
id
int64 393k
2.82B
| repo
stringclasses 68
values | title
stringlengths 1
936
| body
stringlengths 0
256k
⌀ | labels
stringlengths 2
508
| priority
stringclasses 3
values | severity
stringclasses 3
values |
|---|---|---|---|---|---|---|
326,864,065 | pytorch | [Caffe2] convert ONNX to caffe2 | I used this program to generate pb model.
> convert-caffe2-to-onnx trainednet.onnx --output predict_net.pb
My Error
```
WARNING:root:This caffe2 python run does not have GPU support. Will run in CPU only mode.
WARNING:root:Debug message: No module named caffe2_pybind11_state_gpu
Traceback (most recent call last):
File "/Users/rafalpilarczyk/anaconda3/envs/caffe2/bin/convert-caffe2-to-onnx", line 11, in <module>
sys.exit(caffe2_to_onnx())
File "/Users/rafalpilarczyk/anaconda3/envs/caffe2/lib/python2.7/site-packages/click/core.py", line 722, in __call__
return self.main(*args, **kwargs)
File "/Users/rafalpilarczyk/anaconda3/envs/caffe2/lib/python2.7/site-packages/click/core.py", line 697, in main
rv = self.invoke(ctx)
File "/Users/rafalpilarczyk/anaconda3/envs/caffe2/lib/python2.7/site-packages/click/core.py", line 895, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/Users/rafalpilarczyk/anaconda3/envs/caffe2/lib/python2.7/site-packages/click/core.py", line 535, in invoke
return callback(*args, **kwargs)
File "/Users/rafalpilarczyk/anaconda3/envs/caffe2/lib/python2.7/site-packages/onnx_caffe2/bin/conversion.py", line 42, in caffe2_to_onnx
c2_net_proto.ParseFromString(caffe2_net.read())
File "/Users/rafalpilarczyk/anaconda3/envs/caffe2/lib/python2.7/site-packages/google/protobuf/message.py", line 185, in ParseFromString
self.MergeFromString(serialized)
File "/Users/rafalpilarczyk/anaconda3/envs/caffe2/lib/python2.7/site-packages/google/protobuf/internal/python_message.py", line 1083, in MergeFromString
if self._InternalParse(serialized, 0, length) != length:
File "/Users/rafalpilarczyk/anaconda3/envs/caffe2/lib/python2.7/site-packages/google/protobuf/internal/python_message.py", line 1120, in InternalParse
pos = field_decoder(buffer, new_pos, end, self, field_dict)
File "/Users/rafalpilarczyk/anaconda3/envs/caffe2/lib/python2.7/site-packages/google/protobuf/internal/decoder.py", line 612, in DecodeRepeatedField
if value.add()._InternalParse(buffer, pos, new_pos) != new_pos:
File "/Users/rafalpilarczyk/anaconda3/envs/caffe2/lib/python2.7/site-packages/google/protobuf/internal/python_message.py", line 1109, in InternalParse
new_pos = local_SkipField(buffer, new_pos, end, tag_bytes)
File "/Users/rafalpilarczyk/anaconda3/envs/caffe2/lib/python2.7/site-packages/google/protobuf/internal/decoder.py", line 850, in SkipField
return WIRETYPE_TO_SKIPPER[wire_type](buffer, pos, end)
File "/Users/rafalpilarczyk/anaconda3/envs/caffe2/lib/python2.7/site-packages/google/protobuf/internal/decoder.py", line 820, in _RaiseInvalidWireType
raise _DecodeError('Tag had invalid wire type.')
google.protobuf.message.DecodeError: Tag had invalid wire type.
```
I have similar issues with ONNX-MXNet and tensorflow. I assume that my ONNX model is not compatible with current onnx_caffe2 module? I exported this model using Matlab ONNX exporter. https://www.mathworks.com/matlabcentral/fileexchange/67296-neural-network-toolbox-converter-for-onnx-model-format
I work on MacOS with conda enviroment, python 2.7.15. I tried this also on virtual machine with P4000, Cuda 9.0 and 9.1, but results were the same.
| caffe2 | low | Critical |
326,882,364 | pytorch | [feature request] batch_first of RNN hidden weight for Multi GPU training | As we know, the input and output tensor support ```batch_first``` for RNN training, but as for hidden state, the tensor shape is forced to be ```(num_layers * num_directions, batch, hidden_size)```, even we set ```batch_first = True```. So there is a problem when we do multi GPU training by using ```torch.nn.DataParallel```.
For example, if we initialize a hidden state with shape ```(num_layers * num_directions, batch, hidden_size)``` and set ```hidden = init_hidden(batch_size)``` like [word_language_model](https://github.com/pytorch/examples/blob/f9820471d615d848c14661b2d582417ca3aee8a3/word_language_model/main.py#L150),then if we set ```hidden = init_hidden(batch_size)``` and use parallel training, the hidden size will be ```(num_layers * num_directions / num_gpu, batch, hidden_size)``` while the correct shape is ```(num_layers * num_directions, batch / num_gpu, hidden_size)```. So I was wondering if PyTorch Teams prepare to support ```batch_first``` for RNN hidden state.
Another possible way to avoid this problem is to use the following codes:
```
def init_hidden(self, batch_size):
weight = next(self.parameters())
# The hidden weight format is not consisten with PyTorch's LSTM
# impelementation, so we will transpose it
hidden = weight.new_zeros(batch_size, self.num_layers * 2,
self.hidden_size, requires_grad=False)
hidden = [hidden, hidden]
return hidden
def forward(self, inputs, hidden, length):
hidden[0] = hidden[0].permute(1, 0, 2).contiguous()
hidden[1] = hidden[1].permute(1, 0, 2).contiguous()
inputs_pack = pack_padded_sequence(inputs, length, batch_first=True)
# self.blstm.flatten_parameters()
output, hidden = self.blstm(inputs_pack, hidden)
......
hidden = list(hidden)
hidden[0] = hidden[0].permute(1, 0, 2).contiguous()
hidden[1] = hidden[1].permute(1, 0, 2).contiguous()
return output, hidden
```
But this implementation is very ugly. Also, this implementation faces another problem like the following warning log:
```
/mnt/workspace/pytorch/deep_clustering/model/blstm_upit.py:65: UserWarning: RNN module weights are not part of single contiguous chunk of memory. This means they need to be compacted at every call, possibly greatly increasing memory usage. To compact weights again call flatten_parameters().
```
If we add ```self.blstm.flatten_parameters()``` before ```output, hidden = self.blstm(inputs_pack, hidden)```, we will face another problem like #7092
cc @albanD @mruberry | module: nn,triaged,enhancement,module: data parallel | low | Major |
327,013,320 | rust | Defaulted unit types no longer error out (regression?) | This currently compiles (on stable and nightly). Till 1.25, it would trigger a [lint](https://github.com/rust-lang/rust/issues/39216) because it has inference default to `()` instead of throwing an error.
```rust
fn main() {}
struct Err;
fn load<T: Default>() -> Result<T, Err> {
Ok(T::default())
}
fn foo() -> Result<(), Err> {
let val = load()?; // defaults to ()
Ok(())
}
```
([playpen](https://play.rust-lang.org/?gist=6f7cf9dafb9d1651b659c1f029413fc5&version=nightly&mode=debug))
That lint indicates that it would become a hard error in the future, but it's not erroring. It seems like a bunch of this was changed when we [stabilized `!`](https://github.com/rust-lang/rust/issues/48950).
That issue says
> Type inference will now default unconstrained type variables to `!` instead of `()`. The [`resolve_trait_on_defaulted_unit`](https://github.com/rust-lang/rust/issues/39216) lint has been retired. An example of where this comes up is if you have something like:
Though this doesn't really _make sense_, this looks like a safe way to produce nevers, which should, in short, never happen. It seems like this is related to https://github.com/rust-lang/rust/issues/40801 -- but that was closed as it seems to be a more drastic change.
Also, if you print `val`, it's clear that the compiler thought it was a unit type. This seems like one of those cases where attempting to observe the situation changes it.
We _should_ have a hard error here, this looks like a footgun, and as @SimonSapin mentioned has broken some unsafe code already. We had an upgrade lint for the hard error and we'll need to reintroduce it for a cycle or two since we've had a release without it. AFAICT this is a less drastic change than #40801, and we seem to have _intended_ for this to be a hard error before so it probably is minor enough that it's fine.
cc @nikomatsakis @eddyb
h/t @spacekookie for finding this | T-compiler,regression-from-stable-to-stable,A-inference,C-bug | low | Critical |
327,031,030 | pytorch | [caffe2] build from source, cannot find my cudnn7.1 | I am building pytorch from source. My cudnn version is 7.1, however, it seems that caffe2 cannot succeed to use this verion of cudnn 7.1, but found a low version 5 instead.
errors like below:
```
[ 87%] Building CXX object caffe2/CMakeFiles/caffe2_gpu.dir/__/aten/src/ATen/native/cuda/CUDAReduceOps.cpp.o
[ 87%] Building CXX object caffe2/CMakeFiles/caffe2_gpu.dir/__/aten/src/ATen/CUDACharStorage.cpp.o
[ 87%] Building CXX object caffe2/CMakeFiles/caffe2_gpu.dir/__/aten/src/ATen/CUDAByteStorage.cpp.o
[ 87%] Building CXX object caffe2/CMakeFiles/caffe2_gpu.dir/__/aten/src/ATen/CUDAByteTensor.cpp.o
In file included from /home/hxw/Ananaconda_Pytorch_Related/pytorch/aten/src/ATen/cudnn/Exceptions.h:3:0,
from /home/hxw/Ananaconda_Pytorch_Related/pytorch/aten/src/ATen/cudnn/Descriptors.h:3,
from /home/hxw/Ananaconda_Pytorch_Related/pytorch/aten/src/ATen/native/cudnn/BatchNorm.cpp:31:
/home/hxw/Ananaconda_Pytorch_Related/pytorch/aten/src/ATen/cudnn/cudnn-wrapper.h:10:2: error: #error "CuDNN version not supported"
#error "CuDNN version not supported"
^
In file included from /home/hxw/Ananaconda_Pytorch_Related/pytorch/aten/src/ATen/native/cudnn/RNN.cpp:58:0:
/home/hxw/Ananaconda_Pytorch_Related/pytorch/aten/src/ATen/cudnn/cudnn-wrapper.h:10:2: error: #error "CuDNN version not supported"
#error "CuDNN version not supported"
^
In file included from /home/hxw/Ananaconda_Pytorch_Related/pytorch/aten/src/ATen/cudnn/Exceptions.h:3:0,
from /home/hxw/Ananaconda_Pytorch_Related/pytorch/aten/src/ATen/cudnn/Descriptors.h:3,
from /home/hxw/Ananaconda_Pytorch_Related/pytorch/aten/src/ATen/native/cudnn/GridSampler.cpp:27:
/home/hxw/Ananaconda_Pytorch_Related/pytorch/aten/src/ATen/cudnn/cudnn-wrapper.h:10:2: error: #error "CuDNN version not supported"
#error "CuDNN version not supported"
^
In file included from /home/hxw/Ananaconda_Pytorch_Related/pytorch/aten/src/ATen/cuda/detail/CUDAHooks.cpp:11:0:
/home/hxw/Ananaconda_Pytorch_Related/pytorch/aten/src/ATen/cudnn/cudnn-wrapper.h:10:2: error: #error "CuDNN version not supported"
#error "CuDNN version not supported"
```
and
```
n file included from /home/hxw/Ananaconda_Pytorch_Related/pytorch/aten/src/ATen/cudnn/Exceptions.h:3:0,
from /home/hxw/Ananaconda_Pytorch_Related/pytorch/aten/src/ATen/cudnn/Descriptors.h:3,
from /home/hxw/Ananaconda_Pytorch_Related/pytorch/aten/src/ATen/native/cudnn/BatchNorm.cpp:31:
/home/hxw/Ananaconda_Pytorch_Related/pytorch/aten/src/ATen/cudnn/cudnn-wrapper.h:9:198: note: #pragma message: CuDNN v5 found, but need
at least CuDNN v6. You can get the latest version of CuDNN from https://developer.nvidia.com/cudnn or disable CuDNN with NO_CUDNN=1
#pragma message ("CuDNN v" STRING(CUDNN_MAJOR) " found, but need at least CuDNN v6. You can get the latest version of CuDNN from https
://developer.nvidia.com/cudnn or disable CuDNN with NO_CUDNN=1")
^
In file included from /home/hxw/Ananaconda_Pytorch_Related/pytorch/aten/src/ATen/native/cudnn/AffineGridGenerator.cpp:28:0:
/home/hxw/Ananaconda_Pytorch_Related/pytorch/aten/src/ATen/cudnn/cudnn-wrapper.h:9:198: note: #pragma message: CuDNN v5 found, but need
at least CuDNN v6. You can get the latest version of CuDNN from https://developer.nvidia.com/cudnn or disable CuDNN with NO_CUDNN=1
at least CuDNN v6. You can get the latest version of CuDNN from https://developer.nvidia.com/cudnn or disable CuDNN with NO_CUDNN=1")
^
/home/hxw/Ananaconda_Pytorch_Related/pytorch/aten/src/ATen/cudnn/cudnn-wrapper.h:9:198: note: #pragma message: CuDNN v5 found, but need
at least CuDNN v6. You can get the latest version of CuDNN from https://developer.nvidia.com/cudnn or disable CuDNN with NO_CUDNN=1
#pragma message ("CuDNN v" STRING(CUDNN_MAJOR) " found, but need at least CuDNN v6. You can get the latest version of CuDNN from https
://developer.nvidia.com/cudnn or disable CuDNN with NO_CUDNN=1")
```
does anyone know how to solve this problem. | caffe2 | low | Critical |
327,032,058 | three.js | Add shadow map support for RectAreaLights (brainstorming, R&D) | ##### Description of the problem
It would be very useful for realism to support shadows on RectAreaLights.
I am unsure of the best technique to use here as I have not researched it yet beyond some quick Google searches. I am not yet sure what is the accepted best practice in the industry?
Two simple techniques I can think of:
- one could place a PointLightShadowMap at the center of a rect area light and it would sort of work.
- less accurate, one could place a SpotLightShadowMap with a fairly high FOV (upwards of 120 deg, but less than 180 deg as that would cause it to fail) at the center of the rect area light and point it in the light direction.
(I believe with the spot light shadow map you may be able to get better results for large area lights if you moved the shadow map behind the area light surface so that the front near clip plane in the shadow map frustum was roughly the side of the area light as it passed through the area light plane. I believe I read this in some paper once, but I can remember the source of it.) | Enhancement | high | Critical |
327,048,239 | rust | [rustdoc] Implementors section of Sync (and other similar traits) should separate implementors and !implementors | 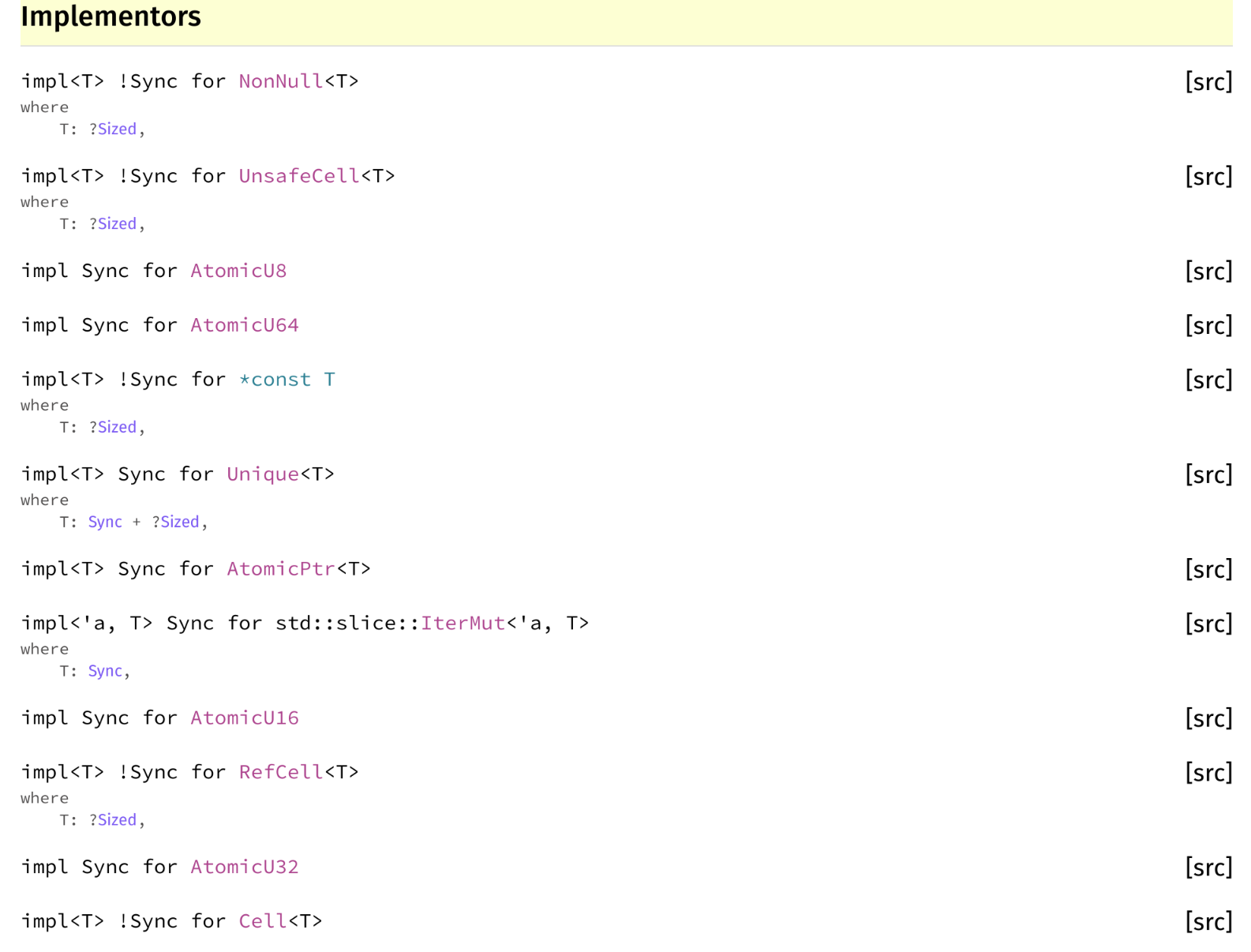
The `!Sync` implementations and the `Sync` implementations really ought to be separated apart, otherwise it makes it harder to skim.
https://doc.rust-lang.org/stable/std/marker/trait.Sync.html#implementors | T-rustdoc,C-enhancement,E-mentor | low | Major |
327,059,337 | opencv | Suggestion for the CUDA stream module | Hi, I'd like to suggest something related to the CUDA stream module.
It seems that `cv::cuda::Stream` class encapsulates a feature related to CUDA memory allocation using `StackAllocator` class and `MemoryPool` class.
This feature is described in detail at [this documentation for `BufferPool`](https://docs.opencv.org/master/d5/d08/classcv_1_1cuda_1_1BufferPool.html). In short, it seems that this feature is designed to bypass CUDA memory allocation API calls to speed up performance as follows:
- When a `Stream` class is constructed, some amount of CUDA memory is pre-allocated and assigned to the `Stream` instance.
- If an OpenCV algorithm is run on that stream, the algorithm internally uses the `BufferPool` class to get buffer memory (if needed) from the pre-allocted area, rather than calling the CUDA memory allocation API.
- This reduces overhead.
Since [there](https://github.com/opencv/opencv/blob/master/modules/cudaimgproc/src/histogram.cpp#L311) [are](https://github.com/opencv/opencv/blob/master/modules/cudaobjdetect/src/cascadeclassifier.cpp#L536) [many](https://github.com/opencv/opencv/blob/master/modules/cudaobjdetect/src/hog.cpp#L494) [cases](https://github.com/opencv/opencv/blob/master/modules/cudaarithm/src/cuda/integral.cu#L93) where CUDA algorithms need some amount of GPU memory (sometimes as small as [a](https://github.com/opencv/opencv/blob/master/modules/cudaarithm/src/cuda/norm.cu#L86) [few](https://github.com/opencv/opencv/blob/master/modules/cudaarithm/src/cuda/normalize.cu#L145) [bytes](https://github.com/opencv/opencv/blob/master/modules/cudaarithm/src/cuda/minmax.cu#L77)) for internal buffer, it seems reasonable to take this memory pre-allocation approach. I suppose that's the original reason behind this design, and this feature was enabled by default before https://github.com/opencv/opencv/pull/10751. It is now disabled by default by the mentioned PR, while users can still turn it on by `cv::cuda::setBufferPoolUsage(true);`.
However, in my opinion, _this feature should not be used since enabling it may lead to some problems_.
The problems are:
1. The current design does not work well with device resetting function. The allocated CUDA memory is deallocated when the CUDA context is reset with `cv::cuda::resetDevice()`, but this is not recognized by the `Stream` module, leading to failures. The following code snippets fail to run due to this.
- https://github.com/nglee/opencv_test/blob/e6e7aab4202d285965d62dd79ff66e410fecc85c/cuda_stream_master/cuda_stream_master.cpp#L11-L28
- https://github.com/nglee/opencv_test/blob/e6e7aab4202d285965d62dd79ff66e410fecc85c/cuda_stream_master/cuda_stream_master.cpp#L30-L48
2. It is error-prone since users would have to consider the deallocation order. The following code will show different images for seemingly unchanged variable.
- https://github.com/nglee/opencv_test/blob/e6e7aab4202d285965d62dd79ff66e410fecc85c/cuda_stream_master/cuda_stream_master.cpp#L50-L77
3. The `Stream` module becomes not safe to multi-threaded application.
- The thread-non-safety of `Stream` is already mentioned in the documentation: https://docs.opencv.org/master/d9/df3/classcv_1_1cuda_1_1Stream.html
- It would be tempting for users to use the default stream for multi-threaded application, but running the following code snippet displays thread-non-safety when using the default stream. Some thread prints different result.
https://github.com/nglee/opencv_test/blob/e6e7aab4202d285965d62dd79ff66e410fecc85c/cuda_stream_master/cuda_stream_master.cpp#L81-L107
All code snippets mentioned above run without error when memory pre-allocation mechanism is disabled by replacing `setBufferPoolUsage(true);` to `setBufferPoolUsage(false);` (or just by deleting the `setBufferPoolUsage(true);` line).
So I'm suggesting that the memory pre-allocation feature of `Stream` module should be blocked. But to achieve this, the `StackAllocator`, `MemoryPool`, and `BufferPool` class should be blocked or removed. Also, existing CUDA memory allocation using `BufferPool` should be replaced by ordinary `GpuMat` allocation using the `DefaultAllocator`.
_Since all these changes seem too radical_, another option I can think of is that we might stay the way as it is right now (disable the feature by default) and warn the users who would like to enable this feature by rewriting the documentation of `setBufferPoolUsage` function. | category: gpu/cuda (contrib),RFC | low | Critical |
327,063,120 | rust | Borrowing an immutable reference of a mutable reference through a function call in a loop is not accepted | This code appears to be sound because `event` should either leave the loop or be thrown away before the next iteration:
```rust
#![feature(nll)]
fn next<'buf>(buffer: &'buf mut String) -> &'buf str {
loop {
let event = parse(buffer);
if true {
return event;
}
}
}
fn parse<'buf>(_buffer: &'buf mut String) -> &'buf str {
unimplemented!()
}
fn main() {}
```
The current (1.28.0-nightly 2018-05-25 990d8aa743b1dda3cc0f) implementation still marks this as an error:
```
error[E0499]: cannot borrow `*buffer` as mutable more than once at a time
--> src/main.rs:5:27
|
5 | let event = parse(buffer);
| ^^^^^^ mutable borrow starts here in previous iteration of loop
|
note: borrowed value must be valid for the lifetime 'buf as defined on the function body at 3:1...
--> src/main.rs:3:1
|
3 | fn next<'buf>(buffer: &'buf mut String) -> &'buf str {
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
```
@nikomatsakis said:
> this should throw an error (for now) but this error should eventually go away. This is precisely a case where "Location sensitivity" is needed, but we removed that feature in the name of performance — once polonius support lands, though, this code would be accepted. That may or may not be before the edition. | C-enhancement,T-lang,A-NLL,NLL-polonius | low | Critical |
327,108,944 | pytorch | Deprecate torch.Tensor | This:
```python
>>> torch.Tensor(torch.tensor(0.5))
RuntimeError: slice() cannot be applied to a 0-dim tensor.
```
should work and be a no-op I guess?
I'm running pytorch CPU, built from source at fece8787d98c99177505c9357850171457397b61. | triaged,module: deprecation,module: tensor creation | low | Critical |
327,150,371 | pytorch | TracedModules don't support parameter sharing between modules | I have a multihead module with 2 heads that share parameters during training. I want to use the JIT compiler to increase the performance only during the inference when only 1 head is used. When I create a jit compiled module, JIT code looks at all of the parameters, even those that will never be used in the 2nd head and raises the exception above. Instead of the exception, please create a warning here:
File "anaconda2/lib/python2.7/site-packages/torch/jit/__init__.py", line 643, in check_unique
raise ValueError("TracedModules don't support parameter sharing between modules")
| oncall: jit | low | Critical |
327,157,973 | go | cmd/objdump: x86 disassembler does not recognize PDEPQ | ### What version of Go are you using (`go version`)?
```
go version go1.10.2 darwin/amd64
```
### Does this issue reproduce with the latest release?
Yes, confirmed on 1.9.2 and 1.10.2. Not tested on master.
### What operating system and processor architecture are you using (`go env`)?
```
GOARCH="amd64"
GOBIN=""
GOCACHE="/Users/michaelmcloughlin/Library/Caches/go-build"
GOEXE=""
GOHOSTARCH="amd64"
GOHOSTOS="darwin"
GOOS="darwin"
GOPATH="/Users/michaelmcloughlin/gocode"
GORACE=""
GOROOT="/usr/local/Cellar/go/1.10.2/libexec"
GOTMPDIR=""
GOTOOLDIR="/usr/local/Cellar/go/1.10.2/libexec/pkg/tool/darwin_amd64"
GCCGO="gccgo"
CC="clang"
CXX="clang++"
CGO_ENABLED="1"
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
PKG_CONFIG="pkg-config"
GOGCCFLAGS="-fPIC -m64 -pthread -fno-caret-diagnostics -Qunused-arguments -fmessage-length=0 -fdebug-prefix-map=/var/folders/p5/84p384bs42v7pbgfx0db9gq80000gn/T/go-build505202882=/tmp/go-build -gno-record-gcc-switches -fno-common"
```
### What did you do?
Compiled package with assembly code using `PDEPQ`. Viewed resulting assembly with `go tool objdump`.
Gist https://gist.github.com/mmcloughlin/b5bf1bcc7f31222ff2bc510f2777cd79 is a minimal example.
### What did you expect to see?
Expect `go tool objdump` to show the `PDEPQ` instruction.
### What did you see instead?
Output from `objdump.sh` script is as follows. The `objdump` tool does not recognize `PDEPQ`, and instead parses it as a sequence of instructions. Note that Apple's LLVM objdump correctly identifies the instruction.
```
+ go version
go version go1.10.2 darwin/amd64
+ go test -c
+ go tool objdump -s bmi.PDep bmi.test
TEXT github.com/mmcloughlin/bmi.PDep(SB) /Users/michaelmcloughlin/gocode/src/github.com/mmcloughlin/bmi/pdep.s
pdep.s:7 0x10e7860 4c8b442408 MOVQ 0x8(SP), R8
pdep.s:8 0x10e7865 4c8b4c2410 MOVQ 0x10(SP), R9
pdep.s:10 0x10e786a c442b3f5 CMC
pdep.s:10 0x10e786e d04c8954 RORB $0x1, 0x54(CX)(CX*4)
pdep.s:12 0x10e7872 2418 ANDL $0x18, AL
pdep.s:13 0x10e7874 c3 RET
:-1 0x10e7875 cc INT $0x3
:-1 0x10e7876 cc INT $0x3
:-1 0x10e7877 cc INT $0x3
:-1 0x10e7878 cc INT $0x3
:-1 0x10e7879 cc INT $0x3
:-1 0x10e787a cc INT $0x3
:-1 0x10e787b cc INT $0x3
:-1 0x10e787c cc INT $0x3
:-1 0x10e787d cc INT $0x3
:-1 0x10e787e cc INT $0x3
:-1 0x10e787f cc INT $0x3
+ objdump -disassemble-all bmi.test
+ grep -A 4 bmi.PDep:
github.com/mmcloughlin/bmi.PDep:
10e7860: 4c 8b 44 24 08 movq 8(%rsp), %r8
10e7865: 4c 8b 4c 24 10 movq 16(%rsp), %r9
10e786a: c4 42 b3 f5 d0 pdepq %r8, %r9, %r10
10e786f: 4c 89 54 24 18 movq %r10, 24(%rsp)
```
| help wanted,NeedsFix,compiler/runtime | low | Critical |
327,226,910 | pytorch | [Caffe2] Operators of Detectron module not registered/compiled when built on windows | ## Issue description
I am using Caffe2+Detectron in Windows. After successfully building Caffe2 (with CUDA, cuDNN, OpenCV), COCOAPI and Detectron modules, I ran the `tools/train_net.py` script in Detectron, trying to train Faster R-CNN on Pascal VOC. But the following errors appeared, reporting a Detectron operator `AffineChannel` not registered. With different configurations, similar errors for other Detectron operators happen.
```
...
File "D:/repo/github/Detectron_facebookresearch\detectron\utils\train.py", line 53, in train_model
model, weights_file, start_iter, checkpoints, output_dir = create_model()
File "D:/repo/github/Detectron_facebookresearch\detectron\utils\train.py", line 132, in create_model
model = model_builder.create(cfg.MODEL.TYPE, train=True)
File "D:/repo/github/Detectron_facebookresearch\detectron\modeling\model_builder.py", line 124, in create
return get_func(model_type_func)(model)
File "D:/repo/github/Detectron_facebookresearch\detectron\modeling\model_builder.py", line 89, in generalized_rcnn
freeze_conv_body=cfg.TRAIN.FREEZE_CONV_BODY
File "D:/repo/github/Detectron_facebookresearch\detectron\modeling\model_builder.py", line 229, in build_generic_detection_model
optim.build_data_parallel_model(model, _single_gpu_build_func)
File "D:/repo/github/Detectron_facebookresearch\detectron\modeling\optimizer.py", line 40, in build_data_parallel_model
all_loss_gradients = _build_forward_graph(model, single_gpu_build_func)
File "D:/repo/github/Detectron_facebookresearch\detectron\modeling\optimizer.py", line 63, in _build_forward_graph
all_loss_gradients.update(single_gpu_build_func(model))
File "D:/repo/github/Detectron_facebookresearch\detectron\modeling\model_builder.py", line 169, in _single_gpu_build_func
blob_conv, dim_conv, spatial_scale_conv = add_conv_body_func(model)
File "D:/repo/github/Detectron_facebookresearch\detectron\modeling\ResNet.py", line 36, in add_ResNet50_conv4_body
return add_ResNet_convX_body(model, (3, 4, 6))
File "D:/repo/github/Detectron_facebookresearch\detectron\modeling\ResNet.py", line 98, in add_ResNet_convX_body
p, dim_in = globals()[cfg.RESNETS.STEM_FUNC](model, 'data')
File "D:/repo/github/Detectron_facebookresearch\detectron\modeling\ResNet.py", line 252, in basic_bn_stem
p = model.AffineChannel(p, 'res_conv1_bn', dim=dim, inplace=True)
File "D:/repo/github/Detectron_facebookresearch\detectron\modeling\detector.py", line 103, in AffineChannel
return self.net.AffineChannel([blob_in, scale, bias], blob_in)
File "D:/repo/github/pytorch/build\caffe2\python\core.py", line 2067, in __getattr__
",".join(workspace.C.nearby_opnames(op_type)) + ']'
AttributeError: Method AffineChannel is not a registered operator. Did you mean: []
```
I have modified `import_detectron_ops()` in `detectron/utils/c2.py` to use my `caffe2_detectron_ops_gpu.dll` path.
I have added the following path with `sys.path.insert(0, path)` in the training script.
- pytorch build directory
- detectron root directory
- COCOAPI PythonAPI directory
I have added the following path to my `PATH` variable.
- cuDNN bin directory
- pytorch build bin directory (`pytorch/build/bin/Release`), which contains `caffe2_detectron_ops_gpu.dll`
- OpenCV bin directory
The `import` commands seem to have all been successful. So I guess the environment setting should be OK.
I used the dumpbin tool to examine my `caffe2_detectron_ops_gpu.dll`, which only has a size of ~5.5MB.
With the `EXPORTS` option, the results are as follows:
```
Microsoft (R) COFF/PE Dumper Version 14.00.24215.1
Copyright (C) Microsoft Corporation. All rights reserved.
Dump of file D:\repo\github\pytorch\build\bin\Release\caffe2_detectron_ops_gpu.dll
File Type: DLL
Section contains the following exports for caffe2_detectron_ops_gpu.dll
00000000 characteristics
5B0CBE13 time date stamp Tue May 29 10:42:27 2018
0.00 version
1 ordinal base
1 number of functions
1 number of names
ordinal hint RVA name
1 0 003393E8 NvOptimusEnablementCuda
Summary
13000 .data
1000 .gfids
1000 .nvFatBi
20C000 .nv_fatb
23000 .pdata
E6000 .rdata
5000 .reloc
1000 .rsrc
252000 .text
1000 .tls
```
With the `SYMBOLS` option, the results are as follows:
```
Microsoft (R) COFF/PE Dumper Version 14.00.24215.1
Copyright (C) Microsoft Corporation. All rights reserved.
Dump of file D:\repo\github\pytorch\build\bin\Release\caffe2_detectron_ops_gpu.dll
File Type: DLL
Summary
13000 .data
1000 .gfids
1000 .nvFatBi
20C000 .nv_fatb
23000 .pdata
E6000 .rdata
5000 .reloc
1000 .rsrc
252000 .text
1000 .tls
```
Does this mean the Detectron operators are actually not compiled? If so, what could possibly be the reason and how can I make them compile?
## Code example
1. Build Caffe2 with CUDA, cuDNN, OpenCV.
2. Build COCOAPI modules.
3. Build Detectron modules.
4. Add all sorts of paths properly (as described above).
5. Run `tools/train_net.py` in Detectron with proper arguments.
## System Info
- PyTorch or Caffe2: **Caffe2**
- How you installed PyTorch (conda, pip, source): **source**
- Build command you used (if compiling from source): **scripts/build_windows.bat**
- OS: **Windows 10 Home Edition**
- PyTorch version: (Latest clone)
- Python version: **Python 2.7.12 :: Anaconda custom (64-bit)**
- CUDA/cuDNN version: **8.0/cudnn-8.0-windows10-x64-v7**
- GPU models and configuration: (GTX 1050)
- GCC version (if compiling from source):
- CMake version: **cmake-3.7.2-win64-x64**
- Versions of any other relevant libraries: **Visual Studio 2015, OpenCV 3.2.0-vc14**
| caffe2 | low | Critical |
327,247,193 | vue | Transition using js hooks always run the initial render | ### Version
2.5.16
### Reproduction link
[https://jsfiddle.net/p1dthw6z/](https://jsfiddle.net/p1dthw6z/)
### Steps to reproduce
In the demo link, toggle checkbox 'odd'.
### What is expected?
When rows appeared, both inner element transition using CSS (fade) and transition using hooks (slide) should not do initial render.
### What is actually happening?
Transition using CSS do not run the initial render, as expected.
But the transition using hooks run the initial render, as if I have used `<transition appear>`, which I didn't.
---
I don't know if it is the intended behavior. If it is, I would like to know how to avoid the initial render in the hooked transition.
<!-- generated by vue-issues. DO NOT REMOVE --> | transition | medium | Minor |
327,252,852 | vscode | Cannot exclude root folders while searching | Testing #50498
- In a MR workspace, try to exclude root folder using **/folder1/** and search. Results are still shown in folder1.
This happens irrespective of setting `search.enableSearchProviders" `
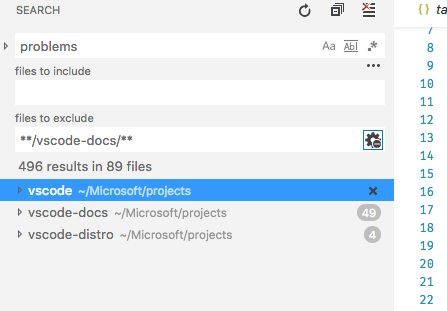
| help wanted,feature-request,search | medium | Major |
327,353,740 | opencv | RTSP streams freeze at version 3.1+ but not at 3.0 | <!--
If you have a question rather than reporting a bug please go to http://answers.opencv.org where you get much faster responses.
If you need further assistance please read [How To Contribute](https://github.com/opencv/opencv/wiki/How_to_contribute).
This is a template helping you to create an issue which can be processed as quickly as possible. This is the bug reporting section for the OpenCV library.
-->
##### System information (version)
<!-- Example
- OpenCV => 3.1
- Operating System / Platform => Windows 64 Bit
- Compiler => Visual Studio 2015
-->
- OpenCV => 3.1+ including 3.4.1
- Operating System / Platform => Windows .Net C# x86
- Compiler => Visual Studio 2017
##### Detailed description
Using an RTSP camera such as "AimCam", the stream freezes after 10 seconds. It does not freeze when using EMGU 3.0. It does not freeze when run through VLC utility either
##### Steps to reproduce
<!-- to add code example fence it with triple backticks and optional file extension
```.cpp
// cpp code
```
or attach as .txt or .zip file
-->
```.cs
_capture = new VideoCapture("rtsp://192.168.1.254/12345678.mov");
_capture.ImageGrabbed += processFrame;
_capture.Start();
…
// processFrame
_capture.Retrieve(_frame);
_frameBmp?.Dispose();
_frameBmp = _frame.Bitmap;
``` | priority: low,category: videoio,incomplete | low | Critical |
327,380,459 | rust | when suggesting to remove a crate, we leave a blank line | As of https://github.com/rust-lang/rust/pull/51015, the rustfix result for:
```rust
#![warn(unused_crates)]
extern crate foo;
fn main() { }
```
is
```rust
#![warn(unused_crates)]
fn main() { }
```
but not
```rust
#![warn(unused_crates)]
fn main() { }
```
| C-enhancement,A-diagnostics,T-compiler,E-help-wanted,WG-epoch | low | Minor |
327,382,289 | rust | unused macros fails some obvious cases due to prelude | This example does not warn, even in Rust 2018 edition:
```rust
// compile-flags: --edition 2018
extern crate foo;
fn main() { foo::bar(); }
```
The reason is that we resolve `foo` against the extern crate, when in fact it could *also* be resolved by the extern prelude fallback. But that's tricky! Something like this could also happen:
```rust
// compile-flags: --edition 2018
mod bar { mod foo { } }
use bar::*; // `foo` here is shadowed by `foo` below
extern crate foo;
fn main() { foo::bar(); }
```
In which case, removing `foo` would result in importing the module, since (I believe) that would shadow the implicit prelude imports.
Therefore: we can do better here, but with caution -- for example, we could suggest removing an extern crate in a scenario like this, but only if there are no glob imports in the current module. Not sure it's worth it though. | C-enhancement,T-compiler,WG-epoch | low | Minor |
327,396,102 | vscode | QuickPick API is no longer type safe | Testing #50574:
I've added `canPickMany: true` to my `vscode.QuickPickOptions` and now I'm receiving an array through a parameter that does not include the array type:
Debugger hover shows:
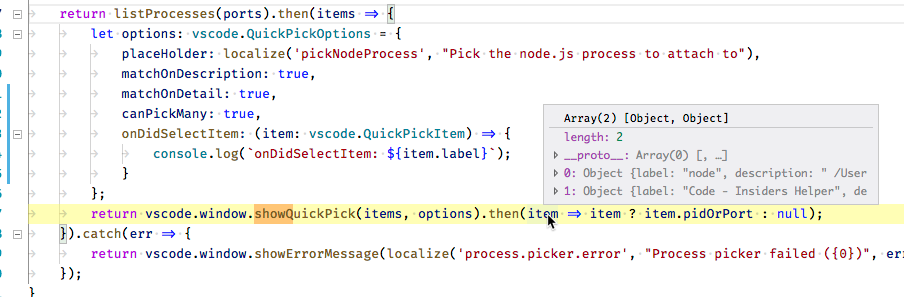
but Intellisense does not offer the array type:

| api,debt | low | Critical |
327,396,229 | rust | libcore: add defaults for empty iterators | I'm looking for a way to create empty iterators.
I have a few places in my application where I keep an iterator around as part of a data structure, and will advance that from time to time. After a few rounds, I will reset the iterator to start from the beginning again. (The iterator is supposed to point into the data structure, so [I got some problems](https://users.rust-lang.org/t/struct-containing-reference-to-own-field/1894/2) with implementing that design even though the data is never dropped, but let's ignore that here).
To initialise my structure, I want to create an empty iterator, i.e. one that has no elements left and will only yield `None`.
```rs
pub struct X;
pub struct Example {
iterator: Once<X>
}
impl Example {
pub fn reset(&mut self) {
self.iterator = once(X);
}
}
let mut e = Example {
iterator: ??? // how to create a consumed Once?
};
e.iterator.next(); // should yield None
e.reset();
e.iterator.next(); // will yield Option(X)
e.iterator.next(); // will yield None
```
In this particular case, I can use `option::IntoIter` directly instead of `Once` and write
```rs
pub struct Example {
iterator: option::IntoIter<X>
}
impl Example {
pub fn reset(&mut self) {
self.iterator = Some(X).into_iter();
}
}
let mut e = Example {
iterator: None.into_iter()
};
```
but that doesn't express my intent as well as using `Once`. Also, given that in my actual code the iterator type is generic, I would need an additional method `get_init` next to `get_reset` in my trait. I'd rather have my trait say that the iterator type needs to implement `Default`, and the default value should be an instance of the iterator that doesn't yield anything.
My suggestion: **Have all builtin iterators implement `Default`**.
For example,
```rs
impl<A> Default for Item<A> {
#[inline]
fn default() -> Item<A> { Item { opt: None } }
}
impl<A> Default for Iter<A> {
fn default() -> Iter<A> { Iter { inner: default() } }
}
impl<A> Default for IterMut<A> {
fn default() -> IterMut<A> { IterMut { inner: default() } }
}
impl<A> Default for IntoIter<A> {
fn default() -> IntoIter<A> { IntoIter { inner: default() } }
}
impl<T> Default for Once<T> {
fn default() -> Once<T> { Once { inner: default() } }
}
// (not sure whether all of these could simply be derived)
```
Does this need to go through the RFC process? Should I simply create a pull request? | T-libs-api,C-feature-request,A-iterators | low | Major |
327,402,320 | angular | Formbuilder group from value object with array | ## I'm submitting a...
<!-- Check one of the following options with "x" -->
<pre><code>
[ ] Regression (a behavior that used to work and stopped working in a new release)
[ x] Bug report <!-- Please search GitHub for a similar issue or PR before submitting -->
[ ] Performance issue
[ ] Feature request
[ ] Documentation issue or request
[ ] Support request => Please do not submit support request here, instead see https://github.com/angular/angular/blob/master/CONTRIBUTING.md#question
[ ] Other... Please describe:
</code></pre>
## Current behavior
<pre><code>
this.myObject = {myobject: [{id: 'test1'}, {id: 'test2'}]};
this.myFormGroup = this.fb.group(this.myObject);
</code></pre>
RESULT
<pre><code>
myFormGroup.value : { "myobject": { "id": "test1" } }
</code></pre>
## Expected behavior
<pre><code>
myFormGroup.value : {myobject: [{id: 'test1'}, {id: 'test2'}]}
</code></pre>
## Minimal reproduction of the problem with instructions
https://stackblitz.com/edit/angular-fromgroup-with-array
## What is the motivation / use case for changing the behavior?
It seems to be a bug, FormGroup build FormControl tree without considering if it's an array or object
It'is ok with a FormArray
## Environment
<pre><code>
Angular version: 5.0.0
Angular version: 6.0.2
| type: bug/fix,effort3: weeks,freq1: low,area: forms,state: confirmed,design complexity: major,P4 | medium | Critical |
327,487,364 | terminal | colortool.exe does not exit after executing | This bug-tracker is monitored by Windows Console development team and other technical types. **We like detail!**
If you have a feature request, please post to [the UserVoice](https://wpdev.uservoice.com/forums/266908).
> **Important: When reporting BSODs or security issues, DO NOT attach memory dumps, logs, or traces to Github issues**. Instead, send dumps/traces to [email protected], referencing this GitHub issue.
Please use this form and describe your issue, concisely but precisely, with as much detail as possible
* Your Windows build number: (Type `ver` at a Windows Command Prompt)
Microsoft Windows [Version 10.0.17134.48]
* What you're doing and what's happening: (Copy & paste specific commands and their output, or include screen shots)
I'm trying to use the color tool to change the color scheme. Whenever I execute it within cmd.exe, it does not exit. Also the effects (even with `--both`) don't seem to persist when I close the hung window and open a new one.
* What's wrong / what should be happening instead:
1. Color tool does not exit and freezes cmd
To repro:
```
cd Downloads
colortool.exe --both OneHalfDark
```
Please see attached screenshot:

| Product-Colortool,Help Wanted,Area-Interaction,Issue-Bug | low | Critical |
327,500,183 | opencv | Cuda 9.1 NVCUVID not working with opencv test program but works with nvidia test source code. | ##### System information (version)
- OpenCV => 3.4 (checkout from git)
- Operating System / Platform => Linux Ubuntu 16.04 64 Bit
- Compiler => gcc (Ubuntu 5.4.0-6ubuntu1~16.04.9) 5.4.0 20160609
##### Detailed description
When using cuda9.1, opencv's own test program does not work:
./example_gpu_video_reader plush1_720p_10s.m2v
It creates with a segfault.
cuda-sample test program works (it includes source code):
cuda-9.1/samples/3_Imaging/cudaDecodeGL/cudaDecodeGL
So, I conclude from this that the cuda drivers are installed correctly and that they work.
There must be something wrong with the opencv software, maybe using the cuda API wrongly.
Both the above test programs are supposed to utilize
libnvcuvid.so.390.30
<!-- your description -->
##### Steps to reproduce
./example_gpu_video_reader plush1_720p_10s.m2v
.... -> segfault.
The "plush1_720p_10s.m2v" is part of cuda-samples, supplied by Nvidia.
This used to work with cuda8.
The cuda supplied source code that tests the NVCUVID api works fine.
| priority: low,category: build/install,category: gpu/cuda (contrib) | low | Major |
327,522,428 | go | cmd/compile: confusing internal error when importing different packages with same name from different paths | This is a follow-up on #25568: It is possible to get an internal compiler error when invoking the compiler with plausible but incorrect `-I` arguments leading to selection of different but identically named packages ("io" in this case). To reproduce:
1) `cd $GOROOT/test`
2) `go tool compile fixedbugs/bug345.dir/io.go`
2) `go tool compile -I . fixedbugs/bug345.dir/main.go`
=>
```
fixedbugs/bug345.dir/main.go:10:2: internal compiler error: conflicting package heights 4 and 0 for path "io"
```
The issue here is an incorrect argument for `-I`. The following invocation:
`go tool compile -I $HOME/test/fixedbugs/bug345.dir fixedbugs/bug345.dir/main.go`
works as expected.
The internal error is confusing. We should be able to provide a better error message.
| NeedsFix,compiler/runtime | low | Critical |
327,532,825 | flutter | Instrument code to give visual cue to developers when their native code is taking too long | Following a discussion with peers I noticed that a pain point and source of misunderstanding around Method Channels running on main native thread.
Following a suggestion from @dnfield, it would be nice if method channels had a way to know if they're taking too long and freezing the UI. That would benefit people coming from different backgrounds that are not aware that method channels use the native UI thread and that's very bad for long operations.
I think the ideal case would have the method channel time the elapsed time in case the response happens in the main thread, or something along these lines. Feedback could flash the screen or something clearer / more obvious like a banner.
My low-hanging-fruit approach would be for debug builds to hook into Strict Mode api and set up some defaults for immediate results
```dart
StrictMode.setThreadPolicy(new StrictMode.ThreadPolicy.Builder()
.detectDiskReads()
.detectDiskWrites()
.detectNetwork()
.penaltyLog()
// .penaltyDialog()
.penaltyFlashScreen()
.build());
```
https://developer.android.com/reference/android/os/StrictMode
| engine,c: performance,c: proposal,P3,team-engine,triaged-engine | low | Critical |
327,542,135 | rust | Command's Debug impl has incorrect shell escaping | On Unix, the Debug impl for Command prints the command using quotes around each argument, e.g.
"ls" "-la" "\"foo \""
The use of spaces as a delimiter suggests that the output is suitable to be passed to a shell. While it's debatable whether users should be depending on any specific debug representation, in practice, at least rustc itself uses it for user-facing output (when passing `-Z print-link-args`).
There are two problems with this:
1. It's insecure! The quoting is performed, via the `Debug` impl for `CStr`, by `ascii::escape_default`, whose escaping rules are
> chosen with a bias toward producing literals that are legal in a variety of languages, including C++11 and similar C-family languages.
However, this does not include escaping the characters $, \`, and !, which have a special meaning within double quotes in Unix shell syntax. So, for example:
```rust
let mut cmd = Command::new("foo");
cmd.arg("`echo 123`");
println!("{:?}", cmd);
```
prints
```
"foo" "`echo 123`"
```
but if you run that in a shell, it won't produce the same behavior as the original command.
2. It's noisy. In a long command line like those produced by `-Z print-link-args`, most arguments don't contain any characters that need to be quoted or escaped, and the output is long enough without unnecessary quotes.
Cargo uses the `shell-escape` crate for this purpose; perhaps that code can be copied into libstd.
| C-bug,T-libs,A-fmt | low | Critical |
327,569,088 | pytorch | Better error message in DataChannelTCP::_receive | ## Issue description
The following code will produce an error from the TCP distributed backend:
```python
import os
import torch
import torch.distributed as dist
import sys
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group('tcp', rank=int(sys.argv[1]), world_size=2)
if dist.get_rank() == 0:
t = torch.arange(9)
dist.send(tensor=t, dst=1)
else:
t = torch.zeros(9)
dist.recv(tensor=t, src=0)
```
Error:
```
Traceback (most recent call last):
File "/Users/shendrickson/pytorch_dist.py", line 19, in <module>
dist.recv(tensor=t, src=0)
File "/Users/shendrickson/anaconda2/envs/torchdev/lib/python3.6/site-packages/torch/distributed/__init__.py", line 230, in recv
return torch._C._dist_recv(tensor, src)
RuntimeError: Tensor sizes do not match
```
This is a bit misleading, since the sizes of the tensors are the same but the types are different. I think it would be better to give a message along the lines of:
```
RuntimeError: Expected to receive 72 bytes, but got 36 bytes instead. Are tensors of same size and type?
```
I'd be happy to submit a PR for this if others agree that the original message should be changed. | triaged,module: backend | low | Critical |
327,577,134 | pytorch | [Caffe2]How to convert Caffe's mean file to Caffe2's ? | I have tried to use Caffe's mean file directly in Caffe2, but it complains the mean file doesn't contain qtensor fields.
Is there any way to translate Caffe's mean file to Caffe2's?
Thansk. | caffe2 | low | Minor |
327,587,604 | pytorch | how to use Softmax when do segmentation | I want implement FCN by caffe2 to do semantic segmentation, but I do not konw how to implement Softmax as FCN in caffe version.
Could you help me, Thanks!
the code of FCN's softmax using caffe is as follows:
```
layer {
name: "upscore"
type: "Deconvolution"
bottom: "score_fr"
top: "upscore"
param {
lr_mult: 0
}
convolution_param {
num_output: 21
bias_term: false
kernel_size: 64
stride: 32
}
}
layer {
name: "score"
type: "Crop"
bottom: "upscore"
bottom: "data"
top: "score"
crop_param {
axis: 2
offset: 19
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "score"
bottom: "label"
top: "loss"
loss_param {
ignore_label: 255
normalize: false
}
}
```
| caffe2 | low | Minor |
327,631,847 | rust | assert_eq!(a,b) fails to compile for slices while assert!(a == b) works fine | Example ([playground](https://play.rust-lang.org/?gist=1515ab97f5153b600fe3542b50aba925&version=stable&mode=debug)):
```rust
pub fn foo(xs: &[u32], k: u32) -> (&[u32], u32) { (xs, 0) }
fn main() {
assert!(foo(&[], 10) == (&[], 0)); // OK
assert_eq!(foo(&[], 10), (&[], 0)); // FAILS
}
````
| C-enhancement,T-libs-api | low | Critical |
327,674,010 | opencv | VideoCapture can't read some png files | ##### System information (version)
- OpenCV => 4.0.0-dev (todays)
- Operating System / Platform => Windows 64 Bit
- Compiler => mingw64
opencv_ffmpeg400_64.dll has 2018-03-01 timestamp
##### Detailed description
the dnn samples make heavy use of loading images through the videocapture, but trying with
http://answers.opencv.org/upfiles/15276026856434307.png or the humble
http://answers.opencv.org/m/opencv/media/images/logo.png?v=6 it fails to open.
<strike>renaming an older opencv_ffmpeg341_64.dll to opencv_ffmpeg400_64 made it work nicely, so there seems to be some regression here.</strike>
##### Steps to reproduce:
VideoCapture cap("logo.png");
cout << cap.isOpened() << endl;
| category: videoio,incomplete | low | Minor |
327,676,172 | gin | Question: How to write request log and error log in a separate manner. | I could write everything into a file with #805 post.
Related to this, how could it be possible to write error into a separate log?
--
I assume to use gin.DefaultErrorWriter, but it seems that log.SetOuput is only possible with a single file.
Current output (everything into a single file)
```
[GIN] 2018/05/30 - 19:21:17 | 404 | 114.656µs | ::1 | GET /comment/view/99999
Error #01: th size of input parameter is not 40
[GIN] 2018/05/30 - 19:21:20 | 200 | 1.82468ms | ::1 | GET /comment/view/00001
```
Current code
```
logfile, err := os.OpenFile(c.GinLogPath, os.O_RDWR|os.O_CREATE|os.O_APPEND, 0666)
if err != nil {
log.Fatalln("Failed to create request log file:", err)
}
errlogfile, err := os.OpenFile(c.GinErrorLogPath, os.O_RDWR|os.O_CREATE|os.O_APPEND, 0666)
if err != nil {
log.Fatalln("Failed to create request log file:", err)
}
// set request logging
gin.DefaultWriter = io.MultiWriter(logfile)
gin.DefaultErrorWriter = io.MultiWriter(errlogfile)
log.SetFlags(log.Ldate | log.Ltime | log.Lshortfile)
log.SetOutput(gin.DefaultWriter)
``` | question | low | Critical |
327,713,679 | create-react-app | Add React version into eslint-config-react-app | Hello everyone,
### Is this a bug report?
No
### Situation
I'm working on a project that use React (**[email protected]**). I use **react-scripts** (1.0.11) to start and build my project.
According to my React version, I use some deprecated function:
- **componentWillMount** (https://reactjs.org/docs/react-component.html#unsafe_componentwillmount)
- **componentWillReceiveProps** (https://reactjs.org/docs/react-component.html#unsafe_componentwillreceiveprops)
These functions are deprecated in 16.3.0 of React.
### Problems
Now, when I start or build my project, I get several warnings inside console and browser for this deprecated function.
### Explanation
I try to understand why I got this message for the React 15.6.2 which are not concern by this warning. In fact, the package **[email protected]** set the ESLint configuration for the actions of **react-scripts**.
The ESLint's plugin **eslint-plugin-react** have a rule: "_react/no-deprecated_" that created the warnings. This rule match on deprecated code, according to the configured React version number given in the ESLint config file. But, in this case, **eslint-config-react-app** does not define React version. So, as explain here: https://github.com/yannickcr/eslint-plugin-react#configuration, the default value is the latest React stable release.
That explain why I got warnings aiming React 16.3 in my project which use React 15.6.2.
### Solution
I suggest as solution to define React version in the configuration file of **eslint-config-react-app**.
I resolve my problem on adding this:
```
settings: {
react: {
version: require('react').version
}
},
```
inside the file index.js of **eslint-config-react-app**.
This solution could have some problems, especially, the package **react** is now mandatory (we could add a verification if package **react** exist before).
I know, that I could also "_eject_" my project and edit the config files, but I think this modification should be helpful for other users.
### Discussion
In first time, I enjoy to know if my solution is correct on the content and the style. In second time, if people agree with me, I will create a pull request to integrate this modification inside the project.
Thanks for the reading. I hope that my post is clear enough.
| issue: proposal | low | Critical |
327,723,946 | vue | Make vue available to other libraries without having to import it | Title needs work, idk what to call this.
### What problem does this feature solve?
Writing a component library with typescript requires importing Vue so you can use `Vue.extend(...)` to get typings. This causes problems when webpack decides to load a different instance of vue.
See https://github.com/vuetifyjs/vuetify/issues/4068
### What does the proposed API look like?
[Local registration](https://vuejs.org/v2/guide/components-registration.html#Local-Registration) to accept a function that **synchronously** returns a component, calling it with the parent vue instance.
The library can then do:
```ts
export default function MyComponent (Vue: VueConstructor) {
return Vue.extend({ ... })
}
```
And be used like:
```js
import MyComponent from 'some-library'
export default {
components: { MyComponent }
}
```
Of course that would then cause other problems, particularly where we use methods directly from other components. Maybe something that adds types like `Vue.extend()` but doesn't have any runtime behaviour would be better instead?
```ts
// When used, this will behave the same as a bare options object, instead of being an entire vue instance
export default Vue.component({
...
})
```
<!-- generated by vue-issues. DO NOT REMOVE --> | discussion | medium | Major |
327,745,880 | flutter | ListTile needs Material Design guidance: title overflow, textScaleFactor != 1.0 | We've updated the Flutter ListTile (like list items) widget to match: https://material.io/design/components/lists.html#specs
There are still some loose ends that the spec doesn't cover:
- Overflow: what happens when the title or subtitle wraps?
- Text scale factor: how should the layout scale when the text scale factor != 1.0?
There were also some issues with centering and the implicit case analysis in the specs. We need to confirm that the following rules are correct:
- If a leading widget is specified then the leading edge of the titles is 56.0, unless the leading widget's intrinsic width is > 40. In that case title's begin at leading_width + 16
- The leading and trailing widgets are always centered within the list tile. | framework,f: material design,P2,team-design,triaged-design | low | Minor |
327,798,737 | rust | Problem with type inference resolution | A problem was found with the type inference resoultion when the env_logger crate was imported. The issue was reported on [reddit](https://old.reddit.com/r/rust/comments/8n83ph/compile_issue_when_adding_a_dependency) and errors on the latest stable and nightly.
```rust
// Uncomment this and it breaks...
extern crate env_logger;
fn main() {
let string = String::new();
let str = <&str>::from(&string);
println!("{:?}", str);
}
``` | A-trait-system,T-compiler,A-inference,T-types | low | Critical |
327,802,686 | flutter | Text does not conform to DefaultTextStyle which is beyond Card | <!-- Thank you for using Flutter!
If you are looking for support, please check out our documentation
or consider asking a question on Stack Overflow:
* https://flutter.io/
* https://docs.flutter.io/
* https://stackoverflow.com/questions/tagged/flutter?sort=frequent
If you have found a bug or if our documentation doesn't have an answer
to what you're looking for, then fill our the template below. Please read
our guide to filing a bug first: https://flutter.io/bug-reports/
-->
## Steps to Reproduce
<!--
Please tell us exactly how to reproduce the problem you are running into.
Please attach a small application (ideally just one main.dart file) that
reproduces the problem. You could use https://gist.github.com/ for this.
If the problem is with your application's rendering, then please attach
a screenshot and explain what the problem is.
-->
I'm using DefaultTextStyle to set default TextStyle to all Text inside a Card. Widget tree:
- DefaultTextStyle -> Card -> Text : not work
- Card -> DefaultTextStyle -> Text : work
```dart
import 'package:flutter/material.dart';
void main() => runApp(MyApp());
class MyApp extends StatelessWidget {
@override
Widget build(BuildContext context) {
return MaterialApp(
title: 'Demo',
theme: ThemeData(
primarySwatch: Colors.blue,
),
home: FooPage(),
);
}
}
class FooPage extends StatefulWidget {
@override
State<StatefulWidget> createState() => FooPageState();
}
class FooPageState extends State<FooPage> {
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(title: new Text("Demo")),
body: Column(
children: <Widget>[
DefaultTextStyle(
style: TextStyle(fontSize: 30.0, color: Colors.blue),
child: Card(
child: Text('DefaultTextStyle outside Card does not work'),
),
),
Card(
child: DefaultTextStyle(
style: TextStyle(fontSize: 30.0, color: Colors.blue),
child: Text('DefaultTextStyle inside Card works'),
),
),
],
),
);
}
}
```
## Logs
<!--
Run your application with `flutter run --verbose` and attach all the
log output below between the lines with the backticks. If there is an
exception, please see if the error message includes enough information
to explain how to solve the issue.
-->
<!--
Run `flutter analyze` and attach any output of that command below.
If there are any analysis errors, try resolving them before filing this issue.
-->
<!-- Finally, paste the output of running `flutter doctor -v` here. -->
```
[✓] Flutter (Channel dev, v0.5.0, on Mac OS X 10.13.4 17E202, locale en-US)
• Flutter version 0.5.0 at /Users/rain/flutter
• Framework revision a863817c04 (4 days ago), 2018-05-26 12:29:21 -0700
• Engine revision 2b1f3dbe25
• Dart version 2.0.0-dev.58.0.flutter-97b6c2e09d
[✓] Android toolchain - develop for Android devices (Android SDK 27.0.3)
• Android SDK at /Users/rain/Library/Android/sdk
• Android NDK at /Users/rain/Library/Android/sdk/ndk-bundle
• Platform android-27, build-tools 27.0.3
• Java binary at: /Applications/Android Studio.app/Contents/jre/jdk/Contents/Home/bin/java
• Java version OpenJDK Runtime Environment (build 1.8.0_152-release-1024-b01)
• All Android licenses accepted.
[✓] iOS toolchain - develop for iOS devices (Xcode 9.3.1)
• Xcode at /Applications/Xcode.app/Contents/Developer
• Xcode 9.3.1, Build version 9E501
• ios-deploy 1.9.2
• CocoaPods version 1.5.2
[✓] Android Studio (version 3.1)
• Android Studio at /Applications/Android Studio.app/Contents
• Flutter plugin version 24.2.1
• Dart plugin version 173.4700
• Java version OpenJDK Runtime Environment (build 1.8.0_152-release-1024-b01)
[✓] VS Code (version 1.23.1)
• VS Code at /Applications/Visual Studio Code.app/Contents
• Dart Code extension version 2.12.1
```
| framework,f: material design,a: typography,has reproducible steps,P2,found in release: 2.5,found in release: 2.6,team-design,triaged-design | low | Critical |
327,873,076 | vscode | Support customisable alias for commands in command palette | - VSCode Version: 1.23.0
- OS Version: Linux
----
**Is there a way to define an alias for a command so that the command can be called under multiple different names (original name and the alias)?**
This is useful in different cases:
- If you switch from a different editor that uses a command palette (like emacs, ... ) you might have learned the names of commands over many years. Relearning takes more time than making an alias once. This would also allow to use two editors in parallel without interference. Before I came to VSCode I used emacs. I regularly want to call `diff-buffer-with-file` and it takes me some time to figure out that in VSCode it's called `Compare active file with saved`.
- You could define abbreviations that are quicker to type than selecting regular command names with the fuzzy search, e.g. `tt`. This is quite popular in emacs, see e.g. http://ergoemacs.org/emacs/emacs_alias.html
- if you regularly hit keys in the wrong order an alias might be useful for command you regularly use.
I think I'm not the only one who likes such a feature: When I used emacs I checked quite a few popular user configurations that users keep on github. A lot of these contain aliases by using the command `(defalias ...)` - including popular/influential ones like [spacemacs](https://github.com/syl20bnr/spacemacs/), [abo-abo's oremacs](https://github.com/abo-abo/oremacs), the [config of the emacs maintainer](https://github.com/jwiegley/dot-emacs) ...
This has been asked on [Reddit](https://www.reddit.com/r/vscode/comments/8bj63w/can_i_set_an_alias_for_the_command_palette/) and [stackoverflow](https://stackoverflow.com/questions/50143258/add-alias-for-commands-in-command-palette) without any useful answer.
| feature-request,quick-open | medium | Major |
327,888,684 | vscode | Support folding ranges inside a line | Hey, I have read through the folding-related issues (like #3422, the linked ones and some other ones related to the `FoldingRangeProvider` API specifically), but I don't seem to have come across a conversation about inline folding ranges.
Has this been discussed - or is it okay to start a discussion on the topic now?
I am interested in these, because I'd like to improve readability of MarkDown documents (using an extension) by collapsing MarkDown link targets (the URLs - which can be quite long) and instead linkifying the text range (using a `DocumentLinkProvider`).
Researching the `FoldingRange` API though, I can see it only has start and end lines, not `Position`s. Is this an immutable deliberate design decision or something open to alternative with enough support behind it?
I think other possible use cases could be folding of ternary expression branches, one-liner `if` statements and stuff like that. (But I'm mostly interested in my use-case described above.) | feature-request,editor-folding | high | Critical |
327,892,047 | rust | rustdoc: accept a "test runner" argument to wrap around doctest executables | Unit tests are currently built and run in separate steps: First you call `rustc --test` to build up a test runner executable, then you run the executable it outputs to actually execute the tests. This provides a great advantage: The unit tests can be built for a different platform than the host. Cargo takes advantage of this by allowing you to hand it a "test runner" command that it will run the tests in.
Rustdoc, on the other hand, collects, compiles, and runs the tests in one fell swoop. Specifically, it compiles the doctest as part of "running" the test, so compile errors in doctests are reported as test errors rather than as compile errors prior to test execution. Moreover, it runs the resulting executable directly:
https://github.com/rust-lang/rust/blob/fddb46eda35be880945348e1ec40260af9306d74/src/librustdoc/test.rs#L338-L354
This can be a problem when you're trying to run doctests for a platform that's fairly far removed from your host platform - e.g. for a different processor architecture. It would be ideal if rustdoc could accept some wrapper command so that people could run their doctests in e.g. qemu rather than on the host environment. | T-rustdoc,C-enhancement,A-doctests | low | Critical |
327,901,269 | flutter | Improve error message when a qualified import should be relative | I had a PR validation fail because I used a fully qualified import where I should have used a relative import. The error message in the out was as follows:
```bash
dart ./dev/bots/test.dart
SHARD=analyze
⏩ RUNNING: cd examples/hello_world; ../../bin/flutter inject-plugins
Unhandled exception:
NoSuchMethodError: The getter 'iterator' was called on null.
Receiver: null
Tried calling: iterator
#0 Object.noSuchMethod (dart:core-patch/dart:core/object_patch.dart:46)
#1 _deepSearch (file:///tmp/flutter%20sdk/dev/bots/test.dart:520:17)
#2 _deepSearch (file:///tmp/flutter%20sdk/dev/bots/test.dart:525:28)
#3 _verifyNoBadImportsInFlutter (file:///tmp/flutter%20sdk/dev/bots/test.dart:454:31)
<asynchronous suspension>
#4 _analyzeRepo (file:///tmp/flutter%20sdk/dev/bots/test.dart:100:9)
<asynchronous suspension>
#5 main (file:///tmp/flutter%20sdk/dev/bots/test.dart:56:26)
<asynchronous suspension>
#6 _startIsolate.<anonymous closure> (dart:isolate-patch/dart:isolate/isolate_patch.dart:277)
#7 _RawReceivePortImpl._handleMessage (dart:isolate-patch/dart:isolate/isolate_patch.dart:165)
```
We should have a better error message that points in the direction of the problem.
The specific import was in:
`circle_avatar.dart`
I initially imported material colors with full qualification:
`import 'package:flutter/src/material/colors.dart';`
The correct import was a relative one:
`import 'colors.dart'` | a: tests,team,framework,a: error message,P2,team-framework,triaged-framework | low | Critical |
327,938,554 | TypeScript | Add a Mutable type (opposite of Readonly) to lib.d.ts | <!-- 🚨 STOP 🚨 𝗦𝗧𝗢𝗣 🚨 𝑺𝑻𝑶𝑷 🚨
Half of all issues filed here are duplicates, answered in the FAQ, or not appropriate for the bug tracker. Please read the FAQ first, especially the "Common Feature Requests" section.
-->
## Search Terms
<!-- List of keywords you searched for before creating this issue. Write them down here so that others can find this suggestion more easily -->
mutable, mutable type
## Suggestion
lib.d.ts contains a `Readonly` type, but not a `Mutable` type. This type would be the opposite of `Readonly`, defined as:
```typescript
type Mutable<T> = {
-readonly[P in keyof T]: T[P]
};
```
## Use Cases
<!--
What do you want to use this for?
What shortcomings exist with current approaches?
-->
This is useful as a lightweight builder for a type with readonly properties (especially useful when some of the properties are optional and conditional logic is needed before assignment).
## Examples
<!-- Show how this would be used and what the behavior would be -->
```typescript
type Mutable<T> = {-readonly[P in keyof T]: T[P]};
interface Foobar {
readonly a: number;
readonly b: number;
readonly x?: string;
}
function newFoobar(baz: string): Foobar {
const foobar: Mutable<Foobar> = {a: 1, b: 2};
if (shouldHaveAnX(baz)) {
foobar.x = 'someValue';
}
return foobar;
}
```
## Checklist
My suggestion meets these guidelines:
* [x] This wouldn't be a breaking change in existing TypeScript / JavaScript code
* [x] This wouldn't change the runtime behavior of existing JavaScript code
* [x] This could be implemented without emitting different JS based on the types of the expressions
* [x] This isn't a runtime feature (e.g. new expression-level syntax)
| Suggestion,Awaiting More Feedback,Fix Available | high | Critical |
327,967,867 | go | runtime/pprof: possible sampling error with large memprofile rate | Split out from #25096, where @hyangah wrote:
> With the default memprofile sampling rate, however, the results look different. The results are different from the results with -memprofilerate=1, too. The order in the top15 list varies a lot. This seems to me errors from sampling-based estimation, not the bug the original report suggested.
This is an issue to investigate that. | NeedsInvestigation,compiler/runtime | low | Critical |
327,978,466 | go | x/image/vector: rasterizer shifts alpha mask and is slow when target is offset and small relative image size | Please answer these questions before submitting your issue. Thanks!
### What version of Go are you using (`go version`)?
1.10.2
### Does this issue reproduce with the latest release?
Yes
### What operating system and processor architecture are you using (`go env`)?
linux/amd64
### What did you do?
In the golang.org/x/image/vector.go there is this function:
```func (z *Rasterizer) Draw(dst draw.Image, r image.Rectangle, src image.Image, sp image.Point)```
r is the target rectangle for rendering the image. When r is a smaller rectangle than the bounds of the destination image dst, and offset into the middle of dst, two problems emerge:
First, the alpha mask, which is the whole point of the Draw command shifts with the target rectangle rather than staying fixed to the upper left corner of the image. I believe this should not be the default behavior. It is not consistent with other rasterizers, such as the free type rasterizer. If the mask shifts with the target and you are rendering a path using, say, Bezier curves, and want to draw that path onto an image, you must either determine before hand the exact boundaries of the path and shift the coordinates accordingly, because as it is, a target drawn somewhere in the middle of an image will always draw the mask relative to the upper left corner of the target rectangle. Having to determine the boundaries before hand requires flattening the curves and either storing the resulting line segments or repeating the process when actually rendering the alpha mask. It is much simpler to keep the alpha mask fixed to the upper left corner of the image boundary rather than move with the target rectangle.
Second, no matter how big the target rectangle is relative to the entire image, the "accumulate step" traverses the entire image, which is inefficient when the target is a small fraction of the image.
I have created a modified version of the rasterizer here: [https://github.com/srwiley/image](https://github.com/srwiley/image)
In the vector_test.go file are modified versions of the TestBasicPathDstAlpha and TestBasicPathDstRGBA test functions. These are changed to test for fixing the alpha mask to the image and not shifting with the target. They will fail with the current version of vector.go, but not the forked version.
There are also a series of benchmarks showing the improved performance when the target is small relative the destination image. This is what the benchmark output looks like:
```
BenchmarkDrawPathBounds1000-16 30 44412739 ns/op
BenchmarkDrawImageBounds1000-16 20 53485352 ns/op
BenchmarkDrawPathBounds100-16 3000 458989 ns/op
BenchmarkDrawImageBounds100-16 20 53309779 ns/op
BenchmarkDrawPathBounds10-16 200000 6054 ns/op
BenchmarkDrawImageBounds10-16 20 55934650 ns/op
BenchmarkDrawPathBounds2-16 1000000 1021 ns/op
BenchmarkDrawImageBounds2-16 20 54077408 ns/op
```
BenchmarkDrawPathBoundsX draw only the path boundary for a path of a hexagon of the indicated radius X in a 2200x2200 sized image. BenchmarkDrawImageBoundsX draws the entire image, which is what the current vector.go file does. So, as the size of the path gets smaller the speed difference increases.
### What did you expect to see?
Significantly greater speed when the target is small compared to the image size and the alpha mask fixed to the upper left of the destination image.
### What did you see instead?
Inefficient speed for small target sizes relative the image size, and the alpha mask fixed relative the target rectangle upper left corner and not the destination image bounds.
| Performance,NeedsInvestigation | low | Major |
328,000,762 | puppeteer | Support ServiceWorkers | We need an API to connect and manage ServiceWorkers.
At the very least, we need to:
- have a way to shut down service worker (requested at https://github.com/GoogleChrome/puppeteer/issues/1396)
- have a way to see service worker traffic (requested at https://github.com/GoogleChrome/puppeteer/issues/2617)
- support code coverage for service workers (requested at https://github.com/GoogleChrome/puppeteer/issues/2092)
| feature,chromium | low | Major |
328,051,788 | rust | Tracking issue for the OOM hook (`alloc_error_hook`) | PR #50880 added an API to override the std OOM handler, similarly to the panic hook. This was discussed previously in issue #49668, after PR #50144 moved OOM handling out of the `Alloc`/`GlobalAlloc` traits. The API is somewhat similar to what existed before PR #42727 removed it without an explanation. This issue tracks the stabilization of this API.
Defined in the `std::alloc` module:
<del>
```rust
pub fn set_oom_hook(hook: fn(Layout) -> !);
pub fn take_oom_hook() -> fn(Layout) -> !;
```
</del>
```rust
pub fn set_alloc_error_hook(hook: fn(Layout));
pub fn take_alloc_error_hook() -> fn(Layout);
```
CC @rust-lang/libs, @SimonSapin
## Unresolved questions
- [x] ~~Name of the functions. The API before #42727 used `_handler`, I made it `_hook` in #50880 because that's the terminology used for the panic hook (OTOH, the panic hook returns, contrary to the OOM hook).~~ #51264
- [ ] Should this move to its own module, or stay in `std::alloc`?
- [x] Interaction with unwinding. `alloc::alloc::oom` is marked `#[rustc_allocator_nounwind]`, so theoretically, the hook shouldn't panic (except when panic=abort). Yet if the hook does panic, unwinding seems to happen properly except it doesn't.
- [ ] Should we have this, or https://github.com/rust-lang/rust/issues/51540, or both?
- [ ] https://github.com/rust-lang/unsafe-code-guidelines/issues/506 | A-allocators,T-libs-api,B-unstable,C-tracking-issue,Libs-Tracked | medium | Critical |
328,053,026 | flutter | [proposal] make flutter compatible with Appium Tests | Hi,
we are writing a new flutter app and want it to be acceptance-tested by a bunch of Appium Tests.
As first we want to test on an iPhone, so we are not sure if the same problem also exsits for Android.
The flutter app cannot be tested because the PageSource always returns the one of the LaunchImage. Although the screenshot in Appium Desktop shows the correct view of the app. We verified it with other flutter apps from the AppStore, they have the same behavior. Means whatever view is open on the app, we always see the same page source.
The page source looks like
```xml
<?xml version="1.0" encoding="UTF-8"?>
<XCUIElementTypeApplication type="XCUIElementTypeApplication" name="test_app" label="test_app" enabled="true" visible="true" x="0" y="0" width="375" height="667">
<XCUIElementTypeWindow type="XCUIElementTypeWindow" enabled="true" visible="true" x="0" y="0" width="375" height="667">
<XCUIElementTypeOther type="XCUIElementTypeOther" enabled="true" visible="true" x="0" y="0" width="375" height="667"/>
</XCUIElementTypeWindow>
<XCUIElementTypeWindow type="XCUIElementTypeWindow" enabled="true" visible="false" x="0" y="0" width="375" height="667">
<XCUIElementTypeOther type="XCUIElementTypeOther" enabled="true" visible="false" x="0" y="0" width="375" height="667">
<XCUIElementTypeOther type="XCUIElementTypeOther" enabled="true" visible="false" x="0" y="667" width="375" height="216"/>
</XCUIElementTypeOther>
</XCUIElementTypeWindow>
<XCUIElementTypeWindow type="XCUIElementTypeWindow" enabled="true" visible="true" x="0" y="0" width="375" height="667">
<XCUIElementTypeStatusBar type="XCUIElementTypeStatusBar" enabled="true" visible="true" x="0" y="0" width="375" height="20">
<XCUIElementTypeOther type="XCUIElementTypeOther" enabled="true" visible="false" x="0" y="0" width="375" height="20"/>
<XCUIElementTypeOther type="XCUIElementTypeOther" enabled="true" visible="true" x="0" y="0" width="375" height="20">
<XCUIElementTypeButton type="XCUIElementTypeButton" name="Return to flutter_flat_app" label="Return to flutter_flat_app" enabled="true" visible="true" x="4" y="0" width="101" height="20"/>
<XCUIElementTypeOther type="XCUIElementTypeOther" value="SSID" name="3 of 3 Wi-Fi bars" label="3 of 3 Wi-Fi bars" enabled="true" visible="true" x="112" y="0" width="15" height="20"/>
<XCUIElementTypeOther type="XCUIElementTypeOther" name="10:49" label="10:49" enabled="true" visible="true" x="172" y="0" width="34" height="20"/>
<XCUIElementTypeOther type="XCUIElementTypeOther" name="100% battery power, On AC Power" label="100% battery power, On AC Power" enabled="true" visible="true" x="335" y="0" width="35" height="20"/>
</XCUIElementTypeOther>
</XCUIElementTypeStatusBar>
</XCUIElementTypeWindow>
</XCUIElementTypeApplication>
```
The problem then is that Appium always tells that the elements are not found what is understandable than they are not within the page source.
The app itself is working without any problems when used by hand.
To reproduce:
- Install a flutter app on an attached iPhone.
- Start the Appium Server.
- Start an Appium Session with the capabilities matching the previously installed app.
- Use Appium Desktop to inspect the elements. The app source always looks the same, irrelevant what screen is opened on the app.
We assume, but are not sure, that the WebDriverAgent cannot see correct page source. Appium consumes it to retrieve the page source.
Further, the problem only exists on a real device. When attaching an iOS-simulator the page source is correct and the tests can run.
Could you help us out?
Is this a bug? What is to be done that the page source is correct?
Would be great the get a response because we are stuck here.
Best regards,
Florian | a: tests,framework,c: proposal,P2,team-framework,triaged-framework | low | Critical |
328,074,971 | angular | Angular remove some of html entities between tags | ## I'm submitting a...
<!-- Check one of the following options with "x" -->
<pre><code>
[x] Bug report <!-- Please search GitHub for a similar issue or PR before submitting -->
</code></pre>
## Current behavior
Angular remove ` `, ` ` and maybe another html entites.
## Expected behavior
Save my entities, please!
## Minimal reproduction of the problem with instructions
https://stackblitz.com/edit/angular-vs-htmlentity?file=src/app/app.component.html
## What is the motivation / use case for changing the behavior?
I want use all of html entities in my html templates.
## Environment
Angular 5.2.0 and actual version at stackblitz.com
| type: bug/fix,freq1: low,area: compiler,state: confirmed,core: basic template syntax,P3,compiler: parser | low | Critical |
328,120,425 | angular | APP_INITIALIZER contract not honoured with TestBed | <!--
PLEASE HELP US PROCESS GITHUB ISSUES FASTER BY PROVIDING THE FOLLOWING INFORMATION.
ISSUES MISSING IMPORTANT INFORMATION MAY BE CLOSED WITHOUT INVESTIGATION.
-->
## I'm submitting a...
<!-- Check one of the following options with "x" -->
<pre><code>
[ ] Regression (a behavior that used to work and stopped working in a new release)
[x] Bug report <!-- Please search GitHub for a similar issue or PR before submitting -->
[ ] Performance issue
[ ] Feature request
[ ] Documentation issue or request
[ ] Support request => Please do not submit support request here, instead see https://github.com/angular/angular/blob/master/CONTRIBUTING.md#question
[ ] Other... Please describe:
</code></pre>
## Current behavior
When importing a Module providing a promise-based APP_INITIALIZER into a TestBed, the tests are executed before the promise is fully resolved.
There was an issue for this very problem (#16204) but the reporter closed because he found a workaround.
## Expected behavior
<!-- Describe what the desired behavior would be. -->
The promise of an APP_INITIALIZER should be fully resolved, exactly as when running the application that uses this module normally.
## Minimal reproduction of the problem with instructions
Hadn't had the time, but I expect that it should be simple to know if is already implemented or not to behave like expected. If yes, I will produce a repro.
## What is the motivation / use case for changing the behavior?
Same contract with tests or real app.
## Environment
<pre><code>
Angular version: 6.0.7
</code></pre>
| type: bug/fix,area: testing,freq1: low,P3 | medium | Critical |
328,127,526 | pytorch | [Caffe2] place some nodes of the same network on GPU and others on CPU? | ## Issue description
When I use multi-GPU to run the baseline X152, I get an error of "out of memory", but I have no better device. Can I run some network nodes on the CPU?
| caffe2 | low | Critical |
328,225,018 | TypeScript | Cannot augment global namespace from module due to shadowing(?) | **TypeScript Version:** 2.8.3, 3.0.0-dev.20180531
**Search Terms:** global augment
**Code**
Briefly, declare a namespace in a script, then attempt to augment it in a module, and it shadows rather than augments.
```ts
// global.d.ts, note: a script
declare namespace X {
interface Iface {
x: string;
}
}
// module.ts
export {} // make it a module
declare global {
namespace X {
// This declaration doesn't matter, it's just showing that
// the user was intending to augment the namespace.
const augment: number;
}
function f(): X.Iface;
}
```
**Expected behavior:**
The module augments the global namespace X.
**Actual behavior:**
module.d.ts:8:19 - error TS2694: Namespace 'global.X' has no exported member 'Iface'.
It appears that the 'X' inside the 'declare global' shadows the other 'X', rather than augmenting it. If you comment out the module.d.ts decl of the X namespace it compiles.
Also it's weird that the error message talks about "global.X", maybe an error reporting bug?
**Playground Link:** n/a, needs multiple files.
**Related Issues:** <!-- Did you find other bugs that looked similar? -->
| Bug | low | Critical |
328,336,675 | pytorch | [Caffe2] VideoInput/LMDB Reader to Standalone Predictor Question | Hey Caffe2/PyTorch team,
I had a question about going from a trained model (.mdl format) to a standalone predictor model. I've been able to load the .mdl file as follows:
```
meta_net_def = pred_exp.load_from_db('trained_model.mdl', 'minidb')
init_net = core.Net(
pred_utils.GetNet(meta_net_def, predictor_constants.GLOBAL_INIT_NET_TYPE)
)
predict_net = core.Net(
pred_utils.GetNet(meta_net_def, predictor_constants.PREDICT_NET_TYPE)
)
```
However, the model, once loaded, is expecting to be executed on a GPU and initiated via an LMDB reader:
**init_net proto:**
```
input: "!!PREDICTOR_DBREADER"
output: "gpu_0/conv1_middle_w"
output: "gpu_0/conv1_middle_spatbn_relu_s"
output: "gpu_0/conv1_middle_spatbn_relu_b"
output: "gpu_0/conv1_w"
output: "gpu_0/conv1_spatbn_relu_s"
output: "gpu_0/conv1_spatbn_relu_b"
output: "gpu_0/comp_0_conv_1_middle_w"
output: "gpu_0/comp_0_spatbn_1_middle_s"
...
name: ""
type: "Load"
```
**first two layers in predict_net proto:**
```
input: "trained_init/CreateDB"
output: "gpu_0/data"
output: "gpu_0/label"
name: "data"
type: "VideoInput"
arg {
... bunch of VideoInput args ...
}
device_option {
device_type: 1
cuda_gpu_id: 0
}
input: "gpu_0/data"
output: "gpu_0/data"
name: ""
type: "StopGradient"
device_option {
device_type: 1
cuda_gpu_id: 0
}
{convolutional layers, etc...}
```
My questions are:
a) how would I go about removing/modifying the top layer(s) of the init and predict nets to allow for individual predictions (without requiring the creation of an LMDB, etc)? (I'd like to be able to point predict.py to a folder or to a single video, load the data into np arrays or otherwise, then feed those into the Caffe2 model for predictions)
b) how would I go about switching from GPU to CPU execution?
c) is there anything else I might be missing when going from a training 'checkpoint' .mdl file to a prediction model?
Thanks so much! | caffe2 | low | Minor |
328,339,777 | go | cmd/compile: inconsistent acceptance of cyclic variable declaration (esoteric) | Another test case for handling of cycle detection:
https://play.golang.org/p/DAftfsYBsrX
is accepted and appears to run correctly. The similar (and functionally identical) program
https://play.golang.org/p/AChHOplAHzp
is not accepted with an incorrect type alias cycle error. And the simplified version eliminating the type name T
https://play.golang.org/p/ozYsLzyDax8
is not accepted with a type checking loop error.
Yet all of them are functionally the same. Either all of them should be accepted or none of them should be accepted. | NeedsInvestigation,compiler/runtime | low | Critical |
328,424,186 | node | async_hooks.triggerAsyncId() don't return the expected value in context of the connection callback of net.Server | <!--
Thank you for reporting an issue.
This issue tracker is for bugs and issues found within Node.js core.
If you require more general support please file an issue on our help
repo. https://github.com/nodejs/help
Please fill in as much of the template below as you're able.
Version: output of `node -v`
Platform: output of `uname -a` (UNIX), or version and 32 or 64-bit (Windows)
Subsystem: if known, please specify affected core module name
If possible, please provide code that demonstrates the problem, keeping it as
simple and free of external dependencies as you are able.
-->
* **Version**: 8.x and 10.x
* **Platform**: all supported
* **Subsystem**:
<!-- Enter your issue details below this comment. -->
async_hooks.triggerAsyncId() is expected to return the async id of the connection in the `onconnection` callback of server. This was specifically declared in the example of the async_hooks documentation which can be found [here](https://nodejs.org/dist/latest-v10.x/docs/api/async_hooks.html#async_hooks_async_hooks_triggerasyncid).
However, after testing the example using both node 10.3.0 and 8.11.2, I found the result was different. Below is the code and output of my test.
my code:
```
let net = require('net');
let async_hooks = require('async_hooks');
let fs = require('fs');
async_hooks.createHook({
init(asyncId, type, triggerAsyncId) {
fs.writeSync(1, `init hook: ${type}, asyncID: ${asyncId}, triggerID: ${triggerAsyncId}\n`);
},
before(asyncId) {
fs.writeSync(1, `before hook: asyncID: ${asyncId}\n`);
},
after(asyncId) {
fs.writeSync(1, `after hook: asyncId: ${asyncId}\n`);
},
}).enable();
const server = net.createServer((conn) => {
// The resource that caused (or triggered) this callback to be called
// was that of the new connection. Thus the return value of triggerAsyncId()
// is the asyncId of "conn".
// fs.wriateSync(1, '-- conn callback, triggerAsyncId:', async_hooks.triggerAsyncId());
let tid = async_hooks.triggerAsyncId();
let eid = async_hooks.executionAsyncId();
fs.writeSync(1, `-- conn callback, triggerAsyncId: ${tid}, executionAsyncId: ${eid}\n`);
}).listen(8000, () => {
// Even though all callbacks passed to .listen() are wrapped in a nextTick()
// the callback itself exists because the call to the server's .listen()
// was made. So the return value would be the ID of the server.
let tid = async_hooks.triggerAsyncId();
let eid = async_hooks.executionAsyncId();
fs.writeSync(1, `-- listen callback, triggerAsyncId: ${tid}, executionAsyncId: ${eid}\n`);
});
```
if I connect the server with another terminal by `connect localhost 8000`, then the output is:
```
init hook: TCPSERVERWRAP, asyncID: 5, triggerID: 1
init hook: TickObject, asyncID: 6, triggerID: 5
before hook: asyncID: 6
-- listen callback, triggerAsyncId: 5, executionAsyncId: 6
after hook: asyncId: 6
init hook: TCPWRAP, asyncID: 7, triggerID: 5
before hook: asyncID: 5
-- conn callback, triggerAsyncId: 1, executionAsyncId: 5
after hook: asyncId: 5
before hook: asyncID: 7
init hook: TickObject, asyncID: 8, triggerID: 7
after hook: asyncId: 7
before hook: asyncID: 8
init hook: TickObject, asyncID: 9, triggerID: 8
init hook: TickObject, asyncID: 10, triggerID: 8
after hook: asyncId: 8
before hook: asyncID: 9
after hook: asyncId: 9
before hook: asyncID: 10
after hook: asyncId: 10
before hook: asyncID: 7
after hook: asyncId: 7
```
Please note the line `-- conn callback, triggerAsyncId: 1, executionAsyncId: 5`. It means in the connection callback, the triggerAsyncId is 1 instead of 7 which is expected.
I investigated the code, and found the root cause is:
When the callback is made, it was made on the TCPWrap instance of the server, and the server's triggerId (1) and asyncId (5) were pushed into the stack, thus lead to this result. While It seems that this mechanism is ok most of the time for normal callbacks, but for this new connection callback, I think we should add some logic to pass the triggerId of the new connection (actually a new TCPWrap instance) to push into the stack. I made a change based on that and verified the result, it could work.
So, I doubt is the issue due to document obsoleted or the code should be changed?
I'd like to make a PR if it is confirmed, thanks. | async_hooks | low | Critical |
328,445,443 | angular | Make possible to configurable style compiler constants | ## I'm submitting a...
<!-- Check one of the following options with "x" -->
<pre><code>
[x] Performance issue
[x] Feature request
</code></pre>
## Current behavior
Compiler variable and attr is constant.
https://github.com/angular/angular/blob/master/packages/compiler/src/style_compiler.ts#L16
```ts
const COMPONENT_VARIABLE = '%COMP%';
const HOST_ATTR = `_nghost-${COMPONENT_VARIABLE}`;
const CONTENT_ATTR = `_ngcontent-${COMPONENT_VARIABLE}`;
```
## Expected behavior
Compiler variable and attr must have default values and possible to configurable.
## What is the motivation / use case for changing the behavior?
Currently that constants is part of build js/css files and made files more large.
For example, statistics for my not very large project (`main.bundle.ts` 1 MB)
```
%COMP% - 1528 matches (9 168 bytes)
_nghost- - 332 matches (2 656 bytes)
_ngcontent- - 1195 matches (13 145 bytes)
Total - 24 969 excess bytes
```
But, maybe I konw what I do and can replace this constatns to `☺`, `☻`, `♥` (just for example).
This action will save 21 914 butes just for my example or more for bigger project with many css rules. | feature,area: core,core: stylesheets,feature: under consideration | low | Major |
328,455,357 | opencv | Windows 10 CMake | OPENCV_EXTRA_MODULES_PATH | Bug | - OpenCV => Latest Github
- Operating System / Platform => Windows 64 Bit
- Compiler => Visual Studio 2015
```
CMake Error at cmake/OpenCVModule.cmake:368 (_glob_locations):
Syntax error in cmake code at
E:/opencv_github/opencv/cmake/OpenCVModule.cmake:368
when parsing string
E:\opencv_github\opencv_contrib\modules
Invalid character escape '\o'.
Call Stack (most recent call first):
modules/CMakeLists.txt:7 (ocv_glob_modules)
```
This error is only generated when i set OPENCV_EXTRA_MODULES_PATH,
I have set the path to the modules folder after taking checkout of opencv_contrib.
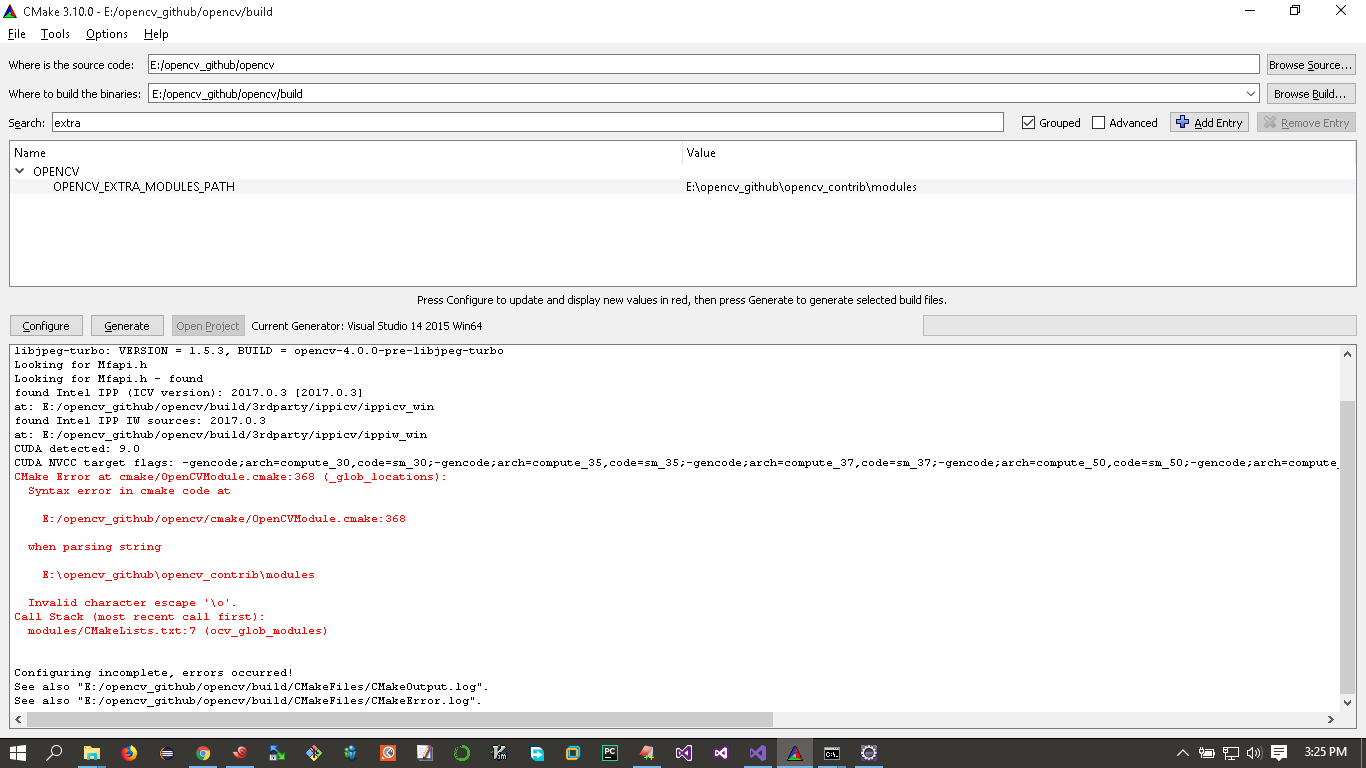
| bug,priority: low,category: build/install | low | Critical |
328,456,191 | go | all: be consistent about the term "embedded field" | The spec very clearly calls fields with no names "embedded fields": https://golang.org/ref/spec#Struct_types
> A field declared with a type but no explicit field name is called an embedded field.
However, the Go standard library and documentation mixes that term with "anonymous field":
```
$ cd tip
$ git grep -i 'embedded field' | wc -l
83
$ git grep -i 'anonymous field' | wc -l
38
```
In particular, I found it in https://golang.org/pkg/go/ast/#Field:
Names []*Ident // field/method/parameter names; or nil if anonymous field
Since the spec only mentions one, and it seems to dominate in usage anyway, I think we should try to be as consistent as possible. Specific cases have been fixed in the past, like https://github.com/golang/go/commit/b396d1143b3e717eb2828a101feeb8eb6810891b.
Of course, this doesn't include names that would break Go1 if changed - it is mainly meant for godocs, comments, and errors messages given by `go/*` and `cmd/*`. I presume that old changelogs, such as `doc/devel/weekly.html`, don't need to be changed.
/cc @griesemer @rsc @mdempsky | NeedsFix | low | Critical |
328,456,248 | pytorch | Build error : mpi/mpi_gpu_test.cc.o: undefined reference to symbol '_ZN3MPI8Datatype4FreeEv' | I get the following error while trying to build the package on ubuntu 16.04:
cc1plus: warning: unrecognized command line option '-Wno-unknown-warning-option'
cc1plus: warning: unrecognized command line option '-Wno-invalid-partial-specialization'
[ 91%] Linking CXX executable ../bin/mpi_gpu_test
/usr/bin/ld: CMakeFiles/mpi_gpu_test.dir/mpi/mpi_gpu_test.cc.o: undefined reference to symbol '_ZN3MPI8Datatype4FreeEv'
//usr/lib/libmpi_cxx.so.1: error adding symbols: DSO missing from command line
collect2: error: ld returned 1 exit status
caffe2/CMakeFiles/mpi_gpu_test.dir/build.make:110: recipe for target 'bin/mpi_gpu_test' failed
make[2]: *** [bin/mpi_gpu_test] Error 1
CMakeFiles/Makefile2:3504: recipe for target 'caffe2/CMakeFiles/mpi_gpu_test.dir/all' failed
make[1]: *** [caffe2/CMakeFiles/mpi_gpu_test.dir/all] Error 2
Makefile:138: recipe for target 'all' failed
make: *** [all] Error 2
| caffe2 | low | Critical |
328,471,620 | angular | minlength validator causes ExpressionChangedAfterItHasBeenCheckedError when its value is dynamically updated | <!--
PLEASE HELP US PROCESS GITHUB ISSUES FASTER BY PROVIDING THE FOLLOWING INFORMATION.
ISSUES MISSING IMPORTANT INFORMATION MAY BE CLOSED WITHOUT INVESTIGATION.
-->
## I'm submitting a...
<!-- Check one of the following options with "x" -->
<pre><code>
[ ] Regression (a behavior that used to work and stopped working in a new release)
[x] Bug report <!-- Please search GitHub for a similar issue or PR before submitting -->
[ ] Performance issue
[ ] Feature request
[ ] Documentation issue or request
[ ] Support request => Please do not submit support request here, instead see https://github.com/angular/angular/blob/master/CONTRIBUTING.md#question
[ ] Other... Please describe:
</code></pre>
## Current behavior
When an input field has a minlength validator directive and minlength value dynamically changes this causes ExpressionChangedAfterItHasBeenCheckedError when the field turns from valid to invalid, and vice-versa, and if you additionally check form validity with *ngIf above the input field. Strangely, when you check form validity below the field with *ngIf there is no error.
## Expected behavior
<!-- Describe what the desired behavior would be. -->
There shouldn't be ExpressionChangedAfterItHasBeenCheckedError after minlenght validation returns a result and field changes state (valid/invalid).
## Minimal reproduction of the problem with instructions
<!--
For bug reports please provide the *STEPS TO REPRODUCE* and if possible a *MINIMAL DEMO* of the problem via
https://stackblitz.com or similar (you can use this template as a starting point: https://stackblitz.com/fork/angular-gitter).
-->
Here is a [demo](https://stackblitz.com/edit/angular-5-minlength-validator-error) which demonstrates the problem and also cases where there is no problem. All the details are described in the demo.
## What is the motivation / use case for changing the behavior?
<!-- Describe the motivation or the concrete use case. -->
It should be possible to dynamically change the value for validation without bumping into ExpressionChangedAfterItHasBeenCheckedError.
## Environment
<pre><code>
Angular version: 5.x
<!-- Check whether this is still an issue in the most recent Angular version -->
Browser:
- [x] Chrome (desktop)
- [x] Firefox
</code></pre>
| type: bug/fix,freq2: medium,workaround2: non-obvious,area: forms,state: confirmed,P3 | low | Critical |
328,556,475 | flutter | App throws "Failed assertion ... labelStyle != null" when applying TextTheme with only Title color defined | Hi! I am working on an app using Android studio using Flutter 4.4 and I get the following issue.
This works fine:
```dart
return new MaterialApp(
title: 'Title',
theme: new ThemeData(primarySwatch: Colors.lightBlue,)
home: new HomePage(title: 'Title'),
);
```
This doesn't:
```dart
return new MaterialApp(
title: 'Title',
theme: new ThemeData(
primarySwatch: Colors.lightBlue,
textTheme: new TextTheme(
title: new TextStyle(color: Colors.white),
)
),
home: new HomePage(title: 'Title'),
);
```
I've looked and I don't see why this shouldn't work. Is it an issue, or am I missing something basic? | framework,f: material design,d: api docs,P2,team-design,triaged-design | low | Critical |
328,560,863 | terminal | Secondary buffer window restore glitch | * Your Windows build number: (Type `ver` at a Windows Command Prompt)
17682
* What you're doing and what's happening: (Copy & paste specific commands and their output, or include screen shots)
Run `vim -u NONE -i NONE "+set tgc"` (needs a recent Windows vim). Maximize the window and then restore it. The buffer will have some visual glitches - the some of the tildes are in random places on the screen. This is a minimal repro, and only happens with termguicolors set (e.g. using ANSI colors in the secondary buffer). The issue is more apparent though if you have some vim plugins installed:
After typing a couple lines with my vimrc:
If you're using no vimrc, it helps to see the issue if you type a couple lines of text and/or `set number` first. The buffer gets pushed about a third of the way down the screen, and the bottom third appears on top.
* What's wrong / what should be happening instead:
The buffer shouldn't be glitchy. | Product-Conhost,Area-Output,Issue-Bug | low | Minor |
328,578,080 | vscode | onEnterRules should be multi-line aware | <!--
Do you have a question? Please ask it on https://stackoverflow.com/questions/tagged/vscode.
For bug reports, please fill in the details below. For feature requests, please describe the desired feature.
-->
<!-- Use Help > Report Issue to prefill these. -->
Use case: Microsoft/vscode-cpptools#2072
Steps to Reproduce:
Type the following text in a .cpp file
```
a = a
* b;
```
Then hit enter at the end of the line to begin a new line. You'll get
```
a = a
* b;
*
```
This is not expected behavior in this context. This is perhaps expected when in the middle of a multiline decorated comment but not otherwise.
This does not happen in an unsaved file, a file with no extension, .txt extension etc. and does not happen if the cpptools extension is disabled and happens when it is re-enabled. | feature-request,languages-basic,editor-autoindent | low | Critical |
328,613,188 | pytorch | [PyTorch] EmbeddingBag comparison vs Embedding fails w/ small max_norm on CUDA | When using small `max_norm` values like `0.1`, `1` or `2`, the comparison on CUDA fails with large error (Half w/ 0.1 fails with error ~`0.16`), but passes on CPU.
Relevant lines: https://github.com/pytorch/pytorch/blob/master/test/test_nn.py#L1674-L1706
Discovered when doing #7959
cc @adamlerer
| triaged,module: norms and normalization | low | Critical |
328,616,452 | neovim | swapfile dialog should check for zombie processes | <!-- Before reporting: search existing issues and check the FAQ. -->
- `nvim --version`: 0.2.2
- Vim (version: ) behaves differently? unknown
- Operating system/version: FreeBSD but probably all OS except Windows
- Terminal name/version: conhost but N/A
- `$TERM`: xterm-256color but N/A
### Steps to reproduce using `nvim -u NORC`
```
nvim -u NORC foo.cpp
# now in another terminal kill the nvim process but don't reap it
# probably easiest to spawn nvim programatically so that you can skip reaping by not checking its exit status
nvim -u NORC foo.cpp
```
### Actual behaviour
neovim presents the swap file warning as the swap file exists, but when querying the parent process it considers it to still be alive since the pid remains in the OS ps tables.
### Expected behaviour
neovim should take into account that the process status for the pid specified in the swap file is zombie and treat it as if it were not running.
(Please note that I experienced this running 0.2.2 but did not have the time to set up a repro case under master, given the complexity in reproducing, however given how straightforward the problem is, I presume this is either a "still exists in master" or "yup, known issue and since fixed".) | enhancement,complexity:low,system | low | Major |
328,621,862 | bitcoin | Notes on Compact Block getdata fallback responses | This came up at a meeting a while back, but I realized it was never materially written down anywhere.
Compact Block high-bandwidth processing can fall back to getdatas when the client belives a short id collision may have occurred (among a few other cases). In such cases, we are required to wait until we have verified the full block before we can respond to the getdata request (hence the few awkward ActivateBestChain calls in net_processing). However, in case we find the block to be invalid (or decide its actually not our best-chain-candidate due to some race receiving another block in parallel) we will simply leave the getdata unresponded to. This will result in us eventually getting disconnected for stalling.
It is important to note that, were an attacker able to generate a block which, when relayed, would cause getdata fallbacks on an invalid block, such an attacker would be able to cause massive disconnections across the network, especially targeting mining nodes or other nodes which receive blocks particularly fastly. I do not believe such creation is currently possible, but definitely could be bad if we did something dumb like fixing the nonce in the future.
During the meeting we discussed using the existing NOTFOUND message for block requests as well, which seemed to have some level of support (or a BLOCK_NOTFOUND or whathaveyou) and using that to allow peers to simply reject providing a block without being disconnected as a staller. | P2P | low | Minor |
328,645,044 | pytorch | [PyTorch] Windows CI CUDA mem leak check on BN tests are flaky | They often report -1024 anti-leaks. Instances:
https://ci.pytorch.org/jenkins/job/pytorch-builds/job/pytorch-win-ws2016-cuda9-cudnn7-py3-test1/44/console
https://ci.pytorch.org/jenkins/job/pytorch-builds/job/pytorch-win-ws2016-cuda9-cudnn7-py3-test1/106/console
https://ci.pytorch.org/jenkins/job/pytorch-builds/job/pytorch-win-ws2016-cuda9-cudnn7-py3-test1/107/console
Can't reproduce on our Win dev CI machine, so temporarily disabling at #8043 . | module: memory usage,triaged,module: flaky-tests | low | Minor |
328,651,197 | flutter | Min width of material button is greater than it should be | Spec says 64dp, but its set to 88dp | framework,f: material design,a: fidelity,P2,team-design,triaged-design | low | Minor |
328,659,101 | go | net/http: consider implementing browser http client at http.Client level instead of http.RoundTripper | The motivation for considering implementing the HTTP client at `http.Client` level rather than `http.RoundTripper`, it has to do with the fact that browser APIs (such as XmlHTTPRequest and Fetch) do not allow making individual HTTP requests without interpreting the response code, they operate at a higher level, closer to what `http.Client.Do` method does.
This issue is a continuation of a [discussion in CL 114515](https://go-review.googlesource.com/c/go/+/114515#message-24f243ca77abe666842f6f24a1019d1bd6f2d5d3). /cc @bradfitz @johanbrandhorst @neelance
I wrote:
> http.Transport type is documented as:
>
> // A Transport is a low-level primitive for making HTTP and HTTPS requests.
> // For high-level functionality, such as cookies and redirects, see Client.
>
> When I originally wrote this functionality in GopherJS, I started by doing it at the http.RoundTripper level and was hoping to implement as much of its semantics as possible. Getting response body streaming was my main motivation, and the XHR transport was already implemented at http.RoundTripper level too, so it was a quick decision.
>
> Over time, I learned that both XHR and Fetch browser APIs are higher level and don't allow making individual HTTP requests. Due to security reasons and things like CORS, the frontend code doesn't actually ever get Redirect responses, only the final redirect destination. Fetch also deals with caching, credentials, etc.
>
> I didn't want to touch this decision for GopherJS because it was more of a prototype, but since this is the real Go tree, perhaps we should revisit the decision of what abstraction level to implement this at. I haven't prototyped it yet, but given what I've seen so far, I suspect that implementing the HTTP client in browsers at the http.Client level may be a closer fit to what browsers allow client code to do.
>
> Thoughts (Brad, Johan, Richard)?
@johanbrandhorst wrote:
> I'm not sure I understand how this would apply here - wouldn't we still need a custom Transport implementation? If we defined a js,wasm specific client presumably it'd still need to have all the same fields as the normal client.
@bradfitz wrote:
> Good point, but I'm more concerned with more code working by default without changes, so I think this is okay to violate for now in Go 1.11. We can revisit in Go 1.12 & later.
I've been thinking about this more, and I have 2 comments (to be posted as replies). It's not clear to me what will end up being the best (least bad) solution. | arch-wasm | low | Minor |
328,660,825 | go | runtime: TestGdbPython flaky on linux-mipsle builder | Examples:
https://build.golang.org/log/e59511fa905a9939c7b85a9f6cefb99140c8915f
https://build.golang.org/log/dc9b43b3eb5e0029089cf9ac53b37f6b8b0e7847
Detail:
```
##### GOMAXPROCS=2 runtime -cpu=1,2,4 -quick
--- FAIL: TestGdbPython (3.10s)
runtime-gdb_test.go:61: gdb version 7.7
runtime-gdb_test.go:195: gdb output: Loading Go Runtime support.
Loaded Script
Yes /data/mipsle/go/src/runtime/runtime-gdb.py
Breakpoint 1 at 0x9b508: file /data/mipsle/go/src/fmt/print.go, line 264.
Failed to read a valid object file image from memory.
Breakpoint 1, fmt.Println (a=..., err=..., n=<optimized out>) at /data/mipsle/go/src/fmt/print.go:264
264 return Fprintln(os.Stdout, a...)
BEGIN info goroutines
* 1 running runtime.systemstack_switch
2 runnable runtime.forcegchelper
3 waiting runtime.gopark
4 runnable runtime.runfinq
END
#1 0x000a24e0 in main.main () at /tmp/go-build482556707/main.go:13
13 slicevar = append(slicevar, mapvar["abc"])
BEGIN print mapvar
$1 = map[string]string = {["abc"] = "def", ["ghi"] = "jkl"}
END
BEGIN print strvar
$2 = "abc"
END
BEGIN info locals
mapvar = map[string]string = {["abc"] = "def", ["ghi"] = "jkl"}
slicevar = []string = {"def"}
strvar = "abc"
END
#0 fmt.Println (a=..., err=..., n=<optimized out>) at /data/mipsle/go/src/fmt/print.go:264
264 return Fprintln(os.Stdout, a...)
BEGIN goroutine 1 bt
#0 fmt.Println (a=..., err=..., n=<optimized out>) at /data/mipsle/go/src/fmt/print.go:264
#1 0x000a24e0 in main.main () at /tmp/go-build482556707/main.go:13
END
BEGIN goroutine 2 bt
#0 runtime.forcegchelper () at /data/mipsle/go/src/runtime/proc.go:243
#1 0x000a24e0 in main.main () at /tmp/go-build482556707/main.go:13
END
Breakpoint 2 at 0xa2514: file /tmp/go-build482556707/main.go, line 18.
Program received signal SIGTRAP, Trace/breakpoint trap.
fmt.Println (a=..., err=..., n=<optimized out>) at /data/mipsle/go/src/fmt/print.go:264
264 return Fprintln(os.Stdout, a...)
BEGIN goroutine 1 bt at the end
#0 fmt.Println (a=..., err=..., n=<optimized out>) at /data/mipsle/go/src/fmt/print.go:264
#1 0x000a24e0 in main.main () at /tmp/go-build482556707/main.go:13
END
runtime-gdb_test.go:264: goroutine 1 bt at the end failed: #0 fmt.Println (a=..., err=..., n=<optimized out>) at /data/mipsle/go/src/fmt/print.go:264
#1 0x000a24e0 in main.main () at /tmp/go-build482556707/main.go:13
FAIL
FAIL runtime 208.804s
```
```
``` | Testing,help wanted,NeedsInvestigation,compiler/runtime | low | Critical |
328,667,976 | angular | Adding property/event bindings to ng-content should error | ### Issue
Adding property/event bindings to `<ng-content>` (attributes that are not explicitly supported APIs) currently no-op. They should be an error, as the attributes will be completely lost.
### Reproduction
https://stackblitz.com/edit/angular-gitter-hm6egs?file=app%2Fapp.component.ts
| type: bug/fix,hotlist: error messages,freq1: low,area: core,state: confirmed,core: content projection,design complexity: low-hanging | low | Critical |
328,692,079 | flutter | DatePicker touch targets are too small | framework,f: material design,a: accessibility,f: date/time picker,P2,team-design,triaged-design | low | Minor |
|
328,696,079 | pytorch | CrossEntropyLoss mishandles weights | ## Issue description
When a `weight` tensor is passed to CrossEntropyLoss, it exhibits unusual behavior, such as occasionally ignoring the weights, and returning different results when it averages losses over examples versus averaging them manually.
## Code example
1) Incorrect size_average result
```
input = torch.tensor([
[-100., 100.],
[-100., 100.]
])
target = torch.tensor([0,1], dtype=torch.long)
weights = torch.tensor([20,10], dtype=torch.float)
ce_noreduce = nn.CrossEntropyLoss(weight=weights, reduce=False)
ce_reduce = nn.CrossEntropyLoss(weight=weights, reduce=True, size_average=True)
loss1 = ce_noreduce(input, target)
loss2 = ce_reduce(input, target)
print(loss1)
print(loss1.mean())
print(loss2)
```
output:
```
tensor([ 4000., -0.])
tensor(2000.)
tensor(133.3333)
```
2) Weights ignored
```
input = torch.tensor([
[-1, 1, -1],
[-1, 1, -1],
[-1, 1, -1],
], dtype=torch.float) * 100
target = torch.tensor([0,0,1], dtype=torch.long)
weights = torch.tensor([1,10,1], dtype=torch.float)
ce_noweights = nn.CrossEntropyLoss(weight=None, reduce=False)
ce_weights = nn.CrossEntropyLoss(weight=weights, reduce=False)
loss1 = ce_noweights(input, target)
loss2 = ce_weights(input, target)
print(loss1.mean())
print(loss2.mean())
```
output:
```
tensor(133.3333)
tensor(133.3333)
```
## System Info
```
PyTorch version: 0.4.0
Is debug build: No
CUDA used to build PyTorch: None
OS: Mac OSX 10.13.4
GCC version: Could not collect
CMake version: Could not collect
Python version: 3.6
Is CUDA available: No
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
Versions of relevant libraries:
[pip3] msgpack-numpy (0.4.1)
[pip3] numpy (1.13.3)
[pip3] numpydoc (0.7.0)
[pip3] torch (0.3.0.post4)
[pip3] torchfile (0.1.0)
[pip3] torchnet (0.0.1)
[pip3] torchtext (0.2.1)
[pip3] torchvision (0.2.0)
[conda] pytorch 0.4.0 py36_cuda0.0_cudnn0.0_1 pytorch
[conda] torchvision 0.2.1 py36_1 pytorch
```
cc @albanD @mruberry @jbschlosser | module: nn,module: loss,triaged | low | Critical |
328,700,461 | godot | UWP export can't find my script | **Godot version:**
Master as of 2/06/2018, UWP template updated with fresh build and using matching editor build.
**OS/device including version:**
Universal Windows Platform running on Windows 10
**Issue description:**
Exporting to UWP gives error:
Parse Error: [ext_resource] referenced nonexistent resource at: res://Main.gd
The project works fine when running on Windows. Extracting the UWP package I can see that main.gd has been changed to main.gdc (I guess parsed GDScript in binary form?) and there is a main.gd.remap file which I'm guessing the resource loader should be picking up but isn't
**Steps to reproduce:**
Create a new Godot project. Add a root node with a script attached to it.
Export to UWP
Install and run.
| bug,topic:porting,confirmed,platform:uwp | low | Critical |
328,708,765 | pytorch | import problem |
I install the caffe2 using the command "conda install -c caffe2 caffe2-cuda8.0-cudnn7". In directory of xx/caffe2, there are the following folds/files:
contrib core distributed experiments __init__.py __init__.pyc perfkernels proto python
But when I execute
import caffe2
dir(caffe2)
It only shows the following results:
['__builtins__', '__doc__', '__file__', '__name__', '__package__', '__path__']
=====================================
Can anyone help solve this problem?
Thanks a lot.
If you have a question or would like help and support, please ask at our
[forums](https://discuss.pytorch.org/).
If you are submitting a feature request, please preface the title with [feature request].
If you are submitting a bug report, please fill in the following details.
## Issue description
Provide a short description.
## Code example
Please try to provide a minimal example to repro the bug.
Error messages and stack traces are also helpful.
## System Info
Please copy and paste the output from our
[environment collection script](https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py)
(or fill out the checklist below manually).
You can get the script and run it with:
```
wget https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py
# For security purposes, please check the contents of collect_env.py before running it.
python collect_env.py
```
- PyTorch or Caffe2:
- How you installed PyTorch (conda, pip, source):
- Build command you used (if compiling from source):
- OS:
- PyTorch version:
- Python version:
- CUDA/cuDNN version:
- GPU models and configuration:
- GCC version (if compiling from source):
- CMake version:
- Versions of any other relevant libraries:
| caffe2 | low | Critical |
328,710,048 | javascript-algorithms | Add B-Tree | I would like to contriblute to adding the [B-Tree](https://en.wikipedia.org/wiki/B-tree) data structure.
It is a rather common data structure that is great for large data, I'll be glad to implement it. | enhancement | low | Major |
328,723,352 | opencv | Extend Python FFI bindings to adopt more languages | It's not a bug report, but it's not a question too, so I think it's an appropriate place to write this proposal.
There is plenty of projects that are trying to implement FFI bindings to opencv, e.g. [this](https://github.com/hybridgroup/gocv) or [this](https://github.com/ruby-opencv/ruby-opencv) among many others. And they are just doing the same things over and over again.
But this repository has already great `gen2.py` that consider all edge cases and may be used to generate all required wrappers. But currently it requires some preinstalled software to be ran (e.g. numpy) as well as it generates python code which makes it hard to use for anything but python.
I have two proposals, the first one is easy to implement, the second is a bit more complicated, but has a great value
1. Create some target that would only generate python wrappers. It shouldn't check any environment dependencies, the only thing it should do is generate some code. That would allow other languages to use this code as an intermediate representation to generate their own wrappers
1. Make `gen2.py` (implement some new mechanism?) to generate more appropriate MIR (middle-level IR) and then generate python bindings from this representation. It requires more effort but it leads to great simplification for wrapper authors as well as it may be considered to be some kind of doogfooding where python bindings uses ther same MIR as others. It guarantees any FFI built on top of that would be full-featured and bugless, with all edge cases covered. The community effort would be focused in one place instead of being dissipated among multiple repositories trying to solve same issues over and over again
This would lead to better language adoption, more contributions, and more spreading overall.
I do believe it's the right way to do it and it's the high priority task for the repo. Let me provide a @berak 's quote from our conversation:
> adapting a ~1000 lines python monster (which to 90% covers weird edge cases) might look daunting, but on the other hand, doing things [manually, like those folks](https://github.com/hybridgroup/gocv/) try will result in a "toy example", that only covers the 5% most used cases. (which again IS cool, too, don't get me wrong. problem is, if you deviate only a millimeter from it, you're staring into an open abyss)
We currently only have python and C++ code that works, and plenty of "toy examples" in others languages. I think it shall be changed. | feature,category: build/install,RFC | medium | Critical |
328,734,047 | pytorch | Document torch.acos() behavior near -1 and 1 | I created a network using torch.acos() and encountered a Nan error during its training.
The reason is that an input value to torch.acos () approaches 1 or -1, causing the grad to diverge, and resulting in value.grad = Nan.
I know that torch.acos () can only handle values in the range from -1 to 1, and limited the input value's range from -1 to 1 using clamp(min=-1,max=1). However this error has occurred.
Finally I solved this by limiting input from -1 + eps to 1-eps with eps = 1e-7.
I think that many users would encounter this error.
I suggest "to alert this in the explanation of torch.acos() function in document" or "to change function to explicitly limit the range of values by including eps as argument". | module: docs,triaged | high | Critical |
328,734,304 | rust | Recursive trait constraints crash compiler with exit code 3221225501 | I've got a crate that doesn't compile, it just starts eating memory until it stops without an error message. Only passing the `--verbose` flag to `cargo build` tells me
```
error: Could not compile `the-crate`.
Caused by:
process didn't exit successfully: `rustc …` (exit code: 3221225501)
```
Seems to be the same exit code as in #42544.
Here's the (not exactly minimal) example to reproduce the issue:
```rs
pub struct Example<A, B, D>
where
A: StrategyA<Example<A, B, D>>,
B: StrategyB<Example<A, B, D>> {
pub a: A,
pub b: B,
pub element: B::Element,
pub data: D,
}
pub trait StrategyA<T: HasData> {
fn do_a(&self, &T::Data);
}
pub trait StrategyB<T> {
type Element;
fn do_b(&self, &T);
}
impl<A: StrategyA<Self>, B: StrategyB<Self>, D> Example<A, B, D> {
pub fn do_it(&self, args: bool) {
if args {
self.a.do_a(self.get_data());
} else {
self.b.do_b(self);
}
}
}
pub trait HasData {
type Data;
fn get_data(&self) -> &Self::Data;
}
impl<A: StrategyA<Self>, B: StrategyB<Self>, D> HasData for Example<A, B, D> {
type Data = D;
fn get_data(&self) -> &D {
&self.data
}
}
pub struct ExampleA;
pub struct ExampleB;
pub struct ExampleData;
impl<E: HasData<Data=ExampleData>> StrategyA<E> for ExampleA {
fn do_a(&self, e: &ExampleData) {
e; // using ExampleData here
}
}
impl<E: HasData<Data=ExampleData>> StrategyB<E> for ExampleB {
type Element = ExampleData;
fn do_b(&self, e: &E) { /* same */}
}
fn x() {
let example = Example { a: ExampleA, b: ExampleB, data: ExampleData };
example.sized.do_it(true);
example.sized.do_it(false);
}
```
Removing the `StrategyA` parts causes it to produce an "overflow evaluating the requirement …" error, not sure whether related. | A-trait-system,I-compiletime,T-compiler,I-compilemem,C-bug | low | Critical |
328,746,436 | flutter | Changing build folder destination issue ( .flutter_settings file) | In native android development we can change the build folder destination adding the line below to the project "build.gradle" file:
```
allprojects {
repositories {
...
}
buildDir = "C:/dev_build/android/${rootProject.name}/${project.name}"
}
```
With Flutter I tried @cbracken instructions to create the `.flutter_settings` file at the home folder with this content: `{"build-dir": "somePath"}` and I found the following issues:
- It affects all flutter projects.
- The path have to be relative or we get an exception
- The path have to exist beforehand or we get an exception
- After an complete build I found only 3 files in this new path: `frontend_server.d`, `app.dill` and `app.dill.incremental.dill`. All the others files went to the default "build" folder inside the project.
Ideally, I think, it should (as in native android):
1. Have an absolute path support
2. Create the path when it does not exist.
3. Have some way to interpolate the project name into the path
4. Be a by project configuration.
The reasons to change the build destination that I can think of are:
1. To avoid polluting the project folder with generated files
2. To avoid copying the build files (>300MB) when doing a backup of the project folder
3. To avoid wearing out a SSD when the project is in one
4. Put the build files on a faster device to reduce building time
I know that this is not a priority issue for now but it would be nice to have it visited in a near future.
By the way, congratulations on building this amazing framework. I'm really loving Flutter.
`flutter build apk --verbose` -->[build.log](https://github.com/flutter/flutter/files/2065002/build.log) | c: new feature,tool,P2,team-tool,triaged-tool | low | Major |
328,755,318 | rust | Unable to make a function for write!ing that is generic over a File or String | write! duck types to calling write_fmt() which happens to work on both std::io::Write and std::fmt::Write. Unfortunately because std::io::Write does not implement std::fmt::Write you can't write a generic function that would accept either a File or String.
One would want to be able to write something like:
```rust
fn write_some_stuff<W: std::fmt::Write>(writer: &mut W) {
write!(writer, "Hello world");
}
```
and be able to pass that function a reference to a File or a String. | C-enhancement,T-lang,T-libs-api | low | Minor |
328,777,034 | ant-design | Menu item grouping and alignment | - [x] I have searched the [issues](https://github.com/ant-design/ant-design/issues) of this repository and believe that this is not a duplicate.
Someone else has requested something similar [1] but the response to that request was hijacked by text alignment (which is not what this is about) and then sadly closed for inactivity...
[1] https://github.com/ant-design/ant-design/issues/6111
### What problem does this feature solve?
The ability to group menu items in a Menu with `mode=horizontal` so that these item groups can be aligned `left` (default) or `right`. It's common for applications to have an Account or Logout option in the top right corner of a main navigation where access to application features might live on the left in the top navigation. There is currently no mechanism to a) divide the top level nav into multiple item groups and b) align these item groups either left or right.
### What does the proposed API look like?
Using the Top Side 2 demo as an example (https://github.com/ant-design/ant-design/blob/master/components/layout/demo/top-side-2.md).
The Menu in the Header would have the ability to group the menu items and then align each group accordingly:
<Header className="header">
<div className="logo" />
<Menu
theme="dark"
mode="horizontal"
defaultSelectedKeys={['11']}
style={{ lineHeight: '64px' }}
>
<Menu.Group> <!-- "align=left" is implied -->
<Menu.Item key="10">nav 1</Menu.Item>
<Menu.Item key="11">nav 2</Menu.Item>
<Menu.Item key="12">nav 3</Menu.Item>
</Menu.Group>
<Menu.Group align="right">
<Menu.Item key="20">Account</Menu.Item>
<Menu.Item key="21">Logout</Menu.Item>
</Menu.Group>
</Menu>
</Header>
I guess for completness it would also be possible to have `align=center` to display the group of items in the centre of the menu. Obviously, this proposal only makes sense for Menu's with `mode=horizontal`.
<!-- generated by ant-design-issue-helper. DO NOT REMOVE --> | Inactive | high | Critical |
328,779,015 | rust | Tracking issue for #[doc(keyword = "...")] | Implemented in #51140. | T-rustdoc,B-unstable,C-tracking-issue,S-tracking-perma-unstable | low | Major |
328,784,268 | three.js | FBXLoader messes the animation up | I dont really know why, but this model here looks like this if animated:
It does work perfectly fine in [autodesk fbx review](https://www.autodesk.com/products/fbx/fbx-review). There are warnings of dropped weights, and some vertices appear to have as much as 12 influences according to FBXLoader, however it is hard to believe that is the cause (hello #12127) and also previous revisions of the same model in dae format had no such problem.
[Head_69.fbx.zip](https://github.com/mrdoob/three.js/files/2065468/Head_69.fbx.zip)
| Bug,Loaders | low | Major |
328,821,336 | godot | Make special C# cases for APIs like get_property_list which return a list of dictionaries. | Just throwing an idea out there, really.
The API for `get_property_list` return an *array of dictionaries*, probably to avoid having to declare a new type for a single function. This is *fine* in dynamically typed languages because there's little difference between `x.y` and `x["y"]`, but it's awful in typed languages like C#. It just makes the API extremely prone to "great what was the exact layout again", because Intellisense becomes useless.
So, I suggest that since C# is still marked unstable, **we refactor these to handle some simple immutable classes/structs**. Shouldn't be too far off the regular API, but still be tons more usable.
Thoughts? | enhancement,topic:core,topic:dotnet | low | Major |
328,833,679 | create-react-app | Create React App removes SSI directives on Build from index.html | I'm trying to add some SSI directives in the index.html so that I can return dynamic meta tags based on the current url. I'm doing this to solve the Facebook Meta Tag issue. Below is the snippet of the if-condition I've added in the index.html.
`<!--#if expr="$DOCUMENT_URI = /movie-review\/(.*)/" -->`
But, realized that the create-react-app seems to delete them on build. The final built index.html is minified and does not have any comments on them. Since SSI directives syntax is similar to html comments, create-react-app is removing them. Is there any way to skip removing them on build? If no, then what other possible solutions exist to solve the dynamic meta tag problem for react app served on apache server? | issue: proposal | low | Minor |
328,868,138 | neovim | win: failed assertion "_osfile(fh) & FOPEN" during debugging | - `nvim --version`: f711b635133f
- Operating system/version: Windows 7 32-bit
### Steps to reproduce using `nvim -u NORC`
1. Using the Visual Studio 2017 [build steps](https://github.com/neovim/neovim/wiki/Building-Neovim#windows--msvc), build Nvim with the `x86-Debug` configuration.
2. Use the Visual Studio debugger to start `nvim.exe` .
3. The execution fails in `fopen_noinh_readbin .. fdopen` with an assertion error: `_osfile(fh) & FOPEN` .
### Notes
There is [this old libuv issue](https://github.com/joyent/libuv/issues/1493) but the problem may just be a [race](https://www.gamedev.net/forums/topic/449745-_osfilefh--fopen-assertion-for-future-ref/).
Need more investigation. | bug,platform:windows,system | low | Critical |
328,877,188 | pytorch | manager.cpp:64: undefined reference to `shm_open (when building with GCC 5.x (sic)) | I attempted to build with GCC 5.x on Linux and the "do I have to link against rt" logic doesn't seem to work correctly:
```
CMakeFiles/torch_shm_manager.dir/manager.cpp.o: In function `object_exists(char const*)':
/home/ezyang/Dev/pytorch-tmp/torch/lib/libshm/manager.cpp:64: undefined reference to `shm_open'
CMakeFiles/torch_shm_manager.dir/manager.cpp.o: In function `main':
/home/ezyang/Dev/pytorch-tmp/torch/lib/libshm/manager.cpp:157: undefined reference to `shm_unlink'
collect2: error: ld returned 1 exit status
ninja: build stopped: subcommand failed.
```
cc @malfet @seemethere @walterddr | module: build,triaged | low | Critical |
328,885,986 | pytorch | Please provide wheel package for windows on PyPI | Hi,
I am a pytorch user on windows, and saw pytorch wheel package for windows on the official site. Would you please also put the win-amd64 wheel package on PyPI, so we can download it easily using "pip install pytorch".
Thanks. | module: binaries,triaged | low | Minor |
328,905,351 | pytorch | load_state_dict unexpectedly does not load Tensor to buffers that currently have None value | ## Issue description
I have some model variations that learn a certain value, while others keep this value fixed. For this purpose I'd like to have a None-able buffer that stores the fixed value and have this value included in the state dict for serialization. The [`_load_from_state_dict` function](https://github.com/pytorch/pytorch/blob/master/torch/nn/modules/module.py#L626) in the Module class however doesn't overwrite buffers and parameters that currently have the None value. I didn't expect this, leading to a bug in my code.
Although this was unexpected behaviour for me, I understand that this could be desired. In that case perhaps it can be included in the docs.
## Code example
```
import torch
import torch.nn as nn
class X(nn.Module):
def __init__(self, buf):
super().__init__()
self.register_buffer('buffer', buf)
x = X(torch.tensor(1.))
state = x.state_dict()
y = X(torch.tensor(2.))
y.load_state_dict(state) # Works fine
z = X(None)
z.load_state_dict(state)
# Raises:
# RuntimeError: Error(s) in loading state_dict for X:
# Unexpected key(s) in state_dict: "buffer".
```
## System Info
```
PyTorch version: 0.4.0
Is debug build: No
CUDA used to build PyTorch: 9.1.85
OS: Ubuntu 18.04 LTS
GCC version: (Ubuntu 7.3.0-16ubuntu3) 7.3.0
CMake version: version 3.10.2
Python version: 3.6
Is CUDA available: Yes
CUDA runtime version: Could not collect
GPU models and configuration: GPU 0: GeForce GTX 1080 Ti
Nvidia driver version: 390.48
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.7.1.3
Versions of relevant libraries:
[pip] numpy (1.14.3)
[pip] torch (0.4.0)
[pip] torchvision (0.2.1)
[conda] Could not collect
```
cc @ezyang @SsnL @gchanan | module: bc-breaking,module: docs,module: nn,triaged | low | Critical |
328,911,307 | godot | ERROR: set_data: Condition ' len % 2 ' is true | commit hash: 8684b631182dffebba27bdf538129818321d0d7d
I'm getting a lot of those errors when dynamically changing the array of segments in ConcavePolygonShape2D (adding points). Collisions on some of the segments don't work. Errors are from `servers/physics_2d/shape_2d_sw.cpp:910`.
What does this error mean? | bug,topic:physics | low | Critical |
328,944,228 | pytorch | Export CC is ignored when I build pytorch | Hi, I tried to build pytorch from source but I knew that it couldn't be compiled with gcc 8 because nccl fails to compile with gcc 8. When I was compiling caffe2 I fixed this issue with compiling gcc 7.3 and installing it under /usr/local/ and exporting CC and CXX and then compiling caffe2. But when I export CC and CXX and then run setup.py it ignores the variables and compiles with gcc8 and fails to compile. these are the commands used:
export CC=/usr/local/gcc-73/bin/gcc73
export CXX=/usr/local/gcc-73/bin/g++73
sudo python setup.py install
OS: fedora 28
GCC: gcc (GCC) 8.1.1 20180502 (Red Hat 8.1.1-1)
Version: I couldn't find pytorch's version in the source dir but caffe's version is 0.8.2
cc @malfet @seemethere @walterddr | module: build,triaged | low | Minor |
328,966,477 | puppeteer | Feature request: create isolated world | I'd like to create an isolated context to execute some js in the same website I'm visiting without polluting the main context. It is possible right now, but it requires to access a lot of internal methods:
const mainFrame = page.mainFrame()
const isolatedWorldInfo = await page._client.send('Page.createIsolatedWorld', {frameId: mainFrame._id, worldName: 'new-isolated-world'})
const executionContextId = isolatedWorldInfo.executionContextId
const JsHandleFactory = page._frameManager.createJSHandle.bind(page._frameManager, executionContextId)
const executionContext = new ExecutionContext(page._client, {id: executionContextId}, JsHandleFactory)
await executionContext.evaluate(..)
It would be nice if puppeteer exposed this as a method. Something like: page.createNewIsolatedContext
If necessary I could write up the code and the tests
| feature,upstream,chromium,P2 | low | Major |
329,025,666 | rust | Seemingly inconsistent behavior when using default trait parameters | I am building a `Length` trait for a `Line` struct that determines the length of a line using various geospatial distance algorithms. It utilizes a default trait parameter to specify a reasonable default to improve the ergonomics. While designing the trait, I noticed some inconsistent behavior.
Consider the next two blocks of code.
- The first has everything parameterized with type `T` which represents a numeric type for the coordinates of the lines and also the return type for the length algorithm.
- The second is the same, but without a parameterized `T`. Instead `f32` is hardcoded everywhere.
A couple questions come up:
1. For the first code block, in the `main` function, why does it claim `Algo` needs to be specified when we call `length` as a method, but when we use UFCS (without specifying `Algo`) it seems to work fine?
2. Why does the UFCS usage in the second code block not work like the first?
[*playpen for code below*](https://play.rust-lang.org/?gist=767c3ed18a280fb246098dd1dc86d29a&version=stable&mode=debug)
```rust
pub struct Line<T> {
start: (T, T),
end: (T, T),
}
////////////
pub trait LengthAlgo<T> {
fn length(line: Line<T>) -> T;
}
////////////
pub enum Haversine {}
impl<T> LengthAlgo<T> for Haversine {
fn length(line: Line<T>) -> T {
unimplemented!()
}
}
pub enum Vincenty {}
impl<T> LengthAlgo<T> for Vincenty {
fn length(line: Line<T>) -> T {
unimplemented!()
}
}
////////////
pub trait Length<T, Algo: LengthAlgo<T> = Haversine> {
fn length(self) -> T;
}
impl<T, Algo: LengthAlgo<T>> Length<T, Algo> for Line<T> {
fn length(self) -> T {
Algo::length(self)
}
}
////////////
fn main() {
let line: Line<i32> = Line {
start: (4, 6),
end: (2, 23),
};
// This doesn't compile – error message says `Algo` type needs to be specified
// let haversine_length = line.length();
// This compiles, despite us not specifying the type for `Algo`
let haversine_length = Length::<i32>::length(line);
}
```
[*playpen for code below*](https://play.rust-lang.org/?gist=d18f2bbaec2131b1fe8dd7b635807708&version=stable&mode=debug)
```rust
pub struct Line {
start: (f32, f32),
end: (f32, f32),
}
////////////
pub trait LengthAlgo {
fn length(line: Line) -> f32;
}
////////////
pub enum Haversine {}
impl LengthAlgo for Haversine {
fn length(line: Line) -> f32 {
unimplemented!()
}
}
pub enum Vincenty {}
impl LengthAlgo for Vincenty {
fn length(line: Line) -> f32 {
unimplemented!()
}
}
////////////
pub trait Length<Algo: LengthAlgo = Haversine> {
fn length(self) -> f32;
}
impl<Algo: LengthAlgo> Length<Algo> for Line {
fn length(self) -> f32 {
Algo::length(self)
}
}
fn main() {
let line: Line = Line {
start: (4., 6.),
end: (2., 23.),
};
// Neither line below compiles – error message says `Algo` type needs to be specified
// let haversine_length = line.length();
// let haversine_length = Length::length(line);
}
``` | A-trait-system,T-compiler,C-bug,T-types | low | Critical |
329,073,512 | angular | Bug(Animations): animation transition :enter delay should delay the appearance of an element | ## I'm submitting a...
<!-- Check one of the following options with "x" -->
<pre><code>
[ ] Regression (a behavior that used to work and stopped working in a new release)
[ ] Bug report <!-- Please search GitHub for a similar issue or PR before submitting -->
[ ] Performance issue
[x] Feature request
[ ] Documentation issue or request
[ ] Support request => Please do not submit support request here, instead see https://github.com/angular/angular/blob/master/CONTRIBUTING.md#question
[ ] Other... Please describe:
</code></pre>
## Current behavior
<!-- Describe how the issue manifests. -->
Animation delay does not delay element appearance during `:enter` transition
## Expected behavior
<!-- Describe what the desired behavior would be. -->
Animation delay should delay appearance of an element during `:enter` transition
## What is the motivation / use case for changing the behavior?
<!-- Describe the motivation or the concrete use case. -->
It's not possible to animate the `display` property which makes it impossible in some cases to delay the appearance of an object using Angular's animation features.
## Environment
<pre><code>
Angular version: 6.0.3
<!-- Check whether this is still an issue in the most recent Angular version -->
Browser:
- [ ] Chrome (desktop) version XX
- [ ] Chrome (Android) version XX
- [ ] Chrome (iOS) version XX
- [ ] Firefox version XX
- [ ] Safari (desktop) version XX
- [ ] Safari (iOS) version XX
- [ ] IE version XX
- [ ] Edge version XX
For Tooling issues:
- Node version: XX <!-- run `node --version` -->
- Platform: <!-- Mac, Linux, Windows -->
Others:
<!-- Anything else relevant? Operating system version, IDE, package manager, HTTP server, ... -->
</code></pre>
| area: animations,freq2: medium,P4,bug | low | Critical |
329,094,970 | go | cmd/vet: spurious "context leak" due to imprecise 'defer' control-flow analysis in lostcancel | Please answer these questions before submitting your issue. Thanks!
### What version of Go are you using (`go version`)?
go version go1.10 windows/amd64
### Does this issue reproduce with the latest release?
yes, tested on go1.10.2 as well
### What operating system and processor architecture are you using (`go env`)?
```
set GOARCH=amd64
set GOBIN=
set GOCACHE=C:\Users\micro\AppData\Local\go-build
set GOEXE=.exe
set GOHOSTARCH=amd64
set GOHOSTOS=windows
set GOOS=windows
set GOPATH=F:\goenv\
set GORACE=
set GOROOT=F:\go
set GOTMPDIR=
set GOTOOLDIR=F:\go\pkg\tool\windows_amd64
set GCCGO=gccgo
set CC=gcc
set CXX=g++
set CGO_ENABLED=1
set CGO_CFLAGS=-g -O2
set CGO_CPPFLAGS=
set CGO_CXXFLAGS=-g -O2
set CGO_FFLAGS=-g -O2
set CGO_LDFLAGS=-g -O2
set PKG_CONFIG=pkg-config
set GOGCCFLAGS=-m64 -mthreads -fmessage-length=0 -fdebug-prefix-map=C:\Users\micro\AppData\Local\Temp\go-build748724598=/tmp/go-build -gno-record-gcc-switches
```
### What did you do?
run `go vet` on https://play.golang.org/p/X_vRJbYf7rO
### What did you expect to see?
no errors
### What did you see instead?
```
issue.go:12: the cancel function is not used on all paths (possible context leak)
issue.go:14: this return statement may be reached without using the cancel var defined on line 12
``` | help wanted,NeedsFix,Analysis | low | Critical |
329,154,367 | rust | compiler error message shows the error path containing parent directory identifier ( `/../` ) | ```
error[E0599]: no method named `map` found for type `std::iter::Map<postgres::rows::Iter<'_>, for<'r, 's> fn(postgres::rows::Row<'r>, &'s extract::CmdOptions) -> std::result::Result<<Q as extract::query::Query>::Message, postgres::Error> {<Q as extract::query::Query>::map}>` in the current scope
--> extract/tests/query/../helper.rs:40:10
|
40 | .map(Result::unwrap)
```
the actual error is in `extract/tests/helper.rs` and that's what I would expect to be displayed instead of `extract/tests/query/../helper.rs`.
```rustc 1.26.1 (827013a31 2018-05-25)
binary: rustc
commit-hash: 827013a31b88e536e85b8e6ceb5b9988042ec335
commit-date: 2018-05-25
host: x86_64-unknown-linux-gnu
release: 1.26.1
LLVM version: 6.0
``` | C-enhancement,A-diagnostics,E-mentor,T-compiler,E-help-wanted | low | Critical |
329,173,607 | vscode | Filter "Problems" by the extension which generated them (Markers Panel Filter) | I'd love to be able to declutter the "Problems" Markers Panel by hiding/showing logs generated by only certain extensions.
Right now, if I type `[ts]` into the filtering box, I get `No results found with provided filter criteria. Clear Filter.`
If I then delete the filter, I can clearly see plenty of warnings and errors generated by `[ts]`. After tinkering with it for a while, I've not been able to figure out how to filter by the extension name. (Maybe it just needs some documentation or UI to help the user write filters?)
Also, for other users finding this issue, after a bit of searching around I realized I could also filter roughly by using the keywords `warning`, `error`, and `info`. E.g: enter `warning, error` into the filter to hide `info` markers. This helps a bit, but doesn't help much when you're trying e.g. to filter out a particularly noisy extension (like a spell checker) generating the same type of marker you're looking for.
| feature-request,error-list,papercut :drop_of_blood: | high | Critical |
329,185,417 | pytorch | PyTorch multiprocessing using single CPU core | ## Issue description
I was trying to load data with DataLoader with multiple workers, and I noticed that although it creates the processes they all run on the same CPU core, thus the data loading is very slow.
I succeeded in creating a minimal example (below). If I run the script below, it uses 4 CPU cores. If I uncomment the "import torch" line, only single core is used. If I also uncomment the taskset command, it will use 4 cores again.
## Code example
```python
#!/usr/bin/env python3
#import torch
import os
def loop():
while True:
pass
#os.system("taskset -p 0xff %d" % os.getpid())
from multiprocessing import Process
for i in range(4):
Process(target=loop).start()
```
## System Info
Although the collect_env.py prints gcc 8.1.0, it was overridden to 7.3.1 during build. Also cudnn detection failed, its version is 7.1.3.
Built from source (commit f24d715e235eb7d188cb610d7b29386b9eaf0ab9), command: "CC=gcc-7 CXX=g++-7 python setup.py bdist_wheel", package installed with pip install --user.
PyTorch version: 0.5.0a0+f24d715
Is debug build: No
CUDA used to build PyTorch: 9.2.88
OS: Antergos Linux
GCC version: (GCC) 8.1.0
CMake version: version 3.11.2
Python version: 3.6
Is CUDA available: Yes
CUDA runtime version: 9.2.88
GPU models and configuration:
GPU 0: TITAN X (Pascal)
GPU 1: GeForce GTX 1070
Nvidia driver version: 396.24
cuDNN version: Could not collect
Versions of relevant libraries:
[pip3] numpy (1.13.1)
[pip3] torch (0.5.0a0+f24d715)
[pip3] torchfile (0.1.0)
[pip3] torchvision (0.1.8)
[conda] Could not collect
| todo,module: multiprocessing,triaged | low | Critical |
329,187,353 | rust | RFE: debug pretty printers for Rc/Arc | It would be nice if `rust-gdb`/etc. could pretty-print the inner value of `Rc` and `Arc`. Right now you only get the raw details, like:
```
(gdb) p foo
$1 = Rc<i32> = {ptr = NonNull<alloc::rc::RcBox<i32>> = {
pointer = NonZero<*const alloc::rc::RcBox<i32>> = {0x555555783a40}},
phantom = PhantomData<i32>}
```
Getting the actual value requires manual field access, `foo.ptr.pointer.0.value`, which could also change if `Rc` internals change.
Maybe this could be approached as more general `Deref` support, so you could `p *foo` here, but right now that just says "Attempt to take contents of a non-pointer value." | T-dev-tools,C-feature-request | low | Critical |
329,188,894 | pytorch | Cmake is getting permission denied when installed system wide | Hi,
Trying to build from source, compiled fine when disabling the `-DBUILD_TEST=OFF` but now I'm trying to use `caffe2` from my own CMakeLists.txt and I get the following interesting error:
```
-- Caffe2: Cannot find gflags automatically. Using legacy find.
-- Caffe2: Found gflags (include: /usr/include, library: /usr/lib/x86_64-linux-gnu/libgflags.so)
-- Caffe2: Cannot find glog automatically. Using legacy find.
-- Caffe2: Found glog (include: /usr/include, library: /usr/lib/x86_64-linux-gnu/libglog.so)
-- Caffe2: Found protobuf with new-style protobuf targets.
-- Caffe2: Protobuf version 3.5.0
-- Caffe2: CUDA detected: 9.0
-- Caffe2: CUDA nvcc is: /usr/local/cuda/bin/nvcc
-- Caffe2: CUDA toolkit directory: /usr/local/cuda
CMake Error at /usr/local/share/cmake/Caffe2/public/cuda.cmake:26 (file):
file failed to open for writing (Permission denied):
/detect_cuda_version.c
Call Stack (most recent call first):
/usr/local/share/cmake/Caffe2/Caffe2Config.cmake:74 (include)
CMakeLists.txt:36 (find_package)
CMake Error: The source directory "CMAKE_FLAGS" does not exist.
Specify --help for usage, or press the help button on the CMake GUI.
CMake Error: Internal CMake error, TryCompile configure of cmake failed
CMake Error: TRY_COMPILE attempt to remove -rf directory that does not contain CMakeTmp:/detect_cuda_version.c
CMake Error at /usr/local/share/cmake/Caffe2/public/cuda.cmake:41 (message):
Caffe2: Couldn't determine version from header:
Call Stack (most recent call first):
/usr/local/share/cmake/Caffe2/Caffe2Config.cmake:74 (include)
CMakeLists.txt:36 (find_package)
```
I've looked under `/usr` with `find . -name "detect_cuda_version.c"` and indeed it is nowhere to be found.
Where is it expected to be?
BTW, all did was `sudo make install`.
System is Ubuntu 16.04 | caffe2 | low | Critical |
329,204,357 | go | cmd/asm: how to test? | The current tests are an inconsistent mess. Some files are hand-written. Others are auto-generated and enormous, and could be generated on the fly instead of being checked in. Some architectures are well tested. Others are not. Some subsets of architectures (AVX) are exhaustively tested. Others are not.
I would like a proper discussion about how to test the assembler (and the compiler, if you like). Without a clear picture, the tests will become enormous, wildly inconsistent, messy, and difficult to maintain. | Testing,NeedsInvestigation,compiler/runtime | low | Major |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.