
id
int64 393k
2.82B
| repo
stringclasses 68
values | title
stringlengths 1
936
| body
stringlengths 0
256k
⌀ | labels
stringlengths 2
508
| priority
stringclasses 3
values | severity
stringclasses 3
values |
|---|---|---|---|---|---|---|
350,998,164 |
flutter
|
Color codes in error messages are probably escaped when using the iOS simulator
|
I'm adding ANSI color codes such as `\u001B[31;1m` (bright red) to error messages.
They render fine when using the Android emulator.
But with the iOS simulator, they seem to get escaped and appear as below:
`**\^[[31;1m**Material widget ancestor required by TextField widgets not found.**<…>**`
|
platform-ios,tool,customer: crowd,has reproducible steps,P3,found in release: 3.0,found in release: 3.1,team-ios,triaged-ios
|
medium
|
Critical
|
351,004,315 |
flutter
|
Binding a Flutter Canvas / PictureRecorder to a Texture?
|
I'm looking into rendering Flutter canvas graphics onto an Android surface from another plugin.
Currently I have the following:
Android flutter plugin that obtains an Android Surface.
- option 1: flutter app renders `Canvas`, save with `PictureRecorder`, copy RGBA bytes to plugin, draw to `Surface`
- option 2: flutter app sends messages to plugin to draw on an Android `Canvas`, draw to `Surface`
option 2 is significantly faster - but requires mirroring `Canvas` methods in the UI with plugin methods,
e.g.
```dart
// Draw UI
canvas
.. drawPaint(paint)
.. drawLine(pt1, pt2, paint);
// Render same thing to plugin
plugin
..drawPaint(paint);
..drawLine(pt1, ot2, paint);
```
In our case - we currently only need a subset of Canvas methods, so this isn't too burdensome for now.
Ideally, however, this could look something like this:
```dart
// Draw UI
canvas
.. drawPaint(paint)
.. drawLine(pt1, pt2, paint);
// Render same thing to plugin
canvas = new Canvas(new PictureRecorder(plugin.textureId))
..drawPaint(paint);
..drawLine(pt1, pt2, paint);
```
Is there a way to let a `PictureRecorder` record canvas operations to a texture?
Thanks!
|
c: new feature,engine,P2,team-engine,triaged-engine
|
low
|
Minor
|
351,010,357 |
go
|
cmd/cover: misleading coverage indicators for channel operations in 'select' statements
|
### What version of Go are you using (`go version`)?
go version go1.10.3 windows/amd64
### Does this issue reproduce with the latest release?
Yes
### What operating system and processor architecture are you using (`go env`)?
set GOHOSTARCH=amd64
set GOHOSTOS=windows
### What did you do?
main.go:
```go
package main
import (
"fmt"
"time"
)
var vars struct {
chanStruct chan struct{}
chanInt chan int
chanOneClosed chan struct{}
spamNumber int
}
func main() {
vars.chanStruct = make(chan struct{})
vars.chanInt = make(chan int, 1024)
vars.chanOneClosed = make(chan struct{})
vars.spamNumber = 20
go feed()
go aLoop()
time.Sleep(time.Second)
close(vars.chanStruct)
select {
case <-vars.chanOneClosed:
}
time.Sleep(time.Second)
}
// a comment
func feed() {
// a comment
for i := 0; i < 10; i++ {
// a comment
vars.chanInt <- i
// a comment
}
// a comment
}
// a comment
func aLoop() {
Loop:
// a comment
for {
// a comment
select {
// a comment
case <-vars.chanStruct:
// a comment
close(vars.chanOneClosed)
// a comment
break Loop
// a comment
case myInt := <-vars.chanInt:
// a comment
if myInt < vars.spamNumber {
// a comment
vars.chanInt <- myInt + 1
// a comment
}
// a comment
}
// a comment
}
// a comment
fmt.Println("closed")
// a comment
}
```
main_test.go:
```go
package main
import (
"testing"
"time"
)
func TestALoop(t *testing.T) {
vars.chanStruct = make(chan struct{})
vars.chanInt = make(chan int, 1024)
vars.chanOneClosed = make(chan struct{})
vars.spamNumber = 20
go feed()
go aLoop()
time.Sleep(time.Second)
close(vars.chanStruct)
select {
case <-vars.chanOneClosed:
}
time.Sleep(time.Second)
}
```
Then run:
```
go test -coverprofile=coverage.out -v test
go tool cover -html=coverage.out
```
### What did you expect to see?
Coverage report with green and black, with only red in main, similar to this:
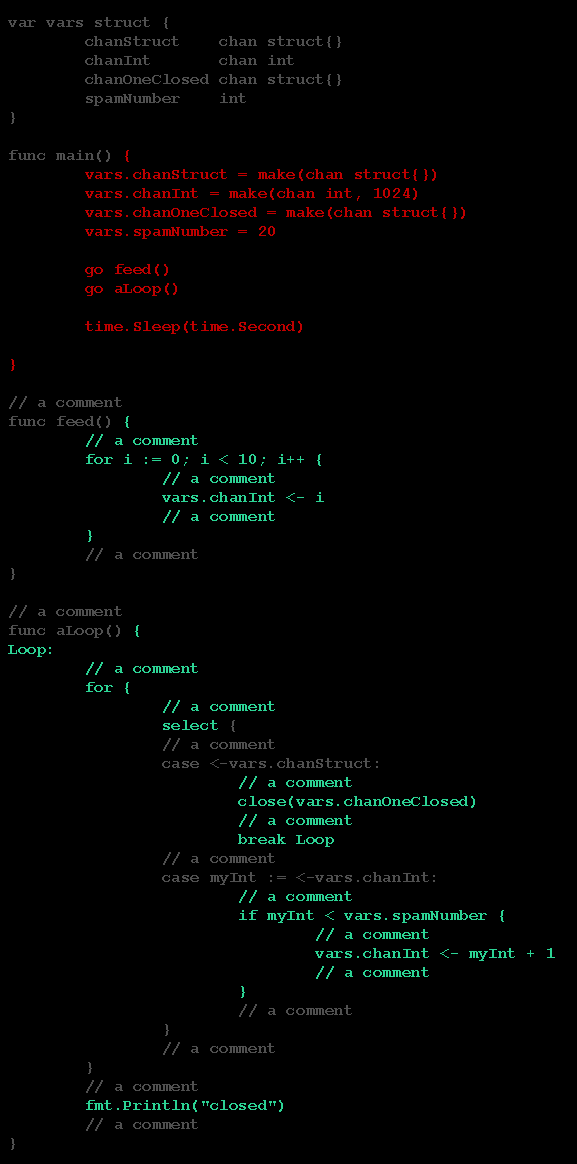
Note, remove the follow code from main to get coverage report to be "correct"
```go
close(vars.chanStruct)
select {
case <-vars.chanOneClosed:
}
time.Sleep(time.Second)
```
### What did you see instead?
Coverage report with red marks in comments, function, and case:
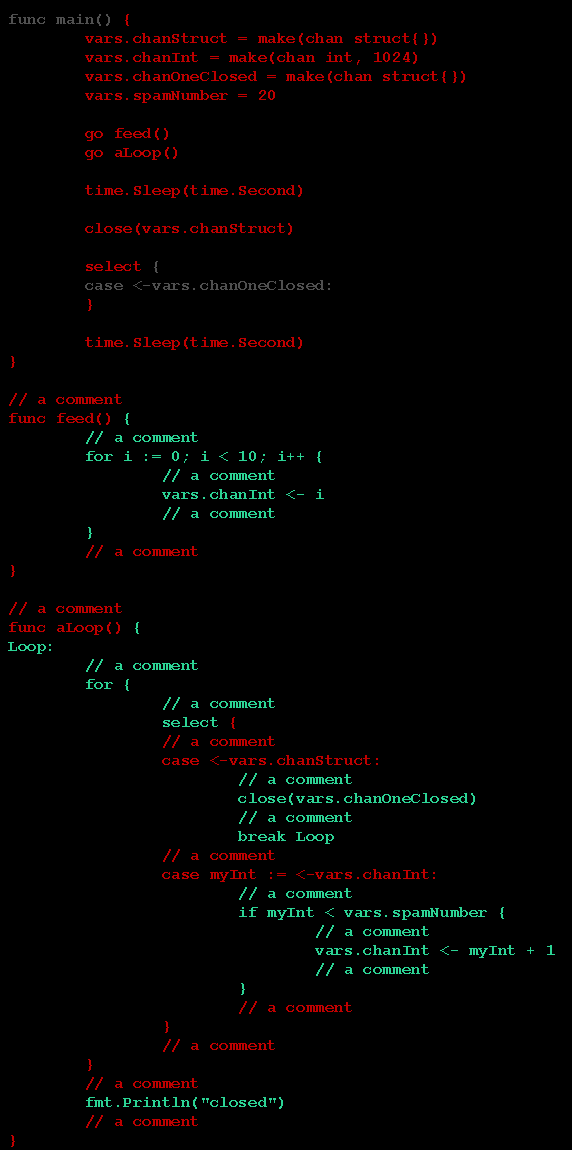
### Note:
This is similar to https://github.com/golang/go/issues/22545 but that one is only comments.
|
NeedsInvestigation,compiler/runtime
|
low
|
Minor
|
351,012,435 |
TypeScript
|
Cannot use type side of a namespace in JsDoc after `declare global ...` workaround for UMD globals
|
I hit this while writing an electron app using `checkJs` where you can both `require` code in (thus making your file a module), and there may also be script tags loading code in the HTML for the app. For example, by main page has the below as it is using D3. Thus the 'd3' object is available globally.
```html
<script src="node_modules/d3/dist/d3.js"></script>
<script src="./app.js"></script>
```
Trying to use the global D3 in my `app.js` however results in the error `'d3' refers to a UMD global, but the current file is a module...`, so I've added the common workaround below to avoid this via a .d.ts file.
```ts
import {default as _d3} from 'd3';
declare global {
// Make the global d3 from directly including the bundle via a script tag available as a global
const d3: typeof _d3;
}
```
When the above .d.ts code is present (and only when), JSDoc gives an error on trying to use types from the namespace, i.e. the below code
```js
/** @type {d3.DefaultArcObject} */
var x;
```
Results in the error `Namespace '"./@types/d3/index".d3' has no exported member 'DefaultArcObject'.` Yet the below TypeScript continues to work fine:
```ts
var x: d3.DefaultArcObject;
```
The below also continues to work fine in JavaScript, but is kind of ugly and a pain to have to repeat (especially if you need to use a lot of type arguments)
```js
/** @type {import('d3').DefaultArcObject} */
var x;
```
Personally I'd rather not have to do the .d.ts workaround at all and just be able to use the `d3` global in my modules (see the highly controversial #10178). That not being the case, JsDoc should be able to access the types still with the workaround in place.
|
Bug,Domain: JSDoc
|
low
|
Critical
|
351,018,556 |
rust
|
Rust should embed /DEFAULTLIB linker directives in staticlibs for pc-windows-msvc
|
This would significantly improve the user experience as they wouldn't have to call `--print native-static-libs` to figure out what libraries they need to link to and then tell their build system to link them. Instead the linker would just know to automatically link to those libraries.
Examples of issues that wouldn't exist with this:
https://github.com/rust-lang/rust/issues/52892
|
A-linkage,A-LLVM,T-compiler,O-windows-msvc
|
low
|
Minor
|
351,029,708 |
TypeScript
|
quick fix for merge duplicate import or export declaration
|
<!-- 🚨 STOP 🚨 𝗦𝗧𝗢𝗣 🚨 𝑺𝑻𝑶𝑷 🚨
Half of all issues filed here are duplicates, answered in the FAQ, or not appropriate for the bug tracker. Please read the FAQ first, especially the "Common Feature Requests" section.
-->
## Search Terms
quickfix, import, export
<!-- List of keywords you searched for before creating this issue. Write them down here so that others can find this suggestion more easily -->
## Suggestion
provide a quickfix for merge two(or more) import or export declaration
<!-- A summary of what you'd like to see added or changed -->
## Use Cases
<!--
What do you want to use this for?
What shortcomings exist with current approaches?
-->
it's useful for resolve git conflict
## Examples
```ts
// ====
import { a, b, c } from 'mod'
// ====
import { b, d, e } from 'mod'
// ====
```
keep each other for git conflict:
```ts
import { a, b, c } from 'mod'
import { b, d, e } from 'mod'
```
<!-- Show how this would be used and what the behavior would be -->
after merge:
```ts
import { a, b, c, d, e } from 'mod'
```
## Checklist
My suggestion meets these guidelines:
* [x] This wouldn't be a breaking change in existing TypeScript / JavaScript code
* [x] This wouldn't change the runtime behavior of existing JavaScript code
* [x] This could be implemented without emitting different JS based on the types of the expressions
* [x] This isn't a runtime feature (e.g. new expression-level syntax)
|
Suggestion,In Discussion,Domain: Refactorings,Experience Enhancement
|
low
|
Critical
|
351,040,720 |
pytorch
|
[Caffe2] Error C2375 when building DLL.
|
## Issue description
VS complains about `C2375` due to missing dllimport/dllexport.
```
caffe2\core\operator_schema.cc(403): error C2375: 'caffe2::operator <<': redefinition; different linkage
caffe2\core\db.cc(15): error C2375: 'caffe2::db::Caffe2DBRegistry': redefinition; different linkage
caffe2\core\blob_serialization.cc(323): error C2375: 'caffe2::BlobSerializerRegistry': redefinition; different linkage
caffe2\core\net.cc(22): error C2375: 'caffe2::NetRegistry': redefinition; different linkage
```
## System Info
- PyTorch or Caffe2: C2
- How you installed PyTorch (conda, pip, source): src
- Build command you used (if compiling from source): cmake
- OS: Win10
- PyTorch version: master
- VS version (if compiling from source): 2017
- CMake version: 3.12
|
caffe2
|
low
|
Critical
|
351,045,644 |
react
|
Umbrella: Chopping Block
|
I wanted to create a list of things whose existence makes React bigger and more complicated than necessary. This makes them more likely to need to be deprecated and actually removed in a future version. No clue of when this will happen and what the recommended upgrade path will be so don't take this issue as advice that you should move away from them until there's clear upgrade advice. You might make it worse by doing so.
(This has some overlap with https://github.com/facebook/react/issues/9475 but those seem more longer term.)
- [ ] __Unsafe Life Cycles without UNSAFE prefix__ - We'll keep the ones prefixed UNSAFE indefinitely but the original ones will likely be deprecated and removed.
- [ ] __Legacy context__ - `.contextTypes`, `.childContextTypes`, `getChildContext` - The old context is full of edge cases for when it is accidentally supposed to work and the way it is designed requires all React code to become slower just to support this feature.
- [ ] __String refs__ - This requires current owner to be exposed at runtime. While it is likely that some form of owner will remain, this particular semantics is likely not what we want out of it. So rather than having two owners, we should just remove this feature. It also requires an extra field on every ReactElement which is otherwise not needed.
- [ ] __Module pattern components__ - This is a little used feature that lets you return a class instance from a regular function without extending `React.Component`. This is not that useful. In practice the ecosystem has moved around ES class like usage, and other language compiling to JS tries to comply with that model as well. The existence of this feature means that we don't know that something is a functional component by just testing if it's a function that is not extending `React.Component`. Instead we have to do some extra feature testing for every functional component there is. It also prevents us from passing the ref as the second argument by default for all functional components without using `forwardRef` since that wouldn't be valid for class components.
- [ ] __Uncontrolled onInput__ - This is described in #9657. Because we support uncontrolled polyfilling of this event, we have to do pretty invasive operations to the DOM like attaching setters. This is all in support of imperative usage of the DOM which should be out-of-scope for React.
- [ ] __setState in componentDidCatch__ - Currently we support error recovery in `componentDidCatch` but once we support `getDerivedStateFromCatch` we might want to consider deprecating the old mechanism which automatically first commits null. The semantics of this are a bit weird and requires complicated code that we likely get wrong sometimes.
- [ ] __Context Object As Consumer__ - Right now it is possible to use the Context object as a Consumer render prop. That's an artifact of reusing the same object allocation but not documented. We'll want to deprecate that and make it the Provider instead.
- [ ] __No GC of not unmounted roots__ - This likely won't come with a warning. We'll just do it. It's not a breaking behavior other than memory usage. You have to call `unmountComponentAtNode` or that component won't be cleaned up. Almost always it is not cleaned up anyway since if you have at least one subscription that still holds onto it. Arguably this is not even a breaking change. #13293
- [ ] __unstable_renderSubtreeIntoContainer__ - This is replaced by Portals. It is already problematic since it can't be used in life-cycles but it also add lots of special case code to transfer the context. Since legacy context itself likely will be deprecated, this serves no purposes.
- [x] __ReactDOM.render with hydration__ - This has already been deprecated. This requires extra code and requires us to generate an extra attribute in the HTML to auto-select hydration. People should be using ReactDOM.hydrate instead. We just need to remove the old behavior and the attribute in ReactDOMServer.
- [ ] __Return value of `ReactDOM.render()`__ - We can't synchronously return an instance when inside a lifecycle/callback/effect, or in concurrent mode. Should use a ref instead.
- [ ] __All of `ReactDOM.render()`__ - Switch everyone over to `createRoot`, with an option to make `createRoot` sync.
|
Type: Umbrella,React Core Team
|
medium
|
Critical
|
351,053,410 |
vscode
|
Method separator
|
Issue Type: <b>Feature Request</b>
Please add method separator in class and shortcut for go back to previous Edit/last edit location ... Thanks
VS Code version: Code 1.26.0 (4e9361845dc28659923a300945f84731393e210d, 2018-08-13T16:20:44.170Z)
OS version: Darwin x64 17.7.0
<!-- generated by issue reporter -->
|
feature-request,editor-rendering
|
high
|
Critical
|
351,054,155 |
pytorch
|
[BUG]: unstable happend in saving model.
|
## Issue description
When I save my model, I met the errors.
My environment:
system: debian 8
python: python3
pytorch: 0.4.1
## Code
```python
def save_model(self, epoch):
# for example: save_path = '~/Documents/my_model_1.pth'.
save_path = self.model_prefix + '_' + str(epoch) + '.pth'
# note that my net: self.net is trained on GPU.
torch.save(self.net.state_dict(), save_path)
self.logging.info('Saved model in {}'.format(save_path))
```
## Error
```
Traceback (most recent call last):
File "train_network.py", line 64, in <module>
main()
File "train_network.py", line 60, in main
netutil.save_model(epoch)
File "/opt/tiger/reid/attribute_net/network.py", line 169, in save_model
torch.save(self.net.state_dict(), save_path)
File "/usr/local/lib/python3.6/site-packages/torch/serialization.py", line 209, in save
return _with_file_like(f, "wb", lambda f: _save(obj, f, pickle_module, pickle_protocol))
File "/usr/local/lib/python3.6/site-packages/torch/serialization.py", line 134, in _with_file_like
return body(f)
File "/usr/local/lib/python3.6/site-packages/torch/serialization.py", line 209, in <lambda>
return _with_file_like(f, "wb", lambda f: _save(obj, f, pickle_module, pickle_protocol))
File "/usr/local/lib/python3.6/site-packages/torch/serialization.py", line 288, in _save
serialized_storages[key]._write_file(f, _should_read_directly(f))
RuntimeError: Unknown error -1
```
|
module: serialization,triaged
|
low
|
Critical
|
351,134,598 |
go
|
x/mobile: manual declaration of uses-sdk in AndroidManifest.xml not supported
|
We need to set the minSdkVersion and targetSdkVersion in the AndroidManifest.xml file. But it won't build, gomobile will exit with err:
```
manual declaration of uses-sdk in AndroidManifest.xml not supported
```
minSdkVersion and targetSdkVersion is a commonly used in Android. If not set, app market like Google Play will refused to accept the app.
|
mobile
|
low
|
Major
|
351,137,812 |
three.js
|
GLTFExporter: Normal Texture handedness
|
GLTF Loader: Fix for handedness in Normal Texture:
https://github.com/mrdoob/three.js/pull/11825
https://github.com/KhronosGroup/glTF/issues/952
https://github.com/mrdoob/three.js/blob/master/examples/js/loaders/GLTFLoader.js#L2204
material.normalScale.y = - material.normalScale.y;
Given that the loader needs to adjust this, should the exporter be adjusting this as well?
Please do correct me if I'm wrong, but the current code does not seem to account for this.
if ( material.normalMap ) {
gltfMaterial.normalTexture = {
index: processTexture( material.normalMap )
};
if ( material.normalScale.x !== - 1 ) {
if ( material.normalScale.x !== material.normalScale.y ) {
console.warn( 'THREE.GLTFExporter: Normal scale components are different, ignoring Y and exporting X.' );
}
gltfMaterial.normalTexture.scale = material.normalScale.x;
}
}
##### Three.js version
- [x ] Dev
- [ ] r95
- [ ] ...
##### Browser
- [x] All of them
- [ ] Chrome
- [ ] Firefox
- [ ] Internet Explorer
##### OS
- [x] All of them
- [ ] Windows
- [ ] macOS
- [ ] Linux
- [ ] Android
- [ ] iOS
##### Hardware Requirements (graphics card, VR Device, ...)
|
Needs Investigation
|
low
|
Major
|
351,139,545 |
opencv
|
Run the official face-detection sample and find the problem
|
<!--
If you have a question rather than reporting a bug please go to http://answers.opencv.org where you get much faster responses.
If you need further assistance please read [How To Contribute](https://github.com/opencv/opencv/wiki/How_to_contribute).
Please:
* Read the documentation to test with the latest developer build.
* Check if other person has already created the same issue to avoid duplicates. You can comment on it if there already is an issue.
* Try to be as detailed as possible in your report.
* Report only one problem per created issue.
This is a template helping you to create an issue which can be processed as quickly as possible. This is the bug reporting section for the OpenCV library.
-->
##### System information (version)
<!-- Example
- OpenCV => 3.4
- Operating System / Platform => Android
- Compiler => cmake
-->
- OpenCV => 3.4
- Operating System / Platform => Android
- Compiler => cmake
##### Detailed description
<!-- your description -->
Run the official face-detection sample and find that the value detected by the face is incorrect. It is clear that the current screen has no face, but the detected rectangular frame is still displayed.
##### Steps to reproduce
code segment
mJavaDetector.detectMultiScale(mGray, faces, 1.1, 2, 2, // TODO: objdetect.CV_HAAR_SCALE_IMAGE
new Size(mAbsoluteFaceSize, mAbsoluteFaceSize), new Size());
Rect[] facesArray = faces.toArray();
for (int i = 0; i < facesArray.length; i++)
Imgproc.rectangle(mRgba, facesArray[i].tl(), facesArray[i].br(), FACE_RECT_COLOR, 3);
<!-- to add code example fence it with triple backticks and optional file extension
```.cpp
// C++ code example
```
or attach as .txt or .zip file
-->
|
incomplete
|
low
|
Critical
|
351,166,166 |
opencv
|
Unable to open video stream
|
<!--
If you have a question rather than reporting a bug please go to http://answers.opencv.org where you get much faster responses.
If you need further assistance please read [How To Contribute](https://github.com/opencv/opencv/wiki/How_to_contribute).
Please:
* Read the documentation to test with the latest developer build.
* Check if other person has already created the same issue to avoid duplicates. You can comment on it if there already is an issue.
* Try to be as detailed as possible in your report.
* Report only one problem per created issue.
This is a template helping you to create an issue which can be processed as quickly as possible. This is the bug reporting section for the OpenCV library.
-->
##### System information (version)
<!-- Example
-->
- OpenCV => 3.4.1
- Operating System / Platform => Ubuntu 16.04 arm64
- Compiler => gcc
##### Detailed description
Not able to open video stream using function cvCaptureFromCAM() in C language.
Gets following error:
```
[ WARN:0] cvCreateFileCaptureWithPreference: backend FFMPEG doesn't support legacy API anymore.
NvMMLiteOpen : Block : BlockType = 261
TVMR: NvMMLiteTVMRDecBlockOpen: 7907: NvMMLiteBlockOpen
NvMMLiteBlockCreate : Block : BlockType = 261
TVMR: cbBeginSequence: 1223: BeginSequence 1280x720, bVPR = 0
TVMR: LowCorner Frequency = 100000
TVMR: cbBeginSequence: 1622: DecodeBuffers = 5, pnvsi->eCodec = 4, codec = 0
TVMR: cbBeginSequence: 1693: Display Resolution : (1280x720)
TVMR: cbBeginSequence: 1694: Display Aspect Ratio : (1280x720)
TVMR: cbBeginSequence: 1762: ColorFormat : 5
TVMR: cbBeginSequence:1776 ColorSpace = NvColorSpace_YCbCr601
TVMR: cbBeginSequence: 1904: SurfaceLayout = 3
TVMR: cbBeginSequence: 2005: NumOfSurfaces = 12, InteraceStream = 0, InterlaceEnabled = 0, bSecure = 0, MVC = 0 Semiplanar = 1, bReinit = 1, BitDepthForSurface = 8 LumaBitDepth = 8, ChromaBitDepth = 8, ChromaFormat = 5
TVMR: cbBeginSequence: 2007: BeginSequence ColorPrimaries = 2, TransferCharacteristics = 2, MatrixCoefficients = 2
Allocating new output: 1280x720 (x 12), ThumbnailMode = 0
OPENMAX: HandleNewStreamFormat: 3464: Send OMX_EventPortSettingsChanged : nFrameWidth = 1280, nFrameHeight = 720
GStreamer-CRITICAL **: gst_query_set_position: assertion 'format == g_value_get_enum (gst_structure_id_get_value (s, GST_QUARK (FORMAT)))' failed
[ WARN:0] cvCreateFileCaptureWithPreference: backend GSTREAMER doesn't support legacy API anymore.
TVMR: TVMRFrameStatusReporting: 6369: Closing TVMR Frame Status Thread -------------
TVMR: TVMRVPRFloorSizeSettingThread: 6179: Closing TVMRVPRFloorSizeSettingThread -------------
TVMR: TVMRFrameDelivery: 6219: Closing TVMR Frame Delivery Thread -------------
TVMR: NvMMLiteTVMRDecBlockClose: 8105: Done
Failed to query video capabilities: Inappropriate ioctl for device
libv4l2: error getting capabilities: Inappropriate ioctl for device
VIDEOIO ERROR: V4L: device test.mp4: Unable to query number of channels
Couldn't connect to webcam.
: Bad file descriptor
Opened the streamAborted (core dumped)
```
|
wontfix,category: videoio
|
low
|
Critical
|
351,182,490 |
kubernetes
|
Kubelet doesn't support dynamic CPU offlining/onlining
|
<!-- This form is for bug reports and feature requests ONLY!
If you're looking for help check [Stack Overflow](https://stackoverflow.com/questions/tagged/kubernetes) and the [troubleshooting guide](https://kubernetes.io/docs/tasks/debug-application-cluster/troubleshooting/).
If the matter is security related, please disclose it privately via https://kubernetes.io/security/.
-->
**Is this a BUG REPORT or FEATURE REQUEST?**:
/kind bug
**What happened**:
Kubelet doesn't follow CPU hotplug events. For example, if I offline a CPU, guaranteed pods might still be assigned there even though there is no real capacity available. Also, the CPU manager static policy might try to assign containers to non-existent CPUs. This would lead to containers not starting, because the CRI cpuset assignment would fail.
**How to reproduce it (as minimally and precisely as possible)**:
On the master node check CPU capacity:
$ kubectl get node worker-node -o json | jq '.status | .capacity | .cpu'
"4"
On the worker node offline a CPU:
# echo 0 > /sys/devices/system/cpu/cpu2/online
On the master node check CPU capacity again:
$ kubectl get node worker-node -o json | jq '.status | .capacity | .cpu'
"4"
**What you expected to happen**:
The cpu capacity should have gone to 3.
**Anything else we need to know?**:
The correct way to fix this would be to listen to udev hotplug events from a netlink socket. When an event telling that a CPU has been added or removed is received, kubelet should do a few things:
1. Inform API server about the new capacity in NodeStatus message.
2. Inform CPU manager that a new topology must be loaded. The containers must be reassigned to CPUs, because either the default pool grew or some container lost a CPU on which it was assigned to.
CPU hotplug functionality is needed for some pretty special use cases. One of them is the possibility to (dynamically) disable SMT support by offlining a sibling core. I know that this bug is not something that a regular user will meet on daily basis, but since kubernetes manages CPU usage and CPU allocations, this is something that it should take into account.
I would be happy to take a look at fixing this bug if there is some sort of consensus that such a patch might be accepted in kubernetes.
**Environment**:
- Kubernetes version (use `kubectl version`):
Client Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.1",
GitCommit:"b1b29978270dc22fecc592ac55d903350454310a", GitTreeState:"clean", BuildDate:"2018-07-17T18:53:20Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.1",
GitCommit:"b1b29978270dc22fecc592ac55d903350454310a", GitTreeState:"clean", BuildDate:"2018-07-17T18:43:26Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}
- Cloud provider or hardware configuration: Local VMs
- OS (e.g. from /etc/os-release):
NAME=Fedora
VERSION="28 (Workstation Edition)"
- Kernel (e.g. `uname -a`):
4.17.12-200.fc28.x86_64
|
sig/node,kind/feature,needs-triage
|
medium
|
Critical
|
351,185,785 |
go
|
x/tools/present: fix rendering on mobile
|
Trying to follow a presentation on a mobile device is currently very difficult. Some of the issues include:
* Scrolling left or right sometimes doesn't move one slide; rather, it scrolls through the visible horizontal slides
* The screens tend to be tall, meaning that the text is too small by default.
* Trying to zoom in our out easily breaks the UI; one can end up with slides that are cut off.
Below is a screenshot I took after zooming in and out on a presentation of mine.
<img src="https://user-images.githubusercontent.com/3576549/44208641-de165680-a158-11e8-9a73-ce07db61b9f1.png" width="300">
My HTML/JS skills are limited, so I don't know if this would be a major rework for mobile, or just some tweaking to have it behave better on small/tall screens.
|
help wanted,NeedsFix,Tools
|
medium
|
Major
|
351,216,770 |
vue-element-admin
|
Is there any ways to set up a new small admin with another backend framwrok
|
So I use laravel node and nuxt js with node. I want to use this admin as an independent library to fit into other projects. How can I easily separate the components, all styles and use in any other project?
|
enhancement :star:
|
low
|
Minor
|
351,237,949 |
go
|
encoding/json, encoding/xml: update documentation to use embedded fields instead of anonymous fields.
|
This is a documentation issue.
The [json.Marshal documentation](https://tip.golang.org/pkg/encoding/json/#Marshal) refers to "anonymous struct fields," which the spec has been calling "embedded" struct fields since f8b4123613a2cb0c453726033a03a1968205ccae. This is confusing to readers who want to know how embedded struct fields are marshaled and aren't aware of the historic terminology.
Searching the codebase for "anonymous struct" suggests that the encoding/xml godoc has the same issue.
|
Documentation,help wanted,NeedsFix
|
low
|
Minor
|
351,239,760 |
pytorch
|
[Caffe2] Unable to use MPI rendezvous in Caffe2
|
## Issue description
Unable to use MPI rendezvous in Caffe2.
I understand that this information may not be sufficient for helping me out. Hence, I request you to ask to perform whatever steps that are required to get more information about the situation.
I am grateful for your help.
## Code example
Details:
For reproducibility, I am using a container made using the following the Dockerfile:
```
FROM nvidia/cuda:8.0-cudnn7-devel-ubuntu16.04
LABEL maintainer="[email protected]"
# caffe2 install with gpu support
RUN apt-get update && apt-get install -y --no-install-recommends \
build-essential \
cmake \
git \
libgflags-dev \
libgoogle-glog-dev \
libgtest-dev \
libiomp-dev \
libleveldb-dev \
liblmdb-dev \
libopencv-dev \
libprotobuf-dev \
libsnappy-dev \
protobuf-compiler \
python-dev \
python-numpy \
python-pip \
python-pydot \
python-setuptools \
python-scipy \
wget \
&& rm -rf /var/lib/apt/lists/*
RUN wget -q http://www.mpich.org/static/downloads/3.1.4/mpich-3.1.4.tar.gz \
&& tar xf mpich-3.1.4.tar.gz \
&& cd mpich-3.1.4 \
&& ./configure --disable-fortran --enable-fast=all,O3 --prefix=/usr \
&& make -j$(nproc) \
&& make install \
&& ldconfig \
&& cd .. \
&& rm -rf mpich-3.1.4 \
&& rm mpich-3.1.4.tar.gz
RUN pip install --no-cache-dir --upgrade pip==9.0.3 setuptools wheel
RUN pip install --no-cache-dir \
flask \
future \
graphviz \
hypothesis \
jupyter \
matplotlib \
numpy \
protobuf \
pydot \
python-nvd3 \
pyyaml \
requests \
scikit-image \
scipy \
setuptools \
six \
tornado
########## INSTALLATION STEPS ###################
RUN git clone --branch master --recursive https://github.com/pytorch/pytorch.git
RUN cd pytorch && mkdir build && cd build \
&& cmake .. \
-DCUDA_ARCH_NAME=Manual \
-DCUDA_ARCH_BIN="35 52 60 61" \
-DCUDA_ARCH_PTX="61" \
-DUSE_NNPACK=OFF \
-DUSE_ROCKSDB=OFF \
&& make -j"$(nproc)" install \
&& ldconfig \
&& make clean \
&& cd .. \
&& rm -rf build
ENV PYTHONPATH /usr/local
```
The command:
```
srun -N 4 -n 4 -C gpu \
shifter run --mpi load/library/caffe2_container_diff \
python resnet50_trainer.py \
--train_data=$SCRATCH/caffe2_notebooks/tutorial_data/resnet_trainer/imagenet_cars_boats_train \
--test_data=$SCRATCH/caffe2_notebooks/tutorial_data/resnet_trainer/imagenet_cars_boats_val \
--db_type=lmdb \
--num_shards=4 \
--num_gpu=1 \
--num_labels=2 \
--batch_size=2 \
--epoch_size=150 \
--num_epochs=2 \
--distributed_transport ibverbs \
--distributed_interface mlx5_0
```
The output/error:
```
srun: job 9059937 queued and waiting for resources
srun: job 9059937 has been allocated resources
E0816 14:14:20.081552 7042 init_intrinsics_check.cc:43] CPU feature avx is present on your machine, but the Caffe2 binary is not compiled with it. It means you may not get the full speed of your CPU.
E0816 14:14:20.081637 7042 init_intrinsics_check.cc:43] CPU feature avx2 is present on your machine, but the Caffe2 binary is not compiled with it. It means you may not get the full speed of your CPU.
E0816 14:14:20.081642 7042 init_intrinsics_check.cc:43] CPU feature fma is present on your machine, but the Caffe2 binary is not compiled with it. It means you may not get the full speed of your CPU.
E0816 14:14:20.083420 6442 init_intrinsics_check.cc:43] CPU feature avx is present on your machine, but the Caffe2 binary is not compiled with it. It means you may not get the full speed of your CPU.
E0816 14:14:20.083504 6442 init_intrinsics_check.cc:43] CPU feature avx2 is present on your machine, but the Caffe2 binary is not compiled with it. It means you may not get the full speed of your CPU.
E0816 14:14:20.083509 6442 init_intrinsics_check.cc:43] CPU feature fma is present on your machine, but the Caffe2 binary is not compiled with it. It means you may not get the full speed of your CPU.
INFO:resnet50_trainer:Running on GPUs: [0]
INFO:resnet50_trainer:Using epoch size: 144
INFO:resnet50_trainer:Running on GPUs: [0]
INFO:resnet50_trainer:Using epoch size: 144
E0816 14:14:20.087043 5987 init_intrinsics_check.cc:43] CPU feature avx is present on your machine, but the Caffe2 binary is not compiled with it. It means you may not get the full speed of your CPU.
E0816 14:14:20.087126 5987 init_intrinsics_check.cc:43] CPU feature avx2 is present on your machine, but the Caffe2 binary is not compiled with it. It means you may not get the full speed of your CPU.
E0816 14:14:20.087131 5987 init_intrinsics_check.cc:43] CPU feature fma is present on your machine, but the Caffe2 binary is not compiled with it. It means you may not get the full speed of your CPU.
INFO:resnet50_trainer:Running on GPUs: [0]
INFO:resnet50_trainer:Using epoch size: 144
INFO:data_parallel_model:Parallelizing model for devices: [0]
INFO:data_parallel_model:Create input and model training operators
INFO:data_parallel_model:Model for GPU : 0
INFO:data_parallel_model:Parallelizing model for devices: [0]
INFO:data_parallel_model:Create input and model training operators
INFO:data_parallel_model:Model for GPU : 0
E0816 14:14:20.102372 11086 init_intrinsics_check.cc:43] CPU feature avx is present on your machine, but the Caffe2 binary is not compiled with it. It means you may not get the full speed of your CPU.
E0816 14:14:20.102452 11086 init_intrinsics_check.cc:43] CPU feature avx2 is present on your machine, but the Caffe2 binary is not compiled with it. It means you may not get the full speed of your CPU.
E0816 14:14:20.102457 11086 init_intrinsics_check.cc:43] CPU feature fma is present on your machine, but the Caffe2 binary is not compiled with it. It means you may not get the full speed of your CPU.
INFO:data_parallel_model:Parallelizing model for devices: [0]
INFO:data_parallel_model:Create input and model training operators
INFO:data_parallel_model:Model for GPU : 0
INFO:resnet50_trainer:Running on GPUs: [0]
INFO:resnet50_trainer:Using epoch size: 144
INFO:data_parallel_model:Parallelizing model for devices: [0]
INFO:data_parallel_model:Create input and model training operators
INFO:data_parallel_model:Model for GPU : 0
INFO:data_parallel_model:Adding gradient operators
INFO:data_parallel_model:Adding gradient operators
INFO:data_parallel_model:Adding gradient operators
INFO:data_parallel_model:Adding gradient operators
INFO:data_parallel_model:Add gradient all-reduces for SyncSGD
WARNING:data_parallel_model:Distributed broadcast of computed params is not implemented yet
INFO:data_parallel_model:Add gradient all-reduces for SyncSGD
INFO:data_parallel_model:Add gradient all-reduces for SyncSGD
WARNING:data_parallel_model:Distributed broadcast of computed params is not implemented yet
WARNING:data_parallel_model:Distributed broadcast of computed params is not implemented yet
INFO:data_parallel_model:Add gradient all-reduces for SyncSGD
WARNING:data_parallel_model:Distributed broadcast of computed params is not implemented yet
INFO:data_parallel_model:Post-iteration operators for updating params
INFO:data_parallel_model:Calling optimizer builder function
INFO:data_parallel_model:Post-iteration operators for updating params
INFO:data_parallel_model:Post-iteration operators for updating params
INFO:data_parallel_model:Calling optimizer builder function
INFO:data_parallel_model:Calling optimizer builder function
INFO:data_parallel_model:Post-iteration operators for updating params
INFO:data_parallel_model:Calling optimizer builder function
INFO:data_parallel_model:Add initial parameter sync
INFO:data_parallel_model:Add initial parameter sync
INFO:data_parallel_model:Add initial parameter sync
INFO:data_parallel_model:Add initial parameter sync
INFO:data_parallel_model:Creating barrier net
INFO:data_parallel_model:Creating barrier net
INFO:data_parallel_model:Creating barrier net
*** Aborted at 1534428860 (unix time) try "date -d @1534428860" if you are using GNU date ***
INFO:data_parallel_model:Creating barrier net
*** Aborted at 1534428860 (unix time) try "date -d @1534428860" if you are using GNU date ***
*** Aborted at 1534428860 (unix time) try "date -d @1534428860" if you are using GNU date ***
PC: @ 0x2aaab0afb108 caffe2::ConvPoolOpBase<>::TensorInferenceForConv()
PC: @ 0x2aaab0afb108 caffe2::ConvPoolOpBase<>::TensorInferenceForConv()
PC: @ 0x2aaab0afb108 caffe2::ConvPoolOpBase<>::TensorInferenceForConv()
*** SIGSEGV (@0x8) received by PID 5987 (TID 0x2aaaaaae5480) from PID 8; stack trace: ***
@ 0x2aaaaace4390 (unknown)
@ 0x2aaab0afb108 caffe2::ConvPoolOpBase<>::TensorInferenceForConv()
*** SIGSEGV (@0x8) received by PID 7042 (TID 0x2aaaaaae5480) from PID 8; stack trace: ***
@ 0x2aaaaace4390 (unknown)
@ 0x2aaab0afb108 caffe2::ConvPoolOpBase<>::TensorInferenceForConv()
*** Aborted at 1534428860 (unix time) try "date -d @1534428860" if you are using GNU date ***
*** SIGSEGV (@0x8) received by PID 6442 (TID 0x2aaaaaae5480) from PID 8; stack trace: ***
@ 0x2aaaaace4390 (unknown)
@ 0x2aaab0afb108 caffe2::ConvPoolOpBase<>::TensorInferenceForConv()
@ 0x2aaab0af78d3 std::_Function_handler<>::_M_invoke()
PC: @ 0x2aaab0afb108 caffe2::ConvPoolOpBase<>::TensorInferenceForConv()
@ 0x2aaab0af78d3 std::_Function_handler<>::_M_invoke()
@ 0x2aaab09e8094 caffe2::InferBlobShapesAndTypes()
@ 0x2aaab09e9659 caffe2::InferBlobShapesAndTypesFromMap()
@ 0x2aaab0af78d3 std::_Function_handler<>::_M_invoke()
@ 0x2aaab09e8094 caffe2::InferBlobShapesAndTypes()
@ 0x2aaab032588e _ZZN8pybind1112cpp_function10initializeIZN6caffe26python16addGlobalMethodsERNS_6moduleEEUlRKSt6vectorINS_5bytesESaIS7_EESt3mapINSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEEES6_IlSaIlEESt4lessISI_ESaISt4pairIKSI_SK_EEEE36_S7_JSB_SR_EJNS_4nameENS_5scopeENS_7siblingEEEEvOT_PFT0_DpT1_EDpRKT2_ENUlRNS_6detail13function_callEE1_4_FUNES19_
@ 0x2aaab09e9659 caffe2::InferBlobShapesAndTypesFromMap()
@ 0x2aaab035273e pybind11::cpp_function::dispatcher()
@ 0x4bc3fa PyEval_EvalFrameEx
@ 0x4b9ab6 PyEval_EvalCodeEx
@ 0x4c16e7 PyEval_EvalFrameEx
@ 0x4b9ab6 PyEval_EvalCodeEx
@ 0x4c1e6f PyEval_EvalFrameEx
@ 0x2aaab032588e _ZZN8pybind1112cpp_function10initializeIZN6caffe26python16addGlobalMethodsERNS_6moduleEEUlRKSt6vectorINS_5bytesESaIS7_EESt3mapINSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEEES6_IlSaIlEESt4lessISI_ESaISt4pairIKSI_SK_EEEE36_S7_JSB_SR_EJNS_4nameENS_5scopeENS_7siblingEEEEvOT_PFT0_DpT1_EDpRKT2_ENUlRNS_6detail13function_callEE1_4_FUNES19_
@ 0x4b9ab6 PyEval_EvalCodeEx
@ 0x4c1e6f PyEval_EvalFrameEx
@ 0x4b9ab6 PyEval_EvalCodeEx
@ 0x4c1e6f PyEval_EvalFrameEx
@ 0x4b9ab6 PyEval_EvalCodeEx
@ 0x2aaab09e8094 caffe2::InferBlobShapesAndTypes()
@ 0x4eb30f (unknown)
@ 0x4e5422 PyRun_FileExFlags
@ 0x4e3cd6 PyRun_SimpleFileExFlags
@ 0x493ae2 Py_Main
@ 0x2aaaaaf10830 __libc_start_main
@ 0x4933e9 _start
@ 0x2aaab09e9659 caffe2::InferBlobShapesAndTypesFromMap()
*** SIGSEGV (@0x8) received by PID 11086 (TID 0x2aaaaaae5480) from PID 8; stack trace: ***
@ 0x2aaab035273e pybind11::cpp_function::dispatcher()
@ 0x0 (unknown)
@ 0x4bc3fa PyEval_EvalFrameEx
@ 0x4b9ab6 PyEval_EvalCodeEx
@ 0x4c16e7 PyEval_EvalFrameEx
@ 0x4b9ab6 PyEval_EvalCodeEx
@ 0x4c1e6f PyEval_EvalFrameEx
@ 0x4b9ab6 PyEval_EvalCodeEx
@ 0x2aaab032588e _ZZN8pybind1112cpp_function10initializeIZN6caffe26python16addGlobalMethodsERNS_6moduleEEUlRKSt6vectorINS_5bytesESaIS7_EESt3mapINSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEEES6_IlSaIlEESt4lessISI_ESaISt4pairIKSI_SK_EEEE36_S7_JSB_SR_EJNS_4nameENS_5scopeENS_7siblingEEEEvOT_PFT0_DpT1_EDpRKT2_ENUlRNS_6detail13function_callEE1_4_FUNES19_
@ 0x2aaaaace4390 (unknown)
@ 0x4c1e6f PyEval_EvalFrameEx
@ 0x4b9ab6 PyEval_EvalCodeEx
@ 0x4c1e6f PyEval_EvalFrameEx
@ 0x4b9ab6 PyEval_EvalCodeEx
@ 0x4eb30f (unknown)
@ 0x4e5422 PyRun_FileExFlags
@ 0x4e3cd6 PyRun_SimpleFileExFlags
@ 0x493ae2 Py_Main
@ 0x2aaaaaf10830 __libc_start_main
@ 0x4933e9 _start
@ 0x2aaab0afb108 caffe2::ConvPoolOpBase<>::TensorInferenceForConv()
@ 0x0 (unknown)
@ 0x2aaab035273e pybind11::cpp_function::dispatcher()
@ 0x4bc3fa PyEval_EvalFrameEx
@ 0x4b9ab6 PyEval_EvalCodeEx
@ 0x4c16e7 PyEval_EvalFrameEx
@ 0x4b9ab6 PyEval_EvalCodeEx
@ 0x4c1e6f PyEval_EvalFrameEx
@ 0x4b9ab6 PyEval_EvalCodeEx
@ 0x4c1e6f PyEval_EvalFrameEx
@ 0x4b9ab6 PyEval_EvalCodeEx
@ 0x4c1e6f PyEval_EvalFrameEx
@ 0x4b9ab6 PyEval_EvalCodeEx
@ 0x4eb30f (unknown)
@ 0x4e5422 PyRun_FileExFlags
@ 0x4e3cd6 PyRun_SimpleFileExFlags
@ 0x493ae2 Py_Main
@ 0x2aaaaaf10830 __libc_start_main
@ 0x4933e9 _start
@ 0x0 (unknown)
@ 0x2aaab0af78d3 std::_Function_handler<>::_M_invoke()
@ 0x2aaab09e8094 caffe2::InferBlobShapesAndTypes()
@ 0x2aaab09e9659 caffe2::InferBlobShapesAndTypesFromMap()
@ 0x2aaab032588e _ZZN8pybind1112cpp_function10initializeIZN6caffe26python16addGlobalMethodsERNS_6moduleEEUlRKSt6vectorINS_5bytesESaIS7_EESt3mapINSt7__cxx1112basic_stringIcSt11char_traitsIcESaIcEEES6_IlSaIlEESt4lessISI_ESaISt4pairIKSI_SK_EEEE36_S7_JSB_SR_EJNS_4nameENS_5scopeENS_7siblingEEEEvOT_PFT0_DpT1_EDpRKT2_ENUlRNS_6detail13function_callEE1_4_FUNES19_
@ 0x2aaab035273e pybind11::cpp_function::dispatcher()
@ 0x4bc3fa PyEval_EvalFrameEx
@ 0x4b9ab6 PyEval_EvalCodeEx
@ 0x4c16e7 PyEval_EvalFrameEx
@ 0x4b9ab6 PyEval_EvalCodeEx
@ 0x4c1e6f PyEval_EvalFrameEx
@ 0x4b9ab6 PyEval_EvalCodeEx
@ 0x4c1e6f PyEval_EvalFrameEx
@ 0x4b9ab6 PyEval_EvalCodeEx
@ 0x4c1e6f PyEval_EvalFrameEx
@ 0x4b9ab6 PyEval_EvalCodeEx
@ 0x4eb30f (unknown)
@ 0x4e5422 PyRun_FileExFlags
@ 0x4e3cd6 PyRun_SimpleFileExFlags
@ 0x493ae2 Py_Main
@ 0x2aaaaaf10830 __libc_start_main
@ 0x4933e9 _start
@ 0x0 (unknown)
srun: error: nid06499: task 2: Segmentation fault
srun: Terminating job step 9059937.0
srun: error: nid06497: task 0: Segmentation fault
srun: error: nid06498: task 1: Segmentation fault
srun: error: nid06500: task 3: Segmentation fault
```
## System Info
- Caffe2:
- How you installed Caffe2 (conda, pip, source): Modified Dockerfile mentioned above
- CUDA/cuDNN version: 8.0/7.0
- GPU models and configuration: Cray XC40/XC50 supercomputer, uses SLURM!
|
caffe2
|
low
|
Critical
|
351,266,005 |
go
|
cmd/compile: split up SSA rewrite passes
|
For Go 1.12 I'd like to experiment with splitting up the rewrite rules for generic optimization, lowering and lowered optimization into more phases. This is a tracking issue for that experimentation. Ideas and feedback welcomed.
As we have added more and more optimizations the rules files have become increasingly large. This introduces a few problems. Firstly 'noopt' builds actually do a lot of optimizations, some of which are quite complex and may make programs much harder to debug. Secondly the ways that rules interact is becoming less clear. For example, adding a new set of rules might introduce 'dead ends' into the optimization passes, because, say, the author hasn't take into account special cases such as indexed versions of memory operations. Thirdly there are some rules which will only ever fire once. For example, the rules to explode small struct accesses('SSAable'). This is inefficient since they need to be re-checked every time the optimization pass is re-run (the optimization passes tend to run over and over again until a steady state is reached).
Here is a summary of the existing passes that use code generated from the rewrite rules (I've ignored the 32-bit passes for now):
* `opt`: first round of generic optimizations [mandatory][iterative]
* `decompose builtins`: split up compound operations, such as complex number operations, into individual operations [mandatory][single pass]
* `late opt`: repeat the generic optimizations after CSE etc. have run [mandatory][iterative]
* `lower`: generate and optimize machine specific operations [mandatory][iterative]
As a rough guide I see the phases looking something like this (will most likely change quite a lot):
Generic phases:
* `optimize initial`: generic optimizations targeting compound types (store-load forwarding etc.) and constant propagation [optional][iterative]
* `decompose compound types`: split up SSAable operations and generate Move and Zero operations etc. for non-SSAable operations [mandatory][single pass]
* `decompose builtins`: (might merge into the previous pass) [mandatory][single pass]
* `optimize main`: generic optimizations before the main optimization passes (CSE, BCE, etc.) [optional][iterative]
* `optimize final`: repeat the generic optimizations after the main optimization passes [optional][iterative]
Architecture specific phases (not all architectures will need all of these):
* `lower`: minimal rules needed to produce executable code [mandatory][iterative]
* `lowered optimize initial`: optimizations that can be applied in one pass (not sure if this will be needed) [optional][single pass]
* `lowered optimize main`: optimizations that need to be executed iteratively [optional][iterative]
* `lowered optimize final:` low priority optimizations that can be applied in one pass (or a small number of passes) such as indexed memory accesses and merging loads into instructions [optional][single pass (maybe iterative)]
I'm hoping the benefits of being able to reduce the number of rules and perhaps more efficient I-cache usage will make up for the increased number of passes. I'll need to experiment to see.
Most likely some rules will need to be duplicated in multiple passes (particularly the generic optimization passes). This will probably involve splitting the rules into more files and then re-combining them in individual passes (for example, constant propagation rules could get their own file and then be called from both the initial and main generic optimization passes).
There are some TODOs along these lines in the compiler source, but I couldn't find any existing issues, so apologies if this is a dup of another issue.
|
compiler/runtime
|
low
|
Critical
|
351,304,898 |
TypeScript
|
Prototype assignment of constructor nested inside a class confuses type resolution
|
From chrome-devtools-frontend, in ui/ListWidget.js:
```js
var UI = {}
UI.ListWidget = class { };
UI.ListWidget.Delegate = function() {};
UI.ListWidget.Delegate.prototype = {
renderItem() {},
};
/** @type {UI.ListWidget} */
var l = new UI.ListWidget();
```
**Expected behavior:**
The type of `l` is the same as `new UI.ListWidget()` — `UI.ListWidget`.
**Actual behavior:**
It's `{ renderItem() {} } & { renderItem() {} }` -- the structural type of UI.ListWidget.Delegate, duplicated. This also causes an assignability error from `new UI.ListWidget()`.
Note that this has been broken for some time; it's not a 3.1 regression.
|
Bug
|
low
|
Critical
|
351,417,363 |
vscode
|
Allow extensions to be installed for all users
|
I'm the instructor a college Python programming course. I'd love to adopt VS Code for this course, but the fact that extensions are installed on a per-user basis is a major problem. For education and enterprise markets, there needs to be support for pre-installing extensions for all users.
It's important that we be able to provide a ready-to-use environment to students on login. I have 50 students in my class. I can't afford to lose class time to making students install the Python extension each time they use a new computer or to help troubleshooting students when they have problems.
I've put together a very hackish workaround where I've created a batch file that installs the plugin and then launches VS Code. I've added shortcuts to this batch file, but it's messy and I fear brittle.
Please add a flag to code --install-extension that allows users to specify the extension is to be installed for all users.
FWIW, @rhyspaterson mentioned needing this same functionality in a comment on Issue #27972.
|
feature-request,extensions
|
high
|
Critical
|
351,418,074 |
pytorch
|
Bilinear interpolation behavior inconsistent with TF, CoreML and Caffe
|
## Issue description
Trying to compare and transfer models between Caffe, TF and Pytorch found difference in output of bilinear interpolations between all. Caffe is using depthwise transposed convolutions instead of straightforward resize, so it's easy to reimplement both in TF and Pytorch.
However, there is difference between output for TF and Pytorch with `align_corners=False`, which is default for both.
## Code example
```Python
img = cv2.resize(cv2.imread('./lenna.png')[:, :, ::-1], (256, 256))
img = img.reshape(1, 256, 256, 3).astype('float32') / 255.
img = tf.convert_to_tensor(img)
output_size = [512, 512]
output = tf.image.resize_bilinear(img, output_size, align_corners=True)
with tf.Session() as sess:
values = sess.run([output])
out_tf = values[0].astype('float32')[0]
img = img.reshape(1, 256, 256, 3).transpose(0, 3, 1, 2).astype('float32') / 255.
out_pt = nn.functional.interpolate(torch.from_numpy(nimg),
scale_factor=2,
mode='bilinear',
align_corners=True)
out_pt = out_pt.data.numpy().transpose(0, 2, 3, 1)[0]
print(np.max(np.abs(out_pt - out_tf)))
# output 5.6624413e-06
```
But
```Python
img = cv2.resize(cv2.imread('./lenna.png')[:, :, ::-1], (256, 256))
img = img.reshape(1, 256, 256, 3).astype('float32') / 255.
img = tf.convert_to_tensor(img)
output_size = [512, 512]
output = tf.image.resize_bilinear(img, output_size, align_corners=False)
with tf.Session() as sess:
values = sess.run([output])
out_tf = values[0].astype('float32')[0]
img = img.reshape(1, 256, 256, 3).transpose(0, 3, 1, 2).astype('float32') / 255.
out_pt = nn.functional.interpolate(torch.from_numpy(nimg),
scale_factor=2,
mode='bilinear',
align_corners=False)
out_pt = out_pt.data.numpy().transpose(0, 2, 3, 1)[0]
print(np.max(np.abs(out_pt - out_tf)))
# output 0.22745097
```
Output diff * 10:

Output of CoreML is consistent with TF, so it seems that there is a bug with implementation of bilinear interpolation with `align_corners=False` in Pytorch.
Diff is reproducible both on cpu and cuda with cudnn 7.1, cuda 9.1.
|
triaged,module: interpolation
|
low
|
Critical
|
351,445,586 |
opencv
|
app link error with iOS framework
|
##### System information (version)
- OpenCV => 3.4.2
- Operating System / Platform => Mac OSX 10.13.6 (17G65)
- Compiler => XCode Version 9.4.1 (9F2000)
##### Detailed description
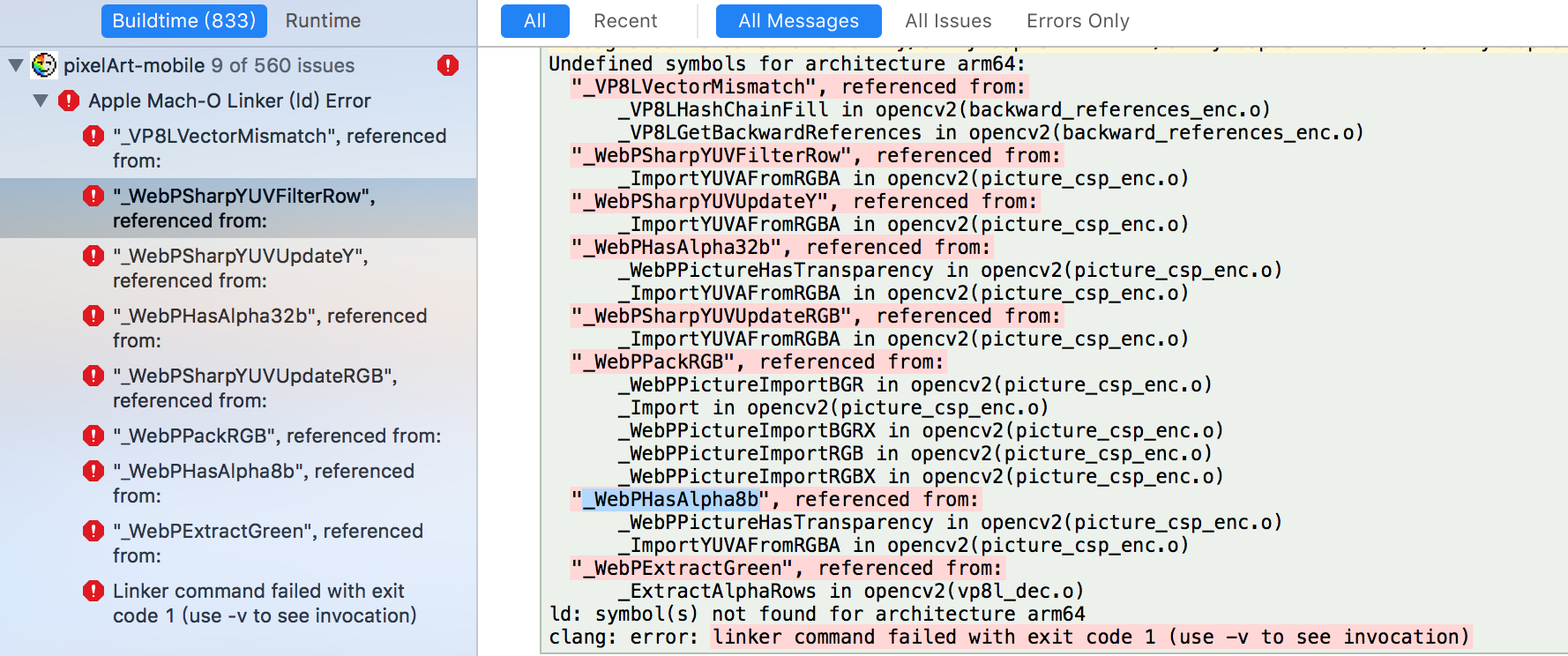
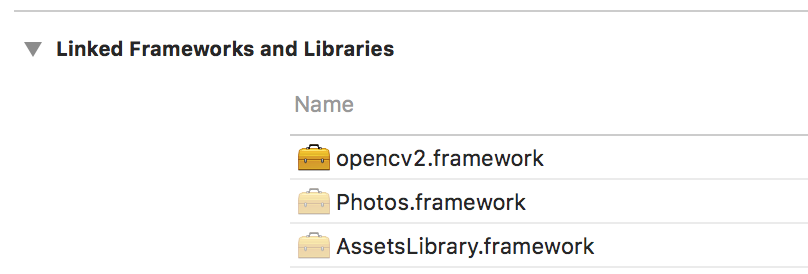
|
category: build/install,platform: ios/osx,needs investigation
|
low
|
Critical
|
351,544,821 |
pytorch
|
Request for better memory management
|
This issue is mainly about how to recover from an `out of memory` exception, previously posted in [forum](https://discuss.pytorch.org/t/whats-the-best-way-to-handle-exception-cuda-runtime-error-2-out-of-memory/11891).
Till now, it's not always possible to recover from OOM exception whether during train or inference. This will pose huge risk when you use pytorch in large-scale training or deployment.
Please pay attention to this problem, I really like pytorch anyway.
|
feature,module: memory usage,triaged
|
low
|
Critical
|
351,565,975 |
rust
|
Unrelated error report for trait bound checking
|
Given the following code:
```rust
use nalgebra::{Dynamic, MatrixMN};
use std::fmt::Debug;
trait CheckedType : Copy + Clone + Debug + Ord {}
struct Foo<T: CheckedType> {
matrix: MatrixMN<T, Dynamic, Dynamic>,
}
```
The compilers reports:
```
error[E0310]: the parameter type `T` may not live long enough
--> src/main.rs:9:5
|
8 | struct Foo<T: CheckedType> {
| -- help: consider adding an explicit lifetime bound `T: 'static`...
9 | matrix: MatrixMN<T, Dynamic, Dynamic>,
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
note: ...so that the type `T` will meet its required lifetime bounds
--> src/main.rs:9:5
|
9 | matrix: MatrixMN<T, Dynamic, Dynamic>,
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
```
Checking the definition of `nalgebra::MatrixMN`, it seems the trait bound needs to include `Scalar`, so if I add `nalgebra::Scalar` to the bound of `CheckedType`, then the code passes compile.
The error report for the original code seems to be completely unrelated to the actual fix. I suspect this is a compiler bug.
|
C-enhancement,A-diagnostics,T-compiler
|
low
|
Critical
|
351,598,174 |
go
|
x/text: gotext with french numbers above 1,000,000
|
Please answer these questions before submitting your issue. Thanks!
### What version of Go are you using (`go version`)?
go version go1.10.3 darwin/amd64
### Does this issue reproduce with the latest release?
YES
### What operating system and processor architecture are you using (`go env`)?
GOARCH="amd64"
GOBIN="/Users/christophe/go/bin"
GOCACHE="/Users/christophe/Library/Caches/go-build"
GOEXE=""
GOHOSTARCH="amd64"
GOHOSTOS="darwin"
GOOS="darwin"
GOPATH="/Users/christophe/go"
GORACE=""
GOROOT="/usr/local/Cellar/go/1.10.3/libexec"
GOTMPDIR=""
GOTOOLDIR="/usr/local/Cellar/go/1.10.3/libexec/pkg/tool/darwin_amd64"
GCCGO="gccgo"
CC="clang"
CXX="clang++"
CGO_ENABLED="1"
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
PKG_CONFIG="pkg-config"
GOGCCFLAGS="-fPIC -m64 -pthread -fno-caret-diagnostics -Qunused-arguments -fmessage-length=0 -fdebug-prefix-map=/var/folders/85/01ftf7594x1_01_ps0ypv76h0000gn/T/go-build291898772=/tmp/go-build -gno-record-gcc-switches -fno-common"
### What did you do?
In french, when expressing quantities, you have to distinguish between less than 1,000,000 and more. For example, one have to say:
* For numbers from 2 up to and including 999'999, we have to say/write:
> Il y a 999'999 habitants.
> Il y a 999'999 chiens.
* And for numbers from 1'000'000 and up, we have to say/write:
> Il y a 1'000'000 **d**'habitants.
> Il y a 1'000'000 **de** chiens.
With the following program:
```
package main
//go:generate gotext -srclang=en update -out=catalog/catalog.go -lang=fr,en
import (
"fmt"
_ "github.com/clamb/arcaciel/aws/scrapbook/catalog"
"golang.org/x/text/language"
"golang.org/x/text/message"
)
func main() {
tr := message.NewPrinter(language.French)
num := 999999
tr.Printf("There are %d dog(s)", num)
fmt.Println()
num = 1000000
tr.Printf("There are %d dog(s)", num)
fmt.Println()
num = 1000001
tr.Printf("There are %d dog(s)", num)
fmt.Println()
}
```
I tried using `many` (not sure how exactly about how to write this, but this is not the point):
```
{
"id": "There are {Num} dog(s)",
"message": "There are {Num} dog(s)",
"translation": {
"select": {
"feature": "plural",
"arg": "Num",
"cases": {
"=0": "Il n'y a pas de chien",
"one": "Il y a {Num} chien",
"many": "Il y a {Num} de chiens",
"other": "Il y a {Num} de chiens"
}
}
},
"placeholders": [{
"id": "Num",
"string": "%[1]d",
"type": "int",
"underlyingType": "int",
"argNum": 1,
"expr": "num"
}]
},
```
However `many` is not supported for language `fr`.
```
gotext: generation failed: error: plural: form "many" not supported for language "fr"
test.go:3: running "gotext": exit status 1
```
Then I tried using `"<1000000"`:
```
{
"id": "There are {Num} dog(s)",
"message": "There are {Num} dog(s)",
"translation": {
"select": {
"feature": "plural",
"arg": "Num",
"cases": {
"=0": "Il n'y a pas de chien",
"one": "Il y a {Num} chien",
"<1000000": "Il y a {Num} chiens",
"other": "Il y a {Num} de chiens"
}
}
},
"placeholders": [{
"id": "Num",
"string": "%[1]d",
"type": "int",
"underlyingType": "int",
"argNum": 1,
"expr": "num"
}]
},
```
As the number `1,000,000` is read as an `int16`, `gotext` raises an error:
```
gotext: generation failed: error: plural: invalid number in selector "<1000000": strconv.ParseUint: parsing "1000000": value out of range
test.go:3: running "gotext": exit status 1
```
### What did you expect to see?
```
Il y a 999 999 chiens
Il y a 1 000 000 de chiens
Il y a 1 000 001 de chiens
```
### What did you see instead?
```
gotext: generation failed: error: plural: invalid number in selector "<1000000": strconv.ParseUint: parsing "1000000": value out of range
test.go:3: running "gotext": exit status 1
```
|
NeedsInvestigation
|
low
|
Critical
|
351,662,938 |
react
|
onChange doesn't fire if input re-renders due to a setState() in a non-React capture phase listener
|
Extracting from https://github.com/facebook/react/issues/12643.
This issue has always been in React. I can reproduce it up to React 0.11. However **it's probably extremely rare in practice and isn't worth fixing**. I'm just filing this for posterity.
Here is a minimal example.
```js
class App extends React.Component {
state = {value: ''}
handleChange = (e) => {
this.setState({
value: e.target.value
});
}
componentDidMount() {
document.addEventListener(
"input",
() => {
// COMMENT OUT THIS LINE TO FIX:
this.setState({});
},
true
);
}
render() {
return (
<div>
<input
value={this.state.value}
onChange={this.handleChange}
/>
</div>
);
}
}
ReactDOM.render(<App />, document.getElementById("container"));
```
Typing doesn't work — unless I comment out that `setState` call in the capture phase listener.
Say the input is empty and we're typing `a`.
What happens here is that `setState({})` in the capture phase non-React listener runs first. When re-rendering due to that first empty `setState({})`, input props still contain the old value (`""`) while the DOM node's value is new (`"a"`). They're not equal, so we'll set the DOM node value to `""` (according to the props) and remember `""` as the current value.
<img width="549" alt="screen shot 2018-08-17 at 1 08 42 am" src="https://user-images.githubusercontent.com/810438/44241204-4b0e0880-a1ba-11e8-847d-bf9ca43eb954.png">
Then, `ChangeEventPlugin` tries to decide whether to emit a change event. It asks the tracker whether the value has changed. The tracker compares the presumably "new" `node.value` (it's `""` — we've just set it earlier!) with the `lastValue` it has stored (also `""` — and also just updated). No changes!
<img width="505" alt="screen shot 2018-08-17 at 1 10 59 am" src="https://user-images.githubusercontent.com/810438/44241293-e0110180-a1ba-11e8-9c5a-b0d808f745cd.png">
Our `"a"` update is lost. We never get the change event, and never actually get a chance to set the correct state.
|
Type: Bug,Component: DOM,React Core Team
|
medium
|
Major
|
351,678,753 |
electron
|
Split session 'Media' permission to 'Camera' and 'Microphone'
|
**Is your feature request related to a problem? Please describe.**
In the actual Electron Session permission request handler, the 'media' permission englobes both microphone and camera.
**Describe the solution you'd like**
I suggest that it should be splited into microphone and camera, in order to work like Chrome, Firefox and other major browsers.
It will also bring a more detailed option for a specific set of applications, that only require access to either microphone or the webcam of the user.
|
enhancement :sparkles:
|
low
|
Minor
|
351,679,975 |
rust
|
Query system cycle errors should be extendable with notes
|
Relevant PR: https://github.com/rust-lang/rust/pull/53316
Relevant Issue: #52985
The [query system](https://rust-lang-nursery.github.io/rustc-guide/query.html) automatically detects and emits a cycle error if a cycle occurs when dependency nodes are added to the query DAG. This error is extensible with a custom main message defined as below to help human readability,
https://github.com/rust-lang/rust/blob/a385095f9a6d4d068102b6c72fbdc86ac2667e51/src/librustc/ty/query/config.rs#L93
but is otherwise closed for modification outside of the query::plumbing module:
https://github.com/rust-lang/rust/blob/b2397437530eecef72a1524a7e0a4b42034fa360/src/librustc/ty/query/plumbing.rs#L248
It would be nice to have a mechanism in addition that allows custom notes and suggestions to be added to these errors to help illustrate why a cycle occurred, not just where. It may be possible to expose the `DiagnosticBuilder` or provide wrappers for methods like `span_suggestion()` and `span_note()`
|
C-enhancement,A-diagnostics,T-compiler
|
low
|
Critical
|
351,698,237 |
go
|
x/net/idna: Display returns invalid label for r4---sn-a5uuxaxjvh-gpm6.googlevideo.com.
|
### What version of Go are you using (`go version`)?
```
go version go1.10.3 linux/amd64 via docker golang:1.10.3-alpine
(also go version go1.10.3 darwin/amd64)
```
### Does this issue reproduce with the latest release?
```
Yes
```
### What operating system and processor architecture are you using (`go env`)?
```
GOARCH="amd64"
GOBIN=""
GOEXE=""
GOHOSTARCH="amd64"
GOHOSTOS="linux"
GOOS="linux"
GOPATH="/go"
GORACE=""
GOROOT="/usr/local/go"
GOTMPDIR=""
GOTOOLDIR="/usr/local/go/pkg/tool/linux_amd64"
GCCGO="gccgo"
CC="gcc"
CXX="g++"
CGO_ENABLED="1"
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
PKG_CONFIG="pkg-config"
GOGCCFLAGS="-fPIC -m64 -pthread -fno-caret-diagnostics -Qunused-arguments -fmessage-length=0 -fdebug-prefix-map=/tmp/go-build623899479=/tmp/go-build -gno-record-gcc-switches"
```
### What did you do?
Transforming domain name to human-readable form with "golang.org/x/net/idna".
```golang
package main
import (
"fmt"
"golang.org/x/net/idna"
)
func main() {
_, e := idna.ToUnicode("r4---sn-a5uuxaxjvh-gpm6.googlevideo.com")
fmt.Println(e)
_, e = idna.Display.ToUnicode("r4---sn-a5uuxaxjvh-gpm6.googlevideo.com")
fmt.Println(e)
}
```
### What did you expect to see?
I expect to see no error.
```
<nil>
<nil>
```
### What did you see instead?
But `idna.Display` does not agree to accept the host name as a valid one.
```
<nil>
idna: invalid label "r4---sn-a5uuxaxjvh-gpm6"
```
`.ToASCII` has the same property.
|
NeedsInvestigation
|
low
|
Critical
|
351,733,588 |
vscode
|
[npm] hover should show relevant latest version
|
In a `package.json`, when you hover the version for a dependency it will show the "[Latest version](https://github.com/Microsoft/vscode/blob/9a03a86c0a54a24c355bd950ddad91a0e74de6dd/extensions/npm/src/features/packageJSONContribution.ts#L303)". I think it would be useful to (also) show the _relevant_ latest version, which might differ if using a version prefix like `^` or `~`.
|
feature-request,json
|
low
|
Minor
|
351,769,355 |
flutter
|
Expose the tri-state checkbox "indeterminate" state in the semantics data
|
Right now we treat "indeterminate" and "unchecked" as the same. This works for Android and iOS since their accessibility APIs don't support tristate checkboxes, but hopefully Fuchsia's API will support tristate checkboxes so we should expose the data there at least.
|
framework,a: accessibility,platform-fuchsia,c: proposal,P2,team-framework,triaged-framework
|
low
|
Minor
|
351,771,464 |
awesome-mac
|
Recategorize Art/Protoyping/Modeling Software
|
It should really be better organized, and the categories we have now are insufficient.
Maybe add a `3D Modeling` category?
Also, maybe rename `Screenshot Tools` to `Screencapturing Software`?
- [x] I have checked for other similar issues
- [x] I have explained why this change is important
|
help wanted,organization
|
low
|
Minor
|
351,783,002 |
flutter
|
Box shadow doesn't have flexible features.
|
I love flutter. I have been using it for a year. I'm working on a client project. And the demand is We need Box-shadow for only 3 sides. How can I achieve this? If it would have been like `BoxShadow.only` as in the case of `EdgeInsted.only`, that would be much better. So that as a Developer, I can't say "No" to my Client. And that's what Flutter is For. I don't know where to suggest this. So I'm reporting here.
|
c: new feature,framework,P2,team-framework,triaged-framework
|
low
|
Major
|
351,789,591 |
flutter
|
[web] Drawer menu button is not reachable by screen readers
|
framework,f: material design,a: accessibility,platform-web,has reproducible steps,P2,found in release: 3.3,found in release: 3.6,team-web,triaged-web
|
low
|
Minor
|
|
351,797,063 |
godot
|
How to Scroll via ScrollContainer in android or touch screen devices
|
Godot version: 3.1.dev
commit 15ee6b7
OS/device including version: MacOSX High Sierra, Android
Issue description:How to scroll via ScrollContainer. It doesnt scroll in android or touch screen or via dragging
Steps to reproduce:
1. Add Scroll Container in the scene
2. Add VBoxContainer as child of scrollContainer
3. Add Panel with min. size with a sprite inside
Note: Scrolling via mouse wheel works or dragging the scrollBar but if its in android It should be able to scroll via dragging the content right?
Thanks for the response in advance
|
bug,platform:android,platform:macos,confirmed,usability,topic:input,topic:gui
|
medium
|
Critical
|
351,804,670 |
TypeScript
|
Add an option to force source maps to use absolute paths?
|
Previous related issue: https://github.com/Microsoft/TypeScript/issues/23180
It seems VS2017 is incompatible with relative paths, when debugging a UWP app now tries to load source maps from the app URI and the host does not support it.
```
'WWAHost.exe' (Script): Loaded 'Script Code (MSAppHost/3.0)'.
SourceMap ms-appx://6b826582-e42b-45b9-b4e6-dd210285d94b/js/require-config.js.map read failed: The URI prefix is not recognized..
```
Hard-coding the full path in `tsconfig.json` is not a good idea here, I hope we have an option to behave as 2.9.2 so that we can get the auto-resolved full path.
Edit: My tsconfig.json that works in TS2.9 but not in TS3.0:
```json
{
"compilerOptions": {
"strict": true,
"noEmitOnError": true,
"removeComments": false,
"sourceMap": true,
"target": "es2017",
"outDir": "js/",
"mapRoot": "js/",
"sourceRoot": "sources/",
"emitBOM": true,
"module": "amd",
"moduleResolution": "node"
},
"exclude": [
"node_modules",
"wwwroot"
]
}
```
My failed trial to fix this: (removed `mapRoot` and changed `sourceRoot`)
```json
{
"compilerOptions": {
"strict": true,
"noEmitOnError": true,
"removeComments": false,
"sourceMap": true,
"target": "es2017",
"outDir": "js/",
"sourceRoot": "../sources/",
"emitBOM": true,
"module": "amd",
"moduleResolution": "node"
},
"exclude": [
"node_modules",
"wwwroot"
]
}
```
|
Suggestion,In Discussion,Add a Flag
|
low
|
Critical
|
351,818,447 |
TypeScript
|
Proposal: `export as namespace` for UMD module output
|
## Current problem
TypeScript supports UMD output but does not support exporting as a global namespace.
## Syntax
_NamespaceExportDeclaration:_
`export` `as` `namespace` _IdentifierPath_
## Behavior
```ts
export var x = 0;
export function y() {}
export default {};
export as namespace My.Custom.Namespace;
// emits:
(function (global, factory) {
if (typeof module === "object" && typeof module.exports === "object") {
var v = factory(require, exports);
if (v !== undefined) module.exports = v;
}
else if (typeof define === "function" && define.amd) {
define(["require", "exports"], factory);
}
else {
global.My = global.My || {};
global.My.Custom = global.My.Custom || {};
global.My.Custom.Namespace = global.My.Custom.Namespace || {};
var exports = global.My.Custom.Namespace;
factory(global.require, exports);
}
})(this, function (require, exports) {
"use strict";
exports.__esModule = true;
exports.x = 0;
function y() { }
exports.y = y;
exports["default"] = {};
});
```
## Note
* This proposal basically follows Babel behavior.
* Importing any module without a module loader will throw in this proposal. A further extension may use global namespaces as Babel does.
* Babel overwrites on the existing namespace whereas this proposal extends the existing one, as TS `namespace` does.
* Rollup has a special behavior where `export default X` works like CommonJS `module.exports = X` whereas this proposal does not.
Prior arts: [Babel exactGlobals](https://babeljs.io/docs/en/babel-plugin-transform-es2015-modules-umd/#more-flexible-semantics-with-exactglobals-true), [Webpack multi part library](https://github.com/webpack/webpack/tree/v4.16.5/examples/multi-part-library), [Rollup `output.name` option with namespace support](https://rollupjs.org/guide/en#core-functionality)
## See also
#8436
#10907
#20990
|
Suggestion,In Discussion
|
low
|
Major
|
351,828,283 |
godot
|
Allow SkeletonIK to ignore target's rotation
|
**Godot version:**
`master` / c93888ae
**OS/device including version:**
Manjaro Linux 17.1
**Issue description:**
Currently, `SkeletonIK` will try to match the bone hierarchy to a given target's transform which is not always desired.
For example, IK can be used to make a character stretch its hand towards an item when picking it up. And in this case, the arm could be twisted in an unnatural manner, if the character is positioned in a 'wrong' direction from the item.
As an item should be picked up from any direction, it would be much easier if the IK system allowed matching a bone chain to its target's position, without affecting rotation of its constiuent parts.
(For those who need such a feature now: you can change `SkeletonIK.Target` in each frame, so that it matches rotation with the assigned target.)
|
enhancement,topic:core
|
low
|
Minor
|
351,833,060 |
flutter
|
FlutterDriver locator and fluent-style improvements
|
To be more like Selenium-WebDriver, FlutterDriver would be better if it had a mechanism to find lists of matches for a given locator.
```java
// WebDriver's Java API:
Element element = webDriver.findElement(locator); // singular match
List<WebElement> elements = webDriver.findElement(locator); // multiple matches, returned as list
String secondElemText = elements.get(1).getText();
```
FlutterDriver only has mechanisms to target single matches to locators, right now.
To be honest, FlutterDriver's API feels more like Selenium-RC from 2004 (I co-created that) rather than the superior Selenium2 API (WebDriver) that came a few years later.
|
a: tests,c: new feature,framework,t: flutter driver,customer: crowd,P2,team-framework,triaged-framework
|
low
|
Major
|
351,835,598 |
go
|
crypto/tls: fix pseudo-constant mitigation for lucky 13
|
As detailed in the paper "Pseudo Constant Time Implementations of TLS
Are Only Pseudo Secure"
https://eprint.iacr.org/2018/747
|
NeedsInvestigation
|
low
|
Major
|
351,885,929 |
youtube-dl
|
HRTi Extractor not working
|
## Please follow the guide below
- You will be asked some questions and requested to provide some information, please read them **carefully** and answer honestly
- Put an `x` into all the boxes [ ] relevant to your *issue* (like this: `[x]`)
- Use the *Preview* tab to see what your issue will actually look like
---
### Make sure you are using the *latest* version: run `youtube-dl --version` and ensure your version is *2018.08.04*. If it's not, read [this FAQ entry](https://github.com/rg3/youtube-dl/blob/master/README.md#how-do-i-update-youtube-dl) and update. Issues with outdated version will be rejected.
- [x] I've **verified** and **I assure** that I'm running youtube-dl **2018.08.04**
### Before submitting an *issue* make sure you have:
- [x] At least skimmed through the [README](https://github.com/rg3/youtube-dl/blob/master/README.md), **most notably** the [FAQ](https://github.com/rg3/youtube-dl#faq) and [BUGS](https://github.com/rg3/youtube-dl#bugs) sections
- [x] [Searched](https://github.com/rg3/youtube-dl/search?type=Issues) the bugtracker for similar issues including closed ones
- [x] Checked that provided video/audio/playlist URLs (if any) are alive and playable in a browser
### What is the purpose of your *issue*?
- [x] Bug report (encountered problems with youtube-dl)
- [x] Site support request (request for adding support for a new site)
- [ ] Feature request (request for a new functionality)
- [ ] Question
- [ ] Other
---
The HRTi extractor is not working anymore. HRTi has changed the web site. Can anyone help with writing a new extractor?
Single Video: https://hrti.hrt.hr/videostore/moviedetails?referenceId=41616AF4-5113-4&refer=videostore%7Cmovies&customCatalogueReferenceId=PUTOPISI&player=True&heading=PUTOPISI
|
account-needed
|
low
|
Critical
|
351,886,239 |
rust
|
Tracking issue for RFC 2504, "Fix the Error trait"
|
This is a tracking issue for the RFC "Fix the Error trait" (rust-lang/rfcs#2504).
**Steps:**
- [x] Implement the RFC (cc @rust-lang/libs)
- [X] `source` method #53533
- [x] Backtrace API #64154
- [x] ~~Implement proof of concept showing stabilizing `backtrace` method won't prevent moving `Error` into `core` later https://github.com/rust-lang/rust/pull/77384~~
- [ ] Fix std::backtrace::Backtrace's fmt representations
- ~~Precision flag support #65280~~ this is non-blocking for stabilization
- [ ] Differences with `panic!` backtraces #71706
- [ ] Adjust documentation ([see instructions on forge][doc-guide])
- [ ] Stabilization PR ([see instructions on forge][stabilization-guide])
[stabilization-guide]: https://forge.rust-lang.org/stabilization-guide.html
[doc-guide]: https://forge.rust-lang.org/stabilization-guide.html#updating-documentation
**Unresolved questions:**
- [x] The choice to implement nullability internal to backtrace may prove to be a mistake: during the period when backtrace APIs are only available on nightly, we will gain more experience and possible change backtrace's constructors to return an `Option<Backtrace>` instead.
**Current status:**
https://github.com/rust-lang/rust/issues/53487#issuecomment-726326510
|
B-RFC-approved,T-libs-api,C-tracking-issue,A-error-handling,Libs-Tracked,PG-error-handling
|
high
|
Critical
|
351,890,685 |
rust
|
Error message for E0453 is missing details when source is out of current crate
|
From <https://travis-ci.org/open-i18n/rust-unic/jobs/417843357>:
```rust
Compiling unic-ucd-version v0.7.0 (file:///home/travis/build/open-i18n/rust-unic/unic/ucd/version)
Running `rustc --crate-name unic_ucd_version unic/ucd/version/src/lib.rs --emit=dep-info,link -C debuginfo=2 --test -C metadata=0f052cf9e92ebfb5 -C extra-filename=-0f052cf9e92ebfb5 --out-dir /home/travis/build/open-i18n/rust-unic/target/debug/deps -C incremental=/home/travis/build/open-i18n/rust-unic/target/debug/incremental -L dependency=/home/travis/build/open-i18n/rust-unic/target/debug/deps --extern unic_common=/home/travis/build/open-i18n/rust-unic/target/debug/deps/libunic_common-4592f220db252de4.rlib`
error[E0453]: allow(unused) overruled by outer forbid(unused)
error: aborting due to previous error
For more information about this error, try `rustc --explain E0453`.
error: Could not compile `unic-ucd-version`.
```
Apparently `allow(unused)` mentioned here is from a file external to the crate being compiled. (There's no allow-unused rule in the `rust-unic` repository.)
IMHO, the error is missing any information on where it is originated (the `allow(unused)` file or crate), and only displays the name of the crate being compiled.
Can we improve this error message in any way?
|
C-enhancement,A-diagnostics,T-compiler
|
low
|
Critical
|
351,890,844 |
go
|
x/mobile: Binding go mobile framework on windows with $GOPATH that contains whitespace fails
|
Please answer these questions before submitting your issue. Thanks!
### What version of Go are you using (`go version`)?
go version go1.10.2 windows/amd64
### Does this issue reproduce with the latest release?
Yes
### What operating system and processor architecture are you using (`go env`)?
set GOARCH=amd64
set GOBIN=
set GOCACHE=C:\Users\Jakub Tomana\AppData\Local\go-build
set GOEXE=.exe
set GOHOSTARCH=amd64
set GOHOSTOS=windows
set GOOS=windows
set GOPATH=C:\Users\Jakub Tomana\go
set GORACE=
set GOROOT=C:\Go
set GOTMPDIR=
set GOTOOLDIR=C:\Go\pkg\tool\windows_amd64
set GCCGO=gccgo
set CC=gcc
set CXX=g++
set CGO_ENABLED=1
set CGO_CFLAGS=-g -O2
set CGO_CPPFLAGS=
set CGO_CXXFLAGS=-g -O2
set CGO_FFLAGS=-g -O2
set CGO_LDFLAGS=-g -O2
set PKG_CONFIG=pkg-config
set GOGCCFLAGS=-m64 -mthreads -fno-caret-diagnostics -Qunused-arguments -fmessage-length=0 -fdebug-prefix-map=C:\tmp\go-build226750162=/tmp/go-build -gno-record-gcc-switches
### What did you do?
Run ```gomobile bind -target=android projectName```command, with ```$GOPATH``` set to directory that contains whitespace
### What did you expect to see?
Generated .aar file
### What did you see instead?
```
gomobile: go build -buildmode=c-shared -o=C:\tmp\gomobile-work-583627471\android\src\main\jniLibs\armeabi-v7a\libgojni.so gobind failed: exit status 2
# runtime/cgo
exec: "C:\\Users\\My": file does not exist
```
In this example user path is `C:\\Users\My Name`
|
OS-Windows,mobile
|
low
|
Critical
|
351,891,390 |
vscode
|
Feature Request: Enable valueSelection for InputBox
|
<!-- Please search existing issues to avoid creating duplicates. -->
<!-- Describe the feature you'd like. -->
# Description
Enable the [`valueSelection`](https://code.visualstudio.com/docs/extensionAPI/vscode-api#InputBoxOptions) option of the `winddow.showInputBox` command for the more extensive [`InputBox`](https://code.visualstudio.com/docs/extensionAPI/vscode-api#InputBox) API, too.
|
feature-request,api,quick-pick
|
low
|
Major
|
351,910,183 |
godot
|
Tree minimum column width completely hides text if set below 13 pixels, even if the text is set to expand
|
Godot 3 master ff8e6f920cd99954c3394412713950c1195199f2
I made a tree with 2 levels:
The first level shows files in a single expanding column.
The second level shows empty cells as the first column (they are conditionally sized), and text as the second column.
In order for the first column of the second level to not expand to half of the width, I usually set the minimum width to 32 and tell them to not expand, but if I want them hidden I set their minimum width to 1 so I don't have to change indexes in my code all over the place (it's a good hack IMO because it's theoretically legit).
Due to this, I also tell the first-level individual items to actually `expand_right`, so I can get this:
But I found a problem:
I ended up in a situation where, if I set the minimum size of the first column below 13, the first-level text completely hides. This is NOT expected, because as said above I've set it to `expand_right` anyways, and 12 is not zero yet it still hides it all.
I haven't tested further, maybe the issue is actually simpler than it looks and minimum width breaks it in any case? Is this all because of the arrow?
Found this while improving #21166, I will have to workaround this by actually changing the amount of columns dynamically.
test project:
[SearchResultsList.zip](https://github.com/godotengine/godot/files/2300412/SearchResultsList.zip)
Go to `tree.gd` and play with the value at line 9
|
bug,confirmed,topic:gui
|
low
|
Minor
|
351,912,937 |
godot
|
Weird behaviours with soft body node under kinematic parent
|
**Godot version:**
`master` / c93888ae71b
**OS/device including version:**
Manjaro Linux 17.1
**Issue description:**
When adding a soft body node under a rigid/kinematic parent, it would act like there's an invisible collider which roughly matches the node's visible position.
Also, if I move the parent kinematic node, the soft body child moves in the opposite direction from its parent, as if it uses a different transform coordinates.
In fact, I found that transform related values returned by the soft body node to be rather off. For instance, if I print the distance from the camera position to such a node, it returns a larger number than that which is returned from a non-soft body mesh instance located further from the camera.
And it also returns a wrong AABB value, apparently.
You can watch a video which shows some of the above mentioned problems from the link below:
* https://youtu.be/YOgK8xNaLns
|
bug,topic:physics
|
low
|
Major
|
351,916,721 |
rust
|
Sort-of RFC: add `min!`, `max!` macros once namespacing lands
|
Since you can namespace macros in rust 2018, maybe consider including min and max macros in `std::cmp`?
From [a post about gamedev on rust](https://users.rust-lang.org/t/my-gamedever-wishlist-for-rust/2859?u=erlend_sh)
> > There’s no min! and max! macro. You need to write max(max(max(max(max(max, a), b), c), d), e) for example. I have a code with 15 max like this.
>
> This seems like a macro you can write yourself easily enough. Is there something I’m missing?
>
> ```
> macro_rules! max {
> ($e: expr) => { $e };
> ($e: expr, $($rest: tt)*) => { max($e, max!($($rest)*)) }
> }
>```
|
T-libs-api,C-feature-request
|
low
|
Minor
|
351,942,722 |
go
|
cmd/go: 'go test --race' needs gcc for main packages on windows
|
### What version of Go are you using (`go version`)?
go version go1.11rc1 windows/amd64
### Does this issue reproduce with the latest release?
- Yes, reproduces with `go 1.11rc1`
- No, doesn't reproduce with `go 1.10.3`
### What operating system and processor architecture are you using (`go env`)?
```
windows/amd64
```
```
set GOARCH=amd64
set GOBIN=
set GOCACHE=C:\Users\jud_white\AppData\Local\go-build
set GOEXE=.exe
set GOFLAGS=
set GOHOSTARCH=amd64
set GOHOSTOS=windows
set GOOS=windows
set GOPATH=C:\Projects\Go
set GOPROXY=
set GORACE=
set GOROOT=C:\Go
set GOTMPDIR=
set GOTOOLDIR=C:\Go\pkg\tool\windows_amd64
set GCCGO=gccgo
set CC=gcc
set CXX=g++
set CGO_ENABLED=1
set GOMOD=
set CGO_CFLAGS=-g -O2
set CGO_CPPFLAGS=
set CGO_CXXFLAGS=-g -O2
set CGO_FFLAGS=-g -O2
set CGO_LDFLAGS=-g -O2
set PKG_CONFIG=pkg-config
set GOGCCFLAGS=-m64 -mthreads -fno-caret-diagnostics -Qunused-arguments -fmessage-length=0 -fdebug-prefix-map=C:\Users\JUD_WH~1\AppData\Local\Temp\go-build672193350=/tmp/go-build -gno-record-gcc-switches
```
### What did you do?
```
$ go test -cpu 1,2,4 -count 1 --race ./hello/...
# runtime/cgo
exec: "gcc": executable file not found in %PATH%
FAIL git.xyz.com/{org}/{repo}/cmd/hello [build failed]
$ go test -cpu 1,2,4 -count 1 ./hello/...
ok git.xyz.com/{org}/{repo}/cmd/hello 0.105s
```
It doesn't happen for non-main packages:
```
$ go test -cpu 1,2,4 -count 1 --race ./hellopkg/...
ok git.xyz.com/{org}/{repo}/pkg/hellopkg 10.220s
```
`--race` by itself is sufficient to repro, you don't need to set the CPU count or disable caching.
### What did you expect to see?
```
ok git.xyz.com/{org}/{repo}/cmd/hello 0.XYZs
```
### What did you see instead?
```
# runtime/cgo
exec: "gcc": executable file not found in %PATH%
FAIL git.xyz.com/{org}/{repo}/cmd/hello [build failed]
```
|
RaceDetector,OS-Windows,NeedsInvestigation
|
medium
|
Critical
|
351,955,169 |
go
|
time: wall and monotonic clocks get out of sync
|
### What version of Go are you using (`go version`)?
go1.10.3 linux/amd64
### Does this issue reproduce with the latest release?
Indeed.
### What operating system and processor architecture are you using (`go env`)?
Running in a Docker container. Here's the output of `go env` on the container:
```
GOARCH="amd64"
GOBIN=""
GOCACHE="/root/.cache/go-build"
GOEXE=""
GOHOSTARCH="amd64"
GOHOSTOS="linux"
GOOS="linux"
GOPATH="/go"
GORACE=""
GOROOT="/usr/local/go"
GOTMPDIR=""
GOTOOLDIR="/usr/local/go/pkg/tool/linux_amd64"
GCCGO="gccgo"
CC="gcc"
CXX="g++"
CGO_ENABLED="1"
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
PKG_CONFIG="pkg-config"
GOGCCFLAGS="-fPIC -m64 -pthread -fno-caret-diagnostics -Qunused-arguments -fmessage-length=0 -fdebug-prefix-map=/tmp/go-build937894194=/tmp/go-build -gno-record-gcc-switches"
```
Strangely, I have not seen, or heard reports of, this happening outside of Docker.
### What did you do?
My program must do some task on a schedule. So it uses the "time" lib to compute the next time to do the task, and to wait till that time. Here's an example:
```
package main
import (
"fmt"
"time"
)
func main() {
now := time.Now()
for {
fmt.Println("")
nrt := now.Add(time.Second * 5)
fmt.Printf("Now: %v; Next run time: %v\n", now.String(), nrt.String())
for now.Before(nrt) {
sleepDur := nrt.Sub(now)
fmt.Printf("Sleeping for %v\n", sleepDur)
afterChan := time.After(sleepDur)
now = <-afterChan
fmt.Printf("Awoke at %v\n", now.String())
}
// do task
fmt.Printf("Doing task at %v (next run time: %v)\n", now.String(), nrt.String())
}
}
```
I ran it in a Docker container (version 18.06.0-ce-mac70):
```
FROM golang:1.10-alpine
WORKDIR /
COPY main.go /
RUN go build /main.go
ENTRYPOINT ["/main"]
```
### What did you expect to see?
For every "Doing task at X (next run time: Y)" line, X should be >= Y.
### What did you see instead?
After a few iterations, I see "Doing task at X (next run time: Y)" lines where X < Y. Example:
```
Doing task at 2018-08-20 00:09:51.9754029 +0000 UTC m=+60.021665301 (next run time: 2018-08-20 00:09:52.0083237 +0000 UTC m=+60.021022301)
```
### Analysis
This does not always happen, and usually only after a few iterations. As I mentioned above, I have only seen this in Docker containers. With this example program, the times will only be off by tens of milliseconds.
Here's a longer output sample, with 3 iterations:
```
Now: 2018-08-20 00:49:33.8226258 +0000 UTC m=+550.358479801; Next run time: 2018-08-20 00:49:38.8226258 +0000 UTC m=+555.358479801
Sleeping for 5s
Awoke at 2018-08-20 00:49:38.8275073 +0000 UTC m=+555.363361401
Doing task at 2018-08-20 00:49:38.8275073 +0000 UTC m=+555.363361401 (next run time: 2018-08-20 00:49:38.8226258 +0000 UTC m=+555.358479801)
Now: 2018-08-20 00:49:38.8275073 +0000 UTC m=+555.363361401; Next run time: 2018-08-20 00:49:43.8275073 +0000 UTC m=+560.363361401
Sleeping for 5s
Awoke at 2018-08-20 00:49:43.8283399 +0000 UTC m=+560.364194401
Doing task at 2018-08-20 00:49:43.8283399 +0000 UTC m=+560.364194401 (next run time: 2018-08-20 00:49:43.8275073 +0000 UTC m=+560.363361401)
Now: 2018-08-20 00:49:43.8283399 +0000 UTC m=+560.364194401; Next run time: 2018-08-20 00:49:48.8283399 +0000 UTC m=+565.364194401
Sleeping for 5s
Awoke at 2018-08-20 00:49:48.799623 +0000 UTC m=+565.368983701
Doing task at 2018-08-20 00:49:48.799623 +0000 UTC m=+565.368983701 (next run time: 2018-08-20 00:49:48.8283399 +0000 UTC m=+565.364194401)
```
The bug shows up in the last iteration, in which `Before` claims that 00:49:48.799623 is not before 00:49:48.8283399. Interestingly, while `Before` is incorrect in terms of the wall-clock times, it is correct in terms of the monotonic times.
The last iteration began with `now` == 00:49:43.8283399 (m=+560.364194401). It then slept, and woke when the `After` channel passed it a new `now` value of 00:49:48.799623 (m=+565.368983701). Note that the difference in wall-clock time is 4.971283099999994 sec, while the difference in monotonic time is 5.004789300000084 sec. So, it seems that the `time` lib is returning time values in which the relation between the monotonic and wall clocks changes a bit. IOW, one of these clocks is not properly keeping time.
Cc. @rsc
### Background
I run the Jobber project, which is an enhanced cron that can be run in Docker. This bug caused some users' jobs to run twice: once a second or two before the scheduled time, and once at the scheduled time. Confer https://github.com/dshearer/jobber/issues/192
|
NeedsInvestigation
|
low
|
Critical
|
351,962,289 |
pytorch
|
GenerateProposals CUDA implementation
|
Hi, Would you please support GenerateProposals CUDA implementation?
thanks.
|
caffe2
|
low
|
Minor
|
352,001,752 |
godot
|
Implicit type conversion from Real to Int differs between branch statements
|
**Godot version:**
faa49c1
**Issue description:**
Reals with integral values seem to be implicitly converted to int for comparisons in `if` blocks, but not with `match` blocks. This probably also affects 3.0.x, but I haven't tested it.
**Steps to reproduce:**
Using parse_json() to produce TYPE_REAL values that match whole number values.
```gdscript
enum matchType { A,B,C }
var chunk = parse_json("[0,1,2]")
func _ready():
match chunk[0]:
matchType.A:
print ("This should be the proper response.")
0:
print("This should also work, but short-circuiting failed?")
_:
print("This shouldn't happen.", matchType.A)
if chunk[0] == 0: print("Implicit conversion to int works with Ifs, though.")
```
Workaround: Explicitly cast `match` value to Int, where applicable.
|
discussion,topic:gdscript
|
low
|
Critical
|
352,029,386 |
three.js
|
three.js documentation Chinese version
|
Hi, We are a team from china who love open source.We want to translate the documentation into
Chinese. About now our plan is to translate pages and convert them into static pages.
So I want to know how we can put these pages into this repo , or merge them into the threejs.org documentation part?
Pleased to hear reply.
|
Documentation
|
medium
|
Critical
|
352,075,068 |
create-react-app
|
Move launch-editor logic to react-error-overlay
|
### Request
It would be awesome if we could move all react-error-overlay logic into the [react-error-overlay](https://github.com/facebook/create-react-app/tree/next/packages/react-error-overlay) package.
### Reason
Currently it is not possible to use all features [react-error-overlay](https://github.com/facebook/create-react-app/tree/next/packages/react-error-overlay) without installing [react-dev-utils](https://github.com/facebook/create-react-app/tree/next/packages/react-dev-utils).
### Files that should be migrated:
- [react-dev-utils/errorOverlayMiddleware.js](https://github.com/facebook/create-react-app/blob/next/packages/react-dev-utils/errorOverlayMiddleware.js)
- [react-dev-utils/launchEditor.js](https://github.com/facebook/create-react-app/blob/next/packages/react-dev-utils/launchEditor.js)
- [react-dev-utils/launchEditorEndpoint.js](https://github.com/facebook/create-react-app/blob/next/packages/react-dev-utils/launchEditorEndpoint.js)
### Related
https://github.com/zeit/next.js/pull/4979#discussion_r211121346
### ~~Alternative~~
Solved by https://github.com/yyx990803/launch-editor/
~~As an alternative it would also make sense to move the [react-dev-utils/launchEditor.js](https://github.com/facebook/create-react-app/blob/next/packages/react-dev-utils/launchEditor.js) into its own package. The electron community might appreciate it.~~
~~Since there is already an [open-editor](https://www.npmjs.com/package/open-editor) package on npm this would be a great place. (https://github.com/sindresorhus/open-editor/issues/4)~~
|
issue: proposal
|
low
|
Critical
|
352,121,179 |
godot
|
TabContainer: switching tabs while editing by clicking on the tab
|
Minor enhancement.
When editing controls inside a _TabContainer_, it's annoying to have to click the _TabContainer_ and changing the _Current Tab_ property to switch the tab. It should be possible to directly click on the tabs and make the _Current Tab_ property automatically change. I've seen this feature in some GUI widgets editors.
Bonus: tabs' content controls that are not the currently selected, are set to visible=false. Clicking on the eye icon near the node should change the currently selected tab too.
|
enhancement,topic:editor,topic:gui
|
low
|
Minor
|
352,149,998 |
pytorch
|
Tensor.register_hook is not passing the tensor object to the hook function
|
I am currently working with `Tensor.register_hook` and I want to manipulate the gradients of a parameter with respect to the values of its data, i.e., the weights or bias itself. This would be very easy if `self` is also passed to the hook function such as for the hooks registered with `Module.register_backward_hook `. Is there a reason why this is not done? This could be achieved by adding:
```
wrapper = functools.partial(hook, self)
functools.update_wrapper(wrapper, hook)
```
to the `register_hook` method.
cc @ezyang @gchanan
|
module: bc-breaking,triaged,enhancement
|
low
|
Minor
|
352,155,976 |
angular
|
SelectControlValueAccessor overwriting NativeElement's value if using custom control value accessor
|
<!--
PLEASE HELP US PROCESS GITHUB ISSUES FASTER BY PROVIDING THE FOLLOWING INFORMATION.
ISSUES MISSING IMPORTANT INFORMATION MAY BE CLOSED WITHOUT INVESTIGATION.
-->
## I'm submitting a...
<!-- Check one of the following options with "x" -->
<pre><code>
[ ] Regression (a behavior that used to work and stopped working in a new release)
[x] Bug report <!-- Please search GitHub for a similar issue or PR before submitting -->
[ ] Performance issue
[ ] Feature request
[ ] Documentation issue or request
[ ] Support request => Please do not submit support request here, instead see https://github.com/angular/angular/blob/master/CONTRIBUTING.md#question
[ ] Other... Please describe:
</code></pre>
## Current behavior
<!-- Describe how the issue manifests. -->
I'm using custom control value accessor UseValueAsNumber with ReactiveForms on SELECT element but default SelectControlValueAccessor from Angular is overwriting values set by UseValueAsNumber.
The problem seems to be following:
1. UseValueAsNumber sets NativeElement value through:
`this.renderer.setProperty(
this.elementRef.nativeElement,
'value',
this.value
);
`
2. After the value is set correctly, the `NgSelectOption.setValue()` method is fired which internally calls `if (this._select) this._select.writeValue(this._select.value);`. However `this._select.value` is `undefined` (as there is only 1 ControlValueAccessor allowed per FormControl) but `this._select` (which is in fact SelectControlValueAccessor instance) overwrites NativeElement's value to `undefined` and in HTML the correct value is never selected.
## Expected behavior
<!-- Describe what the desired behavior would be. -->
Do not overwrite NativeElement's value property in order to display correct value in HTML.
## Minimal reproduction of the problem with instructions
<!--
For bug reports please provide the *STEPS TO REPRODUCE* and if possible a *MINIMAL DEMO* of the problem via
https://stackblitz.com or similar (you can use this template as a starting point: https://stackblitz.com/fork/angular-gitter).
-->
https://stackblitz.com/edit/angular-gitter-marugk
## What is the motivation / use case for changing the behavior?
<!-- Describe the motivation or the concrete use case. -->
## Environment
<pre><code>
Angular version: 6.1.3
<!-- Check whether this is still an issue in the most recent Angular version -->
Browser:
- [x ] Chrome (desktop) version 68.0.3440.106
|
type: bug/fix,freq2: medium,area: forms,state: confirmed,state: needs more investigation,P4
|
low
|
Critical
|
352,157,974 |
pytorch
|
make install error: [third_party/gloo/gloo/CMakeFiles/gloo.dir/all] Error 2
|
when complile at linux: I meet this error,thanks!
In file included from /disk1/g201708021059/gg/pytorch/third_party/gloo/gloo/context.cc:12:0:
/disk1/g201708021059/gg/pytorch/third_party/gloo/gloo/common/error.h:25:46: error: expected class-name before ‘{’ token
/disk1/g201708021059/gg/pytorch/third_party/gloo/gloo/common/error.h: In constructor ‘gloo::Exception::Exception(const string&)’:
/disk1/g201708021059/gg/pytorch/third_party/gloo/gloo/common/error.h:27:66: error: expected class-name before ‘(’ token
/disk1/g201708021059/gg/pytorch/third_party/gloo/gloo/common/error.h:27:66: error: expected ‘{’ before ‘(’ token
make[2]: *** [third_party/gloo/gloo/CMakeFiles/gloo.dir/context.cc.o] Error 1
make[1]: *** [third_party/gloo/gloo/CMakeFiles/gloo.dir/all] Error 2
make: *** [all] Error 2
If you have a question or would like help and support, please ask at our
[forums](https://discuss.pytorch.org/).
If you are submitting a feature request, please preface the title with [feature request].
If you are submitting a bug report, please fill in the following details.
## Issue description
Provide a short description.
## Code example
Please try to provide a minimal example to repro the bug.
Error messages and stack traces are also helpful.
## System Info
Please copy and paste the output from our
[environment collection script](https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py)
(or fill out the checklist below manually).
You can get the script and run it with:
```
wget https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py
# For security purposes, please check the contents of collect_env.py before running it.
python collect_env.py
```
- PyTorch or Caffe2:
- How you installed PyTorch (conda, pip, source):
- Build command you used (if compiling from source):
- OS:
- PyTorch version:
- Python version:
- CUDA/cuDNN version:
- GPU models and configuration:
- GCC version (if compiling from source):
- CMake version:
- Versions of any other relevant libraries:
cc @malfet @seemethere @walterddr
|
module: build,triaged,module: third_party
|
low
|
Critical
|
352,166,961 |
vue
|
Property 'X' does not exist on type CombinedVueInstance using TypeScript Prop Validator
|
### Version
2.5.16
### Reproduction link
[https://codepen.io/muhammadrehansaeed/pen/XPWKyJ](https://codepen.io/muhammadrehansaeed/pen/XPWKyJ)
### Steps to reproduce
Use Typescript to build this component:
```
export default Vue.extend({
props: {
delay: {
default: 600,
type: Number,
validator: function(value: number) {
return value >= 0;
}
},
minValue: {
default: 0,
type: Number
}
},
data() {
return {
valueInternal: 0
};
},
methods: {
reset(): void {
this.valueInternal = this.minValue; <----THIS LINE ERRORS
}
}
});
```
### What is expected?
The component builds.
### What is actually happening?
The following error is thrown:
```
Property 'minValue' does not exist on type 'CombinedVueInstance<Vue, { isVisibleInternal: boolean; valueInternal: number; }, { reset(): void; }, {}, Readonly<{}>>'.
methods: {
reset(): void {
this.valueInternal = this.minValue;
^
}
}
````
If I remove the validator from the prop, the error goes away. If I remove the data section, the error also goes away.
<!-- generated by vue-issues. DO NOT REMOVE -->
|
typescript
|
low
|
Critical
|
352,167,471 |
pytorch
|
[feature request] convtbc with group convolution
|
see title
|
feature,module: convolution,triaged
|
low
|
Minor
|
352,205,389 |
vscode
|
Show file picker for 'path' string settings
|
https://github.com/Microsoft/vscode/issues/50249#issuecomment-414362277
|
feature-request,settings-editor
|
low
|
Major
|
352,211,201 |
flutter
|
Need to provide a hook to prevent tests from timing out when debugging
|
When debugging flutter tests with IntelliJ or another IDE, test timeouts still trigger which makes it frustrating to setbreakpoint within tests. As soon as you resume the debugger after hitting a breakpoint, the test you were trying to debug times out ending your debug session.
The recently added `--pause-after-load` in `package:test` handles this case ignoring timeouts when the flag is set. For consistency it would be nice if the same flag also worked with `flutter test` causing timeouts to be ignored. Currently the workaround is to delete the body of the `_checkTimeout` method in `flutter_test/lib/src/binding.dart`
See
https://github.com/dart-lang/test/pull/876
for the change to `package:test` to implement `--pause-after-load`
@grouma who implemented the feature for `package:test`
|
a: tests,tool,P2,team-tool,triaged-tool
|
low
|
Critical
|
352,211,360 |
kubernetes
|
Make creationTimestamp a pointer
|
Context: https://github.com/kubernetes/kubernetes/pull/67562#discussion_r211267314.
`creationTimestamp` is a struct (metav1.Time) right now:
https://github.com/kubernetes/kubernetes/blob/6d51311735705ecf30025df91216a82f397c9cfb/staging/src/k8s.io/apimachinery/pkg/apis/meta/v1/types.go#L175
However, it also has the `omitempty` json tag. The current behaviour at various places is to remove the field if it is an empty value.
From the [official docs](https://golang.org/pkg/encoding/json/#Marshal),
> The "omitempty" option specifies that the field should be omitted from the encoding if the field has an empty value, defined as false, 0, a nil pointer, a nil interface value, and any empty array, slice, map, or string.
This means that `omitempty` holds no meaning for structs. No matter what value `creationTimestamp` has, it should persist in the object. To truly adapt to it's intended behaviour, it should be a pointer (*time.Time), like `deletionTimestamp`. It also makes sense to have `creationTimestamp` as optional logically.
Right now, we don't allow an empty `creationTimestamp` to persist anyway, so it doesn't create a problem per se.
/sig api-machinery
/cc @sttts @liggitt @deads2k @lavalamp
|
sig/api-machinery,lifecycle/frozen
|
medium
|
Critical
|
352,237,428 |
go
|
x/tools/go/packages: test fails on plan9
|
golang.org/x/tools/go/packages tests are failing on Plan9:
https://build.golang.org/log/a8439e96692e223503e21df34d690fdc2bc75625
Specifically, when TestLoadImportsC loads syscall and net, the package "net [syscall.test]" is not among the loaded set. Disabling test for now. The task of this issue is a principled fix.
|
Tools
|
low
|
Minor
|
352,239,214 |
pytorch
|
Build system doesn't prevent ATen/core from including non-core files
|
Instead, you'll probably only see the failure as a linker error if you build, e.g., a Caffe2 only build.
CC @gchanan
cc @malfet @seemethere @walterddr
|
module: build,triaged
|
low
|
Critical
|
352,258,831 |
vue
|
Cache access to process.env
|
### What problem does this feature solve?
Access to `process.env` is a slow, system-bound call.
After react restructured their project to cache access to `process.env`, they had a 2.4x - 3.8x performance improvement for server-side rendering,
https://github.com/facebook/react/issues/812
This should also be done for vue, vue-server-renderer, vuex ... anything that accesses `process.env`.
### What does the proposed API look like?
An easy strategy might be to replace references to `process.env.NODE_ENV` with a reference to a singleton that checks process.env.NODE_ENV.
```
// foo.js
if (process.env.NODE_ENV !== 'production') {
// do stuff
}
```
becomes
```
// isDevEnv.js
export default process.env.NODE_ENV !== 'production';
// foo.js
import isDevEnv from './isDevEnv';
if (isDevEnv) {
// do stuff
}
```
<!-- generated by vue-issues. DO NOT REMOVE -->
|
feature request
|
medium
|
Major
|
352,265,842 |
TypeScript
|
In the generated description file, the module path needs to be modified to a relative path.
|
<!-- 🚨 STOP 🚨 𝗦𝗧𝗢𝗣 🚨 𝑺𝑻𝑶𝑷 🚨
Half of all issues filed here are duplicates, answered in the FAQ, or not appropriate for the bug tracker. Please read the FAQ first, especially the "Common Feature Requests" section.
-->
## Search Terms
description file, paths, baseURL, relative path
## Suggestion
In the case where compilation parameters `--paths` and `--baseURL` are enabled
#9910
>The compiler does not rewrite module names. module names are considered resource identifiers, and are mapped to the output as they appear in the source
>
>The module names you write are not going to change in the output. the "paths" and "baseURL" are there to tell the compiler where they are going to be at runtime.
This will cause the generated description file to be invalid.
In most cases, `--paths` and `--baseURL` are used to facilitate the import of source code modules without the use of very awkward relative paths.
I think the description file needs to convert the path map into a relative path as much as possible. Because the description file does not have a runtime environment, and there is no special packaging tool.
---
Related bugs: Inferring the type generated description file, fixed issue with import path.
in typescript 3.0.1:
https://github.com/ZSkycat/issue-typescript-20180821/blob/b29f377029aa8d0b1022bd2f703a7773389a760b/dist/types/deep/deep/factory.d.ts#L3
in typescript 3.1.0-dev.20180818:
https://github.com/ZSkycat/issue-typescript-20180821/blob/master/dist/types/deep/deep/factory.d.ts#L3
## Use Cases
https://github.com/ZSkycat/issue-typescript-20180821
This is a use case for packaging into a commonjs module using webpack.
path mapping config:
```
// webpack.config.js
resolve: {
alias: {
src: path.resolve('./src'),
},
},
```
```
// tsconfig.json
"baseUrl": ".",
"paths": {
"src/*": ["./src/*"],
},
```
This will cause the generated description file to be unusable.
https://github.com/ZSkycat/issue-typescript-20180821/blob/master/dist/types/deep/deep/factory.d.ts#L1
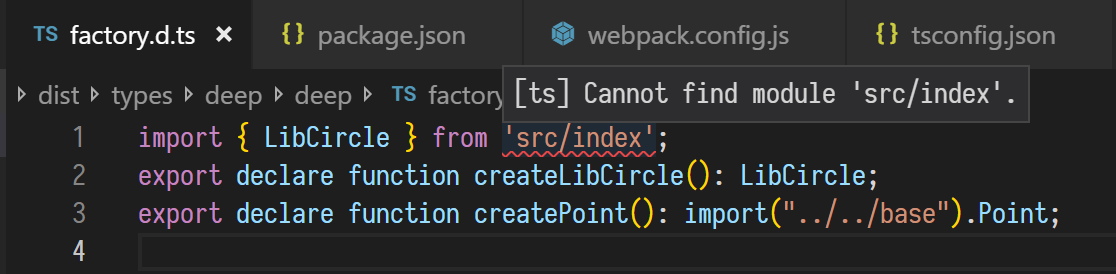
## Examples
<!-- Show how this would be used and what the behavior would be -->
## Checklist
My suggestion meets these guidelines:
* [x] This wouldn't be a breaking change in existing TypeScript / JavaScript code
* [x] This wouldn't change the runtime behavior of existing JavaScript code
* [x] This could be implemented without emitting different JS based on the types of the expressions
* [x] This isn't a runtime feature (e.g. new expression-level syntax)
|
Needs Investigation
|
low
|
Critical
|
352,291,890 |
godot
|
Wasted Space "Preview" in Theme->Edit->Label->Styles
|
https://github.com/godotengine/godot/commit/d88d0d457d2828db2016f4854efff8c5f8b90e91
The "Preview" in Theme->Edit->Label->Styles takes so much space and is a duplicate information.
Is there any useful use case for that in Themes?
|
enhancement,topic:editor,usability
|
low
|
Major
|
352,301,535 |
puppeteer
|
DNT Header does not populate navigator.doNotTrack
|
Env:
MacBook, Node v10.8.0
├─ [email protected]
├─ [email protected]
Issue:
Adding DNT Header doesn't populate navigator.doNotTrack. Please let me know if you have any questions. I was also having trouble activating this using the chrome modHeader extension. I only had luck activating navigator.doNotTrack by changing privacy settings for my user in chrome (not chromium).
```javascript
// in async function
const headerOptions = ['1', '0'];
for (header of headerOptions) {
for (url of urls) {
try {
await page.setExtraHTTPHeaders({'DNT': header})
await page.goto(`${hostName}${url}`, {timeout: 35000, waitUntil: ['networkidle0', 'load']});
await page.waitFor(500);
const doNotTrackValue = await page.evaluate(() => navigator.doNotTrack || window.doNotTrack || navigator.msDoNotTrack);
const currentURL = await page.url();
data.push([currentURL, doNotTrackValue]);
} catch (e) {
console.log(e)
}
}
fs.writeFileSync(`./domState${header}.json`, JSON.stringify(data), {flags: 'w'});
}
```
I expected `navigator.doNotTrack` to equal '1' or '0' depending on the iteration
instead `navigator.doNotTrack` equals null
|
feature,upstream,chromium
|
low
|
Major
|
352,318,520 |
vscode
|
[themes] Allow custom variables and references in workbench color customizations section
|
This is a feature request to allow defining custom color variables in the workbench color customizations section. It would allow creating a small palette of colors and reusing it across the workbench color definitions, saving many repetitions and making it much easier to maintain.
This is just simple text substitution based on some naming convention like the .less `@variable` convention. For example, see the `@PaletteXXX` variables in the sample below:
```
"workbench.colorCustomizations": {
// custom colors
"@Palette000": "#FFFFFF",
"@Palette050": "#ECEFF1",
"@Palette100": "#CFD8DC",
"@Palette200": "#B0BEC5",
"@Palette300": "#90A4AE",
"@Palette700": "#455A64",
// input control
"input.background": "@Palette000",
"input.foreground": "@Palette700",
"input.placeholderForeground": "@Palette200",
"inputOption.activeBorder": "@Palette300",
"input.border": "@Palette100",
// list views
"list.activeSelectionBackground": "@Palette200",
"list.activeSelectionForeground": "@Palette700",
"list.inactiveSelectionBackground": "@Palette100",
"list.hoverBackground": "@Palette100",
"list.dropBackground": "@Palette100",
"list.focusBackground": "@Palette100",
```
|
feature-request,themes
|
medium
|
Major
|
352,324,791 |
rust
|
rustdoc: Add crate=crate_name,file=filename.rs options to doctests for displaying in output
|
Sometimes we write code samples where the crate the example is in and/or the file the example is in matters. Right now we just have to include that information outside of the code sample, but it can be easier to read (especially for people just looking at the example code) if it's included in the example itself. As such, I'm suggesting adding two more attributes to the doctests, `crate` and `file`. When actually running doctests, these are ignored, but when displaying in the output, are shown inside the example block.
For prior art, this is done a lot in hard print books. For example, page 5 of https://nostarch.com/download/samples/Realm_ch14.pdf shows the filename on the top right of the examples.
cc @QuietMisdreavus @alercah @GuillaumeGomez
|
T-rustdoc,C-feature-request
|
low
|
Minor
|
352,348,088 |
go
|
cmd/compile: Fannkuch benchmark performance regression
|
Please answer these questions before submitting your issue. Thanks!
### What version of Go are you using (`go version`)?
go version go1.11rc1 darwin/amd64
### Does this issue reproduce with the latest release?
No.
### What operating system and processor architecture are you using (`go env`)?
macOS 10.13.6 (darwin/amd64)
### What did you do?
tested the benchmark at:
https://benchmarksgame-team.pages.debian.net/benchmarksgame/program/fannkuchredux-go-1.html
using 1.10.3 and 1.11rc1 with:
time go run fannkuchredux.go 12
time go1.11rc1 run fannkuchredux.go 12
results:
1.10.3: go run fannkuchredux.go 12 **44.65s** user 0.21s system 372% cpu **12.033** total
1.11rc1: go1.11rc1 run fannkuchredux.go 12 **57.70s** user 0.24s system 373% cpu **15.528** total
### What did you expect to see?
1.11rc1 timings closer to 1.10.3
### What did you see instead?
1.11rc1 timings slower than 1.10.3
|
Performance,NeedsInvestigation,compiler/runtime
|
low
|
Major
|
352,353,170 |
pytorch
|
[feature request][caffe2] extend FC/FCTranspose op to handle 2d bias.
|
Currently, FC/FCTranspose only accepts 1d bias. The FC's implementation will do the broadcast to create the 2d bias from 1d bias, but we could just provide the whole 2d bias. Then, we can do the better optimization for onnx Gemm op with caffe2 backend.
I will try to implement this idea and create a pull request later.
@houseroad @bddppq
|
caffe2
|
low
|
Minor
|
352,371,912 |
pytorch
|
size mismatch when trying to reconstruct predifined network
|
I tried resnet18 and vgg13, both cases return similar error. is there anything I missed?
```
import torch
from torchvision.models import resnet18, vgg13
import torch.nn as nn
import numpy as np
from collections import OrderedDict
input_size = (10, 3, 224, 224)
def GetSelf(model):
# l = list(model.named_children())[:-1]
l = list(model.named_children())
d = OrderedDict(l)
return nn.Sequential(d)
# m1 = vgg13(pretrained=False)
m1 = resnet18(pretrained=False)
m2 = GetSelf(m1)
inputs = np.random.random(input_size).astype(np.float32)
inputs = torch.from_numpy(inputs)
if torch.cuda.is_available():
m1.cuda()
m2.cuda()
inputs = inputs.cuda()
with torch.no_grad():
o1 = m1(inputs)
o2 = m2(inputs)
o1 = o1.cpu().numpy() if torch.cuda.is_available() else o1.numpy()
o2 = o2.cpu().numpy() if torch.cuda.is_available() else o2.numpy()
```
```
File "<ipython-input-12-044c200d14f5>", line 1, in <module>
runfile('C:/Users/Administrator/Desktop/a.py', wdir='C:/Users/Administrator/Desktop')
File "D:\Program Files\Anaconda3\lib\site-packages\spyder\utils\site\sitecustomize.py", line 866, in runfile
execfile(filename, namespace)
File "D:\Program Files\Anaconda3\lib\site-packages\spyder\utils\site\sitecustomize.py", line 102, in execfile
exec(compile(f.read(), filename, 'exec'), namespace)
File "C:/Users/Administrator/Desktop/a.py", line 27, in <module>
o2 = m2(inputs)
File "D:\Program Files\Anaconda3\lib\site-packages\torch\nn\modules\module.py", line 477, in __call__
result = self.forward(*input, **kwargs)
File "D:\Program Files\Anaconda3\lib\site-packages\torch\nn\modules\container.py", line 91, in forward
input = module(input)
File "D:\Program Files\Anaconda3\lib\site-packages\torch\nn\modules\module.py", line 477, in __call__
result = self.forward(*input, **kwargs)
File "D:\Program Files\Anaconda3\lib\site-packages\torch\nn\modules\linear.py", line 55, in forward
return F.linear(input, self.weight, self.bias)
File "D:\Program Files\Anaconda3\lib\site-packages\torch\nn\functional.py", line 1026, in linear
output = input.matmul(weight.t())
RuntimeError: size mismatch, m1: [5120 x 1], m2: [512 x 1000] at c:\new-builder_3\win-wheel\pytorch\aten\src\thc\generic/THCTensorMathBlas.cu:249
```
cc @fmassa @vfdev-5
|
triaged,module: vision
|
low
|
Critical
|
352,413,184 |
angular
|
Animation trigger with params won't work without a value
|
<!--
## I'm submitting a...
<!-- Check one of the following options with "x" -->
<pre><code>
[ ] Regression (a behavior that used to work and stopped working in a new release)
[x] Bug report <!-- Please search GitHub for a similar issue or PR before submitting -->
[ ] Performance issue
[ ] Feature request
[ ] Documentation issue or request
[ ] Support request => Please do not submit support request here, instead see https://github.com/angular/angular/blob/master/CONTRIBUTING.md#question
[ ] Other... Please describe:
</code></pre>
So i have the following template:
```
<div *ngFor="let image of chapterImages | async"
[@image]="chapterAnimation">...</div>
```
And in the component:
```
animations: [
trigger('image', [
transition(':enter', [
style({ transform: 'translateX({{enter}})' }),
animate('0.7s ease-in-out', style({ transform: 'translateX(0)' }))
], { params: { enter: '0%' } }),
transition(':leave', [
style({ transform: 'translateX(0)' }),
animate('0.7s ease-in-out', style({ transform: 'translateX({{leave}})' }))
], { params: { leave: '-100%' } })
])
]
```
```
chapterAnimation = {
value: 'foo',
params: {
enter: '100%',
leave: '-100%'
}
};
```
If i leave out the ```value: 'foo'``` line, the animation WILL NOT use the provided params and just use the default params. That is the bug (took me quite a while to figure out).
Angular 6.0.7
|
type: bug/fix,area: animations,freq2: medium,P3
|
low
|
Critical
|
352,431,414 |
react
|
UMD builds are not enabled on UNPKG
|
Visiting https://unpkg.com/react displays the CJS build (https://unpkg.com/[email protected]/index.js) when the UMD build (https://unpkg.com/[email protected]/umd/react.development.js) should be displayed instead. I also noticed this issue with react-dom, so I assume all packages need to be fixed.
Please refer to the usage instructions at the bottom of https://unpkg.com/.
|
Type: Discussion
|
low
|
Major
|
352,436,570 |
kubernetes
|
cephfs fuse is not mounted in its own systemd scope
|
<!-- This form is for bug reports and feature requests ONLY!
If you're looking for help check [Stack Overflow](https://stackoverflow.com/questions/tagged/kubernetes) and the [troubleshooting guide](https://kubernetes.io/docs/tasks/debug-application-cluster/troubleshooting/).
If the matter is security related, please disclose it privately via https://kubernetes.io/security/.
-->
**Is this a BUG REPORT or FEATURE REQUEST?**:
> Uncomment only one, leave it on its own line:
>
/kind bug
> /kind feature
cephfs fuse is [not mounted in its own systemd scope](https://github.com/kubernetes/kubernetes/blob/v1.13.0-alpha.0/pkg/volume/cephfs/cephfs.go#L412), fuse daemon processes will be killed when kubelet restarts.
It should be updated to use kubelet mounter, see https://github.com/kubernetes/kubernetes/pull/49640.
/assign
|
kind/bug,sig/storage,lifecycle/frozen
|
low
|
Critical
|
352,497,612 |
vscode
|
"editor.hover.enabled" not showing up when searching "hint" or "info" in settings
|
Settings parameter "editor.hover.enabled" does not convey sense.
I was search that as "hint" or "info" and find nothing.
May be change name of this setting to "editor.hoverHint.enabled?
---
Русский перевод аналогично ничего не объясняет: "... отображается ли наведение".
Может быть "... отображается ли подсказка при наведении"?
|
bug,settings-editor,confirmed,settings-search
|
low
|
Minor
|
352,507,975 |
rust
|
Experiment with a hybrid bitfield + range encoding for Span / DefId.
|
Roughly, if you have a "container" (file/crate/etc.), and sequential indices in it:
* you can use `(container_index, intra_container_index)` (but that takes 2x space)
* you can split an integer's *bitwidth* into two bitfields, one for each half of the pair above
* the point where you choose to split is a tradeoff and you can run out of either half
* you can split an integer's *range*, with each container having its sequential range
* `Span` does this currently, where the files are effectively "concatenated"
* requires binary search to translate into the pair representation
An improvement on all of those is to choose an arbitrary chunk size (e.g. `2^17 = 128kB` for files), and then split each container into a number of chunks (ideally just 1 in the common case).
You can then use bitfields for `(chunk, intra_chunk_index)` (e.g. `15` and `17` bits of `u32`).
The difference is that to translate `chunk` to `container`, we *don't need* to use binary search, because `chunk` is several orders of magnitude smaller than the index space as a whole, and we can use arrays.
That is, `chunk -> container` can be an array, but also, if there is per-container data that would be accessed through `chunk`, we can optimize that by building a `chunk -> Rc<ContainerData>` array.
Translating `intra_chunk_index` to `intra_container_index` is similarly easy, if you can look up per-container data, you can subtract its overall start (if each container is a contiguous range of chunks).
<hr/>
Another reason this might be useful is translating (an unified) `DefId` or `Span` between crates or between incremental (re)compilation sessions - we can have a bitset of changed chunks: if a chunk is unchanged, the index is identical, otherwise we can have an intra-chunk/container binary search for changed ranges (or just a map of changes).
We can grow the number indices within the last chunk of a container, and if we run out of space, we can relocate the container's chunks without a significant cost. Alternatively, another tradeoff we can make is to fragment a container's chunks.
<hr/>
The first step in experimenting with this would have to be take `Span`, and round up the start/end of each file's range to a multiple of a power of `2` (e.g. `2^17` - but an optimal value would require gathering some real-world file-size statistics).
This way we can see if there's a negative performance impact from having unused gaps in the index space, everything else should be an improvement.
We can also try to replace the binary searches to find the `SourceFile` a `Span` is from.
cc @nikomatsakis @michaelwoerister
|
C-enhancement,T-compiler,A-incr-comp,I-compilemem
|
low
|
Major
|
352,632,782 |
pytorch
|
Have all C++ modules expose a __file__ attribute
|
E.g. for `torch._C._VariableFunctions`. That would make it much easier for people to find the C++ code our Python code calls into.
|
module: docs,triaged,enhancement
|
low
|
Major
|
352,636,840 |
pytorch
|
[caffe2] the caffe2 operators document is too old
|
The document at https://caffe2.ai/docs/operators-catalogue.html is too old. A lot of attributes are not in this page.
How to request to update this web page?
|
caffe2
|
low
|
Minor
|
352,648,336 |
rust
|
Bad "Ambiguous Numeric Type" Recommendation from Compiler in for loop
|
The `pow` function cannot be called on an ambiguous numeric type. If `pow` is called on the variable of a `for` loop, the compiler's recommended solution to add a concrete numeric type does not compile.
Example code with ambiguous numeric type:
```rust
pub fn check() {
for i in 0..1000 {
println!("{}", i.pow(2));
}
}
```
Gives the error:
```
error[E0689]: can't call method `pow` on ambiguous numeric type `{integer}`
--> src/lib.rs:22:26
|
22 | println!("{}", i.pow(2));
| ^^^
help: you must specify a type for this binding, like `i32`
|
21 | for i: i32 in 0..1000 {
| ^^^^^^
error: aborting due to previous error
For more information about this error, try `rustc --explain E0689`
```
Implementing this recommendation by adding type to variable `i` as shown in the compiler recommendation and trying to compile again gives the error:
```
error: missing `in` in `for` loop
--> src/lib.rs:21:10
|
21 | for i: i32 in 0..1000 {
| ^ help: try adding `in` here
error: expected expression, found `:`
--> src/lib.rs:21:10
|
21 | for i: i32 in 0..1000 {
| ^ expected expression
error: aborting due to 2 previous errors
```
Not sure if there is a better solution, but adding a cast to the range rather than specifying the type of the variable worked for me:
```rust
pub fn check() {
for i in 0..1000 as i32 {
println!("{}", i.pow(2));
}
}
```
|
C-enhancement,A-diagnostics,T-compiler
|
low
|
Critical
|
352,672,304 |
pytorch
|
[Caffe2] Failed to build dispatch_test. Error LNK2001: unresolved external symbol
|
## Issue description
Getting LNK2001 on Windows for `dispatch_test`.
```
pytorch\build\caffe2\core\dispatch\dispatch_test.vcxproj" (default target) (56) ->
(Link target) ->
KernelRegistration.obj : error LNK2001: unresolved external symbol "__declspec(dllimport) private: __cdecl caffe2::TypeIdentifier::TypeIdentifier(unsigned short)" (__imp_??0TypeIdentifier@caffe2@@AEAA@G@Z) [pytorch\build\caffe2\core\dispatch\dispatch_test.vcxproj]
OpSchema.obj : error LNK2001: unresolved external symbol "__declspec(dllimport) private: __cdecl caffe2::TypeIdentifier::TypeIdentifier(unsigned short)" (__imp_??0TypeIdentifier@caffe2@@AEAA@G@Z) [pytorch\build\caffe2\core\dispatch\dispatch_test.vcxproj]
OpSchemaRegistration.obj : error LNK2001: unresolved external symbol "__declspec(dllimport) private: __cdecl caffe2::TypeIdentifier::TypeIdentifier(unsigned short)" (__imp_??0TypeIdentifier@caffe2@@AEAA@G@Z) [pytorch\build\caffe2\core\dispatch\dispatch_test.vcxproj]
OpSchema_test.obj : error LNK2001: unresolved external symbol "__declspec(dllimport) private: __cdecl caffe2::TypeIdentifier::TypeIdentifier(unsigned short)" (__imp_??0TypeIdentifier@caffe2@@AEAA@G@Z) [pytorch\build\caffe2\core\dispatch\dispatch_test.vcxproj]
Dispatcher.obj : error LNK2001: unresolved external symbol "__declspec(dllimport) private: __cdecl caffe2::TypeIdentifier::TypeIdentifier(unsigned short)" (__imp_??0TypeIdentifier@caffe2@@AEAA@G@Z) [pytorch\build\caffe2\core\dispatch\dispatch_test.vcxproj]
DispatchKey.obj : error LNK2001: unresolved external symbol "__declspec(dllimport) private: __cdecl caffe2::TypeIdentifier::TypeIdentifier(unsigned short)" (__imp_??0TypeIdentifier@caffe2@@AEAA@G@Z) [pytorch\build\caffe2\core\dispatch\dispatch_test.vcxproj]
DispatchTable.obj : error LNK2001: unresolved external symbol "__declspec(dllimport) private: __cdecl caffe2::TypeIdentifier::TypeIdentifier(unsigned short)" (__imp_??0TypeIdentifier@caffe2@@AEAA@G@Z) [pytorch\build\caffe2\core\dispatch\dispatch_test.vcxproj]
pytorch\build\bin\RelWithDebInfo\dispatch_test.exe : fatal error LNK1120: 1 unresolved externals [pytorch\build\caffe2\core\dispatch\dispatch_test.vcxproj]
```
## System Info
- PyTorch or Caffe2: C2
- How you installed PyTorch (conda, pip, source): src
- Build command you used (if compiling from source): cmake
- OS: Win10
- PyTorch version: master
- VS version (if compiling from source): 2017
- CMake version: 3.12
|
caffe2
|
low
|
Critical
|
352,675,555 |
rust
|
Custom attribute used on thing disallowing custom attributes should say that
|
crate: `custom_attr`
```rust
extern crate proc_macro;
use proc_macro::TokenStream;
#[proc_macro_attribute]
pub fn custom(_attr: TokenStream, item: TokenStream) -> TokenStream {
item
}
```
---
crate: not the previous one
```rust
extern crate custom_attr;
use custom_attr::custom;
fn main() {
match () {
#[custom]
() => {}
}
}
```
---
Current Error
```
error[E0658]: The attribute `custom` is currently unknown to the compiler and may have meaning added to it in the future (see issue #29642)
--> src/main.rs:LL:L
|
L | #[custom]
| ^^^^^^^^
|
= help: add #![feature(custom_attribute)] to the crate attributes to enable
```
---
Wanted Error
```
error[E0NNN]: Custom attributes can only be applied to items
--> src/main.rs:LL:L
|
L | #[custom]
| ^^^^^^^^
|
```
(I'm assuming they can only be applied to items in nightly without using feature flags in Rust today. It'd be nice to get that assumption confirmed as well)
|
C-enhancement,A-diagnostics,T-compiler
|
low
|
Critical
|
352,696,953 |
kubernetes
|
kubeconfig config set-context fails with mix of writable & non-writable entries in KUBECONFIG
|
**Is this a BUG REPORT or FEATURE REQUEST?**:
> Uncomment only one, leave it on its own line:
>
/kind bug
> /kind feature
**What happened**:
with `KUBECONFIG=/home/pdbogen/.kube/config:/etc/kube/config`, `kubeconfig config set current-context sandbox` returns `error: open /etc/kube/config.lock: permission denied`
**What you expected to happen**:
kubeconfig should lock only `/home/pdbogen/.kube/config` and set the indicated setting there
**How to reproduce it (as minimally and precisely as possible)**:
```sh
$ mkdir readonly writable
$ chmod -w readonly
$ KUBECONFIG=$PWD/writable/config:$PWD/readonly/config kubectl config set current-context example
error: open /home/pdbogen/readonly/config.lock: permission denied
```
**Anything else we need to know?**:
I want to be able to provide my users a system-managed kubernetes config that describes various clusters. I would like them to be able to specify things like current-context easily, via `kubectl config`.
Even when `~/.kube/config` exists and contains a `current-context` setting, `kubectl config set current-context` still tries to lock /etc/kube/config.
**Environment**:
- Kubernetes version (use `kubectl version`): `Client Version: version.Info{Major:"1", Minor:"10+", GitVersion:"v1.10.5-16", GitCommit:"32ac1c9073b132b8ba18aa830f46b77dcceb0723", GitTreeState:"clean", BuildDate:"2018-06-27T17:46:30Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}` (we build our own, currently can't use 1.11)
- Cloud provider or hardware configuration: n/a; but, Amazon EKS
- OS (e.g. from /etc/os-release): Ubuntu Xenial 16.04.5
- Kernel (e.g. `uname -a`): 4.4.0-1063-aws
- Install tools: na
- Others: na
|
kind/bug,priority/backlog,area/kubectl,sig/cli,lifecycle/frozen
|
medium
|
Critical
|
352,715,593 |
flutter
|
FlutterDriver documentation update needed.
|
SendKeys or type-into-field isn't mentioned in the documentation but now exists as a feature per #12599
|
a: tests,tool,d: api docs,t: flutter driver,P2,team-tool,triaged-tool
|
low
|
Minor
|
352,716,633 |
go
|
x/tools/cmd/gomvpkg: `// import ` not changed
|
Please answer these questions before submitting your issue. Thanks!
### What version of Go are you using (`go version`)?
1.10.3
### Does this issue reproduce with the latest release?
1.10.3 is the latest
### What operating system and processor architecture are you using (`go env`)?
### What did you do?
```
go get -u golang.org/x/tools/cmd/gomvpkg
gomvpkg -from istio.io/fortio -to fortio.org/fortio
# the fnet/network.go file has the other package changed but not itself (same for all files):
package fnet // import "istio.io/fortio/fnet"
import (
"fmt"
"io"
"io/ioutil"
"math/rand"
"net"
"os"
"strconv"
"strings"
"sync"
"fortio.org/fortio/log"
"fortio.org/fortio/version"
)
```
### What did you expect to see?
The import comment to be change to be the new location
### What did you see instead?
No change on the // import
|
Tools
|
low
|
Minor
|
352,730,798 |
node
|
readline: processing \u2028 and \u2029
|
Not sure if we should fix, document, or ignore this and if it has been discussed, so to be on the safe side.
Currently, `\u2028` and `\u2029` are considered as line breaks by JavaScript `RegExp`s, while they are ignored by the `readline`:
```js
'use strict';
const fs = require('fs');
const readline = require('readline');
const str = '123\n456\r123\u{2028}456\u{2029}789';
console.log(str.split(/^/mu));
fs.writeFileSync('readline-test.txt', str, 'utf8');
const rl = readline.createInterface({
input: fs.createReadStream('readline-test.txt', 'utf8'),
crlfDelay: Infinity,
});
rl.on('line', console.log);
```
Feel free to close if this is a wontfix.
|
help wanted,readline
|
low
|
Major
|
352,743,317 |
pytorch
|
Unexpected Behavior when Pointwise Operations Write to Expanded Tensors
|
I discovered this when writing some masking code, it seems that unexpected behavior can arise when using pointwise operations to write to expanded tensors. The code below reproduces and explains the issue:
We start off by constructing an example array and constructing a mask from it:
```python
example_batch = torch.Tensor([
[[1, 2, 0, 0],
[2, 1, 3, 0],
[2, 1, 3, 0]]
])
mask = (example_batch == 0)
>>> mask
tensor([[[0, 0, 1, 1],
[0, 0, 0, 1],
[0, 0, 0, 1]]], dtype=torch.uint8)
```
We then expand a range into our example batch:
```python
index_filled = torch.arange(1, example_batch.size(-1) + 1).expand_as(example_batch)
>>> index_filled
tensor([[[1, 2, 3, 4],
[1, 2, 3, 4],
[1, 2, 3, 4]]])
```
So far, so good, yet the problem appears when we try to do a `masked_fill` on `index_filled` using our masked array:
```python
masked = index_filled.masked_fill_(mask, 0)
>>> masked
tensor([[[1, 2, 0, 0],
[1, 2, 0, 0],
[1, 2, 0, 0]]])
```
This doesn't seem to be what we would expect from our mask operation, what we where expecting was:
```python
tensor([[[1., 2., 0., 0.],
[1., 2., 3., 0.],
[1., 2., 3., 0.]]])
```
This behavior also happens with `.add_` (an ATen operation):
```python
>>> index_filled.add_(mask.long())
tensor([[[1, 2, 4, 7],
[1, 2, 4, 7],
[1, 2, 4, 7]]])
```
Verse if we try with `.contiguous()`...
```python
>>> index_filled.contiguous().add_(mask.long())
tensor([[[1, 2, 4, 5],
[1, 2, 3, 5],
[1, 2, 3, 5]]])
```
The "quick fix" to this is to call `.contiguous()` before `add_` or `masked_fill`, however I feel that this solution is non-obvious if the user is not aware of strides (and non-obvious even if the user is). Maybe a check for this type of case should exist? Thanks to @jekbradbury for helping me figure out this issue.
## System Info
- Python version: 3.6
- CUDA available: No
- PyTorch or Caffe2: PyTorch
- How you installed PyTorch (conda, pip, source): Conda
- OS: Mac OSX 10.13.6
- PyTorch version: 0.4.1
- Python version: 3.6
|
module: internals,good first issue,triaged,module: partial aliasing
|
low
|
Major
|
352,804,331 |
go
|
net/http: custom error handlers for http.FileServer
|
Noticed that in Go 1.11 a error handler field was added to httputil's ReverseProxy to allow sending allow writing a custom error.
I think the same should be done for http.FileServer, http.ServeFile and http.ServeContent.
I don't see an easy way to do this without breaking the API or adding more API so maybe this is better for Go 2.
|
FeatureRequest
|
low
|
Critical
|
352,804,968 |
TypeScript
|
Add support for explicitly indicating that a function's return type is inferred.
|
## Search Terms
explicit infer return type
## Suggestion
Add support for a special `infer` type that can be used to explicitly indicate that the return type of a function should be inferred from its implementation.
The presence of an explicit `infer` return type for a function (or arrow function) would have identical observable behavior as if the return type wasn't specified: the return type is inferred from the implementation.
The difference is that the function now technically has a return type specified to indicate that the developer explicitly made a decision to allow the return type to be inferred, rather than simply forgetting to think about what the return type should be.
## Use Cases
In a project with strict/explicit code style, it is desirable in general to use a linting rule that requires all functions to have a return type specified (The tslint "typedef" rule for "call-signature", for example: https://palantir.github.io/tslint/rules/typedef/).
There are, however, some situations where the return type of a function is a complex type (involving generics, etc.), such that the return type is more naturally inferred from the implementation of the method, as opposed to it being natural to know the intended return type ahead of time.
In such situations, it would be nice to have the option to explicitly indicate the intent for the compiler to infer the return type of the function. This would both clearly communicate this explicit intent to other developers reading the code, and could be used to satisfy code style and linting rules that require functions to have a return type specified.
## Why not just disable the linting rule on a case-by-case basis?
Yes, tslint's support of line-level rule disabling could be used to temporarily disable the linting rule and allow you to omit the return type in such situations. But I feel that language-level support for an explicit `infer` return type would be much more powerfully clear and expressive. It is especially worthwhile if it is fairly low effort/risk to implement.
Additionally, there is not enough granularity to disable the "typedef" rule ONLY for the "call-signature" context. Disabling "typedef" on that line would also disable checks for parameter types in the signature, which is undesirable.
## Examples
A simple example is helper methods for unit tests that use [enzyme](https://github.com/airbnb/enzyme). Let's say you have a custom React component named `MyButtonComponent`, and you would like a helper function to find the "close" button within some other outer component:
```ts
import { ReactWrapper } from "enzyme";
import { MyButtonComponent } from "./MyButtonComponent";
function findCloseButton(wrapper: ReactWrapper): infer {
return wrapper.find(MyButtonComponent).filter(".close-button");
}
```
In this case, the line `return wrapper.find(MyButtonComponent).filter(".close-button")` returns a strictly typed `ReactWrapper<P>` type where `P` is the Props type of the `MyButtonComponent` component, which allows type-safe access to the current values of the component's props via `ReactWrapper`'s `props()` method .
Manually writing out the correct return type of the helper function above would be quite tedious and provide very little benefit. Especially if the Props interface for `MyButtonComponent` is not readily available either because it is not exported, or because `MyButtonComponent` was created by a complex generic higher order component (HOC). The effort of correctly writing out the return type outweighs its benefits in a situation like this.
## Inferring implicit `any`
In the following examples, there is no implementation to infer the return type from:
```ts
declare function foo(a: number): infer;
interface Bar {
bar(b: string): infer;
}
```
The `infer` type is actually quite useless here and is guaranteed to be an implicit `any` type. Perhaps it would make sense to ONLY allow the `infer` type in contexts where there is something to infer from? If so, then the above examples would be compiler errors because there is nothing to infer from.
Another reasonable option may be to allow it to infer an implicit `any` type in such a way that will fail to compile when using the `--noImplicitAny` compiler option. This option is a bit less direct, but perfectly acceptable if it is the most "natural" and low-risk/effort option based on the current structure of code.
## Partially Inferred Types
An expansion on this idea would be partially inferred return types:
```ts
function foo(value: number): Promise<infer> {
// return value must be assignable to Promise<any>
// return type is inferred to be Promise<number>
return Promise.resolve(value);
}
interface Pair<A, B> {
a: A;
b: B
}
function bar(value: number): Pair<infer, infer> {
// return value must be assignable to Pair<any, any>
// return type is inferred to be Pair<number, boolean>
return {
a: value,
b: value % 2 === 0
};
}
```
This would provide a nice blend of compile time validation that you are returning something in the basic format that you intend, but let the compiler infer complicated parts of the type that are not worth the effort of manually constructing/writing.
## Checklist
My suggestion meets these guidelines:
* [x] This wouldn't be a breaking change in existing TypeScript / JavaScript code
* [x] This wouldn't change the runtime behavior of existing JavaScript code
* [x] This could be implemented without emitting different JS based on the types of the expressions
* [x] This isn't a runtime feature (e.g. new expression-level syntax)
|
Suggestion,Awaiting More Feedback
|
low
|
Critical
|
352,814,336 |
rust
|
confusing "unused type parameter" diagnostic
|
I really don't get this diagnostic. It says that U is unused, but removing U causes a " cannot find type `U` in this scope" diagnostic. Is U used or not? I feel like this diagnostic could be improved.
(btw, I arrived at this code while reading https://doc.rust-lang.org/book/2018-edition/ch13-01-closures.html#limitations-of-the-cacher-implementation)
```rust
struct Cacher<T, U: Copy>
where T: Fn(U) -> U
{
calculation: T,
value: Option<u32>,
}
fn main() {
let c = Cacher::new(|x| x);
println!("Hello, world!");
}
```
([Playground](https://play.rust-lang.org/?gist=9234bed2d2121051f9a3d3ac9fafab48&version=nightly&mode=debug&edition=2015))
Errors:
```
Compiling playground v0.0.1 (file:///playground)
error[E0392]: parameter `U` is never used
--> src/main.rs:2:18
|
2 | struct Cacher<T, U: Copy>
| ^ unused type parameter
|
= help: consider removing `U` or using a marker such as `std::marker::PhantomData`
error: aborting due to previous error
For more information about this error, try `rustc --explain E0392`.
error: Could not compile `playground`.
To learn more, run the command again with --verbose.
```
|
C-enhancement,A-diagnostics,T-compiler,A-suggestion-diagnostics,D-papercut
|
low
|
Critical
|
352,814,625 |
rust
|
incremental: hash items' source tokens to generate DefId's.
|
We should strive to handle the "only touched one item" case *very well*, which means *either* knowing the exact modified range, *or inferring it* through a series of heuristics.
The current `DefPath` machinery doesn't know how to properly understand things like e.g. `impl`s haven't changed, and would assume that adding an impl invalidates later ones in the same module.
If we *only* apply the existing machinery between the "leftover" old and new items that didn't have a match in their "source tokens hash", we should be able to get overall more consistent `DefId` matches, even in trickier situations where, for example, the whole file was moved around.
Original source could also be used, but ignoring whitespace & comments seems useful.
<hr/>
One way I can see us proceeding is by gathering some statistics of the hit/miss rate of this scheme for typical editing scenarios, and the cost of actually doing the hashing.
We can probably compute the hash for each `Item` after finishing parsing it, from its `tokens` field (which is there for proc macros, but it should be fine to reuse for our purposes).
cc @nikomatsakis @michaelwoerister
<!-- TRIAGEBOT_START -->
<!-- TRIAGEBOT_ASSIGN_START -->
<!-- TRIAGEBOT_ASSIGN_DATA_START$${"user":null}$$TRIAGEBOT_ASSIGN_DATA_END -->
<!-- TRIAGEBOT_ASSIGN_END -->
<!-- TRIAGEBOT_END -->
|
T-compiler,A-incr-comp
|
low
|
Major
|
352,816,875 |
rust
|
Separate the Res::Local case from hir::ExprKind::Path.
|
All other things an expression can refer to, have `DefId`s.
If we separate them, then we can use a proper `HirId` for `hir::ExprKind::Local`, and maybe even refactor the current `hir::def::Res` enum away.
Somewhat related to #53553.
cc @nikomatsakis @michaelwoerister
|
C-cleanup,T-compiler,A-HIR
|
low
|
Minor
|
352,833,908 |
create-react-app
|
@next react-scripts(webpack.config.js) to resolve `.wasm` extension?
|
I was curious if there was any reason `.wasm` extension was left out from [`resolve.extensions` list](https://github.com/facebook/create-react-app/blob/next/packages/react-scripts/config/webpack.config.dev.js#L146)?
Webpack also default to [include `.wasm`](https://webpack.js.org/configuration/resolve/#resolve-extensions).
It'd be nice to start using/experimenting wasm from create-react-app!
|
issue: proposal
|
medium
|
Critical
|
352,842,784 |
go
|
x/crypto/ssh: concurrent call ssh.Dial will fail
|
Please answer these questions before submitting your issue. Thanks!
### What version of Go are you using (`go version`)?
1.8.3
### Does this issue reproduce with the latest release?
https://github.com/golang/crypto.git
commit : 614d502a4dac94afa3a6ce146bd1736da82514c6
### What operating system and processor architecture are you using (`go env`)?
centos 7
### What did you do?
auth := make([]ssh.AuthMethod, 0)
auth = append(auth, ssh.Password("123456"))
config := &ssh.ClientConfig {
User: "root",
Auth: auth,
HostKeyCallback: func(hostname string, remote net.Addr, key ssh.PublicKey) error {
return nil
},
Timeout: 30 * time.Second,
}
for i:=0;i<2;i++ {
go func() {
client, err := ssh.Dial("tcp", "ip:port", config)
fmt.Println(err) // the 2th thread (maybe 3th or other litter value) will error
time.Sleep(5 * time.Second)
// error is not here, it just a test code
client.Close()
}()
}
### What did you expect to see?
run pass
### What did you see instead?
<nil>
ssh: handshake failed: ssh: unable to authenticate, attempted methods [none password], no supported methods remain
the second thread error , other machines maybe 3 or ...
|
NeedsInvestigation
|
medium
|
Critical
|
352,868,931 |
flutter
|
Request ID token option for google_sign_in plugin
|
With google_sign_in v3.0.4, there is no option to request an ID token.
On iOS, the ID token is always returned, but on Android it is null unless the builder option is provided.
Here is the [documentation](https://developers.google.com/android/reference/com/google/android/gms/auth/api/signin/GoogleSignInOptions.Builder.html#requestIdToken(java.lang.String)) of the missing option method.
|
c: new feature,p: google_sign_in,package,team-ecosystem,P2,triaged-ecosystem
|
low
|
Major
|
352,915,380 |
go
|
x/tools/cmd/gomvpkg: package not changed in files with different OS build tags
|
Please answer these questions before submitting your issue. Thanks!
### What version of Go are you using (`go version`)?
`go version go1.10.2 darwin/amd64`
### Does this issue reproduce with the latest release?
Yes
### What operating system and processor architecture are you using (`go env`)?
```
GOHOSTARCH="amd64"
GOHOSTOS="darwin"
```
### What did you do?
Ran `gomvpkg -from github.com/hashicorp/consul/agent/proxy -to github.com/hashicorp/consul/agent/proxyprocess -vcs_mv_cmd "git mv {{.Src}} {{.Dst}}"`
If you checkout the current head of Consul 4d658f34cfcb5c2e0b29ae5103e923872bddcaa7 and run the same command you should see the same issue.
### What did you expect to see?
All files moved to the new package name and their package declarations updates
### What did you see instead?
All files moved _but_ two files with build tags that didn't match my host OS were not modified and so kept the old `package proxy` declaration.
The two files are https://github.com/hashicorp/consul/blob/4d658f34cfcb5c2e0b29ae5103e923872bddcaa7/agent/proxy/process_windows.go#L1-L3
```go
// +build windows
package proxy
```
and
https://github.com/hashicorp/consul/blob/4d658f34cfcb5c2e0b29ae5103e923872bddcaa7/agent/proxy/exitstatus_other.go#L1-L3
```go
// +build !darwin,!linux,!windows
package proxy
```
This is unpleasant as build and test pass locally still naturally!
This may well be a "known" issue caused by something in the tool chain that is hard to work around, however I don't see an open issue for it and it's certainly surprising to me that this wouldn't work for files with os-dependent build tags. Even if the tooling makes it hard to fix those for some reason, it would be better to at least detect that happening and warn the user to update manually.
Thanks!
|
Tools
|
low
|
Minor
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.