
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
18.9k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 465
23.6k
| num_tokens_prompt
int64 556
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_347
|
rasdani/github-patches
|
git_diff
|
kivy__python-for-android-2436
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
"diff" files are ignored during "pip install ."
in `setup.py` the "diff" is not listed:
https://github.com/kivy/python-for-android/blob/develop/setup.py
```python
package_data = {'': ['*.tmpl',
'*.patch', ], }
```
and therefore this `diff` patch:
https://github.com/kivy/python-for-android/blob/develop/pythonforandroid/recipes/python3/patches/reproducible-buildinfo.diff
is not installed during `pip` invocation:
```sh
cd /tmp
git clone --depth 1 https://github.com/kivy/python-for-android.git
cd python-for-android
pip install .
```
</issue>
<code>
[start of setup.py]
1
2 import glob
3 from io import open # for open(..,encoding=...) parameter in python 2
4 from os import walk
5 from os.path import join, dirname, sep
6 import re
7 from setuptools import setup, find_packages
8
9 # NOTE: All package data should also be set in MANIFEST.in
10
11 packages = find_packages()
12
13 package_data = {'': ['*.tmpl',
14 '*.patch', ], }
15
16 data_files = []
17
18
19 # must be a single statement since buildozer is currently parsing it, refs:
20 # https://github.com/kivy/buildozer/issues/722
21 install_reqs = [
22 'appdirs', 'colorama>=0.3.3', 'jinja2', 'six',
23 'enum34; python_version<"3.4"', 'sh>=1.10; sys_platform!="nt"',
24 'pep517<0.7.0', 'toml',
25 ]
26 # (pep517 and toml are used by pythonpackage.py)
27
28
29 # By specifying every file manually, package_data will be able to
30 # include them in binary distributions. Note that we have to add
31 # everything as a 'pythonforandroid' rule, using '' apparently doesn't
32 # work.
33 def recursively_include(results, directory, patterns):
34 for root, subfolders, files in walk(directory):
35 for fn in files:
36 if not any(glob.fnmatch.fnmatch(fn, pattern) for pattern in patterns):
37 continue
38 filename = join(root, fn)
39 directory = 'pythonforandroid'
40 if directory not in results:
41 results[directory] = []
42 results[directory].append(join(*filename.split(sep)[1:]))
43
44
45 recursively_include(package_data, 'pythonforandroid/recipes',
46 ['*.patch', 'Setup*', '*.pyx', '*.py', '*.c', '*.h',
47 '*.mk', '*.jam', ])
48 recursively_include(package_data, 'pythonforandroid/bootstraps',
49 ['*.properties', '*.xml', '*.java', '*.tmpl', '*.txt', '*.png',
50 '*.mk', '*.c', '*.h', '*.py', '*.sh', '*.jpg', '*.aidl',
51 '*.gradle', '.gitkeep', 'gradlew*', '*.jar', "*.patch", ])
52 recursively_include(package_data, 'pythonforandroid/bootstraps',
53 ['sdl-config', ])
54 recursively_include(package_data, 'pythonforandroid/bootstraps/webview',
55 ['*.html', ])
56 recursively_include(package_data, 'pythonforandroid',
57 ['liblink', 'biglink', 'liblink.sh'])
58
59 with open(join(dirname(__file__), 'README.md'),
60 encoding="utf-8",
61 errors="replace",
62 ) as fileh:
63 long_description = fileh.read()
64
65 init_filen = join(dirname(__file__), 'pythonforandroid', '__init__.py')
66 version = None
67 try:
68 with open(init_filen,
69 encoding="utf-8",
70 errors="replace"
71 ) as fileh:
72 lines = fileh.readlines()
73 except IOError:
74 pass
75 else:
76 for line in lines:
77 line = line.strip()
78 if line.startswith('__version__ = '):
79 matches = re.findall(r'["\'].+["\']', line)
80 if matches:
81 version = matches[0].strip("'").strip('"')
82 break
83 if version is None:
84 raise Exception('Error: version could not be loaded from {}'.format(init_filen))
85
86 setup(name='python-for-android',
87 version=version,
88 description='Android APK packager for Python scripts and apps',
89 long_description=long_description,
90 long_description_content_type='text/markdown',
91 python_requires=">=3.6.0",
92 author='The Kivy team',
93 author_email='[email protected]',
94 url='https://github.com/kivy/python-for-android',
95 license='MIT',
96 install_requires=install_reqs,
97 entry_points={
98 'console_scripts': [
99 'python-for-android = pythonforandroid.entrypoints:main',
100 'p4a = pythonforandroid.entrypoints:main',
101 ],
102 'distutils.commands': [
103 'apk = pythonforandroid.bdistapk:BdistAPK',
104 'aar = pythonforandroid.bdistapk:BdistAAR',
105 ],
106 },
107 classifiers=[
108 'Development Status :: 5 - Production/Stable',
109 'Intended Audience :: Developers',
110 'License :: OSI Approved :: MIT License',
111 'Operating System :: Microsoft :: Windows',
112 'Operating System :: OS Independent',
113 'Operating System :: POSIX :: Linux',
114 'Operating System :: MacOS :: MacOS X',
115 'Operating System :: Android',
116 'Programming Language :: C',
117 'Programming Language :: Python :: 3',
118 'Programming Language :: Python :: 3.6',
119 'Programming Language :: Python :: 3.7',
120 'Programming Language :: Python :: 3.8',
121 'Topic :: Software Development',
122 'Topic :: Utilities',
123 ],
124 packages=packages,
125 package_data=package_data,
126 )
127
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -11,7 +11,8 @@
packages = find_packages()
package_data = {'': ['*.tmpl',
- '*.patch', ], }
+ '*.patch',
+ '*.diff', ], }
data_files = []
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -11,7 +11,8 @@\n packages = find_packages()\n \n package_data = {'': ['*.tmpl',\n- '*.patch', ], }\n+ '*.patch',\n+ '*.diff', ], }\n \n data_files = []\n", "issue": "\"diff\" files are ignored during \"pip install .\"\nin `setup.py` the \"diff\" is not listed: \r\nhttps://github.com/kivy/python-for-android/blob/develop/setup.py\r\n```python\r\npackage_data = {'': ['*.tmpl',\r\n '*.patch', ], }\r\n```\r\n\r\nand therefore this `diff` patch:\r\nhttps://github.com/kivy/python-for-android/blob/develop/pythonforandroid/recipes/python3/patches/reproducible-buildinfo.diff\r\n\r\nis not installed during `pip` invocation:\r\n```sh\r\ncd /tmp\r\ngit clone --depth 1 https://github.com/kivy/python-for-android.git\r\ncd python-for-android\r\npip install .\r\n```\r\n\n", "before_files": [{"content": "\nimport glob\nfrom io import open # for open(..,encoding=...) parameter in python 2\nfrom os import walk\nfrom os.path import join, dirname, sep\nimport re\nfrom setuptools import setup, find_packages\n\n# NOTE: All package data should also be set in MANIFEST.in\n\npackages = find_packages()\n\npackage_data = {'': ['*.tmpl',\n '*.patch', ], }\n\ndata_files = []\n\n\n# must be a single statement since buildozer is currently parsing it, refs:\n# https://github.com/kivy/buildozer/issues/722\ninstall_reqs = [\n 'appdirs', 'colorama>=0.3.3', 'jinja2', 'six',\n 'enum34; python_version<\"3.4\"', 'sh>=1.10; sys_platform!=\"nt\"',\n 'pep517<0.7.0', 'toml',\n]\n# (pep517 and toml are used by pythonpackage.py)\n\n\n# By specifying every file manually, package_data will be able to\n# include them in binary distributions. Note that we have to add\n# everything as a 'pythonforandroid' rule, using '' apparently doesn't\n# work.\ndef recursively_include(results, directory, patterns):\n for root, subfolders, files in walk(directory):\n for fn in files:\n if not any(glob.fnmatch.fnmatch(fn, pattern) for pattern in patterns):\n continue\n filename = join(root, fn)\n directory = 'pythonforandroid'\n if directory not in results:\n results[directory] = []\n results[directory].append(join(*filename.split(sep)[1:]))\n\n\nrecursively_include(package_data, 'pythonforandroid/recipes',\n ['*.patch', 'Setup*', '*.pyx', '*.py', '*.c', '*.h',\n '*.mk', '*.jam', ])\nrecursively_include(package_data, 'pythonforandroid/bootstraps',\n ['*.properties', '*.xml', '*.java', '*.tmpl', '*.txt', '*.png',\n '*.mk', '*.c', '*.h', '*.py', '*.sh', '*.jpg', '*.aidl',\n '*.gradle', '.gitkeep', 'gradlew*', '*.jar', \"*.patch\", ])\nrecursively_include(package_data, 'pythonforandroid/bootstraps',\n ['sdl-config', ])\nrecursively_include(package_data, 'pythonforandroid/bootstraps/webview',\n ['*.html', ])\nrecursively_include(package_data, 'pythonforandroid',\n ['liblink', 'biglink', 'liblink.sh'])\n\nwith open(join(dirname(__file__), 'README.md'),\n encoding=\"utf-8\",\n errors=\"replace\",\n ) as fileh:\n long_description = fileh.read()\n\ninit_filen = join(dirname(__file__), 'pythonforandroid', '__init__.py')\nversion = None\ntry:\n with open(init_filen,\n encoding=\"utf-8\",\n errors=\"replace\"\n ) as fileh:\n lines = fileh.readlines()\nexcept IOError:\n pass\nelse:\n for line in lines:\n line = line.strip()\n if line.startswith('__version__ = '):\n matches = re.findall(r'[\"\\'].+[\"\\']', line)\n if matches:\n version = matches[0].strip(\"'\").strip('\"')\n break\nif version is None:\n raise Exception('Error: version could not be loaded from {}'.format(init_filen))\n\nsetup(name='python-for-android',\n version=version,\n description='Android APK packager for Python scripts and apps',\n long_description=long_description,\n long_description_content_type='text/markdown',\n python_requires=\">=3.6.0\",\n author='The Kivy team',\n author_email='[email protected]',\n url='https://github.com/kivy/python-for-android',\n license='MIT',\n install_requires=install_reqs,\n entry_points={\n 'console_scripts': [\n 'python-for-android = pythonforandroid.entrypoints:main',\n 'p4a = pythonforandroid.entrypoints:main',\n ],\n 'distutils.commands': [\n 'apk = pythonforandroid.bdistapk:BdistAPK',\n 'aar = pythonforandroid.bdistapk:BdistAAR',\n ],\n },\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Operating System :: Microsoft :: Windows',\n 'Operating System :: OS Independent',\n 'Operating System :: POSIX :: Linux',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: Android',\n 'Programming Language :: C',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Topic :: Software Development',\n 'Topic :: Utilities',\n ],\n packages=packages,\n package_data=package_data,\n )\n", "path": "setup.py"}]}
| 2,014 | 71 |
gh_patches_debug_18046
|
rasdani/github-patches
|
git_diff
|
Lightning-AI__pytorch-lightning-3745
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Setting of PYTHONHASHSEED has no effect
<!--
### Common bugs:
1. Tensorboard not showing in Jupyter-notebook see [issue 79](https://github.com/PyTorchLightning/pytorch-lightning/issues/79).
2. PyTorch 1.1.0 vs 1.2.0 support [see FAQ](https://github.com/PyTorchLightning/pytorch-lightning#faq)
-->
## 🐛 Bug
(Previously submitted here: https://github.com/PyTorchLightning/pytorch-lightning/issues/1939, but I didn't use the correct template, so now I'm resubmitting)
In https://github.com/PyTorchLightning/pytorch-lightning/blob/9045b6c599df3871da6aaaa310f62d3f1364c632/pytorch_lightning/trainer/seed.py#L32
, `PYTHONHASHSEED` is assigned a value in order to ensure reproducability. However, this assignment has no effect. In fact, this assignment might mislead the user or any logging software into believing that `PYTHONHASHSEED` has a specific value, when in fact it has another.
To see that setting `PYTHONHASHSEED` inside the current program has no effect, run the following two commands:
```
PYTHONHASHSEED=1 python -c "import os; print(hash('a'))"
PYTHONHASHSEED=1 python -c "import os; os.environ['PYTHONHASHSEED']='2'; print(hash('a'))"
```
The commands should output the same value, meaning that setting `PYTHONHASHSEED` after the process has started has no effect.
The following commands will likely output different values, also indicating that setting `PYTHONHASHSEED` after the process has started has no effect:
```
unset PYTHONHASHSEED # make sure it is not already set
python -c "import os; os.environ['PYTHONHASHSEED']='2'; print(hash('a'))"
python -c "import os; os.environ['PYTHONHASHSEED']='2'; print(hash('a'))"
```
<!-- A clear and concise description of what the bug is. -->
### To Reproduce
Steps to reproduce the behavior:
1. Start python terminal with `PYTHONHASHSEED=1 python`
2. Run
```python
import pytorch_lightning as pl
pl.seed_everything(100)
print(hash('a'))
# >>> 8432517439229126278
```
3. Start new python terminal with `PYTHONHASHSEED=2 python`
4. Run
```python
import pytorch_lightning as pl
pl.seed_everything(100)
print(hash('a'))
# >>> -8333094867672744108
```
### Expected behavior
Expect output of `hash` function to be the same in both cases. The examples demonstrate that this is not possible.
<!-- A clear and concise description of what you expected to happen. -->
### Environment
```
* CUDA:
- GPU:
- available: False
- version: 10.2
* Packages:
- numpy: 1.18.5
- pyTorch_debug: False
- pyTorch_version: 1.5.0
- pytorch-lightning: 0.7.6
- tensorboard: 2.2.2
- tqdm: 4.46.1
* System:
- OS: Linux
- architecture:
- 64bit
- ELF
- processor:
- python: 3.8.3
- version: #1 SMP PREEMPT Wed May 27 20:25:12 UTC 2020
```
</issue>
<code>
[start of pytorch_lightning/utilities/seed.py]
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Helper functions to help with reproducibility of models. """
16
17 import os
18 import random
19 from typing import Optional
20
21 import numpy as np
22 import torch
23
24 from pytorch_lightning import _logger as log
25
26
27 def seed_everything(seed: Optional[int] = None) -> int:
28 """
29 Function that sets seed for pseudo-random number generators in:
30 pytorch, numpy, python.random and sets PYTHONHASHSEED environment variable.
31 In addition, sets the env variable `PL_GLOBAL_SEED` which will be passed to
32 spawned subprocesses (e.g. ddp_spawn backend).
33
34 Args:
35 seed: the integer value seed for global random state in Lightning.
36 If `None`, will read seed from `PL_GLOBAL_SEED` env variable
37 or select it randomly.
38 """
39 max_seed_value = np.iinfo(np.uint32).max
40 min_seed_value = np.iinfo(np.uint32).min
41
42 try:
43 if seed is None:
44 seed = os.environ.get("PL_GLOBAL_SEED", _select_seed_randomly(min_seed_value, max_seed_value))
45 seed = int(seed)
46 except (TypeError, ValueError):
47 seed = _select_seed_randomly(min_seed_value, max_seed_value)
48
49 if (seed > max_seed_value) or (seed < min_seed_value):
50 log.warning(
51 f"{seed} is not in bounds, \
52 numpy accepts from {min_seed_value} to {max_seed_value}"
53 )
54 seed = _select_seed_randomly(min_seed_value, max_seed_value)
55
56 os.environ["PYTHONHASHSEED"] = str(seed)
57 os.environ["PL_GLOBAL_SEED"] = str(seed)
58 random.seed(seed)
59 np.random.seed(seed)
60 torch.manual_seed(seed)
61 torch.cuda.manual_seed_all(seed)
62 return seed
63
64
65 def _select_seed_randomly(min_seed_value: int = 0, max_seed_value: int = 255) -> int:
66 seed = random.randint(min_seed_value, max_seed_value)
67 log.warning(f"No correct seed found, seed set to {seed}")
68 return seed
69
[end of pytorch_lightning/utilities/seed.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pytorch_lightning/utilities/seed.py b/pytorch_lightning/utilities/seed.py
--- a/pytorch_lightning/utilities/seed.py
+++ b/pytorch_lightning/utilities/seed.py
@@ -27,7 +27,7 @@
def seed_everything(seed: Optional[int] = None) -> int:
"""
Function that sets seed for pseudo-random number generators in:
- pytorch, numpy, python.random and sets PYTHONHASHSEED environment variable.
+ pytorch, numpy, python.random
In addition, sets the env variable `PL_GLOBAL_SEED` which will be passed to
spawned subprocesses (e.g. ddp_spawn backend).
@@ -53,7 +53,6 @@
)
seed = _select_seed_randomly(min_seed_value, max_seed_value)
- os.environ["PYTHONHASHSEED"] = str(seed)
os.environ["PL_GLOBAL_SEED"] = str(seed)
random.seed(seed)
np.random.seed(seed)
|
{"golden_diff": "diff --git a/pytorch_lightning/utilities/seed.py b/pytorch_lightning/utilities/seed.py\n--- a/pytorch_lightning/utilities/seed.py\n+++ b/pytorch_lightning/utilities/seed.py\n@@ -27,7 +27,7 @@\n def seed_everything(seed: Optional[int] = None) -> int:\n \"\"\"\n Function that sets seed for pseudo-random number generators in:\n- pytorch, numpy, python.random and sets PYTHONHASHSEED environment variable.\n+ pytorch, numpy, python.random\n In addition, sets the env variable `PL_GLOBAL_SEED` which will be passed to\n spawned subprocesses (e.g. ddp_spawn backend).\n \n@@ -53,7 +53,6 @@\n )\n seed = _select_seed_randomly(min_seed_value, max_seed_value)\n \n- os.environ[\"PYTHONHASHSEED\"] = str(seed)\n os.environ[\"PL_GLOBAL_SEED\"] = str(seed)\n random.seed(seed)\n np.random.seed(seed)\n", "issue": "Setting of PYTHONHASHSEED has no effect\n<!-- \r\n### Common bugs:\r\n1. Tensorboard not showing in Jupyter-notebook see [issue 79](https://github.com/PyTorchLightning/pytorch-lightning/issues/79). \r\n2. PyTorch 1.1.0 vs 1.2.0 support [see FAQ](https://github.com/PyTorchLightning/pytorch-lightning#faq) \r\n-->\r\n\r\n## \ud83d\udc1b Bug\r\n(Previously submitted here: https://github.com/PyTorchLightning/pytorch-lightning/issues/1939, but I didn't use the correct template, so now I'm resubmitting)\r\n\r\nIn https://github.com/PyTorchLightning/pytorch-lightning/blob/9045b6c599df3871da6aaaa310f62d3f1364c632/pytorch_lightning/trainer/seed.py#L32\r\n, `PYTHONHASHSEED` is assigned a value in order to ensure reproducability. However, this assignment has no effect. In fact, this assignment might mislead the user or any logging software into believing that `PYTHONHASHSEED` has a specific value, when in fact it has another.\r\n\r\nTo see that setting `PYTHONHASHSEED` inside the current program has no effect, run the following two commands:\r\n```\r\nPYTHONHASHSEED=1 python -c \"import os; print(hash('a'))\"\r\nPYTHONHASHSEED=1 python -c \"import os; os.environ['PYTHONHASHSEED']='2'; print(hash('a'))\"\r\n```\r\nThe commands should output the same value, meaning that setting `PYTHONHASHSEED` after the process has started has no effect.\r\n\r\nThe following commands will likely output different values, also indicating that setting `PYTHONHASHSEED` after the process has started has no effect:\r\n```\r\nunset PYTHONHASHSEED # make sure it is not already set\r\npython -c \"import os; os.environ['PYTHONHASHSEED']='2'; print(hash('a'))\"\r\npython -c \"import os; os.environ['PYTHONHASHSEED']='2'; print(hash('a'))\"\r\n```\r\n\r\n<!-- A clear and concise description of what the bug is. -->\r\n\r\n### To Reproduce\r\n\r\nSteps to reproduce the behavior:\r\n\r\n1. Start python terminal with `PYTHONHASHSEED=1 python`\r\n2. Run \r\n```python\r\nimport pytorch_lightning as pl\r\npl.seed_everything(100)\r\nprint(hash('a'))\r\n# >>> 8432517439229126278\r\n```\r\n3. Start new python terminal with `PYTHONHASHSEED=2 python`\r\n4. Run\r\n```python\r\nimport pytorch_lightning as pl\r\npl.seed_everything(100)\r\nprint(hash('a'))\r\n# >>> -8333094867672744108\r\n```\r\n\r\n### Expected behavior\r\n\r\nExpect output of `hash` function to be the same in both cases. The examples demonstrate that this is not possible.\r\n<!-- A clear and concise description of what you expected to happen. -->\r\n\r\n### Environment\r\n\r\n```\r\n* CUDA:\r\n\t- GPU:\r\n\t- available: False\r\n\t- version: 10.2\r\n* Packages:\r\n\t- numpy: 1.18.5\r\n\t- pyTorch_debug: False\r\n\t- pyTorch_version: 1.5.0\r\n\t- pytorch-lightning: 0.7.6\r\n\t- tensorboard: 2.2.2\r\n\t- tqdm: 4.46.1\r\n* System:\r\n\t- OS: Linux\r\n\t- architecture:\r\n\t\t- 64bit\r\n\t\t- ELF\r\n\t- processor: \r\n\t- python: 3.8.3\r\n\t- version: #1 SMP PREEMPT Wed May 27 20:25:12 UTC 2020\r\n\r\n```\r\n\n", "before_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Helper functions to help with reproducibility of models. \"\"\"\n\nimport os\nimport random\nfrom typing import Optional\n\nimport numpy as np\nimport torch\n\nfrom pytorch_lightning import _logger as log\n\n\ndef seed_everything(seed: Optional[int] = None) -> int:\n \"\"\"\n Function that sets seed for pseudo-random number generators in:\n pytorch, numpy, python.random and sets PYTHONHASHSEED environment variable.\n In addition, sets the env variable `PL_GLOBAL_SEED` which will be passed to\n spawned subprocesses (e.g. ddp_spawn backend).\n\n Args:\n seed: the integer value seed for global random state in Lightning.\n If `None`, will read seed from `PL_GLOBAL_SEED` env variable\n or select it randomly.\n \"\"\"\n max_seed_value = np.iinfo(np.uint32).max\n min_seed_value = np.iinfo(np.uint32).min\n\n try:\n if seed is None:\n seed = os.environ.get(\"PL_GLOBAL_SEED\", _select_seed_randomly(min_seed_value, max_seed_value))\n seed = int(seed)\n except (TypeError, ValueError):\n seed = _select_seed_randomly(min_seed_value, max_seed_value)\n\n if (seed > max_seed_value) or (seed < min_seed_value):\n log.warning(\n f\"{seed} is not in bounds, \\\n numpy accepts from {min_seed_value} to {max_seed_value}\"\n )\n seed = _select_seed_randomly(min_seed_value, max_seed_value)\n\n os.environ[\"PYTHONHASHSEED\"] = str(seed)\n os.environ[\"PL_GLOBAL_SEED\"] = str(seed)\n random.seed(seed)\n np.random.seed(seed)\n torch.manual_seed(seed)\n torch.cuda.manual_seed_all(seed)\n return seed\n\n\ndef _select_seed_randomly(min_seed_value: int = 0, max_seed_value: int = 255) -> int:\n seed = random.randint(min_seed_value, max_seed_value)\n log.warning(f\"No correct seed found, seed set to {seed}\")\n return seed\n", "path": "pytorch_lightning/utilities/seed.py"}]}
| 2,116 | 220 |
gh_patches_debug_21147
|
rasdani/github-patches
|
git_diff
|
netbox-community__netbox-8565
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Banner edit fields should be larger
### NetBox version
v3.1.6
### Feature type
Change to existing functionality
### Proposed functionality
Currently the Login, Top and Bottom banner edit fields in Config revisions are small input fields: they only show a few words at the time. It makes editing the banners somewhat hard.
I propose that the input fields are shown larger, preferably as multi-line input fields, to make it easier to edit the HTML-containing banners.
### Use case
Communicating upcoming maintenances or specific login instructions is easier when the banner input fields are easier to edit.
### Database changes
None
### External dependencies
None
</issue>
<code>
[start of netbox/netbox/config/parameters.py]
1 from django import forms
2 from django.contrib.postgres.forms import SimpleArrayField
3
4
5 class ConfigParam:
6
7 def __init__(self, name, label, default, description='', field=None, field_kwargs=None):
8 self.name = name
9 self.label = label
10 self.default = default
11 self.field = field or forms.CharField
12 self.description = description
13 self.field_kwargs = field_kwargs or {}
14
15
16 PARAMS = (
17
18 # Banners
19 ConfigParam(
20 name='BANNER_LOGIN',
21 label='Login banner',
22 default='',
23 description="Additional content to display on the login page"
24 ),
25 ConfigParam(
26 name='BANNER_TOP',
27 label='Top banner',
28 default='',
29 description="Additional content to display at the top of every page"
30 ),
31 ConfigParam(
32 name='BANNER_BOTTOM',
33 label='Bottom banner',
34 default='',
35 description="Additional content to display at the bottom of every page"
36 ),
37
38 # IPAM
39 ConfigParam(
40 name='ENFORCE_GLOBAL_UNIQUE',
41 label='Globally unique IP space',
42 default=False,
43 description="Enforce unique IP addressing within the global table",
44 field=forms.BooleanField
45 ),
46 ConfigParam(
47 name='PREFER_IPV4',
48 label='Prefer IPv4',
49 default=False,
50 description="Prefer IPv4 addresses over IPv6",
51 field=forms.BooleanField
52 ),
53
54 # Racks
55 ConfigParam(
56 name='RACK_ELEVATION_DEFAULT_UNIT_HEIGHT',
57 label='Rack unit height',
58 default=22,
59 description="Default unit height for rendered rack elevations",
60 field=forms.IntegerField
61 ),
62 ConfigParam(
63 name='RACK_ELEVATION_DEFAULT_UNIT_WIDTH',
64 label='Rack unit width',
65 default=220,
66 description="Default unit width for rendered rack elevations",
67 field=forms.IntegerField
68 ),
69
70 # Security
71 ConfigParam(
72 name='ALLOWED_URL_SCHEMES',
73 label='Allowed URL schemes',
74 default=(
75 'file', 'ftp', 'ftps', 'http', 'https', 'irc', 'mailto', 'sftp', 'ssh', 'tel', 'telnet', 'tftp', 'vnc',
76 'xmpp',
77 ),
78 description="Permitted schemes for URLs in user-provided content",
79 field=SimpleArrayField,
80 field_kwargs={'base_field': forms.CharField()}
81 ),
82
83 # Pagination
84 ConfigParam(
85 name='PAGINATE_COUNT',
86 label='Default page size',
87 default=50,
88 field=forms.IntegerField
89 ),
90 ConfigParam(
91 name='MAX_PAGE_SIZE',
92 label='Maximum page size',
93 default=1000,
94 field=forms.IntegerField
95 ),
96
97 # Validation
98 ConfigParam(
99 name='CUSTOM_VALIDATORS',
100 label='Custom validators',
101 default={},
102 description="Custom validation rules (JSON)",
103 field=forms.JSONField
104 ),
105
106 # NAPALM
107 ConfigParam(
108 name='NAPALM_USERNAME',
109 label='NAPALM username',
110 default='',
111 description="Username to use when connecting to devices via NAPALM"
112 ),
113 ConfigParam(
114 name='NAPALM_PASSWORD',
115 label='NAPALM password',
116 default='',
117 description="Password to use when connecting to devices via NAPALM"
118 ),
119 ConfigParam(
120 name='NAPALM_TIMEOUT',
121 label='NAPALM timeout',
122 default=30,
123 description="NAPALM connection timeout (in seconds)",
124 field=forms.IntegerField
125 ),
126 ConfigParam(
127 name='NAPALM_ARGS',
128 label='NAPALM arguments',
129 default={},
130 description="Additional arguments to pass when invoking a NAPALM driver (as JSON data)",
131 field=forms.JSONField
132 ),
133
134 # Miscellaneous
135 ConfigParam(
136 name='MAINTENANCE_MODE',
137 label='Maintenance mode',
138 default=False,
139 description="Enable maintenance mode",
140 field=forms.BooleanField
141 ),
142 ConfigParam(
143 name='GRAPHQL_ENABLED',
144 label='GraphQL enabled',
145 default=True,
146 description="Enable the GraphQL API",
147 field=forms.BooleanField
148 ),
149 ConfigParam(
150 name='CHANGELOG_RETENTION',
151 label='Changelog retention',
152 default=90,
153 description="Days to retain changelog history (set to zero for unlimited)",
154 field=forms.IntegerField
155 ),
156 ConfigParam(
157 name='MAPS_URL',
158 label='Maps URL',
159 default='https://maps.google.com/?q=',
160 description="Base URL for mapping geographic locations"
161 ),
162
163 )
164
[end of netbox/netbox/config/parameters.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/netbox/netbox/config/parameters.py b/netbox/netbox/config/parameters.py
--- a/netbox/netbox/config/parameters.py
+++ b/netbox/netbox/config/parameters.py
@@ -20,19 +20,28 @@
name='BANNER_LOGIN',
label='Login banner',
default='',
- description="Additional content to display on the login page"
+ description="Additional content to display on the login page",
+ field_kwargs={
+ 'widget': forms.Textarea(),
+ },
),
ConfigParam(
name='BANNER_TOP',
label='Top banner',
default='',
- description="Additional content to display at the top of every page"
+ description="Additional content to display at the top of every page",
+ field_kwargs={
+ 'widget': forms.Textarea(),
+ },
),
ConfigParam(
name='BANNER_BOTTOM',
label='Bottom banner',
default='',
- description="Additional content to display at the bottom of every page"
+ description="Additional content to display at the bottom of every page",
+ field_kwargs={
+ 'widget': forms.Textarea(),
+ },
),
# IPAM
|
{"golden_diff": "diff --git a/netbox/netbox/config/parameters.py b/netbox/netbox/config/parameters.py\n--- a/netbox/netbox/config/parameters.py\n+++ b/netbox/netbox/config/parameters.py\n@@ -20,19 +20,28 @@\n name='BANNER_LOGIN',\n label='Login banner',\n default='',\n- description=\"Additional content to display on the login page\"\n+ description=\"Additional content to display on the login page\",\n+ field_kwargs={\n+ 'widget': forms.Textarea(),\n+ },\n ),\n ConfigParam(\n name='BANNER_TOP',\n label='Top banner',\n default='',\n- description=\"Additional content to display at the top of every page\"\n+ description=\"Additional content to display at the top of every page\",\n+ field_kwargs={\n+ 'widget': forms.Textarea(),\n+ },\n ),\n ConfigParam(\n name='BANNER_BOTTOM',\n label='Bottom banner',\n default='',\n- description=\"Additional content to display at the bottom of every page\"\n+ description=\"Additional content to display at the bottom of every page\",\n+ field_kwargs={\n+ 'widget': forms.Textarea(),\n+ },\n ),\n \n # IPAM\n", "issue": "Banner edit fields should be larger\n### NetBox version\n\nv3.1.6\n\n### Feature type\n\nChange to existing functionality\n\n### Proposed functionality\n\nCurrently the Login, Top and Bottom banner edit fields in Config revisions are small input fields: they only show a few words at the time. It makes editing the banners somewhat hard.\r\n\r\nI propose that the input fields are shown larger, preferably as multi-line input fields, to make it easier to edit the HTML-containing banners.\n\n### Use case\n\nCommunicating upcoming maintenances or specific login instructions is easier when the banner input fields are easier to edit.\n\n### Database changes\n\nNone\n\n### External dependencies\n\nNone\n", "before_files": [{"content": "from django import forms\nfrom django.contrib.postgres.forms import SimpleArrayField\n\n\nclass ConfigParam:\n\n def __init__(self, name, label, default, description='', field=None, field_kwargs=None):\n self.name = name\n self.label = label\n self.default = default\n self.field = field or forms.CharField\n self.description = description\n self.field_kwargs = field_kwargs or {}\n\n\nPARAMS = (\n\n # Banners\n ConfigParam(\n name='BANNER_LOGIN',\n label='Login banner',\n default='',\n description=\"Additional content to display on the login page\"\n ),\n ConfigParam(\n name='BANNER_TOP',\n label='Top banner',\n default='',\n description=\"Additional content to display at the top of every page\"\n ),\n ConfigParam(\n name='BANNER_BOTTOM',\n label='Bottom banner',\n default='',\n description=\"Additional content to display at the bottom of every page\"\n ),\n\n # IPAM\n ConfigParam(\n name='ENFORCE_GLOBAL_UNIQUE',\n label='Globally unique IP space',\n default=False,\n description=\"Enforce unique IP addressing within the global table\",\n field=forms.BooleanField\n ),\n ConfigParam(\n name='PREFER_IPV4',\n label='Prefer IPv4',\n default=False,\n description=\"Prefer IPv4 addresses over IPv6\",\n field=forms.BooleanField\n ),\n\n # Racks\n ConfigParam(\n name='RACK_ELEVATION_DEFAULT_UNIT_HEIGHT',\n label='Rack unit height',\n default=22,\n description=\"Default unit height for rendered rack elevations\",\n field=forms.IntegerField\n ),\n ConfigParam(\n name='RACK_ELEVATION_DEFAULT_UNIT_WIDTH',\n label='Rack unit width',\n default=220,\n description=\"Default unit width for rendered rack elevations\",\n field=forms.IntegerField\n ),\n\n # Security\n ConfigParam(\n name='ALLOWED_URL_SCHEMES',\n label='Allowed URL schemes',\n default=(\n 'file', 'ftp', 'ftps', 'http', 'https', 'irc', 'mailto', 'sftp', 'ssh', 'tel', 'telnet', 'tftp', 'vnc',\n 'xmpp',\n ),\n description=\"Permitted schemes for URLs in user-provided content\",\n field=SimpleArrayField,\n field_kwargs={'base_field': forms.CharField()}\n ),\n\n # Pagination\n ConfigParam(\n name='PAGINATE_COUNT',\n label='Default page size',\n default=50,\n field=forms.IntegerField\n ),\n ConfigParam(\n name='MAX_PAGE_SIZE',\n label='Maximum page size',\n default=1000,\n field=forms.IntegerField\n ),\n\n # Validation\n ConfigParam(\n name='CUSTOM_VALIDATORS',\n label='Custom validators',\n default={},\n description=\"Custom validation rules (JSON)\",\n field=forms.JSONField\n ),\n\n # NAPALM\n ConfigParam(\n name='NAPALM_USERNAME',\n label='NAPALM username',\n default='',\n description=\"Username to use when connecting to devices via NAPALM\"\n ),\n ConfigParam(\n name='NAPALM_PASSWORD',\n label='NAPALM password',\n default='',\n description=\"Password to use when connecting to devices via NAPALM\"\n ),\n ConfigParam(\n name='NAPALM_TIMEOUT',\n label='NAPALM timeout',\n default=30,\n description=\"NAPALM connection timeout (in seconds)\",\n field=forms.IntegerField\n ),\n ConfigParam(\n name='NAPALM_ARGS',\n label='NAPALM arguments',\n default={},\n description=\"Additional arguments to pass when invoking a NAPALM driver (as JSON data)\",\n field=forms.JSONField\n ),\n\n # Miscellaneous\n ConfigParam(\n name='MAINTENANCE_MODE',\n label='Maintenance mode',\n default=False,\n description=\"Enable maintenance mode\",\n field=forms.BooleanField\n ),\n ConfigParam(\n name='GRAPHQL_ENABLED',\n label='GraphQL enabled',\n default=True,\n description=\"Enable the GraphQL API\",\n field=forms.BooleanField\n ),\n ConfigParam(\n name='CHANGELOG_RETENTION',\n label='Changelog retention',\n default=90,\n description=\"Days to retain changelog history (set to zero for unlimited)\",\n field=forms.IntegerField\n ),\n ConfigParam(\n name='MAPS_URL',\n label='Maps URL',\n default='https://maps.google.com/?q=',\n description=\"Base URL for mapping geographic locations\"\n ),\n\n)\n", "path": "netbox/netbox/config/parameters.py"}]}
| 2,057 | 263 |
gh_patches_debug_22573
|
rasdani/github-patches
|
git_diff
|
HypothesisWorks__hypothesis-689
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Sampled_from() should work with collections.OrderedDict
OrderedDict should satisfy the replayability requirement, so sampling from it should be possible.
Currently it raises exception:
`HypothesisDeprecationWarning: Cannot sample from odict_values`
</issue>
<code>
[start of src/hypothesis/version.py]
1 # coding=utf-8
2 #
3 # This file is part of Hypothesis, which may be found at
4 # https://github.com/HypothesisWorks/hypothesis-python
5 #
6 # Most of this work is copyright (C) 2013-2017 David R. MacIver
7 # ([email protected]), but it contains contributions by others. See
8 # CONTRIBUTING.rst for a full list of people who may hold copyright, and
9 # consult the git log if you need to determine who owns an individual
10 # contribution.
11 #
12 # This Source Code Form is subject to the terms of the Mozilla Public License,
13 # v. 2.0. If a copy of the MPL was not distributed with this file, You can
14 # obtain one at http://mozilla.org/MPL/2.0/.
15 #
16 # END HEADER
17
18 from __future__ import division, print_function, absolute_import
19
20 __version_info__ = (3, 11, 2)
21 __version__ = '.'.join(map(str, __version_info__))
22
[end of src/hypothesis/version.py]
[start of src/hypothesis/internal/conjecture/utils.py]
1 # coding=utf-8
2 #
3 # This file is part of Hypothesis, which may be found at
4 # https://github.com/HypothesisWorks/hypothesis-python
5 #
6 # Most of this work is copyright (C) 2013-2017 David R. MacIver
7 # ([email protected]), but it contains contributions by others. See
8 # CONTRIBUTING.rst for a full list of people who may hold copyright, and
9 # consult the git log if you need to determine who owns an individual
10 # contribution.
11 #
12 # This Source Code Form is subject to the terms of the Mozilla Public License,
13 # v. 2.0. If a copy of the MPL was not distributed with this file, You can
14 # obtain one at http://mozilla.org/MPL/2.0/.
15 #
16 # END HEADER
17
18 from __future__ import division, print_function, absolute_import
19
20 import enum
21 import math
22 from collections import Sequence
23
24 from hypothesis._settings import note_deprecation
25 from hypothesis.internal.compat import hbytes, bit_length, int_to_bytes, \
26 int_from_bytes
27
28
29 def n_byte_unsigned(data, n):
30 return int_from_bytes(data.draw_bytes(n))
31
32
33 def saturate(n):
34 bits = bit_length(n)
35 k = 1
36 while k < bits:
37 n |= (n >> k)
38 k *= 2
39 return n
40
41
42 def integer_range(data, lower, upper, center=None, distribution=None):
43 assert lower <= upper
44 if lower == upper:
45 return int(lower)
46
47 if center is None:
48 center = lower
49 center = min(max(center, lower), upper)
50 if distribution is None:
51 if lower < center < upper:
52 def distribution(random):
53 if random.randint(0, 1):
54 return random.randint(center, upper)
55 else:
56 return random.randint(lower, center)
57 else:
58 def distribution(random):
59 return random.randint(lower, upper)
60
61 gap = upper - lower
62 bits = bit_length(gap)
63 nbytes = bits // 8 + int(bits % 8 != 0)
64 mask = saturate(gap)
65
66 def byte_distribution(random, n):
67 assert n == nbytes
68 v = distribution(random)
69 if v >= center:
70 probe = v - center
71 else:
72 probe = upper - v
73 return int_to_bytes(probe, n)
74
75 probe = gap + 1
76
77 while probe > gap:
78 probe = int_from_bytes(
79 data.draw_bytes(nbytes, byte_distribution)
80 ) & mask
81
82 if center == upper:
83 result = upper - probe
84 elif center == lower:
85 result = lower + probe
86 else:
87 if center + probe <= upper:
88 result = center + probe
89 else:
90 result = upper - probe
91 assert lower <= result <= upper
92 return int(result)
93
94
95 def integer_range_with_distribution(data, lower, upper, nums):
96 return integer_range(
97 data, lower, upper, distribution=nums
98 )
99
100
101 def centered_integer_range(data, lower, upper, center):
102 return integer_range(
103 data, lower, upper, center=center
104 )
105
106
107 def check_sample(values):
108 if not isinstance(values, (Sequence, enum.EnumMeta)):
109 note_deprecation(
110 ('Cannot sample from %r, not a sequence. ' % (values,)) +
111 'Hypothesis goes to some length to ensure that sampling an '
112 'element from a collection (with `sampled_from` or `choices`) is '
113 'replayable and can be minimised. To replay a saved example, '
114 'the sampled values must have the same iteration order on every '
115 'run - ruling out sets, dicts, etc due to hash randomisation. '
116 'Most cases can simply use `sorted(values)`, but mixed types or '
117 'special values such as math.nan require careful handling - and '
118 'note that when simplifying an example, Hypothesis treats '
119 'earlier values as simpler.')
120 return tuple(values)
121
122
123 def choice(data, values):
124 return values[integer_range(data, 0, len(values) - 1)]
125
126
127 def geometric(data, p):
128 denom = math.log1p(-p)
129 n_bytes = 8
130
131 def distribution(random, n):
132 assert n == n_bytes
133 for _ in range(100):
134 try:
135 return int_to_bytes(int(
136 math.log1p(-random.random()) / denom), n)
137 # This is basically impossible to hit but is required for
138 # correctness
139 except OverflowError: # pragma: no cover
140 pass
141 # We got a one in a million chance 100 times in a row. Something is up.
142 assert False # pragma: no cover
143 return int_from_bytes(data.draw_bytes(n_bytes, distribution))
144
145
146 def boolean(data):
147 return bool(n_byte_unsigned(data, 1) & 1)
148
149
150 def biased_coin(data, p):
151 def distribution(random, n):
152 assert n == 1
153 return hbytes([int(random.random() <= p)])
154 return bool(
155 data.draw_bytes(1, distribution)[0] & 1
156 )
157
158
159 def write(data, string):
160 assert isinstance(string, hbytes)
161
162 def distribution(random, n):
163 assert n == len(string)
164 return string
165 x = data.draw_bytes(len(string), distribution)
166 if x != string:
167 data.mark_invalid()
168
[end of src/hypothesis/internal/conjecture/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/hypothesis/internal/conjecture/utils.py b/src/hypothesis/internal/conjecture/utils.py
--- a/src/hypothesis/internal/conjecture/utils.py
+++ b/src/hypothesis/internal/conjecture/utils.py
@@ -19,7 +19,7 @@
import enum
import math
-from collections import Sequence
+from collections import Sequence, OrderedDict
from hypothesis._settings import note_deprecation
from hypothesis.internal.compat import hbytes, bit_length, int_to_bytes, \
@@ -105,7 +105,7 @@
def check_sample(values):
- if not isinstance(values, (Sequence, enum.EnumMeta)):
+ if not isinstance(values, (OrderedDict, Sequence, enum.EnumMeta)):
note_deprecation(
('Cannot sample from %r, not a sequence. ' % (values,)) +
'Hypothesis goes to some length to ensure that sampling an '
diff --git a/src/hypothesis/version.py b/src/hypothesis/version.py
--- a/src/hypothesis/version.py
+++ b/src/hypothesis/version.py
@@ -17,5 +17,5 @@
from __future__ import division, print_function, absolute_import
-__version_info__ = (3, 11, 2)
+__version_info__ = (3, 11, 3)
__version__ = '.'.join(map(str, __version_info__))
|
{"golden_diff": "diff --git a/src/hypothesis/internal/conjecture/utils.py b/src/hypothesis/internal/conjecture/utils.py\n--- a/src/hypothesis/internal/conjecture/utils.py\n+++ b/src/hypothesis/internal/conjecture/utils.py\n@@ -19,7 +19,7 @@\n \n import enum\n import math\n-from collections import Sequence\n+from collections import Sequence, OrderedDict\n \n from hypothesis._settings import note_deprecation\n from hypothesis.internal.compat import hbytes, bit_length, int_to_bytes, \\\n@@ -105,7 +105,7 @@\n \n \n def check_sample(values):\n- if not isinstance(values, (Sequence, enum.EnumMeta)):\n+ if not isinstance(values, (OrderedDict, Sequence, enum.EnumMeta)):\n note_deprecation(\n ('Cannot sample from %r, not a sequence. ' % (values,)) +\n 'Hypothesis goes to some length to ensure that sampling an '\ndiff --git a/src/hypothesis/version.py b/src/hypothesis/version.py\n--- a/src/hypothesis/version.py\n+++ b/src/hypothesis/version.py\n@@ -17,5 +17,5 @@\n \n from __future__ import division, print_function, absolute_import\n \n-__version_info__ = (3, 11, 2)\n+__version_info__ = (3, 11, 3)\n __version__ = '.'.join(map(str, __version_info__))\n", "issue": "Sampled_from() should work with collections.OrderedDict\nOrderedDict should satisfy the replayability requirement, so sampling from it should be possible.\r\nCurrently it raises exception:\r\n`HypothesisDeprecationWarning: Cannot sample from odict_values`\n", "before_files": [{"content": "# coding=utf-8\n#\n# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis-python\n#\n# Most of this work is copyright (C) 2013-2017 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at http://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nfrom __future__ import division, print_function, absolute_import\n\n__version_info__ = (3, 11, 2)\n__version__ = '.'.join(map(str, __version_info__))\n", "path": "src/hypothesis/version.py"}, {"content": "# coding=utf-8\n#\n# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis-python\n#\n# Most of this work is copyright (C) 2013-2017 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at http://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nfrom __future__ import division, print_function, absolute_import\n\nimport enum\nimport math\nfrom collections import Sequence\n\nfrom hypothesis._settings import note_deprecation\nfrom hypothesis.internal.compat import hbytes, bit_length, int_to_bytes, \\\n int_from_bytes\n\n\ndef n_byte_unsigned(data, n):\n return int_from_bytes(data.draw_bytes(n))\n\n\ndef saturate(n):\n bits = bit_length(n)\n k = 1\n while k < bits:\n n |= (n >> k)\n k *= 2\n return n\n\n\ndef integer_range(data, lower, upper, center=None, distribution=None):\n assert lower <= upper\n if lower == upper:\n return int(lower)\n\n if center is None:\n center = lower\n center = min(max(center, lower), upper)\n if distribution is None:\n if lower < center < upper:\n def distribution(random):\n if random.randint(0, 1):\n return random.randint(center, upper)\n else:\n return random.randint(lower, center)\n else:\n def distribution(random):\n return random.randint(lower, upper)\n\n gap = upper - lower\n bits = bit_length(gap)\n nbytes = bits // 8 + int(bits % 8 != 0)\n mask = saturate(gap)\n\n def byte_distribution(random, n):\n assert n == nbytes\n v = distribution(random)\n if v >= center:\n probe = v - center\n else:\n probe = upper - v\n return int_to_bytes(probe, n)\n\n probe = gap + 1\n\n while probe > gap:\n probe = int_from_bytes(\n data.draw_bytes(nbytes, byte_distribution)\n ) & mask\n\n if center == upper:\n result = upper - probe\n elif center == lower:\n result = lower + probe\n else:\n if center + probe <= upper:\n result = center + probe\n else:\n result = upper - probe\n assert lower <= result <= upper\n return int(result)\n\n\ndef integer_range_with_distribution(data, lower, upper, nums):\n return integer_range(\n data, lower, upper, distribution=nums\n )\n\n\ndef centered_integer_range(data, lower, upper, center):\n return integer_range(\n data, lower, upper, center=center\n )\n\n\ndef check_sample(values):\n if not isinstance(values, (Sequence, enum.EnumMeta)):\n note_deprecation(\n ('Cannot sample from %r, not a sequence. ' % (values,)) +\n 'Hypothesis goes to some length to ensure that sampling an '\n 'element from a collection (with `sampled_from` or `choices`) is '\n 'replayable and can be minimised. To replay a saved example, '\n 'the sampled values must have the same iteration order on every '\n 'run - ruling out sets, dicts, etc due to hash randomisation. '\n 'Most cases can simply use `sorted(values)`, but mixed types or '\n 'special values such as math.nan require careful handling - and '\n 'note that when simplifying an example, Hypothesis treats '\n 'earlier values as simpler.')\n return tuple(values)\n\n\ndef choice(data, values):\n return values[integer_range(data, 0, len(values) - 1)]\n\n\ndef geometric(data, p):\n denom = math.log1p(-p)\n n_bytes = 8\n\n def distribution(random, n):\n assert n == n_bytes\n for _ in range(100):\n try:\n return int_to_bytes(int(\n math.log1p(-random.random()) / denom), n)\n # This is basically impossible to hit but is required for\n # correctness\n except OverflowError: # pragma: no cover\n pass\n # We got a one in a million chance 100 times in a row. Something is up.\n assert False # pragma: no cover\n return int_from_bytes(data.draw_bytes(n_bytes, distribution))\n\n\ndef boolean(data):\n return bool(n_byte_unsigned(data, 1) & 1)\n\n\ndef biased_coin(data, p):\n def distribution(random, n):\n assert n == 1\n return hbytes([int(random.random() <= p)])\n return bool(\n data.draw_bytes(1, distribution)[0] & 1\n )\n\n\ndef write(data, string):\n assert isinstance(string, hbytes)\n\n def distribution(random, n):\n assert n == len(string)\n return string\n x = data.draw_bytes(len(string), distribution)\n if x != string:\n data.mark_invalid()\n", "path": "src/hypothesis/internal/conjecture/utils.py"}]}
| 2,458 | 308 |
gh_patches_debug_10090
|
rasdani/github-patches
|
git_diff
|
lutris__lutris-3944
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Won't open configure panel with some icons
```
2021-11-03 02:59:23,691: Unable to load icon from image fl-studio
Traceback (most recent call last):
File "/usr/lib/python3/dist-packages/lutris/game_actions.py", line 178, in on_edit_game_configuration
EditGameConfigDialog(self.window, self.game)
File "/usr/lib/python3/dist-packages/lutris/gui/config/edit_game.py", line 16, in __init__
self.build_tabs("game")
File "/usr/lib/python3/dist-packages/lutris/gui/config/common.py", line 70, in build_tabs
self._build_info_tab()
File "/usr/lib/python3/dist-packages/lutris/gui/config/common.py", line 79, in _build_info_tab
info_box.pack_start(self._get_banner_box(), False, False, 6) # Banner
File "/usr/lib/python3/dist-packages/lutris/gui/config/common.py", line 155, in _get_banner_box
self._set_image("banner")
File "/usr/lib/python3/dist-packages/lutris/gui/config/common.py", line 195, in _set_image
image.set_from_pixbuf(get_pixbuf_for_game(game_slug, size))
File "/usr/lib/python3/dist-packages/lutris/gui/widgets/utils.py", line 127, in get_pixbuf_for_game
return get_pixbuf(image_abspath, size, fallback=get_default_icon(size), is_installed=is_installed)
File "/usr/lib/python3/dist-packages/lutris/gui/widgets/utils.py", line 58, in get_pixbuf
pixbuf = pixbuf.scale_simple(width, height, GdkPixbuf.InterpType.NEAREST)
AttributeError: 'NoneType' object has no attribute 'scale_simple'
```
This seems to happen with the icon for "FL Studio", right click > configure to reproduce.
</issue>
<code>
[start of lutris/gui/widgets/utils.py]
1 """Various utilities using the GObject framework"""
2 import array
3 import os
4
5 from gi.repository import Gdk, GdkPixbuf, Gio, GLib, Gtk
6
7 from lutris import settings
8 from lutris.util import datapath, system
9 from lutris.util.log import logger
10
11 try:
12 from PIL import Image
13 except ImportError:
14 Image = None
15
16 ICON_SIZE = (32, 32)
17 BANNER_SIZE = (184, 69)
18
19
20 def get_main_window(widget):
21 """Return the application's main window from one of its widget"""
22 parent = widget.get_toplevel()
23 if not isinstance(parent, Gtk.Window):
24 # The sync dialog may have closed
25 parent = Gio.Application.get_default().props.active_window
26 for window in parent.application.get_windows():
27 if "LutrisWindow" in window.__class__.__name__:
28 return window
29 return
30
31
32 def open_uri(uri):
33 """Opens a local or remote URI with the default application"""
34 system.reset_library_preloads()
35 try:
36 Gtk.show_uri(None, uri, Gdk.CURRENT_TIME)
37 except GLib.Error as ex:
38 logger.exception("Failed to open URI %s: %s, falling back to xdg-open", uri, ex)
39 system.execute(["xdg-open", uri])
40
41
42 def get_pixbuf(image, size, fallback=None, is_installed=True):
43 """Return a pixbuf from file `image` at `size` or fallback to `fallback`"""
44 width, height = size
45 pixbuf = None
46 if system.path_exists(image, exclude_empty=True):
47 try:
48 pixbuf = GdkPixbuf.Pixbuf.new_from_file_at_size(image, width, height)
49 pixbuf = pixbuf.scale_simple(width, height, GdkPixbuf.InterpType.NEAREST)
50 except GLib.GError:
51 logger.error("Unable to load icon from image %s", image)
52 else:
53 if not fallback:
54 fallback = get_default_icon(size)
55 if system.path_exists(fallback):
56 pixbuf = GdkPixbuf.Pixbuf.new_from_file_at_size(fallback, width, height)
57 if is_installed:
58 pixbuf = pixbuf.scale_simple(width, height, GdkPixbuf.InterpType.NEAREST)
59 return pixbuf
60 overlay = os.path.join(datapath.get(), "media/unavailable.png")
61 transparent_pixbuf = get_overlay(overlay, size).copy()
62 if pixbuf:
63 pixbuf.composite(
64 transparent_pixbuf,
65 0,
66 0,
67 size[0],
68 size[1],
69 0,
70 0,
71 1,
72 1,
73 GdkPixbuf.InterpType.NEAREST,
74 100,
75 )
76 return transparent_pixbuf
77
78
79 def get_stock_icon(name, size):
80 """Return a pixbuf from a stock icon name"""
81 theme = Gtk.IconTheme.get_default()
82 try:
83 return theme.load_icon(name, size, Gtk.IconLookupFlags.GENERIC_FALLBACK)
84 except GLib.GError:
85 logger.error("Failed to read icon %s", name)
86 return None
87
88
89 def get_icon(icon_name, icon_format="image", size=None, icon_type="runner"):
90 """Return an icon based on the given name, format, size and type.
91
92 Keyword arguments:
93 icon_name -- The name of the icon to retrieve
94 format -- The format of the icon, which should be either 'image' or 'pixbuf' (default 'image')
95 size -- The size for the desired image (default None)
96 icon_type -- Retrieve either a 'runner' or 'platform' icon (default 'runner')
97 """
98 filename = icon_name.lower().replace(" ", "") + ".png"
99 icon_path = os.path.join(settings.RUNTIME_DIR, "icons/hicolor/64x64/apps", filename)
100 if not os.path.exists(icon_path):
101 return None
102 if icon_format == "image":
103 icon = Gtk.Image()
104 if size:
105 icon.set_from_pixbuf(get_pixbuf(icon_path, size))
106 else:
107 icon.set_from_file(icon_path)
108 return icon
109 if icon_format == "pixbuf" and size:
110 return get_pixbuf(icon_path, size)
111 raise ValueError("Invalid arguments")
112
113
114 def get_overlay(overlay_path, size):
115 width, height = size
116 transparent_pixbuf = GdkPixbuf.Pixbuf.new_from_file_at_size(overlay_path, width, height)
117 transparent_pixbuf = transparent_pixbuf.scale_simple(width, height, GdkPixbuf.InterpType.NEAREST)
118 return transparent_pixbuf
119
120
121 def get_default_icon(size):
122 if size[0] == size[1]:
123 return os.path.join(datapath.get(), "media/default_icon.png")
124 return os.path.join(datapath.get(), "media/default_banner.png")
125
126
127 def convert_to_background(background_path, target_size=(320, 1080)):
128 """Converts a image to a pane background"""
129 coverart = Image.open(background_path)
130 coverart = coverart.convert("RGBA")
131
132 target_width, target_height = target_size
133 image_height = int(target_height * 0.80) # 80% of the mask is visible
134 orig_width, orig_height = coverart.size
135
136 # Resize and crop coverart
137 width = int(orig_width * (image_height / orig_height))
138 offset = int((width - target_width) / 2)
139 coverart = coverart.resize((width, image_height), resample=Image.BICUBIC)
140 coverart = coverart.crop((offset, 0, target_width + offset, image_height))
141
142 # Resize canvas of coverart by putting transparent pixels on the bottom
143 coverart_bg = Image.new('RGBA', (target_width, target_height), (0, 0, 0, 0))
144 coverart_bg.paste(coverart, (0, 0, target_width, image_height))
145
146 # Apply a tint to the base image
147 # tint = Image.new('RGBA', (target_width, target_height), (0, 0, 0, 255))
148 # coverart = Image.blend(coverart, tint, 0.6)
149
150 # Paste coverart on transparent image while applying a gradient mask
151 background = Image.new('RGBA', (target_width, target_height), (0, 0, 0, 0))
152 mask = Image.open(os.path.join(datapath.get(), "media/mask.png"))
153 background.paste(coverart_bg, mask=mask)
154
155 return background
156
157
158 def thumbnail_image(base_image, target_size):
159 base_width, base_height = base_image.size
160 base_ratio = base_width / base_height
161 target_width, target_height = target_size
162 target_ratio = target_width / target_height
163
164 # Resize and crop coverart
165 if base_ratio >= target_ratio:
166 width = int(base_width * (target_height / base_height))
167 height = target_height
168 else:
169 width = target_width
170 height = int(base_height * (target_width / base_width))
171 x_offset = int((width - target_width) / 2)
172 y_offset = int((height - target_height) / 2)
173 base_image = base_image.resize((width, height), resample=Image.BICUBIC)
174 base_image = base_image.crop((x_offset, y_offset, width - x_offset, height - y_offset))
175 return base_image
176
177
178 def paste_overlay(base_image, overlay_image, position=0.7):
179 base_width, base_height = base_image.size
180 overlay_width, overlay_height = overlay_image.size
181 offset_x = int((base_width - overlay_width) / 2)
182 offset_y = int((base_height - overlay_height) / 2)
183 base_image.paste(
184 overlay_image, (
185 offset_x,
186 offset_y,
187 overlay_width + offset_x,
188 overlay_height + offset_y
189 ),
190 mask=overlay_image
191 )
192 return base_image
193
194
195 def image2pixbuf(image):
196 """Converts a PIL Image to a GDK Pixbuf"""
197 image_array = array.array('B', image.tobytes())
198 width, height = image.size
199 return GdkPixbuf.Pixbuf.new_from_data(image_array, GdkPixbuf.Colorspace.RGB, True, 8, width, height, width * 4)
200
201
202 def get_link_button(text):
203 """Return a transparent text button for the side panels"""
204 button = Gtk.Button(text, visible=True)
205 button.props.relief = Gtk.ReliefStyle.NONE
206 button.get_children()[0].set_alignment(0, 0.5)
207 button.get_style_context().add_class("panel-button")
208 button.set_size_request(-1, 24)
209 return button
210
211
212 def load_icon_theme():
213 """Add the lutris icon folder to the default theme"""
214 icon_theme = Gtk.IconTheme.get_default()
215 local_theme_path = os.path.join(settings.RUNTIME_DIR, "icons")
216 if local_theme_path not in icon_theme.get_search_path():
217 icon_theme.prepend_search_path(local_theme_path)
218
[end of lutris/gui/widgets/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lutris/gui/widgets/utils.py b/lutris/gui/widgets/utils.py
--- a/lutris/gui/widgets/utils.py
+++ b/lutris/gui/widgets/utils.py
@@ -54,7 +54,7 @@
fallback = get_default_icon(size)
if system.path_exists(fallback):
pixbuf = GdkPixbuf.Pixbuf.new_from_file_at_size(fallback, width, height)
- if is_installed:
+ if is_installed and pixbuf:
pixbuf = pixbuf.scale_simple(width, height, GdkPixbuf.InterpType.NEAREST)
return pixbuf
overlay = os.path.join(datapath.get(), "media/unavailable.png")
|
{"golden_diff": "diff --git a/lutris/gui/widgets/utils.py b/lutris/gui/widgets/utils.py\n--- a/lutris/gui/widgets/utils.py\n+++ b/lutris/gui/widgets/utils.py\n@@ -54,7 +54,7 @@\n fallback = get_default_icon(size)\n if system.path_exists(fallback):\n pixbuf = GdkPixbuf.Pixbuf.new_from_file_at_size(fallback, width, height)\n- if is_installed:\n+ if is_installed and pixbuf:\n pixbuf = pixbuf.scale_simple(width, height, GdkPixbuf.InterpType.NEAREST)\n return pixbuf\n overlay = os.path.join(datapath.get(), \"media/unavailable.png\")\n", "issue": "Won't open configure panel with some icons\n```\r\n2021-11-03 02:59:23,691: Unable to load icon from image fl-studio\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python3/dist-packages/lutris/game_actions.py\", line 178, in on_edit_game_configuration\r\n EditGameConfigDialog(self.window, self.game)\r\n File \"/usr/lib/python3/dist-packages/lutris/gui/config/edit_game.py\", line 16, in __init__\r\n self.build_tabs(\"game\")\r\n File \"/usr/lib/python3/dist-packages/lutris/gui/config/common.py\", line 70, in build_tabs\r\n self._build_info_tab()\r\n File \"/usr/lib/python3/dist-packages/lutris/gui/config/common.py\", line 79, in _build_info_tab\r\n info_box.pack_start(self._get_banner_box(), False, False, 6) # Banner\r\n File \"/usr/lib/python3/dist-packages/lutris/gui/config/common.py\", line 155, in _get_banner_box\r\n self._set_image(\"banner\")\r\n File \"/usr/lib/python3/dist-packages/lutris/gui/config/common.py\", line 195, in _set_image\r\n image.set_from_pixbuf(get_pixbuf_for_game(game_slug, size))\r\n File \"/usr/lib/python3/dist-packages/lutris/gui/widgets/utils.py\", line 127, in get_pixbuf_for_game\r\n return get_pixbuf(image_abspath, size, fallback=get_default_icon(size), is_installed=is_installed)\r\n File \"/usr/lib/python3/dist-packages/lutris/gui/widgets/utils.py\", line 58, in get_pixbuf\r\n pixbuf = pixbuf.scale_simple(width, height, GdkPixbuf.InterpType.NEAREST)\r\nAttributeError: 'NoneType' object has no attribute 'scale_simple'\r\n```\r\n\r\n\r\nThis seems to happen with the icon for \"FL Studio\", right click > configure to reproduce.\n", "before_files": [{"content": "\"\"\"Various utilities using the GObject framework\"\"\"\nimport array\nimport os\n\nfrom gi.repository import Gdk, GdkPixbuf, Gio, GLib, Gtk\n\nfrom lutris import settings\nfrom lutris.util import datapath, system\nfrom lutris.util.log import logger\n\ntry:\n from PIL import Image\nexcept ImportError:\n Image = None\n\nICON_SIZE = (32, 32)\nBANNER_SIZE = (184, 69)\n\n\ndef get_main_window(widget):\n \"\"\"Return the application's main window from one of its widget\"\"\"\n parent = widget.get_toplevel()\n if not isinstance(parent, Gtk.Window):\n # The sync dialog may have closed\n parent = Gio.Application.get_default().props.active_window\n for window in parent.application.get_windows():\n if \"LutrisWindow\" in window.__class__.__name__:\n return window\n return\n\n\ndef open_uri(uri):\n \"\"\"Opens a local or remote URI with the default application\"\"\"\n system.reset_library_preloads()\n try:\n Gtk.show_uri(None, uri, Gdk.CURRENT_TIME)\n except GLib.Error as ex:\n logger.exception(\"Failed to open URI %s: %s, falling back to xdg-open\", uri, ex)\n system.execute([\"xdg-open\", uri])\n\n\ndef get_pixbuf(image, size, fallback=None, is_installed=True):\n \"\"\"Return a pixbuf from file `image` at `size` or fallback to `fallback`\"\"\"\n width, height = size\n pixbuf = None\n if system.path_exists(image, exclude_empty=True):\n try:\n pixbuf = GdkPixbuf.Pixbuf.new_from_file_at_size(image, width, height)\n pixbuf = pixbuf.scale_simple(width, height, GdkPixbuf.InterpType.NEAREST)\n except GLib.GError:\n logger.error(\"Unable to load icon from image %s\", image)\n else:\n if not fallback:\n fallback = get_default_icon(size)\n if system.path_exists(fallback):\n pixbuf = GdkPixbuf.Pixbuf.new_from_file_at_size(fallback, width, height)\n if is_installed:\n pixbuf = pixbuf.scale_simple(width, height, GdkPixbuf.InterpType.NEAREST)\n return pixbuf\n overlay = os.path.join(datapath.get(), \"media/unavailable.png\")\n transparent_pixbuf = get_overlay(overlay, size).copy()\n if pixbuf:\n pixbuf.composite(\n transparent_pixbuf,\n 0,\n 0,\n size[0],\n size[1],\n 0,\n 0,\n 1,\n 1,\n GdkPixbuf.InterpType.NEAREST,\n 100,\n )\n return transparent_pixbuf\n\n\ndef get_stock_icon(name, size):\n \"\"\"Return a pixbuf from a stock icon name\"\"\"\n theme = Gtk.IconTheme.get_default()\n try:\n return theme.load_icon(name, size, Gtk.IconLookupFlags.GENERIC_FALLBACK)\n except GLib.GError:\n logger.error(\"Failed to read icon %s\", name)\n return None\n\n\ndef get_icon(icon_name, icon_format=\"image\", size=None, icon_type=\"runner\"):\n \"\"\"Return an icon based on the given name, format, size and type.\n\n Keyword arguments:\n icon_name -- The name of the icon to retrieve\n format -- The format of the icon, which should be either 'image' or 'pixbuf' (default 'image')\n size -- The size for the desired image (default None)\n icon_type -- Retrieve either a 'runner' or 'platform' icon (default 'runner')\n \"\"\"\n filename = icon_name.lower().replace(\" \", \"\") + \".png\"\n icon_path = os.path.join(settings.RUNTIME_DIR, \"icons/hicolor/64x64/apps\", filename)\n if not os.path.exists(icon_path):\n return None\n if icon_format == \"image\":\n icon = Gtk.Image()\n if size:\n icon.set_from_pixbuf(get_pixbuf(icon_path, size))\n else:\n icon.set_from_file(icon_path)\n return icon\n if icon_format == \"pixbuf\" and size:\n return get_pixbuf(icon_path, size)\n raise ValueError(\"Invalid arguments\")\n\n\ndef get_overlay(overlay_path, size):\n width, height = size\n transparent_pixbuf = GdkPixbuf.Pixbuf.new_from_file_at_size(overlay_path, width, height)\n transparent_pixbuf = transparent_pixbuf.scale_simple(width, height, GdkPixbuf.InterpType.NEAREST)\n return transparent_pixbuf\n\n\ndef get_default_icon(size):\n if size[0] == size[1]:\n return os.path.join(datapath.get(), \"media/default_icon.png\")\n return os.path.join(datapath.get(), \"media/default_banner.png\")\n\n\ndef convert_to_background(background_path, target_size=(320, 1080)):\n \"\"\"Converts a image to a pane background\"\"\"\n coverart = Image.open(background_path)\n coverart = coverart.convert(\"RGBA\")\n\n target_width, target_height = target_size\n image_height = int(target_height * 0.80) # 80% of the mask is visible\n orig_width, orig_height = coverart.size\n\n # Resize and crop coverart\n width = int(orig_width * (image_height / orig_height))\n offset = int((width - target_width) / 2)\n coverart = coverart.resize((width, image_height), resample=Image.BICUBIC)\n coverart = coverart.crop((offset, 0, target_width + offset, image_height))\n\n # Resize canvas of coverart by putting transparent pixels on the bottom\n coverart_bg = Image.new('RGBA', (target_width, target_height), (0, 0, 0, 0))\n coverart_bg.paste(coverart, (0, 0, target_width, image_height))\n\n # Apply a tint to the base image\n # tint = Image.new('RGBA', (target_width, target_height), (0, 0, 0, 255))\n # coverart = Image.blend(coverart, tint, 0.6)\n\n # Paste coverart on transparent image while applying a gradient mask\n background = Image.new('RGBA', (target_width, target_height), (0, 0, 0, 0))\n mask = Image.open(os.path.join(datapath.get(), \"media/mask.png\"))\n background.paste(coverart_bg, mask=mask)\n\n return background\n\n\ndef thumbnail_image(base_image, target_size):\n base_width, base_height = base_image.size\n base_ratio = base_width / base_height\n target_width, target_height = target_size\n target_ratio = target_width / target_height\n\n # Resize and crop coverart\n if base_ratio >= target_ratio:\n width = int(base_width * (target_height / base_height))\n height = target_height\n else:\n width = target_width\n height = int(base_height * (target_width / base_width))\n x_offset = int((width - target_width) / 2)\n y_offset = int((height - target_height) / 2)\n base_image = base_image.resize((width, height), resample=Image.BICUBIC)\n base_image = base_image.crop((x_offset, y_offset, width - x_offset, height - y_offset))\n return base_image\n\n\ndef paste_overlay(base_image, overlay_image, position=0.7):\n base_width, base_height = base_image.size\n overlay_width, overlay_height = overlay_image.size\n offset_x = int((base_width - overlay_width) / 2)\n offset_y = int((base_height - overlay_height) / 2)\n base_image.paste(\n overlay_image, (\n offset_x,\n offset_y,\n overlay_width + offset_x,\n overlay_height + offset_y\n ),\n mask=overlay_image\n )\n return base_image\n\n\ndef image2pixbuf(image):\n \"\"\"Converts a PIL Image to a GDK Pixbuf\"\"\"\n image_array = array.array('B', image.tobytes())\n width, height = image.size\n return GdkPixbuf.Pixbuf.new_from_data(image_array, GdkPixbuf.Colorspace.RGB, True, 8, width, height, width * 4)\n\n\ndef get_link_button(text):\n \"\"\"Return a transparent text button for the side panels\"\"\"\n button = Gtk.Button(text, visible=True)\n button.props.relief = Gtk.ReliefStyle.NONE\n button.get_children()[0].set_alignment(0, 0.5)\n button.get_style_context().add_class(\"panel-button\")\n button.set_size_request(-1, 24)\n return button\n\n\ndef load_icon_theme():\n \"\"\"Add the lutris icon folder to the default theme\"\"\"\n icon_theme = Gtk.IconTheme.get_default()\n local_theme_path = os.path.join(settings.RUNTIME_DIR, \"icons\")\n if local_theme_path not in icon_theme.get_search_path():\n icon_theme.prepend_search_path(local_theme_path)\n", "path": "lutris/gui/widgets/utils.py"}]}
| 3,480 | 149 |
gh_patches_debug_20272
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-2596
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
BBC Links stopped working?
Anyone else BBC links stopped working?
</issue>
<code>
[start of src/streamlink/plugins/bbciplayer.py]
1 from __future__ import print_function
2
3 import base64
4 import logging
5 import re
6 from collections import defaultdict
7 from hashlib import sha1
8
9 from streamlink import PluginError
10 from streamlink.compat import parse_qsl, urlparse
11 from streamlink.plugin import Plugin, PluginArguments, PluginArgument
12 from streamlink.plugin.api import validate
13 from streamlink.stream import HDSStream
14 from streamlink.stream import HLSStream
15 from streamlink.stream.dash import DASHStream
16 from streamlink.utils import parse_json
17
18 log = logging.getLogger(__name__)
19
20
21 class BBCiPlayer(Plugin):
22 """
23 Allows streaming of live channels from bbc.co.uk/iplayer/live/* and of iPlayer programmes from
24 bbc.co.uk/iplayer/episode/*
25 """
26 url_re = re.compile(r"""https?://(?:www\.)?bbc.co.uk/iplayer/
27 (
28 episode/(?P<episode_id>\w+)|
29 live/(?P<channel_name>\w+)
30 )
31 """, re.VERBOSE)
32 mediator_re = re.compile(
33 r'window\.__IPLAYER_REDUX_STATE__\s*=\s*({.*?});', re.DOTALL)
34 tvip_re = re.compile(r'channel"\s*:\s*{\s*"id"\s*:\s*"(\w+?)"')
35 tvip_master_re = re.compile(r'event_master_brand=(\w+?)&')
36 account_locals_re = re.compile(r'window.bbcAccount.locals\s*=\s*({.*?});')
37 swf_url = "http://emp.bbci.co.uk/emp/SMPf/1.18.3/StandardMediaPlayerChromelessFlash.swf"
38 hash = base64.b64decode(
39 b"N2RmZjc2NzFkMGM2OTdmZWRiMWQ5MDVkOWExMjE3MTk5MzhiOTJiZg==")
40 api_url = ("http://open.live.bbc.co.uk/mediaselector/6/select/"
41 "version/2.0/mediaset/{platform}/vpid/{vpid}/format/json/atk/{vpid_hash}/asn/1/")
42 platforms = ("pc", "iptv-all")
43 session_url = "https://session.bbc.com/session"
44 auth_url = "https://account.bbc.com/signin"
45
46 mediator_schema = validate.Schema(
47 {
48 "versions": [{"id": validate.text}]
49 },
50 validate.get("versions"), validate.get(0),
51 validate.get("id")
52 )
53 mediaselector_schema = validate.Schema(
54 validate.transform(parse_json),
55 {"media": [
56 {"connection":
57 validate.all([{
58 validate.optional("href"): validate.url(),
59 validate.optional("transferFormat"): validate.text
60 }], validate.filter(lambda c: c.get("href"))),
61 "kind": validate.text}
62 ]},
63 validate.get("media"),
64 validate.filter(lambda x: x["kind"] == "video")
65 )
66 arguments = PluginArguments(
67 PluginArgument(
68 "username",
69 requires=["password"],
70 metavar="USERNAME",
71 help="The username used to register with bbc.co.uk."
72 ),
73 PluginArgument(
74 "password",
75 sensitive=True,
76 metavar="PASSWORD",
77 help="A bbc.co.uk account password to use with --bbciplayer-username.",
78 prompt="Enter bbc.co.uk account password"
79 ),
80 PluginArgument(
81 "hd",
82 action="store_true",
83 help="""
84 Prefer HD streams over local SD streams, some live programmes may
85 not be broadcast in HD.
86 """
87 ),
88 )
89
90 @classmethod
91 def can_handle_url(cls, url):
92 """ Confirm plugin can handle URL """
93 return cls.url_re.match(url) is not None
94
95 @classmethod
96 def _hash_vpid(cls, vpid):
97 return sha1(cls.hash + str(vpid).encode("utf8")).hexdigest()
98
99 @classmethod
100 def _extract_nonce(cls, http_result):
101 """
102 Given an HTTP response from the sessino endpoint, extract the nonce, so we can "sign" requests with it.
103 We don't really sign the requests in the traditional sense of a nonce, we just incude them in the auth requests.
104
105 :param http_result: HTTP response from the bbc session endpoint.
106 :type http_result: requests.Response
107 :return: nonce to "sign" url requests with
108 :rtype: string
109 """
110
111 # Extract the redirect URL from the last call
112 last_redirect_url = urlparse(http_result.history[-1].request.url)
113 last_redirect_query = dict(parse_qsl(last_redirect_url.query))
114 # Extract the nonce from the query string in the redirect URL
115 final_url = urlparse(last_redirect_query['goto'])
116 goto_url = dict(parse_qsl(final_url.query))
117 goto_url_query = parse_json(goto_url['state'])
118
119 # Return the nonce we can use for future queries
120 return goto_url_query['nonce']
121
122 def find_vpid(self, url, res=None):
123 """
124 Find the Video Packet ID in the HTML for the provided URL
125
126 :param url: URL to download, if res is not provided.
127 :param res: Provide a cached version of the HTTP response to search
128 :type url: string
129 :type res: requests.Response
130 :return: Video Packet ID for a Programme in iPlayer
131 :rtype: string
132 """
133 log.debug("Looking for vpid on {0}", url)
134 # Use pre-fetched page if available
135 res = res or self.session.http.get(url)
136 m = self.mediator_re.search(res.text)
137 vpid = m and parse_json(m.group(1), schema=self.mediator_schema)
138 return vpid
139
140 def find_tvip(self, url, master=False):
141 log.debug("Looking for {0} tvip on {1}", "master" if master else "", url)
142 res = self.session.http.get(url)
143 if master:
144 m = self.tvip_master_re.search(res.text)
145 else:
146 m = self.tvip_re.search(res.text)
147 return m and m.group(1)
148
149 def mediaselector(self, vpid):
150 urls = defaultdict(set)
151 for platform in self.platforms:
152 url = self.api_url.format(vpid=vpid, vpid_hash=self._hash_vpid(vpid),
153 platform=platform)
154 log.debug("Info API request: {0}", url)
155 medias = self.session.http.get(url, schema=self.mediaselector_schema)
156 for media in medias:
157 for connection in media["connection"]:
158 urls[connection.get("transferFormat")].add(connection["href"])
159
160 for stream_type, urls in urls.items():
161 log.debug("{0} {1} streams", len(urls), stream_type)
162 for url in list(urls):
163 try:
164 if stream_type == "hds":
165 for s in HDSStream.parse_manifest(self.session,
166 url).items():
167 yield s
168 if stream_type == "hls":
169 for s in HLSStream.parse_variant_playlist(self.session,
170 url).items():
171 yield s
172 if stream_type == "dash":
173 for s in DASHStream.parse_manifest(self.session,
174 url).items():
175 yield s
176 log.debug(" OK: {0}", url)
177 except:
178 log.debug(" FAIL: {0}", url)
179
180 def login(self, ptrt_url):
181 """
182 Create session using BBC ID. See https://www.bbc.co.uk/usingthebbc/account/
183
184 :param ptrt_url: The snapback URL to redirect to after successful authentication
185 :type ptrt_url: string
186 :return: Whether authentication was successful
187 :rtype: bool
188 """
189 def auth_check(res):
190 return ptrt_url in ([h.url for h in res.history] + [res.url])
191
192 # make the session request to get the correct cookies
193 session_res = self.session.http.get(
194 self.session_url,
195 params=dict(ptrt=ptrt_url)
196 )
197
198 if auth_check(session_res):
199 log.debug("Already authenticated, skipping authentication")
200 return True
201
202 http_nonce = self._extract_nonce(session_res)
203 res = self.session.http.post(
204 self.auth_url,
205 params=dict(
206 ptrt=ptrt_url,
207 nonce=http_nonce
208 ),
209 data=dict(
210 jsEnabled=True,
211 username=self.get_option("username"),
212 password=self.get_option('password'),
213 attempts=0
214 ),
215 headers={"Referer": self.url})
216
217 return auth_check(res)
218
219 def _get_streams(self):
220 if not self.get_option("username"):
221 log.error(
222 "BBC iPlayer requires an account you must login using "
223 "--bbciplayer-username and --bbciplayer-password")
224 return
225 log.info(
226 "A TV License is required to watch BBC iPlayer streams, see the BBC website for more "
227 "information: https://www.bbc.co.uk/iplayer/help/tvlicence")
228 if not self.login(self.url):
229 log.error(
230 "Could not authenticate, check your username and password")
231 return
232
233 m = self.url_re.match(self.url)
234 episode_id = m.group("episode_id")
235 channel_name = m.group("channel_name")
236
237 if episode_id:
238 log.debug("Loading streams for episode: {0}", episode_id)
239 vpid = self.find_vpid(self.url)
240 if vpid:
241 log.debug("Found VPID: {0}", vpid)
242 for s in self.mediaselector(vpid):
243 yield s
244 else:
245 log.error("Could not find VPID for episode {0}",
246 episode_id)
247 elif channel_name:
248 log.debug("Loading stream for live channel: {0}", channel_name)
249 if self.get_option("hd"):
250 tvip = self.find_tvip(self.url, master=True) + "_hd"
251 if tvip:
252 log.debug("Trying HD stream {0}...", tvip)
253 try:
254 for s in self.mediaselector(tvip):
255 yield s
256 except PluginError:
257 log.error(
258 "Failed to get HD streams, falling back to SD")
259 else:
260 return
261 tvip = self.find_tvip(self.url)
262 if tvip:
263 log.debug("Found TVIP: {0}", tvip)
264 for s in self.mediaselector(tvip):
265 yield s
266
267
268 __plugin__ = BBCiPlayer
269
[end of src/streamlink/plugins/bbciplayer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/streamlink/plugins/bbciplayer.py b/src/streamlink/plugins/bbciplayer.py
--- a/src/streamlink/plugins/bbciplayer.py
+++ b/src/streamlink/plugins/bbciplayer.py
@@ -34,11 +34,8 @@
tvip_re = re.compile(r'channel"\s*:\s*{\s*"id"\s*:\s*"(\w+?)"')
tvip_master_re = re.compile(r'event_master_brand=(\w+?)&')
account_locals_re = re.compile(r'window.bbcAccount.locals\s*=\s*({.*?});')
- swf_url = "http://emp.bbci.co.uk/emp/SMPf/1.18.3/StandardMediaPlayerChromelessFlash.swf"
- hash = base64.b64decode(
- b"N2RmZjc2NzFkMGM2OTdmZWRiMWQ5MDVkOWExMjE3MTk5MzhiOTJiZg==")
- api_url = ("http://open.live.bbc.co.uk/mediaselector/6/select/"
- "version/2.0/mediaset/{platform}/vpid/{vpid}/format/json/atk/{vpid_hash}/asn/1/")
+ hash = base64.b64decode(b"N2RmZjc2NzFkMGM2OTdmZWRiMWQ5MDVkOWExMjE3MTk5MzhiOTJiZg==")
+ api_url = "https://open.live.bbc.co.uk/mediaselector/6/select/version/2.0/mediaset/{platform}/vpid/{vpid}/format/json/atk/{vpid_hash}/asn/1/"
platforms = ("pc", "iptv-all")
session_url = "https://session.bbc.com/session"
auth_url = "https://account.bbc.com/signin"
|
{"golden_diff": "diff --git a/src/streamlink/plugins/bbciplayer.py b/src/streamlink/plugins/bbciplayer.py\n--- a/src/streamlink/plugins/bbciplayer.py\n+++ b/src/streamlink/plugins/bbciplayer.py\n@@ -34,11 +34,8 @@\n tvip_re = re.compile(r'channel\"\\s*:\\s*{\\s*\"id\"\\s*:\\s*\"(\\w+?)\"')\n tvip_master_re = re.compile(r'event_master_brand=(\\w+?)&')\n account_locals_re = re.compile(r'window.bbcAccount.locals\\s*=\\s*({.*?});')\n- swf_url = \"http://emp.bbci.co.uk/emp/SMPf/1.18.3/StandardMediaPlayerChromelessFlash.swf\"\n- hash = base64.b64decode(\n- b\"N2RmZjc2NzFkMGM2OTdmZWRiMWQ5MDVkOWExMjE3MTk5MzhiOTJiZg==\")\n- api_url = (\"http://open.live.bbc.co.uk/mediaselector/6/select/\"\n- \"version/2.0/mediaset/{platform}/vpid/{vpid}/format/json/atk/{vpid_hash}/asn/1/\")\n+ hash = base64.b64decode(b\"N2RmZjc2NzFkMGM2OTdmZWRiMWQ5MDVkOWExMjE3MTk5MzhiOTJiZg==\")\n+ api_url = \"https://open.live.bbc.co.uk/mediaselector/6/select/version/2.0/mediaset/{platform}/vpid/{vpid}/format/json/atk/{vpid_hash}/asn/1/\"\n platforms = (\"pc\", \"iptv-all\")\n session_url = \"https://session.bbc.com/session\"\n auth_url = \"https://account.bbc.com/signin\"\n", "issue": "BBC Links stopped working?\nAnyone else BBC links stopped working?\n", "before_files": [{"content": "from __future__ import print_function\n\nimport base64\nimport logging\nimport re\nfrom collections import defaultdict\nfrom hashlib import sha1\n\nfrom streamlink import PluginError\nfrom streamlink.compat import parse_qsl, urlparse\nfrom streamlink.plugin import Plugin, PluginArguments, PluginArgument\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream import HDSStream\nfrom streamlink.stream import HLSStream\nfrom streamlink.stream.dash import DASHStream\nfrom streamlink.utils import parse_json\n\nlog = logging.getLogger(__name__)\n\n\nclass BBCiPlayer(Plugin):\n \"\"\"\n Allows streaming of live channels from bbc.co.uk/iplayer/live/* and of iPlayer programmes from\n bbc.co.uk/iplayer/episode/*\n \"\"\"\n url_re = re.compile(r\"\"\"https?://(?:www\\.)?bbc.co.uk/iplayer/\n (\n episode/(?P<episode_id>\\w+)|\n live/(?P<channel_name>\\w+)\n )\n \"\"\", re.VERBOSE)\n mediator_re = re.compile(\n r'window\\.__IPLAYER_REDUX_STATE__\\s*=\\s*({.*?});', re.DOTALL)\n tvip_re = re.compile(r'channel\"\\s*:\\s*{\\s*\"id\"\\s*:\\s*\"(\\w+?)\"')\n tvip_master_re = re.compile(r'event_master_brand=(\\w+?)&')\n account_locals_re = re.compile(r'window.bbcAccount.locals\\s*=\\s*({.*?});')\n swf_url = \"http://emp.bbci.co.uk/emp/SMPf/1.18.3/StandardMediaPlayerChromelessFlash.swf\"\n hash = base64.b64decode(\n b\"N2RmZjc2NzFkMGM2OTdmZWRiMWQ5MDVkOWExMjE3MTk5MzhiOTJiZg==\")\n api_url = (\"http://open.live.bbc.co.uk/mediaselector/6/select/\"\n \"version/2.0/mediaset/{platform}/vpid/{vpid}/format/json/atk/{vpid_hash}/asn/1/\")\n platforms = (\"pc\", \"iptv-all\")\n session_url = \"https://session.bbc.com/session\"\n auth_url = \"https://account.bbc.com/signin\"\n\n mediator_schema = validate.Schema(\n {\n \"versions\": [{\"id\": validate.text}]\n },\n validate.get(\"versions\"), validate.get(0),\n validate.get(\"id\")\n )\n mediaselector_schema = validate.Schema(\n validate.transform(parse_json),\n {\"media\": [\n {\"connection\":\n validate.all([{\n validate.optional(\"href\"): validate.url(),\n validate.optional(\"transferFormat\"): validate.text\n }], validate.filter(lambda c: c.get(\"href\"))),\n \"kind\": validate.text}\n ]},\n validate.get(\"media\"),\n validate.filter(lambda x: x[\"kind\"] == \"video\")\n )\n arguments = PluginArguments(\n PluginArgument(\n \"username\",\n requires=[\"password\"],\n metavar=\"USERNAME\",\n help=\"The username used to register with bbc.co.uk.\"\n ),\n PluginArgument(\n \"password\",\n sensitive=True,\n metavar=\"PASSWORD\",\n help=\"A bbc.co.uk account password to use with --bbciplayer-username.\",\n prompt=\"Enter bbc.co.uk account password\"\n ),\n PluginArgument(\n \"hd\",\n action=\"store_true\",\n help=\"\"\"\n Prefer HD streams over local SD streams, some live programmes may\n not be broadcast in HD.\n \"\"\"\n ),\n )\n\n @classmethod\n def can_handle_url(cls, url):\n \"\"\" Confirm plugin can handle URL \"\"\"\n return cls.url_re.match(url) is not None\n\n @classmethod\n def _hash_vpid(cls, vpid):\n return sha1(cls.hash + str(vpid).encode(\"utf8\")).hexdigest()\n\n @classmethod\n def _extract_nonce(cls, http_result):\n \"\"\"\n Given an HTTP response from the sessino endpoint, extract the nonce, so we can \"sign\" requests with it.\n We don't really sign the requests in the traditional sense of a nonce, we just incude them in the auth requests.\n\n :param http_result: HTTP response from the bbc session endpoint.\n :type http_result: requests.Response\n :return: nonce to \"sign\" url requests with\n :rtype: string\n \"\"\"\n\n # Extract the redirect URL from the last call\n last_redirect_url = urlparse(http_result.history[-1].request.url)\n last_redirect_query = dict(parse_qsl(last_redirect_url.query))\n # Extract the nonce from the query string in the redirect URL\n final_url = urlparse(last_redirect_query['goto'])\n goto_url = dict(parse_qsl(final_url.query))\n goto_url_query = parse_json(goto_url['state'])\n\n # Return the nonce we can use for future queries\n return goto_url_query['nonce']\n\n def find_vpid(self, url, res=None):\n \"\"\"\n Find the Video Packet ID in the HTML for the provided URL\n\n :param url: URL to download, if res is not provided.\n :param res: Provide a cached version of the HTTP response to search\n :type url: string\n :type res: requests.Response\n :return: Video Packet ID for a Programme in iPlayer\n :rtype: string\n \"\"\"\n log.debug(\"Looking for vpid on {0}\", url)\n # Use pre-fetched page if available\n res = res or self.session.http.get(url)\n m = self.mediator_re.search(res.text)\n vpid = m and parse_json(m.group(1), schema=self.mediator_schema)\n return vpid\n\n def find_tvip(self, url, master=False):\n log.debug(\"Looking for {0} tvip on {1}\", \"master\" if master else \"\", url)\n res = self.session.http.get(url)\n if master:\n m = self.tvip_master_re.search(res.text)\n else:\n m = self.tvip_re.search(res.text)\n return m and m.group(1)\n\n def mediaselector(self, vpid):\n urls = defaultdict(set)\n for platform in self.platforms:\n url = self.api_url.format(vpid=vpid, vpid_hash=self._hash_vpid(vpid),\n platform=platform)\n log.debug(\"Info API request: {0}\", url)\n medias = self.session.http.get(url, schema=self.mediaselector_schema)\n for media in medias:\n for connection in media[\"connection\"]:\n urls[connection.get(\"transferFormat\")].add(connection[\"href\"])\n\n for stream_type, urls in urls.items():\n log.debug(\"{0} {1} streams\", len(urls), stream_type)\n for url in list(urls):\n try:\n if stream_type == \"hds\":\n for s in HDSStream.parse_manifest(self.session,\n url).items():\n yield s\n if stream_type == \"hls\":\n for s in HLSStream.parse_variant_playlist(self.session,\n url).items():\n yield s\n if stream_type == \"dash\":\n for s in DASHStream.parse_manifest(self.session,\n url).items():\n yield s\n log.debug(\" OK: {0}\", url)\n except:\n log.debug(\" FAIL: {0}\", url)\n\n def login(self, ptrt_url):\n \"\"\"\n Create session using BBC ID. See https://www.bbc.co.uk/usingthebbc/account/\n\n :param ptrt_url: The snapback URL to redirect to after successful authentication\n :type ptrt_url: string\n :return: Whether authentication was successful\n :rtype: bool\n \"\"\"\n def auth_check(res):\n return ptrt_url in ([h.url for h in res.history] + [res.url])\n\n # make the session request to get the correct cookies\n session_res = self.session.http.get(\n self.session_url,\n params=dict(ptrt=ptrt_url)\n )\n\n if auth_check(session_res):\n log.debug(\"Already authenticated, skipping authentication\")\n return True\n\n http_nonce = self._extract_nonce(session_res)\n res = self.session.http.post(\n self.auth_url,\n params=dict(\n ptrt=ptrt_url,\n nonce=http_nonce\n ),\n data=dict(\n jsEnabled=True,\n username=self.get_option(\"username\"),\n password=self.get_option('password'),\n attempts=0\n ),\n headers={\"Referer\": self.url})\n\n return auth_check(res)\n\n def _get_streams(self):\n if not self.get_option(\"username\"):\n log.error(\n \"BBC iPlayer requires an account you must login using \"\n \"--bbciplayer-username and --bbciplayer-password\")\n return\n log.info(\n \"A TV License is required to watch BBC iPlayer streams, see the BBC website for more \"\n \"information: https://www.bbc.co.uk/iplayer/help/tvlicence\")\n if not self.login(self.url):\n log.error(\n \"Could not authenticate, check your username and password\")\n return\n\n m = self.url_re.match(self.url)\n episode_id = m.group(\"episode_id\")\n channel_name = m.group(\"channel_name\")\n\n if episode_id:\n log.debug(\"Loading streams for episode: {0}\", episode_id)\n vpid = self.find_vpid(self.url)\n if vpid:\n log.debug(\"Found VPID: {0}\", vpid)\n for s in self.mediaselector(vpid):\n yield s\n else:\n log.error(\"Could not find VPID for episode {0}\",\n episode_id)\n elif channel_name:\n log.debug(\"Loading stream for live channel: {0}\", channel_name)\n if self.get_option(\"hd\"):\n tvip = self.find_tvip(self.url, master=True) + \"_hd\"\n if tvip:\n log.debug(\"Trying HD stream {0}...\", tvip)\n try:\n for s in self.mediaselector(tvip):\n yield s\n except PluginError:\n log.error(\n \"Failed to get HD streams, falling back to SD\")\n else:\n return\n tvip = self.find_tvip(self.url)\n if tvip:\n log.debug(\"Found TVIP: {0}\", tvip)\n for s in self.mediaselector(tvip):\n yield s\n\n\n__plugin__ = BBCiPlayer\n", "path": "src/streamlink/plugins/bbciplayer.py"}]}
| 3,508 | 431 |
gh_patches_debug_1073
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-contrib-98
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
EC2 resource detector hangs for a long time outside of an EC2 instance
**Describe your environment** Describe any aspect of your environment relevant to the problem, including your Python version, [platform](https://docs.python.org/3/library/platform.html), version numbers of installed dependencies, information about your cloud hosting provider, etc. If you're reporting a problem with a specific version of a library in this repo, please check whether the problem has been fixed on main.
The environment I initially saw this in was a container running in Docker compose on an AWS EC2 instance but I've been able to reproduce it on my laptop as well. I think it will show up in anything not directly running in AWS.
**Steps to reproduce**
Describe exactly how to reproduce the error. Include a code sample if applicable.
The following code reproduced the issue on my laptop:
```python
from opentelemetry.sdk.extension.aws.resource.ec2 import AwsEc2ResourceDetector
from opentelemetry.sdk.resources import get_aggregated_resources
resource = get_aggregated_resources(
detectors=[AwsEc2ResourceDetector()]
)
```
**What is the expected behavior?**
It should complete quickly (this is the behavior I see running on an EC2 instance).
**What is the actual behavior?**
What did you see instead?
On my laptop, it will hand ~indefinitely.
Note: one solution is just to remove the resource detector but we'd like to be able to include it and just have it fail silently, which is the behavior we've seen in other resource detectors.
**Additional context**
I think the problem is here: https://github.com/open-telemetry/opentelemetry-python-contrib/blob/80969a06da77d1e616124de178d12a1ebe3ffe7f/sdk-extension/opentelemetry-sdk-extension-aws/src/opentelemetry/sdk/extension/aws/resource/ec2.py#L37
It looks like the request is using a 1000 _second_ timeout which I suspect is intended to be a 1000 _millisecond_ timeout. At least with the server program I've been working on that will block the startup of the program until the request completes.
You can verify by running:
```
curl http://169.254.169.254/latest/api/token
```
Which is one of the requests that the resource detector makes -- it should hang indefinitely as well.
</issue>
<code>
[start of instrumentation/opentelemetry-instrumentation-botocore/src/opentelemetry/instrumentation/botocore/version.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 __version__ = "0.15.dev0"
16
[end of instrumentation/opentelemetry-instrumentation-botocore/src/opentelemetry/instrumentation/botocore/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/instrumentation/opentelemetry-instrumentation-botocore/src/opentelemetry/instrumentation/botocore/version.py b/instrumentation/opentelemetry-instrumentation-botocore/src/opentelemetry/instrumentation/botocore/version.py
--- a/instrumentation/opentelemetry-instrumentation-botocore/src/opentelemetry/instrumentation/botocore/version.py
+++ b/instrumentation/opentelemetry-instrumentation-botocore/src/opentelemetry/instrumentation/botocore/version.py
@@ -12,4 +12,4 @@
# See the License for the specific language governing permissions and
# limitations under the License.
-__version__ = "0.15.dev0"
+__version__ = "0.15b0"
|
{"golden_diff": "diff --git a/instrumentation/opentelemetry-instrumentation-botocore/src/opentelemetry/instrumentation/botocore/version.py b/instrumentation/opentelemetry-instrumentation-botocore/src/opentelemetry/instrumentation/botocore/version.py\n--- a/instrumentation/opentelemetry-instrumentation-botocore/src/opentelemetry/instrumentation/botocore/version.py\n+++ b/instrumentation/opentelemetry-instrumentation-botocore/src/opentelemetry/instrumentation/botocore/version.py\n@@ -12,4 +12,4 @@\n # See the License for the specific language governing permissions and\n # limitations under the License.\n \n-__version__ = \"0.15.dev0\"\n+__version__ = \"0.15b0\"\n", "issue": "EC2 resource detector hangs for a long time outside of an EC2 instance\n**Describe your environment** Describe any aspect of your environment relevant to the problem, including your Python version, [platform](https://docs.python.org/3/library/platform.html), version numbers of installed dependencies, information about your cloud hosting provider, etc. If you're reporting a problem with a specific version of a library in this repo, please check whether the problem has been fixed on main.\r\n\r\nThe environment I initially saw this in was a container running in Docker compose on an AWS EC2 instance but I've been able to reproduce it on my laptop as well. I think it will show up in anything not directly running in AWS.\r\n\r\n**Steps to reproduce**\r\nDescribe exactly how to reproduce the error. Include a code sample if applicable.\r\n\r\nThe following code reproduced the issue on my laptop:\r\n\r\n```python\r\nfrom opentelemetry.sdk.extension.aws.resource.ec2 import AwsEc2ResourceDetector\r\nfrom opentelemetry.sdk.resources import get_aggregated_resources\r\n\r\nresource = get_aggregated_resources(\r\n detectors=[AwsEc2ResourceDetector()]\r\n)\r\n```\r\n\r\n**What is the expected behavior?**\r\n\r\nIt should complete quickly (this is the behavior I see running on an EC2 instance).\r\n\r\n**What is the actual behavior?**\r\n\r\nWhat did you see instead?\r\n\r\nOn my laptop, it will hand ~indefinitely.\r\n\r\nNote: one solution is just to remove the resource detector but we'd like to be able to include it and just have it fail silently, which is the behavior we've seen in other resource detectors.\r\n\r\n**Additional context**\r\n\r\nI think the problem is here: https://github.com/open-telemetry/opentelemetry-python-contrib/blob/80969a06da77d1e616124de178d12a1ebe3ffe7f/sdk-extension/opentelemetry-sdk-extension-aws/src/opentelemetry/sdk/extension/aws/resource/ec2.py#L37\r\n\r\nIt looks like the request is using a 1000 _second_ timeout which I suspect is intended to be a 1000 _millisecond_ timeout. At least with the server program I've been working on that will block the startup of the program until the request completes.\r\n\r\nYou can verify by running:\r\n\r\n```\r\ncurl http://169.254.169.254/latest/api/token\r\n```\r\n\r\nWhich is one of the requests that the resource detector makes -- it should hang indefinitely as well.\r\n\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n__version__ = \"0.15.dev0\"\n", "path": "instrumentation/opentelemetry-instrumentation-botocore/src/opentelemetry/instrumentation/botocore/version.py"}]}
| 1,255 | 169 |
gh_patches_debug_4517
|
rasdani/github-patches
|
git_diff
|
TileDB-Inc__TileDB-Py-309
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
array.query no longer works for string attributes
I have a case that looks basically like this:
```
array = tiledb.DenseArray(uri, mode="r")
q = array.query(attrs=["attrname"])
data = q[:]
```
This works when the type of the attribute is a float or an int.
But if the type of the attribute is a string, this fails with an exception:
```
File "tiledb/libtiledb.pyx", line 3874, in tiledb.libtiledb.Query.__getitem__
File "tiledb/libtiledb.pyx", line 4107, in tiledb.libtiledb.DenseArrayImpl.subarray
File "tiledb/libtiledb.pyx", line 4156, in tiledb.libtiledb.DenseArrayImpl._read_dense_subarray
File "tiledb/libtiledb.pyx", line 3760, in tiledb.libtiledb.Array._unpack_varlen_query
File "tiledb/libtiledb.pyx", line 3760, in tiledb.libtiledb.Array._unpack_varlen_query
File "tiledb/libtiledb.pyx", line 3805, in tiledb.libtiledb.Array._unpack_varlen_query
SystemError: Negative size passed to PyUnicode_FromStringAndSize
```
This worked in v1.7.6, and I ran into this problem when porting to 2.0.0.
If there is a better way to pull out just one attribute from the array, then
I'm open to suggestions.
[example.zip](https://github.com/TileDB-Inc/TileDB-Py/files/4589870/example.zip)
Attached is a script, output from 1.7.6, and output from 2.0.0
</issue>
<code>
[start of tiledb/multirange_indexing.py]
1 import tiledb
2 from tiledb import Array, ArraySchema, TileDBError
3 import os, numpy as np
4 import sys, weakref
5 from collections import OrderedDict
6
7 def mr_dense_result_shape(ranges, base_shape = None):
8 # assumptions: len(ranges) matches number of dims
9 if base_shape is not None:
10 assert len(ranges) == len(base_shape), "internal error: mismatched shapes"
11
12 new_shape = list()
13 for i,rr in enumerate(ranges):
14 if rr != ():
15 m = list(map(lambda y: abs(y[1] - y[0]) + 1, rr))
16 new_shape.append(np.sum(m))
17 else:
18 if base_shape is None:
19 raise ValueError("Missing required base_shape for whole-dimension slices")
20 # empty range covers dimension
21 new_shape.append(base_shape[i])
22
23 return tuple(new_shape)
24
25 def mr_dense_result_numel(ranges):
26 return np.prod(mr_dense_result_shape(ranges))
27
28 def sel_to_subranges(dim_sel):
29 subranges = list()
30 for range in dim_sel:
31 if np.isscalar(range):
32 subranges.append( (range, range) )
33 elif isinstance(range, slice):
34 if range.step is not None:
35 raise ValueError("Stepped slice ranges are not supported")
36 elif range.start is None and range.stop is None:
37 # ':' full slice
38 pass
39 else:
40 subranges.append( (range.start, range.stop) )
41 elif isinstance(range, tuple):
42 subranges.extend((range,))
43 elif isinstance(range, list):
44 for el in range:
45 subranges.append( (el, el) )
46 else:
47 raise TypeError("Unsupported selection ")
48
49 return tuple(subranges)
50
51
52 class MultiRangeIndexer(object):
53 """
54 Implements multi-range / outer / orthogonal indexing.
55
56 """
57
58 def __init__(self, array, query = None):
59 if not issubclass(type(array), tiledb.Array):
60 raise ValueError("Internal error: MultiRangeIndexer expected tiledb.Array")
61 self.array_ref = weakref.ref(array)
62 self.schema = array.schema
63 self.query = query
64
65 @property
66 def array(self):
67 assert self.array_ref() is not None, \
68 "Internal error: invariant violation (indexing call w/ dead array_ref)"
69 return self.array_ref()
70
71 @classmethod
72 def __test_init__(cls, array):
73 """
74 Internal helper method for testing getitem range calculation.
75 :param array:
76 :return:
77 """
78 m = cls.__new__(cls)
79 m.array_ref = weakref.ref(array)
80 m.schema = array.schema
81 m.query = None
82 return m
83
84 def getitem_ranges(self, idx):
85 dom = self.schema.domain
86 ndim = dom.ndim
87
88 if isinstance(idx, tuple):
89 idx = list(idx)
90 else:
91 idx = [idx]
92
93 ranges = list()
94 for i,sel in enumerate(idx):
95 if not isinstance(sel, list):
96 sel = [sel]
97 subranges = sel_to_subranges(sel)
98 ranges.append(subranges)
99
100 # extend the list to ndim
101 if len(ranges) < ndim:
102 ranges.extend([ tuple() for _ in range(ndim-len(ranges))])
103
104 rval = tuple(ranges)
105 return rval
106
107 def __getitem__(self, idx):
108 # implements multi-range / outer / orthogonal indexing
109 ranges = self.getitem_ranges(idx)
110
111 schema = self.schema
112 dom = self.schema.domain
113 attr_names = tuple(self.schema.attr(i).name for i in range(self.schema.nattr))
114
115 coords = None
116 if self.query is not None:
117 # if we are called via Query object, then we need to respect Query semantics
118 attr_names = tuple(self.query.attrs) if self.query.attrs else attr_names # query.attrs might be None -> all
119 coords = self.query.coords
120
121 from tiledb.core import PyQuery
122 q = PyQuery(self.array._ctx_(), self.array, attr_names, coords)
123
124 q.set_ranges(ranges)
125 q.submit()
126
127 result_dict = OrderedDict(q.results())
128
129 for name, item in result_dict.items():
130 if len(item[1]) > 0:
131 arr = self.array._unpack_varlen_query(item, name)
132 else:
133 arr = item[0]
134 arr.dtype = schema.attr_or_dim_dtype(name)
135 result_dict[name] = arr
136
137 if self.schema.sparse:
138 return result_dict
139 else:
140 result_shape = mr_dense_result_shape(ranges, self.schema.shape)
141 for arr in result_dict.values():
142 # TODO check/test layout
143 arr.shape = result_shape
144 return result_dict
145
[end of tiledb/multirange_indexing.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/tiledb/multirange_indexing.py b/tiledb/multirange_indexing.py
--- a/tiledb/multirange_indexing.py
+++ b/tiledb/multirange_indexing.py
@@ -128,7 +128,7 @@
for name, item in result_dict.items():
if len(item[1]) > 0:
- arr = self.array._unpack_varlen_query(item, name)
+ arr = q.unpack_buffer(name, item[0], item[1])
else:
arr = item[0]
arr.dtype = schema.attr_or_dim_dtype(name)
|
{"golden_diff": "diff --git a/tiledb/multirange_indexing.py b/tiledb/multirange_indexing.py\n--- a/tiledb/multirange_indexing.py\n+++ b/tiledb/multirange_indexing.py\n@@ -128,7 +128,7 @@\n \n for name, item in result_dict.items():\n if len(item[1]) > 0:\n- arr = self.array._unpack_varlen_query(item, name)\n+ arr = q.unpack_buffer(name, item[0], item[1])\n else:\n arr = item[0]\n arr.dtype = schema.attr_or_dim_dtype(name)\n", "issue": "array.query no longer works for string attributes\nI have a case that looks basically like this:\r\n\r\n```\r\narray = tiledb.DenseArray(uri, mode=\"r\")\r\nq = array.query(attrs=[\"attrname\"])\r\ndata = q[:]\r\n```\r\nThis works when the type of the attribute is a float or an int.\r\nBut if the type of the attribute is a string, this fails with an exception:\r\n\r\n```\r\n File \"tiledb/libtiledb.pyx\", line 3874, in tiledb.libtiledb.Query.__getitem__\r\n File \"tiledb/libtiledb.pyx\", line 4107, in tiledb.libtiledb.DenseArrayImpl.subarray\r\n File \"tiledb/libtiledb.pyx\", line 4156, in tiledb.libtiledb.DenseArrayImpl._read_dense_subarray\r\n File \"tiledb/libtiledb.pyx\", line 3760, in tiledb.libtiledb.Array._unpack_varlen_query\r\n File \"tiledb/libtiledb.pyx\", line 3760, in tiledb.libtiledb.Array._unpack_varlen_query\r\n File \"tiledb/libtiledb.pyx\", line 3805, in tiledb.libtiledb.Array._unpack_varlen_query\r\nSystemError: Negative size passed to PyUnicode_FromStringAndSize\r\n```\r\n\r\nThis worked in v1.7.6, and I ran into this problem when porting to 2.0.0.\r\nIf there is a better way to pull out just one attribute from the array, then\r\nI'm open to suggestions.\r\n\r\n[example.zip](https://github.com/TileDB-Inc/TileDB-Py/files/4589870/example.zip)\r\n\r\nAttached is a script, output from 1.7.6, and output from 2.0.0\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "import tiledb\nfrom tiledb import Array, ArraySchema, TileDBError\nimport os, numpy as np\nimport sys, weakref\nfrom collections import OrderedDict\n\ndef mr_dense_result_shape(ranges, base_shape = None):\n # assumptions: len(ranges) matches number of dims\n if base_shape is not None:\n assert len(ranges) == len(base_shape), \"internal error: mismatched shapes\"\n\n new_shape = list()\n for i,rr in enumerate(ranges):\n if rr != ():\n m = list(map(lambda y: abs(y[1] - y[0]) + 1, rr))\n new_shape.append(np.sum(m))\n else:\n if base_shape is None:\n raise ValueError(\"Missing required base_shape for whole-dimension slices\")\n # empty range covers dimension\n new_shape.append(base_shape[i])\n\n return tuple(new_shape)\n\ndef mr_dense_result_numel(ranges):\n return np.prod(mr_dense_result_shape(ranges))\n\ndef sel_to_subranges(dim_sel):\n subranges = list()\n for range in dim_sel:\n if np.isscalar(range):\n subranges.append( (range, range) )\n elif isinstance(range, slice):\n if range.step is not None:\n raise ValueError(\"Stepped slice ranges are not supported\")\n elif range.start is None and range.stop is None:\n # ':' full slice\n pass\n else:\n subranges.append( (range.start, range.stop) )\n elif isinstance(range, tuple):\n subranges.extend((range,))\n elif isinstance(range, list):\n for el in range:\n subranges.append( (el, el) )\n else:\n raise TypeError(\"Unsupported selection \")\n\n return tuple(subranges)\n\n\nclass MultiRangeIndexer(object):\n \"\"\"\n Implements multi-range / outer / orthogonal indexing.\n\n \"\"\"\n\n def __init__(self, array, query = None):\n if not issubclass(type(array), tiledb.Array):\n raise ValueError(\"Internal error: MultiRangeIndexer expected tiledb.Array\")\n self.array_ref = weakref.ref(array)\n self.schema = array.schema\n self.query = query\n\n @property\n def array(self):\n assert self.array_ref() is not None, \\\n \"Internal error: invariant violation (indexing call w/ dead array_ref)\"\n return self.array_ref()\n\n @classmethod\n def __test_init__(cls, array):\n \"\"\"\n Internal helper method for testing getitem range calculation.\n :param array:\n :return:\n \"\"\"\n m = cls.__new__(cls)\n m.array_ref = weakref.ref(array)\n m.schema = array.schema\n m.query = None\n return m\n\n def getitem_ranges(self, idx):\n dom = self.schema.domain\n ndim = dom.ndim\n\n if isinstance(idx, tuple):\n idx = list(idx)\n else:\n idx = [idx]\n\n ranges = list()\n for i,sel in enumerate(idx):\n if not isinstance(sel, list):\n sel = [sel]\n subranges = sel_to_subranges(sel)\n ranges.append(subranges)\n\n # extend the list to ndim\n if len(ranges) < ndim:\n ranges.extend([ tuple() for _ in range(ndim-len(ranges))])\n\n rval = tuple(ranges)\n return rval\n\n def __getitem__(self, idx):\n # implements multi-range / outer / orthogonal indexing\n ranges = self.getitem_ranges(idx)\n\n schema = self.schema\n dom = self.schema.domain\n attr_names = tuple(self.schema.attr(i).name for i in range(self.schema.nattr))\n\n coords = None\n if self.query is not None:\n # if we are called via Query object, then we need to respect Query semantics\n attr_names = tuple(self.query.attrs) if self.query.attrs else attr_names # query.attrs might be None -> all\n coords = self.query.coords\n\n from tiledb.core import PyQuery\n q = PyQuery(self.array._ctx_(), self.array, attr_names, coords)\n\n q.set_ranges(ranges)\n q.submit()\n\n result_dict = OrderedDict(q.results())\n\n for name, item in result_dict.items():\n if len(item[1]) > 0:\n arr = self.array._unpack_varlen_query(item, name)\n else:\n arr = item[0]\n arr.dtype = schema.attr_or_dim_dtype(name)\n result_dict[name] = arr\n\n if self.schema.sparse:\n return result_dict\n else:\n result_shape = mr_dense_result_shape(ranges, self.schema.shape)\n for arr in result_dict.values():\n # TODO check/test layout\n arr.shape = result_shape\n return result_dict\n", "path": "tiledb/multirange_indexing.py"}]}
| 2,281 | 141 |
gh_patches_debug_3732
|
rasdani/github-patches
|
git_diff
|
oppia__oppia-19587
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Feature Request]: Improve the experience of adding concept cards in the exploration editor.
### Is your feature request related to a problem? Please describe.
The experience of adding skill concept cards in the exploration editor has a number of issues:
- The highlighted text in the RTE does not get transferred to the concept card skill link modal when it is opened.
- Cancelling the operation results in the disappearance of the highlighted text.
- The list of skills takes a long time to load, even if it has already been fetched previously.
- Terms entered in the skill filter input box do not get applied when the skill list finally loads.
- The detailed skill explanations show up in red, which is hard to read (and suggests some kind of error).
See the video below for the current experience:
https://github.com/oppia/oppia/assets/10575562/60c94af1-8550-4be8-b277-ad4084b8daa9
### Describe the solution you'd like
- [x] When the skill link modal is opened, the text input field should be populated with the highlighted text in the RTE, or "concept card" if there is no highlighted text.
- [x] When the modal is cancelled, the RTE contents should stay as they were before the modal was opened. In particular, any highlighted text should not be deleted.
- [x] The skill filter input box should be disabled until the list of skills has loaded.
- [x] Skill explanations should show up in black text.
### Describe alternatives you've considered
- I considered also writing "the list of skills should load faster", but in reality there's always going to be some lag time. It might be possible to cache this list so that it loads fast for the second and subsequent queries, but that could lead to problems with stale data if a skill is created/deleted while an exploration is being edited. So I suggest that we don't solve that problem in this issue, and fix the other points first -- then, we can see if the loading time is still an issue.
### Additional context
_No response_
</issue>
<code>
[start of core/domain/rte_component_registry.py]
1 # coding: utf-8
2 #
3 # Copyright 2014 The Oppia Authors. All Rights Reserved.
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS-IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16
17 """Registry for custom rich-text components."""
18
19 from __future__ import annotations
20
21 import inspect
22 import os
23 import pkgutil
24
25 from core import constants
26 from core import feconf
27 from core import utils
28
29 from typing import Any, Dict, List, Type, TypedDict, Union
30
31 MYPY = False
32 if MYPY: # pragma: no cover
33 # Here, we are importing 'components' from rich_text_components only
34 # for type checking.
35 from extensions.rich_text_components import components
36
37
38 class CustomizationArgSpecDict(TypedDict):
39 """Dictionary representing the customization_arg_specs object."""
40
41 name: str
42 description: str
43 # Here we use type Any because values in schema dictionary can be of
44 # type str, List, Dict and other types too.
45 schema: Dict[str, Any]
46 default_value: Union[str, int, List[str], Dict[str, str]]
47
48
49 class RteComponentDict(TypedDict):
50 """Dictionary representing the RTE component's definition."""
51
52 backend_id: str
53 category: str
54 description: str
55 frontend_id: str
56 tooltip: str
57 icon_data_url: str
58 is_complex: bool
59 requires_internet: bool
60 requires_fs: bool
61 is_block_element: bool
62 customization_arg_specs: List[CustomizationArgSpecDict]
63
64
65 class Registry:
66 """Registry of all custom rich-text components."""
67
68 _rte_components: Dict[str, RteComponentDict] = {}
69
70 @classmethod
71 def _refresh(cls) -> None:
72 """Repopulate the registry."""
73 cls._rte_components.clear()
74 package, filepath = os.path.split(
75 feconf.RTE_EXTENSIONS_DEFINITIONS_PATH)
76 cls._rte_components = constants.parse_json_from_ts(
77 constants.get_package_file_contents(package, filepath))
78
79 @classmethod
80 def get_all_rte_components(cls) -> Dict[str, RteComponentDict]:
81 """Get a dictionary mapping RTE component IDs to their definitions."""
82 if not cls._rte_components:
83 cls._refresh()
84 return cls._rte_components
85
86 @classmethod
87 def get_tag_list_with_attrs(cls) -> Dict[str, List[str]]:
88 """Returns a dict of HTML tag names and attributes for RTE components.
89
90 The keys are tag names starting with 'oppia-noninteractive-', followed
91 by the hyphenated version of the name of the RTE component. The values
92 are lists of allowed attributes of the form
93 [PARAM_NAME]-with-[CUSTOMIZATION_ARG_NAME].
94 """
95 # TODO(sll): Cache this computation and update it on each refresh.
96 # Better still, bring this into the build process so it doesn't have
97 # to be manually computed each time.
98 component_list = list(cls.get_all_rte_components().values())
99
100 component_tags = {}
101 for component_specs in component_list:
102 tag_name = 'oppia-noninteractive-%s' % (
103 utils.camelcase_to_hyphenated(component_specs['backend_id']))
104
105 component_tags[tag_name] = [
106 '%s-with-value' % ca_spec['name']
107 for ca_spec in component_specs['customization_arg_specs']]
108
109 return component_tags
110
111 @classmethod
112 def get_component_types_to_component_classes(
113 cls
114 ) -> Dict[str, Type[components.BaseRteComponent]]:
115 """Get component classes mapping for component types.
116
117 Returns:
118 dict. A dict mapping from rte component types to rte component
119 classes.
120 """
121 rte_path = [feconf.RTE_EXTENSIONS_DIR]
122
123 for loader, name, _ in pkgutil.iter_modules(path=rte_path):
124 if name == 'components':
125 fetched_module = loader.find_module(name)
126 # Ruling out the possibility of None for mypy type checking.
127 assert fetched_module is not None
128 module = fetched_module.load_module(name)
129 break
130
131 component_types_to_component_classes = {}
132 component_names = list(cls.get_all_rte_components().keys())
133 for component_name in component_names:
134 for name, obj in inspect.getmembers(module):
135 if inspect.isclass(obj) and name == component_name:
136 component_types_to_component_classes[
137 'oppia-noninteractive-%s' % component_name.lower()] = (
138 obj)
139
140 return component_types_to_component_classes
141
142 @classmethod
143 def get_component_tag_names(
144 cls, key: str, expected_value: bool
145 ) -> List[str]:
146 """Get a list of component tag names which have the expected
147 value of a key.
148
149 Args:
150 key: str. The key to be checked in component spec.
151 expected_value: bool. The expected value of the key to select
152 the components.
153
154 Returns:
155 list(str). A list of component tag names which have the expected
156 value of a key.
157 """
158 rich_text_components_specs = cls.get_all_rte_components()
159 component_tag_names = []
160 for component_spec in rich_text_components_specs.values():
161 if component_spec.get(key) == expected_value:
162 component_tag_names.append(
163 'oppia-noninteractive-%s' % component_spec['frontend_id'])
164 return component_tag_names
165
166 @classmethod
167 def get_inline_component_tag_names(cls) -> List[str]:
168 """Get a list of inline component tag names.
169
170 Returns:
171 list(str). A list of inline component tag names.
172 """
173 return cls.get_component_tag_names('is_block_element', False)
174
175 @classmethod
176 def get_block_component_tag_names(cls) -> List[str]:
177 """Get a list of block component tag names.
178
179 Returns:
180 list(str). A list of block component tag names.
181 """
182 return cls.get_component_tag_names('is_block_element', True)
183
184 @classmethod
185 def get_simple_component_tag_names(cls) -> List[str]:
186 """Get a list of simple component tag names.
187
188 Returns:
189 list(str). A list of simple component tag names.
190 """
191 return cls.get_component_tag_names('is_complex', False)
192
193 @classmethod
194 def get_complex_component_tag_names(cls) -> List[str]:
195 """Get a list of complex component tag names.
196
197 Returns:
198 list(str). A list of complex component tag names.
199 """
200 return cls.get_component_tag_names('is_complex', True)
201
[end of core/domain/rte_component_registry.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/core/domain/rte_component_registry.py b/core/domain/rte_component_registry.py
--- a/core/domain/rte_component_registry.py
+++ b/core/domain/rte_component_registry.py
@@ -43,6 +43,7 @@
# Here we use type Any because values in schema dictionary can be of
# type str, List, Dict and other types too.
schema: Dict[str, Any]
+ default_value_obtainable_from_highlight: bool
default_value: Union[str, int, List[str], Dict[str, str]]
|
{"golden_diff": "diff --git a/core/domain/rte_component_registry.py b/core/domain/rte_component_registry.py\n--- a/core/domain/rte_component_registry.py\n+++ b/core/domain/rte_component_registry.py\n@@ -43,6 +43,7 @@\n # Here we use type Any because values in schema dictionary can be of\n # type str, List, Dict and other types too.\n schema: Dict[str, Any]\n+ default_value_obtainable_from_highlight: bool\n default_value: Union[str, int, List[str], Dict[str, str]]\n", "issue": "[Feature Request]: Improve the experience of adding concept cards in the exploration editor.\n### Is your feature request related to a problem? Please describe.\r\n\r\nThe experience of adding skill concept cards in the exploration editor has a number of issues:\r\n\r\n- The highlighted text in the RTE does not get transferred to the concept card skill link modal when it is opened.\r\n- Cancelling the operation results in the disappearance of the highlighted text.\r\n- The list of skills takes a long time to load, even if it has already been fetched previously.\r\n- Terms entered in the skill filter input box do not get applied when the skill list finally loads.\r\n- The detailed skill explanations show up in red, which is hard to read (and suggests some kind of error).\r\n\r\nSee the video below for the current experience:\r\n\r\nhttps://github.com/oppia/oppia/assets/10575562/60c94af1-8550-4be8-b277-ad4084b8daa9\r\n\r\n### Describe the solution you'd like\r\n\r\n- [x] When the skill link modal is opened, the text input field should be populated with the highlighted text in the RTE, or \"concept card\" if there is no highlighted text.\r\n- [x] When the modal is cancelled, the RTE contents should stay as they were before the modal was opened. In particular, any highlighted text should not be deleted.\r\n- [x] The skill filter input box should be disabled until the list of skills has loaded.\r\n- [x] Skill explanations should show up in black text.\r\n\r\n### Describe alternatives you've considered\r\n\r\n- I considered also writing \"the list of skills should load faster\", but in reality there's always going to be some lag time. It might be possible to cache this list so that it loads fast for the second and subsequent queries, but that could lead to problems with stale data if a skill is created/deleted while an exploration is being edited. So I suggest that we don't solve that problem in this issue, and fix the other points first -- then, we can see if the loading time is still an issue.\r\n\r\n### Additional context\r\n\r\n_No response_\n", "before_files": [{"content": "# coding: utf-8\n#\n# Copyright 2014 The Oppia Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS-IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Registry for custom rich-text components.\"\"\"\n\nfrom __future__ import annotations\n\nimport inspect\nimport os\nimport pkgutil\n\nfrom core import constants\nfrom core import feconf\nfrom core import utils\n\nfrom typing import Any, Dict, List, Type, TypedDict, Union\n\nMYPY = False\nif MYPY: # pragma: no cover\n # Here, we are importing 'components' from rich_text_components only\n # for type checking.\n from extensions.rich_text_components import components\n\n\nclass CustomizationArgSpecDict(TypedDict):\n \"\"\"Dictionary representing the customization_arg_specs object.\"\"\"\n\n name: str\n description: str\n # Here we use type Any because values in schema dictionary can be of\n # type str, List, Dict and other types too.\n schema: Dict[str, Any]\n default_value: Union[str, int, List[str], Dict[str, str]]\n\n\nclass RteComponentDict(TypedDict):\n \"\"\"Dictionary representing the RTE component's definition.\"\"\"\n\n backend_id: str\n category: str\n description: str\n frontend_id: str\n tooltip: str\n icon_data_url: str\n is_complex: bool\n requires_internet: bool\n requires_fs: bool\n is_block_element: bool\n customization_arg_specs: List[CustomizationArgSpecDict]\n\n\nclass Registry:\n \"\"\"Registry of all custom rich-text components.\"\"\"\n\n _rte_components: Dict[str, RteComponentDict] = {}\n\n @classmethod\n def _refresh(cls) -> None:\n \"\"\"Repopulate the registry.\"\"\"\n cls._rte_components.clear()\n package, filepath = os.path.split(\n feconf.RTE_EXTENSIONS_DEFINITIONS_PATH)\n cls._rte_components = constants.parse_json_from_ts(\n constants.get_package_file_contents(package, filepath))\n\n @classmethod\n def get_all_rte_components(cls) -> Dict[str, RteComponentDict]:\n \"\"\"Get a dictionary mapping RTE component IDs to their definitions.\"\"\"\n if not cls._rte_components:\n cls._refresh()\n return cls._rte_components\n\n @classmethod\n def get_tag_list_with_attrs(cls) -> Dict[str, List[str]]:\n \"\"\"Returns a dict of HTML tag names and attributes for RTE components.\n\n The keys are tag names starting with 'oppia-noninteractive-', followed\n by the hyphenated version of the name of the RTE component. The values\n are lists of allowed attributes of the form\n [PARAM_NAME]-with-[CUSTOMIZATION_ARG_NAME].\n \"\"\"\n # TODO(sll): Cache this computation and update it on each refresh.\n # Better still, bring this into the build process so it doesn't have\n # to be manually computed each time.\n component_list = list(cls.get_all_rte_components().values())\n\n component_tags = {}\n for component_specs in component_list:\n tag_name = 'oppia-noninteractive-%s' % (\n utils.camelcase_to_hyphenated(component_specs['backend_id']))\n\n component_tags[tag_name] = [\n '%s-with-value' % ca_spec['name']\n for ca_spec in component_specs['customization_arg_specs']]\n\n return component_tags\n\n @classmethod\n def get_component_types_to_component_classes(\n cls\n ) -> Dict[str, Type[components.BaseRteComponent]]:\n \"\"\"Get component classes mapping for component types.\n\n Returns:\n dict. A dict mapping from rte component types to rte component\n classes.\n \"\"\"\n rte_path = [feconf.RTE_EXTENSIONS_DIR]\n\n for loader, name, _ in pkgutil.iter_modules(path=rte_path):\n if name == 'components':\n fetched_module = loader.find_module(name)\n # Ruling out the possibility of None for mypy type checking.\n assert fetched_module is not None\n module = fetched_module.load_module(name)\n break\n\n component_types_to_component_classes = {}\n component_names = list(cls.get_all_rte_components().keys())\n for component_name in component_names:\n for name, obj in inspect.getmembers(module):\n if inspect.isclass(obj) and name == component_name:\n component_types_to_component_classes[\n 'oppia-noninteractive-%s' % component_name.lower()] = (\n obj)\n\n return component_types_to_component_classes\n\n @classmethod\n def get_component_tag_names(\n cls, key: str, expected_value: bool\n ) -> List[str]:\n \"\"\"Get a list of component tag names which have the expected\n value of a key.\n\n Args:\n key: str. The key to be checked in component spec.\n expected_value: bool. The expected value of the key to select\n the components.\n\n Returns:\n list(str). A list of component tag names which have the expected\n value of a key.\n \"\"\"\n rich_text_components_specs = cls.get_all_rte_components()\n component_tag_names = []\n for component_spec in rich_text_components_specs.values():\n if component_spec.get(key) == expected_value:\n component_tag_names.append(\n 'oppia-noninteractive-%s' % component_spec['frontend_id'])\n return component_tag_names\n\n @classmethod\n def get_inline_component_tag_names(cls) -> List[str]:\n \"\"\"Get a list of inline component tag names.\n\n Returns:\n list(str). A list of inline component tag names.\n \"\"\"\n return cls.get_component_tag_names('is_block_element', False)\n\n @classmethod\n def get_block_component_tag_names(cls) -> List[str]:\n \"\"\"Get a list of block component tag names.\n\n Returns:\n list(str). A list of block component tag names.\n \"\"\"\n return cls.get_component_tag_names('is_block_element', True)\n\n @classmethod\n def get_simple_component_tag_names(cls) -> List[str]:\n \"\"\"Get a list of simple component tag names.\n\n Returns:\n list(str). A list of simple component tag names.\n \"\"\"\n return cls.get_component_tag_names('is_complex', False)\n\n @classmethod\n def get_complex_component_tag_names(cls) -> List[str]:\n \"\"\"Get a list of complex component tag names.\n\n Returns:\n list(str). A list of complex component tag names.\n \"\"\"\n return cls.get_component_tag_names('is_complex', True)\n", "path": "core/domain/rte_component_registry.py"}]}
| 2,970 | 118 |
gh_patches_debug_4025
|
rasdani/github-patches
|
git_diff
|
buildbot__buildbot-5771
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
_matches_any_tag missing from BuildStartEndStatusGenerator
The [_matches_any_tag function](https://github.com/buildbot/buildbot/blob/e630745771a8bd03a2084d03ea8e43547d3dff4b/master/buildbot/reporters/generators/build.py#L82) is missing from the BuildStartEndStatusGenerator. This causes failures when you try to filter the builders using the tag with GitHubStatusPush and this generator.
```
buildbot_1 | 2021-01-21 13:51:23+0000 [-] Got exception when handling reporter events
buildbot_1 | Traceback (most recent call last):
buildbot_1 | File "/usr/lib/python3.8/site-packages/twisted/internet/defer.py", line 1475, in gotResult
buildbot_1 | _inlineCallbacks(r, g, status)
buildbot_1 | File "/usr/lib/python3.8/site-packages/twisted/internet/defer.py", line 1416, in _inlineCallbacks
buildbot_1 | result = result.throwExceptionIntoGenerator(g)
buildbot_1 | File "/usr/lib/python3.8/site-packages/twisted/python/failure.py", line 512, in throwExceptionIntoGenerator
buildbot_1 | return g.throw(self.type, self.value, self.tb)
buildbot_1 | File "/usr/lib/python3.8/site-packages/buildbot/reporters/base.py", line 183, in _got_event
buildbot_1 | log.err(e, 'Got exception when handling reporter events')
buildbot_1 | --- <exception caught here> ---
buildbot_1 | File "/usr/lib/python3.8/site-packages/buildbot/reporters/base.py", line 176, in _got_event
buildbot_1 | report = yield g.generate(self.master, self, key, msg)
buildbot_1 | File "/usr/lib/python3.8/site-packages/twisted/internet/defer.py", line 1418, in _inlineCallbacks
buildbot_1 | result = g.send(result)
buildbot_1 | File "/usr/lib/python3.8/site-packages/buildbot/reporters/generators/build.py", line 119, in generate
buildbot_1 | if not self.is_message_needed_by_props(build):
buildbot_1 | File "/usr/lib/python3.8/site-packages/buildbot/reporters/generators/utils.py", line 104, in is_message_needed_by_props
buildbot_1 | if self.tags is not None and not self._matches_any_tag(builder['tags']):
buildbot_1 | builtins.AttributeError: 'BuildStartEndStatusGenerator' object has no attribute '_matches_any_tag'
```
This output is from the official docker v2.10
</issue>
<code>
[start of master/buildbot/reporters/generators/build.py]
1 # This file is part of Buildbot. Buildbot is free software: you can
2 # redistribute it and/or modify it under the terms of the GNU General Public
3 # License as published by the Free Software Foundation, version 2.
4 #
5 # This program is distributed in the hope that it will be useful, but WITHOUT
6 # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
7 # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
8 # details.
9 #
10 # You should have received a copy of the GNU General Public License along with
11 # this program; if not, write to the Free Software Foundation, Inc., 51
12 # Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
13 #
14 # Copyright Buildbot Team Members
15
16 from twisted.internet import defer
17 from zope.interface import implementer
18
19 from buildbot import interfaces
20 from buildbot.reporters import utils
21 from buildbot.reporters.message import MessageFormatter
22 from buildbot.reporters.message import MessageFormatterRenderable
23
24 from .utils import BuildStatusGeneratorMixin
25
26
27 @implementer(interfaces.IReportGenerator)
28 class BuildStatusGenerator(BuildStatusGeneratorMixin):
29
30 wanted_event_keys = [
31 ('builds', None, 'finished'),
32 ]
33
34 compare_attrs = ['formatter']
35
36 def __init__(self, mode=("failing", "passing", "warnings"),
37 tags=None, builders=None, schedulers=None, branches=None,
38 subject="Buildbot %(result)s in %(title)s on %(builder)s",
39 add_logs=False, add_patch=False, report_new=False, message_formatter=None,
40 _want_previous_build=None):
41 super().__init__(mode, tags, builders, schedulers, branches, subject, add_logs, add_patch)
42 self.formatter = message_formatter
43 if self.formatter is None:
44 self.formatter = MessageFormatter()
45
46 # TODO: private and deprecated, included only to support HttpStatusPushBase
47 self._want_previous_build_override = _want_previous_build
48
49 if report_new:
50 self.wanted_event_keys = [
51 ('builds', None, 'finished'),
52 ('builds', None, 'new'),
53 ]
54
55 @defer.inlineCallbacks
56 def generate(self, master, reporter, key, build):
57 _, _, event = key
58 is_new = event == 'new'
59 want_previous_build = False if is_new else self._want_previous_build()
60 if self._want_previous_build_override is not None:
61 want_previous_build = self._want_previous_build_override
62
63 yield utils.getDetailsForBuild(master, build,
64 wantProperties=self.formatter.wantProperties,
65 wantSteps=self.formatter.wantSteps,
66 wantPreviousBuild=want_previous_build,
67 wantLogs=self.formatter.wantLogs)
68
69 if not self.is_message_needed_by_props(build):
70 return None
71 if not is_new and not self.is_message_needed_by_results(build):
72 return None
73
74 report = yield self.build_message(self.formatter, master, reporter,
75 build['builder']['name'], [build],
76 build['results'])
77 return report
78
79 def _want_previous_build(self):
80 return "change" in self.mode or "problem" in self.mode
81
82 def _matches_any_tag(self, tags):
83 return self.tags and any(tag for tag in self.tags if tag in tags)
84
85
86 @implementer(interfaces.IReportGenerator)
87 class BuildStartEndStatusGenerator(BuildStatusGeneratorMixin):
88
89 wanted_event_keys = [
90 ('builds', None, 'new'),
91 ('builds', None, 'finished'),
92 ]
93
94 compare_attrs = ['start_formatter', 'end_formatter']
95
96 def __init__(self, tags=None, builders=None, schedulers=None, branches=None, add_logs=False,
97 add_patch=False, start_formatter=None, end_formatter=None):
98
99 super().__init__('all', tags, builders, schedulers, branches, None, add_logs, add_patch)
100 self.start_formatter = start_formatter
101 if self.start_formatter is None:
102 self.start_formatter = MessageFormatterRenderable('Build started.')
103 self.end_formatter = end_formatter
104 if self.end_formatter is None:
105 self.end_formatter = MessageFormatterRenderable('Build done.')
106
107 @defer.inlineCallbacks
108 def generate(self, master, reporter, key, build):
109 _, _, event = key
110 is_new = event == 'new'
111
112 formatter = self.start_formatter if is_new else self.end_formatter
113
114 yield utils.getDetailsForBuild(master, build,
115 wantProperties=formatter.wantProperties,
116 wantSteps=formatter.wantSteps,
117 wantLogs=formatter.wantLogs)
118
119 if not self.is_message_needed_by_props(build):
120 return None
121
122 report = yield self.build_message(formatter, master, reporter, build['builder']['name'],
123 [build], build['results'])
124 return report
125
[end of master/buildbot/reporters/generators/build.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/master/buildbot/reporters/generators/build.py b/master/buildbot/reporters/generators/build.py
--- a/master/buildbot/reporters/generators/build.py
+++ b/master/buildbot/reporters/generators/build.py
@@ -122,3 +122,6 @@
report = yield self.build_message(formatter, master, reporter, build['builder']['name'],
[build], build['results'])
return report
+
+ def _matches_any_tag(self, tags):
+ return self.tags and any(tag for tag in self.tags if tag in tags)
|
{"golden_diff": "diff --git a/master/buildbot/reporters/generators/build.py b/master/buildbot/reporters/generators/build.py\n--- a/master/buildbot/reporters/generators/build.py\n+++ b/master/buildbot/reporters/generators/build.py\n@@ -122,3 +122,6 @@\n report = yield self.build_message(formatter, master, reporter, build['builder']['name'],\n [build], build['results'])\n return report\n+\n+ def _matches_any_tag(self, tags):\n+ return self.tags and any(tag for tag in self.tags if tag in tags)\n", "issue": "_matches_any_tag missing from BuildStartEndStatusGenerator\nThe [_matches_any_tag function](https://github.com/buildbot/buildbot/blob/e630745771a8bd03a2084d03ea8e43547d3dff4b/master/buildbot/reporters/generators/build.py#L82) is missing from the BuildStartEndStatusGenerator. This causes failures when you try to filter the builders using the tag with GitHubStatusPush and this generator.\r\n\r\n```\r\nbuildbot_1 | 2021-01-21 13:51:23+0000 [-] Got exception when handling reporter events\r\nbuildbot_1 | \tTraceback (most recent call last):\r\nbuildbot_1 | \t File \"/usr/lib/python3.8/site-packages/twisted/internet/defer.py\", line 1475, in gotResult\r\nbuildbot_1 | \t _inlineCallbacks(r, g, status)\r\nbuildbot_1 | \t File \"/usr/lib/python3.8/site-packages/twisted/internet/defer.py\", line 1416, in _inlineCallbacks\r\nbuildbot_1 | \t result = result.throwExceptionIntoGenerator(g)\r\nbuildbot_1 | \t File \"/usr/lib/python3.8/site-packages/twisted/python/failure.py\", line 512, in throwExceptionIntoGenerator\r\nbuildbot_1 | \t return g.throw(self.type, self.value, self.tb)\r\nbuildbot_1 | \t File \"/usr/lib/python3.8/site-packages/buildbot/reporters/base.py\", line 183, in _got_event\r\nbuildbot_1 | \t log.err(e, 'Got exception when handling reporter events')\r\nbuildbot_1 | \t--- <exception caught here> ---\r\nbuildbot_1 | \t File \"/usr/lib/python3.8/site-packages/buildbot/reporters/base.py\", line 176, in _got_event\r\nbuildbot_1 | \t report = yield g.generate(self.master, self, key, msg)\r\nbuildbot_1 | \t File \"/usr/lib/python3.8/site-packages/twisted/internet/defer.py\", line 1418, in _inlineCallbacks\r\nbuildbot_1 | \t result = g.send(result)\r\nbuildbot_1 | \t File \"/usr/lib/python3.8/site-packages/buildbot/reporters/generators/build.py\", line 119, in generate\r\nbuildbot_1 | \t if not self.is_message_needed_by_props(build):\r\nbuildbot_1 | \t File \"/usr/lib/python3.8/site-packages/buildbot/reporters/generators/utils.py\", line 104, in is_message_needed_by_props\r\nbuildbot_1 | \t if self.tags is not None and not self._matches_any_tag(builder['tags']):\r\nbuildbot_1 | \tbuiltins.AttributeError: 'BuildStartEndStatusGenerator' object has no attribute '_matches_any_tag'\r\n\r\n```\r\n\r\nThis output is from the official docker v2.10\n", "before_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nfrom twisted.internet import defer\nfrom zope.interface import implementer\n\nfrom buildbot import interfaces\nfrom buildbot.reporters import utils\nfrom buildbot.reporters.message import MessageFormatter\nfrom buildbot.reporters.message import MessageFormatterRenderable\n\nfrom .utils import BuildStatusGeneratorMixin\n\n\n@implementer(interfaces.IReportGenerator)\nclass BuildStatusGenerator(BuildStatusGeneratorMixin):\n\n wanted_event_keys = [\n ('builds', None, 'finished'),\n ]\n\n compare_attrs = ['formatter']\n\n def __init__(self, mode=(\"failing\", \"passing\", \"warnings\"),\n tags=None, builders=None, schedulers=None, branches=None,\n subject=\"Buildbot %(result)s in %(title)s on %(builder)s\",\n add_logs=False, add_patch=False, report_new=False, message_formatter=None,\n _want_previous_build=None):\n super().__init__(mode, tags, builders, schedulers, branches, subject, add_logs, add_patch)\n self.formatter = message_formatter\n if self.formatter is None:\n self.formatter = MessageFormatter()\n\n # TODO: private and deprecated, included only to support HttpStatusPushBase\n self._want_previous_build_override = _want_previous_build\n\n if report_new:\n self.wanted_event_keys = [\n ('builds', None, 'finished'),\n ('builds', None, 'new'),\n ]\n\n @defer.inlineCallbacks\n def generate(self, master, reporter, key, build):\n _, _, event = key\n is_new = event == 'new'\n want_previous_build = False if is_new else self._want_previous_build()\n if self._want_previous_build_override is not None:\n want_previous_build = self._want_previous_build_override\n\n yield utils.getDetailsForBuild(master, build,\n wantProperties=self.formatter.wantProperties,\n wantSteps=self.formatter.wantSteps,\n wantPreviousBuild=want_previous_build,\n wantLogs=self.formatter.wantLogs)\n\n if not self.is_message_needed_by_props(build):\n return None\n if not is_new and not self.is_message_needed_by_results(build):\n return None\n\n report = yield self.build_message(self.formatter, master, reporter,\n build['builder']['name'], [build],\n build['results'])\n return report\n\n def _want_previous_build(self):\n return \"change\" in self.mode or \"problem\" in self.mode\n\n def _matches_any_tag(self, tags):\n return self.tags and any(tag for tag in self.tags if tag in tags)\n\n\n@implementer(interfaces.IReportGenerator)\nclass BuildStartEndStatusGenerator(BuildStatusGeneratorMixin):\n\n wanted_event_keys = [\n ('builds', None, 'new'),\n ('builds', None, 'finished'),\n ]\n\n compare_attrs = ['start_formatter', 'end_formatter']\n\n def __init__(self, tags=None, builders=None, schedulers=None, branches=None, add_logs=False,\n add_patch=False, start_formatter=None, end_formatter=None):\n\n super().__init__('all', tags, builders, schedulers, branches, None, add_logs, add_patch)\n self.start_formatter = start_formatter\n if self.start_formatter is None:\n self.start_formatter = MessageFormatterRenderable('Build started.')\n self.end_formatter = end_formatter\n if self.end_formatter is None:\n self.end_formatter = MessageFormatterRenderable('Build done.')\n\n @defer.inlineCallbacks\n def generate(self, master, reporter, key, build):\n _, _, event = key\n is_new = event == 'new'\n\n formatter = self.start_formatter if is_new else self.end_formatter\n\n yield utils.getDetailsForBuild(master, build,\n wantProperties=formatter.wantProperties,\n wantSteps=formatter.wantSteps,\n wantLogs=formatter.wantLogs)\n\n if not self.is_message_needed_by_props(build):\n return None\n\n report = yield self.build_message(formatter, master, reporter, build['builder']['name'],\n [build], build['results'])\n return report\n", "path": "master/buildbot/reporters/generators/build.py"}]}
| 2,514 | 127 |
gh_patches_debug_36022
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-6357
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
yettel_bg is broken
The spider does not return anything. It seems like they've moved the page for getting their store data. I wasn't able to find the new address or how the data reaches their store locator page.
Store locator: https://www.yettel.bg/faq/digital-customer-service/store-locator
Spider: https://github.com/alltheplaces/alltheplaces/blob/master/locations/spiders/yettel_bg.py
</issue>
<code>
[start of locations/spiders/yettel_bg.py]
1 from scrapy import Selector, Spider
2
3 from locations.items import Feature
4
5
6 class YettelBGSpider(Spider):
7 name = "yettel_bg"
8 item_attributes = {
9 "brand": "Yettel",
10 "brand_wikidata": "Q14915070",
11 "country": "BG",
12 }
13 start_urls = ["https://www.yettel.bg/store-locator/json"]
14
15 def parse(self, response):
16 for store in response.json()["features"]:
17 item = Feature()
18
19 item["lon"], item["lat"] = store["geometry"]["coordinates"]
20
21 item["ref"] = store["properties"]["title"]
22
23 address_block = Selector(text=store["properties"]["gsl_addressfield"])
24
25 item["street_address"] = address_block.xpath('//div[@class="thoroughfare"]/text()').get()
26 item["postcode"] = address_block.xpath('//span[@class="postal-code"]/text()').get()
27 item["city"] = address_block.xpath('//span[@class="locality"]/text()').get()
28
29 yield item
30
[end of locations/spiders/yettel_bg.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/locations/spiders/yettel_bg.py b/locations/spiders/yettel_bg.py
--- a/locations/spiders/yettel_bg.py
+++ b/locations/spiders/yettel_bg.py
@@ -1,5 +1,9 @@
-from scrapy import Selector, Spider
+import io
+from openpyxl import load_workbook
+from scrapy import Spider
+
+from locations.hours import OpeningHours, day_range
from locations.items import Feature
@@ -10,20 +14,50 @@
"brand_wikidata": "Q14915070",
"country": "BG",
}
- start_urls = ["https://www.yettel.bg/store-locator/json"]
+ start_urls = ["https://www.yettel.bg/faq/digital-customer-service/store-locator"]
+ no_refs = True
+ custom_settings = {"ROBOTSTXT_OBEY": False}
def parse(self, response):
- for store in response.json()["features"]:
- item = Feature()
-
- item["lon"], item["lat"] = store["geometry"]["coordinates"]
-
- item["ref"] = store["properties"]["title"]
-
- address_block = Selector(text=store["properties"]["gsl_addressfield"])
-
- item["street_address"] = address_block.xpath('//div[@class="thoroughfare"]/text()').get()
- item["postcode"] = address_block.xpath('//span[@class="postal-code"]/text()').get()
- item["city"] = address_block.xpath('//span[@class="locality"]/text()').get()
-
- yield item
+ yield response.follow(
+ url=response.xpath('//input[@id="hdnExcelFile"]/@value').get(), callback=self.parse_spreadsheet
+ )
+
+ def parse_spreadsheet(self, response):
+ if "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet" in response.headers.get(
+ "Content-Type"
+ ).decode("utf-8"):
+ excel_file = response.body
+
+ excel_data = io.BytesIO(excel_file)
+ workbook = load_workbook(excel_data, read_only=True)
+
+ sheet = workbook.active
+
+ data = []
+ for row in sheet.iter_rows(values_only=True):
+ data.append(row)
+
+ headers = data[0]
+ json_data = []
+ for row in data[1:]:
+ json_data.append({headers[i]: cell for i, cell in enumerate(row)})
+
+ for store in json_data:
+ item = Feature()
+
+ item["lat"] = store["latitude"]
+ item["lon"] = store["longitude"]
+
+ item["street_address"] = store["address_loc"]
+ item["city"] = store["city_loc"]
+
+ item["opening_hours"] = OpeningHours()
+ item["opening_hours"].add_days_range(
+ day_range("Mo", "Fr"), *store["working_time_weekdays"].replace(" ", "").split("-")
+ )
+ if store["is_closed_on_saturday"] == "No":
+ item["opening_hours"].add_range("Sa", *store["working_time_saturday"].replace(" ", "").split("-"))
+ if store["is_closed_on_sunday"] == "No":
+ item["opening_hours"].add_range("Su", *store["working_time_sunday"].replace(" ", "").split("-"))
+ yield item
|
{"golden_diff": "diff --git a/locations/spiders/yettel_bg.py b/locations/spiders/yettel_bg.py\n--- a/locations/spiders/yettel_bg.py\n+++ b/locations/spiders/yettel_bg.py\n@@ -1,5 +1,9 @@\n-from scrapy import Selector, Spider\n+import io\n \n+from openpyxl import load_workbook\n+from scrapy import Spider\n+\n+from locations.hours import OpeningHours, day_range\n from locations.items import Feature\n \n \n@@ -10,20 +14,50 @@\n \"brand_wikidata\": \"Q14915070\",\n \"country\": \"BG\",\n }\n- start_urls = [\"https://www.yettel.bg/store-locator/json\"]\n+ start_urls = [\"https://www.yettel.bg/faq/digital-customer-service/store-locator\"]\n+ no_refs = True\n+ custom_settings = {\"ROBOTSTXT_OBEY\": False}\n \n def parse(self, response):\n- for store in response.json()[\"features\"]:\n- item = Feature()\n-\n- item[\"lon\"], item[\"lat\"] = store[\"geometry\"][\"coordinates\"]\n-\n- item[\"ref\"] = store[\"properties\"][\"title\"]\n-\n- address_block = Selector(text=store[\"properties\"][\"gsl_addressfield\"])\n-\n- item[\"street_address\"] = address_block.xpath('//div[@class=\"thoroughfare\"]/text()').get()\n- item[\"postcode\"] = address_block.xpath('//span[@class=\"postal-code\"]/text()').get()\n- item[\"city\"] = address_block.xpath('//span[@class=\"locality\"]/text()').get()\n-\n- yield item\n+ yield response.follow(\n+ url=response.xpath('//input[@id=\"hdnExcelFile\"]/@value').get(), callback=self.parse_spreadsheet\n+ )\n+\n+ def parse_spreadsheet(self, response):\n+ if \"application/vnd.openxmlformats-officedocument.spreadsheetml.sheet\" in response.headers.get(\n+ \"Content-Type\"\n+ ).decode(\"utf-8\"):\n+ excel_file = response.body\n+\n+ excel_data = io.BytesIO(excel_file)\n+ workbook = load_workbook(excel_data, read_only=True)\n+\n+ sheet = workbook.active\n+\n+ data = []\n+ for row in sheet.iter_rows(values_only=True):\n+ data.append(row)\n+\n+ headers = data[0]\n+ json_data = []\n+ for row in data[1:]:\n+ json_data.append({headers[i]: cell for i, cell in enumerate(row)})\n+\n+ for store in json_data:\n+ item = Feature()\n+\n+ item[\"lat\"] = store[\"latitude\"]\n+ item[\"lon\"] = store[\"longitude\"]\n+\n+ item[\"street_address\"] = store[\"address_loc\"]\n+ item[\"city\"] = store[\"city_loc\"]\n+\n+ item[\"opening_hours\"] = OpeningHours()\n+ item[\"opening_hours\"].add_days_range(\n+ day_range(\"Mo\", \"Fr\"), *store[\"working_time_weekdays\"].replace(\" \", \"\").split(\"-\")\n+ )\n+ if store[\"is_closed_on_saturday\"] == \"No\":\n+ item[\"opening_hours\"].add_range(\"Sa\", *store[\"working_time_saturday\"].replace(\" \", \"\").split(\"-\"))\n+ if store[\"is_closed_on_sunday\"] == \"No\":\n+ item[\"opening_hours\"].add_range(\"Su\", *store[\"working_time_sunday\"].replace(\" \", \"\").split(\"-\"))\n+ yield item\n", "issue": "yettel_bg is broken\nThe spider does not return anything. It seems like they've moved the page for getting their store data. I wasn't able to find the new address or how the data reaches their store locator page.\r\n\r\nStore locator: https://www.yettel.bg/faq/digital-customer-service/store-locator\r\n\r\nSpider: https://github.com/alltheplaces/alltheplaces/blob/master/locations/spiders/yettel_bg.py\n", "before_files": [{"content": "from scrapy import Selector, Spider\n\nfrom locations.items import Feature\n\n\nclass YettelBGSpider(Spider):\n name = \"yettel_bg\"\n item_attributes = {\n \"brand\": \"Yettel\",\n \"brand_wikidata\": \"Q14915070\",\n \"country\": \"BG\",\n }\n start_urls = [\"https://www.yettel.bg/store-locator/json\"]\n\n def parse(self, response):\n for store in response.json()[\"features\"]:\n item = Feature()\n\n item[\"lon\"], item[\"lat\"] = store[\"geometry\"][\"coordinates\"]\n\n item[\"ref\"] = store[\"properties\"][\"title\"]\n\n address_block = Selector(text=store[\"properties\"][\"gsl_addressfield\"])\n\n item[\"street_address\"] = address_block.xpath('//div[@class=\"thoroughfare\"]/text()').get()\n item[\"postcode\"] = address_block.xpath('//span[@class=\"postal-code\"]/text()').get()\n item[\"city\"] = address_block.xpath('//span[@class=\"locality\"]/text()').get()\n\n yield item\n", "path": "locations/spiders/yettel_bg.py"}]}
| 911 | 756 |
gh_patches_debug_1875
|
rasdani/github-patches
|
git_diff
|
mdn__kuma-6598
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Possibly to prefill Reason textarea on $delete
If you're going to have some human-helped automation that deletes the 20% or so non-en-US documents that aren't actually translated, it would be nice if you don't have to type in the same reason every time.
<img width="989" alt="Screen Shot 2020-02-26 at 11 56 40 AM" src="https://user-images.githubusercontent.com/26739/75367987-1be85500-588f-11ea-8ba1-f49e0db69cc7.png">
Would be neat if you could control it with something like `?reason=Sample%20reason`
</issue>
<code>
[start of kuma/wiki/views/delete.py]
1 from django.db import IntegrityError
2 from django.shortcuts import get_object_or_404, redirect, render
3 from django.utils.translation import ugettext
4 from django.views.decorators.cache import never_cache
5
6 from kuma.core.decorators import (
7 block_user_agents,
8 ensure_wiki_domain,
9 login_required,
10 permission_required,
11 )
12 from kuma.core.urlresolvers import reverse
13
14 from ..decorators import check_readonly, process_document_path
15 from ..forms import DocumentDeletionForm
16 from ..models import Document, DocumentDeletionLog, Revision
17 from ..utils import locale_and_slug_from_path
18
19
20 @ensure_wiki_domain
21 @never_cache
22 @block_user_agents
23 @login_required
24 @check_readonly
25 def revert_document(request, document_path, revision_id):
26 """
27 Revert document to a specific revision.
28 """
29 document_locale, document_slug, needs_redirect = locale_and_slug_from_path(
30 document_path, request
31 )
32
33 revision = get_object_or_404(
34 Revision.objects.select_related("document"),
35 pk=revision_id,
36 document__slug=document_slug,
37 )
38
39 if request.method == "GET":
40 # Render the confirmation page
41 return render(
42 request,
43 "wiki/confirm_revision_revert.html",
44 {"revision": revision, "document": revision.document},
45 )
46 else:
47 comment = request.POST.get("comment")
48 document = revision.document
49 old_revision_pk = revision.pk
50 try:
51 new_revision = document.revert(revision, request.user, comment)
52 # schedule a rendering of the new revision if it really was saved
53 if new_revision.pk != old_revision_pk:
54 document.schedule_rendering("max-age=0")
55 except IntegrityError:
56 return render(
57 request,
58 "wiki/confirm_revision_revert.html",
59 {
60 "revision": revision,
61 "document": revision.document,
62 "error": ugettext(
63 "Document already exists. Note: You cannot "
64 "revert a document that has been moved until you "
65 "delete its redirect."
66 ),
67 },
68 )
69 return redirect("wiki.document_revisions", revision.document.slug)
70
71
72 @ensure_wiki_domain
73 @never_cache
74 @block_user_agents
75 @login_required
76 @permission_required("wiki.delete_document")
77 @check_readonly
78 @process_document_path
79 def delete_document(request, document_slug, document_locale):
80 """
81 Delete a Document.
82 """
83 document = get_object_or_404(Document, locale=document_locale, slug=document_slug)
84
85 # HACK: https://bugzil.la/972545 - Don't delete pages that have children
86 # TODO: https://bugzil.la/972541 - Deleting a page that has subpages
87 prevent = document.children.exists()
88
89 first_revision = document.revisions.all()[0]
90
91 if request.method == "POST":
92 form = DocumentDeletionForm(data=request.POST)
93 if form.is_valid():
94 DocumentDeletionLog.objects.create(
95 locale=document.locale,
96 slug=document.slug,
97 user=request.user,
98 reason=form.cleaned_data["reason"],
99 )
100 document.delete()
101 return redirect(document)
102 else:
103 form = DocumentDeletionForm()
104
105 context = {
106 "document": document,
107 "form": form,
108 "request": request,
109 "revision": first_revision,
110 "prevent": prevent,
111 }
112 return render(request, "wiki/confirm_document_delete.html", context)
113
114
115 @ensure_wiki_domain
116 @never_cache
117 @block_user_agents
118 @login_required
119 @permission_required("wiki.restore_document")
120 @check_readonly
121 @process_document_path
122 def restore_document(request, document_slug, document_locale):
123 """
124 Restore a deleted Document.
125 """
126 document = get_object_or_404(
127 Document.deleted_objects.all(), slug=document_slug, locale=document_locale
128 )
129 document.restore()
130 return redirect(document)
131
132
133 @ensure_wiki_domain
134 @never_cache
135 @block_user_agents
136 @login_required
137 @permission_required("wiki.purge_document")
138 @check_readonly
139 @process_document_path
140 def purge_document(request, document_slug, document_locale):
141 """
142 Permanently purge a deleted Document.
143 """
144 document = get_object_or_404(
145 Document.deleted_objects.all(), slug=document_slug, locale=document_locale
146 )
147 deletion_log_entries = DocumentDeletionLog.objects.filter(
148 locale=document_locale, slug=document_slug
149 )
150 if deletion_log_entries.exists():
151 deletion_log = deletion_log_entries.order_by("-pk")[0]
152 else:
153 deletion_log = {}
154
155 if request.method == "POST" and "confirm" in request.POST:
156 document.purge()
157 return redirect(
158 reverse("wiki.document", args=(document_slug,), locale=document_locale)
159 )
160 else:
161 return render(
162 request,
163 "wiki/confirm_purge.html",
164 {"document": document, "deletion_log": deletion_log},
165 )
166
[end of kuma/wiki/views/delete.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kuma/wiki/views/delete.py b/kuma/wiki/views/delete.py
--- a/kuma/wiki/views/delete.py
+++ b/kuma/wiki/views/delete.py
@@ -100,7 +100,8 @@
document.delete()
return redirect(document)
else:
- form = DocumentDeletionForm()
+
+ form = DocumentDeletionForm(initial={"reason": request.GET.get("reason", "")})
context = {
"document": document,
|
{"golden_diff": "diff --git a/kuma/wiki/views/delete.py b/kuma/wiki/views/delete.py\n--- a/kuma/wiki/views/delete.py\n+++ b/kuma/wiki/views/delete.py\n@@ -100,7 +100,8 @@\n document.delete()\n return redirect(document)\n else:\n- form = DocumentDeletionForm()\n+\n+ form = DocumentDeletionForm(initial={\"reason\": request.GET.get(\"reason\", \"\")})\n \n context = {\n \"document\": document,\n", "issue": "Possibly to prefill Reason textarea on $delete\nIf you're going to have some human-helped automation that deletes the 20% or so non-en-US documents that aren't actually translated, it would be nice if you don't have to type in the same reason every time. \r\n<img width=\"989\" alt=\"Screen Shot 2020-02-26 at 11 56 40 AM\" src=\"https://user-images.githubusercontent.com/26739/75367987-1be85500-588f-11ea-8ba1-f49e0db69cc7.png\">\r\n\r\nWould be neat if you could control it with something like `?reason=Sample%20reason`\n", "before_files": [{"content": "from django.db import IntegrityError\nfrom django.shortcuts import get_object_or_404, redirect, render\nfrom django.utils.translation import ugettext\nfrom django.views.decorators.cache import never_cache\n\nfrom kuma.core.decorators import (\n block_user_agents,\n ensure_wiki_domain,\n login_required,\n permission_required,\n)\nfrom kuma.core.urlresolvers import reverse\n\nfrom ..decorators import check_readonly, process_document_path\nfrom ..forms import DocumentDeletionForm\nfrom ..models import Document, DocumentDeletionLog, Revision\nfrom ..utils import locale_and_slug_from_path\n\n\n@ensure_wiki_domain\n@never_cache\n@block_user_agents\n@login_required\n@check_readonly\ndef revert_document(request, document_path, revision_id):\n \"\"\"\n Revert document to a specific revision.\n \"\"\"\n document_locale, document_slug, needs_redirect = locale_and_slug_from_path(\n document_path, request\n )\n\n revision = get_object_or_404(\n Revision.objects.select_related(\"document\"),\n pk=revision_id,\n document__slug=document_slug,\n )\n\n if request.method == \"GET\":\n # Render the confirmation page\n return render(\n request,\n \"wiki/confirm_revision_revert.html\",\n {\"revision\": revision, \"document\": revision.document},\n )\n else:\n comment = request.POST.get(\"comment\")\n document = revision.document\n old_revision_pk = revision.pk\n try:\n new_revision = document.revert(revision, request.user, comment)\n # schedule a rendering of the new revision if it really was saved\n if new_revision.pk != old_revision_pk:\n document.schedule_rendering(\"max-age=0\")\n except IntegrityError:\n return render(\n request,\n \"wiki/confirm_revision_revert.html\",\n {\n \"revision\": revision,\n \"document\": revision.document,\n \"error\": ugettext(\n \"Document already exists. Note: You cannot \"\n \"revert a document that has been moved until you \"\n \"delete its redirect.\"\n ),\n },\n )\n return redirect(\"wiki.document_revisions\", revision.document.slug)\n\n\n@ensure_wiki_domain\n@never_cache\n@block_user_agents\n@login_required\n@permission_required(\"wiki.delete_document\")\n@check_readonly\n@process_document_path\ndef delete_document(request, document_slug, document_locale):\n \"\"\"\n Delete a Document.\n \"\"\"\n document = get_object_or_404(Document, locale=document_locale, slug=document_slug)\n\n # HACK: https://bugzil.la/972545 - Don't delete pages that have children\n # TODO: https://bugzil.la/972541 - Deleting a page that has subpages\n prevent = document.children.exists()\n\n first_revision = document.revisions.all()[0]\n\n if request.method == \"POST\":\n form = DocumentDeletionForm(data=request.POST)\n if form.is_valid():\n DocumentDeletionLog.objects.create(\n locale=document.locale,\n slug=document.slug,\n user=request.user,\n reason=form.cleaned_data[\"reason\"],\n )\n document.delete()\n return redirect(document)\n else:\n form = DocumentDeletionForm()\n\n context = {\n \"document\": document,\n \"form\": form,\n \"request\": request,\n \"revision\": first_revision,\n \"prevent\": prevent,\n }\n return render(request, \"wiki/confirm_document_delete.html\", context)\n\n\n@ensure_wiki_domain\n@never_cache\n@block_user_agents\n@login_required\n@permission_required(\"wiki.restore_document\")\n@check_readonly\n@process_document_path\ndef restore_document(request, document_slug, document_locale):\n \"\"\"\n Restore a deleted Document.\n \"\"\"\n document = get_object_or_404(\n Document.deleted_objects.all(), slug=document_slug, locale=document_locale\n )\n document.restore()\n return redirect(document)\n\n\n@ensure_wiki_domain\n@never_cache\n@block_user_agents\n@login_required\n@permission_required(\"wiki.purge_document\")\n@check_readonly\n@process_document_path\ndef purge_document(request, document_slug, document_locale):\n \"\"\"\n Permanently purge a deleted Document.\n \"\"\"\n document = get_object_or_404(\n Document.deleted_objects.all(), slug=document_slug, locale=document_locale\n )\n deletion_log_entries = DocumentDeletionLog.objects.filter(\n locale=document_locale, slug=document_slug\n )\n if deletion_log_entries.exists():\n deletion_log = deletion_log_entries.order_by(\"-pk\")[0]\n else:\n deletion_log = {}\n\n if request.method == \"POST\" and \"confirm\" in request.POST:\n document.purge()\n return redirect(\n reverse(\"wiki.document\", args=(document_slug,), locale=document_locale)\n )\n else:\n return render(\n request,\n \"wiki/confirm_purge.html\",\n {\"document\": document, \"deletion_log\": deletion_log},\n )\n", "path": "kuma/wiki/views/delete.py"}]}
| 2,152 | 103 |
gh_patches_debug_10882
|
rasdani/github-patches
|
git_diff
|
statsmodels__statsmodels-6292
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
nonparametric.KDEUnivariate returns zero bandwidth
Hi,
Does anyone have an idea why the following dataset makes KDEUnivariate return zero bandwidth?
```
data = np.array([1,1,1,1,2])
kde_sm = sm.nonparametric.KDEUnivariate(data.astype('double'))
kde_sm.fit(bw="silverman")
sup = kde_sm.support
den = kde_sm.density
print(kde_sm.bw) # prints 0
```
when `data = np.array([1,1,1,2])` the returned bandwidth is correct. When I add more 1s, the bandwidth stays zero.
Thank you!
</issue>
<code>
[start of statsmodels/nonparametric/bandwidths.py]
1 import numpy as np
2 from scipy.stats import scoreatpercentile as sap
3
4 from statsmodels.compat.pandas import Substitution
5 from statsmodels.sandbox.nonparametric import kernels
6
7 def _select_sigma(X):
8 """
9 Returns the smaller of std(X, ddof=1) or normalized IQR(X) over axis 0.
10
11 References
12 ----------
13 Silverman (1986) p.47
14 """
15 # normalize = norm.ppf(.75) - norm.ppf(.25)
16 normalize = 1.349
17 # IQR = np.subtract.reduce(percentile(X, [75,25],
18 # axis=axis), axis=axis)/normalize
19 IQR = (sap(X, 75) - sap(X, 25))/normalize
20 return np.minimum(np.std(X, axis=0, ddof=1), IQR)
21
22
23 ## Univariate Rule of Thumb Bandwidths ##
24 def bw_scott(x, kernel=None):
25 """
26 Scott's Rule of Thumb
27
28 Parameters
29 ----------
30 x : array_like
31 Array for which to get the bandwidth
32 kernel : CustomKernel object
33 Unused
34
35 Returns
36 -------
37 bw : float
38 The estimate of the bandwidth
39
40 Notes
41 -----
42 Returns 1.059 * A * n ** (-1/5.) where ::
43
44 A = min(std(x, ddof=1), IQR/1.349)
45 IQR = np.subtract.reduce(np.percentile(x, [75,25]))
46
47 References
48 ----------
49
50 Scott, D.W. (1992) Multivariate Density Estimation: Theory, Practice, and
51 Visualization.
52 """
53 A = _select_sigma(x)
54 n = len(x)
55 return 1.059 * A * n ** (-0.2)
56
57 def bw_silverman(x, kernel=None):
58 """
59 Silverman's Rule of Thumb
60
61 Parameters
62 ----------
63 x : array_like
64 Array for which to get the bandwidth
65 kernel : CustomKernel object
66 Unused
67
68 Returns
69 -------
70 bw : float
71 The estimate of the bandwidth
72
73 Notes
74 -----
75 Returns .9 * A * n ** (-1/5.) where ::
76
77 A = min(std(x, ddof=1), IQR/1.349)
78 IQR = np.subtract.reduce(np.percentile(x, [75,25]))
79
80 References
81 ----------
82
83 Silverman, B.W. (1986) `Density Estimation.`
84 """
85 A = _select_sigma(x)
86 n = len(x)
87 return .9 * A * n ** (-0.2)
88
89
90 def bw_normal_reference(x, kernel=kernels.Gaussian):
91 """
92 Plug-in bandwidth with kernel specific constant based on normal reference.
93
94 This bandwidth minimizes the mean integrated square error if the true
95 distribution is the normal. This choice is an appropriate bandwidth for
96 single peaked distributions that are similar to the normal distribution.
97
98 Parameters
99 ----------
100 x : array_like
101 Array for which to get the bandwidth
102 kernel : CustomKernel object
103 Used to calculate the constant for the plug-in bandwidth.
104
105 Returns
106 -------
107 bw : float
108 The estimate of the bandwidth
109
110 Notes
111 -----
112 Returns C * A * n ** (-1/5.) where ::
113
114 A = min(std(x, ddof=1), IQR/1.349)
115 IQR = np.subtract.reduce(np.percentile(x, [75,25]))
116 C = constant from Hansen (2009)
117
118 When using a Gaussian kernel this is equivalent to the 'scott' bandwidth up
119 to two decimal places. This is the accuracy to which the 'scott' constant is
120 specified.
121
122 References
123 ----------
124
125 Silverman, B.W. (1986) `Density Estimation.`
126 Hansen, B.E. (2009) `Lecture Notes on Nonparametrics.`
127 """
128 C = kernel.normal_reference_constant
129 A = _select_sigma(x)
130 n = len(x)
131 return C * A * n ** (-0.2)
132
133 ## Plug-In Methods ##
134
135 ## Least Squares Cross-Validation ##
136
137 ## Helper Functions ##
138
139 bandwidth_funcs = {
140 "scott": bw_scott,
141 "silverman": bw_silverman,
142 "normal_reference": bw_normal_reference,
143 }
144
145
146 @Substitution(", ".join(sorted(bandwidth_funcs.keys())))
147 def select_bandwidth(x, bw, kernel):
148 """
149 Selects bandwidth for a selection rule bw
150
151 this is a wrapper around existing bandwidth selection rules
152
153 Parameters
154 ----------
155 x : array_like
156 Array for which to get the bandwidth
157 bw : str
158 name of bandwidth selection rule, currently supported are:
159 %s
160 kernel : not used yet
161
162 Returns
163 -------
164 bw : float
165 The estimate of the bandwidth
166
167 """
168 bw = bw.lower()
169 if bw not in bandwidth_funcs:
170 raise ValueError("Bandwidth %s not understood" % bw)
171 #TODO: uncomment checks when we have non-rule of thumb bandwidths for diff. kernels
172 # if kernel == "gauss":
173 return bandwidth_funcs[bw](x, kernel)
174 # else:
175 # raise ValueError("Only Gaussian Kernels are currently supported")
176
[end of statsmodels/nonparametric/bandwidths.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/statsmodels/nonparametric/bandwidths.py b/statsmodels/nonparametric/bandwidths.py
--- a/statsmodels/nonparametric/bandwidths.py
+++ b/statsmodels/nonparametric/bandwidths.py
@@ -168,8 +168,10 @@
bw = bw.lower()
if bw not in bandwidth_funcs:
raise ValueError("Bandwidth %s not understood" % bw)
-#TODO: uncomment checks when we have non-rule of thumb bandwidths for diff. kernels
-# if kernel == "gauss":
- return bandwidth_funcs[bw](x, kernel)
-# else:
-# raise ValueError("Only Gaussian Kernels are currently supported")
+ bandwidth = bandwidth_funcs[bw](x, kernel)
+ if bandwidth == 0:
+ # eventually this can fall back on another selection criterion.
+ err = "Selected KDE bandwidth is 0. Cannot estiamte density."
+ raise RuntimeError(err)
+ else:
+ return bandwidth
|
{"golden_diff": "diff --git a/statsmodels/nonparametric/bandwidths.py b/statsmodels/nonparametric/bandwidths.py\n--- a/statsmodels/nonparametric/bandwidths.py\n+++ b/statsmodels/nonparametric/bandwidths.py\n@@ -168,8 +168,10 @@\n bw = bw.lower()\n if bw not in bandwidth_funcs:\n raise ValueError(\"Bandwidth %s not understood\" % bw)\n-#TODO: uncomment checks when we have non-rule of thumb bandwidths for diff. kernels\n-# if kernel == \"gauss\":\n- return bandwidth_funcs[bw](x, kernel)\n-# else:\n-# raise ValueError(\"Only Gaussian Kernels are currently supported\")\n+ bandwidth = bandwidth_funcs[bw](x, kernel)\n+ if bandwidth == 0:\n+ # eventually this can fall back on another selection criterion.\n+ err = \"Selected KDE bandwidth is 0. Cannot estiamte density.\"\n+ raise RuntimeError(err)\n+ else:\n+ return bandwidth\n", "issue": "nonparametric.KDEUnivariate returns zero bandwidth\nHi,\r\nDoes anyone have an idea why the following dataset makes KDEUnivariate return zero bandwidth?\r\n\r\n```\r\ndata = np.array([1,1,1,1,2])\r\nkde_sm = sm.nonparametric.KDEUnivariate(data.astype('double'))\r\nkde_sm.fit(bw=\"silverman\")\r\nsup = kde_sm.support\r\nden = kde_sm.density\r\nprint(kde_sm.bw) # prints 0\r\n```\r\nwhen `data = np.array([1,1,1,2])` the returned bandwidth is correct. When I add more 1s, the bandwidth stays zero.\r\n\r\nThank you!\n", "before_files": [{"content": "import numpy as np\nfrom scipy.stats import scoreatpercentile as sap\n\nfrom statsmodels.compat.pandas import Substitution\nfrom statsmodels.sandbox.nonparametric import kernels\n\ndef _select_sigma(X):\n \"\"\"\n Returns the smaller of std(X, ddof=1) or normalized IQR(X) over axis 0.\n\n References\n ----------\n Silverman (1986) p.47\n \"\"\"\n# normalize = norm.ppf(.75) - norm.ppf(.25)\n normalize = 1.349\n# IQR = np.subtract.reduce(percentile(X, [75,25],\n# axis=axis), axis=axis)/normalize\n IQR = (sap(X, 75) - sap(X, 25))/normalize\n return np.minimum(np.std(X, axis=0, ddof=1), IQR)\n\n\n## Univariate Rule of Thumb Bandwidths ##\ndef bw_scott(x, kernel=None):\n \"\"\"\n Scott's Rule of Thumb\n\n Parameters\n ----------\n x : array_like\n Array for which to get the bandwidth\n kernel : CustomKernel object\n Unused\n\n Returns\n -------\n bw : float\n The estimate of the bandwidth\n\n Notes\n -----\n Returns 1.059 * A * n ** (-1/5.) where ::\n\n A = min(std(x, ddof=1), IQR/1.349)\n IQR = np.subtract.reduce(np.percentile(x, [75,25]))\n\n References\n ----------\n\n Scott, D.W. (1992) Multivariate Density Estimation: Theory, Practice, and\n Visualization.\n \"\"\"\n A = _select_sigma(x)\n n = len(x)\n return 1.059 * A * n ** (-0.2)\n\ndef bw_silverman(x, kernel=None):\n \"\"\"\n Silverman's Rule of Thumb\n\n Parameters\n ----------\n x : array_like\n Array for which to get the bandwidth\n kernel : CustomKernel object\n Unused\n\n Returns\n -------\n bw : float\n The estimate of the bandwidth\n\n Notes\n -----\n Returns .9 * A * n ** (-1/5.) where ::\n\n A = min(std(x, ddof=1), IQR/1.349)\n IQR = np.subtract.reduce(np.percentile(x, [75,25]))\n\n References\n ----------\n\n Silverman, B.W. (1986) `Density Estimation.`\n \"\"\"\n A = _select_sigma(x)\n n = len(x)\n return .9 * A * n ** (-0.2)\n\n\ndef bw_normal_reference(x, kernel=kernels.Gaussian):\n \"\"\"\n Plug-in bandwidth with kernel specific constant based on normal reference.\n\n This bandwidth minimizes the mean integrated square error if the true\n distribution is the normal. This choice is an appropriate bandwidth for\n single peaked distributions that are similar to the normal distribution.\n\n Parameters\n ----------\n x : array_like\n Array for which to get the bandwidth\n kernel : CustomKernel object\n Used to calculate the constant for the plug-in bandwidth.\n\n Returns\n -------\n bw : float\n The estimate of the bandwidth\n\n Notes\n -----\n Returns C * A * n ** (-1/5.) where ::\n\n A = min(std(x, ddof=1), IQR/1.349)\n IQR = np.subtract.reduce(np.percentile(x, [75,25]))\n C = constant from Hansen (2009)\n\n When using a Gaussian kernel this is equivalent to the 'scott' bandwidth up\n to two decimal places. This is the accuracy to which the 'scott' constant is\n specified.\n\n References\n ----------\n\n Silverman, B.W. (1986) `Density Estimation.`\n Hansen, B.E. (2009) `Lecture Notes on Nonparametrics.`\n \"\"\"\n C = kernel.normal_reference_constant\n A = _select_sigma(x)\n n = len(x)\n return C * A * n ** (-0.2)\n\n## Plug-In Methods ##\n\n## Least Squares Cross-Validation ##\n\n## Helper Functions ##\n\nbandwidth_funcs = {\n \"scott\": bw_scott,\n \"silverman\": bw_silverman,\n \"normal_reference\": bw_normal_reference,\n}\n\n\n@Substitution(\", \".join(sorted(bandwidth_funcs.keys())))\ndef select_bandwidth(x, bw, kernel):\n \"\"\"\n Selects bandwidth for a selection rule bw\n\n this is a wrapper around existing bandwidth selection rules\n\n Parameters\n ----------\n x : array_like\n Array for which to get the bandwidth\n bw : str\n name of bandwidth selection rule, currently supported are:\n %s\n kernel : not used yet\n\n Returns\n -------\n bw : float\n The estimate of the bandwidth\n\n \"\"\"\n bw = bw.lower()\n if bw not in bandwidth_funcs:\n raise ValueError(\"Bandwidth %s not understood\" % bw)\n#TODO: uncomment checks when we have non-rule of thumb bandwidths for diff. kernels\n# if kernel == \"gauss\":\n return bandwidth_funcs[bw](x, kernel)\n# else:\n# raise ValueError(\"Only Gaussian Kernels are currently supported\")\n", "path": "statsmodels/nonparametric/bandwidths.py"}]}
| 2,290 | 223 |
gh_patches_debug_40378
|
rasdani/github-patches
|
git_diff
|
Flexget__Flexget-2117
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
The torrentleech plugin is not working with their V5 api
### Expected behaviour:
The first episode of the series is downloaded
### Actual behaviour:
No results are found from the torrentleech search plugin
### Steps to reproduce:
- Step 1: Run flexget with the config supplied in the issue
#### Config:
```
tasks:
test task:
series:
- Rick and Morty:
begin: S02E01
discover:
what:
- next_series_episodes:
backfill: yes
from:
- torrentleech:
rss_key: ***********
username: ***********
password: ***********
download: ~/downloads
schedules:
# Run every 30 minutes
- tasks: '*'
schedule:
minute: "*/20"
```
### Additional information:
This seems to be a result of the upgrade to the Torrentleech V5 api. I modified the plugin to use the V4 api and this is working for now as long as they don't remove support for it. Would it be reasonable to put a PR with a Torrentleech plugin that uses the V4 api until support for the V5 api has been implemented?
- FlexGet version: 2.13.8.dev
- Python version: Python 2.7.14
- Installation method: Latest git version
- Using daemon (yes/no): no
- OS and version: MacOS and Ubuntu Server
</issue>
<code>
[start of flexget/plugins/sites/torrentleech.py]
1 from __future__ import unicode_literals, division, absolute_import
2 from builtins import * # noqa pylint: disable=unused-import, redefined-builtin
3 from future.moves.urllib.parse import quote
4
5 import re
6 import logging
7
8 from requests.exceptions import RequestException
9
10 from flexget import plugin
11 from flexget.config_schema import one_or_more
12 from flexget.entry import Entry
13 from flexget.event import event
14 from flexget.plugin import PluginError
15 from flexget.plugins.internal.urlrewriting import UrlRewritingError
16 from flexget.utils.soup import get_soup
17 from flexget.utils.search import torrent_availability, normalize_unicode
18 from flexget.utils.tools import parse_filesize
19
20 log = logging.getLogger('torrentleech')
21
22 CATEGORIES = {
23 'all': 0,
24
25 # Movies
26 'Cam': 8,
27 'TS': 9,
28 'R5': 10,
29 'DVDRip': 11,
30 'DVDR': 12,
31 'HD': 13,
32 'BDRip': 14,
33 'Movie Boxsets': 15,
34 'Documentaries': 29,
35
36 # TV
37 'Episodes': 26,
38 'TV Boxsets': 27,
39 'Episodes HD': 32
40 }
41
42
43 class UrlRewriteTorrentleech(object):
44 """
45 Torrentleech urlrewriter and search plugin.
46
47 torrentleech:
48 rss_key: xxxxxxxxx (required)
49 username: xxxxxxxx (required)
50 password: xxxxxxxx (required)
51 category: HD
52
53 Category is any combination of: all, Cam, TS, R5,
54 DVDRip, DVDR, HD, BDRip, Movie Boxsets, Documentaries,
55 Episodes, TV BoxSets, Episodes HD
56 """
57
58 schema = {
59 'type': 'object',
60 'properties': {
61 'rss_key': {'type': 'string'},
62 'username': {'type': 'string'},
63 'password': {'type': 'string'},
64 'category': one_or_more({
65 'oneOf': [
66 {'type': 'integer'},
67 {'type': 'string', 'enum': list(CATEGORIES)},
68 ]
69 }),
70 },
71 'required': ['rss_key', 'username', 'password'],
72 'additionalProperties': False
73 }
74
75 # urlrewriter API
76 def url_rewritable(self, task, entry):
77 url = entry['url']
78 if url.endswith('.torrent'):
79 return False
80 if url.startswith('https://www.torrentleech.org/'):
81 return True
82 return False
83
84 # urlrewriter API
85 def url_rewrite(self, task, entry):
86 if 'url' not in entry:
87 log.error("Didn't actually get a URL...")
88 else:
89 log.debug("Got the URL: %s" % entry['url'])
90 if entry['url'].startswith('https://www.torrentleech.org/torrents/browse/index/query/'):
91 # use search
92 results = self.search(task, entry)
93 if not results:
94 raise UrlRewritingError("No search results found")
95 # TODO: Search doesn't enforce close match to title, be more picky
96 entry['url'] = results[0]['url']
97
98 @plugin.internet(log)
99 def search(self, task, entry, config=None):
100 """
101 Search for name from torrentleech.
102 """
103 rss_key = config['rss_key']
104
105 # build the form request:
106 data = {'username': config['username'], 'password': config['password']}
107 # POST the login form:
108 try:
109 login = task.requests.post('https://www.torrentleech.org/user/account/login/', data=data)
110 except RequestException as e:
111 raise PluginError('Could not connect to torrentleech: %s', str(e))
112
113 if not isinstance(config, dict):
114 config = {}
115 # sort = SORT.get(config.get('sort_by', 'seeds'))
116 # if config.get('sort_reverse'):
117 # sort += 1
118 categories = config.get('category', 'all')
119 # Make sure categories is a list
120 if not isinstance(categories, list):
121 categories = [categories]
122 # If there are any text categories, turn them into their id number
123 categories = [c if isinstance(c, int) else CATEGORIES[c] for c in categories]
124 filter_url = '/categories/%s' % ','.join(str(c) for c in categories)
125 entries = set()
126 for search_string in entry.get('search_strings', [entry['title']]):
127 query = normalize_unicode(search_string).replace(":", "")
128 # urllib.quote will crash if the unicode string has non ascii characters, so encode in utf-8 beforehand
129 url = ('https://www.torrentleech.org/torrents/browse/index/query/' +
130 quote(query.encode('utf-8')) + filter_url)
131 log.debug('Using %s as torrentleech search url' % url)
132
133 page = task.requests.get(url, cookies=login.cookies).content
134 soup = get_soup(page)
135
136 for tr in soup.find_all("tr", ["even", "odd"]):
137 # within each even or odd row, find the torrent names
138 link = tr.find("a", attrs={'href': re.compile('/torrent/\d+')})
139 log.debug('link phase: %s' % link.contents[0])
140 entry = Entry()
141 # extracts the contents of the <a>titlename/<a> tag
142 entry['title'] = link.contents[0]
143
144 # find download link
145 torrent_url = tr.find("a", attrs={'href': re.compile('/download/\d+/.*')}).get('href')
146 # parse link and split along /download/12345 and /name.torrent
147 download_url = re.search('(/download/\d+)/(.+\.torrent)', torrent_url)
148 # change link to rss and splice in rss_key
149 torrent_url = 'https://www.torrentleech.org/rss' + download_url.group(1) + '/' \
150 + rss_key + '/' + download_url.group(2)
151 log.debug('RSS-ified download link: %s' % torrent_url)
152 entry['url'] = torrent_url
153
154 # us tr object for seeders/leechers
155 seeders, leechers = tr.find_all('td', ["seeders", "leechers"])
156 entry['torrent_seeds'] = int(seeders.contents[0])
157 entry['torrent_leeches'] = int(leechers.contents[0])
158 entry['search_sort'] = torrent_availability(entry['torrent_seeds'], entry['torrent_leeches'])
159
160 # use tr object for size
161 size = tr.find("td", text=re.compile('([\.\d]+) ([TGMK]?)B')).contents[0]
162 size = re.search('([\.\d]+) ([TGMK]?)B', size)
163
164 entry['content_size'] = parse_filesize(size.group(0))
165
166 entries.add(entry)
167
168 return sorted(entries, reverse=True, key=lambda x: x.get('search_sort'))
169
170
171 @event('plugin.register')
172 def register_plugin():
173 plugin.register(UrlRewriteTorrentleech, 'torrentleech', interfaces=['urlrewriter', 'search'], api_ver=2)
174
[end of flexget/plugins/sites/torrentleech.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/flexget/plugins/sites/torrentleech.py b/flexget/plugins/sites/torrentleech.py
--- a/flexget/plugins/sites/torrentleech.py
+++ b/flexget/plugins/sites/torrentleech.py
@@ -77,7 +77,7 @@
url = entry['url']
if url.endswith('.torrent'):
return False
- if url.startswith('https://www.torrentleech.org/'):
+ if url.startswith('https://v4.torrentleech.org/'):
return True
return False
@@ -87,7 +87,7 @@
log.error("Didn't actually get a URL...")
else:
log.debug("Got the URL: %s" % entry['url'])
- if entry['url'].startswith('https://www.torrentleech.org/torrents/browse/index/query/'):
+ if entry['url'].startswith('https://v4.torrentleech.org/torrents/browse/index/query/'):
# use search
results = self.search(task, entry)
if not results:
@@ -106,7 +106,7 @@
data = {'username': config['username'], 'password': config['password']}
# POST the login form:
try:
- login = task.requests.post('https://www.torrentleech.org/user/account/login/', data=data)
+ login = task.requests.post('https://v4.torrentleech.org/user/account/login/', data=data)
except RequestException as e:
raise PluginError('Could not connect to torrentleech: %s', str(e))
@@ -126,7 +126,7 @@
for search_string in entry.get('search_strings', [entry['title']]):
query = normalize_unicode(search_string).replace(":", "")
# urllib.quote will crash if the unicode string has non ascii characters, so encode in utf-8 beforehand
- url = ('https://www.torrentleech.org/torrents/browse/index/query/' +
+ url = ('https://v4.torrentleech.org/torrents/browse/index/query/' +
quote(query.encode('utf-8')) + filter_url)
log.debug('Using %s as torrentleech search url' % url)
@@ -146,7 +146,7 @@
# parse link and split along /download/12345 and /name.torrent
download_url = re.search('(/download/\d+)/(.+\.torrent)', torrent_url)
# change link to rss and splice in rss_key
- torrent_url = 'https://www.torrentleech.org/rss' + download_url.group(1) + '/' \
+ torrent_url = 'https://v4.torrentleech.org/rss' + download_url.group(1) + '/' \
+ rss_key + '/' + download_url.group(2)
log.debug('RSS-ified download link: %s' % torrent_url)
entry['url'] = torrent_url
|
{"golden_diff": "diff --git a/flexget/plugins/sites/torrentleech.py b/flexget/plugins/sites/torrentleech.py\n--- a/flexget/plugins/sites/torrentleech.py\n+++ b/flexget/plugins/sites/torrentleech.py\n@@ -77,7 +77,7 @@\n url = entry['url']\n if url.endswith('.torrent'):\n return False\n- if url.startswith('https://www.torrentleech.org/'):\n+ if url.startswith('https://v4.torrentleech.org/'):\n return True\n return False\n \n@@ -87,7 +87,7 @@\n log.error(\"Didn't actually get a URL...\")\n else:\n log.debug(\"Got the URL: %s\" % entry['url'])\n- if entry['url'].startswith('https://www.torrentleech.org/torrents/browse/index/query/'):\n+ if entry['url'].startswith('https://v4.torrentleech.org/torrents/browse/index/query/'):\n # use search\n results = self.search(task, entry)\n if not results:\n@@ -106,7 +106,7 @@\n data = {'username': config['username'], 'password': config['password']}\n # POST the login form:\n try:\n- login = task.requests.post('https://www.torrentleech.org/user/account/login/', data=data)\n+ login = task.requests.post('https://v4.torrentleech.org/user/account/login/', data=data)\n except RequestException as e:\n raise PluginError('Could not connect to torrentleech: %s', str(e))\n \n@@ -126,7 +126,7 @@\n for search_string in entry.get('search_strings', [entry['title']]):\n query = normalize_unicode(search_string).replace(\":\", \"\")\n # urllib.quote will crash if the unicode string has non ascii characters, so encode in utf-8 beforehand\n- url = ('https://www.torrentleech.org/torrents/browse/index/query/' +\n+ url = ('https://v4.torrentleech.org/torrents/browse/index/query/' +\n quote(query.encode('utf-8')) + filter_url)\n log.debug('Using %s as torrentleech search url' % url)\n \n@@ -146,7 +146,7 @@\n # parse link and split along /download/12345 and /name.torrent\n download_url = re.search('(/download/\\d+)/(.+\\.torrent)', torrent_url)\n # change link to rss and splice in rss_key\n- torrent_url = 'https://www.torrentleech.org/rss' + download_url.group(1) + '/' \\\n+ torrent_url = 'https://v4.torrentleech.org/rss' + download_url.group(1) + '/' \\\n + rss_key + '/' + download_url.group(2)\n log.debug('RSS-ified download link: %s' % torrent_url)\n entry['url'] = torrent_url\n", "issue": "The torrentleech plugin is not working with their V5 api \n### Expected behaviour:\r\nThe first episode of the series is downloaded\r\n\r\n### Actual behaviour:\r\nNo results are found from the torrentleech search plugin\r\n\r\n\r\n### Steps to reproduce:\r\n- Step 1: Run flexget with the config supplied in the issue\r\n\r\n#### Config:\r\n```\r\ntasks:\r\n test task:\r\n series:\r\n - Rick and Morty:\r\n begin: S02E01\r\n discover:\r\n what:\r\n - next_series_episodes:\r\n backfill: yes\r\n from:\r\n - torrentleech:\r\n rss_key: ***********\r\n username: ***********\r\n password: ***********\r\n download: ~/downloads\r\n\r\nschedules:\r\n # Run every 30 minutes\r\n - tasks: '*'\r\n schedule:\r\n minute: \"*/20\"\r\n```\r\n \r\n### Additional information:\r\nThis seems to be a result of the upgrade to the Torrentleech V5 api. I modified the plugin to use the V4 api and this is working for now as long as they don't remove support for it. Would it be reasonable to put a PR with a Torrentleech plugin that uses the V4 api until support for the V5 api has been implemented? \r\n\r\n\r\n- FlexGet version: 2.13.8.dev\r\n- Python version: Python 2.7.14\r\n- Installation method: Latest git version\r\n- Using daemon (yes/no): no\r\n- OS and version: MacOS and Ubuntu Server\r\n\n", "before_files": [{"content": "from __future__ import unicode_literals, division, absolute_import\nfrom builtins import * # noqa pylint: disable=unused-import, redefined-builtin\nfrom future.moves.urllib.parse import quote\n\nimport re\nimport logging\n\nfrom requests.exceptions import RequestException\n\nfrom flexget import plugin\nfrom flexget.config_schema import one_or_more\nfrom flexget.entry import Entry\nfrom flexget.event import event\nfrom flexget.plugin import PluginError\nfrom flexget.plugins.internal.urlrewriting import UrlRewritingError\nfrom flexget.utils.soup import get_soup\nfrom flexget.utils.search import torrent_availability, normalize_unicode\nfrom flexget.utils.tools import parse_filesize\n\nlog = logging.getLogger('torrentleech')\n\nCATEGORIES = {\n 'all': 0,\n\n # Movies\n 'Cam': 8,\n 'TS': 9,\n 'R5': 10,\n 'DVDRip': 11,\n 'DVDR': 12,\n 'HD': 13,\n 'BDRip': 14,\n 'Movie Boxsets': 15,\n 'Documentaries': 29,\n\n # TV\n 'Episodes': 26,\n 'TV Boxsets': 27,\n 'Episodes HD': 32\n}\n\n\nclass UrlRewriteTorrentleech(object):\n \"\"\"\n Torrentleech urlrewriter and search plugin.\n\n torrentleech:\n rss_key: xxxxxxxxx (required)\n username: xxxxxxxx (required)\n password: xxxxxxxx (required)\n category: HD\n\n Category is any combination of: all, Cam, TS, R5,\n DVDRip, DVDR, HD, BDRip, Movie Boxsets, Documentaries,\n Episodes, TV BoxSets, Episodes HD\n \"\"\"\n\n schema = {\n 'type': 'object',\n 'properties': {\n 'rss_key': {'type': 'string'},\n 'username': {'type': 'string'},\n 'password': {'type': 'string'},\n 'category': one_or_more({\n 'oneOf': [\n {'type': 'integer'},\n {'type': 'string', 'enum': list(CATEGORIES)},\n ]\n }),\n },\n 'required': ['rss_key', 'username', 'password'],\n 'additionalProperties': False\n }\n\n # urlrewriter API\n def url_rewritable(self, task, entry):\n url = entry['url']\n if url.endswith('.torrent'):\n return False\n if url.startswith('https://www.torrentleech.org/'):\n return True\n return False\n\n # urlrewriter API\n def url_rewrite(self, task, entry):\n if 'url' not in entry:\n log.error(\"Didn't actually get a URL...\")\n else:\n log.debug(\"Got the URL: %s\" % entry['url'])\n if entry['url'].startswith('https://www.torrentleech.org/torrents/browse/index/query/'):\n # use search\n results = self.search(task, entry)\n if not results:\n raise UrlRewritingError(\"No search results found\")\n # TODO: Search doesn't enforce close match to title, be more picky\n entry['url'] = results[0]['url']\n\n @plugin.internet(log)\n def search(self, task, entry, config=None):\n \"\"\"\n Search for name from torrentleech.\n \"\"\"\n rss_key = config['rss_key']\n\n # build the form request:\n data = {'username': config['username'], 'password': config['password']}\n # POST the login form:\n try:\n login = task.requests.post('https://www.torrentleech.org/user/account/login/', data=data)\n except RequestException as e:\n raise PluginError('Could not connect to torrentleech: %s', str(e))\n\n if not isinstance(config, dict):\n config = {}\n # sort = SORT.get(config.get('sort_by', 'seeds'))\n # if config.get('sort_reverse'):\n # sort += 1\n categories = config.get('category', 'all')\n # Make sure categories is a list\n if not isinstance(categories, list):\n categories = [categories]\n # If there are any text categories, turn them into their id number\n categories = [c if isinstance(c, int) else CATEGORIES[c] for c in categories]\n filter_url = '/categories/%s' % ','.join(str(c) for c in categories)\n entries = set()\n for search_string in entry.get('search_strings', [entry['title']]):\n query = normalize_unicode(search_string).replace(\":\", \"\")\n # urllib.quote will crash if the unicode string has non ascii characters, so encode in utf-8 beforehand\n url = ('https://www.torrentleech.org/torrents/browse/index/query/' +\n quote(query.encode('utf-8')) + filter_url)\n log.debug('Using %s as torrentleech search url' % url)\n\n page = task.requests.get(url, cookies=login.cookies).content\n soup = get_soup(page)\n\n for tr in soup.find_all(\"tr\", [\"even\", \"odd\"]):\n # within each even or odd row, find the torrent names\n link = tr.find(\"a\", attrs={'href': re.compile('/torrent/\\d+')})\n log.debug('link phase: %s' % link.contents[0])\n entry = Entry()\n # extracts the contents of the <a>titlename/<a> tag\n entry['title'] = link.contents[0]\n\n # find download link\n torrent_url = tr.find(\"a\", attrs={'href': re.compile('/download/\\d+/.*')}).get('href')\n # parse link and split along /download/12345 and /name.torrent\n download_url = re.search('(/download/\\d+)/(.+\\.torrent)', torrent_url)\n # change link to rss and splice in rss_key\n torrent_url = 'https://www.torrentleech.org/rss' + download_url.group(1) + '/' \\\n + rss_key + '/' + download_url.group(2)\n log.debug('RSS-ified download link: %s' % torrent_url)\n entry['url'] = torrent_url\n\n # us tr object for seeders/leechers\n seeders, leechers = tr.find_all('td', [\"seeders\", \"leechers\"])\n entry['torrent_seeds'] = int(seeders.contents[0])\n entry['torrent_leeches'] = int(leechers.contents[0])\n entry['search_sort'] = torrent_availability(entry['torrent_seeds'], entry['torrent_leeches'])\n\n # use tr object for size\n size = tr.find(\"td\", text=re.compile('([\\.\\d]+) ([TGMK]?)B')).contents[0]\n size = re.search('([\\.\\d]+) ([TGMK]?)B', size)\n\n entry['content_size'] = parse_filesize(size.group(0))\n\n entries.add(entry)\n\n return sorted(entries, reverse=True, key=lambda x: x.get('search_sort'))\n\n\n@event('plugin.register')\ndef register_plugin():\n plugin.register(UrlRewriteTorrentleech, 'torrentleech', interfaces=['urlrewriter', 'search'], api_ver=2)\n", "path": "flexget/plugins/sites/torrentleech.py"}]}
| 2,864 | 649 |
gh_patches_debug_30259
|
rasdani/github-patches
|
git_diff
|
apache__airflow-18119
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Exception within LocalTaskJob._run_mini_scheduler_on_child_tasks brakes Sentry Handler
### Apache Airflow version
2.1.3 (latest released)
### Operating System
Debian GNU/Linux 10 (buster)
### Versions of Apache Airflow Providers
```
apache-airflow-providers-amazon @ file:///root/.cache/pypoetry/artifacts/7f/f7/23/fc7fd3543aa486275ef0385c29063ff0dc391b0fc95dc5aa6cab2cf4e5/apache_airflow_providers_amazon-2.2.0-py3-none-any.whl
apache-airflow-providers-celery @ file:///root/.cache/pypoetry/artifacts/14/80/39/0d9d57205da1d24189ac9c18eb3477664ed2c2618c1467c9809b9a2fbf/apache_airflow_providers_celery-2.0.0-py3-none-any.whl
apache-airflow-providers-ftp @ file:///root/.cache/pypoetry/artifacts/a5/13/da/bf14abc40193a1ee1b82bbd800e3ac230427d7684b9d40998ac3684bef/apache_airflow_providers_ftp-2.0.1-py3-none-any.whl
apache-airflow-providers-http @ file:///root/.cache/pypoetry/artifacts/fc/d7/d2/73c89ef847bbae1704fa403d7e92dba1feead757aae141613980db40ff/apache_airflow_providers_http-2.0.0-py3-none-any.whl
apache-airflow-providers-imap @ file:///root/.cache/pypoetry/artifacts/af/5d/de/21c10bfc7ac076a415dcc3fc909317547e77e38c005487552cf40ddd97/apache_airflow_providers_imap-2.0.1-py3-none-any.whl
apache-airflow-providers-postgres @ file:///root/.cache/pypoetry/artifacts/50/27/e0/9b0d8f4c0abf59967bb87a04a93d73896d9a4558994185dd8bc43bb67f/apache_airflow_providers_postgres-2.2.0-py3-none-any.whl
apache-airflow-providers-redis @ file:///root/.cache/pypoetry/artifacts/7d/95/03/5d2a65ace88ae9a9ce9134b927b1e9639c8680c13a31e58425deae55d1/apache_airflow_providers_redis-2.0.1-py3-none-any.whl
apache-airflow-providers-sqlite @ file:///root/.cache/pypoetry/artifacts/ec/e6/a3/e0d81fef662ccf79609e7d2c4e4440839a464771fd2a002d252c9a401d/apache_airflow_providers_sqlite-2.0.1-py3-none-any.whl
```
### Deployment
Other Docker-based deployment
### Deployment details
We are using the Sentry integration
### What happened
An exception within LocalTaskJobs mini scheduler was handled incorrectly by the Sentry integrations 'enrich_errors' method. This is because it assumes its applied to a method of a TypeInstance task
```
TypeError: cannot pickle 'dict_keys' object
File "airflow/sentry.py", line 166, in wrapper
return func(task_instance, *args, **kwargs)
File "airflow/jobs/local_task_job.py", line 241, in _run_mini_scheduler_on_child_tasks
partial_dag = task.dag.partial_subset(
File "airflow/models/dag.py", line 1487, in partial_subset
dag.task_dict = {
File "airflow/models/dag.py", line 1488, in <dictcomp>
t.task_id: copy.deepcopy(t, {id(t.dag): dag}) # type: ignore
File "copy.py", line 153, in deepcopy
y = copier(memo)
File "airflow/models/baseoperator.py", line 970, in __deepcopy__
setattr(result, k, copy.deepcopy(v, memo))
File "copy.py", line 161, in deepcopy
rv = reductor(4)
AttributeError: 'LocalTaskJob' object has no attribute 'task'
File "airflow", line 8, in <module>
sys.exit(main())
File "airflow/__main__.py", line 40, in main
args.func(args)
File "airflow/cli/cli_parser.py", line 48, in command
return func(*args, **kwargs)
File "airflow/utils/cli.py", line 91, in wrapper
return f(*args, **kwargs)
File "airflow/cli/commands/task_command.py", line 238, in task_run
_run_task_by_selected_method(args, dag, ti)
File "airflow/cli/commands/task_command.py", line 64, in _run_task_by_selected_method
_run_task_by_local_task_job(args, ti)
File "airflow/cli/commands/task_command.py", line 121, in _run_task_by_local_task_job
run_job.run()
File "airflow/jobs/base_job.py", line 245, in run
self._execute()
File "airflow/jobs/local_task_job.py", line 128, in _execute
self.handle_task_exit(return_code)
File "airflow/jobs/local_task_job.py", line 166, in handle_task_exit
self._run_mini_scheduler_on_child_tasks()
File "airflow/utils/session.py", line 70, in wrapper
return func(*args, session=session, **kwargs)
File "airflow/sentry.py", line 168, in wrapper
self.add_tagging(task_instance)
File "airflow/sentry.py", line 119, in add_tagging
task = task_instance.task
```
### What you expected to happen
The error to be handled correctly and passed on to Sentry without raising another exception within the error handling system
### How to reproduce
In this case we were trying to backfill task for a DAG that at that point had a compilation error. This is quite an edge case yes :-)
### Anything else
_No response_
### Are you willing to submit PR?
- [X] Yes I am willing to submit a PR!
### Code of Conduct
- [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md)
</issue>
<code>
[start of airflow/sentry.py]
1 #
2 # Licensed to the Apache Software Foundation (ASF) under one
3 # or more contributor license agreements. See the NOTICE file
4 # distributed with this work for additional information
5 # regarding copyright ownership. The ASF licenses this file
6 # to you under the Apache License, Version 2.0 (the
7 # "License"); you may not use this file except in compliance
8 # with the License. You may obtain a copy of the License at
9 #
10 # http://www.apache.org/licenses/LICENSE-2.0
11 #
12 # Unless required by applicable law or agreed to in writing,
13 # software distributed under the License is distributed on an
14 # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
15 # KIND, either express or implied. See the License for the
16 # specific language governing permissions and limitations
17 # under the License.
18
19 """Sentry Integration"""
20 import logging
21 from functools import wraps
22
23 from airflow.configuration import conf
24 from airflow.utils.session import find_session_idx, provide_session
25 from airflow.utils.state import State
26
27 log = logging.getLogger(__name__)
28
29
30 class DummySentry:
31 """Blank class for Sentry."""
32
33 @classmethod
34 def add_tagging(cls, task_instance):
35 """Blank function for tagging."""
36
37 @classmethod
38 def add_breadcrumbs(cls, task_instance, session=None):
39 """Blank function for breadcrumbs."""
40
41 @classmethod
42 def enrich_errors(cls, run):
43 """Blank function for formatting a TaskInstance._run_raw_task."""
44 return run
45
46 def flush(self):
47 """Blank function for flushing errors."""
48
49
50 Sentry: DummySentry = DummySentry()
51 if conf.getboolean("sentry", 'sentry_on', fallback=False):
52 import sentry_sdk
53
54 # Verify blinker installation
55 from blinker import signal # noqa: F401
56 from sentry_sdk.integrations.flask import FlaskIntegration
57 from sentry_sdk.integrations.logging import ignore_logger
58
59 class ConfiguredSentry(DummySentry):
60 """Configure Sentry SDK."""
61
62 SCOPE_TAGS = frozenset(("task_id", "dag_id", "execution_date", "operator", "try_number"))
63 SCOPE_CRUMBS = frozenset(("task_id", "state", "operator", "duration"))
64
65 UNSUPPORTED_SENTRY_OPTIONS = frozenset(
66 (
67 "integrations",
68 "in_app_include",
69 "in_app_exclude",
70 "ignore_errors",
71 "before_breadcrumb",
72 "before_send",
73 "transport",
74 )
75 )
76
77 def __init__(self):
78 """Initialize the Sentry SDK."""
79 ignore_logger("airflow.task")
80 ignore_logger("airflow.jobs.backfill_job.BackfillJob")
81 executor_name = conf.get("core", "EXECUTOR")
82
83 sentry_flask = FlaskIntegration()
84
85 # LoggingIntegration is set by default.
86 integrations = [sentry_flask]
87
88 if executor_name == "CeleryExecutor":
89 from sentry_sdk.integrations.celery import CeleryIntegration
90
91 sentry_celery = CeleryIntegration()
92 integrations.append(sentry_celery)
93
94 dsn = None
95 sentry_config_opts = conf.getsection("sentry") or {}
96 if sentry_config_opts:
97 sentry_config_opts.pop("sentry_on")
98 old_way_dsn = sentry_config_opts.pop("sentry_dsn", None)
99 new_way_dsn = sentry_config_opts.pop("dsn", None)
100 # supported backward compatibility with old way dsn option
101 dsn = old_way_dsn or new_way_dsn
102
103 unsupported_options = self.UNSUPPORTED_SENTRY_OPTIONS.intersection(sentry_config_opts.keys())
104 if unsupported_options:
105 log.warning(
106 "There are unsupported options in [sentry] section: %s",
107 ", ".join(unsupported_options),
108 )
109
110 if dsn:
111 sentry_sdk.init(dsn=dsn, integrations=integrations, **sentry_config_opts)
112 else:
113 # Setting up Sentry using environment variables.
114 log.debug("Defaulting to SENTRY_DSN in environment.")
115 sentry_sdk.init(integrations=integrations, **sentry_config_opts)
116
117 def add_tagging(self, task_instance):
118 """Function to add tagging for a task_instance."""
119 task = task_instance.task
120
121 with sentry_sdk.configure_scope() as scope:
122 for tag_name in self.SCOPE_TAGS:
123 attribute = getattr(task_instance, tag_name)
124 if tag_name == "operator":
125 attribute = task.__class__.__name__
126 scope.set_tag(tag_name, attribute)
127
128 @provide_session
129 def add_breadcrumbs(self, task_instance, session=None):
130 """Function to add breadcrumbs inside of a task_instance."""
131 if session is None:
132 return
133 dr = task_instance.get_dagrun(session)
134 task_instances = dr.get_task_instances(
135 state={State.SUCCESS, State.FAILED},
136 session=session,
137 )
138
139 for ti in task_instances:
140 data = {}
141 for crumb_tag in self.SCOPE_CRUMBS:
142 data[crumb_tag] = getattr(ti, crumb_tag)
143
144 sentry_sdk.add_breadcrumb(category="completed_tasks", data=data, level="info")
145
146 def enrich_errors(self, func):
147 """Wrap TaskInstance._run_raw_task to support task specific tags and breadcrumbs."""
148 session_args_idx = find_session_idx(func)
149
150 @wraps(func)
151 def wrapper(task_instance, *args, **kwargs):
152 # Wrapping the _run_raw_task function with push_scope to contain
153 # tags and breadcrumbs to a specific Task Instance
154
155 try:
156 session = kwargs.get('session', args[session_args_idx])
157 except IndexError:
158 session = None
159
160 with sentry_sdk.push_scope():
161 try:
162 return func(task_instance, *args, **kwargs)
163 except Exception as e:
164 self.add_tagging(task_instance)
165 self.add_breadcrumbs(task_instance, session=session)
166 sentry_sdk.capture_exception(e)
167 raise
168
169 return wrapper
170
171 def flush(self):
172 sentry_sdk.flush()
173
174 Sentry = ConfiguredSentry()
175
[end of airflow/sentry.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/airflow/sentry.py b/airflow/sentry.py
--- a/airflow/sentry.py
+++ b/airflow/sentry.py
@@ -144,11 +144,14 @@
sentry_sdk.add_breadcrumb(category="completed_tasks", data=data, level="info")
def enrich_errors(self, func):
- """Wrap TaskInstance._run_raw_task to support task specific tags and breadcrumbs."""
+ """
+ Wrap TaskInstance._run_raw_task and LocalTaskJob._run_mini_scheduler_on_child_tasks
+ to support task specific tags and breadcrumbs.
+ """
session_args_idx = find_session_idx(func)
@wraps(func)
- def wrapper(task_instance, *args, **kwargs):
+ def wrapper(_self, *args, **kwargs):
# Wrapping the _run_raw_task function with push_scope to contain
# tags and breadcrumbs to a specific Task Instance
@@ -159,8 +162,14 @@
with sentry_sdk.push_scope():
try:
- return func(task_instance, *args, **kwargs)
+ return func(_self, *args, **kwargs)
except Exception as e:
+ # Is a LocalTaskJob get the task instance
+ if hasattr(_self, 'task_instance'):
+ task_instance = _self.task_instance
+ else:
+ task_instance = _self
+
self.add_tagging(task_instance)
self.add_breadcrumbs(task_instance, session=session)
sentry_sdk.capture_exception(e)
|
{"golden_diff": "diff --git a/airflow/sentry.py b/airflow/sentry.py\n--- a/airflow/sentry.py\n+++ b/airflow/sentry.py\n@@ -144,11 +144,14 @@\n sentry_sdk.add_breadcrumb(category=\"completed_tasks\", data=data, level=\"info\")\n \n def enrich_errors(self, func):\n- \"\"\"Wrap TaskInstance._run_raw_task to support task specific tags and breadcrumbs.\"\"\"\n+ \"\"\"\n+ Wrap TaskInstance._run_raw_task and LocalTaskJob._run_mini_scheduler_on_child_tasks\n+ to support task specific tags and breadcrumbs.\n+ \"\"\"\n session_args_idx = find_session_idx(func)\n \n @wraps(func)\n- def wrapper(task_instance, *args, **kwargs):\n+ def wrapper(_self, *args, **kwargs):\n # Wrapping the _run_raw_task function with push_scope to contain\n # tags and breadcrumbs to a specific Task Instance\n \n@@ -159,8 +162,14 @@\n \n with sentry_sdk.push_scope():\n try:\n- return func(task_instance, *args, **kwargs)\n+ return func(_self, *args, **kwargs)\n except Exception as e:\n+ # Is a LocalTaskJob get the task instance\n+ if hasattr(_self, 'task_instance'):\n+ task_instance = _self.task_instance\n+ else:\n+ task_instance = _self\n+\n self.add_tagging(task_instance)\n self.add_breadcrumbs(task_instance, session=session)\n sentry_sdk.capture_exception(e)\n", "issue": "Exception within LocalTaskJob._run_mini_scheduler_on_child_tasks brakes Sentry Handler\n### Apache Airflow version\r\n\r\n2.1.3 (latest released)\r\n\r\n### Operating System\r\n\r\nDebian GNU/Linux 10 (buster)\r\n\r\n### Versions of Apache Airflow Providers\r\n\r\n```\r\napache-airflow-providers-amazon @ file:///root/.cache/pypoetry/artifacts/7f/f7/23/fc7fd3543aa486275ef0385c29063ff0dc391b0fc95dc5aa6cab2cf4e5/apache_airflow_providers_amazon-2.2.0-py3-none-any.whl\r\napache-airflow-providers-celery @ file:///root/.cache/pypoetry/artifacts/14/80/39/0d9d57205da1d24189ac9c18eb3477664ed2c2618c1467c9809b9a2fbf/apache_airflow_providers_celery-2.0.0-py3-none-any.whl\r\napache-airflow-providers-ftp @ file:///root/.cache/pypoetry/artifacts/a5/13/da/bf14abc40193a1ee1b82bbd800e3ac230427d7684b9d40998ac3684bef/apache_airflow_providers_ftp-2.0.1-py3-none-any.whl\r\napache-airflow-providers-http @ file:///root/.cache/pypoetry/artifacts/fc/d7/d2/73c89ef847bbae1704fa403d7e92dba1feead757aae141613980db40ff/apache_airflow_providers_http-2.0.0-py3-none-any.whl\r\napache-airflow-providers-imap @ file:///root/.cache/pypoetry/artifacts/af/5d/de/21c10bfc7ac076a415dcc3fc909317547e77e38c005487552cf40ddd97/apache_airflow_providers_imap-2.0.1-py3-none-any.whl\r\napache-airflow-providers-postgres @ file:///root/.cache/pypoetry/artifacts/50/27/e0/9b0d8f4c0abf59967bb87a04a93d73896d9a4558994185dd8bc43bb67f/apache_airflow_providers_postgres-2.2.0-py3-none-any.whl\r\napache-airflow-providers-redis @ file:///root/.cache/pypoetry/artifacts/7d/95/03/5d2a65ace88ae9a9ce9134b927b1e9639c8680c13a31e58425deae55d1/apache_airflow_providers_redis-2.0.1-py3-none-any.whl\r\napache-airflow-providers-sqlite @ file:///root/.cache/pypoetry/artifacts/ec/e6/a3/e0d81fef662ccf79609e7d2c4e4440839a464771fd2a002d252c9a401d/apache_airflow_providers_sqlite-2.0.1-py3-none-any.whl\r\n```\r\n\r\n\r\n### Deployment\r\n\r\nOther Docker-based deployment\r\n\r\n### Deployment details\r\n\r\nWe are using the Sentry integration\r\n\r\n### What happened\r\n\r\nAn exception within LocalTaskJobs mini scheduler was handled incorrectly by the Sentry integrations 'enrich_errors' method. This is because it assumes its applied to a method of a TypeInstance task\r\n\r\n```\r\nTypeError: cannot pickle 'dict_keys' object\r\n File \"airflow/sentry.py\", line 166, in wrapper\r\n return func(task_instance, *args, **kwargs)\r\n File \"airflow/jobs/local_task_job.py\", line 241, in _run_mini_scheduler_on_child_tasks\r\n partial_dag = task.dag.partial_subset(\r\n File \"airflow/models/dag.py\", line 1487, in partial_subset\r\n dag.task_dict = {\r\n File \"airflow/models/dag.py\", line 1488, in <dictcomp>\r\n t.task_id: copy.deepcopy(t, {id(t.dag): dag}) # type: ignore\r\n File \"copy.py\", line 153, in deepcopy\r\n y = copier(memo)\r\n File \"airflow/models/baseoperator.py\", line 970, in __deepcopy__\r\n setattr(result, k, copy.deepcopy(v, memo))\r\n File \"copy.py\", line 161, in deepcopy\r\n rv = reductor(4)\r\n\r\nAttributeError: 'LocalTaskJob' object has no attribute 'task'\r\n File \"airflow\", line 8, in <module>\r\n sys.exit(main())\r\n File \"airflow/__main__.py\", line 40, in main\r\n args.func(args)\r\n File \"airflow/cli/cli_parser.py\", line 48, in command\r\n return func(*args, **kwargs)\r\n File \"airflow/utils/cli.py\", line 91, in wrapper\r\n return f(*args, **kwargs)\r\n File \"airflow/cli/commands/task_command.py\", line 238, in task_run\r\n _run_task_by_selected_method(args, dag, ti)\r\n File \"airflow/cli/commands/task_command.py\", line 64, in _run_task_by_selected_method\r\n _run_task_by_local_task_job(args, ti)\r\n File \"airflow/cli/commands/task_command.py\", line 121, in _run_task_by_local_task_job\r\n run_job.run()\r\n File \"airflow/jobs/base_job.py\", line 245, in run\r\n self._execute()\r\n File \"airflow/jobs/local_task_job.py\", line 128, in _execute\r\n self.handle_task_exit(return_code)\r\n File \"airflow/jobs/local_task_job.py\", line 166, in handle_task_exit\r\n self._run_mini_scheduler_on_child_tasks()\r\n File \"airflow/utils/session.py\", line 70, in wrapper\r\n return func(*args, session=session, **kwargs)\r\n File \"airflow/sentry.py\", line 168, in wrapper\r\n self.add_tagging(task_instance)\r\n File \"airflow/sentry.py\", line 119, in add_tagging\r\n task = task_instance.task\r\n```\r\n\r\n### What you expected to happen\r\n\r\nThe error to be handled correctly and passed on to Sentry without raising another exception within the error handling system\r\n\r\n### How to reproduce\r\n\r\nIn this case we were trying to backfill task for a DAG that at that point had a compilation error. This is quite an edge case yes :-)\r\n\r\n### Anything else\r\n\r\n_No response_\r\n\r\n### Are you willing to submit PR?\r\n\r\n- [X] Yes I am willing to submit a PR!\r\n\r\n### Code of Conduct\r\n\r\n- [X] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/main/CODE_OF_CONDUCT.md)\r\n\n", "before_files": [{"content": "#\n# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n\n\"\"\"Sentry Integration\"\"\"\nimport logging\nfrom functools import wraps\n\nfrom airflow.configuration import conf\nfrom airflow.utils.session import find_session_idx, provide_session\nfrom airflow.utils.state import State\n\nlog = logging.getLogger(__name__)\n\n\nclass DummySentry:\n \"\"\"Blank class for Sentry.\"\"\"\n\n @classmethod\n def add_tagging(cls, task_instance):\n \"\"\"Blank function for tagging.\"\"\"\n\n @classmethod\n def add_breadcrumbs(cls, task_instance, session=None):\n \"\"\"Blank function for breadcrumbs.\"\"\"\n\n @classmethod\n def enrich_errors(cls, run):\n \"\"\"Blank function for formatting a TaskInstance._run_raw_task.\"\"\"\n return run\n\n def flush(self):\n \"\"\"Blank function for flushing errors.\"\"\"\n\n\nSentry: DummySentry = DummySentry()\nif conf.getboolean(\"sentry\", 'sentry_on', fallback=False):\n import sentry_sdk\n\n # Verify blinker installation\n from blinker import signal # noqa: F401\n from sentry_sdk.integrations.flask import FlaskIntegration\n from sentry_sdk.integrations.logging import ignore_logger\n\n class ConfiguredSentry(DummySentry):\n \"\"\"Configure Sentry SDK.\"\"\"\n\n SCOPE_TAGS = frozenset((\"task_id\", \"dag_id\", \"execution_date\", \"operator\", \"try_number\"))\n SCOPE_CRUMBS = frozenset((\"task_id\", \"state\", \"operator\", \"duration\"))\n\n UNSUPPORTED_SENTRY_OPTIONS = frozenset(\n (\n \"integrations\",\n \"in_app_include\",\n \"in_app_exclude\",\n \"ignore_errors\",\n \"before_breadcrumb\",\n \"before_send\",\n \"transport\",\n )\n )\n\n def __init__(self):\n \"\"\"Initialize the Sentry SDK.\"\"\"\n ignore_logger(\"airflow.task\")\n ignore_logger(\"airflow.jobs.backfill_job.BackfillJob\")\n executor_name = conf.get(\"core\", \"EXECUTOR\")\n\n sentry_flask = FlaskIntegration()\n\n # LoggingIntegration is set by default.\n integrations = [sentry_flask]\n\n if executor_name == \"CeleryExecutor\":\n from sentry_sdk.integrations.celery import CeleryIntegration\n\n sentry_celery = CeleryIntegration()\n integrations.append(sentry_celery)\n\n dsn = None\n sentry_config_opts = conf.getsection(\"sentry\") or {}\n if sentry_config_opts:\n sentry_config_opts.pop(\"sentry_on\")\n old_way_dsn = sentry_config_opts.pop(\"sentry_dsn\", None)\n new_way_dsn = sentry_config_opts.pop(\"dsn\", None)\n # supported backward compatibility with old way dsn option\n dsn = old_way_dsn or new_way_dsn\n\n unsupported_options = self.UNSUPPORTED_SENTRY_OPTIONS.intersection(sentry_config_opts.keys())\n if unsupported_options:\n log.warning(\n \"There are unsupported options in [sentry] section: %s\",\n \", \".join(unsupported_options),\n )\n\n if dsn:\n sentry_sdk.init(dsn=dsn, integrations=integrations, **sentry_config_opts)\n else:\n # Setting up Sentry using environment variables.\n log.debug(\"Defaulting to SENTRY_DSN in environment.\")\n sentry_sdk.init(integrations=integrations, **sentry_config_opts)\n\n def add_tagging(self, task_instance):\n \"\"\"Function to add tagging for a task_instance.\"\"\"\n task = task_instance.task\n\n with sentry_sdk.configure_scope() as scope:\n for tag_name in self.SCOPE_TAGS:\n attribute = getattr(task_instance, tag_name)\n if tag_name == \"operator\":\n attribute = task.__class__.__name__\n scope.set_tag(tag_name, attribute)\n\n @provide_session\n def add_breadcrumbs(self, task_instance, session=None):\n \"\"\"Function to add breadcrumbs inside of a task_instance.\"\"\"\n if session is None:\n return\n dr = task_instance.get_dagrun(session)\n task_instances = dr.get_task_instances(\n state={State.SUCCESS, State.FAILED},\n session=session,\n )\n\n for ti in task_instances:\n data = {}\n for crumb_tag in self.SCOPE_CRUMBS:\n data[crumb_tag] = getattr(ti, crumb_tag)\n\n sentry_sdk.add_breadcrumb(category=\"completed_tasks\", data=data, level=\"info\")\n\n def enrich_errors(self, func):\n \"\"\"Wrap TaskInstance._run_raw_task to support task specific tags and breadcrumbs.\"\"\"\n session_args_idx = find_session_idx(func)\n\n @wraps(func)\n def wrapper(task_instance, *args, **kwargs):\n # Wrapping the _run_raw_task function with push_scope to contain\n # tags and breadcrumbs to a specific Task Instance\n\n try:\n session = kwargs.get('session', args[session_args_idx])\n except IndexError:\n session = None\n\n with sentry_sdk.push_scope():\n try:\n return func(task_instance, *args, **kwargs)\n except Exception as e:\n self.add_tagging(task_instance)\n self.add_breadcrumbs(task_instance, session=session)\n sentry_sdk.capture_exception(e)\n raise\n\n return wrapper\n\n def flush(self):\n sentry_sdk.flush()\n\n Sentry = ConfiguredSentry()\n", "path": "airflow/sentry.py"}]}
| 3,916 | 338 |
gh_patches_debug_1470
|
rasdani/github-patches
|
git_diff
|
nipy__nipype-2182
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Modelgen SpecifyModel TypeError: apply_along_axis()
@effigies
SpecifyModel rises an error with the new function from
commit cd49748be5d7a8201496548922d85f63bb4034dc
modelgen.py line 399ff
With numpy 1.8.2 I get
TypeError: apply_along_axis() got an unexpected keyword argument 'source'
Interface SpecifyModel failed to run
Joerg
</issue>
<code>
[start of nipype/info.py]
1 """ This file contains defines parameters for nipy that we use to fill
2 settings in setup.py, the nipy top-level docstring, and for building the
3 docs. In setup.py in particular, we exec this file, so it cannot import nipy
4 """
5 from __future__ import print_function, division, unicode_literals, absolute_import
6
7 import sys
8
9 # nipype version information. An empty version_extra corresponds to a
10 # full release. '.dev' as a version_extra string means this is a development
11 # version
12 # Remove -dev for release
13 __version__ = '1.0.0-dev'
14
15
16 def get_nipype_gitversion():
17 """Nipype version as reported by the last commit in git
18
19 Returns
20 -------
21 None or str
22 Version of Nipype according to git.
23 """
24 import os
25 import subprocess
26 try:
27 import nipype
28 gitpath = os.path.realpath(os.path.join(os.path.dirname(nipype.__file__),
29 os.path.pardir))
30 except:
31 gitpath = os.getcwd()
32 gitpathgit = os.path.join(gitpath, '.git')
33 if not os.path.exists(gitpathgit):
34 return None
35 ver = None
36 try:
37 o, _ = subprocess.Popen('git describe', shell=True, cwd=gitpath,
38 stdout=subprocess.PIPE).communicate()
39 except Exception:
40 pass
41 else:
42 ver = o.decode().strip().split('-')[-1]
43 return ver
44
45 if __version__.endswith('-dev'):
46 gitversion = get_nipype_gitversion()
47 if gitversion:
48 __version__ = '{}+{}'.format(__version__, gitversion)
49
50 CLASSIFIERS = ['Development Status :: 5 - Production/Stable',
51 'Environment :: Console',
52 'Intended Audience :: Science/Research',
53 'License :: OSI Approved :: Apache Software License',
54 'Operating System :: MacOS :: MacOS X',
55 'Operating System :: POSIX :: Linux',
56 'Programming Language :: Python :: 2.7',
57 'Programming Language :: Python :: 3.4',
58 'Programming Language :: Python :: 3.5',
59 'Programming Language :: Python :: 3.6',
60 'Topic :: Scientific/Engineering']
61
62 description = 'Neuroimaging in Python: Pipelines and Interfaces'
63
64 # Note: this long_description is actually a copy/paste from the top-level
65 # README.txt, so that it shows up nicely on PyPI. So please remember to edit
66 # it only in one place and sync it correctly.
67 long_description = """========================================================
68 NIPYPE: Neuroimaging in Python: Pipelines and Interfaces
69 ========================================================
70
71 Current neuroimaging software offer users an incredible opportunity to \
72 analyze data using a variety of different algorithms. However, this has \
73 resulted in a heterogeneous collection of specialized applications \
74 without transparent interoperability or a uniform operating interface.
75
76 *Nipype*, an open-source, community-developed initiative under the \
77 umbrella of NiPy_, is a Python project that provides a uniform interface \
78 to existing neuroimaging software and facilitates interaction between \
79 these packages within a single workflow. Nipype provides an environment \
80 that encourages interactive exploration of algorithms from different \
81 packages (e.g., AFNI, ANTS, BRAINS, BrainSuite, Camino, FreeSurfer, FSL, MNE, \
82 MRtrix, MNE, Nipy, Slicer, SPM), eases the design of workflows within and \
83 between packages, and reduces the learning curve necessary to use different \
84 packages. Nipype is creating a collaborative platform for neuroimaging software \
85 development in a high-level language and addressing limitations of existing \
86 pipeline systems.
87
88 *Nipype* allows you to:
89
90 * easily interact with tools from different software packages
91 * combine processing steps from different software packages
92 * develop new workflows faster by reusing common steps from old ones
93 * process data faster by running it in parallel on many cores/machines
94 * make your research easily reproducible
95 * share your processing workflows with the community
96 """
97
98 # versions
99 NIBABEL_MIN_VERSION = '2.1.0'
100 NETWORKX_MIN_VERSION = '1.9'
101 NUMPY_MIN_VERSION = '1.8.2'
102 SCIPY_MIN_VERSION = '0.14'
103 TRAITS_MIN_VERSION = '4.6'
104 DATEUTIL_MIN_VERSION = '2.2'
105 PYTEST_MIN_VERSION = '3.0'
106 FUTURE_MIN_VERSION = '0.16.0'
107 SIMPLEJSON_MIN_VERSION = '3.8.0'
108 PROV_VERSION = '1.5.0'
109 CLICK_MIN_VERSION = '6.6.0'
110
111 NAME = 'nipype'
112 MAINTAINER = 'nipype developers'
113 MAINTAINER_EMAIL = '[email protected]'
114 DESCRIPTION = description
115 LONG_DESCRIPTION = long_description
116 URL = 'http://nipy.org/nipype'
117 DOWNLOAD_URL = 'http://github.com/nipy/nipype/archives/master'
118 LICENSE = 'Apache License, 2.0'
119 CLASSIFIERS = CLASSIFIERS
120 AUTHOR = 'nipype developers'
121 AUTHOR_EMAIL = '[email protected]'
122 PLATFORMS = 'OS Independent'
123 MAJOR = __version__.split('.')[0]
124 MINOR = __version__.split('.')[1]
125 MICRO = __version__.replace('-', '.').split('.')[2]
126 ISRELEASE = (len(__version__.replace('-', '.').split('.')) == 3 or
127 'post' in __version__.replace('-', '.').split('.')[-1])
128 VERSION = __version__
129 PROVIDES = ['nipype']
130 REQUIRES = [
131 'nibabel>=%s' % NIBABEL_MIN_VERSION,
132 'networkx>=%s' % NETWORKX_MIN_VERSION,
133 'numpy>=%s' % NUMPY_MIN_VERSION,
134 'python-dateutil>=%s' % DATEUTIL_MIN_VERSION,
135 'scipy>=%s' % SCIPY_MIN_VERSION,
136 'traits>=%s' % TRAITS_MIN_VERSION,
137 'future>=%s' % FUTURE_MIN_VERSION,
138 'simplejson>=%s' % SIMPLEJSON_MIN_VERSION,
139 'prov==%s' % PROV_VERSION,
140 'click>=%s' % CLICK_MIN_VERSION,
141 'funcsigs',
142 'pytest>=%s' % PYTEST_MIN_VERSION,
143 'mock',
144 'pydotplus',
145 'packaging',
146 ]
147
148 if sys.version_info <= (3, 4):
149 REQUIRES.append('configparser')
150
151 TESTS_REQUIRES = [
152 'pytest-cov',
153 'codecov'
154 ]
155
156 EXTRA_REQUIRES = {
157 'doc': ['Sphinx>=1.4', 'matplotlib', 'pydotplus'],
158 'tests': TESTS_REQUIRES,
159 'nipy': ['nitime', 'nilearn', 'dipy', 'nipy', 'matplotlib'],
160 'profiler': ['psutil'],
161 'duecredit': ['duecredit'],
162 'xvfbwrapper': ['xvfbwrapper'],
163 # 'mesh': ['mayavi'] # Enable when it works
164 }
165
166 # Enable a handle to install all extra dependencies at once
167 EXTRA_REQUIRES['all'] = [val for _, val in list(EXTRA_REQUIRES.items())]
168
169 STATUS = 'stable'
170
[end of nipype/info.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nipype/info.py b/nipype/info.py
--- a/nipype/info.py
+++ b/nipype/info.py
@@ -98,7 +98,7 @@
# versions
NIBABEL_MIN_VERSION = '2.1.0'
NETWORKX_MIN_VERSION = '1.9'
-NUMPY_MIN_VERSION = '1.8.2'
+NUMPY_MIN_VERSION = '1.9.0'
SCIPY_MIN_VERSION = '0.14'
TRAITS_MIN_VERSION = '4.6'
DATEUTIL_MIN_VERSION = '2.2'
|
{"golden_diff": "diff --git a/nipype/info.py b/nipype/info.py\n--- a/nipype/info.py\n+++ b/nipype/info.py\n@@ -98,7 +98,7 @@\n # versions\n NIBABEL_MIN_VERSION = '2.1.0'\n NETWORKX_MIN_VERSION = '1.9'\n-NUMPY_MIN_VERSION = '1.8.2'\n+NUMPY_MIN_VERSION = '1.9.0'\n SCIPY_MIN_VERSION = '0.14'\n TRAITS_MIN_VERSION = '4.6'\n DATEUTIL_MIN_VERSION = '2.2'\n", "issue": "Modelgen SpecifyModel TypeError: apply_along_axis()\n@effigies \r\nSpecifyModel rises an error with the new function from\r\ncommit cd49748be5d7a8201496548922d85f63bb4034dc\r\n\r\nmodelgen.py line 399ff\r\n\r\nWith numpy 1.8.2 I get\r\nTypeError: apply_along_axis() got an unexpected keyword argument 'source'\r\nInterface SpecifyModel failed to run\r\n\r\nJoerg\r\n\n", "before_files": [{"content": "\"\"\" This file contains defines parameters for nipy that we use to fill\nsettings in setup.py, the nipy top-level docstring, and for building the\ndocs. In setup.py in particular, we exec this file, so it cannot import nipy\n\"\"\"\nfrom __future__ import print_function, division, unicode_literals, absolute_import\n\nimport sys\n\n# nipype version information. An empty version_extra corresponds to a\n# full release. '.dev' as a version_extra string means this is a development\n# version\n# Remove -dev for release\n__version__ = '1.0.0-dev'\n\n\ndef get_nipype_gitversion():\n \"\"\"Nipype version as reported by the last commit in git\n\n Returns\n -------\n None or str\n Version of Nipype according to git.\n \"\"\"\n import os\n import subprocess\n try:\n import nipype\n gitpath = os.path.realpath(os.path.join(os.path.dirname(nipype.__file__),\n os.path.pardir))\n except:\n gitpath = os.getcwd()\n gitpathgit = os.path.join(gitpath, '.git')\n if not os.path.exists(gitpathgit):\n return None\n ver = None\n try:\n o, _ = subprocess.Popen('git describe', shell=True, cwd=gitpath,\n stdout=subprocess.PIPE).communicate()\n except Exception:\n pass\n else:\n ver = o.decode().strip().split('-')[-1]\n return ver\n\nif __version__.endswith('-dev'):\n gitversion = get_nipype_gitversion()\n if gitversion:\n __version__ = '{}+{}'.format(__version__, gitversion)\n\nCLASSIFIERS = ['Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: Apache Software License',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: POSIX :: Linux',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Topic :: Scientific/Engineering']\n\ndescription = 'Neuroimaging in Python: Pipelines and Interfaces'\n\n# Note: this long_description is actually a copy/paste from the top-level\n# README.txt, so that it shows up nicely on PyPI. So please remember to edit\n# it only in one place and sync it correctly.\nlong_description = \"\"\"========================================================\nNIPYPE: Neuroimaging in Python: Pipelines and Interfaces\n========================================================\n\nCurrent neuroimaging software offer users an incredible opportunity to \\\nanalyze data using a variety of different algorithms. However, this has \\\nresulted in a heterogeneous collection of specialized applications \\\nwithout transparent interoperability or a uniform operating interface.\n\n*Nipype*, an open-source, community-developed initiative under the \\\numbrella of NiPy_, is a Python project that provides a uniform interface \\\nto existing neuroimaging software and facilitates interaction between \\\nthese packages within a single workflow. Nipype provides an environment \\\nthat encourages interactive exploration of algorithms from different \\\npackages (e.g., AFNI, ANTS, BRAINS, BrainSuite, Camino, FreeSurfer, FSL, MNE, \\\nMRtrix, MNE, Nipy, Slicer, SPM), eases the design of workflows within and \\\nbetween packages, and reduces the learning curve necessary to use different \\\npackages. Nipype is creating a collaborative platform for neuroimaging software \\\ndevelopment in a high-level language and addressing limitations of existing \\\npipeline systems.\n\n*Nipype* allows you to:\n\n* easily interact with tools from different software packages\n* combine processing steps from different software packages\n* develop new workflows faster by reusing common steps from old ones\n* process data faster by running it in parallel on many cores/machines\n* make your research easily reproducible\n* share your processing workflows with the community\n\"\"\"\n\n# versions\nNIBABEL_MIN_VERSION = '2.1.0'\nNETWORKX_MIN_VERSION = '1.9'\nNUMPY_MIN_VERSION = '1.8.2'\nSCIPY_MIN_VERSION = '0.14'\nTRAITS_MIN_VERSION = '4.6'\nDATEUTIL_MIN_VERSION = '2.2'\nPYTEST_MIN_VERSION = '3.0'\nFUTURE_MIN_VERSION = '0.16.0'\nSIMPLEJSON_MIN_VERSION = '3.8.0'\nPROV_VERSION = '1.5.0'\nCLICK_MIN_VERSION = '6.6.0'\n\nNAME = 'nipype'\nMAINTAINER = 'nipype developers'\nMAINTAINER_EMAIL = '[email protected]'\nDESCRIPTION = description\nLONG_DESCRIPTION = long_description\nURL = 'http://nipy.org/nipype'\nDOWNLOAD_URL = 'http://github.com/nipy/nipype/archives/master'\nLICENSE = 'Apache License, 2.0'\nCLASSIFIERS = CLASSIFIERS\nAUTHOR = 'nipype developers'\nAUTHOR_EMAIL = '[email protected]'\nPLATFORMS = 'OS Independent'\nMAJOR = __version__.split('.')[0]\nMINOR = __version__.split('.')[1]\nMICRO = __version__.replace('-', '.').split('.')[2]\nISRELEASE = (len(__version__.replace('-', '.').split('.')) == 3 or\n 'post' in __version__.replace('-', '.').split('.')[-1])\nVERSION = __version__\nPROVIDES = ['nipype']\nREQUIRES = [\n 'nibabel>=%s' % NIBABEL_MIN_VERSION,\n 'networkx>=%s' % NETWORKX_MIN_VERSION,\n 'numpy>=%s' % NUMPY_MIN_VERSION,\n 'python-dateutil>=%s' % DATEUTIL_MIN_VERSION,\n 'scipy>=%s' % SCIPY_MIN_VERSION,\n 'traits>=%s' % TRAITS_MIN_VERSION,\n 'future>=%s' % FUTURE_MIN_VERSION,\n 'simplejson>=%s' % SIMPLEJSON_MIN_VERSION,\n 'prov==%s' % PROV_VERSION,\n 'click>=%s' % CLICK_MIN_VERSION,\n 'funcsigs',\n 'pytest>=%s' % PYTEST_MIN_VERSION,\n 'mock',\n 'pydotplus',\n 'packaging',\n]\n\nif sys.version_info <= (3, 4):\n REQUIRES.append('configparser')\n\nTESTS_REQUIRES = [\n 'pytest-cov',\n 'codecov'\n]\n\nEXTRA_REQUIRES = {\n 'doc': ['Sphinx>=1.4', 'matplotlib', 'pydotplus'],\n 'tests': TESTS_REQUIRES,\n 'nipy': ['nitime', 'nilearn', 'dipy', 'nipy', 'matplotlib'],\n 'profiler': ['psutil'],\n 'duecredit': ['duecredit'],\n 'xvfbwrapper': ['xvfbwrapper'],\n # 'mesh': ['mayavi'] # Enable when it works\n}\n\n# Enable a handle to install all extra dependencies at once\nEXTRA_REQUIRES['all'] = [val for _, val in list(EXTRA_REQUIRES.items())]\n\nSTATUS = 'stable'\n", "path": "nipype/info.py"}]}
| 2,596 | 128 |
gh_patches_debug_2714
|
rasdani/github-patches
|
git_diff
|
sanic-org__sanic-1397
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Logger not work.
**Describe the bug**
Logger did not work at current master commit (https://github.com/huge-success/sanic/commit/7d79a86d4dc48de11cd34e8ba12e41f3a9f9ff18).
**Code snippet**
```python
from sanic import Sanic
from sanic.log import logger
from sanic.response import text
app = Sanic()
@app.listener('before_server_start')
async def setup(app, loop):
logger.info('INFO')
@app.get('/')
async def test(request):
return text('hello world')
if __name__ == '__main__':
app.run()
```
There is no any log/output now.
**Expected behavior**
At `0.8.3` release, it will logging/output some messages like:
```
[2018-11-05 17:34:47 +0800] [12112] [INFO] Goin' Fast @ http://127.0.0.1:8000
[2018-11-05 17:34:47 +0800] [12112] [INFO] INFO
[2018-11-05 17:34:47 +0800] [12112] [INFO] Starting worker [12112]
```
**Environment (please complete the following information):**
- OS: Ubuntu 18.04
- Version: https://github.com/huge-success/sanic/commit/7d79a86d4dc48de11cd34e8ba12e41f3a9f9ff18
**Additional context**
It seems that `getLogger()` does not get the correct logger at [line 56](https://github.com/huge-success/sanic/blob/master/sanic/log.py#L56) in `log.py`. The logger is trying to get a logger named `sanic.root`, but it does not exist. Rename the logger `root` at [line 9](https://github.com/huge-success/sanic/blob/master/sanic/log.py#L9) should fix this bug.
</issue>
<code>
[start of sanic/log.py]
1 import logging
2 import sys
3
4
5 LOGGING_CONFIG_DEFAULTS = dict(
6 version=1,
7 disable_existing_loggers=False,
8 loggers={
9 "root": {"level": "INFO", "handlers": ["console"]},
10 "sanic.error": {
11 "level": "INFO",
12 "handlers": ["error_console"],
13 "propagate": True,
14 "qualname": "sanic.error",
15 },
16 "sanic.access": {
17 "level": "INFO",
18 "handlers": ["access_console"],
19 "propagate": True,
20 "qualname": "sanic.access",
21 },
22 },
23 handlers={
24 "console": {
25 "class": "logging.StreamHandler",
26 "formatter": "generic",
27 "stream": sys.stdout,
28 },
29 "error_console": {
30 "class": "logging.StreamHandler",
31 "formatter": "generic",
32 "stream": sys.stderr,
33 },
34 "access_console": {
35 "class": "logging.StreamHandler",
36 "formatter": "access",
37 "stream": sys.stdout,
38 },
39 },
40 formatters={
41 "generic": {
42 "format": "%(asctime)s [%(process)d] [%(levelname)s] %(message)s",
43 "datefmt": "[%Y-%m-%d %H:%M:%S %z]",
44 "class": "logging.Formatter",
45 },
46 "access": {
47 "format": "%(asctime)s - (%(name)s)[%(levelname)s][%(host)s]: "
48 + "%(request)s %(message)s %(status)d %(byte)d",
49 "datefmt": "[%Y-%m-%d %H:%M:%S %z]",
50 "class": "logging.Formatter",
51 },
52 },
53 )
54
55
56 logger = logging.getLogger("sanic.root")
57 error_logger = logging.getLogger("sanic.error")
58 access_logger = logging.getLogger("sanic.access")
59
[end of sanic/log.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sanic/log.py b/sanic/log.py
--- a/sanic/log.py
+++ b/sanic/log.py
@@ -6,7 +6,7 @@
version=1,
disable_existing_loggers=False,
loggers={
- "root": {"level": "INFO", "handlers": ["console"]},
+ "sanic.root": {"level": "INFO", "handlers": ["console"]},
"sanic.error": {
"level": "INFO",
"handlers": ["error_console"],
|
{"golden_diff": "diff --git a/sanic/log.py b/sanic/log.py\n--- a/sanic/log.py\n+++ b/sanic/log.py\n@@ -6,7 +6,7 @@\n version=1,\n disable_existing_loggers=False,\n loggers={\n- \"root\": {\"level\": \"INFO\", \"handlers\": [\"console\"]},\n+ \"sanic.root\": {\"level\": \"INFO\", \"handlers\": [\"console\"]},\n \"sanic.error\": {\n \"level\": \"INFO\",\n \"handlers\": [\"error_console\"],\n", "issue": "Logger not work.\n**Describe the bug**\r\nLogger did not work at current master commit (https://github.com/huge-success/sanic/commit/7d79a86d4dc48de11cd34e8ba12e41f3a9f9ff18).\r\n\r\n\r\n**Code snippet**\r\n```python\r\nfrom sanic import Sanic\r\nfrom sanic.log import logger\r\nfrom sanic.response import text\r\n\r\n\r\napp = Sanic()\r\n\r\[email protected]('before_server_start')\r\nasync def setup(app, loop):\r\n logger.info('INFO')\r\n\r\n\r\[email protected]('/')\r\nasync def test(request):\r\n return text('hello world')\r\n\r\n\r\nif __name__ == '__main__':\r\n app.run()\r\n```\r\nThere is no any log/output now.\r\n\r\n\r\n\r\n**Expected behavior**\r\nAt `0.8.3` release, it will logging/output some messages like:\r\n```\r\n[2018-11-05 17:34:47 +0800] [12112] [INFO] Goin' Fast @ http://127.0.0.1:8000\r\n[2018-11-05 17:34:47 +0800] [12112] [INFO] INFO\r\n[2018-11-05 17:34:47 +0800] [12112] [INFO] Starting worker [12112]\r\n```\r\n\r\n\r\n**Environment (please complete the following information):**\r\n - OS: Ubuntu 18.04\r\n - Version: https://github.com/huge-success/sanic/commit/7d79a86d4dc48de11cd34e8ba12e41f3a9f9ff18\r\n\r\n\r\n**Additional context**\r\nIt seems that `getLogger()` does not get the correct logger at [line 56](https://github.com/huge-success/sanic/blob/master/sanic/log.py#L56) in `log.py`. The logger is trying to get a logger named `sanic.root`, but it does not exist. Rename the logger `root` at [line 9](https://github.com/huge-success/sanic/blob/master/sanic/log.py#L9) should fix this bug.\r\n\n", "before_files": [{"content": "import logging\nimport sys\n\n\nLOGGING_CONFIG_DEFAULTS = dict(\n version=1,\n disable_existing_loggers=False,\n loggers={\n \"root\": {\"level\": \"INFO\", \"handlers\": [\"console\"]},\n \"sanic.error\": {\n \"level\": \"INFO\",\n \"handlers\": [\"error_console\"],\n \"propagate\": True,\n \"qualname\": \"sanic.error\",\n },\n \"sanic.access\": {\n \"level\": \"INFO\",\n \"handlers\": [\"access_console\"],\n \"propagate\": True,\n \"qualname\": \"sanic.access\",\n },\n },\n handlers={\n \"console\": {\n \"class\": \"logging.StreamHandler\",\n \"formatter\": \"generic\",\n \"stream\": sys.stdout,\n },\n \"error_console\": {\n \"class\": \"logging.StreamHandler\",\n \"formatter\": \"generic\",\n \"stream\": sys.stderr,\n },\n \"access_console\": {\n \"class\": \"logging.StreamHandler\",\n \"formatter\": \"access\",\n \"stream\": sys.stdout,\n },\n },\n formatters={\n \"generic\": {\n \"format\": \"%(asctime)s [%(process)d] [%(levelname)s] %(message)s\",\n \"datefmt\": \"[%Y-%m-%d %H:%M:%S %z]\",\n \"class\": \"logging.Formatter\",\n },\n \"access\": {\n \"format\": \"%(asctime)s - (%(name)s)[%(levelname)s][%(host)s]: \"\n + \"%(request)s %(message)s %(status)d %(byte)d\",\n \"datefmt\": \"[%Y-%m-%d %H:%M:%S %z]\",\n \"class\": \"logging.Formatter\",\n },\n },\n)\n\n\nlogger = logging.getLogger(\"sanic.root\")\nerror_logger = logging.getLogger(\"sanic.error\")\naccess_logger = logging.getLogger(\"sanic.access\")\n", "path": "sanic/log.py"}]}
| 1,548 | 114 |
gh_patches_debug_50906
|
rasdani/github-patches
|
git_diff
|
pymedusa__Medusa-4086
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[APP SUBMITTED]: AttributeError: 'module' object has no attribute 'core'
### INFO
**Python Version**: `2.7.13 (v2.7.13:a06454b1afa1, Dec 17 2016, 20:53:40) [MSC v.1500 64 bit (AMD64)]`
**Operating System**: `Windows-7-6.1.7601-SP1`
**Locale**: `cp1252`
**Branch**: [master](../tree/master)
**Database**: `44.9`
**Commit**: pymedusa/Medusa@77b20916ab577b82112ebc624f816054788c63f2
**Link to Log**: https://gist.github.com/7f6099e1c66cecd44e069bffee91a3ac
### ERROR
<pre>
2018-04-23 16:08:49 ERROR Thread_18 :: [77b2091] Exception generated: 'module' object has no attribute 'core'
Traceback (most recent call last):
File "C:\Medusa\Medusa\medusa\server\web\core\base.py", line 285, in async_call
result = function(**kwargs)
File "C:\Medusa\Medusa\medusa\server\web\home\handler.py", line 357, in testGrowl
result = notifiers.growl_notifier.test_notify(host, password)
File "C:\Medusa\Medusa\medusa\notifiers\growl.py", line 22, in test_notify
self._sendRegistration(host, password)
File "C:\Medusa\Medusa\medusa\notifiers\growl.py", line 174, in _sendRegistration
register = gntp.core.GNTPRegister()
AttributeError: 'module' object has no attribute 'core'
</pre>
---
_STAFF NOTIFIED_: @pymedusa/support @pymedusa/moderators
</issue>
<code>
[start of medusa/notifiers/growl.py]
1 # coding=utf-8
2
3 from __future__ import print_function
4 from __future__ import unicode_literals
5
6 import logging
7 import socket
8 from builtins import object
9
10 import gntp
11
12 from medusa import app, common
13 from medusa.helper.exceptions import ex
14 from medusa.logger.adapters.style import BraceAdapter
15
16 log = BraceAdapter(logging.getLogger(__name__))
17 log.logger.addHandler(logging.NullHandler())
18
19
20 class Notifier(object):
21 def test_notify(self, host, password):
22 self._sendRegistration(host, password)
23 return self._sendGrowl('Test Growl', 'Testing Growl settings from Medusa', 'Test', host, password,
24 force=True)
25
26 def notify_snatch(self, ep_name, is_proper):
27 if app.GROWL_NOTIFY_ONSNATCH:
28 self._sendGrowl(
29 common.notifyStrings[
30 (common.NOTIFY_SNATCH, common.NOTIFY_SNATCH_PROPER)[is_proper]
31 ], ep_name)
32
33 def notify_download(self, ep_name):
34 if app.GROWL_NOTIFY_ONDOWNLOAD:
35 self._sendGrowl(common.notifyStrings[common.NOTIFY_DOWNLOAD], ep_name)
36
37 def notify_subtitle_download(self, ep_name, lang):
38 if app.GROWL_NOTIFY_ONSUBTITLEDOWNLOAD:
39 self._sendGrowl(common.notifyStrings[common.NOTIFY_SUBTITLE_DOWNLOAD], ep_name + ': ' + lang)
40
41 def notify_git_update(self, new_version='??'):
42 update_text = common.notifyStrings[common.NOTIFY_GIT_UPDATE_TEXT]
43 title = common.notifyStrings[common.NOTIFY_GIT_UPDATE]
44 self._sendGrowl(title, update_text + new_version)
45
46 def notify_login(self, ipaddress=''):
47 update_text = common.notifyStrings[common.NOTIFY_LOGIN_TEXT]
48 title = common.notifyStrings[common.NOTIFY_LOGIN]
49 self._sendGrowl(title, update_text.format(ipaddress))
50
51 def _send_growl(self, options, message=None):
52
53 # Initialize Notification
54 notice = gntp.core.GNTPNotice(
55 app=options['app'],
56 name=options['name'],
57 title=options['title'],
58 password=options['password'],
59 )
60
61 # Optional
62 if options['sticky']:
63 notice.add_header('Notification-Sticky', options['sticky'])
64 if options['priority']:
65 notice.add_header('Notification-Priority', options['priority'])
66 if options['icon']:
67 notice.add_header('Notification-Icon', app.LOGO_URL)
68
69 if message:
70 notice.add_header('Notification-Text', message)
71
72 response = self._send(options['host'], options['port'], notice.encode(), options['debug'])
73 return True if isinstance(response, gntp.core.GNTPOK) else False
74
75 @staticmethod
76 def _send(host, port, data, debug=False):
77 if debug:
78 print('<Sending>\n', data, '\n</Sending>')
79
80 s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
81 s.connect((host, port))
82 s.send(data)
83 response = gntp.core.parse_gntp(s.recv(1024))
84 s.close()
85
86 if debug:
87 print('<Received>\n', response, '\n</Received>')
88
89 return response
90
91 def _sendGrowl(self, title='Medusa Notification', message=None, name=None, host=None, password=None,
92 force=False):
93 if not app.USE_GROWL and not force:
94 return False
95
96 if name is None:
97 name = title
98
99 if host is None:
100 hostParts = app.GROWL_HOST.split(':')
101 else:
102 hostParts = host.split(':')
103
104 if len(hostParts) != 2 or hostParts[1] == '':
105 port = 23053
106 else:
107 port = int(hostParts[1])
108
109 growlHosts = [(hostParts[0], port)]
110
111 opts = {
112 'name': name,
113 'title': title,
114 'app': 'Medusa',
115 'sticky': None,
116 'priority': None,
117 'debug': False
118 }
119
120 if password is None:
121 opts['password'] = app.GROWL_PASSWORD
122 else:
123 opts['password'] = password
124
125 opts['icon'] = True
126
127 for pc in growlHosts:
128 opts['host'] = pc[0]
129 opts['port'] = pc[1]
130 log.debug(
131 u'GROWL: Sending growl to {host}:{port} - {msg!r}',
132 {'msg': message, 'host': opts['host'], 'port': opts['port']}
133 )
134 try:
135 if self._send_growl(opts, message):
136 return True
137 else:
138 if self._sendRegistration(host, password):
139 return self._send_growl(opts, message)
140 else:
141 return False
142 except Exception as error:
143 log.warning(
144 u'GROWL: Unable to send growl to {host}:{port} - {msg!r}',
145 {'msg': ex(error), 'host': opts['host'], 'port': opts['port']}
146 )
147 return False
148
149 def _sendRegistration(self, host=None, password=None):
150 opts = {}
151
152 if host is None:
153 hostParts = app.GROWL_HOST.split(':')
154 else:
155 hostParts = host.split(':')
156
157 if len(hostParts) != 2 or hostParts[1] == '':
158 port = 23053
159 else:
160 port = int(hostParts[1])
161
162 opts['host'] = hostParts[0]
163 opts['port'] = port
164
165 if password is None:
166 opts['password'] = app.GROWL_PASSWORD
167 else:
168 opts['password'] = password
169
170 opts['app'] = 'Medusa'
171 opts['debug'] = False
172
173 # Send Registration
174 register = gntp.core.GNTPRegister()
175 register.add_header('Application-Name', opts['app'])
176 register.add_header('Application-Icon', app.LOGO_URL)
177
178 register.add_notification('Test', True)
179 register.add_notification(common.notifyStrings[common.NOTIFY_SNATCH], True)
180 register.add_notification(common.notifyStrings[common.NOTIFY_DOWNLOAD], True)
181 register.add_notification(common.notifyStrings[common.NOTIFY_GIT_UPDATE], True)
182
183 if opts['password']:
184 register.set_password(opts['password'])
185
186 try:
187 return self._send(opts['host'], opts['port'], register.encode(), opts['debug'])
188 except Exception as error:
189 log.warning(
190 u'GROWL: Unable to send growl to {host}:{port} - {msg!r}',
191 {'msg': ex(error), 'host': opts['host'], 'port': opts['port']}
192 )
193 return False
194
[end of medusa/notifiers/growl.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/medusa/notifiers/growl.py b/medusa/notifiers/growl.py
--- a/medusa/notifiers/growl.py
+++ b/medusa/notifiers/growl.py
@@ -7,7 +7,7 @@
import socket
from builtins import object
-import gntp
+import gntp.core
from medusa import app, common
from medusa.helper.exceptions import ex
|
{"golden_diff": "diff --git a/medusa/notifiers/growl.py b/medusa/notifiers/growl.py\n--- a/medusa/notifiers/growl.py\n+++ b/medusa/notifiers/growl.py\n@@ -7,7 +7,7 @@\n import socket\n from builtins import object\n \n-import gntp\n+import gntp.core\n \n from medusa import app, common\n from medusa.helper.exceptions import ex\n", "issue": "[APP SUBMITTED]: AttributeError: 'module' object has no attribute 'core'\n\n### INFO\n**Python Version**: `2.7.13 (v2.7.13:a06454b1afa1, Dec 17 2016, 20:53:40) [MSC v.1500 64 bit (AMD64)]`\n**Operating System**: `Windows-7-6.1.7601-SP1`\n**Locale**: `cp1252`\n**Branch**: [master](../tree/master)\n**Database**: `44.9`\n**Commit**: pymedusa/Medusa@77b20916ab577b82112ebc624f816054788c63f2\n**Link to Log**: https://gist.github.com/7f6099e1c66cecd44e069bffee91a3ac\n### ERROR\n<pre>\n2018-04-23 16:08:49 ERROR Thread_18 :: [77b2091] Exception generated: 'module' object has no attribute 'core'\nTraceback (most recent call last):\n File \"C:\\Medusa\\Medusa\\medusa\\server\\web\\core\\base.py\", line 285, in async_call\n result = function(**kwargs)\n File \"C:\\Medusa\\Medusa\\medusa\\server\\web\\home\\handler.py\", line 357, in testGrowl\n result = notifiers.growl_notifier.test_notify(host, password)\n File \"C:\\Medusa\\Medusa\\medusa\\notifiers\\growl.py\", line 22, in test_notify\n self._sendRegistration(host, password)\n File \"C:\\Medusa\\Medusa\\medusa\\notifiers\\growl.py\", line 174, in _sendRegistration\n register = gntp.core.GNTPRegister()\nAttributeError: 'module' object has no attribute 'core'\n</pre>\n---\n_STAFF NOTIFIED_: @pymedusa/support @pymedusa/moderators\n\n", "before_files": [{"content": "# coding=utf-8\n\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport logging\nimport socket\nfrom builtins import object\n\nimport gntp\n\nfrom medusa import app, common\nfrom medusa.helper.exceptions import ex\nfrom medusa.logger.adapters.style import BraceAdapter\n\nlog = BraceAdapter(logging.getLogger(__name__))\nlog.logger.addHandler(logging.NullHandler())\n\n\nclass Notifier(object):\n def test_notify(self, host, password):\n self._sendRegistration(host, password)\n return self._sendGrowl('Test Growl', 'Testing Growl settings from Medusa', 'Test', host, password,\n force=True)\n\n def notify_snatch(self, ep_name, is_proper):\n if app.GROWL_NOTIFY_ONSNATCH:\n self._sendGrowl(\n common.notifyStrings[\n (common.NOTIFY_SNATCH, common.NOTIFY_SNATCH_PROPER)[is_proper]\n ], ep_name)\n\n def notify_download(self, ep_name):\n if app.GROWL_NOTIFY_ONDOWNLOAD:\n self._sendGrowl(common.notifyStrings[common.NOTIFY_DOWNLOAD], ep_name)\n\n def notify_subtitle_download(self, ep_name, lang):\n if app.GROWL_NOTIFY_ONSUBTITLEDOWNLOAD:\n self._sendGrowl(common.notifyStrings[common.NOTIFY_SUBTITLE_DOWNLOAD], ep_name + ': ' + lang)\n\n def notify_git_update(self, new_version='??'):\n update_text = common.notifyStrings[common.NOTIFY_GIT_UPDATE_TEXT]\n title = common.notifyStrings[common.NOTIFY_GIT_UPDATE]\n self._sendGrowl(title, update_text + new_version)\n\n def notify_login(self, ipaddress=''):\n update_text = common.notifyStrings[common.NOTIFY_LOGIN_TEXT]\n title = common.notifyStrings[common.NOTIFY_LOGIN]\n self._sendGrowl(title, update_text.format(ipaddress))\n\n def _send_growl(self, options, message=None):\n\n # Initialize Notification\n notice = gntp.core.GNTPNotice(\n app=options['app'],\n name=options['name'],\n title=options['title'],\n password=options['password'],\n )\n\n # Optional\n if options['sticky']:\n notice.add_header('Notification-Sticky', options['sticky'])\n if options['priority']:\n notice.add_header('Notification-Priority', options['priority'])\n if options['icon']:\n notice.add_header('Notification-Icon', app.LOGO_URL)\n\n if message:\n notice.add_header('Notification-Text', message)\n\n response = self._send(options['host'], options['port'], notice.encode(), options['debug'])\n return True if isinstance(response, gntp.core.GNTPOK) else False\n\n @staticmethod\n def _send(host, port, data, debug=False):\n if debug:\n print('<Sending>\\n', data, '\\n</Sending>')\n\n s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n s.connect((host, port))\n s.send(data)\n response = gntp.core.parse_gntp(s.recv(1024))\n s.close()\n\n if debug:\n print('<Received>\\n', response, '\\n</Received>')\n\n return response\n\n def _sendGrowl(self, title='Medusa Notification', message=None, name=None, host=None, password=None,\n force=False):\n if not app.USE_GROWL and not force:\n return False\n\n if name is None:\n name = title\n\n if host is None:\n hostParts = app.GROWL_HOST.split(':')\n else:\n hostParts = host.split(':')\n\n if len(hostParts) != 2 or hostParts[1] == '':\n port = 23053\n else:\n port = int(hostParts[1])\n\n growlHosts = [(hostParts[0], port)]\n\n opts = {\n 'name': name,\n 'title': title,\n 'app': 'Medusa',\n 'sticky': None,\n 'priority': None,\n 'debug': False\n }\n\n if password is None:\n opts['password'] = app.GROWL_PASSWORD\n else:\n opts['password'] = password\n\n opts['icon'] = True\n\n for pc in growlHosts:\n opts['host'] = pc[0]\n opts['port'] = pc[1]\n log.debug(\n u'GROWL: Sending growl to {host}:{port} - {msg!r}',\n {'msg': message, 'host': opts['host'], 'port': opts['port']}\n )\n try:\n if self._send_growl(opts, message):\n return True\n else:\n if self._sendRegistration(host, password):\n return self._send_growl(opts, message)\n else:\n return False\n except Exception as error:\n log.warning(\n u'GROWL: Unable to send growl to {host}:{port} - {msg!r}',\n {'msg': ex(error), 'host': opts['host'], 'port': opts['port']}\n )\n return False\n\n def _sendRegistration(self, host=None, password=None):\n opts = {}\n\n if host is None:\n hostParts = app.GROWL_HOST.split(':')\n else:\n hostParts = host.split(':')\n\n if len(hostParts) != 2 or hostParts[1] == '':\n port = 23053\n else:\n port = int(hostParts[1])\n\n opts['host'] = hostParts[0]\n opts['port'] = port\n\n if password is None:\n opts['password'] = app.GROWL_PASSWORD\n else:\n opts['password'] = password\n\n opts['app'] = 'Medusa'\n opts['debug'] = False\n\n # Send Registration\n register = gntp.core.GNTPRegister()\n register.add_header('Application-Name', opts['app'])\n register.add_header('Application-Icon', app.LOGO_URL)\n\n register.add_notification('Test', True)\n register.add_notification(common.notifyStrings[common.NOTIFY_SNATCH], True)\n register.add_notification(common.notifyStrings[common.NOTIFY_DOWNLOAD], True)\n register.add_notification(common.notifyStrings[common.NOTIFY_GIT_UPDATE], True)\n\n if opts['password']:\n register.set_password(opts['password'])\n\n try:\n return self._send(opts['host'], opts['port'], register.encode(), opts['debug'])\n except Exception as error:\n log.warning(\n u'GROWL: Unable to send growl to {host}:{port} - {msg!r}',\n {'msg': ex(error), 'host': opts['host'], 'port': opts['port']}\n )\n return False\n", "path": "medusa/notifiers/growl.py"}]}
| 2,972 | 93 |
gh_patches_debug_31109
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-27457
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
argmin
argmin
</issue>
<code>
[start of ivy/functional/frontends/jax/numpy/searching_sorting.py]
1 # global
2 import logging
3
4 # local
5 import ivy
6 from ivy.functional.frontends.jax.func_wrapper import (
7 to_ivy_arrays_and_back,
8 )
9 from ivy.functional.frontends.numpy.func_wrapper import from_zero_dim_arrays_to_scalar
10 from ivy.func_wrapper import (
11 with_unsupported_dtypes,
12 )
13
14
15 @to_ivy_arrays_and_back
16 @with_unsupported_dtypes(
17 {
18 "0.4.20 and below": (
19 "float16",
20 "bfloat16",
21 )
22 },
23 "jax",
24 )
25 def argmax(a, axis=None, out=None, keepdims=False):
26 return ivy.argmax(a, axis=axis, keepdims=keepdims, out=out, dtype=ivy.int64)
27
28
29 @to_ivy_arrays_and_back
30 def argsort(a, axis=-1, kind="stable", order=None):
31 if kind != "stable":
32 logging.warning(
33 "'kind' argument to argsort is ignored; only 'stable' sorts are supported."
34 )
35 if order is not None:
36 raise ivy.utils.exceptions.IvyError(
37 "'order' argument to argsort is not supported."
38 )
39
40 return ivy.argsort(a, axis=axis)
41
42
43 @to_ivy_arrays_and_back
44 def argwhere(a, /, *, size=None, fill_value=None):
45 if size is None and fill_value is None:
46 return ivy.argwhere(a)
47
48 result = ivy.matrix_transpose(
49 ivy.vstack(ivy.nonzero(a, size=size, fill_value=fill_value))
50 )
51 num_of_dimensions = a.ndim
52
53 if num_of_dimensions == 0:
54 return result[:0].reshape(result.shape[0], 0)
55
56 return result.reshape(result.shape[0], num_of_dimensions)
57
58
59 @with_unsupported_dtypes(
60 {
61 "0.4.20 and below": (
62 "uint8",
63 "int8",
64 "bool",
65 )
66 },
67 "jax",
68 )
69 @to_ivy_arrays_and_back
70 def count_nonzero(a, axis=None, keepdims=False):
71 return ivy.astype(ivy.count_nonzero(a, axis=axis, keepdims=keepdims), "int64")
72
73
74 @to_ivy_arrays_and_back
75 def extract(condition, arr):
76 if condition.dtype is not bool:
77 condition = condition != 0
78 return arr[condition]
79
80
81 @to_ivy_arrays_and_back
82 def flatnonzero(a):
83 return ivy.nonzero(ivy.reshape(a, (-1,)))
84
85
86 @to_ivy_arrays_and_back
87 def lexsort(keys, /, *, axis=-1):
88 return ivy.lexsort(keys, axis=axis)
89
90
91 @to_ivy_arrays_and_back
92 def msort(a):
93 return ivy.msort(a)
94
95
96 @to_ivy_arrays_and_back
97 @from_zero_dim_arrays_to_scalar
98 def nanargmax(a, /, *, axis=None, out=None, keepdims=False):
99 if out is not None:
100 raise NotImplementedError(
101 "The 'out' argument to jnp.nanargmax is not supported."
102 )
103 nan_mask = ivy.isnan(a)
104 if not ivy.any(nan_mask):
105 return ivy.argmax(a, axis=axis, keepdims=keepdims)
106
107 a = ivy.where(nan_mask, -ivy.inf, a)
108 res = ivy.argmax(a, axis=axis, keepdims=keepdims)
109 return ivy.where(ivy.all(nan_mask, axis=axis, keepdims=keepdims), -1, res)
110
111
112 @to_ivy_arrays_and_back
113 @from_zero_dim_arrays_to_scalar
114 def nanargmin(a, /, *, axis=None, out=None, keepdims=None):
115 if out is not None:
116 raise NotImplementedError(
117 "The 'out' argument to jnp.nanargmax is not supported."
118 )
119 nan_mask = ivy.isnan(a)
120 if not ivy.any(nan_mask):
121 return ivy.argmin(a, axis=axis, keepdims=keepdims)
122
123 a = ivy.where(nan_mask, ivy.inf, a)
124 res = ivy.argmin(a, axis=axis, keepdims=keepdims)
125 return ivy.where(ivy.all(nan_mask, axis=axis, keepdims=keepdims), -1, res)
126
127
128 @to_ivy_arrays_and_back
129 def nonzero(a, *, size=None, fill_value=None):
130 return ivy.nonzero(a, size=size, fill_value=fill_value)
131
132
133 @to_ivy_arrays_and_back
134 def searchsorted(a, v, side="left", sorter=None, *, method="scan"):
135 return ivy.searchsorted(a, v, side=side, sorter=sorter, ret_dtype="int32")
136
137
138 @to_ivy_arrays_and_back
139 def sort(a, axis=-1, kind="quicksort", order=None):
140 # todo: handle case where order is not None
141 return ivy.sort(a, axis=axis)
142
143
144 @to_ivy_arrays_and_back
145 def sort_complex(a):
146 return ivy.sort(a)
147
148
149 @to_ivy_arrays_and_back
150 def unique(
151 ar,
152 return_index=False,
153 return_inverse=False,
154 return_counts=False,
155 axis=None,
156 *,
157 size=None,
158 fill_value=None,
159 ):
160 uniques = list(ivy.unique_all(ar, axis=axis))
161 if size is not None:
162 fill_value = fill_value if fill_value is not None else 1 # default fill_value 1
163 pad_len = size - len(uniques[0])
164 if pad_len > 0:
165 # padding
166 num_dims = len(uniques[0].shape) - 1
167 padding = [(0, 0)] * num_dims + [(0, pad_len)]
168 uniques[0] = ivy.pad(uniques[0], padding, constant_values=fill_value)
169 # padding the indices and counts with zeros
170 for i in range(1, len(uniques)):
171 if i == 2:
172 continue
173 uniques[i] = ivy.pad(uniques[i], padding[-1], constant_values=0)
174 else:
175 for i in range(len(uniques)):
176 uniques[i] = uniques[i][..., :size]
177 # constructing a list of bools for indexing
178 bools = [return_index, return_inverse, return_counts]
179 # indexing each element whose condition is True except for the values
180 uniques = [uniques[0]] + [uni for idx, uni in enumerate(uniques[1:]) if bools[idx]]
181 return uniques[0] if len(uniques) == 1 else uniques
182
183
184 @to_ivy_arrays_and_back
185 def where(condition, x=None, y=None, *, size=None, fill_value=0):
186 if x is None and y is None:
187 return nonzero(condition, size=size, fill_value=fill_value)
188 if x is not None and y is not None:
189 return ivy.where(condition, x, y)
190 else:
191 raise ValueError("Both x and y should be given.")
192
[end of ivy/functional/frontends/jax/numpy/searching_sorting.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ivy/functional/frontends/jax/numpy/searching_sorting.py b/ivy/functional/frontends/jax/numpy/searching_sorting.py
--- a/ivy/functional/frontends/jax/numpy/searching_sorting.py
+++ b/ivy/functional/frontends/jax/numpy/searching_sorting.py
@@ -8,6 +8,7 @@
)
from ivy.functional.frontends.numpy.func_wrapper import from_zero_dim_arrays_to_scalar
from ivy.func_wrapper import (
+ with_supported_device_and_dtypes,
with_unsupported_dtypes,
)
@@ -26,6 +27,58 @@
return ivy.argmax(a, axis=axis, keepdims=keepdims, out=out, dtype=ivy.int64)
+# argmin
+@to_ivy_arrays_and_back
+@with_supported_device_and_dtypes(
+ {
+ "0.4.20 and below": {
+ "cpu": (
+ "int16",
+ "int32",
+ "int64",
+ "float32",
+ "float64",
+ "uint8",
+ "uint16",
+ "uint32",
+ "uint64",
+ )
+ }
+ },
+ "jax",
+)
+def argmin(a, axis=None, out=None, keepdims=None):
+ if a is not None:
+ if isinstance(a, list):
+ if all(isinstance(elem, ivy.Array) for elem in a):
+ if len(a) == 1:
+ a = a[0]
+ else:
+ return [
+ ivy.argmin(
+ ivy.to_native_arrays(elem),
+ axis=axis,
+ out=out,
+ keepdims=keepdims,
+ )
+ for elem in a
+ ]
+ else:
+ raise ValueError(
+ "Input 'a' must be an Ivy array or a list of Ivy arrays."
+ )
+
+ if not isinstance(a, ivy.Array):
+ raise TypeError("Input 'a' must be an array.")
+
+ if a.size == 0:
+ raise ValueError("Input 'a' must not be empty.")
+
+ return ivy.argmin(a, axis=axis, out=out, keepdims=keepdims)
+ else:
+ raise ValueError("argmin takes at least 1 argument.")
+
+
@to_ivy_arrays_and_back
def argsort(a, axis=-1, kind="stable", order=None):
if kind != "stable":
|
{"golden_diff": "diff --git a/ivy/functional/frontends/jax/numpy/searching_sorting.py b/ivy/functional/frontends/jax/numpy/searching_sorting.py\n--- a/ivy/functional/frontends/jax/numpy/searching_sorting.py\n+++ b/ivy/functional/frontends/jax/numpy/searching_sorting.py\n@@ -8,6 +8,7 @@\n )\n from ivy.functional.frontends.numpy.func_wrapper import from_zero_dim_arrays_to_scalar\n from ivy.func_wrapper import (\n+ with_supported_device_and_dtypes,\n with_unsupported_dtypes,\n )\n \n@@ -26,6 +27,58 @@\n return ivy.argmax(a, axis=axis, keepdims=keepdims, out=out, dtype=ivy.int64)\n \n \n+# argmin\n+@to_ivy_arrays_and_back\n+@with_supported_device_and_dtypes(\n+ {\n+ \"0.4.20 and below\": {\n+ \"cpu\": (\n+ \"int16\",\n+ \"int32\",\n+ \"int64\",\n+ \"float32\",\n+ \"float64\",\n+ \"uint8\",\n+ \"uint16\",\n+ \"uint32\",\n+ \"uint64\",\n+ )\n+ }\n+ },\n+ \"jax\",\n+)\n+def argmin(a, axis=None, out=None, keepdims=None):\n+ if a is not None:\n+ if isinstance(a, list):\n+ if all(isinstance(elem, ivy.Array) for elem in a):\n+ if len(a) == 1:\n+ a = a[0]\n+ else:\n+ return [\n+ ivy.argmin(\n+ ivy.to_native_arrays(elem),\n+ axis=axis,\n+ out=out,\n+ keepdims=keepdims,\n+ )\n+ for elem in a\n+ ]\n+ else:\n+ raise ValueError(\n+ \"Input 'a' must be an Ivy array or a list of Ivy arrays.\"\n+ )\n+\n+ if not isinstance(a, ivy.Array):\n+ raise TypeError(\"Input 'a' must be an array.\")\n+\n+ if a.size == 0:\n+ raise ValueError(\"Input 'a' must not be empty.\")\n+\n+ return ivy.argmin(a, axis=axis, out=out, keepdims=keepdims)\n+ else:\n+ raise ValueError(\"argmin takes at least 1 argument.\")\n+\n+\n @to_ivy_arrays_and_back\n def argsort(a, axis=-1, kind=\"stable\", order=None):\n if kind != \"stable\":\n", "issue": "argmin\n\nargmin\n\n", "before_files": [{"content": "# global\nimport logging\n\n# local\nimport ivy\nfrom ivy.functional.frontends.jax.func_wrapper import (\n to_ivy_arrays_and_back,\n)\nfrom ivy.functional.frontends.numpy.func_wrapper import from_zero_dim_arrays_to_scalar\nfrom ivy.func_wrapper import (\n with_unsupported_dtypes,\n)\n\n\n@to_ivy_arrays_and_back\n@with_unsupported_dtypes(\n {\n \"0.4.20 and below\": (\n \"float16\",\n \"bfloat16\",\n )\n },\n \"jax\",\n)\ndef argmax(a, axis=None, out=None, keepdims=False):\n return ivy.argmax(a, axis=axis, keepdims=keepdims, out=out, dtype=ivy.int64)\n\n\n@to_ivy_arrays_and_back\ndef argsort(a, axis=-1, kind=\"stable\", order=None):\n if kind != \"stable\":\n logging.warning(\n \"'kind' argument to argsort is ignored; only 'stable' sorts are supported.\"\n )\n if order is not None:\n raise ivy.utils.exceptions.IvyError(\n \"'order' argument to argsort is not supported.\"\n )\n\n return ivy.argsort(a, axis=axis)\n\n\n@to_ivy_arrays_and_back\ndef argwhere(a, /, *, size=None, fill_value=None):\n if size is None and fill_value is None:\n return ivy.argwhere(a)\n\n result = ivy.matrix_transpose(\n ivy.vstack(ivy.nonzero(a, size=size, fill_value=fill_value))\n )\n num_of_dimensions = a.ndim\n\n if num_of_dimensions == 0:\n return result[:0].reshape(result.shape[0], 0)\n\n return result.reshape(result.shape[0], num_of_dimensions)\n\n\n@with_unsupported_dtypes(\n {\n \"0.4.20 and below\": (\n \"uint8\",\n \"int8\",\n \"bool\",\n )\n },\n \"jax\",\n)\n@to_ivy_arrays_and_back\ndef count_nonzero(a, axis=None, keepdims=False):\n return ivy.astype(ivy.count_nonzero(a, axis=axis, keepdims=keepdims), \"int64\")\n\n\n@to_ivy_arrays_and_back\ndef extract(condition, arr):\n if condition.dtype is not bool:\n condition = condition != 0\n return arr[condition]\n\n\n@to_ivy_arrays_and_back\ndef flatnonzero(a):\n return ivy.nonzero(ivy.reshape(a, (-1,)))\n\n\n@to_ivy_arrays_and_back\ndef lexsort(keys, /, *, axis=-1):\n return ivy.lexsort(keys, axis=axis)\n\n\n@to_ivy_arrays_and_back\ndef msort(a):\n return ivy.msort(a)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef nanargmax(a, /, *, axis=None, out=None, keepdims=False):\n if out is not None:\n raise NotImplementedError(\n \"The 'out' argument to jnp.nanargmax is not supported.\"\n )\n nan_mask = ivy.isnan(a)\n if not ivy.any(nan_mask):\n return ivy.argmax(a, axis=axis, keepdims=keepdims)\n\n a = ivy.where(nan_mask, -ivy.inf, a)\n res = ivy.argmax(a, axis=axis, keepdims=keepdims)\n return ivy.where(ivy.all(nan_mask, axis=axis, keepdims=keepdims), -1, res)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef nanargmin(a, /, *, axis=None, out=None, keepdims=None):\n if out is not None:\n raise NotImplementedError(\n \"The 'out' argument to jnp.nanargmax is not supported.\"\n )\n nan_mask = ivy.isnan(a)\n if not ivy.any(nan_mask):\n return ivy.argmin(a, axis=axis, keepdims=keepdims)\n\n a = ivy.where(nan_mask, ivy.inf, a)\n res = ivy.argmin(a, axis=axis, keepdims=keepdims)\n return ivy.where(ivy.all(nan_mask, axis=axis, keepdims=keepdims), -1, res)\n\n\n@to_ivy_arrays_and_back\ndef nonzero(a, *, size=None, fill_value=None):\n return ivy.nonzero(a, size=size, fill_value=fill_value)\n\n\n@to_ivy_arrays_and_back\ndef searchsorted(a, v, side=\"left\", sorter=None, *, method=\"scan\"):\n return ivy.searchsorted(a, v, side=side, sorter=sorter, ret_dtype=\"int32\")\n\n\n@to_ivy_arrays_and_back\ndef sort(a, axis=-1, kind=\"quicksort\", order=None):\n # todo: handle case where order is not None\n return ivy.sort(a, axis=axis)\n\n\n@to_ivy_arrays_and_back\ndef sort_complex(a):\n return ivy.sort(a)\n\n\n@to_ivy_arrays_and_back\ndef unique(\n ar,\n return_index=False,\n return_inverse=False,\n return_counts=False,\n axis=None,\n *,\n size=None,\n fill_value=None,\n):\n uniques = list(ivy.unique_all(ar, axis=axis))\n if size is not None:\n fill_value = fill_value if fill_value is not None else 1 # default fill_value 1\n pad_len = size - len(uniques[0])\n if pad_len > 0:\n # padding\n num_dims = len(uniques[0].shape) - 1\n padding = [(0, 0)] * num_dims + [(0, pad_len)]\n uniques[0] = ivy.pad(uniques[0], padding, constant_values=fill_value)\n # padding the indices and counts with zeros\n for i in range(1, len(uniques)):\n if i == 2:\n continue\n uniques[i] = ivy.pad(uniques[i], padding[-1], constant_values=0)\n else:\n for i in range(len(uniques)):\n uniques[i] = uniques[i][..., :size]\n # constructing a list of bools for indexing\n bools = [return_index, return_inverse, return_counts]\n # indexing each element whose condition is True except for the values\n uniques = [uniques[0]] + [uni for idx, uni in enumerate(uniques[1:]) if bools[idx]]\n return uniques[0] if len(uniques) == 1 else uniques\n\n\n@to_ivy_arrays_and_back\ndef where(condition, x=None, y=None, *, size=None, fill_value=0):\n if x is None and y is None:\n return nonzero(condition, size=size, fill_value=fill_value)\n if x is not None and y is not None:\n return ivy.where(condition, x, y)\n else:\n raise ValueError(\"Both x and y should be given.\")\n", "path": "ivy/functional/frontends/jax/numpy/searching_sorting.py"}]}
| 2,564 | 565 |
gh_patches_debug_1097
|
rasdani/github-patches
|
git_diff
|
openfun__richie-290
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Person plugin form list every pages, not only Person pages
## Bug Report
**Expected behavior/code**
Select box in PersonPlugin form should list only extended page with Person model.
**Actual Behavior**
Currently the select box is listing every CMS pages.
**Steps to Reproduce**
1. Edit a page;
2. Try to add a Person plugin into a placeholder which allow it;
3. Click to open the select box from opened form for added Person plugin.
**Environment**
- Richie version: 0.1.0 (from my own branch synchronized from master 200c8a3)
- Platform: Ubuntu 18.04 LTS
**Possible Solution**
Adding a filter inside plugin form machinery to retain only the extend page with Person.
</issue>
<code>
[start of src/richie/apps/persons/models.py]
1 """
2 Declare and configure the model for the person application
3 """
4 from django.db import models
5 from django.utils.translation import ugettext_lazy as _
6
7 from cms.api import Page
8 from cms.extensions import PageExtension
9 from cms.models.pluginmodel import CMSPlugin
10 from parler.models import TranslatableModel, TranslatedFields
11
12
13 class PersonTitle(TranslatableModel):
14 """
15 PersonTitle define i18ned list of people titles and there abbreviations
16 Instances of this models should only be created by CMS administrators
17 """
18
19 translations = TranslatedFields(
20 title=models.CharField(_("Title"), max_length=200),
21 abbreviation=models.CharField(_("Title abbreviation"), max_length=10),
22 )
23
24 class Meta:
25 verbose_name = _("person title")
26
27 def __str__(self):
28 """Human representation of a person title"""
29 return "{model}: {title} ({abbreviation})".format(
30 model=self._meta.verbose_name.title(),
31 title=self.title,
32 abbreviation=self.abbreviation,
33 )
34
35
36 class Person(PageExtension):
37 """
38 The person page extension represents and records people information.
39 It could be a course or news article author.
40
41 This model should be used to record structured data about the person whereas the
42 associated page object is where we record the less structured information to display on the
43 page to present the person.
44 """
45
46 first_name = models.CharField(max_length=200, verbose_name=_("First name"))
47 last_name = models.CharField(max_length=200, verbose_name=_("Last name"))
48
49 person_title = models.ForeignKey("PersonTitle", related_name="persons")
50
51 ROOT_REVERSE_ID = "persons"
52 TEMPLATE_DETAIL = "persons/cms/person_detail.html"
53
54 class Meta:
55 verbose_name = _("person")
56
57 def __str__(self):
58 """Human representation of a person"""
59 return "{model}: {title} ({full_name})".format(
60 model=self._meta.verbose_name.title(),
61 title=self.extended_object.get_title(),
62 full_name=self.get_full_name(),
63 )
64
65 def save(self, *args, **kwargs):
66 """
67 Enforce validation on each instance save
68 """
69 self.full_clean()
70 super().save(*args, **kwargs)
71
72 def get_full_name(self):
73 """
74 Return person's full name
75 """
76 return "{person_title} {first_name} {last_name}".format(
77 person_title=self.person_title.title,
78 first_name=self.first_name,
79 last_name=self.last_name,
80 )
81
82
83 class PersonPluginModel(CMSPlugin):
84 """
85 Person plugin model handles the relation from PersonPlugin
86 to their Person instance
87 """
88
89 page = models.ForeignKey(Page)
90
91 class Meta:
92 verbose_name = _("person plugin model")
93
94 def __str__(self):
95 """Human representation of a person plugin"""
96 return "{model:s}: {id:d}".format(
97 model=self._meta.verbose_name.title(), id=self.id
98 )
99
[end of src/richie/apps/persons/models.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/richie/apps/persons/models.py b/src/richie/apps/persons/models.py
--- a/src/richie/apps/persons/models.py
+++ b/src/richie/apps/persons/models.py
@@ -86,7 +86,7 @@
to their Person instance
"""
- page = models.ForeignKey(Page)
+ page = models.ForeignKey(Page, limit_choices_to={"person__isnull": False})
class Meta:
verbose_name = _("person plugin model")
|
{"golden_diff": "diff --git a/src/richie/apps/persons/models.py b/src/richie/apps/persons/models.py\n--- a/src/richie/apps/persons/models.py\n+++ b/src/richie/apps/persons/models.py\n@@ -86,7 +86,7 @@\n to their Person instance\n \"\"\"\n \n- page = models.ForeignKey(Page)\n+ page = models.ForeignKey(Page, limit_choices_to={\"person__isnull\": False})\n \n class Meta:\n verbose_name = _(\"person plugin model\")\n", "issue": "Person plugin form list every pages, not only Person pages\n## Bug Report\r\n\r\n**Expected behavior/code**\r\nSelect box in PersonPlugin form should list only extended page with Person model.\r\n\r\n**Actual Behavior**\r\nCurrently the select box is listing every CMS pages.\r\n\r\n**Steps to Reproduce**\r\n1. Edit a page;\r\n2. Try to add a Person plugin into a placeholder which allow it;\r\n3. Click to open the select box from opened form for added Person plugin.\r\n\r\n**Environment**\r\n- Richie version: 0.1.0 (from my own branch synchronized from master 200c8a3) \r\n- Platform: Ubuntu 18.04 LTS\r\n\r\n**Possible Solution**\r\nAdding a filter inside plugin form machinery to retain only the extend page with Person.\r\n\n", "before_files": [{"content": "\"\"\"\nDeclare and configure the model for the person application\n\"\"\"\nfrom django.db import models\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom cms.api import Page\nfrom cms.extensions import PageExtension\nfrom cms.models.pluginmodel import CMSPlugin\nfrom parler.models import TranslatableModel, TranslatedFields\n\n\nclass PersonTitle(TranslatableModel):\n \"\"\"\n PersonTitle define i18ned list of people titles and there abbreviations\n Instances of this models should only be created by CMS administrators\n \"\"\"\n\n translations = TranslatedFields(\n title=models.CharField(_(\"Title\"), max_length=200),\n abbreviation=models.CharField(_(\"Title abbreviation\"), max_length=10),\n )\n\n class Meta:\n verbose_name = _(\"person title\")\n\n def __str__(self):\n \"\"\"Human representation of a person title\"\"\"\n return \"{model}: {title} ({abbreviation})\".format(\n model=self._meta.verbose_name.title(),\n title=self.title,\n abbreviation=self.abbreviation,\n )\n\n\nclass Person(PageExtension):\n \"\"\"\n The person page extension represents and records people information.\n It could be a course or news article author.\n\n This model should be used to record structured data about the person whereas the\n associated page object is where we record the less structured information to display on the\n page to present the person.\n \"\"\"\n\n first_name = models.CharField(max_length=200, verbose_name=_(\"First name\"))\n last_name = models.CharField(max_length=200, verbose_name=_(\"Last name\"))\n\n person_title = models.ForeignKey(\"PersonTitle\", related_name=\"persons\")\n\n ROOT_REVERSE_ID = \"persons\"\n TEMPLATE_DETAIL = \"persons/cms/person_detail.html\"\n\n class Meta:\n verbose_name = _(\"person\")\n\n def __str__(self):\n \"\"\"Human representation of a person\"\"\"\n return \"{model}: {title} ({full_name})\".format(\n model=self._meta.verbose_name.title(),\n title=self.extended_object.get_title(),\n full_name=self.get_full_name(),\n )\n\n def save(self, *args, **kwargs):\n \"\"\"\n Enforce validation on each instance save\n \"\"\"\n self.full_clean()\n super().save(*args, **kwargs)\n\n def get_full_name(self):\n \"\"\"\n Return person's full name\n \"\"\"\n return \"{person_title} {first_name} {last_name}\".format(\n person_title=self.person_title.title,\n first_name=self.first_name,\n last_name=self.last_name,\n )\n\n\nclass PersonPluginModel(CMSPlugin):\n \"\"\"\n Person plugin model handles the relation from PersonPlugin\n to their Person instance\n \"\"\"\n\n page = models.ForeignKey(Page)\n\n class Meta:\n verbose_name = _(\"person plugin model\")\n\n def __str__(self):\n \"\"\"Human representation of a person plugin\"\"\"\n return \"{model:s}: {id:d}\".format(\n model=self._meta.verbose_name.title(), id=self.id\n )\n", "path": "src/richie/apps/persons/models.py"}]}
| 1,518 | 110 |
gh_patches_debug_2871
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-2386
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
E0002 parsing I3013 on AWS::RDS::DBInstance if Engine is a Ref
### CloudFormation Lint Version
0.65.0
### What operating system are you using?
Ubuntu 22.04
### Describe the bug
A cfn-lint exception is raised when parsing I3013 rule.
The trigger seems to be the presence of a reference as a value of the "Engine" resource parameter.


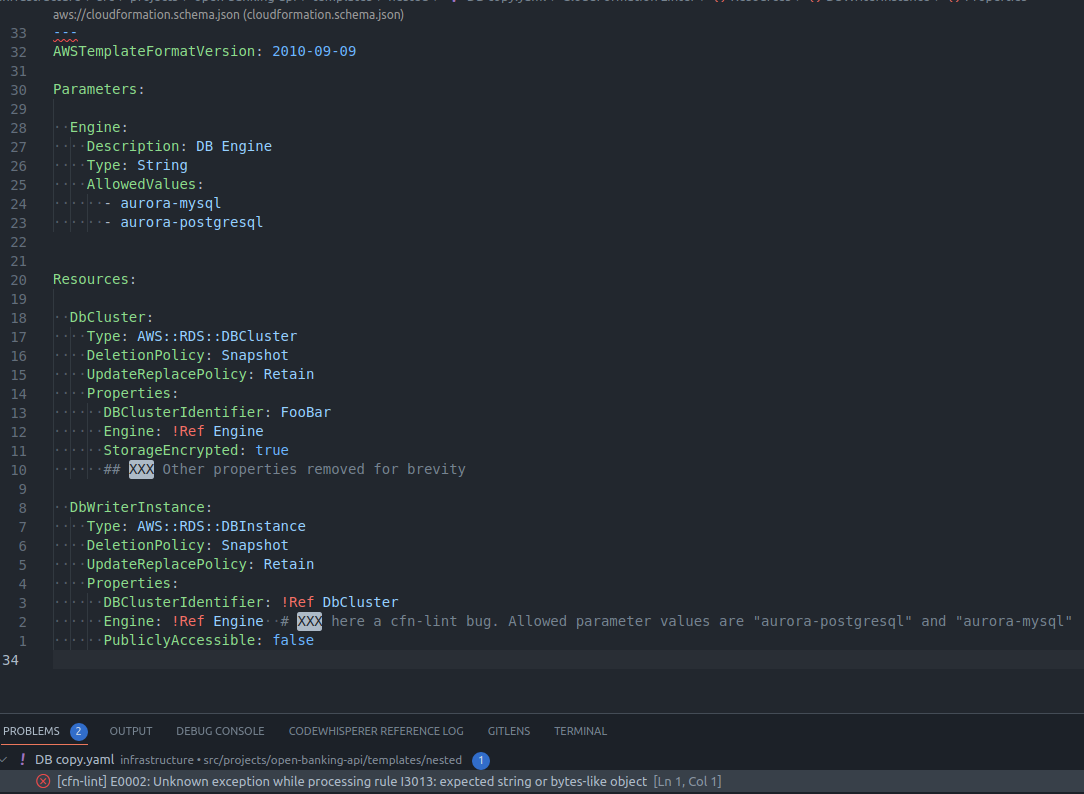
### Expected behavior
No error should be present is `Engine: !Ref Something` is used.
### Reproduction template
```yaml
---
AWSTemplateFormatVersion: 2010-09-09
Parameters:
Engine:
Description: DB Engine
Type: String
AllowedValues:
- aurora-mysql
- aurora-postgresql
Resources:
DbCluster:
Type: AWS::RDS::DBCluster
DeletionPolicy: Snapshot
UpdateReplacePolicy: Retain
Properties:
DBClusterIdentifier: FooBar
Engine: !Ref Engine
StorageEncrypted: true
## XXX Other properties removed for brevity
DbWriterInstance:
Type: AWS::RDS::DBInstance
DeletionPolicy: Snapshot
UpdateReplacePolicy: Retain
Properties:
DBClusterIdentifier: !Ref DbCluster
Engine: !Ref Engine # XXX here a cfn-lint bug. Allowed parameter values are "aurora-postgresql" and "aurora-mysql"
PubliclyAccessible: false
```
</issue>
<code>
[start of src/cfnlint/rules/resources/RetentionPeriodOnResourceTypesWithAutoExpiringContent.py]
1 """
2 Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
3 SPDX-License-Identifier: MIT-0
4 """
5 import re
6 from cfnlint.rules import CloudFormationLintRule
7 from cfnlint.rules import RuleMatch
8
9
10 class RetentionPeriodOnResourceTypesWithAutoExpiringContent(CloudFormationLintRule):
11 """Check for RetentionPeriod """
12 id = 'I3013'
13 shortdesc = 'Check resources with auto expiring content have explicit retention period'
14 description = 'The behaviour for data retention is different across AWS Services.'\
15 'If no retention period is specified the default for some services is to delete the data after a period of time.' \
16 'This check requires you to explicitly set the retention period for those resources to avoid unexpected data losses'
17 source_url = 'https://github.com/aws-cloudformation/cfn-python-lint'
18 tags = ['resources', 'retentionperiod']
19
20 def _check_ref(self, value, parameters, resources, path): # pylint: disable=W0613
21 print(value)
22
23 def match(self, cfn):
24 """Check for RetentionPeriod"""
25 matches = []
26
27 retention_attributes_by_resource_type = {
28 'AWS::Kinesis::Stream': [
29 {
30 'Attribute': 'RetentionPeriodHours',
31 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-kinesis-stream.html#cfn-kinesis-stream-retentionperiodhours'
32 }
33 ],
34 'AWS::SQS::Queue': [
35 {
36 'Attribute': 'MessageRetentionPeriod',
37 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-sqs-queues.html#aws-sqs-queue-msgretentionperiod'
38 }
39 ],
40 'AWS::DocDB::DBCluster': [
41 {
42 'Attribute': 'BackupRetentionPeriod',
43 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-docdb-dbcluster.html#cfn-docdb-dbcluster-backupretentionperiod'
44 }
45 ],
46 'AWS::Synthetics::Canary': [
47 {
48 'Attribute': 'SuccessRetentionPeriod',
49 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-synthetics-canary.html#cfn-synthetics-canary-successretentionperiod'
50 },
51 {
52 'Attribute': 'FailureRetentionPeriod',
53 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-synthetics-canary.html#cfn-synthetics-canary-failureretentionperiod'
54 }
55 ],
56 'AWS::Redshift::Cluster': [
57 {
58 'Attribute': 'AutomatedSnapshotRetentionPeriod',
59 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-redshift-cluster.html#cfn-redshift-cluster-automatedsnapshotretentionperiod'
60 }
61 ],
62 'AWS::RDS::DBInstance': [
63 {
64 'Attribute': 'BackupRetentionPeriod',
65 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-rds-database-instance.html#cfn-rds-dbinstance-backupretentionperiod',
66 'CheckAttribute': 'Engine',
67 'CheckAttributeRegex': re.compile('^((?!aurora).)*$'),
68 }
69 ],
70 'AWS::RDS::DBCluster': [
71 {
72 'Attribute': 'BackupRetentionPeriod',
73 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-rds-dbcluster.html#cfn-rds-dbcluster-backuprententionperiod'
74 }
75 ]
76 }
77
78 resources = cfn.get_resources()
79 for r_name, r_values in resources.items():
80 if r_values.get('Type') in retention_attributes_by_resource_type:
81 for attr_def in retention_attributes_by_resource_type[r_values.get('Type')]:
82 property_sets = r_values.get_safe('Properties')
83 for property_set, path in property_sets:
84 error_path = ['Resources', r_name] + path
85 if not property_set:
86 message = f'The default retention period will delete the data after a pre-defined time. Set an explicit values to avoid data loss on resource : {"/".join(str(x) for x in error_path)}'
87 matches.append(RuleMatch(error_path, message))
88 else:
89 value = property_set.get(attr_def.get('Attribute'))
90 if not value:
91 message = f'The default retention period will delete the data after a pre-defined time. Set an explicit values to avoid data loss on resource : {"/".join(str(x) for x in error_path)}'
92 if attr_def.get('CheckAttribute'):
93 if self._validate_property(property_set.get(attr_def.get('CheckAttribute')), attr_def.get('CheckAttributeRegex')):
94 matches.append(RuleMatch(error_path, message))
95 else:
96 matches.append(RuleMatch(error_path, message))
97 if isinstance(value, dict):
98 # pylint: disable=protected-access
99 refs = cfn._search_deep_keys(
100 'Ref', value, error_path + [attr_def.get('Attribute')])
101 for ref in refs:
102 if ref[-1] == 'AWS::NoValue':
103 message = f'The default retention period will delete the data after a pre-defined time. Set an explicit values to avoid data loss on resource : {"/".join(str(x) for x in ref[0:-1])}'
104 matches.append(RuleMatch(ref[0:-1], message))
105
106 return matches
107
108 def _validate_property(self, value, regex) -> bool:
109 if regex.match(value):
110 return True
111 return False
112
[end of src/cfnlint/rules/resources/RetentionPeriodOnResourceTypesWithAutoExpiringContent.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cfnlint/rules/resources/RetentionPeriodOnResourceTypesWithAutoExpiringContent.py b/src/cfnlint/rules/resources/RetentionPeriodOnResourceTypesWithAutoExpiringContent.py
--- a/src/cfnlint/rules/resources/RetentionPeriodOnResourceTypesWithAutoExpiringContent.py
+++ b/src/cfnlint/rules/resources/RetentionPeriodOnResourceTypesWithAutoExpiringContent.py
@@ -106,6 +106,8 @@
return matches
def _validate_property(self, value, regex) -> bool:
- if regex.match(value):
- return True
- return False
+ if isinstance(value, str):
+ if regex.match(value):
+ return True
+ return False
+ return True
|
{"golden_diff": "diff --git a/src/cfnlint/rules/resources/RetentionPeriodOnResourceTypesWithAutoExpiringContent.py b/src/cfnlint/rules/resources/RetentionPeriodOnResourceTypesWithAutoExpiringContent.py\n--- a/src/cfnlint/rules/resources/RetentionPeriodOnResourceTypesWithAutoExpiringContent.py\n+++ b/src/cfnlint/rules/resources/RetentionPeriodOnResourceTypesWithAutoExpiringContent.py\n@@ -106,6 +106,8 @@\n return matches\n \n def _validate_property(self, value, regex) -> bool:\n- if regex.match(value):\n- return True\n- return False\n+ if isinstance(value, str):\n+ if regex.match(value):\n+ return True\n+ return False\n+ return True\n", "issue": "E0002 parsing I3013 on AWS::RDS::DBInstance if Engine is a Ref\n### CloudFormation Lint Version\n\n0.65.0\n\n### What operating system are you using?\n\nUbuntu 22.04\n\n### Describe the bug\n\nA cfn-lint exception is raised when parsing I3013 rule.\r\n\r\nThe trigger seems to be the presence of a reference as a value of the \"Engine\" resource parameter.\r\n\r\n\r\n\r\n\r\n\r\n\n\n### Expected behavior\n\nNo error should be present is `Engine: !Ref Something` is used.\n\n### Reproduction template\n\n```yaml\r\n---\r\nAWSTemplateFormatVersion: 2010-09-09\r\n\r\nParameters:\r\n\r\n Engine:\r\n Description: DB Engine\r\n Type: String\r\n AllowedValues:\r\n - aurora-mysql\r\n - aurora-postgresql\r\n\r\n\r\nResources:\r\n\r\n DbCluster:\r\n Type: AWS::RDS::DBCluster\r\n DeletionPolicy: Snapshot\r\n UpdateReplacePolicy: Retain\r\n Properties:\r\n DBClusterIdentifier: FooBar\r\n Engine: !Ref Engine\r\n StorageEncrypted: true\r\n ## XXX Other properties removed for brevity\r\n\r\n DbWriterInstance:\r\n Type: AWS::RDS::DBInstance\r\n DeletionPolicy: Snapshot\r\n UpdateReplacePolicy: Retain\r\n Properties:\r\n DBClusterIdentifier: !Ref DbCluster\r\n Engine: !Ref Engine # XXX here a cfn-lint bug. Allowed parameter values are \"aurora-postgresql\" and \"aurora-mysql\"\r\n PubliclyAccessible: false\r\n```\n", "before_files": [{"content": "\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport re\nfrom cfnlint.rules import CloudFormationLintRule\nfrom cfnlint.rules import RuleMatch\n\n\nclass RetentionPeriodOnResourceTypesWithAutoExpiringContent(CloudFormationLintRule):\n \"\"\"Check for RetentionPeriod \"\"\"\n id = 'I3013'\n shortdesc = 'Check resources with auto expiring content have explicit retention period'\n description = 'The behaviour for data retention is different across AWS Services.'\\\n 'If no retention period is specified the default for some services is to delete the data after a period of time.' \\\n 'This check requires you to explicitly set the retention period for those resources to avoid unexpected data losses'\n source_url = 'https://github.com/aws-cloudformation/cfn-python-lint'\n tags = ['resources', 'retentionperiod']\n\n def _check_ref(self, value, parameters, resources, path): # pylint: disable=W0613\n print(value)\n\n def match(self, cfn):\n \"\"\"Check for RetentionPeriod\"\"\"\n matches = []\n\n retention_attributes_by_resource_type = {\n 'AWS::Kinesis::Stream': [\n {\n 'Attribute': 'RetentionPeriodHours',\n 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-kinesis-stream.html#cfn-kinesis-stream-retentionperiodhours'\n }\n ],\n 'AWS::SQS::Queue': [\n {\n 'Attribute': 'MessageRetentionPeriod',\n 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-sqs-queues.html#aws-sqs-queue-msgretentionperiod'\n }\n ],\n 'AWS::DocDB::DBCluster': [\n {\n 'Attribute': 'BackupRetentionPeriod',\n 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-docdb-dbcluster.html#cfn-docdb-dbcluster-backupretentionperiod'\n }\n ],\n 'AWS::Synthetics::Canary': [\n {\n 'Attribute': 'SuccessRetentionPeriod',\n 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-synthetics-canary.html#cfn-synthetics-canary-successretentionperiod'\n },\n {\n 'Attribute': 'FailureRetentionPeriod',\n 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-synthetics-canary.html#cfn-synthetics-canary-failureretentionperiod'\n }\n ],\n 'AWS::Redshift::Cluster': [\n {\n 'Attribute': 'AutomatedSnapshotRetentionPeriod',\n 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-redshift-cluster.html#cfn-redshift-cluster-automatedsnapshotretentionperiod'\n }\n ],\n 'AWS::RDS::DBInstance': [\n {\n 'Attribute': 'BackupRetentionPeriod',\n 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-rds-database-instance.html#cfn-rds-dbinstance-backupretentionperiod',\n 'CheckAttribute': 'Engine',\n 'CheckAttributeRegex': re.compile('^((?!aurora).)*$'),\n }\n ],\n 'AWS::RDS::DBCluster': [\n {\n 'Attribute': 'BackupRetentionPeriod',\n 'SourceUrl': 'http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-rds-dbcluster.html#cfn-rds-dbcluster-backuprententionperiod'\n }\n ]\n }\n\n resources = cfn.get_resources()\n for r_name, r_values in resources.items():\n if r_values.get('Type') in retention_attributes_by_resource_type:\n for attr_def in retention_attributes_by_resource_type[r_values.get('Type')]:\n property_sets = r_values.get_safe('Properties')\n for property_set, path in property_sets:\n error_path = ['Resources', r_name] + path\n if not property_set:\n message = f'The default retention period will delete the data after a pre-defined time. Set an explicit values to avoid data loss on resource : {\"/\".join(str(x) for x in error_path)}'\n matches.append(RuleMatch(error_path, message))\n else:\n value = property_set.get(attr_def.get('Attribute'))\n if not value:\n message = f'The default retention period will delete the data after a pre-defined time. Set an explicit values to avoid data loss on resource : {\"/\".join(str(x) for x in error_path)}'\n if attr_def.get('CheckAttribute'):\n if self._validate_property(property_set.get(attr_def.get('CheckAttribute')), attr_def.get('CheckAttributeRegex')):\n matches.append(RuleMatch(error_path, message))\n else:\n matches.append(RuleMatch(error_path, message))\n if isinstance(value, dict):\n # pylint: disable=protected-access\n refs = cfn._search_deep_keys(\n 'Ref', value, error_path + [attr_def.get('Attribute')])\n for ref in refs:\n if ref[-1] == 'AWS::NoValue':\n message = f'The default retention period will delete the data after a pre-defined time. Set an explicit values to avoid data loss on resource : {\"/\".join(str(x) for x in ref[0:-1])}'\n matches.append(RuleMatch(ref[0:-1], message))\n\n return matches\n\n def _validate_property(self, value, regex) -> bool:\n if regex.match(value):\n return True\n return False\n", "path": "src/cfnlint/rules/resources/RetentionPeriodOnResourceTypesWithAutoExpiringContent.py"}]}
| 2,585 | 163 |
gh_patches_debug_22069
|
rasdani/github-patches
|
git_diff
|
statsmodels__statsmodels-8504
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Gaussian Copula: Add parameter allow_singular
The Gaussian Copula module is using scipy.stats package for the multivariate normal distribution. There is a parameter allow_singular=False which allows the covariance matrix to not have full rank. Unfortunately this parameter is not passed to the Copula interface.
It could be added here:
https://github.com/statsmodels/statsmodels/blob/55aff1e2268f56cc26b45ddcc1f44e5f924f8d05/statsmodels/distributions/copula/elliptical.py#L153
I currently wrote an inherited class, and singular matrixes for the copula seem to work fine.
</issue>
<code>
[start of statsmodels/distributions/copula/elliptical.py]
1 # -*- coding: utf-8 -*-
2 """
3 Created on Fri Jan 29 19:19:45 2021
4
5 Author: Josef Perktold
6 Author: Pamphile Roy
7 License: BSD-3
8
9 """
10 import numpy as np
11 from scipy import stats
12 # scipy compat:
13 from statsmodels.compat.scipy import multivariate_t
14
15 from statsmodels.distributions.copula.copulas import Copula
16
17
18 class EllipticalCopula(Copula):
19 """Base class for elliptical copula
20
21 This class requires subclassing and currently does not have generic
22 methods based on an elliptical generator.
23
24 Notes
25 -----
26 Elliptical copulas require that copula parameters are set when the
27 instance is created. Those parameters currently cannot be provided in the
28 call to methods. (This will most likely change in future versions.)
29 If non-empty ``args`` are provided in methods, then a ValueError is raised.
30 The ``args`` keyword is provided for a consistent interface across
31 copulas.
32
33 """
34 def _handle_args(self, args):
35 if args != () and args is not None:
36 msg = ("Methods in elliptical copulas use copula parameters in"
37 " attributes. `arg` in the method is ignored")
38 raise ValueError(msg)
39 else:
40 return args
41
42 def rvs(self, nobs=1, args=(), random_state=None):
43 self._handle_args(args)
44 x = self.distr_mv.rvs(size=nobs, random_state=random_state)
45 return self.distr_uv.cdf(x)
46
47 def pdf(self, u, args=()):
48 self._handle_args(args)
49 ppf = self.distr_uv.ppf(u)
50 mv_pdf_ppf = self.distr_mv.pdf(ppf)
51
52 return mv_pdf_ppf / np.prod(self.distr_uv.pdf(ppf), axis=-1)
53
54 def cdf(self, u, args=()):
55 self._handle_args(args)
56 ppf = self.distr_uv.ppf(u)
57 return self.distr_mv.cdf(ppf)
58
59 def tau(self, corr=None):
60 """Bivariate kendall's tau based on correlation coefficient.
61
62 Parameters
63 ----------
64 corr : None or float
65 Pearson correlation. If corr is None, then the correlation will be
66 taken from the copula attribute.
67
68 Returns
69 -------
70 Kendall's tau that corresponds to pearson correlation in the
71 elliptical copula.
72 """
73 if corr is None:
74 corr = self.corr
75 if corr.shape == (2, 2):
76 corr = corr[0, 1]
77 rho = 2 * np.arcsin(corr) / np.pi
78 return rho
79
80 def corr_from_tau(self, tau):
81 """Pearson correlation from kendall's tau.
82
83 Parameters
84 ----------
85 tau : array_like
86 Kendall's tau correlation coefficient.
87
88 Returns
89 -------
90 Pearson correlation coefficient for given tau in elliptical
91 copula. This can be used as parameter for an elliptical copula.
92 """
93 corr = np.sin(tau * np.pi / 2)
94 return corr
95
96
97 class GaussianCopula(EllipticalCopula):
98 r"""Gaussian copula.
99
100 It is constructed from a multivariate normal distribution over
101 :math:`\mathbb{R}^d` by using the probability integral transform.
102
103 For a given correlation matrix :math:`R \in[-1, 1]^{d \times d}`,
104 the Gaussian copula with parameter matrix :math:`R` can be written
105 as:
106
107 .. math::
108
109 C_R^{\text{Gauss}}(u) = \Phi_R\left(\Phi^{-1}(u_1),\dots,
110 \Phi^{-1}(u_d) \right),
111
112 where :math:`\Phi^{-1}` is the inverse cumulative distribution function
113 of a standard normal and :math:`\Phi_R` is the joint cumulative
114 distribution function of a multivariate normal distribution with mean
115 vector zero and covariance matrix equal to the correlation
116 matrix :math:`R`.
117
118 Parameters
119 ----------
120 corr : scalar or array_like
121 Correlation or scatter matrix for the elliptical copula. In the
122 bivariate case, ``corr` can be a scalar and is then considered as
123 the correlation coefficient. If ``corr`` is None, then the scatter
124 matrix is the identity matrix.
125 k_dim : int
126 Dimension, number of components in the multivariate random variable.
127
128 Notes
129 -----
130 Elliptical copulas require that copula parameters are set when the
131 instance is created. Those parameters currently cannot be provided in the
132 call to methods. (This will most likely change in future versions.)
133 If non-empty ``args`` are provided in methods, then a ValueError is raised.
134 The ``args`` keyword is provided for a consistent interface across
135 copulas.
136
137 References
138 ----------
139 .. [1] Joe, Harry, 2014, Dependence modeling with copulas. CRC press.
140 p. 163
141
142 """
143
144 def __init__(self, corr=None, k_dim=2):
145 super().__init__(k_dim=k_dim)
146 if corr is None:
147 corr = np.eye(k_dim)
148 elif k_dim == 2 and np.size(corr) == 1:
149 corr = np.array([[1., corr], [corr, 1.]])
150
151 self.corr = np.asarray(corr)
152 self.distr_uv = stats.norm
153 self.distr_mv = stats.multivariate_normal(cov=corr)
154
155 def dependence_tail(self, corr=None):
156 """
157 Bivariate tail dependence parameter.
158
159 Joe (2014) p. 182
160
161 Parameters
162 ----------
163 corr : any
164 Tail dependence for Gaussian copulas is always zero.
165 Argument will be ignored
166
167 Returns
168 -------
169 Lower and upper tail dependence coefficients of the copula with given
170 Pearson correlation coefficient.
171 """
172
173 return 0, 0
174
175 def _arg_from_tau(self, tau):
176 # for generic compat
177 return self.corr_from_tau(tau)
178
179
180 class StudentTCopula(EllipticalCopula):
181 """Student t copula.
182
183 Parameters
184 ----------
185 corr : scalar or array_like
186 Correlation or scatter matrix for the elliptical copula. In the
187 bivariate case, ``corr` can be a scalar and is then considered as
188 the correlation coefficient. If ``corr`` is None, then the scatter
189 matrix is the identity matrix.
190 df : float (optional)
191 Degrees of freedom of the multivariate t distribution.
192 k_dim : int
193 Dimension, number of components in the multivariate random variable.
194
195 Notes
196 -----
197 Elliptical copulas require that copula parameters are set when the
198 instance is created. Those parameters currently cannot be provided in the
199 call to methods. (This will most likely change in future versions.)
200 If non-empty ``args`` are provided in methods, then a ValueError is raised.
201 The ``args`` keyword is provided for a consistent interface across
202 copulas.
203
204 References
205 ----------
206 .. [1] Joe, Harry, 2014, Dependence modeling with copulas. CRC press.
207 p. 181
208 """
209
210 def __init__(self, corr=None, df=None, k_dim=2):
211 super().__init__(k_dim=k_dim)
212 if corr is None:
213 corr = np.eye(k_dim)
214 elif k_dim == 2 and np.size(corr) == 1:
215 corr = np.array([[1., corr], [corr, 1.]])
216
217 self.df = df
218 self.corr = np.asarray(corr)
219 # both uv and mv are frozen distributions
220 self.distr_uv = stats.t(df=df)
221 self.distr_mv = multivariate_t(shape=corr, df=df)
222
223 def cdf(self, u, args=()):
224 raise NotImplementedError("CDF not available in closed form.")
225 # ppf = self.distr_uv.ppf(u)
226 # mvt = MVT([0, 0], self.corr, self.df)
227 # return mvt.cdf(ppf)
228
229 def spearmans_rho(self, corr=None):
230 """
231 Bivariate Spearman's rho based on correlation coefficient.
232
233 Joe (2014) p. 182
234
235 Parameters
236 ----------
237 corr : None or float
238 Pearson correlation. If corr is None, then the correlation will be
239 taken from the copula attribute.
240
241 Returns
242 -------
243 Spearman's rho that corresponds to pearson correlation in the
244 elliptical copula.
245 """
246 if corr is None:
247 corr = self.corr
248 if corr.shape == (2, 2):
249 corr = corr[0, 1]
250
251 tau = 6 * np.arcsin(corr / 2) / np.pi
252 return tau
253
254 def dependence_tail(self, corr=None):
255 """
256 Bivariate tail dependence parameter.
257
258 Joe (2014) p. 182
259
260 Parameters
261 ----------
262 corr : None or float
263 Pearson correlation. If corr is None, then the correlation will be
264 taken from the copula attribute.
265
266 Returns
267 -------
268 Lower and upper tail dependence coefficients of the copula with given
269 Pearson correlation coefficient.
270 """
271 if corr is None:
272 corr = self.corr
273 if corr.shape == (2, 2):
274 corr = corr[0, 1]
275
276 df = self.df
277 t = - np.sqrt((df + 1) * (1 - corr) / 1 + corr)
278 # Note self.distr_uv is frozen, df cannot change, use stats.t instead
279 lam = 2 * stats.t.cdf(t, df + 1)
280 return lam, lam
281
282 def _arg_from_tau(self, tau):
283 # for generic compat
284 # this does not provide an estimate of df
285 return self.corr_from_tau(tau)
286
[end of statsmodels/distributions/copula/elliptical.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/statsmodels/distributions/copula/elliptical.py b/statsmodels/distributions/copula/elliptical.py
--- a/statsmodels/distributions/copula/elliptical.py
+++ b/statsmodels/distributions/copula/elliptical.py
@@ -124,6 +124,8 @@
matrix is the identity matrix.
k_dim : int
Dimension, number of components in the multivariate random variable.
+ allow_singular : bool
+ Allow singular correlation matrix
Notes
-----
@@ -141,7 +143,7 @@
"""
- def __init__(self, corr=None, k_dim=2):
+ def __init__(self, corr=None, k_dim=2, allow_singular=False):
super().__init__(k_dim=k_dim)
if corr is None:
corr = np.eye(k_dim)
@@ -150,7 +152,8 @@
self.corr = np.asarray(corr)
self.distr_uv = stats.norm
- self.distr_mv = stats.multivariate_normal(cov=corr)
+ self.distr_mv = stats.multivariate_normal(
+ cov=corr, allow_singular=allow_singular)
def dependence_tail(self, corr=None):
"""
|
{"golden_diff": "diff --git a/statsmodels/distributions/copula/elliptical.py b/statsmodels/distributions/copula/elliptical.py\n--- a/statsmodels/distributions/copula/elliptical.py\n+++ b/statsmodels/distributions/copula/elliptical.py\n@@ -124,6 +124,8 @@\n matrix is the identity matrix.\n k_dim : int\n Dimension, number of components in the multivariate random variable.\n+ allow_singular : bool\n+ Allow singular correlation matrix\n \n Notes\n -----\n@@ -141,7 +143,7 @@\n \n \"\"\"\n \n- def __init__(self, corr=None, k_dim=2):\n+ def __init__(self, corr=None, k_dim=2, allow_singular=False):\n super().__init__(k_dim=k_dim)\n if corr is None:\n corr = np.eye(k_dim)\n@@ -150,7 +152,8 @@\n \n self.corr = np.asarray(corr)\n self.distr_uv = stats.norm\n- self.distr_mv = stats.multivariate_normal(cov=corr)\n+ self.distr_mv = stats.multivariate_normal(\n+ cov=corr, allow_singular=allow_singular)\n \n def dependence_tail(self, corr=None):\n \"\"\"\n", "issue": "Gaussian Copula: Add parameter allow_singular\nThe Gaussian Copula module is using scipy.stats package for the multivariate normal distribution. There is a parameter allow_singular=False which allows the covariance matrix to not have full rank. Unfortunately this parameter is not passed to the Copula interface.\r\n\r\nIt could be added here:\r\nhttps://github.com/statsmodels/statsmodels/blob/55aff1e2268f56cc26b45ddcc1f44e5f924f8d05/statsmodels/distributions/copula/elliptical.py#L153\r\n\r\nI currently wrote an inherited class, and singular matrixes for the copula seem to work fine.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Jan 29 19:19:45 2021\n\nAuthor: Josef Perktold\nAuthor: Pamphile Roy\nLicense: BSD-3\n\n\"\"\"\nimport numpy as np\nfrom scipy import stats\n# scipy compat:\nfrom statsmodels.compat.scipy import multivariate_t\n\nfrom statsmodels.distributions.copula.copulas import Copula\n\n\nclass EllipticalCopula(Copula):\n \"\"\"Base class for elliptical copula\n\n This class requires subclassing and currently does not have generic\n methods based on an elliptical generator.\n\n Notes\n -----\n Elliptical copulas require that copula parameters are set when the\n instance is created. Those parameters currently cannot be provided in the\n call to methods. (This will most likely change in future versions.)\n If non-empty ``args`` are provided in methods, then a ValueError is raised.\n The ``args`` keyword is provided for a consistent interface across\n copulas.\n\n \"\"\"\n def _handle_args(self, args):\n if args != () and args is not None:\n msg = (\"Methods in elliptical copulas use copula parameters in\"\n \" attributes. `arg` in the method is ignored\")\n raise ValueError(msg)\n else:\n return args\n\n def rvs(self, nobs=1, args=(), random_state=None):\n self._handle_args(args)\n x = self.distr_mv.rvs(size=nobs, random_state=random_state)\n return self.distr_uv.cdf(x)\n\n def pdf(self, u, args=()):\n self._handle_args(args)\n ppf = self.distr_uv.ppf(u)\n mv_pdf_ppf = self.distr_mv.pdf(ppf)\n\n return mv_pdf_ppf / np.prod(self.distr_uv.pdf(ppf), axis=-1)\n\n def cdf(self, u, args=()):\n self._handle_args(args)\n ppf = self.distr_uv.ppf(u)\n return self.distr_mv.cdf(ppf)\n\n def tau(self, corr=None):\n \"\"\"Bivariate kendall's tau based on correlation coefficient.\n\n Parameters\n ----------\n corr : None or float\n Pearson correlation. If corr is None, then the correlation will be\n taken from the copula attribute.\n\n Returns\n -------\n Kendall's tau that corresponds to pearson correlation in the\n elliptical copula.\n \"\"\"\n if corr is None:\n corr = self.corr\n if corr.shape == (2, 2):\n corr = corr[0, 1]\n rho = 2 * np.arcsin(corr) / np.pi\n return rho\n\n def corr_from_tau(self, tau):\n \"\"\"Pearson correlation from kendall's tau.\n\n Parameters\n ----------\n tau : array_like\n Kendall's tau correlation coefficient.\n\n Returns\n -------\n Pearson correlation coefficient for given tau in elliptical\n copula. This can be used as parameter for an elliptical copula.\n \"\"\"\n corr = np.sin(tau * np.pi / 2)\n return corr\n\n\nclass GaussianCopula(EllipticalCopula):\n r\"\"\"Gaussian copula.\n\n It is constructed from a multivariate normal distribution over\n :math:`\\mathbb{R}^d` by using the probability integral transform.\n\n For a given correlation matrix :math:`R \\in[-1, 1]^{d \\times d}`,\n the Gaussian copula with parameter matrix :math:`R` can be written\n as:\n\n .. math::\n\n C_R^{\\text{Gauss}}(u) = \\Phi_R\\left(\\Phi^{-1}(u_1),\\dots,\n \\Phi^{-1}(u_d) \\right),\n\n where :math:`\\Phi^{-1}` is the inverse cumulative distribution function\n of a standard normal and :math:`\\Phi_R` is the joint cumulative\n distribution function of a multivariate normal distribution with mean\n vector zero and covariance matrix equal to the correlation\n matrix :math:`R`.\n\n Parameters\n ----------\n corr : scalar or array_like\n Correlation or scatter matrix for the elliptical copula. In the\n bivariate case, ``corr` can be a scalar and is then considered as\n the correlation coefficient. If ``corr`` is None, then the scatter\n matrix is the identity matrix.\n k_dim : int\n Dimension, number of components in the multivariate random variable.\n\n Notes\n -----\n Elliptical copulas require that copula parameters are set when the\n instance is created. Those parameters currently cannot be provided in the\n call to methods. (This will most likely change in future versions.)\n If non-empty ``args`` are provided in methods, then a ValueError is raised.\n The ``args`` keyword is provided for a consistent interface across\n copulas.\n\n References\n ----------\n .. [1] Joe, Harry, 2014, Dependence modeling with copulas. CRC press.\n p. 163\n\n \"\"\"\n\n def __init__(self, corr=None, k_dim=2):\n super().__init__(k_dim=k_dim)\n if corr is None:\n corr = np.eye(k_dim)\n elif k_dim == 2 and np.size(corr) == 1:\n corr = np.array([[1., corr], [corr, 1.]])\n\n self.corr = np.asarray(corr)\n self.distr_uv = stats.norm\n self.distr_mv = stats.multivariate_normal(cov=corr)\n\n def dependence_tail(self, corr=None):\n \"\"\"\n Bivariate tail dependence parameter.\n\n Joe (2014) p. 182\n\n Parameters\n ----------\n corr : any\n Tail dependence for Gaussian copulas is always zero.\n Argument will be ignored\n\n Returns\n -------\n Lower and upper tail dependence coefficients of the copula with given\n Pearson correlation coefficient.\n \"\"\"\n\n return 0, 0\n\n def _arg_from_tau(self, tau):\n # for generic compat\n return self.corr_from_tau(tau)\n\n\nclass StudentTCopula(EllipticalCopula):\n \"\"\"Student t copula.\n\n Parameters\n ----------\n corr : scalar or array_like\n Correlation or scatter matrix for the elliptical copula. In the\n bivariate case, ``corr` can be a scalar and is then considered as\n the correlation coefficient. If ``corr`` is None, then the scatter\n matrix is the identity matrix.\n df : float (optional)\n Degrees of freedom of the multivariate t distribution.\n k_dim : int\n Dimension, number of components in the multivariate random variable.\n\n Notes\n -----\n Elliptical copulas require that copula parameters are set when the\n instance is created. Those parameters currently cannot be provided in the\n call to methods. (This will most likely change in future versions.)\n If non-empty ``args`` are provided in methods, then a ValueError is raised.\n The ``args`` keyword is provided for a consistent interface across\n copulas.\n\n References\n ----------\n .. [1] Joe, Harry, 2014, Dependence modeling with copulas. CRC press.\n p. 181\n \"\"\"\n\n def __init__(self, corr=None, df=None, k_dim=2):\n super().__init__(k_dim=k_dim)\n if corr is None:\n corr = np.eye(k_dim)\n elif k_dim == 2 and np.size(corr) == 1:\n corr = np.array([[1., corr], [corr, 1.]])\n\n self.df = df\n self.corr = np.asarray(corr)\n # both uv and mv are frozen distributions\n self.distr_uv = stats.t(df=df)\n self.distr_mv = multivariate_t(shape=corr, df=df)\n\n def cdf(self, u, args=()):\n raise NotImplementedError(\"CDF not available in closed form.\")\n # ppf = self.distr_uv.ppf(u)\n # mvt = MVT([0, 0], self.corr, self.df)\n # return mvt.cdf(ppf)\n\n def spearmans_rho(self, corr=None):\n \"\"\"\n Bivariate Spearman's rho based on correlation coefficient.\n\n Joe (2014) p. 182\n\n Parameters\n ----------\n corr : None or float\n Pearson correlation. If corr is None, then the correlation will be\n taken from the copula attribute.\n\n Returns\n -------\n Spearman's rho that corresponds to pearson correlation in the\n elliptical copula.\n \"\"\"\n if corr is None:\n corr = self.corr\n if corr.shape == (2, 2):\n corr = corr[0, 1]\n\n tau = 6 * np.arcsin(corr / 2) / np.pi\n return tau\n\n def dependence_tail(self, corr=None):\n \"\"\"\n Bivariate tail dependence parameter.\n\n Joe (2014) p. 182\n\n Parameters\n ----------\n corr : None or float\n Pearson correlation. If corr is None, then the correlation will be\n taken from the copula attribute.\n\n Returns\n -------\n Lower and upper tail dependence coefficients of the copula with given\n Pearson correlation coefficient.\n \"\"\"\n if corr is None:\n corr = self.corr\n if corr.shape == (2, 2):\n corr = corr[0, 1]\n\n df = self.df\n t = - np.sqrt((df + 1) * (1 - corr) / 1 + corr)\n # Note self.distr_uv is frozen, df cannot change, use stats.t instead\n lam = 2 * stats.t.cdf(t, df + 1)\n return lam, lam\n\n def _arg_from_tau(self, tau):\n # for generic compat\n # this does not provide an estimate of df\n return self.corr_from_tau(tau)\n", "path": "statsmodels/distributions/copula/elliptical.py"}]}
| 3,659 | 279 |
gh_patches_debug_9198
|
rasdani/github-patches
|
git_diff
|
sotetsuk__pgx-792
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Docs] Add PyPI description
Currently, it's empty.
</issue>
<code>
[start of setup.py]
1 from setuptools import find_packages, setup
2
3 setup(
4 name="pgx",
5 version="0.4.0",
6 long_description_content_type="text/markdown",
7 description="",
8 url="",
9 author="Sotetsu KOYAMADA",
10 author_email="[email protected]",
11 keywords="",
12 packages=find_packages(),
13 package_data={"": ["LICENSE", "*.svg"]},
14 include_package_data=True,
15 install_requires=[
16 "jax>=0.3.25", # JAX version on Colab (TPU)
17 "chex>=0.1.6",
18 "svgwrite",
19 "msgpack",
20 "typing_extensions"
21 ],
22 classifiers=[
23 "Programming Language :: Python :: 3.8",
24 "Programming Language :: Python :: 3.9",
25 "Programming Language :: Python :: 3.10",
26 ],
27 )
28
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -1,10 +1,14 @@
from setuptools import find_packages, setup
+from pathlib import Path
+
+long_description = (Path(__file__).parent / "README.md").read_text()
setup(
name="pgx",
version="0.4.0",
- long_description_content_type="text/markdown",
- description="",
+ description="GPU/TPU-accelerated parallel game simulators for reinforcement learning (RL)",
+ long_description=long_description,
+ long_description_content_type='text/markdown',
url="",
author="Sotetsu KOYAMADA",
author_email="[email protected]",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -1,10 +1,14 @@\n from setuptools import find_packages, setup\n+from pathlib import Path\n+\n+long_description = (Path(__file__).parent / \"README.md\").read_text()\n \n setup(\n name=\"pgx\",\n version=\"0.4.0\",\n- long_description_content_type=\"text/markdown\",\n- description=\"\",\n+ description=\"GPU/TPU-accelerated parallel game simulators for reinforcement learning (RL)\",\n+ long_description=long_description,\n+ long_description_content_type='text/markdown',\n url=\"\",\n author=\"Sotetsu KOYAMADA\",\n author_email=\"[email protected]\",\n", "issue": "[Docs] Add PyPI description\nCurrently, it's empty.\n", "before_files": [{"content": "from setuptools import find_packages, setup\n\nsetup(\n name=\"pgx\",\n version=\"0.4.0\",\n long_description_content_type=\"text/markdown\",\n description=\"\",\n url=\"\",\n author=\"Sotetsu KOYAMADA\",\n author_email=\"[email protected]\",\n keywords=\"\",\n packages=find_packages(),\n package_data={\"\": [\"LICENSE\", \"*.svg\"]},\n include_package_data=True,\n install_requires=[\n \"jax>=0.3.25\", # JAX version on Colab (TPU)\n \"chex>=0.1.6\",\n \"svgwrite\",\n \"msgpack\",\n \"typing_extensions\"\n ],\n classifiers=[\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n ],\n)\n", "path": "setup.py"}]}
| 786 | 171 |
gh_patches_debug_4915
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-1856
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Searching a queryset of a specific page class with a child_of/descendant_of filter gives error
Searching on a specific page class with the `child_of`/`descendant_of` filter applied, gives the following error:
```
FieldError at /videos/
Cannot filter search results with field "page_ptr_id". Please add index.FilterField('page_ptr_id') to VideoPage.search_fields.
```
Here's an example query that causes this:
``` python
VideoPage.objects.child_of(parent_page).search("foo")
```
It seems to be a combination of a specific queryset and `child_of`/`descendant_of` filter that causes the issue as the following query (which uses the generic page model) works.
``` python
Page.objects.child_of(parent_page).type(VideoPage).search("foo")
```
</issue>
<code>
[start of wagtail/wagtailsearch/backends/base.py]
1
2 from django.db.models.query import QuerySet
3 from django.db.models.lookups import Lookup
4 from django.db.models.sql.where import SubqueryConstraint, WhereNode
5 from django.utils.six import text_type
6
7 from wagtail.wagtailsearch.index import class_is_indexed
8
9
10 class FilterError(Exception):
11 pass
12
13
14 class FieldError(Exception):
15 pass
16
17
18 class BaseSearchQuery(object):
19 DEFAULT_OPERATOR = 'or'
20
21 def __init__(self, queryset, query_string, fields=None, operator=None, order_by_relevance=True):
22 self.queryset = queryset
23 self.query_string = query_string
24 self.fields = fields
25 self.operator = operator or self.DEFAULT_OPERATOR
26 self.order_by_relevance = order_by_relevance
27
28 def _get_searchable_field(self, field_attname):
29 # Get field
30 field = dict(
31 (field.get_attname(self.queryset.model), field)
32 for field in self.queryset.model.get_searchable_search_fields()
33 ).get(field_attname, None)
34
35 return field
36
37 def _get_filterable_field(self, field_attname):
38 # Get field
39 field = dict(
40 (field.get_attname(self.queryset.model), field)
41 for field in self.queryset.model.get_filterable_search_fields()
42 ).get(field_attname, None)
43
44 return field
45
46 def _process_lookup(self, field, lookup, value):
47 raise NotImplementedError
48
49 def _connect_filters(self, filters, connector, negated):
50 raise NotImplementedError
51
52 def _process_filter(self, field_attname, lookup, value):
53 # Get the field
54 field = self._get_filterable_field(field_attname)
55
56 if field is None:
57 raise FieldError('Cannot filter search results with field "' + field_attname + '". Please add index.FilterField(\'' + field_attname + '\') to ' + self.queryset.model.__name__ + '.search_fields.')
58
59 # Process the lookup
60 result = self._process_lookup(field, lookup, value)
61
62 if result is None:
63 raise FilterError('Could not apply filter on search results: "' + field_attname + '__' + lookup + ' = ' + text_type(value) + '". Lookup "' + lookup + '"" not recognosed.')
64
65 return result
66
67 def _get_filters_from_where_node(self, where_node):
68 # Check if this is a leaf node
69 if isinstance(where_node, Lookup):
70 field_attname = where_node.lhs.target.attname
71 lookup = where_node.lookup_name
72 value = where_node.rhs
73
74 # Process the filter
75 return self._process_filter(field_attname, lookup, value)
76
77 elif isinstance(where_node, SubqueryConstraint):
78 raise FilterError('Could not apply filter on search results: Subqueries are not allowed.')
79
80 elif isinstance(where_node, WhereNode):
81 # Get child filters
82 connector = where_node.connector
83 child_filters = [self._get_filters_from_where_node(child) for child in where_node.children]
84 child_filters = [child_filter for child_filter in child_filters if child_filter]
85
86 return self._connect_filters(child_filters, connector, where_node.negated)
87
88 else:
89 raise FilterError('Could not apply filter on search results: Unknown where node: ' + str(type(where_node)))
90
91 def _get_filters_from_queryset(self):
92 return self._get_filters_from_where_node(self.queryset.query.where)
93
94
95 class BaseSearchResults(object):
96 def __init__(self, backend, query, prefetch_related=None):
97 self.backend = backend
98 self.query = query
99 self.prefetch_related = prefetch_related
100 self.start = 0
101 self.stop = None
102 self._results_cache = None
103 self._count_cache = None
104
105 def _set_limits(self, start=None, stop=None):
106 if stop is not None:
107 if self.stop is not None:
108 self.stop = min(self.stop, self.start + stop)
109 else:
110 self.stop = self.start + stop
111
112 if start is not None:
113 if self.stop is not None:
114 self.start = min(self.stop, self.start + start)
115 else:
116 self.start = self.start + start
117
118 def _clone(self):
119 klass = self.__class__
120 new = klass(self.backend, self.query, prefetch_related=self.prefetch_related)
121 new.start = self.start
122 new.stop = self.stop
123 return new
124
125 def _do_search(self):
126 raise NotImplementedError
127
128 def _do_count(self):
129 raise NotImplementedError
130
131 def results(self):
132 if self._results_cache is None:
133 self._results_cache = self._do_search()
134 return self._results_cache
135
136 def count(self):
137 if self._count_cache is None:
138 if self._results_cache is not None:
139 self._count_cache = len(self._results_cache)
140 else:
141 self._count_cache = self._do_count()
142 return self._count_cache
143
144 def __getitem__(self, key):
145 new = self._clone()
146
147 if isinstance(key, slice):
148 # Set limits
149 start = int(key.start) if key.start else None
150 stop = int(key.stop) if key.stop else None
151 new._set_limits(start, stop)
152
153 # Copy results cache
154 if self._results_cache is not None:
155 new._results_cache = self._results_cache[key]
156
157 return new
158 else:
159 if self._results_cache is not None:
160 return self._results_cache[key]
161
162 new.start = self.start + key
163 new.stop = self.start + key + 1
164 return list(new)[0]
165
166 def __iter__(self):
167 return iter(self.results())
168
169 def __len__(self):
170 return len(self.results())
171
172 def __repr__(self):
173 data = list(self[:21])
174 if len(data) > 20:
175 data[-1] = "...(remaining elements truncated)..."
176 return repr(data)
177
178
179 class BaseSearch(object):
180 search_query_class = None
181 search_results_class = None
182
183 def __init__(self, params):
184 pass
185
186 def get_rebuilder(self):
187 return None
188
189 def reset_index(self):
190 raise NotImplementedError
191
192 def add_type(self, model):
193 raise NotImplementedError
194
195 def refresh_index(self):
196 raise NotImplementedError
197
198 def add(self, obj):
199 raise NotImplementedError
200
201 def add_bulk(self, model, obj_list):
202 raise NotImplementedError
203
204 def delete(self, obj):
205 raise NotImplementedError
206
207 def search(self, query_string, model_or_queryset, fields=None, filters=None, prefetch_related=None, operator=None, order_by_relevance=True):
208 # Find model/queryset
209 if isinstance(model_or_queryset, QuerySet):
210 model = model_or_queryset.model
211 queryset = model_or_queryset
212 else:
213 model = model_or_queryset
214 queryset = model_or_queryset.objects.all()
215
216 # Model must be a class that is in the index
217 if not class_is_indexed(model):
218 return []
219
220 # Check that theres still a query string after the clean up
221 if query_string == "":
222 return []
223
224 # Apply filters to queryset
225 if filters:
226 queryset = queryset.filter(**filters)
227
228 # Prefetch related
229 if prefetch_related:
230 for prefetch in prefetch_related:
231 queryset = queryset.prefetch_related(prefetch)
232
233 # Check operator
234 if operator is not None:
235 operator = operator.lower()
236 if operator not in ['or', 'and']:
237 raise ValueError("operator must be either 'or' or 'and'")
238
239 # Search
240 search_query = self.search_query_class(queryset, query_string, fields=fields, operator=operator, order_by_relevance=order_by_relevance)
241 return self.search_results_class(self, search_query)
242
[end of wagtail/wagtailsearch/backends/base.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/wagtail/wagtailsearch/backends/base.py b/wagtail/wagtailsearch/backends/base.py
--- a/wagtail/wagtailsearch/backends/base.py
+++ b/wagtail/wagtailsearch/backends/base.py
@@ -71,6 +71,10 @@
lookup = where_node.lookup_name
value = where_node.rhs
+ # Ignore pointer fields that show up in specific page type queries
+ if field_attname.endswith('_ptr_id'):
+ return
+
# Process the filter
return self._process_filter(field_attname, lookup, value)
|
{"golden_diff": "diff --git a/wagtail/wagtailsearch/backends/base.py b/wagtail/wagtailsearch/backends/base.py\n--- a/wagtail/wagtailsearch/backends/base.py\n+++ b/wagtail/wagtailsearch/backends/base.py\n@@ -71,6 +71,10 @@\n lookup = where_node.lookup_name\n value = where_node.rhs\n \n+ # Ignore pointer fields that show up in specific page type queries\n+ if field_attname.endswith('_ptr_id'):\n+ return\n+\n # Process the filter\n return self._process_filter(field_attname, lookup, value)\n", "issue": "Searching a queryset of a specific page class with a child_of/descendant_of filter gives error\nSearching on a specific page class with the `child_of`/`descendant_of` filter applied, gives the following error:\n\n```\nFieldError at /videos/\n\nCannot filter search results with field \"page_ptr_id\". Please add index.FilterField('page_ptr_id') to VideoPage.search_fields.\n```\n\nHere's an example query that causes this:\n\n``` python\nVideoPage.objects.child_of(parent_page).search(\"foo\")\n```\n\nIt seems to be a combination of a specific queryset and `child_of`/`descendant_of` filter that causes the issue as the following query (which uses the generic page model) works.\n\n``` python\nPage.objects.child_of(parent_page).type(VideoPage).search(\"foo\")\n```\n\n", "before_files": [{"content": "\nfrom django.db.models.query import QuerySet\nfrom django.db.models.lookups import Lookup\nfrom django.db.models.sql.where import SubqueryConstraint, WhereNode\nfrom django.utils.six import text_type\n\nfrom wagtail.wagtailsearch.index import class_is_indexed\n\n\nclass FilterError(Exception):\n pass\n\n\nclass FieldError(Exception):\n pass\n\n\nclass BaseSearchQuery(object):\n DEFAULT_OPERATOR = 'or'\n\n def __init__(self, queryset, query_string, fields=None, operator=None, order_by_relevance=True):\n self.queryset = queryset\n self.query_string = query_string\n self.fields = fields\n self.operator = operator or self.DEFAULT_OPERATOR\n self.order_by_relevance = order_by_relevance\n\n def _get_searchable_field(self, field_attname):\n # Get field\n field = dict(\n (field.get_attname(self.queryset.model), field)\n for field in self.queryset.model.get_searchable_search_fields()\n ).get(field_attname, None)\n\n return field\n\n def _get_filterable_field(self, field_attname):\n # Get field\n field = dict(\n (field.get_attname(self.queryset.model), field)\n for field in self.queryset.model.get_filterable_search_fields()\n ).get(field_attname, None)\n\n return field\n\n def _process_lookup(self, field, lookup, value):\n raise NotImplementedError\n\n def _connect_filters(self, filters, connector, negated):\n raise NotImplementedError\n\n def _process_filter(self, field_attname, lookup, value):\n # Get the field\n field = self._get_filterable_field(field_attname)\n\n if field is None:\n raise FieldError('Cannot filter search results with field \"' + field_attname + '\". Please add index.FilterField(\\'' + field_attname + '\\') to ' + self.queryset.model.__name__ + '.search_fields.')\n\n # Process the lookup\n result = self._process_lookup(field, lookup, value)\n\n if result is None:\n raise FilterError('Could not apply filter on search results: \"' + field_attname + '__' + lookup + ' = ' + text_type(value) + '\". Lookup \"' + lookup + '\"\" not recognosed.')\n\n return result\n\n def _get_filters_from_where_node(self, where_node):\n # Check if this is a leaf node\n if isinstance(where_node, Lookup):\n field_attname = where_node.lhs.target.attname\n lookup = where_node.lookup_name\n value = where_node.rhs\n\n # Process the filter\n return self._process_filter(field_attname, lookup, value)\n\n elif isinstance(where_node, SubqueryConstraint):\n raise FilterError('Could not apply filter on search results: Subqueries are not allowed.')\n\n elif isinstance(where_node, WhereNode):\n # Get child filters\n connector = where_node.connector\n child_filters = [self._get_filters_from_where_node(child) for child in where_node.children]\n child_filters = [child_filter for child_filter in child_filters if child_filter]\n\n return self._connect_filters(child_filters, connector, where_node.negated)\n\n else:\n raise FilterError('Could not apply filter on search results: Unknown where node: ' + str(type(where_node)))\n\n def _get_filters_from_queryset(self):\n return self._get_filters_from_where_node(self.queryset.query.where)\n\n\nclass BaseSearchResults(object):\n def __init__(self, backend, query, prefetch_related=None):\n self.backend = backend\n self.query = query\n self.prefetch_related = prefetch_related\n self.start = 0\n self.stop = None\n self._results_cache = None\n self._count_cache = None\n\n def _set_limits(self, start=None, stop=None):\n if stop is not None:\n if self.stop is not None:\n self.stop = min(self.stop, self.start + stop)\n else:\n self.stop = self.start + stop\n\n if start is not None:\n if self.stop is not None:\n self.start = min(self.stop, self.start + start)\n else:\n self.start = self.start + start\n\n def _clone(self):\n klass = self.__class__\n new = klass(self.backend, self.query, prefetch_related=self.prefetch_related)\n new.start = self.start\n new.stop = self.stop\n return new\n\n def _do_search(self):\n raise NotImplementedError\n\n def _do_count(self):\n raise NotImplementedError\n\n def results(self):\n if self._results_cache is None:\n self._results_cache = self._do_search()\n return self._results_cache\n\n def count(self):\n if self._count_cache is None:\n if self._results_cache is not None:\n self._count_cache = len(self._results_cache)\n else:\n self._count_cache = self._do_count()\n return self._count_cache\n\n def __getitem__(self, key):\n new = self._clone()\n\n if isinstance(key, slice):\n # Set limits\n start = int(key.start) if key.start else None\n stop = int(key.stop) if key.stop else None\n new._set_limits(start, stop)\n\n # Copy results cache\n if self._results_cache is not None:\n new._results_cache = self._results_cache[key]\n\n return new\n else:\n if self._results_cache is not None:\n return self._results_cache[key]\n\n new.start = self.start + key\n new.stop = self.start + key + 1\n return list(new)[0]\n\n def __iter__(self):\n return iter(self.results())\n\n def __len__(self):\n return len(self.results())\n\n def __repr__(self):\n data = list(self[:21])\n if len(data) > 20:\n data[-1] = \"...(remaining elements truncated)...\"\n return repr(data)\n\n\nclass BaseSearch(object):\n search_query_class = None\n search_results_class = None\n\n def __init__(self, params):\n pass\n\n def get_rebuilder(self):\n return None\n\n def reset_index(self):\n raise NotImplementedError\n\n def add_type(self, model):\n raise NotImplementedError\n\n def refresh_index(self):\n raise NotImplementedError\n\n def add(self, obj):\n raise NotImplementedError\n\n def add_bulk(self, model, obj_list):\n raise NotImplementedError\n\n def delete(self, obj):\n raise NotImplementedError\n\n def search(self, query_string, model_or_queryset, fields=None, filters=None, prefetch_related=None, operator=None, order_by_relevance=True):\n # Find model/queryset\n if isinstance(model_or_queryset, QuerySet):\n model = model_or_queryset.model\n queryset = model_or_queryset\n else:\n model = model_or_queryset\n queryset = model_or_queryset.objects.all()\n\n # Model must be a class that is in the index\n if not class_is_indexed(model):\n return []\n\n # Check that theres still a query string after the clean up\n if query_string == \"\":\n return []\n\n # Apply filters to queryset\n if filters:\n queryset = queryset.filter(**filters)\n\n # Prefetch related\n if prefetch_related:\n for prefetch in prefetch_related:\n queryset = queryset.prefetch_related(prefetch)\n\n # Check operator\n if operator is not None:\n operator = operator.lower()\n if operator not in ['or', 'and']:\n raise ValueError(\"operator must be either 'or' or 'and'\")\n\n # Search\n search_query = self.search_query_class(queryset, query_string, fields=fields, operator=operator, order_by_relevance=order_by_relevance)\n return self.search_results_class(self, search_query)\n", "path": "wagtail/wagtailsearch/backends/base.py"}]}
| 3,019 | 136 |
gh_patches_debug_27075
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-478
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug: Reshape() with -1 fails
When calling the chainer function Reshape() with a -1 value (e.g. Reshape((-1, 10, 10))) I get an error:
```
InvalidType: Expect: prod(in_types[0].shape) == prod((-1, 10, 10))
Actual: 2800 != -100
```
The cupy function reshape does support -1 arguments, so the error seems to be just the check in chainer's Reshape. The problematic check is:
_type_check_prod(in_types[0].shape) == _type_check_prod(self.shape)
If a -1 argument is present, it should instead check if the size of in_types[0] is divisible by the product of the axis-lengths that are not -1.
I would send a PR but I'm not exactly clear on the correct usage of type_check.expect, and had some issues with it in the past. Should be simple enough to fix though.
</issue>
<code>
[start of chainer/functions/array/reshape.py]
1 import numpy
2
3 from chainer import function
4 from chainer.utils import type_check
5
6
7 _type_check_prod = type_check.Variable(numpy.prod, 'prod')
8
9
10 class Reshape(function.Function):
11
12 """Reshapes an input array without copy."""
13
14 def __init__(self, shape):
15 self.shape = shape
16
17 def check_type_forward(self, in_types):
18 type_check.expect(
19 in_types.size() == 1,
20 _type_check_prod(in_types[0].shape) ==
21 _type_check_prod(self.shape)
22 )
23
24 def forward(self, x):
25 return x[0].reshape(self.shape),
26
27 def backward(self, x, gy):
28 return gy[0].reshape(x[0].shape),
29
30
31 def reshape(x, shape):
32 """Reshapes an input variable without copy.
33
34 Args:
35 x (~chainer.Variable): Input variable.
36 shape (tuple of ints): Target shape.
37
38 Returns:
39 ~chainer.Variable: Variable that holds a reshaped version of the input
40 variable.
41
42 """
43 return Reshape(shape)(x)
44
[end of chainer/functions/array/reshape.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/chainer/functions/array/reshape.py b/chainer/functions/array/reshape.py
--- a/chainer/functions/array/reshape.py
+++ b/chainer/functions/array/reshape.py
@@ -1,10 +1,12 @@
-import numpy
-
from chainer import function
from chainer.utils import type_check
-_type_check_prod = type_check.Variable(numpy.prod, 'prod')
+def _count_unknown_dims(shape):
+ cnt = 0
+ for dim in shape:
+ cnt += dim < 0
+ return cnt
class Reshape(function.Function):
@@ -12,15 +14,32 @@
"""Reshapes an input array without copy."""
def __init__(self, shape):
+ cnt = _count_unknown_dims(shape)
+ assert cnt == 0 or cnt == 1
+
self.shape = shape
def check_type_forward(self, in_types):
type_check.expect(
in_types.size() == 1,
- _type_check_prod(in_types[0].shape) ==
- _type_check_prod(self.shape)
)
+ x_type, = in_types
+
+ cnt = _count_unknown_dims(self.shape)
+ if cnt == 0:
+ type_check.expect(
+ type_check.prod(x_type.shape) == type_check.prod(self.shape))
+ else:
+ known_size = 1
+ for s in self.shape:
+ if s > 0:
+ known_size *= s
+ size_var = type_check.Variable(known_size,
+ 'known_size(=%d)' % known_size)
+ type_check.expect(
+ type_check.prod(x_type.shape) % size_var == 0)
+
def forward(self, x):
return x[0].reshape(self.shape),
|
{"golden_diff": "diff --git a/chainer/functions/array/reshape.py b/chainer/functions/array/reshape.py\n--- a/chainer/functions/array/reshape.py\n+++ b/chainer/functions/array/reshape.py\n@@ -1,10 +1,12 @@\n-import numpy\n-\n from chainer import function\n from chainer.utils import type_check\n \n \n-_type_check_prod = type_check.Variable(numpy.prod, 'prod')\n+def _count_unknown_dims(shape):\n+ cnt = 0\n+ for dim in shape:\n+ cnt += dim < 0\n+ return cnt\n \n \n class Reshape(function.Function):\n@@ -12,15 +14,32 @@\n \"\"\"Reshapes an input array without copy.\"\"\"\n \n def __init__(self, shape):\n+ cnt = _count_unknown_dims(shape)\n+ assert cnt == 0 or cnt == 1\n+\n self.shape = shape\n \n def check_type_forward(self, in_types):\n type_check.expect(\n in_types.size() == 1,\n- _type_check_prod(in_types[0].shape) ==\n- _type_check_prod(self.shape)\n )\n \n+ x_type, = in_types\n+\n+ cnt = _count_unknown_dims(self.shape)\n+ if cnt == 0:\n+ type_check.expect(\n+ type_check.prod(x_type.shape) == type_check.prod(self.shape))\n+ else:\n+ known_size = 1\n+ for s in self.shape:\n+ if s > 0:\n+ known_size *= s\n+ size_var = type_check.Variable(known_size,\n+ 'known_size(=%d)' % known_size)\n+ type_check.expect(\n+ type_check.prod(x_type.shape) % size_var == 0)\n+\n def forward(self, x):\n return x[0].reshape(self.shape),\n", "issue": "Bug: Reshape() with -1 fails\nWhen calling the chainer function Reshape() with a -1 value (e.g. Reshape((-1, 10, 10))) I get an error: \n\n```\nInvalidType: Expect: prod(in_types[0].shape) == prod((-1, 10, 10))\nActual: 2800 != -100\n```\n\nThe cupy function reshape does support -1 arguments, so the error seems to be just the check in chainer's Reshape. The problematic check is:\n _type_check_prod(in_types[0].shape) == _type_check_prod(self.shape)\n\nIf a -1 argument is present, it should instead check if the size of in_types[0] is divisible by the product of the axis-lengths that are not -1. \n\nI would send a PR but I'm not exactly clear on the correct usage of type_check.expect, and had some issues with it in the past. Should be simple enough to fix though.\n\n", "before_files": [{"content": "import numpy\n\nfrom chainer import function\nfrom chainer.utils import type_check\n\n\n_type_check_prod = type_check.Variable(numpy.prod, 'prod')\n\n\nclass Reshape(function.Function):\n\n \"\"\"Reshapes an input array without copy.\"\"\"\n\n def __init__(self, shape):\n self.shape = shape\n\n def check_type_forward(self, in_types):\n type_check.expect(\n in_types.size() == 1,\n _type_check_prod(in_types[0].shape) ==\n _type_check_prod(self.shape)\n )\n\n def forward(self, x):\n return x[0].reshape(self.shape),\n\n def backward(self, x, gy):\n return gy[0].reshape(x[0].shape),\n\n\ndef reshape(x, shape):\n \"\"\"Reshapes an input variable without copy.\n\n Args:\n x (~chainer.Variable): Input variable.\n shape (tuple of ints): Target shape.\n\n Returns:\n ~chainer.Variable: Variable that holds a reshaped version of the input\n variable.\n\n \"\"\"\n return Reshape(shape)(x)\n", "path": "chainer/functions/array/reshape.py"}]}
| 1,073 | 394 |
gh_patches_debug_5028
|
rasdani/github-patches
|
git_diff
|
googleapis__python-bigquery-1504
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ipywidgets extra pinned too tightly
https://github.com/googleapis/python-bigquery/blob/v3.4.2/setup.py#L70
I notice we have `"ipywidgets==7.7.1"`. This will likely give folks trouble as ipywidgets is updated. We should try to expand this when we can.
</issue>
<code>
[start of setup.py]
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import io
16 import os
17
18 import setuptools
19
20
21 # Package metadata.
22
23 name = "google-cloud-bigquery"
24 description = "Google BigQuery API client library"
25
26 # Should be one of:
27 # 'Development Status :: 3 - Alpha'
28 # 'Development Status :: 4 - Beta'
29 # 'Development Status :: 5 - Production/Stable'
30 release_status = "Development Status :: 5 - Production/Stable"
31 dependencies = [
32 "grpcio >= 1.47.0, < 2.0dev", # https://github.com/googleapis/python-bigquery/issues/1262
33 "grpcio >= 1.49.1, < 2.0dev; python_version>='3.11'",
34 # NOTE: Maintainers, please do not require google-api-core>=2.x.x
35 # Until this issue is closed
36 # https://github.com/googleapis/google-cloud-python/issues/10566
37 "google-api-core[grpc] >= 1.31.5, <3.0.0dev,!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.0",
38 "proto-plus >= 1.15.0, <2.0.0dev",
39 # NOTE: Maintainers, please do not require google-cloud-core>=2.x.x
40 # Until this issue is closed
41 # https://github.com/googleapis/google-cloud-python/issues/10566
42 "google-cloud-core >= 1.6.0, <3.0.0dev",
43 "google-resumable-media >= 0.6.0, < 3.0dev",
44 "packaging >= 20.0.0",
45 "protobuf>=3.19.5,<5.0.0dev,!=3.20.0,!=3.20.1,!=4.21.0,!=4.21.1,!=4.21.2,!=4.21.3,!=4.21.4,!=4.21.5", # For the legacy proto-based types.
46 "python-dateutil >= 2.7.2, <3.0dev",
47 "requests >= 2.21.0, < 3.0.0dev",
48 ]
49 pyarrow_dependency = "pyarrow >= 3.0.0"
50 extras = {
51 # Keep the no-op bqstorage extra for backward compatibility.
52 # See: https://github.com/googleapis/python-bigquery/issues/757
53 "bqstorage": [
54 "google-cloud-bigquery-storage >= 2.0.0, <3.0.0dev",
55 # Due to an issue in pip's dependency resolver, the `grpc` extra is not
56 # installed, even though `google-cloud-bigquery-storage` specifies it
57 # as `google-api-core[grpc]`. We thus need to explicitly specify it here.
58 # See: https://github.com/googleapis/python-bigquery/issues/83 The
59 # grpc.Channel.close() method isn't added until 1.32.0.
60 # https://github.com/grpc/grpc/pull/15254
61 "grpcio >= 1.47.0, < 2.0dev",
62 "grpcio >= 1.49.1, < 2.0dev; python_version>='3.11'",
63 pyarrow_dependency,
64 ],
65 "pandas": [
66 "pandas>=1.1.0",
67 pyarrow_dependency,
68 "db-dtypes>=0.3.0,<2.0.0dev",
69 ],
70 "ipywidgets": ["ipywidgets==7.7.1"],
71 "geopandas": ["geopandas>=0.9.0, <1.0dev", "Shapely>=1.8.4, <2.0dev"],
72 "ipython": ["ipython>=7.0.1,!=8.1.0"],
73 "tqdm": ["tqdm >= 4.7.4, <5.0.0dev"],
74 "opentelemetry": [
75 "opentelemetry-api >= 1.1.0",
76 "opentelemetry-sdk >= 1.1.0",
77 "opentelemetry-instrumentation >= 0.20b0",
78 ],
79 }
80
81 all_extras = []
82
83 for extra in extras:
84 all_extras.extend(extras[extra])
85
86 extras["all"] = all_extras
87
88 # Setup boilerplate below this line.
89
90 package_root = os.path.abspath(os.path.dirname(__file__))
91
92 readme_filename = os.path.join(package_root, "README.rst")
93 with io.open(readme_filename, encoding="utf-8") as readme_file:
94 readme = readme_file.read()
95
96 version = {}
97 with open(os.path.join(package_root, "google/cloud/bigquery/version.py")) as fp:
98 exec(fp.read(), version)
99 version = version["__version__"]
100
101 # Only include packages under the 'google' namespace. Do not include tests,
102 # benchmarks, etc.
103 packages = [
104 package
105 for package in setuptools.PEP420PackageFinder.find()
106 if package.startswith("google")
107 ]
108
109 # Determine which namespaces are needed.
110 namespaces = ["google"]
111 if "google.cloud" in packages:
112 namespaces.append("google.cloud")
113
114
115 setuptools.setup(
116 name=name,
117 version=version,
118 description=description,
119 long_description=readme,
120 author="Google LLC",
121 author_email="[email protected]",
122 license="Apache 2.0",
123 url="https://github.com/googleapis/python-bigquery",
124 classifiers=[
125 release_status,
126 "Intended Audience :: Developers",
127 "License :: OSI Approved :: Apache Software License",
128 "Programming Language :: Python",
129 "Programming Language :: Python :: 3",
130 "Programming Language :: Python :: 3.7",
131 "Programming Language :: Python :: 3.8",
132 "Programming Language :: Python :: 3.9",
133 "Programming Language :: Python :: 3.10",
134 "Programming Language :: Python :: 3.11",
135 "Operating System :: OS Independent",
136 "Topic :: Internet",
137 ],
138 platforms="Posix; MacOS X; Windows",
139 packages=packages,
140 namespace_packages=namespaces,
141 install_requires=dependencies,
142 extras_require=extras,
143 python_requires=">=3.7",
144 include_package_data=True,
145 zip_safe=False,
146 )
147
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -67,7 +67,7 @@
pyarrow_dependency,
"db-dtypes>=0.3.0,<2.0.0dev",
],
- "ipywidgets": ["ipywidgets==7.7.1"],
+ "ipywidgets": ["ipywidgets>=7.7.0,<8.0.1"],
"geopandas": ["geopandas>=0.9.0, <1.0dev", "Shapely>=1.8.4, <2.0dev"],
"ipython": ["ipython>=7.0.1,!=8.1.0"],
"tqdm": ["tqdm >= 4.7.4, <5.0.0dev"],
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -67,7 +67,7 @@\n pyarrow_dependency,\n \"db-dtypes>=0.3.0,<2.0.0dev\",\n ],\n- \"ipywidgets\": [\"ipywidgets==7.7.1\"],\n+ \"ipywidgets\": [\"ipywidgets>=7.7.0,<8.0.1\"],\n \"geopandas\": [\"geopandas>=0.9.0, <1.0dev\", \"Shapely>=1.8.4, <2.0dev\"],\n \"ipython\": [\"ipython>=7.0.1,!=8.1.0\"],\n \"tqdm\": [\"tqdm >= 4.7.4, <5.0.0dev\"],\n", "issue": "ipywidgets extra pinned too tightly\nhttps://github.com/googleapis/python-bigquery/blob/v3.4.2/setup.py#L70\r\n\r\nI notice we have `\"ipywidgets==7.7.1\"`. This will likely give folks trouble as ipywidgets is updated. We should try to expand this when we can.\n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\n\nimport setuptools\n\n\n# Package metadata.\n\nname = \"google-cloud-bigquery\"\ndescription = \"Google BigQuery API client library\"\n\n# Should be one of:\n# 'Development Status :: 3 - Alpha'\n# 'Development Status :: 4 - Beta'\n# 'Development Status :: 5 - Production/Stable'\nrelease_status = \"Development Status :: 5 - Production/Stable\"\ndependencies = [\n \"grpcio >= 1.47.0, < 2.0dev\", # https://github.com/googleapis/python-bigquery/issues/1262\n \"grpcio >= 1.49.1, < 2.0dev; python_version>='3.11'\",\n # NOTE: Maintainers, please do not require google-api-core>=2.x.x\n # Until this issue is closed\n # https://github.com/googleapis/google-cloud-python/issues/10566\n \"google-api-core[grpc] >= 1.31.5, <3.0.0dev,!=2.0.*,!=2.1.*,!=2.2.*,!=2.3.0\",\n \"proto-plus >= 1.15.0, <2.0.0dev\",\n # NOTE: Maintainers, please do not require google-cloud-core>=2.x.x\n # Until this issue is closed\n # https://github.com/googleapis/google-cloud-python/issues/10566\n \"google-cloud-core >= 1.6.0, <3.0.0dev\",\n \"google-resumable-media >= 0.6.0, < 3.0dev\",\n \"packaging >= 20.0.0\",\n \"protobuf>=3.19.5,<5.0.0dev,!=3.20.0,!=3.20.1,!=4.21.0,!=4.21.1,!=4.21.2,!=4.21.3,!=4.21.4,!=4.21.5\", # For the legacy proto-based types.\n \"python-dateutil >= 2.7.2, <3.0dev\",\n \"requests >= 2.21.0, < 3.0.0dev\",\n]\npyarrow_dependency = \"pyarrow >= 3.0.0\"\nextras = {\n # Keep the no-op bqstorage extra for backward compatibility.\n # See: https://github.com/googleapis/python-bigquery/issues/757\n \"bqstorage\": [\n \"google-cloud-bigquery-storage >= 2.0.0, <3.0.0dev\",\n # Due to an issue in pip's dependency resolver, the `grpc` extra is not\n # installed, even though `google-cloud-bigquery-storage` specifies it\n # as `google-api-core[grpc]`. We thus need to explicitly specify it here.\n # See: https://github.com/googleapis/python-bigquery/issues/83 The\n # grpc.Channel.close() method isn't added until 1.32.0.\n # https://github.com/grpc/grpc/pull/15254\n \"grpcio >= 1.47.0, < 2.0dev\",\n \"grpcio >= 1.49.1, < 2.0dev; python_version>='3.11'\",\n pyarrow_dependency,\n ],\n \"pandas\": [\n \"pandas>=1.1.0\",\n pyarrow_dependency,\n \"db-dtypes>=0.3.0,<2.0.0dev\",\n ],\n \"ipywidgets\": [\"ipywidgets==7.7.1\"],\n \"geopandas\": [\"geopandas>=0.9.0, <1.0dev\", \"Shapely>=1.8.4, <2.0dev\"],\n \"ipython\": [\"ipython>=7.0.1,!=8.1.0\"],\n \"tqdm\": [\"tqdm >= 4.7.4, <5.0.0dev\"],\n \"opentelemetry\": [\n \"opentelemetry-api >= 1.1.0\",\n \"opentelemetry-sdk >= 1.1.0\",\n \"opentelemetry-instrumentation >= 0.20b0\",\n ],\n}\n\nall_extras = []\n\nfor extra in extras:\n all_extras.extend(extras[extra])\n\nextras[\"all\"] = all_extras\n\n# Setup boilerplate below this line.\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nreadme_filename = os.path.join(package_root, \"README.rst\")\nwith io.open(readme_filename, encoding=\"utf-8\") as readme_file:\n readme = readme_file.read()\n\nversion = {}\nwith open(os.path.join(package_root, \"google/cloud/bigquery/version.py\")) as fp:\n exec(fp.read(), version)\nversion = version[\"__version__\"]\n\n# Only include packages under the 'google' namespace. Do not include tests,\n# benchmarks, etc.\npackages = [\n package\n for package in setuptools.PEP420PackageFinder.find()\n if package.startswith(\"google\")\n]\n\n# Determine which namespaces are needed.\nnamespaces = [\"google\"]\nif \"google.cloud\" in packages:\n namespaces.append(\"google.cloud\")\n\n\nsetuptools.setup(\n name=name,\n version=version,\n description=description,\n long_description=readme,\n author=\"Google LLC\",\n author_email=\"[email protected]\",\n license=\"Apache 2.0\",\n url=\"https://github.com/googleapis/python-bigquery\",\n classifiers=[\n release_status,\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet\",\n ],\n platforms=\"Posix; MacOS X; Windows\",\n packages=packages,\n namespace_packages=namespaces,\n install_requires=dependencies,\n extras_require=extras,\n python_requires=\">=3.7\",\n include_package_data=True,\n zip_safe=False,\n)\n", "path": "setup.py"}]}
| 2,465 | 184 |
gh_patches_debug_13895
|
rasdani/github-patches
|
git_diff
|
ethereum__web3.py-2587
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Web3 instantiation from subclass throws error
* Version: 5.30.0
* Python: 3.8
* OS: osx
* pip freeze output is intentionally omitted.
### What was wrong?
We use a sub-class of Web3, for the purpose of this example, call it SubclassWeb3, as follows:
```
class SubclassWeb3(Web3):
def __init__(self, ....):
... do bunch of stuff...
super().__init__(*args, **kwargs)
... do bunch more stuff...
```
This setup worked fine with web3 version == 5.23.1. However, switching to web3==5.30.0 breaks this, with error
```
[rest of callstack omitted]
File “[redacted]/web3/main.py”, line 251, in __init__
self.attach_modules(modules)
File “[redacted]/web3/main.py”, line 340, in attach_modules
_attach_modules(self, modules)
File “[redacted]/web3/_utils/module.py”, line 68, in attach_modules
setattr(parent_module, module_name, module_class(w3))
File “[redacted]/web3/module.py”, line 93, in __init__
self.codec: ABICodec = web3.codec
AttributeError: ‘NoneType’ object has no attribute ‘codec’
```
This used to work in older versions because the parent_module is assumed to be a Web3 object and stored accordingly - [see logic](https://github.com/ethereum/web3.py/blob/2b229d2e16792e52bb47108e665c6a8937c188a2/web3/_utils/module.py#L33-L35).
Compare this to the somewhat brittle name checking that happens in 5.30.0 - [see logic](https://github.com/ethereum/web3.py/blob/ee5f0543ad91e4ba991997e35f50719ceb58135d/web3/_utils/module.py#L58-L60). This doesn't quite work because if this logic is being executed from a subclass of Web3, the name of the parent module appears as SubclassWeb3 (and not Web3).
### How can it be fixed?
Fill this section in if you know how this could or should be fixed.
</issue>
<code>
[start of web3/_utils/module.py]
1 import inspect
2 from io import (
3 UnsupportedOperation,
4 )
5 from typing import (
6 TYPE_CHECKING,
7 Any,
8 Dict,
9 List,
10 Optional,
11 Sequence,
12 Union,
13 )
14
15 from web3.exceptions import (
16 ValidationError,
17 )
18 from web3.module import (
19 Module,
20 )
21
22 if TYPE_CHECKING:
23 from web3 import Web3 # noqa: F401
24
25
26 def _validate_init_params_and_return_if_found(module_class: Any) -> List[str]:
27 init_params_raw = list(inspect.signature(module_class.__init__).parameters)
28 module_init_params = [
29 param for param in init_params_raw if param not in ['self', 'args', 'kwargs']
30 ]
31
32 if len(module_init_params) > 1:
33 raise UnsupportedOperation(
34 "A module class may accept a single `Web3` instance as the first argument of its "
35 f"__init__() method. More than one argument found for {module_class.__name__}: "
36 f"{module_init_params}"
37 )
38
39 return module_init_params
40
41
42 def attach_modules(
43 parent_module: Union["Web3", "Module"],
44 module_definitions: Dict[str, Any],
45 w3: Optional[Union["Web3", "Module"]] = None
46 ) -> None:
47 for module_name, module_info in module_definitions.items():
48 module_info_is_list_like = isinstance(module_info, Sequence)
49
50 module_class = module_info[0] if module_info_is_list_like else module_info
51
52 if hasattr(parent_module, module_name):
53 raise AttributeError(
54 f"Cannot set {parent_module} module named '{module_name}'. The web3 object "
55 "already has an attribute with that name"
56 )
57
58 # The parent module is the ``Web3`` instance on first run of the loop
59 if type(parent_module).__name__ == 'Web3':
60 w3 = parent_module
61
62 module_init_params = _validate_init_params_and_return_if_found(module_class)
63 if len(module_init_params) == 1:
64 # Modules that need access to the ``Web3`` instance may accept the instance as the first
65 # arg in their ``__init__()`` method. This is the case for any module that inherits from
66 # ``web3.module.Module``.
67 # e.g. def __init__(self, w3):
68 setattr(parent_module, module_name, module_class(w3))
69 else:
70 # Modules need not take in a ``Web3`` instance in their ``__init__()`` if not needed
71 setattr(parent_module, module_name, module_class())
72
73 if module_info_is_list_like:
74 if len(module_info) == 2:
75 submodule_definitions = module_info[1]
76 module = getattr(parent_module, module_name)
77 attach_modules(module, submodule_definitions, w3)
78 elif len(module_info) != 1:
79 raise ValidationError("Module definitions can only have 1 or 2 elements.")
80
[end of web3/_utils/module.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/web3/_utils/module.py b/web3/_utils/module.py
--- a/web3/_utils/module.py
+++ b/web3/_utils/module.py
@@ -55,9 +55,13 @@
"already has an attribute with that name"
)
- # The parent module is the ``Web3`` instance on first run of the loop
- if type(parent_module).__name__ == 'Web3':
- w3 = parent_module
+ # The parent module is the ``Web3`` instance on first run of the loop and w3 is
+ # None. Thus, set w3 to the parent_module. The import needs to happen locally
+ # due to circular import issues.
+ if w3 is None:
+ from web3 import Web3
+ if isinstance(parent_module, Web3):
+ w3 = parent_module
module_init_params = _validate_init_params_and_return_if_found(module_class)
if len(module_init_params) == 1:
|
{"golden_diff": "diff --git a/web3/_utils/module.py b/web3/_utils/module.py\n--- a/web3/_utils/module.py\n+++ b/web3/_utils/module.py\n@@ -55,9 +55,13 @@\n \"already has an attribute with that name\"\n )\n \n- # The parent module is the ``Web3`` instance on first run of the loop\n- if type(parent_module).__name__ == 'Web3':\n- w3 = parent_module\n+ # The parent module is the ``Web3`` instance on first run of the loop and w3 is\n+ # None. Thus, set w3 to the parent_module. The import needs to happen locally\n+ # due to circular import issues.\n+ if w3 is None:\n+ from web3 import Web3\n+ if isinstance(parent_module, Web3):\n+ w3 = parent_module\n \n module_init_params = _validate_init_params_and_return_if_found(module_class)\n if len(module_init_params) == 1:\n", "issue": "Web3 instantiation from subclass throws error\n* Version: 5.30.0\r\n* Python: 3.8\r\n* OS: osx\r\n* pip freeze output is intentionally omitted.\r\n\r\n### What was wrong?\r\nWe use a sub-class of Web3, for the purpose of this example, call it SubclassWeb3, as follows:\r\n\r\n```\r\nclass SubclassWeb3(Web3):\r\ndef __init__(self, ....):\r\n ... do bunch of stuff...\r\n super().__init__(*args, **kwargs)\r\n ... do bunch more stuff...\r\n```\r\n\r\nThis setup worked fine with web3 version == 5.23.1. However, switching to web3==5.30.0 breaks this, with error\r\n\r\n```\r\n[rest of callstack omitted]\r\n File \u201c[redacted]/web3/main.py\u201d, line 251, in __init__\r\n self.attach_modules(modules)\r\n File \u201c[redacted]/web3/main.py\u201d, line 340, in attach_modules\r\n _attach_modules(self, modules)\r\n File \u201c[redacted]/web3/_utils/module.py\u201d, line 68, in attach_modules\r\n setattr(parent_module, module_name, module_class(w3))\r\n File \u201c[redacted]/web3/module.py\u201d, line 93, in __init__\r\n self.codec: ABICodec = web3.codec\r\nAttributeError: \u2018NoneType\u2019 object has no attribute \u2018codec\u2019\r\n```\r\n\r\nThis used to work in older versions because the parent_module is assumed to be a Web3 object and stored accordingly - [see logic](https://github.com/ethereum/web3.py/blob/2b229d2e16792e52bb47108e665c6a8937c188a2/web3/_utils/module.py#L33-L35).\r\n\r\nCompare this to the somewhat brittle name checking that happens in 5.30.0 - [see logic](https://github.com/ethereum/web3.py/blob/ee5f0543ad91e4ba991997e35f50719ceb58135d/web3/_utils/module.py#L58-L60). This doesn't quite work because if this logic is being executed from a subclass of Web3, the name of the parent module appears as SubclassWeb3 (and not Web3).\r\n\r\n### How can it be fixed?\r\n\r\nFill this section in if you know how this could or should be fixed.\n", "before_files": [{"content": "import inspect\nfrom io import (\n UnsupportedOperation,\n)\nfrom typing import (\n TYPE_CHECKING,\n Any,\n Dict,\n List,\n Optional,\n Sequence,\n Union,\n)\n\nfrom web3.exceptions import (\n ValidationError,\n)\nfrom web3.module import (\n Module,\n)\n\nif TYPE_CHECKING:\n from web3 import Web3 # noqa: F401\n\n\ndef _validate_init_params_and_return_if_found(module_class: Any) -> List[str]:\n init_params_raw = list(inspect.signature(module_class.__init__).parameters)\n module_init_params = [\n param for param in init_params_raw if param not in ['self', 'args', 'kwargs']\n ]\n\n if len(module_init_params) > 1:\n raise UnsupportedOperation(\n \"A module class may accept a single `Web3` instance as the first argument of its \"\n f\"__init__() method. More than one argument found for {module_class.__name__}: \"\n f\"{module_init_params}\"\n )\n\n return module_init_params\n\n\ndef attach_modules(\n parent_module: Union[\"Web3\", \"Module\"],\n module_definitions: Dict[str, Any],\n w3: Optional[Union[\"Web3\", \"Module\"]] = None\n) -> None:\n for module_name, module_info in module_definitions.items():\n module_info_is_list_like = isinstance(module_info, Sequence)\n\n module_class = module_info[0] if module_info_is_list_like else module_info\n\n if hasattr(parent_module, module_name):\n raise AttributeError(\n f\"Cannot set {parent_module} module named '{module_name}'. The web3 object \"\n \"already has an attribute with that name\"\n )\n\n # The parent module is the ``Web3`` instance on first run of the loop\n if type(parent_module).__name__ == 'Web3':\n w3 = parent_module\n\n module_init_params = _validate_init_params_and_return_if_found(module_class)\n if len(module_init_params) == 1:\n # Modules that need access to the ``Web3`` instance may accept the instance as the first\n # arg in their ``__init__()`` method. This is the case for any module that inherits from\n # ``web3.module.Module``.\n # e.g. def __init__(self, w3):\n setattr(parent_module, module_name, module_class(w3))\n else:\n # Modules need not take in a ``Web3`` instance in their ``__init__()`` if not needed\n setattr(parent_module, module_name, module_class())\n\n if module_info_is_list_like:\n if len(module_info) == 2:\n submodule_definitions = module_info[1]\n module = getattr(parent_module, module_name)\n attach_modules(module, submodule_definitions, w3)\n elif len(module_info) != 1:\n raise ValidationError(\"Module definitions can only have 1 or 2 elements.\")\n", "path": "web3/_utils/module.py"}]}
| 1,851 | 221 |
gh_patches_debug_21409
|
rasdani/github-patches
|
git_diff
|
internetarchive__openlibrary-7232
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Upgrade from Python 3.10.6 to Python 3.10.8
<!-- What issue does this PR close? -->
Closes #
<!-- What does this PR achieve? [feature|hotfix|fix|refactor] -->
Repeat the process discussed in https://github.com/internetarchive/openlibrary/pull/6340#issuecomment-1086270358 to upgrade CPython.
[This update](https://docs.python.org/release/3.10.8/whatsnew/changelog.html) includes a mitigation for [CVE-2020-10735](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-10735) and several other security fixes.
### Technical
<!-- What should be noted about the implementation? -->
### Testing
<!-- Steps for reviewer to reproduce/verify what this PR does/fixes. -->
For testing, please do (from https://github.com/internetarchive/openlibrary/pull/6340#issuecomment-1086270358):
* [x] On `ol-dev1` (in `ol-cclauss`), check out branch and build a new olbase image tagged `-t openlibrary/olbase:py3.10.8`
* [x] `git fetch origin && git checkout python3.10.8`
* [x] `docker build --no-cache -t openlibrary/olbase:py3.10.8 -f docker/Dockerfile.olbase .`
* [x] `hostname ; docker image ls | grep 3.10.8 ` # -> `ol-dev1.us.archive.org`, `repo: openlibrary/olbase, tag: py3.10.8`
* [x] Ask **@cdrini** to push this up to docker hub once it's done
* [ ] Pull it down locally and test the site with the `OLIMAGE` param
* [ ] Also test solr-updater starts up ok ; it's using FnToCLI which has caused issues with types/python handling of types
* [ ] Restart testing.openlibrary.org with the OLIMAGE param ; confirm things work
* [ ] Merge!
### During the `docker build` process -- DISK WARNING - free space: / 8905 MB (15% inode=38%):
### npm deprication warnings --> #7084
### During the `docker build` process -- Warning: apt-key is deprecated.
```
Step 9/27 : RUN wget -O - https://openresty.org/package/pubkey.gpg | apt-key add -
---> Running in d075e06118ad
--2022-10-16 13:25:19-- https://openresty.org/package/pubkey.gpg
Resolving openresty.org (openresty.org)... Warning: apt-key is deprecated. Manage keyring files in trusted.gpg.d instead (see apt-key(8)).
3.131.85.84, 2600:1f1c:9b2:8000:f183:c67e:2c64:855f
Connecting to openresty.org (openresty.org)|3.131.85.84|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1688 (1.6K) [text/plain]
Saving to: 'STDOUT'
0K . 100% 65.4M=0s
2022-10-16 13:25:20 (65.4 MB/s) - written to stdout [1688/1688]
```
### Screenshot
<!-- If this PR touches UI, please post evidence (screenshots) of it behaving correctly. -->
### Stakeholders
<!-- @ tag stakeholders of this bug -->
<!-- Attribution Disclaimer: By proposing this pull request, I affirm to have made a best-effort and exercised my discretion to make sure relevant sections of this code that substantially leverage code suggestions, code generation, or code snippets from sources (e.g. Stack Overflow, GitHub) have been annotated with basic attribution so reviewers & contributors may have confidence and access to the correct context to evaluate and use this code. -->
</issue>
<code>
[start of scripts/oldump.py]
1 #!/usr/bin/env python
2
3 import logging
4 import os
5 import sys
6 from datetime import datetime
7
8 import _init_path # noqa: F401 Imported for its side effect of setting PYTHONPATH
9
10 logger = logging.getLogger(__file__)
11 logger.setLevel(logging.DEBUG)
12
13
14 def log(*args) -> None:
15 args_str = " ".join(str(a) for a in args)
16 msg = f"{datetime.now():%Y-%m-%d %H:%M:%S} [openlibrary.dump] {args_str}"
17 logger.info(msg)
18 print(msg, file=sys.stderr)
19
20
21 if __name__ == "__main__":
22 from contextlib import redirect_stdout
23 from infogami import config
24 from openlibrary.config import load_config
25 from openlibrary.data import dump
26 from openlibrary.utils.sentry import Sentry
27
28 log("{} on Python {}.{}.{}".format(sys.argv, *sys.version_info)) # Python 3.10.4
29
30 ol_config = os.getenv("OL_CONFIG")
31 if ol_config:
32 logger.info(f"loading config from {ol_config}")
33 # Squelch output from infobase (needed for sentry setup)
34 # So it doesn't end up in our data dumps body
35 with open(os.devnull, 'w') as devnull:
36 with redirect_stdout(devnull):
37 load_config(ol_config)
38 sentry = Sentry(getattr(config, "sentry_cron_jobs", {}))
39 if sentry.enabled:
40 sentry.init()
41 log(f"sentry.enabled = {bool(ol_config and sentry.enabled)}")
42
43 dump.main(sys.argv[1], sys.argv[2:])
44
[end of scripts/oldump.py]
[start of scripts/solr_builder/solr_builder/fn_to_cli.py]
1 import asyncio
2 import typing
3 from argparse import (
4 ArgumentParser,
5 ArgumentDefaultsHelpFormatter,
6 BooleanOptionalAction,
7 Namespace,
8 )
9
10
11 class FnToCLI:
12 """
13 A utility class which automatically infers and generates ArgParse command
14 line options from a function based on defaults/type annotations
15
16 This is _very_ basic; supports:
17 * Args of int, str types (same logic as default argparse)
18 * Args of bool type (Uses argparse BooleanOptionalAction)
19 * eg `do_blah=False` becomes `--do-blah, --no-do-blah`
20 * Args of typing.Optional (or anything with a default)
21 * Args of typing.Literal (uses argparse choices)
22 * eg `color: Literal['red, 'black']` becomes `--color red|black` (with docs)
23 * Type deduction of default values
24 * Supports async functions automatically
25 * Includes docstring if it's in `:param my_arg: Description of my arg` format
26
27 Anything else will likely error :)
28
29 Example:
30 if __name__ == '__main__':
31 FnToCLI(my_func).run()
32 """
33
34 def __init__(self, fn: typing.Callable):
35 self.fn = fn
36 arg_names = fn.__code__.co_varnames[: fn.__code__.co_argcount]
37 annotations = typing.get_type_hints(fn)
38 defaults: list = fn.__defaults__ or [] # type: ignore[assignment]
39 num_required = len(arg_names) - len(defaults)
40 default_args = arg_names[num_required:]
41 defaults: dict = { # type: ignore[no-redef]
42 arg: default for [arg, default] in zip(default_args, defaults)
43 }
44
45 docs = fn.__doc__ or ''
46 arg_docs = self.parse_docs(docs)
47 self.parser = ArgumentParser(
48 description=docs.split(':param', 1)[0],
49 formatter_class=ArgumentDefaultsHelpFormatter,
50 )
51 self.args: typing.Optional[Namespace] = None
52 for arg in arg_names:
53 optional = arg in defaults
54 cli_name = arg.replace('_', '-')
55
56 if arg in annotations:
57 arg_opts = self.type_to_argparse(annotations[arg])
58 elif arg in defaults:
59 arg_opts = self.type_to_argparse(type(defaults[arg])) # type: ignore[call-overload]
60 else:
61 raise ValueError(f'{arg} has no type information')
62
63 # Help needs to always be defined, or it won't show the default :/
64 arg_opts['help'] = arg_docs.get(arg) or '-'
65
66 if optional:
67 opt_name = f'--{cli_name}' if len(cli_name) > 1 else f'-{cli_name}'
68 self.parser.add_argument(opt_name, default=defaults[arg], **arg_opts) # type: ignore[call-overload]
69 else:
70 self.parser.add_argument(cli_name, **arg_opts)
71
72 def parse_args(self):
73 self.args = self.parser.parse_args()
74 return self.args
75
76 def args_dict(self):
77 if not self.args:
78 self.parse_args()
79
80 return {k.replace('-', '_'): v for k, v in self.args.__dict__.items()}
81
82 def run(self):
83 args_dicts = self.args_dict()
84 if asyncio.iscoroutinefunction(self.fn):
85 asyncio.run(self.fn(**args_dicts))
86 else:
87 self.fn(**args_dicts)
88
89 @staticmethod
90 def parse_docs(docs):
91 params = docs.strip().split(':param ')[1:]
92 params = [p.strip() for p in params]
93 params = [p.split(':', 1) for p in params if p]
94 return {name: docs.strip() for [name, docs] in params}
95
96 @staticmethod
97 def type_to_argparse(typ: type) -> dict:
98 if FnToCLI.is_optional(typ):
99 return FnToCLI.type_to_argparse(
100 next(t for t in typing.get_args(typ) if not isinstance(t, type(None)))
101 )
102 if typ == bool:
103 return {'type': typ, 'action': BooleanOptionalAction}
104 if typ in (int, str, float):
105 return {'type': typ}
106 if typ == list[str]:
107 return {'nargs': '*'}
108 if typing.get_origin(typ) == typing.Literal:
109 return {'choices': typing.get_args(typ)}
110 raise ValueError(f'Unsupported type: {typ}')
111
112 @staticmethod
113 def is_optional(typ: type) -> bool:
114 return (
115 typing.get_origin(typ) is typing.Union
116 and type(None) in typing.get_args(typ)
117 and len(typing.get_args(typ)) == 2
118 )
119
[end of scripts/solr_builder/solr_builder/fn_to_cli.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scripts/oldump.py b/scripts/oldump.py
--- a/scripts/oldump.py
+++ b/scripts/oldump.py
@@ -25,7 +25,7 @@
from openlibrary.data import dump
from openlibrary.utils.sentry import Sentry
- log("{} on Python {}.{}.{}".format(sys.argv, *sys.version_info)) # Python 3.10.4
+ log("{} on Python {}.{}.{}".format(sys.argv, *sys.version_info)) # Python 3.11.1
ol_config = os.getenv("OL_CONFIG")
if ol_config:
diff --git a/scripts/solr_builder/solr_builder/fn_to_cli.py b/scripts/solr_builder/solr_builder/fn_to_cli.py
--- a/scripts/solr_builder/solr_builder/fn_to_cli.py
+++ b/scripts/solr_builder/solr_builder/fn_to_cli.py
@@ -1,4 +1,5 @@
import asyncio
+import types
import typing
from argparse import (
ArgumentParser,
@@ -112,7 +113,7 @@
@staticmethod
def is_optional(typ: type) -> bool:
return (
- typing.get_origin(typ) is typing.Union
+ (typing.get_origin(typ) is typing.Union or isinstance(typ, types.UnionType))
and type(None) in typing.get_args(typ)
and len(typing.get_args(typ)) == 2
)
|
{"golden_diff": "diff --git a/scripts/oldump.py b/scripts/oldump.py\n--- a/scripts/oldump.py\n+++ b/scripts/oldump.py\n@@ -25,7 +25,7 @@\n from openlibrary.data import dump\n from openlibrary.utils.sentry import Sentry\n \n- log(\"{} on Python {}.{}.{}\".format(sys.argv, *sys.version_info)) # Python 3.10.4\n+ log(\"{} on Python {}.{}.{}\".format(sys.argv, *sys.version_info)) # Python 3.11.1\n \n ol_config = os.getenv(\"OL_CONFIG\")\n if ol_config:\ndiff --git a/scripts/solr_builder/solr_builder/fn_to_cli.py b/scripts/solr_builder/solr_builder/fn_to_cli.py\n--- a/scripts/solr_builder/solr_builder/fn_to_cli.py\n+++ b/scripts/solr_builder/solr_builder/fn_to_cli.py\n@@ -1,4 +1,5 @@\n import asyncio\n+import types\n import typing\n from argparse import (\n ArgumentParser,\n@@ -112,7 +113,7 @@\n @staticmethod\n def is_optional(typ: type) -> bool:\n return (\n- typing.get_origin(typ) is typing.Union\n+ (typing.get_origin(typ) is typing.Union or isinstance(typ, types.UnionType))\n and type(None) in typing.get_args(typ)\n and len(typing.get_args(typ)) == 2\n )\n", "issue": "Upgrade from Python 3.10.6 to Python 3.10.8\n<!-- What issue does this PR close? -->\r\nCloses #\r\n\r\n<!-- What does this PR achieve? [feature|hotfix|fix|refactor] -->\r\nRepeat the process discussed in https://github.com/internetarchive/openlibrary/pull/6340#issuecomment-1086270358 to upgrade CPython.\r\n[This update](https://docs.python.org/release/3.10.8/whatsnew/changelog.html) includes a mitigation for [CVE-2020-10735](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-10735) and several other security fixes.\r\n\r\n### Technical\r\n<!-- What should be noted about the implementation? -->\r\n\r\n### Testing\r\n<!-- Steps for reviewer to reproduce/verify what this PR does/fixes. -->\r\nFor testing, please do (from https://github.com/internetarchive/openlibrary/pull/6340#issuecomment-1086270358):\r\n* [x] On `ol-dev1` (in `ol-cclauss`), check out branch and build a new olbase image tagged `-t openlibrary/olbase:py3.10.8`\r\n * [x] `git fetch origin && git checkout python3.10.8`\r\n * [x] `docker build --no-cache -t openlibrary/olbase:py3.10.8 -f docker/Dockerfile.olbase .`\r\n * [x] `hostname ; docker image ls | grep 3.10.8 ` # -> `ol-dev1.us.archive.org`, `repo: openlibrary/olbase, tag: py3.10.8`\r\n* [x] Ask **@cdrini** to push this up to docker hub once it's done\r\n* [ ] Pull it down locally and test the site with the `OLIMAGE` param\r\n * [ ] Also test solr-updater starts up ok ; it's using FnToCLI which has caused issues with types/python handling of types\r\n* [ ] Restart testing.openlibrary.org with the OLIMAGE param ; confirm things work\r\n* [ ] Merge!\r\n\r\n### During the `docker build` process -- DISK WARNING - free space: / 8905 MB (15% inode=38%):\r\n\r\n### npm deprication warnings --> #7084\r\n\r\n### During the `docker build` process -- Warning: apt-key is deprecated.\r\n```\r\nStep 9/27 : RUN wget -O - https://openresty.org/package/pubkey.gpg | apt-key add -\r\n ---> Running in d075e06118ad\r\n--2022-10-16 13:25:19-- https://openresty.org/package/pubkey.gpg\r\nResolving openresty.org (openresty.org)... Warning: apt-key is deprecated. Manage keyring files in trusted.gpg.d instead (see apt-key(8)).\r\n3.131.85.84, 2600:1f1c:9b2:8000:f183:c67e:2c64:855f\r\nConnecting to openresty.org (openresty.org)|3.131.85.84|:443... connected.\r\nHTTP request sent, awaiting response... 200 OK\r\nLength: 1688 (1.6K) [text/plain]\r\nSaving to: 'STDOUT'\r\n\r\n 0K . 100% 65.4M=0s\r\n\r\n2022-10-16 13:25:20 (65.4 MB/s) - written to stdout [1688/1688]\r\n```\r\n### Screenshot\r\n<!-- If this PR touches UI, please post evidence (screenshots) of it behaving correctly. -->\r\n\r\n### Stakeholders\r\n<!-- @ tag stakeholders of this bug -->\r\n\r\n\r\n<!-- Attribution Disclaimer: By proposing this pull request, I affirm to have made a best-effort and exercised my discretion to make sure relevant sections of this code that substantially leverage code suggestions, code generation, or code snippets from sources (e.g. Stack Overflow, GitHub) have been annotated with basic attribution so reviewers & contributors may have confidence and access to the correct context to evaluate and use this code. -->\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\nimport logging\nimport os\nimport sys\nfrom datetime import datetime\n\nimport _init_path # noqa: F401 Imported for its side effect of setting PYTHONPATH\n\nlogger = logging.getLogger(__file__)\nlogger.setLevel(logging.DEBUG)\n\n\ndef log(*args) -> None:\n args_str = \" \".join(str(a) for a in args)\n msg = f\"{datetime.now():%Y-%m-%d %H:%M:%S} [openlibrary.dump] {args_str}\"\n logger.info(msg)\n print(msg, file=sys.stderr)\n\n\nif __name__ == \"__main__\":\n from contextlib import redirect_stdout\n from infogami import config\n from openlibrary.config import load_config\n from openlibrary.data import dump\n from openlibrary.utils.sentry import Sentry\n\n log(\"{} on Python {}.{}.{}\".format(sys.argv, *sys.version_info)) # Python 3.10.4\n\n ol_config = os.getenv(\"OL_CONFIG\")\n if ol_config:\n logger.info(f\"loading config from {ol_config}\")\n # Squelch output from infobase (needed for sentry setup)\n # So it doesn't end up in our data dumps body\n with open(os.devnull, 'w') as devnull:\n with redirect_stdout(devnull):\n load_config(ol_config)\n sentry = Sentry(getattr(config, \"sentry_cron_jobs\", {}))\n if sentry.enabled:\n sentry.init()\n log(f\"sentry.enabled = {bool(ol_config and sentry.enabled)}\")\n\n dump.main(sys.argv[1], sys.argv[2:])\n", "path": "scripts/oldump.py"}, {"content": "import asyncio\nimport typing\nfrom argparse import (\n ArgumentParser,\n ArgumentDefaultsHelpFormatter,\n BooleanOptionalAction,\n Namespace,\n)\n\n\nclass FnToCLI:\n \"\"\"\n A utility class which automatically infers and generates ArgParse command\n line options from a function based on defaults/type annotations\n\n This is _very_ basic; supports:\n * Args of int, str types (same logic as default argparse)\n * Args of bool type (Uses argparse BooleanOptionalAction)\n * eg `do_blah=False` becomes `--do-blah, --no-do-blah`\n * Args of typing.Optional (or anything with a default)\n * Args of typing.Literal (uses argparse choices)\n * eg `color: Literal['red, 'black']` becomes `--color red|black` (with docs)\n * Type deduction of default values\n * Supports async functions automatically\n * Includes docstring if it's in `:param my_arg: Description of my arg` format\n\n Anything else will likely error :)\n\n Example:\n if __name__ == '__main__':\n FnToCLI(my_func).run()\n \"\"\"\n\n def __init__(self, fn: typing.Callable):\n self.fn = fn\n arg_names = fn.__code__.co_varnames[: fn.__code__.co_argcount]\n annotations = typing.get_type_hints(fn)\n defaults: list = fn.__defaults__ or [] # type: ignore[assignment]\n num_required = len(arg_names) - len(defaults)\n default_args = arg_names[num_required:]\n defaults: dict = { # type: ignore[no-redef]\n arg: default for [arg, default] in zip(default_args, defaults)\n }\n\n docs = fn.__doc__ or ''\n arg_docs = self.parse_docs(docs)\n self.parser = ArgumentParser(\n description=docs.split(':param', 1)[0],\n formatter_class=ArgumentDefaultsHelpFormatter,\n )\n self.args: typing.Optional[Namespace] = None\n for arg in arg_names:\n optional = arg in defaults\n cli_name = arg.replace('_', '-')\n\n if arg in annotations:\n arg_opts = self.type_to_argparse(annotations[arg])\n elif arg in defaults:\n arg_opts = self.type_to_argparse(type(defaults[arg])) # type: ignore[call-overload]\n else:\n raise ValueError(f'{arg} has no type information')\n\n # Help needs to always be defined, or it won't show the default :/\n arg_opts['help'] = arg_docs.get(arg) or '-'\n\n if optional:\n opt_name = f'--{cli_name}' if len(cli_name) > 1 else f'-{cli_name}'\n self.parser.add_argument(opt_name, default=defaults[arg], **arg_opts) # type: ignore[call-overload]\n else:\n self.parser.add_argument(cli_name, **arg_opts)\n\n def parse_args(self):\n self.args = self.parser.parse_args()\n return self.args\n\n def args_dict(self):\n if not self.args:\n self.parse_args()\n\n return {k.replace('-', '_'): v for k, v in self.args.__dict__.items()}\n\n def run(self):\n args_dicts = self.args_dict()\n if asyncio.iscoroutinefunction(self.fn):\n asyncio.run(self.fn(**args_dicts))\n else:\n self.fn(**args_dicts)\n\n @staticmethod\n def parse_docs(docs):\n params = docs.strip().split(':param ')[1:]\n params = [p.strip() for p in params]\n params = [p.split(':', 1) for p in params if p]\n return {name: docs.strip() for [name, docs] in params}\n\n @staticmethod\n def type_to_argparse(typ: type) -> dict:\n if FnToCLI.is_optional(typ):\n return FnToCLI.type_to_argparse(\n next(t for t in typing.get_args(typ) if not isinstance(t, type(None)))\n )\n if typ == bool:\n return {'type': typ, 'action': BooleanOptionalAction}\n if typ in (int, str, float):\n return {'type': typ}\n if typ == list[str]:\n return {'nargs': '*'}\n if typing.get_origin(typ) == typing.Literal:\n return {'choices': typing.get_args(typ)}\n raise ValueError(f'Unsupported type: {typ}')\n\n @staticmethod\n def is_optional(typ: type) -> bool:\n return (\n typing.get_origin(typ) is typing.Union\n and type(None) in typing.get_args(typ)\n and len(typing.get_args(typ)) == 2\n )\n", "path": "scripts/solr_builder/solr_builder/fn_to_cli.py"}]}
| 3,224 | 322 |
gh_patches_debug_61518
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmpose-295
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Pylint: W0105
```bash
mmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py:173:8: W0105: String statement has no effect (pointless-string-statement)
```
</issue>
<code>
[start of mmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py]
1 import copy as cp
2 import os
3 import os.path as osp
4 from collections import OrderedDict
5
6 import json_tricks as json
7 import numpy as np
8
9 from mmpose.datasets.builder import DATASETS
10 from .topdown_base_dataset import TopDownBaseDataset
11
12
13 @DATASETS.register_module()
14 class TopDownMpiiTrbDataset(TopDownBaseDataset):
15 """MPII-TRB Dataset dataset for top-down pose estimation.
16
17 `TRB: A Novel Triplet Representation for Understanding 2D Human Body`
18 ICCV'2019 More details can be found in the `paper
19 <https://arxiv.org/abs/1910.11535>`__ .
20
21 The dataset loads raw features and apply specified transforms
22 to return a dict containing the image tensors and other information.
23
24 Args:
25 ann_file (str): Path to the annotation file.
26 img_prefix (str): Path to a directory where images are held.
27 Default: None.
28 data_cfg (dict): config
29 pipeline (list[dict | callable]): A sequence of data transforms.
30 test_mode (bool): Store True when building test or
31 validation dataset. Default: False.
32 """
33
34 def __init__(self,
35 ann_file,
36 img_prefix,
37 data_cfg,
38 pipeline,
39 test_mode=False):
40
41 super().__init__(
42 ann_file, img_prefix, data_cfg, pipeline, test_mode=test_mode)
43
44 # flip_pairs in MPII-TRB
45 self.ann_info['flip_pairs'] = [[0, 1], [2, 3], [4, 5], [6, 7], [8, 9],
46 [10, 11], [14, 15]]
47 for i in range(6):
48 self.ann_info['flip_pairs'].append([16 + i, 22 + i])
49 self.ann_info['flip_pairs'].append([28 + i, 34 + i])
50
51 self.ann_info['upper_body_ids'] = [0, 1, 2, 3, 4, 5, 12, 13]
52 self.ann_info['lower_body_ids'] = [6, 7, 8, 9, 10, 11]
53 self.ann_info['upper_body_ids'].extend(list(range(14, 28)))
54 self.ann_info['lower_body_ids'].extend(list(range(28, 40)))
55
56 self.ann_info['use_different_joint_weights'] = False
57
58 assert self.ann_info['num_joints'] == 40
59 self.ann_info['joint_weights'] = np.ones(
60 (self.ann_info['num_joints'], 1), dtype=np.float32)
61
62 self.db = self._get_db(ann_file)
63 self.image_set = set(x['image_file'] for x in self.db)
64 self.num_images = len(self.image_set)
65
66 print(f'=> num_images: {self.num_images}')
67 print(f'=> load {len(self.db)} samples')
68
69 def _get_db(self, ann_file):
70 """Load dataset."""
71 with open(ann_file, 'r') as f:
72 data = json.load(f)
73 tmpl = dict(
74 image_file=None,
75 center=None,
76 scale=None,
77 rotation=0,
78 joints_3d=None,
79 joints_3d_visible=None,
80 dataset='mpii_trb')
81
82 imid2info = {
83 int(osp.splitext(x['file_name'])[0]): x
84 for x in data['images']
85 }
86
87 num_joints = self.ann_info['num_joints']
88 gt_db = []
89
90 for anno in data['annotations']:
91 newitem = cp.deepcopy(tmpl)
92 image_id = anno['image_id']
93 newitem['image_file'] = os.path.join(
94 self.img_prefix, imid2info[image_id]['file_name'])
95
96 if max(anno['keypoints']) == 0:
97 continue
98
99 joints_3d = np.zeros((num_joints, 3), dtype=np.float32)
100 joints_3d_visible = np.zeros((num_joints, 3), dtype=np.float32)
101
102 for ipt in range(num_joints):
103 joints_3d[ipt, 0] = anno['keypoints'][ipt * 3 + 0]
104 joints_3d[ipt, 1] = anno['keypoints'][ipt * 3 + 1]
105 joints_3d[ipt, 2] = 0
106 t_vis = min(anno['keypoints'][ipt * 3 + 2], 1)
107 joints_3d_visible[ipt, :] = (t_vis, t_vis, 0)
108
109 center = np.array(anno['center'], dtype=np.float32)
110 scale = self.ann_info['image_size'] / anno['scale'] / 200.0
111 newitem['center'] = center
112 newitem['scale'] = scale
113 newitem['joints_3d'] = joints_3d
114 newitem['joints_3d_visible'] = joints_3d_visible
115 if 'headbox' in anno:
116 newitem['headbox'] = anno['headbox']
117 gt_db.append(newitem)
118
119 return gt_db
120
121 def _evaluate_kernel(self, pred, joints_3d, joints_3d_visible, headbox):
122 """Evaluate one example."""
123 num_joints = self.ann_info['num_joints']
124 headbox = np.array(headbox)
125 threshold = np.linalg.norm(headbox[:2] - headbox[2:]) * 0.3
126 hit = np.zeros(num_joints, dtype=np.float32)
127 exist = np.zeros(num_joints, dtype=np.float32)
128
129 for i in range(num_joints):
130 pred_pt = pred[i]
131 gt_pt = joints_3d[i]
132 vis = joints_3d_visible[i][0]
133 if vis:
134 exist[i] = 1
135 else:
136 continue
137 distance = np.linalg.norm(pred_pt[:2] - gt_pt[:2])
138 if distance < threshold:
139 hit[i] = 1
140 return hit, exist
141
142 def evaluate(self, outputs, res_folder, metric='PCKh', **kwargs):
143 """Evaluate PCKh for MPII-TRB dataset.
144
145 Note:
146 batch_size: N
147 num_keypoints: K
148 heatmap height: H
149 heatmap width: W
150
151 Args:
152 outputs(list(preds, boxes, image_path, heatmap)):
153
154 * preds(np.ndarray[1,K,3]): The first two dimensions are
155 coordinates, score is the third dimension of the array.
156 * boxes(np.ndarray[1,6]): [center[0], center[1], scale[0]
157 , scale[1],area, score]
158 * image_path(list[str]): For example, ['0', '0',
159 '0', '0', '0', '1', '1', '6', '3', '.', 'j', 'p', 'g']
160 * heatmap (np.ndarray[N, K, H, W]): model output heatmap.
161 res_folder(str): Path of directory to save the results.
162 metric (str | list[str]): Metrics to be performed.
163 Defaults: 'PCKh'.
164
165 Returns:
166 dict: PCKh for each joint
167 """
168 metrics = metric if isinstance(metric, list) else [metric]
169 allowed_metrics = ['PCKh']
170 for metric in metrics:
171 if metric not in allowed_metrics:
172 raise KeyError(f'metric {metric} is not supported')
173 """Evaluate MPII-TRB keypoint results."""
174 res_file = os.path.join(res_folder, 'result_keypoints.json')
175
176 kpts = []
177
178 for preds, boxes, image_path, _ in outputs:
179 str_image_path = ''.join(image_path)
180 image_id = int(osp.basename(osp.splitext(str_image_path)[0]))
181
182 kpts.append({
183 'keypoints': preds[0].tolist(),
184 'center': boxes[0][0:2].tolist(),
185 'scale': boxes[0][2:4].tolist(),
186 'area': float(boxes[0][4]),
187 'score': float(boxes[0][5]),
188 'image_id': image_id,
189 })
190
191 self._write_keypoint_results(kpts, res_file)
192 info_str = self._report_metric(res_file)
193 name_value = OrderedDict(info_str)
194
195 return name_value
196
197 @staticmethod
198 def _write_keypoint_results(keypoints, res_file):
199 """Write results into a json file."""
200
201 with open(res_file, 'w') as f:
202 json.dump(keypoints, f, sort_keys=True, indent=4)
203
204 def _report_metric(self, res_file):
205 """Keypoint evaluation.
206
207 Report Mean Acc of skeleton, contour and all joints.
208 """
209 num_joints = self.ann_info['num_joints']
210 hit = np.zeros(num_joints, dtype=np.float32)
211 exist = np.zeros(num_joints, dtype=np.float32)
212
213 with open(res_file, 'r') as fin:
214 preds = json.load(fin)
215
216 assert len(preds) == len(
217 self.db), f'len(preds)={len(preds)}, len(self.db)={len(self.db)}'
218 for pred, item in zip(preds, self.db):
219 h, e = self._evaluate_kernel(pred['keypoints'], item['joints_3d'],
220 item['joints_3d_visible'],
221 item['headbox'])
222 hit += h
223 exist += e
224 skeleton = np.sum(hit[:14]) / np.sum(exist[:14])
225 contour = np.sum(hit[14:]) / np.sum(exist[14:])
226 mean = np.sum(hit) / np.sum(exist)
227
228 info_str = []
229 info_str.append(('Skeleton_acc', skeleton.item()))
230 info_str.append(('Contour_acc', contour.item()))
231 info_str.append(('PCKh', mean.item()))
232 return info_str
233
[end of mmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py b/mmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py
--- a/mmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py
+++ b/mmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py
@@ -170,7 +170,7 @@
for metric in metrics:
if metric not in allowed_metrics:
raise KeyError(f'metric {metric} is not supported')
- """Evaluate MPII-TRB keypoint results."""
+
res_file = os.path.join(res_folder, 'result_keypoints.json')
kpts = []
|
{"golden_diff": "diff --git a/mmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py b/mmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py\n--- a/mmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py\n+++ b/mmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py\n@@ -170,7 +170,7 @@\n for metric in metrics:\n if metric not in allowed_metrics:\n raise KeyError(f'metric {metric} is not supported')\n- \"\"\"Evaluate MPII-TRB keypoint results.\"\"\"\n+\n res_file = os.path.join(res_folder, 'result_keypoints.json')\n \n kpts = []\n", "issue": "Pylint: W0105\n```bash\r\nmmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py:173:8: W0105: String statement has no effect (pointless-string-statement)\r\n```\n", "before_files": [{"content": "import copy as cp\nimport os\nimport os.path as osp\nfrom collections import OrderedDict\n\nimport json_tricks as json\nimport numpy as np\n\nfrom mmpose.datasets.builder import DATASETS\nfrom .topdown_base_dataset import TopDownBaseDataset\n\n\[email protected]_module()\nclass TopDownMpiiTrbDataset(TopDownBaseDataset):\n \"\"\"MPII-TRB Dataset dataset for top-down pose estimation.\n\n `TRB: A Novel Triplet Representation for Understanding 2D Human Body`\n ICCV'2019 More details can be found in the `paper\n <https://arxiv.org/abs/1910.11535>`__ .\n\n The dataset loads raw features and apply specified transforms\n to return a dict containing the image tensors and other information.\n\n Args:\n ann_file (str): Path to the annotation file.\n img_prefix (str): Path to a directory where images are held.\n Default: None.\n data_cfg (dict): config\n pipeline (list[dict | callable]): A sequence of data transforms.\n test_mode (bool): Store True when building test or\n validation dataset. Default: False.\n \"\"\"\n\n def __init__(self,\n ann_file,\n img_prefix,\n data_cfg,\n pipeline,\n test_mode=False):\n\n super().__init__(\n ann_file, img_prefix, data_cfg, pipeline, test_mode=test_mode)\n\n # flip_pairs in MPII-TRB\n self.ann_info['flip_pairs'] = [[0, 1], [2, 3], [4, 5], [6, 7], [8, 9],\n [10, 11], [14, 15]]\n for i in range(6):\n self.ann_info['flip_pairs'].append([16 + i, 22 + i])\n self.ann_info['flip_pairs'].append([28 + i, 34 + i])\n\n self.ann_info['upper_body_ids'] = [0, 1, 2, 3, 4, 5, 12, 13]\n self.ann_info['lower_body_ids'] = [6, 7, 8, 9, 10, 11]\n self.ann_info['upper_body_ids'].extend(list(range(14, 28)))\n self.ann_info['lower_body_ids'].extend(list(range(28, 40)))\n\n self.ann_info['use_different_joint_weights'] = False\n\n assert self.ann_info['num_joints'] == 40\n self.ann_info['joint_weights'] = np.ones(\n (self.ann_info['num_joints'], 1), dtype=np.float32)\n\n self.db = self._get_db(ann_file)\n self.image_set = set(x['image_file'] for x in self.db)\n self.num_images = len(self.image_set)\n\n print(f'=> num_images: {self.num_images}')\n print(f'=> load {len(self.db)} samples')\n\n def _get_db(self, ann_file):\n \"\"\"Load dataset.\"\"\"\n with open(ann_file, 'r') as f:\n data = json.load(f)\n tmpl = dict(\n image_file=None,\n center=None,\n scale=None,\n rotation=0,\n joints_3d=None,\n joints_3d_visible=None,\n dataset='mpii_trb')\n\n imid2info = {\n int(osp.splitext(x['file_name'])[0]): x\n for x in data['images']\n }\n\n num_joints = self.ann_info['num_joints']\n gt_db = []\n\n for anno in data['annotations']:\n newitem = cp.deepcopy(tmpl)\n image_id = anno['image_id']\n newitem['image_file'] = os.path.join(\n self.img_prefix, imid2info[image_id]['file_name'])\n\n if max(anno['keypoints']) == 0:\n continue\n\n joints_3d = np.zeros((num_joints, 3), dtype=np.float32)\n joints_3d_visible = np.zeros((num_joints, 3), dtype=np.float32)\n\n for ipt in range(num_joints):\n joints_3d[ipt, 0] = anno['keypoints'][ipt * 3 + 0]\n joints_3d[ipt, 1] = anno['keypoints'][ipt * 3 + 1]\n joints_3d[ipt, 2] = 0\n t_vis = min(anno['keypoints'][ipt * 3 + 2], 1)\n joints_3d_visible[ipt, :] = (t_vis, t_vis, 0)\n\n center = np.array(anno['center'], dtype=np.float32)\n scale = self.ann_info['image_size'] / anno['scale'] / 200.0\n newitem['center'] = center\n newitem['scale'] = scale\n newitem['joints_3d'] = joints_3d\n newitem['joints_3d_visible'] = joints_3d_visible\n if 'headbox' in anno:\n newitem['headbox'] = anno['headbox']\n gt_db.append(newitem)\n\n return gt_db\n\n def _evaluate_kernel(self, pred, joints_3d, joints_3d_visible, headbox):\n \"\"\"Evaluate one example.\"\"\"\n num_joints = self.ann_info['num_joints']\n headbox = np.array(headbox)\n threshold = np.linalg.norm(headbox[:2] - headbox[2:]) * 0.3\n hit = np.zeros(num_joints, dtype=np.float32)\n exist = np.zeros(num_joints, dtype=np.float32)\n\n for i in range(num_joints):\n pred_pt = pred[i]\n gt_pt = joints_3d[i]\n vis = joints_3d_visible[i][0]\n if vis:\n exist[i] = 1\n else:\n continue\n distance = np.linalg.norm(pred_pt[:2] - gt_pt[:2])\n if distance < threshold:\n hit[i] = 1\n return hit, exist\n\n def evaluate(self, outputs, res_folder, metric='PCKh', **kwargs):\n \"\"\"Evaluate PCKh for MPII-TRB dataset.\n\n Note:\n batch_size: N\n num_keypoints: K\n heatmap height: H\n heatmap width: W\n\n Args:\n outputs(list(preds, boxes, image_path, heatmap)):\n\n * preds(np.ndarray[1,K,3]): The first two dimensions are\n coordinates, score is the third dimension of the array.\n * boxes(np.ndarray[1,6]): [center[0], center[1], scale[0]\n , scale[1],area, score]\n * image_path(list[str]): For example, ['0', '0',\n '0', '0', '0', '1', '1', '6', '3', '.', 'j', 'p', 'g']\n * heatmap (np.ndarray[N, K, H, W]): model output heatmap.\n res_folder(str): Path of directory to save the results.\n metric (str | list[str]): Metrics to be performed.\n Defaults: 'PCKh'.\n\n Returns:\n dict: PCKh for each joint\n \"\"\"\n metrics = metric if isinstance(metric, list) else [metric]\n allowed_metrics = ['PCKh']\n for metric in metrics:\n if metric not in allowed_metrics:\n raise KeyError(f'metric {metric} is not supported')\n \"\"\"Evaluate MPII-TRB keypoint results.\"\"\"\n res_file = os.path.join(res_folder, 'result_keypoints.json')\n\n kpts = []\n\n for preds, boxes, image_path, _ in outputs:\n str_image_path = ''.join(image_path)\n image_id = int(osp.basename(osp.splitext(str_image_path)[0]))\n\n kpts.append({\n 'keypoints': preds[0].tolist(),\n 'center': boxes[0][0:2].tolist(),\n 'scale': boxes[0][2:4].tolist(),\n 'area': float(boxes[0][4]),\n 'score': float(boxes[0][5]),\n 'image_id': image_id,\n })\n\n self._write_keypoint_results(kpts, res_file)\n info_str = self._report_metric(res_file)\n name_value = OrderedDict(info_str)\n\n return name_value\n\n @staticmethod\n def _write_keypoint_results(keypoints, res_file):\n \"\"\"Write results into a json file.\"\"\"\n\n with open(res_file, 'w') as f:\n json.dump(keypoints, f, sort_keys=True, indent=4)\n\n def _report_metric(self, res_file):\n \"\"\"Keypoint evaluation.\n\n Report Mean Acc of skeleton, contour and all joints.\n \"\"\"\n num_joints = self.ann_info['num_joints']\n hit = np.zeros(num_joints, dtype=np.float32)\n exist = np.zeros(num_joints, dtype=np.float32)\n\n with open(res_file, 'r') as fin:\n preds = json.load(fin)\n\n assert len(preds) == len(\n self.db), f'len(preds)={len(preds)}, len(self.db)={len(self.db)}'\n for pred, item in zip(preds, self.db):\n h, e = self._evaluate_kernel(pred['keypoints'], item['joints_3d'],\n item['joints_3d_visible'],\n item['headbox'])\n hit += h\n exist += e\n skeleton = np.sum(hit[:14]) / np.sum(exist[:14])\n contour = np.sum(hit[14:]) / np.sum(exist[14:])\n mean = np.sum(hit) / np.sum(exist)\n\n info_str = []\n info_str.append(('Skeleton_acc', skeleton.item()))\n info_str.append(('Contour_acc', contour.item()))\n info_str.append(('PCKh', mean.item()))\n return info_str\n", "path": "mmpose/datasets/datasets/top_down/topdown_mpii_trb_dataset.py"}]}
| 3,426 | 157 |
gh_patches_debug_4753
|
rasdani/github-patches
|
git_diff
|
apache__tvm-16388
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bugfix] Disable SingleEnvThreadVerifier
During TensorIR scheduling, the `IterVar`s that represent environment threads may duplicate, i.e. it is legal to have two env threads with the same name tag, which may fail the `SingleEnvThreadVerifier` check during schedule creation. This PR disables this check in this case. In the future, it may be worthwhile to bring it back against post-scheduling TIR.
It's related to [this commit](https://github.com/apache/tvm/commit/eb15d04c3bff76062e26d5647fb8af0323de1bed). CC: @jinhongyii @Lunderberg
</issue>
<code>
[start of python/tvm/relax/backend/dispatch_sort_scan.py]
1 # Licensed to the Apache Software Foundation (ASF) under one
2 # or more contributor license agreements. See the NOTICE file
3 # distributed with this work for additional information
4 # regarding copyright ownership. The ASF licenses this file
5 # to you under the Apache License, Version 2.0 (the
6 # "License"); you may not use this file except in compliance
7 # with the License. You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing,
12 # software distributed under the License is distributed on an
13 # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
14 # KIND, either express or implied. See the License for the
15 # specific language governing permissions and limitations
16 # under the License.
17 # pylint: disable=invalid-name, unused-argument, redefined-argument-from-local
18 """Dispatch sort and scan operators to platform dependent implementation."""
19
20 from tvm import topi, dlight, relax
21 from tvm.ir import Op
22 from tvm.ir.module import IRModule
23 from tvm.ir.transform import PassContext, module_pass
24 from tvm.target import Target
25 from tvm.contrib.thrust import can_use_thrust
26 from tvm.relax import PyExprMutator, expr_functor
27
28
29 @expr_functor.mutator
30 class SortScanDispatcher(PyExprMutator):
31 """
32 Dispatcher to dispatch sort and scan.
33
34 """
35
36 def __init__(self, mod):
37 super().__init__(mod)
38
39 def _get_target(self, sinfo: relax.StructInfo) -> Target:
40 # Get target information from TensorStructInfo
41 if isinstance(sinfo, relax.TensorStructInfo):
42 vdevice = sinfo.vdevice
43 if vdevice is not None:
44 return vdevice.target
45 elif isinstance(sinfo, relax.TupleStructInfo):
46 for f in sinfo.fields:
47 tgt = self._get_target(f)
48 if tgt != Target.current():
49 return tgt
50 # Return the target in current context
51 target = Target.current()
52 if target is None:
53 raise ValueError(
54 "Target not found. Please ensure that the target is annotated within the module, "
55 "or alternatively, execute this within a specified target context."
56 )
57 return target
58
59 def _apply_dlight_gpu_fallback(self, target: Target, tir_call: relax.Call) -> None:
60 # Apply dlight.gpu.Fallback() on GPU
61 gvar = tir_call.args[0]
62 assert isinstance(gvar, relax.GlobalVar)
63 scan_prim_func = self.builder_.get()[gvar]
64 sch = dlight.base.transform._apply_rules(
65 scan_prim_func,
66 target,
67 [
68 dlight.gpu.Fallback(),
69 ],
70 False,
71 )
72 if sch is not None:
73 assert len(sch) == 1
74 self.builder_.update_func(gvar, sch[0].mod["main"].with_attr("tir.is_scheduled", 1))
75
76 def visit_call_(self, call: relax.Call) -> relax.Expr:
77 if not isinstance(call.op, Op):
78 return super().visit_call_(call)
79
80 if call.op.name == "relax.sort":
81 tgt = self._get_target(call.struct_info)
82 te_func = topi.sort
83 with tgt:
84 if can_use_thrust(tgt, "tvm.contrib.thrust.sort"):
85 te_func = topi.cuda.sort_thrust
86 elif tgt.kind.name == "cuda":
87 te_func = topi.cuda.sort
88 return self.builder_.call_te(
89 te_func,
90 call.args[0],
91 call.attrs.axis,
92 not call.attrs.descending,
93 )
94 if call.op.name == "relax.argsort":
95 tgt = self._get_target(call.struct_info)
96 te_func = topi.argsort
97 with tgt:
98 if can_use_thrust(tgt, "tvm.contrib.thrust.sort"):
99 te_func = topi.cuda.argsort_thrust
100 elif tgt.kind.name == "cuda":
101 te_func = topi.cuda.argsort
102 return self.builder_.call_te(
103 te_func,
104 call.args[0],
105 axis=call.attrs.axis,
106 is_ascend=not call.attrs.descending,
107 dtype=call.attrs.dtype,
108 )
109 if call.op.name == "relax.topk":
110 tgt = self._get_target(call.struct_info)
111 te_func = topi.topk
112 if can_use_thrust(tgt, "tvm.contrib.thrust.sort"):
113 te_func = topi.cuda.topk_thrust
114 elif tgt.kind.name == "cuda":
115 te_func = topi.cuda.topk
116 tir_call = self.builder_.call_te(
117 te_func,
118 call.args[0],
119 axis=call.attrs.axis,
120 ret_type=call.attrs.ret_type,
121 is_ascend=not call.attrs.largest,
122 dtype=call.attrs.dtype,
123 )
124 if tgt.kind.name != "cuda":
125 return tir_call
126 # apply dlight gpu fallback
127 self._apply_dlight_gpu_fallback(tgt, tir_call)
128 return tir_call
129 if call.op.name in ("relax.cumprod", "relax.cumsum"):
130 tgt = self._get_target(call.struct_info)
131 axis = int(call.attrs.axis) if call.attrs.axis is not None else call.attrs.axis
132 te_func = topi.cuda.cumsum if tgt.kind.name == "cuda" else topi.cumsum
133 if call.op.name == "relax.cumprod":
134 te_func = topi.cuda.cumprod if tgt.kind.name == "cuda" else topi.cumprod
135 tir_call = self.builder_.call_te(
136 te_func,
137 call.args[0],
138 axis,
139 call.attrs.dtype,
140 call.attrs.exclusive,
141 )
142 if tgt.kind.name != "cuda":
143 return tir_call
144 # apply dlight gpu fallback
145 self._apply_dlight_gpu_fallback(tgt, tir_call)
146 return tir_call
147 return super().visit_call_(call)
148
149
150 @module_pass(opt_level=0, name="DispatchSortScan")
151 class DispatchSortScan:
152 """
153 Pass to dispatch scan and sort operators to platform dependent implementation.
154 """
155
156 def transform_module(self, mod: IRModule, ctx: PassContext) -> IRModule:
157 sort_scan_dispater = SortScanDispatcher(mod)
158 for gv, func in mod.functions_items():
159 if isinstance(func, relax.Function):
160 func = sort_scan_dispater.visit_expr(func)
161 sort_scan_dispater.builder_.update_func(gv, func)
162 return sort_scan_dispater.builder_.finalize()
163
[end of python/tvm/relax/backend/dispatch_sort_scan.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/python/tvm/relax/backend/dispatch_sort_scan.py b/python/tvm/relax/backend/dispatch_sort_scan.py
--- a/python/tvm/relax/backend/dispatch_sort_scan.py
+++ b/python/tvm/relax/backend/dispatch_sort_scan.py
@@ -116,6 +116,7 @@
tir_call = self.builder_.call_te(
te_func,
call.args[0],
+ k=call.attrs.k,
axis=call.attrs.axis,
ret_type=call.attrs.ret_type,
is_ascend=not call.attrs.largest,
|
{"golden_diff": "diff --git a/python/tvm/relax/backend/dispatch_sort_scan.py b/python/tvm/relax/backend/dispatch_sort_scan.py\n--- a/python/tvm/relax/backend/dispatch_sort_scan.py\n+++ b/python/tvm/relax/backend/dispatch_sort_scan.py\n@@ -116,6 +116,7 @@\n tir_call = self.builder_.call_te(\n te_func,\n call.args[0],\n+ k=call.attrs.k,\n axis=call.attrs.axis,\n ret_type=call.attrs.ret_type,\n is_ascend=not call.attrs.largest,\n", "issue": "[Bugfix] Disable SingleEnvThreadVerifier\nDuring TensorIR scheduling, the `IterVar`s that represent environment threads may duplicate, i.e. it is legal to have two env threads with the same name tag, which may fail the `SingleEnvThreadVerifier` check during schedule creation. This PR disables this check in this case. In the future, it may be worthwhile to bring it back against post-scheduling TIR.\r\n\r\nIt's related to [this commit](https://github.com/apache/tvm/commit/eb15d04c3bff76062e26d5647fb8af0323de1bed). CC: @jinhongyii @Lunderberg \n", "before_files": [{"content": "# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n# pylint: disable=invalid-name, unused-argument, redefined-argument-from-local\n\"\"\"Dispatch sort and scan operators to platform dependent implementation.\"\"\"\n\nfrom tvm import topi, dlight, relax\nfrom tvm.ir import Op\nfrom tvm.ir.module import IRModule\nfrom tvm.ir.transform import PassContext, module_pass\nfrom tvm.target import Target\nfrom tvm.contrib.thrust import can_use_thrust\nfrom tvm.relax import PyExprMutator, expr_functor\n\n\n@expr_functor.mutator\nclass SortScanDispatcher(PyExprMutator):\n \"\"\"\n Dispatcher to dispatch sort and scan.\n\n \"\"\"\n\n def __init__(self, mod):\n super().__init__(mod)\n\n def _get_target(self, sinfo: relax.StructInfo) -> Target:\n # Get target information from TensorStructInfo\n if isinstance(sinfo, relax.TensorStructInfo):\n vdevice = sinfo.vdevice\n if vdevice is not None:\n return vdevice.target\n elif isinstance(sinfo, relax.TupleStructInfo):\n for f in sinfo.fields:\n tgt = self._get_target(f)\n if tgt != Target.current():\n return tgt\n # Return the target in current context\n target = Target.current()\n if target is None:\n raise ValueError(\n \"Target not found. Please ensure that the target is annotated within the module, \"\n \"or alternatively, execute this within a specified target context.\"\n )\n return target\n\n def _apply_dlight_gpu_fallback(self, target: Target, tir_call: relax.Call) -> None:\n # Apply dlight.gpu.Fallback() on GPU\n gvar = tir_call.args[0]\n assert isinstance(gvar, relax.GlobalVar)\n scan_prim_func = self.builder_.get()[gvar]\n sch = dlight.base.transform._apply_rules(\n scan_prim_func,\n target,\n [\n dlight.gpu.Fallback(),\n ],\n False,\n )\n if sch is not None:\n assert len(sch) == 1\n self.builder_.update_func(gvar, sch[0].mod[\"main\"].with_attr(\"tir.is_scheduled\", 1))\n\n def visit_call_(self, call: relax.Call) -> relax.Expr:\n if not isinstance(call.op, Op):\n return super().visit_call_(call)\n\n if call.op.name == \"relax.sort\":\n tgt = self._get_target(call.struct_info)\n te_func = topi.sort\n with tgt:\n if can_use_thrust(tgt, \"tvm.contrib.thrust.sort\"):\n te_func = topi.cuda.sort_thrust\n elif tgt.kind.name == \"cuda\":\n te_func = topi.cuda.sort\n return self.builder_.call_te(\n te_func,\n call.args[0],\n call.attrs.axis,\n not call.attrs.descending,\n )\n if call.op.name == \"relax.argsort\":\n tgt = self._get_target(call.struct_info)\n te_func = topi.argsort\n with tgt:\n if can_use_thrust(tgt, \"tvm.contrib.thrust.sort\"):\n te_func = topi.cuda.argsort_thrust\n elif tgt.kind.name == \"cuda\":\n te_func = topi.cuda.argsort\n return self.builder_.call_te(\n te_func,\n call.args[0],\n axis=call.attrs.axis,\n is_ascend=not call.attrs.descending,\n dtype=call.attrs.dtype,\n )\n if call.op.name == \"relax.topk\":\n tgt = self._get_target(call.struct_info)\n te_func = topi.topk\n if can_use_thrust(tgt, \"tvm.contrib.thrust.sort\"):\n te_func = topi.cuda.topk_thrust\n elif tgt.kind.name == \"cuda\":\n te_func = topi.cuda.topk\n tir_call = self.builder_.call_te(\n te_func,\n call.args[0],\n axis=call.attrs.axis,\n ret_type=call.attrs.ret_type,\n is_ascend=not call.attrs.largest,\n dtype=call.attrs.dtype,\n )\n if tgt.kind.name != \"cuda\":\n return tir_call\n # apply dlight gpu fallback\n self._apply_dlight_gpu_fallback(tgt, tir_call)\n return tir_call\n if call.op.name in (\"relax.cumprod\", \"relax.cumsum\"):\n tgt = self._get_target(call.struct_info)\n axis = int(call.attrs.axis) if call.attrs.axis is not None else call.attrs.axis\n te_func = topi.cuda.cumsum if tgt.kind.name == \"cuda\" else topi.cumsum\n if call.op.name == \"relax.cumprod\":\n te_func = topi.cuda.cumprod if tgt.kind.name == \"cuda\" else topi.cumprod\n tir_call = self.builder_.call_te(\n te_func,\n call.args[0],\n axis,\n call.attrs.dtype,\n call.attrs.exclusive,\n )\n if tgt.kind.name != \"cuda\":\n return tir_call\n # apply dlight gpu fallback\n self._apply_dlight_gpu_fallback(tgt, tir_call)\n return tir_call\n return super().visit_call_(call)\n\n\n@module_pass(opt_level=0, name=\"DispatchSortScan\")\nclass DispatchSortScan:\n \"\"\"\n Pass to dispatch scan and sort operators to platform dependent implementation.\n \"\"\"\n\n def transform_module(self, mod: IRModule, ctx: PassContext) -> IRModule:\n sort_scan_dispater = SortScanDispatcher(mod)\n for gv, func in mod.functions_items():\n if isinstance(func, relax.Function):\n func = sort_scan_dispater.visit_expr(func)\n sort_scan_dispater.builder_.update_func(gv, func)\n return sort_scan_dispater.builder_.finalize()\n", "path": "python/tvm/relax/backend/dispatch_sort_scan.py"}]}
| 2,491 | 129 |
gh_patches_debug_21967
|
rasdani/github-patches
|
git_diff
|
prowler-cloud__prowler-2772
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug]: iam_policy_allows_privilege_escalation is raising false positives
### Steps to Reproduce
When looking at the scan results for "Ensure no Customer Managed IAM policies allow actions that may lead into Privilege Escalation" it look like we are getting bad results for it now using Prowler version 3.8.2.
If I run a scan on an AWS IAM policy defined with the below json I get the failure -
_Custom Policy arn:aws:iam::xxxxxxxxxxx:policy/app-user-policy-hertzcp-pprd allows privilege escalation using the following actions: {'iam:CreateAccessKey'}_
The below is the AWS IAM policy json that it scanned and as you can see the policy does not have 'iam:CreateAccessKey' within it :
```
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Action": [
"es:List*",
"es:Get*",
"es:Describe*"
],
"Resource": "*"
},
{
"Sid": "",
"Effect": "Allow",
"Action": "es:*",
"Resource": "arn:aws:es:us-west-2:xxxxxxxxxxxx:domain/g-clients-infra-pprd/*"
}
]
}
```
When I used prowler version 3.4.1 it did not find/report on the above issue.
Also -
Prowler version 3.8.2 now reports the below policy as passing for "Ensure no Customer Managed IAM policies allow actions that may lead into Privilege Escalation" :
```
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "arn:aws:iam::*:role/xena-role"
}
]
}
```
When a scan using prowler version 3.4.1 was run the above policy was reported as a failure for "Ensure no Customer Managed IAM policies allow actions that may lead into Privilege Escalation".
I would believe that this policy should still be reported as a failure and that Prowler version 3.8.2 has issues.
### Expected behavior
The first policy should pass and the second policy should fail.
### Actual Result with Screenshots or Logs
[prowler-output-741743798098-20230823103540.csv](https://github.com/prowler-cloud/prowler/files/12421414/prowler-output-741743798098-20230823103540.csv)
### How did you install Prowler?
From pip package (pip install prowler)
### Environment Resource
EKS and ran the scan locally
### OS used
MacOS
### Prowler version
3.8.2
### Pip version
21.1.3
### Context
_No response_
</issue>
<code>
[start of prowler/providers/aws/services/iam/iam_policy_allows_privilege_escalation/iam_policy_allows_privilege_escalation.py]
1 from re import search
2
3 from prowler.lib.check.models import Check, Check_Report_AWS
4 from prowler.providers.aws.services.iam.iam_client import iam_client
5
6 # Does the tool analyze both users and roles, or just one or the other? --> Everything using AttachementCount.
7 # Does the tool take a principal-centric or policy-centric approach? --> Policy-centric approach.
8 # Does the tool handle resource constraints? --> We don't check if the policy affects all resources or not, we check everything.
9 # Does the tool consider the permissions of service roles? --> Just checks policies.
10 # Does the tool handle transitive privesc paths (i.e., attack chains)? --> Not yet.
11 # Does the tool handle the DENY effect as expected? --> Yes, it checks DENY's statements with Action and NotAction.
12 # Does the tool handle NotAction as expected? --> Yes
13 # Does the tool handle Condition constraints? --> Not yet.
14 # Does the tool handle service control policy (SCP) restrictions? --> No, SCP are within Organizations AWS API.
15
16 # Based on:
17 # - https://bishopfox.com/blog/privilege-escalation-in-aws
18 # - https://github.com/RhinoSecurityLabs/Security-Research/blob/master/tools/aws-pentest-tools/aws_escalate.py
19 # - https://rhinosecuritylabs.com/aws/aws-privilege-escalation-methods-mitigation/
20
21
22 class iam_policy_allows_privilege_escalation(Check):
23 def execute(self) -> Check_Report_AWS:
24 privilege_escalation_policies_combination = {
25 "CreatePolicyVersion": {"iam:CreatePolicyVersion"},
26 "SetDefaultPolicyVersion": {"iam:SetDefaultPolicyVersion"},
27 "iam:PassRole": {"iam:PassRole"},
28 "PassRole+EC2": {
29 "iam:PassRole",
30 "ec2:RunInstances",
31 },
32 "PassRole+CreateLambda+Invoke": {
33 "iam:PassRole",
34 "lambda:CreateFunction",
35 "lambda:InvokeFunction",
36 },
37 "PassRole+CreateLambda+ExistingDynamo": {
38 "iam:PassRole",
39 "lambda:CreateFunction",
40 "lambda:CreateEventSourceMapping",
41 },
42 "PassRole+CreateLambda+NewDynamo": {
43 "iam:PassRole",
44 "lambda:CreateFunction",
45 "lambda:CreateEventSourceMapping",
46 "dynamodb:CreateTable",
47 "dynamodb:PutItem",
48 },
49 "PassRole+GlueEndpoint": {
50 "iam:PassRole",
51 "glue:CreateDevEndpoint",
52 "glue:GetDevEndpoint",
53 },
54 "PassRole+GlueEndpoints": {
55 "iam:PassRole",
56 "glue:CreateDevEndpoint",
57 "glue:GetDevEndpoints",
58 },
59 "PassRole+CloudFormation": {
60 "cloudformation:CreateStack",
61 "cloudformation:DescribeStacks",
62 },
63 "PassRole+DataPipeline": {
64 "datapipeline:CreatePipeline",
65 "datapipeline:PutPipelineDefinition",
66 "datapipeline:ActivatePipeline",
67 },
68 "GlueUpdateDevEndpoint": {"glue:UpdateDevEndpoint"},
69 "GlueUpdateDevEndpoints": {"glue:UpdateDevEndpoint"},
70 "lambda:UpdateFunctionCode": {"lambda:UpdateFunctionCode"},
71 "iam:CreateAccessKey": {"iam:CreateAccessKey"},
72 "iam:CreateLoginProfile": {"iam:CreateLoginProfile"},
73 "iam:UpdateLoginProfile": {"iam:UpdateLoginProfile"},
74 "iam:AttachUserPolicy": {"iam:AttachUserPolicy"},
75 "iam:AttachGroupPolicy": {"iam:AttachGroupPolicy"},
76 "iam:AttachRolePolicy": {"iam:AttachRolePolicy"},
77 "AssumeRole+AttachRolePolicy": {"sts:AssumeRole", "iam:AttachRolePolicy"},
78 "iam:PutGroupPolicy": {"iam:PutGroupPolicy"},
79 "iam:PutRolePolicy": {"iam:PutRolePolicy"},
80 "AssumeRole+PutRolePolicy": {"sts:AssumeRole", "iam:PutRolePolicy"},
81 "iam:PutUserPolicy": {"iam:PutUserPolicy"},
82 "iam:AddUserToGroup": {"iam:AddUserToGroup"},
83 "iam:UpdateAssumeRolePolicy": {"iam:UpdateAssumeRolePolicy"},
84 "AssumeRole+UpdateAssumeRolePolicy": {
85 "sts:AssumeRole",
86 "iam:UpdateAssumeRolePolicy",
87 },
88 # TO-DO: We have to handle AssumeRole just if the resource is * and without conditions
89 # "sts:AssumeRole": {"sts:AssumeRole"},
90 }
91
92 findings = []
93
94 # Iterate over all the IAM "Customer Managed" policies
95 for policy in iam_client.policies:
96 if policy.type == "Custom":
97 report = Check_Report_AWS(self.metadata())
98 report.resource_id = policy.name
99 report.resource_arn = policy.arn
100 report.region = iam_client.region
101 report.resource_tags = policy.tags
102 report.status = "PASS"
103 report.status_extended = f"Custom Policy {report.resource_arn} does not allow privilege escalation."
104
105 # List of policy actions
106 allowed_actions = set()
107 denied_actions = set()
108 denied_not_actions = set()
109
110 # Recover all policy actions
111 if policy.document:
112 if not isinstance(policy.document["Statement"], list):
113 policy_statements = [policy.document["Statement"]]
114 else:
115 policy_statements = policy.document["Statement"]
116 for statements in policy_statements:
117 # Recover allowed actions
118 if statements["Effect"] == "Allow":
119 if "Action" in statements:
120 if type(statements["Action"]) is str:
121 allowed_actions.add(statements["Action"])
122 if type(statements["Action"]) is list:
123 allowed_actions.update(statements["Action"])
124
125 # Recover denied actions
126 if statements["Effect"] == "Deny":
127 if "Action" in statements:
128 if type(statements["Action"]) is str:
129 denied_actions.add(statements["Action"])
130 if type(statements["Action"]) is list:
131 denied_actions.update(statements["Action"])
132
133 if "NotAction" in statements:
134 if type(statements["NotAction"]) is str:
135 denied_not_actions.add(statements["NotAction"])
136 if type(statements["NotAction"]) is list:
137 denied_not_actions.update(statements["NotAction"])
138
139 # First, we need to perform a left join with ALLOWED_ACTIONS and DENIED_ACTIONS
140 left_actions = allowed_actions.difference(denied_actions)
141 # Then, we need to find the DENIED_NOT_ACTIONS in LEFT_ACTIONS
142 if denied_not_actions:
143 privileged_actions = left_actions.intersection(
144 denied_not_actions
145 )
146 # If there is no Denied Not Actions
147 else:
148 privileged_actions = left_actions
149
150 # Store all the action's combinations
151 policies_combination = set()
152
153 for values in privilege_escalation_policies_combination.values():
154 for val in values:
155 val_set = set()
156 val_set.add(val)
157 # Look for specific api:action
158 if privileged_actions.intersection(val_set) == val_set:
159 policies_combination.add(val)
160 # Look for api:*
161 else:
162 for permission in privileged_actions:
163 # Here we have to handle if the api-action is admin, so "*"
164 api_action = permission.split(":")
165 # len() == 2, so api:action
166 if len(api_action) == 2:
167 api = api_action[0]
168 action = api_action[1]
169 # Add permissions if the API is present
170 if action == "*":
171 if search(api, val):
172 policies_combination.add(val)
173
174 # len() == 1, so *
175 elif len(api_action) == 1:
176 api = api_action[0]
177 # Add permissions if the API is present
178 if api == "*":
179 policies_combination.add(val)
180
181 # Check all policies combinations and see if matchs with some combo key
182 combos = set()
183 for (
184 key,
185 values,
186 ) in privilege_escalation_policies_combination.items():
187 intersection = policies_combination.intersection(values)
188 if intersection == values:
189 combos.add(key)
190
191 if len(combos) != 0:
192 report.status = "FAIL"
193 policies_affected = ""
194 for key in combos:
195 policies_affected += (
196 str(privilege_escalation_policies_combination[key])
197 + " "
198 )
199
200 report.status_extended = (
201 f"Custom Policy {report.resource_arn} allows privilege escalation using the following actions: {policies_affected}".rstrip()
202 + "."
203 )
204 findings.append(report)
205 return findings
206
[end of prowler/providers/aws/services/iam/iam_policy_allows_privilege_escalation/iam_policy_allows_privilege_escalation.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/prowler/providers/aws/services/iam/iam_policy_allows_privilege_escalation/iam_policy_allows_privilege_escalation.py b/prowler/providers/aws/services/iam/iam_policy_allows_privilege_escalation/iam_policy_allows_privilege_escalation.py
--- a/prowler/providers/aws/services/iam/iam_policy_allows_privilege_escalation/iam_policy_allows_privilege_escalation.py
+++ b/prowler/providers/aws/services/iam/iam_policy_allows_privilege_escalation/iam_policy_allows_privilege_escalation.py
@@ -1,5 +1,3 @@
-from re import search
-
from prowler.lib.check.models import Check, Check_Report_AWS
from prowler.providers.aws.services.iam.iam_client import iam_client
@@ -168,7 +166,8 @@
action = api_action[1]
# Add permissions if the API is present
if action == "*":
- if search(api, val):
+ val_api = val.split(":")[0]
+ if api == val_api:
policies_combination.add(val)
# len() == 1, so *
|
{"golden_diff": "diff --git a/prowler/providers/aws/services/iam/iam_policy_allows_privilege_escalation/iam_policy_allows_privilege_escalation.py b/prowler/providers/aws/services/iam/iam_policy_allows_privilege_escalation/iam_policy_allows_privilege_escalation.py\n--- a/prowler/providers/aws/services/iam/iam_policy_allows_privilege_escalation/iam_policy_allows_privilege_escalation.py\n+++ b/prowler/providers/aws/services/iam/iam_policy_allows_privilege_escalation/iam_policy_allows_privilege_escalation.py\n@@ -1,5 +1,3 @@\n-from re import search\n-\n from prowler.lib.check.models import Check, Check_Report_AWS\n from prowler.providers.aws.services.iam.iam_client import iam_client\n \n@@ -168,7 +166,8 @@\n action = api_action[1]\n # Add permissions if the API is present\n if action == \"*\":\n- if search(api, val):\n+ val_api = val.split(\":\")[0]\n+ if api == val_api:\n policies_combination.add(val)\n \n # len() == 1, so *\n", "issue": "[Bug]: iam_policy_allows_privilege_escalation is raising false positives\n### Steps to Reproduce\r\n\r\nWhen looking at the scan results for \"Ensure no Customer Managed IAM policies allow actions that may lead into Privilege Escalation\" it look like we are getting bad results for it now using Prowler version 3.8.2.\r\n\r\n\r\nIf I run a scan on an AWS IAM policy defined with the below json I get the failure -\r\n\r\n_Custom Policy arn:aws:iam::xxxxxxxxxxx:policy/app-user-policy-hertzcp-pprd allows privilege escalation using the following actions: {'iam:CreateAccessKey'}_\r\n\r\nThe below is the AWS IAM policy json that it scanned and as you can see the policy does not have 'iam:CreateAccessKey' within it :\r\n \r\n```\r\n{\r\n \"Version\": \"2012-10-17\",\r\n \"Statement\": [\r\n {\r\n \"Sid\": \"\",\r\n \"Effect\": \"Allow\",\r\n \"Action\": [\r\n \"es:List*\",\r\n \"es:Get*\",\r\n \"es:Describe*\"\r\n ],\r\n \"Resource\": \"*\"\r\n },\r\n {\r\n \"Sid\": \"\",\r\n \"Effect\": \"Allow\",\r\n \"Action\": \"es:*\",\r\n \"Resource\": \"arn:aws:es:us-west-2:xxxxxxxxxxxx:domain/g-clients-infra-pprd/*\"\r\n }\r\n ]\r\n}\r\n```\r\n\r\nWhen I used prowler version 3.4.1 it did not find/report on the above issue.\r\n\r\n\r\nAlso - \r\nProwler version 3.8.2 now reports the below policy as passing for \"Ensure no Customer Managed IAM policies allow actions that may lead into Privilege Escalation\" :\r\n\r\n```\r\n{\r\n \"Version\": \"2012-10-17\",\r\n \"Statement\": [\r\n {\r\n \"Sid\": \"\",\r\n \"Effect\": \"Allow\",\r\n \"Action\": \"sts:AssumeRole\",\r\n \"Resource\": \"arn:aws:iam::*:role/xena-role\"\r\n }\r\n ]\r\n}\r\n```\r\n\r\nWhen a scan using prowler version 3.4.1 was run the above policy was reported as a failure for \"Ensure no Customer Managed IAM policies allow actions that may lead into Privilege Escalation\". \r\nI would believe that this policy should still be reported as a failure and that Prowler version 3.8.2 has issues.\r\n\r\n### Expected behavior\r\n\r\nThe first policy should pass and the second policy should fail.\r\n\r\n### Actual Result with Screenshots or Logs\r\n\r\n[prowler-output-741743798098-20230823103540.csv](https://github.com/prowler-cloud/prowler/files/12421414/prowler-output-741743798098-20230823103540.csv)\r\n\r\n\r\n### How did you install Prowler?\r\n\r\nFrom pip package (pip install prowler)\r\n\r\n### Environment Resource\r\n\r\nEKS and ran the scan locally\r\n\r\n### OS used\r\n\r\nMacOS\r\n\r\n### Prowler version\r\n\r\n3.8.2\r\n\r\n### Pip version\r\n\r\n21.1.3\r\n\r\n### Context\r\n\r\n_No response_\n", "before_files": [{"content": "from re import search\n\nfrom prowler.lib.check.models import Check, Check_Report_AWS\nfrom prowler.providers.aws.services.iam.iam_client import iam_client\n\n# Does the tool analyze both users and roles, or just one or the other? --> Everything using AttachementCount.\n# Does the tool take a principal-centric or policy-centric approach? --> Policy-centric approach.\n# Does the tool handle resource constraints? --> We don't check if the policy affects all resources or not, we check everything.\n# Does the tool consider the permissions of service roles? --> Just checks policies.\n# Does the tool handle transitive privesc paths (i.e., attack chains)? --> Not yet.\n# Does the tool handle the DENY effect as expected? --> Yes, it checks DENY's statements with Action and NotAction.\n# Does the tool handle NotAction as expected? --> Yes\n# Does the tool handle Condition constraints? --> Not yet.\n# Does the tool handle service control policy (SCP) restrictions? --> No, SCP are within Organizations AWS API.\n\n# Based on:\n# - https://bishopfox.com/blog/privilege-escalation-in-aws\n# - https://github.com/RhinoSecurityLabs/Security-Research/blob/master/tools/aws-pentest-tools/aws_escalate.py\n# - https://rhinosecuritylabs.com/aws/aws-privilege-escalation-methods-mitigation/\n\n\nclass iam_policy_allows_privilege_escalation(Check):\n def execute(self) -> Check_Report_AWS:\n privilege_escalation_policies_combination = {\n \"CreatePolicyVersion\": {\"iam:CreatePolicyVersion\"},\n \"SetDefaultPolicyVersion\": {\"iam:SetDefaultPolicyVersion\"},\n \"iam:PassRole\": {\"iam:PassRole\"},\n \"PassRole+EC2\": {\n \"iam:PassRole\",\n \"ec2:RunInstances\",\n },\n \"PassRole+CreateLambda+Invoke\": {\n \"iam:PassRole\",\n \"lambda:CreateFunction\",\n \"lambda:InvokeFunction\",\n },\n \"PassRole+CreateLambda+ExistingDynamo\": {\n \"iam:PassRole\",\n \"lambda:CreateFunction\",\n \"lambda:CreateEventSourceMapping\",\n },\n \"PassRole+CreateLambda+NewDynamo\": {\n \"iam:PassRole\",\n \"lambda:CreateFunction\",\n \"lambda:CreateEventSourceMapping\",\n \"dynamodb:CreateTable\",\n \"dynamodb:PutItem\",\n },\n \"PassRole+GlueEndpoint\": {\n \"iam:PassRole\",\n \"glue:CreateDevEndpoint\",\n \"glue:GetDevEndpoint\",\n },\n \"PassRole+GlueEndpoints\": {\n \"iam:PassRole\",\n \"glue:CreateDevEndpoint\",\n \"glue:GetDevEndpoints\",\n },\n \"PassRole+CloudFormation\": {\n \"cloudformation:CreateStack\",\n \"cloudformation:DescribeStacks\",\n },\n \"PassRole+DataPipeline\": {\n \"datapipeline:CreatePipeline\",\n \"datapipeline:PutPipelineDefinition\",\n \"datapipeline:ActivatePipeline\",\n },\n \"GlueUpdateDevEndpoint\": {\"glue:UpdateDevEndpoint\"},\n \"GlueUpdateDevEndpoints\": {\"glue:UpdateDevEndpoint\"},\n \"lambda:UpdateFunctionCode\": {\"lambda:UpdateFunctionCode\"},\n \"iam:CreateAccessKey\": {\"iam:CreateAccessKey\"},\n \"iam:CreateLoginProfile\": {\"iam:CreateLoginProfile\"},\n \"iam:UpdateLoginProfile\": {\"iam:UpdateLoginProfile\"},\n \"iam:AttachUserPolicy\": {\"iam:AttachUserPolicy\"},\n \"iam:AttachGroupPolicy\": {\"iam:AttachGroupPolicy\"},\n \"iam:AttachRolePolicy\": {\"iam:AttachRolePolicy\"},\n \"AssumeRole+AttachRolePolicy\": {\"sts:AssumeRole\", \"iam:AttachRolePolicy\"},\n \"iam:PutGroupPolicy\": {\"iam:PutGroupPolicy\"},\n \"iam:PutRolePolicy\": {\"iam:PutRolePolicy\"},\n \"AssumeRole+PutRolePolicy\": {\"sts:AssumeRole\", \"iam:PutRolePolicy\"},\n \"iam:PutUserPolicy\": {\"iam:PutUserPolicy\"},\n \"iam:AddUserToGroup\": {\"iam:AddUserToGroup\"},\n \"iam:UpdateAssumeRolePolicy\": {\"iam:UpdateAssumeRolePolicy\"},\n \"AssumeRole+UpdateAssumeRolePolicy\": {\n \"sts:AssumeRole\",\n \"iam:UpdateAssumeRolePolicy\",\n },\n # TO-DO: We have to handle AssumeRole just if the resource is * and without conditions\n # \"sts:AssumeRole\": {\"sts:AssumeRole\"},\n }\n\n findings = []\n\n # Iterate over all the IAM \"Customer Managed\" policies\n for policy in iam_client.policies:\n if policy.type == \"Custom\":\n report = Check_Report_AWS(self.metadata())\n report.resource_id = policy.name\n report.resource_arn = policy.arn\n report.region = iam_client.region\n report.resource_tags = policy.tags\n report.status = \"PASS\"\n report.status_extended = f\"Custom Policy {report.resource_arn} does not allow privilege escalation.\"\n\n # List of policy actions\n allowed_actions = set()\n denied_actions = set()\n denied_not_actions = set()\n\n # Recover all policy actions\n if policy.document:\n if not isinstance(policy.document[\"Statement\"], list):\n policy_statements = [policy.document[\"Statement\"]]\n else:\n policy_statements = policy.document[\"Statement\"]\n for statements in policy_statements:\n # Recover allowed actions\n if statements[\"Effect\"] == \"Allow\":\n if \"Action\" in statements:\n if type(statements[\"Action\"]) is str:\n allowed_actions.add(statements[\"Action\"])\n if type(statements[\"Action\"]) is list:\n allowed_actions.update(statements[\"Action\"])\n\n # Recover denied actions\n if statements[\"Effect\"] == \"Deny\":\n if \"Action\" in statements:\n if type(statements[\"Action\"]) is str:\n denied_actions.add(statements[\"Action\"])\n if type(statements[\"Action\"]) is list:\n denied_actions.update(statements[\"Action\"])\n\n if \"NotAction\" in statements:\n if type(statements[\"NotAction\"]) is str:\n denied_not_actions.add(statements[\"NotAction\"])\n if type(statements[\"NotAction\"]) is list:\n denied_not_actions.update(statements[\"NotAction\"])\n\n # First, we need to perform a left join with ALLOWED_ACTIONS and DENIED_ACTIONS\n left_actions = allowed_actions.difference(denied_actions)\n # Then, we need to find the DENIED_NOT_ACTIONS in LEFT_ACTIONS\n if denied_not_actions:\n privileged_actions = left_actions.intersection(\n denied_not_actions\n )\n # If there is no Denied Not Actions\n else:\n privileged_actions = left_actions\n\n # Store all the action's combinations\n policies_combination = set()\n\n for values in privilege_escalation_policies_combination.values():\n for val in values:\n val_set = set()\n val_set.add(val)\n # Look for specific api:action\n if privileged_actions.intersection(val_set) == val_set:\n policies_combination.add(val)\n # Look for api:*\n else:\n for permission in privileged_actions:\n # Here we have to handle if the api-action is admin, so \"*\"\n api_action = permission.split(\":\")\n # len() == 2, so api:action\n if len(api_action) == 2:\n api = api_action[0]\n action = api_action[1]\n # Add permissions if the API is present\n if action == \"*\":\n if search(api, val):\n policies_combination.add(val)\n\n # len() == 1, so *\n elif len(api_action) == 1:\n api = api_action[0]\n # Add permissions if the API is present\n if api == \"*\":\n policies_combination.add(val)\n\n # Check all policies combinations and see if matchs with some combo key\n combos = set()\n for (\n key,\n values,\n ) in privilege_escalation_policies_combination.items():\n intersection = policies_combination.intersection(values)\n if intersection == values:\n combos.add(key)\n\n if len(combos) != 0:\n report.status = \"FAIL\"\n policies_affected = \"\"\n for key in combos:\n policies_affected += (\n str(privilege_escalation_policies_combination[key])\n + \" \"\n )\n\n report.status_extended = (\n f\"Custom Policy {report.resource_arn} allows privilege escalation using the following actions: {policies_affected}\".rstrip()\n + \".\"\n )\n findings.append(report)\n return findings\n", "path": "prowler/providers/aws/services/iam/iam_policy_allows_privilege_escalation/iam_policy_allows_privilege_escalation.py"}]}
| 3,653 | 256 |
gh_patches_debug_1968
|
rasdani/github-patches
|
git_diff
|
hylang__hy-358
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Allow macros to return None
```
(defmacro foo [])
(foo)
```
Will break as macros are not handling the NoneType yet
</issue>
<code>
[start of hy/macros.py]
1 # Copyright (c) 2013 Paul Tagliamonte <[email protected]>
2 #
3 # Permission is hereby granted, free of charge, to any person obtaining a
4 # copy of this software and associated documentation files (the "Software"),
5 # to deal in the Software without restriction, including without limitation
6 # the rights to use, copy, modify, merge, publish, distribute, sublicense,
7 # and/or sell copies of the Software, and to permit persons to whom the
8 # Software is furnished to do so, subject to the following conditions:
9 #
10 # The above copyright notice and this permission notice shall be included in
11 # all copies or substantial portions of the Software.
12 #
13 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
14 # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
15 # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
16 # THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
17 # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
18 # FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
19 # DEALINGS IN THE SOFTWARE.
20
21 from hy.models.expression import HyExpression
22 from hy.models.string import HyString
23 from hy.models.symbol import HySymbol
24 from hy.models.list import HyList
25 from hy.models.integer import HyInteger
26 from hy.models.float import HyFloat
27 from hy.models.complex import HyComplex
28 from hy.models.dict import HyDict
29 from hy._compat import str_type
30
31 from collections import defaultdict
32
33
34 CORE_MACROS = [
35 "hy.core.bootstrap",
36 ]
37
38 EXTRA_MACROS = [
39 "hy.core.macros",
40 ]
41
42 _hy_macros = defaultdict(dict)
43
44
45 def macro(name):
46 """Decorator to define a macro called `name`.
47
48 This stores the macro `name` in the namespace for the module where it is
49 defined.
50
51 If the module where it is defined is in `hy.core`, then the macro is stored
52 in the default `None` namespace.
53
54 This function is called from the `defmacro` special form in the compiler.
55
56 """
57 def _(fn):
58 module_name = fn.__module__
59 if module_name.startswith("hy.core"):
60 module_name = None
61 _hy_macros[module_name][name] = fn
62 return fn
63 return _
64
65
66 def require(source_module, target_module):
67 """Load the macros from `source_module` in the namespace of
68 `target_module`.
69
70 This function is called from the `require` special form in the compiler.
71
72 """
73 macros = _hy_macros[source_module]
74 refs = _hy_macros[target_module]
75 for name, macro in macros.items():
76 refs[name] = macro
77
78
79 # type -> wrapping function mapping for _wrap_value
80 _wrappers = {
81 int: HyInteger,
82 bool: lambda x: HySymbol("True") if x else HySymbol("False"),
83 float: HyFloat,
84 complex: HyComplex,
85 str_type: HyString,
86 dict: lambda d: HyDict(_wrap_value(x) for x in sum(d.items(), ())),
87 list: lambda l: HyList(_wrap_value(x) for x in l)
88 }
89
90
91 def _wrap_value(x):
92 """Wrap `x` into the corresponding Hy type.
93
94 This allows a macro to return an unquoted expression transparently.
95
96 """
97 wrapper = _wrappers.get(type(x))
98 if wrapper is None:
99 return x
100 else:
101 return wrapper(x)
102
103
104 def load_macros(module_name):
105 """Load the hy builtin macros for module `module_name`.
106
107 Modules from `hy.core` can only use the macros from CORE_MACROS.
108 Other modules get the macros from CORE_MACROS and EXTRA_MACROS.
109
110 """
111
112 def _import(module, module_name=module_name):
113 "__import__ a module, avoiding recursions"
114 if module != module_name:
115 __import__(module)
116
117 for module in CORE_MACROS:
118 _import(module)
119
120 if module_name.startswith("hy.core"):
121 return
122
123 for module in EXTRA_MACROS:
124 _import(module)
125
126
127 def macroexpand(tree, module_name):
128 """Expand the toplevel macros for the `tree`.
129
130 Load the macros from the given `module_name`, then expand the (top-level)
131 macros in `tree` until it stops changing.
132
133 """
134 load_macros(module_name)
135 old = None
136 while old != tree:
137 old = tree
138 tree = macroexpand_1(tree, module_name)
139 return tree
140
141
142 def macroexpand_1(tree, module_name):
143 """Expand the toplevel macro from `tree` once, in the context of
144 `module_name`."""
145 if isinstance(tree, HyExpression):
146 if tree == []:
147 return tree
148
149 fn = tree[0]
150 if fn in ("quote", "quasiquote"):
151 return tree
152 ntree = HyExpression(tree[:])
153 ntree.replace(tree)
154
155 if isinstance(fn, HyString):
156 m = _hy_macros[module_name].get(fn)
157 if m is None:
158 m = _hy_macros[None].get(fn)
159 if m is not None:
160 obj = _wrap_value(m(*ntree[1:]))
161 obj.replace(tree)
162 return obj
163
164 return ntree
165 return tree
166
[end of hy/macros.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/hy/macros.py b/hy/macros.py
--- a/hy/macros.py
+++ b/hy/macros.py
@@ -84,7 +84,8 @@
complex: HyComplex,
str_type: HyString,
dict: lambda d: HyDict(_wrap_value(x) for x in sum(d.items(), ())),
- list: lambda l: HyList(_wrap_value(x) for x in l)
+ list: lambda l: HyList(_wrap_value(x) for x in l),
+ type(None): lambda foo: HySymbol("None"),
}
|
{"golden_diff": "diff --git a/hy/macros.py b/hy/macros.py\n--- a/hy/macros.py\n+++ b/hy/macros.py\n@@ -84,7 +84,8 @@\n complex: HyComplex,\n str_type: HyString,\n dict: lambda d: HyDict(_wrap_value(x) for x in sum(d.items(), ())),\n- list: lambda l: HyList(_wrap_value(x) for x in l)\n+ list: lambda l: HyList(_wrap_value(x) for x in l),\n+ type(None): lambda foo: HySymbol(\"None\"),\n }\n", "issue": "Allow macros to return None\n```\n (defmacro foo [])\n (foo) \n```\n\nWill break as macros are not handling the NoneType yet\n\n", "before_files": [{"content": "# Copyright (c) 2013 Paul Tagliamonte <[email protected]>\n#\n# Permission is hereby granted, free of charge, to any person obtaining a\n# copy of this software and associated documentation files (the \"Software\"),\n# to deal in the Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish, distribute, sublicense,\n# and/or sell copies of the Software, and to permit persons to whom the\n# Software is furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL\n# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING\n# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER\n# DEALINGS IN THE SOFTWARE.\n\nfrom hy.models.expression import HyExpression\nfrom hy.models.string import HyString\nfrom hy.models.symbol import HySymbol\nfrom hy.models.list import HyList\nfrom hy.models.integer import HyInteger\nfrom hy.models.float import HyFloat\nfrom hy.models.complex import HyComplex\nfrom hy.models.dict import HyDict\nfrom hy._compat import str_type\n\nfrom collections import defaultdict\n\n\nCORE_MACROS = [\n \"hy.core.bootstrap\",\n]\n\nEXTRA_MACROS = [\n \"hy.core.macros\",\n]\n\n_hy_macros = defaultdict(dict)\n\n\ndef macro(name):\n \"\"\"Decorator to define a macro called `name`.\n\n This stores the macro `name` in the namespace for the module where it is\n defined.\n\n If the module where it is defined is in `hy.core`, then the macro is stored\n in the default `None` namespace.\n\n This function is called from the `defmacro` special form in the compiler.\n\n \"\"\"\n def _(fn):\n module_name = fn.__module__\n if module_name.startswith(\"hy.core\"):\n module_name = None\n _hy_macros[module_name][name] = fn\n return fn\n return _\n\n\ndef require(source_module, target_module):\n \"\"\"Load the macros from `source_module` in the namespace of\n `target_module`.\n\n This function is called from the `require` special form in the compiler.\n\n \"\"\"\n macros = _hy_macros[source_module]\n refs = _hy_macros[target_module]\n for name, macro in macros.items():\n refs[name] = macro\n\n\n# type -> wrapping function mapping for _wrap_value\n_wrappers = {\n int: HyInteger,\n bool: lambda x: HySymbol(\"True\") if x else HySymbol(\"False\"),\n float: HyFloat,\n complex: HyComplex,\n str_type: HyString,\n dict: lambda d: HyDict(_wrap_value(x) for x in sum(d.items(), ())),\n list: lambda l: HyList(_wrap_value(x) for x in l)\n}\n\n\ndef _wrap_value(x):\n \"\"\"Wrap `x` into the corresponding Hy type.\n\n This allows a macro to return an unquoted expression transparently.\n\n \"\"\"\n wrapper = _wrappers.get(type(x))\n if wrapper is None:\n return x\n else:\n return wrapper(x)\n\n\ndef load_macros(module_name):\n \"\"\"Load the hy builtin macros for module `module_name`.\n\n Modules from `hy.core` can only use the macros from CORE_MACROS.\n Other modules get the macros from CORE_MACROS and EXTRA_MACROS.\n\n \"\"\"\n\n def _import(module, module_name=module_name):\n \"__import__ a module, avoiding recursions\"\n if module != module_name:\n __import__(module)\n\n for module in CORE_MACROS:\n _import(module)\n\n if module_name.startswith(\"hy.core\"):\n return\n\n for module in EXTRA_MACROS:\n _import(module)\n\n\ndef macroexpand(tree, module_name):\n \"\"\"Expand the toplevel macros for the `tree`.\n\n Load the macros from the given `module_name`, then expand the (top-level)\n macros in `tree` until it stops changing.\n\n \"\"\"\n load_macros(module_name)\n old = None\n while old != tree:\n old = tree\n tree = macroexpand_1(tree, module_name)\n return tree\n\n\ndef macroexpand_1(tree, module_name):\n \"\"\"Expand the toplevel macro from `tree` once, in the context of\n `module_name`.\"\"\"\n if isinstance(tree, HyExpression):\n if tree == []:\n return tree\n\n fn = tree[0]\n if fn in (\"quote\", \"quasiquote\"):\n return tree\n ntree = HyExpression(tree[:])\n ntree.replace(tree)\n\n if isinstance(fn, HyString):\n m = _hy_macros[module_name].get(fn)\n if m is None:\n m = _hy_macros[None].get(fn)\n if m is not None:\n obj = _wrap_value(m(*ntree[1:]))\n obj.replace(tree)\n return obj\n\n return ntree\n return tree\n", "path": "hy/macros.py"}]}
| 2,104 | 131 |
gh_patches_debug_13579
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-2234
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Wrong behavior of SerialIterator if dataset is numpy array.
In `serial_iterator.py` lines [66](https://github.com/pfnet/chainer/blob/master/chainer/iterators/serial_iterator.py#L66) and [68](https://github.com/pfnet/chainer/blob/master/chainer/iterators/serial_iterator.py#L68) contain `+=` to extend lists.
Unfortunately, this does not crash for `numpy` arrays but produces undesired behavior. The dataset itself gets modified (see for `6` in the second example):
```
import numpy as np
from chainer.iterators.serial_iterator import SerialIterator
dataset = [1, 2, 3, 4, 5]
it = SerialIterator(dataset, batch_size=2, shuffle=False)
for _ in range(6):
example = it.next()
print(example)
```
```
[1, 2]
[3, 4]
[5, 1]
[2, 3]
[4, 5]
[1, 2]
```
```
dataset = np.asarray([1, 2, 3, 4, 5])
it = SerialIterator(dataset, batch_size=2, shuffle=False)
for _ in range(6):
example = it.next()
print(example)
```
```
[1 2]
[3 4]
[6]
[2 3]
[4 6]
[1 2]
```
When the two lines get changed to
```
batch.extend(list(self.dataset[:rest]))
```
and
```
batch.extend([self.dataset[index] for index in self._order[:rest]])
```
a useful error is raised.
</issue>
<code>
[start of chainer/iterators/serial_iterator.py]
1 from __future__ import division
2
3 import numpy
4
5 from chainer.dataset import iterator
6
7
8 class SerialIterator(iterator.Iterator):
9
10 """Dataset iterator that serially reads the examples.
11
12 This is a simple implementation of :class:`~chainer.dataset.Iterator`
13 that just visits each example in either the order of indexes or a shuffled
14 order.
15
16 To avoid unintentional performance degradation, the ``shuffle`` option is
17 set to ``True`` by default. For validation, it is better to set it to
18 ``False`` when the underlying dataset supports fast slicing. If the
19 order of examples has an important meaning and the updater depends on the
20 original order, this option should be set to ``False``.
21
22 Args:
23 dataset: Dataset to iterate.
24 batch_size (int): Number of examples within each batch.
25 repeat (bool): If ``True``, it infinitely loops over the dataset.
26 Otherwise, it stops iteration at the end of the first epoch.
27 shuffle (bool): If ``True``, the order of examples is shuffled at the
28 beginning of each epoch. Otherwise, examples are extracted in the
29 order of indexes.
30
31 """
32
33 def __init__(self, dataset, batch_size, repeat=True, shuffle=True):
34 self.dataset = dataset
35 self.batch_size = batch_size
36 self._repeat = repeat
37 if shuffle:
38 self._order = numpy.random.permutation(len(dataset))
39 else:
40 self._order = None
41
42 self.current_position = 0
43 self.epoch = 0
44 self.is_new_epoch = False
45
46 def __next__(self):
47 if not self._repeat and self.epoch > 0:
48 raise StopIteration
49
50 i = self.current_position
51 i_end = i + self.batch_size
52 N = len(self.dataset)
53
54 if self._order is None:
55 batch = self.dataset[i:i_end]
56 else:
57 batch = [self.dataset[index] for index in self._order[i:i_end]]
58
59 if i_end >= N:
60 if self._repeat:
61 rest = i_end - N
62 if self._order is not None:
63 numpy.random.shuffle(self._order)
64 if rest > 0:
65 if self._order is None:
66 batch += list(self.dataset[:rest])
67 else:
68 batch += [self.dataset[index]
69 for index in self._order[:rest]]
70 self.current_position = rest
71 else:
72 self.current_position = N
73
74 self.epoch += 1
75 self.is_new_epoch = True
76 else:
77 self.is_new_epoch = False
78 self.current_position = i_end
79
80 return batch
81
82 next = __next__
83
84 @property
85 def epoch_detail(self):
86 return self.epoch + self.current_position / len(self.dataset)
87
88 def serialize(self, serializer):
89 self.current_position = serializer('current_position',
90 self.current_position)
91 self.epoch = serializer('epoch', self.epoch)
92 self.is_new_epoch = serializer('is_new_epoch', self.is_new_epoch)
93 if self._order is not None:
94 serializer('_order', self._order)
95
[end of chainer/iterators/serial_iterator.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/chainer/iterators/serial_iterator.py b/chainer/iterators/serial_iterator.py
--- a/chainer/iterators/serial_iterator.py
+++ b/chainer/iterators/serial_iterator.py
@@ -63,10 +63,10 @@
numpy.random.shuffle(self._order)
if rest > 0:
if self._order is None:
- batch += list(self.dataset[:rest])
+ batch.extend(self.dataset[:rest])
else:
- batch += [self.dataset[index]
- for index in self._order[:rest]]
+ batch.extend([self.dataset[index]
+ for index in self._order[:rest]])
self.current_position = rest
else:
self.current_position = N
|
{"golden_diff": "diff --git a/chainer/iterators/serial_iterator.py b/chainer/iterators/serial_iterator.py\n--- a/chainer/iterators/serial_iterator.py\n+++ b/chainer/iterators/serial_iterator.py\n@@ -63,10 +63,10 @@\n numpy.random.shuffle(self._order)\n if rest > 0:\n if self._order is None:\n- batch += list(self.dataset[:rest])\n+ batch.extend(self.dataset[:rest])\n else:\n- batch += [self.dataset[index]\n- for index in self._order[:rest]]\n+ batch.extend([self.dataset[index]\n+ for index in self._order[:rest]])\n self.current_position = rest\n else:\n self.current_position = N\n", "issue": "Wrong behavior of SerialIterator if dataset is numpy array.\nIn `serial_iterator.py` lines [66](https://github.com/pfnet/chainer/blob/master/chainer/iterators/serial_iterator.py#L66) and [68](https://github.com/pfnet/chainer/blob/master/chainer/iterators/serial_iterator.py#L68) contain `+=` to extend lists.\r\n\r\nUnfortunately, this does not crash for `numpy` arrays but produces undesired behavior. The dataset itself gets modified (see for `6` in the second example):\r\n\r\n```\r\nimport numpy as np\r\nfrom chainer.iterators.serial_iterator import SerialIterator\r\n\r\ndataset = [1, 2, 3, 4, 5]\r\nit = SerialIterator(dataset, batch_size=2, shuffle=False)\r\n\r\nfor _ in range(6):\r\n example = it.next()\r\n print(example)\r\n```\r\n\r\n```\r\n[1, 2]\r\n[3, 4]\r\n[5, 1]\r\n[2, 3]\r\n[4, 5]\r\n[1, 2]\r\n```\r\n\r\n```\r\ndataset = np.asarray([1, 2, 3, 4, 5])\r\nit = SerialIterator(dataset, batch_size=2, shuffle=False)\r\n\r\nfor _ in range(6):\r\n example = it.next()\r\n print(example)\r\n```\r\n\r\n```\r\n[1 2]\r\n[3 4]\r\n[6]\r\n[2 3]\r\n[4 6]\r\n[1 2]\r\n```\r\n\r\nWhen the two lines get changed to\r\n```\r\nbatch.extend(list(self.dataset[:rest]))\r\n```\r\n\r\nand\r\n```\r\nbatch.extend([self.dataset[index] for index in self._order[:rest]])\r\n```\r\n\r\na useful error is raised.\n", "before_files": [{"content": "from __future__ import division\n\nimport numpy\n\nfrom chainer.dataset import iterator\n\n\nclass SerialIterator(iterator.Iterator):\n\n \"\"\"Dataset iterator that serially reads the examples.\n\n This is a simple implementation of :class:`~chainer.dataset.Iterator`\n that just visits each example in either the order of indexes or a shuffled\n order.\n\n To avoid unintentional performance degradation, the ``shuffle`` option is\n set to ``True`` by default. For validation, it is better to set it to\n ``False`` when the underlying dataset supports fast slicing. If the\n order of examples has an important meaning and the updater depends on the\n original order, this option should be set to ``False``.\n\n Args:\n dataset: Dataset to iterate.\n batch_size (int): Number of examples within each batch.\n repeat (bool): If ``True``, it infinitely loops over the dataset.\n Otherwise, it stops iteration at the end of the first epoch.\n shuffle (bool): If ``True``, the order of examples is shuffled at the\n beginning of each epoch. Otherwise, examples are extracted in the\n order of indexes.\n\n \"\"\"\n\n def __init__(self, dataset, batch_size, repeat=True, shuffle=True):\n self.dataset = dataset\n self.batch_size = batch_size\n self._repeat = repeat\n if shuffle:\n self._order = numpy.random.permutation(len(dataset))\n else:\n self._order = None\n\n self.current_position = 0\n self.epoch = 0\n self.is_new_epoch = False\n\n def __next__(self):\n if not self._repeat and self.epoch > 0:\n raise StopIteration\n\n i = self.current_position\n i_end = i + self.batch_size\n N = len(self.dataset)\n\n if self._order is None:\n batch = self.dataset[i:i_end]\n else:\n batch = [self.dataset[index] for index in self._order[i:i_end]]\n\n if i_end >= N:\n if self._repeat:\n rest = i_end - N\n if self._order is not None:\n numpy.random.shuffle(self._order)\n if rest > 0:\n if self._order is None:\n batch += list(self.dataset[:rest])\n else:\n batch += [self.dataset[index]\n for index in self._order[:rest]]\n self.current_position = rest\n else:\n self.current_position = N\n\n self.epoch += 1\n self.is_new_epoch = True\n else:\n self.is_new_epoch = False\n self.current_position = i_end\n\n return batch\n\n next = __next__\n\n @property\n def epoch_detail(self):\n return self.epoch + self.current_position / len(self.dataset)\n\n def serialize(self, serializer):\n self.current_position = serializer('current_position',\n self.current_position)\n self.epoch = serializer('epoch', self.epoch)\n self.is_new_epoch = serializer('is_new_epoch', self.is_new_epoch)\n if self._order is not None:\n serializer('_order', self._order)\n", "path": "chainer/iterators/serial_iterator.py"}]}
| 1,754 | 164 |
gh_patches_debug_36335
|
rasdani/github-patches
|
git_diff
|
Lightning-Universe__lightning-flash-1329
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
OneCycleLR scheduler does not work with freeze-unfreeze finetuning strategy
## 🐛 Bug
I wanted to create an image classifier by fine-tuning pre-trained model on my dataset. When OneCycleLR scheduler is used alongside the freeze-unfreeze, training throws an exception once the unfreeze epoch is reached.
### To Reproduce / Code Sample
I use flash's built-in `ImageClassifier` as follows:
```python
epochs = 50
model = ImageClassifier(
backbone="efficientnet_b5",
labels=datamodule.labels,
metrics=[
Accuracy(),
],
optimizer="AdamW",
lr_scheduler=(
"onecyclelr",
{
"max_lr": 1e-3,
"epochs": epochs,
"steps_per_epoch": steps_per_epoch,
},
{"interval": "step"},
),
)
```
```python
trainer = flash.Trainer(
max_epochs=epochs,
gpus=torch.cuda.device_count(),
)
trainer.finetune(model, datamodule=datamodule, strategy=("freeze_unfreeze", 5))
```
### Expected behaviour
After specified number of epochs, layers get unfrozen and training continues.
### Actual behaviour
Expection is thrown:
```python
File "/<redacted>/lib/python3.8/site-packages/pytorch_lightning/plugins/training_type/training_type_plugin.py", line 202, in start_training
self._results = trainer.run_stage()
File "/<redacted>/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 1289, in run_stage
return self._run_train()
File "/<redacted>/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py", line 1319, in _run_train
self.fit_loop.run()
File "/<redacted>/lib/python3.8/site-packages/pytorch_lightning/loops/base.py", line 145, in run
self.advance(*args, **kwargs)
File "/<redacted>/lib/python3.8/site-packages/pytorch_lightning/loops/fit_loop.py", line 234, in advance
self.epoch_loop.run(data_fetcher)
File "/<redacted>/lib/python3.8/site-packages/pytorch_lightning/loops/base.py", line 145, in run
self.advance(*args, **kwargs)
File "/<redacted>/lib/python3.8/site-packages/pytorch_lightning/loops/epoch/training_epoch_loop.py", line 199, in advance
self.update_lr_schedulers("step", update_plateau_schedulers=False)
File "/<redacted>/lib/python3.8/site-packages/pytorch_lightning/loops/epoch/training_epoch_loop.py", line 441, in update_lr_schedulers
self._update_learning_rates(
File "/<redacted>/lib/python3.8/site-packages/pytorch_lightning/loops/epoch/training_epoch_loop.py", line 505, in _update_learning_rates
lr_scheduler["scheduler"].step()
File "/<redacted>/lib/python3.8/site-packages/torch/optim/lr_scheduler.py", line 154, in step
values = self.get_lr()
File "/<redacted>/lib/python3.8/site-packages/torch/optim/lr_scheduler.py", line 1597, in get_lr
computed_lr = self.anneal_func(group[phase['start_lr']], group[phase['end_lr']], pct)
KeyError: 'max_lr
```
It seems like the unfreezing strategy creates additional optimizer parameter groups, but when the unfreezing happens, some of the LR scheduler parameters are not copied / passed to the new param group properly in: `pytorch_lightning.callbacks.finetuning.BaseFinetuning.unfreeze_and_add_param_group`.
### Environment
- OS (e.g., Linux): macOS
- Python version: 3.8.12
- PyTorch/Lightning/Flash Version (e.g., 1.10/1.5/0.7): 1.11.0 / 1.5.10 / 0.7.3
- GPU models and configuration: 0 / 1 T4 (happens regardless of cuda)
- Any other relevant information:
### Additional context
https://pytorch-lightning.slack.com/archives/CRBLFHY79/p1651218144224359
</issue>
<code>
[start of flash/core/finetuning.py]
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 import os
15 from functools import partial
16 from typing import Iterable, Optional, Tuple, Union
17
18 from pytorch_lightning import LightningModule
19 from pytorch_lightning.callbacks import BaseFinetuning
20 from pytorch_lightning.utilities.exceptions import MisconfigurationException
21 from torch.nn import Module
22 from torch.optim import Optimizer
23
24 from flash.core.registry import FlashRegistry
25
26 if not os.environ.get("READTHEDOCS", False):
27 from pytorch_lightning.utilities.enums import LightningEnum
28 else:
29 # ReadTheDocs mocks the `LightningEnum` import to be a regular type, so we replace it with a plain Enum here.
30 from enum import Enum
31
32 LightningEnum = Enum
33
34
35 class FinetuningStrategies(LightningEnum):
36 """The ``FinetuningStrategies`` enum contains the keys that are used internally by the ``FlashBaseFinetuning``
37 when choosing the strategy to perform."""
38
39 NO_FREEZE = "no_freeze"
40 FREEZE = "freeze"
41 FREEZE_UNFREEZE = "freeze_unfreeze"
42 UNFREEZE_MILESTONES = "unfreeze_milestones"
43
44 # TODO: Create a FlashEnum class???
45 def __hash__(self) -> int:
46 return hash(self.value)
47
48
49 class FlashBaseFinetuning(BaseFinetuning):
50 """FlashBaseFinetuning can be used to create a custom Flash Finetuning Callback."""
51
52 def __init__(
53 self,
54 strategy_key: Union[str, FinetuningStrategies],
55 strategy_metadata: Optional[Union[int, Tuple[Tuple[int, int], int]]] = None,
56 train_bn: bool = True,
57 ):
58 """
59 Args:
60 strategy_key: The finetuning strategy to be used. See :meth:`~flash.core.trainer.Trainer.finetune`
61 for the available strategies.
62 strategy_metadata: Data that accompanies certain finetuning strategies like epoch number or number of
63 layers.
64 train_bn: Whether to train Batch Norm layer
65 """
66 super().__init__()
67
68 self.strategy: FinetuningStrategies = strategy_key
69 self.strategy_metadata: Optional[Union[int, Tuple[Tuple[int, int], int]]] = strategy_metadata
70 self.train_bn: bool = train_bn
71
72 if self.strategy == FinetuningStrategies.FREEZE_UNFREEZE and not isinstance(self.strategy_metadata, int):
73 raise MisconfigurationException(
74 "The `freeze_unfreeze` strategy requires an integer denoting the epoch number to unfreeze at. Example: "
75 "`strategy=('freeze_unfreeze', 7)`"
76 )
77 if self.strategy == FinetuningStrategies.UNFREEZE_MILESTONES and not (
78 isinstance(self.strategy_metadata, Tuple)
79 and isinstance(self.strategy_metadata[0], Tuple)
80 and isinstance(self.strategy_metadata[1], int)
81 and isinstance(self.strategy_metadata[0][0], int)
82 and isinstance(self.strategy_metadata[0][1], int)
83 ):
84 raise MisconfigurationException(
85 "The `unfreeze_milestones` strategy requires the format Tuple[Tuple[int, int], int]. Example: "
86 "`strategy=('unfreeze_milestones', ((5, 10), 15))`"
87 )
88
89 def _get_modules_to_freeze(self, pl_module: LightningModule) -> Union[Module, Iterable[Union[Module, Iterable]]]:
90 modules_to_freeze = getattr(pl_module, "modules_to_freeze", None)
91 if modules_to_freeze is None:
92 raise AttributeError(
93 "LightningModule missing instance method 'modules_to_freeze'."
94 "Please, implement the method which returns NoneType or a Module or an Iterable of Modules."
95 )
96 return modules_to_freeze()
97
98 def freeze_before_training(self, pl_module: Union[Module, Iterable[Union[Module, Iterable]]]) -> None:
99 if self.strategy != FinetuningStrategies.NO_FREEZE:
100 modules = self._get_modules_to_freeze(pl_module=pl_module)
101 if modules is not None:
102 if isinstance(modules, Module):
103 modules = [modules]
104 self.freeze(modules=modules, train_bn=self.train_bn)
105
106 def _freeze_unfreeze_function(
107 self,
108 pl_module: Union[Module, Iterable[Union[Module, Iterable]]],
109 epoch: int,
110 optimizer: Optimizer,
111 opt_idx: int,
112 strategy_metadata: int,
113 ):
114 unfreeze_epoch: int = strategy_metadata
115 if epoch != unfreeze_epoch:
116 return
117
118 modules = self._get_modules_to_freeze(pl_module=pl_module)
119 if modules is not None:
120 self.unfreeze_and_add_param_group(
121 modules=modules,
122 optimizer=optimizer,
123 train_bn=self.train_bn,
124 )
125
126 def _unfreeze_milestones_function(
127 self,
128 pl_module: Union[Module, Iterable[Union[Module, Iterable]]],
129 epoch: int,
130 optimizer: Optimizer,
131 opt_idx: int,
132 strategy_metadata: Tuple[Tuple[int, int], int],
133 ):
134 unfreeze_milestones: Tuple[int, int] = strategy_metadata[0]
135 num_layers: int = strategy_metadata[1]
136
137 modules = self._get_modules_to_freeze(pl_module=pl_module)
138 if modules is not None:
139 if epoch == unfreeze_milestones[0]:
140 # unfreeze num_layers last layers
141
142 backbone_modules = BaseFinetuning.flatten_modules(modules=modules)[-num_layers:]
143 self.unfreeze_and_add_param_group(
144 modules=backbone_modules,
145 optimizer=optimizer,
146 train_bn=self.train_bn,
147 )
148 elif epoch == unfreeze_milestones[1]:
149 # unfreeze remaining layers
150 backbone_modules = BaseFinetuning.flatten_modules(modules=modules)[:-num_layers]
151 self.unfreeze_and_add_param_group(
152 modules=backbone_modules,
153 optimizer=optimizer,
154 train_bn=self.train_bn,
155 )
156
157 def finetune_function(
158 self,
159 pl_module: Union[Module, Iterable[Union[Module, Iterable]]],
160 epoch: int,
161 optimizer: Optimizer,
162 opt_idx: int,
163 ):
164 if self.strategy == FinetuningStrategies.FREEZE_UNFREEZE:
165 self._freeze_unfreeze_function(pl_module, epoch, optimizer, opt_idx, self.strategy_metadata)
166 elif self.strategy == FinetuningStrategies.UNFREEZE_MILESTONES:
167 self._unfreeze_milestones_function(pl_module, epoch, optimizer, opt_idx, self.strategy_metadata)
168
169
170 _FINETUNING_STRATEGIES_REGISTRY = FlashRegistry("finetuning_strategies")
171
172 for strategy in FinetuningStrategies:
173 _FINETUNING_STRATEGIES_REGISTRY(
174 name=strategy.value,
175 fn=partial(FlashBaseFinetuning, strategy_key=strategy),
176 )
177
178
179 class NoFreeze(FlashBaseFinetuning):
180 def __init__(self, train_bn: bool = True):
181 super().__init__(FinetuningStrategies.NO_FREEZE, train_bn)
182
183
184 class Freeze(FlashBaseFinetuning):
185 def __init__(self, train_bn: bool = True):
186 super().__init__(FinetuningStrategies.FREEZE, train_bn)
187
188
189 class FreezeUnfreeze(FlashBaseFinetuning):
190 def __init__(
191 self,
192 strategy_metadata: int,
193 train_bn: bool = True,
194 ):
195 super().__init__(FinetuningStrategies.FREEZE_UNFREEZE, strategy_metadata, train_bn)
196
197
198 class UnfreezeMilestones(FlashBaseFinetuning):
199 def __init__(
200 self,
201 strategy_metadata: Tuple[Tuple[int, int], int],
202 train_bn: bool = True,
203 ):
204 super().__init__(FinetuningStrategies.UNFREEZE_MILESTONES, strategy_metadata, train_bn)
205
[end of flash/core/finetuning.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/flash/core/finetuning.py b/flash/core/finetuning.py
--- a/flash/core/finetuning.py
+++ b/flash/core/finetuning.py
@@ -103,6 +103,19 @@
modules = [modules]
self.freeze(modules=modules, train_bn=self.train_bn)
+ def unfreeze_and_extend_param_group(
+ self,
+ modules: Union[Module, Iterable[Union[Module, Iterable]]],
+ optimizer: Optimizer,
+ train_bn: bool = True,
+ ) -> None:
+ self.make_trainable(modules)
+
+ params = self.filter_params(modules, train_bn=train_bn, requires_grad=True)
+ params = self.filter_on_optimizer(optimizer, params)
+ if params:
+ optimizer.param_groups[0]["params"].extend(params)
+
def _freeze_unfreeze_function(
self,
pl_module: Union[Module, Iterable[Union[Module, Iterable]]],
@@ -117,7 +130,7 @@
modules = self._get_modules_to_freeze(pl_module=pl_module)
if modules is not None:
- self.unfreeze_and_add_param_group(
+ self.unfreeze_and_extend_param_group(
modules=modules,
optimizer=optimizer,
train_bn=self.train_bn,
@@ -140,7 +153,7 @@
# unfreeze num_layers last layers
backbone_modules = BaseFinetuning.flatten_modules(modules=modules)[-num_layers:]
- self.unfreeze_and_add_param_group(
+ self.unfreeze_and_extend_param_group(
modules=backbone_modules,
optimizer=optimizer,
train_bn=self.train_bn,
@@ -148,7 +161,7 @@
elif epoch == unfreeze_milestones[1]:
# unfreeze remaining layers
backbone_modules = BaseFinetuning.flatten_modules(modules=modules)[:-num_layers]
- self.unfreeze_and_add_param_group(
+ self.unfreeze_and_extend_param_group(
modules=backbone_modules,
optimizer=optimizer,
train_bn=self.train_bn,
|
{"golden_diff": "diff --git a/flash/core/finetuning.py b/flash/core/finetuning.py\n--- a/flash/core/finetuning.py\n+++ b/flash/core/finetuning.py\n@@ -103,6 +103,19 @@\n modules = [modules]\n self.freeze(modules=modules, train_bn=self.train_bn)\n \n+ def unfreeze_and_extend_param_group(\n+ self,\n+ modules: Union[Module, Iterable[Union[Module, Iterable]]],\n+ optimizer: Optimizer,\n+ train_bn: bool = True,\n+ ) -> None:\n+ self.make_trainable(modules)\n+\n+ params = self.filter_params(modules, train_bn=train_bn, requires_grad=True)\n+ params = self.filter_on_optimizer(optimizer, params)\n+ if params:\n+ optimizer.param_groups[0][\"params\"].extend(params)\n+\n def _freeze_unfreeze_function(\n self,\n pl_module: Union[Module, Iterable[Union[Module, Iterable]]],\n@@ -117,7 +130,7 @@\n \n modules = self._get_modules_to_freeze(pl_module=pl_module)\n if modules is not None:\n- self.unfreeze_and_add_param_group(\n+ self.unfreeze_and_extend_param_group(\n modules=modules,\n optimizer=optimizer,\n train_bn=self.train_bn,\n@@ -140,7 +153,7 @@\n # unfreeze num_layers last layers\n \n backbone_modules = BaseFinetuning.flatten_modules(modules=modules)[-num_layers:]\n- self.unfreeze_and_add_param_group(\n+ self.unfreeze_and_extend_param_group(\n modules=backbone_modules,\n optimizer=optimizer,\n train_bn=self.train_bn,\n@@ -148,7 +161,7 @@\n elif epoch == unfreeze_milestones[1]:\n # unfreeze remaining layers\n backbone_modules = BaseFinetuning.flatten_modules(modules=modules)[:-num_layers]\n- self.unfreeze_and_add_param_group(\n+ self.unfreeze_and_extend_param_group(\n modules=backbone_modules,\n optimizer=optimizer,\n train_bn=self.train_bn,\n", "issue": "OneCycleLR scheduler does not work with freeze-unfreeze finetuning strategy\n## \ud83d\udc1b Bug\r\n\r\nI wanted to create an image classifier by fine-tuning pre-trained model on my dataset. When OneCycleLR scheduler is used alongside the freeze-unfreeze, training throws an exception once the unfreeze epoch is reached.\r\n\r\n\r\n### To Reproduce / Code Sample\r\n\r\nI use flash's built-in `ImageClassifier` as follows:\r\n\r\n```python\r\n epochs = 50\r\n model = ImageClassifier(\r\n backbone=\"efficientnet_b5\",\r\n labels=datamodule.labels,\r\n metrics=[\r\n Accuracy(),\r\n ],\r\n optimizer=\"AdamW\",\r\n lr_scheduler=(\r\n \"onecyclelr\",\r\n {\r\n \"max_lr\": 1e-3,\r\n \"epochs\": epochs,\r\n \"steps_per_epoch\": steps_per_epoch,\r\n },\r\n {\"interval\": \"step\"},\r\n ),\r\n )\r\n```\r\n\r\n```python\r\ntrainer = flash.Trainer(\r\n max_epochs=epochs,\r\n gpus=torch.cuda.device_count(),\r\n)\r\ntrainer.finetune(model, datamodule=datamodule, strategy=(\"freeze_unfreeze\", 5))\r\n```\r\n\r\n### Expected behaviour\r\n\r\nAfter specified number of epochs, layers get unfrozen and training continues.\r\n\r\n### Actual behaviour\r\nExpection is thrown:\r\n\r\n```python\r\n File \"/<redacted>/lib/python3.8/site-packages/pytorch_lightning/plugins/training_type/training_type_plugin.py\", line 202, in start_training\r\n self._results = trainer.run_stage()\r\n File \"/<redacted>/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py\", line 1289, in run_stage\r\n return self._run_train()\r\n File \"/<redacted>/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py\", line 1319, in _run_train\r\n self.fit_loop.run()\r\n File \"/<redacted>/lib/python3.8/site-packages/pytorch_lightning/loops/base.py\", line 145, in run\r\n self.advance(*args, **kwargs)\r\n File \"/<redacted>/lib/python3.8/site-packages/pytorch_lightning/loops/fit_loop.py\", line 234, in advance\r\n self.epoch_loop.run(data_fetcher)\r\n File \"/<redacted>/lib/python3.8/site-packages/pytorch_lightning/loops/base.py\", line 145, in run\r\n self.advance(*args, **kwargs)\r\n File \"/<redacted>/lib/python3.8/site-packages/pytorch_lightning/loops/epoch/training_epoch_loop.py\", line 199, in advance\r\n self.update_lr_schedulers(\"step\", update_plateau_schedulers=False)\r\n File \"/<redacted>/lib/python3.8/site-packages/pytorch_lightning/loops/epoch/training_epoch_loop.py\", line 441, in update_lr_schedulers\r\n self._update_learning_rates(\r\n File \"/<redacted>/lib/python3.8/site-packages/pytorch_lightning/loops/epoch/training_epoch_loop.py\", line 505, in _update_learning_rates\r\n lr_scheduler[\"scheduler\"].step()\r\n File \"/<redacted>/lib/python3.8/site-packages/torch/optim/lr_scheduler.py\", line 154, in step\r\n values = self.get_lr()\r\n File \"/<redacted>/lib/python3.8/site-packages/torch/optim/lr_scheduler.py\", line 1597, in get_lr\r\n computed_lr = self.anneal_func(group[phase['start_lr']], group[phase['end_lr']], pct)\r\nKeyError: 'max_lr\r\n```\r\n\r\nIt seems like the unfreezing strategy creates additional optimizer parameter groups, but when the unfreezing happens, some of the LR scheduler parameters are not copied / passed to the new param group properly in: `pytorch_lightning.callbacks.finetuning.BaseFinetuning.unfreeze_and_add_param_group`.\r\n\r\n### Environment\r\n\r\n - OS (e.g., Linux): macOS\r\n - Python version: 3.8.12\r\n - PyTorch/Lightning/Flash Version (e.g., 1.10/1.5/0.7): 1.11.0 / 1.5.10 / 0.7.3\r\n - GPU models and configuration: 0 / 1 T4 (happens regardless of cuda)\r\n - Any other relevant information:\r\n\r\n### Additional context\r\n\r\nhttps://pytorch-lightning.slack.com/archives/CRBLFHY79/p1651218144224359\r\n\r\n\n", "before_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport os\nfrom functools import partial\nfrom typing import Iterable, Optional, Tuple, Union\n\nfrom pytorch_lightning import LightningModule\nfrom pytorch_lightning.callbacks import BaseFinetuning\nfrom pytorch_lightning.utilities.exceptions import MisconfigurationException\nfrom torch.nn import Module\nfrom torch.optim import Optimizer\n\nfrom flash.core.registry import FlashRegistry\n\nif not os.environ.get(\"READTHEDOCS\", False):\n from pytorch_lightning.utilities.enums import LightningEnum\nelse:\n # ReadTheDocs mocks the `LightningEnum` import to be a regular type, so we replace it with a plain Enum here.\n from enum import Enum\n\n LightningEnum = Enum\n\n\nclass FinetuningStrategies(LightningEnum):\n \"\"\"The ``FinetuningStrategies`` enum contains the keys that are used internally by the ``FlashBaseFinetuning``\n when choosing the strategy to perform.\"\"\"\n\n NO_FREEZE = \"no_freeze\"\n FREEZE = \"freeze\"\n FREEZE_UNFREEZE = \"freeze_unfreeze\"\n UNFREEZE_MILESTONES = \"unfreeze_milestones\"\n\n # TODO: Create a FlashEnum class???\n def __hash__(self) -> int:\n return hash(self.value)\n\n\nclass FlashBaseFinetuning(BaseFinetuning):\n \"\"\"FlashBaseFinetuning can be used to create a custom Flash Finetuning Callback.\"\"\"\n\n def __init__(\n self,\n strategy_key: Union[str, FinetuningStrategies],\n strategy_metadata: Optional[Union[int, Tuple[Tuple[int, int], int]]] = None,\n train_bn: bool = True,\n ):\n \"\"\"\n Args:\n strategy_key: The finetuning strategy to be used. See :meth:`~flash.core.trainer.Trainer.finetune`\n for the available strategies.\n strategy_metadata: Data that accompanies certain finetuning strategies like epoch number or number of\n layers.\n train_bn: Whether to train Batch Norm layer\n \"\"\"\n super().__init__()\n\n self.strategy: FinetuningStrategies = strategy_key\n self.strategy_metadata: Optional[Union[int, Tuple[Tuple[int, int], int]]] = strategy_metadata\n self.train_bn: bool = train_bn\n\n if self.strategy == FinetuningStrategies.FREEZE_UNFREEZE and not isinstance(self.strategy_metadata, int):\n raise MisconfigurationException(\n \"The `freeze_unfreeze` strategy requires an integer denoting the epoch number to unfreeze at. Example: \"\n \"`strategy=('freeze_unfreeze', 7)`\"\n )\n if self.strategy == FinetuningStrategies.UNFREEZE_MILESTONES and not (\n isinstance(self.strategy_metadata, Tuple)\n and isinstance(self.strategy_metadata[0], Tuple)\n and isinstance(self.strategy_metadata[1], int)\n and isinstance(self.strategy_metadata[0][0], int)\n and isinstance(self.strategy_metadata[0][1], int)\n ):\n raise MisconfigurationException(\n \"The `unfreeze_milestones` strategy requires the format Tuple[Tuple[int, int], int]. Example: \"\n \"`strategy=('unfreeze_milestones', ((5, 10), 15))`\"\n )\n\n def _get_modules_to_freeze(self, pl_module: LightningModule) -> Union[Module, Iterable[Union[Module, Iterable]]]:\n modules_to_freeze = getattr(pl_module, \"modules_to_freeze\", None)\n if modules_to_freeze is None:\n raise AttributeError(\n \"LightningModule missing instance method 'modules_to_freeze'.\"\n \"Please, implement the method which returns NoneType or a Module or an Iterable of Modules.\"\n )\n return modules_to_freeze()\n\n def freeze_before_training(self, pl_module: Union[Module, Iterable[Union[Module, Iterable]]]) -> None:\n if self.strategy != FinetuningStrategies.NO_FREEZE:\n modules = self._get_modules_to_freeze(pl_module=pl_module)\n if modules is not None:\n if isinstance(modules, Module):\n modules = [modules]\n self.freeze(modules=modules, train_bn=self.train_bn)\n\n def _freeze_unfreeze_function(\n self,\n pl_module: Union[Module, Iterable[Union[Module, Iterable]]],\n epoch: int,\n optimizer: Optimizer,\n opt_idx: int,\n strategy_metadata: int,\n ):\n unfreeze_epoch: int = strategy_metadata\n if epoch != unfreeze_epoch:\n return\n\n modules = self._get_modules_to_freeze(pl_module=pl_module)\n if modules is not None:\n self.unfreeze_and_add_param_group(\n modules=modules,\n optimizer=optimizer,\n train_bn=self.train_bn,\n )\n\n def _unfreeze_milestones_function(\n self,\n pl_module: Union[Module, Iterable[Union[Module, Iterable]]],\n epoch: int,\n optimizer: Optimizer,\n opt_idx: int,\n strategy_metadata: Tuple[Tuple[int, int], int],\n ):\n unfreeze_milestones: Tuple[int, int] = strategy_metadata[0]\n num_layers: int = strategy_metadata[1]\n\n modules = self._get_modules_to_freeze(pl_module=pl_module)\n if modules is not None:\n if epoch == unfreeze_milestones[0]:\n # unfreeze num_layers last layers\n\n backbone_modules = BaseFinetuning.flatten_modules(modules=modules)[-num_layers:]\n self.unfreeze_and_add_param_group(\n modules=backbone_modules,\n optimizer=optimizer,\n train_bn=self.train_bn,\n )\n elif epoch == unfreeze_milestones[1]:\n # unfreeze remaining layers\n backbone_modules = BaseFinetuning.flatten_modules(modules=modules)[:-num_layers]\n self.unfreeze_and_add_param_group(\n modules=backbone_modules,\n optimizer=optimizer,\n train_bn=self.train_bn,\n )\n\n def finetune_function(\n self,\n pl_module: Union[Module, Iterable[Union[Module, Iterable]]],\n epoch: int,\n optimizer: Optimizer,\n opt_idx: int,\n ):\n if self.strategy == FinetuningStrategies.FREEZE_UNFREEZE:\n self._freeze_unfreeze_function(pl_module, epoch, optimizer, opt_idx, self.strategy_metadata)\n elif self.strategy == FinetuningStrategies.UNFREEZE_MILESTONES:\n self._unfreeze_milestones_function(pl_module, epoch, optimizer, opt_idx, self.strategy_metadata)\n\n\n_FINETUNING_STRATEGIES_REGISTRY = FlashRegistry(\"finetuning_strategies\")\n\nfor strategy in FinetuningStrategies:\n _FINETUNING_STRATEGIES_REGISTRY(\n name=strategy.value,\n fn=partial(FlashBaseFinetuning, strategy_key=strategy),\n )\n\n\nclass NoFreeze(FlashBaseFinetuning):\n def __init__(self, train_bn: bool = True):\n super().__init__(FinetuningStrategies.NO_FREEZE, train_bn)\n\n\nclass Freeze(FlashBaseFinetuning):\n def __init__(self, train_bn: bool = True):\n super().__init__(FinetuningStrategies.FREEZE, train_bn)\n\n\nclass FreezeUnfreeze(FlashBaseFinetuning):\n def __init__(\n self,\n strategy_metadata: int,\n train_bn: bool = True,\n ):\n super().__init__(FinetuningStrategies.FREEZE_UNFREEZE, strategy_metadata, train_bn)\n\n\nclass UnfreezeMilestones(FlashBaseFinetuning):\n def __init__(\n self,\n strategy_metadata: Tuple[Tuple[int, int], int],\n train_bn: bool = True,\n ):\n super().__init__(FinetuningStrategies.UNFREEZE_MILESTONES, strategy_metadata, train_bn)\n", "path": "flash/core/finetuning.py"}]}
| 3,833 | 465 |
gh_patches_debug_22005
|
rasdani/github-patches
|
git_diff
|
Lightning-AI__torchmetrics-1447
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Small typo in PESQ docs
## 📚 Documentation
[Perceptual Evaluation Of Speech Quality (PESQ) documentation](https://torchmetrics.readthedocs.io/en/stable/audio/perceptual_evaluation_speech_quality.html) states following for both Module Interface and Functional Interface:
Raises ModuleNotFoundError – If **peqs** package is not installed.
</issue>
<code>
[start of src/torchmetrics/functional/audio/pesq.py]
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 import numpy as np
15 import torch
16 from torch import Tensor
17
18 from torchmetrics.utilities.checks import _check_same_shape
19 from torchmetrics.utilities.imports import _MULTIPROCESSING_AVAILABLE, _PESQ_AVAILABLE
20
21 if _PESQ_AVAILABLE:
22 import pesq as pesq_backend
23 else:
24 pesq_backend = None
25
26
27 __doctest_requires__ = {("perceptual_evaluation_speech_quality",): ["pesq"]}
28
29
30 def perceptual_evaluation_speech_quality(
31 preds: Tensor,
32 target: Tensor,
33 fs: int,
34 mode: str,
35 keep_same_device: bool = False,
36 n_processes: int = 1,
37 ) -> Tensor:
38 r"""Calculates `Perceptual Evaluation of Speech Quality`_ (PESQ). It's a recognized industry standard for audio
39 quality that takes into considerations characteristics such as: audio sharpness, call volume, background noise,
40 clipping, audio interference ect. PESQ returns a score between -0.5 and 4.5 with the higher scores indicating a
41 better quality.
42
43 This metric is a wrapper for the `pesq package`_. Note that input will be moved to `cpu` to perform the metric
44 calculation.
45
46 .. note:: using this metrics requires you to have ``pesq`` install. Either install as ``pip install
47 torchmetrics[audio]`` or ``pip install pesq``. Note that ``pesq`` will compile with your currently
48 installed version of numpy, meaning that if you upgrade numpy at some point in the future you will
49 most likely have to reinstall ``pesq``.
50
51 Args:
52 preds: float tensor with shape ``(...,time)``
53 target: float tensor with shape ``(...,time)``
54 fs: sampling frequency, should be 16000 or 8000 (Hz)
55 mode: ``'wb'`` (wide-band) or ``'nb'`` (narrow-band)
56 keep_same_device: whether to move the pesq value to the device of preds
57 n_processes: integer specifiying the number of processes to run in parallel for the metric calculation.
58 Only applies to batches of data and if ``multiprocessing`` package is installed.
59
60 Returns:
61 Float tensor with shape ``(...,)`` of PESQ values per sample
62
63 Raises:
64 ModuleNotFoundError:
65 If ``peqs`` package is not installed
66 ValueError:
67 If ``fs`` is not either ``8000`` or ``16000``
68 ValueError:
69 If ``mode`` is not either ``"wb"`` or ``"nb"``
70 RuntimeError:
71 If ``preds`` and ``target`` does not have the same shape
72
73 Example:
74 >>> from torchmetrics.functional.audio.pesq import perceptual_evaluation_speech_quality
75 >>> import torch
76 >>> g = torch.manual_seed(1)
77 >>> preds = torch.randn(8000)
78 >>> target = torch.randn(8000)
79 >>> perceptual_evaluation_speech_quality(preds, target, 8000, 'nb')
80 tensor(2.2076)
81 >>> perceptual_evaluation_speech_quality(preds, target, 16000, 'wb')
82 tensor(1.7359)
83 """
84 if not _PESQ_AVAILABLE:
85 raise ModuleNotFoundError(
86 "PESQ metric requires that pesq is installed."
87 " Either install as `pip install torchmetrics[audio]` or `pip install pesq`."
88 )
89 if fs not in (8000, 16000):
90 raise ValueError(f"Expected argument `fs` to either be 8000 or 16000 but got {fs}")
91 if mode not in ("wb", "nb"):
92 raise ValueError(f"Expected argument `mode` to either be 'wb' or 'nb' but got {mode}")
93 _check_same_shape(preds, target)
94
95 if preds.ndim == 1:
96 pesq_val_np = pesq_backend.pesq(fs, target.detach().cpu().numpy(), preds.detach().cpu().numpy(), mode)
97 pesq_val = torch.tensor(pesq_val_np)
98 else:
99 preds_np = preds.reshape(-1, preds.shape[-1]).detach().cpu().numpy()
100 target_np = target.reshape(-1, preds.shape[-1]).detach().cpu().numpy()
101
102 if _MULTIPROCESSING_AVAILABLE and n_processes != 1:
103 pesq_val_np = pesq_backend.pesq_batch(fs, target_np, preds_np, mode, n_processor=n_processes)
104 pesq_val_np = np.array(pesq_val_np)
105 else:
106 pesq_val_np = np.empty(shape=(preds_np.shape[0]))
107 for b in range(preds_np.shape[0]):
108 pesq_val_np[b] = pesq_backend.pesq(fs, target_np[b, :], preds_np[b, :], mode)
109 pesq_val = torch.from_numpy(pesq_val_np)
110 pesq_val = pesq_val.reshape(preds.shape[:-1])
111
112 if keep_same_device:
113 pesq_val = pesq_val.to(preds.device)
114
115 return pesq_val
116
[end of src/torchmetrics/functional/audio/pesq.py]
[start of src/torchmetrics/audio/pesq.py]
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from typing import Any
15
16 from torch import Tensor, tensor
17
18 from torchmetrics.functional.audio.pesq import perceptual_evaluation_speech_quality
19 from torchmetrics.metric import Metric
20 from torchmetrics.utilities.imports import _PESQ_AVAILABLE
21
22 __doctest_requires__ = {"PerceptualEvaluationSpeechQuality": ["pesq"]}
23
24
25 class PerceptualEvaluationSpeechQuality(Metric):
26 """Calculates `Perceptual Evaluation of Speech Quality`_ (PESQ). It's a recognized industry standard for audio
27 quality that takes into considerations characteristics such as: audio sharpness, call volume, background noise,
28 clipping, audio interference ect. PESQ returns a score between -0.5 and 4.5 with the higher scores indicating a
29 better quality.
30
31 This metric is a wrapper for the `pesq package`_. Note that input will be moved to ``cpu`` to perform the metric
32 calculation.
33
34 As input to ``forward`` and ``update`` the metric accepts the following input
35
36 - ``preds`` (:class:`~torch.Tensor`): float tensor with shape ``(...,time)``
37 - ``target`` (:class:`~torch.Tensor`): float tensor with shape ``(...,time)``
38
39 As output of `forward` and `compute` the metric returns the following output
40
41 - ``pesq`` (:class:`~torch.Tensor`): float tensor with shape ``(...,)`` of PESQ value per sample
42
43 .. note:: using this metrics requires you to have ``pesq`` install. Either install as ``pip install
44 torchmetrics[audio]`` or ``pip install pesq``. ``pesq`` will compile with your currently
45 installed version of numpy, meaning that if you upgrade numpy at some point in the future you will
46 most likely have to reinstall ``pesq``.
47
48 Args:
49 fs: sampling frequency, should be 16000 or 8000 (Hz)
50 mode: ``'wb'`` (wide-band) or ``'nb'`` (narrow-band)
51 keep_same_device: whether to move the pesq value to the device of preds
52 n_processes: integer specifiying the number of processes to run in parallel for the metric calculation.
53 Only applies to batches of data and if ``multiprocessing`` package is installed.
54 kwargs: Additional keyword arguments, see :ref:`Metric kwargs` for more info.
55
56 Raises:
57 ModuleNotFoundError:
58 If ``peqs`` package is not installed
59 ValueError:
60 If ``fs`` is not either ``8000`` or ``16000``
61 ValueError:
62 If ``mode`` is not either ``"wb"`` or ``"nb"``
63
64 Example:
65 >>> from torchmetrics.audio.pesq import PerceptualEvaluationSpeechQuality
66 >>> import torch
67 >>> g = torch.manual_seed(1)
68 >>> preds = torch.randn(8000)
69 >>> target = torch.randn(8000)
70 >>> nb_pesq = PerceptualEvaluationSpeechQuality(8000, 'nb')
71 >>> nb_pesq(preds, target)
72 tensor(2.2076)
73 >>> wb_pesq = PerceptualEvaluationSpeechQuality(16000, 'wb')
74 >>> wb_pesq(preds, target)
75 tensor(1.7359)
76 """
77
78 sum_pesq: Tensor
79 total: Tensor
80 full_state_update: bool = False
81 is_differentiable: bool = False
82 higher_is_better: bool = True
83
84 def __init__(
85 self,
86 fs: int,
87 mode: str,
88 n_processes: int = 1,
89 **kwargs: Any,
90 ) -> None:
91 super().__init__(**kwargs)
92 if not _PESQ_AVAILABLE:
93 raise ModuleNotFoundError(
94 "PerceptualEvaluationSpeechQuality metric requires that `pesq` is installed."
95 " Either install as `pip install torchmetrics[audio]` or `pip install pesq`."
96 )
97 if fs not in (8000, 16000):
98 raise ValueError(f"Expected argument `fs` to either be 8000 or 16000 but got {fs}")
99 self.fs = fs
100 if mode not in ("wb", "nb"):
101 raise ValueError(f"Expected argument `mode` to either be 'wb' or 'nb' but got {mode}")
102 self.mode = mode
103 if not isinstance(n_processes, int) and n_processes <= 0:
104 raise ValueError(f"Expected argument `n_processes` to be an int larger than 0 but got {n_processes}")
105 self.n_processes = n_processes
106
107 self.add_state("sum_pesq", default=tensor(0.0), dist_reduce_fx="sum")
108 self.add_state("total", default=tensor(0), dist_reduce_fx="sum")
109
110 def update(self, preds: Tensor, target: Tensor) -> None:
111 """Update state with predictions and targets."""
112 pesq_batch = perceptual_evaluation_speech_quality(
113 preds, target, self.fs, self.mode, False, self.n_processes
114 ).to(self.sum_pesq.device)
115
116 self.sum_pesq += pesq_batch.sum()
117 self.total += pesq_batch.numel()
118
119 def compute(self) -> Tensor:
120 """Computes metric."""
121 return self.sum_pesq / self.total
122
[end of src/torchmetrics/audio/pesq.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/torchmetrics/audio/pesq.py b/src/torchmetrics/audio/pesq.py
--- a/src/torchmetrics/audio/pesq.py
+++ b/src/torchmetrics/audio/pesq.py
@@ -55,7 +55,7 @@
Raises:
ModuleNotFoundError:
- If ``peqs`` package is not installed
+ If ``pesq`` package is not installed
ValueError:
If ``fs`` is not either ``8000`` or ``16000``
ValueError:
diff --git a/src/torchmetrics/functional/audio/pesq.py b/src/torchmetrics/functional/audio/pesq.py
--- a/src/torchmetrics/functional/audio/pesq.py
+++ b/src/torchmetrics/functional/audio/pesq.py
@@ -62,13 +62,13 @@
Raises:
ModuleNotFoundError:
- If ``peqs`` package is not installed
+ If ``pesq`` package is not installed
ValueError:
If ``fs`` is not either ``8000`` or ``16000``
ValueError:
If ``mode`` is not either ``"wb"`` or ``"nb"``
RuntimeError:
- If ``preds`` and ``target`` does not have the same shape
+ If ``preds`` and ``target`` do not have the same shape
Example:
>>> from torchmetrics.functional.audio.pesq import perceptual_evaluation_speech_quality
|
{"golden_diff": "diff --git a/src/torchmetrics/audio/pesq.py b/src/torchmetrics/audio/pesq.py\n--- a/src/torchmetrics/audio/pesq.py\n+++ b/src/torchmetrics/audio/pesq.py\n@@ -55,7 +55,7 @@\n \n Raises:\n ModuleNotFoundError:\n- If ``peqs`` package is not installed\n+ If ``pesq`` package is not installed\n ValueError:\n If ``fs`` is not either ``8000`` or ``16000``\n ValueError:\ndiff --git a/src/torchmetrics/functional/audio/pesq.py b/src/torchmetrics/functional/audio/pesq.py\n--- a/src/torchmetrics/functional/audio/pesq.py\n+++ b/src/torchmetrics/functional/audio/pesq.py\n@@ -62,13 +62,13 @@\n \n Raises:\n ModuleNotFoundError:\n- If ``peqs`` package is not installed\n+ If ``pesq`` package is not installed\n ValueError:\n If ``fs`` is not either ``8000`` or ``16000``\n ValueError:\n If ``mode`` is not either ``\"wb\"`` or ``\"nb\"``\n RuntimeError:\n- If ``preds`` and ``target`` does not have the same shape\n+ If ``preds`` and ``target`` do not have the same shape\n \n Example:\n >>> from torchmetrics.functional.audio.pesq import perceptual_evaluation_speech_quality\n", "issue": "Small typo in PESQ docs\n## \ud83d\udcda Documentation\r\n\r\n[Perceptual Evaluation Of Speech Quality (PESQ) documentation](https://torchmetrics.readthedocs.io/en/stable/audio/perceptual_evaluation_speech_quality.html) states following for both Module Interface and Functional Interface:\r\nRaises ModuleNotFoundError \u2013 If **peqs** package is not installed.\r\n\n", "before_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport numpy as np\nimport torch\nfrom torch import Tensor\n\nfrom torchmetrics.utilities.checks import _check_same_shape\nfrom torchmetrics.utilities.imports import _MULTIPROCESSING_AVAILABLE, _PESQ_AVAILABLE\n\nif _PESQ_AVAILABLE:\n import pesq as pesq_backend\nelse:\n pesq_backend = None\n\n\n__doctest_requires__ = {(\"perceptual_evaluation_speech_quality\",): [\"pesq\"]}\n\n\ndef perceptual_evaluation_speech_quality(\n preds: Tensor,\n target: Tensor,\n fs: int,\n mode: str,\n keep_same_device: bool = False,\n n_processes: int = 1,\n) -> Tensor:\n r\"\"\"Calculates `Perceptual Evaluation of Speech Quality`_ (PESQ). It's a recognized industry standard for audio\n quality that takes into considerations characteristics such as: audio sharpness, call volume, background noise,\n clipping, audio interference ect. PESQ returns a score between -0.5 and 4.5 with the higher scores indicating a\n better quality.\n\n This metric is a wrapper for the `pesq package`_. Note that input will be moved to `cpu` to perform the metric\n calculation.\n\n .. note:: using this metrics requires you to have ``pesq`` install. Either install as ``pip install\n torchmetrics[audio]`` or ``pip install pesq``. Note that ``pesq`` will compile with your currently\n installed version of numpy, meaning that if you upgrade numpy at some point in the future you will\n most likely have to reinstall ``pesq``.\n\n Args:\n preds: float tensor with shape ``(...,time)``\n target: float tensor with shape ``(...,time)``\n fs: sampling frequency, should be 16000 or 8000 (Hz)\n mode: ``'wb'`` (wide-band) or ``'nb'`` (narrow-band)\n keep_same_device: whether to move the pesq value to the device of preds\n n_processes: integer specifiying the number of processes to run in parallel for the metric calculation.\n Only applies to batches of data and if ``multiprocessing`` package is installed.\n\n Returns:\n Float tensor with shape ``(...,)`` of PESQ values per sample\n\n Raises:\n ModuleNotFoundError:\n If ``peqs`` package is not installed\n ValueError:\n If ``fs`` is not either ``8000`` or ``16000``\n ValueError:\n If ``mode`` is not either ``\"wb\"`` or ``\"nb\"``\n RuntimeError:\n If ``preds`` and ``target`` does not have the same shape\n\n Example:\n >>> from torchmetrics.functional.audio.pesq import perceptual_evaluation_speech_quality\n >>> import torch\n >>> g = torch.manual_seed(1)\n >>> preds = torch.randn(8000)\n >>> target = torch.randn(8000)\n >>> perceptual_evaluation_speech_quality(preds, target, 8000, 'nb')\n tensor(2.2076)\n >>> perceptual_evaluation_speech_quality(preds, target, 16000, 'wb')\n tensor(1.7359)\n \"\"\"\n if not _PESQ_AVAILABLE:\n raise ModuleNotFoundError(\n \"PESQ metric requires that pesq is installed.\"\n \" Either install as `pip install torchmetrics[audio]` or `pip install pesq`.\"\n )\n if fs not in (8000, 16000):\n raise ValueError(f\"Expected argument `fs` to either be 8000 or 16000 but got {fs}\")\n if mode not in (\"wb\", \"nb\"):\n raise ValueError(f\"Expected argument `mode` to either be 'wb' or 'nb' but got {mode}\")\n _check_same_shape(preds, target)\n\n if preds.ndim == 1:\n pesq_val_np = pesq_backend.pesq(fs, target.detach().cpu().numpy(), preds.detach().cpu().numpy(), mode)\n pesq_val = torch.tensor(pesq_val_np)\n else:\n preds_np = preds.reshape(-1, preds.shape[-1]).detach().cpu().numpy()\n target_np = target.reshape(-1, preds.shape[-1]).detach().cpu().numpy()\n\n if _MULTIPROCESSING_AVAILABLE and n_processes != 1:\n pesq_val_np = pesq_backend.pesq_batch(fs, target_np, preds_np, mode, n_processor=n_processes)\n pesq_val_np = np.array(pesq_val_np)\n else:\n pesq_val_np = np.empty(shape=(preds_np.shape[0]))\n for b in range(preds_np.shape[0]):\n pesq_val_np[b] = pesq_backend.pesq(fs, target_np[b, :], preds_np[b, :], mode)\n pesq_val = torch.from_numpy(pesq_val_np)\n pesq_val = pesq_val.reshape(preds.shape[:-1])\n\n if keep_same_device:\n pesq_val = pesq_val.to(preds.device)\n\n return pesq_val\n", "path": "src/torchmetrics/functional/audio/pesq.py"}, {"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom typing import Any\n\nfrom torch import Tensor, tensor\n\nfrom torchmetrics.functional.audio.pesq import perceptual_evaluation_speech_quality\nfrom torchmetrics.metric import Metric\nfrom torchmetrics.utilities.imports import _PESQ_AVAILABLE\n\n__doctest_requires__ = {\"PerceptualEvaluationSpeechQuality\": [\"pesq\"]}\n\n\nclass PerceptualEvaluationSpeechQuality(Metric):\n \"\"\"Calculates `Perceptual Evaluation of Speech Quality`_ (PESQ). It's a recognized industry standard for audio\n quality that takes into considerations characteristics such as: audio sharpness, call volume, background noise,\n clipping, audio interference ect. PESQ returns a score between -0.5 and 4.5 with the higher scores indicating a\n better quality.\n\n This metric is a wrapper for the `pesq package`_. Note that input will be moved to ``cpu`` to perform the metric\n calculation.\n\n As input to ``forward`` and ``update`` the metric accepts the following input\n\n - ``preds`` (:class:`~torch.Tensor`): float tensor with shape ``(...,time)``\n - ``target`` (:class:`~torch.Tensor`): float tensor with shape ``(...,time)``\n\n As output of `forward` and `compute` the metric returns the following output\n\n - ``pesq`` (:class:`~torch.Tensor`): float tensor with shape ``(...,)`` of PESQ value per sample\n\n .. note:: using this metrics requires you to have ``pesq`` install. Either install as ``pip install\n torchmetrics[audio]`` or ``pip install pesq``. ``pesq`` will compile with your currently\n installed version of numpy, meaning that if you upgrade numpy at some point in the future you will\n most likely have to reinstall ``pesq``.\n\n Args:\n fs: sampling frequency, should be 16000 or 8000 (Hz)\n mode: ``'wb'`` (wide-band) or ``'nb'`` (narrow-band)\n keep_same_device: whether to move the pesq value to the device of preds\n n_processes: integer specifiying the number of processes to run in parallel for the metric calculation.\n Only applies to batches of data and if ``multiprocessing`` package is installed.\n kwargs: Additional keyword arguments, see :ref:`Metric kwargs` for more info.\n\n Raises:\n ModuleNotFoundError:\n If ``peqs`` package is not installed\n ValueError:\n If ``fs`` is not either ``8000`` or ``16000``\n ValueError:\n If ``mode`` is not either ``\"wb\"`` or ``\"nb\"``\n\n Example:\n >>> from torchmetrics.audio.pesq import PerceptualEvaluationSpeechQuality\n >>> import torch\n >>> g = torch.manual_seed(1)\n >>> preds = torch.randn(8000)\n >>> target = torch.randn(8000)\n >>> nb_pesq = PerceptualEvaluationSpeechQuality(8000, 'nb')\n >>> nb_pesq(preds, target)\n tensor(2.2076)\n >>> wb_pesq = PerceptualEvaluationSpeechQuality(16000, 'wb')\n >>> wb_pesq(preds, target)\n tensor(1.7359)\n \"\"\"\n\n sum_pesq: Tensor\n total: Tensor\n full_state_update: bool = False\n is_differentiable: bool = False\n higher_is_better: bool = True\n\n def __init__(\n self,\n fs: int,\n mode: str,\n n_processes: int = 1,\n **kwargs: Any,\n ) -> None:\n super().__init__(**kwargs)\n if not _PESQ_AVAILABLE:\n raise ModuleNotFoundError(\n \"PerceptualEvaluationSpeechQuality metric requires that `pesq` is installed.\"\n \" Either install as `pip install torchmetrics[audio]` or `pip install pesq`.\"\n )\n if fs not in (8000, 16000):\n raise ValueError(f\"Expected argument `fs` to either be 8000 or 16000 but got {fs}\")\n self.fs = fs\n if mode not in (\"wb\", \"nb\"):\n raise ValueError(f\"Expected argument `mode` to either be 'wb' or 'nb' but got {mode}\")\n self.mode = mode\n if not isinstance(n_processes, int) and n_processes <= 0:\n raise ValueError(f\"Expected argument `n_processes` to be an int larger than 0 but got {n_processes}\")\n self.n_processes = n_processes\n\n self.add_state(\"sum_pesq\", default=tensor(0.0), dist_reduce_fx=\"sum\")\n self.add_state(\"total\", default=tensor(0), dist_reduce_fx=\"sum\")\n\n def update(self, preds: Tensor, target: Tensor) -> None:\n \"\"\"Update state with predictions and targets.\"\"\"\n pesq_batch = perceptual_evaluation_speech_quality(\n preds, target, self.fs, self.mode, False, self.n_processes\n ).to(self.sum_pesq.device)\n\n self.sum_pesq += pesq_batch.sum()\n self.total += pesq_batch.numel()\n\n def compute(self) -> Tensor:\n \"\"\"Computes metric.\"\"\"\n return self.sum_pesq / self.total\n", "path": "src/torchmetrics/audio/pesq.py"}]}
| 3,706 | 331 |
gh_patches_debug_9861
|
rasdani/github-patches
|
git_diff
|
mindsdb__mindsdb-1019
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Error if try create datasource from not existing integration
If send query `PUT api/datasources/ds_name` with data:
```
{
"integration_id": 'unexists_integration',
"name": 'ds_name',
"query": f"select * from test_data.any_data limit 100;"
}
```
then in response will be error:
```
{
"message": 'TypeError: expected str, bytes or os.PathLike object, not dict'
}
```
</issue>
<code>
[start of mindsdb/api/http/namespaces/datasource.py]
1 import datetime
2 import os
3 import threading
4 import tempfile
5 import re
6 import multipart
7
8 import mindsdb
9 from dateutil.parser import parse
10 from flask import request, send_file
11 from flask_restx import Resource, abort # 'abort' using to return errors as json: {'message': 'error text'}
12 from flask import current_app as ca
13
14 from mindsdb.api.http.namespaces.configs.datasources import ns_conf
15 from mindsdb.api.http.namespaces.entitites.datasources.datasource import (
16 datasource_metadata,
17 put_datasource_params
18 )
19 from mindsdb.api.http.namespaces.entitites.datasources.datasource_data import (
20 get_datasource_rows_params,
21 datasource_rows_metadata
22 )
23 from mindsdb.api.http.namespaces.entitites.datasources.datasource_files import (
24 put_datasource_file_params
25 )
26 from mindsdb.api.http.namespaces.entitites.datasources.datasource_missed_files import (
27 datasource_missed_files_metadata,
28 get_datasource_missed_files_params
29 )
30
31
32 def parse_filter(key, value):
33 result = re.search(r'filter(_*.*)\[(.*)\]', key)
34 operator = result.groups()[0].strip('_') or 'like'
35 field = result.groups()[1]
36 operators_map = {
37 'like': 'like',
38 'in': 'in',
39 'nin': 'not in',
40 'gt': '>',
41 'lt': '<',
42 'gte': '>=',
43 'lte': '<=',
44 'eq': '=',
45 'neq': '!='
46 }
47 if operator not in operators_map:
48 return None
49 operator = operators_map[operator]
50 return [field, operator, value]
51
52
53 @ns_conf.route('/')
54 class DatasourcesList(Resource):
55 @ns_conf.doc('get_datasources_list')
56 @ns_conf.marshal_list_with(datasource_metadata)
57 def get(self):
58 '''List all datasources'''
59 return ca.default_store.get_datasources()
60
61
62 @ns_conf.route('/<name>')
63 @ns_conf.param('name', 'Datasource name')
64 class Datasource(Resource):
65 @ns_conf.doc('get_datasource')
66 @ns_conf.marshal_with(datasource_metadata)
67 def get(self, name):
68 '''return datasource metadata'''
69 ds = ca.default_store.get_datasource(name)
70 if ds is not None:
71 return ds
72 return '', 404
73
74 @ns_conf.doc('delete_datasource')
75 def delete(self, name):
76 '''delete datasource'''
77 try:
78 ca.default_store.delete_datasource(name)
79 except Exception as e:
80 print(e)
81 abort(400, str(e))
82 return '', 200
83
84 @ns_conf.doc('put_datasource', params=put_datasource_params)
85 @ns_conf.marshal_with(datasource_metadata)
86 def put(self, name):
87 '''add new datasource'''
88 data = {}
89
90 def on_field(field):
91 name = field.field_name.decode()
92 value = field.value.decode()
93 data[name] = value
94
95 file_object = None
96
97 def on_file(file):
98 nonlocal file_object
99 data['file'] = file.file_name.decode()
100 file_object = file.file_object
101
102 temp_dir_path = tempfile.mkdtemp(prefix='datasource_file_')
103
104 if request.headers['Content-Type'].startswith('multipart/form-data'):
105 parser = multipart.create_form_parser(
106 headers=request.headers,
107 on_field=on_field,
108 on_file=on_file,
109 config={
110 'UPLOAD_DIR': temp_dir_path.encode(), # bytes required
111 'UPLOAD_KEEP_FILENAME': True,
112 'UPLOAD_KEEP_EXTENSIONS': True,
113 'MAX_MEMORY_FILE_SIZE': 0
114 }
115 )
116
117 while True:
118 chunk = request.stream.read(8192)
119 if not chunk:
120 break
121 parser.write(chunk)
122 parser.finalize()
123 parser.close()
124
125 if file_object is not None and not file_object.closed:
126 file_object.close()
127 else:
128 data = request.json
129
130 if 'query' in data:
131 source_type = request.json['integration_id']
132 ca.default_store.save_datasource(name, source_type, request.json)
133 os.rmdir(temp_dir_path)
134 return ca.default_store.get_datasource(name)
135
136 ds_name = data['name'] if 'name' in data else name
137 source = data['source'] if 'source' in data else name
138 source_type = data['source_type']
139
140 if source_type == 'file':
141 file_path = os.path.join(temp_dir_path, data['file'])
142 else:
143 file_path = None
144
145 ca.default_store.save_datasource(ds_name, source_type, source, file_path)
146 os.rmdir(temp_dir_path)
147
148 return ca.default_store.get_datasource(ds_name)
149
150
151 ds_analysis = {}
152
153
154 def analyzing_thread(name, default_store):
155 global ds_analysis
156 ds_analysis[name] = None
157 ds = default_store.get_datasource(name)
158 analysis = default_store.get_analysis(ds['name'])
159 ds_analysis[name] = {
160 'created_at': datetime.datetime.utcnow(),
161 'data': analysis
162 }
163
164
165 @ns_conf.route('/<name>/analyze')
166 @ns_conf.param('name', 'Datasource name')
167 class Analyze(Resource):
168 @ns_conf.doc('analyse_dataset')
169 def get(self, name):
170 global ds_analysis
171 if name in ds_analysis:
172 if ds_analysis[name] is None:
173 return {'status': 'analyzing'}, 200
174 else:
175 analysis = ds_analysis[name]['data']
176 return analysis, 200
177
178 ds = ca.default_store.get_datasource(name)
179 if ds is None:
180 print('No valid datasource given')
181 abort(400, 'No valid datasource given')
182
183 x = threading.Thread(target=analyzing_thread, args=(name, ca.default_store))
184 x.start()
185 return {'status': 'analyzing'}, 200
186
187 @ns_conf.route('/<name>/analyze_refresh')
188 @ns_conf.param('name', 'Datasource name')
189 class Analyze(Resource):
190 @ns_conf.doc('analyze_refresh_dataset')
191 def get(self, name):
192 global ds_analysis
193 if name in ds_analysis:
194 if ds_analysis[name] is None:
195 return {'status': 'analyzing'}, 200
196 else:
197 del ds_analysis[name]
198
199 ds = ca.default_store.get_datasource(name)
200 if ds is None:
201 print('No valid datasource given')
202 abort(400, 'No valid datasource given')
203
204 x = threading.Thread(target=analyzing_thread, args=(name, ca.default_store))
205 x.start()
206 return {'status': 'analyzing'}, 200
207
208
209 @ns_conf.route('/<name>/analyze_subset')
210 @ns_conf.param('name', 'Datasource name')
211 class AnalyzeSubset(Resource):
212 @ns_conf.doc('analyse_datasubset')
213 def get(self, name):
214 ds = ca.default_store.get_datasource(name)
215 if ds is None:
216 print('No valid datasource given')
217 abort(400, 'No valid datasource given')
218
219 where = []
220 for key, value in request.args.items():
221 if key.startswith('filter'):
222 param = parse_filter(key, value)
223 if param is None:
224 abort(400, f'Not valid filter "{key}"')
225 where.append(param)
226
227 data_dict = ca.default_store.get_data(ds['name'], where)
228
229 if data_dict['rowcount'] == 0:
230 return abort(400, 'Empty dataset after filters applying')
231
232 return get_analysis(pd.DataFrame(data_dict['data'])), 200
233
234
235 @ns_conf.route('/<name>/data/')
236 @ns_conf.param('name', 'Datasource name')
237 class DatasourceData(Resource):
238 @ns_conf.doc('get_datasource_data', params=get_datasource_rows_params)
239 @ns_conf.marshal_with(datasource_rows_metadata)
240 def get(self, name):
241 '''return data rows'''
242 ds = ca.default_store.get_datasource(name)
243 if ds is None:
244 abort(400, 'No valid datasource given')
245
246 params = {
247 'page[size]': None,
248 'page[offset]': None
249 }
250 where = []
251 for key, value in request.args.items():
252 if key == 'page[size]':
253 params['page[size]'] = int(value)
254 if key == 'page[offset]':
255 params['page[offset]'] = int(value)
256 elif key.startswith('filter'):
257 param = parse_filter(key, value)
258 if param is None:
259 abort(400, f'Not valid filter "{key}"')
260 where.append(param)
261
262 data_dict = ca.default_store.get_data(name, where, params['page[size]'], params['page[offset]'])
263
264 return data_dict, 200
265
266
267 @ns_conf.route('/<name>/download')
268 @ns_conf.param('name', 'Datasource name')
269 class DatasourceMissedFilesDownload(Resource):
270 @ns_conf.doc('get_datasource_download')
271 def get(self, name):
272 '''download uploaded file'''
273 ds = ca.default_store.get_datasource(name)
274 if not ds:
275 abort(404, "{} not found".format(name))
276 if not os.path.exists(ds['source']):
277 abort(404, "{} not found".format(name))
278
279 return send_file(os.path.abspath(ds['source']), as_attachment=True)
280
[end of mindsdb/api/http/namespaces/datasource.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mindsdb/api/http/namespaces/datasource.py b/mindsdb/api/http/namespaces/datasource.py
--- a/mindsdb/api/http/namespaces/datasource.py
+++ b/mindsdb/api/http/namespaces/datasource.py
@@ -129,6 +129,10 @@
if 'query' in data:
source_type = request.json['integration_id']
+ if source_type not in ca.default_store.config['integrations']:
+ # integration doens't exist
+ abort(400, f"{source_type} integration doesn't exist")
+
ca.default_store.save_datasource(name, source_type, request.json)
os.rmdir(temp_dir_path)
return ca.default_store.get_datasource(name)
|
{"golden_diff": "diff --git a/mindsdb/api/http/namespaces/datasource.py b/mindsdb/api/http/namespaces/datasource.py\n--- a/mindsdb/api/http/namespaces/datasource.py\n+++ b/mindsdb/api/http/namespaces/datasource.py\n@@ -129,6 +129,10 @@\n \n if 'query' in data:\n source_type = request.json['integration_id']\n+ if source_type not in ca.default_store.config['integrations']:\n+ # integration doens't exist\n+ abort(400, f\"{source_type} integration doesn't exist\")\n+\n ca.default_store.save_datasource(name, source_type, request.json)\n os.rmdir(temp_dir_path)\n return ca.default_store.get_datasource(name)\n", "issue": "Error if try create datasource from not existing integration\nIf send query `PUT api/datasources/ds_name` with data:\r\n```\r\n{\r\n \"integration_id\": 'unexists_integration',\r\n \"name\": 'ds_name',\r\n \"query\": f\"select * from test_data.any_data limit 100;\"\r\n}\r\n```\r\nthen in response will be error:\r\n```\r\n{\r\n \"message\": 'TypeError: expected str, bytes or os.PathLike object, not dict'\r\n}\r\n```\n", "before_files": [{"content": "import datetime\nimport os\nimport threading\nimport tempfile\nimport re\nimport multipart\n\nimport mindsdb\nfrom dateutil.parser import parse\nfrom flask import request, send_file\nfrom flask_restx import Resource, abort # 'abort' using to return errors as json: {'message': 'error text'}\nfrom flask import current_app as ca\n\nfrom mindsdb.api.http.namespaces.configs.datasources import ns_conf\nfrom mindsdb.api.http.namespaces.entitites.datasources.datasource import (\n datasource_metadata,\n put_datasource_params\n)\nfrom mindsdb.api.http.namespaces.entitites.datasources.datasource_data import (\n get_datasource_rows_params,\n datasource_rows_metadata\n)\nfrom mindsdb.api.http.namespaces.entitites.datasources.datasource_files import (\n put_datasource_file_params\n)\nfrom mindsdb.api.http.namespaces.entitites.datasources.datasource_missed_files import (\n datasource_missed_files_metadata,\n get_datasource_missed_files_params\n)\n\n\ndef parse_filter(key, value):\n result = re.search(r'filter(_*.*)\\[(.*)\\]', key)\n operator = result.groups()[0].strip('_') or 'like'\n field = result.groups()[1]\n operators_map = {\n 'like': 'like',\n 'in': 'in',\n 'nin': 'not in',\n 'gt': '>',\n 'lt': '<',\n 'gte': '>=',\n 'lte': '<=',\n 'eq': '=',\n 'neq': '!='\n }\n if operator not in operators_map:\n return None\n operator = operators_map[operator]\n return [field, operator, value]\n\n\n@ns_conf.route('/')\nclass DatasourcesList(Resource):\n @ns_conf.doc('get_datasources_list')\n @ns_conf.marshal_list_with(datasource_metadata)\n def get(self):\n '''List all datasources'''\n return ca.default_store.get_datasources()\n\n\n@ns_conf.route('/<name>')\n@ns_conf.param('name', 'Datasource name')\nclass Datasource(Resource):\n @ns_conf.doc('get_datasource')\n @ns_conf.marshal_with(datasource_metadata)\n def get(self, name):\n '''return datasource metadata'''\n ds = ca.default_store.get_datasource(name)\n if ds is not None:\n return ds\n return '', 404\n\n @ns_conf.doc('delete_datasource')\n def delete(self, name):\n '''delete datasource'''\n try:\n ca.default_store.delete_datasource(name)\n except Exception as e:\n print(e)\n abort(400, str(e))\n return '', 200\n\n @ns_conf.doc('put_datasource', params=put_datasource_params)\n @ns_conf.marshal_with(datasource_metadata)\n def put(self, name):\n '''add new datasource'''\n data = {}\n\n def on_field(field):\n name = field.field_name.decode()\n value = field.value.decode()\n data[name] = value\n\n file_object = None\n\n def on_file(file):\n nonlocal file_object\n data['file'] = file.file_name.decode()\n file_object = file.file_object\n\n temp_dir_path = tempfile.mkdtemp(prefix='datasource_file_')\n\n if request.headers['Content-Type'].startswith('multipart/form-data'):\n parser = multipart.create_form_parser(\n headers=request.headers,\n on_field=on_field,\n on_file=on_file,\n config={\n 'UPLOAD_DIR': temp_dir_path.encode(), # bytes required\n 'UPLOAD_KEEP_FILENAME': True,\n 'UPLOAD_KEEP_EXTENSIONS': True,\n 'MAX_MEMORY_FILE_SIZE': 0\n }\n )\n\n while True:\n chunk = request.stream.read(8192)\n if not chunk:\n break\n parser.write(chunk)\n parser.finalize()\n parser.close()\n\n if file_object is not None and not file_object.closed:\n file_object.close()\n else:\n data = request.json\n\n if 'query' in data:\n source_type = request.json['integration_id']\n ca.default_store.save_datasource(name, source_type, request.json)\n os.rmdir(temp_dir_path)\n return ca.default_store.get_datasource(name)\n\n ds_name = data['name'] if 'name' in data else name\n source = data['source'] if 'source' in data else name\n source_type = data['source_type']\n\n if source_type == 'file':\n file_path = os.path.join(temp_dir_path, data['file'])\n else:\n file_path = None\n\n ca.default_store.save_datasource(ds_name, source_type, source, file_path)\n os.rmdir(temp_dir_path)\n\n return ca.default_store.get_datasource(ds_name)\n\n\nds_analysis = {}\n\n\ndef analyzing_thread(name, default_store):\n global ds_analysis\n ds_analysis[name] = None\n ds = default_store.get_datasource(name)\n analysis = default_store.get_analysis(ds['name'])\n ds_analysis[name] = {\n 'created_at': datetime.datetime.utcnow(),\n 'data': analysis\n }\n\n\n@ns_conf.route('/<name>/analyze')\n@ns_conf.param('name', 'Datasource name')\nclass Analyze(Resource):\n @ns_conf.doc('analyse_dataset')\n def get(self, name):\n global ds_analysis\n if name in ds_analysis:\n if ds_analysis[name] is None:\n return {'status': 'analyzing'}, 200\n else:\n analysis = ds_analysis[name]['data']\n return analysis, 200\n\n ds = ca.default_store.get_datasource(name)\n if ds is None:\n print('No valid datasource given')\n abort(400, 'No valid datasource given')\n\n x = threading.Thread(target=analyzing_thread, args=(name, ca.default_store))\n x.start()\n return {'status': 'analyzing'}, 200\n\n@ns_conf.route('/<name>/analyze_refresh')\n@ns_conf.param('name', 'Datasource name')\nclass Analyze(Resource):\n @ns_conf.doc('analyze_refresh_dataset')\n def get(self, name):\n global ds_analysis\n if name in ds_analysis:\n if ds_analysis[name] is None:\n return {'status': 'analyzing'}, 200\n else:\n del ds_analysis[name]\n\n ds = ca.default_store.get_datasource(name)\n if ds is None:\n print('No valid datasource given')\n abort(400, 'No valid datasource given')\n\n x = threading.Thread(target=analyzing_thread, args=(name, ca.default_store))\n x.start()\n return {'status': 'analyzing'}, 200\n\n\n@ns_conf.route('/<name>/analyze_subset')\n@ns_conf.param('name', 'Datasource name')\nclass AnalyzeSubset(Resource):\n @ns_conf.doc('analyse_datasubset')\n def get(self, name):\n ds = ca.default_store.get_datasource(name)\n if ds is None:\n print('No valid datasource given')\n abort(400, 'No valid datasource given')\n\n where = []\n for key, value in request.args.items():\n if key.startswith('filter'):\n param = parse_filter(key, value)\n if param is None:\n abort(400, f'Not valid filter \"{key}\"')\n where.append(param)\n\n data_dict = ca.default_store.get_data(ds['name'], where)\n\n if data_dict['rowcount'] == 0:\n return abort(400, 'Empty dataset after filters applying')\n\n return get_analysis(pd.DataFrame(data_dict['data'])), 200\n\n\n@ns_conf.route('/<name>/data/')\n@ns_conf.param('name', 'Datasource name')\nclass DatasourceData(Resource):\n @ns_conf.doc('get_datasource_data', params=get_datasource_rows_params)\n @ns_conf.marshal_with(datasource_rows_metadata)\n def get(self, name):\n '''return data rows'''\n ds = ca.default_store.get_datasource(name)\n if ds is None:\n abort(400, 'No valid datasource given')\n\n params = {\n 'page[size]': None,\n 'page[offset]': None\n }\n where = []\n for key, value in request.args.items():\n if key == 'page[size]':\n params['page[size]'] = int(value)\n if key == 'page[offset]':\n params['page[offset]'] = int(value)\n elif key.startswith('filter'):\n param = parse_filter(key, value)\n if param is None:\n abort(400, f'Not valid filter \"{key}\"')\n where.append(param)\n\n data_dict = ca.default_store.get_data(name, where, params['page[size]'], params['page[offset]'])\n\n return data_dict, 200\n\n\n@ns_conf.route('/<name>/download')\n@ns_conf.param('name', 'Datasource name')\nclass DatasourceMissedFilesDownload(Resource):\n @ns_conf.doc('get_datasource_download')\n def get(self, name):\n '''download uploaded file'''\n ds = ca.default_store.get_datasource(name)\n if not ds:\n abort(404, \"{} not found\".format(name))\n if not os.path.exists(ds['source']):\n abort(404, \"{} not found\".format(name))\n\n return send_file(os.path.abspath(ds['source']), as_attachment=True)\n", "path": "mindsdb/api/http/namespaces/datasource.py"}]}
| 3,418 | 170 |
gh_patches_debug_39730
|
rasdani/github-patches
|
git_diff
|
carpentries__amy-351
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Deal with breadcrumbs
As Greg mentioned in #296, he hadn't liked the way breadcrumbs repeat current page title (or header) in their last element, for example: page "Event 2015-05-25-something" will have breadcrumbs "Amy / All events / Event 2015-05-25-something".
I took a look at other big websites and how they do breadcrumbs and @gvwilson was right. They don't repeat current site at the end of breadcrumbs.
This means we'd only have breadcrumbs at most 3 links long: Amy / All \* / \* [ / action ], for example:
Was:
- Amy / All events / Event 2015-05-25-something / Edit
Will be:
- Amy / All events / Event 2015-05-25-something
But this does not bug me. In case of `All *` pages, we can just as well drop breadcrumbs (because they'd look like "Amy / ").
So I don't really know what to do:
1. Display breadcrumbs on the same pages as now, but hide the last item.
2. Display breadcrumbs on the pages that would have more than 1 breadcrumbs.
3. Drop breadcrumbs completely.
</issue>
<code>
[start of workshops/templatetags/breadcrumbs.py]
1 import logging
2
3 from django import template
4 from django.core.urlresolvers import reverse
5 from django.utils.encoding import force_text
6 from django.utils.html import escape
7
8 register = template.Library()
9 _LOG = logging.getLogger(__name__)
10
11
12 @register.simple_tag
13 def breadcrumb(title, url):
14 '''
15 Create a simple anchor with provided text and already-resolved URL.
16 Example usage:
17 {% breadcrumb "Title of breadcrumb" resolved_url %}
18 '''
19 return create_crumb(title, url)
20
21
22 @register.simple_tag
23 def breadcrumb_url(title, url_name):
24 '''
25 Add non-active breadcrumb with specified title. Second argument should be
26 a string name of URL that needs to be resolved.
27 Example usage:
28 {% breadcrumb_url "Title of breadcrumb" url_name %}
29 '''
30 url = reverse(url_name)
31 return create_crumb(title, url)
32
33
34 @register.simple_tag
35 def breadcrumb_active(title):
36 '''
37 Add active breadcrumb, but not in an anchor.
38 Example usage:
39 {% breadcrumb_active "Title of breadcrumb" %}
40 '''
41 return create_crumb(str(title), url=None, active=True)
42
43
44 @register.simple_tag
45 def breadcrumb_index_all_objects(model):
46 '''
47 Add breadcrumb linking to the listing of all objects of specific type.
48 This tag accepts both models or model instances as an argument.
49 Example usage:
50 {% breadcrumb_index_all_objects model %}
51 {% breadcrumb_index_all_objects person %}
52 '''
53 plural = force_text(model._meta.verbose_name_plural)
54 title = 'All {}'.format(plural)
55 url_name = 'all_{}'.format(plural)
56 url = reverse(url_name)
57 return create_crumb(title, url)
58
59
60 @register.simple_tag
61 def breadcrumb_edit_object(obj):
62 '''
63 Add an active breadcrumb with the title "Edit MODEL_NAME".
64 This tag accepts model instance as an argument.
65 Example usage:
66 {% breadcrumb_edit_object person %}
67 '''
68 singular = force_text(obj._meta.verbose_name)
69 title = 'Edit {}'.format(singular)
70 return create_crumb(title, url=None, active=True)
71
72
73 @register.simple_tag
74 def breadcrumb_new_object(model):
75 '''
76 Add an active breadcrumb with the title "Add new MODEL_NAME".
77 This tag accepts model class as an argument.
78 Example usage:
79 {% breadcrumb_new_object person %}
80 '''
81 singular = force_text(model._meta.verbose_name)
82 title = 'Add new {}'.format(singular)
83 return create_crumb(title, url=None, active=True)
84
85
86 @register.simple_tag
87 def breadcrumb_object(obj):
88 '''
89 Add non-active breadcrumb with the title "Add new MODEL_NAME".
90 This tag accepts model instance as an argument.
91 Example usage:
92 {% breadcrumb_object person %}
93 '''
94 title = str(obj)
95 url = obj.get_absolute_url()
96 return create_crumb(title, url, active=False)
97
98
99 @register.simple_tag
100 def breadcrumb_main_page():
101 '''
102 Special case of ``breadcrumb_url``. In all templates there's always a link
103 to the main page so I wanted to save everyone thinking & writing by
104 introducing this helper tag.
105 Example usage:
106 {% breadcrumb_main_page %}
107 '''
108 title = 'Amy'
109 url = reverse('index')
110 return create_crumb(title, url)
111
112
113 def create_crumb(title, url=None, active=False):
114 '''
115 Helper function that creates breadcrumb.
116 '''
117 active_str = ''
118 if active:
119 active_str = ' class="active"'
120
121 title = escape(title)
122 inner_str = title
123 if url:
124 inner_str = '<a href="{0}">{1}</a>'.format(url, title)
125
126 crumb = '<li{0}>{1}</li>'.format(active_str, inner_str)
127
128 return crumb
129
[end of workshops/templatetags/breadcrumbs.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/workshops/templatetags/breadcrumbs.py b/workshops/templatetags/breadcrumbs.py
deleted file mode 100644
--- a/workshops/templatetags/breadcrumbs.py
+++ /dev/null
@@ -1,128 +0,0 @@
-import logging
-
-from django import template
-from django.core.urlresolvers import reverse
-from django.utils.encoding import force_text
-from django.utils.html import escape
-
-register = template.Library()
-_LOG = logging.getLogger(__name__)
-
-
[email protected]_tag
-def breadcrumb(title, url):
- '''
- Create a simple anchor with provided text and already-resolved URL.
- Example usage:
- {% breadcrumb "Title of breadcrumb" resolved_url %}
- '''
- return create_crumb(title, url)
-
-
[email protected]_tag
-def breadcrumb_url(title, url_name):
- '''
- Add non-active breadcrumb with specified title. Second argument should be
- a string name of URL that needs to be resolved.
- Example usage:
- {% breadcrumb_url "Title of breadcrumb" url_name %}
- '''
- url = reverse(url_name)
- return create_crumb(title, url)
-
-
[email protected]_tag
-def breadcrumb_active(title):
- '''
- Add active breadcrumb, but not in an anchor.
- Example usage:
- {% breadcrumb_active "Title of breadcrumb" %}
- '''
- return create_crumb(str(title), url=None, active=True)
-
-
[email protected]_tag
-def breadcrumb_index_all_objects(model):
- '''
- Add breadcrumb linking to the listing of all objects of specific type.
- This tag accepts both models or model instances as an argument.
- Example usage:
- {% breadcrumb_index_all_objects model %}
- {% breadcrumb_index_all_objects person %}
- '''
- plural = force_text(model._meta.verbose_name_plural)
- title = 'All {}'.format(plural)
- url_name = 'all_{}'.format(plural)
- url = reverse(url_name)
- return create_crumb(title, url)
-
-
[email protected]_tag
-def breadcrumb_edit_object(obj):
- '''
- Add an active breadcrumb with the title "Edit MODEL_NAME".
- This tag accepts model instance as an argument.
- Example usage:
- {% breadcrumb_edit_object person %}
- '''
- singular = force_text(obj._meta.verbose_name)
- title = 'Edit {}'.format(singular)
- return create_crumb(title, url=None, active=True)
-
-
[email protected]_tag
-def breadcrumb_new_object(model):
- '''
- Add an active breadcrumb with the title "Add new MODEL_NAME".
- This tag accepts model class as an argument.
- Example usage:
- {% breadcrumb_new_object person %}
- '''
- singular = force_text(model._meta.verbose_name)
- title = 'Add new {}'.format(singular)
- return create_crumb(title, url=None, active=True)
-
-
[email protected]_tag
-def breadcrumb_object(obj):
- '''
- Add non-active breadcrumb with the title "Add new MODEL_NAME".
- This tag accepts model instance as an argument.
- Example usage:
- {% breadcrumb_object person %}
- '''
- title = str(obj)
- url = obj.get_absolute_url()
- return create_crumb(title, url, active=False)
-
-
[email protected]_tag
-def breadcrumb_main_page():
- '''
- Special case of ``breadcrumb_url``. In all templates there's always a link
- to the main page so I wanted to save everyone thinking & writing by
- introducing this helper tag.
- Example usage:
- {% breadcrumb_main_page %}
- '''
- title = 'Amy'
- url = reverse('index')
- return create_crumb(title, url)
-
-
-def create_crumb(title, url=None, active=False):
- '''
- Helper function that creates breadcrumb.
- '''
- active_str = ''
- if active:
- active_str = ' class="active"'
-
- title = escape(title)
- inner_str = title
- if url:
- inner_str = '<a href="{0}">{1}</a>'.format(url, title)
-
- crumb = '<li{0}>{1}</li>'.format(active_str, inner_str)
-
- return crumb
|
{"golden_diff": "diff --git a/workshops/templatetags/breadcrumbs.py b/workshops/templatetags/breadcrumbs.py\ndeleted file mode 100644\n--- a/workshops/templatetags/breadcrumbs.py\n+++ /dev/null\n@@ -1,128 +0,0 @@\n-import logging\n-\n-from django import template\n-from django.core.urlresolvers import reverse\n-from django.utils.encoding import force_text\n-from django.utils.html import escape\n-\n-register = template.Library()\n-_LOG = logging.getLogger(__name__)\n-\n-\[email protected]_tag\n-def breadcrumb(title, url):\n- '''\n- Create a simple anchor with provided text and already-resolved URL.\n- Example usage:\n- {% breadcrumb \"Title of breadcrumb\" resolved_url %}\n- '''\n- return create_crumb(title, url)\n-\n-\[email protected]_tag\n-def breadcrumb_url(title, url_name):\n- '''\n- Add non-active breadcrumb with specified title. Second argument should be\n- a string name of URL that needs to be resolved.\n- Example usage:\n- {% breadcrumb_url \"Title of breadcrumb\" url_name %}\n- '''\n- url = reverse(url_name)\n- return create_crumb(title, url)\n-\n-\[email protected]_tag\n-def breadcrumb_active(title):\n- '''\n- Add active breadcrumb, but not in an anchor.\n- Example usage:\n- {% breadcrumb_active \"Title of breadcrumb\" %}\n- '''\n- return create_crumb(str(title), url=None, active=True)\n-\n-\[email protected]_tag\n-def breadcrumb_index_all_objects(model):\n- '''\n- Add breadcrumb linking to the listing of all objects of specific type.\n- This tag accepts both models or model instances as an argument.\n- Example usage:\n- {% breadcrumb_index_all_objects model %}\n- {% breadcrumb_index_all_objects person %}\n- '''\n- plural = force_text(model._meta.verbose_name_plural)\n- title = 'All {}'.format(plural)\n- url_name = 'all_{}'.format(plural)\n- url = reverse(url_name)\n- return create_crumb(title, url)\n-\n-\[email protected]_tag\n-def breadcrumb_edit_object(obj):\n- '''\n- Add an active breadcrumb with the title \"Edit MODEL_NAME\".\n- This tag accepts model instance as an argument.\n- Example usage:\n- {% breadcrumb_edit_object person %}\n- '''\n- singular = force_text(obj._meta.verbose_name)\n- title = 'Edit {}'.format(singular)\n- return create_crumb(title, url=None, active=True)\n-\n-\[email protected]_tag\n-def breadcrumb_new_object(model):\n- '''\n- Add an active breadcrumb with the title \"Add new MODEL_NAME\".\n- This tag accepts model class as an argument.\n- Example usage:\n- {% breadcrumb_new_object person %}\n- '''\n- singular = force_text(model._meta.verbose_name)\n- title = 'Add new {}'.format(singular)\n- return create_crumb(title, url=None, active=True)\n-\n-\[email protected]_tag\n-def breadcrumb_object(obj):\n- '''\n- Add non-active breadcrumb with the title \"Add new MODEL_NAME\".\n- This tag accepts model instance as an argument.\n- Example usage:\n- {% breadcrumb_object person %}\n- '''\n- title = str(obj)\n- url = obj.get_absolute_url()\n- return create_crumb(title, url, active=False)\n-\n-\[email protected]_tag\n-def breadcrumb_main_page():\n- '''\n- Special case of ``breadcrumb_url``. In all templates there's always a link\n- to the main page so I wanted to save everyone thinking & writing by\n- introducing this helper tag.\n- Example usage:\n- {% breadcrumb_main_page %}\n- '''\n- title = 'Amy'\n- url = reverse('index')\n- return create_crumb(title, url)\n-\n-\n-def create_crumb(title, url=None, active=False):\n- '''\n- Helper function that creates breadcrumb.\n- '''\n- active_str = ''\n- if active:\n- active_str = ' class=\"active\"'\n-\n- title = escape(title)\n- inner_str = title\n- if url:\n- inner_str = '<a href=\"{0}\">{1}</a>'.format(url, title)\n-\n- crumb = '<li{0}>{1}</li>'.format(active_str, inner_str)\n-\n- return crumb\n", "issue": "Deal with breadcrumbs\nAs Greg mentioned in #296, he hadn't liked the way breadcrumbs repeat current page title (or header) in their last element, for example: page \"Event 2015-05-25-something\" will have breadcrumbs \"Amy / All events / Event 2015-05-25-something\".\n\nI took a look at other big websites and how they do breadcrumbs and @gvwilson was right. They don't repeat current site at the end of breadcrumbs.\n\nThis means we'd only have breadcrumbs at most 3 links long: Amy / All \\* / \\* [ / action ], for example:\n\nWas:\n- Amy / All events / Event 2015-05-25-something / Edit\n\nWill be:\n- Amy / All events / Event 2015-05-25-something\n\nBut this does not bug me. In case of `All *` pages, we can just as well drop breadcrumbs (because they'd look like \"Amy / \").\n\nSo I don't really know what to do:\n1. Display breadcrumbs on the same pages as now, but hide the last item.\n2. Display breadcrumbs on the pages that would have more than 1 breadcrumbs.\n3. Drop breadcrumbs completely.\n\n", "before_files": [{"content": "import logging\n\nfrom django import template\nfrom django.core.urlresolvers import reverse\nfrom django.utils.encoding import force_text\nfrom django.utils.html import escape\n\nregister = template.Library()\n_LOG = logging.getLogger(__name__)\n\n\[email protected]_tag\ndef breadcrumb(title, url):\n '''\n Create a simple anchor with provided text and already-resolved URL.\n Example usage:\n {% breadcrumb \"Title of breadcrumb\" resolved_url %}\n '''\n return create_crumb(title, url)\n\n\[email protected]_tag\ndef breadcrumb_url(title, url_name):\n '''\n Add non-active breadcrumb with specified title. Second argument should be\n a string name of URL that needs to be resolved.\n Example usage:\n {% breadcrumb_url \"Title of breadcrumb\" url_name %}\n '''\n url = reverse(url_name)\n return create_crumb(title, url)\n\n\[email protected]_tag\ndef breadcrumb_active(title):\n '''\n Add active breadcrumb, but not in an anchor.\n Example usage:\n {% breadcrumb_active \"Title of breadcrumb\" %}\n '''\n return create_crumb(str(title), url=None, active=True)\n\n\[email protected]_tag\ndef breadcrumb_index_all_objects(model):\n '''\n Add breadcrumb linking to the listing of all objects of specific type.\n This tag accepts both models or model instances as an argument.\n Example usage:\n {% breadcrumb_index_all_objects model %}\n {% breadcrumb_index_all_objects person %}\n '''\n plural = force_text(model._meta.verbose_name_plural)\n title = 'All {}'.format(plural)\n url_name = 'all_{}'.format(plural)\n url = reverse(url_name)\n return create_crumb(title, url)\n\n\[email protected]_tag\ndef breadcrumb_edit_object(obj):\n '''\n Add an active breadcrumb with the title \"Edit MODEL_NAME\".\n This tag accepts model instance as an argument.\n Example usage:\n {% breadcrumb_edit_object person %}\n '''\n singular = force_text(obj._meta.verbose_name)\n title = 'Edit {}'.format(singular)\n return create_crumb(title, url=None, active=True)\n\n\[email protected]_tag\ndef breadcrumb_new_object(model):\n '''\n Add an active breadcrumb with the title \"Add new MODEL_NAME\".\n This tag accepts model class as an argument.\n Example usage:\n {% breadcrumb_new_object person %}\n '''\n singular = force_text(model._meta.verbose_name)\n title = 'Add new {}'.format(singular)\n return create_crumb(title, url=None, active=True)\n\n\[email protected]_tag\ndef breadcrumb_object(obj):\n '''\n Add non-active breadcrumb with the title \"Add new MODEL_NAME\".\n This tag accepts model instance as an argument.\n Example usage:\n {% breadcrumb_object person %}\n '''\n title = str(obj)\n url = obj.get_absolute_url()\n return create_crumb(title, url, active=False)\n\n\[email protected]_tag\ndef breadcrumb_main_page():\n '''\n Special case of ``breadcrumb_url``. In all templates there's always a link\n to the main page so I wanted to save everyone thinking & writing by\n introducing this helper tag.\n Example usage:\n {% breadcrumb_main_page %}\n '''\n title = 'Amy'\n url = reverse('index')\n return create_crumb(title, url)\n\n\ndef create_crumb(title, url=None, active=False):\n '''\n Helper function that creates breadcrumb.\n '''\n active_str = ''\n if active:\n active_str = ' class=\"active\"'\n\n title = escape(title)\n inner_str = title\n if url:\n inner_str = '<a href=\"{0}\">{1}</a>'.format(url, title)\n\n crumb = '<li{0}>{1}</li>'.format(active_str, inner_str)\n\n return crumb\n", "path": "workshops/templatetags/breadcrumbs.py"}]}
| 1,887 | 950 |
gh_patches_debug_20266
|
rasdani/github-patches
|
git_diff
|
getnikola__nikola-2725
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Sections conflict with pages that would replace them
> ERROR: Two different tasks can't have a common target.'output/sec1/index.html' is a target for render_pages:output/sec1/index.html and render_taxonomies:output/sec1/index.html.
To reproduce:
* set POSTS and PAGES to output to the root of the site
* create `posts/sec1/foo.rst` and `pages/sec1.rst`
`should_generate_classification_page` is supposed to prevent this, but it fails — `post_list` only contains posts from the section, so it doesn’t check the page, and thus fails. Perhaps we could fix it by giving all posts/pages to that function?
Sections conflict with pages that would replace them
> ERROR: Two different tasks can't have a common target.'output/sec1/index.html' is a target for render_pages:output/sec1/index.html and render_taxonomies:output/sec1/index.html.
To reproduce:
* set POSTS and PAGES to output to the root of the site
* create `posts/sec1/foo.rst` and `pages/sec1.rst`
`should_generate_classification_page` is supposed to prevent this, but it fails — `post_list` only contains posts from the section, so it doesn’t check the page, and thus fails. Perhaps we could fix it by giving all posts/pages to that function?
</issue>
<code>
[start of nikola/plugins/task/sections.py]
1 # -*- coding: utf-8 -*-
2
3 # Copyright © 2012-2017 Roberto Alsina and others.
4
5 # Permission is hereby granted, free of charge, to any
6 # person obtaining a copy of this software and associated
7 # documentation files (the "Software"), to deal in the
8 # Software without restriction, including without limitation
9 # the rights to use, copy, modify, merge, publish,
10 # distribute, sublicense, and/or sell copies of the
11 # Software, and to permit persons to whom the Software is
12 # furnished to do so, subject to the following conditions:
13 #
14 # The above copyright notice and this permission notice
15 # shall be included in all copies or substantial portions of
16 # the Software.
17 #
18 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY
19 # KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
20 # WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
21 # PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS
22 # OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR
23 # OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
24 # OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
25 # SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
26
27 """Render the blog indexes."""
28
29 from __future__ import unicode_literals
30
31 from nikola.plugin_categories import Taxonomy
32 from nikola import utils
33
34
35 class ClassifySections(Taxonomy):
36 """Classify the posts by sections."""
37
38 name = "classify_sections"
39
40 classification_name = "section_index"
41 overview_page_variable_name = "sections"
42 more_than_one_classifications_per_post = False
43 has_hierarchy = False
44 generate_atom_feeds_for_post_lists = False
45 template_for_classification_overview = None
46 apply_to_posts = True
47 apply_to_pages = False
48 omit_empty_classifications = True
49 also_create_classifications_from_other_languages = False
50 path_handler_docstrings = {
51 'section_index_index': False,
52 'section_index': """Link to the index for a section.
53
54 Example:
55
56 link://section_index/cars => /cars/index.html""",
57 'section_index_atom': """Link to the Atom index for a section.
58
59 Example:
60
61 link://section_index_atom/cars => /cars/index.atom""",
62 'section_index_rss': """Link to the RSS feed for a section.
63
64 Example:
65
66 link://section_index_rss/cars => /cars/rss.xml""",
67 }
68
69 def set_site(self, site):
70 """Set Nikola site."""
71 self.show_list_as_index = site.config["POSTS_SECTIONS_ARE_INDEXES"]
72 self.template_for_single_list = "sectionindex.tmpl" if self.show_list_as_index else "list.tmpl"
73 self.enable_for_lang = {}
74 return super(ClassifySections, self).set_site(site)
75
76 def is_enabled(self, lang=None):
77 """Return True if this taxonomy is enabled, or False otherwise."""
78 if not self.site.config['POSTS_SECTIONS']:
79 return False
80 if lang is not None:
81 return self.enable_for_lang.get(lang, False)
82 return True
83
84 def classify(self, post, lang):
85 """Classify the given post for the given language."""
86 return [post.section_slug(lang)]
87
88 def _get_section_name(self, section, lang):
89 # Check whether we have a name for this section
90 if section in self.site.config['POSTS_SECTION_NAME'](lang):
91 return self.site.config['POSTS_SECTION_NAME'](lang)[section]
92 else:
93 return section.replace('-', ' ').title()
94
95 def get_classification_friendly_name(self, section, lang, only_last_component=False):
96 """Extract a friendly name from the classification."""
97 return self._get_section_name(section, lang)
98
99 def get_path(self, section, lang, dest_type='page'):
100 """A path handler for the given classification."""
101 result = [_f for _f in [section] if _f]
102 if dest_type == 'rss':
103 return result + ['rss.xml'], 'never'
104 return result, 'always'
105
106 def provide_context_and_uptodate(self, section, lang, node=None):
107 """Provide data for the context and the uptodate list for the list of the given classifiation."""
108 kw = {
109 "messages": self.site.MESSAGES,
110 }
111 section_name = self._get_section_name(section, lang)
112 # Compose section title
113 section_title = section_name
114 posts_section_title = self.site.config['POSTS_SECTION_TITLE'](lang)
115 if isinstance(posts_section_title, dict):
116 if section in posts_section_title:
117 section_title = posts_section_title[section]
118 elif isinstance(posts_section_title, (utils.bytes_str, utils.unicode_str)):
119 section_title = posts_section_title
120 section_title = section_title.format(name=section_name)
121 # Compose context
122 context = {
123 "title": section_title,
124 "description": self.site.config['POSTS_SECTION_DESCRIPTIONS'](lang)[section] if section in self.site.config['POSTS_SECTION_DESCRIPTIONS'](lang) else "",
125 "pagekind": ["section_page", "index" if self.show_list_as_index else "list"]
126 }
127 kw.update(context)
128 return context, kw
129
130 def postprocess_posts_per_classification(self, posts_per_section_per_language, flat_hierarchy_per_lang=None, hierarchy_lookup_per_lang=None):
131 """Rearrange, modify or otherwise use the list of posts per classification and per language."""
132 for lang, posts_per_section in posts_per_section_per_language.items():
133 # Don't build sections when there is only one, a.k.a. default setups
134 sections = set()
135 for section, posts in posts_per_section.items():
136 for post in posts:
137 if not self.site.config["SHOW_UNTRANSLATED_POSTS"] and not post.is_translation_available(lang):
138 continue
139 sections.add(section)
140 self.enable_for_lang[lang] = (len(sections) > 1)
141
142 def should_generate_classification_page(self, dirname, post_list, lang):
143 """Only generates list of posts for classification if this function returns True."""
144 short_destination = dirname + '/' + self.site.config['INDEX_FILE']
145 for post in post_list:
146 # If there is an index.html pending to be created from a page, do not generate the section page.
147 # The section page would be useless anyways. (via Issue #2613)
148 if post.destination_path(lang, sep='/') == short_destination:
149 return False
150 return True
151
[end of nikola/plugins/task/sections.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nikola/plugins/task/sections.py b/nikola/plugins/task/sections.py
--- a/nikola/plugins/task/sections.py
+++ b/nikola/plugins/task/sections.py
@@ -142,9 +142,11 @@
def should_generate_classification_page(self, dirname, post_list, lang):
"""Only generates list of posts for classification if this function returns True."""
short_destination = dirname + '/' + self.site.config['INDEX_FILE']
- for post in post_list:
- # If there is an index.html pending to be created from a page, do not generate the section page.
- # The section page would be useless anyways. (via Issue #2613)
+ # If there is an index.html pending to be created from a page, do not generate the section page.
+ # The section page would be useless anyways. (via Issue #2613)
+ for post in self.site.timeline:
+ if not self.site.config["SHOW_UNTRANSLATED_POSTS"] and not post.is_translation_available(lang):
+ continue
if post.destination_path(lang, sep='/') == short_destination:
return False
return True
|
{"golden_diff": "diff --git a/nikola/plugins/task/sections.py b/nikola/plugins/task/sections.py\n--- a/nikola/plugins/task/sections.py\n+++ b/nikola/plugins/task/sections.py\n@@ -142,9 +142,11 @@\n def should_generate_classification_page(self, dirname, post_list, lang):\n \"\"\"Only generates list of posts for classification if this function returns True.\"\"\"\n short_destination = dirname + '/' + self.site.config['INDEX_FILE']\n- for post in post_list:\n- # If there is an index.html pending to be created from a page, do not generate the section page.\n- # The section page would be useless anyways. (via Issue #2613)\n+ # If there is an index.html pending to be created from a page, do not generate the section page.\n+ # The section page would be useless anyways. (via Issue #2613)\n+ for post in self.site.timeline:\n+ if not self.site.config[\"SHOW_UNTRANSLATED_POSTS\"] and not post.is_translation_available(lang):\n+ continue\n if post.destination_path(lang, sep='/') == short_destination:\n return False\n return True\n", "issue": "Sections conflict with pages that would replace them\n> ERROR: Two different tasks can't have a common target.'output/sec1/index.html' is a target for render_pages:output/sec1/index.html and render_taxonomies:output/sec1/index.html.\r\n\r\nTo reproduce:\r\n\r\n* set POSTS and PAGES to output to the root of the site\r\n* create `posts/sec1/foo.rst` and `pages/sec1.rst`\r\n\r\n`should_generate_classification_page` is supposed to prevent this, but it fails \u2014 `post_list` only contains posts from the section, so it doesn\u2019t check the page, and thus fails. Perhaps we could fix it by giving all posts/pages to that function?\nSections conflict with pages that would replace them\n> ERROR: Two different tasks can't have a common target.'output/sec1/index.html' is a target for render_pages:output/sec1/index.html and render_taxonomies:output/sec1/index.html.\r\n\r\nTo reproduce:\r\n\r\n* set POSTS and PAGES to output to the root of the site\r\n* create `posts/sec1/foo.rst` and `pages/sec1.rst`\r\n\r\n`should_generate_classification_page` is supposed to prevent this, but it fails \u2014 `post_list` only contains posts from the section, so it doesn\u2019t check the page, and thus fails. Perhaps we could fix it by giving all posts/pages to that function?\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2017 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\n\"\"\"Render the blog indexes.\"\"\"\n\nfrom __future__ import unicode_literals\n\nfrom nikola.plugin_categories import Taxonomy\nfrom nikola import utils\n\n\nclass ClassifySections(Taxonomy):\n \"\"\"Classify the posts by sections.\"\"\"\n\n name = \"classify_sections\"\n\n classification_name = \"section_index\"\n overview_page_variable_name = \"sections\"\n more_than_one_classifications_per_post = False\n has_hierarchy = False\n generate_atom_feeds_for_post_lists = False\n template_for_classification_overview = None\n apply_to_posts = True\n apply_to_pages = False\n omit_empty_classifications = True\n also_create_classifications_from_other_languages = False\n path_handler_docstrings = {\n 'section_index_index': False,\n 'section_index': \"\"\"Link to the index for a section.\n\nExample:\n\nlink://section_index/cars => /cars/index.html\"\"\",\n 'section_index_atom': \"\"\"Link to the Atom index for a section.\n\nExample:\n\nlink://section_index_atom/cars => /cars/index.atom\"\"\",\n 'section_index_rss': \"\"\"Link to the RSS feed for a section.\n\nExample:\n\nlink://section_index_rss/cars => /cars/rss.xml\"\"\",\n }\n\n def set_site(self, site):\n \"\"\"Set Nikola site.\"\"\"\n self.show_list_as_index = site.config[\"POSTS_SECTIONS_ARE_INDEXES\"]\n self.template_for_single_list = \"sectionindex.tmpl\" if self.show_list_as_index else \"list.tmpl\"\n self.enable_for_lang = {}\n return super(ClassifySections, self).set_site(site)\n\n def is_enabled(self, lang=None):\n \"\"\"Return True if this taxonomy is enabled, or False otherwise.\"\"\"\n if not self.site.config['POSTS_SECTIONS']:\n return False\n if lang is not None:\n return self.enable_for_lang.get(lang, False)\n return True\n\n def classify(self, post, lang):\n \"\"\"Classify the given post for the given language.\"\"\"\n return [post.section_slug(lang)]\n\n def _get_section_name(self, section, lang):\n # Check whether we have a name for this section\n if section in self.site.config['POSTS_SECTION_NAME'](lang):\n return self.site.config['POSTS_SECTION_NAME'](lang)[section]\n else:\n return section.replace('-', ' ').title()\n\n def get_classification_friendly_name(self, section, lang, only_last_component=False):\n \"\"\"Extract a friendly name from the classification.\"\"\"\n return self._get_section_name(section, lang)\n\n def get_path(self, section, lang, dest_type='page'):\n \"\"\"A path handler for the given classification.\"\"\"\n result = [_f for _f in [section] if _f]\n if dest_type == 'rss':\n return result + ['rss.xml'], 'never'\n return result, 'always'\n\n def provide_context_and_uptodate(self, section, lang, node=None):\n \"\"\"Provide data for the context and the uptodate list for the list of the given classifiation.\"\"\"\n kw = {\n \"messages\": self.site.MESSAGES,\n }\n section_name = self._get_section_name(section, lang)\n # Compose section title\n section_title = section_name\n posts_section_title = self.site.config['POSTS_SECTION_TITLE'](lang)\n if isinstance(posts_section_title, dict):\n if section in posts_section_title:\n section_title = posts_section_title[section]\n elif isinstance(posts_section_title, (utils.bytes_str, utils.unicode_str)):\n section_title = posts_section_title\n section_title = section_title.format(name=section_name)\n # Compose context\n context = {\n \"title\": section_title,\n \"description\": self.site.config['POSTS_SECTION_DESCRIPTIONS'](lang)[section] if section in self.site.config['POSTS_SECTION_DESCRIPTIONS'](lang) else \"\",\n \"pagekind\": [\"section_page\", \"index\" if self.show_list_as_index else \"list\"]\n }\n kw.update(context)\n return context, kw\n\n def postprocess_posts_per_classification(self, posts_per_section_per_language, flat_hierarchy_per_lang=None, hierarchy_lookup_per_lang=None):\n \"\"\"Rearrange, modify or otherwise use the list of posts per classification and per language.\"\"\"\n for lang, posts_per_section in posts_per_section_per_language.items():\n # Don't build sections when there is only one, a.k.a. default setups\n sections = set()\n for section, posts in posts_per_section.items():\n for post in posts:\n if not self.site.config[\"SHOW_UNTRANSLATED_POSTS\"] and not post.is_translation_available(lang):\n continue\n sections.add(section)\n self.enable_for_lang[lang] = (len(sections) > 1)\n\n def should_generate_classification_page(self, dirname, post_list, lang):\n \"\"\"Only generates list of posts for classification if this function returns True.\"\"\"\n short_destination = dirname + '/' + self.site.config['INDEX_FILE']\n for post in post_list:\n # If there is an index.html pending to be created from a page, do not generate the section page.\n # The section page would be useless anyways. (via Issue #2613)\n if post.destination_path(lang, sep='/') == short_destination:\n return False\n return True\n", "path": "nikola/plugins/task/sections.py"}]}
| 2,551 | 259 |
gh_patches_debug_25587
|
rasdani/github-patches
|
git_diff
|
vllm-project__vllm-148
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Documentation on running basic python server and FastAPI server
</issue>
<code>
[start of vllm/outputs.py]
1 from typing import Dict, List, Optional
2
3 from vllm.sequence import SequenceGroup, SequenceStatus
4
5
6 class CompletionOutput:
7
8 def __init__(
9 self,
10 index: int,
11 text: str,
12 token_ids: List[int],
13 cumulative_logprob: float,
14 logprobs: List[Dict[int, float]],
15 finish_reason: Optional[str] = None,
16 ) -> None:
17 self.index = index
18 self.text = text
19 self.token_ids = token_ids
20 self.cumulative_logprob = cumulative_logprob
21 self.logprobs = logprobs
22 self.finish_reason = finish_reason
23
24 def finished(self) -> bool:
25 return self.finish_reason is not None
26
27 def __repr__(self) -> str:
28 return (f"CompletionOutput(index={self.index}, "
29 f"text={self.text!r}, "
30 f"token_ids={self.token_ids}, "
31 f"cumulative_logprob={self.cumulative_logprob}, "
32 f"logprobs={self.logprobs},"
33 f"finish_reason={self.finish_reason})")
34
35
36 class RequestOutput:
37
38 def __init__(
39 self,
40 request_id: str,
41 prompt: str,
42 prompt_token_ids: List[int],
43 outputs: List[CompletionOutput],
44 ) -> None:
45 self.request_id = request_id
46 self.prompt = prompt
47 self.prompt_token_ids = prompt_token_ids
48 self.outputs = outputs
49
50 @classmethod
51 def from_seq_group(cls, seq_group: SequenceGroup) -> "RequestOutput":
52 # Get the top-n sequences.
53 n = seq_group.sampling_params.n
54 seqs = seq_group.get_seqs()
55 assert n <= len(seqs)
56 sorted_seqs = sorted(
57 seqs, key=lambda seq: seq.get_cumulative_logprob(), reverse=True)
58 top_n_seqs = sorted_seqs[:n]
59
60 # Create the outputs.
61 outputs: List[CompletionOutput] = []
62 for seq in top_n_seqs:
63 logprobs = seq.output_logprobs
64 if seq_group.sampling_params.logprobs is None:
65 # NOTE: We need to take care of this case because the sequence
66 # always has the logprobs of the sampled tokens even if the
67 # logprobs are not requested.
68 logprobs = {}
69 finshed_reason = SequenceStatus.get_finished_reason(seq.status)
70 output = CompletionOutput(seqs.index(seq), seq.output_text,
71 seq.get_output_token_ids(),
72 seq.get_cumulative_logprob(), logprobs,
73 finshed_reason)
74 outputs.append(output)
75
76 # Every sequence in the sequence group should have the same prompt.
77 prompt = top_n_seqs[0].prompt
78 prompt_token_ids = top_n_seqs[0].data.prompt_token_ids
79 return cls(seq_group.request_id, prompt, prompt_token_ids, outputs)
80
81 def __repr__(self) -> str:
82 return (f"RequestOutput(request_id={self.request_id}, "
83 f"prompt={self.prompt!r}, "
84 f"prompt_token_ids={self.prompt_token_ids}, "
85 f"outputs={self.outputs})")
86
87 def finished(self) -> bool:
88 return all(output.finished() for output in self.outputs)
89
[end of vllm/outputs.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/vllm/outputs.py b/vllm/outputs.py
--- a/vllm/outputs.py
+++ b/vllm/outputs.py
@@ -4,6 +4,18 @@
class CompletionOutput:
+ """The output data of one completion output of a request.
+
+ Args:
+ index: The index of the output in the request.
+ text: The generated output text.
+ token_ids: The token IDs of the generated output text.
+ cumulative_logprob: The cumulative log probability of the generated
+ output text.
+ logprobs: The log probabilities of the top probability words at each
+ position if the logprobs are requested.
+ finish_reason: The reason why the sequence is finished.
+ """
def __init__(
self,
@@ -11,7 +23,7 @@
text: str,
token_ids: List[int],
cumulative_logprob: float,
- logprobs: List[Dict[int, float]],
+ logprobs: Optional[List[Dict[int, float]]],
finish_reason: Optional[str] = None,
) -> None:
self.index = index
@@ -34,7 +46,14 @@
class RequestOutput:
+ """The output data of a request to the LLM.
+ Args:
+ request_id: The unique ID of the request.
+ prompt: The prompt string of the request.
+ prompt_token_ids: The token IDs of the prompt.
+ outputs: The output sequences of the request.
+ """
def __init__(
self,
request_id: str,
|
{"golden_diff": "diff --git a/vllm/outputs.py b/vllm/outputs.py\n--- a/vllm/outputs.py\n+++ b/vllm/outputs.py\n@@ -4,6 +4,18 @@\n \n \n class CompletionOutput:\n+ \"\"\"The output data of one completion output of a request.\n+\n+ Args:\n+ index: The index of the output in the request.\n+ text: The generated output text.\n+ token_ids: The token IDs of the generated output text.\n+ cumulative_logprob: The cumulative log probability of the generated\n+ output text.\n+ logprobs: The log probabilities of the top probability words at each\n+ position if the logprobs are requested.\n+ finish_reason: The reason why the sequence is finished.\n+ \"\"\"\n \n def __init__(\n self,\n@@ -11,7 +23,7 @@\n text: str,\n token_ids: List[int],\n cumulative_logprob: float,\n- logprobs: List[Dict[int, float]],\n+ logprobs: Optional[List[Dict[int, float]]],\n finish_reason: Optional[str] = None,\n ) -> None:\n self.index = index\n@@ -34,7 +46,14 @@\n \n \n class RequestOutput:\n+ \"\"\"The output data of a request to the LLM.\n \n+ Args:\n+ request_id: The unique ID of the request.\n+ prompt: The prompt string of the request.\n+ prompt_token_ids: The token IDs of the prompt.\n+ outputs: The output sequences of the request.\n+ \"\"\"\n def __init__(\n self,\n request_id: str,\n", "issue": "Documentation on running basic python server and FastAPI server\n\n", "before_files": [{"content": "from typing import Dict, List, Optional\n\nfrom vllm.sequence import SequenceGroup, SequenceStatus\n\n\nclass CompletionOutput:\n\n def __init__(\n self,\n index: int,\n text: str,\n token_ids: List[int],\n cumulative_logprob: float,\n logprobs: List[Dict[int, float]],\n finish_reason: Optional[str] = None,\n ) -> None:\n self.index = index\n self.text = text\n self.token_ids = token_ids\n self.cumulative_logprob = cumulative_logprob\n self.logprobs = logprobs\n self.finish_reason = finish_reason\n\n def finished(self) -> bool:\n return self.finish_reason is not None\n\n def __repr__(self) -> str:\n return (f\"CompletionOutput(index={self.index}, \"\n f\"text={self.text!r}, \"\n f\"token_ids={self.token_ids}, \"\n f\"cumulative_logprob={self.cumulative_logprob}, \"\n f\"logprobs={self.logprobs},\"\n f\"finish_reason={self.finish_reason})\")\n\n\nclass RequestOutput:\n\n def __init__(\n self,\n request_id: str,\n prompt: str,\n prompt_token_ids: List[int],\n outputs: List[CompletionOutput],\n ) -> None:\n self.request_id = request_id\n self.prompt = prompt\n self.prompt_token_ids = prompt_token_ids\n self.outputs = outputs\n\n @classmethod\n def from_seq_group(cls, seq_group: SequenceGroup) -> \"RequestOutput\":\n # Get the top-n sequences.\n n = seq_group.sampling_params.n\n seqs = seq_group.get_seqs()\n assert n <= len(seqs)\n sorted_seqs = sorted(\n seqs, key=lambda seq: seq.get_cumulative_logprob(), reverse=True)\n top_n_seqs = sorted_seqs[:n]\n\n # Create the outputs.\n outputs: List[CompletionOutput] = []\n for seq in top_n_seqs:\n logprobs = seq.output_logprobs\n if seq_group.sampling_params.logprobs is None:\n # NOTE: We need to take care of this case because the sequence\n # always has the logprobs of the sampled tokens even if the\n # logprobs are not requested.\n logprobs = {}\n finshed_reason = SequenceStatus.get_finished_reason(seq.status)\n output = CompletionOutput(seqs.index(seq), seq.output_text,\n seq.get_output_token_ids(),\n seq.get_cumulative_logprob(), logprobs,\n finshed_reason)\n outputs.append(output)\n\n # Every sequence in the sequence group should have the same prompt.\n prompt = top_n_seqs[0].prompt\n prompt_token_ids = top_n_seqs[0].data.prompt_token_ids\n return cls(seq_group.request_id, prompt, prompt_token_ids, outputs)\n\n def __repr__(self) -> str:\n return (f\"RequestOutput(request_id={self.request_id}, \"\n f\"prompt={self.prompt!r}, \"\n f\"prompt_token_ids={self.prompt_token_ids}, \"\n f\"outputs={self.outputs})\")\n\n def finished(self) -> bool:\n return all(output.finished() for output in self.outputs)\n", "path": "vllm/outputs.py"}]}
| 1,414 | 360 |
gh_patches_debug_36857
|
rasdani/github-patches
|
git_diff
|
HypothesisWorks__hypothesis-2256
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Deprecate use of other decorators without `@given`
This was first suggested in #1135 for `@settings()`, but the approach taken did not scale as each decorator would have to know about all of the others. Fortunately, #2162 gave us a much nicer option: we can just check for other decorators in our pytest plugin, when we already know that `@given` was never applied!
That means adding a deprecation warning for each of `@example`, `@seed`, and `@reproduce_failure` based on the special attributes they attach to the test function.
</issue>
<code>
[start of hypothesis-python/src/hypothesis/extra/pytestplugin.py]
1 # coding=utf-8
2 #
3 # This file is part of Hypothesis, which may be found at
4 # https://github.com/HypothesisWorks/hypothesis/
5 #
6 # Most of this work is copyright (C) 2013-2019 David R. MacIver
7 # ([email protected]), but it contains contributions by others. See
8 # CONTRIBUTING.rst for a full list of people who may hold copyright, and
9 # consult the git log if you need to determine who owns an individual
10 # contribution.
11 #
12 # This Source Code Form is subject to the terms of the Mozilla Public License,
13 # v. 2.0. If a copy of the MPL was not distributed with this file, You can
14 # obtain one at https://mozilla.org/MPL/2.0/.
15 #
16 # END HEADER
17
18 from __future__ import absolute_import, division, print_function
19
20 from distutils.version import LooseVersion
21
22 import pytest
23
24 from hypothesis import Verbosity, core, settings
25 from hypothesis._settings import note_deprecation
26 from hypothesis.errors import InvalidArgument
27 from hypothesis.internal.compat import text_type
28 from hypothesis.internal.detection import is_hypothesis_test
29 from hypothesis.reporting import default as default_reporter, with_reporter
30 from hypothesis.statistics import collector
31
32 LOAD_PROFILE_OPTION = "--hypothesis-profile"
33 VERBOSITY_OPTION = "--hypothesis-verbosity"
34 PRINT_STATISTICS_OPTION = "--hypothesis-show-statistics"
35 SEED_OPTION = "--hypothesis-seed"
36
37
38 class StoringReporter(object):
39 def __init__(self, config):
40 self.config = config
41 self.results = []
42
43 def __call__(self, msg):
44 if self.config.getoption("capture", "fd") == "no":
45 default_reporter(msg)
46 if not isinstance(msg, text_type):
47 msg = repr(msg)
48 self.results.append(msg)
49
50
51 if LooseVersion(pytest.__version__) < "4.3": # pragma: no cover
52 import warnings
53 from hypothesis.errors import HypothesisWarning
54
55 PYTEST_TOO_OLD_MESSAGE = """
56 You are using Pytest version %s. Hypothesis tests work with any test
57 runner, but our Pytest plugin requires Pytest 4.3 or newer.
58 Note that the Pytest developers no longer support this version either!
59 Disabling the Hypothesis pytest plugin...
60 """
61 warnings.warn(PYTEST_TOO_OLD_MESSAGE % (pytest.__version__,), HypothesisWarning)
62
63 else:
64
65 def pytest_addoption(parser):
66 group = parser.getgroup("hypothesis", "Hypothesis")
67 group.addoption(
68 LOAD_PROFILE_OPTION,
69 action="store",
70 help="Load in a registered hypothesis.settings profile",
71 )
72 group.addoption(
73 VERBOSITY_OPTION,
74 action="store",
75 choices=[opt.name for opt in Verbosity],
76 help="Override profile with verbosity setting specified",
77 )
78 group.addoption(
79 PRINT_STATISTICS_OPTION,
80 action="store_true",
81 help="Configure when statistics are printed",
82 default=False,
83 )
84 group.addoption(
85 SEED_OPTION,
86 action="store",
87 help="Set a seed to use for all Hypothesis tests",
88 )
89
90 def pytest_report_header(config):
91 profile = config.getoption(LOAD_PROFILE_OPTION)
92 if not profile:
93 profile = settings._current_profile
94 settings_str = settings.get_profile(profile).show_changed()
95 if settings_str != "":
96 settings_str = " -> %s" % (settings_str)
97 if (
98 config.option.verbose >= 1
99 or settings.default.verbosity >= Verbosity.verbose
100 ):
101 return "hypothesis profile %r%s" % (profile, settings_str)
102
103 def pytest_configure(config):
104 core.running_under_pytest = True
105 profile = config.getoption(LOAD_PROFILE_OPTION)
106 if profile:
107 settings.load_profile(profile)
108 verbosity_name = config.getoption(VERBOSITY_OPTION)
109 if verbosity_name:
110 verbosity_value = Verbosity[verbosity_name]
111 profile_name = "%s-with-%s-verbosity" % (
112 settings._current_profile,
113 verbosity_name,
114 )
115 # register_profile creates a new profile, exactly like the current one,
116 # with the extra values given (in this case 'verbosity')
117 settings.register_profile(profile_name, verbosity=verbosity_value)
118 settings.load_profile(profile_name)
119 seed = config.getoption(SEED_OPTION)
120 if seed is not None:
121 try:
122 seed = int(seed)
123 except ValueError:
124 pass
125 core.global_force_seed = seed
126 config.addinivalue_line("markers", "hypothesis: Tests which use hypothesis.")
127
128 @pytest.hookimpl(hookwrapper=True)
129 def pytest_runtest_call(item):
130 if not hasattr(item, "obj"):
131 yield
132 elif not is_hypothesis_test(item.obj):
133 # If @given was not applied, check whether other hypothesis
134 # decorators were applied, and raise an error if they were.
135 if getattr(item.obj, "_hypothesis_internal_settings_applied", False):
136 raise InvalidArgument(
137 "Using `@settings` on a test without `@given` is completely pointless."
138 )
139 yield
140 else:
141 if item.get_closest_marker("parametrize") is not None:
142 # Give every parametrized test invocation a unique database key
143 key = item.nodeid.encode("utf-8")
144 item.obj.hypothesis.inner_test._hypothesis_internal_add_digest = key
145
146 store = StoringReporter(item.config)
147
148 def note_statistics(stats):
149 lines = [item.nodeid + ":", ""] + stats.get_description() + [""]
150 item.hypothesis_statistics = lines
151
152 with collector.with_value(note_statistics):
153 with with_reporter(store):
154 yield
155 if store.results:
156 item.hypothesis_report_information = list(store.results)
157
158 @pytest.hookimpl(hookwrapper=True)
159 def pytest_runtest_makereport(item, call):
160 report = (yield).get_result()
161 if hasattr(item, "hypothesis_report_information"):
162 report.sections.append(
163 ("Hypothesis", "\n".join(item.hypothesis_report_information))
164 )
165 if hasattr(item, "hypothesis_statistics") and report.when == "teardown":
166 val = ("hypothesis-stats", item.hypothesis_statistics)
167 report.user_properties.append(val)
168
169 def pytest_terminal_summary(terminalreporter):
170 if not terminalreporter.config.getoption(PRINT_STATISTICS_OPTION):
171 return
172 terminalreporter.section("Hypothesis Statistics")
173 # terminalreporter.stats is a dict, where the empty string appears to
174 # always be the key for a list of _pytest.reports.TestReport objects
175 # (where we stored the statistics data in pytest_runtest_makereport above)
176 for test_report in terminalreporter.stats.get("", []):
177 for name, lines in test_report.user_properties:
178 if name == "hypothesis-stats" and test_report.when == "teardown":
179 for li in lines:
180 terminalreporter.write_line(li)
181
182 def pytest_collection_modifyitems(items):
183 for item in items:
184 if not isinstance(item, pytest.Function):
185 continue
186 if is_hypothesis_test(item.obj):
187 item.add_marker("hypothesis")
188 if getattr(item.obj, "is_hypothesis_strategy_function", False):
189
190 def note_strategy_is_not_test(*args, **kwargs):
191 note_deprecation(
192 "%s is a function that returns a Hypothesis strategy, "
193 "but pytest has collected it as a test function. This "
194 "is useless as the function body will never be executed. "
195 "To define a test function, use @given instead of "
196 "@composite." % (item.nodeid,),
197 since="2018-11-02",
198 )
199
200 item.obj = note_strategy_is_not_test
201
202
203 def load():
204 """Required for `pluggy` to load a plugin from setuptools entrypoints."""
205
[end of hypothesis-python/src/hypothesis/extra/pytestplugin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/hypothesis-python/src/hypothesis/extra/pytestplugin.py b/hypothesis-python/src/hypothesis/extra/pytestplugin.py
--- a/hypothesis-python/src/hypothesis/extra/pytestplugin.py
+++ b/hypothesis-python/src/hypothesis/extra/pytestplugin.py
@@ -132,10 +132,24 @@
elif not is_hypothesis_test(item.obj):
# If @given was not applied, check whether other hypothesis
# decorators were applied, and raise an error if they were.
+ message = "Using `@%s` on a test without `@given` is completely pointless."
if getattr(item.obj, "_hypothesis_internal_settings_applied", False):
- raise InvalidArgument(
- "Using `@settings` on a test without `@given` is completely pointless."
+ raise InvalidArgument(message % ("settings",))
+ if getattr(item.obj, "is_hypothesis_strategy_function", False):
+ note_deprecation(
+ "%s is a function that returns a Hypothesis strategy, but pytest "
+ "has collected it as a test function. This is useless as the "
+ "function body will never be executed. To define a test "
+ "function, use @given instead of @composite." % (item.nodeid,),
+ since="2018-11-02",
)
+ for name, attribute in [
+ ("example", "hypothesis_explicit_examples"),
+ ("seed", "_hypothesis_internal_use_seed"),
+ ("reproduce_example", "_hypothesis_internal_use_reproduce_failure"),
+ ]:
+ if hasattr(item.obj, attribute):
+ note_deprecation(message % (name,), since="RELEASEDAY")
yield
else:
if item.get_closest_marker("parametrize") is not None:
@@ -181,23 +195,8 @@
def pytest_collection_modifyitems(items):
for item in items:
- if not isinstance(item, pytest.Function):
- continue
- if is_hypothesis_test(item.obj):
+ if isinstance(item, pytest.Function) and is_hypothesis_test(item.obj):
item.add_marker("hypothesis")
- if getattr(item.obj, "is_hypothesis_strategy_function", False):
-
- def note_strategy_is_not_test(*args, **kwargs):
- note_deprecation(
- "%s is a function that returns a Hypothesis strategy, "
- "but pytest has collected it as a test function. This "
- "is useless as the function body will never be executed. "
- "To define a test function, use @given instead of "
- "@composite." % (item.nodeid,),
- since="2018-11-02",
- )
-
- item.obj = note_strategy_is_not_test
def load():
|
{"golden_diff": "diff --git a/hypothesis-python/src/hypothesis/extra/pytestplugin.py b/hypothesis-python/src/hypothesis/extra/pytestplugin.py\n--- a/hypothesis-python/src/hypothesis/extra/pytestplugin.py\n+++ b/hypothesis-python/src/hypothesis/extra/pytestplugin.py\n@@ -132,10 +132,24 @@\n elif not is_hypothesis_test(item.obj):\n # If @given was not applied, check whether other hypothesis\n # decorators were applied, and raise an error if they were.\n+ message = \"Using `@%s` on a test without `@given` is completely pointless.\"\n if getattr(item.obj, \"_hypothesis_internal_settings_applied\", False):\n- raise InvalidArgument(\n- \"Using `@settings` on a test without `@given` is completely pointless.\"\n+ raise InvalidArgument(message % (\"settings\",))\n+ if getattr(item.obj, \"is_hypothesis_strategy_function\", False):\n+ note_deprecation(\n+ \"%s is a function that returns a Hypothesis strategy, but pytest \"\n+ \"has collected it as a test function. This is useless as the \"\n+ \"function body will never be executed. To define a test \"\n+ \"function, use @given instead of @composite.\" % (item.nodeid,),\n+ since=\"2018-11-02\",\n )\n+ for name, attribute in [\n+ (\"example\", \"hypothesis_explicit_examples\"),\n+ (\"seed\", \"_hypothesis_internal_use_seed\"),\n+ (\"reproduce_example\", \"_hypothesis_internal_use_reproduce_failure\"),\n+ ]:\n+ if hasattr(item.obj, attribute):\n+ note_deprecation(message % (name,), since=\"RELEASEDAY\")\n yield\n else:\n if item.get_closest_marker(\"parametrize\") is not None:\n@@ -181,23 +195,8 @@\n \n def pytest_collection_modifyitems(items):\n for item in items:\n- if not isinstance(item, pytest.Function):\n- continue\n- if is_hypothesis_test(item.obj):\n+ if isinstance(item, pytest.Function) and is_hypothesis_test(item.obj):\n item.add_marker(\"hypothesis\")\n- if getattr(item.obj, \"is_hypothesis_strategy_function\", False):\n-\n- def note_strategy_is_not_test(*args, **kwargs):\n- note_deprecation(\n- \"%s is a function that returns a Hypothesis strategy, \"\n- \"but pytest has collected it as a test function. This \"\n- \"is useless as the function body will never be executed. \"\n- \"To define a test function, use @given instead of \"\n- \"@composite.\" % (item.nodeid,),\n- since=\"2018-11-02\",\n- )\n-\n- item.obj = note_strategy_is_not_test\n \n \n def load():\n", "issue": "Deprecate use of other decorators without `@given`\nThis was first suggested in #1135 for `@settings()`, but the approach taken did not scale as each decorator would have to know about all of the others. Fortunately, #2162 gave us a much nicer option: we can just check for other decorators in our pytest plugin, when we already know that `@given` was never applied!\r\n\r\nThat means adding a deprecation warning for each of `@example`, `@seed`, and `@reproduce_failure` based on the special attributes they attach to the test function.\n", "before_files": [{"content": "# coding=utf-8\n#\n# This file is part of Hypothesis, which may be found at\n# https://github.com/HypothesisWorks/hypothesis/\n#\n# Most of this work is copyright (C) 2013-2019 David R. MacIver\n# ([email protected]), but it contains contributions by others. See\n# CONTRIBUTING.rst for a full list of people who may hold copyright, and\n# consult the git log if you need to determine who owns an individual\n# contribution.\n#\n# This Source Code Form is subject to the terms of the Mozilla Public License,\n# v. 2.0. If a copy of the MPL was not distributed with this file, You can\n# obtain one at https://mozilla.org/MPL/2.0/.\n#\n# END HEADER\n\nfrom __future__ import absolute_import, division, print_function\n\nfrom distutils.version import LooseVersion\n\nimport pytest\n\nfrom hypothesis import Verbosity, core, settings\nfrom hypothesis._settings import note_deprecation\nfrom hypothesis.errors import InvalidArgument\nfrom hypothesis.internal.compat import text_type\nfrom hypothesis.internal.detection import is_hypothesis_test\nfrom hypothesis.reporting import default as default_reporter, with_reporter\nfrom hypothesis.statistics import collector\n\nLOAD_PROFILE_OPTION = \"--hypothesis-profile\"\nVERBOSITY_OPTION = \"--hypothesis-verbosity\"\nPRINT_STATISTICS_OPTION = \"--hypothesis-show-statistics\"\nSEED_OPTION = \"--hypothesis-seed\"\n\n\nclass StoringReporter(object):\n def __init__(self, config):\n self.config = config\n self.results = []\n\n def __call__(self, msg):\n if self.config.getoption(\"capture\", \"fd\") == \"no\":\n default_reporter(msg)\n if not isinstance(msg, text_type):\n msg = repr(msg)\n self.results.append(msg)\n\n\nif LooseVersion(pytest.__version__) < \"4.3\": # pragma: no cover\n import warnings\n from hypothesis.errors import HypothesisWarning\n\n PYTEST_TOO_OLD_MESSAGE = \"\"\"\n You are using Pytest version %s. Hypothesis tests work with any test\n runner, but our Pytest plugin requires Pytest 4.3 or newer.\n Note that the Pytest developers no longer support this version either!\n Disabling the Hypothesis pytest plugin...\n \"\"\"\n warnings.warn(PYTEST_TOO_OLD_MESSAGE % (pytest.__version__,), HypothesisWarning)\n\nelse:\n\n def pytest_addoption(parser):\n group = parser.getgroup(\"hypothesis\", \"Hypothesis\")\n group.addoption(\n LOAD_PROFILE_OPTION,\n action=\"store\",\n help=\"Load in a registered hypothesis.settings profile\",\n )\n group.addoption(\n VERBOSITY_OPTION,\n action=\"store\",\n choices=[opt.name for opt in Verbosity],\n help=\"Override profile with verbosity setting specified\",\n )\n group.addoption(\n PRINT_STATISTICS_OPTION,\n action=\"store_true\",\n help=\"Configure when statistics are printed\",\n default=False,\n )\n group.addoption(\n SEED_OPTION,\n action=\"store\",\n help=\"Set a seed to use for all Hypothesis tests\",\n )\n\n def pytest_report_header(config):\n profile = config.getoption(LOAD_PROFILE_OPTION)\n if not profile:\n profile = settings._current_profile\n settings_str = settings.get_profile(profile).show_changed()\n if settings_str != \"\":\n settings_str = \" -> %s\" % (settings_str)\n if (\n config.option.verbose >= 1\n or settings.default.verbosity >= Verbosity.verbose\n ):\n return \"hypothesis profile %r%s\" % (profile, settings_str)\n\n def pytest_configure(config):\n core.running_under_pytest = True\n profile = config.getoption(LOAD_PROFILE_OPTION)\n if profile:\n settings.load_profile(profile)\n verbosity_name = config.getoption(VERBOSITY_OPTION)\n if verbosity_name:\n verbosity_value = Verbosity[verbosity_name]\n profile_name = \"%s-with-%s-verbosity\" % (\n settings._current_profile,\n verbosity_name,\n )\n # register_profile creates a new profile, exactly like the current one,\n # with the extra values given (in this case 'verbosity')\n settings.register_profile(profile_name, verbosity=verbosity_value)\n settings.load_profile(profile_name)\n seed = config.getoption(SEED_OPTION)\n if seed is not None:\n try:\n seed = int(seed)\n except ValueError:\n pass\n core.global_force_seed = seed\n config.addinivalue_line(\"markers\", \"hypothesis: Tests which use hypothesis.\")\n\n @pytest.hookimpl(hookwrapper=True)\n def pytest_runtest_call(item):\n if not hasattr(item, \"obj\"):\n yield\n elif not is_hypothesis_test(item.obj):\n # If @given was not applied, check whether other hypothesis\n # decorators were applied, and raise an error if they were.\n if getattr(item.obj, \"_hypothesis_internal_settings_applied\", False):\n raise InvalidArgument(\n \"Using `@settings` on a test without `@given` is completely pointless.\"\n )\n yield\n else:\n if item.get_closest_marker(\"parametrize\") is not None:\n # Give every parametrized test invocation a unique database key\n key = item.nodeid.encode(\"utf-8\")\n item.obj.hypothesis.inner_test._hypothesis_internal_add_digest = key\n\n store = StoringReporter(item.config)\n\n def note_statistics(stats):\n lines = [item.nodeid + \":\", \"\"] + stats.get_description() + [\"\"]\n item.hypothesis_statistics = lines\n\n with collector.with_value(note_statistics):\n with with_reporter(store):\n yield\n if store.results:\n item.hypothesis_report_information = list(store.results)\n\n @pytest.hookimpl(hookwrapper=True)\n def pytest_runtest_makereport(item, call):\n report = (yield).get_result()\n if hasattr(item, \"hypothesis_report_information\"):\n report.sections.append(\n (\"Hypothesis\", \"\\n\".join(item.hypothesis_report_information))\n )\n if hasattr(item, \"hypothesis_statistics\") and report.when == \"teardown\":\n val = (\"hypothesis-stats\", item.hypothesis_statistics)\n report.user_properties.append(val)\n\n def pytest_terminal_summary(terminalreporter):\n if not terminalreporter.config.getoption(PRINT_STATISTICS_OPTION):\n return\n terminalreporter.section(\"Hypothesis Statistics\")\n # terminalreporter.stats is a dict, where the empty string appears to\n # always be the key for a list of _pytest.reports.TestReport objects\n # (where we stored the statistics data in pytest_runtest_makereport above)\n for test_report in terminalreporter.stats.get(\"\", []):\n for name, lines in test_report.user_properties:\n if name == \"hypothesis-stats\" and test_report.when == \"teardown\":\n for li in lines:\n terminalreporter.write_line(li)\n\n def pytest_collection_modifyitems(items):\n for item in items:\n if not isinstance(item, pytest.Function):\n continue\n if is_hypothesis_test(item.obj):\n item.add_marker(\"hypothesis\")\n if getattr(item.obj, \"is_hypothesis_strategy_function\", False):\n\n def note_strategy_is_not_test(*args, **kwargs):\n note_deprecation(\n \"%s is a function that returns a Hypothesis strategy, \"\n \"but pytest has collected it as a test function. This \"\n \"is useless as the function body will never be executed. \"\n \"To define a test function, use @given instead of \"\n \"@composite.\" % (item.nodeid,),\n since=\"2018-11-02\",\n )\n\n item.obj = note_strategy_is_not_test\n\n\ndef load():\n \"\"\"Required for `pluggy` to load a plugin from setuptools entrypoints.\"\"\"\n", "path": "hypothesis-python/src/hypothesis/extra/pytestplugin.py"}]}
| 2,905 | 639 |
gh_patches_debug_22017
|
rasdani/github-patches
|
git_diff
|
facebookresearch__CompilerGym-563
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`statistics.py` wrong parameter name
## 🐛 Bug
The functions [here](https://github.com/facebookresearch/CompilerGym/blob/e248330d2475fbcdf473cc3df951f25b5eaf4945/compiler_gym/util/statistics.py#L8) says they take `iterable` as inputs. However, `np.asarray` actually take `array_like`.
[Quote:
](https://numpy.org/doc/stable/reference/generated/numpy.asarray.html)
> Input data, in any form that can be converted to an array. This includes lists, lists of tuples, tuples, tuples of tuples, tuples of lists and ndarrays.
e.g.
```python
geometric_mean(i for i in range(10))
```
This will fail because though it's an `iterable`, it's not an `array_like`.
</issue>
<code>
[start of compiler_gym/util/statistics.py]
1 # Copyright (c) Facebook, Inc. and its affiliates.
2 #
3 # This source code is licensed under the MIT license found in the
4 # LICENSE file in the root directory of this source tree.
5 import numpy as np
6
7
8 def geometric_mean(iterable):
9 """Zero-length-safe geometric mean."""
10 values = np.asarray(iterable)
11 if not values.size:
12 return 0
13 # Shortcut to return 0 when any element of the input is not positive.
14 if not np.all(values > 0):
15 return 0
16 a = np.log(values)
17 return np.exp(a.sum() / len(a))
18
19
20 def arithmetic_mean(iterable):
21 """Zero-length-safe arithmetic mean."""
22 values = np.asarray(iterable)
23 if not values.size:
24 return 0
25 return values.mean()
26
27
28 def stdev(iterable):
29 """Zero-length-safe standard deviation."""
30 values = np.asarray(iterable)
31 if not values.size:
32 return 0
33 return values.std()
34
[end of compiler_gym/util/statistics.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/compiler_gym/util/statistics.py b/compiler_gym/util/statistics.py
--- a/compiler_gym/util/statistics.py
+++ b/compiler_gym/util/statistics.py
@@ -5,9 +5,9 @@
import numpy as np
-def geometric_mean(iterable):
+def geometric_mean(array_like):
"""Zero-length-safe geometric mean."""
- values = np.asarray(iterable)
+ values = np.asarray(array_like)
if not values.size:
return 0
# Shortcut to return 0 when any element of the input is not positive.
@@ -17,17 +17,17 @@
return np.exp(a.sum() / len(a))
-def arithmetic_mean(iterable):
+def arithmetic_mean(array_like):
"""Zero-length-safe arithmetic mean."""
- values = np.asarray(iterable)
+ values = np.asarray(array_like)
if not values.size:
return 0
return values.mean()
-def stdev(iterable):
+def stdev(array_like):
"""Zero-length-safe standard deviation."""
- values = np.asarray(iterable)
+ values = np.asarray(array_like)
if not values.size:
return 0
return values.std()
|
{"golden_diff": "diff --git a/compiler_gym/util/statistics.py b/compiler_gym/util/statistics.py\n--- a/compiler_gym/util/statistics.py\n+++ b/compiler_gym/util/statistics.py\n@@ -5,9 +5,9 @@\n import numpy as np\n \n \n-def geometric_mean(iterable):\n+def geometric_mean(array_like):\n \"\"\"Zero-length-safe geometric mean.\"\"\"\n- values = np.asarray(iterable)\n+ values = np.asarray(array_like)\n if not values.size:\n return 0\n # Shortcut to return 0 when any element of the input is not positive.\n@@ -17,17 +17,17 @@\n return np.exp(a.sum() / len(a))\n \n \n-def arithmetic_mean(iterable):\n+def arithmetic_mean(array_like):\n \"\"\"Zero-length-safe arithmetic mean.\"\"\"\n- values = np.asarray(iterable)\n+ values = np.asarray(array_like)\n if not values.size:\n return 0\n return values.mean()\n \n \n-def stdev(iterable):\n+def stdev(array_like):\n \"\"\"Zero-length-safe standard deviation.\"\"\"\n- values = np.asarray(iterable)\n+ values = np.asarray(array_like)\n if not values.size:\n return 0\n return values.std()\n", "issue": "`statistics.py` wrong parameter name\n## \ud83d\udc1b Bug\r\n\r\nThe functions [here](https://github.com/facebookresearch/CompilerGym/blob/e248330d2475fbcdf473cc3df951f25b5eaf4945/compiler_gym/util/statistics.py#L8) says they take `iterable` as inputs. However, `np.asarray` actually take `array_like`.\r\n\r\n[Quote:\r\n](https://numpy.org/doc/stable/reference/generated/numpy.asarray.html)\r\n\r\n> Input data, in any form that can be converted to an array. This includes lists, lists of tuples, tuples, tuples of tuples, tuples of lists and ndarrays.\r\n\r\ne.g.\r\n```python\r\ngeometric_mean(i for i in range(10))\r\n```\r\nThis will fail because though it's an `iterable`, it's not an `array_like`.\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\nimport numpy as np\n\n\ndef geometric_mean(iterable):\n \"\"\"Zero-length-safe geometric mean.\"\"\"\n values = np.asarray(iterable)\n if not values.size:\n return 0\n # Shortcut to return 0 when any element of the input is not positive.\n if not np.all(values > 0):\n return 0\n a = np.log(values)\n return np.exp(a.sum() / len(a))\n\n\ndef arithmetic_mean(iterable):\n \"\"\"Zero-length-safe arithmetic mean.\"\"\"\n values = np.asarray(iterable)\n if not values.size:\n return 0\n return values.mean()\n\n\ndef stdev(iterable):\n \"\"\"Zero-length-safe standard deviation.\"\"\"\n values = np.asarray(iterable)\n if not values.size:\n return 0\n return values.std()\n", "path": "compiler_gym/util/statistics.py"}]}
| 1,001 | 260 |
gh_patches_debug_26408
|
rasdani/github-patches
|
git_diff
|
mars-project__mars-646
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
We should use numpy.fft only because it is faster than scipy.fftpack
<!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
Maybe at a point in the history, scipy's fftpack is faster than numpy's fft module. Thus we do some optimization in the execution of fft that if scipy is installed, scipy's fftpack would be used to calculate fft. However, recently, I found that numpy's fft is obviously faster than scipy's fftpack. Sample code is shown below.
```python
In [1]: N = 1600000
In [2]: import numpy as np
In [3]: a = np.random.rand(N, 10)
In [4]: %timeit np.fft.fft(a)
118 ms ± 1.33 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
In [6]: import scipy.fftpack as sfft
In [7]: %timeit sfft.fft(a)
290 ms ± 3.65 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
In [9]: np.testing.assert_allclose(np.fft.fft(a), sfft.fft(a))
```
Hence, I suggest to use numpy only to calculate fft.
</issue>
<code>
[start of mars/tensor/fft/core.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 # Copyright 1999-2018 Alibaba Group Holding Ltd.
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16
17 from collections import Iterable
18
19 from ...compat import izip
20 from ...serialize import ValueType, KeyField, StringField, Int32Field, \
21 Int64Field, ListField
22 from ..utils import validate_axis, decide_chunk_sizes, recursive_tile
23 from ..operands import TensorHasInput, TensorOperandMixin
24 import numpy as np
25 from ..array_utils import get_array_module
26
27 try:
28 import scipy.fftpack as scifft
29 except ImportError: # pragma: no cover
30 scifft = None
31
32
33 class TensorFFTBaseMixin(TensorOperandMixin):
34 __slots__ = ()
35
36 @classmethod
37 def _get_shape(cls, op, shape):
38 raise NotImplementedError
39
40 @classmethod
41 def _tile_fft(cls, op, axes):
42 in_tensor = op.inputs[0]
43 out_tensor = op.outputs[0]
44
45 if any(in_tensor.chunk_shape[axis] != 1 for axis in axes):
46 # fft requires only 1 chunk for the specified axis, so we do rechunk first
47 chunks = {validate_axis(in_tensor.ndim, axis): in_tensor.shape[axis] for axis in axes}
48 new_chunks = decide_chunk_sizes(in_tensor.shape, chunks, in_tensor.dtype.itemsize)
49 in_tensor = in_tensor.rechunk(new_chunks).single_tiles()
50
51 out_chunks = []
52 for c in in_tensor.chunks:
53 chunk_op = op.copy().reset_key()
54 chunk_shape = cls._get_shape(op, c.shape)
55 out_chunk = chunk_op.new_chunk([c], shape=chunk_shape,
56 index=c.index, order=out_tensor.order)
57 out_chunks.append(out_chunk)
58
59 nsplits = [tuple(c.shape[i] for c in out_chunks
60 if all(idx == 0 for j, idx in enumerate(c.index) if j != i))
61 for i in range(len(out_chunks[0].shape))]
62 new_op = op.copy()
63 return new_op.new_tensors(op.inputs, out_tensor.shape, order=out_tensor.order,
64 chunks=out_chunks, nsplits=nsplits)
65
66 def __call__(self, a, order=None):
67 shape = self._get_shape(self, a.shape)
68 order = a.order if order is None else order
69 return self.new_tensor([a], shape, order=order)
70
71
72 class TensorFFTMixin(TensorFFTBaseMixin):
73 __slots__ = ()
74
75 @classmethod
76 def tile(cls, op):
77 return cls._tile_fft(op, [op.axis])
78
79
80 class TensorComplexFFTMixin(TensorFFTMixin):
81 @classmethod
82 def _get_shape(cls, op, shape):
83 new_shape = list(shape)
84 if op.n is not None:
85 new_shape[op.axis] = op.n
86 return tuple(new_shape)
87
88
89 def validate_fft(tensor, axis=-1, norm=None):
90 validate_axis(tensor.ndim, axis)
91 if norm is not None and norm not in ('ortho',):
92 raise ValueError('Invalid norm value {0}, should be None or "ortho"'.format(norm))
93
94
95 class TensorFFTNMixin(TensorFFTBaseMixin):
96 @classmethod
97 def tile(cls, op):
98 return cls._tile_fft(op, op.axes)
99
100 @staticmethod
101 def _merge_shape(op, shape):
102 new_shape = list(shape)
103 if op.shape is not None:
104 for ss, axis in izip(op.shape, op.axes):
105 new_shape[axis] = ss
106 return new_shape
107
108
109 class TensorComplexFFTNMixin(TensorFFTNMixin):
110 @classmethod
111 def _get_shape(cls, op, shape):
112 return tuple(cls._merge_shape(op, shape))
113
114
115 class TensorRealFFTNMixin(TensorFFTNMixin):
116 @classmethod
117 def _get_shape(cls, op, shape):
118 new_shape = cls._merge_shape(op, shape)
119 new_shape[op.axes[-1]] = new_shape[op.axes[-1]] // 2 + 1
120 return tuple(new_shape)
121
122
123 class TensorRealIFFTNMixin(TensorFFTNMixin):
124 @classmethod
125 def _get_shape(cls, op, shape):
126 new_shape = list(shape)
127 new_shape[op.axes[-1]] = 2 * (new_shape[op.axes[-1]] - 1)
128 return tuple(cls._merge_shape(op, new_shape))
129
130
131 def validate_fftn(tensor, s=None, axes=None, norm=None):
132 if axes is None:
133 if s is None:
134 axes = tuple(range(tensor.ndim))
135 else:
136 axes = tuple(range(len(s)))
137 else:
138 for axis in axes:
139 validate_axis(tensor.ndim, axis)
140 if len(set(axes)) < len(axes):
141 raise ValueError('Duplicate axes not allowed')
142
143 if norm is not None and norm not in ('ortho',):
144 raise ValueError('Invalid norm value {0}, should be None or "ortho"'.format(norm))
145
146 return axes
147
148
149 class TensorFFTShiftMixin(TensorOperandMixin):
150 __slots__ = ()
151
152 @classmethod
153 def _is_inverse(cls):
154 return False
155
156 @classmethod
157 def _process_axes(cls, x, axes):
158 if axes is None:
159 axes = tuple(range(x.ndim))
160 elif isinstance(axes, Iterable):
161 axes = tuple(axes)
162 else:
163 axes = (axes,)
164
165 return axes
166
167 @classmethod
168 def tile(cls, op):
169 from ..merge import concatenate
170
171 axes = op.axes
172 in_tensor = op.input
173 is_inverse = cls._is_inverse()
174
175 x = in_tensor
176 for axis in axes:
177 size = in_tensor.shape[axis]
178 slice_on = (size + 1) // 2 if not is_inverse else size // 2
179 slc1 = [slice(None)] * axis + [slice(slice_on)]
180 slc2 = [slice(None)] * axis + [slice(slice_on, None)]
181 x = concatenate([x[slc2], x[slc1]], axis=axis)
182
183 recursive_tile(x)
184 new_op = op.copy()
185 return new_op.new_tensors(op.inputs, op.outputs[0].shape,
186 chunks=x.chunks, nsplits=x.nsplits)
187
188
189 class TensorDiscreteFourierTransform(TensorHasInput):
190 __slots__ = ()
191
192
193 class TensorBaseFFT(TensorDiscreteFourierTransform):
194 _input = KeyField('input')
195 _norm = StringField('norm')
196
197 @property
198 def norm(self):
199 return getattr(self, '_norm', None)
200
201
202 class TensorBaseSingleDimensionFFT(TensorBaseFFT):
203 _n = Int64Field('n')
204 _axis = Int32Field('axis')
205
206 @property
207 def n(self):
208 return self._n
209
210 @property
211 def axis(self):
212 return self._axis
213
214 @classmethod
215 def execute(cls, ctx, op):
216 a = ctx[op.inputs[0].key]
217 xp = get_array_module(a)
218 fun = _get_fft_func(op, xp)
219 res = fun(a, n=op.n, axis=op.axis, norm=op.norm)
220 if res.dtype != op.dtype:
221 res = res.astype(op.dtype)
222 ctx[op.outputs[0].key] = res
223
224
225 class TensorBaseMultipleDimensionFFT(TensorBaseFFT):
226 _shape = ListField('shape', ValueType.int64)
227 _axes = ListField('axes', ValueType.int32)
228
229 @property
230 def shape(self):
231 return self._shape
232
233 @property
234 def axes(self):
235 return self._axes
236
237 @classmethod
238 def execute(cls, ctx, op):
239 a = ctx[op.inputs[0].key]
240 xp = get_array_module(a)
241 fun = _get_fft_func(op, xp)
242 res = fun(a, s=op.shape, axes=op.axes, norm=op.norm)
243 if res.dtype != op.dtype:
244 res = res.astype(op.dtype)
245 ctx[op.outputs[0].key] = res
246
247
248 def _get_fft_func(op, xp):
249 from .. import fft as fftop
250
251 fun_name = type(op).__name__.lower()[6:] # all op starts with tensor
252 if type(op) in (fftop.TensorFFT, fftop.TensorIFFT, fftop.TensorFFT2, fftop.TensorIFFT2,
253 fftop.TensorFFTN, fftop.TensorIFFTN):
254 if xp is np and scifft and op.norm is None:
255 def f(*args, **kwargs):
256 kwargs.pop('norm', None)
257 if 's' in kwargs:
258 kwargs['shape'] = kwargs.pop('s', None)
259 return getattr(scifft, fun_name)(*args, **kwargs)
260
261 return f
262 else:
263 return getattr(xp.fft, fun_name)
264 else:
265 return getattr(xp.fft, fun_name)
266
267
268 class TensorStandardFFT(TensorBaseSingleDimensionFFT):
269 pass
270
271
272 class TensorStandardFFTN(TensorBaseMultipleDimensionFFT):
273 pass
274
275
276 class TensorFFTShiftBase(TensorHasInput):
277 _input = KeyField('input')
278 _axes = ListField('axes', ValueType.int32)
279
280 @property
281 def axes(self):
282 return self._axes
283
284
285 class TensorRealFFT(TensorBaseSingleDimensionFFT):
286 pass
287
288
289 class TensorRealFFTN(TensorBaseMultipleDimensionFFT):
290 pass
291
292
293 class TensorHermitianFFT(TensorBaseSingleDimensionFFT):
294 pass
295
[end of mars/tensor/fft/core.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mars/tensor/fft/core.py b/mars/tensor/fft/core.py
--- a/mars/tensor/fft/core.py
+++ b/mars/tensor/fft/core.py
@@ -21,14 +21,8 @@
Int64Field, ListField
from ..utils import validate_axis, decide_chunk_sizes, recursive_tile
from ..operands import TensorHasInput, TensorOperandMixin
-import numpy as np
from ..array_utils import get_array_module
-try:
- import scipy.fftpack as scifft
-except ImportError: # pragma: no cover
- scifft = None
-
class TensorFFTBaseMixin(TensorOperandMixin):
__slots__ = ()
@@ -246,23 +240,8 @@
def _get_fft_func(op, xp):
- from .. import fft as fftop
-
fun_name = type(op).__name__.lower()[6:] # all op starts with tensor
- if type(op) in (fftop.TensorFFT, fftop.TensorIFFT, fftop.TensorFFT2, fftop.TensorIFFT2,
- fftop.TensorFFTN, fftop.TensorIFFTN):
- if xp is np and scifft and op.norm is None:
- def f(*args, **kwargs):
- kwargs.pop('norm', None)
- if 's' in kwargs:
- kwargs['shape'] = kwargs.pop('s', None)
- return getattr(scifft, fun_name)(*args, **kwargs)
-
- return f
- else:
- return getattr(xp.fft, fun_name)
- else:
- return getattr(xp.fft, fun_name)
+ return getattr(xp.fft, fun_name)
class TensorStandardFFT(TensorBaseSingleDimensionFFT):
|
{"golden_diff": "diff --git a/mars/tensor/fft/core.py b/mars/tensor/fft/core.py\n--- a/mars/tensor/fft/core.py\n+++ b/mars/tensor/fft/core.py\n@@ -21,14 +21,8 @@\n Int64Field, ListField\n from ..utils import validate_axis, decide_chunk_sizes, recursive_tile\n from ..operands import TensorHasInput, TensorOperandMixin\n-import numpy as np\n from ..array_utils import get_array_module\n \n-try:\n- import scipy.fftpack as scifft\n-except ImportError: # pragma: no cover\n- scifft = None\n-\n \n class TensorFFTBaseMixin(TensorOperandMixin):\n __slots__ = ()\n@@ -246,23 +240,8 @@\n \n \n def _get_fft_func(op, xp):\n- from .. import fft as fftop\n-\n fun_name = type(op).__name__.lower()[6:] # all op starts with tensor\n- if type(op) in (fftop.TensorFFT, fftop.TensorIFFT, fftop.TensorFFT2, fftop.TensorIFFT2,\n- fftop.TensorFFTN, fftop.TensorIFFTN):\n- if xp is np and scifft and op.norm is None:\n- def f(*args, **kwargs):\n- kwargs.pop('norm', None)\n- if 's' in kwargs:\n- kwargs['shape'] = kwargs.pop('s', None)\n- return getattr(scifft, fun_name)(*args, **kwargs)\n-\n- return f\n- else:\n- return getattr(xp.fft, fun_name)\n- else:\n- return getattr(xp.fft, fun_name)\n+ return getattr(xp.fft, fun_name)\n \n \n class TensorStandardFFT(TensorBaseSingleDimensionFFT):\n", "issue": "We should use numpy.fft only because it is faster than scipy.fftpack\n<!--\r\nThank you for your contribution!\r\n\r\nPlease review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.\r\n-->\r\n\r\nMaybe at a point in the history, scipy's fftpack is faster than numpy's fft module. Thus we do some optimization in the execution of fft that if scipy is installed, scipy's fftpack would be used to calculate fft. However, recently, I found that numpy's fft is obviously faster than scipy's fftpack. Sample code is shown below.\r\n\r\n```python\r\nIn [1]: N = 1600000 \r\n\r\nIn [2]: import numpy as np \r\n\r\nIn [3]: a = np.random.rand(N, 10) \r\n\r\nIn [4]: %timeit np.fft.fft(a) \r\n118 ms \u00b1 1.33 ms per loop (mean \u00b1 std. dev. of 7 runs, 10 loops each)\r\n\r\nIn [6]: import scipy.fftpack as sfft \r\n\r\nIn [7]: %timeit sfft.fft(a) \r\n290 ms \u00b1 3.65 ms per loop (mean \u00b1 std. dev. of 7 runs, 1 loop each)\r\n\r\nIn [9]: np.testing.assert_allclose(np.fft.fft(a), sfft.fft(a))\r\n```\r\n\r\nHence, I suggest to use numpy only to calculate fft.\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n# Copyright 1999-2018 Alibaba Group Holding Ltd.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom collections import Iterable\n\nfrom ...compat import izip\nfrom ...serialize import ValueType, KeyField, StringField, Int32Field, \\\n Int64Field, ListField\nfrom ..utils import validate_axis, decide_chunk_sizes, recursive_tile\nfrom ..operands import TensorHasInput, TensorOperandMixin\nimport numpy as np\nfrom ..array_utils import get_array_module\n\ntry:\n import scipy.fftpack as scifft\nexcept ImportError: # pragma: no cover\n scifft = None\n\n\nclass TensorFFTBaseMixin(TensorOperandMixin):\n __slots__ = ()\n\n @classmethod\n def _get_shape(cls, op, shape):\n raise NotImplementedError\n\n @classmethod\n def _tile_fft(cls, op, axes):\n in_tensor = op.inputs[0]\n out_tensor = op.outputs[0]\n\n if any(in_tensor.chunk_shape[axis] != 1 for axis in axes):\n # fft requires only 1 chunk for the specified axis, so we do rechunk first\n chunks = {validate_axis(in_tensor.ndim, axis): in_tensor.shape[axis] for axis in axes}\n new_chunks = decide_chunk_sizes(in_tensor.shape, chunks, in_tensor.dtype.itemsize)\n in_tensor = in_tensor.rechunk(new_chunks).single_tiles()\n\n out_chunks = []\n for c in in_tensor.chunks:\n chunk_op = op.copy().reset_key()\n chunk_shape = cls._get_shape(op, c.shape)\n out_chunk = chunk_op.new_chunk([c], shape=chunk_shape,\n index=c.index, order=out_tensor.order)\n out_chunks.append(out_chunk)\n\n nsplits = [tuple(c.shape[i] for c in out_chunks\n if all(idx == 0 for j, idx in enumerate(c.index) if j != i))\n for i in range(len(out_chunks[0].shape))]\n new_op = op.copy()\n return new_op.new_tensors(op.inputs, out_tensor.shape, order=out_tensor.order,\n chunks=out_chunks, nsplits=nsplits)\n\n def __call__(self, a, order=None):\n shape = self._get_shape(self, a.shape)\n order = a.order if order is None else order\n return self.new_tensor([a], shape, order=order)\n\n\nclass TensorFFTMixin(TensorFFTBaseMixin):\n __slots__ = ()\n\n @classmethod\n def tile(cls, op):\n return cls._tile_fft(op, [op.axis])\n\n\nclass TensorComplexFFTMixin(TensorFFTMixin):\n @classmethod\n def _get_shape(cls, op, shape):\n new_shape = list(shape)\n if op.n is not None:\n new_shape[op.axis] = op.n\n return tuple(new_shape)\n\n\ndef validate_fft(tensor, axis=-1, norm=None):\n validate_axis(tensor.ndim, axis)\n if norm is not None and norm not in ('ortho',):\n raise ValueError('Invalid norm value {0}, should be None or \"ortho\"'.format(norm))\n\n\nclass TensorFFTNMixin(TensorFFTBaseMixin):\n @classmethod\n def tile(cls, op):\n return cls._tile_fft(op, op.axes)\n\n @staticmethod\n def _merge_shape(op, shape):\n new_shape = list(shape)\n if op.shape is not None:\n for ss, axis in izip(op.shape, op.axes):\n new_shape[axis] = ss\n return new_shape\n\n\nclass TensorComplexFFTNMixin(TensorFFTNMixin):\n @classmethod\n def _get_shape(cls, op, shape):\n return tuple(cls._merge_shape(op, shape))\n\n\nclass TensorRealFFTNMixin(TensorFFTNMixin):\n @classmethod\n def _get_shape(cls, op, shape):\n new_shape = cls._merge_shape(op, shape)\n new_shape[op.axes[-1]] = new_shape[op.axes[-1]] // 2 + 1\n return tuple(new_shape)\n\n\nclass TensorRealIFFTNMixin(TensorFFTNMixin):\n @classmethod\n def _get_shape(cls, op, shape):\n new_shape = list(shape)\n new_shape[op.axes[-1]] = 2 * (new_shape[op.axes[-1]] - 1)\n return tuple(cls._merge_shape(op, new_shape))\n\n\ndef validate_fftn(tensor, s=None, axes=None, norm=None):\n if axes is None:\n if s is None:\n axes = tuple(range(tensor.ndim))\n else:\n axes = tuple(range(len(s)))\n else:\n for axis in axes:\n validate_axis(tensor.ndim, axis)\n if len(set(axes)) < len(axes):\n raise ValueError('Duplicate axes not allowed')\n\n if norm is not None and norm not in ('ortho',):\n raise ValueError('Invalid norm value {0}, should be None or \"ortho\"'.format(norm))\n\n return axes\n\n\nclass TensorFFTShiftMixin(TensorOperandMixin):\n __slots__ = ()\n\n @classmethod\n def _is_inverse(cls):\n return False\n\n @classmethod\n def _process_axes(cls, x, axes):\n if axes is None:\n axes = tuple(range(x.ndim))\n elif isinstance(axes, Iterable):\n axes = tuple(axes)\n else:\n axes = (axes,)\n\n return axes\n\n @classmethod\n def tile(cls, op):\n from ..merge import concatenate\n\n axes = op.axes\n in_tensor = op.input\n is_inverse = cls._is_inverse()\n\n x = in_tensor\n for axis in axes:\n size = in_tensor.shape[axis]\n slice_on = (size + 1) // 2 if not is_inverse else size // 2\n slc1 = [slice(None)] * axis + [slice(slice_on)]\n slc2 = [slice(None)] * axis + [slice(slice_on, None)]\n x = concatenate([x[slc2], x[slc1]], axis=axis)\n\n recursive_tile(x)\n new_op = op.copy()\n return new_op.new_tensors(op.inputs, op.outputs[0].shape,\n chunks=x.chunks, nsplits=x.nsplits)\n\n\nclass TensorDiscreteFourierTransform(TensorHasInput):\n __slots__ = ()\n\n\nclass TensorBaseFFT(TensorDiscreteFourierTransform):\n _input = KeyField('input')\n _norm = StringField('norm')\n\n @property\n def norm(self):\n return getattr(self, '_norm', None)\n\n\nclass TensorBaseSingleDimensionFFT(TensorBaseFFT):\n _n = Int64Field('n')\n _axis = Int32Field('axis')\n\n @property\n def n(self):\n return self._n\n\n @property\n def axis(self):\n return self._axis\n\n @classmethod\n def execute(cls, ctx, op):\n a = ctx[op.inputs[0].key]\n xp = get_array_module(a)\n fun = _get_fft_func(op, xp)\n res = fun(a, n=op.n, axis=op.axis, norm=op.norm)\n if res.dtype != op.dtype:\n res = res.astype(op.dtype)\n ctx[op.outputs[0].key] = res\n\n\nclass TensorBaseMultipleDimensionFFT(TensorBaseFFT):\n _shape = ListField('shape', ValueType.int64)\n _axes = ListField('axes', ValueType.int32)\n\n @property\n def shape(self):\n return self._shape\n\n @property\n def axes(self):\n return self._axes\n\n @classmethod\n def execute(cls, ctx, op):\n a = ctx[op.inputs[0].key]\n xp = get_array_module(a)\n fun = _get_fft_func(op, xp)\n res = fun(a, s=op.shape, axes=op.axes, norm=op.norm)\n if res.dtype != op.dtype:\n res = res.astype(op.dtype)\n ctx[op.outputs[0].key] = res\n\n\ndef _get_fft_func(op, xp):\n from .. import fft as fftop\n\n fun_name = type(op).__name__.lower()[6:] # all op starts with tensor\n if type(op) in (fftop.TensorFFT, fftop.TensorIFFT, fftop.TensorFFT2, fftop.TensorIFFT2,\n fftop.TensorFFTN, fftop.TensorIFFTN):\n if xp is np and scifft and op.norm is None:\n def f(*args, **kwargs):\n kwargs.pop('norm', None)\n if 's' in kwargs:\n kwargs['shape'] = kwargs.pop('s', None)\n return getattr(scifft, fun_name)(*args, **kwargs)\n\n return f\n else:\n return getattr(xp.fft, fun_name)\n else:\n return getattr(xp.fft, fun_name)\n\n\nclass TensorStandardFFT(TensorBaseSingleDimensionFFT):\n pass\n\n\nclass TensorStandardFFTN(TensorBaseMultipleDimensionFFT):\n pass\n\n\nclass TensorFFTShiftBase(TensorHasInput):\n _input = KeyField('input')\n _axes = ListField('axes', ValueType.int32)\n\n @property\n def axes(self):\n return self._axes\n\n\nclass TensorRealFFT(TensorBaseSingleDimensionFFT):\n pass\n\n\nclass TensorRealFFTN(TensorBaseMultipleDimensionFFT):\n pass\n\n\nclass TensorHermitianFFT(TensorBaseSingleDimensionFFT):\n pass\n", "path": "mars/tensor/fft/core.py"}]}
| 3,817 | 394 |
gh_patches_debug_41668
|
rasdani/github-patches
|
git_diff
|
bookwyrm-social__bookwyrm-855
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Goodreads import floods activity streams
When a user does a goodreads import, the activitstreams manager isn't checking if the publication date is older than the oldest status, and adds all the statuses to the feeds, pushing out newer statuses.
</issue>
<code>
[start of bookwyrm/activitystreams.py]
1 """ access the activity streams stored in redis """
2 from abc import ABC
3 from django.dispatch import receiver
4 from django.db.models import signals, Q
5 import redis
6
7 from bookwyrm import models, settings
8 from bookwyrm.views.helpers import privacy_filter
9
10 r = redis.Redis(
11 host=settings.REDIS_ACTIVITY_HOST, port=settings.REDIS_ACTIVITY_PORT, db=0
12 )
13
14
15 class ActivityStream(ABC):
16 """ a category of activity stream (like home, local, federated) """
17
18 def stream_id(self, user):
19 """ the redis key for this user's instance of this stream """
20 return "{}-{}".format(user.id, self.key)
21
22 def unread_id(self, user):
23 """ the redis key for this user's unread count for this stream """
24 return "{}-unread".format(self.stream_id(user))
25
26 def add_status(self, status):
27 """ add a status to users' feeds """
28 # we want to do this as a bulk operation, hence "pipeline"
29 pipeline = r.pipeline()
30 for user in self.stream_users(status):
31 # add the status to the feed
32 pipeline.lpush(self.stream_id(user), status.id)
33 pipeline.ltrim(self.stream_id(user), 0, settings.MAX_STREAM_LENGTH)
34
35 # add to the unread status count
36 pipeline.incr(self.unread_id(user))
37 # and go!
38 pipeline.execute()
39
40 def remove_status(self, status):
41 """ remove a status from all feeds """
42 pipeline = r.pipeline()
43 for user in self.stream_users(status):
44 pipeline.lrem(self.stream_id(user), -1, status.id)
45 pipeline.execute()
46
47 def add_user_statuses(self, viewer, user):
48 """ add a user's statuses to another user's feed """
49 pipeline = r.pipeline()
50 for status in user.status_set.all()[: settings.MAX_STREAM_LENGTH]:
51 pipeline.lpush(self.stream_id(viewer), status.id)
52 pipeline.execute()
53
54 def remove_user_statuses(self, viewer, user):
55 """ remove a user's status from another user's feed """
56 pipeline = r.pipeline()
57 for status in user.status_set.all()[: settings.MAX_STREAM_LENGTH]:
58 pipeline.lrem(self.stream_id(viewer), -1, status.id)
59 pipeline.execute()
60
61 def get_activity_stream(self, user):
62 """ load the ids for statuses to be displayed """
63 # clear unreads for this feed
64 r.set(self.unread_id(user), 0)
65
66 statuses = r.lrange(self.stream_id(user), 0, -1)
67 return (
68 models.Status.objects.select_subclasses()
69 .filter(id__in=statuses)
70 .order_by("-published_date")
71 )
72
73 def get_unread_count(self, user):
74 """ get the unread status count for this user's feed """
75 return int(r.get(self.unread_id(user)))
76
77 def populate_stream(self, user):
78 """ go from zero to a timeline """
79 pipeline = r.pipeline()
80 statuses = self.stream_statuses(user)
81
82 stream_id = self.stream_id(user)
83 for status in statuses.all()[: settings.MAX_STREAM_LENGTH]:
84 pipeline.lpush(stream_id, status.id)
85 pipeline.execute()
86
87 def stream_users(self, status): # pylint: disable=no-self-use
88 """ given a status, what users should see it """
89 # direct messages don't appeard in feeds, direct comments/reviews/etc do
90 if status.privacy == "direct" and status.status_type == "Note":
91 return []
92
93 # everybody who could plausibly see this status
94 audience = models.User.objects.filter(
95 is_active=True,
96 local=True, # we only create feeds for users of this instance
97 ).exclude(
98 Q(id__in=status.user.blocks.all()) | Q(blocks=status.user) # not blocked
99 )
100
101 # only visible to the poster and mentioned users
102 if status.privacy == "direct":
103 audience = audience.filter(
104 Q(id=status.user.id) # if the user is the post's author
105 | Q(id__in=status.mention_users.all()) # if the user is mentioned
106 )
107 # only visible to the poster's followers and tagged users
108 elif status.privacy == "followers":
109 audience = audience.filter(
110 Q(id=status.user.id) # if the user is the post's author
111 | Q(following=status.user) # if the user is following the author
112 )
113 return audience.distinct()
114
115 def stream_statuses(self, user): # pylint: disable=no-self-use
116 """ given a user, what statuses should they see on this stream """
117 return privacy_filter(
118 user,
119 models.Status.objects.select_subclasses(),
120 privacy_levels=["public", "unlisted", "followers"],
121 )
122
123
124 class HomeStream(ActivityStream):
125 """ users you follow """
126
127 key = "home"
128
129 def stream_users(self, status):
130 audience = super().stream_users(status)
131 if not audience:
132 return []
133 return audience.filter(
134 Q(id=status.user.id) # if the user is the post's author
135 | Q(following=status.user) # if the user is following the author
136 ).distinct()
137
138 def stream_statuses(self, user):
139 return privacy_filter(
140 user,
141 models.Status.objects.select_subclasses(),
142 privacy_levels=["public", "unlisted", "followers"],
143 following_only=True,
144 )
145
146
147 class LocalStream(ActivityStream):
148 """ users you follow """
149
150 key = "local"
151
152 def stream_users(self, status):
153 # this stream wants no part in non-public statuses
154 if status.privacy != "public" or not status.user.local:
155 return []
156 return super().stream_users(status)
157
158 def stream_statuses(self, user):
159 # all public statuses by a local user
160 return privacy_filter(
161 user,
162 models.Status.objects.select_subclasses().filter(user__local=True),
163 privacy_levels=["public"],
164 )
165
166
167 class FederatedStream(ActivityStream):
168 """ users you follow """
169
170 key = "federated"
171
172 def stream_users(self, status):
173 # this stream wants no part in non-public statuses
174 if status.privacy != "public":
175 return []
176 return super().stream_users(status)
177
178 def stream_statuses(self, user):
179 return privacy_filter(
180 user,
181 models.Status.objects.select_subclasses(),
182 privacy_levels=["public"],
183 )
184
185
186 streams = {
187 "home": HomeStream(),
188 "local": LocalStream(),
189 "federated": FederatedStream(),
190 }
191
192
193 @receiver(signals.post_save)
194 # pylint: disable=unused-argument
195 def add_status_on_create(sender, instance, created, *args, **kwargs):
196 """ add newly created statuses to activity feeds """
197 # we're only interested in new statuses
198 if not issubclass(sender, models.Status):
199 return
200
201 if instance.deleted:
202 for stream in streams.values():
203 stream.remove_status(instance)
204 return
205
206 if not created:
207 return
208
209 # iterates through Home, Local, Federated
210 for stream in streams.values():
211 stream.add_status(instance)
212
213
214 @receiver(signals.post_delete, sender=models.Boost)
215 # pylint: disable=unused-argument
216 def remove_boost_on_delete(sender, instance, *args, **kwargs):
217 """ boosts are deleted """
218 # we're only interested in new statuses
219 for stream in streams.values():
220 stream.remove_status(instance)
221
222
223 @receiver(signals.post_save, sender=models.UserFollows)
224 # pylint: disable=unused-argument
225 def add_statuses_on_follow(sender, instance, created, *args, **kwargs):
226 """ add a newly followed user's statuses to feeds """
227 if not created or not instance.user_subject.local:
228 return
229 HomeStream().add_user_statuses(instance.user_subject, instance.user_object)
230
231
232 @receiver(signals.post_delete, sender=models.UserFollows)
233 # pylint: disable=unused-argument
234 def remove_statuses_on_unfollow(sender, instance, *args, **kwargs):
235 """ remove statuses from a feed on unfollow """
236 if not instance.user_subject.local:
237 return
238 HomeStream().remove_user_statuses(instance.user_subject, instance.user_object)
239
240
241 @receiver(signals.post_save, sender=models.UserBlocks)
242 # pylint: disable=unused-argument
243 def remove_statuses_on_block(sender, instance, *args, **kwargs):
244 """ remove statuses from all feeds on block """
245 # blocks apply ot all feeds
246 if instance.user_subject.local:
247 for stream in streams.values():
248 stream.remove_user_statuses(instance.user_subject, instance.user_object)
249
250 # and in both directions
251 if instance.user_object.local:
252 for stream in streams.values():
253 stream.remove_user_statuses(instance.user_object, instance.user_subject)
254
255
256 @receiver(signals.post_delete, sender=models.UserBlocks)
257 # pylint: disable=unused-argument
258 def add_statuses_on_unblock(sender, instance, *args, **kwargs):
259 """ remove statuses from all feeds on block """
260 public_streams = [LocalStream(), FederatedStream()]
261 # add statuses back to streams with statuses from anyone
262 if instance.user_subject.local:
263 for stream in public_streams:
264 stream.add_user_statuses(instance.user_subject, instance.user_object)
265
266 # add statuses back to streams with statuses from anyone
267 if instance.user_object.local:
268 for stream in public_streams:
269 stream.add_user_statuses(instance.user_object, instance.user_subject)
270
271
272 @receiver(signals.post_save, sender=models.User)
273 # pylint: disable=unused-argument
274 def populate_feed_on_account_create(sender, instance, created, *args, **kwargs):
275 """ build a user's feeds when they join """
276 if not created or not instance.local:
277 return
278
279 for stream in streams.values():
280 stream.populate_stream(instance)
281
[end of bookwyrm/activitystreams.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bookwyrm/activitystreams.py b/bookwyrm/activitystreams.py
--- a/bookwyrm/activitystreams.py
+++ b/bookwyrm/activitystreams.py
@@ -23,15 +23,21 @@
""" the redis key for this user's unread count for this stream """
return "{}-unread".format(self.stream_id(user))
+ def get_value(self, status): # pylint: disable=no-self-use
+ """ the status id and the rank (ie, published date) """
+ return {status.id: status.published_date.timestamp()}
+
def add_status(self, status):
""" add a status to users' feeds """
+ value = self.get_value(status)
# we want to do this as a bulk operation, hence "pipeline"
pipeline = r.pipeline()
for user in self.stream_users(status):
# add the status to the feed
- pipeline.lpush(self.stream_id(user), status.id)
- pipeline.ltrim(self.stream_id(user), 0, settings.MAX_STREAM_LENGTH)
-
+ pipeline.zadd(self.stream_id(user), value)
+ pipeline.zremrangebyrank(
+ self.stream_id(user), settings.MAX_STREAM_LENGTH, -1
+ )
# add to the unread status count
pipeline.incr(self.unread_id(user))
# and go!
@@ -47,8 +53,13 @@
def add_user_statuses(self, viewer, user):
""" add a user's statuses to another user's feed """
pipeline = r.pipeline()
- for status in user.status_set.all()[: settings.MAX_STREAM_LENGTH]:
- pipeline.lpush(self.stream_id(viewer), status.id)
+ statuses = user.status_set.all()[: settings.MAX_STREAM_LENGTH]
+ for status in statuses:
+ pipeline.zadd(self.stream_id(viewer), self.get_value(status))
+ if statuses:
+ pipeline.zremrangebyrank(
+ self.stream_id(user), settings.MAX_STREAM_LENGTH, -1
+ )
pipeline.execute()
def remove_user_statuses(self, viewer, user):
@@ -63,7 +74,7 @@
# clear unreads for this feed
r.set(self.unread_id(user), 0)
- statuses = r.lrange(self.stream_id(user), 0, -1)
+ statuses = r.zrevrange(self.stream_id(user), 0, -1)
return (
models.Status.objects.select_subclasses()
.filter(id__in=statuses)
@@ -81,7 +92,11 @@
stream_id = self.stream_id(user)
for status in statuses.all()[: settings.MAX_STREAM_LENGTH]:
- pipeline.lpush(stream_id, status.id)
+ pipeline.zadd(stream_id, self.get_value(status))
+
+ # only trim the stream if statuses were added
+ if statuses.exists():
+ pipeline.zremrangebyrank(stream_id, settings.MAX_STREAM_LENGTH, -1)
pipeline.execute()
def stream_users(self, status): # pylint: disable=no-self-use
@@ -271,7 +286,7 @@
@receiver(signals.post_save, sender=models.User)
# pylint: disable=unused-argument
-def populate_feed_on_account_create(sender, instance, created, *args, **kwargs):
+def populate_streams_on_account_create(sender, instance, created, *args, **kwargs):
""" build a user's feeds when they join """
if not created or not instance.local:
return
|
{"golden_diff": "diff --git a/bookwyrm/activitystreams.py b/bookwyrm/activitystreams.py\n--- a/bookwyrm/activitystreams.py\n+++ b/bookwyrm/activitystreams.py\n@@ -23,15 +23,21 @@\n \"\"\" the redis key for this user's unread count for this stream \"\"\"\n return \"{}-unread\".format(self.stream_id(user))\n \n+ def get_value(self, status): # pylint: disable=no-self-use\n+ \"\"\" the status id and the rank (ie, published date) \"\"\"\n+ return {status.id: status.published_date.timestamp()}\n+\n def add_status(self, status):\n \"\"\" add a status to users' feeds \"\"\"\n+ value = self.get_value(status)\n # we want to do this as a bulk operation, hence \"pipeline\"\n pipeline = r.pipeline()\n for user in self.stream_users(status):\n # add the status to the feed\n- pipeline.lpush(self.stream_id(user), status.id)\n- pipeline.ltrim(self.stream_id(user), 0, settings.MAX_STREAM_LENGTH)\n-\n+ pipeline.zadd(self.stream_id(user), value)\n+ pipeline.zremrangebyrank(\n+ self.stream_id(user), settings.MAX_STREAM_LENGTH, -1\n+ )\n # add to the unread status count\n pipeline.incr(self.unread_id(user))\n # and go!\n@@ -47,8 +53,13 @@\n def add_user_statuses(self, viewer, user):\n \"\"\" add a user's statuses to another user's feed \"\"\"\n pipeline = r.pipeline()\n- for status in user.status_set.all()[: settings.MAX_STREAM_LENGTH]:\n- pipeline.lpush(self.stream_id(viewer), status.id)\n+ statuses = user.status_set.all()[: settings.MAX_STREAM_LENGTH]\n+ for status in statuses:\n+ pipeline.zadd(self.stream_id(viewer), self.get_value(status))\n+ if statuses:\n+ pipeline.zremrangebyrank(\n+ self.stream_id(user), settings.MAX_STREAM_LENGTH, -1\n+ )\n pipeline.execute()\n \n def remove_user_statuses(self, viewer, user):\n@@ -63,7 +74,7 @@\n # clear unreads for this feed\n r.set(self.unread_id(user), 0)\n \n- statuses = r.lrange(self.stream_id(user), 0, -1)\n+ statuses = r.zrevrange(self.stream_id(user), 0, -1)\n return (\n models.Status.objects.select_subclasses()\n .filter(id__in=statuses)\n@@ -81,7 +92,11 @@\n \n stream_id = self.stream_id(user)\n for status in statuses.all()[: settings.MAX_STREAM_LENGTH]:\n- pipeline.lpush(stream_id, status.id)\n+ pipeline.zadd(stream_id, self.get_value(status))\n+\n+ # only trim the stream if statuses were added\n+ if statuses.exists():\n+ pipeline.zremrangebyrank(stream_id, settings.MAX_STREAM_LENGTH, -1)\n pipeline.execute()\n \n def stream_users(self, status): # pylint: disable=no-self-use\n@@ -271,7 +286,7 @@\n \n @receiver(signals.post_save, sender=models.User)\n # pylint: disable=unused-argument\n-def populate_feed_on_account_create(sender, instance, created, *args, **kwargs):\n+def populate_streams_on_account_create(sender, instance, created, *args, **kwargs):\n \"\"\" build a user's feeds when they join \"\"\"\n if not created or not instance.local:\n return\n", "issue": "Goodreads import floods activity streams\nWhen a user does a goodreads import, the activitstreams manager isn't checking if the publication date is older than the oldest status, and adds all the statuses to the feeds, pushing out newer statuses.\n", "before_files": [{"content": "\"\"\" access the activity streams stored in redis \"\"\"\nfrom abc import ABC\nfrom django.dispatch import receiver\nfrom django.db.models import signals, Q\nimport redis\n\nfrom bookwyrm import models, settings\nfrom bookwyrm.views.helpers import privacy_filter\n\nr = redis.Redis(\n host=settings.REDIS_ACTIVITY_HOST, port=settings.REDIS_ACTIVITY_PORT, db=0\n)\n\n\nclass ActivityStream(ABC):\n \"\"\" a category of activity stream (like home, local, federated) \"\"\"\n\n def stream_id(self, user):\n \"\"\" the redis key for this user's instance of this stream \"\"\"\n return \"{}-{}\".format(user.id, self.key)\n\n def unread_id(self, user):\n \"\"\" the redis key for this user's unread count for this stream \"\"\"\n return \"{}-unread\".format(self.stream_id(user))\n\n def add_status(self, status):\n \"\"\" add a status to users' feeds \"\"\"\n # we want to do this as a bulk operation, hence \"pipeline\"\n pipeline = r.pipeline()\n for user in self.stream_users(status):\n # add the status to the feed\n pipeline.lpush(self.stream_id(user), status.id)\n pipeline.ltrim(self.stream_id(user), 0, settings.MAX_STREAM_LENGTH)\n\n # add to the unread status count\n pipeline.incr(self.unread_id(user))\n # and go!\n pipeline.execute()\n\n def remove_status(self, status):\n \"\"\" remove a status from all feeds \"\"\"\n pipeline = r.pipeline()\n for user in self.stream_users(status):\n pipeline.lrem(self.stream_id(user), -1, status.id)\n pipeline.execute()\n\n def add_user_statuses(self, viewer, user):\n \"\"\" add a user's statuses to another user's feed \"\"\"\n pipeline = r.pipeline()\n for status in user.status_set.all()[: settings.MAX_STREAM_LENGTH]:\n pipeline.lpush(self.stream_id(viewer), status.id)\n pipeline.execute()\n\n def remove_user_statuses(self, viewer, user):\n \"\"\" remove a user's status from another user's feed \"\"\"\n pipeline = r.pipeline()\n for status in user.status_set.all()[: settings.MAX_STREAM_LENGTH]:\n pipeline.lrem(self.stream_id(viewer), -1, status.id)\n pipeline.execute()\n\n def get_activity_stream(self, user):\n \"\"\" load the ids for statuses to be displayed \"\"\"\n # clear unreads for this feed\n r.set(self.unread_id(user), 0)\n\n statuses = r.lrange(self.stream_id(user), 0, -1)\n return (\n models.Status.objects.select_subclasses()\n .filter(id__in=statuses)\n .order_by(\"-published_date\")\n )\n\n def get_unread_count(self, user):\n \"\"\" get the unread status count for this user's feed \"\"\"\n return int(r.get(self.unread_id(user)))\n\n def populate_stream(self, user):\n \"\"\" go from zero to a timeline \"\"\"\n pipeline = r.pipeline()\n statuses = self.stream_statuses(user)\n\n stream_id = self.stream_id(user)\n for status in statuses.all()[: settings.MAX_STREAM_LENGTH]:\n pipeline.lpush(stream_id, status.id)\n pipeline.execute()\n\n def stream_users(self, status): # pylint: disable=no-self-use\n \"\"\" given a status, what users should see it \"\"\"\n # direct messages don't appeard in feeds, direct comments/reviews/etc do\n if status.privacy == \"direct\" and status.status_type == \"Note\":\n return []\n\n # everybody who could plausibly see this status\n audience = models.User.objects.filter(\n is_active=True,\n local=True, # we only create feeds for users of this instance\n ).exclude(\n Q(id__in=status.user.blocks.all()) | Q(blocks=status.user) # not blocked\n )\n\n # only visible to the poster and mentioned users\n if status.privacy == \"direct\":\n audience = audience.filter(\n Q(id=status.user.id) # if the user is the post's author\n | Q(id__in=status.mention_users.all()) # if the user is mentioned\n )\n # only visible to the poster's followers and tagged users\n elif status.privacy == \"followers\":\n audience = audience.filter(\n Q(id=status.user.id) # if the user is the post's author\n | Q(following=status.user) # if the user is following the author\n )\n return audience.distinct()\n\n def stream_statuses(self, user): # pylint: disable=no-self-use\n \"\"\" given a user, what statuses should they see on this stream \"\"\"\n return privacy_filter(\n user,\n models.Status.objects.select_subclasses(),\n privacy_levels=[\"public\", \"unlisted\", \"followers\"],\n )\n\n\nclass HomeStream(ActivityStream):\n \"\"\" users you follow \"\"\"\n\n key = \"home\"\n\n def stream_users(self, status):\n audience = super().stream_users(status)\n if not audience:\n return []\n return audience.filter(\n Q(id=status.user.id) # if the user is the post's author\n | Q(following=status.user) # if the user is following the author\n ).distinct()\n\n def stream_statuses(self, user):\n return privacy_filter(\n user,\n models.Status.objects.select_subclasses(),\n privacy_levels=[\"public\", \"unlisted\", \"followers\"],\n following_only=True,\n )\n\n\nclass LocalStream(ActivityStream):\n \"\"\" users you follow \"\"\"\n\n key = \"local\"\n\n def stream_users(self, status):\n # this stream wants no part in non-public statuses\n if status.privacy != \"public\" or not status.user.local:\n return []\n return super().stream_users(status)\n\n def stream_statuses(self, user):\n # all public statuses by a local user\n return privacy_filter(\n user,\n models.Status.objects.select_subclasses().filter(user__local=True),\n privacy_levels=[\"public\"],\n )\n\n\nclass FederatedStream(ActivityStream):\n \"\"\" users you follow \"\"\"\n\n key = \"federated\"\n\n def stream_users(self, status):\n # this stream wants no part in non-public statuses\n if status.privacy != \"public\":\n return []\n return super().stream_users(status)\n\n def stream_statuses(self, user):\n return privacy_filter(\n user,\n models.Status.objects.select_subclasses(),\n privacy_levels=[\"public\"],\n )\n\n\nstreams = {\n \"home\": HomeStream(),\n \"local\": LocalStream(),\n \"federated\": FederatedStream(),\n}\n\n\n@receiver(signals.post_save)\n# pylint: disable=unused-argument\ndef add_status_on_create(sender, instance, created, *args, **kwargs):\n \"\"\" add newly created statuses to activity feeds \"\"\"\n # we're only interested in new statuses\n if not issubclass(sender, models.Status):\n return\n\n if instance.deleted:\n for stream in streams.values():\n stream.remove_status(instance)\n return\n\n if not created:\n return\n\n # iterates through Home, Local, Federated\n for stream in streams.values():\n stream.add_status(instance)\n\n\n@receiver(signals.post_delete, sender=models.Boost)\n# pylint: disable=unused-argument\ndef remove_boost_on_delete(sender, instance, *args, **kwargs):\n \"\"\" boosts are deleted \"\"\"\n # we're only interested in new statuses\n for stream in streams.values():\n stream.remove_status(instance)\n\n\n@receiver(signals.post_save, sender=models.UserFollows)\n# pylint: disable=unused-argument\ndef add_statuses_on_follow(sender, instance, created, *args, **kwargs):\n \"\"\" add a newly followed user's statuses to feeds \"\"\"\n if not created or not instance.user_subject.local:\n return\n HomeStream().add_user_statuses(instance.user_subject, instance.user_object)\n\n\n@receiver(signals.post_delete, sender=models.UserFollows)\n# pylint: disable=unused-argument\ndef remove_statuses_on_unfollow(sender, instance, *args, **kwargs):\n \"\"\" remove statuses from a feed on unfollow \"\"\"\n if not instance.user_subject.local:\n return\n HomeStream().remove_user_statuses(instance.user_subject, instance.user_object)\n\n\n@receiver(signals.post_save, sender=models.UserBlocks)\n# pylint: disable=unused-argument\ndef remove_statuses_on_block(sender, instance, *args, **kwargs):\n \"\"\" remove statuses from all feeds on block \"\"\"\n # blocks apply ot all feeds\n if instance.user_subject.local:\n for stream in streams.values():\n stream.remove_user_statuses(instance.user_subject, instance.user_object)\n\n # and in both directions\n if instance.user_object.local:\n for stream in streams.values():\n stream.remove_user_statuses(instance.user_object, instance.user_subject)\n\n\n@receiver(signals.post_delete, sender=models.UserBlocks)\n# pylint: disable=unused-argument\ndef add_statuses_on_unblock(sender, instance, *args, **kwargs):\n \"\"\" remove statuses from all feeds on block \"\"\"\n public_streams = [LocalStream(), FederatedStream()]\n # add statuses back to streams with statuses from anyone\n if instance.user_subject.local:\n for stream in public_streams:\n stream.add_user_statuses(instance.user_subject, instance.user_object)\n\n # add statuses back to streams with statuses from anyone\n if instance.user_object.local:\n for stream in public_streams:\n stream.add_user_statuses(instance.user_object, instance.user_subject)\n\n\n@receiver(signals.post_save, sender=models.User)\n# pylint: disable=unused-argument\ndef populate_feed_on_account_create(sender, instance, created, *args, **kwargs):\n \"\"\" build a user's feeds when they join \"\"\"\n if not created or not instance.local:\n return\n\n for stream in streams.values():\n stream.populate_stream(instance)\n", "path": "bookwyrm/activitystreams.py"}]}
| 3,397 | 752 |
gh_patches_debug_9599
|
rasdani/github-patches
|
git_diff
|
mars-project__mars-3129
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] ImportError: cannot import name 'elliprc' from 'mars.tensor.special.ellip_func_integrals'
<!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
A clear and concise description of what the bug is.
```python
Traceback:
/usr/local/python3/lib/python3.7/importlib/__init__.py:127: in import_module
return _bootstrap._gcd_import(name[level:], package, level)
mars/tensor/special/tests/test_special.py:57: in <module>
from ..ellip_func_integrals import (
E ImportError: cannot import name 'elliprc' from 'mars.tensor.special.ellip_func_integrals' (/home/jenkins/agent/aci/mars/tensor/special/ellip_func_integrals.py)
```
```python
Traceback:
/usr/local/python3/lib/python3.7/importlib/__init__.py:127: in import_module
return _bootstrap._gcd_import(name[level:], package, level)
mars/tensor/special/tests/test_special.py:18: in <module>
from scipy.special import (
E ImportError: cannot import name 'elliprd' from 'scipy.special' (/home/admin/py3/lib/python3.7/site-packages/scipy/special/__init__.py)
```
**To Reproduce**
To help us reproducing this bug, please provide information below:
1. Your Python version 3.7.7
2. The version of Mars you use Latest master
3. Versions of crucial packages, such as numpy, scipy and pandas `scipy==1.5.0`
4. Full stack of the error.
5. Minimized code to reproduce the error.
**Expected behavior**
A clear and concise description of what you expected to happen.
**Additional context**
Add any other context about the problem here.
</issue>
<code>
[start of mars/tensor/special/ellip_func_integrals.py]
1 # Copyright 1999-2021 Alibaba Group Holding Ltd.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import scipy.special as spspecial
16
17 from ..arithmetic.utils import arithmetic_operand
18 from ..utils import infer_dtype, implement_scipy
19 from .core import (
20 _register_special_op,
21 TensorSpecialBinOp,
22 TensorSpecialUnaryOp,
23 TensorSpecialMultiOp,
24 )
25
26
27 @_register_special_op
28 @arithmetic_operand(sparse_mode="unary")
29 class TensorEllipk(TensorSpecialUnaryOp):
30 _func_name = "ellipk"
31
32
33 @_register_special_op
34 @arithmetic_operand(sparse_mode="unary")
35 class TensorEllipkm1(TensorSpecialUnaryOp):
36 _func_name = "ellipkm1"
37
38
39 @_register_special_op
40 @arithmetic_operand(sparse_mode="binary_and")
41 class TensorEllipkinc(TensorSpecialBinOp):
42 _func_name = "ellipkinc"
43
44
45 @_register_special_op
46 @arithmetic_operand(sparse_mode="unary")
47 class TensorEllipe(TensorSpecialUnaryOp):
48 _func_name = "ellipe"
49
50
51 @_register_special_op
52 @arithmetic_operand(sparse_mode="binary_and")
53 class TensorEllipeinc(TensorSpecialBinOp):
54 _func_name = "ellipeinc"
55
56
57 @_register_special_op
58 @arithmetic_operand(sparse_mode="binary_and")
59 class TensorElliprc(TensorSpecialBinOp):
60 _func_name = "elliprc"
61
62
63 @_register_special_op
64 class TensorElliprd(TensorSpecialMultiOp):
65 _ARG_COUNT = 3
66 _func_name = "elliprd"
67
68
69 @_register_special_op
70 class TensorElliprf(TensorSpecialMultiOp):
71 _ARG_COUNT = 3
72 _func_name = "elliprf"
73
74
75 @_register_special_op
76 class TensorElliprg(TensorSpecialMultiOp):
77 _ARG_COUNT = 3
78 _func_name = "elliprg"
79
80
81 @_register_special_op
82 class TensorElliprj(TensorSpecialMultiOp):
83 _ARG_COUNT = 4
84 _func_name = "elliprj"
85
86
87 @implement_scipy(spspecial.ellipk)
88 @infer_dtype(spspecial.ellipk)
89 def ellipk(x, **kwargs):
90 op = TensorEllipk(**kwargs)
91 return op(x)
92
93
94 @implement_scipy(spspecial.ellipkm1)
95 @infer_dtype(spspecial.ellipkm1)
96 def ellipkm1(x, **kwargs):
97 op = TensorEllipkm1(**kwargs)
98 return op(x)
99
100
101 @implement_scipy(spspecial.ellipkinc)
102 @infer_dtype(spspecial.ellipkinc)
103 def ellipkinc(phi, m, **kwargs):
104 op = TensorEllipkinc(**kwargs)
105 return op(phi, m)
106
107
108 @implement_scipy(spspecial.ellipe)
109 @infer_dtype(spspecial.ellipe)
110 def ellipe(x, **kwargs):
111 op = TensorEllipe(**kwargs)
112 return op(x)
113
114
115 @implement_scipy(spspecial.ellipeinc)
116 @infer_dtype(spspecial.ellipeinc)
117 def ellipeinc(phi, m, **kwargs):
118 op = TensorEllipeinc(**kwargs)
119 return op(phi, m)
120
121
122 try:
123
124 @implement_scipy(spspecial.elliprc)
125 @infer_dtype(spspecial.elliprc)
126 def elliprc(x, y, **kwargs):
127 op = TensorElliprc(**kwargs)
128 return op(x, y)
129
130 @implement_scipy(spspecial.elliprd)
131 @infer_dtype(spspecial.elliprd)
132 def elliprd(x, y, z, **kwargs):
133 op = TensorElliprd(**kwargs)
134 return op(x, y, z)
135
136 @implement_scipy(spspecial.elliprf)
137 @infer_dtype(spspecial.elliprf)
138 def elliprf(x, y, z, **kwargs):
139 op = TensorElliprf(**kwargs)
140 return op(x, y, z)
141
142 @implement_scipy(spspecial.elliprg)
143 @infer_dtype(spspecial.elliprg)
144 def elliprg(x, y, z, **kwargs):
145 op = TensorElliprg(**kwargs)
146 return op(x, y, z)
147
148 @implement_scipy(spspecial.elliprj)
149 @infer_dtype(spspecial.elliprj)
150 def elliprj(x, y, z, p, **kwargs):
151 op = TensorElliprj(**kwargs)
152 return op(x, y, z, p)
153
154 except AttributeError:
155 # These functions are not implemented before scipy v1.8 so
156 # spsecial.func may cause AttributeError
157 pass
158
[end of mars/tensor/special/ellip_func_integrals.py]
[start of mars/tensor/special/__init__.py]
1 # Copyright 1999-2021 Alibaba Group Holding Ltd.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 try:
16 import scipy
17
18 from .err_fresnel import (
19 erf,
20 TensorErf,
21 erfc,
22 TensorErfc,
23 erfcx,
24 TensorErfcx,
25 erfi,
26 TensorErfi,
27 erfinv,
28 TensorErfinv,
29 erfcinv,
30 TensorErfcinv,
31 )
32 from .gamma_funcs import (
33 gamma,
34 TensorGamma,
35 gammaln,
36 TensorGammaln,
37 loggamma,
38 TensorLogGamma,
39 gammasgn,
40 TensorGammaSgn,
41 gammainc,
42 TensorGammaInc,
43 gammaincinv,
44 TensorGammaIncInv,
45 gammaincc,
46 TensorGammaIncc,
47 gammainccinv,
48 TensorGammaInccInv,
49 beta,
50 TensorBeta,
51 betaln,
52 TensorBetaLn,
53 betainc,
54 TensorBetaInc,
55 betaincinv,
56 TensorBetaIncInv,
57 psi,
58 TensorPsi,
59 rgamma,
60 TensorRGamma,
61 polygamma,
62 TensorPolyGamma,
63 multigammaln,
64 TensorMultiGammaLn,
65 digamma,
66 TensorDiGamma,
67 poch,
68 TensorPoch,
69 )
70 from .info_theory import (
71 entr,
72 TensorEntr,
73 rel_entr,
74 TensorRelEntr,
75 kl_div,
76 TensorKlDiv,
77 )
78 from .convenience import (
79 xlogy,
80 TensorXLogY,
81 )
82 from .bessel import (
83 jv,
84 TensorJV,
85 jve,
86 TensorJVE,
87 yn,
88 TensorYN,
89 yv,
90 TensorYV,
91 yve,
92 TensorYVE,
93 kn,
94 TensorKN,
95 kv,
96 TensorKV,
97 kve,
98 TensorKVE,
99 iv,
100 TensorIV,
101 ive,
102 TensorIVE,
103 hankel1,
104 TensorHankel1,
105 hankel1e,
106 TensorHankel1e,
107 hankel2,
108 TensorHankel2,
109 hankel2e,
110 TensorHankel2e,
111 )
112 from .hypergeometric_funcs import (
113 hyp2f1,
114 TensorHYP2F1,
115 hyp1f1,
116 TensorHYP1F1,
117 hyperu,
118 TensorHYPERU,
119 hyp0f1,
120 TensorHYP0F1,
121 )
122 from .ellip_harm import (
123 ellip_harm,
124 TensorEllipHarm,
125 ellip_harm_2,
126 TensorEllipHarm2,
127 ellip_normal,
128 TensorEllipNormal,
129 )
130 from .ellip_func_integrals import (
131 ellipk,
132 TensorEllipk,
133 ellipkm1,
134 TensorEllipkm1,
135 ellipkinc,
136 TensorEllipkinc,
137 ellipe,
138 TensorEllipe,
139 ellipeinc,
140 TensorEllipeinc,
141 elliprc,
142 TensorElliprc,
143 elliprd,
144 TensorElliprd,
145 elliprf,
146 TensorElliprf,
147 elliprg,
148 TensorElliprg,
149 elliprj,
150 TensorElliprj,
151 )
152 except ImportError: # pragma: no cover
153 pass
154
[end of mars/tensor/special/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mars/tensor/special/__init__.py b/mars/tensor/special/__init__.py
--- a/mars/tensor/special/__init__.py
+++ b/mars/tensor/special/__init__.py
@@ -151,3 +151,7 @@
)
except ImportError: # pragma: no cover
pass
+
+_names_to_del = [_name for _name, _val in globals().items() if _val is None]
+[globals().pop(_name) for _name in _names_to_del]
+del _names_to_del
diff --git a/mars/tensor/special/ellip_func_integrals.py b/mars/tensor/special/ellip_func_integrals.py
--- a/mars/tensor/special/ellip_func_integrals.py
+++ b/mars/tensor/special/ellip_func_integrals.py
@@ -154,4 +154,4 @@
except AttributeError:
# These functions are not implemented before scipy v1.8 so
# spsecial.func may cause AttributeError
- pass
+ elliprc = elliprd = elliprf = elliprg = elliprj = None
|
{"golden_diff": "diff --git a/mars/tensor/special/__init__.py b/mars/tensor/special/__init__.py\n--- a/mars/tensor/special/__init__.py\n+++ b/mars/tensor/special/__init__.py\n@@ -151,3 +151,7 @@\n )\n except ImportError: # pragma: no cover\n pass\n+\n+_names_to_del = [_name for _name, _val in globals().items() if _val is None]\n+[globals().pop(_name) for _name in _names_to_del]\n+del _names_to_del\ndiff --git a/mars/tensor/special/ellip_func_integrals.py b/mars/tensor/special/ellip_func_integrals.py\n--- a/mars/tensor/special/ellip_func_integrals.py\n+++ b/mars/tensor/special/ellip_func_integrals.py\n@@ -154,4 +154,4 @@\n except AttributeError:\n # These functions are not implemented before scipy v1.8 so\n # spsecial.func may cause AttributeError\n- pass\n+ elliprc = elliprd = elliprf = elliprg = elliprj = None\n", "issue": "[BUG] ImportError: cannot import name 'elliprc' from 'mars.tensor.special.ellip_func_integrals' \n<!--\r\nThank you for your contribution!\r\n\r\nPlease review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.\r\n-->\r\n\r\n**Describe the bug**\r\nA clear and concise description of what the bug is.\r\n\r\n```python\r\nTraceback:\r\n/usr/local/python3/lib/python3.7/importlib/__init__.py:127: in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\nmars/tensor/special/tests/test_special.py:57: in <module>\r\n from ..ellip_func_integrals import (\r\nE ImportError: cannot import name 'elliprc' from 'mars.tensor.special.ellip_func_integrals' (/home/jenkins/agent/aci/mars/tensor/special/ellip_func_integrals.py)\r\n```\r\n\r\n\r\n```python\r\nTraceback:\r\n/usr/local/python3/lib/python3.7/importlib/__init__.py:127: in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\nmars/tensor/special/tests/test_special.py:18: in <module>\r\n from scipy.special import (\r\nE ImportError: cannot import name 'elliprd' from 'scipy.special' (/home/admin/py3/lib/python3.7/site-packages/scipy/special/__init__.py)\r\n```\r\n\r\n**To Reproduce**\r\nTo help us reproducing this bug, please provide information below:\r\n1. Your Python version 3.7.7\r\n2. The version of Mars you use Latest master\r\n3. Versions of crucial packages, such as numpy, scipy and pandas `scipy==1.5.0`\r\n4. Full stack of the error.\r\n5. Minimized code to reproduce the error.\r\n\r\n**Expected behavior**\r\nA clear and concise description of what you expected to happen.\r\n\r\n**Additional context**\r\nAdd any other context about the problem here.\r\n\n", "before_files": [{"content": "# Copyright 1999-2021 Alibaba Group Holding Ltd.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport scipy.special as spspecial\n\nfrom ..arithmetic.utils import arithmetic_operand\nfrom ..utils import infer_dtype, implement_scipy\nfrom .core import (\n _register_special_op,\n TensorSpecialBinOp,\n TensorSpecialUnaryOp,\n TensorSpecialMultiOp,\n)\n\n\n@_register_special_op\n@arithmetic_operand(sparse_mode=\"unary\")\nclass TensorEllipk(TensorSpecialUnaryOp):\n _func_name = \"ellipk\"\n\n\n@_register_special_op\n@arithmetic_operand(sparse_mode=\"unary\")\nclass TensorEllipkm1(TensorSpecialUnaryOp):\n _func_name = \"ellipkm1\"\n\n\n@_register_special_op\n@arithmetic_operand(sparse_mode=\"binary_and\")\nclass TensorEllipkinc(TensorSpecialBinOp):\n _func_name = \"ellipkinc\"\n\n\n@_register_special_op\n@arithmetic_operand(sparse_mode=\"unary\")\nclass TensorEllipe(TensorSpecialUnaryOp):\n _func_name = \"ellipe\"\n\n\n@_register_special_op\n@arithmetic_operand(sparse_mode=\"binary_and\")\nclass TensorEllipeinc(TensorSpecialBinOp):\n _func_name = \"ellipeinc\"\n\n\n@_register_special_op\n@arithmetic_operand(sparse_mode=\"binary_and\")\nclass TensorElliprc(TensorSpecialBinOp):\n _func_name = \"elliprc\"\n\n\n@_register_special_op\nclass TensorElliprd(TensorSpecialMultiOp):\n _ARG_COUNT = 3\n _func_name = \"elliprd\"\n\n\n@_register_special_op\nclass TensorElliprf(TensorSpecialMultiOp):\n _ARG_COUNT = 3\n _func_name = \"elliprf\"\n\n\n@_register_special_op\nclass TensorElliprg(TensorSpecialMultiOp):\n _ARG_COUNT = 3\n _func_name = \"elliprg\"\n\n\n@_register_special_op\nclass TensorElliprj(TensorSpecialMultiOp):\n _ARG_COUNT = 4\n _func_name = \"elliprj\"\n\n\n@implement_scipy(spspecial.ellipk)\n@infer_dtype(spspecial.ellipk)\ndef ellipk(x, **kwargs):\n op = TensorEllipk(**kwargs)\n return op(x)\n\n\n@implement_scipy(spspecial.ellipkm1)\n@infer_dtype(spspecial.ellipkm1)\ndef ellipkm1(x, **kwargs):\n op = TensorEllipkm1(**kwargs)\n return op(x)\n\n\n@implement_scipy(spspecial.ellipkinc)\n@infer_dtype(spspecial.ellipkinc)\ndef ellipkinc(phi, m, **kwargs):\n op = TensorEllipkinc(**kwargs)\n return op(phi, m)\n\n\n@implement_scipy(spspecial.ellipe)\n@infer_dtype(spspecial.ellipe)\ndef ellipe(x, **kwargs):\n op = TensorEllipe(**kwargs)\n return op(x)\n\n\n@implement_scipy(spspecial.ellipeinc)\n@infer_dtype(spspecial.ellipeinc)\ndef ellipeinc(phi, m, **kwargs):\n op = TensorEllipeinc(**kwargs)\n return op(phi, m)\n\n\ntry:\n\n @implement_scipy(spspecial.elliprc)\n @infer_dtype(spspecial.elliprc)\n def elliprc(x, y, **kwargs):\n op = TensorElliprc(**kwargs)\n return op(x, y)\n\n @implement_scipy(spspecial.elliprd)\n @infer_dtype(spspecial.elliprd)\n def elliprd(x, y, z, **kwargs):\n op = TensorElliprd(**kwargs)\n return op(x, y, z)\n\n @implement_scipy(spspecial.elliprf)\n @infer_dtype(spspecial.elliprf)\n def elliprf(x, y, z, **kwargs):\n op = TensorElliprf(**kwargs)\n return op(x, y, z)\n\n @implement_scipy(spspecial.elliprg)\n @infer_dtype(spspecial.elliprg)\n def elliprg(x, y, z, **kwargs):\n op = TensorElliprg(**kwargs)\n return op(x, y, z)\n\n @implement_scipy(spspecial.elliprj)\n @infer_dtype(spspecial.elliprj)\n def elliprj(x, y, z, p, **kwargs):\n op = TensorElliprj(**kwargs)\n return op(x, y, z, p)\n\nexcept AttributeError:\n # These functions are not implemented before scipy v1.8 so\n # spsecial.func may cause AttributeError\n pass\n", "path": "mars/tensor/special/ellip_func_integrals.py"}, {"content": "# Copyright 1999-2021 Alibaba Group Holding Ltd.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\ntry:\n import scipy\n\n from .err_fresnel import (\n erf,\n TensorErf,\n erfc,\n TensorErfc,\n erfcx,\n TensorErfcx,\n erfi,\n TensorErfi,\n erfinv,\n TensorErfinv,\n erfcinv,\n TensorErfcinv,\n )\n from .gamma_funcs import (\n gamma,\n TensorGamma,\n gammaln,\n TensorGammaln,\n loggamma,\n TensorLogGamma,\n gammasgn,\n TensorGammaSgn,\n gammainc,\n TensorGammaInc,\n gammaincinv,\n TensorGammaIncInv,\n gammaincc,\n TensorGammaIncc,\n gammainccinv,\n TensorGammaInccInv,\n beta,\n TensorBeta,\n betaln,\n TensorBetaLn,\n betainc,\n TensorBetaInc,\n betaincinv,\n TensorBetaIncInv,\n psi,\n TensorPsi,\n rgamma,\n TensorRGamma,\n polygamma,\n TensorPolyGamma,\n multigammaln,\n TensorMultiGammaLn,\n digamma,\n TensorDiGamma,\n poch,\n TensorPoch,\n )\n from .info_theory import (\n entr,\n TensorEntr,\n rel_entr,\n TensorRelEntr,\n kl_div,\n TensorKlDiv,\n )\n from .convenience import (\n xlogy,\n TensorXLogY,\n )\n from .bessel import (\n jv,\n TensorJV,\n jve,\n TensorJVE,\n yn,\n TensorYN,\n yv,\n TensorYV,\n yve,\n TensorYVE,\n kn,\n TensorKN,\n kv,\n TensorKV,\n kve,\n TensorKVE,\n iv,\n TensorIV,\n ive,\n TensorIVE,\n hankel1,\n TensorHankel1,\n hankel1e,\n TensorHankel1e,\n hankel2,\n TensorHankel2,\n hankel2e,\n TensorHankel2e,\n )\n from .hypergeometric_funcs import (\n hyp2f1,\n TensorHYP2F1,\n hyp1f1,\n TensorHYP1F1,\n hyperu,\n TensorHYPERU,\n hyp0f1,\n TensorHYP0F1,\n )\n from .ellip_harm import (\n ellip_harm,\n TensorEllipHarm,\n ellip_harm_2,\n TensorEllipHarm2,\n ellip_normal,\n TensorEllipNormal,\n )\n from .ellip_func_integrals import (\n ellipk,\n TensorEllipk,\n ellipkm1,\n TensorEllipkm1,\n ellipkinc,\n TensorEllipkinc,\n ellipe,\n TensorEllipe,\n ellipeinc,\n TensorEllipeinc,\n elliprc,\n TensorElliprc,\n elliprd,\n TensorElliprd,\n elliprf,\n TensorElliprf,\n elliprg,\n TensorElliprg,\n elliprj,\n TensorElliprj,\n )\nexcept ImportError: # pragma: no cover\n pass\n", "path": "mars/tensor/special/__init__.py"}]}
| 3,750 | 268 |
gh_patches_debug_42303
|
rasdani/github-patches
|
git_diff
|
sublimelsp__LSP-1690
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Format JSON on save
Is there a way to get this LSP to format json files ons save?
It works for other LSPs but just not JSON,
Here are my configs:
Preferences
```
{
...
"lsp_format_on_save": true
...
}
```
LSP
```
"lsp_code_actions_on_save": {
"source.organizeImports": true,
"source.fixAll.eslint": true,
}
```
All LSP-JSON settings are default
</issue>
<code>
[start of plugin/formatting.py]
1 from .core.edit import parse_text_edit
2 from .core.protocol import TextEdit
3 from .core.registry import LspTextCommand
4 from .core.sessions import Session
5 from .core.settings import userprefs
6 from .core.typing import Any, Callable, List, Optional, Iterator
7 from .core.views import entire_content_region
8 from .core.views import first_selection_region
9 from .core.views import text_document_formatting
10 from .core.views import text_document_range_formatting
11 from .core.views import will_save_wait_until
12 from .save_command import LspSaveCommand, SaveTask
13 import sublime
14
15
16 def apply_response_to_view(response: Optional[List[TextEdit]], view: sublime.View) -> None:
17 edits = list(parse_text_edit(change) for change in response) if response else []
18 view.run_command('lsp_apply_document_edit', {'changes': edits})
19
20
21 class WillSaveWaitTask(SaveTask):
22 @classmethod
23 def is_applicable(cls, view: sublime.View) -> bool:
24 return bool(view.file_name())
25
26 def __init__(self, task_runner: LspTextCommand, on_complete: Callable[[], None]) -> None:
27 super().__init__(task_runner, on_complete)
28 self._session_iterator = None # type: Optional[Iterator[Session]]
29
30 def run_async(self) -> None:
31 super().run_async()
32 self._session_iterator = self._task_runner.sessions('textDocumentSync.willSaveWaitUntil')
33 self._handle_next_session_async()
34
35 def _handle_next_session_async(self) -> None:
36 session = next(self._session_iterator, None) if self._session_iterator else None
37 if session:
38 self._purge_changes_async()
39 self._will_save_wait_until_async(session)
40 else:
41 self._on_complete()
42
43 def _will_save_wait_until_async(self, session: Session) -> None:
44 session.send_request_async(
45 will_save_wait_until(self._task_runner.view, reason=1), # TextDocumentSaveReason.Manual
46 self._on_response,
47 lambda error: self._on_response(None))
48
49 def _on_response(self, response: Any) -> None:
50 if response and not self._cancelled:
51 apply_response_to_view(response, self._task_runner.view)
52 sublime.set_timeout_async(self._handle_next_session_async)
53
54
55 class FormattingTask(SaveTask):
56 @classmethod
57 def is_applicable(cls, view: sublime.View) -> bool:
58 settings = view.settings()
59 view_format_on_save = settings.get('lsp_format_on_save', None)
60 enabled = view_format_on_save if isinstance(view_format_on_save, bool) else userprefs().lsp_format_on_save
61 return enabled and bool(view.window()) and bool(view.file_name())
62
63 def run_async(self) -> None:
64 super().run_async()
65 self._purge_changes_async()
66 session = self._task_runner.best_session(LspFormatDocumentCommand.capability)
67 if session:
68 session.send_request_async(
69 text_document_formatting(self._task_runner.view), self._on_response,
70 lambda error: self._on_response(None))
71 else:
72 self._on_complete()
73
74 def _on_response(self, response: Any) -> None:
75 if response and not self._cancelled:
76 apply_response_to_view(response, self._task_runner.view)
77 sublime.set_timeout_async(self._on_complete)
78
79
80 LspSaveCommand.register_task(WillSaveWaitTask)
81 LspSaveCommand.register_task(FormattingTask)
82
83
84 class LspFormatDocumentCommand(LspTextCommand):
85
86 capability = 'documentFormattingProvider'
87
88 def is_enabled(self, event: Optional[dict] = None, point: Optional[int] = None) -> bool:
89 return super().is_enabled() or bool(self.best_session(LspFormatDocumentRangeCommand.capability))
90
91 def run(self, edit: sublime.Edit, event: Optional[dict] = None) -> None:
92 session = self.best_session(self.capability)
93 if session:
94 # Either use the documentFormattingProvider ...
95 session.send_request(text_document_formatting(self.view), self.on_result)
96 else:
97 session = self.best_session(LspFormatDocumentRangeCommand.capability)
98 if session:
99 # ... or use the documentRangeFormattingProvider and format the entire range.
100 req = text_document_range_formatting(self.view, entire_content_region(self.view))
101 session.send_request(req, self.on_result)
102
103 def on_result(self, params: Any) -> None:
104 apply_response_to_view(params, self.view)
105
106
107 class LspFormatDocumentRangeCommand(LspTextCommand):
108
109 capability = 'documentRangeFormattingProvider'
110
111 def is_enabled(self, event: Optional[dict] = None, point: Optional[int] = None) -> bool:
112 if super().is_enabled(event, point):
113 if len(self.view.sel()) == 1:
114 region = self.view.sel()[0]
115 if region.begin() != region.end():
116 return True
117 return False
118
119 def run(self, edit: sublime.Edit, event: Optional[dict] = None) -> None:
120 session = self.best_session(self.capability)
121 selection = first_selection_region(self.view)
122 if session and selection is not None:
123 req = text_document_range_formatting(self.view, selection)
124 session.send_request(req, lambda response: apply_response_to_view(response, self.view))
125
[end of plugin/formatting.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugin/formatting.py b/plugin/formatting.py
--- a/plugin/formatting.py
+++ b/plugin/formatting.py
@@ -1,9 +1,11 @@
from .core.edit import parse_text_edit
+from .core.promise import Promise
+from .core.protocol import Error
from .core.protocol import TextEdit
from .core.registry import LspTextCommand
from .core.sessions import Session
from .core.settings import userprefs
-from .core.typing import Any, Callable, List, Optional, Iterator
+from .core.typing import Any, Callable, List, Optional, Iterator, Union
from .core.views import entire_content_region
from .core.views import first_selection_region
from .core.views import text_document_formatting
@@ -13,6 +15,22 @@
import sublime
+FormatResponse = Union[List[TextEdit], None, Error]
+
+
+def format_document(text_command: LspTextCommand) -> Promise[FormatResponse]:
+ view = text_command.view
+ session = text_command.best_session(LspFormatDocumentCommand.capability)
+ if session:
+ # Either use the documentFormattingProvider ...
+ return session.send_request_task(text_document_formatting(view))
+ session = text_command.best_session(LspFormatDocumentRangeCommand.capability)
+ if session:
+ # ... or use the documentRangeFormattingProvider and format the entire range.
+ return session.send_request_task(text_document_range_formatting(view, entire_content_region(view)))
+ return Promise.resolve(None)
+
+
def apply_response_to_view(response: Optional[List[TextEdit]], view: sublime.View) -> None:
edits = list(parse_text_edit(change) for change in response) if response else []
view.run_command('lsp_apply_document_edit', {'changes': edits})
@@ -63,16 +81,10 @@
def run_async(self) -> None:
super().run_async()
self._purge_changes_async()
- session = self._task_runner.best_session(LspFormatDocumentCommand.capability)
- if session:
- session.send_request_async(
- text_document_formatting(self._task_runner.view), self._on_response,
- lambda error: self._on_response(None))
- else:
- self._on_complete()
+ format_document(self._task_runner).then(self._on_response)
- def _on_response(self, response: Any) -> None:
- if response and not self._cancelled:
+ def _on_response(self, response: FormatResponse) -> None:
+ if response and not isinstance(response, Error) and not self._cancelled:
apply_response_to_view(response, self._task_runner.view)
sublime.set_timeout_async(self._on_complete)
@@ -89,19 +101,11 @@
return super().is_enabled() or bool(self.best_session(LspFormatDocumentRangeCommand.capability))
def run(self, edit: sublime.Edit, event: Optional[dict] = None) -> None:
- session = self.best_session(self.capability)
- if session:
- # Either use the documentFormattingProvider ...
- session.send_request(text_document_formatting(self.view), self.on_result)
- else:
- session = self.best_session(LspFormatDocumentRangeCommand.capability)
- if session:
- # ... or use the documentRangeFormattingProvider and format the entire range.
- req = text_document_range_formatting(self.view, entire_content_region(self.view))
- session.send_request(req, self.on_result)
-
- def on_result(self, params: Any) -> None:
- apply_response_to_view(params, self.view)
+ format_document(self).then(self.on_result)
+
+ def on_result(self, result: FormatResponse) -> None:
+ if result and not isinstance(result, Error):
+ apply_response_to_view(result, self.view)
class LspFormatDocumentRangeCommand(LspTextCommand):
|
{"golden_diff": "diff --git a/plugin/formatting.py b/plugin/formatting.py\n--- a/plugin/formatting.py\n+++ b/plugin/formatting.py\n@@ -1,9 +1,11 @@\n from .core.edit import parse_text_edit\n+from .core.promise import Promise\n+from .core.protocol import Error\n from .core.protocol import TextEdit\n from .core.registry import LspTextCommand\n from .core.sessions import Session\n from .core.settings import userprefs\n-from .core.typing import Any, Callable, List, Optional, Iterator\n+from .core.typing import Any, Callable, List, Optional, Iterator, Union\n from .core.views import entire_content_region\n from .core.views import first_selection_region\n from .core.views import text_document_formatting\n@@ -13,6 +15,22 @@\n import sublime\n \n \n+FormatResponse = Union[List[TextEdit], None, Error]\n+\n+\n+def format_document(text_command: LspTextCommand) -> Promise[FormatResponse]:\n+ view = text_command.view\n+ session = text_command.best_session(LspFormatDocumentCommand.capability)\n+ if session:\n+ # Either use the documentFormattingProvider ...\n+ return session.send_request_task(text_document_formatting(view))\n+ session = text_command.best_session(LspFormatDocumentRangeCommand.capability)\n+ if session:\n+ # ... or use the documentRangeFormattingProvider and format the entire range.\n+ return session.send_request_task(text_document_range_formatting(view, entire_content_region(view)))\n+ return Promise.resolve(None)\n+\n+\n def apply_response_to_view(response: Optional[List[TextEdit]], view: sublime.View) -> None:\n edits = list(parse_text_edit(change) for change in response) if response else []\n view.run_command('lsp_apply_document_edit', {'changes': edits})\n@@ -63,16 +81,10 @@\n def run_async(self) -> None:\n super().run_async()\n self._purge_changes_async()\n- session = self._task_runner.best_session(LspFormatDocumentCommand.capability)\n- if session:\n- session.send_request_async(\n- text_document_formatting(self._task_runner.view), self._on_response,\n- lambda error: self._on_response(None))\n- else:\n- self._on_complete()\n+ format_document(self._task_runner).then(self._on_response)\n \n- def _on_response(self, response: Any) -> None:\n- if response and not self._cancelled:\n+ def _on_response(self, response: FormatResponse) -> None:\n+ if response and not isinstance(response, Error) and not self._cancelled:\n apply_response_to_view(response, self._task_runner.view)\n sublime.set_timeout_async(self._on_complete)\n \n@@ -89,19 +101,11 @@\n return super().is_enabled() or bool(self.best_session(LspFormatDocumentRangeCommand.capability))\n \n def run(self, edit: sublime.Edit, event: Optional[dict] = None) -> None:\n- session = self.best_session(self.capability)\n- if session:\n- # Either use the documentFormattingProvider ...\n- session.send_request(text_document_formatting(self.view), self.on_result)\n- else:\n- session = self.best_session(LspFormatDocumentRangeCommand.capability)\n- if session:\n- # ... or use the documentRangeFormattingProvider and format the entire range.\n- req = text_document_range_formatting(self.view, entire_content_region(self.view))\n- session.send_request(req, self.on_result)\n-\n- def on_result(self, params: Any) -> None:\n- apply_response_to_view(params, self.view)\n+ format_document(self).then(self.on_result)\n+\n+ def on_result(self, result: FormatResponse) -> None:\n+ if result and not isinstance(result, Error):\n+ apply_response_to_view(result, self.view)\n \n \n class LspFormatDocumentRangeCommand(LspTextCommand):\n", "issue": "Format JSON on save\nIs there a way to get this LSP to format json files ons save?\r\n\r\nIt works for other LSPs but just not JSON,\r\n\r\nHere are my configs:\r\n\r\nPreferences\r\n```\r\n{\r\n ...\r\n\t\"lsp_format_on_save\": true\r\n ...\r\n}\r\n```\r\n\r\nLSP\r\n```\r\n\t\"lsp_code_actions_on_save\": {\r\n\t\t\"source.organizeImports\": true,\r\n\t\t\"source.fixAll.eslint\": true,\r\n\t}\r\n```\r\n\r\nAll LSP-JSON settings are default\n", "before_files": [{"content": "from .core.edit import parse_text_edit\nfrom .core.protocol import TextEdit\nfrom .core.registry import LspTextCommand\nfrom .core.sessions import Session\nfrom .core.settings import userprefs\nfrom .core.typing import Any, Callable, List, Optional, Iterator\nfrom .core.views import entire_content_region\nfrom .core.views import first_selection_region\nfrom .core.views import text_document_formatting\nfrom .core.views import text_document_range_formatting\nfrom .core.views import will_save_wait_until\nfrom .save_command import LspSaveCommand, SaveTask\nimport sublime\n\n\ndef apply_response_to_view(response: Optional[List[TextEdit]], view: sublime.View) -> None:\n edits = list(parse_text_edit(change) for change in response) if response else []\n view.run_command('lsp_apply_document_edit', {'changes': edits})\n\n\nclass WillSaveWaitTask(SaveTask):\n @classmethod\n def is_applicable(cls, view: sublime.View) -> bool:\n return bool(view.file_name())\n\n def __init__(self, task_runner: LspTextCommand, on_complete: Callable[[], None]) -> None:\n super().__init__(task_runner, on_complete)\n self._session_iterator = None # type: Optional[Iterator[Session]]\n\n def run_async(self) -> None:\n super().run_async()\n self._session_iterator = self._task_runner.sessions('textDocumentSync.willSaveWaitUntil')\n self._handle_next_session_async()\n\n def _handle_next_session_async(self) -> None:\n session = next(self._session_iterator, None) if self._session_iterator else None\n if session:\n self._purge_changes_async()\n self._will_save_wait_until_async(session)\n else:\n self._on_complete()\n\n def _will_save_wait_until_async(self, session: Session) -> None:\n session.send_request_async(\n will_save_wait_until(self._task_runner.view, reason=1), # TextDocumentSaveReason.Manual\n self._on_response,\n lambda error: self._on_response(None))\n\n def _on_response(self, response: Any) -> None:\n if response and not self._cancelled:\n apply_response_to_view(response, self._task_runner.view)\n sublime.set_timeout_async(self._handle_next_session_async)\n\n\nclass FormattingTask(SaveTask):\n @classmethod\n def is_applicable(cls, view: sublime.View) -> bool:\n settings = view.settings()\n view_format_on_save = settings.get('lsp_format_on_save', None)\n enabled = view_format_on_save if isinstance(view_format_on_save, bool) else userprefs().lsp_format_on_save\n return enabled and bool(view.window()) and bool(view.file_name())\n\n def run_async(self) -> None:\n super().run_async()\n self._purge_changes_async()\n session = self._task_runner.best_session(LspFormatDocumentCommand.capability)\n if session:\n session.send_request_async(\n text_document_formatting(self._task_runner.view), self._on_response,\n lambda error: self._on_response(None))\n else:\n self._on_complete()\n\n def _on_response(self, response: Any) -> None:\n if response and not self._cancelled:\n apply_response_to_view(response, self._task_runner.view)\n sublime.set_timeout_async(self._on_complete)\n\n\nLspSaveCommand.register_task(WillSaveWaitTask)\nLspSaveCommand.register_task(FormattingTask)\n\n\nclass LspFormatDocumentCommand(LspTextCommand):\n\n capability = 'documentFormattingProvider'\n\n def is_enabled(self, event: Optional[dict] = None, point: Optional[int] = None) -> bool:\n return super().is_enabled() or bool(self.best_session(LspFormatDocumentRangeCommand.capability))\n\n def run(self, edit: sublime.Edit, event: Optional[dict] = None) -> None:\n session = self.best_session(self.capability)\n if session:\n # Either use the documentFormattingProvider ...\n session.send_request(text_document_formatting(self.view), self.on_result)\n else:\n session = self.best_session(LspFormatDocumentRangeCommand.capability)\n if session:\n # ... or use the documentRangeFormattingProvider and format the entire range.\n req = text_document_range_formatting(self.view, entire_content_region(self.view))\n session.send_request(req, self.on_result)\n\n def on_result(self, params: Any) -> None:\n apply_response_to_view(params, self.view)\n\n\nclass LspFormatDocumentRangeCommand(LspTextCommand):\n\n capability = 'documentRangeFormattingProvider'\n\n def is_enabled(self, event: Optional[dict] = None, point: Optional[int] = None) -> bool:\n if super().is_enabled(event, point):\n if len(self.view.sel()) == 1:\n region = self.view.sel()[0]\n if region.begin() != region.end():\n return True\n return False\n\n def run(self, edit: sublime.Edit, event: Optional[dict] = None) -> None:\n session = self.best_session(self.capability)\n selection = first_selection_region(self.view)\n if session and selection is not None:\n req = text_document_range_formatting(self.view, selection)\n session.send_request(req, lambda response: apply_response_to_view(response, self.view))\n", "path": "plugin/formatting.py"}]}
| 2,050 | 847 |
gh_patches_debug_23027
|
rasdani/github-patches
|
git_diff
|
mirumee__ariadne-172
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unbound enum values are None when used in arguments
When used as a mutation input, enum parameter should be `str`, but actually is `None`.
```python
def test_executing_mutation_takes_enum():
type_defs = """
type Query {
_: String
}
type Mutation {
eat(meal: Meal!): Int!
}
enum Meal {
SPAM
}
"""
mutation = MutationType()
@mutation.field("eat")
def resolve_eat(*_, meal): # pylint: disable=unused-variable
assert meal == "SPAM"
return 42
schema = make_executable_schema(type_defs, mutation)
result = graphql_sync(schema, 'mutation { eat(meal: SPAM) }')
assert result.errors is None
assert result.data == {"eat": 42}
```
</issue>
<code>
[start of ariadne/enums.py]
1 import enum
2
3 from typing import Any, Dict, Optional, Union, cast
4
5 from graphql.type import GraphQLEnumType, GraphQLNamedType, GraphQLSchema
6
7 from .types import SchemaBindable
8
9
10 class EnumType(SchemaBindable):
11 def __init__(
12 self, name: str, values=Union[Dict[str, Any], enum.Enum, enum.IntEnum]
13 ) -> None:
14 self.name = name
15 try:
16 self.values = values.__members__ # pylint: disable=no-member
17 except AttributeError:
18 self.values = values
19
20 def bind_to_schema(self, schema: GraphQLSchema) -> None:
21 graphql_type = schema.type_map.get(self.name)
22 self.validate_graphql_type(graphql_type)
23 graphql_type = cast(GraphQLEnumType, graphql_type)
24
25 for key, value in self.values.items():
26 if key not in graphql_type.values:
27 raise ValueError(
28 "Value %s is not defined on enum %s" % (key, self.name)
29 )
30 graphql_type.values[key].value = value
31
32 def validate_graphql_type(self, graphql_type: Optional[GraphQLNamedType]) -> None:
33 if not graphql_type:
34 raise ValueError("Enum %s is not defined in the schema" % self.name)
35 if not isinstance(graphql_type, GraphQLEnumType):
36 raise ValueError(
37 "%s is defined in the schema, but it is instance of %s (expected %s)"
38 % (self.name, type(graphql_type).__name__, GraphQLEnumType.__name__)
39 )
40
[end of ariadne/enums.py]
[start of ariadne/executable_schema.py]
1 from typing import List, Union
2
3 from graphql import DocumentNode, GraphQLSchema, build_ast_schema, extend_schema, parse
4
5 from .types import SchemaBindable
6
7
8 def make_executable_schema(
9 type_defs: Union[str, List[str]],
10 bindables: Union[SchemaBindable, List[SchemaBindable], None] = None,
11 ) -> GraphQLSchema:
12 if isinstance(type_defs, list):
13 type_defs = join_type_defs(type_defs)
14
15 ast_document = parse(type_defs)
16 schema = build_and_extend_schema(ast_document)
17
18 if isinstance(bindables, list):
19 for obj in bindables:
20 obj.bind_to_schema(schema)
21 elif bindables:
22 bindables.bind_to_schema(schema)
23
24 return schema
25
26
27 def join_type_defs(type_defs: List[str]) -> str:
28 return "\n\n".join(t.strip() for t in type_defs)
29
30
31 def build_and_extend_schema(ast: DocumentNode) -> GraphQLSchema:
32 schema = build_ast_schema(ast)
33 extension_ast = extract_extensions(ast)
34
35 if extension_ast.definitions:
36 schema = extend_schema(schema, extension_ast)
37
38 return schema
39
40
41 EXTENSION_KINDS = [
42 "scalar_type_extension",
43 "object_type_extension",
44 "interface_type_extension",
45 "union_type_extension",
46 "enum_type_extension",
47 "input_object_type_extension",
48 ]
49
50
51 def extract_extensions(ast: DocumentNode) -> DocumentNode:
52 extensions = [node for node in ast.definitions if node.kind in EXTENSION_KINDS]
53 return DocumentNode(definitions=extensions)
54
[end of ariadne/executable_schema.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ariadne/enums.py b/ariadne/enums.py
--- a/ariadne/enums.py
+++ b/ariadne/enums.py
@@ -37,3 +37,15 @@
"%s is defined in the schema, but it is instance of %s (expected %s)"
% (self.name, type(graphql_type).__name__, GraphQLEnumType.__name__)
)
+
+
+def set_default_enum_values_on_schema(schema: GraphQLSchema):
+ for type_object in schema.type_map.values():
+ if isinstance(type_object, GraphQLEnumType):
+ set_default_enum_values(type_object)
+
+
+def set_default_enum_values(graphql_type: GraphQLEnumType):
+ for key in graphql_type.values:
+ if graphql_type.values[key].value is None:
+ graphql_type.values[key].value = key
diff --git a/ariadne/executable_schema.py b/ariadne/executable_schema.py
--- a/ariadne/executable_schema.py
+++ b/ariadne/executable_schema.py
@@ -2,6 +2,7 @@
from graphql import DocumentNode, GraphQLSchema, build_ast_schema, extend_schema, parse
+from .enums import set_default_enum_values_on_schema
from .types import SchemaBindable
@@ -21,6 +22,8 @@
elif bindables:
bindables.bind_to_schema(schema)
+ set_default_enum_values_on_schema(schema)
+
return schema
|
{"golden_diff": "diff --git a/ariadne/enums.py b/ariadne/enums.py\n--- a/ariadne/enums.py\n+++ b/ariadne/enums.py\n@@ -37,3 +37,15 @@\n \"%s is defined in the schema, but it is instance of %s (expected %s)\"\n % (self.name, type(graphql_type).__name__, GraphQLEnumType.__name__)\n )\n+\n+\n+def set_default_enum_values_on_schema(schema: GraphQLSchema):\n+ for type_object in schema.type_map.values():\n+ if isinstance(type_object, GraphQLEnumType):\n+ set_default_enum_values(type_object)\n+\n+\n+def set_default_enum_values(graphql_type: GraphQLEnumType):\n+ for key in graphql_type.values:\n+ if graphql_type.values[key].value is None:\n+ graphql_type.values[key].value = key\ndiff --git a/ariadne/executable_schema.py b/ariadne/executable_schema.py\n--- a/ariadne/executable_schema.py\n+++ b/ariadne/executable_schema.py\n@@ -2,6 +2,7 @@\n \n from graphql import DocumentNode, GraphQLSchema, build_ast_schema, extend_schema, parse\n \n+from .enums import set_default_enum_values_on_schema\n from .types import SchemaBindable\n \n \n@@ -21,6 +22,8 @@\n elif bindables:\n bindables.bind_to_schema(schema)\n \n+ set_default_enum_values_on_schema(schema)\n+\n return schema\n", "issue": "Unbound enum values are None when used in arguments\nWhen used as a mutation input, enum parameter should be `str`, but actually is `None`.\r\n\r\n```python\r\ndef test_executing_mutation_takes_enum():\r\n type_defs = \"\"\"\r\n type Query {\r\n _: String\r\n }\r\n\r\n type Mutation {\r\n eat(meal: Meal!): Int!\r\n }\r\n\r\n enum Meal {\r\n SPAM\r\n }\r\n \"\"\"\r\n\r\n mutation = MutationType()\r\n\r\n @mutation.field(\"eat\")\r\n def resolve_eat(*_, meal): # pylint: disable=unused-variable\r\n assert meal == \"SPAM\"\r\n return 42\r\n\r\n schema = make_executable_schema(type_defs, mutation)\r\n\r\n result = graphql_sync(schema, 'mutation { eat(meal: SPAM) }')\r\n assert result.errors is None\r\n assert result.data == {\"eat\": 42}\r\n```\n", "before_files": [{"content": "import enum\n\nfrom typing import Any, Dict, Optional, Union, cast\n\nfrom graphql.type import GraphQLEnumType, GraphQLNamedType, GraphQLSchema\n\nfrom .types import SchemaBindable\n\n\nclass EnumType(SchemaBindable):\n def __init__(\n self, name: str, values=Union[Dict[str, Any], enum.Enum, enum.IntEnum]\n ) -> None:\n self.name = name\n try:\n self.values = values.__members__ # pylint: disable=no-member\n except AttributeError:\n self.values = values\n\n def bind_to_schema(self, schema: GraphQLSchema) -> None:\n graphql_type = schema.type_map.get(self.name)\n self.validate_graphql_type(graphql_type)\n graphql_type = cast(GraphQLEnumType, graphql_type)\n\n for key, value in self.values.items():\n if key not in graphql_type.values:\n raise ValueError(\n \"Value %s is not defined on enum %s\" % (key, self.name)\n )\n graphql_type.values[key].value = value\n\n def validate_graphql_type(self, graphql_type: Optional[GraphQLNamedType]) -> None:\n if not graphql_type:\n raise ValueError(\"Enum %s is not defined in the schema\" % self.name)\n if not isinstance(graphql_type, GraphQLEnumType):\n raise ValueError(\n \"%s is defined in the schema, but it is instance of %s (expected %s)\"\n % (self.name, type(graphql_type).__name__, GraphQLEnumType.__name__)\n )\n", "path": "ariadne/enums.py"}, {"content": "from typing import List, Union\n\nfrom graphql import DocumentNode, GraphQLSchema, build_ast_schema, extend_schema, parse\n\nfrom .types import SchemaBindable\n\n\ndef make_executable_schema(\n type_defs: Union[str, List[str]],\n bindables: Union[SchemaBindable, List[SchemaBindable], None] = None,\n) -> GraphQLSchema:\n if isinstance(type_defs, list):\n type_defs = join_type_defs(type_defs)\n\n ast_document = parse(type_defs)\n schema = build_and_extend_schema(ast_document)\n\n if isinstance(bindables, list):\n for obj in bindables:\n obj.bind_to_schema(schema)\n elif bindables:\n bindables.bind_to_schema(schema)\n\n return schema\n\n\ndef join_type_defs(type_defs: List[str]) -> str:\n return \"\\n\\n\".join(t.strip() for t in type_defs)\n\n\ndef build_and_extend_schema(ast: DocumentNode) -> GraphQLSchema:\n schema = build_ast_schema(ast)\n extension_ast = extract_extensions(ast)\n\n if extension_ast.definitions:\n schema = extend_schema(schema, extension_ast)\n\n return schema\n\n\nEXTENSION_KINDS = [\n \"scalar_type_extension\",\n \"object_type_extension\",\n \"interface_type_extension\",\n \"union_type_extension\",\n \"enum_type_extension\",\n \"input_object_type_extension\",\n]\n\n\ndef extract_extensions(ast: DocumentNode) -> DocumentNode:\n extensions = [node for node in ast.definitions if node.kind in EXTENSION_KINDS]\n return DocumentNode(definitions=extensions)\n", "path": "ariadne/executable_schema.py"}]}
| 1,576 | 329 |
gh_patches_debug_12133
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-504
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
get_func_args() from scrapy.utils.python crashes on partial functions
I use Python 2.7 and used a partial function (`functools.partial`) as part of an input_processor for the ItemLoader. For instance,
``` python
price = Field(input_processor=Compose(some_partial_func, some_other_func))
```
During execution, `get_func_args() from scrapy.util.python` goes into an infinite loop until
``` python
/usr/local/lib/python2.7/dist-packages/scrapy/utils/python.pyc in get_func_args(func, stripself)
161 return []
162 else:
--> 163 return get_func_args(func.__call__, True)
164 else:
165 raise TypeError('%s is not callable' % type(func))
/usr/local/lib/python2.7/dist-packages/scrapy/utils/python.pyc in get_func_args(func, stripself)
161 return []
162 else:
--> 163 return get_func_args(func.__call__, True)
164 else:
165 raise TypeError('%s is not callable' % type(func))
/usr/local/lib/python2.7/dist-packages/scrapy/utils/python.pyc in get_func_args(func, stripself)
151 if inspect.isfunction(func):
152 func_args, _, _, _ = inspect.getargspec(func)
--> 153 elif inspect.isclass(func):
154 return get_func_args(func.__init__, True)
155 elif inspect.ismethod(func):
/usr/lib/python2.7/inspect.pyc in isclass(object)
63 __doc__ documentation string
64 __module__ name of module in which this class was defined"""
---> 65 return isinstance(object, (type, types.ClassType))
66
67 def ismethod(object):
RuntimeError: maximum recursion depth exceeded while calling a Python object
```
happens. Looks like `get_func_args` needs to handle partial functions as a separate case.
</issue>
<code>
[start of scrapy/utils/python.py]
1 """
2 This module contains essential stuff that should've come with Python itself ;)
3
4 It also contains functions (or functionality) which is in Python versions
5 higher than 2.5 which used to be the lowest version supported by Scrapy.
6
7 """
8 import os
9 import re
10 import inspect
11 import weakref
12 import errno
13 from functools import wraps
14 from sgmllib import SGMLParser
15
16
17 class FixedSGMLParser(SGMLParser):
18 """The SGMLParser that comes with Python has a bug in the convert_charref()
19 method. This is the same class with the bug fixed"""
20
21 def convert_charref(self, name):
22 """This method fixes a bug in Python's SGMLParser."""
23 try:
24 n = int(name)
25 except ValueError:
26 return
27 if not 0 <= n <= 127 : # ASCII ends at 127, not 255
28 return
29 return self.convert_codepoint(n)
30
31
32 def flatten(x):
33 """flatten(sequence) -> list
34
35 Returns a single, flat list which contains all elements retrieved
36 from the sequence and all recursively contained sub-sequences
37 (iterables).
38
39 Examples:
40 >>> [1, 2, [3,4], (5,6)]
41 [1, 2, [3, 4], (5, 6)]
42 >>> flatten([[[1,2,3], (42,None)], [4,5], [6], 7, (8,9,10)])
43 [1, 2, 3, 42, None, 4, 5, 6, 7, 8, 9, 10]"""
44
45 result = []
46 for el in x:
47 if hasattr(el, "__iter__"):
48 result.extend(flatten(el))
49 else:
50 result.append(el)
51 return result
52
53
54 def unique(list_, key=lambda x: x):
55 """efficient function to uniquify a list preserving item order"""
56 seen = set()
57 result = []
58 for item in list_:
59 seenkey = key(item)
60 if seenkey in seen:
61 continue
62 seen.add(seenkey)
63 result.append(item)
64 return result
65
66
67 def str_to_unicode(text, encoding=None, errors='strict'):
68 """Return the unicode representation of text in the given encoding. Unlike
69 .encode(encoding) this function can be applied directly to a unicode
70 object without the risk of double-decoding problems (which can happen if
71 you don't use the default 'ascii' encoding)
72 """
73
74 if encoding is None:
75 encoding = 'utf-8'
76 if isinstance(text, str):
77 return text.decode(encoding, errors)
78 elif isinstance(text, unicode):
79 return text
80 else:
81 raise TypeError('str_to_unicode must receive a str or unicode object, got %s' % type(text).__name__)
82
83 def unicode_to_str(text, encoding=None, errors='strict'):
84 """Return the str representation of text in the given encoding. Unlike
85 .encode(encoding) this function can be applied directly to a str
86 object without the risk of double-decoding problems (which can happen if
87 you don't use the default 'ascii' encoding)
88 """
89
90 if encoding is None:
91 encoding = 'utf-8'
92 if isinstance(text, unicode):
93 return text.encode(encoding, errors)
94 elif isinstance(text, str):
95 return text
96 else:
97 raise TypeError('unicode_to_str must receive a unicode or str object, got %s' % type(text).__name__)
98
99 def re_rsearch(pattern, text, chunk_size=1024):
100 """
101 This function does a reverse search in a text using a regular expression
102 given in the attribute 'pattern'.
103 Since the re module does not provide this functionality, we have to find for
104 the expression into chunks of text extracted from the end (for the sake of efficiency).
105 At first, a chunk of 'chunk_size' kilobytes is extracted from the end, and searched for
106 the pattern. If the pattern is not found, another chunk is extracted, and another
107 search is performed.
108 This process continues until a match is found, or until the whole file is read.
109 In case the pattern wasn't found, None is returned, otherwise it returns a tuple containing
110 the start position of the match, and the ending (regarding the entire text).
111 """
112 def _chunk_iter():
113 offset = len(text)
114 while True:
115 offset -= (chunk_size * 1024)
116 if offset <= 0:
117 break
118 yield (text[offset:], offset)
119 yield (text, 0)
120
121 pattern = re.compile(pattern) if isinstance(pattern, basestring) else pattern
122 for chunk, offset in _chunk_iter():
123 matches = [match for match in pattern.finditer(chunk)]
124 if matches:
125 return (offset + matches[-1].span()[0], offset + matches[-1].span()[1])
126 return None
127
128 def memoizemethod_noargs(method):
129 """Decorator to cache the result of a method (without arguments) using a
130 weak reference to its object
131 """
132 cache = weakref.WeakKeyDictionary()
133 @wraps(method)
134 def new_method(self, *args, **kwargs):
135 if self not in cache:
136 cache[self] = method(self, *args, **kwargs)
137 return cache[self]
138 return new_method
139
140 _BINARYCHARS = set(map(chr, range(32))) - set(["\0", "\t", "\n", "\r"])
141
142 def isbinarytext(text):
143 """Return True if the given text is considered binary, or false
144 otherwise, by looking for binary bytes at their chars
145 """
146 assert isinstance(text, str), "text must be str, got '%s'" % type(text).__name__
147 return any(c in _BINARYCHARS for c in text)
148
149 def get_func_args(func, stripself=False):
150 """Return the argument name list of a callable"""
151 if inspect.isfunction(func):
152 func_args, _, _, _ = inspect.getargspec(func)
153 elif inspect.isclass(func):
154 return get_func_args(func.__init__, True)
155 elif inspect.ismethod(func):
156 return get_func_args(func.__func__, True)
157 elif inspect.ismethoddescriptor(func):
158 return []
159 elif hasattr(func, '__call__'):
160 if inspect.isroutine(func):
161 return []
162 else:
163 return get_func_args(func.__call__, True)
164 else:
165 raise TypeError('%s is not callable' % type(func))
166 if stripself:
167 func_args.pop(0)
168 return func_args
169
170 def get_spec(func):
171 """Returns (args, kwargs) tuple for a function
172 >>> import re
173 >>> get_spec(re.match)
174 (['pattern', 'string'], {'flags': 0})
175
176 >>> class Test(object):
177 ... def __call__(self, val):
178 ... pass
179 ... def method(self, val, flags=0):
180 ... pass
181
182 >>> get_spec(Test)
183 (['self', 'val'], {})
184
185 >>> get_spec(Test.method)
186 (['self', 'val'], {'flags': 0})
187
188 >>> get_spec(Test().method)
189 (['self', 'val'], {'flags': 0})
190 """
191
192 if inspect.isfunction(func) or inspect.ismethod(func):
193 spec = inspect.getargspec(func)
194 elif hasattr(func, '__call__'):
195 spec = inspect.getargspec(func.__call__)
196 else:
197 raise TypeError('%s is not callable' % type(func))
198
199 defaults = spec.defaults or []
200
201 firstdefault = len(spec.args) - len(defaults)
202 args = spec.args[:firstdefault]
203 kwargs = dict(zip(spec.args[firstdefault:], defaults))
204 return args, kwargs
205
206 def equal_attributes(obj1, obj2, attributes):
207 """Compare two objects attributes"""
208 # not attributes given return False by default
209 if not attributes:
210 return False
211
212 for attr in attributes:
213 # support callables like itemgetter
214 if callable(attr):
215 if not attr(obj1) == attr(obj2):
216 return False
217 else:
218 # check that objects has attribute
219 if not hasattr(obj1, attr):
220 return False
221 if not hasattr(obj2, attr):
222 return False
223 # compare object attributes
224 if not getattr(obj1, attr) == getattr(obj2, attr):
225 return False
226 # all attributes equal
227 return True
228
229
230 class WeakKeyCache(object):
231
232 def __init__(self, default_factory):
233 self.default_factory = default_factory
234 self._weakdict = weakref.WeakKeyDictionary()
235
236 def __getitem__(self, key):
237 if key not in self._weakdict:
238 self._weakdict[key] = self.default_factory(key)
239 return self._weakdict[key]
240
241
242 def stringify_dict(dct_or_tuples, encoding='utf-8', keys_only=True):
243 """Return a (new) dict with the unicode keys (and values if, keys_only is
244 False) of the given dict converted to strings. `dct_or_tuples` can be a
245 dict or a list of tuples, like any dict constructor supports.
246 """
247 d = {}
248 for k, v in dict(dct_or_tuples).iteritems():
249 k = k.encode(encoding) if isinstance(k, unicode) else k
250 if not keys_only:
251 v = v.encode(encoding) if isinstance(v, unicode) else v
252 d[k] = v
253 return d
254
255 def is_writable(path):
256 """Return True if the given path can be written (if it exists) or created
257 (if it doesn't exist)
258 """
259 if os.path.exists(path):
260 return os.access(path, os.W_OK)
261 else:
262 return os.access(os.path.dirname(path), os.W_OK)
263
264 def setattr_default(obj, name, value):
265 """Set attribute value, but only if it's not already set. Similar to
266 setdefault() for dicts.
267 """
268 if not hasattr(obj, name):
269 setattr(obj, name, value)
270
271
272 def retry_on_eintr(function, *args, **kw):
273 """Run a function and retry it while getting EINTR errors"""
274 while True:
275 try:
276 return function(*args, **kw)
277 except IOError as e:
278 if e.errno != errno.EINTR:
279 raise
280
[end of scrapy/utils/python.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scrapy/utils/python.py b/scrapy/utils/python.py
--- a/scrapy/utils/python.py
+++ b/scrapy/utils/python.py
@@ -10,7 +10,7 @@
import inspect
import weakref
import errno
-from functools import wraps
+from functools import partial, wraps
from sgmllib import SGMLParser
@@ -156,6 +156,8 @@
return get_func_args(func.__func__, True)
elif inspect.ismethoddescriptor(func):
return []
+ elif isinstance(func, partial):
+ return get_func_args(func.func)
elif hasattr(func, '__call__'):
if inspect.isroutine(func):
return []
|
{"golden_diff": "diff --git a/scrapy/utils/python.py b/scrapy/utils/python.py\n--- a/scrapy/utils/python.py\n+++ b/scrapy/utils/python.py\n@@ -10,7 +10,7 @@\n import inspect\n import weakref\n import errno\n-from functools import wraps\n+from functools import partial, wraps\n from sgmllib import SGMLParser\n \n \n@@ -156,6 +156,8 @@\n return get_func_args(func.__func__, True)\n elif inspect.ismethoddescriptor(func):\n return []\n+ elif isinstance(func, partial):\n+ return get_func_args(func.func)\n elif hasattr(func, '__call__'):\n if inspect.isroutine(func):\n return []\n", "issue": "get_func_args() from scrapy.utils.python crashes on partial functions\nI use Python 2.7 and used a partial function (`functools.partial`) as part of an input_processor for the ItemLoader. For instance,\n\n``` python\nprice = Field(input_processor=Compose(some_partial_func, some_other_func))\n```\n\nDuring execution, `get_func_args() from scrapy.util.python` goes into an infinite loop until\n\n``` python\n/usr/local/lib/python2.7/dist-packages/scrapy/utils/python.pyc in get_func_args(func, stripself)\n 161 return []\n 162 else:\n--> 163 return get_func_args(func.__call__, True)\n 164 else:\n 165 raise TypeError('%s is not callable' % type(func))\n\n/usr/local/lib/python2.7/dist-packages/scrapy/utils/python.pyc in get_func_args(func, stripself)\n 161 return []\n 162 else:\n--> 163 return get_func_args(func.__call__, True)\n 164 else:\n 165 raise TypeError('%s is not callable' % type(func))\n\n/usr/local/lib/python2.7/dist-packages/scrapy/utils/python.pyc in get_func_args(func, stripself)\n 151 if inspect.isfunction(func):\n 152 func_args, _, _, _ = inspect.getargspec(func)\n--> 153 elif inspect.isclass(func):\n 154 return get_func_args(func.__init__, True)\n 155 elif inspect.ismethod(func):\n\n/usr/lib/python2.7/inspect.pyc in isclass(object)\n 63 __doc__ documentation string\n 64 __module__ name of module in which this class was defined\"\"\"\n---> 65 return isinstance(object, (type, types.ClassType))\n 66 \n 67 def ismethod(object):\n\nRuntimeError: maximum recursion depth exceeded while calling a Python object\n```\n\nhappens. Looks like `get_func_args` needs to handle partial functions as a separate case.\n\n", "before_files": [{"content": "\"\"\"\nThis module contains essential stuff that should've come with Python itself ;)\n\nIt also contains functions (or functionality) which is in Python versions\nhigher than 2.5 which used to be the lowest version supported by Scrapy.\n\n\"\"\"\nimport os\nimport re\nimport inspect\nimport weakref\nimport errno\nfrom functools import wraps\nfrom sgmllib import SGMLParser\n\n\nclass FixedSGMLParser(SGMLParser):\n \"\"\"The SGMLParser that comes with Python has a bug in the convert_charref()\n method. This is the same class with the bug fixed\"\"\"\n\n def convert_charref(self, name):\n \"\"\"This method fixes a bug in Python's SGMLParser.\"\"\"\n try:\n n = int(name)\n except ValueError:\n return\n if not 0 <= n <= 127 : # ASCII ends at 127, not 255\n return\n return self.convert_codepoint(n)\n\n\ndef flatten(x):\n \"\"\"flatten(sequence) -> list\n\n Returns a single, flat list which contains all elements retrieved\n from the sequence and all recursively contained sub-sequences\n (iterables).\n\n Examples:\n >>> [1, 2, [3,4], (5,6)]\n [1, 2, [3, 4], (5, 6)]\n >>> flatten([[[1,2,3], (42,None)], [4,5], [6], 7, (8,9,10)])\n [1, 2, 3, 42, None, 4, 5, 6, 7, 8, 9, 10]\"\"\"\n\n result = []\n for el in x:\n if hasattr(el, \"__iter__\"):\n result.extend(flatten(el))\n else:\n result.append(el)\n return result\n\n\ndef unique(list_, key=lambda x: x):\n \"\"\"efficient function to uniquify a list preserving item order\"\"\"\n seen = set()\n result = []\n for item in list_:\n seenkey = key(item)\n if seenkey in seen:\n continue\n seen.add(seenkey)\n result.append(item)\n return result\n\n\ndef str_to_unicode(text, encoding=None, errors='strict'):\n \"\"\"Return the unicode representation of text in the given encoding. Unlike\n .encode(encoding) this function can be applied directly to a unicode\n object without the risk of double-decoding problems (which can happen if\n you don't use the default 'ascii' encoding)\n \"\"\"\n\n if encoding is None:\n encoding = 'utf-8'\n if isinstance(text, str):\n return text.decode(encoding, errors)\n elif isinstance(text, unicode):\n return text\n else:\n raise TypeError('str_to_unicode must receive a str or unicode object, got %s' % type(text).__name__)\n\ndef unicode_to_str(text, encoding=None, errors='strict'):\n \"\"\"Return the str representation of text in the given encoding. Unlike\n .encode(encoding) this function can be applied directly to a str\n object without the risk of double-decoding problems (which can happen if\n you don't use the default 'ascii' encoding)\n \"\"\"\n\n if encoding is None:\n encoding = 'utf-8'\n if isinstance(text, unicode):\n return text.encode(encoding, errors)\n elif isinstance(text, str):\n return text\n else:\n raise TypeError('unicode_to_str must receive a unicode or str object, got %s' % type(text).__name__)\n\ndef re_rsearch(pattern, text, chunk_size=1024):\n \"\"\"\n This function does a reverse search in a text using a regular expression\n given in the attribute 'pattern'.\n Since the re module does not provide this functionality, we have to find for\n the expression into chunks of text extracted from the end (for the sake of efficiency).\n At first, a chunk of 'chunk_size' kilobytes is extracted from the end, and searched for\n the pattern. If the pattern is not found, another chunk is extracted, and another\n search is performed.\n This process continues until a match is found, or until the whole file is read.\n In case the pattern wasn't found, None is returned, otherwise it returns a tuple containing\n the start position of the match, and the ending (regarding the entire text).\n \"\"\"\n def _chunk_iter():\n offset = len(text)\n while True:\n offset -= (chunk_size * 1024)\n if offset <= 0:\n break\n yield (text[offset:], offset)\n yield (text, 0)\n\n pattern = re.compile(pattern) if isinstance(pattern, basestring) else pattern\n for chunk, offset in _chunk_iter():\n matches = [match for match in pattern.finditer(chunk)]\n if matches:\n return (offset + matches[-1].span()[0], offset + matches[-1].span()[1])\n return None\n\ndef memoizemethod_noargs(method):\n \"\"\"Decorator to cache the result of a method (without arguments) using a\n weak reference to its object\n \"\"\"\n cache = weakref.WeakKeyDictionary()\n @wraps(method)\n def new_method(self, *args, **kwargs):\n if self not in cache:\n cache[self] = method(self, *args, **kwargs)\n return cache[self]\n return new_method\n\n_BINARYCHARS = set(map(chr, range(32))) - set([\"\\0\", \"\\t\", \"\\n\", \"\\r\"])\n\ndef isbinarytext(text):\n \"\"\"Return True if the given text is considered binary, or false\n otherwise, by looking for binary bytes at their chars\n \"\"\"\n assert isinstance(text, str), \"text must be str, got '%s'\" % type(text).__name__\n return any(c in _BINARYCHARS for c in text)\n\ndef get_func_args(func, stripself=False):\n \"\"\"Return the argument name list of a callable\"\"\"\n if inspect.isfunction(func):\n func_args, _, _, _ = inspect.getargspec(func)\n elif inspect.isclass(func):\n return get_func_args(func.__init__, True)\n elif inspect.ismethod(func):\n return get_func_args(func.__func__, True)\n elif inspect.ismethoddescriptor(func):\n return []\n elif hasattr(func, '__call__'):\n if inspect.isroutine(func):\n return []\n else:\n return get_func_args(func.__call__, True)\n else:\n raise TypeError('%s is not callable' % type(func))\n if stripself:\n func_args.pop(0)\n return func_args\n\ndef get_spec(func):\n \"\"\"Returns (args, kwargs) tuple for a function\n >>> import re\n >>> get_spec(re.match)\n (['pattern', 'string'], {'flags': 0})\n\n >>> class Test(object):\n ... def __call__(self, val):\n ... pass\n ... def method(self, val, flags=0):\n ... pass\n\n >>> get_spec(Test)\n (['self', 'val'], {})\n\n >>> get_spec(Test.method)\n (['self', 'val'], {'flags': 0})\n\n >>> get_spec(Test().method)\n (['self', 'val'], {'flags': 0})\n \"\"\"\n\n if inspect.isfunction(func) or inspect.ismethod(func):\n spec = inspect.getargspec(func)\n elif hasattr(func, '__call__'):\n spec = inspect.getargspec(func.__call__)\n else:\n raise TypeError('%s is not callable' % type(func))\n\n defaults = spec.defaults or []\n\n firstdefault = len(spec.args) - len(defaults)\n args = spec.args[:firstdefault]\n kwargs = dict(zip(spec.args[firstdefault:], defaults))\n return args, kwargs\n\ndef equal_attributes(obj1, obj2, attributes):\n \"\"\"Compare two objects attributes\"\"\"\n # not attributes given return False by default\n if not attributes:\n return False\n\n for attr in attributes:\n # support callables like itemgetter\n if callable(attr):\n if not attr(obj1) == attr(obj2):\n return False\n else:\n # check that objects has attribute\n if not hasattr(obj1, attr):\n return False\n if not hasattr(obj2, attr):\n return False\n # compare object attributes\n if not getattr(obj1, attr) == getattr(obj2, attr):\n return False\n # all attributes equal\n return True\n\n\nclass WeakKeyCache(object):\n\n def __init__(self, default_factory):\n self.default_factory = default_factory\n self._weakdict = weakref.WeakKeyDictionary()\n\n def __getitem__(self, key):\n if key not in self._weakdict:\n self._weakdict[key] = self.default_factory(key)\n return self._weakdict[key]\n\n\ndef stringify_dict(dct_or_tuples, encoding='utf-8', keys_only=True):\n \"\"\"Return a (new) dict with the unicode keys (and values if, keys_only is\n False) of the given dict converted to strings. `dct_or_tuples` can be a\n dict or a list of tuples, like any dict constructor supports.\n \"\"\"\n d = {}\n for k, v in dict(dct_or_tuples).iteritems():\n k = k.encode(encoding) if isinstance(k, unicode) else k\n if not keys_only:\n v = v.encode(encoding) if isinstance(v, unicode) else v\n d[k] = v\n return d\n\ndef is_writable(path):\n \"\"\"Return True if the given path can be written (if it exists) or created\n (if it doesn't exist)\n \"\"\"\n if os.path.exists(path):\n return os.access(path, os.W_OK)\n else:\n return os.access(os.path.dirname(path), os.W_OK)\n\ndef setattr_default(obj, name, value):\n \"\"\"Set attribute value, but only if it's not already set. Similar to\n setdefault() for dicts.\n \"\"\"\n if not hasattr(obj, name):\n setattr(obj, name, value)\n\n\ndef retry_on_eintr(function, *args, **kw):\n \"\"\"Run a function and retry it while getting EINTR errors\"\"\"\n while True:\n try:\n return function(*args, **kw)\n except IOError as e:\n if e.errno != errno.EINTR:\n raise\n", "path": "scrapy/utils/python.py"}]}
| 3,973 | 149 |
gh_patches_debug_11707
|
rasdani/github-patches
|
git_diff
|
elastic__ecs-1164
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Incorrect output of the "tracing" fields in the Beats yml file
Just like the `base` fields, the `tracing` fields are not nested under the name of the field set. So it's not `base.@timestamp`, it's `@timestamp`, and it's not `tracing.trace.id`, it's `trace.id`.
In the Beats field yaml file the ECS project generates, the tracing fields are incorrectly nested under a `tracing` section, which means Beats interprets the field names incorrectly (`tracing.trace.id`).
This is a bug, these fields shouldn't be nested this way.
In order to fix this issue, we should remove this nesting in the Beats yml output. Just like `@timestamp` and other base fields are not nested under a field group.
I think this bug fix will be at minimum backported to 1.7. Thoughts welcome on this, is there a need to backport to 1.6 as well?
The Beats PR https://github.com/elastic/beats/pull/22571 to import ECS 1.7 should be adjusted with these changes, once the bug fix is ready. cc @andrewstucki
</issue>
<code>
[start of scripts/generators/beats.py]
1 from os.path import join
2 from collections import OrderedDict
3 from generators import ecs_helpers
4
5
6 def generate(ecs_nested, ecs_version, out_dir):
7 # Load temporary whitelist for default_fields workaround.
8 df_whitelist = ecs_helpers.yaml_load('scripts/generators/beats_default_fields_whitelist.yml')
9
10 # base first
11 beats_fields = fieldset_field_array(ecs_nested['base']['fields'], df_whitelist, ecs_nested['base']['prefix'])
12
13 allowed_fieldset_keys = ['name', 'title', 'group', 'description', 'footnote', 'type']
14 # other fieldsets
15 for fieldset_name in sorted(ecs_nested):
16 if 'base' == fieldset_name:
17 continue
18 fieldset = ecs_nested[fieldset_name]
19
20 beats_field = ecs_helpers.dict_copy_keys_ordered(fieldset, allowed_fieldset_keys)
21 beats_field['fields'] = fieldset_field_array(fieldset['fields'], df_whitelist, fieldset['prefix'])
22 beats_fields.append(beats_field)
23
24 beats_file = OrderedDict()
25 beats_file['key'] = 'ecs'
26 beats_file['title'] = 'ECS'
27 beats_file['description'] = 'ECS Fields.'
28 beats_file['fields'] = beats_fields
29
30 write_beats_yaml(beats_file, ecs_version, out_dir)
31
32
33 def fieldset_field_array(source_fields, df_whitelist, fieldset_prefix):
34 allowed_keys = ['name', 'level', 'required', 'type', 'object_type',
35 'ignore_above', 'multi_fields', 'format', 'input_format',
36 'output_format', 'output_precision', 'description',
37 'example', 'enabled', 'index', 'path', 'scaling_factor']
38 multi_fields_allowed_keys = ['name', 'type', 'norms', 'default_field', 'normalizer', 'ignore_above']
39
40 fields = []
41 for nested_field_name in source_fields:
42 ecs_field = source_fields[nested_field_name]
43 beats_field = ecs_helpers.dict_copy_keys_ordered(ecs_field, allowed_keys)
44 if '' == fieldset_prefix:
45 contextual_name = nested_field_name
46 else:
47 contextual_name = '.'.join(nested_field_name.split('.')[1:])
48
49 cleaned_multi_fields = []
50 if 'multi_fields' in ecs_field:
51 for mf in ecs_field['multi_fields']:
52 # Set default_field if necessary. Avoid adding the key if the parent
53 # field already is marked with default_field: false.
54 if not mf['flat_name'] in df_whitelist and ecs_field['flat_name'] in df_whitelist:
55 mf['default_field'] = False
56 cleaned_multi_fields.append(
57 ecs_helpers.dict_copy_keys_ordered(mf, multi_fields_allowed_keys))
58 beats_field['multi_fields'] = cleaned_multi_fields
59
60 beats_field['name'] = contextual_name
61
62 if not ecs_field['flat_name'] in df_whitelist:
63 beats_field['default_field'] = False
64
65 fields.append(beats_field)
66 return sorted(fields, key=lambda x: x['name'])
67
68 # Helpers
69
70
71 def write_beats_yaml(beats_file, ecs_version, out_dir):
72 ecs_helpers.make_dirs(join(out_dir, 'beats'))
73 warning = file_header().format(version=ecs_version)
74 ecs_helpers.yaml_dump(join(out_dir, 'beats/fields.ecs.yml'), [beats_file], preamble=warning)
75
76
77 # Templates
78
79
80 def file_header():
81 return '''
82 # WARNING! Do not edit this file directly, it was generated by the ECS project,
83 # based on ECS version {version}.
84 # Please visit https://github.com/elastic/ecs to suggest changes to ECS fields.
85
86 '''.lstrip()
87
[end of scripts/generators/beats.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scripts/generators/beats.py b/scripts/generators/beats.py
--- a/scripts/generators/beats.py
+++ b/scripts/generators/beats.py
@@ -17,6 +17,11 @@
continue
fieldset = ecs_nested[fieldset_name]
+ # Handle when `root:true`
+ if fieldset.get('root', False):
+ beats_fields.extend(fieldset_field_array(fieldset['fields'], df_whitelist, fieldset['prefix']))
+ continue
+
beats_field = ecs_helpers.dict_copy_keys_ordered(fieldset, allowed_fieldset_keys)
beats_field['fields'] = fieldset_field_array(fieldset['fields'], df_whitelist, fieldset['prefix'])
beats_fields.append(beats_field)
|
{"golden_diff": "diff --git a/scripts/generators/beats.py b/scripts/generators/beats.py\n--- a/scripts/generators/beats.py\n+++ b/scripts/generators/beats.py\n@@ -17,6 +17,11 @@\n continue\n fieldset = ecs_nested[fieldset_name]\n \n+ # Handle when `root:true`\n+ if fieldset.get('root', False):\n+ beats_fields.extend(fieldset_field_array(fieldset['fields'], df_whitelist, fieldset['prefix']))\n+ continue\n+\n beats_field = ecs_helpers.dict_copy_keys_ordered(fieldset, allowed_fieldset_keys)\n beats_field['fields'] = fieldset_field_array(fieldset['fields'], df_whitelist, fieldset['prefix'])\n beats_fields.append(beats_field)\n", "issue": "Incorrect output of the \"tracing\" fields in the Beats yml file\nJust like the `base` fields, the `tracing` fields are not nested under the name of the field set. So it's not `base.@timestamp`, it's `@timestamp`, and it's not `tracing.trace.id`, it's `trace.id`.\r\n\r\nIn the Beats field yaml file the ECS project generates, the tracing fields are incorrectly nested under a `tracing` section, which means Beats interprets the field names incorrectly (`tracing.trace.id`).\r\n\r\nThis is a bug, these fields shouldn't be nested this way.\r\n\r\nIn order to fix this issue, we should remove this nesting in the Beats yml output. Just like `@timestamp` and other base fields are not nested under a field group.\r\n\r\nI think this bug fix will be at minimum backported to 1.7. Thoughts welcome on this, is there a need to backport to 1.6 as well?\r\n\r\nThe Beats PR https://github.com/elastic/beats/pull/22571 to import ECS 1.7 should be adjusted with these changes, once the bug fix is ready. cc @andrewstucki \r\n\n", "before_files": [{"content": "from os.path import join\nfrom collections import OrderedDict\nfrom generators import ecs_helpers\n\n\ndef generate(ecs_nested, ecs_version, out_dir):\n # Load temporary whitelist for default_fields workaround.\n df_whitelist = ecs_helpers.yaml_load('scripts/generators/beats_default_fields_whitelist.yml')\n\n # base first\n beats_fields = fieldset_field_array(ecs_nested['base']['fields'], df_whitelist, ecs_nested['base']['prefix'])\n\n allowed_fieldset_keys = ['name', 'title', 'group', 'description', 'footnote', 'type']\n # other fieldsets\n for fieldset_name in sorted(ecs_nested):\n if 'base' == fieldset_name:\n continue\n fieldset = ecs_nested[fieldset_name]\n\n beats_field = ecs_helpers.dict_copy_keys_ordered(fieldset, allowed_fieldset_keys)\n beats_field['fields'] = fieldset_field_array(fieldset['fields'], df_whitelist, fieldset['prefix'])\n beats_fields.append(beats_field)\n\n beats_file = OrderedDict()\n beats_file['key'] = 'ecs'\n beats_file['title'] = 'ECS'\n beats_file['description'] = 'ECS Fields.'\n beats_file['fields'] = beats_fields\n\n write_beats_yaml(beats_file, ecs_version, out_dir)\n\n\ndef fieldset_field_array(source_fields, df_whitelist, fieldset_prefix):\n allowed_keys = ['name', 'level', 'required', 'type', 'object_type',\n 'ignore_above', 'multi_fields', 'format', 'input_format',\n 'output_format', 'output_precision', 'description',\n 'example', 'enabled', 'index', 'path', 'scaling_factor']\n multi_fields_allowed_keys = ['name', 'type', 'norms', 'default_field', 'normalizer', 'ignore_above']\n\n fields = []\n for nested_field_name in source_fields:\n ecs_field = source_fields[nested_field_name]\n beats_field = ecs_helpers.dict_copy_keys_ordered(ecs_field, allowed_keys)\n if '' == fieldset_prefix:\n contextual_name = nested_field_name\n else:\n contextual_name = '.'.join(nested_field_name.split('.')[1:])\n\n cleaned_multi_fields = []\n if 'multi_fields' in ecs_field:\n for mf in ecs_field['multi_fields']:\n # Set default_field if necessary. Avoid adding the key if the parent\n # field already is marked with default_field: false.\n if not mf['flat_name'] in df_whitelist and ecs_field['flat_name'] in df_whitelist:\n mf['default_field'] = False\n cleaned_multi_fields.append(\n ecs_helpers.dict_copy_keys_ordered(mf, multi_fields_allowed_keys))\n beats_field['multi_fields'] = cleaned_multi_fields\n\n beats_field['name'] = contextual_name\n\n if not ecs_field['flat_name'] in df_whitelist:\n beats_field['default_field'] = False\n\n fields.append(beats_field)\n return sorted(fields, key=lambda x: x['name'])\n\n# Helpers\n\n\ndef write_beats_yaml(beats_file, ecs_version, out_dir):\n ecs_helpers.make_dirs(join(out_dir, 'beats'))\n warning = file_header().format(version=ecs_version)\n ecs_helpers.yaml_dump(join(out_dir, 'beats/fields.ecs.yml'), [beats_file], preamble=warning)\n\n\n# Templates\n\n\ndef file_header():\n return '''\n# WARNING! Do not edit this file directly, it was generated by the ECS project,\n# based on ECS version {version}.\n# Please visit https://github.com/elastic/ecs to suggest changes to ECS fields.\n\n'''.lstrip()\n", "path": "scripts/generators/beats.py"}]}
| 1,739 | 166 |
gh_patches_debug_34022
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-594
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
engine status util references removed engine.slots attribute
```
Traceback (most recent call last): Less
File "/usr/lib/pymodules/python2.7/scrapy/xlib/pydispatch/robustapply.py", line 54, in robustApply
return receiver(*arguments, **named)
File "/usr/lib/pymodules/python2.7/scrapy/contrib/memusage.py", line 63, in engine_started
tsk.start(60.0, now=True)
File "/usr/lib/python2.7/dist-packages/twisted/internet/task.py", line 163, in start
self()
File "/usr/lib/python2.7/dist-packages/twisted/internet/task.py", line 208, in __call__
d = defer.maybeDeferred(self.f, *self.a, **self.kw)
--- <exception caught here> ---
File "/usr/lib/python2.7/dist-packages/twisted/internet/defer.py", line 134, in maybeDeferred
result = f(*args, **kw)
File "/usr/lib/pymodules/python2.7/scrapy/contrib/memusage.py", line 103, in _check_warning
self._send_report(self.notify_mails, subj)
File "/usr/lib/pymodules/python2.7/scrapy/contrib/memusage.py", line 116, in _send_report
s += pformat(get_engine_status(self.crawler.engine))
File "/usr/lib/pymodules/python2.7/scrapy/utils/engine.py", line 33, in get_engine_status
for spider in engine.slots.keys():
exceptions.AttributeError: 'ExecutionEngine' object has no attribute 'slots'
```
</issue>
<code>
[start of scrapy/utils/engine.py]
1 """Some debugging functions for working with the Scrapy engine"""
2
3 from __future__ import print_function
4 from time import time # used in global tests code
5
6 def get_engine_status(engine):
7 """Return a report of the current engine status"""
8 global_tests = [
9 "time()-engine.start_time",
10 "engine.has_capacity()",
11 "len(engine.downloader.active)",
12 "engine.scraper.is_idle()",
13 ]
14 spider_tests = [
15 "engine.spider_is_idle(spider)",
16 "engine.slot.closing",
17 "len(engine.slot.inprogress)",
18 "len(engine.slot.scheduler.dqs or [])",
19 "len(engine.slot.scheduler.mqs)",
20 "len(engine.scraper.slot.queue)",
21 "len(engine.scraper.slot.active)",
22 "engine.scraper.slot.active_size",
23 "engine.scraper.slot.itemproc_size",
24 "engine.scraper.slot.needs_backout()",
25 ]
26
27 status = {'global': [], 'spiders': {}}
28 for test in global_tests:
29 try:
30 status['global'] += [(test, eval(test))]
31 except Exception as e:
32 status['global'] += [(test, "%s (exception)" % type(e).__name__)]
33 for spider in engine.slots.keys():
34 x = []
35 for test in spider_tests:
36 try:
37 x += [(test, eval(test))]
38 except Exception as e:
39 x += [(test, "%s (exception)" % type(e).__name__)]
40 status['spiders'][spider] = x
41 return status
42
43 def format_engine_status(engine=None):
44 status = get_engine_status(engine)
45 s = "Execution engine status\n\n"
46 for test, result in status['global']:
47 s += "%-47s : %s\n" % (test, result)
48 s += "\n"
49 for spider, tests in status['spiders'].items():
50 s += "Spider: %s\n" % spider
51 for test, result in tests:
52 s += " %-50s : %s\n" % (test, result)
53 return s
54
55 def print_engine_status(engine):
56 print(format_engine_status(engine))
57
58
[end of scrapy/utils/engine.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scrapy/utils/engine.py b/scrapy/utils/engine.py
--- a/scrapy/utils/engine.py
+++ b/scrapy/utils/engine.py
@@ -5,14 +5,13 @@
def get_engine_status(engine):
"""Return a report of the current engine status"""
- global_tests = [
+ tests = [
"time()-engine.start_time",
"engine.has_capacity()",
"len(engine.downloader.active)",
"engine.scraper.is_idle()",
- ]
- spider_tests = [
- "engine.spider_is_idle(spider)",
+ "engine.spider.name",
+ "engine.spider_is_idle(engine.spider)",
"engine.slot.closing",
"len(engine.slot.inprogress)",
"len(engine.slot.scheduler.dqs or [])",
@@ -24,34 +23,23 @@
"engine.scraper.slot.needs_backout()",
]
- status = {'global': [], 'spiders': {}}
- for test in global_tests:
+ checks = []
+ for test in tests:
try:
- status['global'] += [(test, eval(test))]
+ checks += [(test, eval(test))]
except Exception as e:
- status['global'] += [(test, "%s (exception)" % type(e).__name__)]
- for spider in engine.slots.keys():
- x = []
- for test in spider_tests:
- try:
- x += [(test, eval(test))]
- except Exception as e:
- x += [(test, "%s (exception)" % type(e).__name__)]
- status['spiders'][spider] = x
- return status
+ checks += [(test, "%s (exception)" % type(e).__name__)]
+
+ return checks
def format_engine_status(engine=None):
- status = get_engine_status(engine)
+ checks = get_engine_status(engine)
s = "Execution engine status\n\n"
- for test, result in status['global']:
+ for test, result in checks:
s += "%-47s : %s\n" % (test, result)
s += "\n"
- for spider, tests in status['spiders'].items():
- s += "Spider: %s\n" % spider
- for test, result in tests:
- s += " %-50s : %s\n" % (test, result)
+
return s
def print_engine_status(engine):
print(format_engine_status(engine))
-
|
{"golden_diff": "diff --git a/scrapy/utils/engine.py b/scrapy/utils/engine.py\n--- a/scrapy/utils/engine.py\n+++ b/scrapy/utils/engine.py\n@@ -5,14 +5,13 @@\n \n def get_engine_status(engine):\n \"\"\"Return a report of the current engine status\"\"\"\n- global_tests = [\n+ tests = [\n \"time()-engine.start_time\",\n \"engine.has_capacity()\",\n \"len(engine.downloader.active)\",\n \"engine.scraper.is_idle()\",\n- ]\n- spider_tests = [\n- \"engine.spider_is_idle(spider)\",\n+ \"engine.spider.name\",\n+ \"engine.spider_is_idle(engine.spider)\",\n \"engine.slot.closing\",\n \"len(engine.slot.inprogress)\",\n \"len(engine.slot.scheduler.dqs or [])\",\n@@ -24,34 +23,23 @@\n \"engine.scraper.slot.needs_backout()\",\n ]\n \n- status = {'global': [], 'spiders': {}}\n- for test in global_tests:\n+ checks = []\n+ for test in tests:\n try:\n- status['global'] += [(test, eval(test))]\n+ checks += [(test, eval(test))]\n except Exception as e:\n- status['global'] += [(test, \"%s (exception)\" % type(e).__name__)]\n- for spider in engine.slots.keys():\n- x = []\n- for test in spider_tests:\n- try:\n- x += [(test, eval(test))]\n- except Exception as e:\n- x += [(test, \"%s (exception)\" % type(e).__name__)]\n- status['spiders'][spider] = x\n- return status\n+ checks += [(test, \"%s (exception)\" % type(e).__name__)]\n+\n+ return checks\n \n def format_engine_status(engine=None):\n- status = get_engine_status(engine)\n+ checks = get_engine_status(engine)\n s = \"Execution engine status\\n\\n\"\n- for test, result in status['global']:\n+ for test, result in checks:\n s += \"%-47s : %s\\n\" % (test, result)\n s += \"\\n\"\n- for spider, tests in status['spiders'].items():\n- s += \"Spider: %s\\n\" % spider\n- for test, result in tests:\n- s += \" %-50s : %s\\n\" % (test, result)\n+\n return s\n \n def print_engine_status(engine):\n print(format_engine_status(engine))\n-\n", "issue": "engine status util references removed engine.slots attribute\n```\nTraceback (most recent call last): Less\n File \"/usr/lib/pymodules/python2.7/scrapy/xlib/pydispatch/robustapply.py\", line 54, in robustApply\n return receiver(*arguments, **named)\n File \"/usr/lib/pymodules/python2.7/scrapy/contrib/memusage.py\", line 63, in engine_started\n tsk.start(60.0, now=True)\n File \"/usr/lib/python2.7/dist-packages/twisted/internet/task.py\", line 163, in start\n self()\n File \"/usr/lib/python2.7/dist-packages/twisted/internet/task.py\", line 208, in __call__\n d = defer.maybeDeferred(self.f, *self.a, **self.kw)\n --- <exception caught here> ---\n File \"/usr/lib/python2.7/dist-packages/twisted/internet/defer.py\", line 134, in maybeDeferred\n result = f(*args, **kw)\n File \"/usr/lib/pymodules/python2.7/scrapy/contrib/memusage.py\", line 103, in _check_warning\n self._send_report(self.notify_mails, subj)\n File \"/usr/lib/pymodules/python2.7/scrapy/contrib/memusage.py\", line 116, in _send_report\n s += pformat(get_engine_status(self.crawler.engine))\n File \"/usr/lib/pymodules/python2.7/scrapy/utils/engine.py\", line 33, in get_engine_status\n for spider in engine.slots.keys():\n exceptions.AttributeError: 'ExecutionEngine' object has no attribute 'slots'\n```\n\n", "before_files": [{"content": "\"\"\"Some debugging functions for working with the Scrapy engine\"\"\"\n\nfrom __future__ import print_function\nfrom time import time # used in global tests code\n\ndef get_engine_status(engine):\n \"\"\"Return a report of the current engine status\"\"\"\n global_tests = [\n \"time()-engine.start_time\",\n \"engine.has_capacity()\",\n \"len(engine.downloader.active)\",\n \"engine.scraper.is_idle()\",\n ]\n spider_tests = [\n \"engine.spider_is_idle(spider)\",\n \"engine.slot.closing\",\n \"len(engine.slot.inprogress)\",\n \"len(engine.slot.scheduler.dqs or [])\",\n \"len(engine.slot.scheduler.mqs)\",\n \"len(engine.scraper.slot.queue)\",\n \"len(engine.scraper.slot.active)\",\n \"engine.scraper.slot.active_size\",\n \"engine.scraper.slot.itemproc_size\",\n \"engine.scraper.slot.needs_backout()\",\n ]\n\n status = {'global': [], 'spiders': {}}\n for test in global_tests:\n try:\n status['global'] += [(test, eval(test))]\n except Exception as e:\n status['global'] += [(test, \"%s (exception)\" % type(e).__name__)]\n for spider in engine.slots.keys():\n x = []\n for test in spider_tests:\n try:\n x += [(test, eval(test))]\n except Exception as e:\n x += [(test, \"%s (exception)\" % type(e).__name__)]\n status['spiders'][spider] = x\n return status\n\ndef format_engine_status(engine=None):\n status = get_engine_status(engine)\n s = \"Execution engine status\\n\\n\"\n for test, result in status['global']:\n s += \"%-47s : %s\\n\" % (test, result)\n s += \"\\n\"\n for spider, tests in status['spiders'].items():\n s += \"Spider: %s\\n\" % spider\n for test, result in tests:\n s += \" %-50s : %s\\n\" % (test, result)\n return s\n\ndef print_engine_status(engine):\n print(format_engine_status(engine))\n\n", "path": "scrapy/utils/engine.py"}]}
| 1,482 | 551 |
gh_patches_debug_44681
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-3316
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add viewer query
With PR #3202 we've added ability to get the data of currently logged in user with the `user` query. I would recommend refactoring it a little bit and introducing a separate query for that. The problem with the `user` query is that it expects the `ID!` argument, but it also accepts passing `""` as ID value to resolve the logged in user. This brakes the single-responsibility rule (which is a good practice for GraphQL queries), is a bit unintuitive and makes to code harder to maintain.
I would propose changing the schema to have the following queries:
`viewer: User` - returns currently authenticated user
`user(id: ID!): User` - resolves a user by ID, where ID is required
</issue>
<code>
[start of saleor/graphql/account/resolvers.py]
1 import graphene
2 import graphene_django_optimizer as gql_optimizer
3 from django.db.models import Q
4 from i18naddress import get_validation_rules
5
6 from ...account import models
7 from ...core.utils import get_client_ip, get_country_by_ip
8 from ..utils import filter_by_query_param
9 from .types import AddressValidationData, ChoiceValue, User
10
11 USER_SEARCH_FIELDS = (
12 'email', 'default_shipping_address__first_name',
13 'default_shipping_address__last_name', 'default_shipping_address__city',
14 'default_shipping_address__country')
15
16
17 def resolve_user(info, id):
18 logged_user = info.context.user
19 if not id:
20 return logged_user
21 user = graphene.Node.get_node_from_global_id(info, id, User)
22 if logged_user.has_perm('account.manage_users') or user == logged_user:
23 return user
24 return None
25
26
27 def resolve_customers(info, query):
28 qs = models.User.objects.filter(
29 Q(is_staff=False) | (Q(is_staff=True) & Q(orders__isnull=False)))
30 qs = filter_by_query_param(
31 queryset=qs, query=query, search_fields=USER_SEARCH_FIELDS)
32 qs = qs.order_by('email')
33 qs = qs.distinct()
34 return gql_optimizer.query(qs, info)
35
36
37 def resolve_staff_users(info, query):
38 qs = models.User.objects.filter(is_staff=True)
39 qs = filter_by_query_param(
40 queryset=qs, query=query, search_fields=USER_SEARCH_FIELDS)
41 qs = qs.order_by('email')
42 qs = qs.distinct()
43 return gql_optimizer.query(qs, info)
44
45
46 def resolve_address_validator(info, input):
47 country_code = input['country_code']
48 if not country_code:
49 client_ip = get_client_ip(info.context)
50 country = get_country_by_ip(client_ip)
51 if country:
52 country_code = country.code
53 else:
54 return None
55 params = {
56 'country_code': country_code,
57 'country_area': input['country_area'],
58 'city_area': input['city_area']}
59 rules = get_validation_rules(params)
60 return AddressValidationData(
61 country_code=rules.country_code,
62 country_name=rules.country_name,
63 address_format=rules.address_format,
64 address_latin_format=rules.address_latin_format,
65 allowed_fields=rules.allowed_fields,
66 required_fields=rules.required_fields,
67 upper_fields=rules.upper_fields,
68 country_area_type=rules.country_area_type,
69 country_area_choices=[
70 ChoiceValue(area[0], area[1])
71 for area in rules.country_area_choices],
72 city_type=rules.city_type,
73 city_area_choices=[
74 ChoiceValue(area[0], area[1]) for area in rules.city_area_choices],
75 postal_code_type=rules.postal_code_type,
76 postal_code_matchers=[
77 compiled.pattern for compiled in rules.postal_code_matchers],
78 postal_code_examples=rules.postal_code_examples,
79 postal_code_prefix=rules.postal_code_prefix)
80
[end of saleor/graphql/account/resolvers.py]
[start of saleor/graphql/account/types.py]
1 import graphene
2 import graphene_django_optimizer as gql_optimizer
3 from django.contrib.auth import get_user_model
4 from graphene import relay
5
6 from ...account import models
7 from ...core.permissions import get_permissions
8 from ..core.types.common import (
9 CountableDjangoObjectType, CountryDisplay, PermissionDisplay)
10 from ..utils import format_permissions_for_display
11
12
13 class AddressInput(graphene.InputObjectType):
14 first_name = graphene.String(description='Given name.')
15 last_name = graphene.String(description='Family name.')
16 company_name = graphene.String(description='Company or organization.')
17 street_address_1 = graphene.String(description='Address.')
18 street_address_2 = graphene.String(description='Address.')
19 city = graphene.String(description='City.')
20 city_area = graphene.String(description='District.')
21 postal_code = graphene.String(description='Postal code.')
22 country = graphene.String(required=True, description='Country.')
23 country_area = graphene.String(description='State or province.')
24 phone = graphene.String(description='Phone number.')
25
26
27 class Address(CountableDjangoObjectType):
28 country = graphene.Field(
29 CountryDisplay, required=True, description='Default shop\'s country')
30
31 class Meta:
32 exclude_fields = ['user_set', 'user_addresses']
33 description = 'Represents user address data.'
34 interfaces = [relay.Node]
35 model = models.Address
36
37 def resolve_country(self, info):
38 return CountryDisplay(
39 code=self.country.code, country=self.country.name)
40
41
42 class User(CountableDjangoObjectType):
43 permissions = graphene.List(
44 PermissionDisplay, description='List of user\'s permissions.')
45 addresses = gql_optimizer.field(
46 graphene.List(
47 Address, description='List of all user\'s addresses.'),
48 model_field='addresses')
49
50 class Meta:
51 exclude_fields = ['password', 'is_superuser', 'OrderEvent_set']
52 description = 'Represents user data.'
53 interfaces = [relay.Node]
54 model = get_user_model()
55
56 def resolve_permissions(self, info, **kwargs):
57 if self.is_superuser:
58 permissions = get_permissions()
59 else:
60 permissions = self.user_permissions.prefetch_related(
61 'content_type').order_by('codename')
62 return format_permissions_for_display(permissions)
63
64 def resolve_addresses(self, info, **kwargs):
65 return self.addresses.all()
66
67
68 class AddressValidationInput(graphene.InputObjectType):
69 country_code = graphene.String()
70 country_area = graphene.String()
71 city_area = graphene.String()
72
73
74 class ChoiceValue(graphene.ObjectType):
75 raw = graphene.String()
76 verbose = graphene.String()
77
78
79 class AddressValidationData(graphene.ObjectType):
80 country_code = graphene.String()
81 country_name = graphene.String()
82 address_format = graphene.String()
83 address_latin_format = graphene.String()
84 allowed_fields = graphene.List(graphene.String)
85 required_fields = graphene.List(graphene.String)
86 upper_fields = graphene.List(graphene.String)
87 country_area_type = graphene.String()
88 country_area_choices = graphene.List(ChoiceValue)
89 city_type = graphene.String()
90 city_area_choices = graphene.List(ChoiceValue)
91 postal_code_type = graphene.String()
92 postal_code_matchers = graphene.List(graphene.String)
93 postal_code_examples = graphene.List(graphene.String)
94 postal_code_prefix = graphene.String()
95
[end of saleor/graphql/account/types.py]
[start of saleor/graphql/account/schema.py]
1 import graphene
2 from graphql_jwt.decorators import login_required, permission_required
3
4 from ..core.fields import PrefetchingConnectionField
5 from ..descriptions import DESCRIPTIONS
6 from .mutations import (
7 AddressCreate, AddressDelete, AddressUpdate, CustomerCreate,
8 CustomerDelete, CustomerPasswordReset, CustomerRegister, CustomerUpdate,
9 LoggedUserUpdate, PasswordReset, SetPassword, StaffCreate, StaffDelete,
10 StaffUpdate)
11 from .resolvers import (
12 resolve_address_validator, resolve_customers, resolve_staff_users,
13 resolve_user)
14 from .types import AddressValidationData, AddressValidationInput, User
15
16
17 class AccountQueries(graphene.ObjectType):
18 address_validator = graphene.Field(
19 AddressValidationData,
20 input=graphene.Argument(AddressValidationInput, required=True))
21 customers = PrefetchingConnectionField(
22 User, description='List of the shop\'s customers.',
23 query=graphene.String(description=DESCRIPTIONS['user']))
24 staff_users = PrefetchingConnectionField(
25 User, description='List of the shop\'s staff users.',
26 query=graphene.String(description=DESCRIPTIONS['user']))
27 user = graphene.Field(
28 User, id=graphene.Argument(graphene.ID, required=True),
29 description='Lookup an user by ID.')
30
31 def resolve_address_validator(self, info, input):
32 return resolve_address_validator(info, input)
33
34 @permission_required('account.manage_users')
35 def resolve_customers(self, info, query=None, **kwargs):
36 return resolve_customers(info, query=query)
37
38 @permission_required('account.manage_staff')
39 def resolve_staff_users(self, info, query=None, **kwargs):
40 return resolve_staff_users(info, query=query)
41
42 @login_required
43 def resolve_user(self, info, id):
44 return resolve_user(info, id)
45
46
47 class AccountMutations(graphene.ObjectType):
48 password_reset = PasswordReset.Field()
49 set_password = SetPassword.Field()
50
51 customer_create = CustomerCreate.Field()
52 customer_delete = CustomerDelete.Field()
53 customer_password_reset = CustomerPasswordReset.Field()
54 customer_register = CustomerRegister.Field()
55 customer_update = CustomerUpdate.Field()
56
57 logged_user_update = LoggedUserUpdate.Field()
58
59 staff_create = StaffCreate.Field()
60 staff_delete = StaffDelete.Field()
61 staff_update = StaffUpdate.Field()
62
63 address_create = AddressCreate.Field()
64 address_delete = AddressDelete.Field()
65 address_update = AddressUpdate.Field()
66
[end of saleor/graphql/account/schema.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/saleor/graphql/account/resolvers.py b/saleor/graphql/account/resolvers.py
--- a/saleor/graphql/account/resolvers.py
+++ b/saleor/graphql/account/resolvers.py
@@ -1,4 +1,3 @@
-import graphene
import graphene_django_optimizer as gql_optimizer
from django.db.models import Q
from i18naddress import get_validation_rules
@@ -6,7 +5,7 @@
from ...account import models
from ...core.utils import get_client_ip, get_country_by_ip
from ..utils import filter_by_query_param
-from .types import AddressValidationData, ChoiceValue, User
+from .types import AddressValidationData, ChoiceValue
USER_SEARCH_FIELDS = (
'email', 'default_shipping_address__first_name',
@@ -14,16 +13,6 @@
'default_shipping_address__country')
-def resolve_user(info, id):
- logged_user = info.context.user
- if not id:
- return logged_user
- user = graphene.Node.get_node_from_global_id(info, id, User)
- if logged_user.has_perm('account.manage_users') or user == logged_user:
- return user
- return None
-
-
def resolve_customers(info, query):
qs = models.User.objects.filter(
Q(is_staff=False) | (Q(is_staff=True) & Q(orders__isnull=False)))
diff --git a/saleor/graphql/account/schema.py b/saleor/graphql/account/schema.py
--- a/saleor/graphql/account/schema.py
+++ b/saleor/graphql/account/schema.py
@@ -9,8 +9,7 @@
LoggedUserUpdate, PasswordReset, SetPassword, StaffCreate, StaffDelete,
StaffUpdate)
from .resolvers import (
- resolve_address_validator, resolve_customers, resolve_staff_users,
- resolve_user)
+ resolve_address_validator, resolve_customers, resolve_staff_users)
from .types import AddressValidationData, AddressValidationInput, User
@@ -21,6 +20,8 @@
customers = PrefetchingConnectionField(
User, description='List of the shop\'s customers.',
query=graphene.String(description=DESCRIPTIONS['user']))
+ me = graphene.Field(
+ User, description='Logged in user data.')
staff_users = PrefetchingConnectionField(
User, description='List of the shop\'s staff users.',
query=graphene.String(description=DESCRIPTIONS['user']))
@@ -35,13 +36,17 @@
def resolve_customers(self, info, query=None, **kwargs):
return resolve_customers(info, query=query)
+ @login_required
+ def resolve_me(self, info):
+ return info.context.user
+
@permission_required('account.manage_staff')
def resolve_staff_users(self, info, query=None, **kwargs):
return resolve_staff_users(info, query=query)
- @login_required
+ @permission_required('account.manage_users')
def resolve_user(self, info, id):
- return resolve_user(info, id)
+ return graphene.Node.get_node_from_global_id(info, id, User)
class AccountMutations(graphene.ObjectType):
diff --git a/saleor/graphql/account/types.py b/saleor/graphql/account/types.py
--- a/saleor/graphql/account/types.py
+++ b/saleor/graphql/account/types.py
@@ -2,6 +2,7 @@
import graphene_django_optimizer as gql_optimizer
from django.contrib.auth import get_user_model
from graphene import relay
+from graphql_jwt.decorators import permission_required
from ...account import models
from ...core.permissions import get_permissions
@@ -47,6 +48,7 @@
PrefetchingConnectionField(
Address, description='List of all user\'s addresses.'),
model_field='addresses')
+ note = graphene.String(description='A note about the customer')
class Meta:
exclude_fields = ['password', 'is_superuser', 'OrderEvent_set']
@@ -65,6 +67,10 @@
def resolve_addresses(self, info, **kwargs):
return self.addresses.all()
+ @permission_required('account.manage_users')
+ def resolve_note(self, info):
+ return self.note
+
class AddressValidationInput(graphene.InputObjectType):
country_code = graphene.String()
|
{"golden_diff": "diff --git a/saleor/graphql/account/resolvers.py b/saleor/graphql/account/resolvers.py\n--- a/saleor/graphql/account/resolvers.py\n+++ b/saleor/graphql/account/resolvers.py\n@@ -1,4 +1,3 @@\n-import graphene\n import graphene_django_optimizer as gql_optimizer\n from django.db.models import Q\n from i18naddress import get_validation_rules\n@@ -6,7 +5,7 @@\n from ...account import models\n from ...core.utils import get_client_ip, get_country_by_ip\n from ..utils import filter_by_query_param\n-from .types import AddressValidationData, ChoiceValue, User\n+from .types import AddressValidationData, ChoiceValue\n \n USER_SEARCH_FIELDS = (\n 'email', 'default_shipping_address__first_name',\n@@ -14,16 +13,6 @@\n 'default_shipping_address__country')\n \n \n-def resolve_user(info, id):\n- logged_user = info.context.user\n- if not id:\n- return logged_user\n- user = graphene.Node.get_node_from_global_id(info, id, User)\n- if logged_user.has_perm('account.manage_users') or user == logged_user:\n- return user\n- return None\n-\n-\n def resolve_customers(info, query):\n qs = models.User.objects.filter(\n Q(is_staff=False) | (Q(is_staff=True) & Q(orders__isnull=False)))\ndiff --git a/saleor/graphql/account/schema.py b/saleor/graphql/account/schema.py\n--- a/saleor/graphql/account/schema.py\n+++ b/saleor/graphql/account/schema.py\n@@ -9,8 +9,7 @@\n LoggedUserUpdate, PasswordReset, SetPassword, StaffCreate, StaffDelete,\n StaffUpdate)\n from .resolvers import (\n- resolve_address_validator, resolve_customers, resolve_staff_users,\n- resolve_user)\n+ resolve_address_validator, resolve_customers, resolve_staff_users)\n from .types import AddressValidationData, AddressValidationInput, User\n \n \n@@ -21,6 +20,8 @@\n customers = PrefetchingConnectionField(\n User, description='List of the shop\\'s customers.',\n query=graphene.String(description=DESCRIPTIONS['user']))\n+ me = graphene.Field(\n+ User, description='Logged in user data.')\n staff_users = PrefetchingConnectionField(\n User, description='List of the shop\\'s staff users.',\n query=graphene.String(description=DESCRIPTIONS['user']))\n@@ -35,13 +36,17 @@\n def resolve_customers(self, info, query=None, **kwargs):\n return resolve_customers(info, query=query)\n \n+ @login_required\n+ def resolve_me(self, info):\n+ return info.context.user\n+\n @permission_required('account.manage_staff')\n def resolve_staff_users(self, info, query=None, **kwargs):\n return resolve_staff_users(info, query=query)\n \n- @login_required\n+ @permission_required('account.manage_users')\n def resolve_user(self, info, id):\n- return resolve_user(info, id)\n+ return graphene.Node.get_node_from_global_id(info, id, User)\n \n \n class AccountMutations(graphene.ObjectType):\ndiff --git a/saleor/graphql/account/types.py b/saleor/graphql/account/types.py\n--- a/saleor/graphql/account/types.py\n+++ b/saleor/graphql/account/types.py\n@@ -2,6 +2,7 @@\n import graphene_django_optimizer as gql_optimizer\n from django.contrib.auth import get_user_model\n from graphene import relay\n+from graphql_jwt.decorators import permission_required\n \n from ...account import models\n from ...core.permissions import get_permissions\n@@ -47,6 +48,7 @@\n PrefetchingConnectionField(\n Address, description='List of all user\\'s addresses.'),\n model_field='addresses')\n+ note = graphene.String(description='A note about the customer')\n \n class Meta:\n exclude_fields = ['password', 'is_superuser', 'OrderEvent_set']\n@@ -65,6 +67,10 @@\n def resolve_addresses(self, info, **kwargs):\n return self.addresses.all()\n \n+ @permission_required('account.manage_users')\n+ def resolve_note(self, info):\n+ return self.note\n+\n \n class AddressValidationInput(graphene.InputObjectType):\n country_code = graphene.String()\n", "issue": "Add viewer query\nWith PR #3202 we've added ability to get the data of currently logged in user with the `user` query. I would recommend refactoring it a little bit and introducing a separate query for that. The problem with the `user` query is that it expects the `ID!` argument, but it also accepts passing `\"\"` as ID value to resolve the logged in user. This brakes the single-responsibility rule (which is a good practice for GraphQL queries), is a bit unintuitive and makes to code harder to maintain.\r\n\r\nI would propose changing the schema to have the following queries:\r\n`viewer: User` - returns currently authenticated user\r\n`user(id: ID!): User` - resolves a user by ID, where ID is required\n", "before_files": [{"content": "import graphene\nimport graphene_django_optimizer as gql_optimizer\nfrom django.db.models import Q\nfrom i18naddress import get_validation_rules\n\nfrom ...account import models\nfrom ...core.utils import get_client_ip, get_country_by_ip\nfrom ..utils import filter_by_query_param\nfrom .types import AddressValidationData, ChoiceValue, User\n\nUSER_SEARCH_FIELDS = (\n 'email', 'default_shipping_address__first_name',\n 'default_shipping_address__last_name', 'default_shipping_address__city',\n 'default_shipping_address__country')\n\n\ndef resolve_user(info, id):\n logged_user = info.context.user\n if not id:\n return logged_user\n user = graphene.Node.get_node_from_global_id(info, id, User)\n if logged_user.has_perm('account.manage_users') or user == logged_user:\n return user\n return None\n\n\ndef resolve_customers(info, query):\n qs = models.User.objects.filter(\n Q(is_staff=False) | (Q(is_staff=True) & Q(orders__isnull=False)))\n qs = filter_by_query_param(\n queryset=qs, query=query, search_fields=USER_SEARCH_FIELDS)\n qs = qs.order_by('email')\n qs = qs.distinct()\n return gql_optimizer.query(qs, info)\n\n\ndef resolve_staff_users(info, query):\n qs = models.User.objects.filter(is_staff=True)\n qs = filter_by_query_param(\n queryset=qs, query=query, search_fields=USER_SEARCH_FIELDS)\n qs = qs.order_by('email')\n qs = qs.distinct()\n return gql_optimizer.query(qs, info)\n\n\ndef resolve_address_validator(info, input):\n country_code = input['country_code']\n if not country_code:\n client_ip = get_client_ip(info.context)\n country = get_country_by_ip(client_ip)\n if country:\n country_code = country.code\n else:\n return None\n params = {\n 'country_code': country_code,\n 'country_area': input['country_area'],\n 'city_area': input['city_area']}\n rules = get_validation_rules(params)\n return AddressValidationData(\n country_code=rules.country_code,\n country_name=rules.country_name,\n address_format=rules.address_format,\n address_latin_format=rules.address_latin_format,\n allowed_fields=rules.allowed_fields,\n required_fields=rules.required_fields,\n upper_fields=rules.upper_fields,\n country_area_type=rules.country_area_type,\n country_area_choices=[\n ChoiceValue(area[0], area[1])\n for area in rules.country_area_choices],\n city_type=rules.city_type,\n city_area_choices=[\n ChoiceValue(area[0], area[1]) for area in rules.city_area_choices],\n postal_code_type=rules.postal_code_type,\n postal_code_matchers=[\n compiled.pattern for compiled in rules.postal_code_matchers],\n postal_code_examples=rules.postal_code_examples,\n postal_code_prefix=rules.postal_code_prefix)\n", "path": "saleor/graphql/account/resolvers.py"}, {"content": "import graphene\nimport graphene_django_optimizer as gql_optimizer\nfrom django.contrib.auth import get_user_model\nfrom graphene import relay\n\nfrom ...account import models\nfrom ...core.permissions import get_permissions\nfrom ..core.types.common import (\n CountableDjangoObjectType, CountryDisplay, PermissionDisplay)\nfrom ..utils import format_permissions_for_display\n\n\nclass AddressInput(graphene.InputObjectType):\n first_name = graphene.String(description='Given name.')\n last_name = graphene.String(description='Family name.')\n company_name = graphene.String(description='Company or organization.')\n street_address_1 = graphene.String(description='Address.')\n street_address_2 = graphene.String(description='Address.')\n city = graphene.String(description='City.')\n city_area = graphene.String(description='District.')\n postal_code = graphene.String(description='Postal code.')\n country = graphene.String(required=True, description='Country.')\n country_area = graphene.String(description='State or province.')\n phone = graphene.String(description='Phone number.')\n\n\nclass Address(CountableDjangoObjectType):\n country = graphene.Field(\n CountryDisplay, required=True, description='Default shop\\'s country')\n\n class Meta:\n exclude_fields = ['user_set', 'user_addresses']\n description = 'Represents user address data.'\n interfaces = [relay.Node]\n model = models.Address\n\n def resolve_country(self, info):\n return CountryDisplay(\n code=self.country.code, country=self.country.name)\n\n\nclass User(CountableDjangoObjectType):\n permissions = graphene.List(\n PermissionDisplay, description='List of user\\'s permissions.')\n addresses = gql_optimizer.field(\n graphene.List(\n Address, description='List of all user\\'s addresses.'),\n model_field='addresses')\n\n class Meta:\n exclude_fields = ['password', 'is_superuser', 'OrderEvent_set']\n description = 'Represents user data.'\n interfaces = [relay.Node]\n model = get_user_model()\n\n def resolve_permissions(self, info, **kwargs):\n if self.is_superuser:\n permissions = get_permissions()\n else:\n permissions = self.user_permissions.prefetch_related(\n 'content_type').order_by('codename')\n return format_permissions_for_display(permissions)\n\n def resolve_addresses(self, info, **kwargs):\n return self.addresses.all()\n\n\nclass AddressValidationInput(graphene.InputObjectType):\n country_code = graphene.String()\n country_area = graphene.String()\n city_area = graphene.String()\n\n\nclass ChoiceValue(graphene.ObjectType):\n raw = graphene.String()\n verbose = graphene.String()\n\n\nclass AddressValidationData(graphene.ObjectType):\n country_code = graphene.String()\n country_name = graphene.String()\n address_format = graphene.String()\n address_latin_format = graphene.String()\n allowed_fields = graphene.List(graphene.String)\n required_fields = graphene.List(graphene.String)\n upper_fields = graphene.List(graphene.String)\n country_area_type = graphene.String()\n country_area_choices = graphene.List(ChoiceValue)\n city_type = graphene.String()\n city_area_choices = graphene.List(ChoiceValue)\n postal_code_type = graphene.String()\n postal_code_matchers = graphene.List(graphene.String)\n postal_code_examples = graphene.List(graphene.String)\n postal_code_prefix = graphene.String()\n", "path": "saleor/graphql/account/types.py"}, {"content": "import graphene\nfrom graphql_jwt.decorators import login_required, permission_required\n\nfrom ..core.fields import PrefetchingConnectionField\nfrom ..descriptions import DESCRIPTIONS\nfrom .mutations import (\n AddressCreate, AddressDelete, AddressUpdate, CustomerCreate,\n CustomerDelete, CustomerPasswordReset, CustomerRegister, CustomerUpdate,\n LoggedUserUpdate, PasswordReset, SetPassword, StaffCreate, StaffDelete,\n StaffUpdate)\nfrom .resolvers import (\n resolve_address_validator, resolve_customers, resolve_staff_users,\n resolve_user)\nfrom .types import AddressValidationData, AddressValidationInput, User\n\n\nclass AccountQueries(graphene.ObjectType):\n address_validator = graphene.Field(\n AddressValidationData,\n input=graphene.Argument(AddressValidationInput, required=True))\n customers = PrefetchingConnectionField(\n User, description='List of the shop\\'s customers.',\n query=graphene.String(description=DESCRIPTIONS['user']))\n staff_users = PrefetchingConnectionField(\n User, description='List of the shop\\'s staff users.',\n query=graphene.String(description=DESCRIPTIONS['user']))\n user = graphene.Field(\n User, id=graphene.Argument(graphene.ID, required=True),\n description='Lookup an user by ID.')\n\n def resolve_address_validator(self, info, input):\n return resolve_address_validator(info, input)\n\n @permission_required('account.manage_users')\n def resolve_customers(self, info, query=None, **kwargs):\n return resolve_customers(info, query=query)\n\n @permission_required('account.manage_staff')\n def resolve_staff_users(self, info, query=None, **kwargs):\n return resolve_staff_users(info, query=query)\n\n @login_required\n def resolve_user(self, info, id):\n return resolve_user(info, id)\n\n\nclass AccountMutations(graphene.ObjectType):\n password_reset = PasswordReset.Field()\n set_password = SetPassword.Field()\n\n customer_create = CustomerCreate.Field()\n customer_delete = CustomerDelete.Field()\n customer_password_reset = CustomerPasswordReset.Field()\n customer_register = CustomerRegister.Field()\n customer_update = CustomerUpdate.Field()\n\n logged_user_update = LoggedUserUpdate.Field()\n\n staff_create = StaffCreate.Field()\n staff_delete = StaffDelete.Field()\n staff_update = StaffUpdate.Field()\n\n address_create = AddressCreate.Field()\n address_delete = AddressDelete.Field()\n address_update = AddressUpdate.Field()\n", "path": "saleor/graphql/account/schema.py"}]}
| 3,009 | 930 |
gh_patches_debug_26974
|
rasdani/github-patches
|
git_diff
|
sanic-org__sanic-2072
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
RecursionError on Sanic subclass initialisation
Discovered at https://github.com/sanic-org/sanic/issues/2071
version: latest sanic master (`8a2ea626c6d04a5eb1e28d071ffa56bf9ad98a12`)
description:
RecursionError occurs when initialising Sanic subclass
minimal code to reproduce:
```python
from sanic import Sanic
class Custom(Sanic):
pass
custom = Custom("custom")
```
Potential fix: https://github.com/sanic-org/sanic/pull/2072
</issue>
<code>
[start of sanic/blueprints.py]
1 from __future__ import annotations
2
3 import asyncio
4
5 from collections import defaultdict
6 from types import SimpleNamespace
7 from typing import TYPE_CHECKING, Dict, Iterable, List, Optional, Set, Union
8
9 from sanic_routing.exceptions import NotFound # type: ignore
10 from sanic_routing.route import Route # type: ignore
11
12 from sanic.base import BaseSanic
13 from sanic.blueprint_group import BlueprintGroup
14 from sanic.exceptions import SanicException
15 from sanic.models.futures import FutureRoute, FutureStatic
16 from sanic.models.handler_types import (
17 ListenerType,
18 MiddlewareType,
19 RouteHandler,
20 )
21
22
23 if TYPE_CHECKING:
24 from sanic import Sanic # noqa
25
26
27 class Blueprint(BaseSanic):
28 """
29 In *Sanic* terminology, a **Blueprint** is a logical collection of
30 URLs that perform a specific set of tasks which can be identified by
31 a unique name.
32
33 It is the main tool for grouping functionality and similar endpoints.
34
35 `See user guide re: blueprints
36 <https://sanicframework.org/guide/best-practices/blueprints.html>`__
37
38 :param name: unique name of the blueprint
39 :param url_prefix: URL to be prefixed before all route URLs
40 :param host: IP Address of FQDN for the sanic server to use.
41 :param version: Blueprint Version
42 :param strict_slashes: Enforce the API urls are requested with a
43 training */*
44 """
45
46 __fake_slots__ = (
47 "_apps",
48 "_future_routes",
49 "_future_statics",
50 "_future_middleware",
51 "_future_listeners",
52 "_future_exceptions",
53 "_future_signals",
54 "ctx",
55 "exceptions",
56 "host",
57 "listeners",
58 "middlewares",
59 "name",
60 "routes",
61 "statics",
62 "strict_slashes",
63 "url_prefix",
64 "version",
65 "websocket_routes",
66 )
67
68 def __init__(
69 self,
70 name: str,
71 url_prefix: Optional[str] = None,
72 host: Optional[str] = None,
73 version: Optional[int] = None,
74 strict_slashes: Optional[bool] = None,
75 ):
76
77 self._apps: Set[Sanic] = set()
78 self.ctx = SimpleNamespace()
79 self.exceptions: List[RouteHandler] = []
80 self.host = host
81 self.listeners: Dict[str, List[ListenerType]] = {}
82 self.middlewares: List[MiddlewareType] = []
83 self.name = name
84 self.routes: List[Route] = []
85 self.statics: List[RouteHandler] = []
86 self.strict_slashes = strict_slashes
87 self.url_prefix = url_prefix
88 self.version = version
89 self.websocket_routes: List[Route] = []
90
91 def __repr__(self) -> str:
92 args = ", ".join(
93 [
94 f'{attr}="{getattr(self, attr)}"'
95 if isinstance(getattr(self, attr), str)
96 else f"{attr}={getattr(self, attr)}"
97 for attr in (
98 "name",
99 "url_prefix",
100 "host",
101 "version",
102 "strict_slashes",
103 )
104 ]
105 )
106 return f"Blueprint({args})"
107
108 @property
109 def apps(self):
110 if not self._apps:
111 raise SanicException(
112 f"{self} has not yet been registered to an app"
113 )
114 return self._apps
115
116 def route(self, *args, **kwargs):
117 kwargs["apply"] = False
118 return super().route(*args, **kwargs)
119
120 def static(self, *args, **kwargs):
121 kwargs["apply"] = False
122 return super().static(*args, **kwargs)
123
124 def middleware(self, *args, **kwargs):
125 kwargs["apply"] = False
126 return super().middleware(*args, **kwargs)
127
128 def listener(self, *args, **kwargs):
129 kwargs["apply"] = False
130 return super().listener(*args, **kwargs)
131
132 def exception(self, *args, **kwargs):
133 kwargs["apply"] = False
134 return super().exception(*args, **kwargs)
135
136 def signal(self, event: str, *args, **kwargs):
137 kwargs["apply"] = False
138 return super().signal(event, *args, **kwargs)
139
140 @staticmethod
141 def group(*blueprints, url_prefix="", version=None, strict_slashes=None):
142 """
143 Create a list of blueprints, optionally grouping them under a
144 general URL prefix.
145
146 :param blueprints: blueprints to be registered as a group
147 :param url_prefix: URL route to be prepended to all sub-prefixes
148 :param version: API Version to be used for Blueprint group
149 :param strict_slashes: Indicate strict slash termination behavior
150 for URL
151 """
152
153 def chain(nested) -> Iterable[Blueprint]:
154 """itertools.chain() but leaves strings untouched"""
155 for i in nested:
156 if isinstance(i, (list, tuple)):
157 yield from chain(i)
158 elif isinstance(i, BlueprintGroup):
159 yield from i.blueprints
160 else:
161 yield i
162
163 bps = BlueprintGroup(
164 url_prefix=url_prefix,
165 version=version,
166 strict_slashes=strict_slashes,
167 )
168 for bp in chain(blueprints):
169 bps.append(bp)
170 return bps
171
172 def register(self, app, options):
173 """
174 Register the blueprint to the sanic app.
175
176 :param app: Instance of :class:`sanic.app.Sanic` class
177 :param options: Options to be used while registering the
178 blueprint into the app.
179 *url_prefix* - URL Prefix to override the blueprint prefix
180 """
181
182 self._apps.add(app)
183 url_prefix = options.get("url_prefix", self.url_prefix)
184
185 routes = []
186 middleware = []
187 exception_handlers = []
188 listeners = defaultdict(list)
189
190 # Routes
191 for future in self._future_routes:
192 # attach the blueprint name to the handler so that it can be
193 # prefixed properly in the router
194 future.handler.__blueprintname__ = self.name
195 # Prepend the blueprint URI prefix if available
196 uri = url_prefix + future.uri if url_prefix else future.uri
197
198 strict_slashes = (
199 self.strict_slashes
200 if future.strict_slashes is None
201 and self.strict_slashes is not None
202 else future.strict_slashes
203 )
204 name = app._generate_name(future.name)
205
206 apply_route = FutureRoute(
207 future.handler,
208 uri[1:] if uri.startswith("//") else uri,
209 future.methods,
210 future.host or self.host,
211 strict_slashes,
212 future.stream,
213 future.version or self.version,
214 name,
215 future.ignore_body,
216 future.websocket,
217 future.subprotocols,
218 future.unquote,
219 future.static,
220 )
221
222 route = app._apply_route(apply_route)
223 operation = (
224 routes.extend if isinstance(route, list) else routes.append
225 )
226 operation(route)
227
228 # Static Files
229 for future in self._future_statics:
230 # Prepend the blueprint URI prefix if available
231 uri = url_prefix + future.uri if url_prefix else future.uri
232 apply_route = FutureStatic(uri, *future[1:])
233 route = app._apply_static(apply_route)
234 routes.append(route)
235
236 route_names = [route.name for route in routes if route]
237
238 # Middleware
239 if route_names:
240 for future in self._future_middleware:
241 middleware.append(app._apply_middleware(future, route_names))
242
243 # Exceptions
244 for future in self._future_exceptions:
245 exception_handlers.append(app._apply_exception_handler(future))
246
247 # Event listeners
248 for listener in self._future_listeners:
249 listeners[listener.event].append(app._apply_listener(listener))
250
251 for signal in self._future_signals:
252 signal.condition.update({"blueprint": self.name})
253 app._apply_signal(signal)
254
255 self.routes = [route for route in routes if isinstance(route, Route)]
256
257 # Deprecate these in 21.6
258 self.websocket_routes = [
259 route for route in self.routes if route.ctx.websocket
260 ]
261 self.middlewares = middleware
262 self.exceptions = exception_handlers
263 self.listeners = dict(listeners)
264
265 async def dispatch(self, *args, **kwargs):
266 condition = kwargs.pop("condition", {})
267 condition.update({"blueprint": self.name})
268 kwargs["condition"] = condition
269 await asyncio.gather(
270 *[app.dispatch(*args, **kwargs) for app in self.apps]
271 )
272
273 def event(self, event: str, timeout: Optional[Union[int, float]] = None):
274 events = set()
275 for app in self.apps:
276 signal = app.signal_router.name_index.get(event)
277 if not signal:
278 raise NotFound("Could not find signal %s" % event)
279 events.add(signal.ctx.event)
280
281 return asyncio.wait(
282 [event.wait() for event in events],
283 return_when=asyncio.FIRST_COMPLETED,
284 timeout=timeout,
285 )
286
[end of sanic/blueprints.py]
[start of sanic/base.py]
1 from typing import Any, Tuple
2 from warnings import warn
3
4 from sanic.mixins.exceptions import ExceptionMixin
5 from sanic.mixins.listeners import ListenerMixin
6 from sanic.mixins.middleware import MiddlewareMixin
7 from sanic.mixins.routes import RouteMixin
8 from sanic.mixins.signals import SignalMixin
9
10
11 class Base(type):
12 def __new__(cls, name, bases, attrs):
13 init = attrs.get("__init__")
14
15 def __init__(self, *args, **kwargs):
16 nonlocal init
17 nonlocal name
18
19 bases = [
20 b for base in type(self).__bases__ for b in base.__bases__
21 ]
22
23 for base in bases:
24 base.__init__(self, *args, **kwargs)
25
26 if init:
27 init(self, *args, **kwargs)
28
29 attrs["__init__"] = __init__
30 return type.__new__(cls, name, bases, attrs)
31
32
33 class BaseSanic(
34 RouteMixin,
35 MiddlewareMixin,
36 ListenerMixin,
37 ExceptionMixin,
38 SignalMixin,
39 metaclass=Base,
40 ):
41 __fake_slots__: Tuple[str, ...]
42
43 def __str__(self) -> str:
44 return f"<{self.__class__.__name__} {self.name}>"
45
46 def __repr__(self) -> str:
47 return f'{self.__class__.__name__}(name="{self.name}")'
48
49 def __setattr__(self, name: str, value: Any) -> None:
50 # This is a temporary compat layer so we can raise a warning until
51 # setting attributes on the app instance can be removed and deprecated
52 # with a proper implementation of __slots__
53 if name not in self.__fake_slots__:
54 warn(
55 f"Setting variables on {self.__class__.__name__} instances is "
56 "deprecated and will be removed in version 21.9. You should "
57 f"change your {self.__class__.__name__} instance to use "
58 f"instance.ctx.{name} instead."
59 )
60 super().__setattr__(name, value)
61
[end of sanic/base.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sanic/base.py b/sanic/base.py
--- a/sanic/base.py
+++ b/sanic/base.py
@@ -8,38 +8,19 @@
from sanic.mixins.signals import SignalMixin
-class Base(type):
- def __new__(cls, name, bases, attrs):
- init = attrs.get("__init__")
-
- def __init__(self, *args, **kwargs):
- nonlocal init
- nonlocal name
-
- bases = [
- b for base in type(self).__bases__ for b in base.__bases__
- ]
-
- for base in bases:
- base.__init__(self, *args, **kwargs)
-
- if init:
- init(self, *args, **kwargs)
-
- attrs["__init__"] = __init__
- return type.__new__(cls, name, bases, attrs)
-
-
class BaseSanic(
RouteMixin,
MiddlewareMixin,
ListenerMixin,
ExceptionMixin,
SignalMixin,
- metaclass=Base,
):
__fake_slots__: Tuple[str, ...]
+ def __init__(self, *args, **kwargs) -> None:
+ for base in BaseSanic.__bases__:
+ base.__init__(self, *args, **kwargs) # type: ignore
+
def __str__(self) -> str:
return f"<{self.__class__.__name__} {self.name}>"
diff --git a/sanic/blueprints.py b/sanic/blueprints.py
--- a/sanic/blueprints.py
+++ b/sanic/blueprints.py
@@ -73,6 +73,7 @@
version: Optional[int] = None,
strict_slashes: Optional[bool] = None,
):
+ super().__init__()
self._apps: Set[Sanic] = set()
self.ctx = SimpleNamespace()
|
{"golden_diff": "diff --git a/sanic/base.py b/sanic/base.py\n--- a/sanic/base.py\n+++ b/sanic/base.py\n@@ -8,38 +8,19 @@\n from sanic.mixins.signals import SignalMixin\n \n \n-class Base(type):\n- def __new__(cls, name, bases, attrs):\n- init = attrs.get(\"__init__\")\n-\n- def __init__(self, *args, **kwargs):\n- nonlocal init\n- nonlocal name\n-\n- bases = [\n- b for base in type(self).__bases__ for b in base.__bases__\n- ]\n-\n- for base in bases:\n- base.__init__(self, *args, **kwargs)\n-\n- if init:\n- init(self, *args, **kwargs)\n-\n- attrs[\"__init__\"] = __init__\n- return type.__new__(cls, name, bases, attrs)\n-\n-\n class BaseSanic(\n RouteMixin,\n MiddlewareMixin,\n ListenerMixin,\n ExceptionMixin,\n SignalMixin,\n- metaclass=Base,\n ):\n __fake_slots__: Tuple[str, ...]\n \n+ def __init__(self, *args, **kwargs) -> None:\n+ for base in BaseSanic.__bases__:\n+ base.__init__(self, *args, **kwargs) # type: ignore\n+\n def __str__(self) -> str:\n return f\"<{self.__class__.__name__} {self.name}>\"\n \ndiff --git a/sanic/blueprints.py b/sanic/blueprints.py\n--- a/sanic/blueprints.py\n+++ b/sanic/blueprints.py\n@@ -73,6 +73,7 @@\n version: Optional[int] = None,\n strict_slashes: Optional[bool] = None,\n ):\n+ super().__init__()\n \n self._apps: Set[Sanic] = set()\n self.ctx = SimpleNamespace()\n", "issue": "RecursionError on Sanic subclass initialisation\nDiscovered at https://github.com/sanic-org/sanic/issues/2071\r\n\r\nversion: latest sanic master (`8a2ea626c6d04a5eb1e28d071ffa56bf9ad98a12`)\r\n\r\ndescription:\r\n\r\nRecursionError occurs when initialising Sanic subclass\r\n\r\nminimal code to reproduce:\r\n\r\n```python\r\nfrom sanic import Sanic\r\n\r\n\r\nclass Custom(Sanic):\r\n pass\r\n\r\ncustom = Custom(\"custom\")\r\n```\r\n\r\n\r\nPotential fix: https://github.com/sanic-org/sanic/pull/2072\n", "before_files": [{"content": "from __future__ import annotations\n\nimport asyncio\n\nfrom collections import defaultdict\nfrom types import SimpleNamespace\nfrom typing import TYPE_CHECKING, Dict, Iterable, List, Optional, Set, Union\n\nfrom sanic_routing.exceptions import NotFound # type: ignore\nfrom sanic_routing.route import Route # type: ignore\n\nfrom sanic.base import BaseSanic\nfrom sanic.blueprint_group import BlueprintGroup\nfrom sanic.exceptions import SanicException\nfrom sanic.models.futures import FutureRoute, FutureStatic\nfrom sanic.models.handler_types import (\n ListenerType,\n MiddlewareType,\n RouteHandler,\n)\n\n\nif TYPE_CHECKING:\n from sanic import Sanic # noqa\n\n\nclass Blueprint(BaseSanic):\n \"\"\"\n In *Sanic* terminology, a **Blueprint** is a logical collection of\n URLs that perform a specific set of tasks which can be identified by\n a unique name.\n\n It is the main tool for grouping functionality and similar endpoints.\n\n `See user guide re: blueprints\n <https://sanicframework.org/guide/best-practices/blueprints.html>`__\n\n :param name: unique name of the blueprint\n :param url_prefix: URL to be prefixed before all route URLs\n :param host: IP Address of FQDN for the sanic server to use.\n :param version: Blueprint Version\n :param strict_slashes: Enforce the API urls are requested with a\n training */*\n \"\"\"\n\n __fake_slots__ = (\n \"_apps\",\n \"_future_routes\",\n \"_future_statics\",\n \"_future_middleware\",\n \"_future_listeners\",\n \"_future_exceptions\",\n \"_future_signals\",\n \"ctx\",\n \"exceptions\",\n \"host\",\n \"listeners\",\n \"middlewares\",\n \"name\",\n \"routes\",\n \"statics\",\n \"strict_slashes\",\n \"url_prefix\",\n \"version\",\n \"websocket_routes\",\n )\n\n def __init__(\n self,\n name: str,\n url_prefix: Optional[str] = None,\n host: Optional[str] = None,\n version: Optional[int] = None,\n strict_slashes: Optional[bool] = None,\n ):\n\n self._apps: Set[Sanic] = set()\n self.ctx = SimpleNamespace()\n self.exceptions: List[RouteHandler] = []\n self.host = host\n self.listeners: Dict[str, List[ListenerType]] = {}\n self.middlewares: List[MiddlewareType] = []\n self.name = name\n self.routes: List[Route] = []\n self.statics: List[RouteHandler] = []\n self.strict_slashes = strict_slashes\n self.url_prefix = url_prefix\n self.version = version\n self.websocket_routes: List[Route] = []\n\n def __repr__(self) -> str:\n args = \", \".join(\n [\n f'{attr}=\"{getattr(self, attr)}\"'\n if isinstance(getattr(self, attr), str)\n else f\"{attr}={getattr(self, attr)}\"\n for attr in (\n \"name\",\n \"url_prefix\",\n \"host\",\n \"version\",\n \"strict_slashes\",\n )\n ]\n )\n return f\"Blueprint({args})\"\n\n @property\n def apps(self):\n if not self._apps:\n raise SanicException(\n f\"{self} has not yet been registered to an app\"\n )\n return self._apps\n\n def route(self, *args, **kwargs):\n kwargs[\"apply\"] = False\n return super().route(*args, **kwargs)\n\n def static(self, *args, **kwargs):\n kwargs[\"apply\"] = False\n return super().static(*args, **kwargs)\n\n def middleware(self, *args, **kwargs):\n kwargs[\"apply\"] = False\n return super().middleware(*args, **kwargs)\n\n def listener(self, *args, **kwargs):\n kwargs[\"apply\"] = False\n return super().listener(*args, **kwargs)\n\n def exception(self, *args, **kwargs):\n kwargs[\"apply\"] = False\n return super().exception(*args, **kwargs)\n\n def signal(self, event: str, *args, **kwargs):\n kwargs[\"apply\"] = False\n return super().signal(event, *args, **kwargs)\n\n @staticmethod\n def group(*blueprints, url_prefix=\"\", version=None, strict_slashes=None):\n \"\"\"\n Create a list of blueprints, optionally grouping them under a\n general URL prefix.\n\n :param blueprints: blueprints to be registered as a group\n :param url_prefix: URL route to be prepended to all sub-prefixes\n :param version: API Version to be used for Blueprint group\n :param strict_slashes: Indicate strict slash termination behavior\n for URL\n \"\"\"\n\n def chain(nested) -> Iterable[Blueprint]:\n \"\"\"itertools.chain() but leaves strings untouched\"\"\"\n for i in nested:\n if isinstance(i, (list, tuple)):\n yield from chain(i)\n elif isinstance(i, BlueprintGroup):\n yield from i.blueprints\n else:\n yield i\n\n bps = BlueprintGroup(\n url_prefix=url_prefix,\n version=version,\n strict_slashes=strict_slashes,\n )\n for bp in chain(blueprints):\n bps.append(bp)\n return bps\n\n def register(self, app, options):\n \"\"\"\n Register the blueprint to the sanic app.\n\n :param app: Instance of :class:`sanic.app.Sanic` class\n :param options: Options to be used while registering the\n blueprint into the app.\n *url_prefix* - URL Prefix to override the blueprint prefix\n \"\"\"\n\n self._apps.add(app)\n url_prefix = options.get(\"url_prefix\", self.url_prefix)\n\n routes = []\n middleware = []\n exception_handlers = []\n listeners = defaultdict(list)\n\n # Routes\n for future in self._future_routes:\n # attach the blueprint name to the handler so that it can be\n # prefixed properly in the router\n future.handler.__blueprintname__ = self.name\n # Prepend the blueprint URI prefix if available\n uri = url_prefix + future.uri if url_prefix else future.uri\n\n strict_slashes = (\n self.strict_slashes\n if future.strict_slashes is None\n and self.strict_slashes is not None\n else future.strict_slashes\n )\n name = app._generate_name(future.name)\n\n apply_route = FutureRoute(\n future.handler,\n uri[1:] if uri.startswith(\"//\") else uri,\n future.methods,\n future.host or self.host,\n strict_slashes,\n future.stream,\n future.version or self.version,\n name,\n future.ignore_body,\n future.websocket,\n future.subprotocols,\n future.unquote,\n future.static,\n )\n\n route = app._apply_route(apply_route)\n operation = (\n routes.extend if isinstance(route, list) else routes.append\n )\n operation(route)\n\n # Static Files\n for future in self._future_statics:\n # Prepend the blueprint URI prefix if available\n uri = url_prefix + future.uri if url_prefix else future.uri\n apply_route = FutureStatic(uri, *future[1:])\n route = app._apply_static(apply_route)\n routes.append(route)\n\n route_names = [route.name for route in routes if route]\n\n # Middleware\n if route_names:\n for future in self._future_middleware:\n middleware.append(app._apply_middleware(future, route_names))\n\n # Exceptions\n for future in self._future_exceptions:\n exception_handlers.append(app._apply_exception_handler(future))\n\n # Event listeners\n for listener in self._future_listeners:\n listeners[listener.event].append(app._apply_listener(listener))\n\n for signal in self._future_signals:\n signal.condition.update({\"blueprint\": self.name})\n app._apply_signal(signal)\n\n self.routes = [route for route in routes if isinstance(route, Route)]\n\n # Deprecate these in 21.6\n self.websocket_routes = [\n route for route in self.routes if route.ctx.websocket\n ]\n self.middlewares = middleware\n self.exceptions = exception_handlers\n self.listeners = dict(listeners)\n\n async def dispatch(self, *args, **kwargs):\n condition = kwargs.pop(\"condition\", {})\n condition.update({\"blueprint\": self.name})\n kwargs[\"condition\"] = condition\n await asyncio.gather(\n *[app.dispatch(*args, **kwargs) for app in self.apps]\n )\n\n def event(self, event: str, timeout: Optional[Union[int, float]] = None):\n events = set()\n for app in self.apps:\n signal = app.signal_router.name_index.get(event)\n if not signal:\n raise NotFound(\"Could not find signal %s\" % event)\n events.add(signal.ctx.event)\n\n return asyncio.wait(\n [event.wait() for event in events],\n return_when=asyncio.FIRST_COMPLETED,\n timeout=timeout,\n )\n", "path": "sanic/blueprints.py"}, {"content": "from typing import Any, Tuple\nfrom warnings import warn\n\nfrom sanic.mixins.exceptions import ExceptionMixin\nfrom sanic.mixins.listeners import ListenerMixin\nfrom sanic.mixins.middleware import MiddlewareMixin\nfrom sanic.mixins.routes import RouteMixin\nfrom sanic.mixins.signals import SignalMixin\n\n\nclass Base(type):\n def __new__(cls, name, bases, attrs):\n init = attrs.get(\"__init__\")\n\n def __init__(self, *args, **kwargs):\n nonlocal init\n nonlocal name\n\n bases = [\n b for base in type(self).__bases__ for b in base.__bases__\n ]\n\n for base in bases:\n base.__init__(self, *args, **kwargs)\n\n if init:\n init(self, *args, **kwargs)\n\n attrs[\"__init__\"] = __init__\n return type.__new__(cls, name, bases, attrs)\n\n\nclass BaseSanic(\n RouteMixin,\n MiddlewareMixin,\n ListenerMixin,\n ExceptionMixin,\n SignalMixin,\n metaclass=Base,\n):\n __fake_slots__: Tuple[str, ...]\n\n def __str__(self) -> str:\n return f\"<{self.__class__.__name__} {self.name}>\"\n\n def __repr__(self) -> str:\n return f'{self.__class__.__name__}(name=\"{self.name}\")'\n\n def __setattr__(self, name: str, value: Any) -> None:\n # This is a temporary compat layer so we can raise a warning until\n # setting attributes on the app instance can be removed and deprecated\n # with a proper implementation of __slots__\n if name not in self.__fake_slots__:\n warn(\n f\"Setting variables on {self.__class__.__name__} instances is \"\n \"deprecated and will be removed in version 21.9. You should \"\n f\"change your {self.__class__.__name__} instance to use \"\n f\"instance.ctx.{name} instead.\"\n )\n super().__setattr__(name, value)\n", "path": "sanic/base.py"}]}
| 3,964 | 418 |
gh_patches_debug_38969
|
rasdani/github-patches
|
git_diff
|
sql-machine-learning__elasticdl-397
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
worker_test failure
```
python -m unittest elasticdl/worker/*_test.py
/usr/local/anaconda3/lib/python3.6/site-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_converters
2019-05-21 13:57:07.262725: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
WARNING:tensorflow:From /usr/local/anaconda3/lib/python3.6/site-packages/tensorflow/python/ops/resource_variable_ops.py:642: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
must be str, not NoneType
FLoss is 3.090042
Loss is 1.4608976
Loss is 0.913306
Loss is 0.5969497
Loss is 0.66515267
Loss is 0.3935135
Loss is 0.37774342
Loss is 0.289928
.
======================================================================
FAIL: test_distributed_train (elasticdl.worker.worker_test.WorkerTest)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/Users/l.zou/git/elasticdl/elasticdl/worker/worker_test.py", line 96, in test_distributed_train
self.assertTrue(res)
AssertionError: False is not true
----------------------------------------------------------------------
Ran 2 tests in 0.165s
```
</issue>
<code>
[start of elasticdl/worker/worker.py]
1 import traceback
2 import tensorflow as tf
3 assert tf.executing_eagerly()
4
5 from google.protobuf import empty_pb2
6 from tensorflow.python.ops import math_ops
7 from elasticdl.proto import master_pb2_grpc
8 from elasticdl.proto import master_pb2
9 from elasticdl.common.ndarray import ndarray_to_tensor, tensor_to_ndarray
10 from elasticdl.common.model_helper import load_user_model, build_model
11 from edl_data.codec import TFExampleCodec
12 from edl_data.codec import BytesCodec
13 import itertools
14 import recordio
15
16 # the default max number of a minibatch retrain as its gradients are not accepted by master.
17 DEFAULT_MAX_MINIBATCH_RETRAIN_NUM = 64
18
19 class Worker(object):
20 """ElasticDL worker"""
21
22 def __init__(self,
23 model_file,
24 channel=None,
25 max_retrain_num=DEFAULT_MAX_MINIBATCH_RETRAIN_NUM,
26 codec_type=None):
27 """
28 Arguments:
29 model_module: A module to define the model
30 channel: grpc channel
31 max_retrain_num: max number of a minibatch retrain as its gradients are not accepted by master
32 """
33
34 model_module = load_user_model(model_file)
35 self._model = model_module.model
36 self._feature_columns = model_module.feature_columns()
37 self._all_columns = self._feature_columns + model_module.label_columns()
38 build_model(self._model, self._feature_columns)
39 self._input_fn = model_module.input_fn
40 self._opt_fn = model_module.optimizer
41 self._loss = model_module.loss
42
43 if channel is None:
44 self._stub = None
45 else:
46 self._stub = master_pb2_grpc.MasterStub(channel)
47 self._max_retrain_num = max_retrain_num
48 self._model_version = -1
49 self._codec_type = codec_type
50
51 def get_task(self):
52 """
53 get task from master
54 """
55 return self._stub.GetTask(empty_pb2.Empty())
56
57 def get_model(self, min_version):
58 """
59 get model from master, and update model_version
60 """
61 req = master_pb2.GetModelRequest()
62 req.min_version = min_version
63 model = self._stub.GetModel(req)
64
65 for var in self._model.trainable_variables:
66 # Assumes all trainable variables exist in model.param.
67 var.assign(
68 tensor_to_ndarray(model.param[var.name]))
69 self._model_version = model.version
70
71 def report_task_result(self, task_id, err_msg):
72 """
73 report task result to master
74 """
75 report = master_pb2.ReportTaskResultRequest()
76 report.task_id = task_id
77 report.err_message = err_msg
78 return self._stub.ReportTaskResult(report)
79
80 def report_gradient(self, grads):
81 """
82 report gradient to ps, return (accepted, model_version) from rpc call.
83 """
84 req = master_pb2.ReportGradientRequest()
85 for g, v in zip(grads, self._model.trainable_variables):
86 req.gradient[v.name].CopyFrom(
87 ndarray_to_tensor(g.numpy()))
88 req.model_version = self._model_version
89 res = self._stub.ReportGradient(req)
90 return res.accepted, res.model_version
91
92 def distributed_train(self):
93 """
94 Distributed training.
95 """
96 if self._codec_type == "tf_example":
97 codec = TFExampleCodec(self._all_columns)
98 elif self._codec_type == "bytes":
99 codec = BytesCodec(self._all_columns)
100 else:
101 raise ValueError("invalid codec_type: " + self._codec_type)
102 while True:
103 task = self.get_task()
104 if not task.shard_file_name:
105 # No more task
106 break
107 batch_size = task.minibatch_size
108 err_msg = ""
109 try:
110 with recordio.File(task.shard_file_name, "r", decoder=codec.decode) as rdio_r:
111 reader = rdio_r.get_reader(task.start, task.end)
112 min_model_version = task.model_version
113 while True:
114 record_buf = list(
115 itertools.islice(reader, 0, batch_size))
116 if not record_buf:
117 break
118
119 for _ in range(self._max_retrain_num):
120 # TODO: optimize the logic to avoid unnecessary get_model call.
121 self.get_model(
122 max(self._model_version, min_model_version))
123
124 batch_input_data, batch_label = self._input_fn(record_buf)
125
126 with tf.GradientTape() as tape:
127 inputs = []
128 for f_col in self._feature_columns:
129 inputs.append(batch_input_data[f_col.key])
130 if len(inputs) == 1:
131 inputs = inputs[0]
132 outputs = self._model.call(inputs, training=True)
133 loss = self._loss(outputs, batch_label.flatten())
134
135 # TODO: Add regularization loss if any,
136 # which should be divided by the number of contributing workers.
137 grads = tape.gradient(
138 loss, self._model.trainable_variables)
139 print("Loss is ", loss.numpy())
140
141 accepted, min_model_version = self.report_gradient(
142 grads)
143 if accepted:
144 break
145 else:
146 # Worker got stuck, fail the task.
147 # TODO: stop the worker if it fails to make any progress for some time.
148 raise RuntimeError("Worker got stuck")
149
150
151 except Exception as ex:
152 err_msg = str(ex)
153 traceback.print_exc()
154 self.report_task_result(task.task_id, err_msg)
155
156 def local_train(self, file_list, batch_size, epoch=1, kwargs=None):
157 """
158 Local training for local testing. Must in eager mode.
159 Argments:
160 batch_size: batch size in training
161 epoch: the number of epoch in training
162 kwargs: contains a dict of parameters used in training
163 """
164 optimizer = self._opt_fn()
165 for _ in range(epoch):
166 for f in file_list:
167 with recordio.File(f, "r") as rdio_r:
168 reader = rdio_r.get_reader(0, rdio_r.count())
169 while True:
170 record_buf = list(
171 itertools.islice(reader, 0, batch_size))
172 if not record_buf:
173 break
174
175 data, labels = self._input_fn(record_buf)
176
177 with tf.GradientTape() as tape:
178 inputs = []
179 for f_col in self._feature_columns:
180 inputs.append(data[f_col.key])
181 if len(inputs) == 1:
182 inputs = inputs[0]
183 outputs = self._model.call(inputs, training=True)
184 loss = self._loss(outputs, labels)
185
186 # Add regularization loss if any.
187 # Note: for distributed training, the regularization loss should
188 # be divided by the number of contributing workers, which
189 # might be difficult for elasticdl.
190 if self._model.losses:
191 loss += math_ops.add_n(self._model.losses)
192 grads = tape.gradient(
193 loss, self._model.trainable_variables)
194 optimizer.apply_gradients(
195 zip(grads, self._model.trainable_variables))
196 print("Loss is ", loss.numpy())
197
[end of elasticdl/worker/worker.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/elasticdl/worker/worker.py b/elasticdl/worker/worker.py
--- a/elasticdl/worker/worker.py
+++ b/elasticdl/worker/worker.py
@@ -30,15 +30,21 @@
channel: grpc channel
max_retrain_num: max number of a minibatch retrain as its gradients are not accepted by master
"""
-
model_module = load_user_model(model_file)
self._model = model_module.model
self._feature_columns = model_module.feature_columns()
- self._all_columns = self._feature_columns + model_module.label_columns()
build_model(self._model, self._feature_columns)
self._input_fn = model_module.input_fn
self._opt_fn = model_module.optimizer
self._loss = model_module.loss
+ all_columns = self._feature_columns + model_module.label_columns()
+ if codec_type == "tf_example":
+ self._codec = TFExampleCodec(all_columns)
+ elif codec_type == "bytes":
+ self._codec = BytesCodec(all_columns)
+ else:
+ raise ValueError("invalid codec_type: " + codec_type)
+
if channel is None:
self._stub = None
@@ -93,12 +99,6 @@
"""
Distributed training.
"""
- if self._codec_type == "tf_example":
- codec = TFExampleCodec(self._all_columns)
- elif self._codec_type == "bytes":
- codec = BytesCodec(self._all_columns)
- else:
- raise ValueError("invalid codec_type: " + self._codec_type)
while True:
task = self.get_task()
if not task.shard_file_name:
@@ -107,7 +107,7 @@
batch_size = task.minibatch_size
err_msg = ""
try:
- with recordio.File(task.shard_file_name, "r", decoder=codec.decode) as rdio_r:
+ with recordio.File(task.shard_file_name, "r", decoder=self._codec.decode) as rdio_r:
reader = rdio_r.get_reader(task.start, task.end)
min_model_version = task.model_version
while True:
@@ -164,7 +164,7 @@
optimizer = self._opt_fn()
for _ in range(epoch):
for f in file_list:
- with recordio.File(f, "r") as rdio_r:
+ with recordio.File(f, "r", decoder=self._codec.decode) as rdio_r:
reader = rdio_r.get_reader(0, rdio_r.count())
while True:
record_buf = list(
|
{"golden_diff": "diff --git a/elasticdl/worker/worker.py b/elasticdl/worker/worker.py\n--- a/elasticdl/worker/worker.py\n+++ b/elasticdl/worker/worker.py\n@@ -30,15 +30,21 @@\n channel: grpc channel\n max_retrain_num: max number of a minibatch retrain as its gradients are not accepted by master\n \"\"\"\n-\n model_module = load_user_model(model_file)\n self._model = model_module.model\n self._feature_columns = model_module.feature_columns()\n- self._all_columns = self._feature_columns + model_module.label_columns()\n build_model(self._model, self._feature_columns)\n self._input_fn = model_module.input_fn \n self._opt_fn = model_module.optimizer\n self._loss = model_module.loss\n+ all_columns = self._feature_columns + model_module.label_columns()\n+ if codec_type == \"tf_example\":\n+ self._codec = TFExampleCodec(all_columns)\n+ elif codec_type == \"bytes\":\n+ self._codec = BytesCodec(all_columns)\n+ else:\n+ raise ValueError(\"invalid codec_type: \" + codec_type)\n+\n \n if channel is None:\n self._stub = None\n@@ -93,12 +99,6 @@\n \"\"\"\n Distributed training.\n \"\"\"\n- if self._codec_type == \"tf_example\":\n- codec = TFExampleCodec(self._all_columns)\n- elif self._codec_type == \"bytes\":\n- codec = BytesCodec(self._all_columns)\n- else:\n- raise ValueError(\"invalid codec_type: \" + self._codec_type)\n while True:\n task = self.get_task()\n if not task.shard_file_name:\n@@ -107,7 +107,7 @@\n batch_size = task.minibatch_size\n err_msg = \"\"\n try:\n- with recordio.File(task.shard_file_name, \"r\", decoder=codec.decode) as rdio_r:\n+ with recordio.File(task.shard_file_name, \"r\", decoder=self._codec.decode) as rdio_r:\n reader = rdio_r.get_reader(task.start, task.end)\n min_model_version = task.model_version\n while True:\n@@ -164,7 +164,7 @@\n optimizer = self._opt_fn()\n for _ in range(epoch):\n for f in file_list:\n- with recordio.File(f, \"r\") as rdio_r:\n+ with recordio.File(f, \"r\", decoder=self._codec.decode) as rdio_r:\n reader = rdio_r.get_reader(0, rdio_r.count())\n while True:\n record_buf = list(\n", "issue": "worker_test failure\n```\r\npython -m unittest elasticdl/worker/*_test.py\r\n/usr/local/anaconda3/lib/python3.6/site-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\r\n from ._conv import register_converters as _register_converters\r\n2019-05-21 13:57:07.262725: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA\r\nWARNING:tensorflow:From /usr/local/anaconda3/lib/python3.6/site-packages/tensorflow/python/ops/resource_variable_ops.py:642: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.\r\nInstructions for updating:\r\nColocations handled automatically by placer.\r\nmust be str, not NoneType\r\nFLoss is 3.090042\r\nLoss is 1.4608976\r\nLoss is 0.913306\r\nLoss is 0.5969497\r\nLoss is 0.66515267\r\nLoss is 0.3935135\r\nLoss is 0.37774342\r\nLoss is 0.289928\r\n.\r\n======================================================================\r\nFAIL: test_distributed_train (elasticdl.worker.worker_test.WorkerTest)\r\n----------------------------------------------------------------------\r\nTraceback (most recent call last):\r\n File \"/Users/l.zou/git/elasticdl/elasticdl/worker/worker_test.py\", line 96, in test_distributed_train\r\n self.assertTrue(res)\r\nAssertionError: False is not true\r\n\r\n----------------------------------------------------------------------\r\nRan 2 tests in 0.165s\r\n\r\n```\n", "before_files": [{"content": "import traceback\nimport tensorflow as tf\nassert tf.executing_eagerly()\n\nfrom google.protobuf import empty_pb2\nfrom tensorflow.python.ops import math_ops\nfrom elasticdl.proto import master_pb2_grpc\nfrom elasticdl.proto import master_pb2\nfrom elasticdl.common.ndarray import ndarray_to_tensor, tensor_to_ndarray\nfrom elasticdl.common.model_helper import load_user_model, build_model\nfrom edl_data.codec import TFExampleCodec\nfrom edl_data.codec import BytesCodec\nimport itertools\nimport recordio\n\n# the default max number of a minibatch retrain as its gradients are not accepted by master.\nDEFAULT_MAX_MINIBATCH_RETRAIN_NUM = 64\n\nclass Worker(object):\n \"\"\"ElasticDL worker\"\"\"\n\n def __init__(self,\n model_file,\n channel=None,\n max_retrain_num=DEFAULT_MAX_MINIBATCH_RETRAIN_NUM,\n codec_type=None):\n \"\"\"\n Arguments:\n model_module: A module to define the model\n channel: grpc channel\n max_retrain_num: max number of a minibatch retrain as its gradients are not accepted by master\n \"\"\"\n\n model_module = load_user_model(model_file)\n self._model = model_module.model\n self._feature_columns = model_module.feature_columns()\n self._all_columns = self._feature_columns + model_module.label_columns()\n build_model(self._model, self._feature_columns)\n self._input_fn = model_module.input_fn \n self._opt_fn = model_module.optimizer\n self._loss = model_module.loss\n\n if channel is None:\n self._stub = None\n else:\n self._stub = master_pb2_grpc.MasterStub(channel)\n self._max_retrain_num = max_retrain_num\n self._model_version = -1\n self._codec_type = codec_type\n\n def get_task(self):\n \"\"\"\n get task from master\n \"\"\"\n return self._stub.GetTask(empty_pb2.Empty())\n\n def get_model(self, min_version):\n \"\"\"\n get model from master, and update model_version\n \"\"\"\n req = master_pb2.GetModelRequest()\n req.min_version = min_version\n model = self._stub.GetModel(req)\n\n for var in self._model.trainable_variables:\n # Assumes all trainable variables exist in model.param.\n var.assign(\n tensor_to_ndarray(model.param[var.name]))\n self._model_version = model.version\n\n def report_task_result(self, task_id, err_msg):\n \"\"\"\n report task result to master\n \"\"\"\n report = master_pb2.ReportTaskResultRequest()\n report.task_id = task_id\n report.err_message = err_msg\n return self._stub.ReportTaskResult(report)\n\n def report_gradient(self, grads):\n \"\"\"\n report gradient to ps, return (accepted, model_version) from rpc call.\n \"\"\"\n req = master_pb2.ReportGradientRequest()\n for g, v in zip(grads, self._model.trainable_variables):\n req.gradient[v.name].CopyFrom(\n ndarray_to_tensor(g.numpy()))\n req.model_version = self._model_version\n res = self._stub.ReportGradient(req)\n return res.accepted, res.model_version\n\n def distributed_train(self):\n \"\"\"\n Distributed training.\n \"\"\"\n if self._codec_type == \"tf_example\":\n codec = TFExampleCodec(self._all_columns)\n elif self._codec_type == \"bytes\":\n codec = BytesCodec(self._all_columns)\n else:\n raise ValueError(\"invalid codec_type: \" + self._codec_type)\n while True:\n task = self.get_task()\n if not task.shard_file_name:\n # No more task\n break\n batch_size = task.minibatch_size\n err_msg = \"\"\n try:\n with recordio.File(task.shard_file_name, \"r\", decoder=codec.decode) as rdio_r:\n reader = rdio_r.get_reader(task.start, task.end)\n min_model_version = task.model_version\n while True:\n record_buf = list(\n itertools.islice(reader, 0, batch_size))\n if not record_buf:\n break\n\n for _ in range(self._max_retrain_num):\n # TODO: optimize the logic to avoid unnecessary get_model call.\n self.get_model(\n max(self._model_version, min_model_version))\n\n batch_input_data, batch_label = self._input_fn(record_buf)\n\n with tf.GradientTape() as tape:\n inputs = []\n for f_col in self._feature_columns:\n inputs.append(batch_input_data[f_col.key])\n if len(inputs) == 1:\n inputs = inputs[0]\n outputs = self._model.call(inputs, training=True)\n loss = self._loss(outputs, batch_label.flatten())\n\n # TODO: Add regularization loss if any,\n # which should be divided by the number of contributing workers.\n grads = tape.gradient(\n loss, self._model.trainable_variables)\n print(\"Loss is \", loss.numpy())\n\n accepted, min_model_version = self.report_gradient(\n grads)\n if accepted:\n break\n else:\n # Worker got stuck, fail the task.\n # TODO: stop the worker if it fails to make any progress for some time.\n raise RuntimeError(\"Worker got stuck\")\n\n\n except Exception as ex:\n err_msg = str(ex)\n traceback.print_exc()\n self.report_task_result(task.task_id, err_msg)\n\n def local_train(self, file_list, batch_size, epoch=1, kwargs=None):\n \"\"\"\n Local training for local testing. Must in eager mode.\n Argments:\n batch_size: batch size in training\n epoch: the number of epoch in training\n kwargs: contains a dict of parameters used in training\n \"\"\"\n optimizer = self._opt_fn()\n for _ in range(epoch):\n for f in file_list:\n with recordio.File(f, \"r\") as rdio_r:\n reader = rdio_r.get_reader(0, rdio_r.count())\n while True:\n record_buf = list(\n itertools.islice(reader, 0, batch_size))\n if not record_buf:\n break\n\n data, labels = self._input_fn(record_buf)\n\n with tf.GradientTape() as tape:\n inputs = []\n for f_col in self._feature_columns:\n inputs.append(data[f_col.key])\n if len(inputs) == 1:\n inputs = inputs[0]\n outputs = self._model.call(inputs, training=True)\n loss = self._loss(outputs, labels)\n\n # Add regularization loss if any.\n # Note: for distributed training, the regularization loss should\n # be divided by the number of contributing workers, which\n # might be difficult for elasticdl.\n if self._model.losses:\n loss += math_ops.add_n(self._model.losses)\n grads = tape.gradient(\n loss, self._model.trainable_variables)\n optimizer.apply_gradients(\n zip(grads, self._model.trainable_variables))\n print(\"Loss is \", loss.numpy())\n", "path": "elasticdl/worker/worker.py"}]}
| 2,971 | 586 |
gh_patches_debug_22797
|
rasdani/github-patches
|
git_diff
|
quantumlib__Cirq-2681
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Make cirq.GridQubit + cirq.GridQubit work
```cirq.GridQubit(a, b) + (c, d)``` works
```cirq.GridQubit(a, b) + cirq.GridQubit(c, d)``` does not work
The latter should act like the former.
</issue>
<code>
[start of cirq/devices/grid_qubit.py]
1 # Copyright 2018 The Cirq Developers
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15
16 from typing import Iterable, List, Optional, Set, Tuple, TYPE_CHECKING
17
18 from cirq import ops, protocols
19
20 if TYPE_CHECKING:
21 import cirq
22
23
24 class GridQubit(ops.Qid):
25 """A qubit on a 2d square lattice.
26
27 GridQubits use row-major ordering:
28
29 GridQubit(0, 0) < GridQubit(0, 1) < GridQubit(1, 0) < GridQubit(1, 1)
30
31 New GridQubits can be constructed by adding or subtracting tuples
32
33 >>> cirq.GridQubit(2, 3) + (3, 1)
34 cirq.GridQubit(5, 4)
35
36 >>> cirq.GridQubit(2, 3) - (1, 2)
37 cirq.GridQubit(1, 1)
38 """
39
40 def __init__(self, row: int, col: int):
41 self.row = row
42 self.col = col
43
44 def _comparison_key(self):
45 return self.row, self.col
46
47 @property
48 def dimension(self) -> int:
49 return 2
50
51 def is_adjacent(self, other: 'cirq.Qid') -> bool:
52 """Determines if two qubits are adjacent qubits."""
53 return (isinstance(other, GridQubit) and
54 abs(self.row - other.row) + abs(self.col - other.col) == 1)
55
56 def neighbors(self,
57 qids: Optional[Iterable[ops.Qid]] = None) -> Set['GridQubit']:
58 """Returns qubits that are potential neighbors to this GridQubit
59
60 Args:
61 qids: optional Iterable of qubits to constrain neighbors to.
62 """
63 neighbors = set()
64 for q in [self + (0, 1), self + (1, 0), self + (-1, 0), self + (0, -1)]:
65 if qids is None or q in qids:
66 neighbors.add(q)
67 return neighbors
68
69 @staticmethod
70 def square(diameter: int, top: int = 0, left: int = 0) -> List['GridQubit']:
71 """Returns a square of GridQubits.
72
73 Args:
74 diameter: Length of a side of the square
75 top: Row number of the topmost row
76 left: Column number of the leftmost row
77
78 Returns:
79 A list of GridQubits filling in a square grid
80 """
81 return GridQubit.rect(diameter, diameter, top=top, left=left)
82
83 @staticmethod
84 def rect(rows: int, cols: int, top: int = 0,
85 left: int = 0) -> List['GridQubit']:
86 """Returns a rectangle of GridQubits.
87
88 Args:
89 rows: Number of rows in the rectangle
90 cols: Number of columns in the rectangle
91 top: Row number of the topmost row
92 left: Column number of the leftmost row
93
94 Returns:
95 A list of GridQubits filling in a rectangular grid
96 """
97 return [
98 GridQubit(row, col)
99 for row in range(top, top + rows)
100 for col in range(left, left + cols)
101 ]
102
103 @staticmethod
104 def from_diagram(diagram: str) -> List['GridQubit']:
105 """Parse ASCII art device layout into info about qubits and
106 connectivity. As an example, the below diagram will create a list of
107 GridQubits in a pyramid structure.
108 ---A---
109 --AAA--
110 -AAAAA-
111 AAAAAAA
112
113 You can use any character other than a hyphen to mark a qubit. As an
114 example, the qubits for the Bristlecone device could be represented by
115 the below diagram. This produces a diamond-shaped grid of qubits, and
116 qubits with the same letter correspond to the same readout line.
117
118 .....AB.....
119 ....ABCD....
120 ...ABCDEF...
121 ..ABCDEFGH..
122 .ABCDEFGHIJ.
123 ABCDEFGHIJKL
124 .CDEFGHIJKL.
125 ..EFGHIJKL..
126 ...GHIJKL...
127 ....IJKL....
128 .....KL.....
129
130 Args:
131 diagram: String representing the qubit layout. Each line represents
132 a row. Alphanumeric characters are assigned as qubits.
133 Dots ('.'), dashes ('-'), and spaces (' ') are treated as
134 empty locations in the grid. If diagram has characters other
135 than alphanumerics, spacers, and newlines ('\n'), an error will
136 be thrown. The top-left corner of the diagram will be have
137 coordinate (0,0).
138
139 Returns:
140 A list of GridQubits corresponding to the provided diagram
141
142 Raises:
143 ValueError: If the input string contains an invalid character.
144 """
145 lines = diagram.strip().split('\n')
146 no_qubit_characters = ['.', '-', ' ']
147 qubits = []
148 for row, line in enumerate(lines):
149 for col, c in enumerate(line.strip()):
150 if c not in no_qubit_characters:
151 if not c.isalnum():
152 raise ValueError("Input string has invalid character")
153 qubits.append(GridQubit(row, col))
154 return qubits
155
156 def __repr__(self):
157 return 'cirq.GridQubit({}, {})'.format(self.row, self.col)
158
159 def __str__(self):
160 return '({}, {})'.format(self.row, self.col)
161
162 def _json_dict_(self):
163 return protocols.obj_to_dict_helper(self, ['row', 'col'])
164
165 def __add__(self, other: Tuple[int, int]) -> 'GridQubit':
166 if not (isinstance(other, tuple) and len(other) == 2 and
167 all(isinstance(x, int) for x in other)):
168 raise TypeError(
169 'Can only add tuples of length 2 to GridQubits. Was {}'.format(
170 other))
171 return GridQubit(row=self.row + other[0], col=self.col + other[1])
172
173 def __sub__(self, other: Tuple[int, int]) -> 'GridQubit':
174 if not (isinstance(other, tuple) and len(other) == 2 and
175 all(isinstance(x, int) for x in other)):
176 raise TypeError(
177 'Can only subtract tuples of length 2 to GridQubits. Was {}'.
178 format(other))
179 return GridQubit(row=self.row - other[0], col=self.col - other[1])
180
181 def __radd__(self, other: Tuple[int, int]) -> 'GridQubit':
182 return self + other
183
184 def __rsub__(self, other: Tuple[int, int]) -> 'GridQubit':
185 return -self + other
186
187 def __neg__(self) -> 'GridQubit':
188 return GridQubit(row=-self.row, col=-self.col)
189
[end of cirq/devices/grid_qubit.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/cirq/devices/grid_qubit.py b/cirq/devices/grid_qubit.py
--- a/cirq/devices/grid_qubit.py
+++ b/cirq/devices/grid_qubit.py
@@ -163,6 +163,8 @@
return protocols.obj_to_dict_helper(self, ['row', 'col'])
def __add__(self, other: Tuple[int, int]) -> 'GridQubit':
+ if isinstance(other, GridQubit):
+ return GridQubit(row=self.row + other.row, col=self.col + other.col)
if not (isinstance(other, tuple) and len(other) == 2 and
all(isinstance(x, int) for x in other)):
raise TypeError(
@@ -171,6 +173,8 @@
return GridQubit(row=self.row + other[0], col=self.col + other[1])
def __sub__(self, other: Tuple[int, int]) -> 'GridQubit':
+ if isinstance(other, GridQubit):
+ return GridQubit(row=self.row - other.row, col=self.col - other.col)
if not (isinstance(other, tuple) and len(other) == 2 and
all(isinstance(x, int) for x in other)):
raise TypeError(
|
{"golden_diff": "diff --git a/cirq/devices/grid_qubit.py b/cirq/devices/grid_qubit.py\n--- a/cirq/devices/grid_qubit.py\n+++ b/cirq/devices/grid_qubit.py\n@@ -163,6 +163,8 @@\n return protocols.obj_to_dict_helper(self, ['row', 'col'])\n \n def __add__(self, other: Tuple[int, int]) -> 'GridQubit':\n+ if isinstance(other, GridQubit):\n+ return GridQubit(row=self.row + other.row, col=self.col + other.col)\n if not (isinstance(other, tuple) and len(other) == 2 and\n all(isinstance(x, int) for x in other)):\n raise TypeError(\n@@ -171,6 +173,8 @@\n return GridQubit(row=self.row + other[0], col=self.col + other[1])\n \n def __sub__(self, other: Tuple[int, int]) -> 'GridQubit':\n+ if isinstance(other, GridQubit):\n+ return GridQubit(row=self.row - other.row, col=self.col - other.col)\n if not (isinstance(other, tuple) and len(other) == 2 and\n all(isinstance(x, int) for x in other)):\n raise TypeError(\n", "issue": "Make cirq.GridQubit + cirq.GridQubit work\n```cirq.GridQubit(a, b) + (c, d)``` works\r\n\r\n```cirq.GridQubit(a, b) + cirq.GridQubit(c, d)``` does not work\r\n\r\nThe latter should act like the former.\n", "before_files": [{"content": "# Copyright 2018 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nfrom typing import Iterable, List, Optional, Set, Tuple, TYPE_CHECKING\n\nfrom cirq import ops, protocols\n\nif TYPE_CHECKING:\n import cirq\n\n\nclass GridQubit(ops.Qid):\n \"\"\"A qubit on a 2d square lattice.\n\n GridQubits use row-major ordering:\n\n GridQubit(0, 0) < GridQubit(0, 1) < GridQubit(1, 0) < GridQubit(1, 1)\n\n New GridQubits can be constructed by adding or subtracting tuples\n\n >>> cirq.GridQubit(2, 3) + (3, 1)\n cirq.GridQubit(5, 4)\n\n >>> cirq.GridQubit(2, 3) - (1, 2)\n cirq.GridQubit(1, 1)\n \"\"\"\n\n def __init__(self, row: int, col: int):\n self.row = row\n self.col = col\n\n def _comparison_key(self):\n return self.row, self.col\n\n @property\n def dimension(self) -> int:\n return 2\n\n def is_adjacent(self, other: 'cirq.Qid') -> bool:\n \"\"\"Determines if two qubits are adjacent qubits.\"\"\"\n return (isinstance(other, GridQubit) and\n abs(self.row - other.row) + abs(self.col - other.col) == 1)\n\n def neighbors(self,\n qids: Optional[Iterable[ops.Qid]] = None) -> Set['GridQubit']:\n \"\"\"Returns qubits that are potential neighbors to this GridQubit\n\n Args:\n qids: optional Iterable of qubits to constrain neighbors to.\n \"\"\"\n neighbors = set()\n for q in [self + (0, 1), self + (1, 0), self + (-1, 0), self + (0, -1)]:\n if qids is None or q in qids:\n neighbors.add(q)\n return neighbors\n\n @staticmethod\n def square(diameter: int, top: int = 0, left: int = 0) -> List['GridQubit']:\n \"\"\"Returns a square of GridQubits.\n\n Args:\n diameter: Length of a side of the square\n top: Row number of the topmost row\n left: Column number of the leftmost row\n\n Returns:\n A list of GridQubits filling in a square grid\n \"\"\"\n return GridQubit.rect(diameter, diameter, top=top, left=left)\n\n @staticmethod\n def rect(rows: int, cols: int, top: int = 0,\n left: int = 0) -> List['GridQubit']:\n \"\"\"Returns a rectangle of GridQubits.\n\n Args:\n rows: Number of rows in the rectangle\n cols: Number of columns in the rectangle\n top: Row number of the topmost row\n left: Column number of the leftmost row\n\n Returns:\n A list of GridQubits filling in a rectangular grid\n \"\"\"\n return [\n GridQubit(row, col)\n for row in range(top, top + rows)\n for col in range(left, left + cols)\n ]\n\n @staticmethod\n def from_diagram(diagram: str) -> List['GridQubit']:\n \"\"\"Parse ASCII art device layout into info about qubits and\n connectivity. As an example, the below diagram will create a list of\n GridQubits in a pyramid structure.\n ---A---\n --AAA--\n -AAAAA-\n AAAAAAA\n\n You can use any character other than a hyphen to mark a qubit. As an\n example, the qubits for the Bristlecone device could be represented by\n the below diagram. This produces a diamond-shaped grid of qubits, and\n qubits with the same letter correspond to the same readout line.\n\n .....AB.....\n ....ABCD....\n ...ABCDEF...\n ..ABCDEFGH..\n .ABCDEFGHIJ.\n ABCDEFGHIJKL\n .CDEFGHIJKL.\n ..EFGHIJKL..\n ...GHIJKL...\n ....IJKL....\n .....KL.....\n\n Args:\n diagram: String representing the qubit layout. Each line represents\n a row. Alphanumeric characters are assigned as qubits.\n Dots ('.'), dashes ('-'), and spaces (' ') are treated as\n empty locations in the grid. If diagram has characters other\n than alphanumerics, spacers, and newlines ('\\n'), an error will\n be thrown. The top-left corner of the diagram will be have\n coordinate (0,0).\n\n Returns:\n A list of GridQubits corresponding to the provided diagram\n\n Raises:\n ValueError: If the input string contains an invalid character.\n \"\"\"\n lines = diagram.strip().split('\\n')\n no_qubit_characters = ['.', '-', ' ']\n qubits = []\n for row, line in enumerate(lines):\n for col, c in enumerate(line.strip()):\n if c not in no_qubit_characters:\n if not c.isalnum():\n raise ValueError(\"Input string has invalid character\")\n qubits.append(GridQubit(row, col))\n return qubits\n\n def __repr__(self):\n return 'cirq.GridQubit({}, {})'.format(self.row, self.col)\n\n def __str__(self):\n return '({}, {})'.format(self.row, self.col)\n\n def _json_dict_(self):\n return protocols.obj_to_dict_helper(self, ['row', 'col'])\n\n def __add__(self, other: Tuple[int, int]) -> 'GridQubit':\n if not (isinstance(other, tuple) and len(other) == 2 and\n all(isinstance(x, int) for x in other)):\n raise TypeError(\n 'Can only add tuples of length 2 to GridQubits. Was {}'.format(\n other))\n return GridQubit(row=self.row + other[0], col=self.col + other[1])\n\n def __sub__(self, other: Tuple[int, int]) -> 'GridQubit':\n if not (isinstance(other, tuple) and len(other) == 2 and\n all(isinstance(x, int) for x in other)):\n raise TypeError(\n 'Can only subtract tuples of length 2 to GridQubits. Was {}'.\n format(other))\n return GridQubit(row=self.row - other[0], col=self.col - other[1])\n\n def __radd__(self, other: Tuple[int, int]) -> 'GridQubit':\n return self + other\n\n def __rsub__(self, other: Tuple[int, int]) -> 'GridQubit':\n return -self + other\n\n def __neg__(self) -> 'GridQubit':\n return GridQubit(row=-self.row, col=-self.col)\n", "path": "cirq/devices/grid_qubit.py"}]}
| 2,716 | 276 |
gh_patches_debug_26859
|
rasdani/github-patches
|
git_diff
|
SeldonIO__MLServer-850
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
MLServer to hide http health request logs to avoid polluting the logs
As part of the Seldon Core addition https://github.com/SeldonIO/seldon-core/pull/4028 which moves the TCP ready checks into proper HTTP request ready checks to `v2/health/ready` there is now a lot of noise from the readiness checks every 5 seconds. We should explore ways in which we avoid this noise, perhaps making it completely silent by default, or eventually once the prometheus server is created on a separate server this could also be added (And both of them could be muted)

</issue>
<code>
[start of mlserver/rest/server.py]
1 import uvicorn
2
3 from ..settings import Settings
4 from ..handlers import DataPlane, ModelRepositoryHandlers, get_custom_handlers
5 from ..model import MLModel
6
7 from .utils import matches
8 from .app import create_app
9 from .logging import logger
10 from typing import Optional
11
12
13 class _NoSignalServer(uvicorn.Server):
14 def install_signal_handlers(self):
15 pass
16
17
18 class RESTServer:
19 def __init__(
20 self,
21 settings: Settings,
22 data_plane: DataPlane,
23 model_repository_handlers: ModelRepositoryHandlers,
24 ):
25 self._settings = settings
26 self._data_plane = data_plane
27 self._model_repository_handlers = model_repository_handlers
28 self._app = create_app(
29 self._settings,
30 data_plane=self._data_plane,
31 model_repository_handlers=self._model_repository_handlers,
32 )
33
34 async def add_custom_handlers(self, model: MLModel) -> MLModel:
35 handlers = get_custom_handlers(model)
36 for custom_handler, handler_method in handlers:
37 self._app.add_api_route(
38 custom_handler.rest_path,
39 handler_method,
40 methods=[custom_handler.rest_method],
41 )
42
43 return model
44
45 async def delete_custom_handlers(self, model: MLModel) -> MLModel:
46 handlers = get_custom_handlers(model)
47 if len(handlers) == 0:
48 return model
49
50 # NOTE: Loop in reverse, so that it's quicker to find all the recently
51 # added routes and we can remove routes on-the-fly
52 for i, route in reversed(list(enumerate(self._app.routes))):
53 for j, (custom_handler, handler_method) in enumerate(handlers):
54 if matches(route, custom_handler, handler_method): # type: ignore
55 self._app.routes.pop(i)
56 handlers.pop(j)
57
58 return model
59
60 async def start(self):
61 cfg = self._get_config()
62 self._server = _NoSignalServer(cfg)
63 await self._server.serve()
64
65 def _get_config(self):
66 kwargs = {}
67
68 if self._settings._custom_rest_server_settings:
69 logger.warning(
70 "REST custom configuration is out of support. Use as your own risk"
71 )
72 kwargs.update(self._settings._custom_rest_server_settings)
73
74 kwargs.update(
75 {
76 "host": self._settings.host,
77 "port": self._settings.http_port,
78 "root_path": self._settings.root_path,
79 "access_log": self._settings.debug,
80 }
81 )
82
83 if self._settings.logging_settings:
84 # If not None, use ours. Otherwise, let Uvicorn fall back on its
85 # own config.
86 kwargs.update({"log_config": self._settings.logging_settings})
87
88 return uvicorn.Config(self._app, **kwargs)
89
90 async def stop(self, sig: Optional[int] = None):
91 self._server.handle_exit(sig=sig, frame=None)
92
[end of mlserver/rest/server.py]
[start of mlserver/rest/logging.py]
1 import logging
2
3 loggerName = "mlserver.rest"
4 logger = logging.getLogger(loggerName)
5
[end of mlserver/rest/logging.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mlserver/rest/logging.py b/mlserver/rest/logging.py
--- a/mlserver/rest/logging.py
+++ b/mlserver/rest/logging.py
@@ -1,4 +1,35 @@
import logging
+
+class HealthEndpointFilter(logging.Filter):
+ """
+ Filter to avoid logging health endpoints.
+ From:
+ https://github.com/encode/starlette/issues/864#issuecomment-653076434
+ """
+
+ def filter(self, record: logging.LogRecord) -> bool:
+ if not isinstance(record.args, tuple):
+ return True
+
+ if len(record.args) < 3:
+ return True
+
+ request_method = record.args[1]
+ query_string = record.args[2]
+ if request_method != "GET":
+ return True
+
+ if query_string in ["/v2/health/live", "/v2/health/ready"]:
+ return False
+
+ return True
+
+
+def disable_health_access_logs() -> None:
+ uvicorn_logger = logging.getLogger("uvicorn.access")
+ uvicorn_logger.addFilter(HealthEndpointFilter())
+
+
loggerName = "mlserver.rest"
logger = logging.getLogger(loggerName)
diff --git a/mlserver/rest/server.py b/mlserver/rest/server.py
--- a/mlserver/rest/server.py
+++ b/mlserver/rest/server.py
@@ -6,7 +6,7 @@
from .utils import matches
from .app import create_app
-from .logging import logger
+from .logging import logger, disable_health_access_logs
from typing import Optional
@@ -60,6 +60,9 @@
async def start(self):
cfg = self._get_config()
self._server = _NoSignalServer(cfg)
+ if not self._settings.debug:
+ disable_health_access_logs()
+
await self._server.serve()
def _get_config(self):
|
{"golden_diff": "diff --git a/mlserver/rest/logging.py b/mlserver/rest/logging.py\n--- a/mlserver/rest/logging.py\n+++ b/mlserver/rest/logging.py\n@@ -1,4 +1,35 @@\n import logging\n \n+\n+class HealthEndpointFilter(logging.Filter):\n+ \"\"\"\n+ Filter to avoid logging health endpoints.\n+ From:\n+ https://github.com/encode/starlette/issues/864#issuecomment-653076434\n+ \"\"\"\n+\n+ def filter(self, record: logging.LogRecord) -> bool:\n+ if not isinstance(record.args, tuple):\n+ return True\n+\n+ if len(record.args) < 3:\n+ return True\n+\n+ request_method = record.args[1]\n+ query_string = record.args[2]\n+ if request_method != \"GET\":\n+ return True\n+\n+ if query_string in [\"/v2/health/live\", \"/v2/health/ready\"]:\n+ return False\n+\n+ return True\n+\n+\n+def disable_health_access_logs() -> None:\n+ uvicorn_logger = logging.getLogger(\"uvicorn.access\")\n+ uvicorn_logger.addFilter(HealthEndpointFilter())\n+\n+\n loggerName = \"mlserver.rest\"\n logger = logging.getLogger(loggerName)\ndiff --git a/mlserver/rest/server.py b/mlserver/rest/server.py\n--- a/mlserver/rest/server.py\n+++ b/mlserver/rest/server.py\n@@ -6,7 +6,7 @@\n \n from .utils import matches\n from .app import create_app\n-from .logging import logger\n+from .logging import logger, disable_health_access_logs\n from typing import Optional\n \n \n@@ -60,6 +60,9 @@\n async def start(self):\n cfg = self._get_config()\n self._server = _NoSignalServer(cfg)\n+ if not self._settings.debug:\n+ disable_health_access_logs()\n+\n await self._server.serve()\n \n def _get_config(self):\n", "issue": "MLServer to hide http health request logs to avoid polluting the logs\nAs part of the Seldon Core addition https://github.com/SeldonIO/seldon-core/pull/4028 which moves the TCP ready checks into proper HTTP request ready checks to `v2/health/ready` there is now a lot of noise from the readiness checks every 5 seconds. We should explore ways in which we avoid this noise, perhaps making it completely silent by default, or eventually once the prometheus server is created on a separate server this could also be added (And both of them could be muted)\r\n\r\n\r\n\n", "before_files": [{"content": "import uvicorn\n\nfrom ..settings import Settings\nfrom ..handlers import DataPlane, ModelRepositoryHandlers, get_custom_handlers\nfrom ..model import MLModel\n\nfrom .utils import matches\nfrom .app import create_app\nfrom .logging import logger\nfrom typing import Optional\n\n\nclass _NoSignalServer(uvicorn.Server):\n def install_signal_handlers(self):\n pass\n\n\nclass RESTServer:\n def __init__(\n self,\n settings: Settings,\n data_plane: DataPlane,\n model_repository_handlers: ModelRepositoryHandlers,\n ):\n self._settings = settings\n self._data_plane = data_plane\n self._model_repository_handlers = model_repository_handlers\n self._app = create_app(\n self._settings,\n data_plane=self._data_plane,\n model_repository_handlers=self._model_repository_handlers,\n )\n\n async def add_custom_handlers(self, model: MLModel) -> MLModel:\n handlers = get_custom_handlers(model)\n for custom_handler, handler_method in handlers:\n self._app.add_api_route(\n custom_handler.rest_path,\n handler_method,\n methods=[custom_handler.rest_method],\n )\n\n return model\n\n async def delete_custom_handlers(self, model: MLModel) -> MLModel:\n handlers = get_custom_handlers(model)\n if len(handlers) == 0:\n return model\n\n # NOTE: Loop in reverse, so that it's quicker to find all the recently\n # added routes and we can remove routes on-the-fly\n for i, route in reversed(list(enumerate(self._app.routes))):\n for j, (custom_handler, handler_method) in enumerate(handlers):\n if matches(route, custom_handler, handler_method): # type: ignore\n self._app.routes.pop(i)\n handlers.pop(j)\n\n return model\n\n async def start(self):\n cfg = self._get_config()\n self._server = _NoSignalServer(cfg)\n await self._server.serve()\n\n def _get_config(self):\n kwargs = {}\n\n if self._settings._custom_rest_server_settings:\n logger.warning(\n \"REST custom configuration is out of support. Use as your own risk\"\n )\n kwargs.update(self._settings._custom_rest_server_settings)\n\n kwargs.update(\n {\n \"host\": self._settings.host,\n \"port\": self._settings.http_port,\n \"root_path\": self._settings.root_path,\n \"access_log\": self._settings.debug,\n }\n )\n\n if self._settings.logging_settings:\n # If not None, use ours. Otherwise, let Uvicorn fall back on its\n # own config.\n kwargs.update({\"log_config\": self._settings.logging_settings})\n\n return uvicorn.Config(self._app, **kwargs)\n\n async def stop(self, sig: Optional[int] = None):\n self._server.handle_exit(sig=sig, frame=None)\n", "path": "mlserver/rest/server.py"}, {"content": "import logging\n\nloggerName = \"mlserver.rest\"\nlogger = logging.getLogger(loggerName)\n", "path": "mlserver/rest/logging.py"}]}
| 1,556 | 424 |
gh_patches_debug_23720
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-22870
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
lstsq
</issue>
<code>
[start of ivy/functional/frontends/jax/numpy/linalg.py]
1 # local
2 import ivy
3 from ivy.functional.frontends.jax import Array
4 from ivy.functional.frontends.jax.func_wrapper import to_ivy_arrays_and_back
5 from ivy.func_wrapper import with_unsupported_dtypes, with_supported_dtypes
6 from ivy.functional.frontends.jax.numpy import promote_types_of_jax_inputs
7
8
9 @to_ivy_arrays_and_back
10 def cholesky(a):
11 return ivy.cholesky(a)
12
13
14 @to_ivy_arrays_and_back
15 def cond(x, p=None):
16 return ivy.cond(x, p=p)
17
18
19 @to_ivy_arrays_and_back
20 def det(a):
21 return ivy.det(a)
22
23
24 @to_ivy_arrays_and_back
25 def eig(a):
26 return ivy.eig(a)
27
28
29 @to_ivy_arrays_and_back
30 def eigh(a, UPLO="L", symmetrize_input=True):
31 def symmetrize(x):
32 # TODO : Take Hermitian transpose after complex numbers added
33 return (x + ivy.swapaxes(x, -1, -2)) / 2
34
35 if symmetrize_input:
36 a = symmetrize(a)
37
38 return ivy.eigh(a, UPLO=UPLO)
39
40
41 @to_ivy_arrays_and_back
42 def eigvals(a):
43 return ivy.eigvals(a)
44
45
46 @to_ivy_arrays_and_back
47 def eigvalsh(a, UPLO="L"):
48 return ivy.eigvalsh(a, UPLO=UPLO)
49
50
51 @to_ivy_arrays_and_back
52 def inv(a):
53 return ivy.inv(a)
54
55
56 @to_ivy_arrays_and_back
57 def matrix_power(a, n):
58 return ivy.matrix_power(a, n)
59
60
61 @to_ivy_arrays_and_back
62 def matrix_rank(M, tol=None):
63 return ivy.matrix_rank(M, atol=tol)
64
65
66 @to_ivy_arrays_and_back
67 def multi_dot(arrays, *, precision=None):
68 return ivy.multi_dot(arrays)
69
70
71 @to_ivy_arrays_and_back
72 @with_supported_dtypes(
73 {"0.4.14 and below": ("float32", "float64")},
74 "jax",
75 )
76 def norm(x, ord=None, axis=None, keepdims=False):
77 if ord is None:
78 ord = 2
79 if type(axis) in [list, tuple] and len(axis) == 2:
80 return Array(ivy.matrix_norm(x, ord=ord, axis=axis, keepdims=keepdims))
81 return Array(ivy.vector_norm(x, ord=ord, axis=axis, keepdims=keepdims))
82
83
84 @to_ivy_arrays_and_back
85 def pinv(a, rcond=None):
86 return ivy.pinv(a, rtol=rcond)
87
88
89 @to_ivy_arrays_and_back
90 def qr(a, mode="reduced"):
91 return ivy.qr(a, mode=mode)
92
93
94 @to_ivy_arrays_and_back
95 def slogdet(a, method=None):
96 return ivy.slogdet(a)
97
98
99 @to_ivy_arrays_and_back
100 def solve(a, b):
101 return ivy.solve(a, b)
102
103
104 @to_ivy_arrays_and_back
105 def svd(a, /, *, full_matrices=True, compute_uv=True, hermitian=None):
106 if not compute_uv:
107 return ivy.svdvals(a)
108 return ivy.svd(a, full_matrices=full_matrices)
109
110
111 @to_ivy_arrays_and_back
112 @with_unsupported_dtypes({"0.4.14 and below": ("float16", "bfloat16")}, "jax")
113 def tensorinv(a, ind=2):
114 old_shape = ivy.shape(a)
115 prod = 1
116 if ind > 0:
117 invshape = old_shape[ind:] + old_shape[:ind]
118 for k in old_shape[ind:]:
119 prod *= k
120 else:
121 raise ValueError("Invalid ind argument.")
122 a = ivy.reshape(a, shape=(prod, -1))
123 ia = ivy.inv(a)
124 new_shape = tuple([*invshape])
125 return Array(ivy.reshape(ia, shape=new_shape))
126
127
128 @to_ivy_arrays_and_back
129 def tensorsolve(a, b, axes=None):
130 a, b = promote_types_of_jax_inputs(a, b)
131 return ivy.tensorsolve(a, b, axes=axes)
132
[end of ivy/functional/frontends/jax/numpy/linalg.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ivy/functional/frontends/jax/numpy/linalg.py b/ivy/functional/frontends/jax/numpy/linalg.py
--- a/ivy/functional/frontends/jax/numpy/linalg.py
+++ b/ivy/functional/frontends/jax/numpy/linalg.py
@@ -4,6 +4,7 @@
from ivy.functional.frontends.jax.func_wrapper import to_ivy_arrays_and_back
from ivy.func_wrapper import with_unsupported_dtypes, with_supported_dtypes
from ivy.functional.frontends.jax.numpy import promote_types_of_jax_inputs
+from ivy.functional.frontends.numpy.linalg import lstsq as numpy_lstsq
@to_ivy_arrays_and_back
@@ -53,6 +54,23 @@
return ivy.inv(a)
+# TODO: replace this with function from API
+# As the composition provides numerically unstable results
+@to_ivy_arrays_and_back
+def lstsq(a, b, rcond=None, *, numpy_resid=False):
+ if numpy_resid:
+ return numpy_lstsq(a, b, rcond=rcond)
+ least_squares_solution = ivy.matmul(
+ ivy.pinv(a, rtol=1e-15).astype(ivy.float64), b.astype(ivy.float64)
+ )
+ residuals = ivy.sum((b - ivy.matmul(a, least_squares_solution)) ** 2).astype(
+ ivy.float64
+ )
+ svd_values = ivy.svd(a, compute_uv=False)
+ rank = ivy.matrix_rank(a).astype(ivy.int32)
+ return (least_squares_solution, residuals, rank, svd_values[0])
+
+
@to_ivy_arrays_and_back
def matrix_power(a, n):
return ivy.matrix_power(a, n)
|
{"golden_diff": "diff --git a/ivy/functional/frontends/jax/numpy/linalg.py b/ivy/functional/frontends/jax/numpy/linalg.py\n--- a/ivy/functional/frontends/jax/numpy/linalg.py\n+++ b/ivy/functional/frontends/jax/numpy/linalg.py\n@@ -4,6 +4,7 @@\n from ivy.functional.frontends.jax.func_wrapper import to_ivy_arrays_and_back\n from ivy.func_wrapper import with_unsupported_dtypes, with_supported_dtypes\n from ivy.functional.frontends.jax.numpy import promote_types_of_jax_inputs\n+from ivy.functional.frontends.numpy.linalg import lstsq as numpy_lstsq\n \n \n @to_ivy_arrays_and_back\n@@ -53,6 +54,23 @@\n return ivy.inv(a)\n \n \n+# TODO: replace this with function from API\n+# As the composition provides numerically unstable results\n+@to_ivy_arrays_and_back\n+def lstsq(a, b, rcond=None, *, numpy_resid=False):\n+ if numpy_resid:\n+ return numpy_lstsq(a, b, rcond=rcond)\n+ least_squares_solution = ivy.matmul(\n+ ivy.pinv(a, rtol=1e-15).astype(ivy.float64), b.astype(ivy.float64)\n+ )\n+ residuals = ivy.sum((b - ivy.matmul(a, least_squares_solution)) ** 2).astype(\n+ ivy.float64\n+ )\n+ svd_values = ivy.svd(a, compute_uv=False)\n+ rank = ivy.matrix_rank(a).astype(ivy.int32)\n+ return (least_squares_solution, residuals, rank, svd_values[0])\n+\n+\n @to_ivy_arrays_and_back\n def matrix_power(a, n):\n return ivy.matrix_power(a, n)\n", "issue": "lstsq\n\n", "before_files": [{"content": "# local\nimport ivy\nfrom ivy.functional.frontends.jax import Array\nfrom ivy.functional.frontends.jax.func_wrapper import to_ivy_arrays_and_back\nfrom ivy.func_wrapper import with_unsupported_dtypes, with_supported_dtypes\nfrom ivy.functional.frontends.jax.numpy import promote_types_of_jax_inputs\n\n\n@to_ivy_arrays_and_back\ndef cholesky(a):\n return ivy.cholesky(a)\n\n\n@to_ivy_arrays_and_back\ndef cond(x, p=None):\n return ivy.cond(x, p=p)\n\n\n@to_ivy_arrays_and_back\ndef det(a):\n return ivy.det(a)\n\n\n@to_ivy_arrays_and_back\ndef eig(a):\n return ivy.eig(a)\n\n\n@to_ivy_arrays_and_back\ndef eigh(a, UPLO=\"L\", symmetrize_input=True):\n def symmetrize(x):\n # TODO : Take Hermitian transpose after complex numbers added\n return (x + ivy.swapaxes(x, -1, -2)) / 2\n\n if symmetrize_input:\n a = symmetrize(a)\n\n return ivy.eigh(a, UPLO=UPLO)\n\n\n@to_ivy_arrays_and_back\ndef eigvals(a):\n return ivy.eigvals(a)\n\n\n@to_ivy_arrays_and_back\ndef eigvalsh(a, UPLO=\"L\"):\n return ivy.eigvalsh(a, UPLO=UPLO)\n\n\n@to_ivy_arrays_and_back\ndef inv(a):\n return ivy.inv(a)\n\n\n@to_ivy_arrays_and_back\ndef matrix_power(a, n):\n return ivy.matrix_power(a, n)\n\n\n@to_ivy_arrays_and_back\ndef matrix_rank(M, tol=None):\n return ivy.matrix_rank(M, atol=tol)\n\n\n@to_ivy_arrays_and_back\ndef multi_dot(arrays, *, precision=None):\n return ivy.multi_dot(arrays)\n\n\n@to_ivy_arrays_and_back\n@with_supported_dtypes(\n {\"0.4.14 and below\": (\"float32\", \"float64\")},\n \"jax\",\n)\ndef norm(x, ord=None, axis=None, keepdims=False):\n if ord is None:\n ord = 2\n if type(axis) in [list, tuple] and len(axis) == 2:\n return Array(ivy.matrix_norm(x, ord=ord, axis=axis, keepdims=keepdims))\n return Array(ivy.vector_norm(x, ord=ord, axis=axis, keepdims=keepdims))\n\n\n@to_ivy_arrays_and_back\ndef pinv(a, rcond=None):\n return ivy.pinv(a, rtol=rcond)\n\n\n@to_ivy_arrays_and_back\ndef qr(a, mode=\"reduced\"):\n return ivy.qr(a, mode=mode)\n\n\n@to_ivy_arrays_and_back\ndef slogdet(a, method=None):\n return ivy.slogdet(a)\n\n\n@to_ivy_arrays_and_back\ndef solve(a, b):\n return ivy.solve(a, b)\n\n\n@to_ivy_arrays_and_back\ndef svd(a, /, *, full_matrices=True, compute_uv=True, hermitian=None):\n if not compute_uv:\n return ivy.svdvals(a)\n return ivy.svd(a, full_matrices=full_matrices)\n\n\n@to_ivy_arrays_and_back\n@with_unsupported_dtypes({\"0.4.14 and below\": (\"float16\", \"bfloat16\")}, \"jax\")\ndef tensorinv(a, ind=2):\n old_shape = ivy.shape(a)\n prod = 1\n if ind > 0:\n invshape = old_shape[ind:] + old_shape[:ind]\n for k in old_shape[ind:]:\n prod *= k\n else:\n raise ValueError(\"Invalid ind argument.\")\n a = ivy.reshape(a, shape=(prod, -1))\n ia = ivy.inv(a)\n new_shape = tuple([*invshape])\n return Array(ivy.reshape(ia, shape=new_shape))\n\n\n@to_ivy_arrays_and_back\ndef tensorsolve(a, b, axes=None):\n a, b = promote_types_of_jax_inputs(a, b)\n return ivy.tensorsolve(a, b, axes=axes)\n", "path": "ivy/functional/frontends/jax/numpy/linalg.py"}]}
| 1,793 | 404 |
gh_patches_debug_21108
|
rasdani/github-patches
|
git_diff
|
mesonbuild__meson-5585
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ccache cannot work on dist builds
Due to how the dist build is implemented in Meson, it will always result in ccache being unable to work.
The reason for this is the forced use of `mkdtemp` for directories within the `check_dist` function (in `dist.py`). The source is unpacked into `$tmpdir/tmp$string` which is random and thus unable to produce cache hits for subsequent builds. If I am trying to do e.g., a CI dist build, this is not ideal since it makes the build very long.
There are two possible solutions I've come up with which could solve the issue:
* Add a `DISTBUILDDIR` (or similar) environment variable which is used instead of `mkdtemp` during a dist build; this directory would take the place of the `mkdtemp` directories and would not be deleted when the build stopped
* Add a `TMPBUILDSTRING` (or similar) environment variable which is used in place of the random part of the tempdir string (resulting in e.g., /tmp/tmp$string); this directory can still be created and deleted normally, or even deleted if it already exists since we can assume this should only be used for meson dist builds
Other solutions would be great too, as long as ccache becomes usable.
</issue>
<code>
[start of mesonbuild/scripts/dist.py]
1 # Copyright 2017 The Meson development team
2
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6
7 # http://www.apache.org/licenses/LICENSE-2.0
8
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15
16 import lzma
17 import os
18 import sys
19 import shutil
20 import subprocess
21 import pickle
22 import hashlib
23 import tarfile, zipfile
24 import tempfile
25 from glob import glob
26 from mesonbuild.environment import detect_ninja
27 from mesonbuild.mesonlib import windows_proof_rmtree
28 from mesonbuild import mlog
29
30 def create_hash(fname):
31 hashname = fname + '.sha256sum'
32 m = hashlib.sha256()
33 m.update(open(fname, 'rb').read())
34 with open(hashname, 'w') as f:
35 f.write('%s %s\n' % (m.hexdigest(), os.path.basename(fname)))
36
37
38 def create_zip(zipfilename, packaging_dir):
39 prefix = os.path.dirname(packaging_dir)
40 removelen = len(prefix) + 1
41 with zipfile.ZipFile(zipfilename,
42 'w',
43 compression=zipfile.ZIP_DEFLATED,
44 allowZip64=True) as zf:
45 zf.write(packaging_dir, packaging_dir[removelen:])
46 for root, dirs, files in os.walk(packaging_dir):
47 for d in dirs:
48 dname = os.path.join(root, d)
49 zf.write(dname, dname[removelen:])
50 for f in files:
51 fname = os.path.join(root, f)
52 zf.write(fname, fname[removelen:])
53
54 def del_gitfiles(dirname):
55 for f in glob(os.path.join(dirname, '.git*')):
56 if os.path.isdir(f) and not os.path.islink(f):
57 windows_proof_rmtree(f)
58 else:
59 os.unlink(f)
60
61 def process_submodules(dirname):
62 module_file = os.path.join(dirname, '.gitmodules')
63 if not os.path.exists(module_file):
64 return
65 subprocess.check_call(['git', 'submodule', 'update', '--init', '--recursive'], cwd=dirname)
66 for line in open(module_file):
67 line = line.strip()
68 if '=' not in line:
69 continue
70 k, v = line.split('=', 1)
71 k = k.strip()
72 v = v.strip()
73 if k != 'path':
74 continue
75 del_gitfiles(os.path.join(dirname, v))
76
77
78 def run_dist_scripts(dist_root, dist_scripts):
79 assert(os.path.isabs(dist_root))
80 env = os.environ.copy()
81 env['MESON_DIST_ROOT'] = dist_root
82 for d in dist_scripts:
83 script = d['exe']
84 args = d['args']
85 name = ' '.join(script + args)
86 print('Running custom dist script {!r}'.format(name))
87 try:
88 rc = subprocess.call(script + args, env=env)
89 if rc != 0:
90 sys.exit('Dist script errored out')
91 except OSError:
92 print('Failed to run dist script {!r}'.format(name))
93 sys.exit(1)
94
95
96 def git_have_dirty_index(src_root):
97 '''Check whether there are uncommitted changes in git'''
98 ret = subprocess.call(['git', '-C', src_root, 'diff-index', '--quiet', 'HEAD'])
99 return ret == 1
100
101 def create_dist_git(dist_name, src_root, bld_root, dist_sub, dist_scripts):
102 if git_have_dirty_index(src_root):
103 mlog.warning('Repository has uncommitted changes that will not be included in the dist tarball')
104 distdir = os.path.join(dist_sub, dist_name)
105 if os.path.exists(distdir):
106 shutil.rmtree(distdir)
107 os.makedirs(distdir)
108 subprocess.check_call(['git', 'clone', '--shared', src_root, distdir])
109 process_submodules(distdir)
110 del_gitfiles(distdir)
111 run_dist_scripts(distdir, dist_scripts)
112 xzname = distdir + '.tar.xz'
113 # Should use shutil but it got xz support only in 3.5.
114 with tarfile.open(xzname, 'w:xz') as tf:
115 tf.add(distdir, dist_name)
116 # Create only .tar.xz for now.
117 # zipname = distdir + '.zip'
118 # create_zip(zipname, distdir)
119 shutil.rmtree(distdir)
120 return (xzname, )
121
122
123 def hg_have_dirty_index(src_root):
124 '''Check whether there are uncommitted changes in hg'''
125 out = subprocess.check_output(['hg', '-R', src_root, 'summary'])
126 return b'commit: (clean)' not in out
127
128 def create_dist_hg(dist_name, src_root, bld_root, dist_sub, dist_scripts):
129 if hg_have_dirty_index(src_root):
130 mlog.warning('Repository has uncommitted changes that will not be included in the dist tarball')
131
132 os.makedirs(dist_sub, exist_ok=True)
133 tarname = os.path.join(dist_sub, dist_name + '.tar')
134 xzname = tarname + '.xz'
135 subprocess.check_call(['hg', 'archive', '-R', src_root, '-S', '-t', 'tar', tarname])
136 if dist_scripts:
137 mlog.warning('dist scripts are not supported in Mercurial projects')
138 with lzma.open(xzname, 'wb') as xf, open(tarname, 'rb') as tf:
139 shutil.copyfileobj(tf, xf)
140 os.unlink(tarname)
141 # Create only .tar.xz for now.
142 # zipname = os.path.join(dist_sub, dist_name + '.zip')
143 # subprocess.check_call(['hg', 'archive', '-R', src_root, '-S', '-t', 'zip', zipname])
144 return (xzname, )
145
146
147 def check_dist(packagename, meson_command):
148 print('Testing distribution package %s' % packagename)
149 unpackdir = tempfile.mkdtemp()
150 builddir = tempfile.mkdtemp()
151 installdir = tempfile.mkdtemp()
152 ninja_bin = detect_ninja()
153 try:
154 tf = tarfile.open(packagename)
155 tf.extractall(unpackdir)
156 srcdir = glob(os.path.join(unpackdir, '*'))[0]
157 if subprocess.call(meson_command + ['--backend=ninja', srcdir, builddir]) != 0:
158 print('Running Meson on distribution package failed')
159 return 1
160 if subprocess.call([ninja_bin], cwd=builddir) != 0:
161 print('Compiling the distribution package failed')
162 return 1
163 if subprocess.call([ninja_bin, 'test'], cwd=builddir) != 0:
164 print('Running unit tests on the distribution package failed')
165 return 1
166 myenv = os.environ.copy()
167 myenv['DESTDIR'] = installdir
168 if subprocess.call([ninja_bin, 'install'], cwd=builddir, env=myenv) != 0:
169 print('Installing the distribution package failed')
170 return 1
171 finally:
172 shutil.rmtree(unpackdir)
173 shutil.rmtree(builddir)
174 shutil.rmtree(installdir)
175 print('Distribution package %s tested' % packagename)
176 return 0
177
178 def run(args):
179 src_root = args[0]
180 bld_root = args[1]
181 meson_command = args[2:]
182 priv_dir = os.path.join(bld_root, 'meson-private')
183 dist_sub = os.path.join(bld_root, 'meson-dist')
184
185 buildfile = os.path.join(priv_dir, 'build.dat')
186
187 build = pickle.load(open(buildfile, 'rb'))
188
189 dist_name = build.project_name + '-' + build.project_version
190
191 _git = os.path.join(src_root, '.git')
192 if os.path.isdir(_git) or os.path.isfile(_git):
193 names = create_dist_git(dist_name, src_root, bld_root, dist_sub, build.dist_scripts)
194 elif os.path.isdir(os.path.join(src_root, '.hg')):
195 names = create_dist_hg(dist_name, src_root, bld_root, dist_sub, build.dist_scripts)
196 else:
197 print('Dist currently only works with Git or Mercurial repos')
198 return 1
199 if names is None:
200 return 1
201 error_count = 0
202 for name in names:
203 rc = check_dist(name, meson_command) # Check only one.
204 if rc == 0:
205 create_hash(name)
206 error_count += rc
207 return 1 if error_count else 0
208
[end of mesonbuild/scripts/dist.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mesonbuild/scripts/dist.py b/mesonbuild/scripts/dist.py
--- a/mesonbuild/scripts/dist.py
+++ b/mesonbuild/scripts/dist.py
@@ -144,11 +144,15 @@
return (xzname, )
-def check_dist(packagename, meson_command):
+def check_dist(packagename, meson_command, privdir):
print('Testing distribution package %s' % packagename)
- unpackdir = tempfile.mkdtemp()
- builddir = tempfile.mkdtemp()
- installdir = tempfile.mkdtemp()
+ unpackdir = os.path.join(privdir, 'dist-unpack')
+ builddir = os.path.join(privdir, 'dist-build')
+ installdir = os.path.join(privdir, 'dist-install')
+ for p in (unpackdir, builddir, installdir):
+ if os.path.exists(p):
+ shutil.rmtree(p)
+ os.mkdir(p)
ninja_bin = detect_ninja()
try:
tf = tarfile.open(packagename)
@@ -200,7 +204,7 @@
return 1
error_count = 0
for name in names:
- rc = check_dist(name, meson_command) # Check only one.
+ rc = check_dist(name, meson_command, priv_dir) # Check only one.
if rc == 0:
create_hash(name)
error_count += rc
|
{"golden_diff": "diff --git a/mesonbuild/scripts/dist.py b/mesonbuild/scripts/dist.py\n--- a/mesonbuild/scripts/dist.py\n+++ b/mesonbuild/scripts/dist.py\n@@ -144,11 +144,15 @@\n return (xzname, )\n \n \n-def check_dist(packagename, meson_command):\n+def check_dist(packagename, meson_command, privdir):\n print('Testing distribution package %s' % packagename)\n- unpackdir = tempfile.mkdtemp()\n- builddir = tempfile.mkdtemp()\n- installdir = tempfile.mkdtemp()\n+ unpackdir = os.path.join(privdir, 'dist-unpack')\n+ builddir = os.path.join(privdir, 'dist-build')\n+ installdir = os.path.join(privdir, 'dist-install')\n+ for p in (unpackdir, builddir, installdir):\n+ if os.path.exists(p):\n+ shutil.rmtree(p)\n+ os.mkdir(p)\n ninja_bin = detect_ninja()\n try:\n tf = tarfile.open(packagename)\n@@ -200,7 +204,7 @@\n return 1\n error_count = 0\n for name in names:\n- rc = check_dist(name, meson_command) # Check only one.\n+ rc = check_dist(name, meson_command, priv_dir) # Check only one.\n if rc == 0:\n create_hash(name)\n error_count += rc\n", "issue": "ccache cannot work on dist builds\nDue to how the dist build is implemented in Meson, it will always result in ccache being unable to work.\r\n\r\nThe reason for this is the forced use of `mkdtemp` for directories within the `check_dist` function (in `dist.py`). The source is unpacked into `$tmpdir/tmp$string` which is random and thus unable to produce cache hits for subsequent builds. If I am trying to do e.g., a CI dist build, this is not ideal since it makes the build very long.\r\n\r\nThere are two possible solutions I've come up with which could solve the issue:\r\n* Add a `DISTBUILDDIR` (or similar) environment variable which is used instead of `mkdtemp` during a dist build; this directory would take the place of the `mkdtemp` directories and would not be deleted when the build stopped\r\n* Add a `TMPBUILDSTRING` (or similar) environment variable which is used in place of the random part of the tempdir string (resulting in e.g., /tmp/tmp$string); this directory can still be created and deleted normally, or even deleted if it already exists since we can assume this should only be used for meson dist builds\r\n\r\nOther solutions would be great too, as long as ccache becomes usable.\n", "before_files": [{"content": "# Copyright 2017 The Meson development team\n\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n\n# http://www.apache.org/licenses/LICENSE-2.0\n\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nimport lzma\nimport os\nimport sys\nimport shutil\nimport subprocess\nimport pickle\nimport hashlib\nimport tarfile, zipfile\nimport tempfile\nfrom glob import glob\nfrom mesonbuild.environment import detect_ninja\nfrom mesonbuild.mesonlib import windows_proof_rmtree\nfrom mesonbuild import mlog\n\ndef create_hash(fname):\n hashname = fname + '.sha256sum'\n m = hashlib.sha256()\n m.update(open(fname, 'rb').read())\n with open(hashname, 'w') as f:\n f.write('%s %s\\n' % (m.hexdigest(), os.path.basename(fname)))\n\n\ndef create_zip(zipfilename, packaging_dir):\n prefix = os.path.dirname(packaging_dir)\n removelen = len(prefix) + 1\n with zipfile.ZipFile(zipfilename,\n 'w',\n compression=zipfile.ZIP_DEFLATED,\n allowZip64=True) as zf:\n zf.write(packaging_dir, packaging_dir[removelen:])\n for root, dirs, files in os.walk(packaging_dir):\n for d in dirs:\n dname = os.path.join(root, d)\n zf.write(dname, dname[removelen:])\n for f in files:\n fname = os.path.join(root, f)\n zf.write(fname, fname[removelen:])\n\ndef del_gitfiles(dirname):\n for f in glob(os.path.join(dirname, '.git*')):\n if os.path.isdir(f) and not os.path.islink(f):\n windows_proof_rmtree(f)\n else:\n os.unlink(f)\n\ndef process_submodules(dirname):\n module_file = os.path.join(dirname, '.gitmodules')\n if not os.path.exists(module_file):\n return\n subprocess.check_call(['git', 'submodule', 'update', '--init', '--recursive'], cwd=dirname)\n for line in open(module_file):\n line = line.strip()\n if '=' not in line:\n continue\n k, v = line.split('=', 1)\n k = k.strip()\n v = v.strip()\n if k != 'path':\n continue\n del_gitfiles(os.path.join(dirname, v))\n\n\ndef run_dist_scripts(dist_root, dist_scripts):\n assert(os.path.isabs(dist_root))\n env = os.environ.copy()\n env['MESON_DIST_ROOT'] = dist_root\n for d in dist_scripts:\n script = d['exe']\n args = d['args']\n name = ' '.join(script + args)\n print('Running custom dist script {!r}'.format(name))\n try:\n rc = subprocess.call(script + args, env=env)\n if rc != 0:\n sys.exit('Dist script errored out')\n except OSError:\n print('Failed to run dist script {!r}'.format(name))\n sys.exit(1)\n\n\ndef git_have_dirty_index(src_root):\n '''Check whether there are uncommitted changes in git'''\n ret = subprocess.call(['git', '-C', src_root, 'diff-index', '--quiet', 'HEAD'])\n return ret == 1\n\ndef create_dist_git(dist_name, src_root, bld_root, dist_sub, dist_scripts):\n if git_have_dirty_index(src_root):\n mlog.warning('Repository has uncommitted changes that will not be included in the dist tarball')\n distdir = os.path.join(dist_sub, dist_name)\n if os.path.exists(distdir):\n shutil.rmtree(distdir)\n os.makedirs(distdir)\n subprocess.check_call(['git', 'clone', '--shared', src_root, distdir])\n process_submodules(distdir)\n del_gitfiles(distdir)\n run_dist_scripts(distdir, dist_scripts)\n xzname = distdir + '.tar.xz'\n # Should use shutil but it got xz support only in 3.5.\n with tarfile.open(xzname, 'w:xz') as tf:\n tf.add(distdir, dist_name)\n # Create only .tar.xz for now.\n # zipname = distdir + '.zip'\n # create_zip(zipname, distdir)\n shutil.rmtree(distdir)\n return (xzname, )\n\n\ndef hg_have_dirty_index(src_root):\n '''Check whether there are uncommitted changes in hg'''\n out = subprocess.check_output(['hg', '-R', src_root, 'summary'])\n return b'commit: (clean)' not in out\n\ndef create_dist_hg(dist_name, src_root, bld_root, dist_sub, dist_scripts):\n if hg_have_dirty_index(src_root):\n mlog.warning('Repository has uncommitted changes that will not be included in the dist tarball')\n\n os.makedirs(dist_sub, exist_ok=True)\n tarname = os.path.join(dist_sub, dist_name + '.tar')\n xzname = tarname + '.xz'\n subprocess.check_call(['hg', 'archive', '-R', src_root, '-S', '-t', 'tar', tarname])\n if dist_scripts:\n mlog.warning('dist scripts are not supported in Mercurial projects')\n with lzma.open(xzname, 'wb') as xf, open(tarname, 'rb') as tf:\n shutil.copyfileobj(tf, xf)\n os.unlink(tarname)\n # Create only .tar.xz for now.\n # zipname = os.path.join(dist_sub, dist_name + '.zip')\n # subprocess.check_call(['hg', 'archive', '-R', src_root, '-S', '-t', 'zip', zipname])\n return (xzname, )\n\n\ndef check_dist(packagename, meson_command):\n print('Testing distribution package %s' % packagename)\n unpackdir = tempfile.mkdtemp()\n builddir = tempfile.mkdtemp()\n installdir = tempfile.mkdtemp()\n ninja_bin = detect_ninja()\n try:\n tf = tarfile.open(packagename)\n tf.extractall(unpackdir)\n srcdir = glob(os.path.join(unpackdir, '*'))[0]\n if subprocess.call(meson_command + ['--backend=ninja', srcdir, builddir]) != 0:\n print('Running Meson on distribution package failed')\n return 1\n if subprocess.call([ninja_bin], cwd=builddir) != 0:\n print('Compiling the distribution package failed')\n return 1\n if subprocess.call([ninja_bin, 'test'], cwd=builddir) != 0:\n print('Running unit tests on the distribution package failed')\n return 1\n myenv = os.environ.copy()\n myenv['DESTDIR'] = installdir\n if subprocess.call([ninja_bin, 'install'], cwd=builddir, env=myenv) != 0:\n print('Installing the distribution package failed')\n return 1\n finally:\n shutil.rmtree(unpackdir)\n shutil.rmtree(builddir)\n shutil.rmtree(installdir)\n print('Distribution package %s tested' % packagename)\n return 0\n\ndef run(args):\n src_root = args[0]\n bld_root = args[1]\n meson_command = args[2:]\n priv_dir = os.path.join(bld_root, 'meson-private')\n dist_sub = os.path.join(bld_root, 'meson-dist')\n\n buildfile = os.path.join(priv_dir, 'build.dat')\n\n build = pickle.load(open(buildfile, 'rb'))\n\n dist_name = build.project_name + '-' + build.project_version\n\n _git = os.path.join(src_root, '.git')\n if os.path.isdir(_git) or os.path.isfile(_git):\n names = create_dist_git(dist_name, src_root, bld_root, dist_sub, build.dist_scripts)\n elif os.path.isdir(os.path.join(src_root, '.hg')):\n names = create_dist_hg(dist_name, src_root, bld_root, dist_sub, build.dist_scripts)\n else:\n print('Dist currently only works with Git or Mercurial repos')\n return 1\n if names is None:\n return 1\n error_count = 0\n for name in names:\n rc = check_dist(name, meson_command) # Check only one.\n if rc == 0:\n create_hash(name)\n error_count += rc\n return 1 if error_count else 0\n", "path": "mesonbuild/scripts/dist.py"}]}
| 3,259 | 328 |
gh_patches_debug_20082
|
rasdani/github-patches
|
git_diff
|
deepchecks__deepchecks-600
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] Top Trust Score Samples produces an error
**Describe the bug**
The `Top Trust Score Samples` check produces an error. The full stack trace of the error is attached below.
**To Reproduce**
Checkout my `urlnb` branch, which is up-to-date with `main` at the moment of opening this issue, and run the `deepchecks/deepchecks/docs/source/examples/use-cases/phishing_urls.ipynb` notebook.
The full stack trace of the error is attached below.
**Expected behavior**
The `Top Trust Score Samples` check should render correctly, as it did up until now.
**Screenshots**
If applicable, add screenshots to help explain your problem.
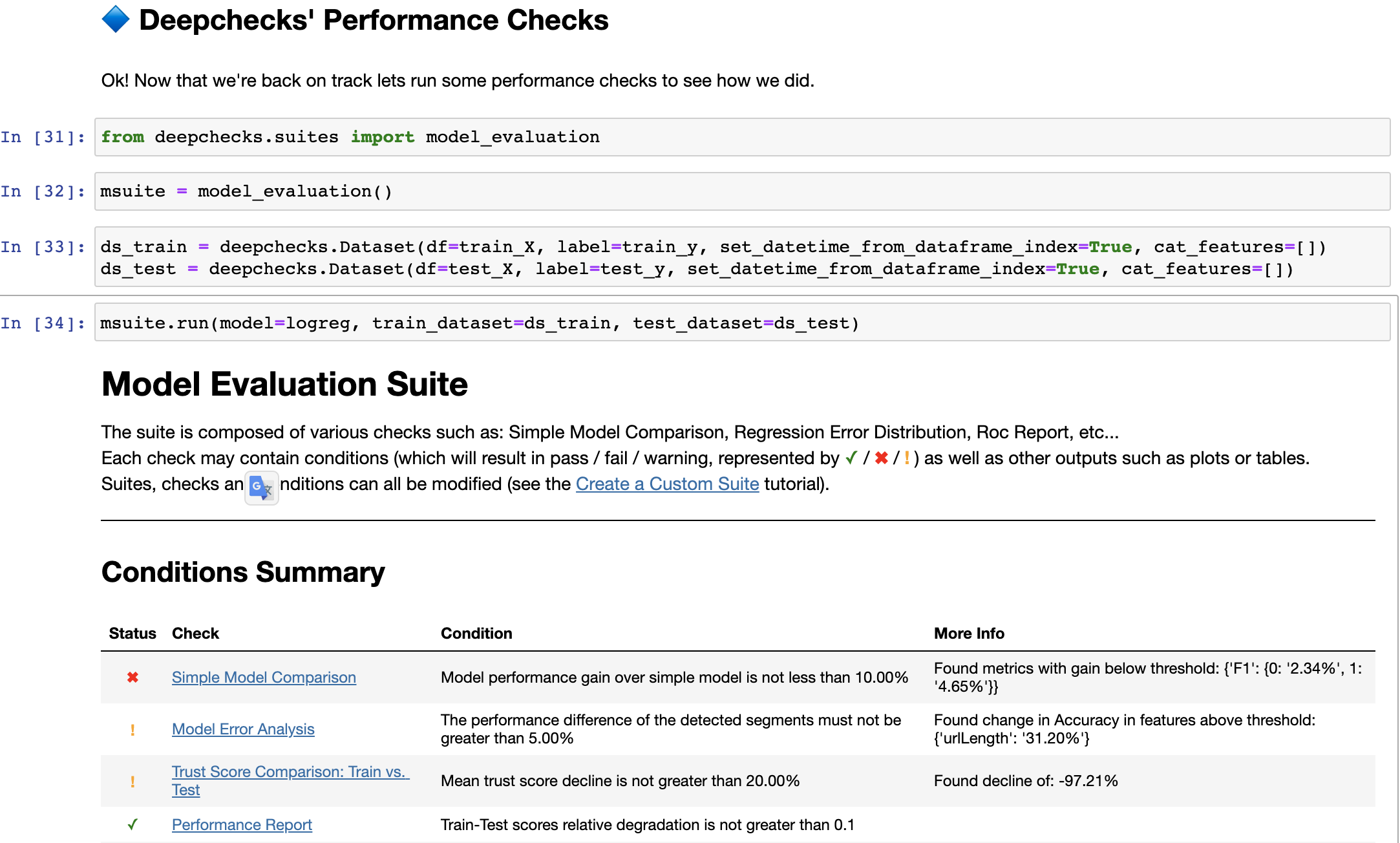
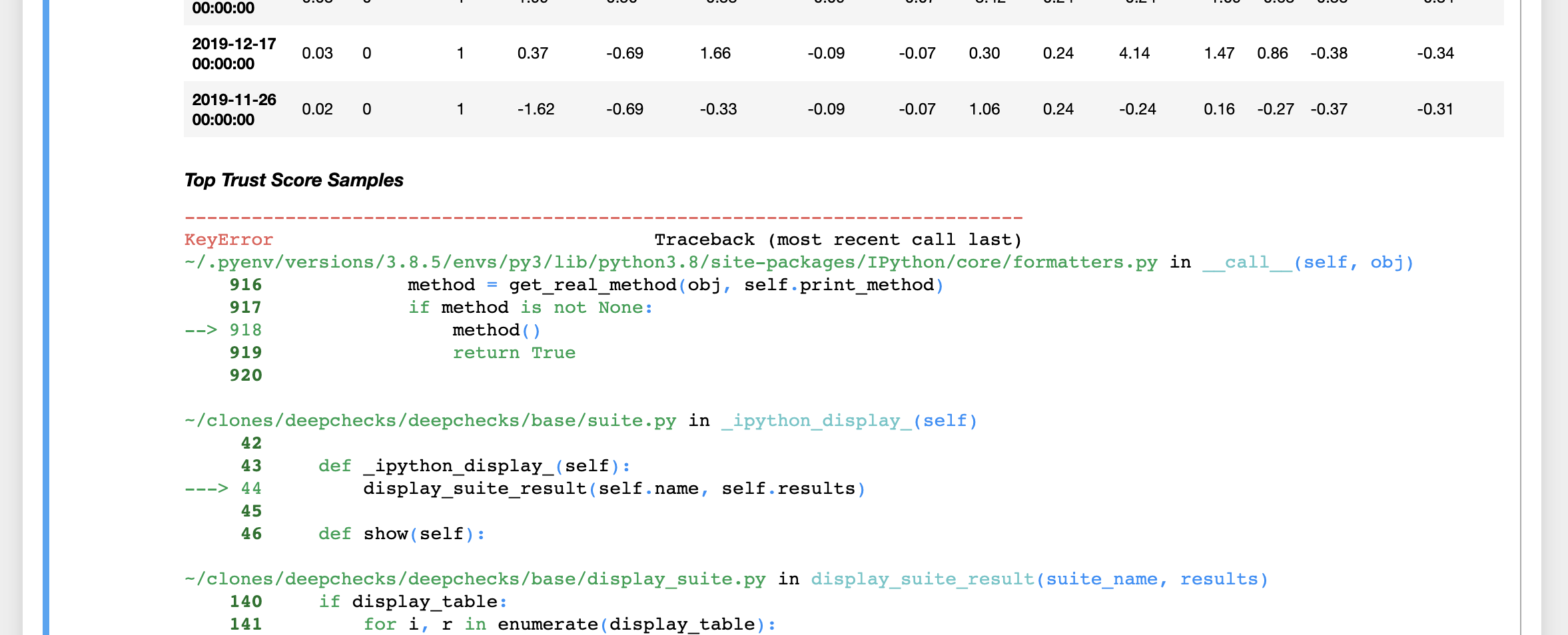
**Environment (please complete the following information):**
- OS: macOS Big Sur 11.6.1
- Python Version: 3.8.5
- Deepchecks Version: Latest commit on the `urlnb` branch.
**Additional context**
Log here:
```python
Top Trust Score Samples
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
~/.pyenv/versions/3.8.5/envs/py3/lib/python3.8/site-packages/IPython/core/formatters.py in __call__(self, obj)
916 method = get_real_method(obj, self.print_method)
917 if method is not None:
--> 918 method()
919 return True
920
~/clones/deepchecks/deepchecks/base/suite.py in _ipython_display_(self)
42
43 def _ipython_display_(self):
---> 44 display_suite_result(self.name, self.results)
45
46 def show(self):
~/clones/deepchecks/deepchecks/base/display_suite.py in display_suite_result(suite_name, results)
140 if display_table:
141 for i, r in enumerate(display_table):
--> 142 r.show(show_conditions=False, unique_id=unique_id)
143 if i < len(display_table) - 1:
144 display_html(light_hr, raw=True)
~/clones/deepchecks/deepchecks/base/check.py in show(self, show_conditions, unique_id)
173 """Display check result."""
174 if is_ipython_display():
--> 175 self._ipython_display_(show_conditions=show_conditions, unique_id=unique_id)
176 else:
177 print(self)
~/clones/deepchecks/deepchecks/base/check.py in _ipython_display_(self, show_conditions, unique_id)
103 for item in self.display:
104 if isinstance(item, (pd.DataFrame, Styler)):
--> 105 display_dataframe(item)
106 elif isinstance(item, str):
107 display_html(item, raw=True)
~/clones/deepchecks/deepchecks/base/display_pandas.py in display_dataframe(df)
29 df (Union[pd.DataFrame, Styler]): Dataframe to display
30 """
---> 31 display_html(dataframe_to_html(df), raw=True)
32
33
~/clones/deepchecks/deepchecks/base/display_pandas.py in dataframe_to_html(df)
53 # https://developer.mozilla.org/en-US/docs/Web/CSS/white-space#values
54 df_styler.set_properties(**{'white-space': 'pre-wrap'})
---> 55 return df_styler.render()
56 # Because of MLC-154. Dataframe with Multi-index or non unique indices does not have a style
57 # attribute, hence we need to display as a regular pd html format.
~/.pyenv/versions/3.8.5/envs/py3/lib/python3.8/site-packages/pandas/io/formats/style.py in render(self, sparse_index, sparse_columns, **kwargs)
270 if sparse_columns is None:
271 sparse_columns = get_option("styler.sparse.columns")
--> 272 return self._render_html(sparse_index, sparse_columns, **kwargs)
273
274 def set_tooltips(
~/.pyenv/versions/3.8.5/envs/py3/lib/python3.8/site-packages/pandas/io/formats/style_render.py in _render_html(self, sparse_index, sparse_columns, **kwargs)
119 Generates a dict with necessary kwargs passed to jinja2 template.
120 """
--> 121 self._compute()
122 # TODO: namespace all the pandas keys
123 d = self._translate(sparse_index, sparse_columns)
~/.pyenv/versions/3.8.5/envs/py3/lib/python3.8/site-packages/pandas/io/formats/style_render.py in _compute(self)
158 r = self
159 for func, args, kwargs in self._todo:
--> 160 r = func(self)(*args, **kwargs)
161 return r
162
~/.pyenv/versions/3.8.5/envs/py3/lib/python3.8/site-packages/pandas/io/formats/style.py in _applymap(self, func, subset, **kwargs)
1171 subset = non_reducing_slice(subset)
1172 result = self.data.loc[subset].applymap(func)
-> 1173 self._update_ctx(result)
1174 return self
1175
~/.pyenv/versions/3.8.5/envs/py3/lib/python3.8/site-packages/pandas/io/formats/style.py in _update_ctx(self, attrs)
953 """
954 if not self.index.is_unique or not self.columns.is_unique:
--> 955 raise KeyError(
956 "`Styler.apply` and `.applymap` are not compatible "
957 "with non-unique index or columns."
KeyError: '`Styler.apply` and `.applymap` are not compatible with non-unique index or columns.'
Model Evaluation Suite
```
</issue>
<code>
[start of deepchecks/base/display_pandas.py]
1 # ----------------------------------------------------------------------------
2 # Copyright (C) 2021 Deepchecks (https://www.deepchecks.com)
3 #
4 # This file is part of Deepchecks.
5 # Deepchecks is distributed under the terms of the GNU Affero General
6 # Public License (version 3 or later).
7 # You should have received a copy of the GNU Affero General Public License
8 # along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.
9 # ----------------------------------------------------------------------------
10 #
11 """Handle displays of pandas objects."""
12 from typing import List, Union
13 import warnings
14
15 from IPython.core.display import display_html
16 import pandas as pd
17 from pandas.io.formats.style import Styler
18
19 from . import check # pylint: disable=unused-import
20
21
22 __all__ = ['display_dataframe', 'dataframe_to_html', 'display_conditions_table']
23
24
25 def display_dataframe(df: Union[pd.DataFrame, Styler]):
26 """Display in IPython given dataframe.
27
28 Args:
29 df (Union[pd.DataFrame, Styler]): Dataframe to display
30 """
31 display_html(dataframe_to_html(df), raw=True)
32
33
34 def dataframe_to_html(df: Union[pd.DataFrame, Styler]):
35 """Convert dataframe to html.
36
37 Args:
38 df (Union[pd.DataFrame, Styler]): Dataframe to convert to html
39 """
40 try:
41 if isinstance(df, pd.DataFrame):
42 df_styler = df.style
43 else:
44 df_styler = df
45 # Using deprecated pandas method so hiding the warning
46 with warnings.catch_warnings():
47 warnings.simplefilter(action='ignore', category=FutureWarning)
48 df_styler.set_precision(2)
49
50 # Align everything to the left
51 df_styler.set_table_styles([dict(selector='table,thead,tbody,th,td', props=[('text-align', 'left')])])
52 # Define how to handle white space characters (like \n)
53 # https://developer.mozilla.org/en-US/docs/Web/CSS/white-space#values
54 df_styler.set_properties(**{'white-space': 'pre-wrap'})
55 return df_styler.render()
56 # Because of MLC-154. Dataframe with Multi-index or non unique indices does not have a style
57 # attribute, hence we need to display as a regular pd html format.
58 except ValueError:
59 return df.to_html()
60
61
62 def display_conditions_table(check_results: Union['check.CheckResult', List['check.CheckResult']],
63 unique_id=None):
64 """Display the conditions table as DataFrame.
65
66 Args:
67 check_results (Union['CheckResult', List['CheckResult']]): check results to show conditions of.
68 unique_id (str): the unique id to append for the check names to create links
69 (won't create links if None/empty).
70 """
71 if not isinstance(check_results, List):
72 show_check_column = False
73 check_results = [check_results]
74 else:
75 show_check_column = True
76
77 table = []
78 for check_result in check_results:
79 for cond_result in check_result.conditions_results:
80 sort_value = cond_result.priority
81 icon = cond_result.get_icon()
82 check_header = check_result.get_header()
83 if unique_id and check_result.have_display():
84 check_id = f'{check_result.check.__class__.__name__}_{unique_id}'
85 link = f'<a href=#{check_id}>{check_header}</a>'
86 else:
87 link = check_header
88 sort_value = 1 if sort_value == 1 else 5 # if it failed but has no display still show on top
89 table.append([icon, link, cond_result.name,
90 cond_result.details, sort_value])
91
92 conditions_table = pd.DataFrame(data=table,
93 columns=['Status', 'Check', 'Condition', 'More Info', 'sort'])
94 conditions_table.sort_values(by=['sort'], inplace=True)
95 conditions_table.drop('sort', axis=1, inplace=True)
96 if show_check_column is False:
97 conditions_table.drop('Check', axis=1, inplace=True)
98 display_dataframe(conditions_table.style.hide_index())
99
[end of deepchecks/base/display_pandas.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/deepchecks/base/display_pandas.py b/deepchecks/base/display_pandas.py
--- a/deepchecks/base/display_pandas.py
+++ b/deepchecks/base/display_pandas.py
@@ -47,11 +47,11 @@
warnings.simplefilter(action='ignore', category=FutureWarning)
df_styler.set_precision(2)
- # Align everything to the left
- df_styler.set_table_styles([dict(selector='table,thead,tbody,th,td', props=[('text-align', 'left')])])
- # Define how to handle white space characters (like \n)
- # https://developer.mozilla.org/en-US/docs/Web/CSS/white-space#values
- df_styler.set_properties(**{'white-space': 'pre-wrap'})
+ table_css_props = [
+ ('text-align', 'left'), # Align everything to the left
+ ('white-space', 'pre-wrap') # Define how to handle white space characters (like \n)
+ ]
+ df_styler.set_table_styles([dict(selector='table,thead,tbody,th,td', props=table_css_props)])
return df_styler.render()
# Because of MLC-154. Dataframe with Multi-index or non unique indices does not have a style
# attribute, hence we need to display as a regular pd html format.
|
{"golden_diff": "diff --git a/deepchecks/base/display_pandas.py b/deepchecks/base/display_pandas.py\n--- a/deepchecks/base/display_pandas.py\n+++ b/deepchecks/base/display_pandas.py\n@@ -47,11 +47,11 @@\n warnings.simplefilter(action='ignore', category=FutureWarning)\n df_styler.set_precision(2)\n \n- # Align everything to the left\n- df_styler.set_table_styles([dict(selector='table,thead,tbody,th,td', props=[('text-align', 'left')])])\n- # Define how to handle white space characters (like \\n)\n- # https://developer.mozilla.org/en-US/docs/Web/CSS/white-space#values\n- df_styler.set_properties(**{'white-space': 'pre-wrap'})\n+ table_css_props = [\n+ ('text-align', 'left'), # Align everything to the left\n+ ('white-space', 'pre-wrap') # Define how to handle white space characters (like \\n)\n+ ]\n+ df_styler.set_table_styles([dict(selector='table,thead,tbody,th,td', props=table_css_props)])\n return df_styler.render()\n # Because of MLC-154. Dataframe with Multi-index or non unique indices does not have a style\n # attribute, hence we need to display as a regular pd html format.\n", "issue": "[BUG] Top Trust Score Samples produces an error\n**Describe the bug**\r\nThe `Top Trust Score Samples` check produces an error. The full stack trace of the error is attached below.\r\n\r\n**To Reproduce**\r\nCheckout my `urlnb` branch, which is up-to-date with `main` at the moment of opening this issue, and run the `deepchecks/deepchecks/docs/source/examples/use-cases/phishing_urls.ipynb` notebook.\r\n\r\nThe full stack trace of the error is attached below.\r\n\r\n**Expected behavior**\r\nThe `Top Trust Score Samples` check should render correctly, as it did up until now.\r\n\r\n**Screenshots**\r\nIf applicable, add screenshots to help explain your problem.\r\n\r\n\r\n\r\n\r\n**Environment (please complete the following information):**\r\n - OS: macOS Big Sur 11.6.1 \r\n - Python Version: 3.8.5\r\n - Deepchecks Version: Latest commit on the `urlnb` branch.\r\n\r\n**Additional context**\r\nLog here:\r\n```python\r\nTop Trust Score Samples\r\n---------------------------------------------------------------------------\r\nKeyError Traceback (most recent call last)\r\n~/.pyenv/versions/3.8.5/envs/py3/lib/python3.8/site-packages/IPython/core/formatters.py in __call__(self, obj)\r\n 916 method = get_real_method(obj, self.print_method)\r\n 917 if method is not None:\r\n--> 918 method()\r\n 919 return True\r\n 920 \r\n\r\n~/clones/deepchecks/deepchecks/base/suite.py in _ipython_display_(self)\r\n 42 \r\n 43 def _ipython_display_(self):\r\n---> 44 display_suite_result(self.name, self.results)\r\n 45 \r\n 46 def show(self):\r\n\r\n~/clones/deepchecks/deepchecks/base/display_suite.py in display_suite_result(suite_name, results)\r\n 140 if display_table:\r\n 141 for i, r in enumerate(display_table):\r\n--> 142 r.show(show_conditions=False, unique_id=unique_id)\r\n 143 if i < len(display_table) - 1:\r\n 144 display_html(light_hr, raw=True)\r\n\r\n~/clones/deepchecks/deepchecks/base/check.py in show(self, show_conditions, unique_id)\r\n 173 \"\"\"Display check result.\"\"\"\r\n 174 if is_ipython_display():\r\n--> 175 self._ipython_display_(show_conditions=show_conditions, unique_id=unique_id)\r\n 176 else:\r\n 177 print(self)\r\n\r\n~/clones/deepchecks/deepchecks/base/check.py in _ipython_display_(self, show_conditions, unique_id)\r\n 103 for item in self.display:\r\n 104 if isinstance(item, (pd.DataFrame, Styler)):\r\n--> 105 display_dataframe(item)\r\n 106 elif isinstance(item, str):\r\n 107 display_html(item, raw=True)\r\n\r\n~/clones/deepchecks/deepchecks/base/display_pandas.py in display_dataframe(df)\r\n 29 df (Union[pd.DataFrame, Styler]): Dataframe to display\r\n 30 \"\"\"\r\n---> 31 display_html(dataframe_to_html(df), raw=True)\r\n 32 \r\n 33 \r\n\r\n~/clones/deepchecks/deepchecks/base/display_pandas.py in dataframe_to_html(df)\r\n 53 # https://developer.mozilla.org/en-US/docs/Web/CSS/white-space#values\r\n 54 df_styler.set_properties(**{'white-space': 'pre-wrap'})\r\n---> 55 return df_styler.render()\r\n 56 # Because of MLC-154. Dataframe with Multi-index or non unique indices does not have a style\r\n 57 # attribute, hence we need to display as a regular pd html format.\r\n\r\n~/.pyenv/versions/3.8.5/envs/py3/lib/python3.8/site-packages/pandas/io/formats/style.py in render(self, sparse_index, sparse_columns, **kwargs)\r\n 270 if sparse_columns is None:\r\n 271 sparse_columns = get_option(\"styler.sparse.columns\")\r\n--> 272 return self._render_html(sparse_index, sparse_columns, **kwargs)\r\n 273 \r\n 274 def set_tooltips(\r\n\r\n~/.pyenv/versions/3.8.5/envs/py3/lib/python3.8/site-packages/pandas/io/formats/style_render.py in _render_html(self, sparse_index, sparse_columns, **kwargs)\r\n 119 Generates a dict with necessary kwargs passed to jinja2 template.\r\n 120 \"\"\"\r\n--> 121 self._compute()\r\n 122 # TODO: namespace all the pandas keys\r\n 123 d = self._translate(sparse_index, sparse_columns)\r\n\r\n~/.pyenv/versions/3.8.5/envs/py3/lib/python3.8/site-packages/pandas/io/formats/style_render.py in _compute(self)\r\n 158 r = self\r\n 159 for func, args, kwargs in self._todo:\r\n--> 160 r = func(self)(*args, **kwargs)\r\n 161 return r\r\n 162 \r\n\r\n~/.pyenv/versions/3.8.5/envs/py3/lib/python3.8/site-packages/pandas/io/formats/style.py in _applymap(self, func, subset, **kwargs)\r\n 1171 subset = non_reducing_slice(subset)\r\n 1172 result = self.data.loc[subset].applymap(func)\r\n-> 1173 self._update_ctx(result)\r\n 1174 return self\r\n 1175 \r\n\r\n~/.pyenv/versions/3.8.5/envs/py3/lib/python3.8/site-packages/pandas/io/formats/style.py in _update_ctx(self, attrs)\r\n 953 \"\"\"\r\n 954 if not self.index.is_unique or not self.columns.is_unique:\r\n--> 955 raise KeyError(\r\n 956 \"`Styler.apply` and `.applymap` are not compatible \"\r\n 957 \"with non-unique index or columns.\"\r\n\r\nKeyError: '`Styler.apply` and `.applymap` are not compatible with non-unique index or columns.'\r\n\r\nModel Evaluation Suite\r\n```\r\n\n", "before_files": [{"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\n\"\"\"Handle displays of pandas objects.\"\"\"\nfrom typing import List, Union\nimport warnings\n\nfrom IPython.core.display import display_html\nimport pandas as pd\nfrom pandas.io.formats.style import Styler\n\nfrom . import check # pylint: disable=unused-import\n\n\n__all__ = ['display_dataframe', 'dataframe_to_html', 'display_conditions_table']\n\n\ndef display_dataframe(df: Union[pd.DataFrame, Styler]):\n \"\"\"Display in IPython given dataframe.\n\n Args:\n df (Union[pd.DataFrame, Styler]): Dataframe to display\n \"\"\"\n display_html(dataframe_to_html(df), raw=True)\n\n\ndef dataframe_to_html(df: Union[pd.DataFrame, Styler]):\n \"\"\"Convert dataframe to html.\n\n Args:\n df (Union[pd.DataFrame, Styler]): Dataframe to convert to html\n \"\"\"\n try:\n if isinstance(df, pd.DataFrame):\n df_styler = df.style\n else:\n df_styler = df\n # Using deprecated pandas method so hiding the warning\n with warnings.catch_warnings():\n warnings.simplefilter(action='ignore', category=FutureWarning)\n df_styler.set_precision(2)\n\n # Align everything to the left\n df_styler.set_table_styles([dict(selector='table,thead,tbody,th,td', props=[('text-align', 'left')])])\n # Define how to handle white space characters (like \\n)\n # https://developer.mozilla.org/en-US/docs/Web/CSS/white-space#values\n df_styler.set_properties(**{'white-space': 'pre-wrap'})\n return df_styler.render()\n # Because of MLC-154. Dataframe with Multi-index or non unique indices does not have a style\n # attribute, hence we need to display as a regular pd html format.\n except ValueError:\n return df.to_html()\n\n\ndef display_conditions_table(check_results: Union['check.CheckResult', List['check.CheckResult']],\n unique_id=None):\n \"\"\"Display the conditions table as DataFrame.\n\n Args:\n check_results (Union['CheckResult', List['CheckResult']]): check results to show conditions of.\n unique_id (str): the unique id to append for the check names to create links\n (won't create links if None/empty).\n \"\"\"\n if not isinstance(check_results, List):\n show_check_column = False\n check_results = [check_results]\n else:\n show_check_column = True\n\n table = []\n for check_result in check_results:\n for cond_result in check_result.conditions_results:\n sort_value = cond_result.priority\n icon = cond_result.get_icon()\n check_header = check_result.get_header()\n if unique_id and check_result.have_display():\n check_id = f'{check_result.check.__class__.__name__}_{unique_id}'\n link = f'<a href=#{check_id}>{check_header}</a>'\n else:\n link = check_header\n sort_value = 1 if sort_value == 1 else 5 # if it failed but has no display still show on top\n table.append([icon, link, cond_result.name,\n cond_result.details, sort_value])\n\n conditions_table = pd.DataFrame(data=table,\n columns=['Status', 'Check', 'Condition', 'More Info', 'sort'])\n conditions_table.sort_values(by=['sort'], inplace=True)\n conditions_table.drop('sort', axis=1, inplace=True)\n if show_check_column is False:\n conditions_table.drop('Check', axis=1, inplace=True)\n display_dataframe(conditions_table.style.hide_index())\n", "path": "deepchecks/base/display_pandas.py"}]}
| 3,130 | 307 |
gh_patches_debug_3684
|
rasdani/github-patches
|
git_diff
|
napari__napari-5474
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Visual Bug: Labels Layer Controls get squished when toggling 3D
## 🐛 Bug
When toggling to 3D, the labels layer Layer Controls widget gains an extra line `rendering`.
However the widget doesn't resize for this, so it results in a visual bug of everything squished and partially cut off:
<img width="267" alt="image" src="https://user-images.githubusercontent.com/76622105/212083289-a7333963-f66a-4875-bd11-e49965ef7a77.png">
If you manually expand the widget, it will look fine. However, in contrast to the 2D version of the widget, it will let you resize it vertically to be too small, squishing the contents again.
## To Reproduce
Steps to reproduce the behavior:
1. open napari
2. make a labels layer (can be empty)
3. toggle 3D
<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->
## Expected behavior
The widget should either resize to permit the extra line item or start out sufficiently large that when the line item is added the visual isn't squished.
## Environment
macOS 13.1, pyqt5, 0.4.17
## Additional context
<!-- Add any other context about the problem here. -->
</issue>
<code>
[start of napari/_qt/layer_controls/qt_layer_controls_container.py]
1 from qtpy.QtWidgets import QFrame, QStackedWidget
2
3 from napari._qt.layer_controls.qt_image_controls import QtImageControls
4 from napari._qt.layer_controls.qt_labels_controls import QtLabelsControls
5 from napari._qt.layer_controls.qt_points_controls import QtPointsControls
6 from napari._qt.layer_controls.qt_shapes_controls import QtShapesControls
7 from napari._qt.layer_controls.qt_surface_controls import QtSurfaceControls
8 from napari._qt.layer_controls.qt_tracks_controls import QtTracksControls
9 from napari._qt.layer_controls.qt_vectors_controls import QtVectorsControls
10 from napari.layers import (
11 Image,
12 Labels,
13 Points,
14 Shapes,
15 Surface,
16 Tracks,
17 Vectors,
18 )
19 from napari.utils import config
20 from napari.utils.translations import trans
21
22 layer_to_controls = {
23 Labels: QtLabelsControls,
24 Image: QtImageControls,
25 Points: QtPointsControls,
26 Shapes: QtShapesControls,
27 Surface: QtSurfaceControls,
28 Vectors: QtVectorsControls,
29 Tracks: QtTracksControls,
30 }
31
32 if config.async_loading:
33 from napari.layers.image.experimental.octree_image import _OctreeImageBase
34
35 # The user visible layer controls for OctreeImage layers are identical
36 # to the regular image layer controls, for now.
37 layer_to_controls[_OctreeImageBase] = QtImageControls
38
39
40 def create_qt_layer_controls(layer):
41 """
42 Create a qt controls widget for a layer based on its layer type.
43
44 In case of a subclass, the type higher in the layer's method resolution
45 order will be used.
46
47 Parameters
48 ----------
49 layer : napari.layers._base_layer.Layer
50 Layer that needs its controls widget created.
51
52 Returns
53 -------
54 controls : napari.layers.base.QtLayerControls
55 Qt controls widget
56 """
57 candidates = []
58 for layer_type in layer_to_controls:
59 if isinstance(layer, layer_type):
60 candidates.append(layer_type)
61
62 if not candidates:
63 raise TypeError(
64 trans._(
65 'Could not find QtControls for layer of type {type_}',
66 deferred=True,
67 type_=type(layer),
68 )
69 )
70
71 layer_cls = layer.__class__
72 # Sort the list of candidates by 'lineage'
73 candidates.sort(key=lambda layer_type: layer_cls.mro().index(layer_type))
74 controls = layer_to_controls[candidates[0]]
75 return controls(layer)
76
77
78 class QtLayerControlsContainer(QStackedWidget):
79 """Container widget for QtLayerControl widgets.
80
81 Parameters
82 ----------
83 viewer : napari.components.ViewerModel
84 Napari viewer containing the rendered scene, layers, and controls.
85
86 Attributes
87 ----------
88 empty_widget : qtpy.QtWidgets.QFrame
89 Empty placeholder frame for when no layer is selected.
90 viewer : napari.components.ViewerModel
91 Napari viewer containing the rendered scene, layers, and controls.
92 widgets : dict
93 Dictionary of key value pairs matching layer with its widget controls.
94 widgets[layer] = controls
95 """
96
97 def __init__(self, viewer):
98 super().__init__()
99 self.setProperty("emphasized", True)
100 self.viewer = viewer
101
102 self.setMouseTracking(True)
103 self.empty_widget = QFrame()
104 self.widgets = {}
105 self.addWidget(self.empty_widget)
106 self.setCurrentWidget(self.empty_widget)
107
108 self.viewer.layers.events.inserted.connect(self._add)
109 self.viewer.layers.events.removed.connect(self._remove)
110 viewer.layers.selection.events.active.connect(self._display)
111
112 def _display(self, event):
113 """Change the displayed controls to be those of the target layer.
114
115 Parameters
116 ----------
117 event : Event
118 Event with the target layer at `event.item`.
119 """
120 layer = event.value
121 if layer is None:
122 self.setCurrentWidget(self.empty_widget)
123 else:
124 controls = self.widgets[layer]
125 self.setCurrentWidget(controls)
126
127 def _add(self, event):
128 """Add the controls target layer to the list of control widgets.
129
130 Parameters
131 ----------
132 event : Event
133 Event with the target layer at `event.value`.
134 """
135 layer = event.value
136 controls = create_qt_layer_controls(layer)
137 self.addWidget(controls)
138 self.widgets[layer] = controls
139
140 def _remove(self, event):
141 """Remove the controls target layer from the list of control widgets.
142
143 Parameters
144 ----------
145 event : Event
146 Event with the target layer at `event.value`.
147 """
148 layer = event.value
149 controls = self.widgets[layer]
150 self.removeWidget(controls)
151 # controls.close()
152 controls.hide()
153 controls.deleteLater()
154 controls = None
155 del self.widgets[layer]
156
[end of napari/_qt/layer_controls/qt_layer_controls_container.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/napari/_qt/layer_controls/qt_layer_controls_container.py b/napari/_qt/layer_controls/qt_layer_controls_container.py
--- a/napari/_qt/layer_controls/qt_layer_controls_container.py
+++ b/napari/_qt/layer_controls/qt_layer_controls_container.py
@@ -101,6 +101,7 @@
self.setMouseTracking(True)
self.empty_widget = QFrame()
+ self.empty_widget.setObjectName("empty_controls_widget")
self.widgets = {}
self.addWidget(self.empty_widget)
self.setCurrentWidget(self.empty_widget)
|
{"golden_diff": "diff --git a/napari/_qt/layer_controls/qt_layer_controls_container.py b/napari/_qt/layer_controls/qt_layer_controls_container.py\n--- a/napari/_qt/layer_controls/qt_layer_controls_container.py\n+++ b/napari/_qt/layer_controls/qt_layer_controls_container.py\n@@ -101,6 +101,7 @@\n \n self.setMouseTracking(True)\n self.empty_widget = QFrame()\n+ self.empty_widget.setObjectName(\"empty_controls_widget\")\n self.widgets = {}\n self.addWidget(self.empty_widget)\n self.setCurrentWidget(self.empty_widget)\n", "issue": "Visual Bug: Labels Layer Controls get squished when toggling 3D\n## \ud83d\udc1b Bug\r\n\r\nWhen toggling to 3D, the labels layer Layer Controls widget gains an extra line `rendering`.\r\nHowever the widget doesn't resize for this, so it results in a visual bug of everything squished and partially cut off:\r\n<img width=\"267\" alt=\"image\" src=\"https://user-images.githubusercontent.com/76622105/212083289-a7333963-f66a-4875-bd11-e49965ef7a77.png\">\r\n\r\nIf you manually expand the widget, it will look fine. However, in contrast to the 2D version of the widget, it will let you resize it vertically to be too small, squishing the contents again.\r\n\r\n## To Reproduce\r\n\r\nSteps to reproduce the behavior:\r\n\r\n1. open napari\r\n2. make a labels layer (can be empty)\r\n3. toggle 3D\r\n\r\n<!-- If you have a code sample, error messages, stack traces, please provide it here as well -->\r\n\r\n## Expected behavior\r\n\r\nThe widget should either resize to permit the extra line item or start out sufficiently large that when the line item is added the visual isn't squished.\r\n\r\n## Environment\r\n\r\nmacOS 13.1, pyqt5, 0.4.17\r\n\r\n## Additional context\r\n\r\n<!-- Add any other context about the problem here. -->\r\n\n", "before_files": [{"content": "from qtpy.QtWidgets import QFrame, QStackedWidget\n\nfrom napari._qt.layer_controls.qt_image_controls import QtImageControls\nfrom napari._qt.layer_controls.qt_labels_controls import QtLabelsControls\nfrom napari._qt.layer_controls.qt_points_controls import QtPointsControls\nfrom napari._qt.layer_controls.qt_shapes_controls import QtShapesControls\nfrom napari._qt.layer_controls.qt_surface_controls import QtSurfaceControls\nfrom napari._qt.layer_controls.qt_tracks_controls import QtTracksControls\nfrom napari._qt.layer_controls.qt_vectors_controls import QtVectorsControls\nfrom napari.layers import (\n Image,\n Labels,\n Points,\n Shapes,\n Surface,\n Tracks,\n Vectors,\n)\nfrom napari.utils import config\nfrom napari.utils.translations import trans\n\nlayer_to_controls = {\n Labels: QtLabelsControls,\n Image: QtImageControls,\n Points: QtPointsControls,\n Shapes: QtShapesControls,\n Surface: QtSurfaceControls,\n Vectors: QtVectorsControls,\n Tracks: QtTracksControls,\n}\n\nif config.async_loading:\n from napari.layers.image.experimental.octree_image import _OctreeImageBase\n\n # The user visible layer controls for OctreeImage layers are identical\n # to the regular image layer controls, for now.\n layer_to_controls[_OctreeImageBase] = QtImageControls\n\n\ndef create_qt_layer_controls(layer):\n \"\"\"\n Create a qt controls widget for a layer based on its layer type.\n\n In case of a subclass, the type higher in the layer's method resolution\n order will be used.\n\n Parameters\n ----------\n layer : napari.layers._base_layer.Layer\n Layer that needs its controls widget created.\n\n Returns\n -------\n controls : napari.layers.base.QtLayerControls\n Qt controls widget\n \"\"\"\n candidates = []\n for layer_type in layer_to_controls:\n if isinstance(layer, layer_type):\n candidates.append(layer_type)\n\n if not candidates:\n raise TypeError(\n trans._(\n 'Could not find QtControls for layer of type {type_}',\n deferred=True,\n type_=type(layer),\n )\n )\n\n layer_cls = layer.__class__\n # Sort the list of candidates by 'lineage'\n candidates.sort(key=lambda layer_type: layer_cls.mro().index(layer_type))\n controls = layer_to_controls[candidates[0]]\n return controls(layer)\n\n\nclass QtLayerControlsContainer(QStackedWidget):\n \"\"\"Container widget for QtLayerControl widgets.\n\n Parameters\n ----------\n viewer : napari.components.ViewerModel\n Napari viewer containing the rendered scene, layers, and controls.\n\n Attributes\n ----------\n empty_widget : qtpy.QtWidgets.QFrame\n Empty placeholder frame for when no layer is selected.\n viewer : napari.components.ViewerModel\n Napari viewer containing the rendered scene, layers, and controls.\n widgets : dict\n Dictionary of key value pairs matching layer with its widget controls.\n widgets[layer] = controls\n \"\"\"\n\n def __init__(self, viewer):\n super().__init__()\n self.setProperty(\"emphasized\", True)\n self.viewer = viewer\n\n self.setMouseTracking(True)\n self.empty_widget = QFrame()\n self.widgets = {}\n self.addWidget(self.empty_widget)\n self.setCurrentWidget(self.empty_widget)\n\n self.viewer.layers.events.inserted.connect(self._add)\n self.viewer.layers.events.removed.connect(self._remove)\n viewer.layers.selection.events.active.connect(self._display)\n\n def _display(self, event):\n \"\"\"Change the displayed controls to be those of the target layer.\n\n Parameters\n ----------\n event : Event\n Event with the target layer at `event.item`.\n \"\"\"\n layer = event.value\n if layer is None:\n self.setCurrentWidget(self.empty_widget)\n else:\n controls = self.widgets[layer]\n self.setCurrentWidget(controls)\n\n def _add(self, event):\n \"\"\"Add the controls target layer to the list of control widgets.\n\n Parameters\n ----------\n event : Event\n Event with the target layer at `event.value`.\n \"\"\"\n layer = event.value\n controls = create_qt_layer_controls(layer)\n self.addWidget(controls)\n self.widgets[layer] = controls\n\n def _remove(self, event):\n \"\"\"Remove the controls target layer from the list of control widgets.\n\n Parameters\n ----------\n event : Event\n Event with the target layer at `event.value`.\n \"\"\"\n layer = event.value\n controls = self.widgets[layer]\n self.removeWidget(controls)\n # controls.close()\n controls.hide()\n controls.deleteLater()\n controls = None\n del self.widgets[layer]\n", "path": "napari/_qt/layer_controls/qt_layer_controls_container.py"}]}
| 2,228 | 125 |
gh_patches_debug_29600
|
rasdani/github-patches
|
git_diff
|
enthought__chaco-905
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
changing TextPlot color & font
Hello,
I would like to change TextPlot color & font.
Initialization is ok, but when the color trait is changed for instance, the color is not changed in the display.
There is the same issue with the font trait.
Here's the CME.
```python
#! /usr/bin/env python3
import numpy as np
from chaco.api import ArrayPlotData, Plot
from enable.api import ComponentEditor
from traits.api import (
Array,
Color,
Font,
HasTraits,
Instance,
List
)
from traitsui.api import Item, UItem, View
class Data(HasTraits):
data = Array
labels = List
color = Color
font = Font
plot = Instance(Plot)
def _data_default(self):
data = np.array([[0, 0], [0, 1], [1, 1], [1, 0]])
return (data)
def _labels_default(self):
labels = ['A', 'B', 'C', 'D']
return (labels)
def _plot_default(self):
self.plotdata = ArrayPlotData()
self.plotdata.set_data('x', self.data[:, 0])
self.plotdata.set_data('y', self.data[:, 1])
self.plotdata.set_data('labels', self.labels)
plot = Plot(self.plotdata)
plot.range2d.set_bounds((-1, -1), (2, 2))
plot.plot(("x", "y"),
type='scatter',
marker='dot',
color=self.color)
plot.plot(("x", "y", "labels"),
type='text',
text_margin=4,
h_position='right',
text_offset=(4, 4),
text_color=self.color)
return plot
traits_view = View(
UItem(
"plot",
editor=ComponentEditor(),
resizable=True
),
UItem('color',
style='simple'),
UItem('font'),
resizable=True,
buttons=["OK"],
width=900,
height=800,
)
def _color_changed(self):
self.plot.plots['plot0'][0].color = self.color
self.plot.plots['plot1'][0].text_color = self.color
def _font_changed(self):
name = self.font.family()
size = self.font.pointSize()
self.plot.plots['plot1'][0].text_font = '%s %d' % (name, size)
if __name__ == '__main__':
viewer = Data(color=(255, 128, 64))
viewer.configure_traits()
```
Thanks in advance for any help.
Regards
Debian 10 x86_64, Python 3.7.3, ETS source code from git repo
</issue>
<code>
[start of chaco/plots/text_plot.py]
1 # (C) Copyright 2005-2021 Enthought, Inc., Austin, TX
2 # All rights reserved.
3 #
4 # This software is provided without warranty under the terms of the BSD
5 # license included in LICENSE.txt and may be redistributed only under
6 # the conditions described in the aforementioned license. The license
7 # is also available online at http://www.enthought.com/licenses/BSD.txt
8 #
9 # Thanks for using Enthought open source!
10
11 """
12 A plot that renders text values in two dimensions
13
14 """
15
16
17 from numpy import array, column_stack, empty, isfinite
18
19 # Enthought library imports
20 from enable.api import black_color_trait
21 from kiva.trait_defs.kiva_font_trait import KivaFont
22 from traits.api import Bool, Enum, Float, Int, Instance, List, Tuple, observe
23
24 # local imports
25 from chaco.array_data_source import ArrayDataSource
26 from chaco.label import Label
27 from chaco.base_xy_plot import BaseXYPlot
28
29
30 class TextPlot(BaseXYPlot):
31 """ A plot that positions textual labels in 2D """
32
33 #: text values corresponding to indices
34 text = Instance(ArrayDataSource)
35
36 #: The font of the tick labels.
37 text_font = KivaFont("sans-serif 10")
38
39 #: The color of the tick labels.
40 text_color = black_color_trait
41
42 #: The rotation of the tick labels.
43 text_rotate_angle = Float(0)
44
45 #: The margin around the label.
46 text_margin = Int(2)
47
48 #: horizontal position of text relative to target point
49 h_position = Enum("center", "left", "right")
50
51 #: vertical position of text relative to target point
52 v_position = Enum("center", "top", "bottom")
53
54 #: offset of text relative to non-index direction in pixels
55 text_offset = Tuple(Float, Float)
56
57 # ------------------------------------------------------------------------
58 # Private traits
59 # ------------------------------------------------------------------------
60
61 #: flag for whether the cache of Label instances is valid
62 _label_cache_valid = Bool(False, transient=True)
63
64 #: cache of Label instances for faster rendering
65 _label_cache = List(transient=True)
66
67 #: cache of bounding boxes of labels
68 _label_box_cache = List(transient=True)
69
70 # ------------------------------------------------------------------------
71 # Private methods
72 # ------------------------------------------------------------------------
73
74 def _compute_labels(self, gc):
75 """Generate the Label instances for the plot. """
76 self._label_cache = [
77 Label(
78 text=text,
79 font=self.text_font,
80 color=self.text_color,
81 rotate_angle=self.text_rotate_angle,
82 margin=self.text_margin,
83 )
84 for text in self.text.get_data()
85 ]
86 self._label_box_cache = [
87 array(label.get_bounding_box(gc), float)
88 for label in self._label_cache
89 ]
90 self._label_cache_valid = True
91
92 def _gather_points(self):
93 """Abstract method to collect data points that are within the range of
94 the plot, and cache them.
95 """
96 if self._cache_valid:
97 return
98
99 if not self.index or not self.value:
100 return
101
102 index, index_mask = self.index.get_data_mask()
103 value, value_mask = self.value.get_data_mask()
104
105 if len(index) == 0 or len(value) == 0 or len(index) != len(value):
106 self._cached_data_pts = []
107 self._cached_point_mask = []
108 self._cache_valid = True
109 return
110
111 index_range_mask = self.index_mapper.range.mask_data(index)
112 value_range_mask = self.value_mapper.range.mask_data(value)
113
114 nan_mask = isfinite(index) & index_mask & isfinite(value) & value_mask
115 point_mask = nan_mask & index_range_mask & value_range_mask
116
117 if not self._cache_valid:
118 if not point_mask.all():
119 points = column_stack([index[point_mask], value[point_mask]])
120 else:
121 points = column_stack([index, value])
122 self._cached_data_pts = points
123 self._cached_point_mask = point_mask
124 self._cache_valid = True
125
126 def _render(self, gc, pts):
127 if not self._label_cache_valid:
128 self._compute_labels(gc)
129
130 labels = [
131 label
132 for label, mask in zip(self._label_cache, self._cached_point_mask)
133 if mask
134 ]
135 boxes = [
136 label
137 for label, mask in zip(
138 self._label_box_cache, self._cached_point_mask
139 )
140 if mask
141 ]
142 offset = empty((2,), float)
143
144 with gc:
145 gc.clip_to_rect(self.x, self.y, self.width, self.height)
146 for pt, label, box in zip(pts, labels, boxes):
147 with gc:
148 if self.h_position == "center":
149 offset[0] = -box[0] / 2 + self.text_offset[0]
150 elif self.h_position == "right":
151 offset[0] = self.text_offset[0]
152 elif self.h_position == "left":
153 offset[0] = -box[0] / 2 + self.text_offset[0]
154 if self.v_position == "center":
155 offset[1] = -box[1] / 2 + self.text_offset[1]
156 elif self.v_position == "top":
157 offset[1] = self.text_offset[1]
158 elif self.v_position == "bottom":
159 offset[1] = -box[1] / 2 - self.text_offset[1]
160
161 pt += offset
162 gc.translate_ctm(*pt)
163
164 label.draw(gc)
165
166 # ------------------------------------------------------------------------
167 # Trait events
168 # ------------------------------------------------------------------------
169
170 @observe("index.data_changed")
171 def _invalidate(self, event):
172 self._cache_valid = False
173 self._screen_cache_valid = False
174 self._label_cache_valid = False
175
176 @observe("value.data_changed")
177 def _invalidate_labels(self, event):
178 self._label_cache_valid = False
179
[end of chaco/plots/text_plot.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/chaco/plots/text_plot.py b/chaco/plots/text_plot.py
--- a/chaco/plots/text_plot.py
+++ b/chaco/plots/text_plot.py
@@ -34,25 +34,25 @@
text = Instance(ArrayDataSource)
#: The font of the tick labels.
- text_font = KivaFont("sans-serif 10")
+ text_font = KivaFont("sans-serif 10", redraw=True)
#: The color of the tick labels.
- text_color = black_color_trait
+ text_color = black_color_trait(redraw=True)
#: The rotation of the tick labels.
- text_rotate_angle = Float(0)
+ text_rotate_angle = Float(0, redraw=True)
#: The margin around the label.
- text_margin = Int(2)
+ text_margin = Int(2, redraw=True)
#: horizontal position of text relative to target point
- h_position = Enum("center", "left", "right")
+ h_position = Enum("center", "left", "right", redraw=True)
#: vertical position of text relative to target point
- v_position = Enum("center", "top", "bottom")
+ v_position = Enum("center", "top", "bottom", redraw=True)
#: offset of text relative to non-index direction in pixels
- text_offset = Tuple(Float, Float)
+ text_offset = Tuple(Float, Float, redraw=True)
# ------------------------------------------------------------------------
# Private traits
@@ -173,6 +173,6 @@
self._screen_cache_valid = False
self._label_cache_valid = False
- @observe("value.data_changed")
+ @observe("value.data_changed,+redraw")
def _invalidate_labels(self, event):
self._label_cache_valid = False
|
{"golden_diff": "diff --git a/chaco/plots/text_plot.py b/chaco/plots/text_plot.py\n--- a/chaco/plots/text_plot.py\n+++ b/chaco/plots/text_plot.py\n@@ -34,25 +34,25 @@\n text = Instance(ArrayDataSource)\n \n #: The font of the tick labels.\n- text_font = KivaFont(\"sans-serif 10\")\n+ text_font = KivaFont(\"sans-serif 10\", redraw=True)\n \n #: The color of the tick labels.\n- text_color = black_color_trait\n+ text_color = black_color_trait(redraw=True)\n \n #: The rotation of the tick labels.\n- text_rotate_angle = Float(0)\n+ text_rotate_angle = Float(0, redraw=True)\n \n #: The margin around the label.\n- text_margin = Int(2)\n+ text_margin = Int(2, redraw=True)\n \n #: horizontal position of text relative to target point\n- h_position = Enum(\"center\", \"left\", \"right\")\n+ h_position = Enum(\"center\", \"left\", \"right\", redraw=True)\n \n #: vertical position of text relative to target point\n- v_position = Enum(\"center\", \"top\", \"bottom\")\n+ v_position = Enum(\"center\", \"top\", \"bottom\", redraw=True)\n \n #: offset of text relative to non-index direction in pixels\n- text_offset = Tuple(Float, Float)\n+ text_offset = Tuple(Float, Float, redraw=True)\n \n # ------------------------------------------------------------------------\n # Private traits\n@@ -173,6 +173,6 @@\n self._screen_cache_valid = False\n self._label_cache_valid = False\n \n- @observe(\"value.data_changed\")\n+ @observe(\"value.data_changed,+redraw\")\n def _invalidate_labels(self, event):\n self._label_cache_valid = False\n", "issue": "changing TextPlot color & font\nHello,\r\n\r\nI would like to change TextPlot color & font.\r\n\r\nInitialization is ok, but when the color trait is changed for instance, the color is not changed in the display.\r\n\r\nThere is the same issue with the font trait.\r\n\r\nHere's the CME.\r\n\r\n```python\r\n#! /usr/bin/env python3\r\n\r\nimport numpy as np\r\n\r\nfrom chaco.api import ArrayPlotData, Plot\r\nfrom enable.api import ComponentEditor\r\nfrom traits.api import (\r\n Array,\r\n Color,\r\n Font,\r\n HasTraits,\r\n Instance,\r\n List\r\n)\r\nfrom traitsui.api import Item, UItem, View\r\n\r\n\r\nclass Data(HasTraits):\r\n\r\n data = Array\r\n labels = List\r\n color = Color\r\n font = Font\r\n plot = Instance(Plot)\r\n\r\n def _data_default(self):\r\n data = np.array([[0, 0], [0, 1], [1, 1], [1, 0]])\r\n return (data)\r\n\r\n def _labels_default(self):\r\n labels = ['A', 'B', 'C', 'D']\r\n return (labels)\r\n\r\n def _plot_default(self):\r\n self.plotdata = ArrayPlotData()\r\n self.plotdata.set_data('x', self.data[:, 0])\r\n self.plotdata.set_data('y', self.data[:, 1])\r\n self.plotdata.set_data('labels', self.labels)\r\n\r\n plot = Plot(self.plotdata)\r\n plot.range2d.set_bounds((-1, -1), (2, 2))\r\n plot.plot((\"x\", \"y\"),\r\n type='scatter',\r\n marker='dot',\r\n color=self.color)\r\n plot.plot((\"x\", \"y\", \"labels\"),\r\n type='text',\r\n text_margin=4,\r\n h_position='right',\r\n text_offset=(4, 4),\r\n text_color=self.color)\r\n\r\n return plot\r\n\r\n traits_view = View(\r\n UItem(\r\n \"plot\",\r\n editor=ComponentEditor(),\r\n resizable=True\r\n ),\r\n UItem('color',\r\n style='simple'),\r\n UItem('font'),\r\n resizable=True,\r\n buttons=[\"OK\"],\r\n width=900,\r\n height=800,\r\n )\r\n\r\n def _color_changed(self):\r\n self.plot.plots['plot0'][0].color = self.color\r\n self.plot.plots['plot1'][0].text_color = self.color\r\n\r\n def _font_changed(self):\r\n name = self.font.family()\r\n size = self.font.pointSize()\r\n self.plot.plots['plot1'][0].text_font = '%s %d' % (name, size)\r\n\r\n\r\nif __name__ == '__main__':\r\n viewer = Data(color=(255, 128, 64))\r\n viewer.configure_traits()\r\n```\r\n\r\nThanks in advance for any help.\r\n\r\nRegards\r\n\r\nDebian 10 x86_64, Python 3.7.3, ETS source code from git repo\r\n\n", "before_files": [{"content": "# (C) Copyright 2005-2021 Enthought, Inc., Austin, TX\n# All rights reserved.\n#\n# This software is provided without warranty under the terms of the BSD\n# license included in LICENSE.txt and may be redistributed only under\n# the conditions described in the aforementioned license. The license\n# is also available online at http://www.enthought.com/licenses/BSD.txt\n#\n# Thanks for using Enthought open source!\n\n\"\"\"\nA plot that renders text values in two dimensions\n\n\"\"\"\n\n\nfrom numpy import array, column_stack, empty, isfinite\n\n# Enthought library imports\nfrom enable.api import black_color_trait\nfrom kiva.trait_defs.kiva_font_trait import KivaFont\nfrom traits.api import Bool, Enum, Float, Int, Instance, List, Tuple, observe\n\n# local imports\nfrom chaco.array_data_source import ArrayDataSource\nfrom chaco.label import Label\nfrom chaco.base_xy_plot import BaseXYPlot\n\n\nclass TextPlot(BaseXYPlot):\n \"\"\" A plot that positions textual labels in 2D \"\"\"\n\n #: text values corresponding to indices\n text = Instance(ArrayDataSource)\n\n #: The font of the tick labels.\n text_font = KivaFont(\"sans-serif 10\")\n\n #: The color of the tick labels.\n text_color = black_color_trait\n\n #: The rotation of the tick labels.\n text_rotate_angle = Float(0)\n\n #: The margin around the label.\n text_margin = Int(2)\n\n #: horizontal position of text relative to target point\n h_position = Enum(\"center\", \"left\", \"right\")\n\n #: vertical position of text relative to target point\n v_position = Enum(\"center\", \"top\", \"bottom\")\n\n #: offset of text relative to non-index direction in pixels\n text_offset = Tuple(Float, Float)\n\n # ------------------------------------------------------------------------\n # Private traits\n # ------------------------------------------------------------------------\n\n #: flag for whether the cache of Label instances is valid\n _label_cache_valid = Bool(False, transient=True)\n\n #: cache of Label instances for faster rendering\n _label_cache = List(transient=True)\n\n #: cache of bounding boxes of labels\n _label_box_cache = List(transient=True)\n\n # ------------------------------------------------------------------------\n # Private methods\n # ------------------------------------------------------------------------\n\n def _compute_labels(self, gc):\n \"\"\"Generate the Label instances for the plot. \"\"\"\n self._label_cache = [\n Label(\n text=text,\n font=self.text_font,\n color=self.text_color,\n rotate_angle=self.text_rotate_angle,\n margin=self.text_margin,\n )\n for text in self.text.get_data()\n ]\n self._label_box_cache = [\n array(label.get_bounding_box(gc), float)\n for label in self._label_cache\n ]\n self._label_cache_valid = True\n\n def _gather_points(self):\n \"\"\"Abstract method to collect data points that are within the range of\n the plot, and cache them.\n \"\"\"\n if self._cache_valid:\n return\n\n if not self.index or not self.value:\n return\n\n index, index_mask = self.index.get_data_mask()\n value, value_mask = self.value.get_data_mask()\n\n if len(index) == 0 or len(value) == 0 or len(index) != len(value):\n self._cached_data_pts = []\n self._cached_point_mask = []\n self._cache_valid = True\n return\n\n index_range_mask = self.index_mapper.range.mask_data(index)\n value_range_mask = self.value_mapper.range.mask_data(value)\n\n nan_mask = isfinite(index) & index_mask & isfinite(value) & value_mask\n point_mask = nan_mask & index_range_mask & value_range_mask\n\n if not self._cache_valid:\n if not point_mask.all():\n points = column_stack([index[point_mask], value[point_mask]])\n else:\n points = column_stack([index, value])\n self._cached_data_pts = points\n self._cached_point_mask = point_mask\n self._cache_valid = True\n\n def _render(self, gc, pts):\n if not self._label_cache_valid:\n self._compute_labels(gc)\n\n labels = [\n label\n for label, mask in zip(self._label_cache, self._cached_point_mask)\n if mask\n ]\n boxes = [\n label\n for label, mask in zip(\n self._label_box_cache, self._cached_point_mask\n )\n if mask\n ]\n offset = empty((2,), float)\n\n with gc:\n gc.clip_to_rect(self.x, self.y, self.width, self.height)\n for pt, label, box in zip(pts, labels, boxes):\n with gc:\n if self.h_position == \"center\":\n offset[0] = -box[0] / 2 + self.text_offset[0]\n elif self.h_position == \"right\":\n offset[0] = self.text_offset[0]\n elif self.h_position == \"left\":\n offset[0] = -box[0] / 2 + self.text_offset[0]\n if self.v_position == \"center\":\n offset[1] = -box[1] / 2 + self.text_offset[1]\n elif self.v_position == \"top\":\n offset[1] = self.text_offset[1]\n elif self.v_position == \"bottom\":\n offset[1] = -box[1] / 2 - self.text_offset[1]\n\n pt += offset\n gc.translate_ctm(*pt)\n\n label.draw(gc)\n\n # ------------------------------------------------------------------------\n # Trait events\n # ------------------------------------------------------------------------\n\n @observe(\"index.data_changed\")\n def _invalidate(self, event):\n self._cache_valid = False\n self._screen_cache_valid = False\n self._label_cache_valid = False\n\n @observe(\"value.data_changed\")\n def _invalidate_labels(self, event):\n self._label_cache_valid = False\n", "path": "chaco/plots/text_plot.py"}]}
| 2,866 | 405 |
gh_patches_debug_10802
|
rasdani/github-patches
|
git_diff
|
interlegis__sapl-2147
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Audiências Públicas sem possibilidade de Edição
Ao criar uma Audiência Pública e salva-la, não aparecem os metadados da matéria legislativa inseridas no preenchimento.
Ao clicar em Editar, só aparece o título da audiência criada.
grato
</issue>
<code>
[start of sapl/audiencia/views.py]
1 from django.http import HttpResponse
2 from django.views.decorators.clickjacking import xframe_options_exempt
3 from django.views.generic import UpdateView
4 from sapl.crud.base import RP_DETAIL, RP_LIST, Crud
5
6 from .forms import AudienciaForm
7 from .models import AudienciaPublica
8
9
10 def index(request):
11 return HttpResponse("Audiência Pública")
12
13
14 class AudienciaCrud(Crud):
15 model = AudienciaPublica
16 public = [RP_LIST, RP_DETAIL, ]
17
18 class BaseMixin(Crud.BaseMixin):
19 list_field_names = ['numero', 'nome', 'tipo', 'materia',
20 'data']
21 ordering = 'nome', 'numero', 'tipo', 'data'
22
23 class ListView(Crud.ListView):
24 paginate_by = 10
25
26 class CreateView(Crud.CreateView):
27 form_class = AudienciaForm
28
29 def form_valid(self, form):
30 return super(Crud.CreateView, self).form_valid(form)
31
32 class UpdateView(Crud.UpdateView):
33 form_class = AudienciaForm
34
35 def get_initial(self):
36 initial = super(UpdateView, self).get_initial()
37 initial['tipo_materia'] = self.object.materia.tipo.id
38 initial['numero_materia'] = self.object.materia.numero
39 initial['ano_materia'] = self.object.materia.ano
40 return initial
41
42 class DeleteView(Crud.DeleteView):
43 pass
44
45 class DetailView(Crud.DetailView):
46
47 layout_key = 'AudienciaPublicaDetail'
48
49 @xframe_options_exempt
50 def get(self, request, *args, **kwargs):
51 return super().get(request, *args, **kwargs)
52
53
[end of sapl/audiencia/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sapl/audiencia/views.py b/sapl/audiencia/views.py
--- a/sapl/audiencia/views.py
+++ b/sapl/audiencia/views.py
@@ -34,9 +34,10 @@
def get_initial(self):
initial = super(UpdateView, self).get_initial()
- initial['tipo_materia'] = self.object.materia.tipo.id
- initial['numero_materia'] = self.object.materia.numero
- initial['ano_materia'] = self.object.materia.ano
+ if self.object.materia:
+ initial['tipo_materia'] = self.object.materia.tipo.id
+ initial['numero_materia'] = self.object.materia.numero
+ initial['ano_materia'] = self.object.materia.ano
return initial
class DeleteView(Crud.DeleteView):
|
{"golden_diff": "diff --git a/sapl/audiencia/views.py b/sapl/audiencia/views.py\n--- a/sapl/audiencia/views.py\n+++ b/sapl/audiencia/views.py\n@@ -34,9 +34,10 @@\n \n def get_initial(self):\n initial = super(UpdateView, self).get_initial()\n- initial['tipo_materia'] = self.object.materia.tipo.id\n- initial['numero_materia'] = self.object.materia.numero\n- initial['ano_materia'] = self.object.materia.ano\n+ if self.object.materia:\n+ initial['tipo_materia'] = self.object.materia.tipo.id\n+ initial['numero_materia'] = self.object.materia.numero\n+ initial['ano_materia'] = self.object.materia.ano\n return initial\n \n class DeleteView(Crud.DeleteView):\n", "issue": "Audi\u00eancias P\u00fablicas sem possibilidade de Edi\u00e7\u00e3o\nAo criar uma Audi\u00eancia P\u00fablica e salva-la, n\u00e3o aparecem os metadados da mat\u00e9ria legislativa inseridas no preenchimento. \r\nAo clicar em Editar, s\u00f3 aparece o t\u00edtulo da audi\u00eancia criada.\r\ngrato\n", "before_files": [{"content": "from django.http import HttpResponse\nfrom django.views.decorators.clickjacking import xframe_options_exempt\nfrom django.views.generic import UpdateView\nfrom sapl.crud.base import RP_DETAIL, RP_LIST, Crud\n\nfrom .forms import AudienciaForm\nfrom .models import AudienciaPublica\n\n\ndef index(request):\n return HttpResponse(\"Audi\u00eancia P\u00fablica\")\n\n\nclass AudienciaCrud(Crud):\n model = AudienciaPublica\n public = [RP_LIST, RP_DETAIL, ]\n\n class BaseMixin(Crud.BaseMixin):\n list_field_names = ['numero', 'nome', 'tipo', 'materia',\n 'data']\n ordering = 'nome', 'numero', 'tipo', 'data'\n\n class ListView(Crud.ListView):\n paginate_by = 10\n\n class CreateView(Crud.CreateView):\n form_class = AudienciaForm\n\n def form_valid(self, form):\n return super(Crud.CreateView, self).form_valid(form)\n\n class UpdateView(Crud.UpdateView):\n form_class = AudienciaForm\n\n def get_initial(self):\n initial = super(UpdateView, self).get_initial()\n initial['tipo_materia'] = self.object.materia.tipo.id\n initial['numero_materia'] = self.object.materia.numero\n initial['ano_materia'] = self.object.materia.ano\n return initial\n \n class DeleteView(Crud.DeleteView):\n pass\n\n class DetailView(Crud.DetailView):\n\n layout_key = 'AudienciaPublicaDetail'\n\n @xframe_options_exempt\n def get(self, request, *args, **kwargs):\n return super().get(request, *args, **kwargs)\n\n ", "path": "sapl/audiencia/views.py"}]}
| 1,066 | 188 |
gh_patches_debug_4666
|
rasdani/github-patches
|
git_diff
|
cupy__cupy-498
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
cupy.nonzero fails with some corner-case inputs
Code:
```
import sys
import cupy, numpy
shapes = [
(),
(0,),
(1,),
(0,2),
(0,0,2,0),
]
f = sys.stdout
for xp in (numpy, cupy):
print(xp.__name__)
for shape in shapes:
a = xp.ones(shape)
f.write('shape={:<15} => '.format(str(shape)))
try:
b = xp.nonzero(a)
f.write('{}\n'.format(b))
except Exception as e:
f.write('FAIL: {}\n'.format(e))
# get stack trace
cupy.nonzero(cupy.ones((0,)))
```
Result:
```
numpy
shape=() => (array([0]),)
shape=(0,) => (array([], dtype=int64),)
shape=(1,) => (array([0]),)
shape=(0, 2) => (array([], dtype=int64), array([], dtype=int64))
shape=(0, 0, 2, 0) => (array([], dtype=int64), array([], dtype=int64), array([], dtype=int64), array([], dtype=int64))
cupy
shape=() => (array([0]),)
shape=(0,) => FAIL: CUDA_ERROR_INVALID_VALUE: invalid argument
shape=(1,) => (array([0]),)
shape=(0, 2) => FAIL: CUDA_ERROR_INVALID_VALUE: invalid argument
shape=(0, 0, 2, 0) => FAIL: CUDA_ERROR_INVALID_VALUE: invalid argument
Traceback (most recent call last):
File "test-nonzero.py", line 26, in <module>
cupy.nonzero(cupy.ones((0,)))
File "/niboshi/repos/cupy/cupy/sorting/search.py", line 72, in nonzero
return a.nonzero()
File "cupy/core/core.pyx", line 810, in cupy.core.core.ndarray.nonzero (cupy/core/core.cpp:16210)
scan_index = scan(condition.astype(dtype).ravel())
File "cupy/core/core.pyx", line 3883, in cupy.core.core.scan (cupy/core/core.cpp:83826)
kern_scan(grid=((a.size - 1) // (2 * block_size) + 1,),
File "cupy/cuda/function.pyx", line 118, in cupy.cuda.function.Function.__call__ (cupy/cuda/function.cpp:3794)
_launch(
File "cupy/cuda/function.pyx", line 100, in cupy.cuda.function._launch (cupy/cuda/function.cpp:3431)
driver.launchKernel(
File "cupy/cuda/driver.pyx", line 170, in cupy.cuda.driver.launchKernel (cupy/cuda/driver.cpp:3262)
check_status(status)
File "cupy/cuda/driver.pyx", line 70, in cupy.cuda.driver.check_status (cupy/cuda/driver.cpp:1481)
raise CUDADriverError(status)
cupy.cuda.driver.CUDADriverError: CUDA_ERROR_INVALID_VALUE: invalid argument
```
CuPy version: latest master(v2.0.0a1)
</issue>
<code>
[start of cupy/sorting/search.py]
1 from cupy import core
2
3
4 def argmax(a, axis=None, dtype=None, out=None, keepdims=False):
5 """Returns the indices of the maximum along an axis.
6
7 Args:
8 a (cupy.ndarray): Array to take argmax.
9 axis (int): Along which axis to find the maximum. ``a`` is flattened by
10 default.
11 dtype: Data type specifier.
12 out (cupy.ndarray): Output array.
13 keepdims (bool): If ``True``, the axis ``axis`` is preserved as an axis
14 of length one.
15
16 Returns:
17 cupy.ndarray: The indices of the maximum of ``a`` along an axis.
18
19 .. seealso:: :func:`numpy.argmax`
20
21 """
22 # TODO(okuta): check type
23 return a.argmax(axis=axis, dtype=dtype, out=out, keepdims=keepdims)
24
25
26 # TODO(okuta): Implement nanargmax
27
28
29 def argmin(a, axis=None, dtype=None, out=None, keepdims=False):
30 """Returns the indices of the minimum along an axis.
31
32 Args:
33 a (cupy.ndarray): Array to take argmin.
34 axis (int): Along which axis to find the minimum. ``a`` is flattened by
35 default.
36 dtype: Data type specifier.
37 out (cupy.ndarray): Output array.
38 keepdims (bool): If ``True``, the axis ``axis`` is preserved as an axis
39 of length one.
40
41 Returns:
42 cupy.ndarray: The indices of the minimum of ``a`` along an axis.
43
44 .. seealso:: :func:`numpy.argmin`
45
46 """
47 # TODO(okuta): check type
48 return a.argmin(axis=axis, dtype=dtype, out=out, keepdims=keepdims)
49
50
51 # TODO(okuta): Implement nanargmin
52
53
54 # TODO(okuta): Implement argwhere
55
56
57 def nonzero(a):
58 """Return the indices of the elements that are non-zero.
59
60 Returns a tuple of arrays, one for each dimension of a,
61 containing the indices of the non-zero elements in that dimension.
62
63 Args:
64 a (cupy.ndarray): array
65
66 Returns:
67 tuple of arrays: Indices of elements that are non-zero.
68
69 .. seealso:: :func:`numpy.nonzero`
70
71 """
72 return a.nonzero()
73
74
75 def flatnonzero(a):
76 """Return indices that are non-zero in the flattened version of a.
77
78 This is equivalent to a.ravel().nonzero()[0].
79
80 Args:
81 a (cupy.ndarray): input array
82
83 Returns:
84 cupy.ndarray: Output array,
85 containing the indices of the elements of a.ravel() that are non-zero.
86
87 .. seealso:: :func:`numpy.flatnonzero`
88 """
89 return a.ravel().nonzero()[0]
90
91
92 def where(condition, x=None, y=None):
93 """Return elements, either from x or y, depending on condition.
94
95 If only condition is given, return ``condition.nonzero()``.
96
97 Args:
98 condition (cupy.ndarray): When True, take x, otherwise take y.
99 x (cupy.ndarray): Values from which to choose on ``True``.
100 y (cupy.ndarray): Values from which to choose on ``False``.
101
102 Returns:
103 cupy.ndarray: Each element of output contains elements of ``x`` when
104 ``condition`` is ``True``, otherwise elements of ``y``. If only
105 ``condition`` is given, return the tuple ``condition.nonzero()``,
106 the indices where ``condition`` is True.
107
108 .. seealso:: :func:`numpy.where`
109
110 """
111
112 missing = (x is None, y is None).count(True)
113
114 if missing == 1:
115 raise ValueError("Must provide both 'x' and 'y' or neither.")
116 if missing == 2:
117 return nonzero(condition)
118
119 return _where_ufunc(condition.astype('?'), x, y)
120
121
122 _where_ufunc = core.create_ufunc(
123 'cupy_where',
124 ('???->?', '?bb->b', '?BB->B', '?hh->h', '?HH->H', '?ii->i', '?II->I',
125 '?ll->l', '?LL->L', '?qq->q', '?QQ->Q', '?ee->e', '?ff->f',
126 # On CUDA 6.5 these combinations don't work correctly (on CUDA >=7.0, it
127 # works).
128 # See issue #551.
129 '?hd->d', '?Hd->d',
130 '?dd->d'),
131 'out0 = in0 ? in1 : in2')
132
133
134 # TODO(okuta): Implement searchsorted
135
136
137 # TODO(okuta): Implement extract
138
[end of cupy/sorting/search.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/cupy/sorting/search.py b/cupy/sorting/search.py
--- a/cupy/sorting/search.py
+++ b/cupy/sorting/search.py
@@ -69,6 +69,7 @@
.. seealso:: :func:`numpy.nonzero`
"""
+ assert isinstance(a, core.ndarray)
return a.nonzero()
@@ -86,6 +87,7 @@
.. seealso:: :func:`numpy.flatnonzero`
"""
+ assert isinstance(a, core.ndarray)
return a.ravel().nonzero()[0]
|
{"golden_diff": "diff --git a/cupy/sorting/search.py b/cupy/sorting/search.py\n--- a/cupy/sorting/search.py\n+++ b/cupy/sorting/search.py\n@@ -69,6 +69,7 @@\n .. seealso:: :func:`numpy.nonzero`\n \n \"\"\"\n+ assert isinstance(a, core.ndarray)\n return a.nonzero()\n \n \n@@ -86,6 +87,7 @@\n \n .. seealso:: :func:`numpy.flatnonzero`\n \"\"\"\n+ assert isinstance(a, core.ndarray)\n return a.ravel().nonzero()[0]\n", "issue": "cupy.nonzero fails with some corner-case inputs\nCode:\r\n```\r\nimport sys\r\nimport cupy, numpy\r\n\r\nshapes = [\r\n (),\r\n (0,),\r\n (1,),\r\n (0,2),\r\n (0,0,2,0),\r\n]\r\n\r\nf = sys.stdout\r\nfor xp in (numpy, cupy):\r\n print(xp.__name__)\r\n for shape in shapes:\r\n a = xp.ones(shape)\r\n f.write('shape={:<15} => '.format(str(shape)))\r\n\r\n try:\r\n b = xp.nonzero(a)\r\n f.write('{}\\n'.format(b))\r\n except Exception as e:\r\n f.write('FAIL: {}\\n'.format(e))\r\n\r\n# get stack trace\r\ncupy.nonzero(cupy.ones((0,)))\r\n```\r\n\r\nResult:\r\n```\r\nnumpy\r\nshape=() => (array([0]),)\r\nshape=(0,) => (array([], dtype=int64),)\r\nshape=(1,) => (array([0]),)\r\nshape=(0, 2) => (array([], dtype=int64), array([], dtype=int64))\r\nshape=(0, 0, 2, 0) => (array([], dtype=int64), array([], dtype=int64), array([], dtype=int64), array([], dtype=int64))\r\ncupy\r\nshape=() => (array([0]),)\r\nshape=(0,) => FAIL: CUDA_ERROR_INVALID_VALUE: invalid argument\r\nshape=(1,) => (array([0]),)\r\nshape=(0, 2) => FAIL: CUDA_ERROR_INVALID_VALUE: invalid argument\r\nshape=(0, 0, 2, 0) => FAIL: CUDA_ERROR_INVALID_VALUE: invalid argument\r\nTraceback (most recent call last):\r\n File \"test-nonzero.py\", line 26, in <module>\r\n cupy.nonzero(cupy.ones((0,)))\r\n File \"/niboshi/repos/cupy/cupy/sorting/search.py\", line 72, in nonzero\r\n return a.nonzero()\r\n File \"cupy/core/core.pyx\", line 810, in cupy.core.core.ndarray.nonzero (cupy/core/core.cpp:16210)\r\n scan_index = scan(condition.astype(dtype).ravel())\r\n File \"cupy/core/core.pyx\", line 3883, in cupy.core.core.scan (cupy/core/core.cpp:83826)\r\n kern_scan(grid=((a.size - 1) // (2 * block_size) + 1,),\r\n File \"cupy/cuda/function.pyx\", line 118, in cupy.cuda.function.Function.__call__ (cupy/cuda/function.cpp:3794)\r\n _launch(\r\n File \"cupy/cuda/function.pyx\", line 100, in cupy.cuda.function._launch (cupy/cuda/function.cpp:3431)\r\n driver.launchKernel(\r\n File \"cupy/cuda/driver.pyx\", line 170, in cupy.cuda.driver.launchKernel (cupy/cuda/driver.cpp:3262)\r\n check_status(status)\r\n File \"cupy/cuda/driver.pyx\", line 70, in cupy.cuda.driver.check_status (cupy/cuda/driver.cpp:1481)\r\n raise CUDADriverError(status)\r\ncupy.cuda.driver.CUDADriverError: CUDA_ERROR_INVALID_VALUE: invalid argument\r\n```\r\nCuPy version: latest master(v2.0.0a1)\n", "before_files": [{"content": "from cupy import core\n\n\ndef argmax(a, axis=None, dtype=None, out=None, keepdims=False):\n \"\"\"Returns the indices of the maximum along an axis.\n\n Args:\n a (cupy.ndarray): Array to take argmax.\n axis (int): Along which axis to find the maximum. ``a`` is flattened by\n default.\n dtype: Data type specifier.\n out (cupy.ndarray): Output array.\n keepdims (bool): If ``True``, the axis ``axis`` is preserved as an axis\n of length one.\n\n Returns:\n cupy.ndarray: The indices of the maximum of ``a`` along an axis.\n\n .. seealso:: :func:`numpy.argmax`\n\n \"\"\"\n # TODO(okuta): check type\n return a.argmax(axis=axis, dtype=dtype, out=out, keepdims=keepdims)\n\n\n# TODO(okuta): Implement nanargmax\n\n\ndef argmin(a, axis=None, dtype=None, out=None, keepdims=False):\n \"\"\"Returns the indices of the minimum along an axis.\n\n Args:\n a (cupy.ndarray): Array to take argmin.\n axis (int): Along which axis to find the minimum. ``a`` is flattened by\n default.\n dtype: Data type specifier.\n out (cupy.ndarray): Output array.\n keepdims (bool): If ``True``, the axis ``axis`` is preserved as an axis\n of length one.\n\n Returns:\n cupy.ndarray: The indices of the minimum of ``a`` along an axis.\n\n .. seealso:: :func:`numpy.argmin`\n\n \"\"\"\n # TODO(okuta): check type\n return a.argmin(axis=axis, dtype=dtype, out=out, keepdims=keepdims)\n\n\n# TODO(okuta): Implement nanargmin\n\n\n# TODO(okuta): Implement argwhere\n\n\ndef nonzero(a):\n \"\"\"Return the indices of the elements that are non-zero.\n\n Returns a tuple of arrays, one for each dimension of a,\n containing the indices of the non-zero elements in that dimension.\n\n Args:\n a (cupy.ndarray): array\n\n Returns:\n tuple of arrays: Indices of elements that are non-zero.\n\n .. seealso:: :func:`numpy.nonzero`\n\n \"\"\"\n return a.nonzero()\n\n\ndef flatnonzero(a):\n \"\"\"Return indices that are non-zero in the flattened version of a.\n\n This is equivalent to a.ravel().nonzero()[0].\n\n Args:\n a (cupy.ndarray): input array\n\n Returns:\n cupy.ndarray: Output array,\n containing the indices of the elements of a.ravel() that are non-zero.\n\n .. seealso:: :func:`numpy.flatnonzero`\n \"\"\"\n return a.ravel().nonzero()[0]\n\n\ndef where(condition, x=None, y=None):\n \"\"\"Return elements, either from x or y, depending on condition.\n\n If only condition is given, return ``condition.nonzero()``.\n\n Args:\n condition (cupy.ndarray): When True, take x, otherwise take y.\n x (cupy.ndarray): Values from which to choose on ``True``.\n y (cupy.ndarray): Values from which to choose on ``False``.\n\n Returns:\n cupy.ndarray: Each element of output contains elements of ``x`` when\n ``condition`` is ``True``, otherwise elements of ``y``. If only\n ``condition`` is given, return the tuple ``condition.nonzero()``,\n the indices where ``condition`` is True.\n\n .. seealso:: :func:`numpy.where`\n\n \"\"\"\n\n missing = (x is None, y is None).count(True)\n\n if missing == 1:\n raise ValueError(\"Must provide both 'x' and 'y' or neither.\")\n if missing == 2:\n return nonzero(condition)\n\n return _where_ufunc(condition.astype('?'), x, y)\n\n\n_where_ufunc = core.create_ufunc(\n 'cupy_where',\n ('???->?', '?bb->b', '?BB->B', '?hh->h', '?HH->H', '?ii->i', '?II->I',\n '?ll->l', '?LL->L', '?qq->q', '?QQ->Q', '?ee->e', '?ff->f',\n # On CUDA 6.5 these combinations don't work correctly (on CUDA >=7.0, it\n # works).\n # See issue #551.\n '?hd->d', '?Hd->d',\n '?dd->d'),\n 'out0 = in0 ? in1 : in2')\n\n\n# TODO(okuta): Implement searchsorted\n\n\n# TODO(okuta): Implement extract\n", "path": "cupy/sorting/search.py"}]}
| 2,627 | 126 |
gh_patches_debug_21969
|
rasdani/github-patches
|
git_diff
|
easybuilders__easybuild-easyblocks-1663
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CUDA_{ROOT,HOME,PATH} are PATH-like?
See: https://github.com/easybuilders/easybuild-easyblocks/blob/e3a4cd70357103e1fa463751df13378f217c7ad1/easybuild/easyblocks/c/cuda.py#L191-L193
This creates `prepend_path` module commands, instead of `setenv`! Is there a particular reason to do so?
</issue>
<code>
[start of easybuild/easyblocks/c/cuda.py]
1 ##
2 # This file is an EasyBuild reciPY as per https://github.com/easybuilders/easybuild
3 #
4 # Copyright:: Copyright 2012-2019 Cyprus Institute / CaSToRC, Uni.Lu, NTUA, Ghent University, Forschungszentrum Juelich GmbH
5 # Authors:: George Tsouloupas <[email protected]>, Fotis Georgatos <[email protected]>, Kenneth Hoste, Damian Alvarez
6 # License:: MIT/GPL
7 # $Id$
8 #
9 # This work implements a part of the HPCBIOS project and is a component of the policy:
10 # http://hpcbios.readthedocs.org/en/latest/HPCBIOS_2012-99.html
11 ##
12 """
13 EasyBuild support for CUDA, implemented as an easyblock
14
15 Ref: https://speakerdeck.com/ajdecon/introduction-to-the-cuda-toolkit-for-building-applications
16
17 @author: George Tsouloupas (Cyprus Institute)
18 @author: Fotis Georgatos (Uni.lu)
19 @author: Kenneth Hoste (Ghent University)
20 @author: Damian Alvarez (Forschungszentrum Juelich)
21 @author: Ward Poelmans (Free University of Brussels)
22 """
23 import os
24 import re
25 import stat
26
27 from distutils.version import LooseVersion
28
29 from easybuild.easyblocks.generic.binary import Binary
30 from easybuild.framework.easyconfig import CUSTOM
31 from easybuild.tools.build_log import EasyBuildError
32 from easybuild.tools.filetools import adjust_permissions, patch_perl_script_autoflush, read_file, write_file
33 from easybuild.tools.run import run_cmd, run_cmd_qa
34 from easybuild.tools.systemtools import get_shared_lib_ext
35
36 # Wrapper script definition
37 WRAPPER_TEMPLATE = """#!/bin/sh
38 echo "$@" | grep -e '-ccbin' -e '--compiler-bindir' > /dev/null
39 if [ $? -eq 0 ];
40 then
41 echo "ERROR: do not set -ccbin or --compiler-bindir when using the `basename $0` wrapper"
42 else
43 nvcc -ccbin=%s "$@"
44 exit $?
45 fi """
46
47 class EB_CUDA(Binary):
48 """
49 Support for installing CUDA.
50 """
51
52 @staticmethod
53 def extra_options():
54 """Create a set of wrappers based on a list determined by the easyconfig file"""
55 extra_vars = {
56 'host_compilers': [None, "Host compilers for which a wrapper will be generated", CUSTOM]
57 }
58 return Binary.extra_options(extra_vars)
59
60 def extract_step(self):
61 """Extract installer to have more control, e.g. options, patching Perl scripts, etc."""
62 execpath = self.src[0]['path']
63 run_cmd("/bin/sh " + execpath + " --noexec --nox11 --target " + self.builddir)
64 self.src[0]['finalpath'] = self.builddir
65
66 def install_step(self):
67 """Install CUDA using Perl install script."""
68
69 # define how to run the installer
70 # script has /usr/bin/perl hardcoded, but we want to have control over which perl is being used
71 if LooseVersion(self.version) <= LooseVersion("5"):
72 install_interpreter = "perl"
73 install_script = "install-linux.pl"
74 self.cfg.update('installopts', '--prefix=%s' % self.installdir)
75 elif LooseVersion(self.version) > LooseVersion("5") and LooseVersion(self.version) < LooseVersion("10.1"):
76 install_interpreter = "perl"
77 install_script = "cuda-installer.pl"
78 # note: also including samples (via "-samplespath=%(installdir)s -samples") would require libglut
79 self.cfg.update('installopts', "-verbose -silent -toolkitpath=%s -toolkit" % self.installdir)
80 else:
81 install_interpreter = ""
82 install_script = "./cuda-installer"
83 # note: also including samples (via "-samplespath=%(installdir)s -samples") would require libglut
84 self.cfg.update('installopts', "--silent --toolkit --toolkitpath=%s --defaultroot=%s" % (
85 self.installdir, self.installdir))
86
87 cmd = "%(preinstallopts)s %(interpreter)s %(script)s %(installopts)s" % {
88 'preinstallopts': self.cfg['preinstallopts'],
89 'interpreter': install_interpreter,
90 'script': install_script,
91 'installopts': self.cfg['installopts']
92 }
93
94 # prepare for running install script autonomously
95 qanda = {}
96 stdqa = {
97 # this question is only asked if CUDA tools are already available system-wide
98 r"Would you like to remove all CUDA files under .*? (yes/no/abort): ": "no",
99 }
100 noqanda = [
101 r"^Configuring",
102 r"Installation Complete",
103 r"Verifying archive integrity.*",
104 r"^Uncompressing NVIDIA CUDA",
105 r".* -> .*",
106 ]
107
108 # patch install script to handle Q&A autonomously
109 if install_interpreter == "perl":
110 patch_perl_script_autoflush(os.path.join(self.builddir, install_script))
111
112 # make sure $DISPLAY is not defined, which may lead to (weird) problems
113 # this is workaround for not being able to specify --nox11 to the Perl install scripts
114 if 'DISPLAY' in os.environ:
115 os.environ.pop('DISPLAY')
116
117 # overriding maxhits default value to 300 (300s wait for nothing to change in the output without seeing a known
118 # question)
119 run_cmd_qa(cmd, qanda, std_qa=stdqa, no_qa=noqanda, log_all=True, simple=True, maxhits=300)
120
121 # check if there are patches to apply
122 if len(self.src) > 1:
123 for patch in self.src[1:]:
124 self.log.debug("Running patch %s", patch['name'])
125 run_cmd("/bin/sh " + patch['path'] + " --accept-eula --silent --installdir=" + self.installdir)
126
127 def post_install_step(self):
128 """Create wrappers for the specified host compilers and generate the appropriate stub symlinks"""
129 def create_wrapper(wrapper_name, wrapper_comp):
130 """Create for a particular compiler, with a particular name"""
131 wrapper_f = os.path.join(self.installdir, 'bin', wrapper_name)
132 write_file(wrapper_f, WRAPPER_TEMPLATE % wrapper_comp)
133 adjust_permissions(wrapper_f, stat.S_IXUSR|stat.S_IRUSR|stat.S_IXGRP|stat.S_IRGRP|stat.S_IXOTH|stat.S_IROTH)
134
135 # Prepare wrappers to handle a default host compiler other than g++
136 for comp in (self.cfg['host_compilers'] or []):
137 create_wrapper('nvcc_%s' % comp, comp)
138
139 # Run ldconfig to create missing symlinks in the stubs directory (libcuda.so.1, etc)
140 run_cmd("ldconfig -N " + os.path.join(self.installdir, 'lib64', 'stubs'))
141
142 super(EB_CUDA, self).post_install_step()
143
144 def sanity_check_step(self):
145 """Custom sanity check for CUDA."""
146
147 if LooseVersion(self.version) > LooseVersion("9"):
148 versionfile = read_file(os.path.join(self.installdir, "version.txt"))
149 if not re.search("Version %s$" % self.version, versionfile):
150 raise EasyBuildError("Unable to find the correct version (%s) in the version.txt file", self.version)
151
152 shlib_ext = get_shared_lib_ext()
153
154 chk_libdir = ["lib64"]
155
156 # Versions higher than 6 do not provide 32 bit libraries
157 if LooseVersion(self.version) < LooseVersion("6"):
158 chk_libdir += ["lib"]
159
160 culibs = ["cublas", "cudart", "cufft", "curand", "cusparse"]
161 custom_paths = {
162 'files': [os.path.join("bin", x) for x in ["fatbinary", "nvcc", "nvlink", "ptxas"]] +
163 [os.path.join("%s", "lib%s.%s") % (x, y, shlib_ext) for x in chk_libdir for y in culibs],
164 'dirs': ["include"],
165 }
166
167 if LooseVersion(self.version) < LooseVersion('7'):
168 custom_paths['files'].append(os.path.join('open64', 'bin', 'nvopencc'))
169 if LooseVersion(self.version) >= LooseVersion('7'):
170 custom_paths['files'].append(os.path.join("extras", "CUPTI", "lib64", "libcupti.%s") % shlib_ext)
171 custom_paths['dirs'].append(os.path.join("extras", "CUPTI", "include"))
172
173
174 super(EB_CUDA, self).sanity_check_step(custom_paths=custom_paths)
175
176 def make_module_req_guess(self):
177 """Specify CUDA custom values for PATH etc."""
178
179 guesses = super(EB_CUDA, self).make_module_req_guess()
180
181 # The dirs should be in the order ['open64/bin', 'bin']
182 bin_path = []
183 if LooseVersion(self.version) < LooseVersion('7'):
184 bin_path.append(os.path.join('open64', 'bin'))
185 bin_path.append('bin')
186
187 lib_path = ['lib64']
188 inc_path = ['include']
189 if LooseVersion(self.version) >= LooseVersion('7'):
190 lib_path.append(os.path.join('extras', 'CUPTI', 'lib64'))
191 inc_path.append(os.path.join('extras', 'CUPTI', 'include'))
192 bin_path.append(os.path.join('nvvm', 'bin'))
193 lib_path.append(os.path.join('nvvm', 'lib64'))
194 inc_path.append(os.path.join('nvvm', 'include'))
195
196 guesses.update({
197 'PATH': bin_path,
198 'LD_LIBRARY_PATH': lib_path,
199 'LIBRARY_PATH': ['lib64', os.path.join('lib64', 'stubs')],
200 'CPATH': inc_path,
201 'CUDA_HOME': [''],
202 'CUDA_ROOT': [''],
203 'CUDA_PATH': [''],
204 })
205
206 return guesses
207
[end of easybuild/easyblocks/c/cuda.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/easybuild/easyblocks/c/cuda.py b/easybuild/easyblocks/c/cuda.py
--- a/easybuild/easyblocks/c/cuda.py
+++ b/easybuild/easyblocks/c/cuda.py
@@ -173,6 +173,15 @@
super(EB_CUDA, self).sanity_check_step(custom_paths=custom_paths)
+ def make_module_extra(self):
+ """Set the install directory as CUDA_HOME, CUDA_ROOT, CUDA_PATH."""
+ txt = super(EB_CUDA, self).make_module_extra()
+ txt += self.module_generator.set_environment('CUDA_HOME', self.installdir)
+ txt += self.module_generator.set_environment('CUDA_ROOT', self.installdir)
+ txt += self.module_generator.set_environment('CUDA_PATH', self.installdir)
+ self.log.debug("make_module_extra added this: %s", txt)
+ return txt
+
def make_module_req_guess(self):
"""Specify CUDA custom values for PATH etc."""
@@ -198,9 +207,6 @@
'LD_LIBRARY_PATH': lib_path,
'LIBRARY_PATH': ['lib64', os.path.join('lib64', 'stubs')],
'CPATH': inc_path,
- 'CUDA_HOME': [''],
- 'CUDA_ROOT': [''],
- 'CUDA_PATH': [''],
})
return guesses
|
{"golden_diff": "diff --git a/easybuild/easyblocks/c/cuda.py b/easybuild/easyblocks/c/cuda.py\n--- a/easybuild/easyblocks/c/cuda.py\n+++ b/easybuild/easyblocks/c/cuda.py\n@@ -173,6 +173,15 @@\n \n super(EB_CUDA, self).sanity_check_step(custom_paths=custom_paths)\n \n+ def make_module_extra(self):\n+ \"\"\"Set the install directory as CUDA_HOME, CUDA_ROOT, CUDA_PATH.\"\"\"\n+ txt = super(EB_CUDA, self).make_module_extra()\n+ txt += self.module_generator.set_environment('CUDA_HOME', self.installdir)\n+ txt += self.module_generator.set_environment('CUDA_ROOT', self.installdir)\n+ txt += self.module_generator.set_environment('CUDA_PATH', self.installdir)\n+ self.log.debug(\"make_module_extra added this: %s\", txt)\n+ return txt\n+\n def make_module_req_guess(self):\n \"\"\"Specify CUDA custom values for PATH etc.\"\"\"\n \n@@ -198,9 +207,6 @@\n 'LD_LIBRARY_PATH': lib_path,\n 'LIBRARY_PATH': ['lib64', os.path.join('lib64', 'stubs')],\n 'CPATH': inc_path,\n- 'CUDA_HOME': [''],\n- 'CUDA_ROOT': [''],\n- 'CUDA_PATH': [''],\n })\n \n return guesses\n", "issue": "CUDA_{ROOT,HOME,PATH} are PATH-like?\nSee: https://github.com/easybuilders/easybuild-easyblocks/blob/e3a4cd70357103e1fa463751df13378f217c7ad1/easybuild/easyblocks/c/cuda.py#L191-L193\r\n\r\nThis creates `prepend_path` module commands, instead of `setenv`! Is there a particular reason to do so?\n", "before_files": [{"content": "##\n# This file is an EasyBuild reciPY as per https://github.com/easybuilders/easybuild\n#\n# Copyright:: Copyright 2012-2019 Cyprus Institute / CaSToRC, Uni.Lu, NTUA, Ghent University, Forschungszentrum Juelich GmbH\n# Authors:: George Tsouloupas <[email protected]>, Fotis Georgatos <[email protected]>, Kenneth Hoste, Damian Alvarez\n# License:: MIT/GPL\n# $Id$\n#\n# This work implements a part of the HPCBIOS project and is a component of the policy:\n# http://hpcbios.readthedocs.org/en/latest/HPCBIOS_2012-99.html\n##\n\"\"\"\nEasyBuild support for CUDA, implemented as an easyblock\n\nRef: https://speakerdeck.com/ajdecon/introduction-to-the-cuda-toolkit-for-building-applications\n\n@author: George Tsouloupas (Cyprus Institute)\n@author: Fotis Georgatos (Uni.lu)\n@author: Kenneth Hoste (Ghent University)\n@author: Damian Alvarez (Forschungszentrum Juelich)\n@author: Ward Poelmans (Free University of Brussels)\n\"\"\"\nimport os\nimport re\nimport stat\n\nfrom distutils.version import LooseVersion\n\nfrom easybuild.easyblocks.generic.binary import Binary\nfrom easybuild.framework.easyconfig import CUSTOM\nfrom easybuild.tools.build_log import EasyBuildError\nfrom easybuild.tools.filetools import adjust_permissions, patch_perl_script_autoflush, read_file, write_file\nfrom easybuild.tools.run import run_cmd, run_cmd_qa\nfrom easybuild.tools.systemtools import get_shared_lib_ext\n\n# Wrapper script definition\nWRAPPER_TEMPLATE = \"\"\"#!/bin/sh\necho \"$@\" | grep -e '-ccbin' -e '--compiler-bindir' > /dev/null\nif [ $? -eq 0 ];\nthen\n echo \"ERROR: do not set -ccbin or --compiler-bindir when using the `basename $0` wrapper\"\nelse\n nvcc -ccbin=%s \"$@\"\n exit $?\nfi \"\"\"\n\nclass EB_CUDA(Binary):\n \"\"\"\n Support for installing CUDA.\n \"\"\"\n\n @staticmethod\n def extra_options():\n \"\"\"Create a set of wrappers based on a list determined by the easyconfig file\"\"\"\n extra_vars = {\n 'host_compilers': [None, \"Host compilers for which a wrapper will be generated\", CUSTOM]\n }\n return Binary.extra_options(extra_vars)\n\n def extract_step(self):\n \"\"\"Extract installer to have more control, e.g. options, patching Perl scripts, etc.\"\"\"\n execpath = self.src[0]['path']\n run_cmd(\"/bin/sh \" + execpath + \" --noexec --nox11 --target \" + self.builddir)\n self.src[0]['finalpath'] = self.builddir\n\n def install_step(self):\n \"\"\"Install CUDA using Perl install script.\"\"\"\n\n # define how to run the installer\n # script has /usr/bin/perl hardcoded, but we want to have control over which perl is being used\n if LooseVersion(self.version) <= LooseVersion(\"5\"):\n install_interpreter = \"perl\"\n install_script = \"install-linux.pl\"\n self.cfg.update('installopts', '--prefix=%s' % self.installdir)\n elif LooseVersion(self.version) > LooseVersion(\"5\") and LooseVersion(self.version) < LooseVersion(\"10.1\"):\n install_interpreter = \"perl\"\n install_script = \"cuda-installer.pl\"\n # note: also including samples (via \"-samplespath=%(installdir)s -samples\") would require libglut\n self.cfg.update('installopts', \"-verbose -silent -toolkitpath=%s -toolkit\" % self.installdir)\n else:\n install_interpreter = \"\"\n install_script = \"./cuda-installer\"\n # note: also including samples (via \"-samplespath=%(installdir)s -samples\") would require libglut\n self.cfg.update('installopts', \"--silent --toolkit --toolkitpath=%s --defaultroot=%s\" % (\n self.installdir, self.installdir))\n\n cmd = \"%(preinstallopts)s %(interpreter)s %(script)s %(installopts)s\" % {\n 'preinstallopts': self.cfg['preinstallopts'],\n 'interpreter': install_interpreter,\n 'script': install_script,\n 'installopts': self.cfg['installopts']\n }\n\n # prepare for running install script autonomously\n qanda = {}\n stdqa = {\n # this question is only asked if CUDA tools are already available system-wide\n r\"Would you like to remove all CUDA files under .*? (yes/no/abort): \": \"no\",\n }\n noqanda = [\n r\"^Configuring\",\n r\"Installation Complete\",\n r\"Verifying archive integrity.*\",\n r\"^Uncompressing NVIDIA CUDA\",\n r\".* -> .*\",\n ]\n\n # patch install script to handle Q&A autonomously\n if install_interpreter == \"perl\":\n patch_perl_script_autoflush(os.path.join(self.builddir, install_script))\n\n # make sure $DISPLAY is not defined, which may lead to (weird) problems\n # this is workaround for not being able to specify --nox11 to the Perl install scripts\n if 'DISPLAY' in os.environ:\n os.environ.pop('DISPLAY')\n\n # overriding maxhits default value to 300 (300s wait for nothing to change in the output without seeing a known\n # question)\n run_cmd_qa(cmd, qanda, std_qa=stdqa, no_qa=noqanda, log_all=True, simple=True, maxhits=300)\n\n # check if there are patches to apply\n if len(self.src) > 1:\n for patch in self.src[1:]:\n self.log.debug(\"Running patch %s\", patch['name'])\n run_cmd(\"/bin/sh \" + patch['path'] + \" --accept-eula --silent --installdir=\" + self.installdir)\n\n def post_install_step(self):\n \"\"\"Create wrappers for the specified host compilers and generate the appropriate stub symlinks\"\"\"\n def create_wrapper(wrapper_name, wrapper_comp):\n \"\"\"Create for a particular compiler, with a particular name\"\"\"\n wrapper_f = os.path.join(self.installdir, 'bin', wrapper_name)\n write_file(wrapper_f, WRAPPER_TEMPLATE % wrapper_comp)\n adjust_permissions(wrapper_f, stat.S_IXUSR|stat.S_IRUSR|stat.S_IXGRP|stat.S_IRGRP|stat.S_IXOTH|stat.S_IROTH)\n\n # Prepare wrappers to handle a default host compiler other than g++\n for comp in (self.cfg['host_compilers'] or []):\n create_wrapper('nvcc_%s' % comp, comp)\n\n # Run ldconfig to create missing symlinks in the stubs directory (libcuda.so.1, etc)\n run_cmd(\"ldconfig -N \" + os.path.join(self.installdir, 'lib64', 'stubs'))\n\n super(EB_CUDA, self).post_install_step()\n\n def sanity_check_step(self):\n \"\"\"Custom sanity check for CUDA.\"\"\"\n\n if LooseVersion(self.version) > LooseVersion(\"9\"):\n versionfile = read_file(os.path.join(self.installdir, \"version.txt\"))\n if not re.search(\"Version %s$\" % self.version, versionfile):\n raise EasyBuildError(\"Unable to find the correct version (%s) in the version.txt file\", self.version)\n\n shlib_ext = get_shared_lib_ext()\n\n chk_libdir = [\"lib64\"]\n\n # Versions higher than 6 do not provide 32 bit libraries\n if LooseVersion(self.version) < LooseVersion(\"6\"):\n chk_libdir += [\"lib\"]\n\n culibs = [\"cublas\", \"cudart\", \"cufft\", \"curand\", \"cusparse\"]\n custom_paths = {\n 'files': [os.path.join(\"bin\", x) for x in [\"fatbinary\", \"nvcc\", \"nvlink\", \"ptxas\"]] +\n [os.path.join(\"%s\", \"lib%s.%s\") % (x, y, shlib_ext) for x in chk_libdir for y in culibs],\n 'dirs': [\"include\"],\n }\n\n if LooseVersion(self.version) < LooseVersion('7'):\n custom_paths['files'].append(os.path.join('open64', 'bin', 'nvopencc'))\n if LooseVersion(self.version) >= LooseVersion('7'):\n custom_paths['files'].append(os.path.join(\"extras\", \"CUPTI\", \"lib64\", \"libcupti.%s\") % shlib_ext)\n custom_paths['dirs'].append(os.path.join(\"extras\", \"CUPTI\", \"include\"))\n\n\n super(EB_CUDA, self).sanity_check_step(custom_paths=custom_paths)\n\n def make_module_req_guess(self):\n \"\"\"Specify CUDA custom values for PATH etc.\"\"\"\n\n guesses = super(EB_CUDA, self).make_module_req_guess()\n\n # The dirs should be in the order ['open64/bin', 'bin']\n bin_path = []\n if LooseVersion(self.version) < LooseVersion('7'):\n bin_path.append(os.path.join('open64', 'bin'))\n bin_path.append('bin')\n\n lib_path = ['lib64']\n inc_path = ['include']\n if LooseVersion(self.version) >= LooseVersion('7'):\n lib_path.append(os.path.join('extras', 'CUPTI', 'lib64'))\n inc_path.append(os.path.join('extras', 'CUPTI', 'include'))\n bin_path.append(os.path.join('nvvm', 'bin'))\n lib_path.append(os.path.join('nvvm', 'lib64'))\n inc_path.append(os.path.join('nvvm', 'include'))\n\n guesses.update({\n 'PATH': bin_path,\n 'LD_LIBRARY_PATH': lib_path,\n 'LIBRARY_PATH': ['lib64', os.path.join('lib64', 'stubs')],\n 'CPATH': inc_path,\n 'CUDA_HOME': [''],\n 'CUDA_ROOT': [''],\n 'CUDA_PATH': [''],\n })\n\n return guesses\n", "path": "easybuild/easyblocks/c/cuda.py"}]}
| 3,420 | 311 |
gh_patches_debug_5571
|
rasdani/github-patches
|
git_diff
|
certbot__certbot-6099
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
certbot-nginx requires acme >= 0.25
Because of the import of symbols `from acme.magic_typing`, the nginx plugin released in 0.25 depends on acme 0.25 or better. However, setup.py only lists `acme>0.21.1`, leading to a failure to build from source (and potential run-time failures).
</issue>
<code>
[start of certbot-nginx/setup.py]
1 from setuptools import setup
2 from setuptools import find_packages
3
4
5 version = '0.26.0.dev0'
6
7 # Remember to update local-oldest-requirements.txt when changing the minimum
8 # acme/certbot version.
9 install_requires = [
10 # This plugin works with an older version of acme, but Certbot does not.
11 # 0.22.0 is specified here to work around
12 # https://github.com/pypa/pip/issues/988.
13 'acme>0.21.1',
14 'certbot>0.21.1',
15 'mock',
16 'PyOpenSSL',
17 'pyparsing>=1.5.5', # Python3 support; perhaps unnecessary?
18 'setuptools',
19 'zope.interface',
20 ]
21
22 docs_extras = [
23 'Sphinx>=1.0', # autodoc_member_order = 'bysource', autodoc_default_flags
24 'sphinx_rtd_theme',
25 ]
26
27 setup(
28 name='certbot-nginx',
29 version=version,
30 description="Nginx plugin for Certbot",
31 url='https://github.com/letsencrypt/letsencrypt',
32 author="Certbot Project",
33 author_email='[email protected]',
34 license='Apache License 2.0',
35 python_requires='>=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*',
36 classifiers=[
37 'Development Status :: 3 - Alpha',
38 'Environment :: Plugins',
39 'Intended Audience :: System Administrators',
40 'License :: OSI Approved :: Apache Software License',
41 'Operating System :: POSIX :: Linux',
42 'Programming Language :: Python',
43 'Programming Language :: Python :: 2',
44 'Programming Language :: Python :: 2.7',
45 'Programming Language :: Python :: 3',
46 'Programming Language :: Python :: 3.4',
47 'Programming Language :: Python :: 3.5',
48 'Programming Language :: Python :: 3.6',
49 'Topic :: Internet :: WWW/HTTP',
50 'Topic :: Security',
51 'Topic :: System :: Installation/Setup',
52 'Topic :: System :: Networking',
53 'Topic :: System :: Systems Administration',
54 'Topic :: Utilities',
55 ],
56
57 packages=find_packages(),
58 include_package_data=True,
59 install_requires=install_requires,
60 extras_require={
61 'docs': docs_extras,
62 },
63 entry_points={
64 'certbot.plugins': [
65 'nginx = certbot_nginx.configurator:NginxConfigurator',
66 ],
67 },
68 test_suite='certbot_nginx',
69 )
70
[end of certbot-nginx/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/certbot-nginx/setup.py b/certbot-nginx/setup.py
--- a/certbot-nginx/setup.py
+++ b/certbot-nginx/setup.py
@@ -7,10 +7,7 @@
# Remember to update local-oldest-requirements.txt when changing the minimum
# acme/certbot version.
install_requires = [
- # This plugin works with an older version of acme, but Certbot does not.
- # 0.22.0 is specified here to work around
- # https://github.com/pypa/pip/issues/988.
- 'acme>0.21.1',
+ 'acme>=0.25.0',
'certbot>0.21.1',
'mock',
'PyOpenSSL',
|
{"golden_diff": "diff --git a/certbot-nginx/setup.py b/certbot-nginx/setup.py\n--- a/certbot-nginx/setup.py\n+++ b/certbot-nginx/setup.py\n@@ -7,10 +7,7 @@\n # Remember to update local-oldest-requirements.txt when changing the minimum\n # acme/certbot version.\n install_requires = [\n- # This plugin works with an older version of acme, but Certbot does not.\n- # 0.22.0 is specified here to work around\n- # https://github.com/pypa/pip/issues/988.\n- 'acme>0.21.1',\n+ 'acme>=0.25.0',\n 'certbot>0.21.1',\n 'mock',\n 'PyOpenSSL',\n", "issue": "certbot-nginx requires acme >= 0.25\nBecause of the import of symbols `from acme.magic_typing`, the nginx plugin released in 0.25 depends on acme 0.25 or better. However, setup.py only lists `acme>0.21.1`, leading to a failure to build from source (and potential run-time failures).\n", "before_files": [{"content": "from setuptools import setup\nfrom setuptools import find_packages\n\n\nversion = '0.26.0.dev0'\n\n# Remember to update local-oldest-requirements.txt when changing the minimum\n# acme/certbot version.\ninstall_requires = [\n # This plugin works with an older version of acme, but Certbot does not.\n # 0.22.0 is specified here to work around\n # https://github.com/pypa/pip/issues/988.\n 'acme>0.21.1',\n 'certbot>0.21.1',\n 'mock',\n 'PyOpenSSL',\n 'pyparsing>=1.5.5', # Python3 support; perhaps unnecessary?\n 'setuptools',\n 'zope.interface',\n]\n\ndocs_extras = [\n 'Sphinx>=1.0', # autodoc_member_order = 'bysource', autodoc_default_flags\n 'sphinx_rtd_theme',\n]\n\nsetup(\n name='certbot-nginx',\n version=version,\n description=\"Nginx plugin for Certbot\",\n url='https://github.com/letsencrypt/letsencrypt',\n author=\"Certbot Project\",\n author_email='[email protected]',\n license='Apache License 2.0',\n python_requires='>=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*',\n classifiers=[\n 'Development Status :: 3 - Alpha',\n 'Environment :: Plugins',\n 'Intended Audience :: System Administrators',\n 'License :: OSI Approved :: Apache Software License',\n 'Operating System :: POSIX :: Linux',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Topic :: Internet :: WWW/HTTP',\n 'Topic :: Security',\n 'Topic :: System :: Installation/Setup',\n 'Topic :: System :: Networking',\n 'Topic :: System :: Systems Administration',\n 'Topic :: Utilities',\n ],\n\n packages=find_packages(),\n include_package_data=True,\n install_requires=install_requires,\n extras_require={\n 'docs': docs_extras,\n },\n entry_points={\n 'certbot.plugins': [\n 'nginx = certbot_nginx.configurator:NginxConfigurator',\n ],\n },\n test_suite='certbot_nginx',\n)\n", "path": "certbot-nginx/setup.py"}]}
| 1,315 | 182 |
gh_patches_debug_20003
|
rasdani/github-patches
|
git_diff
|
searx__searx-925
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add a software categorie and add the Free software directory search engine
Shame on me I forgot to ask this.
I am a volunteer on the [FSD](https://directory.fsf.org/wiki/Main_Page) (Free software directory)
It would be nice if people could look for free/libre software in the searx engine.
When possible could someone please add the free software directory so that people can easily find free software.
</issue>
<code>
[start of searx/engines/mediawiki.py]
1 """
2 general mediawiki-engine (Web)
3
4 @website websites built on mediawiki (https://www.mediawiki.org)
5 @provide-api yes (http://www.mediawiki.org/wiki/API:Search)
6
7 @using-api yes
8 @results JSON
9 @stable yes
10 @parse url, title
11
12 @todo content
13 """
14
15 from json import loads
16 from string import Formatter
17 from searx.url_utils import urlencode, quote
18
19 # engine dependent config
20 categories = ['general']
21 language_support = True
22 paging = True
23 number_of_results = 1
24
25 # search-url
26 base_url = 'https://{language}.wikipedia.org/'
27 search_postfix = 'w/api.php?action=query'\
28 '&list=search'\
29 '&{query}'\
30 '&format=json'\
31 '&sroffset={offset}'\
32 '&srlimit={limit}'\
33 '&srwhat=nearmatch' # search for a near match in the title
34
35
36 # do search-request
37 def request(query, params):
38 offset = (params['pageno'] - 1) * number_of_results
39
40 string_args = dict(query=urlencode({'srsearch': query}),
41 offset=offset,
42 limit=number_of_results)
43
44 format_strings = list(Formatter().parse(base_url))
45
46 if params['language'] == 'all':
47 language = 'en'
48 else:
49 language = params['language'].split('-')[0]
50
51 # format_string [('https://', 'language', '', None), ('.wikipedia.org/', None, None, None)]
52 if any(x[1] == 'language' for x in format_strings):
53 string_args['language'] = language
54
55 # write search-language back to params, required in response
56 params['language'] = language
57
58 search_url = base_url + search_postfix
59
60 params['url'] = search_url.format(**string_args)
61
62 return params
63
64
65 # get response from search-request
66 def response(resp):
67 results = []
68
69 search_results = loads(resp.text)
70
71 # return empty array if there are no results
72 if not search_results.get('query', {}).get('search'):
73 return []
74
75 # parse results
76 for result in search_results['query']['search']:
77 if result.get('snippet', '').startswith('#REDIRECT'):
78 continue
79 url = base_url.format(language=resp.search_params['language']) +\
80 'wiki/' + quote(result['title'].replace(' ', '_').encode('utf-8'))
81
82 # append result
83 results.append({'url': url,
84 'title': result['title'],
85 'content': ''})
86
87 # return results
88 return results
89
[end of searx/engines/mediawiki.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/searx/engines/mediawiki.py b/searx/engines/mediawiki.py
--- a/searx/engines/mediawiki.py
+++ b/searx/engines/mediawiki.py
@@ -21,6 +21,7 @@
language_support = True
paging = True
number_of_results = 1
+search_type = 'nearmatch' # possible values: title, text, nearmatch
# search-url
base_url = 'https://{language}.wikipedia.org/'
@@ -30,7 +31,7 @@
'&format=json'\
'&sroffset={offset}'\
'&srlimit={limit}'\
- '&srwhat=nearmatch' # search for a near match in the title
+ '&srwhat={searchtype}'
# do search-request
@@ -39,7 +40,8 @@
string_args = dict(query=urlencode({'srsearch': query}),
offset=offset,
- limit=number_of_results)
+ limit=number_of_results,
+ searchtype=search_type)
format_strings = list(Formatter().parse(base_url))
|
{"golden_diff": "diff --git a/searx/engines/mediawiki.py b/searx/engines/mediawiki.py\n--- a/searx/engines/mediawiki.py\n+++ b/searx/engines/mediawiki.py\n@@ -21,6 +21,7 @@\n language_support = True\n paging = True\n number_of_results = 1\n+search_type = 'nearmatch' # possible values: title, text, nearmatch\n \n # search-url\n base_url = 'https://{language}.wikipedia.org/'\n@@ -30,7 +31,7 @@\n '&format=json'\\\n '&sroffset={offset}'\\\n '&srlimit={limit}'\\\n- '&srwhat=nearmatch' # search for a near match in the title\n+ '&srwhat={searchtype}'\n \n \n # do search-request\n@@ -39,7 +40,8 @@\n \n string_args = dict(query=urlencode({'srsearch': query}),\n offset=offset,\n- limit=number_of_results)\n+ limit=number_of_results,\n+ searchtype=search_type)\n \n format_strings = list(Formatter().parse(base_url))\n", "issue": "Add a software categorie and add the Free software directory search engine\nShame on me I forgot to ask this.\r\nI am a volunteer on the [FSD](https://directory.fsf.org/wiki/Main_Page) (Free software directory)\r\nIt would be nice if people could look for free/libre software in the searx engine.\r\nWhen possible could someone please add the free software directory so that people can easily find free software.\n", "before_files": [{"content": "\"\"\"\n general mediawiki-engine (Web)\n\n @website websites built on mediawiki (https://www.mediawiki.org)\n @provide-api yes (http://www.mediawiki.org/wiki/API:Search)\n\n @using-api yes\n @results JSON\n @stable yes\n @parse url, title\n\n @todo content\n\"\"\"\n\nfrom json import loads\nfrom string import Formatter\nfrom searx.url_utils import urlencode, quote\n\n# engine dependent config\ncategories = ['general']\nlanguage_support = True\npaging = True\nnumber_of_results = 1\n\n# search-url\nbase_url = 'https://{language}.wikipedia.org/'\nsearch_postfix = 'w/api.php?action=query'\\\n '&list=search'\\\n '&{query}'\\\n '&format=json'\\\n '&sroffset={offset}'\\\n '&srlimit={limit}'\\\n '&srwhat=nearmatch' # search for a near match in the title\n\n\n# do search-request\ndef request(query, params):\n offset = (params['pageno'] - 1) * number_of_results\n\n string_args = dict(query=urlencode({'srsearch': query}),\n offset=offset,\n limit=number_of_results)\n\n format_strings = list(Formatter().parse(base_url))\n\n if params['language'] == 'all':\n language = 'en'\n else:\n language = params['language'].split('-')[0]\n\n # format_string [('https://', 'language', '', None), ('.wikipedia.org/', None, None, None)]\n if any(x[1] == 'language' for x in format_strings):\n string_args['language'] = language\n\n # write search-language back to params, required in response\n params['language'] = language\n\n search_url = base_url + search_postfix\n\n params['url'] = search_url.format(**string_args)\n\n return params\n\n\n# get response from search-request\ndef response(resp):\n results = []\n\n search_results = loads(resp.text)\n\n # return empty array if there are no results\n if not search_results.get('query', {}).get('search'):\n return []\n\n # parse results\n for result in search_results['query']['search']:\n if result.get('snippet', '').startswith('#REDIRECT'):\n continue\n url = base_url.format(language=resp.search_params['language']) +\\\n 'wiki/' + quote(result['title'].replace(' ', '_').encode('utf-8'))\n\n # append result\n results.append({'url': url,\n 'title': result['title'],\n 'content': ''})\n\n # return results\n return results\n", "path": "searx/engines/mediawiki.py"}]}
| 1,394 | 258 |
gh_patches_debug_30277
|
rasdani/github-patches
|
git_diff
|
plone__Products.CMFPlone-3719
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Can't edit the modal property of an action in Plone UI
Most settings of actions can be edited in the actions control panel in the Plone UI. See the classic demo:
https://6-classic.demo.plone.org/@@actions-controlpanel
Some actions have a modal property, for example the `object_buttons/delete` action. You can see it in the ZMI:
https://6-classic.demo.plone.org/portal_actions/object_buttons/delete/manage_propertiesForm
The property value is this:
```
{"actionOptions": {"disableAjaxFormSubmit":true, "redirectOnResponse":true}}
```
It would be nice if this could also be edited in the control panel. Currently this property is now shown at all.
I guess there could be other non-standard properties as well, so bonus points if this shows all properties.
My use case today was actually on Plone 5.2 where I wanted to change the modal property of `user/login`. In Plone 6.0.0 this is an empty dictionary, but on 5.2 it was this:
```
{"prependContent": ".portalMessage", "title": "Log in", "width": "26em", "actionOptions": {"redirectOnResponse": true}}
```
I had to change the width to 18em in a client project today because their base font size was a lot bigger, which led to the login modal being only half visible on mobile. :-)
With my release manager hat on: no I don't want this changed in 5.2, people will have to use the ZMI there. Depending on scale and impact of the needed changes, a fix for this could be done either in a 6.0.x bugfix release, or in 6.1.
</issue>
<code>
[start of Products/CMFPlone/controlpanel/browser/actions.py]
1 from plone.autoform.form import AutoExtensibleForm
2 from plone.base.interfaces import IActionSchema
3 from plone.base.interfaces import INewActionSchema
4 from Products.CMFCore.ActionInformation import Action
5 from Products.CMFCore.interfaces import IAction
6 from Products.CMFCore.interfaces import IActionCategory
7 from Products.CMFCore.utils import getToolByName
8 from Products.CMFPlone import PloneMessageFactory as _
9 from Products.Five import BrowserView
10 from Products.Five.browser.pagetemplatefile import ViewPageTemplateFile
11 from z3c.form import form
12 from zope.component import adapts
13 from zope.event import notify
14 from zope.interface import implementer
15 from zope.lifecycleevent import ObjectCreatedEvent
16
17
18 class ActionListControlPanel(BrowserView):
19 """Control panel for the portal actions."""
20
21 template = ViewPageTemplateFile("actions.pt")
22
23 def __init__(self, context, request):
24 self.context = context
25 self.request = request
26 self.portal_actions = getToolByName(self.context, 'portal_actions')
27
28 def display(self):
29 actions = []
30 for category in self.portal_actions.objectValues():
31 if category.id == 'controlpanel':
32 continue
33 if not IActionCategory.providedBy(category):
34 continue
35 cat_infos = {
36 'id': category.id,
37 'title': category.title or category.id,
38 }
39 action_list = []
40 for action in category.objectValues():
41 if IAction.providedBy(action):
42 action_list.append({
43 'id': action.id,
44 'title': action.title,
45 'url': action.absolute_url(),
46 'visible': action.visible,
47 })
48 cat_infos['actions'] = action_list
49 actions.append(cat_infos)
50
51 self.actions = actions
52 return self.template()
53
54 def __call__(self):
55 if self.request.get('delete'):
56 action_id = self.request['actionid']
57 category = self.portal_actions[self.request['category']]
58 category.manage_delObjects([action_id])
59 self.request.RESPONSE.redirect('@@actions-controlpanel')
60 if self.request.get('hide'):
61 action_id = self.request['actionid']
62 category = self.portal_actions[self.request['category']]
63 category[action_id].visible = False
64 self.request.RESPONSE.redirect('@@actions-controlpanel')
65 if self.request.get('show'):
66 action_id = self.request['actionid']
67 category = self.portal_actions[self.request['category']]
68 category[action_id].visible = True
69 self.request.RESPONSE.redirect('@@actions-controlpanel')
70 return self.display()
71
72
73 @implementer(IActionSchema)
74 class ActionControlPanelAdapter:
75 """Adapter for action form."""
76
77 adapts(IAction)
78
79 def __init__(self, context):
80 self.context = context
81 self.current_category = self.context.getParentNode()
82
83 def get_category(self):
84 return self.current_category.id
85
86 def set_category(self, value):
87 portal_actions = getToolByName(self.context, 'portal_actions')
88 new_category = portal_actions.get(value)
89 cookie = self.current_category.manage_cutObjects(ids=[self.context.id])
90 new_category.manage_pasteObjects(cookie)
91
92 category = property(get_category, set_category)
93
94 def get_title(self):
95 return self.context.title
96
97 def set_title(self, value):
98 self.context._setPropValue('title', value)
99
100 title = property(get_title, set_title)
101
102 def get_description(self):
103 return self.context.description
104
105 def set_description(self, value):
106 self.context._setPropValue('description', value)
107
108 description = property(get_description, set_description)
109
110 def get_i18n_domain(self):
111 return self.context.i18n_domain
112
113 def set_i18n_domain(self, value):
114 self.context._setPropValue('i18n_domain', value)
115
116 i18n_domain = property(get_i18n_domain, set_i18n_domain)
117
118 def get_url_expr(self):
119 return self.context.url_expr
120
121 def set_url_expr(self, value):
122 self.context._setPropValue('url_expr', value)
123
124 url_expr = property(get_url_expr, set_url_expr)
125
126 def get_available_expr(self):
127 return self.context.available_expr
128
129 def set_available_expr(self, value):
130 self.context._setPropValue('available_expr', value)
131
132 available_expr = property(get_available_expr, set_available_expr)
133
134 def get_permissions(self):
135 return self.context.permissions
136
137 def set_permissions(self, value):
138 self.context._setPropValue('permissions', value)
139
140 permissions = property(get_permissions, set_permissions)
141
142 def get_visible(self):
143 return self.context.visible
144
145 def set_visible(self, value):
146 self.context._setPropValue('visible', value)
147
148 visible = property(get_visible, set_visible)
149
150 def get_position(self):
151 position = self.current_category.objectIds().index(self.context.id)
152 return position + 1
153
154 def set_position(self, value):
155 current_position = self.current_category.objectIds().index(
156 self.context.id)
157 all_actions = list(self.current_category._objects)
158 current_action = all_actions.pop(current_position)
159 new_position = value - 1
160 all_actions = all_actions[0:new_position] + [current_action] + \
161 all_actions[new_position:]
162 self.current_category._objects = tuple(all_actions)
163
164 position = property(get_position, set_position)
165
166
167 class ActionControlPanel(AutoExtensibleForm, form.EditForm):
168 """A form to edit a portal action."""
169
170 schema = IActionSchema
171 ignoreContext = False
172 label = _('Action Settings')
173
174
175 class NewActionControlPanel(AutoExtensibleForm, form.AddForm):
176 """A form to add a new portal action."""
177
178 schema = INewActionSchema
179 ignoreContext = True
180 label = _('New action')
181
182 def createAndAdd(self, data):
183 portal_actions = getToolByName(self.context, 'portal_actions')
184 category = portal_actions.get(data['category'])
185 action_id = data['id']
186 action = Action(
187 action_id,
188 title=action_id,
189 i18n_domain='plone',
190 permissions=['View'],
191 )
192 category[action_id] = action
193 notify(ObjectCreatedEvent(action))
194
[end of Products/CMFPlone/controlpanel/browser/actions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/Products/CMFPlone/controlpanel/browser/actions.py b/Products/CMFPlone/controlpanel/browser/actions.py
--- a/Products/CMFPlone/controlpanel/browser/actions.py
+++ b/Products/CMFPlone/controlpanel/browser/actions.py
@@ -1,6 +1,7 @@
from plone.autoform.form import AutoExtensibleForm
from plone.base.interfaces import IActionSchema
from plone.base.interfaces import INewActionSchema
+from plone.base.utils import base_hasattr
from Products.CMFCore.ActionInformation import Action
from Products.CMFCore.interfaces import IAction
from Products.CMFCore.interfaces import IActionCategory
@@ -14,6 +15,8 @@
from zope.interface import implementer
from zope.lifecycleevent import ObjectCreatedEvent
+import json
+
class ActionListControlPanel(BrowserView):
"""Control panel for the portal actions."""
@@ -163,6 +166,22 @@
position = property(get_position, set_position)
+ def get_modal(self):
+ return self.context.modal
+
+ def set_modal(self, value):
+ # This property may not exist yet on the context.
+ if not self.context.hasProperty("modal"):
+ if base_hasattr(self.context, "modal"):
+ # We cannot define a property when an attribute with the same
+ # name already exists.
+ delattr(self.context, "modal")
+ self.context._setProperty('modal', value, 'string')
+ else:
+ self.context._setPropValue('modal', value)
+
+ modal = property(get_modal, set_modal)
+
class ActionControlPanel(AutoExtensibleForm, form.EditForm):
"""A form to edit a portal action."""
|
{"golden_diff": "diff --git a/Products/CMFPlone/controlpanel/browser/actions.py b/Products/CMFPlone/controlpanel/browser/actions.py\n--- a/Products/CMFPlone/controlpanel/browser/actions.py\n+++ b/Products/CMFPlone/controlpanel/browser/actions.py\n@@ -1,6 +1,7 @@\n from plone.autoform.form import AutoExtensibleForm\n from plone.base.interfaces import IActionSchema\n from plone.base.interfaces import INewActionSchema\n+from plone.base.utils import base_hasattr\n from Products.CMFCore.ActionInformation import Action\n from Products.CMFCore.interfaces import IAction\n from Products.CMFCore.interfaces import IActionCategory\n@@ -14,6 +15,8 @@\n from zope.interface import implementer\n from zope.lifecycleevent import ObjectCreatedEvent\n \n+import json\n+\n \n class ActionListControlPanel(BrowserView):\n \"\"\"Control panel for the portal actions.\"\"\"\n@@ -163,6 +166,22 @@\n \n position = property(get_position, set_position)\n \n+ def get_modal(self):\n+ return self.context.modal\n+\n+ def set_modal(self, value):\n+ # This property may not exist yet on the context.\n+ if not self.context.hasProperty(\"modal\"):\n+ if base_hasattr(self.context, \"modal\"):\n+ # We cannot define a property when an attribute with the same\n+ # name already exists.\n+ delattr(self.context, \"modal\")\n+ self.context._setProperty('modal', value, 'string')\n+ else:\n+ self.context._setPropValue('modal', value)\n+\n+ modal = property(get_modal, set_modal)\n+\n \n class ActionControlPanel(AutoExtensibleForm, form.EditForm):\n \"\"\"A form to edit a portal action.\"\"\"\n", "issue": "Can't edit the modal property of an action in Plone UI\nMost settings of actions can be edited in the actions control panel in the Plone UI. See the classic demo:\r\nhttps://6-classic.demo.plone.org/@@actions-controlpanel\r\n\r\nSome actions have a modal property, for example the `object_buttons/delete` action. You can see it in the ZMI:\r\nhttps://6-classic.demo.plone.org/portal_actions/object_buttons/delete/manage_propertiesForm\r\nThe property value is this:\r\n\r\n```\r\n{\"actionOptions\": {\"disableAjaxFormSubmit\":true, \"redirectOnResponse\":true}}\r\n```\r\n\r\nIt would be nice if this could also be edited in the control panel. Currently this property is now shown at all.\r\nI guess there could be other non-standard properties as well, so bonus points if this shows all properties.\r\n\r\nMy use case today was actually on Plone 5.2 where I wanted to change the modal property of `user/login`. In Plone 6.0.0 this is an empty dictionary, but on 5.2 it was this:\r\n\r\n```\r\n{\"prependContent\": \".portalMessage\", \"title\": \"Log in\", \"width\": \"26em\", \"actionOptions\": {\"redirectOnResponse\": true}}\r\n```\r\n\r\nI had to change the width to 18em in a client project today because their base font size was a lot bigger, which led to the login modal being only half visible on mobile. :-)\r\n\r\nWith my release manager hat on: no I don't want this changed in 5.2, people will have to use the ZMI there. Depending on scale and impact of the needed changes, a fix for this could be done either in a 6.0.x bugfix release, or in 6.1.\n", "before_files": [{"content": "from plone.autoform.form import AutoExtensibleForm\nfrom plone.base.interfaces import IActionSchema\nfrom plone.base.interfaces import INewActionSchema\nfrom Products.CMFCore.ActionInformation import Action\nfrom Products.CMFCore.interfaces import IAction\nfrom Products.CMFCore.interfaces import IActionCategory\nfrom Products.CMFCore.utils import getToolByName\nfrom Products.CMFPlone import PloneMessageFactory as _\nfrom Products.Five import BrowserView\nfrom Products.Five.browser.pagetemplatefile import ViewPageTemplateFile\nfrom z3c.form import form\nfrom zope.component import adapts\nfrom zope.event import notify\nfrom zope.interface import implementer\nfrom zope.lifecycleevent import ObjectCreatedEvent\n\n\nclass ActionListControlPanel(BrowserView):\n \"\"\"Control panel for the portal actions.\"\"\"\n\n template = ViewPageTemplateFile(\"actions.pt\")\n\n def __init__(self, context, request):\n self.context = context\n self.request = request\n self.portal_actions = getToolByName(self.context, 'portal_actions')\n\n def display(self):\n actions = []\n for category in self.portal_actions.objectValues():\n if category.id == 'controlpanel':\n continue\n if not IActionCategory.providedBy(category):\n continue\n cat_infos = {\n 'id': category.id,\n 'title': category.title or category.id,\n }\n action_list = []\n for action in category.objectValues():\n if IAction.providedBy(action):\n action_list.append({\n 'id': action.id,\n 'title': action.title,\n 'url': action.absolute_url(),\n 'visible': action.visible,\n })\n cat_infos['actions'] = action_list\n actions.append(cat_infos)\n\n self.actions = actions\n return self.template()\n\n def __call__(self):\n if self.request.get('delete'):\n action_id = self.request['actionid']\n category = self.portal_actions[self.request['category']]\n category.manage_delObjects([action_id])\n self.request.RESPONSE.redirect('@@actions-controlpanel')\n if self.request.get('hide'):\n action_id = self.request['actionid']\n category = self.portal_actions[self.request['category']]\n category[action_id].visible = False\n self.request.RESPONSE.redirect('@@actions-controlpanel')\n if self.request.get('show'):\n action_id = self.request['actionid']\n category = self.portal_actions[self.request['category']]\n category[action_id].visible = True\n self.request.RESPONSE.redirect('@@actions-controlpanel')\n return self.display()\n\n\n@implementer(IActionSchema)\nclass ActionControlPanelAdapter:\n \"\"\"Adapter for action form.\"\"\"\n\n adapts(IAction)\n\n def __init__(self, context):\n self.context = context\n self.current_category = self.context.getParentNode()\n\n def get_category(self):\n return self.current_category.id\n\n def set_category(self, value):\n portal_actions = getToolByName(self.context, 'portal_actions')\n new_category = portal_actions.get(value)\n cookie = self.current_category.manage_cutObjects(ids=[self.context.id])\n new_category.manage_pasteObjects(cookie)\n\n category = property(get_category, set_category)\n\n def get_title(self):\n return self.context.title\n\n def set_title(self, value):\n self.context._setPropValue('title', value)\n\n title = property(get_title, set_title)\n\n def get_description(self):\n return self.context.description\n\n def set_description(self, value):\n self.context._setPropValue('description', value)\n\n description = property(get_description, set_description)\n\n def get_i18n_domain(self):\n return self.context.i18n_domain\n\n def set_i18n_domain(self, value):\n self.context._setPropValue('i18n_domain', value)\n\n i18n_domain = property(get_i18n_domain, set_i18n_domain)\n\n def get_url_expr(self):\n return self.context.url_expr\n\n def set_url_expr(self, value):\n self.context._setPropValue('url_expr', value)\n\n url_expr = property(get_url_expr, set_url_expr)\n\n def get_available_expr(self):\n return self.context.available_expr\n\n def set_available_expr(self, value):\n self.context._setPropValue('available_expr', value)\n\n available_expr = property(get_available_expr, set_available_expr)\n\n def get_permissions(self):\n return self.context.permissions\n\n def set_permissions(self, value):\n self.context._setPropValue('permissions', value)\n\n permissions = property(get_permissions, set_permissions)\n\n def get_visible(self):\n return self.context.visible\n\n def set_visible(self, value):\n self.context._setPropValue('visible', value)\n\n visible = property(get_visible, set_visible)\n\n def get_position(self):\n position = self.current_category.objectIds().index(self.context.id)\n return position + 1\n\n def set_position(self, value):\n current_position = self.current_category.objectIds().index(\n self.context.id)\n all_actions = list(self.current_category._objects)\n current_action = all_actions.pop(current_position)\n new_position = value - 1\n all_actions = all_actions[0:new_position] + [current_action] + \\\n all_actions[new_position:]\n self.current_category._objects = tuple(all_actions)\n\n position = property(get_position, set_position)\n\n\nclass ActionControlPanel(AutoExtensibleForm, form.EditForm):\n \"\"\"A form to edit a portal action.\"\"\"\n\n schema = IActionSchema\n ignoreContext = False\n label = _('Action Settings')\n\n\nclass NewActionControlPanel(AutoExtensibleForm, form.AddForm):\n \"\"\"A form to add a new portal action.\"\"\"\n\n schema = INewActionSchema\n ignoreContext = True\n label = _('New action')\n\n def createAndAdd(self, data):\n portal_actions = getToolByName(self.context, 'portal_actions')\n category = portal_actions.get(data['category'])\n action_id = data['id']\n action = Action(\n action_id,\n title=action_id,\n i18n_domain='plone',\n permissions=['View'],\n )\n category[action_id] = action\n notify(ObjectCreatedEvent(action))\n", "path": "Products/CMFPlone/controlpanel/browser/actions.py"}]}
| 2,745 | 387 |
gh_patches_debug_6063
|
rasdani/github-patches
|
git_diff
|
openstates__openstates-scrapers-1627
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
MI scraper failing since at least 2017-04-01
MI has been failing since 2017-04-01
Based on automated runs it appears that MI has not run successfully in 5 days (2017-04-01).
```
06:00:31 INFO billy: billy-update abbr=mi
actions=scrape,import,report
types=bills,legislators,votes,committees,alldata,events
sessions=2017-2018
terms=2017-2018
06:00:31 INFO scrapelib: GET - http://www.senate.michigan.gov/senatorinfo.html
File "/usr/local/bin/billy-update", line 9, in <module>
load_entry_point('billy==1.9.0', 'console_scripts', 'billy-update')()
File "/opt/openstates/billy/billy/bin/update.py", line 368, in main
Traceback (most recent call last):
run_record += _run_scraper(stype, args, metadata)
File "/opt/openstates/billy/billy/bin/update.py", line 102, in _run_scraper
response = self.get(url)
File "/usr/local/lib/python2.7/dist-packages/requests/sessions.py", line 501, in get
return self.request('GET', url, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/scrapelib/__init__.py", line 272, in request
raise HTTPError(resp)
scrapelib.HTTPError: 500 while retrieving http://www.senate.michigan.gov/senatorinfo.html
File "/srv/openstates-web/openstates/mi/legislators.py", line 77, in scrape_upper
scraper.scrape(chamber, time)
File "/srv/openstates-web/openstates/mi/legislators.py", line 16, in scrape
return self.scrape_upper(chamber, term)
doc = self.lxmlize(url)
File "/srv/openstates-web/openstates/utils/lxmlize.py", line 19, in lxmlize
```
Visit http://bobsled.openstates.org/ for more info.
</issue>
<code>
[start of openstates/mi/legislators.py]
1 import re
2
3 from billy.scrape.legislators import LegislatorScraper, Legislator
4 from openstates.utils import LXMLMixin
5
6 abbr = {'D': 'Democratic', 'R': 'Republican'}
7
8
9 class MILegislatorScraper(LegislatorScraper, LXMLMixin):
10 jurisdiction = 'mi'
11
12 def scrape(self, chamber, term):
13 self.validate_term(term, latest_only=True)
14 if chamber == 'lower':
15 return self.scrape_lower(chamber, term)
16 return self.scrape_upper(chamber, term)
17
18 def scrape_lower(self, chamber, term):
19 url = 'http://www.house.mi.gov/mhrpublic/frmRepList.aspx'
20 table = [
21 "website",
22 "district",
23 "name",
24 "party",
25 "location",
26 "phone",
27 "email"
28 ]
29 doc = self.lxmlize(url)
30 # skip two rows at top
31 for row in doc.xpath('//table[@id="grvRepInfo"]/*'):
32 tds = row.xpath('.//td')
33 if len(tds) == 0:
34 continue
35 metainf = {}
36 for i in range(0, len(table)):
37 metainf[table[i]] = tds[i]
38 district = str(int(metainf['district'].text_content().strip()))
39 party = metainf['party'].text_content().strip()
40 phone = metainf['phone'].text_content().strip()
41 email = metainf['email'].text_content().strip()
42 leg_url = metainf['website'].xpath("./a")[0].attrib['href']
43 name = metainf['name'].text_content().strip()
44 if name == 'Vacant' or re.match(r'^District \d{1,3}$', name):
45 self.warning('District {} appears vacant, and will be skipped'.format(district))
46 continue
47
48 office = metainf['location'].text_content().strip()
49 office = re.sub(
50 ' HOB',
51 ' Anderson House Office Building\n124 North Capitol Avenue\nLansing, MI 48933',
52 office
53 )
54 office = re.sub(
55 ' CB',
56 ' State Capitol Building\nLansing, MI 48909',
57 office
58 )
59
60 leg = Legislator(term=term,
61 chamber=chamber,
62 full_name=name,
63 district=district,
64 party=abbr[party],
65 url=leg_url)
66
67 leg.add_office('capitol', 'Capitol Office',
68 address=office,
69 phone=phone,
70 email=email)
71
72 leg.add_source(url)
73 self.save_legislator(leg)
74
75 def scrape_upper(self, chamber, term):
76 url = 'http://www.senate.michigan.gov/senatorinfo.html'
77 doc = self.lxmlize(url)
78 for row in doc.xpath('//table[not(@class="calendar")]//tr')[3:]:
79 if len(row) != 7:
80 continue
81
82 # party, dist, member, office_phone, office_fax, office_loc
83 party, dist, member, contact, phone, fax, loc = row.getchildren()
84 if (party.text_content().strip() == "" or
85 'Lieutenant Governor' in member.text_content()):
86 continue
87
88 party = abbr[party.text]
89 district = dist.text_content().strip()
90 name = member.text_content().strip()
91 name = re.sub(r'\s+', " ", name)
92
93 if name == 'Vacant':
94 self.info('district %s is vacant', district)
95 continue
96
97 leg_url = member.xpath('a/@href')[0]
98 office_phone = phone.text
99 office_fax = fax.text
100
101 office_loc = loc.text
102 office_loc = re.sub(
103 ' Farnum Bldg',
104 ' Farnum Office Building\n125 West Allegan Street\nLansing, MI 48933',
105 office_loc
106 )
107 office_loc = re.sub(
108 ' Capitol Bldg',
109 ' State Capitol Building\nLansing, MI 48909',
110 office_loc
111 )
112
113 leg = Legislator(term=term, chamber=chamber,
114 district=district,
115 full_name=name,
116 party=party,
117 url=leg_url)
118
119 leg.add_office('capitol', 'Capitol Office',
120 address=office_loc,
121 fax=office_fax,
122 phone=office_phone)
123
124 leg.add_source(url)
125 self.save_legislator(leg)
126
[end of openstates/mi/legislators.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/openstates/mi/legislators.py b/openstates/mi/legislators.py
--- a/openstates/mi/legislators.py
+++ b/openstates/mi/legislators.py
@@ -73,7 +73,7 @@
self.save_legislator(leg)
def scrape_upper(self, chamber, term):
- url = 'http://www.senate.michigan.gov/senatorinfo.html'
+ url = 'http://www.senate.michigan.gov/senatorinfo_list.html'
doc = self.lxmlize(url)
for row in doc.xpath('//table[not(@class="calendar")]//tr')[3:]:
if len(row) != 7:
|
{"golden_diff": "diff --git a/openstates/mi/legislators.py b/openstates/mi/legislators.py\n--- a/openstates/mi/legislators.py\n+++ b/openstates/mi/legislators.py\n@@ -73,7 +73,7 @@\n self.save_legislator(leg)\n \n def scrape_upper(self, chamber, term):\n- url = 'http://www.senate.michigan.gov/senatorinfo.html'\n+ url = 'http://www.senate.michigan.gov/senatorinfo_list.html'\n doc = self.lxmlize(url)\n for row in doc.xpath('//table[not(@class=\"calendar\")]//tr')[3:]:\n if len(row) != 7:\n", "issue": "MI scraper failing since at least 2017-04-01\nMI has been failing since 2017-04-01\n\nBased on automated runs it appears that MI has not run successfully in 5 days (2017-04-01).\n\n\n```\n 06:00:31 INFO billy: billy-update abbr=mi\n actions=scrape,import,report\n types=bills,legislators,votes,committees,alldata,events\n sessions=2017-2018\n terms=2017-2018\n06:00:31 INFO scrapelib: GET - http://www.senate.michigan.gov/senatorinfo.html\n File \"/usr/local/bin/billy-update\", line 9, in <module>\n load_entry_point('billy==1.9.0', 'console_scripts', 'billy-update')()\n File \"/opt/openstates/billy/billy/bin/update.py\", line 368, in main\nTraceback (most recent call last):\n run_record += _run_scraper(stype, args, metadata)\n File \"/opt/openstates/billy/billy/bin/update.py\", line 102, in _run_scraper\n response = self.get(url)\n File \"/usr/local/lib/python2.7/dist-packages/requests/sessions.py\", line 501, in get\n return self.request('GET', url, **kwargs)\n File \"/usr/local/lib/python2.7/dist-packages/scrapelib/__init__.py\", line 272, in request\n raise HTTPError(resp)\nscrapelib.HTTPError: 500 while retrieving http://www.senate.michigan.gov/senatorinfo.html\n File \"/srv/openstates-web/openstates/mi/legislators.py\", line 77, in scrape_upper\n scraper.scrape(chamber, time)\n File \"/srv/openstates-web/openstates/mi/legislators.py\", line 16, in scrape\n return self.scrape_upper(chamber, term)\n doc = self.lxmlize(url)\n File \"/srv/openstates-web/openstates/utils/lxmlize.py\", line 19, in lxmlize\n```\n\nVisit http://bobsled.openstates.org/ for more info.\n\n", "before_files": [{"content": "import re\n\nfrom billy.scrape.legislators import LegislatorScraper, Legislator\nfrom openstates.utils import LXMLMixin\n\nabbr = {'D': 'Democratic', 'R': 'Republican'}\n\n\nclass MILegislatorScraper(LegislatorScraper, LXMLMixin):\n jurisdiction = 'mi'\n\n def scrape(self, chamber, term):\n self.validate_term(term, latest_only=True)\n if chamber == 'lower':\n return self.scrape_lower(chamber, term)\n return self.scrape_upper(chamber, term)\n\n def scrape_lower(self, chamber, term):\n url = 'http://www.house.mi.gov/mhrpublic/frmRepList.aspx'\n table = [\n \"website\",\n \"district\",\n \"name\",\n \"party\",\n \"location\",\n \"phone\",\n \"email\"\n ]\n doc = self.lxmlize(url)\n # skip two rows at top\n for row in doc.xpath('//table[@id=\"grvRepInfo\"]/*'):\n tds = row.xpath('.//td')\n if len(tds) == 0:\n continue\n metainf = {}\n for i in range(0, len(table)):\n metainf[table[i]] = tds[i]\n district = str(int(metainf['district'].text_content().strip()))\n party = metainf['party'].text_content().strip()\n phone = metainf['phone'].text_content().strip()\n email = metainf['email'].text_content().strip()\n leg_url = metainf['website'].xpath(\"./a\")[0].attrib['href']\n name = metainf['name'].text_content().strip()\n if name == 'Vacant' or re.match(r'^District \\d{1,3}$', name):\n self.warning('District {} appears vacant, and will be skipped'.format(district))\n continue\n\n office = metainf['location'].text_content().strip()\n office = re.sub(\n ' HOB',\n ' Anderson House Office Building\\n124 North Capitol Avenue\\nLansing, MI 48933',\n office\n )\n office = re.sub(\n ' CB',\n ' State Capitol Building\\nLansing, MI 48909',\n office\n )\n\n leg = Legislator(term=term,\n chamber=chamber,\n full_name=name,\n district=district,\n party=abbr[party],\n url=leg_url)\n\n leg.add_office('capitol', 'Capitol Office',\n address=office,\n phone=phone,\n email=email)\n\n leg.add_source(url)\n self.save_legislator(leg)\n\n def scrape_upper(self, chamber, term):\n url = 'http://www.senate.michigan.gov/senatorinfo.html'\n doc = self.lxmlize(url)\n for row in doc.xpath('//table[not(@class=\"calendar\")]//tr')[3:]:\n if len(row) != 7:\n continue\n\n # party, dist, member, office_phone, office_fax, office_loc\n party, dist, member, contact, phone, fax, loc = row.getchildren()\n if (party.text_content().strip() == \"\" or\n 'Lieutenant Governor' in member.text_content()):\n continue\n\n party = abbr[party.text]\n district = dist.text_content().strip()\n name = member.text_content().strip()\n name = re.sub(r'\\s+', \" \", name)\n\n if name == 'Vacant':\n self.info('district %s is vacant', district)\n continue\n\n leg_url = member.xpath('a/@href')[0]\n office_phone = phone.text\n office_fax = fax.text\n\n office_loc = loc.text\n office_loc = re.sub(\n ' Farnum Bldg',\n ' Farnum Office Building\\n125 West Allegan Street\\nLansing, MI 48933',\n office_loc\n )\n office_loc = re.sub(\n ' Capitol Bldg',\n ' State Capitol Building\\nLansing, MI 48909',\n office_loc\n )\n\n leg = Legislator(term=term, chamber=chamber,\n district=district,\n full_name=name,\n party=party,\n url=leg_url)\n\n leg.add_office('capitol', 'Capitol Office',\n address=office_loc,\n fax=office_fax,\n phone=office_phone)\n\n leg.add_source(url)\n self.save_legislator(leg)\n", "path": "openstates/mi/legislators.py"}]}
| 2,322 | 159 |
gh_patches_debug_25714
|
rasdani/github-patches
|
git_diff
|
mkdocs__mkdocs-443
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`mkdocs new` broken under python2
current master, python 2.7.9 virtualenv
only top directory and mkdocs.yml created, no docs dir or index.md
```
(karasu)[lashni@orphan src]$ mkdocs new karasu
Creating project directory: karasu
Writing config file: karasu/mkdocs.yml
Traceback (most recent call last):
File "/home/lashni/dev/karasu/bin/mkdocs", line 9, in <module>
load_entry_point('mkdocs==0.11.1', 'console_scripts', 'mkdocs')()
File "/home/lashni/dev/karasu/src/mkdocs/mkdocs/main.py", line 74, in run_main
main(cmd, args=sys.argv[2:], options=dict(opts))
File "/home/lashni/dev/karasu/src/mkdocs/mkdocs/main.py", line 58, in main
new(args, options)
File "/home/lashni/dev/karasu/src/mkdocs/mkdocs/new.py", line 47, in new
open(config_path, 'w', encoding='utf-8').write(config_text)
TypeError: must be unicode, not str
```
current master, python 3.4.3 virtualenv, files/dirs created successfully
```
(test)[lashni@orphan src]$ mkdocs new karasu
Creating project directory: karasu
Writing config file: karasu/mkdocs.yml
Writing initial docs: karasu/docs/index.md
```
</issue>
<code>
[start of mkdocs/new.py]
1 # coding: utf-8
2 from __future__ import print_function
3 import os
4 from io import open
5
6 config_text = 'site_name: My Docs\n'
7 index_text = """# Welcome to MkDocs
8
9 For full documentation visit [mkdocs.org](http://mkdocs.org).
10
11 ## Commands
12
13 * `mkdocs new [dir-name]` - Create a new project.
14 * `mkdocs serve` - Start the live-reloading docs server.
15 * `mkdocs build` - Build the documentation site.
16 * `mkdocs help` - Print this help message.
17
18 ## Project layout
19
20 mkdocs.yml # The configuration file.
21 docs/
22 index.md # The documentation homepage.
23 ... # Other markdown pages, images and other files.
24 """
25
26
27 def new(args, options):
28 if len(args) != 1:
29 print("Usage 'mkdocs new [directory-name]'")
30 return
31
32 output_dir = args[0]
33
34 docs_dir = os.path.join(output_dir, 'docs')
35 config_path = os.path.join(output_dir, 'mkdocs.yml')
36 index_path = os.path.join(docs_dir, 'index.md')
37
38 if os.path.exists(config_path):
39 print('Project already exists.')
40 return
41
42 if not os.path.exists(output_dir):
43 print('Creating project directory: %s' % output_dir)
44 os.mkdir(output_dir)
45
46 print('Writing config file: %s' % config_path)
47 open(config_path, 'w', encoding='utf-8').write(config_text)
48
49 if os.path.exists(index_path):
50 return
51
52 print('Writing initial docs: %s' % index_path)
53 if not os.path.exists(docs_dir):
54 os.mkdir(docs_dir)
55 open(index_path, 'w', encoding='utf-8').write(index_text)
56
[end of mkdocs/new.py]
[start of mkdocs/main.py]
1 #!/usr/bin/env python
2 # coding: utf-8
3 from __future__ import print_function
4
5 import logging
6 import sys
7
8 from mkdocs import __version__
9 from mkdocs.build import build
10 from mkdocs.config import load_config
11 from mkdocs.exceptions import MkDocsException
12 from mkdocs.gh_deploy import gh_deploy
13 from mkdocs.new import new
14 from mkdocs.serve import serve
15
16
17 def configure_logging(options):
18 '''When a --verbose flag is passed, increase the verbosity of mkdocs'''
19 logger = logging.getLogger('mkdocs')
20 logger.addHandler(logging.StreamHandler())
21 if 'verbose' in options:
22 logger.setLevel(logging.DEBUG)
23 else:
24 logger.setLevel(logging.WARNING)
25
26
27 def arg_to_option(arg):
28 """
29 Convert command line arguments into two-tuples of config key/value pairs.
30 """
31 arg = arg.lstrip('--')
32 option = True
33 if '=' in arg:
34 arg, option = arg.split('=', 1)
35 return (arg.replace('-', '_'), option)
36
37
38 def main(cmd, args, options=None):
39 """
40 Build the documentation, and optionally start the devserver.
41 """
42 configure_logging(options)
43 clean_site_dir = 'clean' in options
44 if cmd == 'serve':
45 config = load_config(options=options)
46 serve(config, options=options)
47 elif cmd == 'build':
48 config = load_config(options=options)
49 build(config, clean_site_dir=clean_site_dir)
50 elif cmd == 'json':
51 config = load_config(options=options)
52 build(config, dump_json=True, clean_site_dir=clean_site_dir)
53 elif cmd == 'gh-deploy':
54 config = load_config(options=options)
55 build(config, clean_site_dir=clean_site_dir)
56 gh_deploy(config)
57 elif cmd == 'new':
58 new(args, options)
59 else:
60 print('MkDocs (version {0})'.format(__version__))
61 print('mkdocs [help|new|build|serve|gh-deploy|json] {options}')
62
63
64 def run_main():
65 """
66 Invokes main() with the contents of sys.argv
67
68 This is a separate function so it can be invoked
69 by a setuptools console_script.
70 """
71 cmd = sys.argv[1] if len(sys.argv) >= 2 else None
72 opts = [arg_to_option(arg) for arg in sys.argv[2:] if arg.startswith('--')]
73 try:
74 main(cmd, args=sys.argv[2:], options=dict(opts))
75 except MkDocsException as e:
76 print(e.args[0], file=sys.stderr)
77
78
79 if __name__ == '__main__':
80 run_main()
81
[end of mkdocs/main.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mkdocs/main.py b/mkdocs/main.py
--- a/mkdocs/main.py
+++ b/mkdocs/main.py
@@ -55,7 +55,7 @@
build(config, clean_site_dir=clean_site_dir)
gh_deploy(config)
elif cmd == 'new':
- new(args, options)
+ new(args)
else:
print('MkDocs (version {0})'.format(__version__))
print('mkdocs [help|new|build|serve|gh-deploy|json] {options}')
diff --git a/mkdocs/new.py b/mkdocs/new.py
--- a/mkdocs/new.py
+++ b/mkdocs/new.py
@@ -1,10 +1,13 @@
# coding: utf-8
from __future__ import print_function
+
import os
from io import open
-config_text = 'site_name: My Docs\n'
-index_text = """# Welcome to MkDocs
+from mkdocs import compat
+
+config_text = compat.unicode('site_name: My Docs\n')
+index_text = compat.unicode("""# Welcome to MkDocs
For full documentation visit [mkdocs.org](http://mkdocs.org).
@@ -21,10 +24,11 @@
docs/
index.md # The documentation homepage.
... # Other markdown pages, images and other files.
-"""
+""")
+
+def new(args):
-def new(args, options):
if len(args) != 1:
print("Usage 'mkdocs new [directory-name]'")
return
|
{"golden_diff": "diff --git a/mkdocs/main.py b/mkdocs/main.py\n--- a/mkdocs/main.py\n+++ b/mkdocs/main.py\n@@ -55,7 +55,7 @@\n build(config, clean_site_dir=clean_site_dir)\n gh_deploy(config)\n elif cmd == 'new':\n- new(args, options)\n+ new(args)\n else:\n print('MkDocs (version {0})'.format(__version__))\n print('mkdocs [help|new|build|serve|gh-deploy|json] {options}')\ndiff --git a/mkdocs/new.py b/mkdocs/new.py\n--- a/mkdocs/new.py\n+++ b/mkdocs/new.py\n@@ -1,10 +1,13 @@\n # coding: utf-8\n from __future__ import print_function\n+\n import os\n from io import open\n \n-config_text = 'site_name: My Docs\\n'\n-index_text = \"\"\"# Welcome to MkDocs\n+from mkdocs import compat\n+\n+config_text = compat.unicode('site_name: My Docs\\n')\n+index_text = compat.unicode(\"\"\"# Welcome to MkDocs\n \n For full documentation visit [mkdocs.org](http://mkdocs.org).\n \n@@ -21,10 +24,11 @@\n docs/\n index.md # The documentation homepage.\n ... # Other markdown pages, images and other files.\n-\"\"\"\n+\"\"\")\n+\n \n+def new(args):\n \n-def new(args, options):\n if len(args) != 1:\n print(\"Usage 'mkdocs new [directory-name]'\")\n return\n", "issue": "`mkdocs new` broken under python2\ncurrent master, python 2.7.9 virtualenv\nonly top directory and mkdocs.yml created, no docs dir or index.md\n\n```\n(karasu)[lashni@orphan src]$ mkdocs new karasu\nCreating project directory: karasu\nWriting config file: karasu/mkdocs.yml\nTraceback (most recent call last):\n File \"/home/lashni/dev/karasu/bin/mkdocs\", line 9, in <module>\n load_entry_point('mkdocs==0.11.1', 'console_scripts', 'mkdocs')()\n File \"/home/lashni/dev/karasu/src/mkdocs/mkdocs/main.py\", line 74, in run_main\n main(cmd, args=sys.argv[2:], options=dict(opts))\n File \"/home/lashni/dev/karasu/src/mkdocs/mkdocs/main.py\", line 58, in main\n new(args, options)\n File \"/home/lashni/dev/karasu/src/mkdocs/mkdocs/new.py\", line 47, in new\n open(config_path, 'w', encoding='utf-8').write(config_text)\nTypeError: must be unicode, not str\n```\n\ncurrent master, python 3.4.3 virtualenv, files/dirs created successfully\n\n```\n(test)[lashni@orphan src]$ mkdocs new karasu\nCreating project directory: karasu\nWriting config file: karasu/mkdocs.yml\nWriting initial docs: karasu/docs/index.md\n```\n\n", "before_files": [{"content": "# coding: utf-8\nfrom __future__ import print_function\nimport os\nfrom io import open\n\nconfig_text = 'site_name: My Docs\\n'\nindex_text = \"\"\"# Welcome to MkDocs\n\nFor full documentation visit [mkdocs.org](http://mkdocs.org).\n\n## Commands\n\n* `mkdocs new [dir-name]` - Create a new project.\n* `mkdocs serve` - Start the live-reloading docs server.\n* `mkdocs build` - Build the documentation site.\n* `mkdocs help` - Print this help message.\n\n## Project layout\n\n mkdocs.yml # The configuration file.\n docs/\n index.md # The documentation homepage.\n ... # Other markdown pages, images and other files.\n\"\"\"\n\n\ndef new(args, options):\n if len(args) != 1:\n print(\"Usage 'mkdocs new [directory-name]'\")\n return\n\n output_dir = args[0]\n\n docs_dir = os.path.join(output_dir, 'docs')\n config_path = os.path.join(output_dir, 'mkdocs.yml')\n index_path = os.path.join(docs_dir, 'index.md')\n\n if os.path.exists(config_path):\n print('Project already exists.')\n return\n\n if not os.path.exists(output_dir):\n print('Creating project directory: %s' % output_dir)\n os.mkdir(output_dir)\n\n print('Writing config file: %s' % config_path)\n open(config_path, 'w', encoding='utf-8').write(config_text)\n\n if os.path.exists(index_path):\n return\n\n print('Writing initial docs: %s' % index_path)\n if not os.path.exists(docs_dir):\n os.mkdir(docs_dir)\n open(index_path, 'w', encoding='utf-8').write(index_text)\n", "path": "mkdocs/new.py"}, {"content": "#!/usr/bin/env python\n# coding: utf-8\nfrom __future__ import print_function\n\nimport logging\nimport sys\n\nfrom mkdocs import __version__\nfrom mkdocs.build import build\nfrom mkdocs.config import load_config\nfrom mkdocs.exceptions import MkDocsException\nfrom mkdocs.gh_deploy import gh_deploy\nfrom mkdocs.new import new\nfrom mkdocs.serve import serve\n\n\ndef configure_logging(options):\n '''When a --verbose flag is passed, increase the verbosity of mkdocs'''\n logger = logging.getLogger('mkdocs')\n logger.addHandler(logging.StreamHandler())\n if 'verbose' in options:\n logger.setLevel(logging.DEBUG)\n else:\n logger.setLevel(logging.WARNING)\n\n\ndef arg_to_option(arg):\n \"\"\"\n Convert command line arguments into two-tuples of config key/value pairs.\n \"\"\"\n arg = arg.lstrip('--')\n option = True\n if '=' in arg:\n arg, option = arg.split('=', 1)\n return (arg.replace('-', '_'), option)\n\n\ndef main(cmd, args, options=None):\n \"\"\"\n Build the documentation, and optionally start the devserver.\n \"\"\"\n configure_logging(options)\n clean_site_dir = 'clean' in options\n if cmd == 'serve':\n config = load_config(options=options)\n serve(config, options=options)\n elif cmd == 'build':\n config = load_config(options=options)\n build(config, clean_site_dir=clean_site_dir)\n elif cmd == 'json':\n config = load_config(options=options)\n build(config, dump_json=True, clean_site_dir=clean_site_dir)\n elif cmd == 'gh-deploy':\n config = load_config(options=options)\n build(config, clean_site_dir=clean_site_dir)\n gh_deploy(config)\n elif cmd == 'new':\n new(args, options)\n else:\n print('MkDocs (version {0})'.format(__version__))\n print('mkdocs [help|new|build|serve|gh-deploy|json] {options}')\n\n\ndef run_main():\n \"\"\"\n Invokes main() with the contents of sys.argv\n\n This is a separate function so it can be invoked\n by a setuptools console_script.\n \"\"\"\n cmd = sys.argv[1] if len(sys.argv) >= 2 else None\n opts = [arg_to_option(arg) for arg in sys.argv[2:] if arg.startswith('--')]\n try:\n main(cmd, args=sys.argv[2:], options=dict(opts))\n except MkDocsException as e:\n print(e.args[0], file=sys.stderr)\n\n\nif __name__ == '__main__':\n run_main()\n", "path": "mkdocs/main.py"}]}
| 2,091 | 346 |
gh_patches_debug_10062
|
rasdani/github-patches
|
git_diff
|
celery__celery-3752
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Celery Worker crashing after first task with TypeError: 'NoneType' object is not callable
## Checklist
- [X] I have included the output of ``celery -A proj report`` in the issue.
(if you are not able to do this, then at least specify the Celery
version affected).
```
software -> celery:4.0.0 (latentcall) kombu:4.0.0 py:3.4.3
billiard:3.5.0.2 py-amqp:2.1.1
platform -> system:Linux arch:64bit, ELF imp:CPython
loader -> celery.loaders.default.Loader
settings -> transport:amqp results:disabled
```
- [X] I have verified that the issue exists against the `master` branch of Celery.
Yes I've tested and it behaves the same using master.
## Steps to reproduce
Not exactly sure, because other machines with the same specs and requirements are working.
## Expected behavior
Should consume tasks.
## Actual behavior
A task is accepted, then a traceback is logged, then the worker reconnects to the broker for some reason. This repeats forever:
```
[2016-11-23 23:09:00,468: INFO/MainProcess] Connected to amqp://user:**@10.136.131.6:5672//
[2016-11-23 23:09:00,484: INFO/MainProcess] mingle: searching for neighbors
[2016-11-23 23:09:01,921: INFO/MainProcess] mingle: sync with 1 nodes
[2016-11-23 23:09:01,922: INFO/MainProcess] mingle: sync complete
[2016-11-23 23:09:01,970: INFO/MainProcess] Received task: tasks.calculate_user_running_total[ddd103af-d527-4564-83f8-96b747767a0c]
[2016-11-23 23:09:01,972: CRITICAL/MainProcess] Unrecoverable error: TypeError("'NoneType' object is not callable",)
Traceback (most recent call last):
File "./venv/lib/python3.4/site-packages/celery/worker/worker.py", line 203, in start
self.blueprint.start(self)
File "./venv/lib/python3.4/site-packages/celery/bootsteps.py", line 119, in start
step.start(parent)
File "./venv/lib/python3.4/site-packages/celery/bootsteps.py", line 370, in start
return self.obj.start()
File "./venv/lib/python3.4/site-packages/celery/worker/consumer/consumer.py", line 318, in start
blueprint.start(self)
File "./venv/lib/python3.4/site-packages/celery/bootsteps.py", line 119, in start
step.start(parent)
File "./venv/lib/python3.4/site-packages/celery/worker/consumer/consumer.py", line 584, in start
c.loop(*c.loop_args())
File "./venv/lib/python3.4/site-packages/celery/worker/loops.py", line 47, in asynloop
consumer.consume()
File "./venv/lib/python3.4/site-packages/kombu/messaging.py", line 470, in consume
self._basic_consume(T, no_ack=no_ack, nowait=False)
File "./venv/lib/python3.4/site-packages/kombu/messaging.py", line 591, in _basic_consume
no_ack=no_ack, nowait=nowait)
File "./venv/lib/python3.4/site-packages/kombu/entity.py", line 737, in consume
arguments=self.consumer_arguments)
File "./venv/lib/python3.4/site-packages/amqp/channel.py", line 1578, in basic_consume
wait=None if nowait else spec.Basic.ConsumeOk,
File "./venv/lib/python3.4/site-packages/amqp/abstract_channel.py", line 73, in send_method
return self.wait(wait, returns_tuple=returns_tuple)
File "./venv/lib/python3.4/site-packages/amqp/abstract_channel.py", line 93, in wait
self.connection.drain_events(timeout=timeout)
File "./venv/lib/python3.4/site-packages/amqp/connection.py", line 464, in drain_events
return self.blocking_read(timeout)
File "./venv/lib/python3.4/site-packages/amqp/connection.py", line 469, in blocking_read
return self.on_inbound_frame(frame)
File "./venv/lib/python3.4/site-packages/amqp/method_framing.py", line 88, in on_frame
callback(channel, msg.frame_method, msg.frame_args, msg)
File "./venv/lib/python3.4/site-packages/amqp/connection.py", line 473, in on_inbound_method
method_sig, payload, content,
File "./venv/lib/python3.4/site-packages/amqp/abstract_channel.py", line 142, in dispatch_method
listener(*args)
File "./venv/lib/python3.4/site-packages/amqp/channel.py", line 1613, in _on_basic_deliver
fun(msg)
File "./venv/lib/python3.4/site-packages/kombu/messaging.py", line 617, in _receive_callback
return on_m(message) if on_m else self.receive(decoded, message)
File "./venv/lib/python3.4/site-packages/celery/worker/consumer/consumer.py", line 558, in on_task_received
callbacks,
File "./venv/lib/python3.4/site-packages/celery/worker/strategy.py", line 145, in task_message_handler
handle(req)
File "./venv/lib/python3.4/site-packages/celery/worker/worker.py", line 221, in _process_task_sem
return self._quick_acquire(self._process_task, req)
File "./venv/lib/python3.4/site-packages/kombu/async/semaphore.py", line 62, in acquire
callback(*partial_args, **partial_kwargs)
File "./venv/lib/python3.4/site-packages/celery/worker/worker.py", line 226, in _process_task
req.execute_using_pool(self.pool)
File "./venv/lib/python3.4/site-packages/celery/worker/request.py", line 532, in execute_using_pool
correlation_id=task_id,
File "./venv/lib/python3.4/site-packages/celery/concurrency/base.py", line 155, in apply_async
**options)
File "./venv/lib/python3.4/site-packages/billiard/pool.py", line 1487, in apply_async
self._quick_put((TASK, (result._job, None, func, args, kwds)))
TypeError: 'NoneType' object is not callable
```
The above lines are keep repeating every few seconds and no tasks are consumed from the queue.
</issue>
<code>
[start of celery/worker/loops.py]
1 """The consumers highly-optimized inner loop."""
2 from __future__ import absolute_import, unicode_literals
3 import errno
4 import socket
5 from celery import bootsteps
6 from celery.exceptions import WorkerShutdown, WorkerTerminate, WorkerLostError
7 from celery.utils.log import get_logger
8 from . import state
9
10 __all__ = ['asynloop', 'synloop']
11
12 # pylint: disable=redefined-outer-name
13 # We cache globals and attribute lookups, so disable this warning.
14
15 logger = get_logger(__name__)
16
17
18 def _quick_drain(connection, timeout=0.1):
19 try:
20 connection.drain_events(timeout=timeout)
21 except Exception as exc: # pylint: disable=broad-except
22 exc_errno = getattr(exc, 'errno', None)
23 if exc_errno is not None and exc_errno != errno.EAGAIN:
24 raise
25
26
27 def _enable_amqheartbeats(timer, connection, rate=2.0):
28 if connection:
29 tick = connection.heartbeat_check
30 heartbeat = connection.get_heartbeat_interval() # negotiated
31 if heartbeat and connection.supports_heartbeats:
32 timer.call_repeatedly(heartbeat / rate, tick, (rate,))
33
34
35 def asynloop(obj, connection, consumer, blueprint, hub, qos,
36 heartbeat, clock, hbrate=2.0):
37 """Non-blocking event loop."""
38 RUN = bootsteps.RUN
39 update_qos = qos.update
40 errors = connection.connection_errors
41
42 on_task_received = obj.create_task_handler()
43
44 _enable_amqheartbeats(hub.timer, connection, rate=hbrate)
45
46 consumer.on_message = on_task_received
47 consumer.consume()
48 obj.on_ready()
49 obj.controller.register_with_event_loop(hub)
50 obj.register_with_event_loop(hub)
51
52 # did_start_ok will verify that pool processes were able to start,
53 # but this will only work the first time we start, as
54 # maxtasksperchild will mess up metrics.
55 if not obj.restart_count and not obj.pool.did_start_ok():
56 raise WorkerLostError('Could not start worker processes')
57
58 # consumer.consume() may have prefetched up to our
59 # limit - drain an event so we're in a clean state
60 # prior to starting our event loop.
61 if connection.transport.driver_type == 'amqp':
62 hub.call_soon(_quick_drain, connection)
63
64 # FIXME: Use loop.run_forever
65 # Tried and works, but no time to test properly before release.
66 hub.propagate_errors = errors
67 loop = hub.create_loop()
68
69 try:
70 while blueprint.state == RUN and obj.connection:
71 # shutdown if signal handlers told us to.
72 should_stop, should_terminate = (
73 state.should_stop, state.should_terminate,
74 )
75 # False == EX_OK, so must use is not False
76 if should_stop is not None and should_stop is not False:
77 raise WorkerShutdown(should_stop)
78 elif should_terminate is not None and should_stop is not False:
79 raise WorkerTerminate(should_terminate)
80
81 # We only update QoS when there's no more messages to read.
82 # This groups together qos calls, and makes sure that remote
83 # control commands will be prioritized over task messages.
84 if qos.prev != qos.value:
85 update_qos()
86
87 try:
88 next(loop)
89 except StopIteration:
90 loop = hub.create_loop()
91 finally:
92 try:
93 hub.reset()
94 except Exception as exc: # pylint: disable=broad-except
95 logger.exception(
96 'Error cleaning up after event loop: %r', exc)
97
98
99 def synloop(obj, connection, consumer, blueprint, hub, qos,
100 heartbeat, clock, hbrate=2.0, **kwargs):
101 """Fallback blocking event loop for transports that doesn't support AIO."""
102 RUN = bootsteps.RUN
103 on_task_received = obj.create_task_handler()
104 perform_pending_operations = obj.perform_pending_operations
105 if getattr(obj.pool, 'is_green', False):
106 _enable_amqheartbeats(obj.timer, connection, rate=hbrate)
107 consumer.on_message = on_task_received
108 consumer.consume()
109
110 obj.on_ready()
111
112 while blueprint.state == RUN and obj.connection:
113 state.maybe_shutdown()
114 if qos.prev != qos.value:
115 qos.update()
116 try:
117 perform_pending_operations()
118 connection.drain_events(timeout=2.0)
119 except socket.timeout:
120 pass
121 except socket.error:
122 if blueprint.state == RUN:
123 raise
124
[end of celery/worker/loops.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/celery/worker/loops.py b/celery/worker/loops.py
--- a/celery/worker/loops.py
+++ b/celery/worker/loops.py
@@ -44,10 +44,10 @@
_enable_amqheartbeats(hub.timer, connection, rate=hbrate)
consumer.on_message = on_task_received
- consumer.consume()
- obj.on_ready()
obj.controller.register_with_event_loop(hub)
obj.register_with_event_loop(hub)
+ consumer.consume()
+ obj.on_ready()
# did_start_ok will verify that pool processes were able to start,
# but this will only work the first time we start, as
|
{"golden_diff": "diff --git a/celery/worker/loops.py b/celery/worker/loops.py\n--- a/celery/worker/loops.py\n+++ b/celery/worker/loops.py\n@@ -44,10 +44,10 @@\n _enable_amqheartbeats(hub.timer, connection, rate=hbrate)\n \n consumer.on_message = on_task_received\n- consumer.consume()\n- obj.on_ready()\n obj.controller.register_with_event_loop(hub)\n obj.register_with_event_loop(hub)\n+ consumer.consume()\n+ obj.on_ready()\n \n # did_start_ok will verify that pool processes were able to start,\n # but this will only work the first time we start, as\n", "issue": "Celery Worker crashing after first task with TypeError: 'NoneType' object is not callable\n## Checklist\r\n\r\n- [X] I have included the output of ``celery -A proj report`` in the issue.\r\n (if you are not able to do this, then at least specify the Celery\r\n version affected).\r\n```\r\nsoftware -> celery:4.0.0 (latentcall) kombu:4.0.0 py:3.4.3\r\n billiard:3.5.0.2 py-amqp:2.1.1\r\nplatform -> system:Linux arch:64bit, ELF imp:CPython\r\nloader -> celery.loaders.default.Loader\r\nsettings -> transport:amqp results:disabled\r\n```\r\n- [X] I have verified that the issue exists against the `master` branch of Celery.\r\nYes I've tested and it behaves the same using master.\r\n\r\n## Steps to reproduce\r\nNot exactly sure, because other machines with the same specs and requirements are working.\r\n\r\n## Expected behavior\r\nShould consume tasks.\r\n\r\n## Actual behavior\r\nA task is accepted, then a traceback is logged, then the worker reconnects to the broker for some reason. This repeats forever:\r\n\r\n```\r\n[2016-11-23 23:09:00,468: INFO/MainProcess] Connected to amqp://user:**@10.136.131.6:5672//\r\n[2016-11-23 23:09:00,484: INFO/MainProcess] mingle: searching for neighbors\r\n[2016-11-23 23:09:01,921: INFO/MainProcess] mingle: sync with 1 nodes\r\n[2016-11-23 23:09:01,922: INFO/MainProcess] mingle: sync complete\r\n[2016-11-23 23:09:01,970: INFO/MainProcess] Received task: tasks.calculate_user_running_total[ddd103af-d527-4564-83f8-96b747767a0c]\r\n[2016-11-23 23:09:01,972: CRITICAL/MainProcess] Unrecoverable error: TypeError(\"'NoneType' object is not callable\",)\r\nTraceback (most recent call last):\r\n File \"./venv/lib/python3.4/site-packages/celery/worker/worker.py\", line 203, in start\r\n self.blueprint.start(self)\r\n File \"./venv/lib/python3.4/site-packages/celery/bootsteps.py\", line 119, in start\r\n step.start(parent)\r\n File \"./venv/lib/python3.4/site-packages/celery/bootsteps.py\", line 370, in start\r\n return self.obj.start()\r\n File \"./venv/lib/python3.4/site-packages/celery/worker/consumer/consumer.py\", line 318, in start\r\n blueprint.start(self)\r\n File \"./venv/lib/python3.4/site-packages/celery/bootsteps.py\", line 119, in start\r\n step.start(parent)\r\n File \"./venv/lib/python3.4/site-packages/celery/worker/consumer/consumer.py\", line 584, in start\r\n c.loop(*c.loop_args())\r\n File \"./venv/lib/python3.4/site-packages/celery/worker/loops.py\", line 47, in asynloop\r\n consumer.consume()\r\n File \"./venv/lib/python3.4/site-packages/kombu/messaging.py\", line 470, in consume\r\n self._basic_consume(T, no_ack=no_ack, nowait=False)\r\n File \"./venv/lib/python3.4/site-packages/kombu/messaging.py\", line 591, in _basic_consume\r\n no_ack=no_ack, nowait=nowait)\r\n File \"./venv/lib/python3.4/site-packages/kombu/entity.py\", line 737, in consume\r\n arguments=self.consumer_arguments)\r\n File \"./venv/lib/python3.4/site-packages/amqp/channel.py\", line 1578, in basic_consume\r\n wait=None if nowait else spec.Basic.ConsumeOk,\r\n File \"./venv/lib/python3.4/site-packages/amqp/abstract_channel.py\", line 73, in send_method\r\n return self.wait(wait, returns_tuple=returns_tuple)\r\n File \"./venv/lib/python3.4/site-packages/amqp/abstract_channel.py\", line 93, in wait\r\n self.connection.drain_events(timeout=timeout)\r\n File \"./venv/lib/python3.4/site-packages/amqp/connection.py\", line 464, in drain_events\r\n return self.blocking_read(timeout)\r\n File \"./venv/lib/python3.4/site-packages/amqp/connection.py\", line 469, in blocking_read\r\n return self.on_inbound_frame(frame)\r\n File \"./venv/lib/python3.4/site-packages/amqp/method_framing.py\", line 88, in on_frame\r\n callback(channel, msg.frame_method, msg.frame_args, msg)\r\n File \"./venv/lib/python3.4/site-packages/amqp/connection.py\", line 473, in on_inbound_method\r\n method_sig, payload, content,\r\n File \"./venv/lib/python3.4/site-packages/amqp/abstract_channel.py\", line 142, in dispatch_method\r\n listener(*args)\r\n File \"./venv/lib/python3.4/site-packages/amqp/channel.py\", line 1613, in _on_basic_deliver\r\n fun(msg)\r\n File \"./venv/lib/python3.4/site-packages/kombu/messaging.py\", line 617, in _receive_callback\r\n return on_m(message) if on_m else self.receive(decoded, message)\r\n File \"./venv/lib/python3.4/site-packages/celery/worker/consumer/consumer.py\", line 558, in on_task_received\r\n callbacks,\r\n File \"./venv/lib/python3.4/site-packages/celery/worker/strategy.py\", line 145, in task_message_handler\r\n handle(req)\r\n File \"./venv/lib/python3.4/site-packages/celery/worker/worker.py\", line 221, in _process_task_sem\r\n return self._quick_acquire(self._process_task, req)\r\n File \"./venv/lib/python3.4/site-packages/kombu/async/semaphore.py\", line 62, in acquire\r\n callback(*partial_args, **partial_kwargs)\r\n File \"./venv/lib/python3.4/site-packages/celery/worker/worker.py\", line 226, in _process_task\r\n req.execute_using_pool(self.pool)\r\n File \"./venv/lib/python3.4/site-packages/celery/worker/request.py\", line 532, in execute_using_pool\r\n correlation_id=task_id,\r\n File \"./venv/lib/python3.4/site-packages/celery/concurrency/base.py\", line 155, in apply_async\r\n **options)\r\n File \"./venv/lib/python3.4/site-packages/billiard/pool.py\", line 1487, in apply_async\r\n self._quick_put((TASK, (result._job, None, func, args, kwds)))\r\nTypeError: 'NoneType' object is not callable\r\n```\r\nThe above lines are keep repeating every few seconds and no tasks are consumed from the queue.\n", "before_files": [{"content": "\"\"\"The consumers highly-optimized inner loop.\"\"\"\nfrom __future__ import absolute_import, unicode_literals\nimport errno\nimport socket\nfrom celery import bootsteps\nfrom celery.exceptions import WorkerShutdown, WorkerTerminate, WorkerLostError\nfrom celery.utils.log import get_logger\nfrom . import state\n\n__all__ = ['asynloop', 'synloop']\n\n# pylint: disable=redefined-outer-name\n# We cache globals and attribute lookups, so disable this warning.\n\nlogger = get_logger(__name__)\n\n\ndef _quick_drain(connection, timeout=0.1):\n try:\n connection.drain_events(timeout=timeout)\n except Exception as exc: # pylint: disable=broad-except\n exc_errno = getattr(exc, 'errno', None)\n if exc_errno is not None and exc_errno != errno.EAGAIN:\n raise\n\n\ndef _enable_amqheartbeats(timer, connection, rate=2.0):\n if connection:\n tick = connection.heartbeat_check\n heartbeat = connection.get_heartbeat_interval() # negotiated\n if heartbeat and connection.supports_heartbeats:\n timer.call_repeatedly(heartbeat / rate, tick, (rate,))\n\n\ndef asynloop(obj, connection, consumer, blueprint, hub, qos,\n heartbeat, clock, hbrate=2.0):\n \"\"\"Non-blocking event loop.\"\"\"\n RUN = bootsteps.RUN\n update_qos = qos.update\n errors = connection.connection_errors\n\n on_task_received = obj.create_task_handler()\n\n _enable_amqheartbeats(hub.timer, connection, rate=hbrate)\n\n consumer.on_message = on_task_received\n consumer.consume()\n obj.on_ready()\n obj.controller.register_with_event_loop(hub)\n obj.register_with_event_loop(hub)\n\n # did_start_ok will verify that pool processes were able to start,\n # but this will only work the first time we start, as\n # maxtasksperchild will mess up metrics.\n if not obj.restart_count and not obj.pool.did_start_ok():\n raise WorkerLostError('Could not start worker processes')\n\n # consumer.consume() may have prefetched up to our\n # limit - drain an event so we're in a clean state\n # prior to starting our event loop.\n if connection.transport.driver_type == 'amqp':\n hub.call_soon(_quick_drain, connection)\n\n # FIXME: Use loop.run_forever\n # Tried and works, but no time to test properly before release.\n hub.propagate_errors = errors\n loop = hub.create_loop()\n\n try:\n while blueprint.state == RUN and obj.connection:\n # shutdown if signal handlers told us to.\n should_stop, should_terminate = (\n state.should_stop, state.should_terminate,\n )\n # False == EX_OK, so must use is not False\n if should_stop is not None and should_stop is not False:\n raise WorkerShutdown(should_stop)\n elif should_terminate is not None and should_stop is not False:\n raise WorkerTerminate(should_terminate)\n\n # We only update QoS when there's no more messages to read.\n # This groups together qos calls, and makes sure that remote\n # control commands will be prioritized over task messages.\n if qos.prev != qos.value:\n update_qos()\n\n try:\n next(loop)\n except StopIteration:\n loop = hub.create_loop()\n finally:\n try:\n hub.reset()\n except Exception as exc: # pylint: disable=broad-except\n logger.exception(\n 'Error cleaning up after event loop: %r', exc)\n\n\ndef synloop(obj, connection, consumer, blueprint, hub, qos,\n heartbeat, clock, hbrate=2.0, **kwargs):\n \"\"\"Fallback blocking event loop for transports that doesn't support AIO.\"\"\"\n RUN = bootsteps.RUN\n on_task_received = obj.create_task_handler()\n perform_pending_operations = obj.perform_pending_operations\n if getattr(obj.pool, 'is_green', False):\n _enable_amqheartbeats(obj.timer, connection, rate=hbrate)\n consumer.on_message = on_task_received\n consumer.consume()\n\n obj.on_ready()\n\n while blueprint.state == RUN and obj.connection:\n state.maybe_shutdown()\n if qos.prev != qos.value:\n qos.update()\n try:\n perform_pending_operations()\n connection.drain_events(timeout=2.0)\n except socket.timeout:\n pass\n except socket.error:\n if blueprint.state == RUN:\n raise\n", "path": "celery/worker/loops.py"}]}
| 3,413 | 158 |
gh_patches_debug_31150
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-834
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
W2030 - Number expected as String
cfn-lint 0.19.0
W2030 - Number expected as String
The following warning has started to appear in the latest version:
W2030 You must specify a valid allowed value for NAME_OF_THE_PARAMETER
Template example:
```
LogsRetentionLength:
AllowedValues:
- 1
- 3
Default: 1
Description: The retention length of the logs.
Type: Number
```
```
LogGroup:
Type: AWS::Logs::LogGroup
Properties:
RetentionInDays: !Ref LogsRetentionLength
LogGroupName: '/name'
```
Error:
```
W2030 You must specify a valid allowed value for LogsRetentionLength (1).
Valid values are ['1', '3', '5', '7', '14', '30', '60', '90', '120', '150', '180', '365', '400', '545', '731', '1827', '3653']
W2030 You must specify a valid allowed value for LogsRetentionLength (3).
Valid values are ['1', '3', '5', '7', '14', '30', '60', '90', '120', '150', '180', '365', '400', '545', '731', '1827', '3653']
W2030 You must specify a valid Default value for LogsRetentionLength (1).
Valid values are ['1', '3', '5', '7', '14', '30', '60', '90', '120', '150', '180', '365', '400', '545', '731', '1827', '3653']
```
Changing the templates as follow fixes the issue but it's incorrect:
```
LogsRetentionLength:
AllowedValues:
- '1'
- '3'
Default: '1'
Description: The retention length of the logs.
Type: Number
```
</issue>
<code>
[start of src/cfnlint/rules/parameters/AllowedValue.py]
1 """
2 Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.
3
4 Permission is hereby granted, free of charge, to any person obtaining a copy of this
5 software and associated documentation files (the "Software"), to deal in the Software
6 without restriction, including without limitation the rights to use, copy, modify,
7 merge, publish, distribute, sublicense, and/or sell copies of the Software, and to
8 permit persons to whom the Software is furnished to do so.
9
10 THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
11 INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
12 PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
13 HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
14 OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
15 SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
16 """
17 import six
18 from cfnlint import CloudFormationLintRule
19 from cfnlint import RuleMatch
20
21 from cfnlint.helpers import RESOURCE_SPECS
22
23
24 class AllowedValue(CloudFormationLintRule):
25 """Check if parameters have a valid value"""
26 id = 'W2030'
27 shortdesc = 'Check if parameters have a valid value'
28 description = 'Check if parameters have a valid value in case of an enumator. The Parameter''s allowed values is based on the usages in property (Ref)'
29 source_url = 'https://github.com/aws-cloudformation/cfn-python-lint/blob/master/docs/cfn-resource-specification.md#allowedvalue'
30 tags = ['resources', 'property', 'allowed value']
31
32 def initialize(self, cfn):
33 """Initialize the rule"""
34 for resource_type_spec in RESOURCE_SPECS.get(cfn.regions[0]).get('ResourceTypes'):
35 self.resource_property_types.append(resource_type_spec)
36 for property_type_spec in RESOURCE_SPECS.get(cfn.regions[0]).get('PropertyTypes'):
37 self.resource_sub_property_types.append(property_type_spec)
38
39 def check_value_ref(self, value, **kwargs):
40 """Check Ref"""
41 matches = []
42
43 allowed_value_specs = kwargs.get('value_specs', {}).get('AllowedValues', {})
44 cfn = kwargs.get('cfn')
45
46 if allowed_value_specs:
47 if value in cfn.template.get('Parameters', {}):
48 param = cfn.template.get('Parameters').get(value, {})
49 parameter_values = param.get('AllowedValues')
50 default_value = param.get('Default')
51 parameter_type = param.get('Type')
52 if isinstance(parameter_type, six.string_types):
53 if ((not parameter_type.startswith('List<')) and
54 (not parameter_type.startswith('AWS::SSM::Parameter::Value<')) and
55 parameter_type not in ['CommaDelimitedList']):
56 # Check Allowed Values
57 if parameter_values:
58 for index, allowed_value in enumerate(parameter_values):
59 if allowed_value not in allowed_value_specs:
60 param_path = ['Parameters', value, 'AllowedValues', index]
61 message = 'You must specify a valid allowed value for {0} ({1}).\nValid values are {2}'
62 matches.append(RuleMatch(param_path, message.format(value, allowed_value, allowed_value_specs)))
63 elif default_value:
64 # Check Default, only if no allowed Values are specified in the parameter (that's covered by E2015)
65 if default_value not in allowed_value_specs:
66 param_path = ['Parameters', value, 'Default']
67 message = 'You must specify a valid Default value for {0} ({1}).\nValid values are {2}'
68 matches.append(RuleMatch(param_path, message.format(value, default_value, allowed_value_specs)))
69
70 return matches
71
72 def check(self, cfn, properties, value_specs, property_specs, path):
73 """Check itself"""
74 matches = list()
75 for p_value, p_path in properties.items_safe(path[:]):
76 for prop in p_value:
77 if prop in value_specs:
78 value = value_specs.get(prop).get('Value', {})
79 if value:
80 value_type = value.get('ValueType', '')
81 property_type = property_specs.get('Properties').get(prop).get('Type')
82 matches.extend(
83 cfn.check_value(
84 p_value, prop, p_path,
85 check_ref=self.check_value_ref,
86 value_specs=RESOURCE_SPECS.get(cfn.regions[0]).get('ValueTypes').get(value_type, {}),
87 cfn=cfn, property_type=property_type, property_name=prop
88 )
89 )
90
91 return matches
92
93 def match_resource_sub_properties(self, properties, property_type, path, cfn):
94 """Match for sub properties"""
95 matches = list()
96
97 specs = RESOURCE_SPECS.get(cfn.regions[0]).get('PropertyTypes').get(property_type, {}).get('Properties', {})
98 property_specs = RESOURCE_SPECS.get(cfn.regions[0]).get('PropertyTypes').get(property_type)
99 matches.extend(self.check(cfn, properties, specs, property_specs, path))
100
101 return matches
102
103 def match_resource_properties(self, properties, resource_type, path, cfn):
104 """Check CloudFormation Properties"""
105 matches = list()
106
107 specs = RESOURCE_SPECS.get(cfn.regions[0]).get('ResourceTypes').get(resource_type, {}).get('Properties', {})
108 resource_specs = RESOURCE_SPECS.get(cfn.regions[0]).get('ResourceTypes').get(resource_type)
109 matches.extend(self.check(cfn, properties, specs, resource_specs, path))
110
111 return matches
112
[end of src/cfnlint/rules/parameters/AllowedValue.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cfnlint/rules/parameters/AllowedValue.py b/src/cfnlint/rules/parameters/AllowedValue.py
--- a/src/cfnlint/rules/parameters/AllowedValue.py
+++ b/src/cfnlint/rules/parameters/AllowedValue.py
@@ -56,13 +56,13 @@
# Check Allowed Values
if parameter_values:
for index, allowed_value in enumerate(parameter_values):
- if allowed_value not in allowed_value_specs:
+ if str(allowed_value) not in allowed_value_specs:
param_path = ['Parameters', value, 'AllowedValues', index]
message = 'You must specify a valid allowed value for {0} ({1}).\nValid values are {2}'
matches.append(RuleMatch(param_path, message.format(value, allowed_value, allowed_value_specs)))
- elif default_value:
+ if default_value:
# Check Default, only if no allowed Values are specified in the parameter (that's covered by E2015)
- if default_value not in allowed_value_specs:
+ if str(default_value) not in allowed_value_specs:
param_path = ['Parameters', value, 'Default']
message = 'You must specify a valid Default value for {0} ({1}).\nValid values are {2}'
matches.append(RuleMatch(param_path, message.format(value, default_value, allowed_value_specs)))
|
{"golden_diff": "diff --git a/src/cfnlint/rules/parameters/AllowedValue.py b/src/cfnlint/rules/parameters/AllowedValue.py\n--- a/src/cfnlint/rules/parameters/AllowedValue.py\n+++ b/src/cfnlint/rules/parameters/AllowedValue.py\n@@ -56,13 +56,13 @@\n # Check Allowed Values\n if parameter_values:\n for index, allowed_value in enumerate(parameter_values):\n- if allowed_value not in allowed_value_specs:\n+ if str(allowed_value) not in allowed_value_specs:\n param_path = ['Parameters', value, 'AllowedValues', index]\n message = 'You must specify a valid allowed value for {0} ({1}).\\nValid values are {2}'\n matches.append(RuleMatch(param_path, message.format(value, allowed_value, allowed_value_specs)))\n- elif default_value:\n+ if default_value:\n # Check Default, only if no allowed Values are specified in the parameter (that's covered by E2015)\n- if default_value not in allowed_value_specs:\n+ if str(default_value) not in allowed_value_specs:\n param_path = ['Parameters', value, 'Default']\n message = 'You must specify a valid Default value for {0} ({1}).\\nValid values are {2}'\n matches.append(RuleMatch(param_path, message.format(value, default_value, allowed_value_specs)))\n", "issue": "W2030 - Number expected as String \ncfn-lint 0.19.0\r\n\r\nW2030 - Number expected as String\r\n\r\nThe following warning has started to appear in the latest version:\r\nW2030 You must specify a valid allowed value for NAME_OF_THE_PARAMETER\r\n\r\nTemplate example:\r\n```\r\n LogsRetentionLength:\r\n AllowedValues:\r\n - 1\r\n - 3\r\n Default: 1\r\n Description: The retention length of the logs.\r\n Type: Number\r\n```\r\n\r\n```\r\n LogGroup:\r\n Type: AWS::Logs::LogGroup\r\n Properties:\r\n RetentionInDays: !Ref LogsRetentionLength\r\n LogGroupName: '/name'\r\n```\r\n\r\nError:\r\n```\r\nW2030 You must specify a valid allowed value for LogsRetentionLength (1).\r\nValid values are ['1', '3', '5', '7', '14', '30', '60', '90', '120', '150', '180', '365', '400', '545', '731', '1827', '3653']\r\nW2030 You must specify a valid allowed value for LogsRetentionLength (3).\r\nValid values are ['1', '3', '5', '7', '14', '30', '60', '90', '120', '150', '180', '365', '400', '545', '731', '1827', '3653']\r\nW2030 You must specify a valid Default value for LogsRetentionLength (1).\r\nValid values are ['1', '3', '5', '7', '14', '30', '60', '90', '120', '150', '180', '365', '400', '545', '731', '1827', '3653']\r\n```\r\n\r\nChanging the templates as follow fixes the issue but it's incorrect:\r\n\r\n```\r\n LogsRetentionLength:\r\n AllowedValues:\r\n - '1'\r\n - '3'\r\n Default: '1'\r\n Description: The retention length of the logs.\r\n Type: Number\r\n```\n", "before_files": [{"content": "\"\"\"\n Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nimport six\nfrom cfnlint import CloudFormationLintRule\nfrom cfnlint import RuleMatch\n\nfrom cfnlint.helpers import RESOURCE_SPECS\n\n\nclass AllowedValue(CloudFormationLintRule):\n \"\"\"Check if parameters have a valid value\"\"\"\n id = 'W2030'\n shortdesc = 'Check if parameters have a valid value'\n description = 'Check if parameters have a valid value in case of an enumator. The Parameter''s allowed values is based on the usages in property (Ref)'\n source_url = 'https://github.com/aws-cloudformation/cfn-python-lint/blob/master/docs/cfn-resource-specification.md#allowedvalue'\n tags = ['resources', 'property', 'allowed value']\n\n def initialize(self, cfn):\n \"\"\"Initialize the rule\"\"\"\n for resource_type_spec in RESOURCE_SPECS.get(cfn.regions[0]).get('ResourceTypes'):\n self.resource_property_types.append(resource_type_spec)\n for property_type_spec in RESOURCE_SPECS.get(cfn.regions[0]).get('PropertyTypes'):\n self.resource_sub_property_types.append(property_type_spec)\n\n def check_value_ref(self, value, **kwargs):\n \"\"\"Check Ref\"\"\"\n matches = []\n\n allowed_value_specs = kwargs.get('value_specs', {}).get('AllowedValues', {})\n cfn = kwargs.get('cfn')\n\n if allowed_value_specs:\n if value in cfn.template.get('Parameters', {}):\n param = cfn.template.get('Parameters').get(value, {})\n parameter_values = param.get('AllowedValues')\n default_value = param.get('Default')\n parameter_type = param.get('Type')\n if isinstance(parameter_type, six.string_types):\n if ((not parameter_type.startswith('List<')) and\n (not parameter_type.startswith('AWS::SSM::Parameter::Value<')) and\n parameter_type not in ['CommaDelimitedList']):\n # Check Allowed Values\n if parameter_values:\n for index, allowed_value in enumerate(parameter_values):\n if allowed_value not in allowed_value_specs:\n param_path = ['Parameters', value, 'AllowedValues', index]\n message = 'You must specify a valid allowed value for {0} ({1}).\\nValid values are {2}'\n matches.append(RuleMatch(param_path, message.format(value, allowed_value, allowed_value_specs)))\n elif default_value:\n # Check Default, only if no allowed Values are specified in the parameter (that's covered by E2015)\n if default_value not in allowed_value_specs:\n param_path = ['Parameters', value, 'Default']\n message = 'You must specify a valid Default value for {0} ({1}).\\nValid values are {2}'\n matches.append(RuleMatch(param_path, message.format(value, default_value, allowed_value_specs)))\n\n return matches\n\n def check(self, cfn, properties, value_specs, property_specs, path):\n \"\"\"Check itself\"\"\"\n matches = list()\n for p_value, p_path in properties.items_safe(path[:]):\n for prop in p_value:\n if prop in value_specs:\n value = value_specs.get(prop).get('Value', {})\n if value:\n value_type = value.get('ValueType', '')\n property_type = property_specs.get('Properties').get(prop).get('Type')\n matches.extend(\n cfn.check_value(\n p_value, prop, p_path,\n check_ref=self.check_value_ref,\n value_specs=RESOURCE_SPECS.get(cfn.regions[0]).get('ValueTypes').get(value_type, {}),\n cfn=cfn, property_type=property_type, property_name=prop\n )\n )\n\n return matches\n\n def match_resource_sub_properties(self, properties, property_type, path, cfn):\n \"\"\"Match for sub properties\"\"\"\n matches = list()\n\n specs = RESOURCE_SPECS.get(cfn.regions[0]).get('PropertyTypes').get(property_type, {}).get('Properties', {})\n property_specs = RESOURCE_SPECS.get(cfn.regions[0]).get('PropertyTypes').get(property_type)\n matches.extend(self.check(cfn, properties, specs, property_specs, path))\n\n return matches\n\n def match_resource_properties(self, properties, resource_type, path, cfn):\n \"\"\"Check CloudFormation Properties\"\"\"\n matches = list()\n\n specs = RESOURCE_SPECS.get(cfn.regions[0]).get('ResourceTypes').get(resource_type, {}).get('Properties', {})\n resource_specs = RESOURCE_SPECS.get(cfn.regions[0]).get('ResourceTypes').get(resource_type)\n matches.extend(self.check(cfn, properties, specs, resource_specs, path))\n\n return matches\n", "path": "src/cfnlint/rules/parameters/AllowedValue.py"}]}
| 2,477 | 298 |
gh_patches_debug_63962
|
rasdani/github-patches
|
git_diff
|
redis__redis-py-1678
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CI run to install the built package
In light of bug #1645 we should amend our CI run to install the built package, in a new virtual env and run something simple like a redis.Redis().ping(). Eventually we could build up to running the full integration test against the package.
CI run to install the built package
In light of bug #1645 we should amend our CI run to install the built package, in a new virtual env and run something simple like a redis.Redis().ping(). Eventually we could build up to running the full integration test against the package.
</issue>
<code>
[start of tasks.py]
1 import os
2 import shutil
3 from invoke import task, run
4
5 with open('tox.ini') as fp:
6 lines = fp.read().split("\n")
7 dockers = [line.split("=")[1].strip() for line in lines
8 if line.find("name") != -1]
9
10
11 @task
12 def devenv(c):
13 """Builds a development environment: downloads, and starts all dockers
14 specified in the tox.ini file.
15 """
16 clean(c)
17 cmd = 'tox -e devenv'
18 for d in dockers:
19 cmd += " --docker-dont-stop={}".format(d)
20 run(cmd)
21
22
23 @task
24 def linters(c):
25 """Run code linters"""
26 run("tox -e linters")
27
28
29 @task
30 def all_tests(c):
31 """Run all linters, and tests in redis-py. This assumes you have all
32 the python versions specified in the tox.ini file.
33 """
34 linters(c)
35 tests(c)
36
37
38 @task
39 def tests(c):
40 """Run the redis-py test suite against the current python,
41 with and without hiredis.
42 """
43 run("tox -e plain -e hiredis")
44
45
46 @task
47 def clean(c):
48 """Stop all dockers, and clean up the built binaries, if generated."""
49 if os.path.isdir("build"):
50 shutil.rmtree("build")
51 if os.path.isdir("dist"):
52 shutil.rmtree("dist")
53 run("docker rm -f {}".format(' '.join(dockers)))
54
55
56 @task
57 def package(c):
58 """Create the python packages"""
59 run("python setup.py build install")
60
[end of tasks.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/tasks.py b/tasks.py
--- a/tasks.py
+++ b/tasks.py
@@ -56,4 +56,4 @@
@task
def package(c):
"""Create the python packages"""
- run("python setup.py build install")
+ run("python setup.py sdist bdist_wheel")
|
{"golden_diff": "diff --git a/tasks.py b/tasks.py\n--- a/tasks.py\n+++ b/tasks.py\n@@ -56,4 +56,4 @@\n @task\n def package(c):\n \"\"\"Create the python packages\"\"\"\n- run(\"python setup.py build install\")\n+ run(\"python setup.py sdist bdist_wheel\")\n", "issue": "CI run to install the built package\nIn light of bug #1645 we should amend our CI run to install the built package, in a new virtual env and run something simple like a redis.Redis().ping(). Eventually we could build up to running the full integration test against the package.\nCI run to install the built package\nIn light of bug #1645 we should amend our CI run to install the built package, in a new virtual env and run something simple like a redis.Redis().ping(). Eventually we could build up to running the full integration test against the package.\n", "before_files": [{"content": "import os\nimport shutil\nfrom invoke import task, run\n\nwith open('tox.ini') as fp:\n lines = fp.read().split(\"\\n\")\n dockers = [line.split(\"=\")[1].strip() for line in lines\n if line.find(\"name\") != -1]\n\n\n@task\ndef devenv(c):\n \"\"\"Builds a development environment: downloads, and starts all dockers\n specified in the tox.ini file.\n \"\"\"\n clean(c)\n cmd = 'tox -e devenv'\n for d in dockers:\n cmd += \" --docker-dont-stop={}\".format(d)\n run(cmd)\n\n\n@task\ndef linters(c):\n \"\"\"Run code linters\"\"\"\n run(\"tox -e linters\")\n\n\n@task\ndef all_tests(c):\n \"\"\"Run all linters, and tests in redis-py. This assumes you have all\n the python versions specified in the tox.ini file.\n \"\"\"\n linters(c)\n tests(c)\n\n\n@task\ndef tests(c):\n \"\"\"Run the redis-py test suite against the current python,\n with and without hiredis.\n \"\"\"\n run(\"tox -e plain -e hiredis\")\n\n\n@task\ndef clean(c):\n \"\"\"Stop all dockers, and clean up the built binaries, if generated.\"\"\"\n if os.path.isdir(\"build\"):\n shutil.rmtree(\"build\")\n if os.path.isdir(\"dist\"):\n shutil.rmtree(\"dist\")\n run(\"docker rm -f {}\".format(' '.join(dockers)))\n\n\n@task\ndef package(c):\n \"\"\"Create the python packages\"\"\"\n run(\"python setup.py build install\")\n", "path": "tasks.py"}]}
| 1,122 | 69 |
gh_patches_debug_32160
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-3322
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Spider holiday_stationstores is broken
During the global build at 2021-08-18-14-42-26, spider **holiday_stationstores** failed with **552 features** and **10 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-08-18-14-42-26/logs/holiday_stationstores.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-08-18-14-42-26/output/holiday_stationstores.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-08-18-14-42-26/output/holiday_stationstores.geojson))
</issue>
<code>
[start of locations/spiders/holiday_stationstores.py]
1 # -*- coding: utf-8 -*-
2 import scrapy
3 import json
4 import re
5
6 from locations.items import GeojsonPointItem
7
8
9 class HolidayStationstoreSpider(scrapy.Spider):
10 name = "holiday_stationstores"
11 item_attributes = {'brand': 'Holiday Stationstores',
12 'brand_wikidata': 'Q5880490'}
13 allowed_domains = ["www.holidaystationstores.com"]
14 download_delay = 0.2
15
16 def start_requests(self):
17 yield scrapy.Request('https://www.holidaystationstores.com/Locations/GetAllStores',
18 method='POST',
19 callback=self.parse_all_stores)
20
21 def parse_all_stores(self, response):
22 all_stores = json.loads(response.text)
23
24 for store_id, store in all_stores.items():
25 # GET requests get blocked by their Incapsula bot protection, but POST works fine
26 yield scrapy.Request(f"https://www.holidaystationstores.com/Locations/Detail?storeNumber={store_id}",
27 method='POST',
28 meta={'store': store})
29
30 def parse(self, response):
31 store = response.meta['store']
32
33 address = response.xpath('//div[@class="col-lg-4 col-sm-12"]/text()')[1].extract().strip()
34 phone = response.xpath('//div[@class="HolidayFontColorRed"]/text()').extract_first().strip()
35 services = '|'.join(response.xpath('//ul[@style="list-style-type: none; padding-left: 1.0em; font-size: 12px;"]/li/text()').extract()).lower()
36 open_24_hours = '24 hours' in response.css(
37 '.body-content .col-lg-4').get().lower()
38
39 properties = {
40 'name': f"Holiday #{store['Name']}",
41 'lon': store['Lng'],
42 'lat': store['Lat'],
43 'addr_full': address,
44 'phone': phone,
45 'ref': store['ID'],
46 'opening_hours': '24/7' if open_24_hours else self.opening_hours(response),
47 'extras': {
48 'amenity:fuel': True,
49 'fuel:diesel': 'diesel' in services or None,
50 'atm': 'atm' in services or None,
51 'fuel:e85': 'e85' in services or None,
52 'hgv': 'truck' in services or None,
53 'fuel:propane': 'propane' in services or None,
54 'car_wash': 'car wash' in services or None,
55 'fuel:cng': 'cng' in services or None
56 }
57 }
58
59 yield GeojsonPointItem(**properties)
60
61 def opening_hours(self, response):
62 hour_part_elems = response.xpath('//div[@class="row"][@style="font-size: 12px;"]')
63 day_groups = []
64 this_day_group = None
65
66 if hour_part_elems:
67 for hour_part_elem in hour_part_elems:
68 day = hour_part_elem.xpath('.//div[@class="col-3"]/text()').extract_first()
69 hours = hour_part_elem.xpath('.//div[@class="col-9"]/text()').extract_first()
70
71 if not hours:
72 continue
73
74 day = day[:2]
75 match = re.search(
76 r'^(\d{1,2}):(\d{2})\s*(a|p)m - (\d{1,2}):(\d{2})\s*(a|p)m?$', hours.lower())
77 (f_hr, f_min, f_ampm, t_hr, t_min, t_ampm) = match.groups()
78
79 f_hr = int(f_hr)
80 if f_ampm == 'p':
81 f_hr += 12
82 elif f_ampm == 'a' and f_hr == 12:
83 f_hr = 0
84 t_hr = int(t_hr)
85 if t_ampm == 'p':
86 t_hr += 12
87 elif t_ampm == 'a' and t_hr == 12:
88 t_hr = 0
89
90 hours = '{:02d}:{}-{:02d}:{}'.format(
91 f_hr,
92 f_min,
93 t_hr,
94 t_min,
95 )
96
97 if not this_day_group:
98 this_day_group = {
99 'from_day': day,
100 'to_day': day,
101 'hours': hours
102 }
103 elif this_day_group['hours'] != hours:
104 day_groups.append(this_day_group)
105 this_day_group = {
106 'from_day': day,
107 'to_day': day,
108 'hours': hours
109 }
110 elif this_day_group['hours'] == hours:
111 this_day_group['to_day'] = day
112
113 if this_day_group:
114 day_groups.append(this_day_group)
115
116 hour_part_elems = response.xpath('//span[@style="font-size:90%"]/text()').extract()
117 if hour_part_elems:
118 day_groups.append({'from_day': 'Mo', 'to_day': 'Su', 'hours': '00:00-23:59'})
119
120 opening_hours = ""
121 if len(day_groups) == 1 and day_groups[0]['hours'] in ('00:00-23:59', '00:00-00:00'):
122 opening_hours = '24/7'
123 else:
124 for day_group in day_groups:
125 if day_group['from_day'] == day_group['to_day']:
126 opening_hours += '{from_day} {hours}; '.format(**day_group)
127 elif day_group['from_day'] == 'Su' and day_group['to_day'] == 'Sa':
128 opening_hours += '{hours}; '.format(**day_group)
129 else:
130 opening_hours += '{from_day}-{to_day} {hours}; '.format(
131 **day_group)
132 opening_hours = opening_hours[:-2]
133
134 return opening_hours
135
[end of locations/spiders/holiday_stationstores.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/locations/spiders/holiday_stationstores.py b/locations/spiders/holiday_stationstores.py
--- a/locations/spiders/holiday_stationstores.py
+++ b/locations/spiders/holiday_stationstores.py
@@ -31,6 +31,8 @@
store = response.meta['store']
address = response.xpath('//div[@class="col-lg-4 col-sm-12"]/text()')[1].extract().strip()
+ city_state = response.xpath('//div[@class="col-lg-4 col-sm-12"]/text()')[2].extract().strip()
+ city, state = city_state.split(", ")
phone = response.xpath('//div[@class="HolidayFontColorRed"]/text()').extract_first().strip()
services = '|'.join(response.xpath('//ul[@style="list-style-type: none; padding-left: 1.0em; font-size: 12px;"]/li/text()').extract()).lower()
open_24_hours = '24 hours' in response.css(
@@ -43,6 +45,9 @@
'addr_full': address,
'phone': phone,
'ref': store['ID'],
+ 'city': city.strip(),
+ 'state': state.strip(),
+ 'website': response.url,
'opening_hours': '24/7' if open_24_hours else self.opening_hours(response),
'extras': {
'amenity:fuel': True,
@@ -68,7 +73,7 @@
day = hour_part_elem.xpath('.//div[@class="col-3"]/text()').extract_first()
hours = hour_part_elem.xpath('.//div[@class="col-9"]/text()').extract_first()
- if not hours:
+ if not hours or hours.lower() == 'closed':
continue
day = day[:2]
|
{"golden_diff": "diff --git a/locations/spiders/holiday_stationstores.py b/locations/spiders/holiday_stationstores.py\n--- a/locations/spiders/holiday_stationstores.py\n+++ b/locations/spiders/holiday_stationstores.py\n@@ -31,6 +31,8 @@\n store = response.meta['store']\n \n address = response.xpath('//div[@class=\"col-lg-4 col-sm-12\"]/text()')[1].extract().strip()\n+ city_state = response.xpath('//div[@class=\"col-lg-4 col-sm-12\"]/text()')[2].extract().strip()\n+ city, state = city_state.split(\", \")\n phone = response.xpath('//div[@class=\"HolidayFontColorRed\"]/text()').extract_first().strip()\n services = '|'.join(response.xpath('//ul[@style=\"list-style-type: none; padding-left: 1.0em; font-size: 12px;\"]/li/text()').extract()).lower()\n open_24_hours = '24 hours' in response.css(\n@@ -43,6 +45,9 @@\n 'addr_full': address,\n 'phone': phone,\n 'ref': store['ID'],\n+ 'city': city.strip(),\n+ 'state': state.strip(),\n+ 'website': response.url,\n 'opening_hours': '24/7' if open_24_hours else self.opening_hours(response),\n 'extras': {\n 'amenity:fuel': True,\n@@ -68,7 +73,7 @@\n day = hour_part_elem.xpath('.//div[@class=\"col-3\"]/text()').extract_first()\n hours = hour_part_elem.xpath('.//div[@class=\"col-9\"]/text()').extract_first()\n \n- if not hours:\n+ if not hours or hours.lower() == 'closed':\n continue\n \n day = day[:2]\n", "issue": "Spider holiday_stationstores is broken\nDuring the global build at 2021-08-18-14-42-26, spider **holiday_stationstores** failed with **552 features** and **10 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-08-18-14-42-26/logs/holiday_stationstores.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-08-18-14-42-26/output/holiday_stationstores.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-08-18-14-42-26/output/holiday_stationstores.geojson))\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport scrapy\nimport json\nimport re\n\nfrom locations.items import GeojsonPointItem\n\n\nclass HolidayStationstoreSpider(scrapy.Spider):\n name = \"holiday_stationstores\"\n item_attributes = {'brand': 'Holiday Stationstores',\n 'brand_wikidata': 'Q5880490'}\n allowed_domains = [\"www.holidaystationstores.com\"]\n download_delay = 0.2\n\n def start_requests(self):\n yield scrapy.Request('https://www.holidaystationstores.com/Locations/GetAllStores',\n method='POST',\n callback=self.parse_all_stores)\n\n def parse_all_stores(self, response):\n all_stores = json.loads(response.text)\n\n for store_id, store in all_stores.items():\n # GET requests get blocked by their Incapsula bot protection, but POST works fine\n yield scrapy.Request(f\"https://www.holidaystationstores.com/Locations/Detail?storeNumber={store_id}\",\n method='POST',\n meta={'store': store})\n\n def parse(self, response):\n store = response.meta['store']\n\n address = response.xpath('//div[@class=\"col-lg-4 col-sm-12\"]/text()')[1].extract().strip()\n phone = response.xpath('//div[@class=\"HolidayFontColorRed\"]/text()').extract_first().strip()\n services = '|'.join(response.xpath('//ul[@style=\"list-style-type: none; padding-left: 1.0em; font-size: 12px;\"]/li/text()').extract()).lower()\n open_24_hours = '24 hours' in response.css(\n '.body-content .col-lg-4').get().lower()\n\n properties = {\n 'name': f\"Holiday #{store['Name']}\",\n 'lon': store['Lng'],\n 'lat': store['Lat'],\n 'addr_full': address,\n 'phone': phone,\n 'ref': store['ID'],\n 'opening_hours': '24/7' if open_24_hours else self.opening_hours(response),\n 'extras': {\n 'amenity:fuel': True,\n 'fuel:diesel': 'diesel' in services or None,\n 'atm': 'atm' in services or None,\n 'fuel:e85': 'e85' in services or None,\n 'hgv': 'truck' in services or None,\n 'fuel:propane': 'propane' in services or None,\n 'car_wash': 'car wash' in services or None,\n 'fuel:cng': 'cng' in services or None\n }\n }\n\n yield GeojsonPointItem(**properties)\n\n def opening_hours(self, response):\n hour_part_elems = response.xpath('//div[@class=\"row\"][@style=\"font-size: 12px;\"]')\n day_groups = []\n this_day_group = None\n\n if hour_part_elems:\n for hour_part_elem in hour_part_elems:\n day = hour_part_elem.xpath('.//div[@class=\"col-3\"]/text()').extract_first()\n hours = hour_part_elem.xpath('.//div[@class=\"col-9\"]/text()').extract_first()\n\n if not hours:\n continue\n\n day = day[:2]\n match = re.search(\n r'^(\\d{1,2}):(\\d{2})\\s*(a|p)m - (\\d{1,2}):(\\d{2})\\s*(a|p)m?$', hours.lower())\n (f_hr, f_min, f_ampm, t_hr, t_min, t_ampm) = match.groups()\n\n f_hr = int(f_hr)\n if f_ampm == 'p':\n f_hr += 12\n elif f_ampm == 'a' and f_hr == 12:\n f_hr = 0\n t_hr = int(t_hr)\n if t_ampm == 'p':\n t_hr += 12\n elif t_ampm == 'a' and t_hr == 12:\n t_hr = 0\n\n hours = '{:02d}:{}-{:02d}:{}'.format(\n f_hr,\n f_min,\n t_hr,\n t_min,\n )\n\n if not this_day_group:\n this_day_group = {\n 'from_day': day,\n 'to_day': day,\n 'hours': hours\n }\n elif this_day_group['hours'] != hours:\n day_groups.append(this_day_group)\n this_day_group = {\n 'from_day': day,\n 'to_day': day,\n 'hours': hours\n }\n elif this_day_group['hours'] == hours:\n this_day_group['to_day'] = day\n\n if this_day_group:\n day_groups.append(this_day_group)\n\n hour_part_elems = response.xpath('//span[@style=\"font-size:90%\"]/text()').extract()\n if hour_part_elems:\n day_groups.append({'from_day': 'Mo', 'to_day': 'Su', 'hours': '00:00-23:59'})\n\n opening_hours = \"\"\n if len(day_groups) == 1 and day_groups[0]['hours'] in ('00:00-23:59', '00:00-00:00'):\n opening_hours = '24/7'\n else:\n for day_group in day_groups:\n if day_group['from_day'] == day_group['to_day']:\n opening_hours += '{from_day} {hours}; '.format(**day_group)\n elif day_group['from_day'] == 'Su' and day_group['to_day'] == 'Sa':\n opening_hours += '{hours}; '.format(**day_group)\n else:\n opening_hours += '{from_day}-{to_day} {hours}; '.format(\n **day_group)\n opening_hours = opening_hours[:-2]\n\n return opening_hours\n", "path": "locations/spiders/holiday_stationstores.py"}]}
| 2,319 | 407 |
gh_patches_debug_49047
|
rasdani/github-patches
|
git_diff
|
arviz-devs__arviz-1403
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Error plotting a single variable with plot_density and bokeh backend
**Describe the bug**
Over in ArviZ.jl, we use the Julia equivalent to the below snippet to test Bokeh integration for `plot_density`. It worked fine until recently, where we now get an error with bokeh only but not matplotlib, though I'm not certain whether a change in arviz or bokeh is responsible.
**To Reproduce**
```python
>>> import arviz
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> arr1 = np.random.randn(4, 100)
>>> arr2 = np.random.randn(4, 100)
>>> arviz.plot_density([{"x": arr1}, {"x": arr2}], var_names = ["x"]) # matplotlib works fine
>>> plt.show()
```
<img src=https://user-images.githubusercontent.com/8673634/94775414-9bce2480-0374-11eb-8938-f74a486f97de.png width=400></img>
```python
>>> arviz.plot_density([{"x": arr1}, {"x": arr2}], var_names = ["x"], backend="bokeh") # errors
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/saxen/.julia/conda/3/lib/python3.8/site-packages/arviz/plots/densityplot.py", line 252, in plot_density
ax = plot(**plot_density_kwargs)
File "/Users/saxen/.julia/conda/3/lib/python3.8/site-packages/arviz/plots/backends/bokeh/densityplot.py", line 74, in plot_density
for label, ax_ in zip(all_labels, (item for item in ax.flatten() if item is not None))
AttributeError: 'Figure' object has no attribute 'flatten'
```
**Additional context**
Relevant package versions in the conda environment used:
```
arviz 0.10.0 py_0 conda-forge
bokeh 2.2.1 py38h32f6830_0 conda-forge
matplotlib 3.1.3 py38_0 conda-forge
numpy 1.19.1 py38h3b9f5b6_0
```
</issue>
<code>
[start of arviz/plots/backends/bokeh/densityplot.py]
1 """Bokeh Densityplot."""
2 from collections import defaultdict
3 from itertools import cycle
4
5 import matplotlib.pyplot as plt
6 import numpy as np
7 from bokeh.models.annotations import Legend, Title
8
9 from ....stats import hdi
10 from ....stats.density_utils import get_bins, histogram, kde
11 from ...plot_utils import _scale_fig_size, calculate_point_estimate, make_label, vectorized_to_hex
12 from .. import show_layout
13 from . import backend_kwarg_defaults, create_axes_grid
14
15
16 def plot_density(
17 ax,
18 all_labels,
19 to_plot,
20 colors,
21 bw,
22 circular,
23 figsize,
24 length_plotters,
25 rows,
26 cols,
27 textsize,
28 hdi_prob,
29 point_estimate,
30 hdi_markers,
31 outline,
32 shade,
33 n_data,
34 data_labels,
35 backend_kwargs,
36 show,
37 ):
38 """Bokeh density plot."""
39 if backend_kwargs is None:
40 backend_kwargs = {}
41
42 backend_kwargs = {
43 **backend_kwarg_defaults(),
44 **backend_kwargs,
45 }
46
47 if colors == "cycle":
48 colors = [
49 prop
50 for _, prop in zip(
51 range(n_data), cycle(plt.rcParams["axes.prop_cycle"].by_key()["color"])
52 )
53 ]
54 elif isinstance(colors, str):
55 colors = [colors for _ in range(n_data)]
56 colors = vectorized_to_hex(colors)
57
58 (figsize, _, _, _, line_width, markersize) = _scale_fig_size(figsize, textsize, rows, cols)
59
60 if ax is None:
61 ax = create_axes_grid(
62 length_plotters,
63 rows,
64 cols,
65 figsize=figsize,
66 squeeze=True,
67 backend_kwargs=backend_kwargs,
68 )
69 else:
70 ax = np.atleast_2d(ax)
71
72 axis_map = {
73 label: ax_
74 for label, ax_ in zip(all_labels, (item for item in ax.flatten() if item is not None))
75 }
76 if data_labels is None:
77 data_labels = {}
78
79 legend_items = defaultdict(list)
80 for m_idx, plotters in enumerate(to_plot):
81 for var_name, selection, values in plotters:
82 label = make_label(var_name, selection)
83
84 if data_labels:
85 data_label = data_labels[m_idx]
86 else:
87 data_label = None
88
89 plotted = _d_helper(
90 values.flatten(),
91 label,
92 colors[m_idx],
93 bw,
94 circular,
95 line_width,
96 markersize,
97 hdi_prob,
98 point_estimate,
99 hdi_markers,
100 outline,
101 shade,
102 axis_map[label],
103 )
104 if data_label is not None:
105 legend_items[axis_map[label]].append((data_label, plotted))
106
107 for ax1, legend in legend_items.items():
108 legend = Legend(
109 items=legend,
110 location="center_right",
111 orientation="horizontal",
112 )
113 ax1.add_layout(legend, "above")
114 ax1.legend.click_policy = "hide"
115
116 show_layout(ax, show)
117
118 return ax
119
120
121 def _d_helper(
122 vec,
123 vname,
124 color,
125 bw,
126 circular,
127 line_width,
128 markersize,
129 hdi_prob,
130 point_estimate,
131 hdi_markers,
132 outline,
133 shade,
134 ax,
135 ):
136
137 extra = dict()
138 plotted = []
139
140 if vec.dtype.kind == "f":
141 if hdi_prob != 1:
142 hdi_ = hdi(vec, hdi_prob, multimodal=False)
143 new_vec = vec[(vec >= hdi_[0]) & (vec <= hdi_[1])]
144 else:
145 new_vec = vec
146
147 x, density = kde(new_vec, circular=circular, bw=bw)
148 density *= hdi_prob
149 xmin, xmax = x[0], x[-1]
150 ymin, ymax = density[0], density[-1]
151
152 if outline:
153 plotted.append(ax.line(x, density, line_color=color, line_width=line_width, **extra))
154 plotted.append(
155 ax.line(
156 [xmin, xmin],
157 [-ymin / 100, ymin],
158 line_color=color,
159 line_dash="solid",
160 line_width=line_width,
161 muted_color=color,
162 muted_alpha=0.2,
163 )
164 )
165 plotted.append(
166 ax.line(
167 [xmax, xmax],
168 [-ymax / 100, ymax],
169 line_color=color,
170 line_dash="solid",
171 line_width=line_width,
172 muted_color=color,
173 muted_alpha=0.2,
174 )
175 )
176
177 if shade:
178 plotted.append(
179 ax.patch(
180 np.r_[x[::-1], x, x[-1:]],
181 np.r_[np.zeros_like(x), density, [0]],
182 fill_color=color,
183 fill_alpha=shade,
184 muted_color=color,
185 muted_alpha=0.2,
186 **extra
187 )
188 )
189
190 else:
191 xmin, xmax = hdi(vec, hdi_prob, multimodal=False)
192 bins = get_bins(vec)
193
194 _, hist, edges = histogram(vec, bins=bins)
195
196 if outline:
197 plotted.append(
198 ax.quad(
199 top=hist,
200 bottom=0,
201 left=edges[:-1],
202 right=edges[1:],
203 line_color=color,
204 fill_color=None,
205 muted_color=color,
206 muted_alpha=0.2,
207 **extra
208 )
209 )
210 else:
211 plotted.append(
212 ax.quad(
213 top=hist,
214 bottom=0,
215 left=edges[:-1],
216 right=edges[1:],
217 line_color=color,
218 fill_color=color,
219 fill_alpha=shade,
220 muted_color=color,
221 muted_alpha=0.2,
222 **extra
223 )
224 )
225
226 if hdi_markers:
227 plotted.append(ax.diamond(xmin, 0, line_color="black", fill_color=color, size=markersize))
228 plotted.append(ax.diamond(xmax, 0, line_color="black", fill_color=color, size=markersize))
229
230 if point_estimate is not None:
231 est = calculate_point_estimate(point_estimate, vec, bw, circular)
232 plotted.append(ax.circle(est, 0, fill_color=color, line_color="black", size=markersize))
233
234 _title = Title()
235 _title.text = vname
236 ax.title = _title
237 ax.title.text_font_size = "13pt"
238
239 return plotted
240
[end of arviz/plots/backends/bokeh/densityplot.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/arviz/plots/backends/bokeh/densityplot.py b/arviz/plots/backends/bokeh/densityplot.py
--- a/arviz/plots/backends/bokeh/densityplot.py
+++ b/arviz/plots/backends/bokeh/densityplot.py
@@ -63,7 +63,7 @@
rows,
cols,
figsize=figsize,
- squeeze=True,
+ squeeze=False,
backend_kwargs=backend_kwargs,
)
else:
|
{"golden_diff": "diff --git a/arviz/plots/backends/bokeh/densityplot.py b/arviz/plots/backends/bokeh/densityplot.py\n--- a/arviz/plots/backends/bokeh/densityplot.py\n+++ b/arviz/plots/backends/bokeh/densityplot.py\n@@ -63,7 +63,7 @@\n rows,\n cols,\n figsize=figsize,\n- squeeze=True,\n+ squeeze=False,\n backend_kwargs=backend_kwargs,\n )\n else:\n", "issue": "Error plotting a single variable with plot_density and bokeh backend\n**Describe the bug**\r\nOver in ArviZ.jl, we use the Julia equivalent to the below snippet to test Bokeh integration for `plot_density`. It worked fine until recently, where we now get an error with bokeh only but not matplotlib, though I'm not certain whether a change in arviz or bokeh is responsible.\r\n\r\n**To Reproduce**\r\n```python\r\n>>> import arviz\r\n>>> import numpy as np\r\n>>> import matplotlib.pyplot as plt\r\n>>> arr1 = np.random.randn(4, 100)\r\n>>> arr2 = np.random.randn(4, 100)\r\n>>> arviz.plot_density([{\"x\": arr1}, {\"x\": arr2}], var_names = [\"x\"]) # matplotlib works fine\r\n>>> plt.show()\r\n```\r\n<img src=https://user-images.githubusercontent.com/8673634/94775414-9bce2480-0374-11eb-8938-f74a486f97de.png width=400></img>\r\n```python\r\n>>> arviz.plot_density([{\"x\": arr1}, {\"x\": arr2}], var_names = [\"x\"], backend=\"bokeh\") # errors\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/Users/saxen/.julia/conda/3/lib/python3.8/site-packages/arviz/plots/densityplot.py\", line 252, in plot_density\r\n ax = plot(**plot_density_kwargs)\r\n File \"/Users/saxen/.julia/conda/3/lib/python3.8/site-packages/arviz/plots/backends/bokeh/densityplot.py\", line 74, in plot_density\r\n for label, ax_ in zip(all_labels, (item for item in ax.flatten() if item is not None))\r\nAttributeError: 'Figure' object has no attribute 'flatten'\r\n```\r\n\r\n**Additional context**\r\nRelevant package versions in the conda environment used:\r\n```\r\narviz 0.10.0 py_0 conda-forge\r\nbokeh 2.2.1 py38h32f6830_0 conda-forge\r\nmatplotlib 3.1.3 py38_0 conda-forge\r\nnumpy 1.19.1 py38h3b9f5b6_0 \r\n```\n", "before_files": [{"content": "\"\"\"Bokeh Densityplot.\"\"\"\nfrom collections import defaultdict\nfrom itertools import cycle\n\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom bokeh.models.annotations import Legend, Title\n\nfrom ....stats import hdi\nfrom ....stats.density_utils import get_bins, histogram, kde\nfrom ...plot_utils import _scale_fig_size, calculate_point_estimate, make_label, vectorized_to_hex\nfrom .. import show_layout\nfrom . import backend_kwarg_defaults, create_axes_grid\n\n\ndef plot_density(\n ax,\n all_labels,\n to_plot,\n colors,\n bw,\n circular,\n figsize,\n length_plotters,\n rows,\n cols,\n textsize,\n hdi_prob,\n point_estimate,\n hdi_markers,\n outline,\n shade,\n n_data,\n data_labels,\n backend_kwargs,\n show,\n):\n \"\"\"Bokeh density plot.\"\"\"\n if backend_kwargs is None:\n backend_kwargs = {}\n\n backend_kwargs = {\n **backend_kwarg_defaults(),\n **backend_kwargs,\n }\n\n if colors == \"cycle\":\n colors = [\n prop\n for _, prop in zip(\n range(n_data), cycle(plt.rcParams[\"axes.prop_cycle\"].by_key()[\"color\"])\n )\n ]\n elif isinstance(colors, str):\n colors = [colors for _ in range(n_data)]\n colors = vectorized_to_hex(colors)\n\n (figsize, _, _, _, line_width, markersize) = _scale_fig_size(figsize, textsize, rows, cols)\n\n if ax is None:\n ax = create_axes_grid(\n length_plotters,\n rows,\n cols,\n figsize=figsize,\n squeeze=True,\n backend_kwargs=backend_kwargs,\n )\n else:\n ax = np.atleast_2d(ax)\n\n axis_map = {\n label: ax_\n for label, ax_ in zip(all_labels, (item for item in ax.flatten() if item is not None))\n }\n if data_labels is None:\n data_labels = {}\n\n legend_items = defaultdict(list)\n for m_idx, plotters in enumerate(to_plot):\n for var_name, selection, values in plotters:\n label = make_label(var_name, selection)\n\n if data_labels:\n data_label = data_labels[m_idx]\n else:\n data_label = None\n\n plotted = _d_helper(\n values.flatten(),\n label,\n colors[m_idx],\n bw,\n circular,\n line_width,\n markersize,\n hdi_prob,\n point_estimate,\n hdi_markers,\n outline,\n shade,\n axis_map[label],\n )\n if data_label is not None:\n legend_items[axis_map[label]].append((data_label, plotted))\n\n for ax1, legend in legend_items.items():\n legend = Legend(\n items=legend,\n location=\"center_right\",\n orientation=\"horizontal\",\n )\n ax1.add_layout(legend, \"above\")\n ax1.legend.click_policy = \"hide\"\n\n show_layout(ax, show)\n\n return ax\n\n\ndef _d_helper(\n vec,\n vname,\n color,\n bw,\n circular,\n line_width,\n markersize,\n hdi_prob,\n point_estimate,\n hdi_markers,\n outline,\n shade,\n ax,\n):\n\n extra = dict()\n plotted = []\n\n if vec.dtype.kind == \"f\":\n if hdi_prob != 1:\n hdi_ = hdi(vec, hdi_prob, multimodal=False)\n new_vec = vec[(vec >= hdi_[0]) & (vec <= hdi_[1])]\n else:\n new_vec = vec\n\n x, density = kde(new_vec, circular=circular, bw=bw)\n density *= hdi_prob\n xmin, xmax = x[0], x[-1]\n ymin, ymax = density[0], density[-1]\n\n if outline:\n plotted.append(ax.line(x, density, line_color=color, line_width=line_width, **extra))\n plotted.append(\n ax.line(\n [xmin, xmin],\n [-ymin / 100, ymin],\n line_color=color,\n line_dash=\"solid\",\n line_width=line_width,\n muted_color=color,\n muted_alpha=0.2,\n )\n )\n plotted.append(\n ax.line(\n [xmax, xmax],\n [-ymax / 100, ymax],\n line_color=color,\n line_dash=\"solid\",\n line_width=line_width,\n muted_color=color,\n muted_alpha=0.2,\n )\n )\n\n if shade:\n plotted.append(\n ax.patch(\n np.r_[x[::-1], x, x[-1:]],\n np.r_[np.zeros_like(x), density, [0]],\n fill_color=color,\n fill_alpha=shade,\n muted_color=color,\n muted_alpha=0.2,\n **extra\n )\n )\n\n else:\n xmin, xmax = hdi(vec, hdi_prob, multimodal=False)\n bins = get_bins(vec)\n\n _, hist, edges = histogram(vec, bins=bins)\n\n if outline:\n plotted.append(\n ax.quad(\n top=hist,\n bottom=0,\n left=edges[:-1],\n right=edges[1:],\n line_color=color,\n fill_color=None,\n muted_color=color,\n muted_alpha=0.2,\n **extra\n )\n )\n else:\n plotted.append(\n ax.quad(\n top=hist,\n bottom=0,\n left=edges[:-1],\n right=edges[1:],\n line_color=color,\n fill_color=color,\n fill_alpha=shade,\n muted_color=color,\n muted_alpha=0.2,\n **extra\n )\n )\n\n if hdi_markers:\n plotted.append(ax.diamond(xmin, 0, line_color=\"black\", fill_color=color, size=markersize))\n plotted.append(ax.diamond(xmax, 0, line_color=\"black\", fill_color=color, size=markersize))\n\n if point_estimate is not None:\n est = calculate_point_estimate(point_estimate, vec, bw, circular)\n plotted.append(ax.circle(est, 0, fill_color=color, line_color=\"black\", size=markersize))\n\n _title = Title()\n _title.text = vname\n ax.title = _title\n ax.title.text_font_size = \"13pt\"\n\n return plotted\n", "path": "arviz/plots/backends/bokeh/densityplot.py"}]}
| 3,091 | 110 |
gh_patches_debug_34978
|
rasdani/github-patches
|
git_diff
|
horovod__horovod-915
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
mxnet+hvd with different random seed won't work with Gluon API
**Environment:**
1. Framework: (MXNet)
2. Framework version: 1.4
3. Horovod version: v0.16.0
4. MPI version:
5. CUDA version:
6. NCCL version:
7. Python version: 2.7/3.6
8. OS and version:
**Checklist:**
1. Did you search issues to find if somebody asked this question before?
2. If your question is about hang, did you read [this doc](https://github.com/horovod/horovod/blob/master/docs/running.md)?
3. If your question is about docker, did you read [this doc](https://github.com/horovod/horovod/blob/master/docs/docker.md)?
**Bug report:**
Please describe errorneous behavior you're observing and steps to reproduce it.
If the shape of a parameter has to be inferred after a batch of data is seen, the parameter will not be broadcast. Therefore, the correctness of the program depends on whether all workers are initialized with the same random seed. So the following program will not work:
```
random.seed(hvd.local_rank())
data = ..
model = mx.gluon.nn.Dense(10)
model.initialize()
// no parameters are broadcast, because initialization is deferred.
hvd.broadcast_parameters(model.collect_parameters())
for batch in data:
// params are initialized after shape is known
pred = model(batch.data[0])
...
...
```
</issue>
<code>
[start of examples/mxnet_mnist.py]
1 import argparse
2 import logging
3 import os
4 import zipfile
5 import time
6
7 import mxnet as mx
8 import horovod.mxnet as hvd
9 from mxnet import autograd, gluon, nd
10 from mxnet.test_utils import download
11
12 # Training settings
13 parser = argparse.ArgumentParser(description='MXNet MNIST Example')
14
15 parser.add_argument('--batch-size', type=int, default=64,
16 help='training batch size (default: 64)')
17 parser.add_argument('--dtype', type=str, default='float32',
18 help='training data type (default: float32)')
19 parser.add_argument('--epochs', type=int, default=5,
20 help='number of training epochs (default: 5)')
21 parser.add_argument('--lr', type=float, default=0.01,
22 help='learning rate (default: 0.01)')
23 parser.add_argument('--momentum', type=float, default=0.9,
24 help='SGD momentum (default: 0.9)')
25 parser.add_argument('--no-cuda', action='store_true', default=False,
26 help='disable training on GPU (default: False)')
27 args = parser.parse_args()
28
29 if not args.no_cuda:
30 # Disable CUDA if there are no GPUs.
31 if not mx.test_utils.list_gpus():
32 args.no_cuda = True
33
34 logging.basicConfig(level=logging.INFO)
35 logging.info(args)
36
37
38 # Function to get mnist iterator given a rank
39 def get_mnist_iterator(rank):
40 data_dir = "data-%d" % rank
41 if not os.path.isdir(data_dir):
42 os.makedirs(data_dir)
43 zip_file_path = download('http://data.mxnet.io/mxnet/data/mnist.zip',
44 dirname=data_dir)
45 with zipfile.ZipFile(zip_file_path) as zf:
46 zf.extractall(data_dir)
47
48 input_shape = (1, 28, 28)
49 batch_size = args.batch_size
50
51 train_iter = mx.io.MNISTIter(
52 image="%s/train-images-idx3-ubyte" % data_dir,
53 label="%s/train-labels-idx1-ubyte" % data_dir,
54 input_shape=input_shape,
55 batch_size=batch_size,
56 shuffle=True,
57 flat=False,
58 num_parts=hvd.size(),
59 part_index=hvd.rank()
60 )
61
62 val_iter = mx.io.MNISTIter(
63 image="%s/t10k-images-idx3-ubyte" % data_dir,
64 label="%s/t10k-labels-idx1-ubyte" % data_dir,
65 input_shape=input_shape,
66 batch_size=batch_size,
67 flat=False,
68 )
69
70 return train_iter, val_iter
71
72
73 # Function to define neural network
74 def conv_nets():
75 net = gluon.nn.HybridSequential()
76 with net.name_scope():
77 net.add(gluon.nn.Conv2D(channels=20, kernel_size=5, activation='relu'))
78 net.add(gluon.nn.MaxPool2D(pool_size=2, strides=2))
79 net.add(gluon.nn.Conv2D(channels=50, kernel_size=5, activation='relu'))
80 net.add(gluon.nn.MaxPool2D(pool_size=2, strides=2))
81 net.add(gluon.nn.Flatten())
82 net.add(gluon.nn.Dense(512, activation="relu"))
83 net.add(gluon.nn.Dense(10))
84 return net
85
86
87 # Function to evaluate accuracy for a model
88 def evaluate(model, data_iter, context):
89 data_iter.reset()
90 metric = mx.metric.Accuracy()
91 for _, batch in enumerate(data_iter):
92 data = batch.data[0].as_in_context(context)
93 label = batch.label[0].as_in_context(context)
94 output = model(data.astype(args.dtype, copy=False))
95 metric.update([label], [output])
96
97 return metric.get()
98
99
100 # Initialize Horovod
101 hvd.init()
102
103 # Horovod: pin context to local rank
104 context = mx.cpu(hvd.local_rank()) if args.no_cuda else mx.gpu(hvd.local_rank())
105 num_workers = hvd.size()
106
107 # Load training and validation data
108 train_data, val_data = get_mnist_iterator(hvd.rank())
109
110 # Build model
111 model = conv_nets()
112 model.cast(args.dtype)
113 model.hybridize()
114
115 # Define hyper parameters
116 optimizer_params = {'momentum': args.momentum,
117 'learning_rate': args.lr * hvd.size(),
118 'rescale_grad': 1.0 / args.batch_size}
119
120 # Add Horovod Distributed Optimizer
121 opt = mx.optimizer.create('sgd', **optimizer_params)
122 opt = hvd.DistributedOptimizer(opt)
123
124 # Initialize parameters
125 initializer = mx.init.Xavier(rnd_type='gaussian', factor_type="in",
126 magnitude=2)
127 model.initialize(initializer, ctx=context)
128
129 # Fetch and broadcast parameters
130 params = model.collect_params()
131 if params is not None:
132 hvd.broadcast_parameters(params, root_rank=0)
133
134 # Create trainer, loss function and train metric
135 trainer = gluon.Trainer(params, opt, kvstore=None)
136 loss_fn = gluon.loss.SoftmaxCrossEntropyLoss()
137 metric = mx.metric.Accuracy()
138
139 # Train model
140 for epoch in range(args.epochs):
141 tic = time.time()
142 train_data.reset()
143 metric.reset()
144 for nbatch, batch in enumerate(train_data, start=1):
145 data = batch.data[0].as_in_context(context)
146 label = batch.label[0].as_in_context(context)
147 with autograd.record():
148 output = model(data.astype(args.dtype, copy=False))
149 loss = loss_fn(output, label)
150 loss.backward()
151 trainer.step(args.batch_size)
152 metric.update([label], [output])
153
154 if nbatch % 100 == 0:
155 name, acc = metric.get()
156 logging.info('[Epoch %d Batch %d] Training: %s=%f' %
157 (epoch, nbatch, name, acc))
158
159 if hvd.rank() == 0:
160 elapsed = time.time() - tic
161 speed = nbatch * args.batch_size * hvd.size() / elapsed
162 logging.info('Epoch[%d]\tSpeed=%.2f samples/s\tTime cost=%f',
163 epoch, speed, elapsed)
164
165 # Evaluate model accuracy
166 _, train_acc = metric.get()
167 name, val_acc = evaluate(model, val_data, context)
168 if hvd.rank() == 0:
169 logging.info('Epoch[%d]\tTrain: %s=%f\tValidation: %s=%f', epoch, name,
170 train_acc, name, val_acc)
171
172 if hvd.rank() == 0 and epoch == args.epochs - 1:
173 assert val_acc > 0.96, "Achieved accuracy (%f) is lower than expected\
174 (0.96)" % val_acc
175
[end of examples/mxnet_mnist.py]
[start of horovod/mxnet/__init__.py]
1 # Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15
16 from __future__ import absolute_import
17 from __future__ import division
18 from __future__ import print_function
19
20 from horovod.common import check_extension
21
22 check_extension('horovod.mxnet', 'HOROVOD_WITH_MXNET',
23 __file__, 'mpi_lib')
24
25 from horovod.mxnet.mpi_ops import allgather
26 from horovod.mxnet.mpi_ops import allreduce, allreduce_
27 from horovod.mxnet.mpi_ops import broadcast, broadcast_
28 from horovod.mxnet.mpi_ops import init, shutdown
29 from horovod.mxnet.mpi_ops import size, local_size, rank, local_rank
30 from horovod.mxnet.mpi_ops import mpi_threads_supported
31
32 import mxnet as mx
33
34
35 # This is where Horovod's DistributedOptimizer wrapper for MXNet goes
36 class DistributedOptimizer(mx.optimizer.Optimizer):
37 def __init__(self, optimizer):
38 self._optimizer = optimizer
39
40 def __getattr__(self, item):
41 return getattr(self._optimizer, item)
42
43 def create_state_multi_precision(self, index, weight):
44 return self._optimizer.create_state_multi_precision(index, weight)
45
46 def _do_allreduce(self, index, grad):
47 if isinstance(index, (tuple, list)):
48 for i in range(len(index)):
49 allreduce_(grad[i], average=True, name=str(index[i]))
50 else:
51 allreduce_(grad, average=True, name=str(index))
52
53 def update(self, index, weight, grad, state):
54 self._do_allreduce(index, grad)
55 self._optimizer.update(index, weight, grad, state)
56
57 def update_multi_precision(self, index, weight, grad, state):
58 self._do_allreduce(index, grad)
59 self._optimizer.update_multi_precision(index, weight, grad, state)
60
61 def set_learning_rate(self, lr):
62 self._optimizer.set_learning_rate(lr)
63
64 def set_lr_mult(self, args_lr_mult):
65 self._optimizer.set_lr_mult(args_lr_mult)
66
67 def set_wd_mult(self, args_wd_mult):
68 self._optimizer.set_wd_mult(args_wd_mult)
69
70
71 def broadcast_parameters(params, root_rank=0):
72 """
73 Broadcasts the parameters from root rank to all other processes.
74 Typical usage is to broadcast the `Module.get_params()` or the
75 `Block.collect_params()`.
76
77 Arguments:
78 params: One of the following:
79 - dict of parameters to broadcast
80 - ParameterDict to broadcast
81 root_rank: The rank of the process from which parameters will be
82 broadcasted to all other processes.
83 """
84 tensors = []
85 if isinstance(params, dict):
86 tensors = [p for _, p in sorted(params.items())]
87 elif isinstance(params, mx.gluon.parameter.ParameterDict):
88 for _, p in sorted(params.items()):
89 try:
90 tensors.append(p.data())
91 except mx.gluon.parameter.DeferredInitializationError:
92 # skip broadcasting deferred init param
93 pass
94 else:
95 raise ValueError('invalid params of type: %s' % type(params))
96
97 # Run broadcasts.
98 for i, tensor in enumerate(tensors):
99 broadcast_(tensor, root_rank, str(i))
100
101 # Make sure tensors pushed to MXNet engine get processed such that all
102 # workers are synced before starting training.
103 for tensor in tensors:
104 tensor.wait_to_read()
105
[end of horovod/mxnet/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/mxnet_mnist.py b/examples/mxnet_mnist.py
--- a/examples/mxnet_mnist.py
+++ b/examples/mxnet_mnist.py
@@ -112,13 +112,12 @@
model.cast(args.dtype)
model.hybridize()
-# Define hyper parameters
+# Create optimizer
optimizer_params = {'momentum': args.momentum,
'learning_rate': args.lr * hvd.size(),
'rescale_grad': 1.0 / args.batch_size}
-
-# Add Horovod Distributed Optimizer
opt = mx.optimizer.create('sgd', **optimizer_params)
+# Horovod: wrap optimizer with DistributedOptimizer
opt = hvd.DistributedOptimizer(opt)
# Initialize parameters
diff --git a/horovod/mxnet/__init__.py b/horovod/mxnet/__init__.py
--- a/horovod/mxnet/__init__.py
+++ b/horovod/mxnet/__init__.py
@@ -30,6 +30,7 @@
from horovod.mxnet.mpi_ops import mpi_threads_supported
import mxnet as mx
+import types
# This is where Horovod's DistributedOptimizer wrapper for MXNet goes
@@ -68,6 +69,16 @@
self._optimizer.set_wd_mult(args_wd_mult)
+# Wrapper to inject Horovod broadcast after parameter initialization
+def _append_broadcast_init(param, root_rank):
+ init_impl = getattr(param, '_init_impl')
+ def wrapped_init_impl(self, *args, **kwargs):
+ init_impl(*args, **kwargs)
+ broadcast_(self.data(), root_rank=root_rank)
+ self.data().wait_to_read()
+ return wrapped_init_impl
+
+
def broadcast_parameters(params, root_rank=0):
"""
Broadcasts the parameters from root rank to all other processes.
@@ -89,8 +100,10 @@
try:
tensors.append(p.data())
except mx.gluon.parameter.DeferredInitializationError:
- # skip broadcasting deferred init param
- pass
+ # Inject wrapper method with post-initialization broadcast to
+ # handle parameters with deferred initialization
+ new_init = _append_broadcast_init(p, root_rank)
+ p._init_impl = types.MethodType(new_init, p)
else:
raise ValueError('invalid params of type: %s' % type(params))
|
{"golden_diff": "diff --git a/examples/mxnet_mnist.py b/examples/mxnet_mnist.py\n--- a/examples/mxnet_mnist.py\n+++ b/examples/mxnet_mnist.py\n@@ -112,13 +112,12 @@\n model.cast(args.dtype)\n model.hybridize()\n \n-# Define hyper parameters\n+# Create optimizer\n optimizer_params = {'momentum': args.momentum,\n 'learning_rate': args.lr * hvd.size(),\n 'rescale_grad': 1.0 / args.batch_size}\n-\n-# Add Horovod Distributed Optimizer\n opt = mx.optimizer.create('sgd', **optimizer_params)\n+# Horovod: wrap optimizer with DistributedOptimizer\n opt = hvd.DistributedOptimizer(opt)\n \n # Initialize parameters\ndiff --git a/horovod/mxnet/__init__.py b/horovod/mxnet/__init__.py\n--- a/horovod/mxnet/__init__.py\n+++ b/horovod/mxnet/__init__.py\n@@ -30,6 +30,7 @@\n from horovod.mxnet.mpi_ops import mpi_threads_supported\n \n import mxnet as mx\n+import types\n \n \n # This is where Horovod's DistributedOptimizer wrapper for MXNet goes\n@@ -68,6 +69,16 @@\n self._optimizer.set_wd_mult(args_wd_mult)\n \n \n+# Wrapper to inject Horovod broadcast after parameter initialization\n+def _append_broadcast_init(param, root_rank):\n+ init_impl = getattr(param, '_init_impl')\n+ def wrapped_init_impl(self, *args, **kwargs):\n+ init_impl(*args, **kwargs)\n+ broadcast_(self.data(), root_rank=root_rank)\n+ self.data().wait_to_read()\n+ return wrapped_init_impl\n+\n+\n def broadcast_parameters(params, root_rank=0):\n \"\"\"\n Broadcasts the parameters from root rank to all other processes.\n@@ -89,8 +100,10 @@\n try:\n tensors.append(p.data())\n except mx.gluon.parameter.DeferredInitializationError:\n- # skip broadcasting deferred init param\n- pass\n+ # Inject wrapper method with post-initialization broadcast to\n+ # handle parameters with deferred initialization\n+ new_init = _append_broadcast_init(p, root_rank)\n+ p._init_impl = types.MethodType(new_init, p)\n else:\n raise ValueError('invalid params of type: %s' % type(params))\n", "issue": "mxnet+hvd with different random seed won't work with Gluon API\n**Environment:**\r\n1. Framework: (MXNet)\r\n2. Framework version: 1.4\r\n3. Horovod version: v0.16.0 \r\n4. MPI version: \r\n5. CUDA version:\r\n6. NCCL version:\r\n7. Python version: 2.7/3.6\r\n8. OS and version: \r\n\r\n**Checklist:**\r\n1. Did you search issues to find if somebody asked this question before?\r\n2. If your question is about hang, did you read [this doc](https://github.com/horovod/horovod/blob/master/docs/running.md)?\r\n3. If your question is about docker, did you read [this doc](https://github.com/horovod/horovod/blob/master/docs/docker.md)?\r\n\r\n**Bug report:**\r\nPlease describe errorneous behavior you're observing and steps to reproduce it.\r\n\r\nIf the shape of a parameter has to be inferred after a batch of data is seen, the parameter will not be broadcast. Therefore, the correctness of the program depends on whether all workers are initialized with the same random seed. So the following program will not work:\r\n\r\n```\r\nrandom.seed(hvd.local_rank())\r\ndata = ..\r\nmodel = mx.gluon.nn.Dense(10)\r\nmodel.initialize()\r\n\r\n// no parameters are broadcast, because initialization is deferred.\r\nhvd.broadcast_parameters(model.collect_parameters())\r\n\r\nfor batch in data:\r\n // params are initialized after shape is known\r\n pred = model(batch.data[0])\r\n ...\r\n...\r\n```\r\n\n", "before_files": [{"content": "import argparse\nimport logging\nimport os\nimport zipfile\nimport time\n\nimport mxnet as mx\nimport horovod.mxnet as hvd\nfrom mxnet import autograd, gluon, nd\nfrom mxnet.test_utils import download\n\n# Training settings\nparser = argparse.ArgumentParser(description='MXNet MNIST Example')\n\nparser.add_argument('--batch-size', type=int, default=64,\n help='training batch size (default: 64)')\nparser.add_argument('--dtype', type=str, default='float32',\n help='training data type (default: float32)')\nparser.add_argument('--epochs', type=int, default=5,\n help='number of training epochs (default: 5)')\nparser.add_argument('--lr', type=float, default=0.01,\n help='learning rate (default: 0.01)')\nparser.add_argument('--momentum', type=float, default=0.9,\n help='SGD momentum (default: 0.9)')\nparser.add_argument('--no-cuda', action='store_true', default=False,\n help='disable training on GPU (default: False)')\nargs = parser.parse_args()\n\nif not args.no_cuda:\n # Disable CUDA if there are no GPUs.\n if not mx.test_utils.list_gpus():\n args.no_cuda = True\n\nlogging.basicConfig(level=logging.INFO)\nlogging.info(args)\n\n\n# Function to get mnist iterator given a rank\ndef get_mnist_iterator(rank):\n data_dir = \"data-%d\" % rank\n if not os.path.isdir(data_dir):\n os.makedirs(data_dir)\n zip_file_path = download('http://data.mxnet.io/mxnet/data/mnist.zip',\n dirname=data_dir)\n with zipfile.ZipFile(zip_file_path) as zf:\n zf.extractall(data_dir)\n\n input_shape = (1, 28, 28)\n batch_size = args.batch_size\n\n train_iter = mx.io.MNISTIter(\n image=\"%s/train-images-idx3-ubyte\" % data_dir,\n label=\"%s/train-labels-idx1-ubyte\" % data_dir,\n input_shape=input_shape,\n batch_size=batch_size,\n shuffle=True,\n flat=False,\n num_parts=hvd.size(),\n part_index=hvd.rank()\n )\n\n val_iter = mx.io.MNISTIter(\n image=\"%s/t10k-images-idx3-ubyte\" % data_dir,\n label=\"%s/t10k-labels-idx1-ubyte\" % data_dir,\n input_shape=input_shape,\n batch_size=batch_size,\n flat=False,\n )\n\n return train_iter, val_iter\n\n\n# Function to define neural network\ndef conv_nets():\n net = gluon.nn.HybridSequential()\n with net.name_scope():\n net.add(gluon.nn.Conv2D(channels=20, kernel_size=5, activation='relu'))\n net.add(gluon.nn.MaxPool2D(pool_size=2, strides=2))\n net.add(gluon.nn.Conv2D(channels=50, kernel_size=5, activation='relu'))\n net.add(gluon.nn.MaxPool2D(pool_size=2, strides=2))\n net.add(gluon.nn.Flatten())\n net.add(gluon.nn.Dense(512, activation=\"relu\"))\n net.add(gluon.nn.Dense(10))\n return net\n\n\n# Function to evaluate accuracy for a model\ndef evaluate(model, data_iter, context):\n data_iter.reset()\n metric = mx.metric.Accuracy()\n for _, batch in enumerate(data_iter):\n data = batch.data[0].as_in_context(context)\n label = batch.label[0].as_in_context(context)\n output = model(data.astype(args.dtype, copy=False))\n metric.update([label], [output])\n\n return metric.get()\n\n\n# Initialize Horovod\nhvd.init()\n\n# Horovod: pin context to local rank\ncontext = mx.cpu(hvd.local_rank()) if args.no_cuda else mx.gpu(hvd.local_rank())\nnum_workers = hvd.size()\n\n# Load training and validation data\ntrain_data, val_data = get_mnist_iterator(hvd.rank())\n\n# Build model\nmodel = conv_nets()\nmodel.cast(args.dtype)\nmodel.hybridize()\n\n# Define hyper parameters\noptimizer_params = {'momentum': args.momentum,\n 'learning_rate': args.lr * hvd.size(),\n 'rescale_grad': 1.0 / args.batch_size}\n\n# Add Horovod Distributed Optimizer\nopt = mx.optimizer.create('sgd', **optimizer_params)\nopt = hvd.DistributedOptimizer(opt)\n\n# Initialize parameters\ninitializer = mx.init.Xavier(rnd_type='gaussian', factor_type=\"in\",\n magnitude=2)\nmodel.initialize(initializer, ctx=context)\n\n# Fetch and broadcast parameters\nparams = model.collect_params()\nif params is not None:\n hvd.broadcast_parameters(params, root_rank=0)\n\n# Create trainer, loss function and train metric\ntrainer = gluon.Trainer(params, opt, kvstore=None)\nloss_fn = gluon.loss.SoftmaxCrossEntropyLoss()\nmetric = mx.metric.Accuracy()\n\n# Train model\nfor epoch in range(args.epochs):\n tic = time.time()\n train_data.reset()\n metric.reset()\n for nbatch, batch in enumerate(train_data, start=1):\n data = batch.data[0].as_in_context(context)\n label = batch.label[0].as_in_context(context)\n with autograd.record():\n output = model(data.astype(args.dtype, copy=False))\n loss = loss_fn(output, label)\n loss.backward()\n trainer.step(args.batch_size)\n metric.update([label], [output])\n\n if nbatch % 100 == 0:\n name, acc = metric.get()\n logging.info('[Epoch %d Batch %d] Training: %s=%f' %\n (epoch, nbatch, name, acc))\n\n if hvd.rank() == 0:\n elapsed = time.time() - tic\n speed = nbatch * args.batch_size * hvd.size() / elapsed\n logging.info('Epoch[%d]\\tSpeed=%.2f samples/s\\tTime cost=%f',\n epoch, speed, elapsed)\n\n # Evaluate model accuracy\n _, train_acc = metric.get()\n name, val_acc = evaluate(model, val_data, context)\n if hvd.rank() == 0:\n logging.info('Epoch[%d]\\tTrain: %s=%f\\tValidation: %s=%f', epoch, name,\n train_acc, name, val_acc)\n\n if hvd.rank() == 0 and epoch == args.epochs - 1:\n assert val_acc > 0.96, \"Achieved accuracy (%f) is lower than expected\\\n (0.96)\" % val_acc\n", "path": "examples/mxnet_mnist.py"}, {"content": "# Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nfrom horovod.common import check_extension\n\ncheck_extension('horovod.mxnet', 'HOROVOD_WITH_MXNET',\n __file__, 'mpi_lib')\n\nfrom horovod.mxnet.mpi_ops import allgather\nfrom horovod.mxnet.mpi_ops import allreduce, allreduce_\nfrom horovod.mxnet.mpi_ops import broadcast, broadcast_\nfrom horovod.mxnet.mpi_ops import init, shutdown\nfrom horovod.mxnet.mpi_ops import size, local_size, rank, local_rank\nfrom horovod.mxnet.mpi_ops import mpi_threads_supported\n\nimport mxnet as mx\n\n\n# This is where Horovod's DistributedOptimizer wrapper for MXNet goes\nclass DistributedOptimizer(mx.optimizer.Optimizer):\n def __init__(self, optimizer):\n self._optimizer = optimizer\n\n def __getattr__(self, item):\n return getattr(self._optimizer, item)\n\n def create_state_multi_precision(self, index, weight):\n return self._optimizer.create_state_multi_precision(index, weight)\n\n def _do_allreduce(self, index, grad):\n if isinstance(index, (tuple, list)):\n for i in range(len(index)):\n allreduce_(grad[i], average=True, name=str(index[i]))\n else:\n allreduce_(grad, average=True, name=str(index))\n\n def update(self, index, weight, grad, state):\n self._do_allreduce(index, grad)\n self._optimizer.update(index, weight, grad, state)\n\n def update_multi_precision(self, index, weight, grad, state):\n self._do_allreduce(index, grad)\n self._optimizer.update_multi_precision(index, weight, grad, state)\n\n def set_learning_rate(self, lr):\n self._optimizer.set_learning_rate(lr)\n\n def set_lr_mult(self, args_lr_mult):\n self._optimizer.set_lr_mult(args_lr_mult)\n\n def set_wd_mult(self, args_wd_mult):\n self._optimizer.set_wd_mult(args_wd_mult)\n\n\ndef broadcast_parameters(params, root_rank=0):\n \"\"\"\n Broadcasts the parameters from root rank to all other processes.\n Typical usage is to broadcast the `Module.get_params()` or the\n `Block.collect_params()`.\n\n Arguments:\n params: One of the following:\n - dict of parameters to broadcast\n - ParameterDict to broadcast\n root_rank: The rank of the process from which parameters will be\n broadcasted to all other processes.\n \"\"\"\n tensors = []\n if isinstance(params, dict):\n tensors = [p for _, p in sorted(params.items())]\n elif isinstance(params, mx.gluon.parameter.ParameterDict):\n for _, p in sorted(params.items()):\n try:\n tensors.append(p.data())\n except mx.gluon.parameter.DeferredInitializationError:\n # skip broadcasting deferred init param\n pass\n else:\n raise ValueError('invalid params of type: %s' % type(params))\n\n # Run broadcasts.\n for i, tensor in enumerate(tensors):\n broadcast_(tensor, root_rank, str(i))\n\n # Make sure tensors pushed to MXNet engine get processed such that all\n # workers are synced before starting training.\n for tensor in tensors:\n tensor.wait_to_read()\n", "path": "horovod/mxnet/__init__.py"}]}
| 3,856 | 532 |
gh_patches_debug_1769
|
rasdani/github-patches
|
git_diff
|
googleapis__google-auth-library-python-697
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Missing pyOpenSSL Dependency
Thanks for stopping by to let us know something could be better!
**PLEASE READ**: If you have a support contract with Google, please create an issue in the [support console](https://cloud.google.com/support/) instead of filing on GitHub. This will ensure a timely response.
Please run down the following list and make sure you've tried the usual "quick fixes":
- Search the issues already opened: https://github.com/googleapis/google-auth-library-python/issues
If you are still having issues, please be sure to include as much information as possible:
#### Environment details
- OS:
- Python version:
- pip version:
- `google-auth` version:
#### Steps to reproduce
1. Missing pyOpenSSL dependency in setup.py
For the tests there is a requirement in https://github.com/googleapis/google-auth-library-python/blob/master/noxfile.py against pyOpenSSL. But there are imports for pyOpenSSL in multiple modules in the code. Should pyOpenSSL be added to the requirements in setup.py?
I created https://github.com/googleapis/google-auth-library-python/pull/550 with the proposal but wanted to get feedback from an issue first as I don't see this showing up in previous issues or pull requests.
Making sure to follow these steps will guarantee the quickest resolution possible.
Thanks!
</issue>
<code>
[start of setup.py]
1 # Copyright 2014 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import io
16
17 from setuptools import find_packages
18 from setuptools import setup
19
20
21 DEPENDENCIES = (
22 "cachetools>=2.0.0,<5.0",
23 "pyasn1-modules>=0.2.1",
24 # rsa==4.5 is the last version to support 2.7
25 # https://github.com/sybrenstuvel/python-rsa/issues/152#issuecomment-643470233
26 'rsa<4.6; python_version < "3.6"',
27 'rsa>=3.1.4,<5; python_version >= "3.6"',
28 "setuptools>=40.3.0",
29 "six>=1.9.0",
30 )
31
32 extras = {"aiohttp": "aiohttp >= 3.6.2, < 4.0.0dev; python_version>='3.6'"}
33
34 with io.open("README.rst", "r") as fh:
35 long_description = fh.read()
36
37 version = "1.26.1"
38
39 setup(
40 name="google-auth",
41 version=version,
42 author="Google Cloud Platform",
43 author_email="[email protected]",
44 description="Google Authentication Library",
45 long_description=long_description,
46 url="https://github.com/googleapis/google-auth-library-python",
47 packages=find_packages(exclude=("tests*", "system_tests*")),
48 namespace_packages=("google",),
49 install_requires=DEPENDENCIES,
50 extras_require=extras,
51 python_requires=">=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*,!=3.4.*,!=3.5.*",
52 license="Apache 2.0",
53 keywords="google auth oauth client",
54 classifiers=[
55 "Programming Language :: Python :: 2",
56 "Programming Language :: Python :: 2.7",
57 "Programming Language :: Python :: 3",
58 "Programming Language :: Python :: 3.6",
59 "Programming Language :: Python :: 3.7",
60 "Programming Language :: Python :: 3.8",
61 "Programming Language :: Python :: 3.9",
62 "Development Status :: 5 - Production/Stable",
63 "Intended Audience :: Developers",
64 "License :: OSI Approved :: Apache Software License",
65 "Operating System :: POSIX",
66 "Operating System :: Microsoft :: Windows",
67 "Operating System :: MacOS :: MacOS X",
68 "Operating System :: OS Independent",
69 "Topic :: Internet :: WWW/HTTP",
70 ],
71 )
72
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -29,7 +29,10 @@
"six>=1.9.0",
)
-extras = {"aiohttp": "aiohttp >= 3.6.2, < 4.0.0dev; python_version>='3.6'"}
+extras = {
+ "aiohttp": "aiohttp >= 3.6.2, < 4.0.0dev; python_version>='3.6'",
+ "pyopenssl": "pyopenssl>=20.0.0",
+}
with io.open("README.rst", "r") as fh:
long_description = fh.read()
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -29,7 +29,10 @@\n \"six>=1.9.0\",\n )\n \n-extras = {\"aiohttp\": \"aiohttp >= 3.6.2, < 4.0.0dev; python_version>='3.6'\"}\n+extras = {\n+ \"aiohttp\": \"aiohttp >= 3.6.2, < 4.0.0dev; python_version>='3.6'\",\n+ \"pyopenssl\": \"pyopenssl>=20.0.0\",\n+}\n \n with io.open(\"README.rst\", \"r\") as fh:\n long_description = fh.read()\n", "issue": "Missing pyOpenSSL Dependency\nThanks for stopping by to let us know something could be better!\r\n\r\n**PLEASE READ**: If you have a support contract with Google, please create an issue in the [support console](https://cloud.google.com/support/) instead of filing on GitHub. This will ensure a timely response.\r\n\r\nPlease run down the following list and make sure you've tried the usual \"quick fixes\":\r\n\r\n - Search the issues already opened: https://github.com/googleapis/google-auth-library-python/issues\r\n\r\nIf you are still having issues, please be sure to include as much information as possible:\r\n\r\n#### Environment details\r\n\r\n - OS:\r\n - Python version:\r\n - pip version:\r\n - `google-auth` version:\r\n\r\n#### Steps to reproduce\r\n\r\n 1. Missing pyOpenSSL dependency in setup.py\r\n\r\nFor the tests there is a requirement in https://github.com/googleapis/google-auth-library-python/blob/master/noxfile.py against pyOpenSSL. But there are imports for pyOpenSSL in multiple modules in the code. Should pyOpenSSL be added to the requirements in setup.py?\r\n\r\nI created https://github.com/googleapis/google-auth-library-python/pull/550 with the proposal but wanted to get feedback from an issue first as I don't see this showing up in previous issues or pull requests.\r\n\r\nMaking sure to follow these steps will guarantee the quickest resolution possible.\r\n\r\nThanks!\r\n\n", "before_files": [{"content": "# Copyright 2014 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\n\nfrom setuptools import find_packages\nfrom setuptools import setup\n\n\nDEPENDENCIES = (\n \"cachetools>=2.0.0,<5.0\",\n \"pyasn1-modules>=0.2.1\",\n # rsa==4.5 is the last version to support 2.7\n # https://github.com/sybrenstuvel/python-rsa/issues/152#issuecomment-643470233\n 'rsa<4.6; python_version < \"3.6\"',\n 'rsa>=3.1.4,<5; python_version >= \"3.6\"',\n \"setuptools>=40.3.0\",\n \"six>=1.9.0\",\n)\n\nextras = {\"aiohttp\": \"aiohttp >= 3.6.2, < 4.0.0dev; python_version>='3.6'\"}\n\nwith io.open(\"README.rst\", \"r\") as fh:\n long_description = fh.read()\n\nversion = \"1.26.1\"\n\nsetup(\n name=\"google-auth\",\n version=version,\n author=\"Google Cloud Platform\",\n author_email=\"[email protected]\",\n description=\"Google Authentication Library\",\n long_description=long_description,\n url=\"https://github.com/googleapis/google-auth-library-python\",\n packages=find_packages(exclude=(\"tests*\", \"system_tests*\")),\n namespace_packages=(\"google\",),\n install_requires=DEPENDENCIES,\n extras_require=extras,\n python_requires=\">=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*,!=3.4.*,!=3.5.*\",\n license=\"Apache 2.0\",\n keywords=\"google auth oauth client\",\n classifiers=[\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: POSIX\",\n \"Operating System :: Microsoft :: Windows\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet :: WWW/HTTP\",\n ],\n)\n", "path": "setup.py"}]}
| 1,624 | 164 |
gh_patches_debug_31620
|
rasdani/github-patches
|
git_diff
|
kedro-org__kedro-1822
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix case in docs
As mentioned in https://github.com/kedro-org/kedro/pull/1760#pullrequestreview-1069581386_
Change `excel`(lowercase) to `Excel`(uppercase).
</issue>
<code>
[start of kedro/extras/datasets/pandas/excel_dataset.py]
1 """``ExcelDataSet`` loads/saves data from/to a Excel file using an underlying
2 filesystem (e.g.: local, S3, GCS). It uses pandas to handle the Excel file.
3 """
4 import logging
5 from copy import deepcopy
6 from io import BytesIO
7 from pathlib import PurePosixPath
8 from typing import Any, Dict, Union
9
10 import fsspec
11 import pandas as pd
12
13 from kedro.io.core import (
14 PROTOCOL_DELIMITER,
15 AbstractVersionedDataSet,
16 DataSetError,
17 Version,
18 get_filepath_str,
19 get_protocol_and_path,
20 )
21
22 logger = logging.getLogger(__name__)
23
24
25 class ExcelDataSet(
26 AbstractVersionedDataSet[
27 Union[pd.DataFrame, Dict[str, pd.DataFrame]],
28 Union[pd.DataFrame, Dict[str, pd.DataFrame]],
29 ]
30 ):
31 """``ExcelDataSet`` loads/saves data from/to a Excel file using an underlying
32 filesystem (e.g.: local, S3, GCS). It uses pandas to handle the Excel file.
33
34 Example adding a catalog entry with the ``YAML API``:
35
36 .. code-block:: yaml
37
38 >>> rockets:
39 >>> type: pandas.ExcelDataSet
40 >>> filepath: gcs://your_bucket/rockets.xlsx
41 >>> fs_args:
42 >>> project: my-project
43 >>> credentials: my_gcp_credentials
44 >>> save_args:
45 >>> sheet_name: Sheet1
46 >>> load_args:
47 >>> sheet_name: Sheet1
48 >>>
49 >>> shuttles:
50 >>> type: pandas.ExcelDataSet
51 >>> filepath: data/01_raw/shuttles.xlsx
52
53 Example using Python API:
54 ::
55
56 >>> from kedro.extras.datasets.pandas import ExcelDataSet
57 >>> import pandas as pd
58 >>>
59 >>> data = pd.DataFrame({'col1': [1, 2], 'col2': [4, 5],
60 >>> 'col3': [5, 6]})
61 >>>
62 >>> # data_set = ExcelDataSet(filepath="gcs://bucket/test.xlsx")
63 >>> data_set = ExcelDataSet(filepath="test.xlsx")
64 >>> data_set.save(data)
65 >>> reloaded = data_set.load()
66 >>> assert data.equals(reloaded)
67
68 Note: To save a multi-sheet excel file, no special ``save_args`` are required.
69 Instead, return a dictionary of ``Dict[str, pd.DataFrame]`` where the string
70 keys are your sheet names.
71
72 Example adding a catalog entry for multi-sheet excel file with the ``YAML API``:
73
74 .. code-block:: yaml
75
76 >>> trains:
77 >>> type: pandas.ExcelDataSet
78 >>> filepath: data/02_intermediate/company/trains.xlsx
79 >>> load_args:
80 >>> sheet_name: [Sheet1, Sheet2, Sheet3]
81
82 Example multi-sheet excel file using Python API:
83 ::
84
85 >>> from kedro.extras.datasets.pandas import ExcelDataSet
86 >>> import pandas as pd
87 >>>
88 >>> dataframe = pd.DataFrame({'col1': [1, 2], 'col2': [4, 5],
89 >>> 'col3': [5, 6]})
90 >>> another_dataframe = pd.DataFrame({"x": [10, 20], "y": ["hello", "world"]})
91 >>> multiframe = {"Sheet1": dataframe, "Sheet2": another_dataframe}
92 >>> data_set = ExcelDataSet(filepath="test.xlsx", load_args = {"sheet_name": None})
93 >>> data_set.save(multiframe)
94 >>> reloaded = data_set.load()
95 >>> assert multiframe["Sheet1"].equals(reloaded["Sheet1"])
96 >>> assert multiframe["Sheet2"].equals(reloaded["Sheet2"])
97
98 """
99
100 DEFAULT_LOAD_ARGS = {"engine": "openpyxl"}
101 DEFAULT_SAVE_ARGS = {"index": False}
102
103 # pylint: disable=too-many-arguments
104 def __init__(
105 self,
106 filepath: str,
107 engine: str = "openpyxl",
108 load_args: Dict[str, Any] = None,
109 save_args: Dict[str, Any] = None,
110 version: Version = None,
111 credentials: Dict[str, Any] = None,
112 fs_args: Dict[str, Any] = None,
113 ) -> None:
114 """Creates a new instance of ``ExcelDataSet`` pointing to a concrete Excel file
115 on a specific filesystem.
116
117 Args:
118 filepath: Filepath in POSIX format to a Excel file prefixed with a protocol like
119 `s3://`. If prefix is not provided, `file` protocol (local filesystem) will be used.
120 The prefix should be any protocol supported by ``fsspec``.
121 Note: `http(s)` doesn't support versioning.
122 engine: The engine used to write to excel files. The default
123 engine is 'openpyxl'.
124 load_args: Pandas options for loading Excel files.
125 Here you can find all available arguments:
126 https://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_excel.html
127 All defaults are preserved, but "engine", which is set to "openpyxl".
128 Supports multi-sheet Excel files (include `sheet_name = None` in `load_args`).
129 save_args: Pandas options for saving Excel files.
130 Here you can find all available arguments:
131 https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.to_excel.html
132 All defaults are preserved, but "index", which is set to False.
133 If you would like to specify options for the `ExcelWriter`,
134 you can include them under the "writer" key. Here you can
135 find all available arguments:
136 https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.ExcelWriter.html
137 version: If specified, should be an instance of
138 ``kedro.io.core.Version``. If its ``load`` attribute is
139 None, the latest version will be loaded. If its ``save``
140 attribute is None, save version will be autogenerated.
141 credentials: Credentials required to get access to the underlying filesystem.
142 E.g. for ``GCSFileSystem`` it should look like `{"token": None}`.
143 fs_args: Extra arguments to pass into underlying filesystem class constructor
144 (e.g. `{"project": "my-project"}` for ``GCSFileSystem``).
145
146 Raises:
147 DataSetError: If versioning is enabled while in append mode.
148 """
149 _fs_args = deepcopy(fs_args) or {}
150 _credentials = deepcopy(credentials) or {}
151
152 protocol, path = get_protocol_and_path(filepath, version)
153 if protocol == "file":
154 _fs_args.setdefault("auto_mkdir", True)
155
156 self._protocol = protocol
157 self._storage_options = {**_credentials, **_fs_args}
158 self._fs = fsspec.filesystem(self._protocol, **self._storage_options)
159
160 super().__init__(
161 filepath=PurePosixPath(path),
162 version=version,
163 exists_function=self._fs.exists,
164 glob_function=self._fs.glob,
165 )
166
167 # Handle default load arguments
168 self._load_args = deepcopy(self.DEFAULT_LOAD_ARGS)
169 if load_args is not None:
170 self._load_args.update(load_args)
171
172 # Handle default save arguments
173 self._save_args = deepcopy(self.DEFAULT_SAVE_ARGS)
174 if save_args is not None:
175 self._save_args.update(save_args)
176 self._writer_args = self._save_args.pop("writer", {}) # type: ignore
177 self._writer_args.setdefault("engine", engine or "openpyxl") # type: ignore
178
179 if version and self._writer_args.get("mode") == "a": # type: ignore
180 raise DataSetError(
181 "'ExcelDataSet' doesn't support versioning in append mode."
182 )
183
184 if "storage_options" in self._save_args or "storage_options" in self._load_args:
185 logger.warning(
186 "Dropping 'storage_options' for %s, "
187 "please specify them under 'fs_args' or 'credentials'.",
188 self._filepath,
189 )
190 self._save_args.pop("storage_options", None)
191 self._load_args.pop("storage_options", None)
192
193 def _describe(self) -> Dict[str, Any]:
194 return dict(
195 filepath=self._filepath,
196 protocol=self._protocol,
197 load_args=self._load_args,
198 save_args=self._save_args,
199 writer_args=self._writer_args,
200 version=self._version,
201 )
202
203 def _load(self) -> Union[pd.DataFrame, Dict[str, pd.DataFrame]]:
204 load_path = str(self._get_load_path())
205 if self._protocol == "file":
206 # file:// protocol seems to misbehave on Windows
207 # (<urlopen error file not on local host>),
208 # so we don't join that back to the filepath;
209 # storage_options also don't work with local paths
210 return pd.read_excel(load_path, **self._load_args)
211
212 load_path = f"{self._protocol}{PROTOCOL_DELIMITER}{load_path}"
213 return pd.read_excel(
214 load_path, storage_options=self._storage_options, **self._load_args
215 )
216
217 def _save(self, data: Union[pd.DataFrame, Dict[str, pd.DataFrame]]) -> None:
218 output = BytesIO()
219 save_path = get_filepath_str(self._get_save_path(), self._protocol)
220
221 # pylint: disable=abstract-class-instantiated
222 with pd.ExcelWriter(output, **self._writer_args) as writer:
223 if isinstance(data, dict):
224 for sheet_name, sheet_data in data.items():
225 sheet_data.to_excel(
226 writer, sheet_name=sheet_name, **self._save_args
227 )
228 else:
229 data.to_excel(writer, **self._save_args)
230
231 with self._fs.open(save_path, mode="wb") as fs_file:
232 fs_file.write(output.getvalue())
233
234 self._invalidate_cache()
235
236 def _exists(self) -> bool:
237 try:
238 load_path = get_filepath_str(self._get_load_path(), self._protocol)
239 except DataSetError:
240 return False
241
242 return self._fs.exists(load_path)
243
244 def _release(self) -> None:
245 super()._release()
246 self._invalidate_cache()
247
248 def _invalidate_cache(self) -> None:
249 """Invalidate underlying filesystem caches."""
250 filepath = get_filepath_str(self._filepath, self._protocol)
251 self._fs.invalidate_cache(filepath)
252
[end of kedro/extras/datasets/pandas/excel_dataset.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kedro/extras/datasets/pandas/excel_dataset.py b/kedro/extras/datasets/pandas/excel_dataset.py
--- a/kedro/extras/datasets/pandas/excel_dataset.py
+++ b/kedro/extras/datasets/pandas/excel_dataset.py
@@ -65,11 +65,11 @@
>>> reloaded = data_set.load()
>>> assert data.equals(reloaded)
- Note: To save a multi-sheet excel file, no special ``save_args`` are required.
+ Note: To save a multi-sheet Excel file, no special ``save_args`` are required.
Instead, return a dictionary of ``Dict[str, pd.DataFrame]`` where the string
keys are your sheet names.
- Example adding a catalog entry for multi-sheet excel file with the ``YAML API``:
+ Example adding a catalog entry for multi-sheet Excel file with the ``YAML API``:
.. code-block:: yaml
@@ -79,7 +79,7 @@
>>> load_args:
>>> sheet_name: [Sheet1, Sheet2, Sheet3]
- Example multi-sheet excel file using Python API:
+ Example multi-sheet Excel file using Python API:
::
>>> from kedro.extras.datasets.pandas import ExcelDataSet
@@ -119,7 +119,7 @@
`s3://`. If prefix is not provided, `file` protocol (local filesystem) will be used.
The prefix should be any protocol supported by ``fsspec``.
Note: `http(s)` doesn't support versioning.
- engine: The engine used to write to excel files. The default
+ engine: The engine used to write to Excel files. The default
engine is 'openpyxl'.
load_args: Pandas options for loading Excel files.
Here you can find all available arguments:
|
{"golden_diff": "diff --git a/kedro/extras/datasets/pandas/excel_dataset.py b/kedro/extras/datasets/pandas/excel_dataset.py\n--- a/kedro/extras/datasets/pandas/excel_dataset.py\n+++ b/kedro/extras/datasets/pandas/excel_dataset.py\n@@ -65,11 +65,11 @@\n >>> reloaded = data_set.load()\n >>> assert data.equals(reloaded)\n \n- Note: To save a multi-sheet excel file, no special ``save_args`` are required.\n+ Note: To save a multi-sheet Excel file, no special ``save_args`` are required.\n Instead, return a dictionary of ``Dict[str, pd.DataFrame]`` where the string\n keys are your sheet names.\n \n- Example adding a catalog entry for multi-sheet excel file with the ``YAML API``:\n+ Example adding a catalog entry for multi-sheet Excel file with the ``YAML API``:\n \n .. code-block:: yaml\n \n@@ -79,7 +79,7 @@\n >>> load_args:\n >>> sheet_name: [Sheet1, Sheet2, Sheet3]\n \n- Example multi-sheet excel file using Python API:\n+ Example multi-sheet Excel file using Python API:\n ::\n \n >>> from kedro.extras.datasets.pandas import ExcelDataSet\n@@ -119,7 +119,7 @@\n `s3://`. If prefix is not provided, `file` protocol (local filesystem) will be used.\n The prefix should be any protocol supported by ``fsspec``.\n Note: `http(s)` doesn't support versioning.\n- engine: The engine used to write to excel files. The default\n+ engine: The engine used to write to Excel files. The default\n engine is 'openpyxl'.\n load_args: Pandas options for loading Excel files.\n Here you can find all available arguments:\n", "issue": "Fix case in docs\nAs mentioned in https://github.com/kedro-org/kedro/pull/1760#pullrequestreview-1069581386_\r\n\r\nChange `excel`(lowercase) to `Excel`(uppercase).\n", "before_files": [{"content": "\"\"\"``ExcelDataSet`` loads/saves data from/to a Excel file using an underlying\nfilesystem (e.g.: local, S3, GCS). It uses pandas to handle the Excel file.\n\"\"\"\nimport logging\nfrom copy import deepcopy\nfrom io import BytesIO\nfrom pathlib import PurePosixPath\nfrom typing import Any, Dict, Union\n\nimport fsspec\nimport pandas as pd\n\nfrom kedro.io.core import (\n PROTOCOL_DELIMITER,\n AbstractVersionedDataSet,\n DataSetError,\n Version,\n get_filepath_str,\n get_protocol_and_path,\n)\n\nlogger = logging.getLogger(__name__)\n\n\nclass ExcelDataSet(\n AbstractVersionedDataSet[\n Union[pd.DataFrame, Dict[str, pd.DataFrame]],\n Union[pd.DataFrame, Dict[str, pd.DataFrame]],\n ]\n):\n \"\"\"``ExcelDataSet`` loads/saves data from/to a Excel file using an underlying\n filesystem (e.g.: local, S3, GCS). It uses pandas to handle the Excel file.\n\n Example adding a catalog entry with the ``YAML API``:\n\n .. code-block:: yaml\n\n >>> rockets:\n >>> type: pandas.ExcelDataSet\n >>> filepath: gcs://your_bucket/rockets.xlsx\n >>> fs_args:\n >>> project: my-project\n >>> credentials: my_gcp_credentials\n >>> save_args:\n >>> sheet_name: Sheet1\n >>> load_args:\n >>> sheet_name: Sheet1\n >>>\n >>> shuttles:\n >>> type: pandas.ExcelDataSet\n >>> filepath: data/01_raw/shuttles.xlsx\n\n Example using Python API:\n ::\n\n >>> from kedro.extras.datasets.pandas import ExcelDataSet\n >>> import pandas as pd\n >>>\n >>> data = pd.DataFrame({'col1': [1, 2], 'col2': [4, 5],\n >>> 'col3': [5, 6]})\n >>>\n >>> # data_set = ExcelDataSet(filepath=\"gcs://bucket/test.xlsx\")\n >>> data_set = ExcelDataSet(filepath=\"test.xlsx\")\n >>> data_set.save(data)\n >>> reloaded = data_set.load()\n >>> assert data.equals(reloaded)\n\n Note: To save a multi-sheet excel file, no special ``save_args`` are required.\n Instead, return a dictionary of ``Dict[str, pd.DataFrame]`` where the string\n keys are your sheet names.\n\n Example adding a catalog entry for multi-sheet excel file with the ``YAML API``:\n\n .. code-block:: yaml\n\n >>> trains:\n >>> type: pandas.ExcelDataSet\n >>> filepath: data/02_intermediate/company/trains.xlsx\n >>> load_args:\n >>> sheet_name: [Sheet1, Sheet2, Sheet3]\n\n Example multi-sheet excel file using Python API:\n ::\n\n >>> from kedro.extras.datasets.pandas import ExcelDataSet\n >>> import pandas as pd\n >>>\n >>> dataframe = pd.DataFrame({'col1': [1, 2], 'col2': [4, 5],\n >>> 'col3': [5, 6]})\n >>> another_dataframe = pd.DataFrame({\"x\": [10, 20], \"y\": [\"hello\", \"world\"]})\n >>> multiframe = {\"Sheet1\": dataframe, \"Sheet2\": another_dataframe}\n >>> data_set = ExcelDataSet(filepath=\"test.xlsx\", load_args = {\"sheet_name\": None})\n >>> data_set.save(multiframe)\n >>> reloaded = data_set.load()\n >>> assert multiframe[\"Sheet1\"].equals(reloaded[\"Sheet1\"])\n >>> assert multiframe[\"Sheet2\"].equals(reloaded[\"Sheet2\"])\n\n \"\"\"\n\n DEFAULT_LOAD_ARGS = {\"engine\": \"openpyxl\"}\n DEFAULT_SAVE_ARGS = {\"index\": False}\n\n # pylint: disable=too-many-arguments\n def __init__(\n self,\n filepath: str,\n engine: str = \"openpyxl\",\n load_args: Dict[str, Any] = None,\n save_args: Dict[str, Any] = None,\n version: Version = None,\n credentials: Dict[str, Any] = None,\n fs_args: Dict[str, Any] = None,\n ) -> None:\n \"\"\"Creates a new instance of ``ExcelDataSet`` pointing to a concrete Excel file\n on a specific filesystem.\n\n Args:\n filepath: Filepath in POSIX format to a Excel file prefixed with a protocol like\n `s3://`. If prefix is not provided, `file` protocol (local filesystem) will be used.\n The prefix should be any protocol supported by ``fsspec``.\n Note: `http(s)` doesn't support versioning.\n engine: The engine used to write to excel files. The default\n engine is 'openpyxl'.\n load_args: Pandas options for loading Excel files.\n Here you can find all available arguments:\n https://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_excel.html\n All defaults are preserved, but \"engine\", which is set to \"openpyxl\".\n Supports multi-sheet Excel files (include `sheet_name = None` in `load_args`).\n save_args: Pandas options for saving Excel files.\n Here you can find all available arguments:\n https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.to_excel.html\n All defaults are preserved, but \"index\", which is set to False.\n If you would like to specify options for the `ExcelWriter`,\n you can include them under the \"writer\" key. Here you can\n find all available arguments:\n https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.ExcelWriter.html\n version: If specified, should be an instance of\n ``kedro.io.core.Version``. If its ``load`` attribute is\n None, the latest version will be loaded. If its ``save``\n attribute is None, save version will be autogenerated.\n credentials: Credentials required to get access to the underlying filesystem.\n E.g. for ``GCSFileSystem`` it should look like `{\"token\": None}`.\n fs_args: Extra arguments to pass into underlying filesystem class constructor\n (e.g. `{\"project\": \"my-project\"}` for ``GCSFileSystem``).\n\n Raises:\n DataSetError: If versioning is enabled while in append mode.\n \"\"\"\n _fs_args = deepcopy(fs_args) or {}\n _credentials = deepcopy(credentials) or {}\n\n protocol, path = get_protocol_and_path(filepath, version)\n if protocol == \"file\":\n _fs_args.setdefault(\"auto_mkdir\", True)\n\n self._protocol = protocol\n self._storage_options = {**_credentials, **_fs_args}\n self._fs = fsspec.filesystem(self._protocol, **self._storage_options)\n\n super().__init__(\n filepath=PurePosixPath(path),\n version=version,\n exists_function=self._fs.exists,\n glob_function=self._fs.glob,\n )\n\n # Handle default load arguments\n self._load_args = deepcopy(self.DEFAULT_LOAD_ARGS)\n if load_args is not None:\n self._load_args.update(load_args)\n\n # Handle default save arguments\n self._save_args = deepcopy(self.DEFAULT_SAVE_ARGS)\n if save_args is not None:\n self._save_args.update(save_args)\n self._writer_args = self._save_args.pop(\"writer\", {}) # type: ignore\n self._writer_args.setdefault(\"engine\", engine or \"openpyxl\") # type: ignore\n\n if version and self._writer_args.get(\"mode\") == \"a\": # type: ignore\n raise DataSetError(\n \"'ExcelDataSet' doesn't support versioning in append mode.\"\n )\n\n if \"storage_options\" in self._save_args or \"storage_options\" in self._load_args:\n logger.warning(\n \"Dropping 'storage_options' for %s, \"\n \"please specify them under 'fs_args' or 'credentials'.\",\n self._filepath,\n )\n self._save_args.pop(\"storage_options\", None)\n self._load_args.pop(\"storage_options\", None)\n\n def _describe(self) -> Dict[str, Any]:\n return dict(\n filepath=self._filepath,\n protocol=self._protocol,\n load_args=self._load_args,\n save_args=self._save_args,\n writer_args=self._writer_args,\n version=self._version,\n )\n\n def _load(self) -> Union[pd.DataFrame, Dict[str, pd.DataFrame]]:\n load_path = str(self._get_load_path())\n if self._protocol == \"file\":\n # file:// protocol seems to misbehave on Windows\n # (<urlopen error file not on local host>),\n # so we don't join that back to the filepath;\n # storage_options also don't work with local paths\n return pd.read_excel(load_path, **self._load_args)\n\n load_path = f\"{self._protocol}{PROTOCOL_DELIMITER}{load_path}\"\n return pd.read_excel(\n load_path, storage_options=self._storage_options, **self._load_args\n )\n\n def _save(self, data: Union[pd.DataFrame, Dict[str, pd.DataFrame]]) -> None:\n output = BytesIO()\n save_path = get_filepath_str(self._get_save_path(), self._protocol)\n\n # pylint: disable=abstract-class-instantiated\n with pd.ExcelWriter(output, **self._writer_args) as writer:\n if isinstance(data, dict):\n for sheet_name, sheet_data in data.items():\n sheet_data.to_excel(\n writer, sheet_name=sheet_name, **self._save_args\n )\n else:\n data.to_excel(writer, **self._save_args)\n\n with self._fs.open(save_path, mode=\"wb\") as fs_file:\n fs_file.write(output.getvalue())\n\n self._invalidate_cache()\n\n def _exists(self) -> bool:\n try:\n load_path = get_filepath_str(self._get_load_path(), self._protocol)\n except DataSetError:\n return False\n\n return self._fs.exists(load_path)\n\n def _release(self) -> None:\n super()._release()\n self._invalidate_cache()\n\n def _invalidate_cache(self) -> None:\n \"\"\"Invalidate underlying filesystem caches.\"\"\"\n filepath = get_filepath_str(self._filepath, self._protocol)\n self._fs.invalidate_cache(filepath)\n", "path": "kedro/extras/datasets/pandas/excel_dataset.py"}]}
| 3,501 | 414 |
gh_patches_debug_13430
|
rasdani/github-patches
|
git_diff
|
huggingface__text-generation-inference-201
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Request failed during generation: Server error: Expected is_sm90 || is_sm8x || is_sm75 to be true, but got false. (Could this error message be improved? If so, please report an enhancement request to PyTorch.)
Using the docker container ala these instructions:
https://github.com/huggingface/text-generation-inference#docker
in order to run the server locally. I'm using an app very similar to the one here:
https://huggingface.co/spaces/olivierdehaene/chat-llm-streaming to hit that local server.
I'm seeing this error in the server logs:
```
send_error: text_generation_router::infer: router/src/infer.rs:390: Request failed during generation: Server error: Expected is_sm90 || is_sm8x || is_sm75 to be true, but got false. (Could this error message be improved? If so, please report an enhancement request to PyTorch.)
```
Any ideas?
</issue>
<code>
[start of server/text_generation_server/models/__init__.py]
1 import torch
2
3 from loguru import logger
4 from transformers import AutoConfig
5 from transformers.models.auto import modeling_auto
6 from typing import Optional
7
8 from text_generation_server.models.model import Model
9 from text_generation_server.models.causal_lm import CausalLM
10 from text_generation_server.models.flash_causal_lm import FlashCausalLM
11 from text_generation_server.models.bloom import BLOOM, BLOOMSharded
12 from text_generation_server.models.seq2seq_lm import Seq2SeqLM
13 from text_generation_server.models.opt import OPT, OPTSharded
14 from text_generation_server.models.galactica import Galactica, GalacticaSharded
15 from text_generation_server.models.santacoder import SantaCoder
16 from text_generation_server.models.gpt_neox import GPTNeoxSharded
17 from text_generation_server.models.t5 import T5Sharded
18
19 try:
20 from text_generation_server.models.flash_neox import FlashNeoX, FlashNeoXSharded
21 from text_generation_server.models.flash_llama import FlashLlama, FlashLlamaSharded
22 from text_generation_server.models.flash_santacoder import (
23 FlashSantacoder,
24 FlashSantacoderSharded,
25 )
26
27 FLASH_ATTENTION = torch.cuda.is_available()
28 except ImportError:
29 logger.opt(exception=True).warning("Could not import Flash Attention enabled models")
30 FLASH_ATTENTION = False
31
32 __all__ = [
33 "Model",
34 "BLOOM",
35 "BLOOMSharded",
36 "CausalLM",
37 "FlashCausalLM",
38 "Galactica",
39 "GalacticaSharded",
40 "GPTNeoxSharded",
41 "Seq2SeqLM",
42 "Galactica",
43 "GalacticaSharded",
44 "SantaCoder",
45 "OPT",
46 "OPTSharded",
47 "T5Sharded",
48 "get_model",
49 ]
50
51 if FLASH_ATTENTION:
52 __all__.append(FlashNeoX)
53 __all__.append(FlashNeoXSharded)
54 __all__.append(FlashSantacoder)
55 __all__.append(FlashSantacoderSharded)
56 __all__.append(FlashLlama)
57 __all__.append(FlashLlamaSharded)
58
59 FLASH_ATT_ERROR_MESSAGE = (
60 "{} requires Flash Attention CUDA kernels to be installed.\n"
61 "Use the official Docker image (ghcr.io/huggingface/text-generation-inference:latest) "
62 "or install flash attention with `cd server && make install install-flash-attention`"
63 )
64
65 # The flag below controls whether to allow TF32 on matmul. This flag defaults to False
66 # in PyTorch 1.12 and later.
67 torch.backends.cuda.matmul.allow_tf32 = True
68
69 # The flag below controls whether to allow TF32 on cuDNN. This flag defaults to True.
70 torch.backends.cudnn.allow_tf32 = True
71
72 # Disable gradients
73 torch.set_grad_enabled(False)
74
75
76 def get_model(
77 model_id: str, revision: Optional[str], sharded: bool, quantize: bool
78 ) -> Model:
79 if "facebook/galactica" in model_id:
80 if sharded:
81 return GalacticaSharded(model_id, revision, quantize=quantize)
82 else:
83 return Galactica(model_id, revision, quantize=quantize)
84
85 if "bigcode" in model_id:
86 if sharded:
87 if not FLASH_ATTENTION:
88 raise NotImplementedError(
89 FLASH_ATT_ERROR_MESSAGE.format(f"Sharded Santacoder")
90 )
91 return FlashSantacoderSharded(model_id, revision=revision)
92 else:
93 santacoder_cls = FlashSantacoder if FLASH_ATTENTION else SantaCoder
94 return santacoder_cls(model_id, revision, quantize)
95
96 config = AutoConfig.from_pretrained(model_id, revision=revision)
97 model_type = config.model_type
98
99 if model_type == "bloom":
100 if sharded:
101 return BLOOMSharded(model_id, revision, quantize=quantize)
102 else:
103 return BLOOM(model_id, revision, quantize=quantize)
104
105 if model_type == "gpt_neox":
106 if sharded:
107 neox_cls = FlashNeoXSharded if FLASH_ATTENTION else GPTNeoxSharded
108 return neox_cls(model_id, revision, quantize=quantize)
109 else:
110 neox_cls = FlashNeoX if FLASH_ATTENTION else CausalLM
111 return neox_cls(model_id, revision, quantize=quantize)
112
113 if model_type == "llama":
114 if sharded:
115 if FLASH_ATTENTION:
116 return FlashLlamaSharded(model_id, revision, quantize=quantize)
117 raise NotImplementedError(FLASH_ATT_ERROR_MESSAGE.format(f"Sharded Llama"))
118 else:
119 llama_cls = FlashLlama if FLASH_ATTENTION else CausalLM
120 return llama_cls(model_id, revision, quantize=quantize)
121
122 if config.model_type == "opt":
123 if sharded:
124 return OPTSharded(model_id, revision, quantize=quantize)
125 else:
126 return OPT(model_id, revision, quantize=quantize)
127
128 if model_type == "t5":
129 if sharded:
130 return T5Sharded(model_id, revision, quantize=quantize)
131 else:
132 return Seq2SeqLM(model_id, revision, quantize=quantize)
133
134 if sharded:
135 raise ValueError("sharded is not supported for AutoModel")
136
137 if model_type in modeling_auto.MODEL_FOR_CAUSAL_LM_MAPPING_NAMES:
138 return CausalLM(model_id, revision, quantize=quantize)
139 if model_type in modeling_auto.MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING_NAMES:
140 return Seq2SeqLM(model_id, revision, quantize=quantize)
141
142 raise ValueError(f"Unsupported model type {model_type}")
143
[end of server/text_generation_server/models/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/server/text_generation_server/models/__init__.py b/server/text_generation_server/models/__init__.py
--- a/server/text_generation_server/models/__init__.py
+++ b/server/text_generation_server/models/__init__.py
@@ -24,7 +24,18 @@
FlashSantacoderSharded,
)
- FLASH_ATTENTION = torch.cuda.is_available()
+ if torch.cuda.is_available():
+ major, minor = torch.cuda.get_device_capability()
+ is_sm75 = major == 7 and minor == 5
+ is_sm8x = major == 8 and minor >= 0
+ is_sm90 = major == 9 and minor == 0
+
+ supported = is_sm75 or is_sm8x or is_sm90
+ if not supported:
+ raise ImportError(f"GPU with CUDA capability {major} {minor} is not supported")
+ FLASH_ATTENTION = True
+ else:
+ FLASH_ATTENTION = False
except ImportError:
logger.opt(exception=True).warning("Could not import Flash Attention enabled models")
FLASH_ATTENTION = False
|
{"golden_diff": "diff --git a/server/text_generation_server/models/__init__.py b/server/text_generation_server/models/__init__.py\n--- a/server/text_generation_server/models/__init__.py\n+++ b/server/text_generation_server/models/__init__.py\n@@ -24,7 +24,18 @@\n FlashSantacoderSharded,\n )\n \n- FLASH_ATTENTION = torch.cuda.is_available()\n+ if torch.cuda.is_available():\n+ major, minor = torch.cuda.get_device_capability()\n+ is_sm75 = major == 7 and minor == 5\n+ is_sm8x = major == 8 and minor >= 0\n+ is_sm90 = major == 9 and minor == 0\n+\n+ supported = is_sm75 or is_sm8x or is_sm90\n+ if not supported:\n+ raise ImportError(f\"GPU with CUDA capability {major} {minor} is not supported\")\n+ FLASH_ATTENTION = True\n+ else:\n+ FLASH_ATTENTION = False\n except ImportError:\n logger.opt(exception=True).warning(\"Could not import Flash Attention enabled models\")\n FLASH_ATTENTION = False\n", "issue": "Request failed during generation: Server error: Expected is_sm90 || is_sm8x || is_sm75 to be true, but got false. (Could this error message be improved? If so, please report an enhancement request to PyTorch.)\nUsing the docker container ala these instructions:\r\nhttps://github.com/huggingface/text-generation-inference#docker\r\nin order to run the server locally. I'm using an app very similar to the one here:\r\nhttps://huggingface.co/spaces/olivierdehaene/chat-llm-streaming to hit that local server. \r\n\r\nI'm seeing this error in the server logs:\r\n\r\n```\r\nsend_error: text_generation_router::infer: router/src/infer.rs:390: Request failed during generation: Server error: Expected is_sm90 || is_sm8x || is_sm75 to be true, but got false. (Could this error message be improved? If so, please report an enhancement request to PyTorch.)\r\n```\r\nAny ideas?\n", "before_files": [{"content": "import torch\n\nfrom loguru import logger\nfrom transformers import AutoConfig\nfrom transformers.models.auto import modeling_auto\nfrom typing import Optional\n\nfrom text_generation_server.models.model import Model\nfrom text_generation_server.models.causal_lm import CausalLM\nfrom text_generation_server.models.flash_causal_lm import FlashCausalLM\nfrom text_generation_server.models.bloom import BLOOM, BLOOMSharded\nfrom text_generation_server.models.seq2seq_lm import Seq2SeqLM\nfrom text_generation_server.models.opt import OPT, OPTSharded\nfrom text_generation_server.models.galactica import Galactica, GalacticaSharded\nfrom text_generation_server.models.santacoder import SantaCoder\nfrom text_generation_server.models.gpt_neox import GPTNeoxSharded\nfrom text_generation_server.models.t5 import T5Sharded\n\ntry:\n from text_generation_server.models.flash_neox import FlashNeoX, FlashNeoXSharded\n from text_generation_server.models.flash_llama import FlashLlama, FlashLlamaSharded\n from text_generation_server.models.flash_santacoder import (\n FlashSantacoder,\n FlashSantacoderSharded,\n )\n\n FLASH_ATTENTION = torch.cuda.is_available()\nexcept ImportError:\n logger.opt(exception=True).warning(\"Could not import Flash Attention enabled models\")\n FLASH_ATTENTION = False\n\n__all__ = [\n \"Model\",\n \"BLOOM\",\n \"BLOOMSharded\",\n \"CausalLM\",\n \"FlashCausalLM\",\n \"Galactica\",\n \"GalacticaSharded\",\n \"GPTNeoxSharded\",\n \"Seq2SeqLM\",\n \"Galactica\",\n \"GalacticaSharded\",\n \"SantaCoder\",\n \"OPT\",\n \"OPTSharded\",\n \"T5Sharded\",\n \"get_model\",\n]\n\nif FLASH_ATTENTION:\n __all__.append(FlashNeoX)\n __all__.append(FlashNeoXSharded)\n __all__.append(FlashSantacoder)\n __all__.append(FlashSantacoderSharded)\n __all__.append(FlashLlama)\n __all__.append(FlashLlamaSharded)\n\nFLASH_ATT_ERROR_MESSAGE = (\n \"{} requires Flash Attention CUDA kernels to be installed.\\n\"\n \"Use the official Docker image (ghcr.io/huggingface/text-generation-inference:latest) \"\n \"or install flash attention with `cd server && make install install-flash-attention`\"\n)\n\n# The flag below controls whether to allow TF32 on matmul. This flag defaults to False\n# in PyTorch 1.12 and later.\ntorch.backends.cuda.matmul.allow_tf32 = True\n\n# The flag below controls whether to allow TF32 on cuDNN. This flag defaults to True.\ntorch.backends.cudnn.allow_tf32 = True\n\n# Disable gradients\ntorch.set_grad_enabled(False)\n\n\ndef get_model(\n model_id: str, revision: Optional[str], sharded: bool, quantize: bool\n) -> Model:\n if \"facebook/galactica\" in model_id:\n if sharded:\n return GalacticaSharded(model_id, revision, quantize=quantize)\n else:\n return Galactica(model_id, revision, quantize=quantize)\n\n if \"bigcode\" in model_id:\n if sharded:\n if not FLASH_ATTENTION:\n raise NotImplementedError(\n FLASH_ATT_ERROR_MESSAGE.format(f\"Sharded Santacoder\")\n )\n return FlashSantacoderSharded(model_id, revision=revision)\n else:\n santacoder_cls = FlashSantacoder if FLASH_ATTENTION else SantaCoder\n return santacoder_cls(model_id, revision, quantize)\n\n config = AutoConfig.from_pretrained(model_id, revision=revision)\n model_type = config.model_type\n\n if model_type == \"bloom\":\n if sharded:\n return BLOOMSharded(model_id, revision, quantize=quantize)\n else:\n return BLOOM(model_id, revision, quantize=quantize)\n\n if model_type == \"gpt_neox\":\n if sharded:\n neox_cls = FlashNeoXSharded if FLASH_ATTENTION else GPTNeoxSharded\n return neox_cls(model_id, revision, quantize=quantize)\n else:\n neox_cls = FlashNeoX if FLASH_ATTENTION else CausalLM\n return neox_cls(model_id, revision, quantize=quantize)\n\n if model_type == \"llama\":\n if sharded:\n if FLASH_ATTENTION:\n return FlashLlamaSharded(model_id, revision, quantize=quantize)\n raise NotImplementedError(FLASH_ATT_ERROR_MESSAGE.format(f\"Sharded Llama\"))\n else:\n llama_cls = FlashLlama if FLASH_ATTENTION else CausalLM\n return llama_cls(model_id, revision, quantize=quantize)\n\n if config.model_type == \"opt\":\n if sharded:\n return OPTSharded(model_id, revision, quantize=quantize)\n else:\n return OPT(model_id, revision, quantize=quantize)\n\n if model_type == \"t5\":\n if sharded:\n return T5Sharded(model_id, revision, quantize=quantize)\n else:\n return Seq2SeqLM(model_id, revision, quantize=quantize)\n\n if sharded:\n raise ValueError(\"sharded is not supported for AutoModel\")\n\n if model_type in modeling_auto.MODEL_FOR_CAUSAL_LM_MAPPING_NAMES:\n return CausalLM(model_id, revision, quantize=quantize)\n if model_type in modeling_auto.MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING_NAMES:\n return Seq2SeqLM(model_id, revision, quantize=quantize)\n\n raise ValueError(f\"Unsupported model type {model_type}\")\n", "path": "server/text_generation_server/models/__init__.py"}]}
| 2,347 | 247 |
gh_patches_debug_36382
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-5862
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Letter misprint in jemalloc recipe
https://github.com/conan-io/conan-center-index/blob/a40f8d2e097ffb1f98797011f7694ba7b9efe91d/recipes/jemalloc/all/conanfile.py#L96
Instead of --enable-initial-exec-tld must be --enbal-initial-exec-tls
</issue>
<code>
[start of recipes/jemalloc/all/conanfile.py]
1 from conans import AutoToolsBuildEnvironment, ConanFile, MSBuild, tools
2 from conans.errors import ConanInvalidConfiguration
3 import os
4 import shutil
5 import string
6
7
8 class JemallocConan(ConanFile):
9 name = "jemalloc"
10 description = "jemalloc is a general purpose malloc(3) implementation that emphasizes fragmentation avoidance and scalable concurrency support."
11 url = "https://github.com/conan-io/conan-center-index"
12 license = "BSD-2-Clause"
13 homepage = "http://jemalloc.net/"
14 topics = ("conan", "jemalloc", "malloc", "free")
15 settings = "os", "arch", "compiler", "build_type"
16 options = {
17 "shared": [True, False],
18 "fPIC": [True, False],
19 "prefix": "ANY",
20 "enable_cxx": [True, False],
21 "enable_fill": [True, False],
22 "enable_xmalloc": [True, False],
23 "enable_readlinkat": [True, False],
24 "enable_syscall": [True, False],
25 "enable_lazy_lock": [True, False],
26 "enable_debug_logging": [True, False],
27 "enable_initial_exec_tls": [True, False],
28 "enable_libdl": [True, False],
29 }
30 default_options = {
31 "shared": False,
32 "fPIC": True,
33 "prefix": "",
34 "enable_cxx": True,
35 "enable_fill": True,
36 "enable_xmalloc": False,
37 "enable_readlinkat": False,
38 "enable_syscall": True,
39 "enable_lazy_lock": False,
40 "enable_debug_logging": False,
41 "enable_initial_exec_tls": True,
42 "enable_libdl": True,
43 }
44
45 _autotools = None
46
47 _source_subfolder = "source_subfolder"
48
49 def config_options(self):
50 if self.settings.os == "Windows":
51 del self.options.fPIC
52
53 def configure(self):
54 if self.options.enable_cxx and \
55 self.settings.compiler.get_safe("libcxx") == "libc++" and \
56 self.settings.compiler == "clang" and \
57 tools.Version(self.settings.compiler.version) < "10":
58 raise ConanInvalidConfiguration("clang and libc++ version {} (< 10) is missing a mutex implementation".format(self.settings.compiler.version))
59 if self.settings.compiler == "Visual Studio" and \
60 self.options.shared and \
61 "MT" in self.settings.compiler.runtime:
62 raise ConanInvalidConfiguration("Visual Studio build for shared library with MT runtime is not supported")
63 if self.settings.compiler == "Visual Studio" and self.settings.compiler.version != "15":
64 # https://github.com/jemalloc/jemalloc/issues/1703
65 raise ConanInvalidConfiguration("Only Visual Studio 15 2017 is supported. Please fix this if other versions are supported")
66 if self.options.shared:
67 del self.options.fPIC
68 if not self.options.enable_cxx:
69 del self.settings.compiler.libcxx
70 del self.settings.compiler.cppstd
71 if self.settings.build_type not in ("Release", "Debug", None):
72 raise ConanInvalidConfiguration("Only Release and Debug build_types are supported")
73 if self.settings.compiler == "Visual Studio" and self.settings.arch not in ("x86_64", "x86"):
74 raise ConanInvalidConfiguration("Unsupported arch")
75
76 def source(self):
77 tools.get(**self.conan_data["sources"][self.version])
78 os.rename("{}-{}".format(self.name, self.version), self._source_subfolder)
79
80 def build_requirements(self):
81 if tools.os_info.is_windows and not os.environ.get("CONAN_BASH_PATH", None):
82 self.build_requires("msys2/20200517")
83
84 @property
85 def _autotools_args(self):
86 conf_args = [
87 "--with-jemalloc-prefix={}".format(self.options.prefix),
88 "--enable-debug" if self.settings.build_type == "Debug" else "--disable-debug",
89 "--enable-cxx" if self.options.enable_cxx else "--disable-cxx",
90 "--enable-fill" if self.options.enable_fill else "--disable-fill",
91 "--enable-xmalloc" if self.options.enable_cxx else "--disable-xmalloc",
92 "--enable-readlinkat" if self.options.enable_readlinkat else "--disable-readlinkat",
93 "--enable-syscall" if self.options.enable_syscall else "--disable-syscall",
94 "--enable-lazy-lock" if self.options.enable_lazy_lock else "--disable-lazy-lock",
95 "--enable-log" if self.options.enable_debug_logging else "--disable-log",
96 "--enable-initial-exec-tld" if self.options.enable_initial_exec_tls else "--disable-initial-exec-tls",
97 "--enable-libdl" if self.options.enable_libdl else "--disable-libdl",
98 ]
99 if self.options.shared:
100 conf_args.extend(["--enable-shared", "--disable-static"])
101 else:
102 conf_args.extend(["--disable-shared", "--enable-static"])
103 return conf_args
104
105 def _configure_autotools(self):
106 if self._autotools:
107 return self._autotools
108 self._autotools = AutoToolsBuildEnvironment(self, win_bash=tools.os_info.is_windows)
109 self._autotools.configure(args=self._autotools_args, configure_dir=self._source_subfolder)
110 return self._autotools
111
112 @property
113 def _msvc_build_type(self):
114 build_type = str(self.settings.build_type) or "Release"
115 if not self.options.shared:
116 build_type += "-static"
117 return build_type
118
119 def _patch_sources(self):
120 if self.settings.os == "Windows":
121 makefile_in = os.path.join(self._source_subfolder, "Makefile.in")
122 tools.replace_in_file(makefile_in,
123 "DSO_LDFLAGS = @DSO_LDFLAGS@",
124 "DSO_LDFLAGS = @DSO_LDFLAGS@ -Wl,--out-implib,lib/libjemalloc.a")
125 tools.replace_in_file(makefile_in,
126 "\t$(INSTALL) -d $(LIBDIR)\n"
127 "\t$(INSTALL) -m 755 $(objroot)lib/$(LIBJEMALLOC).$(SOREV) $(LIBDIR)",
128 "\t$(INSTALL) -d $(BINDIR)\n"
129 "\t$(INSTALL) -d $(LIBDIR)\n"
130 "\t$(INSTALL) -m 755 $(objroot)lib/$(LIBJEMALLOC).$(SOREV) $(BINDIR)\n"
131 "\t$(INSTALL) -m 644 $(objroot)lib/libjemalloc.a $(LIBDIR)")
132
133 def build(self):
134 self._patch_sources()
135 if self.settings.compiler == "Visual Studio":
136 with tools.vcvars(self.settings) if self.settings.compiler == "Visual Studio" else tools.no_op():
137 with tools.environment_append({"CC": "cl", "CXX": "cl"}) if self.settings.compiler == "Visual Studio" else tools.no_op():
138 with tools.chdir(self._source_subfolder):
139 # Do not use AutoToolsBuildEnvironment because we want to run configure as ./configure
140 self.run("./configure {}".format(" ".join(self._autotools_args)), win_bash=tools.os_info.is_windows)
141 msbuild = MSBuild(self)
142 # Do not use the 2015 solution: unresolved external symbols: test_hooks_libc_hook and test_hooks_arena_new_hook
143 sln_file = os.path.join(self._source_subfolder, "msvc", "jemalloc_vc2017.sln")
144 msbuild.build(sln_file, targets=["jemalloc"], build_type=self._msvc_build_type)
145 else:
146 autotools = self._configure_autotools()
147 autotools.make()
148
149 @property
150 def _library_name(self):
151 libname = "jemalloc"
152 if self.settings.compiler == "Visual Studio":
153 if self.options.shared:
154 if self.settings.build_type == "Debug":
155 libname += "d"
156 else:
157 toolset = tools.msvs_toolset(self.settings)
158 toolset_number = "".join(c for c in toolset if c in string.digits)
159 libname += "-vc{}-{}".format(toolset_number, self._msvc_build_type)
160 else:
161 if self.settings.os == "Windows":
162 if not self.options.shared:
163 libname += "_s"
164 else:
165 if not self.options.shared and self.options.fPIC:
166 libname += "_pic"
167 return libname
168
169 def package(self):
170 self.copy(pattern="COPYING", src=self._source_subfolder, dst="licenses")
171 if self.settings.compiler == "Visual Studio":
172 arch_subdir = {
173 "x86_64": "x64",
174 "x86": "x86",
175 }[str(self.settings.arch)]
176 self.copy("*.lib", src=os.path.join(self._source_subfolder, "msvc", arch_subdir, self._msvc_build_type), dst=os.path.join(self.package_folder, "lib"))
177 self.copy("*.dll", src=os.path.join(self._source_subfolder, "msvc", arch_subdir, self._msvc_build_type), dst=os.path.join(self.package_folder, "bin"))
178 self.copy("jemalloc.h", src=os.path.join(self._source_subfolder, "include", "jemalloc"), dst=os.path.join(self.package_folder, "include", "jemalloc"), keep_path=True)
179 shutil.copytree(os.path.join(self._source_subfolder, "include", "msvc_compat"),
180 os.path.join(self.package_folder, "include", "msvc_compat"))
181 else:
182 autotools = self._configure_autotools()
183 # Use install_lib_XXX and install_include to avoid mixing binaries and dll's
184 autotools.make(target="install_lib_shared" if self.options.shared else "install_lib_static")
185 autotools.make(target="install_include")
186 if self.settings.os == "Windows" and self.settings.compiler == "gcc":
187 os.rename(os.path.join(self.package_folder, "lib", "{}.lib".format(self._library_name)),
188 os.path.join(self.package_folder, "lib", "lib{}.a".format(self._library_name)))
189 if not self.options.shared:
190 os.unlink(os.path.join(self.package_folder, "lib", "jemalloc.lib"))
191
192 def package_id(self):
193 if not self.settings.build_type:
194 self.info.settings.build_type = "Release"
195
196 def package_info(self):
197 self.cpp_info.libs = [self._library_name]
198 self.cpp_info.includedirs = [os.path.join(self.package_folder, "include"),
199 os.path.join(self.package_folder, "include", "jemalloc")]
200 if self.settings.compiler == "Visual Studio":
201 self.cpp_info.includedirs.append(os.path.join(self.package_folder, "include", "msvc_compat"))
202 if not self.options.shared:
203 self.cpp_info.defines = ["JEMALLOC_EXPORT="]
204 if self.settings.os == "Linux":
205 self.cpp_info.system_libs.extend(["dl", "pthread", "rt"])
206
[end of recipes/jemalloc/all/conanfile.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/recipes/jemalloc/all/conanfile.py b/recipes/jemalloc/all/conanfile.py
--- a/recipes/jemalloc/all/conanfile.py
+++ b/recipes/jemalloc/all/conanfile.py
@@ -41,6 +41,7 @@
"enable_initial_exec_tls": True,
"enable_libdl": True,
}
+ exports_sources = ["patches/**"]
_autotools = None
@@ -72,6 +73,8 @@
raise ConanInvalidConfiguration("Only Release and Debug build_types are supported")
if self.settings.compiler == "Visual Studio" and self.settings.arch not in ("x86_64", "x86"):
raise ConanInvalidConfiguration("Unsupported arch")
+ if self.settings.compiler == "clang" and tools.Version(self.settings.compiler.version) <= "3.9":
+ raise ConanInvalidConfiguration("Unsupported compiler version")
def source(self):
tools.get(**self.conan_data["sources"][self.version])
@@ -93,7 +96,7 @@
"--enable-syscall" if self.options.enable_syscall else "--disable-syscall",
"--enable-lazy-lock" if self.options.enable_lazy_lock else "--disable-lazy-lock",
"--enable-log" if self.options.enable_debug_logging else "--disable-log",
- "--enable-initial-exec-tld" if self.options.enable_initial_exec_tls else "--disable-initial-exec-tls",
+ "--enable-initial-exec-tls" if self.options.enable_initial_exec_tls else "--disable-initial-exec-tls",
"--enable-libdl" if self.options.enable_libdl else "--disable-libdl",
]
if self.options.shared:
@@ -130,6 +133,9 @@
"\t$(INSTALL) -m 755 $(objroot)lib/$(LIBJEMALLOC).$(SOREV) $(BINDIR)\n"
"\t$(INSTALL) -m 644 $(objroot)lib/libjemalloc.a $(LIBDIR)")
+ for patch in self.conan_data.get("patches", {}).get(self.version, []):
+ tools.patch(**patch)
+
def build(self):
self._patch_sources()
if self.settings.compiler == "Visual Studio":
|
{"golden_diff": "diff --git a/recipes/jemalloc/all/conanfile.py b/recipes/jemalloc/all/conanfile.py\n--- a/recipes/jemalloc/all/conanfile.py\n+++ b/recipes/jemalloc/all/conanfile.py\n@@ -41,6 +41,7 @@\n \"enable_initial_exec_tls\": True,\n \"enable_libdl\": True,\n }\n+ exports_sources = [\"patches/**\"]\n \n _autotools = None\n \n@@ -72,6 +73,8 @@\n raise ConanInvalidConfiguration(\"Only Release and Debug build_types are supported\")\n if self.settings.compiler == \"Visual Studio\" and self.settings.arch not in (\"x86_64\", \"x86\"):\n raise ConanInvalidConfiguration(\"Unsupported arch\")\n+ if self.settings.compiler == \"clang\" and tools.Version(self.settings.compiler.version) <= \"3.9\":\n+ raise ConanInvalidConfiguration(\"Unsupported compiler version\")\n \n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n@@ -93,7 +96,7 @@\n \"--enable-syscall\" if self.options.enable_syscall else \"--disable-syscall\",\n \"--enable-lazy-lock\" if self.options.enable_lazy_lock else \"--disable-lazy-lock\",\n \"--enable-log\" if self.options.enable_debug_logging else \"--disable-log\",\n- \"--enable-initial-exec-tld\" if self.options.enable_initial_exec_tls else \"--disable-initial-exec-tls\",\n+ \"--enable-initial-exec-tls\" if self.options.enable_initial_exec_tls else \"--disable-initial-exec-tls\",\n \"--enable-libdl\" if self.options.enable_libdl else \"--disable-libdl\",\n ]\n if self.options.shared:\n@@ -130,6 +133,9 @@\n \"\\t$(INSTALL) -m 755 $(objroot)lib/$(LIBJEMALLOC).$(SOREV) $(BINDIR)\\n\"\n \"\\t$(INSTALL) -m 644 $(objroot)lib/libjemalloc.a $(LIBDIR)\")\n \n+ for patch in self.conan_data.get(\"patches\", {}).get(self.version, []):\n+ tools.patch(**patch)\n+\n def build(self):\n self._patch_sources()\n if self.settings.compiler == \"Visual Studio\":\n", "issue": "Letter misprint in jemalloc recipe\nhttps://github.com/conan-io/conan-center-index/blob/a40f8d2e097ffb1f98797011f7694ba7b9efe91d/recipes/jemalloc/all/conanfile.py#L96\r\n\r\nInstead of --enable-initial-exec-tld must be --enbal-initial-exec-tls\n", "before_files": [{"content": "from conans import AutoToolsBuildEnvironment, ConanFile, MSBuild, tools\nfrom conans.errors import ConanInvalidConfiguration\nimport os\nimport shutil\nimport string\n\n\nclass JemallocConan(ConanFile):\n name = \"jemalloc\"\n description = \"jemalloc is a general purpose malloc(3) implementation that emphasizes fragmentation avoidance and scalable concurrency support.\"\n url = \"https://github.com/conan-io/conan-center-index\"\n license = \"BSD-2-Clause\"\n homepage = \"http://jemalloc.net/\"\n topics = (\"conan\", \"jemalloc\", \"malloc\", \"free\")\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n options = {\n \"shared\": [True, False],\n \"fPIC\": [True, False],\n \"prefix\": \"ANY\",\n \"enable_cxx\": [True, False],\n \"enable_fill\": [True, False],\n \"enable_xmalloc\": [True, False],\n \"enable_readlinkat\": [True, False],\n \"enable_syscall\": [True, False],\n \"enable_lazy_lock\": [True, False],\n \"enable_debug_logging\": [True, False],\n \"enable_initial_exec_tls\": [True, False],\n \"enable_libdl\": [True, False],\n }\n default_options = {\n \"shared\": False,\n \"fPIC\": True,\n \"prefix\": \"\",\n \"enable_cxx\": True,\n \"enable_fill\": True,\n \"enable_xmalloc\": False,\n \"enable_readlinkat\": False,\n \"enable_syscall\": True,\n \"enable_lazy_lock\": False,\n \"enable_debug_logging\": False,\n \"enable_initial_exec_tls\": True,\n \"enable_libdl\": True,\n }\n\n _autotools = None\n\n _source_subfolder = \"source_subfolder\"\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n del self.options.fPIC\n\n def configure(self):\n if self.options.enable_cxx and \\\n self.settings.compiler.get_safe(\"libcxx\") == \"libc++\" and \\\n self.settings.compiler == \"clang\" and \\\n tools.Version(self.settings.compiler.version) < \"10\":\n raise ConanInvalidConfiguration(\"clang and libc++ version {} (< 10) is missing a mutex implementation\".format(self.settings.compiler.version))\n if self.settings.compiler == \"Visual Studio\" and \\\n self.options.shared and \\\n \"MT\" in self.settings.compiler.runtime:\n raise ConanInvalidConfiguration(\"Visual Studio build for shared library with MT runtime is not supported\")\n if self.settings.compiler == \"Visual Studio\" and self.settings.compiler.version != \"15\":\n # https://github.com/jemalloc/jemalloc/issues/1703\n raise ConanInvalidConfiguration(\"Only Visual Studio 15 2017 is supported. Please fix this if other versions are supported\")\n if self.options.shared:\n del self.options.fPIC\n if not self.options.enable_cxx:\n del self.settings.compiler.libcxx\n del self.settings.compiler.cppstd\n if self.settings.build_type not in (\"Release\", \"Debug\", None):\n raise ConanInvalidConfiguration(\"Only Release and Debug build_types are supported\")\n if self.settings.compiler == \"Visual Studio\" and self.settings.arch not in (\"x86_64\", \"x86\"):\n raise ConanInvalidConfiguration(\"Unsupported arch\")\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n os.rename(\"{}-{}\".format(self.name, self.version), self._source_subfolder)\n\n def build_requirements(self):\n if tools.os_info.is_windows and not os.environ.get(\"CONAN_BASH_PATH\", None):\n self.build_requires(\"msys2/20200517\")\n\n @property\n def _autotools_args(self):\n conf_args = [\n \"--with-jemalloc-prefix={}\".format(self.options.prefix),\n \"--enable-debug\" if self.settings.build_type == \"Debug\" else \"--disable-debug\",\n \"--enable-cxx\" if self.options.enable_cxx else \"--disable-cxx\",\n \"--enable-fill\" if self.options.enable_fill else \"--disable-fill\",\n \"--enable-xmalloc\" if self.options.enable_cxx else \"--disable-xmalloc\",\n \"--enable-readlinkat\" if self.options.enable_readlinkat else \"--disable-readlinkat\",\n \"--enable-syscall\" if self.options.enable_syscall else \"--disable-syscall\",\n \"--enable-lazy-lock\" if self.options.enable_lazy_lock else \"--disable-lazy-lock\",\n \"--enable-log\" if self.options.enable_debug_logging else \"--disable-log\",\n \"--enable-initial-exec-tld\" if self.options.enable_initial_exec_tls else \"--disable-initial-exec-tls\",\n \"--enable-libdl\" if self.options.enable_libdl else \"--disable-libdl\",\n ]\n if self.options.shared:\n conf_args.extend([\"--enable-shared\", \"--disable-static\"])\n else:\n conf_args.extend([\"--disable-shared\", \"--enable-static\"])\n return conf_args\n\n def _configure_autotools(self):\n if self._autotools:\n return self._autotools\n self._autotools = AutoToolsBuildEnvironment(self, win_bash=tools.os_info.is_windows)\n self._autotools.configure(args=self._autotools_args, configure_dir=self._source_subfolder)\n return self._autotools\n\n @property\n def _msvc_build_type(self):\n build_type = str(self.settings.build_type) or \"Release\"\n if not self.options.shared:\n build_type += \"-static\"\n return build_type\n\n def _patch_sources(self):\n if self.settings.os == \"Windows\":\n makefile_in = os.path.join(self._source_subfolder, \"Makefile.in\")\n tools.replace_in_file(makefile_in,\n \"DSO_LDFLAGS = @DSO_LDFLAGS@\",\n \"DSO_LDFLAGS = @DSO_LDFLAGS@ -Wl,--out-implib,lib/libjemalloc.a\")\n tools.replace_in_file(makefile_in,\n \"\\t$(INSTALL) -d $(LIBDIR)\\n\"\n \"\\t$(INSTALL) -m 755 $(objroot)lib/$(LIBJEMALLOC).$(SOREV) $(LIBDIR)\",\n \"\\t$(INSTALL) -d $(BINDIR)\\n\"\n \"\\t$(INSTALL) -d $(LIBDIR)\\n\"\n \"\\t$(INSTALL) -m 755 $(objroot)lib/$(LIBJEMALLOC).$(SOREV) $(BINDIR)\\n\"\n \"\\t$(INSTALL) -m 644 $(objroot)lib/libjemalloc.a $(LIBDIR)\")\n\n def build(self):\n self._patch_sources()\n if self.settings.compiler == \"Visual Studio\":\n with tools.vcvars(self.settings) if self.settings.compiler == \"Visual Studio\" else tools.no_op():\n with tools.environment_append({\"CC\": \"cl\", \"CXX\": \"cl\"}) if self.settings.compiler == \"Visual Studio\" else tools.no_op():\n with tools.chdir(self._source_subfolder):\n # Do not use AutoToolsBuildEnvironment because we want to run configure as ./configure\n self.run(\"./configure {}\".format(\" \".join(self._autotools_args)), win_bash=tools.os_info.is_windows)\n msbuild = MSBuild(self)\n # Do not use the 2015 solution: unresolved external symbols: test_hooks_libc_hook and test_hooks_arena_new_hook\n sln_file = os.path.join(self._source_subfolder, \"msvc\", \"jemalloc_vc2017.sln\")\n msbuild.build(sln_file, targets=[\"jemalloc\"], build_type=self._msvc_build_type)\n else:\n autotools = self._configure_autotools()\n autotools.make()\n\n @property\n def _library_name(self):\n libname = \"jemalloc\"\n if self.settings.compiler == \"Visual Studio\":\n if self.options.shared:\n if self.settings.build_type == \"Debug\":\n libname += \"d\"\n else:\n toolset = tools.msvs_toolset(self.settings)\n toolset_number = \"\".join(c for c in toolset if c in string.digits)\n libname += \"-vc{}-{}\".format(toolset_number, self._msvc_build_type)\n else:\n if self.settings.os == \"Windows\":\n if not self.options.shared:\n libname += \"_s\"\n else:\n if not self.options.shared and self.options.fPIC:\n libname += \"_pic\"\n return libname\n\n def package(self):\n self.copy(pattern=\"COPYING\", src=self._source_subfolder, dst=\"licenses\")\n if self.settings.compiler == \"Visual Studio\":\n arch_subdir = {\n \"x86_64\": \"x64\",\n \"x86\": \"x86\",\n }[str(self.settings.arch)]\n self.copy(\"*.lib\", src=os.path.join(self._source_subfolder, \"msvc\", arch_subdir, self._msvc_build_type), dst=os.path.join(self.package_folder, \"lib\"))\n self.copy(\"*.dll\", src=os.path.join(self._source_subfolder, \"msvc\", arch_subdir, self._msvc_build_type), dst=os.path.join(self.package_folder, \"bin\"))\n self.copy(\"jemalloc.h\", src=os.path.join(self._source_subfolder, \"include\", \"jemalloc\"), dst=os.path.join(self.package_folder, \"include\", \"jemalloc\"), keep_path=True)\n shutil.copytree(os.path.join(self._source_subfolder, \"include\", \"msvc_compat\"),\n os.path.join(self.package_folder, \"include\", \"msvc_compat\"))\n else:\n autotools = self._configure_autotools()\n # Use install_lib_XXX and install_include to avoid mixing binaries and dll's\n autotools.make(target=\"install_lib_shared\" if self.options.shared else \"install_lib_static\")\n autotools.make(target=\"install_include\")\n if self.settings.os == \"Windows\" and self.settings.compiler == \"gcc\":\n os.rename(os.path.join(self.package_folder, \"lib\", \"{}.lib\".format(self._library_name)),\n os.path.join(self.package_folder, \"lib\", \"lib{}.a\".format(self._library_name)))\n if not self.options.shared:\n os.unlink(os.path.join(self.package_folder, \"lib\", \"jemalloc.lib\"))\n\n def package_id(self):\n if not self.settings.build_type:\n self.info.settings.build_type = \"Release\"\n\n def package_info(self):\n self.cpp_info.libs = [self._library_name]\n self.cpp_info.includedirs = [os.path.join(self.package_folder, \"include\"),\n os.path.join(self.package_folder, \"include\", \"jemalloc\")]\n if self.settings.compiler == \"Visual Studio\":\n self.cpp_info.includedirs.append(os.path.join(self.package_folder, \"include\", \"msvc_compat\"))\n if not self.options.shared:\n self.cpp_info.defines = [\"JEMALLOC_EXPORT=\"]\n if self.settings.os == \"Linux\":\n self.cpp_info.system_libs.extend([\"dl\", \"pthread\", \"rt\"])\n", "path": "recipes/jemalloc/all/conanfile.py"}]}
| 3,541 | 487 |
gh_patches_debug_40269
|
rasdani/github-patches
|
git_diff
|
ddionrails__ddionrails-624
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Move import_path() method into mixin
### Subject of the issue
The System and Study model both implement the same `import_path()` method.
</issue>
<code>
[start of ddionrails/base/mixins.py]
1 # -*- coding: utf-8 -*-
2
3 """ Mixins for ddionrails.base app """
4
5 from typing import Dict
6
7 from django import forms
8
9 from config.helpers import render_markdown
10
11
12 class ModelMixin:
13 """
14 Default mixins for all classes in DDI on Rails.
15
16 Requires two definition in the ``DOR`` class:
17
18 * io_fields: Fields that are used for the default form and in the default dict.
19 * id_fields: Fields that are used for the get_or_create default method.
20
21 Example:
22
23 ::
24
25 from django.db import models
26 from ddionrails.mixins import ModelMixin
27
28 class Test(models.Model, ModelMixin):
29
30 name = models.CharField(max_length=255, unique=True)
31
32 class DOR:
33 id_fields = ["name"]
34 io_fields = ["name"]
35
36 The default value for DOR is:
37
38 ::
39
40 class DOR:
41 id_fields = ["name"]
42 io_fields = ["name", "label", "description"]
43
44 The ``id_fields`` are also use to construct a default string identifier.
45 It is therefore recommended, to order them from the most general to the
46 most specific one.
47
48 """
49
50 class DOR:
51 id_fields = ["name"]
52 io_fields = ["name", "label", "description"]
53
54 @classmethod
55 def get_or_create(cls, parameters: Dict, lower_strings: bool = True):
56 """
57 Default for the get_or_create based on a dict.
58
59 The method uses only relevant identifiers based on ``DOR.id_fields``.
60
61 By default, all strings are set to lower case (option ``lower_strings``).
62 """
63 definition = {key: parameters[key] for key in cls.DOR.id_fields}
64 for key, value in definition.items():
65 if value.__class__ == str and lower_strings:
66 definition[key] = value.lower()
67 return cls.objects.get_or_create(**definition)[0]
68
69 @classmethod
70 def get(cls, parameters: Dict):
71 """
72 Default for the get_or_create based on a dict.
73
74 The method uses only relevant identifiers based on ``DOR.id_fields``.
75 """
76 try:
77 definition = {key: parameters[key] for key in cls.DOR.id_fields}
78 result = cls.objects.get(**definition)
79 except cls.DoesNotExist:
80 result = None
81 return result
82
83 @classmethod
84 def default_form(cls):
85 """
86 Creates a default form for all attributes defined in ``DOR.io_fields``.
87 """
88
89 class DefaultForm(forms.ModelForm):
90 class Meta:
91 model = cls
92 fields = cls.DOR.io_fields
93
94 return DefaultForm
95
96 def to_dict(self) -> Dict:
97 """
98 Uses the ``DOR.io_fields`` attribute to generate a default
99 dict object for the current instance.
100 """
101 dictionary = dict()
102 for field in self.DOR.io_fields:
103 value = getattr(self, field)
104 try:
105 dictionary[field] = value.pk
106 except AttributeError:
107 dictionary[field] = value
108 return dictionary
109
110 def title(self):
111 """
112 Default for the title. It first looks for a valid label, next for a
113 valid name, and otherwise returns an empty string.
114 """
115 try:
116 name = self.name
117 except AttributeError:
118 name = ""
119 try:
120 label = self.label
121 except AttributeError:
122 label = ""
123 return name if label == "" else label
124
125 def html_description(self):
126 """
127 Uses the ddionrails Markdown parser (ddionrails.helpers) to render
128 the description into HTML.
129 """
130 try:
131 html = render_markdown(self.description)
132 except AttributeError:
133 html = ""
134 return html
135
136 def __str__(self):
137 """ Returns a string reprensentation of the instance, using DOR.id_fields """
138 result = []
139 for field in self.DOR.id_fields:
140 value = getattr(self, field)
141 try:
142 result.append(value.string_id())
143 except AttributeError:
144 result.append(str(value))
145 return "/".join(result)
146
147
148 class AdminMixin:
149 """ A mixin for ModelAdmins to query related models via methods """
150
151 @staticmethod
152 def study_name(obj):
153 """ Return the name of the related study """
154 try:
155 return obj.study.name
156 except AttributeError:
157 return None
158
159 @staticmethod
160 def period_name(obj):
161 """ Return the name of the related period """
162 try:
163 return obj.period.name
164 except AttributeError:
165 return None
166
167 @staticmethod
168 def analysis_unit_name(obj):
169 """ Return the name of the related analysis_unit """
170 try:
171 return obj.analysis_unit.name
172 except AttributeError:
173 return None
174
175 @staticmethod
176 def dataset_name(obj):
177 """ Return the name of the related dataset """
178 try:
179 return obj.dataset.name
180 except AttributeError:
181 return None
182
183 @staticmethod
184 def dataset_study_name(obj):
185 """ Return the name of the related dataset.study """
186 try:
187 return obj.dataset.study.name
188 except AttributeError:
189 return None
190
191 @staticmethod
192 def instrument_name(obj):
193 """ Return the name of the related instrument """
194 try:
195 return obj.instrument.name
196 except AttributeError:
197 return None
198
199 @staticmethod
200 def instrument_study_name(obj):
201 """ Return the name of the related instrument.study """
202 try:
203 return obj.instrument.study.name
204 except AttributeError:
205 return None
206
207 @staticmethod
208 def basket_name(obj):
209 """ Return the name of the related basket """
210 try:
211 return obj.basket.name
212 except AttributeError:
213 return None
214
215 @staticmethod
216 def basket_study_name(obj):
217 """ Return the name of the related basket.study """
218 try:
219 return obj.basket.study.name
220 except AttributeError:
221 return None
222
223 @staticmethod
224 def user_name(obj):
225 """ Return the name of the related basket.user """
226 try:
227 return obj.basket.user.username
228 except AttributeError:
229 return None
230
[end of ddionrails/base/mixins.py]
[start of ddionrails/studies/models.py]
1 # -*- coding: utf-8 -*-
2 """ Model definitions for ddionrails.studies app """
3
4 import os
5 from typing import List, Optional
6
7 from django.conf import settings
8 from django.contrib.postgres.fields import ArrayField, JSONField
9 from django.contrib.postgres.fields.jsonb import JSONField as JSONBField
10 from django.db import models
11 from django.urls import reverse
12 from model_utils.models import TimeStampedModel
13
14 from ddionrails.base.mixins import ModelMixin
15
16
17 class TopicList(models.Model):
18
19 # attributes
20 topiclist = JSONBField(
21 default=list,
22 null=True,
23 blank=True,
24 help_text="Topics of the related study (JSON)",
25 )
26
27 # relations
28 study = models.OneToOneField(
29 "Study",
30 blank=True,
31 null=True,
32 related_name="topiclist",
33 on_delete=models.CASCADE,
34 help_text="OneToOneField to studies.Study",
35 )
36
37
38 class Study(ModelMixin, TimeStampedModel):
39 """
40 Stores a single study,
41 related to :model:`data.Dataset`, :model:`instruments.Instrument`,
42 :model:`concepts.Period` and :model:`workspace.Basket`.
43 """
44
45 # attributes
46 name = models.CharField(
47 max_length=255, unique=True, db_index=True, help_text="Name of the study"
48 )
49 label = models.CharField(
50 max_length=255,
51 blank=True,
52 verbose_name="Label (English)",
53 help_text="Label of the study (English)",
54 )
55 label_de = models.CharField(
56 max_length=255,
57 blank=True,
58 null=True,
59 verbose_name="Label (German)",
60 help_text="Label of the study (German)",
61 )
62 description = models.TextField(
63 blank=True, help_text="Description of the study (Markdown)"
64 )
65 repo = models.CharField(
66 max_length=255,
67 blank=True,
68 help_text="Reference to the Git repository without definition of the protocol (e.g. https)",
69 )
70 current_commit = models.CharField(
71 max_length=255,
72 blank=True,
73 help_text="Commit hash of the last metadata import. This field is automatically filled by DDI on Rails",
74 )
75 config = JSONField(
76 default=dict, blank=True, null=True, help_text="Configuration of the study (JSON)"
77 )
78
79 topic_languages = ArrayField(
80 models.CharField(max_length=200),
81 blank=True,
82 default=list,
83 help_text="Topic languages of the study (Array)",
84 )
85
86 class Meta: # pylint: disable=too-few-public-methods
87 """ Django's metadata options """
88
89 verbose_name_plural = "Studies"
90
91 class DOR: # pylint: disable=too-few-public-methods
92 """ ddionrails' metadata options """
93
94 io_fields = ["name", "label", "description"]
95 id_fields = ["name"]
96
97 def __str__(self) -> str:
98 """ Returns a string representation using the "name" field """
99 return f"/{self.name}"
100
101 def get_absolute_url(self) -> str:
102 """ Returns a canonical URL for the model using the "name" field """
103 return reverse("study_detail", kwargs={"study_name": self.name})
104
105 def import_path(self):
106 path = os.path.join(
107 settings.IMPORT_REPO_PATH, self.name, settings.IMPORT_SUB_DIRECTORY
108 )
109 return path
110
111 def repo_url(self) -> str:
112 if settings.GIT_PROTOCOL == "https":
113 return f"https://{self.repo}.git"
114 elif settings.GIT_PROTOCOL == "ssh":
115 return f"git@{self.repo}.git"
116 else:
117 raise Exception("Specify a protocol for Git in your settings.")
118
119 def set_topiclist(self, body: List) -> None:
120 _topiclist, _ = TopicList.objects.get_or_create(study=self)
121 _topiclist.topiclist = body
122 _topiclist.save()
123
124 def has_topics(self) -> bool:
125 """ Returns True if the study has topics False otherwise (evaluates the length of self.topic_languages) """
126 return len(self.topic_languages) > 0
127
128 def get_topiclist(self, language: str = "en") -> Optional[List]:
129 """ Returns the list of topics for a given language or None """
130 try:
131 for topiclist in self.topiclist.topiclist:
132 if topiclist.get("language", "") == language:
133 return topiclist.get("topics")
134 except TopicList.DoesNotExist:
135 return None
136
137
138 def context(request):
139 return dict(all_studies=Study.objects.all().only("name", "label", "description"))
140
[end of ddionrails/studies/models.py]
[start of ddionrails/base/models.py]
1 # -*- coding: utf-8 -*-
2
3 """ Model definitions for ddionrails.base app """
4
5 from __future__ import annotations
6
7 import pathlib
8
9 from django.conf import settings
10 from django.db import models
11
12
13 class System(models.Model):
14 """ Stores a single system instance """
15
16 name = settings.SYSTEM_NAME
17 current_commit = models.CharField(max_length=255, blank=True)
18
19 @staticmethod
20 def repo_url() -> str:
21 """ Returns the system's repo url from the settings """
22 return settings.SYSTEM_REPO_URL
23
24 def import_path(self) -> pathlib.Path:
25 """ Returns the system's import path """
26 return pathlib.Path(settings.IMPORT_REPO_PATH).joinpath(
27 self.name, settings.IMPORT_SUB_DIRECTORY
28 )
29
30 @classmethod
31 def get(cls) -> System:
32 """ Returns a single system instance """
33 if cls.objects.count() == 0:
34 system = System()
35 system.save()
36 else:
37 system = System.objects.first()
38 return system
39
[end of ddionrails/base/models.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ddionrails/base/mixins.py b/ddionrails/base/mixins.py
--- a/ddionrails/base/mixins.py
+++ b/ddionrails/base/mixins.py
@@ -2,9 +2,11 @@
""" Mixins for ddionrails.base app """
+import pathlib
from typing import Dict
from django import forms
+from django.conf import settings
from config.helpers import render_markdown
@@ -145,6 +147,16 @@
return "/".join(result)
+class ImportPathMixin:
+ """ A mixin for models to return an import_path based on their name attribute """
+
+ def import_path(self) -> pathlib.Path:
+ """ Returns the instance's import path """
+ return pathlib.Path(settings.IMPORT_REPO_PATH).joinpath(
+ self.name, settings.IMPORT_SUB_DIRECTORY
+ )
+
+
class AdminMixin:
""" A mixin for ModelAdmins to query related models via methods """
diff --git a/ddionrails/base/models.py b/ddionrails/base/models.py
--- a/ddionrails/base/models.py
+++ b/ddionrails/base/models.py
@@ -4,13 +4,13 @@
from __future__ import annotations
-import pathlib
-
from django.conf import settings
from django.db import models
+from .mixins import ImportPathMixin
+
-class System(models.Model):
+class System(ImportPathMixin, models.Model):
""" Stores a single system instance """
name = settings.SYSTEM_NAME
@@ -21,12 +21,6 @@
""" Returns the system's repo url from the settings """
return settings.SYSTEM_REPO_URL
- def import_path(self) -> pathlib.Path:
- """ Returns the system's import path """
- return pathlib.Path(settings.IMPORT_REPO_PATH).joinpath(
- self.name, settings.IMPORT_SUB_DIRECTORY
- )
-
@classmethod
def get(cls) -> System:
""" Returns a single system instance """
diff --git a/ddionrails/studies/models.py b/ddionrails/studies/models.py
--- a/ddionrails/studies/models.py
+++ b/ddionrails/studies/models.py
@@ -11,7 +11,7 @@
from django.urls import reverse
from model_utils.models import TimeStampedModel
-from ddionrails.base.mixins import ModelMixin
+from ddionrails.base.mixins import ImportPathMixin, ModelMixin
class TopicList(models.Model):
@@ -35,7 +35,7 @@
)
-class Study(ModelMixin, TimeStampedModel):
+class Study(ImportPathMixin, ModelMixin, TimeStampedModel):
"""
Stores a single study,
related to :model:`data.Dataset`, :model:`instruments.Instrument`,
@@ -102,12 +102,6 @@
""" Returns a canonical URL for the model using the "name" field """
return reverse("study_detail", kwargs={"study_name": self.name})
- def import_path(self):
- path = os.path.join(
- settings.IMPORT_REPO_PATH, self.name, settings.IMPORT_SUB_DIRECTORY
- )
- return path
-
def repo_url(self) -> str:
if settings.GIT_PROTOCOL == "https":
return f"https://{self.repo}.git"
|
{"golden_diff": "diff --git a/ddionrails/base/mixins.py b/ddionrails/base/mixins.py\n--- a/ddionrails/base/mixins.py\n+++ b/ddionrails/base/mixins.py\n@@ -2,9 +2,11 @@\n \n \"\"\" Mixins for ddionrails.base app \"\"\"\n \n+import pathlib\n from typing import Dict\n \n from django import forms\n+from django.conf import settings\n \n from config.helpers import render_markdown\n \n@@ -145,6 +147,16 @@\n return \"/\".join(result)\n \n \n+class ImportPathMixin:\n+ \"\"\" A mixin for models to return an import_path based on their name attribute \"\"\"\n+\n+ def import_path(self) -> pathlib.Path:\n+ \"\"\" Returns the instance's import path \"\"\"\n+ return pathlib.Path(settings.IMPORT_REPO_PATH).joinpath(\n+ self.name, settings.IMPORT_SUB_DIRECTORY\n+ )\n+\n+\n class AdminMixin:\n \"\"\" A mixin for ModelAdmins to query related models via methods \"\"\"\n \ndiff --git a/ddionrails/base/models.py b/ddionrails/base/models.py\n--- a/ddionrails/base/models.py\n+++ b/ddionrails/base/models.py\n@@ -4,13 +4,13 @@\n \n from __future__ import annotations\n \n-import pathlib\n-\n from django.conf import settings\n from django.db import models\n \n+from .mixins import ImportPathMixin\n+\n \n-class System(models.Model):\n+class System(ImportPathMixin, models.Model):\n \"\"\" Stores a single system instance \"\"\"\n \n name = settings.SYSTEM_NAME\n@@ -21,12 +21,6 @@\n \"\"\" Returns the system's repo url from the settings \"\"\"\n return settings.SYSTEM_REPO_URL\n \n- def import_path(self) -> pathlib.Path:\n- \"\"\" Returns the system's import path \"\"\"\n- return pathlib.Path(settings.IMPORT_REPO_PATH).joinpath(\n- self.name, settings.IMPORT_SUB_DIRECTORY\n- )\n-\n @classmethod\n def get(cls) -> System:\n \"\"\" Returns a single system instance \"\"\"\ndiff --git a/ddionrails/studies/models.py b/ddionrails/studies/models.py\n--- a/ddionrails/studies/models.py\n+++ b/ddionrails/studies/models.py\n@@ -11,7 +11,7 @@\n from django.urls import reverse\n from model_utils.models import TimeStampedModel\n \n-from ddionrails.base.mixins import ModelMixin\n+from ddionrails.base.mixins import ImportPathMixin, ModelMixin\n \n \n class TopicList(models.Model):\n@@ -35,7 +35,7 @@\n )\n \n \n-class Study(ModelMixin, TimeStampedModel):\n+class Study(ImportPathMixin, ModelMixin, TimeStampedModel):\n \"\"\"\n Stores a single study,\n related to :model:`data.Dataset`, :model:`instruments.Instrument`,\n@@ -102,12 +102,6 @@\n \"\"\" Returns a canonical URL for the model using the \"name\" field \"\"\"\n return reverse(\"study_detail\", kwargs={\"study_name\": self.name})\n \n- def import_path(self):\n- path = os.path.join(\n- settings.IMPORT_REPO_PATH, self.name, settings.IMPORT_SUB_DIRECTORY\n- )\n- return path\n-\n def repo_url(self) -> str:\n if settings.GIT_PROTOCOL == \"https\":\n return f\"https://{self.repo}.git\"\n", "issue": "Move import_path() method into mixin\n### Subject of the issue\r\n\r\nThe System and Study model both implement the same `import_path()` method.\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\" Mixins for ddionrails.base app \"\"\"\n\nfrom typing import Dict\n\nfrom django import forms\n\nfrom config.helpers import render_markdown\n\n\nclass ModelMixin:\n \"\"\"\n Default mixins for all classes in DDI on Rails.\n\n Requires two definition in the ``DOR`` class:\n\n * io_fields: Fields that are used for the default form and in the default dict.\n * id_fields: Fields that are used for the get_or_create default method.\n\n Example:\n\n ::\n\n from django.db import models\n from ddionrails.mixins import ModelMixin\n\n class Test(models.Model, ModelMixin):\n\n name = models.CharField(max_length=255, unique=True)\n\n class DOR:\n id_fields = [\"name\"]\n io_fields = [\"name\"]\n\n The default value for DOR is:\n\n ::\n\n class DOR:\n id_fields = [\"name\"]\n io_fields = [\"name\", \"label\", \"description\"]\n\n The ``id_fields`` are also use to construct a default string identifier.\n It is therefore recommended, to order them from the most general to the\n most specific one.\n\n \"\"\"\n\n class DOR:\n id_fields = [\"name\"]\n io_fields = [\"name\", \"label\", \"description\"]\n\n @classmethod\n def get_or_create(cls, parameters: Dict, lower_strings: bool = True):\n \"\"\"\n Default for the get_or_create based on a dict.\n\n The method uses only relevant identifiers based on ``DOR.id_fields``.\n\n By default, all strings are set to lower case (option ``lower_strings``).\n \"\"\"\n definition = {key: parameters[key] for key in cls.DOR.id_fields}\n for key, value in definition.items():\n if value.__class__ == str and lower_strings:\n definition[key] = value.lower()\n return cls.objects.get_or_create(**definition)[0]\n\n @classmethod\n def get(cls, parameters: Dict):\n \"\"\"\n Default for the get_or_create based on a dict.\n\n The method uses only relevant identifiers based on ``DOR.id_fields``.\n \"\"\"\n try:\n definition = {key: parameters[key] for key in cls.DOR.id_fields}\n result = cls.objects.get(**definition)\n except cls.DoesNotExist:\n result = None\n return result\n\n @classmethod\n def default_form(cls):\n \"\"\"\n Creates a default form for all attributes defined in ``DOR.io_fields``.\n \"\"\"\n\n class DefaultForm(forms.ModelForm):\n class Meta:\n model = cls\n fields = cls.DOR.io_fields\n\n return DefaultForm\n\n def to_dict(self) -> Dict:\n \"\"\"\n Uses the ``DOR.io_fields`` attribute to generate a default\n dict object for the current instance.\n \"\"\"\n dictionary = dict()\n for field in self.DOR.io_fields:\n value = getattr(self, field)\n try:\n dictionary[field] = value.pk\n except AttributeError:\n dictionary[field] = value\n return dictionary\n\n def title(self):\n \"\"\"\n Default for the title. It first looks for a valid label, next for a\n valid name, and otherwise returns an empty string.\n \"\"\"\n try:\n name = self.name\n except AttributeError:\n name = \"\"\n try:\n label = self.label\n except AttributeError:\n label = \"\"\n return name if label == \"\" else label\n\n def html_description(self):\n \"\"\"\n Uses the ddionrails Markdown parser (ddionrails.helpers) to render\n the description into HTML.\n \"\"\"\n try:\n html = render_markdown(self.description)\n except AttributeError:\n html = \"\"\n return html\n\n def __str__(self):\n \"\"\" Returns a string reprensentation of the instance, using DOR.id_fields \"\"\"\n result = []\n for field in self.DOR.id_fields:\n value = getattr(self, field)\n try:\n result.append(value.string_id())\n except AttributeError:\n result.append(str(value))\n return \"/\".join(result)\n\n\nclass AdminMixin:\n \"\"\" A mixin for ModelAdmins to query related models via methods \"\"\"\n\n @staticmethod\n def study_name(obj):\n \"\"\" Return the name of the related study \"\"\"\n try:\n return obj.study.name\n except AttributeError:\n return None\n\n @staticmethod\n def period_name(obj):\n \"\"\" Return the name of the related period \"\"\"\n try:\n return obj.period.name\n except AttributeError:\n return None\n\n @staticmethod\n def analysis_unit_name(obj):\n \"\"\" Return the name of the related analysis_unit \"\"\"\n try:\n return obj.analysis_unit.name\n except AttributeError:\n return None\n\n @staticmethod\n def dataset_name(obj):\n \"\"\" Return the name of the related dataset \"\"\"\n try:\n return obj.dataset.name\n except AttributeError:\n return None\n\n @staticmethod\n def dataset_study_name(obj):\n \"\"\" Return the name of the related dataset.study \"\"\"\n try:\n return obj.dataset.study.name\n except AttributeError:\n return None\n\n @staticmethod\n def instrument_name(obj):\n \"\"\" Return the name of the related instrument \"\"\"\n try:\n return obj.instrument.name\n except AttributeError:\n return None\n\n @staticmethod\n def instrument_study_name(obj):\n \"\"\" Return the name of the related instrument.study \"\"\"\n try:\n return obj.instrument.study.name\n except AttributeError:\n return None\n\n @staticmethod\n def basket_name(obj):\n \"\"\" Return the name of the related basket \"\"\"\n try:\n return obj.basket.name\n except AttributeError:\n return None\n\n @staticmethod\n def basket_study_name(obj):\n \"\"\" Return the name of the related basket.study \"\"\"\n try:\n return obj.basket.study.name\n except AttributeError:\n return None\n\n @staticmethod\n def user_name(obj):\n \"\"\" Return the name of the related basket.user \"\"\"\n try:\n return obj.basket.user.username\n except AttributeError:\n return None\n", "path": "ddionrails/base/mixins.py"}, {"content": "# -*- coding: utf-8 -*-\n\"\"\" Model definitions for ddionrails.studies app \"\"\"\n\nimport os\nfrom typing import List, Optional\n\nfrom django.conf import settings\nfrom django.contrib.postgres.fields import ArrayField, JSONField\nfrom django.contrib.postgres.fields.jsonb import JSONField as JSONBField\nfrom django.db import models\nfrom django.urls import reverse\nfrom model_utils.models import TimeStampedModel\n\nfrom ddionrails.base.mixins import ModelMixin\n\n\nclass TopicList(models.Model):\n\n # attributes\n topiclist = JSONBField(\n default=list,\n null=True,\n blank=True,\n help_text=\"Topics of the related study (JSON)\",\n )\n\n # relations\n study = models.OneToOneField(\n \"Study\",\n blank=True,\n null=True,\n related_name=\"topiclist\",\n on_delete=models.CASCADE,\n help_text=\"OneToOneField to studies.Study\",\n )\n\n\nclass Study(ModelMixin, TimeStampedModel):\n \"\"\"\n Stores a single study,\n related to :model:`data.Dataset`, :model:`instruments.Instrument`,\n :model:`concepts.Period` and :model:`workspace.Basket`.\n \"\"\"\n\n # attributes\n name = models.CharField(\n max_length=255, unique=True, db_index=True, help_text=\"Name of the study\"\n )\n label = models.CharField(\n max_length=255,\n blank=True,\n verbose_name=\"Label (English)\",\n help_text=\"Label of the study (English)\",\n )\n label_de = models.CharField(\n max_length=255,\n blank=True,\n null=True,\n verbose_name=\"Label (German)\",\n help_text=\"Label of the study (German)\",\n )\n description = models.TextField(\n blank=True, help_text=\"Description of the study (Markdown)\"\n )\n repo = models.CharField(\n max_length=255,\n blank=True,\n help_text=\"Reference to the Git repository without definition of the protocol (e.g. https)\",\n )\n current_commit = models.CharField(\n max_length=255,\n blank=True,\n help_text=\"Commit hash of the last metadata import. This field is automatically filled by DDI on Rails\",\n )\n config = JSONField(\n default=dict, blank=True, null=True, help_text=\"Configuration of the study (JSON)\"\n )\n\n topic_languages = ArrayField(\n models.CharField(max_length=200),\n blank=True,\n default=list,\n help_text=\"Topic languages of the study (Array)\",\n )\n\n class Meta: # pylint: disable=too-few-public-methods\n \"\"\" Django's metadata options \"\"\"\n\n verbose_name_plural = \"Studies\"\n\n class DOR: # pylint: disable=too-few-public-methods\n \"\"\" ddionrails' metadata options \"\"\"\n\n io_fields = [\"name\", \"label\", \"description\"]\n id_fields = [\"name\"]\n\n def __str__(self) -> str:\n \"\"\" Returns a string representation using the \"name\" field \"\"\"\n return f\"/{self.name}\"\n\n def get_absolute_url(self) -> str:\n \"\"\" Returns a canonical URL for the model using the \"name\" field \"\"\"\n return reverse(\"study_detail\", kwargs={\"study_name\": self.name})\n\n def import_path(self):\n path = os.path.join(\n settings.IMPORT_REPO_PATH, self.name, settings.IMPORT_SUB_DIRECTORY\n )\n return path\n\n def repo_url(self) -> str:\n if settings.GIT_PROTOCOL == \"https\":\n return f\"https://{self.repo}.git\"\n elif settings.GIT_PROTOCOL == \"ssh\":\n return f\"git@{self.repo}.git\"\n else:\n raise Exception(\"Specify a protocol for Git in your settings.\")\n\n def set_topiclist(self, body: List) -> None:\n _topiclist, _ = TopicList.objects.get_or_create(study=self)\n _topiclist.topiclist = body\n _topiclist.save()\n\n def has_topics(self) -> bool:\n \"\"\" Returns True if the study has topics False otherwise (evaluates the length of self.topic_languages) \"\"\"\n return len(self.topic_languages) > 0\n\n def get_topiclist(self, language: str = \"en\") -> Optional[List]:\n \"\"\" Returns the list of topics for a given language or None \"\"\"\n try:\n for topiclist in self.topiclist.topiclist:\n if topiclist.get(\"language\", \"\") == language:\n return topiclist.get(\"topics\")\n except TopicList.DoesNotExist:\n return None\n\n\ndef context(request):\n return dict(all_studies=Study.objects.all().only(\"name\", \"label\", \"description\"))\n", "path": "ddionrails/studies/models.py"}, {"content": "# -*- coding: utf-8 -*-\n\n\"\"\" Model definitions for ddionrails.base app \"\"\"\n\nfrom __future__ import annotations\n\nimport pathlib\n\nfrom django.conf import settings\nfrom django.db import models\n\n\nclass System(models.Model):\n \"\"\" Stores a single system instance \"\"\"\n\n name = settings.SYSTEM_NAME\n current_commit = models.CharField(max_length=255, blank=True)\n\n @staticmethod\n def repo_url() -> str:\n \"\"\" Returns the system's repo url from the settings \"\"\"\n return settings.SYSTEM_REPO_URL\n\n def import_path(self) -> pathlib.Path:\n \"\"\" Returns the system's import path \"\"\"\n return pathlib.Path(settings.IMPORT_REPO_PATH).joinpath(\n self.name, settings.IMPORT_SUB_DIRECTORY\n )\n\n @classmethod\n def get(cls) -> System:\n \"\"\" Returns a single system instance \"\"\"\n if cls.objects.count() == 0:\n system = System()\n system.save()\n else:\n system = System.objects.first()\n return system\n", "path": "ddionrails/base/models.py"}]}
| 4,087 | 715 |
gh_patches_debug_20706
|
rasdani/github-patches
|
git_diff
|
archlinux__archinstall-668
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
use_mirrors bug
https://github.com/archlinux/archinstall/blob/ba725517fd290a60cd4e1ea570dbbf94a47ede05/archinstall/lib/mirrors.py#L116-L123
This code doesn't open destination file in append mode. So, if we pass a dict of mirrors with multiple regions, file will be rewritten `len(regions)` times and only the last entry will be preserved.
</issue>
<code>
[start of archinstall/lib/mirrors.py]
1 import urllib.error
2 import urllib.request
3 from typing import Union
4
5 from .general import *
6 from .output import log
7
8 def sort_mirrorlist(raw_data :bytes, sort_order=["https", "http"]) -> bytes:
9 """
10 This function can sort /etc/pacman.d/mirrorlist according to the
11 mirror's URL prefix. By default places HTTPS before HTTP but it also
12 preserves the country/rank-order.
13
14 This assumes /etc/pacman.d/mirrorlist looks like the following:
15
16 ## Comment
17 Server = url
18
19 or
20
21 ## Comment
22 #Server = url
23
24 But the Comments need to start with double-hashmarks to be distringuished
25 from server url definitions (commented or uncommented).
26 """
27 comments_and_whitespaces = b""
28
29 categories = {key: [] for key in sort_order+["Unknown"]}
30 for line in raw_data.split(b"\n"):
31 if line[0:2] in (b'##', b''):
32 comments_and_whitespaces += line + b'\n'
33 elif line[:6].lower() == b'server' or line[:7].lower() == b'#server':
34 opening, url = line.split(b'=', 1)
35 opening, url = opening.strip(), url.strip()
36 if (category := url.split(b'://',1)[0].decode('UTF-8')) in categories:
37 categories[category].append(comments_and_whitespaces)
38 categories[category].append(opening+b' = '+url+b'\n')
39 else:
40 categories["Unknown"].append(comments_and_whitespaces)
41 categories["Unknown"].append(opening+b' = '+url+b'\n')
42
43 comments_and_whitespaces = b""
44
45
46 new_raw_data = b''
47 for category in sort_order+["Unknown"]:
48 for line in categories[category]:
49 new_raw_data += line
50
51 return new_raw_data
52
53
54 def filter_mirrors_by_region(regions, destination='/etc/pacman.d/mirrorlist', sort_order=["https", "http"], *args, **kwargs) -> Union[bool, bytes]:
55 """
56 This function will change the active mirrors on the live medium by
57 filtering which regions are active based on `regions`.
58
59 :param regions: A series of country codes separated by `,`. For instance `SE,US` for sweden and United States.
60 :type regions: str
61 """
62 region_list = [f'country={region}' for region in regions.split(',')]
63 response = urllib.request.urlopen(urllib.request.Request(f"https://archlinux.org/mirrorlist/?{'&'.join(region_list)}&protocol=https&protocol=http&ip_version=4&ip_version=6&use_mirror_status=on'", headers={'User-Agent': 'ArchInstall'}))
64 new_list = response.read().replace(b"#Server", b"Server")
65
66 if sort_order:
67 new_list = sort_mirrorlist(new_list, sort_order=sort_order)
68
69 if destination:
70 with open(destination, "wb") as mirrorlist:
71 mirrorlist.write(new_list)
72
73 return True
74 else:
75 return new_list.decode('UTF-8')
76
77
78 def add_custom_mirrors(mirrors: list, *args, **kwargs):
79 """
80 This will append custom mirror definitions in pacman.conf
81
82 :param mirrors: A list of mirror data according to: `{'url': 'http://url.com', 'signcheck': 'Optional', 'signoptions': 'TrustAll', 'name': 'testmirror'}`
83 :type mirrors: dict
84 """
85 with open('/etc/pacman.conf', 'a') as pacman:
86 for mirror in mirrors:
87 pacman.write(f"[{mirror['name']}]\n")
88 pacman.write(f"SigLevel = {mirror['signcheck']} {mirror['signoptions']}\n")
89 pacman.write(f"Server = {mirror['url']}\n")
90
91 return True
92
93
94 def insert_mirrors(mirrors, *args, **kwargs):
95 """
96 This function will insert a given mirror-list at the top of `/etc/pacman.d/mirrorlist`.
97 It will not flush any other mirrors, just insert new ones.
98
99 :param mirrors: A dictionary of `{'url' : 'country', 'url2' : 'country'}`
100 :type mirrors: dict
101 """
102 original_mirrorlist = ''
103 with open('/etc/pacman.d/mirrorlist', 'r') as original:
104 original_mirrorlist = original.read()
105
106 with open('/etc/pacman.d/mirrorlist', 'w') as new_mirrorlist:
107 for mirror, country in mirrors.items():
108 new_mirrorlist.write(f'## {country}\n')
109 new_mirrorlist.write(f'Server = {mirror}\n')
110 new_mirrorlist.write('\n')
111 new_mirrorlist.write(original_mirrorlist)
112
113 return True
114
115
116 def use_mirrors(regions: dict, destination='/etc/pacman.d/mirrorlist'):
117 log(f'A new package mirror-list has been created: {destination}', level=logging.INFO)
118 for region, mirrors in regions.items():
119 with open(destination, 'w') as mirrorlist:
120 for mirror in mirrors:
121 mirrorlist.write(f'## {region}\n')
122 mirrorlist.write(f'Server = {mirror}\n')
123 return True
124
125
126 def re_rank_mirrors(top=10, *positionals, **kwargs):
127 if SysCommand(f'/usr/bin/rankmirrors -n {top} /etc/pacman.d/mirrorlist > /etc/pacman.d/mirrorlist').exit_code == 0:
128 return True
129 return False
130
131
132 def list_mirrors(sort_order=["https", "http"]):
133 url = "https://archlinux.org/mirrorlist/?protocol=https&protocol=http&ip_version=4&ip_version=6&use_mirror_status=on"
134 regions = {}
135
136 try:
137 response = urllib.request.urlopen(url)
138 except urllib.error.URLError as err:
139 log(f'Could not fetch an active mirror-list: {err}', level=logging.WARNING, fg="yellow")
140 return regions
141
142 mirrorlist = response.read()
143 if sort_order:
144 mirrorlist = sort_mirrorlist(mirrorlist, sort_order=sort_order)
145
146 region = 'Unknown region'
147 for line in mirrorlist.split(b'\n'):
148 if len(line.strip()) == 0:
149 continue
150
151 line = line.decode('UTF-8').strip('\n').strip('\r')
152 if line[:3] == '## ':
153 region = line[3:]
154 elif line[:10] == '#Server = ':
155 regions.setdefault(region, {})
156
157 url = line.lstrip('#Server = ')
158 regions[region][url] = True
159
160 return regions
161
[end of archinstall/lib/mirrors.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/archinstall/lib/mirrors.py b/archinstall/lib/mirrors.py
--- a/archinstall/lib/mirrors.py
+++ b/archinstall/lib/mirrors.py
@@ -1,6 +1,6 @@
import urllib.error
import urllib.request
-from typing import Union
+from typing import Union, Mapping, Iterable
from .general import *
from .output import log
@@ -113,14 +113,16 @@
return True
-def use_mirrors(regions: dict, destination='/etc/pacman.d/mirrorlist'):
+def use_mirrors(
+ regions: Mapping[str, Iterable[str]],
+ destination: str ='/etc/pacman.d/mirrorlist'
+) -> None:
log(f'A new package mirror-list has been created: {destination}', level=logging.INFO)
- for region, mirrors in regions.items():
- with open(destination, 'w') as mirrorlist:
+ with open(destination, 'w') as mirrorlist:
+ for region, mirrors in regions.items():
for mirror in mirrors:
mirrorlist.write(f'## {region}\n')
mirrorlist.write(f'Server = {mirror}\n')
- return True
def re_rank_mirrors(top=10, *positionals, **kwargs):
|
{"golden_diff": "diff --git a/archinstall/lib/mirrors.py b/archinstall/lib/mirrors.py\n--- a/archinstall/lib/mirrors.py\n+++ b/archinstall/lib/mirrors.py\n@@ -1,6 +1,6 @@\n import urllib.error\n import urllib.request\n-from typing import Union\n+from typing import Union, Mapping, Iterable\n \n from .general import *\n from .output import log\n@@ -113,14 +113,16 @@\n \treturn True\n \n \n-def use_mirrors(regions: dict, destination='/etc/pacman.d/mirrorlist'):\n+def use_mirrors(\n+\tregions: Mapping[str, Iterable[str]],\n+\tdestination: str ='/etc/pacman.d/mirrorlist'\n+) -> None:\n \tlog(f'A new package mirror-list has been created: {destination}', level=logging.INFO)\n-\tfor region, mirrors in regions.items():\n-\t\twith open(destination, 'w') as mirrorlist:\n+\twith open(destination, 'w') as mirrorlist:\n+\t\tfor region, mirrors in regions.items():\n \t\t\tfor mirror in mirrors:\n \t\t\t\tmirrorlist.write(f'## {region}\\n')\n \t\t\t\tmirrorlist.write(f'Server = {mirror}\\n')\n-\treturn True\n \n \n def re_rank_mirrors(top=10, *positionals, **kwargs):\n", "issue": "use_mirrors bug\nhttps://github.com/archlinux/archinstall/blob/ba725517fd290a60cd4e1ea570dbbf94a47ede05/archinstall/lib/mirrors.py#L116-L123\r\n\r\nThis code doesn't open destination file in append mode. So, if we pass a dict of mirrors with multiple regions, file will be rewritten `len(regions)` times and only the last entry will be preserved.\n", "before_files": [{"content": "import urllib.error\nimport urllib.request\nfrom typing import Union\n\nfrom .general import *\nfrom .output import log\n\ndef sort_mirrorlist(raw_data :bytes, sort_order=[\"https\", \"http\"]) -> bytes:\n\t\"\"\"\n\tThis function can sort /etc/pacman.d/mirrorlist according to the\n\tmirror's URL prefix. By default places HTTPS before HTTP but it also\n\tpreserves the country/rank-order.\n\n\tThis assumes /etc/pacman.d/mirrorlist looks like the following:\n\n\t## Comment\n\tServer = url\n\n\tor\n\n\t## Comment\n\t#Server = url\n\n\tBut the Comments need to start with double-hashmarks to be distringuished\n\tfrom server url definitions (commented or uncommented).\n\t\"\"\"\n\tcomments_and_whitespaces = b\"\"\n\n\tcategories = {key: [] for key in sort_order+[\"Unknown\"]}\n\tfor line in raw_data.split(b\"\\n\"):\n\t\tif line[0:2] in (b'##', b''):\n\t\t\tcomments_and_whitespaces += line + b'\\n'\n\t\telif line[:6].lower() == b'server' or line[:7].lower() == b'#server':\n\t\t\topening, url = line.split(b'=', 1)\n\t\t\topening, url = opening.strip(), url.strip()\n\t\t\tif (category := url.split(b'://',1)[0].decode('UTF-8')) in categories:\n\t\t\t\tcategories[category].append(comments_and_whitespaces)\n\t\t\t\tcategories[category].append(opening+b' = '+url+b'\\n')\n\t\t\telse:\n\t\t\t\tcategories[\"Unknown\"].append(comments_and_whitespaces)\n\t\t\t\tcategories[\"Unknown\"].append(opening+b' = '+url+b'\\n')\n\n\t\t\tcomments_and_whitespaces = b\"\"\n\n\n\tnew_raw_data = b''\n\tfor category in sort_order+[\"Unknown\"]:\n\t\tfor line in categories[category]:\n\t\t\tnew_raw_data += line\n\n\treturn new_raw_data\n\n\ndef filter_mirrors_by_region(regions, destination='/etc/pacman.d/mirrorlist', sort_order=[\"https\", \"http\"], *args, **kwargs) -> Union[bool, bytes]:\n\t\"\"\"\n\tThis function will change the active mirrors on the live medium by\n\tfiltering which regions are active based on `regions`.\n\n\t:param regions: A series of country codes separated by `,`. For instance `SE,US` for sweden and United States.\n\t:type regions: str\n\t\"\"\"\n\tregion_list = [f'country={region}' for region in regions.split(',')]\n\tresponse = urllib.request.urlopen(urllib.request.Request(f\"https://archlinux.org/mirrorlist/?{'&'.join(region_list)}&protocol=https&protocol=http&ip_version=4&ip_version=6&use_mirror_status=on'\", headers={'User-Agent': 'ArchInstall'}))\n\tnew_list = response.read().replace(b\"#Server\", b\"Server\")\n\n\tif sort_order:\n\t\tnew_list = sort_mirrorlist(new_list, sort_order=sort_order)\n\n\tif destination:\n\t\twith open(destination, \"wb\") as mirrorlist:\n\t\t\tmirrorlist.write(new_list)\n\n\t\treturn True\n\telse:\n\t\treturn new_list.decode('UTF-8')\n\n\ndef add_custom_mirrors(mirrors: list, *args, **kwargs):\n\t\"\"\"\n\tThis will append custom mirror definitions in pacman.conf\n\n\t:param mirrors: A list of mirror data according to: `{'url': 'http://url.com', 'signcheck': 'Optional', 'signoptions': 'TrustAll', 'name': 'testmirror'}`\n\t:type mirrors: dict\n\t\"\"\"\n\twith open('/etc/pacman.conf', 'a') as pacman:\n\t\tfor mirror in mirrors:\n\t\t\tpacman.write(f\"[{mirror['name']}]\\n\")\n\t\t\tpacman.write(f\"SigLevel = {mirror['signcheck']} {mirror['signoptions']}\\n\")\n\t\t\tpacman.write(f\"Server = {mirror['url']}\\n\")\n\n\treturn True\n\n\ndef insert_mirrors(mirrors, *args, **kwargs):\n\t\"\"\"\n\tThis function will insert a given mirror-list at the top of `/etc/pacman.d/mirrorlist`.\n\tIt will not flush any other mirrors, just insert new ones.\n\n\t:param mirrors: A dictionary of `{'url' : 'country', 'url2' : 'country'}`\n\t:type mirrors: dict\n\t\"\"\"\n\toriginal_mirrorlist = ''\n\twith open('/etc/pacman.d/mirrorlist', 'r') as original:\n\t\toriginal_mirrorlist = original.read()\n\n\twith open('/etc/pacman.d/mirrorlist', 'w') as new_mirrorlist:\n\t\tfor mirror, country in mirrors.items():\n\t\t\tnew_mirrorlist.write(f'## {country}\\n')\n\t\t\tnew_mirrorlist.write(f'Server = {mirror}\\n')\n\t\tnew_mirrorlist.write('\\n')\n\t\tnew_mirrorlist.write(original_mirrorlist)\n\n\treturn True\n\n\ndef use_mirrors(regions: dict, destination='/etc/pacman.d/mirrorlist'):\n\tlog(f'A new package mirror-list has been created: {destination}', level=logging.INFO)\n\tfor region, mirrors in regions.items():\n\t\twith open(destination, 'w') as mirrorlist:\n\t\t\tfor mirror in mirrors:\n\t\t\t\tmirrorlist.write(f'## {region}\\n')\n\t\t\t\tmirrorlist.write(f'Server = {mirror}\\n')\n\treturn True\n\n\ndef re_rank_mirrors(top=10, *positionals, **kwargs):\n\tif SysCommand(f'/usr/bin/rankmirrors -n {top} /etc/pacman.d/mirrorlist > /etc/pacman.d/mirrorlist').exit_code == 0:\n\t\treturn True\n\treturn False\n\n\ndef list_mirrors(sort_order=[\"https\", \"http\"]):\n\turl = \"https://archlinux.org/mirrorlist/?protocol=https&protocol=http&ip_version=4&ip_version=6&use_mirror_status=on\"\n\tregions = {}\n\n\ttry:\n\t\tresponse = urllib.request.urlopen(url)\n\texcept urllib.error.URLError as err:\n\t\tlog(f'Could not fetch an active mirror-list: {err}', level=logging.WARNING, fg=\"yellow\")\n\t\treturn regions\n\n\tmirrorlist = response.read()\n\tif sort_order:\n\t\tmirrorlist = sort_mirrorlist(mirrorlist, sort_order=sort_order)\n\n\tregion = 'Unknown region'\n\tfor line in mirrorlist.split(b'\\n'):\n\t\tif len(line.strip()) == 0:\n\t\t\tcontinue\n\n\t\tline = line.decode('UTF-8').strip('\\n').strip('\\r')\n\t\tif line[:3] == '## ':\n\t\t\tregion = line[3:]\n\t\telif line[:10] == '#Server = ':\n\t\t\tregions.setdefault(region, {})\n\n\t\t\turl = line.lstrip('#Server = ')\n\t\t\tregions[region][url] = True\n\n\treturn regions\n", "path": "archinstall/lib/mirrors.py"}]}
| 2,527 | 280 |
gh_patches_debug_12271
|
rasdani/github-patches
|
git_diff
|
cloud-custodian__cloud-custodian-3464
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Tagging CloudFormation - Error: Parameters must have value
Initially the stack is created with an input parameter.
**c7n policy**
```
policies:
- name: add-cfn-tag
resource: cfn
filters:
- "tag:testcfn": present
actions:
- type: tag
value: abc
key: BusinessUnit
```
**Error**
An error occurred (ValidationError) when calling the UpdateStack operation: Parameters: [input_param] must have values
</issue>
<code>
[start of c7n/resources/cfn.py]
1 # Copyright 2015-2017 Capital One Services, LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from __future__ import absolute_import, division, print_function, unicode_literals
15
16 import logging
17
18 from concurrent.futures import as_completed
19
20 from c7n.actions import BaseAction
21 from c7n.manager import resources
22 from c7n.query import QueryResourceManager
23 from c7n.utils import local_session, type_schema
24 from c7n.tags import RemoveTag, Tag
25
26 log = logging.getLogger('custodian.cfn')
27
28
29 @resources.register('cfn')
30 class CloudFormation(QueryResourceManager):
31
32 class resource_type(object):
33 service = 'cloudformation'
34 type = 'stack'
35 enum_spec = ('describe_stacks', 'Stacks[]', None)
36 id = 'StackName'
37 filter_name = 'StackName'
38 filter_type = 'scalar'
39 name = 'StackName'
40 date = 'CreationTime'
41 dimension = None
42 config_type = 'AWS::CloudFormation::Stack'
43
44
45 @CloudFormation.action_registry.register('delete')
46 class Delete(BaseAction):
47 """Action to delete cloudformation stacks
48
49 It is recommended to use a filter to avoid unwanted deletion of stacks
50
51 :example:
52
53 .. code-block:: yaml
54
55 policies:
56 - name: cloudformation-delete-failed-stacks
57 resource: cfn
58 filters:
59 - StackStatus: ROLLBACK_COMPLETE
60 actions:
61 - delete
62 """
63
64 schema = type_schema('delete')
65 permissions = ("cloudformation:DeleteStack",)
66
67 def process(self, stacks):
68 with self.executor_factory(max_workers=10) as w:
69 list(w.map(self.process_stacks, stacks))
70
71 def process_stacks(self, stack):
72 client = local_session(
73 self.manager.session_factory).client('cloudformation')
74 client.delete_stack(StackName=stack['StackName'])
75
76
77 @CloudFormation.action_registry.register('set-protection')
78 class SetProtection(BaseAction):
79 """Action to disable termination protection
80
81 It is recommended to use a filter to avoid unwanted deletion of stacks
82
83 :example:
84
85 .. code-block:: yaml
86
87 policies:
88 - name: cloudformation-disable-protection
89 resource: cfn
90 filters:
91 - StackStatus: CREATE_COMPLETE
92 actions:
93 - type: set-protection
94 state: False
95 """
96
97 schema = type_schema(
98 'set-protection', state={'type': 'boolean', 'default': False})
99
100 permissions = ('cloudformation:UpdateStack',)
101
102 def process(self, stacks):
103 client = local_session(
104 self.manager.session_factory).client('cloudformation')
105
106 with self.executor_factory(max_workers=3) as w:
107 futures = {}
108 for s in stacks:
109 futures[w.submit(self.process_stacks, client, s)] = s
110 for f in as_completed(futures):
111 s = futures[f]
112 if f.exception():
113 self.log.error(
114 "Error updating protection stack:%s error:%s",
115 s['StackName'], f.exception())
116
117 def process_stacks(self, client, stack):
118 client.update_termination_protection(
119 EnableTerminationProtection=self.data.get('state', False),
120 StackName=stack['StackName'])
121
122
123 @CloudFormation.action_registry.register('tag')
124 class CloudFormationAddTag(Tag):
125 """Action to tag a cloudformation stack
126
127 :example:
128
129 .. code-block: yaml
130
131 policies:
132 - name: add-cfn-tag
133 resource: cfn
134 filters:
135 - 'tag:DesiredTag': absent
136 actions:
137 - type: tag
138 key: DesiredTag
139 value: DesiredValue
140 """
141 permissions = ('cloudformation:UpdateStack',)
142
143 def process_resource_set(self, stacks, tags):
144 client = local_session(
145 self.manager.session_factory).client('cloudformation')
146
147 def _tag_stacks(s):
148 client.update_stack(
149 StackName=s['StackName'],
150 UsePreviousTemplate=True,
151 Tags=tags)
152
153 with self.executor_factory(max_workers=2) as w:
154 list(w.map(_tag_stacks, stacks))
155
156
157 @CloudFormation.action_registry.register('remove-tag')
158 class CloudFormationRemoveTag(RemoveTag):
159 """Action to remove tags from a cloudformation stack
160
161 :example:
162
163 .. code-block: yaml
164
165 policies:
166 - name: add-cfn-tag
167 resource: cfn
168 filters:
169 - 'tag:DesiredTag': present
170 actions:
171 - type: remove-tag
172 tags: ['DesiredTag']
173 """
174
175 def process_resource_set(self, stacks, keys):
176 client = local_session(
177 self.manager.session_factory).client('cloudformation')
178
179 def _remove_tag(s):
180 tags = [t for t in s['Tags'] if t['Key'] not in keys]
181 client.update_stack(
182 StackName=s['StackName'],
183 UsePreviousTemplate=True,
184 Tags=tags)
185
186 with self.executor_factory(max_workers=2) as w:
187 list(w.map(_remove_tag, stacks))
188
[end of c7n/resources/cfn.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/c7n/resources/cfn.py b/c7n/resources/cfn.py
--- a/c7n/resources/cfn.py
+++ b/c7n/resources/cfn.py
@@ -145,9 +145,14 @@
self.manager.session_factory).client('cloudformation')
def _tag_stacks(s):
+ params = []
+ for p in s.get('Parameters', []):
+ params.append({'ParameterKey': p['ParameterKey'],
+ 'UsePreviousValue': True})
client.update_stack(
StackName=s['StackName'],
UsePreviousTemplate=True,
+ Parameters=params,
Tags=tags)
with self.executor_factory(max_workers=2) as w:
|
{"golden_diff": "diff --git a/c7n/resources/cfn.py b/c7n/resources/cfn.py\n--- a/c7n/resources/cfn.py\n+++ b/c7n/resources/cfn.py\n@@ -145,9 +145,14 @@\n self.manager.session_factory).client('cloudformation')\n \n def _tag_stacks(s):\n+ params = []\n+ for p in s.get('Parameters', []):\n+ params.append({'ParameterKey': p['ParameterKey'],\n+ 'UsePreviousValue': True})\n client.update_stack(\n StackName=s['StackName'],\n UsePreviousTemplate=True,\n+ Parameters=params,\n Tags=tags)\n \n with self.executor_factory(max_workers=2) as w:\n", "issue": "Tagging CloudFormation - Error: Parameters must have value\nInitially the stack is created with an input parameter.\r\n\r\n**c7n policy**\r\n```\r\npolicies:\r\n - name: add-cfn-tag\r\n resource: cfn\r\n filters:\r\n - \"tag:testcfn\": present\r\n actions:\r\n - type: tag\r\n value: abc\r\n key: BusinessUnit\r\n```\r\n**Error**\r\nAn error occurred (ValidationError) when calling the UpdateStack operation: Parameters: [input_param] must have values\n", "before_files": [{"content": "# Copyright 2015-2017 Capital One Services, LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport logging\n\nfrom concurrent.futures import as_completed\n\nfrom c7n.actions import BaseAction\nfrom c7n.manager import resources\nfrom c7n.query import QueryResourceManager\nfrom c7n.utils import local_session, type_schema\nfrom c7n.tags import RemoveTag, Tag\n\nlog = logging.getLogger('custodian.cfn')\n\n\[email protected]('cfn')\nclass CloudFormation(QueryResourceManager):\n\n class resource_type(object):\n service = 'cloudformation'\n type = 'stack'\n enum_spec = ('describe_stacks', 'Stacks[]', None)\n id = 'StackName'\n filter_name = 'StackName'\n filter_type = 'scalar'\n name = 'StackName'\n date = 'CreationTime'\n dimension = None\n config_type = 'AWS::CloudFormation::Stack'\n\n\[email protected]_registry.register('delete')\nclass Delete(BaseAction):\n \"\"\"Action to delete cloudformation stacks\n\n It is recommended to use a filter to avoid unwanted deletion of stacks\n\n :example:\n\n .. code-block:: yaml\n\n policies:\n - name: cloudformation-delete-failed-stacks\n resource: cfn\n filters:\n - StackStatus: ROLLBACK_COMPLETE\n actions:\n - delete\n \"\"\"\n\n schema = type_schema('delete')\n permissions = (\"cloudformation:DeleteStack\",)\n\n def process(self, stacks):\n with self.executor_factory(max_workers=10) as w:\n list(w.map(self.process_stacks, stacks))\n\n def process_stacks(self, stack):\n client = local_session(\n self.manager.session_factory).client('cloudformation')\n client.delete_stack(StackName=stack['StackName'])\n\n\[email protected]_registry.register('set-protection')\nclass SetProtection(BaseAction):\n \"\"\"Action to disable termination protection\n\n It is recommended to use a filter to avoid unwanted deletion of stacks\n\n :example:\n\n .. code-block:: yaml\n\n policies:\n - name: cloudformation-disable-protection\n resource: cfn\n filters:\n - StackStatus: CREATE_COMPLETE\n actions:\n - type: set-protection\n state: False\n \"\"\"\n\n schema = type_schema(\n 'set-protection', state={'type': 'boolean', 'default': False})\n\n permissions = ('cloudformation:UpdateStack',)\n\n def process(self, stacks):\n client = local_session(\n self.manager.session_factory).client('cloudformation')\n\n with self.executor_factory(max_workers=3) as w:\n futures = {}\n for s in stacks:\n futures[w.submit(self.process_stacks, client, s)] = s\n for f in as_completed(futures):\n s = futures[f]\n if f.exception():\n self.log.error(\n \"Error updating protection stack:%s error:%s\",\n s['StackName'], f.exception())\n\n def process_stacks(self, client, stack):\n client.update_termination_protection(\n EnableTerminationProtection=self.data.get('state', False),\n StackName=stack['StackName'])\n\n\[email protected]_registry.register('tag')\nclass CloudFormationAddTag(Tag):\n \"\"\"Action to tag a cloudformation stack\n\n :example:\n\n .. code-block: yaml\n\n policies:\n - name: add-cfn-tag\n resource: cfn\n filters:\n - 'tag:DesiredTag': absent\n actions:\n - type: tag\n key: DesiredTag\n value: DesiredValue\n \"\"\"\n permissions = ('cloudformation:UpdateStack',)\n\n def process_resource_set(self, stacks, tags):\n client = local_session(\n self.manager.session_factory).client('cloudformation')\n\n def _tag_stacks(s):\n client.update_stack(\n StackName=s['StackName'],\n UsePreviousTemplate=True,\n Tags=tags)\n\n with self.executor_factory(max_workers=2) as w:\n list(w.map(_tag_stacks, stacks))\n\n\[email protected]_registry.register('remove-tag')\nclass CloudFormationRemoveTag(RemoveTag):\n \"\"\"Action to remove tags from a cloudformation stack\n\n :example:\n\n .. code-block: yaml\n\n policies:\n - name: add-cfn-tag\n resource: cfn\n filters:\n - 'tag:DesiredTag': present\n actions:\n - type: remove-tag\n tags: ['DesiredTag']\n \"\"\"\n\n def process_resource_set(self, stacks, keys):\n client = local_session(\n self.manager.session_factory).client('cloudformation')\n\n def _remove_tag(s):\n tags = [t for t in s['Tags'] if t['Key'] not in keys]\n client.update_stack(\n StackName=s['StackName'],\n UsePreviousTemplate=True,\n Tags=tags)\n\n with self.executor_factory(max_workers=2) as w:\n list(w.map(_remove_tag, stacks))\n", "path": "c7n/resources/cfn.py"}]}
| 2,319 | 157 |
gh_patches_debug_7223
|
rasdani/github-patches
|
git_diff
|
pretix__pretix-687
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Documentation of order_paid-signal unclear
This might be just me not being able to english, but I think that the documentation at https://github.com/pretix/pretix/blob/a08cb3b8e4adaa300868e3f730e045bc8e6d0203/src/pretix/base/signals.py#L152-L154 is missing something.
</issue>
<code>
[start of src/pretix/base/signals.py]
1 import warnings
2 from typing import Any, Callable, List, Tuple
3
4 import django.dispatch
5 from django.apps import apps
6 from django.conf import settings
7 from django.dispatch.dispatcher import NO_RECEIVERS
8
9 from .models import Event
10
11 app_cache = {}
12
13
14 def _populate_app_cache():
15 global app_cache
16 apps.check_apps_ready()
17 for ac in apps.app_configs.values():
18 app_cache[ac.name] = ac
19
20
21 class EventPluginSignal(django.dispatch.Signal):
22 """
23 This is an extension to Django's built-in signals which differs in a way that it sends
24 out it's events only to receivers which belong to plugins that are enabled for the given
25 Event.
26 """
27
28 def send(self, sender: Event, **named) -> List[Tuple[Callable, Any]]:
29 """
30 Send signal from sender to all connected receivers that belong to
31 plugins enabled for the given Event.
32
33 sender is required to be an instance of ``pretix.base.models.Event``.
34 """
35 if sender and not isinstance(sender, Event):
36 raise ValueError("Sender needs to be an event.")
37
38 responses = []
39 if not self.receivers or self.sender_receivers_cache.get(sender) is NO_RECEIVERS:
40 return responses
41
42 if not app_cache:
43 _populate_app_cache()
44
45 for receiver in self._live_receivers(sender):
46 # Find the Django application this belongs to
47 searchpath = receiver.__module__
48 core_module = any([searchpath.startswith(cm) for cm in settings.CORE_MODULES])
49 app = None
50 if not core_module:
51 while True:
52 app = app_cache.get(searchpath)
53 if "." not in searchpath or app:
54 break
55 searchpath, _ = searchpath.rsplit(".", 1)
56
57 # Only fire receivers from active plugins and core modules
58 if core_module or (sender and app and app.name in sender.get_plugins()):
59 if not hasattr(app, 'compatibility_errors') or not app.compatibility_errors:
60 response = receiver(signal=self, sender=sender, **named)
61 responses.append((receiver, response))
62 return sorted(responses, key=lambda r: (receiver.__module__, receiver.__name__))
63
64
65 class DeprecatedSignal(django.dispatch.Signal):
66
67 def connect(self, receiver, sender=None, weak=True, dispatch_uid=None):
68 warnings.warn('This signal is deprecated and will soon be removed', stacklevel=3)
69 super().connect(receiver, sender=None, weak=True, dispatch_uid=None)
70
71
72 event_live_issues = EventPluginSignal(
73 providing_args=[]
74 )
75 """
76 This signal is sent out to determine whether an event can be taken live. If you want to
77 prevent the event from going live, return a string that will be displayed to the user
78 as the error message. If you don't, your receiver should return ``None``.
79
80 As with all event-plugin signals, the ``sender`` keyword argument will contain the event.
81 """
82
83
84 register_payment_providers = EventPluginSignal(
85 providing_args=[]
86 )
87 """
88 This signal is sent out to get all known payment providers. Receivers should return a
89 subclass of pretix.base.payment.BasePaymentProvider
90
91 As with all event-plugin signals, the ``sender`` keyword argument will contain the event.
92 """
93
94 register_invoice_renderers = EventPluginSignal(
95 providing_args=[]
96 )
97 """
98 This signal is sent out to get all known invoice renderers. Receivers should return a
99 subclass of pretix.base.invoice.BaseInvoiceRenderer
100
101 As with all event-plugin signals, the ``sender`` keyword argument will contain the event.
102 """
103
104 register_ticket_outputs = EventPluginSignal(
105 providing_args=[]
106 )
107 """
108 This signal is sent out to get all known ticket outputs. Receivers should return a
109 subclass of pretix.base.ticketoutput.BaseTicketOutput
110
111 As with all event-plugin signals, the ``sender`` keyword argument will contain the event.
112 """
113
114 register_data_exporters = EventPluginSignal(
115 providing_args=[]
116 )
117 """
118 This signal is sent out to get all known data exporters. Receivers should return a
119 subclass of pretix.base.exporter.BaseExporter
120
121 As with all event-plugin signals, the ``sender`` keyword argument will contain the event.
122 """
123
124 validate_cart = EventPluginSignal(
125 providing_args=["positions"]
126 )
127 """
128 This signal is sent out before the user starts checkout. It includes an iterable
129 with the current CartPosition objects.
130 The response of receivers will be ignored, but you can raise a CartError with an
131 appropriate exception message.
132
133 As with all event-plugin signals, the ``sender`` keyword argument will contain the event.
134 """
135
136 order_placed = EventPluginSignal(
137 providing_args=["order"]
138 )
139 """
140 This signal is sent out every time an order is placed. The order object is given
141 as the first argument. This signal is *not* sent out if an order is created through
142 splitting an existing order, so you can not expect to see all orders by listening
143 to this signal.
144
145 As with all event-plugin signals, the ``sender`` keyword argument will contain the event.
146 """
147
148 order_paid = EventPluginSignal(
149 providing_args=["order"]
150 )
151 """
152 This signal is sent out every time an order is paid. The order object is given
153 as the first argument. This signal is *not* sent out if an order is marked as paid
154 because it an already-paid order has been splitted.
155
156 As with all event-plugin signals, the ``sender`` keyword argument will contain the event.
157 """
158
159 logentry_display = EventPluginSignal(
160 providing_args=["logentry"]
161 )
162 """
163 To display an instance of the ``LogEntry`` model to a human user,
164 ``pretix.base.signals.logentry_display`` will be sent out with a ``logentry`` argument.
165
166 The first received response that is not ``None`` will be used to display the log entry
167 to the user. The receivers are expected to return plain text.
168
169 As with all event-plugin signals, the ``sender`` keyword argument will contain the event.
170 """
171
172 logentry_object_link = EventPluginSignal(
173 providing_args=["logentry"]
174 )
175 """
176 To display the relationship of an instance of the ``LogEntry`` model to another model
177 to a human user, ``pretix.base.signals.logentry_object_link`` will be sent out with a
178 ``logentry`` argument.
179
180 The first received response that is not ``None`` will be used to display the related object
181 to the user. The receivers are expected to return a HTML link. The internal implementation
182 builds the links like this::
183
184 a_text = _('Tax rule {val}')
185 a_map = {
186 'href': reverse('control:event.settings.tax.edit', kwargs={
187 'event': sender.slug,
188 'organizer': sender.organizer.slug,
189 'rule': logentry.content_object.id
190 }),
191 'val': escape(logentry.content_object.name),
192 }
193 a_map['val'] = '<a href="{href}">{val}</a>'.format_map(a_map)
194 return a_text.format_map(a_map)
195
196 Make sure that any user content in the HTML code you return is properly escaped!
197 As with all event-plugin signals, the ``sender`` keyword argument will contain the event.
198 """
199
200 requiredaction_display = EventPluginSignal(
201 providing_args=["action", "request"]
202 )
203 """
204 To display an instance of the ``RequiredAction`` model to a human user,
205 ``pretix.base.signals.requiredaction_display`` will be sent out with a ``action`` argument.
206 You will also get the current ``request`` in a different argument.
207
208 The first received response that is not ``None`` will be used to display the log entry
209 to the user. The receivers are expected to return HTML code.
210
211 As with all event-plugin signals, the ``sender`` keyword argument will contain the event.
212 """
213
214 event_copy_data = EventPluginSignal(
215 providing_args=["other"]
216 )
217 """
218 This signal is sent out when a new event is created as a clone of an existing event, i.e.
219 the settings from the older event are copied to the newer one. You can listen to this
220 signal to copy data or configuration stored within your plugin's models as well.
221
222 You don't need to copy data inside the general settings storage which is cloned automatically,
223 but you might need to modify that data.
224
225 The ``sender`` keyword argument will contain the event of the **new** event. The ``other``
226 keyword argument will contain the event to **copy from**.
227 """
228
229 periodic_task = django.dispatch.Signal()
230 """
231 This is a regular django signal (no pretix event signal) that we send out every
232 time the periodic task cronjob runs. This interval is not sharply defined, it can
233 be everything between a minute and a day. The actions you perform should be
234 idempotent, i.e. it should not make a difference if this is sent out more often
235 than expected.
236 """
237
238 register_global_settings = django.dispatch.Signal()
239 """
240 All plugins that are installed may send fields for the global settings form, as
241 an OrderedDict of (setting name, form field).
242 """
243
244 order_fee_calculation = EventPluginSignal(
245 providing_args=['request']
246 )
247 """
248 This signals allows you to add fees to an order while it is being created. You are expected to
249 return a list of ``OrderFee`` objects that are not yet saved to the database
250 (because there is no order yet).
251
252 As with all plugin signals, the ``sender`` keyword argument will contain the event. A ``positions``
253 argument will contain the cart positions and ``invoice_address`` the invoice address (useful for
254 tax calculation). The argument ``meta_info`` contains the order's meta dictionary.
255 """
256
257 order_fee_type_name = EventPluginSignal(
258 providing_args=['request', 'fee']
259 )
260 """
261 This signals allows you to return a human-readable description for a fee type based on the ``fee_type``
262 and ``internal_type`` attributes of the ``OrderFee`` model that you get as keyword arguments. You are
263 expected to return a string or None, if you don't know about this fee.
264
265 As with all plugin signals, the ``sender`` keyword argument will contain the event.
266 """
267
268 allow_ticket_download = EventPluginSignal(
269 providing_args=['order']
270 )
271 """
272 This signal is sent out to check if tickets for an order can be downloaded. If any receiver returns false,
273 a download will not be offered.
274
275 As with all event-plugin signals, the ``sender`` keyword argument will contain the event.
276 """
277
[end of src/pretix/base/signals.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/pretix/base/signals.py b/src/pretix/base/signals.py
--- a/src/pretix/base/signals.py
+++ b/src/pretix/base/signals.py
@@ -151,7 +151,7 @@
"""
This signal is sent out every time an order is paid. The order object is given
as the first argument. This signal is *not* sent out if an order is marked as paid
-because it an already-paid order has been splitted.
+because an already-paid order has been split.
As with all event-plugin signals, the ``sender`` keyword argument will contain the event.
"""
|
{"golden_diff": "diff --git a/src/pretix/base/signals.py b/src/pretix/base/signals.py\n--- a/src/pretix/base/signals.py\n+++ b/src/pretix/base/signals.py\n@@ -151,7 +151,7 @@\n \"\"\"\n This signal is sent out every time an order is paid. The order object is given\n as the first argument. This signal is *not* sent out if an order is marked as paid\n-because it an already-paid order has been splitted.\n+because an already-paid order has been split.\n \n As with all event-plugin signals, the ``sender`` keyword argument will contain the event.\n \"\"\"\n", "issue": "Documentation of order_paid-signal unclear\nThis might be just me not being able to english, but I think that the documentation at https://github.com/pretix/pretix/blob/a08cb3b8e4adaa300868e3f730e045bc8e6d0203/src/pretix/base/signals.py#L152-L154 is missing something.\n", "before_files": [{"content": "import warnings\nfrom typing import Any, Callable, List, Tuple\n\nimport django.dispatch\nfrom django.apps import apps\nfrom django.conf import settings\nfrom django.dispatch.dispatcher import NO_RECEIVERS\n\nfrom .models import Event\n\napp_cache = {}\n\n\ndef _populate_app_cache():\n global app_cache\n apps.check_apps_ready()\n for ac in apps.app_configs.values():\n app_cache[ac.name] = ac\n\n\nclass EventPluginSignal(django.dispatch.Signal):\n \"\"\"\n This is an extension to Django's built-in signals which differs in a way that it sends\n out it's events only to receivers which belong to plugins that are enabled for the given\n Event.\n \"\"\"\n\n def send(self, sender: Event, **named) -> List[Tuple[Callable, Any]]:\n \"\"\"\n Send signal from sender to all connected receivers that belong to\n plugins enabled for the given Event.\n\n sender is required to be an instance of ``pretix.base.models.Event``.\n \"\"\"\n if sender and not isinstance(sender, Event):\n raise ValueError(\"Sender needs to be an event.\")\n\n responses = []\n if not self.receivers or self.sender_receivers_cache.get(sender) is NO_RECEIVERS:\n return responses\n\n if not app_cache:\n _populate_app_cache()\n\n for receiver in self._live_receivers(sender):\n # Find the Django application this belongs to\n searchpath = receiver.__module__\n core_module = any([searchpath.startswith(cm) for cm in settings.CORE_MODULES])\n app = None\n if not core_module:\n while True:\n app = app_cache.get(searchpath)\n if \".\" not in searchpath or app:\n break\n searchpath, _ = searchpath.rsplit(\".\", 1)\n\n # Only fire receivers from active plugins and core modules\n if core_module or (sender and app and app.name in sender.get_plugins()):\n if not hasattr(app, 'compatibility_errors') or not app.compatibility_errors:\n response = receiver(signal=self, sender=sender, **named)\n responses.append((receiver, response))\n return sorted(responses, key=lambda r: (receiver.__module__, receiver.__name__))\n\n\nclass DeprecatedSignal(django.dispatch.Signal):\n\n def connect(self, receiver, sender=None, weak=True, dispatch_uid=None):\n warnings.warn('This signal is deprecated and will soon be removed', stacklevel=3)\n super().connect(receiver, sender=None, weak=True, dispatch_uid=None)\n\n\nevent_live_issues = EventPluginSignal(\n providing_args=[]\n)\n\"\"\"\nThis signal is sent out to determine whether an event can be taken live. If you want to\nprevent the event from going live, return a string that will be displayed to the user\nas the error message. If you don't, your receiver should return ``None``.\n\nAs with all event-plugin signals, the ``sender`` keyword argument will contain the event.\n\"\"\"\n\n\nregister_payment_providers = EventPluginSignal(\n providing_args=[]\n)\n\"\"\"\nThis signal is sent out to get all known payment providers. Receivers should return a\nsubclass of pretix.base.payment.BasePaymentProvider\n\nAs with all event-plugin signals, the ``sender`` keyword argument will contain the event.\n\"\"\"\n\nregister_invoice_renderers = EventPluginSignal(\n providing_args=[]\n)\n\"\"\"\nThis signal is sent out to get all known invoice renderers. Receivers should return a\nsubclass of pretix.base.invoice.BaseInvoiceRenderer\n\nAs with all event-plugin signals, the ``sender`` keyword argument will contain the event.\n\"\"\"\n\nregister_ticket_outputs = EventPluginSignal(\n providing_args=[]\n)\n\"\"\"\nThis signal is sent out to get all known ticket outputs. Receivers should return a\nsubclass of pretix.base.ticketoutput.BaseTicketOutput\n\nAs with all event-plugin signals, the ``sender`` keyword argument will contain the event.\n\"\"\"\n\nregister_data_exporters = EventPluginSignal(\n providing_args=[]\n)\n\"\"\"\nThis signal is sent out to get all known data exporters. Receivers should return a\nsubclass of pretix.base.exporter.BaseExporter\n\nAs with all event-plugin signals, the ``sender`` keyword argument will contain the event.\n\"\"\"\n\nvalidate_cart = EventPluginSignal(\n providing_args=[\"positions\"]\n)\n\"\"\"\nThis signal is sent out before the user starts checkout. It includes an iterable\nwith the current CartPosition objects.\nThe response of receivers will be ignored, but you can raise a CartError with an\nappropriate exception message.\n\nAs with all event-plugin signals, the ``sender`` keyword argument will contain the event.\n\"\"\"\n\norder_placed = EventPluginSignal(\n providing_args=[\"order\"]\n)\n\"\"\"\nThis signal is sent out every time an order is placed. The order object is given\nas the first argument. This signal is *not* sent out if an order is created through\nsplitting an existing order, so you can not expect to see all orders by listening\nto this signal.\n\nAs with all event-plugin signals, the ``sender`` keyword argument will contain the event.\n\"\"\"\n\norder_paid = EventPluginSignal(\n providing_args=[\"order\"]\n)\n\"\"\"\nThis signal is sent out every time an order is paid. The order object is given\nas the first argument. This signal is *not* sent out if an order is marked as paid\nbecause it an already-paid order has been splitted.\n\nAs with all event-plugin signals, the ``sender`` keyword argument will contain the event.\n\"\"\"\n\nlogentry_display = EventPluginSignal(\n providing_args=[\"logentry\"]\n)\n\"\"\"\nTo display an instance of the ``LogEntry`` model to a human user,\n``pretix.base.signals.logentry_display`` will be sent out with a ``logentry`` argument.\n\nThe first received response that is not ``None`` will be used to display the log entry\nto the user. The receivers are expected to return plain text.\n\nAs with all event-plugin signals, the ``sender`` keyword argument will contain the event.\n\"\"\"\n\nlogentry_object_link = EventPluginSignal(\n providing_args=[\"logentry\"]\n)\n\"\"\"\nTo display the relationship of an instance of the ``LogEntry`` model to another model\nto a human user, ``pretix.base.signals.logentry_object_link`` will be sent out with a\n``logentry`` argument.\n\nThe first received response that is not ``None`` will be used to display the related object\nto the user. The receivers are expected to return a HTML link. The internal implementation\nbuilds the links like this::\n\n a_text = _('Tax rule {val}')\n a_map = {\n 'href': reverse('control:event.settings.tax.edit', kwargs={\n 'event': sender.slug,\n 'organizer': sender.organizer.slug,\n 'rule': logentry.content_object.id\n }),\n 'val': escape(logentry.content_object.name),\n }\n a_map['val'] = '<a href=\"{href}\">{val}</a>'.format_map(a_map)\n return a_text.format_map(a_map)\n\nMake sure that any user content in the HTML code you return is properly escaped!\nAs with all event-plugin signals, the ``sender`` keyword argument will contain the event.\n\"\"\"\n\nrequiredaction_display = EventPluginSignal(\n providing_args=[\"action\", \"request\"]\n)\n\"\"\"\nTo display an instance of the ``RequiredAction`` model to a human user,\n``pretix.base.signals.requiredaction_display`` will be sent out with a ``action`` argument.\nYou will also get the current ``request`` in a different argument.\n\nThe first received response that is not ``None`` will be used to display the log entry\nto the user. The receivers are expected to return HTML code.\n\nAs with all event-plugin signals, the ``sender`` keyword argument will contain the event.\n\"\"\"\n\nevent_copy_data = EventPluginSignal(\n providing_args=[\"other\"]\n)\n\"\"\"\nThis signal is sent out when a new event is created as a clone of an existing event, i.e.\nthe settings from the older event are copied to the newer one. You can listen to this\nsignal to copy data or configuration stored within your plugin's models as well.\n\nYou don't need to copy data inside the general settings storage which is cloned automatically,\nbut you might need to modify that data.\n\nThe ``sender`` keyword argument will contain the event of the **new** event. The ``other``\nkeyword argument will contain the event to **copy from**.\n\"\"\"\n\nperiodic_task = django.dispatch.Signal()\n\"\"\"\nThis is a regular django signal (no pretix event signal) that we send out every\ntime the periodic task cronjob runs. This interval is not sharply defined, it can\nbe everything between a minute and a day. The actions you perform should be\nidempotent, i.e. it should not make a difference if this is sent out more often\nthan expected.\n\"\"\"\n\nregister_global_settings = django.dispatch.Signal()\n\"\"\"\nAll plugins that are installed may send fields for the global settings form, as\nan OrderedDict of (setting name, form field).\n\"\"\"\n\norder_fee_calculation = EventPluginSignal(\n providing_args=['request']\n)\n\"\"\"\nThis signals allows you to add fees to an order while it is being created. You are expected to\nreturn a list of ``OrderFee`` objects that are not yet saved to the database\n(because there is no order yet).\n\nAs with all plugin signals, the ``sender`` keyword argument will contain the event. A ``positions``\nargument will contain the cart positions and ``invoice_address`` the invoice address (useful for\ntax calculation). The argument ``meta_info`` contains the order's meta dictionary.\n\"\"\"\n\norder_fee_type_name = EventPluginSignal(\n providing_args=['request', 'fee']\n)\n\"\"\"\nThis signals allows you to return a human-readable description for a fee type based on the ``fee_type``\nand ``internal_type`` attributes of the ``OrderFee`` model that you get as keyword arguments. You are\nexpected to return a string or None, if you don't know about this fee.\n\nAs with all plugin signals, the ``sender`` keyword argument will contain the event.\n\"\"\"\n\nallow_ticket_download = EventPluginSignal(\n providing_args=['order']\n)\n\"\"\"\nThis signal is sent out to check if tickets for an order can be downloaded. If any receiver returns false,\na download will not be offered.\n\nAs with all event-plugin signals, the ``sender`` keyword argument will contain the event.\n\"\"\"\n", "path": "src/pretix/base/signals.py"}]}
| 3,530 | 139 |
gh_patches_debug_26653
|
rasdani/github-patches
|
git_diff
|
aio-libs__aiohttp-6309
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Connecting to IPv6-only hosts fails with a `RuntimeError`
### Describe the bug
When aiohttp tries to connect to a host with only IPv6 address (with no IPv4 address), the exception `RuntimeError: coroutine raised StopIteration` is raised in [`TCPConnector._create_direct_connection`](https://github.com/aio-libs/aiohttp/blob/v3.8.0/aiohttp/connector.py#L1153) caused by the `StopIteration` in [`_DNSCacheTable.next_addrs`](https://github.com/aio-libs/aiohttp/blob/v3.8.0/aiohttp/connector.py#L716).
### To Reproduce
1. Create `aiohttp.ClientSession`.
2. Try to request an URL with IPv6-only host, e.g. `ipv6.google.com`.
E.g: `await ClientSession().get('https://ipv6.google.com')`
### Expected behavior
`await ClientSession().get('https://ipv6.google.com')` does not fail and returns a response.
### Logs/tracebacks
```python-traceback
$ python -m asyncio
asyncio REPL 3.9.7 (default, Oct 10 2021, 15:13:22)
[GCC 11.1.0] on linux
>>> import asyncio
>>> from aiohttp import ClientSession
>>> await ClientSession().get('https://ipv6.google.com')
Traceback (most recent call last):
File "/home/***/.local/lib/python3.9/site-packages/aiohttp/connector.py", line 894, in _resolve_host
return self._cached_hosts.next_addrs(key)
File "/home/***/.local/lib/python3.9/site-packages/aiohttp/connector.py", line 716, in next_addrs
next(loop)
StopIteration
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/usr/lib/python3.9/concurrent/futures/_base.py", line 445, in result
return self.__get_result()
File "/usr/lib/python3.9/concurrent/futures/_base.py", line 390, in __get_result
raise self._exception
File "<console>", line 1, in <module>
File "/home/***/.local/lib/python3.9/site-packages/aiohttp/client.py", line 535, in _request
conn = await self._connector.connect(
File "/home/***/.local/lib/python3.9/site-packages/aiohttp/connector.py", line 543, in connect
proto = await self._create_connection(req, traces, timeout)
File "/home/***/.local/lib/python3.9/site-packages/aiohttp/connector.py", line 906, in _create_connection
_, proto = await self._create_direct_connection(req, traces, timeout)
File "/home/***/.local/lib/python3.9/site-packages/aiohttp/connector.py", line 1153, in _create_direct_connection
hosts = await asyncio.shield(host_resolved)
RuntimeError: coroutine raised StopIteration
```
### Python Version
```console
$ python --version
Python 3.9.7
```
### aiohttp Version
```console
$ python -m pip show aiohttp
Name: aiohttp
Version: 3.8.0
Summary: Async http client/server framework (asyncio)
Home-page: https://github.com/aio-libs/aiohttp
Author:
Author-email:
License: Apache 2
Location: /home/***/.local/lib/python3.9/site-packages
Requires: aiosignal, async-timeout, attrs, charset-normalizer, frozenlist, multidict, yarl
Required-by:
```
### multidict Version
```console
$ python -m pip show multidict
Name: multidict
Version: 5.1.0
Summary: multidict implementation
Home-page: https://github.com/aio-libs/multidict
Author: Andrew Svetlov
Author-email: [email protected]
License: Apache 2
Location: /home/***/.local/lib/python3.9/site-packages
Requires:
Required-by: aiohttp, grpclib, yarl
```
### yarl Version
```console
$ python -m pip show yarl
Name: yarl
Version: 1.6.3
Summary: Yet another URL library
Home-page: https://github.com/aio-libs/yarl/
Author: Andrew Svetlov
Author-email: [email protected]
License: Apache 2
Location: /home/***/.local/lib/python3.9/site-packages
Requires: idna, multidict
Required-by: aiohttp
```
### OS
Linux
### Related component
Client
### Additional context
_No response_
### Code of Conduct
- [X] I agree to follow the aio-libs Code of Conduct
</issue>
<code>
[start of aiohttp/resolver.py]
1 import asyncio
2 import socket
3 from typing import Any, Dict, List, Type, Union
4
5 from .abc import AbstractResolver
6
7 __all__ = ("ThreadedResolver", "AsyncResolver", "DefaultResolver")
8
9 try:
10 import aiodns
11
12 # aiodns_default = hasattr(aiodns.DNSResolver, 'gethostbyname')
13 except ImportError: # pragma: no cover
14 aiodns = None
15
16 aiodns_default = False
17
18
19 class ThreadedResolver(AbstractResolver):
20 """Threaded resolver.
21
22 Uses an Executor for synchronous getaddrinfo() calls.
23 concurrent.futures.ThreadPoolExecutor is used by default.
24 """
25
26 def __init__(self) -> None:
27 self._loop = asyncio.get_running_loop()
28
29 async def resolve(
30 self, hostname: str, port: int = 0, family: int = socket.AF_INET
31 ) -> List[Dict[str, Any]]:
32 infos = await self._loop.getaddrinfo(
33 hostname,
34 port,
35 type=socket.SOCK_STREAM,
36 family=family,
37 flags=socket.AI_ADDRCONFIG,
38 )
39
40 hosts = []
41 for family, _, proto, _, address in infos:
42 if family == socket.AF_INET6:
43 if not (socket.has_ipv6 and address[3]): # type: ignore[misc]
44 continue
45 # This is essential for link-local IPv6 addresses.
46 # LL IPv6 is a VERY rare case. Strictly speaking, we should use
47 # getnameinfo() unconditionally, but performance makes sense.
48 host, _port = socket.getnameinfo(
49 address, socket.NI_NUMERICHOST | socket.NI_NUMERICSERV
50 )
51 port = int(_port)
52 else:
53 host, port = address[:2]
54 hosts.append(
55 {
56 "hostname": hostname,
57 "host": host,
58 "port": port,
59 "family": family,
60 "proto": proto,
61 "flags": socket.AI_NUMERICHOST | socket.AI_NUMERICSERV,
62 }
63 )
64
65 return hosts
66
67 async def close(self) -> None:
68 pass
69
70
71 class AsyncResolver(AbstractResolver):
72 """Use the `aiodns` package to make asynchronous DNS lookups"""
73
74 def __init__(self, *args: Any, **kwargs: Any) -> None:
75 if aiodns is None:
76 raise RuntimeError("Resolver requires aiodns library")
77
78 self._loop = asyncio.get_running_loop()
79 self._resolver = aiodns.DNSResolver(*args, loop=self._loop, **kwargs)
80
81 async def resolve(
82 self, host: str, port: int = 0, family: int = socket.AF_INET
83 ) -> List[Dict[str, Any]]:
84 try:
85 resp = await self._resolver.gethostbyname(host, family)
86 except aiodns.error.DNSError as exc:
87 msg = exc.args[1] if len(exc.args) >= 1 else "DNS lookup failed"
88 raise OSError(msg) from exc
89 hosts = []
90 for address in resp.addresses:
91 hosts.append(
92 {
93 "hostname": host,
94 "host": address,
95 "port": port,
96 "family": family,
97 "proto": 0,
98 "flags": socket.AI_NUMERICHOST | socket.AI_NUMERICSERV,
99 }
100 )
101
102 if not hosts:
103 raise OSError("DNS lookup failed")
104
105 return hosts
106
107 async def close(self) -> None:
108 self._resolver.cancel()
109
110
111 _DefaultType = Type[Union[AsyncResolver, ThreadedResolver]]
112 DefaultResolver: _DefaultType = AsyncResolver if aiodns_default else ThreadedResolver
113
[end of aiohttp/resolver.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/aiohttp/resolver.py b/aiohttp/resolver.py
--- a/aiohttp/resolver.py
+++ b/aiohttp/resolver.py
@@ -40,17 +40,23 @@
hosts = []
for family, _, proto, _, address in infos:
if family == socket.AF_INET6:
- if not (socket.has_ipv6 and address[3]): # type: ignore[misc]
+ if len(address) < 3:
+ # IPv6 is not supported by Python build,
+ # or IPv6 is not enabled in the host
continue
- # This is essential for link-local IPv6 addresses.
- # LL IPv6 is a VERY rare case. Strictly speaking, we should use
- # getnameinfo() unconditionally, but performance makes sense.
- host, _port = socket.getnameinfo(
- address, socket.NI_NUMERICHOST | socket.NI_NUMERICSERV
- )
- port = int(_port)
- else:
- host, port = address[:2]
+ if address[3]: # type: ignore[misc]
+ # This is essential for link-local IPv6 addresses.
+ # LL IPv6 is a VERY rare case. Strictly speaking, we should use
+ # getnameinfo() unconditionally, but performance makes sense.
+ host, _port = socket.getnameinfo(
+ address, socket.NI_NUMERICHOST | socket.NI_NUMERICSERV
+ )
+ port = int(_port)
+ else:
+ host, port = address[:2]
+ else: # IPv4
+ assert family == socket.AF_INET
+ host, port = address # type: ignore[misc]
hosts.append(
{
"hostname": hostname,
|
{"golden_diff": "diff --git a/aiohttp/resolver.py b/aiohttp/resolver.py\n--- a/aiohttp/resolver.py\n+++ b/aiohttp/resolver.py\n@@ -40,17 +40,23 @@\n hosts = []\n for family, _, proto, _, address in infos:\n if family == socket.AF_INET6:\n- if not (socket.has_ipv6 and address[3]): # type: ignore[misc]\n+ if len(address) < 3:\n+ # IPv6 is not supported by Python build,\n+ # or IPv6 is not enabled in the host\n continue\n- # This is essential for link-local IPv6 addresses.\n- # LL IPv6 is a VERY rare case. Strictly speaking, we should use\n- # getnameinfo() unconditionally, but performance makes sense.\n- host, _port = socket.getnameinfo(\n- address, socket.NI_NUMERICHOST | socket.NI_NUMERICSERV\n- )\n- port = int(_port)\n- else:\n- host, port = address[:2]\n+ if address[3]: # type: ignore[misc]\n+ # This is essential for link-local IPv6 addresses.\n+ # LL IPv6 is a VERY rare case. Strictly speaking, we should use\n+ # getnameinfo() unconditionally, but performance makes sense.\n+ host, _port = socket.getnameinfo(\n+ address, socket.NI_NUMERICHOST | socket.NI_NUMERICSERV\n+ )\n+ port = int(_port)\n+ else:\n+ host, port = address[:2]\n+ else: # IPv4\n+ assert family == socket.AF_INET\n+ host, port = address # type: ignore[misc]\n hosts.append(\n {\n \"hostname\": hostname,\n", "issue": "Connecting to IPv6-only hosts fails with a `RuntimeError`\n### Describe the bug\r\n\r\nWhen aiohttp tries to connect to a host with only IPv6 address (with no IPv4 address), the exception `RuntimeError: coroutine raised StopIteration` is raised in [`TCPConnector._create_direct_connection`](https://github.com/aio-libs/aiohttp/blob/v3.8.0/aiohttp/connector.py#L1153) caused by the `StopIteration` in [`_DNSCacheTable.next_addrs`](https://github.com/aio-libs/aiohttp/blob/v3.8.0/aiohttp/connector.py#L716).\r\n\r\n### To Reproduce\r\n\r\n1. Create `aiohttp.ClientSession`.\r\n2. Try to request an URL with IPv6-only host, e.g. `ipv6.google.com`.\r\nE.g: `await ClientSession().get('https://ipv6.google.com')`\r\n\r\n### Expected behavior\r\n\r\n`await ClientSession().get('https://ipv6.google.com')` does not fail and returns a response.\r\n\r\n### Logs/tracebacks\r\n\r\n```python-traceback\r\n$ python -m asyncio\r\nasyncio REPL 3.9.7 (default, Oct 10 2021, 15:13:22)\r\n[GCC 11.1.0] on linux\r\n>>> import asyncio\r\n>>> from aiohttp import ClientSession\r\n>>> await ClientSession().get('https://ipv6.google.com')\r\nTraceback (most recent call last):\r\n File \"/home/***/.local/lib/python3.9/site-packages/aiohttp/connector.py\", line 894, in _resolve_host\r\n return self._cached_hosts.next_addrs(key)\r\n File \"/home/***/.local/lib/python3.9/site-packages/aiohttp/connector.py\", line 716, in next_addrs\r\n next(loop)\r\nStopIteration\r\n\r\nThe above exception was the direct cause of the following exception:\r\n\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python3.9/concurrent/futures/_base.py\", line 445, in result\r\n return self.__get_result()\r\n File \"/usr/lib/python3.9/concurrent/futures/_base.py\", line 390, in __get_result\r\n raise self._exception\r\n File \"<console>\", line 1, in <module>\r\n File \"/home/***/.local/lib/python3.9/site-packages/aiohttp/client.py\", line 535, in _request\r\n conn = await self._connector.connect(\r\n File \"/home/***/.local/lib/python3.9/site-packages/aiohttp/connector.py\", line 543, in connect\r\n proto = await self._create_connection(req, traces, timeout)\r\n File \"/home/***/.local/lib/python3.9/site-packages/aiohttp/connector.py\", line 906, in _create_connection\r\n _, proto = await self._create_direct_connection(req, traces, timeout)\r\n File \"/home/***/.local/lib/python3.9/site-packages/aiohttp/connector.py\", line 1153, in _create_direct_connection\r\n hosts = await asyncio.shield(host_resolved)\r\nRuntimeError: coroutine raised StopIteration\r\n```\r\n\r\n\r\n### Python Version\r\n\r\n```console\r\n$ python --version\r\nPython 3.9.7\r\n```\r\n\r\n\r\n### aiohttp Version\r\n\r\n```console\r\n$ python -m pip show aiohttp\r\nName: aiohttp\r\nVersion: 3.8.0\r\nSummary: Async http client/server framework (asyncio)\r\nHome-page: https://github.com/aio-libs/aiohttp\r\nAuthor:\r\nAuthor-email:\r\nLicense: Apache 2\r\nLocation: /home/***/.local/lib/python3.9/site-packages\r\nRequires: aiosignal, async-timeout, attrs, charset-normalizer, frozenlist, multidict, yarl\r\nRequired-by:\r\n```\r\n\r\n\r\n### multidict Version\r\n\r\n```console\r\n$ python -m pip show multidict\r\nName: multidict\r\nVersion: 5.1.0\r\nSummary: multidict implementation\r\nHome-page: https://github.com/aio-libs/multidict\r\nAuthor: Andrew Svetlov\r\nAuthor-email: [email protected]\r\nLicense: Apache 2\r\nLocation: /home/***/.local/lib/python3.9/site-packages\r\nRequires:\r\nRequired-by: aiohttp, grpclib, yarl\r\n```\r\n\r\n\r\n### yarl Version\r\n\r\n```console\r\n$ python -m pip show yarl\r\nName: yarl\r\nVersion: 1.6.3\r\nSummary: Yet another URL library\r\nHome-page: https://github.com/aio-libs/yarl/\r\nAuthor: Andrew Svetlov\r\nAuthor-email: [email protected]\r\nLicense: Apache 2\r\nLocation: /home/***/.local/lib/python3.9/site-packages\r\nRequires: idna, multidict\r\nRequired-by: aiohttp\r\n```\r\n\r\n\r\n### OS\r\n\r\nLinux\r\n\r\n### Related component\r\n\r\nClient\r\n\r\n### Additional context\r\n\r\n_No response_\r\n\r\n### Code of Conduct\r\n\r\n- [X] I agree to follow the aio-libs Code of Conduct\n", "before_files": [{"content": "import asyncio\nimport socket\nfrom typing import Any, Dict, List, Type, Union\n\nfrom .abc import AbstractResolver\n\n__all__ = (\"ThreadedResolver\", \"AsyncResolver\", \"DefaultResolver\")\n\ntry:\n import aiodns\n\n # aiodns_default = hasattr(aiodns.DNSResolver, 'gethostbyname')\nexcept ImportError: # pragma: no cover\n aiodns = None\n\naiodns_default = False\n\n\nclass ThreadedResolver(AbstractResolver):\n \"\"\"Threaded resolver.\n\n Uses an Executor for synchronous getaddrinfo() calls.\n concurrent.futures.ThreadPoolExecutor is used by default.\n \"\"\"\n\n def __init__(self) -> None:\n self._loop = asyncio.get_running_loop()\n\n async def resolve(\n self, hostname: str, port: int = 0, family: int = socket.AF_INET\n ) -> List[Dict[str, Any]]:\n infos = await self._loop.getaddrinfo(\n hostname,\n port,\n type=socket.SOCK_STREAM,\n family=family,\n flags=socket.AI_ADDRCONFIG,\n )\n\n hosts = []\n for family, _, proto, _, address in infos:\n if family == socket.AF_INET6:\n if not (socket.has_ipv6 and address[3]): # type: ignore[misc]\n continue\n # This is essential for link-local IPv6 addresses.\n # LL IPv6 is a VERY rare case. Strictly speaking, we should use\n # getnameinfo() unconditionally, but performance makes sense.\n host, _port = socket.getnameinfo(\n address, socket.NI_NUMERICHOST | socket.NI_NUMERICSERV\n )\n port = int(_port)\n else:\n host, port = address[:2]\n hosts.append(\n {\n \"hostname\": hostname,\n \"host\": host,\n \"port\": port,\n \"family\": family,\n \"proto\": proto,\n \"flags\": socket.AI_NUMERICHOST | socket.AI_NUMERICSERV,\n }\n )\n\n return hosts\n\n async def close(self) -> None:\n pass\n\n\nclass AsyncResolver(AbstractResolver):\n \"\"\"Use the `aiodns` package to make asynchronous DNS lookups\"\"\"\n\n def __init__(self, *args: Any, **kwargs: Any) -> None:\n if aiodns is None:\n raise RuntimeError(\"Resolver requires aiodns library\")\n\n self._loop = asyncio.get_running_loop()\n self._resolver = aiodns.DNSResolver(*args, loop=self._loop, **kwargs)\n\n async def resolve(\n self, host: str, port: int = 0, family: int = socket.AF_INET\n ) -> List[Dict[str, Any]]:\n try:\n resp = await self._resolver.gethostbyname(host, family)\n except aiodns.error.DNSError as exc:\n msg = exc.args[1] if len(exc.args) >= 1 else \"DNS lookup failed\"\n raise OSError(msg) from exc\n hosts = []\n for address in resp.addresses:\n hosts.append(\n {\n \"hostname\": host,\n \"host\": address,\n \"port\": port,\n \"family\": family,\n \"proto\": 0,\n \"flags\": socket.AI_NUMERICHOST | socket.AI_NUMERICSERV,\n }\n )\n\n if not hosts:\n raise OSError(\"DNS lookup failed\")\n\n return hosts\n\n async def close(self) -> None:\n self._resolver.cancel()\n\n\n_DefaultType = Type[Union[AsyncResolver, ThreadedResolver]]\nDefaultResolver: _DefaultType = AsyncResolver if aiodns_default else ThreadedResolver\n", "path": "aiohttp/resolver.py"}]}
| 2,638 | 401 |
gh_patches_debug_33575
|
rasdani/github-patches
|
git_diff
|
Cog-Creators__Red-DiscordBot-1770
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[V3] CLI prefix display
### Type:
- [ ] Suggestion
- [X] Bug
### Brief description of the problem
When using the `--prefix` flag, the bot's loaded message still displays the prefix(es) it had stored prior (in some cases, this could be none)
### Expected behavior
The new prefix(es) should be displayed
### Actual behavior
New prefix is usable, but not reflected in the CLI
### Steps to reproduce
1. launch the bot using the prefix flag and observe
[v3] - Invalid version number.
# Other bugs
<!--
Did you find a bug with something other than a command? Fill out the following:
-->
#### What were you trying to do?
Load the bot
#### What were you expecting to happen?
Bot stays quiet, or shows a splash
#### What actually happened?
```[29/05/2018 20:59] ERROR events on_error 181: Exception in on_ready
Traceback (most recent call last):
File "/root/.pyenv/versions/3.6.5/lib/python3.6/site-packages/discord/client.py", line 224, in _run_event
yield from coro(*args, **kwargs)
File "/root/.pyenv/versions/3.6.5/lib/python3.6/site-packages/redbot/core/events.py", line 125, in on_ready
if StrictVersion(data["info"]["version"]) > StrictVersion(red_version):
File "/root/.pyenv/versions/3.6.5/lib/python3.6/distutils/version.py", line 40, in __init__
self.parse(vstring)
File "/root/.pyenv/versions/3.6.5/lib/python3.6/distutils/version.py", line 137, in parse
raise ValueError("invalid version number '%s'" % vstring)
ValueError: invalid version number '3.0.0b15.post2'
```
#### How can we reproduce this issue?
Unsure. I just loaded the bot on a fresh and clean server.
</issue>
<code>
[start of redbot/core/events.py]
1 import sys
2 import codecs
3 import datetime
4 import logging
5 from distutils.version import StrictVersion
6
7 import aiohttp
8 import pkg_resources
9 import traceback
10 from pkg_resources import DistributionNotFound
11
12
13 import discord
14 from discord.ext import commands
15
16 from . import __version__
17 from .data_manager import storage_type
18 from .utils.chat_formatting import inline, bordered, pagify, box
19 from .utils import fuzzy_command_search
20 from colorama import Fore, Style, init
21
22 log = logging.getLogger("red")
23 sentry_log = logging.getLogger("red.sentry")
24 init()
25
26 INTRO = """
27 ______ _ ______ _ _ ______ _
28 | ___ \ | | | _ (_) | | | ___ \ | |
29 | |_/ /___ __| | ______ | | | |_ ___ ___ ___ _ __ __| | | |_/ / ___ | |_
30 | // _ \/ _` | |______| | | | | / __|/ __/ _ \| '__/ _` | | ___ \/ _ \| __|
31 | |\ \ __/ (_| | | |/ /| \__ \ (_| (_) | | | (_| | | |_/ / (_) | |_
32 \_| \_\___|\__,_| |___/ |_|___/\___\___/|_| \__,_| \____/ \___/ \__|
33 """
34
35
36 def should_log_sentry(exception) -> bool:
37 e = exception
38 while e.__cause__ is not None:
39 e = e.__cause__
40
41 tb = e.__traceback__
42 tb_frame = None
43 while tb is not None:
44 tb_frame = tb.tb_frame
45 tb = tb.tb_next
46
47 module = tb_frame.f_globals.get("__name__")
48 return module.startswith("redbot")
49
50
51 def init_events(bot, cli_flags):
52 @bot.event
53 async def on_connect():
54 if bot.uptime is None:
55 print("Connected to Discord. Getting ready...")
56
57 @bot.event
58 async def on_ready():
59 if bot.uptime is not None:
60 return
61
62 bot.uptime = datetime.datetime.utcnow()
63 packages = []
64
65 if cli_flags.no_cogs is False:
66 packages.extend(await bot.db.packages())
67
68 if cli_flags.load_cogs:
69 packages.extend(cli_flags.load_cogs)
70
71 if packages:
72 to_remove = []
73 print("Loading packages...")
74 for package in packages:
75 try:
76 spec = await bot.cog_mgr.find_cog(package)
77 await bot.load_extension(spec)
78 except Exception as e:
79 log.exception("Failed to load package {}".format(package), exc_info=e)
80 await bot.remove_loaded_package(package)
81 to_remove.append(package)
82 for package in to_remove:
83 packages.remove(package)
84 if packages:
85 print("Loaded packages: " + ", ".join(packages))
86
87 guilds = len(bot.guilds)
88 users = len(set([m for m in bot.get_all_members()]))
89
90 try:
91 data = await bot.application_info()
92 invite_url = discord.utils.oauth_url(data.id)
93 except:
94 if bot.user.bot:
95 invite_url = "Could not fetch invite url"
96 else:
97 invite_url = None
98
99 prefixes = await bot.db.prefix()
100 lang = await bot.db.locale()
101 red_version = __version__
102 red_pkg = pkg_resources.get_distribution("Red-DiscordBot")
103 dpy_version = discord.__version__
104
105 INFO = [
106 str(bot.user),
107 "Prefixes: {}".format(", ".join(prefixes)),
108 "Language: {}".format(lang),
109 "Red Bot Version: {}".format(red_version),
110 "Discord.py Version: {}".format(dpy_version),
111 "Shards: {}".format(bot.shard_count),
112 ]
113
114 if guilds:
115 INFO.extend(("Servers: {}".format(guilds), "Users: {}".format(users)))
116 else:
117 print("Ready. I'm not in any server yet!")
118
119 INFO.append("{} cogs with {} commands".format(len(bot.cogs), len(bot.commands)))
120
121 async with aiohttp.ClientSession() as session:
122 async with session.get("https://pypi.python.org/pypi/red-discordbot/json") as r:
123 data = await r.json()
124 if StrictVersion(data["info"]["version"]) > StrictVersion(red_version):
125 INFO.append(
126 "Outdated version! {} is available "
127 "but you're using {}".format(data["info"]["version"], red_version)
128 )
129 owner = discord.utils.get(bot.get_all_members(), id=bot.owner_id)
130 try:
131 await owner.send(
132 "Your Red instance is out of date! {} is the current "
133 "version, however you are using {}!".format(
134 data["info"]["version"], red_version
135 )
136 )
137 except:
138 pass
139 INFO2 = []
140
141 sentry = await bot.db.enable_sentry()
142 mongo_enabled = storage_type() != "JSON"
143 reqs_installed = {"voice": None, "docs": None, "test": None}
144 for key in reqs_installed.keys():
145 reqs = [x.name for x in red_pkg._dep_map[key]]
146 try:
147 pkg_resources.require(reqs)
148 except DistributionNotFound:
149 reqs_installed[key] = False
150 else:
151 reqs_installed[key] = True
152
153 options = (
154 ("Error Reporting", sentry),
155 ("MongoDB", mongo_enabled),
156 ("Voice", reqs_installed["voice"]),
157 ("Docs", reqs_installed["docs"]),
158 ("Tests", reqs_installed["test"]),
159 )
160
161 on_symbol, off_symbol, ascii_border = _get_startup_screen_specs()
162
163 for option, enabled in options:
164 enabled = on_symbol if enabled else off_symbol
165 INFO2.append("{} {}".format(enabled, option))
166
167 print(Fore.RED + INTRO)
168 print(Style.RESET_ALL)
169 print(bordered(INFO, INFO2, ascii_border=ascii_border))
170
171 if invite_url:
172 print("\nInvite URL: {}\n".format(invite_url))
173
174 bot.color = discord.Colour(await bot.db.color())
175 if bot.rpc_enabled:
176 await bot.rpc.initialize()
177
178 @bot.event
179 async def on_error(event_method, *args, **kwargs):
180 sentry_log.exception("Exception in {}".format(event_method))
181
182 @bot.event
183 async def on_command_error(ctx, error):
184 if isinstance(error, commands.MissingRequiredArgument):
185 await ctx.send_help()
186 elif isinstance(error, commands.BadArgument):
187 await ctx.send_help()
188 elif isinstance(error, commands.DisabledCommand):
189 await ctx.send("That command is disabled.")
190 elif isinstance(error, commands.CommandInvokeError):
191 # Need to test if the following still works
192 """
193 no_dms = "Cannot send messages to this user"
194 is_help_cmd = ctx.command.qualified_name == "help"
195 is_forbidden = isinstance(error.original, discord.Forbidden)
196 if is_help_cmd and is_forbidden and error.original.text == no_dms:
197 msg = ("I couldn't send the help message to you in DM. Either"
198 " you blocked me or you disabled DMs in this server.")
199 await ctx.send(msg)
200 return
201 """
202 log.exception(
203 "Exception in command '{}'" "".format(ctx.command.qualified_name),
204 exc_info=error.original,
205 )
206 if should_log_sentry(error):
207 sentry_log.exception(
208 "Exception in command '{}'" "".format(ctx.command.qualified_name),
209 exc_info=error.original,
210 )
211
212 message = (
213 "Error in command '{}'. Check your console or "
214 "logs for details."
215 "".format(ctx.command.qualified_name)
216 )
217 exception_log = "Exception in command '{}'\n" "".format(ctx.command.qualified_name)
218 exception_log += "".join(
219 traceback.format_exception(type(error), error, error.__traceback__)
220 )
221 bot._last_exception = exception_log
222 if not hasattr(ctx.cog, "_{0.command.cog_name}__error".format(ctx)):
223 await ctx.send(inline(message))
224 elif isinstance(error, commands.CommandNotFound):
225 term = ctx.invoked_with + " "
226 if len(ctx.args) > 1:
227 term += " ".join(ctx.args[1:])
228 await ctx.maybe_send_embed(fuzzy_command_search(ctx, ctx.invoked_with))
229 elif isinstance(error, commands.CheckFailure):
230 pass
231 elif isinstance(error, commands.NoPrivateMessage):
232 await ctx.send("That command is not available in DMs.")
233 elif isinstance(error, commands.CommandOnCooldown):
234 await ctx.send(
235 "This command is on cooldown. " "Try again in {:.2f}s" "".format(error.retry_after)
236 )
237 else:
238 log.exception(type(error).__name__, exc_info=error)
239 try:
240 sentry_error = error.original
241 except AttributeError:
242 sentry_error = error
243
244 if should_log_sentry(sentry_error):
245 sentry_log.exception("Unhandled command error.", exc_info=sentry_error)
246
247 @bot.event
248 async def on_message(message):
249 bot.counter["messages_read"] += 1
250 await bot.process_commands(message)
251
252 @bot.event
253 async def on_resumed():
254 bot.counter["sessions_resumed"] += 1
255
256 @bot.event
257 async def on_command(command):
258 bot.counter["processed_commands"] += 1
259
260
261 def _get_startup_screen_specs():
262 """Get specs for displaying the startup screen on stdout.
263
264 This is so we don't get encoding errors when trying to print unicode
265 emojis to stdout (particularly with Windows Command Prompt).
266
267 Returns
268 -------
269 `tuple`
270 Tuple in the form (`str`, `str`, `bool`) containing (in order) the
271 on symbol, off symbol and whether or not the border should be pure ascii.
272
273 """
274 encoder = codecs.getencoder(sys.stdout.encoding)
275 check_mark = "\N{SQUARE ROOT}"
276 try:
277 encoder(check_mark)
278 except UnicodeEncodeError:
279 on_symbol = "[X]"
280 off_symbol = "[ ]"
281 else:
282 on_symbol = check_mark
283 off_symbol = "X"
284
285 try:
286 encoder("┌┐└┘─│") # border symbols
287 except UnicodeEncodeError:
288 ascii_border = True
289 else:
290 ascii_border = False
291
292 return on_symbol, off_symbol, ascii_border
293
[end of redbot/core/events.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/redbot/core/events.py b/redbot/core/events.py
--- a/redbot/core/events.py
+++ b/redbot/core/events.py
@@ -96,7 +96,7 @@
else:
invite_url = None
- prefixes = await bot.db.prefix()
+ prefixes = cli_flags.prefix or (await bot.db.prefix())
lang = await bot.db.locale()
red_version = __version__
red_pkg = pkg_resources.get_distribution("Red-DiscordBot")
@@ -118,24 +118,24 @@
INFO.append("{} cogs with {} commands".format(len(bot.cogs), len(bot.commands)))
- async with aiohttp.ClientSession() as session:
- async with session.get("https://pypi.python.org/pypi/red-discordbot/json") as r:
- data = await r.json()
- if StrictVersion(data["info"]["version"]) > StrictVersion(red_version):
- INFO.append(
- "Outdated version! {} is available "
- "but you're using {}".format(data["info"]["version"], red_version)
- )
- owner = discord.utils.get(bot.get_all_members(), id=bot.owner_id)
- try:
+ try:
+ async with aiohttp.ClientSession() as session:
+ async with session.get("https://pypi.python.org/pypi/red-discordbot/json") as r:
+ data = await r.json()
+ if StrictVersion(data["info"]["version"]) > StrictVersion(red_version):
+ INFO.append(
+ "Outdated version! {} is available "
+ "but you're using {}".format(data["info"]["version"], red_version)
+ )
+ owner = discord.utils.get(bot.get_all_members(), id=bot.owner_id)
await owner.send(
"Your Red instance is out of date! {} is the current "
"version, however you are using {}!".format(
data["info"]["version"], red_version
)
)
- except:
- pass
+ except:
+ pass
INFO2 = []
sentry = await bot.db.enable_sentry()
|
{"golden_diff": "diff --git a/redbot/core/events.py b/redbot/core/events.py\n--- a/redbot/core/events.py\n+++ b/redbot/core/events.py\n@@ -96,7 +96,7 @@\n else:\n invite_url = None\n \n- prefixes = await bot.db.prefix()\n+ prefixes = cli_flags.prefix or (await bot.db.prefix())\n lang = await bot.db.locale()\n red_version = __version__\n red_pkg = pkg_resources.get_distribution(\"Red-DiscordBot\")\n@@ -118,24 +118,24 @@\n \n INFO.append(\"{} cogs with {} commands\".format(len(bot.cogs), len(bot.commands)))\n \n- async with aiohttp.ClientSession() as session:\n- async with session.get(\"https://pypi.python.org/pypi/red-discordbot/json\") as r:\n- data = await r.json()\n- if StrictVersion(data[\"info\"][\"version\"]) > StrictVersion(red_version):\n- INFO.append(\n- \"Outdated version! {} is available \"\n- \"but you're using {}\".format(data[\"info\"][\"version\"], red_version)\n- )\n- owner = discord.utils.get(bot.get_all_members(), id=bot.owner_id)\n- try:\n+ try:\n+ async with aiohttp.ClientSession() as session:\n+ async with session.get(\"https://pypi.python.org/pypi/red-discordbot/json\") as r:\n+ data = await r.json()\n+ if StrictVersion(data[\"info\"][\"version\"]) > StrictVersion(red_version):\n+ INFO.append(\n+ \"Outdated version! {} is available \"\n+ \"but you're using {}\".format(data[\"info\"][\"version\"], red_version)\n+ )\n+ owner = discord.utils.get(bot.get_all_members(), id=bot.owner_id)\n await owner.send(\n \"Your Red instance is out of date! {} is the current \"\n \"version, however you are using {}!\".format(\n data[\"info\"][\"version\"], red_version\n )\n )\n- except:\n- pass\n+ except:\n+ pass\n INFO2 = []\n \n sentry = await bot.db.enable_sentry()\n", "issue": "[V3] CLI prefix display\n\r\n\r\n### Type:\r\n\r\n- [ ] Suggestion\r\n- [X] Bug\r\n\r\n### Brief description of the problem\r\nWhen using the `--prefix` flag, the bot's loaded message still displays the prefix(es) it had stored prior (in some cases, this could be none)\r\n### Expected behavior\r\nThe new prefix(es) should be displayed\r\n### Actual behavior\r\nNew prefix is usable, but not reflected in the CLI\r\n### Steps to reproduce\r\n\r\n1. launch the bot using the prefix flag and observe\r\n\r\n\n[v3] - Invalid version number.\n# Other bugs\r\n\r\n<!-- \r\nDid you find a bug with something other than a command? Fill out the following:\r\n-->\r\n\r\n#### What were you trying to do?\r\nLoad the bot\r\n\r\n#### What were you expecting to happen?\r\n\r\nBot stays quiet, or shows a splash\r\n\r\n#### What actually happened?\r\n\r\n```[29/05/2018 20:59] ERROR events on_error 181: Exception in on_ready\r\nTraceback (most recent call last):\r\n File \"/root/.pyenv/versions/3.6.5/lib/python3.6/site-packages/discord/client.py\", line 224, in _run_event\r\n yield from coro(*args, **kwargs)\r\n File \"/root/.pyenv/versions/3.6.5/lib/python3.6/site-packages/redbot/core/events.py\", line 125, in on_ready\r\n if StrictVersion(data[\"info\"][\"version\"]) > StrictVersion(red_version):\r\n File \"/root/.pyenv/versions/3.6.5/lib/python3.6/distutils/version.py\", line 40, in __init__\r\n self.parse(vstring)\r\n File \"/root/.pyenv/versions/3.6.5/lib/python3.6/distutils/version.py\", line 137, in parse\r\n raise ValueError(\"invalid version number '%s'\" % vstring)\r\nValueError: invalid version number '3.0.0b15.post2'\r\n```\r\n\r\n#### How can we reproduce this issue?\r\n\r\nUnsure. I just loaded the bot on a fresh and clean server.\r\n\n", "before_files": [{"content": "import sys\nimport codecs\nimport datetime\nimport logging\nfrom distutils.version import StrictVersion\n\nimport aiohttp\nimport pkg_resources\nimport traceback\nfrom pkg_resources import DistributionNotFound\n\n\nimport discord\nfrom discord.ext import commands\n\nfrom . import __version__\nfrom .data_manager import storage_type\nfrom .utils.chat_formatting import inline, bordered, pagify, box\nfrom .utils import fuzzy_command_search\nfrom colorama import Fore, Style, init\n\nlog = logging.getLogger(\"red\")\nsentry_log = logging.getLogger(\"red.sentry\")\ninit()\n\nINTRO = \"\"\"\n______ _ ______ _ _ ______ _ \n| ___ \\ | | | _ (_) | | | ___ \\ | | \n| |_/ /___ __| | ______ | | | |_ ___ ___ ___ _ __ __| | | |_/ / ___ | |_ \n| // _ \\/ _` | |______| | | | | / __|/ __/ _ \\| '__/ _` | | ___ \\/ _ \\| __|\n| |\\ \\ __/ (_| | | |/ /| \\__ \\ (_| (_) | | | (_| | | |_/ / (_) | |_ \n\\_| \\_\\___|\\__,_| |___/ |_|___/\\___\\___/|_| \\__,_| \\____/ \\___/ \\__|\n\"\"\"\n\n\ndef should_log_sentry(exception) -> bool:\n e = exception\n while e.__cause__ is not None:\n e = e.__cause__\n\n tb = e.__traceback__\n tb_frame = None\n while tb is not None:\n tb_frame = tb.tb_frame\n tb = tb.tb_next\n\n module = tb_frame.f_globals.get(\"__name__\")\n return module.startswith(\"redbot\")\n\n\ndef init_events(bot, cli_flags):\n @bot.event\n async def on_connect():\n if bot.uptime is None:\n print(\"Connected to Discord. Getting ready...\")\n\n @bot.event\n async def on_ready():\n if bot.uptime is not None:\n return\n\n bot.uptime = datetime.datetime.utcnow()\n packages = []\n\n if cli_flags.no_cogs is False:\n packages.extend(await bot.db.packages())\n\n if cli_flags.load_cogs:\n packages.extend(cli_flags.load_cogs)\n\n if packages:\n to_remove = []\n print(\"Loading packages...\")\n for package in packages:\n try:\n spec = await bot.cog_mgr.find_cog(package)\n await bot.load_extension(spec)\n except Exception as e:\n log.exception(\"Failed to load package {}\".format(package), exc_info=e)\n await bot.remove_loaded_package(package)\n to_remove.append(package)\n for package in to_remove:\n packages.remove(package)\n if packages:\n print(\"Loaded packages: \" + \", \".join(packages))\n\n guilds = len(bot.guilds)\n users = len(set([m for m in bot.get_all_members()]))\n\n try:\n data = await bot.application_info()\n invite_url = discord.utils.oauth_url(data.id)\n except:\n if bot.user.bot:\n invite_url = \"Could not fetch invite url\"\n else:\n invite_url = None\n\n prefixes = await bot.db.prefix()\n lang = await bot.db.locale()\n red_version = __version__\n red_pkg = pkg_resources.get_distribution(\"Red-DiscordBot\")\n dpy_version = discord.__version__\n\n INFO = [\n str(bot.user),\n \"Prefixes: {}\".format(\", \".join(prefixes)),\n \"Language: {}\".format(lang),\n \"Red Bot Version: {}\".format(red_version),\n \"Discord.py Version: {}\".format(dpy_version),\n \"Shards: {}\".format(bot.shard_count),\n ]\n\n if guilds:\n INFO.extend((\"Servers: {}\".format(guilds), \"Users: {}\".format(users)))\n else:\n print(\"Ready. I'm not in any server yet!\")\n\n INFO.append(\"{} cogs with {} commands\".format(len(bot.cogs), len(bot.commands)))\n\n async with aiohttp.ClientSession() as session:\n async with session.get(\"https://pypi.python.org/pypi/red-discordbot/json\") as r:\n data = await r.json()\n if StrictVersion(data[\"info\"][\"version\"]) > StrictVersion(red_version):\n INFO.append(\n \"Outdated version! {} is available \"\n \"but you're using {}\".format(data[\"info\"][\"version\"], red_version)\n )\n owner = discord.utils.get(bot.get_all_members(), id=bot.owner_id)\n try:\n await owner.send(\n \"Your Red instance is out of date! {} is the current \"\n \"version, however you are using {}!\".format(\n data[\"info\"][\"version\"], red_version\n )\n )\n except:\n pass\n INFO2 = []\n\n sentry = await bot.db.enable_sentry()\n mongo_enabled = storage_type() != \"JSON\"\n reqs_installed = {\"voice\": None, \"docs\": None, \"test\": None}\n for key in reqs_installed.keys():\n reqs = [x.name for x in red_pkg._dep_map[key]]\n try:\n pkg_resources.require(reqs)\n except DistributionNotFound:\n reqs_installed[key] = False\n else:\n reqs_installed[key] = True\n\n options = (\n (\"Error Reporting\", sentry),\n (\"MongoDB\", mongo_enabled),\n (\"Voice\", reqs_installed[\"voice\"]),\n (\"Docs\", reqs_installed[\"docs\"]),\n (\"Tests\", reqs_installed[\"test\"]),\n )\n\n on_symbol, off_symbol, ascii_border = _get_startup_screen_specs()\n\n for option, enabled in options:\n enabled = on_symbol if enabled else off_symbol\n INFO2.append(\"{} {}\".format(enabled, option))\n\n print(Fore.RED + INTRO)\n print(Style.RESET_ALL)\n print(bordered(INFO, INFO2, ascii_border=ascii_border))\n\n if invite_url:\n print(\"\\nInvite URL: {}\\n\".format(invite_url))\n\n bot.color = discord.Colour(await bot.db.color())\n if bot.rpc_enabled:\n await bot.rpc.initialize()\n\n @bot.event\n async def on_error(event_method, *args, **kwargs):\n sentry_log.exception(\"Exception in {}\".format(event_method))\n\n @bot.event\n async def on_command_error(ctx, error):\n if isinstance(error, commands.MissingRequiredArgument):\n await ctx.send_help()\n elif isinstance(error, commands.BadArgument):\n await ctx.send_help()\n elif isinstance(error, commands.DisabledCommand):\n await ctx.send(\"That command is disabled.\")\n elif isinstance(error, commands.CommandInvokeError):\n # Need to test if the following still works\n \"\"\"\n no_dms = \"Cannot send messages to this user\"\n is_help_cmd = ctx.command.qualified_name == \"help\"\n is_forbidden = isinstance(error.original, discord.Forbidden)\n if is_help_cmd and is_forbidden and error.original.text == no_dms:\n msg = (\"I couldn't send the help message to you in DM. Either\"\n \" you blocked me or you disabled DMs in this server.\")\n await ctx.send(msg)\n return\n \"\"\"\n log.exception(\n \"Exception in command '{}'\" \"\".format(ctx.command.qualified_name),\n exc_info=error.original,\n )\n if should_log_sentry(error):\n sentry_log.exception(\n \"Exception in command '{}'\" \"\".format(ctx.command.qualified_name),\n exc_info=error.original,\n )\n\n message = (\n \"Error in command '{}'. Check your console or \"\n \"logs for details.\"\n \"\".format(ctx.command.qualified_name)\n )\n exception_log = \"Exception in command '{}'\\n\" \"\".format(ctx.command.qualified_name)\n exception_log += \"\".join(\n traceback.format_exception(type(error), error, error.__traceback__)\n )\n bot._last_exception = exception_log\n if not hasattr(ctx.cog, \"_{0.command.cog_name}__error\".format(ctx)):\n await ctx.send(inline(message))\n elif isinstance(error, commands.CommandNotFound):\n term = ctx.invoked_with + \" \"\n if len(ctx.args) > 1:\n term += \" \".join(ctx.args[1:])\n await ctx.maybe_send_embed(fuzzy_command_search(ctx, ctx.invoked_with))\n elif isinstance(error, commands.CheckFailure):\n pass\n elif isinstance(error, commands.NoPrivateMessage):\n await ctx.send(\"That command is not available in DMs.\")\n elif isinstance(error, commands.CommandOnCooldown):\n await ctx.send(\n \"This command is on cooldown. \" \"Try again in {:.2f}s\" \"\".format(error.retry_after)\n )\n else:\n log.exception(type(error).__name__, exc_info=error)\n try:\n sentry_error = error.original\n except AttributeError:\n sentry_error = error\n\n if should_log_sentry(sentry_error):\n sentry_log.exception(\"Unhandled command error.\", exc_info=sentry_error)\n\n @bot.event\n async def on_message(message):\n bot.counter[\"messages_read\"] += 1\n await bot.process_commands(message)\n\n @bot.event\n async def on_resumed():\n bot.counter[\"sessions_resumed\"] += 1\n\n @bot.event\n async def on_command(command):\n bot.counter[\"processed_commands\"] += 1\n\n\ndef _get_startup_screen_specs():\n \"\"\"Get specs for displaying the startup screen on stdout.\n\n This is so we don't get encoding errors when trying to print unicode\n emojis to stdout (particularly with Windows Command Prompt).\n\n Returns\n -------\n `tuple`\n Tuple in the form (`str`, `str`, `bool`) containing (in order) the\n on symbol, off symbol and whether or not the border should be pure ascii.\n\n \"\"\"\n encoder = codecs.getencoder(sys.stdout.encoding)\n check_mark = \"\\N{SQUARE ROOT}\"\n try:\n encoder(check_mark)\n except UnicodeEncodeError:\n on_symbol = \"[X]\"\n off_symbol = \"[ ]\"\n else:\n on_symbol = check_mark\n off_symbol = \"X\"\n\n try:\n encoder(\"\u250c\u2510\u2514\u2518\u2500\u2502\") # border symbols\n except UnicodeEncodeError:\n ascii_border = True\n else:\n ascii_border = False\n\n return on_symbol, off_symbol, ascii_border\n", "path": "redbot/core/events.py"}]}
| 3,995 | 463 |
gh_patches_debug_235
|
rasdani/github-patches
|
git_diff
|
scikit-hep__pyhf-1460
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Logging configuration in contrib/utils
# Question
`pyhf.contrib.utils` sets up logging:
https://github.com/scikit-hep/pyhf/blob/6b769fd6f5e1473deba2b4c55d49ebdb3db5b447/src/pyhf/contrib/utils.py#L9
This interferes with custom logging users may want to set up. To achieve this now, they would have to do so before `from pyhf.contrib.utils import download`. To avoid this issue, the logging should not be configured in this part of the code (and only for the CLI).
# Relevant Issues and Pull Requests
#865
User-defined log formatting
# Description
`pyhf` uses `logging` for outputs, and calls `logging.basicConfig()` in a few places.
This has the effect of preventing the user to set their desired logging behavior after `pyhf` import.
While calling this a bug might be a bit of a stretch, I think it might be unintentional since `pyhf` does not apply any logging formatting as far as I can tell.
# Expected Behavior
I expect no calls to `logging.basicConfig()` within `pyhf` to leave the formatting fully up to the user, no matter whether they want to set it before or after importing `pyhf`.
# Actual Behavior
User-defined `logging` formatting only works before importing `pyhf`.
# Steps to Reproduce
importing `pyhf` before formatting:
```
import logging
import pyhf
print(pyhf.__version__)
logging.basicConfig(level=logging.INFO)
log = logging.getLogger(__name__)
log.info("message")
```
output:
```
0.4.1
```
and when applying formatting before input, the expected behavior:
```
import logging
logging.basicConfig(level=logging.INFO)
import pyhf
print(pyhf.__version__)
log = logging.getLogger(__name__)
log.info("message")
```
output:
```
0.4.1
INFO:__main__:message
```
# Checklist
- [ ] Run `git fetch` to get the most up to date version of `master`
- no, but checked code on master to confirm that the relevant part is unchanged
- [X] Searched through existing Issues to confirm this is not a duplicate issue
- [X] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue
</issue>
<code>
[start of src/pyhf/contrib/utils.py]
1 """Helper utilities for common tasks."""
2
3 from urllib.parse import urlparse
4 import tarfile
5 from io import BytesIO
6 import logging
7 from .. import exceptions
8
9 logging.basicConfig()
10 log = logging.getLogger(__name__)
11
12 __all__ = ["download"]
13
14
15 def __dir__():
16 return __all__
17
18
19 try:
20 import requests
21
22 def download(archive_url, output_directory, force=False, compress=False):
23 """
24 Download the patchset archive from the remote URL and extract it in a
25 directory at the path given.
26
27 Example:
28
29 >>> from pyhf.contrib.utils import download
30 >>> download("https://doi.org/10.17182/hepdata.90607.v3/r3", "1Lbb-likelihoods")
31 >>> import os
32 >>> sorted(os.listdir("1Lbb-likelihoods"))
33 ['BkgOnly.json', 'README.md', 'patchset.json']
34 >>> download("https://doi.org/10.17182/hepdata.90607.v3/r3", "1Lbb-likelihoods.tar.gz", compress=True)
35 >>> import glob
36 >>> glob.glob("1Lbb-likelihoods.tar.gz")
37 ['1Lbb-likelihoods.tar.gz']
38
39 Args:
40 archive_url (:obj:`str`): The URL of the :class:`~pyhf.patchset.PatchSet` archive to download.
41 output_directory (:obj:`str`): Name of the directory to unpack the archive into.
42 force (:obj:`bool`): Force download from non-approved host. Default is ``False``.
43 compress (:obj:`bool`): Keep the archive in a compressed ``tar.gz`` form. Default is ``False``.
44
45 Raises:
46 :class:`~pyhf.exceptions.InvalidArchiveHost`: if the provided archive host name is not known to be valid
47 """
48 if not force:
49 valid_hosts = ["www.hepdata.net", "doi.org"]
50 netloc = urlparse(archive_url).netloc
51 if netloc not in valid_hosts:
52 raise exceptions.InvalidArchiveHost(
53 f"{netloc} is not an approved archive host: {', '.join(str(host) for host in valid_hosts)}\n"
54 + "To download an archive from this host use the --force option."
55 )
56
57 with requests.get(archive_url) as response:
58 if compress:
59 with open(output_directory, "wb") as archive:
60 archive.write(response.content)
61 else:
62 with tarfile.open(
63 mode="r|gz", fileobj=BytesIO(response.content)
64 ) as archive:
65 archive.extractall(output_directory)
66
67
68 except ModuleNotFoundError:
69 log.error(
70 "\nInstallation of the contrib extra is required to use pyhf.contrib.utils.download"
71 + "\nPlease install with: python -m pip install pyhf[contrib]\n",
72 exc_info=True,
73 )
74
[end of src/pyhf/contrib/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/pyhf/contrib/utils.py b/src/pyhf/contrib/utils.py
--- a/src/pyhf/contrib/utils.py
+++ b/src/pyhf/contrib/utils.py
@@ -6,7 +6,6 @@
import logging
from .. import exceptions
-logging.basicConfig()
log = logging.getLogger(__name__)
__all__ = ["download"]
|
{"golden_diff": "diff --git a/src/pyhf/contrib/utils.py b/src/pyhf/contrib/utils.py\n--- a/src/pyhf/contrib/utils.py\n+++ b/src/pyhf/contrib/utils.py\n@@ -6,7 +6,6 @@\n import logging\n from .. import exceptions\n \n-logging.basicConfig()\n log = logging.getLogger(__name__)\n \n __all__ = [\"download\"]\n", "issue": "Logging configuration in contrib/utils\n# Question\r\n\r\n`pyhf.contrib.utils` sets up logging:\r\nhttps://github.com/scikit-hep/pyhf/blob/6b769fd6f5e1473deba2b4c55d49ebdb3db5b447/src/pyhf/contrib/utils.py#L9 \r\n\r\nThis interferes with custom logging users may want to set up. To achieve this now, they would have to do so before `from pyhf.contrib.utils import download`. To avoid this issue, the logging should not be configured in this part of the code (and only for the CLI).\r\n\r\n# Relevant Issues and Pull Requests\r\n\r\n#865\r\n\nUser-defined log formatting\n# Description\r\n\r\n`pyhf` uses `logging` for outputs, and calls `logging.basicConfig()` in a few places.\r\nThis has the effect of preventing the user to set their desired logging behavior after `pyhf` import.\r\nWhile calling this a bug might be a bit of a stretch, I think it might be unintentional since `pyhf` does not apply any logging formatting as far as I can tell.\r\n\r\n# Expected Behavior\r\n\r\nI expect no calls to `logging.basicConfig()` within `pyhf` to leave the formatting fully up to the user, no matter whether they want to set it before or after importing `pyhf`.\r\n\r\n# Actual Behavior\r\n\r\nUser-defined `logging` formatting only works before importing `pyhf`.\r\n\r\n# Steps to Reproduce\r\n\r\nimporting `pyhf` before formatting:\r\n```\r\nimport logging\r\nimport pyhf\r\nprint(pyhf.__version__)\r\nlogging.basicConfig(level=logging.INFO)\r\nlog = logging.getLogger(__name__)\r\nlog.info(\"message\")\r\n```\r\noutput:\r\n```\r\n0.4.1\r\n```\r\nand when applying formatting before input, the expected behavior:\r\n```\r\nimport logging\r\nlogging.basicConfig(level=logging.INFO)\r\nimport pyhf\r\nprint(pyhf.__version__)\r\nlog = logging.getLogger(__name__)\r\nlog.info(\"message\")\r\n```\r\noutput:\r\n```\r\n0.4.1\r\nINFO:__main__:message\r\n``` \r\n\r\n# Checklist\r\n\r\n- [ ] Run `git fetch` to get the most up to date version of `master`\r\n - no, but checked code on master to confirm that the relevant part is unchanged\r\n- [X] Searched through existing Issues to confirm this is not a duplicate issue\r\n- [X] Filled out the Description, Expected Behavior, Actual Behavior, and Steps to Reproduce sections above or have edited/removed them in a way that fully describes the issue\r\n\n", "before_files": [{"content": "\"\"\"Helper utilities for common tasks.\"\"\"\n\nfrom urllib.parse import urlparse\nimport tarfile\nfrom io import BytesIO\nimport logging\nfrom .. import exceptions\n\nlogging.basicConfig()\nlog = logging.getLogger(__name__)\n\n__all__ = [\"download\"]\n\n\ndef __dir__():\n return __all__\n\n\ntry:\n import requests\n\n def download(archive_url, output_directory, force=False, compress=False):\n \"\"\"\n Download the patchset archive from the remote URL and extract it in a\n directory at the path given.\n\n Example:\n\n >>> from pyhf.contrib.utils import download\n >>> download(\"https://doi.org/10.17182/hepdata.90607.v3/r3\", \"1Lbb-likelihoods\")\n >>> import os\n >>> sorted(os.listdir(\"1Lbb-likelihoods\"))\n ['BkgOnly.json', 'README.md', 'patchset.json']\n >>> download(\"https://doi.org/10.17182/hepdata.90607.v3/r3\", \"1Lbb-likelihoods.tar.gz\", compress=True)\n >>> import glob\n >>> glob.glob(\"1Lbb-likelihoods.tar.gz\")\n ['1Lbb-likelihoods.tar.gz']\n\n Args:\n archive_url (:obj:`str`): The URL of the :class:`~pyhf.patchset.PatchSet` archive to download.\n output_directory (:obj:`str`): Name of the directory to unpack the archive into.\n force (:obj:`bool`): Force download from non-approved host. Default is ``False``.\n compress (:obj:`bool`): Keep the archive in a compressed ``tar.gz`` form. Default is ``False``.\n\n Raises:\n :class:`~pyhf.exceptions.InvalidArchiveHost`: if the provided archive host name is not known to be valid\n \"\"\"\n if not force:\n valid_hosts = [\"www.hepdata.net\", \"doi.org\"]\n netloc = urlparse(archive_url).netloc\n if netloc not in valid_hosts:\n raise exceptions.InvalidArchiveHost(\n f\"{netloc} is not an approved archive host: {', '.join(str(host) for host in valid_hosts)}\\n\"\n + \"To download an archive from this host use the --force option.\"\n )\n\n with requests.get(archive_url) as response:\n if compress:\n with open(output_directory, \"wb\") as archive:\n archive.write(response.content)\n else:\n with tarfile.open(\n mode=\"r|gz\", fileobj=BytesIO(response.content)\n ) as archive:\n archive.extractall(output_directory)\n\n\nexcept ModuleNotFoundError:\n log.error(\n \"\\nInstallation of the contrib extra is required to use pyhf.contrib.utils.download\"\n + \"\\nPlease install with: python -m pip install pyhf[contrib]\\n\",\n exc_info=True,\n )\n", "path": "src/pyhf/contrib/utils.py"}]}
| 1,828 | 77 |
gh_patches_debug_8585
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-4759
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add a job for Python 3.9 to .travis.yml
It looks like Travis support specifying such a Python version as `3.9-dev`.
While I’m not sure we should officially support Python 3.9 it until its release, running tests on it will allow us to catch any issue early.
</issue>
<code>
[start of setup.py]
1 from os.path import dirname, join
2 from pkg_resources import parse_version
3 from setuptools import setup, find_packages, __version__ as setuptools_version
4
5
6 with open(join(dirname(__file__), 'scrapy/VERSION'), 'rb') as f:
7 version = f.read().decode('ascii').strip()
8
9
10 def has_environment_marker_platform_impl_support():
11 """Code extracted from 'pytest/setup.py'
12 https://github.com/pytest-dev/pytest/blob/7538680c/setup.py#L31
13
14 The first known release to support environment marker with range operators
15 it is 18.5, see:
16 https://setuptools.readthedocs.io/en/latest/history.html#id235
17 """
18 return parse_version(setuptools_version) >= parse_version('18.5')
19
20
21 install_requires = [
22 'Twisted>=17.9.0',
23 'cryptography>=2.0',
24 'cssselect>=0.9.1',
25 'itemloaders>=1.0.1',
26 'parsel>=1.5.0',
27 'pyOpenSSL>=16.2.0',
28 'queuelib>=1.4.2',
29 'service_identity>=16.0.0',
30 'w3lib>=1.17.0',
31 'zope.interface>=4.1.3',
32 'protego>=0.1.15',
33 'itemadapter>=0.1.0',
34 ]
35 extras_require = {}
36 cpython_dependencies = [
37 'lxml>=3.5.0',
38 'PyDispatcher>=2.0.5',
39 ]
40 if has_environment_marker_platform_impl_support():
41 extras_require[':platform_python_implementation == "CPython"'] = cpython_dependencies
42 extras_require[':platform_python_implementation == "PyPy"'] = [
43 # Earlier lxml versions are affected by
44 # https://foss.heptapod.net/pypy/pypy/-/issues/2498,
45 # which was fixed in Cython 0.26, released on 2017-06-19, and used to
46 # generate the C headers of lxml release tarballs published since then, the
47 # first of which was:
48 'lxml>=4.0.0',
49 'PyPyDispatcher>=2.1.0',
50 ]
51 else:
52 install_requires.extend(cpython_dependencies)
53
54
55 setup(
56 name='Scrapy',
57 version=version,
58 url='https://scrapy.org',
59 project_urls={
60 'Documentation': 'https://docs.scrapy.org/',
61 'Source': 'https://github.com/scrapy/scrapy',
62 'Tracker': 'https://github.com/scrapy/scrapy/issues',
63 },
64 description='A high-level Web Crawling and Web Scraping framework',
65 long_description=open('README.rst').read(),
66 author='Scrapy developers',
67 maintainer='Pablo Hoffman',
68 maintainer_email='[email protected]',
69 license='BSD',
70 packages=find_packages(exclude=('tests', 'tests.*')),
71 include_package_data=True,
72 zip_safe=False,
73 entry_points={
74 'console_scripts': ['scrapy = scrapy.cmdline:execute']
75 },
76 classifiers=[
77 'Framework :: Scrapy',
78 'Development Status :: 5 - Production/Stable',
79 'Environment :: Console',
80 'Intended Audience :: Developers',
81 'License :: OSI Approved :: BSD License',
82 'Operating System :: OS Independent',
83 'Programming Language :: Python',
84 'Programming Language :: Python :: 3',
85 'Programming Language :: Python :: 3.6',
86 'Programming Language :: Python :: 3.7',
87 'Programming Language :: Python :: 3.8',
88 'Programming Language :: Python :: Implementation :: CPython',
89 'Programming Language :: Python :: Implementation :: PyPy',
90 'Topic :: Internet :: WWW/HTTP',
91 'Topic :: Software Development :: Libraries :: Application Frameworks',
92 'Topic :: Software Development :: Libraries :: Python Modules',
93 ],
94 python_requires='>=3.6',
95 install_requires=install_requires,
96 extras_require=extras_require,
97 )
98
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -85,6 +85,7 @@
'Programming Language :: Python :: 3.6',
'Programming Language :: Python :: 3.7',
'Programming Language :: Python :: 3.8',
+ 'Programming Language :: Python :: 3.9',
'Programming Language :: Python :: Implementation :: CPython',
'Programming Language :: Python :: Implementation :: PyPy',
'Topic :: Internet :: WWW/HTTP',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -85,6 +85,7 @@\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n+ 'Programming Language :: Python :: 3.9',\n 'Programming Language :: Python :: Implementation :: CPython',\n 'Programming Language :: Python :: Implementation :: PyPy',\n 'Topic :: Internet :: WWW/HTTP',\n", "issue": "Add a job for Python 3.9 to .travis.yml\nIt looks like Travis support specifying such a Python version as `3.9-dev`.\r\n\r\nWhile I\u2019m not sure we should officially support Python 3.9 it until its release, running tests on it will allow us to catch any issue early.\n", "before_files": [{"content": "from os.path import dirname, join\nfrom pkg_resources import parse_version\nfrom setuptools import setup, find_packages, __version__ as setuptools_version\n\n\nwith open(join(dirname(__file__), 'scrapy/VERSION'), 'rb') as f:\n version = f.read().decode('ascii').strip()\n\n\ndef has_environment_marker_platform_impl_support():\n \"\"\"Code extracted from 'pytest/setup.py'\n https://github.com/pytest-dev/pytest/blob/7538680c/setup.py#L31\n\n The first known release to support environment marker with range operators\n it is 18.5, see:\n https://setuptools.readthedocs.io/en/latest/history.html#id235\n \"\"\"\n return parse_version(setuptools_version) >= parse_version('18.5')\n\n\ninstall_requires = [\n 'Twisted>=17.9.0',\n 'cryptography>=2.0',\n 'cssselect>=0.9.1',\n 'itemloaders>=1.0.1',\n 'parsel>=1.5.0',\n 'pyOpenSSL>=16.2.0',\n 'queuelib>=1.4.2',\n 'service_identity>=16.0.0',\n 'w3lib>=1.17.0',\n 'zope.interface>=4.1.3',\n 'protego>=0.1.15',\n 'itemadapter>=0.1.0',\n]\nextras_require = {}\ncpython_dependencies = [\n 'lxml>=3.5.0',\n 'PyDispatcher>=2.0.5',\n]\nif has_environment_marker_platform_impl_support():\n extras_require[':platform_python_implementation == \"CPython\"'] = cpython_dependencies\n extras_require[':platform_python_implementation == \"PyPy\"'] = [\n # Earlier lxml versions are affected by\n # https://foss.heptapod.net/pypy/pypy/-/issues/2498,\n # which was fixed in Cython 0.26, released on 2017-06-19, and used to\n # generate the C headers of lxml release tarballs published since then, the\n # first of which was:\n 'lxml>=4.0.0',\n 'PyPyDispatcher>=2.1.0',\n ]\nelse:\n install_requires.extend(cpython_dependencies)\n\n\nsetup(\n name='Scrapy',\n version=version,\n url='https://scrapy.org',\n project_urls={\n 'Documentation': 'https://docs.scrapy.org/',\n 'Source': 'https://github.com/scrapy/scrapy',\n 'Tracker': 'https://github.com/scrapy/scrapy/issues',\n },\n description='A high-level Web Crawling and Web Scraping framework',\n long_description=open('README.rst').read(),\n author='Scrapy developers',\n maintainer='Pablo Hoffman',\n maintainer_email='[email protected]',\n license='BSD',\n packages=find_packages(exclude=('tests', 'tests.*')),\n include_package_data=True,\n zip_safe=False,\n entry_points={\n 'console_scripts': ['scrapy = scrapy.cmdline:execute']\n },\n classifiers=[\n 'Framework :: Scrapy',\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: BSD License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: Implementation :: CPython',\n 'Programming Language :: Python :: Implementation :: PyPy',\n 'Topic :: Internet :: WWW/HTTP',\n 'Topic :: Software Development :: Libraries :: Application Frameworks',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n ],\n python_requires='>=3.6',\n install_requires=install_requires,\n extras_require=extras_require,\n)\n", "path": "setup.py"}]}
| 1,671 | 115 |
gh_patches_debug_41196
|
rasdani/github-patches
|
git_diff
|
pytorch__pytorch-4444
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
torch.nn.InstanceNorm1d has inconsistent semantics of train and eval
For `torch.nn.InstanceNorm1d` the docs say:
*At evaluation time (.eval()), the default behaviour of the InstanceNorm module stays the same i.e. running mean/variance is NOT used for normalization. One can force using stored mean and variance with .train(False) method.*
However, the source for `.eval()` shows that it simply calls `.train(False)`.
</issue>
<code>
[start of torch/nn/modules/instancenorm.py]
1 from .batchnorm import _BatchNorm
2 from .. import functional as F
3
4
5 class _InstanceNorm(_BatchNorm):
6 def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=False):
7 super(_InstanceNorm, self).__init__(
8 num_features, eps, momentum, affine)
9
10 def forward(self, input):
11 b, c = input.size(0), input.size(1)
12
13 # Repeat stored stats and affine transform params
14 running_mean = self.running_mean.repeat(b)
15 running_var = self.running_var.repeat(b)
16
17 weight, bias = None, None
18 if self.affine:
19 weight = self.weight.repeat(b)
20 bias = self.bias.repeat(b)
21
22 # Apply instance norm
23 input_reshaped = input.contiguous().view(1, b * c, *input.size()[2:])
24
25 out = F.batch_norm(
26 input_reshaped, running_mean, running_var, weight, bias,
27 True, self.momentum, self.eps)
28
29 # Reshape back
30 self.running_mean.copy_(running_mean.view(b, c).mean(0, keepdim=False))
31 self.running_var.copy_(running_var.view(b, c).mean(0, keepdim=False))
32
33 return out.view(b, c, *input.size()[2:])
34
35 def eval(self):
36 return self
37
38
39 class InstanceNorm1d(_InstanceNorm):
40 r"""Applies Instance Normalization over a 3d input that is seen as a mini-batch.
41
42 .. math::
43
44 y = \frac{x - mean[x]}{ \sqrt{Var[x]} + \epsilon} * gamma + beta
45
46 The mean and standard-deviation are calculated per-dimension separately
47 for each object in a mini-batch. Gamma and beta are learnable parameter vectors
48 of size C (where C is the input size).
49
50 During training, this layer keeps a running estimate of its computed mean
51 and variance. The running sum is kept with a default momentum of 0.1.
52
53 At evaluation time (`.eval()`), the default behaviour of the InstanceNorm module stays the same
54 i.e. running mean/variance is NOT used for normalization. One can force using stored
55 mean and variance with `.train(False)` method.
56
57 Args:
58 num_features: num_features from an expected input of size `batch_size x num_features x width`
59 eps: a value added to the denominator for numerical stability. Default: 1e-5
60 momentum: the value used for the running_mean and running_var computation. Default: 0.1
61 affine: a boolean value that when set to ``True``, gives the layer learnable
62 affine parameters. Default: ``False``
63
64 Shape:
65 - Input: :math:`(N, C, L)`
66 - Output: :math:`(N, C, L)` (same shape as input)
67
68 Examples:
69 >>> # Without Learnable Parameters
70 >>> m = nn.InstanceNorm1d(100)
71 >>> # With Learnable Parameters
72 >>> m = nn.InstanceNorm1d(100, affine=True)
73 >>> input = autograd.Variable(torch.randn(20, 100, 40))
74 >>> output = m(input)
75 """
76
77 def _check_input_dim(self, input):
78 if input.dim() != 3:
79 raise ValueError('expected 3D input (got {}D input)'
80 .format(input.dim()))
81 super(InstanceNorm1d, self)._check_input_dim(input)
82
83
84 class InstanceNorm2d(_InstanceNorm):
85 r"""Applies Instance Normalization over a 4d input that is seen as a mini-batch of 3d inputs
86
87 .. math::
88
89 y = \frac{x - mean[x]}{ \sqrt{Var[x]} + \epsilon} * gamma + beta
90
91 The mean and standard-deviation are calculated per-dimension separately
92 for each object in a mini-batch. Gamma and beta are learnable parameter vectors
93 of size C (where C is the input size).
94
95 During training, this layer keeps a running estimate of its computed mean
96 and variance. The running sum is kept with a default momentum of 0.1.
97
98 At evaluation time (`.eval()`), the default behaviour of the InstanceNorm module stays the same
99 i.e. running mean/variance is NOT used for normalization. One can force using stored
100 mean and variance with `.train(False)` method.
101
102 Args:
103 num_features: num_features from an expected input of size batch_size x num_features x height x width
104 eps: a value added to the denominator for numerical stability. Default: 1e-5
105 momentum: the value used for the running_mean and running_var computation. Default: 0.1
106 affine: a boolean value that when set to ``True``, gives the layer learnable
107 affine parameters. Default: ``False``
108
109 Shape:
110 - Input: :math:`(N, C, H, W)`
111 - Output: :math:`(N, C, H, W)` (same shape as input)
112
113 Examples:
114 >>> # Without Learnable Parameters
115 >>> m = nn.InstanceNorm2d(100)
116 >>> # With Learnable Parameters
117 >>> m = nn.InstanceNorm2d(100, affine=True)
118 >>> input = autograd.Variable(torch.randn(20, 100, 35, 45))
119 >>> output = m(input)
120 """
121
122 def _check_input_dim(self, input):
123 if input.dim() != 4:
124 raise ValueError('expected 4D input (got {}D input)'
125 .format(input.dim()))
126 super(InstanceNorm2d, self)._check_input_dim(input)
127
128
129 class InstanceNorm3d(_InstanceNorm):
130 r"""Applies Instance Normalization over a 5d input that is seen as a mini-batch of 4d inputs
131
132 .. math::
133
134 y = \frac{x - mean[x]}{ \sqrt{Var[x]} + \epsilon} * gamma + beta
135
136 The mean and standard-deviation are calculated per-dimension separately for each object in a mini-batch.
137 Gamma and beta are learnable parameter vectors
138 of size C (where C is the input size).
139
140 During training, this layer keeps a running estimate of its computed mean
141 and variance. The running sum is kept with a default momentum of 0.1.
142
143 At evaluation time (`.eval()`), the default behaviour of the InstanceNorm module stays the same
144 i.e. running mean/variance is NOT used for normalization. One can force using stored
145 mean and variance with `.train(False)` method.
146
147
148 Args:
149 num_features: num_features from an expected input of size batch_size x num_features x depth x height x width
150 eps: a value added to the denominator for numerical stability. Default: 1e-5
151 momentum: the value used for the running_mean and running_var computation. Default: 0.1
152 affine: a boolean value that when set to ``True``, gives the layer learnable
153 affine parameters. Default: ``False``
154
155 Shape:
156 - Input: :math:`(N, C, D, H, W)`
157 - Output: :math:`(N, C, D, H, W)` (same shape as input)
158
159 Examples:
160 >>> # Without Learnable Parameters
161 >>> m = nn.InstanceNorm3d(100)
162 >>> # With Learnable Parameters
163 >>> m = nn.InstanceNorm3d(100, affine=True)
164 >>> input = autograd.Variable(torch.randn(20, 100, 35, 45, 10))
165 >>> output = m(input)
166 """
167
168 def _check_input_dim(self, input):
169 if input.dim() != 5:
170 raise ValueError('expected 5D input (got {}D input)'
171 .format(input.dim()))
172 super(InstanceNorm3d, self)._check_input_dim(input)
173
[end of torch/nn/modules/instancenorm.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/torch/nn/modules/instancenorm.py b/torch/nn/modules/instancenorm.py
--- a/torch/nn/modules/instancenorm.py
+++ b/torch/nn/modules/instancenorm.py
@@ -6,6 +6,7 @@
def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=False):
super(_InstanceNorm, self).__init__(
num_features, eps, momentum, affine)
+ self.use_running_stats = False
def forward(self, input):
b, c = input.size(0), input.size(1)
@@ -24,7 +25,7 @@
out = F.batch_norm(
input_reshaped, running_mean, running_var, weight, bias,
- True, self.momentum, self.eps)
+ not self.use_running_stats, self.momentum, self.eps)
# Reshape back
self.running_mean.copy_(running_mean.view(b, c).mean(0, keepdim=False))
@@ -32,8 +33,14 @@
return out.view(b, c, *input.size()[2:])
- def eval(self):
- return self
+ def use_running_stats(self, mode=True):
+ r"""Set using running statistics or instance statistics.
+
+ Instance normalization usually use instance statistics in both training
+ and evaluation modes. But users can set this method to use running
+ statistics in the fashion similar to batch normalization in eval mode.
+ """
+ self.use_running_stats = mode
class InstanceNorm1d(_InstanceNorm):
@@ -52,7 +59,8 @@
At evaluation time (`.eval()`), the default behaviour of the InstanceNorm module stays the same
i.e. running mean/variance is NOT used for normalization. One can force using stored
- mean and variance with `.train(False)` method.
+ mean and variance with `.use_running_stats(mode=True)` method, and switch back to normal
+ behavior with `.use_running_stats(mode=False)` method.
Args:
num_features: num_features from an expected input of size `batch_size x num_features x width`
@@ -97,7 +105,8 @@
At evaluation time (`.eval()`), the default behaviour of the InstanceNorm module stays the same
i.e. running mean/variance is NOT used for normalization. One can force using stored
- mean and variance with `.train(False)` method.
+ mean and variance with `.use_running_stats(mode=True)` method, and switch back to normal
+ behavior with `.use_running_stats(mode=False)` method.
Args:
num_features: num_features from an expected input of size batch_size x num_features x height x width
@@ -142,7 +151,8 @@
At evaluation time (`.eval()`), the default behaviour of the InstanceNorm module stays the same
i.e. running mean/variance is NOT used for normalization. One can force using stored
- mean and variance with `.train(False)` method.
+ mean and variance with `.use_running_stats(mode=True)` method, and switch back to normal
+ behavior with `.use_running_stats(mode=False)` method.
Args:
|
{"golden_diff": "diff --git a/torch/nn/modules/instancenorm.py b/torch/nn/modules/instancenorm.py\n--- a/torch/nn/modules/instancenorm.py\n+++ b/torch/nn/modules/instancenorm.py\n@@ -6,6 +6,7 @@\n def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=False):\n super(_InstanceNorm, self).__init__(\n num_features, eps, momentum, affine)\n+ self.use_running_stats = False\n \n def forward(self, input):\n b, c = input.size(0), input.size(1)\n@@ -24,7 +25,7 @@\n \n out = F.batch_norm(\n input_reshaped, running_mean, running_var, weight, bias,\n- True, self.momentum, self.eps)\n+ not self.use_running_stats, self.momentum, self.eps)\n \n # Reshape back\n self.running_mean.copy_(running_mean.view(b, c).mean(0, keepdim=False))\n@@ -32,8 +33,14 @@\n \n return out.view(b, c, *input.size()[2:])\n \n- def eval(self):\n- return self\n+ def use_running_stats(self, mode=True):\n+ r\"\"\"Set using running statistics or instance statistics.\n+\n+ Instance normalization usually use instance statistics in both training\n+ and evaluation modes. But users can set this method to use running\n+ statistics in the fashion similar to batch normalization in eval mode.\n+ \"\"\"\n+ self.use_running_stats = mode\n \n \n class InstanceNorm1d(_InstanceNorm):\n@@ -52,7 +59,8 @@\n \n At evaluation time (`.eval()`), the default behaviour of the InstanceNorm module stays the same\n i.e. running mean/variance is NOT used for normalization. One can force using stored\n- mean and variance with `.train(False)` method.\n+ mean and variance with `.use_running_stats(mode=True)` method, and switch back to normal\n+ behavior with `.use_running_stats(mode=False)` method.\n \n Args:\n num_features: num_features from an expected input of size `batch_size x num_features x width`\n@@ -97,7 +105,8 @@\n \n At evaluation time (`.eval()`), the default behaviour of the InstanceNorm module stays the same\n i.e. running mean/variance is NOT used for normalization. One can force using stored\n- mean and variance with `.train(False)` method.\n+ mean and variance with `.use_running_stats(mode=True)` method, and switch back to normal\n+ behavior with `.use_running_stats(mode=False)` method.\n \n Args:\n num_features: num_features from an expected input of size batch_size x num_features x height x width\n@@ -142,7 +151,8 @@\n \n At evaluation time (`.eval()`), the default behaviour of the InstanceNorm module stays the same\n i.e. running mean/variance is NOT used for normalization. One can force using stored\n- mean and variance with `.train(False)` method.\n+ mean and variance with `.use_running_stats(mode=True)` method, and switch back to normal\n+ behavior with `.use_running_stats(mode=False)` method.\n \n \n Args:\n", "issue": "torch.nn.InstanceNorm1d has inconsistent semantics of train and eval\nFor `torch.nn.InstanceNorm1d` the docs say:\r\n\r\n*At evaluation time (.eval()), the default behaviour of the InstanceNorm module stays the same i.e. running mean/variance is NOT used for normalization. One can force using stored mean and variance with .train(False) method.*\r\n\r\nHowever, the source for `.eval()` shows that it simply calls `.train(False)`.\n", "before_files": [{"content": "from .batchnorm import _BatchNorm\nfrom .. import functional as F\n\n\nclass _InstanceNorm(_BatchNorm):\n def __init__(self, num_features, eps=1e-5, momentum=0.1, affine=False):\n super(_InstanceNorm, self).__init__(\n num_features, eps, momentum, affine)\n\n def forward(self, input):\n b, c = input.size(0), input.size(1)\n\n # Repeat stored stats and affine transform params\n running_mean = self.running_mean.repeat(b)\n running_var = self.running_var.repeat(b)\n\n weight, bias = None, None\n if self.affine:\n weight = self.weight.repeat(b)\n bias = self.bias.repeat(b)\n\n # Apply instance norm\n input_reshaped = input.contiguous().view(1, b * c, *input.size()[2:])\n\n out = F.batch_norm(\n input_reshaped, running_mean, running_var, weight, bias,\n True, self.momentum, self.eps)\n\n # Reshape back\n self.running_mean.copy_(running_mean.view(b, c).mean(0, keepdim=False))\n self.running_var.copy_(running_var.view(b, c).mean(0, keepdim=False))\n\n return out.view(b, c, *input.size()[2:])\n\n def eval(self):\n return self\n\n\nclass InstanceNorm1d(_InstanceNorm):\n r\"\"\"Applies Instance Normalization over a 3d input that is seen as a mini-batch.\n\n .. math::\n\n y = \\frac{x - mean[x]}{ \\sqrt{Var[x]} + \\epsilon} * gamma + beta\n\n The mean and standard-deviation are calculated per-dimension separately\n for each object in a mini-batch. Gamma and beta are learnable parameter vectors\n of size C (where C is the input size).\n\n During training, this layer keeps a running estimate of its computed mean\n and variance. The running sum is kept with a default momentum of 0.1.\n\n At evaluation time (`.eval()`), the default behaviour of the InstanceNorm module stays the same\n i.e. running mean/variance is NOT used for normalization. One can force using stored\n mean and variance with `.train(False)` method.\n\n Args:\n num_features: num_features from an expected input of size `batch_size x num_features x width`\n eps: a value added to the denominator for numerical stability. Default: 1e-5\n momentum: the value used for the running_mean and running_var computation. Default: 0.1\n affine: a boolean value that when set to ``True``, gives the layer learnable\n affine parameters. Default: ``False``\n\n Shape:\n - Input: :math:`(N, C, L)`\n - Output: :math:`(N, C, L)` (same shape as input)\n\n Examples:\n >>> # Without Learnable Parameters\n >>> m = nn.InstanceNorm1d(100)\n >>> # With Learnable Parameters\n >>> m = nn.InstanceNorm1d(100, affine=True)\n >>> input = autograd.Variable(torch.randn(20, 100, 40))\n >>> output = m(input)\n \"\"\"\n\n def _check_input_dim(self, input):\n if input.dim() != 3:\n raise ValueError('expected 3D input (got {}D input)'\n .format(input.dim()))\n super(InstanceNorm1d, self)._check_input_dim(input)\n\n\nclass InstanceNorm2d(_InstanceNorm):\n r\"\"\"Applies Instance Normalization over a 4d input that is seen as a mini-batch of 3d inputs\n\n .. math::\n\n y = \\frac{x - mean[x]}{ \\sqrt{Var[x]} + \\epsilon} * gamma + beta\n\n The mean and standard-deviation are calculated per-dimension separately\n for each object in a mini-batch. Gamma and beta are learnable parameter vectors\n of size C (where C is the input size).\n\n During training, this layer keeps a running estimate of its computed mean\n and variance. The running sum is kept with a default momentum of 0.1.\n\n At evaluation time (`.eval()`), the default behaviour of the InstanceNorm module stays the same\n i.e. running mean/variance is NOT used for normalization. One can force using stored\n mean and variance with `.train(False)` method.\n\n Args:\n num_features: num_features from an expected input of size batch_size x num_features x height x width\n eps: a value added to the denominator for numerical stability. Default: 1e-5\n momentum: the value used for the running_mean and running_var computation. Default: 0.1\n affine: a boolean value that when set to ``True``, gives the layer learnable\n affine parameters. Default: ``False``\n\n Shape:\n - Input: :math:`(N, C, H, W)`\n - Output: :math:`(N, C, H, W)` (same shape as input)\n\n Examples:\n >>> # Without Learnable Parameters\n >>> m = nn.InstanceNorm2d(100)\n >>> # With Learnable Parameters\n >>> m = nn.InstanceNorm2d(100, affine=True)\n >>> input = autograd.Variable(torch.randn(20, 100, 35, 45))\n >>> output = m(input)\n \"\"\"\n\n def _check_input_dim(self, input):\n if input.dim() != 4:\n raise ValueError('expected 4D input (got {}D input)'\n .format(input.dim()))\n super(InstanceNorm2d, self)._check_input_dim(input)\n\n\nclass InstanceNorm3d(_InstanceNorm):\n r\"\"\"Applies Instance Normalization over a 5d input that is seen as a mini-batch of 4d inputs\n\n .. math::\n\n y = \\frac{x - mean[x]}{ \\sqrt{Var[x]} + \\epsilon} * gamma + beta\n\n The mean and standard-deviation are calculated per-dimension separately for each object in a mini-batch.\n Gamma and beta are learnable parameter vectors\n of size C (where C is the input size).\n\n During training, this layer keeps a running estimate of its computed mean\n and variance. The running sum is kept with a default momentum of 0.1.\n\n At evaluation time (`.eval()`), the default behaviour of the InstanceNorm module stays the same\n i.e. running mean/variance is NOT used for normalization. One can force using stored\n mean and variance with `.train(False)` method.\n\n\n Args:\n num_features: num_features from an expected input of size batch_size x num_features x depth x height x width\n eps: a value added to the denominator for numerical stability. Default: 1e-5\n momentum: the value used for the running_mean and running_var computation. Default: 0.1\n affine: a boolean value that when set to ``True``, gives the layer learnable\n affine parameters. Default: ``False``\n\n Shape:\n - Input: :math:`(N, C, D, H, W)`\n - Output: :math:`(N, C, D, H, W)` (same shape as input)\n\n Examples:\n >>> # Without Learnable Parameters\n >>> m = nn.InstanceNorm3d(100)\n >>> # With Learnable Parameters\n >>> m = nn.InstanceNorm3d(100, affine=True)\n >>> input = autograd.Variable(torch.randn(20, 100, 35, 45, 10))\n >>> output = m(input)\n \"\"\"\n\n def _check_input_dim(self, input):\n if input.dim() != 5:\n raise ValueError('expected 5D input (got {}D input)'\n .format(input.dim()))\n super(InstanceNorm3d, self)._check_input_dim(input)\n", "path": "torch/nn/modules/instancenorm.py"}]}
| 2,798 | 715 |
gh_patches_debug_18993
|
rasdani/github-patches
|
git_diff
|
mampfes__hacs_waste_collection_schedule-2062
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug]: Typo in icon specification: "varient" should be "variant"
### I Have A Problem With:
The integration in general
### What's Your Problem
There is no Material Design Icon with the spelling "varient", it should be "variant".
In the following files:
* `custom_components/waste_collection_schedule/waste_collection_schedule/source/basildon_gov_uk.py`
* `custom_components/waste_collection_schedule/waste_collection_schedule/source/bristol_gov_uk.py`

### Source (if relevant)
_No response_
### Logs
_No response_
### Relevant Configuration
_No response_
### Checklist Source Error
- [ ] Use the example parameters for your source (often available in the documentation) (don't forget to restart Home Assistant after changing the configuration)
- [ ] Checked that the website of your service provider is still working
- [ ] Tested my attributes on the service provider website (if possible)
- [X] I have tested with the latest version of the integration (master) (for HACS in the 3 dot menu of the integration click on "Redownload" and choose master as version)
### Checklist Sensor Error
- [ ] Checked in the Home Assistant Calendar tab if the event names match the types names (if types argument is used)
### Required
- [X] I have searched past (closed AND opened) issues to see if this bug has already been reported, and it hasn't been.
- [X] I understand that people give their precious time for free, and thus I've done my very best to make this problem as easy as possible to investigate.
</issue>
<code>
[start of custom_components/waste_collection_schedule/waste_collection_schedule/source/basildon_gov_uk.py]
1 # Credit where it's due:
2 # This is predominantly a refactoring of the Bristol City Council script from the UKBinCollectionData repo
3 # https://github.com/robbrad/UKBinCollectionData
4
5 from datetime import datetime
6
7 import requests
8 from waste_collection_schedule import Collection # type: ignore[attr-defined]
9
10 TITLE = "Basildon Council"
11 DESCRIPTION = "Source for basildon.gov.uk services for Basildon Council, UK."
12 URL = "https://basildon.gov.uk"
13
14 TEST_CASES = {
15 "Test_Addres_001": {"postcode": "CM111BJ", "address": "6, HEADLEY ROAD"},
16 "Test_Addres_002": {"postcode": "SS14 1QU", "address": "25 LONG RIDING"},
17 "Test_UPRN_001": {"uprn": "100090277795"},
18 "Test_UPRN_002": {"uprn": 10024197625},
19 "Test_UPRN_003": {"uprn": "10090455610"},
20 }
21 ICON_MAP = {
22 "green_waste": "mdi:leaf",
23 "general_waste": "mdi:trash-can",
24 "food_waste": "mdi:food",
25 "glass_waste": "mdi:bottle-wine",
26 "papercard_waste": "mdi:package-varient",
27 "plasticcans_waste": "mdi:bottle-soda-classic",
28 }
29 NAME_MAP = {
30 "green_waste": "Garden",
31 "general_waste": "General",
32 "food_waste": "Food",
33 "glass_waste": "Glass",
34 "papercard_waste": "Paper/Cardboard",
35 "plasticcans_waste": "Plastic/Cans",
36 }
37 HEADERS = {
38 "Accept": "*/*",
39 "Accept-Language": "en-GB,en;q=0.9",
40 "Connection": "keep-alive",
41 "Ocp-Apim-Trace": "true",
42 "Origin": "https://mybasildon.powerappsportals.com",
43 "Referer": "https://mybasildon.powerappsportals.com/",
44 "Sec-Fetch-Dest": "empty",
45 "Sec-Fetch-Mode": "cors",
46 "Sec-Fetch-Site": "cross-site",
47 "Sec-GPC": "1",
48 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36",
49 }
50
51
52 class Source:
53 def __init__(self, postcode=None, address=None, uprn=None):
54 if uprn is None and (postcode is None or address is None):
55 raise ValueError("Either uprn or postcode and address must be provided")
56
57 self._uprn = str(uprn).zfill(12) if uprn is not None else None
58 self._postcode = postcode
59 self._address = address
60
61 def compare_address(self, address) -> bool:
62 return (
63 self._address.replace(",", "").replace(" ", "").upper()
64 == address.replace(",", "").replace(" ", "").upper()
65 )
66
67 def get_uprn(self, s):
68 r = s.post(
69 "https://basildonportal.azurewebsites.net/api/listPropertiesByPostcode",
70 headers=HEADERS,
71 json={"postcode": self._postcode},
72 )
73 r.raise_for_status()
74 data = r.json()
75 if data["result"] != "success":
76 raise ValueError("Invalid postcode")
77 for item in data["properties"]:
78 if self.compare_address(item["line1"]):
79 self._uprn = item["uprn"]
80 break
81 if self._uprn is None:
82 raise ValueError("Invalid address")
83
84 def fetch(self):
85 s = requests.Session()
86 if self._uprn is None:
87 self.get_uprn(s)
88
89 # Retrieve the schedule
90 payload = {"uprn": self._uprn}
91 response = s.post(
92 "https://basildonportal.azurewebsites.net/api/getPropertyRefuseInformation",
93 headers=HEADERS,
94 json=payload,
95 )
96 data = response.json()["refuse"]["available_services"]
97 entries = []
98 for item in ICON_MAP:
99 for collection_date_key in [
100 "current_collection_",
101 "next_collection_",
102 "last_collection_",
103 ]:
104 if data[item][collection_date_key + "active"]:
105 date_string = data[item][collection_date_key + "date"]
106 entries.append(
107 Collection(
108 date=datetime.strptime(
109 date_string,
110 "%Y-%m-%d",
111 ).date(),
112 t=NAME_MAP[item],
113 icon=ICON_MAP.get(item),
114 )
115 )
116
117 return entries
118
[end of custom_components/waste_collection_schedule/waste_collection_schedule/source/basildon_gov_uk.py]
[start of custom_components/waste_collection_schedule/waste_collection_schedule/source/bristol_gov_uk.py]
1 # Credit where it's due:
2 # This is predominantly a refactoring of the Bristol City Council script from the UKBinCollectionData repo
3 # https://github.com/robbrad/UKBinCollectionData
4
5 from datetime import datetime
6
7 import requests
8 from waste_collection_schedule import Collection # type: ignore[attr-defined]
9
10 TITLE = "Bristol City Council"
11 DESCRIPTION = "Source for bristol.gov.uk services for Bristol City Council, UK."
12 URL = "https://bristol.gov.uk"
13
14 TEST_CASES = {
15 "Test_001": {"uprn": "107652"},
16 "Test_002": {"uprn": "2987"},
17 "Test_003": {"uprn": 17929},
18 }
19 ICON_MAP = {
20 "90L BLUE SACK": "mdi:recycle",
21 "240L GARDEN WASTE BIN": "mdi:leaf",
22 "180L GENERAL WASTE": "mdi:trash-can",
23 "45L BLACK RECYCLING BOX": "mdi:recycle",
24 "23L FOOD WASTE BIN": "mdi:food",
25 "55L GREEN RECYCLING BOX": "mdi:recycle",
26 "140L FOOD WASTE BIN": "mdi:food",
27 "240L RECYCLING MIXED GLASS": "mdi:bottle-wine",
28 "240L RECYCLING PAPER": "mdi:newspaper",
29 "1100L GENERAL WASTE": "mdi:trash-can",
30 "1100L RECYCLING CARD": "mdi:package-varient",
31 "360L RECYCLING PLASTIC/CANS": "mdi:bottle-soda-classic",
32 }
33 HEADERS = {
34 "Accept": "*/*",
35 "Accept-Language": "en-GB,en;q=0.9",
36 "Connection": "keep-alive",
37 "Ocp-Apim-Subscription-Key": "47ffd667d69c4a858f92fc38dc24b150",
38 "Ocp-Apim-Trace": "true",
39 "Origin": "https://bristolcouncil.powerappsportals.com",
40 "Referer": "https://bristolcouncil.powerappsportals.com/",
41 "Sec-Fetch-Dest": "empty",
42 "Sec-Fetch-Mode": "cors",
43 "Sec-Fetch-Site": "cross-site",
44 "Sec-GPC": "1",
45 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36",
46 }
47
48
49 class Source:
50 def __init__(self, uprn):
51 self._uprn = str(uprn).zfill(12)
52
53 def fetch(self):
54 s = requests.Session()
55
56 # Initialise form
57 payload = {"servicetypeid": "7dce896c-b3ba-ea11-a812-000d3a7f1cdc"}
58 response = s.get(
59 "https://bristolcouncil.powerappsportals.com/completedynamicformunauth/",
60 headers=HEADERS,
61 params=payload,
62 )
63
64 # Set the search criteria
65 payload = {"Uprn": "UPRN" + self._uprn}
66 response = s.post(
67 "https://bcprdapidyna002.azure-api.net/bcprdfundyna001-llpg/DetailedLLPG",
68 headers=HEADERS,
69 json=payload,
70 )
71
72 # Retrieve the schedule
73 payload = {"uprn": self._uprn}
74 response = s.post(
75 "https://bcprdapidyna002.azure-api.net/bcprdfundyna001-alloy/NextCollectionDates",
76 headers=HEADERS,
77 json=payload,
78 )
79 data = response.json()["data"]
80
81 entries = []
82 for item in data:
83 for collection in item["collection"]:
84 for collection_date_key in ["nextCollectionDate", "lastCollectionDate"]:
85 date_string = collection[collection_date_key].split("T")[0]
86 entries.append(
87 Collection(
88 date=datetime.strptime(
89 date_string,
90 "%Y-%m-%d",
91 ).date(),
92 t=item["containerName"],
93 icon=ICON_MAP.get(item["containerName"].upper()),
94 )
95 )
96
97 return entries
98
[end of custom_components/waste_collection_schedule/waste_collection_schedule/source/bristol_gov_uk.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/basildon_gov_uk.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/basildon_gov_uk.py
--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/basildon_gov_uk.py
+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/basildon_gov_uk.py
@@ -23,7 +23,7 @@
"general_waste": "mdi:trash-can",
"food_waste": "mdi:food",
"glass_waste": "mdi:bottle-wine",
- "papercard_waste": "mdi:package-varient",
+ "papercard_waste": "mdi:package-variant",
"plasticcans_waste": "mdi:bottle-soda-classic",
}
NAME_MAP = {
diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/bristol_gov_uk.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/bristol_gov_uk.py
--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/bristol_gov_uk.py
+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/bristol_gov_uk.py
@@ -27,7 +27,7 @@
"240L RECYCLING MIXED GLASS": "mdi:bottle-wine",
"240L RECYCLING PAPER": "mdi:newspaper",
"1100L GENERAL WASTE": "mdi:trash-can",
- "1100L RECYCLING CARD": "mdi:package-varient",
+ "1100L RECYCLING CARD": "mdi:package-variant",
"360L RECYCLING PLASTIC/CANS": "mdi:bottle-soda-classic",
}
HEADERS = {
|
{"golden_diff": "diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/basildon_gov_uk.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/basildon_gov_uk.py\n--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/basildon_gov_uk.py\n+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/basildon_gov_uk.py\n@@ -23,7 +23,7 @@\n \"general_waste\": \"mdi:trash-can\",\n \"food_waste\": \"mdi:food\",\n \"glass_waste\": \"mdi:bottle-wine\",\n- \"papercard_waste\": \"mdi:package-varient\",\n+ \"papercard_waste\": \"mdi:package-variant\",\n \"plasticcans_waste\": \"mdi:bottle-soda-classic\",\n }\n NAME_MAP = {\ndiff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/bristol_gov_uk.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/bristol_gov_uk.py\n--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/bristol_gov_uk.py\n+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/bristol_gov_uk.py\n@@ -27,7 +27,7 @@\n \"240L RECYCLING MIXED GLASS\": \"mdi:bottle-wine\",\n \"240L RECYCLING PAPER\": \"mdi:newspaper\",\n \"1100L GENERAL WASTE\": \"mdi:trash-can\",\n- \"1100L RECYCLING CARD\": \"mdi:package-varient\",\n+ \"1100L RECYCLING CARD\": \"mdi:package-variant\",\n \"360L RECYCLING PLASTIC/CANS\": \"mdi:bottle-soda-classic\",\n }\n HEADERS = {\n", "issue": "[Bug]: Typo in icon specification: \"varient\" should be \"variant\"\n### I Have A Problem With:\n\nThe integration in general\n\n### What's Your Problem\n\nThere is no Material Design Icon with the spelling \"varient\", it should be \"variant\".\r\n\r\nIn the following files:\r\n* `custom_components/waste_collection_schedule/waste_collection_schedule/source/basildon_gov_uk.py`\r\n* `custom_components/waste_collection_schedule/waste_collection_schedule/source/bristol_gov_uk.py`\r\n\r\n\r\n\n\n### Source (if relevant)\n\n_No response_\n\n### Logs\n\n_No response_\n\n### Relevant Configuration\n\n_No response_\n\n### Checklist Source Error\n\n- [ ] Use the example parameters for your source (often available in the documentation) (don't forget to restart Home Assistant after changing the configuration)\n- [ ] Checked that the website of your service provider is still working\n- [ ] Tested my attributes on the service provider website (if possible)\n- [X] I have tested with the latest version of the integration (master) (for HACS in the 3 dot menu of the integration click on \"Redownload\" and choose master as version)\n\n### Checklist Sensor Error\n\n- [ ] Checked in the Home Assistant Calendar tab if the event names match the types names (if types argument is used)\n\n### Required\n\n- [X] I have searched past (closed AND opened) issues to see if this bug has already been reported, and it hasn't been.\n- [X] I understand that people give their precious time for free, and thus I've done my very best to make this problem as easy as possible to investigate.\n", "before_files": [{"content": "# Credit where it's due:\n# This is predominantly a refactoring of the Bristol City Council script from the UKBinCollectionData repo\n# https://github.com/robbrad/UKBinCollectionData\n\nfrom datetime import datetime\n\nimport requests\nfrom waste_collection_schedule import Collection # type: ignore[attr-defined]\n\nTITLE = \"Basildon Council\"\nDESCRIPTION = \"Source for basildon.gov.uk services for Basildon Council, UK.\"\nURL = \"https://basildon.gov.uk\"\n\nTEST_CASES = {\n \"Test_Addres_001\": {\"postcode\": \"CM111BJ\", \"address\": \"6, HEADLEY ROAD\"},\n \"Test_Addres_002\": {\"postcode\": \"SS14 1QU\", \"address\": \"25 LONG RIDING\"},\n \"Test_UPRN_001\": {\"uprn\": \"100090277795\"},\n \"Test_UPRN_002\": {\"uprn\": 10024197625},\n \"Test_UPRN_003\": {\"uprn\": \"10090455610\"},\n}\nICON_MAP = {\n \"green_waste\": \"mdi:leaf\",\n \"general_waste\": \"mdi:trash-can\",\n \"food_waste\": \"mdi:food\",\n \"glass_waste\": \"mdi:bottle-wine\",\n \"papercard_waste\": \"mdi:package-varient\",\n \"plasticcans_waste\": \"mdi:bottle-soda-classic\",\n}\nNAME_MAP = {\n \"green_waste\": \"Garden\",\n \"general_waste\": \"General\",\n \"food_waste\": \"Food\",\n \"glass_waste\": \"Glass\",\n \"papercard_waste\": \"Paper/Cardboard\",\n \"plasticcans_waste\": \"Plastic/Cans\",\n}\nHEADERS = {\n \"Accept\": \"*/*\",\n \"Accept-Language\": \"en-GB,en;q=0.9\",\n \"Connection\": \"keep-alive\",\n \"Ocp-Apim-Trace\": \"true\",\n \"Origin\": \"https://mybasildon.powerappsportals.com\",\n \"Referer\": \"https://mybasildon.powerappsportals.com/\",\n \"Sec-Fetch-Dest\": \"empty\",\n \"Sec-Fetch-Mode\": \"cors\",\n \"Sec-Fetch-Site\": \"cross-site\",\n \"Sec-GPC\": \"1\",\n \"User-Agent\": \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36\",\n}\n\n\nclass Source:\n def __init__(self, postcode=None, address=None, uprn=None):\n if uprn is None and (postcode is None or address is None):\n raise ValueError(\"Either uprn or postcode and address must be provided\")\n\n self._uprn = str(uprn).zfill(12) if uprn is not None else None\n self._postcode = postcode\n self._address = address\n\n def compare_address(self, address) -> bool:\n return (\n self._address.replace(\",\", \"\").replace(\" \", \"\").upper()\n == address.replace(\",\", \"\").replace(\" \", \"\").upper()\n )\n\n def get_uprn(self, s):\n r = s.post(\n \"https://basildonportal.azurewebsites.net/api/listPropertiesByPostcode\",\n headers=HEADERS,\n json={\"postcode\": self._postcode},\n )\n r.raise_for_status()\n data = r.json()\n if data[\"result\"] != \"success\":\n raise ValueError(\"Invalid postcode\")\n for item in data[\"properties\"]:\n if self.compare_address(item[\"line1\"]):\n self._uprn = item[\"uprn\"]\n break\n if self._uprn is None:\n raise ValueError(\"Invalid address\")\n\n def fetch(self):\n s = requests.Session()\n if self._uprn is None:\n self.get_uprn(s)\n\n # Retrieve the schedule\n payload = {\"uprn\": self._uprn}\n response = s.post(\n \"https://basildonportal.azurewebsites.net/api/getPropertyRefuseInformation\",\n headers=HEADERS,\n json=payload,\n )\n data = response.json()[\"refuse\"][\"available_services\"]\n entries = []\n for item in ICON_MAP:\n for collection_date_key in [\n \"current_collection_\",\n \"next_collection_\",\n \"last_collection_\",\n ]:\n if data[item][collection_date_key + \"active\"]:\n date_string = data[item][collection_date_key + \"date\"]\n entries.append(\n Collection(\n date=datetime.strptime(\n date_string,\n \"%Y-%m-%d\",\n ).date(),\n t=NAME_MAP[item],\n icon=ICON_MAP.get(item),\n )\n )\n\n return entries\n", "path": "custom_components/waste_collection_schedule/waste_collection_schedule/source/basildon_gov_uk.py"}, {"content": "# Credit where it's due:\n# This is predominantly a refactoring of the Bristol City Council script from the UKBinCollectionData repo\n# https://github.com/robbrad/UKBinCollectionData\n\nfrom datetime import datetime\n\nimport requests\nfrom waste_collection_schedule import Collection # type: ignore[attr-defined]\n\nTITLE = \"Bristol City Council\"\nDESCRIPTION = \"Source for bristol.gov.uk services for Bristol City Council, UK.\"\nURL = \"https://bristol.gov.uk\"\n\nTEST_CASES = {\n \"Test_001\": {\"uprn\": \"107652\"},\n \"Test_002\": {\"uprn\": \"2987\"},\n \"Test_003\": {\"uprn\": 17929},\n}\nICON_MAP = {\n \"90L BLUE SACK\": \"mdi:recycle\",\n \"240L GARDEN WASTE BIN\": \"mdi:leaf\",\n \"180L GENERAL WASTE\": \"mdi:trash-can\",\n \"45L BLACK RECYCLING BOX\": \"mdi:recycle\",\n \"23L FOOD WASTE BIN\": \"mdi:food\",\n \"55L GREEN RECYCLING BOX\": \"mdi:recycle\",\n \"140L FOOD WASTE BIN\": \"mdi:food\",\n \"240L RECYCLING MIXED GLASS\": \"mdi:bottle-wine\",\n \"240L RECYCLING PAPER\": \"mdi:newspaper\",\n \"1100L GENERAL WASTE\": \"mdi:trash-can\",\n \"1100L RECYCLING CARD\": \"mdi:package-varient\",\n \"360L RECYCLING PLASTIC/CANS\": \"mdi:bottle-soda-classic\",\n}\nHEADERS = {\n \"Accept\": \"*/*\",\n \"Accept-Language\": \"en-GB,en;q=0.9\",\n \"Connection\": \"keep-alive\",\n \"Ocp-Apim-Subscription-Key\": \"47ffd667d69c4a858f92fc38dc24b150\",\n \"Ocp-Apim-Trace\": \"true\",\n \"Origin\": \"https://bristolcouncil.powerappsportals.com\",\n \"Referer\": \"https://bristolcouncil.powerappsportals.com/\",\n \"Sec-Fetch-Dest\": \"empty\",\n \"Sec-Fetch-Mode\": \"cors\",\n \"Sec-Fetch-Site\": \"cross-site\",\n \"Sec-GPC\": \"1\",\n \"User-Agent\": \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36\",\n}\n\n\nclass Source:\n def __init__(self, uprn):\n self._uprn = str(uprn).zfill(12)\n\n def fetch(self):\n s = requests.Session()\n\n # Initialise form\n payload = {\"servicetypeid\": \"7dce896c-b3ba-ea11-a812-000d3a7f1cdc\"}\n response = s.get(\n \"https://bristolcouncil.powerappsportals.com/completedynamicformunauth/\",\n headers=HEADERS,\n params=payload,\n )\n\n # Set the search criteria\n payload = {\"Uprn\": \"UPRN\" + self._uprn}\n response = s.post(\n \"https://bcprdapidyna002.azure-api.net/bcprdfundyna001-llpg/DetailedLLPG\",\n headers=HEADERS,\n json=payload,\n )\n\n # Retrieve the schedule\n payload = {\"uprn\": self._uprn}\n response = s.post(\n \"https://bcprdapidyna002.azure-api.net/bcprdfundyna001-alloy/NextCollectionDates\",\n headers=HEADERS,\n json=payload,\n )\n data = response.json()[\"data\"]\n\n entries = []\n for item in data:\n for collection in item[\"collection\"]:\n for collection_date_key in [\"nextCollectionDate\", \"lastCollectionDate\"]:\n date_string = collection[collection_date_key].split(\"T\")[0]\n entries.append(\n Collection(\n date=datetime.strptime(\n date_string,\n \"%Y-%m-%d\",\n ).date(),\n t=item[\"containerName\"],\n icon=ICON_MAP.get(item[\"containerName\"].upper()),\n )\n )\n\n return entries\n", "path": "custom_components/waste_collection_schedule/waste_collection_schedule/source/bristol_gov_uk.py"}]}
| 3,530 | 427 |
gh_patches_debug_3332
|
rasdani/github-patches
|
git_diff
|
electricitymaps__electricitymaps-contrib-3241
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
NL Down
ENTSO-E data seems fine, so is there a problem with energieopwek.nl?
</issue>
<code>
[start of parsers/NL.py]
1 #!/usr/bin/env python3
2
3 import arrow
4 import math
5
6 from . import statnett
7 from . import ENTSOE
8 from . import DK
9 import logging
10 import pandas as pd
11 import requests
12
13
14 def fetch_production(zone_key='NL', session=None, target_datetime=None,
15 logger=logging.getLogger(__name__), energieopwek_nl=True):
16 if target_datetime is None:
17 target_datetime = arrow.utcnow()
18 else:
19 target_datetime = arrow.get(target_datetime)
20 r = session or requests.session()
21
22 consumptions = ENTSOE.fetch_consumption(zone_key=zone_key,
23 session=r,
24 target_datetime=target_datetime,
25 logger=logger)
26 if not consumptions:
27 return
28 for c in consumptions:
29 del c['source']
30 df_consumptions = pd.DataFrame.from_dict(consumptions).set_index(
31 'datetime')
32
33 # NL has exchanges with BE, DE, NO, GB, DK-DK1
34 exchanges = []
35 for exchange_key in ['BE', 'DE', 'GB']:
36 zone_1, zone_2 = sorted([exchange_key, zone_key])
37 exchange = ENTSOE.fetch_exchange(zone_key1=zone_1,
38 zone_key2=zone_2,
39 session=r,
40 target_datetime=target_datetime,
41 logger=logger)
42 if not exchange:
43 return
44 exchanges.extend(exchange or [])
45
46 # add NO data, fetch once for every hour
47 # This introduces an error, because it doesn't use the average power flow
48 # during the hour, but rather only the value during the first minute of the
49 # hour!
50 zone_1, zone_2 = sorted(['NO', zone_key])
51 exchange_NO = [statnett.fetch_exchange(zone_key1=zone_1, zone_key2=zone_2,
52 session=r, target_datetime=dt.datetime,
53 logger=logger)
54 for dt in arrow.Arrow.range(
55 'hour',
56 arrow.get(min([e['datetime']
57 for e in exchanges])).replace(minute=0),
58 arrow.get(max([e['datetime']
59 for e in exchanges])).replace(minute=0))]
60 exchanges.extend(exchange_NO)
61
62 # add DK1 data (only for dates after operation)
63 if target_datetime > arrow.get('2019-08-24', 'YYYY-MM-DD') :
64 zone_1, zone_2 = sorted(['DK-DK1', zone_key])
65 df_dk = pd.DataFrame(DK.fetch_exchange(zone_key1=zone_1, zone_key2=zone_2,
66 session=r, target_datetime=target_datetime,
67 logger=logger))
68
69 # Because other exchanges and consumption data is only available per hour
70 # we floor the timpstamp to hour and group by hour with averaging of netFlow
71 df_dk['datetime'] = df_dk['datetime'].dt.floor('H')
72 exchange_DK = df_dk.groupby(['datetime']).aggregate({'netFlow' : 'mean',
73 'sortedZoneKeys': 'max', 'source' : 'max'}).reset_index()
74
75 # because averaging with high precision numbers leads to rounding errors
76 exchange_DK = exchange_DK.round({'netFlow': 3})
77
78 exchanges.extend(exchange_DK.to_dict(orient='records'))
79
80 # We want to know the net-imports into NL, so if NL is in zone_1 we need
81 # to flip the direction of the flow. E.g. 100MW for NL->DE means 100MW
82 # export to DE and needs to become -100MW for import to NL.
83 for e in exchanges:
84 if(e['sortedZoneKeys'].startswith('NL->')):
85 e['NL_import'] = -1 * e['netFlow']
86 else:
87 e['NL_import'] = e['netFlow']
88 del e['source']
89 del e['netFlow']
90
91 df_exchanges = pd.DataFrame.from_dict(exchanges).set_index('datetime')
92 # Sum all exchanges to NL imports
93 df_exchanges = df_exchanges.groupby('datetime').sum()
94
95 # Fill missing values by propagating the value forward
96 df_consumptions_with_exchanges = df_consumptions.join(df_exchanges).fillna(
97 method='ffill', limit=3) # Limit to 3 x 15min
98
99 # Load = Generation + netImports
100 # => Generation = Load - netImports
101 df_total_generations = (df_consumptions_with_exchanges['consumption']
102 - df_consumptions_with_exchanges['NL_import'])
103
104 # Fetch all production
105 # The energieopwek_nl parser is backwards compatible with ENTSOE parser.
106 # Because of data quality issues we switch to using energieopwek, but if
107 # data quality of ENTSOE improves we can switch back to using a single
108 # source.
109 productions_ENTSOE = ENTSOE.fetch_production(zone_key=zone_key, session=r,
110 target_datetime=target_datetime, logger=logger)
111 if energieopwek_nl:
112 productions_eopwek = fetch_production_energieopwek_nl(session=r,
113 target_datetime=target_datetime, logger=logger)
114 # For every production value we look up the corresponding ENTSOE
115 # values and copy the nuclear, gas, coal, biomass and unknown production.
116 productions = []
117 for p in productions_eopwek:
118 entsoe_value = next((pe for pe in productions_ENTSOE
119 if pe["datetime"] == p["datetime"]), None)
120 if entsoe_value:
121 p["production"]["nuclear"] = entsoe_value["production"]["nuclear"]
122 p["production"]["gas"] = entsoe_value["production"]["gas"]
123 p["production"]["coal"] = entsoe_value["production"]["coal"]
124 p["production"]["biomass"] = entsoe_value["production"]["biomass"]
125 p["production"]["unknown"] = entsoe_value["production"]["unknown"]
126 productions.append(p)
127 else:
128 productions = productions_ENTSOE
129 if not productions:
130 return
131
132 # Flatten production dictionaries (we ignore storage)
133 for p in productions:
134 # if for some reason theré's no unknown value
135 if not 'unknown' in p['production'] or p['production']['unknown'] == None:
136 p['production']['unknown'] = 0
137
138 Z = sum([x or 0 for x in p['production'].values()])
139 # Only calculate the difference if the datetime exists
140 # If total ENTSOE reported production (Z) is less than total generation
141 # (calculated from consumption and imports), then there must be some
142 # unknown production missing, so we add the difference.
143 # The difference can actually be negative, because consumption is based
144 # on TSO network load, but locally generated electricity may never leave
145 # the DSO network and be substantial (e.g. Solar).
146 if p['datetime'] in df_total_generations and Z < df_total_generations[p['datetime']]:
147 p['production']['unknown'] = round((
148 df_total_generations[p['datetime']] - Z + p['production']['unknown']), 3)
149
150 # Filter invalid
151 # We should probably add logging to this
152 return [p for p in productions if p['production']['unknown'] > 0]
153
154
155 def fetch_production_energieopwek_nl(session=None, target_datetime=None,
156 logger=logging.getLogger(__name__)) -> list:
157 if target_datetime is None:
158 target_datetime = arrow.utcnow()
159
160 # Get production values for target and target-1 day
161 df_current = get_production_data_energieopwek(
162 target_datetime, session=session)
163 df_previous = get_production_data_energieopwek(
164 target_datetime.shift(days=-1), session=session)
165
166 # Concat them, oldest first to keep chronological order intact
167 df = pd.concat([df_previous, df_current])
168
169 output = []
170 base_time = arrow.get(target_datetime.date(), 'Europe/Paris').shift(days=-1).to('utc')
171
172 for i, prod in enumerate(df.to_dict(orient='records')):
173 output.append(
174 {
175 'zoneKey': 'NL',
176 'datetime': base_time.shift(minutes=i*15).datetime,
177 'production': prod,
178 'source': 'energieopwek.nl, entsoe.eu'
179 }
180 )
181 return output
182
183 def get_production_data_energieopwek(date, session=None):
184 r = session or requests.session()
185
186 # The API returns values per day from local time midnight until the last
187 # round 10 minutes if the requested date is today or for the entire day if
188 # it's in the past. 'sid' can be anything.
189 url = 'http://energieopwek.nl/jsonData.php?sid=2ecde3&Day=%s' % date.format('YYYY-MM-DD')
190 response = r.get(url)
191 obj = response.json()
192 production_input = obj['TenMin']['Country']
193
194 # extract the power values in kW from the different production types
195 # we only need column 0, 1 and 3 contain energy sum values
196 df_solar = pd.DataFrame(production_input['Solar']) .drop(['1','3'], axis=1).astype(int).rename(columns={"0" : "solar"})
197 df_offshore = pd.DataFrame(production_input['WindOffshore']).drop(['1','3'], axis=1).astype(int)
198 df_onshore = pd.DataFrame(production_input['Wind']) .drop(['1','3'], axis=1).astype(int)
199
200 # We don't differentiate between onshore and offshore wind so we sum them
201 # toghether and build a single data frame with named columns
202 df_wind = df_onshore.add(df_offshore).rename(columns={"0": "wind"})
203 df = pd.concat([df_solar, df_wind], axis=1)
204
205 # resample from 10min resolution to 15min resolution to align with ENTSOE data
206 # we duplicate every row and then group them per 3 and take the mean
207 df = pd.concat([df]*2).sort_index(axis=0).reset_index(drop=True).groupby(by=lambda x : math.floor(x/3)).mean()
208
209 # Convert kW to MW with kW resolution
210 df = df.apply(lambda x: round(x / 1000, 3))
211
212 return df
213
214 if __name__ == '__main__':
215 print(fetch_production())
216
[end of parsers/NL.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/parsers/NL.py b/parsers/NL.py
--- a/parsers/NL.py
+++ b/parsers/NL.py
@@ -12,7 +12,7 @@
def fetch_production(zone_key='NL', session=None, target_datetime=None,
- logger=logging.getLogger(__name__), energieopwek_nl=True):
+ logger=logging.getLogger(__name__), energieopwek_nl=False):
if target_datetime is None:
target_datetime = arrow.utcnow()
else:
|
{"golden_diff": "diff --git a/parsers/NL.py b/parsers/NL.py\n--- a/parsers/NL.py\n+++ b/parsers/NL.py\n@@ -12,7 +12,7 @@\n \n \n def fetch_production(zone_key='NL', session=None, target_datetime=None,\n- logger=logging.getLogger(__name__), energieopwek_nl=True):\n+ logger=logging.getLogger(__name__), energieopwek_nl=False):\n if target_datetime is None:\n target_datetime = arrow.utcnow()\n else:\n", "issue": "NL Down\nENTSO-E data seems fine, so is there a problem with energieopwek.nl?\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nimport arrow\nimport math\n\nfrom . import statnett\nfrom . import ENTSOE\nfrom . import DK\nimport logging\nimport pandas as pd\nimport requests\n\n\ndef fetch_production(zone_key='NL', session=None, target_datetime=None,\n logger=logging.getLogger(__name__), energieopwek_nl=True):\n if target_datetime is None:\n target_datetime = arrow.utcnow()\n else:\n target_datetime = arrow.get(target_datetime)\n r = session or requests.session()\n\n consumptions = ENTSOE.fetch_consumption(zone_key=zone_key,\n session=r,\n target_datetime=target_datetime,\n logger=logger)\n if not consumptions:\n return\n for c in consumptions:\n del c['source']\n df_consumptions = pd.DataFrame.from_dict(consumptions).set_index(\n 'datetime')\n\n # NL has exchanges with BE, DE, NO, GB, DK-DK1\n exchanges = []\n for exchange_key in ['BE', 'DE', 'GB']:\n zone_1, zone_2 = sorted([exchange_key, zone_key])\n exchange = ENTSOE.fetch_exchange(zone_key1=zone_1,\n zone_key2=zone_2,\n session=r,\n target_datetime=target_datetime,\n logger=logger)\n if not exchange:\n return\n exchanges.extend(exchange or [])\n\n # add NO data, fetch once for every hour\n # This introduces an error, because it doesn't use the average power flow\n # during the hour, but rather only the value during the first minute of the\n # hour!\n zone_1, zone_2 = sorted(['NO', zone_key])\n exchange_NO = [statnett.fetch_exchange(zone_key1=zone_1, zone_key2=zone_2,\n session=r, target_datetime=dt.datetime,\n logger=logger)\n for dt in arrow.Arrow.range(\n 'hour',\n arrow.get(min([e['datetime']\n for e in exchanges])).replace(minute=0),\n arrow.get(max([e['datetime']\n for e in exchanges])).replace(minute=0))]\n exchanges.extend(exchange_NO)\n\n # add DK1 data (only for dates after operation)\n if target_datetime > arrow.get('2019-08-24', 'YYYY-MM-DD') :\n zone_1, zone_2 = sorted(['DK-DK1', zone_key])\n df_dk = pd.DataFrame(DK.fetch_exchange(zone_key1=zone_1, zone_key2=zone_2,\n session=r, target_datetime=target_datetime,\n logger=logger))\n\n # Because other exchanges and consumption data is only available per hour\n # we floor the timpstamp to hour and group by hour with averaging of netFlow\n df_dk['datetime'] = df_dk['datetime'].dt.floor('H')\n exchange_DK = df_dk.groupby(['datetime']).aggregate({'netFlow' : 'mean', \n 'sortedZoneKeys': 'max', 'source' : 'max'}).reset_index()\n\n # because averaging with high precision numbers leads to rounding errors\n exchange_DK = exchange_DK.round({'netFlow': 3})\n\n exchanges.extend(exchange_DK.to_dict(orient='records'))\n\n # We want to know the net-imports into NL, so if NL is in zone_1 we need\n # to flip the direction of the flow. E.g. 100MW for NL->DE means 100MW\n # export to DE and needs to become -100MW for import to NL.\n for e in exchanges:\n if(e['sortedZoneKeys'].startswith('NL->')):\n e['NL_import'] = -1 * e['netFlow']\n else:\n e['NL_import'] = e['netFlow']\n del e['source']\n del e['netFlow']\n\n df_exchanges = pd.DataFrame.from_dict(exchanges).set_index('datetime')\n # Sum all exchanges to NL imports\n df_exchanges = df_exchanges.groupby('datetime').sum()\n\n # Fill missing values by propagating the value forward\n df_consumptions_with_exchanges = df_consumptions.join(df_exchanges).fillna(\n method='ffill', limit=3) # Limit to 3 x 15min\n\n # Load = Generation + netImports\n # => Generation = Load - netImports\n df_total_generations = (df_consumptions_with_exchanges['consumption']\n - df_consumptions_with_exchanges['NL_import'])\n\n # Fetch all production\n # The energieopwek_nl parser is backwards compatible with ENTSOE parser.\n # Because of data quality issues we switch to using energieopwek, but if\n # data quality of ENTSOE improves we can switch back to using a single\n # source.\n productions_ENTSOE = ENTSOE.fetch_production(zone_key=zone_key, session=r,\n target_datetime=target_datetime, logger=logger)\n if energieopwek_nl:\n productions_eopwek = fetch_production_energieopwek_nl(session=r,\n target_datetime=target_datetime, logger=logger)\n # For every production value we look up the corresponding ENTSOE\n # values and copy the nuclear, gas, coal, biomass and unknown production. \n productions = []\n for p in productions_eopwek:\n entsoe_value = next((pe for pe in productions_ENTSOE\n if pe[\"datetime\"] == p[\"datetime\"]), None)\n if entsoe_value:\n p[\"production\"][\"nuclear\"] = entsoe_value[\"production\"][\"nuclear\"]\n p[\"production\"][\"gas\"] = entsoe_value[\"production\"][\"gas\"]\n p[\"production\"][\"coal\"] = entsoe_value[\"production\"][\"coal\"]\n p[\"production\"][\"biomass\"] = entsoe_value[\"production\"][\"biomass\"]\n p[\"production\"][\"unknown\"] = entsoe_value[\"production\"][\"unknown\"]\n productions.append(p)\n else:\n productions = productions_ENTSOE\n if not productions:\n return\n\n # Flatten production dictionaries (we ignore storage)\n for p in productions:\n # if for some reason ther\u00e9's no unknown value\n if not 'unknown' in p['production'] or p['production']['unknown'] == None:\n p['production']['unknown'] = 0\n\n Z = sum([x or 0 for x in p['production'].values()])\n # Only calculate the difference if the datetime exists\n # If total ENTSOE reported production (Z) is less than total generation\n # (calculated from consumption and imports), then there must be some\n # unknown production missing, so we add the difference.\n # The difference can actually be negative, because consumption is based\n # on TSO network load, but locally generated electricity may never leave\n # the DSO network and be substantial (e.g. Solar).\n if p['datetime'] in df_total_generations and Z < df_total_generations[p['datetime']]:\n p['production']['unknown'] = round((\n df_total_generations[p['datetime']] - Z + p['production']['unknown']), 3)\n\n # Filter invalid\n # We should probably add logging to this\n return [p for p in productions if p['production']['unknown'] > 0]\n\n\ndef fetch_production_energieopwek_nl(session=None, target_datetime=None,\n logger=logging.getLogger(__name__)) -> list:\n if target_datetime is None:\n target_datetime = arrow.utcnow()\n\n # Get production values for target and target-1 day\n df_current = get_production_data_energieopwek(\n target_datetime, session=session)\n df_previous = get_production_data_energieopwek(\n target_datetime.shift(days=-1), session=session)\n\n # Concat them, oldest first to keep chronological order intact\n df = pd.concat([df_previous, df_current])\n\n output = []\n base_time = arrow.get(target_datetime.date(), 'Europe/Paris').shift(days=-1).to('utc')\n\n for i, prod in enumerate(df.to_dict(orient='records')):\n output.append(\n {\n 'zoneKey': 'NL',\n 'datetime': base_time.shift(minutes=i*15).datetime,\n 'production': prod,\n 'source': 'energieopwek.nl, entsoe.eu'\n }\n )\n return output\n\ndef get_production_data_energieopwek(date, session=None):\n r = session or requests.session()\n\n # The API returns values per day from local time midnight until the last\n # round 10 minutes if the requested date is today or for the entire day if\n # it's in the past. 'sid' can be anything.\n url = 'http://energieopwek.nl/jsonData.php?sid=2ecde3&Day=%s' % date.format('YYYY-MM-DD')\n response = r.get(url)\n obj = response.json()\n production_input = obj['TenMin']['Country']\n\n # extract the power values in kW from the different production types\n # we only need column 0, 1 and 3 contain energy sum values\n df_solar = pd.DataFrame(production_input['Solar']) .drop(['1','3'], axis=1).astype(int).rename(columns={\"0\" : \"solar\"})\n df_offshore = pd.DataFrame(production_input['WindOffshore']).drop(['1','3'], axis=1).astype(int)\n df_onshore = pd.DataFrame(production_input['Wind']) .drop(['1','3'], axis=1).astype(int)\n\n # We don't differentiate between onshore and offshore wind so we sum them\n # toghether and build a single data frame with named columns\n df_wind = df_onshore.add(df_offshore).rename(columns={\"0\": \"wind\"})\n df = pd.concat([df_solar, df_wind], axis=1)\n\n # resample from 10min resolution to 15min resolution to align with ENTSOE data\n # we duplicate every row and then group them per 3 and take the mean\n df = pd.concat([df]*2).sort_index(axis=0).reset_index(drop=True).groupby(by=lambda x : math.floor(x/3)).mean()\n\n # Convert kW to MW with kW resolution\n df = df.apply(lambda x: round(x / 1000, 3))\n\n return df\n\nif __name__ == '__main__':\n print(fetch_production())\n", "path": "parsers/NL.py"}]}
| 3,381 | 109 |
gh_patches_debug_1345
|
rasdani/github-patches
|
git_diff
|
castorini__pyserini-667
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Switch to jnius_config.add_classpath
Currently, pyserini replaces any previously registered jars on the classpath in its setup code. Is there any reason to not use add_classpath() instead of set_classpath()?
Here is the pyjnius relevant code:
```python
def set_classpath(*path):
"""
Sets the classpath for the JVM to use. Replaces any existing classpath, overriding the CLASSPATH environment variable.
"""
check_vm_running()
global classpath
classpath = list(path)
def add_classpath(*path):
"""
Appends items to the classpath for the JVM to use.
Replaces any existing classpath, overriding the CLASSPATH environment variable.
"""
check_vm_running()
global classpath
if classpath is None:
classpath = list(path)
else:
classpath.extend(path)
```
</issue>
<code>
[start of pyserini/setup.py]
1 #
2 # Pyserini: Reproducible IR research with sparse and dense representations
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 #
16
17 """
18 Module for adding Anserini jar to classpath for pyjnius usage
19 """
20
21 import glob
22 import os
23
24 import jnius_config
25
26
27 def configure_classpath(anserini_root="."):
28 """
29 Parameters
30 ----------
31 anserini_root : str
32 (Optional) path to root anserini directory.
33
34 """
35 paths = glob.glob(os.path.join(anserini_root, 'anserini-*-fatjar.jar'))
36 if not paths:
37 raise Exception('No matching jar file found in {}'.format(os.path.abspath(anserini_root)))
38
39 latest = max(paths, key=os.path.getctime)
40 jnius_config.set_classpath(latest)
41
[end of pyserini/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pyserini/setup.py b/pyserini/setup.py
--- a/pyserini/setup.py
+++ b/pyserini/setup.py
@@ -37,4 +37,4 @@
raise Exception('No matching jar file found in {}'.format(os.path.abspath(anserini_root)))
latest = max(paths, key=os.path.getctime)
- jnius_config.set_classpath(latest)
+ jnius_config.add_classpath(latest)
|
{"golden_diff": "diff --git a/pyserini/setup.py b/pyserini/setup.py\n--- a/pyserini/setup.py\n+++ b/pyserini/setup.py\n@@ -37,4 +37,4 @@\n raise Exception('No matching jar file found in {}'.format(os.path.abspath(anserini_root)))\n \n latest = max(paths, key=os.path.getctime)\n- jnius_config.set_classpath(latest)\n+ jnius_config.add_classpath(latest)\n", "issue": "Switch to jnius_config.add_classpath\nCurrently, pyserini replaces any previously registered jars on the classpath in its setup code. Is there any reason to not use add_classpath() instead of set_classpath()?\r\n\r\nHere is the pyjnius relevant code:\r\n```python\r\ndef set_classpath(*path):\r\n \"\"\"\r\n Sets the classpath for the JVM to use. Replaces any existing classpath, overriding the CLASSPATH environment variable.\r\n \"\"\"\r\n check_vm_running()\r\n global classpath\r\n classpath = list(path)\r\n\r\n\r\ndef add_classpath(*path):\r\n \"\"\"\r\n Appends items to the classpath for the JVM to use.\r\n Replaces any existing classpath, overriding the CLASSPATH environment variable.\r\n \"\"\"\r\n check_vm_running()\r\n global classpath\r\n if classpath is None:\r\n classpath = list(path)\r\n else:\r\n classpath.extend(path)\r\n```\n", "before_files": [{"content": "#\n# Pyserini: Reproducible IR research with sparse and dense representations\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\n\"\"\"\nModule for adding Anserini jar to classpath for pyjnius usage\n\"\"\"\n\nimport glob\nimport os\n\nimport jnius_config\n\n\ndef configure_classpath(anserini_root=\".\"):\n \"\"\"\n Parameters\n ----------\n anserini_root : str\n (Optional) path to root anserini directory.\n\n \"\"\"\n paths = glob.glob(os.path.join(anserini_root, 'anserini-*-fatjar.jar'))\n if not paths:\n raise Exception('No matching jar file found in {}'.format(os.path.abspath(anserini_root)))\n\n latest = max(paths, key=os.path.getctime)\n jnius_config.set_classpath(latest)\n", "path": "pyserini/setup.py"}]}
| 1,079 | 101 |
gh_patches_debug_21488
|
rasdani/github-patches
|
git_diff
|
WeblateOrg__weblate-10189
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
"Add missing languages" add-on not working
### Describe the issue
I have enabled the "Add missing languages" add-on on https://hosted.weblate.org/projects/catima/. However, despite waiting over 24 hours as the documentation on https://docs.weblate.org/en/latest/admin/addons.html#addon-weblate-consistency-languages states, it has not put the different components of the same project in sync.
This is most noticeable when comparing https://hosted.weblate.org/projects/catima/catima/ with https://hosted.weblate.org/projects/catima/android-debug/
### I already tried
- [X] I've read and searched [the documentation](https://docs.weblate.org/).
- [X] I've searched for similar issues in this repository.
### Steps to reproduce the behavior
1. Enable the "Add missing languages" add-on in a project with multiple components where one component has less languages than the other
2. Wait at least 24 hours as the add-on states
### Expected behavior
All components have the same languages, missing languages on components get created
### Screenshots
Android component:

Android (Debug) component:

### Exception traceback
_No response_
### How do you run Weblate?
weblate.org service
### Weblate versions
_No response_
### Weblate deploy checks
_No response_
### Additional context
_No response_
</issue>
<code>
[start of weblate/addons/consistency.py]
1 # Copyright © Michal Čihař <[email protected]>
2 #
3 # SPDX-License-Identifier: GPL-3.0-or-later
4
5 from django.db.models import Q
6 from django.utils.translation import gettext_lazy
7
8 from weblate.addons.base import BaseAddon
9 from weblate.addons.events import EVENT_DAILY, EVENT_POST_ADD
10 from weblate.addons.tasks import language_consistency
11 from weblate.lang.models import Language
12
13
14 class LangaugeConsistencyAddon(BaseAddon):
15 events = (EVENT_DAILY, EVENT_POST_ADD)
16 name = "weblate.consistency.languages"
17 verbose = gettext_lazy("Add missing languages")
18 description = gettext_lazy(
19 "Ensures a consistent set of languages is used for all components "
20 "within a project."
21 )
22 icon = "language.svg"
23 project_scope = True
24
25 def daily(self, component):
26 language_consistency.delay(
27 component.project_id,
28 list(
29 Language.objects.filter(
30 Q(translation__component=component) | Q(component=component)
31 ).values_list("pk", flat=True)
32 ),
33 )
34
35 def post_add(self, translation):
36 language_consistency.delay(
37 translation.component.project_id,
38 [translation.language_id],
39 )
40
[end of weblate/addons/consistency.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/weblate/addons/consistency.py b/weblate/addons/consistency.py
--- a/weblate/addons/consistency.py
+++ b/weblate/addons/consistency.py
@@ -2,13 +2,11 @@
#
# SPDX-License-Identifier: GPL-3.0-or-later
-from django.db.models import Q
from django.utils.translation import gettext_lazy
from weblate.addons.base import BaseAddon
from weblate.addons.events import EVENT_DAILY, EVENT_POST_ADD
from weblate.addons.tasks import language_consistency
-from weblate.lang.models import Language
class LangaugeConsistencyAddon(BaseAddon):
@@ -25,11 +23,7 @@
def daily(self, component):
language_consistency.delay(
component.project_id,
- list(
- Language.objects.filter(
- Q(translation__component=component) | Q(component=component)
- ).values_list("pk", flat=True)
- ),
+ [language.id for language in component.project.languages],
)
def post_add(self, translation):
|
{"golden_diff": "diff --git a/weblate/addons/consistency.py b/weblate/addons/consistency.py\n--- a/weblate/addons/consistency.py\n+++ b/weblate/addons/consistency.py\n@@ -2,13 +2,11 @@\n #\n # SPDX-License-Identifier: GPL-3.0-or-later\n \n-from django.db.models import Q\n from django.utils.translation import gettext_lazy\n \n from weblate.addons.base import BaseAddon\n from weblate.addons.events import EVENT_DAILY, EVENT_POST_ADD\n from weblate.addons.tasks import language_consistency\n-from weblate.lang.models import Language\n \n \n class LangaugeConsistencyAddon(BaseAddon):\n@@ -25,11 +23,7 @@\n def daily(self, component):\n language_consistency.delay(\n component.project_id,\n- list(\n- Language.objects.filter(\n- Q(translation__component=component) | Q(component=component)\n- ).values_list(\"pk\", flat=True)\n- ),\n+ [language.id for language in component.project.languages],\n )\n \n def post_add(self, translation):\n", "issue": "\"Add missing languages\" add-on not working\n### Describe the issue\n\nI have enabled the \"Add missing languages\" add-on on https://hosted.weblate.org/projects/catima/. However, despite waiting over 24 hours as the documentation on https://docs.weblate.org/en/latest/admin/addons.html#addon-weblate-consistency-languages states, it has not put the different components of the same project in sync.\r\n\r\nThis is most noticeable when comparing https://hosted.weblate.org/projects/catima/catima/ with https://hosted.weblate.org/projects/catima/android-debug/\n\n### I already tried\n\n- [X] I've read and searched [the documentation](https://docs.weblate.org/).\n- [X] I've searched for similar issues in this repository.\n\n### Steps to reproduce the behavior\n\n1. Enable the \"Add missing languages\" add-on in a project with multiple components where one component has less languages than the other\r\n2. Wait at least 24 hours as the add-on states\n\n### Expected behavior\n\nAll components have the same languages, missing languages on components get created\n\n### Screenshots\n\nAndroid component:\r\n\r\n\r\nAndroid (Debug) component:\r\n\r\n\n\n### Exception traceback\n\n_No response_\n\n### How do you run Weblate?\n\nweblate.org service\n\n### Weblate versions\n\n_No response_\n\n### Weblate deploy checks\n\n_No response_\n\n### Additional context\n\n_No response_\n", "before_files": [{"content": "# Copyright \u00a9 Michal \u010ciha\u0159 <[email protected]>\n#\n# SPDX-License-Identifier: GPL-3.0-or-later\n\nfrom django.db.models import Q\nfrom django.utils.translation import gettext_lazy\n\nfrom weblate.addons.base import BaseAddon\nfrom weblate.addons.events import EVENT_DAILY, EVENT_POST_ADD\nfrom weblate.addons.tasks import language_consistency\nfrom weblate.lang.models import Language\n\n\nclass LangaugeConsistencyAddon(BaseAddon):\n events = (EVENT_DAILY, EVENT_POST_ADD)\n name = \"weblate.consistency.languages\"\n verbose = gettext_lazy(\"Add missing languages\")\n description = gettext_lazy(\n \"Ensures a consistent set of languages is used for all components \"\n \"within a project.\"\n )\n icon = \"language.svg\"\n project_scope = True\n\n def daily(self, component):\n language_consistency.delay(\n component.project_id,\n list(\n Language.objects.filter(\n Q(translation__component=component) | Q(component=component)\n ).values_list(\"pk\", flat=True)\n ),\n )\n\n def post_add(self, translation):\n language_consistency.delay(\n translation.component.project_id,\n [translation.language_id],\n )\n", "path": "weblate/addons/consistency.py"}]}
| 1,295 | 242 |
gh_patches_debug_42186
|
rasdani/github-patches
|
git_diff
|
pypa__virtualenv-1870
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
virtualenv parallel run silently breaks
When running virtualenv creation in parallel, the app-data image builder is not synchronized and inconsistent states might break the virtual environment creation. Furthermore, in this case no error is raised in case of the failed commands.
</issue>
<code>
[start of src/virtualenv/seed/embed/via_app_data/via_app_data.py]
1 """Bootstrap"""
2 from __future__ import absolute_import, unicode_literals
3
4 import logging
5 from contextlib import contextmanager
6 from subprocess import CalledProcessError
7 from threading import Lock, Thread
8
9 import six
10
11 from virtualenv.info import fs_supports_symlink
12 from virtualenv.seed.embed.base_embed import BaseEmbed
13 from virtualenv.seed.wheels import get_wheel
14 from virtualenv.util.path import Path
15
16 from .pip_install.copy import CopyPipInstall
17 from .pip_install.symlink import SymlinkPipInstall
18
19
20 class FromAppData(BaseEmbed):
21 def __init__(self, options):
22 super(FromAppData, self).__init__(options)
23 self.symlinks = options.symlink_app_data
24
25 @classmethod
26 def add_parser_arguments(cls, parser, interpreter, app_data):
27 super(FromAppData, cls).add_parser_arguments(parser, interpreter, app_data)
28 can_symlink = app_data.transient is False and fs_supports_symlink()
29 parser.add_argument(
30 "--symlink-app-data",
31 dest="symlink_app_data",
32 action="store_true" if can_symlink else "store_false",
33 help="{} symlink the python packages from the app-data folder (requires seed pip>=19.3)".format(
34 "" if can_symlink else "not supported - ",
35 ),
36 default=False,
37 )
38
39 def run(self, creator):
40 if not self.enabled:
41 return
42 with self._get_seed_wheels(creator) as name_to_whl:
43 pip_version = name_to_whl["pip"].version_tuple if "pip" in name_to_whl else None
44 installer_class = self.installer_class(pip_version)
45
46 def _install(name, wheel):
47 logging.debug("install %s from wheel %s via %s", name, wheel, installer_class.__name__)
48 key = Path(installer_class.__name__) / wheel.path.stem
49 wheel_img = self.app_data.wheel_image(creator.interpreter.version_release_str, key)
50 installer = installer_class(wheel.path, creator, wheel_img)
51 if not installer.has_image():
52 installer.build_image()
53 installer.install(creator.interpreter.version_info)
54
55 threads = list(Thread(target=_install, args=(n, w)) for n, w in name_to_whl.items())
56 for thread in threads:
57 thread.start()
58 for thread in threads:
59 thread.join()
60
61 @contextmanager
62 def _get_seed_wheels(self, creator):
63 name_to_whl, lock, fail = {}, Lock(), {}
64
65 def _get(distribution, version):
66 for_py_version = creator.interpreter.version_release_str
67 failure, result = None, None
68 # fallback to download in case the exact version is not available
69 for download in [True] if self.download else [False, True]:
70 failure = None
71 try:
72 result = get_wheel(
73 distribution=distribution,
74 version=version,
75 for_py_version=for_py_version,
76 search_dirs=self.extra_search_dir,
77 download=download,
78 app_data=self.app_data,
79 do_periodic_update=self.periodic_update,
80 )
81 if result is not None:
82 break
83 except Exception as exception: # noqa
84 logging.exception("fail")
85 failure = exception
86 if failure:
87 if isinstance(failure, CalledProcessError):
88 msg = "failed to download {}".format(distribution)
89 if version is not None:
90 msg += " version {}".format(version)
91 msg += ", pip download exit code {}".format(failure.returncode)
92 output = failure.output if six.PY2 else (failure.output + failure.stderr)
93 if output:
94 msg += "\n"
95 msg += output
96 else:
97 msg = repr(failure)
98 logging.error(msg)
99 with lock:
100 fail[distribution] = version
101 else:
102 with lock:
103 name_to_whl[distribution] = result
104
105 threads = list(
106 Thread(target=_get, args=(distribution, version))
107 for distribution, version in self.distribution_to_versions().items()
108 )
109 for thread in threads:
110 thread.start()
111 for thread in threads:
112 thread.join()
113 if fail:
114 raise RuntimeError("seed failed due to failing to download wheels {}".format(", ".join(fail.keys())))
115 yield name_to_whl
116
117 def installer_class(self, pip_version_tuple):
118 if self.symlinks and pip_version_tuple:
119 # symlink support requires pip 19.3+
120 if pip_version_tuple >= (19, 3):
121 return SymlinkPipInstall
122 return CopyPipInstall
123
124 def __unicode__(self):
125 base = super(FromAppData, self).__unicode__()
126 msg = ", via={}, app_data_dir={}".format("symlink" if self.symlinks else "copy", self.app_data)
127 return base[:-1] + msg + base[-1]
128
[end of src/virtualenv/seed/embed/via_app_data/via_app_data.py]
[start of src/virtualenv/util/lock.py]
1 """holds locking functionality that works across processes"""
2 from __future__ import absolute_import, unicode_literals
3
4 import logging
5 import os
6 from contextlib import contextmanager
7 from threading import Lock, RLock
8
9 from filelock import FileLock, Timeout
10
11 from virtualenv.util.path import Path
12
13
14 class _CountedFileLock(FileLock):
15 def __init__(self, lock_file):
16 super(_CountedFileLock, self).__init__(lock_file)
17 self.count = 0
18 self.thread_safe = RLock()
19
20 def acquire(self, timeout=None, poll_intervall=0.05):
21 with self.thread_safe:
22 if self.count == 0:
23 super(_CountedFileLock, self).acquire(timeout=timeout, poll_intervall=poll_intervall)
24 self.count += 1
25
26 def release(self, force=False):
27 with self.thread_safe:
28 if self.count == 1:
29 super(_CountedFileLock, self).release()
30 self.count = max(self.count - 1, 0)
31
32
33 _lock_store = {}
34 _store_lock = Lock()
35
36
37 class ReentrantFileLock(object):
38 def __init__(self, folder):
39 self._lock = None
40 path = Path(folder)
41 self.path = path.resolve() if path.exists() else path
42
43 def __repr__(self):
44 return "{}({})".format(self.__class__.__name__, self.path)
45
46 def __div__(self, other):
47 return ReentrantFileLock(self.path / other)
48
49 def __truediv__(self, other):
50 return self.__div__(other)
51
52 def _create_lock(self, name=""):
53 lock_file = str(self.path / "{}.lock".format(name))
54 with _store_lock:
55 if lock_file not in _lock_store:
56 _lock_store[lock_file] = _CountedFileLock(lock_file)
57 return _lock_store[lock_file]
58
59 @staticmethod
60 def _del_lock(lock):
61 with _store_lock:
62 if lock is not None:
63 with lock.thread_safe:
64 if lock.count == 0:
65 _lock_store.pop(lock.lock_file, None)
66
67 def __del__(self):
68 self._del_lock(self._lock)
69
70 def __enter__(self):
71 self._lock = self._create_lock()
72 self._lock_file(self._lock)
73
74 def __exit__(self, exc_type, exc_val, exc_tb):
75 self._release(self._lock)
76
77 def _lock_file(self, lock, no_block=False):
78 # multiple processes might be trying to get a first lock... so we cannot check if this directory exist without
79 # a lock, but that lock might then become expensive, and it's not clear where that lock should live.
80 # Instead here we just ignore if we fail to create the directory.
81 try:
82 os.makedirs(str(self.path))
83 except OSError:
84 pass
85 try:
86 lock.acquire(0.0001)
87 except Timeout:
88 if no_block:
89 raise
90 logging.debug("lock file %s present, will block until released", lock.lock_file)
91 lock.release() # release the acquire try from above
92 lock.acquire()
93
94 @staticmethod
95 def _release(lock):
96 lock.release()
97
98 @contextmanager
99 def lock_for_key(self, name, no_block=False):
100 lock = self._create_lock(name)
101 try:
102 try:
103 self._lock_file(lock, no_block)
104 yield
105 finally:
106 self._release(lock)
107 finally:
108 self._del_lock(lock)
109
110
111 __all__ = (
112 "Timeout",
113 "ReentrantFileLock",
114 )
115
[end of src/virtualenv/util/lock.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/virtualenv/seed/embed/via_app_data/via_app_data.py b/src/virtualenv/seed/embed/via_app_data/via_app_data.py
--- a/src/virtualenv/seed/embed/via_app_data/via_app_data.py
+++ b/src/virtualenv/seed/embed/via_app_data/via_app_data.py
@@ -2,6 +2,8 @@
from __future__ import absolute_import, unicode_literals
import logging
+import sys
+import traceback
from contextlib import contextmanager
from subprocess import CalledProcessError
from threading import Lock, Thread
@@ -11,7 +13,9 @@
from virtualenv.info import fs_supports_symlink
from virtualenv.seed.embed.base_embed import BaseEmbed
from virtualenv.seed.wheels import get_wheel
+from virtualenv.util.lock import _CountedFileLock
from virtualenv.util.path import Path
+from virtualenv.util.six import ensure_text
from .pip_install.copy import CopyPipInstall
from .pip_install.symlink import SymlinkPipInstall
@@ -42,21 +46,32 @@
with self._get_seed_wheels(creator) as name_to_whl:
pip_version = name_to_whl["pip"].version_tuple if "pip" in name_to_whl else None
installer_class = self.installer_class(pip_version)
+ exceptions = {}
def _install(name, wheel):
- logging.debug("install %s from wheel %s via %s", name, wheel, installer_class.__name__)
- key = Path(installer_class.__name__) / wheel.path.stem
- wheel_img = self.app_data.wheel_image(creator.interpreter.version_release_str, key)
- installer = installer_class(wheel.path, creator, wheel_img)
- if not installer.has_image():
- installer.build_image()
- installer.install(creator.interpreter.version_info)
+ try:
+ logging.debug("install %s from wheel %s via %s", name, wheel, installer_class.__name__)
+ key = Path(installer_class.__name__) / wheel.path.stem
+ wheel_img = self.app_data.wheel_image(creator.interpreter.version_release_str, key)
+ installer = installer_class(wheel.path, creator, wheel_img)
+ with _CountedFileLock(ensure_text(str(wheel_img.parent / "{}.lock".format(wheel_img.name)))):
+ if not installer.has_image():
+ installer.build_image()
+ installer.install(creator.interpreter.version_info)
+ except Exception: # noqa
+ exceptions[name] = sys.exc_info()
threads = list(Thread(target=_install, args=(n, w)) for n, w in name_to_whl.items())
for thread in threads:
thread.start()
for thread in threads:
thread.join()
+ if exceptions:
+ messages = ["failed to build image {} because:".format(", ".join(exceptions.keys()))]
+ for value in exceptions.values():
+ exc_type, exc_value, exc_traceback = value
+ messages.append("".join(traceback.format_exception(exc_type, exc_value, exc_traceback)))
+ raise RuntimeError("\n".join(messages))
@contextmanager
def _get_seed_wheels(self, creator):
diff --git a/src/virtualenv/util/lock.py b/src/virtualenv/util/lock.py
--- a/src/virtualenv/util/lock.py
+++ b/src/virtualenv/util/lock.py
@@ -13,6 +13,12 @@
class _CountedFileLock(FileLock):
def __init__(self, lock_file):
+ parent = os.path.dirname(lock_file)
+ if not os.path.exists(parent):
+ try:
+ os.makedirs(parent)
+ except OSError:
+ pass
super(_CountedFileLock, self).__init__(lock_file)
self.count = 0
self.thread_safe = RLock()
|
{"golden_diff": "diff --git a/src/virtualenv/seed/embed/via_app_data/via_app_data.py b/src/virtualenv/seed/embed/via_app_data/via_app_data.py\n--- a/src/virtualenv/seed/embed/via_app_data/via_app_data.py\n+++ b/src/virtualenv/seed/embed/via_app_data/via_app_data.py\n@@ -2,6 +2,8 @@\n from __future__ import absolute_import, unicode_literals\n \n import logging\n+import sys\n+import traceback\n from contextlib import contextmanager\n from subprocess import CalledProcessError\n from threading import Lock, Thread\n@@ -11,7 +13,9 @@\n from virtualenv.info import fs_supports_symlink\n from virtualenv.seed.embed.base_embed import BaseEmbed\n from virtualenv.seed.wheels import get_wheel\n+from virtualenv.util.lock import _CountedFileLock\n from virtualenv.util.path import Path\n+from virtualenv.util.six import ensure_text\n \n from .pip_install.copy import CopyPipInstall\n from .pip_install.symlink import SymlinkPipInstall\n@@ -42,21 +46,32 @@\n with self._get_seed_wheels(creator) as name_to_whl:\n pip_version = name_to_whl[\"pip\"].version_tuple if \"pip\" in name_to_whl else None\n installer_class = self.installer_class(pip_version)\n+ exceptions = {}\n \n def _install(name, wheel):\n- logging.debug(\"install %s from wheel %s via %s\", name, wheel, installer_class.__name__)\n- key = Path(installer_class.__name__) / wheel.path.stem\n- wheel_img = self.app_data.wheel_image(creator.interpreter.version_release_str, key)\n- installer = installer_class(wheel.path, creator, wheel_img)\n- if not installer.has_image():\n- installer.build_image()\n- installer.install(creator.interpreter.version_info)\n+ try:\n+ logging.debug(\"install %s from wheel %s via %s\", name, wheel, installer_class.__name__)\n+ key = Path(installer_class.__name__) / wheel.path.stem\n+ wheel_img = self.app_data.wheel_image(creator.interpreter.version_release_str, key)\n+ installer = installer_class(wheel.path, creator, wheel_img)\n+ with _CountedFileLock(ensure_text(str(wheel_img.parent / \"{}.lock\".format(wheel_img.name)))):\n+ if not installer.has_image():\n+ installer.build_image()\n+ installer.install(creator.interpreter.version_info)\n+ except Exception: # noqa\n+ exceptions[name] = sys.exc_info()\n \n threads = list(Thread(target=_install, args=(n, w)) for n, w in name_to_whl.items())\n for thread in threads:\n thread.start()\n for thread in threads:\n thread.join()\n+ if exceptions:\n+ messages = [\"failed to build image {} because:\".format(\", \".join(exceptions.keys()))]\n+ for value in exceptions.values():\n+ exc_type, exc_value, exc_traceback = value\n+ messages.append(\"\".join(traceback.format_exception(exc_type, exc_value, exc_traceback)))\n+ raise RuntimeError(\"\\n\".join(messages))\n \n @contextmanager\n def _get_seed_wheels(self, creator):\ndiff --git a/src/virtualenv/util/lock.py b/src/virtualenv/util/lock.py\n--- a/src/virtualenv/util/lock.py\n+++ b/src/virtualenv/util/lock.py\n@@ -13,6 +13,12 @@\n \n class _CountedFileLock(FileLock):\n def __init__(self, lock_file):\n+ parent = os.path.dirname(lock_file)\n+ if not os.path.exists(parent):\n+ try:\n+ os.makedirs(parent)\n+ except OSError:\n+ pass\n super(_CountedFileLock, self).__init__(lock_file)\n self.count = 0\n self.thread_safe = RLock()\n", "issue": "virtualenv parallel run silently breaks\nWhen running virtualenv creation in parallel, the app-data image builder is not synchronized and inconsistent states might break the virtual environment creation. Furthermore, in this case no error is raised in case of the failed commands.\n", "before_files": [{"content": "\"\"\"Bootstrap\"\"\"\nfrom __future__ import absolute_import, unicode_literals\n\nimport logging\nfrom contextlib import contextmanager\nfrom subprocess import CalledProcessError\nfrom threading import Lock, Thread\n\nimport six\n\nfrom virtualenv.info import fs_supports_symlink\nfrom virtualenv.seed.embed.base_embed import BaseEmbed\nfrom virtualenv.seed.wheels import get_wheel\nfrom virtualenv.util.path import Path\n\nfrom .pip_install.copy import CopyPipInstall\nfrom .pip_install.symlink import SymlinkPipInstall\n\n\nclass FromAppData(BaseEmbed):\n def __init__(self, options):\n super(FromAppData, self).__init__(options)\n self.symlinks = options.symlink_app_data\n\n @classmethod\n def add_parser_arguments(cls, parser, interpreter, app_data):\n super(FromAppData, cls).add_parser_arguments(parser, interpreter, app_data)\n can_symlink = app_data.transient is False and fs_supports_symlink()\n parser.add_argument(\n \"--symlink-app-data\",\n dest=\"symlink_app_data\",\n action=\"store_true\" if can_symlink else \"store_false\",\n help=\"{} symlink the python packages from the app-data folder (requires seed pip>=19.3)\".format(\n \"\" if can_symlink else \"not supported - \",\n ),\n default=False,\n )\n\n def run(self, creator):\n if not self.enabled:\n return\n with self._get_seed_wheels(creator) as name_to_whl:\n pip_version = name_to_whl[\"pip\"].version_tuple if \"pip\" in name_to_whl else None\n installer_class = self.installer_class(pip_version)\n\n def _install(name, wheel):\n logging.debug(\"install %s from wheel %s via %s\", name, wheel, installer_class.__name__)\n key = Path(installer_class.__name__) / wheel.path.stem\n wheel_img = self.app_data.wheel_image(creator.interpreter.version_release_str, key)\n installer = installer_class(wheel.path, creator, wheel_img)\n if not installer.has_image():\n installer.build_image()\n installer.install(creator.interpreter.version_info)\n\n threads = list(Thread(target=_install, args=(n, w)) for n, w in name_to_whl.items())\n for thread in threads:\n thread.start()\n for thread in threads:\n thread.join()\n\n @contextmanager\n def _get_seed_wheels(self, creator):\n name_to_whl, lock, fail = {}, Lock(), {}\n\n def _get(distribution, version):\n for_py_version = creator.interpreter.version_release_str\n failure, result = None, None\n # fallback to download in case the exact version is not available\n for download in [True] if self.download else [False, True]:\n failure = None\n try:\n result = get_wheel(\n distribution=distribution,\n version=version,\n for_py_version=for_py_version,\n search_dirs=self.extra_search_dir,\n download=download,\n app_data=self.app_data,\n do_periodic_update=self.periodic_update,\n )\n if result is not None:\n break\n except Exception as exception: # noqa\n logging.exception(\"fail\")\n failure = exception\n if failure:\n if isinstance(failure, CalledProcessError):\n msg = \"failed to download {}\".format(distribution)\n if version is not None:\n msg += \" version {}\".format(version)\n msg += \", pip download exit code {}\".format(failure.returncode)\n output = failure.output if six.PY2 else (failure.output + failure.stderr)\n if output:\n msg += \"\\n\"\n msg += output\n else:\n msg = repr(failure)\n logging.error(msg)\n with lock:\n fail[distribution] = version\n else:\n with lock:\n name_to_whl[distribution] = result\n\n threads = list(\n Thread(target=_get, args=(distribution, version))\n for distribution, version in self.distribution_to_versions().items()\n )\n for thread in threads:\n thread.start()\n for thread in threads:\n thread.join()\n if fail:\n raise RuntimeError(\"seed failed due to failing to download wheels {}\".format(\", \".join(fail.keys())))\n yield name_to_whl\n\n def installer_class(self, pip_version_tuple):\n if self.symlinks and pip_version_tuple:\n # symlink support requires pip 19.3+\n if pip_version_tuple >= (19, 3):\n return SymlinkPipInstall\n return CopyPipInstall\n\n def __unicode__(self):\n base = super(FromAppData, self).__unicode__()\n msg = \", via={}, app_data_dir={}\".format(\"symlink\" if self.symlinks else \"copy\", self.app_data)\n return base[:-1] + msg + base[-1]\n", "path": "src/virtualenv/seed/embed/via_app_data/via_app_data.py"}, {"content": "\"\"\"holds locking functionality that works across processes\"\"\"\nfrom __future__ import absolute_import, unicode_literals\n\nimport logging\nimport os\nfrom contextlib import contextmanager\nfrom threading import Lock, RLock\n\nfrom filelock import FileLock, Timeout\n\nfrom virtualenv.util.path import Path\n\n\nclass _CountedFileLock(FileLock):\n def __init__(self, lock_file):\n super(_CountedFileLock, self).__init__(lock_file)\n self.count = 0\n self.thread_safe = RLock()\n\n def acquire(self, timeout=None, poll_intervall=0.05):\n with self.thread_safe:\n if self.count == 0:\n super(_CountedFileLock, self).acquire(timeout=timeout, poll_intervall=poll_intervall)\n self.count += 1\n\n def release(self, force=False):\n with self.thread_safe:\n if self.count == 1:\n super(_CountedFileLock, self).release()\n self.count = max(self.count - 1, 0)\n\n\n_lock_store = {}\n_store_lock = Lock()\n\n\nclass ReentrantFileLock(object):\n def __init__(self, folder):\n self._lock = None\n path = Path(folder)\n self.path = path.resolve() if path.exists() else path\n\n def __repr__(self):\n return \"{}({})\".format(self.__class__.__name__, self.path)\n\n def __div__(self, other):\n return ReentrantFileLock(self.path / other)\n\n def __truediv__(self, other):\n return self.__div__(other)\n\n def _create_lock(self, name=\"\"):\n lock_file = str(self.path / \"{}.lock\".format(name))\n with _store_lock:\n if lock_file not in _lock_store:\n _lock_store[lock_file] = _CountedFileLock(lock_file)\n return _lock_store[lock_file]\n\n @staticmethod\n def _del_lock(lock):\n with _store_lock:\n if lock is not None:\n with lock.thread_safe:\n if lock.count == 0:\n _lock_store.pop(lock.lock_file, None)\n\n def __del__(self):\n self._del_lock(self._lock)\n\n def __enter__(self):\n self._lock = self._create_lock()\n self._lock_file(self._lock)\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n self._release(self._lock)\n\n def _lock_file(self, lock, no_block=False):\n # multiple processes might be trying to get a first lock... so we cannot check if this directory exist without\n # a lock, but that lock might then become expensive, and it's not clear where that lock should live.\n # Instead here we just ignore if we fail to create the directory.\n try:\n os.makedirs(str(self.path))\n except OSError:\n pass\n try:\n lock.acquire(0.0001)\n except Timeout:\n if no_block:\n raise\n logging.debug(\"lock file %s present, will block until released\", lock.lock_file)\n lock.release() # release the acquire try from above\n lock.acquire()\n\n @staticmethod\n def _release(lock):\n lock.release()\n\n @contextmanager\n def lock_for_key(self, name, no_block=False):\n lock = self._create_lock(name)\n try:\n try:\n self._lock_file(lock, no_block)\n yield\n finally:\n self._release(lock)\n finally:\n self._del_lock(lock)\n\n\n__all__ = (\n \"Timeout\",\n \"ReentrantFileLock\",\n)\n", "path": "src/virtualenv/util/lock.py"}]}
| 2,978 | 854 |
gh_patches_debug_3297
|
rasdani/github-patches
|
git_diff
|
liberapay__liberapay.com-1484
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Requests access to GitHub private repos?
Hi. I'm a brand-new user. I have a question I didn't see in the FAQ or when I searched issues here.
I was going to connect my GitHub account and saw this:
> Liberapay by liberapay
> wants to access your greghendershott account
>
> Organizations and teams
> Read-only access
>
> This application will be able to read your organization and team membership and private Projects.
I almost clicked OK, but noticed "**private** Projects". I stopped. I don't want to do that.
Is this as-intended?
</issue>
<code>
[start of liberapay/elsewhere/github.py]
1 from liberapay.elsewhere._base import PlatformOAuth2
2 from liberapay.elsewhere._exceptions import CantReadMembership
3 from liberapay.elsewhere._extractors import key, drop_keys
4 from liberapay.elsewhere._paginators import header_links_paginator
5
6
7 class GitHub(PlatformOAuth2):
8
9 # Platform attributes
10 name = 'github'
11 display_name = 'GitHub'
12 fontawesome_name = name
13 account_url = 'https://github.com/{user_name}'
14 repo_url = 'https://github.com/{slug}'
15 has_teams = True
16
17 # Auth attributes
18 auth_url = 'https://github.com/login/oauth/authorize'
19 access_token_url = 'https://github.com/login/oauth/access_token'
20 oauth_email_scope = 'user:email'
21 oauth_default_scope = ['read:org']
22
23 # API attributes
24 api_format = 'json'
25 api_paginator = header_links_paginator()
26 api_url = 'https://api.github.com'
27 api_app_auth_params = 'client_id={api_key}&client_secret={api_secret}'
28 api_user_info_path = '/user/{user_id}'
29 api_user_name_info_path = '/users/{user_name}'
30 api_user_self_info_path = '/user'
31 api_team_members_path = '/orgs/{user_name}/public_members'
32 api_friends_path = '/users/{user_name}/following'
33 api_repos_path = '/users/{user_name}/repos?type=owner&sort=updated&per_page=100'
34 api_starred_path = '/users/{user_name}/starred'
35 ratelimit_headers_prefix = 'x-ratelimit-'
36
37 # User info extractors
38 x_user_id = key('id')
39 x_user_name = key('login')
40 x_display_name = key('name')
41 x_email = key('email')
42 x_gravatar_id = key('gravatar_id')
43 x_avatar_url = key('avatar_url')
44 x_is_team = key('type', clean=lambda t: t.lower() == 'organization')
45 x_description = key('bio')
46 x_extra_info_drop = drop_keys(lambda k: k.endswith('_url'))
47
48 # Repo info extractors
49 x_repo_id = key('id')
50 x_repo_name = key('name')
51 x_repo_slug = key('full_name')
52 x_repo_description = key('description')
53 x_repo_last_update = key('pushed_at')
54 x_repo_is_fork = key('fork')
55 x_repo_stars_count = key('stargazers_count')
56 x_repo_owner_id = key('owner', clean=lambda d: d['id'])
57 x_repo_extra_info_drop = drop_keys(lambda k: k.endswith('_url'))
58
59 def get_CantReadMembership_url(self, **kw):
60 return 'https://github.com/settings/connections/applications/'+self.api_key
61
62 def is_team_member(self, org_name, sess, account):
63 org_name = org_name.lower()
64
65 # Check public membership first
66 response = self.api_get(
67 '', '/orgs/'+org_name+'/public_members/'+account.user_name,
68 sess=sess, error_handler=None
69 )
70 if response.status_code == 204:
71 return True
72 elif response.status_code != 404:
73 self.api_error_handler(response, True, self.domain)
74
75 # Check private membership
76 response = self.api_get(
77 '', '/user/memberships/orgs/'+org_name, sess=sess, error_handler=None
78 )
79 if response.status_code == 403:
80 raise CantReadMembership
81 elif response.status_code >= 400:
82 self.api_error_handler(response, True, self.domain)
83 membership = self.api_parser(response)
84 if membership['state'] == 'active':
85 return True
86
87 # Try the endpoint we were using before
88 user_orgs = self.api_parser(self.api_get('', '/user/orgs', sess=sess))
89 return any(org.get('login') == org_name for org in user_orgs)
90
[end of liberapay/elsewhere/github.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/liberapay/elsewhere/github.py b/liberapay/elsewhere/github.py
--- a/liberapay/elsewhere/github.py
+++ b/liberapay/elsewhere/github.py
@@ -18,7 +18,6 @@
auth_url = 'https://github.com/login/oauth/authorize'
access_token_url = 'https://github.com/login/oauth/access_token'
oauth_email_scope = 'user:email'
- oauth_default_scope = ['read:org']
# API attributes
api_format = 'json'
|
{"golden_diff": "diff --git a/liberapay/elsewhere/github.py b/liberapay/elsewhere/github.py\n--- a/liberapay/elsewhere/github.py\n+++ b/liberapay/elsewhere/github.py\n@@ -18,7 +18,6 @@\n auth_url = 'https://github.com/login/oauth/authorize'\n access_token_url = 'https://github.com/login/oauth/access_token'\n oauth_email_scope = 'user:email'\n- oauth_default_scope = ['read:org']\n \n # API attributes\n api_format = 'json'\n", "issue": "Requests access to GitHub private repos?\nHi. I'm a brand-new user. I have a question I didn't see in the FAQ or when I searched issues here.\r\n\r\nI was going to connect my GitHub account and saw this:\r\n\r\n> Liberapay by liberapay\r\n> wants to access your greghendershott account\r\n> \r\n> Organizations and teams\r\n> Read-only access\r\n>\r\n> This application will be able to read your organization and team membership and private Projects.\r\n\r\nI almost clicked OK, but noticed \"**private** Projects\". I stopped. I don't want to do that.\r\n\r\nIs this as-intended?\n", "before_files": [{"content": "from liberapay.elsewhere._base import PlatformOAuth2\nfrom liberapay.elsewhere._exceptions import CantReadMembership\nfrom liberapay.elsewhere._extractors import key, drop_keys\nfrom liberapay.elsewhere._paginators import header_links_paginator\n\n\nclass GitHub(PlatformOAuth2):\n\n # Platform attributes\n name = 'github'\n display_name = 'GitHub'\n fontawesome_name = name\n account_url = 'https://github.com/{user_name}'\n repo_url = 'https://github.com/{slug}'\n has_teams = True\n\n # Auth attributes\n auth_url = 'https://github.com/login/oauth/authorize'\n access_token_url = 'https://github.com/login/oauth/access_token'\n oauth_email_scope = 'user:email'\n oauth_default_scope = ['read:org']\n\n # API attributes\n api_format = 'json'\n api_paginator = header_links_paginator()\n api_url = 'https://api.github.com'\n api_app_auth_params = 'client_id={api_key}&client_secret={api_secret}'\n api_user_info_path = '/user/{user_id}'\n api_user_name_info_path = '/users/{user_name}'\n api_user_self_info_path = '/user'\n api_team_members_path = '/orgs/{user_name}/public_members'\n api_friends_path = '/users/{user_name}/following'\n api_repos_path = '/users/{user_name}/repos?type=owner&sort=updated&per_page=100'\n api_starred_path = '/users/{user_name}/starred'\n ratelimit_headers_prefix = 'x-ratelimit-'\n\n # User info extractors\n x_user_id = key('id')\n x_user_name = key('login')\n x_display_name = key('name')\n x_email = key('email')\n x_gravatar_id = key('gravatar_id')\n x_avatar_url = key('avatar_url')\n x_is_team = key('type', clean=lambda t: t.lower() == 'organization')\n x_description = key('bio')\n x_extra_info_drop = drop_keys(lambda k: k.endswith('_url'))\n\n # Repo info extractors\n x_repo_id = key('id')\n x_repo_name = key('name')\n x_repo_slug = key('full_name')\n x_repo_description = key('description')\n x_repo_last_update = key('pushed_at')\n x_repo_is_fork = key('fork')\n x_repo_stars_count = key('stargazers_count')\n x_repo_owner_id = key('owner', clean=lambda d: d['id'])\n x_repo_extra_info_drop = drop_keys(lambda k: k.endswith('_url'))\n\n def get_CantReadMembership_url(self, **kw):\n return 'https://github.com/settings/connections/applications/'+self.api_key\n\n def is_team_member(self, org_name, sess, account):\n org_name = org_name.lower()\n\n # Check public membership first\n response = self.api_get(\n '', '/orgs/'+org_name+'/public_members/'+account.user_name,\n sess=sess, error_handler=None\n )\n if response.status_code == 204:\n return True\n elif response.status_code != 404:\n self.api_error_handler(response, True, self.domain)\n\n # Check private membership\n response = self.api_get(\n '', '/user/memberships/orgs/'+org_name, sess=sess, error_handler=None\n )\n if response.status_code == 403:\n raise CantReadMembership\n elif response.status_code >= 400:\n self.api_error_handler(response, True, self.domain)\n membership = self.api_parser(response)\n if membership['state'] == 'active':\n return True\n\n # Try the endpoint we were using before\n user_orgs = self.api_parser(self.api_get('', '/user/orgs', sess=sess))\n return any(org.get('login') == org_name for org in user_orgs)\n", "path": "liberapay/elsewhere/github.py"}]}
| 1,703 | 123 |
gh_patches_debug_17032
|
rasdani/github-patches
|
git_diff
|
e-valuation__EvaP-1661
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Wrong grade document edit form title
When editing a grade document that holds final grades, the title of the form wrongly shows "Upload midterm grades" (should be "Upload final grades" instead) because the parameter `final_grades` is not correctly set for the template.
This can for example be seen at the course "Operating Systems I (Summer term 2014)" in the test data.
</issue>
<code>
[start of evap/grades/views.py]
1 from django.conf import settings
2 from django.contrib import messages
3 from django.core.exceptions import PermissionDenied
4 from django.http import HttpResponse
5 from django.shortcuts import get_object_or_404, redirect, render
6 from django.utils.translation import gettext as _
7 from django.views.decorators.http import require_GET, require_POST
8 from django_sendfile import sendfile
9
10 from evap.evaluation.auth import (
11 grade_downloader_required,
12 grade_publisher_or_manager_required,
13 grade_publisher_required,
14 )
15 from evap.evaluation.models import Course, EmailTemplate, Evaluation, Semester
16 from evap.grades.forms import GradeDocumentForm
17 from evap.grades.models import GradeDocument
18
19
20 @grade_publisher_required
21 def index(request):
22 template_data = dict(
23 semesters=Semester.objects.filter(grade_documents_are_deleted=False),
24 disable_breadcrumb_grades=True,
25 )
26 return render(request, "grades_index.html", template_data)
27
28
29 def prefetch_data(courses):
30 courses = courses.prefetch_related("degrees", "responsibles")
31
32 course_data = []
33 for course in courses:
34 course_data.append((course, course.midterm_grade_documents.count(), course.final_grade_documents.count()))
35
36 return course_data
37
38
39 @grade_publisher_required
40 def semester_view(request, semester_id):
41 semester = get_object_or_404(Semester, id=semester_id)
42 if semester.grade_documents_are_deleted:
43 raise PermissionDenied
44
45 courses = (
46 semester.courses.filter(evaluations__wait_for_grade_upload_before_publishing=True)
47 .exclude(evaluations__state=Evaluation.State.NEW)
48 .distinct()
49 )
50 courses = prefetch_data(courses)
51
52 template_data = dict(
53 semester=semester,
54 courses=courses,
55 disable_if_archived="disabled" if semester.grade_documents_are_deleted else "",
56 disable_breadcrumb_semester=True,
57 )
58 return render(request, "grades_semester_view.html", template_data)
59
60
61 @grade_publisher_or_manager_required
62 def course_view(request, semester_id, course_id):
63 semester = get_object_or_404(Semester, id=semester_id)
64 if semester.grade_documents_are_deleted:
65 raise PermissionDenied
66 course = get_object_or_404(Course, id=course_id, semester=semester)
67
68 template_data = dict(
69 semester=semester,
70 course=course,
71 grade_documents=course.grade_documents.all(),
72 disable_if_archived="disabled" if semester.grade_documents_are_deleted else "",
73 disable_breadcrumb_course=True,
74 )
75 return render(request, "grades_course_view.html", template_data)
76
77
78 def on_grading_process_finished(course):
79 evaluations = course.evaluations.all()
80 if all(evaluation.state == Evaluation.State.REVIEWED for evaluation in evaluations):
81 for evaluation in evaluations:
82 assert evaluation.grading_process_is_finished
83 for evaluation in evaluations:
84 evaluation.publish()
85 evaluation.save()
86
87 EmailTemplate.send_participant_publish_notifications(evaluations)
88 EmailTemplate.send_contributor_publish_notifications(evaluations)
89
90
91 @grade_publisher_required
92 def upload_grades(request, semester_id, course_id):
93 semester = get_object_or_404(Semester, id=semester_id)
94 if semester.grade_documents_are_deleted:
95 raise PermissionDenied
96 course = get_object_or_404(Course, id=course_id, semester=semester)
97
98 final_grades = request.GET.get("final") == "true" # if parameter is not given, assume midterm grades
99
100 grade_document = GradeDocument(course=course)
101 if final_grades:
102 grade_document.type = GradeDocument.Type.FINAL_GRADES
103 grade_document.description_en = settings.DEFAULT_FINAL_GRADES_DESCRIPTION_EN
104 grade_document.description_de = settings.DEFAULT_FINAL_GRADES_DESCRIPTION_DE
105 else:
106 grade_document.type = GradeDocument.Type.MIDTERM_GRADES
107 grade_document.description_en = settings.DEFAULT_MIDTERM_GRADES_DESCRIPTION_EN
108 grade_document.description_de = settings.DEFAULT_MIDTERM_GRADES_DESCRIPTION_DE
109
110 form = GradeDocumentForm(request.POST or None, request.FILES or None, instance=grade_document)
111
112 if form.is_valid():
113 form.save(modifying_user=request.user)
114
115 if final_grades:
116 on_grading_process_finished(course)
117
118 messages.success(request, _("Successfully uploaded grades."))
119 return redirect("grades:course_view", semester.id, course.id)
120
121 template_data = dict(
122 semester=semester,
123 course=course,
124 form=form,
125 final_grades=final_grades,
126 show_automated_publishing_info=final_grades,
127 )
128 return render(request, "grades_upload_form.html", template_data)
129
130
131 @require_POST
132 @grade_publisher_required
133 def toggle_no_grades(request):
134 course_id = request.POST.get("course_id")
135 course = get_object_or_404(Course, id=course_id)
136 if course.semester.grade_documents_are_deleted:
137 raise PermissionDenied
138
139 course.gets_no_grade_documents = not course.gets_no_grade_documents
140 course.save()
141
142 if course.gets_no_grade_documents:
143 on_grading_process_finished(course)
144
145 return HttpResponse() # 200 OK
146
147
148 @require_GET
149 @grade_downloader_required
150 def download_grades(request, grade_document_id):
151 grade_document = get_object_or_404(GradeDocument, id=grade_document_id)
152 if grade_document.course.semester.grade_documents_are_deleted:
153 raise PermissionDenied
154
155 return sendfile(request, grade_document.file.path, attachment=True, attachment_filename=grade_document.filename())
156
157
158 @grade_publisher_required
159 def edit_grades(request, semester_id, course_id, grade_document_id):
160 semester = get_object_or_404(Semester, id=semester_id)
161 if semester.grade_documents_are_deleted:
162 raise PermissionDenied
163 course = get_object_or_404(Course, id=course_id, semester=semester)
164 grade_document = get_object_or_404(GradeDocument, id=grade_document_id, course=course)
165
166 form = GradeDocumentForm(request.POST or None, request.FILES or None, instance=grade_document)
167
168 if form.is_valid():
169 form.save(modifying_user=request.user)
170 messages.success(request, _("Successfully updated grades."))
171 return redirect("grades:course_view", semester.id, course.id)
172
173 template_data = dict(
174 semester=semester,
175 course=course,
176 form=form,
177 show_automated_publishing_info=False,
178 )
179 return render(request, "grades_upload_form.html", template_data)
180
181
182 @require_POST
183 @grade_publisher_required
184 def delete_grades(request):
185 grade_document_id = request.POST.get("grade_document_id")
186 grade_document = get_object_or_404(GradeDocument, id=grade_document_id)
187
188 grade_document.delete()
189 return HttpResponse() # 200 OK
190
[end of evap/grades/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/evap/grades/views.py b/evap/grades/views.py
--- a/evap/grades/views.py
+++ b/evap/grades/views.py
@@ -165,6 +165,10 @@
form = GradeDocumentForm(request.POST or None, request.FILES or None, instance=grade_document)
+ final_grades = (
+ grade_document.type == GradeDocument.Type.FINAL_GRADES
+ ) # if parameter is not given, assume midterm grades
+
if form.is_valid():
form.save(modifying_user=request.user)
messages.success(request, _("Successfully updated grades."))
@@ -175,6 +179,7 @@
course=course,
form=form,
show_automated_publishing_info=False,
+ final_grades=final_grades,
)
return render(request, "grades_upload_form.html", template_data)
|
{"golden_diff": "diff --git a/evap/grades/views.py b/evap/grades/views.py\n--- a/evap/grades/views.py\n+++ b/evap/grades/views.py\n@@ -165,6 +165,10 @@\n \n form = GradeDocumentForm(request.POST or None, request.FILES or None, instance=grade_document)\n \n+ final_grades = (\n+ grade_document.type == GradeDocument.Type.FINAL_GRADES\n+ ) # if parameter is not given, assume midterm grades\n+\n if form.is_valid():\n form.save(modifying_user=request.user)\n messages.success(request, _(\"Successfully updated grades.\"))\n@@ -175,6 +179,7 @@\n course=course,\n form=form,\n show_automated_publishing_info=False,\n+ final_grades=final_grades,\n )\n return render(request, \"grades_upload_form.html\", template_data)\n", "issue": "Wrong grade document edit form title\nWhen editing a grade document that holds final grades, the title of the form wrongly shows \"Upload midterm grades\" (should be \"Upload final grades\" instead) because the parameter `final_grades` is not correctly set for the template.\r\nThis can for example be seen at the course \"Operating Systems I (Summer term 2014)\" in the test data.\n", "before_files": [{"content": "from django.conf import settings\nfrom django.contrib import messages\nfrom django.core.exceptions import PermissionDenied\nfrom django.http import HttpResponse\nfrom django.shortcuts import get_object_or_404, redirect, render\nfrom django.utils.translation import gettext as _\nfrom django.views.decorators.http import require_GET, require_POST\nfrom django_sendfile import sendfile\n\nfrom evap.evaluation.auth import (\n grade_downloader_required,\n grade_publisher_or_manager_required,\n grade_publisher_required,\n)\nfrom evap.evaluation.models import Course, EmailTemplate, Evaluation, Semester\nfrom evap.grades.forms import GradeDocumentForm\nfrom evap.grades.models import GradeDocument\n\n\n@grade_publisher_required\ndef index(request):\n template_data = dict(\n semesters=Semester.objects.filter(grade_documents_are_deleted=False),\n disable_breadcrumb_grades=True,\n )\n return render(request, \"grades_index.html\", template_data)\n\n\ndef prefetch_data(courses):\n courses = courses.prefetch_related(\"degrees\", \"responsibles\")\n\n course_data = []\n for course in courses:\n course_data.append((course, course.midterm_grade_documents.count(), course.final_grade_documents.count()))\n\n return course_data\n\n\n@grade_publisher_required\ndef semester_view(request, semester_id):\n semester = get_object_or_404(Semester, id=semester_id)\n if semester.grade_documents_are_deleted:\n raise PermissionDenied\n\n courses = (\n semester.courses.filter(evaluations__wait_for_grade_upload_before_publishing=True)\n .exclude(evaluations__state=Evaluation.State.NEW)\n .distinct()\n )\n courses = prefetch_data(courses)\n\n template_data = dict(\n semester=semester,\n courses=courses,\n disable_if_archived=\"disabled\" if semester.grade_documents_are_deleted else \"\",\n disable_breadcrumb_semester=True,\n )\n return render(request, \"grades_semester_view.html\", template_data)\n\n\n@grade_publisher_or_manager_required\ndef course_view(request, semester_id, course_id):\n semester = get_object_or_404(Semester, id=semester_id)\n if semester.grade_documents_are_deleted:\n raise PermissionDenied\n course = get_object_or_404(Course, id=course_id, semester=semester)\n\n template_data = dict(\n semester=semester,\n course=course,\n grade_documents=course.grade_documents.all(),\n disable_if_archived=\"disabled\" if semester.grade_documents_are_deleted else \"\",\n disable_breadcrumb_course=True,\n )\n return render(request, \"grades_course_view.html\", template_data)\n\n\ndef on_grading_process_finished(course):\n evaluations = course.evaluations.all()\n if all(evaluation.state == Evaluation.State.REVIEWED for evaluation in evaluations):\n for evaluation in evaluations:\n assert evaluation.grading_process_is_finished\n for evaluation in evaluations:\n evaluation.publish()\n evaluation.save()\n\n EmailTemplate.send_participant_publish_notifications(evaluations)\n EmailTemplate.send_contributor_publish_notifications(evaluations)\n\n\n@grade_publisher_required\ndef upload_grades(request, semester_id, course_id):\n semester = get_object_or_404(Semester, id=semester_id)\n if semester.grade_documents_are_deleted:\n raise PermissionDenied\n course = get_object_or_404(Course, id=course_id, semester=semester)\n\n final_grades = request.GET.get(\"final\") == \"true\" # if parameter is not given, assume midterm grades\n\n grade_document = GradeDocument(course=course)\n if final_grades:\n grade_document.type = GradeDocument.Type.FINAL_GRADES\n grade_document.description_en = settings.DEFAULT_FINAL_GRADES_DESCRIPTION_EN\n grade_document.description_de = settings.DEFAULT_FINAL_GRADES_DESCRIPTION_DE\n else:\n grade_document.type = GradeDocument.Type.MIDTERM_GRADES\n grade_document.description_en = settings.DEFAULT_MIDTERM_GRADES_DESCRIPTION_EN\n grade_document.description_de = settings.DEFAULT_MIDTERM_GRADES_DESCRIPTION_DE\n\n form = GradeDocumentForm(request.POST or None, request.FILES or None, instance=grade_document)\n\n if form.is_valid():\n form.save(modifying_user=request.user)\n\n if final_grades:\n on_grading_process_finished(course)\n\n messages.success(request, _(\"Successfully uploaded grades.\"))\n return redirect(\"grades:course_view\", semester.id, course.id)\n\n template_data = dict(\n semester=semester,\n course=course,\n form=form,\n final_grades=final_grades,\n show_automated_publishing_info=final_grades,\n )\n return render(request, \"grades_upload_form.html\", template_data)\n\n\n@require_POST\n@grade_publisher_required\ndef toggle_no_grades(request):\n course_id = request.POST.get(\"course_id\")\n course = get_object_or_404(Course, id=course_id)\n if course.semester.grade_documents_are_deleted:\n raise PermissionDenied\n\n course.gets_no_grade_documents = not course.gets_no_grade_documents\n course.save()\n\n if course.gets_no_grade_documents:\n on_grading_process_finished(course)\n\n return HttpResponse() # 200 OK\n\n\n@require_GET\n@grade_downloader_required\ndef download_grades(request, grade_document_id):\n grade_document = get_object_or_404(GradeDocument, id=grade_document_id)\n if grade_document.course.semester.grade_documents_are_deleted:\n raise PermissionDenied\n\n return sendfile(request, grade_document.file.path, attachment=True, attachment_filename=grade_document.filename())\n\n\n@grade_publisher_required\ndef edit_grades(request, semester_id, course_id, grade_document_id):\n semester = get_object_or_404(Semester, id=semester_id)\n if semester.grade_documents_are_deleted:\n raise PermissionDenied\n course = get_object_or_404(Course, id=course_id, semester=semester)\n grade_document = get_object_or_404(GradeDocument, id=grade_document_id, course=course)\n\n form = GradeDocumentForm(request.POST or None, request.FILES or None, instance=grade_document)\n\n if form.is_valid():\n form.save(modifying_user=request.user)\n messages.success(request, _(\"Successfully updated grades.\"))\n return redirect(\"grades:course_view\", semester.id, course.id)\n\n template_data = dict(\n semester=semester,\n course=course,\n form=form,\n show_automated_publishing_info=False,\n )\n return render(request, \"grades_upload_form.html\", template_data)\n\n\n@require_POST\n@grade_publisher_required\ndef delete_grades(request):\n grade_document_id = request.POST.get(\"grade_document_id\")\n grade_document = get_object_or_404(GradeDocument, id=grade_document_id)\n\n grade_document.delete()\n return HttpResponse() # 200 OK\n", "path": "evap/grades/views.py"}]}
| 2,540 | 200 |
gh_patches_debug_18121
|
rasdani/github-patches
|
git_diff
|
numba__numba-7733
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Compiler not found: /tmp/tmp bug
```
$ pip install numba
Collecting numba
Downloading numba-0.53.1-cp39-cp39-manylinux2014_x86_64.whl (3.4 MB)
|████████████████████████████████| 3.4 MB 1.2 MB/s
Collecting numpy>=1.15
Downloading numpy-1.21.0-cp39-cp39-manylinux_2_12_x86_64.manylinux2010_x86_64.whl (15.7 MB)
|████████████████████████████████| 15.7 MB 1.1 MB/s
Requirement already satisfied: setuptools in /usr/lib/python3/dist-packages (from numba) (52.0.0)
Collecting llvmlite<0.37,>=0.36.0rc1
Downloading llvmlite-0.36.0-cp39-cp39-manylinux2010_x86_64.whl (25.3 MB)
|████████████████████████████████| 25.3 MB 829 kB/s
Installing collected packages: numpy, llvmlite, numba
WARNING: The scripts f2py, f2py3 and f2py3.9 are installed in '/home/olaf/.local/bin' which is not on PATH.
Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location.
Successfully installed llvmlite-0.36.0 numba-0.53.1 numpy-1.21.0
$ ./t.py
$ ./t.py
$ chmod 000 /tmp/tmp
$ ./t.py
Traceback (most recent call last):
File "/home/olaf/./t.py", line 5, in <module>
cc = CC('interpolation')
File "/home/olaf/.local/lib/python3.9/site-packages/numba/pycc/cc.py", line 65, in __init__
self._toolchain = Toolchain()
File "/home/olaf/.local/lib/python3.9/site-packages/numba/pycc/platform.py", line 78, in __init__
self._raise_external_compiler_error()
File "/home/olaf/.local/lib/python3.9/site-packages/numba/pycc/platform.py", line 121, in _raise_external_compiler_error
raise RuntimeError(msg)
RuntimeError: Attempted to compile AOT function without the compiler used by `numpy.distutils` present. If using conda try:
#> conda install gcc_linux-64 gxx_linux-64
$ cat t.py
#!/usr/bin/python3
from numba.pycc import CC
cc = CC('interpolation')
# cc.compile()
$ pip list|grep numba
numba 0.53.1
```
</issue>
<code>
[start of numba/pycc/platform.py]
1 from distutils.ccompiler import CCompiler, new_compiler
2 from distutils.command.build_ext import build_ext
3 from distutils.sysconfig import customize_compiler
4 from distutils import log
5
6 import numpy.distutils.misc_util as np_misc
7
8 import functools
9 import os
10 import subprocess
11 import sys
12 from tempfile import NamedTemporaryFile, mkdtemp, gettempdir
13 from contextlib import contextmanager
14
15 _configs = {
16 # DLL suffix, Python C extension suffix
17 'win': ('.dll', '.pyd'),
18 'default': ('.so', '.so'),
19 }
20
21
22 def get_configs(arg):
23 return _configs.get(sys.platform[:3], _configs['default'])[arg]
24
25
26 find_shared_ending = functools.partial(get_configs, 0)
27 find_pyext_ending = functools.partial(get_configs, 1)
28
29 @contextmanager
30 def _gentmpfile(suffix):
31 # windows locks the tempfile so use a tempdir + file, see
32 # https://github.com/numba/numba/issues/3304
33 try:
34 tmpdir = mkdtemp()
35 ntf = open(os.path.join(tmpdir, "temp%s" % suffix), 'wt')
36 yield ntf
37 finally:
38 try:
39 ntf.close()
40 os.remove(ntf)
41 except:
42 pass
43 else:
44 os.rmdir(tmpdir)
45
46 def _check_external_compiler():
47 # see if the external compiler bound in numpy.distutil is present
48 # and working
49 compiler = new_compiler()
50 customize_compiler(compiler)
51 for suffix in ['.c', '.cxx']:
52 try:
53 with _gentmpfile(suffix) as ntf:
54 simple_c = "int main(void) { return 0; }"
55 ntf.write(simple_c)
56 ntf.flush()
57 ntf.close()
58 # *output_dir* is set to avoid the compiler putting temp files
59 # in the current directory.
60 compiler.compile([ntf.name], output_dir=gettempdir())
61 except Exception: # likely CompileError or file system issue
62 return False
63 return True
64
65 # boolean on whether the externally provided compiler is present and
66 # functioning correctly
67 _external_compiler_ok = _check_external_compiler()
68
69
70 class _DummyExtension(object):
71 libraries = []
72
73
74 class Toolchain(object):
75
76 def __init__(self):
77 if not _external_compiler_ok:
78 self._raise_external_compiler_error()
79
80 # Need to import it here since setuptools may monkeypatch it
81 from distutils.dist import Distribution
82 self._verbose = False
83 self._compiler = new_compiler()
84 customize_compiler(self._compiler)
85 self._build_ext = build_ext(Distribution())
86 self._build_ext.finalize_options()
87 self._py_lib_dirs = self._build_ext.library_dirs
88 self._py_include_dirs = self._build_ext.include_dirs
89 self._math_info = np_misc.get_info('npymath')
90
91 @property
92 def verbose(self):
93 return self._verbose
94
95 @verbose.setter
96 def verbose(self, value):
97 self._verbose = value
98 # DEBUG will let Numpy spew many messages, so stick to INFO
99 # to print commands executed by distutils
100 log.set_threshold(log.INFO if value else log.WARN)
101
102 def _raise_external_compiler_error(self):
103 basemsg = ("Attempted to compile AOT function without the "
104 "compiler used by `numpy.distutils` present.")
105 conda_msg = "If using conda try:\n\n#> conda install %s"
106 plt = sys.platform
107 if plt.startswith('linux'):
108 if sys.maxsize <= 2 ** 32:
109 compilers = ['gcc_linux-32', 'gxx_linux-32']
110 else:
111 compilers = ['gcc_linux-64', 'gxx_linux-64']
112 msg = "%s %s" % (basemsg, conda_msg % ' '.join(compilers))
113 elif plt.startswith('darwin'):
114 compilers = ['clang_osx-64', 'clangxx_osx-64']
115 msg = "%s %s" % (basemsg, conda_msg % ' '.join(compilers))
116 elif plt.startswith('win32'):
117 winmsg = "Cannot find suitable msvc."
118 msg = "%s %s" % (basemsg, winmsg)
119 else:
120 msg = "Unknown platform %s" % plt
121 raise RuntimeError(msg)
122
123 def compile_objects(self, sources, output_dir,
124 include_dirs=(), depends=(), macros=(),
125 extra_cflags=None):
126 """
127 Compile the given source files into a separate object file each,
128 all beneath the *output_dir*. A list of paths to object files
129 is returned.
130
131 *macros* has the same format as in distutils: a list of 1- or 2-tuples.
132 If a 1-tuple (name,), the given name is considered undefined by
133 the C preprocessor.
134 If a 2-tuple (name, value), the given name is expanded into the
135 given value by the C preprocessor.
136 """
137 objects = self._compiler.compile(sources,
138 output_dir=output_dir,
139 include_dirs=include_dirs,
140 depends=depends,
141 macros=macros or [],
142 extra_preargs=extra_cflags)
143 return objects
144
145 def link_shared(self, output, objects, libraries=(),
146 library_dirs=(), export_symbols=(),
147 extra_ldflags=None):
148 """
149 Create a shared library *output* linking the given *objects*
150 and *libraries* (all strings).
151 """
152 output_dir, output_filename = os.path.split(output)
153 self._compiler.link(CCompiler.SHARED_OBJECT, objects,
154 output_filename, output_dir,
155 libraries, library_dirs,
156 export_symbols=export_symbols,
157 extra_preargs=extra_ldflags)
158
159 def get_python_libraries(self):
160 """
161 Get the library arguments necessary to link with Python.
162 """
163 libs = self._build_ext.get_libraries(_DummyExtension())
164 if sys.platform == 'win32':
165 # Under Windows, need to link explicitly against the CRT,
166 # as the MSVC compiler would implicitly do.
167 # (XXX msvcrtd in pydebug mode?)
168 libs = libs + ['msvcrt']
169 return libs + self._math_info['libraries']
170
171 def get_python_library_dirs(self):
172 """
173 Get the library directories necessary to link with Python.
174 """
175 return list(self._py_lib_dirs) + self._math_info['library_dirs']
176
177 def get_python_include_dirs(self):
178 """
179 Get the include directories necessary to compile against the Python
180 and Numpy C APIs.
181 """
182 return list(self._py_include_dirs) + self._math_info['include_dirs']
183
184 def get_ext_filename(self, ext_name):
185 """
186 Given a C extension's module name, return its intended filename.
187 """
188 return self._build_ext.get_ext_filename(ext_name)
189
190
191 #
192 # Patch Numpy's exec_command() to avoid random crashes on Windows in test_pycc
193 # see https://github.com/numpy/numpy/pull/7614
194 # and https://github.com/numpy/numpy/pull/7862
195 #
196
197 def _patch_exec_command():
198 # Patch the internal worker _exec_command()
199 import numpy.distutils.exec_command as mod
200 orig_exec_command = mod._exec_command
201 mod._exec_command = _exec_command
202
203
204 def _exec_command(command, use_shell=None, use_tee=None, **env):
205 """
206 Internal workhorse for exec_command().
207 Code from https://github.com/numpy/numpy/pull/7862
208 """
209 if use_shell is None:
210 use_shell = os.name == 'posix'
211 if use_tee is None:
212 use_tee = os.name == 'posix'
213
214 executable = None
215
216 if os.name == 'posix' and use_shell:
217 # On POSIX, subprocess always uses /bin/sh, override
218 sh = os.environ.get('SHELL', '/bin/sh')
219 if _is_sequence(command):
220 command = [sh, '-c', ' '.join(command)]
221 else:
222 command = [sh, '-c', command]
223 use_shell = False
224
225 elif os.name == 'nt' and _is_sequence(command):
226 # On Windows, join the string for CreateProcess() ourselves as
227 # subprocess does it a bit differently
228 command = ' '.join(_quote_arg(arg) for arg in command)
229
230 # Inherit environment by default
231 env = env or None
232 try:
233 proc = subprocess.Popen(command, shell=use_shell, env=env,
234 stdout=subprocess.PIPE,
235 stderr=subprocess.PIPE,
236 universal_newlines=True)
237 except OSError:
238 # Return 127, as os.spawn*() and /bin/sh do
239 return '', 127
240 text, err = proc.communicate()
241 # Only append stderr if the command failed, as otherwise
242 # the output may become garbled for parsing
243 if proc.returncode:
244 if text:
245 text += "\n"
246 text += err
247 # Another historical oddity
248 if text[-1:] == '\n':
249 text = text[:-1]
250 if use_tee:
251 print(text)
252 return proc.returncode, text
253
254
255 def _quote_arg(arg):
256 """
257 Quote the argument for safe use in a shell command line.
258 """
259 # If there is a quote in the string, assume relevants parts of the
260 # string are already quoted (e.g. '-I"C:\\Program Files\\..."')
261 if '"' not in arg and ' ' in arg:
262 return '"%s"' % arg
263 return arg
264
265
266 def _is_sequence(arg):
267 if isinstance(arg, (str, bytes)):
268 return False
269 try:
270 len(arg)
271 return True
272 except Exception:
273 return False
274
[end of numba/pycc/platform.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/numba/pycc/platform.py b/numba/pycc/platform.py
--- a/numba/pycc/platform.py
+++ b/numba/pycc/platform.py
@@ -9,8 +9,9 @@
import os
import subprocess
import sys
-from tempfile import NamedTemporaryFile, mkdtemp, gettempdir
+from tempfile import mkdtemp
from contextlib import contextmanager
+from pathlib import Path
_configs = {
# DLL suffix, Python C extension suffix
@@ -57,7 +58,7 @@
ntf.close()
# *output_dir* is set to avoid the compiler putting temp files
# in the current directory.
- compiler.compile([ntf.name], output_dir=gettempdir())
+ compiler.compile([ntf.name], output_dir=Path(ntf.name).anchor)
except Exception: # likely CompileError or file system issue
return False
return True
|
{"golden_diff": "diff --git a/numba/pycc/platform.py b/numba/pycc/platform.py\n--- a/numba/pycc/platform.py\n+++ b/numba/pycc/platform.py\n@@ -9,8 +9,9 @@\n import os\n import subprocess\n import sys\n-from tempfile import NamedTemporaryFile, mkdtemp, gettempdir\n+from tempfile import mkdtemp\n from contextlib import contextmanager\n+from pathlib import Path\n \n _configs = {\n # DLL suffix, Python C extension suffix\n@@ -57,7 +58,7 @@\n ntf.close()\n # *output_dir* is set to avoid the compiler putting temp files\n # in the current directory.\n- compiler.compile([ntf.name], output_dir=gettempdir())\n+ compiler.compile([ntf.name], output_dir=Path(ntf.name).anchor)\n except Exception: # likely CompileError or file system issue\n return False\n return True\n", "issue": "Compiler not found: /tmp/tmp bug\n\r\n\r\n```\r\n$ pip install numba\r\nCollecting numba\r\n Downloading numba-0.53.1-cp39-cp39-manylinux2014_x86_64.whl (3.4 MB)\r\n |\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588| 3.4 MB 1.2 MB/s \r\nCollecting numpy>=1.15\r\n Downloading numpy-1.21.0-cp39-cp39-manylinux_2_12_x86_64.manylinux2010_x86_64.whl (15.7 MB)\r\n |\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588| 15.7 MB 1.1 MB/s \r\nRequirement already satisfied: setuptools in /usr/lib/python3/dist-packages (from numba) (52.0.0)\r\nCollecting llvmlite<0.37,>=0.36.0rc1\r\n Downloading llvmlite-0.36.0-cp39-cp39-manylinux2010_x86_64.whl (25.3 MB)\r\n |\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588\u2588| 25.3 MB 829 kB/s \r\nInstalling collected packages: numpy, llvmlite, numba\r\n WARNING: The scripts f2py, f2py3 and f2py3.9 are installed in '/home/olaf/.local/bin' which is not on PATH.\r\n Consider adding this directory to PATH or, if you prefer to suppress this warning, use --no-warn-script-location.\r\nSuccessfully installed llvmlite-0.36.0 numba-0.53.1 numpy-1.21.0\r\n\r\n$ ./t.py \r\n \r\n$ ./t.py \r\n\r\n$ chmod 000 /tmp/tmp\r\n\r\n$ ./t.py \r\nTraceback (most recent call last):\r\n File \"/home/olaf/./t.py\", line 5, in <module>\r\n cc = CC('interpolation')\r\n File \"/home/olaf/.local/lib/python3.9/site-packages/numba/pycc/cc.py\", line 65, in __init__\r\n self._toolchain = Toolchain()\r\n File \"/home/olaf/.local/lib/python3.9/site-packages/numba/pycc/platform.py\", line 78, in __init__\r\n self._raise_external_compiler_error()\r\n File \"/home/olaf/.local/lib/python3.9/site-packages/numba/pycc/platform.py\", line 121, in _raise_external_compiler_error\r\n raise RuntimeError(msg)\r\nRuntimeError: Attempted to compile AOT function without the compiler used by `numpy.distutils` present. If using conda try:\r\n\r\n#> conda install gcc_linux-64 gxx_linux-64\r\n\r\n$ cat t.py \r\n#!/usr/bin/python3\r\n\r\nfrom numba.pycc import CC\r\n\r\ncc = CC('interpolation')\r\n\r\n# cc.compile()\r\n\r\n$ pip list|grep numba\r\nnumba 0.53.1\r\n```\n", "before_files": [{"content": "from distutils.ccompiler import CCompiler, new_compiler\nfrom distutils.command.build_ext import build_ext\nfrom distutils.sysconfig import customize_compiler\nfrom distutils import log\n\nimport numpy.distutils.misc_util as np_misc\n\nimport functools\nimport os\nimport subprocess\nimport sys\nfrom tempfile import NamedTemporaryFile, mkdtemp, gettempdir\nfrom contextlib import contextmanager\n\n_configs = {\n # DLL suffix, Python C extension suffix\n 'win': ('.dll', '.pyd'),\n 'default': ('.so', '.so'),\n}\n\n\ndef get_configs(arg):\n return _configs.get(sys.platform[:3], _configs['default'])[arg]\n\n\nfind_shared_ending = functools.partial(get_configs, 0)\nfind_pyext_ending = functools.partial(get_configs, 1)\n\n@contextmanager\ndef _gentmpfile(suffix):\n # windows locks the tempfile so use a tempdir + file, see\n # https://github.com/numba/numba/issues/3304\n try:\n tmpdir = mkdtemp()\n ntf = open(os.path.join(tmpdir, \"temp%s\" % suffix), 'wt')\n yield ntf\n finally:\n try:\n ntf.close()\n os.remove(ntf)\n except:\n pass\n else:\n os.rmdir(tmpdir)\n\ndef _check_external_compiler():\n # see if the external compiler bound in numpy.distutil is present\n # and working\n compiler = new_compiler()\n customize_compiler(compiler)\n for suffix in ['.c', '.cxx']:\n try:\n with _gentmpfile(suffix) as ntf:\n simple_c = \"int main(void) { return 0; }\"\n ntf.write(simple_c)\n ntf.flush()\n ntf.close()\n # *output_dir* is set to avoid the compiler putting temp files\n # in the current directory.\n compiler.compile([ntf.name], output_dir=gettempdir())\n except Exception: # likely CompileError or file system issue\n return False\n return True\n\n# boolean on whether the externally provided compiler is present and\n# functioning correctly\n_external_compiler_ok = _check_external_compiler()\n\n\nclass _DummyExtension(object):\n libraries = []\n\n\nclass Toolchain(object):\n\n def __init__(self):\n if not _external_compiler_ok:\n self._raise_external_compiler_error()\n\n # Need to import it here since setuptools may monkeypatch it\n from distutils.dist import Distribution\n self._verbose = False\n self._compiler = new_compiler()\n customize_compiler(self._compiler)\n self._build_ext = build_ext(Distribution())\n self._build_ext.finalize_options()\n self._py_lib_dirs = self._build_ext.library_dirs\n self._py_include_dirs = self._build_ext.include_dirs\n self._math_info = np_misc.get_info('npymath')\n\n @property\n def verbose(self):\n return self._verbose\n\n @verbose.setter\n def verbose(self, value):\n self._verbose = value\n # DEBUG will let Numpy spew many messages, so stick to INFO\n # to print commands executed by distutils\n log.set_threshold(log.INFO if value else log.WARN)\n\n def _raise_external_compiler_error(self):\n basemsg = (\"Attempted to compile AOT function without the \"\n \"compiler used by `numpy.distutils` present.\")\n conda_msg = \"If using conda try:\\n\\n#> conda install %s\"\n plt = sys.platform\n if plt.startswith('linux'):\n if sys.maxsize <= 2 ** 32:\n compilers = ['gcc_linux-32', 'gxx_linux-32']\n else:\n compilers = ['gcc_linux-64', 'gxx_linux-64']\n msg = \"%s %s\" % (basemsg, conda_msg % ' '.join(compilers))\n elif plt.startswith('darwin'):\n compilers = ['clang_osx-64', 'clangxx_osx-64']\n msg = \"%s %s\" % (basemsg, conda_msg % ' '.join(compilers))\n elif plt.startswith('win32'):\n winmsg = \"Cannot find suitable msvc.\"\n msg = \"%s %s\" % (basemsg, winmsg)\n else:\n msg = \"Unknown platform %s\" % plt\n raise RuntimeError(msg)\n\n def compile_objects(self, sources, output_dir,\n include_dirs=(), depends=(), macros=(),\n extra_cflags=None):\n \"\"\"\n Compile the given source files into a separate object file each,\n all beneath the *output_dir*. A list of paths to object files\n is returned.\n\n *macros* has the same format as in distutils: a list of 1- or 2-tuples.\n If a 1-tuple (name,), the given name is considered undefined by\n the C preprocessor.\n If a 2-tuple (name, value), the given name is expanded into the\n given value by the C preprocessor.\n \"\"\"\n objects = self._compiler.compile(sources,\n output_dir=output_dir,\n include_dirs=include_dirs,\n depends=depends,\n macros=macros or [],\n extra_preargs=extra_cflags)\n return objects\n\n def link_shared(self, output, objects, libraries=(),\n library_dirs=(), export_symbols=(),\n extra_ldflags=None):\n \"\"\"\n Create a shared library *output* linking the given *objects*\n and *libraries* (all strings).\n \"\"\"\n output_dir, output_filename = os.path.split(output)\n self._compiler.link(CCompiler.SHARED_OBJECT, objects,\n output_filename, output_dir,\n libraries, library_dirs,\n export_symbols=export_symbols,\n extra_preargs=extra_ldflags)\n\n def get_python_libraries(self):\n \"\"\"\n Get the library arguments necessary to link with Python.\n \"\"\"\n libs = self._build_ext.get_libraries(_DummyExtension())\n if sys.platform == 'win32':\n # Under Windows, need to link explicitly against the CRT,\n # as the MSVC compiler would implicitly do.\n # (XXX msvcrtd in pydebug mode?)\n libs = libs + ['msvcrt']\n return libs + self._math_info['libraries']\n\n def get_python_library_dirs(self):\n \"\"\"\n Get the library directories necessary to link with Python.\n \"\"\"\n return list(self._py_lib_dirs) + self._math_info['library_dirs']\n\n def get_python_include_dirs(self):\n \"\"\"\n Get the include directories necessary to compile against the Python\n and Numpy C APIs.\n \"\"\"\n return list(self._py_include_dirs) + self._math_info['include_dirs']\n\n def get_ext_filename(self, ext_name):\n \"\"\"\n Given a C extension's module name, return its intended filename.\n \"\"\"\n return self._build_ext.get_ext_filename(ext_name)\n\n\n#\n# Patch Numpy's exec_command() to avoid random crashes on Windows in test_pycc\n# see https://github.com/numpy/numpy/pull/7614\n# and https://github.com/numpy/numpy/pull/7862\n#\n\ndef _patch_exec_command():\n # Patch the internal worker _exec_command()\n import numpy.distutils.exec_command as mod\n orig_exec_command = mod._exec_command\n mod._exec_command = _exec_command\n\n\ndef _exec_command(command, use_shell=None, use_tee=None, **env):\n \"\"\"\n Internal workhorse for exec_command().\n Code from https://github.com/numpy/numpy/pull/7862\n \"\"\"\n if use_shell is None:\n use_shell = os.name == 'posix'\n if use_tee is None:\n use_tee = os.name == 'posix'\n\n executable = None\n\n if os.name == 'posix' and use_shell:\n # On POSIX, subprocess always uses /bin/sh, override\n sh = os.environ.get('SHELL', '/bin/sh')\n if _is_sequence(command):\n command = [sh, '-c', ' '.join(command)]\n else:\n command = [sh, '-c', command]\n use_shell = False\n\n elif os.name == 'nt' and _is_sequence(command):\n # On Windows, join the string for CreateProcess() ourselves as\n # subprocess does it a bit differently\n command = ' '.join(_quote_arg(arg) for arg in command)\n\n # Inherit environment by default\n env = env or None\n try:\n proc = subprocess.Popen(command, shell=use_shell, env=env,\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE,\n universal_newlines=True)\n except OSError:\n # Return 127, as os.spawn*() and /bin/sh do\n return '', 127\n text, err = proc.communicate()\n # Only append stderr if the command failed, as otherwise\n # the output may become garbled for parsing\n if proc.returncode:\n if text:\n text += \"\\n\"\n text += err\n # Another historical oddity\n if text[-1:] == '\\n':\n text = text[:-1]\n if use_tee:\n print(text)\n return proc.returncode, text\n\n\ndef _quote_arg(arg):\n \"\"\"\n Quote the argument for safe use in a shell command line.\n \"\"\"\n # If there is a quote in the string, assume relevants parts of the\n # string are already quoted (e.g. '-I\"C:\\\\Program Files\\\\...\"')\n if '\"' not in arg and ' ' in arg:\n return '\"%s\"' % arg\n return arg\n\n\ndef _is_sequence(arg):\n if isinstance(arg, (str, bytes)):\n return False\n try:\n len(arg)\n return True\n except Exception:\n return False\n", "path": "numba/pycc/platform.py"}]}
| 4,073 | 204 |
gh_patches_debug_7347
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-10645
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
🎛️ Migrate header search Stimulus Controller
> ℹ️ **Part of the [Stimulus 🎛️ RFC 78](https://github.com/wagtail/rfcs/pull/78)**
### Is your proposal related to a problem?
We have a core.js implementations of JavaScript code that, when a matching search input receives changes, will trigger an async request to the relevant search results listing. Once the endpoint returns with HTML, it will be patched into the results container HTML element.
### Describe the solution you'd like
* Create a stimulus controller `w-search` that will replace the existing ad-hoc JS implementation
* The behaviour should be exactly the same as current state but using Stimulus data attributes for the behaviour & classes declaration (note: likely we will drop the `autofocus` and may not re-introduce the `slide` jQuery animation)
* Controller should be written in TypeScript
* Ensure that the existing unit tests are created to reflect this new behaviour
* We will need to document an upgrade consideration that the previous `window.headerSearch` approach will not work in a future release.
* We may want to introduce a console warning once all the Wagtail usage of `window.headerSearch` has been removed
* Nice to have - a Storybook story for this component
### Additional context
* Implementation https://github.com/wagtail/wagtail/blob/main/client/src/entrypoints/admin/core.js#L251-L306
* There is a very similar (almost cut & paste) of logic that is used in the chooser modals for searching here https://github.com/wagtail/wagtail/blob/main/client/src/includes/chooserModal.js#L109-L176 (the Stimulus will likely replace this but may be out of scope for this issue
### Potential approach
#### Support `input` only usage (with using `window.headerSearch` config)
```JS
window.headerSearch = {
url: "{% url 'wagtailimages:listing_results' %}",
targetOutput: "#image-results"
}
```
```html
<div class="w-field__input" data-field-input="">
<svg class="icon icon-search w-field__icon" aria-hidden="true">
<use href="#icon-search"></use>
</svg>
<input
type="text"
name="q"
placeholder="Search images"
data-controller="w-search"
data-action="change->w-search#search cut->w-search#search keyup->w-search#search paste->w-search#search"
id="id_q"
/>
</div>
```
#### Support `input` only usage
```html
<div class="w-field__input" data-field-input="">
<svg class="icon icon-search w-field__icon" aria-hidden="true">
<use href="#icon-search"></use>
</svg>
<input
type="text"
name="q"
placeholder="Search images"
data-controller="w-search"
data-action="change->w-search#search cut->w-search#search keyup->w-search#search paste->w-search#search"
id="id_q"
data-w-search-results-value="#image-results"
data-w-search-url-value="/admin/images/results/"
/>
</div>
```
#### Support controlled form with search input as a target
```html
<form
class="col search-form"
action="/admin/images/"
method="get"
novalidate=""
role="search"
data-controller="w-search"
data-w-search-url-value="/admin/images/results/"
>
<div class="w-field__wrapper w-mb-0" data-field-wrapper="">
<label class="w-field__label w-sr-only" for="id_q" id="id_q-label">Search term</label>
<div class="w-field w-field--char_field w-field--text_input">
<div class="w-field__input" data-field-input="">
<svg class="icon icon-search w-field__icon" aria-hidden="true"><use href="#icon-search"></use></svg>
<input
type="text"
name="q"
placeholder="Search images"
data-w-search-target="input"
data-action="change->w-search#search cut->w-search#search keyup->w-search#search paste->w-search#search"
id="id_q"
/>
</div>
</div>
</div>
<div class="visuallyhidden"><input disabled="" type="submit" aria-hidden="true" /></div>
</form>
```
</issue>
<code>
[start of wagtail/admin/forms/search.py]
1 from django import forms
2 from django.utils.translation import gettext as _
3 from django.utils.translation import gettext_lazy
4
5
6 class SearchForm(forms.Form):
7 def __init__(self, *args, **kwargs):
8 placeholder = kwargs.pop("placeholder", _("Search"))
9 super().__init__(*args, **kwargs)
10 self.fields["q"].widget.attrs = {"placeholder": placeholder}
11
12 q = forms.CharField(
13 label=gettext_lazy("Search term"),
14 widget=forms.TextInput(),
15 required=False,
16 )
17
[end of wagtail/admin/forms/search.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/wagtail/admin/forms/search.py b/wagtail/admin/forms/search.py
--- a/wagtail/admin/forms/search.py
+++ b/wagtail/admin/forms/search.py
@@ -7,7 +7,10 @@
def __init__(self, *args, **kwargs):
placeholder = kwargs.pop("placeholder", _("Search"))
super().__init__(*args, **kwargs)
- self.fields["q"].widget.attrs = {"placeholder": placeholder}
+ self.fields["q"].widget.attrs = {
+ "placeholder": placeholder,
+ "data-w-swap-target": "input",
+ }
q = forms.CharField(
label=gettext_lazy("Search term"),
|
{"golden_diff": "diff --git a/wagtail/admin/forms/search.py b/wagtail/admin/forms/search.py\n--- a/wagtail/admin/forms/search.py\n+++ b/wagtail/admin/forms/search.py\n@@ -7,7 +7,10 @@\n def __init__(self, *args, **kwargs):\n placeholder = kwargs.pop(\"placeholder\", _(\"Search\"))\n super().__init__(*args, **kwargs)\n- self.fields[\"q\"].widget.attrs = {\"placeholder\": placeholder}\n+ self.fields[\"q\"].widget.attrs = {\n+ \"placeholder\": placeholder,\n+ \"data-w-swap-target\": \"input\",\n+ }\n \n q = forms.CharField(\n label=gettext_lazy(\"Search term\"),\n", "issue": "\ud83c\udf9b\ufe0f Migrate header search Stimulus Controller\n> \u2139\ufe0f **Part of the [Stimulus \ud83c\udf9b\ufe0f RFC 78](https://github.com/wagtail/rfcs/pull/78)**\r\n\r\n### Is your proposal related to a problem?\r\n\r\nWe have a core.js implementations of JavaScript code that, when a matching search input receives changes, will trigger an async request to the relevant search results listing. Once the endpoint returns with HTML, it will be patched into the results container HTML element.\r\n\r\n### Describe the solution you'd like\r\n\r\n* Create a stimulus controller `w-search` that will replace the existing ad-hoc JS implementation\r\n* The behaviour should be exactly the same as current state but using Stimulus data attributes for the behaviour & classes declaration (note: likely we will drop the `autofocus` and may not re-introduce the `slide` jQuery animation)\r\n* Controller should be written in TypeScript\r\n* Ensure that the existing unit tests are created to reflect this new behaviour\r\n* We will need to document an upgrade consideration that the previous `window.headerSearch` approach will not work in a future release.\r\n* We may want to introduce a console warning once all the Wagtail usage of `window.headerSearch` has been removed\r\n* Nice to have - a Storybook story for this component\r\n\r\n### Additional context\r\n\r\n* Implementation https://github.com/wagtail/wagtail/blob/main/client/src/entrypoints/admin/core.js#L251-L306\r\n* There is a very similar (almost cut & paste) of logic that is used in the chooser modals for searching here https://github.com/wagtail/wagtail/blob/main/client/src/includes/chooserModal.js#L109-L176 (the Stimulus will likely replace this but may be out of scope for this issue\r\n\r\n### Potential approach\r\n\r\n#### Support `input` only usage (with using `window.headerSearch` config)\r\n\r\n```JS\r\nwindow.headerSearch = {\r\n url: \"{% url 'wagtailimages:listing_results' %}\",\r\n targetOutput: \"#image-results\"\r\n}\r\n```\r\n\r\n```html\r\n<div class=\"w-field__input\" data-field-input=\"\">\r\n <svg class=\"icon icon-search w-field__icon\" aria-hidden=\"true\">\r\n <use href=\"#icon-search\"></use>\r\n </svg>\r\n <input\r\n type=\"text\"\r\n name=\"q\"\r\n placeholder=\"Search images\"\r\n data-controller=\"w-search\"\r\n data-action=\"change->w-search#search cut->w-search#search keyup->w-search#search paste->w-search#search\"\r\n id=\"id_q\"\r\n />\r\n</div>\r\n```\r\n\r\n#### Support `input` only usage\r\n\r\n```html\r\n<div class=\"w-field__input\" data-field-input=\"\">\r\n <svg class=\"icon icon-search w-field__icon\" aria-hidden=\"true\">\r\n <use href=\"#icon-search\"></use>\r\n </svg>\r\n <input\r\n type=\"text\"\r\n name=\"q\"\r\n placeholder=\"Search images\"\r\n data-controller=\"w-search\"\r\n data-action=\"change->w-search#search cut->w-search#search keyup->w-search#search paste->w-search#search\"\r\n id=\"id_q\"\r\n data-w-search-results-value=\"#image-results\"\r\n data-w-search-url-value=\"/admin/images/results/\"\r\n />\r\n</div>\r\n```\r\n\r\n#### Support controlled form with search input as a target\r\n\r\n```html\r\n<form\r\n class=\"col search-form\"\r\n action=\"/admin/images/\"\r\n method=\"get\"\r\n novalidate=\"\"\r\n role=\"search\"\r\n data-controller=\"w-search\"\r\n data-w-search-url-value=\"/admin/images/results/\"\r\n>\r\n <div class=\"w-field__wrapper w-mb-0\" data-field-wrapper=\"\">\r\n <label class=\"w-field__label w-sr-only\" for=\"id_q\" id=\"id_q-label\">Search term</label>\r\n <div class=\"w-field w-field--char_field w-field--text_input\">\r\n <div class=\"w-field__input\" data-field-input=\"\">\r\n <svg class=\"icon icon-search w-field__icon\" aria-hidden=\"true\"><use href=\"#icon-search\"></use></svg>\r\n <input\r\n type=\"text\"\r\n name=\"q\"\r\n placeholder=\"Search images\"\r\n data-w-search-target=\"input\"\r\n data-action=\"change->w-search#search cut->w-search#search keyup->w-search#search paste->w-search#search\"\r\n id=\"id_q\"\r\n />\r\n </div>\r\n </div>\r\n </div>\r\n <div class=\"visuallyhidden\"><input disabled=\"\" type=\"submit\" aria-hidden=\"true\" /></div>\r\n</form>\r\n```\n", "before_files": [{"content": "from django import forms\nfrom django.utils.translation import gettext as _\nfrom django.utils.translation import gettext_lazy\n\n\nclass SearchForm(forms.Form):\n def __init__(self, *args, **kwargs):\n placeholder = kwargs.pop(\"placeholder\", _(\"Search\"))\n super().__init__(*args, **kwargs)\n self.fields[\"q\"].widget.attrs = {\"placeholder\": placeholder}\n\n q = forms.CharField(\n label=gettext_lazy(\"Search term\"),\n widget=forms.TextInput(),\n required=False,\n )\n", "path": "wagtail/admin/forms/search.py"}]}
| 1,648 | 149 |
gh_patches_debug_23092
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-6430
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Tor2web warning page still using outdated pre-SI-redesign resources
## Description
In the SI redesign, we overlooked the Tor2web page which tries to render an old location for the icon and does not show an icon for the flash warning message.
## Steps to Reproduce
Visit https://demo-source.securedrop.org/tor2web-warning
## Expected Behavior

## Actual Behavior

"Tor Browser" link in tor2web warning is broken
## Description
The "Tor Browser" link in the tor2web warning is broken because it does not specify a protocol, so the browser treats it as a relative link.
## Steps to Reproduce
* Visit `/tor2web-warning` in the SI
* Hover over or click on the "Tor Browser" link, it should send you to a non-existent `/www.torproject.org/projects/torbrowser.html` on the SI's domain.
## Expected Behavior
* Link takes you to Tor Project website.
## Comments
Fix should be as simple as adding "https://" in front.
</issue>
<code>
[start of securedrop/source_app/info.py]
1 # -*- coding: utf-8 -*-
2 import flask
3 from flask import Blueprint, render_template, send_file, redirect, url_for, flash
4 from flask_babel import gettext
5 import werkzeug
6
7 from io import BytesIO # noqa
8
9 from encryption import EncryptionManager
10 from sdconfig import SDConfig
11 from source_app.utils import get_sourcev3_url
12
13
14 def make_blueprint(config: SDConfig) -> Blueprint:
15 view = Blueprint('info', __name__)
16
17 @view.route('/tor2web-warning')
18 def tor2web_warning() -> flask.Response:
19 flash(gettext("Your connection is not anonymous right now!"), "error")
20 return flask.Response(
21 render_template("tor2web-warning.html", source_url=get_sourcev3_url()),
22 403)
23
24 @view.route('/use-tor')
25 def recommend_tor_browser() -> str:
26 return render_template("use-tor-browser.html")
27
28 @view.route('/public-key')
29 def download_public_key() -> flask.Response:
30 journalist_pubkey = EncryptionManager.get_default().get_journalist_public_key()
31 data = BytesIO(journalist_pubkey.encode('utf-8'))
32 return send_file(data,
33 mimetype="application/pgp-keys",
34 attachment_filename=config.JOURNALIST_KEY + ".asc",
35 as_attachment=True)
36
37 @view.route('/journalist-key')
38 def download_journalist_key() -> werkzeug.wrappers.Response:
39 return redirect(url_for('.download_public_key'), code=301)
40
41 @view.route('/why-public-key')
42 def why_download_public_key() -> str:
43 return render_template("why-public-key.html")
44
45 return view
46
[end of securedrop/source_app/info.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/securedrop/source_app/info.py b/securedrop/source_app/info.py
--- a/securedrop/source_app/info.py
+++ b/securedrop/source_app/info.py
@@ -1,6 +1,6 @@
# -*- coding: utf-8 -*-
import flask
-from flask import Blueprint, render_template, send_file, redirect, url_for, flash
+from flask import Blueprint, render_template, send_file, redirect, url_for
from flask_babel import gettext
import werkzeug
@@ -8,7 +8,7 @@
from encryption import EncryptionManager
from sdconfig import SDConfig
-from source_app.utils import get_sourcev3_url
+from source_app.utils import get_sourcev3_url, flash_msg
def make_blueprint(config: SDConfig) -> Blueprint:
@@ -16,7 +16,7 @@
@view.route('/tor2web-warning')
def tor2web_warning() -> flask.Response:
- flash(gettext("Your connection is not anonymous right now!"), "error")
+ flash_msg("error", None, gettext("Your connection is not anonymous right now!"))
return flask.Response(
render_template("tor2web-warning.html", source_url=get_sourcev3_url()),
403)
|
{"golden_diff": "diff --git a/securedrop/source_app/info.py b/securedrop/source_app/info.py\n--- a/securedrop/source_app/info.py\n+++ b/securedrop/source_app/info.py\n@@ -1,6 +1,6 @@\n # -*- coding: utf-8 -*-\n import flask\n-from flask import Blueprint, render_template, send_file, redirect, url_for, flash\n+from flask import Blueprint, render_template, send_file, redirect, url_for\n from flask_babel import gettext\n import werkzeug\n \n@@ -8,7 +8,7 @@\n \n from encryption import EncryptionManager\n from sdconfig import SDConfig\n-from source_app.utils import get_sourcev3_url\n+from source_app.utils import get_sourcev3_url, flash_msg\n \n \n def make_blueprint(config: SDConfig) -> Blueprint:\n@@ -16,7 +16,7 @@\n \n @view.route('/tor2web-warning')\n def tor2web_warning() -> flask.Response:\n- flash(gettext(\"Your connection is not anonymous right now!\"), \"error\")\n+ flash_msg(\"error\", None, gettext(\"Your connection is not anonymous right now!\"))\n return flask.Response(\n render_template(\"tor2web-warning.html\", source_url=get_sourcev3_url()),\n 403)\n", "issue": "Tor2web warning page still using outdated pre-SI-redesign resources\n## Description\r\n\r\nIn the SI redesign, we overlooked the Tor2web page which tries to render an old location for the icon and does not show an icon for the flash warning message.\r\n\r\n## Steps to Reproduce\r\n\r\nVisit https://demo-source.securedrop.org/tor2web-warning\r\n\r\n## Expected Behavior\r\n\r\n\r\n\r\n## Actual Behavior\r\n\r\n\r\n\n\"Tor Browser\" link in tor2web warning is broken\n## Description\r\n\r\nThe \"Tor Browser\" link in the tor2web warning is broken because it does not specify a protocol, so the browser treats it as a relative link.\r\n\r\n## Steps to Reproduce\r\n\r\n* Visit `/tor2web-warning` in the SI\r\n* Hover over or click on the \"Tor Browser\" link, it should send you to a non-existent `/www.torproject.org/projects/torbrowser.html` on the SI's domain.\r\n\r\n## Expected Behavior\r\n\r\n* Link takes you to Tor Project website.\r\n\r\n## Comments\r\n\r\nFix should be as simple as adding \"https://\" in front.\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport flask\nfrom flask import Blueprint, render_template, send_file, redirect, url_for, flash\nfrom flask_babel import gettext\nimport werkzeug\n\nfrom io import BytesIO # noqa\n\nfrom encryption import EncryptionManager\nfrom sdconfig import SDConfig\nfrom source_app.utils import get_sourcev3_url\n\n\ndef make_blueprint(config: SDConfig) -> Blueprint:\n view = Blueprint('info', __name__)\n\n @view.route('/tor2web-warning')\n def tor2web_warning() -> flask.Response:\n flash(gettext(\"Your connection is not anonymous right now!\"), \"error\")\n return flask.Response(\n render_template(\"tor2web-warning.html\", source_url=get_sourcev3_url()),\n 403)\n\n @view.route('/use-tor')\n def recommend_tor_browser() -> str:\n return render_template(\"use-tor-browser.html\")\n\n @view.route('/public-key')\n def download_public_key() -> flask.Response:\n journalist_pubkey = EncryptionManager.get_default().get_journalist_public_key()\n data = BytesIO(journalist_pubkey.encode('utf-8'))\n return send_file(data,\n mimetype=\"application/pgp-keys\",\n attachment_filename=config.JOURNALIST_KEY + \".asc\",\n as_attachment=True)\n\n @view.route('/journalist-key')\n def download_journalist_key() -> werkzeug.wrappers.Response:\n return redirect(url_for('.download_public_key'), code=301)\n\n @view.route('/why-public-key')\n def why_download_public_key() -> str:\n return render_template(\"why-public-key.html\")\n\n return view\n", "path": "securedrop/source_app/info.py"}]}
| 1,314 | 270 |
gh_patches_debug_61790
|
rasdani/github-patches
|
git_diff
|
electricitymaps__electricitymaps-contrib-3796
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CA-PE production parser down
## Description
This is an automatic error report generated for Canada Prince Edward Island (CA-PE).
Issues:
- No recent data found for `production` parser
## Suggestions
- Try running the parser locally using the command `poetry run test_parser CA-PE production`
- <a href="https://storage.googleapis.com/electricitymap-parser-logs/CA-PE.html">Explore the runtime logs</a>
You can see an overview of all parser issues [here](https://github.com/tmrowco/electricitymap-contrib/wiki/Parser-issues).
</issue>
<code>
[start of parsers/CA_PE.py]
1 #!/usr/bin/env python3
2
3 import json
4
5 # The arrow library is used to handle datetimes consistently with other parsers
6 import arrow
7
8 # The request library is used to fetch content through HTTP
9 import requests
10
11
12 timezone = 'Canada/Atlantic'
13
14
15 def _find_pei_key(pei_list, sought_key):
16 matching_item = [item for item in pei_list
17 if 'header' in item['data']
18 and item['data']['header'].startswith(sought_key)]
19
20 if not matching_item:
21 return None
22
23 return matching_item[0]['data']['actualValue']
24
25
26 def _get_pei_info(requests_obj):
27 url = 'https://wdf.princeedwardisland.ca/workflow'
28 request = {'featureName': 'WindEnergy', 'queryName': 'WindEnergy'}
29 headers = {'Content-Type': 'application/json'}
30 response = requests_obj.post(url, data=json.dumps(request), headers=headers)
31
32 raw_data = response.json().get('data', [])
33
34 datetime_item = [item['data']['text'] for item in raw_data
35 if 'text' in item['data']]
36 if not datetime_item:
37 # unable to get a timestamp, return empty
38 return None
39 datetime_text = datetime_item[0][len('Last updated '):]
40 data_timestamp = arrow.get(datetime_text, 'MMMM D, YYYY HH:mm A').replace(tzinfo='Canada/Atlantic')
41
42 # see https://ruk.ca/content/new-api-endpoint-pei-wind for more info
43 data = {
44 'pei_load': _find_pei_key(raw_data, 'Total On-Island Load'),
45 'pei_wind_gen': _find_pei_key(raw_data, 'Total On-Island Wind Generation'),
46 'pei_fossil_gen': _find_pei_key(raw_data, 'Total On-Island Fossil Fuel Generation'),
47 'pei_wind_used': _find_pei_key(raw_data, 'Wind Power Used On Island'),
48 'pei_wind_exported': _find_pei_key(raw_data, 'Wind Power Exported Off Island'),
49 'datetime': data_timestamp.datetime
50 }
51
52 # the following keys are always required downstream, if we don't have them, no sense returning
53 if data['pei_wind_gen'] is None or data['pei_fossil_gen'] is None:
54 return None
55
56 return data
57
58
59 def fetch_production(zone_key='CA-PE', session=None, target_datetime=None, logger=None) -> dict:
60 """Requests the last known production mix (in MW) of a given country."""
61 if target_datetime:
62 raise NotImplementedError('This parser is not yet able to parse past dates')
63
64 requests_obj = session or requests.session()
65 pei_info = _get_pei_info(requests_obj)
66
67 if pei_info is None:
68 return None
69
70 data = {
71 'datetime': pei_info['datetime'],
72 'zoneKey': zone_key,
73 'production': {
74 'wind': pei_info['pei_wind_gen'],
75
76 # These are oil-fueled ("heavy fuel oil" and "diesel") generators
77 # used as peakers and back-up
78 'oil': pei_info['pei_fossil_gen'],
79
80 # specify some sources that definitely aren't present on PEI as zero,
81 # this allows the analyzer to better estimate CO2eq
82 'coal': 0,
83 'hydro': 0,
84 'nuclear': 0,
85 'geothermal': 0
86 },
87 'storage': {},
88 'source': 'princeedwardisland.ca'
89 }
90
91 return data
92
93
94 def fetch_exchange(zone_key1, zone_key2, session=None, target_datetime=None, logger=None) -> dict:
95 """Requests the last known power exchange (in MW) between two regions."""
96 if target_datetime:
97 raise NotImplementedError('This parser is not yet able to parse past dates')
98
99 sorted_zone_keys = '->'.join(sorted([zone_key1, zone_key2]))
100
101 if sorted_zone_keys != 'CA-NB->CA-PE':
102 raise NotImplementedError('This exchange pair is not implemented')
103
104 requests_obj = session or requests.session()
105 pei_info = _get_pei_info(requests_obj)
106
107 if pei_info is None or pei_info['pei_load'] is None:
108 return None
109
110 # PEI imports most of its electricity. Everything not generated on island
111 # is imported from New Brunswick.
112 # In case of wind, some is paper-"exported" even if there is a net import,
113 # and 'pei_wind_used'/'data5' indicates their accounting of part of the load
114 # served by non-exported wind.
115 # https://www.princeedwardisland.ca/en/feature/pei-wind-energy says:
116 # "Wind Power Exported Off-Island is that portion of wind generation that is supplying
117 # contracts elsewhere. The actual electricity from this portion of wind generation
118 # may stay within PEI but is satisfying a contractual arrangement in another jurisdiction."
119 # We are ignoring these paper exports, as they are an accounting/legal detail
120 # that doesn't actually reflect what happens on the wires.
121 # (New Brunswick being the only interconnection with PEI, "exporting" wind power to NB
122 # then "importing" a balance of NB electricity likely doesn't actually happen.)
123 imported_from_nb = (pei_info['pei_load'] - pei_info['pei_fossil_gen'] - pei_info['pei_wind_gen'])
124
125 # In expected result, "net" represents an export.
126 # We have sorted_zone_keys 'CA-NB->CA-PE', so it's export *from* NB,
127 # and import *to* PEI.
128 data = {
129 'datetime': pei_info['datetime'],
130 'sortedZoneKeys': sorted_zone_keys,
131 'netFlow': imported_from_nb,
132 'source': 'princeedwardisland.ca'
133 }
134
135 return data
136
137
138 if __name__ == '__main__':
139 """Main method, never used by the Electricity Map backend, but handy for testing."""
140
141 print('fetch_production() ->')
142 print(fetch_production())
143
144 print('fetch_exchange("CA-PE", "CA-NB") ->')
145 print(fetch_exchange("CA-PE", "CA-NB"))
146
[end of parsers/CA_PE.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/parsers/CA_PE.py b/parsers/CA_PE.py
--- a/parsers/CA_PE.py
+++ b/parsers/CA_PE.py
@@ -24,7 +24,7 @@
def _get_pei_info(requests_obj):
- url = 'https://wdf.princeedwardisland.ca/workflow'
+ url = 'https://wdf.princeedwardisland.ca/api/workflow'
request = {'featureName': 'WindEnergy', 'queryName': 'WindEnergy'}
headers = {'Content-Type': 'application/json'}
response = requests_obj.post(url, data=json.dumps(request), headers=headers)
|
{"golden_diff": "diff --git a/parsers/CA_PE.py b/parsers/CA_PE.py\n--- a/parsers/CA_PE.py\n+++ b/parsers/CA_PE.py\n@@ -24,7 +24,7 @@\n \n \n def _get_pei_info(requests_obj):\n- url = 'https://wdf.princeedwardisland.ca/workflow'\n+ url = 'https://wdf.princeedwardisland.ca/api/workflow'\n request = {'featureName': 'WindEnergy', 'queryName': 'WindEnergy'}\n headers = {'Content-Type': 'application/json'}\n response = requests_obj.post(url, data=json.dumps(request), headers=headers)\n", "issue": "CA-PE production parser down\n## Description\n\nThis is an automatic error report generated for Canada Prince Edward Island (CA-PE).\n\nIssues:\n- No recent data found for `production` parser\n\n## Suggestions\n- Try running the parser locally using the command `poetry run test_parser CA-PE production`\n- <a href=\"https://storage.googleapis.com/electricitymap-parser-logs/CA-PE.html\">Explore the runtime logs</a>\n\nYou can see an overview of all parser issues [here](https://github.com/tmrowco/electricitymap-contrib/wiki/Parser-issues).\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nimport json\n\n# The arrow library is used to handle datetimes consistently with other parsers\nimport arrow\n\n# The request library is used to fetch content through HTTP\nimport requests\n\n\ntimezone = 'Canada/Atlantic'\n\n\ndef _find_pei_key(pei_list, sought_key):\n matching_item = [item for item in pei_list\n if 'header' in item['data']\n and item['data']['header'].startswith(sought_key)]\n\n if not matching_item:\n return None\n\n return matching_item[0]['data']['actualValue']\n\n\ndef _get_pei_info(requests_obj):\n url = 'https://wdf.princeedwardisland.ca/workflow'\n request = {'featureName': 'WindEnergy', 'queryName': 'WindEnergy'}\n headers = {'Content-Type': 'application/json'}\n response = requests_obj.post(url, data=json.dumps(request), headers=headers)\n\n raw_data = response.json().get('data', [])\n\n datetime_item = [item['data']['text'] for item in raw_data\n if 'text' in item['data']]\n if not datetime_item:\n # unable to get a timestamp, return empty\n return None\n datetime_text = datetime_item[0][len('Last updated '):]\n data_timestamp = arrow.get(datetime_text, 'MMMM D, YYYY HH:mm A').replace(tzinfo='Canada/Atlantic')\n\n # see https://ruk.ca/content/new-api-endpoint-pei-wind for more info\n data = {\n 'pei_load': _find_pei_key(raw_data, 'Total On-Island Load'),\n 'pei_wind_gen': _find_pei_key(raw_data, 'Total On-Island Wind Generation'),\n 'pei_fossil_gen': _find_pei_key(raw_data, 'Total On-Island Fossil Fuel Generation'),\n 'pei_wind_used': _find_pei_key(raw_data, 'Wind Power Used On Island'),\n 'pei_wind_exported': _find_pei_key(raw_data, 'Wind Power Exported Off Island'),\n 'datetime': data_timestamp.datetime\n }\n\n # the following keys are always required downstream, if we don't have them, no sense returning\n if data['pei_wind_gen'] is None or data['pei_fossil_gen'] is None:\n return None\n\n return data\n\n\ndef fetch_production(zone_key='CA-PE', session=None, target_datetime=None, logger=None) -> dict:\n \"\"\"Requests the last known production mix (in MW) of a given country.\"\"\"\n if target_datetime:\n raise NotImplementedError('This parser is not yet able to parse past dates')\n\n requests_obj = session or requests.session()\n pei_info = _get_pei_info(requests_obj)\n\n if pei_info is None:\n return None\n\n data = {\n 'datetime': pei_info['datetime'],\n 'zoneKey': zone_key,\n 'production': {\n 'wind': pei_info['pei_wind_gen'],\n\n # These are oil-fueled (\"heavy fuel oil\" and \"diesel\") generators\n # used as peakers and back-up\n 'oil': pei_info['pei_fossil_gen'],\n\n # specify some sources that definitely aren't present on PEI as zero,\n # this allows the analyzer to better estimate CO2eq\n 'coal': 0,\n 'hydro': 0,\n 'nuclear': 0,\n 'geothermal': 0\n },\n 'storage': {},\n 'source': 'princeedwardisland.ca'\n }\n\n return data\n\n\ndef fetch_exchange(zone_key1, zone_key2, session=None, target_datetime=None, logger=None) -> dict:\n \"\"\"Requests the last known power exchange (in MW) between two regions.\"\"\"\n if target_datetime:\n raise NotImplementedError('This parser is not yet able to parse past dates')\n\n sorted_zone_keys = '->'.join(sorted([zone_key1, zone_key2]))\n\n if sorted_zone_keys != 'CA-NB->CA-PE':\n raise NotImplementedError('This exchange pair is not implemented')\n\n requests_obj = session or requests.session()\n pei_info = _get_pei_info(requests_obj)\n\n if pei_info is None or pei_info['pei_load'] is None:\n return None\n\n # PEI imports most of its electricity. Everything not generated on island\n # is imported from New Brunswick.\n # In case of wind, some is paper-\"exported\" even if there is a net import,\n # and 'pei_wind_used'/'data5' indicates their accounting of part of the load\n # served by non-exported wind.\n # https://www.princeedwardisland.ca/en/feature/pei-wind-energy says:\n # \"Wind Power Exported Off-Island is that portion of wind generation that is supplying\n # contracts elsewhere. The actual electricity from this portion of wind generation\n # may stay within PEI but is satisfying a contractual arrangement in another jurisdiction.\"\n # We are ignoring these paper exports, as they are an accounting/legal detail\n # that doesn't actually reflect what happens on the wires.\n # (New Brunswick being the only interconnection with PEI, \"exporting\" wind power to NB\n # then \"importing\" a balance of NB electricity likely doesn't actually happen.)\n imported_from_nb = (pei_info['pei_load'] - pei_info['pei_fossil_gen'] - pei_info['pei_wind_gen'])\n\n # In expected result, \"net\" represents an export.\n # We have sorted_zone_keys 'CA-NB->CA-PE', so it's export *from* NB,\n # and import *to* PEI.\n data = {\n 'datetime': pei_info['datetime'],\n 'sortedZoneKeys': sorted_zone_keys,\n 'netFlow': imported_from_nb,\n 'source': 'princeedwardisland.ca'\n }\n\n return data\n\n\nif __name__ == '__main__':\n \"\"\"Main method, never used by the Electricity Map backend, but handy for testing.\"\"\"\n\n print('fetch_production() ->')\n print(fetch_production())\n\n print('fetch_exchange(\"CA-PE\", \"CA-NB\") ->')\n print(fetch_exchange(\"CA-PE\", \"CA-NB\"))\n", "path": "parsers/CA_PE.py"}]}
| 2,358 | 144 |
gh_patches_debug_23623
|
rasdani/github-patches
|
git_diff
|
kedro-org__kedro-1760
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Document how to read and write a multi-sheet excel
## Introduction
>A high-level, short overview of the problem(s) you are designing a solution for.
We have the implementation, but it is not easy to point to a documented example:
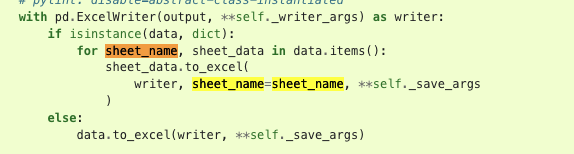
## Background
> Provide the reader with the context surrounding the problem(s) you are trying to solve.
This is a common feature and something Kedro can already do.
</issue>
<code>
[start of kedro/extras/datasets/pandas/excel_dataset.py]
1 """``ExcelDataSet`` loads/saves data from/to a Excel file using an underlying
2 filesystem (e.g.: local, S3, GCS). It uses pandas to handle the Excel file.
3 """
4 import logging
5 from copy import deepcopy
6 from io import BytesIO
7 from pathlib import PurePosixPath
8 from typing import Any, Dict, Union
9
10 import fsspec
11 import pandas as pd
12
13 from kedro.io.core import (
14 PROTOCOL_DELIMITER,
15 AbstractVersionedDataSet,
16 DataSetError,
17 Version,
18 get_filepath_str,
19 get_protocol_and_path,
20 )
21
22 logger = logging.getLogger(__name__)
23
24
25 class ExcelDataSet(
26 AbstractVersionedDataSet[
27 Union[pd.DataFrame, Dict[str, pd.DataFrame]],
28 Union[pd.DataFrame, Dict[str, pd.DataFrame]],
29 ]
30 ):
31 """``ExcelDataSet`` loads/saves data from/to a Excel file using an underlying
32 filesystem (e.g.: local, S3, GCS). It uses pandas to handle the Excel file.
33
34 Example adding a catalog entry with the ``YAML API``:
35
36 .. code-block:: yaml
37
38 >>> rockets:
39 >>> type: pandas.ExcelDataSet
40 >>> filepath: gcs://your_bucket/rockets.xlsx
41 >>> fs_args:
42 >>> project: my-project
43 >>> credentials: my_gcp_credentials
44 >>> save_args:
45 >>> sheet_name: Sheet1
46 >>> load_args:
47 >>> sheet_name: Sheet1
48 >>>
49 >>> shuttles:
50 >>> type: pandas.ExcelDataSet
51 >>> filepath: data/01_raw/shuttles.xlsx
52
53 Example using Python API:
54 ::
55
56 >>> from kedro.extras.datasets.pandas import ExcelDataSet
57 >>> import pandas as pd
58 >>>
59 >>> data = pd.DataFrame({'col1': [1, 2], 'col2': [4, 5],
60 >>> 'col3': [5, 6]})
61 >>>
62 >>> # data_set = ExcelDataSet(filepath="gcs://bucket/test.xlsx")
63 >>> data_set = ExcelDataSet(filepath="test.xlsx")
64 >>> data_set.save(data)
65 >>> reloaded = data_set.load()
66 >>> assert data.equals(reloaded)
67
68 """
69
70 DEFAULT_LOAD_ARGS = {"engine": "openpyxl"}
71 DEFAULT_SAVE_ARGS = {"index": False}
72
73 # pylint: disable=too-many-arguments
74 def __init__(
75 self,
76 filepath: str,
77 engine: str = "openpyxl",
78 load_args: Dict[str, Any] = None,
79 save_args: Dict[str, Any] = None,
80 version: Version = None,
81 credentials: Dict[str, Any] = None,
82 fs_args: Dict[str, Any] = None,
83 ) -> None:
84 """Creates a new instance of ``ExcelDataSet`` pointing to a concrete Excel file
85 on a specific filesystem.
86
87 Args:
88 filepath: Filepath in POSIX format to a Excel file prefixed with a protocol like
89 `s3://`. If prefix is not provided, `file` protocol (local filesystem) will be used.
90 The prefix should be any protocol supported by ``fsspec``.
91 Note: `http(s)` doesn't support versioning.
92 engine: The engine used to write to excel files. The default
93 engine is 'openpyxl'.
94 load_args: Pandas options for loading Excel files.
95 Here you can find all available arguments:
96 https://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_excel.html
97 All defaults are preserved, but "engine", which is set to "openpyxl".
98 Supports multi-sheet Excel files (include `sheet_name = None` in `load_args`).
99 save_args: Pandas options for saving Excel files.
100 Here you can find all available arguments:
101 https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.to_excel.html
102 All defaults are preserved, but "index", which is set to False.
103 If you would like to specify options for the `ExcelWriter`,
104 you can include them under the "writer" key. Here you can
105 find all available arguments:
106 https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.ExcelWriter.html
107 version: If specified, should be an instance of
108 ``kedro.io.core.Version``. If its ``load`` attribute is
109 None, the latest version will be loaded. If its ``save``
110 attribute is None, save version will be autogenerated.
111 credentials: Credentials required to get access to the underlying filesystem.
112 E.g. for ``GCSFileSystem`` it should look like `{"token": None}`.
113 fs_args: Extra arguments to pass into underlying filesystem class constructor
114 (e.g. `{"project": "my-project"}` for ``GCSFileSystem``).
115
116 Raises:
117 DataSetError: If versioning is enabled while in append mode.
118 """
119 _fs_args = deepcopy(fs_args) or {}
120 _credentials = deepcopy(credentials) or {}
121
122 protocol, path = get_protocol_and_path(filepath, version)
123 if protocol == "file":
124 _fs_args.setdefault("auto_mkdir", True)
125
126 self._protocol = protocol
127 self._storage_options = {**_credentials, **_fs_args}
128 self._fs = fsspec.filesystem(self._protocol, **self._storage_options)
129
130 super().__init__(
131 filepath=PurePosixPath(path),
132 version=version,
133 exists_function=self._fs.exists,
134 glob_function=self._fs.glob,
135 )
136
137 # Handle default load arguments
138 self._load_args = deepcopy(self.DEFAULT_LOAD_ARGS)
139 if load_args is not None:
140 self._load_args.update(load_args)
141
142 # Handle default save arguments
143 self._save_args = deepcopy(self.DEFAULT_SAVE_ARGS)
144 if save_args is not None:
145 self._save_args.update(save_args)
146 self._writer_args = self._save_args.pop("writer", {}) # type: ignore
147 self._writer_args.setdefault("engine", engine or "openpyxl") # type: ignore
148
149 if version and self._writer_args.get("mode") == "a": # type: ignore
150 raise DataSetError(
151 "'ExcelDataSet' doesn't support versioning in append mode."
152 )
153
154 if "storage_options" in self._save_args or "storage_options" in self._load_args:
155 logger.warning(
156 "Dropping 'storage_options' for %s, "
157 "please specify them under 'fs_args' or 'credentials'.",
158 self._filepath,
159 )
160 self._save_args.pop("storage_options", None)
161 self._load_args.pop("storage_options", None)
162
163 def _describe(self) -> Dict[str, Any]:
164 return dict(
165 filepath=self._filepath,
166 protocol=self._protocol,
167 load_args=self._load_args,
168 save_args=self._save_args,
169 writer_args=self._writer_args,
170 version=self._version,
171 )
172
173 def _load(self) -> Union[pd.DataFrame, Dict[str, pd.DataFrame]]:
174 load_path = str(self._get_load_path())
175 if self._protocol == "file":
176 # file:// protocol seems to misbehave on Windows
177 # (<urlopen error file not on local host>),
178 # so we don't join that back to the filepath;
179 # storage_options also don't work with local paths
180 return pd.read_excel(load_path, **self._load_args)
181
182 load_path = f"{self._protocol}{PROTOCOL_DELIMITER}{load_path}"
183 return pd.read_excel(
184 load_path, storage_options=self._storage_options, **self._load_args
185 )
186
187 def _save(self, data: Union[pd.DataFrame, Dict[str, pd.DataFrame]]) -> None:
188 output = BytesIO()
189 save_path = get_filepath_str(self._get_save_path(), self._protocol)
190
191 # pylint: disable=abstract-class-instantiated
192 with pd.ExcelWriter(output, **self._writer_args) as writer:
193 if isinstance(data, dict):
194 for sheet_name, sheet_data in data.items():
195 sheet_data.to_excel(
196 writer, sheet_name=sheet_name, **self._save_args
197 )
198 else:
199 data.to_excel(writer, **self._save_args)
200
201 with self._fs.open(save_path, mode="wb") as fs_file:
202 fs_file.write(output.getvalue())
203
204 self._invalidate_cache()
205
206 def _exists(self) -> bool:
207 try:
208 load_path = get_filepath_str(self._get_load_path(), self._protocol)
209 except DataSetError:
210 return False
211
212 return self._fs.exists(load_path)
213
214 def _release(self) -> None:
215 super()._release()
216 self._invalidate_cache()
217
218 def _invalidate_cache(self) -> None:
219 """Invalidate underlying filesystem caches."""
220 filepath = get_filepath_str(self._filepath, self._protocol)
221 self._fs.invalidate_cache(filepath)
222
[end of kedro/extras/datasets/pandas/excel_dataset.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kedro/extras/datasets/pandas/excel_dataset.py b/kedro/extras/datasets/pandas/excel_dataset.py
--- a/kedro/extras/datasets/pandas/excel_dataset.py
+++ b/kedro/extras/datasets/pandas/excel_dataset.py
@@ -65,6 +65,36 @@
>>> reloaded = data_set.load()
>>> assert data.equals(reloaded)
+ Note: To save a multi-sheet excel file, no special ``save_args`` are required.
+ Instead, return a dictionary of ``Dict[str, pd.DataFrame]`` where the string
+ keys are your sheet names.
+
+ Example adding a catalog entry for multi-sheet excel file with the ``YAML API``:
+
+ .. code-block:: yaml
+
+ >>> trains:
+ >>> type: pandas.ExcelDataSet
+ >>> filepath: data/02_intermediate/company/trains.xlsx
+ >>> load_args:
+ >>> sheet_name: [Sheet1, Sheet2, Sheet3]
+
+ Example multi-sheet excel file using Python API:
+ ::
+
+ >>> from kedro.extras.datasets.pandas import ExcelDataSet
+ >>> import pandas as pd
+ >>>
+ >>> dataframe = pd.DataFrame({'col1': [1, 2], 'col2': [4, 5],
+ >>> 'col3': [5, 6]})
+ >>> another_dataframe = pd.DataFrame({"x": [10, 20], "y": ["hello", "world"]})
+ >>> multiframe = {"Sheet1": dataframe, "Sheet2": another_dataframe}
+ >>> data_set = ExcelDataSet(filepath="test.xlsx", load_args = {"sheet_name": None})
+ >>> data_set.save(multiframe)
+ >>> reloaded = data_set.load()
+ >>> assert multiframe["Sheet1"].equals(reloaded["Sheet1"])
+ >>> assert multiframe["Sheet2"].equals(reloaded["Sheet2"])
+
"""
DEFAULT_LOAD_ARGS = {"engine": "openpyxl"}
|
{"golden_diff": "diff --git a/kedro/extras/datasets/pandas/excel_dataset.py b/kedro/extras/datasets/pandas/excel_dataset.py\n--- a/kedro/extras/datasets/pandas/excel_dataset.py\n+++ b/kedro/extras/datasets/pandas/excel_dataset.py\n@@ -65,6 +65,36 @@\n >>> reloaded = data_set.load()\n >>> assert data.equals(reloaded)\n \n+ Note: To save a multi-sheet excel file, no special ``save_args`` are required.\n+ Instead, return a dictionary of ``Dict[str, pd.DataFrame]`` where the string\n+ keys are your sheet names.\n+\n+ Example adding a catalog entry for multi-sheet excel file with the ``YAML API``:\n+\n+ .. code-block:: yaml\n+\n+ >>> trains:\n+ >>> type: pandas.ExcelDataSet\n+ >>> filepath: data/02_intermediate/company/trains.xlsx\n+ >>> load_args:\n+ >>> sheet_name: [Sheet1, Sheet2, Sheet3]\n+\n+ Example multi-sheet excel file using Python API:\n+ ::\n+\n+ >>> from kedro.extras.datasets.pandas import ExcelDataSet\n+ >>> import pandas as pd\n+ >>>\n+ >>> dataframe = pd.DataFrame({'col1': [1, 2], 'col2': [4, 5],\n+ >>> 'col3': [5, 6]})\n+ >>> another_dataframe = pd.DataFrame({\"x\": [10, 20], \"y\": [\"hello\", \"world\"]})\n+ >>> multiframe = {\"Sheet1\": dataframe, \"Sheet2\": another_dataframe}\n+ >>> data_set = ExcelDataSet(filepath=\"test.xlsx\", load_args = {\"sheet_name\": None})\n+ >>> data_set.save(multiframe)\n+ >>> reloaded = data_set.load()\n+ >>> assert multiframe[\"Sheet1\"].equals(reloaded[\"Sheet1\"])\n+ >>> assert multiframe[\"Sheet2\"].equals(reloaded[\"Sheet2\"])\n+\n \"\"\"\n \n DEFAULT_LOAD_ARGS = {\"engine\": \"openpyxl\"}\n", "issue": "Document how to read and write a multi-sheet excel\n## Introduction\r\n\r\n>A high-level, short overview of the problem(s) you are designing a solution for.\r\n\r\nWe have the implementation, but it is not easy to point to a documented example:\r\n\r\n\r\n\r\n## Background\r\n\r\n> Provide the reader with the context surrounding the problem(s) you are trying to solve.\r\n\r\nThis is a common feature and something Kedro can already do.\r\n\n", "before_files": [{"content": "\"\"\"``ExcelDataSet`` loads/saves data from/to a Excel file using an underlying\nfilesystem (e.g.: local, S3, GCS). It uses pandas to handle the Excel file.\n\"\"\"\nimport logging\nfrom copy import deepcopy\nfrom io import BytesIO\nfrom pathlib import PurePosixPath\nfrom typing import Any, Dict, Union\n\nimport fsspec\nimport pandas as pd\n\nfrom kedro.io.core import (\n PROTOCOL_DELIMITER,\n AbstractVersionedDataSet,\n DataSetError,\n Version,\n get_filepath_str,\n get_protocol_and_path,\n)\n\nlogger = logging.getLogger(__name__)\n\n\nclass ExcelDataSet(\n AbstractVersionedDataSet[\n Union[pd.DataFrame, Dict[str, pd.DataFrame]],\n Union[pd.DataFrame, Dict[str, pd.DataFrame]],\n ]\n):\n \"\"\"``ExcelDataSet`` loads/saves data from/to a Excel file using an underlying\n filesystem (e.g.: local, S3, GCS). It uses pandas to handle the Excel file.\n\n Example adding a catalog entry with the ``YAML API``:\n\n .. code-block:: yaml\n\n >>> rockets:\n >>> type: pandas.ExcelDataSet\n >>> filepath: gcs://your_bucket/rockets.xlsx\n >>> fs_args:\n >>> project: my-project\n >>> credentials: my_gcp_credentials\n >>> save_args:\n >>> sheet_name: Sheet1\n >>> load_args:\n >>> sheet_name: Sheet1\n >>>\n >>> shuttles:\n >>> type: pandas.ExcelDataSet\n >>> filepath: data/01_raw/shuttles.xlsx\n\n Example using Python API:\n ::\n\n >>> from kedro.extras.datasets.pandas import ExcelDataSet\n >>> import pandas as pd\n >>>\n >>> data = pd.DataFrame({'col1': [1, 2], 'col2': [4, 5],\n >>> 'col3': [5, 6]})\n >>>\n >>> # data_set = ExcelDataSet(filepath=\"gcs://bucket/test.xlsx\")\n >>> data_set = ExcelDataSet(filepath=\"test.xlsx\")\n >>> data_set.save(data)\n >>> reloaded = data_set.load()\n >>> assert data.equals(reloaded)\n\n \"\"\"\n\n DEFAULT_LOAD_ARGS = {\"engine\": \"openpyxl\"}\n DEFAULT_SAVE_ARGS = {\"index\": False}\n\n # pylint: disable=too-many-arguments\n def __init__(\n self,\n filepath: str,\n engine: str = \"openpyxl\",\n load_args: Dict[str, Any] = None,\n save_args: Dict[str, Any] = None,\n version: Version = None,\n credentials: Dict[str, Any] = None,\n fs_args: Dict[str, Any] = None,\n ) -> None:\n \"\"\"Creates a new instance of ``ExcelDataSet`` pointing to a concrete Excel file\n on a specific filesystem.\n\n Args:\n filepath: Filepath in POSIX format to a Excel file prefixed with a protocol like\n `s3://`. If prefix is not provided, `file` protocol (local filesystem) will be used.\n The prefix should be any protocol supported by ``fsspec``.\n Note: `http(s)` doesn't support versioning.\n engine: The engine used to write to excel files. The default\n engine is 'openpyxl'.\n load_args: Pandas options for loading Excel files.\n Here you can find all available arguments:\n https://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_excel.html\n All defaults are preserved, but \"engine\", which is set to \"openpyxl\".\n Supports multi-sheet Excel files (include `sheet_name = None` in `load_args`).\n save_args: Pandas options for saving Excel files.\n Here you can find all available arguments:\n https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.to_excel.html\n All defaults are preserved, but \"index\", which is set to False.\n If you would like to specify options for the `ExcelWriter`,\n you can include them under the \"writer\" key. Here you can\n find all available arguments:\n https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.ExcelWriter.html\n version: If specified, should be an instance of\n ``kedro.io.core.Version``. If its ``load`` attribute is\n None, the latest version will be loaded. If its ``save``\n attribute is None, save version will be autogenerated.\n credentials: Credentials required to get access to the underlying filesystem.\n E.g. for ``GCSFileSystem`` it should look like `{\"token\": None}`.\n fs_args: Extra arguments to pass into underlying filesystem class constructor\n (e.g. `{\"project\": \"my-project\"}` for ``GCSFileSystem``).\n\n Raises:\n DataSetError: If versioning is enabled while in append mode.\n \"\"\"\n _fs_args = deepcopy(fs_args) or {}\n _credentials = deepcopy(credentials) or {}\n\n protocol, path = get_protocol_and_path(filepath, version)\n if protocol == \"file\":\n _fs_args.setdefault(\"auto_mkdir\", True)\n\n self._protocol = protocol\n self._storage_options = {**_credentials, **_fs_args}\n self._fs = fsspec.filesystem(self._protocol, **self._storage_options)\n\n super().__init__(\n filepath=PurePosixPath(path),\n version=version,\n exists_function=self._fs.exists,\n glob_function=self._fs.glob,\n )\n\n # Handle default load arguments\n self._load_args = deepcopy(self.DEFAULT_LOAD_ARGS)\n if load_args is not None:\n self._load_args.update(load_args)\n\n # Handle default save arguments\n self._save_args = deepcopy(self.DEFAULT_SAVE_ARGS)\n if save_args is not None:\n self._save_args.update(save_args)\n self._writer_args = self._save_args.pop(\"writer\", {}) # type: ignore\n self._writer_args.setdefault(\"engine\", engine or \"openpyxl\") # type: ignore\n\n if version and self._writer_args.get(\"mode\") == \"a\": # type: ignore\n raise DataSetError(\n \"'ExcelDataSet' doesn't support versioning in append mode.\"\n )\n\n if \"storage_options\" in self._save_args or \"storage_options\" in self._load_args:\n logger.warning(\n \"Dropping 'storage_options' for %s, \"\n \"please specify them under 'fs_args' or 'credentials'.\",\n self._filepath,\n )\n self._save_args.pop(\"storage_options\", None)\n self._load_args.pop(\"storage_options\", None)\n\n def _describe(self) -> Dict[str, Any]:\n return dict(\n filepath=self._filepath,\n protocol=self._protocol,\n load_args=self._load_args,\n save_args=self._save_args,\n writer_args=self._writer_args,\n version=self._version,\n )\n\n def _load(self) -> Union[pd.DataFrame, Dict[str, pd.DataFrame]]:\n load_path = str(self._get_load_path())\n if self._protocol == \"file\":\n # file:// protocol seems to misbehave on Windows\n # (<urlopen error file not on local host>),\n # so we don't join that back to the filepath;\n # storage_options also don't work with local paths\n return pd.read_excel(load_path, **self._load_args)\n\n load_path = f\"{self._protocol}{PROTOCOL_DELIMITER}{load_path}\"\n return pd.read_excel(\n load_path, storage_options=self._storage_options, **self._load_args\n )\n\n def _save(self, data: Union[pd.DataFrame, Dict[str, pd.DataFrame]]) -> None:\n output = BytesIO()\n save_path = get_filepath_str(self._get_save_path(), self._protocol)\n\n # pylint: disable=abstract-class-instantiated\n with pd.ExcelWriter(output, **self._writer_args) as writer:\n if isinstance(data, dict):\n for sheet_name, sheet_data in data.items():\n sheet_data.to_excel(\n writer, sheet_name=sheet_name, **self._save_args\n )\n else:\n data.to_excel(writer, **self._save_args)\n\n with self._fs.open(save_path, mode=\"wb\") as fs_file:\n fs_file.write(output.getvalue())\n\n self._invalidate_cache()\n\n def _exists(self) -> bool:\n try:\n load_path = get_filepath_str(self._get_load_path(), self._protocol)\n except DataSetError:\n return False\n\n return self._fs.exists(load_path)\n\n def _release(self) -> None:\n super()._release()\n self._invalidate_cache()\n\n def _invalidate_cache(self) -> None:\n \"\"\"Invalidate underlying filesystem caches.\"\"\"\n filepath = get_filepath_str(self._filepath, self._protocol)\n self._fs.invalidate_cache(filepath)\n", "path": "kedro/extras/datasets/pandas/excel_dataset.py"}]}
| 3,180 | 456 |
gh_patches_debug_955
|
rasdani/github-patches
|
git_diff
|
Textualize__rich-2108
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] Rich's IPython extension doesn't work
**Describe the bug**
When trying to use `%load_ext rich` in **IPython** on Terminal it says following:
```
%Python 3.10.3 (main, Mar 17 2022, 04:46:20) [Clang 12.0.8 (https://android.googlesource.com/toolchain/llvm-project c935d99d7
Type 'copyright', 'credits' or 'license' for more information
IPython 8.1.1 -- An enhanced Interactive Python. Type '?' for help.
In [1]: %load_ext rich
The rich module is not an IPython extension.
```
**Platform**
<details>
<summary>Click to expand</summary>
What platform (Win/Linux/Mac) are you running on? What terminal software are you using?
I may ask you to copy and paste the output of the following commands. It may save some time if you do it now.
If you're using Rich in a terminal:
```
python -m rich.diagnose
pip freeze | grep rich
```
If you're using Rich in a Jupyter Notebook, run the following snippet in a cell
and paste the output in your bug report.
```python
from rich.diagnose import report
report()
```
</details>
```
❯ python -m rich.diagnose
pip freeze | grep rich
╭────────────────── <class 'rich.console.Console'> ──────────────────╮
│ A high level console interface. │
│ │
│ ╭────────────────────────────────────────────────────────────────╮ │
│ │ <console width=70 ColorSystem.TRUECOLOR> │ │
│ ╰────────────────────────────────────────────────────────────────╯ │
│ │
│ color_system = 'truecolor' │
│ encoding = 'utf-8' │
│ file = <_io.TextIOWrapper name='<stdout>' mode='w' │
│ encoding='utf-8'> │
│ height = 45 │
│ is_alt_screen = False │
│ is_dumb_terminal = False │
│ is_interactive = True │
│ is_jupyter = False │
│ is_terminal = True │
│ legacy_windows = False │
│ no_color = False │
│ options = ConsoleOptions( │
│ size=ConsoleDimensions( │
│ width=70, │
│ height=45 │
│ ), │
│ legacy_windows=False, │
│ min_width=1, │
│ max_width=70, │
│ is_terminal=True, │
│ encoding='utf-8', │
│ max_height=45, │
│ justify=None, │
│ overflow=None, │
│ no_wrap=False, │
│ highlight=None, │
│ markup=None, │
│ height=None │
│ ) │
│ quiet = False │
│ record = False │
│ safe_box = True │
│ size = ConsoleDimensions(width=70, height=45) │
│ soft_wrap = False │
│ stderr = False │
│ style = None │
│ tab_size = 8 │
│ width = 70 │
╰────────────────────────────────────────────────────────────────────╯
╭─── <class 'rich._windows.WindowsConsoleFeatures'> ────╮
│ Windows features available. │
│ │
│ ╭───────────────────────────────────────────────────╮ │
│ │ WindowsConsoleFeatures(vt=False, truecolor=False) │ │
│ ╰───────────────────────────────────────────────────╯ │
│ │
│ truecolor = False │
│ vt = False │
╰───────────────────────────────────────────────────────╯
╭────── Environment Variables ───────╮
│ { │
│ 'TERM': 'xterm-256color', │
│ 'COLORTERM': 'truecolor', │
│ 'CLICOLOR': None, │
│ 'NO_COLOR': None, │
│ 'TERM_PROGRAM': None, │
│ 'COLUMNS': None, │
│ 'LINES': None, │
│ 'JPY_PARENT_PID': None, │
│ 'VSCODE_VERBOSE_LOGGING': None │
│ } │
╰────────────────────────────────────╯
platform="Linux"
rich @ file:///storage/emulated/0/Projects/rich
```
[](https://asciinema.org/a/Xd3qDv897tjdEll0csW5XZk0T)
</issue>
<code>
[start of rich/__init__.py]
1 """Rich text and beautiful formatting in the terminal."""
2
3 import os
4 from typing import Callable, IO, TYPE_CHECKING, Any, Optional, Union
5
6
7 __all__ = ["get_console", "reconfigure", "print", "inspect"]
8
9 if TYPE_CHECKING:
10 from .console import Console
11
12 # Global console used by alternative print
13 _console: Optional["Console"] = None
14
15 _IMPORT_CWD = os.path.abspath(os.getcwd())
16
17
18 def get_console() -> "Console":
19 """Get a global :class:`~rich.console.Console` instance. This function is used when Rich requires a Console,
20 and hasn't been explicitly given one.
21
22 Returns:
23 Console: A console instance.
24 """
25 global _console
26 if _console is None:
27 from .console import Console
28
29 _console = Console()
30
31 return _console
32
33
34 def reconfigure(*args: Any, **kwargs: Any) -> None:
35 """Reconfigures the global console by replacing it with another.
36
37 Args:
38 console (Console): Replacement console instance.
39 """
40 from rich.console import Console
41
42 new_console = Console(*args, **kwargs)
43 _console = get_console()
44 _console.__dict__ = new_console.__dict__
45
46
47 def print(
48 *objects: Any,
49 sep: str = " ",
50 end: str = "\n",
51 file: Optional[IO[str]] = None,
52 flush: bool = False,
53 ) -> None:
54 r"""Print object(s) supplied via positional arguments.
55 This function has an identical signature to the built-in print.
56 For more advanced features, see the :class:`~rich.console.Console` class.
57
58 Args:
59 sep (str, optional): Separator between printed objects. Defaults to " ".
60 end (str, optional): Character to write at end of output. Defaults to "\\n".
61 file (IO[str], optional): File to write to, or None for stdout. Defaults to None.
62 flush (bool, optional): Has no effect as Rich always flushes output. Defaults to False.
63
64 """
65 from .console import Console
66
67 write_console = get_console() if file is None else Console(file=file)
68 return write_console.print(*objects, sep=sep, end=end)
69
70
71 def print_json(
72 json: Optional[str] = None,
73 *,
74 data: Any = None,
75 indent: Union[None, int, str] = 2,
76 highlight: bool = True,
77 skip_keys: bool = False,
78 ensure_ascii: bool = True,
79 check_circular: bool = True,
80 allow_nan: bool = True,
81 default: Optional[Callable[[Any], Any]] = None,
82 sort_keys: bool = False,
83 ) -> None:
84 """Pretty prints JSON. Output will be valid JSON.
85
86 Args:
87 json (str): A string containing JSON.
88 data (Any): If json is not supplied, then encode this data.
89 indent (int, optional): Number of spaces to indent. Defaults to 2.
90 highlight (bool, optional): Enable highlighting of output: Defaults to True.
91 skip_keys (bool, optional): Skip keys not of a basic type. Defaults to False.
92 ensure_ascii (bool, optional): Escape all non-ascii characters. Defaults to False.
93 check_circular (bool, optional): Check for circular references. Defaults to True.
94 allow_nan (bool, optional): Allow NaN and Infinity values. Defaults to True.
95 default (Callable, optional): A callable that converts values that can not be encoded
96 in to something that can be JSON encoded. Defaults to None.
97 sort_keys (bool, optional): Sort dictionary keys. Defaults to False.
98 """
99
100 get_console().print_json(
101 json,
102 data=data,
103 indent=indent,
104 highlight=highlight,
105 skip_keys=skip_keys,
106 ensure_ascii=ensure_ascii,
107 check_circular=check_circular,
108 allow_nan=allow_nan,
109 default=default,
110 sort_keys=sort_keys,
111 )
112
113
114 def inspect(
115 obj: Any,
116 *,
117 console: Optional["Console"] = None,
118 title: Optional[str] = None,
119 help: bool = False,
120 methods: bool = False,
121 docs: bool = True,
122 private: bool = False,
123 dunder: bool = False,
124 sort: bool = True,
125 all: bool = False,
126 value: bool = True,
127 ) -> None:
128 """Inspect any Python object.
129
130 * inspect(<OBJECT>) to see summarized info.
131 * inspect(<OBJECT>, methods=True) to see methods.
132 * inspect(<OBJECT>, help=True) to see full (non-abbreviated) help.
133 * inspect(<OBJECT>, private=True) to see private attributes (single underscore).
134 * inspect(<OBJECT>, dunder=True) to see attributes beginning with double underscore.
135 * inspect(<OBJECT>, all=True) to see all attributes.
136
137 Args:
138 obj (Any): An object to inspect.
139 title (str, optional): Title to display over inspect result, or None use type. Defaults to None.
140 help (bool, optional): Show full help text rather than just first paragraph. Defaults to False.
141 methods (bool, optional): Enable inspection of callables. Defaults to False.
142 docs (bool, optional): Also render doc strings. Defaults to True.
143 private (bool, optional): Show private attributes (beginning with underscore). Defaults to False.
144 dunder (bool, optional): Show attributes starting with double underscore. Defaults to False.
145 sort (bool, optional): Sort attributes alphabetically. Defaults to True.
146 all (bool, optional): Show all attributes. Defaults to False.
147 value (bool, optional): Pretty print value. Defaults to True.
148 """
149 _console = console or get_console()
150 from rich._inspect import Inspect
151
152 # Special case for inspect(inspect)
153 is_inspect = obj is inspect
154
155 _inspect = Inspect(
156 obj,
157 title=title,
158 help=is_inspect or help,
159 methods=is_inspect or methods,
160 docs=is_inspect or docs,
161 private=private,
162 dunder=dunder,
163 sort=sort,
164 all=all,
165 value=value,
166 )
167 _console.print(_inspect)
168
169
170 if __name__ == "__main__": # pragma: no cover
171 print("Hello, **World**")
172
[end of rich/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/rich/__init__.py b/rich/__init__.py
--- a/rich/__init__.py
+++ b/rich/__init__.py
@@ -3,6 +3,7 @@
import os
from typing import Callable, IO, TYPE_CHECKING, Any, Optional, Union
+from ._extension import load_ipython_extension
__all__ = ["get_console", "reconfigure", "print", "inspect"]
|
{"golden_diff": "diff --git a/rich/__init__.py b/rich/__init__.py\n--- a/rich/__init__.py\n+++ b/rich/__init__.py\n@@ -3,6 +3,7 @@\n import os\n from typing import Callable, IO, TYPE_CHECKING, Any, Optional, Union\n \n+from ._extension import load_ipython_extension\n \n __all__ = [\"get_console\", \"reconfigure\", \"print\", \"inspect\"]\n", "issue": "[BUG] Rich's IPython extension doesn't work\n**Describe the bug**\r\n\r\nWhen trying to use `%load_ext rich` in **IPython** on Terminal it says following:\r\n```\r\n%Python 3.10.3 (main, Mar 17 2022, 04:46:20) [Clang 12.0.8 (https://android.googlesource.com/toolchain/llvm-project c935d99d7\r\nType 'copyright', 'credits' or 'license' for more information\r\nIPython 8.1.1 -- An enhanced Interactive Python. Type '?' for help.\r\n\r\nIn [1]: %load_ext rich\r\nThe rich module is not an IPython extension.\r\n```\r\n\r\n**Platform**\r\n<details>\r\n<summary>Click to expand</summary>\r\n\r\nWhat platform (Win/Linux/Mac) are you running on? What terminal software are you using?\r\n\r\nI may ask you to copy and paste the output of the following commands. It may save some time if you do it now.\r\n\r\nIf you're using Rich in a terminal:\r\n\r\n```\r\npython -m rich.diagnose\r\npip freeze | grep rich\r\n```\r\n\r\nIf you're using Rich in a Jupyter Notebook, run the following snippet in a cell\r\nand paste the output in your bug report.\r\n\r\n```python\r\nfrom rich.diagnose import report\r\nreport()\r\n```\r\n\r\n</details>\r\n\r\n```\r\n\u276f python -m rich.diagnose\r\npip freeze | grep rich\r\n\u256d\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500 <class 'rich.console.Console'> \u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u256e\r\n\u2502 A high level console interface. \u2502\r\n\u2502 \u2502\r\n\u2502 \u256d\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u256e \u2502\r\n\u2502 \u2502 <console width=70 ColorSystem.TRUECOLOR> \u2502 \u2502\r\n\u2502 \u2570\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u256f \u2502\r\n\u2502 \u2502\r\n\u2502 color_system = 'truecolor' \u2502\r\n\u2502 encoding = 'utf-8' \u2502\r\n\u2502 file = <_io.TextIOWrapper name='<stdout>' mode='w' \u2502\r\n\u2502 encoding='utf-8'> \u2502\r\n\u2502 height = 45 \u2502\r\n\u2502 is_alt_screen = False \u2502\r\n\u2502 is_dumb_terminal = False \u2502\r\n\u2502 is_interactive = True \u2502\r\n\u2502 is_jupyter = False \u2502\r\n\u2502 is_terminal = True \u2502\r\n\u2502 legacy_windows = False \u2502\r\n\u2502 no_color = False \u2502\r\n\u2502 options = ConsoleOptions( \u2502\r\n\u2502 size=ConsoleDimensions( \u2502\r\n\u2502 width=70, \u2502\r\n\u2502 height=45 \u2502\r\n\u2502 ), \u2502\r\n\u2502 legacy_windows=False, \u2502\r\n\u2502 min_width=1, \u2502\r\n\u2502 max_width=70, \u2502\r\n\u2502 is_terminal=True, \u2502\r\n\u2502 encoding='utf-8', \u2502\r\n\u2502 max_height=45, \u2502\r\n\u2502 justify=None, \u2502\r\n\u2502 overflow=None, \u2502\r\n\u2502 no_wrap=False, \u2502\r\n\u2502 highlight=None, \u2502\r\n\u2502 markup=None, \u2502\r\n\u2502 height=None \u2502\r\n\u2502 ) \u2502\r\n\u2502 quiet = False \u2502\r\n\u2502 record = False \u2502\r\n\u2502 safe_box = True \u2502\r\n\u2502 size = ConsoleDimensions(width=70, height=45) \u2502\r\n\u2502 soft_wrap = False \u2502\r\n\u2502 stderr = False \u2502\r\n\u2502 style = None \u2502\r\n\u2502 tab_size = 8 \u2502\r\n\u2502 width = 70 \u2502\r\n\u2570\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u256f\r\n\u256d\u2500\u2500\u2500 <class 'rich._windows.WindowsConsoleFeatures'> \u2500\u2500\u2500\u2500\u256e\r\n\u2502 Windows features available. \u2502\r\n\u2502 \u2502\r\n\u2502 \u256d\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u256e \u2502\r\n\u2502 \u2502 WindowsConsoleFeatures(vt=False, truecolor=False) \u2502 \u2502\r\n\u2502 \u2570\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u256f \u2502\r\n\u2502 \u2502\r\n\u2502 truecolor = False \u2502\r\n\u2502 vt = False \u2502\r\n\u2570\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u256f\r\n\u256d\u2500\u2500\u2500\u2500\u2500\u2500 Environment Variables \u2500\u2500\u2500\u2500\u2500\u2500\u2500\u256e\r\n\u2502 { \u2502\r\n\u2502 'TERM': 'xterm-256color', \u2502\r\n\u2502 'COLORTERM': 'truecolor', \u2502\r\n\u2502 'CLICOLOR': None, \u2502\r\n\u2502 'NO_COLOR': None, \u2502\r\n\u2502 'TERM_PROGRAM': None, \u2502\r\n\u2502 'COLUMNS': None, \u2502\r\n\u2502 'LINES': None, \u2502\r\n\u2502 'JPY_PARENT_PID': None, \u2502\r\n\u2502 'VSCODE_VERBOSE_LOGGING': None \u2502\r\n\u2502 } \u2502\r\n\u2570\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u256f\r\nplatform=\"Linux\"\r\nrich @ file:///storage/emulated/0/Projects/rich\r\n```\r\n\r\n[](https://asciinema.org/a/Xd3qDv897tjdEll0csW5XZk0T)\n", "before_files": [{"content": "\"\"\"Rich text and beautiful formatting in the terminal.\"\"\"\n\nimport os\nfrom typing import Callable, IO, TYPE_CHECKING, Any, Optional, Union\n\n\n__all__ = [\"get_console\", \"reconfigure\", \"print\", \"inspect\"]\n\nif TYPE_CHECKING:\n from .console import Console\n\n# Global console used by alternative print\n_console: Optional[\"Console\"] = None\n\n_IMPORT_CWD = os.path.abspath(os.getcwd())\n\n\ndef get_console() -> \"Console\":\n \"\"\"Get a global :class:`~rich.console.Console` instance. This function is used when Rich requires a Console,\n and hasn't been explicitly given one.\n\n Returns:\n Console: A console instance.\n \"\"\"\n global _console\n if _console is None:\n from .console import Console\n\n _console = Console()\n\n return _console\n\n\ndef reconfigure(*args: Any, **kwargs: Any) -> None:\n \"\"\"Reconfigures the global console by replacing it with another.\n\n Args:\n console (Console): Replacement console instance.\n \"\"\"\n from rich.console import Console\n\n new_console = Console(*args, **kwargs)\n _console = get_console()\n _console.__dict__ = new_console.__dict__\n\n\ndef print(\n *objects: Any,\n sep: str = \" \",\n end: str = \"\\n\",\n file: Optional[IO[str]] = None,\n flush: bool = False,\n) -> None:\n r\"\"\"Print object(s) supplied via positional arguments.\n This function has an identical signature to the built-in print.\n For more advanced features, see the :class:`~rich.console.Console` class.\n\n Args:\n sep (str, optional): Separator between printed objects. Defaults to \" \".\n end (str, optional): Character to write at end of output. Defaults to \"\\\\n\".\n file (IO[str], optional): File to write to, or None for stdout. Defaults to None.\n flush (bool, optional): Has no effect as Rich always flushes output. Defaults to False.\n\n \"\"\"\n from .console import Console\n\n write_console = get_console() if file is None else Console(file=file)\n return write_console.print(*objects, sep=sep, end=end)\n\n\ndef print_json(\n json: Optional[str] = None,\n *,\n data: Any = None,\n indent: Union[None, int, str] = 2,\n highlight: bool = True,\n skip_keys: bool = False,\n ensure_ascii: bool = True,\n check_circular: bool = True,\n allow_nan: bool = True,\n default: Optional[Callable[[Any], Any]] = None,\n sort_keys: bool = False,\n) -> None:\n \"\"\"Pretty prints JSON. Output will be valid JSON.\n\n Args:\n json (str): A string containing JSON.\n data (Any): If json is not supplied, then encode this data.\n indent (int, optional): Number of spaces to indent. Defaults to 2.\n highlight (bool, optional): Enable highlighting of output: Defaults to True.\n skip_keys (bool, optional): Skip keys not of a basic type. Defaults to False.\n ensure_ascii (bool, optional): Escape all non-ascii characters. Defaults to False.\n check_circular (bool, optional): Check for circular references. Defaults to True.\n allow_nan (bool, optional): Allow NaN and Infinity values. Defaults to True.\n default (Callable, optional): A callable that converts values that can not be encoded\n in to something that can be JSON encoded. Defaults to None.\n sort_keys (bool, optional): Sort dictionary keys. Defaults to False.\n \"\"\"\n\n get_console().print_json(\n json,\n data=data,\n indent=indent,\n highlight=highlight,\n skip_keys=skip_keys,\n ensure_ascii=ensure_ascii,\n check_circular=check_circular,\n allow_nan=allow_nan,\n default=default,\n sort_keys=sort_keys,\n )\n\n\ndef inspect(\n obj: Any,\n *,\n console: Optional[\"Console\"] = None,\n title: Optional[str] = None,\n help: bool = False,\n methods: bool = False,\n docs: bool = True,\n private: bool = False,\n dunder: bool = False,\n sort: bool = True,\n all: bool = False,\n value: bool = True,\n) -> None:\n \"\"\"Inspect any Python object.\n\n * inspect(<OBJECT>) to see summarized info.\n * inspect(<OBJECT>, methods=True) to see methods.\n * inspect(<OBJECT>, help=True) to see full (non-abbreviated) help.\n * inspect(<OBJECT>, private=True) to see private attributes (single underscore).\n * inspect(<OBJECT>, dunder=True) to see attributes beginning with double underscore.\n * inspect(<OBJECT>, all=True) to see all attributes.\n\n Args:\n obj (Any): An object to inspect.\n title (str, optional): Title to display over inspect result, or None use type. Defaults to None.\n help (bool, optional): Show full help text rather than just first paragraph. Defaults to False.\n methods (bool, optional): Enable inspection of callables. Defaults to False.\n docs (bool, optional): Also render doc strings. Defaults to True.\n private (bool, optional): Show private attributes (beginning with underscore). Defaults to False.\n dunder (bool, optional): Show attributes starting with double underscore. Defaults to False.\n sort (bool, optional): Sort attributes alphabetically. Defaults to True.\n all (bool, optional): Show all attributes. Defaults to False.\n value (bool, optional): Pretty print value. Defaults to True.\n \"\"\"\n _console = console or get_console()\n from rich._inspect import Inspect\n\n # Special case for inspect(inspect)\n is_inspect = obj is inspect\n\n _inspect = Inspect(\n obj,\n title=title,\n help=is_inspect or help,\n methods=is_inspect or methods,\n docs=is_inspect or docs,\n private=private,\n dunder=dunder,\n sort=sort,\n all=all,\n value=value,\n )\n _console.print(_inspect)\n\n\nif __name__ == \"__main__\": # pragma: no cover\n print(\"Hello, **World**\")\n", "path": "rich/__init__.py"}]}
| 3,432 | 94 |
gh_patches_debug_10336
|
rasdani/github-patches
|
git_diff
|
replicate__cog-555
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`choices` turn input to enum type
With 'choices' of strings, the input is no long string but changed to enum type.
Refer to https://github.com/wty-ustc/HairCLIP/pull/16/files#diff-73c1982d8a085dc10fda2ac7b6f202ae3ff9530ee6a15991c5339051eb10a49aR61, where `editing_type` should be string eg. "both" but the value shows `editing_type.both` and type `<enum 'editing_type'>`
</issue>
<code>
[start of python/cog/predictor.py]
1 from abc import ABC, abstractmethod
2 from collections.abc import Iterator
3 import enum
4 import importlib
5 import inspect
6 import os.path
7 from pathlib import Path
8 from pydantic import create_model, BaseModel
9 from pydantic.fields import FieldInfo
10 from typing import List
11
12 # Added in Python 3.8. Can be from typing if we drop support for <3.8.
13 from typing_extensions import get_origin, get_args
14 import yaml
15
16 from .errors import ConfigDoesNotExist, PredictorNotSet
17 from .types import Input, Path as CogPath, File as CogFile
18
19
20 ALLOWED_INPUT_TYPES = [str, int, float, bool, CogFile, CogPath]
21
22
23 class BasePredictor(ABC):
24 def setup(self):
25 """
26 An optional method to prepare the model so multiple predictions run efficiently.
27 """
28
29 @abstractmethod
30 def predict(self, **kwargs):
31 """
32 Run a single prediction on the model
33 """
34
35
36 def run_prediction(predictor, inputs, cleanup_functions):
37 """
38 Run the predictor on the inputs, and append resulting paths
39 to cleanup functions for removal.
40 """
41 result = predictor.predict(**inputs)
42 if isinstance(result, Path):
43 cleanup_functions.append(result.unlink)
44 return result
45
46
47 def load_predictor():
48 """
49 Reads cog.yaml and constructs an instance of the user-defined Predictor class.
50 """
51
52 # Assumes the working directory is /src
53 config_path = os.path.abspath("cog.yaml")
54 try:
55 with open(config_path) as fh:
56 config = yaml.safe_load(fh)
57 except FileNotFoundError:
58 raise ConfigDoesNotExist(
59 f"Could not find {config_path}",
60 )
61
62 if "predict" not in config:
63 raise PredictorNotSet(
64 "Can't run predictions: 'predict' option not found in cog.yaml"
65 )
66
67 predict_string = config["predict"]
68 module_path, class_name = predict_string.split(":", 1)
69 module_name = os.path.basename(module_path).split(".py", 1)[0]
70 spec = importlib.util.spec_from_file_location(module_name, module_path)
71 module = importlib.util.module_from_spec(spec)
72 spec.loader.exec_module(module)
73 predictor_class = getattr(module, class_name)
74 return predictor_class()
75
76
77 # Base class for inputs, constructed dynamically in get_input_type().
78 # (This can't be a docstring or it gets passed through to the schema.)
79 class BaseInput(BaseModel):
80 def cleanup(self):
81 """
82 Cleanup any temporary files created by the input.
83 """
84 for _, value in self:
85 # Note this is pathlib.Path, which cog.Path is a subclass of. A pathlib.Path object shouldn't make its way here,
86 # but both have an unlink() method, so may as well be safe.
87 if isinstance(value, Path):
88 # This could be missing_ok=True when we drop support for Python 3.7
89 if value.exists():
90 value.unlink()
91
92
93 def get_input_type(predictor: BasePredictor):
94 """
95 Creates a Pydantic Input model from the arguments of a Predictor's predict() method.
96
97 class Predictor(BasePredictor):
98 def predict(self, text: str):
99 ...
100
101 programmatically creates a model like this:
102
103 class Input(BaseModel):
104 text: str
105 """
106
107 signature = inspect.signature(predictor.predict)
108 create_model_kwargs = {}
109
110 order = 0
111
112 for name, parameter in signature.parameters.items():
113 InputType = parameter.annotation
114
115 if InputType is inspect.Signature.empty:
116 raise TypeError(
117 f"No input type provided for parameter `{name}`. Supported input types are: {readable_types_list(ALLOWED_INPUT_TYPES)}."
118 )
119 elif InputType not in ALLOWED_INPUT_TYPES:
120 raise TypeError(
121 f"Unsupported input type {human_readable_type_name(InputType)} for parameter `{name}`. Supported input types are: {readable_types_list(ALLOWED_INPUT_TYPES)}."
122 )
123
124 # if no default is specified, create an empty, required input
125 if parameter.default is inspect.Signature.empty:
126 default = Input()
127 else:
128 default = parameter.default
129 # If user hasn't used `Input`, then wrap it in that
130 if not isinstance(default, FieldInfo):
131 default = Input(default=default)
132
133 # Fields aren't ordered, so use this pattern to ensure defined order
134 # https://github.com/go-openapi/spec/pull/116
135 default.extra["x-order"] = order
136 order += 1
137
138 # Choices!
139 if default.extra.get("choices"):
140 choices = default.extra["choices"]
141 # It will be passed automatically as 'enum' in the schema, so remove it as an extra field.
142 del default.extra["choices"]
143 if InputType == str:
144
145 class StringEnum(str, enum.Enum):
146 pass
147
148 InputType = StringEnum(name, {value: value for value in choices})
149 elif InputType == int:
150 InputType = enum.IntEnum(name, {str(value): value for value in choices})
151 else:
152 raise TypeError(
153 f"The input {name} uses the option choices. Choices can only be used with str or int types."
154 )
155
156 create_model_kwargs[name] = (InputType, default)
157
158 return create_model("Input", **create_model_kwargs, __base__=BaseInput)
159
160
161 def get_output_type(predictor: BasePredictor):
162 """
163 Creates a Pydantic Output model from the return type annotation of a Predictor's predict() method.
164 """
165
166 signature = inspect.signature(predictor.predict)
167 if signature.return_annotation is inspect.Signature.empty:
168 raise TypeError(
169 """You must set an output type. If your model can return multiple output types, you can explicitly set `Any` as the output type.
170
171 For example:
172
173 from typing import Any
174
175 def predict(
176 self,
177 image: Path = Input(description="Input image"),
178 ) -> Any:
179 ...
180 """
181 )
182 else:
183 OutputType = signature.return_annotation
184
185 # The type that goes in the response is a list of the yielded type
186 if get_origin(OutputType) is Iterator:
187 OutputType = List[get_args(OutputType)[0]]
188
189 if not hasattr(OutputType, "__name__") or OutputType.__name__ != "Output":
190 # Wrap the type in a model called "Output" so it is a consistent name in the OpenAPI schema
191 class Output(BaseModel):
192 __root__: OutputType
193
194 OutputType = Output
195
196 return OutputType
197
198
199 def human_readable_type_name(t):
200 """
201 Generates a useful-for-humans label for a type. For builtin types, it's just the class name (eg "str" or "int"). For other types, it includes the module (eg "pathlib.Path" or "cog.File").
202
203 The special case for Cog modules is because the type lives in `cog.types` internally, but just `cog` when included as a dependency.
204 """
205 module = t.__module__
206 if module == "builtins":
207 return t.__qualname__
208 elif module.split(".")[0] == "cog":
209 module = "cog"
210 return module + "." + t.__qualname__
211
212
213 def readable_types_list(type_list):
214 return ", ".join(human_readable_type_name(t) for t in type_list)
215
[end of python/cog/predictor.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/python/cog/predictor.py b/python/cog/predictor.py
--- a/python/cog/predictor.py
+++ b/python/cog/predictor.py
@@ -77,6 +77,11 @@
# Base class for inputs, constructed dynamically in get_input_type().
# (This can't be a docstring or it gets passed through to the schema.)
class BaseInput(BaseModel):
+ class Config:
+ # When using `choices`, the type is converted into an enum to validate
+ # But, after validation, we want to pass the actual value to predict(), not the enum object
+ use_enum_values = True
+
def cleanup(self):
"""
Cleanup any temporary files created by the input.
|
{"golden_diff": "diff --git a/python/cog/predictor.py b/python/cog/predictor.py\n--- a/python/cog/predictor.py\n+++ b/python/cog/predictor.py\n@@ -77,6 +77,11 @@\n # Base class for inputs, constructed dynamically in get_input_type().\n # (This can't be a docstring or it gets passed through to the schema.)\n class BaseInput(BaseModel):\n+ class Config:\n+ # When using `choices`, the type is converted into an enum to validate\n+ # But, after validation, we want to pass the actual value to predict(), not the enum object\n+ use_enum_values = True\n+\n def cleanup(self):\n \"\"\"\n Cleanup any temporary files created by the input.\n", "issue": "`choices` turn input to enum type\nWith 'choices' of strings, the input is no long string but changed to enum type. \r\nRefer to https://github.com/wty-ustc/HairCLIP/pull/16/files#diff-73c1982d8a085dc10fda2ac7b6f202ae3ff9530ee6a15991c5339051eb10a49aR61, where `editing_type` should be string eg. \"both\" but the value shows `editing_type.both` and type `<enum 'editing_type'>`\r\n\r\n\n", "before_files": [{"content": "from abc import ABC, abstractmethod\nfrom collections.abc import Iterator\nimport enum\nimport importlib\nimport inspect\nimport os.path\nfrom pathlib import Path\nfrom pydantic import create_model, BaseModel\nfrom pydantic.fields import FieldInfo\nfrom typing import List\n\n# Added in Python 3.8. Can be from typing if we drop support for <3.8.\nfrom typing_extensions import get_origin, get_args\nimport yaml\n\nfrom .errors import ConfigDoesNotExist, PredictorNotSet\nfrom .types import Input, Path as CogPath, File as CogFile\n\n\nALLOWED_INPUT_TYPES = [str, int, float, bool, CogFile, CogPath]\n\n\nclass BasePredictor(ABC):\n def setup(self):\n \"\"\"\n An optional method to prepare the model so multiple predictions run efficiently.\n \"\"\"\n\n @abstractmethod\n def predict(self, **kwargs):\n \"\"\"\n Run a single prediction on the model\n \"\"\"\n\n\ndef run_prediction(predictor, inputs, cleanup_functions):\n \"\"\"\n Run the predictor on the inputs, and append resulting paths\n to cleanup functions for removal.\n \"\"\"\n result = predictor.predict(**inputs)\n if isinstance(result, Path):\n cleanup_functions.append(result.unlink)\n return result\n\n\ndef load_predictor():\n \"\"\"\n Reads cog.yaml and constructs an instance of the user-defined Predictor class.\n \"\"\"\n\n # Assumes the working directory is /src\n config_path = os.path.abspath(\"cog.yaml\")\n try:\n with open(config_path) as fh:\n config = yaml.safe_load(fh)\n except FileNotFoundError:\n raise ConfigDoesNotExist(\n f\"Could not find {config_path}\",\n )\n\n if \"predict\" not in config:\n raise PredictorNotSet(\n \"Can't run predictions: 'predict' option not found in cog.yaml\"\n )\n\n predict_string = config[\"predict\"]\n module_path, class_name = predict_string.split(\":\", 1)\n module_name = os.path.basename(module_path).split(\".py\", 1)[0]\n spec = importlib.util.spec_from_file_location(module_name, module_path)\n module = importlib.util.module_from_spec(spec)\n spec.loader.exec_module(module)\n predictor_class = getattr(module, class_name)\n return predictor_class()\n\n\n# Base class for inputs, constructed dynamically in get_input_type().\n# (This can't be a docstring or it gets passed through to the schema.)\nclass BaseInput(BaseModel):\n def cleanup(self):\n \"\"\"\n Cleanup any temporary files created by the input.\n \"\"\"\n for _, value in self:\n # Note this is pathlib.Path, which cog.Path is a subclass of. A pathlib.Path object shouldn't make its way here,\n # but both have an unlink() method, so may as well be safe.\n if isinstance(value, Path):\n # This could be missing_ok=True when we drop support for Python 3.7\n if value.exists():\n value.unlink()\n\n\ndef get_input_type(predictor: BasePredictor):\n \"\"\"\n Creates a Pydantic Input model from the arguments of a Predictor's predict() method.\n\n class Predictor(BasePredictor):\n def predict(self, text: str):\n ...\n\n programmatically creates a model like this:\n\n class Input(BaseModel):\n text: str\n \"\"\"\n\n signature = inspect.signature(predictor.predict)\n create_model_kwargs = {}\n\n order = 0\n\n for name, parameter in signature.parameters.items():\n InputType = parameter.annotation\n\n if InputType is inspect.Signature.empty:\n raise TypeError(\n f\"No input type provided for parameter `{name}`. Supported input types are: {readable_types_list(ALLOWED_INPUT_TYPES)}.\"\n )\n elif InputType not in ALLOWED_INPUT_TYPES:\n raise TypeError(\n f\"Unsupported input type {human_readable_type_name(InputType)} for parameter `{name}`. Supported input types are: {readable_types_list(ALLOWED_INPUT_TYPES)}.\"\n )\n\n # if no default is specified, create an empty, required input\n if parameter.default is inspect.Signature.empty:\n default = Input()\n else:\n default = parameter.default\n # If user hasn't used `Input`, then wrap it in that\n if not isinstance(default, FieldInfo):\n default = Input(default=default)\n\n # Fields aren't ordered, so use this pattern to ensure defined order\n # https://github.com/go-openapi/spec/pull/116\n default.extra[\"x-order\"] = order\n order += 1\n\n # Choices!\n if default.extra.get(\"choices\"):\n choices = default.extra[\"choices\"]\n # It will be passed automatically as 'enum' in the schema, so remove it as an extra field.\n del default.extra[\"choices\"]\n if InputType == str:\n\n class StringEnum(str, enum.Enum):\n pass\n\n InputType = StringEnum(name, {value: value for value in choices})\n elif InputType == int:\n InputType = enum.IntEnum(name, {str(value): value for value in choices})\n else:\n raise TypeError(\n f\"The input {name} uses the option choices. Choices can only be used with str or int types.\"\n )\n\n create_model_kwargs[name] = (InputType, default)\n\n return create_model(\"Input\", **create_model_kwargs, __base__=BaseInput)\n\n\ndef get_output_type(predictor: BasePredictor):\n \"\"\"\n Creates a Pydantic Output model from the return type annotation of a Predictor's predict() method.\n \"\"\"\n\n signature = inspect.signature(predictor.predict)\n if signature.return_annotation is inspect.Signature.empty:\n raise TypeError(\n \"\"\"You must set an output type. If your model can return multiple output types, you can explicitly set `Any` as the output type.\n\nFor example:\n\n from typing import Any\n\n def predict(\n self,\n image: Path = Input(description=\"Input image\"),\n ) -> Any:\n ...\n\"\"\"\n )\n else:\n OutputType = signature.return_annotation\n\n # The type that goes in the response is a list of the yielded type\n if get_origin(OutputType) is Iterator:\n OutputType = List[get_args(OutputType)[0]]\n\n if not hasattr(OutputType, \"__name__\") or OutputType.__name__ != \"Output\":\n # Wrap the type in a model called \"Output\" so it is a consistent name in the OpenAPI schema\n class Output(BaseModel):\n __root__: OutputType\n\n OutputType = Output\n\n return OutputType\n\n\ndef human_readable_type_name(t):\n \"\"\"\n Generates a useful-for-humans label for a type. For builtin types, it's just the class name (eg \"str\" or \"int\"). For other types, it includes the module (eg \"pathlib.Path\" or \"cog.File\").\n\n The special case for Cog modules is because the type lives in `cog.types` internally, but just `cog` when included as a dependency.\n \"\"\"\n module = t.__module__\n if module == \"builtins\":\n return t.__qualname__\n elif module.split(\".\")[0] == \"cog\":\n module = \"cog\"\n return module + \".\" + t.__qualname__\n\n\ndef readable_types_list(type_list):\n return \", \".join(human_readable_type_name(t) for t in type_list)\n", "path": "python/cog/predictor.py"}]}
| 2,815 | 162 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.