
id
int64 393k
2.82B
| repo
stringclasses 68
values | title
stringlengths 1
936
| body
stringlengths 0
256k
⌀ | labels
stringlengths 2
508
| priority
stringclasses 3
values | severity
stringclasses 3
values |
|---|---|---|---|---|---|---|
656,784,787 |
pytorch
|
[jit] support for generators and `yield`
|
Background on what generators are: https://wiki.python.org/moin/Generators
The use cases for TorchScript are
1. some classes want to use generates to implement `__iter__` and such, especially in Torchtext
2. the PyTorch optimizers make use of generators
cc @suo @gmagogsfm
|
oncall: jit,months,TSUsability,TSRootCause:UnsupportedConstructs
|
low
|
Minor
|
656,785,699 |
pytorch
|
[jit] support class polymorphism
|
Today, classes cannot inherit from other classes. This is a surprising limitation for people who want to use inheritance for code re-use, or are scripting already-existing codebases that use inheritance. Also: the PyTorch optimizers are polymorphic.
cc @suo @gmagogsfm
|
oncall: jit,months,TSRootCause:DynamicBehaviors,TSUsability,TSRootCause:UnsupportedConstructs
|
low
|
Major
|
656,787,164 |
pytorch
|
[jit] support `rpc_remote` and `rpc_sync`
|
We registered the `rpc_async` in TorchScript, but not `rpc_remote` and `rpc_sync`. We should register these two as well, as they are exactly the same semantics with `rpc_async`. This is a mid-pri request from PyPER
cc @suo @gmagogsfm
|
oncall: jit,days
|
low
|
Minor
|
656,787,950 |
pytorch
|
[jit] Support NamedTuple in tracing
|
We should be able to take `NamedTuples` as input and output of traced modules. As a starting point, can look at https://github.com/pytorch/pytorch/pull/29751 for a rough implementation
cc @suo @gmagogsfm
|
oncall: jit,module: bootcamp,days
|
low
|
Minor
|
656,811,631 |
TypeScript
|
No error using imports/exports with --module=none and --target=es2015+
|
<!-- 🚨 STOP 🚨 STOP 🚨 STOP 🚨
Half of all issues filed here are duplicates, answered in the FAQ, or not appropriate for the bug tracker. Even if you think you've found a *bug*, please read the FAQ first, especially the Common "Bugs" That Aren't Bugs section!
Please help us by doing the following steps before logging an issue:
* Search: https://github.com/Microsoft/TypeScript/search?type=Issues
* Read the FAQ: https://github.com/Microsoft/TypeScript/wiki/FAQ
Please fill in the *entire* template below.
-->
<!--
Please try to reproduce the issue with the latest published version. It may have already been fixed.
For npm: `typescript@next`
This is also the 'Nightly' version in the playground: http://www.typescriptlang.org/play/?ts=Nightly
-->
**TypeScript Version:** 4.0.0-dev.20200713
<!-- Search terms you tried before logging this (so others can find this issue more easily) -->
**Search Terms:** module none target
**Code**
```ts
// @module: none
// @target: es2015
export class Foo {}
```
**Expected behavior:**
`TS1148 Cannot use imports, exports, or module augmentations when '--module' is 'none'` and emits `export class Foo {}`
**Actual behavior:**
No error, and emits as CommonJS.
**Playground Link:** https://www.typescriptlang.org/play/?module=0#code/KYDwDg9gTgLgBAYwDYEMDOa4DEITgbwF8AoIA
**Related issues:** #39597
|
Bug,Breaking Change,Rescheduled
|
low
|
Critical
|
656,908,826 |
pytorch
|
Add a done() API to torch.futures.Future and ProcessGroup::Work
|
Discussion in https://discuss.pytorch.org/t/how-to-check-if-irecv-got-a-message/55725 asks for an API to check the completion of a `ProcessGroup::Work` from `isend` / `irecv`. A temporary solution would be implementing the `isCompleted` API properly, which is already exposed to Python.
https://github.com/pytorch/pytorch/blob/e2c4c2f102af3bf81b1a7a7e4d2165cebda4995b/torch/lib/c10d/ProcessGroup.hpp#L43
https://github.com/pytorch/pytorch/blob/e2c4c2f102af3bf81b1a7a7e4d2165cebda4995b/torch/csrc/distributed/c10d/init.cpp#L660-L674
In the long run, as we are going to replace `ProcessGroup::Work` with `torch.futures.Future`, we should also add a [`done`](https://docs.python.org/3/library/asyncio-future.html#asyncio.Future.done) API to the Future type.
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @xush6528 @osalpekar @jiayisuse @agolynski
|
oncall: distributed,triaged
|
low
|
Minor
|
656,920,012 |
godot
|
Crash when overriding _set (?)
|
<!-- Please search existing issues for potential duplicates before filing yours:
https://github.com/godotengine/godot/issues?q=is%3Aissue
-->
**Godot version:**
v3.2.2.stable.official / Steam
<!-- Specify commit hash if using non-official build. -->
**OS/device including version:**
Windows 10 / 2004
<!-- Specify GPU model, drivers, and the backend (GLES2, GLES3, Vulkan) if graphics-related. -->
**Issue description:**
Godot crashs, it is almost reproduceable everytime. It crashs when executing the example project.
I override `_set(property, value)`, which may lead to that crash.
Error message:
```
ERROR: get: FATAL: Index p_index = 7 is out of bounds (size() = 7).
At: ./core/cowdata.h:152
```
<!-- What happened, and what was expected. -->
**Steps to reproduce:**
Execute the main scene.
**Minimal reproduction project:**
[gd_crash.zip](https://github.com/godotengine/godot/files/4921701/gd_crash.zip)
<!-- A small Godot project which reproduces the issue. Drag and drop a zip archive to upload it. -->
Another example replace the `_read():` function with this
```gdscript
func _ready():
#self.my_dict["_"] = MyType.new("1", 1)
self._non_existent
```
Will lead to a crash too.
|
bug,topic:gdscript,topic:editor,confirmed,crash
|
low
|
Critical
|
656,958,986 |
pytorch
|
[JIT][to-backend] `selective_to_backend` infra
|
Now that #41146 has landed, we need to create and make available some utility functions to help users write code that selectively lowers some modules in a module hierarchy. The main consideration here is that the JIT type of the lowered module and all of its ancestors needs to be updated after lowering to a backend.
cc @suo @gmagogsfm
|
oncall: jit
|
low
|
Minor
|
656,971,413 |
PowerToys
|
Touchscreen Gesture Customization
|
I feel with how many touchscreen devices out there we would benefit from customizable touch gestures. There are many different touch gestures that could be implemented.
- swipe up from the bottom to go to desktop (similar to iPhone/Android)
- swipe from the sides to switch desktops/applications
- swipe to display multi-view of currently open apps
- swipe and hold to quick split screen apps
|
Idea-New PowerToy
|
low
|
Major
|
656,991,642 |
rust
|
Documentation for stdout does not mention flushing
|
From https://github.com/rust-dc/fish-manpage-completions/pull/96#discussion_r453728093.
The documentation for [`std::io::stdout()`](https://doc.rust-lang.org/stable/std/io/fn.stdout.html) does not mention "flush" anywhere, neither does `Stdout` or `StdoutLock`. I think it would be helpful for the documentation to indicate the behaviour, i.e. if it should be flushed manually or it's flushed once it goes out of scope.
The same would apply for `stderr`. I'm not sure if the behaviour of #23205 has changed since, or whether not documenting flushing was an oversight or intended to allow breakage in that regard.
|
C-enhancement,T-libs-api,A-docs
|
low
|
Minor
|
657,004,263 |
youtube-dl
|
--datebefore now-1day doesn't download videos which are 24 hours old or older
|
<!--
######################################################################
WARNING!
IGNORING THE FOLLOWING TEMPLATE WILL RESULT IN ISSUE CLOSED AS INCOMPLETE
######################################################################
-->
## Checklist
<!--
Carefully read and work through this check list in order to prevent the most common mistakes and misuse of youtube-dl:
- Look through the README (http://yt-dl.org/readme) and FAQ (http://yt-dl.org/faq) for similar questions
- Search the bugtracker for similar questions: http://yt-dl.org/search-issues
- Finally, put x into all relevant boxes (like this [x])
-->
- [x] I'm asking a question
- [ ] I've looked through the README and FAQ for similar questions
- [x] I've searched the bugtracker for similar questions including closed ones
## Question
<!--
Ask your question in an arbitrary form. Please make sure it's worded well enough to be understood, see https://github.com/ytdl-org/youtube-dl#is-the-description-of-the-issue-itself-sufficient.
-->
WRITE QUESTION HERE
I used --datebefore now-1day when downloading all videos on this channel: https://www.youtube.com/channel/UCfwE_ODI1YTbdjkzuSi1Nag/videos
However instead of downloading videos which were created 24 hours ago or older, it downloaded videos which were created 4 hours ago or older. I have to use this instead which does indeed download videos created 2 days ago or older:
--datebefore now-1day
|
question
|
low
|
Critical
|
657,079,895 |
opencv
|
openCV DNN:: cv::ocl::Queue segfault 'scalar deleting destructor' [OpenCL]
|
##### System information (version) #################
- OpenCV => 4.3
- Operating System / Platform => Windows 10, 64 Bit
- Compiler => Visual Studio 2019
##### Detailed description #################
When running a SSD-MobileNet v2 converted from Tensorflow model (pb) using the DNN module. It gives out a result and throws a segfault in the destructor.
` objectDetectionNet.setInput(blob);
cv::Mat output = objectDetectionNet.forward();`
Throws a segfault error.
I could see a [INFO] message that OpenCL is initialized. Hardware is Intel HD graphics.
########### ############
PID 10620 received SIGSEGV for address: 0x718ffb65
OS-Version: 10.0.18362 () 0x100-0x1
00007FFF719385B6 (ntdll): (filename not available): RtlIsGenericTableEmpty
00007FFF7192A056 (ntdll): (filename not available): RtlRaiseException
00007FFF7195FE3E (ntdll): (filename not available): KiUserExceptionDispatcher
00007FFF718FFB65 (ntdll): (filename not available): RtlFreeHeap
00007FFF34B3078C (igdrcl64): (filename not available): clGetCLObjectInfoINTEL
00007FFF34B1E4BE (igdrcl64): (filename not available): clGetCLObjectInfoINTEL
00007FFF3491B634 (igdrcl64): (filename not available): (function-name not available)
00007FFF349197D9 (igdrcl64): (filename not available): (function-name not available)
00007FFF34919284 (igdrcl64): (filename not available): (function-name not available)
00007FFF34903D02 (igdrcl64): (filename not available): (function-name not available)
00007FFF34927876 (igdrcl64): (filename not available): (function-name not available)
D:\cosmos\libs\opencv-4.3.0\modules\core\src\opencl\runtime\autogenerated\opencl_core_impl.hpp (391): OPENCL_FN_clFinish_switch_fn
D:\cosmos\libs\opencv-4.3.0\modules\core\src\ocl.cpp (2656): cv::ocl::Queue::Impl::~Impl
00007FFF0DD90E0C (SiviVision): (filename not available): cv::ocl::Queue::Impl::`scalar deleting destructor'
D:\cosmos\libs\opencv-4.3.0\modules\core\src\ocl.cpp (2689): cv::ocl::Queue::Impl::release
D:\cosmos\libs\opencv-4.3.0\modules\core\src\ocl.cpp (2728): cv::ocl::Queue::~Queue
00007FFF0DB9E5EF (SiviVision): (filename not available): cv::CoreTLSData::~CoreTLSData
00007FFF0DB9F81C (SiviVision): (filename not available): cv::CoreTLSData::`scalar deleting destructor'
D:\cosmos\libs\opencv-4.3.0\modules\core\include\opencv2\core\utils\tls.hpp (80): cv::TLSData<cv::CoreTLSData>::deleteDataInstance
D:\cosmos\libs\opencv-4.3.0\modules\core\src\system.cpp (1543): cv::details::TlsStorage::releaseThread
D:\cosmos\libs\opencv-4.3.0\modules\core\src\system.cpp (1719): cv::details::opencv_fls_destructor
00007FFF719340C9 (ntdll): (filename not available): RtlFlsFree
00007FFF6F2DAA7B (KERNELBASE): (filename not available): FlsFree
D:\cosmos\libs\opencv-4.3.0\modules\core\src\system.cpp (1442): cv::details::TlsAbstraction::~TlsAbstraction
00007FFF106CC3F1 (SiviVision): (filename not available): `cv::details::getTlsAbstraction_'::`2'::`dynamic atexit destructor for 'g_tls''
minkernel\crts\ucrt\src\appcrt\startup\onexit.cpp (206): <lambda_d121dba8a4adeaf3a9819e48611155df>::operator()
vccrt\vcruntime\inc\internal_shared.h (204): __crt_seh_guarded_call<int>::operator()<<lambda_6a47f4c8fd0152770a780fc1d70204eb>,<lambda_d121dba8a4adeaf3a9819e48611155df> &,<lambda_6aaa2265f5b6a89667e7d7630012e97a> >
minkernel\crts\ucrt\inc\corecrt_internal.h (975): __acrt_lock_and_call<<lambda_d121dba8a4adeaf3a9819e48611155df> >
minkernel\crts\ucrt\src\appcrt\startup\onexit.cpp (231): _execute_onexit_table
minkernel\crts\ucrt\src\appcrt\startup\exit.cpp (226): <lambda_6e4b09c48022b2350581041d5f6b0c4c>::operator()
vccrt\vcruntime\inc\internal_shared.h (224): __crt_seh_guarded_call<void>::operator()<<lambda_d80eeec6fff315bfe5c115232f3240e3>,<lambda_6e4b09c48022b2350581041d5f6b0c4c> &,<lambda_2358e3775559c9db80273638284d5e45> >
minkernel\crts\ucrt\inc\corecrt_internal.h (975): __acrt_lock_and_call<<lambda_6e4b09c48022b2350581041d5f6b0c4c> >
minkernel\crts\ucrt\src\appcrt\startup\exit.cpp (259): common_exit
minkernel\crts\ucrt\src\appcrt\startup\exit.cpp (314): _cexit
d:\A01\_work\6\s\src\vctools\crt\vcstartup\src\utility\utility.cpp (407): __scrt_dllmain_uninitialize_c
d:\A01\_work\6\s\src\vctools\crt\vcstartup\src\startup\dll_dllmain.cpp (182): dllmain_crt_process_detach
d:\A01\_work\6\s\src\vctools\crt\vcstartup\src\startup\dll_dllmain.cpp (220): dllmain_crt_dispatch
d:\A01\_work\6\s\src\vctools\crt\vcstartup\src\startup\dll_dllmain.cpp (293): dllmain_dispatch
d:\A01\_work\6\s\src\vctools\crt\vcstartup\src\startup\dll_dllmain.cpp (335): _DllMainCRTStartup
00007FFF718E5021 (ntdll): (filename not available): RtlActivateActivationContextUnsafeFast
00007FFF7192AA82 (ntdll): (filename not available): LdrShutdownProcess
00007FFF7192A92D (ntdll): (filename not available): RtlExitUserProcess
00007FFF6FE1CD8A (KERNEL32): (filename not available): ExitProcess
00007FF702271B49 (node): (filename not available): v8::internal::SetupIsolateDelegate::SetupHeap
00007FF702271AFF (node): (filename not available): v8::internal::SetupIsolateDelegate::SetupHeap
00007FF702245DBF (node): (filename not available): v8::internal::SetupIsolateDelegate::SetupHeap
00007FFF6FE17BD4 (KERNEL32): (filename not available): BaseThreadInitThunk
00007FFF7192CE51 (ntdll): (filename not available): RtlUserThreadStart
|
bug,category: core,category: ocl,platform: win32
|
low
|
Critical
|
657,109,591 |
vscode
|
User settings for language configurations
|
<!-- ⚠️⚠️ Do Not Delete This! feature_request_template ⚠️⚠️ -->
<!-- Please read our Rules of Conduct: https://opensource.microsoft.com/codeofconduct/ -->
<!-- Please search existing issues to avoid creating duplicates. -->
<!-- Describe the feature you'd like. -->
Please add functionality to: set all Autoclosing, Surrounding, Indentation settings and enable Intendation Folding (if possible, on top of language specific one); so they could not be overwritten by Language configs.
When multiple languages are used, the kaleidoscope switching of these settings are disturbing and/or loading the memory for no use. And editing the config files for each language is inconsistent and long.
|
feature-request,languages-basic
|
low
|
Major
|
657,172,495 |
create-react-app
|
Creat react app script not working in vscode
|
PS E:\jitsi\MERN> create-react-app MERN
create-react-app : File C:\Users\marsec developer\AppData\Roaming\npm\create-react-app.ps1 cannot be loaded because running scripts is disabled
on this system. For more information, see about_Execution_Policies at https:/go.microsoft.com/fwlink/?LinkID=135170.
At line:1 char:1
+ create-react-app MERN
+ CategoryInfo : SecurityError: (:) [], PSSecurityException
+ FullyQualifiedErrorId : UnauthorizedAccess
PS E:\jitsi\MERN> create-react-app mern
create-react-app : File C:\Users\marsec developer\AppData\Roaming\npm\create-react-app.ps1 cannot be loaded because running scripts is disabled
on this system. For more information, see about_Execution_Policies at https:/go.microsoft.com/fwlink/?LinkID=135170.
At line:1 char:1
+ create-react-app mern
+ ~~~~~~~~~~~~~~~~
+ CategoryInfo : SecurityError: (:) [], PSSecurityException
+ FullyQualifiedErrorId : UnauthorizedAccess
PS E:\jitsi\MERN> create-react-app
create-react-app : File C:\Users\marsec developer\AppData\Roaming\npm\create-react-app.ps1 cannot be loaded because running scripts is disabled
on this system. For more information, see about_Execution_Policies at https:/go.microsoft.com/fwlink/?LinkID=135170.
At line:1 char:1
+ create-react-app
+ ~~~~~~~~~~~~~~~~
+ CategoryInfo : SecurityError: (:) [], PSSecurityException
+ FullyQualifiedErrorId : UnauthorizedAccess
If you're looking for general information on using React, the React docs have a list of resources: https://reactjs.org/community/support.html
If you've discovered a bug or would like to propose a change please use one of the other issue templates.
Thanks!
|
stale,needs triage
|
low
|
Critical
|
657,203,549 |
godot
|
Cryptic GDScript Error Message for A Beginner Programming Mistake - "Unexpected token"
|
**Godot version:** v3.2.2 stable
**OS/device including version:** Windows 7
**Issue description:**
This 1-line beginner program throws a cryptic error message:
> print("Hello World")
Corresponding error message:
> "Unexpected token: Built-In Func:"
And it's elaborated on in the Errors tab as:
> "get_token_identifier: Condition "tk_rb[ofs].type != TK_IDENTIFIER" is true. Returned: StringName()"
**Expected Behavior**: GDScript is advertised to new users for its similarity to Python. So it's bad when trivial code doesn't work for incomprehensible reasons - nobody should have to check documentation or have to google to debug a "Hello World" program.
**How to Fix it**: GDScript doesn't like the code above because you aren't allowed to do much of anything but define variables or functions at the base level of a script. So either make the reason for this specific error message crystal clear, or make the "Unexpected token" error message in general more clear.
**Elaboration**: Comprehensible error messages are very important for programming. Personally, I tried Godot Engine and GDScript for the reasons mentioned above, then got this bizarre error even when following basic, community-approved programming tutorials. For instance, I followed this tutorial by GDQuest (https://www.youtube.com/watch?v=UcdwP1Q2UlU ), and copying the code on most of the slides in that video causes the error mentioned in this issue, unless you code inside a function like _ready. Naturally, an incomprehensible error message in that situation is *really bad*.
|
enhancement,topic:gdscript,usability
|
low
|
Critical
|
657,207,623 |
flutter
|
CupertinoTextSelectionToolbar doesn't vertically centre align text in Chinese language
|
1. Setup localizations settings
pubspec.yaml
```
flutter_localizations:
sdk: flutter
```
MyApp
```
class MyApp extends StatelessWidget {
// This widget is the root of your application.
@override
Widget build(BuildContext context) {
return MaterialApp(
title: 'Flutter Demo',
theme: ThemeData(
primarySwatch: Colors.blue,
visualDensity: VisualDensity.adaptivePlatformDensity,
),
localizationsDelegates: [
GlobalCupertinoLocalizations.delegate,
DefaultCupertinoLocalizations.delegate,
GlobalMaterialLocalizations.delegate,
GlobalWidgetsLocalizations.delegate,
],
supportedLocales: [
const Locale('zh', 'CH'),
const Locale('en', 'US'),
],
locale: Locale('zh', 'CH'),
home: MyHomePage(title: 'Flutter Demo Home Page'),
);
}
}
```
2. Put a TextField to page.
```
Padding(
padding: EdgeInsets.fromLTRB(20, 0, 20, 0),
child: TextField(),
),
```
3. Double tap TextField will show CupertinoTextSelectionToolbar in Chinese, it will not display center.
<img width="406" alt="WX20200715-172840@2x" src="https://user-images.githubusercontent.com/11239033/87528825-a7d50f00-c6c0-11ea-8de4-12fbf416ef22.png">
when I change the language to en, it will display correct.
```
locale: Locale('en', 'US'),
// locale: Locale('zh', 'CH'),
```
<img width="442" alt="WX20200715-173057@2x" src="https://user-images.githubusercontent.com/11239033/87529029-f682a900-c6c0-11ea-995a-1f736a1ee052.png">
flutter doctor -v
```
[✓] Flutter (Channel stable, v1.17.5, on Mac OS X 10.15.5 19F101, locale en)
• Flutter version 1.17.5 at /Users/wangyu/Yu/flutter
• Framework revision 8af6b2f038 (2 weeks ago), 2020-06-30 12:53:55 -0700
• Engine revision ee76268252
• Dart version 2.8.4
[!] Android toolchain - develop for Android devices (Android SDK version 29.0.3)
• Android SDK at /Users/wangyu/Library/Android/sdk
• Platform android-29, build-tools 29.0.3
• Java binary at: /Applications/Android
Studio.app/Contents/jre/jdk/Contents/Home/bin/java
• Java version OpenJDK Runtime Environment (build
1.8.0_242-release-1644-b3-6222593)
✗ Android license status unknown.
Try re-installing or updating your Android SDK Manager.
See https://developer.android.com/studio/#downloads or visit visit
https://flutter.dev/docs/get-started/install/macos#android-setup for
detailed instructions.
[✓] Xcode - develop for iOS and macOS (Xcode 11.5)
• Xcode at /Applications/Xcode.app/Contents/Developer
• Xcode 11.5, Build version 11E608c
• CocoaPods version 1.9.1
[!] Android Studio (version 4.0)
• Android Studio at /Applications/Android Studio.app/Contents
✗ Flutter plugin not installed; this adds Flutter specific functionality.
✗ Dart plugin not installed; this adds Dart specific functionality.
• Java version OpenJDK Runtime Environment (build
1.8.0_242-release-1644-b3-6222593)
[✓] IntelliJ IDEA Ultimate Edition (version 2019.2.2)
• IntelliJ at /Applications/IntelliJ IDEA.app
• Flutter plugin version 31.3.3
• Dart plugin version 182.5124
[✓] VS Code (version 1.47.0)
• VS Code at /Applications/Visual Studio Code.app/Contents
• Flutter extension version 3.12.2
[✓] Connected device (1 available)
• iPhone 11 Pro Max • B3A87334-6C79-4ADD-A38E-BF76EC71D171 • ios •
com.apple.CoreSimulator.SimRuntime.iOS-13-5 (simulator)
! Doctor found issues in 2 categories.
```
|
a: text input,framework,a: internationalization,f: cupertino,has reproducible steps,P2,found in release: 3.3,found in release: 3.7,team-design,triaged-design
|
low
|
Major
|
657,211,837 |
realworld
|
Bearer Authentication
|
In the API spec `swagger.json`, the authentication scheme is defined as:
```
"Token": {
"description": "For accessing the protected API resources, you must have received a a valid JWT token after registering or logging in. This JWT token must then be used for all protected resources by passing it in via the 'Authorization' header.\n\nA JWT token is generated by the API by either registering via /users or logging in via /users/login.\n\nThe following format must be in the 'Authorization' header :\n\n Token: xxxxxx.yyyyyyy.zzzzzz\n \n",
"type": "apiKey",
"name": "Authorization",
"in": "header"
}
```
Shouldn't it be of `"type": "http"`, `"scheme": "bearer"`, `"bearerFormat": "JWT"`?
|
help wanted,good first issue,Status: Approved,v2 changelog
|
low
|
Minor
|
657,257,334 |
go
|
runtime: reducing preemption in suspendG when G is running large nosplit functions
|
<!--
Please answer these questions before submitting your issue. Thanks!
For questions please use one of our forums: https://github.com/golang/go/wiki/Questions
-->
### What version of Go are you using (`go version`)?
<pre>
$ go version
tip version, on arm64
</pre>
### Does this issue reproduce with the latest release?
Yes.
### What operating system and processor architecture are you using (`go env`)?
<details><summary><code>go env</code> Output</summary><br><pre>
$ go env
</pre></details>
GO111MODULE=""
GOARCH="arm64"
GOBIN=""
GOCACHE="/home/xiaji01/.cache/go-build"
GOENV="/home/xiaji01/.config/go/env"
GOEXE=""
GOFLAGS=""
GOHOSTARCH="arm64"
GOHOSTOS="linux"
GOINSECURE=""
GOMODCACHE="/home/xiaji01/.go/pkg/mod"
GONOPROXY=""
GONOSUMDB=""
GOOS="linux"
GOPATH="/home/xiaji01/.go"
GOPRIVATE=""
GOPROXY="https://proxy.golang.org,direct"
GOROOT="/home/xiaji01/src/go.gc"
GOSUMDB="sum.golang.org"
GOTMPDIR=""
GOTOOLDIR="/home/xiaji01/src/go.gc/pkg/tool/linux_arm64"
GCCGO="gccgo"
AR="ar"
CC="gcc"
CXX="g++"
CGO_ENABLED="1"
GOMOD="/home/xiaji01/src/go.gc/src/go.mod"
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
PKG_CONFIG="pkg-config"
GOGCCFLAGS="-fPIC -pthread -fmessage-length=0 -fdebug-prefix-map=/tmp/go-build944660995=/tmp/go-build -gno-record-gcc-switches"
### What did you do?
<!--
If possible, provide a recipe for reproducing the error.
A complete runnable program is good.
A link on play.golang.org is best.
-->
live-lock problems are spotted on arm64 in a couple of micro benchmarks from text/tabwriter (there should be more similar cases).
If a goroutine is running 'nosplit' functions which are time consuming, like
bulkBarrierPreWriteSrcOnly
memmove
called in growslice when the slice is a large one, and its background worker tries to suspend it to do stack scanning, the G under preemption may hardly make progress, especially on arm64 machines which seem to experience poor signal handling performance.
pprof data of BenchmarkTable/1x100000/new on an arm64 machine:
```
(pprof) top
Showing nodes accounting for 12.46s, 95.70% of 13.02s total
Dropped 118 nodes (cum <= 0.07s)
Showing top 10 nodes out of 40
flat flat% sum% cum cum%
5.41s 41.55% 41.55% 5.41s 41.55% runtime.futex
3.22s 24.73% 66.28% 3.59s 27.57% runtime.nanotime (inline)
0.99s 7.60% 73.89% 0.99s 7.60% runtime.tgkill
0.84s 6.45% 80.34% 0.84s 6.45% runtime.osyield
0.77s 5.91% 86.25% 0.77s 5.91% runtime.epollwait
0.37s 2.84% 89.09% 0.37s 2.84% runtime.nanotime1
0.33s 2.53% 91.63% 6.38s 49.00% runtime.suspendG
0.30s 2.30% 93.93% 0.30s 2.30% runtime.getpid
0.14s 1.08% 95.01% 0.14s 1.08% runtime.procyield
0.09s 0.69% 95.70% 1.38s 10.60% runtime.preemptM (inline)
```
I'm thinking to introduce a flag into G to indicate whether it's running a time-consuming nosplit function and let suspendG yield to avoid the live-lock, the flag is set manually for known functions, I tried it for bulkBarrierPreWriteSrcOnly and memmove in runtime.growslice and runtime.makeslicecopy when the slice is longer than a threshold (select 4K for now), the text/tabwriter package witnessed significant improvement on arm64:
arm64-1 perf:
```
name old time/op new time/op delta
Table/1x10/new-224 6.59µs ± 8% 6.67µs ± 7% ~ (p=0.841 n=5+5)
Table/1x10/reuse-224 1.94µs ± 1% 1.94µs ± 1% ~ (p=0.802 n=5+5)
Table/1x1000/new-224 494µs ±13% 381µs ± 3% -22.85% (p=0.008 n=5+5)
Table/1x1000/reuse-224 185µs ± 0% 185µs ± 0% -0.37% (p=0.016 n=5+4)
Table/1x100000/new-224 2.73s ±73% 0.04s ± 2% -98.46% (p=0.008 n=5+5)
Table/1x100000/reuse-224 4.25s ±76% 0.02s ± 1% -99.55% (p=0.008 n=5+5)
Table/10x10/new-224 20.7µs ± 6% 20.1µs ± 5% ~ (p=0.421 n=5+5)
Table/10x10/reuse-224 8.89µs ± 0% 8.91µs ± 0% +0.21% (p=0.032 n=5+5)
Table/10x1000/new-224 1.70ms ± 7% 1.59ms ± 6% ~ (p=0.151 n=5+5)
Table/10x1000/reuse-224 908µs ± 0% 902µs ± 0% -0.59% (p=0.032 n=5+5)
Table/10x100000/new-224 2.34s ±62% 0.14s ± 2% -94.21% (p=0.008 n=5+5)
Table/10x100000/reuse-224 911ms ±72% 103ms ± 2% -88.66% (p=0.008 n=5+5)
Table/100x10/new-224 143µs ±15% 138µs ± 5% ~ (p=0.841 n=5+5)
Table/100x10/reuse-224 78.1µs ± 0% 78.1µs ± 0% ~ (p=0.841 n=5+5)
Table/100x1000/new-224 13.1ms ± 6% 11.9ms ± 5% -9.16% (p=0.008 n=5+5)
Table/100x1000/reuse-224 8.13ms ± 0% 8.15ms ± 1% ~ (p=1.000 n=5+5)
Table/100x100000/new-224 1.29s ±17% 1.31s ±10% ~ (p=0.310 n=5+5)
Table/100x100000/reuse-224 1.23s ± 2% 1.26s ± 5% ~ (p=0.286 n=4+5)
```
arm64-2 perf:
```
name old time/op new time/op delta
Table/1x10/new-64 4.33µs ± 1% 5.40µs ± 4% +24.92% (p=0.004 n=6+5)
Table/1x10/reuse-64 1.77µs ± 0% 1.77µs ± 0% -0.36% (p=0.024 n=6+6)
Table/1x1000/new-64 318µs ±10% 379µs ±10% +19.04% (p=0.008 n=5+5)
Table/1x1000/reuse-64 172µs ± 0% 171µs ± 0% ~ (p=0.537 n=6+5)
Table/1x100000/new-64 4.26s ±88% 0.05s ± 4% -98.77% (p=0.002 n=6+6)
Table/1x100000/reuse-64 4.79s ±73% 0.02s ± 2% -99.61% (p=0.004 n=6+5)
Table/10x10/new-64 14.6µs ± 3% 16.4µs ± 9% +12.51% (p=0.004 n=5+6)
Table/10x10/reuse-64 8.76µs ± 0% 8.79µs ± 0% ~ (p=0.329 n=5+6)
Table/10x1000/new-64 1.18ms ± 3% 1.32ms ± 4% +12.12% (p=0.002 n=6+6)
Table/10x1000/reuse-64 890µs ± 0% 897µs ± 0% +0.84% (p=0.002 n=6+6)
Table/10x100000/new-64 1.43s ±36% 0.16s ± 3% -88.56% (p=0.004 n=5+6)
Table/10x100000/reuse-64 375ms ±55% 138ms ±11% -63.31% (p=0.004 n=5+6)
Table/100x10/new-64 103µs ± 0% 105µs ± 4% ~ (p=0.429 n=5+6)
Table/100x10/reuse-64 79.6µs ± 0% 80.0µs ± 1% ~ (p=0.329 n=5+6)
Table/100x1000/new-64 10.2ms ± 3% 10.5ms ± 1% ~ (p=0.052 n=6+5)
Table/100x1000/reuse-64 8.75ms ± 0% 9.23ms ± 6% ~ (p=0.126 n=5+6)
Table/100x100000/new-64 1.42s ± 6% 1.46s ±11% ~ (p=0.394 n=6+6)
Table/100x100000/reuse-64 1.40s ± 0% 1.45s ± 6% ~ (p=0.690 n=5+5)
Pyramid/10-64 15.3µs ±45% 14.5µs ±20% ~ (p=0.662 n=6+5)
Pyramid/100-64 1.16ms ±13% 0.88ms ±11% -23.90% (p=0.002 n=6+6)
Pyramid/1000-64 71.6ms ± 8% 77.8ms ±12% ~ (p=0.056 n=5+5)
Ragged/10-64 13.2µs ±17% 14.0µs ± 2% ~ (p=0.792 n=6+5)
Ragged/100-64 104µs ± 3% 123µs ± 2% +18.21% (p=0.008 n=5+5)
Ragged/1000-64 1.12ms ±12% 1.35ms ± 9% +20.55% (p=0.002 n=6+6)
Code-64 3.51µs ± 1% 3.80µs ± 3% +8.46% (p=0.004 n=5+6)
```
x86 perf:
```
name old time/op new time/op delta
Table/1x10/new-32 5.36µs ± 2% 5.58µs ± 3% +4.03% (p=0.004 n=6+6)
Table/1x10/reuse-32 1.50µs ± 8% 1.48µs ± 0% ~ (p=0.433 n=6+5)
Table/1x1000/new-32 318µs ± 2% 355µs ± 2% +11.43% (p=0.004 n=5+6)
Table/1x1000/reuse-32 127µs ± 0% 134µs ± 1% +5.36% (p=0.004 n=6+5)
Table/1x100000/new-32 49.9ms ± 3% 48.1ms ± 3% -3.57% (p=0.026 n=6+6)
Table/1x100000/reuse-32 13.8ms ± 1% 15.2ms ± 1% +9.87% (p=0.002 n=6+6)
Table/10x10/new-32 17.4µs ± 3% 17.6µs ± 2% ~ (p=0.310 n=6+6)
Table/10x10/reuse-32 7.20µs ± 1% 7.21µs ± 0% ~ (p=0.429 n=5+6)
Table/10x1000/new-32 1.38ms ± 1% 1.43ms ± 2% +4.16% (p=0.002 n=6+6)
Table/10x1000/reuse-32 687µs ± 1% 693µs ± 0% ~ (p=0.052 n=6+5)
Table/10x100000/new-32 131ms ± 2% 133ms ± 5% ~ (p=0.699 n=6+6)
Table/10x100000/reuse-32 89.2ms ± 2% 90.3ms ± 2% ~ (p=0.177 n=5+6)
Table/100x10/new-32 122µs ± 1% 122µs ± 1% ~ (p=0.632 n=6+5)
Table/100x10/reuse-32 62.3µs ± 0% 62.4µs ± 0% ~ (p=0.429 n=5+6)
Table/100x1000/new-32 12.2ms ± 4% 12.0ms ± 3% ~ (p=0.180 n=6+6)
Table/100x1000/reuse-32 6.29ms ± 0% 6.32ms ± 0% +0.54% (p=0.015 n=6+6)
Table/100x100000/new-32 1.01s ± 2% 1.00s ± 4% ~ (p=0.429 n=6+5)
Table/100x100000/reuse-32 972ms ±10% 962ms ±18% ~ (p=1.000 n=6+6)
Pyramid/10-32 14.3µs ± 4% 14.8µs ± 6% ~ (p=0.240 n=6+6)
Pyramid/100-32 833µs ± 2% 841µs ± 2% ~ (p=0.394 n=6+6)
Pyramid/1000-32 53.5ms ± 1% 56.2ms ± 3% +4.98% (p=0.004 n=5+6)
Ragged/10-32 15.1µs ± 0% 14.8µs ± 1% -1.75% (p=0.008 n=5+5)
Ragged/100-32 127µs ± 4% 130µs ± 2% ~ (p=0.180 n=6+6)
Ragged/1000-32 1.27ms ± 5% 1.33ms ± 3% +3.96% (p=0.026 n=6+6)
Code-32 3.75µs ± 1% 3.81µs ± 2% +1.67% (p=0.048 n=5+6)
```
The potential overhead is acquiring the current G in the two slice functions, which seem to be tiny.
I'm working on benchmarking more packages and evaluate its impact to x86 platform.
Any comment is highly appreciated.
### What did you expect to see?
Better performance.
### What did you see instead?
|
Performance,NeedsInvestigation,compiler/runtime
|
low
|
Critical
|
657,293,506 |
electron
|
WebAuthn FIDO/FIDO2 Support
|
<!-- As an open source project with a dedicated but small maintainer team, it can sometimes take a long time for issues to be addressed so please be patient and we will get back to you as soon as we can.
-->
### Preflight Checklist
<!-- Please ensure you've completed the following steps by replacing [ ] with [x]-->
* [x] I have read the [Contributing Guidelines](https://github.com/electron/electron/blob/master/CONTRIBUTING.md) for this project.
* [x] I agree to follow the [Code of Conduct](https://github.com/electron/electron/blob/master/CODE_OF_CONDUCT.md) that this project adheres to.
* [x] I have searched the issue tracker for an issue that matches the one I want to file, without success.
### Issue Details
* **Electron Version:**
* <!-- (output of `node_modules/.bin/electron --version`) e.g. 4.0.3 --> 8.4.0, 9, 10, (added 07.04.2021) 11, 12
* **Operating System:**
* <!-- (Platform and Version) e.g. macOS 10.13.6 / Windows 10 (1803) / Ubuntu 18.04 x64 --> macOS 10.15.5
* **Last Known Working Electron version:**
* <!-- (if applicable) e.g. 3.1.0 --> -
It is not clear how to make [WebAuthn](https://w3c.github.io/webauthn/) works in Electron app if page is local not from webserver.
### Expected Behavior
<!-- A clear and concise description of what you expected to happen. -->
WebAuthn works if page loaded from `standard` and `secure` scheme: https://www.electronjs.org/docs/api/protocol#protocolregisterschemesasprivilegedcustomschemes
### Actual Behavior
<!-- A clear and concise description of what actually happened. -->
I've faced with the following error:
```
Uncaught (in promise) DOMException: Public-key credentials are only available to HTTPS origin or HTTP origins that fall under 'localhost'. See https://crbug.com/824383
```
### To Reproduce
<!--
Your best chance of getting this bug looked at quickly is to provide an example.
-->
https://gist.github.com/mahnunchik/165a117564ebc632a3723d2666f5024c
<!--
For bugs that can be encapsulated in a small experiment, you can use Electron Fiddle (https://github.com/electron/fiddle) to publish your example to a GitHub Gist and link it your bug report.
-->
<!--
If Fiddle is insufficient to produce an example, please provide an example REPOSITORY that can be cloned and run. You can fork electron-quick-start (https://github.com/electron/electron-quick-start) and include a link to the branch with your changes.
-->
<!--
If you provide a URL, please list the commands required to clone/setup/run your repo e.g.
```sh
$ git clone $YOUR_URL -b $BRANCH
$ npm install
$ npm start || electron .
```
-->
### Additional Information
<!-- Add any other context about the problem here. -->
Related issues:
* [WebAuthn Support #15404](https://github.com/electron/electron/issues/15404)
* [protocol.intercept{Any}Protocol handler ability to call original handler #15434](https://github.com/electron/electron/issues/15434)
|
enhancement :sparkles:
|
high
|
Critical
|
657,489,534 |
pytorch
|
Implement backend fallback for Tracer
|
Now that @ljk53 has extracted tracing functionality into a separate dispatch key, we should now be able to write a single generic fallback for tracing. This is in two parts:
1. Write the generic fallback. This will give us automatic support for tracing custom ops
2. Remove all code generated tracing for anything that is subsumed by the fallback
cc @ezyang @bhosmer @smessmer @ljk53
|
module: internals,triaged
|
low
|
Minor
|
657,534,592 |
pytorch
|
GLOO infiniband with PyTorch
|
## 🚀 Feature
## Motivation
* From https://discuss.pytorch.org/t/gloo-and-infiniband/89303. Some GPUs like RTX2080ti GPUs do not support GPUDirect/RDMA anyway.
* With GPUs w/ GPUDirect/RDMA, in some scenarios we still would like to do CPU RDMA to avoid DtoH memory copy which causes certain synchronicity and breaks the pipelining.
For these use cases, GLOO infiniband could help achieve lower latency and higher bandwidth, and remove host/device synchronicity.
## Pitch
GLOO has an ibverbs transport in place https://github.com/facebookincubator/gloo/tree/master/gloo/transport/ibverbs. However it was not tested or used with PyTorch. We would like to test and integrate with PyTorch c10d library.
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @xush6528 @osalpekar @jiayisuse @agolynski
|
oncall: distributed,feature,triaged
|
low
|
Minor
|
657,547,107 |
pytorch
|
LSTMs leak memory in CPU PyTorch 1.5.1, 1.6, and 1.7 on Linux
|
## 🐛 Bug
On Linux, when using the CPU (whether a CPU device in a CUDA-capable PyTorch, or using a CPU-only PyTorch distribution), merely _instantiating_ modules with an LSTM in them claims memory that is never released until the process is killed. _Training_ using one of these modules consumes more and more memory during training, in what seems to be a nondeterministic way. I have reproduced this in PyTorch 1.5.1, 1.6.0, and 1.7.0 on Linux.
Oddly, the _MacOS_ CPU-only PyTorch distribution _does not_ leak in this way.
I was not able to resolve the leak in the below allocation test (tested with the 1.6 nightly) using any combination of `MKL_DISABLE_FAST_MM=1` or `OMP_NUM_THREADS=4`, so I believe this leak is distinct from other issues I came across trying to troubleshoot it.
## To Reproduce
Steps to reproduce the behavior:
1. On Linux, using any of PyTorch `1.5.1+cpu`, `1.6.0.dev20200625+cpu`, or `1.7.0.dev20200715+cpu`, run the below allocation_test.py script
1. Using `htop`, find the PID output near the top of the script. You should see that the resident set (`RES`) for this process in memory is near 1GB (on my machine, 946M).
1. Once it finishes the deallocation step, note that a very small amount of memory has been recovered, but most of it has not been.
1. Repeat these steps on MacOS and notice that the memory is almost entirely recovered (on my machine, a little under 100MB is left resident, and increasing the size of the test doesn't increase this much on MacOS).
```{python}
# allocation_test.py
import os
import torch
import torch.nn as nn
import gc
from time import sleep
print(os.getpid())
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
throwaway = torch.ones((1,1)).to(device) # load CUDA context
class Encoder(nn.Module):
def __init__(self, input_dim, hidden_dim, n_layers, dropout_perc):
super().__init__()
self.hidden_dim, self.n_layers = (hidden_dim, n_layers)
self.rnn = nn.LSTM(input_dim,hidden_dim,n_layers,dropout=dropout_perc)
def forward(self,x):
outputs, (hidden, cell) = self.rnn(x)
return hidden, cell
print('allocating memory')
pile=[]
for i in range(1500):
pile.append(Encoder(102,64,4,0.5).to(device))
print('waiting two seconds')
sleep(2)
print('hypothetically de-allocating memory')
del pile
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
print('waiting forever')
while True:
sleep(1)
```
## Expected behavior
The MacOS behavior (near-immediate full recovery of all memory allocated by the LSTM module) is expected on Linux as well.
## Environment
Collecting environment information...
PyTorch version: 1.5.1+cpu
Is debug build: No
CUDA used to build PyTorch: Could not collect
OS: Ubuntu 18.04.4 LTS
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
CMake version: version 3.10.2
Python version: 3.8
Is CUDA available: No
CUDA runtime version: Could not collect
GPU models and configuration:
GPU 0: GeForce GTX 1080 Ti
GPU 1: GeForce GTX 1080 Ti
Nvidia driver version: 440.100
cuDNN version: /usr/local/cuda-9.2/targets/x86_64-linux/lib/libcudnn.so.7.2.1
Versions of relevant libraries:
[pip3] numpy==1.19.0
[pip3] torch==1.5.1+cpu
[conda] Could not collect
## Additional context
There is some other diagnostic information and discussion here:
https://discuss.pytorch.org/t/lstm-on-cpu-wont-release-memory-when-all-refs-deleted/89026
cc @ezyang @gchanan @zou3519 @VitalyFedyunin
|
high priority,module: rnn,module: cpu,module: memory usage,triaged
|
medium
|
Critical
|
657,582,430 |
rust
|
Emit noundef LLVM attribute
|
LLVM 11 introduces a new `noundef` attribute, with the following semantics:
> This attribute applies to parameters and return values. If the value representation contains any undefined or poison bits, the behavior is undefined. Note that this does not refer to padding introduced by the type’s storage representation.
In LLVM 11 itself it doesn't do anything yet, but this will become important in the future to reduce the impact of `freeze` instructions.
We need to figure out for which parameters / return values we can emit this attribute. We generally can't do so if any bits are unspecified, e.g. due to padding. More problematic for Rust is https://github.com/rust-lang/unsafe-code-guidelines/issues/71, i.e. the question of whether integers are allowed to contain uninitialized bits without going through something like MaybeUninit.
If we go with aggressive emission of noundef, we probably need to ~~punish~~ safe-guard `mem::uninitialized()` users with liberal application of `freeze`.
cc @RalfJung
|
A-LLVM,T-compiler
|
low
|
Major
|
657,592,151 |
pytorch
|
Make torch.iinfo/torch.finfo torchscriptable
|
It would be helpful for torch.iinfo, torch.finfo, and other dtype attributes like is_floating_point to be torch scriptable.
## Motivation
Information like `torch.iinfo(dtype).max` (and `dtype.is_floating_point`) can be helpful in image transformations, but can't be used in transformations that need to be scriptable.
E.g.:
https://github.com/pytorch/vision/blob/master/torchvision/transforms/functional.py#L164
## Alternatives
for dtype.is_floating_point we can workaround by using torch.empty(0, dtype=dtype).is_floating_point(), but I'm not aware of a scriptable alternative for getting other dtype info like `max`.
## Additional context
This came up as part of this PR:
https://github.com/pytorch/vision/pull/2459
cc @ezyang @gchanan @zou3519 @suo @gmagogsfm
|
triage review,oncall: jit,days
|
low
|
Minor
|
657,599,927 |
rust
|
Should include crate name in error message for E0391 (and perhaps others)
|
While doing a bootstrap build of the compiler with some other build artifacts lying around, I saw the following error message (a small snippet from whole output):
```
[RUSTC-TIMING] cfg_if test:false 0.035
Compiling lock_api v0.3.4
[RUSTC-TIMING] scopeguard test:false 0.068
Compiling crossbeam-utils v0.6.5
Compiling tracing-core v0.1.10
Compiling log_settings v0.1.2
error[E0391]: cycle detected when running analysis passes on this crate
|
= note: ...which again requires running analysis passes on this crate, completing the cycle
error: aborting due to previous error
For more information about this error, try `rustc --explain E0391`.
error[E0391]: cycle detected when running analysis passes on this crate
|
= note: ...which again requires running analysis passes on this crate, completing the cycle
[RUSTC-TIMING] lazy_static test:false 0.079
error: aborting due to previous error
```
It is sub-optimal to say "on this crate" in a diagnostic like this.
Multiple crates can be compiled in parallel, and thus it can be ambiguous which crate a diagnostic like that is associated with.
In general it would be better to extract a crate name, if possible, and include that in the message, rather than using the simpler-but-potentially-ambiguous "on this crate."
|
A-diagnostics,T-compiler,C-bug
|
low
|
Critical
|
657,617,744 |
godot
|
[4.0] External changes to shader overwritten if builtin editor has ever shown that shader
|
**Godot version:**
4.0.dev.calinou.3ed5ff244
**OS/device including version:**
Windows 10.0.18362.900, NVIDIA / Vulkan
**Issue description:**
When a shader is changed from an external program, it is updated as expected. However, if the shader is opened in the text editor (double clicking the shader resource, or selecting it in a material), the original contents of the shader are displayed.
If the text editor is hidden/closed, the in-memory shader is replaced with the original version, even though the on-disk contents contain the external shader, and this state persists until the project is closed and later reopened. (When the project is closed or saved, the shader on disk is overwritten with an old copy.)
So basically, the behavior here depends on whether the shader code editor at the bottom has ever been viewed for a given shader (such as by expanding a ShaderMaterial) or not, within a given godot editor session.
**Steps to reproduce:**
(If using the attached project, open BUG.tscn and skip steps 1-2)
1. Create sprite with a simple shader, and save it to file:
```
shader_type canvas_item;
render_mode unshaded;
void fragment() {
COLOR = vec4(1.0,1.0,0.0,1.0);
}
```
2. Quit to Project List and reopen (optional).
3. Open the shader in VS Code or another external text editor.
4. Open the scene, and observe the object is yellow.
5. In the external editor, modify the color to `vec4(0.0,1.0,0.0,1.0);` (green)
6. Alt-tab back to Godot, observe that the object is now green.
7. Double-click the shader, or expand the ShaderMaterial section of the inspector.
8. Observe that the code editor shows the new code: `vec4(0.0,1.0,0.0,1.0)` (green).
9. In the external editor, modify the color to `vec4(1.0,0.0,1.0,1.0);` (pink)
10. Alt-tab back to Godot, observe that the object is now pink.
11. Observe that the code editor still shows the previous code: `vec4(0.0,1.0,0.0,1.0)` (green).
12. select the root Node2d in the scene, such that the code editor closes.
13. The object color has reverted to green.
14. Quit to Project List and reopen. (Alternatively hit ctrl-S to save all resources).
15. The object in the scene is still green.
16. Observe that the shader on disk is overwritten with the old version previous visible in the code editor: both the code editor and the external editor show `vec4(0.0,1.0,0.0,1.0);` (green)
---
17. This process can now be repeated indefinitely: undo and save the old shader in the external editor, and observe that it is reflected.
18. Hit ctrl-s in godot editor and the shader is reverted both in scene and on disk.
etc.
19. Quit to Project List and reopen.
20. Now, never open the shader in the text editor (do not select the shader or expand the ShaderMaterial).
21. Change the shader externally and save.
22. Open godot and observe that the shader is updated.
23. Hit ctrl-s in godot. The shader on disk is *not* reverted, and nothing changes in the scene. This is the same result we observed in steps 5-8 earlier.
**Minimal reproduction project:**
[ExternalEditTest.zip](https://github.com/godotengine/godot/files/4927636/ExternalEditTest.zip)
|
bug,topic:editor,topic:shaders
|
low
|
Critical
|
657,643,862 |
opencv
|
Moves for basic types have copy semantics
|
PR 11899 manually implemented moves for types like Point and Rect. std::move() leaves source POD values unchanged, so all this extra code has no apparent effect.
A better idiom would be e.g. `width(std::exchange(r.width, 0))`.
|
category: build/install,RFC
|
low
|
Minor
|
657,676,538 |
pytorch
|
Helping test example code blocks in the docs
|
## 📚 Documentation
<!-- A clear and concise description of what content in https://pytorch.org/docs is an issue. If this has to do with the general https://pytorch.org website, please file an issue at https://github.com/pytorch/pytorch.github.io/issues/new/choose instead. If this has to do with https://pytorch.org/tutorials, please file an issue at https://github.com/pytorch/tutorials/issues/new -->
Hello, I noticed this older issue https://github.com/pytorch/pytorch/issues/6662 is still open and looked through this PR https://github.com/pytorch/pytorch/pull/24435 about adding `doctest` to jit. If it would be helpful I can work on other parts of the docs to convert code blocks to use `doctest`. Currently it seems there are over 400 code blocks in the docs using the format `Example::` that are not being tested, e.g. a bunch are in this [file](https://github.com/pytorch/pytorch/blob/master/torch/_torch_docs.py).
cc @jlin27 @mruberry @VitalyFedyunin
|
module: docs,feature,module: tests,triaged
|
low
|
Major
|
657,734,703 |
vscode
|
Allow tooltips/hovering on symbols in outline view and breadcrumbs
|
<!-- ⚠️⚠️ Do Not Delete This! feature_request_template ⚠️⚠️ -->
<!-- Please read our Rules of Conduct: https://opensource.microsoft.com/codeofconduct/ -->
<!-- Please search existing issues to avoid creating duplicates. -->
<!-- Describe the feature you'd like. -->
Currently, the information which breadcrumbs and the outline view can provide is limited to two strings: the title and the "detail" (breadcrumbs are not even able to display the detail string). For the underlying complexity of the information being presented, this seems quite limiting.
In order to optionally provide more information about a symbol (and without cluttering the UI), it would be really nice if if symbols could at least provide a tooltip, through an extremely simple `DocumentSymbol.tooltip: string` property (basically identical to the underlying tooltip property of `TreeItem`).
If this feature were to be taken all the way, hovering over symbols in the breadcrumbs or outline view could display information about the symbol from the document's registered HoverProvider for the symbol's selectionRange. This could be enabled/disabled on a symbol-by-symbol basis (something along the lines of `DocumentSymbol.triggerhoverprovider: boolean`). This would make the breadcrumbs and outline view significantly more useful for understanding the structure of a document without fully diving into the code.
### Bad behaviour
*unhelpful, repetitive, ugly: i already know the name of the symbol, it's just there*
### Good behaviour

*helpful, useful, and pretty: the only way I could know what this part of the document does is by clicking the symbol and hovering over it in the editor*
DocumentSymbols help explain the structure of the code - why limit this explanation to the name, especially when there's more information about them so readily available?
|
feature-request,outline,breadcrumbs
|
low
|
Minor
|
657,738,751 |
pytorch
|
nn.MultiheadAttention causes gradients to become NaN under some use cases
|
## 🐛 Bug
Using key_padding_mask and attn_mask with nn.MultiheadAttention causes gradients to become NaN under some use cases.
## To Reproduce
Steps to reproduce the behavior:
Backwards pass through nn.MultiheadAttention layer where the forward pass used:
1. attn_mask limiting context in both directions (e.g. bucketed attention)
2. key_padding_mask where there is padding for at least one sequence (and there is also at least one valid entry for every sequence, as expected)
3. The dimensions that were masked are not used to calculate the loss
4. The loss is a real number (not NaN)
```python
import torch
torch.manual_seed(0)
'''Create attention layer'''
attn = torch.nn.MultiheadAttention(embed_dim=1, num_heads=1)
'''Create dummy input'''
x = torch.rand(3, 2, 1)
'''Padding mask, second sequence can only see first embedding'''
key_padding_mask = torch.as_tensor([[False, False, False], [False, True, True]], dtype=torch.bool)
'''Attention mask, bucketing attention to current and previous time steps'''
attn_mask = torch.as_tensor([[0., float('-inf'), float('-inf')], [0., 0., float('-inf')], [float('-inf'), 0., 0.]])
'''Generate attention embedding'''
output, scores = attn(x, x, x, key_padding_mask=key_padding_mask, attn_mask=attn_mask)
print("scores")
print(scores)
'''Create a dummy loss, only use the first embedding which is defined for all sequences'''
loss = output[0, :].sum()
print("loss")
print(loss)
'''Backwards pass and gradients'''
loss.backward()
print("grads")
for n, p in attn.named_parameters():
print(n, p.grad)
> scores
> tensor([[[1.0000, 0.0000, 0.0000],
> [0.4468, 0.5532, 0.0000],
> [0.0000, 0.5379, 0.4621]],
> [[1.0000, 0.0000, 0.0000],
> [1.0000, 0.0000, 0.0000],
> [ nan, nan, nan]]], grad_fn=<DivBackward0>)
> loss
> tensor(0.0040, grad_fn=<SumBackward0>)
> grads
> in_proj_weight tensor([[nan],
> [nan],
> [nan]])
> in_proj_bias tensor([nan, nan, nan])
> out_proj.weight tensor([[nan]])
> out_proj.bias tensor([2.])
```
## Expected behavior
Gradients should not be NaN
## Environment
PyTorch version: 1.5.1
Is debug build: No
CUDA used to build PyTorch: None
OS: Ubuntu 18.04.4 LTS
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
CMake version: version 3.10.2
Python version: 3.7
Is CUDA available: No
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
Versions of relevant libraries:
[pip3] numpy==1.18.5
[pip3] torch==1.5.1
[conda] blas 1.0 mkl
[conda] cpuonly 1.0 0 pytorch
[conda] mkl 2020.1 217
[conda] mkl-service 2.3.0 py37he904b0f_0
[conda] mkl_fft 1.1.0 py37h23d657b_0
[conda] mkl_random 1.1.1 py37h0573a6f_0
[conda] numpy 1.18.5 py37ha1c710e_0
[conda] numpy-base 1.18.5 py37hde5b4d6_0
[conda] pytorch 1.5.1 py3.7_cpu_0 [cpuonly] pytorch
Also fails when using GPU.
cc @ezyang @gchanan @zou3519 @bdhirsh @jbschlosser @albanD @mruberry @zhangguanheng66
|
high priority,module: nn,triaged,module: NaNs and Infs
|
high
|
Critical
|
657,753,167 |
pytorch
|
Tensor.new_tensor is not supported
|
This comes up as a common error in Parity Bench. (scripting)
Here is the error message:
```
Tried to access nonexistent attribute or method 'new_tensor' of type 'Tensor (inferred)'.:
File ""/tmp/paritybench1zfkgifq/pbqmuageme.py"", line 15
:param x: Long tensor of size ``(batch_size, num_fields)``
""""""
x = x + x.new_tensor(self.offsets).unsqueeze(0)
~~~~~~~~~~~~ <--- HERE
xs = [self.embeddings[i](x) for i in range(self.num_fields)]
ix = list()
```
[Concrete example](https://github.com/jansel/pytorch-jit-paritybench/blob/570400b612332ecaec0cf850cdc70a6d4ddc374b/generated/test_rixwew_pytorch_fm.py#L126)
cc @suo @gmagogsfm
|
oncall: jit,days,TSUsability,TSRootCause:BetterEngineering
|
low
|
Critical
|
657,754,260 |
pytorch
|
Python object None check not supported
|
This comes up as a common error in Parity Bench.
It is common to check for the None-ness of an object to determine next steps of calculation in a dynamic model. But this is not supported well in JIT today.
Error message:
```
compile,97,RuntimeError: Could not cast value of type __torch__.torch.nn.modules.instancenorm.InstanceNorm2d to bool:,"RuntimeError:
Could not cast value of type __torch__.torch.nn.modules.instancenorm.InstanceNorm2d to bool:
File ""/tmp/paritybench819sw5wj/pbzmu661cu.py"", line 41
def forward(self, x):
x = self.conv(self.pad(x))
if self.norm:
~~~~~~~~~ <--- HERE
x = self.norm(x)
if self.activation:
```
Concrete [example](https://github.com/jansel/pytorch-jit-paritybench/blob/570400b612332ecaec0cf850cdc70a6d4ddc374b/generated/test_junyanz_VON.py#L685)
cc @suo @gmagogsfm
|
oncall: jit,days,TSUsability,TSRootCause:UnsupportedConstructs
|
low
|
Critical
|
657,768,330 |
rust
|
LLVM unrolls loops fully, leading to non-linear compilation time
|
<!--
Thank you for filing a bug report! 🐛 Please provide a short summary of the bug,
along with any information you feel relevant to replicating the bug.
-->
I tried this code:
```rust
#[derive(Copy, Clone)]
pub enum Foo {
A,
B(u8),
}
pub fn foo() -> Box<[[[Foo; 50]; 50]; 50]> {
Box::new([[[Foo::A; 50]; 50]; 50])
}
```
I expected to see this happen:
```sh
cargo build --release
```
(Above command eventually should terminate)
Instead, this happened: Compiler doesn't terminate.
### Meta
<!--
If you're using the stable version of the compiler, you should also check if the
bug also exists in the beta or nightly versions.
-->
`rustc --version --verbose`:
```
rustc 1.44.1 (c7087fe00 2020-06-17)
rustc 1.46.0-nightly (346aec9b0 2020-07-11)
```
A crate with the repro can be found here: https://github.com/io12/llvm-rustc-bug-repro.
It seems like this is an LLVM bug.
|
A-LLVM,P-medium,T-compiler,C-bug,I-hang,ICEBreaker-LLVM
|
medium
|
Critical
|
657,830,774 |
godot
|
Input Map action doesn't support two directions of same joy axis
|
**Godot version:**
3.2.2
**OS/device including version:**
Windows 10
**Issue description:**
If you set both directions of the same joy axis of the same device to one action, `Input.is_action_pressed` only is true when the first joy axis direction is pressed
**Steps to reproduce:**
1. Add a new action `test` to the Input Map
2. Add Joy Axis `Device 0, Axis 0 - (Left Stick Left)` to `test`
3. Add Joy Axis `Device 0, Axis 0 + (Left Stick Right)` to `test`
4. On `_process` check for `Input.is_action_pressed("test")`
**Minimal reproduction project:**
[InputMapBug.zip](https://github.com/godotengine/godot/files/4929246/InputMapBug.zip)
|
topic:input
|
low
|
Critical
|
657,862,693 |
godot
|
[Mono] 3.2.1 don't work virtual method
|
<!-- Please search existing issues for potential duplicates before filing yours:
https://github.com/godotengine/godot/issues?q=is%3Aissue
-->
**Godot version:**
<!-- Specify commit hash if using non-official build. -->
3.2.1
**OS/device including version:**
<!-- Specify GPU model, drivers, and the backend (GLES2, GLES3, Vulkan) if graphics-related. -->
Windows 10
**Issue description:**
<!-- What happened, and what was expected. -->
The problem was when compiling Godot with the Zylann voxel module. The most interesting thing is that Godot does not want to compile virtual methods and mark them as such. Because of what I cannot carry out full-fledged inheritance and create my own stream for generation.
Issue: https://github.com/Zylann/godot_voxel/issues/81
**Steps to reproduce:**
Compile godot with this module and create you successor class from VoxelStream
|
topic:dotnet
|
low
|
Minor
|
657,897,862 |
pytorch
|
c++ indexing vs python
|
## 🐛 Bug
i am working on translating pytorch code to c++ environment.
at the pytorch code there is support to take and provide tensors of indexes along different dimensions, which change the output tensor shape,
this feature is not supported at the c++ framework
Steps to reproduce the behavior:
at pytorch:
1. tensor = torch.arange(25*4*96*170).reshape(25,4,96,170)
2. a = torch.arange(25)
3. x=a
4. y=a
5. output = tensor[a, :, y, x]
output shape is: [25,4]
thought maybe to use the torch::index function, but it fails when number of dimensions is larger than 3.
how do i produce the same behavior at the c++ framework?
- PyTorch Version (e.g., 1.0): torch==1.3.0
- OS (e.g., Linux): Linux
- Python version: Python 3.6.8
cc @yf225 @glaringlee
|
module: cpp,triaged
|
low
|
Critical
|
657,959,278 |
next.js
|
Inconsistent css import order between Prod and Dev for Material-UI
|
# Bug report
## Describe the bug
When using Material-UI components, the import order the related css within output html is not static. This outputs inconsistent styling due to inconsistent overrides.
Affected by three different situations
1. Whether we are using destructuring to import the components or direct imports
```tsx
import Button from '@material-ui/core/Button'
import Typography from '@material-ui/core/Typography'
```
have different results than
```tsx
import { Button, Typography } from '@material-ui/core'
```
2. The order of direct imports
```tsx
import Button from '@material-ui/core/Button'
import Typography from '@material-ui/core/Typography'
```
have different results to
```tsx
import Typography from '@material-ui/core/Typography'
import Button from '@material-ui/core/Button'
```
3. Prod vs dev
`yarn dev` have different results to `yarn build && yarn start`
## To Reproduce
Steps to reproduce the behavior, please provide code snippets or a repository:
1. Clone https://github.com/karpkarp/mui-next-repo
2. Run in Dev vs Prod to see difference
3. Change component import in `/src/SideNav.component.tsx` and run in Prod to see difference
change
```tsx
import { Button, Typography } from '@material-ui/core'
```
to
``` tsx
import Button from '@material-ui/core/Button'
import Typography from '@material-ui/core/Typography'
```
4. Change import order and run in Prod to see difference
```tsx
import Button from '@material-ui/core/Button'
import Typography from '@material-ui/core/Typography'
```
to
```tsx
import Typography from '@material-ui/core/Typography'
import Button from '@material-ui/core/Button'
```
## Expected behavior
There an expectation for a static order of css load order on the HTML. The lack of it makes development very tedious and unpredictable in styling overrides.
## Screenshots
Using dev

Using prod

## System information
- OS: MacOS
- Browser: Chrome
- Version of Next.js: 9.4.4
- Version of Node.js: v10.16.0
|
bug,Webpack
|
low
|
Critical
|
657,963,834 |
pytorch
|
torch.nn.functional.grid_sample()is doing bilinear interpolation when the input is 5D, i think the mode should add 'trilinear'
|
## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
## To Reproduce
Steps to reproduce the behavior:
1.
1.
1.
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
## Environment
Please copy and paste the output from our
[environment collection script](https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py)
(or fill out the checklist below manually).
You can get the script and run it with:
```
wget https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py
# For security purposes, please check the contents of collect_env.py before running it.
python collect_env.py
```
- PyTorch Version (e.g., 1.0):
- OS (e.g., Linux):
- How you installed PyTorch (`conda`, `pip`, source):
- Build command you used (if compiling from source):
- Python version:
- CUDA/cuDNN version:
- GPU models and configuration:
- Any other relevant information:
## Additional context
<!-- Add any other context about the problem here. -->
cc @ezyang @gchanan @zou3519 @jlin27 @albanD @mruberry
|
module: nn,triaged
|
low
|
Critical
|
657,996,513 |
flutter
|
Implement PrimaryScrollController inside CupertinoTabScaffold
|
iOS native widgets have to feature that CupertinoTabScaffold doesn't support yet.
- Scroll to the top when the status bar is tapped. (This is only possible yet with material Scaffold)
- Scroll to the top when the active tab inside the CupertinoTabBar is tapped again.
I would like to propose to add a `PrimaryScrollController` that handle both cases. The implementation would be very similar to the one in Scaffold [here](https://github.com/flutter/flutter/blob/9c4a5ef1ed2bc88960fbf3b04d7bafd1c630414b/packages/flutter/lib/src/material/scaffold.dart#L2117).
I would be able to do a PR if you are interested in implement this.
<img height="400" src="https://user-images.githubusercontent.com/19904063/87650810-891f5880-c752-11ea-91ef-f57016af9047.gif" />
|
c: new feature,framework,a: fidelity,f: scrolling,f: cupertino,c: proposal,P3,team-design,triaged-design
|
low
|
Minor
|
658,055,781 |
tensorflow
|
tf.keras cannot weight classes when using multiple outputs
|
This post is a mirror of https://github.com/keras-team/keras/issues/11735, showing the need to handle class weight for multiple outputs.
Version 2.2.0 used.
------
This is a minimal source code, by @GalAvineri, to reproduce the issue (please comment/uncomment the class weight line):
````python3
from tensorflow.python.keras.models import Model
from tensorflow.python.keras.layers import Input, Dense
from tensorflow.python.data import Dataset
import tensorflow as tf
import numpy as np
def preprocess_sample(features, labels):
label1, label2 = labels
label1 = tf.one_hot(label1, 2)
label2 = tf.one_hot(label2, 3)
return features, (label1, label2)
batch_size = 32
num_samples = 1000
num_features = 10
features = np.random.rand(num_samples, num_features)
labels1 = np.random.randint(2, size=num_samples)
labels2 = np.random.randint(3, size=num_samples)
train = Dataset.from_tensor_slices((features, (labels1, labels2))).map(preprocess_sample).batch(batch_size).repeat()
# Model
inputs = Input(shape=(num_features, ))
output1 = Dense(2, activation='softmax', name='output1')(inputs)
output2 = Dense(3, activation='softmax', name='output2')(inputs)
model = Model(inputs, [output1, output2])
model.compile(loss='categorical_crossentropy', optimizer='adam')
class_weights = {'output1': {0: 1, 1: 10}, 'output2': {0: 5, 1: 1, 2: 10}}
model.fit(train, epochs=10, steps_per_epoch=num_samples // batch_size,
# class_weight=class_weights
)
````
Uncommenting yields this error:
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-38-d137ff6fb3f9> in <module>
33 class_weights = {'output1': {0: 1, 1: 10}, 'output2': {0: 5, 1: 1, 2: 10}}
34 model.fit(train, epochs=10, steps_per_epoch=num_samples // batch_size,
---> 35 class_weight=class_weights
36 )
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/training.py in _method_wrapper(self, *args, **kwargs)
64 def _method_wrapper(self, *args, **kwargs):
65 if not self._in_multi_worker_mode(): # pylint: disable=protected-access
---> 66 return method(self, *args, **kwargs)
67
68 # Running inside `run_distribute_coordinator` already.
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/training.py in fit(self, x, y, batch_size, epochs, verbose, callbacks, validation_split, validation_data, shuffle, class_weight, sample_weight, initial_epoch, steps_per_epoch, validation_steps, validation_batch_size, validation_freq, max_queue_size, workers, use_multiprocessing)
813 workers=workers,
814 use_multiprocessing=use_multiprocessing,
--> 815 model=self)
816
817 # Container that configures and calls `tf.keras.Callback`s.
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/data_adapter.py in __init__(self, x, y, sample_weight, batch_size, steps_per_epoch, initial_epoch, epochs, shuffle, class_weight, max_queue_size, workers, use_multiprocessing, model)
1115 dataset = self._adapter.get_dataset()
1116 if class_weight:
-> 1117 dataset = dataset.map(_make_class_weight_map_fn(class_weight))
1118 self._inferred_steps = self._infer_steps(steps_per_epoch, dataset)
1119 self._dataset = strategy.experimental_distribute_dataset(dataset)
/usr/local/lib/python3.6/dist-packages/tensorflow/python/keras/engine/data_adapter.py in _make_class_weight_map_fn(class_weight)
1233 "Expected `class_weight` to be a dict with keys from 0 to one less "
1234 "than the number of classes, found {}").format(class_weight)
-> 1235 raise ValueError(error_msg)
1236
1237 class_weight_tensor = ops.convert_to_tensor_v2(
ValueError: Expected `class_weight` to be a dict with keys from 0 to one less than the number of classes, found {'output1': {0: 1, 1: 10}, 'output2': {0: 5, 1: 1, 2: 10}}
````
|
stat:awaiting tensorflower,type:bug,comp:keras,TF 2.5
|
high
|
Critical
|
658,076,441 |
TypeScript
|
Cast Method of a class to a certain type
|
<!-- 🚨 STOP 🚨 𝗦𝗧𝗢𝗣 🚨 𝑺𝑻𝑶𝑷 🚨
Half of all issues filed here are duplicates, answered in the FAQ, or not appropriate for the bug tracker.
Please help us by doing the following steps before logging an issue:
* Search: https://github.com/Microsoft/TypeScript/search?type=Issues
* Read the FAQ, especially the "Common Feature Requests" section: https://github.com/Microsoft/TypeScript/wiki/FAQ
-->
## Search Terms
casting
type
interface
method
function
parameters
inference
class
<!-- List of keywords you searched for before creating this issue. Write them down here so that others can find this suggestion more easily -->
## Suggestion
<!-- A summary of what you'd like to see added or changed -->
Currently, it is impossible to infer the parameters and the return types of a method of a class using a type
The goal is to be able to declare a method without repeating the param types and the return type. I used typescript `Type` for that.
But there is currently no way to do this without changing the compiled javascript code.
type IBar = (x:number, y: number)=>number;
I tried
type IBar = (x:number, y: number)=>number;
class Foo {
sum:IBar=(x,y)=>{
return x+y;
}
}
BUT unfortunately, this changes the javascript code compiled into:
class Foo {
constructor() {
this.sum = (x, y) => {
return x + y;
};
}
}
I am looking for something that compiles into:
class Foo {
sum(x, y) {
return x + y;
}
}
Another option currently is to declare an interface and implement it on the class like so:
```
interface IBar { sum(x: number, y: number): number; }
class Foo implements IBar {
public sum(x: number, y: number): number {
return x + y;
}
}
```
HOWEVER, this approach would bnd the method name to only `sum` . What if I want to use the same method type with a different name like `divide` or `multiply`
## Use Cases
<!--
What do you want to use this for?
What shortcomings exist with current approaches?
-->
It will be used like this
class Foo {
sum(x,y){
return x+y;
} as IBar
}
## Examples
class Foo {
sum(x,y){
return x+y;
} as IBar
}
or
class Foo {
divide(x,y){
return x+y;
} as IBar
}
or
class Foo {
multiply(x,y){
return x+y;
} as IBar
}
<!-- Show how this would be used and what the behavior would be -->
## Checklist
My suggestion meets these guidelines:
* [x] This wouldn't change the runtime behavior of existing JavaScript code
* [x] This could be implemented without emitting different JS based on the types of the expressions
* [x] This isn't a runtime feature (e.g. library functionality, non-ECMAScript syntax with JavaScript output, etc.)
* [x] This feature would agree with the rest of [TypeScript's Design Goals](https://github.com/Microsoft/TypeScript/wiki/TypeScript-Design-Goals).
* [x] This wouldn't be a breaking change in existing TypeScript/JavaScript code
|
Suggestion,Awaiting More Feedback
|
low
|
Critical
|
658,078,322 |
flutter
|
Support custom ADB sockets while debugging
|
Hi,
I am working with a vscode devcontainer that contains the flutter installation.
My environment is Windows 10 with WSL2 and Docker (WSL2-backend). The devcontainer runs on this WSL2-backend-Docker instance.
First I created this issue https://github.com/Dart-Code/Dart-Code/issues/2640 but it turned out that it looks like a problem with flutter itself.
Due to the fact that it is currently not possible to attach USB devices directly in WSL2 we need ADB (in the devcontainer) to communicate with the ADB on Windows.
ADB supports this by having the possibility to override its SOCKET (flag `-L` or as we did it by setting the environment variable `ADB_SERVER_SOCKET`). In the devcontainer (where flutter runs) we changed to socket to `tcp:host.docker.internal:5037` via environment variable. On the Windows-side we run `adb -a -P 5037 nodaemon server`. With this setup ADB in the devcontainer has the same output as ADB on Windows (e.g. for `adb devices`).
Unfortunately, with this setup it is not possible to debug a flutter app from the devcontainer.
On startup it says
```
Exception attempting to connect to the VM Service: SocketException: OS Error: Connection refused, errno = 111, address = 127.0.0.1, port = 48590
This was attempt #1. Will retry in 0:00:00.100000.
```
and on the device I get a white screen.
I also tried by setting the argument `--host-vmservice-port=9999` but this has no effect. The output then is
```
Forwarded host port 9999 to device port 46347 for Observatory
Connecting to service protocol: http://127.0.0.1:9999/PH5EDsAqjMw=/
Exception attempting to connect to the VM Service: SocketException: OS Error: Connection refused, errno = 111, address = 127.0.0.1, port = 48590
This was attempt #1. Will retry in 0:00:00.100000.
```
With `adb tcpip 5555` and `adb connect <deviceip>:5555` it works. The probems here are
- because the ip of the device has to be known this is no stable approach that can be automated
- it is not possible to connect to an emulator
The output of flutter doctor is
```
[4781 ms] [✓] Flutter (Channel dev, 1.20.0-7.1.pre, on Linux, locale en_US)
[4782 ms] • Flutter version 1.20.0-7.1.pre at /flutter
[4782 ms] • Framework revision 7736f3bc90 (5 days ago), 2020-07-10 16:33:05 -0700
[4783 ms] • Engine revision d48085141c
• Dart version 2.9.0 (build 2.9.0-21.2.beta)
[4784 ms]
[9737 ms] [✓] Android toolchain - develop for Android devices (Android SDK version 28.0.3)
• Android SDK at /android-sdk
[9738 ms] • Platform android-28, build-tools 28.0.3
• Java binary at: /usr/bin/java
[9738 ms] • Java version OpenJDK Runtime Environment (build 1.8.0_252-8u252-b09-1~18.04-b09)
[9738 ms] • All Android licenses accepted.
[9739 ms] [!] Android Studio (not installed)
[9739 ms] • Android Studio not found; download from https://developer.android.com/studio/index.html
[9740 ms] (or visit https://flutter.dev/docs/get-started/install/linux#android-setup for detailed instructions).
[9740 ms]
[9741 ms] [✓] Connected device (1 available)
[9741 ms] • Nexus 5X • 0263ecc816b81901 • android-arm64 • Android 8.1.0 (API 27)
```
Am I missing something or is this a bug/missing feature?
Regards,
Florian
|
c: new feature,platform-android,tool,platform-windows,P3,team-android,triaged-android
|
medium
|
Critical
|
658,158,903 |
pytorch
|
Parallel computation of the diagonal of a Jacobian
|
## 🚀 Feature
<!-- A clear and concise description of the feature proposal -->
Add a parallel method to compute the diagonal of a Jacobian in parallel without computing the whole Jacobian.
## Motivation
If one wants the diagonal elements of a jacobian, e.g., if you want to get d^2 f(x)/dx_i^2, one has to do multiple backward passes. There are several method on how one could achieve this at the moment but either it is memory or time inefficient.
<!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too -->
## Pitch
A function like [tf.diag_jacobian](https://www.tensorflow.org/probability/api_docs/python/tfp/math/diag_jacobian) would be great. In tensorflow this function allows to comput the diagonal of the Jacobian in parallel.
<!-- A clear and concise description of what you want to happen. -->
## Alternatives
This implementation is space efficient but takes a lot of compute time:
```python
X = x.unbind(-1)
x = torch.stack(x, -1)
y = f(x)
Y = y.unbind(-1)
dx = torch.stack([torch.autograd.grad(y_, x_, retain_graph=True) for x_, y_ zip(X, Y)], -1)
```
In contrast to that this is very space consuming (it computes the whole jacobian) but very fast:
```python
# assuming x is (batch_size, inp_dim) and f: inp_dim-> inp_dim
x = x.unsqueeze(1).repeat(1, inp_dim, 1)
y = f(x)
dx = torch.diagonal(toch.autograd.grad(torch.diagonal(y, 0, -2, -1), x), 0, -2, -1)
```
<!-- A clear and concise description of any alternative solutions or features you've considered, if any. -->
## Additional context
<!-- Add any other context or screenshots about the feature request here. -->
cc @ezyang @SsnL @albanD @zou3519 @gqchen
|
feature,module: autograd,triaged
|
low
|
Minor
|
658,172,986 |
rust
|
cc long double targeting wasm32-wasi links incorrectly
|
A Rust crate with C dependency that uses `long double` targeting `wasm32-wasi` links incorrectly, while clang can compile such programs to WebAssembly.
I tried this code:
```rust
// main.rs
fn main() {
unsafe { print_long_double() };
}
extern "C" {
fn print_long_double();
}
// build.rs
cc::Build::new()
.file("src/foo.c")
.include("src")
.compile("foo");
```
```c
// foo.c
void print_long_double() {
srand(0);
long double x = rand();
printf("x = %Lf\n", x);
}
```
```sh
export CC_wasm32_wasi=/opt/wasi-sdk/bin/clang
export CARGO_TARGET_WASM32_WASI_LINKER=/opt/wasi-sdk/bin/clang
export RUSTFLAGS='-C target-feature=-crt-static -C link-arg=-lc-printscan-long-double'
cargo build --target wasm32-wasi
wasmtime target/wasm32-wasi/debug/long-double.wasm
```
I expected to see this happen: the program should run and print a random number, just like when I compile with clang.
Instead, this happened:
```
Error: failed to run main module `target/wasm32-wasi/debug/long-double.wasm`
Caused by:
0: failed to instantiate "target/wasm32-wasi/debug/long-double.wasm"
1: unknown import: `env::__floatsitf` has not been defined
```
Simple repo to **reproduce with Docker**: https://github.com/TjeuKayim/wasi-long-double
### Motivation
I tried to compile rusqlite to WASI following the instructions at https://doc.rust-lang.org/nightly/nightly-rustc/rustc_target/spec/wasm32_wasi/index.html. This was one of the issues I ran into. A work-around is to pass this flag `-DLONGDOUBLE_TYPE=double`. The weird thing is that when I compile sqlite with clang and wasi-sdk, it compiles and runs correctly. Also, other projects manage to compile sqlite to WebAssembly, like https://wapm.io/package/sqlite#shell.
|
A-linkage,T-compiler,O-wasm,C-bug
|
low
|
Critical
|
658,185,414 |
pytorch
|
Test failure in test_shared_allgather_nccl: NCCL error in: ../torch/lib/c10d/ProcessGroupNCCL.cpp:537
|
## 🐛 Bug
For the past couple weeks, the pytorch CPU-based build on platform ppc64le has been failing (and subsequently hanging) in the test_shared_allgather_nccl testcase, as seen in recent nightly runs observed here:
https://powerci.osuosl.org/job/pytorch-master-nightly-py3-linux-ppc64le/
For example, to see error messages at the end of a test run, one example is seen at the end of this output log:
https://powerci.osuosl.org/job/pytorch-master-nightly-py3-linux-ppc64le/1137/console
(After the failure, the test run hangs and the final abort seen here is a kill of the run after timing out; the failure
is immediately proceeding it).
## To Reproduce
Steps to reproduce the behavior:
You'd need a ppc64le Power hardware system as seen above (presumably; I don't know if it occurs on any other platforms.)
You can see the execution as in the log at the CI link above.
I can reproduce it locally in a docker container within my lab, using the same OSU CUDA 10.2 docker image that is used in the CI environment.
In my local environment, I set NCCL_DEBUG=TRACE and found that there is a "No space left on device" while doing a posix_fallocate, as seen here:
```8950d9e0cb8d:42345:44067 [0] NCCL INFO Ring 02 : 0[0] -> 1[1] via P2P/direct pointer
8950d9e0cb8d:42345:44070 [3] NCCL INFO Ring 02 : 3[3] -> 0[0] via direct shared memory
8950d9e0cb8d:42345:44069 [2] include/shm.h:28 NCCL WARN Call to posix_fallocate failed : No space left on device
8950d9e0cb8d:42345:44069 [2] NCCL INFO include/shm.h:41 -> 2
8950d9e0cb8d:42345:44069 [2] include/shm.h:48 NCCL WARN Error while creating shared memory segment nccl-shm-recv-ff91c9f3656b19f9-3-1-2 (size 4460544)
8950d9e0cb8d:42345:44069 [2] NCCL INFO transport/shm.cc:173 -> 2
8950d9e0cb8d:42345:44069 [2] NCCL INFO init.cc:340 -> 2
8950d9e0cb8d:42345:44069 [2] NCCL INFO init.cc:650 -> 2
8950d9e0cb8d:42345:44069 [2] NCCL INFO init.cc:815 -> 2
8950d9e0cb8d:42345:44069 [2] NCCL INFO init.cc:951 -> 2
8950d9e0cb8d:42345:44069 [2] NCCL INFO misc/group.cc:69 -> 2 [Async thread]
8950d9e0cb8d:42345:44067 [0] include/shm.h:28 NCCL WARN Call to posix_fallocate failed : No space left on device
8950d9e0cb8d:42345:44067 [0] NCCL INFO include/shm.h:41 -> 2
8950d9e0cb8d:42345:44067 [0] include/shm.h:48 NCCL WARN Error while creating shared memory segment nccl-shm-recv-ff91c9f3656b19f9-3-3-0 (size 4460544)
```
However, monitoring of both the container and the host (with "df") show that we never get close to running out of space on any physical device. And this happens at the same point in both the official OSULAB CI environment and my local lab system, so it seems it's something impacting this point of the testing rather than an actual space issue coincidental at the same point in both environments.
## Expected behavior
Test should pass without error.
## Environment
ppc64le, CUDA 10.2, docker container as used in the pytorch CI at the link farther above.
I've been trying to figure this out myself without any luck. **I'm opening this as a bug, due to the test failure -- any ideas? I'll be happy to troubleshoot with any ideas offered.** (Of course, the build of pytorch itself completes fine, and numerous other tests run prior to this failure point.)
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @xush6528 @osalpekar @jiayisuse @agolynski
|
oncall: distributed,triaged,module: POWER
|
low
|
Critical
|
658,214,753 |
youtube-dl
|
Add flag Keep spaces in file names
|
<!--
######################################################################
WARNING!
IGNORING THE FOLLOWING TEMPLATE WILL RESULT IN ISSUE CLOSED AS INCOMPLETE
######################################################################
-->
## Checklist
<!--
Carefully read and work through this check list in order to prevent the most common mistakes and misuse of youtube-dl:
- First of, make sure you are using the latest version of youtube-dl. Run `youtube-dl --version` and ensure your version is 2020.06.16.1. If it's not, see https://yt-dl.org/update on how to update. Issues with outdated version will be REJECTED.
- Search the bugtracker for similar feature requests: http://yt-dl.org/search-issues. DO NOT post duplicates.
- Finally, put x into all relevant boxes (like this [x])
-->
- [x] I'm reporting a feature request
- [x] I've verified that I'm running youtube-dl version **2020.06.16.1**
- [x] I've searched the bugtracker for similar feature requests including closed ones
## Description
<!--
Provide an explanation of your issue in an arbitrary form. Please make sure the description is worded well enough to be understood, see https://github.com/ytdl-org/youtube-dl#is-the-description-of-the-issue-itself-sufficient. Provide any additional information, suggested solution and as much context and examples as possible.
-->
The `--restrict-filenames` is great except that it results in filenames which many search programs do not search effectively. For example, `youtube-dl_test_video_a` downloaded from `BaW_jenozKc` cannot be found with a search term of `test video` in many file systems.
I propose a `--restrict-filenames-allow-spaces` option which would result in a file name of `youtube-dl test video`.
This was opened as a question here: https://github.com/ytdl-org/youtube-dl/issues/25962
|
request
|
low
|
Critical
|
658,221,176 |
angular
|
@angular/core/testing imports @angular/compiler without it being a listed dependency
|
# 🐞 bug report
### Affected Package
`@angular/core`
### Is this a regression?
No
### Description
`@angular/core/testing` imports `@angular/compiler`, which results in an error in environments where dependencies are enforced strictly, e.g. yarn 2's PnP.
There's a simple workaround in yarn 2, via package extensions in the `.yarnrc.yml`. The repro shows this as well. As such this isn't very blocking.
The actual solution would be to add an (optional) peer dependency on `@angular/compiler` in `@angular/core`. Optional peer dependencies are supported in yarn, pnpm, and npm >= 6.11. I'm not sure about cnpm.
## 🔬 Minimal Reproduction
1. Clone https://github.com/bgotink/angular-core-dependency-repro.git
2. Run `yarn ng test` to see the issue.
3. To see it work with the workaround, uncomment the commented lines in `.yarnrc.yml`, run `yarn` and try `yarn ng test` again.
## 🔥 Exception or Error
<pre><code>
ERROR in ./.yarn/$$virtual/@angular-core-virtual-211be554a0/0/cache/@angular-core-npm-10.0.4-7ac9451da3-086e71325b.zip/node_modules/@angular/core/fesm2015/testing.js
Module not found: Error: @angular/core tried to access @angular/compiler, but it isn't declared in its dependencies; this makes the require call ambiguous and unsound.
Required package: @angular/compiler (via "@angular/compiler")
Required by: @angular/core@virtual:bb6003ff96d426a26f646cc35ceffa141c24878228a2fef52d1ec249699aa32723eb66782cadf256682b54695969dc1ed6146429985526143c5b0e1086b2e58a#npm:10.0.4 (via /private/var/folders/_d/ch2kc4h960d10cy_2c41qqzw0000gn/T/tmp.xuExZBos3m/repro-core-dependency/.yarn/$$virtual/@angular-core-virtual-211be554a0/0/cache/@angular-core-npm-10.0.4-7ac9451da3-086e71325b.zip/node_modules/@angular/core/fesm2015/testing.js)
@ ./.yarn/$$virtual/@angular-core-virtual-211be554a0/0/cache/@angular-core-npm-10.0.4-7ac9451da3-086e71325b.zip/node_modules/@angular/core/fesm2015/testing.js 9:0-51 1164:59-73
@ ./src/test.ts
</code></pre>
## 🌍 Your Environment
**Angular Version:**
<pre><code>
$ yarn ng version
An unhandled exception occurred: ENOENT: no such file or directory, scandir '/private/var/folders/_d/ch2kc4h960d10cy_2c41qqzw0000gn/T/tmp.xuExZBos3m/repro-core-dependency/node_modules'
See "/private/var/folders/_d/ch2kc4h960d10cy_2c41qqzw0000gn/T/ng-nvGAj1/angular-errors.log" for further details.
</code></pre>
**Anything else relevant?**
Using yarn 2 (aka berry) with the PnP linker
|
area: build & ci,area: core,area: dev-infra,P3
|
low
|
Critical
|
658,282,700 |
youtube-dl
|
youtube-dl.exe recompile frequency
|
<!--
######################################################################
WARNING!
IGNORING THE FOLLOWING TEMPLATE WILL RESULT IN ISSUE CLOSED AS INCOMPLETE
######################################################################
-->
## Checklist
<!--
Carefully read and work through this check list in order to prevent the most common mistakes and misuse of youtube-dl:
- Look through the README (http://yt-dl.org/readme) and FAQ (http://yt-dl.org/faq) for similar questions
- Search the bugtracker for similar questions: http://yt-dl.org/search-issues
- Finally, put x into all relevant boxes (like this [x])
-->
- [x] I'm asking a question
- [x] I've looked through the README and FAQ for similar questions
- [x] I've searched the bugtracker for similar questions including closed ones
## Question
<!--
Ask your question in an arbitrary form. Please make sure it's worded well enough to be understood, see https://github.com/ytdl-org/youtube-dl#is-the-description-of-the-issue-itself-sufficient.
-->
I'm a Windows user using the .exe, and was curious how often it gets recompiled? There have been some recent fixes for audio artist/title metadata, but that appears limited to the full install w/ the affected .py file. As it's embedded in the .exe, I assume I'll need a newer version to make use of these updates.
|
question
|
low
|
Critical
|
658,343,540 |
angular
|
HostListener is still listening after ngOnDestroy started
|
# 🐞 bug report
### Affected Package
@angular/core
### Is this a regression?
No, I caught this bug in a version 7 first
### Description
There can be some situations in that we need to dispatch an event on component destroy.
If we have HostListener listening type of event we dispatch, it catches this.
So, in other words, HostListener continues listening even after ngOnDestroy has already started.
Is it a bug or by design?
## 🔬 Minimal Reproduction
https://stackblitz.com/edit/angular-hostlintener-bug?file=src%2Fapp%2Fhello.component.ts
## 🔥 Exception or Error
-
## 🌍 Your Environment
**Angular Version:**
<pre>10.0.1<code> and <pre>7.22.0<code>
</code></pre>
|
area: core,core: lifecycle hooks,type: confusing,P3
|
low
|
Critical
|
658,363,615 |
flutter
|
Error message for mismatched platform attach on Flutter on device is misleading
|
https://b.corp.google.com/issues/161382063.
|
customer: fuchsia,engine,P3,team-engine,triaged-engine
|
low
|
Critical
|
658,381,691 |
go
|
cmd/cover: clarify the format of cover profile generated with go test -coverprofile
|
Processing the coverage profile generated from `go test -coverprofile` to integrate it with editors,
we need clarification of the output format.
The profile looks like
```
mode: set
mvdan.cc/xurls/v2/xurls.go:56.35,59.25 3 1
...
```
and the first element of each item ([link](https://github.com/golang/go/blob/c5d7f2f1cbaca8938a31a022058b1a3300817e33/src/cmd/cover/profile.go#L138)) is often called FileName, but this is not the true file name.
Code [here](https://github.com/golang/go/blob/c5d7f2f1cbaca8938a31a022058b1a3300817e33/src/cmd/go/internal/test/test.go#L1025-L1029) determines what this is. It is either the import path and the base file name, or the absolute path (isn't it platform dependent?)
See how `go tool cover -html=...` [parses](https://github.com/golang/go/blob/master/src/cmd/cover/func.go#L178-L196) the profile output. Any editor integration work requires to implement the same to associate the coverage info with the source code.
This detail is hidden deep in the source code. We need to document this.
The cover tool documentation can be the first place users would search.
cc @ianthehat @pjweinbgo @jayconrod
|
NeedsFix,compiler/runtime
|
low
|
Minor
|
658,470,203 |
go
|
x/mobile: gomobile bind does not create reproducible builds, ignores -trimpath
|
A full setup/build log is here:
https://gitlab.torproject.org/eighthave/snowflake/-/jobs/634
### What version of Go are you using (`go version`)?
<pre>
$ go version
go version go1.14 linux/amd64
</pre>
### Does this issue reproduce with the latest release?
yes
### What operating system and processor architecture are you using (`go env`)?
<details><summary><code>go env</code> Output</summary><br><pre>
$ go env
GO111MODULE=""
GOARCH="amd64"
GOBIN=""
GOCACHE="/root/.cache/go-build"
GOENV="/root/.config/go/env"
GOEXE=""
GOFLAGS=""
GOHOSTARCH="amd64"
GOHOSTOS="linux"
GOINSECURE=""
GONOPROXY=""
GONOSUMDB=""
GOOS="linux"
GOPATH="/go"
GOPRIVATE=""
GOPROXY="https://proxy.golang.org,direct"
GOROOT="/usr/lib/go-1.14"
GOSUMDB="sum.golang.org"
GOTMPDIR=""
GOTOOLDIR="/usr/lib/go-1.14/pkg/tool/linux_amd64"
GCCGO="gccgo"
AR="ar"
CC="gcc"
CXX="g++"
CGO_ENABLED="1"
GOMOD="/builds/eighthave/snowflake/go.mod"
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
PKG_CONFIG="pkg-config"
GOGCCFLAGS="-fPIC -m64 -pthread -fmessage-length=0 -fdebug-prefix-map=/tmp/go-build833562092=/tmp/go-build -gno-record-gcc-switches"
</pre></details>
### What did you do?
Ran a build with `gomobile bind -v -target=android -trimpath -ldflags=-buildid= .` in both gitlab-ci and a local vagrant/libvirt VM.
### What did you expect to see?
Reproducible builds between the two.
### What did you see instead?
Diffs between the two builds in 3 of the 4 architectures, including diffs caused by build paths, which `-trimpath` is specifically meant to disable. Full diff is here:
[diffoscope-output.html.zip](https://github.com/golang/go/files/4933587/diffoscope-output.html.zip)
|
NeedsInvestigation,mobile
|
low
|
Critical
|
658,473,889 |
scrcpy
|
Connect to a device on another pc
|
I have a device connected on a computer half across the world, i have acces to the computer and i can run adb commands on that device by 'set ADB_SERVER_SOCKET=tcp:servername:port' on my computer and running a nodaemon server on the other, i wanna be able to run scrcpy on my computer to see the device connected to the other computer, is it posible?
|
question
|
low
|
Major
|
658,501,129 |
godot
|
Boot splash override images are not packed when exporting
|
**Godot version:**
3.2.2
**OS/device including version:**
Tested on Win + Android build, and OSX + iOS build
**Issue description:**
I keep all my platform assets (iOS icons, Android icons, launcher screens etc) in a folder excluded from the Godot Editor with a `.gdignore` file. This is done so that the assets are not bundled twice, or bundled by exports that wouldn't use them (e.g. the iOS icons for an Android build). This excluded platform folder also contains my boot splash image.
The project settings dialog allows you to browse to the boot image png and set it. After I export the project, the boot image will be correctly included in the exported APK/IPA etc, even though it wasn't an imported asset in the project. If a platform specific override is added, the override image is not included in the final bundle, and the image will fail to load.
This does not apply if the image is also included in your project as an asset already. In that case the override will load correctly.
Either the override images also need to be bundled (this is preferred way of fixing the issue), or the boot splash image shouldn't be included either as the behaviour is inconsistent.
**Steps to reproduce:**
1. Create a new project.
2. Add an assets folder with 2 different boot splash examples.
3. Exclude the folder with a .gdignore file
4 Set the boot splash image to one of the images in the folder (this image will be correctly included).
5. Set a platform override boot splash using the other image (this image will not be included on export).
6. Export the project (and either examine the archive, or run it )
**Minimal reproduction project:**
[Testing-BootSplashOverride.zip](https://github.com/godotengine/godot/files/4933808/Testing-BootSplashOverride.zip)
|
bug,topic:editor
|
low
|
Minor
|
658,510,811 |
flutter
|
Issues leading to rebuilding more of the RenderObject and Layer trees than necessary
|
Flutter consists of a number of levels of trees (as described in the [Mahogany Staircase talk](https://www.youtube.com/watch?v=dkyY9WCGMi0)). When a change is made to the Widget tree, those changes must be propagated into the Element, RenderObject, and Layer trees. Each level has code that attempts to reuse parts of the lower level trees on each pass to minimize the work. Unfortunately, there is still a lot of rebuilding going on for some simple changes to a tree, and a fair bit of developer involvement in minimizing the effect in their apps. In particular:
- One of the few tools at the disposal of the developer for minimizing the scope of rebuilds is the RepaintBoundary which acts as a wall between parts of the tree to keep a change inside its children from causing a rebuild of any of the widgets outside of it (and vice versa).
- Animating widgets don't protect their children or ancestors by default, but require the developer to insert a RepaintBoundary to keep their constant rebuilds from affecting the rest of the tree.
- One of the most common inter-dependencies between RenderObjects is the sharing of paint commands being dealt to a single shared Picture object. The Picture object will be shared from the first RenderObject that issues a paint command all the way until the end of the tree or until the first RenderObject that requires an engine layer to be pushed to do its work. The Picture can be shared outside of the scope of the first RenderObject that initiated it as it is shared across any subset of the flattened tree traversal with no regard to scope. If any of these RenderObjects needs to change what it painted then all of them must repaint. If there is a RepaintBoundary somewhere in the list, then that will break the Picture into multiple Picture objects and reduce the scope of sharing and repainting, but this requires detection by the app developer and a change to their Widget hierarchy.
These are some of the issues discovered while attempting to minimize repaints at the engine level (see https://github.com/flutter/flutter/issues/33939) and represent areas where we could achieve better efficiency both for minimizing the work done at the framework level when a widget changes and, by extension, the work needed to repaint the scene.
|
framework,c: performance,perf: speed,P2,team-framework,triaged-framework
|
low
|
Minor
|
658,515,451 |
TypeScript
|
Enumerating an enum: Wrong thing is allowed and right thing is not with with noImplicityAny
|
Consider this code:
enum Test1 {
One = 1,
Two = 2
}
enum Test2 {
One = "one",
Two = 2
}
enum Test3 {
One = "one",
Two = "two"
}
for (const key **in** Test1) {
const aValue = Test1[key];
console.log(aValue);
}
This code compiles but because in an enum a reverse value->key map is also set up **for numeric values**, the outcome is not what one would expect: 1, 2. It's: One, Two, 1, 2 instead. Similarly, replacing Test1 with Test2 in the for..in loop compiles but gives unexpected result: "Two", "one", 2. However, with Test3, for which the result would've been correct: "one", "two", there's a compile error with the noImplicitAny compiler option:
Element implicitly has an 'any' type because expression of type 'string' can't be used to index type 'typeof Test3'.
No index signature with a parameter of type 'string' was found on type 'typeof Test3'.
This seems backwards of what the behavior should be: With Test1 and Test2, the compile should fail and it should succeed with Test3. If not that, the compile should either fail or succeed with all 3. FYI, the reason I noticed this was because converting an all numeric enum to all string enum caused compile failure for some other code that was using "for..in" which originally had a logical flaw which the compiler didn't catch but it's flagging it now when the logical flaw has (inadvertently) been fixed.
It seems like there are at least a couple of independent problems here.
1. With enums that have at least one numeric member (Test1 and Test2), the inferred type of loop variable (key) should ideally be the union of all keys and **numeric** values or at least string | number, not just string.
2. Indexing enums by a string (that cannot be narrowed down specific literals representing keys of an enum) should consistently return any. It may acceptable to return union type of all possible values: number for Test1, string|number for Test2 and string for Test3 and not string for Test1 and Test2 and any for Test3.
3. In addition to the issues above, a for..in over an enum should somehow be flagged and fail to compile regardless of noImplicitAny flag because it only yields the expected result in the enum has all string values but even with all string-enums, that would be fragile as adding a single numeric value to the enum will cause compile failures at that point. It should just not be allowed at least by default.
Issue #18409 seems related but not quite the same.
|
Suggestion,Needs Proposal
|
low
|
Critical
|
658,554,563 |
pytorch
|
Implement LSH Optimizations for Enhanced CPU-Only Performance
|
I am writing to inquire if the PyTorch team has any interest or plans for implementing locality sensitive hashing based optimizations for enhanced CPU only performance and reduced overall computational resource consumption as detailed in this paper?
https://www.cs.rice.edu/~as143/Papers/SLIDE_MLSys.pdf
It would appear that these techniques have reached a level maturity to consider implementation and that this would be a great benefit to reducing the GPU barrier of entry for developers, reduce complexity and expense for both training and deploying large deep learning models, and also reduce waste in terms of not only hardware expense but also energy usage and ecological impact.
cc @VitalyFedyunin @ngimel
|
module: performance,feature,module: cpu,triaged,needs research
|
low
|
Major
|
658,560,111 |
go
|
x/tools/gopls: consider disambiguating same-score completion candidates using candidate length
|
Currently completion candidates are sorted by score, and then secondarily sorted lexicographically to provide a predictable order. I propose we instead do a secondary sort by candidate length, preferring shorter candidates. My intuition is that shorter names are used more frequently than longer names, so it is a somewhat better heuristic to put shorter items first, all else being equal.
Edit: Note that this proposal only comes in to play when candidates have identical scores. Currently the tie-break sorting is alphabetical; I'm proposing we switch to a potentially better heuristic. This will have a very small impact in general.
Contrived example:
```go
package main
type myStr struct {
s string
}
func (m myStr) Get() string {
return m.s
}
type foo struct {
ID myStr
AardvarkID myStr
}
func main() {
var f foo
var _ string = f // want "f.ID.s" but got "f.AardvarkID.s"
var _ string = fidget // want "f.ID.Get()" but got "f.AardvarkID.Get()"
}
```
/cc @heschik because you had an opinion in slack
|
gopls,Tools
|
low
|
Major
|
658,564,613 |
excalidraw
|
sentry doesn't map source for console.error events
|
Stack traces coming from `console.error` logged to sentry aren't using source maps for some reason.
|
bug
|
low
|
Critical
|
658,570,526 |
pytorch
|
momentum in BatchNorm
|
# 📚 Documentation
## PyTorch docs
What's going on with `momentum` in BatchNorm? `0.9` of momentum means I keep `0.9` of the old stuff and add `0.1` of the new one. Why is it reversed here? `momentum` equal `0` means I'm running with no memory of the past.
Also, the default value is way off! It should be `0.99`, not `0.9`.


## Keras docs
A more sensible approach.

cc @jlin27 @albanD @mruberry
|
module: docs,module: nn,triaged,needs research
|
low
|
Major
|
658,573,850 |
pytorch
|
[RPC] Should we support users _not_ calling rpc.shutdown()?
|
In https://github.com/pytorch/pytorch/issues/41474 we saw that due to global static variables being destroyed in a certain order, not calling `rpc.shutdown()` explicitly before terminating a program could cause a SIGABRT. The problem comes from a event loop thread of TensorPipe trying to acquire a glog mutex that may be already gone. Avoiding this might be complicated, so before we attempt it, let's clarify whether this is even a supported scenario or whether we require users to always shut down explicitly.
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @gqchen @aazzolini @rohan-varma @xush6528 @jjlilley @osalpekar @jiayisuse
|
triaged,module: rpc
|
low
|
Major
|
658,602,161 |
flutter
|
Run clang tidy on more targets
|
Today, we run clang-tidy on the host sources only on Linux.
This means we miss the following variants:
- [ ] macOS desktop
- [x] iOS embedding
- [x] Android embedding
- [ ] Fuchsia
- [ ] Windows desktop
It would be great to enable it for these variants.
|
c: new feature,team,engine,P3,team-engine,triaged-engine
|
low
|
Major
|
658,609,380 |
flutter
|
Filter MacStadium bots from analytics
|
Since June 1, there has been a disproportionate spike in analytics events coming from Atlanta, GA. The events report themselves to be from Mac devices, which indicates that they are probably CI bots in the MacStadium datacenter there. We need to filter these out in the Flutter tool's bot detector.
|
c: new feature,team,tool,P3,team-tool,triaged-tool
|
low
|
Minor
|
658,624,423 |
flutter
|
`flutter channel` output channels that can't be used later
|
For example, `flutter channel` prints:
```
flutter-0.0-candidate.1
flutter-1.19-candidate.2
flutter-1.19-candidate.3
flutter-1.19-candidate.4
flutter-1.19-candidate.5
flutter-1.20-candidate.0
flutter-1.20-candidate.1
flutter-1.20-candidate.2
flutter-1.20-candidate.3
flutter-1.20-candidate.3.renyou_experiment
flutter-1.20-candidate.4
flutter-1.20-candidate.5
flutter-1.20-candidate.6
flutter-1.20-candidate.7
....
```
However, `flutter channel flutter-1.20-candidate.7` outputs:
```
Switching to flutter channel 'flutter-1.20-candidate.7'...
This is not an official channel. For a list of available channels, try "flutter channel".
git: fatal: 'origin/flutter-1.20-candidate.7' is not a commit and a branch 'flutter-1.20-candidate.7' cannot be created from it
Switching channels failed with error code 128.
```
|
tool,P2,team-tool,triaged-tool
|
low
|
Critical
|
658,643,078 |
deno
|
Dynamically generating import maps
|
There’s a pattern emerging for creating cross-platform ESM modules using the `exports` property in `package.json`. To be perfectly honest, I wish there were a conditional import syntax for this use case instead, but there isn’t so this is what we’ve got.
Rollup, webpack, and of course Node.js, all now support this property.
This means that internally in the module, and in the module’s tests, you can’t use relative imports but instead have to use the package name because relative imports skip the export map loader. And of course, tests all have to do the same.
The nice part of authoring this way is that my modules and all the tests can be run and loaded in the browser and Node.js without a compiler, and the module works as expected when people consume it **with** a compiler.
When I run tests in the browser I generate an export map and stick it in the page before loading my tests.
Similarly, I can generate an import map for Deno and pass it as a command line flag.
The thing is though, I have my test runner **running in Deno natively**. I’d like to generate an import map from package.json **in Deno** and then load it, rather than passing as a command line flag because that would require another subprocess launch and additional permissions.
There are security concerns here. The browser doesn’t allow dynamic import map loading, it requires that it’s in the page you load from the origin. Perhaps something similar could be done with Deno by passing a `.js` or `.ts` file instead of `.json` file as the importMap argument? There could be an API in `Deno` to set the import map and it would only be accessible to that module, creating a similar security pattern to what the browser uses. Or the default export of that file could be the import map?
Thoughts?
|
cli,suggestion
|
low
|
Major
|
658,655,852 |
rust
|
Spotlight shows traits with generic impls that do not apply to the specific type
|
In both these cases, the mutability or the generic parameter is not dealt with when showing spotlight impls:


https://github.com/rust-lang/rust/pull/74370#discussion_r455233545
We should do something similar to what we do for auto traits and blanket impls.
|
T-rustdoc
|
low
|
Minor
|
658,668,234 |
rust
|
rustc is now dynamically linked to zlib
|
Discovered in https://github.com/rust-lang/rust/pull/74395, the current beta links to libz dynamically (through LLVM).
This is new, and is perhaps something we don't want. On the other hand, zlib is pretty ubiquitous so it may be fine to leave it as is. I would like to see us add tests that the set of dynamically linked libraries is stable so we're at least aware of this happening (it slipped into rustc this time in #72696 without that being noticed by the primary reviewer of that PR).
Separately, we should decide if zlib is sufficiently common that it's fine to dynamically link to it.
```
/home/mark/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/bin/rustc:
linux-vdso.so.1 (0x00007ffeec130000)
librustc_driver-a07dcbb4ed0bdde8.so => /home/mark/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/bin/../lib/librustc_driver-a07dcbb4ed0bdde8.so (0x00007f858d5f7000)
libstd-c147cd9c030850ef.so => /home/mark/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/bin/../lib/libstd-c147cd9c030850ef.so (0x00007f858d2f6000)
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007f858d2ca000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007f858d2c4000)
librt.so.1 => /lib/x86_64-linux-gnu/librt.so.1 (0x00007f858d2b9000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f858d0c7000)
/lib64/ld-linux-x86-64.so.2 (0x00007f8591b6a000)
libLLVM-10-rust-1.45.0-stable.so => /home/mark/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/bin/../lib/../lib/libLLVM-10-rust-1.45.0-stable.so (0x00007f8588aca000)
libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007f8588aaf000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007f8588960000)
/home/mark/.rustup/toolchains/beta-x86_64-unknown-linux-gnu/bin/rustc:
linux-vdso.so.1 (0x00007ffd5ddb6000)
librustc_driver-e231ac240cfaf689.so => /home/mark/.rustup/toolchains/beta-x86_64-unknown-linux-gnu/bin/../lib/librustc_driver-e231ac240cfaf689.so (0x00007f4a387a4000)
libstd-d66e0ceb8eaec9b8.so => /home/mark/.rustup/toolchains/beta-x86_64-unknown-linux-gnu/bin/../lib/libstd-d66e0ceb8eaec9b8.so (0x00007f4a384a1000)
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007f4a38475000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007f4a3846f000)
librt.so.1 => /lib/x86_64-linux-gnu/librt.so.1 (0x00007f4a38464000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f4a38272000)
/lib64/ld-linux-x86-64.so.2 (0x00007f4a3cdd2000)
libLLVM-10-rust-1.46.0-beta.so => /home/mark/.rustup/toolchains/beta-x86_64-unknown-linux-gnu/bin/../lib/../lib/libLLVM-10-rust-1.46.0-beta.so (0x00007f4a33c07000)
libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007f4a33bec000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007f4a33a9d000)
libz.so.1 => /lib/x86_64-linux-gnu/libz.so.1 (0x00007f4a33a81000)
```
<!-- TRIAGEBOT_START -->
<!-- TRIAGEBOT_ASSIGN_START -->
<!-- TRIAGEBOT_ASSIGN_DATA_START$${"user":null}$$TRIAGEBOT_ASSIGN_DATA_END -->
<!-- TRIAGEBOT_ASSIGN_END -->
<!-- TRIAGEBOT_END -->
|
A-LLVM,T-compiler,regression-from-stable-to-stable,T-release
|
low
|
Major
|
658,692,835 |
neovim
|
:terminal scrolls if scrollback is full
|
<!-- Before reporting: search existing issues and check the FAQ. -->
- `:ver`:
```
NVIM v0.4.3
Build type: Release
LuaJIT 2.0.5
Compilation: /usr/bin/cc -march=x86-64 -mtune=generic -O2 -pipe -fno-plt -O2 -DNDEBUG -DMIN_LOG_LEVEL=3 -Wall -Wextra -pedantic -Wno-unused-parameter -Wstrict-prototypes -std=gnu99 -Wshadow -Wconversion -Wmissing-prototypes -Wimplicit-fallthrough -Wvla -fstack-protector-strong -fdiagnostics-color=always -DINCLUDE_GE
NERATED_DECLARATIONS -D_GNU_SOURCE -DNVIM_MSGPACK_HAS_FLOAT32 -DNVIM_UNIBI_HAS_VAR_FROM -I/build/neovim/src/build/config -I/build/neovim/src/neovim-0.4.3/src -I/usr/include -I/build/neovim/src/build/src/nvim/auto -I/build/neovim/src/build/include
Compiled by builduser
Features: +acl +iconv +tui
See ":help feature-compile"
system vimrc file: "$VIM/sysinit.vim"
fall-back for $VIM: "/usr/share/nvim"
```
- `vim -u DEFAULTS` (version: 8.2) behaves differently?
Yes, vim pauses rendering new lines of input in its terminal buffers when you go into normal mode, but I assume this is because it has a very different implementation than Neovim.
- Operating system/version: Arch Linux
- Terminal name/version: mintty (wsltty)
- `$TERM`: xterm-256color
### Steps to reproduce using `nvim -u NORC`
```
nvim -u NORC
:terminal
seq 100000
# then very quickly afterwards,
<C-\><C-n>
<C-b><C-b><C-b>
```
### Actual behaviour
Cursor should stay on the same number.
### Expected behaviour
The cursor is scrolled downwards as lines past 10000 are dropped.
|
enhancement,terminal,has:workaround
|
low
|
Critical
|
658,725,721 |
pytorch
|
torch.cuda.BoolTensor uses 8 bits per element, not 1 bit as reported by element_size()
|
## 🐛 Bug
I could not find this in the documentation, but it seems like `torch.cuda.BoolTensor` actually uses a byte for each element instead of a bit.
## To Reproduce
Steps to reproduce the behavior:
```python
import torch
x = torch.empty([], device="cuda") # load something on GPU to get a baseline
# running nvidia-smi, I see the GPU has 715 MiB of RAM in use
# let's create a tensor which should take 10 MiB:
x = torch.empty(10*8*1024**2, dtype=torch.bool, device="cuda")
assert x.element_size() == 1
# running nvidia-smi, the GPU has 795 MiB of RAM used, or ~ 80 MiB additional (instead of the 10 MiB expected)
```
Checking repeatedly with different sizes of tensors indicated that a `torch.cuda.BoolTensor` takes 8 bits per element on GPU.
## Expected behavior
Either `torch.cuda.BoolTensor` should only take 1 bit per element (not sure if there is a GPU limitation here) or `x.element_size()` should return 8
## Environment
PyTorch version: 1.5.1
Is debug build: No
CUDA used to build PyTorch: 10.1
OS: CentOS Linux release 7.6.1810 (Core)
GCC version: (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36)
CMake version: version 2.8.12.2
Python version: 3.7
Is CUDA available: Yes
CUDA runtime version: 10.1.168
GPU models and configuration:
GPU 0: GeForce RTX 2080 Ti
Nvidia driver version: 418.87.00
cuDNN version: Could not collect
Versions of relevant libraries:
[pip3] numpy==1.18.5
[pip3] pytorch-utils==0.1
[pip3] torch==1.5.1
[conda] blas 1.0 mkl
[conda] cudatoolkit 10.1.243 h6bb024c_0
[conda] mkl 2020.1 217
[conda] mkl-service 2.3.0 py37he904b0f_0
[conda] mkl_fft 1.1.0 py37h23d657b_0
[conda] mkl_random 1.1.1 py37h0573a6f_0
[conda] numpy 1.18.5 py37ha1c710e_0
[conda] numpy-base 1.18.5 py37hde5b4d6_0
[conda] pytorch 1.5.1 py3.7_cuda10.1.243_cudnn7.6.3_0 pytorch
[conda] pytorch-utils 0.1 dev_0 <develop>
cc @jlin27
|
module: docs,triaged
|
medium
|
Critical
|
658,774,193 |
youtube-dl
|
Get formats and thumbnails and title in one call
|
## Checklist
- [x] I'm asking a question
- [x] I've looked through the README and FAQ for similar questions
- [x] I've searched the bugtracker for similar questions including closed ones
## Question
e.g: youtube-dl.exe --get-title --list-thumbnails --list-formats URL
It seems if I combine these options, I get "No info from page"
This means I need to call 3 times and combine all output
|
question
|
low
|
Critical
|
658,834,636 |
youtube-dl
|
Option to write number of audio channels into filename
|
<!--
######################################################################
WARNING!
IGNORING THE FOLLOWING TEMPLATE WILL RESULT IN ISSUE CLOSED AS INCOMPLETE
######################################################################
-->
## Checklist
<!--
Carefully read and work through this check list in order to prevent the most common mistakes and misuse of youtube-dl:
- First of, make sure you are using the latest version of youtube-dl. Run `youtube-dl --version` and ensure your version is 2020.06.16.1. If it's not, see https://yt-dl.org/update on how to update. Issues with outdated version will be REJECTED.
- Search the bugtracker for similar feature requests: http://yt-dl.org/search-issues. DO NOT post duplicates.
- Finally, put x into all relevant boxes (like this [x])
-->
- [x] I'm reporting a feature request
- [x] I've verified that I'm running youtube-dl version **2020.06.16.1**
- [x] I've searched the bugtracker for similar feature requests including closed ones
## Description
<!--
Provide an explanation of your issue in an arbitrary form. Please make sure the description is worded well enough to be understood, see https://github.com/ytdl-org/youtube-dl#is-the-description-of-the-issue-itself-sufficient. Provide any additional information, suggested solution and as much context and examples as possible.
-->
WRITE DESCRIPTION HERE
Please add the ability for the program to automatically put the number of audio channels into the filename when downloading videos from YouTube. Some videos are 1 channel and some are 2 channels.
|
request
|
low
|
Critical
|
658,965,311 |
storybook
|
Generating source maps slow the build significantly, should they be opt-in?
|
**Is your feature request related to a problem? Please describe.**
I'm looking to optimise the time taken by `build-storybook`. Simply setting the `devtool` webpack option to `undefined` reduces my build times by half.
**Describe the solution you'd like**
I'd argue the average storybook user would benefit more from faster builds than they would from source maps. Therefore, I think source maps should be an opt-in feature due to the performance gains in not generating them. Obviously this might be controversial, so I'd love to hear any thoughts on this.
**Describe alternatives you've considered**
N/A
**Are you able to assist bring the feature to reality?**
Sure!
|
performance issue,build-storybook
|
low
|
Major
|
659,053,451 |
rust
|
Consider changing "mono item" terminology
|
Requested by @eddyb in [this comment](https://github.com/rust-lang/rust/pull/69749#discussion_r455909581). After polymorphisation (#69749) lands, mono items may not actually be monomorphic and so it might be worth changing the terminology here, e.g. "codegen item".
|
C-cleanup,A-codegen,T-compiler,-Zpolymorphize
|
low
|
Minor
|
659,159,574 |
node
|
addons/register-signal-handler/test and abort/test-addon-register-signal-handler failed
|
<!--
Thank you for reporting a flaky test.
Flaky tests are tests that fail occasionally in the Node.js CI, but not
consistently enough to block PRs from landing, or that are failing in CI jobs or
test modes that are not run for every PR.
Please fill in as much of the template below as you're able.
Test: The test that is flaky - e.g. `test-fs-stat-bigint`
Platform: The platform the test is flaky on - e.g. `macos` or `linux`
Console Output: A pasted console output from a failed CI job showing the whole
failure of the test
Build Links: Links to builds affected by the flaky test
If any investigation has been done, please include any information found, such
as how consistently the test fails, whether the failure could be reproduced
locally, when the test started failing, or anything else you think is relevant.
-->
* **Test**: addons/register-signal-handler/test and abort/test-addon-register-signal-handler
* **Platform**: IBM i
* **Console Output:**
```
09:41:12 not ok 2801 addons/register-signal-handler/test
09:41:12 ---
09:41:12 duration_ms: 8.21
09:41:12 severity: fail
09:41:12 exitcode: 1
09:41:12 stack: |-
09:41:12 Running: node /home/iojs/build/workspace/node-test-commit-ibmi/nodes/ibmi72-ppc64/test/addons/register-signal-handler/test.js child 6 reset 1
09:41:12 Running: node /home/iojs/build/workspace/node-test-commit-ibmi/nodes/ibmi72-ppc64/test/addons/register-signal-handler/test.js child 6 1
09:41:12 Running: node /home/iojs/build/workspace/node-test-commit-ibmi/nodes/ibmi72-ppc64/test/addons/register-signal-handler/test.js child 6 2
09:41:12 Running: node /home/iojs/build/workspace/node-test-commit-ibmi/nodes/ibmi72-ppc64/test/addons/register-signal-handler/test.js child 11 1
09:41:12 Running: node /home/iojs/build/workspace/node-test-commit-ibmi/nodes/ibmi72-ppc64/test/addons/register-signal-handler/test.js child 11 2
09:41:12 assert.js:103
09:41:12 throw new AssertionError(obj);
09:41:12 ^
09:41:12
09:41:12 AssertionError [ERR_ASSERTION]: Expected values to be strictly deep-equal:
09:41:12 + actual - expected
09:41:12
09:41:12 [
09:41:12 - 11,
09:41:12 11
09:41:12 ]
09:41:12 at Object.<anonymous> (/home/iojs/build/workspace/node-test-commit-ibmi/nodes/ibmi72-ppc64/test/addons/register-signal-handler/test.js:54:12)
09:41:12 at Module._compile (internal/modules/cjs/loader.js:1252:30)
09:41:12 at Object.Module._extensions..js (internal/modules/cjs/loader.js:1273:10)
09:41:12 at Module.load (internal/modules/cjs/loader.js:1101:32)
09:41:12 at Function.Module._load (internal/modules/cjs/loader.js:966:14)
09:41:12 at Function.executeUserEntryPoint [as runMain] (internal/modules/run_main.js:60:12)
09:41:12 at internal/main/run_main_module.js:17:47 {
09:41:12 generatedMessage: true,
09:41:12 code: 'ERR_ASSERTION',
09:41:12 actual: [ 11 ],
09:41:12 expected: [ 11, 11 ],
09:41:12 operator: 'deepStrictEqual'
09:41:12 }
09:41:12 ...
...
09:44:59 not ok 2901 abort/test-addon-register-signal-handler
09:44:59 ---
09:44:59 duration_ms: 9.300
09:44:59 severity: fail
09:44:59 exitcode: 1
09:44:59 stack: |-
09:44:59 Running: node /home/iojs/build/workspace/node-test-commit-ibmi/nodes/ibmi72-ppc64/test/addons/register-signal-handler/test.js child 6 reset 1
09:44:59 Running: node /home/iojs/build/workspace/node-test-commit-ibmi/nodes/ibmi72-ppc64/test/addons/register-signal-handler/test.js child 6 reset 2
09:44:59 Running: node /home/iojs/build/workspace/node-test-commit-ibmi/nodes/ibmi72-ppc64/test/addons/register-signal-handler/test.js child 6 1
09:44:59 Running: node /home/iojs/build/workspace/node-test-commit-ibmi/nodes/ibmi72-ppc64/test/addons/register-signal-handler/test.js child 6 2
09:44:59 Running: node /home/iojs/build/workspace/node-test-commit-ibmi/nodes/ibmi72-ppc64/test/addons/register-signal-handler/test.js child 11 1
09:44:59 Running: node /home/iojs/build/workspace/node-test-commit-ibmi/nodes/ibmi72-ppc64/test/addons/register-signal-handler/test.js child 11 2
09:44:59 assert.js:103
09:44:59 throw new AssertionError(obj);
09:44:59 ^
09:44:59
09:44:59 AssertionError [ERR_ASSERTION]: Expected values to be strictly deep-equal:
09:44:59 + actual - expected
09:44:59
09:44:59 [
09:44:59 - 11,
09:44:59 11
09:44:59 ]
09:44:59 at Object.<anonymous> (/home/iojs/build/workspace/node-test-commit-ibmi/nodes/ibmi72-ppc64/test/addons/register-signal-handler/test.js:54:12)
09:44:59 at Module._compile (internal/modules/cjs/loader.js:1252:30)
09:44:59 at Object.Module._extensions..js (internal/modules/cjs/loader.js:1273:10)
09:44:59 at Module.load (internal/modules/cjs/loader.js:1101:32)
09:44:59 at Function.Module._load (internal/modules/cjs/loader.js:966:14)
09:44:59 at Module.require (internal/modules/cjs/loader.js:1141:19)
09:44:59 at require (internal/modules/cjs/helpers.js:75:18)
09:44:59 at Object.<anonymous> (/home/iojs/build/workspace/node-test-commit-ibmi/nodes/ibmi72-ppc64/test/abort/test-addon-register-signal-handler.js:7:1)
09:44:59 at Module._compile (internal/modules/cjs/loader.js:1252:30)
09:44:59 at Object.Module._extensions..js (internal/modules/cjs/loader.js:1273:10) {
09:44:59 generatedMessage: true,
09:44:59 code: 'ERR_ASSERTION',
09:44:59 actual: [ 11 ],
09:44:59 expected: [ 11, 11 ],
09:44:59 operator: 'deepStrictEqual'
09:44:59 }
09:44:59 ...
```
abort/test-addon-register-signal-handler runs the test from addons/register-signal-handler/test with environment variable `ALLOW_CRASHES = true`.
https://github.com/nodejs/node/blob/08e8997d54e2e16a191267a1c8b5676a7486e130/test/abort/test-addon-register-signal-handler.js#L4-L7
cc @nodejs/platform-ibmi
* **Build Links**:
- https://ci.nodejs.org/job/node-daily-master/2004/
- https://ci.nodejs.org/job/node-test-commit-ibmi/34/nodes=ibmi72-ppc64/
|
flaky-test,ibm i
|
medium
|
Critical
|
659,176,941 |
TypeScript
|
Suggestion: noInferredAny
|
#### Search Terms
noImplicitAny inference any noInferredAny
## Suggestion
Symbols typed as `any` reduce the type safety of a program. That's fair if the programmer intended to use `any`. However it's relatively easy to end up with symbols typed `any` through type inference chains that are not obvious:
* 3rd party libraries might return `any`
* complex type expressions might infer to any
* some `.d.ts` types default generic arguments to `any` (e.g. `Set`)
In all these situations, a programmer might write `const foo = something();` and expect `foo` to have a reasonable inferred type. `foo` being inferred to `any` is easy to miss in such code, both while editing and while reviewing code.
Proposal: add a compiler option `noInferredAny` that flags symbols whose type is any and that do not have an explicit type annotation.
## Use Cases
* better type safety for programs
* detect weak typings in your dependencies
* more
## Examples
```ts
const foo1 = returnsAny(); // error
const foo2: any = returnsAny(); // ok
const foo3: string = returnsAny(); // probably ok, programmer gave an explicit type? could also require an explicit cast.
const foo4 = returnsAny() as string; // ok
const {foo5}: {foo5: string} = returnsAny(); // ok
```
## Checklist
My suggestion meets these guidelines:
* [ ] This wouldn't be a breaking change in existing TypeScript/JavaScript code
* [x] This wouldn't change the runtime behavior of existing JavaScript code
* [x] This could be implemented without emitting different JS based on the types of the expressions
* [x] This isn't a runtime feature (e.g. library functionality, non-ECMAScript syntax with JavaScript output, etc.)
* [x] This feature would agree with the rest of [TypeScript's Design Goals](https://github.com/Microsoft/TypeScript/wiki/TypeScript-Design-Goals).
|
Suggestion,Needs Proposal
|
low
|
Critical
|
659,203,534 |
angular
|
Why is Route#data a type instead of an interface?
|
<!--🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅
Oh hi there! 😄
To expedite issue processing please search open and closed issues before submitting a new one.
Existing issues often contain information about workarounds, resolution, or progress updates.
🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅🔅-->
# 🐞 bug report
### Affected Package
<!-- Can you pin-point one or more @angular/* packages as the source of the bug? -->
<!-- ✍️edit: --> The issue is caused by package @angular/router
### Description
<!-- ✍️--> A clear and concise description of the problem...
When we work on the routing configuration, sometimes we leverage the `Route#data` property to add metadata for a specific route. Eg: `permissions` information like the following:

In my use-case, I'd like to type `Route#data` to have an optional property `requiredPermission` which is a Tuple of `[PermissionNames, Privilege]`. And I want to enforce this type specifically for `requiredPermission` if it is added to a `Route#data`. Normally, I'd just go to `typings.d.ts` (or whatever `*.d.ts` you have at root) and override a library's interface there. Eg:

But for the case of `Route#data`, it has `type Data = {}` tied to it and `Type` does not allow for Declaration Merging so TypeScript doesn't allow me to override `Route#data` as the above screenshot shows. This prevents me from enforcing the correct typings for `requiredPermission`, hence leads to bad Developer Experience (in our cases) and Runtime bugs (instead of Compilation time).
If `Route#data` was an interface (which allows for Declaration Merging), I could indeed achieve the following:



Before writing up this issue, I was going to submit a PR right away to "fix" the bug. But looking at the source code, there are many different places (other than `Route#data`) being given types with `Type` instead of `interface`.
- Is there a reason for using `Type` rather than `Interface` for these cases?
- If I were to submit a PR, would I need to take into consideration of other `Type` other than `Route#data` to change those into `Interface`?
## 🔬 Minimal Reproduction
<!--
Please create and share minimal reproduction of the issue starting with this template: https://stackblitz.com/fork/angular-ivy
-->
A good way to reproduce this (as the screenshots above have shown) is to:
1. Create a new Angular app (or use existing Angular app)
2. Create a `typings.d.ts` on the same level as `main.ts` (or use existing `*.d.ts` on that same level)
3. Try to merge `Data` to have custom typed properties:
```ts
declare module '@angular/router' {
interface Data {
requiredPermission?: [number, string]
}
}
```
4. TypeScript will show error: Duplicate identifier Data
Issues that don't have enough info and can't be reproduced will be closed.
You can read more about issue submission guidelines here: https://github.com/angular/angular/blob/master/CONTRIBUTING.md#-submitting-an-issue
-->
## 🌍 Your Environment
**Angular Version:**
<pre><code>
<!-- run `ng version` and paste output below -->
<!-- ✍️-->
_ _ ____ _ ___
/ \ _ __ __ _ _ _| | __ _ _ __ / ___| | |_ _|
/ △ \ | '_ \ / _` | | | | |/ _` | '__| | | | | | |
/ ___ \| | | | (_| | |_| | | (_| | | | |___| |___ | |
/_/ \_\_| |_|\__, |\__,_|_|\__,_|_| \____|_____|___|
|___/
Angular CLI: 9.1.8
Node: 12.13.0
OS: darwin x64
Angular:
...
Ivy Workspace:
Package Version
------------------------------------------------------
@angular-devkit/architect 0.901.8
@angular-devkit/core 9.1.8
@angular-devkit/schematics 9.1.8
@schematics/angular 9.1.8
@schematics/update 0.901.8
rxjs 6.5.4
</code></pre>
|
feature,freq4: critical,area: router,state: confirmed,cross-cutting: types,P4,feature: under consideration,feature: votes required
|
medium
|
Critical
|
659,269,101 |
electron
|
A similar of BrowserWindow.setBackgroundColor to tray
|
### Preflight Checklist
* [x] I have read the [Contributing Guidelines](https://github.com/electron/electron/blob/master/CONTRIBUTING.md) for this project.
* [x] I agree to follow the [Code of Conduct](https://github.com/electron/electron/blob/master/CODE_OF_CONDUCT.md) that this project adheres to.
* [x] I have searched the issue tracker for a feature request that matches the one I want to file, without success.
### Problem Description
I'm creating a code tray in electron for open favorites projects in vscode but
I've come across a problem: the Tray object don't have a prop or method to change easily your background color like in BroswerWindow object.
Chaging this:
to this:
### Proposed Solution
Create a method that work like BrowserWindow.setBackgroundColor()
like this:
```js
const { Tray } = require('electron')
const { resolve } = require('path')
const mainTray = new Tray(resolve(__dirname, 'assets', 'myIcon.png'))
mainTray.setBackgroundColor('#383838')
```
### Alternatives Considered
Create a prop that when set to true change tray background color to #383838 when system theme is set to dark
Like this:
```js
const { Tray } = require('electron')
const { resolve } = require('path')
const mainTray = new Tray(resolve(__dirname, 'assets', 'myIcon.png'),
{
updateBackgroundColorWhenSystemThemeIsDark: true
}
)
```
### Additional Information
|
enhancement :sparkles:
|
low
|
Minor
|
659,427,569 |
TypeScript
|
"Extract to function" refactor is not suggested if selection contains `if` statement (conditional return)
|
<!-- 🚨 STOP 🚨 STOP 🚨 STOP 🚨
Half of all issues filed here are duplicates, answered in the FAQ, or not appropriate for the bug tracker. Even if you think you've found a *bug*, please read the FAQ first, especially the Common "Bugs" That Aren't Bugs section!
Please help us by doing the following steps before logging an issue:
* Search: https://github.com/Microsoft/TypeScript/search?type=Issues
* Read the FAQ: https://github.com/Microsoft/TypeScript/wiki/FAQ
Please fill in the *entire* template below.
-->
<!--
Please try to reproduce the issue with the latest published version. It may have already been fixed.
For npm: `typescript@next`
This is also the 'Nightly' version in the playground: http://www.typescriptlang.org/play/?ts=Nightly
-->
**TypeScript Version:** 3.9.2
<!-- Search terms you tried before logging this (so others can find this issue more easily) -->
**Search Terms:**
**Code**
```ts
const fn = ({ condition }: { condition: boolean }) => {
if (condition) {
return 1;
} else {
return 2;
}
};
```
Select the whole `if` statement, including the `else`, like this:

**Expected behavior:**
The "extract to function" refactor should be suggested. When the refactor is used, it should produce code that looks like this:
```ts
const fn = ({ condition }: { condition: boolean }) => {
return newFunction(condition);
};
function newFunction(condition: boolean) {
if (condition) {
return 1;
} else {
return 2;
}
}
```
**Actual behavior:**
The "extract to function" refactor is not suggested (testing in VS Code).
**Playground Link:** <!-- A link to a TypeScript Playground "Share" link which demonstrates this behavior -->
**Related Issues:** <!-- Did you find other bugs that looked similar? -->
|
Suggestion,Experience Enhancement
|
low
|
Critical
|
659,439,708 |
go
|
crypto/tls: TLS handshake issue with Eclipse Paho MQTT client and RabbitMQ
|
Hi All,
I'm trying to connect to my RabbitMQ broker using the Eclipse Paho MQTT client (go lang version).
I'm using go1.14.6 linux/arm.
My goal is to establish a secure connection with mutual authentication between my Go client and RabbitMQ broker.
I got the following TLS error from the Go client:
panic: Network Error : remote error: tls: handshake failure
I cannot see any relevant logs on my RabitMQ broker:
2020-07-17 16:43:42.936 [debug] <0.17255.19> Supervisor {<0.17255.19>,rabbit_mqtt_connection_sup} started rabbit_mqtt_connection_sup:start_keepalive_link() at pid <0.17256.19>
2020-07-17 16:43:42.936 [debug] <0.17255.19> Supervisor {<0.17255.19>,rabbit_mqtt_connection_sup} started rabbit_mqtt_reader:start_link(<0.17256.19>, {acceptor,{0,0,0,0,0,0,0,0},8883}) at pid <0.17257.19>
Please note that if i use openssl CLI it works fine with the same broker and certificates:
openssl s_client -connect <server-host>:8883 -debug -CAfile /tmp/ca.crt -key /tmp/private-key.crt -cert /tmp/client-cert.crt
Could you help me to solve this issue? I can share privately rootCA + client cert + private key + server host.
Below the code that i'm using:
#############
# GO CLIENT #
#############
```go
package main
import (
MQTT "github.com/eclipse/paho.mqtt.golang"
"fmt"
"time"
"io/ioutil"
"crypto/tls"
"crypto/x509"
)
var (
brokerUrl = "ssl://<server-host>:8883"
)
func main() {
opts := MQTT.NewClientOptions()
opts.SetClientID("MY-CLIENT-ID")
opts.AddBroker(brokerUrl)
opts.SetPingTimeout(1 * time.Second)
opts.SetAutoReconnect(true)
opts.SetCleanSession(true)
opts.SetKeepAlive(10 * time.Second)
opts.SetConnectTimeout(10 * time.Second)
opts.SetTLSConfig(NewTLSConfig())
client := MQTT.NewClient(opts)
if token := client.Connect(); token.Wait() && token.Error() != nil {
panic(token.Error())
}
fmt.Println("Client Connected")
}
func NewTLSConfig() *tls.Config {
certpool, err := x509.SystemCertPool()
if err != nil {
return nil
}
pemCert, err := ioutil.ReadFile("ca.crt")
if err != nil {
return nil
}
certpool.AppendCertsFromPEM(pemCert)
// Import client certificate/key pair
cert, err := tls.LoadX509KeyPair("client-cert.crt", "private-key.crt.key")
if err != nil {
return nil
}
// Just to print out the client certificate...
cert.Leaf, err = x509.ParseCertificate(cert.Certificate[0])
if err != nil {
return nil
}
// Create tls.Config with desired tls properties
return &tls.Config{
// RootCAs = certs used to verify server cert.
RootCAs: certpool,
// Certificates = list of certs client sends to server.
Certificates: []tls.Certificate{cert},
PreferServerCipherSuites: true,
CipherSuites: []uint16{
tls.TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384,
tls.TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384,
tls.TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256,
tls.TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256,
tls.TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384,
},
}
}
```
```python
######################
# RabbitMQ configuration #
######################
{versions, ['tlsv1.2']},
{ciphers, [
{ecdhe_ecdsa,aes_256_gcm,aead,sha384}, TLS_ECDHE_ECDSA_WITH_AES_256_GCM_SHA384 ECDHE-RSA-AES256-GCM-SHA384
{ecdhe_rsa,aes_256_gcm,aead,sha384}, TLS_RSA_WITH_AES_256_GCM_SHA384
{ecdh_ecdsa,aes_256_gcm,aead,sha384},
{ecdh_rsa,aes_256_gcm,aead,sha384},
{dhe_rsa,aes_256_gcm,aead,sha384},
{dhe_dss,aes_256_gcm,aead,sha384},
{ecdhe_ecdsa,aes_128_gcm,aead,sha256}, TLS_ECDHE_ECDSA_WITH_AES_128_GCM_SHA256
{ecdhe_rsa,aes_128_gcm,aead,sha256}, TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
{ecdh_ecdsa,aes_128_gcm,aead,sha256},
{ecdh_rsa,aes_128_gcm,aead,sha256},
{dhe_rsa,aes_128_gcm,aead,sha256},
{dhe_dss,aes_128_gcm,aead,sha256}
]},
{honor_cipher_order, true},
{honor_ecc_order, true},
{client_renegotiation, false},
{secure_renegotiate, true},
{verify, verify_peer},
{fail_if_no_peer_cert, true}]
```
Thanks in advance,
Dario
|
NeedsInvestigation
|
low
|
Critical
|
659,468,435 |
flutter
|
Offline integration test for zip artifacts
|
We need to validate that downloading the zip and running precache is sufficient to build without network connectivity. Some possible solutions involve: 1) running in a container with limited network access 2) overriding pub/maven artifact URL to something bogus.
This test will guide future updates to the zip artifacts
|
tool,customer: product,team-infra,P3,triaged-infra,fyi-release
|
low
|
Major
|
659,470,008 |
flutter
|
Update prepare-packages script to remove dev dependencies, binary artifacts
|
We should only include the minimum set of packages needed for flutter run on the template. We should be able to exclude tool deps by uploading the snapshot, as well as the non-univeral binaries.
Blocked by https://github.com/flutter/flutter/issues/61751
|
c: new feature,tool,customer: product,P3,team-tool,triaged-tool
|
low
|
Major
|
659,486,985 |
rust
|
Internal compiler error: find_vtable_types_for_unsizing: invalid coercion
|
I tried this code (modified version of `src/test/ui/specialization/issue-44861.rs`):
```rust
#![feature(specialization)]
#![feature(unsize, coerce_unsized)]
use std::ops::CoerceUnsized;
pub struct SmartassPtr<A: Smartass+?Sized>(A::Data);
pub trait Smartass {
type Data;
type Data2: CoerceUnsized<*const [u8]>;
}
pub trait MaybeObjectSafe {}
impl MaybeObjectSafe for () {}
impl<T> Smartass for T {
type Data = <Self as Smartass>::Data2;
default type Data2 = *const [u8; 0];
}
impl Smartass for () {
type Data2 = *const [u8; 1];
}
impl Smartass for dyn MaybeObjectSafe {
type Data = *const [u8];
type Data2 = *const [u8; 0];
}
impl<U: Smartass+?Sized, T: Smartass+?Sized> CoerceUnsized<SmartassPtr<T>> for SmartassPtr<U>
where <U as Smartass>::Data: std::ops::CoerceUnsized<<T as Smartass>::Data>
{}
pub fn conv(s: SmartassPtr<()>) -> SmartassPtr<dyn MaybeObjectSafe> {
s // This shouldn't coerce
}
```
I expected to see this happen: mismatched types error in conv due to mismatched types
Instead, this happened: ICE
[Playground](https://play.rust-lang.org/?version=nightly&mode=debug&edition=2021&gist=d507a3c12e29d16097b94e13ef6401dd)
### Meta
`rustc --version --verbose`:
```
rustc 1.46.0-nightly (346aec9b0 2020-07-11)
binary: rustc
commit-hash: 346aec9b02f3c74f3fce97fd6bda24709d220e49
commit-date: 2020-07-11
host: x86_64-unknown-linux-gnu
release: 1.46.0-nightly
LLVM version: 10.0
```
<details><summary>Backtrace</summary>
<p>
```
warning: the feature `specialization` is incomplete and may not be safe to use and/or cause compiler crashes
--> tmp/coerce-unsize-spec.rs:2:12
|
2 | #![feature(specialization)]
| ^^^^^^^^^^^^^^
|
= note: `#[warn(incomplete_features)]` on by default
= note: see issue #31844 <https://github.com/rust-lang/rust/issues/31844> for more information
error: internal compiler error: src/librustc_mir/monomorphize/collector.rs:898:14: find_vtable_types_for_unsizing: invalid coercion <() as Smartass>::Data -> <dyn MaybeObjectSafe as Smartass>::Data
thread 'rustc' panicked at 'Box<Any>', src/librustc_errors/lib.rs:916:9
stack backtrace:
0: backtrace::backtrace::libunwind::trace
at /cargo/registry/src/github.com-1ecc6299db9ec823/backtrace-0.3.46/src/backtrace/libunwind.rs:86
1: backtrace::backtrace::trace_unsynchronized
at /cargo/registry/src/github.com-1ecc6299db9ec823/backtrace-0.3.46/src/backtrace/mod.rs:66
2: std::sys_common::backtrace::_print_fmt
at src/libstd/sys_common/backtrace.rs:78
3: <std::sys_common::backtrace::_print::DisplayBacktrace as core::fmt::Display>::fmt
at src/libstd/sys_common/backtrace.rs:59
4: core::fmt::write
at src/libcore/fmt/mod.rs:1076
5: std::io::Write::write_fmt
at src/libstd/io/mod.rs:1537
6: std::sys_common::backtrace::_print
at src/libstd/sys_common/backtrace.rs:62
7: std::sys_common::backtrace::print
at src/libstd/sys_common/backtrace.rs:49
8: std::panicking::default_hook::{{closure}}
at src/libstd/panicking.rs:198
9: std::panicking::default_hook
at src/libstd/panicking.rs:217
10: rustc_driver::report_ice
11: std::panicking::rust_panic_with_hook
at src/libstd/panicking.rs:530
12: std::panicking::begin_panic
13: rustc_errors::HandlerInner::bug
14: rustc_errors::Handler::bug
15: rustc_middle::util::bug::opt_span_bug_fmt::{{closure}}
16: rustc_middle::ty::context::tls::with_opt::{{closure}}
17: rustc_middle::ty::context::tls::with_opt
18: rustc_middle::util::bug::opt_span_bug_fmt
19: rustc_middle::util::bug::bug_fmt
20: rustc_mir::monomorphize::collector::find_vtable_types_for_unsizing
21: rustc_mir::monomorphize::collector::find_vtable_types_for_unsizing
22: <rustc_mir::monomorphize::collector::MirNeighborCollector as rustc_middle::mir::visit::Visitor>::visit_rvalue
23: rustc_mir::monomorphize::collector::collect_neighbours
24: rustc_mir::monomorphize::collector::collect_items_rec
25: rustc_session::utils::<impl rustc_session::session::Session>::time
26: rustc_mir::monomorphize::collector::collect_crate_mono_items
27: rustc_mir::monomorphize::partitioning::collect_and_partition_mono_items
28: rustc_middle::ty::query::<impl rustc_query_system::query::config::QueryAccessors<rustc_middle::ty::context::TyCtxt> for rustc_middle::ty::query::queries::collect_and_partition_mono_items>::compute
29: rustc_query_system::dep_graph::graph::DepGraph<K>::with_task_impl
30: rustc_data_structures::stack::ensure_sufficient_stack
31: rustc_query_system::query::plumbing::get_query_impl
32: rustc_codegen_ssa::back::symbol_export::exported_symbols_provider_local
33: rustc_middle::ty::query::<impl rustc_query_system::query::config::QueryAccessors<rustc_middle::ty::context::TyCtxt> for rustc_middle::ty::query::queries::exported_symbols>::compute
34: rustc_query_system::dep_graph::graph::DepGraph<K>::with_task_impl
35: rustc_data_structures::stack::ensure_sufficient_stack
36: rustc_query_system::query::plumbing::get_query_impl
37: rustc_metadata::rmeta::encoder::encode_metadata_impl
38: rustc_data_structures::sync::join
39: rustc_metadata::rmeta::decoder::cstore_impl::<impl rustc_middle::middle::cstore::CrateStore for rustc_metadata::creader::CStore>::encode_metadata
40: rustc_middle::ty::context::TyCtxt::encode_metadata
41: rustc_interface::passes::start_codegen
42: rustc_middle::ty::context::tls::enter_global
43: rustc_interface::queries::Queries::ongoing_codegen
44: rustc_interface::queries::<impl rustc_interface::interface::Compiler>::enter
45: rustc_span::with_source_map
46: rustc_interface::interface::create_compiler_and_run
47: scoped_tls::ScopedKey<T>::set
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
note: the compiler unexpectedly panicked. this is a bug.
note: we would appreciate a bug report: https://github.com/rust-lang/rust/blob/master/CONTRIBUTING.md#bug-reports
note: rustc 1.46.0-nightly (346aec9b0 2020-07-11) running on x86_64-unknown-linux-gnu
note: compiler flags: --crate-type lib
query stack during panic:
#0 [collect_and_partition_mono_items] collect_and_partition_mono_items
#1 [exported_symbols] exported_symbols
end of query stack
error: aborting due to previous error; 1 warning emitted
```
</p>
</details>
|
I-ICE,T-compiler,A-specialization,C-bug,requires-nightly,F-specialization,glacier,F-coerce_unsized,S-bug-has-test
|
low
|
Critical
|
659,514,407 |
godot
|
Erasing tiles with SHIFT + RIGHT CLICK is very buggy with tile atlases
|
<!-- Please search existing issues for potential duplicates before filing yours:
https://github.com/godotengine/godot/issues?q=is%3Aissue
-->
**Godot version:**
<!-- Specify commit hash if using non-official build. -->
3.2.2
**OS/device including version:**
<!-- Specify GPU model, drivers, and the backend (GLES2, GLES3, Vulkan) if graphics-related. -->
Windows 10
**Issue description:**
<!-- What happened, and what was expected. -->
Hold Shift + Right Click, it should let you erase a straight line of tiles. It works normally when erasing a single tile, but breaks when erasing an atlas tile.
While hovering the erase line around, it replaces the hovered tile with the first tile in the atlas.
If another atlas tile is selected, it will replace tiles with that tile while hovering.
**Steps to reproduce:**
- I will be erasing a straight line from corner to corner on these two shapes of tiles. The one on the left (yellow) is from an atlas while the one on the right (X) is a single tile.
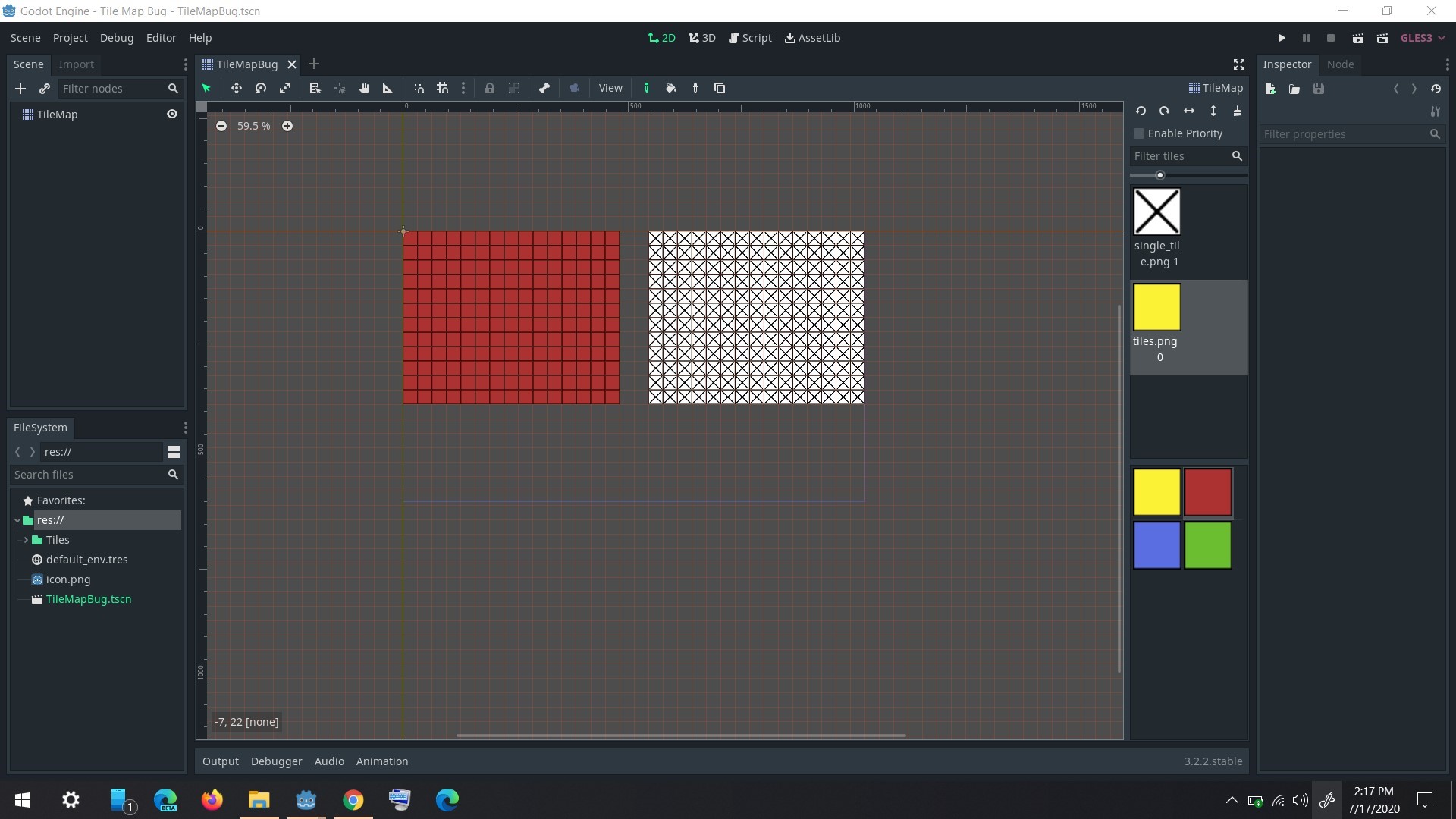
- While the single tile (X tile) is selected, hold SHIFT + RIGHT CLICK, and try to erase a straight line from one corner to the opposite corner. The one on the right erases normally, but the left one is replaced by yellow tiles wherever it was hovered over. (Yellow is the first tile in that atlas)
- Undo the changes. Now do the same thing, but this time hold Shift + Right Click while another atlas tile is selected. It will now replace the tiles on the left case with the tile that is selected.
- Undo the changes. If the red tile is selected, however, while trying to erase a straight line, then it works normally.
**Minimal reproduction project:**
<!-- A small Godot project which reproduces the issue. Drag and drop a zip archive to upload it. -->
[TileEraseBug.zip](https://github.com/godotengine/godot/files/4939513/TileEraseBug.zip)
|
bug,topic:editor
|
low
|
Critical
|
659,560,078 |
terminal
|
wpf: cursor is same color as last rendered foreground (?)
|


|
Issue-Bug,Product-Terminal,Priority-3,Area-WPFControl
|
low
|
Minor
|
659,609,857 |
terminal
|
Let terminal consumers provide click handlers and pattern recognizers for buffer text
|
<!--
🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
I ACKNOWLEDGE THE FOLLOWING BEFORE PROCEEDING:
1. If I delete this entire template and go my own path, the core team may close my issue without further explanation or engagement.
2. If I list multiple bugs/concerns in this one issue, the core team may close my issue without further explanation or engagement.
3. If I write an issue that has many duplicates, the core team may close my issue without further explanation or engagement (and without necessarily spending time to find the exact duplicate ID number).
4. If I leave the title incomplete when filing the issue, the core team may close my issue without further explanation or engagement.
5. If I file something completely blank in the body, the core team may close my issue without further explanation or engagement.
All good? Then proceed!
-->
# Description of the new feature/enhancement
Terminal consumers have a need to provide their own handlers for clickable regions of text in the terminal. For example: In VS this could enable clicking on build errors and opening up a document to the line and column called out in the error.
<!--
A clear and concise description of what the problem is that the new feature would solve.
Describe why and how a user would use this new functionality (if applicable).
-->
# Proposed technical implementation details (optional)
There needs to be two additions to the terminal in order to enable this:
- Consumers of the terminal must be able to provide a pattern that will identify regions of clickable text
- Consumers will provide a callback that is called with the clicked text as a parameter
<!--
A clear and concise description of what you want to happen.
-->
|
Issue-Feature,Area-Output,Product-Terminal,Area-WPFControl
|
low
|
Critical
|
659,611,179 |
rust
|
rustdoc: Intra doc links from Deref/etc do not link to the same page
|
A slight degradation in quality [from manual links] is that the `#method.foo` links would previously link to the same page on `String`'s documentation, and now they will navigate to `str`.
Originally posted by @manishearth in https://github.com/rust-lang/rust/pull/74453.
|
T-rustdoc,C-enhancement,A-intra-doc-links
|
low
|
Minor
|
659,717,992 |
vscode
|
Allow extensions to contribute to peek widget title navigation action item
|
<!-- ⚠️⚠️ Do Not Delete This! feature_request_template ⚠️⚠️ -->
<!-- Please read our Rules of Conduct: https://opensource.microsoft.com/codeofconduct/ -->
<!-- Please search existing issues to avoid creating duplicates. -->
<!-- Describe the feature you'd like. -->
In my extension, I'm creating peek view widgets through `editor.action.peekLocations` and `editor.action.showReferences` commands. But I would like to give the user ways to interact with the content shown.
It would be great if extensions can contribute add commands to the peek widgets, like the ones in `Peek Call Hierarchy` or `Peek Diff`.

I see in the documentation that it is possible to contribute to the editor title navigation, but it doesn't seem to be possible to contribute to the peek widget title navigation yet.
```
"menus": {
"editor/title": [
{
"when": "resourceLangId == markdown",
"command": "markdown.showPreview",
"alt": "markdown.showPreviewToSide",
"group": "navigation"
}
]
}
```
|
feature-request,references-viewlet
|
low
|
Minor
|
659,790,932 |
TypeScript
|
Spreading tuple into generic/type arguments
|
## Search Terms
- spreading generic parameters
- generic parameter spread
- tuple generic spread
- spreading generic argument
- spreading typeArgument
- spreading type argument
## Suggestion
Allow spreading of a tuple type into type arguments.
The idea is that a tuple of _n_ elements gets spread into generic arguments with _r_ arguments. If _n_ is larger than _r_, only the first _r_ items are used. If _n_ is smaller than _r_ it is possible to add elements after the spread argument. E.g.
```ts
function foo<A, B, C, D>() {
}
type ThreeType = [Foo, Bar, Baz];
foo<...ThreeType, Delta>();
```
## Use Cases
I find myself repeating complex generic types. Ideally I could shorten lengthy repetition into a single type.
## Examples
`dialog.open` takes three generic arguments, these have to be repeated each call. This makes the call less legible and reduces DRYness.
```ts
const dialogRef = this.dialog.open<
PrinterSelectDialogComponent,
PrinterSelectDialogData,
OfferProductPrinter>(
PrinterSelectDialogComponent,
{
data: {
printer,
},
},
);
```
**After this proposal**
```ts
export type PrinterSelectDialog = [
PrinterSelectDialogComponent,
PrinterSelectDialogData,
OfferProductPrinter,
];
const dialogRef = this.dialog.open<...PrinterSelectDialog>(PrinterSelectDialogComponent, {
data: {
service,
},
});
```
## Checklist
My suggestion meets these guidelines:
* [x] This wouldn't be a breaking change in existing TypeScript/JavaScript code
* [x] This wouldn't change the runtime behavior of existing JavaScript code
* [x] This could be implemented without emitting different JS based on the types of the expressions
* [x] This isn't a runtime feature (e.g. library functionality, non-ECMAScript syntax with JavaScript output, etc.)
* [x] This feature would agree with the rest of [TypeScript's Design Goals](https://github.com/Microsoft/TypeScript/wiki/TypeScript-Design-Goals).
|
Suggestion,In Discussion
|
medium
|
Major
|
659,823,145 |
PowerToys
|
Text Replacement / expander
|
A simple text replacement tool, my examples are from macOS and iOS, it is also a feature in Android.
Basically this feature: [Text Replacements](https://support.apple.com/guide/mac-help/replace-text-punctuation-documents-mac-mh35735/mac)
On your Mac, choose Apple menu > System Preferences, click Keyboard, then click Text.
Another example: [Third one down](https://support.apple.com/en-us/HT207525) "Set up text replacement"
It's very handy if you have things you need to type regularly, and just typing one word and having my system fill in a whole sentence saves a lot of time and effort at work instead of keeping a copy past text file. I have many web addresses I send to customers and many full sentences for my notes at work that used repeatedly and this kind of feature is surprisingly missing from Windows.
Sorry to open a new issue for this, but my last one was closed already.


|
Idea-New PowerToy
|
high
|
Critical
|
659,827,416 |
go
|
database/sql: improve documentation for closing prepared statement on Tx
|
The [https://golang.org/pkg/database/sql/#Tx](https://golang.org/pkg/database/sql/#Tx) documentation says:
> The statements prepared for a transaction by calling the transaction's Prepare or Stmt methods **are closed by the call to Commit or Rollback**.
But in the example of [https://golang.org/pkg/database/sql/#Tx.Prepare](https://golang.org/pkg/database/sql/#Tx.Prepare) there's a comment ("Prepared statements take up server resources **and should be closed after use**.") that can cause some doubts about how to handle it
```golang
package main
import (
"context"
"database/sql"
"log"
)
var (
ctx context.Context
db *sql.DB
)
func main() {
projects := []struct {
mascot string
release int
}{
{"tux", 1991},
{"duke", 1996},
{"gopher", 2009},
{"moby dock", 2013},
}
tx, err := db.Begin()
if err != nil {
log.Fatal(err)
}
defer tx.Rollback() // The rollback will be ignored if the tx has been committed later in the function.
stmt, err := tx.Prepare("INSERT INTO projects(id, mascot, release, category) VALUES( ?, ?, ?, ? )")
if err != nil {
log.Fatal(err)
}
defer stmt.Close() // Prepared statements take up server resources and should be closed after use.
for id, project := range projects {
if _, err := stmt.Exec(id+1, project.mascot, project.release, "open source"); err != nil {
log.Fatal(err)
}
}
if err := tx.Commit(); err != nil {
log.Fatal(err)
}
}
```
|
Documentation,NeedsInvestigation
|
low
|
Minor
|
659,874,031 |
godot
|
weird output when printing empty Array
|
<!-- Please search existing issues for potential duplicates before filing yours:
https://github.com/godotengine/godot/issues?q=is%3Aissue
-->
**Godot version:**
3.2.1
**OS/device including version:**
Windows 7 64 bits
**Issue description:**
Code:
> var test = []
> for i in range(2) : test.append([])
> print(test)
Expected:
> [[], []]
Output:
> [[], [...]]
**Steps to reproduce:**
Just copy the code in any node.
|
bug,topic:core,confirmed
|
low
|
Minor
|
659,887,880 |
youtube-dl
|
How to build from source?
|
I have read through your readme file, you only say
````
If you want to create a build of youtube-dl yourself, you'll need
python
make (only GNU make is supported)
pandoc
zip
nosetests
````
I still don't know how to build.
If I want to add feature, or some small customized, I need to build, right?
|
question
|
low
|
Minor
|
659,898,910 |
TypeScript
|
In JSDoc @type is not a type declaration, which it is much more like type conversion.
|
I don't kown whether its a bug or feature.
In Javascript, actually i need an error emit which ```other_props``` is not in ```Entity```

In Typescript, ```entityB``` act just same as the Javascript codes above

|
Bug,Has Repro
|
low
|
Critical
|
659,930,588 |
godot
|
[Mono] 3.2.2 Android Plugin fails to call GodotLib.calldeferred with Mono Object
|
<!-- Please search existing issues for potential duplicates before filing yours:
https://github.com/godotengine/godot/issues?q=is%3Aissue
-->
**Godot version:**
<!-- Specify commit hash if using non-official build. -->
3.2.2.stable.mono.official
**OS/device including version:**
<!-- Specify GPU model, drivers, and the backend (GLES2, GLES3, Vulkan) if graphics-related. -->
Android with GLES3
**Issue description:**
<!-- What happened, and what was expected. -->
Using this plugin from community https://github.com/Shin-NiL/Godot-Android-Admob-Plugin
I tried to migrate the admob.gd to C#
from https://github.com/Shin-NiL/Godot-Android-Admob-Plugin/blob/main/demo/main.gd
to https://gist.github.com/ricardoalcantara/6dddf96f35f26d168a66757f8ab1109f
I achieve to init and call methods from C# but when the Java plugin tries to call GodotLib.calldeferred it fails with this error message
```
07-18 02:16:06.284 16880 16880 W godot : AdMob: onAdLoaded
07-18 02:16:06.284 16880 16880 E godot : **ERROR**: Condition "!obj" is true.
07-18 02:16:06.284 16880 16880 E godot : At: platform/android/java_godot_lib_jni.cpp:484:Java_org_godotengine_godot_GodotLib_calldeferred() - Condition "!obj" is true.
07-18 02:16:06.449 16880 16880 W godot : AdMob: onRewardedVideoAdLoaded
07-18 02:16:06.449 16880 16880 E godot : **ERROR**: Condition "!obj" is true.
07-18 02:16:06.449 16880 16880 E godot : At: platform/android/java_godot_lib_jni.cpp:484:Java_org_godotengine_godot_GodotLib_calldeferred() - Condition "!obj" is true.
07-18 02:16:06.490 16880 16880 W godot : AdMob: onAdLoaded
07-18 02:16:06.490 16880 16880 E godot : **ERROR**: Condition "!obj" is true.
07-18 02:16:06.490 16880 16880 E godot : At: platform/android/java_godot_lib_jni.cpp:484:Java_org_godotengine_godot_GodotLib_calldeferred() - Condition "!obj" is true.
```
this line fails https://github.com/Shin-NiL/Godot-Android-Admob-Plugin/blob/main/admob-plugin/godotadmob/src/main/java/shinnil/godot/plugin/android/godotadmob/Banner.java#L52
the get_instance_id() shows the same ID with GDScript, it's just cannot call back the Object from Java when it's C#
**Steps to reproduce:**
Download the demo.zip from the following section

Install Android Build Template

Add the sample ID in AndroidManifest.xml
```xml
<!-- Sample AdMob App ID: ca-app-pub-3940256099942544~3347511713 -->
<meta-data
android:name="com.google.android.gms.ads.APPLICATION_ID"
android:value="ca-app-pub-3940256099942544~3347511713"/>
```
Build and Run on Android Device
**Minimal reproduction project:**
<!-- A small Godot project which reproduces the issue. Drag and drop a zip archive to upload it. -->
[demo.zip](https://github.com/godotengine/godot/files/4941140/demo.zip)
** Workaround **
I Created a C# class that proxy the GDScript class.
https://gist.github.com/ricardoalcantara/c238cd07286b33d6ffbcecc87adb3684
> In my project both gd and c# were set as autoload (Singletons).
|
bug,platform:android,topic:porting,topic:dotnet
|
low
|
Critical
|
659,934,618 |
pytorch
|
New Feature : A very fast algorithm for computing matrix rank
|
## 🚀 Feature
I have devised an LUP based [matrix rank computing algorithm](https://github.com/touqir14/LUP-rank-computer) that outperforms significantly the standard Numpy's [matrix_rank](https://numpy.org/doc/stable/reference/generated/numpy.linalg.matrix_rank.html) function and PyTorch's GPU accelerated [matrix_rank](https://pytorch.org/docs/master/generated/torch.matrix_rank.html) algorithm for most cases. For instance, for large matrices it offers a speedup of at least 200 times over Numpy's matrix_rank and 10 times over PyTorch's matrix_rank function as tested on Google Colab running on Tesla K80. See the [benchmarks](https://github.com/touqir14/LUP-rank-computer/blob/master/README.md). Unlike the LU factorization, LUP is stable in practice and I have thoroughly tested the correctness of my implementation.
## Motivation
Computing the matrix rank can be rather slow, particularly if one deals with large matrices and needs to run multiple times for at least tens of times. This motivated me to come up with a much faster approach than the standard rank computing methods.
## Pitch
I would like to consider the prospect of implementing this as a PyTorch function. My implementation uses scipy's [LUP](https://docs.scipy.org/doc/scipy/reference/generated/scipy.linalg.lu.html) function and a couple of Cython optimized functions along with the standard Numpy matrix operations. When GPU acceleration is enabled, it additionally uses PyTorch's [LUP](https://pytorch.org/docs/master/generated/torch.lu.html) function.
Let me know if you need to know more about the algorithm's specifics and testing/benchmarks.
cc @mruberry @rgommers @vincentqb @vishwakftw @SsnL @jianyuh
|
triaged,enhancement,module: numpy,module: linear algebra
|
low
|
Major
|
659,972,110 |
godot
|
Setting RigidBody global_transform into the `_input` function fails.
|
**Godot version:**
3.2 custom build, issue bisected to commit e7d8464f
**OS/device including version:**
Linux Mint 20
**Issue description:**
When setting the `global_transform` property of a RigidBody, the expected result sometimes happens, sometimes does not, seemingly at random.
**Steps to reproduce:**
Add a RigidBody to a scene, add a script that sets its `global_transform` property following an input event, run the game and press the key to confirm whether the transform actually changes.
**Minimal reproduction project:**
[BulletGlobalTransform.zip](https://github.com/godotengine/godot/files/4941240/BulletGlobalTransform.zip)
This project contains a workaround for the issue. First run the project and press space to reset the falling cube's position. Doing so should fail most of the time.
Open the RigidBody script and uncomment the yield line: now the transform should only be set during a physics update, and pressing space will always work.
Is this issue a regression or expected behavior following PR #40185?
This PR has also completely changed the behavior of my physics-based game (a drone simulator), with the drone getting its thrust more or less halved, even though thrust is calculated during physics frames only.
|
bug,topic:physics
|
low
|
Major
|
659,995,888 |
vscode
|
Git - Bulk merge conflict resolving issue on large files
|
Issue Type: <b>Performance Issue</b>
We need to include production build files of react in git as per our server configuration. Often the build files face merge conflict and we need to simply accept all incoming/current. But as the build files are too large, vscode can not resolve the conflict when I click accept all incoming/current. Where as, phpstorm can easily handle the action. I use vscode as my daily driver but when I need to resolve bulk merge conflict, I have to rely on phpstorm. This is getting annoying. This is the issue i am referring.

VS Code version: Code 1.47.2 (17299e413d5590b14ab0340ea477cdd86ff13daf, 2020-07-15T18:22:06.216Z)
OS version: Windows_NT x64 10.0.18363
<details>
<summary>System Info</summary>
|Item|Value|
|---|---|
|CPUs|Intel(R) Core(TM) i7-5500U CPU @ 2.40GHz (4 x 2394)|
|GPU Status|2d_canvas: enabled<br>flash_3d: enabled<br>flash_stage3d: enabled<br>flash_stage3d_baseline: enabled<br>gpu_compositing: enabled<br>multiple_raster_threads: enabled_on<br>oop_rasterization: disabled_off<br>protected_video_decode: unavailable_off<br>rasterization: enabled<br>skia_renderer: disabled_off_ok<br>video_decode: enabled<br>viz_display_compositor: enabled_on<br>viz_hit_test_surface_layer: disabled_off_ok<br>webgl: enabled<br>webgl2: enabled|
|Load (avg)|undefined|
|Memory (System)|11.93GB (3.70GB free)|
|Process Argv||
|Screen Reader|no|
|VM|0%|
</details><details>
<summary>Process Info</summary>
```
CPU % Mem MB PID Process
1 78 8744 code main
11 65 4668 shared-process
0 12 5308 electron-crash-reporter
2 71 9424 window (Issue Reporter)
0 234 9896 window (Untitled-1 - pypepro - Visual Studio Code)
0 23 2936 searchService
0 156 4036 extensionHost
0 29 1504 "C:\Users\swaza\AppData\Local\Programs\Microsoft VS Code\Code.exe" "c:\Users\swaza\AppData\Local\Programs\Microsoft VS Code\resources\app\extensions\json-language-features\server\dist\node\jsonServerMain" --node-ipc --clientProcessId=4036
0 63 1892 electron_node intelephense.js
0 62 2888 "C:\Users\swaza\AppData\Local\Programs\Microsoft VS Code\Code.exe" "c:\Users\swaza\AppData\Local\Programs\Microsoft VS Code\resources\app\extensions\html-language-features\server\dist\node\htmlServerMain" --node-ipc --clientProcessId=4036
0 34 7352 "C:\Users\swaza\AppData\Local\Programs\Microsoft VS Code\Code.exe" "c:\Users\swaza\AppData\Local\Programs\Microsoft VS Code\resources\app\extensions\css-language-features\server\dist\node\cssServerMain" --node-ipc --clientProcessId=4036
0 681 8436 electron_node tsserver.js
25 187 9848 electron_node server.js
0 38 14104 electron_node tsserver.js
0 60 9256 "C:\Program Files\PowerShell\7\pwsh.exe"
0 14 12264 watcherService
0 6 3720 console-window-host (Windows internal process)
0 6 12864 console-window-host (Windows internal process)
0 208 10212 gpu-process
0 24 11196 utility
```
</details>
<details>
<summary>Workspace Info</summary>
```
| Window (Untitled-1 - pypepro - Visual Studio Code)
| Folder (pypepro): more than 29483 files
| File types: php(7664) js(3397) png(1270) jpg(952) html(754) css(751)
| svg(639) md(222) gif(172) json(120)
| Conf files: package.json(8) gulp.js(3) launch.json(1) grunt.js(1)
| Launch Configs: pwa-chrome;
```
</details>
<details><summary>Extensions (14)</summary>
Extension|Author (truncated)|Version
---|---|---
Bookmarks|ale|11.3.1
vscode-intelephense-client|bme|1.5.2
htmltagwrap|bra|0.0.7
laravel-goto-view|cod|1.3.3
bracket-pair-colorizer-2|Coe|0.2.0
gitlens|eam|10.2.2
vsc-material-theme|Equ|32.8.0
vsc-material-theme-icons|equ|1.1.4
auto-close-tag|for|0.5.8
remote-wsl|ms-|0.44.4
laravel-blade|one|1.22.1
code-spell-checker|str|1.9.0
highlight-matching-tag|vin|0.9.9
better-align|wwm|1.1.6
(1 theme extensions excluded)
</details>
<!-- generated by issue reporter -->
|
feature-request,git
|
low
|
Critical
|
660,024,890 |
pytorch
|
Can we have a way to reset a scheduler back to epoch -1
|
## 🚀 Feature
<!-- A clear and concise description of the feature proposal -->
## Motivation
I'm tring to calculate the minimun loss of a NN.
## Pitch
something like .step(-1) but that's going away as deprecated.
## Alternatives
<!-- A clear and concise description of any alternative solutions or features you've considered, if any. -->
Make a new scheduler.
cc @vincentqb
|
module: optimizer,triaged,enhancement
|
low
|
Minor
|
660,088,636 |
pytorch
|
[feature request] New function `torch.slice(...)` mirroring TorchScript op signature or add step argument to `torch.narrow`
|
Maybe a separate issue is a better place for discussion: https://github.com/pytorch/pytorch/pull/7924#issuecomment-660249077 (@albanD, @t-vi )
Original discussion: https://discuss.pytorch.org/t/use-python-like-slice-indexing-across-a-given-dimension/89606/8
The usecase: packbits https://github.com/pytorch/ao/issues/292
https://gist.github.com/vadimkantorov/30ea6d278bc492abf6ad328c6965613a#file-packbits-py-L6
|
triaged,enhancement,needs research,function request
|
low
|
Major
|
660,120,814 |
PowerToys
|
[Run] Open app in a wanted size window
|
For example, now if I open word with Run, the word window will be a full-screen one by default.
Can we add some feature to set the window we open by Run to the size we want?
For instance, open word in a default half-screen window, instead of a full-screen one.
|
Idea-Enhancement,Product-PowerToys Run
|
low
|
Minor
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.