
id
int64 393k
2.82B
| repo
stringclasses 68
values | title
stringlengths 1
936
| body
stringlengths 0
256k
⌀ | labels
stringlengths 2
508
| priority
stringclasses 3
values | severity
stringclasses 3
values |
|---|---|---|---|---|---|---|
324,212,268 |
TypeScript
|
In JS, prototype-assignment methods can't find method-local type parameters
|
```js
/**
* @constructor
* @template K, V
*/
var Multimap = function() {
/** @type {!Map.<K, !Set.<!V>>} */
this._map = new Map();
};
/**
* @param {!S} o <------ error here, cannot find name 'S'
* @template S
*/
Multimap.prototype.lowerBound = function(o) {
};
```
**Expected behavior:**
No error, and `o: S`
**Actual behavior:**
Error on o's param tag: "cannot find name 'S'".
It looks like type resolution on prototype-assignment methods only looks at the class to find type parameters, meaning that method-local type parameters are missed. You can refer to `K` in the above example:
```js
/**
* @param {!K} object
* @template S
*/
Multimap.prototype.lowerBound = function(o) {
return 0;
};
```
And you can refer to `S` on a standalone function:
```js
/**
* @param {!S} object
* @template S
*/
var lowerBound = function(o) {
return 0;
};
```
|
Bug,Domain: JSDoc,Domain: JavaScript
|
low
|
Critical
|
324,280,512 |
go
|
x/build/cmd/gitmirror: lock conversations on GitHub commits
|
Occasionally a GitHub user will post a comment on a commit. Frequently these are spam which leads to nuisance emails generated if you watch the repo. Very occasionally these are requests for help, which currently require a human to reply, reminding the OP to raise an issue. This also generates nuisance emails.
I propose that the bot should blanket lock discussion on all commits in this repo.
|
Builders,Proposal,Proposal-Accepted,NeedsFix,FeatureRequest
|
low
|
Major
|
324,301,876 |
electron
|
Feature Request: Add query methods for Visual/Layout ZoomLevelLimits
|
**Is your feature request related to a problem? Please describe.**
The related PR - Microsoft/vscode#49858 (Issue: Microsoft/vscode#48357) - The UI setting of the zoom level was unbounded, although the actual zoom level has clear limits (`+9` <-> `-8`).
We use the `webFrame` module of `electron` the get the zoom level, but it seems to be unbounded, at least not to reasonable values.
I've looked at the `.d.ts` declaration and at the `web-frame.js` and the `c++` header which defines `WebFrame`, and I can only see a method to `Set` the layout and visual zoom level limits, but not retrieve them.
**Describe the solution you'd like**
I want to be able to logically bind the UI settings the values that `electron` itself bounds, not hard coded values that might be right for one screen/resolution/etc.
Currently in the PR listed above, the bounds are hard-coded, and I enforce them myself, logically, because `webFrame.setZoomLevel` and `webFrame.getZoomLevel` do not match the visual zoom level bounds.
I would want to have methods in [webFrame](https://github.com/electron/electron/blob/4fcd178c368e67e543ee10ee84a0947342412a4c/atom/renderer/api/atom_api_web_frame.h), probably called:
```cpp
v8::Local<v8::Value> GetVisualZoomLevelLimits() const;
v8::Local<v8::Value> GetLayoutZoomLevelLimits() const;
```
Which would be exported to the `js` `webFrame` module, which would in-turn allow me to query for the electron bounds value instead of hard coded ones, specifically [here](https://github.com/Microsoft/vscode/pull/49858/files#diff-c93a0e42070e15efe5973a7aa2f71f53), since currently, `webFrame.getZoomLevel`/`webFrame.setZoomLevel` are not limiting values to the visual zoom level limits.
**Describe alternatives you've considered**
Currently, the PR is not in yet in production, but the workaround was to get the `min`/`max` zoom level limits via trial and error, and hard code those limits.
Thanks a lot for reading, perhaps tho I've just missed the methods which allow to do this in my research. But if not, that could help a lot.
If it's not too complicated, I'd love to PR it as well.
|
enhancement :sparkles:
|
low
|
Critical
|
324,316,303 |
pytorch
|
Caffe2 network exported from ONNX does not initialize the model inputs
|
## Issue description
When exporting an ONNX model to Caffe2 with the [conversion tool](pytorch/pytorch/blob/master/caffe2/python/onnx/bin/conversion.py), the resulting init net does not initialize the model inputs. When running this network in Caffe2, you therefore get the error `Encountered a non-existing input blob: <name of input blob>`, unless you explicitly create the input blob before running the network.
I would like the network to create the blob automatically, so that I don't have to specify the name and size of the input blob manually (this information should be part of the exported network imho).
This problem was already fixed in onnx/onnx-caffe2#48, but it was later changed again by https://github.com/onnx/onnx-caffe2/commit/ff82dca5551fce84d781bb23719fbe2913b30327. I'm not sure which behavior is actually intended.
This is probably related to #6505, but I'm not sure whether it's the same problem.
## System Info
- PyTorch or Caffe2: Caffe2
- How you installed Caffe2: conda
- OS: Ubuntu 16.04
- Caffe2 version: 0.8.dev
- Versions of any other relevant libraries: onnx 1.1.1 from pip
|
caffe2
|
low
|
Critical
|
324,328,682 |
vscode
|
Git - Support Co-Authored-By
|
Issue Type: <b>Feature Request</b>
Github introduced a convention where the commit message contains a list of co-authors, for use when pairing.
Example:
```
commit 032db38255275dd7372f575e3d06947c878ef4c6
Author: Tommy Brunn <[email protected]>
Date: Thu May 17 10:21:16 2018 +0200
Encode int64
Co-Authored-By: Tulio Ornelas <[email protected]>
```
Both Github and Atom then displays both authors whenever they are showing author information. See http://blog.atom.io/2018/04/18/atom-1-26.html#github-package-improvements-1 for an example of what it looks like in Atom.
VS Code version: Code 1.23.1 (d0182c3417d225529c6d5ad24b7572815d0de9ac, 2018-05-10T16:03:31.083Z)
OS version: Darwin x64 16.7.0
<!-- generated by issue reporter -->
|
help wanted,feature-request,git
|
medium
|
Major
|
324,357,767 |
kubernetes
|
StatefulSet with long name can not create pods
|
**Is this a BUG REPORT or FEATURE REQUEST?**:
/kind bug
**What happened**:
Creating a StatefulSet with a name containing 57 characters resulted could not start any pods as kubernetes added the label "controller-revision-hash" to the pod which apparently contains the StatefulSet name and a hash appended.
The label is not truncated to 63 characters, therefore the creation of the pod fails with the error message
`statefulset-controller create Pod long-redacted-statefulset-name-xxxxxxxxxxxxxxxxxxxxxxxxx-0 in StatefulSet long-redacted-statefulset-name-xxxxxxxxxxxxxxxxxxxxxxxxx failed error: Pod "long-redacted-statefulset-name-xxxxxxxxxxxxxxxxxxxxxxxxx-0" is invalid: metadata.labels: Invalid value: "long-redacted-statefulset-name-xxxxxxxxxxxxxxxxxxxxxxxxx-58d5fbb889": must be no more than 63 characters
`
**What you expected to happen**:
The label should be truncated or StatefulSets should enforce shorter names.
**How to reproduce it (as minimally and precisely as possible)**:
Create a StatefulSet with a name longer than 57 characters:
```apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app: sset
name: long-redacted-statefulset-name-xxxxxxxxxxxxxxxxxxxxxxxxx
spec:
serviceName: ""
replicas: 1
selector:
matchLabels:
app: sset
template:
metadata:
labels:
app: sset
spec:
containers:
- image: alpine
name: sset-container
command:
- sleep
- "300"
```
**Anything else we need to know?**:
**Environment**:
- Kubernetes version (use `kubectl version`): Server Version: "v1.10.2"
- Cloud provider or hardware configuration: baremetal
- OS (e.g. from /etc/os-release): CentOS-7.5.1804
- Kernel (e.g. `uname -a`): 3.10.0-862.2.3.el7.x86_64
- Install tools: kubeadm
|
kind/bug,sig/apps,lifecycle/frozen,needs-triage
|
medium
|
Critical
|
324,369,541 |
godot
|
Ragdoll / Physical Bones issue
|
As described in #11973
I've attached an example project below:
[Ragdoll Test.zip](https://github.com/godotengine/godot/files/2016597/Ragdoll.Test.zip)
Example contains 1 scene with 2 skeletons.
First example - a simple worm skeleton that contorts wildly.
Second Example - Robot from 3D platformer, by default I've set the physics simulation to just his arms. They don't stop moving, as if he's very excited about something.
If you hit Enter (ui_accept) the rest of his bones are activated, and he crumples to the floor in quite an unnatural way, not like in the example posted by Andrea (https://godotengine.org/article/godot-ragdoll-system)
|
bug,confirmed,topic:physics,topic:3d
|
medium
|
Major
|
324,395,107 |
three.js
|
Improved Alpha Testing via Alpha Distributions
|
Improved alpha testing in mipmapped texture hierarchies via alpha distributions, rather than averaging.
http://www.cemyuksel.com/research/alphadistribution/
http://www.cemyuksel.com/research/alphadistribution/alpha_distribution.pdf
|
Enhancement
|
low
|
Minor
|
324,506,615 |
rust
|
Confusing error message when using Self in where clause bounds errornously
|
The source `trait SelfReferential<T> where T: Self {}` gives the error
```
error[E0411]: expected trait, found self type `Self`
--> src/main.rs:13:35
|
13 | trait SelfReferential<T> where T: Self {}
| ^^^^ `Self` is only available in traits and impls
```
This is confusing because the `Self` is in a trait. It just doesn't seem to be valid to use it as the trait bounds of a type in a where clause.
|
C-enhancement,A-diagnostics,A-trait-system,T-compiler,D-papercut
|
low
|
Critical
|
324,506,658 |
rust
|
Calling `borrow_mut` on a `Box`ed trait object and passing the result to a function can cause a spurious compile error
|
This code does not compile:
```rust
use std::borrow::BorrowMut;
pub trait Trait {}
pub struct Struct {}
impl Trait for Struct {}
fn func(_: &mut Trait) {}
fn main() {
let mut foo: Box<Trait> = Box::new(Struct{});
func(foo.borrow_mut());
}
```
However, if you use `as` to be clear on what you expect `borrow_mut()` to return:
```rust
func(foo.borrow_mut() as &mut Trait);
```
It will then compile.
This does not happen when the boxed type is a struct, only a trait. Simple assignments don't seem to trigger it either. (**Edit:** Forgot to add that this happens both on current stable and current nightly.)
Here is the output when compiling on the Playground:
```
Compiling playground v0.0.1 (file:///playground)
error[E0597]: `foo` does not live long enough
--> src/main.rs:11:10
|
11 | func(foo.borrow_mut());
| ^^^ borrowed value does not live long enough
12 | }
| - `foo` dropped here while still borrowed
|
= note: values in a scope are dropped in the opposite order they are created
warning: variable does not need to be mutable
--> src/main.rs:10:9
|
10 | let mut foo: Box<Trait> = Box::new(Struct{});
| ----^^^
| |
| help: remove this `mut`
|
= note: #[warn(unused_mut)] on by default
error: aborting due to previous error
For more information about this error, try `rustc --explain E0597`.
error: Could not compile `playground`.
To learn more, run the command again with --verbose.
```
|
A-lifetimes,T-compiler,C-bug,T-types,A-trait-objects
|
low
|
Critical
|
324,522,844 |
pytorch
|
Only one thread is used on macOS (super slow on CPU)
|
## Issue description
Computations on my macbook's CPU are extremely slow.
`torch.get_num_threads()` always says 1, and `torch.set_num_threads(n)` has no effect.
I also tried building from source using the workaround described [here](https://github.com/pytorch/pytorch/issues/6328#issuecomment-383290539) in order to enable libomp support, but nothing changed.
## System Info
PyTorch version: 0.5.0a0+cf0c585
Is debug build: No
CUDA used to build PyTorch: None
OS: Mac OSX 10.13.4
GCC version: Could not collect
CMake version: version 3.11.0
Python version: 3.6
Is CUDA available: No
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
Versions of relevant libraries:
[pip3] numpy (1.14.3)
[pip3] torch (0.5.0a0+cf0c585)
[pip3] torchvision (0.2.1)
[conda] Could not collect
|
triaged,module: macos,module: multithreading
|
medium
|
Critical
|
324,552,759 |
angular
|
Calling formGroup.updateValueAndValidity() does not update child controls that have `onUpdate` set to `'submit'`
|
<!--
PLEASE HELP US PROCESS GITHUB ISSUES FASTER BY PROVIDING THE FOLLOWING INFORMATION.
ISSUES MISSING IMPORTANT INFORMATION MAY BE CLOSED WITHOUT INVESTIGATION.
-->
## I'm submitting a...
<!-- Check one of the following options with "x" -->
<pre><code>
[ ] Regression (a behavior that used to work and stopped working in a new release)
[x] Bug report <!-- Please search GitHub for a similar issue or PR before submitting -->
[ ] Performance issue
[x] Feature request
[ ] Documentation issue or request
[ ] Support request => Please do not submit support request here, instead see https://github.com/angular/angular/blob/master/CONTRIBUTING.md#question
[ ] Other... Please describe:
</code></pre>
## Current behavior
Calling formGroup.updateValueAndValidity() does not update child control and therefore form.value with data pending in child controls if child controls onUpdate is set to 'submit' .
## Expected behavior
The **formGroup.updateValueAndValidity()** should raise child validation and update values. What would also be acceptable is **formhooks** having a 'manual' value that if a control's **onUpdate** is set to this, **formGroup.updateValueAndValidity()** would update it.
## Minimal reproduction of the problem with instructions
the demo has instructions
https://stackblitz.com/edit/angular-rx-validation-form-bug-demo
## What is the motivation / use case for changing the behavior?
calling **formGroup.updateValueAndValidity()** should mean that regardless of what **onUpdate** is, the child controls should be validated and updated.
## Environment
<pre><code>
Angular version: 5.2.0
Browser:
- [x ] Chrome (desktop) version XX
- [ ] Chrome (Android) version XX
- [ ] Chrome (iOS) version XX
- [ ] Firefox version XX
- [ ] Safari (desktop) version XX
- [ ] Safari (iOS) version XX
- [ ] IE version XX
- [ ] Edge version XX
</code></pre>
|
type: bug/fix,freq1: low,area: forms,state: needs more investigation,P4
|
low
|
Critical
|
324,591,315 |
vscode
|
Support syntax highlighting with tree-sitter
|
Please consider supporting [tree-sitter](https://github.com/tree-sitter/tree-sitter) grammars in addition to TextMate grammars. TextMate grammars are incredibly difficult to author and maintain and impossible to get right. The over 500 (!) issues reported against https://github.com/Microsoft/TypeScript-TmLanguage are a living proof of this.
This presentation explains the motivation and goals for tree-sitter: https://www.youtube.com/watch?v=a1rC79DHpmY
tree-sitter already ships with Atom and is also used on github.com.
|
feature-request,languages-basic,tokenization
|
high
|
Critical
|
324,600,855 |
go
|
x/build/maintner: growing files are not cleaned up
|
When the full file is downloaded, the corresponding growing file is not removed, so over time growing files accumulate. For example this is my cache directory at the moment:
```
[...]
0033.7b5b6f92e2eecdbfcfb06d7ed7a4f95f66092b2bb3693f41407bb546.mutlog
0034.435067e2842b0a7363a09a259e5aa1a2006787d95fae3a14a33b79b2.mutlog
0034.growing.mutlog
0035.f59248bfa6248f1cd081601c2d0331c97ecfd7807c3a4805d8fb65a8.mutlog
0035.growing.mutlog
0036.growing.mutlog
```
/cc @bradfitz
|
help wanted,Builders,NeedsFix
|
low
|
Minor
|
324,602,741 |
TypeScript
|
[SALSA] @callback's @param tags should not require names
|
<!-- 🚨 STOP 🚨 𝗦𝗧𝗢𝗣 🚨 𝑺𝑻𝑶𝑷 🚨
Half of all issues filed here are duplicates, answered in the FAQ, or not appropriate for the bug tracker. Even if you think you've found a *bug*, please read the FAQ first, especially the Common "Bugs" That Aren't Bugs section!
Please help us by doing the following steps before logging an issue:
* Search: https://github.com/Microsoft/TypeScript/search?type=Issues
* Read the FAQ: https://github.com/Microsoft/TypeScript/wiki/FAQ
Please fill in the *entire* template below.
-->
<!-- Please try to reproduce the issue with `typescript@next`. It may have already been fixed. -->
**TypeScript Version:** 2.9.0-dev.20180518
<!-- Search terms you tried before logging this (so others can find this issue more easily) -->
**Search Terms:**
`@callback` `@params` duplicate identifier error
**Code**
```js
/**
* @callback ModuleSortPredicate
* @param {Module} a
* @param {Module} b
* @returns {-1|0|1}
*/
/**
* @callback ModuleFilterPredicate
* @param {Module}
* @param {Chunk}
* @returns {boolean}
*/
/**
* @callback ChunkFilterPredicate
* @param {Chunk} c
* @returns {boolean}
*/
```
**Expected behavior:**
No errors, or syntax highlighting errors.
**Actual behavior:**
```
lib/Chunk.js:44:18 - error TS1003: Identifier expected.
44 * @param {Chunk}
lib/Chunk.js:44:18 - error TS2300: Duplicate identifier '(Missing)'.
44 * @param {Chunk}
```
**Playground Link:** <!-- A link to a TypeScript Playground "Share" link which demonstrates this behavior -->
**Related Issues:** <!-- Did you find other bugs that looked similar? -->
Here is an image of it in action. I'm not sure if it is interaction with other things at the same time. I'm happy to pull information for you @sandersn. If you goto webpack/webpack#feature/type-compiler-compilation-save branch you can go to those lines of the code and test it as well.
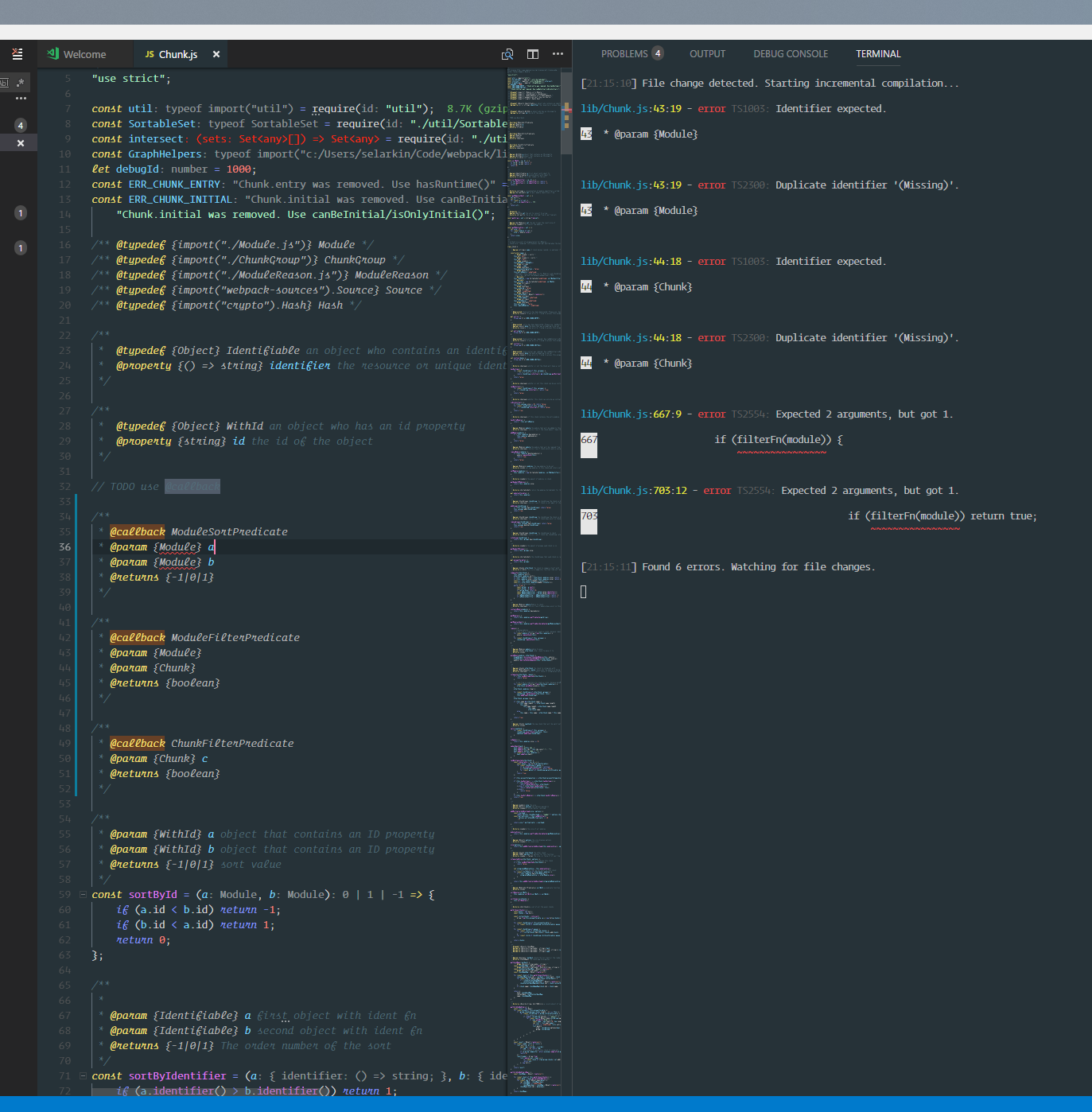
|
Suggestion,Awaiting More Feedback,Domain: JavaScript
|
low
|
Critical
|
324,615,175 |
opencv
|
I hope 2 features could be added into opencv 4.0.
|
1. Can set OpenCL device by thread in program. Like cuda::setDevice().
2. Adapt more functions for CUDA or OpenCL device, e.g. findHomography, findContours...
|
feature,category: ocl,RFC
|
low
|
Minor
|
324,621,600 |
angular
|
[Feature] Allow to clear Service Worker cache
|
<!--
PLEASE HELP US PROCESS GITHUB ISSUES FASTER BY PROVIDING THE FOLLOWING INFORMATION.
ISSUES MISSING IMPORTANT INFORMATION MAY BE CLOSED WITHOUT INVESTIGATION.
-->
## I'm submitting a...
<!-- Check one of the following options with "x" -->
<pre><code>
[ ] Regression (a behavior that used to work and stopped working in a new release)
[ ] Bug report <!-- Please search GitHub for a similar issue or PR before submitting -->
[ ] Performance issue
[X] Feature request
[ ] Documentation issue or request
[ ] Support request => Please do not submit support request here, instead see https://github.com/angular/angular/blob/master/CONTRIBUTING.md#question
[ ] Other... Please describe:
</code></pre>
## Current behavior
As a developer, I clear the cookies, data and relevant user information from the browser when the user logs out.
For privacy and security reasons and to avoid keeping relevant data in the browser's cache, I delete all the relevant data of the user from the cookies and localStorage.
However I cannot do the same from the service worker cache.
## Expected behavior
I'd like to be able to clear the Service Worker cache whenever a user logs out, to make sure no other user has access to the cache in any way.
This could be added as a function in the Service Worker provider.
## What is the motivation / use case for changing the behavior?
A problem is that if a user [bob] does log in with his/her user account after a logout from another user [alice], the cache of the Service Worker might answer with data from alice's requests, having a privacy problem here... The only difference between the requests is the access Token, and is set in the header, which is not taken in account when caching in the service worker. Thus a properly made request while being offline, would be able to answer the data from another user.
Another problem is that a user could access the cache from the browser web tools and check the contents of the cache, even after the user has logged out.
## Environment
<pre><code>
Angular version: 6.0.2
<!-- Check whether this is still an issue in the most recent Angular version -->
Browser:
- All
|
feature,area: service-worker,feature: under consideration
|
medium
|
Critical
|
324,635,104 |
TypeScript
|
Wrong createElementNS() type definitions
|
`Document.createElementNS()` allows to create a few nonexistent SVG elements. In particular, this function has signatures that allow creating `componentTransferFunction`, `textContent` and `textPositioning`, but these correspond to SVG interfaces which do not have any real element associated.
This can be easily verified by running:
```ts
document.createElementNS('http://www.w3.org/2000/svg', 'textContent') instanceof SVGTextElement; // false
document.createElementNS('http://www.w3.org/2000/svg', 'text') instanceof SVGTextElement; // true
```
(Note that [SVGTextElement](https://developer.mozilla.org/en-US/docs/Web/API/SVGTextElement) implements [SVGTextContentElement](https://developer.mozilla.org/en-US/docs/Web/API/SVGTextContentElement).)
|
Bug,Help Wanted,Domain: lib.d.ts
|
low
|
Major
|
324,643,787 |
rust
|
Bogus note with duplicate function names in --test / --bench mode and elsewhere.
|
This file:
```
#[test]
pub fn test() { }
#[test]
pub fn test() { }
```
When run with `rustc --test`.
Produces this error:
```
error[E0428]: the name `test` is defined multiple times
--> t.rs:5:1
|
2 | pub fn test() { }
| ------------- previous definition of the value `test` here
...
5 | pub fn test() { }
| ^^^^^^^^^^^^^ `test` redefined here
|
= note: `test` must be defined only once in the value namespace of this module
error[E0252]: the name `test` is defined multiple times
|
= note: `test` must be defined only once in the value namespace of this module
help: You can use `as` to change the binding name of the import
|
1 | as other_test#[test]
| ^^^^^^^^^^^^^
error: aborting due to 2 previous errors
Some errors occurred: E0252, E0428.
For more information about an error, try `rustc --explain E0252`.
```
The note is producing bogus syntax, possibly from the reexport magic that makes testing work.
Tested on
```
rustc 1.26.0 (a77568041 2018-05-07)
rustc 1.27.0-beta.5 (84b5a46f8 2018-05-15)
rustc 1.27.0-nightly (2f2a11dfc 2018-05-16)
```
|
A-diagnostics,T-compiler,C-bug
|
low
|
Critical
|
324,662,294 |
TypeScript
|
Suggestion: Allow interfaces to "implement" (vs extend) other interfaces
|
## Search Terms
interface, implements
## Suggestion
Allow declaring that an interface "implements" another interface or interfaces, which means the compiler checks conformance, but unlike the "extends" clause, no members are inherited:
```
interface Foo {
foo(): void;
}
interface Bar implements Foo {
foo(): void; // must be present to satisfy type-checker
bar(): void;
}
```
## Use Cases
It is very common for one interface to be an "extension" of another, but the "extends" keyword is not a universal way to make this fact explicit in code. Because of structural typing, the fact that one interface is assignable to another is true with or without "extends," so you might say the "extends" keyword serves primarily to inherit members, and secondarily to document and enforce the relationship between the two types. Inheriting members comes with a readability trade-off and is not always desirable, so it would be useful to be able to document and enforce the relationship between two interfaces without inheriting members.
Consider code such as:
```
import { GestureHandler } from './GestureHandler'
import { DropTarget } from './DropTarget'
export interface DragAndDropHandler extends GestureHandler {
updateDropTarget(dropTarget: DropTaget): void;
}
function createDragAndDropHandler(/*...*/): DragAndDropHandler {
//...
}
```
While this code is not bad, it is notable that DragAndDropHandler omits some of its members simply because it has a relationship with GestureHandler. What are those members? What if I would like to declare them explicitly, just as I would if GestureHandler didn't exist, or if DragAndDropHandler were a class that implemented GestureHandler? I could write them in, but the compiler won't check that I have included all of them. I could omit `extends GestureHandler`, but then the type-checking will happen where DragAndDropHandler is used as a GestureHandler, not where it is defined.
What I really want to do is be explicit about — _and have the compiler check_ — that I am specifying all members of this interface, and also that it conforms to GestureHandler.
I would like to be able to write:
```
export interface DragAndDropHandler implements GestureHandler {
updateDropTarget(dropTarget: DropTaget): void;
move(gestureInfo: GestureInfo): void
finish(gestureInfo: GestureInfo, success: boolean): void
}
```
## Examples
See above
## Checklist
My suggestion meets these guidelines:
* [X] This wouldn't be a breaking change in existing TypeScript / JavaScript code
* [X] This wouldn't change the runtime behavior of existing JavaScript code
* [X] This could be implemented without emitting different JS based on the types of the expressions
* [X] This isn't a runtime feature (e.g. new expression-level syntax)
|
Suggestion,Awaiting More Feedback
|
high
|
Critical
|
324,663,304 |
neovim
|
extended registers: associate more info with a register
|
This might be a bit of a stretch, but would you consider making available certain information about the buffer the contents of a register were copied from, so that it may be retrieved at the time the buffer contents are pasted?
Use case: copy text from buffer a and paste it into new buffer b, and since there is no ft in buffer b, deduce ft from that of buffer a and apply it to buffer b?
I can understand if it's just not happening :)
Cheers!
|
enhancement
|
low
|
Minor
|
324,663,503 |
rust
|
Highlighting still assumes a dark background
|
Like #7737.
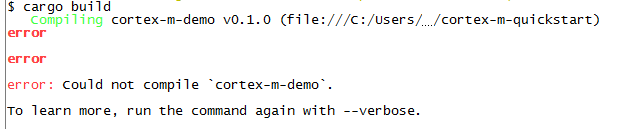
I'm using Git's MINGW64 with a white background, and the error message is not visible at all. Using the verbose flag didn't show any further information but that `rustc` failed with exit code 101. It wasn't until I tried to copy the terminal output into a bug report that I realised there actually was some text.
```
Compiling cortex-m-demo v0.1.0 (file:///C:/Users/…/cortex-m-quickstart)
error: language item required, but not found: `panic_fmt`
error: aborting due to previous error
error: Could not compile `cortex-m-demo`.
To learn more, run the command again with --verbose.
```
|
O-windows,A-diagnostics,T-compiler,C-bug,D-papercut
|
low
|
Critical
|
324,669,130 |
flutter
|
flutter doctor issue with symbolic links ?
|
my /opt is linked to /data/opt and flutter doctor see 2 installations, which are the same path, and one is failing
my emulators shows up in flutter and not in android studio (which has plugin)
```
flutter doctor -v
[✓] Flutter (Channel beta, v0.3.2, on Linux, locale en_CA.UTF-8)
• Flutter version 0.3.2 at /data/opt/flutter
• Framework revision 44b7e7d3f4 (il y a 4 semaines), 2018-04-20 01:02:44 -0700
• Engine revision 09d05a3891
• Dart version 2.0.0-dev.48.0.flutter-fe606f890b
[✓] Android toolchain - develop for Android devices (Android SDK 27.0.3)
• Android SDK at /data/opt/android-sdk
• Android NDK at /data/opt/android-sdk/ndk-bundle
• Platform android-27, build-tools 27.0.3
• ANDROID_HOME = /data/opt/android-sdk
• Java binary at: /data/opt/android-studio/jre/bin/java
• Java version OpenJDK Runtime Environment (build 1.8.0_152-release-1024-b01)
• All Android licenses accepted.
[✓] Android Studio (version 3.1)
• Android Studio at /data/opt/android-studio
• Flutter plugin version 24.2.1
• Dart plugin version 173.4700
• Java version OpenJDK Runtime Environment (build 1.8.0_152-release-1024-b01)
[✓] Android Studio
• Android Studio at /opt/android-studio
✗ Flutter plugin not installed; this adds Flutter specific functionality.
✗ Dart plugin not installed; this adds Dart specific functionality.
• Java version OpenJDK Runtime Environment (build 1.8.0_152-release-1024-b01)
[✓] Connected devices (2 available)
• Android SDK built for x86 • emulator-5556 • android-x86 • Android 8.1.0 (API 27) (emulator)
• Android SDK built for x86 • emulator-5554 • android-x86 • Android 8.1.0 (API 27) (emulator)
```
|
tool,t: flutter doctor,P3,team-tool,triaged-tool
|
low
|
Minor
|
324,699,040 |
TypeScript
|
Generics; ReturnType<Foo> != ReturnType<typeof foo>
|
<!-- 🚨 STOP 🚨 𝗦𝗧𝗢𝗣 🚨 𝑺𝑻𝑶𝑷 🚨
Half of all issues filed here are duplicates, answered in the FAQ, or not appropriate for the bug tracker. Even if you think you've found a *bug*, please read the FAQ first, especially the Common "Bugs" That Aren't Bugs section!
Please help us by doing the following steps before logging an issue:
* Search: https://github.com/Microsoft/TypeScript/search?type=Issues
* Read the FAQ: https://github.com/Microsoft/TypeScript/wiki/FAQ
Please fill in the *entire* template below.
-->
<!-- Please try to reproduce the issue with `typescript@next`. It may have already been fixed. -->
**TypeScript Version:** Version 2.9.0-dev.20180516
<!-- Search terms you tried before logging this (so others can find this issue more easily) -->
**Search Terms:** generic function returntype
I couldn't think of a good title for this,
**Code**
```ts
type Delegate<T> = () => T;
function executeGeneric<
X,
DelegateT extends Delegate<X>
>(delegate: DelegateT): ReturnType<DelegateT> {
//Type 'X' is not assignable to type 'ReturnType<DelegateT>'.
const x: ReturnType<typeof delegate> = delegate();
//Type 'X' is not assignable to type 'ReturnType<DelegateT>'.
const y: ReturnType<DelegateT> = delegate();
//Type 'X' is not assignable to type 'ReturnType<DelegateT>'.
return delegate();
}
```
**Expected behavior:**
Return successfully.
Intuitively, to me,
1. `delegate` is of type`DelegateT`.
1. `ReturnType<DelegateT>` and `ReturnType<typeof delegate>` should be the same
However,
**Actual behavior:**
`Type 'X' is not assignable to type 'ReturnType<DelegateT>'.`
**Playground Link:** [Here](http://www.typescriptlang.org/play/#src=type%20Delegate%3CT%3E%20%3D%20()%20%3D%3E%20T%3B%0D%0A%0D%0Afunction%20executeGeneric%3C%0D%0A%20%20%20%20X%2C%0D%0A%20%20%20%20DelegateT%20extends%20Delegate%3CX%3E%20%0D%0A%3E(delegate%3A%20DelegateT)%3A%20ReturnType%3CDelegateT%3E%20%7B%0D%0A%20%20%20%20%2F%2FType%20'X'%20is%20not%20assignable%20to%20type%20'ReturnType%3CDelegateT%3E'.%0D%0A%20%20%20%20const%20x%3A%20ReturnType%3Ctypeof%20delegate%3E%20%3D%20delegate()%3B%0D%0A%20%20%20%20%2F%2FType%20'X'%20is%20not%20assignable%20to%20type%20'ReturnType%3CDelegateT%3E'.%0D%0A%20%20%20%20const%20y%3A%20ReturnType%3CDelegateT%3E%20%3D%20delegate()%3B%0D%0A%20%20%20%20%2F%2FType%20'X'%20is%20not%20assignable%20to%20type%20'ReturnType%3CDelegateT%3E'.%0D%0A%20%20%20%20return%20delegate()%3B%0D%0A%7D)
**Related Issues:** <!-- Did you find other bugs that looked similar? -->
|
Suggestion,Awaiting More Feedback
|
low
|
Critical
|
324,722,858 |
nvm
|
Add a new command nvm local which creates a .nvmrc in the cwd
|
This is a simple feature request - add a new command nvm local <version> which creates a new .nvmrc file with the version provided.
|
feature requests
|
low
|
Minor
|
324,743,038 |
go
|
time: Sleep requires ~7 syscalls
|
### What version of Go are you using (`go version`)?
`go version go1.10.1 linux/amd64`
### Does this issue reproduce with the latest release?
Yes (`1.10.2`).
### What operating system and processor architecture are you using (`go env`)?
```
GOARCH="amd64"
GOBIN=""
GOCACHE="/home/bas/.cache/go-build"
GOEXE=""
GOHOSTARCH="amd64"
GOHOSTOS="linux"
GOOS="linux"
GOPATH="/home/bas/go"
GORACE=""
GOROOT="/usr/lib/go-1.10"
GOTMPDIR=""
GOTOOLDIR="/usr/lib/go-1.10/pkg/tool/linux_amd64"
GCCGO="gccgo"
CC="gcc"
CXX="g++"
CGO_ENABLED="1"
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
PKG_CONFIG="pkg-config"
GOGCCFLAGS="-fPIC -m64 -pthread -fmessage-length=0 -fdebug-prefix-map=/tmp/go-build723289083=/tmp/go-build -gno-record-gcc-switches"
```
### What did you do?
The following Go program calls `time.Sleep` the number of times given as a commandline argument.
```go
package main
import (
"os"
"strconv"
"time"
)
var max int
func main() {
max, _ = strconv.Atoi(os.Args[1])
n := 0
for {
time.Sleep(time.Second / 100)
n += 1
if n >= max {
return
}
}
}
```
If track the number of sys calls using `strace -f -c`, we find
```
bas@fourier2:~/gosleeptest$ strace -c -f ./gosleeptest 1
strace: Process 3115 attached
strace: Process 3114 attached
strace: Process 3116 attached
strace: Process 3117 attached
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
0.00 0.000000 0 8 mmap
0.00 0.000000 0 1 munmap
0.00 0.000000 0 114 rt_sigaction
0.00 0.000000 0 14 rt_sigprocmask
0.00 0.000000 0 4 clone
0.00 0.000000 0 1 execve
0.00 0.000000 0 10 sigaltstack
0.00 0.000000 0 5 arch_prctl
0.00 0.000000 0 9 gettid
0.00 0.000000 0 8 1 futex
0.00 0.000000 0 1 sched_getaffinity
0.00 0.000000 0 1 readlinkat
0.00 0.000000 0 22 pselect6
------ ----------- ----------- --------- --------- ----------------
100.00 0.000000 198 1 total
bas@fourier2:~/gosleeptest$ strace -c -f ./gosleeptest 10
strace: Process 3919 attached
strace: Process 3918 attached
strace: Process 3917 attached
strace: Process 3927 attached
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
0.00 0.000000 0 8 mmap
0.00 0.000000 0 1 munmap
0.00 0.000000 0 114 rt_sigaction
0.00 0.000000 0 14 rt_sigprocmask
0.00 0.000000 0 2 sched_yield
0.00 0.000000 0 4 clone
0.00 0.000000 0 1 execve
0.00 0.000000 0 10 sigaltstack
0.00 0.000000 0 5 arch_prctl
0.00 0.000000 0 9 gettid
0.00 0.000000 0 74 12 futex
0.00 0.000000 0 1 sched_getaffinity
0.00 0.000000 0 1 readlinkat
0.00 0.000000 0 69 pselect6
------ ----------- ----------- --------- --------- ----------------
100.00 0.000000 313 12 total
bas@fourier2:~/gosleeptest$ strace -c -f ./gosleeptest 100
strace: Process 4491 attached
strace: Process 4490 attached
strace: Process 4489 attached
strace: Process 4532 attached
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
89.01 0.043330 82 530 104 futex
9.76 0.004751 21 228 pselect6
0.27 0.000131 1 114 rt_sigaction
0.23 0.000114 23 5 arch_prctl
0.19 0.000091 9 10 sigaltstack
0.18 0.000086 10 9 gettid
0.13 0.000061 4 14 rt_sigprocmask
0.07 0.000035 4 8 mmap
0.07 0.000033 33 1 readlinkat
0.03 0.000017 4 4 clone
0.03 0.000017 17 1 execve
0.02 0.000009 9 1 munmap
0.01 0.000003 3 1 sched_getaffinity
------ ----------- ----------- --------- --------- ----------------
100.00 0.048678 926 104 total
```
### What did you expect to see?
A single `time.Sleep` should use approximately one syscall. (Python's `time.sleep` does only use one syscall, for instance.)
### What did you see instead?
Approximately seven sys calls per `time.Sleep`. As a consequence, the go process also uses quite a bit of CPU time per `time.Sleep`: 500us (compared to 13us for Python's `time.sleep`).
### Notes
I encountered this issue while debugging unexpectedly high idle CPU usage by `wireguard-go`.
|
Performance,NeedsInvestigation
|
medium
|
Critical
|
324,744,503 |
godot
|
Scaled Controls don't align properly
|
**Godot version:** 3.0
**OS/device including version:**
**Issue description:**
Margins ignore the scale of the control.
The top-left corner is set as if the node was not scaled.
Scale: 1x1, Anchor: center right
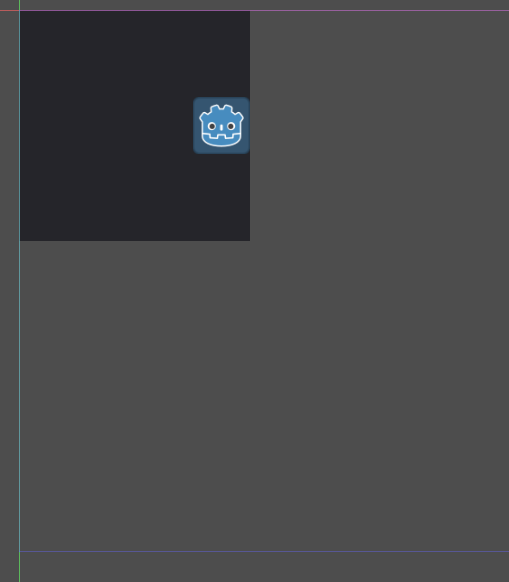
Scale: 2x2, Anchor: center right (the transparent panel is also scaled 2x2, but the textureRect didn't align to it's center right)
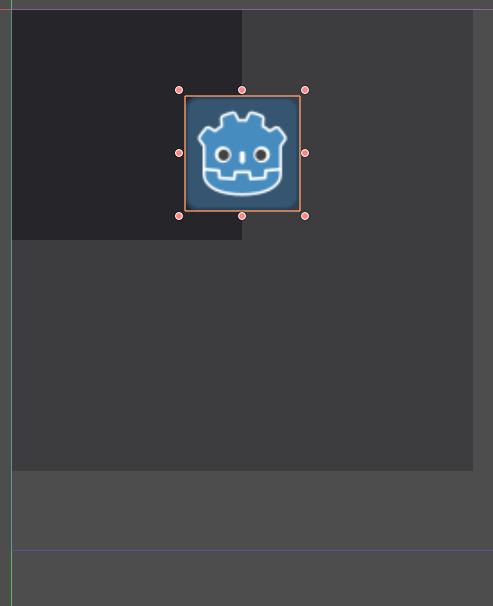
What was expected: (with Anchor: center left)
**Steps to reproduce:**
Add a Control to a parent Control.
Change the child's scale.
Change the child's anchor from the Layout menu (to a layout different from top left).
**Minimal reproduction project:**
[align-scaled-issue.zip](https://github.com/godotengine/godot/files/2020719/align-scaled-issue.zip)
|
bug,confirmed,topic:gui
|
medium
|
Major
|
324,750,503 |
neovim
|
Numeric prefixes not always rehighlighted when arabicshape is off
|
- `nvim --version`: #8421, 60dae5a9efe6c8b928ebc278ac4aa9d87bafa660
- Vim (version: ) behaves differently? no such feature in Vim
### Steps to reproduce
```
# nvim -u NONE -i NONE --cmd 'set noarabicshape' --cmd 'syntax on'
i<C-r>=0x1F<BS>
```
### Actual behaviour
`0x` is highlighted the same before and after typing `1F`, but gets rehighlighted as numeric prefix once `<BS>` is typed.
### Expected behaviour
`0x` is highlighted as error before typing `1` and as numeric prefix after that event.
|
bug,vimscript,syntax
|
low
|
Critical
|
324,806,676 |
youtube-dl
|
Support Xiami MV (Taobao video player)
|
Hi,
I'm using linux YouTube-dl to download a video from xiami.com;
the command is:
```shell
youtube-dl -v 'https://www.xiami.com/mv/K6YmI0'
```
And I got the following output:
```shell
[debug] System config: []
[debug] User config: []
[debug] Custom config: []
[debug] Command-line args: [u'-v', u'https://www.xiami.com/mv/K6YmI0']
[debug] Encodings: locale UTF-8, fs UTF-8, out UTF-8, pref UTF-8
[debug] youtube-dl version 2017.12.23
[debug] Python version 2.7.12 - Linux-4.4.0-119-generic-x86_64-with-Ubuntu-16.04-xenial
[debug] exe versions: avconv 2.8.14-0ubuntu0.16.04.1, avprobe 2.8.14-0ubuntu0.16.04.1, ffmpeg 2.8.14-0ubuntu0.16.04.1, ffprobe 2.8.14-0ubuntu0.16.04.1
[debug] Proxy map: {}
[generic] K6YmI0: Requesting header
WARNING: Falling back on generic information extractor.
[generic] K6YmI0: Downloading webpage
[generic] K6YmI0: Extracting information
ERROR: Unsupported URL: https://www.xiami.com/mv/K6YmI0
Traceback (most recent call last):
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/generic.py", line 2163, in _real_extract
doc = compat_etree_fromstring(webpage.encode('utf-8'))
File "/usr/local/bin/youtube-dl/youtube_dl/compat.py", line 2539, in compat_etree_fromstring
doc = _XML(text, parser=etree.XMLParser(target=_TreeBuilder(element_factory=_element_factory)))
File "/usr/local/bin/youtube-dl/youtube_dl/compat.py", line 2528, in _XML
parser.feed(text)
File "/usr/lib/python2.7/xml/etree/ElementTree.py", line 1653, in feed
self._raiseerror(v)
File "/usr/lib/python2.7/xml/etree/ElementTree.py", line 1517, in _raiseerror
raise err
ParseError: syntax error: line 4, column 0
Traceback (most recent call last):
File "/usr/local/bin/youtube-dl/youtube_dl/YoutubeDL.py", line 784, in extract_info
ie_result = ie.extract(url)
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/common.py", line 438, in extract
ie_result = self._real_extract(url)
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/generic.py", line 3063, in _real_extract
raise UnsupportedError(url)
UnsupportedError: Unsupported URL: https://www.xiami.com/mv/K6YmI0
```
Seems like YouTube-dl don't support it.
FIX IT plz, thx
|
site-support-request
|
low
|
Critical
|
324,817,108 |
youtube-dl
|
Support Better Homes and Gardens (BHG)
|
## Please follow the guide below
- You will be asked some questions and requested to provide some information, please read them **carefully** and answer honestly
- Put an `x` into all the boxes [ ] relevant to your *issue* (like this: `[x]`)
- Use the *Preview* tab to see what your issue will actually look like
---
### Make sure you are using the *latest* version: run `youtube-dl --version` and ensure your version is *2018.05.18*. If it's not, read [this FAQ entry](https://github.com/rg3/youtube-dl/blob/master/README.md#how-do-i-update-youtube-dl) and update. Issues with outdated version will be rejected.
- [x] I've **verified** and **I assure** that I'm running youtube-dl **2018.05.18**
### Before submitting an *issue* make sure you have:
- [x] At least skimmed through the [README](https://github.com/rg3/youtube-dl/blob/master/README.md), **most notably** the [FAQ](https://github.com/rg3/youtube-dl#faq) and [BUGS](https://github.com/rg3/youtube-dl#bugs) sections
- [x] [Searched](https://github.com/rg3/youtube-dl/search?type=Issues) the bugtracker for similar issues including closed ones
- [x] Checked that provided video/audio/playlist URLs (if any) are alive and playable in a browser
### What is the purpose of your *issue*?
- [ ] Bug report (encountered problems with youtube-dl)
- [x] Site support request (request for adding support for a new site)
- [ ] Feature request (request for a new functionality)
- [ ] Question
- [ ] Other
---
### If the purpose of this *issue* is a *site support request* please provide all kinds of example URLs support for which should be included (replace following example URLs by **yours**):
- Single video: https://www.bhg.com.au/koala-hospital?category=TV
- Single video: https://www.bhg.com.au/magnolia-manor?category=TV
Note that **youtube-dl does not support sites dedicated to [copyright infringement](https://github.com/rg3/youtube-dl#can-you-add-support-for-this-anime-video-site-or-site-which-shows-current-movies-for-free)**. In order for site support request to be accepted all provided example URLs should not violate any copyrights.
---
### Description of your *issue*, suggested solution and other information
Please add support for https://www.bhg.com.au/ site. Thank you
|
site-support-request
|
low
|
Critical
|
324,817,672 |
pytorch
|
[Caffe2][Caffe] Caffe to Caffe2 ParseError
|
`google.protobuf.text_format.ParseError: 78:5 : Message type "caffe.PoolingParameter" has no field named "torch_pooling".
`
So I am trying to convert from Caffe to Caffe 2 with custom pooling parameter using floor and ceil.
implemented it like this in `pooling_layer.cpp`
```
template <typename Dtype>
void PoolingLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
//unrelated code
switch (this->layer_param_.pooling_param().torch_pooling()) {
/// implementation
}
}
```
Found out on [caffe_translator.py](https://github.com/caffe2/caffe2/blob/master/caffe2/python/caffe_translator.py) line 521, that facebook has basically the same thing.
```
# In the Facebook port of Caffe, a torch_pooling field was added to
# map the pooling computation of Torch. Essentially, it uses
# floor((height + 2 * padding - kernel) / stride) + 1
# instead of
# ceil((height + 2 * padding - kernel) / stride) + 1
# which is Caffe's version.
# Torch pooling is actually the same as Caffe2 pooling, so we don't
# need to do anything.
```
I dont exactly understand how to register it so the parser will understand it.
I tried, in `caffe.proto`:
```
message LayerParameter {
optional PoolingParameter torch_pooling = 149;
```
Is there any documentation how facebook implemented its torch_pooling? I didn't find any information on the internet.
If the question above is unansverable, can you help me to register that pooling parameter to be parsed succesfully?
|
caffe2
|
low
|
Critical
|
324,865,207 |
gin
|
how do i get response body in after router middleware?
|
rt
```
r := gin.Default()
r.GET("/test",handler,middleware())
func middleware() gin.HandlerFunc{
// get response body in here;
...
}
```
|
question
|
low
|
Major
|
324,909,575 |
rust
|
Higher ranked trivial bounds are not checked
|
As can be seen in the example:
```rust
trait Trait {}
// Checked
fn foo() where i32 : Trait {}
// Not checked.
fn bar() where for<'a> fn(&'a ()) : Trait {}
```
In light of #2056 this will become just a lint, but still we should lint in both cases rather than just the first. This would be fixed by having well-formedness not ignore higher-ranked predicates. See #50815 for an attempted fix which resulted in too many regressions, probably for other bugs in handling higher-ranked stuff. We can try revisiting this after more chalkification.
|
C-enhancement,A-trait-system,T-compiler,T-types,S-types-tracked,A-higher-ranked
|
low
|
Critical
|
324,961,942 |
electron
|
Electron defaults to en-US and MM/dd/YY date formats regardless of system settings
|
* Electron Version: 2.0.0, 4.2.5
* Operating System (Platform and Version): Windows 10
* Last known working Electron version: Unknown
**Expected Behavior**
Electron should default to the OS's current culture/locale and date format settings.
**Actual behavior**
Electron defaults to en-US and the MM/dd/YY format for dates. More specifically:
- Entering `navigator.language` should return whatever my OS is set to.
- Entering `new Date().toLocaleString()` should return a date string in the format set by my OS.
**To Reproduce**
1. If in the US, change your OS language/region to something else (like United Kingdom or Sweden).
2. Install and run the Electron Quick Start sample application.
3. Open the developer tools and enter `navigator.language` in the console window.
4. In the console window, enter `new Date().toLocaleString()`.
|
platform/windows,bug :beetle:,blocked/upstream ❌,2-0-x,4-2-x,5-0-x,6-1-x,7-1-x,10-x-y,stale-exempt
|
high
|
Critical
|
324,978,186 |
pytorch
|
Inserting a tensor into a python dict causes strange behavior
|
Reported from https://discuss.pytorch.org/t/why-tensor-is-hashable/18225
```
T = torch.randn(5,5)
c = hash(T) # i.e. c = 140676925984200
dic = dict()
dic[T] = 100
dic[c]
RuntimeError: bool value of Tensor with more than one value is ambiguous.
```
I'm not sure if we support using Tensors as keys in python dicts; but Tensor does have a __hash__ method.
cc @albanD @mruberry
|
todo,module: nn,triaged
|
medium
|
Critical
|
325,023,266 |
pytorch
|
Conv3D can be optimized for cases when kernel is spatial (probably)
|
While using 3D CNNs we may need to use kernels with temporal dimension 1 (i.e. 1xHxW kernel), example 3D Resnet.
It would be similar to using a 2D Conv on reshaped input. What I have observed is that if i reshape, then do a 2D conv and then reshape back I get quicker results than 3D conv (which is maybe not very surprising).
[Here](https://discuss.pytorch.org/t/conv3d-can-be-optimized-for-case-when-no-temporal-stride-done/18184) is link to form post I created referencing this issue.
While measuring speed I used `torch.cuda.synchronize` so I hope my calculations were correct.
[Here](https://www.cse.iitb.ac.in/~namanjain/test2DConv.py) is the script I used for method using 2D Convolutions and [here](https://www.cse.iitb.ac.in/~namanjain/test3DConv.py)
is the one that used plane 3D convs.
I might have miscalculated the times but my observations showed scope of improvement which I believe would be useful..
What do you guys think???
cc @VitalyFedyunin @ngimel
|
module: performance,module: convolution,triaged
|
low
|
Minor
|
325,047,510 |
flutter
|
Let’s Rewrite Buildroot
|
The current buildroot was forked from Chromium many years ago. Due to different project priorities, a lot of features were tacked on in an entirely ad-hoc fashion. Changing project priorities and the lack of a clear owner has left a lot of unused cruft in the source tree.
For instance, there are definitions for platforms that don’t exist (fnl), or, have no users in the engine source tree (cros). Many toolchain definitions reference toolchains that don’t exist at all (GCC toolchains and many of the toolchains for architectures that we don’t target). There are also tools and templates for features that we no longer use (like preparing APKs in the source tree). Many unused python and shell utilities reference Chromium infrastructure.
Many of the features we want to add support for are not fully implemented and the existing definitions cause confusion. This includes adding support for sanitizers or supporting custom toolchains and sysroots. This technical debt is currently limiting development velocity and developer productivity.
The Flutter engine is a relatively simple project that would be better served with a simpler buildroot. I propose we write one from scratch.
|
team,engine,P2,team-engine,triaged-engine
|
low
|
Major
|
325,047,950 |
TypeScript
|
Support @param tag on function type
|
## Examples
```ts
/**
* @param a A doc
* @param b B doc
*/
type F = (a: number, b: number) => number;
```
Hover over `a` or `b` -- I would expect to see parameter documentation.
It would also be nice to get it at `a` in `const f: F = (a, b) => a + b;`.
|
Suggestion,In Discussion,Domain: JSDoc,Domain: Signature Help,Domain: Quick Info
|
low
|
Minor
|
325,064,131 |
go
|
net/http: investigate and fix uncaught allocations and regressions
|
I just made a fix for https://golang.org/issue/25383 with https://go-review.googlesource.com/c/go/+/113996 and that CL just puts a bandaid on the issue which was a regression that was manually noticed by @Quasilyte.
The real issue as raised by @bradfitz is that there have been a bunch of allocations and regressions that have crept into net/http code over the past couple of months/years, that are more concerning.
This issue is to track the mentioned the problem raised. I am currently too swamped to comprehensively do investigative and performance work but if anyone would like to take on this issue or would like to work on this for Go1.11 or perhaps during Go1.12 or so, I would be very happy to help out whether pairing or as a "bounty", please feel free to reach out to me.
|
Performance,NeedsInvestigation
|
low
|
Major
|
325,075,565 |
go
|
x/tools: write release tool to run your package's callers' tests
|
In https://github.com/golang/go/issues/24301#issuecomment-390788506 I proposed in a comment:
> We've been discussing some sort of `go release` command that both makes releases/tagging easy, but also checks API compatibility (like the Go-internal `go tool api` checker I wrote for Go releases). It might also be able to query `godoc.org` and find callers of your package and run their tests against your new version too at pre-release time, before any tag is pushed. etc.
And later in that issue, I said:
> With all the cloud providers starting to offer pay-by-the-second containers-as-a-service, I see no reason we couldn't provide this as an open source tool that anybody can run and pay the $0.57 or $1.34 they need to to run a bazillion tests over a bunch of hosts for a few minutes.
@SamWhited and @mattfarina had objections (https://github.com/golang/go/issues/24301#issuecomment-390792056, https://github.com/golang/go/issues/24301#issuecomment-390794717) about the inclusivity of such a tool, so I'm opening this bug so we don't cause too much noise in the other issue.
Such a tool would involve:
* querying a service (such as godoc.org or anything implementing the "Go workspace abstraction") to find your callers
* running the tests (or a fraction thereof) either
* locally, possibly overnight
* on a cloud provider of your choice (AWS Fargate, Azure Container Service, Digital Ocean, GCP, etc)
... and telling you if they pass before your change, but fail after your change, so you can release a new version of your package with confidence.
In local mode, it'd use your local GOOS/GOARCH. On cloud, Linux containers are cheapest, but it could also spin up Windows VMs like we do with Go. (Each Go commit gets a fresh new Windows VM that boots in under a minute and runs a few tests and then the VM is destroyed).
None of this costs much, and the assumption is that this would be used by people (optionally) who are willing to pay for the extra assurance, and/or those whose time needed to fix regressions later is worth more than the cloud costs.
And maybe some cloud CI/CD company(s) could sponsor such builders.
|
NeedsFix
|
medium
|
Critical
|
325,087,482 |
pytorch
|
[Caffe2] Align Element-Wise Ops Broadcasting to Numpy
|
- [x] Add
- [x] Div
- [x] Mul
- [ ] Pow
- [x] Sub
- [ ] And
- [ ] Or
- [ ] Xor
- [x] Equal
- [x] Greater
- [x] Less
- [ ] Gemm
- [ ] PRelu
|
caffe2
|
low
|
Minor
|
325,131,988 |
angular
|
bug happened when animations work with ng-content
|
<!--
PLEASE HELP US PROCESS GITHUB ISSUES FASTER BY PROVIDING THE FOLLOWING INFORMATION.
ISSUES MISSING IMPORTANT INFORMATION MAY BE CLOSED WITHOUT INVESTIGATION.
-->
## I'm submitting a...
<!-- Check one of the following options with "x" -->
<pre><code>
[ ] Regression (a behavior that used to work and stopped working in a new release)
[x] Bug report <!-- Please search GitHub for a similar issue or PR before submitting -->
[ ] Performance issue
[ ] Feature request
[ ] Documentation issue or request
[ ] Support request => Please do not submit support request here, instead see https://github.com/angular/angular/blob/master/CONTRIBUTING.md#question
[ ] Other... Please describe:
</code></pre>
## Current behavior
<!-- Describe how the issue manifests. -->
When there is an animation in the parent div of ng-content, the animation in ng-content will break and go wrong.
## Expected behavior
<!-- Describe what the desired behavior would be. -->
animation works fine.
## Minimal reproduction of the problem with instructions
<!--
For bug reports please provide the *STEPS TO REPRODUCE* and if possible a *MINIMAL DEMO* of the problem via
https://stackblitz.com or similar (you can use this template as a starting point: https://stackblitz.com/fork/angular-gitter).
-->
https://stackblitz.com/edit/angular-36yemx?file=src%2Fapp%2Fcontent.component.html
click toggle button twice, you can see all `span` are gone, which expected to display again with animations
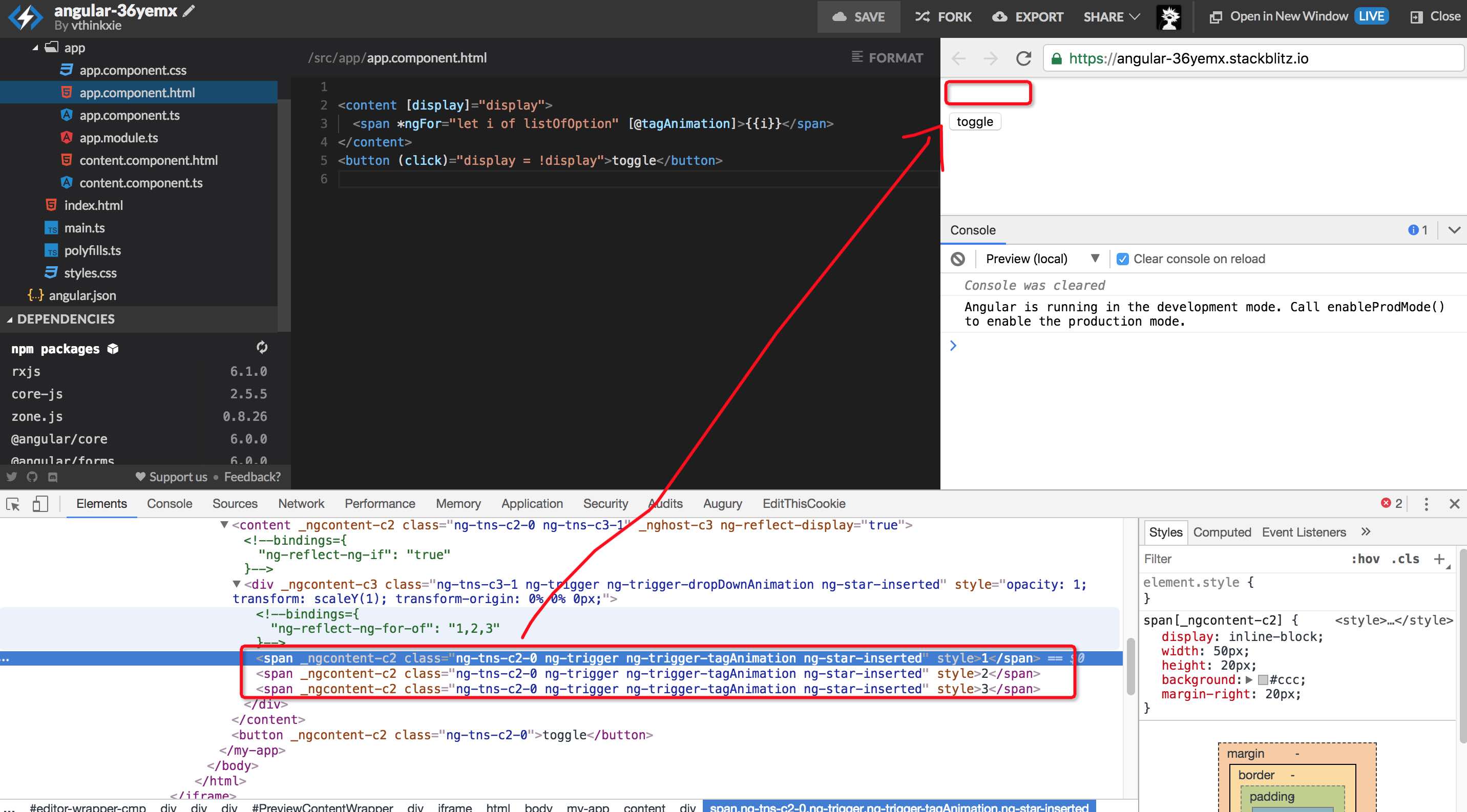
## What is the motivation / use case for changing the behavior?
<!-- Describe the motivation or the concrete use case. -->
## Environment
<pre><code>
Angular version: latest
<!-- Check whether this is still an issue in the most recent Angular version -->
Browser:
- [x] Chrome (desktop) version latest
- [ ] Chrome (Android) version XX
- [ ] Chrome (iOS) version XX
- [ ] Firefox version XX
- [ ] Safari (desktop) version XX
- [ ] Safari (iOS) version XX
- [ ] IE version XX
- [ ] Edge version XX
For Tooling issues:
- Node version: XX <!-- run `node --version` -->
- Platform: <!-- Mac, Linux, Windows -->
Others:
<!-- Anything else relevant? Operating system version, IDE, package manager, HTTP server, ... -->
</code></pre>
remove animation in the `content component` or do it without `ng-content`, every thing will be ok
|
type: bug/fix,area: animations,freq2: medium,P3
|
medium
|
Critical
|
325,134,333 |
flutter
|
Circular Progress Indicator CPU Spike
|
My Flutter application heats up my MacBook Pro Late 2015 15" whenever I use a Circular Progress Indicator on the Android Emulator (Running Nougat)
## Steps to Reproduce
<!--
Please tell us exactly how to reproduce the problem you are running into.
Please attach a small application (ideally just one main.dart file) that
reproduces the problem. You could use https://gist.github.com/ for this.
If the problem is with your application's rendering, then please attach
a screenshot and explain what the problem is.
-->
1. Use CircleProgressIndicator Widget
|
framework,f: material design,c: performance,has reproducible steps,P2,found in release: 3.3,found in release: 3.7,team-design,triaged-design
|
low
|
Major
|
325,341,009 |
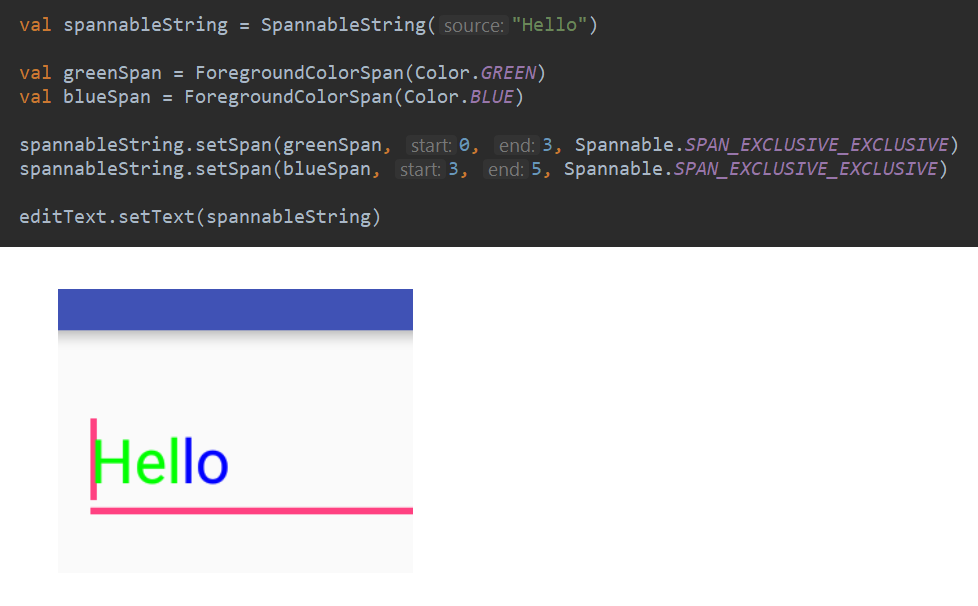
flutter
|
Support TextSpan in TextFields
|
Android's `EditText` and `TextView` both support rich text spans.
But in Flutter, only `RichText` widget support rich text spans.
`TextField` should support rich text spans natively using `TextSpan`.
Android example of using text span in edit text component:
|
a: text input,c: new feature,framework,P3,team-framework,triaged-framework
|
medium
|
Major
|
325,348,066 |
youtube-dl
|
vlive extractor recognition error
|
## Please follow the guide below
- You will be asked some questions and requested to provide some information, please read them **carefully** and answer honestly
- Put an `x` into all the boxes [ ] relevant to your *issue* (like this: `[x]`)
- Use the *Preview* tab to see what your issue will actually look like
---
### Make sure you are using the *latest* version: run `youtube-dl --version` and ensure your version is *2018.05.18*. If it's not, read [this FAQ entry](https://github.com/rg3/youtube-dl/blob/master/README.md#how-do-i-update-youtube-dl) and update. Issues with outdated version will be rejected.
- [ x ] I've **verified** and **I assure** that I'm running youtube-dl **2018.05.18**
### Before submitting an *issue* make sure you have:
- [x ] At least skimmed through the [README](https://github.com/rg3/youtube-dl/blob/master/README.md), **most notably** the [FAQ](https://github.com/rg3/youtube-dl#faq) and [BUGS](https://github.com/rg3/youtube-dl#bugs) sections
- [ ] [Searched](https://github.com/rg3/youtube-dl/search?type=Issues) the bugtracker for similar issues including closed ones
- [ x ] Checked that provided video/audio/playlist URLs (if any) are alive and playable in a browser
### What is the purpose of your *issue*?
- [ x ] Bug report (encountered problems with youtube-dl)
- [ ] Site support request (request for adding support for a new site)
- [ ] Feature request (request for a new functionality)
- [ ] Question
- [ ] Other
---
### The following sections concretize particular purposed issues, you can erase any section (the contents between triple ---) not applicable to your *issue*
---
### If the purpose of this *issue* is a *bug report*, *site support request* or you are not completely sure provide the full verbose output as follows:
Add the `-v` flag to **your command line** you run youtube-dl with (`youtube-dl -v <your command line>`), copy the **whole** output and insert it here. It should look similar to one below (replace it with **your** log inserted between triple ```):
```
C:\Users\nichi_000\Desktop\youtube_dl>youtube-dl.exe --config-location C:\Users\nichi_000\AppData\Roaming\youtube-dl\vlive.txt --cookies C:\Users\nichi_000\Desktop\youtube_dl\Cookies\vlive_cookies.txt -v https://www.vlive.tv/video/vplus/9427
[debug] System config: []
[debug] User config: []
[debug] Custom config: ['--prefer-ffmpeg', '--no-mark-watched', '-f', 'bestvideo[ext=mp4]+bestaudio[ext=m4a]/best[ext=mp4]/best', '--merge-output-format', 'mp4', '--ffmpeg-location', 'C:\\video\\ffmpeg.exe', '-o', 'C:\\Vlive\\%(uploader)s - %(title)s.%(ext)s', '--no-check-certificate', '--abort-on-unavailable-fragment', '--write-sub', '--sub-lang', 'en', '--write-auto-sub', '--convert-subs', 'srt', '--write-thumbnail', '--add-metadata']
[debug] Command-line args: ['--config-location', 'C:\\Users\\nichi_000\\AppData\\Roaming\\youtube-dl\\vlive.txt', '--cookies', 'C:\\Users\\nichi_000\\Desktop\\youtube_dl\\Cookies\\vlive_cookies.txt', '-v', 'https://www.vlive.tv/video/vplus/9427']
[debug] Encodings: locale cp1250, fs mbcs, out cp852, pref cp1250
[debug] youtube-dl version 2018.05.18
[debug] Python version 3.4.4 (CPython) - Windows-10-10.0.16299
[debug] exe versions: ffmpeg N-65426-gd6af706, ffprobe N-65426-gd6af706
[debug] Proxy map: {}
[generic] 9427: Requesting header
WARNING: Falling back on generic information extractor.
[generic] 9427: Downloading webpage
[generic] 9427: Extracting information
ERROR: Unsupported URL: https://www.vlive.tv/video/vplus/9427
Traceback (most recent call last):
File "C:\Users\dst\AppData\Roaming\Build archive\youtube-dl\rg3\tmpco7jv88i\build\youtube_dl\YoutubeDL.py", line 792, in extract_info
File "C:\Users\dst\AppData\Roaming\Build archive\youtube-dl\rg3\tmpco7jv88i\build\youtube_dl\extractor\common.py", line 503, in extract
File "C:\Users\dst\AppData\Roaming\Build archive\youtube-dl\rg3\tmpco7jv88i\build\youtube_dl\extractor\generic.py", line 3201, in _real_extract
youtube_dl.utils.UnsupportedError: Unsupported URL: https://www.vlive.tv/video/vplus/9427
---
### Description of your *issue*, suggested solution and other information
Explanation of your *issue* in arbitrary form goes here. Please make sure the [description is worded well enough to be understood](https://github.com/rg3/youtube-dl#is-the-description-of-the-issue-itself-sufficient). Provide as much context and examples as possible.
If work on your *issue* requires account credentials please provide them or explain how one can obtain them.
|
account-needed
|
low
|
Critical
|
325,378,167 |
vscode
|
Intellisense tooltip with filter category like Visual Studio
|

It would be awesome if in the moment to bring the intellisense of properties or classes on Typescript and C# or other language we can filter this like the little icons on the bottom of the tooltip as visual studio,
or control + shift + p + @: but for the intellisense.
|
feature-request,suggest
|
high
|
Critical
|
325,391,243 |
TypeScript
|
Add `SharedWorker` to the library
|
Details in https://developer.mozilla.org/en-US/docs/Web/API/SharedWorker
This should work
```ts
var myWorker = new SharedWorker('worker.js');
```
|
Bug,Help Wanted,Domain: lib.d.ts
|
low
|
Major
|
325,403,852 |
electron
|
serviceWorkerRegistration.showNotification does not work
|
* Electron Version: 1.8.x - 2.x
* Operating System (Platform and Version): Win, Linux, MacOSX
* Last known working Electron version: no
**Expected Behavior**
notification should be shown
**Actual behavior**
notification not shown
**To Reproduce**
here example: https://github.com/dregenor/showNotification.git
1) clone,
2) npm install,
3) npm start
click "Show Notification"
```sh
$ git clone https://github.com/dregenor/showNotification.git -b master
$ npm install
$ npm start
```
in browser all works fine.
example:
1) open src folder and start simpleHttp server
```sh
python -m SimpleHTTPServer 8080
```
2) open in Google Chrome http://127.0.0.1:8080
3) press "Show Notification" button
result:
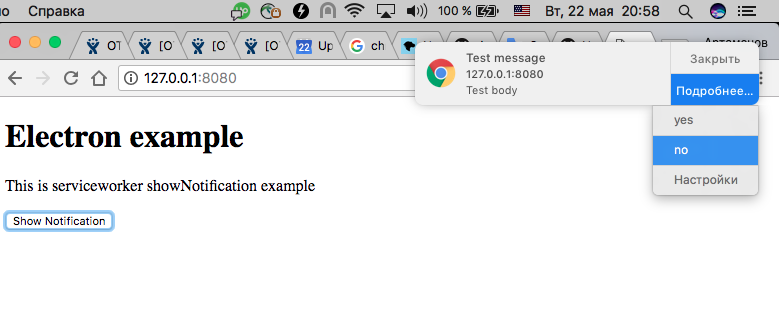
|
enhancement :sparkles:,platform/all,2-0-x,5-0-x,6-0-x,6-1-x,9-x-y,11-x-y
|
medium
|
Major
|
325,474,335 |
pytorch
|
[feature request] Add Local Contrast Normalization
|
## Issue description
As mentioned in this paper :- http://yann.lecun.com/exdb/publis/pdf/jarrett-iccv-09.pdf
I noticed that Local Response Norm is present. This is will be a good addition too.
I have an implementation ready and can create a PR soon, if approved.
cc @albanD @mruberry
|
module: nn,triaged,enhancement
|
low
|
Minor
|
325,508,978 |
opencv
|
JVM crash while reading from camera
|
##### System information (version)
- OpenCV => 3.4.1
- Operating System / Platform => OpenSUSE Leap
- Compiler => gcc 4.8.5
##### Detailed description
```
uvcvideo: Failed to query (GET_CUR) UVC control 4 on unit 1: -110 (exp. 4).
uvcvideo: Failed to query (GET_CUR) UVC control 3 on unit 1: -110 (exp. 1).
libv4l2: error setting pixformat: Input/output error
VIDEOIO ERROR: libv4l unable to ioctl S_FMT
uvcvideo: Failed to set UVC probe control : -32 (exp. 26).
VIDIOC_G_FMT: Bad file descriptor
ERROR: V4L: Unable to determine size of incoming image
*** Error in `/usr/lib64/jvm/jre/bin/java': double free or corruption (fasttop): 0x00007f93200a40e0 ***
======= Backtrace: =========
/lib64/libc.so.6(+0x740ef)[0x7f937f4bc0ef]
/lib64/libc.so.6(+0x79646)[0x7f937f4c1646]
/lib64/libc.so.6(+0x7a393)[0x7f937f4c2393]
/usr/lib64/libopencv_videoio.so.3.4(+0x173c2)[0x7f93243993c2]
/usr/lib64/libopencv_videoio.so.3.4(+0x175e4)[0x7f93243995e4]
/usr/lib64/libopencv_videoio.so.3.4(cvReleaseCapture+0x1f)[0x7f93243891df]
/usr/lib64/libopencv_videoio.so.3.4(_ZNK2cv14DefaultDeleterI9CvCaptureEclEPS1_+0x15)[0x7f9324389205]
/usr/lib64/libopencv_videoio.so.3.4(+0x7229)[0x7f9324389229]
/usr/lib64/libopencv_videoio.so.3.4(_ZN2cv12VideoCapture7releaseEv+0x86)[0x7f9324388e36]
/usr/share/OpenCV/java/libopencv_java341.so(Java_org_opencv_videoio_VideoCapture_release_10+0x15)[0x7f932533a7c5]
[0x7f9369017e47]
```
This doesn't happen consistently (maybe one out of 50 attempts to open the camera), but it always includes the uvcvideo errors (from the kernel) and v4l errors.
When this happens the calls to `open` and `isOpen` on `VideoCamera` both return true, but I can detect that there's a problem by setting the resolution, reading back the resolution and seeing that it didn't take. If at that point I don't call `release` i can avoid this particular crash, but then the JVM still crashes a few seconds later in some random place.
I saw the same issue with OpenCV 3.1.
|
bug,category: videoio(camera)
|
low
|
Critical
|
325,529,323 |
pytorch
|
[Caffe2] Fail to build after upgrading to cuda 9.2
|
## Issue description
I am baffled by this actually (probably because I don't understand cmake very well). After I upgraded to cuda-9.2, wiped out the whole build directory, and reran the build flow, Caffe2 cannot be run:
`WARNING:root:Debug message: libcurand.so.9.1: cannot open shared object file: No such file or directory`
While 'ldd libcaffe2_gpu.so' gives:
` libcurand.so.9.2 => /usr/local/cuda-9.2/targets/x86_64-linux/lib/libcurand.so.9.2 (0x00007f7b4965c000)`
## Code example
## System Info
- PyTorch or Caffe2: Caffe2
- How you installed PyTorch (conda, pip, source): Source build
- Build command you used (if compiling from source): `mkdir build && cd mkdir && cmake $(python3 ../scripts/get_python_cmake_flags.py) -DUSE_NATIVE_ARCH=ON -DUSE_CUDA=ON .. && make && sudo make install`
- OS: Ubuntu 1604
- PyTorch version:
- Python version: 3.5.2
- CUDA/cuDNN version: 9.2
- GPU models and configuration: GTX 1070
- GCC version (if compiling from source): gcc (Ubuntu 5.4.0-6ubuntu1~16.04.9) 5.4.0 20160609
- CMake version: 3.5.1
- Versions of any other relevant libraries:
|
caffe2
|
low
|
Critical
|
325,557,821 |
TypeScript
|
Assume arity of tuples when declared as literal
|
## Search Terms
tuples, length, arity
## Suggestion
Now that #17765 is out I'm curious about if we could change the arity of tuples declared as literals. This was proposed as part of #16896 but I thought it might be better to pull this part out to have a discussion about this part of that proposal.
With fixed length tuples TypeScript allows you to convert `[number, number]` to `number[]` but not the other way around (which is great).
```ts
const foo = [1, 2];
const bar = [1, 2] as [number, number];
const foo2: [number, number] = foo;
const bar2: number[] = bar;
```
If you declare a constant such as `foo` above it would be nice if it would be nice if it would have the length as part of its type, that is, if `foo` was assumed to be of type `[number, number]` not `number[]`.
This would have potential issues with mutable arrays allowing you to call `push` and `pop` although this isn't different to present and was discussed a bit in #6229.
```ts
const foo = [1, 2] as [number, number]; // After this proposal TypeScript would infer the type as `[number, number]` not `number[]`.
foo.push(3); // foo is of type `[number, number]` even though it now has 3 elements.
foo.splice(2); // And now it has 2 elements again.
```
## Use Cases
When using a function such as `fromPairs` from lodash it requires that the type is a list of tuples. A simplified version is
```ts
function fromPairs<T>(values: [PropertyKey, T][]): { [key: string]: T } {
return values.reduce((acc, [key, value]) => ({ ...acc, [key]: value }), {});
}
```
If I do
```ts
const foo = fromPairs(Object.entries({ a: 1, b: 2 }));
```
it works because the type passed into `fromPairs` is `[string, number][]`, but if I try to say map the values to double their value I get a compile error:
```ts
const bar = fromPairs(Object.entries({ a: 1, b: 2 }).map(([key, value]) => [key, value * 2]));
```
as the parameter is of type `(string | number)[][]`
This can be fixed by going
```ts
const bar = fromPairs(Object.entries({ a: 1, b: 2 }).map(([key, value]) => [key, value * 2] as [string, number]));
```
but this is cumbersome.
## Checklist
My suggestion meets these guidelines:
* [ ] This wouldn't be a breaking change in existing TypeScript / JavaScript code
* [x] This wouldn't change the runtime behavior of existing JavaScript code
* [x] This could be implemented without emitting different JS based on the types of the expressions
* [x] This isn't a runtime feature (e.g. new expression-level syntax)
|
Suggestion,Revisit
|
medium
|
Critical
|
325,590,018 |
pytorch
|
[feature request] Simple and Efficient way to get gradients of each element of a sum
|
For some application, I need to get gradients for each elements of a sum.
I am aware that this issue has already been raised previously, in various forms ([here](https://discuss.pytorch.org/t/gradient-w-r-t-each-sample/1433/2), [here](https://discuss.pytorch.org/t/efficient-per-example-gradient-computations/17204), [here](https://discuss.pytorch.org/t/quickly-get-individual-gradients-not-sum-of-gradients-of-all-network-outputs/8405) and possibly related to [here](https://github.com/pytorch/pytorch/issues/1407))
and has also been raised for other autodifferentiation libraries (some examples for TensorFlow: [here](https://github.com/tensorflow/tensorflow/issues/675), long discussion [here](https://github.com/tensorflow/tensorflow/issues/4897))
While the feature does exists in that there is a way to get the desired output,
I have not found an efficient way of computing it after investing a significant amount of time.
I am bringing it up again, with some numbers showing the inefficiency of the existing solutions I have been able to find.
It is possible that the running time I observed is not an issue with the existing solutions but only with my implementation of them,
or that my attempts have been misguided and that a simpler solution exists.
If there is a way to make that operation in an efficient way, I would love to know about it.
I can spend more time working on this issue, but as of now I do not know of a way forward.
The following contains a description of the desired feature, existing "workaround" and some evaluation of their performance.
---
## Feature description:
Given an objective that is a sum of functions, `f(x) = f_1(x) + ... + f_N(x)`,
a _simple to use_ and _efficient_ way to compute the gradient with respect to `x` for each of the individual function `f_n`, i.e., getting
`[∇f_1(x), ..., ∇f_N(x)]`
If there already is a way to do so, an example would be very nice.
(I understand that this would involve additional memory overhead if `N` is large, as pointed out [here](https://discuss.pytorch.org/t/quickly-get-individual-gradients-not-sum-of-gradients-of-all-network-outputs/8405/2) - my setting is not bound by memory but by time)
## Use case:
- Computing approximate second-order information (Generalized Gauss-Newton type of algorithm).
- Computing gradient statistics such as the variance at a given point.
Some papers based on those ideas: [here](https://pdfs.semanticscholar.org/42e2/1cd78f578fa6ce61b06b99848697da85ed76.pdf), [here](http://www.cs.toronto.edu/~jmartens/docs/Deep_HessianFree.pdf)
## Existing workarounds:
- The `naive` implementation: do the forward pass in batch up to the last part of the function to minimize overhead, and then call backward on each individual `f_n(x)`.
- Goodfellow showed how to recover the individual gradients from gradients with respect to the activation functions in the case of feed-forward neural networks [here](https://arxiv.org/abs/1510.01799). This requires an additional derivation and performs the linear parts of the transformation in Python instead of C, making it scale badly.
- What I call "Multiple Models": Define copies of the parameters `x_1, ..., x_N` and compute `grad(f_1(x_1) + ... + f_N(x_N))`. This ensures that the gradients are not accumulated, however it scales poorly. Adapted from the original formulation [here](https://github.com/tensorflow/tensorflow/issues/4897#issuecomment-290997283)
## Evaluation of existing workarounds
I have tried to make the simplest example of a sufficiently complex problem where this becomes an issue.
The code to reproduce these is available [here](https://github.com/fKunstner/fast-individual-gradients-with-autodiff).
Running on a simple Multi-Layer Perceptron, I am comparing the running time of
* `full`: computing the gradient of the full objective function
* `naive`, `goodf`, `multi`: computing the gradient of the sum by first computing individual gradients with the methods described above, and then taking the sum[1].
I am taking a sum over `N = 1000` elements, and tried different network configurations;
```
# D: Dimension of input and of each Layer
# L: Number of hidden layers
```
For a (relatively) wide and shallow network (`D, L = 500, 1`), I get the following running time
```
Full : 0.04s
naive : 15.42s
goodf : 4.42s
multi : 1.89s
```
For a narrower and deeper network (`D, L = 100, 10`) I get
```
Full : 0.03s
naive : 11.40s
goodf : 1.70s
multi : 1.60s
```
While `goodf` and `multi` definitely are improvements on the naive method, they are still ~50 time slower than simply computing the sum. I would not expect any method that stores individual gradients to perform as well as a method that can simply throw them away, but they are essentially doing the same operations so it should be possible to do better.
With those numbers, training a small-ish neural network that would normally take ~10 minutes would take 10 hours, making experimentation very difficult.
From the [information I have been able to find](https://discuss.pytorch.org/t/how-the-hook-works/2222/2), it seems difficult to get access to the un-aggregated gradients.
It is a bit frustrating to know that the backward pass on the function computes the sum in almost no time, and all that is needed for this feature is a way to intercept elements of this sum.
A hook that would allow to store individual gradients on the fly in some list or tensor - maybe with the use of those hooks or by defining a new sum function that intercepts gradients - would be amazing, but I do not understand the codebase and/or AD to do it.
Some pointers in that direction would already be a big help
[1] _Note: I am not looking for an expensive way of computing the sum by computing individual gradients - I am taking the sum in the end so that all methods do the "same thing", but what is really needed is the intermediate matrix containing individual gradients_
cc @ezyang @SsnL @albanD @zou3519
|
feature,module: autograd,triaged
|
medium
|
Major
|
325,672,776 |
pytorch
|
detectron net create error
|
I changed detectron pkl model to caffe2 pb model,
errors happened when called
CAFFE_ENFORCE(workspace.CreateNet(model.predict.net));
terminate called after throwing an instance of 'caffe2::EnforceNotMet'
what(): [enforce fail at operator.cc:185] op. Cannot create operator of type 'GenerateProposals' on the device 'CUDA'. Verify that implementation for the corresponding device exist. It might also happen if the binary is not linked with the operator implementation code. If Python frontend is used it might happen if dyndep.InitOpsLibrary call is missing. Operator def: input: "rpn_cls_probs_fpn2_cpu" input: "rpn_bbox_pred_fpn2_cpu" input: "im_info" input: "anchor2_cpu" output: "rpn_rois_fpn2" output: "rpn_roi_probs_fpn2" name: "" type: "GenerateProposals" arg { name: "nms_thres" f: 0.7 } arg { name: "min_size" f: 0 } arg { name: "spatial_scale" f: 0.25 } arg { name: "correct_transform_coords" i: 1 } arg { name: "post_nms_topN" i: 1000 } arg { name: "pre_nms_topN" i: 1000 } device_option { device_type: 1 }
|
caffe2
|
low
|
Critical
|
325,675,456 |
vue
|
👋 Vue reactivity engine and MobX 🖖
|
Hey,
Vue is cool, over at React land MobX ( https://github.com/mobxjs/mobx/ ) takes a similar approach by defining getters/setters.
The architectural nature of Vue apps is much closer to React+MobX than the typical React architecture and MobX is used and trusted by some [big companies](https://github.com/mobxjs/mobx/issues/681)
I am not aware of any knowledge sharing or idea sharing between the projects. I think it would be really cool if we explore possibilities to collaborate.
Some areas of collaboration which could be cool:
- Standardized benchmarks.
- Optimization tips and what things that worked out and didn't.
- Good user experience for things like circular references.
- What code can be shared between libraries or extracted.
- Discuss the transition to from getters/setters to proxies.
- Discuss what's hard from the language PoV to provide feedback to TC39.
I am explicitly not suggesting anything concrete. Just to get the discussion started. I got the idea after I started participating in SinonJS and someone from Jest reached out to us in order to use a shared code component.
What do you think?
(And I want to point out that "no" is also a perfectly acceptable response here)
----
Full disclosure - I am a part of the MobX team - MobX is written and is the brainchild of @mweststrate - I am also probably quite terrible at Vue itself :D
It's possible Michel reached out in the past (or vice versa) and the discussion simply isn't public.
|
discussion
|
low
|
Major
|
325,710,526 |
angular
|
Expose '_loadedConfig' in a public way.
|
<!--
PLEASE HELP US PROCESS GITHUB ISSUES FASTER BY PROVIDING THE FOLLOWING INFORMATION.
ISSUES MISSING IMPORTANT INFORMATION MAY BE CLOSED WITHOUT INVESTIGATION.
-->
## I'm submitting a...
<!-- Check one of the following options with "x" -->
<pre><code>
[ ] Regression (a behavior that used to work and stopped working in a new release)
[ ] Bug report <!-- Please search GitHub for a similar issue or PR before submitting -->
[ ] Performance issue
[x ] Feature request
[ ] Documentation issue or request
[ ] Support request => Please do not submit support request here, instead see https://github.com/angular/angular/blob/master/CONTRIBUTING.md#question
[ ] Other... Please describe:
</code></pre>
## Current behavior
From a component that is loaded at bootstrap time I would like to dynamically instantiate a component that is loaded lazily on the current route. For that purpose I need access to the ComponentFactoryResolver for that route.
The only way I could find to access that resolver is via the private "_loadedConfig" property on the active route.
## Expected behavior
I would like to be able to access the resolved via a public API, not relying on an implementation detail.
## What is the motivation / use case for changing the behavior?
Better stability of my code by relying on public APIs, only.
## Environment
<pre><code>
Angular version: 6.0.2
<!-- Check whether this is still an issue in the most recent Angular version -->
Browser:
- [x ] Chrome (desktop) version XX
- [x] Chrome (Android) version XX
- [x] Chrome (iOS) version XX
- [x] Firefox version XX
- [x] Safari (desktop) version XX
- [x] Safari (iOS) version XX
- [x] IE version XX
- [x] Edge version XX
</code></pre>
|
feature,area: router,router: lazy loading,feature: under consideration
|
medium
|
Critical
|
325,721,098 |
go
|
all: some pkg tests fail for -test.count>1 but pass with -test.count=1
|
### What version of Go are you using (`go version`)?
tip
### Does this issue reproduce with the latest release?
yes
### What operating system and processor architecture are you using (`go env`)?
linux ppc64le
### What did you do?
Trying to run some tests multiple times to determine variations in times, but noticed that some tests fail when using count > 1 which pass for 1.
### What did you expect to see?
I would expect the count not to affect whether the test passes or fails.
### What did you see instead?
Failures in net/http/httputil, reflect, runtime/pprof.
2018/05/23 09:25:14 http: proxy error: EOF
2018/05/23 09:25:14 httputil: ReverseProxy read error during body copy: unexpected EOF
--- FAIL: TestDumpRequest (0.00s)
dump_test.go:224: DumpRequest #7: http: invalid Read on closed Body
2018/05/23 09:25:14 http: proxy error: EOF
2018/05/23 09:25:14 httputil: ReverseProxy read error during body copy: unexpected EOF
--- FAIL: TestDumpRequest (0.00s)
dump_test.go:224: DumpRequest #7: http: invalid Read on closed Body
2018/05/23 09:25:14 http: proxy error: EOF
2018/05/23 09:25:14 httputil: ReverseProxy read error during body copy: unexpected EOF
--- FAIL: TestDumpRequest (0.00s)
dump_test.go:224: DumpRequest #7: http: invalid Read on closed Body
2018/05/23 09:25:14 http: proxy error: EOF
2018/05/23 09:25:14 httputil: ReverseProxy read error during body copy: unexpected EOF
FAIL
FAIL net/http/httputil 0.346s
...
--- FAIL: TestCallReturnsEmpty (5.03s)
all_test.go:1706: finalizer did not run
--- FAIL: TestCallReturnsEmpty (5.01s)
all_test.go:1706: finalizer did not run
--- FAIL: TestCallReturnsEmpty (5.03s)
all_test.go:1706: finalizer did not run
FAIL
FAIL reflect 24.984s
...
--- FAIL: TestMutexProfile (0.08s)
--- FAIL: TestMutexProfile/debug=1 (0.00s)
pprof_test.go:689: received profile: --- mutex:
cycles/second=511980172
sampling period=1
14132620 2 @ 0x701f8 0x17e08c 0x68bf4
# 0x701f7 sync.(*Mutex).Unlock+0xb7 /home/boger/golang/fresh/go/src/sync/mutex.go:201
# 0x17e08b runtime/pprof.blockMutex.func1+0x3b /home/boger/golang/fresh/go/src/runtime/pprof/pprof_test.go:651
pprof_test.go:706: "14132620 2 @ 0x701f8 0x17e08c 0x68bf4" didn't match "^\\d+ 1 @(?: 0x[[:xdigit:]]+)+"
pprof_test.go:712: --- mutex:
cycles/second=511980172
sampling period=1
14132620 2 @ 0x701f8 0x17e08c 0x68bf4
# 0x701f7 sync.(*Mutex).Unlock+0xb7 /home/boger/golang/fresh/go/src/sync/mutex.go:201
# 0x17e08b runtime/pprof.blockMutex.func1+0x3b /home/boger/golang/fresh/go/src/runtime/pprof/pprof_test.go:651
--- FAIL: TestEmptyCallStack (0.00s)
panic: pprof: NewProfile name already in use: test18836 [recovered]
panic: pprof: NewProfile name already in use: test18836
goroutine 711 [running]:
testing.tRunner.func1(0xc000694400)
/home/boger/golang/fresh/go/src/testing/testing.go:792 +0x344
panic(0x1afa40, 0xc0000906e0)
/home/boger/golang/fresh/go/src/runtime/panic.go:494 +0x1c0
runtime/pprof.NewProfile(0x1f5382, 0x9, 0x0)
/home/boger/golang/fresh/go/src/runtime/pprof/pprof.go:214 +0x210
runtime/pprof.TestEmptyCallStack(0xc000694400)
/home/boger/golang/fresh/go/src/runtime/pprof/pprof_test.go:830 +0x60
testing.tRunner(0xc000694400, 0x2022c0)
/home/boger/golang/fresh/go/src/testing/testing.go:827 +0xc0
created by testing.(*T).Run
/home/boger/golang/fresh/go/src/testing/testing.go:878 +0x2e0
FAIL runtime/pprof 77.152s
Also, I have been trying to run benchmarks for atomics multiple times and while the tests don't fail, the first run (count=1) gives me a time that looks reasonable, but results for count>1 are really high. This has me wondering if runs after the first are running with uninitialized data somewhere.
For example, the results when running -test.count=2
BenchmarkChanNonblocking-16 1000000000 3.15 ns/op
BenchmarkChanNonblocking-16 1000000000 32.7 ns/op
If I run the program for ChanNonblocking multiple times I consistently get results that are close to the first time within an expected variance.
|
NeedsInvestigation
|
low
|
Critical
|
325,803,651 |
rust
|
rewrite `liveness` analysis to be based on MIR
|
The current liveness code does a simple liveness computation (actually a few such things) and tells you when e.g. assignments are dead and that sort of thing. It does this on the HIR. It would be better to do this on the MIR — in fact, the NLL computation is already computing liveness across all of MIR, so we ought to be able to piggy back on those results I imagine.
It may be a good idea to wait though until the MIR borrowck stuff "settles down" a bit before attempting this.
|
C-cleanup,T-compiler,A-MIR
|
medium
|
Major
|
325,812,670 |
rust
|
Closure type mismatch on higher-ranked bounds
|
In the following code, identical impls for a concrete type, a `fn` type, and a closure exist yet the only the closure fails to meet the higher-ranked bound:
```rust
trait FnLt<'a> {
fn apply(self, input: &'a u8) -> &'a u8;
}
// Struct impl
struct Foo;
impl<'a> FnLt<'a> for Foo {
fn apply(self, input: &'a u8) -> &'a u8 {
input
}
}
// Closure impl
impl<'a, T> FnLt<'a> for T
where
T: FnOnce(&'a u8) -> &'a u8,
{
fn apply(self, input: &'a u8) -> &'a u8 {
(self)(input)
}
}
fn take_fn_lt(_: impl for<'a> FnLt<'a>) {}
fn main() {
take_fn_lt(Foo); // Works
fn foo(x: &u8) -> &u8 { x }
take_fn_lt(foo); // Works
take_fn_lt(|x: &u8| -> &u8 { x }); // Doesn't work
}
```
The error is this:
```
error[E0271]: type mismatch resolving `for<'a> <[closure@src/main.rs:31:16: 31:37] as std::ops::FnOnce<(&'a u8,)>>::Output == &'a u8`
--> src/main.rs:31:5
|
31 | take_fn_lt(|x: &u8| -> &u8 { x }); // Doesn't work
| ^^^^^^^^^^ expected bound lifetime parameter 'a, found concrete lifetime
|
= note: required because of the requirements on the impl of `for<'a> FnLt<'a>` for `[closure@src/main.rs:31:16: 31:37]`
note: required by `take_fn_lt`
--> src/main.rs:23:1
|
23 | fn take_fn_lt(_: impl for<'a> FnLt<'a>) {}
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
```
Edit: the closure can be made to work through coercion to a `fn` pointer (which is unsurprising, since it's then the same as `foo`). `take_fn_lt({ |x: &u8| -> &u8 { x } } as fn(&u8) -> &u8);` compiles.
|
A-lifetimes,A-closures,T-compiler,C-bug,A-higher-ranked
|
low
|
Critical
|
325,831,545 |
TypeScript
|
Should resolveJsonModule resolve json files without a .json file extension?
|
<!-- 🚨 STOP 🚨 𝗦𝗧𝗢𝗣 🚨 𝑺𝑻𝑶𝑷 🚨
Half of all issues filed here are duplicates, answered in the FAQ, or not appropriate for the bug tracker. Even if you think you've found a *bug*, please read the FAQ first, especially the Common "Bugs" That Aren't Bugs section!
Please help us by doing the following steps before logging an issue:
* Search: https://github.com/Microsoft/TypeScript/search?type=Issues
* Read the FAQ: https://github.com/Microsoft/TypeScript/wiki/FAQ
Please fill in the *entire* template below.
-->
<!-- Please try to reproduce the issue with `typescript@next`. It may have already been fixed. -->
**TypeScript Version:** 2.9.0-dev.20180521
<!-- Search terms you tried before logging this (so others can find this issue more easily) -->
**Search Terms:**
- json
- resolveJsonModule
**Code**
In a project using `resolveJsonModule`.
For a file:
```ts
import foo = require('./foo')
import foo2 = require('./foo.json')
console.log(foo, foo2);
```
**Expected behavior:**
If we follow node, both imports are resolved
**Actual behavior:**
Only the `foo2` import is resolved. The import without the `.json` file extension is not resolved
|
Suggestion,Awaiting More Feedback
|
low
|
Critical
|
325,849,159 |
rust
|
LTO ignored for all crate types when building multiple crate types and one doesn't support it
|
https://github.com/rustwasm/rust_wasm_template has
```toml
[lib]
crate-type = [
# Build a cdylib to make a `.wasm` library.
"cdylib",
# Build an rlib for testing and benching.
"rlib"
]
[profile.release]
lto = true
```
The `lto = true` is ignored for everything because rlibs don't support LTO. I would expect that the cdylib has LTO and that only the rlib ignores the LTO options.
@alexcrichton tells me this is a rust compiler bug, not a cargo bug.
FWIW, this command does not work either:
```
cargo rustc -- -C lto=fat --crate-type cdylib
```
|
T-compiler,C-bug,A-LTO
|
low
|
Critical
|
325,860,334 |
pytorch
|
[feature request] Add cudaification API for distributions
|
Right now it's possible to have a distribution "live" on the GPU, so that you can sample to directly get cuda tensors. You'll have to do something like the following though:
N = Normal(0.0, 1.0)
N.loc = N.loc.cuda()
N.scale = N.scale.cuda()
Alternatively, you can directly initialize the parameters on the GPU:
N_cuda = Normal(torch.tensor([0.0], device='cuda'), torch.tensor([1.0], device='cuda'))
Both of these methods are somewhat verbose and cumbersome. It would be great having something simpler like the following:
Ncuda = Normal(0.0, 1.0).cuda()
Basically, one would just have to make sure that `.cuda()` gets called on all relevant parameters of the respective distribution.
Some background on my use case: I'm using distributions to create more abstract notions of priors, which I register inside some Modules. Ideally, I'd just be able to call `.cuda()` on the top Module and have everything moved to GPU, like is the case with most modules - the above feature request is the basis for that.
cc @fritzo @neerajprad @alicanb @vishwakftw
|
module: distributions,triaged,enhancement
|
medium
|
Critical
|
325,861,219 |
kubernetes
|
Missing proto struct tags incompatible with latest golang/protobuf changes
|
> /kind bug
**What happened**:
Imported proto files and tried to use with latest `golang/protobuf` lib. https://github.com/golang/protobuf/blob/master/proto/table_unmarshal.go#L331 mandates that all struct fields have proto tags. The TypeMeta fields in kubernetes structs do not contain a proto tag, https://github.com/kubernetes/apiserver/blob/master/pkg/apis/audit/v1beta1/types.go#L145 is a typical example.
**What you expected to happen**:
Be able to import proto files and have them serialize/deserialize properly
**How to reproduce it (as minimally and precisely as possible)**:
Import a kubernetes proto file and use with latest `golang/protobuf` lib
**Anything else we need to know?**:
I filed an issue with `golang/protobuf` https://github.com/golang/protobuf/issues/617 as it seems like a breaking change but they are pushing back
**Environment**:
- Kubernetes version: 1.10.3
- golang/protobuf version: master
|
kind/bug,sig/api-machinery,lifecycle/frozen
|
medium
|
Critical
|
325,896,013 |
javascript-algorithms
|
What about rope?
|
I found this repo while looking for a good example of [rope](https://en.wikipedia.org/wiki/Rope_(data_structure)). But I can't find one :(
|
enhancement
|
low
|
Minor
|
325,897,408 |
flutter
|
AnimatedIcons should have Cupertino-specific versions
|
The Cupertino lib should include AnimatedIcons similar to the ones provided for Material that animated from the hamburger menu to the Cupertino style back button and vice versa.
https://docs.flutter.io/flutter/material/AnimatedIcons-class.html, specifically talking about `menu_arrow` and `arrow_menu`, which should have equivalents in Cupertino.
/cc @xster @amirh
|
c: new feature,framework,f: material design,a: fidelity,P2,team-design,triaged-design
|
low
|
Major
|
325,901,979 |
pytorch
|
Checkpointing is slow on nn.DataParallel models
|
@wandering007 pointed out this issue in https://github.com/gpleiss/efficient_densenet_pytorch/blob/master/models/densenet.py
I have a model that uses checkpointing on several layers. On a single GPU, the model runs fairly fast (e.g. only a 15-20% overhead). On multiple GPUs, using an `nn.DataParallel` @wandering007 claims that the model runs up to 100x slower.
Here's the important snippets of the model.
```python
def _bn_function_factory(norm, relu, conv):
def bn_function(*inputs):
concated_features = torch.cat(inputs, 1)
bottleneck_output = conv(relu(norm(concated_features)))
return bottleneck_output
return bn_function
class _DenseLayer(nn.Module):
# ...
def forward(self, *prev_features):
bn_function = _bn_function_factory(self.norm1, self.relu1, self.conv1)
bottleneck_output = cp.checkpoint(bn_function, *prev_features)
# ...
```
There are several `_DenseLayer`s throughout the model.
@wandering007 seems to think that the issue has to do with GPU synchronization? As in, the models must synchronize at every checkpoint during the backward pass.
Original issue is here: https://github.com/gpleiss/efficient_densenet_pytorch/issues/36
Full code of the model is here: https://github.com/gpleiss/efficient_densenet_pytorch/blob/master/models/densenet.py
|
module: performance,module: checkpoint,triaged
|
low
|
Major
|
325,918,670 |
vue
|
VueSSRServerPlugin produces a slow-to-parse JSON for large projects
|
### What problem does this feature solve?
Makes for a better development experience with vue SSR.
I was looking into why it takes 500ms to render an single-component page from the server in our fairly large application and found an interesting issue. Webpack creates ~40 bundles for us. Altogether, these weigh ~20MB. The way `VueSSRServerPlugin` plugin works, as you know, is it combines all of these files into a single `vue-ssr-server-bundle.json` file. Reading that file in node is fast (5ms on average) for us, but after reading it we need to `JSON.parse` it before providing to `createBundleRenderer` and _that_ takes ~400ms.
Initially I was thinking of using webpack's `splitChunks`, to reduce the file-size (our router dynamically imports top-level pages, so each chunk could benefit from not having to bring in common component) but `VueSSRServerPlugin` does not support that (and throws the "Server-side bundle should have one single entry file" error).
### What does the proposed API look like?
I'm not exactly sure what to do here at this point as I just noticed this issue. I'm concerned that as the app grows, the json parse time will increase adding seconds to the load-time in development.
<!-- generated by vue-issues. DO NOT REMOVE -->
|
improvement
|
low
|
Critical
|
326,014,159 |
javascript-algorithms
|
A* algorithm?
|
Hey! This repo is awesome! Nice job!
While I was reading through the algorithms, I found weird that the [A* algorithm](https://en.m.wikipedia.org/wiki/A*_search_algorithm) was missing, which is one of the few I know.
I'm just gonna leave this as a suggestion, sorry if I can't do a pull request!
|
enhancement
|
low
|
Major
|
326,015,888 |
pytorch
|
OOM Exception when using torch.nn.grad.conv2d_weight (apparently because CuDNN backwards is not used)
|
## Issue description
I encountered an out of memory exception when using torch.nn.grad.conv2d_weight even though using torch.nn.functional.conv2d works (forward and backward, and I assume the same calculations done in torch.nn.grad.conv2d_weight are done at some point during conv2d()'s backward pass).
## Code example
I'm using the following custom convolutional layer:
```
class MyConv(Function):
@staticmethod
def forward(ctx, x, w):
ctx.save_for_backward(x, w)
return F.conv2d(x, w)
@staticmethod
def backward(ctx, grad_output):
x, w = ctx.saved_variables
x_grad = w_grad = None
if ctx.needs_input_grad[0]:
x_grad = torch.nn.grad.conv2d_input(x.shape, w, grad_output)
if ctx.needs_input_grad[1]:
w_grad = torch.nn.grad.conv2d_weight(x, w.shape, grad_output)
return x_grad, w_grad
```
Using torch.nn.functional.conv2d works, Using MyConv does not. It fails during torch.nn.grad.conv2d_weight and gives an out of memory exception. As I said before, I don't understand how that can happen since, I assume, at some point during conv2d back-prop, it performs the same calculations that are done in torch.nn.grad.conv2d_weight.
I can give a more detailed code example if needed.
## System Info
- PyTorch or Caffe2: Pytorch
- How you installed PyTorch (conda, pip, source): conda
- Build command you used (if compiling from source):
- OS: Ubuntu 16.04
- PyTorch version: 0.4
- Python version: 3.6
- CUDA/cuDNN version: 9.0/7.0.5
- GPU models and configuration: Tesla V100-SXM2-16GB
- GCC version (if compiling from source): (Ubuntu 5.4.0-6ubuntu1~16.04.9) 5.4.0 20160609
- CMake version: 3.5.1
- Versions of any other relevant libraries:
[pip3] numpy (1.14.2)
[conda] cuda90 1.0 h6433d27_0 pytorch
[conda] pytorch 0.4.0 py36_cuda9.0.176_cudnn7.1.2_1 [cuda90] pytorch
[conda] torchvision 0.2.1 py36_1 pytorch
|
module: performance,module: cudnn,module: memory usage,module: convolution,triaged,has workaround
|
low
|
Major
|
326,074,198 |
pytorch
|
LMDB read error for Mnist
|
If you have a question or would like help and support, please ask at our
[forums](https://discuss.pytorch.org/).
If you are submitting a feature request, please preface the title with [feature request].
If you are submitting a bug report, please fill in the following details.
## Issue description
Provide a short description.
I am trying to learn caffe2, and I tried to run the provided MNIST tutorial but i get lmdb error on lmdb read.
## Code example
workspace.RunNetOnce(train_model.param_init_net)
Please try to provide a minimal example to repro the bug.
Error messages and stack traces are also helpful.
RuntimeError: [enforce fail at db.h:190] db_. Cannot open db: /home/rohit/caffe2_notebooks/tutorial_data/mnist/mnist-train-nchw-lmdb of type lmdb Error from operator:
output: "dbreader_/home/rohit/caffe2_notebooks/tutorial_data/mnist/mnist-train-nchw-lmdb" name: "" type: "CreateDB" arg { name: "db" s: "/home/rohit/caffe2_notebooks/tutorial_data/mnist/mnist-train-nchw-lmdb" } arg { name: "db_type" s: "lmdb" }
## System Info
Please copy and paste the output from our
[environment collection script](https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py)
(or fill out the checklist below manually).
You can get the script and run it with:
```
wget https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py
# For security purposes, please check the contents of collect_env.py before running it.
python collect_env.py
```
- PyTorch or Caffe2: Caffe2
- How you installed PyTorch (conda, pip, source): conda install -c caffe2 caffe2
- Build command you used (if compiling from source): N/A
- OS: Ubuntu 16.04.4 LTS
- PyTorch version: N/A
- Python version:Python 3.6.4 :: Anaconda custom (64-bit)
- CUDA/cuDNN version: N/A
- GPU models and configuration:N/A
- GCC version (if compiling from source):N/A
- CMake version:N/A
- Versions of any other relevant libraries:N/A
Any pointers to resolve this problem would be really helpful
|
caffe2
|
low
|
Critical
|
326,078,247 |
TypeScript
|
Comments before a decorator produces a weird comma in the emitted JS output
|
**TypeScript Version:** 3.0.0-dev.20180522
<!-- Search terms you tried before logging this (so others can find this issue more easily) -->
**Search Terms:** decorator comma comment
**Code**
```ts
function decorator1(target) {}
function decorator2(target) {}
function decorator3(target) {}
@decorator1
// this is a comment
@decorator2
@decorator3
class Foo {
}
```
**Expected behavior:**
```js
function decorator1(target) { }
function decorator2(target) { }
function decorator3(target) { }
let Foo = class Foo {
};
Foo = __decorate([
decorator1,
// this is a comment
decorator2,
decorator3
], Foo);
```
**Actual behavior:**
```js
// ... _decorate helper ...
function decorator1(target) { }
function decorator2(target) { }
function decorator3(target) { }
let Foo = class Foo {
};
Foo = __decorate([
decorator1
// this is a comment
,
decorator2,
decorator3
], Foo);
```
**Playground Link:** https://www.typescriptlang.org/play/#src=function%20decorator1(target)%20%7B%7D%0D%0Afunction%20decorator2(target)%20%7B%7D%0D%0Afunction%20decorator3(target)%20%7B%7D%0D%0A%0D%0A%40decorator1%0D%0A%2F%2F%20this%20is%20a%20comment%0D%0A%40decorator2%0D%0A%40decorator3%0D%0Aclass%20Foo%20%7B%0D%0A%0D%0A%7D
**Related Issues:** found none
|
Bug,Domain: Comment Emit
|
low
|
Minor
|
326,084,957 |
go
|
os: ModeSetgid has no effect while using with Mkdir() on Linux
|
Please answer these questions before submitting your issue. Thanks!
### What version of Go are you using (`go version`)?
go version go1.9.4 linux/amd64
### Does this issue reproduce with the latest release?
Yes
### What operating system and processor architecture are you using (`go env`)?
GOARCH="amd64"
GOBIN=""
GOEXE=""
GOHOSTARCH="amd64"
GOHOSTOS="linux"
GOOS="linux"
GOPATH="/root/go"
GORACE=""
GOROOT="/usr/lib/golang"
GOTOOLDIR="/usr/lib/golang/pkg/tool/linux_amd64"
GCCGO="gccgo"
CC="gcc"
GOGCCFLAGS="-fPIC -m64 -pthread -fmessage-length=0 -fdebug-prefix-map=/tmp/go-build203196509=/tmp/go-build -gno-record-gcc-switches"
CXX="g++"
CGO_ENABLED="1"
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
PKG_CONFIG="pkg-config"
### What did you do?
```go
package main
import (
"os"
)
func main() {
os.Mkdir("test", 0770 | os.ModeSetgid)
}
```
### What did you expect to see?
```
# ls -la test
insgesamt 4
drwxr-s---. 2 root root 6 24. Mai 04:09 .
dr-xr-x---. 13 root root 4096 24. Mai 04:09 ..
#
```
### What did you see instead?
```
# ls -la test
insgesamt 4
drwxr-x---. 2 root root 6 24. Mai 04:09 .
dr-xr-x---. 13 root root 4096 24. Mai 04:09 ..
#
```
### Why did this happen?
According to `strace -f ./mkdir` the Go stdlib behaves as expected...
```
[pid 6782] mkdirat(AT_FDCWD, "test", 02770 <unfinished ...>
[pid 6782] <... mkdirat resumed> ) = 0
```
... but on Linux this is not enough, see `mkdirat(2)`:
```
The mkdirat() system call operates in exactly the same way as mkdir(2), (...)
```
... and `mkdir(2)`:
```
The argument mode specifies the permissions to use.
It is modified (...): the permissions of the created directory are (mode & ~umask & 0777).
Other mode bits of the created directory depend on the operating system.
For Linux, see below.
(...)
That is, under Linux the created directory actually gets mode (mode & ~umask & 01777)
```
### How could this be fixed?
Similar to #8383, [via Chmod](https://codereview.appspot.com/102640045/patch/120001/130001).
|
help wanted,OS-Linux,NeedsFix
|
medium
|
Critical
|
326,159,353 |
godot
|
CSG shapes textures are mapped different than normal meshes
|
**Godot version:**
3.1.dev.5b11d16
**OS/device including version:**
Win10 64 bit. Geforce gtx 950M
**Issue description:**
added texture to a CSGcube and it did not align as you would expect. Works fine if you create a CSGmesh
**Steps to reproduce:**
Create a mesh and a CSGshape of same type. add texture to both and see.
|
bug,discussion,confirmed,topic:3d
|
low
|
Major
|
326,193,866 |
neovim
|
Windows: console: <C-2>, <C-/>
|
A couple control key combos are missing on Windows, notably `^@` which prevents `<C-space>` mappings.
- `nvim --version`: 0.2.2 (still present in 0.3)
- Vim (version: 8.1) behaves differently? Yes
- Operating system/version: Win10 17672
- Terminal name/version: conhost
- `$TERM`: N/A
### Steps to reproduce using `nvim -u NORC`
Type the following keys in insert mode preceded by `<C-v>`: `<C-2> <C-space> <C-/>`
### Actual behaviour
`<C-2>` and `<C-/>` are not recognized at all, `<C-space>` is recognized as regular space.
### Expected behaviour
The control characters `^@^@^_` are inserted.
There is slightly different behavior between Windows vim and Linux vim/nvim here. On Windows vim, `^_` is not generated when pressing `<C-/>` (but it can be generated by the _ key still), and `<C-space>` does not generate `^@`, it types a space, but `<C-space>` itself is mappable. Copying either behavior would probably be fine, although I'd prefer to mimic Linux as it leads to a less complicated vimrc.
|
status:blocked-external,platform:windows,tui
|
medium
|
Critical
|
326,194,263 |
opencv
|
opencv js - cv.resize causes exceptions when fx and fy randomly changed very fast
|
##### System information (version)
- OpenCV => 3.4.1
- Operating System / Platform => JavaScript
- Compiler => Emscripten SDK
##### Detailed description
Function cv.resize is very unstable and causes all Mat to throw exception, when trying to get Mat.data.
**Situation:**
An image should be scaled to some size every frame captured from Web Cam, then combined with this captured frame and displayed.
**Conditions:**
_src_ Mat - image gotten from canvas, loaded once at the beginning.
_dst_ Mat - temporary Mat
_dsize_ - zero
_fx, fy_ - randomly changed doubles every captured frame from web cam. Everything is OK when fx and fy are decimal or when fx and fy stays same every frame. But if fx and fy are randomly changed every captured frame, all Mat in the script loses their reference.
Algorithm - does not matter.
##### Steps to reproduce
Launching below script will cause this error after a few moments:
> v Uncaught abort(13). Build with -s ASSERTIONS=1 for more info.
> abort | @opencv.js?ver=4.9.6:55
> Zlc | @opencv.js?ver=4.9.6:48
> Vt | @opencv.js?ver=4.9.6:24
> kjc | @opencv.js?ver=4.9.6:48
> dynCall_iii_384 | @VM210:4
> Mat$type | @VM211:8
> Module.imshow | @opencv.js:55
Try use high resolution image to cause exception faster.
```.js
function Launch(video, imageCanvas) {
let img = cv.imread(imageCanvas);
let cap = new cv.VideoCapture(video);
const FPS = 30;
navigator.mediaDevices.getUserMedia({ video: true, audio: false })
.then(function(stream) {
video.srcObject = stream;
video.play();
})
.catch(function(err) {
console.log('An error occurred! ' + err);
});
function processVideo() {
let imgScaled = new cv.Mat();
let begin = Date.now();
let srcVid = new cv.Mat(video.height, video.width, cv.CV_8UC4);
cap.read(srcVid);
let numb = (Math.random() * (0.12 - 5.0) + 5.0);
cv.resize(img, imgScaled, new cv.Size(0,0),numb,numb, cv.INTER_NEAREST );
imgScaled.delete();
cv.imshow('canvasOutput', srcVid);
srcVid.delete();
// schedule next one.
let delay = 1000/FPS - (Date.now() - begin);
setTimeout(processVideo, delay);
}
// schedule first one.
setTimeout(processVideo, 0);
}
```
|
incomplete,category: javascript (js)
|
low
|
Critical
|
326,218,277 |
TypeScript
|
ts.createJsxOpeningElement throws `Debug Failure. False expression.`
|
<!-- 🚨 STOP 🚨 𝗦𝗧𝗢𝗣 🚨 𝑺𝑻𝑶𝑷 🚨
Half of all issues filed here are duplicates, answered in the FAQ, or not appropriate for the bug tracker. Even if you think you've found a *bug*, please read the FAQ first, especially the Common "Bugs" That Aren't Bugs section!
Please help us by doing the following steps before logging an issue:
* Search: https://github.com/Microsoft/TypeScript/search?type=Issues
* Read the FAQ: https://github.com/Microsoft/TypeScript/wiki/FAQ
Please fill in the *entire* template below.
-->
<!-- Please try to reproduce the issue with `typescript@next`. It may have already been fixed. -->
**TypeScript Version:** 2.8.3 (I used this version because I was getting a completely different error when I updated to the latest @next version. Probably caused by ttypescript or some other dependency that's not updated to the latest version)
<!-- Search terms you tried before logging this (so others can find this issue more easily) -->
**Search Terms:** compiler API, transform
**Code**
```ts
import * as ts from 'typescript'
export default function transformer() {
return (context: ts.TransformationContext) => {
return (sourceFile: ts.SourceFile) => {
return visitNodeAndChildren(sourceFile)
function visitNodeAndChildren(node: ts.Node): ts.VisitResult<ts.Node> {
return ts.visitEachChild(visitNode(node), (childNode) => visitNodeAndChildren(childNode), context)
}
function visitNode(node: ts.Node): ts.Node {
switch (node.kind) {
case ts.SyntaxKind.JsxElement:
const element = node as ts.JsxElement
return ts.createJsxElement(ts.createJsxOpeningElement(element.openingElement.tagName, element.openingElement.attributes), element.children, element.closingElement)
default:
return node
}
}
}
}
}
```
I'm running this using [ttsc](https://github.com/cevek/ttypescript/tree/master) but I don't think that's the issue.
**Expected behavior:**
No error.
**Actual behavior:**
```(node:23136) UnhandledPromiseRejectionWarning: Error: Debug Failure. False expression.
at resolveNameHelper (node_modules\typescript\lib\typescript.js:26726:30)
at resolveName (node_modules\typescript\lib\typescript.js:26489:20)
at getReferencedValueSymbol (node_modules\typescript\lib\typescript.js:48917:20)
at Object.getReferencedDeclarationWithCollidingName (node_modules\typescript\lib\typescript.js:48672:34)
at substituteExpressionIdentifier (node_modules\typescript\lib\typescript.js:63756:44)
at substituteExpression (node_modules\typescript\lib\typescript.js:63743:28)
at onSubstituteNode (node_modules\typescript\lib\typescript.js:63696:24)
at onSubstituteNode (node_modules\typescript\lib\typescript.js:65555:20)
at onSubstituteNode (node_modules\typescript\lib\typescript.js:69452:20)
at substituteNode (node_modules\typescript\lib\typescript.js:69643:59)
at trySubstituteNode (node_modules\typescript\lib\typescript.js:73151:46)
at pipelineEmitWithComments (node_modules\typescript\lib\typescript.js:72765:20)
at emitNodeWithNotification (node_modules\typescript\lib\typescript.js:69674:21)
at pipelineEmitWithNotification (node_modules\typescript\lib\typescript.js:72758:17)
at emitExpression (node_modules\typescript\lib\typescript.js:72754:13)
at emitPropertyAccessExpression (node_modules\typescript\lib\typescript.js:73547:13)
at pipelineEmitExpression (node_modules\typescript\lib\typescript.js:73087:28)
at pipelineEmitWithHint (node_modules\typescript\lib\typescript.js:72785:49)
at emitNodeWithSourceMap (node_modules\typescript\lib\typescript.js:70051:21)
at pipelineEmitWithSourceMap (node_modules\typescript\lib\typescript.js:72775:17)
at emitNodeWithNestedComments (node_modules\typescript\lib\typescript.js:70340:17)
at emitNodeWithSynthesizedComments (node_modules\typescript\lib\typescript.js:70290:13)
at emitNodeWithComments (node_modules\typescript\lib\typescript.js:70226:21)
at pipelineEmitWithComments (node_modules\typescript\lib\typescript.js:72767:17)
at emitNodeWithNotification (node_modules\typescript\lib\typescript.js:69674:21)
at pipelineEmitWithNotification (node_modules\typescript\lib\typescript.js:72758:17)
at emitExpression (node_modules\typescript\lib\typescript.js:72754:13)
at emitCallExpression (node_modules\typescript\lib\typescript.js:73584:13)
at pipelineEmitExpression (node_modules\typescript\lib\typescript.js:73091:28)
at pipelineEmitWithHint (node_modules\typescript\lib\typescript.js:72785:49)
(node:23136) UnhandledPromiseRejectionWarning: Unhandled promise rejection. This error originated either by throwing inside of an async function without a catch block, or by rejecting a
promise which was not handled with .catch(). (rejection id: 1)
```
**Workaround**: This seems to actually error sometimes and I can't figure out how to reproduce the fail so I don't recommend to use this workaround. To work around this, I had to remove the ts.createJsxOpeningElement call and alter the properties myself. Example:
```diff
import * as ts from 'typescript'
export default function transformer() {
return (context: ts.TransformationContext) => {
return (sourceFile: ts.SourceFile) => {
return visitNodeAndChildren(sourceFile)
function visitNodeAndChildren(node: ts.Node): ts.VisitResult<ts.Node> {
return ts.visitEachChild(visitNode(node), (childNode) => visitNodeAndChildren(childNode), context)
}
function visitNode(node: ts.Node): ts.Node {
switch (node.kind) {
case ts.SyntaxKind.JsxElement:
const element = node as ts.JsxElement
+ element.openingElement.tagName = ts.createLiteral('whatever') // I wanted to alter the tag name in my case but should be the same for altering the attributes
- return ts.createJsxElement(ts.createJsxOpeningElement(element.openingElement.tagName, element.openingElement.attributes), element.children, element.closingElement)
+ return ts.createJsxElement(element.openingElement, element.children, element.closingElement)
default:
return node
}
}
}
}
}
```
|
Bug,API
|
low
|
Critical
|
326,223,402 |
go
|
x/tools/go/buildutil: make ExpandPatterns support all go tool patterns
|
This TODO exists within the ExpandPatterns function:
// TODO(adonovan): support other features of 'go list':
// - "std"/"cmd"/"all" meta-packages
// - "..." not at the end of a pattern
// - relative patterns using "./" or "../" prefix
I'd very much like to use `golang.org/x/tools/go/buildutil` instead of `github.com/kisielk/gotool` but the current limitations mean that I can't do so without breaking backward compatibility.
|
Tools
|
low
|
Minor
|
326,335,491 |
flutter
|
flutter_image handling of exceptions from http clients not allowing retries.
|
In the flutter_image library, the FetchStrategyBuilder.build method returns a FetchStrategy that requires a non-null FetchFailure.httpStatusCode to return FetchInstructions.attempt any time after the first call to FetchStrategyBuilder.build. However, in NetworkImageWithRetry._loadWithRetry, when the http client throws an exception, a FetchFailure with a httpStatusCode of null is created, so no retry occurs on exceptions from the http client (in my case on a timeout). Is this the expected behaviour or should FetchFailure.httpStatusCode be 0 (to correspond with the Network Error code in defaultTransientHttpStatusCodes) when there's an exception thrown by the http client?
|
package,team-ecosystem,P3,p: flutter_image,triaged-ecosystem
|
low
|
Critical
|
326,339,414 |
godot
|
Light2D "Add" mode does not appear to be additive
|
**Godot version:**
3.0.2
**OS/device including version:**
Windows 10.0.16299; Solus Linux
**Issue description:**
When I create a Light2D in "Add" mode and with energy 1, and I apply it to a texture, the light texture does not appear to be applied linearly. In particular, if the background texture is black, there is no effect, and as the brightness of the background texture increases, the amount of light value applied to the texture seems to increase. See screenshots:
Here, the background is black and the light has no effect on the background (disregard the white circle, it's a sprite):
Here, the background is `#202020`, so it is not significantly brighter, but now the light texture is being applied to the background.
Here, the background is `#282828`, so it is only very slightly brighter than the above screenshot, but the light appears disproportionately brighter:
It definitely seems like there's some sort of multiplicative effect happening here. Am I completely misunderstanding how 2D lighting is supposed to work, or is this not right? The docs definitely seem to suggest that the pixel values will be directly added together.
**Steps to reproduce:**
Open the "2D Lights and Shadows" sample project and brighten or darken the `bg.png` image to observe the effects.
**Minimal reproduction project:**
Open the "2D Lights and Shadows" sample project
|
discussion,topic:rendering
|
low
|
Minor
|
326,340,888 |
flutter
|
flutter tool should check for consistency between --local-engine, --debug/profile/release and --target-platform
|
For example, if you use an ARM32 local engine, don't specify a target-platform and have a Pixel connected, the target-platform will be auto detected as ARM64, flutter tool won't pass --no-use-integer-division to gen_snapshot, and the engine will crash with a SIGILL on sdiv.
@cbracken
|
team,tool,P2,team-tool,triaged-tool
|
low
|
Critical
|
326,346,727 |
go
|
x/text/internal/colltab: numeric.go should not skip "0" when is followed by a non-number
|
Please answer these questions before submitting your issue. Thanks!
### What version of Go are you using (`go version`)?
go1.8.5
### Does this issue reproduce with the latest release?
yes
### What operating system and processor architecture are you using (`go env`)?
GOARCH="amd64"
GOBIN=""
GOEXE=""
GOHOSTARCH="amd64"
GOHOSTOS="darwin"
GOOS="darwin"
GOPATH="/Users/tlin/go"
GORACE=""
GOROOT="/usr/local/go"
GOTOOLDIR="/usr/local/go/pkg/tool/darwin_amd64"
GCCGO="gccgo"
CC="clang"
GOGCCFLAGS="-fPIC -m64 -pthread -fno-caret-diagnostics -Qunused-arguments -fmessage-length=0 -fdebug-prefix-map=/var/folders/9g/342mj7bd3h776hmqdw5c9xdn5wch_k/T/go-build934806691=/tmp/go-build -gno-record-gcc-switches -fno-common"
CXX="clang++"
CGO_ENABLED="1"
PKG_CONFIG="pkg-config"
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
### What did you do?
If possible, provide a recipe for reproducing the error.
A complete runnable program is good.
A link on play.golang.org is best.
```go
package main
import (
"fmt"
"golang.org/x/text/collate"
"golang.org/x/text/language"
)
func main() {
strings := []string{
"file0_1",
"file1_1",
}
collator := collate.New(language.English, collate.Numeric)
collator.SortStrings(strings)
for _, s := range strings {
fmt.Println(s)
}
}
```
### What did you expect to see?
The output to be:
```
file0_1
file1_1
```
### What did you see instead?
The actual output is:
```
file1_1
file0_1
```
Possible fix would be:
```diff
+++ golang.org/x/text/internal/colltab/numeric.go
@@ -79,7 +79,11 @@
return ce, n
}
// ce might have been grown already, so take it instead of buf.
- nc.init(ce, len(buf), isZero)
+ nextByte := byte('0');
+ if n < len(s) {
+ nextByte = s[n]
+ }
+ nc.init(ce, len(buf), isZero, nextByte)
for n < len(s) {
ce, sz := nw.Weighter.AppendNext(nc.elems, s[n:])
nc.b = s
@@ -104,7 +108,11 @@
if !ok {
return ce, n
}
- nc.init(ce, len(buf), isZero)
+ nextByte := byte('0');
+ if n < len(s) {
+ nextByte = s[n]
+ }
+ nc.init(ce, len(buf), isZero, nextByte)
for n < len(s) {
ce, sz := nw.Weighter.AppendNextString(nc.elems, s[n:])
nc.s = s
@@ -129,10 +137,10 @@
// init completes initialization of a numberConverter and prepares it for adding
// more digits. elems is assumed to have a digit starting at oldLen.
-func (nc *numberConverter) init(elems []Elem, oldLen int, isZero bool) {
+func (nc *numberConverter) init(elems []Elem, oldLen int, isZero bool, nextByte byte) {
// Insert a marker indicating the start of a number and and a placeholder
// for the number of digits.
- if isZero {
+ if isZero && nextByte >= byte('0') && nextByte <= byte('9') {
elems = append(elems[:oldLen], nc.w.numberStart, 0)
} else {
elems = append(elems, 0, 0)
```
|
NeedsInvestigation,FixPending
|
low
|
Critical
|
326,358,376 |
flutter
|
[google_maps_flutter] Plugin Crashes Without a Helpful Error message on iOS If No API Key Specified
|
https://github.com/flutter/plugins/tree/master/packages/google_maps_flutter
If you don't include the API key in an iOS app the google_maps_flutter plugin will crash hard with the following with no indication as to why:
```
*** First throw call stack:
(
0 CoreFoundation 0x000000010cd3912b __exceptionPreprocess + 171
1 libobjc.A.dylib 0x000000010c3cdf41 objc_exception_throw + 48
2 CoreFoundation 0x000000010cdae245 +[NSException raise:format:] + 197
3 Runner 0x00000001058b5723 +[GMSServices checkServicePreconditions] + 182
4 Runner 0x00000001058b2562 +[GMSServices sharedServicesSync] + 110
5 Runner 0x00000001058a1fb9 -[GMSMapView sharedInitWithServices:camera:forPlaces:] + 156
6 Runner 0x00000001058a1421 -[GMSMapView initWithFrame:camera:] + 123
7 Runner 0x00000001058a1245 +[GMSMapView mapWithFrame:camera:] + 104
8 Runner <…>
```
Only if you run "flutter run -v" will you get the actual reason:
```
[ +111 ms] [DEVICE LOG] 2018-05-24 20:41:34.563396-0500 localhost Runner[72738]: (CoreFoundation) *** Terminating app due to uncaught exception 'GMSServicesException', reason: 'Google Maps SDK for iOS must be initialized via [GMSServices provideAPIKey:...] prior to use'
[ ] [DEVICE LOG] *** First throw call stack:
```
It seems kind of harsh. If possible it would be nice to display a console message at the minimum.
|
c: crash,platform-ios,p: maps,package,a: error message,has reproducible steps,P2,c: fatal crash,found in release: 2.0,found in release: 2.2,team-ios,triaged-ios
|
low
|
Critical
|
326,364,894 |
pytorch
|
torch.Tensor.new() disappeared in 0.4 doc
|
There are only `torch.new_*()` in 0.4 doc now.
But I can still use this function, no deprecated warning, and I do not found any deprecated note about it in 0.4 release too.
cc @jlin27 @mruberry
|
module: docs,triaged,module: deprecation,module: tensor creation
|
low
|
Minor
|
326,367,177 |
pytorch
|
[caffe2] how to using the Mul operator to mul the input vetor
|
Hi! In my project, i need to mul some blobs [x1,x2,x3,x4],
but i found that the Mul opeartor only support 2 inputs in caffe2,
Any using the loop will cost too much memory of my graphics card,
So is there any good solution to help this problem? Thank you !
|
caffe2
|
low
|
Minor
|
326,561,567 |
TypeScript
|
Missing type description in suggestion popup
|
Note, this issue was discovered while trying to reproduce https://github.com/Microsoft/TypeScript/issues/24408.
**TypeScript Version:** `[email protected]`
**Code**
```ts
// x.ts
import { Enum } from '~/types'
type ObjectFromEnum<T, R extends string = Enum> = {
[S in R]: T
}
export const SYMBOLS: ObjectFromEnum| // <- cursor for ctrl+space hints here
// types.d.ts
export type Enum = 'a' | 'b' | 'c'
export type EnumX = 'd' | 'e' | 'f'
export type ObjectFromEnumX<T, R extends string = EnumX> = {
[S in R]: T
}
```
**Expected behavior:**
Expected is that suggested types are fully described for both local and imported types.
In this case locally defined type `ObjectFromEnum`.

**Actual behavior:**
Type `ObjectFromEnumX` is not fully described for external type.

After the import is done and suggestion popup is invoked again, the missing generics are presented.

<hr/>
Also note that in the linked issue above, the actual behavior is different (v2.9. vs v3.0.), the referenced `EnumX` in the generic is also resolved.

|
Bug
|
low
|
Minor
|
326,591,219 |
go
|
x/build/cmd/gopherbot: follow-up backport comments are ignored
|
In https://github.com/golang/go/issues/25242#issuecomment-392110768 I ask for gopherbot to create a backport for 1.9 as well (the original backport was only for 1.10). But an issue was not created (had to create it manually).
/cc @FiloSottile
|
help wanted,Builders,NeedsFix,Friction
|
low
|
Major
|
326,644,190 |
pytorch
|
Feature Request: Logistic Distribution
|
Could we have logistic distribution in PyTorch?
https://github.com/tensorflow/tensorflow/blob/r1.8/tensorflow/contrib/distributions/python/ops/logistic.py
cc @fritzo @neerajprad @alicanb @nikitaved @brianjo @mruberry
|
module: distributions,feature,triaged
|
low
|
Major
|
326,647,955 |
go
|
runtime: support resuming a single goroutine under debuggers
|
[CL 109699](https://golang.org/cl/109699) added support for debugger function call injection, but has an annoying limitation: it requires that the debugger resume the entire Go process after injecting the function call (and, to inject into a runnable but not running goroutine, it requires resuming the entire process even before injecting the call).
@heschik argued that this is a pretty bad experience. E.g., all the user wants to do is call String() to format something, and the entire process moves under them in the meantime. It's also different from what other debuggers do, which could surprise users.
This is tricky to solve. Simply resuming only the thread where the call was injected doesn't work because 1) it could easily lead to runtime-level deadlocks if any other thread is in the runtime, 2) the runtime could just switch to a different goroutine on that thread, and 3) if the GC kicks in it will try to cooperatively stop the other threads and deadlock.
I think solving this requires at least a little help from the runtime to pause all other user goroutines during the injected call. I'm not sure what exact form this should take, but I'm imagining the debugger could use call injection to first inject a runtime call to stop user goroutines, and then inject the real call.
However, even this gets tricky with non-cooperative safe points (e.g., the runtime would need to use the register maps to immediately preempt the other goroutines rather than waiting for them to reach a cooperative safe point) and with goroutines that are at unsafe points (particularly goroutines that are in the runtime). One possibility would be to have the debugger inject this "stop" call on every running thread. Using the call injection mechanism takes care of stopping at non-cooperative points, and would give the debugger the opportunity to step other goroutines past unsafe points and out of the runtime before injecting the stop. This puts some complexity into the debugger, but it should already have most of the core mechanisms necessary to do this (such as single stepping ability). Specifically, I'm picturing a protocol like:
1. For each thread, attempt to inject a `runtime.debugStop` call. Let all threads resume.
2. These calls will notify the debugger when the goroutine is successfully stopped, or the debug call injection will fail.
3. For injection that failed because the thread is in the runtime, unwind the stack and insert a breakpoint at the first return to user code. At that breakpoint attempt another `debugStop`. For injection that failed because the thread is at an unsafe point, single step the thread, attempting to inject `debugStop` at each step.
4. Let the remaining threads continue running. Repeat steps 2 through 4 until all threads are stopped.
This is basically a debugger-assisted non-cooperative stop-the-world. For Go 1.12, I plan to implement non-cooperative preemption directly in the runtime, which may move much of this logic into the runtime itself.
/cc @aarzilli
|
NeedsInvestigation,Debugging,compiler/runtime
|
low
|
Critical
|
326,681,864 |
pytorch
|
[PyTorch] weight tensor dimension assumption
|
Now in both inits <del>and spectral norm</del>, we assume that dim `0` of `weight` is the output feature dim. However, this is incorrect for `ConvTranspose`.
We need to figure out how to properly handle those.
cc @albanD @mruberry
|
module: nn,triaged
|
low
|
Major
|
326,696,662 |
go
|
math/big: improve threshold calibration
|
For multiplication and squaring we use different algorithms depending on the input length. We currently have 3 threshold constants to decide which algorithm to use. These are calibrated with TestCalibrate.
This calibration takes multiple minutes to run and the outcome doesn't seem to be that reliable. Last noticed in [cl 105075](https://go-review.googlesource.com/c/go/+/105075).
Quote @griesemer :
> On my machine, the threshold is much lower (less than 200). At some point we need to find a better way to determine these values.
I see three issues:
1. Reliable result on a single machine: this worked on my machine, but didn't for @ALTree.
2. Similar results on different machines: for calibrating `karatsubaSqrThreshold` we got differences of more than 100% between our 3 machines
3. Slowness. This might be less important, but if this wouldn't take multiple minutes where you shouldn't run other programs it might be easier to ask more people to run the calibration.
|
Performance,NeedsInvestigation
|
low
|
Major
|
326,717,494 |
rust
|
`<Default>::default()` makes the compiler very mad at me
|
Suppose I learned
- That `[f32; 2]::deserialize(deserializer)` doesn't work, and I need to do `<[f32; 2]>::deserialize(deserializer)` instead (thank you https://github.com/rust-lang/rust/pull/46788), and
- That I can do `Default::default()`, instead of `ConcreteType::default()`
If I combine those two things together and [try](https://play.rust-lang.org/?gist=0e860a077545909836dd4d0de6324ed4&version=nightly&mode=debug)
```rust
let x: u32 = <Default>::default();
```
Then I get this spew of errors:
```rust
error[E0277]: the trait bound `std::default::Default: std::default::Default` is not satisfied
--> src/main.rs:2:18
|
2 | let x: u32 = <Default>::default();
| ^^^^^^^^^^^^^^^^^^ the trait `std::default::Default` is not implemented for `std::default::Default`
|
= note: required by `std::default::Default::default`
error[E0038]: the trait `std::default::Default` cannot be made into an object
--> src/main.rs:2:19
|
2 | let x: u32 = <Default>::default();
| ^^^^^^^ the trait `std::default::Default` cannot be made into an object
|
= note: the trait cannot require that `Self : Sized`
error[E0308]: mismatched types
--> src/main.rs:2:18
|
2 | let x: u32 = <Default>::default();
| ^^^^^^^^^^^^^^^^^^^^ expected u32, found trait std::default::Default
|
= note: expected type `u32`
found type `std::default::Default`
error[E0038]: the trait `std::default::Default` cannot be made into an object
--> src/main.rs:2:18
|
2 | let x: u32 = <Default>::default();
| ^^^^^^^^^^^^^^^^^^^^ the trait `std::default::Default` cannot be made into an object
|
= note: the trait cannot require that `Self : Sized`
error: aborting due to 4 previous errors
Some errors occurred: E0038, E0277, E0308.
For more information about an error, try `rustc --explain E0038`.
```
I don't know what I'm concretely asking for here (please retitle better), so here are some thoughts:
- The second error is the valuable one here
- "found trait std::default::Default" should perhaps be "found trait *object* std::default::Default"?
- Maybe this all will just work in Rust 2021 when `<Default>` can mean `Default`, not `dyn Default>`...
|
A-frontend,A-diagnostics,A-trait-system,T-compiler,C-feature-request,WG-diagnostics,D-verbose
|
low
|
Critical
|
326,744,336 |
rust
|
Tracking issue for RFC 1872: `exhaustive_patterns` feature
|
This tracks the `exhaustive_patterns` feature which allows uninhabited variant to be omitted
(bug report: #12609; relevant RFC: rust-lang/rfcs#1872).
```rust
fn safe_unwrap<T>(x: Result<T, !>) -> T {
match x {
Ok(y) => y,
}
}
```
- [x] Implementation (separated out from `never_type` in #47630)
- [x] blocking issue: https://github.com/rust-lang/rust/issues/117119
- [ ] Stabilization
|
T-lang,B-unstable,C-tracking-issue,A-patterns,A-exhaustiveness-checking,S-tracking-needs-summary,F-exhaustive_patterns
|
high
|
Critical
|
326,744,435 |
opencv
|
Android OpenCV 3.4.1 - Cannot call stitching methods in JNI C++ methods
|
<!--
If you have a question rather than reporting a bug please go to http://answers.opencv.org where you get much faster responses.
If you need further assistance please read [How To Contribute](https://github.com/opencv/opencv/wiki/How_to_contribute).
This is a template helping you to create an issue which can be processed as quickly as possible. This is the bug reporting section for the OpenCV library.
-->
##### System information (version)
- OpenCV => 3.4.1
- Operating System / Platform => Android
##### Detailed description
Android OpenCV 3.4.1 libopencv_java3.so doesn't have `stitching/stitcher` support/symbols compiled in.
More specifically, calling the Stitcher class makes the project not to compile as references to `cv::Stitcher` cannot be found.
##### Steps to reproduce
<!-- to add code example fence it with triple backticks and optional file extension
```.cpp
// C++ code example
```
or attach as .txt or .zip file
-->
This is my JNI
```.cpp
JNIEXPORT void JNICALL Java_za_co_palota_opencvtest_MainActivity_incrementalStitch(JNIEnv *env, jobject instance, jlong stitchingFrameAddr, jlong additionalFrameAddr) {
Mat &srcM = *(Mat *) stitchingFrameAddr;
Mat &dstM = *(Mat *) additionalFrameAddr;
vector<Mat> frames;
frames.push_back(srcM);
frames.push_back(dstM);
Mat panorama;
Ptr<Stitcher> stitcher = Stitcher::create(mode, try_use_gpu);
Stitcher::Status status = stitcher->stitch(frames, panorama);
if (status != Stitcher::OK)
{
LOGD("CV: STITCHING FAILED");
} else {
LOGD("CV: STITCHING SUCCESSFUL");
}
}
```
When building my android app I get these errors
```
/Users/.../app/src/main/cpp/native-lib.cpp:61: error: undefined reference to 'cv::Stitcher::create(cv::Stitcher::Mode, bool)'
/Users/.../app/src/main/cpp/native-lib.cpp:62: error: undefined reference to 'cv::Stitcher::stitch(cv::_InputArray const&, cv::_OutputArray const&)'
clang++: error: linker command failed with exit code 1 (use -v to see invocation)
ninja: build stopped: subcommand failed.
```
Upon further I looked at the symbols inside `libopencv_java3.so` (libopencv_java3.so comes straight from the latest package served from SourceForge - https://sourceforge.net/projects/opencvlibrary/files/opencv-android/3.4.1/) by running the following command:
```bash
nm -D libopencv_java3.so
```
When looking at the output I couldn't see references to any of the stitching methods.
|
feature,category: java bindings,category: stitching
|
low
|
Critical
|
326,747,535 |
rust
|
wasm32-unknown-unknown does not export $start.
|
When compiling a binary crate to wasm using the `wasm32-unknown-unknown` target, a `$start` function is not inserted into the resulting wasm binary,
This is a continuation of https://github.com/rust-lang-nursery/rust-wasm/issues/108
|
O-wasm,C-bug
|
low
|
Minor
|
326,764,409 |
electron
|
Extend DataTransfer object to support custom / native drag & drop formats
|
**Is your feature request related to a problem? Please describe.**
My app needs the ability to send custom data formats via drag and drop to a legacy win32 application. Using the [datatransfer](https://developer.mozilla.org/en-US/docs/Web/API/DataTransfer/DataTransfer) object does not allow adding native custom formats. The [setData](https://developer.mozilla.org/en-US/docs/Web/API/DataTransfer/setData) function updates the "Chromium Web Custom MIME Data Format".
**Describe the solution you'd like**
I would like the ability to add native data formats to the DataTransfer object with a new function such as setNativeData that accepts the format and a Buffer for the format payload. The new function would not interfere with the existing setData implemenation.
**Describe alternatives you've considered**
I've written a nodejs addon to support my needs when running in Win32. My addon is called during the HTML dragstart event and completely hijacks the chromium / electron drag / drop functionality. I really don't like this approach and would prefer a way to set the data formats and let chromium / electron do the drag & drop work.
**Additional context**
N/A
|
enhancement :sparkles:
|
low
|
Minor
|
326,827,265 |
go
|
proposal: spec: treat s[-1] as equivalent to s[len(s)-1]
|
# Overview
This is a backwards-compatible language change proposal. It will not be as thorough as it could be, since I do not think it should be adopted. I am writing it up merely for future reference.
I propose to treat negative constant literals in slicing and indexing expressions as offsets from the end of the slice or array. For example:
* `s[-1]` is equivalent to `s[len(s)-1]`
* `s[:-1]` is equivalent to `s[:len(s)-1]`
* `s[:-2:-1]` is equivalent to `s[:len(s)-2:len(s)-1]`
The motivation is to improve readability. Slice and index expressions like this occur commonly when treating slices as stacks.
Consider this code from the compiler:
```go
func (f *Func) newPoset() *poset {
if len(f.Cache.scrPoset) > 0 {
po := f.Cache.scrPoset[len(f.Cache.scrPoset)-1]
f.Cache.scrPoset = f.Cache.scrPoset[:len(f.Cache.scrPoset)-1]
return po
}
return newPoset()
}
```
Using the proposed syntactic sugar, it would read:
```go
func (f *Func) newPoset() *poset {
if len(f.Cache.scrPoset) > 0 {
po := f.Cache.scrPoset[-1]
f.Cache.scrPoset = f.Cache.scrPoset[:-1]
return po
}
return newPoset()
}
```
# Scope
The proposed sugar would only apply to negative constant literals.
```go
var b [10]byte
var v int = -1
const c = -1
var (
_ = b[v] // unchanged: results in runtime panic
_ = b[c] // unchanged: results in compile time error: index bounds out of range
_ = b[-1] // new: evaluates to b[len(b)-1]
)
```
The rationale for `b[v]` to panic at runtime is that negative indices often arise due to overflow and programmer error.
The same rationale discourages allowing constant expressions such as `b[c]` as syntactic sugar. Constant expressions can be complex, non-local, and build-tag controlled.
However, a constant literal displays clear, obvious, local intent, and overflow-free, and affords little room for programmer error.
# Order of evaluation and side-effects
Currently, the slice/array is evaluated before any index or slice indices. See https://play.golang.org/p/kTr9Az5HoDj.
This allows a natural order of evaluation for the proposal. Given `expr[-1]` or `expr[:-1]`, `expr` is evaluated exactly once, and its length is used in subsequent `len(expr)-c` calculations.
# Data
A quick-and-dirty AST parsing program examining slice expressions suggests that such expressions occur, but not with particularly high frequency.
Running over GOROOT yields that 2.51% of slice expressions could be rewritten to use this syntactic sugar. Running over my GOPATH yields 3.17%. Searching for candidate index expressions yields 0.35% and 0.91% respectively.
This is an underestimate. In many cases, for clarity, the code will already have been rewritten like:
```go
n := len(s)-1
x = s[n]
s = s[:n]
```
And all index expressions were considered candidates for this analysis, which includes map accesses and assignments.
Nevertheless, this analysis suggests that this sugar is unlikely to be transformative in how Go code is written, and therefore probably does not pull its weight.
|
LanguageChange,Proposal,LanguageChangeReview
|
medium
|
Critical
|
326,838,688 |
youtube-dl
|
Add Site Support for addatimes
|
## Please follow the guide below
- You will be asked some questions and requested to provide some information, please read them **carefully** and answer honestly
- Put an `x` into all the boxes [ ] relevant to your *issue* (like this: `[x]`)
- Use the *Preview* tab to see what your issue will actually look like
---
### Make sure you are using the *latest* version: run `youtube-dl --version` and ensure your version is *2018.05.26*. If it's not, read [this FAQ entry](https://github.com/rg3/youtube-dl/blob/master/README.md#how-do-i-update-youtube-dl) and update. Issues with outdated version will be rejected.
- [x] I've **verified** and **I assure** that I'm running youtube-dl **2018.05.26**
### Before submitting an *issue* make sure you have:
- [x] At least skimmed through the [README](https://github.com/rg3/youtube-dl/blob/master/README.md), **most notably** the [FAQ](https://github.com/rg3/youtube-dl#faq) and [BUGS](https://github.com/rg3/youtube-dl#bugs) sections
- [x] [Searched](https://github.com/rg3/youtube-dl/search?type=Issues) the bugtracker for similar issues including closed ones
- [x] Checked that provided video/audio/playlist URLs (if any) are alive and playable in a browser
### What is the purpose of your *issue*?
- [ ] Bug report (encountered problems with youtube-dl)
- [x] Site support request (request for adding support for a new site)
- [ ] Feature request (request for a new functionality)
- [ ] Question
- [ ] Other
---
### The following sections concretize particular purposed issues, you can erase any section (the contents between triple ---) not applicable to your *issue*
---
### If the purpose of this *issue* is a *bug report*, *site support request* or you are not completely sure provide the full verbose output as follows:
Add the `-v` flag to **your command line** you run youtube-dl with (`youtube-dl -v <your command line>`), copy the **whole** output and insert it here. It should look similar to one below (replace it with **your** log inserted between triple ```):
```
```
---
### If the purpose of this *issue* is a *site support request* please provide all kinds of example URLs support for which should be included (replace following example URLs by **yours**):
Please add support for https://www.addatimes.com/
-example video: https://www.addatimes.com/show/virgin-mohito/episode-1
---
### Description of your *issue*, suggested solution and other information
Just simply login with google plus or facebook and u ll be able to see them
My experiments: To get the details of the programme u need to use this type of URL
: https://www.addatimes.com/api/getVideo?video=episode-2&category=virgin-mohito&token="Token_Generated_By_Angular’s_XSRF"
It will be a great help if you can add this site support in youtube-dl.
|
site-support-request
|
low
|
Critical
|
326,838,924 |
neovim
|
build/cmake: consider Hunter (vcpkg, ?) for bundled dependencies
|
[This thread](https://news.ycombinator.com/item?id=17163194) discusses CMake state-of-the-art.
Currently we use `ExternalProject_Add` combined with our own recipes for building external projects. This obviously is painful to maintain because if an upstream project changes it may break our bundled-deps build when we bump our dependency version of that project.
Some recommend [hunter](https://github.com/cpp-pm/hunter) for pulling in external projects with CMake.
> Hunter aims to be a full package manager, so it strives to build a project and all of its depedendencies recursively. This is fundamentally different than just adding one external project and ignoring the depedencies (what ExternalProject_Add does). The downside is this forces Hunter to maintain many forks of original repos just to keep track of the dependency information.
[Quick introduction to Hunter](https://geokon-gh.github.io/hunterintro.html):
> * **Dependencies are built at configuration time:** Hunter will download the source and build all your dependencies during configuration time.
> * **Dependencies are built independently:** Each dependency is configured/built/installed independently and the only thing they inherit from the parent project is the toolchain file you passed in at the command line.
> * **Dependencies share their own dependencies:** If two dependencies need zlib then Hunter will install just one zlib and link both dependencies to it
# Evaluation
### conan
- conan is missing many of our deps (libtermkey, libuv at least)
- fast to install on Arch Linux (Python package)
### vcpkg
- vcpkg appears to provide more deps, but still also misses libtermkey, libvterm at least.
- slow to install (only vcpkg-git in Arch, requires to be built)
### hunter
- hunter does not need to be installed really (via CMake)
- [min cmake version](https://hunter.readthedocs.io/en/latest/quick-start/cmake.html)
- also misses a lot of our deps, including LuaJIT: https://hunter.readthedocs.io/en/latest/packages.html
### nix
- ?
|
enhancement,build
|
medium
|
Major
|
326,844,294 |
tensorflow
|
Prebuilt binaries do not work with CPUs that do not have AVX instruction sets.
|
As announced in release notes, TensorFlow release binaries version 1.6 and higher are prebuilt with AVX instruction sets. This means on any CPU that do not have these instruction sets either CPU or GPU version of TF will fail to load with any of the following errors:
- `ImportError: DLL load failed:`
- A crash with return code 132
Our recommendation is to build TF from sources on these systems.
### System information
- **Have I written custom code (as opposed to using a stock example script provided in TensorFlow)**: No
- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**: ubuntu/windows/macos
- **TensorFlow installed from (source or binary)**: binary
- **TensorFlow version (use command below)**: 1.6 and up
- **Python version**: 2.7, 3.3, 3.4, 3.5, 3.6 and any newer
- **Bazel version (if compiling from source)**: n/a
- **GCC/Compiler version (if compiling from source)**: n/a
- **CUDA/cuDNN version**: any
- **GPU model and memory**: any
- **Exact command to reproduce**: python -c "import tensorflow as tf"
|
stat:community support,type:feature
|
high
|
Critical
|
326,856,232 |
rust
|
Tracking issue for RFC 2294, "if let guard"
|
This is a tracking issue for the RFC "if let guard" (rust-lang/rfcs#2294).
**Steps:**
- [x] Implement the RFC (implemented in #79051)
- [ ] Adjust documentation ([see instructions on forge][doc-guide])
- [ ] Stabilization PR ([see instructions on forge][stabilization-guide])
[stabilization-guide]: https://forge.rust-lang.org/stabilization-guide.html
[doc-guide]: https://forge.rust-lang.org/stabilization-guide.html#updating-documentation
**Unresolved questions:**
- [ ] Work out the exact semantics / borrowck (cc @nikomatsakis, @pnkfelix)
* [ ] Add unit tests analogous to the existing `if` guard ones that test `if let` guard instead
* [ ] Ensure that the documentation of these details, if any, give equal footing to `if` and `if let` guards.
* [ ] (If there is no documentation of `if` guards behavior w.r.t. move semantics, I do not think that should hold up stabilizing this feature. We can just file an issue that those things need to be documented.)
- [ ] pnkfelix: The fact that both this feature and `let else` were implemented but had problems discovered relatively late with their handling of certain details w.r.t. locals and temporary r-values is a hint that we may need to revisit our approach to testing features like this more broadly, in terms of how we advise implementors of such features on how to probe for such cases (and maybe also in the form of some kind of language-oriented test-generation tooling?)
|
T-lang,B-unstable,B-RFC-implemented,C-tracking-issue,F-if_let_guard,S-tracking-impl-incomplete
|
high
|
Critical
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.