Spaces:
Running

Running
Commit
·
3aa4060
1
Parent(s):
c79c2bf
Upload 39 files
Browse files- LICENSE +21 -0
- bigvgan/LICENSE +21 -0
- bigvgan/README.md +138 -0
- bigvgan/configs/nsf_bigvgan.yaml +60 -0
- bigvgan/inference.py +71 -0
- bigvgan/model/__init__.py +1 -0
- bigvgan/model/alias/__init__.py +6 -0
- bigvgan/model/alias/act.py +129 -0
- bigvgan/model/alias/filter.py +95 -0
- bigvgan/model/alias/resample.py +49 -0
- bigvgan/model/bigv.py +64 -0
- bigvgan/model/generator.py +143 -0
- bigvgan/model/nsf.py +394 -0
- bigvgan_pretrain/README.md +5 -0
- bigvgan_pretrain/nsf_bigvgan_pretrain_32K.pth +3 -0
- configs/base.yaml +41 -0
- grad/LICENSE +19 -0
- grad/__init__.py +0 -0
- grad/base.py +29 -0
- grad/diffusion.py +253 -0
- grad/encoder.py +327 -0
- grad/model.py +148 -0
- grad/reversal.py +62 -0
- grad/solver.py +190 -0
- grad/ssim.py +59 -0
- grad/utils.py +99 -0
- grad_extend/data.py +135 -0
- grad_extend/train.py +188 -0
- grad_extend/utils.py +77 -0
- grad_pretrain/README.md +3 -0
- hubert/__init__.py +0 -0
- hubert/hubert_model.py +229 -0
- hubert/inference.py +67 -0
- hubert_pretrain/README.md +3 -0
- hubert_pretrain/hubert-soft-0d54a1f4.pt +3 -0
- pitch/__init__.py +1 -0
- pitch/inference.py +86 -0
- requirements.txt +11 -0
- spec/inference.py +113 -0
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 PlayVoice
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
bigvgan/LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2022 PlayVoice
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
bigvgan/README.md
ADDED
|
@@ -0,0 +1,138 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
<h1> Neural Source-Filter BigVGAN </h1>
|
| 3 |
+
Just For Fun
|
| 4 |
+
</div>
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
## Dataset preparation
|
| 9 |
+
|
| 10 |
+
Put the dataset into the data_raw directory according to the following file structure
|
| 11 |
+
```shell
|
| 12 |
+
data_raw
|
| 13 |
+
├───speaker0
|
| 14 |
+
│ ├───000001.wav
|
| 15 |
+
│ ├───...
|
| 16 |
+
│ └───000xxx.wav
|
| 17 |
+
└───speaker1
|
| 18 |
+
├───000001.wav
|
| 19 |
+
├───...
|
| 20 |
+
└───000xxx.wav
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
## Install dependencies
|
| 24 |
+
|
| 25 |
+
- 1 software dependency
|
| 26 |
+
|
| 27 |
+
> pip install -r requirements.txt
|
| 28 |
+
|
| 29 |
+
- 2 download [release](https://github.com/PlayVoice/NSF-BigVGAN/releases/tag/debug) model, and test
|
| 30 |
+
|
| 31 |
+
> python nsf_bigvgan_inference.py --config configs/nsf_bigvgan.yaml --model nsf_bigvgan_g.pth --wave test.wav
|
| 32 |
+
|
| 33 |
+
## Data preprocessing
|
| 34 |
+
|
| 35 |
+
- 1, re-sampling: 32kHz
|
| 36 |
+
|
| 37 |
+
> python prepare/preprocess_a.py -w ./data_raw -o ./data_bigvgan/waves-32k
|
| 38 |
+
|
| 39 |
+
- 3, extract pitch
|
| 40 |
+
|
| 41 |
+
> python prepare/preprocess_f0.py -w data_bigvgan/waves-32k/ -p data_bigvgan/pitch
|
| 42 |
+
|
| 43 |
+
- 4, extract mel: [100, length]
|
| 44 |
+
|
| 45 |
+
> python prepare/preprocess_spec.py -w data_bigvgan/waves-32k/ -s data_bigvgan/mel
|
| 46 |
+
|
| 47 |
+
- 5, generate training index
|
| 48 |
+
|
| 49 |
+
> python prepare/preprocess_train.py
|
| 50 |
+
|
| 51 |
+
```shell
|
| 52 |
+
data_bigvgan/
|
| 53 |
+
│
|
| 54 |
+
└── waves-32k
|
| 55 |
+
│ └── speaker0
|
| 56 |
+
│ │ ├── 000001.wav
|
| 57 |
+
│ │ └── 000xxx.wav
|
| 58 |
+
│ └── speaker1
|
| 59 |
+
│ ├── 000001.wav
|
| 60 |
+
│ └── 000xxx.wav
|
| 61 |
+
└── pitch
|
| 62 |
+
│ └── speaker0
|
| 63 |
+
│ │ ├── 000001.pit.npy
|
| 64 |
+
│ │ └── 000xxx.pit.npy
|
| 65 |
+
│ └── speaker1
|
| 66 |
+
│ ├── 000001.pit.npy
|
| 67 |
+
│ └── 000xxx.pit.npy
|
| 68 |
+
└── mel
|
| 69 |
+
└── speaker0
|
| 70 |
+
│ ├── 000001.mel.pt
|
| 71 |
+
│ └── 000xxx.mel.pt
|
| 72 |
+
└── speaker1
|
| 73 |
+
├── 000001.mel.pt
|
| 74 |
+
└── 000xxx.mel.pt
|
| 75 |
+
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
## Train
|
| 79 |
+
|
| 80 |
+
- 1, start training
|
| 81 |
+
|
| 82 |
+
> python nsf_bigvgan_trainer.py -c configs/nsf_bigvgan.yaml -n nsf_bigvgan
|
| 83 |
+
|
| 84 |
+
- 2, resume training
|
| 85 |
+
|
| 86 |
+
> python nsf_bigvgan_trainer.py -c configs/nsf_bigvgan.yaml -n nsf_bigvgan -p chkpt/nsf_bigvgan/***.pth
|
| 87 |
+
|
| 88 |
+
- 3, view log
|
| 89 |
+
|
| 90 |
+
> tensorboard --logdir logs/
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
## Inference
|
| 94 |
+
|
| 95 |
+
- 1, export inference model
|
| 96 |
+
|
| 97 |
+
> python nsf_bigvgan_export.py --config configs/maxgan.yaml --checkpoint_path chkpt/nsf_bigvgan/***.pt
|
| 98 |
+
|
| 99 |
+
- 2, extract mel
|
| 100 |
+
|
| 101 |
+
> python spec/inference.py -w test.wav -m test.mel.pt
|
| 102 |
+
|
| 103 |
+
- 3, extract F0
|
| 104 |
+
|
| 105 |
+
> python pitch/inference.py -w test.wav -p test.csv
|
| 106 |
+
|
| 107 |
+
- 4, infer
|
| 108 |
+
|
| 109 |
+
> python nsf_bigvgan_inference.py --config configs/nsf_bigvgan.yaml --model nsf_bigvgan_g.pth --wave test.wav
|
| 110 |
+
|
| 111 |
+
or
|
| 112 |
+
|
| 113 |
+
> python nsf_bigvgan_inference.py --config configs/nsf_bigvgan.yaml --model nsf_bigvgan_g.pth --mel test.mel.pt --pit test.csv
|
| 114 |
+
|
| 115 |
+
## Augmentation of mel
|
| 116 |
+
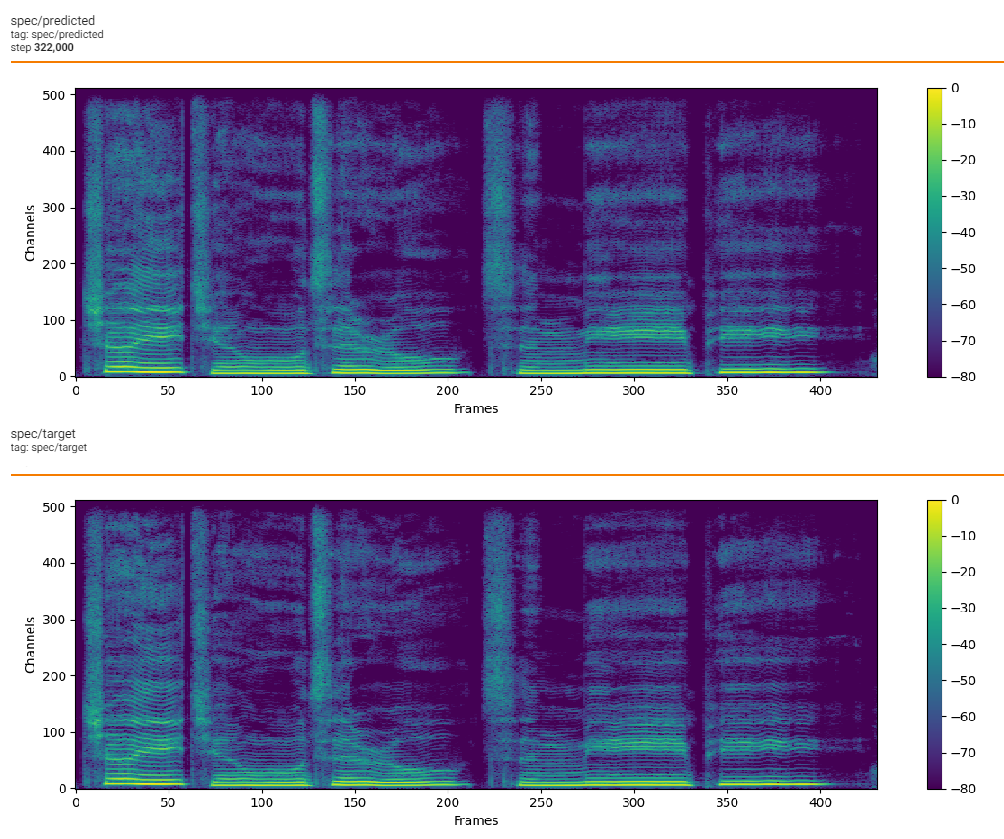
For the over smooth output of acoustic model, we use gaussian blur for mel when train vocoder
|
| 117 |
+
```
|
| 118 |
+
# gaussian blur
|
| 119 |
+
model_b = get_gaussian_kernel(kernel_size=5, sigma=2, channels=1).to(device)
|
| 120 |
+
# mel blur
|
| 121 |
+
mel_b = mel[:, None, :, :]
|
| 122 |
+
mel_b = model_b(mel_b)
|
| 123 |
+
mel_b = torch.squeeze(mel_b, 1)
|
| 124 |
+
mel_r = torch.rand(1).to(device) * 0.5
|
| 125 |
+
mel_b = (1 - mel_r) * mel_b + mel_r * mel
|
| 126 |
+
# generator
|
| 127 |
+
optim_g.zero_grad()
|
| 128 |
+
fake_audio = model_g(mel_b, pit)
|
| 129 |
+
```
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
## Source of code and References
|
| 133 |
+
|
| 134 |
+
https://github.com/nii-yamagishilab/project-NN-Pytorch-scripts/tree/master/project/01-nsf
|
| 135 |
+
|
| 136 |
+
https://github.com/mindslab-ai/univnet [[paper]](https://arxiv.org/abs/2106.07889)
|
| 137 |
+
|
| 138 |
+
https://github.com/NVIDIA/BigVGAN [[paper]](https://arxiv.org/abs/2206.04658)
|
bigvgan/configs/nsf_bigvgan.yaml
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
data:
|
| 2 |
+
train_file: 'files/train.txt'
|
| 3 |
+
val_file: 'files/valid.txt'
|
| 4 |
+
#############################
|
| 5 |
+
train:
|
| 6 |
+
num_workers: 4
|
| 7 |
+
batch_size: 8
|
| 8 |
+
optimizer: 'adam'
|
| 9 |
+
seed: 1234
|
| 10 |
+
adam:
|
| 11 |
+
lr: 0.0002
|
| 12 |
+
beta1: 0.8
|
| 13 |
+
beta2: 0.99
|
| 14 |
+
mel_lamb: 5
|
| 15 |
+
stft_lamb: 2.5
|
| 16 |
+
pretrain: ''
|
| 17 |
+
lora: False
|
| 18 |
+
#############################
|
| 19 |
+
audio:
|
| 20 |
+
n_mel_channels: 100
|
| 21 |
+
segment_length: 12800 # Should be multiple of 320
|
| 22 |
+
filter_length: 1024
|
| 23 |
+
hop_length: 320 # WARNING: this can't be changed.
|
| 24 |
+
win_length: 1024
|
| 25 |
+
sampling_rate: 32000
|
| 26 |
+
mel_fmin: 40.0
|
| 27 |
+
mel_fmax: 16000.0
|
| 28 |
+
#############################
|
| 29 |
+
gen:
|
| 30 |
+
mel_channels: 100
|
| 31 |
+
upsample_rates: [5,4,2,2,2,2]
|
| 32 |
+
upsample_kernel_sizes: [15,8,4,4,4,4]
|
| 33 |
+
upsample_initial_channel: 320
|
| 34 |
+
resblock_kernel_sizes: [3,7,11]
|
| 35 |
+
resblock_dilation_sizes: [[1,3,5], [1,3,5], [1,3,5]]
|
| 36 |
+
#############################
|
| 37 |
+
mpd:
|
| 38 |
+
periods: [2,3,5,7,11]
|
| 39 |
+
kernel_size: 5
|
| 40 |
+
stride: 3
|
| 41 |
+
use_spectral_norm: False
|
| 42 |
+
lReLU_slope: 0.2
|
| 43 |
+
#############################
|
| 44 |
+
mrd:
|
| 45 |
+
resolutions: "[(1024, 120, 600), (2048, 240, 1200), (4096, 480, 2400), (512, 50, 240)]" # (filter_length, hop_length, win_length)
|
| 46 |
+
use_spectral_norm: False
|
| 47 |
+
lReLU_slope: 0.2
|
| 48 |
+
#############################
|
| 49 |
+
dist_config:
|
| 50 |
+
dist_backend: "nccl"
|
| 51 |
+
dist_url: "tcp://localhost:54321"
|
| 52 |
+
world_size: 1
|
| 53 |
+
#############################
|
| 54 |
+
log:
|
| 55 |
+
info_interval: 100
|
| 56 |
+
eval_interval: 1000
|
| 57 |
+
save_interval: 10000
|
| 58 |
+
num_audio: 6
|
| 59 |
+
pth_dir: 'chkpt'
|
| 60 |
+
log_dir: 'logs'
|
bigvgan/inference.py
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys,os
|
| 2 |
+
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
|
| 3 |
+
import torch
|
| 4 |
+
import argparse
|
| 5 |
+
|
| 6 |
+
from omegaconf import OmegaConf
|
| 7 |
+
from scipy.io.wavfile import write
|
| 8 |
+
from bigvgan.model.generator import Generator
|
| 9 |
+
from pitch import load_csv_pitch
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def load_bigv_model(checkpoint_path, model):
|
| 13 |
+
assert os.path.isfile(checkpoint_path)
|
| 14 |
+
checkpoint_dict = torch.load(checkpoint_path, map_location="cpu")
|
| 15 |
+
saved_state_dict = checkpoint_dict["model_g"]
|
| 16 |
+
state_dict = model.state_dict()
|
| 17 |
+
new_state_dict = {}
|
| 18 |
+
for k, v in state_dict.items():
|
| 19 |
+
try:
|
| 20 |
+
new_state_dict[k] = saved_state_dict[k]
|
| 21 |
+
except:
|
| 22 |
+
print("%s is not in the checkpoint" % k)
|
| 23 |
+
new_state_dict[k] = v
|
| 24 |
+
model.load_state_dict(new_state_dict)
|
| 25 |
+
return model
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def main(args):
|
| 29 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 30 |
+
hp = OmegaConf.load(args.config)
|
| 31 |
+
model = Generator(hp)
|
| 32 |
+
load_bigv_model(args.model, model)
|
| 33 |
+
model.eval()
|
| 34 |
+
model.to(device)
|
| 35 |
+
|
| 36 |
+
mel = torch.load(args.mel)
|
| 37 |
+
|
| 38 |
+
pit = load_csv_pitch(args.pit)
|
| 39 |
+
pit = torch.FloatTensor(pit)
|
| 40 |
+
|
| 41 |
+
len_pit = pit.size()[0]
|
| 42 |
+
len_mel = mel.size()[1]
|
| 43 |
+
len_min = min(len_pit, len_mel)
|
| 44 |
+
pit = pit[:len_min]
|
| 45 |
+
mel = mel[:, :len_min]
|
| 46 |
+
|
| 47 |
+
with torch.no_grad():
|
| 48 |
+
mel = mel.unsqueeze(0).to(device)
|
| 49 |
+
pit = pit.unsqueeze(0).to(device)
|
| 50 |
+
audio = model.inference(mel, pit)
|
| 51 |
+
audio = audio.cpu().detach().numpy()
|
| 52 |
+
|
| 53 |
+
pitwav = model.pitch2wav(pit)
|
| 54 |
+
pitwav = pitwav.cpu().detach().numpy()
|
| 55 |
+
|
| 56 |
+
write("gvc_out.wav", hp.audio.sampling_rate, audio)
|
| 57 |
+
write("gvc_pitch.wav", hp.audio.sampling_rate, pitwav)
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
if __name__ == '__main__':
|
| 61 |
+
parser = argparse.ArgumentParser()
|
| 62 |
+
parser.add_argument('--mel', type=str,
|
| 63 |
+
help="Path of content vector.")
|
| 64 |
+
parser.add_argument('--pit', type=str,
|
| 65 |
+
help="Path of pitch csv file.")
|
| 66 |
+
args = parser.parse_args()
|
| 67 |
+
|
| 68 |
+
args.config = "./bigvgan/configs/nsf_bigvgan.yaml"
|
| 69 |
+
args.model = "./bigvgan_pretrain/nsf_bigvgan_pretrain_32K.pth"
|
| 70 |
+
|
| 71 |
+
main(args)
|
bigvgan/model/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .alias.act import SnakeAlias
|
bigvgan/model/alias/__init__.py
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Adapted from https://github.com/junjun3518/alias-free-torch under the Apache License 2.0
|
| 2 |
+
# LICENSE is in incl_licenses directory.
|
| 3 |
+
|
| 4 |
+
from .filter import *
|
| 5 |
+
from .resample import *
|
| 6 |
+
from .act import *
|
bigvgan/model/alias/act.py
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Adapted from https://github.com/junjun3518/alias-free-torch under the Apache License 2.0
|
| 2 |
+
# LICENSE is in incl_licenses directory.
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
|
| 8 |
+
from torch import sin, pow
|
| 9 |
+
from torch.nn import Parameter
|
| 10 |
+
from .resample import UpSample1d, DownSample1d
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class Activation1d(nn.Module):
|
| 14 |
+
def __init__(self,
|
| 15 |
+
activation,
|
| 16 |
+
up_ratio: int = 2,
|
| 17 |
+
down_ratio: int = 2,
|
| 18 |
+
up_kernel_size: int = 12,
|
| 19 |
+
down_kernel_size: int = 12):
|
| 20 |
+
super().__init__()
|
| 21 |
+
self.up_ratio = up_ratio
|
| 22 |
+
self.down_ratio = down_ratio
|
| 23 |
+
self.act = activation
|
| 24 |
+
self.upsample = UpSample1d(up_ratio, up_kernel_size)
|
| 25 |
+
self.downsample = DownSample1d(down_ratio, down_kernel_size)
|
| 26 |
+
|
| 27 |
+
# x: [B,C,T]
|
| 28 |
+
def forward(self, x):
|
| 29 |
+
x = self.upsample(x)
|
| 30 |
+
x = self.act(x)
|
| 31 |
+
x = self.downsample(x)
|
| 32 |
+
|
| 33 |
+
return x
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class SnakeBeta(nn.Module):
|
| 37 |
+
'''
|
| 38 |
+
A modified Snake function which uses separate parameters for the magnitude of the periodic components
|
| 39 |
+
Shape:
|
| 40 |
+
- Input: (B, C, T)
|
| 41 |
+
- Output: (B, C, T), same shape as the input
|
| 42 |
+
Parameters:
|
| 43 |
+
- alpha - trainable parameter that controls frequency
|
| 44 |
+
- beta - trainable parameter that controls magnitude
|
| 45 |
+
References:
|
| 46 |
+
- This activation function is a modified version based on this paper by Liu Ziyin, Tilman Hartwig, Masahito Ueda:
|
| 47 |
+
https://arxiv.org/abs/2006.08195
|
| 48 |
+
Examples:
|
| 49 |
+
>>> a1 = snakebeta(256)
|
| 50 |
+
>>> x = torch.randn(256)
|
| 51 |
+
>>> x = a1(x)
|
| 52 |
+
'''
|
| 53 |
+
|
| 54 |
+
def __init__(self, in_features, alpha=1.0, alpha_trainable=True, alpha_logscale=False):
|
| 55 |
+
'''
|
| 56 |
+
Initialization.
|
| 57 |
+
INPUT:
|
| 58 |
+
- in_features: shape of the input
|
| 59 |
+
- alpha - trainable parameter that controls frequency
|
| 60 |
+
- beta - trainable parameter that controls magnitude
|
| 61 |
+
alpha is initialized to 1 by default, higher values = higher-frequency.
|
| 62 |
+
beta is initialized to 1 by default, higher values = higher-magnitude.
|
| 63 |
+
alpha will be trained along with the rest of your model.
|
| 64 |
+
'''
|
| 65 |
+
super(SnakeBeta, self).__init__()
|
| 66 |
+
self.in_features = in_features
|
| 67 |
+
# initialize alpha
|
| 68 |
+
self.alpha_logscale = alpha_logscale
|
| 69 |
+
if self.alpha_logscale: # log scale alphas initialized to zeros
|
| 70 |
+
self.alpha = Parameter(torch.zeros(in_features) * alpha)
|
| 71 |
+
self.beta = Parameter(torch.zeros(in_features) * alpha)
|
| 72 |
+
else: # linear scale alphas initialized to ones
|
| 73 |
+
self.alpha = Parameter(torch.ones(in_features) * alpha)
|
| 74 |
+
self.beta = Parameter(torch.ones(in_features) * alpha)
|
| 75 |
+
self.alpha.requires_grad = alpha_trainable
|
| 76 |
+
self.beta.requires_grad = alpha_trainable
|
| 77 |
+
self.no_div_by_zero = 0.000000001
|
| 78 |
+
|
| 79 |
+
def forward(self, x):
|
| 80 |
+
'''
|
| 81 |
+
Forward pass of the function.
|
| 82 |
+
Applies the function to the input elementwise.
|
| 83 |
+
SnakeBeta = x + 1/b * sin^2 (xa)
|
| 84 |
+
'''
|
| 85 |
+
alpha = self.alpha.unsqueeze(
|
| 86 |
+
0).unsqueeze(-1) # line up with x to [B, C, T]
|
| 87 |
+
beta = self.beta.unsqueeze(0).unsqueeze(-1)
|
| 88 |
+
if self.alpha_logscale:
|
| 89 |
+
alpha = torch.exp(alpha)
|
| 90 |
+
beta = torch.exp(beta)
|
| 91 |
+
x = x + (1.0 / (beta + self.no_div_by_zero)) * pow(sin(x * alpha), 2)
|
| 92 |
+
return x
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
class Mish(nn.Module):
|
| 96 |
+
"""
|
| 97 |
+
Mish activation function is proposed in "Mish: A Self
|
| 98 |
+
Regularized Non-Monotonic Neural Activation Function"
|
| 99 |
+
paper, https://arxiv.org/abs/1908.08681.
|
| 100 |
+
"""
|
| 101 |
+
|
| 102 |
+
def __init__(self):
|
| 103 |
+
super().__init__()
|
| 104 |
+
|
| 105 |
+
def forward(self, x):
|
| 106 |
+
return x * torch.tanh(F.softplus(x))
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
class SnakeAlias(nn.Module):
|
| 110 |
+
def __init__(self,
|
| 111 |
+
channels,
|
| 112 |
+
up_ratio: int = 2,
|
| 113 |
+
down_ratio: int = 2,
|
| 114 |
+
up_kernel_size: int = 12,
|
| 115 |
+
down_kernel_size: int = 12):
|
| 116 |
+
super().__init__()
|
| 117 |
+
self.up_ratio = up_ratio
|
| 118 |
+
self.down_ratio = down_ratio
|
| 119 |
+
self.act = SnakeBeta(channels, alpha_logscale=True)
|
| 120 |
+
self.upsample = UpSample1d(up_ratio, up_kernel_size)
|
| 121 |
+
self.downsample = DownSample1d(down_ratio, down_kernel_size)
|
| 122 |
+
|
| 123 |
+
# x: [B,C,T]
|
| 124 |
+
def forward(self, x):
|
| 125 |
+
x = self.upsample(x)
|
| 126 |
+
x = self.act(x)
|
| 127 |
+
x = self.downsample(x)
|
| 128 |
+
|
| 129 |
+
return x
|
bigvgan/model/alias/filter.py
ADDED
|
@@ -0,0 +1,95 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Adapted from https://github.com/junjun3518/alias-free-torch under the Apache License 2.0
|
| 2 |
+
# LICENSE is in incl_licenses directory.
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
import math
|
| 8 |
+
|
| 9 |
+
if 'sinc' in dir(torch):
|
| 10 |
+
sinc = torch.sinc
|
| 11 |
+
else:
|
| 12 |
+
# This code is adopted from adefossez's julius.core.sinc under the MIT License
|
| 13 |
+
# https://adefossez.github.io/julius/julius/core.html
|
| 14 |
+
# LICENSE is in incl_licenses directory.
|
| 15 |
+
def sinc(x: torch.Tensor):
|
| 16 |
+
"""
|
| 17 |
+
Implementation of sinc, i.e. sin(pi * x) / (pi * x)
|
| 18 |
+
__Warning__: Different to julius.sinc, the input is multiplied by `pi`!
|
| 19 |
+
"""
|
| 20 |
+
return torch.where(x == 0,
|
| 21 |
+
torch.tensor(1., device=x.device, dtype=x.dtype),
|
| 22 |
+
torch.sin(math.pi * x) / math.pi / x)
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
# This code is adopted from adefossez's julius.lowpass.LowPassFilters under the MIT License
|
| 26 |
+
# https://adefossez.github.io/julius/julius/lowpass.html
|
| 27 |
+
# LICENSE is in incl_licenses directory.
|
| 28 |
+
def kaiser_sinc_filter1d(cutoff, half_width, kernel_size): # return filter [1,1,kernel_size]
|
| 29 |
+
even = (kernel_size % 2 == 0)
|
| 30 |
+
half_size = kernel_size // 2
|
| 31 |
+
|
| 32 |
+
#For kaiser window
|
| 33 |
+
delta_f = 4 * half_width
|
| 34 |
+
A = 2.285 * (half_size - 1) * math.pi * delta_f + 7.95
|
| 35 |
+
if A > 50.:
|
| 36 |
+
beta = 0.1102 * (A - 8.7)
|
| 37 |
+
elif A >= 21.:
|
| 38 |
+
beta = 0.5842 * (A - 21)**0.4 + 0.07886 * (A - 21.)
|
| 39 |
+
else:
|
| 40 |
+
beta = 0.
|
| 41 |
+
window = torch.kaiser_window(kernel_size, beta=beta, periodic=False)
|
| 42 |
+
|
| 43 |
+
# ratio = 0.5/cutoff -> 2 * cutoff = 1 / ratio
|
| 44 |
+
if even:
|
| 45 |
+
time = (torch.arange(-half_size, half_size) + 0.5)
|
| 46 |
+
else:
|
| 47 |
+
time = torch.arange(kernel_size) - half_size
|
| 48 |
+
if cutoff == 0:
|
| 49 |
+
filter_ = torch.zeros_like(time)
|
| 50 |
+
else:
|
| 51 |
+
filter_ = 2 * cutoff * window * sinc(2 * cutoff * time)
|
| 52 |
+
# Normalize filter to have sum = 1, otherwise we will have a small leakage
|
| 53 |
+
# of the constant component in the input signal.
|
| 54 |
+
filter_ /= filter_.sum()
|
| 55 |
+
filter = filter_.view(1, 1, kernel_size)
|
| 56 |
+
|
| 57 |
+
return filter
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
class LowPassFilter1d(nn.Module):
|
| 61 |
+
def __init__(self,
|
| 62 |
+
cutoff=0.5,
|
| 63 |
+
half_width=0.6,
|
| 64 |
+
stride: int = 1,
|
| 65 |
+
padding: bool = True,
|
| 66 |
+
padding_mode: str = 'replicate',
|
| 67 |
+
kernel_size: int = 12):
|
| 68 |
+
# kernel_size should be even number for stylegan3 setup,
|
| 69 |
+
# in this implementation, odd number is also possible.
|
| 70 |
+
super().__init__()
|
| 71 |
+
if cutoff < -0.:
|
| 72 |
+
raise ValueError("Minimum cutoff must be larger than zero.")
|
| 73 |
+
if cutoff > 0.5:
|
| 74 |
+
raise ValueError("A cutoff above 0.5 does not make sense.")
|
| 75 |
+
self.kernel_size = kernel_size
|
| 76 |
+
self.even = (kernel_size % 2 == 0)
|
| 77 |
+
self.pad_left = kernel_size // 2 - int(self.even)
|
| 78 |
+
self.pad_right = kernel_size // 2
|
| 79 |
+
self.stride = stride
|
| 80 |
+
self.padding = padding
|
| 81 |
+
self.padding_mode = padding_mode
|
| 82 |
+
filter = kaiser_sinc_filter1d(cutoff, half_width, kernel_size)
|
| 83 |
+
self.register_buffer("filter", filter)
|
| 84 |
+
|
| 85 |
+
#input [B, C, T]
|
| 86 |
+
def forward(self, x):
|
| 87 |
+
_, C, _ = x.shape
|
| 88 |
+
|
| 89 |
+
if self.padding:
|
| 90 |
+
x = F.pad(x, (self.pad_left, self.pad_right),
|
| 91 |
+
mode=self.padding_mode)
|
| 92 |
+
out = F.conv1d(x, self.filter.expand(C, -1, -1),
|
| 93 |
+
stride=self.stride, groups=C)
|
| 94 |
+
|
| 95 |
+
return out
|
bigvgan/model/alias/resample.py
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Adapted from https://github.com/junjun3518/alias-free-torch under the Apache License 2.0
|
| 2 |
+
# LICENSE is in incl_licenses directory.
|
| 3 |
+
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
from torch.nn import functional as F
|
| 6 |
+
from .filter import LowPassFilter1d
|
| 7 |
+
from .filter import kaiser_sinc_filter1d
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class UpSample1d(nn.Module):
|
| 11 |
+
def __init__(self, ratio=2, kernel_size=None):
|
| 12 |
+
super().__init__()
|
| 13 |
+
self.ratio = ratio
|
| 14 |
+
self.kernel_size = int(6 * ratio // 2) * 2 if kernel_size is None else kernel_size
|
| 15 |
+
self.stride = ratio
|
| 16 |
+
self.pad = self.kernel_size // ratio - 1
|
| 17 |
+
self.pad_left = self.pad * self.stride + (self.kernel_size - self.stride) // 2
|
| 18 |
+
self.pad_right = self.pad * self.stride + (self.kernel_size - self.stride + 1) // 2
|
| 19 |
+
filter = kaiser_sinc_filter1d(cutoff=0.5 / ratio,
|
| 20 |
+
half_width=0.6 / ratio,
|
| 21 |
+
kernel_size=self.kernel_size)
|
| 22 |
+
self.register_buffer("filter", filter)
|
| 23 |
+
|
| 24 |
+
# x: [B, C, T]
|
| 25 |
+
def forward(self, x):
|
| 26 |
+
_, C, _ = x.shape
|
| 27 |
+
|
| 28 |
+
x = F.pad(x, (self.pad, self.pad), mode='replicate')
|
| 29 |
+
x = self.ratio * F.conv_transpose1d(
|
| 30 |
+
x, self.filter.expand(C, -1, -1), stride=self.stride, groups=C)
|
| 31 |
+
x = x[..., self.pad_left:-self.pad_right]
|
| 32 |
+
|
| 33 |
+
return x
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class DownSample1d(nn.Module):
|
| 37 |
+
def __init__(self, ratio=2, kernel_size=None):
|
| 38 |
+
super().__init__()
|
| 39 |
+
self.ratio = ratio
|
| 40 |
+
self.kernel_size = int(6 * ratio // 2) * 2 if kernel_size is None else kernel_size
|
| 41 |
+
self.lowpass = LowPassFilter1d(cutoff=0.5 / ratio,
|
| 42 |
+
half_width=0.6 / ratio,
|
| 43 |
+
stride=ratio,
|
| 44 |
+
kernel_size=self.kernel_size)
|
| 45 |
+
|
| 46 |
+
def forward(self, x):
|
| 47 |
+
xx = self.lowpass(x)
|
| 48 |
+
|
| 49 |
+
return xx
|
bigvgan/model/bigv.py
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
|
| 4 |
+
from torch.nn import Conv1d
|
| 5 |
+
from torch.nn.utils import weight_norm, remove_weight_norm
|
| 6 |
+
from .alias.act import SnakeAlias
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def init_weights(m, mean=0.0, std=0.01):
|
| 10 |
+
classname = m.__class__.__name__
|
| 11 |
+
if classname.find("Conv") != -1:
|
| 12 |
+
m.weight.data.normal_(mean, std)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def get_padding(kernel_size, dilation=1):
|
| 16 |
+
return int((kernel_size*dilation - dilation)/2)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class AMPBlock(torch.nn.Module):
|
| 20 |
+
def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):
|
| 21 |
+
super(AMPBlock, self).__init__()
|
| 22 |
+
self.convs1 = nn.ModuleList([
|
| 23 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[0],
|
| 24 |
+
padding=get_padding(kernel_size, dilation[0]))),
|
| 25 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[1],
|
| 26 |
+
padding=get_padding(kernel_size, dilation[1]))),
|
| 27 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=dilation[2],
|
| 28 |
+
padding=get_padding(kernel_size, dilation[2])))
|
| 29 |
+
])
|
| 30 |
+
self.convs1.apply(init_weights)
|
| 31 |
+
|
| 32 |
+
self.convs2 = nn.ModuleList([
|
| 33 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
|
| 34 |
+
padding=get_padding(kernel_size, 1))),
|
| 35 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
|
| 36 |
+
padding=get_padding(kernel_size, 1))),
|
| 37 |
+
weight_norm(Conv1d(channels, channels, kernel_size, 1, dilation=1,
|
| 38 |
+
padding=get_padding(kernel_size, 1)))
|
| 39 |
+
])
|
| 40 |
+
self.convs2.apply(init_weights)
|
| 41 |
+
|
| 42 |
+
# total number of conv layers
|
| 43 |
+
self.num_layers = len(self.convs1) + len(self.convs2)
|
| 44 |
+
|
| 45 |
+
# periodic nonlinearity with snakebeta function and anti-aliasing
|
| 46 |
+
self.activations = nn.ModuleList([
|
| 47 |
+
SnakeAlias(channels) for _ in range(self.num_layers)
|
| 48 |
+
])
|
| 49 |
+
|
| 50 |
+
def forward(self, x):
|
| 51 |
+
acts1, acts2 = self.activations[::2], self.activations[1::2]
|
| 52 |
+
for c1, c2, a1, a2 in zip(self.convs1, self.convs2, acts1, acts2):
|
| 53 |
+
xt = a1(x)
|
| 54 |
+
xt = c1(xt)
|
| 55 |
+
xt = a2(xt)
|
| 56 |
+
xt = c2(xt)
|
| 57 |
+
x = xt + x
|
| 58 |
+
return x
|
| 59 |
+
|
| 60 |
+
def remove_weight_norm(self):
|
| 61 |
+
for l in self.convs1:
|
| 62 |
+
remove_weight_norm(l)
|
| 63 |
+
for l in self.convs2:
|
| 64 |
+
remove_weight_norm(l)
|
bigvgan/model/generator.py
ADDED
|
@@ -0,0 +1,143 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
import numpy as np
|
| 5 |
+
|
| 6 |
+
from torch.nn import Conv1d
|
| 7 |
+
from torch.nn import ConvTranspose1d
|
| 8 |
+
from torch.nn.utils import weight_norm
|
| 9 |
+
from torch.nn.utils import remove_weight_norm
|
| 10 |
+
|
| 11 |
+
from .nsf import SourceModuleHnNSF
|
| 12 |
+
from .bigv import init_weights, AMPBlock, SnakeAlias
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class Generator(torch.nn.Module):
|
| 16 |
+
# this is our main BigVGAN model. Applies anti-aliased periodic activation for resblocks.
|
| 17 |
+
def __init__(self, hp):
|
| 18 |
+
super(Generator, self).__init__()
|
| 19 |
+
self.hp = hp
|
| 20 |
+
self.num_kernels = len(hp.gen.resblock_kernel_sizes)
|
| 21 |
+
self.num_upsamples = len(hp.gen.upsample_rates)
|
| 22 |
+
# pre conv
|
| 23 |
+
self.conv_pre = nn.utils.weight_norm(
|
| 24 |
+
Conv1d(hp.gen.mel_channels, hp.gen.upsample_initial_channel, 7, 1, padding=3))
|
| 25 |
+
# nsf
|
| 26 |
+
self.f0_upsamp = torch.nn.Upsample(
|
| 27 |
+
scale_factor=np.prod(hp.gen.upsample_rates))
|
| 28 |
+
self.m_source = SourceModuleHnNSF(sampling_rate=hp.audio.sampling_rate)
|
| 29 |
+
self.noise_convs = nn.ModuleList()
|
| 30 |
+
# transposed conv-based upsamplers. does not apply anti-aliasing
|
| 31 |
+
self.ups = nn.ModuleList()
|
| 32 |
+
for i, (u, k) in enumerate(zip(hp.gen.upsample_rates, hp.gen.upsample_kernel_sizes)):
|
| 33 |
+
# print(f'ups: {i} {k}, {u}, {(k - u) // 2}')
|
| 34 |
+
# base
|
| 35 |
+
self.ups.append(
|
| 36 |
+
weight_norm(
|
| 37 |
+
ConvTranspose1d(
|
| 38 |
+
hp.gen.upsample_initial_channel // (2 ** i),
|
| 39 |
+
hp.gen.upsample_initial_channel // (2 ** (i + 1)),
|
| 40 |
+
k,
|
| 41 |
+
u,
|
| 42 |
+
padding=(k - u) // 2)
|
| 43 |
+
)
|
| 44 |
+
)
|
| 45 |
+
# nsf
|
| 46 |
+
if i + 1 < len(hp.gen.upsample_rates):
|
| 47 |
+
stride_f0 = np.prod(hp.gen.upsample_rates[i + 1:])
|
| 48 |
+
stride_f0 = int(stride_f0)
|
| 49 |
+
self.noise_convs.append(
|
| 50 |
+
Conv1d(
|
| 51 |
+
1,
|
| 52 |
+
hp.gen.upsample_initial_channel // (2 ** (i + 1)),
|
| 53 |
+
kernel_size=stride_f0 * 2,
|
| 54 |
+
stride=stride_f0,
|
| 55 |
+
padding=stride_f0 // 2,
|
| 56 |
+
)
|
| 57 |
+
)
|
| 58 |
+
else:
|
| 59 |
+
self.noise_convs.append(
|
| 60 |
+
Conv1d(1, hp.gen.upsample_initial_channel //
|
| 61 |
+
(2 ** (i + 1)), kernel_size=1)
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
# residual blocks using anti-aliased multi-periodicity composition modules (AMP)
|
| 65 |
+
self.resblocks = nn.ModuleList()
|
| 66 |
+
for i in range(len(self.ups)):
|
| 67 |
+
ch = hp.gen.upsample_initial_channel // (2 ** (i + 1))
|
| 68 |
+
for k, d in zip(hp.gen.resblock_kernel_sizes, hp.gen.resblock_dilation_sizes):
|
| 69 |
+
self.resblocks.append(AMPBlock(ch, k, d))
|
| 70 |
+
|
| 71 |
+
# post conv
|
| 72 |
+
self.activation_post = SnakeAlias(ch)
|
| 73 |
+
self.conv_post = Conv1d(ch, 1, 7, 1, padding=3, bias=False)
|
| 74 |
+
# weight initialization
|
| 75 |
+
self.ups.apply(init_weights)
|
| 76 |
+
|
| 77 |
+
def forward(self, x, f0, train=True):
|
| 78 |
+
# nsf
|
| 79 |
+
f0 = f0[:, None]
|
| 80 |
+
f0 = self.f0_upsamp(f0).transpose(1, 2)
|
| 81 |
+
har_source = self.m_source(f0)
|
| 82 |
+
har_source = har_source.transpose(1, 2)
|
| 83 |
+
# pre conv
|
| 84 |
+
if train:
|
| 85 |
+
x = x + torch.randn_like(x) * 0.1 # Perturbation
|
| 86 |
+
x = self.conv_pre(x)
|
| 87 |
+
x = x * torch.tanh(F.softplus(x))
|
| 88 |
+
|
| 89 |
+
for i in range(self.num_upsamples):
|
| 90 |
+
# upsampling
|
| 91 |
+
x = self.ups[i](x)
|
| 92 |
+
# nsf
|
| 93 |
+
x_source = self.noise_convs[i](har_source)
|
| 94 |
+
x = x + x_source
|
| 95 |
+
# AMP blocks
|
| 96 |
+
xs = None
|
| 97 |
+
for j in range(self.num_kernels):
|
| 98 |
+
if xs is None:
|
| 99 |
+
xs = self.resblocks[i * self.num_kernels + j](x)
|
| 100 |
+
else:
|
| 101 |
+
xs += self.resblocks[i * self.num_kernels + j](x)
|
| 102 |
+
x = xs / self.num_kernels
|
| 103 |
+
|
| 104 |
+
# post conv
|
| 105 |
+
x = self.activation_post(x)
|
| 106 |
+
x = self.conv_post(x)
|
| 107 |
+
x = torch.tanh(x)
|
| 108 |
+
return x
|
| 109 |
+
|
| 110 |
+
def remove_weight_norm(self):
|
| 111 |
+
for l in self.ups:
|
| 112 |
+
remove_weight_norm(l)
|
| 113 |
+
for l in self.resblocks:
|
| 114 |
+
l.remove_weight_norm()
|
| 115 |
+
remove_weight_norm(self.conv_pre)
|
| 116 |
+
|
| 117 |
+
def eval(self, inference=False):
|
| 118 |
+
super(Generator, self).eval()
|
| 119 |
+
# don't remove weight norm while validation in training loop
|
| 120 |
+
if inference:
|
| 121 |
+
self.remove_weight_norm()
|
| 122 |
+
|
| 123 |
+
def inference(self, mel, f0):
|
| 124 |
+
MAX_WAV_VALUE = 32768.0
|
| 125 |
+
audio = self.forward(mel, f0, False)
|
| 126 |
+
audio = audio.squeeze() # collapse all dimension except time axis
|
| 127 |
+
audio = MAX_WAV_VALUE * audio
|
| 128 |
+
audio = audio.clamp(min=-MAX_WAV_VALUE, max=MAX_WAV_VALUE-1)
|
| 129 |
+
audio = audio.short()
|
| 130 |
+
return audio
|
| 131 |
+
|
| 132 |
+
def pitch2wav(self, f0):
|
| 133 |
+
MAX_WAV_VALUE = 32768.0
|
| 134 |
+
# nsf
|
| 135 |
+
f0 = f0[:, None]
|
| 136 |
+
f0 = self.f0_upsamp(f0).transpose(1, 2)
|
| 137 |
+
har_source = self.m_source(f0)
|
| 138 |
+
audio = har_source.transpose(1, 2)
|
| 139 |
+
audio = audio.squeeze() # collapse all dimension except time axis
|
| 140 |
+
audio = MAX_WAV_VALUE * audio
|
| 141 |
+
audio = audio.clamp(min=-MAX_WAV_VALUE, max=MAX_WAV_VALUE-1)
|
| 142 |
+
audio = audio.short()
|
| 143 |
+
return audio
|
bigvgan/model/nsf.py
ADDED
|
@@ -0,0 +1,394 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import numpy as np
|
| 3 |
+
import sys
|
| 4 |
+
import torch.nn.functional as torch_nn_func
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class PulseGen(torch.nn.Module):
|
| 8 |
+
"""Definition of Pulse train generator
|
| 9 |
+
|
| 10 |
+
There are many ways to implement pulse generator.
|
| 11 |
+
Here, PulseGen is based on SinGen. For a perfect
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
def __init__(self, samp_rate, pulse_amp=0.1, noise_std=0.003, voiced_threshold=0):
|
| 15 |
+
super(PulseGen, self).__init__()
|
| 16 |
+
self.pulse_amp = pulse_amp
|
| 17 |
+
self.sampling_rate = samp_rate
|
| 18 |
+
self.voiced_threshold = voiced_threshold
|
| 19 |
+
self.noise_std = noise_std
|
| 20 |
+
self.l_sinegen = SineGen(
|
| 21 |
+
self.sampling_rate,
|
| 22 |
+
harmonic_num=0,
|
| 23 |
+
sine_amp=self.pulse_amp,
|
| 24 |
+
noise_std=0,
|
| 25 |
+
voiced_threshold=self.voiced_threshold,
|
| 26 |
+
flag_for_pulse=True,
|
| 27 |
+
)
|
| 28 |
+
|
| 29 |
+
def forward(self, f0):
|
| 30 |
+
"""Pulse train generator
|
| 31 |
+
pulse_train, uv = forward(f0)
|
| 32 |
+
input F0: tensor(batchsize=1, length, dim=1)
|
| 33 |
+
f0 for unvoiced steps should be 0
|
| 34 |
+
output pulse_train: tensor(batchsize=1, length, dim)
|
| 35 |
+
output uv: tensor(batchsize=1, length, 1)
|
| 36 |
+
|
| 37 |
+
Note: self.l_sine doesn't make sure that the initial phase of
|
| 38 |
+
a voiced segment is np.pi, the first pulse in a voiced segment
|
| 39 |
+
may not be at the first time step within a voiced segment
|
| 40 |
+
"""
|
| 41 |
+
with torch.no_grad():
|
| 42 |
+
sine_wav, uv, noise = self.l_sinegen(f0)
|
| 43 |
+
|
| 44 |
+
# sine without additive noise
|
| 45 |
+
pure_sine = sine_wav - noise
|
| 46 |
+
|
| 47 |
+
# step t corresponds to a pulse if
|
| 48 |
+
# sine[t] > sine[t+1] & sine[t] > sine[t-1]
|
| 49 |
+
# & sine[t-1], sine[t+1], and sine[t] are voiced
|
| 50 |
+
# or
|
| 51 |
+
# sine[t] is voiced, sine[t-1] is unvoiced
|
| 52 |
+
# we use torch.roll to simulate sine[t+1] and sine[t-1]
|
| 53 |
+
sine_1 = torch.roll(pure_sine, shifts=1, dims=1)
|
| 54 |
+
uv_1 = torch.roll(uv, shifts=1, dims=1)
|
| 55 |
+
uv_1[:, 0, :] = 0
|
| 56 |
+
sine_2 = torch.roll(pure_sine, shifts=-1, dims=1)
|
| 57 |
+
uv_2 = torch.roll(uv, shifts=-1, dims=1)
|
| 58 |
+
uv_2[:, -1, :] = 0
|
| 59 |
+
|
| 60 |
+
loc = (pure_sine > sine_1) * (pure_sine > sine_2) \
|
| 61 |
+
* (uv_1 > 0) * (uv_2 > 0) * (uv > 0) \
|
| 62 |
+
+ (uv_1 < 1) * (uv > 0)
|
| 63 |
+
|
| 64 |
+
# pulse train without noise
|
| 65 |
+
pulse_train = pure_sine * loc
|
| 66 |
+
|
| 67 |
+
# additive noise to pulse train
|
| 68 |
+
# note that noise from sinegen is zero in voiced regions
|
| 69 |
+
pulse_noise = torch.randn_like(pure_sine) * self.noise_std
|
| 70 |
+
|
| 71 |
+
# with additive noise on pulse, and unvoiced regions
|
| 72 |
+
pulse_train += pulse_noise * loc + pulse_noise * (1 - uv)
|
| 73 |
+
return pulse_train, sine_wav, uv, pulse_noise
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
class SignalsConv1d(torch.nn.Module):
|
| 77 |
+
"""Filtering input signal with time invariant filter
|
| 78 |
+
Note: FIRFilter conducted filtering given fixed FIR weight
|
| 79 |
+
SignalsConv1d convolves two signals
|
| 80 |
+
Note: this is based on torch.nn.functional.conv1d
|
| 81 |
+
|
| 82 |
+
"""
|
| 83 |
+
|
| 84 |
+
def __init__(self):
|
| 85 |
+
super(SignalsConv1d, self).__init__()
|
| 86 |
+
|
| 87 |
+
def forward(self, signal, system_ir):
|
| 88 |
+
"""output = forward(signal, system_ir)
|
| 89 |
+
|
| 90 |
+
signal: (batchsize, length1, dim)
|
| 91 |
+
system_ir: (length2, dim)
|
| 92 |
+
|
| 93 |
+
output: (batchsize, length1, dim)
|
| 94 |
+
"""
|
| 95 |
+
if signal.shape[-1] != system_ir.shape[-1]:
|
| 96 |
+
print("Error: SignalsConv1d expects shape:")
|
| 97 |
+
print("signal (batchsize, length1, dim)")
|
| 98 |
+
print("system_id (batchsize, length2, dim)")
|
| 99 |
+
print("But received signal: {:s}".format(str(signal.shape)))
|
| 100 |
+
print(" system_ir: {:s}".format(str(system_ir.shape)))
|
| 101 |
+
sys.exit(1)
|
| 102 |
+
padding_length = system_ir.shape[0] - 1
|
| 103 |
+
groups = signal.shape[-1]
|
| 104 |
+
|
| 105 |
+
# pad signal on the left
|
| 106 |
+
signal_pad = torch_nn_func.pad(signal.permute(0, 2, 1), (padding_length, 0))
|
| 107 |
+
# prepare system impulse response as (dim, 1, length2)
|
| 108 |
+
# also flip the impulse response
|
| 109 |
+
ir = torch.flip(system_ir.unsqueeze(1).permute(2, 1, 0), dims=[2])
|
| 110 |
+
# convolute
|
| 111 |
+
output = torch_nn_func.conv1d(signal_pad, ir, groups=groups)
|
| 112 |
+
return output.permute(0, 2, 1)
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
class CyclicNoiseGen_v1(torch.nn.Module):
|
| 116 |
+
"""CyclicnoiseGen_v1
|
| 117 |
+
Cyclic noise with a single parameter of beta.
|
| 118 |
+
Pytorch v1 implementation assumes f_t is also fixed
|
| 119 |
+
"""
|
| 120 |
+
|
| 121 |
+
def __init__(self, samp_rate, noise_std=0.003, voiced_threshold=0):
|
| 122 |
+
super(CyclicNoiseGen_v1, self).__init__()
|
| 123 |
+
self.samp_rate = samp_rate
|
| 124 |
+
self.noise_std = noise_std
|
| 125 |
+
self.voiced_threshold = voiced_threshold
|
| 126 |
+
|
| 127 |
+
self.l_pulse = PulseGen(
|
| 128 |
+
samp_rate,
|
| 129 |
+
pulse_amp=1.0,
|
| 130 |
+
noise_std=noise_std,
|
| 131 |
+
voiced_threshold=voiced_threshold,
|
| 132 |
+
)
|
| 133 |
+
self.l_conv = SignalsConv1d()
|
| 134 |
+
|
| 135 |
+
def noise_decay(self, beta, f0mean):
|
| 136 |
+
"""decayed_noise = noise_decay(beta, f0mean)
|
| 137 |
+
decayed_noise = n[t]exp(-t * f_mean / beta / samp_rate)
|
| 138 |
+
|
| 139 |
+
beta: (dim=1) or (batchsize=1, 1, dim=1)
|
| 140 |
+
f0mean (batchsize=1, 1, dim=1)
|
| 141 |
+
|
| 142 |
+
decayed_noise (batchsize=1, length, dim=1)
|
| 143 |
+
"""
|
| 144 |
+
with torch.no_grad():
|
| 145 |
+
# exp(-1.0 n / T) < 0.01 => n > -log(0.01)*T = 4.60*T
|
| 146 |
+
# truncate the noise when decayed by -40 dB
|
| 147 |
+
length = 4.6 * self.samp_rate / f0mean
|
| 148 |
+
length = length.int()
|
| 149 |
+
time_idx = torch.arange(0, length, device=beta.device)
|
| 150 |
+
time_idx = time_idx.unsqueeze(0).unsqueeze(2)
|
| 151 |
+
time_idx = time_idx.repeat(beta.shape[0], 1, beta.shape[2])
|
| 152 |
+
|
| 153 |
+
noise = torch.randn(time_idx.shape, device=beta.device)
|
| 154 |
+
|
| 155 |
+
# due to Pytorch implementation, use f0_mean as the f0 factor
|
| 156 |
+
decay = torch.exp(-time_idx * f0mean / beta / self.samp_rate)
|
| 157 |
+
return noise * self.noise_std * decay
|
| 158 |
+
|
| 159 |
+
def forward(self, f0s, beta):
|
| 160 |
+
"""Producde cyclic-noise"""
|
| 161 |
+
# pulse train
|
| 162 |
+
pulse_train, sine_wav, uv, noise = self.l_pulse(f0s)
|
| 163 |
+
pure_pulse = pulse_train - noise
|
| 164 |
+
|
| 165 |
+
# decayed_noise (length, dim=1)
|
| 166 |
+
if (uv < 1).all():
|
| 167 |
+
# all unvoiced
|
| 168 |
+
cyc_noise = torch.zeros_like(sine_wav)
|
| 169 |
+
else:
|
| 170 |
+
f0mean = f0s[uv > 0].mean()
|
| 171 |
+
|
| 172 |
+
decayed_noise = self.noise_decay(beta, f0mean)[0, :, :]
|
| 173 |
+
# convolute
|
| 174 |
+
cyc_noise = self.l_conv(pure_pulse, decayed_noise)
|
| 175 |
+
|
| 176 |
+
# add noise in invoiced segments
|
| 177 |
+
cyc_noise = cyc_noise + noise * (1.0 - uv)
|
| 178 |
+
return cyc_noise, pulse_train, sine_wav, uv, noise
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
class SineGen(torch.nn.Module):
|
| 182 |
+
"""Definition of sine generator
|
| 183 |
+
SineGen(samp_rate, harmonic_num = 0,
|
| 184 |
+
sine_amp = 0.1, noise_std = 0.003,
|
| 185 |
+
voiced_threshold = 0,
|
| 186 |
+
flag_for_pulse=False)
|
| 187 |
+
|
| 188 |
+
samp_rate: sampling rate in Hz
|
| 189 |
+
harmonic_num: number of harmonic overtones (default 0)
|
| 190 |
+
sine_amp: amplitude of sine-wavefrom (default 0.1)
|
| 191 |
+
noise_std: std of Gaussian noise (default 0.003)
|
| 192 |
+
voiced_thoreshold: F0 threshold for U/V classification (default 0)
|
| 193 |
+
flag_for_pulse: this SinGen is used inside PulseGen (default False)
|
| 194 |
+
|
| 195 |
+
Note: when flag_for_pulse is True, the first time step of a voiced
|
| 196 |
+
segment is always sin(np.pi) or cos(0)
|
| 197 |
+
"""
|
| 198 |
+
|
| 199 |
+
def __init__(
|
| 200 |
+
self,
|
| 201 |
+
samp_rate,
|
| 202 |
+
harmonic_num=0,
|
| 203 |
+
sine_amp=0.1,
|
| 204 |
+
noise_std=0.003,
|
| 205 |
+
voiced_threshold=0,
|
| 206 |
+
flag_for_pulse=False,
|
| 207 |
+
):
|
| 208 |
+
super(SineGen, self).__init__()
|
| 209 |
+
self.sine_amp = sine_amp
|
| 210 |
+
self.noise_std = noise_std
|
| 211 |
+
self.harmonic_num = harmonic_num
|
| 212 |
+
self.dim = self.harmonic_num + 1
|
| 213 |
+
self.sampling_rate = samp_rate
|
| 214 |
+
self.voiced_threshold = voiced_threshold
|
| 215 |
+
self.flag_for_pulse = flag_for_pulse
|
| 216 |
+
|
| 217 |
+
def _f02uv(self, f0):
|
| 218 |
+
# generate uv signal
|
| 219 |
+
uv = torch.ones_like(f0)
|
| 220 |
+
uv = uv * (f0 > self.voiced_threshold)
|
| 221 |
+
return uv
|
| 222 |
+
|
| 223 |
+
def _f02sine(self, f0_values):
|
| 224 |
+
"""f0_values: (batchsize, length, dim)
|
| 225 |
+
where dim indicates fundamental tone and overtones
|
| 226 |
+
"""
|
| 227 |
+
# convert to F0 in rad. The interger part n can be ignored
|
| 228 |
+
# because 2 * np.pi * n doesn't affect phase
|
| 229 |
+
rad_values = (f0_values / self.sampling_rate) % 1
|
| 230 |
+
|
| 231 |
+
# initial phase noise (no noise for fundamental component)
|
| 232 |
+
rand_ini = torch.rand(
|
| 233 |
+
f0_values.shape[0], f0_values.shape[2], device=f0_values.device
|
| 234 |
+
)
|
| 235 |
+
rand_ini[:, 0] = 0
|
| 236 |
+
rad_values[:, 0, :] = rad_values[:, 0, :] + rand_ini
|
| 237 |
+
|
| 238 |
+
# instantanouse phase sine[t] = sin(2*pi \sum_i=1 ^{t} rad)
|
| 239 |
+
if not self.flag_for_pulse:
|
| 240 |
+
# for normal case
|
| 241 |
+
|
| 242 |
+
# To prevent torch.cumsum numerical overflow,
|
| 243 |
+
# it is necessary to add -1 whenever \sum_k=1^n rad_value_k > 1.
|
| 244 |
+
# Buffer tmp_over_one_idx indicates the time step to add -1.
|
| 245 |
+
# This will not change F0 of sine because (x-1) * 2*pi = x * 2*pi
|
| 246 |
+
tmp_over_one = torch.cumsum(rad_values, 1) % 1
|
| 247 |
+
tmp_over_one_idx = (tmp_over_one[:, 1:, :] - tmp_over_one[:, :-1, :]) < 0
|
| 248 |
+
cumsum_shift = torch.zeros_like(rad_values)
|
| 249 |
+
cumsum_shift[:, 1:, :] = tmp_over_one_idx * -1.0
|
| 250 |
+
|
| 251 |
+
sines = torch.sin(
|
| 252 |
+
torch.cumsum(rad_values + cumsum_shift, dim=1) * 2 * np.pi
|
| 253 |
+
)
|
| 254 |
+
else:
|
| 255 |
+
# If necessary, make sure that the first time step of every
|
| 256 |
+
# voiced segments is sin(pi) or cos(0)
|
| 257 |
+
# This is used for pulse-train generation
|
| 258 |
+
|
| 259 |
+
# identify the last time step in unvoiced segments
|
| 260 |
+
uv = self._f02uv(f0_values)
|
| 261 |
+
uv_1 = torch.roll(uv, shifts=-1, dims=1)
|
| 262 |
+
uv_1[:, -1, :] = 1
|
| 263 |
+
u_loc = (uv < 1) * (uv_1 > 0)
|
| 264 |
+
|
| 265 |
+
# get the instantanouse phase
|
| 266 |
+
tmp_cumsum = torch.cumsum(rad_values, dim=1)
|
| 267 |
+
# different batch needs to be processed differently
|
| 268 |
+
for idx in range(f0_values.shape[0]):
|
| 269 |
+
temp_sum = tmp_cumsum[idx, u_loc[idx, :, 0], :]
|
| 270 |
+
temp_sum[1:, :] = temp_sum[1:, :] - temp_sum[0:-1, :]
|
| 271 |
+
# stores the accumulation of i.phase within
|
| 272 |
+
# each voiced segments
|
| 273 |
+
tmp_cumsum[idx, :, :] = 0
|
| 274 |
+
tmp_cumsum[idx, u_loc[idx, :, 0], :] = temp_sum
|
| 275 |
+
|
| 276 |
+
# rad_values - tmp_cumsum: remove the accumulation of i.phase
|
| 277 |
+
# within the previous voiced segment.
|
| 278 |
+
i_phase = torch.cumsum(rad_values - tmp_cumsum, dim=1)
|
| 279 |
+
|
| 280 |
+
# get the sines
|
| 281 |
+
sines = torch.cos(i_phase * 2 * np.pi)
|
| 282 |
+
return sines
|
| 283 |
+
|
| 284 |
+
def forward(self, f0):
|
| 285 |
+
"""sine_tensor, uv = forward(f0)
|
| 286 |
+
input F0: tensor(batchsize=1, length, dim=1)
|
| 287 |
+
f0 for unvoiced steps should be 0
|
| 288 |
+
output sine_tensor: tensor(batchsize=1, length, dim)
|
| 289 |
+
output uv: tensor(batchsize=1, length, 1)
|
| 290 |
+
"""
|
| 291 |
+
with torch.no_grad():
|
| 292 |
+
f0_buf = torch.zeros(f0.shape[0], f0.shape[1], self.dim, device=f0.device)
|
| 293 |
+
# fundamental component
|
| 294 |
+
f0_buf[:, :, 0] = f0[:, :, 0]
|
| 295 |
+
for idx in np.arange(self.harmonic_num):
|
| 296 |
+
# idx + 2: the (idx+1)-th overtone, (idx+2)-th harmonic
|
| 297 |
+
f0_buf[:, :, idx + 1] = f0_buf[:, :, 0] * (idx + 2)
|
| 298 |
+
|
| 299 |
+
# generate sine waveforms
|
| 300 |
+
sine_waves = self._f02sine(f0_buf) * self.sine_amp
|
| 301 |
+
|
| 302 |
+
# generate uv signal
|
| 303 |
+
# uv = torch.ones(f0.shape)
|
| 304 |
+
# uv = uv * (f0 > self.voiced_threshold)
|
| 305 |
+
uv = self._f02uv(f0)
|
| 306 |
+
|
| 307 |
+
# noise: for unvoiced should be similar to sine_amp
|
| 308 |
+
# std = self.sine_amp/3 -> max value ~ self.sine_amp
|
| 309 |
+
# . for voiced regions is self.noise_std
|
| 310 |
+
noise_amp = uv * self.noise_std + (1 - uv) * self.sine_amp / 3
|
| 311 |
+
noise = noise_amp * torch.randn_like(sine_waves)
|
| 312 |
+
|
| 313 |
+
# first: set the unvoiced part to 0 by uv
|
| 314 |
+
# then: additive noise
|
| 315 |
+
sine_waves = sine_waves * uv + noise
|
| 316 |
+
return sine_waves
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
class SourceModuleCycNoise_v1(torch.nn.Module):
|
| 320 |
+
"""SourceModuleCycNoise_v1
|
| 321 |
+
SourceModule(sampling_rate, noise_std=0.003, voiced_threshod=0)
|
| 322 |
+
sampling_rate: sampling_rate in Hz
|
| 323 |
+
|
| 324 |
+
noise_std: std of Gaussian noise (default: 0.003)
|
| 325 |
+
voiced_threshold: threshold to set U/V given F0 (default: 0)
|
| 326 |
+
|
| 327 |
+
cyc, noise, uv = SourceModuleCycNoise_v1(F0_upsampled, beta)
|
| 328 |
+
F0_upsampled (batchsize, length, 1)
|
| 329 |
+
beta (1)
|
| 330 |
+
cyc (batchsize, length, 1)
|
| 331 |
+
noise (batchsize, length, 1)
|
| 332 |
+
uv (batchsize, length, 1)
|
| 333 |
+
"""
|
| 334 |
+
|
| 335 |
+
def __init__(self, sampling_rate, noise_std=0.003, voiced_threshod=0):
|
| 336 |
+
super(SourceModuleCycNoise_v1, self).__init__()
|
| 337 |
+
self.sampling_rate = sampling_rate
|
| 338 |
+
self.noise_std = noise_std
|
| 339 |
+
self.l_cyc_gen = CyclicNoiseGen_v1(sampling_rate, noise_std, voiced_threshod)
|
| 340 |
+
|
| 341 |
+
def forward(self, f0_upsamped, beta):
|
| 342 |
+
"""
|
| 343 |
+
cyc, noise, uv = SourceModuleCycNoise_v1(F0, beta)
|
| 344 |
+
F0_upsampled (batchsize, length, 1)
|
| 345 |
+
beta (1)
|
| 346 |
+
cyc (batchsize, length, 1)
|
| 347 |
+
noise (batchsize, length, 1)
|
| 348 |
+
uv (batchsize, length, 1)
|
| 349 |
+
"""
|
| 350 |
+
# source for harmonic branch
|
| 351 |
+
cyc, pulse, sine, uv, add_noi = self.l_cyc_gen(f0_upsamped, beta)
|
| 352 |
+
|
| 353 |
+
# source for noise branch, in the same shape as uv
|
| 354 |
+
noise = torch.randn_like(uv) * self.noise_std / 3
|
| 355 |
+
return cyc, noise, uv
|
| 356 |
+
|
| 357 |
+
|
| 358 |
+
class SourceModuleHnNSF(torch.nn.Module):
|
| 359 |
+
def __init__(
|
| 360 |
+
self,
|
| 361 |
+
sampling_rate=32000,
|
| 362 |
+
sine_amp=0.1,
|
| 363 |
+
add_noise_std=0.003,
|
| 364 |
+
voiced_threshod=0,
|
| 365 |
+
):
|
| 366 |
+
super(SourceModuleHnNSF, self).__init__()
|
| 367 |
+
harmonic_num = 10
|
| 368 |
+
self.sine_amp = sine_amp
|
| 369 |
+
self.noise_std = add_noise_std
|
| 370 |
+
|
| 371 |
+
# to produce sine waveforms
|
| 372 |
+
self.l_sin_gen = SineGen(
|
| 373 |
+
sampling_rate, harmonic_num, sine_amp, add_noise_std, voiced_threshod
|
| 374 |
+
)
|
| 375 |
+
|
| 376 |
+
# to merge source harmonics into a single excitation
|
| 377 |
+
self.l_tanh = torch.nn.Tanh()
|
| 378 |
+
self.register_buffer('merge_w', torch.FloatTensor([[
|
| 379 |
+
0.2942, -0.2243, 0.0033, -0.0056, -0.0020, -0.0046,
|
| 380 |
+
0.0221, -0.0083, -0.0241, -0.0036, -0.0581]]))
|
| 381 |
+
self.register_buffer('merge_b', torch.FloatTensor([0.0008]))
|
| 382 |
+
|
| 383 |
+
def forward(self, x):
|
| 384 |
+
"""
|
| 385 |
+
Sine_source = SourceModuleHnNSF(F0_sampled)
|
| 386 |
+
F0_sampled (batchsize, length, 1)
|
| 387 |
+
Sine_source (batchsize, length, 1)
|
| 388 |
+
"""
|
| 389 |
+
# source for harmonic branch
|
| 390 |
+
sine_wavs = self.l_sin_gen(x)
|
| 391 |
+
sine_wavs = torch_nn_func.linear(
|
| 392 |
+
sine_wavs, self.merge_w) + self.merge_b
|
| 393 |
+
sine_merge = self.l_tanh(sine_wavs)
|
| 394 |
+
return sine_merge
|
bigvgan_pretrain/README.md
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Path for:
|
| 2 |
+
|
| 3 |
+
nsf_bigvgan_pretrain_32K.pth
|
| 4 |
+
|
| 5 |
+
DownLoad link:https://github.com/PlayVoice/NSF-BigVGAN/releases/tag/augment
|
bigvgan_pretrain/nsf_bigvgan_pretrain_32K.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0e32aaea5fd26bcba47c18d3b0a44f5371dfce25a099aa468420d9d605eda225
|
| 3 |
+
size 116020827
|
configs/base.yaml
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
train:
|
| 2 |
+
seed: 37
|
| 3 |
+
train_files: "files/train.txt"
|
| 4 |
+
valid_files: "files/valid.txt"
|
| 5 |
+
log_dir: 'logs/grad_svc'
|
| 6 |
+
full_epochs: 500
|
| 7 |
+
fast_epochs: 100
|
| 8 |
+
learning_rate: 2e-4
|
| 9 |
+
batch_size: 8
|
| 10 |
+
test_size: 4
|
| 11 |
+
test_step: 5
|
| 12 |
+
save_step: 10
|
| 13 |
+
pretrain: "grad_pretrain/gvc.pretrain.pth"
|
| 14 |
+
#############################
|
| 15 |
+
data:
|
| 16 |
+
segment_size: 16000 # WARNING: base on hop_length
|
| 17 |
+
max_wav_value: 32768.0
|
| 18 |
+
sampling_rate: 32000
|
| 19 |
+
filter_length: 1024
|
| 20 |
+
hop_length: 320
|
| 21 |
+
win_length: 1024
|
| 22 |
+
mel_channels: 100
|
| 23 |
+
mel_fmin: 40.0
|
| 24 |
+
mel_fmax: 16000.0
|
| 25 |
+
#############################
|
| 26 |
+
grad:
|
| 27 |
+
n_mels: 100
|
| 28 |
+
n_vecs: 256
|
| 29 |
+
n_pits: 256
|
| 30 |
+
n_spks: 256
|
| 31 |
+
n_embs: 64
|
| 32 |
+
|
| 33 |
+
# encoder parameters
|
| 34 |
+
n_enc_channels: 192
|
| 35 |
+
filter_channels: 512
|
| 36 |
+
|
| 37 |
+
# decoder parameters
|
| 38 |
+
dec_dim: 96
|
| 39 |
+
beta_min: 0.05
|
| 40 |
+
beta_max: 20.0
|
| 41 |
+
pe_scale: 1000
|
grad/LICENSE
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Copyright (c) 2021 Huawei Technologies Co., Ltd.
|
| 2 |
+
|
| 3 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 4 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 5 |
+
in the Software without restriction, including without limitation the rights
|
| 6 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 7 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 8 |
+
furnished to do so, subject to the following conditions:
|
| 9 |
+
|
| 10 |
+
The above copyright notice and this permission notice shall be included in all
|
| 11 |
+
copies or substantial portions of the Software.
|
| 12 |
+
|
| 13 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 14 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 15 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 16 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 17 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 18 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 19 |
+
SOFTWARE.
|
grad/__init__.py
ADDED
|
File without changes
|
grad/base.py
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class BaseModule(torch.nn.Module):
|
| 6 |
+
def __init__(self):
|
| 7 |
+
super(BaseModule, self).__init__()
|
| 8 |
+
|
| 9 |
+
@property
|
| 10 |
+
def nparams(self):
|
| 11 |
+
"""
|
| 12 |
+
Returns number of trainable parameters of the module.
|
| 13 |
+
"""
|
| 14 |
+
num_params = 0
|
| 15 |
+
for name, param in self.named_parameters():
|
| 16 |
+
if param.requires_grad:
|
| 17 |
+
num_params += np.prod(param.detach().cpu().numpy().shape)
|
| 18 |
+
return num_params
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def relocate_input(self, x: list):
|
| 22 |
+
"""
|
| 23 |
+
Relocates provided tensors to the same device set for the module.
|
| 24 |
+
"""
|
| 25 |
+
device = next(self.parameters()).device
|
| 26 |
+
for i in range(len(x)):
|
| 27 |
+
if isinstance(x[i], torch.Tensor) and x[i].device != device:
|
| 28 |
+
x[i] = x[i].to(device)
|
| 29 |
+
return x
|
grad/diffusion.py
ADDED
|
@@ -0,0 +1,253 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import torch
|
| 3 |
+
from einops import rearrange
|
| 4 |
+
from grad.base import BaseModule
|
| 5 |
+
from grad.solver import NoiseScheduleVP, MaxLikelihood, GradRaw
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class Mish(BaseModule):
|
| 9 |
+
def forward(self, x):
|
| 10 |
+
return x * torch.tanh(torch.nn.functional.softplus(x))
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class Upsample(BaseModule):
|
| 14 |
+
def __init__(self, dim):
|
| 15 |
+
super(Upsample, self).__init__()
|
| 16 |
+
self.conv = torch.nn.ConvTranspose2d(dim, dim, 4, 2, 1)
|
| 17 |
+
|
| 18 |
+
def forward(self, x):
|
| 19 |
+
return self.conv(x)
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class Downsample(BaseModule):
|
| 23 |
+
def __init__(self, dim):
|
| 24 |
+
super(Downsample, self).__init__()
|
| 25 |
+
self.conv = torch.nn.Conv2d(dim, dim, 3, 2, 1)
|
| 26 |
+
|
| 27 |
+
def forward(self, x):
|
| 28 |
+
return self.conv(x)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
class Rezero(BaseModule):
|
| 32 |
+
def __init__(self, fn):
|
| 33 |
+
super(Rezero, self).__init__()
|
| 34 |
+
self.fn = fn
|
| 35 |
+
self.g = torch.nn.Parameter(torch.zeros(1))
|
| 36 |
+
|
| 37 |
+
def forward(self, x):
|
| 38 |
+
return self.fn(x) * self.g
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
class Block(BaseModule):
|
| 42 |
+
def __init__(self, dim, dim_out, groups=8):
|
| 43 |
+
super(Block, self).__init__()
|
| 44 |
+
self.block = torch.nn.Sequential(torch.nn.Conv2d(dim, dim_out, 3,
|
| 45 |
+
padding=1), torch.nn.GroupNorm(
|
| 46 |
+
groups, dim_out), Mish())
|
| 47 |
+
|
| 48 |
+
def forward(self, x, mask):
|
| 49 |
+
output = self.block(x * mask)
|
| 50 |
+
return output * mask
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
class ResnetBlock(BaseModule):
|
| 54 |
+
def __init__(self, dim, dim_out, time_emb_dim, groups=8):
|
| 55 |
+
super(ResnetBlock, self).__init__()
|
| 56 |
+
self.mlp = torch.nn.Sequential(Mish(), torch.nn.Linear(time_emb_dim,
|
| 57 |
+
dim_out))
|
| 58 |
+
|
| 59 |
+
self.block1 = Block(dim, dim_out, groups=groups)
|
| 60 |
+
self.block2 = Block(dim_out, dim_out, groups=groups)
|
| 61 |
+
if dim != dim_out:
|
| 62 |
+
self.res_conv = torch.nn.Conv2d(dim, dim_out, 1)
|
| 63 |
+
else:
|
| 64 |
+
self.res_conv = torch.nn.Identity()
|
| 65 |
+
|
| 66 |
+
def forward(self, x, mask, time_emb):
|
| 67 |
+
h = self.block1(x, mask)
|
| 68 |
+
h += self.mlp(time_emb).unsqueeze(-1).unsqueeze(-1)
|
| 69 |
+
h = self.block2(h, mask)
|
| 70 |
+
output = h + self.res_conv(x * mask)
|
| 71 |
+
return output
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
class LinearAttention(BaseModule):
|
| 75 |
+
def __init__(self, dim, heads=4, dim_head=32):
|
| 76 |
+
super(LinearAttention, self).__init__()
|
| 77 |
+
self.heads = heads
|
| 78 |
+
hidden_dim = dim_head * heads
|
| 79 |
+
self.to_qkv = torch.nn.Conv2d(dim, hidden_dim * 3, 1, bias=False)
|
| 80 |
+
self.to_out = torch.nn.Conv2d(hidden_dim, dim, 1)
|
| 81 |
+
|
| 82 |
+
def forward(self, x):
|
| 83 |
+
b, c, h, w = x.shape
|
| 84 |
+
qkv = self.to_qkv(x)
|
| 85 |
+
q, k, v = rearrange(qkv, 'b (qkv heads c) h w -> qkv b heads c (h w)',
|
| 86 |
+
heads = self.heads, qkv=3)
|
| 87 |
+
k = k.softmax(dim=-1)
|
| 88 |
+
context = torch.einsum('bhdn,bhen->bhde', k, v)
|
| 89 |
+
out = torch.einsum('bhde,bhdn->bhen', context, q)
|
| 90 |
+
out = rearrange(out, 'b heads c (h w) -> b (heads c) h w',
|
| 91 |
+
heads=self.heads, h=h, w=w)
|
| 92 |
+
return self.to_out(out)
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
class Residual(BaseModule):
|
| 96 |
+
def __init__(self, fn):
|
| 97 |
+
super(Residual, self).__init__()
|
| 98 |
+
self.fn = fn
|
| 99 |
+
|
| 100 |
+
def forward(self, x, *args, **kwargs):
|
| 101 |
+
output = self.fn(x, *args, **kwargs) + x
|
| 102 |
+
return output
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
class SinusoidalPosEmb(BaseModule):
|
| 106 |
+
def __init__(self, dim):
|
| 107 |
+
super(SinusoidalPosEmb, self).__init__()
|
| 108 |
+
self.dim = dim
|
| 109 |
+
|
| 110 |
+
def forward(self, x, scale=1000):
|
| 111 |
+
device = x.device
|
| 112 |
+
half_dim = self.dim // 2
|
| 113 |
+
emb = math.log(10000) / (half_dim - 1)
|
| 114 |
+
emb = torch.exp(torch.arange(half_dim, device=device).float() * -emb)
|
| 115 |
+
emb = scale * x.unsqueeze(1) * emb.unsqueeze(0)
|
| 116 |
+
emb = torch.cat((emb.sin(), emb.cos()), dim=-1)
|
| 117 |
+
return emb
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
class GradLogPEstimator2d(BaseModule):
|
| 121 |
+
def __init__(self, dim, dim_mults=(1, 2, 4), emb_dim=64, n_mels=100,
|
| 122 |
+
groups=8, pe_scale=1000):
|
| 123 |
+
super(GradLogPEstimator2d, self).__init__()
|
| 124 |
+
self.dim = dim
|
| 125 |
+
self.dim_mults = dim_mults
|
| 126 |
+
self.emb_dim = emb_dim
|
| 127 |
+
self.groups = groups
|
| 128 |
+
self.pe_scale = pe_scale
|
| 129 |
+
|
| 130 |
+
self.spk_mlp = torch.nn.Sequential(torch.nn.Linear(emb_dim, emb_dim * 4), Mish(),
|
| 131 |
+
torch.nn.Linear(emb_dim * 4, n_mels))
|
| 132 |
+
self.time_pos_emb = SinusoidalPosEmb(dim)
|
| 133 |
+
self.mlp = torch.nn.Sequential(torch.nn.Linear(dim, dim * 4), Mish(),
|
| 134 |
+
torch.nn.Linear(dim * 4, dim))
|
| 135 |
+
|
| 136 |
+
dims = [2 + 1, *map(lambda m: dim * m, dim_mults)]
|
| 137 |
+
in_out = list(zip(dims[:-1], dims[1:]))
|
| 138 |
+
self.downs = torch.nn.ModuleList([])
|
| 139 |
+
self.ups = torch.nn.ModuleList([])
|
| 140 |
+
num_resolutions = len(in_out)
|
| 141 |
+
|
| 142 |
+
for ind, (dim_in, dim_out) in enumerate(in_out): # 2 downs
|
| 143 |
+
is_last = ind >= (num_resolutions - 1)
|
| 144 |
+
self.downs.append(torch.nn.ModuleList([
|
| 145 |
+
ResnetBlock(dim_in, dim_out, time_emb_dim=dim),
|
| 146 |
+
ResnetBlock(dim_out, dim_out, time_emb_dim=dim),
|
| 147 |
+
Residual(Rezero(LinearAttention(dim_out))),
|
| 148 |
+
Downsample(dim_out) if not is_last else torch.nn.Identity()]))
|
| 149 |
+
|
| 150 |
+
mid_dim = dims[-1]
|
| 151 |
+
self.mid_block1 = ResnetBlock(mid_dim, mid_dim, time_emb_dim=dim)
|
| 152 |
+
self.mid_attn = Residual(Rezero(LinearAttention(mid_dim)))
|
| 153 |
+
self.mid_block2 = ResnetBlock(mid_dim, mid_dim, time_emb_dim=dim)
|
| 154 |
+
|
| 155 |
+
for ind, (dim_in, dim_out) in enumerate(reversed(in_out[1:])): # 2 ups
|
| 156 |
+
self.ups.append(torch.nn.ModuleList([
|
| 157 |
+
ResnetBlock(dim_out * 2, dim_in, time_emb_dim=dim),
|
| 158 |
+
ResnetBlock(dim_in, dim_in, time_emb_dim=dim),
|
| 159 |
+
Residual(Rezero(LinearAttention(dim_in))),
|
| 160 |
+
Upsample(dim_in)]))
|
| 161 |
+
self.final_block = Block(dim, dim)
|
| 162 |
+
self.final_conv = torch.nn.Conv2d(dim, 1, 1)
|
| 163 |
+
|
| 164 |
+
def forward(self, spk, x, mask, mu, t):
|
| 165 |
+
s = self.spk_mlp(spk)
|
| 166 |
+
|
| 167 |
+
t = self.time_pos_emb(t, scale=self.pe_scale)
|
| 168 |
+
t = self.mlp(t)
|
| 169 |
+
|
| 170 |
+
s = s.unsqueeze(-1).repeat(1, 1, x.shape[-1])
|
| 171 |
+
x = torch.stack([mu, x, s], 1)
|
| 172 |
+
mask = mask.unsqueeze(1)
|
| 173 |
+
|
| 174 |
+
hiddens = []
|
| 175 |
+
masks = [mask]
|
| 176 |
+
for resnet1, resnet2, attn, downsample in self.downs:
|
| 177 |
+
mask_down = masks[-1]
|
| 178 |
+
x = resnet1(x, mask_down, t)
|
| 179 |
+
x = resnet2(x, mask_down, t)
|
| 180 |
+
x = attn(x)
|
| 181 |
+
hiddens.append(x)
|
| 182 |
+
x = downsample(x * mask_down)
|
| 183 |
+
masks.append(mask_down[:, :, :, ::2])
|
| 184 |
+
|
| 185 |
+
masks = masks[:-1]
|
| 186 |
+
mask_mid = masks[-1]
|
| 187 |
+
x = self.mid_block1(x, mask_mid, t)
|
| 188 |
+
x = self.mid_attn(x)
|
| 189 |
+
x = self.mid_block2(x, mask_mid, t)
|
| 190 |
+
|
| 191 |
+
for resnet1, resnet2, attn, upsample in self.ups:
|
| 192 |
+
mask_up = masks.pop()
|
| 193 |
+
x = torch.cat((x, hiddens.pop()), dim=1)
|
| 194 |
+
x = resnet1(x, mask_up, t)
|
| 195 |
+
x = resnet2(x, mask_up, t)
|
| 196 |
+
x = attn(x)
|
| 197 |
+
x = upsample(x * mask_up)
|
| 198 |
+
|
| 199 |
+
x = self.final_block(x, mask)
|
| 200 |
+
output = self.final_conv(x * mask)
|
| 201 |
+
|
| 202 |
+
return (output * mask).squeeze(1)
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
def get_noise(t, beta_init, beta_term, cumulative=False):
|
| 206 |
+
if cumulative:
|
| 207 |
+
noise = beta_init*t + 0.5*(beta_term - beta_init)*(t**2)
|
| 208 |
+
else:
|
| 209 |
+
noise = beta_init + (beta_term - beta_init)*t
|
| 210 |
+
return noise
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
class Diffusion(BaseModule):
|
| 214 |
+
def __init__(self, n_mels, dim, emb_dim=64,
|
| 215 |
+
beta_min=0.05, beta_max=20, pe_scale=1000):
|
| 216 |
+
super(Diffusion, self).__init__()
|
| 217 |
+
self.n_mels = n_mels
|
| 218 |
+
self.beta_min = beta_min
|
| 219 |
+
self.beta_max = beta_max
|
| 220 |
+
# self.solver = NoiseScheduleVP()
|
| 221 |
+
self.solver = MaxLikelihood()
|
| 222 |
+
# self.solver = GradRaw()
|
| 223 |
+
self.estimator = GradLogPEstimator2d(dim,
|
| 224 |
+
n_mels=n_mels,
|
| 225 |
+
emb_dim=emb_dim,
|
| 226 |
+
pe_scale=pe_scale)
|
| 227 |
+
|
| 228 |
+
def forward_diffusion(self, mel, mask, mu, t):
|
| 229 |
+
time = t.unsqueeze(-1).unsqueeze(-1)
|
| 230 |
+
cum_noise = get_noise(time, self.beta_min, self.beta_max, cumulative=True)
|
| 231 |
+
mean = mel*torch.exp(-0.5*cum_noise) + mu*(1.0 - torch.exp(-0.5*cum_noise))
|
| 232 |
+
variance = 1.0 - torch.exp(-cum_noise)
|
| 233 |
+
z = torch.randn(mel.shape, dtype=mel.dtype, device=mel.device,
|
| 234 |
+
requires_grad=False)
|
| 235 |
+
xt = mean + z * torch.sqrt(variance)
|
| 236 |
+
return xt * mask, z * mask
|
| 237 |
+
|
| 238 |
+
def forward(self, spk, z, mask, mu, n_timesteps, stoc=False):
|
| 239 |
+
return self.solver.reverse_diffusion(self.estimator, spk, z, mask, mu, n_timesteps, stoc)
|
| 240 |
+
|
| 241 |
+
def loss_t(self, spk, mel, mask, mu, t):
|
| 242 |
+
xt, z = self.forward_diffusion(mel, mask, mu, t)
|
| 243 |
+
time = t.unsqueeze(-1).unsqueeze(-1)
|
| 244 |
+
cum_noise = get_noise(time, self.beta_min, self.beta_max, cumulative=True)
|
| 245 |
+
noise_estimation = self.estimator(spk, xt, mask, mu, t)
|
| 246 |
+
noise_estimation *= torch.sqrt(1.0 - torch.exp(-cum_noise))
|
| 247 |
+
loss = torch.sum((noise_estimation + z)**2) / (torch.sum(mask)*self.n_mels)
|
| 248 |
+
return loss, xt
|
| 249 |
+
|
| 250 |
+
def compute_loss(self, spk, mel, mask, mu, offset=1e-5):
|
| 251 |
+
t = torch.rand(mel.shape[0], dtype=mel.dtype, device=mel.device, requires_grad=False)
|
| 252 |
+
t = torch.clamp(t, offset, 1.0 - offset)
|
| 253 |
+
return self.loss_t(spk, mel, mask, mu, t)
|
grad/encoder.py
ADDED
|
@@ -0,0 +1,327 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
from grad.base import BaseModule
|
| 5 |
+
from grad.reversal import SpeakerClassifier
|
| 6 |
+
from grad.utils import sequence_mask, convert_pad_shape
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class LayerNorm(BaseModule):
|
| 10 |
+
def __init__(self, channels, eps=1e-4):
|
| 11 |
+
super(LayerNorm, self).__init__()
|
| 12 |
+
self.channels = channels
|
| 13 |
+
self.eps = eps
|
| 14 |
+
|
| 15 |
+
self.gamma = torch.nn.Parameter(torch.ones(channels))
|
| 16 |
+
self.beta = torch.nn.Parameter(torch.zeros(channels))
|
| 17 |
+
|
| 18 |
+
def forward(self, x):
|
| 19 |
+
n_dims = len(x.shape)
|
| 20 |
+
mean = torch.mean(x, 1, keepdim=True)
|
| 21 |
+
variance = torch.mean((x - mean)**2, 1, keepdim=True)
|
| 22 |
+
|
| 23 |
+
x = (x - mean) * torch.rsqrt(variance + self.eps)
|
| 24 |
+
|
| 25 |
+
shape = [1, -1] + [1] * (n_dims - 2)
|
| 26 |
+
x = x * self.gamma.view(*shape) + self.beta.view(*shape)
|
| 27 |
+
return x
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class ConvReluNorm(BaseModule):
|
| 31 |
+
def __init__(self, in_channels, hidden_channels, out_channels, kernel_size,
|
| 32 |
+
n_layers, p_dropout, eps=1e-5):
|
| 33 |
+
super(ConvReluNorm, self).__init__()
|
| 34 |
+
self.in_channels = in_channels
|
| 35 |
+
self.hidden_channels = hidden_channels
|
| 36 |
+
self.out_channels = out_channels
|
| 37 |
+
self.kernel_size = kernel_size
|
| 38 |
+
self.n_layers = n_layers
|
| 39 |
+
self.p_dropout = p_dropout
|
| 40 |
+
self.eps = eps
|
| 41 |
+
|
| 42 |
+
self.conv_layers = torch.nn.ModuleList()
|
| 43 |
+
self.conv_layers.append(torch.nn.Conv1d(in_channels, hidden_channels,
|
| 44 |
+
kernel_size, padding=kernel_size//2))
|
| 45 |
+
self.relu_drop = torch.nn.Sequential(torch.nn.ReLU(), torch.nn.Dropout(p_dropout))
|
| 46 |
+
for _ in range(n_layers - 1):
|
| 47 |
+
self.conv_layers.append(torch.nn.Conv1d(hidden_channels, hidden_channels,
|
| 48 |
+
kernel_size, padding=kernel_size//2))
|
| 49 |
+
self.proj = torch.nn.Conv1d(hidden_channels, out_channels, 1)
|
| 50 |
+
self.proj.weight.data.zero_()
|
| 51 |
+
self.proj.bias.data.zero_()
|
| 52 |
+
|
| 53 |
+
def forward(self, x, x_mask):
|
| 54 |
+
for i in range(self.n_layers):
|
| 55 |
+
x = self.conv_layers[i](x * x_mask)
|
| 56 |
+
x = self.instance_norm(x, x_mask)
|
| 57 |
+
x = self.relu_drop(x)
|
| 58 |
+
x = self.proj(x)
|
| 59 |
+
return x * x_mask
|
| 60 |
+
|
| 61 |
+
def instance_norm(self, x, mask, return_mean_std=False):
|
| 62 |
+
mean, std = self.calc_mean_std(x, mask)
|
| 63 |
+
x = (x - mean) / std
|
| 64 |
+
if return_mean_std:
|
| 65 |
+
return x, mean, std
|
| 66 |
+
else:
|
| 67 |
+
return x
|
| 68 |
+
|
| 69 |
+
def calc_mean_std(self, x, mask=None):
|
| 70 |
+
x = x * mask
|
| 71 |
+
B, C = x.shape[:2]
|
| 72 |
+
mn = x.view(B, C, -1).mean(-1)
|
| 73 |
+
sd = (x.view(B, C, -1).var(-1) + self.eps).sqrt()
|
| 74 |
+
mn = mn.view(B, C, *((len(x.shape) - 2) * [1]))
|
| 75 |
+
sd = sd.view(B, C, *((len(x.shape) - 2) * [1]))
|
| 76 |
+
return mn, sd
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
class MultiHeadAttention(BaseModule):
|
| 80 |
+
def __init__(self, channels, out_channels, n_heads, window_size=None,
|
| 81 |
+
heads_share=True, p_dropout=0.0, proximal_bias=False,
|
| 82 |
+
proximal_init=False):
|
| 83 |
+
super(MultiHeadAttention, self).__init__()
|
| 84 |
+
assert channels % n_heads == 0
|
| 85 |
+
|
| 86 |
+
self.channels = channels
|
| 87 |
+
self.out_channels = out_channels
|
| 88 |
+
self.n_heads = n_heads
|
| 89 |
+
self.window_size = window_size
|
| 90 |
+
self.heads_share = heads_share
|
| 91 |
+
self.proximal_bias = proximal_bias
|
| 92 |
+
self.p_dropout = p_dropout
|
| 93 |
+
self.attn = None
|
| 94 |
+
|
| 95 |
+
self.k_channels = channels // n_heads
|
| 96 |
+
self.conv_q = torch.nn.Conv1d(channels, channels, 1)
|
| 97 |
+
self.conv_k = torch.nn.Conv1d(channels, channels, 1)
|
| 98 |
+
self.conv_v = torch.nn.Conv1d(channels, channels, 1)
|
| 99 |
+
if window_size is not None:
|
| 100 |
+
n_heads_rel = 1 if heads_share else n_heads
|
| 101 |
+
rel_stddev = self.k_channels**-0.5
|
| 102 |
+
self.emb_rel_k = torch.nn.Parameter(torch.randn(n_heads_rel,
|
| 103 |
+
window_size * 2 + 1, self.k_channels) * rel_stddev)
|
| 104 |
+
self.emb_rel_v = torch.nn.Parameter(torch.randn(n_heads_rel,
|
| 105 |
+
window_size * 2 + 1, self.k_channels) * rel_stddev)
|
| 106 |
+
self.conv_o = torch.nn.Conv1d(channels, out_channels, 1)
|
| 107 |
+
self.drop = torch.nn.Dropout(p_dropout)
|
| 108 |
+
|
| 109 |
+
torch.nn.init.xavier_uniform_(self.conv_q.weight)
|
| 110 |
+
torch.nn.init.xavier_uniform_(self.conv_k.weight)
|
| 111 |
+
if proximal_init:
|
| 112 |
+
self.conv_k.weight.data.copy_(self.conv_q.weight.data)
|
| 113 |
+
self.conv_k.bias.data.copy_(self.conv_q.bias.data)
|
| 114 |
+
torch.nn.init.xavier_uniform_(self.conv_v.weight)
|
| 115 |
+
|
| 116 |
+
def forward(self, x, c, attn_mask=None):
|
| 117 |
+
q = self.conv_q(x)
|
| 118 |
+
k = self.conv_k(c)
|
| 119 |
+
v = self.conv_v(c)
|
| 120 |
+
|
| 121 |
+
x, self.attn = self.attention(q, k, v, mask=attn_mask)
|
| 122 |
+
|
| 123 |
+
x = self.conv_o(x)
|
| 124 |
+
return x
|
| 125 |
+
|
| 126 |
+
def attention(self, query, key, value, mask=None):
|
| 127 |
+
b, d, t_s, t_t = (*key.size(), query.size(2))
|
| 128 |
+
query = query.view(b, self.n_heads, self.k_channels, t_t).transpose(2, 3)
|
| 129 |
+
key = key.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
|
| 130 |
+
value = value.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)
|
| 131 |
+
|
| 132 |
+
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(self.k_channels)
|
| 133 |
+
if self.window_size is not None:
|
| 134 |
+
assert t_s == t_t, "Relative attention is only available for self-attention."
|
| 135 |
+
key_relative_embeddings = self._get_relative_embeddings(self.emb_rel_k, t_s)
|
| 136 |
+
rel_logits = self._matmul_with_relative_keys(query, key_relative_embeddings)
|
| 137 |
+
rel_logits = self._relative_position_to_absolute_position(rel_logits)
|
| 138 |
+
scores_local = rel_logits / math.sqrt(self.k_channels)
|
| 139 |
+
scores = scores + scores_local
|
| 140 |
+
if self.proximal_bias:
|
| 141 |
+
assert t_s == t_t, "Proximal bias is only available for self-attention."
|
| 142 |
+
scores = scores + self._attention_bias_proximal(t_s).to(device=scores.device,
|
| 143 |
+
dtype=scores.dtype)
|
| 144 |
+
if mask is not None:
|
| 145 |
+
scores = scores.masked_fill(mask == 0, -1e4)
|
| 146 |
+
p_attn = torch.nn.functional.softmax(scores, dim=-1)
|
| 147 |
+
p_attn = self.drop(p_attn)
|
| 148 |
+
output = torch.matmul(p_attn, value)
|
| 149 |
+
if self.window_size is not None:
|
| 150 |
+
relative_weights = self._absolute_position_to_relative_position(p_attn)
|
| 151 |
+
value_relative_embeddings = self._get_relative_embeddings(self.emb_rel_v, t_s)
|
| 152 |
+
output = output + self._matmul_with_relative_values(relative_weights,
|
| 153 |
+
value_relative_embeddings)
|
| 154 |
+
output = output.transpose(2, 3).contiguous().view(b, d, t_t)
|
| 155 |
+
return output, p_attn
|
| 156 |
+
|
| 157 |
+
def _matmul_with_relative_values(self, x, y):
|
| 158 |
+
ret = torch.matmul(x, y.unsqueeze(0))
|
| 159 |
+
return ret
|
| 160 |
+
|
| 161 |
+
def _matmul_with_relative_keys(self, x, y):
|
| 162 |
+
ret = torch.matmul(x, y.unsqueeze(0).transpose(-2, -1))
|
| 163 |
+
return ret
|
| 164 |
+
|
| 165 |
+
def _get_relative_embeddings(self, relative_embeddings, length):
|
| 166 |
+
pad_length = max(length - (self.window_size + 1), 0)
|
| 167 |
+
slice_start_position = max((self.window_size + 1) - length, 0)
|
| 168 |
+
slice_end_position = slice_start_position + 2 * length - 1
|
| 169 |
+
if pad_length > 0:
|
| 170 |
+
padded_relative_embeddings = torch.nn.functional.pad(
|
| 171 |
+
relative_embeddings, convert_pad_shape([[0, 0],
|
| 172 |
+
[pad_length, pad_length], [0, 0]]))
|
| 173 |
+
else:
|
| 174 |
+
padded_relative_embeddings = relative_embeddings
|
| 175 |
+
used_relative_embeddings = padded_relative_embeddings[:,
|
| 176 |
+
slice_start_position:slice_end_position]
|
| 177 |
+
return used_relative_embeddings
|
| 178 |
+
|
| 179 |
+
def _relative_position_to_absolute_position(self, x):
|
| 180 |
+
batch, heads, length, _ = x.size()
|
| 181 |
+
x = torch.nn.functional.pad(x, convert_pad_shape([[0,0],[0,0],[0,0],[0,1]]))
|
| 182 |
+
x_flat = x.view([batch, heads, length * 2 * length])
|
| 183 |
+
x_flat = torch.nn.functional.pad(x_flat, convert_pad_shape([[0,0],[0,0],[0,length-1]]))
|
| 184 |
+
x_final = x_flat.view([batch, heads, length+1, 2*length-1])[:, :, :length, length-1:]
|
| 185 |
+
return x_final
|
| 186 |
+
|
| 187 |
+
def _absolute_position_to_relative_position(self, x):
|
| 188 |
+
batch, heads, length, _ = x.size()
|
| 189 |
+
x = torch.nn.functional.pad(x, convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, length-1]]))
|
| 190 |
+
x_flat = x.view([batch, heads, length**2 + length*(length - 1)])
|
| 191 |
+
x_flat = torch.nn.functional.pad(x_flat, convert_pad_shape([[0, 0], [0, 0], [length, 0]]))
|
| 192 |
+
x_final = x_flat.view([batch, heads, length, 2*length])[:,:,:,1:]
|
| 193 |
+
return x_final
|
| 194 |
+
|
| 195 |
+
def _attention_bias_proximal(self, length):
|
| 196 |
+
r = torch.arange(length, dtype=torch.float32)
|
| 197 |
+
diff = torch.unsqueeze(r, 0) - torch.unsqueeze(r, 1)
|
| 198 |
+
return torch.unsqueeze(torch.unsqueeze(-torch.log1p(torch.abs(diff)), 0), 0)
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
class FFN(BaseModule):
|
| 202 |
+
def __init__(self, in_channels, out_channels, filter_channels, kernel_size,
|
| 203 |
+
p_dropout=0.0):
|
| 204 |
+
super(FFN, self).__init__()
|
| 205 |
+
self.in_channels = in_channels
|
| 206 |
+
self.out_channels = out_channels
|
| 207 |
+
self.filter_channels = filter_channels
|
| 208 |
+
self.kernel_size = kernel_size
|
| 209 |
+
self.p_dropout = p_dropout
|
| 210 |
+
|
| 211 |
+
self.conv_1 = torch.nn.Conv1d(in_channels, filter_channels, kernel_size,
|
| 212 |
+
padding=kernel_size//2)
|
| 213 |
+
self.conv_2 = torch.nn.Conv1d(filter_channels, out_channels, kernel_size,
|
| 214 |
+
padding=kernel_size//2)
|
| 215 |
+
self.drop = torch.nn.Dropout(p_dropout)
|
| 216 |
+
|
| 217 |
+
def forward(self, x, x_mask):
|
| 218 |
+
x = self.conv_1(x * x_mask)
|
| 219 |
+
x = torch.relu(x)
|
| 220 |
+
x = self.drop(x)
|
| 221 |
+
x = self.conv_2(x * x_mask)
|
| 222 |
+
return x * x_mask
|
| 223 |
+
|
| 224 |
+
|
| 225 |
+
class Encoder(BaseModule):
|
| 226 |
+
def __init__(self, hidden_channels, filter_channels, n_heads, n_layers,
|
| 227 |
+
kernel_size=1, p_dropout=0.0, window_size=None, **kwargs):
|
| 228 |
+
super(Encoder, self).__init__()
|
| 229 |
+
self.hidden_channels = hidden_channels
|
| 230 |
+
self.filter_channels = filter_channels
|
| 231 |
+
self.n_heads = n_heads
|
| 232 |
+
self.n_layers = n_layers
|
| 233 |
+
self.kernel_size = kernel_size
|
| 234 |
+
self.p_dropout = p_dropout
|
| 235 |
+
self.window_size = window_size
|
| 236 |
+
|
| 237 |
+
self.drop = torch.nn.Dropout(p_dropout)
|
| 238 |
+
self.attn_layers = torch.nn.ModuleList()
|
| 239 |
+
self.norm_layers_1 = torch.nn.ModuleList()
|
| 240 |
+
self.ffn_layers = torch.nn.ModuleList()
|
| 241 |
+
self.norm_layers_2 = torch.nn.ModuleList()
|
| 242 |
+
for _ in range(self.n_layers):
|
| 243 |
+
self.attn_layers.append(MultiHeadAttention(hidden_channels, hidden_channels,
|
| 244 |
+
n_heads, window_size=window_size, p_dropout=p_dropout))
|
| 245 |
+
self.norm_layers_1.append(LayerNorm(hidden_channels))
|
| 246 |
+
self.ffn_layers.append(FFN(hidden_channels, hidden_channels,
|
| 247 |
+
filter_channels, kernel_size, p_dropout=p_dropout))
|
| 248 |
+
self.norm_layers_2.append(LayerNorm(hidden_channels))
|
| 249 |
+
|
| 250 |
+
def forward(self, x, x_mask):
|
| 251 |
+
attn_mask = x_mask.unsqueeze(2) * x_mask.unsqueeze(-1)
|
| 252 |
+
for i in range(self.n_layers):
|
| 253 |
+
x = x * x_mask
|
| 254 |
+
y = self.attn_layers[i](x, x, attn_mask)
|
| 255 |
+
y = self.drop(y)
|
| 256 |
+
x = self.norm_layers_1[i](x + y)
|
| 257 |
+
y = self.ffn_layers[i](x, x_mask)
|
| 258 |
+
y = self.drop(y)
|
| 259 |
+
x = self.norm_layers_2[i](x + y)
|
| 260 |
+
x = x * x_mask
|
| 261 |
+
return x
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
class TextEncoder(BaseModule):
|
| 265 |
+
def __init__(self, n_vecs, n_mels, n_embs,
|
| 266 |
+
n_channels,
|
| 267 |
+
filter_channels,
|
| 268 |
+
n_heads=2,
|
| 269 |
+
n_layers=6,
|
| 270 |
+
kernel_size=3,
|
| 271 |
+
p_dropout=0.1,
|
| 272 |
+
window_size=4):
|
| 273 |
+
super(TextEncoder, self).__init__()
|
| 274 |
+
self.n_vecs = n_vecs
|
| 275 |
+
self.n_mels = n_mels
|
| 276 |
+
self.n_embs = n_embs
|
| 277 |
+
self.n_channels = n_channels
|
| 278 |
+
self.filter_channels = filter_channels
|
| 279 |
+
self.n_heads = n_heads
|
| 280 |
+
self.n_layers = n_layers
|
| 281 |
+
self.kernel_size = kernel_size
|
| 282 |
+
self.p_dropout = p_dropout
|
| 283 |
+
self.window_size = window_size
|
| 284 |
+
|
| 285 |
+
self.prenet = ConvReluNorm(n_vecs,
|
| 286 |
+
n_channels,
|
| 287 |
+
n_channels,
|
| 288 |
+
kernel_size=5,
|
| 289 |
+
n_layers=5,
|
| 290 |
+
p_dropout=0.5)
|
| 291 |
+
|
| 292 |
+
self.speaker = SpeakerClassifier(
|
| 293 |
+
n_channels,
|
| 294 |
+
256, # n_spks: 256
|
| 295 |
+
)
|
| 296 |
+
|
| 297 |
+
self.encoder = Encoder(n_channels + n_embs + n_embs,
|
| 298 |
+
filter_channels,
|
| 299 |
+
n_heads,
|
| 300 |
+
n_layers,
|
| 301 |
+
kernel_size,
|
| 302 |
+
p_dropout,
|
| 303 |
+
window_size=window_size)
|
| 304 |
+
|
| 305 |
+
self.proj_m = torch.nn.Conv1d(n_channels + n_embs + n_embs, n_mels, 1)
|
| 306 |
+
|
| 307 |
+
def forward(self, x_lengths, x, pit, spk, training=False):
|
| 308 |
+
x_mask = torch.unsqueeze(sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype)
|
| 309 |
+
# IN
|
| 310 |
+
x = self.prenet(x, x_mask)
|
| 311 |
+
if training:
|
| 312 |
+
r = self.speaker(x)
|
| 313 |
+
else:
|
| 314 |
+
r = None
|
| 315 |
+
# pitch + speaker
|
| 316 |
+
spk = spk.unsqueeze(-1).repeat(1, 1, x.shape[-1])
|
| 317 |
+
x = torch.cat([x, pit], dim=1)
|
| 318 |
+
x = torch.cat([x, spk], dim=1)
|
| 319 |
+
x = self.encoder(x, x_mask)
|
| 320 |
+
mu = self.proj_m(x) * x_mask
|
| 321 |
+
return mu, x_mask, r
|
| 322 |
+
|
| 323 |
+
def fine_tune(self):
|
| 324 |
+
for p in self.prenet.parameters():
|
| 325 |
+
p.requires_grad = False
|
| 326 |
+
for p in self.speaker.parameters():
|
| 327 |
+
p.requires_grad = False
|
grad/model.py
ADDED
|
@@ -0,0 +1,148 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import torch
|
| 3 |
+
|
| 4 |
+
from grad.ssim import SSIM
|
| 5 |
+
from grad.base import BaseModule
|
| 6 |
+
from grad.encoder import TextEncoder
|
| 7 |
+
from grad.diffusion import Diffusion
|
| 8 |
+
from grad.utils import f0_to_coarse, rand_ids_segments, slice_segments
|
| 9 |
+
|
| 10 |
+
SpeakerLoss = torch.nn.CosineEmbeddingLoss()
|
| 11 |
+
SsimLoss = SSIM()
|
| 12 |
+
|
| 13 |
+
class GradTTS(BaseModule):
|
| 14 |
+
def __init__(self, n_mels, n_vecs, n_pits, n_spks, n_embs,
|
| 15 |
+
n_enc_channels, filter_channels,
|
| 16 |
+
dec_dim, beta_min, beta_max, pe_scale):
|
| 17 |
+
super(GradTTS, self).__init__()
|
| 18 |
+
# common
|
| 19 |
+
self.n_mels = n_mels
|
| 20 |
+
self.n_vecs = n_vecs
|
| 21 |
+
self.n_spks = n_spks
|
| 22 |
+
self.n_embs = n_embs
|
| 23 |
+
# encoder
|
| 24 |
+
self.n_enc_channels = n_enc_channels
|
| 25 |
+
self.filter_channels = filter_channels
|
| 26 |
+
# decoder
|
| 27 |
+
self.dec_dim = dec_dim
|
| 28 |
+
self.beta_min = beta_min
|
| 29 |
+
self.beta_max = beta_max
|
| 30 |
+
self.pe_scale = pe_scale
|
| 31 |
+
|
| 32 |
+
self.pit_emb = torch.nn.Embedding(n_pits, n_embs)
|
| 33 |
+
self.spk_emb = torch.nn.Linear(n_spks, n_embs)
|
| 34 |
+
self.encoder = TextEncoder(n_vecs,
|
| 35 |
+
n_mels,
|
| 36 |
+
n_embs,
|
| 37 |
+
n_enc_channels,
|
| 38 |
+
filter_channels)
|
| 39 |
+
self.decoder = Diffusion(n_mels, dec_dim, n_embs, beta_min, beta_max, pe_scale)
|
| 40 |
+
|
| 41 |
+
def fine_tune(self):
|
| 42 |
+
for p in self.pit_emb.parameters():
|
| 43 |
+
p.requires_grad = False
|
| 44 |
+
for p in self.spk_emb.parameters():
|
| 45 |
+
p.requires_grad = False
|
| 46 |
+
self.encoder.fine_tune()
|
| 47 |
+
|
| 48 |
+
@torch.no_grad()
|
| 49 |
+
def forward(self, lengths, vec, pit, spk, n_timesteps, temperature=1.0, stoc=False):
|
| 50 |
+
"""
|
| 51 |
+
Generates mel-spectrogram from vec. Returns:
|
| 52 |
+
1. encoder outputs
|
| 53 |
+
2. decoder outputs
|
| 54 |
+
|
| 55 |
+
Args:
|
| 56 |
+
lengths (torch.Tensor): lengths of texts in batch.
|
| 57 |
+
vec (torch.Tensor): batch of speech vec
|
| 58 |
+
pit (torch.Tensor): batch of speech pit
|
| 59 |
+
spk (torch.Tensor): batch of speaker
|
| 60 |
+
|
| 61 |
+
n_timesteps (int): number of steps to use for reverse diffusion in decoder.
|
| 62 |
+
temperature (float, optional): controls variance of terminal distribution.
|
| 63 |
+
stoc (bool, optional): flag that adds stochastic term to the decoder sampler.
|
| 64 |
+
Usually, does not provide synthesis improvements.
|
| 65 |
+
"""
|
| 66 |
+
lengths, vec, pit, spk = self.relocate_input([lengths, vec, pit, spk])
|
| 67 |
+
|
| 68 |
+
# Get pitch embedding
|
| 69 |
+
pit = self.pit_emb(f0_to_coarse(pit))
|
| 70 |
+
|
| 71 |
+
# Get speaker embedding
|
| 72 |
+
spk = self.spk_emb(spk)
|
| 73 |
+
|
| 74 |
+
# Transpose
|
| 75 |
+
vec = torch.transpose(vec, 1, -1)
|
| 76 |
+
pit = torch.transpose(pit, 1, -1)
|
| 77 |
+
|
| 78 |
+
# Get encoder_outputs `mu_x`
|
| 79 |
+
mu_x, mask_x, _ = self.encoder(lengths, vec, pit, spk)
|
| 80 |
+
encoder_outputs = mu_x
|
| 81 |
+
|
| 82 |
+
# Sample latent representation from terminal distribution N(mu_y, I)
|
| 83 |
+
z = mu_x + torch.randn_like(mu_x, device=mu_x.device) / temperature
|
| 84 |
+
# Generate sample by performing reverse dynamics
|
| 85 |
+
decoder_outputs = self.decoder(spk, z, mask_x, mu_x, n_timesteps, stoc)
|
| 86 |
+
encoder_outputs = encoder_outputs + torch.randn_like(encoder_outputs)
|
| 87 |
+
return encoder_outputs, decoder_outputs
|
| 88 |
+
|
| 89 |
+
def compute_loss(self, lengths, vec, pit, spk, mel, out_size, skip_diff=False):
|
| 90 |
+
"""
|
| 91 |
+
Computes 2 losses:
|
| 92 |
+
1. prior loss: loss between mel-spectrogram and encoder outputs.
|
| 93 |
+
2. diffusion loss: loss between gaussian noise and its reconstruction by diffusion-based decoder.
|
| 94 |
+
|
| 95 |
+
Args:
|
| 96 |
+
lengths (torch.Tensor): lengths of texts in batch.
|
| 97 |
+
vec (torch.Tensor): batch of speech vec
|
| 98 |
+
pit (torch.Tensor): batch of speech pit
|
| 99 |
+
spk (torch.Tensor): batch of speaker
|
| 100 |
+
mel (torch.Tensor): batch of corresponding mel-spectrogram
|
| 101 |
+
|
| 102 |
+
out_size (int, optional): length (in mel's sampling rate) of segment to cut, on which decoder will be trained.
|
| 103 |
+
Should be divisible by 2^{num of UNet downsamplings}. Needed to increase batch size.
|
| 104 |
+
"""
|
| 105 |
+
lengths, vec, pit, spk, mel = self.relocate_input([lengths, vec, pit, spk, mel])
|
| 106 |
+
|
| 107 |
+
# Get pitch embedding
|
| 108 |
+
pit = self.pit_emb(f0_to_coarse(pit))
|
| 109 |
+
|
| 110 |
+
# Get speaker embedding
|
| 111 |
+
spk_64 = self.spk_emb(spk)
|
| 112 |
+
|
| 113 |
+
# Transpose
|
| 114 |
+
vec = torch.transpose(vec, 1, -1)
|
| 115 |
+
pit = torch.transpose(pit, 1, -1)
|
| 116 |
+
|
| 117 |
+
# Get encoder_outputs `mu_x`
|
| 118 |
+
mu_x, mask_x, spk_preds = self.encoder(lengths, vec, pit, spk_64, training=True)
|
| 119 |
+
|
| 120 |
+
# Compute loss between aligned encoder outputs and mel-spectrogram
|
| 121 |
+
prior_loss = torch.sum(0.5 * ((mel - mu_x) ** 2 + math.log(2 * math.pi)) * mask_x)
|
| 122 |
+
prior_loss = prior_loss / (torch.sum(mask_x) * self.n_mels)
|
| 123 |
+
|
| 124 |
+
# Mel ssim
|
| 125 |
+
mel_loss = SsimLoss(mu_x, mel, mask_x)
|
| 126 |
+
|
| 127 |
+
# Compute loss of speaker for GRL
|
| 128 |
+
spk_loss = SpeakerLoss(spk, spk_preds, torch.Tensor(spk_preds.size(0))
|
| 129 |
+
.to(spk.device).fill_(1.0))
|
| 130 |
+
|
| 131 |
+
# Compute loss of score-based decoder
|
| 132 |
+
if skip_diff:
|
| 133 |
+
diff_loss = prior_loss.clone()
|
| 134 |
+
diff_loss.fill_(0)
|
| 135 |
+
else:
|
| 136 |
+
# Cut a small segment of mel-spectrogram in order to increase batch size
|
| 137 |
+
if not isinstance(out_size, type(None)):
|
| 138 |
+
ids = rand_ids_segments(lengths, out_size)
|
| 139 |
+
mel = slice_segments(mel, ids, out_size)
|
| 140 |
+
|
| 141 |
+
mask_y = slice_segments(mask_x, ids, out_size)
|
| 142 |
+
mu_y = slice_segments(mu_x, ids, out_size)
|
| 143 |
+
mu_y = mu_y + torch.randn_like(mu_y)
|
| 144 |
+
|
| 145 |
+
diff_loss, xt = self.decoder.compute_loss(
|
| 146 |
+
spk_64, mel, mask_y, mu_y)
|
| 147 |
+
|
| 148 |
+
return prior_loss, diff_loss, mel_loss, spk_loss
|
grad/reversal.py
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Adapted from https://github.com/ubisoft/ubisoft-laforge-daft-exprt Apache License Version 2.0
|
| 2 |
+
# Unsupervised Domain Adaptation by Backpropagation
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
|
| 7 |
+
from torch.autograd import Function
|
| 8 |
+
from torch.nn.utils import weight_norm
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class GradientReversalFunction(Function):
|
| 12 |
+
@staticmethod
|
| 13 |
+
def forward(ctx, x, lambda_):
|
| 14 |
+
ctx.lambda_ = lambda_
|
| 15 |
+
return x.clone()
|
| 16 |
+
|
| 17 |
+
@staticmethod
|
| 18 |
+
def backward(ctx, grads):
|
| 19 |
+
lambda_ = ctx.lambda_
|
| 20 |
+
lambda_ = grads.new_tensor(lambda_)
|
| 21 |
+
dx = -lambda_ * grads
|
| 22 |
+
return dx, None
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class GradientReversal(torch.nn.Module):
|
| 26 |
+
''' Gradient Reversal Layer
|
| 27 |
+
Y. Ganin, V. Lempitsky,
|
| 28 |
+
"Unsupervised Domain Adaptation by Backpropagation",
|
| 29 |
+
in ICML, 2015.
|
| 30 |
+
Forward pass is the identity function
|
| 31 |
+
In the backward pass, upstream gradients are multiplied by -lambda (i.e. gradient are reversed)
|
| 32 |
+
'''
|
| 33 |
+
|
| 34 |
+
def __init__(self, lambda_reversal=1):
|
| 35 |
+
super(GradientReversal, self).__init__()
|
| 36 |
+
self.lambda_ = lambda_reversal
|
| 37 |
+
|
| 38 |
+
def forward(self, x):
|
| 39 |
+
return GradientReversalFunction.apply(x, self.lambda_)
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class SpeakerClassifier(nn.Module):
|
| 43 |
+
|
| 44 |
+
def __init__(self, idim, odim):
|
| 45 |
+
super(SpeakerClassifier, self).__init__()
|
| 46 |
+
self.classifier = nn.Sequential(
|
| 47 |
+
GradientReversal(lambda_reversal=1),
|
| 48 |
+
weight_norm(nn.Conv1d(idim, 1024, kernel_size=5, padding=2)),
|
| 49 |
+
nn.ReLU(),
|
| 50 |
+
weight_norm(nn.Conv1d(1024, 1024, kernel_size=5, padding=2)),
|
| 51 |
+
nn.ReLU(),
|
| 52 |
+
weight_norm(nn.Conv1d(1024, odim, kernel_size=5, padding=2))
|
| 53 |
+
)
|
| 54 |
+
|
| 55 |
+
def forward(self, x):
|
| 56 |
+
''' Forward function of Speaker Classifier:
|
| 57 |
+
x = (B, idim, len)
|
| 58 |
+
'''
|
| 59 |
+
# pass through classifier
|
| 60 |
+
outputs = self.classifier(x) # (B, nb_speakers)
|
| 61 |
+
outputs = torch.mean(outputs, dim=-1)
|
| 62 |
+
return outputs
|
grad/solver.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class NoiseScheduleVP:
|
| 5 |
+
|
| 6 |
+
def __init__(self, beta_min=0.05, beta_max=20):
|
| 7 |
+
self.beta_min = beta_min
|
| 8 |
+
self.beta_max = beta_max
|
| 9 |
+
self.T = 1.
|
| 10 |
+
|
| 11 |
+
def get_noise(self, t, beta_init, beta_term, cumulative=False):
|
| 12 |
+
if cumulative:
|
| 13 |
+
noise = beta_init*t + 0.5*(beta_term - beta_init)*(t**2)
|
| 14 |
+
else:
|
| 15 |
+
noise = beta_init + (beta_term - beta_init)*t
|
| 16 |
+
return noise
|
| 17 |
+
|
| 18 |
+
def marginal_log_mean_coeff(self, t):
|
| 19 |
+
return -0.25 * t**2 * (self.beta_max -
|
| 20 |
+
self.beta_min) - 0.5 * t * self.beta_min
|
| 21 |
+
|
| 22 |
+
def marginal_std(self, t):
|
| 23 |
+
return torch.sqrt(1. - torch.exp(2. * self.marginal_log_mean_coeff(t)))
|
| 24 |
+
|
| 25 |
+
def marginal_lambda(self, t):
|
| 26 |
+
log_mean_coeff = self.marginal_log_mean_coeff(t)
|
| 27 |
+
log_std = 0.5 * torch.log(1. - torch.exp(2. * log_mean_coeff))
|
| 28 |
+
return log_mean_coeff - log_std
|
| 29 |
+
|
| 30 |
+
def inverse_lambda(self, lamb):
|
| 31 |
+
tmp = 2. * (self.beta_max - self.beta_min) * torch.logaddexp(
|
| 32 |
+
-2. * lamb,
|
| 33 |
+
torch.zeros((1, )).to(lamb))
|
| 34 |
+
Delta = self.beta_min**2 + tmp
|
| 35 |
+
return tmp / (torch.sqrt(Delta) + self.beta_min) / (self.beta_max -
|
| 36 |
+
self.beta_min)
|
| 37 |
+
|
| 38 |
+
def get_time_steps(self, t_T, t_0, N):
|
| 39 |
+
lambda_T = self.marginal_lambda(torch.tensor(t_T))
|
| 40 |
+
lambda_0 = self.marginal_lambda(torch.tensor(t_0))
|
| 41 |
+
logSNR_steps = torch.linspace(lambda_T, lambda_0, N + 1)
|
| 42 |
+
return self.inverse_lambda(logSNR_steps)
|
| 43 |
+
|
| 44 |
+
@torch.no_grad()
|
| 45 |
+
def reverse_diffusion(self, estimator, spk, z, mask, mu, n_timesteps, stoc):
|
| 46 |
+
print("use dpm-solver reverse")
|
| 47 |
+
xt = z * mask
|
| 48 |
+
yt = xt - mu
|
| 49 |
+
T = 1
|
| 50 |
+
eps = 1e-3
|
| 51 |
+
time = self.get_time_steps(T, eps, n_timesteps)
|
| 52 |
+
for i in range(n_timesteps):
|
| 53 |
+
s = torch.ones((xt.shape[0], )).to(xt.device) * time[i]
|
| 54 |
+
t = torch.ones((xt.shape[0], )).to(xt.device) * time[i + 1]
|
| 55 |
+
|
| 56 |
+
lambda_s = self.marginal_lambda(s)
|
| 57 |
+
lambda_t = self.marginal_lambda(t)
|
| 58 |
+
h = lambda_t - lambda_s
|
| 59 |
+
|
| 60 |
+
log_alpha_s = self.marginal_log_mean_coeff(s)
|
| 61 |
+
log_alpha_t = self.marginal_log_mean_coeff(t)
|
| 62 |
+
|
| 63 |
+
sigma_t = self.marginal_std(t)
|
| 64 |
+
phi_1 = torch.expm1(h)
|
| 65 |
+
|
| 66 |
+
noise_s = estimator(spk, yt + mu, mask, mu, s)
|
| 67 |
+
lt = 1 - torch.exp(-self.get_noise(s, self.beta_min, self.beta_max, cumulative=True))
|
| 68 |
+
a = torch.exp(log_alpha_t - log_alpha_s)
|
| 69 |
+
b = sigma_t * phi_1 * torch.sqrt(lt)
|
| 70 |
+
yt = a * yt + (b * noise_s)
|
| 71 |
+
xt = yt + mu
|
| 72 |
+
return xt
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
class MaxLikelihood:
|
| 76 |
+
|
| 77 |
+
def __init__(self, beta_min=0.05, beta_max=20):
|
| 78 |
+
self.beta_min = beta_min
|
| 79 |
+
self.beta_max = beta_max
|
| 80 |
+
|
| 81 |
+
def get_noise(self, t, beta_init, beta_term, cumulative=False):
|
| 82 |
+
if cumulative:
|
| 83 |
+
noise = beta_init*t + 0.5*(beta_term - beta_init)*(t**2)
|
| 84 |
+
else:
|
| 85 |
+
noise = beta_init + (beta_term - beta_init)*t
|
| 86 |
+
return noise
|
| 87 |
+
|
| 88 |
+
def get_gamma(self, s, t, beta_init, beta_term):
|
| 89 |
+
gamma = beta_init*(t-s) + 0.5*(beta_term-beta_init)*(t**2-s**2)
|
| 90 |
+
gamma = torch.exp(-0.5*gamma)
|
| 91 |
+
return gamma
|
| 92 |
+
|
| 93 |
+
def get_mu(self, s, t):
|
| 94 |
+
gamma_0_s = self.get_gamma(0, s, self.beta_min, self.beta_max)
|
| 95 |
+
gamma_0_t = self.get_gamma(0, t, self.beta_min, self.beta_max)
|
| 96 |
+
gamma_s_t = self.get_gamma(s, t, self.beta_min, self.beta_max)
|
| 97 |
+
mu = gamma_s_t * ((1-gamma_0_s**2) / (1-gamma_0_t**2))
|
| 98 |
+
return mu
|
| 99 |
+
|
| 100 |
+
def get_nu(self, s, t):
|
| 101 |
+
gamma_0_s = self.get_gamma(0, s, self.beta_min, self.beta_max)
|
| 102 |
+
gamma_0_t = self.get_gamma(0, t, self.beta_min, self.beta_max)
|
| 103 |
+
gamma_s_t = self.get_gamma(s, t, self.beta_min, self.beta_max)
|
| 104 |
+
nu = gamma_0_s * ((1-gamma_s_t**2) / (1-gamma_0_t**2))
|
| 105 |
+
return nu
|
| 106 |
+
|
| 107 |
+
def get_sigma(self, s, t):
|
| 108 |
+
gamma_0_s = self.get_gamma(0, s, self.beta_min, self.beta_max)
|
| 109 |
+
gamma_0_t = self.get_gamma(0, t, self.beta_min, self.beta_max)
|
| 110 |
+
gamma_s_t = self.get_gamma(s, t, self.beta_min, self.beta_max)
|
| 111 |
+
sigma = torch.sqrt(((1 - gamma_0_s**2) * (1 - gamma_s_t**2)) / (1 - gamma_0_t**2))
|
| 112 |
+
return sigma
|
| 113 |
+
|
| 114 |
+
def get_kappa(self, t, h, noise):
|
| 115 |
+
nu = self.get_nu(t-h, t)
|
| 116 |
+
gamma_0_t = self.get_gamma(0, t, self.beta_min, self.beta_max)
|
| 117 |
+
kappa = (nu*(1-gamma_0_t**2)/(gamma_0_t*noise*h) - 1)
|
| 118 |
+
return kappa
|
| 119 |
+
|
| 120 |
+
def get_omega(self, t, h, noise):
|
| 121 |
+
mu = self.get_mu(t-h, t)
|
| 122 |
+
kappa = self.get_kappa(t, h, noise)
|
| 123 |
+
gamma_0_t = self.get_gamma(0, t, self.beta_min, self.beta_max)
|
| 124 |
+
omega = (mu-1)/(noise*h) + (1+kappa)/(1-gamma_0_t**2) - 0.5
|
| 125 |
+
return omega
|
| 126 |
+
|
| 127 |
+
@torch.no_grad()
|
| 128 |
+
def reverse_diffusion(self, estimator, spk, z, mask, mu, n_timesteps, stoc=False):
|
| 129 |
+
print("use MaxLikelihood reverse")
|
| 130 |
+
h = 1.0 / n_timesteps
|
| 131 |
+
xt = z * mask
|
| 132 |
+
for i in range(n_timesteps):
|
| 133 |
+
t = (1.0 - i*h) * torch.ones(z.shape[0], dtype=z.dtype,
|
| 134 |
+
device=z.device)
|
| 135 |
+
time = t.unsqueeze(-1).unsqueeze(-1)
|
| 136 |
+
noise_t = self.get_noise(time, self.beta_min, self.beta_max,
|
| 137 |
+
cumulative=False)
|
| 138 |
+
|
| 139 |
+
kappa_t_h = self.get_kappa(t, h, noise_t)
|
| 140 |
+
omega_t_h = self.get_omega(t, h, noise_t)
|
| 141 |
+
sigma_t_h = self.get_sigma(t-h, t)
|
| 142 |
+
|
| 143 |
+
es = estimator(spk, xt, mask, mu, t)
|
| 144 |
+
|
| 145 |
+
dxt = ((0.5+omega_t_h)*(xt - mu) + (1+kappa_t_h) * es)
|
| 146 |
+
dxt_stoc = torch.randn(z.shape, dtype=z.dtype, device=z.device,
|
| 147 |
+
requires_grad=False)
|
| 148 |
+
dxt_stoc = dxt_stoc * sigma_t_h
|
| 149 |
+
|
| 150 |
+
dxt = dxt * noise_t * h + dxt_stoc
|
| 151 |
+
xt = (xt + dxt) * mask
|
| 152 |
+
return xt
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
class GradRaw:
|
| 156 |
+
|
| 157 |
+
def __init__(self, beta_min=0.05, beta_max=20):
|
| 158 |
+
self.beta_min = beta_min
|
| 159 |
+
self.beta_max = beta_max
|
| 160 |
+
|
| 161 |
+
def get_noise(self, t, beta_init, beta_term, cumulative=False):
|
| 162 |
+
if cumulative:
|
| 163 |
+
noise = beta_init*t + 0.5*(beta_term - beta_init)*(t**2)
|
| 164 |
+
else:
|
| 165 |
+
noise = beta_init + (beta_term - beta_init)*t
|
| 166 |
+
return noise
|
| 167 |
+
|
| 168 |
+
@torch.no_grad()
|
| 169 |
+
def reverse_diffusion(self, estimator, spk, z, mask, mu, n_timesteps, stoc=False):
|
| 170 |
+
print("use grad-raw reverse")
|
| 171 |
+
h = 1.0 / n_timesteps
|
| 172 |
+
xt = z * mask
|
| 173 |
+
for i in range(n_timesteps):
|
| 174 |
+
t = (1.0 - (i + 0.5)*h) * \
|
| 175 |
+
torch.ones(z.shape[0], dtype=z.dtype, device=z.device)
|
| 176 |
+
time = t.unsqueeze(-1).unsqueeze(-1)
|
| 177 |
+
noise_t = self.get_noise(time, self.beta_min, self.beta_max,
|
| 178 |
+
cumulative=False)
|
| 179 |
+
if stoc: # adds stochastic term
|
| 180 |
+
dxt_det = 0.5 * (mu - xt) - estimator(spk, xt, mask, mu, t)
|
| 181 |
+
dxt_det = dxt_det * noise_t * h
|
| 182 |
+
dxt_stoc = torch.randn(z.shape, dtype=z.dtype, device=z.device,
|
| 183 |
+
requires_grad=False)
|
| 184 |
+
dxt_stoc = dxt_stoc * torch.sqrt(noise_t * h)
|
| 185 |
+
dxt = dxt_det + dxt_stoc
|
| 186 |
+
else:
|
| 187 |
+
dxt = 0.5 * (mu - xt - estimator(spk, xt, mask, mu, t))
|
| 188 |
+
dxt = dxt * noise_t * h
|
| 189 |
+
xt = (xt - dxt) * mask
|
| 190 |
+
return xt
|
grad/ssim.py
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Adapted from https://github.com/Po-Hsun-Su/pytorch-ssim
|
| 3 |
+
"""
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn.functional as F
|
| 6 |
+
from torch.autograd import Variable
|
| 7 |
+
from math import exp
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def gaussian(window_size, sigma):
|
| 11 |
+
gauss = torch.Tensor([exp(-(x - window_size // 2) ** 2 / float(2 * sigma ** 2)) for x in range(window_size)])
|
| 12 |
+
return gauss / gauss.sum()
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def create_window(window_size, channel):
|
| 16 |
+
_1D_window = gaussian(window_size, 1.5).unsqueeze(1)
|
| 17 |
+
_2D_window = _1D_window.mm(_1D_window.t()).float().unsqueeze(0).unsqueeze(0)
|
| 18 |
+
window = Variable(_2D_window.expand(channel, 1, window_size, window_size).contiguous())
|
| 19 |
+
return window
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def _ssim(img1, img2, window, window_size, channel, size_average=True):
|
| 23 |
+
mu1 = F.conv2d(img1, window, padding=window_size // 2, groups=channel)
|
| 24 |
+
mu2 = F.conv2d(img2, window, padding=window_size // 2, groups=channel)
|
| 25 |
+
|
| 26 |
+
mu1_sq = mu1.pow(2)
|
| 27 |
+
mu2_sq = mu2.pow(2)
|
| 28 |
+
mu1_mu2 = mu1 * mu2
|
| 29 |
+
|
| 30 |
+
sigma1_sq = F.conv2d(img1 * img1, window, padding=window_size // 2, groups=channel) - mu1_sq
|
| 31 |
+
sigma2_sq = F.conv2d(img2 * img2, window, padding=window_size // 2, groups=channel) - mu2_sq
|
| 32 |
+
sigma12 = F.conv2d(img1 * img2, window, padding=window_size // 2, groups=channel) - mu1_mu2
|
| 33 |
+
|
| 34 |
+
C1 = 0.01 ** 2
|
| 35 |
+
C2 = 0.03 ** 2
|
| 36 |
+
|
| 37 |
+
ssim_map = ((2 * mu1_mu2 + C1) * (2 * sigma12 + C2)) / ((mu1_sq + mu2_sq + C1) * (sigma1_sq + sigma2_sq + C2))
|
| 38 |
+
|
| 39 |
+
if size_average:
|
| 40 |
+
return ssim_map.mean()
|
| 41 |
+
else:
|
| 42 |
+
return ssim_map.mean(1)
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
class SSIM(torch.nn.Module):
|
| 46 |
+
def __init__(self, window_size=11, size_average=True):
|
| 47 |
+
super(SSIM, self).__init__()
|
| 48 |
+
self.window_size = window_size
|
| 49 |
+
self.size_average = size_average
|
| 50 |
+
self.channel = 1
|
| 51 |
+
self.window = create_window(window_size, self.channel)
|
| 52 |
+
|
| 53 |
+
def forward(self, fake, real, mask, bias=6.0):
|
| 54 |
+
fake = fake[:, None, :, :] + bias # [B, 1, T, 80]
|
| 55 |
+
real = real[:, None, :, :] + bias # [B, 1, T, 80]
|
| 56 |
+
self.window = self.window.to(dtype=fake.dtype, device=fake.device)
|
| 57 |
+
loss = 1 - _ssim(fake, real, self.window, self.window_size, self.channel, self.size_average)
|
| 58 |
+
loss = (loss * mask).sum() / mask.sum()
|
| 59 |
+
return loss
|
grad/utils.py
ADDED
|
@@ -0,0 +1,99 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import numpy as np
|
| 3 |
+
import inspect
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def sequence_mask(length, max_length=None):
|
| 7 |
+
if max_length is None:
|
| 8 |
+
max_length = length.max()
|
| 9 |
+
x = torch.arange(int(max_length), dtype=length.dtype, device=length.device)
|
| 10 |
+
return x.unsqueeze(0) < length.unsqueeze(1)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def fix_len_compatibility(length, num_downsamplings_in_unet=2):
|
| 14 |
+
while True:
|
| 15 |
+
if length % (2**num_downsamplings_in_unet) == 0:
|
| 16 |
+
return length
|
| 17 |
+
length += 1
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def convert_pad_shape(pad_shape):
|
| 21 |
+
l = pad_shape[::-1]
|
| 22 |
+
pad_shape = [item for sublist in l for item in sublist]
|
| 23 |
+
return pad_shape
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def generate_path(duration, mask):
|
| 27 |
+
device = duration.device
|
| 28 |
+
|
| 29 |
+
b, t_x, t_y = mask.shape
|
| 30 |
+
cum_duration = torch.cumsum(duration, 1)
|
| 31 |
+
path = torch.zeros(b, t_x, t_y, dtype=mask.dtype).to(device=device)
|
| 32 |
+
|
| 33 |
+
cum_duration_flat = cum_duration.view(b * t_x)
|
| 34 |
+
path = sequence_mask(cum_duration_flat, t_y).to(mask.dtype)
|
| 35 |
+
path = path.view(b, t_x, t_y)
|
| 36 |
+
path = path - torch.nn.functional.pad(path, convert_pad_shape([[0, 0],
|
| 37 |
+
[1, 0], [0, 0]]))[:, :-1]
|
| 38 |
+
path = path * mask
|
| 39 |
+
return path
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
def duration_loss(logw, logw_, lengths):
|
| 43 |
+
loss = torch.sum((logw - logw_)**2) / torch.sum(lengths)
|
| 44 |
+
return loss
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
f0_bin = 256
|
| 48 |
+
f0_max = 1100.0
|
| 49 |
+
f0_min = 50.0
|
| 50 |
+
f0_mel_min = 1127 * np.log(1 + f0_min / 700)
|
| 51 |
+
f0_mel_max = 1127 * np.log(1 + f0_max / 700)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def f0_to_coarse(f0):
|
| 55 |
+
is_torch = isinstance(f0, torch.Tensor)
|
| 56 |
+
f0_mel = 1127 * (1 + f0 / 700).log() if is_torch else 1127 * \
|
| 57 |
+
np.log(1 + f0 / 700)
|
| 58 |
+
f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - f0_mel_min) * \
|
| 59 |
+
(f0_bin - 2) / (f0_mel_max - f0_mel_min) + 1
|
| 60 |
+
|
| 61 |
+
f0_mel[f0_mel <= 1] = 1
|
| 62 |
+
f0_mel[f0_mel > f0_bin - 1] = f0_bin - 1
|
| 63 |
+
f0_coarse = (
|
| 64 |
+
f0_mel + 0.5).long() if is_torch else np.rint(f0_mel).astype(np.int)
|
| 65 |
+
assert f0_coarse.max() <= 255 and f0_coarse.min(
|
| 66 |
+
) >= 1, (f0_coarse.max(), f0_coarse.min())
|
| 67 |
+
return f0_coarse
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def rand_ids_segments(lengths, segment_size=200):
|
| 71 |
+
b = lengths.shape[0]
|
| 72 |
+
ids_str_max = lengths - segment_size
|
| 73 |
+
ids_str = (torch.rand([b]).to(device=lengths.device) * ids_str_max).to(dtype=torch.long)
|
| 74 |
+
return ids_str
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def slice_segments(x, ids_str, segment_size=200):
|
| 78 |
+
ret = torch.zeros_like(x[:, :, :segment_size])
|
| 79 |
+
for i in range(x.size(0)):
|
| 80 |
+
idx_str = ids_str[i]
|
| 81 |
+
idx_end = idx_str + segment_size
|
| 82 |
+
ret[i] = x[i, :, idx_str:idx_end]
|
| 83 |
+
return ret
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
def retrieve_name(var):
|
| 87 |
+
for fi in reversed(inspect.stack()):
|
| 88 |
+
names = [var_name for var_name,
|
| 89 |
+
var_val in fi.frame.f_locals.items() if var_val is var]
|
| 90 |
+
if len(names) > 0:
|
| 91 |
+
return names[0]
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
Debug_Enable = True
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def debug_shapes(var):
|
| 98 |
+
if Debug_Enable:
|
| 99 |
+
print(retrieve_name(var), var.shape)
|
grad_extend/data.py
ADDED
|
@@ -0,0 +1,135 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import random
|
| 3 |
+
import numpy as np
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
|
| 7 |
+
from grad.utils import fix_len_compatibility
|
| 8 |
+
from grad_extend.utils import parse_filelist
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class TextMelSpeakerDataset(torch.utils.data.Dataset):
|
| 12 |
+
def __init__(self, filelist_path):
|
| 13 |
+
super().__init__()
|
| 14 |
+
self.filelist = parse_filelist(filelist_path, split_char='|')
|
| 15 |
+
self._filter()
|
| 16 |
+
print(f'----------{len(self.filelist)}----------')
|
| 17 |
+
|
| 18 |
+
def _filter(self):
|
| 19 |
+
items_new = []
|
| 20 |
+
# segment = 200
|
| 21 |
+
items_min = 250 # 10ms * 250 = 2.5 S
|
| 22 |
+
items_max = 500 # 10ms * 400 = 5.0 S
|
| 23 |
+
for mel, vec, pit, spk in self.filelist:
|
| 24 |
+
if not os.path.isfile(mel):
|
| 25 |
+
continue
|
| 26 |
+
if not os.path.isfile(vec):
|
| 27 |
+
continue
|
| 28 |
+
if not os.path.isfile(pit):
|
| 29 |
+
continue
|
| 30 |
+
if not os.path.isfile(spk):
|
| 31 |
+
continue
|
| 32 |
+
temp = np.load(pit)
|
| 33 |
+
usel = int(temp.shape[0] - 1) # useful length
|
| 34 |
+
if (usel < items_min):
|
| 35 |
+
continue
|
| 36 |
+
if (usel >= items_max):
|
| 37 |
+
usel = items_max
|
| 38 |
+
items_new.append([mel, vec, pit, spk, usel])
|
| 39 |
+
self.filelist = items_new
|
| 40 |
+
|
| 41 |
+
def get_triplet(self, item):
|
| 42 |
+
# print(item)
|
| 43 |
+
mel = item[0]
|
| 44 |
+
vec = item[1]
|
| 45 |
+
pit = item[2]
|
| 46 |
+
spk = item[3]
|
| 47 |
+
use = item[4]
|
| 48 |
+
|
| 49 |
+
mel = torch.load(mel)
|
| 50 |
+
vec = np.load(vec)
|
| 51 |
+
vec = np.repeat(vec, 2, 0) # 320 VEC -> 160 * 2
|
| 52 |
+
pit = np.load(pit)
|
| 53 |
+
spk = np.load(spk)
|
| 54 |
+
|
| 55 |
+
vec = torch.FloatTensor(vec)
|
| 56 |
+
pit = torch.FloatTensor(pit)
|
| 57 |
+
spk = torch.FloatTensor(spk)
|
| 58 |
+
|
| 59 |
+
vec = vec + torch.randn_like(vec) # Perturbation
|
| 60 |
+
|
| 61 |
+
len_vec = vec.size()[0] - 2 # for safe
|
| 62 |
+
len_pit = pit.size()[0]
|
| 63 |
+
len_min = min(len_pit, len_vec)
|
| 64 |
+
|
| 65 |
+
mel = mel[:, :len_min]
|
| 66 |
+
vec = vec[:len_min, :]
|
| 67 |
+
pit = pit[:len_min]
|
| 68 |
+
|
| 69 |
+
if len_min > use:
|
| 70 |
+
max_frame_start = vec.size(0) - use - 1
|
| 71 |
+
frame_start = random.randint(0, max_frame_start)
|
| 72 |
+
frame_end = frame_start + use
|
| 73 |
+
|
| 74 |
+
mel = mel[:, frame_start:frame_end]
|
| 75 |
+
vec = vec[frame_start:frame_end, :]
|
| 76 |
+
pit = pit[frame_start:frame_end]
|
| 77 |
+
# print(mel.shape)
|
| 78 |
+
# print(vec.shape)
|
| 79 |
+
# print(pit.shape)
|
| 80 |
+
# print(spk.shape)
|
| 81 |
+
return (mel, vec, pit, spk)
|
| 82 |
+
|
| 83 |
+
def __getitem__(self, index):
|
| 84 |
+
mel, vec, pit, spk = self.get_triplet(self.filelist[index])
|
| 85 |
+
item = {'mel': mel, 'vec': vec, 'pit': pit, 'spk': spk}
|
| 86 |
+
return item
|
| 87 |
+
|
| 88 |
+
def __len__(self):
|
| 89 |
+
return len(self.filelist)
|
| 90 |
+
|
| 91 |
+
def sample_test_batch(self, size):
|
| 92 |
+
idx = np.random.choice(range(len(self)), size=size, replace=False)
|
| 93 |
+
test_batch = []
|
| 94 |
+
for index in idx:
|
| 95 |
+
test_batch.append(self.__getitem__(index))
|
| 96 |
+
return test_batch
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
class TextMelSpeakerBatchCollate(object):
|
| 100 |
+
# mel: [freq, length]
|
| 101 |
+
# vec: [len, 256]
|
| 102 |
+
# pit: [len]
|
| 103 |
+
# spk: [256]
|
| 104 |
+
def __call__(self, batch):
|
| 105 |
+
B = len(batch)
|
| 106 |
+
mel_max_length = max([item['mel'].shape[-1] for item in batch])
|
| 107 |
+
max_length = fix_len_compatibility(mel_max_length)
|
| 108 |
+
|
| 109 |
+
d_mel = batch[0]['mel'].shape[0]
|
| 110 |
+
d_vec = batch[0]['vec'].shape[1]
|
| 111 |
+
d_spk = batch[0]['spk'].shape[0]
|
| 112 |
+
# print("d_mel", d_mel)
|
| 113 |
+
# print("d_vec", d_vec)
|
| 114 |
+
# print("d_spk", d_spk)
|
| 115 |
+
mel = torch.zeros((B, d_mel, max_length), dtype=torch.float32)
|
| 116 |
+
vec = torch.zeros((B, max_length, d_vec), dtype=torch.float32)
|
| 117 |
+
pit = torch.zeros((B, max_length), dtype=torch.float32)
|
| 118 |
+
spk = torch.zeros((B, d_spk), dtype=torch.float32)
|
| 119 |
+
lengths = torch.LongTensor(B)
|
| 120 |
+
|
| 121 |
+
for i, item in enumerate(batch):
|
| 122 |
+
y_, x_, p_, s_ = item['mel'], item['vec'], item['pit'], item['spk']
|
| 123 |
+
|
| 124 |
+
mel[i, :, :y_.shape[1]] = y_
|
| 125 |
+
vec[i, :x_.shape[0], :] = x_
|
| 126 |
+
pit[i, :p_.shape[0]] = p_
|
| 127 |
+
spk[i] = s_
|
| 128 |
+
|
| 129 |
+
lengths[i] = y_.shape[1]
|
| 130 |
+
# print("lengths", lengths.shape)
|
| 131 |
+
# print("vec", vec.shape)
|
| 132 |
+
# print("pit", pit.shape)
|
| 133 |
+
# print("spk", spk.shape)
|
| 134 |
+
# print("mel", mel.shape)
|
| 135 |
+
return {'lengths': lengths, 'vec': vec, 'pit': pit, 'spk': spk, 'mel': mel}
|
grad_extend/train.py
ADDED
|
@@ -0,0 +1,188 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import torch
|
| 3 |
+
import numpy as np
|
| 4 |
+
|
| 5 |
+
from torch.utils.data import DataLoader
|
| 6 |
+
from torch.utils.tensorboard import SummaryWriter
|
| 7 |
+
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
from grad_extend.data import TextMelSpeakerDataset, TextMelSpeakerBatchCollate
|
| 10 |
+
from grad_extend.utils import plot_tensor, save_plot, load_model, print_error
|
| 11 |
+
from grad.utils import fix_len_compatibility
|
| 12 |
+
from grad.model import GradTTS
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
# 200 frames
|
| 16 |
+
out_size = fix_len_compatibility(200)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def train(hps, chkpt_path=None):
|
| 20 |
+
|
| 21 |
+
print('Initializing logger...')
|
| 22 |
+
logger = SummaryWriter(log_dir=hps.train.log_dir)
|
| 23 |
+
|
| 24 |
+
print('Initializing data loaders...')
|
| 25 |
+
train_dataset = TextMelSpeakerDataset(hps.train.train_files)
|
| 26 |
+
batch_collate = TextMelSpeakerBatchCollate()
|
| 27 |
+
loader = DataLoader(dataset=train_dataset,
|
| 28 |
+
batch_size=hps.train.batch_size,
|
| 29 |
+
collate_fn=batch_collate,
|
| 30 |
+
drop_last=True,
|
| 31 |
+
num_workers=8,
|
| 32 |
+
shuffle=True)
|
| 33 |
+
test_dataset = TextMelSpeakerDataset(hps.train.valid_files)
|
| 34 |
+
|
| 35 |
+
print('Initializing model...')
|
| 36 |
+
model = GradTTS(hps.grad.n_mels, hps.grad.n_vecs, hps.grad.n_pits, hps.grad.n_spks, hps.grad.n_embs,
|
| 37 |
+
hps.grad.n_enc_channels, hps.grad.filter_channels,
|
| 38 |
+
hps.grad.dec_dim, hps.grad.beta_min, hps.grad.beta_max, hps.grad.pe_scale).cuda()
|
| 39 |
+
print('Number of encoder parameters = %.2fm' % (model.encoder.nparams/1e6))
|
| 40 |
+
print('Number of decoder parameters = %.2fm' % (model.decoder.nparams/1e6))
|
| 41 |
+
|
| 42 |
+
# Load Pretrain
|
| 43 |
+
if os.path.isfile(hps.train.pretrain):
|
| 44 |
+
print("Start from Grad_SVC pretrain model: %s" % hps.train.pretrain)
|
| 45 |
+
checkpoint = torch.load(hps.train.pretrain, map_location='cpu')
|
| 46 |
+
load_model(model, checkpoint['model'])
|
| 47 |
+
hps.train.learning_rate = 2e-5
|
| 48 |
+
# fine_tune
|
| 49 |
+
model.fine_tune()
|
| 50 |
+
else:
|
| 51 |
+
print_error(10 * '~' + "No Pretrain Model" + 10 * '~')
|
| 52 |
+
|
| 53 |
+
print('Initializing optimizer...')
|
| 54 |
+
optim = torch.optim.Adam(params=model.parameters(), lr=hps.train.learning_rate)
|
| 55 |
+
|
| 56 |
+
initepoch = 1
|
| 57 |
+
iteration = 0
|
| 58 |
+
|
| 59 |
+
# Load Continue
|
| 60 |
+
if chkpt_path is not None:
|
| 61 |
+
print("Resuming from checkpoint: %s" % chkpt_path)
|
| 62 |
+
checkpoint = torch.load(chkpt_path, map_location='cpu')
|
| 63 |
+
model.load_state_dict(checkpoint['model'])
|
| 64 |
+
optim.load_state_dict(checkpoint['optim'])
|
| 65 |
+
initepoch = checkpoint['epoch']
|
| 66 |
+
iteration = checkpoint['steps']
|
| 67 |
+
|
| 68 |
+
print('Logging test batch...')
|
| 69 |
+
test_batch = test_dataset.sample_test_batch(size=hps.train.test_size)
|
| 70 |
+
for i, item in enumerate(test_batch):
|
| 71 |
+
mel = item['mel']
|
| 72 |
+
logger.add_image(f'image_{i}/ground_truth', plot_tensor(mel.squeeze()),
|
| 73 |
+
global_step=0, dataformats='HWC')
|
| 74 |
+
save_plot(mel.squeeze(), f'{hps.train.log_dir}/original_{i}.png')
|
| 75 |
+
|
| 76 |
+
print('Start training...')
|
| 77 |
+
skip_diff_train = True
|
| 78 |
+
if initepoch >= hps.train.fast_epochs:
|
| 79 |
+
skip_diff_train = False
|
| 80 |
+
for epoch in range(initepoch, hps.train.full_epochs + 1):
|
| 81 |
+
|
| 82 |
+
if epoch % hps.train.test_step == 0:
|
| 83 |
+
model.eval()
|
| 84 |
+
print('Synthesis...')
|
| 85 |
+
|
| 86 |
+
with torch.no_grad():
|
| 87 |
+
for i, item in enumerate(test_batch):
|
| 88 |
+
l_vec = item['vec'].shape[0]
|
| 89 |
+
d_vec = item['vec'].shape[1]
|
| 90 |
+
|
| 91 |
+
lengths_fix = fix_len_compatibility(l_vec)
|
| 92 |
+
lengths = torch.LongTensor([l_vec]).cuda()
|
| 93 |
+
|
| 94 |
+
vec = torch.zeros((1, lengths_fix, d_vec), dtype=torch.float32).cuda()
|
| 95 |
+
pit = torch.zeros((1, lengths_fix), dtype=torch.float32).cuda()
|
| 96 |
+
spk = item['spk'].to(torch.float32).unsqueeze(0).cuda()
|
| 97 |
+
vec[0, :l_vec, :] = item['vec']
|
| 98 |
+
pit[0, :l_vec] = item['pit']
|
| 99 |
+
|
| 100 |
+
y_enc, y_dec = model(lengths, vec, pit, spk, n_timesteps=50)
|
| 101 |
+
|
| 102 |
+
logger.add_image(f'image_{i}/generated_enc',
|
| 103 |
+
plot_tensor(y_enc.squeeze().cpu()),
|
| 104 |
+
global_step=iteration, dataformats='HWC')
|
| 105 |
+
logger.add_image(f'image_{i}/generated_dec',
|
| 106 |
+
plot_tensor(y_dec.squeeze().cpu()),
|
| 107 |
+
global_step=iteration, dataformats='HWC')
|
| 108 |
+
save_plot(y_enc.squeeze().cpu(),
|
| 109 |
+
f'{hps.train.log_dir}/generated_enc_{i}.png')
|
| 110 |
+
save_plot(y_dec.squeeze().cpu(),
|
| 111 |
+
f'{hps.train.log_dir}/generated_dec_{i}.png')
|
| 112 |
+
|
| 113 |
+
model.train()
|
| 114 |
+
|
| 115 |
+
prior_losses = []
|
| 116 |
+
diff_losses = []
|
| 117 |
+
mel_losses = []
|
| 118 |
+
spk_losses = []
|
| 119 |
+
with tqdm(loader, total=len(train_dataset)//hps.train.batch_size) as progress_bar:
|
| 120 |
+
for batch in progress_bar:
|
| 121 |
+
model.zero_grad()
|
| 122 |
+
|
| 123 |
+
lengths = batch['lengths'].cuda()
|
| 124 |
+
vec = batch['vec'].cuda()
|
| 125 |
+
pit = batch['pit'].cuda()
|
| 126 |
+
spk = batch['spk'].cuda()
|
| 127 |
+
mel = batch['mel'].cuda()
|
| 128 |
+
|
| 129 |
+
prior_loss, diff_loss, mel_loss, spk_loss = model.compute_loss(
|
| 130 |
+
lengths, vec, pit, spk,
|
| 131 |
+
mel, out_size=out_size,
|
| 132 |
+
skip_diff=skip_diff_train)
|
| 133 |
+
loss = sum([prior_loss, diff_loss, mel_loss, spk_loss])
|
| 134 |
+
loss.backward()
|
| 135 |
+
|
| 136 |
+
enc_grad_norm = torch.nn.utils.clip_grad_norm_(model.encoder.parameters(),
|
| 137 |
+
max_norm=1)
|
| 138 |
+
dec_grad_norm = torch.nn.utils.clip_grad_norm_(model.decoder.parameters(),
|
| 139 |
+
max_norm=1)
|
| 140 |
+
optim.step()
|
| 141 |
+
|
| 142 |
+
logger.add_scalar('training/mel_loss', mel_loss,
|
| 143 |
+
global_step=iteration)
|
| 144 |
+
logger.add_scalar('training/prior_loss', prior_loss,
|
| 145 |
+
global_step=iteration)
|
| 146 |
+
logger.add_scalar('training/diffusion_loss', diff_loss,
|
| 147 |
+
global_step=iteration)
|
| 148 |
+
logger.add_scalar('training/encoder_grad_norm', enc_grad_norm,
|
| 149 |
+
global_step=iteration)
|
| 150 |
+
logger.add_scalar('training/decoder_grad_norm', dec_grad_norm,
|
| 151 |
+
global_step=iteration)
|
| 152 |
+
|
| 153 |
+
msg = f'Epoch: {epoch}, iteration: {iteration} | '
|
| 154 |
+
msg = msg + f'prior_loss: {prior_loss.item():.3f}, '
|
| 155 |
+
msg = msg + f'diff_loss: {diff_loss.item():.3f}, '
|
| 156 |
+
msg = msg + f'mel_loss: {mel_loss.item():.3f}, '
|
| 157 |
+
msg = msg + f'spk_loss: {spk_loss.item():.3f}, '
|
| 158 |
+
progress_bar.set_description(msg)
|
| 159 |
+
|
| 160 |
+
prior_losses.append(prior_loss.item())
|
| 161 |
+
diff_losses.append(diff_loss.item())
|
| 162 |
+
mel_losses.append(mel_loss.item())
|
| 163 |
+
spk_losses.append(spk_loss.item())
|
| 164 |
+
iteration += 1
|
| 165 |
+
|
| 166 |
+
msg = 'Epoch %d: ' % (epoch)
|
| 167 |
+
msg += '| spk loss = %.3f ' % np.mean(spk_losses)
|
| 168 |
+
msg += '| mel loss = %.3f ' % np.mean(mel_losses)
|
| 169 |
+
msg += '| prior loss = %.3f ' % np.mean(prior_losses)
|
| 170 |
+
msg += '| diffusion loss = %.3f\n' % np.mean(diff_losses)
|
| 171 |
+
with open(f'{hps.train.log_dir}/train.log', 'a') as f:
|
| 172 |
+
f.write(msg)
|
| 173 |
+
# if (np.mean(prior_losses) < 1.05):
|
| 174 |
+
# skip_diff_train = False
|
| 175 |
+
if epoch > hps.train.fast_epochs:
|
| 176 |
+
skip_diff_train = False
|
| 177 |
+
if epoch % hps.train.save_step > 0:
|
| 178 |
+
continue
|
| 179 |
+
|
| 180 |
+
save_path = f"{hps.train.log_dir}/grad_svc_{epoch}.pt"
|
| 181 |
+
torch.save({
|
| 182 |
+
'model': model.state_dict(),
|
| 183 |
+
'optim': optim.state_dict(),
|
| 184 |
+
'epoch': epoch,
|
| 185 |
+
'steps': iteration,
|
| 186 |
+
|
| 187 |
+
}, save_path)
|
| 188 |
+
print("Saved checkpoint to: %s" % save_path)
|
grad_extend/utils.py
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import glob
|
| 3 |
+
import numpy as np
|
| 4 |
+
import matplotlib.pyplot as plt
|
| 5 |
+
|
| 6 |
+
import torch
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def parse_filelist(filelist_path, split_char="|"):
|
| 10 |
+
with open(filelist_path, encoding='utf-8') as f:
|
| 11 |
+
filepaths_and_text = [line.strip().split(split_char) for line in f]
|
| 12 |
+
return filepaths_and_text
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def load_model(model, saved_state_dict):
|
| 16 |
+
state_dict = model.state_dict()
|
| 17 |
+
new_state_dict = {}
|
| 18 |
+
for k, v in state_dict.items():
|
| 19 |
+
try:
|
| 20 |
+
new_state_dict[k] = saved_state_dict[k]
|
| 21 |
+
except:
|
| 22 |
+
print("%s is not in the checkpoint" % k)
|
| 23 |
+
new_state_dict[k] = v
|
| 24 |
+
model.load_state_dict(new_state_dict)
|
| 25 |
+
return model
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def latest_checkpoint_path(dir_path, regex="grad_svc_*.pt"):
|
| 29 |
+
f_list = glob.glob(os.path.join(dir_path, regex))
|
| 30 |
+
f_list.sort(key=lambda f: int("".join(filter(str.isdigit, f))))
|
| 31 |
+
x = f_list[-1]
|
| 32 |
+
return x
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def load_checkpoint(logdir, model, num=None):
|
| 36 |
+
if num is None:
|
| 37 |
+
model_path = latest_checkpoint_path(logdir, regex="grad_svc_*.pt")
|
| 38 |
+
else:
|
| 39 |
+
model_path = os.path.join(logdir, f"grad_svc_{num}.pt")
|
| 40 |
+
print(f'Loading checkpoint {model_path}...')
|
| 41 |
+
model_dict = torch.load(model_path, map_location=lambda loc, storage: loc)
|
| 42 |
+
model.load_state_dict(model_dict, strict=False)
|
| 43 |
+
return model
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def save_figure_to_numpy(fig):
|
| 47 |
+
data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='')
|
| 48 |
+
data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
|
| 49 |
+
return data
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def plot_tensor(tensor):
|
| 53 |
+
plt.style.use('default')
|
| 54 |
+
fig, ax = plt.subplots(figsize=(12, 3))
|
| 55 |
+
im = ax.imshow(tensor, aspect="auto", origin="lower", interpolation='none')
|
| 56 |
+
plt.colorbar(im, ax=ax)
|
| 57 |
+
plt.tight_layout()
|
| 58 |
+
fig.canvas.draw()
|
| 59 |
+
data = save_figure_to_numpy(fig)
|
| 60 |
+
plt.close()
|
| 61 |
+
return data
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def save_plot(tensor, savepath):
|
| 65 |
+
plt.style.use('default')
|
| 66 |
+
fig, ax = plt.subplots(figsize=(12, 3))
|
| 67 |
+
im = ax.imshow(tensor, aspect="auto", origin="lower", interpolation='none')
|
| 68 |
+
plt.colorbar(im, ax=ax)
|
| 69 |
+
plt.tight_layout()
|
| 70 |
+
fig.canvas.draw()
|
| 71 |
+
plt.savefig(savepath)
|
| 72 |
+
plt.close()
|
| 73 |
+
return
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def print_error(info):
|
| 77 |
+
print(f"\033[31m {info} \033[0m")
|
grad_pretrain/README.md
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Path for:
|
| 2 |
+
|
| 3 |
+
gvc.pretrain.pth
|
hubert/__init__.py
ADDED
|
File without changes
|
hubert/hubert_model.py
ADDED
|
@@ -0,0 +1,229 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import copy
|
| 2 |
+
import random
|
| 3 |
+
from typing import Optional, Tuple
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
import torch.nn.functional as t_func
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class Hubert(nn.Module):
|
| 11 |
+
def __init__(self, num_label_embeddings: int = 100, mask: bool = True):
|
| 12 |
+
super().__init__()
|
| 13 |
+
self._mask = mask
|
| 14 |
+
self.feature_extractor = FeatureExtractor()
|
| 15 |
+
self.feature_projection = FeatureProjection()
|
| 16 |
+
self.positional_embedding = PositionalConvEmbedding()
|
| 17 |
+
self.norm = nn.LayerNorm(768)
|
| 18 |
+
self.dropout = nn.Dropout(0.1)
|
| 19 |
+
self.encoder = TransformerEncoder(
|
| 20 |
+
nn.TransformerEncoderLayer(
|
| 21 |
+
768, 12, 3072, activation="gelu", batch_first=True
|
| 22 |
+
),
|
| 23 |
+
12,
|
| 24 |
+
)
|
| 25 |
+
self.proj = nn.Linear(768, 256)
|
| 26 |
+
|
| 27 |
+
self.masked_spec_embed = nn.Parameter(torch.FloatTensor(768).uniform_())
|
| 28 |
+
self.label_embedding = nn.Embedding(num_label_embeddings, 256)
|
| 29 |
+
|
| 30 |
+
def mask(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 31 |
+
mask = None
|
| 32 |
+
if self.training and self._mask:
|
| 33 |
+
mask = _compute_mask((x.size(0), x.size(1)), 0.8, 10, x.device, 2)
|
| 34 |
+
x[mask] = self.masked_spec_embed.to(x.dtype)
|
| 35 |
+
return x, mask
|
| 36 |
+
|
| 37 |
+
def encode(
|
| 38 |
+
self, x: torch.Tensor, layer: Optional[int] = None
|
| 39 |
+
) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 40 |
+
x = self.feature_extractor(x)
|
| 41 |
+
x = self.feature_projection(x.transpose(1, 2))
|
| 42 |
+
x, mask = self.mask(x)
|
| 43 |
+
x = x + self.positional_embedding(x)
|
| 44 |
+
x = self.dropout(self.norm(x))
|
| 45 |
+
x = self.encoder(x, output_layer=layer)
|
| 46 |
+
return x, mask
|
| 47 |
+
|
| 48 |
+
def logits(self, x: torch.Tensor) -> torch.Tensor:
|
| 49 |
+
logits = torch.cosine_similarity(
|
| 50 |
+
x.unsqueeze(2),
|
| 51 |
+
self.label_embedding.weight.unsqueeze(0).unsqueeze(0),
|
| 52 |
+
dim=-1,
|
| 53 |
+
)
|
| 54 |
+
return logits / 0.1
|
| 55 |
+
|
| 56 |
+
def forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 57 |
+
x, mask = self.encode(x)
|
| 58 |
+
x = self.proj(x)
|
| 59 |
+
logits = self.logits(x)
|
| 60 |
+
return logits, mask
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
class HubertSoft(Hubert):
|
| 64 |
+
def __init__(self):
|
| 65 |
+
super().__init__()
|
| 66 |
+
|
| 67 |
+
@torch.inference_mode()
|
| 68 |
+
def units(self, wav: torch.Tensor) -> torch.Tensor:
|
| 69 |
+
wav = t_func.pad(wav, ((400 - 320) // 2, (400 - 320) // 2))
|
| 70 |
+
x, _ = self.encode(wav)
|
| 71 |
+
return self.proj(x)
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
class FeatureExtractor(nn.Module):
|
| 75 |
+
def __init__(self):
|
| 76 |
+
super().__init__()
|
| 77 |
+
self.conv0 = nn.Conv1d(1, 512, 10, 5, bias=False)
|
| 78 |
+
self.norm0 = nn.GroupNorm(512, 512)
|
| 79 |
+
self.conv1 = nn.Conv1d(512, 512, 3, 2, bias=False)
|
| 80 |
+
self.conv2 = nn.Conv1d(512, 512, 3, 2, bias=False)
|
| 81 |
+
self.conv3 = nn.Conv1d(512, 512, 3, 2, bias=False)
|
| 82 |
+
self.conv4 = nn.Conv1d(512, 512, 3, 2, bias=False)
|
| 83 |
+
self.conv5 = nn.Conv1d(512, 512, 2, 2, bias=False)
|
| 84 |
+
self.conv6 = nn.Conv1d(512, 512, 2, 2, bias=False)
|
| 85 |
+
|
| 86 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 87 |
+
x = t_func.gelu(self.norm0(self.conv0(x)))
|
| 88 |
+
x = t_func.gelu(self.conv1(x))
|
| 89 |
+
x = t_func.gelu(self.conv2(x))
|
| 90 |
+
x = t_func.gelu(self.conv3(x))
|
| 91 |
+
x = t_func.gelu(self.conv4(x))
|
| 92 |
+
x = t_func.gelu(self.conv5(x))
|
| 93 |
+
x = t_func.gelu(self.conv6(x))
|
| 94 |
+
return x
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
class FeatureProjection(nn.Module):
|
| 98 |
+
def __init__(self):
|
| 99 |
+
super().__init__()
|
| 100 |
+
self.norm = nn.LayerNorm(512)
|
| 101 |
+
self.projection = nn.Linear(512, 768)
|
| 102 |
+
self.dropout = nn.Dropout(0.1)
|
| 103 |
+
|
| 104 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 105 |
+
x = self.norm(x)
|
| 106 |
+
x = self.projection(x)
|
| 107 |
+
x = self.dropout(x)
|
| 108 |
+
return x
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
class PositionalConvEmbedding(nn.Module):
|
| 112 |
+
def __init__(self):
|
| 113 |
+
super().__init__()
|
| 114 |
+
self.conv = nn.Conv1d(
|
| 115 |
+
768,
|
| 116 |
+
768,
|
| 117 |
+
kernel_size=128,
|
| 118 |
+
padding=128 // 2,
|
| 119 |
+
groups=16,
|
| 120 |
+
)
|
| 121 |
+
self.conv = nn.utils.weight_norm(self.conv, name="weight", dim=2)
|
| 122 |
+
|
| 123 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 124 |
+
x = self.conv(x.transpose(1, 2))
|
| 125 |
+
x = t_func.gelu(x[:, :, :-1])
|
| 126 |
+
return x.transpose(1, 2)
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
class TransformerEncoder(nn.Module):
|
| 130 |
+
def __init__(
|
| 131 |
+
self, encoder_layer: nn.TransformerEncoderLayer, num_layers: int
|
| 132 |
+
) -> None:
|
| 133 |
+
super(TransformerEncoder, self).__init__()
|
| 134 |
+
self.layers = nn.ModuleList(
|
| 135 |
+
[copy.deepcopy(encoder_layer) for _ in range(num_layers)]
|
| 136 |
+
)
|
| 137 |
+
self.num_layers = num_layers
|
| 138 |
+
|
| 139 |
+
def forward(
|
| 140 |
+
self,
|
| 141 |
+
src: torch.Tensor,
|
| 142 |
+
mask: torch.Tensor = None,
|
| 143 |
+
src_key_padding_mask: torch.Tensor = None,
|
| 144 |
+
output_layer: Optional[int] = None,
|
| 145 |
+
) -> torch.Tensor:
|
| 146 |
+
output = src
|
| 147 |
+
for layer in self.layers[:output_layer]:
|
| 148 |
+
output = layer(
|
| 149 |
+
output, src_mask=mask, src_key_padding_mask=src_key_padding_mask
|
| 150 |
+
)
|
| 151 |
+
return output
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
def _compute_mask(
|
| 155 |
+
shape: Tuple[int, int],
|
| 156 |
+
mask_prob: float,
|
| 157 |
+
mask_length: int,
|
| 158 |
+
device: torch.device,
|
| 159 |
+
min_masks: int = 0,
|
| 160 |
+
) -> torch.Tensor:
|
| 161 |
+
batch_size, sequence_length = shape
|
| 162 |
+
|
| 163 |
+
if mask_length < 1:
|
| 164 |
+
raise ValueError("`mask_length` has to be bigger than 0.")
|
| 165 |
+
|
| 166 |
+
if mask_length > sequence_length:
|
| 167 |
+
raise ValueError(
|
| 168 |
+
f"`mask_length` has to be smaller than `sequence_length`, but got `mask_length`: {mask_length} and `sequence_length`: {sequence_length}`"
|
| 169 |
+
)
|
| 170 |
+
|
| 171 |
+
# compute number of masked spans in batch
|
| 172 |
+
num_masked_spans = int(mask_prob * sequence_length / mask_length + random.random())
|
| 173 |
+
num_masked_spans = max(num_masked_spans, min_masks)
|
| 174 |
+
|
| 175 |
+
# make sure num masked indices <= sequence_length
|
| 176 |
+
if num_masked_spans * mask_length > sequence_length:
|
| 177 |
+
num_masked_spans = sequence_length // mask_length
|
| 178 |
+
|
| 179 |
+
# SpecAugment mask to fill
|
| 180 |
+
mask = torch.zeros((batch_size, sequence_length), device=device, dtype=torch.bool)
|
| 181 |
+
|
| 182 |
+
# uniform distribution to sample from, make sure that offset samples are < sequence_length
|
| 183 |
+
uniform_dist = torch.ones(
|
| 184 |
+
(batch_size, sequence_length - (mask_length - 1)), device=device
|
| 185 |
+
)
|
| 186 |
+
|
| 187 |
+
# get random indices to mask
|
| 188 |
+
mask_indices = torch.multinomial(uniform_dist, num_masked_spans)
|
| 189 |
+
|
| 190 |
+
# expand masked indices to masked spans
|
| 191 |
+
mask_indices = (
|
| 192 |
+
mask_indices.unsqueeze(dim=-1)
|
| 193 |
+
.expand((batch_size, num_masked_spans, mask_length))
|
| 194 |
+
.reshape(batch_size, num_masked_spans * mask_length)
|
| 195 |
+
)
|
| 196 |
+
offsets = (
|
| 197 |
+
torch.arange(mask_length, device=device)[None, None, :]
|
| 198 |
+
.expand((batch_size, num_masked_spans, mask_length))
|
| 199 |
+
.reshape(batch_size, num_masked_spans * mask_length)
|
| 200 |
+
)
|
| 201 |
+
mask_idxs = mask_indices + offsets
|
| 202 |
+
|
| 203 |
+
# scatter indices to mask
|
| 204 |
+
mask = mask.scatter(1, mask_idxs, True)
|
| 205 |
+
|
| 206 |
+
return mask
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
def consume_prefix(state_dict, prefix: str) -> None:
|
| 210 |
+
keys = sorted(state_dict.keys())
|
| 211 |
+
for key in keys:
|
| 212 |
+
if key.startswith(prefix):
|
| 213 |
+
newkey = key[len(prefix):]
|
| 214 |
+
state_dict[newkey] = state_dict.pop(key)
|
| 215 |
+
|
| 216 |
+
|
| 217 |
+
def hubert_soft(
|
| 218 |
+
path: str,
|
| 219 |
+
) -> HubertSoft:
|
| 220 |
+
r"""HuBERT-Soft from `"A Comparison of Discrete and Soft Speech Units for Improved Voice Conversion"`.
|
| 221 |
+
Args:
|
| 222 |
+
path (str): path of a pretrained model
|
| 223 |
+
"""
|
| 224 |
+
hubert = HubertSoft()
|
| 225 |
+
checkpoint = torch.load(path)
|
| 226 |
+
consume_prefix(checkpoint, "module.")
|
| 227 |
+
hubert.load_state_dict(checkpoint)
|
| 228 |
+
hubert.eval()
|
| 229 |
+
return hubert
|
hubert/inference.py
ADDED
|
@@ -0,0 +1,67 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys,os
|
| 2 |
+
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
|
| 3 |
+
import numpy as np
|
| 4 |
+
import argparse
|
| 5 |
+
import torch
|
| 6 |
+
import librosa
|
| 7 |
+
|
| 8 |
+
from hubert import hubert_model
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def load_audio(file: str, sr: int = 16000):
|
| 12 |
+
x, sr = librosa.load(file, sr=sr)
|
| 13 |
+
return x
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def load_model(path, device):
|
| 17 |
+
model = hubert_model.hubert_soft(path)
|
| 18 |
+
model.eval()
|
| 19 |
+
if not (device == "cpu"):
|
| 20 |
+
model.half()
|
| 21 |
+
model.to(device)
|
| 22 |
+
return model
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def pred_vec(model, wavPath, vecPath, device):
|
| 26 |
+
audio = load_audio(wavPath)
|
| 27 |
+
audln = audio.shape[0]
|
| 28 |
+
vec_a = []
|
| 29 |
+
idx_s = 0
|
| 30 |
+
while (idx_s + 20 * 16000 < audln):
|
| 31 |
+
feats = audio[idx_s:idx_s + 20 * 16000]
|
| 32 |
+
feats = torch.from_numpy(feats).to(device)
|
| 33 |
+
feats = feats[None, None, :]
|
| 34 |
+
if not (device == "cpu"):
|
| 35 |
+
feats = feats.half()
|
| 36 |
+
with torch.no_grad():
|
| 37 |
+
vec = model.units(feats).squeeze().data.cpu().float().numpy()
|
| 38 |
+
vec_a.extend(vec)
|
| 39 |
+
idx_s = idx_s + 20 * 16000
|
| 40 |
+
if (idx_s < audln):
|
| 41 |
+
feats = audio[idx_s:audln]
|
| 42 |
+
feats = torch.from_numpy(feats).to(device)
|
| 43 |
+
feats = feats[None, None, :]
|
| 44 |
+
if not (device == "cpu"):
|
| 45 |
+
feats = feats.half()
|
| 46 |
+
with torch.no_grad():
|
| 47 |
+
vec = model.units(feats).squeeze().data.cpu().float().numpy()
|
| 48 |
+
# print(vec.shape) # [length, dim=256] hop=320
|
| 49 |
+
vec_a.extend(vec)
|
| 50 |
+
np.save(vecPath, vec_a, allow_pickle=False)
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
if __name__ == "__main__":
|
| 54 |
+
parser = argparse.ArgumentParser()
|
| 55 |
+
parser.add_argument("-w", "--wav", help="wav", dest="wav")
|
| 56 |
+
parser.add_argument("-v", "--vec", help="vec", dest="vec")
|
| 57 |
+
args = parser.parse_args()
|
| 58 |
+
print(args.wav)
|
| 59 |
+
print(args.vec)
|
| 60 |
+
|
| 61 |
+
wavPath = args.wav
|
| 62 |
+
vecPath = args.vec
|
| 63 |
+
|
| 64 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 65 |
+
hubert = load_model(os.path.join(
|
| 66 |
+
"hubert_pretrain", "hubert-soft-0d54a1f4.pt"), device)
|
| 67 |
+
pred_vec(hubert, wavPath, vecPath, device)
|
hubert_pretrain/README.md
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Path for:
|
| 2 |
+
|
| 3 |
+
hubert-soft-0d54a1f4.pt
|
hubert_pretrain/hubert-soft-0d54a1f4.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e82e7d079df05fe3aa535f6f7d42d309bdae1d2a53324e2b2386c56721f4f649
|
| 3 |
+
size 378435957
|
pitch/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .inference import load_csv_pitch
|
pitch/inference.py
ADDED
|
@@ -0,0 +1,86 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys,os
|
| 2 |
+
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
|
| 3 |
+
import librosa
|
| 4 |
+
import argparse
|
| 5 |
+
import numpy as np
|
| 6 |
+
import parselmouth
|
| 7 |
+
# pip install praat-parselmouth
|
| 8 |
+
|
| 9 |
+
def compute_f0_mouth(path):
|
| 10 |
+
x, sr = librosa.load(path, sr=16000)
|
| 11 |
+
assert sr == 16000
|
| 12 |
+
lpad = 1024 // 160
|
| 13 |
+
rpad = lpad
|
| 14 |
+
f0 = parselmouth.Sound(x, sr).to_pitch_ac(
|
| 15 |
+
time_step=160 / sr,
|
| 16 |
+
voicing_threshold=0.5,
|
| 17 |
+
pitch_floor=30,
|
| 18 |
+
pitch_ceiling=1000).selected_array['frequency']
|
| 19 |
+
f0 = np.pad(f0, [[lpad, rpad]], mode='constant')
|
| 20 |
+
return f0
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def compute_f0_crepe(filename):
|
| 24 |
+
import torch
|
| 25 |
+
import torchcrepe
|
| 26 |
+
|
| 27 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 28 |
+
audio, sr = librosa.load(filename, sr=16000)
|
| 29 |
+
assert sr == 16000
|
| 30 |
+
audio = torch.tensor(np.copy(audio))[None]
|
| 31 |
+
audio = audio + torch.randn_like(audio) * 0.001
|
| 32 |
+
# Here we'll use a 20 millisecond hop length
|
| 33 |
+
hop_length = 320
|
| 34 |
+
fmin = 50
|
| 35 |
+
fmax = 1000
|
| 36 |
+
model = "full"
|
| 37 |
+
batch_size = 512
|
| 38 |
+
pitch = torchcrepe.predict(
|
| 39 |
+
audio,
|
| 40 |
+
sr,
|
| 41 |
+
hop_length,
|
| 42 |
+
fmin,
|
| 43 |
+
fmax,
|
| 44 |
+
model,
|
| 45 |
+
batch_size=batch_size,
|
| 46 |
+
device=device,
|
| 47 |
+
return_periodicity=False,
|
| 48 |
+
)
|
| 49 |
+
pitch = np.repeat(pitch, 2, -1) # 320 -> 160 * 2
|
| 50 |
+
pitch = torchcrepe.filter.mean(pitch, 5)
|
| 51 |
+
pitch = pitch.squeeze(0)
|
| 52 |
+
return pitch
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def save_csv_pitch(pitch, path):
|
| 56 |
+
with open(path, "w", encoding='utf-8') as pitch_file:
|
| 57 |
+
for i in range(len(pitch)):
|
| 58 |
+
t = i * 10
|
| 59 |
+
minute = t // 60000
|
| 60 |
+
seconds = (t - minute * 60000) // 1000
|
| 61 |
+
millisecond = t % 1000
|
| 62 |
+
print(
|
| 63 |
+
f"{minute}m {seconds}s {millisecond:3d},{int(pitch[i])}", file=pitch_file)
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def load_csv_pitch(path):
|
| 67 |
+
pitch = []
|
| 68 |
+
with open(path, "r", encoding='utf-8') as pitch_file:
|
| 69 |
+
for line in pitch_file.readlines():
|
| 70 |
+
pit = line.strip().split(",")[-1]
|
| 71 |
+
pitch.append(int(pit))
|
| 72 |
+
return pitch
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
if __name__ == "__main__":
|
| 76 |
+
parser = argparse.ArgumentParser()
|
| 77 |
+
parser.add_argument("-w", "--wav", help="wav", dest="wav")
|
| 78 |
+
parser.add_argument("-p", "--pit", help="pit", dest="pit") # csv for excel
|
| 79 |
+
args = parser.parse_args()
|
| 80 |
+
print(args.wav)
|
| 81 |
+
print(args.pit)
|
| 82 |
+
|
| 83 |
+
pitch = compute_f0_mouth(args.wav)
|
| 84 |
+
save_csv_pitch(pitch, args.pit)
|
| 85 |
+
#tmp = load_csv_pitch(args.pit)
|
| 86 |
+
#save_csv_pitch(tmp, "tmp.csv")
|
requirements.txt
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
librosa
|
| 2 |
+
soundfile
|
| 3 |
+
matplotlib
|
| 4 |
+
tensorboard
|
| 5 |
+
transformers
|
| 6 |
+
tqdm
|
| 7 |
+
einops
|
| 8 |
+
fsspec
|
| 9 |
+
omegaconf
|
| 10 |
+
pyworld
|
| 11 |
+
praat-parselmouth
|
spec/inference.py
ADDED
|
@@ -0,0 +1,113 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import torch
|
| 3 |
+
import torch.utils.data
|
| 4 |
+
import numpy as np
|
| 5 |
+
import librosa
|
| 6 |
+
from omegaconf import OmegaConf
|
| 7 |
+
from librosa.filters import mel as librosa_mel_fn
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
MAX_WAV_VALUE = 32768.0
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def load_wav_to_torch(full_path, sample_rate):
|
| 14 |
+
wav, _ = librosa.load(full_path, sr=sample_rate)
|
| 15 |
+
wav = wav / np.abs(wav).max() * 0.6
|
| 16 |
+
return torch.FloatTensor(wav)
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def dynamic_range_compression(x, C=1, clip_val=1e-5):
|
| 20 |
+
return np.log(np.clip(x, a_min=clip_val, a_max=None) * C)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def dynamic_range_decompression(x, C=1):
|
| 24 |
+
return np.exp(x) / C
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def dynamic_range_compression_torch(x, C=1, clip_val=1e-5):
|
| 28 |
+
return torch.log(torch.clamp(x, min=clip_val) * C)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def dynamic_range_decompression_torch(x, C=1):
|
| 32 |
+
return torch.exp(x) / C
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def spectral_normalize_torch(magnitudes):
|
| 36 |
+
output = dynamic_range_compression_torch(magnitudes)
|
| 37 |
+
return output
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def spectral_de_normalize_torch(magnitudes):
|
| 41 |
+
output = dynamic_range_decompression_torch(magnitudes)
|
| 42 |
+
return output
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
mel_basis = {}
|
| 46 |
+
hann_window = {}
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def mel_spectrogram(y, n_fft, num_mels, sampling_rate, hop_size, win_size, fmin, fmax, center=False):
|
| 50 |
+
if torch.min(y) < -1.:
|
| 51 |
+
print('min value is ', torch.min(y))
|
| 52 |
+
if torch.max(y) > 1.:
|
| 53 |
+
print('max value is ', torch.max(y))
|
| 54 |
+
|
| 55 |
+
global mel_basis, hann_window
|
| 56 |
+
if fmax not in mel_basis:
|
| 57 |
+
mel = librosa_mel_fn(sr=sampling_rate, n_fft=n_fft, n_mels=num_mels, fmin=fmin, fmax=fmax)
|
| 58 |
+
mel_basis[str(fmax)+'_'+str(y.device)] = torch.from_numpy(mel).float().to(y.device)
|
| 59 |
+
hann_window[str(y.device)] = torch.hann_window(win_size).to(y.device)
|
| 60 |
+
|
| 61 |
+
y = torch.nn.functional.pad(y.unsqueeze(1), (int((n_fft-hop_size)/2), int((n_fft-hop_size)/2)), mode='reflect')
|
| 62 |
+
y = y.squeeze(1)
|
| 63 |
+
|
| 64 |
+
# complex tensor as default, then use view_as_real for future pytorch compatibility
|
| 65 |
+
spec = torch.stft(y, n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[str(y.device)],
|
| 66 |
+
center=center, pad_mode='reflect', normalized=False, onesided=True, return_complex=True)
|
| 67 |
+
spec = torch.view_as_real(spec)
|
| 68 |
+
spec = torch.sqrt(spec.pow(2).sum(-1)+(1e-9))
|
| 69 |
+
|
| 70 |
+
spec = torch.matmul(mel_basis[str(fmax)+'_'+str(y.device)], spec)
|
| 71 |
+
spec = spectral_normalize_torch(spec)
|
| 72 |
+
|
| 73 |
+
return spec
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def mel_spectrogram_file(path, hps):
|
| 77 |
+
audio = load_wav_to_torch(path, hps.data.sampling_rate)
|
| 78 |
+
audio = audio.unsqueeze(0)
|
| 79 |
+
|
| 80 |
+
# match audio length to self.hop_length * n for evaluation
|
| 81 |
+
if (audio.size(1) % hps.data.hop_length) != 0:
|
| 82 |
+
audio = audio[:, :-(audio.size(1) % hps.data.hop_length)]
|
| 83 |
+
mel = mel_spectrogram(audio, hps.data.filter_length, hps.data.mel_channels, hps.data.sampling_rate,
|
| 84 |
+
hps.data.hop_length, hps.data.win_length, hps.data.mel_fmin, hps.data.mel_fmax, center=False)
|
| 85 |
+
return mel
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
def print_mel(mel, path="mel.png"):
|
| 89 |
+
import matplotlib.pyplot as plt
|
| 90 |
+
fig = plt.figure(figsize=(12, 4))
|
| 91 |
+
if isinstance(mel, torch.Tensor):
|
| 92 |
+
mel = mel.cpu().numpy()
|
| 93 |
+
plt.pcolor(mel)
|
| 94 |
+
plt.savefig(path, format="png")
|
| 95 |
+
plt.close(fig)
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
if __name__ == "__main__":
|
| 99 |
+
parser = argparse.ArgumentParser()
|
| 100 |
+
parser.add_argument("-w", "--wav", help="wav", dest="wav")
|
| 101 |
+
parser.add_argument("-m", "--mel", help="mel", dest="mel") # csv for excel
|
| 102 |
+
args = parser.parse_args()
|
| 103 |
+
print(args.wav)
|
| 104 |
+
print(args.mel)
|
| 105 |
+
|
| 106 |
+
hps = OmegaConf.load(f"./configs/base.yaml")
|
| 107 |
+
|
| 108 |
+
mel = mel_spectrogram_file(args.wav, hps)
|
| 109 |
+
# TODO
|
| 110 |
+
mel = torch.squeeze(mel, 0)
|
| 111 |
+
# [100, length]
|
| 112 |
+
torch.save(mel, args.mel)
|
| 113 |
+
print_mel(mel, "debug.mel.png")
|