要在 “asm” 内更新一个 C 变量,而又不想使用寄存器去保存它的值,使用内存最为有效。例如,IDTR 寄存器的值存储于内存位置 loc 处:
`asm("sidt %0\n" : :"m"(loc));`
3. **匹配(数字)约束**
在某些情况下,一个变量可能既充当输入操作数,也充当输出操作数。可以通过使用匹配约束在 "asm" 中指定这种情况。
`asm ("incl %0" :"=a"(var):"0"(var));`
在操作数那一节中,我们也看到了一些类似的示例。在这个匹配约束的示例中,寄存器 "%eax" 既用作输入变量,也用作输出变量。 var 输入被读进 %eax,并且等递增后更新的 %eax 再次被存储进 var。这里的 "0" 用于指定与第 0 个输出变量相同的约束。也就是,它指定 var 输出实例应只被存储在 "%eax" 中。该约束可用于:
* 在输入从变量读取或变量修改后且修改被写回同一变量的情况
* 在不需要将输入操作数实例和输出操作数实例分开的情况使用匹配约束最重要的意义在于它们可以有效地使用可用寄存器。
其他一些约束:
1. "m" : 允许一个内存操作数,可以使用机器普遍支持的任一种地址。
2. "o" : 允许一个内存操作数,但只有当地址是可偏移的。即,该地址加上一个小的偏移量可以得到一个有效地址。
3. "V" : 一个不允许偏移的内存操作数。换言之,任何适合 "m" 约束而不适合 "o" 约束的操作数。
4. "i" : 允许一个(带有常量)的立即整形操作数。这包括其值仅在汇编时期知道的符号常量。
5. "n" : 允许一个带有已知数字的立即整形操作数。许多系统不支持汇编时期的常量,因为操作数少于一个字宽。对于此种操作数,约束应该使用 'n' 而不是'i'。
6. "g" : 允许任一寄存器、内存或者立即整形操作数,不包括通用寄存器之外的寄存器。
以下约束为 x86 特有。
1. "r" : 寄存器操作数约束,查看上面给定的表格。
2. "q" : 寄存器 a、b、c 或者 d。
3. "I" : 范围从 0 到 31 的常量(对于 32 位移位)。
4. "J" : 范围从 0 到 63 的常量(对于 64 位移位)。
5. "K" : 0xff。
6. "L" : 0xffff。
7. "M" : 0、1、2 或 3 (lea 指令的移位)。
8. "N" : 范围从 0 到 255 的常量(对于 out 指令)。
9. "f" : 浮点寄存器
10. "t" : 第一个(栈顶)浮点寄存器
11. "u" : 第二个浮点寄存器
12. "A" : 指定 `a` 或 `d` 寄存器。这主要用于想要返回 64 位整形数,使用 `d` 寄存器保存最高有效位和 `a` 寄存器保存最低有效位。
#### 6.2 约束修饰符
当使用约束时,对于更精确的控制超过了对约束作用的需求,GCC 给我们提供了约束修饰符。最常用的约束修饰符为:
1. "=" : 意味着对于这条指令,操作数为只写的;旧值会被忽略并被输出数据所替换。
2. "&" : 意味着这个操作数为一个早期改动的操作数,其在该指令完成前通过使用输入操作数被修改了。因此,这个操作数不可以位于一个被用作输出操作数或任何内存地址部分的寄存器。如果在旧值被写入之前它仅用作输入而已,一个输入操作数可以为一个早期改动操作数。
上述的约束列表和解释并不完整。示例可以让我们对内联汇编的用途和用法更好的理解。在下一节,我们会看到一些示例,在那里我们会发现更多关于修饰寄存器列表的东西。
### 7. 一些实用的诀窍
现在我们已经介绍了关于 GCC 内联汇编的基础理论,现在我们将专注于一些简单的例子。将内联汇编函数写成宏的形式总是非常方便的。我们可以在 Linux 内核代码里看到许多汇编函数。(usr/src/linux/include/asm/\*.h)。
1. 首先我们从一个简单的例子入手。我们将写一个两个数相加的程序。
```
int main(void)
{
int foo = 10, bar = 15;
__asm__ __volatile__("addl %%ebx,%%eax"
:"=a"(foo)
:"a"(foo), "b"(bar)
);
printf("foo+bar=%d\n", foo);
return 0;
}
```
这里我们要求 GCC 将 foo 存放于 %eax,将 bar 存放于 %ebx,同时我们也想要在 %eax 中存放结果。'=' 符号表示它是一个输出寄存器。现在我们可以以其他方式将一个整数加到一个变量。
```
__asm__ __volatile__(
" lock ;\n"
" addl %1,%0 ;\n"
: "=m" (my_var)
: "ir" (my_int), "m" (my_var)
: /* 无修饰寄存器列表 */
);
```
这是一个原子加法。为了移除原子性,我们可以移除指令 'lock'。在输出域中,"=m" 表明 my*var 是一个输出且位于内存。类似地,"ir" 表明 my*int 是一个整型,并应该存在于其他寄存器(回想我们上面看到的表格)。没有寄存器位于修饰寄存器列表中。
2. 现在我们将在一些寄存器/变量上展示一些操作,并比较值。
```
__asm__ __volatile__( "decl %0; sete %1"
: "=m" (my_var), "=q" (cond)
: "m" (my_var)
: "memory"
);
```
这里,my\_var 的值减 1 ,并且如果结果的值为 0,则变量 cond 置 1。我们可以通过将指令 "lock;\n\t" 添加为汇编模板的第一条指令以增加原子性。
以类似的方式,为了增加 my\_var,我们可以使用 "incl %0" 而不是 "decl %0"。
这里需要注意的地方是(i)my\_var 是一个存储于内存的变量。(ii)cond 位于寄存器 eax、ebx、ecx、edx 中的任何一个。约束 "=q" 保证了这一点。(iii)同时我们可以看到 memory 位于修饰寄存器列表中。也就是说,代码将改变内存中的内容。
3. 如何置 1 或清 0 寄存器中的一个比特位。作为下一个诀窍,我们将会看到它。
```
__asm__ __volatile__( "btsl %1,%0"
: "=m" (ADDR)
: "Ir" (pos)
: "cc"
);
```
这里,ADDR 变量(一个内存变量)的 'pos' 位置上的比特被设置为 1。我们可以使用 'btrl' 来清除由 'btsl' 设置的比特位。pos 的约束 "Ir" 表明 pos 位于寄存器,并且它的值为 0-31(x86 相关约束)。也就是说,我们可以设置/清除 ADDR 变量上第 0 到 31 位的任一比特位。因为条件码会被改变,所以我们将 "cc" 添加进修饰寄存器列表。
4. 现在我们看看一些更为复杂而有用的函数。字符串拷贝。
```
static inline char * strcpy(char * dest,const char *src)
{
int d0, d1, d2;
__asm__ __volatile__( "1:\tlodsb\n\t"
"stosb\n\t"
"testb %%al,%%al\n\t"
"jne 1b"
: "=&S" (d0), "=&D" (d1), "=&a" (d2)
: "0" (src),"1" (dest)
: "memory");
return dest;
}
```
源地址存放于 esi,目标地址存放于 edi,同时开始拷贝,当我们到达 **0** 时,拷贝完成。约束 "&S"、"&D"、"&a" 表明寄存器 esi、edi 和 eax 早期修饰寄存器,也就是说,它们的内容在函数完成前会被改变。这里很明显可以知道为什么 "memory" 会放在修饰寄存器列表。
我们可以看到一个类似的函数,它能移动双字块数据。注意函数被声明为一个宏。
```
#define mov_blk(src, dest, numwords) \
__asm__ __volatile__ ( \
"cld\n\t" \
"rep\n\t" \
"movsl" \
: \
: "S" (src), "D" (dest), "c" (numwords) \
: "%ecx", "%esi", "%edi" \
)
```
这里我们没有输出,寄存器 ecx、esi和 edi 的内容发生了改变,这是块移动的副作用。因此我们必须将它们添加进修饰寄存器列表。
5. 在 Linux 中,系统调用使用 GCC 内联汇编实现。让我们看看如何实现一个系统调用。所有的系统调用被写成宏(linux/unistd.h)。例如,带有三个参数的系统调用被定义为如下所示的宏。
```
type name(type1 arg1,type2 arg2,type3 arg3) \
{ \
long __res; \
__asm__ volatile ( "int $0x80" \
: "=a" (__res) \
: "0" (__NR_##name),"b" ((long)(arg1)),"c" ((long)(arg2)), \
"d" ((long)(arg3))); \
__syscall_return(type,__res); \
}
```
无论何时调用带有三个参数的系统调用,以上展示的宏就会用于执行调用。系统调用号位于 eax 中,每个参数位于 ebx、ecx、edx 中。最后 "int 0x80" 是一条用于执行系统调用的指令。返回值被存储于 eax 中。
每个系统调用都以类似的方式实现。Exit 是一个单一参数的系统调用,让我们看看它的代码看起来会是怎样。它如下所示。
```
{
asm("movl $1,%%eax; /* SYS_exit is 1 */
xorl %%ebx,%%ebx; /* Argument is in ebx, it is 0 */
int $0x80" /* Enter kernel mode */
);
}
```
Exit 的系统调用号是 1,同时它的参数是 0。因此我们分配 eax 包含 1,ebx 包含 0,同时通过 `int $0x80` 执行 `exit(0)`。这就是 exit 的工作原理。
### 8. 结束语
这篇文档已经将 GCC 内联汇编过了一遍。一旦你理解了基本概念,你就可以按照自己的需求去使用它们了。我们看了许多例子,它们有助于理解 GCC 内联汇编的常用特性。
GCC 内联是一个极大的主题,这篇文章是不完整的。更多关于我们讨论过的语法细节可以在 GNU 汇编器的官方文档上获取。类似地,要获取完整的约束列表,可以参考 GCC 的官方文档。
当然,Linux 内核大量地使用了 GCC 内联。因此我们可以在内核源码中发现许多各种各样的例子。它们可以帮助我们很多。
如果你发现任何的错别字,或者本文中的信息已经过时,请告诉我们。
### 9. 参考
1. [Brennan’s Guide to Inline Assembly](http://www.delorie.com/djgpp/doc/brennan/brennan_att_inline_djgpp.html)
2. [Using Assembly Language in Linux](http://linuxassembly.org/articles/linasm.html)
3. [Using as, The GNU Assembler](http://www.gnu.org/manual/gas-2.9.1/html_mono/as.html)
4. [Using and Porting the GNU Compiler Collection (GCC)](http://gcc.gnu.org/onlinedocs/gcc_toc.html)
5. [Linux Kernel Source](http://ftp.kernel.org/)
---
via: <http://www.ibiblio.org/gferg/ldp/GCC-Inline-Assembly-HOWTO.html>
作者:[Sandeep.S](mailto:[email protected]) 译者:[cposture](https://github.com/cposture) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
| 200 | OK | Copyright (C)2003 Sandeep S.
This document is free; you can redistribute and/or modify this under the terms of the GNU General Public License as published by the Free Software Foundation; either version 2 of the License, or (at your option) any later version.
This document is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
Kindly forward feedback and criticism to
[Sandeep.S](mailto:[email protected]).
I will be indebted to anybody who points out errors and inaccuracies in this
document; I shall rectify them as soon as I am informed.
I express my sincere appreciation to GNU people for providing such a great feature. Thanks to Mr.Pramode C E for all the helps he did. Thanks to friends at the Govt Engineering College, Trichur for their moral-support and cooperation, especially to Nisha Kurur and Sakeeb S. Thanks to my dear teachers at Govt Engineering College, Trichur for their cooperation.
Additionally, thanks to Phillip, Brennan Underwood and [email protected]; Many things here are shamelessly stolen from their works.
We are here to learn about GCC inline assembly. What this inline stands for?
We can instruct the compiler to insert the code of a function into the code of its callers, to the point where actually the call is to be made. Such functions are inline functions. Sounds similar to a Macro? Indeed there are similarities.
What is the benefit of inline functions?
This method of inlining reduces the function-call overhead. And if any of the
actual argument values are constant, their known values may permit
simplifications at compile time so that not all of the inline function’s code
needs to be included. The effect on code size is less predictable, it depends
on the particular case. To declare an inline function, we’ve to use the keyword
`inline`
in its declaration.
Now we are in a position to guess what is inline assembly. Its just some
assembly routines written as inline functions. They are handy, speedy and very
much useful in system programming. Our main focus is to study the basic format
and usage of (GCC) inline assembly functions. To declare inline assembly
functions, we use the keyword `asm`
.
Inline assembly is important primarily because of its ability to operate and make its output visible on C variables. Because of this capability, "asm" works as an interface between the assembly instructions and the "C" program that contains it.
GCC, the GNU C Compiler for Linux, uses **AT&T**/**UNIX**
assembly syntax. Here we’ll be using AT&T syntax for assembly coding. Don’t
worry if you are not familiar with AT&T syntax, I will teach you. This is
quite different from Intel syntax. I shall give the major differences.
The direction of the operands in AT&T syntax is opposite to that of Intel. In Intel syntax the first operand is the destination, and the second operand is the source whereas in AT&T syntax the first operand is the source and the second operand is the destination. ie,
"Op-code dst src" in Intel syntax changes to
"Op-code src dst" in AT&T syntax.
Register names are prefixed by % ie, if eax is to be used, write %eax.
AT&T immediate operands are preceded by ’$’. For static "C" variables also prefix a ’$’. In Intel syntax, for hexadecimal constants an ’h’ is suffixed, instead of that, here we prefix ’0x’ to the constant. So, for hexadecimals, we first see a ’$’, then ’0x’ and finally the constants.
In AT&T syntax the size of memory operands is determined from the last character of the op-code name. Op-code suffixes of ’b’, ’w’, and ’l’ specify byte(8-bit), word(16-bit), and long(32-bit) memory references. Intel syntax accomplishes this by prefixing memory operands (not the op-codes) with ’byte ptr’, ’word ptr’, and ’dword ptr’.
Thus, Intel "mov al, byte ptr foo" is "movb foo, %al" in AT&T syntax.
In Intel syntax the base register is enclosed in ’[’ and ’]’ where as in AT&T they change to ’(’ and ’)’. Additionally, in Intel syntax an indirect memory reference is like
section:[base + index*scale + disp], which changes to
section:disp(base, index, scale) in AT&T.
One point to bear in mind is that, when a constant is used for disp/scale, ’$’ shouldn’t be prefixed.
Now we saw some of the major differences between Intel syntax and AT&T syntax. I’ve wrote only a few of them. For a complete information, refer to GNU Assembler documentations. Now we’ll look at some examples for better understanding.
```
```
+------------------------------+------------------------------------+
| Intel Code | AT&T Code |
+------------------------------+------------------------------------+
| mov eax,1 | movl $1,%eax |
| mov ebx,0ffh | movl $0xff,%ebx |
| int 80h | int $0x80 |
| mov ebx, eax | movl %eax, %ebx |
| mov eax,[ecx] | movl (%ecx),%eax |
| mov eax,[ebx+3] | movl 3(%ebx),%eax |
| mov eax,[ebx+20h] | movl 0x20(%ebx),%eax |
| add eax,[ebx+ecx*2h] | addl (%ebx,%ecx,0x2),%eax |
| lea eax,[ebx+ecx] | leal (%ebx,%ecx),%eax |
| sub eax,[ebx+ecx*4h-20h] | subl -0x20(%ebx,%ecx,0x4),%eax |
+------------------------------+------------------------------------+
The format of basic inline assembly is very much straight forward. Its basic form is
`asm("assembly code");`
Example.
```
```
asm("movl %ecx %eax"); /* moves the contents of ecx to eax */
__asm__("movb %bh (%eax)"); /*moves the byte from bh to the memory pointed by eax */
You might have noticed that here I’ve used `asm`
and `__asm__`
. Both
are valid. We can use `__asm__`
if the keyword `asm`
conflicts with
something in our program. If we have more than one instructions, we write one per
line in double quotes, and also suffix a ’\n’ and ’\t’ to the
instruction. This is because gcc sends each instruction as a string to **as**(GAS) and
by using the newline/tab we send correctly formatted lines to the assembler.
Example.
```
```
__asm__ ("movl %eax, %ebx\n\t"
"movl $56, %esi\n\t"
"movl %ecx, $label(%edx,%ebx,$4)\n\t"
"movb %ah, (%ebx)");
If in our code we touch (ie, change the contents) some registers and return from asm without fixing those changes, something bad is going to happen. This is because GCC have no idea about the changes in the register contents and this leads us to trouble, especially when compiler makes some optimizations. It will suppose that some register contains the value of some variable that we might have changed without informing GCC, and it continues like nothing happened. What we can do is either use those instructions having no side effects or fix things when we quit or wait for something to crash. This is where we want some extended functionality. Extended asm provides us with that functionality.
In basic inline assembly, we had only instructions. In extended assembly, we can also specify the operands. It allows us to specify the input registers, output registers and a list of clobbered registers. It is not mandatory to specify the registers to use, we can leave that head ache to GCC and that probably fit into GCC’s optimization scheme better. Anyway the basic format is:
```
```
asm ( assembler template
: output operands /* optional */
: input operands /* optional */
: list of clobbered registers /* optional */
);
The assembler template consists of assembly instructions. Each operand is described by an operand-constraint string followed by the C expression in parentheses. A colon separates the assembler template from the first output operand and another separates the last output operand from the first input, if any. Commas separate the operands within each group. The total number of operands is limited to ten or to the maximum number of operands in any instruction pattern in the machine description, whichever is greater.
If there are no output operands but there are input operands, you must place two consecutive colons surrounding the place where the output operands would go.
Example:
```
```
asm ("cld\n\t"
"rep\n\t"
"stosl"
: /* no output registers */
: "c" (count), "a" (fill_value), "D" (dest)
: "%ecx", "%edi"
);
Now, what does this code do? The above inline fills the `fill_value`
`count`
times to the location pointed to by the register `edi`
. It
also says to gcc that, the contents of registers `eax`
and `edi`
are no
longer valid. Let us see one more example to make things more clearer.
```
```
int a=10, b;
asm ("movl %1, %%eax;
movl %%eax, %0;"
:"=r"(b) /* output */
:"r"(a) /* input */
:"%eax" /* clobbered register */
);
Here what we did is we made the value of ’b’ equal to that of ’a’ using assembly instructions. Some points of interest are:
When the execution of "asm" is complete, "b" will reflect the updated value, as it is specified as an output operand. In other words, the change made to "b" inside "asm" is supposed to be reflected outside the "asm".
Now we may look each field in detail.
The assembler template contains the set of assembly instructions that gets inserted inside the C program. The format is like: either each instruction should be enclosed within double quotes, or the entire group of instructions should be within double quotes. Each instruction should also end with a delimiter. The valid delimiters are newline(\n) and semicolon(;). ’\n’ may be followed by a tab(\t). We know the reason of newline/tab, right?. Operands corresponding to the C expressions are represented by %0, %1 ... etc.
C expressions serve as operands for the assembly instructions inside "asm". Each operand is written as first an operand constraint in double quotes. For output operands, there’ll be a constraint modifier also within the quotes and then follows the C expression which stands for the operand. ie,
"constraint" (C expression) is the general form. For output operands an additional modifier will be there. Constraints are primarily used to decide the addressing modes for operands. They are also used in specifying the registers to be used.
If we use more than one operand, they are separated by comma.
In the assembler template, each operand is referenced by numbers. Numbering is done as follows. If there are a total of n operands (both input and output inclusive), then the first output operand is numbered 0, continuing in increasing order, and the last input operand is numbered n-1. The maximum number of operands is as we saw in the previous section.
Output operand expressions must be lvalues. The input operands are not restricted like this. They may be expressions. The extended asm feature is most often used for machine instructions the compiler itself does not know as existing ;-). If the output expression cannot be directly addressed (for example, it is a bit-field), our constraint must allow a register. In that case, GCC will use the register as the output of the asm, and then store that register contents into the output.
As stated above, ordinary output operands must be write-only; GCC will assume that the values in these operands before the instruction are dead and need not be generated. Extended asm also supports input-output or read-write operands.
So now we concentrate on some examples. We want to multiply a number by 5.
For that we use the instruction `lea`
.
```
```
asm ("leal (%1,%1,4), %0"
: "=r" (five_times_x)
: "r" (x)
);
Here our input is in ’x’. We didn’t specify the register to be used. GCC will choose some register for input, one for output and does what we desired. If we want the input and output to reside in the same register, we can instruct GCC to do so. Here we use those types of read-write operands. By specifying proper constraints, here we do it.
```
```
asm ("leal (%0,%0,4), %0"
: "=r" (five_times_x)
: "0" (x)
);
Now the input and output operands are in the same register. But we don’t know which register. Now if we want to specify that also, there is a way.
```
```
asm ("leal (%%ecx,%%ecx,4), %%ecx"
: "=c" (x)
: "c" (x)
);
In all the three examples above, we didn’t put any register to the clobber
list. why? In the first two examples, GCC decides the registers and it knows
what changes happen. In the last one, we don’t have to put `ecx`
on the c
lobberlist, gcc knows it goes into x. Therefore, since it can know the value
of `ecx`
, it isn’t considered clobbered.
Some instructions clobber some hardware registers. We have to list those
registers in the clobber-list, ie the field after the third ’**:**’ in the
asm function. This is to inform gcc that we will use and modify them
ourselves. So gcc will not assume that the values it loads into these
registers will be valid. We shoudn’t list the input and output registers in
this list. Because, gcc knows that "asm" uses them
(because they are specified explicitly as constraints).
If the instructions use any other registers, implicitly or explicitly
(and the registers are not present either in input or in the output
constraint list), then those registers have to be specified in the
clobbered list.
If our instruction can alter the condition code register, we have to add "cc" to the list of clobbered registers.
If our instruction modifies memory in an unpredictable fashion, add
"memory" to the list of clobbered registers. This will cause GCC to not keep
memory values cached in registers across the assembler instruction. We also
have to add the **volatile** keyword if the memory affected is not listed
in the inputs or outputs of the asm.
We can read and write the clobbered registers as many times as we like.
Consider the example of multiple instructions in a template; it assumes the
subroutine _foo accepts arguments in registers `eax`
and `ecx`
.
```
```
asm ("movl %0,%%eax;
movl %1,%%ecx;
call _foo"
: /* no outputs */
: "g" (from), "g" (to)
: "eax", "ecx"
);
If you are familiar with kernel sources or some beautiful code like that,
you must have seen many functions declared as `volatile`
or
`__volatile__`
which follows an `asm`
or `__asm__`
. I mentioned
earlier about the keywords `asm`
and `__asm__`
. So what is this
`volatile`
?
If our assembly statement must execute where we put it,
(i.e. must not be moved out of a loop as an optimization), put the keyword
`volatile`
after asm and before the ()’s. So to keep it from moving,
deleting and all, we declare it as
`asm volatile ( ... : ... : ... : ...);`
Use `__volatile__`
when we have to be verymuch careful.
If our assembly is just for doing some calculations and doesn’t have any
side effects, it’s better not to use the keyword `volatile`
. Avoiding it
helps gcc in optimizing the code and making it more beautiful.
In the section `Some Useful Recipes`
, I have provided many examples for inline asm
functions. There we can see the clobber-list in detail.
By this time, you might have understood that constraints have got a lot to do with inline assembly. But we’ve said little about constraints. Constraints can say whether an operand may be in a register, and which kinds of register; whether the operand can be a memory reference, and which kinds of address; whether the operand may be an immediate constant, and which possible values (ie range of values) it may have.... etc.
There are a number of constraints of which only a few are used frequently. We’ll have a look at those constraints.
When operands are specified using this constraint, they get stored in General Purpose Registers(GPR). Take the following example:
` asm ("movl %%eax, %0\n" :"=r"(myval)); `
Here the variable myval is kept in a register, the value in register
`eax`
is copied onto that register, and the value of `myval`
is
updated into the memory from this register. When the "r" constraint is
specified, gcc may keep the variable in any of the available GPRs.
To specify the register, you must directly specify the register names by
using specific register constraints. They are:
```
```
+---+--------------------+
| r | Register(s) |
+---+--------------------+
| a | %eax, %ax, %al |
| b | %ebx, %bx, %bl |
| c | %ecx, %cx, %cl |
| d | %edx, %dx, %dl |
| S | %esi, %si |
| D | %edi, %di |
+---+--------------------+
When the operands are in the memory, any operations performed on them will occur directly in the memory location, as opposed to register constraints, which first store the value in a register to be modified and then write it back to the memory location. But register constraints are usually used only when they are absolutely necessary for an instruction or they significantly speed up the process. Memory constraints can be used most efficiently in cases where a C variable needs to be updated inside "asm" and you really don’t want to use a register to hold its value. For example, the value of idtr is stored in the memory location loc:
`asm("sidt %0\n" : :"m"(loc));`
In some cases, a single variable may serve as both the input and the output operand. Such cases may be specified in "asm" by using matching constraints.
` asm ("incl %0" :"=a"(var):"0"(var));`
We saw similar examples in operands subsection also. In this example for matching constraints, the register %eax is used as both the input and the output variable. var input is read to %eax and updated %eax is stored in var again after increment. "0" here specifies the same constraint as the 0th output variable. That is, it specifies that the output instance of var should be stored in %eax only. This constraint can be used:
The most important effect of using matching restraints is that they lead to the efficient use of available registers.
Some other constraints used are:
Following constraints are x86 specific.
While using constraints, for more precise control over the effects of constraints, GCC provides us with constraint modifiers. Mostly used constraint modifiers are
The list and explanation of constraints is by no means complete. Examples can give a better understanding of the use and usage of inline asm. In the next section we’ll see some examples, there we’ll find more about clobber-lists and constraints.
Now we have covered the basic theory about GCC inline assembly, now we shall concentrate on some simple examples. It is always handy to write inline asm functions as MACRO’s. We can see many asm functions in the kernel code. (/usr/src/linux/include/asm/*.h).
First we start with a simple example. We’ll write a program to add two numbers.
```
```
int main(void)
{
int foo = 10, bar = 15;
__asm__ __volatile__("addl %%ebx,%%eax"
:"=a"(foo)
:"a"(foo), "b"(bar)
);
printf("foo+bar=%d\n", foo);
return 0;
}
Here we insist GCC to store foo in %eax, bar in %ebx and we also want the result in %eax. The ’=’ sign shows that it is an output register. Now we can add an integer to a variable in some other way.
```
```
__asm__ __volatile__(
" lock ;\n"
" addl %1,%0 ;\n"
: "=m" (my_var)
: "ir" (my_int), "m" (my_var)
: /* no clobber-list */
);
This is an atomic addition. We can remove the instruction ’lock’ to remove the atomicity. In the output field, "=m" says that my_var is an output and it is in memory. Similarly, "ir" says that, my_int is an integer and should reside in some register (recall the table we saw above). No registers are in the clobber list.
Now we’ll perform some action on some registers/variables and compare the value.
```
```
__asm__ __volatile__( "decl %0; sete %1"
: "=m" (my_var), "=q" (cond)
: "m" (my_var)
: "memory"
);
Here, the value of my_var is decremented by one and if the resulting value is `0`
then, the variable cond is set. We can add atomicity by adding an instruction "lock;\n\t"
as the first instruction in assembler template.
In a similar way we can use "incl %0" instead of "decl %0", so as to increment my_var.
Points to note here are that (i) my_var is a variable residing in memory. (ii) cond is in any of the registers eax, ebx, ecx and edx. The constraint "=q" guarantees it. (iii) And we can see that memory is there in the clobber list. ie, the code is changing the contents of memory.
How to set/clear a bit in a register? As next recipe, we are going to see it.
```
```
__asm__ __volatile__( "btsl %1,%0"
: "=m" (ADDR)
: "Ir" (pos)
: "cc"
);
Here, the bit at the position ’pos’ of variable at ADDR ( a memory variable ) is set to `1`
We can use ’btrl’ for ’btsl’ to clear the bit. The constraint "Ir" of pos says that, pos is in a register,
and it’s value ranges from 0-31 (x86 dependant constraint). ie, we can set/clear any bit from 0th to 31st
of the variable at ADDR. As the condition codes will be changed, we are adding "cc" to clobberlist.
Now we look at some more complicated but useful function. String copy.
```
```
static inline char * strcpy(char * dest,const char *src)
{
int d0, d1, d2;
__asm__ __volatile__( "1:\tlodsb\n\t"
"stosb\n\t"
"testb %%al,%%al\n\t"
"jne 1b"
: "=&S" (d0), "=&D" (d1), "=&a" (d2)
: "0" (src),"1" (dest)
: "memory");
return dest;
}
The source address is stored in esi, destination in edi, and then starts the
copy, when we reach at **0**, copying is complete. Constraints "&S", "&D", "&a"
say that the registers esi, edi and eax are early clobber registers, ie, their contents will
change before the completion of the function. Here also it’s clear that why memory is in clobberlist.
We can see a similar function which moves a block of double words. Notice that the function is declared as a macro.
```
```
#define mov_blk(src, dest, numwords) \
__asm__ __volatile__ ( \
"cld\n\t" \
"rep\n\t" \
"movsl" \
: \
: "S" (src), "D" (dest), "c" (numwords) \
: "%ecx", "%esi", "%edi" \
)
Here we have no outputs, so the changes that happen to the contents of the registers ecx, esi and edi are side effects of the block movement. So we have to add them to the clobber list.
In Linux, system calls are implemented using GCC inline assembly. Let us look how a system call is implemented. All the system calls are written as macros (linux/unistd.h). For example, a system call with three arguments is defined as a macro as shown below.
```
```
#define _syscall3(type,name,type1,arg1,type2,arg2,type3,arg3) \
type name(type1 arg1,type2 arg2,type3 arg3) \
{ \
long __res; \
__asm__ volatile ( "int $0x80" \
: "=a" (__res) \
: "0" (__NR_##name),"b" ((long)(arg1)),"c" ((long)(arg2)), \
"d" ((long)(arg3))); \
__syscall_return(type,__res); \
}
Whenever a system call with three arguments is made, the macro shown above is used to make the call. The syscall number is placed in eax, then each parameters in ebx, ecx, edx. And finally "int 0x80" is the instruction which makes the system call work. The return value can be collected from eax.
Every system calls are implemented in a similar way. Exit is a single parameter syscall and let’s see how it’s code will look like. It is as shown below.
```
```
{
asm("movl $1,%%eax; /* SYS_exit is 1 */
xorl %%ebx,%%ebx; /* Argument is in ebx, it is 0 */
int $0x80" /* Enter kernel mode */
);
}
The number of exit is "1" and here, it’s parameter is 0. So we arrange eax to
contain 1 and ebx to contain 0 and by `int $0x80`
, the `exit(0)`
is
executed. This is how exit works.
This document has gone through the basics of GCC Inline Assembly. Once you have understood the basic concept it is not difficult to take steps by your own. We saw some examples which are helpful in understanding the frequently used features of GCC Inline Assembly.
GCC Inlining is a vast subject and this article is by no means complete. More details about the syntax’s we discussed about is available in the official documentation for GNU Assembler. Similarly, for a complete list of the constraints refer to the official documentation of GCC.
And of-course, the Linux kernel use GCC Inline in a large scale. So we can find many examples of various kinds in the kernel sources. They can help us a lot.
If you have found any glaring typos, or outdated info in this document, please let us know. |
7,691 | 生日快乐,Debian GNU/Linux 23 岁啦! | http://news.softpedia.com/news/debian-gnu-linux-operating-system-turns-23-happy-birthday-507364.shtml | 2016-08-17T12:22:00 | [
"Debian"
] | https://linux.cn/article-7691-1.html | 今天,2016 年 8 月 16 日,Debian 项目组的 Laura Arjona Reina 宣布,Debian GNU/Linux 操作系统 23 岁啦!
是的,你没看错,就是 23 年前, 1993 年的今天, Debian GNU/Linux 发行版呱呱落地,项目创始人 Ian Murdock 发布了第一个开发版 0.01。并于三年后,发布了第一个官方正式版本 1.0。

“这个我们珍爱的操作系统来自于我们这些年的努力,感谢这 23 年来所有的贡献者,Debian 生日快乐!” 在今天的[公告](https://bits.debian.org/2016/08/debian-turns-23.html)中写到,“如果你附近有 Debian Day 2016 庆祝活动的话,欢迎你参加!如果没有的话,那你可以自己组织一场小小的庆祝活动!”
### 生日快乐,Debian!
从 1993 年 8 月 16 日发布 0.01 版开始,Debian GNU/Linux 操作系统已经经历了 14 个版本,它们的名字是: Debian 1.1 "Buzz"、Debian 1.2 "Rex"、 Debian 1.3 "Bo"、 Debian 2.0 "Hamm"、 Debian 2.1 "Slink"、 Debian 2.2 "Potato"、 Debian 3.0 "Woody"、 Debian 3.1 "Sarge"、 Debian 4.0 "Etch"、 Debian 5.0 "Lenny"、 Debian 6.0 "Squeeze"、 Debian 7.0 "Wheezy" 和 Debian 8 "Jessie"。
下一个 Debian GNU/Linux 版本是 Debian 9 "Stretch",将在今年年底到来,但是现在还没有定下具体发布时间。现在 Debian 项目正在寻求优秀的设计师来为即将到来的新操作系统打造漂亮的设计,更多细节可参见 [Wiki 页面](https://wiki.debian.org/DebianDesktop/Artwork/Stretch)。
Happy birthday, Debian!
| 301 | Moved Permanently | null |
7,692 | 在推特上我关注的人 72% 都是男性 | https://emptysqua.re/blog/gender-of-twitter-users-i-follow/ | 2016-08-18T00:37:31 | [] | https://linux.cn/article-7692-1.html | 
至少,这是我的估计。推特并不会询问用户的性别,因此我 [写了一个程序](https://www.proporti.onl/) ,根据姓名猜测他们的性别。在那些关注我的人当中,性别分布甚至更糟,83% 的是男性。据我所知,其他的还不全都是女性。
修正第一个数字并不是什么神秘的事:我注意寻找更多支持我兴趣的女性专家,并且关注他们。
另一方面,第二个数字,我只能只能轻微影响一点,但是我也打算改进下。我在推特上的关系网应该代表的是软件行业的多元化未来,而不是不公平的现状。
### 我应该怎么估算呢
我开始估算我关注的人(推特的上的术语是“朋友”)的性别分布,然后发现这格外的难。[推特的分析](https://analytics.twitter.com/)给我展示了如下的结果, 关于关注我的人的性别估算:

因此,推特的分析将我的关注者分成了三类:男性、女性、未知,并且给我们展示了前面两组的比例。(性别二值化现象在这里并不存在——未知性别的人都集中在组织的推特账号上。)但是我关注的人的性别比例,推特并没有告诉我。 [而这就是可以改进的](http://english.stackexchange.com/questions/14952/that-which-is-measured-improves),然后我开始搜索能够帮我估算这个数字的服务,最终发现了 [FollowerWonk](https://moz.com/followerwonk/) 。
FollowerWonk 估算我关注的人里面有 71% 都是男性。这个估算准确吗? 为了评估一下,我把 FollowerWonk 和 Twitter 对我关注的人的进行了估算,结果如下:
**推特分析**
| | 男性 | 女性 |
| --- | --- | --- |
| **我的关注者** | 83% | 17% |
**FollowerWonk**
| | 男性 | 女性 |
| --- | --- | --- |
| **我的关注者** | 81% | 19% |
| **我关注的人** | 72% | 28% |
FollowerWonk 的分析显示我的关注者中 81% 的人都是男性,很接近推特分析的数字。这个结果还说得过去。如果FollowerWonk 和 Twitter 在我的关注者的性别比例上是一致的,这就表明 FollowerWonk 对我关注的人的性别估算也应当是合理的。使用 FollowerWonk 我就能养成估算这些数字的爱好,并且做出改进。
然而,使用 FollowerWonk 检测我关注的人的性别分布一个月需要 30 美元,这真是一个昂贵的爱好。我并不需要FollowerWonk 的所有的功能。我能很经济的解决只需要性别分布的问题吗?
因为 FollowerWonk 的估算数字看起来比较合理,我试图做一个自己的 FollowerWonk 。使用 Python 和[一些好心的费城人写的 Twitter API 封装类](https://github.com/bear/python-twitter/graphs/contributors)(LCTT 译注:Twitter API 封装类是由 Mike Taylor 等一批费城人在 github 上开源的一个项目),我开始下载我所有关注的人和我所有的关注者的简介。我马上就发现推特的速率限制是很低,因此我随机的采样了一部分用户。
我写了一个初步的程序,在所有我关注的人的简介中搜索一个和性别相关的代词。例如,如果简介中包含了“she”或者“her”这样的字眼,可能这就属于一个女性,如果简介中包含了“they”或者“them”,那么可能这就是性别未知的。但是大多数简介中不会出现这些代词。对于这种简介,和性别关联最紧密的信息就是姓名了。例如:@gvanrossum 的姓名那一栏是“Guido van Rossum”,第一姓名是“Guido”,这表明 @gvanrossum 是一个女的。当找不到代词的时候,我就使用名字来评估性别估算数字。
我的脚本把每个名字的一部分传到性别检测机中去检测性别。[性别检测机](https://pypi.python.org/pypi/SexMachine/)也有可预见的失败,比如错误的把“Brooklyn Zen Center”当做一个名叫“Brooklyn”的女性,但是它的评估结果与 FollowerWonk 和 Twitter 的相比也是很合理的:
| | 非男非女 | 男性 | 女性 | 性别未知的 |
| --- | --- | --- | --- | --- |
| 我关注的人 | 1 | 168 | 66 | 173 |
| | 0% | 72% | 28% | |
| 我的关注者 | 0 | 459 | 108 | 433 |
| | 0% | 81% | 19% | |
(数据基于我所有的408个关注的人和1000个关注者。)
### 了解你的数字
我想你们也能检测你们推特关系网的性别分布。所以我将“Proportional”应用发布到 PythonAnywhere 这个便利的服务上,每月仅需 10 美元:
这个应用可能会在速率上有限制,超过会失败,因此请温柔的对待它。github 上放了源代码[代码](https://github.com/ajdavis/twitter-gender-distribution) ,也有命令行的工具。
是谁代表了你的推特关系网?你还在忍受那些在过去几十年里一直在谈论的软件行业的不公平的男女分布吗?或者你的关系网看起来像软件行业的未来吗?让我们了解我们的数字并且改善他们。
---
via: <https://emptysqua.re/blog/gender-of-twitter-users-i-follow/>
作者:[A. Jesse Jiryu Davis](https://disqus.com/by/AJesseJiryuDavis/) 译者:[Flowsnow](https://github.com/Flowsnow) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | null |
7,693 | Linux 平台下 Python 脚本编程入门(一) | http://www.tecmint.com/learn-python-programming-and-scripting-in-linux/ | 2016-08-18T08:09:00 | [
"Python"
] | https://linux.cn/article-7693-1.html | 众所周知,系统管理员需要精通一门脚本语言,而且招聘机构列出的职位需求上也会这么写。大多数人会认为 Bash (或者其他的 shell 语言)用起来很方便,但一些强大的语言(比如 Python)会给你带来一些其它的好处。

*在 Linux 中学习 Python 脚本编程*
首先,我们会使用 Python 的命令行工具,还会接触到 Python 的面向对象特性(这篇文章的后半部分会谈到它)。
学习 Python 可以助力于你在[桌面应用开发](http://www.tecmint.com/create-gui-applications-in-linux/)及[数据科学领域](http://www.datasciencecentral.com/profiles/blogs/the-guide-to-learning-python-for-data-science-2)的职业发展。
容易上手,广泛使用,拥有海量“开箱即用”的模块(它是一组包含 Python 语句的外部文件),Python 理所当然地成为了美国计算机专业大学生在一年级时所上的程序设计课所用语言的不二之选。
在这个由两篇文章构成的系列中,我们将回顾 Python 的基础部分,希望初学编程的你能够将这篇实用的文章作为一个编程入门的跳板,和日后使用 Python 时的一篇快速指引。
### Linux 中的 Python
Python 2.x 和 3.x 通常已经内置在现代 Linux 发行版中,你可以立刻使用它。你可以终端模拟器中输入 `python` 或 `python3` 来进入 Python shell, 并输入 `quit()` 退出。
```
$ which python
$ which python3
$ python -v
$ python3 -v
$ python
>>> quit()
$ python3
>>> quit()
```

*在 Linux 中运行 Python 命令*
如果你希望在键入 `python` 时使用 Python 3.x 而不是 2.x,你可以像下面一样更改对应的符号链接:
```
$ sudo rm /usr/bin/python
$ cd /usr/bin
$ ln -s python3.2 python # Choose the Python 3.x binary here
```

*删除 Python 2,使用 Python 3*
顺便一提,有一点需要注意:尽管 Python 2.x 仍旧被使用,但它并不会被积极维护。因此,你可能要考虑像上面指示的那样来切换到 3.x。2.x 和 3.x 的语法有一些不同,我们会在这个系列文章中使用后者。
另一个在 Linux 中使用 Python 的方法是通过 IDLE (<ruby> Python 集成开发环境 <rp> ( </rp> <rt> the Python Integrated Development Environment </rt> <rp> ) </rp></ruby>),这是一个为编写 Python 代码而生的图形用户界面。在安装它之前,你最好查看一下适用于你的 Linux 发行版的 IDLE 可用版本。
```
# aptitude search idle [Debian 及其衍生发行版]
# yum search idle [CentOS 和 Fedora]
# dnf search idle [Fedora 23+ 版本]
```
然后,你可以像下面一样安装它:
```
$ sudo aptitude install idle-python3.2 # I'm using Linux Mint 13
```
安装成功后,你会看到 IDLE 的运行画面。它很像 Python shell,但是你可以用它做更多 Python shell 做不了的事。
比如,你可以:
1. 轻松打开外部文件 (File → Open);

*Python Shell*
2. 复制 (`Ctrl + C`) 和粘贴 (`Ctrl + V`) 文本;
3. 查找和替换文本;
4. 显示可能的代码补全(一个在其他 IDE 里可能叫做“智能感知”或者“自动补完”的功能);
5. 更改字体和字号,等等。
最厉害的是,你可以用 IDLE 创建桌面应用。
我们在这两篇文章中不会开发桌面应用,所以你可以根据喜好来选择 IDLE 或 Python shell 去运行下面的例子。
### Python 中的基本运算
就像你预料的那样,你能够直接进行算术操作(你可以在你的所有运算中使用足够多的括号!),还可以轻松地使用 Python 拼接字符串。
你还可以将运算结果赋给一个变量,然后在屏幕上显示它。Python 有一个叫做拼接 (concatenation) 的实用功能——给 print 函数提供一串用逗号分隔的变量和/或字符串,它会返回一个由你刚才提供的变量依序构成的句子:
```
>>> a = 5
>>> b = 8
>>> x = b / a
>>> x
1.6
>>> print(b, "divided by", a, "equals", x)
```
注意,你可以将不同类型的变量(数字,字符串,布尔符号等等)混合在一起。当你将一个值赋给一个变量后,你可以随后更改它的类型,不会有任何问题(因此,Python 被称为动态类型语言)。
如果你尝试在静态类型语言中(如 Java 或 C#)做这件事,它将抛出一个错误。

*学习 Python 的基本操作*
### 面向对象编程的简单介绍
在面向对象编程(OOP)中,程序中的所有实体都会由对象的形式呈现,并且它们可以与其他对象交互。因此,对象拥有属性,而且大多数对象可以执行动作(这被称为对象的方法)。
举个例子:我们来想象一下,创建一个对象“狗”。它可能拥有的一些属性有`颜色`、`品种`、`年龄`等等,而它可以完成的动作有 `叫()`、`吃()`、`睡觉()`,诸如此类。
你可以看到,方法名后面会跟着一对括号,括号当中可能会包含一个或多个参数(向方法中传递的值),也有可能什么都不包含。
我们用 Python 的基本对象类型之一——列表来解释这些概念。
### 解释对象的属性和方法:Python 中的列表
列表是条目的有序组合,而这些条目所属的数据类型并不需要相同。我们像下面一样来使用一对方括号,来创建一个名叫 `rockBands` 的列表:
你可以向 `rockBands` 的 `append()` 方法传递条目,来将它添加到列表的尾部,就像下面这样:
```
>>> rockBands = []
>>> rockBands.append("The Beatles")
>>> rockBands.append("Pink Floyd")
>>> rockBands.append("The Rolling Stones")
```
为了从列表中移除元素,我们可以向 `remove()` 方法传递特定元素,或向 `pop()` 中传递列表中待删除元素的位置(从 0 开始计数)。
换句话说,我们可以用下面这种方法来从列表中删除 “The Beatles”:
```
>>> rockBands.remove("The Beatles")
```
或者用这种方法:
```
>>> rockBands.pop(0)
```
如果你输入了对象的名字,然后在后面输入了一个点,你可以按 `Ctrl + space` 来显示这个对象的可用方法列表。

*列出可用的 Python 方法*
列表中含有的元素个数是它的一个属性。它通常被叫做“长度”,你可以通过向内建函数 `len` 传递一个列表作为它的参数来显示该列表的长度(顺便一提,之前的例子中提到的 print 语句,是 Python 的另一个内建函数)。
如果你在 IDLE 中输入 `len`,然后跟上一个不闭合的括号,你会看到这个函数的默认语法:

*Python 的 len 函数*
现在我们来看看列表中的特定条目。它们也有属性和方法吗?答案是肯定的。比如,你可以将一个字符串条目转换为大写形式,并获取这个字符串所包含的字符数量。像下面这样做:
```
>>> rockBands[0].upper()
'THE BEATLES'
>>> len(rockBands[0])
11
```
### 总结
在这篇文章中,我们简要介绍了 Python、它的命令行 shell、IDLE,展示了如何执行算术运算,如何在变量中存储数据,如何使用 `print` 函数在屏幕上重新显示那些数据(无论是它们本身还是它们的一部分),还通过一个实际的例子解释了对象的属性和方法。
下一篇文章中,我们会展示如何使用条件语句和循环语句来实现流程控制。我们也会解释如何编写一个脚本来帮助我们完成系统管理任务。
你是不是想继续学习一些有关 Python 的知识呢?敬请期待本系列的第二部分(我们会在脚本中将 Python 和命令行工具的优点结合在一起),你还可以考虑购买我们的《终极 Python 编程》系列教程([这里](http://www.tecmint.com/learn-python-programming-online-with-ultimate-python-coding/)有详细信息)。
像往常一样,如果你对这篇文章有什么问题,可以向我们寻求帮助。你可以使用下面的联系表单向我们发送留言,我们会尽快回复你。
---
via: <http://www.tecmint.com/learn-python-programming-and-scripting-in-linux/>
作者:[Gabriel Cánepa](http://www.tecmint.com/author/gacanepa/) 译者:[StdioA](https://github.com/StdioA) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,694 | Upstart 将被放弃,Ubuntu 投入 Systemd 怀抱 | http://news.softpedia.com/news/canonical-to-replace-upstart-with-systemd-for-ubuntu-16-10-s-session-startup-507413.shtml | 2016-08-18T10:02:24 | [
"Upstart",
"Systemd"
] | https://linux.cn/article-7694-1.html | Canonical 的 Martin Pitt [宣布](https://lists.ubuntu.com/archives/ubuntu-devel/2016-July/039465.html)将不再使用他们自己的 Upstart 初始化系统来启动 Ubuntu 桌面会话,取而代之的是更现代化的、却仍有争议的 Systemd。

每次 Systemd 发布,我们都对发现这个所谓的“初始化系统”又做了比原来的设计目标还要多得多的工作。它慢慢地接管了 GNU/Linux 操作系统越来越多的内部组件的工作,甚至,我们毫不怀疑,它将会完全取代它们,而这一天并不远了,或许,将来你会看到 Systemd/Linux 操作系统——除了 Linux 内核,其它的都叫 Systemd。
Upstart 是 Canonical/Ubuntu 自己的项目,它同 Systemd 一样,目标都是取代传统的初始化系统,用在几乎所有的 Ubuntu Linux 上。然而,从 Ubuntu 15.04 开始,Ubuntu 开始逐步使用 Systemd 替代 Upstart 初始化系统,这让许多用户很愤怒。
目前,Upstart 仍被用来控制各种启动过程中的服务和任务的运行和停止,比如桌面会话的启动还是使用 Upstart 控制的。不过 Canonical 计划使用 Systemd 来替代 Upstart 来管理桌面会话。
“按照 Ubuntu 开发者峰会上的讨论,我们准备放弃用 Upstart 来启动图形桌面会话,而使用 Systemd 来管理它,”[Martin Pitt 说](https://lists.ubuntu.com/archives/ubuntu-devel/2016-July/039465.html),“这样,一半的桌面会话将会由 Systemd unit 来管理。”
主要是将 /usr/share/xsessions/\*.desktop 里面的 Exec= 行切换为 Systemd 管理,显示管理器使用它们来显示哪些桌面会话可用,以及了解如何启动它们。这会影响到 Ubuntu 16.10 的 ubuntu-desktop 3.18.1.2-1ubuntu5 和 xubuntu-default-settings 16.10.1 软件包。Unity 、HUD 和指示器这些目前仍然由 Upstart 运行,它们会在之后的 CI 过程中转换,此外,dbus、gnome-session 等 Upstart 管理的任务还会继续由 Upstart 运行。
| 301 | Moved Permanently | null |
7,696 | Linux 平台下 Python 脚本编程入门(二) | http://www.tecmint.com/learn-python-programming-to-write-linux-shell-scripts/ | 2016-08-19T17:24:00 | [
"脚本",
"Python"
] | https://linux.cn/article-7696-1.html | 在“[Linux 平台下 Python 脚本编程入门](/article-7693-1.html)”系列之前的文章里,我们向你介绍了 Python 的简介,它的命令行 shell 和 IDLE(LCTT 译注:python 自带的一个 IDE)。我们也演示了如何进行算术运算、如何在变量中存储值、还有如何打印那些值到屏幕上。最后,我们通过一个练习示例讲解了面向对象编程中方法和属性概念。

*在 Python 编程中写 Linux Shell 脚本*
本篇中,我们会讨论控制流(根据用户输入的信息、计算的结果,或者一个变量的当前值选择不同的动作行为)和循环(自动重复执行任务),接着应用我们目前所学东西来编写一个简单的 shell 脚本,这个脚本会显示操作系统类型、主机名、内核版本、版本号和机器硬件架构。
这个例子尽管很基础,但是会帮助我们证明,比起使用一般的 bash 工具,我们通过发挥 Python 面向对象的特性来编写 shell 脚本会更简单些。
换句话说,我们想从这里出发:
```
# uname -snrvm
```

*检查 Linux 的主机名*
到

*用 Python 脚本来检查 Linux 的主机名*
或者

*用脚本检查 Linux 系统信息*
看着不错,不是吗?那我们就挽起袖子,开干吧。
### Python 中的控制流
如我们刚说那样,控制流允许我们根据一个给定的条件,选择不同的输出结果。在 Python 中最简单的实现就是一个 `if`/`else` 语句。
基本语法是这样的:
```
if 条件:
# 动作 1
else:
# 动作 2
```
当“条件”求值为真(true),下面的代码块就会被执行(`# 动作 1`代表的部分)。否则,else 下面的代码就会运行。 “条件”可以是任何表达式,只要可以求得值为真或者假。
举个例子:
1. `1 < 3` # 真
2. `firstName == "Gabriel"` # 对 firstName 为 Gabriel 的人是真,对其他不叫 Gabriel 的人为假
* 在第一个例子中,我们比较了两个值,判断 1 是否小于 3。
* 在第二个例子中,我们比较了 firstName(一个变量)与字符串 “Gabriel”,看在当前执行的位置,firstName 的值是否等于该字符串。
* 条件和 else 表达式都必须跟着一个冒号(`:`)。
* **缩进在 Python 中非常重要**。同样缩进下的行被认为是相同的代码块。
请注意,`if`/`else` 表达式只是 Python 中许多控制流工具的一个而已。我们先在这里了解以下,后面会用在我们的脚本中。你可以在[官方文档](http://please%20note%20that%20the%20if%20/%20else%20statement%20is%20only%20one%20of%20the%20many%20control%20flow%20tools%20available%20in%20Python.%20We%20reviewed%20it%20here%20since%20we%20will%20use%20it%20in%20our%20script%20later.%20You%20can%20learn%20more%20about%20the%20rest%20of%20the%20tools%20in%20the%20official%20docs.)中学到更多工具。
### Python 中的循环
简单来说,一个循环就是一组指令或者表达式序列,可以按顺序一直执行,只要条件为真,或者对列表里每个项目执行一一次。
Python 中最简单的循环,就是用 for 循环迭代一个给定列表的元素,或者对一个字符串从第一个字符开始到执行到最后一个字符结束。
基本语句:
```
for x in example:
# do this
```
这里的 example 可以是一个列表或者一个字符串。如果是列表,变量 x 就代表列表中每个元素;如果是字符串,x 就代表字符串中每个字符。
```
>>> rockBands = []
>>> rockBands.append("Roxette")
>>> rockBands.append("Guns N' Roses")
>>> rockBands.append("U2")
>>> for x in rockBands:
print(x)
或
>>> firstName = "Gabriel"
>>> for x in firstName:
print(x)
```
上面例子的输出如下图所示:

*学习 Python 中的循环*
### Python 模块
很明显,必须有个办法将一系列的 Python 指令和表达式保存到文件里,然后在需要的时候取出来。
准确来说模块就是这样的。比如,os 模块提供了一个到操作系统的底层的接口,可以允许我们做许多通常在命令行下执行的操作。
没错,os 模块包含了许多可以用来调用的方法和属性,就如我们之前文章里讲解的那样。不过,我们需要使用 `import` 关键词导入(或者叫包含)模块到运行环境里来:
```
>>> import os
```
我们来打印出当前的工作目录:
```
>>> os.getcwd()
```

*学习 Python 模块*
现在,让我们把这些结合在一起(包括之前文章里讨论的概念),编写需要的脚本。
### Python 脚本
以一段声明文字开始一个脚本是个不错的想法,它可以表明脚本的目的、发布所依据的许可证,以及一个列出做出的修改的修订历史。尽管这主要是个人喜好,但这会让我们的工作看起来比较专业。
这里有个脚本,可以输出这篇文章最前面展示的那样。脚本做了大量的注释,可以让大家可以理解发生了什么。
在进行下一步之前,花点时间来理解它。注意,我们是如何使用一个 `if`/`else` 结构,判断每个字段标题的长度是否比字段本身的值还大。
基于比较结果,我们用空字符去填充一个字段标题和下一个之间的空格。同时,我们使用一定数量的短线作为字段标题与其值之间的分割符。
```
#!/usr/bin/python3
# 如果你没有安装 Python 3 ,那么修改这一行为 #!/usr/bin/python
# Script name: uname.py
# Purpose: Illustrate Python OOP capabilities to write shell scripts more easily
# License: GPL v3 (http://www.gnu.org/licenses/gpl.html)
# Copyright (C) 2016 Gabriel Alejandro Cánepa
# Facebook / Skype / G+ / Twitter / Github: gacanepa
# Email: gacanepa (at) gmail (dot) com
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
# You should have received a copy of the GNU General Public License
# along with this program. If not, see .
# REVISION HISTORY
# DATE VERSION AUTHOR CHANGE DESCRIPTION
# ---------- ------- --------------
# 2016-05-28 1.0 Gabriel Cánepa Initial version
### 导入 os 模块
import os
### 将 os.uname() 的输出赋值给 systemInfo 变量
### os.uname() 会返回五个字符串元组(sysname, nodename, release, version, machine)
### 参见文档:https://docs.python.org/3.2/library/os.html#module-os
systemInfo = os.uname()
### 这是一个固定的数组,用于描述脚本输出的字段标题
headers = ["Operating system","Hostname","Release","Version","Machine"]
### 初始化索引值,用于定义每一步迭代中
### systemInfo 和字段标题的索引
index = 0
### 字段标题变量的初始值
caption = ""
### 值变量的初始值
values = ""
### 分隔线变量的初始值
separators = ""
### 开始循环
for item in systemInfo:
if len(item) < len(headers[index]):
### 一个包含横线的字符串,横线长度等于item[index] 或 headers[index]
### 要重复一个字符,用引号圈起来并用星号(*)乘以所需的重复次数
separators = separators + "-" * len(headers[index]) + " "
caption = caption + headers[index] + " "
values = values + systemInfo[index] + " " * (len(headers[index]) - len(item)) + " "
else:
separators = separators + "-" * len(item) + " "
caption = caption + headers[index] + " " * (len(item) - len(headers[index]) + 1)
values = values + item + " "
### 索引加 1
index = index + 1
### 终止循环
### 输出转换为大写的变量(字段标题)名
print(caption.upper())
### 输出分隔线
print(separators)
# 输出值(systemInfo 中的项目)
print(values)
### 步骤:
### 1) 保持该脚本为 uname.py (或任何你想要的名字)
### 并通过如下命令给其执行权限:
### chmod +x uname.py
### 2) 执行它;
### ./uname.py
```
如果你已经按照上述描述将上面的脚本保存到一个文件里,并给文件增加了执行权限,那么运行它:
```
# chmod +x uname.py
# ./uname.py
```
如果试图运行脚本时你得到了如下的错误:
```
-bash: ./uname.py: /usr/bin/python3: bad interpreter: No such file or directory
```
这意味着你没有安装 Python3。如果那样的话,你要么安装 Python3 的包,要么替换解释器那行(如果如之前文章里概述的那样,跟着下面的步骤去更新 Python 执行文件的软连接,要特别注意并且非常小心):
```
#!/usr/bin/python3
```
为
```
#!/usr/bin/python
```
这样会通过使用已经安装好的 Python 2 去执行该脚本。
**注意**:该脚本在 Python 2.x 与 Pyton 3.x 上都测试成功过了。
尽管比较粗糙,你可以认为该脚本就是一个 Python 模块。这意味着你可以在 IDLE 中打开它(File → Open… → Select file):

*在 IDLE 中打开 Python*
一个包含有文件内容的新窗口就会打开。然后执行 Run → Run module(或者按 F5)。脚本的输出就会在原始的 Shell 里显示出来:

*执行 Python 脚本*
如果你想纯粹用 bash 写一个脚本,也获得同样的结果,你可能需要结合使用 [awk](http://www.tecmint.com/use-linux-awk-command-to-filter-text-string-in-files/)、[sed](http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/),并且借助复杂的方法来存储与获得列表中的元素(不要忘了使用 tr 命令将小写字母转为大写)。
另外,在所有的 Linux 系统版本中都至少集成了一个 Python 版本(2.x 或者 3.x,或者两者都有)。你还需要依赖 shell 去完成同样的目标吗?那样你可能需要为不同的 shell 编写不同的版本。
这里演示了面向对象编程的特性,它会成为一个系统管理员得力的助手。
**注意**:你可以在我的 Github 仓库里获得 [这个 python 脚本](https://github.com/gacanepa/scripts/blob/master/python/uname.py)(或者其他的)。
### 总结
这篇文章里,我们讲解了 Python 中控制流、循环/迭代、和模块的概念。我们也演示了如何利用 Python 中面向对象编程的方法和属性来简化复杂的 shell 脚本。
你有任何其他希望去验证的想法吗?开始吧,写出自己的 Python 脚本,如果有任何问题可以咨询我们。不必犹豫,在分割线下面留下评论,我们会尽快回复你。
---
via: <http://www.tecmint.com/learn-python-programming-to-write-linux-shell-scripts/>
作者:[Gabriel Cánepa](http://www.tecmint.com/author/gacanepa/) 译者:[wi-cuckoo](https://github.com/wi-cuckoo) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,697 | 在 Linux 下如何查看一个进程的运行时间 | http://www.cyberciti.biz/faq/how-to-check-how-long-a-process-has-been-running/ | 2016-08-20T15:17:00 | [
"进程",
"时间"
] | https://linux.cn/article-7697-1.html | 
>
> 我是一个 Linux 系统的新手。我该如何在我的 Ubuntu 服务器上查看一个进程(或者根据进程 id 查看)已经运行了多久?
>
>
>
你需要使用 ps 命令来查看关于一组正在运行的进程的信息。ps 命令提供了如下的两种格式化选项。
1. etime 显示了自从该进程启动以来,经历过的时间,格式为 `[[DD-]hh:]mm:ss`。
2. etimes 显示了自该进程启动以来,经历过的时间,以秒的形式。
### 如何查看一个进程已经运行的时间?
你需要在 ps 命令之后添加 -o etimes 或者 -o etime 参数。它的语法如下:
```
ps -p {PID-HERE} -o etime
ps -p {PID-HERE} -o etimes
```
#### 第一步:找到一个进程的 PID (openvpn 为例)
```
$ pidof openvpn
6176
```
#### 第二步:openvpn 进程运行了多长时间?
```
$ ps -p 6176 -o etime
```
或者
```
$ ps -p 6176 -o etimes
```
隐藏输出头部:
```
$ ps -p 6176 -o etime=
$ ps -p 6176 -o etimes=
```
样例输出:

这个 6176 就是你想查看的进程的 PID。在这个例子中,我查看的是 openvpn 进程。你可以按照你的需求随意的更换 openvpn 进程名或者是 PID。在下面的例子中,我打印了 PID、执行命令、运行时间、用户 ID、和用户组 ID:
```
$ ps -p 6176 -o pid,cmd,etime,uid,gid
```
样例输出:
```
PID CMD ELAPSED UID GID
6176 /usr/sbin/openvpn --daemon 15:25 65534 65534
```
---
via: <http://www.cyberciti.biz/faq/how-to-check-how-long-a-process-has-been-running/>
作者:[VIVEK GITE](http://www.cyberciti.biz/faq/how-to-check-how-long-a-process-has-been-running/) 译者:[MikeCoder](https://github.com/MikeCoder) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,698 | Git 系列(五):三个 Git 图形化工具 | https://opensource.com/life/16/8/graphical-tools-git | 2016-08-20T16:13:52 | [
"Git",
"Sparkleshare",
"Git-cola"
] | https://linux.cn/article-7698-1.html | 
在本文里,我们来了解几个能帮你在日常工作中舒服地用上 Git 的工具。
我是在这许多漂亮界面出来之前学习的 Git,而且我的日常工作经常是基于字符界面的,所以 Git 本身自带的大部分功能已经足够我用了。在我看来,最好能理解 Git 的工作原理。不过,能有的选也不错,下面这些就是能让你不用终端就可以开始使用 Git 的一些方式。
### KDE Dolphin 里的 Git
我是一个 KDE 用户,如果不在 Plasma 桌面环境下,就是在 Fluxbox 的应用层。Dolphin 是一个非常优秀的文件管理器,有很多配置项以及大量秘密小功能。大家为它开发的插件都特别好用,其中一个几乎就是完整的 Git 界面。是的,你可以直接在自己的桌面上很方便地管理你的 Git 仓库。
但首先,你得先确认已经安装了这个插件。有些发行版带的 KDE 将各种插件都装的满满的,而有些只装了一些最基本的,所以如果你在下面的步骤里没有看到 Git 相关选项,就在你的软件仓库里找找类似 dolphin-extras 或者 dolphin-plugins 的包。
要打开 Git 集成功能,在 Dolphin 的任一窗口里点击 Settings 菜单,并选择 Configure Dolphin。
在弹出的 Configure Dolphin 窗口里,点击左边侧栏里的 Services 图标。
在 Services 面板里,滚动可用的插件列表找到 Git。

(勾选上它,)然后保存你的改动并关闭 Dolphin 窗口。重新启动 Dolphin,浏览一个 Git 仓库试试看。你会发现现在所有文件图标都带有标记:绿色方框表示已经提交的文件,绿色实心方块表示文件有改动,没加入库里的文件没有标记,等等。
之后你在 Git 仓库目录下点击鼠标右键弹出的菜单里就会有 Git 选项了。你在 Dolphin 窗口里点击鼠标就可以检出一个版本,推送或提交改动,还可以对文件进行 `git add` 或 `git remove` 操作。

不过 Dolphin 不支持克隆仓库或是改变远端仓库路径,需要到终端窗口操作,按下 F4 就可以很方便地进行切换。
坦白地说,KDE 的这个功能太牛了,这篇文章已经可以到此为止。将 Git 集成到原生文件管理器里可以让 Git 操作非常清晰;不管你在工作流程的哪个阶段,一切都能直接地摆在面前。在终端里 Git,切换到 GUI 后也是一样 Git。完美。
不过别急,还有好多呢!
### Sparkleshare
SparkleShare 来自桌面环境的另一大阵营,由一些 GNOME 开发人员发起,一个使用文件同步模型 (“就像 Dropbox 一样!”) 的项目。不过它并没有集成任何 GNOME 特有的组件,所以你可以在任何平台使用。
如果你在用 Linux,可以从你的软件仓库直接安装 SparkleShare。如果是其它操作系统,可以去 SparkleShare 网站下载。你可以不用看 SparkleShare 网站上的指引,那个是告诉你如何架设 SparkleShare 服务器的,不是我们这里讨论的。当然你想的话也可以架设 SparkleShare 服务器,但是 SparkleShare 能兼容 Git 仓库,所以其实没必要再架一个自己的。
在安装完成后,从应用程序菜单里启动 SparkleShare。走一遍设置向导,只有两个步骤外加一个简单介绍,然后可以选择是否将 SparkleShare 设置为随桌面自动启动。

之后在你的系统托盘里会出现一个橙色的 SparkleShare 目录。目前,SparkleShare 对你电脑上的任何东西都一无所知,所以你需要添加一个项目。
要添加一个目录给 SparkleShare 追踪,可以点击系统托盘里的 SparkleShare 图标然后选择 Add Hosted Project。

SparkleShare 支持本地 Git 项目,也可以是存放在像 GitHub 和 Bitbucket 这样的公共 Git 服务器上的项目。要获得完整访问权限,你可能会需要使用 SparkleShare 生成的客户端 ID。这是一个 SSH 密钥,作为你所用到服务的授权令牌,包括你自己的 Git 服务器,应该也使用 SSH 公钥认证而不是用户名密码。将客户端 ID 拷贝到你服务器上 Git 用户的 `authorized_hosts` 文件里,或者是你的 Git 主机的 SSH 密钥面板里。
在配置要你要用的主机后,SparkleShare 会下载整个 Git 项目,包括(你可以自己选择)提交历史。可以在 ~/SparkleShare 目录下找到同步完成的文件。
不像 Dolphin 那样的集成方式,SparkleShare 是不透明的,让人心里没底。在你做出改动后,它会悄悄地把改动同步到服务器远端项目中。对大部分人来说,这样做有一个很大的好处:可以用到 Git 的全部威力但是不用维护。对我来说,这样有些乱,因为我想自己管理我的提交以及要用的分支。
SparkleShare 可能不适合所有人,但是它是一个强大而且简单的 Git 解决方案,展示了不同的开源项目完美地协调整合到一起后所创造出的独特项目。
### Git-cola
另一种配合 Git 仓库工作的模型,没那么原生,更多的是监视方式;不是使用一个集成的应用程序和你的 Git 项目直接交互,而是你可以使用一个桌面客户端来监视项目改动,并随意处理每一个改动。这种方式的一个优势就是专注。当你实际只用到项目里的三个文件的时候,你可能不会关心所有的 125 个文件,能将这三个文件挑出来就很方便了。
如果你觉得有好多 Git 托管网站,那只是你还不知道 Git 客户端有多少。[桌面上的 Git 客户端](https://git-scm.com/downloads/guis) 上有一大把。实际上,Git 默认自带一个图形客户端。它们中最跨平台、最可配置的就是开源的 [Git-cola](https://git-cola.github.io/) 客户端,用 Python 和 Qt 写的。
如果你在用 Linux,Git-cola 应该在你的软件仓库里就有。不是的话,可以直接从它的[网站下载](https://git-cola.github.io/)并安装:
```
$ python setup.py install
```
启动 git-cola 后,会有三个按钮用来打开仓库,创建新仓库,或克隆仓库。
不管选哪个,最终都会停在一个 Git 仓库中。和大多数我用过的客户端一样,Git-cola 不会尝试成为你的仓库的接口;它们一般会让操作系统工具来做这个。换句话说,我可以通过 Git-cola 创建一个仓库,但随后我就在 Thunar 或 Emacs 里打开仓库开始工作。打开 Git-cola 来监视仓库很不错,因为当你创建新文件,或者改动文件的时候,它们都会出现在 Git-cola 的状态面板里。
Git-cola 的默认布局不是线性的。我喜欢从左向右分布,因为 Git-cola 是高度可配置的,所以你可以随便修改布局。我自己设置成最左边是状态面板,显示当前分支的任何改动,然后右边是差异面板,可以浏览当前改动,然后是动作面板,放一些常用任务的快速按钮,最后,最右边是提交面板,可以写提交信息。

不管怎么改布局,下面是 Git-cola 的通用流程:
改动会出现在状态面板里。右键点击一个改动或选中一个文件,然后在动作面板里点击 Stage 按钮来将文件加入待提交暂存区。
待提交文件的图标会变成绿色三角形,表示该文件有改动并且正等待提交。你也可以右键点击并选择 Unstage Selected 将改动移出待提交暂存区,或者点击动作面板里的 Unstage 按钮。
在差异面板里检查你的改动。
当准备好提交后,输入提交信息并点击 Commit 按钮。
在动作面板里还有其它按钮用来处理其它普通任务,比如拉取或推送。菜单里有更多的任务列表,比如用于操作分支,改动审查,变基等等的专用操作。
我更愿意将 Git-cola 当作文件管理器的一个浮动面板(在不能用 Dolphin 的时候我只用 Git-cola)。虽然它的交互性没有完全集成 Git 的文件管理器那么强,但另一方面,它几乎提供了原始 Git 命令的所有功能,所以它实际上更为强大。
有很多 Git 图形客户端。有些是不提供源代码的付费软件,有些只是用来查看,有些尝试加入新的特定术语(用 "sync" 替代 "push" ...?) 来重造 Git,也有一些只适合特定的平台。Git-cola 一直是能在任意平台上使用的最简单的客户端,也是最贴近纯粹 Git 命令的,可以让用户在使用过程中学习 Git,即便是高手也会很满意它的界面和术语。
### Git 命令还是图形界面?
我一般不用图形工具来操作 Git;一般我使用上面介绍的工具时,只是帮助其他人找出适合他们的界面。不过,最终归结于怎么适合你的工作。我喜欢基于终端的 Git 命令是因为它可以很好地集成到 Emacs 里,但如果某天我几乎都在用 Inkscape 工作时,我一般会很自然地使用 Dolphin 里带的 Git,因为我在 Dolphin 环境里。
如何使用 Git 你可以自己选择;但要记住 Git 是一种让生活更轻松的方式,也是让你在工作中更安全地尝试一些疯狂点子的方法。熟悉 Git 的工作模式,然后不管以什么方式使用 Git,只要能让你觉得最适合就可以。
在下一期文章里,我们将了解如何架设和管理 Git 服务器,包括用户权限和管理,以及运行定制脚本。
---
via: <https://opensource.com/life/16/8/graphical-tools-git>
作者:[Seth Kenlon](https://opensource.com/users/seth) 译者:[zpl1025](https://github.com/zpl1025) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | *Read:*
[Part 1: What is Git?](https://opensource.com/resources/what-is-git)*Part 2: Getting started with Git*[Part 3: Creating your first Git repository](https://opensource.com/life/16/7/creating-your-first-git-repository)*Part 4: How to restore older file versions in Git**Part 5: 3 graphical tools for Git**Part 6: How to build your own Git server**Part 7: How to manage binary blobs with Git*
In this article, we'll take a look at some convenience add-ons to help you integrate Git comfortably into your everyday workflow.
I learned Git before many of these fancy interfaces existed, and my workflow is frequently text-based anyway, so most of the inbuilt conveniences of Git suit me pretty well. It is always best, in my opinion, to understand how Git works natively. However, it is always nice to have options, so these are some of the ways you can start using Git outside of the terminal.
## Git in KDE Dolphin
I am a KDE user, if not always within the Plasma desktop, then as my application layer in Fluxbox. Dolphin is an excellent file manager with lots of options and plenty of secret little features. Particularly useful are all the plugins people develop for it, one of which is a nearly-complete Git interface. Yes, you can manage your Git repositories natively from the comfort of your own desktop.
But first, you'll need to make sure the add-ons are installed. Some distros come with a filled-to-the-brim KDE, while others give you just the basics, so if you don't see the Git options in the next few steps, search your repository for something like *dolphin-extras* or *dolphin-plugins*.
To activate Git integration, go to the **Settings** menu in any Dolphin window and select **Configure Dolphin**.
In the **Configure Dolphin** window, click on the **Services** icon in the left column.
In the **Services** panel, scroll through the list of available plugins until you find **Git**.
Save your changes and close your Dolphin window. When you re-launch Dolphin, navigate to a Git repository and have a look around. Notice that all icons now have emblems: green boxes for committed files, solid green boxes for modified files, no icon for untracked files, and so on.
Your right-click menu now has contextual Git options when invoked inside a Git repository. You can initiate a checkout, push or pull when clicking inside a Dolphin window, and you can even do a `git add`
or `git remove`
on your files.
You can't clone a repository or change remote paths in Dolphin, but will have to drop to a terminal, which is just an **F4** away.
Frankly, this feature of KDE is so kool [sic] that this article could just end here. The integration of Git in your native file manager makes working with Git almost transparent; everything you need to do *just happens* no matter what stage of the process you are in. Git in the terminal, and Git waiting for you when you switch to the GUI. It is perfection.
But wait, there's more!
## Sparkleshare
From the other side of the desktop pond comes [SparkleShare](http://www.sparkleshare.org), a project that uses a file synchronization model ("like Dropbox!") that got started by some GNOME developers. It is not integrated into any specific part of GNOME, so you can use it on all platforms.
If you run Linux, install SparkleShare from your software repository. Other operating systems should download from the SparkleShare website. You can safely ignore the instructions on the SparkleShare website, which are for setting up a SparkleShare *server*, which is not what we will do here. You certainly *can* set up a SparkleShare server if you want, but SparkleShare is compatible with any Git repository, so you don't need to create your own server.
After it is installed, launch SparkleShare from your applications menu. Step through the setup wizard, which is two steps plus a brief tutorial, and optionally set SparkleShare as a startup item for your desktop.
https://opensource.com/sites/default/files/4_sparklesetup.jpg" title="Creating a SparkleShare account." typeof="foaf:Image" width="520" height="430">
An orange SparkleShare directory is now in your system tray. Currently, SparkleShare is oblivious to anything on your computer, so you need to add a hosted project.
To add a directory for SparkleShare to track, click the SparkleShare icon in your system tray and select **Add Hosted Project**.
https://opensource.com/sites/default/files/4_sparklehost.jpg" title="New SparkleShare project." typeof="foaf:Image" width="530" height="380">
SparkleShare can work with self-hosted Git projects, or projects hosted on public Git services like GitHub and Bitbucket. For full access, you'll probably need to use the Client ID that SparkleShare provides to you. This is an SSH key acting as the authentication token for the service you use for hosting, including your own Git server, which should also use SSH public key authentication rather than password login. Copy the Client ID into the *authorized_hosts* file of your Git user on your server, or into the SSH key panel of your Git host.
After configuring the host you want to use, SparkleShare downloads the Git project, including, at your option, the commit history. Find the files in *~/SparkleShare*.
Unlike Dolphin's Git integration, SparkleShare is unnervingly invisible. When you make a change, it quietly syncs the change to your remote project. For many people, that is a huge benefit: all the power of Git with none of the maintenance. To me, it is unsettling, because I like to govern what I commit and which branch I use.
SparkleShare may not be for everyone, but it is a powerful and simple Git solution that shows how different open source projects fit together in perfect harmony to create something unique.
## Git-cola
Yet another model of working with Git repositories is less native and more of a monitoring approach; rather than using an integrated application to interact directly with your Git project, you can use a desktop client to monitor changes in your project and deal with each change in whatever way you choose. An advantage to this approach is focus. You might not care about all 125 files in your project when only three of them are actively being worked on, so it is helpful to bring them to the forefront.
If you thought there were a lot of Git web hosts out there, you haven't seen anything yet. [Git clients for your desktop](https://Git-scm.com/downloads/guis) are a dime-a-dozen. In fact, Git actually ships with an inbuilt graphical Git client. The most cross-platform and most configurable of them all is the open source [Git-cola](https://Git-cola.Github.io) client, written in Python and Qt.
If you're on Linux, Git-cola may be in your software repository. Otherwise, just download it from the site and install it:
$ python setup.py install
When Git-cola launches, you're given three buttons to open an existing repository, create a new repo, or clone an existing repository.
Whichever you choose, at some point you end up with a Git repository. Git-cola, and indeed most desktop clients that I've used, don't try to be your interface into your repository; they leave that up to your normal operating system tools. In other words, I might start a repository with Git-cola, but then I would open that repository in Thunar or Emacs to start my work. Leaving Git-cola open as a monitor works quite well, because as you create new files, or change existing ones, they appear in Git-cola's **Status** panel.
The default layout of Git-cola is a little non-linear. I prefer to move from left-to-right, and because Git-cola happens to be very configurable, you're welcome to change your layout. I set mine up so that the left-most panel is **Status**, showing any changes made to my current branch, then to the right, a **Diff** panel in case I want to review a change, and the **Actions** panel for quick-access buttons to common tasks, and finally the right-most panel is a **Commit** panel where I can write commit messages.
https://opensource.com/sites/default/files/4_gitcola.jpg" title="Git-cola interface." typeof="foaf:Image" width="520" height="312">
Even if you use a different layout, this is the general flow of Git-cola:
Changes appear in the **Status** panel. Right-click a change entry, or select a file and click the **Stage** button in the **Action** panel, to stage a file.
A staged file's icon changes to a green triangle to indicate that it has been both modified and staged. You can unstage a file by right-clicking and selecting **Unstage Selected,** or by clicking the **Unstage** button in the **Actions** panel.
Review your changes in the **Diff** panel.
When you are ready to commit, enter a commit message and click the **Commit** button.
There are other buttons in the **Actions** panel for other common tasks like a git `pull`
or `git push`
. The menus round out the task list, with dedicated actions for branching, reviewing diffs, rebasing, and a lot more.
I tend to think of Git-cola as a kind of floating panel for my file manager (and I only use Git-cola when Dolphin is not available). On one hand, it's less interactive than a fully integrated and Git-aware file manager, but on the other, it offers practically everything that raw Git does, so it's actually more powerful.
There are plenty of graphical Git clients. Some are paid software with no source code available, others are viewers only, others attempt to reinvent Git with special terms that are specific to the client ("sync" instead of "push"..?), and still others are platform-specific. Git-Cola has consistently been the easiest to use on any platform, and the one that stays closest to pure Git so that users learn Git whilst using it, and experts feel comfortable with the interface and terminology.
## Git or graphical?
I don't generally use graphical tools to access Git; mostly I use the ones I've discussed when helping other people find a comfortable interface for themselves. At the end of the day, though, it comes down to what fits with how you work. I like terminal-based Git because it integrates well with Emacs, but on a day where I'm working mostly in Inkscape, I might naturally fall back to using Git in Dolphin because I'm in Dolphin anyway.
It's up to you how you use Git; the most important thing to remember is that Git is meant to make your life easier and those crazy ideas you have for your work safer to try out. Get familiar with the way Git works, and then use Git from whatever angle you find works best for you.
In our next installment, we will learn how to set up and manage a Git server, including user access and management, and running custom scripts.
## 17 Comments |
7,699 | 微软开源 PowerShell,支持 Linux 和 Mac | http://news.softpedia.com/news/microsoft-makes-powershell-open-source-releases-it-on-linux-and-mac-507466.shtml | 2016-08-21T08:57:00 | [
"PowerShell",
"微软",
"开源"
] | https://linux.cn/article-7699-1.html | “微软爱 Linux”,这是微软高管们在几个场合都宣称过的事情,微软公司也正不断将之付诸实施,对一些重要的软件进行了开源和维持更新。这家软件巨头正在不断地贴近开源世界。
而这种举动的最近一个动向是关于 PowerShell 的,它是微软的一种强大的基于任务的命令行外壳和脚本语言,使用于 Windows。而现在,微软宣布开源了 PowerShell,并支持 Linux 和 Mac OS X,这意味着它变成了跨平台的了。

该公司称这样将可以使 Windows 和 Linux 团队不再“各行其是,而是更容易彼此协作”,这是开源 PowerShell 的一个主要原因。
“我们以开源 PowerShell 的一小部分开始,并与一些在开源方面有经验、了解该如何做开源的合作伙伴们进行了沟通,”微软说,“我们发现 PowerShell 很适合开源,因为原来的 PowerShell 团队成员大多都具有深厚的 Unix 背景。”
在 Linux 上,目前 PowerShell 已经可以用在 Ubuntu、 CentOS 和 RedHat 上了,其 Alpha 版已经可从 [GitHub](https://github.com/PowerShell/PowerShell/tree/master/docs/learning-powershell) 上下载了。
### 微软越来越爱 Linux 了
曾经有段时间,微软称 Linux 是“癌症”,但是随着时光流逝,现在微软已经认识到了开源世界的不断增长,除了在这个领域加大投入之外别无选择。
微软已经启动了几个开源项目,希望能吸引一些 Linux 用户,其中一个新的 Skype 版本就是建立在社区反馈之上的。该公司也试着将这种模式应用到 Windows 10 之中,它的许多面世的产品中的部分功能就是基于用户反馈进行开发和改进的。
Linux 世界已经越来越大了,微软从其中看到了成长的机会。微软披露说, 其 Azure 云上面有 1/3 的虚拟机是 Linux,而 Azure 云市场中的第三方 IaaS 有 60% 包括了开源软件。
| 301 | Moved Permanently | null |
7,704 | 17 个 Linux 下用于 C/C++ 的最好的 IDE /编辑器 | http://www.tecmint.com/best-linux-ide-editors-source-code-editors/ | 2016-08-21T18:20:00 | [
"编辑器",
"IDC",
"C++"
] | https://linux.cn/article-7704-1.html | C++,一个众所周知的 C 语言的扩展,是一个优秀的、强大的、通用编程语言,它能够提供现代化的、通用的编程功能,可以用于开发包括视频游戏、搜索引擎、其他计算机软件乃至操作系统等在内的各种大型应用。
C++,提供高度可靠性的同时还能够允许操作底层内存来满足更高级的编程要求。

虽然已经有了一些供程序员用来写 C/C++ 代码的文本编辑器,但 IDE 可以为轻松、完美的编程提供综合的环境和组件。
在这篇文章里,我们会向你展示一些可以在 Linux 平台上找到的用于 C++ 或者其他编程语言编程的最好的 IDE。
### 1. 用于 C/C++ 开发的 Netbeans
Netbeans 是一个自由而开源的、流行的跨平台 IDE ,可用于 C/C++ 以及其他编程语言,可以使用由社区开发的插件展现了其完全的扩展性。
它包含了用于 C/C++ 开发的项目类型和模版,并且你可以使用静态和动态函数库来构建应用程序。此外,你可以利用现有的代码去创造你的工程,并且也可以通过拖放的方式导入二进制文件来从头构建应用。
让我们来看看关于它的特性:
* C/C++ 编辑器很好的整合了多线程的 [GNU GDB 调试工具](http://www.tecmint.com/debug-source-code-in-linux-using-gdb/)
* 支持代码协助
* 支持 C++11 标准
* 在里面创建和运行 C/C++ 测试程序
* 支持 QT 工具包
* 支持将已编译的应用程序自动打包到 .tar,.zip 等归档文件
* 支持多个编译器,例如: GNU、Clang/LLVM、Cygwin、Oracle Solaris Studio 和 MinGW
* 支持远程开发
* 文件导航
* 源代码检查

主页:<https://netbeans.org/features/cpp/index.html>
### 2. Code::Blocks
Code::Blocks 是一个免费的、具有高度扩展性的、并且可以配置的跨平台 C++ IDE,它为用户提供了必备而典范的功能。它具有一致的界面和体验。
最重要的是,你可以通过用户开发的插件扩展它的功能,一些插件是随同 Code::Blocks 发布的,而另外一些则不是,它们由 Code::Block 开发团队之外的个人用户所编写的。
其功能分为编译器、调试器、界面功能,它们包括:
* 支持多种编译器如 GCC、clang、Borland C++ 5.5、digital mars 等等
* 非常快,不需要 makefile
* 支持多个目标平台的项目
* 支持将项目组合起来的工作空间
* GNU GDB 接口
* 支持完整的断点功能,包括代码断点,数据断点,断点条件等等
* 显示本地函数的符号和参数
* 用户内存导出和语法高亮显示
* 可自定义、可扩展的界面以及许多其他的的功能,包括那些用户开发的插件添加功能

主页: <http://www.codeblocks.org>
### 3. Eclipse CDT (C/C++ Development Tooling)
Eclipse 在编程界是一款著名的、开源的、跨平台的 IDE。它给用户提供了一个很棒的界面,并支持拖拽功能以方便界面元素的布置。
Eclipse CDT 是一个基于 Eclipse 主平台的项目,它提供了一个完整功能的 C/C++ IDE,并具有以下功能:
* 支持项目创建
* 管理各种工具链的构建
* 标准的 make 构建
* 源代码导航
* 一些知识工具,如调用图、类型分级结构,内置浏览器,宏定义浏览器
* 支持语法高亮的代码编辑器
* 支持代码折叠和超链接导航
* 代码重构与代码生成
* 可视化调试存储器、寄存器的工具
* 反汇编查看器以及更多功能

主页: <http://www.eclipse.org/cdt/>
### 4. CodeLite IDE
CodeLite 也是一款为 C/C++、JavaScript(Node.js)和 PHP 编程专门设计打造的自由而开源的、跨平台的 IDE。
它的一些主要特点包括:
* 代码补完,提供了两个代码补完引擎
* 支持多种编译器,包括 GCC、clang/VC++
* 以代码词汇的方式显示错误
* 构建选项卡中的错误消息可点击
* 支持下一代 LLDB 调试器
* 支持 GDB
* 支持重构
* 代码导航
* 使用内置的 SFTP 进行远程开发
* 源代码控制插件
* 开发基于 wxWidgets 应用的 RAD(快速应用程序开发)工具,以及更多的特性

主页: <http://codelite.org/>
### 5. Bluefish 编辑器
Bluefish 不仅仅是一个一般的编辑器,它是一个轻量级的、快捷的编辑器,为程序员提供了如开发网站、编写脚本和软件代码的 IDE 特性。它支持多平台,可以在 Linux、Mac OSX、FreeBSD、OpenBSD、Solaris 和 Windows 上运行,同时支持包括 C/C++ 在内的众多编程语言。
下面列出的是它众多功能的一部分:
* 多文档界面
* 支持递归打开文件,基于文件名通配模式或者内容模式
* 提供一个非常强大的搜索和替换功能
* 代码片段边栏
* 支持整合个人的外部过滤器,可使用命令如 awk,sed,sort 以及自定义构建脚本组成(过滤器的)管道文件
* 支持全屏编辑
* 网站上传和下载
* 支持多种编码等许多其他功能

主页: <http://bluefish.openoffice.nl>
### 6. Brackets 代码编辑器
Brackets 是一个现代化风格的、开源的文本编辑器,专为 Web 设计与开发打造。它可以通过插件进行高度扩展,因此 C/C++ 程序员通过安装 C/C++/Objective-C 包来使用它来开发,这个包用来在辅助 C/C++ 代码编写的同时提供了 IDE 之类的特性。

主页: <http://brackets.io/>
### 7. Atom 代码编辑器
Atom 也是一个现代化风格、开源的多平台文本编辑器,它能运行在 Linux、Windows 或是 Mac OS X 平台。它的定制可深入底层,用户可以自定义它,以便满足各种编写代码的需求。
它功能完整,主要的功能包括:
* 内置了包管理器
* 智能的自动补完
* 内置文件浏览器
* 查找、替换以及其他更多的功能

主页: <https://atom.io/>
安装指南: <http://www.tecmint.com/atom-text-and-source-code-editor-for-linux/>
### 8. Sublime Text 编辑器
Sublime Text 是一个完善的、跨平台的文本编辑器,可用于代码、标记语言和一般文字。它可以用来编写 C/C++ 代码,并且提供了非常棒的用户界面。
它的功能列表包括:
* 多重选择
* 按模式搜索命令
* 抵达任何一处的功能
* 免打扰模式
* 窗口分割
* 支持项目之间快速的切换
* 高度可定制
* 支持基于 Python 的 API 插件以及其他特性

主页: <https://www.sublimetext.com>
安装指南: <http://www.tecmint.com/install-sublime-text-editor-in-linux/>
### 9. JetBrains CLion
JetBrains CLion 是一个收费的、强大的跨平台 C/C++ IDE。它是一个完全整合的 C/C++ 程序开发环境,并提供 Cmake 项目模型、一个嵌入式终端窗口和一个主要以键盘操作的编码环境。
它还提供了一个智能而现代化的编辑器,具有许多令人激动的功能,提供了理想的编码环境,这些功能包括:
* 除了 C/C++ 还支持其他多种语言
* 在符号声明和上下文中轻松导航
* 代码生成和重构
* 可定制的编辑器
* 即时代码分析
* 集成的代码调试器
* 支持 Git、Subversion、Mercurial、CVS、Perforcevia(通过插件)和 TFS
* 无缝集成了 Google 测试框架
* 通过 Vim 仿真插件支持 Vim 编辑体验

主页: <https://www.jetbrains.com/clion/>
### 10. 微软的 Visual Studio Code 编辑器
Visual Studio 是一个功能丰富的、完全整合的、跨平台开发环境,运行在 Linux、Windows 和 Mac OS X 上。 最近它向 Linux 用户开源了,它重新定义了代码编辑这件事,为用户提供了在 Windows、Android、iOS 和 Web 等多个平台开发不同应用所需的一切工具。
它功能完备,功能分类为应用程序开发、应用生命周期管理、扩展和集成特性。你可以从 Visual Studio 官网阅读全面的功能列表。

主页: <https://www.visualstudio.com>
### 11. KDevelop
KDevelop 是另一个自由而开源的跨平台 IDE,能够运行在 Linux、Solaris、FreeBSD、Windows、Mac OS X 和其他类 Unix 操作系统上。它基于 KDevPlatform、KDE 和 Qt 库。KDevelop 可以通过插件高度扩展,功能丰富且具有以下显著特色:
* 支持基于 Clang 的 C/C++ 插件
* 支持 KDE 4 配置迁移
* 支持调用二进制编辑器 Oketa
* 支持众多视图插件下的差异行编辑
* 支持 Grep 视图,使用窗口小部件节省垂直空间等

主页: <https://www.kdevelop.org>
### 12. Geany IDE
Geany 是一个免费的、快速的、轻量级跨平台 IDE,只需要很少的依赖包就可以工作,独立于流行的 Linux 桌面环境下,比如 GNOME 和 KDE。它需要 GTK2 库实现功能。
它的特性包括以下列出的内容:
* 支持语法高亮显示
* 代码折叠
* 调用提示
* 符号名自动补完
* 符号列表
* 代码导航
* 一个简单的项目管理工具
* 可以编译并运行用户代码的内置系统
* 可以通过插件扩展

主页: <http://www.geany.org/>
### 13. Ajunta DeveStudio
Ajunta DevStudio 是一个简单,强大的 GNOME 界面的软件开发工作室,支持包括 C/C++ 在内的几种编程语言。
它提供了先进的编程工具,比如项目管理、GUI 设计、交互式调试器、应用程序向导、源代码编辑器、版本控制等。此外,除了以上特点,Ajunta DeveStudio 也有其他很多不错的 IDE 功能,包括:
* 简单的用户界面
* 可通过插件扩展
* 整合了 Glade 用于所见即所得的 UI 开发
* 项目向导和模板
* 整合了 GDB 调试器
* 内置文件管理器
* 使用 DevHelp 提供上下文敏感的编程辅助
* 源代码编辑器支持语法高亮显示、智能缩进、自动缩进、代码折叠/隐藏、文本缩放等

主页: <http://anjuta.org/>
### 14. GNAT Programming Studio
GNAT Programming Studio 是一个免费的、易于使用的 IDE,设计的目的用于统一开发人员与他/她的代码和软件之间的交互。
它通过高亮程序的重要部分和逻辑从而提升源代码导航体验,打造了一个理想的编程环境。它的设计目标是为你带来更舒适的编程体验,使用户能够从头开始开发全面的系统。
它丰富的特性包括以下这些:
* 直观的用户界面
* 对开发者的友好性
* 支持多种编程语言,跨平台
* 灵活的 MDI(多文档界面)
* 高度可定制
* 使用喜欢的工具获得全面的可扩展性

主页: <http://libre.adacore.com/tools/gps/>
### 15. Qt Creator
这是一款收费的、跨平台的 IDE,用于创建连接设备、用户界面和应用程序。Qt Creator 可以让用户比应用的编码做到更多的创新。
它可以用来创建移动和桌面应用程序,也可以连接到嵌入式设备。
它的优点包含以下几点:
* 复杂的代码编辑器
* 支持版本控制
* 项目和构建管理工具
* 支持多屏幕和多平台,易于构建目标之间的切换等等

主页: <https://www.qt.io/ide/>
### 16. Emacs 编辑器
Emacs 是一个自由的、强大的、可高度扩展的、可定制的、跨平台文本编辑器,你可以在 Linux、Solaris、FreeBSD、NetBSD、OpenBSD、Windows 和 Mac OS X 这些系统中使用该编辑器。
Emacs 的核心也是一个 Emacs Lisp 的解释器,Emacs Lisp 是一种基于 Lisp 的编程语言。在撰写本文时,GNU Emacs 的最新版本是 24.5,Emacs 的基本功能包括:
* 内容识别编辑模式
* Unicode 的完全支持
* 可使用 GUI 或 Emacs Lisp 代码高度定制
* 下载和安装扩展的打包系统
* 超出了正常文本编辑的功能生态系统,包括项目策划、邮件、日历和新闻阅读器等
* 完整的内置文档,以及用户指南等等

主页: <https://www.gnu.org/software/emacs/>
### 17. VI/VIM 编辑器
Vim,一款 VI 编辑器的改进版本,是一款自由的、强大的、流行的并且高度可配置的文本编辑器。它为有效率地文本编辑而生,并且为 Unix/Linux 使用者提供了激动人心的编辑器特性,因此,它对于撰写和编辑 C/C++ 代码也是一个好的选择。
总的来说,与传统的文本编辑器相比,IDE 为编程提供了更多的便利,因此使用它们是一个很好的选择。它们带有激动人心的特征并且提供了一个综合性的开发环境,有时候程序员不得不陷入对最好的 C/C++ IDE 的选择。
在互联网上你还可以找到许多 IDE 来下载,但不妨试试我们推荐的这几款,可以帮助你尽快找到哪一款是你需要的。
---
via: <http://www.tecmint.com/best-linux-ide-editors-source-code-editors/>
作者:[Aaron Kili](http://www.tecmint.com/author/aaronkili/) 译者:[ZenMoore](https://github.com/ZenMoore) ,[LiBrad](https://github.com/LiBrad) ,[WangYueScream](https://github.com/WangYueScream) ,[LemonDemo](https://github.com/LemonDemo) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,705 | Fabric - 通过 SSH 来自动化管理 Linux 任务和布署应用 | http://www.tecmint.com/automating-linux-system-administration-tasks/ | 2016-08-22T09:55:32 | [
"Fabric",
"远程",
"ssh",
"自动化"
] | https://linux.cn/article-7705-1.html | 当要管理远程机器或者要布署应用时,虽然你有多种命令行工具可以选择,但是其中很多工具都缺少详细的使用文档。
在这篇教程中,我们将会一步一步地向你介绍如何使用 fabric 来帮助你更好得管理多台服务器。

*使用 Fabric 来自动化地管理 Linux 任务*
Fabric 是一个用 Python 编写的命令行工具库,它可以帮助系统管理员高效地执行某些任务,比如通过 SSH 到多台机器上执行某些命令,远程布署应用等。
在使用之前,如果你拥有使用 Python 的经验能帮你更好的使用 Fabric。当然,如果没有那也不影响使用 Fabric。
我们为什么要选择 Fabric:
* 简单
* 完备的文档
* 如果你会 Python,不用增加学习其他语言的成本
* 易于安装使用
* 使用便捷
* 支持多台机器并行操作
### 在 Linux 上如何安装 Fabric
Fabric 有一个特点就是要远程操作的机器只需要支持标准的 OpenSSH 服务即可。只要保证在机器上安装并开启了这个服务就能使用 Fabric 来管理机器。
#### 依赖
* Python 2.5 或更新版本,以及对应的开发组件
* Python-setuptools 和 pip(可选,但是非常推荐)gcc
我们推荐使用 pip 安装 Fabric,但是你也可以使用系统自带的包管理器如 `yum`, `dnf` 或 `apt-get` 来安装,包名一般是 `fabric` 或 `python-fabric`。
如果是基于 RHEL/CentOS 的发行版本的系统,你可以使用系统自带的 [EPEL 源](/article-2324-1.html) 来安装 fabric。
```
# yum install fabric [适用于基于 RedHat 系统]
# dnf install fabric [适用于 Fedora 22+ 版本]
```
如果你是 Debian 或者其派生的系统如 Ubuntu 和 Mint 的用户,你可以使用 apt-get 来安装,如下所示:
```
# apt-get install fabric
```
如果你要安装开发版的 Fabric,你需要安装 pip 来安装 master 分支上最新版本。
```
# yum install python-pip [适用于基于 RedHat 系统]
# dnf install python-pip [适用于Fedora 22+ 版本]
# apt-get install python-pip [适用于基于 Debian 系统]
```
安装好 pip 后,你可以使用 pip 获取最新版本的 Fabric。
```
# pip install fabric
```
### 如何使用 Fabric 来自动化管理 Linux 任务
现在我们来开始使用 Fabric,在之前的安装的过程中,Fabric Python 脚本已经被放到我们的系统目录,当我们要运行 Fabric 时输入 `fab` 命令即可。
#### 在本地 Linux 机器上运行命令行
按照惯例,先用你喜欢的编辑器创建一个名为 fabfile.py 的 Python 脚本。你可以使用其他名字来命名脚本,但是就需要指定这个脚本的路径,如下所示:
```
# fabric --fabfile /path/to/the/file.py
```
Fabric 使用 `fabfile.py` 来执行任务,这个文件应该放在你执行 Fabric 命令的目录里面。
**例子 1**:创建入门的 `Hello World` 任务:
```
# vi fabfile.py
```
在文件内输入如下内容:
```
def hello():
print('Hello world, Tecmint community')
```
保存文件并执行以下命令:
```
# fab hello
```

*Fabric 工具使用说明*
**例子 2**:新建一个名为 fabfile.py 的文件并打开:
粘贴以下代码至文件:
```
#! /usr/bin/env python
from fabric.api import local
def uptime():
local('uptime')
```
保存文件并执行以下命令:
```
# fab uptime
```

*Fabric: 检查系统运行时间*
让我们看看这个例子,fabfile.py 文件在本机执行了 uptime 这个命令。
#### 在远程 Linux 机器上运行命令来执行自动化任务
Fabric API 使用了一个名为 `env` 的关联数组(Python 中的词典)作为配置目录,来储存 Fabric 要控制的机器的相关信息。
`env.hosts` 是一个用来存储你要执行 Fabric 任务的机器的列表,如果你的 IP 地址是 192.168.0.0,想要用 Fabric 来管理地址为 192.168.0.2 和 192.168.0.6 的机器,需要的配置如下所示:
```
#!/usr/bin/env python
from fabric.api import env
env.hosts = [ '192.168.0.2', '192.168.0.6' ]
```
上面这几行代码只是声明了你要执行 Fabric 任务的主机地址,但是实际上并没有执行任何任务,下面我们就来定义一些任务。Fabric 提供了一系列可以与远程服务器交互的方法。
Fabric 提供了众多的方法,这里列出几个经常会用到的:
* run - 可以在远程机器上运行的 shell 命令
* local - 可以在本机上运行的 shell 命令
* sudo - 使用 root 权限在远程机器上运行的 shell 命令
* get - 从远程机器上下载一个或多个文件
* put - 上传一个或多个文件到远程机器
**例子 3**:在多台机子上输出信息,新建新的 fabfile.py 文件如下所示
```
#!/usr/bin/env python
from fabric.api import env, run
env.hosts = ['192.168.0.2','192.168.0.6']
def echo():
run("echo -n 'Hello, you are tuned to Tecmint ' ")
```
运行以下命令执行 Fabric 任务
```
# fab echo
```

*fabric: 自动在远程 Linux 机器上执行任务*
**例子 4**:你可以继续改进之前创建的执行 uptime 任务的 fabfile.py 文件,让它可以在多台服务器上运行 uptime 命令,也可以检查其磁盘使用情况,如下所示:
```
#!/usr/bin/env python
from fabric.api import env, run
env.hosts = ['192.168.0.2','192.168.0.6']
def uptime():
run('uptime')
def disk_space():
run('df -h')
```
保存并执行以下命令
```
# fab uptime
# fab disk_space
```

*Fabric:自动在多台服务器上执行任务*
#### 在远程服务器上自动化布署 LAMP
**例子 5**:我们来尝试一下在远程服务器上布署 LAMP(Linux, Apache, MySQL/MariaDB and PHP)
我们要写个函数在远程使用 root 权限安装 LAMP。
##### 在 RHEL/CentOS 或 Fedora 上
```
#!/usr/bin/env python
from fabric.api import env, run
env.hosts = ['192.168.0.2','192.168.0.6']
def deploy_lamp():
run ("yum install -y httpd mariadb-server php php-mysql")
```
##### 在 Debian/Ubuntu 或 Linux Mint 上
```
#!/usr/bin/env python
from fabric.api import env, run
env.hosts = ['192.168.0.2','192.168.0.6']
def deploy_lamp():
sudo("apt-get install -q apache2 mysql-server libapache2-mod-php5 php5-mysql")
```
保存并执行以下命令:
```
# fab deploy_lamp
```
注:由于安装时会输出大量信息,这个例子我们就不提供屏幕 gif 图了
现在你可以使用 Fabric 和上文例子所示的功能来[自动化的管理 Linux 服务器上的任务](http://www.tecmint.com/use-ansible-playbooks-to-automate-complex-tasks-on-multiple-linux-servers/)了。
#### 一些 Fabric 有用的选项
* 你可以运行 `fab -help` 输出帮助信息,里面列出了所有可以使用的命令行信息
* `–fabfile=PATH` 选项可以让你定义除了名为 fabfile.py 之外的模块
* 如果你想用指定的用户名登录远程主机,请使用 `-user=USER` 选项
* 如果你需要密码进行验证或者 sudo 提权,请使用 `–password=PASSWORD` 选项
* 如果需要输出某个命令的详细信息,请使用 `–display=命令名` 选项
* 使用 `--list` 输出所有可用的任务
* 使用 `--list-format=FORMAT` 选项能格式化 `-list` 选项输出的信息,可选的有 short、normal、 nested
* `--config=PATH` 选项可以指定读取配置文件的地址
* `-–colorize-errors` 能显示彩色的错误输出信息
* `--version` 输出当前版本
### 总结
Fabric 是一个强大并且文档完备的工具,对于新手来说也能很快上手,阅读提供的文档能帮助你更好的了解它。如果你在安装和使用 Fabric 时发现什么问题可以在评论区留言,我们会及时回复。
参考:[Fabric 文档](http://docs.fabfile.org/en/1.4.0/usage/env.html)
---
via: <http://www.tecmint.com/automating-linux-system-administration-tasks/>
作者:[Aaron Kili](http://www.tecmint.com/author/aaronkili/) 译者:[NearTan](https://github.com/NearTan) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,706 | LXD 2.0 系列(三):你的第一个 LXD 容器 | https://www.stgraber.org/216/03/19/lxd-2-0-your-first-lxd-container-312/ | 2016-08-22T12:14:00 | [
"容器",
"LXC",
"LXD"
] | https://linux.cn/article-7706-1.html | 
这是 LXD 2.0 系列介绍文章的第三篇博客。
1. [LXD 入门](/article-7618-1.html)
2. [安装与配置](/article-7687-1.html)
3. [你的第一个 LXD 容器](/article-7706-1.html)
4. [资源控制](/article-8072-1.html)
5. [镜像管理](/article-8107-1.html)
6. [远程主机及容器迁移](/article-8169-1.html)
7. [LXD 中的 Docker](/article-8235-1.html)
8. [LXD 中的 LXD](/article-8257-1.html)
9. [实时迁移](/article-8263-1.html)
10. [LXD 和 Juju](/article-8273-1.html)
11. [LXD 和 OpenStack](/article-8274-1.html)
12. [调试,及给 LXD 做贡献](/article-8282-1.html)
由于在管理 LXD 容器时涉及到大量的命令,所以这篇文章的篇幅是比较长的,如果你更喜欢使用同样的命令来快速的一步步实现整个过程,你可以[尝试我们的在线示例](https://linuxcontainers.org/lxd/try-it)!
### 创建并启动一个新的容器
正如我在先前的文章中提到的一样,LXD 命令行客户端预配置了几个镜像源。Ubuntu 的所有发行版和架构平台全都提供了官方镜像,但是对于其他的发行版也有大量的非官方镜像,那些镜像都是由社区制作并且被 LXC 上游贡献者所维护。
#### Ubuntu
如果你想要支持最为完善的 Ubuntu 版本,你可以按照下面的去做:
```
lxc launch ubuntu:
```
注意,这里意味着会随着 Ubuntu LTS 的发布而变化。因此,如果用于脚本,你需要指明你具体安装的版本(参见下面)。
#### Ubuntu14.04 LTS
得到最新更新的、已经测试过的、稳定的 Ubuntu 14.04 LTS 镜像,你可以简单的执行:
```
lxc launch ubuntu:14.04
```
在该模式下,会指定一个随机的容器名。
如果你更喜欢指定一个你自己的名字,你可以这样做:
```
lxc launch ubuntu:14.04 c1
```
如果你想要指定一个特定的体系架构(非主流平台),比如 32 位 Intel 镜像,你可以这样做:
```
lxc launch ubuntu:14.04/i386 c2
```
#### 当前的 Ubuntu 开发版本
上面使用的“ubuntu:”远程仓库只会给你提供官方的并经过测试的 Ubuntu 镜像。但是如果你想要未经测试过的日常构建版本,开发版可能对你来说是合适的,你需要使用“ubuntu-daily:”远程仓库。
```
lxc launch ubuntu-daily:devel c3
```
在这个例子中,将会自动选中最新的 Ubuntu 开发版本。
你也可以更加精确,比如你可以使用代号名:
```
lxc launch ubuntu-daily:xenial c4
```
#### 最新的Alpine Linux
Alpine 镜像可以在“Images:”远程仓库中找到,通过如下命令执行:
```
lxc launch images:alpine/3.3/amd64 c5
```
#### 其他
全部的 Ubuntu 镜像列表可以这样获得:
```
lxc image list ubuntu:
lxc image list ubuntu-daily:
```
全部的非官方镜像:
```
lxc image list images:
```
某个给定的原程仓库的全部别名(易记名称)可以这样获得(比如对于“ubuntu:”远程仓库):
```
lxc image alias list ubuntu:
```
### 创建但不启动一个容器
如果你想创建一个容器或者一批容器,但是你不想马上启动它们,你可以使用`lxc init`替换掉`lxc launch`。所有的选项都是相同的,唯一的不同就是它并不会在你创建完成之后启动容器。
```
lxc init ubuntu:
```
### 关于你的容器的信息
#### 列出所有的容器
要列出你的所有容器,你可以这样这做:
```
lxc list
```
有大量的选项供你选择来改变被显示出来的列。在一个拥有大量容器的系统上,默认显示的列可能会有点慢(因为必须获取容器中的网络信息),你可以这样做来避免这种情况:
```
lxc list --fast
```
上面的命令显示了另外一套列的组合,这个组合在服务器端需要处理的信息更少。
你也可以基于名字或者属性来过滤掉一些东西:
```
stgraber@dakara:~$ lxc list security.privileged=true
+------+---------+---------------------+-----------------------------------------------+------------+-----------+
| NAME | STATE | IPV4 | IPV6 | TYPE | SNAPSHOTS |
+------+---------+---------------------+-----------------------------------------------+------------+-----------+
| suse | RUNNING | 172.17.0.105 (eth0) | 2607:f2c0:f00f:2700:216:3eff:fef2:aff4 (eth0) | PERSISTENT | 0 |
+------+---------+---------------------+-----------------------------------------------+------------+-----------+
```
在这个例子中,只有那些特权容器(禁用了用户命名空间)才会被列出来。
```
stgraber@dakara:~$ lxc list --fast alpine
+-------------+---------+--------------+----------------------+----------+------------+
| NAME | STATE | ARCHITECTURE | CREATED AT | PROFILES | TYPE |
+-------------+---------+--------------+----------------------+----------+------------+
| alpine | RUNNING | x86_64 | 2016/03/20 02:11 UTC | default | PERSISTENT |
+-------------+---------+--------------+----------------------+----------+------------+
| alpine-edge | RUNNING | x86_64 | 2016/03/20 02:19 UTC | default | PERSISTENT |
+-------------+---------+--------------+----------------------+----------+------------+
```
在这个例子中,只有在名字中带有“alpine”的容器才会被列出来(也支持复杂的正则表达式)。
#### 获取容器的详细信息
由于 list 命令显然不能以一种友好的可读方式显示容器的所有信息,因此你可以使用如下方式来查询单个容器的信息:
```
lxc info <container>
```
例如:
```
stgraber@dakara:~$ lxc info zerotier
Name: zerotier
Architecture: x86_64
Created: 2016/02/20 20:01 UTC
Status: Running
Type: persistent
Profiles: default
Pid: 31715
Processes: 32
Ips:
eth0: inet 172.17.0.101
eth0: inet6 2607:f2c0:f00f:2700:216:3eff:feec:65a8
eth0: inet6 fe80::216:3eff:feec:65a8
lo: inet 127.0.0.1
lo: inet6 ::1
lxcbr0: inet 10.0.3.1
lxcbr0: inet6 fe80::c0a4:ceff:fe52:4d51
zt0: inet 29.17.181.59
zt0: inet6 fd80:56c2:e21c:0:199:9379:e711:b3e1
zt0: inet6 fe80::79:e7ff:fe0d:5123
Snapshots:
zerotier/blah (taken at 2016/03/08 23:55 UTC) (stateless)
```
### 生命周期管理命令
这些命令对于任何容器或者虚拟机管理器或许都是最普通的命令,但是它们仍然需要讲到。
所有的这些命令在批量操作时都能接受多个容器名。
#### 启动
启动一个容器就向下面一样简单:
```
lxc start <container>
```
#### 停止
停止一个容器可以这样来完成:
```
lxc stop <container>
```
如果容器不合作(即没有对发出的 SIGPWR 信号产生回应),这时候,你可以使用下面的方式强制执行:
```
lxc stop <container> --force
```
#### 重启
通过下面的命令来重启一个容器:
```
lxc restart <container>
```
如果容器不合作(即没有对发出的 SIGINT 信号产生回应),你可以使用下面的方式强制执行:
```
lxc restart <container> --force
```
#### 暂停
你也可以“暂停”一个容器,在这种模式下,所有的容器任务将会被发送相同的 SIGSTOP 信号,这也意味着它们将仍然是可见的,并且仍然会占用内存,但是它们不会从调度程序中得到任何的 CPU 时间片。
如果你有一个很占用 CPU 的容器,而这个容器需要一点时间来启动,但是你却并不会经常用到它。这时候,你可以先启动它,然后将它暂停,并在你需要它的时候再启动它。
```
lxc pause <container>
```
#### 删除
最后,如果你不需要这个容器了,你可以用下面的命令删除它:
```
lxc delete <container>
```
注意,如果容器还处于运行状态时你将必须使用“-force”。
### 容器的配置
LXD 拥有大量的容器配置设定,包括资源限制,容器启动控制以及对各种设备是否允许访问的配置选项。完整的清单因为太长所以并没有在本文中列出,但是,你可以从[这里]获取它。
就设备而言,LXD 当前支持下面列出的这些设备类型:
* 磁盘 既可以是一块物理磁盘,也可以只是一个被挂挂载到容器上的分区,还可以是一个来自主机的绑定挂载路径。
* 网络接口卡 一块网卡。它可以是一块桥接的虚拟网卡,或者是一块点对点设备,还可以是一块以太局域网设备或者一块已经被连接到容器的真实物理接口。
* unix 块设备 一个 UNIX 块设备,比如 /dev/sda
* unix 字符设备 一个 UNIX 字符设备,比如 /dev/kvm
* none 这种特殊类型被用来隐藏那种可以通过配置文件被继承的设备。
#### 配置 profile 文件
所有可用的配置文件列表可以这样获取:
```
lxc profile list
```
为了看到给定配置文件的内容,最简单的方式是这样做:
```
lxc profile show <profile>
```
你可能想要改变文件里面的内容,可以这样做:
```
lxc profile edit <profile>
```
你可以使用如下命令来改变应用到给定容器的配置文件列表:
```
lxc profile apply <container> <profile1>,<profile2>,<profile3>,...
```
#### 本地配置
有些配置是某个容器特定的,你并不想将它放到配置文件中,你可直接对容器设置它们:
```
lxc config edit <container>
```
上面的命令做的和“profile edit”命令是一样。
如果不想在文本编辑器中打开整个文件的内容,你也可以像这样修改单独的配置:
```
lxc config set <container> <key> <value>
```
或者添加设备,例如:
```
lxc config device add my-container kvm unix-char path=/dev/kvm
```
上面的命令将会为名为“my-container”的容器设置一个 /dev/kvm 项。
对一个配置文件使用`lxc profile set`和`lxc profile device add`命令也能实现上面的功能。
#### 读取配置
你可以使用如下命令来读取容器的本地配置:
```
lxc config show <container>
```
或者得到已经被展开了的配置(包含了所有的配置值):
```
lxc config show --expanded <container>
```
例如:
```
stgraber@dakara:~$ lxc config show --expanded zerotier
name: zerotier
profiles:
- default
config:
security.nesting: "true"
user.a: b
volatile.base_image: a49d26ce5808075f5175bf31f5cb90561f5023dcd408da8ac5e834096d46b2d8
volatile.eth0.hwaddr: 00:16:3e:ec:65:a8
volatile.last_state.idmap: '[{"Isuid":true,"Isgid":false,"Hostid":100000,"Nsid":0,"Maprange":65536},{"Isuid":false,"Isgid":true,"Hostid":100000,"Nsid":0,"Maprange":65536}]'
devices:
eth0:
name: eth0
nictype: macvlan
parent: eth0
type: nic
limits.ingress: 10Mbit
limits.egress: 10Mbit
root:
path: /
size: 30GB
type: disk
tun:
path: /dev/net/tun
type: unix-char
ephemeral: false
```
这样做可以很方便的检查有哪些配置属性被应用到了给定的容器。
#### 实时配置更新
注意,除非在文档中已经被明确指出,否则所有的配置值和设备项的设置都会对容器实时发生影响。这意味着在不重启正在运行的容器的情况下,你可以添加和移除某些设备或者修改安全配置文件。
### 获得一个 shell
LXD 允许你直接在容器中执行任务。最常用的做法是在容器中得到一个 shell 或者执行一些管理员任务。
和 SSH 相比,这样做的好处是你不需要容器是网络可达的,也不需要任何软件和特定的配置。
#### 执行环境
与 LXD 在容器内执行命令的方式相比,有一点是不同的,那就是 shell 并不是在容器中运行。这也意味着容器不知道使用的是什么样的 shell,以及设置了什么样的环境变量和你的家目录在哪里。
通过 LXD 来执行命令总是使用最小的路径环境变量设置,并且 HOME 环境变量必定为 /root,以容器的超级用户身份来执行(即 uid 为 0,gid 为 0)。
其他的环境变量可以通过命令行来设置,或者在“environment.”配置中设置成永久环境变量。
#### 执行命令
在容器中获得一个 shell 可以简单的执行下列命令得到:
```
lxc exec <container> bash
```
当然,这样做的前提是容器内已经安装了 bash。
更复杂的命令要求使用分隔符来合理分隔参数。
```
lxc exec <container> -- ls -lh /
```
如果想要设置或者重写变量,你可以使用“-env”参数,例如:
```
stgraber@dakara:~$ lxc exec zerotier --env mykey=myvalue env | grep mykey
mykey=myvalue
```
### 管理文件
因为 LXD 可以直接访问容器的文件系统,因此,它可以直接读取和写入容器中的任意文件。当我们需要提取日志文件或者与容器传递文件时,这个特性是很有用的。
#### 从容器中取回一个文件
想要从容器中获得一个文件,简单的执行下列命令:
```
lxc file pull <container>/<path> <dest>
```
例如:
```
stgraber@dakara:~$ lxc file pull zerotier/etc/hosts hosts
```
或者将它读取到标准输出:
```
stgraber@dakara:~$ lxc file pull zerotier/etc/hosts -
127.0.0.1 localhost
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
ff02::3 ip6-allhosts
```
#### 向容器发送一个文件
发送以另一种简单的方式完成:
```
lxc file push <source> <container>/<path>
```
#### 直接编辑一个文件
编辑是一个方便的功能,其实就是简单的提取一个给定的路径,在你的默认文本编辑器中打开它,在你关闭编辑器时会自动将编辑的内容保存到容器。
```
lxc file edit <container>/<path>
```
### 快照管理
LXD 允许你对容器执行快照功能并恢复它。快照包括了容器在某一时刻的完整状态(如果`-stateful`被使用的话将会包括运行状态),这也意味着所有的容器配置,容器设备和容器文件系统也会被保存。
#### 创建一个快照
你可以使用下面的命令来执行快照功能:
```
lxc snapshot <container>
```
命令执行完成之后将会生成名为snapX(X 为一个自动增长的数)的记录。
除此之外,你还可以使用如下命令命名你的快照:
```
lxc snapshot <container> <snapshot name>
```
#### 列出所有的快照
一个容器的所有快照的数量可以使用`lxc list`来得到,但是具体的快照列表只能执行`lxc info`命令才能看到。
```
lxc info <container>
```
#### 恢复快照
为了恢复快照,你可以简单的执行下面的命令:
```
lxc restore <container> <snapshot name>
```
#### 给快照重命名
可以使用如下命令来给快照重命名:
```
lxc move <container>/<snapshot name> <container>/<new snapshot name>
```
#### 从快照中创建一个新的容器
你可以使用快照来创建一个新的容器,而这个新的容器除了一些可变的信息将会被重置之外(例如 MAC 地址)其余所有信息都将和快照完全相同。
```
lxc copy <source container>/<snapshot name> <destination container>
```
#### 删除一个快照
最后,你可以执行下面的命令来删除一个快照:
```
lxc delete <container>/<snapshot name>
```
### 克隆并重命名
得到一个纯净的发行版镜像总是让人感到愉悦,但是,有时候你想要安装一系列的软件到你的容器中,这时,你需要配置它然后将它分支成多个其他的容器。
#### 复制一个容器
为了复制一个容器并有效的将它克隆到一个新的容器中,你可以执行下面的命令:
```
lxc copy <source container> <destination container>
```
目标容器在所有方面将会完全和源容器等同。除了新的容器没有任何源容器的快照以及一些可变值将会被重置之外(例如 MAC 地址)。
#### 移动一个快照
LXD 允许你复制容器并在主机之间移动它。但是,关于这一点将在后面的文章中介绍。
现在,“move”命令将会被用作给容器重命名。
```
lxc move <old name> <new name>
```
唯一的要求就是当容器应该被停止,容器内的任何事情都会被保存成它本来的样子,包括可变化的信息(类似 MAC 地址等)。
### 结论
这篇如此长的文章介绍了大多数你可能会在日常操作中使用到的命令。
很显然,这些如此之多的命令都会有不少选项,可以让你的命令更加有效率,或者可以让你指定你的 LXD 容器的某个具体方面。最好的学习这些命令的方式就是深入学习它们的帮助文档( -help)。
### 更多信息
* LXD 的主要网站是:<https://linuxcontainers.org/lxd>
* Github 上的开发动态: <https://github.com/lxc/lxd>
* 邮件列表支持:<https://lists.linuxcontainers.org>
* IRC 支持: #lxcontainers on irc.freenode.net
如果你不想或者不能在你的机器上安装 LXD,你可以[试试在线版本](https://linuxcontainers.org/lxd/try-it)!
---
作者简介:我是 Stéphane Graber。我是 LXC 和 LXD 项目的领导者,目前在加拿大魁北克蒙特利尔的家所在的Canonical 有限公司担任 LXD 的技术主管。
---
来自于:<https://www.stgraber.org/2016/03/19/lxd-2-0-your-first-lxd-container-312/> 作者:[Stéphane Graber](https://www.stgraber.org/author/stgraber/) 译者:[kylepeng93](https://github.com/kylepeng93) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,707 | Linux 内核里的数据结构——位数组 | https://github.com/0xAX/linux-insides/blob/master/DataStructures/bitmap.md | 2016-08-23T11:05:00 | [
"内核",
"数据结构",
"位数组"
] | https://linux.cn/article-7707-1.html | ### Linux 内核中的位数组和位操作

除了不同的基于[链式](https://en.wikipedia.org/wiki/Linked_data_structure)和[树](https://en.wikipedia.org/wiki/Tree_%28data_structure%29)的数据结构以外,Linux 内核也为[位数组](https://en.wikipedia.org/wiki/Bit_array)(或称为<ruby> 位图 <rp> ( </rp> <rt> bitmap </rt> <rp> ) </rp></ruby>)提供了 [API](https://en.wikipedia.org/wiki/Application_programming_interface)。位数组在 Linux 内核里被广泛使用,并且在以下的源代码文件中包含了与这样的结构搭配使用的通用 `API`:
* [lib/bitmap.c](https://github.com/torvalds/linux/blob/master/lib/bitmap.c)
* [include/linux/bitmap.h](https://github.com/torvalds/linux/blob/master/include/linux/bitmap.h)
除了这两个文件之外,还有体系结构特定的头文件,它们为特定的体系结构提供优化的位操作。我们将探讨 [x86\_64](https://en.wikipedia.org/wiki/X86-64) 体系结构,因此在我们的例子里,它会是
* [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h)
头文件。正如我上面所写的,`位图`在 Linux 内核中被广泛地使用。例如,`位数组`常常用于保存一组在线/离线处理器,以便系统支持[热插拔](https://www.kernel.org/doc/Documentation/cpu-hotplug.txt)的 CPU(你可以在 [cpumasks](https://0xax.gitbooks.io/linux-insides/content/Concepts/cpumask.html) 部分阅读更多相关知识 ),一个<ruby> 位数组 <rp> ( </rp> <rt> bit array </rt> <rp> ) </rp></ruby>可以在 Linux 内核初始化等期间保存一组已分配的[中断处理](https://en.wikipedia.org/wiki/Interrupt_request_%28PC_architecture%29)。
因此,本部分的主要目的是了解<ruby> 位数组 <rp> ( </rp> <rt> bit array </rt> <rp> ) </rp></ruby>是如何在 Linux 内核中实现的。让我们现在开始吧。
### 位数组声明
在我们开始查看`位图`操作的 `API` 之前,我们必须知道如何在 Linux 内核中声明它。有两种声明位数组的通用方法。第一种简单的声明一个位数组的方法是,定义一个 `unsigned long` 的数组,例如:
```
unsigned long my_bitmap[8]
```
第二种方法,是使用 `DECLARE_BITMAP` 宏,它定义于 [include/linux/types.h](https://github.com/torvalds/linux/blob/master/include/linux/types.h) 头文件:
```
#define DECLARE_BITMAP(name,bits) \
unsigned long name[BITS_TO_LONGS(bits)]
```
我们可以看到 `DECLARE_BITMAP` 宏使用两个参数:
* `name` - 位图名称;
* `bits` - 位图中位数;
并且只是使用 `BITS_TO_LONGS(bits)` 元素展开 `unsigned long` 数组的定义。 `BITS_TO_LONGS` 宏将一个给定的位数转换为 `long` 的个数,换言之,就是计算 `bits` 中有多少个 `8` 字节元素:
```
#define BITS_PER_BYTE 8
#define DIV_ROUND_UP(n,d) (((n) + (d) - 1) / (d))
#define BITS_TO_LONGS(nr) DIV_ROUND_UP(nr, BITS_PER_BYTE * sizeof(long))
```
因此,例如 `DECLARE_BITMAP(my_bitmap, 64)` 将产生:
```
>>> (((64) + (64) - 1) / (64))
1
```
与:
```
unsigned long my_bitmap[1];
```
在能够声明一个位数组之后,我们便可以使用它了。
### 体系结构特定的位操作
我们已经看了上面提及的一对源文件和头文件,它们提供了位数组操作的 [API](https://en.wikipedia.org/wiki/Application_programming_interface)。其中重要且广泛使用的位数组 API 是体系结构特定的且位于已提及的头文件中 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h)。
首先让我们查看两个最重要的函数:
* `set_bit`;
* `clear_bit`.
我认为没有必要解释这些函数的作用。从它们的名字来看,这已经很清楚了。让我们直接查看它们的实现。如果你浏览 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 头文件,你将会注意到这些函数中的每一个都有[原子性](https://en.wikipedia.org/wiki/Linearizability)和非原子性两种变体。在我们开始深入这些函数的实现之前,首先,我们必须了解一些有关<ruby> 原子 <rp> ( </rp> <rt> atomic </rt> <rp> ) </rp></ruby>操作的知识。
简而言之,原子操作保证两个或以上的操作不会并发地执行同一数据。`x86` 体系结构提供了一系列原子指令,例如, [xchg](http://x86.renejeschke.de/html/file_module_x86_id_328.html)、[cmpxchg](http://x86.renejeschke.de/html/file_module_x86_id_41.html) 等指令。除了原子指令,一些非原子指令可以在 [lock](http://x86.renejeschke.de/html/file_module_x86_id_159.html) 指令的帮助下具有原子性。现在你已经对原子操作有了足够的了解,我们可以接着探讨 `set_bit` 和 `clear_bit` 函数的实现。
我们先考虑函数的<ruby> 非原子性 <rp> ( </rp> <rt> non-atomic </rt> <rp> ) </rp></ruby>变体。非原子性的 `set_bit` 和 `clear_bit` 的名字以双下划线开始。正如我们所知道的,所有这些函数都定义于 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 头文件,并且第一个函数就是 `__set_bit`:
```
static inline void __set_bit(long nr, volatile unsigned long *addr)
{
asm volatile("bts %1,%0" : ADDR : "Ir" (nr) : "memory");
}
```
正如我们所看到的,它使用了两个参数:
* `nr` - 位数组中的位号(LCTT 译注:从 0 开始)
* `addr` - 我们需要置位的位数组地址
注意,`addr` 参数使用 `volatile` 关键字定义,以告诉编译器给定地址指向的变量可能会被修改。 `__set_bit` 的实现相当简单。正如我们所看到的,它仅包含一行[内联汇编代码](https://en.wikipedia.org/wiki/Inline_assembler)。在我们的例子中,我们使用 [bts](http://x86.renejeschke.de/html/file_module_x86_id_25.html) 指令,从位数组中选出一个第一操作数(我们的例子中的 `nr`)所指定的位,存储选出的位的值到 [CF](https://en.wikipedia.org/wiki/FLAGS_register) 标志寄存器并设置该位(LCTT 译注:即 `nr` 指定的位置为 1)。
注意,我们了解了 `nr` 的用法,但这里还有一个参数 `addr` 呢!你或许已经猜到秘密就在 `ADDR`。 `ADDR` 是一个定义在同一个头文件中的宏,它展开为一个包含给定地址和 `+m` 约束的字符串:
```
#define ADDR BITOP_ADDR(addr)
#define BITOP_ADDR(x) "+m" (*(volatile long *) (x))
```
除了 `+m` 之外,在 `__set_bit` 函数中我们可以看到其他约束。让我们查看并试着理解它们所表示的意义:
* `+m` - 表示内存操作数,这里的 `+` 表明给定的操作数为输入输出操作数;
* `I` - 表示整型常量;
* `r` - 表示寄存器操作数
除了这些约束之外,我们也能看到 `memory` 关键字,其告诉编译器这段代码会修改内存中的变量。到此为止,现在我们看看相同的<ruby> 原子性 <rp> ( </rp> <rt> atomic </rt> <rp> ) </rp></ruby>变体函数。它看起来比<ruby> 非原子性 <rp> ( </rp> <rt> non-atomic </rt> <rp> ) </rp></ruby>变体更加复杂:
```
static __always_inline void
set_bit(long nr, volatile unsigned long *addr)
{
if (IS_IMMEDIATE(nr)) {
asm volatile(LOCK_PREFIX "orb %1,%0"
: CONST_MASK_ADDR(nr, addr)
: "iq" ((u8)CONST_MASK(nr))
: "memory");
} else {
asm volatile(LOCK_PREFIX "bts %1,%0"
: BITOP_ADDR(addr) : "Ir" (nr) : "memory");
}
}
```
(LCTT 译注:BITOP\_ADDR 的定义为:`#define BITOP_ADDR(x) "=m" (*(volatile long *) (x))`,ORB 为字节按位或。)
首先注意,这个函数使用了与 `__set_bit` 相同的参数集合,但额外地使用了 `__always_inline` 属性标记。 `__always_inline` 是一个定义于 [include/linux/compiler-gcc.h](https://github.com/torvalds/linux/blob/master/include/linux/compiler-gcc.h) 的宏,并且只是展开为 `always_inline` 属性:
```
#define __always_inline inline __attribute__((always_inline))
```
其意味着这个函数总是内联的,以减少 Linux 内核映像的大小。现在让我们试着了解下 `set_bit` 函数的实现。首先我们在 `set_bit` 函数的开头检查给定的位的数量。`IS_IMMEDIATE` 宏定义于相同的[头文件](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h),并展开为 [gcc](https://en.wikipedia.org/wiki/GNU_Compiler_Collection) 内置函数的调用:
```
#define IS_IMMEDIATE(nr) (__builtin_constant_p(nr))
```
如果给定的参数是编译期已知的常量,`__builtin_constant_p` 内置函数则返回 `1`,其他情况返回 `0`。假若给定的位数是编译期已知的常量,我们便无须使用效率低下的 `bts` 指令去设置位。我们可以只需在给定地址指向的字节上执行 [按位或](https://en.wikipedia.org/wiki/Bitwise_operation#OR) 操作,其字节包含给定的位,掩码位数表示高位为 `1`,其他位为 0 的掩码。在其他情况下,如果给定的位号不是编译期已知常量,我们便做和 `__set_bit` 函数一样的事。`CONST_MASK_ADDR` 宏:
```
#define CONST_MASK_ADDR(nr, addr) BITOP_ADDR((void *)(addr) + ((nr)>>3))
```
展开为带有到包含给定位的字节偏移的给定地址,例如,我们拥有地址 `0x1000` 和位号 `0x9`。因为 `0x9` 代表 `一个字节 + 一位`,所以我们的地址是 `addr + 1`:
```
>>> hex(0x1000 + (0x9 >> 3))
'0x1001'
```
`CONST_MASK` 宏将我们给定的位号表示为字节,位号对应位为高位 `1`,其他位为 `0`:
```
#define CONST_MASK(nr) (1 << ((nr) & 7))
```
```
>>> bin(1 << (0x9 & 7))
'0b10'
```
最后,我们应用 `按位或` 运算到这些变量上面,因此,假如我们的地址是 `0x4097` ,并且我们需要置位号为 `9` 的位为 1:
```
>>> bin(0x4097)
'0b100000010010111'
>>> bin((0x4097 >> 0x9) | (1 << (0x9 & 7)))
'0b100010'
```
`第 9 位` 将会被置位。(LCTT 译注:这里的 9 是从 0 开始计数的,比如0010,按照作者的意思,其中的 1 是第 1 位)
注意,所有这些操作使用 `LOCK_PREFIX` 标记,其展开为 [lock](http://x86.renejeschke.de/html/file_module_x86_id_159.html) 指令,保证该操作的原子性。
正如我们所知,除了 `set_bit` 和 `__set_bit` 操作之外,Linux 内核还提供了两个功能相反的函数,在原子性和非原子性的上下文中清位。它们是 `clear_bit` 和 `__clear_bit`。这两个函数都定义于同一个[头文件](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 并且使用相同的参数集合。不仅参数相似,一般而言,这些函数与 `set_bit` 和 `__set_bit` 也非常相似。让我们查看非原子性 `__clear_bit` 的实现吧:
```
static inline void __clear_bit(long nr, volatile unsigned long *addr)
{
asm volatile("btr %1,%0" : ADDR : "Ir" (nr));
}
```
没错,正如我们所见,`__clear_bit` 使用相同的参数集合,并包含极其相似的内联汇编代码块。它只是使用 [btr](http://x86.renejeschke.de/html/file_module_x86_id_24.html) 指令替换了 `bts`。正如我们从函数名所理解的一样,通过给定地址,它清除了给定的位。`btr` 指令表现得像 `bts`(LCTT 译注:原文这里为 btr,可能为笔误,修正为 bts)。该指令选出第一操作数所指定的位,存储它的值到 `CF` 标志寄存器,并且清除第二操作数指定的位数组中的对应位。
`__clear_bit` 的原子性变体为 `clear_bit`:
```
static __always_inline void
clear_bit(long nr, volatile unsigned long *addr)
{
if (IS_IMMEDIATE(nr)) {
asm volatile(LOCK_PREFIX "andb %1,%0"
: CONST_MASK_ADDR(nr, addr)
: "iq" ((u8)~CONST_MASK(nr)));
} else {
asm volatile(LOCK_PREFIX "btr %1,%0"
: BITOP_ADDR(addr)
: "Ir" (nr));
}
}
```
并且正如我们所看到的,它与 `set_bit` 非常相似,只有两处不同。第一处差异为 `clear_bit` 使用 `btr` 指令来清位,而 `set_bit` 使用 `bts` 指令来置位。第二处差异为 `clear_bit` 使用否定的位掩码和 `按位与` 在给定的字节上置位,而 `set_bit` 使用 `按位或` 指令。
到此为止,我们可以在任意位数组置位和清位了,我们将看看位掩码上的其他操作。
在 Linux 内核中对位数组最广泛使用的操作是设置和清除位,但是除了这两个操作外,位数组上其他操作也是非常有用的。Linux 内核里另一种广泛使用的操作是知晓位数组中一个给定的位是否被置位。我们能够通过 `test_bit` 宏的帮助实现这一功能。这个宏定义于 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 头文件,并根据位号分别展开为 `constant_test_bit` 或 `variable_test_bit` 调用。
```
#define test_bit(nr, addr) \
(__builtin_constant_p((nr)) \
? constant_test_bit((nr), (addr)) \
: variable_test_bit((nr), (addr)))
```
因此,如果 `nr` 是编译期已知常量,`test_bit` 将展开为 `constant_test_bit` 函数的调用,而其他情况则为 `variable_test_bit`。现在让我们看看这些函数的实现,让我们从 `variable_test_bit` 开始看起:
```
static inline int variable_test_bit(long nr, volatile const unsigned long *addr)
{
int oldbit;
asm volatile("bt %2,%1\n\t"
"sbb %0,%0"
: "=r" (oldbit)
: "m" (*(unsigned long *)addr), "Ir" (nr));
return oldbit;
}
```
`variable_test_bit` 函数使用了与 `set_bit` 及其他函数使用的相似的参数集合。我们也可以看到执行 [bt](http://x86.renejeschke.de/html/file_module_x86_id_22.html) 和 [sbb](http://x86.renejeschke.de/html/file_module_x86_id_286.html) 指令的内联汇编代码。`bt` (或称 `bit test`)指令从第二操作数指定的位数组选出第一操作数指定的一个指定位,并且将该位的值存进标志寄存器的 [CF](https://en.wikipedia.org/wiki/FLAGS_register) 位。第二个指令 `sbb` 从第二操作数中减去第一操作数,再减去 `CF` 的值。因此,这里将一个从给定位数组中的给定位号的值写进标志寄存器的 `CF` 位,并且执行 `sbb` 指令计算: `00000000 - CF`,并将结果写进 `oldbit` 变量。
`constant_test_bit` 函数做了和我们在 `set_bit` 所看到的一样的事:
```
static __always_inline int constant_test_bit(long nr, const volatile unsigned long *addr)
{
return ((1UL << (nr & (BITS_PER_LONG-1))) &
(addr[nr >> _BITOPS_LONG_SHIFT])) != 0;
}
```
它生成了一个位号对应位为高位 `1`,而其他位为 `0` 的字节(正如我们在 `CONST_MASK` 所看到的),并将 [按位与](https://en.wikipedia.org/wiki/Bitwise_operation#AND) 应用于包含给定位号的字节。
下一个被广泛使用的位数组相关操作是改变一个位数组中的位。为此,Linux 内核提供了两个辅助函数:
* `__change_bit`;
* `change_bit`.
你可能已经猜测到,就拿 `set_bit` 和 `__set_bit` 例子说,这两个变体分别是原子和非原子版本。首先,让我们看看 `__change_bit` 函数的实现:
```
static inline void __change_bit(long nr, volatile unsigned long *addr)
{
asm volatile("btc %1,%0" : ADDR : "Ir" (nr));
}
```
相当简单,不是吗? `__change_bit` 的实现和 `__set_bit` 一样,只是我们使用 [btc](http://x86.renejeschke.de/html/file_module_x86_id_23.html) 替换 `bts` 指令而已。 该指令从一个给定位数组中选出一个给定位,将该为位的值存进 `CF` 并使用求反操作改变它的值,因此值为 `1` 的位将变为 `0`,反之亦然:
```
>>> int(not 1)
0
>>> int(not 0)
1
```
`__change_bit` 的原子版本为 `change_bit` 函数:
```
static inline void change_bit(long nr, volatile unsigned long *addr)
{
if (IS_IMMEDIATE(nr)) {
asm volatile(LOCK_PREFIX "xorb %1,%0"
: CONST_MASK_ADDR(nr, addr)
: "iq" ((u8)CONST_MASK(nr)));
} else {
asm volatile(LOCK_PREFIX "btc %1,%0"
: BITOP_ADDR(addr)
: "Ir" (nr));
}
}
```
它和 `set_bit` 函数很相似,但也存在两点不同。第一处差异为 `xor` 操作而不是 `or`。第二处差异为 `btc`( LCTT 译注:原文为 `bts`,为作者笔误) 而不是 `bts`。
目前,我们了解了最重要的体系特定的位数组操作,是时候看看一般的位图 API 了。
### 通用位操作
除了 [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 中体系特定的 API 外,Linux 内核提供了操作位数组的通用 API。正如我们本部分开头所了解的一样,我们可以在 [include/linux/bitmap.h](https://github.com/torvalds/linux/blob/master/include/linux/bitmap.h) 头文件和 [lib/bitmap.c](https://github.com/torvalds/linux/blob/master/lib/bitmap.c) 源文件中找到它。但在查看这些源文件之前,我们先看看 [include/linux/bitops.h](https://github.com/torvalds/linux/blob/master/include/linux/bitops.h) 头文件,其提供了一系列有用的宏,让我们看看它们当中一部分。
首先我们看看以下 4 个 宏:
* `for_each_set_bit`
* `for_each_set_bit_from`
* `for_each_clear_bit`
* `for_each_clear_bit_from`
所有这些宏都提供了遍历位数组中某些位集合的迭代器。第一个宏迭代那些被置位的位。第二个宏也是一样,但它是从某一个确定的位开始。最后两个宏做的一样,但是迭代那些被清位的位。让我们看看 `for_each_set_bit` 宏:
```
#define for_each_set_bit(bit, addr, size) \
for ((bit) = find_first_bit((addr), (size)); \
(bit) < (size); \
(bit) = find_next_bit((addr), (size), (bit) + 1))
```
正如我们所看到的,它使用了三个参数,并展开为一个循环,该循环从作为 `find_first_bit` 函数返回结果的第一个置位开始,到小于给定大小的最后一个置位为止。
除了这四个宏, [arch/x86/include/asm/bitops.h](https://github.com/torvalds/linux/blob/master/arch/x86/include/asm/bitops.h) 也提供了 `64-bit` 或 `32-bit` 变量循环的 API 等等。
下一个 [头文件](https://github.com/torvalds/linux/blob/master/include/linux/bitmap.h) 提供了操作位数组的 API。例如,它提供了以下两个函数:
* `bitmap_zero`;
* `bitmap_fill`.
它们分别可以清除一个位数组和用 `1` 填充位数组。让我们看看 `bitmap_zero` 函数的实现:
```
static inline void bitmap_zero(unsigned long *dst, unsigned int nbits)
{
if (small_const_nbits(nbits))
*dst = 0UL;
else {
unsigned int len = BITS_TO_LONGS(nbits) * sizeof(unsigned long);
memset(dst, 0, len);
}
}
```
首先我们可以看到对 `nbits` 的检查。 `small_const_nbits` 是一个定义在同一个[头文件](https://github.com/torvalds/linux/blob/master/include/linux/bitmap.h) 的宏:
```
#define small_const_nbits(nbits) \
(__builtin_constant_p(nbits) && (nbits) <= BITS_PER_LONG)
```
正如我们可以看到的,它检查 `nbits` 是否为编译期已知常量,并且其值不超过 `BITS_PER_LONG` 或 `64`。如果位数目没有超过一个 `long` 变量的位数,我们可以仅仅设置为 0。在其他情况,我们需要计算有多少个需要填充位数组的 `long` 变量并且使用 [memset](http://man7.org/linux/man-pages/man3/memset.3.html) 进行填充。
`bitmap_fill` 函数的实现和 `biramp_zero` 函数很相似,除了我们需要在给定的位数组中填写 `0xff` 或 `0b11111111`:
```
static inline void bitmap_fill(unsigned long *dst, unsigned int nbits)
{
unsigned int nlongs = BITS_TO_LONGS(nbits);
if (!small_const_nbits(nbits)) {
unsigned int len = (nlongs - 1) * sizeof(unsigned long);
memset(dst, 0xff, len);
}
dst[nlongs - 1] = BITMAP_LAST_WORD_MASK(nbits);
}
```
除了 `bitmap_fill` 和 `bitmap_zero`,[include/linux/bitmap.h](https://github.com/torvalds/linux/blob/master/include/linux/bitmap.h) 头文件也提供了和 `bitmap_zero` 很相似的 `bitmap_copy`,只是仅仅使用 [memcpy](http://man7.org/linux/man-pages/man3/memcpy.3.html) 而不是 [memset](http://man7.org/linux/man-pages/man3/memset.3.html) 这点差异而已。它也提供了位数组的按位操作,像 `bitmap_and`, `bitmap_or`, `bitamp_xor`等等。我们不会探讨这些函数的实现了,因为如果你理解了本部分的所有内容,这些函数的实现是很容易理解的。无论如何,如果你对这些函数是如何实现的感兴趣,你可以打开并研究 [include/linux/bitmap.h](https://github.com/torvalds/linux/blob/master/include/linux/bitmap.h) 头文件。
本部分到此为止。
### 链接
* [bitmap](https://en.wikipedia.org/wiki/Bit_array)
* [linked data structures](https://en.wikipedia.org/wiki/Linked_data_structure)
* [tree data structures](https://en.wikipedia.org/wiki/Tree_%28data_structure%29)
* [hot-plug](https://www.kernel.org/doc/Documentation/cpu-hotplug.txt)
* [cpumasks](https://0xax.gitbooks.io/linux-insides/content/Concepts/cpumask.html)
* [IRQs](https://en.wikipedia.org/wiki/Interrupt_request_%28PC_architecture%29)
* [API](https://en.wikipedia.org/wiki/Application_programming_interface)
* [atomic operations](https://en.wikipedia.org/wiki/Linearizability)
* [xchg instruction](http://x86.renejeschke.de/html/file_module_x86_id_328.html)
* [cmpxchg instruction](http://x86.renejeschke.de/html/file_module_x86_id_41.html)
* [lock instruction](http://x86.renejeschke.de/html/file_module_x86_id_159.html)
* [bts instruction](http://x86.renejeschke.de/html/file_module_x86_id_25.html)
* [btr instruction](http://x86.renejeschke.de/html/file_module_x86_id_24.html)
* [bt instruction](http://x86.renejeschke.de/html/file_module_x86_id_22.html)
* [sbb instruction](http://x86.renejeschke.de/html/file_module_x86_id_286.html)
* [btc instruction](http://x86.renejeschke.de/html/file_module_x86_id_23.html)
* [man memcpy](http://man7.org/linux/man-pages/man3/memcpy.3.html)
* [man memset](http://man7.org/linux/man-pages/man3/memset.3.html)
* [CF](https://en.wikipedia.org/wiki/FLAGS_register)
* [inline assembler](https://en.wikipedia.org/wiki/Inline_assembler)
* [gcc](https://en.wikipedia.org/wiki/GNU_Compiler_Collection)
---
via: <https://github.com/0xAX/linux-insides/blob/master/DataStructures/bitmap.md>
作者:[0xAX](https://twitter.com/0xAX) 译者:[cposture](https://github.com/cposture) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
| 404 | Not Found | null |
7,711 | 使用 Docker Swarm 部署可扩展的 Python3 应用 | http://www.giantflyingsaucer.com/blog/?p=5923 | 2016-08-24T09:00:00 | [
"Docker",
"Swarm"
] | https://linux.cn/article-7711-1.html | [Ben Firshman](https://blog.docker.com/author/bfirshman/) 最近在 [Dockercon](http://dockercon.com/) 做了一个关于使用 Docker 构建无服务应用的演讲,你可以在[这里查看详情](https://blog.docker.com/author/bfirshman/)(还有视频)。之后,我写了一篇关于如何使用 [AWS Lambda](https://aws.amazon.com/lambda/) 构建微服务系统的[文章](http://www.giantflyingsaucer.com/blog/?p=5730)。

今天,我想展示给你的就是如何使用 [Docker Swarm](https://docs.docker.com/swarm/) 部署一个简单的 Python Falcon REST 应用。这里我不会使用[dockerrun](https://github.com/bfirsh/dockerrun) 或者是其他无服务特性,你可能会惊讶,使用 Docker Swarm 部署(复制)一个 Python(Java、Go 都一样)应用是如此的简单。
注意:这展示的部分步骤是截取自 [Swarm Tutorial](https://docs.docker.com/engine/swarm/swarm-tutorial/),我已经修改了部分内容,并且[增加了一个 Vagrant Helper 的仓库](https://github.com/chadlung/vagrant-docker-swarm)来启动一个可以让 Docker Swarm 工作起来的本地测试环境。请确保你使用的是 1.12 或以上版本的 Docker Engine。我写这篇文章的时候,使用的是 1.12RC2 版本。注意的是,这只是一个测试版本,可能还会有修改。
你要做的第一件事,就是如果你想本地运行的话,你要保证 [Vagrant](https://www.vagrantup.com/) 已经正确的安装和运行了。你也可以按如下步骤使用你最喜欢的云服务提供商部署 Docker Swarm 虚拟机系统。
我们将会使用这三台 VM:一个简单的 Docker Swarm 管理平台和两台 worker。
安全注意事项:Vagrantfile 代码中包含了部分位于 Docker 测试服务器上的 shell 脚本。这是一个潜在的安全问题,它会运行你不能控制的脚本,所以请确保你会在运行代码之前[审查过这部分的脚本](https://test.docker.com/)。
```
$ git clone https://github.com/chadlung/vagrant-docker-swarm
$ cd vagrant-docker-swarm
$ vagrant plugin install vagrant-vbguest
$ vagrant up
```
Vagrant up 命令需要一些时间才能完成。
SSH 登录进入 manager1 虚拟机:
```
$ vagrant ssh manager1
```
在 manager1 的 ssh 终端会话中执行如下命令:
```
$ sudo docker swarm init --listen-addr 192.168.99.100:2377
```
现在还没有 worker 注册上来:
```
$ sudo docker node ls
```
让我们注册两个新的 worker,请打开两个新的终端会话(保持 manager1 会话继续运行):
```
$ vagrant ssh worker1
```
在 worker1 的 ssh 终端会话上执行如下命令:
```
$ sudo docker swarm join 192.168.99.100:2377
```
在 worker2 的 ssh 终端会话上重复这些命令。
在 manager1 终端上执行如下命令:
```
$ docker node ls
```
你将会看到:

在 manager1 的终端里部署一个简单的服务。
```
sudo docker service create --replicas 1 --name pinger alpine ping google.com
```
这个命令将会部署一个服务,它会从 worker 之一 ping google.com。(或者 manager,manager 也可以运行服务,不过如果你只是想 worker 运行容器的话,[也可以禁用这一点](https://docs.docker.com/engine/reference/commandline/swarm_init/))。可以使用如下命令,查看哪些节点正在执行服务:
```
$ sudo docker service tasks pinger
```
结果会和这个比较类似:

所以,我们知道了服务正跑在 worker1 上。我们可以回到 worker1 的会话里,然后进入正在运行的容器:
```
$ sudo docker ps
```

你可以看到容器的 id 是: ae56769b9d4d,在我的例子中,我运行如下的代码:
```
$ sudo docker attach ae56769b9d4d
```

你可以按下 CTRL-C 来停止服务。
回到 manager1,然后移除这个 pinger 服务。
```
$ sudo docker service rm pinger
```
现在,我们将会部署可复制的 Python 应用。注意,为了保持文章的简洁,而且容易复制,所以部署的是一个简单的应用。
你需要做的第一件事就是将镜像放到 [Docker Hub](https://hub.docker.com/)上,或者使用我[已经上传的一个](https://hub.docker.com/r/chadlung/hello-app/)。这是一个简单的 Python 3 Falcon REST 应用。它有一个简单的入口: /hello 带一个 value 参数。
放在 [chadlung/hello-app](https://hub.docker.com/r/chadlung/hello-app/) 上的 Python 代码看起来像这样:
```
import json
from wsgiref import simple_server
import falcon
class HelloResource(object):
def on_get(self, req, resp):
try:
value = req.get_param('value')
resp.content_type = 'application/json'
resp.status = falcon.HTTP_200
resp.body = json.dumps({'message': str(value)})
except Exception as ex:
resp.status = falcon.HTTP_500
resp.body = str(ex)
if __name__ == '__main__':
app = falcon.API()
hello_resource = HelloResource()
app.add_route('/hello', hello_resource)
httpd = simple_server.make_server('0.0.0.0', 8080, app)
httpd.serve_forever()
```
Dockerfile 很简单:
```
FROM python:3.4.4
RUN pip install -U pip
RUN pip install -U falcon
EXPOSE 8080
COPY . /hello-app
WORKDIR /hello-app
CMD ["python", "app.py"]
```
上面表示的意思很简单,如果你想,你可以在本地运行该进行来访问这个入口: <http://127.0.0.1:8080/hello?value=Fred>
这将返回如下结果:
```
{"message": "Fred"}
```
在 Docker Hub 上构建和部署这个 hello-app(修改成你自己的 Docker Hub 仓库或者[使用这个](https://hub.docker.com/r/chadlung/hello-app/)):
```
$ sudo docker build . -t chadlung/hello-app:2
$ sudo docker push chadlung/hello-app:2
```
现在,我们可以将应用部署到之前的 Docker Swarm 了。登录 manager1 的 ssh 终端会话,并且执行:
```
$ sudo docker service create -p 8080:8080 --replicas 2 --name hello-app chadlung/hello-app:2
$ sudo docker service inspect --pretty hello-app
$ sudo docker service tasks hello-app
```
现在,我们已经可以测试了。使用任何一个 Swarm 节点的 IP 来访问 /hello 入口。在本例中,我在 manager1 的终端里使用 curl 命令:
注意,Swarm 中的所有的 IP 都可以,不管这个服务是运行在一台还是更多的节点上。
```
$ curl -v -X GET "http://192.168.99.100:8080/hello?value=Chad"
$ curl -v -X GET "http://192.168.99.101:8080/hello?value=Test"
$ curl -v -X GET "http://192.168.99.102:8080/hello?value=Docker"
```
结果:
```
* Hostname was NOT found in DNS cache
* Trying 192.168.99.101...
* Connected to 192.168.99.101 (192.168.99.101) port 8080 (#0)
> GET /hello?value=Chad HTTP/1.1
> User-Agent: curl/7.35.0
> Host: 192.168.99.101:8080
> Accept: */*
>
* HTTP 1.0, assume close after body
< HTTP/1.0 200 OK
< Date: Tue, 28 Jun 2016 23:52:55 GMT
< Server: WSGIServer/0.2 CPython/3.4.4
< content-type: application/json
< content-length: 19
<
{"message": "Chad"}
```
从浏览器中访问其他节点:

如果你想看运行的所有服务,你可以在 manager1 节点上运行如下代码:
```
$ sudo docker service ls
```
如果你想添加可视化控制平台,你可以安装 [Docker Swarm Visualizer](https://github.com/ManoMarks/docker-swarm-visualizer)(这对于展示非常方便)。在 manager1 的终端中执行如下代码:
```
$ sudo docker run -it -d -p 5000:5000 -e HOST=192.168.99.100 -e PORT=5000 -v /var/run/docker.sock:/var/run/docker.sock manomarks/visualizer
```
打开你的浏览器,并且访问: <http://192.168.99.100:5000/>
结果如下(假设已经运行了两个 Docker Swarm 服务):

要停止运行 hello-app(已经在两个节点上运行了),可以在 manager1 上执行这个代码:
```
$ sudo docker service rm hello-app
```
如果想停止 Visualizer, 那么在 manager1 的终端中执行:
```
$ sudo docker ps
```
获得容器的 ID,这里是: f71fec0d3ce1,从 manager1 的终端会话中执行这个代码:
```
$ sudo docker stop f71fec0d3ce1
```
祝你成功使用 Docker Swarm。这篇文章主要是以 1.12 版本来进行描述的。
---
via: <http://www.giantflyingsaucer.com/blog/?p=5923>
作者:[Chad Lung](http://www.giantflyingsaucer.com/blog/?author=2) 译者:[MikeCoder](https://github.com/MikeCoder) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,712 | 海量的超赞 Linux 软件 | https://github.com/VoLuong/Awesome-Linux-Software | 2016-08-24T16:01:00 | [
"软件"
] | https://linux.cn/article-7712-1.html | 
* 这个仓库收集了对任何用户/开发者都超赞的 Linux 应用软件。
* 请随意 contribute / star / fork / pull request。欢迎一切推荐和建议。
*更新:原英文库已经在 [Gitbook](https://voluong.gitbooks.io/awesome-linux-software/content/) 上发布,中文版阅读地址戳[这里](https://alim0x.gitbooks.io/awesome-linux-software-zh_cn/content/)。你可以将这个链接分享给新用户,因为在上面阅读相比于在 github 上阅读会更加友好。可以在[这里](https://goo.gl/xhiKla)下载英文 pdf 版本。*
### 应用
#### 音频
* [Airtime](https://www.sourcefabric.org/en/airtime/download/) - Airtime 是一款用于调度和远程站点管理的开放广播软件 [](https://github.com/sourcefabric/Airtime) 
* [Ardour](https://ardour.org/) - 在 Linux 上录音,编辑,和混音 
* [Audacious](http://audacious-media-player.org/) - 开源音频播放器,按你想要的方式播放你的音乐,不占用你其它任务的电脑资源。[](http://audacious-media-player.org/developers) 
* [Audacity](http://www.audacityteam.org/download/linux/) - 免费,开源,跨平台的声音录制、编辑软件。 [](https://github.com/audacity/audacity) 
* [Audio Recorder](https://launchpad.net/~audio-recorder/+archive/ubuntu/ppa) - 简单的声音录制软件,就在 ubuntu ppa。 
* [Clementine](https://www.clementine-player.org/) - 播放无数的有损和无损音频格式。 [](https://github.com/clementine-player/Clementine) 
* [Google Play Music](https://www.googleplaymusicdesktopplayer.com/) - 非官方但很漂亮的跨平台 Google Play Music 桌面客户端。[](https://github.com/MarshallOfSound/Google-Play-Music-Desktop-Player-UNOFFICIAL-) 
* [Hydrogen](http://www.hydrogen-music.org/hcms/node/21) - GNU/Linux 上的高级电子鼓。 
* [K3b](http://www.k3b.org/) - K3b - Linux 上的 CD/DVD 创建工具 - 为 KDE 特别优化。[](https://github.com/KDE/k3b) 
* [Kid3Qt](https://apps.ubuntu.com/cat/applications/precise/kid3-qt/) - 编辑多媒体文件的标签,如一个专辑所有 mp3 文件的艺术家,专辑,年代,流派。 
* [KxStudio](http://kxstudio.linuxaudio.org/) - KXStudio 是专业声音创作应用和插件的集合。 
* [Let's make music](https://lmms.io/download/#linux) - 在你的 PC 上制作音乐,创造旋律和节拍,合成,混音,编曲小样以及更多内容。 
* [Lollypop](http://gnumdk.github.io/lollypop-web) - Lollypop 是一款新的 GNOME 音乐播放应用。 [](https://github.com/gnumdk/lollypop) 
* [Mixxx](http://www.mixxx.org/download/) - 免费的 DJ 软件,给你一切现场混音所需要的,名副其实的 Traktor 替代品。 [](https://github.com/mixxxdj/mixxx) 
* [OSD Lyrics](https://aur.archlinux.org/packages/osdlyrics-git/) - 与你最爱的媒体播放器显示歌词。 [](https://github.com/PedroHLC/osdlyrics) 
* [Rhythmbox](https://wiki.gnome.org/Apps/Rhythmbox) - 来自 GNOME 的音乐播放器。[](https://github.com/GNOME/rhythmbox) 
* [SoundJuicer](http://www.howtogeek.com/howto/20126/rip-audio-cds-with-sound-juicer/) - CD 抓取工具,for GNOME 
* [Tomahawk](https://www.tomahawk-player.org/) - 一种新的音乐播放器,集合你所有的流媒体,下载,音乐云存储,播放列表,电台等。 [](https://github.com/tomahawk-player/tomahawk) 
#### 聊天客户端
* [GhettoSkype](https://github.com/stanfieldr/ghetto-skype) - Skype 的开源 web 封装。 [](https://github.com/stanfieldr/ghetto-skype) 
* [HexChat](https://hexchat.github.io/) - HexChat 是一款基于 XChat 的 IRC 客户端,但和 XChat 不一样的是它对 Windows 和 Unix-like 系统都是完全自由的。[](https://github.com/hexchat) 
* [Jitsi](https://jitsi.org/) - Jitsi 是一款免费,开源的多平台语音,视频会议以及即时通讯应用,在 Windows, Linux, Mac OS X 和 Android 上可用。[](https://github.com/jitsi) 
* [Messenger for Desktop](https://messengerfordesktop.com/#download) - Facebook messenger 应用。 [](https://github.com/Aluxian/Facebook-Messenger-Desktop) 
* [Pidgin](http://askubuntu.com/questions/307622/update-pidgin-using-apt-get) - 一款通用聊天客户端。 
* [qTox](https://qtox.github.io/) - 一款简单的分布式,安全的通讯软件,支持音频和视频聊天。 [](https://github.com/qTox/qTox) 
* [ScudCloud](https://github.com/raelgc/scudcloud/) - 一款 Linux 下的 Slack 客户端。 [](https://github.com/raelgc/scudcloud/) 
* [Skype](https://www.skype.com/en/) - Skype 让世界保持沟通,免费的。 
* [Telegram](https://desktop.telegram.org/) - 一款专注于速度和安全的消息应用,它非常快,简单而且免费。 [](https://github.com/telegramdesktop/tdesktop) 
* [Viber](https://www.viber.com/en/products/linux) - Viber for Linux 让你在任何设备,网络和国家给其他 Viber 用户免费发送消息和通话。 
* [Weechat](https://weechat.org/) - WeeChat 是一款快速,轻量级,可扩展的聊天客户端。 [](https://github.com/weechat) 
* [Whatsie](https://github.com/Aluxian/Whatsie) - Whatsapp ubuntu/linux 非官方客户端。 [](https://github.com/Aluxian/Whatsie) 
#### 数据备份与恢复
* [Borg Backup](https://borgbackup.readthedocs.io/en/stable/) - 一款不错的的备份工具。[](https://borgbackup.readthedocs.io/en/stable/development.html) 
* [Photorec](http://www.cgsecurity.org/wiki/PhotoRec) - PhotoRec 一款数据恢复应用,为恢复硬盘,CD-ROM 上包括视频,文档以及归档等文件而设计,以及数码相机存储中丢失的相片(Photorec 的由来)。 
* [Qt4-fsarchiver](https://sourceforge.net/projects/qt4-fsarchiver/) - qt4-fsarchiver 是 fsarchiver 的图形化界面,能够保存/恢复分区,文件夹和 MBR/GPT 分区。这个程序是基于 Debian 的系统,Suse 以及 Fedora 适用的。 [](https://borgbackup.readthedocs.io/en/stable/) 
* [System Rescue CD](http://www.system-rescue-cd.org/SystemRescueCd_Homepage) - SystemRescueCd 是一款 Linux 系统急救盘,提供可启动的 CD-ROM 或 U 盘,用于管理系统在崩溃后修复系统和数据。 
* [Test Disk](http://www.cgsecurity.org/wiki/TestDisk) - TestDisk 是一款强大的免费数据恢复软件!它主要设计用于帮助回去丢失的分区和/或修复由软件错误导致的硬盘无法启动引导。 
* [Timeshift](https://launchpad.net/timeshift) - TimeShift 是一款系统还原工具,它用 rsync 和硬链接创建系统的增量快照。快照可以在一段时间后用于恢复,撤销快照生成以来所做的所有更改。快照可以手动生成或用定时任务自动生成。 
#### 桌面个性化
* [Adapta Theme](https://github.com/tista500/Adapta) - 一款自适应的 Gtk+ 主题,遵循 Material 设计指南。[](https://camo.githubusercontent.com/123c212a73b8dd36e355c193788ea3d8baa36f73/68747470733a2f2f63646e2e7261776769742e636f6d2f6943484149542f617765736f6d652d6f73782f6d61737465722f6d656469612f6f73732e737667) 
* [Arc Icon Theme](https://github.com/horst3180/arc-icon-theme) - 一款可以和 Moka 图标主题一同使用的现代图标主题。 [](https://camo.githubusercontent.com/123c212a73b8dd36e355c193788ea3d8baa36f73/68747470733a2f2f63646e2e7261776769742e636f6d2f6943484149542f617765736f6d652d6f73782f6d61737465722f6d656469612f6f73732e737667) 
* [Arc Theme](https://github.com/horst3180/arc-theme) - 带有透明元素的扁平化主题 [](https://camo.githubusercontent.com/123c212a73b8dd36e355c193788ea3d8baa36f73/68747470733a2f2f63646e2e7261776769742e636f6d2f6943484149542f617765736f6d652d6f73782f6d61737465722f6d656469612f6f73732e737667) 
* [Compiz Config settings manager](https://apps.ubuntu.com/cat/applications/compizconfig-settings-manager/) - OpenCompositing 项目带来的提高 X Window 系统可用性和生产力的 3D 桌面视觉特效。 
* [Conky](https://github.com/brndnmtthws/conky) - Conky 是 X 下一款免费,轻量的系统监视器,可以在你桌面显示任何类型的信息。 [](https://github.com/brndnmtthws/conky) 
* [Flatabulous](https://github.com/anmoljagetia/Flatabulous) - 一款扁平化主题,适用于 Ubuntu 以及其它基于 Gnome 的 Linux 系统。 [](https://camo.githubusercontent.com/123c212a73b8dd36e355c193788ea3d8baa36f73/68747470733a2f2f63646e2e7261776769742e636f6d2f6943484149542f617765736f6d652d6f73782f6d61737465722f6d656469612f6f73732e737667) 
* [Flatabulous Arc Theme](https://github.com/andreisergiu98/arc-flatabulous-theme) - 我最爱的 ubuntu 主题。[](https://github.com/andreisergiu98/arc-flatabulous-theme) 
* [Gnome Extensions](http://extensions.gnome.org/) - Gnome 桌面环境扩展插件。 
* [Gnome Look](https://www.gnome-look.org/) - 大量社区创建的图标,shell 主题,字体,以及其他更多的可用来个性化你的 Gnome 桌面环境的资源,都在这一个站点。 [Freeware](https://cdn.rawgit.com/iCHAIT/awesome-osx/master/media/free.svg)
* [Irradiance Theme](https://github.com/bsundman/Irradiance) - 一款受 OSX Yosemite 启发的 Unity 主题,基于 Radiance。[](https://github.com/bsundman/Irradiance) 
* [Numix Icon Theme](http://www.noobslab.com/2014/04/install-numix-icon-packs-in-ubuntulinux.html) - Ubuntu 最好的图标主题之一。[](https://github.com/numixproject/numix-icon-theme) 
* [Numix Theme](https://itsfoss.com/install-numix-ubuntu/) - 一款很流行的主题。 [](https://github.com/numixproject/numix-gtk-theme) 
* [Paper Icon Theme](https://snwh.org/paper/icons) - Paper 是一款现代 freedesktop 图标主题,它的图表设计注重强烈的色彩和简单的几何形状。 
* [Papirus Icon Theme](https://github.com/PapirusDevelopmentTeam/papirus-icon-theme-gtk/) - Ubuntu 最好的图标主题之一。[](https://github.com/PapirusDevelopmentTeam/papirus-icon-theme-gtk/) 
* [Unity Tweak Tool](https://apps.ubuntu.com/cat/applications/unity-tweak-tool/) - Ubuntu unity 个性化必备应用。 [](https://github.com/ianyh/Amethyst) 
* [Yosembiance theme](https://github.com/bsundman/Yosembiance) - 一款受 OSX Yosemite 启发的 Ambiance 改款主题。 [](https://github.com/bsundman/Yosembiance) 
#### 开发
* [Android studio](https://developer.android.com/studio/index.html) - Android 的官方 IDE:Android Studio 提供在各种类型的安卓设备上构建应用最快的工具。 
* [Aptana](http://www.aptana.com/) - Aptana Studio 利用了 Eclipse 的灵活性并且专注于让它成为强大的 web 开发引擎。 
* [Arduino IDE](https://www.arduino.cc/en/Main/Software) - 开源的 Arduino 软件(IDE)让编写代码和上传代码到开发板变得简单。 
* [BlueJ](http://bluej.org/) - 一款为新手设计的免费 Java 开发环境,世界范围内数百万人使用。 
* [Clion](https://www.jetbrains.com/clion/) - 一款强大的跨平台 C 以及 C++ IDE。
* [Code::Blocks](http://www.codeblocks.org/) - Code::Blocks 是一款为满足大部分用户需求构建的免费的 C,C++ 以及 Fortran IDE。它可扩展并且可配置性强。 
* [Codelite](http://codelite.org/) - 一款免费,开源,跨平台的 C,C++,PHP,以及 Node.js IDE。 
* [Eclipse](https://eclipse.org/ide/) - Eclipse 以 Java 集成开发环境而闻名,但它的 C/C++ IDE 和 PHP IDE 同样出色。 
* [Fritzing](http://fritzing.org/) - Fritzing 是一个开源硬件项目,它让电子部件变成人人都能接触到的创造性材料。[](https://github.com/fritzing/fritzing-app) 
* [Geany](https://www.geany.org/) - Geany 是一款基于 GTK+ 的文本编辑器,带有基本的集成开发环境特性。它的开发是为了提供一个小型并且快速的 IDE,对其它包只有很少的的依赖。 [](https://www.geany.org/Download/Git) 
* [Genymotion](https://www.genymotion.com/features/) - Genymotion 是一款可以用来替代默认安卓模拟器的第三方模拟器。 
* [Git](https://git-scm.com/) - Git 是一款免费和开源的分布式版本管理系统,被设计用来快速和高效地处理从小项目到大项目的一切内容。 
* [IntelliJ IDEA](https://www.jetbrains.com/idea/) - 强大的 Java IDE。 
* [Ipython](https://ipython.org/) - 强大的 Python shell。 [](https://github.com/ipython/ipython) 
* [Jupyter Notebook](https://jupyter.org/) - 开源,交互式数据科学和科学计算,支持超过 40 种编程语言。 [](https://jupyter.readthedocs.io/en/latest/install.html) 
* [KDevelop](https://www.kdevelop.org/) - 免费,开源 IDE,全功能,支持插件扩展的 C/C++ 以及其它编程语言 IDE。 
* [Komodo Edit](http://komodoide.com/komodo-edit/) - 免费,开源的多语言开发环境。 
* [MariaDB](https://mariadb.org/) - 最流行的数据库服务器之一。由原 MySQL 开发者打造。  [](https://mariadb.org/get-involved/getting-started-for-developers/)
* [MonoDevelop](http://www.monodevelop.com/) - 跨平台的 C#,F# 以及更多语言的 IDE。  [](http://www.monodevelop.com/developers/)
* [Nemiver](https://github.com/GNOME/nemiver) - Nemiver 项目编写集成到 GNOME 桌面环境的独立图形调试器。[](https://github.com/GNOME/nemiver) 
* [Netbeans](https://netbeans.org/downloads/) - NetBeans IDE 让你快速而且容易地开发 Java 桌面,移动以及 web 应用,还有基于 HTML,JavaScript 以及 CSS 的 HTML5 应用。 
* [NodeJS](https://nodejs.org/en/) - Node.js® 是一个基于 Chrome V8 JavaScript 引擎的 JavaScript 运行时环境。 
* [Oh-my-zsh](https://github.com/robbyrussell/oh-my-zsh) - 一个由社区驱动,优雅的 zsh 配置管理框架。  [](https://github.com/robbyrussell/oh-my-zsh)
* [Postgresql](https://www.postgresql.org/download/) - PostgreSQL 是一款强大,开源的对象-关系型数据库系统。 
* [Postman](https://www.getpostman.com/) - Postman,帮助我们快速测试 API。 
* [PyCharm](https://www.jetbrains.com/pycharm/) - 强大的 Python IDE。 
* [QT Creator](https://www.qt.io/ide/) - 全功能跨平台集成开发环境,轻松创建互联设备,用户界面以及应用程序。 
* [Rabbit VCS](http://rabbitvcs.org/) - RabbitVCS 是一个图形工具的集合,提供一个与你使用的版本控制系统简单而直接的访问方式。 [](https://github.com/rabbitvcs/rabbitvcs) 
* [Sqlite Browser](http://sqlitebrowser.org/) - 可视化创建,管理,以及查看 sqlite 数据库文件。  [](https://github.com/sqlitebrowser/sqlitebrowser)
* [Swift](https://swift.org/download/) - Swift 是一个通用编程语言,基于更现代的安全,性能,和软件设计模式为目标设计。 
* [Ubuntu-SDK](https://developer.ubuntu.com/en/phone/platform/sdk/installing-the-sdk/) - Ubuntu 官方 SDK。 
* [Zsh](http://www.zsh.org/) - 一款强大的命令行 shell。 [](http://sourceforge.net/p/zsh/code/ci/master/tree/)
#### 电子书工具
* [Calibre](http://calibre-ebook.com/) - 难以置信的丑但很强大的电子书管理和转换软件。 [](https://github.com/kovidgoyal/calibre) 
* [Evince](https://wiki.gnome.org/Apps/Evince) - Evince 是一款支持多种格式的文档查看器。Evince 的目标是用一个简单的应用取代已经存在于 GNOME 桌面的多种文档查看器。[](https://wiki.gnome.org/Apps/Evince/GettingEvince) 
* [FBReader](https://fbreader.org/content/fbreader-beta-linux-desktop) - 最流行的电子阅读应用之一。 
* [Foxit](https://www.foxitsoftware.com/products/pdf-reader/) - Foxit Reader 8.0——获得殊荣的 PDF 阅读器。 
* [Lucidor](http://www.lucidor.org/lucidor/) - Lucidor 是一个阅读和处理电子书的电脑软件。Lucidor 支持 EPUB 格式的电子书和 OPDS 格式的目录。 
* [MasterPDF editor](https://code-industry.net/free-pdf-editor/) - Master PDF Editor 一款方便而智能的 Linux PDF 编辑器。 
* [MuPDF](http://mupdf.com/) - 一款轻量级的 PDF 和 XPS 查看器。 [](http://git.ghostscript.com/?p=mupdf.git;a=summary) 
* [Okular](https://okular.kde.org/) - Okular 由 KDE 原始开发的通用文档查看器。Okular 可以在多个平台上工作,包括但不限于 Linux,Windows,Mac OS X,\*BSD 等等。 
* [qpdf](https://launchpad.net/qpdfview) - qpdfview 是一款标签页式文档查看器。 [](https://launchpad.net/qpdfview) 
* [Sigil](https://github.com/Sigil-Ebook/Sigil) - Sigil 是一款多平台 EPUB 电子书编辑器。[](https://github.com/Sigil-Ebook/Sigil) 
#### 编辑器
* [Atom](https://atom.io/) - 21 世纪的可 hack 文本编辑器。 [](https://github.com/atom/atom) 
* [Bluefish](http://bluefish.openoffice.nl/index.html) - Bluefish 是一款面向程序员和 web 开发者的强大编辑器,带有很多编写网站,脚本和代码的选项。 
* [Brackets](http://brackets.io/) - 懂 web 设计的现代文本编辑器。 [](https://github.com/adobe/brackets) 
* [Emacs](https://www.gnu.org/software/emacs/) - 可扩展,可个性化,免费/自由的文本编辑器——还有更多。 [](https://github.com/emacs-mirror/emacs) 
* [Geany](https://www.geany.org/) - Geany 是一款使用了 GTK+ 工具集的文本编辑器,带有基本的集成开发环境功能。它的开发是为了成为一个小型又快速的 IDE,对其它包仅有不多的依赖。 [](https://www.geany.org/Download/Git) 
* [Gedit](https://wiki.gnome.org/Apps/Gedit) - gedit 是 GNOME 文本编辑器。尽管以简单易用为目标,gedit 仍然是个强大的多功能编辑器。 
* [Kate](https://kate-editor.org/get-it/) - Kate 是一个多文档编辑器,从 KDE 2.2 开始就是 KDE 的一部分了。 [](https://kate-editor.org/build-it/) 
* [Lighttable](http://lighttable.com/) - 下一代代码编辑器!支持实时编码。 
* [Sublime](https://www.sublimetext.com/) - 有史以来最好的编辑器之一。 
* [Vim](http://www.vim.org/download.php) -Vim 是一个高级文本编辑器,寻求以更完整的功能集提供事实上的 Unix 编辑器“Vi”的强大功能。无论你已经在使用 vi 或其它编辑器,它都十分有用。 [](https://github.com/vim/vim) 
* [VSCode](https://code.visualstudio.com/) - Visual Studio Code 是一款轻量但强大的代码编辑器,提供 Windows,OS X 以及 Linux 版本。它内置了 JavaScript,TypeScript 以及 Node.js 支持,并且对其它语言(C++,C#,Python,PHP)还有丰富的插件系统和运行环境。 
#### 教育
* [BibleTime](http://bibletime.info/) - BibleTime 是一款基于 Sword 库和 Qt 工具集的圣经学习应用。 [](https://github.com/bibletime/bibletime) 
* [Celestia](http://celestiaproject.net/) - 免费的空间模拟器,让你在三维空间中探索我们的宇宙。[](https://sourceforge.net/projects/celestia/files/Celestia-source/1.6.1/celestia-1.6.1.tar.gz/download) 
* [Chemtool](http://ruby.chemie.uni-freiburg.de/~martin/chemtool/) - Chemtool 是一款在 Linux 上绘制化学结构的小程序。 [](https://github.com/opp11/chemtool/blob/master/README.md) 
* [Epoptes](http://www.epoptes.org/) - 一款开源的计算机实验室管理和监视工具。 [](https://code.launchpad.net/epoptes) 
* [Gcompris](http://gcompris.net/index-en.html) - GCompris 是一款高质量教育软件,由无数适合 2 到 10 岁儿童的活动组成。[](http://gcompris.net/wiki/Developer%27s_corner) 
* [Geogebra](https://www.geogebra.org/download) - 图形计算器,支持函数,几何,代数,微积分,统计以及 3D 数学。 
* [GNU Typist](https://www.gnu.org/software/gtypist/index.html) - 基于 ncurses 的免费打字教学软件 [](http://ftp.gnu.org/gnu/gtypist/) 
* [GNUKhata](http://www.gnukhata.in/) - 开源会计软件。 [](https://github.com/kinitrupti/GNUKhata) 
* [Google Earth](https://itsfoss.com/install-google-earth-ubunu/) - Google Earth 是一款虚拟地球,地图以及地理信息程序。 
* [GPeriodic](http://gperiodic.seul.org/) - GPeriodic 是一个 Linux 上的元素周期表应用。 
* [ITalc](https://github.com/iTALC/italc/releases) - iTALC 是一款为老师准备的实用并且强大的教学工具。它让你有多种方式查看和控制你网络中的其它计算机。 [](https://github.com/iTALC/italc) 
* [KDE Edu Suite](https://edu.kde.org/) - 基于 KDE 技术的免费教育软件。 
* [MAPLE](http://www.maplesoft.com/products/maple/) - Maple 是一款数学软件,它结合了世界上最强大的数学引擎以及一个让它十分易于分析,探索,可视化以及解决数学问题的界面。
* [MATLAB](http://www.mathworks.com/products/matlab/?requestedDomain=www.mathworks.com) - MATLAB 平台专为剞劂工程和科学问题优化。MATLAB 让你的想法不仅仅停留在桌面。你可以在巨大的数据集上进行你的分析并按比例增加你的集群和云。
* [Maxima](http://maxima.sourceforge.net/) - Maxima 是一个处理符号和数值表达式的系统,包括微分,积分,泰勒级数,拉普拉斯变换,常微分方程,线性方程组.... [](http://maxima.sourceforge.net/project.html) 
* [Moodle](https://download.moodle.org/) - Course management system for online learning.[](https://github.com/moodle/moodle) 
* [OpenEuclid](http://coulon.publi.free.fr/openeuclide/) - OpenEuclide 是一款 2D 几何软件:数据由描述形式化的几何约束动态定义。 
* [OpenSIS](http://www.opensis.com/home) - 学校管理软件。
* [Scipy](https://scipy.org/install.html) - SciPy 是一个基于 Python 的开源软件生态系统,面向数学,科学,以及工程学。[](https://scipy.org/stackspec.html#stackspec) 
* [Scratch](https://scratch.mit.edu/) - 有了 Scratch,你可以编程你自己的互动故事,游戏,以及动画——并且在在线社区和其他人分享你的创造。 
* [Stellarium](http://www.stellarium.org/) - Stellarium 是一个为你电脑准备的免费开源天文馆。[](https://sourceforge.net/p/stellarium/code/HEAD/tree/) 
* [Tux4Kids](http://tux4kids.alioth.debian.org/) - Tux4Kids 为孩子们开发高质量软件,目标是将乐趣和学习结合到一起。 [](http://tux4kids.alioth.debian.org/dev.php) 
* [UGENE](http://ugene.net/) - UGENE 是一款免费开源,跨平台,基于图形界面的生物信息学软件。[](https://github.com/ugeneunipro/ugene) 
#### 电子邮件
* [Evolution](https://wiki.gnome.org/Apps/Evolution/) - Evolution 是一款个人信息管理应用,集成了邮件,日历以及地址簿功能。 
* [Geary](https://wiki.gnome.org/Apps/Geary) - Geary 是一款为 GNOME 3 构建的电子邮件应用。它让你可以在一个简单,现代的界面上阅读和发送邮件。 
* [Mailnag](https://launchpad.net/~pulb/+archive/ubuntu/mailnag) - Mailnag 是一个向 POP3 和 IMAP 服务器检查新邮件的守护程序。 [](https://github.com/pulb/mailnag) 
* [N1](https://nylas.com/N1) - 在现代 web 上构建的可扩展桌面邮件应用。 [](https://github.com/nylas/N1) 
* [Sylpheed](http://sylpheed.sraoss.jp/en/) - 轻量化,用户友好的电子邮件客户端。 [](http://sylpheed.sraoss.jp/en/download.html#stable) 
* [Thunderbird](https://www.mozilla.org/en-US/thunderbird/) - Thunderbird 是一款免费的电子邮件客户端,设置以及个性化简单方便,功能强大。 
* [Wmail](https://github.com/Thomas101/wmail) - Gmail & Google Inbox 的非官方 Linux 桌面客户端。 [](https://github.com/Thomas101/wmail) 
#### 文件管理器
* [7Zip](http://www.7-zip.org/download.html) - 解压任何压缩文件 
* [AngrySearch](https://github.com/DoTheEvo/ANGRYsearch) - Linux 文件搜索,结果输入即得。 [](https://github.com/DoTheEvo/ANGRYsearch) 
* [Double Commander](http://doublecmd.sourceforge.net/) - Double Commander 是一款跨平台的开源双栏文件管理器。它受 Total Commander 启发并有自己的新想法。 
* [Marlin](https://launchpad.net/marlin) - 文件管理器界最性感的成员,Marlin 为速度,简单和易用精心设计。 
* [Nautilus](https://wiki.gnome.org/Apps/Nautilus) - Nautilus(Files)鹦鹉螺是为适配 Gnome 桌面设计和行为所设计的文件管理器,给用户一个简单的方式导航和管理文件。 
* [Nemo](http://askubuntu.com/questions/294421/how-do-i-install-nemo-file-manager) - Nemo 是一款 Cinnamon 桌面环境下的文件管理器。[](https://github.com/linuxmint/nemo) 
* [QDirStat](https://github.com/shundhammer/qdirstat#ubuntu) - 基于 Qt 的文件夹统计——不用 KDE 的 KDirStat,来自原 KDirStat 开发者的作品。[](https://github.com/shundhammer/qdirstat) 
* [Ranger](http://ranger.nongnu.org/) - Ranger 是一款使用 VI 快捷键的终端文件管理器。[](https://github.com/ranger/ranger) 
* [Synapse](https://launchpad.net/ubuntu/xenial/+source/synapse) - Linux 上最好的应用启动器。 
* [Thunar](https://apps.ubuntu.com/cat/applications/precise/thunar/) - Thunar 被设计成为 Xfce 4.6 的默认文件管理器,为快速和易用设计。 [](https://github.com/luisgg/thunar) 
#### 游戏
* [0 A.D](https://play0ad.com/) - 类帝国时代的开源即时战略游戏。
* [Civilization5](http://www.civilization5.com/) - 席德梅尔的文明®被认为是有史以来最伟大的策略经营类游戏之一。
* [Cockatrice](https://cockatrice.github.io/) - Cockatrice 是一个开源的多平台网络桌面卡牌游戏支持程序。[](https://github.com/Cockatrice) 
* [Desura](http://www.desura.com/about) - Desura 是一个社区驱动的游戏玩家数字分发服务,将来自开发者的最好的游戏,模组,以及可下载内容放在玩家的指尖,随时可以购买和游玩。
* [GBrainy](https://wiki.gnome.org/action/show/Apps/gbrainy?action=show&redirect=gbrainy) - Gbrainy 是一个脑筋急转弯游戏,获得乐趣并且锻炼你的大脑。 [](https://wiki.gnome.org/action/show/Apps/gbrainy?action=show&redirect=gbrainy#Source_code) 
* [Minecraft](https://minecraft.net/en/download/?ref=m) - Minecraft 是一个关于放置方块和冒险的游戏。探索随机生成的世界,建造惊奇的事物,从最简单的家到最伟大的城堡。 
* [Minetest](http://www.minetest.net/) - 开源的 Minecraft 实现,由 C++ 写就(占用更少的资源),还包含模组扩展 API。 [](https://github.com/minetest) 
* [PlayOnLinux](https://www.playonlinux.com/en/) - 在 Linux 玩 Windows 游戏。 [](https://github.com/PlayOnLinux/POL-POM-4) 
* [Simutrans](https://www.simutrans.com/en/) - Simutrans 是一个免费而且开源的运输模拟器。 [](https://www.simutrans.com/en/develop/) 
* [Steam](http://store.steampowered.com/) - 超赞的游戏平台,打开众多游戏的大门。 
* [SuperTuxCar](https://supertuxkart.net/Main_Page) - SuperTuxKart 是一款 3D 开源的赛车竞技游戏,有不同的人物,赛道以及模式。[](https://github.com/supertuxkart/stk-code) 
* [The Battle for Wesnoth](http://www.wesnoth.org/) - 免费,回合制策略游戏,幻想世界主题,有单人以及在线多人对战模式。 [](https://github.com/wesnoth/wesnoth) 
* [Warzone2100](https://wz2100.net/) - 开源即时策略/即时战术游戏。 [](http://developer.wz2100.net/) 
* [Wine](https://www.winehq.org/) - Wine(“Wine Is Not an Emulator”的首字母缩写)是一个兼容层,可以在若干 POSIX 兼容的系统上运行 Windows 程序,比如 Linux,Mac OS X,以及 BSD [](https://github.com/wine-mirror/wine) 
* [Xonotic](http://xonotic.org/) - 受 Unreal Tournament 以及 Quake 启发的竞技场射击游戏。 [](https://gitlab.com/groups/xonotic) 
#### 图形
* [Aftershot](http://www.aftershotpro.com/en/products/aftershot/pro/) - 一个强大的 Adobe Photoshop 替代品!
* [Agave](http://home.gna.org/colorscheme/) - Agave 是 GNOME 桌面下一个很简单的程序,让你可以从一个颜色开始生成各种不同的配色方案 
* [Blender](https://www.blender.org/) - 面向艺术家和小团队的免费开源的完整 3D 创作流水线。 
* [Cinepaint](http://www.cinepaint.org/) - 开源绘画软件 
* [Darktable](http://www.darktable.org/) - darktable 是一个开源的摄影处理软件,支持 RAW 文件处理 
* [Digikam](http://www.digikam.org/) - digiKam 是一个高级的 Linux 数字相片管理应用 
* [Feh](https://feh.finalrewind.org/) - 轻量且快速的图片查看器。 [](http://git.finalrewind.org/feh)
* [Fotoxx](http://www.kornelix.net/fotoxx/fotoxx.html) - Fotoxx 是一个免费开源的图像编辑和收藏管理程序。 
* [GIMP](https://www.gimp.org/downloads/) - GIMP 是一个自由分发的程序,可以进行照片修版,图像合成,图像编辑等操作 [](https://github.com/GNOME/gimp)
* [gThumb](https://wiki.gnome.org/Apps/gthumb) - gThumb 是一款图片查看和浏览器(它还包含一个导入工具,用于从相机导入照片)。  [](https://git.gnome.org/browse/gthumb/)
* [Hugin](http://hugin.sourceforge.net/) - 基于 Panorama Tools 的一款易用的跨平台全景图像工具链。 
* [Inkscape](https://inkscape.org/en/) - 不管你是插画家,设计师,web 设计师还是仅仅是需要创建一些矢量图像,它都是一款强大,免费的设计工具 
* [Krita](https://krita.org/en/) - 面向概念艺术家,数字画家以及插画艺术家的开源软件。 
* [Lightworks](https://www.lwks.com/) - 专业的非线性视频编辑程序,有免费版本可用
* [Luminance HDR](http://qtpfsgui.sourceforge.net/) - Luminance HDR 是一款开源的图形化用户界面应用,它的目标是提供一整套的 HDR 图像工作流程。  [](https://github.com/LuminanceHDR/LuminanceHDR)
* [Mypaint](http://mypaint.org/about/) - Mypaint 是一款配合画板使用的绘画程序。  [](https://github.com/mypaint/mypaint/releases)
* [Ojo](https://github.com/peterlevi/ojo) - 一款快速且漂亮的图像查看器。  [](https://github.com/peterlevi/ojo)
* [OpenShot](http://www.openshot.org/) - OpenShot 是一款免费,易用,功能丰富的 Linxu 视频编辑器。 
* [Photonic](https://github.com/oferkv/phototonic) - Phototonic 是一款图片查看和组织工具。  [](https://github.com/oferkv/phototonic)
* [Pinta](https://pinta-project.com/pintaproject/pinta/) - Pinta 是一款免费,开源的绘画及图片编辑程序。  [](https://pinta-project.com/pintaproject/pinta/contribute)
* [Pitivi](http://www.pitivi.org/) - 一款带有漂亮直观的用户界面的免费视频编辑器,有干净的代码库和出色的社区。 
* [Radiance](http://www.radiance-online.org/) - Radiance - 一款经过验证的光照模拟工具 
* [RawTherapee](http://rawtherapee.com/) - 一款漂亮的但不那么著名的照片编辑应用。  [](https://github.com/Beep6581/RawTherapee)
* [Shotwell](https://wiki.gnome.org/Apps/Shotwell) - Shotwell 是 GNOME 3 的图片管理器。 
* [StopMotion](http://linuxstopmotion.org/) - Linux Stopmotion 是一款免费,开源的定格动画创作应用。它可以帮你捕捉和编辑你动画的帧,并导出为一个单独的文件。 
* [Xara Extreme](http://www.xaraxtreme.org/) - Xara Xtreme for Linux 是一款强大,通用,适用于 Unix 平台(包括 Linux, FreeBSD)的图形处理程序。 
#### 互联网
* [Anatine](https://github.com/sindresorhus/anatine) - 带有众多个性化的 twitter 桌面客户端。  [](https://github.com/sindresorhus/anatine)
* [Brave](https://brave.com/) - Brave 是 macOS,Windows,Linux 平台上一款快速,优秀的桌面浏览器。  [](https://github.com/brave/browser-laptop)
* [Chrome](https://www.google.com/chrome/browser/desktop/index.html) - 一款流行的浏览器,有着无数插件和应用。 
* [Chromium](http://askubuntu.com/questions/250773/how-do-i-install-chromium-from-the-command-line) - Chromium 是一个开源浏览器项目,专注于为所有用户带来更安全、快速和稳定的 web 体验。  [](https://www.chromium.org/)
* [Corebird](http://corebird.baedert.org/) - corebird 是一款原生 gtk+ twitter 桌面客户端。  [](https://github.com/baedert/corebird)
* [Firefox](https://www.mozilla.org/en-US/firefox/new/) - 一款流行的浏览器,有着无数插件和应用。  [](https://developer.mozilla.org/en-US/docs/Mozilla/Developer_guide)
* [Midori](http://midori-browser.org/) - 一款轻量级的免费浏览器,在低端机器上可以完美运行。  [](https://launchpad.net/~midori/+archive/ubuntu/ppa).
* [Opera](http://www.opera.com/) - Opera 浏览器是你畅游网络所需的一切。 
* [Tor](https://www.torproject.org/) - Tor 是免费软件和一个开放网络,帮助你对抗流量分析(一种网络检测的方式,威胁个人自由与隐私)。 
* [Vivaldi](https://vivaldi.com/?lang=en) - 一款新兴的浏览器,有着许多的个性化配置。 
* [Yandex](https://browser.yandex.com/desktop/main/) - 快速方便的浏览器。 
#### 办公
* Gummi [gtk2](https://github.com/alexandervdm/gummi)|[gtk3](https://github.com/aitjcize/Gummi) - 带有模板,拼写检查以及向导的简单 latex 编辑器。  [](https://github.com/alexandervdm/gummi)
* [Caligra Office](https://www.calligra.org/) - 提供满足办公,图形以及管理需要的综合应用套件。 
* [GnuCash](https://www.gnucash.org/) - GnuCash 是一款自由的会计程序,实现了复式记账系统。它最初的目标是开发出与 Intuit, Inc. 的 Quicken 类似的功能,但它还有针对小企业会计的功能。  [](https://github.com/Gnucash/)
* [KMyMoney](https://kmymoney.org/) - KMyMoney 是 KDE 的一款个人金融管理器。它的操作类似 Microsoft Money 以及 Quicken。  [](https://github.com/KDE/kmymoney)
* [LibreOffice](https://www.libreoffice.org/) - Linux 上的最佳办公套件。  [](https://www.libreoffice.org/about-us/source-code/)
* [LyX](http://www.lyx.org/) - 成熟的 LaTeX 渲染文档编辑器。  [](https://github.com/yihui/lyx)
* [WPS office](http://wps-community.org/) - Linux 上的最佳办公套件之一。 
#### 生产力
* [Alarm Clock](http://alarm-clock.pseudoberries.com/) - Alarm Clock 是一款全功能的 GNOME 或其它面板的闹钟。 [](http://bazaar.launchpad.net/~joh/alarm-clock/trunk/files) 
* [Ambient Noise](https://itsfoss.com/ambient-noise-music-player-ubuntu/) - 在 Linux 上安装环境噪声提高专注。 
* [Autokey](https://code.google.com/archive/p/autokey/) - 一款 Linux 桌面自动化工具,让你可以管理你的脚本和短语集合,并给它们分配缩写或者快捷键。 
* [Basket Note Pads](http://basket.kde.org/) - 这个多用途的笔记应用帮助你记下所有类型的笔记。 [](http://basket.kde.org/svnaccess.php) 
* [Brightness](https://launchpad.net/indicator-brightness) - Ubuntu 下的一个亮度指示器。 
* [Cairo-Dock](http://glx-dock.org/) - Cairo-Dock 是一个可自定义 dock,插件,面板等的桌面界面。 [](https://github.com/Cairo-Dock) 
* [California](https://wiki.gnome.org/Apps/California) - Calendar 应用的完整替代方案,可使用自然语言创建事件。 
* [CopyQ](http://hluk.github.io/CopyQ/) -CopyQ 是一款高级剪贴板管理器,带有编辑和脚本功能。 
* [Docky](https://github.com/alim0x/Awesome-Linux-Software-zh_CN/blob/master/www.go-docky.com) -Docky 是一款成熟的 dock 应用,让打开常用应用和管理窗口变得更加简单和快速。 [](https://launchpad.net/docky/+download) 
* [f.lux](https://justgetflux.com/linux.html) - 根据光线自动调节你的电脑屏屏幕显示。 
* [Gnome-dictionary](https://wiki.gnome.org/Apps/Dictionary) - GNOME 下的一款强大的字典。
* [Go For It](http://manuel-kehl.de/projects/go-for-it/) - Go For It! 是一款简单又时尚的生产力工具,主打待办清单,结合定时器让你专注于当前的任务。 
* [Gpick](http://www.gpick.org/) - Gpick 让你可以从桌面任何地方取色,并且它还提供一些其它的高级特性! [](https://github.com/thezbyg/gpick) 
* [My Todo](https://github.com/mohamed-aziz/mytodo) - Mytodo 是一款开源的待办事项程序,让你能够掌控一切。[](https://github.com/mohamed-aziz/mytodo) 
* [My Weather Indicator](http://ubuntuhandbook.org/index.php/2016/04/weather-indicator-desktop-widget-ubuntu-16-04/) - Ubuntu 下的天气指示器和插件。 
* [Notepadqq](http://notepadqq.altervista.org/wp/) - Notepadqq 是 Linux 下一款类 Notepad++ 的编辑器。[](https://github.com/notepadqq/notepadqq) 
* [Notes](http://www.get-notes.com/) - 一款干净又简单的 Linux 笔记应用。[](https://github.com/nuttyartist/notes) 
* [Papyrus](http://aseman.co/en/products/papyrus/) - Papyrus 是一款不一样的笔记管理器,它专注于安全和更佳的用户界面。Papyrus 尝试给用户提供一个易用和智能的用户界面。 [](https://github.com/Aseman-Land/Papyrus) 
* [Plank](https://launchpad.net/plank) - Plank 注定要成为这个星球上最简洁的应用 dock。
* [Pomodone App](http://pomodoneapp.com/) - PomoDoneApp 使用番茄钟技术®,是在你当前任务管理服务上追踪你的工作流最简单的方法。 
* [Recent Noti](https://itsfoss.com/7-best-indicator-applets-for-ubuntu-13-10/) - 一款显示最近通知消息的指示器。 
* [Redshift](http://jonls.dk/redshift/) - Redshift 根据你的周边调整你屏幕的色温。当你夜晚在屏幕前工作时,它也许能帮助你减少对眼睛的伤害。[](https://github.com/jonls/redshift) 
* [Shutter](http://shutter-project.org/) - Shutter 基于 Linux 的系统上(比如 Ubuntu)的一款功能丰富的截屏软件。 
* [Simplenote](https://simplenote.com/) - 跨平台笔记软件。Evernote 的竞争者。 
* [SpeedCrunch](http://www.speedcrunch.org/) - 一个漂亮,开源,高精度的科学计算器。 [](http://www.speedcrunch.org/) 
* [Springseed](https://github.com/spsdco/notes) - 面向日常用户简单又漂亮的一款笔记软件。[](https://github.com/spsdco/notes) 
* [Stickynote](https://itsfoss.com/indicator-stickynotes-windows-like-sticky-note-app-for-ubuntu/) - Linux 桌面的便利贴。 
* [TaskWarrior](https://taskwarrior.org/) - Taskwarrior 是一款免费,开源的的软件,它可以从命令行管理你的待办事项列表。[](https://git.tasktools.org/projects) 
* [Todo.txt](http://todotxt.com/) - todo.txt-专注的编辑器,用最少的组合键和点击帮助你管理你的任务。 
* [Todoist](https://github.com/kamhix/todoist-linux) - Todoist 的非官方客户端。Todoist 是带有移动客户端的跨平台待办事项管理器,有着优秀的用户界面以及一些可选的高级特性。[](https://github.com/kamhix/todoist-linux) 
* [Tomboy](https://wiki.gnome.org/Apps/Tomboy) - Tomboy 是一款简单易用的桌面笔记应用。 [](https://wiki.gnome.org/Apps/Tomboy) 
* [Undistract me](https://github.com/jml/undistract-me) - 在长时间执行的终端命令结束的时候提醒你。 [](https://github.com/jml/undistract-me) 
* [WizNote](https://github.com/wizteam/wizqtclient) - 一个跨平台云笔记客户端。 [](https://github.com/wizteam/wizqtclient) 
* [Xmind](http://www.xmind.net/) - 脑图工具。
* [Zim](http://zim-wiki.org/) - 一款图形化的文本编辑器,用来维护一系列的维基页面,对笔记和文档而言也很棒。资料以纯文本的形式保存,更便于版本管理。[](https://launchpad.net/zim) 
#### 安全
* [ClamAV](https://www.clamav.net/) - Clam 防病毒 
* [Fail2ban](http://www.fail2ban.org/wiki/index.php/Main_Page) - Fail2ban 扫描日志文件(例如 /var/log/apache/error\_log)并将有恶意气息的 IP 封禁——过多的错误密码尝试,寻找可利用漏洞等行为。 
* [GnuPG](https://www.gnupg.org/) - Gnu 隐私守卫 
* [GuFW](http://gufw.org/) - Linux 世界中最简单的防火墙之一。 [](https://code.launchpad.net/gui-ufw)
* [OpenSSH](http://www.openssh.com/) - OpenSSH 安全 Shell 服务器以及客户端。 
* [Seahorse](https://wiki.gnome.org/Apps/Seahorse) - GnuPG 的 Gnome 前端。 
* [Tcpdump](http://www.tcpdump.org/) - TCP 调试/抓包工具。 
#### 文件共享
* [aria2](https://aria2.github.io/) - aria2 是一个轻量级的多协议以及多来源命令行下载工具。 [](https://github.com/aria2/aria2) 
* [CrossFTP](http://www.crossftp.com/ftp-client.htm) - CrossFTP 让 FTP 相关的任务管理变得无比简单。 
* [D-lan](http://www.d-lan.net/) - 一个免费的局域网文件分享软件。 
* [Deluge](http://deluge-torrent.org/) - Deluge 是一款轻量级,免费的跨平台 BT 客户端。[](http://dev.deluge-torrent.org/wiki/Development#SourceCode) 
* [Dropbox](https://www.dropbox.com/install?os=lnx) - Dropbox 是一个免费的云存储服务,让你可以将照片,文档和视频带到任何地方并轻松分享。 
* [Filezilla](https://filezilla-project.org/) - 免费的 FTP 解决方案 [](https://filezilla-project.org/sourcecode.php) 
* [Flareget](https://flareget.com/) - 全功能,多线程下载管理器以及加速器。 
* [Meiga](http://meiga.igalia.com/) - 一个让你可以通过 web 共享你选定的本地文件夹的工具。 [](http://git.igalia.com/meiga.git) 
* [ownCloud](https://owncloud.com/products/desktop-clients/) - ownCloud 的目标是不论在哪都能让你访问到你的文件。 
* [PushBullet](https://www.pushbullet.com/) - Pushbullet 将你的设备连接,让它们感觉像是一体的。 
* [qBittorent](http://www.qbittorrent.org/) - qBittorrent 计划的目标是提提供一个 µTorrent 的自由软件替代方案。[](https://github.com/qbittorrent/qBittorrent) 
* [Quazaa](https://sourceforge.net/projects/quazaa/) - 一款跨平台的多重网络点对点(P2P)文件分享客户端。 
* [SpiderOak](https://spideroak.com/) - 关注隐私的团队及商业实时协作。 
* [Syncthing](https://syncthing.net/) - Syncthing 用开放,值得信赖,去中心化的方案取代专有的同步和云服务。[](https://github.com/syncthing/syncthing) 
* [Teamviewer](https://www.teamviewer.com/) - PC 远程控制/远程访问软件,对个人使用免费。 
* [Transmission](https://www.transmissionbt.com/download/) - 简单,轻量级,多平台的 torrent 客户端。 [](https://trac.transmissionbt.com/browser/trunk) 
* [uGet](http://ugetdm.com/) - Linux 下最好的下载管理器。 [](http://ugetdm.com/contribute/code) 
* [uTorrent](http://www.utorrent.com/) - 优雅,高效的 torrent 下载。 
* [Vuze](http://www.vuze.com/) - Bittorrent 点对点下载客户端,满足你的所有 torrent 下载需要。 
#### 终端
* [GnomeTerminal](https://help.gnome.org/users/gnome-terminal/stable/) - Linux 世界广泛预装的终端模拟器。 
* [Guake](http://guake.org/) - Guake 是 Gnome 下的一款顶部下拉式的终端。 
* [Konsole](https://konsole.kde.org/) - KDE 桌面环境的最佳终端。 
* [RXVT-Unicode](http://software.schmorp.de/pkg/rxvt-unicode.html) - rxvt-unicode 是著名的终端模拟器的一个分支。[](https://camo.githubusercontent.com/123c212a73b8dd36e355c193788ea3d8baa36f73/68747470733a2f2f63646e2e7261776769742e636f6d2f6943484149542f617765736f6d652d6f73782f6d61737465722f6d656469612f6f73732e737667) 
* [RXVT](http://rxvt.sourceforge.net/) - 一款 X11 终端模拟器,流行的‘xterm’替代品。[](https://sourceforge.net/projects/rxvt/) 
* [Sakura](https://launchpad.net/sakura) - 简单但是强大,基于 libvte 的终端模拟器,支持 utf-8 并且通过 gtk+ 和 pango 库提供输入法。[](https://launchpad.net/sakura) 
* [Terminator](http://gnometerminator.blogspot.com/p/introduction.html) - 很明显 Linux 上最强大的终端模拟器是功能丰富的 Terminator(终结者)。 
* [Termit](https://github.com/nonstop/termit/wiki) - 基于 vte 库的简单终端模拟器,可通过 Lua 扩展。[](https://github.com/nonstop/termit/wiki) 
* [Xterm](http://invisible-island.net/xterm/) - Xterm 是一个 X 窗口系统的终端模拟器。它给不直接使用窗口系统的程序提供了 DEC VT102 和 Tektronix 4014 兼容终端。 
* [Yakuake](https://yakuake.kde.org/) - 一款基于 KDE Konsole 技术的 Quake 风格的终端模拟器。 
#### 实用工具
* [Actionaz](http://actionaz.org/) - Ubuntu/Linux 下的任务自动化工具。 
* [Bleach bit](https://www.bleachbit.org/) - BleachBit 快速释放磁盘空间并不知疲倦地守卫你的隐私。释放缓存,删除 cookie,清除互联网浏览历史,清理临时文件,删除日志,以及更多功能... 
* [Brasero](https://wiki.gnome.org/Apps/Brasero) - CD/DVD 烧录软件。 
* [Caffeine](https://launchpad.net/caffeine) - 防止 ubuntu 自动睡眠。 
* [Clonezilla](http://clonezilla.org/) - Clonezilla 是一款分区以及磁盘镜像/克隆程序,类似 True Image® 或 Norton Ghost®。 [](http://clonezilla.org/related-links/)
* [Convertall](https://sourceforge.net/projects/convertall/) - 全能单位换算。 
* [EasyStroke](https://github.com/thjaeger/easystroke/wiki#download) - Easystroke 是一个 X11 手势识别应用。[](https://github.com/thjaeger/easystroke) 
* [Enpass](https://www.enpass.io/) - Enpass 安全地管理你的密码和重要信息,让你的生活更轻松。 
* [GD map](http://gdmap.sourceforge.net/) - 可视化磁盘使用量的工具。 
* [Gloobus-Preview](https://github.com/antonio-malcolm/gloobus-preview) - 它能给你提供文件的快速预览,类似 [Sushi](https://github.com/GNOME/sushi)。 [](https://github.com/antonio-malcolm/gloobus-preview) 
* [Gnormalize](http://gnormalize.sourceforge.net/) - 音频转换工具。 
* [GParted](http://gparted.org/) - Ubuntu/Linux 磁盘分区工具。 
* [GRadio](https://github.com/haecker-felix/gradio/releases/) - Ubuntu linux 无线电广播软件。[](https://github.com/haecker-felix/gradio/releases/) 
* [Handbrake](https://handbrake.fr/) - 视频转换工具。 
* [ImageMagik](http://www.imagemagick.org/script/index.php) - ImageMagick 是一套图片修改和处理的命令行工具。 
* [Indicator-SysMonitor](https://github.com/fossfreedom/indicator-sysmonitor) - 一款可显示 cpu 温度,内存,网速,cpu 使用率,公网 IP 地址以及联网状态的应用指示器。 [](https://github.com/fossfreedom/indicator-sysmonitor) 
* [KeePassX](https://www.keepassx.org/) - 跨平台密码管理器。KeePass 的移植成果。 [](https://github.com/keepassx/keepassx) 
* [KeePass](https://www.keepass.info/) - 专注于 Windows 的密码管理器,通过 Mono 提供一些跨平台支持。 
* [LastPass](https://lastpass.com/misc_download2.php) - 跨平台密码管理器。
* [Peazip](http://www.peazip.org/) - 解压任何文件的工具。 
* [Powertop](https://01.org/powertop/downloads) - 能源消耗诊断工具。 
* [Psensor](http://wpitchoune.net/psensor/) - Linux 图形化硬件温度监视器。[](http://git.wpitchoune.net/psensor.git/) 
* [Pulse Audio](https://wiki.ubuntu.com/PulseAudio) - 通过个性化的配置改善 Linux 的音频。 
* [Remarkable](https://remarkableapp.github.io/) - Ubuntu/Linux 上最佳的 Markdown 编辑器。 
* [Remmina](http://www.remmina.org/wp/) - 一款功能丰富的远程桌面应用,支持 Linux 以及其它 Unix。[](https://github.com/FreeRDP/Remmina) 
* [Sushi](https://github.com/GNOME/sushi) - Sushi 是 GNOME 桌面文件管理器鹦鹉螺(Nautilus)的快速预览工具。 [](https://github.com/GNOME/sushi) 
* [Synaptic](http://www.nongnu.org/synaptic/) - Synaptic 是一款图形化的 apt 包管理程序。 
* [Systemload](http://www.omgubuntu.co.uk/2014/06/system-monitor-indicator-ubuntu-ppa) - 在状态栏显示系统负载。 
* [TLP](http://linrunner.de/en/tlp/docs/tlp-linux-advanced-power-management.html) - 优化 Linux 下的电池表现。 
* [Variety](http://peterlevi.com/variety/) - Variety 是一款开源的 Linux 壁纸更换软件,拥有众多功能,轻巧又易用。[](https://github.com/peterlevi/variety-slideshow) 
* [Virtualbox](https://www.virtualbox.org/wiki/Downloads) - VirtualBox 是一款通用的 x86 硬件虚拟机软件,面向服务器,桌面以及嵌入式。[](https://www.virtualbox.org/wiki/Contributor_information) 
* [WallpaperChange](https://apps.ubuntu.com/cat/applications/raring/wallch/) - 自动更换你的壁纸。 
* [Workrave](http://www.workrave.org/) - 一款帮助恢复以及防止重复性劳损的程序(RSI)。 [](https://github.com/rcaelers/workrave) 
* [Xtreme Download Manager](http://xdman.sourceforge.net/) - 一款有着新鲜用户界面的下载管理器。[](https://github.com/KaOS-Community-Packages/xdm) 
#### 视频
* [Bomi Player](https://bomi-player.github.io/) - 一款强大易用的多媒体播放器。[](https://github.com/xylosper/bomi) 
* [Cheese](https://wiki.gnome.org/Apps/Cheese) - Cheese 用你的摄像头拍照和录像,还能加上神奇的特效,让你能够和别人分享快乐。 [](https://github.com/GNOME/cheese) 
* [Kodi](https://kodi.tv/about/) - 一款获得殊荣的免费开源(GPL)软件,支持视频,音乐,图片,游戏以及更多内容的媒体中心。[](https://github.com/xbmc/xbmc) 
* [Miro](http://www.getmiro.com/) - 免费,开放的视频,音乐以及互联网电视应用;它从成千上万的资源中带来视频频道,并且还有比其它平台更丰富的免费高清资源。 
* [MPlayer](http://www.mplayerhq.hu/design7/news.html) - MPlayer 是一款支持多种系统和各种视频的视频播放器。 
* [MPV](https://www.mpv.io/) - 一款免费,开源,跨平台的媒体播放器。[](https://github.com/mpv-player/mpv) 
* [SMPlayer](http://smplayer.sourceforge.net/) - 内置解码器的免费媒体播放器。可播放所有的音频和视频格式。[](https://sourceforge.net/p/smplayer/code/HEAD/tree/) 
* [SVP](https://www.svp-team.com/w/index.php?title=Main_Page) - SVP 让你可以使用帧插值在你的桌面电脑上观看任何视频,就像高端电视和投影仪支持的那样。 
* [VLC](http://www.videolan.org/vlc/index.html) - VLC 是一个免费且开源的跨平台媒体播放器以及框架,可以播放大多数格式的多媒体文件以及 DVS,音频 CD,VCD,以及各种流媒体协议。 
#### 其它
* [GrubCustomizer](https://launchpad.net/grub-customizer) - Grub Customizer 是一个让你可以配置 GRUB2/BURG 设置和启动项的图形化界面。 [](https://code.launchpad.net/grub-customizer) 
* [Mycroft](https://github.com/MycroftAI/mycroft-core) - 给所有人的 A.I. [](https://github.com/MycroftAI/mycroft-core) 
### 命令行工具
* [Bastet](https://github.com/fph/bastet) - 在命令行玩俄罗斯方块。[](https://github.com/fph/bastet) 
* [Daily Reddit Wallpaper](https://github.com/ssimunic/Daily-Reddit-Wallpaper) - 开机时将壁纸更换为 /r/wallpapers 或其它子版块的今日最高票壁纸。 [](https://github.com/ssimunic/Daily-Reddit-Wallpaper) 
* [Fishfry](https://github.com/LubuntuFu/fishfry) - 将 fish 的历史记录替换成为渗透测试人员量身定制的高效版本以及方便新手学习。[](https://github.com/LubuntuFu/fishfry) 
* [htop](http://hisham.hm/htop/) - 带有改进的特性和用户体验的 top。[](https://github.com/hishamhm/htop) 
* [Pacman4console](https://launchpad.net/ubuntu/+source/pacman4console) - 在控制台玩吃豆人。[](https://github.com/alexdantas/pacman4console.debian) 
* [Tmux](https://tmux.github.io/) - 它让你在一个终端中在多个程序间方便地切换,分离他们(保持在后台运行)并另一个终端中重新连接上去。以及还有好多事情可以做。[](https://github.com/tmux/tmux) 
* [十佳命令行工具](http://lifehacker.com/399468/top-10-command-line-tools)
* [wicd-curses](https://wiki.archlinux.org/index.php/wicd#Running_Wicd_in_Text_Mode) - 命令行 WiFi 连接管理器。
### 桌面环境
* [Budgie](https://solus-project.com/budgie/) - Budgie 是一个面向现代用户思想设计的桌面环境,专注于简洁与优雅。[](https://github.com/solus-project/budgie-desktop) 
* [Cinammon](http://cinnamon.linuxmint.com/) - Cinnamon 努力提供一种传统的用户体验。Cinnamon 是一个 GNOME 3 的 fork。[](https://github.com/linuxmint/Cinnamon) 
* [GNOME Flashback](https://wiki.gnome.org/Projects/GnomeFlashback) - GNOME Flashback 是 GNOME 3 的一个 shell,最初叫 GNOME fallback 模式。桌面的布局和底层技术都与 GNOME 2 相似。[](https://github.com/GNOME/gnome-flashback) 
* [Gnome](https://www.gnome.org/gnome-3/) - GNOME 桌面环境是一个有吸引力且直观的的桌面,同时有现代(GNOME)和经典(GNOME Classic)会话模式。 [](https://github.com/GNOME/gnome-desktop) 
* [KDE Plasma](https://www.kde.org/workspaces/plasmadesktop/) - KDE Plasma 桌面环境是一个熟悉的工作环境。Plasma Desktop 提供现代桌面环境体验所需的所有工具,所以你可以从开始就充满生产力。[](https://github.com/KDE/plasma-desktop) 
* [LXDE](http://lxde.org/) - Lightweight X11 Desktop Environment (轻量化 X11 桌面环境)是一个快速且节能的桌面环境。[](https://github.com/lxde) 
* [LXQt](http://lxqt.org/) - LXQt 是 LXDE 的 Qt 移植和即将到来的版本,轻量化的桌面环境。[](https://github.com/lxde/lxqt) 
* [Mate](http://mate-desktop.com/) - Mate 用传统隐喻给 Linux 用户提供一个直观又有吸引力的桌面。MATE 是 GNOME 2 的一个 fork。 [](https://github.com/mate-desktop/) 
* [Pantheon](https://elementary.io/) - Pantheon 是最初为发行版 elementary OS 创建的桌面环境,同时也是它的默认桌面环境。 
* [Unity](https://unity.ubuntu.com/) - Unity 是 GNOME 的一个 shell,由 Canonical 为 Ubuntu 设计。 
* [Xfce](https://www.xfce.org/) - Xfce 体现了模块化和可重用的传统 UNIX 哲学。 [](https://github.com/xfce-mirror) 
### 显示管理
#### 控制台
* [CDM](https://github.com/ghost1227/cdm) - 超简化,又功能丰富,用 bash 写就的登陆管理器。 [](https://github.com/ghost1227/cdm) 
* [Console TDM](https://github.com/dopsi/console-tdm) - 纯 bash 写就的 xinit 扩展。[](https://github.com/dopsi/console-tdm) 
* [nodm](https://github.com/spanezz/nodm) - 简约的自动登陆显示管理器。[](https://github.com/spanezz/nodm) 
#### 图形界面
* [Entrance](http://enlightenment.org/) - 基于 EFL 的显示管理器,高度实验性质。[](https://github.com/tomas/entrance) 
* [GDM](https://wiki.gnome.org/Projects/GDM) - GNOME 显示管理器。[](https://github.com/GNOME/gdm) 
* [KDM](http://www.kde.org/) - KDE4 显示管理器(不再继续开发)。 
* [LightDM](http://www.freedesktop.org/wiki/Software/LightDM) - 跨桌面显示管理器,可以使用任何工具集写就的各种前端。[](https://github.com/davvid/lightdm) 
* [LXDM](http://sourceforge.net/projects/lxdm/) - LXDE 显示管理器,可以独立于 LXDE 桌面环境使用。 
* [MDM](https://github.com/linuxmint/mdm) - MDM 显示管理器,在 Linux Mint 中使用, GDM 2 的一个 fork。 [](https://github.com/linuxmint/mdm) 
* [SDDM](https://github.com/sddm/sddm) - 基于 QML 的显示管理器,KDE 4 的 kdm 的继任者;Plasma 5 以及 LXQt 推荐。[](https://github.com/sddm/sddm) 
* [SLiM](http://sourceforge.net/projects/slim.berlios/) - 轻量且优雅的图形化登录解决方案(不再继续开发)。[](https://github.com/gsingh93/slim-display-manager) 
* [XDM](http://www.x.org/archive/X11R7.5/doc/man/man1/xdm.1.html) - 带有 XDMCP,主机选择支持的 X 显示管理器。[](https://github.com/bbidulock/xdm) 
### 窗口管理
#### 合成器
* [Compton](https://github.com/chjj/compton/wiki) - Compton 是一款独立的合成管理器,适合同没有原生提供合成功能的窗口管理器一同使用。 [](https://camo.githubusercontent.com/123c212a73b8dd36e355c193788ea3d8baa36f73/68747470733a2f2f63646e2e7261776769742e636f6d2f6943484149542f617765736f6d652d6f73782f6d61737465722f6d656469612f6f73732e737667) 
* [Xcompmgr](https://cgit.freedesktop.org/xorg/app/xcompmgr) - Xcompmgr 是一个简单的合成管理器,能够渲染下拉阴影,使用 transset 工具的话,还可以实现简单的窗口透明。 [](https://cgit.freedesktop.org/xorg/app/xcompmgr) 
#### 叠加式窗口管理器
* [2bwm](https://github.com/venam/2bwm) - 快速的浮动窗口管理,有两个特殊边界,基于 XCB 库,由 mcwm 衍生。[](https://github.com/venam/2bwm) 
* [Blackbox](http://blackboxwm.sourceforge.net/) - 快速,轻量化的 X 窗口系统窗口管理器,没有那些烦人的库依赖。[](https://github.com/bbidulock/blackboxwm) 
* [Fluxbox](http://fluxbox.org/) - 基于 Blackbox 0.61.1 代码的 X 窗口管理器。[](https://github.com/fluxbox/fluxbox) 
* [Openbox](http://openbox.org/) - 高度可配置,带有可扩展标准支持的下一代窗口管理器。[](https://github.com/danakj/openbox) 
#### 平铺式窗口管理器
* [Bspwm](https://github.com/baskerville/bspwm/wiki) - bspwm 是一个平铺式窗口管理器,将窗口以二叉树的叶结点的方式展现。[](https://github.com/baskerville/bspwm) 
* [Herbstluftwm](https://herbstluftwm.org/) - 使用 Xlib 和 Glib 的手工平铺式窗口管理器。[](https://github.com/herbstluftwm/herbstluftwm) 
#### 动态窗口管理器
* [awesome](https://awesome.naquadah.org/) - 高度可配置,下一代 X 框架窗口管理器。[](https://github.com/awesomeWM/awesome) 
* [dwm](http://dwm.suckless.org/) - X 动态窗口管理器。它以平铺,单片镜以及浮动布局的方式管理窗口。[](https://github.com/cdown/dwm) 
* [i3](https://i3wm.org/) - 完全重写的平铺式窗口管理器。[](https://github.com/i3/i3) 
* [spectrwm](https://github.com/conformal/spectrwm/wiki) - X11 小型动态窗口管理器,很大程度上受了 xmonad 和 dwm 的启发。[](https://github.com/conformal/spectrwm) 
* [xmonad](http://xmonad.org/) - 动态平铺式 X11 窗口管理器,用 Haskell 写就和配置。[](https://github.com/xmonad/xmonad) 
### 设置
#### Ubuntu
* [什么是 Linux](https://www.linux.com/what-is-linux)
* [Linux 基础术语](http://www.makeuseof.com/tag/linux-confusing-key-terms-definitions/)
* [什么是 Ubuntu](https://en.wikipedia.org/wiki/Ubuntu_(operating_system))
* [如何安装 Ubuntu](http://www.ubuntu.com/download/desktop/install-ubuntu-desktop)
* [如何安装 Ubuntu 和 Windows 双系统启动](http://www.everydaylinuxuser.com/2014/05/install-ubuntu-1404-alongside-windows.html)
* [安装 ubuntu 后要做什么](http://www.omgubuntu.co.uk/2016/04/10-things-to-do-after-installing-ubuntu-16-04-lts)
#### Arch Linux
* [新手指南](https://wiki.archlinux.org/index.php/Beginners%27_guide)
* [安装指南](https://wiki.archlinux.org/index.php/Installation_guide)
* [通用推荐](https://wiki.archlinux.org/index.php/General_recommendations)
* [应用列表](https://wiki.archlinux.org/index.php/List_of_applications)
#### 其它发行版
>
> 待添加
>
>
>
### 论坛
#### Ubuntu
* [Ubuntu 论坛](https://ubuntuforums.org/)
* [Ask Ubuntu](https://github.com/alim0x/Awesome-Linux-Software-zh_CN/blob/master/askubuntu.com)
#### Arch Linux
* [Arch Linux 论坛](https://bbs.archlinux.org/)
* [Arch Linux ARM 论坛](https://archlinuxarm.org/forum/viewforum.php?f=31)
#### IRC 频道
* [#ubuntu](https://webchat.freenode.net/?channels=ubuntu)
#### Linux 新闻,应用,以及更多...
* [OMG!Ubuntu](http://www.omgubuntu.co.uk/)
* [ITSFOSS](https://itsfoss.com/)
* [Linux 官方](https://www.linux.com/)
* [Webupd8](http://www.webupd8.org/)
* [Noobslab](http://www.noobslab.com/)
* [Make use of](http://www.makeuseof.com/service/linux/)
* [TecMint](http://www.tecmint.com/)
* [AllTop](http://linux.alltop.com/)
* [Unixmen](https://www.unixmen.com/)
* [DistroWatch](http://distrowatch.com/)
* [Phoronix](http://www.phoronix.com/)
* [Dedoimedo](http://www.dedoimedo.com/)
* [How-To Geek](http://www.howtogeek.com/t/linux/)
* [Liliputing](http://liliputing.com/)
* [FAMILUG](http://www.familug.org/)
* [Ubuntu Geek](http://www.ubuntugeek.com/)
#### Reddit
* [Ubuntu](https://www.reddit.com/r/Ubuntu/)
* [Arch Linux](https://www.reddit.com/r/archlinux/)
* [Linux](https://www.reddit.com/r/linux/)
* [Open Source](https://www.reddit.com/r/opensource/)
* [Unix Porn](https://www.reddit.com/r/unixporn/)
* [Linux Kernel](https://www.reddit.com/r/kernel/)
* [Linux Gaming](https://www.reddit.com/r/linux_gaming/)
### 学习 Linux
* [学习 Linux 命令](http://linuxcommand.org/)
* [GNU/Linux 命令行工具总结](http://tldp.org/LDP/GNU-Linux-Tools-Summary/html/book1.htm)
* [学习 Linux](https://linuxjourney.com/)
* [Linux 课程](https://www.edx.org/course/introduction-linux-linuxfoundationx-lfs101x-0)
* [Linus 口袋指南](http://www.opencore.eesc.usp.br/bruno/livros/Linux_Pocket_Guide.pdf)
* [Linux Bash 命令行 - Tek Linux](https://www.youtube.com/watch?v=ltjPIpilqow)
### Linux Hacking/开发
* [内核新手](https://kernelnewbies.org/)
* [Linux Insides](https://0xax.gitbooks.io/linux-insides/content/index.html)
* [Linux 内核](http://www.tldp.org/LDP/tlk/tlk.html)
* [Linux 内核归档(官方站点)](https://www.kernel.org/)
* [Linux Kernel Internals (PDF)](http://www.tldp.org/LDP/lki/lki.pdf)
* [Linux 内核邮件列表归档](https://lkml.org/)
* [Linux 内核模块编程指南(PDF)](http://www.tldp.org/LDP/lkmpg/2.6/lkmpg.pdf)
### 贡献者
[贡献者列表](https://github.com/VoLuong/Awesome-Ubuntu-Linux/graphs/contributors) :
1. [LuongVo](https://github.com/VoLuong)
2. [anewuser](https://github.com/anewuser)
3. [nathanmusoke](https://github.com/nathanmusoke)
4. [bpearson](https://github.com/bpearson)
5. [orestisf1993](https://github.com/orestisf1993)
6. [lasseborly](https://github.com/lasseborly)
7. [sebasspf](https://github.com/sebasspf)
8. [buivnhai](https://github.com/buivnhai)
9. [ankurk91](https://github.com/ankurk91)
10. [mAzurkovic](https://github.com/mAzurkovic)
11. [bocklund](https://github.com/bocklund)
12. [grebenschikov](https://github.com/grebenschikov)
13. [fareez-ahamed](https://github.com/fareezahamed)
14. [MichaelAquilina](https://github.com/MichaelAquilina)
15. [Wamadahama](https://github.com/wamadahama)
16. [Alasin](https://github.com/alasin)
17. [LYF610400210](https://github.com/LYF610400210)
18. [willmtemple](https://github.com/willmtemple) 纠正库名称
19. [jakub-olczyk](https://github.com/jakub-olczyk)
20. [shakib609](https://github.com/shakib609)
21. [talisk](https://github.com/talisk)
22. [smdrz](https://github.com/smdrz)
23. [bishoyh](https://github.com/bishoyh)
24. [Voicu](https://github.com/vpop)
25. [ryandaniels](https://github.com/ryandaniels)
26. [mame98](https://github.com/mame98)
27. [Kastmeski](https://github.com/kasmetski)
28. [johnjago](https://github.com/johnjago)
29. [shuliandre](https://github.com/shuliandre)
30. [stelariusinfinitek](https://github.com/stelariusinfinitek)
31. [tnga](https://github.com/tnga)
32. [hg8](https://github.com/hg8)
33. [ChrisLeeGit](https://github.com/ChrisLeeGit)
34. 在 @ reddit.com/r/linux & reddit.com/r/ubuntu & vozforums.com 上每个提出建议和赞赏的人 ...
(以上列表更新于 15th August 2016)
### 贡献指南
>
> 将应用的名称放入列表。 链接到它的主页或安装指南。 再给应用写一小段简短的介绍 + 添加图标。 确保应用放在了合适的主题下。 如果应用不在以上任何一个已有的主题内,为它新建一个主题。 确保所有项都是按字母表顺序排序的。
>
>
>
*标有  的是开源软件并且链接到源代码。标有  的意为免费(就如免费的啤酒)。*
*原作者注:最近我收到了一些关于列表中一些应用软件的质量的反馈。我自己测试了其中的大部分应用(但不是全部)。如果你对应用有任何问题:-> 去往开发页面(如果有的话)-> 给开发提个 issue -> 在这里提个 issue 以便我考虑是否将应用移出列表。记住:所有东西都有它自己的质量,所以这里永远不会有“最佳应用”或“选择性的列表”,谢谢。*
### 许可证
该作品签署于 [Creative Commons Attribution 4.0 International License](http://creativecommons.org/licenses/by/4.0/)。
| 301 | Moved Permanently | null |
7,714 | Ubuntu Snap 软件包接管 Linux 桌面和 IoT 软件的发行 | http://www.zdnet.com/article/ubuntu-snap-takes-charge-of-linux-desktop-and-iot-software-distribution/ | 2016-08-25T10:19:00 | [
"Snap"
] | https://linux.cn/article-7714-1.html | [Canonical](http://www.canonical.com/) 和 [Ubuntu](http://www.ubuntu.com/) 创始人 Mark Shuttleworth 在一次采访中说他不准备宣布 Ubuntu 的新 [Snap 程序包格式](https://insights.ubuntu.com/2016/04/13/snaps-for-classic-ubuntu/)。但是就在几个月之后,很多 Linux 发行版的开发者和公司都宣布他们会把 Snap 作为通用 Linux 程序包格式。

*Linux 供应商,独立软件开发商和公司门全都采用 Ubuntu Snap 作为多种 Linux 系统的配置和更新程序包。*
为什么呢?因为 Snap 能使一个单一的二进制程序包可以完美、安全地运行在任何 Linux 台式机、服务器、云或物联网设备上。据 Canonical 的 Ubuntu 客户端产品和版本负责人 Olli Ries 说:
>
> [Snap 程序包的安全机制](https://insights.ubuntu.com/2016/04/13/snaps-for-classic-ubuntu/)让我们在更快的跨发行版应用更新中打开了新的局面,因为 Snap 应用是与系统的其它部分想隔离的。用户可以安装一个 Snap 而不用担心是否会影响其他的应用程序和操作系统。
>
>
>
当然了,如 Linux 内核的早期开发者和 CoreOS 安全维护者 Matthew Garrett 指出的那样:如果你[将 Snap 用在不安全的程序中,比如 X11 窗口系统](http://www.zdnet.com/article/linux-expert-matthew-garrett-ubuntu-16-04s-new-snap-format-is-a-security-risk/),实际上您并不会获得安全性。(LCTT 译注:X11 也叫做 X Window 系统,X Window 系统 ( X11 或 X )是一种位图显示的视窗系统 。它是在 Unix 和类 Unix 操作系统 ,以及 OpenVMS 上建立图形用户界面的标准工具包和协议,并可用于几乎所有已有的现代操作系统。)
Shuttleworth 同意 Garrett 的观点,但是他也说你可以控制 Snap 应用是如何与系统的其它部分如何交互的。比如,一个 web 浏览器可以包含在一个安全的 Snap 程序包中,这个 Snap 使用 Ubuntu 打包的 [openssl](https://www.openssl.org/) TLS 和 SSL 库。除此之外,即使有些东西影响到了浏览器实例内部,也不能进入到底层的操作系统。
很多公司也这样认为。戴尔、三星、Mozilla、[krita](https://krita.org/en/)(LCTT 译注:Krita 是一个位图形编辑软件,KOffice 套装的一部份。包含一个绘画程式和照片编辑器,Krita 是自由软件,并根据GNU通用公共许可证发布)、[Mycroft](https://mycroft.ai/)(LCTT 译注:Mycroft 是一个开源AI智能家居平台,配置 Raspberry Pi 2 和 Arduino 控制器),以及 [Horizon Computing](http://www.horizon-computing.com/)(LCTT 译注:为客户提供优质的硬件架构为其运行云平台)都将使用 Snap。Arch Linux、Debain、Gentoo 和 OpenWrt 开发团队也已经拥抱了 Snap,也会把 Snap 加入到他们各自的发行版中。
Snap 包又叫做“Snaps”,现在已经可以原生的运行在 Arch、Debian、Fedora、Kubuntu、Lubuntu、Ubuntu GNOME、Ubuntu Kylin、Ubuntu MATE、Ubuntu Unity 和 Xubuntu 之上。 Snap 也在 CentOS、Elementary、Gentoo、Mint、OpenSUSE 和 Red Hat Enterprise Linux (RHEL) 上取得了验证,并且也很容易运行在其他 Linux 发行版上。
这些发行版正在使用 Snaps,Shuttleworth 声称:“Snaps 为每个 Linux 台式机、服务器、设备和云机器带来了很多应用程序,在让用户使用最好的应用的同时也给了用户选择发行版的自由。”
这些发行版共同代表了 Linux 桌面、服务器和云系统发行版的主流。为什么它们从现有的软件包管理系统换了过来呢? Arch Linux 的贡献者 Tim Jester-Pfadt 解释说,“Snaps 最棒的一点是它支持先锐和测试通道,这可以让用户选择使用预发布的开发者版本或跟着最新的稳定版本。”
除过这些 Linux 分支,独立软件开发商也将会因为 Snap 很好的简化了第三方 Linux 应用程序分发和安全维护问题而拥抱 Snap。例如,[文档基金会](https://www.documentfoundation.org/)也将会让流行的开源办公套件 [LibreOffice](https://www.libreoffice.org/download/libreoffice-fresh/) 支持 Snap 程序包。
文档基金会的联合创始人 Thorsten Behrens 这样说:
>
> 我们的目标是尽可能的使 LibreOffice 能被大多数人更容易使用。Snap 使我们的用户能够在不同的桌面系统和发行版上更快捷、更容易、持续地获取最新的 LibreOffice 版本。更好的是,它也会帮助我们的发布工程师最终从周而复始的、自产的、陈旧的 Linux 开发解决方案中解放出来,很多东西都可以一同维护了。
>
>
>
Mozilla 的 Firefix 副总裁 Nick Nguyen 在该声明中提到:
>
> 我们力求为用户提供良好的使用体验,并且使火狐浏览器能够在更多平台、设备和操作系统上运行。随着引入 Snaps ,对火狐浏览器的持续优化成为可能,使它可以为 Linux 用户提供最新的特性。
>
>
>
[Krita 基金会](https://krita.org/en/about/krita-foundation/) (基于 KDE 的图形程序)项目领导 Boudewijn Rempt 说:
>
> 在一个私有仓库中维护 DEB 包是复杂而耗时的。Snaps 更容易维护、打包和分发。把 Snap 放进软件商店也特别容易,这是我发布软件用过的最舒服的软件商店了。[Krita 3.0](https://krita.org/en/item/krita-3-0-released/) 刚刚作为一个 snap 程序包发行,新版本出现时它会自动更新。
>
>
>
不仅 Linux 桌面系统程序为 Snap 而激动。物联网(IoT)和嵌入式开发者也以双手拥抱了 Snap。
由于 Snaps 彼此隔离,带来了数据安全性,它们还可以自动更新或回滚,这对于硬件设备是极好的。多个厂商都发布了运行着 snappy 的设备(LCTT 译注:Snap 基于 snappy 进行构建),这带来了一种新的带有物联网应用商店的“智能新锐”设备。Snappy 设备能够自动接收系统更新,并且连同安装在设备上的应用程序也会得到更新。
据 Shuttleworth 说,戴尔公司是最早一批认识到 Snap 的巨大潜力的物联网供应商之一,也决定在他们的设备上使用 Snap 了。
戴尔公司的物联网战略和合作伙伴主管 Jason Shepherd 说:“我们认为,Snaps 能解决在单一物联网网关上部署和运行多个第三方应用程序所带来的安全风险和可管理性挑战。这种可信赖的通用的应用程序格式才是戴尔真正需要的,我们的物联网解决方案合作伙伴和商业客户都对构建一个可扩展的、IT 级的、充满活力的物联网应用生态系统有极大的兴趣。”
OpenWrt 的开发者 Matteo Croce 说:“这很简单, Snaps 可以在保持核心系统不变的情况下递送新的应用... Snaps 是为 OpenWrt AP 和路由器提供大量软件的最快方式。”
Shuttleworth 并不认为 Snaps 会取代已经存在的 Linux 程序包比如 [RPM](http://rpm5.org/) 和 [DEB](https://www.debian.org/doc/manuals/debian-faq/ch-pkg_basics.en.html)。相反,他认为它们将会相辅相成。Snaps 将会与现有软件包共存。每个发行版都有其自己提供和更新核心系统及其更新的机制。Snap 为桌面系统带来的是通用的应用程序,这些应用程序不会影响到操作系统的基础。
每个 Snap 都通过使用大量的内核隔离和安全机制而限制,以满足 Snap 应用的需求。谨慎的审核过程可以确保 Snap 仅仅得到其完成请求操作的权限。用户在安装 Snap 的时候也不必考虑复杂的安全问题。
Snap 本质上是一个自包容的 zip 文件,能够快速地在包内执行。流行的[优麒麟](http://www.ubuntu.com/desktop/ubuntu-kylin)团队的负责人 Jack Yu 称:“Snaps 比传统的 Linux 包更容易构建,允许我们独立于操作系统解决依赖性,所以我们很容易地跨发行版为所有用户提供最好、最新的中国 Linux 应用。”
由 Canonical 设计的 Snap 程序包格式由 [snapd](https://launchpad.net/ubuntu/+source/snapd) 所处理。它的开发工作放在 GitHub 上。将其移植到更多的 Linux 发行版已经被证明是很简单的,社区还在不断增长,吸引了大量具有 Linux 经验的贡献者。
Snap 程序包使用 snapcraft 工具来构建。项目官网是 [snapcraft.io](http://snapcraft.io/),其上有构建 Snap 的指导和逐步指南,以及给项目开发者和使用者的文档。Snap 能够基于现有的发行版程序包构建,但通常使用源代码来构建,以获得优化和减小软件包大小。
如果你不是 Ubuntu 的忠实粉丝或者一个专业的 Linux 开发者,你可能还不知道 Snap。未来,在任何平台上需要用 Linux 完成工作的任何人都会知道这个软件。它会成为主流,尤其是在 Linux 应用程序的安装和更新机制方面。
---
via: <http://www.zdnet.com/article/ubuntu-snap-takes-charge-of-linux-desktop-and-iot-software-distribution/>
作者:[Steven J. Vaughan-Nichols](http://www.zdnet.com/meet-the-team/us/steven-j-vaughan-nichols/) 译者:[vim-kakali](https://github.com/vim-kakali) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,715 | 给学习 OpenStack 架构的新手入门指南 | https://opensource.com/business/16/4/interview-openstack-infrastructure-beginners | 2016-08-25T12:58:00 | [
"OpenStack"
] | https://linux.cn/article-7715-1.html | OpenStack 欢迎新成员的到来,但是,对于这个发展趋近成熟并且快速迭代的开源社区而言,能够拥有一个新手指南并不是件坏事。在奥斯汀举办的 OpenStack 峰会上,[Paul Belanger](https://twitter.com/pabelanger) (来自红帽公司)、 [Elizabeth K. Joseph](https://twitter.com/pleia2) (来自 HPE 公司)和 [Christopher Aedo](https://twitter.com/docaedo) (来自 IBM 公司)就[针对新人的 OpenStack 架构](https://www.openstack.org/summit/austin-2016/summit-schedule/events/7337)作了一场专门的讲演。在这次采访中,他们提供了一些建议和资源来帮助新人成为 OpenStack 贡献者中的一员。

**你的讲演介绍中说你将“深入架构核心,并解释你需要知道的关于让 OpenStack 工作起来的每一件事情”。这对于 40 分钟的讲演来说是一个艰巨的任务。那么,对于学习 OpenStack 架构的新手来说最需要知道那些事情呢?**
**Elizabeth K. Joseph (EKJ)**: 我们没有为 OpenStack 使用 GitHub 这种提交补丁的方式,这是因为这样做会对新手造成巨大的困扰,尽管由于历史原因我们还是在 GitHub 上维护了所有库的一个镜像。相反,我们使用了一种完全开源的评审形式,而且持续集成(CI)是由 OpenStack 架构团队维护的。与之有关的,自从我们使用了 CI 系统,每一个提交给 OpenStack 的改变都会在被合并之前进行测试。
**Paul Belanger (PB)**: 这个项目中的大多数都是富有激情的人,因此当你提交的补丁被某个人否定时不要感到沮丧。
**Christopher Aedo (CA)**:社区会帮助你取得成功,因此不要害怕提问或者寻求更多的那些能够促进你理解某些事物的引导者。
**在你的讲话中,对于一些你无法涉及到的方面,你会向新手推荐哪些在线资源来让他们更加容易入门?**
**PB**:当然是我们的 [OpenStack 项目架构文档](http://docs.openstack.org/infra/system-config/)。我们已经花了足够大的努力来尽可能让这些文档能够随时保持最新状态。在 OpenStack 运行中使用的每个系统都作为一个项目,都制作了专门的页面来进行说明。甚至于连 OpenStack 云这种架构团队也会放到线上。
**EKJ**:我对于架构文档这件事上的观点和 Paul 是一致的,另外,我们十分乐意看到来自那些正在学习项目的人们提交上来的补丁。我们通常不会意识到我们忽略了文档中的某些内容,除非它们恰好被人问起。因此,阅读、学习,会帮助我们修补这些知识上的漏洞。你可以在 [OpenStack 架构邮件清单]提出你的问题,或者在我们位于 FreeNode 上的 #OpenStack-infra 的 IRC 专栏发起你的提问。
**CA**:我喜欢[这个详细的帖子](https://www.technovelty.org/openstack/image-building-in-openstack-ci.html),它是由 Ian Wienand 写的一篇关于构建镜像的文章。
**"gotchas" 会是 OpenStack 新的贡献者们所寻找的吗?**
**EKJ**:向项目作出贡献并不仅仅是提交新的代码和新的特性;OpenStack 社区高度重视代码评审。如果你想要别人查看你的补丁,那你最好先看看其他人是如何做的,然后参考他们的风格,最后一步步做到你也能够向其他人一样提交清晰且结构分明的代码补丁。你越是能让你的同伴了解你的工作并知道你正在做的评审,那他们也就越有可能及时评审你的代码。
**CA**:我看到过大量的新手在面对 [Gerrit](https://code.google.com/p/gerrit/) 时受挫,阅读开发者引导中的[开发者工作步骤](http://docs.openstack.org/infra/manual/developers.html#development-workflow),有可能的话多读几遍。如果你没有用过 Gerrit,那你最初对它的感觉可能是困惑和无力的。但是,如果你随后做了一些代码评审的工作,那么你就能轻松应对它。此外,我是 IRC 的忠实粉丝,它可能是一个获得帮助的好地方,但是,你最好保持一个长期在线的状态,这样,尽管你在某个时候没有出现,人们也可以回答你的问题。(阅读 [IRC,开源成功的秘诀](https://developer.ibm.com/opentech/2015/12/20/irc-the-secret-to-success-in-open-source/))你不必总是在线,但是你最好能够轻松的在一个频道中回溯之前信息,以此来跟上最新的动态,这种能力非常重要。
**PB**:我同意 Elizabeth 和 Chris 的观点, Gerrit 是需要花点精力的,它将汇聚你的开发方面的努力。你不仅仅要提交代码给别人去评审,同时,你也要能够评审其他人的代码。看到 Gerrit 的界面,你可能一时会变的很困惑。我推荐新手去尝试 [Gertty](https://pypi.python.org/pypi/gertty),它是一个基于控制台的终端界面,用于 Gerrit 代码评审系统,而它恰好也是 OpenStack 架构所驱动的一个项目。
**你对于 OpenStack 新手如何通过网络与其他贡献者交流方面有什么好的建议?**
**PB**:对我来说,是通过 IRC 并在 Freenode 上参加 #OpenStack-infra 频道([IRC 日志](http://eavesdrop.openstack.org/irclogs/%23openstack-infra/))。这频道上面有很多对新手来说很有价值的资源。你可以看到 OpenStack 项目日复一日的运作情况,同时,一旦你知道了 OpenStack 项目的工作原理,你将更好的知道如何为 OpenStack 的未来发展作出贡献。
**CA**:我想要为 IRC 再次说明一点,在 IRC 上保持全天在线记录对我来说有非常重大的意义,因为我会时刻保持连接并随时接到提醒。这也是一种非常好的获得帮助的方式,特别是当你和某人卡在了项目中出现的某一个难题的时候,而在一个活跃的 IRC 频道中,总会有一些人很乐意为你解决问题。
**EKJ**:[OpenStack 开发邮件列表](http://lists.openstack.org/cgi-bin/mailman/listinfo/openstack-dev)对于能够时刻查看到你所致力于的 OpenStack 项目的最新情况是非常重要的。因此,我推荐一定要订阅它。邮件列表使用主题标签来区分项目,因此你可以设置你的邮件客户端来使用它来专注于你所关心的项目。除了在线资源之外,全世界范围内也成立了一些 OpenStack 小组,他们被用来为 OpenStack 的用户和贡献者提供服务。这些小组可能会定期要求 OpenStack 主要贡献者们举办座谈和活动。你可以在 MeetUp.com 上搜素你所在地域的贡献者活动聚会,或者在 [groups.openstack.org](https://groups.openstack.org/) 上查看你所在的地域是否存在 OpenStack 小组。最后,还有一个每六个月举办一次的 [OpenStack 峰会](https://www.openstack.org/summit/),这个峰会上会作一些关于架构的演说。当前状态下,这个峰会包含了用户会议和开发者会议,会议内容都是和 OpenStack 相关的东西,包括它的过去,现在和未来。
**OpenStack 需要在那些方面得到提升来让新手更加容易学会并掌握?**
**PB**: 我认为我们的 [account-setup](http://docs.openstack.org/infra/manual/developers.html#account-setup) 环节对于新的贡献者已经做的比较容易了,特别是教他们如何提交他们的第一个补丁。真正参与到 OpenStack 开发者模式中是需要花费很大的努力的,相比贡献者来说已经显得非常多了;然而,一旦融入进去了,这个模式将会运转的十分高效和令人满意。
**CA**: 我们拥有一个由专业开发者组成的社区,而且我们的关注点都是发展 OpenStack 本身,同时,我们致力于让用户付出更小的代价去使用 OpenStack 云架构平台。我们需要发掘更多的应用开发者,并且鼓励更多的人去开发能在 OpenStack 云上完美运行的云应用程序,我们还鼓励他们在[社区 App 目录](https://apps.openstack.org/)上去贡献那些由他们开发的应用。我们可以通过不断提升我们的 API 标准和保证我们不同的库(比如 libcloud,phpopencloud 以及其他一些库)持续地为开发者提供可信赖的支持来实现这一目标。还有一点就是通过举办更多的 OpenStack 黑客比赛。所有的这些事情都可以降低新人的学习门槛,这样也能引导他们与这个社区之间的关系更加紧密。
**EKJ**: 我已经致力于开源软件很多年了。但是,对于大量的 OpenStack 开发者而言,这是一个他们自己所从事的第一个开源项目。我发现他们之前使用私有软件的背景并没有为他们塑造开源的观念、方法论,以及在开源项目中需要具备的合作技巧。我乐于看到我们能够让那些曾经一直在使用私有软件工作的人能够真正的明白他们在开源如软件社区所从事的事情的巨大价值。
**我想把 2016 年打造成开源俳句之年。请用俳句来向新手解释 OpenStack 一下。**
(LCTT 译注:俳句(Haiku)是一种日本古典短诗,以5-7-5音节为三句,校对者不揣浅陋,诌了几句歪诗,勿笑 :D,另外 OpenStack 本身音节太长,就捏造了一个中文译名“开栈”——明白就好。)
**PB**: <ruby> 开栈在云上 <rp> ( </rp> <rt> OpenStack runs clouds </rt> <rp> ) </rp></ruby>//<ruby> 倘钟情自由软件 <rp> ( </rp> <rt> If you enjoy free software </rt> <rp> ) </rp></ruby>//<ruby> 先当造补丁 <rp> ( </rp> <rt> Submit your first patch </rt> <rp> ) </rp></ruby>
**CA**:<ruby> 时光不必久 <rp> ( </rp> <rt> In the near future </rt> <rp> ) </rp></ruby>//<ruby> 开栈将支配世界 <rp> ( </rp> <rt> OpenStack will rule the world </rt> <rp> ) </rp></ruby>//<ruby> 协力早来到 <rp> ( </rp> <rt> Help make it happen! </rt> <rp> ) </rp></ruby>
**EKJ**:<ruby> 开栈有自由 <rp> ( </rp> <rt> OpenStack is free </rt> <rp> ) </rp></ruby>//<ruby> 放在自家服务器 <rp> ( </rp> <rt> Deploy on your own servers </rt> <rp> ) </rp></ruby>//<ruby> 运行你的云 <rp> ( </rp> <rt> And run your own cloud! </rt> <rp> ) </rp></ruby>
*Paul、Elizabeth 和 Christopher 在 4 月 25 号星期一上午 11:15 于奥斯汀举办的 OpenStack 峰会发表了[演说](https://www.openstack.org/summit/austin-2016/summit-schedule/events/7337)。*
---
via: <https://opensource.com/business/16/4/interview-openstack-infrastructure-beginners>
作者:[Rikki Endsley](http://rikkiendsley.com/) 译者:[kylepeng93](https://github.com/kylepeng93) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | New contributors to OpenStack are welcome, but having a road map for navigating within this maturing, fast-paced open source community doesn't hurt. At OpenStack Summit in Austin, [Paul Belanger](https://twitter.com/pabelanger) (Red Hat, Inc.), [Elizabeth K. Joseph](https://twitter.com/pleia2) (HPE), and [Christopher Aedo](https://twitter.com/docaedo) (IBM) will lead a session on * OpenStack Infrastructure for Beginners*. In this interview, they offer tips and resources to help onboard new OpenStack contributors.
### Your talk description says you'll be "diving into the heart of infrastructure and explain everything you need to know about the systems that keep OpenStack working." That's a tall order for a 40-minute time slot. What are the top things beginners should know about OpenStack infrastructure?
**Elizabeth K. Joseph (EKJ):** We don't use GitHub for OpenStack patches. This is something that trips up a lot of new contributors because we do maintain mirrors of all our repositories on GitHub for historical reasons. Instead we use a fully open source code review and continuous integration (CI) system maintained by the OpenStack Infrastructure team. Relatedly, since we run a CI system, every change proposed to OpenStack is tested before merging.
**Paul Belanger (PB):** A lot of passionate people in the project, so don't get discouraged if your patch gets a -1.
**Christopher Aedo (CA):** The community wants to help you succeed, don't be afraid to ask questions or ask for pointers to more information to improve your understanding.
### Which online resources would you recommend for beginners to fill in the holes for what you can't cover in your talk?
**PB:** Definitely our [OpenStack Project Infrastructure documentation](http://docs.openstack.org/infra/system-config/). At lot of effort has been taken to keep it up to date as much as possible. Every system used in running OpenStack as a project has a dedicated page, even the OpenStack cloud the Infrastructure teams is bringing online.
**EKJ:** I'll echo what Paul said about the Infrastructure documentation, and add that we love seeing patches from folks who are learning. We often don't realize what we're missing in terms of documentation until someone asks. So read, learn, and then help us fill in the gaps. You can ask questions on the [openstack-infra mailing list](http://lists.openstack.org/cgi-bin/mailman/listinfo/openstack-infra) or in our IRC channel at #openstack-infra on Freenode.
**CA:** I love [this detailed post](https://www.technovelty.org/openstack/image-building-in-openstack-ci.html) about building images, by Ian Wienand.
### Which "gotchas" should new OpenStack contributors look out for?
**EKJ:** Contributing is not just about submitting new code and new features; the OpenStack community places a very high value on doing code reviews. If you want people to look at a patch you submitted, consider reviewing some of the work of others and providing clear and constructive feedback. The more your fellow contributors know about your work and see you doing reviews, the more likely you'll get your code reviewed in a timely manner.
**CA:** I see a lot of newcomers getting tripped up with [Gerrit](https://code.google.com/p/gerrit/). Read through the [developer workflow](http://docs.openstack.org/infra/manual/developers.html#development-workflow) in the Developers Guide, and then maybe read through it one more time. If you're not used to Gerrit, it can seem confusing and overwhelming at first, but walking through a few code reviews usually makes it all come together. Also, I'm a big fan of IRC. It can be a great place to get help, but it's best if you can maintain a persistent presence so people can answer your questions even if you're not "there" at that particular moment. (Read [IRC, the secret to success in open source](https://developer.ibm.com/opentech/2015/12/20/irc-the-secret-to-success-in-open-source/).) You don't need to be "always on," but the ability to easily scroll back in a channel and catch up on a conversation can be invaluable.
**PB:** I agree with both Elizabeth and Chris—Gerrit is what to look out for. It is going to be the hub of your development effort. Not only will you be submitting code for people to review, but you'll also be reviewing other contributors' code. Watch out for the Gerrit UI; it can be confusing at times. I'd recommend trying out [Gertty](https://pypi.python.org/pypi/gertty), which is a console-based interface to the Gerrit Code Review system, which happens to be a project driven by OpenStack Infrastructure.
### What resources do you recommend for beginners to help them network with other OpenStack contributors?
**PB:** For me, it was using IRC and joining the #openstack-infra channel on Freenode ([IRC logs](http://eavesdrop.openstack.org/irclogs/%23openstack-infra/)). There is a lot of fantastic information and people in that channel. You get to see the day-to-day operations of the OpenStack project, and once you know how the project works, you'll have a better understanding on how to contribute to its future.
**CA:** I want to second that note for IRC; staying on IRC throughout the day made a huge difference for me in terms of feeling informed and connected. It's also such a great way to get help when you're stuck with someone on one of the projects—the ones with active IRC channels always have someone around willing to get your issues sorted out.
**EKJ:** The [openstack-dev mailing list](http://lists.openstack.org/cgi-bin/mailman/listinfo/openstack-dev) is quite important for staying up to date with news about projects you're working on inside of OpenStack, so I recommend subscribing to that. The mailing list uses subject tags to separate projects, so you can instruct your email client to use those and focus on threads that impact projects you care about. Beyond online resources, many OpenStack groups have popped up all over the world that serve the needs of both users and contributors to OpenStack, and many of them routinely have talks and events with key OpenStack contributors. You can search on Meetup.com in your area, or search on [groups.openstack.org](https://groups.openstack.org/) to see if there is an OpenStack group in your area. Finally, there are the [OpenStack Summits](https://www.openstack.org/summit/), which happen every six months, and where we'll be giving our Infrastructure talk. In their current format, the summits consist of both a user conference and a developer conference in one space to talk about everything related to OpenStack, past, present, and future.
### In which areas does OpenStack need to improve to become more beginner-friendly?
**PB:** I think our [account-setup](http://docs.openstack.org/infra/manual/developers.html#account-setup) process could be made easier for new contributors, especially how many steps are needed to submit your first patch. There is a large cost to enroll into OpenStack development model, which maybe be too much for contributors; however, once enrolled, the model works fantastic for developers.
**CA:** We have a very pro-developer community, but the focus is on developing OpenStack itself, with less consideration given to the users of OpenStack clouds. We need to bring in application developers and encourage more people to develop things that run beautifully on OpenStack clouds, and encourage them to share those apps in the [Community App Catalog](https://apps.openstack.org). We can do this by continuing to improve our API standards and by ensuring different libraries (like libcloud, phpopencloud, and others) continue to work reliably for developers. Oh, also by sponsoring more OpenStack hackathons! All these things can ease entry for newcomers, which will lead to them sticking around.
**EKJ:** I've worked on open source software for many years, but for a large number of OpenStack developers, this is the first open source project they've every worked on. I've found that their proprietary software background doesn't prepare them for the open source ideals, methodologies, and collaboration techniques used in an open source project. I'd love to see us do a better job of welcoming people who have this proprietary software background and working with them so they can truly understand the value of what they're working on in the open source software community.
### I think 2016 is shaping up to be the Year of the Open Source Haiku. Explain OpenStack to beginners via Haiku.
**PB:** OpenStack runs clouds
If you enjoy free software
Submit your first patch
**CA:** In the near future
OpenStack will rule the world
Help make it happen!
**EKJ:** OpenStack is free
Deploy on your own servers
And run your own cloud!
*Paul, Elizabeth, and Christopher will be speaking at OpenStack Summit in Austin on Monday, April 25, starting at 11:15am.*
## 1 Comment |
7,716 | Mock 在 Python 单元测试中的使用 | https://www.toptal.com/python/an-introduction-to-mocking-in-python | 2016-08-25T18:22:34 | [
"Python",
"单元测试",
"mock"
] | https://linux.cn/article-7716-1.html |
>
> 本文讲述的是 Python 中 Mock 的使用。
>
>
>
### 如何执行单元测试而不用考验你的耐心
很多时候,我们编写的软件会直接与那些被标记为“垃圾”的服务交互。用外行人的话说:服务对我们的应用程序很重要,但是我们想要的是交互,而不是那些不想要的副作用,这里的“不想要”是在自动化测试运行的语境中说的。例如:我们正在写一个社交 app,并且想要测试一下 "发布到 Facebook" 的新功能,但是不想每次运行测试集的时候真的发布到 Facebook。
Python 的 `unittest` 库包含了一个名为 `unittest.mock` 或者可以称之为依赖的子包,简称为 `mock` —— 其提供了极其强大和有用的方法,通过它们可以<ruby> 模拟 <rp> ( </rp> <rt> mock </rt> <rp> ) </rp></ruby>并去除那些我们不希望的副作用。

注意:`mock` [最近被收录](http://www.python.org/dev/peps/pep-0417/)到了 Python 3.3 的标准库中;先前发布的版本必须通过 [PyPI](https://pypi.python.org/pypi/mock) 下载 Mock 库。
### 恐惧系统调用
再举另一个例子,我们在接下来的部分都会用到它,这是就是**系统调用**。不难发现,这些系统调用都是主要的模拟对象:无论你是正在写一个可以弹出 CD 驱动器的脚本,还是一个用来删除 /tmp 下过期的缓存文件的 Web 服务,或者一个绑定到 TCP 端口的 socket 服务器,这些调用都是在你的单元测试上下文中不希望产生的副作用。
作为一个开发者,你需要更关心你的库是否成功地调用了一个可以弹出 CD 的系统函数(使用了正确的参数等等),而不是切身经历 CD 托盘每次在测试执行的时候都打开了。(或者更糟糕的是,弹出了很多次,在一个单元测试运行期间多个测试都引用了弹出代码!)
同样,保持单元测试的效率和性能意味着需要让如此多的“缓慢代码”远离自动测试,比如文件系统和网络访问。
对于第一个例子来说,我们要从原始形式换成使用 `mock` 重构一个标准 Python 测试用例。我们会演示如何使用 mock 写一个测试用例,使我们的测试更加智能、快速,并展示更多关于我们软件的工作原理。
### 一个简单的删除函数
我们都有过需要从文件系统中一遍又一遍的删除文件的时候,因此,让我们在 Python 中写一个可以使我们的脚本更加轻易完成此功能的函数。
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import os
def rm(filename):
os.remove(filename)
```
很明显,我们的 `rm` 方法此时无法提供比 `os.remove` 方法更多的相关功能,但我们可以在这里添加更多的功能,使我们的基础代码逐步改善。
让我们写一个传统的测试用例,即,没有使用 `mock`:
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from mymodule import rm
import os.path
import tempfile
import unittest
class RmTestCase(unittest.TestCase):
tmpfilepath = os.path.join(tempfile.gettempdir(), "tmp-testfile")
def setUp(self):
with open(self.tmpfilepath, "wb") as f:
f.write("Delete me!")
def test_rm(self):
# remove the file
rm(self.tmpfilepath)
# test that it was actually removed
self.assertFalse(os.path.isfile(self.tmpfilepath), "Failed to remove the file.")
```
我们的测试用例相当简单,但是在它每次运行的时候,它都会创建一个临时文件并且随后删除。此外,我们没有办法测试我们的 `rm` 方法是否正确地将我们的参数向下传递给 `os.remove` 调用。我们可以基于以上的测试*认为*它做到了,但还有很多需要改进的地方。
#### 使用 Mock 重构
让我们使用 mock 重构我们的测试用例:
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from mymodule import rm
import mock
import unittest
class RmTestCase(unittest.TestCase):
@mock.patch('mymodule.os')
def test_rm(self, mock_os):
rm("any path")
# test that rm called os.remove with the right parameters
mock_os.remove.assert_called_with("any path")
```
使用这些重构,我们从根本上改变了测试用例的操作方式。现在,我们有一个可以用于验证其他功能的内部对象。
##### 潜在陷阱
第一件需要注意的事情就是,我们使用了 `mock.patch` 方法装饰器,用于模拟位于 `mymodule.os` 的对象,并且将 mock 注入到我们的测试用例方法。那么只是模拟 `os` 本身,而不是 `mymodule.os` 下 `os` 的引用(LCTT 译注:注意 `@mock.patch('mymodule.os')` 便是模拟 `mymodule.os` 下的 `os`),会不会更有意义呢?
当然,当涉及到导入和管理模块,Python 的用法就像蛇一样灵活。在运行时,`mymodule` 模块有它自己的被导入到本模块局部作用域的 `os`。因此,如果我们模拟 `os`,我们是看不到 mock 在 `mymodule` 模块中的模仿作用的。
这句话需要深刻地记住:
>
> 模拟一个东西要看它用在何处,而不是来自哪里。
>
>
>
如果你需要为 `myproject.app.MyElaborateClass` 模拟 `tempfile` 模块,你可能需要将 mock 用于 `myproject.app.tempfile`,而其他模块保持自己的导入。
先将那个陷阱放一边,让我们继续模拟。
#### 向 ‘rm’ 中加入验证
之前定义的 rm 方法相当的简单。在盲目地删除之前,我们倾向于验证一个路径是否存在,并验证其是否是一个文件。让我们重构 rm 使其变得更加智能:
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import os
import os.path
def rm(filename):
if os.path.isfile(filename):
os.remove(filename)
```
很好。现在,让我们调整测试用例来保持测试的覆盖率。
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from mymodule import rm
import mock
import unittest
class RmTestCase(unittest.TestCase):
@mock.patch('mymodule.os.path')
@mock.patch('mymodule.os')
def test_rm(self, mock_os, mock_path):
# set up the mock
mock_path.isfile.return_value = False
rm("any path")
# test that the remove call was NOT called.
self.assertFalse(mock_os.remove.called, "Failed to not remove the file if not present.")
# make the file 'exist'
mock_path.isfile.return_value = True
rm("any path")
mock_os.remove.assert_called_with("any path")
```
我们的测试用例完全改变了。现在我们可以在没有任何副作用的情况下核实并验证方法的内部功能。
#### 将文件删除作为服务
到目前为止,我们只是将 mock 应用在函数上,并没应用在需要传递参数的对象和实例的方法上。我们现在开始涵盖对象的方法。
首先,我们将 `rm` 方法重构成一个服务类。实际上将这样一个简单的函数转换成一个对象,在本质上这不是一个合理的需求,但它能够帮助我们了解 `mock` 的关键概念。让我们开始重构:
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import os
import os.path
class RemovalService(object):
"""A service for removing objects from the filesystem."""
def rm(filename):
if os.path.isfile(filename):
os.remove(filename)
```
你会注意到我们的测试用例没有太大变化:
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from mymodule import RemovalService
import mock
import unittest
class RemovalServiceTestCase(unittest.TestCase):
@mock.patch('mymodule.os.path')
@mock.patch('mymodule.os')
def test_rm(self, mock_os, mock_path):
# instantiate our service
reference = RemovalService()
# set up the mock
mock_path.isfile.return_value = False
reference.rm("any path")
# test that the remove call was NOT called.
self.assertFalse(mock_os.remove.called, "Failed to not remove the file if not present.")
# make the file 'exist'
mock_path.isfile.return_value = True
reference.rm("any path")
mock_os.remove.assert_called_with("any path")
```
很好,我们知道 `RemovalService` 会如预期般的工作。接下来让我们创建另一个服务,将 `RemovalService` 声明为它的一个依赖:
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import os
import os.path
class RemovalService(object):
"""A service for removing objects from the filesystem."""
def rm(self, filename):
if os.path.isfile(filename):
os.remove(filename)
class UploadService(object):
def __init__(self, removal_service):
self.removal_service = removal_service
def upload_complete(self, filename):
self.removal_service.rm(filename)
```
因为我们的测试覆盖了 `RemovalService`,因此我们不会对我们测试用例中 `UploadService` 的内部函数 `rm` 进行验证。相反,我们将调用 `UploadService` 的 `RemovalService.rm` 方法来进行简单测试(当然没有其他副作用),我们通过之前的测试用例便能知道它可以正确地工作。
这里有两种方法来实现测试:
1. 模拟 RemovalService.rm 方法本身。
2. 在 UploadService 的构造函数中提供一个模拟实例。
因为这两种方法都是单元测试中非常重要的方法,所以我们将同时对这两种方法进行回顾。
##### 方法 1:模拟实例的方法
`mock` 库有一个特殊的方法装饰器,可以模拟对象实例的方法和属性,即 `@mock.patch.object decorator` 装饰器:
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from mymodule import RemovalService, UploadService
import mock
import unittest
class RemovalServiceTestCase(unittest.TestCase):
@mock.patch('mymodule.os.path')
@mock.patch('mymodule.os')
def test_rm(self, mock_os, mock_path):
# instantiate our service
reference = RemovalService()
# set up the mock
mock_path.isfile.return_value = False
reference.rm("any path")
# test that the remove call was NOT called.
self.assertFalse(mock_os.remove.called, "Failed to not remove the file if not present.")
# make the file 'exist'
mock_path.isfile.return_value = True
reference.rm("any path")
mock_os.remove.assert_called_with("any path")
class UploadServiceTestCase(unittest.TestCase):
@mock.patch.object(RemovalService, 'rm')
def test_upload_complete(self, mock_rm):
# build our dependencies
removal_service = RemovalService()
reference = UploadService(removal_service)
# call upload_complete, which should, in turn, call `rm`:
reference.upload_complete("my uploaded file")
# check that it called the rm method of any RemovalService
mock_rm.assert_called_with("my uploaded file")
# check that it called the rm method of _our_ removal_service
removal_service.rm.assert_called_with("my uploaded file")
```
非常棒!我们验证了 `UploadService` 成功调用了我们实例的 `rm` 方法。你是否注意到一些有趣的地方?这种修补机制(patching mechanism)实际上替换了我们测试用例中的所有 `RemovalService` 实例的 `rm` 方法。这意味着我们可以检查实例本身。如果你想要了解更多,可以试着在你模拟的代码下断点,以对这种修补机制的原理获得更好的认识。
##### 陷阱:装饰顺序
当我们在测试方法中使用多个装饰器,其顺序是很重要的,并且很容易混乱。基本上,当装饰器被映射到方法参数时,[装饰器的工作顺序是反向的](http://www.voidspace.org.uk/python/mock/patch.html#nesting-patch-decorators)。思考这个例子:
```
@mock.patch('mymodule.sys')
@mock.patch('mymodule.os')
@mock.patch('mymodule.os.path')
def test_something(self, mock_os_path, mock_os, mock_sys):
pass
```
注意到我们的参数和装饰器的顺序是反向匹配了吗?这部分是由 [Python 的工作方式](http://docs.python.org/2/reference/compound_stmts.html#function-definitions)所导致的。这里是使用多个装饰器的情况下它们执行顺序的伪代码:
```
patch_sys(patch_os(patch_os_path(test_something)))
```
因为 `sys` 补丁位于最外层,所以它最晚执行,使得它成为实际测试方法参数的最后一个参数。请特别注意这一点,并且在运行你的测试用例时,使用调试器来保证正确的参数以正确的顺序注入。
##### 方法 2:创建 Mock 实例
我们可以使用构造函数为 `UploadService` 提供一个 Mock 实例,而不是模拟特定的实例方法。我更推荐方法 1,因为它更加精确,但在多数情况,方法 2 或许更加有效和必要。让我们再次重构测试用例:
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from mymodule import RemovalService, UploadService
import mock
import unittest
class RemovalServiceTestCase(unittest.TestCase):
@mock.patch('mymodule.os.path')
@mock.patch('mymodule.os')
def test_rm(self, mock_os, mock_path):
# instantiate our service
reference = RemovalService()
# set up the mock
mock_path.isfile.return_value = False
reference.rm("any path")
# test that the remove call was NOT called.
self.assertFalse(mock_os.remove.called, "Failed to not remove the file if not present.")
# make the file 'exist'
mock_path.isfile.return_value = True
reference.rm("any path")
mock_os.remove.assert_called_with("any path")
class UploadServiceTestCase(unittest.TestCase):
def test_upload_complete(self, mock_rm):
# build our dependencies
mock_removal_service = mock.create_autospec(RemovalService)
reference = UploadService(mock_removal_service)
# call upload_complete, which should, in turn, call `rm`:
reference.upload_complete("my uploaded file")
# test that it called the rm method
mock_removal_service.rm.assert_called_with("my uploaded file")
```
在这个例子中,我们甚至不需要修补任何功能,只需为 `RemovalService` 类创建一个 auto-spec,然后将实例注入到我们的 `UploadService` 以验证功能。
`mock.create_autospec` 方法为类提供了一个同等功能实例。实际上来说,这意味着在使用返回的实例进行交互的时候,如果使用了非法的方式将会引发异常。更具体地说,如果一个方法被调用时的参数数目不正确,将引发一个异常。这对于重构来说是非常重要。当一个库发生变化的时候,中断测试正是所期望的。如果不使用 auto-spec,尽管底层的实现已经被破坏,我们的测试仍然会通过。
##### 陷阱:mock.Mock 和 mock.MagicMock 类
`mock` 库包含了两个重要的类 [mock.Mock](http://www.voidspace.org.uk/python/mock/mock.html) 和 [mock.MagicMock](http://www.voidspace.org.uk/python/mock/magicmock.html#magic-mock),大多数内部函数都是建立在这两个类之上的。当在选择使用 `mock.Mock` 实例、`mock.MagicMock` 实例还是 auto-spec 的时候,通常倾向于选择使用 auto-spec,因为对于未来的变化,它更能保持测试的健全。这是因为 `mock.Mock` 和 `mock.MagicMock` 会无视底层的 API,接受所有的方法调用和属性赋值。比如下面这个用例:
```
class Target(object):
def apply(value):
return value
def method(target, value):
return target.apply(value)
```
我们可以像下面这样使用 mock.Mock 实例进行测试:
```
class MethodTestCase(unittest.TestCase):
def test_method(self):
target = mock.Mock()
method(target, "value")
target.apply.assert_called_with("value")
```
这个逻辑看似合理,但如果我们修改 `Target.apply` 方法接受更多参数:
```
class Target(object):
def apply(value, are_you_sure):
if are_you_sure:
return value
else:
return None
```
重新运行你的测试,你会发现它仍能通过。这是因为它不是针对你的 API 创建的。这就是为什么你总是应该使用 `create_autospec` 方法,并且在使用 `@patch`和 `@patch.object` 装饰方法时使用 `autospec` 参数。
### 现实例子:模拟 Facebook API 调用
作为这篇文章的结束,我们写一个更加适用的现实例子,一个在介绍中提及的功能:发布消息到 Facebook。我将写一个不错的包装类及其对应的测试用例。
```
import facebook
class SimpleFacebook(object):
def __init__(self, oauth_token):
self.graph = facebook.GraphAPI(oauth_token)
def post_message(self, message):
"""Posts a message to the Facebook wall."""
self.graph.put_object("me", "feed", message=message)
```
这是我们的测试用例,它可以检查我们发布的消息,而不是真正地发布消息:
```
import facebook
import simple_facebook
import mock
import unittest
class SimpleFacebookTestCase(unittest.TestCase):
@mock.patch.object(facebook.GraphAPI, 'put_object', autospec=True)
def test_post_message(self, mock_put_object):
sf = simple_facebook.SimpleFacebook("fake oauth token")
sf.post_message("Hello World!")
# verify
mock_put_object.assert_called_with(message="Hello World!")
```
正如我们所看到的,在 Python 中,通过 mock,我们可以非常容易地动手写一个更加智能的测试用例。
### Python Mock 总结
即使对它的使用还有点不太熟悉,对[单元测试](http://www.toptal.com/qa/how-to-write-testable-code-and-why-it-matters)来说,Python 的 `mock` 库可以说是一个规则改变者。我们已经演示了常见的用例来了解了 `mock` 在单元测试中的使用,希望这篇文章能够帮助 [Python 开发者](http://www.toptal.com/python)克服初期的障碍,写出优秀、经受过考验的代码。
---
via: <https://www.toptal.com/python/an-introduction-to-mocking-in-python>
作者:[NAFTULI TZVI KAY](http://www.slviki.com/) 译者:[cposture](https://github.com/cposture) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](https://linux.cn/) 荣誉推出
| 403 | Forbidden | null |
7,719 | 在 Linux 上用 SELinux 或 AppArmor 实现强制访问控制(MAC) | http://www.tecmint.com/mandatory-access-control-with-selinux-or-apparmor-linux/ | 2016-08-26T08:29:00 | [
"SELinux",
"AppArmor",
"访问控制",
"权限"
] | https://linux.cn/article-7719-1.html | 为了解决标准的“用户-组-其他/读-写-执行”权限以及[访问控制列表](http://www.tecmint.com/secure-files-using-acls-in-linux/)的限制以及加强安全机制,美国国家安全局(NSA)设计出一个灵活的<ruby> 强制访问控制 <rp> ( </rp> <rt> Mandatory Access Control </rt> <rp> ) </rp></ruby>(MAC)方法 SELinux(Security Enhanced Linux 的缩写),来限制标准的权限之外的种种权限,在仍然允许对这个控制模型后续修改的情况下,让进程尽可能以最小权限访问或在系统对象(如文件,文件夹,网络端口等)上执行其他操作。

*SELinux 和 AppArmor 加固 Linux 安全*
另一个流行并且被广泛使用的 MAC 是 AppArmor,相比于 SELinux 它提供更多的特性,包括一个学习模式,可以让系统“学习”一个特定应用的行为,以及通过配置文件设置限制实现安全的应用使用。
在 CentOS 7 中,SELinux 合并进了内核并且默认启用<ruby> 强制 <rp> ( </rp> <rt> Enforcing </rt> <rp> ) </rp></ruby>模式(下一节会介绍这方面更多的内容),与之不同的是,openSUSE 和 Ubuntu 使用的是 AppArmor 。
在这篇文章中我们会解释 SELinux 和 AppArmor 的本质,以及如何在你选择的发行版上使用这两个工具之一并从中获益。
### SELinux 介绍以及如何在 CentOS 7 中使用
Security Enhanced Linux 可以以两种不同模式运行:
* <ruby> 强制 <rp> ( </rp> <rt> Enforcing </rt> <rp> ) </rp></ruby>:这种情况下,SELinux 基于 SELinux 策略规则拒绝访问,策略规则是一套控制安全引擎的规则。
* <ruby> 宽容 <rp> ( </rp> <rt> Permissive </rt> <rp> ) </rp></ruby>:这种情况下,SELinux 不拒绝访问,但如果在强制模式下会被拒绝的操作会被记录下来。
SELinux 也能被禁用。尽管这不是它的一个操作模式,不过也是一种选择。但学习如何使用这个工具强过只是忽略它。时刻牢记这一点!
使用 `getenforce` 命令来显示 SELinux 的当前模式。如果你想要更改模式,使用 `setenforce 0`(设置为宽容模式)或 `setenforce 1`(强制模式)。
因为这些设置重启后就失效了,你需要编辑 `/etc/selinux/config` 配置文件并设置 `SELINUX` 变量为 `enforcing`、`permissive` 或 `disabled` ,保存设置让其重启后也有效:

*如何启用和禁用 SELinux 模式*
还有一点要注意,如果 `getenforce` 返回 Disabled,你得编辑 `/etc/selinux/config` 配置文件为你想要的操作模式并重启。否则你无法利用 `setenforce` 设置(或切换)操作模式。
`setenforce` 的典型用法之一包括在 SELinux 模式之间切换(从强制到宽容或相反)来定位一个应用是否行为不端或没有像预期一样工作。如果它在你将 SELinux 设置为宽容模式正常工作,你就可以确定你遇到的是 SELinux 权限问题。
有两种我们使用 SELinux 可能需要解决的典型案例:
* 改变一个守护进程监听的默认端口。
* 给一个虚拟主机设置 /var/www/html 以外的文档根路径值。
让我们用以下例子来看看这两种情况。
#### 例 1:更改 sshd 守护进程的默认端口
大部分系统管理员为了加强服务器安全首先要做的事情之一就是更改 SSH 守护进程监听的端口,主要是为了阻止端口扫描和外部攻击。要达到这个目的,我们要更改 `/etc/ssh/sshd_config` 中的 Port 值为以下值(我们在这里使用端口 9999 为例):
```
Port 9999
```
在尝试重启服务并检查它的状态之后,我们会看到它启动失败:
```
# systemctl restart sshd
# systemctl status sshd
```

*检查 SSH 服务状态*
如果我们看看 `/var/log/audit/audit.log`,就会看到 sshd 被 SELinux 阻止在端口 9999 上启动,因为它是 JBoss 管理服务的保留端口(SELinux 日志信息包含了词语“AVC”,所以应该很容易把它同其他信息区分开来):
```
# cat /var/log/audit/audit.log | grep AVC | tail -1
```

*检查 Linux 审计日志*
在这种情况下大部分人可能会禁用 SELinux,但我们不这么做。我们会看到有个让 SELinux 和监听其他端口的 sshd 和谐共处的方法。首先确保你有 `policycoreutils-python` 这个包,执行:
```
# yum install policycoreutils-python
```
查看 SELinux 允许 sshd 监听的端口列表。在接下来的图片中我们还能看到端口 9999 是为其他服务保留的,所以我们暂时无法用它来运行其他服务:
```
# semanage port -l | grep ssh
```
当然我们可以给 SSH 选择其他端口,但如果我们确定我们不会使用这台机器跑任何 JBoss 相关的服务,我们就可以修改 SELinux 已存在的规则,转而给 SSH 分配那个端口:
```
# semanage port -m -t ssh_port_t -p tcp 9999
```
这之后,我们就可以用前一个 `semanage` 命令检查端口是否正确分配了,即使用 `-lC` 参数(list custom 的简称):
```
# semanage port -lC
# semanage port -l | grep ssh
```

*给 SSH 分配端口*
我们现在可以重启 SSH 服务并通过端口 9999 连接了。注意这个更改重启之后依然有效。
#### 例 2:给一个虚拟主机设置 /var/www/html 以外的<ruby> 文档根路径 <rp> ( </rp> <rt> DocumentRoot </rt> <rp> ) </rp></ruby>
如果你需要用除 `/var/www/html` 以外目录作为<ruby> 文档根目录 <rp> ( </rp> <rt> DocumentRoot </rt> <rp> ) </rp></ruby>[设置一个 Apache 虚拟主机](http://www.tecmint.com/apache-virtual-hosting-in-centos/)(也就是说,比如 `/websrv/sites/gabriel/public_html`):
```
DocumentRoot “/websrv/sites/gabriel/public_html”
```
Apache 会拒绝提供内容,因为 `index.html` 已经被标记为了 `default_t SELinux` 类型,Apache 无法访问它:
```
# wget http://localhost/index.html
# ls -lZ /websrv/sites/gabriel/public_html/index.html
```

*被标记为 default\_t SELinux 类型*
和之前的例子一样,你可以用以下命令验证这是不是 SELinux 相关的问题:
```
# cat /var/log/audit/audit.log | grep AVC | tail -1
```

*检查日志确定是不是 SELinux 的问题*
要将 `/websrv/sites/gabriel/public_html` 整个目录内容标记为 `httpd_sys_content_t`,执行:
```
# semanage fcontext -a -t httpd_sys_content_t "/websrv/sites/gabriel/public_html(/.*)?"
```
上面这个命令会赋予 Apache 对那个目录以及其内容的读取权限。
最后,要应用这条策略(并让更改的标记立即生效),执行:
```
# restorecon -R -v /websrv/sites/gabriel/public_html
```
现在你应该可以访问这个目录了:
```
# wget http://localhost/index.html
```

*访问 Apache 目录*
要获取关于 SELinux 的更多信息,参阅 Fedora 22 中的 [SELinux 用户及管理员指南](https://docs.fedoraproject.org/en-US/Fedora/22/html/SELinux_Users_and_Administrators_Guide/index.html)。
### AppArmor 介绍以及如何在 OpenSUSE 和 Ubuntu 上使用它
AppArmor 的操作是基于写在纯文本文件中的规则定义,该文件中含有允许权限和访问控制规则。安全配置文件用来限制应用程序如何与系统中的进程和文件进行交互。
系统初始就提供了一系列的配置文件,但其它的也可以由应用程序在安装的时候设置或由系统管理员手动设置。
像 SELinux 一样,AppArmor 以两种模式运行。在 <ruby> 强制 <rp> ( </rp> <rt> enforce </rt> <rp> ) </rp></ruby> 模式下,应用被赋予它们运行所需要的最小权限,但在 <ruby> 抱怨 <rp> ( </rp> <rt> complain </rt> <rp> ) </rp></ruby> 模式下 AppArmor 允许一个应用执行受限的操作并将操作造成的“抱怨”记录到日志里(`/var/log/kern.log`,`/var/log/audit/audit.log`,和其它放在 `/var/log/apparmor` 中的日志)。
日志中会显示配置文件在强制模式下运行时会产生错误的记录,它们中带有 `audit` 这个词。因此,你可以在 AppArmor 的 <ruby> 强制 <rp> ( </rp> <rt> enforce </rt> <rp> ) </rp></ruby> 模式下运行之前,先在 <ruby> 抱怨 <rp> ( </rp> <rt> complain </rt> <rp> ) </rp></ruby> 模式下尝试运行一个应用并调整它的行为。
可以用这个命令显示 AppArmor 的当前状态:
```
$ sudo apparmor_status
```

*查看 AppArmor 的状态*
上面的图片指明配置 `/sbin/dhclient`,`/usr/sbin/`,和 `/usr/sbin/tcpdump` 等处在 <ruby> 强制 <rp> ( </rp> <rt> enforce </rt> <rp> ) </rp></ruby> 模式下(在 Ubuntu 下默认就是这样的)。
因为不是所有的应用都包含相关的 AppArmor 配置,apparmor-profiles 包给其它没有提供限制的包提供了配置。默认它们配置在 <ruby> 抱怨 <rp> ( </rp> <rt> complain </rt> <rp> ) </rp></ruby> 模式下运行,以便系统管理员能够测试并选择一个所需要的配置。
我们将会利用 apparmor-profiles,因为写一份我们自己的配置已经超出了 LFCS [认证](http://www.tecmint.com/sed-command-to-create-edit-and-manipulate-files-in-linux/)的范围了。但是,由于配置都是纯文本文件,你可以查看并学习它们,为以后创建自己的配置做准备。
AppArmor 配置保存在 `/etc/apparmor.d` 中。让我们来看看这个文件夹在安装 apparmor-profiles 之前和之后有什么不同:
```
$ ls /etc/apparmor.d
```

*查看 AppArmor 文件夹内容*
如果你再次执行 `sudo apparmor_status`,你会在 <ruby> 抱怨 <rp> ( </rp> <rt> complain </rt> <rp> ) </rp></ruby> 模式看到更长的配置文件列表。你现在可以执行下列操作。
将当前在 <ruby> 强制 <rp> ( </rp> <rt> enforce </rt> <rp> ) </rp></ruby> 模式下的配置文件切换到 <ruby> 抱怨 <rp> ( </rp> <rt> complain </rt> <rp> ) </rp></ruby> 模式:
```
$ sudo aa-complain /path/to/file
```
以及相反的操作(抱怨 –> 强制):
```
$ sudo aa-enforce /path/to/file
```
上面这些例子是允许使用通配符的。举个例子:
```
$ sudo aa-complain /etc/apparmor.d/*
```
会将 `/etc/apparmor.d` 中的所有配置文件设置为 <ruby> 抱怨 <rp> ( </rp> <rt> complain </rt> <rp> ) </rp></ruby> 模式,反之
```
$ sudo aa-enforce /etc/apparmor.d/*
```
会将所有配置文件设置为 <ruby> 强制 <rp> ( </rp> <rt> enforce </rt> <rp> ) </rp></ruby> 模式。
要完全禁用一个配置,在 `/etc/apparmor.d/disabled` 目录中创建一个符号链接:
```
$ sudo ln -s /etc/apparmor.d/profile.name /etc/apparmor.d/disable/
```
要获取关于 AppArmor 的更多信息,参阅[官方的 AppArmor wiki](http://wiki.apparmor.net/index.php/Main_Page) 以及 [Ubuntu 提供的](https://help.ubuntu.com/community/AppArmor)文档。
### 总结
在这篇文章中我们学习了一些 SELinux 和 AppArmor 这两个著名的强制访问控制系统的基本知识。什么时候使用两者中的一个或是另一个?为了避免提高难度,你可能需要考虑专注于你选择的发行版自带的那一个。不管怎样,它们会帮助你限制进程和系统资源的访问,以提高你服务器的安全性。
关于本文你有任何的问题,评论,或建议,欢迎在下方发表。不要犹豫,让我们知道你是否有疑问或评论。
---
via: <http://www.tecmint.com/mandatory-access-control-with-selinux-or-apparmor-linux/>
作者:[Gabriel Cánepa](http://www.tecmint.com/author/gacanepa/) 译者:[alim0x](https://github.com/alim0x) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,723 | awk 系列:在 awk 中如何使用流程控制语句 | http://www.tecmint.com/use-flow-control-statements-with-awk-command/ | 2016-08-27T17:31:47 | [
"awk"
] | https://linux.cn/article-7723-1.html | 当你回顾所有到目前为止我们已经覆盖的 awk 实例,从 awk 系列的开始,你会注意到各种实例的所有指令是顺序执行的,即一个接一个地执行。但在某些情况下,我们可能希望基于一些条件进行文本过滤操作,即流程控制语句允许的那些语句。

在 awk 编程中有各种各样的流程控制语句,其中包括:
* if-else 语句
* for 语句
* while 语句
* do-while 语句
* break 语句
* continue 语句
* next 语句
* nextfile 语句
* exit 语句
然而,对于本系列的这一部分,我们将阐述:`if-else`、`for`、`while` 和 `do while` 语句。请记住,我们已经在这个 [awk 系列的第 6 部分](/article-7609-1.html)介绍过如何使用 awk 的 `next` 语句。
### 1. if-else 语句
如你想的那样。if 语句的语法类似于 shell 中的 if 语句:
```
if (条件 1) {
动作 1
}
else {
动作 2
}
```
在上述语法中,`条件 1` 和`条件 2` 是 awk 表达式,而`动作 1` 和`动作 2` 是当各自的条件得到满足时所执行的 awk 命令。
当`条件 1` 满足时,意味着它为真,那么`动作 1` 被执行并退出 `if 语句`,否则`动作 2` 被执行。
if 语句还能扩展为如下的 `if-else_if-else` 语句:
```
if (条件 1){
动作 1
}
else if (条件 2){
动作 2
}
else{
动作 3
}
```
对于上面的形式,如果`条件 1` 为真,那么`动作 1` 被执行并退出 `if 语句`,否则`条件 2` 被求值且如果值为真,那么`动作 2` 被执行并退出 `if 语句`。然而,当`条件 2` 为假时,那么`动作 3` 被执行并退出 `if 语句`。
这是在使用 if 语句的一个实例,我们有一个用户和他们年龄的列表,存储在文件 users.txt 中。
我们要打印一个清单,显示用户的名称和用户的年龄是否小于或超过 25 岁。
```
aaronkilik@tecMint ~ $ cat users.txt
Sarah L 35 F
Aaron Kili 40 M
John Doo 20 M
Kili Seth 49 M
```
我们可以写一个简短的 shell 脚本来执行上文中我们的工作,这是脚本的内容:
```
#!/bin/bash
awk ' {
if ( $3 <= 25 ){
print "User",$1,$2,"is less than 25 years old." ;
}
else {
print "User",$1,$2,"is more than 25 years old" ;
}
}' ~/users.txt
```
然后保存文件并退出,按如下方式使脚本可执行并运行它:
```
$ chmod +x test.sh
$ ./test.sh
```
输出样例
```
User Sarah L is more than 25 years old
User Aaron Kili is more than 25 years old
User John Doo is less than 25 years old.
User Kili Seth is more than 25 years old
```
### 2. for 语句
如果你想在一个循环中执行一些 awk 命令,那么 `for 语句`为你提供一个做这个的合适方式,格式如下:
```
for ( 计数器的初始化 ; 测试条件 ; 计数器增加 ){
动作
}
```
这里,该方法是通过一个计数器来控制循环执行来定义的,首先你需要初始化这个计数器,然后针对测试条件运行它,如果它为真,执行这些动作并最终增加这个计数器。当计数器不满足条件时,循环终止。
在我们想要打印数字 0 到 10 时,以下 awk 命令显示 for 语句是如何工作的:
```
$ awk 'BEGIN{ for(counter=0;counter<=10;counter++){ print counter} }'
```
输出样例
```
0
1
2
3
4
5
6
7
8
9
10
```
### 3. while 语句
while 语句的传统语法如下:
```
while ( 条件 ) {
动作
}
```
这个`条件`是一个 awk 表达式而`动作`是当条件为真时被执行的 awk 命令。
下面是一个说明使用 `while` 语句来打印数字 0 到 10 的脚本:
```
#!/bin/bash
awk ' BEGIN{ counter=0;
while(counter<=10){
print counter;
counter+=1;
}
}'
```
保存文件并使脚本可执行,然后运行它:
```
$ chmod +x test.sh
$ ./test.sh
```
输出样例
```
0
1
2
3
4
5
6
7
8
9
10
```
### 4. do while 语句
它是上文中 `while` 语句的一个变型,具有以下语法:
```
do {
动作
}
while (条件)
```
这轻微的区别在于,在 `do while` 语句下,awk 的命令在求值条件之前执行。使用上文 `while` 语句的例子,我们可以通过按如下所述修改 test.sh 脚本中的 awk 命令来说明 `do while` 语句的用法:
```
#!/bin/bash
awk ' BEGIN{ counter=0;
do{
print counter;
counter+=1;
}
while (counter<=10)
}'
```
修改脚本之后,保存文件并退出。按如下方式使脚本可执行并执行它:
```
$ chmod +x test.sh
$ ./test.sh
```
输出样例
```
0
1
2
3
4
5
6
7
8
9
10
```
### 总结
这不是关于 awk 的流程控制语句的一个全面的指南,正如我早先提到的,在 awk 里还有其他几个流程控制语句。
尽管如此,awk 系列的这一部分使应该你明白了一个明确的基于某些条件控制的 awk 命令是如何执行的基本概念。
你还可以了解其余更多的流程控制语句以获得更多关于该主题的理解。最后,在 awk 的系列下一节,我们将进入编写 awk 脚本。
---
via: <http://www.tecmint.com/use-flow-control-statements-with-awk-command/> 作者:[Aaron Kili](http://www.tecmint.com/author/aaronkili/) 译者:[robot527](https://github.com/robot527) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux 中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,726 | 如何在 nginx 中缓存静态文件 | https://www.howtoforge.com/tutorial/how-to-cache-static-files-on-nginx/ | 2016-08-28T17:42:00 | [
"缓存",
"静态文件",
"Nginx"
] | https://linux.cn/article-7726-1.html | 这篇教程说明你应该怎样配置 nginx、设置 HTTP 头部过期时间,用 Cache-Control 中的 max-age 标记为静态文件(比如图片、 CSS 和 Javascript 文件)设置一个时间,这样用户的浏览器就会缓存这些文件。这样能节省带宽,并且在访问你的网站时会显得更快些(如果用户第二次访问你的网站,将会使用浏览器缓存中的静态文件)。

### 1、准备事项
我想你需要一个正常工作的 nginx 软件,就像这篇教程里展示的:[在 Ubuntu 16.04 LTS 上安装 Nginx,PHP 7 和 MySQL 5.7 (LEMP)](/article-7551-1.html)。
### 2 配置 nginx
可以参考 [expires](http://nginx.org/en/docs/http/ngx_http_headers_module.html#expires) 指令手册来设置 HTTP 头部过期时间,这个标记可以放在 `http {}`、`server {}`、`location {}` 等语句块或者 `location {}` 语句块中的条件语句中。一般会在 `location` 语句块中用 `expires` 指令控制你的静态文件,就像下面一样:
```
location ~* \.(jpg|jpeg|png|gif|ico|css|js)$ {
expires 365d;
}
```
在上面的例子中,所有后缀名是 `.jpg`、 `.jpeg`、 `.png`、 `.gif`、 `.ico`、 `.css` 和 `.js` 的文件会在浏览器访问该文件之后的 365 天后过期。因此你要确保 `location {}` 语句块仅仅包含能被浏览器缓存的静态文件。
然后重启 nginx 进程:
```
/etc/init.d/nginx reload
```
你可以在 `expires` 指令中使用以下的时间设置:
* `off` 让 `Expires` 和 `Cache-Control` 头部不能被更改。
* `epoch` 将 `Expires` 头部设置成 1970 年 1 月 1 日 00:00:01。
* `max` 设置 `Expires` 头部为 2037 年 12 月 31 日 23:59:59,设置 `Cache-Control` 的最大存活时间为 10 年
* 没有 `@` 前缀的时间意味着这是一个与浏览器访问时间有关的过期时间。可以指定一个负值的时间,就会把 Cache-Control 头部设置成 no-cache。例如:`expires 10d` 或者 `expires 14w3d`。
* 有 `@` 前缀的时间指定在一天中的某个时间过期,格式是 Hh 或者 Hh:Mm,H 的范围是 0 到 24,M 的范围是 0 到 59,例如:`expires @15:34`。
你可以用以下的时间单位:
* `ms`: 毫秒
* `s`: 秒
* `m`: 分钟
* `h`: 小时
* `d`: 天
* `w`: 星期
* `M`: 月 (30 天)
* `y`: 年 (365 天)
例如:`1h30m` 表示一小时三十分钟,`1y6M` 表示一年六个月。
注意,要是你用一个在将来很久才会过期的头部,当组件修改时你就要改变组件的文件名。因此给文件指定版本是一个不错的方法。例如,如果你有个 javascript.js 文件 并且你要修改它,你可以在修改的文件名字后面添加一个版本号。这样浏览器就要下载这个文件,如果你没有更改文件名,浏览器将从缓存里面加载(旧的)文件。
除了把基于浏览器访问时间设置 `Expires` 头部(比如 `expires 10d`)之外,也可以通过在时间前面的 `modified` 关键字,将 `Expires` 头部的基准设为文件修改的时间(请注意这仅仅对存储在硬盘的实际文件有效)。
```
expires modified 10d;
```
### 3 测试
要测试你的配置是否有效,可以用火狐浏览器的开发者工具中的网络分析功能,然后用火狐访问一个静态文件(比如一张图片)。在输出的头部信息里,应该能看到 `Expires` 头部和有 `max-age` 标记的 `Cache-Control` 头部(`max-age` 标记包含了一个以秒为单位的值,比如 31536000 就是指今后的一年)

### 4 链接
nginx 的 Http 头部模块(HttpHeadersModule): <http://wiki.nginx.org/HttpHeadersModule>
---
via: <https://www.howtoforge.com/tutorial/how-to-cache-static-files-on-nginx/>
作者:[Falko Timme](https://www.howtoforge.com/tutorial/how-to-cache-static-files-on-nginx/) 译者:[GitFuture](https://github.com/GitFuture) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | # How to cache static files on nginx
This tutorial explains how you can configure nginx to set the Expires HTTP header and the max-age directive of the Cache-Control HTTP header of static files (such as images, CSS and Javascript files) to a date in the future so that these files will be cached by your visitors' browsers. This saves bandwidth and makes your web site appear faster (if a user visits your site for a second time, static files will be fetched from the browser cache).
## 1 Preliminary Note
I'm assuming you have a working nginx setup, e.g. as shown in this tutorial: [Installing Nginx with PHP 7 and MySQL 5.7 (LEMP) on Ubuntu 16.04 LTS](https://www.howtoforge.com/tutorial/installing-nginx-with-php7-fpm-and-mysql-on-ubuntu-16.04-lts-lemp/)
## 2 Configuring nginx
The Expires HTTP header can be set with the help of the [expires](http://nginx.org/en/docs/http/ngx_http_headers_module.html#expires) directive which can be placed in inside http {}, server {}, location {}, or an if statement inside a location {} block. Usually you will use it in a location block for your static files, e.g. as follows:
location ~* \.(jpg|jpeg|png|gif|ico|css|js)$ {
expires 365d;
}
In the above example, all .jpg, .jpeg, .png, .gif, .ico, .css, and .js files get an Expires header with a date 365 days in the future from the browser access time. Therefore, you should make sure that the location {} block really only contain static files that can be cached by browsers.
Reload nginx after your changes:
/etc/init.d/nginx reload
You can use the following time settings with the expires directive:
- off makes that the Expires and Cache-Control headers will not be modified.
- epoch sets the Expires header to 1 January, 1970 00:00:01 GMT.
- max sets the Expires header to 31 December 2037 23:59:59 GMT, and the Cache-Control max-age to 10 years.
- A time without an @ prefix means an expiry time relative to the browser access time. A negative time can be specified, which sets the Cache-Control header to no-cache. Example: expires 10d; or expires 14w3d;
- A time with an @ prefix specifies an absolute time-of-day expiry, written in either the form Hh or Hh:Mm, where H ranges from 0 to 24, and M ranges from 0 to 59. Exmaple: expires @15:34;
You can use the following time units:
- ms: milliseconds
- s: seconds
- m: minutes
- h: hours
- d: days
- w: weeks
- M: months (30 days)
- y: years (365 days)
Examples: 1h30m for one hour thirty minutes, 1y6M for one year and six months.
Also note that if you use a far future Expires header you have to change the component's filename whenever the component changes. Therefore it's a good idea to version your files. For example, if you have a file javascript.js and want to modify it, you should add a version number to the file name of the modified file (e.g. javascript-1.1.js) so that browsers have to download it. If you don't change the file name, browsers will load the (old) file from their cache.
Instead of basing the Expires header on the access time of the browser (e.g. expires 10d;), you can also base it on the modification date of a file (please note that this works only for real files that are stored on the hard drive!) by using the modified keyword which precedes the time:
expires modified 10d;
## 3 Testing
To test if your configuration works, you can use the Network analysis function of the Developer tools in the Firefox Browser and access a static file through Firefox (e.g. an image). In the Header output, you should now see an Expires header and a Cache-Control header with a max-age directive (max-age contains a value in seconds, for example 31536000 is one year in the future):
## 4 Links
- nginx HttpHeadersModule:
[http://wiki.nginx.org/HttpHeadersModule](http://wiki.nginx.org/HttpHeadersModule)
**About The Author**
Falko Timme is the owner of [Timme Hosting](https://timmehosting.de/) (ultra-fast nginx web hosting). He is the lead maintainer of HowtoForge (since 2005) and one of the core developers of
[ISPConfig](http://www.ispconfig.org/)(since 2000). He has also contributed to the O'Reilly book "Linux System Administration". |
7,727 | DevOps 的弹性合作 | http://devops.com/2016/05/16/scaling-collaboration-devops/ | 2016-08-29T10:54:12 | [
"DevOps"
] | https://linux.cn/article-7727-1.html | 
那些熟悉 DevOps 的人通常认为与其说 DevOps 是一种技术不如说是一种文化。在 DevOps 的有效实践上需要一些特定的工具和经验,但是 DevOps 成功的基础在于企业内如何做好[团队和个体协作](http://devops.com/2014/12/15/four-strategies-supporting-devops-collaboration/),从而可以让事情更快、更高效而有效的完成。
大多数的 DevOps 平台和工具都是以可扩展性为设计理念的。DevOps 环境通常运行在云端,并且容易发生变化。对于DevOps 软件来说,支持实时伸缩以解决冲突和摩擦是重要的。这同样对于人的因素也是一样的,但弹性合作却是完全不同的。
跨企业协同是 DevOps 成功的关键。好的代码和开发最终需要形成产品才能给用户带来价值。公司所面临的挑战是如何做到无缝衔接和尽可能的提高速度及自动化水平,而不是牺牲质量或性能。企业如何才能流水线化代码的开发和部署,同时保持维护工作的明晰、可控和合规?
### 新兴趋势
首先,我先提供一些背景,分享一些 [451 Research](https://451research.com/) 在 DevOps 及其常规应用方面获取的数据。云、敏捷和Devops 的能力在今天是非常重要的,不管是理念还是现实。451 研究公司发现采用这些东西以及容器技术的企业在不断增多,包括在生产环境中的大量使用。
拥抱这些技术和方式有许多优点,比如提高灵活性和速度,降低成本,提高适应能力和可靠性,适应新的或新兴的应用。据 451 Research 称,团队也面临着一些障碍,包括缺乏熟悉其中所需的技能的人、这些新兴技术的不成熟、成本和安全问题等。
在 “[Voice of the Enterprise: SDI Q4 2015 survey](https://451research.com/)” 报告中,451 Research 发现超过一半的受访者(57.1%)考虑他们稍晚些再采用,甚至会最后才采用这些新技术。另一方面,近半受访者(48.3 %)认为自己是率先或早期的采用者。
这些普遍性的情绪也表现在对其他问题的调查中。当问起容器的执行情况时,50.3% 的人表示这根本不在他们的计划中。剩下 49.7% 的人则是在计划、试点或积极使用容器技术。近 2/3(65.1%)的人表示,他们用敏捷开发方式来开发应用,但是只有 39.6% 的人回应称他们正在积极拥抱 DevOps。然而,敏捷软件开发已经在行业内存在了多年,451 Research 注意到容器和 Devops 的采用率显著提升,这是一个新的趋势。
当被问及首要的三个 IT 痛点是什么,被提及最多的是成本或预算、人员不足和遗留软件问题。随着企业向云、DevOps、和容器等转型,这些问题都需要加以解决,以及如何规划技术和有效协作。
### 当前状况
软件行业正处于急剧变化之中,这很大程度是由 DevOps 所推动的,它使得软件开发变得越来越横跨整个业务高度集成。软件的开发变得不再闭门造车,而越来越体现协作和社交化的功能。
几年还是在小说和展板中的理念和方法迅速成熟,成为了今天推动价值的主流技术和框架。企业依靠如敏捷、精益、虚拟化、云计算、自动化和微服务等概念来简化开发,同时使工作更加有效和高效。
为了适应和发展,企业需要完成一系列的关键任务。当今面临的挑战是如何加快发展的同时降低成本。团队需要消除 IT 和其他业务之间存在的障碍,并在一个由技术驱动的竞争环境中提供更多有效的战略合作。
敏捷、云计算、DevOps 和容器在这个过程中起着重要的作用,而将它们连接在一起的是有效的合作。每一种技术和方法都提供了独特的优势,但真正的价值来自于团队作为一个整体能够进行规模协同,以及团队所使用的工具和平台。成功的 DevOps 的实现也需要开发和 IT 运营团队之外其他利益相关者的参与,包括安全、数据库、存储和业务队伍。
### 合作即平台
有一些在线的服务和平台,比如 Github 促进和增进了协作。这个在线平台的功能是一个在线代码库,但是所产生的价值远超乎存储代码。
这样一个[协作平台](http://devops.com/events/analytics-of-collaboration-on-github/)之所以有助于开发人员和团队合作,是因为它提供了一个可以分享和讨论代码和流程的社区。管理者可以监视进度和跟踪将要发布的代码。开发人员在将实验性的想法放到实际的产品环境中之前,可以在一个安全的环境中进行实验,新的想法和实验可以有效地与适当的团队进行沟通。
更加敏捷的开发和 DevOps 的关键之一是允许开发人员测试一些东西并快速收集相关的反馈。目标是生产高质量的代码和功能,而不是浪费时间建立和管理基础设施或者安排更多的会议来讨论这个问题。比如 GitHub 平台,能够更有效的和可扩展的协作是因为当参与者想要进行代码审查时很方便。不需要尝试协调和安排代码审查会议,所以开发人员可以继续工作而不被打断,从而产生更大的生产力和工作满意度。
Sendachi 的 Steven Anderson 指出,Github 是一个协作平台,但它也是一个和你一起工作的工具。这样意味着它不仅可以帮助协作和持续集成,还影响了代码质量。
合作平台的好处之一是,大型团队的开发人员可以分解成更小的团队,可以更有效地专注于特定的组件。它还提供了诸如文件共享这样的代码之外的功能,模糊了技术和非技术的贡献,增加了协作和可见性。
### 合作是关键
合作的重要性不言而喻。合作是 DevOps 文化的关键,也是在当今世界能够进行敏捷开发并保持竞争优势的决定因素。执行或管理支持以及内部传道是很重要的。团队还需要拥抱文化的转变---迈向共同目标的跨职能部门的技能融合。
要建立起来这样的文化,有效的合作是至关重要的。一个合作平台是弹性合作的必要组件,因为简化了生产活动,并且减少了冗余和尝试,同时还产生了更高质量的结果。
---
via: <http://devops.com/2016/05/16/scaling-collaboration-devops/>
作者:[TONY BRADLEY](http://devops.com/author/tonybsg/) 译者:[Bestony](https://github.com/Bestony) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
7,728 | 爱 Vim 的七个理由 | https://opensource.com/business/16/8/7-reasons-love-vim | 2016-08-29T15:42:00 | [
"编辑器",
"vi",
"vim"
] | https://linux.cn/article-7728-1.html | 
当我刚刚开始用 vi 文本编辑器的时候,我憎恨它!我认为这是有史以来设计上最痛苦和反人类的编辑器。但我还是决定我必须学会它,因为如果你使用的是 Unix,vi 无处不在并且是唯一一个保证你可以使用的编辑器。在 1998 年是如此,但是直到今天 vi 也仍然是可用的,现有的几乎每个发行版中,vi 基本上都是基础安装的一部分。
在我学会能使用任何功能前,我已经在 vi 上花费差不多 1 个月的时间,但是我仍然不喜欢它。不过那时我已经意识到有个强大的编辑器隐藏在这个古怪的外表后面。所以我坚持使用它,并且最终发现一旦你知道你在干什么,它就是一个快的令人难以置信的编辑器。
“vi” 这个名称是 “<ruby> 可视 <rp> ( </rp> <rt> visual </rt> <rp> ) </rp></ruby>” 的缩写。在 vi 出现的时候,行编辑器是很普遍的,能一次性显示并编辑多个行是非同寻常的。Vim,来自“Vi IMproved”的缩写,最初由 Bram Moolenaar 发布于 1991 年,它成为了主要的仿 vi 软件,并且扩展了这个强大的编辑器已有的功能。Vim 强大的正则表达式和“:”命令行语法开始于行编辑和电传打字机时代。
Vim,有 40 年的历史了,有足够的时间发展出海量而复杂的技巧,即使是懂得最多的用户都不能完全掌握它。这里列出了一些爱 Vim 的理由:
1. 配色方案:你可能知道 Vim 有彩色语法高亮。但你知道可以下载数以百计的配色方案么?[在这找到些更好的](http://www.gilesorr.com/blog/vim-colours.html)。
2. 你再也不需要让你的手离开键盘或者去碰触鼠标。
3. Vi 或者 Vim 存在任何地方,甚至在 [OpenWRT](https://www.openwrt.org/) 里面也有 vi(好吧,其实是在 [BusyBox](https://busybox.net/)中,它挺好用的)。
4. Vimscript:你可能会想重映射几个键,但是你知道 Vim 有自己的编程语言么?你可以重新定义你的编辑器的行为,或者创造特定语言的编辑器扩展。(最近我在定制 Vim 用于 Ansible 的行为。)学习这个语言最佳的切入点是看 Steve Losh 著名的书《[Learn Vimscript the Hard Way](http://learnvimscriptthehardway.stevelosh.com/)》。
5. Vim 有插件。使用 [vundle](https://github.com/VundleVim/Vundle.vim)(我用的就是它)或者 [Pathogen](https://github.com/tpope/vim-pathogen) 来管理你的插件来提升 Vim 的功能。
6. 插件可以将 git(或者你选择的 VCS)集成到 Vim 中。
7. 有庞大而活跃的线上社区,如果你在线上提问关于 Vim 的问题,肯定会有人回答。
我一开始讨厌 vi 的可笑之处在于,这 5 年来不断的在尝试新的编辑器中碰壁,总是想找到“一些更好的”。我从来没有像讨厌 vi 一样讨厌过其它的编辑器,现在我已经使用它 17 年了,因为我想象不出一个更好的编辑器。额,或许有稍微好一点的:可以尝试下 Neovim -这是未来的主流。看起来 Bram Moolenaar 将会把 Neovim 的大部分融入到 Vim 第 8 版中,这意味着将会在现有的代码基础上减少 30%、更好的代码补全功能、真正的异步、内置终端、内置鼠标支持、完全兼容。
*在本文作者在多伦多的 [LinuxCon 演讲](http://sched.co/7JWz)中(LCTT 译注:LinuxCon 是 Linux 基金会举办的年度会议),他解释了一些在你可能错过的、过去四十年增加的杂乱的扩展和改进。这个内容不适合初学者,所以如果你不知道为什么“hjklia:wq”是很重要的,这就可能不是讲给你听的。它还会涉及一点关于 vi 的历史,因为知道一些历史能帮助我们理解我们的处境。关注他的演讲能让你知道如何使你最喜欢的编辑器更好更快。*
---
via: <https://opensource.com/business/16/8/7-reasons-love-vim>
作者:[Giles Orr](https://opensource.com/users/gilesorr) 译者:[hkurj](https://github.com/hkurj) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | When I started using the vi text editor, I hated it. I thought it was the most painful and counter-intuitive editor ever designed. But I'd decided I had to learn the thing, because if you're using Unix, vi was everywhere and was the only editor you were guaranteed to have access to. That was back in 1998, but it remains true today—vi is available, usually as part of the base install, on almost every Linux distribution in existence.
It took about a month before I could do anything with any proficiency in vi and I still didn't love it, but by then I'd realized that there was an insanely powerful editor hiding behind this bizarre facade. So I stuck with it, and eventually found out that once you know what you're doing, it's an incredibly fast editor.
The name "vi" is short for "visual." When vi originated, line editing was the norm and being able to display and edit multiple lines at once was unusual. Vim, a contraction of "Vi IMproved" and originally released by Bram Moolenaar in 1991, has become the dominant vi clone and continued to extend the capabilities of an already powerful editor. Vim's powerful regex and ":" command-line syntax started in the world of line editing and teletypes.
Vim, with its 40 years of history, has had time to develop a massive and complex bag of tricks that even the most knowledgeable users don't fully grasp. Here are a few reasons to love Vim:
- Colour schemes: You probably know Vim has colour syntax highlighting. Did you know you can download literally hundreds of colour schemes?
[Find some of the better ones here](http://www.gilesorr.com/blog/vim-colours.html). - You never need to take your hands off the keyboard or reach for the mouse.
- Vi or Vim is everywhere. Even
[OpenWRT](https://www.openwrt.org/)has vi (okay, it's[BusyBox](https://busybox.net/), but it works). - Vimscript: You've probably remapped a few keys, but did you know that Vim has its own programming language? You can rewrite the behaviour of your editor, or create language-specific editor extensions. (Recently I've spent time customizing Vim's behaviour with Ansible.) The best entry point to the language is Steve Losh's brilliant
.[Learn Vimscript the Hard Way](http://learnvimscriptthehardway.stevelosh.com/) - Vim has plugins. Use
[Vundle](https://github.com/VundleVim/Vundle.vim)(my choice) or[Pathogen](https://github.com/tpope/vim-pathogen)to manage your plugins to improve Vim's capabilities. - Plugins to integrate git (or your VCS of choice) into Vim are available.
- The online community is huge and active, and if you ask your question about Vim online, it will be answered.
The irony of my original hatred of vi is that I'd been bouncing from editor to editor for five years, always looking for "something better." I never hated any editor as much as I hated vi, and now I've stuck with it for 17 years because I can no longer imagine a better editor. Well, maybe a little better: Go try [Neovim](https://neovim.io/)—it's the future. It looks like Bram Moolenaar will be merging most of Neovim into Vim version 8, which will mean a 30% reduction in the code base, better tab completion, real async, built-in terminal, built-in mouse support, and complete compatibility.
*In his LinuxCon talk in Toronto, Giles will explain some of the features you may have missed in the welter of extensions and improvements added in the past four decades. The class isn't for beginners, so if you don't know why "hjklia:wq" are important, this probably isn't the talk for you. He'll also cover a bit about the history of vi, because knowing some history helps to understand how we've ended up where we are now. Attend his talk to find out how to make your favourite editor better and faster.*
## 13 Comments |
7,729 | Linux 历史上 25 个里程碑事件回顾 | http://www.zdnet.com/pictures/the-25-biggest-events-in-linuxs-25-year-history/ | 2016-08-30T11:28:00 | [
"Linux",
"历史"
] | https://linux.cn/article-7729-1.html | 
*Linus Torvalds 和他的朋友们*
虽然对 Linux 正式生日是哪天还有些争论,甚至 Linus Torvalds 认为在 1991 那一年有四个日子都可以算作 Linux 的生日。但是不管怎么说,Linux 已经 25 岁了,这里我们为您展示一下这 25 年来发生过的 25 件重大里程碑事件。
### 1991:Linus Torvalds 向世界宣告 Linux 诞生

这封邮件是 1991 年 8 月 25 日 Linus 发在 Minix Usenet 新闻组的,这个日期通常被认为是 Linux 的生日。那时候 Linus 还没有什么名气,他说它的新操作系统“只是一个兴趣,并不想着像 GNU for 386(486) AT 那么庞大和专业。”
### 1992:第一次 Linux 之战

Andrew Tannenbaum 是一位操作系统专家,也是当时著名的 [Minix](http://www.minix3.org/) 操作系统的作者,这是一个用于教学用途的 Unix 版本。Andrew 声称 “[LINUX 是过时的](http://www.linfo.org/obsolete.html)”,从而打响了 Linux 的第一次操作系统之战。在由此而来的论战中,Linus 发表了一个至今看起来仍然正确的观点,“如果 GNU 内核(指 Hurd,这是另外一个尝试建立自由的类 Unix 操作系统的项目)去年春天就已经好了的话,我绝不会启动我的项目:事实上它根本没有完成,估计永远也完成不了。Linux 能胜出的很大原因就在于它现在就能用!”
### 1993:Slackware Linux

这时已经有了一些早期的 Linux 发行版,比如 MCC 和 Yggdrasil Linux,但是 Patrick Volkerding 的 [Slackware](http://www.slackware.com/) 其中最成功的一个,而且直到今天它仍然在不断更新和有人使用。
### 1993:Debian Linux 项目启动

最流行的社区版 Linux:[Debian Linux](https://www.debian.org/) 项目启动了。今天,它是 Mint、Ubuntu 以及许许多多的流行的 Linux 发行版的上游发行版。
### 1994:Red Hat Linux 诞生

Marc Ewing 创建了 Red Hat Linux 公司,随后 Bob Young 买下了 Ewing 的公司,并与他自己的公司合并,重组为 [Red Hat](http://www.redhat.com/)——这是当今最成功的 Linux 公司。
### 1995:Linux 大会召开

Linux 召开了其首次商业会议 Linux Expo。今天 Linux 方面的大会越来越多了,仅在美国每年就会召开十多场全球性或地区性的 Linux 会议。
### 1996:KDE

第一个主流 Linux 桌面系统 [KDE](http://www.kde.org/) 项目启动。
### 1996:SUSE 公司创建

同年,继 Slackware 和 Red Hat Linux 之后,[SUSE](http://www.suse.com/) 这个来自欧洲的 Linux 公司发布了其首个独立的 Linux 发行版。
### 1997:GNOME

[GNOME 桌面](http://www.gnome.org/)项目启动。今天,它和 KDE 成为了 Linux 上最重要的两个桌面系统。
### 1998:万圣节备忘录

微软开始敌视 Linux。Eric S. Raymond 是一位早期的 Linux 及开源领袖,他披露了这份[万圣节备忘录](http://www.catb.org/~esr/halloween/halloween1.html)),其中展示了微软视 Linux 为重大威胁,开始制定它的反开源战略和反对 Linux 的活动。然而还不到十年,微软就改变了初衷。
### 1999:Corel Linux 桌面

[Corel 发布了其第一个主流 Linux 桌面](http://practical-tech.com/operating-system/corel-puts-a-penguin-the-desktop/293/?preview=true&preview_id=293&preview_nonce=a618c6de4b)。虽然没有成功,但是它为其它流行的 Linux 桌面发行版指明了道路,比如 Ubuntu。
### 1999:Linux 与 Windows 的服务器之争

[Linux 与 Windows NT 首次在文件服务器方面展开竞争,Linux 获胜。](http://practical-tech.com/infrastructure/linux-up-close-time-to-switch/9) Linux 与 Windows 服务器操作系统之间的战争开始了。
### 2000:IBM 为 Linux 投资 10 亿美金

2000 年的时候,IBM 宣布将在下一年对 Linux 投资 10 亿美金。这已经被证明是 IBM 有史以来最明智的投资。
### 2001:Linux 2.4 发布

经过了几次延期之后, [Linux 2.4 发布了](http://practical-tech.com/operating-system/linux-2-4-its-here/2405/)。随着这个版本,Linux 成为了可以与 Solaris 和其它的高端服务器操作系统相提并论的操作系统了。
### 2003:SCO Linux 战争开始

由 SCO Unix 公司和 Caldera Linux 公司组成的 SCO 公司开始翻 Linux 的旧账,起诉 IBM 和其它公司,指控 Linux 抄袭 Unix。虽然这个公司最终破产,但这场官司困扰了 Linux 的商业发展很多年。
### 2004:Ubuntu 来了

[Ubuntu](http://www.ubuntu.com/) 创建!它架构于 [Debian Linux](http://www.debian.org/) 之上,Ubuntu 成为了一个非常流行的 Linux 桌面操作系统,同时也是最重要的云端 Linux 发行版之一。
### 2004:Linux 统治超级计算机

世界上最快的超级计算机中超过半数运行着 Linux。而到了 2016 年,仅有少数超级计算机没有运行 Linux。
### 2005:大企业拥抱 Linux

任何对 Linux 成为主流的怀疑都被 Linus Torvalds 出现在《商业周刊》封面上所击碎。头条?显然是 Linux Inc. 。
### 2007:Android 出现

由谷歌和一些硬件厂商组成的[开放手机联盟](http://www.openhandsetalliance.com/)发布了 Android。它现在已经成为了最流行的终端用户操作系统,运行在超过 10 亿的智能电话上。
### 2008:证券交易所换到了 Linux 上

纽约证券交易所和世界上许多著名的证券交易所一样切换到了 Linux 上,将其作为核心操作系统。Linux 没有变成大企业,但是成了巨大的业务。
### 2011:Watson 赢了 Jeopardy

[IBM 的 Watson 计算机运行在 Linux 上](http://www.zdnet.com/blog/open-source/what-makes-ibms-watson-run/8208),赢得了 Jeopardy 智力挑战,为智能专家系统订立了新的标准。
### 2011: Chromebook 兴起

谷歌发布了第一台 Chromebook: CR-48。它运行着[基于 Gentoo-Linux 的 ChromeOS](http://www.zdnet.com/article/the-secret-origins-of-googles-chrome-os/)。到 2015,[Chromebook 的销售额已经超过了运行着 Windows 的笔记本](http://www.zdnet.com/article/npd-chromebooks-outsell-windows-laptops/)。
### 2012:云运行在 Linux 上

IT 基础设施从服务器和数据中心移动到了云端,而[云运行在 Linux 上](/article-7589-1.html)。即使是在微软 Azure 上,2016 年的时候[超过 1/3 的虚拟机运行在 Linux 上](/article-7589-1.html)。
### 2012:Red Hat 营收首次达到 10 亿美金

[Red Hat 成为第一家年收入达 10 亿美金的开源公司](http://www.zdnet.com/article/red-hat-the-first-billion-dollar-linux-company-has-arrived/http://www.zdnet.com/article/red-hat-the-first-billion-dollar-linux-company-has-arrived/)。而在 2016,它成为首家达到 20 亿美金的 Linux 公司。
### 2014:微软爱 Linux

谁说豹子不能没有斑点的?微软新任 CEO Satya Nadella 说,[微软爱 Linux](http://www.zdnet.com/article/why-microsoft-loves-linux/)。这个公司通过在他们的云端和公司内部支持 Linux 和开源软件证明真爱。
| 301 | Moved Permanently | null |
7,730 | 25 个你可能不知道的 Linux 真相 | https://medium.freecodecamp.com/linux-is-25-yay-lets-celebrate-with-25-rad-facts-about-linux-c8d8ac30076d | 2016-08-31T10:21:00 | [
"Linux"
] | https://linux.cn/article-7730-1.html | 
25 年前,一个芬兰的大学生在一个[邮件列表](https://groups.google.com/forum/#!topic/comp.os.minix/dlNtH7RRrGA%5B1-25%5D)中分享了他的项目:
>
> From: [email protected] (Linus Benedict Torvalds)
> Newsgroups: comp.os.minix
> Subject: What would you like to see most in minix?
> Summary: small poll for my new operating system
> Message-ID: <[email protected]>
> Date: 25 Aug 91 20:57:08 GMT
> Organization: University of Helsinki
>
>
> Hello everybody out there using minix —
>
>
> I’m doing a (free) operating system (just a hobby, won’t be big and
> professional like gnu) for 386(486) AT clones. This has been brewing
> since april, and is starting to get ready. I’d like any feedback on
> things people like/dislike in minix, as my OS resembles it somewhat
> (same physical layout of the file-system (due to practical reasons)
> among other things).
>
>
> I’ve currently ported bash(1.08) and gcc(1.40), and things seem to work.
> This implies that I’ll get something practical within a few months, and
> I’d like to know what features most people would want. Any suggestions
> are welcome, but I won’t promise I’ll implement them :-)
>
>
> Linus (torv…@kruuna.helsinki.fi)
>
>
> PS. Yes — it’s free of any minix code, and it has a multi-threaded fs.
> It is NOT protable (uses 386 task switching etc), and it probably never
> will support anything other than AT-harddisks, as that’s all I have :-(.
>
>
>
“就是个个人爱好”,他说,“不会像 gnu 那样庞大而专业。”
这个孩子并不知道他的操作系统将永远的改变了软件世界。
今天,Linux 统治了服务器操作系统。它也是 Android 的基础——统治了手机操作系统。而且,它还是 100% 自由而开源的。
让我们回溯时光,看看 Linux 这 25 年来的 25 个少为人知的真相:
**真相 1:**在这个 [Linux 基金会的协作项目](http://collabprojects.linuxfoundation.org/)里有 1.15 亿行代码。而与之相比,Windows XP 只有 [0.45 亿行代码](https://www.facebook.com/windows/posts/155741344475532)。
**真相 2:**Linux 内核项目是世界上最活跃的开源项目。它平均每天会接受 185 个补丁。
**真相 3:**每年大约有 4.1 万人参与开发 Linux,如果要给他们发薪水的话,差不多每年需要 50 亿美金。
**真相 4:**Linux 基金会为了让 Linus Torvalds 继续开发 Linux,每年给他发 1000 万美金的薪水。他的净资产已达 1.5 亿美金。
**真相 5:**尽管加起来有这么多的钱,还有那么多运行在 Linux 上的系统, 但是 Linus 仍然工作在家里,哦,还有他的猫在陪着他。下图是他在他的站立式工作桌前工作的照片:

**真相 6:**在 Linus 还在芬兰军队服役时,他那时从事弹道计算,他买了一本 Andrew Tanenbaum 的《[操作系统:设计与实现](http://amzn.to/2bQyDGB)》。那本书介绍了 Minix ,这是一个用于教育用途的简化版 Unix,正是这本书开启了 Linus 的 Unix 思想之路。
**真相 7:**虽然 Linux 的第一版全是由 Linus 写就的,但是他最初的贡献仅占今天全部的代码的不到 1%。他说他现在忙于合并代码而没空自己写代码了。
> 我没有一个五年计划,也没有登月计划。我很高兴我周围的人可以看着星星说“我要去那里!”,但是我会看着脚底下,把那些我前行时会掉进去的坑填上。
> —— Linus Torvalds
**真相** **8:**其它的软件界著名人物,比如比尔盖茨、扎克伯格都放弃了他们的学业而投身于事业之中。而 Linus 不仅在 Linux 取得了一定成功之后继续上学,而且一直念到了硕士毕业。
**真相 9:**虽然 Linus 创造了 Git,但是他从不通过 GitHub [接受补丁](http://www.wired.com/2012/05/torvalds_github/),即便 Linux 也放在 GitHub 上,而且有[多达 35000 个星](https://github.com/torvalds/linux)!
**真相 10:**Linux 的吉祥物是一个名为 “Tux” 的企鹅:

**真相 11:**来自各行各业的公司的开发者们给 Linux 贡献了代码,以下是按贡献进行的排名:
| | | |
| --- | --- | --- |
| **公司** | **变更数量** | **占总数比例** |
| 英特尔 | 14384 | 12.9% |
| 红帽 | 8987 | 8.0% |
| “无” | 8571 | 7.7% |
| “未知” | 7582 | 6.8% |
| Linaro | 4515 | 4.0% |
| 三星 | 4338 | 3.9% |
| SUSE | 3619 | 3.2% |
| IBM | 2995 | 2.7% |
| Consultants | 2938 | 2.6% |
| Renesas Electronics | 2239 | 2.0% |
**真相 12:**世界上 97% 的超级计算机[运行在 Linux 上](http://www.zdnet.com/article/linux-dominates-supercomputers-as-never-before/),包括 NASA 的集群。
**真相 13:**SpaceX 在其 Merlin 火箭引擎中使用了一个特殊的容错设计的 Linux,帮助完成了 [32 次空间任务](http://www.spacex.com/missions)。
**真相 14:**2009 年德国慕尼黑政府从 Windows 切换到了 Linux。他们声称在软件许可证费用上大约节约了 1000 万欧元。不过这个切换让他们在[生产效率方面损失](http://www.techrepublic.com/article/after-three-years-of-linux-munich-reveals-draft-of-crunch-report-that-could-decide-its-open-source/)不小。
**真相 15:**Linux 可以运行在仅售 5 美元的微型树莓派计算机上。

**真相 16:**Linux 已经成为世界之王了吗?《泰坦尼克号》是首部使用 Linux 服务器制作的大片。
**真相 17:**虽然视频游戏开发商 Valve 的创始人 Gabe Newell 公开宣称他认为 Linux 是游戏的未来,但是他的公司基于 Linux 的 Steam Machine 游戏机却失败了。相比 2010 年,[使用 Linux 玩游戏的人](https://en.wikipedia.org/wiki/Linux_gaming#Adoption_by_game_engines)更少了。
**真相 18:**Dronecode 是一个 [Linux 无人机项目](https://www.dronecode.org/)。大约有一千家公司在这个系统的基础上开发他们的无人机产品。
**真相 19:**丰田和猎豹计划将来在他们的汽车中使用 [汽车级 Linux(AGL)](https://www.automotivelinux.org/)。
**真相 20:**Linux 有很多发行版,大多数发行版都是基于别的发行版的。最流行的发行版是 Ubuntu,它是基于 Debian 的。
**真相 21:**Red Hat 是一家开发针对企业的 Linux 发行版的公司。它是开源软件领域最大的公司,今年[准备达成营收 50 亿美元的目标](https://techcrunch.com/2016/06/21/as-red-hat-aims-for-5-billion-in-revenue-linux-wont-be-only-driver/)。
**真相 22:**Linux 并不一定需要图形界面。许多开发者都是使用命令行来操作它的,比如 [Bash](https://www.gnu.org/software/bash/)。你也可以从很多种图形界面中选择一个,比如 Xfce 和 KDE。你可能听说过 “Xubuntu” 这个词,它的意思是 “Ubuntu with Xfce” 。你想必能猜出 “Kubuntu”的意思吧?
**真相 23:**Linux 使用的是 GPL 许可证。
> **“大多数软件的许可证都为了夺走你分享和修改它的自由。相比之下,GNU GPL 许可证力图捍卫你分享和修改自由软件的自由——以确保软件对它的任何用户都是自由的。**”
> —— GNU GPL 序言
**真相 24:**Linux 采用 “类 Unix”设计,它的单体 Linux 内核控制着文件系统、网络和进程管理。剩下的功能部分由模块来控制——大部分来自 [GNU 项目](https://www.gnu.org/home.en.html)。
**真相 25:**即使是微软的 Windows ,这个 Linux 的最大的竞争对手,也在拥抱 Linux。它最近将 [Ubuntu Bash](http://thenextweb.com/opinion/2016/03/31/bash-windows-incredibly-exciting-frightening/#gref) 集成到了 Windows 10 之中。
**赠品真相:**Linux 的灵感来自于 Richard Stallman 的 GNU 项目,它是自由软件运动和黑客伦理。你可用从 [Steven Levy](https://medium.com/u/2fff2fb3e70a) 的经典著作《[黑客](http://amzn.to/2bIHlYP)》中了解到这些以及其它比如 Apple I 计算机等重要项目的历史。
此外,这里还有一份对 Linus 的简单采访,他谈及了 Linux 和 Git,以及他是如何创造他们来解决他自己的问题的。
让我们期待接下来 25 年的 Linux。开源软件将继续打造一个更完美的世界!
| 301 | Moved Permanently | null |
7,734 | 浅谈 Linux 容器和镜像签名 | https://opensource.com/bus/16/8/introduction-linux-containers-and-image-signing | 2016-08-31T11:31:00 | [
"容器",
"Docker",
"LXD",
"RKT"
] | https://linux.cn/article-7734-1.html | 
从根本上说,几乎所有的主要软件,即使是开源软件,都是在基于镜像的容器技术出现之前设计的。这意味着把软件放到容器中相当于是一次平台移植。这也意味着一些程序可以很容易就迁移,[而另一些就更困难](http://rhelblog.redhat.com/2016/04/21/architecting-containers-part-4-workload-characteristics-and-candidates-for-containerization/)。
我大约在三年半前开展基于镜像的容器相关工作。到目前为止,我已经容器化了大量应用。我了解到什么是现实情况,什么是迷信。今天,我想简要介绍一下 Linux 容器是如何设计的,以及谈谈镜像签名。
### Linux 容器是如何设计的
对于基于镜像的 Linux 容器,让大多数人感到困惑的是,它把操作系统分割成两个部分:[内核空间与用户空间](http://rhelblog.redhat.com/2015/07/29/architecting-containers-part-1-user-space-vs-kernel-space/)。在传统操作系统中,内核运行在硬件上,你无法直接与其交互。用户空间才是你真正能交互的,这包括所有你可以通过文件浏览器或者运行`ls`命令能看到的文件、类库、程序。当你使用`ifconfig`命令调整 IP 地址时,你实际上正在借助用户空间的程序来使内核根据 TCP 协议栈改变。这点经常让没有研究过 [Linux/Unix 基础](http://rhelblog.redhat.com/tag/architecting-containers/)的人大吃一惊。
过去,用户空间中的类库支持了与内核交互的程序(比如 ifconfig、sysctl、tuned-adm)以及如网络服务器和数据库之类的面向用户的程序。这些所有的东西都堆积在一个单一的文件系统结构中。用户可以在 /sbin 或者 /lib 文件夹中找到所有操作系统本身支持的程序和类库,或者可以在 /usr/sbin 或 /usr/lib 文件夹中找到所有面向用户的程序或类库(参阅[文件系统层次结构标准](/article-6132-1.html))。这个模型的问题在于操作系统程序和业务支持程序没有绝对的隔离。/usr/bin 中的程序可能依赖 /lib 中的类库。如果一个应用所有者需要改变一些东西,就很有可能破坏操作系统。相反地,如果负责安全更新的团队需要改变一个类库,就(常常)有可能破坏面向业务的应用。这真是一团糟。
借助基于镜像的容器,比如 Docker、LXD、RKT,应用程序所有者可以打包和调整所有放在 /sbin、/lib、/usr/bin 和 /usr/lib 中的依赖部分,而不用担心破坏底层操作系统。本质上讲,容器技术再次干净地将操作系统隔离为两部分:内核空间与用户空间。现在开发人员和运维人员可以分别独立地更新各自的东西。
然而还是有些令人困扰的地方。通常,每个应用所有者(或开发者)并不想负责更新这些应用依赖:像 openssl、glibc,或很底层的基础组件,比如,XML 解析器、JVM,再或者处理与性能相关的设置。过去,这些问题都委托给运维团队来处理。由于我们在容器中打包了很多依赖,对于很多组织来讲,对容器内的所有东西负责仍是个严峻的问题。
### 迁移现有应用到 Linux 容器
把应用放到容器中算得上是平台移植,我准备突出介绍究竟是什么让移植某些应用到容器当中这么困难。
(通过容器,)开发者现在对 /sbin 、/lib、 /usr/bin、 /usr/lib 中的内容有完全的控制权。但是,他们面临的挑战是,他们仍需要将数据和配置放到 /etc 或者 /var/lib 文件夹中。对于基于镜像的容器来说,这是一个糟糕的想法。我们真正需要的是代码、配置以及数据的隔离。我们希望开发者把代码放在容器当中,而数据和配置通过不同的环境(比如,开发、测试或生产环境)来获得。
这意味着我们(或者说平台)在实例化容器时,需要挂载 /etc 或 /var/lib 中的一些文件或文件夹。这会允许我们到处移动容器并仍能从环境中获得数据和配置。听起来很酷吧?这里有个问题,我们需要能够干净地隔离配置和数据。很多现代开源软件比如 Apache、MySQL、MongoDB、Nginx 默认就这么做了。[但很多自产的、历史遗留的、或专有程序并未默认这么设计](http://rhelblog.redhat.com/2016/04/21/architecting-containers-part-4-workload-characteristics-and-candidates-for-containerization/)。对于很多组织来讲,这是主要的痛点。对于开发者来讲的最佳实践是,开始架构新的应用,移植遗留代码,以完成配置和数据的完全隔离。
### 镜像签名简介
信任机制是容器的重要议题。容器镜像签名允许用户添加数字指纹到镜像中。这个指纹随后可被加密算法测试验证。这使得容器镜像的用户可以验证其来源并信任。
容器社区经常使用“容器镜像”这个词组,但这个命名方法会让人相当困惑。Docker、LXD 和 RKT 推行获取远程文件来当作容器运行这样的概念。这些技术各自通过不同的方式处理容器镜像。LXD 用单独的一层来获取单独一个容器,而 Docker 和 RKT 使用基于开放容器镜像(OCI)格式,可由多层组成。糟糕的是,会出现不同团队和组织对容器镜像中的不同层负责的情况。容器镜像概念下隐含的是容器镜像格式的概念。拥有标准的镜像格式比如 OCI 会让容器生态系统围绕着镜像扫描、签名,和在不同云服务提供商间转移而繁荣发展。
现在谈到签名了。
容器存在一个问题,我们把一堆代码、二进制文件和类库放入其中。一旦我们打包了代码,我们就要把它和必要的文件服务器(注册服务器)共享。代码只要被共享,它基本上就是不具名的,缺少某种密文签名。更糟糕的是,容器镜像经常由不同人或团队控制的各个镜像层组成。每个团队都需要能够检查上一个团队的工作,增加他们自己的工作内容,并在上面添加他们自己的批准印记。然后他们需要继续把工作交给下个团队。
(由很多镜像组成的)容器镜像的最终用户需要检查监管链。他们需要验证每个往其中添加文件的团队的可信度。对于最终用户而言,对容器镜像中的每一层都有信心是极其重要的。
*作者 Scott McCarty 于 8 月 24 日在 ContainerCon 会议上作了题为 [Containers for Grownups: Migrating Traditional & Existing Applications](https://lcccna2016.sched.org/event/7JUc/containers-for-grownups-migrating-traditional-existing-applications-scott-mccarty-red-hat) 的报告,更多内容请参阅报告[幻灯片](http://schd.ws/hosted_files/lcccna2016/91/Containers%20for%20Grownups_%20Migrating%20Traditional%20%26%20Existing%20Applications.pdf)。*
---
via: <https://opensource.com/bus/16/8/introduction-linux-containers-and-image-signing>
作者:[Scott McCarty](https://opensource.com/users/fatherlinux) 译者:[Tanete](https://github.com/Tanete) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 200 | OK | Fundamentally, all major software, even open source, was designed before image-based containers. This means that putting software inside of containers is fundamentally a platform migration. This also means that some programs are easy to migrate into containers, while [others are more difficult](http://rhelblog.redhat.com/2016/04/21/architecting-containers-part-4-workload-characteristics-and-candidates-for-containerization/).
I started working with image-based containers nearly 3.5 years ago. In this time I have containerized a ton of applications. I have learned what's real, and what is superstition. Today, I'd like to give a brief introduction to how Linux containers are designed and talk briefly about image signing.
## How Linux containers are designed
What most people find confusing about the image based Linux containers, is that it's really about breaking an operating system into two parts: [the kernel and the user space](http://rhelblog.redhat.com/2015/07/29/architecting-containers-part-1-user-space-vs-kernel-space/). In a traditional operating system, the kernel runs on the hardware and you never interact with it directly. The user space is what you actually interact with and this includes all the files, libraries, and programs that you see when you look at a file browser or run the `ls`
command. When you use the `ifconfig`
command to change an IP address, you are actually leveraging a user space program to make kernel changes to the TCP stack. This often blows people's minds if they haven't studied [Linux/Unix fundamentals](http://rhelblog.redhat.com/tag/architecting-containers/).
Historically, the libraries in the user space supported programs that interacted with the kernel (`ifconfig`
, `sysctl`
, `tuned-adm`
) and user-facing programs such as web servers or databases. Everything was dumped together in a single filesystem hierarchy. Users could inspect the */sbin* or* /lib* directories and see all of the applications and libraries that support the operating system itself, or inspect the */usr/sbin* or */usr/lib* directory to see all of the user-facing programs and libraries (Check out the [Filesystem Hierarchy Standard](https://en.wikipedia.org/wiki/Filesystem_Hierarchy_Standard)). The problem with this model was that there was never complete isolation between operating system programs and business supporting applications. Programs in */usr/bin* might rely on libraries which live in */lib*. If an application owner needed to change something, it could break the operating system. Conversely, if the team in charge of doing security updates needed to change a library, it could (and often did) break business facing applications. It was a mess.
With image-based containers such as Docker, LXD, and RKT, an application owner can package and modify all of the dependencies in */sbin, /lib, /usr/bin*, and */usr/lib* without worrying about breaking the underlying operating system. Essentially, using image-based containers cleanly isolates the operating system into two parts, again, the kernel and the user space. Now dev and ops can update things independently of each other, kinda...
There is some serous confusion though. Often, each application owner (or developer) doesn't want to be responsible for updating application dependencies such as `openssl`
, `glibc`
, or hardening underlying components, such as XML parsers, or JVMs, or dealing with performance settings. Historically, these problems were delegated to the operations team. Since we are packing a lot of dependencies in the container, the delegation of responsibility for all of the pieces in the container is still a real problem for many organizations.
## Migrating existing applications to Linux containers
Putting software inside of containers is basically a platform migration. I'd like to highlight what makes this difficult to migrate some applications into containers.
Developers now have complete control over what's in */sbin, /lib, /usr/bin*, and */usr/lib*. But, one of the challenges they have is, they still need to put data and configuration in folders such as */etc* or */var/lib*. With image-based containers, this is a bad idea. We really want good separation of code, configuration, and data. We want the developers to provide the code in the container, but we want the data and configuration to come from the environment, e.g. development, testing, or production.
This means we need to mount some files from */etc* or directories from */var/lib* when we (or better, the platform) instantiate a container. This will allow us to move the containers around and still get its configuration and data from the environment. Cool, right? Well, there is a problem, that means we have to be able to isolate configuration and data cleanly. Many modern open source programs like Apache, MySQL, MongoDB, or Nginx do this by default, [but many home-grown, legacy, or proprietary programs are not designed to do this by default](http://rhelblog.redhat.com/2016/04/21/architecting-containers-part-4-workload-characteristics-and-candidates-for-containerization/). This is a major pain point for many organizations. A best practice for developers would be to start architecting new applications and migrating legacy code so that configuration and data are cleanly isolated.
## Introduction to image signing
Trust is a major issue with containers. Container image signing allows a user to add a *digital fingerprint* to an image. This fingerprint can later be cryptographically tested to verify trust. This allows the user of a container image to verify the source and trust the container image.
The container community uses the words “container image" quite a lot, but this nomenclature can be quite confusing. Docker, LXD, and RKT operate on the concept of pulling remote files and running them as a container. Each of these technologies treats containers images in different ways. LXD pulls a single container image with a single layer, while Docker and RKT use Open Container Image (OCI)-based images which can be made up of multiple layers. Worse, different teams or even organization may be responsible for different layers of a container image. Implicit in the concept of a container image is the concept of a Container Image Format. Having a standard image format such as OCI will allow an ecosystem to flourish around container scanning, signing, and movement between cloud providers.
Now on to signing.
One of the problems with containers is we package a bunch of code, binaries, and libraries into a container image. Once we package the code, we share it with essentially fancy file servers which we call Registry Servers. Once the code is shared, it is basically anonymous without some form of cryptographic signing. Worse yet, container images are often made up of image layers which are controlled by different people or teams of people. Each team needs to have the ability to check the last team's work, add their work, and then put their stamp of approval on it. They then need to send it on to the next team.
The final user of the container image (really made up of multiple images) really needs to check the chain of custody. They need to verify trust with every team that added files to the container image. It is critical for end users to have confidence about every single layer of the container image.
*Scott McCarty will give a talk called Containers for Grownups: Migrating Traditional & Existing Applications at ContainerCon on August 24. Talk attendees will gain a new understanding of how containers work, and be able to leverage their current architectural knowledge to the world of containers. He will teach attendees which applications are easy to put in containers and why, and he'll explain which types of programs are more difficult and why. He will provide tons of examples and help attendees gain confidence in building and migrating their own applications into containers. *
## Comments are closed. |
7,735 | 谷歌是怎样做开源的? | http://www.datamation.com/open-source/how-google-does-open-source.html | 2016-09-01T08:57:12 | [
"谷歌",
"开源",
"许可证"
] | https://linux.cn/article-7735-1.html | *谷歌是开源领域领先的贡献者之一,但是这个搜索巨头不是所有的开源许可证都喜欢。*
来自多伦多的报道:Marc Merlin 从 2002 年起就在谷歌担任工程师,至今已经做了许多开源和 Linux 相关的工作。在本周召开的 LinuxCon 北美峰会上,Merlin 发表了演讲,为大家揭示了谷歌是如何使用开源和为开源做贡献的。
“没有开源软件就没有今天的谷歌”,Merlin 说。
Merlin 讲到,谷歌早期回馈到开源社区的资源有限,谷歌的第一代软件全都是写给内部用的,最初并不是为开源而设计的。他接着补充说,事实上开源并不是一件简单的事。也就是说,谷歌早期的软件最初并没有准备开源,不过谷歌发表了技术性论文描述了使用的方法和代码,以便其他人也可以用同样的原理来实现。

*Marc Merlin at LinuxCon North America*
在各种开源技术领域,谷歌早期的贡献主要是错误修复。
“我们通常是第一个发现并修复那些只在我们这个量级出现的错误的”,Merlin 说。
到现在,Merlin 说谷歌已经为 Linux 内核贡献了超过 5000 个补丁,补丁涵盖了从小的修复到完整的驱动程序和类似容器这样的子系统。
随着谷歌在开源领域的努力,现在已经在 GitHub 上发布了超过 3000 个开源项目。为了以法律的角度来管理整个过程,Merlin 说谷歌有六个人专门在内部从事使用和发布开源软件的合规管理。
为了保证法律上的一致性,谷歌将所有外部的开源代码存储在一个第三方体系内。Merlin 补充说,谷歌只允许使用谷歌能够遵循的许可证的开源软件。其中一个不能接受的许可证是 [AGPL](https://www.gnu.org/licenses/agpl-3.0.en.html) (Affero General Public License),它是一个互惠的许可证,要求使用该代码需提供一个到源代码的链接。
“确保我们没有在任何对外的产品中使用 AGPL 代码的代价太高,相较而言,不如找一个限制性更少的替代品或我们自己写一个”,Merlin 说。
对于那些贡献给谷歌项目的代码,谷歌要求开发者接受一个<ruby> 贡献者许可协议 <rp> ( </rp> <rt> Contributor License Agreement </rt> <rp> ) </rp></ruby>(CLA),该 CLA 主要是让谷歌可以对贡献的代码重新颁发许可证,并为谷歌提供代码的专利授权。
“你仍然拥有你的代码,你只是授予谷歌一个许可而已”,Merlin 说。
| 301 | Moved Permanently | null |
7,740 | TypeScript 2.0 与 AngularJS 2.0 的新动态 | http://news.softpedia.com/news/typescrypt-2-0-angularjs-2-0-and-other-javascript-news-507859.shtml | 2016-09-02T09:57:36 | [
"TypeScript",
"AngularJS",
"JavaScript"
] | https://linux.cn/article-7740-1.html | 
微软终于发布了 TypeScript 2.0 的第一个 RC 版本。TypeScript 是一个简化版的 JavaScript 语言,被大量用于各种 Web 项目,包括下面提到的著名的 AngularJS 框架。
TypeScript 2.0 中主要的特性是“<ruby> 标签结合 <rp> ( </rp> <rt> tagged unions </rt> <rp> ) </rp></ruby>”,这个特性可以将两个不同的数据结构联合到一起。你可以把它想象成将一个圆圈和一个方块放一起,这个隐喻来自微软[解释标签结合](https://blogs.msdn.microsoft.com/typescript/2016/08/30/announcing-typescript-2-0-rc/)的博文中。
支持标签结合的语言包括 C++、 Scala、 F#、Rust 和 Swift 等等。支持这种特性的原因是,标签结合可以改进类型安全,并减少经常困扰开发者的类型错误。
而另外一方面,Google 也有一些动作……
Google 已经谈论 AngularJS 2.0 很久了。很多人都期望 Google 能在去年底发布 2.0 的稳定版,不过我们听说,就算是到了今年年底也不会见到稳定版。
不过,也快了!Google 今天宣布发布了 [Angular 2.0 RC6](http://angularjs.blogspot.com/2016/09/angular-2-rc6_1.html),支持国际化(I18N)、更多的表单功能,并由于对 Ahead of Time (AoT) 的兼容和支持 ES6 2015 模块而改进了性能。
同时 Google 也[宣布](http://angularjs.blogspot.com/2016/08/angular-material-11-and-2x.html)发布了 Angular Material 1.1,这是一个 AngularJS 的 UI 组件包。Angular Material 2.x 当前还处于 alpha 阶段,看起来会在 AngularJS 2.0 发布之后才会面世。当前,Angular Material 2.x 已经从 6 个组件增加到了 18 个组件了。
| 301 | Moved Permanently | null |
7,742 | MySQL 中你应该使用什么数据类型表示时间? | http://www.vertabelo.com/blog/technical-articles/what-datatype-should-you-use-to-represent-time-in-mysql-we-compare-datetime-timestamp-and-int | 2016-09-03T08:01:00 | [
"日期",
"时间戳",
"MySQL"
] | https://linux.cn/article-7742-1.html | 
>
> 当你需要保存日期时间数据时,一个问题来了:你应该使用 MySQL 中的什么类型?使用 MySQL 原生的 DATE 类型还是使用 INT 字段把日期和时间保存为一个纯数字呢?
>
>
>
在这篇文章中,我将解释 MySQL 原生的方案,并给出一个最常用数据类型的对比表。我们也将对一些典型的查询做基准测试,然后得出在给定场景下应该使用什么数据类型的结论。
如果你想直接看结论,请翻到文章最下方。
### 原生的 MySQL Datetime 数据类型
Datetime 数据表示一个时间点。这可以用作日志记录、物联网时间戳、日历事件数据,等等。MySQL 有两种原生的类型可以将这种信息保存在单个字段中:Datetime 和 Timestamp。MySQL 文档中是这么介绍这些数据类型的:
>
> DATETIME 类型用于保存同时包含日期和时间两部分的值。MySQL 以 'YYYY-MM-DD HH:MM:SS' 形式接收和显示 DATETIME 类型的值。
>
>
> TIMESTAMP 类型用于保存同时包含日期和时间两部分的值。
>
>
> DATETIME 或 TIMESTAMP 类型的值可以在尾部包含一个毫秒部分,精确度最高到微秒(6 位数)。
>
>
> TIMESTAMP 和 DATETIME 数据类型提供自动初始化和更新到当前的日期和时间的功能,只需在列的定义中设置 DEFAULT CURRENT*TIMESTAMP 和 ON UPDATE CURRENT*TIMESTAMP。
>
>
>
作为一个例子:
```
CREATE TABLE `datetime_example` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`measured_on` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `measured_on` (`measured_on`)
) ENGINE=InnoDB;
```
```
CREATE TABLE `timestamp_example` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`measured_on` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `measured_on` (`measured_on`)
) ENGINE=InnoDB;
```
除了原生的日期时间表示方法,还有另一种常用的存储日期和时间信息的方法。即使用 INT 字段保存 Unix 时间(从1970 年 1 月 1 日协调世界时(UTC)建立所经过的秒数)。
MySQL 也提供了只保存时间信息中的一部分的方式,通过使用 Date、Year 或 Time 类型。由于这篇文章是关于保存准确时间点的最佳方式的,我们没有讨论这些不那么精确的局部类型。
### 使用 INT 类型保存 Unix 时间
使用一个简单的 INT 列保存 Unix 时间是最普通的方法。使用 INT,你可以确保你要保存的数字可以快速、可靠地插入到表中,就像这样:
```
INSERT INTO `vertabelo`.`sampletable`
(
`id`,
`measured_on` ### INT 类型的列
)
VALUES
(
1,
946684801
### 至 01/01/2000 @ 12:00am (UTC) 的 UNIX 时间戳 http://unixtimestamp.com
);
```
这就是关于它的所有内容了。它仅仅是个简单的 INT 列,MySQL 的处理方式是这样的:在内部使用 4 个字节保存那些数据。所以如果你在这个列上使用 SELECT 你将会得到一个数字。如果你想把这个列用作日期进行比较,下面的查询并不能正确工作:
```
SELECT
id, measured_on, FROM_UNIXTIME(measured_on)
FROM
vertabelo.inttimestampmeasures
WHERE
measured_on > '2016-01-01' ### measured_on 会被作为字符串比较以进行查询
LIMIT 5;
```
这是因为 MySQL 把 INT 视为数字,而非日期。为了进行日期比较,你必须要么获取( LCTT 译注:从 1970-01-01 00:00:00)到 2016-01-01 经过的秒数,要么使用 MySQL 的 FROM\_UNIXTIME() 函数把 INT 列转为 Date 类型。下面的查询展示了 FROM\_UNIXTIME() 函数的用法:
```
SELECT
id, measured_on, FROM_UNIXTIME(measured_on)
FROM
vertabelo.inttimestampmeasures
WHERE
FROM_UNIXTIME(measured_on) > '2016-01-01'
LIMIT 5;
```
这会正确地获取到日期在 2016-01-01 之后的记录。你也可以直接比较数字和 2016-01-01 的 Unix 时间戳表示形式,即 1451606400。这样做意味着不用使用任何特殊的函数,因为你是在直接比较数字。查询如下:
```
SELECT
id, measured_on, FROM_UNIXTIME(measured_on)
FROM
vertabelo.inttimestampmeasures
WHERE
measured_on > 1451606400
LIMIT 5;
```
假如这种方式不够高效甚至提前做这种转换是不可行的话,那该怎么办?例如,你想获取 2016 年所有星期三的记录。要做到这样而不使用任何 MySQL 日期函数,你就不得不查出 2016 年每个星期三的开始和结束时间的 Unix 时间戳。然后你不得不写很大的查询,至少要在 WHERE 中包含 104 个比较。(2016 年有 52 个星期三,你不得不考虑一天的开始(0:00 am)和结束(11:59:59 pm)...)
结果是你很可能最终会使用 FROM\_UNIXTIME() 转换函数。既然如此,为什么不试下真正的日期类型呢?
### 使用 Datetime 和 Timestamp
Datetime 和 Timestamp 几乎以同样的方式工作。两种都保存日期和时间信息,毫秒部分最高精确度都是 6 位数。同时,使用人类可读的日期形式如 "2016-01-01" (为了便于比较)都能工作。查询时两种类型都支持“宽松格式”。宽松的语法允许任何标点符号作为分隔符。例如,"YYYY-MM-DD HH:MM:SS" 和 "YY-MM-DD HH:MM:SS" 两种形式都可以。在宽松格式情况下以下任何一种形式都能工作:
```
2012-12-31 11:30:45
2012^12^31 11+30+45
2012/12/31 11*30*45
2012@12@31 11^30^45
```
其它宽松格式也是允许的;你可以在 [MySQL 参考手册](https://dev.mysql.com/doc/refman/5.7/en/date-and-time-literals.html) 找到所有的格式。
默认情况下,Datetime 和 Timestamp 两种类型查询结果都以标准输出格式显示 —— 年-月-日 时:分:秒 (如 2016-01-01 23:59:59)。如果使用了毫秒部分,它们应该以小数值出现在秒后面 (如 2016-01-01 23:59:59.5)。
Timestamp 和 Datetime 的核心不同点主要在于 MySQL 在内部如何表示这些信息:两种都以二进制而非字符串形式存储,但在表示日期/时间部分时 Timestamp (4 字节) 比 Datetime (5 字节) 少使用 1 字节。当保存毫秒部分时两种都使用额外的空间 (1-3 字节)。如果你存储 150 万条记录,这种 1 字节的差异是微不足道的:
>
> 150 万条记录 \* 每条记录 1 字节 / (1048576 字节/MB) = **1.43 MB**
>
>
>
Timestamp 节省的 1 字节是有代价的:你只能存储从 '1970-01-01 00:00:01.000000' 到 '2038-01-19 03:14:07.999999' 之间的时间。而 Datetime 允许你存储从 '1000-01-01 00:00:00.000000' 到 '9999-12-31 23:59:59.999999' 之间的任何时间。
另一个重要的差别 —— 很多 MySQL 开发者没意识到的 —— 是 MySQL 使用**服务器的时区**转换 Timestamp 值到它的 UTC 等价值再保存。当获取值是它会再次进行时区转换,所以你得回了你“原始的”日期/时间值。有可能,下面这些情况会发生。
理想情况下,如果你一直使用同一个时区,MySQL 会获取到和你存储的同样的值。以我的经验,如果你的数据库涉及时区变换,你可能会遇到问题。例如,服务器变化(比如,你把数据库从都柏林的一台服务器迁移到加利福尼亚的一台服务器上,或者你只是修改了一下服务器的时区)时可能会发生这种情况。不管哪种方式,如果你获取数据时的时区是不同的,数据就会受影响。
Datetime 列不会被数据库改变。无论时区怎样配置,每次都会保存和获取到同样的值。就我而言,我认为这是一个更可靠的选择。
>
> **MySQL 文档:**
>
>
> MySQL 把 TIMESTAMP 值从当前的时区转换到 UTC 再存储,获取时再从 UTC 转回当前的时区。(其它类型如 DATETIME 不会这样,它们会“原样”保存。) 默认情况下,每个连接的当前时区都是服务器的时区。时区可以基于连接设置。只要时区设置保持一致,你就能得到和保存的相同的值。如果你保存了一个 TIMESTAMP 值,然后改变了时区再获取这个值,获取到的值和你存储的是不同的。这是因为在写入和查询的会话上没有使用同一个时区。当前时区可以通过系统变量 [time\_zone](https://dev.mysql.com/doc/refman/5.7/en/server-system-variables.html#sysvar_time_zone) 的值得到。更多信息,请查看 [MySQL Server Time Zone Support](https://dev.mysql.com/doc/refman/5.7/en/time-zone-support.html)。
>
>
>
### 对比总结
在深入探讨使用各数据类型的性能差异之前,让我们先看一个总结表格以给你更多了解。每种类型的弱点以红色显示。
| 特性 | Datetime | Timestamp | Int (保存 Unix 时间) |
| --- | --- | --- | --- |
| 原生时间表示 | 是 | 是 | 否,所以大多数操作需要先使用转换函数,如 FROM\_UNIXTIME() |
| 能保存毫秒 | 是,最高 6 位精度 | 是,最高 6 位精度 | **否** |
| 合法范围 | '1000-01-01 00:00:00.000000' 到 '9999-12-31 23:59:59.999999 | **'1970-01-01 00:00:01.000000' 到 '2038-01-19 03:14:07.999999'** | 若使用 unsigned, '1970-01-01 00:00:01.000000; 理论上最大到 '2106-2-07 06:28:15' |
| 自动初始化(MySQL 5.6.5+) | 是 | 是 | **否** |
| 宽松解释 ([MySQL docs](https://dev.mysql.com/doc/refman/5.7/en/date-and-time-literals.html)) | 是 | 是 | **否,必须使用正确的格式** |
| 值被转换到 UTC 存储 | 否 | **是** | 否 |
| 可转换到其它类型 | 是,如果值在合法的 Timestamp 范围中 | 是,总是 | 是,如果值在合法的范围中并使用转换函数 |
| 存储需求([MySQL 5.6.4+](https://dev.mysql.com/doc/refman/5.7/en/storage-requirements.html)) | **5 字节**(如果使用了毫秒部分,再加最多 3 字节) | 4 字节 (如果使用了毫秒部分,再加最多 3 字节) | 4 字节 (不允许毫秒部分) |
| 无需使用函数即可作为真实日期可读 | 是 | 是 | **否,你必须格式化输出** |
| 数据分区 | 是 | 是,使用 [UNIX\_TIMESTAMP()](https://dev.mysql.com/doc/refman/5.7/en/date-and-time-functions.html#function_unix-timestamp);在 MySQL 5.7 中其它表达式是不允许包含 [TIMESTAMP](https://dev.mysql.com/doc/refman/5.7/en/datetime.html) 值的。同时,注意[分区裁剪时的这些考虑](https://dev.mysql.com/doc/refman/5.7/en/partitioning-pruning.html) | 是,使用 INT 上的任何合法操作 |
### 基准测试 INT、Timestamp 和 Datetime 的性能
为了比较这些类型的性能,我会使用我创建的一个天气预报网络的 150 万记录(准确说是 1,497,421)。这个网络每分钟都收集数据。为了让这些测试可复现,我已经删除了一些私有列,所以你可以使用这些数据运行你自己的测试。
基于我原始的表格,我创建了三个版本:
* `datetimemeasures` 表在 `measured_on` 列使用 Datetime 类型,表示天气预报记录的测量时间
* `timestampmeasures` 表在 `measured_on` 列使用 Timestamp 类型
* `inttimestampmeasures` 表在 `measured_on` 列使用 INT (unsigned) 类型
这三个表拥有完全相同的数据;唯一的差别就是 `measured_on` 字段的类型。所有表都在 `measured_on` 列上设置了一个索引。
#### 基准测试工具
为了评估这些数据类型的性能,我使用了两种方法。一种基于 [Sysbench](https://github.com/akopytov/sysbench),它的官网是这么描述的:
>
> *“*... 一个模块化、跨平台和多线程的基准测试工具,用以评估那些对运行高负载数据库的系统非常重要的系统参数。*”*
>
>
>
这个工具是 [MySQL 文档](https://dev.mysql.com/downloads/benchmarks.html)中推荐的。
如果你使用 Windows (就像我),你可以下载一个包含可执行文件和我使用的测试查询的 zip 文件。它们基于 [一种推荐的基准测试方法](https://dba.stackexchange.com/questions/39221/stress-test-mysql-with-queries-captured-with-general-log-in-mysql)。
为了执行一个给定的测试,你可以使用下面的命令(插入你自己的连接参数):
```
sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=sysbench_test_file.lua --num-threads=8 --max-requests=100 run
```
这会正常工作,这里 `sysbench_test_file.lua` 是测试文件,并包含了各个测试中指向各个表的 SQL 查询。
为了进一步验证结果,我也运行了 [mysqlslap](https://dev.mysql.com/doc/refman/5.7/en/mysqlslap.html)。它的官网是这么描述的:
>
> “[mysqlslap](https://dev.mysql.com/doc/refman/5.7/en/mysqlslap.html) 是一个诊断程序,为模拟 MySQL 服务器的客户端负载并报告各个阶段的用时而设计。它工作起来就像是很多客户端在同时访问服务器。”
>
>
>
记得这些测试中最重要的不是所需的*绝对*时间。而是在不同数据类型上执行相同查询时的*相对*时间。这两个基准测试工具的测试时间不一定相同,因为不同工具的工作方式不同。重要的是数据类型的比较,随着我们深入到测试中,这将会变得清楚。
#### 基准测试
我将使用三种可以评估几个性能方面的查询:
* 时间范围选择
+ 在 Datetime 和 Timestamp 数据类型上这允许我们直接比较而不需要使用任何特殊的日期函数。
+ 同时,我们可以评估在 INT 类型的列上使用日期函数相对于使用简单的数值比较的影响。为了做到这些我们需要把范围转换为 Unix 时间戳数值。
* 日期函数选择
+ 与前个测试中比较操作针对一个简单的 DATE 值相反,这个测试使得我们可以评估使用日期函数作为 “WHERE” 子句的一部分的性能。
+ 我们还可以测试一个场景,即我们必须使用一个函数将 INT 列转换为一个合法的 DATE 类型然后执行查询。
* count() 查询
+ 作为对前面测试的补充,这将评估在三种不同的表示类型上进行典型的统计查询的性能。
我们将在这些测试中覆盖一些常见的场景,并看到三种类型上的性能表现。
#### 关于 SQL\_NO\_CACHE
当在查询中使用 SQL\_NO\_CACHE 时,服务器不使用查询缓存。它既不检查查询缓存以确认结果是不是已经在那儿了,也不会保存查询结果。因此,每个查询将反映真实的性能影响,就像每次查询都是第一次被调用。
#### 测试 1:选择一个日期范围中的值
这个查询返回总计 1,497,421 行记录中的 75,706 行。
**查询 1 和 Datetime:**
```
SELECT SQL_NO_CACHE
measured_on
FROM
vertabelo.datetimemeasures m
WHERE
m.measured_on > '2016-01-01 00:00:00.0'
AND m.measured_on < '2016-02-01 00:00:00.0';
```
**性能**
| 响应时间 (ms) | Sysbench | mysqlslap |
| --- | --- | --- |
| 最小 | 152 | 296 |
| 最大 | 1261 | 3203 |
| 平均 | 362 | 809 |
```
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=datetime.lua --num-threads=8 --max-requests=100 run
```
```
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE measured_on FROM vertabelo.datetimemeasures m WHERE m.measured_on > '2016-01-01 00:00:00.0' AND m.measured_on < '2016-02-01 00:00:00.0'" --host=localhost --user=root --concurrency=8 --iterations=100 --no-drop --create-schema=vertabelo
```
**查询 1 和 Timestamp:**
```
SELECT SQL_NO_CACHE
measured_on
FROM
vertabelo.timestampmeasures m
WHERE
m.measured_on > '2016-01-01 00:00:00.0'
AND m.measured_on < '2016-02-01 00:00:00.0';
```
**性能**
| 响应时间 (ms) | Sysbench | mysqlslap |
| --- | --- | --- |
| 最小 | 214 | 359 |
| 最大 | 1389 | 3313 |
| 平均 | 431 | 1004 |
```
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=timestamp.lua --num-threads=8 --max-requests=100 run
```
```
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE measured_on FROM vertabelo.timestampmeasures m WHERE m.measured_on > '2016-01-01 00:00:00.0' AND m.measured_on < '2016-02-01 00:00:00.0'" --host=localhost --user=root --concurrency=8 --iterations=100 --no-drop --create-schema=vertabelo
```
**查询 1 和 INT:**
```
SELECT SQL_NO_CACHE
measured_on
FROM
vertabelo.inttimestampmeasures m
WHERE
FROM_UNIXTIME(m.measured_on) > '2016-01-01 00:00:00.0'
AND FROM_UNIXTIME(m.measured_on) < '2016-02-01 00:00:00.0';
```
**性能**
| 响应时间 (ms) | Sysbench | mysqlslap |
| --- | --- | --- |
| 最小 | 2472 | 7968 |
| 最大 | 6554 | 10312 |
| 平均 | 4107 | 8527 |
```
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=int.lua --num-threads=8 --max-requests=100 run
```
```
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE measured_on FROM vertabelo.inttimestampmeasures m WHERE FROM_UNIXTIME(m.measured_on) > '2016-01-01 00:00:00.0' AND FROM_UNIXTIME(m.measured_on) < '2016-02-01 00:00:00.0'" --host=localhost --user=root --concurrency=8 --iterations=100 --no-drop --create-schema=vertabelo
```
**另一种 INT 上的查询 1:**
由于这是个相当直接的范围搜索,而且查询中的日期可以轻易地转为简单的数值比较,我将它包含在了这个测试中。结果证明这是最快的方法 (你大概已经预料到了),因为它仅仅是比较数字而没有使用任何日期转换函数:
```
SELECT SQL_NO_CACHE
measured_on
FROM
vertabelo.inttimestampmeasures m
WHERE
m.measured_on > 1451617200
AND m.measured_on < 1454295600;
```
**性能**
| 响应时间 (ms) | Sysbench | mysqlslap |
| --- | --- | --- |
| 最小 | 88 | 171 |
| 最大 | 275 | 2157 |
| 平均 | 165 | 514 |
```
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=basic_int.lua --num-threads=8 --max-requests=100 run
```
```
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE measured_on FROM vertabelo.inttimestampmeasures m WHERE m.measured_on > 1451617200 AND m.measured_on < 1454295600" --host=localhost --user=root --concurrency=8 --iterations=100 --no-drop --create-schema=vertabelo
```
**测试 1 总结**
| 平均响应时间 (ms) | Sysbench | 相对于 Datetime 的速度 | mysqlslap | 相对于 Datetime 的速度 |
| --- | --- | --- | --- | --- |
| Datetime | 362 | - | 809 | - |
| Timestamp | 431 | 慢 19% | 1004 | 慢 24% |
| INT | 4107 | 慢 1134% | 8527 | 慢 1054% |
| 另一种 INT 查询 | 165 | 快 55% | 514 | 快 36% |
两种基准测试工具都显示 Datetime 比 Timestamp 和 INT 更快。但 Datetime 没有我们在另一种 INT 查询中使用的简单数值比较快。
#### 测试 2:选择星期一产生的记录
这个查询返回总计 1,497,421 行记录中的 221,850 行。
**查询 2 和 Datetime:**
```
SELECT SQL_NO_CACHE measured_on
FROM
vertabelo.datetimemeasures m
WHERE
WEEKDAY(m.measured_on) = 0; # MONDAY
```
**性能**
| 响应时间 (ms) | Sysbench | mysqlslap |
| --- | --- | --- |
| 最小 | 1874 | 4343 |
| 最大 | 6168 | 7797 |
| 平均 | 3127 | 6103 |
```
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=datetime_1.lua --num-threads=8 --max-requests=100 run
```
```
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE measured_on FROM vertabelo.datetimemeasures m WHERE WEEKDAY(m.measured_on) = 0" --host=localhost --user=root --concurrency=8 --iterations=25 --no-drop --create-schema=vertabelo
```
**查询 2 和 Timestamp:**
```
SELECT SQL_NO_CACHE
measured_on
FROM
vertabelo.timestampmeasures m
WHERE
WEEKDAY(m.measured_on) = 0; # MONDAY
```
**性能**
| 响应时间 (ms) | Sysbench | mysqlslap |
| --- | --- | --- |
| 最小 | 2688 | 5953 |
| 最大 | 6666 | 13531 |
| 平均 | 3653 | 8412 |
```
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=timestamp_1.lua --num-threads=8 --max-requests=100 run
```
```
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE measured_on FROM vertabelo.timestampmeasures m WHERE WEEKDAY(m.measured_on) = 0" --host=localhost --user=root --concurrency=8 --iterations=25 --no-drop --create-schema=vertabelo
```
**查询 2 和 INT:**
```
SELECT SQL_NO_CACHE
measured_on
FROM
vertabelo.inttimestampmeasures m
WHERE
WEEKDAY(FROM_UNIXTIME(m.measured_on)) = 0; # MONDAY
```
**性能**
| 响应时间 (ms) | Sysbench | mysqlslap |
| --- | --- | --- |
| 最小 | 2051 | 5844 |
| 最大 | 7007 | 10469 |
| 平均 | 3486 | 8088 |
```
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=int_1.lua --num-threads=8 --max-requests=100 run
```
```
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE measured_on FROM vertabelo.inttimestampmeasures m WHERE WEEKDAY(FROM_UNIXTIME(m.measured_on)) = 0" --host=localhost --user=root --concurrency=8 --iterations=25 --no-drop --create-schema=vertabelo
```
**测试 2 总结**
| 平均响应时间 (ms) | Sysbench | 相对于 Datetime 的速度 | mysqlslap | 相对于 Datetime 的速度 |
| --- | --- | --- | --- | --- |
| Datetime | 3127 | - | 6103 | - |
| Timestamp | 3653 | 慢 17% | 8412 | 慢 38% |
| INT | 3486 | 慢 11% | 8088 | 慢 32% |
再次,在两个基准测试工具中 Datetime 比 Timestamp 和 INT 快。但在这个测试中,INT 查询 —— 即使它使用了一个函数以转换日期 —— 比 Timestamp 查询更快得到结果。
#### 测试 3:选择星期一产生的记录总数
这个查询返回一行,包含产生于星期一的所有记录的总数(从总共 1,497,421 行可用记录中)。
**查询 3 和 Datetime:**
```
SELECT SQL_NO_CACHE
COUNT(measured_on)
FROM
vertabelo.datetimemeasures m
WHERE
WEEKDAY(m.measured_on) = 0; # MONDAY
```
**性能**
| 响应时间 (ms) | Sysbench | mysqlslap |
| --- | --- | --- |
| 最小 | 1720 | 4063 |
| 最大 | 4594 | 7812 |
| 平均 | 2797 | 5540 |
```
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=datetime_1_count.lua --num-threads=8 --max-requests=100 run
```
```
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE COUNT(measured_on) FROM vertabelo.datetimemeasures m WHERE WEEKDAY(m.measured_on) = 0" --host=localhost --user=root --concurrency=8 --iterations=25 --no-drop --create-schema=vertabelo
```
**查询 3 和 Timestamp:**
```
SELECT SQL_NO_CACHE
COUNT(measured_on)
FROM
vertabelo.timestampmeasures m
WHERE
WEEKDAY(m.measured_on) = 0; # MONDAY
```
**性能**
| 响应时间 (ms) | Sysbench | mysqlslap |
| --- | --- | --- |
| 最小 | 1907 | 4578 |
| 最大 | 5437 | 10235 |
| 平均 | 3408 | 7102 |
```
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=timestamp_1_count.lua --num-threads=8 --max-requests=100 run
```
```
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE COUNT(measured_on) FROM vertabelo.timestampmeasures m WHERE WEEKDAY(m.measured_on) = 0" --host=localhost --user=root --concurrency=8 --iterations=25 --no-drop --create-schema=vertabelo
```
**查询 3 和 INT:**
```
SELECT SQL_NO_CACHE
COUNT(measured_on)
FROM
vertabelo.inttimestampmeasures m
WHERE
WEEKDAY(FROM_UNIXTIME(m.measured_on)) = 0; # MONDAY
```
**性能**
| 响应时间 (ms) | Sysbench | mysqlslap |
| --- | --- | --- |
| 最小 | 2108 | 5609 |
| 最大 | 4764 | 9735 |
| 平均 | 3307 | 7416 |
```
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=int_1_count.lua --num-threads=8 --max-requests=100 run
```
```
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE COUNT(measured_on) FROM vertabelo.inttimestampmeasures m WHERE WEEKDAY(FROM_UNIXTIME(m.measured_on)) = 0" --host=localhost --user=root --concurrency=8 --iterations=25 --no-drop --create-schema=vertabelo
```
**测试 3 总结**
| 平均响应时间 (ms) | Sysbench | 相对于 Datetime 的速度 | mysqlslap | 相对于 Datetime 的速度 |
| --- | --- | --- | --- | --- |
| Datetime | 2797 | - | 5540 | - |
| Timestamp | 3408 | 慢 22% | 7102 | 慢 28% |
| INT | 3307 | 慢 18% | 7416 | 慢 33% |
再一次,两个基准测试工具都显示 Datetime 比 Timestamp 和 INT 快。不能判断 INT 是否比 Timestamp 快,因为 mysqlslap 显示 INT 比 Timestamp 略快而 Sysbench 却相反。
**注意:** 所有测试都是在一台 Windows 10 机器上本地运行的,这台机器拥有一个双核 i7 CPU,16GB 内存,运行 MariaDB v10.1.9,使用 innoDB 引擎。
### 结论
基于这些数据,我确信 Datetime 是大多数场景下的最佳选择。原因是:
* 更快(根据我们的三个基准测试)。
* 无需任何转换即是人类可读的。
* 不会因为时区变换产生问题。
* 只比它的对手们多用 1 字节
* 支持更大的日期范围(从 1000 年到 9999 年)
如果你只是存储 Unix 时间戳(并且在它的合法日期范围内),而且你真的不打算在它上面使用任何基于日期的查询,我觉得使用 INT 是可以的。我们已经看到,它执行简单数值比较查询时非常快,因为只是在处理简单的数字。
Timestamp 怎么样呢?如果 Datetime 相对于 Timestamp 的优势不适用于你特殊的场景,你最好使用时间戳。阅读这篇文章后,你对三种类型间的区别应该有了更好的理解,可以根据你的需要做出最佳的选择。
---
via: <http://www.vertabelo.com/blog/technical-articles/what-datatype-should-you-use-to-represent-time-in-mysql-we-compare-datetime-timestamp-and-int>
作者:[Francisco Claria](http://www.axones.com.ar/) 译者:[bianjp](https://github.com/bianjp) 校对:[wxy](https://github.com/wxy)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创编译,[Linux中国](https://linux.cn/) 荣誉推出
| 301 | Moved Permanently | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.