
id
int64 393k
2.82B
| repo
stringclasses 68
values | title
stringlengths 1
936
| body
stringlengths 0
256k
⌀ | labels
stringlengths 2
508
| priority
stringclasses 3
values | severity
stringclasses 3
values |
|---|---|---|---|---|---|---|
250,462,294
|
rust
|
struct pass-by-value failing on SPARC
|
There are a handful of testsuite failures on SPARC that seem to be related, and they have to do with passing structs by value into C. Although in at least one case (`extern-fn-struct-passing-abi`), the C code isn't getting the right values (but there it's a floating-point value), in the integer case Shawn and I have dived into (`extern-pass-TwoU8s`), that part appears to be correct. It's the retrieval of the struct's return value that seems to be wrong.
The problem becomes a bit more apparent if we rebuild the test with `-g` instead of `-O`. I can attach full files if necessary, but here is (what I think is the relevant part of) the IR for the `main()` function:
```
; extern_pass_TwoU8s::main
; Function Attrs: uwtable
define internal void @_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE() unnamed_addr #0 !dbg !294 {
start:
%tmp_ret1 = alloca %"core::fmt::ArgumentV1"
%tmp_ret = alloca %"core::fmt::ArgumentV1"
%abi_cast = alloca i16
%arg = alloca %TwoU8s
%__arg1 = alloca %TwoU8s**
%__arg0 = alloca %TwoU8s**
%_22 = alloca { %TwoU8s**, [0 x i8], %TwoU8s**, [0 x i8] }
%_21 = alloca [2 x %"core::fmt::ArgumentV1"]
%_16 = alloca %"core::fmt::Arguments"
%right_val = alloca %TwoU8s*
%left_val = alloca %TwoU8s*
%_5 = alloca { %TwoU8s*, [0 x i8], %TwoU8s*, [0 x i8] }
%y = alloca %TwoU8s
%x = alloca %TwoU8s
call void @llvm.dbg.declare(metadata %TwoU8s* %x, metadata !297, metadata !144), !dbg !299
call void @llvm.dbg.declare(metadata %TwoU8s* %y, metadata !300, metadata !144), !dbg !302
call void @llvm.dbg.declare(metadata %TwoU8s** %left_val, metadata !303, metadata !144), !dbg !306
call void @llvm.dbg.declare(metadata %TwoU8s** %right_val, metadata !307, metadata !144), !dbg !306
call void @llvm.dbg.declare(metadata %TwoU8s*** %__arg0, metadata !308, metadata !144), !dbg !311
call void @llvm.dbg.declare(metadata %TwoU8s*** %__arg1, metadata !312, metadata !144), !dbg !311
%0 = getelementptr inbounds %TwoU8s, %TwoU8s* %x, i32 0, i32 0, !dbg !313
store i8 22, i8* %0, !dbg !313
%1 = getelementptr inbounds %TwoU8s, %TwoU8s* %x, i32 0, i32 2, !dbg !313
store i8 23, i8* %1, !dbg !313
%2 = getelementptr inbounds %TwoU8s, %TwoU8s* %x, i32 0, i32 0, !dbg !314
%3 = getelementptr inbounds %TwoU8s, %TwoU8s* %x, i32 0, i32 2, !dbg !314
%4 = load i8, i8* %2, !dbg !314
%5 = load i8, i8* %3, !dbg !314
%6 = getelementptr inbounds %TwoU8s, %TwoU8s* %arg, i32 0, i32 0, !dbg !314
store i8 %4, i8* %6, !dbg !314
%7 = getelementptr inbounds %TwoU8s, %TwoU8s* %arg, i32 0, i32 2, !dbg !314
store i8 %5, i8* %7, !dbg !314
%8 = bitcast %TwoU8s* %arg to i64*, !dbg !314
%9 = load i64, i64* %8, align 1, !dbg !314
%10 = call i16 @rust_dbg_extern_identity_TwoU8s(i64 %9), !dbg !314
store i16 %10, i16* %abi_cast, !dbg !314
%11 = bitcast %TwoU8s* %y to i8*, !dbg !314
%12 = bitcast i16* %abi_cast to i8*, !dbg !314
call void @llvm.memcpy.p0i8.p0i8.i64(i8* %11, i8* %12, i64 2, i32 1, i1 false), !dbg !314
br label %bb1, !dbg !314
bb1: ; preds = %start
%13 = getelementptr inbounds { %TwoU8s*, [0 x i8], %TwoU8s*, [0 x i8] }, { %TwoU8s*, [0 x i8], %TwoU8s*, [0 x i8] }* %_5, i32 0, i32 0, !dbg !315
store %TwoU8s* %x, %TwoU8s** %13, !dbg !315
%14 = getelementptr inbounds { %TwoU8s*, [0 x i8], %TwoU8s*, [0 x i8] }, { %TwoU8s*, [0 x i8], %TwoU8s*, [0 x i8] }* %_5, i32 0, i32 2, !dbg !315
store %TwoU8s* %y, %TwoU8s** %14, !dbg !315
%15 = getelementptr inbounds { %TwoU8s*, [0 x i8], %TwoU8s*, [0 x i8] }, { %TwoU8s*, [0 x i8], %TwoU8s*, [0 x i8] }* %_5, i32 0, i32 0, !dbg !315
%16 = load %TwoU8s*, %TwoU8s** %15, !dbg !315, !nonnull !91
store %TwoU8s* %16, %TwoU8s** %left_val, !dbg !315
%17 = getelementptr inbounds { %TwoU8s*, [0 x i8], %TwoU8s*, [0 x i8] }, { %TwoU8s*, [0 x i8], %TwoU8s*, [0 x i8] }* %_5, i32 0, i32 2, !dbg !315
%18 = load %TwoU8s*, %TwoU8s** %17, !dbg !315, !nonnull !91
store %TwoU8s* %18, %TwoU8s** %right_val, !dbg !315
%19 = load %TwoU8s*, %TwoU8s** %left_val, !dbg !306, !nonnull !91
%20 = load %TwoU8s*, %TwoU8s** %right_val, !dbg !306, !nonnull !91
; call <extern_pass_TwoU8s::TwoU8s as core::cmp::PartialEq>::eq
%21 = call zeroext i1 @"_ZN67_$LT$extern_pass_TwoU8s..TwoU8s$u20$as$u20$core..cmp..PartialEq$GT$2eq17h9059cf2eb03b4778E"(%TwoU8s* noalias readonly dereferenceable(2) %19, %TwoU8s* noalias readonly dereferenceable(2) %20), !dbg !306
br label %bb2, !dbg !306
```
and the resulting assembly (more or less):
```
extern-pass-TwoU8s.stage2-sparcv> _ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE::dis
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE: save %sp, -0x1c0, %sp
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+4: call +0x8 <_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0xc>
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+8: sethi %hi(0x106c00), %i0
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0xc: or %i0, 0x168, %i0
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x10: add %i0, %o7, %i0
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x14: mov 0x16, %i1
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x18: stb %i1, [%fp + 0x737]
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x1c: add %fp, 0x737, %i1
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x20: or %i1, 0x1, %i1
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x24: mov 0x17, %i2
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x28: stb %i2, [%i1]
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x2c: ldub [%fp + 0x737], %i1
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x30: stb %i1, [%fp + 0x7d7]
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x34: add %fp, 0x7d7, %i1
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x38: or %i1, 0x1, %i1
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x3c: stb %i2, [%i1]
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x40: ldx [%fp + 0x7d7], %o0
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x44: call +0x724 <rust_dbg_extern_identity_TwoU8s>
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x48: stx %i0, [%fp + 0x72f]
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x4c: sth %o0, [%fp + 0x7dd]
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x50: lduh [%fp + 0x7dd], %i0
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x54: ba +0x8 <_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x5c>
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x58: sth %i0, [%fp + 0x73f]
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x5c: add %fp, 0x737, %i0
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x60: stx %i0, [%fp + 0x747]
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x64: add %fp, 0x73f, %i0
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x68: stx %i0, [%fp + 0x74f]
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x6c: ldx [%fp + 0x747], %i0
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x70: stx %i0, [%fp + 0x757]
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x74: ldx [%fp + 0x74f], %i0
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x78: stx %i0, [%fp + 0x75f]
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x7c: ldx [%fp + 0x757], %o0
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x80: call +0x240 <_ZN67_$LT$extern_pass_TwoU8s..TwoU8s$u20$as$u20$core..cmp..PartialEq$GT$2eq17h9059cf2eb03b4778E>
_ZN18extern_pass_TwoU8s4main17h7a27acd65aa2f60dE+0x84: mov %i0, %o1
```
We believe the `sth` instruction after the call to `rust_dbg_extern_identity_TwoU8s` is where it goes wrong, implying something wrong with the `store` instruction in the IR.
Here is the IR for the equivalent C function (albeit compiled by clang from a different version of LLVM):
```
; Function Attrs: nounwind
define signext i32 @main() #0 {
%1 = alloca i32, align 4
%t = alloca %struct.TwoU8s, align 1
%u = alloca %struct.TwoU8s, align 1
%2 = alloca i64, align 8
%3 = alloca %struct.TwoU8s, align 1
%4 = alloca i64, align 8
store i32 0, i32* %1, align 4
%5 = getelementptr inbounds %struct.TwoU8s, %struct.TwoU8s* %t, i32 0, i32 0
store i8 22, i8* %5, align 1
%6 = getelementptr inbounds %struct.TwoU8s, %struct.TwoU8s* %t, i32 0, i32 1
store i8 23, i8* %6, align 1
%7 = bitcast i64* %2 to i8*
%8 = bitcast %struct.TwoU8s* %t to i8*
call void @llvm.memcpy.p0i8.p0i8.i64(i8* %7, i8* %8, i64 2, i32 1, i1 false)
%9 = load i64, i64* %2, align 8
%10 = call i64 @rust_dbg_extern_identity_TwoU8s(i64 %9)
store i64 %10, i64* %4, align 8
%11 = bitcast i64* %4 to i8*
%12 = bitcast %struct.TwoU8s* %3 to i8*
call void @llvm.memcpy.p0i8.p0i8.i64(i8* %12, i8* %11, i64 2, i32 1, i1 false)
%13 = bitcast %struct.TwoU8s* %u to i8*
%14 = bitcast %struct.TwoU8s* %3 to i8*
call void @llvm.memcpy.p0i8.p0i8.i64(i8* %13, i8* %14, i64 2, i32 1, i1 false)
%15 = getelementptr inbounds %struct.TwoU8s, %struct.TwoU8s* %u, i32 0, i32 0
%16 = load i8, i8* %15, align 1
%17 = zext i8 %16 to i32
%18 = icmp eq i32 %17, 22
br i1 %18, label %21, label %19
```
Anyway, this was about as far as we got before we needed to take a break, but figured it was worth writing up and seeing if anyone here had any insights. This is all on the beta branch, at commit f38ffa8d7b, though the failure happens on all versions of rust I've run the testsuite for.
@binarycrusader
|
A-codegen,A-FFI,I-unsound,O-SPARC,C-bug,A-ABI
|
low
|
Critical
|
250,483,611
|
go
|
proposal: regexp: Optimize fixed-length patterns
|
The `regexp` package has 3 different matchers (NFA, onepass, backtrack). One of them is selected depending on the pattern.
I suggest adding a 4th matcher optimized for fixed-length patterns like `a.ab$` on strings.
I wrote a [proof-of-concept implementation](https://github.com/sylvinus/regexp-bypass) which provides constant-time matching relative to the size of the input string in many cases, whereas the current matchers from `regexp` perform linearly. Performance becomes close to what can be achieved with methods like `strings.Index`.
Here is a sample benchmark result of `regexp.MatchString("a.ab$", strings.Repeat("a", M)+"b")`:
```
M=1000
BenchmarkRegexpBypass/DotSuffix/bypass-8 30000000 109 ns/op # New matcher implementation
BenchmarkRegexpBypass/DotSuffix/std-8 50000 69882 ns/op # Go's current standard library
BenchmarkRegexpBypass/DotSuffix/pcre-8 100000 41359 ns/op # PCRE
BenchmarkRegexpBypass/DotSuffix/rust-8 20000000 157 ns/op # Rust regexp engine
```
I've added more details, benchmarks and tests (with fuzzing!) to [the repository](https://github.com/sylvinus/regexp-bypass). Not sure how much should be inlined here.
The obvious cons of this proposal are:
- Adding more code to the standard library
- Adding more work at compilation time.
The pros are:
- Constant-time matching for many simple regexps (relative to the size of the input string)
- No overhead for regexps that are not supported
- Go's `regexp` package is usually considered immature performance-wise. This proposal plays a small role in fixing that by adding optimizations that can reasonably be expected from the end-user.
- This matcher keeps very little state and bypasses the mutex from `regexp.go`
- There are already 3 different matchers in the standard library (4 with the upcoming DFA), so adding a new one for a specific kind of patterns is not surprising.
- `regexp.MatchString("(?:png|jpg)$")` could obviously be rewritten as `strings.HasSuffix("png") or strings.HasSuffix("jpg")` but sometimes it is not practical because the pattern to be matched is user-supplied or part of a long list of patterns. Examples include interactive log search or lists of paths in HTTP routers.
- Limited risk due to exhaustive tests in the standard library and additional fuzzing
Feedback would be highly appreciated. Thanks!!
|
Performance,Proposal,Proposal-Hold
|
medium
|
Major
|
250,561,913
|
angular
|
Input element's value attribute is not set
|
## I'm submitting a...
<!-- Check one of the following options with "x" -->
<pre><code>
[ ] Regression (a behavior that used to work and stopped working in a new release)
[ X ] Bug report <!-- Please search GitHub for a similar issue or PR before submitting -->
[ ] Feature request
[ ] Documentation issue or request
[ ] Support request => Please do not submit support request here, instead see https://github.com/angular/angular/blob/master/CONTRIBUTING.md#question
</code></pre>
## Current behavior
<!-- Describe how the issue manifests. -->
When initializing a FormControl with an initial value, the html input element's value attribute is not set.
## Expected behavior
<!-- Describe what the desired behavior would be. -->
The value attribute of an input element to be set like the specs describe:
[https://www.w3.org/TR/html5/forms.html#attr-input-value]
> The value content attribute gives the default value of the input element. When the value content attribute is added, set, or removed, if the control's dirty value flag is false, the user agent must set the value of the element to the value of the value content attribute, if there is one, or the empty string otherwise, and then run the current value sanitization algorithm, if one is defined.
## Minimal reproduction of the problem with instructions
create a new FormControl with an initial value:
`const control = new FormControl('initial value', [Validators.required]);`
Inspect the input element, and see that the input element does not have the value attribute:
`<input _ngcontent-c13="" formcontrolname="myProperty" type="number" ng-reflect-name="myProperty" class="ng-untouched ng-pristine">`
## What is the motivation / use case for changing the behavior?
Without the value attribute screenreaders cannot get the element's value.
It also makes automatic testing more difficult, since element properties are not accessible by css selectors or xpath. (We have to use a hack: [attr.value]="myForm.get('key').value)
## Environment
angular version: 4.3.4
Browser:
- [ X ] Chrome (desktop) version 60.0.3112.78
- [ X ] Firefox version 54.0
and probably the others as well.
|
feature,state: Needs Design,freq2: medium,area: forms,feature: under consideration
|
medium
|
Critical
|
250,595,197
|
TypeScript
|
Improve CSSStyleDeclaration typings
|
Not every string should be allowed in properties of the `CSSStyleDeclaration` interface, such as `display`, `overflow`, etc. The [TypeStyle](https://github.com/typestyle/typestyle/) project seems to have put quite some effort into this already, from which _inspiration_ could be taken.
|
Suggestion,In Discussion,Domain: lib.d.ts
|
medium
|
Major
|
250,597,778
|
axios
|
Requests fully buffered by default
|
#### Summary
By default, when making a streaming request using Axios setting data to a stream, the request is fully buffered. E.g. if you use Axios to send a 10GB file over a network using a file stream, it will consume 10GB of RAM, minimum. This is due to the default behaviour of maxRedirects, which is to allow redirects, which means that the follow-redirects module buffers all data written in case there's a redirect.
I think a section in the docs on streams and buffering with a prominent warning in the docs for maxRedirects that setting it to any value other than 0 (or not setting it at all) will cause writes to be fully buffered would be valuable.
axios({
url: "http://somewhere",
method: 'post',
responseType: 'json',
data: fs.createReadStream('huge10GBFile.txt'),
headers: {
'Content-Type': 'text/plain'
}
});`
#### Context
- axios version: v0.16.2
- Environment: Mac OS X Sierra
|
state::triage
|
low
|
Major
|
250,617,123
|
go
|
proposal: permit iota, omission of init expressions in var declarations
|
This was discussed very early in the language design, at the same time when we also introduced iota for constant declarations: Permit iota and the omission of initialization expressions not only in constant but also variable declarations. For instance, this would permit code like:
```
var (
mercury = NewPlanet(iota + 1)
venus
earth
mars
...
)
```
If my memory serves me right, we didn't pursue it at the time because there was no compelling or urgent argument in favor of it.
Such a mechanism could simplify the construction of related named objects and open the door to "enum" values that are not restricted to constant values and their respective types.
As such it may be a more elementary building block towards more complex "enums" in Go (see also the discussion in #19814).
Implementation:
- Straight-forward changes would be required in the front-end of the compiler.
Language:
- This would be a fully backward-compatible language change.
- The change is fully orthogonal to existing features and would make variable and constant declarations more symmetric (and thus the language simpler).
- No new concepts are introduced as this is essentially syntactic sugar.
|
LanguageChange,Proposal,LanguageChangeReview
|
medium
|
Critical
|
250,666,295
|
javascript
|
Please explain using inline styles comment about expensive stylesheets
|
The [css-in-javascript page](https://github.com/airbnb/javascript/tree/master/css-in-javascript) states
* Use inline styles for styles that have a high cardinality (e.g. uses the value of a prop) and not for styles that have a low cardinality.
> Why? Generating themed stylesheets can be expensive, so they are best for discrete sets of styles.
In the example, you have ` css(styles.periodic, { margin: spacing })`, but this still requires you to use the `withStyles` HOC, so aren't you generated a themed stylesheet regardless of the prop? What makes this less expensive?
For another example that I'm actually using and am wondering about, I have these various column classes, which I then spread into the styles returned by `withStyles`.
```js
const sizes = [10, 20, 30, 40, 50, 60, 70, 80, 90, 25, 75];
const sizeStyles = sizes.reduce((object, size) => ({
...object,
[`columnOffset${size}`]: {marginLeft: `${size}%`},
[`columnPercent${size}`]: {flex: `0 0 ${size}%`, maxWidth: `${size}%`},
}), {});
withStyles(() => ({
// other styles above
...sizeStyles,
}))(Column);
```
And my `css` call is ``css(styles.column, styles[`columnPercent${size}`], styles[`columnOffset${offset}`])``.
But would it be somehow better to skip adding it to the returned styles and instead do ``css(styles.column, sizeStyles[`columnPercent${size}`], sizeStyles[`columnOffset${offset}`])``?
|
question
|
low
|
Minor
|
250,680,952
|
rust
|
"The following implementations were found" should also mention the trait bounds.
|
Test case:
```rust
struct Index;
fn iterate(s: std::collections::HashSet<Index>) {
for _ in s {}
}
```
This errors with:
```
error[E0277]: the trait bound `std::collections::HashSet<Index>: std::iter::IntoIterator` is not satisfied
--> src/main.rs:3:5
|
3 | for _ in s {}
| ^^^^^^^^^^^^^ the trait `std::iter::IntoIterator` is not implemented for `std::collections::HashSet<Index>`
|
= help: the following implementations were found:
<std::collections::HashSet<T, S> as std::iter::IntoIterator>
<&'a std::collections::HashSet<T, S> as std::iter::IntoIterator>
= note: required by `std::iter::IntoIterator::into_iter`
```
So, the error is `HashSet<Index>` does not implement `IntoIterator`, but the help also suggests that `HashSet<T, S>` does implement `IntoIterator`, so what is it??
The help should also mention the bounds `T: Eq + Hash`. Or even better, points out that this impl is not chosen because `Index` does not implement `Eq + Hash`.
(Original source code: https://stackoverflow.com/revisions/45717092/2. Tested on playground, `rustc 1.21.0-nightly (df511d554 2017-08-14) running on x86_64-unknown-linux-gnu`)
|
C-enhancement,A-diagnostics,T-compiler
|
low
|
Critical
|
250,688,342
|
go
|
x/tools/cmd/goimports: support gofmt option to simplify code
|
```
go version go1.8.3 darwin/amd64
```
Using `goimports` as of https://github.com/golang/tools/commit/84a35ef54dff3c5596983e180ec10919fc432242
The `goimports` command handles import fixing and `gofmt` code formatting. It does not, however, implement the code simplification option `-s`.
This means that `goimports` cannot be used as a drop-in replacement to save-hooks that use `gofmt -s` (for example, when using `-s` as the `gofmt-args` value for the save-hook with `go-mode.el`).
```
package main
import "fmt"
type Thing struct {
value int
}
func main() {
things := []Thing{
Thing{value: 42},
}
fmt.Printf("things: %+v\n", things)
}
```
There are no problems identified by `goimports`:
```
$ goimports -d complex.go
```
With `gofmt -s`, we get:
```
$ gofmt -s -d complex.go
diff complex.go gofmt/complex.go
--- /var/folders/ts/s940qvdj5vj1czr9qh07fvtw0000gn/T/gofmt822245016 2017-08-16 12:34:31.000000000 -0400
+++ /var/folders/ts/s940qvdj5vj1czr9qh07fvtw0000gn/T/gofmt235716375 2017-08-16 12:34:31.000000000 -0400
@@ -8,7 +8,7 @@
func main() {
things := []Thing{
- Thing{value: 42},
+ {value: 42},
}
fmt.Printf("things: %+v\n", things)
}
```
|
Tools
|
medium
|
Major
|
250,712,698
|
rust
|
Precision for debug formatting works with empty tuple, but not other things (odd inconsistency)
|
It may be intentional that precision doesn't work with debug formatting (only with display), but this inconsistency is odd.
```rust
println!("{:?}", ()); // prints '()'
println!("{:.0?}", ()); // prints ''
println!("{:.1?}", ()); // prints '('
// In all of the below, the precision specifier has no effect at all;
// the full debug text is printed
println!("{:.0?}", 125);
println!("{:.1?}", 125);
println!("{:.0?}", (1, 2, 3));
println!("{:.1?}", (1, 2, 3));
println!("{:.0?}", ((), (), ()));
println!("{:.1?}", ((), (), ()));
println!("{:.0?}", "test");
println!("{:.1?}", "test");
```
I presume this is unintended (I can't imagine why it would be intentional)? Although any change may technically be breaking. Of course, if it is desired that precision doesn't work with debug, it doesn't really matter since there's no reason to use it.
|
T-libs-api,C-bug,A-fmt
|
low
|
Critical
|
250,720,341
|
puppeteer
|
Question: How do I get puppeteer to download a file?
|
Question: How do I get puppeteer to download a file or make additional http requests and save the response?
|
feature,upstream,confirmed
|
high
|
Critical
|
250,734,072
|
react
|
The fake event trick for rethrowing errors in DEV fires unexpected global error handlers and makes testing harder
|
I'm trying to make use of componentDidCatch in the React 16 beta. I already had a global window error handler which was working fine, but it unexpectedly catches errors that I would expect componentDidCatch to have handled. That is, component-local errors are being treated as window-global errors in dev builds.
The problem seems to stem from `invokeGuardedCallbackDev` in `ReactErrorUtils.js`. I think that this entire `__DEV__` block of code is problematic. The stated rational is:
```
// In DEV mode, we swap out invokeGuardedCallback for a special version
// that plays more nicely with the browser's DevTools. The idea is to preserve
// "Pause on exceptions" behavior. Because React wraps all user-provided
// functions in invokeGuardedCallback, and the production version of
// invokeGuardedCallback uses a try-catch, all user exceptions are treated
// like caught exceptions, and the DevTools won't pause unless the developer
// takes the extra step of enabling pause on caught exceptions. This is
// untintuitive, though, because even though React has caught the error, from
// the developer's perspective, the error is uncaught.
```
This is misguided because it's not about pausing on exceptions, it's about "pause on _uncaught_ exceptions." However, `componentDidCatch` makes exceptions _caught_!
Rather than switching on prod vs dev and using try/catch in prod and window's error handler in dev, React should always use try/catch, but rethrow if you reach the root without hitting a componentDidCatch handler. This would preserve the correct "pause on uncaught exceptions" behavior without messing with global error handlers.
|
Component: DOM,Type: Discussion
|
high
|
Critical
|
250,745,342
|
kubernetes
|
Move selector immutability check to validation after v1beta1 retires
|
The check for selector immutability is located at `PrepareForUpdate` functions of `deploymentStrategy`, `rsStrategy` and `daemonSetStrategy`. We are not able to have the check at validation before _v1beta1_ API version retires due to breaking change to some tests (discussed in this closed [PR](https://github.com/kubernetes/kubernetes/pull/50348)). Once _v1beta1_ retires, we should move the check to validation.
|
kind/bug,sig/apps,help wanted,lifecycle/frozen,good first issue
|
low
|
Major
|
250,773,566
|
neovim
|
Lua: vim.firstline, vim.lastline
|
Currently the only command actually supporting `[range]` is `luado`, but documentation (copied from Vim) states that `:lua` and `:luafile` also should, by storing the range in `vim.firstline` and `vim.lastline`. In the current state other commands ignore range completely.
Regarding the implementation I currently more like the idea of adding a metatable to `vim` “module” which will do the following two things:
1. Make `vim` module read-only.
2. Provide firstline and lastline.
This would protect vim module from accidental changes (and similar metatable is to be applied to `vim.types` and `vim.api`; “similar” = “read-only, but no `*line`”). It would still be not impossible to modify our tables, metatable can only protect from some accidental modifications.
|
compatibility,complexity:low,lua
|
low
|
Major
|
250,796,070
|
pytorch
|
Autograd test failure on ppc64le
|
After building PyTorch on IBM's ppc64le architecture I ran into test failure in test_autograd.py. The script segfaults when exceptions are being handled on the following lines with the signal SIGABRT:
```
self.assertRaises(RuntimeError, lambda: w.backward(torch.ones(5, 5))):810
self.assertRaises(RuntimeError, lambda: q.backward(torch.ones(5, 5))): 814
self.assertRaises(RuntimeError, lambda: q.backward(torch.ones(5, 5))): 828
self.assertRaises(RuntimeError, lambda: z.backward(torch.ones(5, 5))): 865
```
Which creates the following error output:
```
terminate called after throwing an instance of 'std::runtime_error'
what(): one of the variables needed for gradient computation has been modified by an inplace operation
./run_test.sh: line 27: 89711 Aborted (core dumped) $PYCMD test_autograd.py $@
```
Below is the backtrace log from GDB.
```
#0 0x00003fffb79aedb0 in __GI_raise (sig=<optimized out>) at ../sysdeps/unix/sysv/linux/raise.c:54
#1 0x00003fffb79b1270 in __GI_abort () at abort.c:89
#2 0x00003fff44b6c304 in __gnu_cxx::__verbose_terminate_handler() () from /usr/lib/powerpc64le-linux-gnu/libstdc++.so.6
#3 0x00003fff44b68b34 in ?? () from /usr/lib/powerpc64le-linux-gnu/libstdc++.so.6
#4 0x00003fff44b68bf0 in std::terminate() () from /usr/lib/powerpc64le-linux-gnu/libstdc++.so.6
#5 0x00003fff44b69034 in __cxa_throw () from /usr/lib/powerpc64le-linux-gnu/libstdc++.so.6
#6 0x00003fff9485a9a8 in torch::autograd::Variable::SavedVariable::unpack (this=0x10f51c30, saved_for=...) at torch/csrc/autograd/variable.cpp:74
#7 0x00003fff94862538 in unpack_saved_variables(THPFunction *, std::function<_object*(std::shared_ptr<torch::autograd::Variable>)>) (self=<optimized out>, unpack_fn=...)
at torch/csrc/autograd/python_function.cpp:864
#8 0x00003fff94862bfc in THPFunction_saved_variables (self=<optimized out>, _unused=<optimized out>) at torch/csrc/autograd/python_function.cpp:888
#9 0x00003fffb7d81f28 in getset_get (descr=0x3fff956e87a0, obj=0x3fff3ecf7ce8, type=<optimized out>) at Objects/descrobject.c:146
#10 0x00003fffb7dc5e30 in _PyObject_GenericGetAttrWithDict (obj=<optimized out>, name=0x3fffb77efab0, dict=0x0) at Objects/object.c:1439
#11 0x00003fffb7dc613c in PyObject_GenericGetAttr (obj=<optimized out>, name=<optimized out>) at Objects/object.c:1461
#12 0x00003fffb7dc4d9c in PyObject_GetAttr (v=0x3fff3ecf7ce8, name=<optimized out>) at Objects/object.c:1196
#13 0x00003fffb7e54738 in PyEval_EvalFrameEx (f=0x3fff3ea635f0, throwflag=<optimized out>) at Python/ceval.c:2543
#14 0x00003fffb7e5c420 in PyEval_EvalCodeEx (co=0x3fff3f1293b0, globals=<optimized out>, locals=<optimized out>, args=<optimized out>, argcount=<optimized out>, kws=<optimized out>, kwcount=<optimized out>,
defs=0x0, defcount=0, closure=0x0) at Python/ceval.c:3584
#15 0x00003fffb7d9d718 in function_call (func=0x3fff3f13c230, arg=0x3fff3e221b00, kw=0x0) at Objects/funcobject.c:523
#16 0x00003fffb7d52014 in PyObject_Call (func=0x3fff3f13c230, arg=<optimized out>, kw=<optimized out>) at Objects/abstract.c:2547
#17 0x00003fffb7e56750 in ext_do_call (nk=<optimized out>, na=1, flags=<optimized out>, pp_stack=0x3fff3ea5d9a0, func=0x3fff3f13c230) at Python/ceval.c:4666
#18 PyEval_EvalFrameEx (f=0x3fff3ea615a8, throwflag=<optimized out>) at Python/ceval.c:3028
#19 0x00003fffb7e5c420 in PyEval_EvalCodeEx (co=0x3fff3f12e430, globals=<optimized out>, locals=<optimized out>, args=<optimized out>, argcount=<optimized out>, kws=<optimized out>, kwcount=<optimized out>,
defs=0x0, defcount=0, closure=0x0) at Python/ceval.c:3584
#20 0x00003fffb7d9d718 in function_call (func=0x3fff3f138398, arg=0x3fff9587fa70, kw=0x0) at Objects/funcobject.c:523
#21 0x00003fffb7d52014 in PyObject_Call (func=0x3fff3f138398, arg=<optimized out>, kw=<optimized out>) at Objects/abstract.c:2547
#22 0x00003fffb7d68140 in instancemethod_call (func=0x3fff3f138398, arg=0x3fff9587fa70, kw=0x0) at Objects/classobject.c:2602
#23 0x00003fffb7d52014 in PyObject_Call (func=0x3fff3f0b1d70, arg=<optimized out>, kw=<optimized out>) at Objects/abstract.c:2547
#24 0x00003fffb7e50d28 in PyEval_CallObjectWithKeywords (func=0x3fff3f0b1d70, arg=0x3fff3e256690, kw=<optimized out>) at Python/ceval.c:4221
#25 0x00003fffb7d51f7c in PyObject_CallObject (o=<optimized out>, a=<optimized out>) at Objects/abstract.c:2535
#26 0x00003fff9486314c in torch::autograd::PyFunction::apply (this=0x3fff3ecf7d40, inputs=std::vector of length 1, capacity 1 = {...}) at torch/csrc/autograd/python_function.cpp:155
#27 0x00003fff94850ab0 in torch::autograd::call_function (task=...) at torch/csrc/autograd/engine.cpp:162
#28 torch::autograd::Engine::evaluate_function (this=<optimized out>, task=...) at torch/csrc/autograd/engine.cpp:167
#29 0x00003fff94850fd0 in torch::autograd::Engine::thread_main (this=0x3fff956cce70 <engine>, queue=std::shared_ptr (count 3, weak 0) 0x10dc2960, device=<optimized out>) at torch/csrc/autograd/engine.cpp:117
#30 0x00003fff948788c0 in PythonEngine::thread_main (this=0x3fff956cce70 <engine>, queue=std::shared_ptr (count 3, weak 0) 0x10dc2960, device=<optimized out>) at torch/csrc/autograd/python_engine.cpp:23
#31 0x00003fff94857958 in std::_Mem_fn_base<void (torch::autograd::Engine::*)(std::shared_ptr<torch::autograd::ReadyQueue>, int), true>::operator()<std::shared_ptr<torch::autograd::ReadyQueue>, int, void>(torch::autograd::Engine*, std::shared_ptr<torch::autograd::ReadyQueue>&&, int&&) const (__object=<optimized out>, this=<optimized out>) at /usr/include/c++/5/functional:600
#32 std::_Bind_simple<std::_Mem_fn<void (torch::autograd::Engine::*)(std::shared_ptr<torch::autograd::ReadyQueue>, int)> (torch::autograd::Engine*, std::shared_ptr<torch::autograd::ReadyQueue>, int)>::_M_invoke<0ul, 1ul, 2ul>(std::_Index_tuple<0ul, 1ul, 2ul>) (this=<optimized out>) at /usr/include/c++/5/functional:1531
#33 std::_Bind_simple<std::_Mem_fn<void (torch::autograd::Engine::*)(std::shared_ptr<torch::autograd::ReadyQueue>, int)> (torch::autograd::Engine*, std::shared_ptr<torch::autograd::ReadyQueue>, int)>::operator()() (this=<optimized out>) at /usr/include/c++/5/functional:1520
#34 std::thread::_Impl<std::_Bind_simple<std::_Mem_fn<void (torch::autograd::Engine::*)(std::shared_ptr<torch::autograd::ReadyQueue>, int)> (torch::autograd::Engine*, std::shared_ptr<torch::autograd::ReadyQueue>, int)> >::_M_run() (this=<optimized out>) at /usr/include/c++/5/thread:115
#35 0x00003fff44ba49a4 in ?? () from /usr/lib/powerpc64le-linux-gnu/libstdc++.so.6
#36 0x00003fffb7c98070 in start_thread (arg=0x3fff3ea5f1a0) at pthread_create.c:335
#37 0x00003fffb7a93a30 in clone () at ../sysdeps/unix/sysv/linux/powerpc/powerpc64/clone.S:96
```
|
triaged,module: POWER
|
low
|
Critical
|
250,810,580
|
go
|
debug/macho: add missing load commands
|
There are nearly 50 load commands. Current code supports few of them.
|
NeedsFix
|
low
|
Critical
|
250,840,238
|
vscode
|
Monolithic structure, multiple project settings
|
I was wondering if it is possible for VSCode to pick up on multiple `.vscode/settings.json`
For instance if you are working in an monolithic environment with multiple smaller projects inside it, and each have their own `.vscode/settings.json`.
Can VSCode pickup on that, and apply the settings from the smaller projects `.vscode/settings.json` to their subtree and descendant files?
```
monolithic-project/
├── small-project1/
│ ├── .vsocde
│ │ └── settings.json
│ └── src/
│ └── index.ts
└── small-project2/
├── .vsocde
│ └── settings.json
└── src/
└── index.ts
```
**Wanted effect:**
`monolithic-project/small-project1/.vscode/settings.json` applies to `monolithic-project/small-project1` and all descendant files.
`monolithic-project/small-project2/.vscode/settings.json` applies to `monolithic-project/small-project2` and all descendant files.
|
feature-request,config
|
high
|
Critical
|
250,846,906
|
opencv
|
Adjusting Viz camera parameters yields stuttering effect
|
##### System information (version)
- OpenCV => 3.3
- Operating System / Platform => Ubuntu 16.04 (x86-64)
- Compiler => g++ 5.4.0
##### Detailed description
Adjusting the intrinsic camera parameters of a `Viz3d` window yields a strange stuttering effect. For example, when adjusting the focal length, there is a slight up-and-down movement every second time. The movement is reproducible (albeit unwanted) and always between the same two (relative) positions. Consider the following minimum example:
##### Steps to reproduce
```
#include <iostream>
#include <opencv2/viz.hpp>
using namespace std;
using namespace cv;
using namespace cv::viz;
int main()
{
Viz3d window("Test");
window.showWidget("Test object", WCone(1, 0.5, 100));
window.spinOnce(1, true); //(unrelated) If this is not called here, getCamera returns different values and setCamera below throws a stack underflow exception!?
const auto camera = window.getCamera();
const auto focal_length = camera.getFocalLength();
const int fx = focal_length[0]; //Deliberate round to int
const int fy = focal_length[1];
const auto principal_point = camera.getPrincipalPoint();
const int px = principal_point[0];
const int py = principal_point[1];
for (int i = 1; i <= 30; i++)
{
cout << "Iteration " << i << endl;
const auto old_camera = window.getCamera();
Matx44d matrix;
old_camera.computeProjectionMatrix(matrix);
cout << "Old proj. matrix: " << matrix << endl;
Camera new_camera(fx - 10 * i, fy, px, py, old_camera.getWindowSize());
new_camera.computeProjectionMatrix(matrix);
cout << "New proj. matrix: " << matrix << endl;
window.setCamera(new_camera);
window.spinOnce(500, true);
}
return 0;
}
```
I am aware that numerical inaccuracies could be to blame for this, but the effect is far to severe for it only being that. The effect becomes even stronger for larger deviations from the initial parameters and increases when I change multiple parameters at once (it remains to the same extent even when I change `10 * i` to `i` for very small animation steps.). It goes so far as to make the object disappear for relatively sane values of focal length and principal point after a few dozen changes to the parameters.
I also posted this [here](http://answers.opencv.org/question/171647/adjusting-viz-camera-parameters-yields-stuttering-effect/) and [here](https://stackoverflow.com/questions/45542117/adjusting-camera-parameters-yields-stuttering-effect), but did not get any replies. I assume that this is a bug.
|
bug,category: viz
|
low
|
Critical
|
250,893,518
|
angular
|
ExpressionChangedAfterItHasBeenCheckedError is thrown by ngModel.invalid above the ngModel control declaration
|
## I'm submitting a...
<pre><code>
[ ] Regression (a behavior that used to work and stopped working in a new release)
[ X] Bug report <!-- Please search GitHub for a similar issue or PR before submitting -->
[ ] Feature request
[ ] Documentation issue or request
[ ] Support request => Please do not submit support request here, instead see https://github.com/angular/angular/blob/master/CONTRIBUTING.md#question
</code></pre>
## Current behavior
When you use NgModel.invalid in an expression above the ngModel control in the dom an ExpressionChangedAfterItHasBeenCheckedError is thrown. when you put the same expression below the ngModel control there is no issue.
## Expected behavior
No errors to be thrown
## Minimal reproduction of the problem with instructions
see https://plnkr.co/edit/0BSoP7SskyE3tD6FzPRy for an example.
## What is the motivation / use case for changing the behavior?
I need to set a 'has-error' class on the parent DomElement when given ngModel control is in an invalid state which doesn't work now.
## Environment
<pre><code>
Angular version: 4.3.5
</code></pre>
|
type: bug/fix,freq3: high,area: forms,hotlist: google,state: confirmed,forms: change detection,P3
|
medium
|
Critical
|
250,940,638
|
angular
|
`*` token not working in AnimationBuilder
|
## I'm submitting a...
<!-- Check one of the following options with "x" -->
<pre><code>
[ ] Regression (a behavior that used to work and stopped working in a new release)
[x] Bug report <!-- Please search GitHub for a similar issue or PR before submitting -->
[ ] Feature request
[ ] Documentation issue or request
[ ] Support request => Please do not submit support request here, instead see https://github.com/angular/angular/blob/master/CONTRIBUTING.md#question
</code></pre>
## Current behavior
I noticed that If I use the AnimationBuilder and have an animation that sets the height example 141px, and than after x amount of time another animation is triggered to remove this height by the "*" token, this has no effect at all, as the height still stays the same.
For the time being I had to replace the "*" with 100%, however this comes with another problem that the animation effect is not working.
## Expected behavior
When the second animation is triggered the full element height is used and have a transition when going from 141px to the full heigh.
## Minimal reproduction
```ts
this.collapseAnimation = this.animationBuilder.build([
animate("200ms ease-out", style({
height: `141px`
}))
]);
this.expandAnimation.create(this.content.nativeElement).play();
// run the below a couple of seconds after
this.expandAnimation = this.animationBuilder.build([
animate("200ms ease-in", style({
height: "*"
}))
]);
this.collapseAnimation.create(this.content.nativeElement).play();
```
## Environment
```
Angular version: 4.3.5
```
https://stackblitz.com/edit/angular-animation-star-token
|
type: bug/fix,area: animations,freq2: medium,P3
|
low
|
Critical
|
250,996,436
|
rust
|
Is automatic insertion of type inference placeholders possible?
|
Would it be possible to automatically insert `_` type inference placeholders where none (or not enough) type placeholders are provided, or does this conflict with any other tokens the parser has to deal with?
i.e. can `["foo", "bar"].iter().collect::Vec::()` be turned into `["foo", "bar"].iter().collect::Vec<_>::()` automatically?
and given a `Struct<X,Y>`, can `Struct<Foo>` automatically be understood as `Struct<Foo, _>`?
These would both simplify boilerplate considerably, and the latter could obviate the need to revisit old code when a type is expanded with an additional generic type parameter that can be inferred from its usage.
|
T-lang,C-feature-request
|
low
|
Minor
|
250,997,472
|
flutter
|
LocalHistoryEntry api docs are sparse
|
It's just a one liner:
https://docs.flutter.io/flutter/widgets/LocalHistoryEntry-class.html
"An entry in the history of a LocalHistoryRoute."
Which links to a slightly larger description in LocalHistoryRoute.
Maybe this just needs to link to a navigation tutorial? @alardizabal expressed some confusion attempting to use the API.
|
framework,d: api docs,f: routes,has reproducible steps,P2,found in release: 3.3,found in release: 3.5,team-framework,triaged-framework
|
low
|
Minor
|
250,998,311
|
rust
|
Type mismatch with generic parameter returns less than helpful errors
|
When a type does not match a generic parameter (I'm not sure if it's treated differently if it's because a generic constraint failed or because a previous usage dictated a particular variant of that generic), the resulting error message is not helpful because it seems to indicate that everything is OK.
As an example:
```rust
error[E0308]: mismatched types
--> src/main.rs:80:23
|
80 | return Ok(response);
| ^^^^^^^^ expected type parameter, found struct `std::io::Cursor`
|
= note: expected type `tiny_http::Response<R>`
found type `tiny_http::Response<std::io::Cursor<std::vec::Vec<u8>>>`
= help: here are some functions which might fulfill your needs:
- .with_data(...)
- .with_header(...)
- .with_status_code(...)
```
the method in question was declared as
```rust
fn send_email<R>(req: &mut Request) -> Result<Response<R>, String>
where R: std::io::Read
```
I believe the compiler message should at least indicate the constraints on `R`, because as it currently reads, `tiny_http::Response<std::io::Cursor<std::vec::Vec<u8>>>` _is_ a valid form of `tiny_http::Response<R>` for `R=std::io::Cursor<std::vec::Vec<u8>>`
|
A-type-system,C-enhancement,A-diagnostics,T-compiler,A-impl-trait,WG-diagnostics,A-suggestion-diagnostics,T-types
|
low
|
Critical
|
251,022,691
|
go
|
proposal: spec: permit eliding the type of struct fields in nested composite literals
|
> Within a composite literal of array, slice, or map type T, elements or map keys that are themselves composite literals may elide the respective literal type if it is identical to the element or key type of T. Similarly, elements or keys that are addresses of composite literals may elide the &T when the element or key type is *T.
When the type of a nested composite literal may derived from its context, that type may be elided in all cases except when the composite literal is the value of a struct field.
```go
type T struct{ V int }
var _ = map[T]T{{1}: {1}} // type elided from map key and element
var _ = []T{{1}} // type elided from slice element
var _ = [...]T{{1}} // type elided from array element
var _ = struct{ F T }{F: T{1}} // type is required
```
I propose that elision be permitted in this case as well.
```go
var _ = struct{ F T }{F: {1}}
var _ = struct{ F *T }{F: {1}}
```
I submit that the arguments in favor are the same as for eliding the type in other contexts, as well as conceptually simplifying the language--it is simpler to say that types may always be elided in nested literals (when the type can be derived from context) than to say that types may be elided in all but one case.
Proposed spec change:
> Within a composite literal of array, slice, **struct,** or map type T, ...
This proposal is a subset of #12854, which proposes elision of types in all composite literals, not just nested ones.
|
LanguageChange,Proposal,LanguageChangeReview
|
high
|
Critical
|
251,030,631
|
godot
|
Blend shapes glitches in the event that the node is duplicated
|
**Operating system or device - Godot version:**
Ubuntu16.04, Godot3.0 Alpha1
**Issue description:**
The change in the form keys of the mesh is spoiled, in the event that the node is duplicated.
**Steps to reproduce:**
[Video Bug shape key.flv.zip](https://github.com/godotengine/godot/files/1232221/Video.Bug.shape.key.flv.zip)
**Link to minimal example project:**
[Bug shape keys.zip](https://github.com/godotengine/godot/files/1232233/Bug.shape.keys.zip)
|
bug,topic:editor,confirmed
|
low
|
Critical
|
251,032,224
|
go
|
proposal: spec: lightweight anonymous function syntax
|
Many languages provide a lightweight syntax for specifying anonymous functions, in which the function type is derived from the surrounding context.
Consider a slightly contrived example from the Go tour (https://tour.golang.org/moretypes/24):
```go
func compute(fn func(float64, float64) float64) float64 {
return fn(3, 4)
}
var _ = compute(func(a, b float64) float64 { return a + b })
```
Many languages permit eliding the parameter and return types of the anonymous function in this case, since they may be derived from the context. For example:
```scala
// Scala
compute((x: Double, y: Double) => x + y)
compute((x, y) => x + y) // Parameter types elided.
compute(_ + _) // Or even shorter.
```
```rust
// Rust
compute(|x: f64, y: f64| -> f64 { x + y })
compute(|x, y| { x + y }) // Parameter and return types elided.
```
I propose considering adding such a form to Go 2. I am not proposing any specific syntax. In terms of the language specification, this may be thought of as a form of untyped function literal that is assignable to any compatible variable of function type. Literals of this form would have no default type and could not be used on the right hand side of a `:=` in the same way that `x := nil` is an error.
# Uses 1: Cap'n Proto
Remote calls using Cap'n Proto take an function parameter which is passed a request message to populate. From https://github.com/capnproto/go-capnproto2/wiki/Getting-Started:
```go
s.Write(ctx, func(p hashes.Hash_write_Params) error {
err := p.SetData([]byte("Hello, "))
return err
})
```
Using the Rust syntax (just as an example):
```go
s.Write(ctx, |p| {
err := p.SetData([]byte("Hello, "))
return err
})
```
# Uses 2: errgroup
The errgroup package (http://godoc.org/golang.org/x/sync/errgroup) manages a group of goroutines:
```go
g.Go(func() error {
// perform work
return nil
})
```
Using the Scala syntax:
```go
g.Go(() => {
// perform work
return nil
})
```
(Since the function signature is quite small in this case, this might arguably be a case where the lightweight syntax is less clear.)
|
LanguageChange,Proposal,LanguageChangeReview
|
high
|
Critical
|
251,034,966
|
TypeScript
|
Seemingly wrong arguments object when both es6 and commonjs options are present
|
**TypeScript Version:** 2.4.2
**Code**
```ts
export const foo = (bar: number) => {
console.log(arguments)
}
```
**Expected behavior:**
The code either produces errors or prints the arguments object of `foo` consistently in all targets and module types
**Actual behavior:**
- When the module is built with `tsc bug.ts` command line, ` error TS2496: The 'arguments' object cannot be referenced in an arrow function` is produced and no code is generated.
- With `tsc -t es6 bug.ts` it builds an es6 module and the code prints the arguments of `foo` at runtime
- With `tsc -t es6 -m commonjs` the generatesd `commonjs` module prints a strange object with 4 arguments, which seems to be an implementation detail of commonjs modules in node.js.
So I'd like at least to produce a warning in the third case, because I hit this problem in my program and the resulting bug was hard to locate.
|
Bug
|
low
|
Critical
|
251,036,542
|
TypeScript
|
Need way to express hybrid types that are indexable for a subset of properties
|
**Edit by @DanielRosenwasser**: This might be thought of as a "rest index signature" or a catch-all index signature.
__________
This is a feature request.
**TypeScript Version:** 2.4
**Code**
```ts
interface CSSProperties {
marginLeft?: string | number
[key: string]: CSSProperties
}
```
Based on the [docs](https://www.typescriptlang.org/docs/handbook/interfaces.html), this is not allowed:
> While string index signatures are a powerful way to describe the “dictionary” pattern, they also enforce that all properties match their return type. This is because a string index declares that obj.property is also available as obj[“property”]. In the following example, name’s type does not match the string index’s type, and the type-checker gives an error:
Unfortunately, it seems to make this type (which is common amongst jss-in-css solutions) not expressible. Coming from flow, which handles index types by assuming they refer to the properties that are not explicitly typed, this is frustrating.
As it stands, you can workaround it with:
```ts
interface CSSProperties {
marginLeft?: string | number
[key: string]: CSSProperties | string | number
}
```
But this is not sound. It allows this:
```ts
const style: CSSProperties = {
margarineLeft: 3
}
```
This could potentially be solved with subtraction types if they allowed subtracting from `string` (and you were allowed to specify key types in this way):
```ts
interface CSSProperties {
marginLeft?: string | number
}
interface NestedCSSProperties extends CSSProperties {
[key: string - keyof CSSProperties]: CSSProperties
}
```
I asked about this on [stackoverflow](http://stackoverflow.com/questions/43357734/typescript-recursive-type-with-indexer/43359686) to confirm that I wasn't missing something. It seems I'm not, so I guess I'd consider this a suggestion/discussion starter, since it's probably not a "bug". Thanks!
|
Suggestion,Awaiting More Feedback
|
high
|
Critical
|
251,038,341
|
youtube-dl
|
[Bet] Only part of the video is downloaded
|
FastHub doesn't support issue templates, sorry. I'm using the latest version and have searched for existing issues.
Log:
```
[debug] System config: []
[debug] User config: ['-f', 'bestvideo[ext=mp4]+bestaudio[ext=m4a]/best[ext=mp4]/best', '--write-sub', '--sub-format', 'srt/ssa/ass/vtt/dfxp/ttml/best', '--convert-subs', 'srt']
[debug] Custom config: []
[debug] Command-line args: ['-v', 'http://www.bet.com/video/a-very-soul-train-special/r-and-b-groups/2017/full-show-hosted-by-sevyn-streeter-and-luke-james.html']
[debug] Encodings: locale UTF-8, fs utf-8, out UTF-8, pref UTF-8
[debug] youtube-dl version 2017.08.18
[debug] Python version 3.6.1+ - Linux-4.9.0-3-amd64-x86_64-with-debian-9.0
[debug] exe versions: ffmpeg 3.2.5-1, ffprobe 3.2.5-1, rtmpdump 2.4
[debug] Proxy map: {}
[Bet] full-show-hosted-by-sevyn-streeter-and-luke-james: Downloading webpage
[Bet] 02055062-4fa5-3c6e-9031-48f7bb07a572: Downloading info
[Bet] 9f57fb50-8c28-3608-a9b6-e2369e40a5a9: Extracting information
[Bet] 9f57fb50-8c28-3608-a9b6-e2369e40a5a9: Downloading video urls
[Bet] 9f57fb50-8c28-3608-a9b6-e2369e40a5a9: Downloading m3u8 information
[Bet] 5e0e4d91-be86-35fe-bb4d-99092cdf13ee: Extracting information
[Bet] 5e0e4d91-be86-35fe-bb4d-99092cdf13ee: Downloading video urls
[Bet] 5e0e4d91-be86-35fe-bb4d-99092cdf13ee: Downloading m3u8 information
[Bet] 0be9a2d3-e5af-3b01-b31f-7b71509dfe86: Extracting information
[Bet] 0be9a2d3-e5af-3b01-b31f-7b71509dfe86: Downloading video urls
[Bet] 0be9a2d3-e5af-3b01-b31f-7b71509dfe86: Downloading m3u8 information
[Bet] 0269d9c2-2cb5-30bf-b7bf-f361f8c96cbc: Extracting information
[Bet] 0269d9c2-2cb5-30bf-b7bf-f361f8c96cbc: Downloading video urls
[Bet] 0269d9c2-2cb5-30bf-b7bf-f361f8c96cbc: Downloading m3u8 information
[Bet] 81604e1a-6ea5-3652-afca-e4fa84d35097: Extracting information
[Bet] 81604e1a-6ea5-3652-afca-e4fa84d35097: Downloading video urls
[Bet] 81604e1a-6ea5-3652-afca-e4fa84d35097: Downloading m3u8 information
[Bet] 4ce75047-af8b-32ba-a7b8-91509199ec74: Extracting information
[Bet] 4ce75047-af8b-32ba-a7b8-91509199ec74: Downloading video urls
[Bet] 4ce75047-af8b-32ba-a7b8-91509199ec74: Downloading m3u8 information
[Bet] 5ad019d9-d302-3207-93d7-66ff105c3fcc: Extracting information
[Bet] 5ad019d9-d302-3207-93d7-66ff105c3fcc: Downloading video urls
[Bet] 5ad019d9-d302-3207-93d7-66ff105c3fcc: Downloading m3u8 information
[info] Writing video subtitles to: A Very Soul Train R&B House Party-9f57fb50-8c28-3608-a9b6-e2369e40a5a9.en.vtt
[debug] Invoking downloader on 'https://cp541865-vh.akamaihd.net/i/videohub/specials/2017/hdbesp185a/full-episode/hdbesp185a1_,384x216_278,512x288_498,640x360_1028,768x432_1528,960x540_2128,1280x720_3128,1920x1080_5128,.mp4.csmil/index_6_av.m3u8?null=0&hdntl=exp=1503081990~acl=%2fi%2fvideohub%2fspecials%2f2017%2fhdbesp185a%2ffull-episode%2fhdbesp185a1_,384x216_278,512x288_498,640x360_1028,768x432_1528,960x540_2128,1280x720_3128,1920x1080_5128,.mp4.csmil%2f*~data=hdntl~hmac=5d9a145ace04f1f85113075744be345e5debf9a39dffce699f942728dde14857'
[hlsnative] Downloading m3u8 manifest
[hlsnative] Total fragments: 57
[download] Destination: A Very Soul Train R&B House Party-9f57fb50-8c28-3608-a9b6-e2369e40a5a9.mp4
[download] 100% of 206.49MiB in 00:08
[debug] ffmpeg command line: ffprobe -show_streams 'file:A Very Soul Train R&B House Party-9f57fb50-8c28-3608-a9b6-e2369e40a5a9.mp4'
[ffmpeg] Fixing malformed AAC bitstream in "A Very Soul Train R&B House Party-9f57fb50-8c28-3608-a9b6-e2369e40a5a9.mp4"
[debug] ffmpeg command line: ffmpeg -y -i 'file:A Very Soul Train R&B House Party-9f57fb50-8c28-3608-a9b6-e2369e40a5a9.mp4' -c copy -f mp4 -bsf:a aac_adtstoasc 'file:A Very Soul Train R&B House Party-9f57fb50-8c28-3608-a9b6-e2369e40a5a9.temp.mp4'
[ffmpeg] Converting subtitles
[debug] ffmpeg command line: ffmpeg -y -i 'file:A Very Soul Train R&B House Party-9f57fb50-8c28-3608-a9b6-e2369e40a5a9.en.vtt' -f srt 'file:A Very Soul Train R&B House Party-9f57fb50-8c28-3608-a9b6-e2369e40a5a9.en.srt'
Deleting original file A Very Soul Train R&B House Party-9f57fb50-8c28-3608-a9b6-e2369e40a5a9.en.vtt (pass -k to keep)
```
Link: http://www.bet.com/video/a-very-soul-train-special/r-and-b-groups/2017/full-show-hosted-by-sevyn-streeter-and-luke-james.html
The resulting file is 5 minutes and 40 seconds, despite the site listing it as 38 minutes 57 seconds. TV provider account is normally required but youtube-dl bypasses this for MTVN network sites.
|
tv-provider-account-needed
|
low
|
Critical
|
251,062,173
|
flutter
|
showOnScreen should only scroll if new offset is within bounds
|
In accessibility mode, if showOnScreen [1] calculates an offset that is outside of the minExtent and maxExtent of the scrollable, we still attempt to scroll. This results in an overscroll animation, which is misplaced in a11y mode. Instead, if scrolling is not possible, nothing should happen.
Related: https://github.com/flutter/flutter/issues/11663
[1] https://github.com/flutter/flutter/blob/8f56f6fdd1c6b4586518b927623bc87341452b50/packages/flutter/lib/src/widgets/single_child_scroll_view.dart#L431
|
framework,a: accessibility,f: scrolling,customer: mulligan (g3),P2,team-framework,triaged-framework
|
low
|
Major
|
251,066,083
|
TypeScript
|
Error inferring types of promise function
|
**TypeScript Version:** nightly (Version 2.5.0-dev.20170816)
**Code**
(based on `DefinitelyTyped/types/bluebird/index.d.ts`)
```ts
declare function props<K, V>(x: PromiseLike<Map<K, PromiseLike<V> | V>>): Promise<Map<K, V>>;
declare const input: Promise<Map<number, Promise<string>>>;
const out: Promise<Map<number, string>> = props(input);
```
**Expected behavior:**
No error.
**Actual behavior:**
```
src/a.ts(3,7): error TS2322: Type 'Promise<Map<number, Promise<string>>>' is not assignable to type 'Promise<Map<number, string>>'.
Type 'Map<number, Promise<string>>' is not assignable to type 'Map<number, string>'.
Type 'Promise<string>' is not assignable to type 'string'.
```
It works if I explicitly specify `props<number, string>(input)`.
The error only reproduces with `"lib": ["es6"]`.
|
Bug,Has Repro
|
low
|
Critical
|
251,080,150
|
pytorch
|
ReduceLROnPlateau with a naive Backtracking
|
Is it possible to implement a simple backtracking for the `ReduceLROnPlateau` module?
That is, store the best model coefficients and reload it upon rate reduction.
In my experiments, this helps speed up learning, though it might be expensive for very large models.
cc @vincentqb
|
feature,module: optimizer,triaged
|
low
|
Major
|
251,190,006
|
flutter
|
Should be possible to indicate to the refresh indicator that a reload is in progress.
|
There is presently no clean way to create a RefreshIndicator which is already visible.
How creating this might look:
```dart
new RefreshIndicator(child: widget, onRefresh: refreshAction, refreshing:true)
```
|
c: new feature,framework,f: material design,customer: crowd,c: proposal,P3,team-design,triaged-design
|
medium
|
Critical
|
251,243,195
|
opencv
|
resizeWindow is a few pixels off with WINDOW_GUI_EXPANDED
|
##### System information (version)
- OpenCV => 3.3
- Operating System / Platform => Ubuntu 16.04 (x86-64) with QT 5
- Compiler => g++ 5.4.0
##### Detailed description
`resizeWindow` supposedly (http://docs.opencv.org/3.3.0/d7/dfc/group__highgui.html#ga9e80e080f7ef33f897e415358aee7f7e) resizes so that
> [t]he specified window size is for the image area. Toolbars are not counted.
However, this is not the case, at least with QT. Consider the following example:
##### Steps to reproduce
```
#include <iostream>
#include <opencv2/highgui.hpp>
using namespace std;
using namespace cv;
int main()
{
const auto size = 20;
namedWindow("Test window", WINDOW_GUI_NORMAL); //Use WINDOW_GUI_EXPANDED to see the values missing
imshow("Test window", Mat(size, size, CV_8UC1, Scalar(128)));
resizeWindow("Test window", 30 * size, 30 * size);
waitKey(0);
return 0;
}
```
This program resizes the image area so that it is exactly 30 times larger than the shown image, which should reveal the pixel values like this:

However, when using `WINDOW_GUI_EXPANDED` above, the result looks like this:
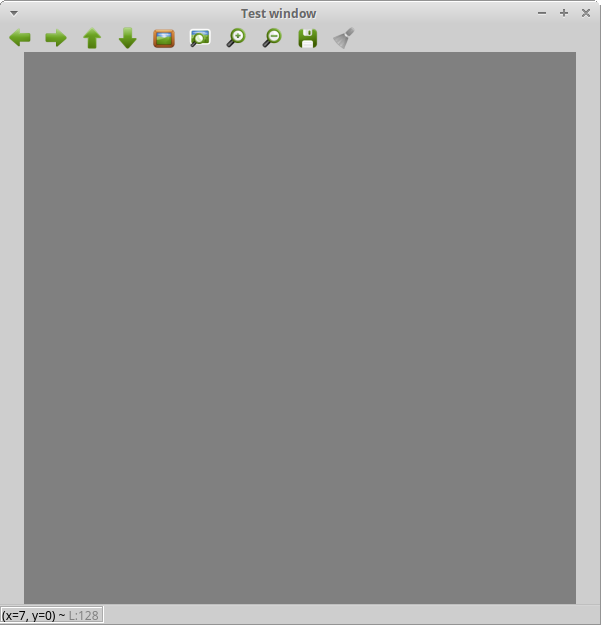
The values are not revealed which means that the image area is not 30 times the image size (or larger) which means that there is either a bug in the calculation of the image area in `resizeWindow` in combination with `WINDOW_GUI_EXPANDED` or the documentation is incorrect (i.e., the toolbars do actually count and the size specified is *not* the image area). I consider this to be a bug in either case.
Note that the size calculation does not seem to be too far off, since zooming once (in the `WINDOW_GUI_EXPANDED` case) already reveals the values. Also note that the illustration of the values is not the point of this issue, but they make it easier to see the effect because one does not have to measure the actual image area.
|
bug,category: highgui-gui
|
low
|
Critical
|
251,278,364
|
pytorch
|
"Shared memory manager connection has timed out"
|
This _seems_ to be a new error as of 0.2.0. I'm using a `torch.multiprocessing` Pool via `pool.map`.
```
Process ForkPoolWorker-5:
Traceback (most recent call last):
File "/home/wwhitney/anaconda3/lib/python3.6/multiprocessing/process.py", line 249, in _bootstrap
self.run()
File "/home/wwhitney/anaconda3/lib/python3.6/multiprocessing/process.py", line 93, in run
self._target(*self._args, **self._kwargs)
File "/home/wwhitney/anaconda3/lib/python3.6/multiprocessing/pool.py", line 108, in worker
task = get()
File "/home/wwhitney/anaconda3/lib/python3.6/multiprocessing/queues.py", line 345, in get
return _ForkingPickler.loads(res)
File "/home/wwhitney/anaconda3/lib/python3.6/site-packages/torch/multiprocessing/reductions.py", line 86, in rebuild_storage_filename
storage = cls._new_shared_filename(manager, handle, size)
RuntimeError: Shared memory manager connection has timed out at /opt/conda/conda-bld/pytorch_1502009910772/work/torch/lib/libshm/core.cpp:125
```
|
needs reproduction,module: multiprocessing,triaged
|
low
|
Critical
|
251,287,437
|
flutter
|
Make flutter inspector accessible
|
The flutter inspector does not currently support accessibility.
It isn't clear exactly what accessibility support for the inspector should look like. For example, if the semantics debugger is made accessible perhaps it should be used when using the inspector in accessibility mode.
|
framework,a: accessibility,f: inspector,P3,team-framework,triaged-framework
|
low
|
Critical
|
251,303,250
|
youtube-dl
|
[alarabiya.net] Site support request
|
- [x] I've **verified** and **I assure** that I'm running youtube-dl **2017.08.18**
- [x] At least skimmed through the [README](https://github.com/rg3/youtube-dl/blob/master/README.md), **most notably** the [FAQ](https://github.com/rg3/youtube-dl#faq) and [BUGS](https://github.com/rg3/youtube-dl#bugs) sections
- [x] [Searched](https://github.com/rg3/youtube-dl/search?type=Issues) the bugtracker for similar issues including closed ones
- [x] Site support request (request for adding support for a new site)
Dear youtube-dl. I appreciate adding support (if possible) to the following sites:
- Single video: http://ara.tv/gbetq
- Single video: http://www.iranproud.online/iran-movies/drama/adat-nemikonim?ghiXbed2Vi8MrhmpgJYi
Thanks a million!
|
site-support-request
|
low
|
Critical
|
251,317,395
|
go
|
crypto: understand performance differences compared to BoringSSL
|
I ran all the crypto benchmarks with standard Go crypto and with BoringCrypto. Results below.
In general there is about a 200ns overhead to calling into BoringCrypto via cgo for a particular call. So for example aes.BenchmarkEncrypt (testing encryption of a single 16-byte block) went from 13ns to 209ns, or +1500%. That we can't do much about except hope that bulk operations call into cgo once instead of once per 16 bytes.
But there are also some mysteries or things to consider fixing. I've put this in milestone Go 1.10 because some of them may be bugs in the Go distribution that we should at least understand. Once we know that the problems are all on the dev.boringcrypto side, we can switch the milestone to Unreleased.
crypto/aes
- AESCFBEncrypt1K, AESCFBDecrypt1K, AESOFB1K are much slower because there is no bulk CFB operation (no cipher.cfbAble interface). Should there be? Probably.
- AESCTR1K looks like it is not using the ctrAble implementation that boring.aesCipher is offering.
- AESCBCEncrypt1K looks like it is not using the cbcEncAble implementation that boring.aesCipher is offering.
- AESCBCDecrypt1K looks like it is not using the cbcDecAble implementation that boring.aesCipher is offering.
crypto/ecdsa
- Why does SignP256 take an extra 9µs in BoringCrypto? That's too big to be cgo. Should the signature conversion be improved?
- SignP384 drops from 5.54ms to 0.85ms, indicating that the Go implementation has 6X room for improvement.
- Even after the 6X, I don't understand why P384 is so much slower than P256.
- KeyGeneration is 10X slower in BoringCrypto than in Go. We should make sure the Go version is not missing something important.
crypto/hmac
- How is it that HMACSHA256_1K takes the same amount of time as HMACSHA256_32 in BoringCrypto?
- For that matter, how it is that, in BoringCrypto, HMACSHA256_1K takes 2µs but crypto/sha256's Hash1K takes 4µs?
crypto/rsa
- Why is RSA2048Sign 3X faster in BoringCrypto?
Benchmark results (also at https://perf.golang.org/search?q=upload:20170818.4):
name old time/op new time/op delta
pkg:crypto/aes goos:linux goarch:amd64
Encrypt-4 13.3ns ± 2% 208.6ns ± 5% +1473.15% (p=0.008 n=5+5)
Decrypt-4 13.2ns ± 1% 255.0ns ± 0% +1828.90% (p=0.016 n=5+4)
Expand-4 75.8ns ± 0% 76.4ns ± 1% ~ (p=0.056 n=5+5)
pkg:crypto/cipher goos:linux goarch:amd64
AESGCMSeal1K-4 341ns ± 1% 503ns ± 0% +47.71% (p=0.008 n=5+5)
AESGCMOpen1K-4 321ns ± 0% 496ns ± 1% +54.68% (p=0.008 n=5+5)
AESGCMSeal8K-4 2.04µs ± 0% 2.21µs ± 1% +8.27% (p=0.008 n=5+5)
AESGCMOpen8K-4 1.97µs ± 1% 2.18µs ± 0% +10.84% (p=0.008 n=5+5)
AESCFBEncrypt1K-4 2.37µs ± 0% 14.48µs ± 0% +512.17% (p=0.008 n=5+5)
AESCFBDecrypt1K-4 2.27µs ± 1% 14.48µs ± 1% +538.94% (p=0.008 n=5+5)
AESOFB1K-4 1.46µs ± 1% 13.76µs ± 1% +844.07% (p=0.008 n=5+5)
AESCTR1K-4 1.66µs ± 1% 8.99µs ± 0% +442.57% (p=0.008 n=5+5)
AESCBCEncrypt1K-4 2.27µs ± 1% 8.13µs ± 0% +257.59% (p=0.008 n=5+5)
AESCBCDecrypt1K-4 1.67µs ± 2% 11.65µs ± 2% +598.98% (p=0.008 n=5+5)
pkg:crypto/des goos:linux goarch:amd64
Encrypt-4 162ns ± 3% 159ns ± 1% ~ (p=0.222 n=5+5)
Decrypt-4 157ns ± 1% 158ns ± 2% ~ (p=0.722 n=5+5)
TDESEncrypt-4 380ns ± 0% 381ns ± 1% ~ (p=0.857 n=5+5)
TDESDecrypt-4 386ns ± 0% 386ns ± 0% ~ (p=1.000 n=5+5)
pkg:crypto/ecdsa goos:linux goarch:amd64
SignP256-4 36.2µs ± 2% 45.3µs ± 1% +24.91% (p=0.008 n=5+5)
SignP384-4 5.54ms ± 0% 0.85ms ± 1% -84.63% (p=0.008 n=5+5)
VerifyP256-4 104µs ± 1% 102µs ± 0% -1.29% (p=0.016 n=5+4)
KeyGeneration-4 21.9µs ± 1% 200.3µs ± 0% +815.39% (p=0.008 n=5+5)
pkg:crypto/elliptic goos:linux goarch:amd64
BaseMult-4 979µs ± 3% 954µs ± 1% -2.62% (p=0.008 n=5+5)
BaseMultP256-4 19.8µs ± 0% 19.7µs ± 1% ~ (p=0.151 n=5+5)
ScalarMultP256-4 77.3µs ± 0% 76.7µs ± 0% -0.70% (p=0.008 n=5+5)
pkg:crypto/hmac goos:linux goarch:amd64
HMACSHA256_1K-4 4.46µs ± 0% 1.92µs ± 0% -56.91% (p=0.008 n=5+5)
HMACSHA256_32-4 1.16µs ± 0% 1.94µs ± 2% +66.17% (p=0.008 n=5+5)
pkg:crypto/md5 goos:linux goarch:amd64
Hash8Bytes-4 184ns ± 0% 183ns ± 0% -0.54% (p=0.029 n=4+4)
Hash1K-4 2.01µs ± 0% 2.01µs ± 1% ~ (p=0.087 n=5+5)
Hash8K-4 14.8µs ± 1% 14.8µs ± 0% ~ (p=0.651 n=5+5)
Hash8BytesUnaligned-4 184ns ± 0% 183ns ± 0% -0.89% (p=0.000 n=5+4)
Hash1KUnaligned-4 2.01µs ± 0% 2.00µs ± 0% -0.41% (p=0.040 n=5+5)
Hash8KUnaligned-4 14.9µs ± 1% 15.2µs ± 3% ~ (p=0.690 n=5+5)
pkg:crypto/rand goos:linux goarch:amd64
Prime-4 146ms ±57% 143ms ± 8% ~ (p=0.548 n=5+5)
pkg:crypto/rc4 goos:linux goarch:amd64
RC4_128-4 313ns ± 3% 287ns ± 2% -8.19% (p=0.008 n=5+5)
RC4_1K-4 2.72µs ± 2% 2.70µs ± 1% ~ (p=0.151 n=5+5)
RC4_8K-4 21.8µs ± 2% 22.0µs ± 2% ~ (p=0.056 n=5+5)
pkg:crypto/rsa goos:linux goarch:amd64
RSA2048Sign-4 2.90ms ± 1% 1.08ms ± 1% -62.64% (p=0.008 n=5+5)
pkg:crypto/sha1 goos:linux goarch:amd64
Hash8Bytes-4 215ns ± 0% 562ns ± 1% +161.58% (p=0.016 n=4+5)
Hash320Bytes-4 821ns ± 1% 1096ns ± 0% +33.45% (p=0.008 n=5+5)
Hash1K-4 1.64µs ± 0% 2.26µs ± 0% +37.21% (p=0.008 n=5+5)
Hash8K-4 10.6µs ± 0% 12.5µs ± 0% +18.04% (p=0.008 n=5+5)
pkg:crypto/sha256 goos:linux goarch:amd64
Hash8Bytes-4 310ns ± 1% 679ns ± 1% +118.96% (p=0.008 n=5+5)
Hash1K-4 3.61µs ± 0% 3.99µs ± 0% +10.50% (p=0.008 n=5+5)
Hash8K-4 26.8µs ± 3% 26.6µs ± 1% ~ (p=0.548 n=5+5)
pkg:crypto/sha512 goos:linux goarch:amd64
Hash8Bytes-4 419ns ± 1% 805ns ± 1% +91.94% (p=0.008 n=5+5)
Hash1K-4 2.67µs ± 1% 3.13µs ± 1% +17.25% (p=0.008 n=5+5)
Hash8K-4 18.0µs ± 0% 18.8µs ± 1% +4.07% (p=0.008 n=5+5)
pkg:crypto/tls goos:linux goarch:amd64
Throughput/MaxPacket/1MB-4 4.02ms ± 1% 3.48ms ± 1% -13.48% (p=0.008 n=5+5)
Throughput/MaxPacket/2MB-4 6.11ms ± 2% 5.66ms ± 1% -7.46% (p=0.008 n=5+5)
Throughput/MaxPacket/4MB-4 10.3ms ± 1% 10.0ms ± 1% -3.65% (p=0.008 n=5+5)
Throughput/MaxPacket/8MB-4 18.6ms ± 1% 18.5ms ± 0% ~ (p=0.151 n=5+5)
Throughput/MaxPacket/16MB-4 35.1ms ± 1% 35.5ms ± 1% ~ (p=0.222 n=5+5)
Throughput/MaxPacket/32MB-4 68.0ms ± 1% 69.9ms ± 2% +2.67% (p=0.008 n=5+5)
Throughput/MaxPacket/64MB-4 133ms ± 1% 137ms ± 0% +2.90% (p=0.008 n=5+5)
Throughput/DynamicPacket/1MB-4 4.11ms ± 1% 3.55ms ± 2% -13.55% (p=0.008 n=5+5)
Throughput/DynamicPacket/2MB-4 6.32ms ± 4% 5.70ms ± 2% -9.80% (p=0.008 n=5+5)
Throughput/DynamicPacket/4MB-4 10.5ms ± 1% 10.1ms ± 1% -3.51% (p=0.008 n=5+5)
Throughput/DynamicPacket/8MB-4 18.7ms ± 1% 18.6ms ± 0% ~ (p=0.222 n=5+5)
Throughput/DynamicPacket/16MB-4 35.3ms ± 1% 35.7ms ± 1% +1.18% (p=0.032 n=5+5)
Throughput/DynamicPacket/32MB-4 67.9ms ± 0% 69.6ms ± 1% +2.44% (p=0.008 n=5+5)
Throughput/DynamicPacket/64MB-4 134ms ± 0% 137ms ± 1% +2.21% (p=0.016 n=4+5)
Latency/MaxPacket/200kbps-4 699ms ± 1% 697ms ± 0% ~ (p=0.151 n=5+5)
Latency/MaxPacket/500kbps-4 286ms ± 0% 283ms ± 0% -0.84% (p=0.008 n=5+5)
Latency/MaxPacket/1000kbps-4 147ms ± 0% 145ms ± 0% -1.62% (p=0.008 n=5+5)
Latency/MaxPacket/2000kbps-4 77.9ms ± 1% 74.6ms ± 2% -4.22% (p=0.008 n=5+5)
Latency/MaxPacket/5000kbps-4 35.5ms ± 0% 33.2ms ± 4% -6.46% (p=0.008 n=5+5)
Latency/DynamicPacket/200kbps-4 139ms ± 3% 138ms ± 0% ~ (p=0.151 n=5+5)
Latency/DynamicPacket/500kbps-4 60.7ms ± 1% 58.9ms ± 1% -2.97% (p=0.008 n=5+5)
Latency/DynamicPacket/1000kbps-4 34.0ms ± 2% 32.1ms ± 1% -5.51% (p=0.008 n=5+5)
Latency/DynamicPacket/2000kbps-4 20.0ms ± 1% 18.1ms ± 3% -9.52% (p=0.008 n=5+5)
Latency/DynamicPacket/5000kbps-4 10.2ms ± 4% 10.1ms ± 8% ~ (p=1.000 n=5+5)
|
Performance,help wanted
|
medium
|
Critical
|
251,374,516
|
flutter
|
Have flutter_test track when Timers are created
|
Since Zones let you override when Timers are created, maybe we can also track when they're created so that when there's any left we can report where it was created, the way we do with tickers.
|
a: tests,framework,c: proposal,P3,team-framework,triaged-framework
|
low
|
Minor
|
251,387,236
|
vscode
|
No way to have tab show as eight spaces, indent with something else
|
It does not appear to me that there is a way to make it so tabs show up as 8 spaces distinct from the actual indent size or tabs/spaces preference.
Pretty simple feature request, actually. I have an existing codebase that I am converting over piecemeal to use 4 space indents. Trouble is, the codebase is already full of a mixture of spaces and tabs which assumes that a tab character indents by 8 spaces, despite nominally having an indent of four spaces. So you get fun horrors like:
```
····foo();
····if (bar) {
⭾ baz();
····}
```
It'd be nice to have it both ways. VS Community seems to allow this, but I haven't found a combination of features that allows this in VS Code
|
feature-request,editor-core
|
low
|
Major
|
251,387,814
|
opencv
|
mingw32 build with IPP
|
A solution for building OpenCV 3.3 under mingw32-w64 with the IPP support. This has been tested with mxe for macOS.
- OpenCV 3.3
- Operating System: mxe macOS
- Compiler mingw32-w64
##### Detailed description
IPP is not found using mingw due to a name mismatch, and then some stack checking symbols present in the library ippicv.
Bonus: little fixes to dshow and gstreamer
##### Steps to reproduce
Approach:
1) stub library for the missing RunTmChk providing the required functions (e.g. __chkstk)
2) copy of 3rdparty/ippicv/ippicv_win/lib/intel64/ippicvmt.lib to 3rdparty/ippicv/ippicv_win/lib/intel64/libippicvmt.a
Full details here: https://github.com/eruffaldi/eruffaldi.github.io/blob/master/opencv3build.md#mxe
The following is needed for building RunTmChk:
add_library(RunTmChk STATIC code.c)
then code.c
void __fastcall __GSHandlerCheck() {}
void __fastcall __security_check_cookie(unsigned* p) {}
void __fastcall __chkstk() {}
unsigned* __security_cookie;
##### Addition 1: sprintf bug
modules/videoio/cap_dshow.cpp
Requires: #define STRSAFE_NO_DEPRECATE
##### Addition 2: fullpath missing
inline char *realpath(const char *path, char *resolved_path)
{
return _fullpath(resolved_path,path,PATH_MAX);
}
|
feature,priority: low,category: build/install
|
low
|
Critical
|
251,388,977
|
vscode
|
[theming] Access theme's colors programmatically
|
I think we should add support for accessing theme's colors programmatically.
For instance let's take as an example the popular [OneDark Pro](https://github.com/Binaryify/OneDark-Pro/blob/master/themes/OneDark-Pro.json) theme, I'd like to access colors defined under [tokenColors](https://github.com/Binaryify/OneDark-Pro/blob/master/themes/OneDark-Pro.json#L67).
My use case: I'm making an extension that decorates some tokens, and I'd like them to have the same color that comments have in my theme, the problem is that the regex I use to find those tokens depends on some configurable value, so I cannot pre-compute it in advance and just put it in a `.tmLanguage` file.
It's already possible to somehow access colors defined under the [colors](https://github.com/Binaryify/OneDark-Pro/blob/master/themes/OneDark-Pro.json#L4) key, via something like `new vscode.ThemeColor ( 'activityBar.background' )`, adding support for this sounds like a useful generalization to me.
What do you think?
|
feature-request,themes,api-proposal
|
high
|
Critical
|
251,405,072
|
angular
|
AnimationPlayer instance can only be used once
|
## I'm submitting a...
<!-- Check one of the following options with "x" -->
<pre><code>
[ ] Regression (a behavior that used to work and stopped working in a new release)
[X] Bug report <!-- Please search GitHub for a similar issue or PR before submitting -->
[ ] Feature request
[ ] Documentation issue or request
[ ] Support request => Please do not submit support request here, instead see https://github.com/angular/angular/blob/master/CONTRIBUTING.md#question
</code></pre>
## Current behavior
I am using the AnimationFactory and AnimationPlayer to create some animations. I noticed that the animationPlayer can only be used once, when the animation has finished it cannot be replayed, I am not sure if this is by design to destroy the animationPlayer onFinish or a bug
## Expected behavior
For me, it should be reusable, thus when doing `.reset()/.restart()` the animation can be re-played even when it has finished. This would make sense if you want to keep using the same animation over and over again.
## Minimal reproduction of the problem with instructions
```ts
ngAfterViewInit() {
this.collapseAnimation = this.animationBuilder.build([
style({ overflow: "hidden" }),
animate("200ms ease-out", style({
height: "50px"
}))
]).create(this.content.nativeElement)
this.expandAnimation = this.animationBuilder.build([
style({ overflow: "hidden" }),
animate("200ms ease-in", style({
height: "100%"
}))
]).create(this.content.nativeElement);
}
toggle() {
if (this.isExpanded) {
this.collapseAnimation.restart();
} else {
this.expandAnimation.restart();
}
this.isExpanded = !this.isExpanded;
}
```
Live example:
https://stackblitz.com/edit/animation-player-re-create
Note: I havn't included the animations shims in the demo.
Angular version: 4.3.4
|
type: bug/fix,area: animations,freq2: medium,P4
|
low
|
Critical
|
251,407,762
|
vscode
|
Drag markdown preview to New Window
|
- VSCode Version: 1.15.1, 64 bit
- OS Version: Windows 10 64 bit
Steps to Reproduce:
1. Open markdown file, click the preview button
2. File/New Window
3. Try and drag just the preview part to the new window
It would be really nice if I could drag the markdown preview to a new window so I can edit the markdown on one monitor and see the preview result on another monitor.
|
feature-request,markdown,webview
|
high
|
Critical
|
251,421,550
|
rust
|
Warn when `crate_type` attribute is ignored because of `--crate-type`
|
I just learned the hard way (i.e. after lots of scratching my head) that the `crate_type` attribute is entirely ignored when Cargo is used. This is hinted at in <https://doc.rust-lang.org/nightly/reference/linkage.html>, but only if you know that cargo always passes `--crate-type`. The first hit when I search for the attribute is <https://rustbyexample.com/attribute/crate.html> which doesn't mention this at all.
Those sites should probably be fixed, but moreover, I think the compiler shouldn't just silently ignore these attributes. It should tell me. That would have saved me lots of time.
(There may be other attributes which are similarly ignored. `crate_name` comes to my mind. But I don't know for sure.)
|
C-enhancement,A-attributes,T-compiler,A-CLI
|
low
|
Minor
|
251,422,572
|
opencv
|
empty() methods of Mat class always returns true on Universal Windows Platform x86 build.
|
<!--
If you have a question rather than reporting a bug please go to http://answers.opencv.org where you get much faster responses.
If you need further assistance please read [How To Contribute](https://github.com/opencv/opencv/wiki/How_to_contribute).
This is a template helping you to create an issue which can be processed as quickly as possible. This is the bug reporting section for the OpenCV library.
-->
##### System information (version)
<!-- Example
- OpenCV => 3.1
- Operating System / Platform => Windows 64 Bit
- Compiler => Visual Studio 2015
-->
- OpenCV => 3.3.0
- Operating System / Platform => Universal Windows Platform x86
- Compiler => Visual Studio 15 2017
- Cmake => 3.9.0
##### Detailed description
empty() methods of Mat class always returns true on Universal Windows Platform x86 build.
However, empty() methods returns correct results on Universal Windows Platform x64 and ARM build.
##### Steps to reproduce
cd opencv/platforms/winrt
setup_winrt.bat "WS" "10.0" "x86"
Test Code
```
cv::Mat testMat(100, 200, CV_8UC3);
if(testMat.empty()){
print('empty() returns true')
}else{
print('empty() returns false')
}
```
<!-- to add code example fence it with triple backticks and optional file extension
```.cpp
// C++ code example
```
or attach as .txt or .zip file
-->
|
feature,platform: winrt/uwp
|
low
|
Critical
|
251,437,092
|
neovim
|
Disabling netrw disables the spelling files download suggestion
|
```
$ nvim --version
NVIM v0.2.0
Build type: Release
Compilation: /usr/bin/cc -march=x86-64 -mtune=generic -O2 -pipe -fstack-protector-strong -Wconversion -DNVIM_MSGPACK_HAS_FLOAT32 -O2 -DNDEBUG -DDISABLE_LOG -Wall -Wextra -pedantic -Wno-unused-parameter -Wstrict-prototypes -std=gnu99 -Wvla -fstack-protector-strong -fdiagnostics-color=auto -DINCLUDE_GENERATED_DECLARATIONS -D_GNU_SOURCE -I/build/neovim/src/build/config -I/build/neovim/src/neovim-0.2.0/src -I/usr/include -I/usr/include -I/usr/include -I/usr/include -I/usr/include -I/usr/include -I/usr/include -I/build/neovim/src/build/src/nvim/auto -I/build/neovim/src/build/include
Compiled by builduser
Optional features included (+) or not (-): +acl +iconv +jemalloc +tui
For differences from Vim, see :help vim-differences
system vimrc file: "$VIM/sysinit.vim"
fall-back for $VIM: "/usr/share/nvim"
```
- Vim (version: ) behaves differently? no
- Operating system/version: Arch Linux
- Terminal name/version (`$TERM`): `rxvt-unicode-256color`
### Steps to reproduce
1. Put in `init.vim`:
```
let g:loaded_netrwPlugin = 1
```
Thus prevents loading netrw. In the [help file](https://github.com/neovim/neovim/blob/master/runtime/doc/pi_netrw.txt#L180), it is also suggested to `let g:loaded_netrw = 1` as well but it is not nescesarry to prove the bug.
2. run `nvim` or `vim`:
```
nvim # or vim
```
3. run inside it:
```
set spell
set spelllang=he " Just for example..
```
### Actual behaviour
`{n,}vim` don't suggest to download the spell files from public ftp server of vim.
### Expected behaviour
downloading spell files from vim's public ftp server is suggested although netrw is disabled.
|
bug,enhancement,runtime,complexity:low,netrw
|
low
|
Critical
|
251,442,271
|
angular
|
ngIf transition inside another animated element does not work
|
<!--
PLEASE HELP US PROCESS GITHUB ISSUES FASTER BY PROVIDING THE FOLLOWING INFORMATION.
ISSUES MISSING IMPORTANT INFORMATION MAY BE CLOSED WITHOUT INVESTIGATION.
-->
## I'm submitting a...
<!-- Check one of the following options with "x" -->
<pre><code>
[ ] Regression (a behavior that used to work and stopped working in a new release)
[x] Bug report <!-- Please search GitHub for a similar issue or PR before submitting -->
[ ] Feature request
[ ] Documentation issue or request
[ ] Support request => Please do not submit support request here, instead see https://github.com/angular/angular/blob/master/CONTRIBUTING.md#question
</code></pre>
## Current behavior
A transition on a :enter/:leave state change for an element with an *ngIf is not displayed if at the same time an ancestor element has another animation triggered at the same time. However, it does wait the appropriate amount of time before actually removing the element.
## Expected behavior
Both transitions should work.
## Minimal reproduction of the problem with instructions
Have a look at the following example: https://plnkr.co/edit/27EFz3h16icnh3qDzQbY?p=preview
When clicking the button what should happen is that the spacing between the two frames increases and another frame grows inside that space. However, what happens is that the other frame just pops in place ignoring the transition that is defined on it. The transition works if the animation on the first div is removed. It also works if the inside div is placed outside of the first div.
## What is the motivation / use case for changing the behavior?
It seems counterintuitive that this doesn't work.
## Environment
<pre><code>
Angular version: 4.3.5
Browser:
- [x] Chrome (desktop) version 60.0.3112.78
</code></pre>
|
type: bug/fix,area: animations,freq3: high,P3
|
low
|
Critical
|
251,464,682
|
vscode
|
Cannot display emoji ✔️, 🙋♂️
|
Steps to Reproduce:
1. Open a new file
2. Copy these two emoji ✔️❌ to it
3. See this result

Expected 
on Windows 10
----
> 2022.12: Edited to add a workaround:
**Workaround**. Append a color emoji font to the editor font family e.g.:
* Windows: `Consolas, 'Courier New', monospace, 'Segoe UI Emoji'`
* MacOS: `Menlo, Monaco, 'Courier New', monospace, 'Apple Color Emoji'`
* Linux: `'Droid Sans Mono', 'monospace', monospace, 'Droid Sans Fallback', 'Noto Color Emoji'`
e.g. on macOS
* `"editor.fontFamily": "Roboto Mono, 'Apple Color Emoji'",`
or for a cross-platform solution:
* `"editor.fontFamily": "Consolas, 'Segoe UI Emoji', 'Apple Color Emoji', 'Noto Color Emoji'"`
|
upstream,font-rendering,chromium
|
high
|
Critical
|
251,520,453
|
vscode
|
Inline text adornments break word wrapping
|
<!-- Do you have a question? Please ask it on http://stackoverflow.com/questions/tagged/vscode. -->
<!-- Use Help > Report Issues to prefill these. -->
- VSCode Version: 1.15.1
- OS Version: Windows 10 x64
Steps to Reproduce:
1. Settings:
```
"editor.wordWrap": "on",
"css.colorDecorators.enable": true
```
2. Code example:
```
.form-control:focus { border-color: #141d36; box-shadow: 0 1px 1px rgba(0, 0, 0, 0.075) inset, 0 0 4px rgba(165,128,57,0.6); -webkit-box-shadow: 0 1px 1px rgba(0, 0, 0, 0.075) inset, 0 0 4px rgba(165,128,57,0.6); }
```
With colorDecorators disabled word wrapping works fine. After enabling it wordWrap completely ignores the width of added decorators and wrapes the code as they are not there what makes parts of the code to be pushed out of viewport.
I think it would be better to just underline the colors accordingly instead adding new elements next to it.
Also it would be great to add some margin between wrapped code and minimap (or whatever is on the right).
<!-- Launch with `code --disable-extensions` to check. -->
Reproduces without extensions: Yes
**Edit**: Added a screenshot to demonstrate the issue:
<img width="1072" alt="screen shot 2018-05-15 at 1 09 33 am" src="https://user-images.githubusercontent.com/8781353/40044668-f200623c-57dc-11e8-841f-a32a06e54b5a.png">
|
feature-request,editor-wrapping
|
high
|
Critical
|
251,543,124
|
TypeScript
|
MethodDecorator gets TS2322/TS2315
|
<!-- BUGS: Please use this template. -->
<!-- QUESTIONS: This is not a general support forum! Ask Qs at http://stackoverflow.com/questions/tagged/typescript -->
<!-- SUGGESTIONS: See https://github.com/Microsoft/TypeScript-wiki/blob/master/Writing-Good-Design-Proposals.md -->
**TypeScript Version:** 2.4.2
**Code**
```ts
export function route(method: string, path: string): MethodDecorator {
return (target: any, name: string, descriptor: TypedPropertyDescriptor<Function>) => {
routeManager.regeisterRoute({
constructor: target.constructor,
function: descriptor.value,
method,
path
});
}
}
```
```ts
export function route(method: string, path: string): MethodDecorator<Function> {
return (target: any, name: string, descriptor: TypedPropertyDescriptor<Function>) => {
routeManager.regeisterRoute({
constructor: target.constructor,
function: descriptor.value,
method,
path
});
}
}
```
**Expected behavior:**
No error
**Actual behavior:**
```
error TS2322: Type '(target: any, name: string, descriptor: TypedPropertyDescriptor<Function>) => void' is not assignable to type 'MethodDecorate
or'.
Types of parameters 'descriptor' and 'descriptor' are incompatible.
Type 'TypedPropertyDescriptor<T>' is not assignable to type 'TypedPropertyDescriptor<Function>'.
Type 'T' is not assignable to type 'Function'.
```
```
error TS2315: Type 'MethodDecorator' is not generic.
```
|
Bug,Domain: Decorators
|
low
|
Critical
|
251,687,969
|
TypeScript
|
Use a consistent ordering when writing union types
|
In DefinitelyTyped, `$ExpectType` assertions depend on a type having a consistent string represenation across TypeScript versions.
It looks like the ordering of union types is dependent on some implementation details that change between versions. When we output unions as strings, we should sort them in some consistent way first instead of just using whatever order we happened to use internally.
I would suggest this ordering:
* numeric literals, low to high
* string literals, low to high (by `<`)
* named types (including type aliases, enum, class and interface names), by name
* function literals: by length (`() => void` before `(x: number) => void`), then by parameter name, then by parameter type
* type literals: Sorted smallest to largest (`{ x: number }` before `{ x: number, y: number }`); and type literals of the same size should be alphabetically sorted by property (`{ a: number }`) before `{ b: number }`) or by the sorting of values (`{ s: "a" }` before `{ s: "b" }`)
Of course, another solution would be to try to handle this in `$ExpectType` by parsing out unions and allowing it if any sorting is valid. But it is strange in TS to see a string literal union displayed in a seemingly random order.
|
Suggestion,Awaiting More Feedback,Domain: Type Display
|
medium
|
Major
|
251,702,200
|
rust
|
"Use of undeclared type or module" doesn't detect accidental use of variable
|
```rust
trait Foo {
type Bar;
fn bar(&self) -> Self::Bar;
}
impl Foo for i32 {
type Bar = i32;
fn bar(&self) -> i32 {
*self
}
}
fn main() {
let x = 5i32;
let y = x::Bar;
}
```
reports
```
error[E0433]: failed to resolve. Use of undeclared type or module `x`
--> src/main.rs:15:13
|
15 | let y = x::Bar;
| ^ Use of undeclared type or module `x`
```
Which is correct, but not helpful.
Imo this should at minimum tell the programmer that you cannot statically access elements of the variable `x`. At best it it suggests to call a method that yields a type that's reachable via `typeof(x)::Bar`.
|
C-enhancement,A-diagnostics,A-resolve,T-compiler,D-terse
|
low
|
Critical
|
251,735,742
|
go
|
runtime: audit mapfast routines for indirectvalue support
|
On reflection, the most recent CLs I mailed suggest that mapdelete_fast* might not be handing indirect value maps correctly. I'm out of computer time for today and maybe tomorrow as well. Filing this as a reminder, and because these were newly introduced in 1.9, and if they're not well-handled, it could cause memory corruption. Should double check all routines, really.
|
Testing,NeedsFix,compiler/runtime
|
low
|
Minor
|
251,761,732
|
go
|
net/http: Add Error Callbacks
|
I've written a little REST server on net/http that's *supposed* to only ever return JSON contents. At least, that's what the parts I wrote do. However, there are certain errors that net/http encounters before my code is ever called. In those situations, I have no access to any code to determine what the content type and message should be for a given error. For example, take this stupid simple implementation:
package main
import (
"encoding/json"
"net/http"
)
type Server struct{}
func (server *Server) ServeHTTP(w http.ResponseWriter, r *http.Request) {
w.Header().Set("Content-Type", "application/json; charset=UTF-8")
w.WriteHeader(http.StatusOK)
if err := json.NewEncoder(w).Encode(http.StatusText(http.StatusOK)); err != nil {
panic(err)
}
}
func main() {
http.ListenAndServe(":8080", &Server{})
}
If I submit a request with borked headers (this one has a wayward newline in the `Authorization` header), my `ServeHTTP()` method is never called, presumably because there's an error when parsing the request to create the Request object:
> curl -i -H 'Authorization: Basic hi
there' 'http://localhost:8080/'
HTTP/1.1 400 Bad Request
Content-Type: text/plain; charset=utf-8
Connection: close
400 Bad Request
This makes complete sense to me, but if I'm creating an API with a contract to only ever return JSON, I'd like to have some way to plug into this error response and set the content-type and the body. I think the same challenge exists for `Not Found` errors. Perhaps there could be special handlers to configure these situations, similar to how Gorilla mux [provides](http://www.gorillatoolkit.org/pkg/mux#Router) an assignable `NotFoundHandler` field in its Router object?
I'm not sure exactly what a generalized interface would look like for such error handlers (methods on Handler protocol?), but some way to hook in and get some control over net/http-initiated error responses would be very useful for guaranteeing the content-type contract of a web API.
|
NeedsFix,FeatureRequest
|
medium
|
Critical
|
251,803,547
|
rust
|
Generated doc pages for types should include more info about the type's relationships
|
It would be useful if the generated doc page for each type had an expandable section at the bottom that shows functions (incl. methods of other types) in the crate where the type appears in the function's argument types or return type to see possible uses of a type that aren't apparent from its methods and trait impls.
It could be divided into two sections, one for where the type appears as input (so you'd look at the section when you already know how to get an instance of the type), and one for where the type appears as output (for where you'd look if you want to get an instance of the type when it's constructed by another function).
Another useful thing would be to have another expandable section of other types that this type is a (public) constituent of.
Together these sections paint a fuller picture of the the role this type plays in the crate and its relationships to everything else in the crate.
(This approach could then also be extended to inter-crate references.)
Of course it's encouraged to include info about the type's relationship in the doc comments but many crates's docs don't do that enough. Making the type's relationships more obvious in the above way would complement the doc comments.
Example: This page for [DeviceHandle](https://dcuddeback.github.io/libusb-rs/libusb/struct.DeviceHandle.html) would have a link to [Context.html::open_device_with_vid_pid](https://dcuddeback.github.io/libusb-rs/libusb/struct.Context.html#method.open_device_with_vid_pid()) and [Device::open()](https://dcuddeback.github.io/libusb-rs/libusb/struct.Device.html#method.open) and the page for [Device](https://dcuddeback.github.io/libusb-rs/libusb/struct.Device.html) would have a link to the [Iterator impl for Devices](https://dcuddeback.github.io/libusb-rs/libusb/struct.Devices.html) and the page for Devices would have a link to [DeviceList::iter()](https://dcuddeback.github.io/libusb-rs/libusb/struct.DeviceList.html#method.iter) and DeviceList would have a link to [Context::devices()](https://dcuddeback.github.io/libusb-rs/libusb/struct.Context.html#method.devices)...
Another example: [PortSettings](https://docs.rs/serial-core/0.4.0/serial_core/struct.PortSettings.html) would have a link to [SerialPort::configure()](https://docs.rs/serial-core/0.4.0/serial_core/trait.SerialPort.html#tymethod.configure).
This would make it much easier to find out all the necessary info from reading the doc.
|
T-rustdoc,C-feature-request
|
low
|
Minor
|
251,810,580
|
react
|
Symbol Tagging for dangerouslySetInnerHTML to Help Prevent XSS
|
If you're spreading props from a user provided source we have a XSS. E.g.
```js
var data = JSON.parse(decodeURI(location.search.substr(1)));
function Foo(props) {
return <div><div {...props} /><span>{props.content}</span></div>;
}
ReactDOM.render(<Foo {...data} />, container);
```
That's already true today because this URL is now an XSS hole:
```
?{"content":"Hello","dangerouslySetInnerHTML":{"__html":"<a%20onclick=\"alert(%27p0wned%27)\">Click%20me</a>"}}
```
This is very uncommon. There are many different ways to screw up getting user data. However doing that + also spreading is unusual. We decided in #3473 that React should add an extra layer of protection for these types of mistakes. This one is __much__ more uncommon than the one in #3473 though.
You should already have a pretty centralized way of sanitizing these objects so it seems to me that adding a Symbol to this object shouldn't be that big of a deal though.
Either:
```js
{ $$typeof:Symbol.for('react.rawhtml'), __html: myHTML }
```
or:
```js
{ [Symbol.for('react.rawhtml')]: myHTML }
```
|
Component: DOM,Type: Discussion,React Core Team
|
low
|
Major
|
251,814,512
|
rust
|
Tracking issue for `#[doc(masked)]`
|
At time of implementation, i'm not sure the utility of this outside the standard library, but in case anyone else wants to prune their documentation, here's the place to be.
|
T-rustdoc,B-unstable,C-tracking-issue,S-tracking-needs-summary,F-doc_masked
|
low
|
Minor
|
251,884,898
|
opencv
|
NSObject error when build source with mac
|
I clone the source code of opencv from git and build using cmake:
cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local/Cellar -D BUILD_SHARED_LIBS=ON -D WITH_CUDA=OFF -D OPENCV_EXTRA_MODULES_PATH=../../opencv_contrib/modules -G "Unix Makefiles" -D BUILD_JAVA_SUPPORT=ON -D WITH_IPP=OFF ..
However, i got NSObject error when compling vtk module:
```
[ 28%] Building CXX object modules/imgproc/CMakeFiles/opencv_imgproc.dir/src/segmentation.cpp.o
[ 28%] Building CXX object modules/imgproc/CMakeFiles/opencv_imgproc.dir/src/shapedescr.cpp.o
In file included from /Users/universe/Program/opencv/modules/viz/src/vtk/vtkCocoaInteractorFix.mm:47:
In file included from /System/Library/Frameworks/Cocoa.framework/Headers/Cocoa.h:12:
In file included from /System/Library/Frameworks/Foundation.framework/Headers/Foundation.h:10:
In file included from /System/Library/Frameworks/Foundation.framework/Headers/NSArray.h:5:
/System/Library/Frameworks/Foundation.framework/Headers/NSObject.h:19:21: error: expected a type
- (id)copyWithZone:(nullable NSZone *)zone;
^
/System/Library/Frameworks/Foundation.framework/Headers/NSObject.h:25:28: error: expected a type
- (id)mutableCopyWithZone:(nullable NSZone *)zone;
^
/System/Library/Frameworks/Foundation.framework/Headers/NSObject.h:32:4: error: expected a type
- (nullable instancetype)initWithCoder:(NSCoder *)aDecoder; // NS_DESIGNATED_INITIALIZER
^
/System/Library/Frameworks/Foundation.framework/Headers/NSObject.h:53:4: error: expected a type
- (nullable id)replacementObjectForCoder:(NSCoder *)aCoder;
^
/System/Library/Frameworks/Foundation.framework/Headers/NSObject.h:54:4: error: expected a type
- (nullable id)awakeAfterUsingCoder:(NSCoder *)aDecoder NS_REPLACES_RECEIVER;
^
In file included from /Users/universe/Program/opencv/modules/viz/src/vtk/vtkCocoaInteractorFix.mm:47:
In file included from /System/Library/Frameworks/Cocoa.framework/Headers/Cocoa.h:12:
In file included from /System/Library/Frameworks/Foundation.framework/Headers/Foundation.h:10:
In file included from /System/Library/Frameworks/Foundation.framework/Headers/NSArray.h:6:
/System/Library/Frameworks/Foundation.framework/Headers/NSEnumerator.h:7:15: error: expected ';' after @class
@class NSArray<ObjectType>;
^
/System/Library/Frameworks/Foundation.framework/Headers/NSEnumerator.h:7:16: error: cannot find protocol declaration for 'ObjectType'
@class NSArray<ObjectType>;
^
/System/Library/Frameworks/Foundation.framework/Headers/NSEnumerator.h:34:25: error: cannot find protocol declaration for 'ObjectType'
@interface NSEnumerator<ObjectType> : NSObject <NSFastEnumeration>
^
/System/Library/Frameworks/Foundation.framework/Headers/NSEnumerator.h:34:37: error: expected unqualified-id
@interface NSEnumerator<ObjectType> : NSObject <NSFastEnumeration>
^
/System/Library/Frameworks/Foundation.framework/Headers/NSEnumerator.h:36:4: error: expected a type
- (nullable ObjectType)nextObject;
^
/System/Library/Frameworks/Foundation.framework/Headers/NSEnumerator.h:40:25: error: cannot find protocol declaration for 'ObjectType'
@interface NSEnumerator<ObjectType> (NSExtendedEnumerator)
^
/System/Library/Frameworks/Foundation.framework/Headers/NSEnumerator.h:40:1: error: duplicate interface definition for class 'NSEnumerator'
@interface NSEnumerator<ObjectType> (NSExtendedEnumerator)
^
/System/Library/Frameworks/Foundation.framework/Headers/NSEnumerator.h:34:12: note: previous definition is here
@interface NSEnumerator<ObjectType> : NSObject <NSFastEnumeration>
^
/System/Library/Frameworks/Foundation.framework/Headers/NSEnumerator.h:40:37: error: method type specifier must start with '-' or '+'
@interface NSEnumerator<ObjectType> (NSExtendedEnumerator)
^
/System/Library/Frameworks/Foundation.framework/Headers/NSEnumerator.h:40:38: error: expected a type
@interface NSEnumerator<ObjectType> (NSExtendedEnumerator)
^
/System/Library/Frameworks/Foundation.framework/Headers/NSEnumerator.h:42:1: error: expected selector for Objective-C method
@property (readonly, copy) NSArray<ObjectType> *allObjects;
^
/System/Library/Frameworks/Foundation.framework/Headers/NSEnumerator.h:42:28: error: unknown type name 'NSArray'
@property (readonly, copy) NSArray<ObjectType> *allObjects;
^
/System/Library/Frameworks/Foundation.framework/Headers/NSEnumerator.h:42:35: error: expected member name or ';' after declaration specifiers
@property (readonly, copy) NSArray<ObjectType> *allObjects;
~~~~~~~^
/System/Library/Frameworks/Foundation.framework/Headers/NSEnumerator.h:42:1: error: property requires fields to be named
@property (readonly, copy) NSArray<ObjectType> *allObjects;
^ ~~~~~~~
/System/Library/Frameworks/Foundation.framework/Headers/NSEnumerator.h:42:35: error: expected ';' at end of declaration list
@property (readonly, copy) NSArray<ObjectType> *allObjects;
^
fatal error: too many errors emitted, stopping now [-ferror-limit=]
20 errors generated.
make[2]: *** [modules/viz/CMakeFiles/opencv_viz.dir/src/vtk/vtkCocoaInteractorFix.mm.o] Error 1
make[1]: *** [modules/viz/CMakeFiles/opencv_viz.dir/all] Error 2
make[1]: *** Waiting for unfinished jobs....
```
|
category: build/install,category: viz,incomplete
|
low
|
Critical
|
251,941,322
|
rust
|
Crate local state for procedural macros?
|
I'm tinkering a bit with procedural macros and encountered a problem that can be solved by keeping state in between proc macro invocations.
Example from my real application: assume my `proc-macro` crate exposes two macros: `config! {}` and `do_it {}`. The user of my lib is supposed to call `config! {}` only once, but may call `do_it! {}` multiple times. But `do_it!{}` needs data from the `config!{}` invocation.
Another example: we want to write a `macro_unique_id!()` macro returning a `u64` by counting internally.
---
How am I supposed to solve those problems? I know that somewhat-global state is usually bad. But I do see applications for crate-local state for proc macros.
|
A-macros,T-lang,C-feature-request,A-proc-macros
|
high
|
Critical
|
251,953,129
|
rust
|
Expose target cpu to conditional compilation
|
I've recently created a crate that provides IO/microcontroller specific constants to Rust programs written for the [AVR architecture](https://github.com/avr-rust/rust).
[avrd on GitHub](https://github.com/avr-rust/avrd)
[avrd on Docs.rs](https://docs.rs/avrd)
I've made it so that there is always a `current` module in the crate root that reexports all items from a microcontroller-specific crate, depending on what CPU is being targeted.
In order to achieve this, I needed to add a `target_cpu` conditional compilation flag to my fork of the Rust compiler
https://github.com/avr-rust/rust/commit/1f5f6bd8f85e905ffb5da6389e879277f7f6b708
I would like to upstream this (with cleanups like more documentation), as it seems generally useful, but it also would make it easier to merge the fork into mainline if that were to ever happen in the future. On top of this, it would be quite a useful feature to other people who fork Rust for more esoteric architectures.
The in-tree targets don't seem to specify CPUs most of the time - looking in the `librustc_back` module, it looks like some targets set CPU to `cortex-a8`, some to a CPU name used by Sparc, but almost everything else is left blank, generic, or "x86_64", etc.
Before I file a PR, are there any glaring objections to this?
|
T-lang,C-feature-request
|
medium
|
Major
|
251,970,039
|
pytorch
|
detach_() variant that affects all past uses too
|
Right now `detach_()` only modifies the current Variable, without modifying the graph in any way, which doesn't stop backprop for its previous uses. This behavior is sometimes wanted when e.g. doing BPTT and reusing some of the steps (say you do BPTT over 20 steps with stride of 2 steps).
Current behavior:
```python
a = Variable(torch.randn(2, 2), requires_grad=True)
b = a * 2
c = b * 2
b.detach_()
c.sum().backward()
assert a.grad is not None
```
Proposed fix:
```python
a = Variable(torch.randn(2, 2), requires_grad=True)
b = a * 2
c = b * 2
b.detach_(with_uses=True)
c.sum().backward()
assert a.grad is None
```
Implementation is not straightforward at this point and some parts still need to be worked out.
cc @ezyang @SsnL @albanD @zou3519 @gqchen
|
feature,module: autograd,triaged
|
low
|
Minor
|
251,976,898
|
youtube-dl
|
I can't download the spanish caps from pluralsight
|
Hello, thanks for this tool, i have this issue, and i don't know how to fix it, i have tried with this command line
youtube-dl --username XXXXXXXXXXXXXXXXX --password XXXXXXXXXXXXX https://www.pluralsight.com/courses/bash-shell-scripting --all-subs -o "%USERPROFILE%\Downloads\%(playlist)s\%(chapter_number)s. %(chapter)s\%(playlist_index)s. %(title)s.%(ext)s"
and it only downloads the english captions, thank you in advance.
|
subtitles
|
low
|
Minor
|
252,106,546
|
flutter
|
getOffsetForCaret should return two values at an LTR/RTL boundary
|
In `editable.dart`, `getEndpointsForSelection` says:
```
// TODO(mpcomplete): This doesn't work well at an RTL/LTR boundary.
```
|
a: text input,framework,a: internationalization,has reproducible steps,P2,found in release: 3.3,found in release: 3.4,team-text-input,triaged-text-input
|
low
|
Major
|
252,211,103
|
go
|
runtime/cgo: bad debug_frame entry for crosscall2
|
```
go version go1.9rc1 linux/amd64
```
```
go env:
GOARCH="amd64"
GOBIN=""
GOEXE=""
GOHOSTARCH="amd64"
GOHOSTOS="linux"
GOOS="linux"
GOPATH="/home/a/n/go/"
GORACE=""
GOROOT="/usr/local/go19rc1"
GOTOOLDIR="/usr/local/go19rc1/pkg/tool/linux_amd64"
GCCGO="gccgo"
CC="gcc"
GOGCCFLAGS="-fPIC -m64 -pthread -fmessage-length=0 -fdebug-prefix-map=/tmp/go-build839946921=/tmp/go-build -gno-record-gcc-switches"
CXX="g++"
CGO_ENABLED="1"
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
PKG_CONFIG="pkg-config"
```
The debug_frame entry for crosscall2 is wrong in any cgo program.
This is crosscall2:
```
asm_amd64.s:12 0x457cc0 4883ec58 SUBQ $0x58, SP
asm_amd64.s:16 0x457cc4 48895c2418 MOVQ BX, 0x18(SP)
asm_amd64.s:17 0x457cc9 48896c2420 MOVQ BP, 0x20(SP)
asm_amd64.s:18 0x457cce 4c89642428 MOVQ R12, 0x28(SP)
asm_amd64.s:19 0x457cd3 4c896c2430 MOVQ R13, 0x30(SP)
asm_amd64.s:20 0x457cd8 4c89742438 MOVQ R14, 0x38(SP)
asm_amd64.s:21 0x457cdd 4c897c2440 MOVQ R15, 0x40(SP)
asm_amd64.s:57 0x457ce2 48893424 MOVQ SI, 0(SP)
asm_amd64.s:58 0x457ce6 4889542408 MOVQ DX, 0x8(SP)
asm_amd64.s:59 0x457ceb 48894c2410 MOVQ CX, 0x10(SP)
asm_amd64.s:61 0x457cf0 ffd7 CALL DI
asm_amd64.s:64 0x457cf2 488b5c2418 MOVQ 0x18(SP), BX
asm_amd64.s:65 0x457cf7 488b6c2420 MOVQ 0x20(SP), BP
asm_amd64.s:66 0x457cfc 4c8b642428 MOVQ 0x28(SP), R12
asm_amd64.s:67 0x457d01 4c8b6c2430 MOVQ 0x30(SP), R13
asm_amd64.s:68 0x457d06 4c8b742438 MOVQ 0x38(SP), R14
asm_amd64.s:69 0x457d0b 4c8b7c2440 MOVQ 0x40(SP), R15
asm_amd64.s:72 0x457d10 4883c458 ADDQ $0x58, SP
asm_amd64.s:76 0x457d14 c3 RET
```
The debug_info entry:
```
<1><169bb>: Abbrev Number: 2 (DW_TAG_subprogram)
<169bc> DW_AT_name : crosscall2
<169c7> DW_AT_low_pc : 0x457cc0
<169cf> DW_AT_high_pc : 0x457d15
<169d7> DW_AT_frame_base : 1 byte block: 9c (DW_OP_call_frame_cfa)
<169d9> DW_AT_external : 1
<2><169da>: Abbrev Number: 0
```
the debug_frame CIE:
```
00000000 0000000000000010 ffffffff CIE
Version: 3
Augmentation: ""
Code alignment factor: 1
Data alignment factor: -4
Return address column: 16
DW_CFA_def_cfa: r7 (rsp) ofs 8
DW_CFA_offset_extended: r16 (rip) at cfa-8
DW_CFA_nop
```
and the debug_frame entry for crosscall2:
```
0000b4d4 000000000000001c 00000000 FDE cie=00000000 pc=0000000000457cc0..0000000000457d15
DW_CFA_def_cfa_offset_sf: 8
DW_CFA_advance_loc1: 84 to 0000000000457d14
DW_CFA_nop
DW_CFA_nop
DW_CFA_nop
DW_CFA_nop
```
the cfa offset is 8, it should be 0x58 + 0x8 after the first instruction.
|
help wanted,NeedsFix,Debugging,compiler/runtime
|
low
|
Critical
|
252,297,987
|
TypeScript
|
React and defaultProps cant pass correct props to inner function
|
<!-- BUGS: Please use this template. -->
<!-- QUESTIONS: This is not a general support forum! Ask Qs at http://stackoverflow.com/questions/tagged/typescript -->
<!-- SUGGESTIONS: See https://github.com/Microsoft/TypeScript-wiki/blob/master/Writing-Good-Design-Proposals.md -->
**TypeScript Version:** 2.4.0
**Code**
```ts
import * as React from 'react';
interface CircleProps {
percent?: number
}
export default class Circle extends React.Component<CircleProps> {
public static defaultProps: Partial<CircleProps> = {
percent: 100
}
calculateDashArray(percent: number): string {
return `${percent}`
}
render() {
const strokeDasharray = this.calculateDashArray(this.props.percent)
return (
<div>{strokeDasharray}</div>
)
}
}
```
**Expected behavior:**
`this.calculateDashArray` should correct accept value of defalutProps
**Actual behavior:**
`Argument of type 'number | undefined' is not assignable to parameter of type 'number'.
Type 'undefined' is not assignable to type 'number'.`
|
Suggestion,Needs Proposal
|
low
|
Critical
|
252,299,682
|
go
|
cmd/compile: optimize away some MOVQconverts
|
We have to keep uintptrs and unsafe.Pointers separate, to get accurate stackmaps for the compiler. However, in some cases, this generates unnecessary register moves.
Here's the example from the runtime I'm looking at. `mapaccess1_fast32` currently ends:
```go
for {
for i, k := uintptr(0), b.keys(); i < bucketCnt; i, k = i+1, add(k, 4) {
if *(*uint32)(k) == key && b.tophash[i] != empty {
return add(unsafe.Pointer(b), dataOffset+bucketCnt*4+i*uintptr(t.valuesize))
}
}
b = b.overflow(t)
if b == nil {
return unsafe.Pointer(&zeroVal[0])
}
}
```
This has an unnecessary nil check of b in the inner loop when evaluating `b.tophash`, so I'd like to change the outer loop structure to remove it:
```go
for ; b != nil; b = b.overflow(t) {
for i, k := uintptr(0), b.keys(); i < bucketCnt; i, k = i+1, add(k, 4) {
if *(*uint32)(k) == key && b.tophash[i] != empty {
return add(unsafe.Pointer(b), dataOffset+bucketCnt*4+i*uintptr(t.valuesize))
}
}
}
return unsafe.Pointer(&zeroVal[0])
```
With this new structure, the nil check is gone, but we now have an extra register-register move, instruction 0x009f:
```
0x0096 00150 (hashmap_fast.go:42) MOVQ "".t+40(SP), CX
0x009b 00155 (hashmap_fast.go:42) MOVWLZX 84(CX), DX
0x009f 00159 (hashmap_fast.go:42) MOVQ AX, BX
0x00a2 00162 (hashmap_fast.go:42) LEAQ -8(BX)(DX*1), DX
0x00a7 00167 (hashmap_fast.go:42) TESTB AL, (CX)
0x00a9 00169 (hashmap_fast.go:42) MOVQ (DX), AX
0x00ac 00172 (hashmap_fast.go:42) TESTQ AX, AX
0x00af 00175 (hashmap_fast.go:42) JEQ 185
```
The register-register move is there because calculating `b.overflow` involves a uintptr/unsafe.Pointer conversion, which gets translated into a MOVQconvert; regalloc allocates a register for the converted value. However, the register move is pointless; the destination register (BX) is used in an LEAQ instruction and is dead thereafter.
In general, it seems that we should be able to rewrite away some MOVQconverts when they are used once, immediately, as part of some pointer math, which is the typical usage. The hard part is making sure that the rewrite rules are safe.
This should help codegen for the runtime, which does lots of pointer arithmetic.
cc @randall77
|
Performance,compiler/runtime
|
low
|
Minor
|
252,343,338
|
angular
|
NgFor with animations displays incorrectly if NgFor array elements are reordered in-place
|
<!--
PLEASE HELP US PROCESS GITHUB ISSUES FASTER BY PROVIDING THE FOLLOWING INFORMATION.
ISSUES MISSING IMPORTANT INFORMATION MAY BE CLOSED WITHOUT INVESTIGATION.
-->
## I'm submitting a...
<!-- Check one of the following options with "x" -->
<pre><code>
[ ] Regression (a behavior that used to work and stopped working in a new release)
[x] Bug report <!-- Please search GitHub for a similar issue or PR before submitting -->
[ ] Feature request
[ ] Documentation issue or request
[ ] Support request => Please do not submit support request here, instead see https://github.com/angular/angular/blob/master/CONTRIBUTING.md#question
</code></pre>
## Current behavior
<!-- Describe how the issue manifests. -->
When you apply an a `void <=> *` animation to elements in an `NgFor` then rearrange the elements in the array, the animations do not display correctly. In the plunkr example below, elements are positioned on top of each other once the array is rearranged even though they initially display correctly.
## Expected behavior
<!-- Describe what the desired behavior would be. -->
The elements should animate correctly.
## Minimal reproduction of the problem with instructions
<!--
For bug reports please provide the *STEPS TO REPRODUCE* and if possible a *MINIMAL DEMO* of the problem via
https://plnkr.co or similar (you can use this template as a starting point: http://plnkr.co/edit/tpl:AvJOMERrnz94ekVua0u5).
-->
See this plunkr: http://plnkr.co/edit/qGFuVngxgIcEojZaFZPd?p=preview
Note that when the application first runs, the animations display correctly. Clicking "Rearrange" will cause the elements in the `NgFor`-ed array to be reordered using `Array.splice` but without creating a new array object. The view updates and the animations cause the elements to collapse into each other. The list displays correctly when the animation is removed.
## What is the motivation / use case for changing the behavior?
<!-- Describe the motivation or the concrete use case. -->
I want the animation to display properly in a similar use case in my app.
## Environment
<pre><code>
Angular version: 4.3.5
<!-- Check whether this is still an issue in the most recent Angular version -->
Browser:
- [x] Chrome (desktop) version XX
- [ ] Chrome (Android) version XX
- [ ] Chrome (iOS) version XX
- [ ] Firefox version XX
- [ ] Safari (desktop) version XX
- [ ] Safari (iOS) version XX
- [ ] IE version XX
- [ ] Edge version XX
For Tooling issues:
- Node version: XX <!-- run `node --version` -->
- Platform: <!-- Mac, Linux, Windows -->
Others:
<!-- Anything else relevant? Operating system version, IDE, package manager, HTTP server, ... -->
</code></pre>
|
type: bug/fix,area: animations,hotlist: components team,freq3: high,P2,canonical
|
low
|
Critical
|
252,356,209
|
flutter
|
Allow release mode builds to run on simulators
|
Current documentation (https://github.com/flutter/flutter/wiki/Flutter%27s-modes) states that Flutter release mode builds cannot be run on the Simulator. For many applications, the iOS Simulators are sufficiently high fidelity to do 99% of development work without going through the additional friction of deploying to devices regularly. It's unfortunate that, unlike in native application development, you can't get an accurate understanding of your release mode behaviors with Flutter.
|
c: new feature,tool,engine,customer: crowd,P3,customer: castaway,team-engine,triaged-engine
|
high
|
Critical
|
252,356,589
|
flutter
|
FocusNode and FocusScopeNode should take debug labels.
|
Currently printing the focus tree results in something like this:
```
[00059.830] 10004.10040> FocusScopeNode#5f96b
[00059.830] 10004.10040> child 1: FocusScopeNode#6de7b
[00059.830] 10004.10040> focus: FocusNode#96399
[00059.830] 10004.10040>
```
It would better to have names for each of these.
|
framework,a: debugging,c: proposal,P3,team-framework,triaged-framework
|
low
|
Critical
|
252,436,934
|
bitcoin
|
bumpfee behavior with "Subtract fee from amount"
|
When using the bumpfee command on a tx that was sent using "Subtract fee from amount", the current response is this error. "Transaction does not have a change output (code -1)". Since "Subtract fee from amount" was specified, the expected behavior would be to subtract the fee from the sent amount which would not require a change output.
|
RPC/REST/ZMQ
|
low
|
Critical
|
252,446,944
|
puppeteer
|
Ability to pause all animations completely
|
I need to be able to take deterministic screenshots and when animations are running you'll get a different frame from an animation each time.
There does appear to be some control of animations in the devtools protocol here: https://chromedevtools.github.io/devtools-protocol/tot/Animation/
I've tried these without success:
```javascript
await page._client.send('Animation.setPlaybackRate', { playbackRate: 0.0 });
```
```javascript
await page._client.send('Animation.disable');
```
There's also an official extension that disables animations: https://chrome.google.com/webstore/detail/animation-policy/ncigbofjfbodhkaffojakplpmnleeoee?hl=en
Looking at the source code of that extension it calls this:
```javascript
chrome.accessibilityFeatures.animationPolicy.set({'value': setting}, function (callback) {});
```
Where the ideal value would be 'none'. (https://codereview.chromium.org/785723002/diff/20001/chrome/common/extensions/api/accessibility_features.json#newcode48chrome/common/extensions/api/accessibility_features.json:48)
Related: #453
|
feature,chromium
|
medium
|
Major
|
252,505,354
|
puppeteer
|
Detect sound
|
I would like to detect if a page is playing some sound. Is there a way to do that?
|
feature,upstream,chromium
|
medium
|
Critical
|
252,519,627
|
youtube-dl
|
[safari] Add support for learning paths
|
## Please follow the guide below
- You will be asked some questions and requested to provide some information, please read them **carefully** and answer honestly
- Put an `x` into all the boxes [ ] relevant to your *issue* (like this: `[x]`)
- Use the *Preview* tab to see what your issue will actually look like
---
### Make sure you are using the *latest* version: run `youtube-dl --version` and ensure your version is *2017.08.23*. If it's not, read [this FAQ entry](https://github.com/rg3/youtube-dl/blob/master/README.md#how-do-i-update-youtube-dl) and update. Issues with outdated version will be rejected.
- [x] I've **verified** and **I assure** that I'm running youtube-dl **2017.08.23**
### Before submitting an *issue* make sure you have:
- [x] At least skimmed through the [README](https://github.com/rg3/youtube-dl/blob/master/README.md), **most notably** the [FAQ](https://github.com/rg3/youtube-dl#faq) and [BUGS](https://github.com/rg3/youtube-dl#bugs) sections
- [x] [Searched](https://github.com/rg3/youtube-dl/search?type=Issues) the bugtracker for similar issues including closed ones
### What is the purpose of your *issue*?
- [x] Bug report (encountered problems with youtube-dl)
- [x] Site support request (request for adding support for a new site)
- [ ] Feature request (request for a new functionality)
- [ ] Question
- [ ] Other
---
### The following sections concretize particular purposed issues, you can erase any section (the contents between triple ---) not applicable to your *issue*
---
Debug log:
```
[debug] System config: []
[debug] User config: []
[debug] Custom config: []
[debug] Command-line args: [u'--console-title', u'--restrict-filenames', u'-f', u'mp4[height<=480]', u'--cache-dir', u'/Users/brennebeck/.cache/youtube-dl', u'-o', u'%(autonumber)s-%(title)s.%(ext)s', u'-v', u'--format', u'best', u'https://www.safaribooksonline.com/learning-paths/learning-path-server-side/9781491992289', u'--username=PRIVATE', u'--password=PRIVATE']
[debug] Encodings: locale UTF-8, fs utf-8, out UTF-8, pref UTF-8
[debug] youtube-dl version 2017.08.18
[debug] Python version 2.7.12 - Darwin-16.7.0-x86_64-i386-64bit
[debug] exe versions: ffmpeg 3.3.3, ffprobe 3.3.3, rtmpdump 2.4
[debug] Proxy map: {}
[generic] 9781491992289: Requesting header
[redirect] Following redirect to https://www.safaribooksonline.com/learning-paths/learning-path-server-side/9781491992289/
[generic] 9781491992289: Requesting header
WARNING: Falling back on generic information extractor.
[generic] 9781491992289: Downloading webpage
[generic] 9781491992289: Extracting information
ERROR: Unsupported URL: https://www.safaribooksonline.com/learning-paths/learning-path-server-side/9781491992289/
Traceback (most recent call last):
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/generic.py", line 2103, in _real_extract
doc = compat_etree_fromstring(webpage.encode('utf-8'))
File "/usr/local/bin/youtube-dl/youtube_dl/compat.py", line 2539, in compat_etree_fromstring
doc = _XML(text, parser=etree.XMLParser(target=_TreeBuilder(element_factory=_element_factory)))
File "/usr/local/bin/youtube-dl/youtube_dl/compat.py", line 2528, in _XML
parser.feed(text)
File "/Users/brennebeck/.pyenv/versions/2.7.12/lib/python2.7/xml/etree/ElementTree.py", line 1653, in feed
self._raiseerror(v)
File "/Users/brennebeck/.pyenv/versions/2.7.12/lib/python2.7/xml/etree/ElementTree.py", line 1517, in _raiseerror
raise err
ParseError: not well-formed (invalid token): line 111, column 386
Traceback (most recent call last):
File "/usr/local/bin/youtube-dl/youtube_dl/YoutubeDL.py", line 776, in extract_info
ie_result = ie.extract(url)
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/common.py", line 433, in extract
ie_result = self._real_extract(url)
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/generic.py", line 2976, in _real_extract
raise UnsupportedError(url)
UnsupportedError: Unsupported URL: https://www.safaribooksonline.com/learning-paths/learning-path-server-side/9781491992289/
```
---
Unsupported URLs:
- https//www.safaribooksonline.com/learning-paths/learning-path-server-side/9781491992289/
---
Previously, the 'Learning Paths' in SafariBooksOnline.com would download as a course. Unfortunately, this seems to have stopped working within the last few days (I used this a recently the beginning of the week). I'm not sure what changed that would've broken the compatibility.
|
request
|
low
|
Critical
|
252,602,870
|
TypeScript
|
warning on emitDecoratorMetadata for interface in esnext
|
**TypeScript Version:** 2.4.2
**Code**
(using Angular 4)
```ts
// other-file.ts
export interface MyInterface { a: string }
// my-class.ts
import { Input } from '@angular/core'
import { MyInterface } from './otherFile'
class MyClass {
@Input() myi: MyInterface;
}
```
**tsconfig.json**
```
{
"compilerOptions": {
...
"target": "es2017",
"module": "esnext",
"emitDecoratorMetadata": true,
...
}
}
```
**Expected behavior:**
Working, no errors. I'd expect no type information emitted for interfaces, as they're only a Typescript compile construct.
**Actual behavior:**
Although this isn't a bug per se, TypeScript generates a decorator for type information, referencing MyInterface from `otherFile`. Only...this interface doesn't exist runtime. So bundlers (webpack in my case) produce a warning for this (something like `otherFile doesn't export MyInterface`). You can workaround this by creating a local type in `my-class.ts`. Or just accept warnings.
|
Bug,Domain: Decorators
|
medium
|
Critical
|
252,642,652
|
TypeScript
|
Suggestion: Change `Diagnostic.file` to be `SourceFileLike` instead of `SourceFile`.
|
`Diagnostic.file` is of type `SourceFile` which forces plugins to cast a non-`SourceFile` to a `SourceFile` to report diagnostic messages and guess which parts of `SourceFile` are not used by `tsserver`.
Consider changing `file` to be something like `SourceFileLIke` or `SourceMapSource` that specifies the exact requirements that must be supplied by plugins for this field.
|
Suggestion,Help Wanted,API
|
low
|
Minor
|
252,702,869
|
go
|
net/http: (*Transport).getConn traces through stale contexts
|
`(*http.Transport).getConn` currently starts a `dialConn` call in a background goroutine:
https://github.com/golang/go/blob/0b0cc4154e1defed07e73ca1304b9a68c7134577/src/net/http/transport.go#L942-L945
That records traces to the provided `Context` and eventually invokes `t.DialContext` with it:
https://github.com/golang/go/blob/0b0cc4154e1defed07e73ca1304b9a68c7134577/src/net/http/transport.go#L1029
https://github.com/golang/go/blob/0b0cc4154e1defed07e73ca1304b9a68c7134577/src/net/http/transport.go#L1060
This is pretty much a textbook illustration of the problem described in #19643 (Context API for continuing work). If `(*Transport).getConn` returns early (due to cancellation or to availability of an idle connection), the caller may have already written out the corresponding traces, and `dialConn` (and/or the user-provided `DialContext` callback) will unexpectedly access a `Context` that the caller believes to be unreachable.
`httptrace.ClientTrace` says, "Functions may be called concurrently from different goroutines and some may be called after the request has completed or failed." However, that is not true of `Context` instances in general: if the `http` package wants to save a trace after a call has returned, it should call `Value` ahead of time and save only the `ClientTrace` pointer. If `dialConn` calls a user-provided `DialContext` function, then `getConn` should cancel the `Context` passed to it and wait for `DialContext` to return before itself returning.
----
See also #20617 (Context race in `http.Transport`).
|
Thinking,help wanted,NeedsFix
|
low
|
Critical
|
252,725,089
|
rust
|
Check the well-formed-ness of type aliases.
|
Currently, these compile:
```rust
struct Foo<T: Copy>(T);
type X = Foo<String>;
type Y = <() as Iterator>::Item;
```
Using them does produce an error *at the use site*, but not in the definition.
|
A-type-system,C-enhancement,T-compiler,T-types
|
low
|
Critical
|
252,757,534
|
go
|
net: DialContext can use a stale context via happy eyeballs
|
When happy eyeballs is enabled, DialContext makes parallel calls to dialSingle via dialParallel:
https://github.com/golang/go/blob/424b0654f8e6c72f69e096f69009096de16e30fa/src/net/dial.go#L415
Each dialSingle call may call ctx.Value, such as here:
https://github.com/golang/go/blob/424b0654f8e6c72f69e096f69009096de16e30fa/src/net/dial.go#L533
dialParallel doesn't wait for all dialSingle calls to complete. This means, in theory, dialSingle can call ctx.Value on a ctx that has gone out of scope. This is effectively the same problem as #21597.
/cc @bcmills
|
NeedsInvestigation
|
low
|
Major
|
252,793,216
|
go
|
cmd/go: compilation order of fortran files is significant
|
Please answer these questions before submitting your issue. Thanks!
### What version of Go are you using (`go version`)?
go version go1.9 linux/amd64
### Does this issue reproduce with the latest release?
Yes
### What operating system and processor architecture are you using (`go env`)?
GOARCH="amd64"
GOBIN=""
GOEXE=""
GOHOSTARCH="amd64"
GOHOSTOS="linux"
GOOS="linux"
GOPATH="{....}"
GORACE=""
GOROOT="/usr/local/go"
GOTOOLDIR="/usr/local/go/pkg/tool/linux_amd64"
GCCGO="gccgo"
CC="gcc"
GOGCCFLAGS="-fPIC -m64 -pthread -fmessage-length=0 -fdebug-prefix-map=/tmp/go-build881373539=/tmp/go-build -gno-record-gcc-switches"
CXX="g++"
CGO_ENABLED="1"
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
PKG_CONFIG="pkg-config"
### What did you do?
I would like to build a go package that includes fortran source code files, similar to https://github.com/golang/go/tree/master/misc/cgo/fortran. The important difference from this example is that the package that I would like to compile includes fortran modules, for example:
```
package.go // depends on code in a_subroutine.f90
a_subroutine.f90 // depends on code in b_module.f90
b_module.90
```
I would expect to be able to compile this with ```go build```.
### What did you expect to see?
successful compilation.
### What did you see instead?
```
# {...}
<command-line>:12:6:
Fatal Error: Can't open module file ‘b_module.mod’ for reading at (1): No such file or directory
```
I think the problem might be that [the order that fortran files are fed into the compiler is significant](http://pages.mtu.edu/~shene/COURSES/cs201/NOTES/chap06/mod-files.html), and the go tool does not appear to account for this.
### Potential fixes for this problem:
1. renaming all of the fortran files in the directory so that their alphabetical order is also their required compilation order. While this (usually?) works, it appears to depend on undocumented behavior.
2. resolving the fortran dependencies and figuring out the file order within the go tool. This seems unlikely to happen.
3. Allowing the specification of files to be compiled (and their order) a la #12953.
4. Others?
|
NeedsInvestigation
|
low
|
Critical
|
252,803,550
|
youtube-dl
|
[Youtube] support for video watched percentage
|
## Please follow the guide below
- You will be asked some questions and requested to provide some information, please read them **carefully** and answer honestly
- Put an `x` into all the boxes [ ] relevant to your *issue* (like this: `[x]`)
- Use the *Preview* tab to see what your issue will actually look like
---
### Make sure you are using the *latest* version: run `youtube-dl --version` and ensure your version is *2017.08.23*. If it's not, read [this FAQ entry](https://github.com/rg3/youtube-dl/blob/master/README.md#how-do-i-update-youtube-dl) and update. Issues with outdated version will be rejected.
- [x] I've **verified** and **I assure** that I'm running youtube-dl **2017.08.23**
### Before submitting an *issue* make sure you have:
- [x] At least skimmed through the [README](https://github.com/rg3/youtube-dl/blob/master/README.md), **most notably** the [FAQ](https://github.com/rg3/youtube-dl#faq) and [BUGS](https://github.com/rg3/youtube-dl#bugs) sections
- [x] [Searched](https://github.com/rg3/youtube-dl/search?type=Issues) the bugtracker for similar issues including closed ones
### What is the purpose of your *issue*?
- [ ] Bug report (encountered problems with youtube-dl)
- [ ] Site support request (request for adding support for a new site)
- [x] Feature request (request for a new functionality)
- [ ] Question
- [ ] Other
---
### Description of your *issue*, suggested solution and other information
Partially watched youtube videos have a corresponding partially filled progress bar on the thumbnail, in the youtube UI. Currently the mark-watched does not have proper support for this and you get a very slightly filled progress bar.
It would be good to have a way to mark it as 100% watched progress, either with the default behavior of --mark-watched or through some new --mark-completely-watched flag.
|
request
|
low
|
Critical
|
252,845,724
|
puppeteer
|
How do I get rid of popup for chromium certificates selection, can I set it programmatically ?
|
Is there another way without disabling the popup via puppeteer launch ? I tried dialog stuff but it seems not the way.
<img width="1116" alt="screen shot 2017-08-25 at 5 20 42 pm" src="https://user-images.githubusercontent.com/642874/29708177-5db7c8a4-89ba-11e7-8827-917c0d09fa4d.png">
|
feature,chromium
|
medium
|
Critical
|
252,866,771
|
go
|
install: Windows: MSI Upgrade should default to previous install folder, not insist on C:\Go\
|
Please answer these questions before submitting your issue. Thanks!
### What version of Go are you using (`go version`)?
1.9 release
### Does this issue reproduce with the latest release?
Yes
### What operating system and processor architecture are you using (`go env`)?
Windows
### What did you do?
Had Go 1.9rc2 installed in C:\Program Files\Go\
Wizard asked if I wanted to uninstall old during upgrade, I chose YES
Wizard asks where I want to install new version, defaults to C:\Go\
### What did you expect to see?
I expected it to suggest installation in the previously selected folder, as this is an upgrade, and everything in environment is set for that path.
### What did you see instead?
It insists on suggesting C:\Go\ which fills up my root folder with more directories. I don't get it why you don't use Program Files as everything else on Windows. This is not Linux (and you would never suggest to install in /go/ on a Linux system anyway)
|
help wanted,OS-Windows,NeedsFix
|
low
|
Major
|
252,933,483
|
go
|
gofrontend/gccgo: Improve identity comparison
|
### The issue
`gofrontend` currently generates very inefficient code for `T$equal` and `t1 == t2` when dealing with identity-comparable types (i.e. integers, pointers, and unpadded structs and arrays of such).
For example:
- The following code does two 4-byte compares and a jump in `T$equal`, and calls memcmp in `t1 == t2`. For `t1 == t2`, `gofrontend` has a trick to turn this into a single 8-byte compare if the struct is aligned and size<=16 bytes, but it's not the case here.
```
type T struct {
a int32
b int32
}
```
- the following code always generates a call to memcmp:
```
type T struct {
a int32
b int32
c int32
d int32
}
```
### A solution
In 2016 gcc introduced the `__builtin_memcmp_eq` builtin that knows how to lower memcmp efficiently when the result is only used for equality comparison (i.e. equality with 0 instead of 3-way ordering). This is typically useful when the size is a constexpr (as is the case here).
The basic idea is to replace a *larger chain* of integer comparisons loaded from contiguous memory locations into a *smaller chain* of bigger integer comparisons. Benefits are twofold:
- There are *less jumps*, and therefore less opportunities for *mispredictions* and I-*cache misses*.
- *The code is smaller*, both because jumps are removed and because the encoding of a 2*n byte compare is smaller than that of two n-byte compares.
As a first step, I’m simply proposing to replace calls to `runtime.memequal` with calls to `__builtin_memcmp_eq`. This only improves the generated code.
In first second example above, this would change the generated code (`gccgo -march=haswell -m64 -O3 -c test.go`) from:
- `t1 == t2`
```
b: 8b 56 04 mov 0x4(%rsi),%edx
e: 8b 4f 04 mov 0x4(%rdi),%ecx
11: 31 c0 xor %eax,%eax
13: 8b 36 mov (%rsi),%esi
15: 39 37 cmp %esi,(%rdi)
17: 74 07 je 20 <go.test.DoStuff+0x20>
19: c3 retq
1a: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)
20: 39 d1 cmp %edx,%ecx
22: 0f 94 c0 sete %al
25: c3 retq
```
- `T$equal`
```
7b: 48 83 ec 08 sub $0x8,%rsp
7f: ba 08 00 00 00 mov $0x8,%edx
84: e8 00 00 00 00 callq 89 <go.test.T$equal+0x19>
85: R_X86_64_PC32 runtime.memequal-0x4
89: 48 83 c4 08 add $0x8,%rsp
8d: c3 retq
```
To (in both cases):
```
7b: 48 8b 06 mov (%rsi),%rax
7e: 48 39 07 cmp %rax,(%rdi)
81: 0f 94 c0 sete %al
84: c3 retq
```
This is both smaller in terms of code size and much more efficient.
### Going further
#### Simplifying `gofrontend`
This also allows removing any specific code for handling sizes smaller than 16 bytes since they are already handled by gcc.
#### More performance improvements
This should be extended to piecewise-identity-comparable structs. For example, the following structure should be compared with three builtin calls (`{a}`, `{c,d,e}`, and `{f,g}`) and a float compare.
```
type T struct {
a int32
b float32 // Floats are not identity-comparable
c int32
d int32
e byte
// Implicit _ [3]byte padding
f int32
g int32
}
```
|
NeedsInvestigation
|
low
|
Major
|
252,983,289
|
pytorch
|
DataLoader converts cuda FloatTensor into cpu DoubleTensor when shape is (n,)
|
In version 0.2.0, it appears that the DataLoader will convert a cuda.FloatTensor into a DoubleTensor when the shape is (n,)
```python
X = torch.rand(64,8).cuda()
y = torch.rand(64).cuda()
dataset = TensorDataset(X,y)
loader = DataLoader(dataset)
next((y for (X,y) in loader))
```
```
0.1309
[torch.DoubleTensor of size 1x1 (GPU 0)]
```
Using `unsqueeze` to convert the (n,) tensor to (n,1) fixes the issue.
```python
X = torch.rand(64,8).cuda()
y = torch.rand(64).cuda().unsqueeze(1)
dataset = TensorDataset(X,y)
loader = DataLoader(dataset)
next((y for (X,y) in loader))
```
```
0.8397
[torch.cuda.FloatTensor of size 1x1 (GPU 0)]
```
The workaround is easy enough, but I'm assuming this is a bug with either TensorDataset or DataLoader.
EDIT:
This seems to be independent of CUDA, as it still converts the FloatTensor to DoubleTensor in cpu mode.
```python
X = torch.rand(64,8)
y = torch.rand(64)
dataset = TensorDataset(X,y)
loader = DataLoader(dataset)
next((y for (X,y) in loader))
```
```
0.4935
[torch.DoubleTensor of size 1]
```
```python
X = torch.rand(64,8)
y = torch.rand(64).unsqueeze(1)
dataset = TensorDataset(X,y)
loader = DataLoader(dataset)
next((y for (X,y) in loader))
```
```
0.9419
[torch.FloatTensor of size 1x1]
```
|
needs reproduction,module: dataloader,triaged
|
low
|
Critical
|
253,036,517
|
opencv
|
cuda::BackgroundSubtractor::apply only allows CV_8UCx images while CPU version allows CV_16UCx images
|
##### System information (version)
- OpenCV => 3.2
- Operating System / Platform => Windows 64 Bit
- Compiler => Visual Studio 2013
##### Detailed description
Code that uses the openCV background subtractor on the CPU can pass in a 16 bit image (very useful for depth images where char is not enough resolution) but converting that function over to the cuda implemetation throws the assertion:
> OpenCV Error: Assertion failed (frameType == CV_8UC1 || frameType == CV_8UC3 || frameType == CV_8UC4) in `anonymous-namespace'::MOG2Impl::initialize, file C:\OpenCV32\source\modules\cudabgsegm\src\mog2.cpp, line 223
This same code runs fine in the CPU implementation of BackgroundSubtractorMOG2.
##### Steps to reproduce
```.cpp
cv::Mat newBackgroundImage = cv::Mat(1024, 1024, CV_16UC1);
// fill new background image with unsigned short data
cv::cuda::GpuMat fgMask;
BackgroundModel = cv::cuda::createBackgroundSubtractorMOG2();
// first-run initialization
if (fgMask.rows == 0 || fgMask.cols == 0)
{
fgMask = cv::cuda::GpuMat(newBackgroundImage.rows, newBackgroundImage.cols, CV_8UC1);
}
cv::cuda::GpuMat input = cv::cuda::GpuMat(newBackgroundImage.rows, newBackgroundImage.cols, newBackgroundImage.type());
input.upload(newBackgroundImage);
BackgroundModel->apply(newBackgroundImage, fgMask, -1);
```
Running the above code will throw the error. Running the below code will work without error
```.cpp
cv::Mat newBackgroundImage = cv::Mat(1024, 1024, CV_16UC1);
// fill new background image with unsigned short data
cv::Mat fgMask;
// first-run initialization
if (fgMask.rows == 0 || fgMask.cols == 0)
{
fgMask = Mat(inputImage.rows, inputImage.cols, CV_8UC1);
}
BackgroundModel->apply(inputImage, fgMask, -1);
```
|
feature,priority: low,category: gpu/cuda (contrib),RFC
|
low
|
Critical
|
253,036,886
|
rust
|
Object safety "method references the `Self` type" check does not normalize.
|
Example (using an associated type that matches a blanket `impl`):
```rust
trait Foo {
type X;
}
impl<T: ?Sized> Foo for T {
type X = ();
}
trait Bar {
// Note how this is allowed without a bound.
fn foo(&self) -> <Self as Foo>::X;
}
// error: the trait `Bar` cannot be made into an object
fn foo(_: Box<dyn Bar>) {}
fn main() {}
```
|
A-type-system,T-compiler,C-bug,T-types,A-trait-objects
|
low
|
Critical
|
253,082,877
|
gin
|
[PROJECT] Future steps
|
# TL;DR
- API stability and deprecation policy
- v2?
---
cc @appleboy @tboerger @nazwa @easonlin404 @thinkerou
I'm worried on how to keep going and scale the API without breaking everything in a v2. Some people who use Gin love the new activity and features, but want Gin as it is now, somehow API stable. Others want a continuous development and deprecation of prior versions.
Because this is not JS, and there is no `package.json` pre-included, I see it's hard for beginners to understand the difference between `go get ...` and `vendor/` folder and tools.
Projects that use Gin like `drone-io` have it vendor on a version from January 2016.
I was thinking on ways of allowing API changes with deprecation notices like it's being done now in `deprecated.go`.
An idea from the jsonite contribution and the build flags:
- added to *_experimental.go
- moved to *.go
- deprecated to deprecated.go (with printf warning)
- deprecated to *_deprecated.go (for very old builds)
I would like to know your thoughts on this, not just the idea above. Thanks 😃
PD: everyone is encouraged to participate too.
|
help wanted
|
low
|
Major
|
253,096,960
|
go
|
runtime: apply strength reduction optimizations to generic map routines
|
CL 57590 applied strength reduction to the key pointers in some mapfast routines. This is a reminder issue to check whether similar optimizations can fruitfully be applied to any of the generic map routines (access, assign, delete, etc.).
cc @martisch
|
Performance,compiler/runtime
|
low
|
Minor
|
253,098,231
|
rust
|
Write on &mut [u8] and Cursor<&mut [u8]> doesn't optimize very well.
|
Calling write on a mutable slice (or one wrapped in a Cursor) with one, or a small amount of bytes results in function call to memcpy call after optimization (opt-level=3), rather than simply using a store as one would expect:
```rust
pub fn one_byte(mut buf: &mut [u8], byte: u8) {
buf.write(&[byte]);
}
```
Results in:
```llvm
define void @_ZN6cursor8one_byte17h68c172d435558ab9E(i8* nonnull, i64, i8) unnamed_addr #0 personality i32 (i32, i32, i64, %"unwind::libunwind::_Unwind_Exception"*, %"unwind::libunwind::_Unwind_Context"*)* @rust_eh_personality {
_ZN4core3ptr13drop_in_place17hc17de44f7e6456c9E.exit:
%_10.sroa.0 = alloca i8, align 1
call void @llvm.lifetime.start(i64 1, i8* nonnull %_10.sroa.0)
store i8 %2, i8* %_10.sroa.0, align 1
%3 = icmp ne i64 %1, 0
%_0.0.sroa.speculated.i.i.i = zext i1 %3 to i64
call void @llvm.memcpy.p0i8.p0i8.i64(i8* nonnull %0, i8* nonnull %_10.sroa.0, i64 %_0.0.sroa.speculated.i.i.i, i32 1, i1 false), !noalias !0
call void @llvm.lifetime.end(i64 1, i8* nonnull %_10.sroa.0)
ret void
}
```
`copy_from_slice` seems to be part of the issue here, if I change the [write implementation on mutable slices](https://github.com/rust-lang/rust/blob/e7070dd019d70b089a9983571dc40b2f9ee16cf5/src/libstd/io/impls.rs#L228) to use this instead of `copy_from_slice`:
```rust
for (&input, output) in data[..amt].iter().zip(a.iter_mut()) {
*output = input;
}
```
the llvm ir looks much nicer:
```llvm
define void @_ZN6cursor8one_byte17h68c172d435558ab9E(i8* nonnull, i64, i8) unnamed_addr #0 personality i32 (i32, i32, i64, %"unwind::libunwind::_Unwind_Exception"*, %"unwind::libunwind::_Unwind_Context"*)* @rust_eh_personality {
start:
%3 = icmp eq i64 %1, 0
br i1 %3, label %_ZN4core3ptr13drop_in_place17hc17de44f7e6456c9E.exit, label %"_ZN84_$LT$core..iter..Zip$LT$A$C$$u20$B$GT$$u20$as$u20$core..iter..iterator..Iterator$GT$4next17he84ad69753d1c347E.exit.preheader.i"
"_ZN84_$LT$core..iter..Zip$LT$A$C$$u20$B$GT$$u20$as$u20$core..iter..iterator..Iterator$GT$4next17he84ad69753d1c347E.exit.preheader.i": ; preds = %start
store i8 %2, i8* %0, align 1, !noalias !0
br label %_ZN4core3ptr13drop_in_place17hc17de44f7e6456c9E.exit
_ZN4core3ptr13drop_in_place17hc17de44f7e6456c9E.exit: ; preds = %start, %"_ZN84_$LT$core..iter..Zip$LT$A$C$$u20$B$GT$$u20$as$u20$core..iter..iterator..Iterator$GT$4next17he84ad69753d1c347E.exit.preheader.i"
ret void
}
```
The for loop will result in vector operations on longer slices, but I'm still unsure about whether doing this change could cause some slowdown on very long slices as the memcpy implementation may be more optimized for the specific system, and it doesn't really solve the underlying issue. There seems to be some problem with optimizing `copy_from_slice` calls that follow `split_at_mut` and probably some other calls that involve slice operations (I tried to alter the write function to use unsafe and creating a temporary slice using pointers instead, but that didn't help.)
Happens on both nightly `rustc 1.21.0-nightly (2aeb5930f 2017-08-25)` and stable (1.19) x86_64-unknown-linux-gnu` (Not sure if memcpy behaviour could be different on other platforms).
|
I-slow,C-enhancement,T-compiler,C-optimization
|
low
|
Major
|
253,098,844
|
go
|
runtime: improve barrier implementation layering
|
This is a migration of some discussion in [CL 37628](https://golang.org/37628).
bulkBarrierPreWrite calls writebarrierptr_prewrite1 repeatedly. Every call to writebarrierptr_prewrite1 does some sanity checks and hops on and off the system stack. This seems silly.
@aclements wrote:
> What do you think about instead lifting some of the setup from writebarrierptr_prewrite1 (like switching to the system stack) into bulkBarrierPreWrite and just calling gcmarkwb_m directly from bulkBarrierPreWrite? Then, as a possible second step, unrolling the bulkBarrierPreWrite loop that calls gcmarkwb_m?
I wrote:
> That was my first instinct, but I wasn't sure whether for a very large bulk pre-write this might exceed the latency budget in a way that hopping back and forth off of the system stack might not.
@aclements wrote:
> bulkBarrierPreWrite is already non-preemptible, so this wouldn't be making it any worse. In fact, it would be kind of nice for it to be *obviously* non-preemptible, rather than subtly non-preemptible like it is now. :)
> This isn't great, obviously. But if we wanted to fix this (which we might have to), I think we would need to do it at the typedmemmove and friends level by breaking it up into smaller bulkBarrierPreWrite and memmove segments with a preemption point after each segment.
---
There are several TODOs here:
1. Improve the layering.
2. Figure out whether typedmemmove and friends need to break their work up into chunks to avoid long pauses.
3. Check whether loop unrolling in bulkBarrierPreWrite improves performance.
|
NeedsFix,compiler/runtime
|
low
|
Major
|
253,129,146
|
youtube-dl
|
[littlethings] Add support for littlethings.com
|
## Please follow the guide below
- You will be asked some questions and requested to provide some information, please read them **carefully** and answer honestly
- Put an `x` into all the boxes [ ] relevant to your *issue* (like this: `[x]`)
- Use the *Preview* tab to see what your issue will actually look like
---
### Make sure you are using the *latest* version: run `youtube-dl --version` and ensure your version is *2017.08.27.1*. If it's not, read [this FAQ entry](https://github.com/rg3/youtube-dl/blob/master/README.md#how-do-i-update-youtube-dl) and update. Issues with outdated version will be rejected.
- [x] I've **verified** and **I assure** that I'm running youtube-dl **2017.08.27.1**
### Before submitting an *issue* make sure you have:
- [x] At least skimmed through the [README](https://github.com/rg3/youtube-dl/blob/master/README.md), **most notably** the [FAQ](https://github.com/rg3/youtube-dl#faq) and [BUGS](https://github.com/rg3/youtube-dl#bugs) sections
- [x] [Searched](https://github.com/rg3/youtube-dl/search?type=Issues) the bugtracker for similar issues including closed ones
### What is the purpose of your *issue*?
- [ ] Bug report (encountered problems with youtube-dl)
- [x] Site support request (request for adding support for a new site)
- [ ] Feature request (request for a new functionality)
- [ ] Question
- [ ] Other
---
### The following sections concretize particular purposed issues, you can erase any section (the contents between triple ---) not applicable to your *issue*
---
### If the purpose of this *issue* is a *bug report*, *site support request* or you are not completely sure provide the full verbose output as follows:
Add the `-v` flag to **your command line** you run youtube-dl with (`youtube-dl -v <your command line>`), copy the **whole** output and insert it here. It should look similar to one below (replace it with **your** log inserted between triple ```):
```
youtube-dl -v "https://www.littlethings.com/ryan-baker-foul-baseball/?utm_source=cusm&utm_medium=Facebook&utm_campaign=shocking"
[debug] System config: []
[debug] User config: []
[debug] Custom config: []
[debug] Command-line args: [u'-v', u'https://www.littlethings.com/ryan-baker-foul-baseball/?utm_source=cusm&utm_medium=Facebook&utm_campaign=shocking']
WARNING: Assuming --restrict-filenames since file system encoding cannot encode all characters. Set the LC_ALL environment variable to fix this.
[debug] Encodings: locale ANSI_X3.4-1968, fs ANSI_X3.4-1968, out ANSI_X3.4-1968, pref ANSI_X3.4-1968
[debug] youtube-dl version 2017.08.27
[debug] Python version 2.7.12 - Linux-4.4.0-72-generic-x86_64-with-Ubuntu-16.04-xenial
[debug] exe versions: ffmpeg 2.8.11-0ubuntu0.16.04.1, ffprobe 2.8.11-0ubuntu0.16.04.1
[debug] Proxy map: {}
[generic] ?utm_source=cusm&utm_medium=Facebook&utm_campaign=shocking: Requesting header
WARNING: Falling back on generic information extractor.
[generic] ?utm_source=cusm&utm_medium=Facebook&utm_campaign=shocking: Downloading webpage
[generic] ?utm_source=cusm&utm_medium=Facebook&utm_campaign=shocking: Extracting information
ERROR: Unsupported URL: https://www.littlethings.com/ryan-baker-foul-baseball/?utm_source=cusm&utm_medium=Facebook&utm_campaign=shocking
Traceback (most recent call last):
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/generic.py", line 2116, in _real_extract
doc = compat_etree_fromstring(webpage.encode('utf-8'))
File "/usr/local/bin/youtube-dl/youtube_dl/compat.py", line 2539, in compat_etree_fromstring
doc = _XML(text, parser=etree.XMLParser(target=_TreeBuilder(element_factory=_element_factory)))
File "/usr/local/bin/youtube-dl/youtube_dl/compat.py", line 2528, in _XML
parser.feed(text)
File "/usr/lib/python2.7/xml/etree/ElementTree.py", line 1653, in feed
self._raiseerror(v)
File "/usr/lib/python2.7/xml/etree/ElementTree.py", line 1517, in _raiseerror
raise err
ParseError: not well-formed (invalid token): line 15, column 42
Traceback (most recent call last):
File "/usr/local/bin/youtube-dl/youtube_dl/YoutubeDL.py", line 776, in extract_info
ie_result = ie.extract(url)
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/common.py", line 434, in extract
ie_result = self._real_extract(url)
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/generic.py", line 2989, in _real_extract
raise UnsupportedError(url)
UnsupportedError: Unsupported URL: https://www.littlethings.com/ryan-baker-foul-baseball/?utm_source=cusm&utm_medium=Facebook&utm_campaign=shocking
```
|
site-support-request
|
low
|
Critical
|
253,132,052
|
opencv
|
corrupt JPEG data: # extraneous bytes before marker 0x##
|
##### System information (version)
- OpenCV => 3.3
- Operating System / Platform => Ubuntu 16.04.3 LTS (x86_64)
- Compiler => gcc 5.4.0 20160609
##### Detailed description
When accessing a Logitech C310 webcam with Java OpenCV 3.3 the following error message is repeatedly printed to the terminal (with varying values for number of bytes and marker)
`Corrupt JPEG data: 2 extraneous bytes before marker 0xd3`
The error message comes from 3rdparty/libjpeg/jdmarker.c
usage of JWRN_EXTRANEOUS_DATA
The problem appears to be caused by a bug with the libjpeg that ships with OpenCV. A fix is to build OpenCV with the option `WITH_JPEG` switched OFF causing OpenCV to use the platform's copy of libjpeg.
I recommend updating the instructions [here](http://docs.opencv.org/2.4/doc/tutorials/introduction/desktop_java/java_dev_intro.html)
to include `WITH_JPEG=OFF`
##### Steps to reproduce
Build OpenCV for Java and run in Linux using the settings recommended in the [Introduction to Java Development](http://docs.opencv.org/2.4/doc/tutorials/introduction/desktop_java/java_dev_intro.html)
|
bug,category: videoio(camera),category: 3rdparty
|
medium
|
Critical
|
253,132,827
|
pytorch
|
Counter-intuitive Patience & Cooldown of ReduceLROnPlateau
|
https://github.com/pytorch/pytorch/pull/1370 provides a LR scheduler that reduces LR when the validation metrics stops improving.
It works like this: when ```patience=2, cooldown=0```,
``` Python
import torch
from torch.optim.lr_scheduler import ReduceLROnPlateau
n=torch.nn.Linear(1,1)
opt = torch.optim.SGD(n.parameters(), lr=0.1)
rp = ReduceLROnPlateau(opt, patience=2, cooldown=0)
for _ in range(10):
print(opt.param_groups[0]['lr'])
# train_one_epoch(...)
# metrics = validate(...)
rp.step(metrics=0) # metrics "stops improving" after the first epoch
```
Output LR for each epoch:
```
0.1
0.1
0.1
0.1
0.01
0.01
0.01
0.001
0.001
0.001
```
when `patience=2, cooldown=1`,
```
0.1
0.1
0.1
0.1
0.01
0.01
0.01
0.01
0.001
0.001
```
IMO the two examples' outcomes should instead match `patience=3, cooldown=0` and `patience=3, cooldown=1` respectively. Any idea?
Edited: change the position of `print`
cc @vincentqb
|
todo,module: optimizer,triaged
|
low
|
Minor
|
253,177,428
|
angular
|
Animation using `display` in `query` not working
|
<!--
PLEASE HELP US PROCESS GITHUB ISSUES FASTER BY PROVIDING THE FOLLOWING INFORMATION.
ISSUES MISSING IMPORTANT INFORMATION MAY BE CLOSED WITHOUT INVESTIGATION.
-->
## I'm submitting a...
<!-- Check one of the following options with "x" -->
<pre><code>
[ ] Regression (a behavior that used to work and stopped working in a new release)
[x] Bug report <!-- Please search GitHub for a similar issue or PR before submitting -->
[ ] Feature request
[ ] Documentation issue or request
[ ] Support request => Please do not submit support request here, instead see https://github.com/angular/angular/blob/master/CONTRIBUTING.md#question
</code></pre>
[See plunkr here.](https://embed.plnkr.co/8BOdpQTCzxxtSLGBWKYb/)
I'm attempting a simple animation of 2 children. It appears that using display is not working at all inside `query`. So I had to use `height:0` + `overflow:hidden` instead. (Please see the plunkr)
## Environment
<pre><code>
Angular version: 4.3.5
Browser: all
</code></pre>
|
type: bug/fix,area: animations,freq2: medium,P4
|
low
|
Critical
|
253,198,123
|
rust
|
Document traits from #[derive(...)]
|
Moving here from https://github.com/rust-lang/cargo/issues/4406 on @dns2utf8's behalf:
While documenting every public function of [ThreadPool](https://github.com/rust-threadpool/rust-threadpool) I had to implement `#[derive(Clone)` manually so I would be able to add an example.
I assume `cargo doc` has a default template for the derive-able traits.
So I propose something like this:
```rust
#[derive(Clone)
/// My custom doc
/// ```
/// let my = custom.example();
/// ```
#[derive(PartialEq, Eq)
/// My custom doc for both traits
/// ```
/// let my = custom.example();
/// ```
struct CustomStruct;
```
The template would have to include something like "yield" within the code it is generating.
In this case it should generate something equal to:
```rust
impl Clone for CustomStruct {
/// My custom doc
/// ```
/// let my = custom.example();
/// ```
fn clone(&self) -> Self { CustomStruct }
}
/* similar for the other two traits */
struct CustomStruct;
```
What do you think?
|
T-rustdoc,C-feature-request
|
low
|
Major
|
253,365,955
|
go
|
wiki: Would like a page to list community benchmarks
|
### What did you expect to see?
A table listing important benchmarks from the open source community, so that Go compiler and runtime developers can get a better idea of which optimizations matter and which do not, and to avoid performance surprises late in the release cycle. The existing go1 benchmark suite is not that good.
Ideally these benchmarks would have the following properties:
- they should matter; does it cost money if the benchmarked code runs slowly?
- they should be go-gettable and not require customized steps for building the benchmark
- they should run relatively quickly; ideally each individual benchmark iteration runs in less than a second (we'll probably want different sets of benchmarks for runtime and compiler)
- ideally their timings are not noisy
- they should run cleanly in a restricted environment, such as a Docker container
- because only a few benchmarks from each suite can be run, they should not overlap other benchmarks in the list; we don't need a half-dozen benchmarks of the same transcendental functions
Information for each benchmark would include:
- a short name for the benchmark
- the path to the benchmark directory
- a regexp for the benchmark specifying the one or two best benchmarks to run
- a contact person for questions about the benchmarks
There may be more than one directory in a project containing benchmarks, and that's okay, these can be listed as separate benchmarks.
For example:
```
Name = "gonum_blas_native"
Repo = "github.com/gonum/blas/native"
Benchmarks = "Benchmark(DasumMediumUnitaryInc|Dnrm2MediumPosInc)"
Contact = "[email protected]"
```
and
```
Name = "gonum_matrix_mat64"
Repo = "github.com/gonum/matrix/mat64"
Benchmarks = "Benchmark(MulWorkspaceDense1000Hundredth|ScaleVec10000Inc20)"
Contact = "[email protected]"
```
I've done some work creating a preliminary list of benchmarks I think is likely to be interesting, and it includes code from the following github projects:
```
ethereum_bitutil (repo=github.com/ethereum/go-ethereum/common/bitutil)
ethereum_storage (repo=github.com/ethereum/go-ethereum/swarm/storage)
ethereum_ethash (repo=github.com/ethereum/go-ethereum/consensus/ethash)
ethereum_core (repo=github.com/ethereum/go-ethereum/core)
ethereum_sha3 (repo=github.com/ethereum/go-ethereum/crypto/sha3)
ethereum_ecies (repo=github.com/ethereum/go-ethereum/crypto/ecies)
ethereum_corevm (repo=github.com/ethereum/go-ethereum/core/vm)
ethereum_trie (repo=github.com/ethereum/go-ethereum/trie)
eolian_dsp (repo=buddin.us/eolian/dsp)
spexs2 (repo=github.com/egonelbre/spexs2/_benchmark)
minio (repo=github.com/minio/minio/cmd)
gonum_blas_native (repo=github.com/gonum/blas/native)
gonum_lapack_native (repo=github.com/gonum/lapack/native)
gonum_matrix_mat64 (repo=github.com/gonum/matrix/mat64)
semver (repo=github.com/Masterminds/semver)
hugo_helpers (repo=github.com/gohugoio/hugo/helpers)
hugo_hugolib (repo=github.com/gohugoio/hugo/hugolib)
k8s_api (repo=k8s.io/kubernetes/pkg/api)
k8s_schedulercache (repo=k8s.io/kubernetes/plugin/pkg/scheduler/schedulercache)
```
In the list above, `ethereum_whisperv5` does not appear because all the benchmarks were noisy.
I also don't have official contacts for these benchmarks, and I don't know if the benchmarks I selected are representative or not.
### What did you see instead?
No such page.
@aclements
|
NeedsInvestigation
|
medium
|
Major
|
253,400,719
|
TypeScript
|
JSDoc function annotations not working for chain assignment
|
From https://github.com/Microsoft/vscode/issues/33221
**TypeScript Version:** 2.5.1
**Code**
For the JS code:
```js
/**
* @return {Number}
*/
const f = exports.z = () => ({})
const x = f();
```
**Expected behavior:**
Type of `x` is `number`
**Actual behavior:**
Type of `x` is `{ [x: string]: any}`
If you get rid of the chained assignment and instead write`const f= () => ({})`, the types work as expected
|
Bug,VS Code Tracked,Domain: JavaScript
|
low
|
Minor
|
253,419,355
|
go
|
x/website: add support for languages other than English
|
Right now the docs are only in English. There's [some support](https://github.com/golang/go/wiki/NonEnglish) for languages other than English, but the wiki page is merely a footnote.
Other projects—[like React](https://crowdin.com/project/react)—are attempting this as well. Not only does it give newcomers a (somewhat) easy way to contribute to Go, it also makes Go a more welcoming and inclusive place for non-English speakers. Obviously the English version would remain the "master" version of the docs.
Ideally, golang.org would respect the `Accept-Language` header or support some sort of `en/`, `fr/`, etc. URL path option.
I'm not sure how much of a proposal this needs to be, but it's something I'm willing to put further thought into if needed. (It's not a language change or anything, so I didn't write out a full proposal.)
Projects with their docs and/or websites in multiple languages:
- [React](https://github.com/facebook/react/issues/8063)
- Rust
- Python
- Java ([sorta](https://www.oracle.com/fr/index.html))
- PHP
- JavaScript (via MDN)
- Perl (third party)
- Ruby
- [Babel](https://medium.com/@thejameskyle/the-language-of-programming-7983b8f6910d)
- LaTeX
- Scala (like how Go currently does it, but more uniform)
- ...
|
Documentation,NeedsDecision
|
low
|
Major
|
253,507,703
|
go
|
net: Buffers makes multiple Write calls on Writers that don't implement buffersWriter
|
The `writev` syscall is supposed to act like a single write. The `WriteTo` method of `net.Buffers` will make a single write syscall on writers that have the unexported `writeBuffers` method. However, for writers that do not have such a method, it will call `Write` multiple times. This becomes significant if you are wrapping a `*net.TCPConn` without embedding, for instance, since it has different performance characteristics with respect to [Nagle's algorithm](https://en.wikipedia.org/wiki/Nagle%27s_algorithm). Frustratingly, since the `writeBuffers` method is unexported, there's no way for the application to know the behavior of `Buffers.WriteTo` in order to work around the issue.
Repro case: https://play.golang.org/p/rF0JRZs8z8
|
NeedsDecision,early-in-cycle
|
medium
|
Major
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.