Spaces:
Running

Running
| <div align="center"> | |
| <h1> Neural Source-Filter BigVGAN </h1> | |
| Just For Fun | |
| </div> | |
| 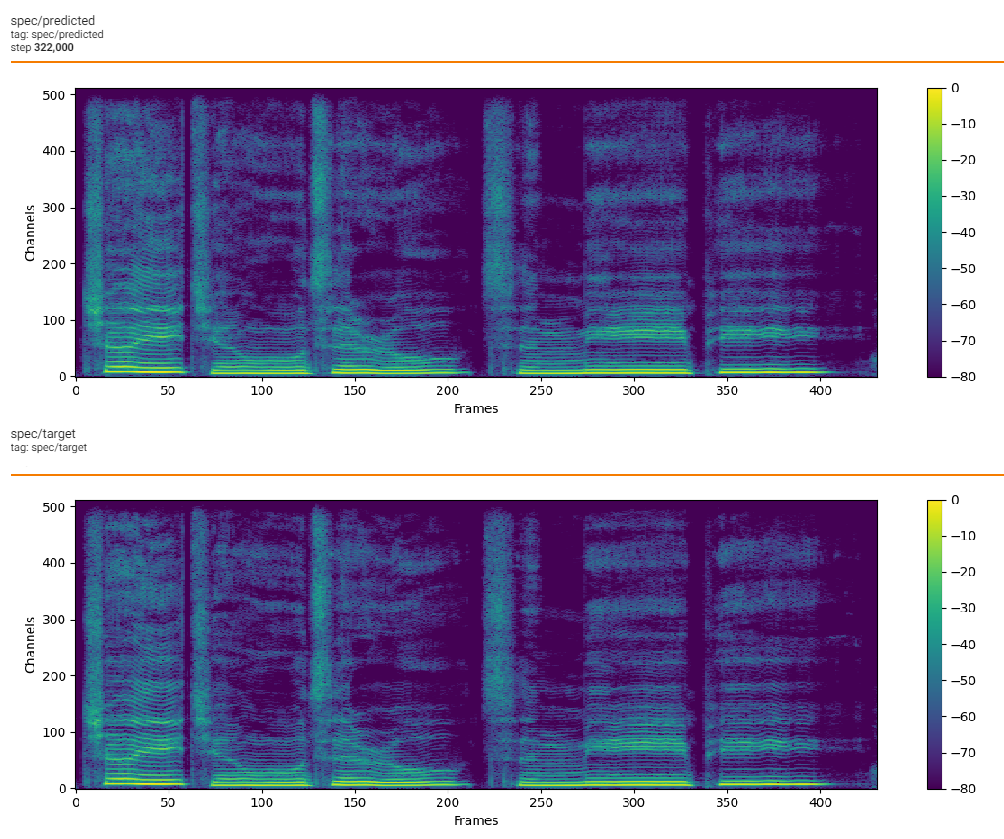 | |
| ## Dataset preparation | |
| Put the dataset into the data_raw directory according to the following file structure | |
| ```shell | |
| data_raw | |
| ├───speaker0 | |
| │ ├───000001.wav | |
| │ ├───... | |
| │ └───000xxx.wav | |
| └───speaker1 | |
| ├───000001.wav | |
| ├───... | |
| └───000xxx.wav | |
| ``` | |
| ## Install dependencies | |
| - 1 software dependency | |
| > pip install -r requirements.txt | |
| - 2 download [release](https://github.com/PlayVoice/NSF-BigVGAN/releases/tag/debug) model, and test | |
| > python nsf_bigvgan_inference.py --config configs/nsf_bigvgan.yaml --model nsf_bigvgan_g.pth --wave test.wav | |
| ## Data preprocessing | |
| - 1, re-sampling: 32kHz | |
| > python prepare/preprocess_a.py -w ./data_raw -o ./data_bigvgan/waves-32k | |
| - 3, extract pitch | |
| > python prepare/preprocess_f0.py -w data_bigvgan/waves-32k/ -p data_bigvgan/pitch | |
| - 4, extract mel: [100, length] | |
| > python prepare/preprocess_spec.py -w data_bigvgan/waves-32k/ -s data_bigvgan/mel | |
| - 5, generate training index | |
| > python prepare/preprocess_train.py | |
| ```shell | |
| data_bigvgan/ | |
| │ | |
| └── waves-32k | |
| │ └── speaker0 | |
| │ │ ├── 000001.wav | |
| │ │ └── 000xxx.wav | |
| │ └── speaker1 | |
| │ ├── 000001.wav | |
| │ └── 000xxx.wav | |
| └── pitch | |
| │ └── speaker0 | |
| │ │ ├── 000001.pit.npy | |
| │ │ └── 000xxx.pit.npy | |
| │ └── speaker1 | |
| │ ├── 000001.pit.npy | |
| │ └── 000xxx.pit.npy | |
| └── mel | |
| └── speaker0 | |
| │ ├── 000001.mel.pt | |
| │ └── 000xxx.mel.pt | |
| └── speaker1 | |
| ├── 000001.mel.pt | |
| └── 000xxx.mel.pt | |
| ``` | |
| ## Train | |
| - 1, start training | |
| > python nsf_bigvgan_trainer.py -c configs/nsf_bigvgan.yaml -n nsf_bigvgan | |
| - 2, resume training | |
| > python nsf_bigvgan_trainer.py -c configs/nsf_bigvgan.yaml -n nsf_bigvgan -p chkpt/nsf_bigvgan/***.pth | |
| - 3, view log | |
| > tensorboard --logdir logs/ | |
| ## Inference | |
| - 1, export inference model | |
| > python nsf_bigvgan_export.py --config configs/maxgan.yaml --checkpoint_path chkpt/nsf_bigvgan/***.pt | |
| - 2, extract mel | |
| > python spec/inference.py -w test.wav -m test.mel.pt | |
| - 3, extract F0 | |
| > python pitch/inference.py -w test.wav -p test.csv | |
| - 4, infer | |
| > python nsf_bigvgan_inference.py --config configs/nsf_bigvgan.yaml --model nsf_bigvgan_g.pth --wave test.wav | |
| or | |
| > python nsf_bigvgan_inference.py --config configs/nsf_bigvgan.yaml --model nsf_bigvgan_g.pth --mel test.mel.pt --pit test.csv | |
| ## Augmentation of mel | |
| For the over smooth output of acoustic model, we use gaussian blur for mel when train vocoder | |
| ``` | |
| # gaussian blur | |
| model_b = get_gaussian_kernel(kernel_size=5, sigma=2, channels=1).to(device) | |
| # mel blur | |
| mel_b = mel[:, None, :, :] | |
| mel_b = model_b(mel_b) | |
| mel_b = torch.squeeze(mel_b, 1) | |
| mel_r = torch.rand(1).to(device) * 0.5 | |
| mel_b = (1 - mel_r) * mel_b + mel_r * mel | |
| # generator | |
| optim_g.zero_grad() | |
| fake_audio = model_g(mel_b, pit) | |
| ``` | |
| 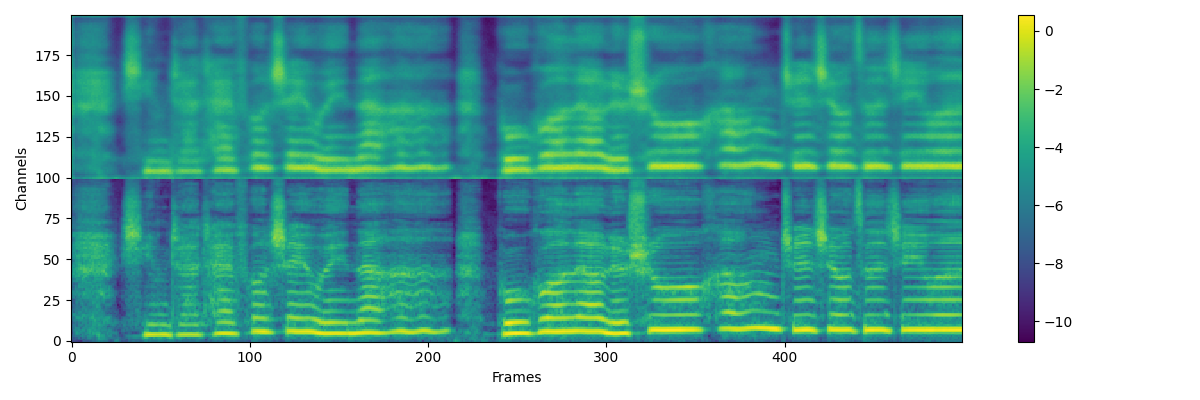 | |
| ## Source of code and References | |
| https://github.com/nii-yamagishilab/project-NN-Pytorch-scripts/tree/master/project/01-nsf | |
| https://github.com/mindslab-ai/univnet [[paper]](https://arxiv.org/abs/2106.07889) | |
| https://github.com/NVIDIA/BigVGAN [[paper]](https://arxiv.org/abs/2206.04658) |