
id
int64 393k
2.82B
| repo
stringclasses 68
values | title
stringlengths 1
936
| body
stringlengths 0
256k
⌀ | labels
stringlengths 2
508
| priority
stringclasses 3
values | severity
stringclasses 3
values |
|---|---|---|---|---|---|---|
617,453,878 |
TypeScript
|
Much better comment preservation
|
some comments are removed (even even removeComments to false)
**TypeScript Version:** Version 3.9.1-rc
**Search Terms:**
Much better comment preservation
**Code**
```ts
// my comment 1
import { something } from './somefile.js';
// my comment 2
declare let test1: something;
let test = new something( {} );
// also
let item = [
// my comment 3
{ a: 0 },
{ a: 0 },
{ a: 0 },
// my comment 4
];
```
```js
**Expected behavior:**
// my comment 1
import { something } from './somefile.js';
// my comment 2
let test = new something( {} );
// also
let item = [
// my comment 3
{ a: 0 },
{ a: 0 },
{ a: 0 },
// my comment 4
];
```
**Actual behavior:**
```js
// my comment 1
import { something }from '/lib/backend/./somefile.js';
let test = new something({});
// also
let item = [
// my comment 3
{ a: 0 },
{ a: 0 },
{ a: 0 },
];
```
**Related Issues:**
sound like previous bugs report but not.
#1665
#16727
|
Needs Investigation
|
low
|
Critical
|
617,471,220 |
go
|
cmd/compile: generated DWARF triggers objdump warning for large uint64 const
|
### What version of Go are you using (`go version`)?
<pre>
$ go version
go version go1.14.2 linux/amd64
</pre>
### Does this issue reproduce with the latest release?
Yes.
### What did you do?
The Go compiler is emitting DWARF information for certain constants that is causing warnings from 'objdump --dwarf', details below. This is a comparatively minor problem (since as far as I can tell the debugging experience is not impacted) but the warning makes it a pain to read objdump output while looking for other problems (as a Go developer, not a Go user).
Code:
```
package main
import "fmt"
const neg64 uint64 = 1 << 63
func main() {
fmt.Println(neg64)
}
```
Symptoms:
```
$ go build neg64.go
$ objdump --dwarf=info neg64 > /dev/null
objdump: Error: LEB value too large
objdump: Error: LEB value too large
objdump: Error: LEB value too large
objdump: Error: LEB value too large
objdump: Error: LEB value too large
objdump: Error: LEB value too large
```
### What did you expect to see?
clean objdump output with no warnings
### What did you see instead?
LEB value too large warnings.
DWARF output excerpt:
```
<1><79f2b>: Abbrev Number: 9 (DW_TAG_constant)
<79f2c> DW_AT_name : main.neg64
<79f37> DW_AT_type : <0x3bf51>
<79f3b> DW_AT_const_value :objdump: Error: LEB value too large
-9223372036854775808
```
where the type in question is listed as
```
<1><3bf51>: Abbrev Number: 27 (DW_TAG_base_type)
<3bf52> DW_AT_name : uint64
<3bf59> DW_AT_encoding : 7 (unsigned)
<3bf5a> DW_AT_byte_size : 8
<3bf5b> Unknown AT value: 2900: 11
<3bf5c> Unknown AT value: 2904: 0xdec0
```
I think what's happening here is that the abbrev entry looks like this:
```
DW_TAG_constant [no children]
DW_AT_name DW_FORM_string
DW_AT_type DW_FORM_ref_addr
DW_AT_const_value DW_FORM_sdata
DW_AT value: 0 DW_FORM value: 0
```
Note the DW_FORM_sdata payload -- this is a signed value. I am assuming that objdump is interpreting this combination as something along the lines of "take this signed value and put it into an 8-byte signed container" (at which point it decides it can't fit).
A possible workaround would be to use a different abbrev with FORM_udata instead.
It's also arguable that we should instead file a binutils bug and ask them to change the objdump behavior -- you can make case that the Go DWARF is ok and it should be getting the "signedness" from the destination type and not the form (just depends on how you interpret things).
|
NeedsInvestigation,compiler/runtime
|
low
|
Critical
|
617,475,820 |
rust
|
clippy is not installed to destination dir if 'tools' config variable not explicitly defined.
|
Found whilst performing a extended tools release bootstrap build on aarch64:
Unless 'tools' is explicitly specified in config.toml with an extended build config, clippy is not installed, it is explicitly skipped as it does not appear in builder.config.tools (src/install.rs, Line: Line: 158, Line: 222)
Clippy is actually built for stage 2, but not installed by install.py.
Of the default extended tools built when extended-tools are enabled, only clippy seems to behave like this.
If this is intended behaviour, then a note in the config.toml indicating this would be helpful :-)
This occurs using the default channel (dev) in config.toml, constructed only using ./configure --enable-full-tools --prefix=$RUST_TOOLCHAIN_DIR --sysconfdir=$RUST_TOOLCHAIN_DIR on aarch64 native host.
<!-- TRIAGEBOT_START -->
<!-- TRIAGEBOT_ASSIGN_START -->
<!-- TRIAGEBOT_ASSIGN_DATA_START$${"user":null}$$TRIAGEBOT_ASSIGN_DATA_END -->
<!-- TRIAGEBOT_ASSIGN_END -->
<!-- TRIAGEBOT_END -->
|
T-bootstrap
|
low
|
Major
|
617,531,113 |
flutter
|
GeneratedPluginRegistrant.java still no re-generated using FlutterEngine still using PluginRegistry
|
I have a real project that already published on Play Store and App Store, but when I want to use [file_picker](https://pub.dev/packages/file_picker) it's giving me an [error](https://github.com/miguelpruivo/flutter_file_picker/issues/225).
As mentioned, the solution it's to `upgrading pre 1.12 Android projects` and I follow this [instruction](https://github.com/flutter/flutter/wiki/Upgrading-pre-1.12-Android-projects).
I also already add
```
<meta-data
android:name="flutterEmbedding"
android:value="2" />
```
Already update splash screen behavior and etc. Also on MainActivity.kt use this code.
```
package com.rifafauzi.fluttertestcamera
import androidx.annotation.NonNull;
import io.flutter.embedding.android.FlutterActivity
import io.flutter.embedding.engine.FlutterEngine
import io.flutter.plugins.GeneratedPluginRegistrant
class MainActivity: FlutterActivity() {
override fun configureFlutterEngine(@NonNull flutterEngine: FlutterEngine) {
GeneratedPluginRegistrant.registerWith(flutterEngine);
// My logic native side here
}
}
```
But after I upgrading that, I get the error too:
```
Type mismatch: inferred type is FlutterEngine but PluginRegistry! was expected
```
That because of my `GeneratedPluginRegistrant` not re-generate so still using `PluginRegistry` not using `FlutterEngine` like in `pre 1.12 Android projects` or if we create `new project` will generating `GeneratedPluginRegistrant` with `FlutterEngine` not with `PluginRegistry`.
So my question is, how to re-generate `GeneratedPluginRegistrant` class so I can use new classic with `FlutterEngine`?
Fyi, I already run `flutter clean`, `clean project`, `rebuild project`, and also `Invalidate Cache and Restart` but still not re-generate.
|
platform-android,engine,a: quality,P2,team-android,triaged-android
|
low
|
Critical
|
617,553,927 |
go
|
runtime/race: potential false positive from race detector
|
I've gone over this so many times, thinking I must've missed something, but I do believe I have found a case where the race detector returns a false positive (ie data race where there really isn't a data race). It seems to be something that happens when writing to a channel in a `select-case` statement directly.
The unit tests trigger the race detector, even though I'm ensuring all calls accessing the channel have been made using a callback and a waitgroup.
I have the channels in a map, which I access through a mutex. The data race vanishes the moment I explicitly remove the type that holds the channel from this map. The only way I am able to do is because the mutex is released, so once again: I'm certain everything behaves correctly. Code below
### What version of Go are you using (`go version`)?
<pre>
$ go version
go version go1.14.2 linux/amd64
</pre>
### Does this issue reproduce with the latest release?
Yes
### What operating system and processor architecture are you using (`go env`)?
<details><summary><code>go env</code> Output</summary><br><pre>
$ go env
GO111MODULE=""
GOARCH="amd64"
GOBIN=""
GOCACHE="/home/XXXX/.cache/go-build"
GOENV="/home/XXXX/.config/go/env"
GOEXE=""
GOFLAGS=""
GOHOSTARCH="amd64"
GOHOSTOS="linux"
GOINSECURE=""
GONOPROXY=""
GONOSUMDB=""
GOOS="linux"
GOPATH="/home/XXXX/go"
GOPRIVATE=""
GOPROXY="direct"
GOROOT="/usr/lib/golang"
GOSUMDB="off"
GOTMPDIR=""
GOTOOLDIR="/usr/lib/golang/pkg/tool/linux_amd64"
GCCGO="gccgo"
AR="ar"
CC="gcc"
CXX="g++"
CGO_ENABLED="1"
GOMOD="/home/XXXX/projects/datarace/go.mod"
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
PKG_CONFIG="pkg-config"
GOGCCFLAGS="-fPIC -m64 -pthread -fmessage-length=0 -fdebug-prefix-map=/tmp/go-build729449265=/tmp/go-build -gno-record-gcc-switches"
</pre></details>
### What did you do?
I'm writing a simple message event bus where the broker pushes data onto a channel of its subscribers/consumers. If the channel buffer is full, I don't want the broker to block, so I'm using routines, and a `select` statement to skip writes to a channel with a full buffer. To make life easier WRT testing, I'm mocking a subscriber interface, and I'm exposing the channels through functions (similar to `context.Context.Done()` and the like).
My tests all pass, and everything behaves as expected. However, running the same tests with the race detector, I'm getting what I believe to be a false positive. I have a test where I send data to a subscriber that isn't consuming the messages. The channel buffer is full, and I want to ensure that the broker doesn't block. To make sure I've tried to send all data, I'm using a waitgroup to check if the subscriber has indeed been accessed N number of times (where N is the number of events I'm sending). Once the waitgroup is done, I validate what data is on the channel, make sure it's empty, and then close it. The statement where I close the channel is marked as a data race.
If I do the exact same thing, but remove the subscriber from the broker, the data race magically is no more. Here's the code to reproduce the issue:
broker.go
```go
package broker
import (
"context"
"log"
"sync"
)
//go:generate go run github.com/golang/mock/mockgen -destination mocks/sub_mock.go -package mocks my.pkg/race/broker Sub
type Sub interface {
C() chan<- interface{}
Done() <-chan struct{}
}
type Broker struct {
mu sync.Mutex
ctx context.Context
subs map[int]Sub
keys []int
}
func New(ctx context.Context) *Broker {
return &Broker{
ctx: ctx,
subs: map[int]Sub{},
keys: []int{},
}
}
func (b *Broker) Send(v interface{}) {
b.mu.Lock()
go func() {
rm := make([]int, 0, len(b.subs))
defer func() {
if len(rm) > 0 {
b.unsub(rm...)
}
b.mu.Unlock()
}()
for k, s := range b.subs {
select {
case <-b.ctx.Done():
return
case <-s.Done():
rm = append(rm, k)
case s.C() <- v:
continue
default:
log.Printf("Skipped sub %d", k)
}
}
}()
}
func (b *Broker) Subscribe(s Sub) int {
b.mu.Lock()
k := b.key()
b.subs[k] = s
b.mu.Unlock()
return k
}
func (b *Broker) Unsubscribe(k int) {
b.mu.Lock()
b.unsub(k)
b.mu.Unlock()
}
func (b *Broker) key() int {
if len(b.keys) > 0 {
k := b.keys[0]
b.keys = b.keys[1:]
return k
}
return len(b.subs) + 1
}
func (b *Broker) unsub(keys ...int) {
for _, k := range keys {
if _, ok := b.subs[k]; !ok {
return
}
delete(b.subs, k)
b.keys = append(b.keys, k)
}
}
```
broker_test.go
```go
package broker_test
import (
"context"
"sync"
"testing"
"my.pkg/race/broker"
"my.pkg/race/broker/mocks"
"github.com/golang/mock/gomock"
"github.com/tj/assert"
)
type tstBroker struct {
*broker.Broker
cfunc context.CancelFunc
ctx context.Context
ctrl *gomock.Controller
}
func getBroker(t *testing.T) *tstBroker {
ctx, cfunc := context.WithCancel(context.Background())
ctrl := gomock.NewController(t)
return &tstBroker{
Broker: broker.New(ctx),
cfunc: cfunc,
ctx: ctx,
ctrl: ctrl,
}
}
func TestRace(t *testing.T) {
broker := getBroker(t)
defer broker.Finish()
sub := mocks.NewMockSub(broker.ctrl)
cCh, dCh := make(chan interface{}, 1), make(chan struct{})
vals := []interface{}{1, 2, 3}
wg := sync.WaitGroup{}
wg.Add(len(vals))
sub.EXPECT().Done().Times(len(vals)).Return(dCh)
sub.EXPECT().C().Times(len(vals)).Return(cCh).Do(func() {
wg.Done()
})
k := broker.Subscribe(sub)
assert.NotZero(t, k)
for _, v := range vals {
broker.Send(v)
}
wg.Wait()
// I've tried to send all 3 values, channels should be safe to close now
close(dCh)
// channel had buffer of 1, so first value should be present
assert.Equal(t, vals[0], <-cCh)
// other values should be skipped due to default select
assert.Equal(t, 0, len(cCh))
close(cCh)
}
func TestNoRace(t *testing.T) {
broker := getBroker(t)
defer broker.Finish()
sub := mocks.NewMockSub(broker.ctrl)
cCh, dCh := make(chan interface{}, 1), make(chan struct{})
vals := []interface{}{1, 2, 3}
wg := sync.WaitGroup{}
wg.Add(len(vals))
sub.EXPECT().Done().Times(len(vals)).Return(dCh)
sub.EXPECT().C().Times(len(vals)).Return(cCh).Do(func() {
wg.Done()
})
k := broker.Subscribe(sub)
assert.NotZero(t, k)
for _, v := range vals {
broker.Send(v)
}
wg.Wait()
// I've tried to send all 3 values, channels should be safe to close now
close(dCh)
// channel had buffer of 1, so first value should be present
assert.Equal(t, vals[0], <-cCh)
// other values should be skipped due to default select
assert.Equal(t, 0, len(cCh))
// add this line, and data race magically vanishes
broker.Unsubscribe(k)
close(cCh)
}
func (b *tstBroker) Finish() {
b.cfunc()
b.ctrl.Finish()
}
```
See the data race by running: `go test -v -race ./broker/... -run TestRace`
### What did you expect to see?
I expect to see log output showing that the subscriber was skipped twice (output I do indeed see), and *no* data race
### What did you see instead?
I still saw the code behaved as expected, but I do see a data race reported:
```
go test -v -race ./broker/... -run TestRace
=== RUN TestRace
2020/05/13 16:24:06 Skipped sub 1
2020/05/13 16:24:06 Skipped sub 1
==================
WARNING: DATA RACE
Write at 0x00c00011a4f0 by goroutine 7:
runtime.closechan()
/usr/lib/golang/src/runtime/chan.go:335 +0x0
my.pkg/race/broker_test.TestRace()
/home/XXXX/projects/race/broker/stuff_test.go:56 +0x7c8
testing.tRunner()
/usr/lib/golang/src/testing/testing.go:991 +0x1eb
Previous read at 0x00c00011a4f0 by goroutine 10:
runtime.chansend()
/usr/lib/golang/src/runtime/chan.go:142 +0x0
my.pkg/race/broker.(*Broker).Send.func1()
/home/XXXX/projects/race/broker/stuff.go:46 +0x369
Goroutine 7 (running) created at:
testing.(*T).Run()
/usr/lib/golang/src/testing/testing.go:1042 +0x660
testing.runTests.func1()
/usr/lib/golang/src/testing/testing.go:1284 +0xa6
testing.tRunner()
/usr/lib/golang/src/testing/testing.go:991 +0x1eb
testing.runTests()
/usr/lib/golang/src/testing/testing.go:1282 +0x527
testing.(*M).Run()
/usr/lib/golang/src/testing/testing.go:1199 +0x2ff
main.main()
_testmain.go:48 +0x223
Goroutine 10 (finished) created at:
my.pkg/race/broker.(*Broker).Send()
/home/XXXX/projects/race/broker/stuff.go:32 +0x70
my.pkg/race/broker_test.TestRace()
/home/XXXX/projects/race/broker/stuff_test.go:47 +0x664
testing.tRunner()
/usr/lib/golang/src/testing/testing.go:991 +0x1eb
==================
TestRace: testing.go:906: race detected during execution of test
--- FAIL: TestRace (0.00s)
: testing.go:906: race detected during execution of test
FAIL
FAIL my.pkg/race/broker 0.009s
? my.pkg/race/broker/mocks [no test files]
```
Though I'm not certain, my guess is that the expression `s.C() <- v`, because it's a case expression, is what trips the race detector up here. The channel buffer is full, so any writes would be blocking if I'd put the channel write in the `default` case. As it stands, the write cannot possibly be executed, so instead my code logs the fact that a subscriber is being skipped, the routine ends (defer func unlocks the mutex), and the mock callback decrements the waitgroup. Once the waitgroup is empty, all calls to my mock subscriber have been made, and the channel can be safely closed.
It seems, however, that I need to add the additional call, removing the mock from the broker to _"reset"_ the race detector state. I'll try and have a look at the source, maybe something jumps out.
|
RaceDetector,NeedsInvestigation,compiler/runtime
|
low
|
Critical
|
617,564,169 |
go
|
cmd/link: include per-package aggregate static temp symbols?
|
I've been working on a Go [binary size analysis tool](https://github.com/bradfitz/shotizam) that aims to attribute ~each byte of the binary back to a function or package.
One thing it's not great at doing at the moment in the general case is summing the size of static temp (..stmp_NNN) because those symbols are removed by default (except in external linking mode).
Worse, with Macho-O binaries not having sizes on symbols, I can't even accurately count the sizes of symbols that do exist because the stmp values are in the DATA, but lacking symbols, so I end up calculating the wrong size of existing symbols:
e.g. this `float64info` should actually be the same size as the `float32info`, but a bunch of stmp_NNN are omitted between `float64info` and `hash..inittask`:
```
sym "debug/dwarf._Class_index" (at 19138544), size=464
sym "strconv.float32info" (at 19139008), size=32
sym "strconv.float64info" (at 19139040), size=1664
sym "hash..inittask" (at 19140704), size=32
sym "internal/bytealg..inittask" (at 19140736), size=32
sym "internal/reflectlite..inittask" (at 19140768), size=32
sym "internal/singleflight..inittask" (at 19140800), size=32
```
Looking at a binary with the `stmp` symbols, I get the accurate size for `float64info`:
```
sym "unicode..stmp_539" (at 1005d4260), size=32
sym "unicode..stmp_553" (at 1005d4280), size=32
sym "unicode..stmp_558" (at 1005d42a0), size=32
sym "crypto..stmp_2" (at 1005d42c0), size=32
sym "crypto/tls..stmp_205" (at 1005d42e0), size=32
sym "strconv.float32info" (at 1005d4300), size=32
sym "strconv.float64info" (at 1005d4320), size=32
sym "unicode..stmp_11" (at 1005d4340), size=32
sym "unicode..stmp_113" (at 1005d4360), size=32
sym "unicode..stmp_121" (at 1005d4380), size=32
sym "unicode..stmp_147" (at 1005d43a0), size=32
sym "unicode..stmp_150" (at 1005d43c0), size=32
```
So, my request: can we aggregate all the `stmp_NNN` symbols together per-package and emit one symbol per section per Go package, like:
```
unicode..stmp_pkg
```
Then I can both calculate the sum stmp sizes per package (e.g. unicode is 68KB, crypto/tls is 12KB), and I can also accurately calculate the size of other symbols (Mach-o symbols without a size)
This would make binaries a tiny bit bigger (but bounded by number of packages at least) but would permit more analysis at making them much smaller, IMO. (Or output it to a separate file.)
It would also require sorting the stmp values all together in the binary. They're currently scattered around:
```
sym "vendor/golang.org/x/net/route.rtmVersion" (at 100615964), size=2
sym "runtime..stmp_40" (at 100615966), size=2
sym "context.goroutines" (at 100615968), size=4
sym "runtime..stmp_41" (at 10061596c), size=4
sym "runtime.argc" (at 100615970), size=4
sym "runtime.crashing" (at 100615974), size=4
```
(Note a `context` symbol between `runtime.stmp_40` and `stmp_41` )
What I'd like to see is something like:
```
sym "vendor/golang.org/x/net/route.rtmVersion" (at 100615964), size=2
sym "context.goroutines" (at 100615966), size=4
sym "runtime..stmp_pkg" (at 100615970), size=6
sym "runtime.argc" (at 100615970), size=4
sym "runtime.crashing" (at 100615974), size=4
```
Thoughts? Alternatives?
/cc @ianlancetaylor (who schooled me on some of this), @cherrymui, @thanm, @randall77, @josharian, @jeremyfaller
|
NeedsInvestigation,compiler/runtime
|
low
|
Critical
|
617,591,257 |
go
|
x/build: reduce ambiguity in long test of main Go repo
|
Taking into account the build infrastructure at [build.golang.org](https://build.golang.org), local development, and issues such as #26473, #34707, I understand we currently have the goal of having good support for two well-known testing configurations (for a given GOOS/GOARCH pair) for the main Go repository:
- Short, as implemented by `all.bash`
- target of 3-4 minutes, acceptable to skip slow tests as implemented by `go test -short`
- Long, as implemented by `-longtest` post-submit builders (e.g., `linux-amd64-longtest`)
- no goal of skipping tests for performance reasons
While investigating #29252, I found that there is some ambiguity in what it means to test the main Go repo in long mode. It's not easy to say "in order to run a long test, do this" and have a predictable outcome. We currently say "run `all.bash` and `go test std cmd`" in some places, but there's room for improvement.
We want to ensure long tests are passing for Go releases. To support that goal, I think it will helpful to reduce ambiguity in what it means to run a long test on the Go repo.
This is a high level tracking issue for improvements in this area, and for any discussion that may need to happen.
/cc @andybons @cagedmantis @toothrot @golang/osp-team @bradfitz @rsc
|
Builders,NeedsInvestigation
|
low
|
Major
|
617,654,600 |
go
|
github: consider downscoping "GitHub Editors" access to Triage role
|
The Go project offers access to a set of people to edit metadata on GitHub issues, in order to help with [gardening](https://golang.org/wiki/Gardening). This access is documented at https://golang.org/wiki/GithubAccess#editors.
Back when the "go-approvers" group was created, GitHub did not offer granular access levels, it was either Read (no access to triage), Write (access to triage and push), Admin. We used Write since it was the most fitting option.
The GitHub repository at https://github.com/golang/go is a mirror of the canonical repository at https://go.googlesource.com/go where code review happens, and any changes to it are automatically overwritten by [`gitmirror`](https://pkg.go.dev/golang.org/x/build/cmd/gitmirror). However, accidents happen occasionally, and people may unintentionally create new branches (e.g., see https://groups.google.com/d/msg/golang-dev/EqqZf5kTRqI/9BEDmjHwBwAJ).
By now, GitHub seems to offer more granularity in access controls, including a "Triage" role:
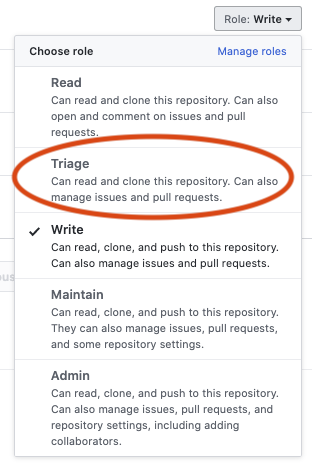
It's documented in more details at https://help.github.com/en/github/setting-up-and-managing-organizations-and-teams/repository-permission-levels-for-an-organization.
We should investigate and confirm whether it's safe to downscope the go-approvers team to Triage access without causing unintended inconvenience to people who rely on it, and if so, apply the change.
/cc @golang/osp-team @katiehockman @FiloSottile
|
Security,Builders,NeedsInvestigation,Community
|
low
|
Major
|
617,656,164 |
pytorch
|
No MKL Compatible Conda installation for PyTorch 1.5
|
## 🚀 Feature
Right now having the conda nomkl package installed is a comfortable way to ensure that numpy is linking to openblas instead of Intel mkl, which is (in my experience) slower for AMD processors. If the no mkl package is installed, the conda pytorch installation resolves to an older pytorch version.
I.e. the command (in an otherwise empty conda environment)
`conda install pytorch torchvision cudatoolkit=10.2 -c pytorch`
installs WITHOUT the nomkl package
`pytorch pytorch/linux-64::pytorch-1.5.0-py3.7_cuda10.2.89_cudnn7.6.5_0`
and WITH the nomkl package
`pytorch pytorch/linux-64::pytorch-1.0.0-py3.7_cuda9.0.176_cudnn7.4.1_1`
It would be great to have a conda compatible installation with nomkl, as AMD processors have gotten good in terms of # of fast cores and value. So if it would not require to much effort it would be great to have. And also a bit of documentation on how to ensure linking to openblas instead of mkl would be great as AMD processor have become more widespread in recent years.
## Alternatives
To get pytorch 1.5 with nomkl, one can simply install pytorch 1.5 via pip.
cc @ezyang @seemethere
|
module: binaries,triaged,module: mkl
|
medium
|
Major
|
617,670,965 |
flutter
|
Allow copying engine artifacts before starting native build tool
|
Currently, for all of the desktop builds, we trigger the native build (Xcode, make, etc.) and that eventually calls into the backend script that copies engine artifacts like the library and the C++ client wrappers.
I'm in the process of converting Linux (and maybe Windows) to CMake, and with CMake the best option is to have the build files live next to the things they are building; in the case of then engine artifacts it would not only make the build structure cleaner and more modular, but it would mean that we could retain long-term control over those files. For instance, the client wrapper targets could be updated if the set of client wrapper files changed, without breaking existing consumers.
However, the CMake step is the very first step in the build, so we can't call it without already having all the `CMakeLists.txt` files in place. In order for them to live with the artifacts, we'd need to be able to trigger the artifact copying earlier, from, e.g., build_linux.dart, just before doing CMake generation.
/cc @jonahwilliams
|
tool,platform-windows,platform-linux,a: desktop,a: build,P3,team-tool,triaged-tool
|
low
|
Major
|
617,677,740 |
pytorch
|
[RFC] Add tar-based IterableDataset implementation to PyTorch
|
Problem
=======
As datasets become larger and larger, storing training samples as individual files becomes impractical and inefficient. This can be addressed using sequential storage formats and sharding (see "Alternatives Considered" for other implementations). PyTorch lacks such a common storage format right now.
Proposal
========
[WebDataset](http://github.com/tmbdev/webdataset) provides an implementation of `IterableDataset` based on sharded tar archives. This format provides efficient I/O for very large datasets, makes migration from file-based I/O easy, and works well locally, with cloud storage, and web servers. It also provides a simple, standard format in which large datasets can be distributed easily and used directly without unpacking.
The implementation is small (1000-1800 LOC) and has no external dependencies. The proposal is to incorporate the `webdataset.Dataset` class into the PyTorch base distribution. The source repository is here:
http://github.com/tmbdev/webdataset
My suggestion would be to incorporate the library with minimal changes into its own subpackage. I can perform the integration and generate a PR once there is general agreement.
More Background
===============
For a general introduction to how we handle large scale training with WebDataset, see [this YouTube playlist](https://www.youtube.com/playlist?list=PL0dsKxFNMcX4XcB0w1Wm-pvSfQu-eWM26)
The WebDataset library (github.com/tmbdev/webdataset) provides an implementation of `IterableDataset` that uses POSIX tar archives as its native storage format. The format itself is based on a simple convention:
- datasets are POSIX tar archives
- each training sample consists of adjacent files with the same basename
- shards are numbered consecutively
For example, ImageNet is stored in 147 separate 1 Gbyte shards with names `imagenet-train-0000.tar` to `imagenet-train-0147.tar`; the contents of the first shard are:
```
-r--r--r-- bigdata/bigdata 3 2020-05-08 21:23 n03991062_24866.cls
-r--r--r-- bigdata/bigdata 108611 2020-05-08 21:23 n03991062_24866.jpg
-r--r--r-- bigdata/bigdata 3 2020-05-08 21:23 n07749582_9506.cls
-r--r--r-- bigdata/bigdata 129044 2020-05-08 21:23 n07749582_9506.jpg
-r--r--r-- bigdata/bigdata 3 2020-05-08 21:23 n03425413_23604.cls
-r--r--r-- bigdata/bigdata 106255 2020-05-08 21:23 n03425413_23604.jpg
-r--r--r-- bigdata/bigdata 3 2020-05-08 21:23 n02795169_27274.cls
```
Datasets in WebDataset format can be used directly after downloading without unpacking; they can also be mounted as a file system. Content in WebDataset format can used any file-based compression scheme. In addition, the tar file itself can also be compressed and WebDataset will transparently decompress it.
WebDatsets can be used directly from local disk, from web servers (hence the name), from cloud storage, and from object stores, just by changing a URL.
WebDataset readers/writers are easy to implement (we have Python, Golang, and C++ implementations).
WebDataset performs shuffling both at the shard level and at the sample level. Splitting of data across multiple workers is performed at the shard level using a user-provided `shard_selection` function that defaults to a function that splits based on `get_worker_info`. (WebDataset can be combined with the `tensorcom` library to offload decompression/data augmentation and provide RDMA and direct-to-GPU loading; see below.)
We are storing and processing petabytes of training data as tar archives and are using the format for unsupervised learning from video, OCR and scene text recognition, and large scale object recognition experiments. The same code and I/O pipelines work efficiently on the desktop, on a local cluster, or in the cloud. [Our benchmarks](https://arxiv.org/abs/2001.01858) show scalability and the ability to take advantage of the full I/O bandwidth of each disk drive across very large training jobs and storage clusters.
Code Sample
===========
This shows how to use WebDataset with ImageNet.
```Python
import webdataset as wds
improt ...
shardurl = "/imagenet/imagenet-train-{0000..0147}.tar"
normalize = transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
preproc = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
])
dataset = (
wds.Dataset(shardurl)
.shuffle(1000)
.decode("pil")
.rename(image="jpg;png", data="json")
.map_dict(image=preproc)
.to_tuple("image", "data")
)
loader = torch.utils.data.DataLoader(dataset, batch_size=64, num_workers=8)
for inputs, targets in loader:
...
```
WebDataset uses a fluent API for configuration that internally builds up a processing pipeline. Without any added processing stages, WebDataset just iterates through each training sample as a dictionary:
```Python
# load from a web server using a separate client process
shardurl = "pipe:curl -s http://server/imagenet/imagenet-train-{0000..0147}.tar"
dataset = wds.Dataset(shardurl)
for sample in dataset:
# sample["jpg"] contains the raw image data
# sample["cls"] contains the class
...
```
Alternatives Considered
=======================
Keeping WebDataset as as Separate Library
-----------------------------------------
WebDataset is perfectly usable as a separate library, so why not keep it that way?
- Users of deep learning libraries expect an efficient data format that avoids the "many small file" problem; Tensorflow provides TFRecord/tf.Example Making WebDataset part of PyTorch itself provides a straightforward solution for most users and reduces dependencies.
- Providing a format reader in the standard library encourages dataset standardization, tool building, and adoption of the same format by other libraries.
- Having a realistic implementation of `IterableDataset` in PyTorch provides a common reference against which to address issues and provide test cases in the `DataLoader` implementation and its use of `IterableDataset`
Many of the larger datasets distributed in `torchvision` could be distributed easily in WebDataset format. This would allow users to either train directly against web-hosted data, or to train on the datasets immediately after downloading without unpacking. The way data is arranged in WebDataset also allows users to download just a few shards for testing code locally, and then use the entire dataset when running on a cluster. Furthermore, the way `webdataset.Dataset` works in most cases, no special code is needed in order to read them; many training jobs can be retargeted to different datasets simply by using a different URL for the dataset.
TFRecord+protobuf, Parquet
----------------------------
These formats are suitable for large scale data processing for machine learning and deep learning applications and some datasets exist in this format and more will continue to be generated for the Tensorflow ecosystem. However, they are not good candidates for incorporating into PyTorch as core feature because:
- TFRecord+protobuf (tf.Example) and Parquet have significant external library dependencies; in contrast, WebDataset is pure Python, using the built-in libraries for tar decoding.
- Protobuf and Parquet represent serialized data structures, while WebDataset uses file-based representations. File based representations make creation of WebDatasets easy, result in bit-identical representations of data in WebDatasets, and allow existing file-based codecs and I/O pipelines to be reused easily.
- Except for their native frameworks, there is not much third party support for these formats; in contrast, POSIX tar archive libraries exist in all major programming languages and are easily processed, either by unpacking shards or using tools like `tarp`.
Note that WebDataset supports usage scenarios similar to TFRecord+protobuf, since serialized data structures can be incorporated as files, and WebDataset will decode them automatically. For example, OpenImages multi-instance data is simply stored in a `.json` file accompanying each `.jpg` file:
```
$ curl -s http://storage.googleapis.com/nvdata-openimages/openimages-train-000554.tar | tar tf -
0b946d1d5201c06c.jpg
0b946d1d5201c06c.json
05c9d72ff9e64010.jpg
05c9d72ff9e64010.json
...
$
```
zip instead of tar
--------------------
The zip format is another archival format. Unlike tar format, which is just a sequence of records, zip format stores a file index at the very end of the file, making it unsuitable for streaming. Tar files can be made random access (and, in fact, can be mounted as file systems), but they use a separate index file to support that functionality.
LMDB, HDF5, Databases
---------------------
These formats are not suitable for streaming and require the entire dataset to fit onto local disk. In addition, while they nominally solve the "many small file problems", they don't solve the problem that indexing into the dataset still results in expensive seek operations.
Local File System Caches
------------------------
An approach for extending file-system based I/O pipelines to large distributed storage systems is to use some form of "pre-caching" or "staging" on a local NVMe drive. Generally, there is little advantage to this. For large datasets, it does not increase throughput. Input pipelines still need to be modified to schedule the pre-caching. And generally, this requires volume plugins or virtual file system support. A similar effect can be achieved with WebDataset by simply unpacking shards to the local file system when direct file access is required.
Related Software
================
[AIStore](http://github.com/NVIDIA/AIStore) is an open source object store capable of full bandwidth disk-to-GPU data delivery (meaning that if you have 1000 rotational drives with 200 MB/s read speed, AIStore actually delivers an aggregate bandwidth of 200 GB/s to the GPUs). AIStore is fully compatible with WebDataset as a client, and in addition understands the WebDataset format, permitting it to perform shuffling, sorting, ETL, and some map-reduce operations directly in the storage system.
[tarp](http://github.com/tmbdev/tarp) is a small command line program for splitting, merging, shuffling, and processing tar archives and WebDataset datasets.
[tensorcom](http://github.com/NVLabs/tensorcom) is a library supporting distributed data augmentation and RDMA to GPU.
[webdataset-examples](http://github.com/tmbdev/webdataset-examples) contains an example (and soon more examples) of how to use WebDataset in practice.
[Bigdata 2019 Paper with Benchmarks](https://arxiv.org/abs/2001.01858)
cc @SsnL
|
feature,module: dataloader,triaged
|
high
|
Critical
|
617,683,936 |
angular
|
Angular Module instance never get destroyed
|
No matter what we do lazy loading or eager loading Angular Module instance never gets destroyed.
When we route across components or use *ngIF Components get destroyed and recreated but its not the same case when we navigate from one module to another.
While lazy loading every module gets loaded dynamically. Also, the instance get created but that instance never gets destroyed.
To check the same I put the breakpoint in Module constructor.
Anybody know the reason for such behavior. I feel it bad because all services registered on those modules get remain forever then too.
I felt like it a bug than a feature request.
|
type: bug/fix,feature,area: router,core: NgModule,router: lazy loading,needs: discussion,feature: under consideration
|
high
|
Critical
|
617,722,117 |
flutter
|
[webview_flutter] Error while trying to play a Google Drive video preview link
|
I have an app that needs to play Google Drive videos preview, using webview_flutter plugin, the thumbnail appears but when I tap play I get the errors below:
**Code:**
```dart
String url = 'https://drive.google.com/file/d/1O8WF2MsdyoKpQZE2973IFPRpqwKUjm_q/preview';
WebView(
onWebViewCreated: (WebViewController controller){
webViewController = controller;
},
initialUrl: url,
javascriptMode: JavascriptMode.unrestricted,
initialMediaPlaybackPolicy: AutoMediaPlaybackPolicy.always_allow,
),
```
**Errors:**
```
"The deviceorientation events are blocked by feature policy. See https://github.com/WICG/feature-policy/blo
b/master/features.md#sensor-features", source: https://youtube.googleapis.com/s/player/64dddad9/player_ias.vflset/pt_BR/base.js (263)
```
**The second time I tap play button:**
```
I/chromium(29212): [INFO:CONSOLE(1472)] "Uncaught (in promise) Error: Untrusted URL: https://youtube.googleapis.com/videoplayback?expire=158836583
1&ei=x1GsXtyWNuzPj-8Px_eH2Aw&ip=2804:431:c7da:c52b:854e:e83e:e7c5:eb3e&cp=QVNNWkRfVFhRQlhOOk5mQ0FhT0J5Y0k2T3ZDdjJLa0UzQVRiaHNoQlVHeXpjV3BtYW9YT2Rk
YUM&id=eb79141269cc6ad3&itag=18&source=webdrive&requiressl=yes&mh=F-&mm=32&mn=sn-bg0eznll&ms=su&mv=m&mvi=4&pl=47&ttl=transient&susc=dr&driveid=1O8
WF2MsdyoKpQZE2973IFPRpqwKUjm_q&app=explorer&mime=video/mp4&dur=2.043&lmt=1551969798109476&mt=1588351334&sparams=expire,ei,ip,cp,id,itag,source,req
uiressl,ttl,susc,driveid,app,mime,dur,lmt&sig=AOq0QJ8wRAIgEzxYGpS8RI0CRVPdZrMxdDGfkYfCezdOkiJ7iUcl5XMCIHiDsmbGel8tWT6XIU8dWdfjLJWdOlI_WHNtDNwYszU9
&lsparams=mh,mm,mn,ms,mv,mvi,pl&lsig=AG3C_xAwRAIgTq3W38roufwBwSPXe4fxB25kANk3s42N5x2oBvVWonoCIDaYJVrPpmNzcoU6q4bqogHP6W-Mw4p_5CRrwh59kZM4&cpn=bCev
241Hx8eXmwyo&c=WEB_EMBEDDED_PLAYER&cver=20200429", source: https://youtube.googleapis.com/s/player/64dddad9/player_ias.vflset/pt_BR/base.js (1472)
```
Does anyone can explain me this errors please? Through browser the link is working.
<details>
<summary>flutter doctor -v</summary>
```bash
**flutter doctor -v**
[√] Flutter (Channel master, 1.18.0-12.0.pre, on Microsoft Windows [versão 10.0.18363.778], locale pt-BR)
• Flutter version 1.18.0-12.0.pre at C:\src\flutter
• Framework revision c2b7342ca4 (7 days ago), 2020-05-06 23:16:03 +0800
• Engine revision 33d2367950
• Dart version 2.9.0 (build 2.9.0-5.0.dev 9c94f08410)
[√] Android toolchain - develop for Android devices (Android SDK version 29.0.3)
• Android SDK at C:\Users\Dih\AppData\Local\Android\sdk
• Platform android-29, build-tools 29.0.3
• Java binary at: C:\Program Files\Android\Android Studio\jre\bin\java
• Java version OpenJDK Runtime Environment (build 1.8.0_212-release-1586-b04)
• All Android licenses accepted.
[√] Chrome - develop for the web
• Chrome at C:\Program Files (x86)\Google\Chrome\Application\chrome.exe
[√] Android Studio (version 3.6)
• Android Studio at C:\Program Files\Android\Android Studio
• Flutter plugin version 45.1.1
• Dart plugin version 192.7761
• Java version OpenJDK Runtime Environment (build 1.8.0_212-release-1586-b04)
[√] Connected device (3 available)
• LG K430 • LGK4305DKZJJKN • android-arm • Android 6.0 (API 23)
• Web Server • web-server • web-javascript • Flutter Tools
• Chrome • chrome • web-javascript • Google Chrome 81.0.4044.138
• No issues found!
```
</details>
|
platform-android,a: video,p: video_player,package,has reproducible steps,P3,found in release: 2.2,found in release: 2.3,team-android,triaged-android
|
low
|
Critical
|
617,739,531 |
kubernetes
|
Add a `Plan` kind
|
**What would you like to be added**:
A way (through a `Plan` kind?) to save a list of changes to be applied later, with
the guarantee to not cause any additional conflicts/resource addition/resource deletion.
The workflow would look like:
- Generate a `Plan` with `kubectl diff --recursive --server-side -oyaml -f manifests.yaml > plan.yaml`
- This would be even more useful if/when `kubectl diff` supports `--prune` and `--selector` flags (that behave like their kubectl apply counterparts).
- Apply it with `kubectl apply --server-side -f plan.yaml`
**Why is this needed**:
Reviewing a change before applying it (`kubectl apply --dry-run` or `kubectl diff`) currently does not give confidence that the real change made to the cluster will match what was expected.
For example, if I want to update an already deployed resource:
- I run `kubectl diff` and validate that the output corresponds to what I expect
- Meanwhile, the resource is deleted in the cluster (I am not aware of that)
- I run `kubectl apply` expecting to update a field, but I actually create a resource
The same can lead to unexpected resource deletion (with `--prune` flag) or unexpected update of fields not owned by my workflow (with `--force-conflicts`).
This is especially true in a GitOps workflow where the diff is automatically printed in the PR to help the reviewer and the apply can take place several hours later.
Having a structured "plan" is also useful:
- For automated policy enforcement, e.g. using OPA
- To make `kubectl apply --recursive --prune` safer
/kind feature
/sig api-machinery
/wg api-expression
|
sig/api-machinery,kind/feature,lifecycle/frozen,wg/api-expression
|
low
|
Major
|
617,752,294 |
create-react-app
|
Allow full URL with hostname/port for PUBLIC_URL in development
|
### Is your proposal related to a problem?
Recently there was a change so that PUBLIC_URL is no longer ignored in development mode. This is a great change, however it seems limited in that PUBLIC_URL in development can only be a path
while environments outside of development can be full URLs with hostname/port, etc.
### Describe the solution you'd like
<!--
Provide a clear and concise description of what you want to happen.
-->
Please allow for PUBLIC_URL to specify a URL in development, not just a path.
### Describe alternatives you've considered
<!--
Let us know about other solutions you've tried or researched.
-->
Only other solution we have to work with is change our entire server-side setup (quite involved) or utilize patch-package (ew)
|
issue: proposal,needs triage
|
medium
|
Major
|
617,759,692 |
flutter
|
"resizeToAvoidBottomInset property" Documentation should have a video to demonstrate how it changes the view
|
In the [documentation page](https://api.flutter.dev/flutter/material/Scaffold/resizeToAvoidBottomInset.html), there must be a video to show how changing the boolean value of "resizeToAvoidBottomInset" changes the view in the actual app.
For example, such a demonstration must be added ⬇
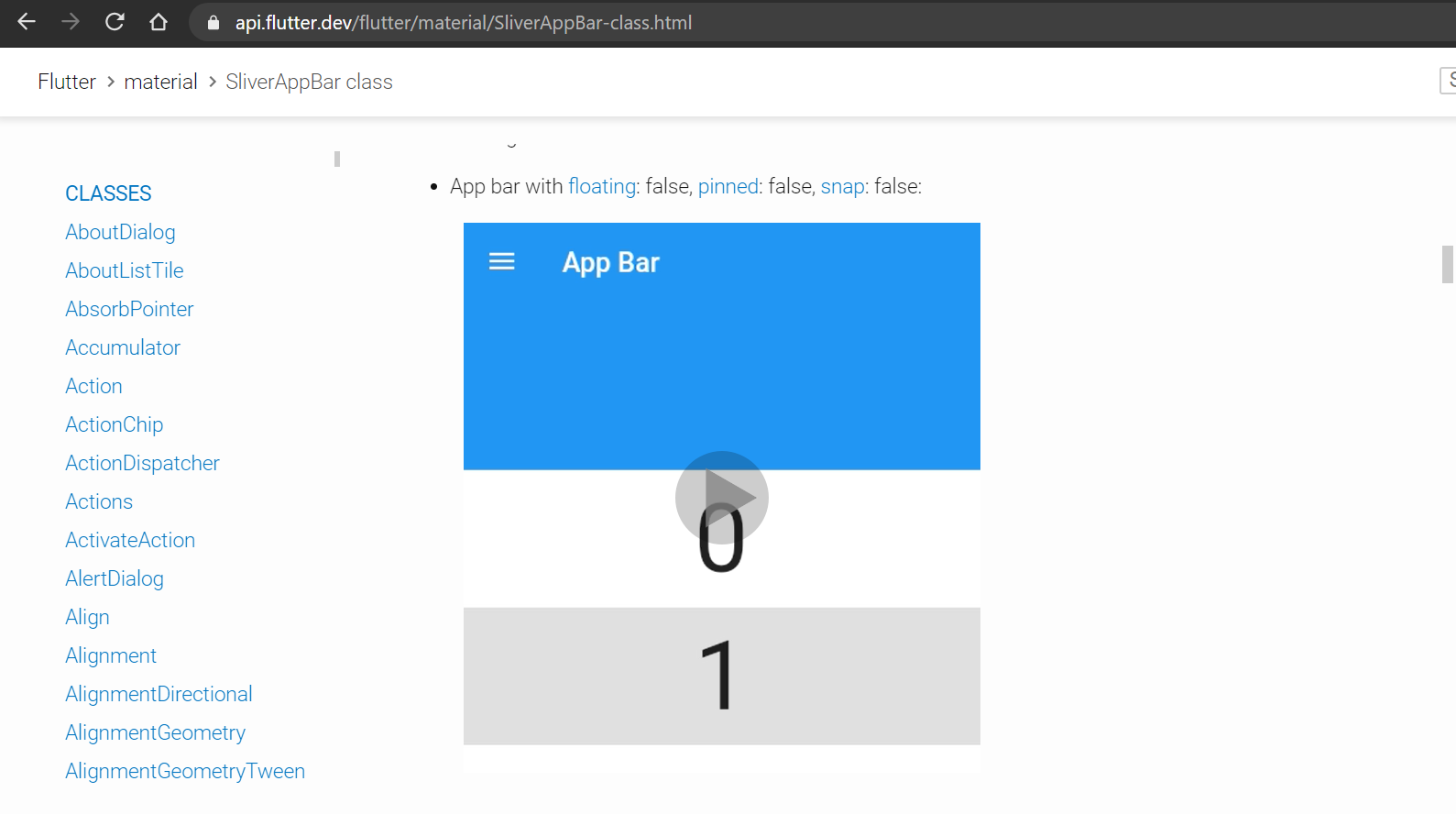
https://flutter.github.io/assets-for-api-docs/assets/material/app_bar.mp4
|
framework,f: material design,d: api docs,d: examples,c: proposal,team-design,triaged-design
|
low
|
Minor
|
617,771,285 |
pytorch
|
[JIT] torch.tensor needs a Tensor overload
|
## 🐛 Bug
`torch.tensor` in python eager can accept a Tensor, which it then copies into a new tensor. Because JIT does not have a tensor overload, an implicit conversion to float gets inserted which will fail at runtime.
```
import torch
import torch.nn as nn
from typing import List
def foo(x):
return torch.tensor(x)
input = torch.rand([2, 2])
foo(input)
# fine
torch.jit.script(foo)(input)
```
> ... <--- HERERuntimeError: Cannot input a tensor of dimension other than 0 as a scalar argument
cc @suo
|
oncall: jit,module: bootcamp,triaged,small
|
low
|
Critical
|
617,776,344 |
flutter
|
Tool crashes when launching adb when getcwd fails with EACCES.
|
Sometimes when launched from an IDE, the tool can crash when the tool process does not have read/list permissions from / up to the cwd.
```
FileSystemException: FileSystemException: Getting current working directory failed, path = '' (OS Error: Operation not permitted, errno = 1)
| at _Directory.current | (directory_impl.dart:49)
| at Directory.current | (directory.dart:161)
| at LocalFileSystem.currentDirectory | (local_file_system.dart:44)
| at getExecutablePath | (common.dart:59)
| at _getExecutable | (local_process_manager.dart:125)
| at LocalProcessManager.run | (local_process_manager.dart:68)
| at _DefaultProcessUtils.run | (process.dart:313)
| at AndroidDevices.pollingGetDevices | (android_device_discovery.dart:54)
| at PollingDeviceDiscovery._initTimer.<anonymous closure> | (device.dart:295)
| at _rootRun | (zone.dart:1180)
| at _CustomZone.run | (zone.dart:1077)
| at _CustomZone.runGuarded | (zone.dart:979)
| at _CustomZone.bindCallbackGuarded.<anonymous closure> | (zone.dart:1019)
| at _rootRun | (zone.dart:1184)
| at _CustomZone.run | (zone.dart:1077)
| at _CustomZone.bindCallback.<anonymous closure> | (zone.dart:1003)
| at Timer._createTimer.<anonymous closure> | (timer_patch.dart:23)
| at _Timer._runTimers | (timer_impl.dart:398)
| at _Timer._handleMessage | (timer_impl.dart:429)
| at _RawReceivePortImpl._handleMessage | (isolate_patch.dart:168)
```
Supposing that `getAdbPath` ([here](https://github.com/flutter/flutter/blob/master/packages/flutter_tools/lib/src/android/android_device_discovery.dart#L48)) is giving an absolute path, the problem seems to be in `package:process`, which tries to grab the cwd even though the path might be absolute ([here](https://github.com/google/process.dart/blob/master/lib/src/interface/common.dart#L59)). `package:process` should probably skip the cwd relative search if grabbing the cwd fails.
|
c: crash,tool,P2,team-tool,triaged-tool
|
low
|
Critical
|
617,791,934 |
vscode
|
No images in jsdoc hover or notebooks in remote/web
|
- Add an image in markdown syntax to a jsdoc comment
- In a local vscode window, hover the identifier with the command
- The image is rendered
- Do the same in a remote window
- The image is broken
Same issue with notebooks. @mjbvz Is it possible to hook into the same system that webviews use, or is that only tied to webviews?
|
bug,typescript,javascript,web,notebook-workbench-integration
|
low
|
Critical
|
617,805,498 |
opencv
|
OpenCV 4.3.0 RELEASE build error in traits.hpp
|
##### System information (version)
- OpenCV => 4.3.0
- Operating System / Platform => Windows 10 64 Bit v 1909
- Compiler => Visual Studio 2019 community
- CUDA => v10.2.89
- GSTREAMER => v1.16.2
- NINJA => v1.10.0
- CMAKE => v3.17.2
- NVIDIA RTX2070 with Q-Max design
Please refer to the attached build config "BuildCONFIG.txt"
[BuildCONFIG.txt](https://github.com/opencv/opencv/files/4625103/BuildCONFIG.txt)
Please refer to the build file (NinjaRELEASECuDNNGStreamerNonFree.txt) here:
[NinjaRELEASECuDNNGStreamerNonFree.txt](https://github.com/opencv/opencv/files/4625106/NinjaRELEASECuDNNGStreamerNonFree.txt)
##### Detailed description
When i build "RELEASE" version, I see the following error in building gpu_mat.cu
And the error is:
**gpu_mat.cu**
C:/Nitin/OpenCVCode/opencv4_3_0/modules/core/include\opencv2/core/traits.hpp(374): **error C2993: 'T': illegal type for non-type template parameter '__formal'**
C:/Nitin/OpenCVCode/opencv4_3_0/modules/core/include\opencv2/core/traits.hpp(374): note: see reference to class template instantiation 'cv::traits::internal::CheckMember_fmt<T>' being compiled
C:/Nitin/OpenCVCode/opencv4_3_0/modules/core/include\opencv2/core/traits.hpp(374): **error C2065: '__T0': undeclared identifier**
C:/Nitin/OpenCVCode/opencv4_3_0/modules/core/include\opencv2/core/traits.hpp(374): **error C2923: 'std::_Select<__formal>::_Apply': '__T0' is not a valid template type argument for parameter '<unnamed-symbol>'**
C:/Nitin/OpenCVCode/opencv4_3_0/modules/core/include\opencv2/core/traits.hpp(374): e**rror C2062: type 'unknown-type' unexpected
CMake Error at cuda_compile_1_generated_gpu_mat.cu.obj.Release.cmake:280 (message):
Error generating file**
C:/Nitin/OpenCVCode/opencv4_3_0/build/modules/world/CMakeFiles/cuda_compile_1.dir/__/core/src/cuda/./cuda_compile_1_generated_gpu_mat.cu.obj
Whereas, DEBUG build builds just fine !
|
category: build/install,category: gpu/cuda (contrib),platform: win32
|
low
|
Critical
|
617,809,065 |
electron
|
I can still interact with disabled windows after a call to setEnabled(false)
|
### Preflight Checklist
* [x] I have read the [Contributing Guidelines](https://github.com/electron/electron/blob/master/CONTRIBUTING.md) for this project.
* [x] I agree to follow the [Code of Conduct](https://github.com/electron/electron/blob/master/CODE_OF_CONDUCT.md) that this project adheres to.
* [x] I have searched the issue tracker for an issue that matches the one I want to file, without success.
### Issue Details
* **Electron Version:** 8.2.0
* **Operating System:** Windows 10
### Expected Behavior
When I call `win.setEnabled(false)`, I expect that I won't be able to interact with the window.
### Actual Behavior
I can still interact if I Alt+Tab to it.
### To Reproduce
main.js:
```
const { app, BrowserWindow, ipcMain } = require('electron')
async function createWindow() {
const mainWindow = new BrowserWindow({ webPreferences: { nodeIntegration: true } });
await mainWindow.loadFile("./index.html");
mainWindow.webContents.openDevTools({ mode: "detach" });
ipcMain.on("disableWindows", (e, arg) => {
BrowserWindow.getAllWindows().forEach((win) => {
if (win.id != mainWindow.id) {
win.setEnabled(false);
}
});
});
}
app.on('ready', createWindow)
```
index.html:
```
<body>
<button id="b">Cliek me</button>
<script src="./renderer.js">
</script>
</body>
```
renderer.js:
```
const { ipcRenderer } = require("electron");
var b = document.getElementById("b");
b.onclick = () => {
ipcRenderer.send("disableWindows");
}
```
Launch the app. In the devtools, open a window to google. Make sure focus is in the search field.
Then click the button in the main window to disable the window. Alt+tab back to the disabled window and type something. notice that that still works and I can search for results.
Gif:
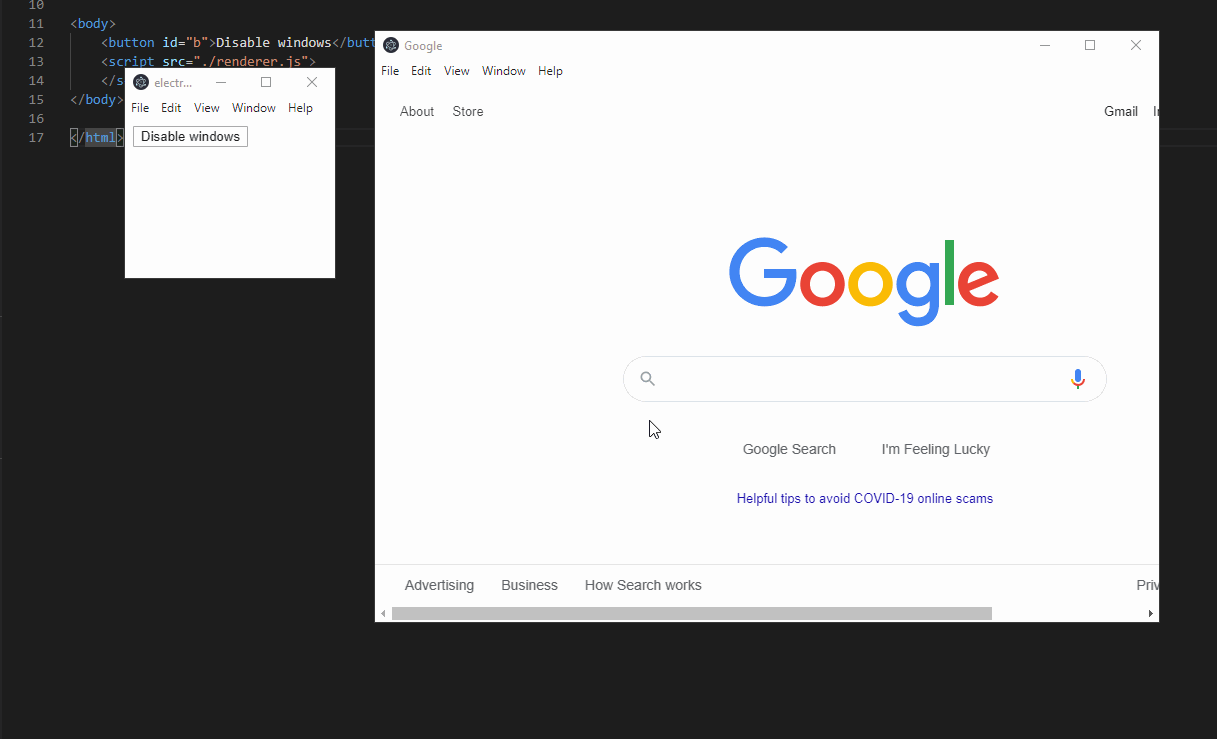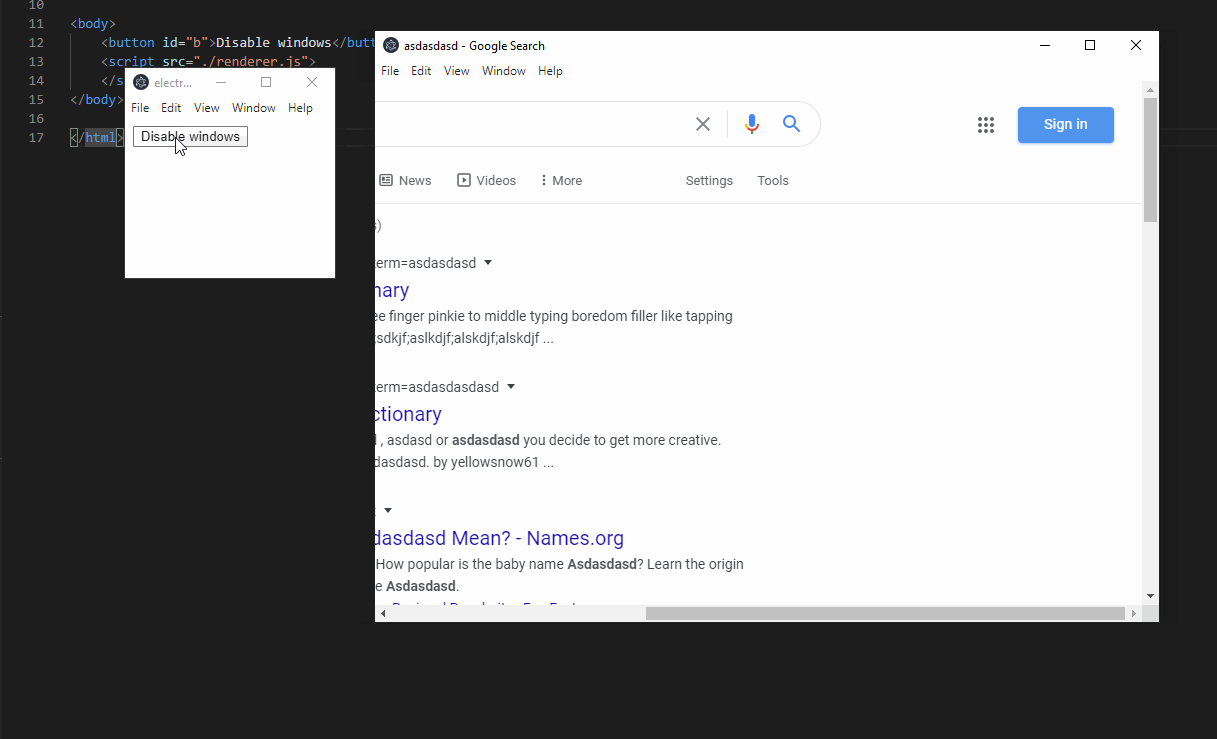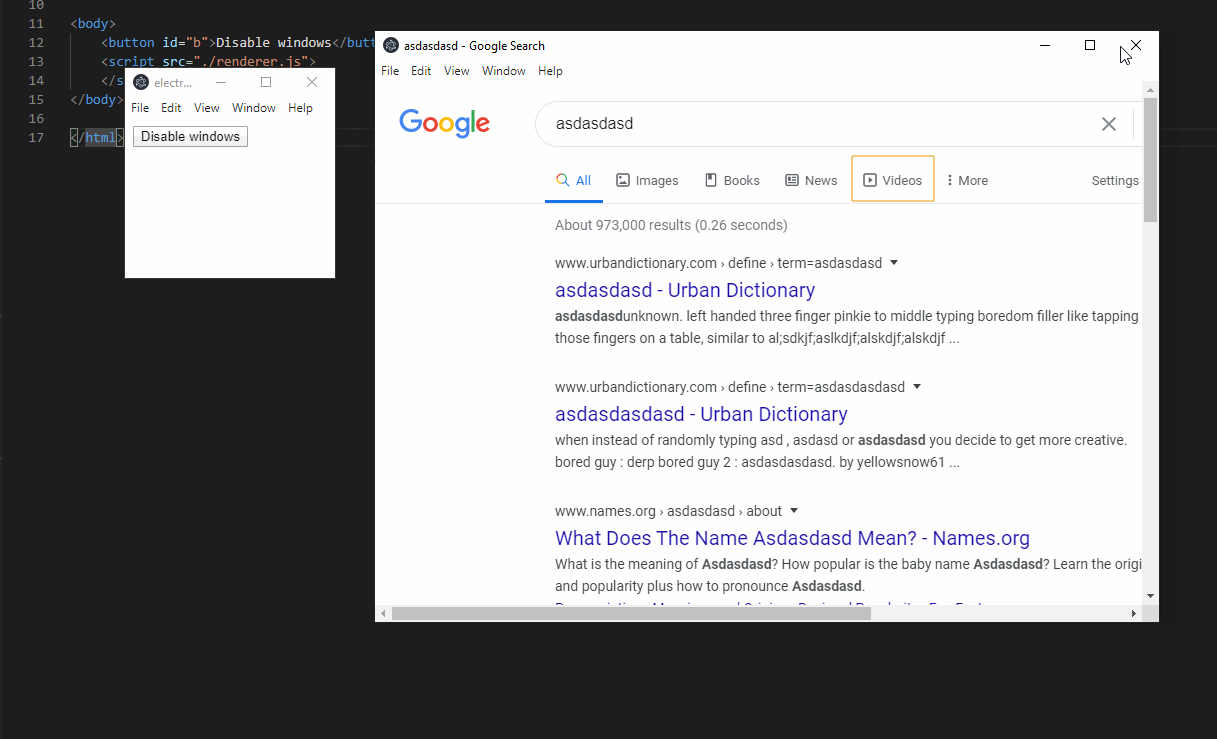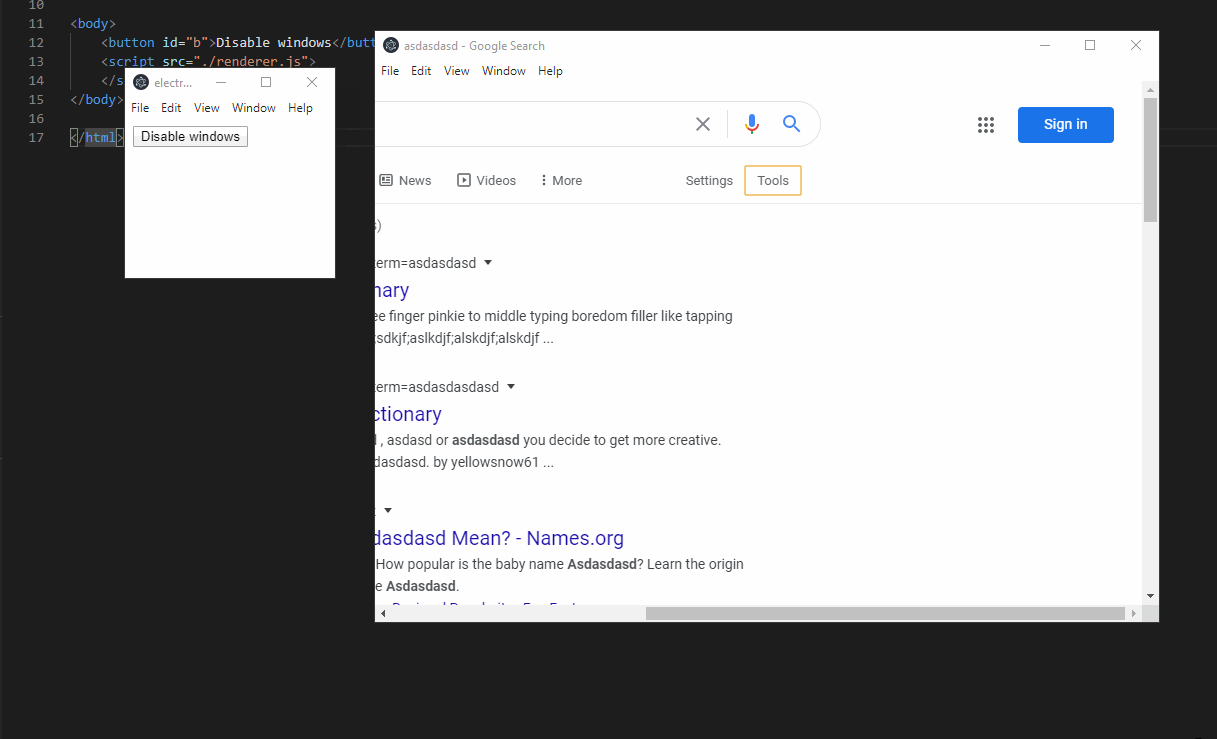
|
platform/windows,bug :beetle:,8-x-y,10-x-y
|
medium
|
Major
|
617,857,226 |
godot
|
Scrollcontainer which doesn't show the last element when supposed to spawn outside of Scrollbox
|
**Godot version:** v3.2.stable.official and v3.2.1.stable.official
**OS/device including version:** Windows 64bit
**Issue description:** If your Scrollcontainer is too small, then the last element of an array wont load into the "scrolling" of the Container.
Like you see in this picture I do have 5 elements in my array but as you'll see in the next screenshot the 5th element isn't loaded / properly spawned.
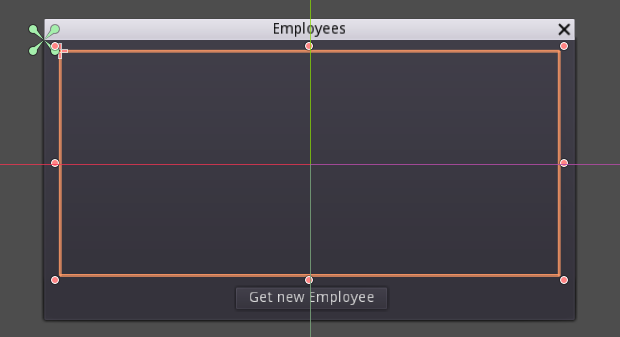
What I did find out is that the fifth element **is** loading but it doesn't spawn it into the scrolling of the container. It spawns outside of the box so you'll never see it (That's what I saw. It could also be another problem with maybe the sizing of the Scrollcontainer or even a bug in the Vertical- and HorizontalBox).
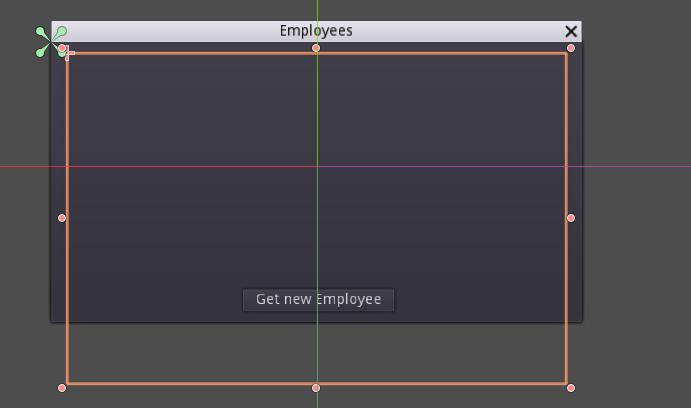
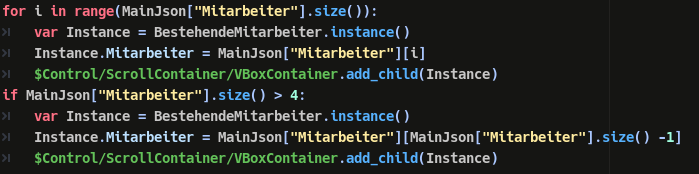
So I only found out one solution to this problem that is to manually spawn the last element of the array you are using.
**Steps to reproduce:**
- make an array (a good number is 10)
- make a little scene you want to instance into the scrollingcontainer and then try to run a for loop to instance all elements
**Minimal reproduction project:**
[Scrollingcontainer Bug.zip](https://github.com/godotengine/godot/files/4625485/Scrollingcontainer.Bug.zip)
In this project you should see a difference between the size of the array and how many actually spawned. (The instances are numbered, It goes from 0 to 7 with an array of 9 elements)
|
bug,confirmed,topic:gui
|
low
|
Critical
|
617,866,941 |
go
|
x/tools/gopls: use RelatedInformation for diagnostics on interface implementation errors
|
See the example in https://play.golang.org/p/2TrSYmBsdLU.
In this case, both the compiler and go/types report error messages on L17 where the error occurs. However, in cases like these, the user is most likely interested in fixing their mistake on L9 by changing the return type of `Hello`. We should add this position in the `RelatedInformation` field of diagnostics.
|
FeatureRequest,gopls,Tools
|
low
|
Critical
|
617,877,489 |
terminal
|
Include a profile that will connect to Visual Studio Codespaces
|
# Description of the new feature/enhancement
When using VSCode with [Visual Studio Codespaces ](https://online.visualstudio.com/), the integrated terminal is "connected" to the codespace and all commands execute in the Codespace environment.
I would like a profile in Terminal that connects to a Codespace. I would expect it to function similar to the Azure Cloud Shell profile.
|
Issue-Feature,Help Wanted,Area-Extensibility,Product-Terminal
|
low
|
Minor
|
617,883,309 |
go
|
net/http: Transport doesn't discard connections which received a 408 Request Timeout
|
<!--
Please answer these questions before submitting your issue. Thanks!
For questions please use one of our forums: https://github.com/golang/go/wiki/Questions
-->
### What version of Go are you using (`go version`)?
<pre>
$ go version
go version go1.14.2 linux/amd64
</pre>
### Does this issue reproduce with the latest release?
Yes.
### What operating system and processor architecture are you using (`go env`)?
<details><summary><code>go env</code> Output</summary><br><pre>
$ go env
GO111MODULE=""
GOARCH="amd64"
GOBIN=""
GOCACHE="/root/.cache/go-build"
GOENV="/root/.config/go/env"
GOEXE=""
GOFLAGS=""
GOHOSTARCH="amd64"
GOHOSTOS="linux"
GOINSECURE=""
GONOPROXY=""
GONOSUMDB=""
GOOS="linux"
GOPATH="/go"
GOPRIVATE=""
GOPROXY="https://proxy.golang.org,direct"
GOROOT="/usr/local/go"
GOSUMDB="sum.golang.org"
GOTMPDIR=""
GOTOOLDIR="/usr/local/go/pkg/tool/linux_amd64"
GCCGO="gccgo"
AR="ar"
CC="gcc"
CXX="g++"
CGO_ENABLED="1"
GOMOD=""
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
PKG_CONFIG="pkg-config"
GOGCCFLAGS="-fPIC -m64 -pthread -fmessage-length=0 -fdebug-prefix-map=/tmp/go-build338312077=/tmp/go-build -gno-record-gcc-switches"
</pre></details>
### What did you do?
I'm reading net/http for implementing HTTP client in Go. I want to use connections pool functionality of it but not sure how to deal with the stale connections.
`*http.Transport` says it retries the request if a connection got closed by server `while it was trying to read the response`.
https://github.com/golang/go/blob/a88c26eb286098b4c8f322f5076e933556fce5ac/src/net/http/transport.go#L640-L645
Since #32310, the connection is discarded also when `408 Request Timeout` is sent on it.
https://github.com/golang/go/blob/a88c26eb286098b4c8f322f5076e933556fce5ac/src/net/http/transport.go#L2127-L2135
But if a connection receives `408` *as a response to the request*, no retry is held and that connection doesn't get discarded. So the client of `*http.Transport` sees `408` response repeatedly until that connection actually gets closed from the server.
Two open questions:
- Is it the client(of `*http.Transport`)'s responsibility to retry the request when it sees `408`?
- And why `*http.Transport` doesn't discard connections which got `408`?
You can reproduce this situation with the server which responses `408` for requests but doesn't close the connection immediately:
```go
package main
import (
"context"
"fmt"
"io"
"io/ioutil"
"net/http"
"net/http/httptest"
"net/http/httptrace"
"runtime"
"time"
)
func main() {
fmt.Println(runtime.Version())
server := httptest.NewServer(http.HandlerFunc(func(rw http.ResponseWriter, req *http.Request) {
http.Error(rw, "", http.StatusRequestTimeout)
}))
defer server.Close()
req, err := http.NewRequestWithContext(
httptrace.WithClientTrace(context.Background(), &httptrace.ClientTrace{
GotConn: func(info httptrace.GotConnInfo) {
fmt.Printf("WasIdle: %v\n", info.WasIdle)
},
}),
"GET", server.URL, nil,
)
if err != nil {
panic(err)
}
for i := 0; i < 3; i++ {
fmt.Printf("===== %d =====\n", i)
res, err := http.DefaultTransport.RoundTrip(req)
if err != nil {
panic(err)
}
fmt.Println(res)
io.Copy(ioutil.Discard, res.Body)
res.Body.Close()
time.Sleep(time.Second)
}
}
```
Then the client always sees `408` through the cached connection.
```console
go1.14.2
===== 0 =====
WasIdle: false
&{408 Request Timeout 408 HTTP/1.1 1 1 map[Content-Length:[1] Content-Type:[text/plain; charset=utf-8] Date:[Thu, 14 May 2020 02:00:53 GMT] X-Content-Type-Options:[nosniff]] 0xc000190080 1 [] false false map[] 0xc000142000 <nil>}
===== 1 =====
WasIdle: true
&{408 Request Timeout 408 HTTP/1.1 1 1 map[Content-Length:[1] Content-Type:[text/plain; charset=utf-8] Date:[Thu, 14 May 2020 02:00:54 GMT] X-Content-Type-Options:[nosniff]] 0xc000092240 1 [] false false map[] 0xc000142000 <nil>}
===== 2 =====
WasIdle: true
&{408 Request Timeout 408 HTTP/1.1 1 1 map[Content-Length:[1] Content-Type:[text/plain; charset=utf-8] Date:[Thu, 14 May 2020 02:00:55 GMT] X-Content-Type-Options:[nosniff]] 0xc00021e080 1 [] false false map[] 0xc000142000 <nil>}
```
### What did you expect to see?
When `*http.Transport` get 408 as a response, it should discard the connection and retry with another.
### What did you see instead?
When `*http.Transport` get 408 as a response, it doesn't discard the connection nor retry.
|
NeedsInvestigation
|
low
|
Critical
|
617,889,112 |
PowerToys
|
Nightly releases
|
Not really a feature request, more like a helpful suggestion I could do.
I have a server and maybe if you guys think I should setup a release system?
Such as: Master, Stable, Nightly builds?
Up to you! Please react with reactions if you think this is a good idea, -3 reactions and i'll close this.
(I'm not sure how I would do this but, it's up to the person running this!).
More information on how I would run this:
1) It would run jenkins.
2) Links could be in readme.md
3) I'll give the operator of this repository full access of the Jenkins website.
Thank's all!
|
Area-Setup/Install
|
low
|
Major
|
617,906,801 |
flutter
|
type 'MaterialPageRoute<dynamic>' is not a subtype of type 'Route<String?>?' of ' in type cast'
|
### Hi, I found an uncertain problem!
#### Problem description:
> I expect to use `Navigator.of(context).pop<String>` to return a value of a certain type, but the result is always a value of dynamic type.
#### Code:
```dart
// First screen
Navigator.of(context).pushNamed<String>('login').then((String result){
print('login.result runtimeType: ${result.runtimeType}');
});
// Second screen
Navigator.of(context).pop<String>('success');
```
#### A type error will occur in the above code:
```bash
E/flutter (16614): [ERROR:flutter/lib/ui/ui_dart_state.cc(157)] Unhandled Exception: type 'MaterialPageRoute<dynamic>' is not a subtype of type 'Route<String>' in type cast
E/flutter (16614): #0 NavigatorState._routeNamed (package:flutter/src/widgets/navigator.dart:3138:55)
E/flutter (16614): #1 NavigatorState.pushNamed (package:flutter/src/widgets/navigator.dart:3190:20)
E/flutter (16614): #2 _Transfer.build.<anonymous closure> (package:panda_exchange/views/FirstScreen.dart:157:55)
E/flutter (16614): #3 GestureRecognizer.invokeCallback (package:flutter/src/gestures/recognizer.dart:182:24)
E/flutter (16614): #4 TapGestureRecognizer.handleTapUp (package:flutter/src/gestures/tap.dart:504:11)
E/flutter (16614): #5 BaseTapGestureRecognizer._checkUp (package:flutter/src/gestures/tap.dart:282:5)
E/flutter (16614): #6 BaseTapGestureRecognizer.acceptGesture (package:flutter/src/gestures/tap.dart:254:7)
E/flutter (16614): #7 GestureArenaManager.sweep (package:flutter/src/gestures/arena.dart:156:27)
E/flutter (16614): #8 GestureBinding.handleEvent (package:flutter/src/gestures/binding.dart:222:20)
E/flutter (16614): #9 GestureBinding.dispatchEvent (package:flutter/src/gestures/binding.dart:198:22)
E/flutter (16614): #10 GestureBinding._handlePointerEvent (package:flutter/src/gestures/binding.dart:156:7)
E/flutter (16614): #11 GestureBinding._flushPointerEventQueue (package:flutter/src/gestures/binding.dart:102:7)
E/flutter (16614): #12 GestureBinding._handlePointerDataPacket (package:flutter/src/gestures/binding.dart:86:7)
E/flutter (16614): #13 _rootRunUnary (dart:async/zone.dart:1196:13)
E/flutter (16614): #14 _CustomZone.runUnary (dart:async/zone.dart:1085:19)
E/flutter (16614): #15 _CustomZone.runUnaryGuarded (dart:async/zone.dart:987:7)
E/flutter (16614): #16 _invoke1 (dart:ui/hooks.dart:275:10)
E/flutter (16614): #17 _dispatchPointerDataPacket (dart:ui/hooks.dart:184:5)
E/flutter (16614):
```
|
framework,f: material design,f: routes,has reproducible steps,P2,found in release: 3.3,found in release: 3.7,team-design,triaged-design
|
low
|
Critical
|
617,907,544 |
ant-design
|
How could I format the week num in WeekPicker
|
- [x] I have searched the [issues](https://github.com/ant-design/ant-design/issues) of this repository and believe that this is not a duplicate.
### What problem does this feature solve?
Now the week num in WeekPicker is the number of year , but for some one that is not clear, they want the number of month.
现在WeekPicker的组件里,周数指的是一年当中的第几周,但对一些客户来说,这个不够明确,他们比较希望的表达是某个月的第几周。
### What does the proposed API look like?
I hope there is a method to format the week number, just like this.
```
<WeekPicker
weekNumberFormatter = {(beginDate, endDate) => ''}
/>
```
<!-- generated by ant-design-issue-helper. DO NOT REMOVE -->
|
Inactive
|
low
|
Minor
|
617,930,185 |
vscode
|
Tab key when indenting with spaces does not insert correct number of spaces
|
<!-- ⚠️⚠️ Do Not Delete This! bug_report_template ⚠️⚠️ -->
<!-- Please read our Rules of Conduct: https://opensource.microsoft.com/codeofconduct/ -->
<!-- Please search existing issues to avoid creating duplicates. -->
<!-- Also please test using the latest insiders build to make sure your issue has not already been fixed: https://code.visualstudio.com/insiders/ -->
<!-- Use Help > Report Issue to prefill these. -->
- VSCode Version: 1.45.0
- OS Version: macOS Catalina 10.15.4
This is a re-filing of #80129 which was closed erroneously. This is NOT caused by an extension and reproduces when editing even a plain text document when extensions are all disabled.
Related to #2798.
If the insertion point is *anywhere* inside the indentation at the start of the line, and I press <kbd>Tab</kbd>, the indentation should be increased to the next full tab stop (multiple of the tab width).
I'll use the period `.` character instead of spaces in indentation so that it is easier to see what I'm talking about.
If I have a line of code indented by 4 spaces like this:
```python
....do_something()
```
If I place the insertion point on column 2 and press tab, I get _7_ spaces. That's really irritating, it means I have to be hyper precise placing my cursor when I want to indent a line, even when there's a very wide click target I should be able to hit anywhere.
```python
.......do_something()
```
**Xcode** does this properly, it increases the indentation to 8 spaces and moves the cursor to the end of the indentation. **TextMate** behaves the same as Xcode.
<!-- Launch with `code --disable-extensions` to check. -->
Does this issue occur when all extensions are disabled?: Yes
|
feature-request,editor-commands
|
low
|
Critical
|
617,946,963 |
pytorch
|
Named Tensor and Indexing
|
First of all, thanks for all the great work on PyTorch! It's been a pleasure to use, and to watch it continue to improve. I was also excited about Named Tensor, for all the reasons described in the initial proposal: there's painful gotchas in unnamed dimensions, and opportunity to write clearer, safer code with named dimensions.
However, when we tried to use named tensors, we ran into some trouble, mostly around indexing. This post will be part feature request, and part general observation / comment.
### Indexing Not Supported - Feature Request
We make use of indexing, primarily for embedding lookups, which is not supported with named tensors (as of 1.5):
```
named_tensor = torch.tensor([100, 101, 102], names=('foo',))
named_tensor[[0,2]] # -> RuntimeError: index is not yet supported with named tensors.
```
Similarly for `index_select`. The runtime error recommends removing the names and recreating them. Since this is rather cumbersome, it would be great if named tensor could support indexing more naturally.
### Named Dimension vs Labeled Index
One slightly unexpected observation in our exploration of named tensor is that we realized we actually had more cases where a labeled index would help with legibility and safety, than for named dimensions. Of course, both together would be better still. As a reference, consider the popular pandas dataframe API. For a concrete example, imagine we have a grocery model with a fruit embedding tensor represented as a pandas dataframe:
```
df = pd.DataFrame({'apple':[0,0],'pear':[1,1],'orange':[2,2]})
```
We can also make things even more explicit if we wish, analogous to named tensor, by assigning names to the index/columns (the pandas analogy breaks down slightly because dataframes are inherently 2-dimensional and don't fully generalize to tensors, so I'll stick with a 2 dimensional example here for clarity). But either way, we can index into this dataframe with labels rather than numeric indices:
```
df[['apple','orange']]
```
This is handy because it lets us standardize a label vocabulary, and avoids exposing the internal implementation detail of an arbitrary numeric index. When working with pytorch I find myself rolling my own indexing solutions, which would be simple enough in this toy example but can get quite messy as things become more complicated. Besides the potential complexity and error-prone nature of bespoke index tracking, there's also the drawback of missing out on a tighter integration of indexing with pytorch, which could be helpful for inspecting model objects.
Overall, it would simplify our model interface substantially if pytorch could provide built-in support for a labled index, possibly augmenting tensors in a similar fashion to named tensor. Of course this is way beyond the scope of named tensor itself, but perhaps this can help motivate future exploration, or if there is existing work in this direction I'd love to hear about it!
cc @zou3519
|
triaged,module: named tensor
|
low
|
Critical
|
618,063,771 |
TypeScript
|
templated function with multiple signatures does not have options merged for autocomplete.
|
```ts
function regular(options: {abc: 'hello'});
function regular(options: {abc: 'world'});
function regular(options: any) {
}
regular({abc: '' });
function templated<K extends string>(options: {abc: 'hello'});
function templated<K extends string>(options: {abc: 'world'});
function templated(options: any) {
}
templated({abc: ''});
```
With the `regular` function, asking for autocomplete inside the quotes for `abc` gives `"hello"` and `"world"`. With the `templated` function, only `"hello"` is given. Type checking itself works fine.
|
Bug,Domain: Completion Lists
|
low
|
Minor
|
618,079,361 |
youtube-dl
|
ondamedia.cl
|
<!--
######################################################################
WARNING!
IGNORING THE FOLLOWING TEMPLATE WILL RESULT IN ISSUE CLOSED AS INCOMPLETE
######################################################################
-->
## Checklist
<!--
Carefully read and work through this check list in order to prevent the most common mistakes and misuse of youtube-dl:
- First of, make sure you are using the latest version of youtube-dl. Run `youtube-dl --version` and ensure your version is 2020.05.08. If it's not, see https://yt-dl.org/update on how to update. Issues with outdated version will be REJECTED.
- Make sure that all provided video/audio/playlist URLs (if any) are alive and playable in a browser.
- Make sure that site you are requesting is not dedicated to copyright infringement, see https://yt-dl.org/copyright-infringement. youtube-dl does not support such sites. In order for site support request to be accepted all provided example URLs should not violate any copyrights.
- Search the bugtracker for similar site support requests: http://yt-dl.org/search-issues. DO NOT post duplicates.
- Finally, put x into all relevant boxes (like this [x])
-->
- [x] I'm reporting a new site support request
- [x] I've verified that I'm running youtube-dl version **2020.05.08**
- [x] I've checked that all provided URLs are alive and playable in a browser
- [x] I've checked that none of provided URLs violate any copyrights
- [x] I've searched the bugtracker for similar site support requests including closed ones
## Example URLs
<!--
Provide all kinds of example URLs support for which should be included. Replace following example URLs by yours.
-->
- Single video: https://ondamedia.cl/#/player/velodromo
- Single video: https://ondamedia.cl/#/player/hoy-y-no-manana
- Playlist: https://ondamedia.cl/#/result?query=ondasinfronteras
## Description
<!--
Provide any additional information.
If work on your issue requires account credentials please provide them or explain how one can obtain them.
-->
Collection of Chilean movies, documentaries and similar items hosted by the Chilean Ministry of Culture
|
site-support-request
|
low
|
Critical
|
618,126,175 |
pytorch
|
[Feature] Option to have zeros/ones/full output tensor with zero strides
|
## 🚀 Feature
An option to return a tensor with all strides set to 0 for `torch.zeros`, `torch.ones`, `torch.Tensor.new_ones`, `torch.Tensor.new_zeros`, etc. for smaller memory usage and better performance.
## Motivation
For now, an alternative way of doing this is by calling two methods, e.g.:
`x.new_full((1,), value).expand_as(x)`
But it is a pretty unfriendly approach, therefore, I have mostly seen a simple `torch.full_like(x, value)` being used instead, which can unnecessarily allocate a huge chunk of the memory.
## Pitch
Possible implementations:
* The most user-friendly way I can think of is to output zero-strided tensor by default and allocate additional memory only when a different value is assigned to some elements, but I can see this breaking many C++/CUDA extensions that expect a contiguous output from these methods (this could still be deprecated and changed in far future).
* Adding an additional [`torch.memory_format`](https://pytorch.org/docs/stable/tensor_attributes.html#torch.torch.memory_format) or [`torch.layout`](https://pytorch.org/docs/stable/tensor_attributes.html#torch.torch.layout) that handles this
* Adding an additional argument for each of the functions
## Additional context
A real-life example where this would have been useful in the [NVIDIA SPADE code with a dedicated method](https://github.com/NVlabs/SPADE/blob/0ff661e70131c9b85091d11a66e019c0f2062d4c/models/networks/loss.py#L51) for what could be potentially done as simple as `torch.zeros_like(input, expanded=False)`
|
triaged,enhancement,module: tensor creation,function request
|
low
|
Major
|
618,155,457 |
pytorch
|
Immediate mode API (with functional flavor) for optimizers
|
## 🚀 Feature
_Not really formally designed. Just a seed of an idea._
Example methods:
```py
optim.apply_grad(param, **update_args)
```
Uses `param.grad`. Throws if `param` was never under `optim`
```py
optim.apply_grad(param, grad, **update_args)
```
Very vaguely feels like there might be something to salvage here. But feels like it would be quite awkward for stateful optimizers (Adam, etc.)
```py
ggraph = optim.new_gradient_graph()
ggraph = loss.backward(ggraph)
params, grads = select_params(ggraph)
modify_grad(grads)
optim.apply_grad(params, grads, **update_args)
```
And so on.
`update_args` would be per-optimizer usable variables. E.g. learning rate.
## Motivation
The current API is awkward to work around for extending gradient calculations or custom update regimes.
This would make customizing LR, gradient clipping, selective freezing, etc., doable through an explicit loop. Like decoupling evaluation, grad calculation, and optimizer step did for the overall training loop.
A more advanced scenario I haven't worked with yet is dynamically generated networks. `add_param_group` and `del .param_groups[i]` are pretty awkward and require keeping track of parameter groups externally.
## Pitch
Let's discuss this. I don't have enough of the full picture to push for it. Just felt it would be interesting.
## Alternatives
Same as today. Gradients are hidden in an associated graph, `requires_grad` loops, only in-place mutation for grad changes, etc.
## Additional context
N/A
cc @vincentqb
|
module: optimizer,triaged,enhancement
|
low
|
Minor
|
618,161,573 |
create-react-app
|
Allow importing SVG as inline SVG
|
### Is your proposal related to a problem?
<!--
Provide a clear and concise description of what the problem is.
For example, "I'm always frustrated when..."
-->
I'm converting a React app with custom config that hasn't been updated for a while to a CRA app.
We're using fabric: https://www.npmjs.com/package/fabric, which allows importing SVG's into a canvas. For that to work it needs an inline SVG which https://webpack.js.org/loaders/svg-inline-loader/ can provide.
It would be awesome if like `import {ReactComponent as Svg} from …` the's a `import {inlineSvg as svg} from …`
### Describe the solution you'd like
It would be awesome if like `import {ReactComponent as Svg} from …` the's a `import {inlineSvg as svg} from …`
It's possible to use this loader; https://webpack.js.org/loaders/svg-inline-loader
(Describe your proposed solution here.)
### Describe alternatives you've considered
<!--
Let us know about other solutions you've tried or researched.
-->
(Write your answer here.)
### Additional context
<!--
Is there anything else you can add about the proposal?
You might want to link to related issues here, if you haven't already.
-->
(Write your answer here.)
|
issue: proposal,needs triage
|
low
|
Minor
|
618,173,820 |
pytorch
|
[torch.jit.trace] torch.jit.trace fixed batch size CNN
|
I use python 3.6.10 and pytorch 1.5.0
Using torch.jit.trace on a function that feeds inputs to CNN produces a graph with a hard-coded batch size. This makes it impossible to use the traced function with inputs of different batch sizes.
cc @suo
|
oncall: jit,triaged
|
low
|
Minor
|
618,195,984 |
pytorch
|
Python builtin function next() is currently not supported in Torchscript
|
## 🐛 Bug
Python builtin function next() is currently not supported in Torchscript
## To Reproduce
Steps to reproduce the behavior:
```bash
import torch
from torch import nn
class Next(nn.Module):
def __init__(self):
super(Next, self).__init__()
def forward(self, x):
device = next(self.parameters()).device
x = x.to(device)
return x
model = Next()
model.cuda()
jitted_model = torch.jit.script(model)
```
```bash
Traceback (most recent call last):
File "next.py", line 15, in <module>
jitted_model = torch.jit.script(model)
File "/opt/conda/lib/python3.6/site-packages/torch/jit/__init__.py", line 1267, in script
return torch.jit._recursive.create_script_module(obj, torch.jit._recursive.infer_methods_to_compile)
File "/opt/conda/lib/python3.6/site-packages/torch/jit/_recursive.py", line 299, in create_script_module
return create_script_module_impl(nn_module, concrete_type, stubs_fn)
File "/opt/conda/lib/python3.6/site-packages/torch/jit/_recursive.py", line 346, in create_script_module_impl
create_methods_from_stubs(concrete_type, stubs)
File "/opt/conda/lib/python3.6/site-packages/torch/jit/_recursive.py", line 273, in create_methods_from_stubs
concrete_type._create_methods(defs, rcbs, defaults)
RuntimeError:
Python builtin <built-in function next> is currently not supported in Torchscript:
File "next.py", line 8
def forward(self, x):
device = next(self.parameters()).device
~~~~ <--- HERE
x = x.to(device)
return x
```
## Expected behavior
Successful conversion to TorchScript
## Environment
PYTORCH_VERSION=1.5.0a0+8f84ded
cc @suo
|
oncall: jit,triaged
|
low
|
Critical
|
618,199,868 |
terminal
|
WT should start up fast: profile the startup path and trim anything that takes a while
|
# Steps to reproduce
1. Click to launch Windows Terminal
# Expected behavior
Windows Terminal should be ready instantaneously like windows console, or like Sublime Text.
Windows Terminal can't be slower than windows console.
While Windows Terminal is fast compared with other tools like Visual Studio, or iTunes, it is still not fast enough for a Terminal application.
# Actual behavior
It takes too long to startup. It is not ready instantaneously. It's not as fast as windows console.
<hr>
_maintainer note: hijacking OP for task list:_
* [x] Use exactly one `ColorPickerFlyout` for all tabs, and just redirect it to whatever tab activated it.
* [x] Delayload the `ColorPickerFlyout`.
* [ ] Add a setting to disable ALL fragments / dynamic profiles. The app catalog search is expensive.
- ~Maybe we can just skip loading dynamic profiles on initial launch, unless we discover that the defaultProfile is a dynamic one...~ Nah, cause what about for defterm launches that end up matching a dynamic profile.
|
Help Wanted,Area-Performance,Product-Terminal,Issue-Task
|
high
|
Major
|
618,244,405 |
pytorch
|
Scale parameter downcasted and rounded down in pytorch.distributions.Normal
|
## 🐛 Bug
Normal distribution's scale parameter is casted from float to int and rounded down. This is a bug or at least very unexpected, undocumented behavior. Documentation of the `pytorch.distributions.Normal` does not mention casting `loc` and `scale` to the same data type and potentially causing rounding errors.
## To Reproduce
Steps to reproduce the behavior:
1. Create a normal distribution with the following parameters: `loc` is `Tensor` with `dtype=int`, `scale` is `float`.
2. Values of the distribution parameters are casted to integers and `scale` parameter is rounded down.
Example code
```
import torch
import torch.distributions as td
td.Normal(torch.tensor(1), 0.5)
```
returns
```
Normal(loc: 1, scale: 0)
```
## Expected behavior
Normal distribution with the given values of parameters and the data types of the parameters casted to the float.
In the example `Normal(loc: 1.0, scale: 0.5)` is expected.
Another way to formulate this is that behavior for the following three alternatives should be same
```
(Normal(torch.tensor(1), torch.tensor(0.5)),
Normal(torch.tensor(1), 0.5),
Normal(1, torch.tensor(0.5))
(Normal(loc: 1, scale: 0.5),
Normal(loc: 1, scale: 0),
Normal(loc: 1.0, scale: 0.5))
```
## Environment
- PyTorch Version (e.g., 1.0): 1.4.0
- OS (e.g., Linux): Mac OSX 10.15.4
- How you installed PyTorch (`conda`, `pip`, source): conda
- Python version: 3.7
- CUDA/cuDNN version: No CUDA
## Additional context
This can lead to difficult to track down bugs and probably affects also other probability distribution implementations in PyTorch.
cc @vincentqb @fritzo @neerajprad @alicanb @vishwakftw
|
module: distributions,triaged
|
low
|
Critical
|
618,253,974 |
pytorch
|
TopK implementation slower than a custom divide and conquer implementation
|
## 🐛 Bug
TopK is slower than a divide and conquer implementation with k=100 and dimension of the input 2_000_000
## To Reproduce
Steps to reproduce the behavior:
```python
def gpu_time(f, reps=100):
start_event = torch.cuda.Event(enable_timing=True)
end_event = torch.cuda.Event(enable_timing=True)
start_event.record()
for i in range(reps):
y = f()
end_event.record()
torch.cuda.synchronize() # Wait for the events to be recorded!
elapsed_time_ms = start_event.elapsed_time(end_event)
print("{} ms".format(elapsed_time_ms / reps))
return y
def divide_and_conquer_topk(x, divide, k):
num_outputs = x.shape[1]
batch_size = x.shape[0]
assert num_outputs % divide == 0
partial = torch.topk(x.view(-1, divide, num_outputs // divide), k=k, dim=-1)
indices_view = torch.arange(num_outputs, device='cuda').view(1, divide, num_outputs // divide)
indices_view_2 = indices_view.expand((batch_size, divide, num_outputs // divide)).gather(index=partial.indices, dim=2).view(batch_size, -1)
values_2d = partial.values.view(batch_size, -1)
topk_2 = torch.topk(values_2d, k=k, dim=-1)
return indices_view_2.gather(index=topk_2.indices, dim=-1), topk_2.values
b = 512
n = 2000000
k = 100
cuda = torch.device('cuda')
```
```python
gpu_time(lambda: torch.topk(x, k, dim=-1));
```
Took 104.4182421875 ms,
while
```python
gpu_time(lambda: divide_and_conquer_topk(x, 100, k));
```
took 86.761689453125 ms
On the CPU
```python
x = torch.rand(b,n,device='cpu')
```
The output of this is
```python
%%time
torch.topk(x, k, dim=-1)
```
CPU times: user 10.3 s, sys: 11.9 ms, total: 10.3 s
while the following
```python
%%time
divide_and_conquer_topk(x, 100, k)
```
outputs CPU times: user 7.19 s, sys: 88.8 ms, total: 7.28 s.
## Expected behavior
I did not expect such a simple implementation of topk outperforming pytorch native one.
I wonder if there is something suboptimal in topk. It might be specific for this case and so not very interesting but I thought it was surprising enough to report.
## Environment
Collecting environment information...
PyTorch version: 1.4.0
Is debug build: No
CUDA used to build PyTorch: 10.1
OS: Amazon Linux AMI 2018.03
GCC version: (GCC) 4.8.5 20150623 (Red Hat 4.8.5-28)
CMake version: version 3.13.3
Python version: 3.6
Is CUDA available: Yes
CUDA runtime version: 10.0.130
GPU models and configuration: GPU 0: Tesla V100-SXM2-16GB
Nvidia driver version: 440.33.01
cuDNN version: Probably one of the following:
/usr/local/cuda-10.1/targets/x86_64-linux/lib/libcudnn.so.7.6.5
/usr/local/cuda-10.2/targets/x86_64-linux/lib/libcudnn.so.7.6.5
Versions of relevant libraries:
[pip3] numpy==1.15.4
[pip3] numpydoc==0.8.0
[pip3] torch==1.4.0
[pip3] torchvision==0.5.0
[conda] blas 1.0 mkl
[conda] cudatoolkit 10.1.243 h6bb024c_0
[conda] mkl 2018.0.3 1
[conda] mkl-service 1.1.2 py36h17a0993_4
[conda] mkl_fft 1.0.6 py36h7dd41cf_0
[conda] mkl_random 1.0.1 py36h629b387_0
[conda] numpy 1.15.4 py36h1d66e8a_0
[conda] numpy-base 1.15.4 py36h81de0dd_0
[conda] numpydoc 0.8.0 py36_0
[conda] pytorch 1.4.0 py3.6_cuda10.1.243_cudnn7.6.3_0 pytorch
[conda] torchvision 0.5.0 py36_cu101 pytorch
cc @VitalyFedyunin @ngimel @heitorschueroff
|
module: performance,module: cuda,good first issue,module: cpu,triaged,module: sorting and selection
|
low
|
Critical
|
618,302,171 |
flutter
|
Adding support for a third-party locale does not change text direction to RTL
|
I'm developing a [package ](https://pub.dev/packages/kurdish_localization)to add support for Kurdish language which is RTL. I'm following [this guide ](https://flutter.dev/docs/development/accessibility-and-localization/internationalization#adding-support-for-a-new-language) which does not talk about changing directions. I added the following to support the direction but it does not help.
```dart
class _KuMaterialLocalizationsDelegate
extends LocalizationsDelegate<WidgetsLocalizations> {
const _KuMaterialLocalizationsDelegate();
@override
bool isSupported(Locale locale) => locale.languageCode == 'ku';
@override
Future<WidgetsLocalizations> load(Locale locale) async {
const String localeName = "ku";
await intl.initializeDateFormatting(localeName, null);
return SynchronousFuture<WidgetsLocalizations>(
KuWidgetLocalizations(),
);
}
@override
bool shouldReload(_KuMaterialLocalizationsDelegate old) => false;
}
class KuWidgetLocalizations extends WidgetsLocalizations {
static const LocalizationsDelegate<WidgetsLocalizations> delegate =
_KuMaterialLocalizationsDelegate();
@override
TextDirection get textDirection => TextDirection.rtl;
}
```
|
c: new feature,framework,a: internationalization,d: api docs,would be a good package,c: proposal,P3,team-framework,triaged-framework
|
medium
|
Critical
|
618,317,668 |
excalidraw
|
iPad + Pencil Support: UX Improvements
|
## Brief Intro
Excalidraw now supports drawing shapes, which is amazing! I thought of trying it out with my iPad + Pencil. I've noticed a couple of UX problems.
1. Discussion on UX of Selection/Exploration Modes on iPad
### Current Behavior
When using both fingers and a pencil to interact, it's very natural that the hand is used to move the canvas, and the pencil is used to draw things. Other note taking apps (native to iPad) solve this problem by having another cursor (hand cursor) if one wants to move the canvas with a pencil (as shown in the picture below, middle part, next to scissors). And another tool for selecting objects. This separation is key to iPad users.
.
I just realized that the pinching with two fingers does the same thing as I was expecting that it would do if I just used one finger to do it. I feel that my way the UX would be slightly better, but I'm open to hear your opinion on this.
### Expected Behavior
The hand gestures in my opinion should not be used for text selection, but for moving the canvas. Selection tool should be introduced for selecting things. Writing with a pencil should immediately trigger the shape-drawing mode.
2. Pencil shape-drawing switches to selection tool when pencil is lift up from the screen
### Current Behavior
When I try to write a word, as soon as the pencil stops touching the screen, Excalidraw immediately switches to the selection tool, and I need to click back on tool 7 (shape drawing) again. Basically I need to write everything without lifting the pencil from the screen. This is bad UX for both drawing and manual text writing.
### Expected Behavior
I'd be great if it could remain in the 7 mode (shape-drawing) as long as I tell it to switch to some other mode.
|
discussion
|
low
|
Major
|
618,331,301 |
rust
|
Primitive vs struct antipattern?
|
This is coming from a stack overflow [question](https://stackoverflow.com/questions/61732690/why-is-it-allowed-to-have-both-immutable-and-mutable-borrows-of-a-vector-of-nume/61734260#61734260).
My answer didn't sit well with me. While it's true that the `add_assign` isn't called in the primitive case, the fact that it's called shouldn't cause a compilation failure because the Vec isn't being passed in.
The below fails to compile:
```rust
use std::ops::AddAssign;
#[derive(Clone, Copy, PartialEq, Debug, Default)]
struct MyNum(i32);
impl AddAssign for MyNum {
fn add_assign(&mut self, rhs: MyNum) {
*self = MyNum(self.0 + rhs.0)
}
}
fn main() {
let mut b = vec![MyNum(0), MyNum(1)];
b[0] += b[1];
}
```
With this message:
```none
error[E0502]: cannot borrow `b` as immutable because it is also borrowed as mutable
--> src/main.rs:14:13
|
14 | b[0] += b[1];
| --------^---
| | |
| | immutable borrow occurs here
| mutable borrow occurs here
| mutable borrow later used here
```
However this works:
```rust
fn main() {
let mut b = vec![1, 2];
b[0] += b[1];
}
```
Looking at the MIR, the only difference I can see is in the primitive case Index is called _before_ IndexMut whereas in the struct case that is reversed. I don't see why the struct needs to behave differently.
I expected to see this happen: the primitive case and the struct case should either both fail or both succeed. In my mind, they should both succeed as the dereference for `b[1]` can complete before `b[0]`.
If the mutable struct needs to exist first for some reason then the slice version should also fail, but this works:
```rust
use std::ops::AddAssign;
#[derive(Clone, Copy, PartialEq, Debug, Default)]
struct MyNum(i32);
impl AddAssign for MyNum {
fn add_assign(&mut self, rhs: MyNum) {
*self = MyNum(self.0 + rhs.0)
}
}
fn main() {
let mut b = vec![MyNum(0), MyNum(1)];
let slice = b.as_mut_slice();
slice[0] += slice[1];
}
```
### Meta
`rustc --version --verbose`:
```
rustc 1.45.0-nightly (75e1463c5 2020-05-13)
binary: rustc
commit-hash: 75e1463c52aaea25bd32ed53c73797357e561cce
commit-date: 2020-05-13
host: x86_64-apple-darwin
release: 1.45.0-nightly
LLVM version: 9.0
```
|
A-borrow-checker,T-compiler,C-bug
|
low
|
Critical
|
618,347,644 |
terminal
|
Support for `compact`, `default`, and `touch` friendly tab row sizes
|
Make the tabs, caption buttons smaller at `compact`.
Make the tabs, caption buttons bigger at `touch`.
I can't recall which app I saw this in recently, but I thought it was a good idea. Firefox maybe? Definitely plays in to the work being outlined in #3327 / #5772.
Should this be it's own property, or a collection of other ones?
```json
tabRow.height
tab.fontSize
tab.padding
```
All seem like properties the user would need to configure, but I'm not really sure now if all of them make sense atomically, or if a user would even want to tune them separately.
|
Area-Settings,Product-Terminal,Issue-Task,Area-Theming
|
low
|
Minor
|
618,355,662 |
go
|
encoding/asn1: Marshal doesn't handle nil interface values correctly
|
### What version of Go are you using (`go version`)?
<pre>
$ go version go1.14.2 linux/amd64
</pre>
### Does this issue reproduce with the latest release?
yes
### What operating system and processor architecture are you using (`go env`)?
<details><summary><code>go env</code> Output</summary><br><pre>
$ go env
GO111MODULE=""
GOARCH="amd64"
GOBIN=""
GOCACHE="/home/christoph/.cache/go-build"
GOENV="/home/christoph/.config/go/env"
GOEXE=""
GOFLAGS=""
GOHOSTARCH="amd64"
GOHOSTOS="linux"
GOINSECURE=""
GOOS="linux"
GOPATH="/home/christoph/.gopath"
GOPROXY="https://proxy.golang.org,direct"
GOROOT="/usr/local/go"
GOSUMDB="sum.golang.org"
GOTMPDIR=""
GOTOOLDIR="/usr/local/go/pkg/tool/linux_amd64"
GCCGO="gccgo"
AR="ar"
CC="gcc"
CXX="g++"
CGO_ENABLED="1"
GOMOD=""
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
PKG_CONFIG="pkg-config"
GOGCCFLAGS="-fPIC -m64 -pthread -fmessage-length=0 -fdebug-prefix-map=/tmp/go-build641307088=/tmp/go-build -gno-record-gcc-switches"
</pre></details>
### What did you do?
`asn1.Marshal` a struct containing a `nil` interface with `omitempty` tag.
https://play.golang.org/p/x-hrKEJH0Fe
### What did you expect to see?
No error and the corresponding field should be omitted from the output.
It works with nil slices (see example).
### What did you see instead?
Error: `asn1: cannot marshal nil value`
|
NeedsInvestigation
|
low
|
Critical
|
618,371,005 |
flutter
|
hot_mode_dev_cycle_linux__benchmark hotRestartMillisecondsToFrame trending upwards, now overwhelmingly red
|

Difficult to tell a culprit from this.
|
tool,c: performance,perf: speed,team: benchmark,found in release: 1.19,P2,team-tool,triaged-tool
|
low
|
Major
|
618,373,999 |
go
|
go/types: UsesCgo exposes mangled names
|
When UsesCgo is enabled, cgo symbols appear in the package as their mangled names, e.g. `_CFunc_GoString`. This breaks autocomplete in gopls for `C` symbols. Also, it exposes things that are implementation details, like the `_cgo_` and `__cgofn` symbols.
We can try to fix this in gopls, but probably it'd be better in `go/types`. I'm not sure offhand how it'll work, given that each package needs its own version of "C". Maybe the package path could be rewritten to something specific?
|
NeedsFix
|
medium
|
Major
|
618,374,154 |
flutter
|
smoke_catalina_start_up_ios timeToFirstFrameMicros and timeToFirstFrameRasterizedMicros benchmarks now consistently red...
|
Here's timeToFirstFrameMicros recently:
And here's
timeToFirstFrameRasterizedMicros

Hard to tell a culprit.
|
c: regression,engine,c: performance,perf: speed,team: benchmark,found in release: 1.19,P3,team-engine,triaged-engine
|
low
|
Major
|
618,398,865 |
pytorch
|
expected scalar type Half but found Float with torch.cuda.amp and torch.nn.DataParallel
|
## 🐛 Bug
I try to using amp in Pytorch core with torch.nn.DataParallel for multi-gpu training. I wrap forward pass in model in autocast, but get error
## To Reproduce
Steps to reproduce the behavior:
1. install sinkhorn_transformer==0.4.4, transformers
2. run following script
```python
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import sinkhorn_transformer
from sinkhorn_transformer import SinkhornTransformerLM
from transformers import BertTokenizer, AdamW
from torch.cuda.amp import autocast, GradScaler
def mask_tokens(inputs: torch.Tensor, tokenizer, mlm_probability=0.15, pad=True):
""" Prepare masked tokens inputs/labels for masked language modeling: 80% MASK, 10% random, 10% original. """
labels = inputs.clone()
# mlm_probability defaults to 0.15 in Bert
probability_matrix = torch.full(labels.shape, mlm_probability)
special_tokens_mask = [
tokenizer.get_special_tokens_mask(val, already_has_special_tokens=True) for val in labels.tolist()
]
probability_matrix.masked_fill_(torch.tensor(special_tokens_mask, dtype=torch.bool), value=0.0)
if tokenizer._pad_token is not None:
padding_mask = labels.eq(tokenizer.pad_token_id)
probability_matrix.masked_fill_(padding_mask, value=0.0)
masked_indices = torch.bernoulli(probability_matrix).bool()
labels[~masked_indices] = -100 # We only compute loss on masked tokens
# 80% of the time, we replace masked input tokens with tokenizer.mask_token ([MASK])
indices_replaced = torch.bernoulli(torch.full(labels.shape, 0.8)).bool() & masked_indices
inputs[indices_replaced] = tokenizer.convert_tokens_to_ids(tokenizer.mask_token)
# 10% of the time, we replace masked input tokens with random word
indices_random = torch.bernoulli(torch.full(labels.shape, 0.5)).bool() & masked_indices & ~indices_replaced
random_words = torch.randint(len(tokenizer), labels.shape, dtype=torch.long)
inputs[indices_random] = random_words[indices_random]
if pad:
input_pads = tokenizer.max_len - inputs.shape[-1]
label_pads = tokenizer.max_len - labels.shape[-1]
inputs = F.pad(inputs, pad=(0,input_pads), value=tokenizer.pad_token_id)
labels = F.pad(labels, pad=(0,label_pads), value=tokenizer.pad_token_id)
# The rest of the time (10% of the time) we keep the masked input tokens unchanged
return inputs, labels
def read_batch_from_dataset_restored(tokenizer):
batch = []
iterat = 0
for it in range(1000):
yield torch.randint(3, tokenizer.vocab_size, (4, 40960))
class LossWraper(nn.Module):
def __init__(self, model, loss=None):
super(LossWraper, self).__init__()
self.model = model
self.loss = loss
@autocast()
def forward(self, inputs, labels=None):
loss_mx = labels != -100
output = self.model(inputs)
output = output[loss_mx].view(-1, tokenizer.vocab_size)
labels = labels[loss_mx].view(-1)
loss = self.loss(output, labels)
return loss, output
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = SinkhornTransformerLM(
num_tokens= tokenizer.vocab_size,
dim = 768,
depth = 12,
max_seq_len = 40960,
heads = 16,
buckets = 64,
causal = False, # auto-regressive or not
sinkhorn_iter = 7, # number of sinkhorn iterations - default is set at reported best in paper
n_sortcut = 2, # use sortcut to reduce complexity to linear time
temperature = 0.75, # gumbel temperature - default is set at reported best in paper
non_permutative = False, # allow buckets of keys to be sorted to queries more than once
attn_sort_net = True, # attention to reorder the buckets, unlocks flexible sequence lengths
ff_chunks = 10, # feedforward chunking, from Reformer paper
reversible = True, # make network reversible, from Reformer paper
ff_dropout = 0.1, # feedforward dropout
attn_dropout = 0.1, # post attention dropout
attn_layer_dropout = 0.1, # post attention layer dropout
layer_dropout = 0.1, # add layer dropout, from 'Reducing Transformer Depth on Demand' paper
weight_tie = True, # tie layer parameters, from Albert paper
emb_dim = 128, # embedding factorization, from Albert paper
ff_glu = True, # use GLU in feedforward, from paper 'GLU Variants Improve Transformer'
n_local_attn_heads = 4, # replace N heads with local attention, suggested to work well from Routing Transformer paper
)
device = torch.device("cuda")
loss_fn = nn.CrossEntropyLoss()
model = LossWraper(model, loss_fn)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
model.to(device)
scaler = GradScaler()
model = torch.nn.DataParallel(model)
model.train()
for ep in range(50):
for it in read_batch_from_dataset_restored(tokenizer):
optimizer.zero_grad()
torch.cuda.empty_cache()
inp, mask = mask_tokens(it, tokenizer)
inputs, labels = inp.to("cuda"), mask.to("cuda")
with autocast():
output = model(inputs, labels)
loss = output[0]
loss = loss.mean()
scaler.scale(loss).backward()
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.25)
scaler.step(optimizer)
scaler.update()
```
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
```python
RuntimeError Traceback (most recent call last)
<ipython-input-7-7a29bfd8a4a8> in <module>
63 loss = loss.mean()
---> 64 scaler.scale(loss).backward()
65 scaler.unscale_(optimizer)
/opt/anaconda/envs/pytorch_apex_core_cuda_10.1/lib/python3.8/site-packages/torch/tensor.py in backward(self, gradient, retain_graph, create_graph)
182 products. Defaults to ``False``.
183 """
--> 184 torch.autograd.backward(self, gradient, retain_graph, create_graph)
185
186 def register_hook(self, hook):
/opt/anaconda/envs/pytorch_apex_core_cuda_10.1/lib/python3.8/site-packages/torch/autograd/__init__.py in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables)
119 retain_graph = create_graph
120
--> 121 Variable._execution_engine.run_backward(
122 tensors, grad_tensors, retain_graph, create_graph,
123 allow_unreachable=True) # allow_unreachable flag
RuntimeError: expected scalar type Half but found Float
```
## Environment
PyTorch version: 1.6.0.dev20200514
Is debug build: No
CUDA used to build PyTorch: 10.1
OS: Ubuntu 18.04 LTS
GCC version: (Ubuntu 7.4.0-1ubuntu1~18.04.1) 7.4.0
CMake version: Could not collect
Python version: 3.8
Is CUDA available: Yes
CUDA runtime version: Could not collect
GPU models and configuration:
GPU 0: Quadro RTX 8000
GPU 1: Quadro RTX 8000
Nvidia driver version: 440.33.01
cuDNN version: Could not collect
Versions of relevant libraries:
[pip] numpy==1.18.1
[pip] torch==1.6.0.dev20200514
[pip] torchvision==0.7.0.dev20200514
[conda] blas 1.0 mkl
[conda] cudatoolkit 10.1.243 h6bb024c_0
[conda] mkl 2020.1 217
[conda] mkl-service 2.3.0 py38he904b0f_0
[conda] mkl_fft 1.0.15 py38ha843d7b_0
[conda] mkl_random 1.1.0 py38h962f231_0
[conda] numpy 1.18.1 py38h4f9e942_0
[conda] numpy-base 1.18.1 py38hde5b4d6_1
[conda] pytorch 1.6.0.dev20200514 py3.8_cuda10.1.243_cudnn7.6.3_0 pytorch-nightly
[conda] torchvision 0.7.0.dev20200514 py38_cu101 pytorch-nightly
cc @mcarilli
|
triaged,module: data parallel,module: amp (automated mixed precision)
|
low
|
Critical
|
618,422,773 |
flutter
|
Explain the memory metrics reported by tools like Instruments and ADB memstats
|
ADB reports metrics such as:
Java Heap
Native Heap
Code
Stack
Graphics
Private Other
System
We should have explanation of each of these metrics in **Flutter context**.
We are exposing them in DevTools, people need to understand what "native heap" or "graphics" means w.r.t. Flutter.
This should include ways typical usage patterns affect each bucket, such as loading an asset, using shadows/ripples, loading plugins, etc.
For instance the double allocation in native heap + graphics memory while decoding PNGs is likely surprising to a lot of Flutter developers (https://github.com/flutter/flutter/issues/56483).
|
engine,c: performance,d: api docs,customer: money (g3),perf: memory,P3,team-engine,triaged-engine
|
low
|
Minor
|
618,442,296 |
rust
|
Specifying one associated type makes Rust forget about the constraint on the other ones
|
I tried this code (which is actually the minimum reproduction I could find, as the bug seems to disappear when I try to reduce it more):
```rust
use std::marker::PhantomData;
pub struct XImpl<T, E, F2, F1>
where
F2: Fn(E),
{
f1: F1,
f2: F2,
_ghost: PhantomData<(T, E)>,
}
pub trait X<T>: Sized {
type F1;
type F2: Fn(Self::E);
type E;
fn and<NewF1, NewF1Generator>(self, f: NewF1Generator) -> XImpl<T, Self::E, Self::F2, NewF1>
where
NewF1Generator: FnOnce(Self::F1) -> NewF1;
}
impl<T, E, F2, F1> X<T> for XImpl<T, E, F2, F1>
where
F2: Fn(E),
{
type E = E;
type F2 = F2;
type F1 = F1;
fn and<NewF1, NewF1Generator>(self, f: NewF1Generator) -> XImpl<T, E, F2, NewF1>
where
NewF1Generator: FnOnce(F1) -> NewF1,
{
XImpl {
f1: f(self.f1),
f2: self.f2,
_ghost: PhantomData,
}
}
}
fn f() -> impl X<()> {
XImpl {
f1: || (),
f2: |()| (),
_ghost: PhantomData,
}
}
fn f2() -> impl X<()> {
f().and(|rb| rb)
}
```
It does compile: https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=54e239ced207241c8438dddbc325ef19
If however we specify the value for the associated type `E` in `f` and `f2`, so that code calling `f2()` can depend on knowing the type `E`:
```rust
fn f() -> impl X<(), E = ()> {
XImpl {
f1: || (),
f2: |()| (),
_ghost: PhantomData,
}
}
fn f2() -> impl X<(), E = ()> {
f().and(|rb| rb)
}
```
The compiler seems to forget that any `X::F2` implements `Fn(Self::E)`, and stops compiling: https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=1e84aea4402bd45da498aace9682b1ad
```
Compiling playground v0.0.1 (/playground)
error[E0277]: expected a `std::ops::Fn<((),)>` closure, found `<impl X<()> as X<()>>::F2`
--> src/lib.rs:51:6
|
51 | f().and(|rb| rb)
| ^^^ expected an `Fn<((),)>` closure, found `<impl X<()> as X<()>>::F2`
|
= help: the trait `std::ops::Fn<((),)>` is not implemented for `<impl X<()> as X<()>>::F2`
error[E0277]: expected a `std::ops::Fn<((),)>` closure, found `<impl X<()> as X<()>>::F2`
--> src/lib.rs:51:2
|
12 | pub trait X<T>: Sized {
| --------------------- required by `X`
...
51 | f().and(|rb| rb)
| ^^^^^^^^^^^^^^^^ expected an `Fn<((),)>` closure, found `<impl X<()> as X<()>>::F2`
|
= help: the trait `std::ops::Fn<((),)>` is not implemented for `<impl X<()> as X<()>>::F2`
error[E0277]: expected a `std::ops::Fn<((),)>` closure, found `<impl X<()> as X<()>>::F2`
--> src/lib.rs:50:12
|
50 | fn f2() -> impl X<(), E = ()> {
| ^^^^^^^^^^^^^^^^^^ expected an `Fn<((),)>` closure, found `<impl X<()> as X<()>>::F2`
51 | f().and(|rb| rb)
| ---------------- this returned value is of type `XImpl<(), (), <impl X<()> as X<()>>::F2, <impl X<()> as X<()>>::F1>`
|
= help: the trait `std::ops::Fn<((),)>` is not implemented for `<impl X<()> as X<()>>::F2`
= note: required because of the requirements on the impl of `X<()>` for `XImpl<(), (), <impl X<()> as X<()>>::F2, <impl X<()> as X<()>>::F1>`
= note: the return type of a function must have a statically known size
```
Note that the bug does not happen if `F2: Fn()` instead of `F2: Fn(E)`:
https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=266f91f2ba2f0730148c4dea8c3732a4
It does not happen either if `F2: Fn(T)` instead of `F2: Fn(E)`:
https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=e37b04bfdeec2a1ebddc10a4422931e8
### Meta
`rustc --version --verbose`:
```
rustc 1.43.1 (8d69840ab 2020-05-04)
binary: rustc
commit-hash: 8d69840ab92ea7f4d323420088dd8c9775f180cd
commit-date: 2020-05-04
host: x86_64-unknown-linux-gnu
release: 1.43.1
LLVM version: 9.0
```
This also happens on nightly.
|
A-trait-system,E-needs-test,A-closures,A-associated-items,T-compiler,A-impl-trait,C-bug,E-needs-bisection,T-types
|
low
|
Critical
|
618,445,112 |
flutter
|
libflutter.so is not included in the "armeabi-v7a" folder when other "armeabi-v7a" libraries are included
|
libflutter.so is not included in the "armeabi-v7a" folder when other "armeabi-v7a" libraries are included.
## Steps to Reproduce
1. Run `flutter create -a java -i objc --androidx reprosteps`.
2. Build the app in debug and look inside the APK (for example using 7-zip).
Notice that libflutter.so is included in "lib\armeabi-v7a", "lib\x86", "lib\x86_64"
3. Put a .so library in the folder android\app\src\main\jniLibs\armeabi-v7a
4. Build the app in debug mode and look inside the APK.
Notice that libflutter.so is now gone from the folder "lib\armeabi-v7a"
## Flutter doctor
```console
[√] Flutter (Channel stable, v1.17.0, on Microsoft Windows [Version 10.0.17763.1158], locale de-DE)
• Flutter version 1.17.0 at D:\src\flutter
• Framework revision e6b34c2b5c (12 days ago), 2020-05-02 11:39:18 -0700
• Engine revision 540786dd51
• Dart version 2.8.1
[√] Android toolchain - develop for Android devices (Android SDK version 29.0.3)
• Android SDK at D:\src\Android\sdk
• Platform android-R, build-tools 29.0.3
• ANDROID_HOME = D:\src\Android\sdk
• Java binary at: D:\Program Files\Android\Android Studio\jre\bin\java
• Java version OpenJDK Runtime Environment (build 1.8.0_212-release-1586-b04)
• All Android licenses accepted.
[!] Android Studio (version 3.6)
• Android Studio at D:\Program Files\Android\Android Studio
X Flutter plugin not installed; this adds Flutter specific functionality.
X Dart plugin not installed; this adds Dart specific functionality.
• Java version OpenJDK Runtime Environment (build 1.8.0_212-release-1586-b04)
[√] VS Code (version 1.45.0)
• VS Code at C:\Users\sad1lo\AppData\Local\Programs\Microsoft VS Code
• Flutter extension version 3.10.1
[√] Proxy Configuration
• HTTP_PROXY is set
• NO_PROXY is localhost,*.bosch.com,127.0.0.1
• NO_PROXY contains 127.0.0.1
• NO_PROXY contains localhost
[√] Connected device (1 available)
• sdk gphone x86 64 arm64 • emulator-5554 • android-x64 • Android 10 (API 29) (emulator)
```
|
c: crash,platform-android,tool,a: build,P2,team-android,triaged-android
|
low
|
Critical
|
618,455,909 |
flutter
|
Create a top level navigationRail param in the Scaffold
|
Currently, the NavigationRail is recommended to be inserted inside of a Row in the Scaffold body. Part of the reason to do this is to leave it flexible for adding dividers.
The proposal is to make a top level widget param in the Scaffold, that can take in a NavigationRail. When a NavigationRail is provided through this param, the body would be recreated as a Row of the NavigationRail and the original body.
|
framework,f: material design,c: proposal,team-design,triaged-design
|
low
|
Major
|
618,470,068 |
TypeScript
|
Add TS Server API for mapping TS file to output file
|
## Search Terms
- Debug / debugger
- compile
- tsserver
## Problem
VS Code would like to make it easy to debug the active TS file just by pressing F5. To implement this, we need a way to map from a TypeScript file to its JavaScript output.
See https://github.com/microsoft/vscode/issues/95544#issuecomment-628577083 for details
## Proposal
Add a new TS Server API that takes a typescript file and returns the path to the output JavaScript file for it.
|
Suggestion,Committed
|
low
|
Critical
|
618,475,173 |
terminal
|
Triggers(Including Text Strings) and Actions (internal or external calls)
|
<!--
🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
I ACKNOWLEDGE THE FOLLOWING BEFORE PROCEEDING:
1. If I delete this entire template and go my own path, the core team may close my issue without further explanation or engagement.
2. If I list multiple bugs/concerns in this one issue, the core team may close my issue without further explanation or engagement.
3. If I write an issue that has many duplicates, the core team may close my issue without further explanation or engagement (and without necessarily spending time to find the exact duplicate ID number).
4. If I leave the title incomplete when filing the issue, the core team may close my issue without further explanation or engagement.
5. If I file something completely blank in the body, the core team may close my issue without further explanation or engagement.
All good? Then proceed!
-->
# Description of the new feature/enhancement
A Trigger system that will monitor several types o events, including text strings on the screen, that will be able to call several types of actions, like scripts, commands, or any resources possible of Windows Terminal.
<!--
A clear and concise description of what the problem is that the new feature would solve.
Describe why and how a user would use this new functionality (if applicable).
-->
# Proposed technical implementation details (optional)
"Nothing is created, everything is copied."
As you you may see, I'm a fan of iTerm2, my buddy for several years.
But I like this new Microsoft Style, so I'm trying to help.
The Suggestion her is a bit bold.
Provide an complementar Framework that will allow user execute almost any possible predefined action based on almost any event on the Windows Terminal.
A sub-system the will be monitoring events, and if it matches with some pre-activated event, it will trigger the action.
The triggers could be a simple match with a string on the text, or even something like an server-ended-session if it was an SSH/Telnet connection.
The actions could be the automatic highlight of the text, a long beep, open a new tab, or call an external app passing some parameters and receiving back some answer.
---
As I'm not a developer, and also not good with descriptions like these, I will bring the description of this Feature in iTerm2:
https://www.iterm2.com/documentation-one-page.html#documentation-triggers.html
<!--
A clear and concise description of what you want to happen.
-->
|
Issue-Feature,Area-Extensibility,Product-Terminal
|
low
|
Critical
|
618,483,359 |
rust
|
Improve error message when moving a captured value out of a closure
|
I tried this code:
```rust
fn main() {
let foo = String::new();
bar(move || std::mem::forget(foo));
}
fn bar<F: Fn()>(a: F) {
}
```
I got this error:
```
error[E0507]: cannot move out of `foo`, a captured variable in an `Fn` closure
--> src/main.rs:4:34
|
2 | let foo = String::new();
| --- captured outer variable
3 |
4 | bar(move || std::mem::forget(foo));
| ^^^ move occurs because `foo` has type `std::string::String`, which does not implement the `Copy` trait
```
The error message is because the closure is not `FnOnce()` – it could be called multiple times. So this is correct.
But I think the error message is confusing, because it says something about moving **out of** `foo`. What’s happening instead is that the captured `foo` is moved out of the closure that needs it to stay there for a second call.
### Meta
`rustc --version --verbose`:
```
rustc 1.45.0-nightly (a08c47310 2020-05-07)
binary: rustc
commit-hash: a08c47310c7d49cbdc5d7afb38408ba519967ecd
commit-date: 2020-05-07
host: x86_64-unknown-linux-gnu
release: 1.45.0-nightly
LLVM version: 9.0
```
|
C-enhancement,A-diagnostics,A-closures,T-compiler
|
low
|
Critical
|
618,489,539 |
rust
|
Huge stack allocation is generated when assigning a huge piece of memory to a reference
|
Hi!
I am developing an application for an armv7 embedded device. I'm holding the application state in a stack-allocated enum, where one of the enum variations is 16k (total memory is 64k)
Switching to the huge app state, my microcontroller hard faults. I have played with a short repro on [godbolt.org](https://godbolt.org/z/fosnuv) and I found that a particular pattern reserves stack space where I don't believe is necessary.
I tried this code:
```rust
pub fn init(a: usize) -> [usize; 1600] {
[a; 1600]
}
pub fn fun(bar: &mut [usize; 1600], w: bool, a: usize) {
*bar = init(a);
}
```
I expected to see this happen:
generated machine code fills `bar` directly
Instead, this happened:
generated machine code fills stack then copies to `bar`
Code generated with `-C opt-level=3 --target=armv7-unknown-linux-gnueabihf` on godbolt.org
```asm
example::fun:
push {r7, lr}
sub.w sp, sp, #2000 ; I don't like this stack alloc
movs r1, #0
mov r3, sp
.LBB1_1:
str r2, [r3, r1]
adds r1, #4
cmp.w r1, #2000
bne .LBB1_1
mov r1, sp
mov.w r2, #2000
bl __aeabi_memcpy4
add.w sp, sp, #2000
pop {r7, pc}
```
`rustc --version --verbose`:
```
1.43 and newer
```
|
I-slow,C-enhancement,T-compiler,I-heavy,A-mir-opt,A-mir-opt-nrvo,C-optimization
|
low
|
Major
|
618,491,464 |
rust
|
static `extern "stdcall" fn()` causes linker error on i686-msvc
|
Trying to compile the following code on i686-pc-windows-msvc fails.
The issue seems to be that for some reason `fn second`'s name is being mangled without `@0` that stdcall functions are expected to have?
`rustc main.rs --crate-type bin -C opt-level=2 -C codegen-units=5 -Clto=no`
```rust
// Removing either of these modules causes the bug to disappear
mod inner {
pub static FIRST: extern "stdcall" fn() = super::inner2::first;
pub static SECOND: extern "stdcall" fn() = super::inner2::second;
}
mod inner2 {
pub extern "stdcall" fn first() {
}
pub extern "stdcall" fn second() {
}
}
fn main() {
Box::new(&inner::FIRST);
Box::new(&inner::SECOND);
}
```
link.exe is VS2019 version, though I believe the issue would reproduce on other Visual Studio versions as well.
```
= note: main.main.7rcbfp3g-cgu.3.rcgu.o : error LNK2001: unresolved external symbol __ZN4main6inner26second17h87d24d2e635c1bfdE@0
Hint on symbols that are defined and could potentially match:
__ZN4main6inner26second17h87d24d2e635c1bfdE
main.exe : fatal error LNK1120: 1 unresolved externals
```
Reducing the value of either `-C opt-level` or `-C codegen-units` or using `-Clto=fat` makes the linking succeed.
I tested that this issue occurs on `1.45.0-nightly (75e1463c5 2020-05-13)`, stable 1.32.0, and various other releases between those two. 1.31.0 does not have this issue. x86_64-pc-windows-msvc also works correctly.
|
A-linkage,A-FFI,T-compiler,O-windows-msvc,C-bug,O-x86_32
|
low
|
Critical
|
618,496,631 |
TypeScript
|
Type Inference In Switch Statement Not Work With &&
|
<!-- 🚨 STOP 🚨 𝗦𝗧𝗢𝗣 🚨 𝑺𝑻𝑶𝑷 🚨
Half of all issues filed here are duplicates, answered in the FAQ, or not appropriate for the bug tracker. Even if you think you've found a *bug*, please read the FAQ first, especially the Common "Bugs" That Aren't Bugs section!
Please help us by doing the following steps before logging an issue:
* Search: https://github.com/Microsoft/TypeScript/search?type=Issues
* Read the FAQ: https://github.com/Microsoft/TypeScript/wiki/FAQ
Please fill in the *entire* template below.
-->
<!--
Please try to reproduce the issue with the latest published version. It may have already been fixed.
For npm: `typescript@next`
This is also the 'Nightly' version in the playground: http://www.typescriptlang.org/play/?ts=Nightly
-->
**TypeScript Version:** 4.0.0-dev.20200512
<!-- Search terms you tried before logging this (so others can find this issue more easily) -->
**Search Terms:** switch, inference, switch and inference
**Code**
```ts
interface I1 {
type: 'I1';
value: string;
}
interface I2 {
type: 'I2';
value: number;
}
type T = I1 | I2;
let t: T | undefined;
if (t && t.type == 'I1') {
t.value; // Type string
}
switch (t?.type) {
case 'I1':
t.value; // Type string
break;
}
switch (t && t.type) {
case 'I1':
t.value; // Uh oh, error
t!.value; // Uh oh, string | number
break;
}
```
**Expected behavior:**
The compile should understand that `t && t.type` is like as `t?.type` except that has also other falsy values.
**Actual behavior:**
The compiler does not infer from such expression.
**Playground Link:** https://www.typescriptlang.org/play/?ts=4.0.0-dev.20200512#code/JYOwLgpgTgZghgYwgAgJIEZkG8BQz-JgCeADhAFzIDkGVA3HgQG5wA2ArhcgM5hSgBzBgF8cOUJFiIUqAEzZG+YmUo1Z9RchYcuIdgFsARtBFjlKACrIAvGkwAfNLIY5WEMIUpXH7EABMIGFAIPxdgGGQACg8AMhjCADpzG1sadCoASgUCRO1OOmQAekLkC1IUXn4QARxRHG4Ad2AwBAALKLAAfiTyrNwchDhuFDSqck0csAS8iALi0vKePkEJgkMoCDgAa1N6ppb26OQ4xPM+zUHh6lpxnMnptnyikoBVdoB7VoAaZGgod6gqyUAEIHjo5q8Pt8llUBMhHHojNAgch1psdrUcEA
|
Bug
|
low
|
Critical
|
618,542,796 |
flutter
|
Error: Error when reading '../../bin/cache/dart-sdk/bin/snapshots/pub.dart.snapshot': No such file or directory
|
I have a mac OS Catalina and every time when I turn on my mac this error appeared when I try a compilation in the android studio. For solving the problem I need to download the Flutter again but I want to know a permanently alternative because keep doing download the same thing every day isn't normal!
I put my flutter doctor on attachment!

|
c: crash,tool,P2,team-tool,triaged-tool
|
low
|
Critical
|
618,564,710 |
pytorch
|
[DISCUSSION] RPC server-side ThreadLocalState
|
This is a followup discussion of #38439. We fix #38439 by restoring `ThreadLocalState` and distributed autograd context separately. Creating this issue to track discussion on whether distributed autograd context id belongs to `ThreadLocalState.h` or we should create `RpcThreadLocalState.h` or else. Below are some concerns and notes from an offline discussion with @xush6528 @ilia-cher and @pritamdamania87,
* the reason we didn't put ctx id in ThreadLocalState was because there was a concern that it would get passed to the backward pass and might trigger autograd recording for RPC calls in the backward pass.
* There is not preferred to add another flag to `ThreadLocalState.h` to set/skip autograd context id.
* If we add context id into `ThreadLocalState.h`, we should also dedup the similar logic added for RPC's TorchScript support. See #36395
cc @suo @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @gqchen @aazzolini @rohan-varma @xush6528 @jjlilley @osalpekar
|
oncall: jit,triaged,module: multithreading,module: rpc
|
low
|
Minor
|
618,592,011 |
tensorflow
|
Recursive support for tf.io.gfile.glob
|
Currently, the `tf.io.gfile.glob` API do not support `recursive=True` kwargs, which is inconsistent with Python [glob.glob](https://docs.python.org/3/library/glob.html).
Example to demonstrate the issue:
```py
import glob
import tensorflow as tf
tf.io.gfile.makedirs('/tmp/a/b/c')
tf.io.gfile.glob('/tmp/a/**') # ['/tmp/a/b']
glob.glob('/tmp/a/**', recursive=True) # ['/tmp/a/', '/tmp/a/b', '/tmp/a/b/c']
```
It would be nice to support `recursive=True` for the Gfile API:
```py
tf.io.gfile.glob('/tmp/a/**', recursive=True) # ['/tmp/a/', '/tmp/a/b', '/tmp/a/b/c']
```
|
stat:awaiting tensorflower,type:feature
|
low
|
Major
|
618,592,960 |
TypeScript
|
Suggestion: Reorder properties in HtmlAttribute
|
After discussing #38399 with @ahejlsberg, @RyanCavanaugh, and @DanielRosenwasser it sounds like one possible improvement we could make to the check time of code consuming [JSX.IntrinsicElements](https://github.com/preactjs/preact/blob/7f5cac7cbcf2645a0b55d316736575062505c7c5/src/jsx.d.ts#L765) (and related libraries) would be to reorder some of the properties in `HTMLAttributes` so that the ones depending on the type parameter are resolved first when comparing types structurally (i.e. so we hit the variance short-circuit ASAP). We could consider submitting PRs to that effect.
|
Suggestion,In Discussion,Domain: Performance
|
low
|
Minor
|
618,593,765 |
TypeScript
|
Suggestion: Can we check properties in a more efficient order during structural comparisons?
|
A generalization of #38583: we can't tell without (expensively) resolving a property's type/signature whether it depends on a type variable, but we can heuristically check whether it syntactically appears to depend on one. If this heuristic is good enough, we might be able to check properties in a more efficient order.
|
Needs Investigation,Domain: Performance
|
low
|
Minor
|
618,622,546 |
rust
|
precision loss in Fp mul
|
Fp Multiplication result should be normalized for the extended 128-bit mantissa representation before round-to-even rounding. Otherwise, it may lose a bit of precision if both arguments are normalized and more bits if they weren't.
https://github.com/rust-lang/rust/blob/a74d1862d4d87a56244958416fd05976c58ca1a8/src/libcore/num/diy_float.rs#L24
Affects dec2float conversion.
https://github.com/rust-lang/rust/blob/7c34d8d6629506a596215886e5fc4bb2b04b00ae/src/libcore/num/dec2flt/algorithm.rs#L156
|
C-bug,T-libs,A-floating-point
|
low
|
Major
|
618,646,218 |
flutter
|
Dumping logs at the end of running tests is causing timeouts on Fuchsia
|
customer: fuchsia,framework,dependency: fuchsia,platform-fuchsia,P3,team-framework,triaged-framework
|
low
|
Minor
|
|
618,677,074 |
vscode
|
Cursor changes to arrow when switching windows (macOS)
|
## Summary:
When I switch between VSCode windows, the macOS cursor gets stuck on the "Arrow", and does not return to the proper "I-Beam" cursor. This behavior started in VSCode v1.45, but is also reproducible in v1.45.1.
## Steps:
1. Activate VSCode application. Notice that the cursor is the proper "I-Beam" cursor.
2. Switch to another VSCode window either using the "Window" menu, or a keyboard shortcut such as `Cmd-Tilde`.
3. The cursor will be an "Arrow" cursor on the new window, and will remain that way. It gets "stuck" in this state.
## Screencast illustrating the issue:
https://youtu.be/XLCP7F811Zs
## System Information
- macOS Catalina 10.15.3 (19D76)
- VSCode v1.45 & v1.45.1
CPUs | Intel(R) Core(TM) i9-9980HK CPU @ 2.40GHz (16 x 2400)
-- | --
GPU Status | 2d_canvas: enabledflash_3d: enabledflash_stage3d: enabledflash_stage3d_baseline: enabledgpu_compositing: enabledmetal: disabled_offmultiple_raster_threads: enabled_onoop_rasterization: disabled_offprotected_video_decode: unavailable_offrasterization: enabledskia_renderer: disabled_off_okvideo_decode: enabledviz_display_compositor: enabled_onviz_hit_test_surface_layer: disabled_off_okwebgl: enabledwebgl2: enabled
Load (avg) | 2, 2, 2
Memory (System) | 32.00GB (12.30GB free)
Process Argv | -psn_0_8435723
Screen Reader | no
VM | 0%
## Enabled Extensions
Extension | Author (truncated) | Version
-- | -- | --
project-manager | ale | 11.0.0
spellright | ban | 3.0.50
php-symbols | lin | 2.1.0
sublime-keybindings | ms- | 4.0.7
vscode-icons | vsc | 10.1.1
vscode-todo-highlight | way | 1.0.4
material-theme | zhu | 3.6.1
|
bug,upstream,macos,electron,confirmed,editor-highlight,upstream-issue-pending
|
medium
|
Major
|
618,678,073 |
pytorch
|
build libtorch problem: Configuring incomplete, errors occurred! _mm256_abs_epi16
|
I'm trying to build libtorch to use libtorch(c++) with cuda 9.0 , just follow the doc:
```
mkdir build_libtorch && cd build_libtorch
python ../tools/build_libtorch.py
```
but always meet this problem:
```
-- Configuring incomplete, errors occurred!
See also "/root/pytorch/build_libtorch/build/CMakeFiles/CMakeOutput.log".
See also "/root/pytorch/build_libtorch/build/CMakeFiles/CMakeError.log".
Traceback (most recent call last):
File "../tools/build_libtorch.py", line 23, in <module>
rerun_cmake=True, cmake_only=False, cmake=CMake())
File "/root/pytorch/tools/build_pytorch_libs.py", line 59, in build_caffe2
rerun_cmake)
File "/root/pytorch/tools/setup_helpers/cmake.py", line 323, in generate
self.run(args, env=my_env)
File "/root/pytorch/tools/setup_helpers/cmake.py", line 141, in run
check_call(command, cwd=self.build_dir, env=env)
File "/root/anaconda3/lib/python3.7/subprocess.py", line 363, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command '['cmake', '-DBUILD_PYTHON=False', '-DBUILD_TEST=True', '-DCMAKE_BUILD_TYPE=Release', '-DCMAKE_INSTALL_PREFIX=/root/pytorch/torch', '-DCMAKE_PREFIX_PATH=/root/anaconda3/lib/python3.7/site-packages', '-DNUMPY_INCLUDE_DIR=/root/anaconda3/lib/python3.7/site-packages/numpy/core/include', '-DPYTHON_EXECUTABLE=/root/anaconda3/bin/python', '-DPYTHON_INCLUDE_DIR=/root/anaconda3/include/python3.7m', '-DUSE_NUMPY=True', '/root/pytorch']' returned non-zero exit status 1.
```
here is my env:
```
(base) root@53081c1ffdbf:~/pytorch/build_libtorch# python -m torch.utils.collect_env
Collecting environment information...
OS: Ubuntu 16.04.6 LTS
GCC version: (Ubuntu 5.4.0-6ubuntu1~16.04.12) 5.4.0 20160609
CMake version: version 3.14.0
Python version: 3.7
Is CUDA available: No
CUDA runtime version: 9.0.176
GPU models and configuration: Could not collect
Nvidia driver version: Could not collect
cuDNN version: /usr/lib/x86_64-linux-gnu/libcudnn.so.7.6.4
Versions of relevant libraries:
[pip] numpy==1.18.1
[pip] numpydoc==0.9.2
[conda] blas 1.0 mkl
[conda] mkl 2020.0 166
[conda] mkl-service 2.3.0 py37he904b0f_0
[conda] mkl_fft 1.0.15 py37ha843d7b_0
[conda] mkl_random 1.1.0 py37hd6b4f25_0
```
and here is the "/root/pytorch/build_libtorch/build/CMakeFiles/CMakeError.log":
```
Performing C++ SOURCE FILE Test CAFFE2_NEED_TO_TURN_OFF_DEPRECATION_WARNING failed with the following output:
Change Dir: /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp
Run Build Command(s):/usr/bin/make cmTC_1c31b/fast
/usr/bin/make -f CMakeFiles/cmTC_1c31b.dir/build.make CMakeFiles/cmTC_1c31b.dir/build
make[1]: Entering directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Building CXX object CMakeFiles/cmTC_1c31b.dir/src.cxx.o
/usr/bin/c++ -DCAFFE2_NEED_TO_TURN_OFF_DEPRECATION_WARNING -std=c++14 -o CMakeFiles/cmTC_1c31b.dir/src.cxx.o -c /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.cxx
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.cxx:1:30: fatal error: glog/stl_logging.h: No such file or directory
compilation terminated.
CMakeFiles/cmTC_1c31b.dir/build.make:65: recipe for target 'CMakeFiles/cmTC_1c31b.dir/src.cxx.o' failed
make[1]: *** [CMakeFiles/cmTC_1c31b.dir/src.cxx.o] Error 1
make[1]: Leaving directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Makefile:121: recipe for target 'cmTC_1c31b/fast' failed
make: *** [cmTC_1c31b/fast] Error 2
Source file was:
#include <glog/stl_logging.h>
int main(int argc, char** argv) {
return 0;
}
Determining if the pthread_create exist failed with the following output:
Change Dir: /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp
Run Build Command(s):/usr/bin/make cmTC_f27de/fast
/usr/bin/make -f CMakeFiles/cmTC_f27de.dir/build.make CMakeFiles/cmTC_f27de.dir/build
make[1]: Entering directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Building C object CMakeFiles/cmTC_f27de.dir/CheckSymbolExists.c.o
/usr/bin/cc -fPIE -o CMakeFiles/cmTC_f27de.dir/CheckSymbolExists.c.o -c /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/CheckSymbolExists.c
Linking C executable cmTC_f27de
/root/anaconda3/bin/cmake -E cmake_link_script CMakeFiles/cmTC_f27de.dir/link.txt --verbose=1
/usr/bin/cc -rdynamic CMakeFiles/cmTC_f27de.dir/CheckSymbolExists.c.o -o cmTC_f27de
CMakeFiles/cmTC_f27de.dir/CheckSymbolExists.c.o: In function `main':
CheckSymbolExists.c:(.text+0x1b): undefined reference to `pthread_create'
collect2: error: ld returned 1 exit status
CMakeFiles/cmTC_f27de.dir/build.make:86: recipe for target 'cmTC_f27de' failed
make[1]: *** [cmTC_f27de] Error 1
make[1]: Leaving directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Makefile:121: recipe for target 'cmTC_f27de/fast' failed
make: *** [cmTC_f27de/fast] Error 2
File /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/CheckSymbolExists.c:
/* */
#include <pthread.h>
int main(int argc, char** argv)
{
(void)argv;
#ifndef pthread_create
return ((int*)(&pthread_create))[argc];
#else
(void)argc;
return 0;
#endif
}
Determining if the function pthread_create exists in the pthreads failed with the following output:
Change Dir: /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp
Run Build Command(s):/usr/bin/make cmTC_42684/fast
/usr/bin/make -f CMakeFiles/cmTC_42684.dir/build.make CMakeFiles/cmTC_42684.dir/build
make[1]: Entering directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Building C object CMakeFiles/cmTC_42684.dir/CheckFunctionExists.c.o
/usr/bin/cc -DCHECK_FUNCTION_EXISTS=pthread_create -fPIE -o CMakeFiles/cmTC_42684.dir/CheckFunctionExists.c.o -c /root/anaconda3/share/cmake-3.14/Modules/CheckFunctionExists.c
Linking C executable cmTC_42684
/root/anaconda3/bin/cmake -E cmake_link_script CMakeFiles/cmTC_42684.dir/link.txt --verbose=1
/usr/bin/cc -DCHECK_FUNCTION_EXISTS=pthread_create -rdynamic CMakeFiles/cmTC_42684.dir/CheckFunctionExists.c.o -o cmTC_42684 -lpthreads
/usr/bin/ld: cannot find -lpthreads
collect2: error: ld returned 1 exit status
CMakeFiles/cmTC_42684.dir/build.make:86: recipe for target 'cmTC_42684' failed
make[1]: *** [cmTC_42684] Error 1
make[1]: Leaving directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Makefile:121: recipe for target 'cmTC_42684/fast' failed
make: *** [cmTC_42684/fast] Error 2
Performing C SOURCE FILE Test C_HAS_AVX_1 failed with the following output:
Change Dir: /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp
Run Build Command(s):/usr/bin/make cmTC_bedc0/fast
/usr/bin/make -f CMakeFiles/cmTC_bedc0.dir/build.make CMakeFiles/cmTC_bedc0.dir/build
make[1]: Entering directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Building C object CMakeFiles/cmTC_bedc0.dir/src.c.o
/usr/bin/cc -fopenmp -DNDEBUG -DC_HAS_AVX_1 -fPIE -o CMakeFiles/cmTC_bedc0.dir/src.c.o -c /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c: In function ‘main’:
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:7:7: warning: AVX vector return without AVX enabled changes the ABI [-Wpsabi]
a = _mm256_set1_ps(0);
^
In file included from /usr/lib/gcc/x86_64-linux-gnu/5/include/immintrin.h:41:0,
from /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:2:
/usr/lib/gcc/x86_64-linux-gnu/5/include/avxintrin.h:1285:1: error: inlining failed in call to always_inline ‘_mm256_set1_ps’: target specific option mismatch
_mm256_set1_ps (float __A)
^
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:7:7: error: called from here
a = _mm256_set1_ps(0);
^
CMakeFiles/cmTC_bedc0.dir/build.make:65: recipe for target 'CMakeFiles/cmTC_bedc0.dir/src.c.o' failed
make[1]: *** [CMakeFiles/cmTC_bedc0.dir/src.c.o] Error 1
make[1]: Leaving directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Makefile:121: recipe for target 'cmTC_bedc0/fast' failed
make: *** [cmTC_bedc0/fast] Error 2
Source file was:
#include <immintrin.h>
int main()
{
__m256 a;
a = _mm256_set1_ps(0);
return 0;
}
Performing C SOURCE FILE Test C_HAS_AVX2_1 failed with the following output:
Change Dir: /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp
Run Build Command(s):/usr/bin/make cmTC_cd591/fast
/usr/bin/make -f CMakeFiles/cmTC_cd591.dir/build.make CMakeFiles/cmTC_cd591.dir/build
make[1]: Entering directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Building C object CMakeFiles/cmTC_cd591.dir/src.c.o
/usr/bin/cc -fopenmp -DNDEBUG -DC_HAS_AVX2_1 -fPIE -o CMakeFiles/cmTC_cd591.dir/src.c.o -c /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c: In function ‘main’:
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:7:7: warning: AVX vector return without AVX enabled changes the ABI [-Wpsabi]
a = _mm256_abs_epi16(a);
^
In file included from /usr/lib/gcc/x86_64-linux-gnu/5/include/immintrin.h:43:0,
from /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:2:
/usr/lib/gcc/x86_64-linux-gnu/5/include/avx2intrin.h:63:1: error: inlining failed in call to always_inline ‘_mm256_abs_epi16’: target specific option mismatch
_mm256_abs_epi16 (__m256i __A)
^
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:7:7: error: called from here
a = _mm256_abs_epi16(a);
^
CMakeFiles/cmTC_cd591.dir/build.make:65: recipe for target 'CMakeFiles/cmTC_cd591.dir/src.c.o' failed
make[1]: *** [CMakeFiles/cmTC_cd591.dir/src.c.o] Error 1
make[1]: Leaving directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Makefile:121: recipe for target 'cmTC_cd591/fast' failed
make: *** [cmTC_cd591/fast] Error 2
Source file was:
#include <immintrin.h>
int main()
{
__m256i a = {0};
a = _mm256_abs_epi16(a);
__m256i x;
_mm256_extract_epi64(x, 0); // we rely on this in our AVX2 code
return 0;
}
Performing C SOURCE FILE Test CXX_HAS_AVX_1 failed with the following output:
Change Dir: /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp
Run Build Command(s):/usr/bin/make cmTC_e3a60/fast
/usr/bin/make -f CMakeFiles/cmTC_e3a60.dir/build.make CMakeFiles/cmTC_e3a60.dir/build
make[1]: Entering directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Building C object CMakeFiles/cmTC_e3a60.dir/src.c.o
/usr/bin/cc -fopenmp -DNDEBUG -DCXX_HAS_AVX_1 -fPIE -o CMakeFiles/cmTC_e3a60.dir/src.c.o -c /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c: In function ‘main’:
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:7:7: warning: AVX vector return without AVX enabled changes the ABI [-Wpsabi]
a = _mm256_set1_ps(0);
^
In file included from /usr/lib/gcc/x86_64-linux-gnu/5/include/immintrin.h:41:0,
from /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:2:
/usr/lib/gcc/x86_64-linux-gnu/5/include/avxintrin.h:1285:1: error: inlining failed in call to always_inline ‘_mm256_set1_ps’: target specific option mismatch
_mm256_set1_ps (float __A)
^
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:7:7: error: called from here
a = _mm256_set1_ps(0);
^
CMakeFiles/cmTC_e3a60.dir/build.make:65: recipe for target 'CMakeFiles/cmTC_e3a60.dir/src.c.o' failed
make[1]: *** [CMakeFiles/cmTC_e3a60.dir/src.c.o] Error 1
make[1]: Leaving directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Makefile:121: recipe for target 'cmTC_e3a60/fast' failed
make: *** [cmTC_e3a60/fast] Error 2
Source file was:
#include <immintrin.h>
int main()
{
__m256 a;
a = _mm256_set1_ps(0);
return 0;
}
Performing C SOURCE FILE Test CXX_HAS_AVX2_1 failed with the following output:
Change Dir: /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp
Run Build Command(s):/usr/bin/make cmTC_7f99a/fast
/usr/bin/make -f CMakeFiles/cmTC_7f99a.dir/build.make CMakeFiles/cmTC_7f99a.dir/build
make[1]: Entering directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Building C object CMakeFiles/cmTC_7f99a.dir/src.c.o
/usr/bin/cc -fopenmp -DNDEBUG -DCXX_HAS_AVX2_1 -fPIE -o CMakeFiles/cmTC_7f99a.dir/src.c.o -c /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c: In function ‘main’:
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:7:7: warning: AVX vector return without AVX enabled changes the ABI [-Wpsabi]
a = _mm256_abs_epi16(a);
^
In file included from /usr/lib/gcc/x86_64-linux-gnu/5/include/immintrin.h:43:0,
from /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:2:
/usr/lib/gcc/x86_64-linux-gnu/5/include/avx2intrin.h:63:1: error: inlining failed in call to always_inline ‘_mm256_abs_epi16’: target specific option mismatch
_mm256_abs_epi16 (__m256i __A)
^
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:7:7: error: called from here
a = _mm256_abs_epi16(a);
^
CMakeFiles/cmTC_7f99a.dir/build.make:65: recipe for target 'CMakeFiles/cmTC_7f99a.dir/src.c.o' failed
make[1]: *** [CMakeFiles/cmTC_7f99a.dir/src.c.o] Error 1
make[1]: Leaving directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Makefile:121: recipe for target 'cmTC_7f99a/fast' failed
make: *** [cmTC_7f99a/fast] Error 2
Source file was:
#include <immintrin.h>
int main()
{
__m256i a = {0};
a = _mm256_abs_epi16(a);
__m256i x;
_mm256_extract_epi64(x, 0); // we rely on this in our AVX2 code
return 0;
}
Performing C++ SOURCE FILE Test CAFFE2_NEED_TO_TURN_OFF_DEPRECATION_WARNING failed with the following output:
Change Dir: /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp
Run Build Command(s):/usr/bin/make cmTC_caaf1/fast
/usr/bin/make -f CMakeFiles/cmTC_caaf1.dir/build.make CMakeFiles/cmTC_caaf1.dir/build
make[1]: Entering directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Building CXX object CMakeFiles/cmTC_caaf1.dir/src.cxx.o
/usr/bin/c++ -DCAFFE2_NEED_TO_TURN_OFF_DEPRECATION_WARNING -std=c++14 -o CMakeFiles/cmTC_caaf1.dir/src.cxx.o -c /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.cxx
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.cxx:1:30: fatal error: glog/stl_logging.h: No such file or directory
compilation terminated.
CMakeFiles/cmTC_caaf1.dir/build.make:65: recipe for target 'CMakeFiles/cmTC_caaf1.dir/src.cxx.o' failed
make[1]: *** [CMakeFiles/cmTC_caaf1.dir/src.cxx.o] Error 1
make[1]: Leaving directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Makefile:121: recipe for target 'cmTC_caaf1/fast' failed
make: *** [cmTC_caaf1/fast] Error 2
Source file was:
#include <glog/stl_logging.h>
int main(int argc, char** argv) {
return 0;
}
Determining if the pthread_create exist failed with the following output:
Change Dir: /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp
Run Build Command(s):/usr/bin/make cmTC_7fbd2/fast
/usr/bin/make -f CMakeFiles/cmTC_7fbd2.dir/build.make CMakeFiles/cmTC_7fbd2.dir/build
make[1]: Entering directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Building C object CMakeFiles/cmTC_7fbd2.dir/CheckSymbolExists.c.o
/usr/bin/cc -fPIE -o CMakeFiles/cmTC_7fbd2.dir/CheckSymbolExists.c.o -c /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/CheckSymbolExists.c
Linking C executable cmTC_7fbd2
/root/anaconda3/bin/cmake -E cmake_link_script CMakeFiles/cmTC_7fbd2.dir/link.txt --verbose=1
/usr/bin/cc -rdynamic CMakeFiles/cmTC_7fbd2.dir/CheckSymbolExists.c.o -o cmTC_7fbd2
CMakeFiles/cmTC_7fbd2.dir/CheckSymbolExists.c.o: In function `main':
CheckSymbolExists.c:(.text+0x1b): undefined reference to `pthread_create'
collect2: error: ld returned 1 exit status
CMakeFiles/cmTC_7fbd2.dir/build.make:86: recipe for target 'cmTC_7fbd2' failed
make[1]: *** [cmTC_7fbd2] Error 1
make[1]: Leaving directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Makefile:121: recipe for target 'cmTC_7fbd2/fast' failed
make: *** [cmTC_7fbd2/fast] Error 2
File /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/CheckSymbolExists.c:
/* */
#include <pthread.h>
int main(int argc, char** argv)
{
(void)argv;
#ifndef pthread_create
return ((int*)(&pthread_create))[argc];
#else
(void)argc;
return 0;
#endif
}
Determining if the function pthread_create exists in the pthreads failed with the following output:
Change Dir: /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp
Run Build Command(s):/usr/bin/make cmTC_574f5/fast
/usr/bin/make -f CMakeFiles/cmTC_574f5.dir/build.make CMakeFiles/cmTC_574f5.dir/build
make[1]: Entering directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Building C object CMakeFiles/cmTC_574f5.dir/CheckFunctionExists.c.o
/usr/bin/cc -DCHECK_FUNCTION_EXISTS=pthread_create -fPIE -o CMakeFiles/cmTC_574f5.dir/CheckFunctionExists.c.o -c /root/anaconda3/share/cmake-3.14/Modules/CheckFunctionExists.c
Linking C executable cmTC_574f5
/root/anaconda3/bin/cmake -E cmake_link_script CMakeFiles/cmTC_574f5.dir/link.txt --verbose=1
/usr/bin/cc -DCHECK_FUNCTION_EXISTS=pthread_create -rdynamic CMakeFiles/cmTC_574f5.dir/CheckFunctionExists.c.o -o cmTC_574f5 -lpthreads
/usr/bin/ld: cannot find -lpthreads
collect2: error: ld returned 1 exit status
CMakeFiles/cmTC_574f5.dir/build.make:86: recipe for target 'cmTC_574f5' failed
make[1]: *** [cmTC_574f5] Error 1
make[1]: Leaving directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Makefile:121: recipe for target 'cmTC_574f5/fast' failed
make: *** [cmTC_574f5/fast] Error 2
Performing C SOURCE FILE Test C_HAS_AVX_1 failed with the following output:
Change Dir: /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp
Run Build Command(s):/usr/bin/make cmTC_d3ffb/fast
/usr/bin/make -f CMakeFiles/cmTC_d3ffb.dir/build.make CMakeFiles/cmTC_d3ffb.dir/build
make[1]: Entering directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Building C object CMakeFiles/cmTC_d3ffb.dir/src.c.o
/usr/bin/cc -fopenmp -DNDEBUG -DC_HAS_AVX_1 -fPIE -o CMakeFiles/cmTC_d3ffb.dir/src.c.o -c /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c: In function ‘main’:
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:7:7: warning: AVX vector return without AVX enabled changes the ABI [-Wpsabi]
a = _mm256_set1_ps(0);
^
In file included from /usr/lib/gcc/x86_64-linux-gnu/5/include/immintrin.h:41:0,
from /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:2:
/usr/lib/gcc/x86_64-linux-gnu/5/include/avxintrin.h:1285:1: error: inlining failed in call to always_inline ‘_mm256_set1_ps’: target specific option mismatch
_mm256_set1_ps (float __A)
^
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:7:7: error: called from here
a = _mm256_set1_ps(0);
^
CMakeFiles/cmTC_d3ffb.dir/build.make:65: recipe for target 'CMakeFiles/cmTC_d3ffb.dir/src.c.o' failed
make[1]: *** [CMakeFiles/cmTC_d3ffb.dir/src.c.o] Error 1
make[1]: Leaving directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Makefile:121: recipe for target 'cmTC_d3ffb/fast' failed
make: *** [cmTC_d3ffb/fast] Error 2
Source file was:
#include <immintrin.h>
int main()
{
__m256 a;
a = _mm256_set1_ps(0);
return 0;
}
Performing C SOURCE FILE Test C_HAS_AVX2_1 failed with the following output:
Change Dir: /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp
Run Build Command(s):/usr/bin/make cmTC_fd2c4/fast
/usr/bin/make -f CMakeFiles/cmTC_fd2c4.dir/build.make CMakeFiles/cmTC_fd2c4.dir/build
make[1]: Entering directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Building C object CMakeFiles/cmTC_fd2c4.dir/src.c.o
/usr/bin/cc -fopenmp -DNDEBUG -DC_HAS_AVX2_1 -fPIE -o CMakeFiles/cmTC_fd2c4.dir/src.c.o -c /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c: In function ‘main’:
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:7:7: warning: AVX vector return without AVX enabled changes the ABI [-Wpsabi]
a = _mm256_abs_epi16(a);
^
In file included from /usr/lib/gcc/x86_64-linux-gnu/5/include/immintrin.h:43:0,
from /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:2:
/usr/lib/gcc/x86_64-linux-gnu/5/include/avx2intrin.h:63:1: error: inlining failed in call to always_inline ‘_mm256_abs_epi16’: target specific option mismatch
_mm256_abs_epi16 (__m256i __A)
^
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:7:7: error: called from here
a = _mm256_abs_epi16(a);
^
CMakeFiles/cmTC_fd2c4.dir/build.make:65: recipe for target 'CMakeFiles/cmTC_fd2c4.dir/src.c.o' failed
make[1]: *** [CMakeFiles/cmTC_fd2c4.dir/src.c.o] Error 1
make[1]: Leaving directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Makefile:121: recipe for target 'cmTC_fd2c4/fast' failed
make: *** [cmTC_fd2c4/fast] Error 2
Source file was:
#include <immintrin.h>
int main()
{
__m256i a = {0};
a = _mm256_abs_epi16(a);
__m256i x;
_mm256_extract_epi64(x, 0); // we rely on this in our AVX2 code
return 0;
}
Performing C SOURCE FILE Test CXX_HAS_AVX_1 failed with the following output:
Change Dir: /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp
Run Build Command(s):/usr/bin/make cmTC_3eba8/fast
/usr/bin/make -f CMakeFiles/cmTC_3eba8.dir/build.make CMakeFiles/cmTC_3eba8.dir/build
make[1]: Entering directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Building C object CMakeFiles/cmTC_3eba8.dir/src.c.o
/usr/bin/cc -fopenmp -DNDEBUG -DCXX_HAS_AVX_1 -fPIE -o CMakeFiles/cmTC_3eba8.dir/src.c.o -c /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c: In function ‘main’:
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:7:7: warning: AVX vector return without AVX enabled changes the ABI [-Wpsabi]
a = _mm256_set1_ps(0);
^
In file included from /usr/lib/gcc/x86_64-linux-gnu/5/include/immintrin.h:41:0,
from /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:2:
/usr/lib/gcc/x86_64-linux-gnu/5/include/avxintrin.h:1285:1: error: inlining failed in call to always_inline ‘_mm256_set1_ps’: target specific option mismatch
_mm256_set1_ps (float __A)
^
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:7:7: error: called from here
a = _mm256_set1_ps(0);
^
CMakeFiles/cmTC_3eba8.dir/build.make:65: recipe for target 'CMakeFiles/cmTC_3eba8.dir/src.c.o' failed
make[1]: *** [CMakeFiles/cmTC_3eba8.dir/src.c.o] Error 1
make[1]: Leaving directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Makefile:121: recipe for target 'cmTC_3eba8/fast' failed
make: *** [cmTC_3eba8/fast] Error 2
Source file was:
#include <immintrin.h>
int main()
{
__m256 a;
a = _mm256_set1_ps(0);
return 0;
}
Performing C SOURCE FILE Test CXX_HAS_AVX2_1 failed with the following output:
Change Dir: /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp
Run Build Command(s):/usr/bin/make cmTC_3b3d2/fast
/usr/bin/make -f CMakeFiles/cmTC_3b3d2.dir/build.make CMakeFiles/cmTC_3b3d2.dir/build
make[1]: Entering directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Building C object CMakeFiles/cmTC_3b3d2.dir/src.c.o
/usr/bin/cc -fopenmp -DNDEBUG -DCXX_HAS_AVX2_1 -fPIE -o CMakeFiles/cmTC_3b3d2.dir/src.c.o -c /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c: In function ‘main’:
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:7:7: warning: AVX vector return without AVX enabled changes the ABI [-Wpsabi]
a = _mm256_abs_epi16(a);
^
In file included from /usr/lib/gcc/x86_64-linux-gnu/5/include/immintrin.h:43:0,
from /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:2:
/usr/lib/gcc/x86_64-linux-gnu/5/include/avx2intrin.h:63:1: error: inlining failed in call to always_inline ‘_mm256_abs_epi16’: target specific option mismatch
_mm256_abs_epi16 (__m256i __A)
^
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:7:7: error: called from here
a = _mm256_abs_epi16(a);
^
CMakeFiles/cmTC_3b3d2.dir/build.make:65: recipe for target 'CMakeFiles/cmTC_3b3d2.dir/src.c.o' failed
make[1]: *** [CMakeFiles/cmTC_3b3d2.dir/src.c.o] Error 1
make[1]: Leaving directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Makefile:121: recipe for target 'cmTC_3b3d2/fast' failed
make: *** [cmTC_3b3d2/fast] Error 2
Source file was:
#include <immintrin.h>
int main()
{
__m256i a = {0};
a = _mm256_abs_epi16(a);
__m256i x;
_mm256_extract_epi64(x, 0); // we rely on this in our AVX2 code
return 0;
}
Performing C++ SOURCE FILE Test CAFFE2_NEED_TO_TURN_OFF_DEPRECATION_WARNING failed with the following output:
Change Dir: /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp
Run Build Command(s):/usr/bin/make cmTC_992ee/fast
/usr/bin/make -f CMakeFiles/cmTC_992ee.dir/build.make CMakeFiles/cmTC_992ee.dir/build
make[1]: Entering directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Building CXX object CMakeFiles/cmTC_992ee.dir/src.cxx.o
/usr/bin/c++ -DCAFFE2_NEED_TO_TURN_OFF_DEPRECATION_WARNING -std=c++14 -o CMakeFiles/cmTC_992ee.dir/src.cxx.o -c /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.cxx
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.cxx:1:30: fatal error: glog/stl_logging.h: No such file or directory
compilation terminated.
CMakeFiles/cmTC_992ee.dir/build.make:65: recipe for target 'CMakeFiles/cmTC_992ee.dir/src.cxx.o' failed
make[1]: *** [CMakeFiles/cmTC_992ee.dir/src.cxx.o] Error 1
make[1]: Leaving directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Makefile:121: recipe for target 'cmTC_992ee/fast' failed
make: *** [cmTC_992ee/fast] Error 2
Source file was:
#include <glog/stl_logging.h>
int main(int argc, char** argv) {
return 0;
}
Determining if the pthread_create exist failed with the following output:
Change Dir: /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp
Run Build Command(s):/usr/bin/make cmTC_24124/fast
/usr/bin/make -f CMakeFiles/cmTC_24124.dir/build.make CMakeFiles/cmTC_24124.dir/build
make[1]: Entering directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Building C object CMakeFiles/cmTC_24124.dir/CheckSymbolExists.c.o
/usr/bin/cc -fPIE -o CMakeFiles/cmTC_24124.dir/CheckSymbolExists.c.o -c /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/CheckSymbolExists.c
Linking C executable cmTC_24124
/root/anaconda3/bin/cmake -E cmake_link_script CMakeFiles/cmTC_24124.dir/link.txt --verbose=1
/usr/bin/cc -rdynamic CMakeFiles/cmTC_24124.dir/CheckSymbolExists.c.o -o cmTC_24124
CMakeFiles/cmTC_24124.dir/CheckSymbolExists.c.o: In function `main':
CheckSymbolExists.c:(.text+0x1b): undefined reference to `pthread_create'
collect2: error: ld returned 1 exit status
CMakeFiles/cmTC_24124.dir/build.make:86: recipe for target 'cmTC_24124' failed
make[1]: *** [cmTC_24124] Error 1
make[1]: Leaving directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Makefile:121: recipe for target 'cmTC_24124/fast' failed
make: *** [cmTC_24124/fast] Error 2
File /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/CheckSymbolExists.c:
/* */
#include <pthread.h>
int main(int argc, char** argv)
{
(void)argv;
#ifndef pthread_create
return ((int*)(&pthread_create))[argc];
#else
(void)argc;
return 0;
#endif
}
Determining if the function pthread_create exists in the pthreads failed with the following output:
Change Dir: /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp
Run Build Command(s):/usr/bin/make cmTC_20a20/fast
/usr/bin/make -f CMakeFiles/cmTC_20a20.dir/build.make CMakeFiles/cmTC_20a20.dir/build
make[1]: Entering directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Building C object CMakeFiles/cmTC_20a20.dir/CheckFunctionExists.c.o
/usr/bin/cc -DCHECK_FUNCTION_EXISTS=pthread_create -fPIE -o CMakeFiles/cmTC_20a20.dir/CheckFunctionExists.c.o -c /root/anaconda3/share/cmake-3.14/Modules/CheckFunctionExists.c
Linking C executable cmTC_20a20
/root/anaconda3/bin/cmake -E cmake_link_script CMakeFiles/cmTC_20a20.dir/link.txt --verbose=1
/usr/bin/cc -DCHECK_FUNCTION_EXISTS=pthread_create -rdynamic CMakeFiles/cmTC_20a20.dir/CheckFunctionExists.c.o -o cmTC_20a20 -lpthreads
/usr/bin/ld: cannot find -lpthreads
collect2: error: ld returned 1 exit status
CMakeFiles/cmTC_20a20.dir/build.make:86: recipe for target 'cmTC_20a20' failed
make[1]: *** [cmTC_20a20] Error 1
make[1]: Leaving directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Makefile:121: recipe for target 'cmTC_20a20/fast' failed
make: *** [cmTC_20a20/fast] Error 2
Performing C SOURCE FILE Test C_HAS_AVX_1 failed with the following output:
Change Dir: /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp
Run Build Command(s):/usr/bin/make cmTC_e0f9c/fast
/usr/bin/make -f CMakeFiles/cmTC_e0f9c.dir/build.make CMakeFiles/cmTC_e0f9c.dir/build
make[1]: Entering directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Building C object CMakeFiles/cmTC_e0f9c.dir/src.c.o
/usr/bin/cc -fopenmp -DNDEBUG -DC_HAS_AVX_1 -fPIE -o CMakeFiles/cmTC_e0f9c.dir/src.c.o -c /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c: In function ‘main’:
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:7:7: warning: AVX vector return without AVX enabled changes the ABI [-Wpsabi]
a = _mm256_set1_ps(0);
^
In file included from /usr/lib/gcc/x86_64-linux-gnu/5/include/immintrin.h:41:0,
from /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:2:
/usr/lib/gcc/x86_64-linux-gnu/5/include/avxintrin.h:1285:1: error: inlining failed in call to always_inline ‘_mm256_set1_ps’: target specific option mismatch
_mm256_set1_ps (float __A)
^
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:7:7: error: called from here
a = _mm256_set1_ps(0);
^
CMakeFiles/cmTC_e0f9c.dir/build.make:65: recipe for target 'CMakeFiles/cmTC_e0f9c.dir/src.c.o' failed
make[1]: *** [CMakeFiles/cmTC_e0f9c.dir/src.c.o] Error 1
make[1]: Leaving directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Makefile:121: recipe for target 'cmTC_e0f9c/fast' failed
make: *** [cmTC_e0f9c/fast] Error 2
Source file was:
#include <immintrin.h>
int main()
{
__m256 a;
a = _mm256_set1_ps(0);
return 0;
}
Performing C SOURCE FILE Test C_HAS_AVX2_1 failed with the following output:
Change Dir: /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp
Run Build Command(s):/usr/bin/make cmTC_31e86/fast
/usr/bin/make -f CMakeFiles/cmTC_31e86.dir/build.make CMakeFiles/cmTC_31e86.dir/build
make[1]: Entering directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Building C object CMakeFiles/cmTC_31e86.dir/src.c.o
/usr/bin/cc -fopenmp -DNDEBUG -DC_HAS_AVX2_1 -fPIE -o CMakeFiles/cmTC_31e86.dir/src.c.o -c /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c: In function ‘main’:
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:7:7: warning: AVX vector return without AVX enabled changes the ABI [-Wpsabi]
a = _mm256_abs_epi16(a);
^
In file included from /usr/lib/gcc/x86_64-linux-gnu/5/include/immintrin.h:43:0,
from /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:2:
/usr/lib/gcc/x86_64-linux-gnu/5/include/avx2intrin.h:63:1: error: inlining failed in call to always_inline ‘_mm256_abs_epi16’: target specific option mismatch
_mm256_abs_epi16 (__m256i __A)
^
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:7:7: error: called from here
a = _mm256_abs_epi16(a);
^
CMakeFiles/cmTC_31e86.dir/build.make:65: recipe for target 'CMakeFiles/cmTC_31e86.dir/src.c.o' failed
make[1]: *** [CMakeFiles/cmTC_31e86.dir/src.c.o] Error 1
make[1]: Leaving directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Makefile:121: recipe for target 'cmTC_31e86/fast' failed
make: *** [cmTC_31e86/fast] Error 2
Source file was:
#include <immintrin.h>
int main()
{
__m256i a = {0};
a = _mm256_abs_epi16(a);
__m256i x;
_mm256_extract_epi64(x, 0); // we rely on this in our AVX2 code
return 0;
}
Performing C SOURCE FILE Test CXX_HAS_AVX_1 failed with the following output:
Change Dir: /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp
Run Build Command(s):/usr/bin/make cmTC_783c4/fast
/usr/bin/make -f CMakeFiles/cmTC_783c4.dir/build.make CMakeFiles/cmTC_783c4.dir/build
make[1]: Entering directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Building C object CMakeFiles/cmTC_783c4.dir/src.c.o
/usr/bin/cc -fopenmp -DNDEBUG -DCXX_HAS_AVX_1 -fPIE -o CMakeFiles/cmTC_783c4.dir/src.c.o -c /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c: In function ‘main’:
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:7:7: warning: AVX vector return without AVX enabled changes the ABI [-Wpsabi]
a = _mm256_set1_ps(0);
^
In file included from /usr/lib/gcc/x86_64-linux-gnu/5/include/immintrin.h:41:0,
from /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:2:
/usr/lib/gcc/x86_64-linux-gnu/5/include/avxintrin.h:1285:1: error: inlining failed in call to always_inline ‘_mm256_set1_ps’: target specific option mismatch
_mm256_set1_ps (float __A)
^
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:7:7: error: called from here
a = _mm256_set1_ps(0);
^
CMakeFiles/cmTC_783c4.dir/build.make:65: recipe for target 'CMakeFiles/cmTC_783c4.dir/src.c.o' failed
make[1]: *** [CMakeFiles/cmTC_783c4.dir/src.c.o] Error 1
make[1]: Leaving directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Makefile:121: recipe for target 'cmTC_783c4/fast' failed
make: *** [cmTC_783c4/fast] Error 2
Source file was:
#include <immintrin.h>
int main()
{
__m256 a;
a = _mm256_set1_ps(0);
return 0;
}
Performing C SOURCE FILE Test CXX_HAS_AVX2_1 failed with the following output:
Change Dir: /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp
Run Build Command(s):/usr/bin/make cmTC_66b17/fast
/usr/bin/make -f CMakeFiles/cmTC_66b17.dir/build.make CMakeFiles/cmTC_66b17.dir/build
make[1]: Entering directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Building C object CMakeFiles/cmTC_66b17.dir/src.c.o
/usr/bin/cc -fopenmp -DNDEBUG -DCXX_HAS_AVX2_1 -fPIE -o CMakeFiles/cmTC_66b17.dir/src.c.o -c /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c: In function ‘main’:
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:7:7: warning: AVX vector return without AVX enabled changes the ABI [-Wpsabi]
a = _mm256_abs_epi16(a);
^
In file included from /usr/lib/gcc/x86_64-linux-gnu/5/include/immintrin.h:43:0,
from /root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:2:
/usr/lib/gcc/x86_64-linux-gnu/5/include/avx2intrin.h:63:1: error: inlining failed in call to always_inline ‘_mm256_abs_epi16’: target specific option mismatch
_mm256_abs_epi16 (__m256i __A)
^
/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp/src.c:7:7: error: called from here
a = _mm256_abs_epi16(a);
^
CMakeFiles/cmTC_66b17.dir/build.make:65: recipe for target 'CMakeFiles/cmTC_66b17.dir/src.c.o' failed
make[1]: *** [CMakeFiles/cmTC_66b17.dir/src.c.o] Error 1
make[1]: Leaving directory '/root/pytorch/build_libtorch/build/CMakeFiles/CMakeTmp'
Makefile:121: recipe for target 'cmTC_66b17/fast' failed
make: *** [cmTC_66b17/fast] Error 2
Source file was:
#include <immintrin.h>
int main()
{
__m256i a = {0};
a = _mm256_abs_epi16(a);
__m256i x;
_mm256_extract_epi64(x, 0); // we rely on this in our AVX2 code
return 0;
}
```
Anyone could help me about this??????
Thank you!
cc @malfet
|
module: build,triaged
|
low
|
Critical
|
618,723,624 |
flutter
|
SizedBox docs missing what happens if height or width are bigger than the Parent
|
`SizedBox` docs specify what would happen if `width` or `height` are `null` or `double.infinity`, but it just makes a hint at `widget forces its child to have a specific width and/or height (assuming values are permitted by this widget's parent)`. but it doesn't specify what happens if the values aren't permitted by the parent.
Also, I have seen a different behavior from setting `height: double.maxFinite` instead of `height: double.infinity`, where `double.maxFinite` correctly sizes a `TabBarView`'s unbounded `ViewPort`, but `double.infinity` doesn't. This difference in behavior should be documented as well, as this is a hack I am seeing on the wild.
|
framework,d: api docs,P2,team-framework,triaged-framework
|
low
|
Minor
|
618,736,448 |
pytorch
|
Doc update regarding predictability of experiments using Seeds and Workers
|
## 🚀 Feature
The current official docs don't have specific examples regarding the use of seeds and worker_init_fn in order to attain a certain degree of reproducibility.
Following the suggestion by @ptrblck in the [thread](https://discuss.pytorch.org/t/reproducibility-with-all-the-bells-and-whistles/81097), I would like to add the solutions mentioned to the official docs.
## Motivation
While participating in a Kaggle competition I ended up spending countless hours of GPU compute on reproducing my results across followup runs of the pipeline but I realized it too late that the number of workers, the seeds **inside** these works all affect the outcome of the run. I searched a lot of discussions and docs to end up realizing how to use the worker_init_fn and what to expect from it. I would not want people to end up where I did so I would like to give them a heads up with whatever I have understood.
## Pitch
As suggested by @ptrblck , I would like to update the [doc](https://pytorch.org/docs/stable/notes/randomness.html) with the code examples and give people a clear heads-up regarding the dependency of the results on the workers and seeds and how they may be able to reach an acceptable level of reproducibility.
## Alternatives
As far as I can tell, this would be the most thorough example.
## Additional context
N/A
cc @jlin27
|
module: docs,triaged,module: determinism
|
low
|
Minor
|
618,774,096 |
svelte
|
Support two-way-data-binding with custom-input-elements
|
Custom (Input) Elements like ui5-input uses the propname value for the inputvalue attribute.
But svelte only permit value as propname when the element's name is input, textarea or select
https://github.com/sveltejs/svelte/blob/bdabd89f093afe06d5a4bfb8ee0362b0a9634cfc/src/compiler/compile/nodes/Element.ts#L532
otherwise svelte throws an error that value is not a valid binding-element
pls have a look here:
https://codesandbox.io/s/divine-architecture-3qvlc?file=/App.svelte
|
awaiting submitter,custom element
|
medium
|
Critical
|
618,774,209 |
pytorch
|
Make rebuildBucket() to be async in c10d reducer
|
Follow up #35137, right now rebuildBucket() is blocking during broadcast communication, we can make broadcast communication call in this function to be async and overlap with next forward() call when rebuildBucket() is called multiple times during whole training processes in the future. Right now, it is not a concern, as rebuildBucket() is only called once during whole training.
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @xush6528 @osalpekar
|
oncall: distributed,triaged,module: data parallel
|
low
|
Minor
|
618,801,853 |
godot
|
HTTPRequest sometimes returning response code "502" to a POST request
|
**Godot version:**
3.2.2 beta2
**OS/device including version:**
Windows
**Issue description:**
HTTPRequest sometimes returns response code 502 when doing a POST request with simple body.
The request is sent to Github API v3, with a body of
```
{
"content":content,
"encoding":encoding,
}
```
where `content` is the content of a file, in this case an .obj file.
I don't know if it may be linked to reading issues or just the Github API not responding correctly, but the response code is not always 502.
The script that contains this code is "Commit.gd" in `addons/github-integration/scripts/`
**Steps to reproduce:**
1. Download and import the project
2. Activate Github Integration plugin, and log in your Github profile with mail and token
3. Select a repository of your choice double clicking it
4. Press "Commit to Repo"
5. Press "Select Files" and choose "newWater.obj"
6. Press "Commit and Push" and wait for the debug messages in output.
**Minimal reproduction project:**
https://gofile.io/d/gMDnIp
Thank you very much.
|
bug,platform:windows,topic:core
|
low
|
Critical
|
618,825,820 |
create-react-app
|
Why Can't We Allow Developers To Override Proxy Behaviour For text/html Requests?
|
Firstly great project and apologies if this is not the correct repository to log this question. Please let me know if it belongs elsewhere and I will move it.
Question:
When developing with CRA, we can specify a proxy that allows us to route requests to one or more backends whilst the CRA server handles serving the actual UI. To determine whether to proxy a request or forward it to a backend, the request’s Accept header is checked to see if it expects a text or html response - if so, no proxying occurs. I understand why this is usually a good idea.
The problem comes when a developer needs to get a specific response to such a request from the backend. An example of such a scenario might be authorization flows that rely on redirects that are triggered by a navigation event that needs a specific response from the backed. Thus the developer may set the `window.location.href` from react to a specific path on the server, allowing the server to trigger a challenge and redirect to an IDP and complete an OAuth/OIDC flow, for example. Even if you feel the developer should really be using a different approach for OAuth/OIDC, other scenarios exist where responding to a URL navigation by forwarding the request to the backend may be helpful.
Since the developer knows which paths should serve which contents, why not let them say for a given path “No, don’t even try to serve index.html here, just go to the configured backend no matter what the accept header says”? It would seem reasonable to let the developer specify this in `setupProxy.js`.
|
needs triage
|
low
|
Minor
|
618,831,175 |
angular
|
service-worker(safari): POST requests getting blocked with 504 by Service Worker
|
# 🐞 bug report
### Affected Package
`@angular/service-worker`
### Is this a regression?
I don't know if this has even worked properly in Safari, but it's supposed to be production ready.
### Description
Service Workers shouldn't block POST requests AFAIK, but that's happening on Safari `Version 13.1 (15609.1.20.111.8)` on macOS Catalina `10.15.4 (19E287)`.
## 🔬 Minimal Reproduction
- Go to https://angular.io/ in Safari on macOS
- Open your Dev tools Console
- Browse around to some different pages like resources, guides, events, etc
- Observe the following error in the console
```
https://www.google-analytics.com/j/collect?v=1&_v=j82&a=557396380&t=pageview&_s=1&dl=https%3A%2F%2Fangular.io%2Fresources%3Fcategory%3Ddevelopment&dp=%2Fresources&ul=en&de=UTF-8&dt=Angular&sd=24-bit&sr=1920x1080&vp=1914x532&je=1&_u=QACAAEABAAAAAC~&jid=43561559&gjid=590323957&cid=498157216.1589533208&tid=UA-8594346-15&_gid=406270144.1589533208&_r=1&z=73615628
Failed to load resource: the server responded with a status of 504 (Gateway Timeout)
```
## 🔥 Exception or Error
```
Cannot use wildcard in Access-Control-Allow-Origin when credentials flag is true., undefined
```
<pre><code>
NGSW Debug Info:
Driver state: NORMAL ((nominal))
Latest manifest hash: a51465926eaa708ba14e763b3c654f2dc464f776
Last update check: 1m3s560u
=== Version a51465926eaa708ba14e763b3c654f2dc464f776 ===
Clients: 1692-8, 1692-33, 1692-59, 1692-63, 1692-70
=== Idle Task Queue ===
Last update tick: 28s363u
Last update run: 1m3s868u
Task queue:
Debug log:
[1m31s277u] TypeError(Cannot use wildcard in Access-Control-Allow-Origin when credentials flag is true., undefined) Driver.fetch(https://www.google-analytics.com/j/collect?v=1&_v=j82&a=1196111008&t=pageview&_s=1&dl=https%3A%2F%2Fangular.io%2Fguide%2Fservice-worker-communications&dp=%2Fguide%2Fservice-worker-communications&ul=en&de=UTF-8&dt=Angular&sd=24-bit&sr=1920x1080&vp=1914x532&je=1&_u=QACAAEABAAAAAC~&jid=323136214&gjid=1958337307&cid=498157216.1589533208&tid=UA-8594346-15&_gid=406270144.1589533208&_r=1&z=559832955)
[28s598u] TypeError(Cannot use wildcard in Access-Control-Allow-Origin when credentials flag is true., undefined) Driver.fetch(https://www.google-analytics.com/j/collect?v=1&_v=j82&a=1715609439&t=pageview&_s=5&dl=https%3A%2F%2Fangular.io%2Fguide%2Faccessibility&dp=%2Fresources&ul=en&de=UTF-8&dt=Angular%20-%20EVENTS&sd=24-bit&sr=1920x1080&vp=1914x532&je=1&_u=SACAAEABAAAAAC~&jid=721523635&gjid=563131875&cid=498157216.1589533208&tid=UA-8594346-15&_gid=406270144.1589533208&_r=1&z=882809832)
...
[3m52s] TypeError(Cannot use wildcard in Access-Control-Allow-Origin when credentials flag is true., undefined) Driver.fetch(https://www.google-analytics.com/j/collect?v=1&_v=j82&a=1121528947&t=pageview&_s=1&dl=https%3A%2F%2Fangular.io%2Fresources%3Fcategory%3Ddevelopment&dp=%2Fresources&ul=en&de=UTF-8&dt=Angular&sd=24-bit&sr=1920x1080&vp=1914x523&je=1&_u=QACAAEABAAAAAC~&jid=1658082190&gjid=2097738465&cid=498157216.1589533208&tid=UA-8594346-15&_gid=406270144.1589533208&_r=1&z=747985136)
[52s802u] TypeError(Cannot use wildcard in Access-Control-Allow-Origin when credentials flag is true., undefined) Driver.fetch(https://www.google-analytics.com/j/collect?v=1&_v=j82&a=1121528947&t=pageview&_s=3&dl=https%3A%2F%2Fangular.io%2Fresources%3Fcategory%3Ddevelopment&dp=%2Ffeatures&ul=en&de=UTF-8&dt=Angular%20-%20Angular%20Contributors&sd=24-bit&sr=1920x1080&vp=1914x523&je=1&_u=SACAAEABAAAAAC~&jid=2000655573&gjid=1284227509&cid=498157216.1589533208&tid=UA-8594346-15&_gid=406270144.1589533208&_r=1&z=1228242795)
</code></pre>


## 🌍 Your Environment
**Angular Version:** `10.0.0-next.5`
**Anything else relevant?**
I'm also seeing this on my site when using LogRocket (another kind of analytics service), but the Headers it complains about are different:
```ts
Request header field Pragma is not allowed by Access-Control-Allow-Headers., undefined
```
```
NGSW Debug Info:
Driver state: EXISTING_CLIENTS_ONLY (Degraded due to failed initialization: Internal error
undefined)
Latest manifest hash: 5642c5e828814d3dae722eae1783dc4724682328
Last update check: 4s519u
=== Version 5642c5e828814d3dae722eae1783dc4724682328 ===
Clients: 779-37
=== Idle Task Queue ===
Last update tick: 3s197u
Last update run: 46s658u
Task queue:
* check-updates-on-navigation
Debug log:
[5m51s257u] TypeError(Request header field Pragma is not allowed by Access-Control-Allow-Headers., undefined) Driver.fetch(https://r.lr-ingest.io/i?a=buymic%2Fdevintent-website&r=4-e8456afb-9941-460d-a17c-fddff8c6183e&t=e8d3692a-bb84-48ad-8f91-7dd31c74115c&ir=f&ht=f&s=0)
[5m48s165u] TypeError(Request header field Pragma is not allowed by Access-Control-Allow-Headers., undefined) Driver.fetch(https://r.lr-ingest.io/i?a=buymic%2Fdevintent-website&r=4-e8456afb-9941-460d-a17c-fddff8c6183e&t=e8d3692a-bb84-48ad-8f91-7dd31c74115c&ir=f&ht=f&s=0)
```



|
help wanted,area: service-worker,browser: safari,state: needs more investigation,P3
|
low
|
Critical
|
618,958,793 |
PowerToys
|
[Image Resizer] Support only showing in extended context menu
|
## Feature Request
Can Image Resizer include a setting where it can be configured to only show in *extended* context menu (i.e. Shift + Right click). It is already supported by Powerrename, and it would be great to also have this setting in Image Resizer.
|
Idea-Enhancement,Product-Settings,Product-Image Resizer
|
low
|
Minor
|
618,960,556 |
node
|
internalModuleStat & internalModuleReadJSON prevent resolution override
|
### What steps will reproduce the bug?
Imagine that the `fs` module is overriden to add support for a virtual filesystem. Make a `require` call towards a virtual file.
### What is the expected behavior?
The resolution should succeed, since the `fs` methods know how to access the file.
### What do you see instead?
Cannot find module 'virtual'.
### Additional information
This occurs because Node cheats and doesn't actually use all of the `fs` methods. In most cases it does (for example `fs.realpath`, `fs.readFile`, `fs.readdir`), but not for all. Two methods in particular goes into unique native bindings that cannot be overriden:
- `internalModuleStat` is used instead of `fs.stat`: https://github.com/nodejs/node/blob/master/lib/internal/modules/cjs/loader.js#L151
- `internalModuleReadJSON` is used instead of `fs.readFile`:
https://github.com/nodejs/node/blob/master/lib/internal/modules/cjs/loader.js#L257
Since those functions aren't exposed (not only do they come from `internalBinding`, they're also [`destructured`](https://github.com/nodejs/node/blob/master/lib/internal/modules/cjs/loader.js#L62-L65) so we never have a chance to change their references), we cannot even add the virtual layer to them at all.
Would it be possible to use the `fs` primitives or, at least, to expose `internalModuleStat` & friends in a way we can wrap them?
|
fs,module
|
low
|
Critical
|
618,995,508 |
terminal
|
Enable focusing tabs by mouse scrolling on the tab row
| ERROR: type should be string, got "\r\n\r\nhttps://code.visualstudio.com/updates/v1_45#_switch-tabs-using-mouse-wheel\r\n\r\n> When you use the mouse wheel to scroll over editor tabs, you currently cannot switch tabs, only reveal tabs that are out of view. Now with a new setting `workbench.editor.scrollToSwitchTabs`, you can change the behavior to switch the active editor tab.\r\n>\r\n> Below when the cursor focus in the editor tab region, if the user scrolls their mouse wheel, the active editor changes.\r\n>\r\n> Note: You can also press and hold the Shift key while scrolling to get the opposite behavior (for example, you can switch editor tabs even when the `scrollToSwitchTabs` setting is off).\r\n\r\nThis seemed like a cool idea, so I figured I'd add it here." |
Help Wanted,Area-UserInterface,Product-Terminal,Issue-Task
|
low
|
Minor
|
619,011,867 |
pytorch
|
Add Distributed LR Scheduler to RPC
|
The original request is from [this discussion](https://discuss.pytorch.org/t/does-distributedoptimizer-suppor-zero-grad-and-lr-scheduling) on forum. Currently, applications need to use the raw RPC APIs to implement LR scheduling in user code. It will be useful provide a helper for this.
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @gqchen @aazzolini @rohan-varma @xush6528 @jjlilley @osalpekar
|
module: bootcamp,feature,triaged,module: rpc
|
low
|
Minor
|
619,021,047 |
go
|
x/pkgsite: confusing display of constants block when there are unexported constants
|
If you look at documentation on this page: https://golang.org/pkg/text/template/parse/#NodeType
The NodeDot is 6 and NodeField is 8, but there is nothing between these two constants. however the source has two unexported consts between NodeDot and NodeField, which makes NodeField 8.
When you debug the code you can easly misunderstand the node types but simply counting them from the top.
The documentation should indicate actual values of constants
|
Documentation,help wanted,NeedsInvestigation,Tools,pkgsite
|
low
|
Critical
|
619,034,579 |
pytorch
|
Returning a tensor instead of a list in split and chunk
|
## 🚀 Feature
It would be nice to be able to get a tensor instead of a list of tensors when splitting or chunking if the dimensions match. What I propose is to add a flag (that could be called something like `return_tensor`) to split and chunk to do so. Here is an example of implementation.
```python
def view_chunk(tensor, chunks, dim=0):
assert tensor.shape[dim] % chunks == 0
if dim < 0: # Support negative indexing
dim = len(tensor.shape) + dim
cur_shape = tensor.shape
new_shape = cur_shape[:dim] + (chunks, tensor.shape[dim] // chunks) + cur_shape[dim + 1:]
return tensor.reshape(*new_shape)
def view_split(tensor, split_size, dim=0):
assert tensor.shape[dim] % split_size == 0
if dim < 0: # Support negative indexing
dim = len(tensor.shape) + dim
cur_shape = tensor.shape
new_shape = cur_shape[:dim] + (tensor.shape[dim] // split_size, split_size) + cur_shape[dim + 1:]
return tensor.reshape(*new_shape)
```
## Motivation
Essentially, the goal is to avoid copying memory when subsequently stacking the split afterwards if desirable. For instance, this can be useful when wanting to separate the dimensions of the output of an RNN.
## Pitch
```python
torch.chunk(tensor, chunks, dim=dim) # returns a list of tensors
torch.chunk(tensor, chunks, dim=dim, return_tensor=True) # returns a tensor with a new dimension
```
cc @ezyang @VitalyFedyunin @ngimel
|
feature,triaged,has workaround,shadow review
|
low
|
Minor
|
619,053,246 |
TypeScript
|
Support Implicit Generics Inference
|
<!-- 🚨 STOP 🚨 𝗦𝗧𝗢𝗣 🚨 𝑺𝑻𝑶𝑷 🚨
Half of all issues filed here are duplicates, answered in the FAQ, or not appropriate for the bug tracker.
Please help us by doing the following steps before logging an issue:
* Search: https://github.com/Microsoft/TypeScript/search?type=Issues
* Read the FAQ, especially the "Common Feature Requests" section: https://github.com/Microsoft/TypeScript/wiki/FAQ
-->
## Search Terms
<!-- List of keywords you searched for before creating this issue. Write them down here so that others can find this suggestion more easily -->
implicit generics, broader type inference, better type inference
## Suggestion
<!-- A summary of what you'd like to see added or changed -->
I'd like TypeScript to know when two types are **unknown**, but **equal**.
That is, say I've function `equals()`:
```ts
type T = { type: 'a', p1: boolean } | { type: 'b', p2: string };
function equals(a: T, b: T) {
// Currently, we have to write:
if (a.type === 'a' && b.type === 'a') { return a.p1 === b.p1; }
if (a.type === 'b' && b.type === 'b') { return a.p2 === b.p2; }
return false;
// But I'd like to be able to write:
if (a.type !== b.type) { return false; }
return a.type === 'a' ? a.p1 === b.p1 : a.p2 === b.p2;
}
```
## Use Cases
<!--
What do you want to use this for?
What shortcomings exist with current approaches?
-->
I can't think about other use cases except comparisons (if you know let me know), but I think they're common enough. This will also make them somewhat faster (no need to check both's type).
## Checklist
My suggestion meets these guidelines:
* [x] This wouldn't be a breaking change in existing TypeScript/JavaScript code
* [x] This wouldn't change the runtime behavior of existing JavaScript code
* [x] This could be implemented without emitting different JS based on the types of the expressions
* [x] This isn't a runtime feature (e.g. library functionality, non-ECMAScript syntax with JavaScript output, etc.)
* [x] This feature would agree with the rest of [TypeScript's Design Goals](https://github.com/Microsoft/TypeScript/wiki/TypeScript-Design-Goals).
|
Suggestion,Awaiting More Feedback
|
low
|
Critical
|
619,105,400 |
pytorch
|
When I use cuda(), wg = th.matmul(extra_obs, extra_obs.transpose(-2, -1)) take a mistake
|
there is the error, RuntimeError: cublas runtime error : the GPU program failed to execute at /pytorch/aten/src/THC/THCBlas.cu:411
it is ok when I run on cpu().
cuda9.0 torch 0.4.1
cc @csarofeen @ptrblck
|
triaged,module: cublas
|
low
|
Critical
|
619,107,632 |
TypeScript
|
`RegExp.lastIndex` has no doc comment in `lib.es5.d.ts`
|
<!-- 🚨 STOP 🚨 𝗦𝗧𝗢𝗣 🚨 𝑺𝑻𝑶𝑷 🚨
Half of all issues filed here are duplicates, answered in the FAQ, or not appropriate for the bug tracker.
Please help us by doing the following steps before logging an issue:
* Search: https://github.com/Microsoft/TypeScript/search?type=Issues
* Read the FAQ, especially the "Common Feature Requests" section: https://github.com/Microsoft/TypeScript/wiki/FAQ
-->
## Search Terms
"lastIndex"
## Suggestion
`RegExp.lastIndex` should have a doc comment - you can see it lacks one here: https://github.com/microsoft/TypeScript/blob/7fc456f2d70348725bbef92732b98a33c07f85ad/lib/lib.es5.d.ts#L944
MDN doc for the property can be found [here](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/RegExp/lastIndex).
|
Bug,Help Wanted,Domain: lib.d.ts
|
low
|
Critical
|
619,133,418 |
rust
|
Make lang items private
|
#72170 and #72216 put some effort in to try and prevent some potential ICEs that can occur in `#![no_core]` due to how we currently reference lang items.
@oli-obk pointed out:
> Oh, that's a very good idea. I wonder if we can make `lang_items` private at some point and just have sensible wrappers like `require_lang_item`.
I'm opening this issue to start a discussion about how we could take this forward.
<!-- TRIAGEBOT_START -->
<!-- TRIAGEBOT_ASSIGN_START -->
<!-- TRIAGEBOT_ASSIGN_DATA_START$${"user":null}$$TRIAGEBOT_ASSIGN_DATA_END -->
<!-- TRIAGEBOT_ASSIGN_END -->
<!-- TRIAGEBOT_END -->
|
C-enhancement,T-compiler,A-lang-item
|
medium
|
Major
|
619,159,860 |
pytorch
|
tensorboard projector mode with custom metadata_header with only one label name
|
## 🐛 Bug
`.add_embeddings(metadata_header=['some-name'])` breaks the tensorboard to parse the metadata. Reaching http://localhost:6006/#projector shows the error
```
Error merging metadata
Number of tensors (20) do not match the number of lines in metadata (21). Single column metadata should not have a header row.
```

## To Reproduce
```python
import torch
from torch.utils.tensorboard import SummaryWriter
mat = torch.randn(20, 10)
units = torch.arange(20).unsqueeze(1).tolist()
writer = SummaryWriter('runs/example')
writer.add_embedding(mat, units, metadata_header=['unit'])
writer.close()
```
Then navigate to localhost:6006 in a browser.
Note: using the default `metadata_header` does not break tensorboard to parse the metadata file.
## Expected behavior
A browser opens Projector tab and shows the data in PCA space.
## Environment
PyTorch version: 1.5.0
Is debug build: No
CUDA used to build PyTorch: None
OS: Ubuntu 18.04.4 LTS
GCC version: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0
CMake version: version 3.10.2
Python version: 3.8
Is CUDA available: No
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
Versions of relevant libraries:
[pip] numpy==1.18.1
[pip] torch==1.5.0
[pip] torchvision==0.6.0a0+82fd1c8
[pip] tensorboard==2.2.1
[conda] blas 1.0 mkl
[conda] cpuonly 1.0 0 pytorch
[conda] mkl 2020.1 217
[conda] mkl-service 2.3.0 py38he904b0f_0
[conda] mkl_fft 1.0.15 py38ha843d7b_0
[conda] mkl_random 1.1.0 py38h962f231_0
[conda] numpy 1.18.1 py38h4f9e942_0
[conda] numpy-base 1.18.1 py38hde5b4d6_1
[conda] pytorch 1.5.0 py3.8_cpu_0 [cpuonly] pytorch
[conda] torchvision 0.6.0 py38_cpu [cpuonly] pytorch
## Additional context
If it's a bug on tensorflow/tensorboard side, let me know to move the issue there.
The `metadata.tsv` file has 21 lines because it starts with the label name:
```
unit
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
```
-------
Update
> Single column metadata should not have a header row.
makes me think that it's done by design. If so,
1) it's not user friendly. How do I change `label` -> `unit` in the viewer then?
2) I'd like to receive the error during `.add_embeddings()` rather than ignoring it silently and then realizing something wrong has happened only when you open a browser.
|
triaged,module: tensorboard
|
low
|
Critical
|
619,167,221 |
go
|
x/pkgsite: support removing packages in the top-level module, but not in nested modules
|
### What is the URL of the page with the issue?
https://pkg.go.dev/mod/go.opentelemetry.io?tab=packages
### What did you do?
Initially using https://github.com/GoogleCloudPlatform/govanityurls.git we publish modules directly under `go.opentelemetry.io` but later because we found that we will have more repos we decided to use different paths to export different repositories
```yaml
/otel:
repo: https://github.com/open-telemetry/opentelemetry-go
/collector:
repo: https://github.com/open-telemetry/opentelemetry-collector
/contrib/otel:
repo: https://github.com/open-telemetry/opentelemetry-go-contrib
/contrib/collector:
repo: https://github.com/open-telemetry/opentelemetry-collector-contrib
```
Before we had (which we replaced 6 moths ago, and never used):
```yaml
/:
repo: https://github.com/open-telemetry/opentelemetry-go
```
### What did you expect to see?
I would expect all the old packages that we exported previously https://pkg.go.dev/mod/go.opentelemetry.io?tab=packages to be gone.
### What did you see instead?
I would expect to have only packages under https://pkg.go.dev/mod/go.opentelemetry.io/otel?tab=packages
|
NeedsFix,FeatureRequest,pkgsite
|
low
|
Minor
|
619,196,904 |
pytorch
|
[quantization] Version support for quantization BC tests
|
The quantization BC tests (https://github.com/pytorch/pytorch/blob/master/test/quantization/test_backward_compatibility.py) currently only have one serialized model per class type/dtype, however some of the quantized modules have gone through several revisions, with version counter bumps (e.g. https://github.com/pytorch/pytorch/blob/dc918162b7cbf5a81b946780a985b00df4795baf/torch/nn/quantized/modules/linear.py#L11). We should add versioning support to the BC tests to make sure that all versions of the serialized modules are supported as we keep developing the code
cc @jerryzh168 @jianyuh @raghuramank100 @vkuzo @jgong5 @Xia-Weiwen @leslie-fang-intel @dzhulgakov @jamesr66a
|
oncall: quantization,low priority,triaged
|
low
|
Minor
|
619,263,073 |
vscode
|
[html] don't let '/' trigger a suggest in embedded JavaScript
|
Issue Type: <b>Bug</b>
Create and save a new .html file. Add a script tag, such as:
```
<script>
function main() {
/**/
}
</script>
```
You will notice that after typing the closing slash, IntelliSense pops up (leading to potential unintended insertions if Enter is pressed, for example). If the identical JavaScript code is put into a .js file, the behavior does not occur.
VS Code version: Code 1.45.1 (5763d909d5f12fe19f215cbfdd29a91c0fa9208a, 2020-05-14T08:27:35.169Z)
OS version: Windows_NT x64 10.0.18363
<details>
<summary>System Info</summary>
|Item|Value|
|---|---|
|CPUs|Intel(R) Core(TM) i7-7700HQ CPU @ 2.80GHz (8 x 2808)|
|GPU Status|2d_canvas: enabled<br>flash_3d: enabled<br>flash_stage3d: enabled<br>flash_stage3d_baseline: enabled<br>gpu_compositing: enabled<br>multiple_raster_threads: enabled_on<br>oop_rasterization: disabled_off<br>protected_video_decode: enabled<br>rasterization: enabled<br>skia_renderer: disabled_off_ok<br>video_decode: enabled<br>viz_display_compositor: enabled_on<br>viz_hit_test_surface_layer: disabled_off_ok<br>webgl: enabled<br>webgl2: enabled|
|Load (avg)|undefined|
|Memory (System)|15.86GB (8.52GB free)|
|Process Argv||
|Screen Reader|no|
|VM|0%|
</details><details><summary>Extensions (2)</summary>
Extension|Author (truncated)|Version
---|---|---
vscode-eslint|dba|2.1.5
python|ms-|2020.5.78807
</details>
<!-- generated by issue reporter -->
|
feature-request,html
|
low
|
Critical
|
619,295,091 |
godot
|
Cyclic dependencies between References, even without any static typing, cause memory leaks / errors on exit
|
**Godot version:**
3.2.1-stable
**Steps to reproduce:**
Simply have two objects reference each other through properties, for instance by having this script attached to the root node of a scene:
```gdscript
func _ready() -> void:
var a = A.new()
var b = B.new()
a.b = b
b.a = a
class A:
var b
class B:
var a
```
Then exit the game. The following errors will be reported in the console:
> ERROR: ~List: Condition "_first != __null" is true.
> At: ./core/self_list.h:112
> ERROR: ~List: Condition "_first != __null" is true.
> At: ./core/self_list.h:112
> WARNING: cleanup: ObjectDB Instances still exist!
> At: core/object.cpp:2071
Note: this is the simplest reproducible example, but **this also occurs if A and B are `class_name`s in their own scripts**. Then you get all of the previous errors, plus this one:
> ERROR: clear: Resources Still in use at Exit!
> At: core/resource.cpp:476
If you remove `b.a = a`, then the error disappears, in both cases.
This also happens if you have any longer cycle, e.g. a -> b -> c -> a,
I believe this issue is different from #30668, which is about referencing the current class via a variable, param or return type through static typing. It's also not exactly the same as #21461 since it doesn't prevent the game from running (and doesn't yield any warnings when editing), and happens without having two types explicitly referencing each other.
|
bug,topic:gdscript
|
low
|
Critical
|
619,320,043 |
TypeScript
|
Better intellisense for unions of tuple types
|
VSCode - Version 1.45.1
Typescript - Version 3.8.3
## Search Terms
intellisense tuple
## Suggestion
Have the suggestions of unions of tuple types only suggest valid things
## Use Cases
I have a function which takes a 'path' to a property in a fixed object, say the object is like { a: { b: 1 } }, allowed paths are ["a"], or ["a", "b"].
I have some type which generates for me the union of allowed tuples, which is to be the type of the 'path'.
The fixed object the function takes paths in is very large and I don't want to have to remember the names of things, when I use the union, the intellisense correctly identifies if a path is invalid, but when using ctrl + space to get the suggestions, it suggests strings which if used are immediately afterwards recognised as invalid.
## Examples
Consider a type like
`type X = ["A"] | ["A", "B"]`
Then if I write something like `const x: X = []`, when pressing ctrl + space in the array I would like to just be suggested "A" (in fact this is already the behaviour), after filling in "A", if I try to add another element it would just suggest "B", not "A", "B"
## Checklist
My suggestion meets these guidelines:
* [x ] This wouldn't be a breaking change in existing TypeScript/JavaScript code
* [x ] This wouldn't change the runtime behavior of existing JavaScript code
* [x ] This could be implemented without emitting different JS based on the types of the expressions
* [x ] This isn't a runtime feature (e.g. library functionality, non-ECMAScript syntax with JavaScript output, etc.)
* [x ] This feature would agree with the rest of [TypeScript's Design Goals](https://github.com/Microsoft/TypeScript/wiki/TypeScript-Design-Goals).
|
Suggestion,Awaiting More Feedback
|
low
|
Major
|
619,326,030 |
flutter
|
Shutdown hooks shouldn't crash the tool
|
We should probably handle a shutdown hook that throws an exception similarly to how we handle exceptions from signal handlers. See shutdown hook processing here:
https://github.com/flutter/flutter/blob/master/packages/flutter_tools/lib/src/base/process.dart#L118
and signal handler processing here:
https://github.com/flutter/flutter/blob/master/packages/flutter_tools/lib/src/base/signals.dart#L134
|
team,tool,a: quality,team-tool
|
low
|
Critical
|
619,349,837 |
rust
|
LLVM can reorder rounding-mode-sensitive float operations outside rounding mode changes in SSE
|
In release mode, this code can break:
```rust
/// Converts these packed floats to integers via the floor function.
#[inline]
pub fn floor_to_i32x4(self) -> I32x4 {
unsafe {
x86::_MM_SET_ROUNDING_MODE(x86::_MM_ROUND_DOWN);
let value = I32x4(x86::_mm_cvtps_epi32(self.0));
x86::_MM_SET_ROUNDING_MODE(x86::_MM_ROUND_NEAREST);
value
}
}
```
Because `value` can get reordered after all the rounding mode switches. I'm not sure what the right thing to do here is.
|
A-LLVM,A-codegen,T-compiler,C-bug,A-floating-point
|
low
|
Major
|
619,388,054 |
pytorch
|
torch.norm p/ord parameter documentation is wrong
|
## 📚 Documentation
There are three minor problems in the `torch.norm` docs:
The default value of `torch.norm`'s `p` parameter is `fro`, but at the same time, the table of values for `ord` (Bug 1: mismatch to the parameter name) lists no vector norm for `ord="fro"` (only for `ord=None`) (Bug 2). Finally, the quote signs are wrong (Bug 3).
|
module: docs,triaged
|
low
|
Critical
|
619,394,695 |
svelte
|
data passed to animations is always stale
|
https://svelte.dev/repl/ddf5358e78144925b47874d8a6a558ff?version=3.22.2
the `animation-js-delay` test uses indexes to delay animations, and asserts based on stale values
will fix with #4742
|
stale-bot,temp-stale
|
low
|
Major
|
619,402,604 |
flutter
|
Stepper buttons use `ColorScheme.primary` instead of inheriting from buttonTheme
|
Stepper buttons are using primaryColor as button background color instead of accentColor like the rest of the buttons do...
https://stackoverflow.com/questions/53337392/flutter-change-stepper-step-color
Try defining in ThemeData a button like this, it wont work
```
buttonTheme: ButtonThemeData(
buttonColor: Colors.yellow[100],
shape: RoundedRectangleBorder(
borderRadius: new BorderRadius.circular(15.0),
//side: BorderSide(color: Colors.brown),
),
padding: EdgeInsets.all(10.0),
),
```
<!-- Thank you for using Flutter!
If you are looking for support, please check out our documentation
or consider asking a question on Stack Overflow:
* https://flutter.dev/
* https://api.flutter.dev/
* https://stackoverflow.com/questions/tagged/flutter?sort=frequent
If you have found a bug or if our documentation doesn't have an answer
to what you're looking for, then fill our the template below. Please read
our guide to filing a bug first: https://flutter.dev/docs/resources/bug-reports
-->
## Steps to Reproduce
<!-- You must include full steps to reproduce so that we can reproduce the problem. -->
1. Run `flutter create bug`.
2. Update the files as follows: ... <!-- include every file that is different from the template app! -->
3. ... <!-- describe how to reproduce the problem -->
**Expected results:** <!-- what did you want to see? -->
**Actual results:** <!-- what did you see? -->
<details>
<summary>Logs</summary>
<!--
Run your application with `flutter run --verbose` and attach all the
log output below between the lines with the backticks. If there is an
exception, please see if the error message includes enough information
to explain how to solve the issue.
-->
```
```
<!--
Run `flutter analyze` and attach any output of that command below.
If there are any analysis errors, try resolving them before filing this issue.
-->
```
```
<!-- Finally, paste the output of running `flutter doctor -v` here. -->
```
```
</details>
|
framework,f: material design,has reproducible steps,found in release: 3.3,found in release: 3.6,team-design,triaged-design
|
low
|
Critical
|
619,440,475 |
flutter
|
flutter doctor --android-licenses may crash if findJavaBinary selects JAVA_HOME instead of AS Java
|
```bash
PS D:\Flutter Projects\flutter_quiz> flutter doctor --android-licenses
Exception in thread "main" java.lang.NoClassDefFoundError: javax/xml/bind/annotation/XmlSchema
at com.android.repository.api.SchemaModule$SchemaModuleVersion.<init>(SchemaModule.java:156)
at com.android.repository.api.SchemaModule.<init>(SchemaModule.java:75)
at com.android.sdklib.repository.AndroidSdkHandler.<clinit>(AndroidSdkHandler.java:81)
at com.android.sdklib.tool.sdkmanager.SdkManagerCli.main(SdkManagerCli.java:73)
at com.android.sdklib.tool.sdkmanager.SdkManagerCli.main(SdkManagerCli.java:48)
Caused by: java.lang.ClassNotFoundException: javax.xml.bind.annotation.XmlSchema
at java.base/jdk.internal.loader.BuiltinClassLoader.loadClass(BuiltinClassLoader.java:581)
at java.base/jdk.internal.loader.ClassLoaders$AppClassLoader.loadClass(ClassLoaders.java:178)
at java.base/java.lang.ClassLoader.loadClass(ClassLoader.java:521)
... 5 more
```
|
platform-android,tool,P2,team-android,triaged-android
|
low
|
Critical
|
619,460,931 |
godot
|
Physics2D weird CollisionPolygon2D interaction with 3 consecutive points on the same line
|
**Godot version:**
tested on 3.2.1 and 3.2.2 beta 2
**OS/device including version:**
tested on OSX
**Issue description:**
When having a CollisionPolygon2D with 3 consecutive points on the same line, interaction with rigid-bodies becomes unstable and janky.
When enabling collision shapes, the middle point on the collision polygon is visible although the colliding object is nowhere near it. (see image)

The most apparent effect is that applying torque in that direction will cause the object not to spin (most of the time), while applying torque in the other direction will behave normally
**Steps to reproduce:**
Create a floor from static body with CollisionBodyPolygon2D
Create the floor collision shape as a rectangle from a polygon using 5 points (1 extra point), for example:
PoolVector2Array( 64, 384, 554, 384, 832, 384, 832, 448, 64, 448 )
Create a box with controllable torque that lays on the floor, and try to apply torque in each direction, the box is expected to move, but sometimes it gets "stuck".
make sure to:
- give enough torque (100 torque for 1 weight works for me)
- disable "can sleep" on the box
**Minimal reproduction project:**
attached a minimal reproduction.
A and D keys apply torque to the box
deleting point 1 in the CollisionPolygon2D for floor fixes the issue
[Archive.zip](https://github.com/godotengine/godot/files/4638330/Archive.zip)
|
bug,confirmed,topic:physics
|
low
|
Minor
|
619,462,703 |
terminal
|
Intermittent error saving properties in shortcut link
|
# Environment
Windows build number: Version 10.0.18362.719
Windows Terminal version (if applicable): Commit b46d39306124363a4104afb74fa9b6657b1d17d0
# Steps to reproduce
1. Checkout and build a recent version of the _OpenConsole_ solution (I'm using an x64 release build in case that makes a difference).
2. Create a shortcut to the `OpenConsole.exe` that has just been built (in the `bin\x64\Release` directory).
3. Start the app from the shortcut.
4. Open the properties dialog.
5. Press <kbd>Enter</kbd> to save and close the dialog.
6. Repeat steps 4 and 5 a few dozen times.
# Expected behavior
You should be able to open and close the dialog without any problems.
# Actual behavior
After a couple of repeats, it'll eventually fail when closing the dialog with the error:
Unable to modify the shortcut:
C:\...\OpenConsole.exe - Shortcut.lnk.
Check to make sure it has not been deleted or renamed.
I added a bunch of `OutputDebugString` logging in the code, and I tracked down the problem to the `s_GetLoadedShellLinkForShortcut` method when called from `s_SetLinkValues`. It tries to load the shortcut with mode `STGM_READWRITE | STGM_SHARE_EXCLUSIVE` and the `IPersistFile::Load` fails with error `0x80070020`, which is the `HRESULT` equivalent of `ERROR_SHARING_VIOLATION`.
This is not always easy to reproduce - sometimes I can repeat the process hundreds of times without an error, but other times it'll fail on the first or second attempt. I don't whether maybe it's just something wrong with my system.
|
Product-Conhost,Issue-Bug,Area-Settings,Priority-3
|
low
|
Critical
|
619,469,560 |
deno
|
Detached processes in deno
|
Currently node has the capability to run a child process in detached mode (`setsid()`), which is lacking in deno (?)
It seems the Tokio `Command` doesn't expose any specific functionality for this.
Is it possible for Deno to provide this functionality?
Also, this specific default (kill if handle is dropped from the scope) in rust std and tokio is overridden in Deno (`cli/ops/process.rs`). Is that related to detached mode?
```rust
fn op_run(...) {
....
// We want to kill child when it's closed
c.kill_on_drop(true);
}
```
Is there a better place to ask such questions than cluttering the issues section?
|
feat
|
medium
|
Critical
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.