
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
18.9k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 465
23.6k
| num_tokens_prompt
int64 556
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_16186
|
rasdani/github-patches
|
git_diff
|
bookwyrm-social__bookwyrm-909
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Make user handle search case insensitive
**Is your feature request related to a problem? Please describe.**
I'm not sure if this is intentional, but currently, you can only look up users if you spell their name witht he correct cases. This is also the case when you try to find BW users from Mastodon. I don't think case sensitivity makes much sense here.
**Additional context**
Mastodon hase case insensitive user names as well.
One can also register `Tofuwabohu` when there is a `tofuwabohu` already. I think that should be prevented before instances get opened?
</issue>
<code>
[start of bookwyrm/views/helpers.py]
1 """ helper functions used in various views """
2 import re
3 from requests import HTTPError
4 from django.core.exceptions import FieldError
5 from django.db.models import Count, Max, Q
6
7 from bookwyrm import activitypub, models
8 from bookwyrm.connectors import ConnectorException, get_data
9 from bookwyrm.status import create_generated_note
10 from bookwyrm.utils import regex
11
12
13 def get_user_from_username(viewer, username):
14 """ helper function to resolve a localname or a username to a user """
15 # raises DoesNotExist if user is now found
16 try:
17 return models.User.viewer_aware_objects(viewer).get(localname=username)
18 except models.User.DoesNotExist:
19 return models.User.viewer_aware_objects(viewer).get(username=username)
20
21
22 def is_api_request(request):
23 """ check whether a request is asking for html or data """
24 return "json" in request.headers.get("Accept", "") or request.path[-5:] == ".json"
25
26
27 def is_bookwyrm_request(request):
28 """ check if the request is coming from another bookwyrm instance """
29 user_agent = request.headers.get("User-Agent")
30 if user_agent is None or re.search(regex.bookwyrm_user_agent, user_agent) is None:
31 return False
32 return True
33
34
35 def object_visible_to_user(viewer, obj):
36 """ is a user authorized to view an object? """
37 if not obj:
38 return False
39
40 # viewer can't see it if the object's owner blocked them
41 if viewer in obj.user.blocks.all():
42 return False
43
44 # you can see your own posts and any public or unlisted posts
45 if viewer == obj.user or obj.privacy in ["public", "unlisted"]:
46 return True
47
48 # you can see the followers only posts of people you follow
49 if obj.privacy == "followers" and obj.user.followers.filter(id=viewer.id).first():
50 return True
51
52 # you can see dms you are tagged in
53 if isinstance(obj, models.Status):
54 if obj.privacy == "direct" and obj.mention_users.filter(id=viewer.id).first():
55 return True
56 return False
57
58
59 def privacy_filter(viewer, queryset, privacy_levels=None, following_only=False):
60 """ filter objects that have "user" and "privacy" fields """
61 privacy_levels = privacy_levels or ["public", "unlisted", "followers", "direct"]
62 # if there'd a deleted field, exclude deleted items
63 try:
64 queryset = queryset.filter(deleted=False)
65 except FieldError:
66 pass
67
68 # exclude blocks from both directions
69 if not viewer.is_anonymous:
70 blocked = models.User.objects.filter(id__in=viewer.blocks.all()).all()
71 queryset = queryset.exclude(Q(user__in=blocked) | Q(user__blocks=viewer))
72
73 # you can't see followers only or direct messages if you're not logged in
74 if viewer.is_anonymous:
75 privacy_levels = [p for p in privacy_levels if not p in ["followers", "direct"]]
76
77 # filter to only privided privacy levels
78 queryset = queryset.filter(privacy__in=privacy_levels)
79
80 # only include statuses the user follows
81 if following_only:
82 queryset = queryset.exclude(
83 ~Q( # remove everythign except
84 Q(user__in=viewer.following.all())
85 | Q(user=viewer) # user following
86 | Q(mention_users=viewer) # is self # mentions user
87 ),
88 )
89 # exclude followers-only statuses the user doesn't follow
90 elif "followers" in privacy_levels:
91 queryset = queryset.exclude(
92 ~Q( # user isn't following and it isn't their own status
93 Q(user__in=viewer.following.all()) | Q(user=viewer)
94 ),
95 privacy="followers", # and the status is followers only
96 )
97
98 # exclude direct messages not intended for the user
99 if "direct" in privacy_levels:
100 try:
101 queryset = queryset.exclude(
102 ~Q(Q(user=viewer) | Q(mention_users=viewer)), privacy="direct"
103 )
104 except FieldError:
105 queryset = queryset.exclude(~Q(user=viewer), privacy="direct")
106
107 return queryset
108
109
110 def handle_remote_webfinger(query):
111 """ webfingerin' other servers """
112 user = None
113
114 # usernames could be @user@domain or user@domain
115 if not query:
116 return None
117
118 if query[0] == "@":
119 query = query[1:]
120
121 try:
122 domain = query.split("@")[1]
123 except IndexError:
124 return None
125
126 try:
127 user = models.User.objects.get(username=query)
128 except models.User.DoesNotExist:
129 url = "https://%s/.well-known/webfinger?resource=acct:%s" % (domain, query)
130 try:
131 data = get_data(url)
132 except (ConnectorException, HTTPError):
133 return None
134
135 for link in data.get("links"):
136 if link.get("rel") == "self":
137 try:
138 user = activitypub.resolve_remote_id(
139 link["href"], model=models.User
140 )
141 except (KeyError, activitypub.ActivitySerializerError):
142 return None
143 return user
144
145
146 def get_edition(book_id):
147 """ look up a book in the db and return an edition """
148 book = models.Book.objects.select_subclasses().get(id=book_id)
149 if isinstance(book, models.Work):
150 book = book.get_default_edition()
151 return book
152
153
154 def handle_reading_status(user, shelf, book, privacy):
155 """ post about a user reading a book """
156 # tell the world about this cool thing that happened
157 try:
158 message = {
159 "to-read": "wants to read",
160 "reading": "started reading",
161 "read": "finished reading",
162 }[shelf.identifier]
163 except KeyError:
164 # it's a non-standard shelf, don't worry about it
165 return
166
167 status = create_generated_note(user, message, mention_books=[book], privacy=privacy)
168 status.save()
169
170
171 def is_blocked(viewer, user):
172 """ is this viewer blocked by the user? """
173 if viewer.is_authenticated and viewer in user.blocks.all():
174 return True
175 return False
176
177
178 def get_discover_books():
179 """ list of books for the discover page """
180 return list(
181 set(
182 models.Edition.objects.filter(
183 review__published_date__isnull=False,
184 review__deleted=False,
185 review__user__local=True,
186 review__privacy__in=["public", "unlisted"],
187 )
188 .exclude(cover__exact="")
189 .annotate(Max("review__published_date"))
190 .order_by("-review__published_date__max")[:6]
191 )
192 )
193
194
195 def get_suggested_users(user):
196 """ bookwyrm users you don't already know """
197 return (
198 get_annotated_users(
199 user,
200 ~Q(id=user.id),
201 ~Q(followers=user),
202 ~Q(follower_requests=user),
203 bookwyrm_user=True,
204 )
205 .order_by("-mutuals", "-last_active_date")
206 .all()[:5]
207 )
208
209
210 def get_annotated_users(user, *args, **kwargs):
211 """ Users, annotated with things they have in common """
212 return (
213 models.User.objects.filter(discoverable=True, is_active=True, *args, **kwargs)
214 .exclude(Q(id__in=user.blocks.all()) | Q(blocks=user))
215 .annotate(
216 mutuals=Count(
217 "following",
218 filter=Q(
219 ~Q(id=user.id),
220 ~Q(id__in=user.following.all()),
221 following__in=user.following.all(),
222 ),
223 distinct=True,
224 ),
225 shared_books=Count(
226 "shelfbook",
227 filter=Q(
228 ~Q(id=user.id),
229 shelfbook__book__parent_work__in=[
230 s.book.parent_work for s in user.shelfbook_set.all()
231 ],
232 ),
233 distinct=True,
234 ),
235 )
236 )
237
[end of bookwyrm/views/helpers.py]
[start of bookwyrm/views/search.py]
1 """ search views"""
2 import re
3
4 from django.contrib.postgres.search import TrigramSimilarity
5 from django.db.models.functions import Greatest
6 from django.http import JsonResponse
7 from django.template.response import TemplateResponse
8 from django.views import View
9
10 from bookwyrm import models
11 from bookwyrm.connectors import connector_manager
12 from bookwyrm.utils import regex
13 from .helpers import is_api_request, privacy_filter
14 from .helpers import handle_remote_webfinger
15
16
17 # pylint: disable= no-self-use
18 class Search(View):
19 """ search users or books """
20
21 def get(self, request):
22 """ that search bar up top """
23 query = request.GET.get("q")
24 min_confidence = request.GET.get("min_confidence", 0.1)
25
26 if is_api_request(request):
27 # only return local book results via json so we don't cascade
28 book_results = connector_manager.local_search(
29 query, min_confidence=min_confidence
30 )
31 return JsonResponse([r.json() for r in book_results], safe=False)
32
33 # use webfinger for mastodon style [email protected] username
34 if query and re.match(regex.full_username, query):
35 handle_remote_webfinger(query)
36
37 # do a user search
38 user_results = (
39 models.User.viewer_aware_objects(request.user)
40 .annotate(
41 similarity=Greatest(
42 TrigramSimilarity("username", query),
43 TrigramSimilarity("localname", query),
44 )
45 )
46 .filter(
47 similarity__gt=0.5,
48 )
49 .order_by("-similarity")[:10]
50 )
51
52 # any relevent lists?
53 list_results = (
54 privacy_filter(
55 request.user,
56 models.List.objects,
57 privacy_levels=["public", "followers"],
58 )
59 .annotate(
60 similarity=Greatest(
61 TrigramSimilarity("name", query),
62 TrigramSimilarity("description", query),
63 )
64 )
65 .filter(
66 similarity__gt=0.1,
67 )
68 .order_by("-similarity")[:10]
69 )
70
71 book_results = connector_manager.search(query, min_confidence=min_confidence)
72 data = {
73 "book_results": book_results,
74 "user_results": user_results,
75 "list_results": list_results,
76 "query": query or "",
77 }
78 return TemplateResponse(request, "search_results.html", data)
79
[end of bookwyrm/views/search.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bookwyrm/views/helpers.py b/bookwyrm/views/helpers.py
--- a/bookwyrm/views/helpers.py
+++ b/bookwyrm/views/helpers.py
@@ -124,7 +124,7 @@
return None
try:
- user = models.User.objects.get(username=query)
+ user = models.User.objects.get(username__iexact=query)
except models.User.DoesNotExist:
url = "https://%s/.well-known/webfinger?resource=acct:%s" % (domain, query)
try:
diff --git a/bookwyrm/views/search.py b/bookwyrm/views/search.py
--- a/bookwyrm/views/search.py
+++ b/bookwyrm/views/search.py
@@ -34,7 +34,7 @@
if query and re.match(regex.full_username, query):
handle_remote_webfinger(query)
- # do a user search
+ # do a user search
user_results = (
models.User.viewer_aware_objects(request.user)
.annotate(
|
{"golden_diff": "diff --git a/bookwyrm/views/helpers.py b/bookwyrm/views/helpers.py\n--- a/bookwyrm/views/helpers.py\n+++ b/bookwyrm/views/helpers.py\n@@ -124,7 +124,7 @@\n return None\n \n try:\n- user = models.User.objects.get(username=query)\n+ user = models.User.objects.get(username__iexact=query)\n except models.User.DoesNotExist:\n url = \"https://%s/.well-known/webfinger?resource=acct:%s\" % (domain, query)\n try:\ndiff --git a/bookwyrm/views/search.py b/bookwyrm/views/search.py\n--- a/bookwyrm/views/search.py\n+++ b/bookwyrm/views/search.py\n@@ -34,7 +34,7 @@\n if query and re.match(regex.full_username, query):\n handle_remote_webfinger(query)\n \n- # do a user search\n+ # do a user search\n user_results = (\n models.User.viewer_aware_objects(request.user)\n .annotate(\n", "issue": "Make user handle search case insensitive\n**Is your feature request related to a problem? Please describe.**\r\nI'm not sure if this is intentional, but currently, you can only look up users if you spell their name witht he correct cases. This is also the case when you try to find BW users from Mastodon. I don't think case sensitivity makes much sense here.\r\n\r\n**Additional context**\r\nMastodon hase case insensitive user names as well.\r\n\r\nOne can also register `Tofuwabohu` when there is a `tofuwabohu` already. I think that should be prevented before instances get opened?\n", "before_files": [{"content": "\"\"\" helper functions used in various views \"\"\"\nimport re\nfrom requests import HTTPError\nfrom django.core.exceptions import FieldError\nfrom django.db.models import Count, Max, Q\n\nfrom bookwyrm import activitypub, models\nfrom bookwyrm.connectors import ConnectorException, get_data\nfrom bookwyrm.status import create_generated_note\nfrom bookwyrm.utils import regex\n\n\ndef get_user_from_username(viewer, username):\n \"\"\" helper function to resolve a localname or a username to a user \"\"\"\n # raises DoesNotExist if user is now found\n try:\n return models.User.viewer_aware_objects(viewer).get(localname=username)\n except models.User.DoesNotExist:\n return models.User.viewer_aware_objects(viewer).get(username=username)\n\n\ndef is_api_request(request):\n \"\"\" check whether a request is asking for html or data \"\"\"\n return \"json\" in request.headers.get(\"Accept\", \"\") or request.path[-5:] == \".json\"\n\n\ndef is_bookwyrm_request(request):\n \"\"\" check if the request is coming from another bookwyrm instance \"\"\"\n user_agent = request.headers.get(\"User-Agent\")\n if user_agent is None or re.search(regex.bookwyrm_user_agent, user_agent) is None:\n return False\n return True\n\n\ndef object_visible_to_user(viewer, obj):\n \"\"\" is a user authorized to view an object? \"\"\"\n if not obj:\n return False\n\n # viewer can't see it if the object's owner blocked them\n if viewer in obj.user.blocks.all():\n return False\n\n # you can see your own posts and any public or unlisted posts\n if viewer == obj.user or obj.privacy in [\"public\", \"unlisted\"]:\n return True\n\n # you can see the followers only posts of people you follow\n if obj.privacy == \"followers\" and obj.user.followers.filter(id=viewer.id).first():\n return True\n\n # you can see dms you are tagged in\n if isinstance(obj, models.Status):\n if obj.privacy == \"direct\" and obj.mention_users.filter(id=viewer.id).first():\n return True\n return False\n\n\ndef privacy_filter(viewer, queryset, privacy_levels=None, following_only=False):\n \"\"\" filter objects that have \"user\" and \"privacy\" fields \"\"\"\n privacy_levels = privacy_levels or [\"public\", \"unlisted\", \"followers\", \"direct\"]\n # if there'd a deleted field, exclude deleted items\n try:\n queryset = queryset.filter(deleted=False)\n except FieldError:\n pass\n\n # exclude blocks from both directions\n if not viewer.is_anonymous:\n blocked = models.User.objects.filter(id__in=viewer.blocks.all()).all()\n queryset = queryset.exclude(Q(user__in=blocked) | Q(user__blocks=viewer))\n\n # you can't see followers only or direct messages if you're not logged in\n if viewer.is_anonymous:\n privacy_levels = [p for p in privacy_levels if not p in [\"followers\", \"direct\"]]\n\n # filter to only privided privacy levels\n queryset = queryset.filter(privacy__in=privacy_levels)\n\n # only include statuses the user follows\n if following_only:\n queryset = queryset.exclude(\n ~Q( # remove everythign except\n Q(user__in=viewer.following.all())\n | Q(user=viewer) # user following\n | Q(mention_users=viewer) # is self # mentions user\n ),\n )\n # exclude followers-only statuses the user doesn't follow\n elif \"followers\" in privacy_levels:\n queryset = queryset.exclude(\n ~Q( # user isn't following and it isn't their own status\n Q(user__in=viewer.following.all()) | Q(user=viewer)\n ),\n privacy=\"followers\", # and the status is followers only\n )\n\n # exclude direct messages not intended for the user\n if \"direct\" in privacy_levels:\n try:\n queryset = queryset.exclude(\n ~Q(Q(user=viewer) | Q(mention_users=viewer)), privacy=\"direct\"\n )\n except FieldError:\n queryset = queryset.exclude(~Q(user=viewer), privacy=\"direct\")\n\n return queryset\n\n\ndef handle_remote_webfinger(query):\n \"\"\" webfingerin' other servers \"\"\"\n user = None\n\n # usernames could be @user@domain or user@domain\n if not query:\n return None\n\n if query[0] == \"@\":\n query = query[1:]\n\n try:\n domain = query.split(\"@\")[1]\n except IndexError:\n return None\n\n try:\n user = models.User.objects.get(username=query)\n except models.User.DoesNotExist:\n url = \"https://%s/.well-known/webfinger?resource=acct:%s\" % (domain, query)\n try:\n data = get_data(url)\n except (ConnectorException, HTTPError):\n return None\n\n for link in data.get(\"links\"):\n if link.get(\"rel\") == \"self\":\n try:\n user = activitypub.resolve_remote_id(\n link[\"href\"], model=models.User\n )\n except (KeyError, activitypub.ActivitySerializerError):\n return None\n return user\n\n\ndef get_edition(book_id):\n \"\"\" look up a book in the db and return an edition \"\"\"\n book = models.Book.objects.select_subclasses().get(id=book_id)\n if isinstance(book, models.Work):\n book = book.get_default_edition()\n return book\n\n\ndef handle_reading_status(user, shelf, book, privacy):\n \"\"\" post about a user reading a book \"\"\"\n # tell the world about this cool thing that happened\n try:\n message = {\n \"to-read\": \"wants to read\",\n \"reading\": \"started reading\",\n \"read\": \"finished reading\",\n }[shelf.identifier]\n except KeyError:\n # it's a non-standard shelf, don't worry about it\n return\n\n status = create_generated_note(user, message, mention_books=[book], privacy=privacy)\n status.save()\n\n\ndef is_blocked(viewer, user):\n \"\"\" is this viewer blocked by the user? \"\"\"\n if viewer.is_authenticated and viewer in user.blocks.all():\n return True\n return False\n\n\ndef get_discover_books():\n \"\"\" list of books for the discover page \"\"\"\n return list(\n set(\n models.Edition.objects.filter(\n review__published_date__isnull=False,\n review__deleted=False,\n review__user__local=True,\n review__privacy__in=[\"public\", \"unlisted\"],\n )\n .exclude(cover__exact=\"\")\n .annotate(Max(\"review__published_date\"))\n .order_by(\"-review__published_date__max\")[:6]\n )\n )\n\n\ndef get_suggested_users(user):\n \"\"\" bookwyrm users you don't already know \"\"\"\n return (\n get_annotated_users(\n user,\n ~Q(id=user.id),\n ~Q(followers=user),\n ~Q(follower_requests=user),\n bookwyrm_user=True,\n )\n .order_by(\"-mutuals\", \"-last_active_date\")\n .all()[:5]\n )\n\n\ndef get_annotated_users(user, *args, **kwargs):\n \"\"\" Users, annotated with things they have in common \"\"\"\n return (\n models.User.objects.filter(discoverable=True, is_active=True, *args, **kwargs)\n .exclude(Q(id__in=user.blocks.all()) | Q(blocks=user))\n .annotate(\n mutuals=Count(\n \"following\",\n filter=Q(\n ~Q(id=user.id),\n ~Q(id__in=user.following.all()),\n following__in=user.following.all(),\n ),\n distinct=True,\n ),\n shared_books=Count(\n \"shelfbook\",\n filter=Q(\n ~Q(id=user.id),\n shelfbook__book__parent_work__in=[\n s.book.parent_work for s in user.shelfbook_set.all()\n ],\n ),\n distinct=True,\n ),\n )\n )\n", "path": "bookwyrm/views/helpers.py"}, {"content": "\"\"\" search views\"\"\"\nimport re\n\nfrom django.contrib.postgres.search import TrigramSimilarity\nfrom django.db.models.functions import Greatest\nfrom django.http import JsonResponse\nfrom django.template.response import TemplateResponse\nfrom django.views import View\n\nfrom bookwyrm import models\nfrom bookwyrm.connectors import connector_manager\nfrom bookwyrm.utils import regex\nfrom .helpers import is_api_request, privacy_filter\nfrom .helpers import handle_remote_webfinger\n\n\n# pylint: disable= no-self-use\nclass Search(View):\n \"\"\" search users or books \"\"\"\n\n def get(self, request):\n \"\"\" that search bar up top \"\"\"\n query = request.GET.get(\"q\")\n min_confidence = request.GET.get(\"min_confidence\", 0.1)\n\n if is_api_request(request):\n # only return local book results via json so we don't cascade\n book_results = connector_manager.local_search(\n query, min_confidence=min_confidence\n )\n return JsonResponse([r.json() for r in book_results], safe=False)\n\n # use webfinger for mastodon style [email protected] username\n if query and re.match(regex.full_username, query):\n handle_remote_webfinger(query)\n\n # do a user search\n user_results = (\n models.User.viewer_aware_objects(request.user)\n .annotate(\n similarity=Greatest(\n TrigramSimilarity(\"username\", query),\n TrigramSimilarity(\"localname\", query),\n )\n )\n .filter(\n similarity__gt=0.5,\n )\n .order_by(\"-similarity\")[:10]\n )\n\n # any relevent lists?\n list_results = (\n privacy_filter(\n request.user,\n models.List.objects,\n privacy_levels=[\"public\", \"followers\"],\n )\n .annotate(\n similarity=Greatest(\n TrigramSimilarity(\"name\", query),\n TrigramSimilarity(\"description\", query),\n )\n )\n .filter(\n similarity__gt=0.1,\n )\n .order_by(\"-similarity\")[:10]\n )\n\n book_results = connector_manager.search(query, min_confidence=min_confidence)\n data = {\n \"book_results\": book_results,\n \"user_results\": user_results,\n \"list_results\": list_results,\n \"query\": query or \"\",\n }\n return TemplateResponse(request, \"search_results.html\", data)\n", "path": "bookwyrm/views/search.py"}]}
| 3,672 | 220 |
gh_patches_debug_6496
|
rasdani/github-patches
|
git_diff
|
interlegis__sapl-3150
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Períodos de parlamentares sumiram
## Comportamento Esperado
Devem aparecer todos os períodos dos parlamentares, correspondentes às legislaturas.
## Comportamento Atual
Aparecem apenas da 6ª legislatura à atual.
Passos para Reproduzir (para bugs)
https://sapl.agudo.rs.leg.br/parlamentar/
## Contexto
Pesquisa de parlamentares por legislatura.
## Imagens do Ocorrido

## Seu Ambiente
Versão usada (Release): 3.1.160-RC11
Nome e versão do navegador: Versão 80.0.3987.163 (Versão oficial)
Nome e versão do Sistema Operacional (desktop ou mobile): Ubuntu 16.04 64 bits
</issue>
<code>
[start of sapl/api/pagination.py]
1 from django.core.paginator import EmptyPage
2 from rest_framework import pagination
3 from rest_framework.response import Response
4
5
6 class StandardPagination(pagination.PageNumberPagination):
7 page_size = 10
8 page_size_query_param = 'page_size'
9 max_page_size = 50
10
11 def get_paginated_response(self, data):
12 try:
13 previous_page_number = self.page.previous_page_number()
14 except EmptyPage:
15 previous_page_number = None
16
17 try:
18 next_page_number = self.page.next_page_number()
19 except EmptyPage:
20 next_page_number = None
21
22 return Response({
23 'pagination': {
24 'previous_page': previous_page_number,
25 'next_page': next_page_number,
26 'start_index': self.page.start_index(),
27 'end_index': self.page.end_index(),
28 'total_entries': self.page.paginator.count,
29 'total_pages': self.page.paginator.num_pages,
30 'page': self.page.number,
31 },
32 'results': data,
33
34 })
35
[end of sapl/api/pagination.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sapl/api/pagination.py b/sapl/api/pagination.py
--- a/sapl/api/pagination.py
+++ b/sapl/api/pagination.py
@@ -8,6 +8,11 @@
page_size_query_param = 'page_size'
max_page_size = 50
+ def paginate_queryset(self, queryset, request, view=None):
+ if request.query_params.get('get_all', False) == 'true':
+ return None
+ return super().paginate_queryset(queryset, request, view=view)
+
def get_paginated_response(self, data):
try:
previous_page_number = self.page.previous_page_number()
|
{"golden_diff": "diff --git a/sapl/api/pagination.py b/sapl/api/pagination.py\n--- a/sapl/api/pagination.py\n+++ b/sapl/api/pagination.py\n@@ -8,6 +8,11 @@\n page_size_query_param = 'page_size'\n max_page_size = 50\n \n+ def paginate_queryset(self, queryset, request, view=None):\n+ if request.query_params.get('get_all', False) == 'true':\n+ return None\n+ return super().paginate_queryset(queryset, request, view=view)\n+\n def get_paginated_response(self, data):\n try:\n previous_page_number = self.page.previous_page_number()\n", "issue": "Per\u00edodos de parlamentares sumiram\n## Comportamento Esperado\r\nDevem aparecer todos os per\u00edodos dos parlamentares, correspondentes \u00e0s legislaturas.\r\n\r\n## Comportamento Atual\r\nAparecem apenas da 6\u00aa legislatura \u00e0 atual.\r\n\r\nPassos para Reproduzir (para bugs)\r\nhttps://sapl.agudo.rs.leg.br/parlamentar/\r\n\r\n## Contexto\r\nPesquisa de parlamentares por legislatura.\r\n\r\n## Imagens do Ocorrido\r\n\r\n\r\n## Seu Ambiente\r\nVers\u00e3o usada (Release): 3.1.160-RC11\r\nNome e vers\u00e3o do navegador: Vers\u00e3o 80.0.3987.163 (Vers\u00e3o oficial)\r\nNome e vers\u00e3o do Sistema Operacional (desktop ou mobile): Ubuntu 16.04 64 bits\r\n\r\n\n", "before_files": [{"content": "from django.core.paginator import EmptyPage\nfrom rest_framework import pagination\nfrom rest_framework.response import Response\n\n\nclass StandardPagination(pagination.PageNumberPagination):\n page_size = 10\n page_size_query_param = 'page_size'\n max_page_size = 50\n\n def get_paginated_response(self, data):\n try:\n previous_page_number = self.page.previous_page_number()\n except EmptyPage:\n previous_page_number = None\n\n try:\n next_page_number = self.page.next_page_number()\n except EmptyPage:\n next_page_number = None\n\n return Response({\n 'pagination': {\n 'previous_page': previous_page_number,\n 'next_page': next_page_number,\n 'start_index': self.page.start_index(),\n 'end_index': self.page.end_index(),\n 'total_entries': self.page.paginator.count,\n 'total_pages': self.page.paginator.num_pages,\n 'page': self.page.number,\n },\n 'results': data,\n\n })\n", "path": "sapl/api/pagination.py"}]}
| 1,084 | 142 |
gh_patches_debug_20074
|
rasdani/github-patches
|
git_diff
|
litestar-org__litestar-3430
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug: regular handler under asgi mount path conflicts with routing to asgi app
### Description
If we have a regular handler mounted under an asgi mounted path, and the path of the regular handler is a non-prefix sub-string of the a request path the request will not get routed to the asgi app.
I.e., if we have an asgi mounted on `"/"`, and a regular handler at `"/path"`, a request to `"/some/path"` does not get routed to the asgi app.
### URL to code causing the issue
_No response_
### MCVE
```python
from __future__ import annotations
from typing import TYPE_CHECKING
from litestar import Litestar, asgi, get
from litestar.testing import TestClient
if TYPE_CHECKING:
from litestar.types.asgi_types import Receive, Scope, Send
async def asgi_app(scope: Scope, receive: Receive, send: Send) -> None:
assert scope["type"] == "http"
await send({
"type": "http.response.start",
"status": 200,
"headers": [
(b"content-type", b"text/plain"),
(b"content-length", b"%d" % len(scope["raw_path"])),
],
})
await send({
"type": "http.response.body",
"body": scope["raw_path"],
})
asgi_handler = asgi("/", is_mount=True)(asgi_app)
@get("/path")
def get_handler() -> str:
return "Hello, world!"
def test_regular_handler_under_mounted_asgi_app() -> None:
app = Litestar(
route_handlers=[asgi("/", is_mount=True)(asgi_app), get_handler],
openapi_config=None,
debug=True,
)
with TestClient(app) as client:
resp = client.get("/some/path") # currently this is a 404
assert resp.content == b"/some/path"
```
### Steps to reproduce
```bash
1. Go to '...'
2. Click on '....'
3. Scroll down to '....'
4. See error
```
### Screenshots
```bash
""
```
### Logs
_No response_
### Litestar Version
main
### Platform
- [X] Linux
- [ ] Mac
- [ ] Windows
- [ ] Other (Please specify in the description above)
<!-- POLAR PLEDGE BADGE START -->
---
> [!NOTE]
> While we are open for sponsoring on [GitHub Sponsors](https://github.com/sponsors/litestar-org/) and
> [OpenCollective](https://opencollective.com/litestar), we also utilize [Polar.sh](https://polar.sh/) to engage in pledge-based sponsorship.
>
> Check out all issues funded or available for funding [on our Polar.sh dashboard](https://polar.sh/litestar-org)
> * If you would like to see an issue prioritized, make a pledge towards it!
> * We receive the pledge once the issue is completed & verified
> * This, along with engagement in the community, helps us know which features are a priority to our users.
<a href="https://polar.sh/litestar-org/litestar/issues/3429">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://polar.sh/api/github/litestar-org/litestar/issues/3429/pledge.svg?darkmode=1">
<img alt="Fund with Polar" src="https://polar.sh/api/github/litestar-org/litestar/issues/3429/pledge.svg">
</picture>
</a>
<!-- POLAR PLEDGE BADGE END -->
</issue>
<code>
[start of litestar/_asgi/routing_trie/traversal.py]
1 from __future__ import annotations
2
3 from functools import lru_cache
4 from typing import TYPE_CHECKING, Any, Pattern
5
6 from litestar._asgi.routing_trie.types import PathParameterSentinel
7 from litestar.exceptions import MethodNotAllowedException, NotFoundException
8 from litestar.utils import normalize_path
9
10 __all__ = ("parse_node_handlers", "parse_path_params", "parse_path_to_route", "traverse_route_map")
11
12
13 if TYPE_CHECKING:
14 from litestar._asgi.routing_trie.types import ASGIHandlerTuple, RouteTrieNode
15 from litestar.types import ASGIApp, Method, RouteHandlerType
16 from litestar.types.internal_types import PathParameterDefinition
17
18
19 def traverse_route_map(
20 root_node: RouteTrieNode,
21 path: str,
22 ) -> tuple[RouteTrieNode, list[str], str]:
23 """Traverses the application route mapping and retrieves the correct node for the request url.
24
25 Args:
26 root_node: The root trie node.
27 path: The request's path.
28
29 Raises:
30 NotFoundException: If no correlating node is found.
31
32 Returns:
33 A tuple containing the target RouteMapNode and a list containing all path parameter values.
34 """
35 current_node = root_node
36 path_params: list[str] = []
37 path_components = [p for p in path.split("/") if p]
38
39 for i, component in enumerate(path_components):
40 if component in current_node.child_keys:
41 current_node = current_node.children[component]
42 continue
43
44 if current_node.is_path_param_node:
45 current_node = current_node.children[PathParameterSentinel]
46
47 if current_node.is_path_type:
48 path_params.append(normalize_path("/".join(path_components[i:])))
49 break
50
51 path_params.append(component)
52 continue
53
54 raise NotFoundException()
55
56 if not current_node.asgi_handlers:
57 raise NotFoundException()
58
59 return current_node, path_params, path
60
61
62 def parse_node_handlers(
63 node: RouteTrieNode,
64 method: Method | None,
65 ) -> ASGIHandlerTuple:
66 """Retrieve the handler tuple from the node.
67
68 Args:
69 node: The trie node to parse.
70 method: The scope's method.
71
72 Raises:
73 KeyError: If no matching method is found.
74
75 Returns:
76 An ASGI Handler tuple.
77 """
78
79 if node.is_asgi:
80 return node.asgi_handlers["asgi"]
81 if method:
82 return node.asgi_handlers[method]
83 return node.asgi_handlers["websocket"]
84
85
86 @lru_cache(1024)
87 def parse_path_params(
88 parameter_definitions: tuple[PathParameterDefinition, ...], path_param_values: tuple[str, ...]
89 ) -> dict[str, Any]:
90 """Parse path parameters into a dictionary of values.
91
92 Args:
93 parameter_definitions: The parameter definitions tuple from the route.
94 path_param_values: The string values extracted from the url
95
96 Raises:
97 ValueError: If any of path parameters can not be parsed into a value.
98
99 Returns:
100 A dictionary of parsed path parameters.
101 """
102 return {
103 param_definition.name: param_definition.parser(value) if param_definition.parser else value
104 for param_definition, value in zip(parameter_definitions, path_param_values)
105 }
106
107
108 def parse_path_to_route(
109 method: Method | None,
110 mount_paths_regex: Pattern | None,
111 mount_routes: dict[str, RouteTrieNode],
112 path: str,
113 plain_routes: set[str],
114 root_node: RouteTrieNode,
115 ) -> tuple[ASGIApp, RouteHandlerType, str, dict[str, Any]]:
116 """Given a scope object, retrieve the asgi_handlers and is_mount boolean values from correct trie node.
117
118 Args:
119 method: The scope's method, if any.
120 root_node: The root trie node.
121 path: The path to resolve scope instance.
122 plain_routes: The set of plain routes.
123 mount_routes: Mapping of mount routes to trie nodes.
124 mount_paths_regex: A compiled regex to match the mount routes.
125
126 Raises:
127 MethodNotAllowedException: if no matching method is found.
128 NotFoundException: If no correlating node is found or if path params can not be parsed into values according to the node definition.
129
130 Returns:
131 A tuple containing the stack of middlewares and the route handler that is wrapped by it.
132 """
133
134 try:
135 if path in plain_routes:
136 asgi_app, handler = parse_node_handlers(node=root_node.children[path], method=method)
137 return asgi_app, handler, path, {}
138
139 if mount_paths_regex and (match := mount_paths_regex.search(path)):
140 mount_path = path[match.start() : match.end()]
141 mount_node = mount_routes[mount_path]
142 remaining_path = path[match.end() :]
143 # since we allow regular handlers under static paths, we must validate that the request does not match
144 # any such handler.
145 children = [sub_route for sub_route in mount_node.children or [] if sub_route != mount_path]
146 if not children or all(sub_route not in path for sub_route in children): # type: ignore[operator]
147 asgi_app, handler = parse_node_handlers(node=mount_node, method=method)
148 remaining_path = remaining_path or "/"
149 if not mount_node.is_static:
150 remaining_path = remaining_path if remaining_path.endswith("/") else f"{remaining_path}/"
151 return asgi_app, handler, remaining_path, {}
152
153 node, path_parameters, path = traverse_route_map(
154 root_node=root_node,
155 path=path,
156 )
157 asgi_app, handler = parse_node_handlers(node=node, method=method)
158 key = method or ("asgi" if node.is_asgi else "websocket")
159 parsed_path_parameters = parse_path_params(node.path_parameters[key], tuple(path_parameters))
160
161 return (
162 asgi_app,
163 handler,
164 path,
165 parsed_path_parameters,
166 )
167 except KeyError as e:
168 raise MethodNotAllowedException() from e
169 except ValueError as e:
170 raise NotFoundException() from e
171
[end of litestar/_asgi/routing_trie/traversal.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/litestar/_asgi/routing_trie/traversal.py b/litestar/_asgi/routing_trie/traversal.py
--- a/litestar/_asgi/routing_trie/traversal.py
+++ b/litestar/_asgi/routing_trie/traversal.py
@@ -142,8 +142,12 @@
remaining_path = path[match.end() :]
# since we allow regular handlers under static paths, we must validate that the request does not match
# any such handler.
- children = [sub_route for sub_route in mount_node.children or [] if sub_route != mount_path]
- if not children or all(sub_route not in path for sub_route in children): # type: ignore[operator]
+ children = (
+ normalize_path(sub_route)
+ for sub_route in mount_node.children or []
+ if sub_route != mount_path and isinstance(sub_route, str)
+ )
+ if not any(remaining_path.startswith(f"{sub_route}/") for sub_route in children):
asgi_app, handler = parse_node_handlers(node=mount_node, method=method)
remaining_path = remaining_path or "/"
if not mount_node.is_static:
|
{"golden_diff": "diff --git a/litestar/_asgi/routing_trie/traversal.py b/litestar/_asgi/routing_trie/traversal.py\n--- a/litestar/_asgi/routing_trie/traversal.py\n+++ b/litestar/_asgi/routing_trie/traversal.py\n@@ -142,8 +142,12 @@\n remaining_path = path[match.end() :]\n # since we allow regular handlers under static paths, we must validate that the request does not match\n # any such handler.\n- children = [sub_route for sub_route in mount_node.children or [] if sub_route != mount_path]\n- if not children or all(sub_route not in path for sub_route in children): # type: ignore[operator]\n+ children = (\n+ normalize_path(sub_route)\n+ for sub_route in mount_node.children or []\n+ if sub_route != mount_path and isinstance(sub_route, str)\n+ )\n+ if not any(remaining_path.startswith(f\"{sub_route}/\") for sub_route in children):\n asgi_app, handler = parse_node_handlers(node=mount_node, method=method)\n remaining_path = remaining_path or \"/\"\n if not mount_node.is_static:\n", "issue": "Bug: regular handler under asgi mount path conflicts with routing to asgi app\n### Description\r\n\r\nIf we have a regular handler mounted under an asgi mounted path, and the path of the regular handler is a non-prefix sub-string of the a request path the request will not get routed to the asgi app.\r\n\r\nI.e., if we have an asgi mounted on `\"/\"`, and a regular handler at `\"/path\"`, a request to `\"/some/path\"` does not get routed to the asgi app.\r\n\r\n### URL to code causing the issue\r\n\r\n_No response_\r\n\r\n### MCVE\r\n\r\n```python\r\nfrom __future__ import annotations\r\n\r\nfrom typing import TYPE_CHECKING\r\n\r\nfrom litestar import Litestar, asgi, get\r\nfrom litestar.testing import TestClient\r\n\r\nif TYPE_CHECKING:\r\n from litestar.types.asgi_types import Receive, Scope, Send\r\n\r\n\r\nasync def asgi_app(scope: Scope, receive: Receive, send: Send) -> None:\r\n assert scope[\"type\"] == \"http\"\r\n await send({\r\n \"type\": \"http.response.start\",\r\n \"status\": 200,\r\n \"headers\": [\r\n (b\"content-type\", b\"text/plain\"),\r\n (b\"content-length\", b\"%d\" % len(scope[\"raw_path\"])),\r\n ],\r\n })\r\n await send({\r\n \"type\": \"http.response.body\",\r\n \"body\": scope[\"raw_path\"],\r\n })\r\n\r\nasgi_handler = asgi(\"/\", is_mount=True)(asgi_app)\r\n\r\n\r\n@get(\"/path\")\r\ndef get_handler() -> str:\r\n return \"Hello, world!\"\r\n\r\n\r\ndef test_regular_handler_under_mounted_asgi_app() -> None:\r\n app = Litestar(\r\n route_handlers=[asgi(\"/\", is_mount=True)(asgi_app), get_handler],\r\n openapi_config=None,\r\n debug=True,\r\n )\r\n\r\n with TestClient(app) as client:\r\n resp = client.get(\"/some/path\") # currently this is a 404\r\n assert resp.content == b\"/some/path\"\r\n```\r\n\r\n\r\n### Steps to reproduce\r\n\r\n```bash\r\n1. Go to '...'\r\n2. Click on '....'\r\n3. Scroll down to '....'\r\n4. See error\r\n```\r\n\r\n\r\n### Screenshots\r\n\r\n```bash\r\n\"\"\r\n```\r\n\r\n\r\n### Logs\r\n\r\n_No response_\r\n\r\n### Litestar Version\r\n\r\nmain\r\n\r\n### Platform\r\n\r\n- [X] Linux\r\n- [ ] Mac\r\n- [ ] Windows\r\n- [ ] Other (Please specify in the description above)\r\n\r\n<!-- POLAR PLEDGE BADGE START -->\r\n---\r\n> [!NOTE] \r\n> While we are open for sponsoring on [GitHub Sponsors](https://github.com/sponsors/litestar-org/) and \r\n> [OpenCollective](https://opencollective.com/litestar), we also utilize [Polar.sh](https://polar.sh/) to engage in pledge-based sponsorship.\r\n>\r\n> Check out all issues funded or available for funding [on our Polar.sh dashboard](https://polar.sh/litestar-org)\r\n> * If you would like to see an issue prioritized, make a pledge towards it!\r\n> * We receive the pledge once the issue is completed & verified\r\n> * This, along with engagement in the community, helps us know which features are a priority to our users.\r\n\r\n<a href=\"https://polar.sh/litestar-org/litestar/issues/3429\">\r\n<picture>\r\n <source media=\"(prefers-color-scheme: dark)\" srcset=\"https://polar.sh/api/github/litestar-org/litestar/issues/3429/pledge.svg?darkmode=1\">\r\n <img alt=\"Fund with Polar\" src=\"https://polar.sh/api/github/litestar-org/litestar/issues/3429/pledge.svg\">\r\n</picture>\r\n</a>\r\n<!-- POLAR PLEDGE BADGE END -->\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom functools import lru_cache\nfrom typing import TYPE_CHECKING, Any, Pattern\n\nfrom litestar._asgi.routing_trie.types import PathParameterSentinel\nfrom litestar.exceptions import MethodNotAllowedException, NotFoundException\nfrom litestar.utils import normalize_path\n\n__all__ = (\"parse_node_handlers\", \"parse_path_params\", \"parse_path_to_route\", \"traverse_route_map\")\n\n\nif TYPE_CHECKING:\n from litestar._asgi.routing_trie.types import ASGIHandlerTuple, RouteTrieNode\n from litestar.types import ASGIApp, Method, RouteHandlerType\n from litestar.types.internal_types import PathParameterDefinition\n\n\ndef traverse_route_map(\n root_node: RouteTrieNode,\n path: str,\n) -> tuple[RouteTrieNode, list[str], str]:\n \"\"\"Traverses the application route mapping and retrieves the correct node for the request url.\n\n Args:\n root_node: The root trie node.\n path: The request's path.\n\n Raises:\n NotFoundException: If no correlating node is found.\n\n Returns:\n A tuple containing the target RouteMapNode and a list containing all path parameter values.\n \"\"\"\n current_node = root_node\n path_params: list[str] = []\n path_components = [p for p in path.split(\"/\") if p]\n\n for i, component in enumerate(path_components):\n if component in current_node.child_keys:\n current_node = current_node.children[component]\n continue\n\n if current_node.is_path_param_node:\n current_node = current_node.children[PathParameterSentinel]\n\n if current_node.is_path_type:\n path_params.append(normalize_path(\"/\".join(path_components[i:])))\n break\n\n path_params.append(component)\n continue\n\n raise NotFoundException()\n\n if not current_node.asgi_handlers:\n raise NotFoundException()\n\n return current_node, path_params, path\n\n\ndef parse_node_handlers(\n node: RouteTrieNode,\n method: Method | None,\n) -> ASGIHandlerTuple:\n \"\"\"Retrieve the handler tuple from the node.\n\n Args:\n node: The trie node to parse.\n method: The scope's method.\n\n Raises:\n KeyError: If no matching method is found.\n\n Returns:\n An ASGI Handler tuple.\n \"\"\"\n\n if node.is_asgi:\n return node.asgi_handlers[\"asgi\"]\n if method:\n return node.asgi_handlers[method]\n return node.asgi_handlers[\"websocket\"]\n\n\n@lru_cache(1024)\ndef parse_path_params(\n parameter_definitions: tuple[PathParameterDefinition, ...], path_param_values: tuple[str, ...]\n) -> dict[str, Any]:\n \"\"\"Parse path parameters into a dictionary of values.\n\n Args:\n parameter_definitions: The parameter definitions tuple from the route.\n path_param_values: The string values extracted from the url\n\n Raises:\n ValueError: If any of path parameters can not be parsed into a value.\n\n Returns:\n A dictionary of parsed path parameters.\n \"\"\"\n return {\n param_definition.name: param_definition.parser(value) if param_definition.parser else value\n for param_definition, value in zip(parameter_definitions, path_param_values)\n }\n\n\ndef parse_path_to_route(\n method: Method | None,\n mount_paths_regex: Pattern | None,\n mount_routes: dict[str, RouteTrieNode],\n path: str,\n plain_routes: set[str],\n root_node: RouteTrieNode,\n) -> tuple[ASGIApp, RouteHandlerType, str, dict[str, Any]]:\n \"\"\"Given a scope object, retrieve the asgi_handlers and is_mount boolean values from correct trie node.\n\n Args:\n method: The scope's method, if any.\n root_node: The root trie node.\n path: The path to resolve scope instance.\n plain_routes: The set of plain routes.\n mount_routes: Mapping of mount routes to trie nodes.\n mount_paths_regex: A compiled regex to match the mount routes.\n\n Raises:\n MethodNotAllowedException: if no matching method is found.\n NotFoundException: If no correlating node is found or if path params can not be parsed into values according to the node definition.\n\n Returns:\n A tuple containing the stack of middlewares and the route handler that is wrapped by it.\n \"\"\"\n\n try:\n if path in plain_routes:\n asgi_app, handler = parse_node_handlers(node=root_node.children[path], method=method)\n return asgi_app, handler, path, {}\n\n if mount_paths_regex and (match := mount_paths_regex.search(path)):\n mount_path = path[match.start() : match.end()]\n mount_node = mount_routes[mount_path]\n remaining_path = path[match.end() :]\n # since we allow regular handlers under static paths, we must validate that the request does not match\n # any such handler.\n children = [sub_route for sub_route in mount_node.children or [] if sub_route != mount_path]\n if not children or all(sub_route not in path for sub_route in children): # type: ignore[operator]\n asgi_app, handler = parse_node_handlers(node=mount_node, method=method)\n remaining_path = remaining_path or \"/\"\n if not mount_node.is_static:\n remaining_path = remaining_path if remaining_path.endswith(\"/\") else f\"{remaining_path}/\"\n return asgi_app, handler, remaining_path, {}\n\n node, path_parameters, path = traverse_route_map(\n root_node=root_node,\n path=path,\n )\n asgi_app, handler = parse_node_handlers(node=node, method=method)\n key = method or (\"asgi\" if node.is_asgi else \"websocket\")\n parsed_path_parameters = parse_path_params(node.path_parameters[key], tuple(path_parameters))\n\n return (\n asgi_app,\n handler,\n path,\n parsed_path_parameters,\n )\n except KeyError as e:\n raise MethodNotAllowedException() from e\n except ValueError as e:\n raise NotFoundException() from e\n", "path": "litestar/_asgi/routing_trie/traversal.py"}]}
| 3,054 | 262 |
gh_patches_debug_32196
|
rasdani/github-patches
|
git_diff
|
Lightning-AI__pytorch-lightning-543
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Summary not working for model on GPU with multiple inputs
**Describe the bug**
When you want a summary for a model that requires multiple input parameters for forward, then this doesn't work. You can set self.example_input_array to be a tuple and there is some code for passing this to the forward method. However, if the model is on cuda, it tries to pass to move this input directly to cuda without a check whether it is a tuple or list.
the line with the error is here:
[pytorch-lightning/blob/master/pytorch_lightning/root_module/memory.py#L53](https://github.com/williamFalcon/pytorch-lightning/blob/7324dd902b8d071f4889ab1274a4d4dc09de9a78/pytorch_lightning/root_module/memory.py#L53)
example of how it should be checked:
[pytorch-lightning/blob/master/pytorch_lightning/root_module/memory.py#L61](https://github.com/williamFalcon/pytorch-lightning/blob/7324dd902b8d071f4889ab1274a4d4dc09de9a78/pytorch_lightning/root_module/memory.py#L61)
**To Reproduce**
Steps to reproduce the behavior:
1. create a model that requires multiple inputs in the forward method.
2. set self.example_input_array to be a tuple
3. run the model on GPU
**Expected behavior**
a list with all layers and the input and output shapes of these layers.
**Screenshots**

**Desktop (please complete the following information):**
- OS: Linux Mint 19.2
- Browser chrome
- Version 8.0.3904.97 (Official Build) (64-bit)
</issue>
<code>
[start of pytorch_lightning/core/memory.py]
1 '''
2 Generates a summary of a model's layers and dimensionality
3 '''
4
5 import gc
6 import os
7 import subprocess
8
9 import numpy as np
10 import pandas as pd
11 import torch
12 import logging
13
14
15 class ModelSummary(object):
16
17 def __init__(self, model, mode='full'):
18 '''
19 Generates summaries of model layers and dimensions.
20 '''
21 self.model = model
22 self.mode = mode
23 self.in_sizes = []
24 self.out_sizes = []
25
26 self.summarize()
27
28 def __str__(self):
29 return self.summary.__str__()
30
31 def __repr__(self):
32 return self.summary.__str__()
33
34 def named_modules(self):
35 if self.mode == 'full':
36 mods = self.model.named_modules()
37 mods = list(mods)[1:] # do not include root module (LightningModule)
38 elif self.mode == 'top':
39 # the children are the top-level modules
40 mods = self.model.named_children()
41 else:
42 mods = []
43 return list(mods)
44
45 def get_variable_sizes(self):
46 '''Run sample input through each layer to get output sizes'''
47 mods = self.named_modules()
48 in_sizes = []
49 out_sizes = []
50 input_ = self.model.example_input_array
51
52 if self.model.on_gpu:
53 input_ = input_.cuda(0)
54
55 if self.model.trainer.use_amp:
56 input_ = input_.half()
57
58 with torch.no_grad():
59
60 for _, m in mods:
61 if type(input_) is list or type(input_) is tuple: # pragma: no cover
62 out = m(*input_)
63 else:
64 out = m(input_)
65
66 if type(input_) is tuple or type(input_) is list: # pragma: no cover
67 in_size = []
68 for x in input_:
69 if type(x) is list:
70 in_size.append(len(x))
71 else:
72 in_size.append(x.size())
73 else:
74 in_size = np.array(input_.size())
75
76 in_sizes.append(in_size)
77
78 if type(out) is tuple or type(out) is list: # pragma: no cover
79 out_size = np.asarray([x.size() for x in out])
80 else:
81 out_size = np.array(out.size())
82
83 out_sizes.append(out_size)
84 input_ = out
85
86 self.in_sizes = in_sizes
87 self.out_sizes = out_sizes
88 assert len(in_sizes) == len(out_sizes)
89 return
90
91 def get_layer_names(self):
92 '''Collect Layer Names'''
93 mods = self.named_modules()
94 names = []
95 layers = []
96 for name, m in mods:
97 names += [name]
98 layers += [str(m.__class__)]
99
100 layer_types = [x.split('.')[-1][:-2] for x in layers]
101
102 self.layer_names = names
103 self.layer_types = layer_types
104 return
105
106 def get_parameter_sizes(self):
107 '''Get sizes of all parameters in `model`'''
108 mods = self.named_modules()
109 sizes = []
110 for _, m in mods:
111 p = list(m.parameters())
112 modsz = []
113 for j in range(len(p)):
114 modsz.append(np.array(p[j].size()))
115 sizes.append(modsz)
116
117 self.param_sizes = sizes
118 return
119
120 def get_parameter_nums(self):
121 '''Get number of parameters in each layer'''
122 param_nums = []
123 for mod in self.param_sizes:
124 all_params = 0
125 for p in mod:
126 all_params += np.prod(p)
127 param_nums.append(all_params)
128 self.param_nums = param_nums
129 return
130
131 def make_summary(self):
132 '''
133 Makes a summary listing with:
134
135 Layer Name, Layer Type, Input Size, Output Size, Number of Parameters
136 '''
137
138 cols = ['Name', 'Type', 'Params']
139 if self.model.example_input_array is not None:
140 cols.extend(['In_sizes', 'Out_sizes'])
141
142 df = pd.DataFrame(np.zeros((len(self.layer_names), len(cols))))
143 df.columns = cols
144
145 df['Name'] = self.layer_names
146 df['Type'] = self.layer_types
147 df['Params'] = self.param_nums
148 df['Params'] = df['Params'].map(get_human_readable_count)
149
150 if self.model.example_input_array is not None:
151 df['In_sizes'] = self.in_sizes
152 df['Out_sizes'] = self.out_sizes
153
154 self.summary = df
155 return
156
157 def summarize(self):
158 self.get_layer_names()
159 self.get_parameter_sizes()
160 self.get_parameter_nums()
161
162 if self.model.example_input_array is not None:
163 self.get_variable_sizes()
164 self.make_summary()
165
166
167 def print_mem_stack(): # pragma: no cover
168 for obj in gc.get_objects():
169 try:
170 if torch.is_tensor(obj) or (hasattr(obj, 'data') and torch.is_tensor(obj.data)):
171 logging.info(type(obj), obj.size())
172 except Exception:
173 pass
174
175
176 def count_mem_items(): # pragma: no cover
177 num_params = 0
178 num_tensors = 0
179 for obj in gc.get_objects():
180 try:
181 if torch.is_tensor(obj) or (hasattr(obj, 'data') and torch.is_tensor(obj.data)):
182 obj_type = str(type(obj))
183 if 'parameter' in obj_type:
184 num_params += 1
185 else:
186 num_tensors += 1
187 except Exception:
188 pass
189
190 return num_params, num_tensors
191
192
193 def get_memory_profile(mode):
194 """
195 'all' means return memory for all gpus
196 'min_max' means return memory for max and min
197 :param mode:
198 :return:
199 """
200 memory_map = get_gpu_memory_map()
201
202 if mode == 'min_max':
203 min_index, min_memory = min(memory_map.items(), key=lambda item: item[1])
204 max_index, max_memory = max(memory_map.items(), key=lambda item: item[1])
205
206 memory_map = {min_index: min_memory, max_index: max_memory}
207
208 return memory_map
209
210
211 def get_gpu_memory_map():
212 """Get the current gpu usage.
213
214 Returns
215 -------
216 usage: dict
217 Keys are device ids as integers.
218 Values are memory usage as integers in MB.
219 """
220 result = subprocess.run(
221 [
222 'nvidia-smi',
223 '--query-gpu=memory.used',
224 '--format=csv,nounits,noheader',
225 ],
226 encoding='utf-8',
227 capture_output=True,
228 check=True)
229 # Convert lines into a dictionary
230 gpu_memory = [int(x) for x in result.stdout.strip().split(os.linesep)]
231 gpu_memory_map = {f'gpu_{index}': memory for index, memory in enumerate(gpu_memory)}
232 return gpu_memory_map
233
234
235 def get_human_readable_count(number):
236 """
237 Abbreviates an integer number with K, M, B, T for thousands, millions,
238 billions and trillions, respectively.
239 Examples:
240 123 -> 123
241 1234 -> 1 K (one thousand)
242 2e6 -> 2 M (two million)
243 3e9 -> 3 B (three billion)
244 4e12 -> 4 T (four trillion)
245 5e15 -> 5,000 T
246 :param number: a positive integer number
247 :returns a string formatted according to the pattern described above.
248 """
249 assert number >= 0
250 labels = [' ', 'K', 'M', 'B', 'T']
251 num_digits = int(np.floor(np.log10(number)) + 1 if number > 0 else 1)
252 num_groups = int(np.ceil(num_digits / 3))
253 num_groups = min(num_groups, len(labels)) # don't abbreviate beyond trillions
254 shift = -3 * (num_groups - 1)
255 number = number * (10 ** shift)
256 index = num_groups - 1
257 return f'{int(number):,d} {labels[index]}'
258
[end of pytorch_lightning/core/memory.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pytorch_lightning/core/memory.py b/pytorch_lightning/core/memory.py
--- a/pytorch_lightning/core/memory.py
+++ b/pytorch_lightning/core/memory.py
@@ -50,20 +50,31 @@
input_ = self.model.example_input_array
if self.model.on_gpu:
- input_ = input_.cuda(0)
+ device = next(self.model.parameters()).get_device()
+ # test if input is a list or a tuple
+ if isinstance(input_, (list, tuple)):
+ input_ = [input_i.cuda(device) if torch.is_tensor(input_i) else input_i
+ for input_i in input_]
+ else:
+ input_ = input_.cuda(device)
if self.model.trainer.use_amp:
- input_ = input_.half()
+ # test if it is not a list or a tuple
+ if isinstance(input_, (list, tuple)):
+ input_ = [input_i.half() if torch.is_tensor(input_i) else input_i
+ for input_i in input_]
+ else:
+ input_ = input_.half()
with torch.no_grad():
for _, m in mods:
- if type(input_) is list or type(input_) is tuple: # pragma: no cover
+ if isinstance(input_, (list, tuple)): # pragma: no cover
out = m(*input_)
else:
out = m(input_)
- if type(input_) is tuple or type(input_) is list: # pragma: no cover
+ if isinstance(input_, (list, tuple)): # pragma: no cover
in_size = []
for x in input_:
if type(x) is list:
@@ -75,7 +86,7 @@
in_sizes.append(in_size)
- if type(out) is tuple or type(out) is list: # pragma: no cover
+ if isinstance(out, (list, tuple)): # pragma: no cover
out_size = np.asarray([x.size() for x in out])
else:
out_size = np.array(out.size())
|
{"golden_diff": "diff --git a/pytorch_lightning/core/memory.py b/pytorch_lightning/core/memory.py\n--- a/pytorch_lightning/core/memory.py\n+++ b/pytorch_lightning/core/memory.py\n@@ -50,20 +50,31 @@\n input_ = self.model.example_input_array\n \n if self.model.on_gpu:\n- input_ = input_.cuda(0)\n+ device = next(self.model.parameters()).get_device()\n+ # test if input is a list or a tuple\n+ if isinstance(input_, (list, tuple)):\n+ input_ = [input_i.cuda(device) if torch.is_tensor(input_i) else input_i\n+ for input_i in input_]\n+ else:\n+ input_ = input_.cuda(device)\n \n if self.model.trainer.use_amp:\n- input_ = input_.half()\n+ # test if it is not a list or a tuple\n+ if isinstance(input_, (list, tuple)):\n+ input_ = [input_i.half() if torch.is_tensor(input_i) else input_i\n+ for input_i in input_]\n+ else:\n+ input_ = input_.half()\n \n with torch.no_grad():\n \n for _, m in mods:\n- if type(input_) is list or type(input_) is tuple: # pragma: no cover\n+ if isinstance(input_, (list, tuple)): # pragma: no cover\n out = m(*input_)\n else:\n out = m(input_)\n \n- if type(input_) is tuple or type(input_) is list: # pragma: no cover\n+ if isinstance(input_, (list, tuple)): # pragma: no cover\n in_size = []\n for x in input_:\n if type(x) is list:\n@@ -75,7 +86,7 @@\n \n in_sizes.append(in_size)\n \n- if type(out) is tuple or type(out) is list: # pragma: no cover\n+ if isinstance(out, (list, tuple)): # pragma: no cover\n out_size = np.asarray([x.size() for x in out])\n else:\n out_size = np.array(out.size())\n", "issue": "Summary not working for model on GPU with multiple inputs\n**Describe the bug**\r\nWhen you want a summary for a model that requires multiple input parameters for forward, then this doesn't work. You can set self.example_input_array to be a tuple and there is some code for passing this to the forward method. However, if the model is on cuda, it tries to pass to move this input directly to cuda without a check whether it is a tuple or list.\r\n\r\nthe line with the error is here: \r\n[pytorch-lightning/blob/master/pytorch_lightning/root_module/memory.py#L53](https://github.com/williamFalcon/pytorch-lightning/blob/7324dd902b8d071f4889ab1274a4d4dc09de9a78/pytorch_lightning/root_module/memory.py#L53)\r\n\r\nexample of how it should be checked: \r\n[pytorch-lightning/blob/master/pytorch_lightning/root_module/memory.py#L61](https://github.com/williamFalcon/pytorch-lightning/blob/7324dd902b8d071f4889ab1274a4d4dc09de9a78/pytorch_lightning/root_module/memory.py#L61)\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. create a model that requires multiple inputs in the forward method. \r\n2. set self.example_input_array to be a tuple\r\n3. run the model on GPU\r\n\r\n**Expected behavior**\r\na list with all layers and the input and output shapes of these layers. \r\n\r\n**Screenshots**\r\n\r\n\r\n**Desktop (please complete the following information):**\r\n - OS: Linux Mint 19.2\r\n - Browser chrome\r\n - Version 8.0.3904.97 (Official Build) (64-bit)\r\n\n", "before_files": [{"content": "'''\nGenerates a summary of a model's layers and dimensionality\n'''\n\nimport gc\nimport os\nimport subprocess\n\nimport numpy as np\nimport pandas as pd\nimport torch\nimport logging\n\n\nclass ModelSummary(object):\n\n def __init__(self, model, mode='full'):\n '''\n Generates summaries of model layers and dimensions.\n '''\n self.model = model\n self.mode = mode\n self.in_sizes = []\n self.out_sizes = []\n\n self.summarize()\n\n def __str__(self):\n return self.summary.__str__()\n\n def __repr__(self):\n return self.summary.__str__()\n\n def named_modules(self):\n if self.mode == 'full':\n mods = self.model.named_modules()\n mods = list(mods)[1:] # do not include root module (LightningModule)\n elif self.mode == 'top':\n # the children are the top-level modules\n mods = self.model.named_children()\n else:\n mods = []\n return list(mods)\n\n def get_variable_sizes(self):\n '''Run sample input through each layer to get output sizes'''\n mods = self.named_modules()\n in_sizes = []\n out_sizes = []\n input_ = self.model.example_input_array\n\n if self.model.on_gpu:\n input_ = input_.cuda(0)\n\n if self.model.trainer.use_amp:\n input_ = input_.half()\n\n with torch.no_grad():\n\n for _, m in mods:\n if type(input_) is list or type(input_) is tuple: # pragma: no cover\n out = m(*input_)\n else:\n out = m(input_)\n\n if type(input_) is tuple or type(input_) is list: # pragma: no cover\n in_size = []\n for x in input_:\n if type(x) is list:\n in_size.append(len(x))\n else:\n in_size.append(x.size())\n else:\n in_size = np.array(input_.size())\n\n in_sizes.append(in_size)\n\n if type(out) is tuple or type(out) is list: # pragma: no cover\n out_size = np.asarray([x.size() for x in out])\n else:\n out_size = np.array(out.size())\n\n out_sizes.append(out_size)\n input_ = out\n\n self.in_sizes = in_sizes\n self.out_sizes = out_sizes\n assert len(in_sizes) == len(out_sizes)\n return\n\n def get_layer_names(self):\n '''Collect Layer Names'''\n mods = self.named_modules()\n names = []\n layers = []\n for name, m in mods:\n names += [name]\n layers += [str(m.__class__)]\n\n layer_types = [x.split('.')[-1][:-2] for x in layers]\n\n self.layer_names = names\n self.layer_types = layer_types\n return\n\n def get_parameter_sizes(self):\n '''Get sizes of all parameters in `model`'''\n mods = self.named_modules()\n sizes = []\n for _, m in mods:\n p = list(m.parameters())\n modsz = []\n for j in range(len(p)):\n modsz.append(np.array(p[j].size()))\n sizes.append(modsz)\n\n self.param_sizes = sizes\n return\n\n def get_parameter_nums(self):\n '''Get number of parameters in each layer'''\n param_nums = []\n for mod in self.param_sizes:\n all_params = 0\n for p in mod:\n all_params += np.prod(p)\n param_nums.append(all_params)\n self.param_nums = param_nums\n return\n\n def make_summary(self):\n '''\n Makes a summary listing with:\n\n Layer Name, Layer Type, Input Size, Output Size, Number of Parameters\n '''\n\n cols = ['Name', 'Type', 'Params']\n if self.model.example_input_array is not None:\n cols.extend(['In_sizes', 'Out_sizes'])\n\n df = pd.DataFrame(np.zeros((len(self.layer_names), len(cols))))\n df.columns = cols\n\n df['Name'] = self.layer_names\n df['Type'] = self.layer_types\n df['Params'] = self.param_nums\n df['Params'] = df['Params'].map(get_human_readable_count)\n\n if self.model.example_input_array is not None:\n df['In_sizes'] = self.in_sizes\n df['Out_sizes'] = self.out_sizes\n\n self.summary = df\n return\n\n def summarize(self):\n self.get_layer_names()\n self.get_parameter_sizes()\n self.get_parameter_nums()\n\n if self.model.example_input_array is not None:\n self.get_variable_sizes()\n self.make_summary()\n\n\ndef print_mem_stack(): # pragma: no cover\n for obj in gc.get_objects():\n try:\n if torch.is_tensor(obj) or (hasattr(obj, 'data') and torch.is_tensor(obj.data)):\n logging.info(type(obj), obj.size())\n except Exception:\n pass\n\n\ndef count_mem_items(): # pragma: no cover\n num_params = 0\n num_tensors = 0\n for obj in gc.get_objects():\n try:\n if torch.is_tensor(obj) or (hasattr(obj, 'data') and torch.is_tensor(obj.data)):\n obj_type = str(type(obj))\n if 'parameter' in obj_type:\n num_params += 1\n else:\n num_tensors += 1\n except Exception:\n pass\n\n return num_params, num_tensors\n\n\ndef get_memory_profile(mode):\n \"\"\"\n 'all' means return memory for all gpus\n 'min_max' means return memory for max and min\n :param mode:\n :return:\n \"\"\"\n memory_map = get_gpu_memory_map()\n\n if mode == 'min_max':\n min_index, min_memory = min(memory_map.items(), key=lambda item: item[1])\n max_index, max_memory = max(memory_map.items(), key=lambda item: item[1])\n\n memory_map = {min_index: min_memory, max_index: max_memory}\n\n return memory_map\n\n\ndef get_gpu_memory_map():\n \"\"\"Get the current gpu usage.\n\n Returns\n -------\n usage: dict\n Keys are device ids as integers.\n Values are memory usage as integers in MB.\n \"\"\"\n result = subprocess.run(\n [\n 'nvidia-smi',\n '--query-gpu=memory.used',\n '--format=csv,nounits,noheader',\n ],\n encoding='utf-8',\n capture_output=True,\n check=True)\n # Convert lines into a dictionary\n gpu_memory = [int(x) for x in result.stdout.strip().split(os.linesep)]\n gpu_memory_map = {f'gpu_{index}': memory for index, memory in enumerate(gpu_memory)}\n return gpu_memory_map\n\n\ndef get_human_readable_count(number):\n \"\"\"\n Abbreviates an integer number with K, M, B, T for thousands, millions,\n billions and trillions, respectively.\n Examples:\n 123 -> 123\n 1234 -> 1 K (one thousand)\n 2e6 -> 2 M (two million)\n 3e9 -> 3 B (three billion)\n 4e12 -> 4 T (four trillion)\n 5e15 -> 5,000 T\n :param number: a positive integer number\n :returns a string formatted according to the pattern described above.\n \"\"\"\n assert number >= 0\n labels = [' ', 'K', 'M', 'B', 'T']\n num_digits = int(np.floor(np.log10(number)) + 1 if number > 0 else 1)\n num_groups = int(np.ceil(num_digits / 3))\n num_groups = min(num_groups, len(labels)) # don't abbreviate beyond trillions\n shift = -3 * (num_groups - 1)\n number = number * (10 ** shift)\n index = num_groups - 1\n return f'{int(number):,d} {labels[index]}'\n", "path": "pytorch_lightning/core/memory.py"}]}
| 3,425 | 471 |
gh_patches_debug_37700
|
rasdani/github-patches
|
git_diff
|
optuna__optuna-587
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Dashboard only supports direction="minimize"
I used `optuna create-study --direction maximize --storage sqlite:///example.db` to create my study but the curve on the dashboard tracks only the minimum, not the maximum.
Maybe this is an error of `create-study` that doesn't take my argument into account…
</issue>
<code>
[start of optuna/dashboard.py]
1 try:
2 import bokeh.command.bootstrap
3 import bokeh.document # NOQA
4 import bokeh.layouts
5 import bokeh.models
6 import bokeh.models.widgets
7 import bokeh.plotting
8 import bokeh.themes
9 import tornado.gen
10 _available = True
11 except ImportError as e:
12 _available = False
13 _import_error = e
14
15 import collections
16 import numpy as np
17 import threading
18 import time
19
20 import optuna.logging
21 import optuna.structs
22 import optuna.study
23 from optuna import type_checking
24
25 if type_checking.TYPE_CHECKING:
26 from typing import Any # NOQA
27 from typing import Dict # NOQA
28 from typing import List # NOQA
29 from typing import Optional # NOQA
30
31 _mode = None # type: Optional[str]
32 _study = None # type: Optional[optuna.study.Study]
33
34 _HEADER_FORMAT = '''
35 <style>
36 body {{
37 margin: 20px;
38 }}
39 h1, p {{
40 margin: 10px 0px;
41 }}
42 </style>
43
44 <h1>Optuna Dashboard (Beta)</h1>
45 <p>
46 <b>Study name:</b> {study_name}<br>
47 </p>
48 '''
49
50 _DATETIME_FORMAT = '%Y-%m-%d %H:%M:%S'
51
52 if _available:
53
54 class _CompleteTrialsWidget(object):
55 def __init__(self, trials):
56 # type: (List[optuna.structs.FrozenTrial]) -> None
57
58 complete_trials = [
59 trial for trial in trials if trial.state == optuna.structs.TrialState.COMPLETE
60 ]
61 self.trial_ids = set([trial.trial_id for trial in complete_trials])
62
63 values = [trial.value for trial in complete_trials]
64 best_values = np.minimum.accumulate(values, axis=0)
65 self.cds = bokeh.models.ColumnDataSource({
66 '#': list(range(len(complete_trials))),
67 'value': values,
68 'best_value': best_values,
69 })
70
71 self.best_value = best_values[-1] if complete_trials else np.inf
72
73 def create_figure(self):
74 # type: () -> bokeh.plotting.Figure
75
76 figure = bokeh.plotting.figure(height=150)
77 figure.circle(x='#', y='value', source=self.cds, alpha=0.3, color='navy')
78 figure.line(x='#', y='best_value', source=self.cds, color='firebrick')
79 figure.xaxis[0].axis_label = 'Number of Trials'
80 figure.yaxis[0].axis_label = 'Objective Value'
81 return figure
82
83 def update(self, new_trials):
84 # type: (List[optuna.structs.FrozenTrial]) -> None
85
86 stream_dict = collections.defaultdict(list) # type: Dict[str, List[Any]]
87
88 for trial in new_trials:
89 if trial.state != optuna.structs.TrialState.COMPLETE:
90 continue
91 if trial.trial_id in self.trial_ids:
92 continue
93 stream_dict['#'].append(len(self.trial_ids))
94 stream_dict['value'].append(trial.value)
95 self.best_value = min(self.best_value, trial.value)
96 stream_dict['best_value'].append(self.best_value)
97 self.trial_ids.add(trial.trial_id)
98
99 if stream_dict:
100 self.cds.stream(stream_dict)
101
102 class _AllTrialsWidget(object):
103 def __init__(self, trials):
104 # type: (List[optuna.structs.FrozenTrial]) -> None
105
106 self.cds = bokeh.models.ColumnDataSource(self.trials_to_dict(trials))
107
108 def create_table(self):
109 # type: () -> bokeh.models.widgets.DataTable
110
111 return bokeh.models.widgets.DataTable(
112 source=self.cds,
113 columns=[
114 bokeh.models.widgets.TableColumn(field=field, title=field) for field in
115 ['number', 'state', 'value', 'params', 'datetime_start', 'datetime_complete']
116 ])
117
118 def update(
119 self,
120 old_trials, # type: List[optuna.structs.FrozenTrial]
121 new_trials, # type: List[optuna.structs.FrozenTrial]
122 ):
123 # type: (...) -> None
124
125 modified_indices = []
126 modified_trials = []
127 for i, old_trial in enumerate(old_trials):
128 new_trial = new_trials[i]
129 if old_trial != new_trial:
130 modified_indices.append(i)
131 modified_trials.append(new_trial)
132
133 patch_dict = self.trials_to_dict(modified_trials)
134 patch_dict = {k: list(zip(modified_indices, v)) for k, v in patch_dict.items()}
135 self.cds.patch(patch_dict)
136
137 self.cds.stream(self.trials_to_dict(new_trials[len(old_trials):]))
138
139 @staticmethod
140 def trials_to_dict(trials):
141 # type: (List[optuna.structs.FrozenTrial]) -> Dict[str, List[Any]]
142
143 return {
144 'number': [trial.number for trial in trials],
145 'state': [trial.state.name for trial in trials],
146 'value': [trial.value for trial in trials],
147 'params': [str(trial.params) for trial in trials],
148 'datetime_start': [
149 trial.datetime_start.strftime(_DATETIME_FORMAT)
150 if trial.datetime_start is not None else None for trial in trials
151 ],
152 'datetime_complete': [
153 trial.datetime_complete.strftime(_DATETIME_FORMAT)
154 if trial.datetime_complete is not None else None for trial in trials
155 ],
156 }
157
158 class _DashboardApp(object):
159 def __init__(self, study, launch_update_thread):
160 # type: (optuna.study.Study, bool) -> None
161
162 self.study = study
163 self.launch_update_thread = launch_update_thread
164 self.lock = threading.Lock()
165
166 def __call__(self, doc):
167 # type: (bokeh.document.Document) -> None
168
169 self.doc = doc
170 self.current_trials = \
171 self.study.trials # type: Optional[List[optuna.structs.FrozenTrial]]
172 self.new_trials = None # type: Optional[List[optuna.structs.FrozenTrial]]
173 self.complete_trials_widget = _CompleteTrialsWidget(self.current_trials)
174 self.all_trials_widget = _AllTrialsWidget(self.current_trials)
175
176 self.doc.title = 'Optuna Dashboard (Beta)'
177 header = _HEADER_FORMAT.format(study_name=self.study.study_name)
178 self.doc.add_root(
179 bokeh.layouts.layout([[bokeh.models.widgets.Div(text=header)],
180 [self.complete_trials_widget.create_figure()],
181 [self.all_trials_widget.create_table()]],
182 sizing_mode='scale_width'))
183
184 if self.launch_update_thread:
185 thread = threading.Thread(target=self.thread_loop)
186 thread.daemon = True
187 thread.start()
188
189 def thread_loop(self):
190 # type: () -> None
191
192 while True:
193 time.sleep(1)
194 new_trials = self.study.trials
195 with self.lock:
196 need_to_add_callback = (self.new_trials is None)
197 self.new_trials = new_trials
198 if need_to_add_callback:
199 self.doc.add_next_tick_callback(self.update_callback)
200
201 @tornado.gen.coroutine
202 def update_callback(self):
203 # type: () -> None
204
205 with self.lock:
206 current_trials = self.current_trials
207 new_trials = self.new_trials
208 self.current_trials = self.new_trials
209 self.new_trials = None
210
211 assert current_trials is not None
212 assert new_trials is not None
213 self.complete_trials_widget.update(new_trials)
214 self.all_trials_widget.update(current_trials, new_trials)
215
216
217 def _check_bokeh_availability():
218 # type: () -> None
219
220 if not _available:
221 raise ImportError(
222 'Bokeh is not available. Please install Bokeh to use the dashboard. '
223 'Bokeh can be installed by executing `$ pip install bokeh`. '
224 'For further information, please refer to the installation guide of Bokeh. '
225 '(The actual import error is as follows: ' + str(_import_error) + ')')
226
227
228 def _show_experimental_warning():
229 # type: () -> None
230
231 logger = optuna.logging.get_logger(__name__)
232 logger.warning('Optuna dashboard is still highly experimental. Please use with caution!')
233
234
235 def _get_this_source_path():
236 # type: () -> str
237
238 path = __file__
239
240 # Sometimes __file__ points to a *.pyc file, but Bokeh doesn't accept it.
241 if path.endswith('.pyc'):
242 path = path[:-1]
243 return path
244
245
246 def serve(study, bokeh_allow_websocket_origins=None):
247 # type: (optuna.study.Study, Optional[List[str]]) -> None
248
249 global _mode, _study
250
251 _check_bokeh_availability()
252 _show_experimental_warning()
253
254 # We want to pass the mode (launching a server? or, just writing an HTML?) and a target study
255 # to our Bokeh app. Unfortunately, as we are using `bokeh.command.bootstrap.main` to launch
256 # our Bokeh app, we cannot directly pass Python objects to it. Therefore, we have no choice but
257 # to use global variables to pass them.
258 _mode = 'serve'
259 _study = study
260
261 # TODO(akiba): Stop using Bokeh's CLI entry point, and start the HTTP server by ourselves.
262
263 # This is not a very clean way to launch Bokeh server.
264 # Another seemingly better way is to
265 # instantiate and launch `bokeh.server.server.Server` by ourselves. However, in this way,
266 # for some reason, we found that the CDS update is not reflected to browsers, at least on Bokeh
267 # version 0.12.15. In addition, we will need to do many configuration to servers, which can be
268 # done automatically with the following one line. So, for now, we decided to use this way.
269 command = ['bokeh', 'serve', '--show', _get_this_source_path()]
270 if bokeh_allow_websocket_origins is not None:
271 for bokeh_allow_websocket_origin in bokeh_allow_websocket_origins:
272 command.extend(['--allow-websocket-origin', bokeh_allow_websocket_origin])
273 bokeh.command.bootstrap.main(command)
274
275
276 def write(study, out_path):
277 # type: (optuna.study.Study, str) -> None
278
279 global _mode, _study
280
281 _check_bokeh_availability()
282 _show_experimental_warning()
283
284 _mode = 'html'
285 _study = study
286 bokeh.command.bootstrap.main(['bokeh', 'html', _get_this_source_path(), '-o', out_path])
287
288
289 def _run():
290 # type: () -> None
291
292 # Please note that `_study` and `optuna.dashboard._study` are different here. Here, this module
293 # is loaded inside Bokeh, and thus it is not `optuna.dashboard`, but `bk_script_????`.
294 study = optuna.dashboard._study
295 mode = optuna.dashboard._mode
296
297 assert study is not None
298 app = _DashboardApp(study, launch_update_thread=(mode == 'serve'))
299 doc = bokeh.plotting.curdoc()
300 app(doc)
301
302
303 if __name__.startswith('bk_script_'):
304 # Here, this module is loaded inside Bokeh. Therefore, we should launch the Bokeh app.
305 _run()
306
[end of optuna/dashboard.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/optuna/dashboard.py b/optuna/dashboard.py
--- a/optuna/dashboard.py
+++ b/optuna/dashboard.py
@@ -52,16 +52,21 @@
if _available:
class _CompleteTrialsWidget(object):
- def __init__(self, trials):
- # type: (List[optuna.structs.FrozenTrial]) -> None
+ def __init__(self, trials, direction):
+ # type: (List[optuna.structs.FrozenTrial], optuna.structs.StudyDirection) -> None
complete_trials = [
trial for trial in trials if trial.state == optuna.structs.TrialState.COMPLETE
]
self.trial_ids = set([trial.trial_id for trial in complete_trials])
+ self.direction = direction
values = [trial.value for trial in complete_trials]
- best_values = np.minimum.accumulate(values, axis=0)
+ if direction == optuna.structs.StudyDirection.MINIMIZE:
+ best_values = np.minimum.accumulate(values, axis=0)
+ else:
+ best_values = np.maximum.accumulate(values, axis=0)
+
self.cds = bokeh.models.ColumnDataSource({
'#': list(range(len(complete_trials))),
'value': values,
@@ -92,7 +97,10 @@
continue
stream_dict['#'].append(len(self.trial_ids))
stream_dict['value'].append(trial.value)
- self.best_value = min(self.best_value, trial.value)
+ if self.direction == optuna.structs.StudyDirection.MINIMIZE:
+ self.best_value = min(self.best_value, trial.value)
+ else:
+ self.best_value = max(self.best_value, trial.value)
stream_dict['best_value'].append(self.best_value)
self.trial_ids.add(trial.trial_id)
@@ -170,7 +178,8 @@
self.current_trials = \
self.study.trials # type: Optional[List[optuna.structs.FrozenTrial]]
self.new_trials = None # type: Optional[List[optuna.structs.FrozenTrial]]
- self.complete_trials_widget = _CompleteTrialsWidget(self.current_trials)
+ self.complete_trials_widget = _CompleteTrialsWidget(
+ self.current_trials, self.study.direction)
self.all_trials_widget = _AllTrialsWidget(self.current_trials)
self.doc.title = 'Optuna Dashboard (Beta)'
|
{"golden_diff": "diff --git a/optuna/dashboard.py b/optuna/dashboard.py\n--- a/optuna/dashboard.py\n+++ b/optuna/dashboard.py\n@@ -52,16 +52,21 @@\n if _available:\n \n class _CompleteTrialsWidget(object):\n- def __init__(self, trials):\n- # type: (List[optuna.structs.FrozenTrial]) -> None\n+ def __init__(self, trials, direction):\n+ # type: (List[optuna.structs.FrozenTrial], optuna.structs.StudyDirection) -> None\n \n complete_trials = [\n trial for trial in trials if trial.state == optuna.structs.TrialState.COMPLETE\n ]\n self.trial_ids = set([trial.trial_id for trial in complete_trials])\n \n+ self.direction = direction\n values = [trial.value for trial in complete_trials]\n- best_values = np.minimum.accumulate(values, axis=0)\n+ if direction == optuna.structs.StudyDirection.MINIMIZE:\n+ best_values = np.minimum.accumulate(values, axis=0)\n+ else:\n+ best_values = np.maximum.accumulate(values, axis=0)\n+\n self.cds = bokeh.models.ColumnDataSource({\n '#': list(range(len(complete_trials))),\n 'value': values,\n@@ -92,7 +97,10 @@\n continue\n stream_dict['#'].append(len(self.trial_ids))\n stream_dict['value'].append(trial.value)\n- self.best_value = min(self.best_value, trial.value)\n+ if self.direction == optuna.structs.StudyDirection.MINIMIZE:\n+ self.best_value = min(self.best_value, trial.value)\n+ else:\n+ self.best_value = max(self.best_value, trial.value)\n stream_dict['best_value'].append(self.best_value)\n self.trial_ids.add(trial.trial_id)\n \n@@ -170,7 +178,8 @@\n self.current_trials = \\\n self.study.trials # type: Optional[List[optuna.structs.FrozenTrial]]\n self.new_trials = None # type: Optional[List[optuna.structs.FrozenTrial]]\n- self.complete_trials_widget = _CompleteTrialsWidget(self.current_trials)\n+ self.complete_trials_widget = _CompleteTrialsWidget(\n+ self.current_trials, self.study.direction)\n self.all_trials_widget = _AllTrialsWidget(self.current_trials)\n \n self.doc.title = 'Optuna Dashboard (Beta)'\n", "issue": "Dashboard only supports direction=\"minimize\"\n\r\n\r\n\r\nI used `optuna create-study --direction maximize --storage sqlite:///example.db` to create my study but the curve on the dashboard tracks only the minimum, not the maximum.\r\n\r\nMaybe this is an error of `create-study` that doesn't take my argument into account\u2026\n", "before_files": [{"content": "try:\n import bokeh.command.bootstrap\n import bokeh.document # NOQA\n import bokeh.layouts\n import bokeh.models\n import bokeh.models.widgets\n import bokeh.plotting\n import bokeh.themes\n import tornado.gen\n _available = True\nexcept ImportError as e:\n _available = False\n _import_error = e\n\nimport collections\nimport numpy as np\nimport threading\nimport time\n\nimport optuna.logging\nimport optuna.structs\nimport optuna.study\nfrom optuna import type_checking\n\nif type_checking.TYPE_CHECKING:\n from typing import Any # NOQA\n from typing import Dict # NOQA\n from typing import List # NOQA\n from typing import Optional # NOQA\n\n_mode = None # type: Optional[str]\n_study = None # type: Optional[optuna.study.Study]\n\n_HEADER_FORMAT = '''\n<style>\nbody {{\n margin: 20px;\n}}\nh1, p {{\n margin: 10px 0px;\n}}\n</style>\n\n<h1>Optuna Dashboard (Beta)</h1>\n<p>\n<b>Study name:</b> {study_name}<br>\n</p>\n'''\n\n_DATETIME_FORMAT = '%Y-%m-%d %H:%M:%S'\n\nif _available:\n\n class _CompleteTrialsWidget(object):\n def __init__(self, trials):\n # type: (List[optuna.structs.FrozenTrial]) -> None\n\n complete_trials = [\n trial for trial in trials if trial.state == optuna.structs.TrialState.COMPLETE\n ]\n self.trial_ids = set([trial.trial_id for trial in complete_trials])\n\n values = [trial.value for trial in complete_trials]\n best_values = np.minimum.accumulate(values, axis=0)\n self.cds = bokeh.models.ColumnDataSource({\n '#': list(range(len(complete_trials))),\n 'value': values,\n 'best_value': best_values,\n })\n\n self.best_value = best_values[-1] if complete_trials else np.inf\n\n def create_figure(self):\n # type: () -> bokeh.plotting.Figure\n\n figure = bokeh.plotting.figure(height=150)\n figure.circle(x='#', y='value', source=self.cds, alpha=0.3, color='navy')\n figure.line(x='#', y='best_value', source=self.cds, color='firebrick')\n figure.xaxis[0].axis_label = 'Number of Trials'\n figure.yaxis[0].axis_label = 'Objective Value'\n return figure\n\n def update(self, new_trials):\n # type: (List[optuna.structs.FrozenTrial]) -> None\n\n stream_dict = collections.defaultdict(list) # type: Dict[str, List[Any]]\n\n for trial in new_trials:\n if trial.state != optuna.structs.TrialState.COMPLETE:\n continue\n if trial.trial_id in self.trial_ids:\n continue\n stream_dict['#'].append(len(self.trial_ids))\n stream_dict['value'].append(trial.value)\n self.best_value = min(self.best_value, trial.value)\n stream_dict['best_value'].append(self.best_value)\n self.trial_ids.add(trial.trial_id)\n\n if stream_dict:\n self.cds.stream(stream_dict)\n\n class _AllTrialsWidget(object):\n def __init__(self, trials):\n # type: (List[optuna.structs.FrozenTrial]) -> None\n\n self.cds = bokeh.models.ColumnDataSource(self.trials_to_dict(trials))\n\n def create_table(self):\n # type: () -> bokeh.models.widgets.DataTable\n\n return bokeh.models.widgets.DataTable(\n source=self.cds,\n columns=[\n bokeh.models.widgets.TableColumn(field=field, title=field) for field in\n ['number', 'state', 'value', 'params', 'datetime_start', 'datetime_complete']\n ])\n\n def update(\n self,\n old_trials, # type: List[optuna.structs.FrozenTrial]\n new_trials, # type: List[optuna.structs.FrozenTrial]\n ):\n # type: (...) -> None\n\n modified_indices = []\n modified_trials = []\n for i, old_trial in enumerate(old_trials):\n new_trial = new_trials[i]\n if old_trial != new_trial:\n modified_indices.append(i)\n modified_trials.append(new_trial)\n\n patch_dict = self.trials_to_dict(modified_trials)\n patch_dict = {k: list(zip(modified_indices, v)) for k, v in patch_dict.items()}\n self.cds.patch(patch_dict)\n\n self.cds.stream(self.trials_to_dict(new_trials[len(old_trials):]))\n\n @staticmethod\n def trials_to_dict(trials):\n # type: (List[optuna.structs.FrozenTrial]) -> Dict[str, List[Any]]\n\n return {\n 'number': [trial.number for trial in trials],\n 'state': [trial.state.name for trial in trials],\n 'value': [trial.value for trial in trials],\n 'params': [str(trial.params) for trial in trials],\n 'datetime_start': [\n trial.datetime_start.strftime(_DATETIME_FORMAT)\n if trial.datetime_start is not None else None for trial in trials\n ],\n 'datetime_complete': [\n trial.datetime_complete.strftime(_DATETIME_FORMAT)\n if trial.datetime_complete is not None else None for trial in trials\n ],\n }\n\n class _DashboardApp(object):\n def __init__(self, study, launch_update_thread):\n # type: (optuna.study.Study, bool) -> None\n\n self.study = study\n self.launch_update_thread = launch_update_thread\n self.lock = threading.Lock()\n\n def __call__(self, doc):\n # type: (bokeh.document.Document) -> None\n\n self.doc = doc\n self.current_trials = \\\n self.study.trials # type: Optional[List[optuna.structs.FrozenTrial]]\n self.new_trials = None # type: Optional[List[optuna.structs.FrozenTrial]]\n self.complete_trials_widget = _CompleteTrialsWidget(self.current_trials)\n self.all_trials_widget = _AllTrialsWidget(self.current_trials)\n\n self.doc.title = 'Optuna Dashboard (Beta)'\n header = _HEADER_FORMAT.format(study_name=self.study.study_name)\n self.doc.add_root(\n bokeh.layouts.layout([[bokeh.models.widgets.Div(text=header)],\n [self.complete_trials_widget.create_figure()],\n [self.all_trials_widget.create_table()]],\n sizing_mode='scale_width'))\n\n if self.launch_update_thread:\n thread = threading.Thread(target=self.thread_loop)\n thread.daemon = True\n thread.start()\n\n def thread_loop(self):\n # type: () -> None\n\n while True:\n time.sleep(1)\n new_trials = self.study.trials\n with self.lock:\n need_to_add_callback = (self.new_trials is None)\n self.new_trials = new_trials\n if need_to_add_callback:\n self.doc.add_next_tick_callback(self.update_callback)\n\n @tornado.gen.coroutine\n def update_callback(self):\n # type: () -> None\n\n with self.lock:\n current_trials = self.current_trials\n new_trials = self.new_trials\n self.current_trials = self.new_trials\n self.new_trials = None\n\n assert current_trials is not None\n assert new_trials is not None\n self.complete_trials_widget.update(new_trials)\n self.all_trials_widget.update(current_trials, new_trials)\n\n\ndef _check_bokeh_availability():\n # type: () -> None\n\n if not _available:\n raise ImportError(\n 'Bokeh is not available. Please install Bokeh to use the dashboard. '\n 'Bokeh can be installed by executing `$ pip install bokeh`. '\n 'For further information, please refer to the installation guide of Bokeh. '\n '(The actual import error is as follows: ' + str(_import_error) + ')')\n\n\ndef _show_experimental_warning():\n # type: () -> None\n\n logger = optuna.logging.get_logger(__name__)\n logger.warning('Optuna dashboard is still highly experimental. Please use with caution!')\n\n\ndef _get_this_source_path():\n # type: () -> str\n\n path = __file__\n\n # Sometimes __file__ points to a *.pyc file, but Bokeh doesn't accept it.\n if path.endswith('.pyc'):\n path = path[:-1]\n return path\n\n\ndef serve(study, bokeh_allow_websocket_origins=None):\n # type: (optuna.study.Study, Optional[List[str]]) -> None\n\n global _mode, _study\n\n _check_bokeh_availability()\n _show_experimental_warning()\n\n # We want to pass the mode (launching a server? or, just writing an HTML?) and a target study\n # to our Bokeh app. Unfortunately, as we are using `bokeh.command.bootstrap.main` to launch\n # our Bokeh app, we cannot directly pass Python objects to it. Therefore, we have no choice but\n # to use global variables to pass them.\n _mode = 'serve'\n _study = study\n\n # TODO(akiba): Stop using Bokeh's CLI entry point, and start the HTTP server by ourselves.\n\n # This is not a very clean way to launch Bokeh server.\n # Another seemingly better way is to\n # instantiate and launch `bokeh.server.server.Server` by ourselves. However, in this way,\n # for some reason, we found that the CDS update is not reflected to browsers, at least on Bokeh\n # version 0.12.15. In addition, we will need to do many configuration to servers, which can be\n # done automatically with the following one line. So, for now, we decided to use this way.\n command = ['bokeh', 'serve', '--show', _get_this_source_path()]\n if bokeh_allow_websocket_origins is not None:\n for bokeh_allow_websocket_origin in bokeh_allow_websocket_origins:\n command.extend(['--allow-websocket-origin', bokeh_allow_websocket_origin])\n bokeh.command.bootstrap.main(command)\n\n\ndef write(study, out_path):\n # type: (optuna.study.Study, str) -> None\n\n global _mode, _study\n\n _check_bokeh_availability()\n _show_experimental_warning()\n\n _mode = 'html'\n _study = study\n bokeh.command.bootstrap.main(['bokeh', 'html', _get_this_source_path(), '-o', out_path])\n\n\ndef _run():\n # type: () -> None\n\n # Please note that `_study` and `optuna.dashboard._study` are different here. Here, this module\n # is loaded inside Bokeh, and thus it is not `optuna.dashboard`, but `bk_script_????`.\n study = optuna.dashboard._study\n mode = optuna.dashboard._mode\n\n assert study is not None\n app = _DashboardApp(study, launch_update_thread=(mode == 'serve'))\n doc = bokeh.plotting.curdoc()\n app(doc)\n\n\nif __name__.startswith('bk_script_'):\n # Here, this module is loaded inside Bokeh. Therefore, we should launch the Bokeh app.\n _run()\n", "path": "optuna/dashboard.py"}]}
| 3,956 | 532 |
gh_patches_debug_6395
|
rasdani/github-patches
|
git_diff
|
litestar-org__litestar-1883
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
StaticFilesConfig and virtual directories
I'm trying to write a ``FileSystemProtocol`` to load files from the package data using [importlib_resources](https://importlib-resources.readthedocs.io/en/latest/using.html#). But because ``directories`` is defined as ``DirectoryPath``, pydantic checks if the given directories exist in the local filesystem.
This is not generally true, especially in any kind of virtual filesystem (e.g. a zipped package). I think this condition should be relaxed to support virtual filesystems.
https://github.com/starlite-api/starlite/blob/9bb6dcd57c10a591377cf8e3a537e9292566d5b9/starlite/config/static_files.py#L32
</issue>
<code>
[start of litestar/contrib/sqlalchemy/dto.py]
1 from __future__ import annotations
2
3 from functools import singledispatchmethod
4 from typing import TYPE_CHECKING, Generic, Optional, TypeVar
5
6 from sqlalchemy import Column, inspect, orm, sql
7 from sqlalchemy.ext.associationproxy import AssociationProxy, AssociationProxyExtensionType
8 from sqlalchemy.ext.hybrid import HybridExtensionType, hybrid_property
9 from sqlalchemy.orm import (
10 ColumnProperty,
11 DeclarativeBase,
12 InspectionAttr,
13 Mapped,
14 NotExtension,
15 QueryableAttribute,
16 RelationshipDirection,
17 RelationshipProperty,
18 )
19
20 from litestar.dto.factory.abc import AbstractDTOFactory
21 from litestar.dto.factory.data_structures import FieldDefinition
22 from litestar.dto.factory.field import DTO_FIELD_META_KEY, DTOField, Mark
23 from litestar.dto.factory.utils import get_model_type_hints
24 from litestar.exceptions import ImproperlyConfiguredException
25 from litestar.types.empty import Empty
26 from litestar.typing import ParsedType
27 from litestar.utils.helpers import get_fully_qualified_class_name
28 from litestar.utils.signature import ParsedSignature
29
30 if TYPE_CHECKING:
31 from typing import Any, ClassVar, Collection, Generator
32
33 from typing_extensions import TypeAlias
34
35 __all__ = ("SQLAlchemyDTO",)
36
37 T = TypeVar("T", bound="DeclarativeBase | Collection[DeclarativeBase]")
38 ElementType: TypeAlias = "Column[Any] | RelationshipProperty[Any]"
39
40 SQLA_NS = {**vars(orm), **vars(sql)}
41
42
43 class SQLAlchemyDTO(AbstractDTOFactory[T], Generic[T]):
44 """Support for domain modelling with SQLAlchemy."""
45
46 __slots__ = ()
47
48 model_type: ClassVar[type[DeclarativeBase]]
49
50 @singledispatchmethod
51 @classmethod
52 def handle_orm_descriptor(
53 cls,
54 extension_type: NotExtension | AssociationProxyExtensionType | HybridExtensionType,
55 orm_descriptor: InspectionAttr,
56 key: str,
57 model_type_hints: dict[str, ParsedType],
58 model_name: str,
59 ) -> list[FieldDefinition]:
60 raise NotImplementedError(f"Unsupported extension type: {extension_type}")
61
62 @handle_orm_descriptor.register(NotExtension)
63 @classmethod
64 def _(
65 cls,
66 extension_type: NotExtension,
67 key: str,
68 orm_descriptor: InspectionAttr,
69 model_type_hints: dict[str, ParsedType],
70 model_name: str,
71 ) -> list[FieldDefinition]:
72 if not isinstance(orm_descriptor, QueryableAttribute):
73 raise NotImplementedError(f"Unexpected descriptor type for '{extension_type}': '{orm_descriptor}'")
74
75 elem: ElementType
76 if isinstance(orm_descriptor.property, ColumnProperty):
77 if not isinstance(orm_descriptor.property.expression, Column):
78 raise NotImplementedError(f"Expected 'Column', got: '{orm_descriptor.property.expression}'")
79 elem = orm_descriptor.property.expression
80 elif isinstance(orm_descriptor.property, RelationshipProperty):
81 elem = orm_descriptor.property
82 else:
83 raise NotImplementedError(f"Unhandled property type: '{orm_descriptor.property}'")
84
85 default, default_factory = _detect_defaults(elem)
86
87 try:
88 if (parsed_type := model_type_hints[key]).origin is Mapped:
89 (parsed_type,) = parsed_type.inner_types
90 else:
91 raise NotImplementedError(f"Expected 'Mapped' origin, got: '{parsed_type.origin}'")
92 except KeyError:
93 parsed_type = parse_type_from_element(elem)
94
95 return [
96 FieldDefinition(
97 name=key,
98 default=default,
99 parsed_type=parsed_type,
100 default_factory=default_factory,
101 dto_field=elem.info.get(DTO_FIELD_META_KEY, DTOField()),
102 unique_model_name=model_name,
103 dto_for=None,
104 )
105 ]
106
107 @handle_orm_descriptor.register(AssociationProxyExtensionType)
108 @classmethod
109 def _(
110 cls,
111 extension_type: AssociationProxyExtensionType,
112 key: str,
113 orm_descriptor: InspectionAttr,
114 model_type_hints: dict[str, ParsedType],
115 model_name: str,
116 ) -> list[FieldDefinition]:
117 if not isinstance(orm_descriptor, AssociationProxy):
118 raise NotImplementedError(f"Unexpected descriptor type '{orm_descriptor}' for '{extension_type}'")
119
120 if (parsed_type := model_type_hints[key]).origin is AssociationProxy:
121 (parsed_type,) = parsed_type.inner_types
122 else:
123 raise NotImplementedError(f"Expected 'AssociationProxy' origin, got: '{parsed_type.origin}'")
124
125 return [
126 FieldDefinition(
127 name=key,
128 default=Empty,
129 parsed_type=parsed_type,
130 default_factory=None,
131 dto_field=orm_descriptor.info.get(DTO_FIELD_META_KEY, DTOField(mark=Mark.READ_ONLY)),
132 unique_model_name=model_name,
133 dto_for=None,
134 )
135 ]
136
137 @handle_orm_descriptor.register(HybridExtensionType)
138 @classmethod
139 def _(
140 cls,
141 extension_type: HybridExtensionType,
142 key: str,
143 orm_descriptor: InspectionAttr,
144 model_type_hints: dict[str, ParsedType],
145 model_name: str,
146 ) -> list[FieldDefinition]:
147 if not isinstance(orm_descriptor, hybrid_property):
148 raise NotImplementedError(f"Unexpected descriptor type '{orm_descriptor}' for '{extension_type}'")
149
150 getter_sig = ParsedSignature.from_fn(orm_descriptor.fget, {})
151
152 field_defs = [
153 FieldDefinition(
154 name=orm_descriptor.__name__,
155 default=Empty,
156 parsed_type=getter_sig.return_type,
157 default_factory=None,
158 dto_field=orm_descriptor.info.get(DTO_FIELD_META_KEY, DTOField(mark=Mark.READ_ONLY)),
159 unique_model_name=model_name,
160 dto_for="return",
161 )
162 ]
163
164 if orm_descriptor.fset is not None:
165 setter_sig = ParsedSignature.from_fn(orm_descriptor.fset, {})
166 field_defs.append(
167 FieldDefinition(
168 name=orm_descriptor.__name__,
169 default=Empty,
170 parsed_type=next(iter(setter_sig.parameters.values())).parsed_type,
171 default_factory=None,
172 dto_field=orm_descriptor.info.get(DTO_FIELD_META_KEY, DTOField(mark=Mark.WRITE_ONLY)),
173 unique_model_name=model_name,
174 dto_for="data",
175 )
176 )
177
178 return field_defs
179
180 @classmethod
181 def generate_field_definitions(cls, model_type: type[DeclarativeBase]) -> Generator[FieldDefinition, None, None]:
182 if (mapper := inspect(model_type)) is None: # pragma: no cover
183 raise RuntimeError("Unexpected `None` value for mapper.")
184
185 # includes SQLAlchemy names and other mapped class names in the forward reference resolution namespace
186 namespace = {**SQLA_NS, **{m.class_.__name__: m.class_ for m in mapper.registry.mappers if m is not mapper}}
187 model_type_hints = get_model_type_hints(model_type, namespace=namespace)
188 model_name = get_fully_qualified_class_name(model_type)
189
190 # the same hybrid property descriptor can be included in `all_orm_descriptors` multiple times, once
191 # for each method name it is bound to. We only need to see it once, so track views of it here.
192 seen_hybrid_descriptors: set[hybrid_property] = set()
193 for key, orm_descriptor in mapper.all_orm_descriptors.items():
194 if isinstance(orm_descriptor, hybrid_property):
195 if orm_descriptor in seen_hybrid_descriptors:
196 continue
197 seen_hybrid_descriptors.add(orm_descriptor)
198
199 yield from cls.handle_orm_descriptor(
200 orm_descriptor.extension_type, key, orm_descriptor, model_type_hints, model_name
201 )
202
203 @classmethod
204 def detect_nested_field(cls, parsed_type: ParsedType) -> bool:
205 return parsed_type.is_subclass_of(DeclarativeBase)
206
207
208 def _detect_defaults(elem: ElementType) -> tuple[Any, Any]:
209 default: Any = Empty
210 default_factory: Any = None # pyright:ignore
211 if sqla_default := getattr(elem, "default", None):
212 if sqla_default.is_scalar:
213 default = sqla_default.arg
214 elif sqla_default.is_callable:
215
216 def default_factory(d: Any = sqla_default) -> Any:
217 return d.arg({})
218
219 else:
220 raise ValueError("Unexpected default type")
221 else:
222 if (
223 isinstance(elem, RelationshipProperty)
224 and detect_nullable_relationship(elem)
225 or getattr(elem, "nullable", False)
226 ):
227 default = None
228
229 return default, default_factory
230
231
232 def parse_type_from_element(elem: ElementType) -> ParsedType:
233 """Parses a type from a SQLAlchemy element.
234
235 Args:
236 elem: The SQLAlchemy element to parse.
237
238 Returns:
239 ParsedType: The parsed type.
240
241 Raises:
242 ImproperlyConfiguredException: If the type cannot be parsed.
243 """
244
245 if isinstance(elem, Column):
246 if elem.nullable:
247 return ParsedType(Optional[elem.type.python_type])
248 return ParsedType(elem.type.python_type)
249
250 if isinstance(elem, RelationshipProperty):
251 if elem.direction in (RelationshipDirection.ONETOMANY, RelationshipDirection.MANYTOMANY):
252 collection_type = ParsedType(elem.collection_class or list)
253 return ParsedType(collection_type.safe_generic_origin[elem.mapper.class_])
254
255 if detect_nullable_relationship(elem):
256 return ParsedType(Optional[elem.mapper.class_])
257
258 return ParsedType(elem.mapper.class_)
259
260 raise ImproperlyConfiguredException(
261 f"Unable to parse type from element '{elem}'. Consider adding a type hint.",
262 )
263
264
265 def detect_nullable_relationship(elem: RelationshipProperty) -> bool:
266 """Detects if a relationship is nullable.
267
268 This attempts to decide if we should allow a ``None`` default value for a relationship by looking at the
269 foreign key fields. If all foreign key fields are nullable, then we allow a ``None`` default value.
270
271 Args:
272 elem: The relationship to check.
273
274 Returns:
275 bool: ``True`` if the relationship is nullable, ``False`` otherwise.
276 """
277 return elem.direction == RelationshipDirection.MANYTOONE and all(c.nullable for c in elem.local_columns)
278
[end of litestar/contrib/sqlalchemy/dto.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/litestar/contrib/sqlalchemy/dto.py b/litestar/contrib/sqlalchemy/dto.py
--- a/litestar/contrib/sqlalchemy/dto.py
+++ b/litestar/contrib/sqlalchemy/dto.py
@@ -216,6 +216,11 @@
def default_factory(d: Any = sqla_default) -> Any:
return d.arg({})
+ elif sqla_default.is_sequence:
+ # SQLAlchemy sequences represent server side defaults
+ # so we cannot infer a reasonable default value for
+ # them on the client side
+ pass
else:
raise ValueError("Unexpected default type")
else:
|
{"golden_diff": "diff --git a/litestar/contrib/sqlalchemy/dto.py b/litestar/contrib/sqlalchemy/dto.py\n--- a/litestar/contrib/sqlalchemy/dto.py\n+++ b/litestar/contrib/sqlalchemy/dto.py\n@@ -216,6 +216,11 @@\n def default_factory(d: Any = sqla_default) -> Any:\n return d.arg({})\n \n+ elif sqla_default.is_sequence:\n+ # SQLAlchemy sequences represent server side defaults\n+ # so we cannot infer a reasonable default value for\n+ # them on the client side\n+ pass\n else:\n raise ValueError(\"Unexpected default type\")\n else:\n", "issue": "StaticFilesConfig and virtual directories\nI'm trying to write a ``FileSystemProtocol`` to load files from the package data using [importlib_resources](https://importlib-resources.readthedocs.io/en/latest/using.html#). But because ``directories`` is defined as ``DirectoryPath``, pydantic checks if the given directories exist in the local filesystem. \r\n\r\nThis is not generally true, especially in any kind of virtual filesystem (e.g. a zipped package). I think this condition should be relaxed to support virtual filesystems.\r\n\r\nhttps://github.com/starlite-api/starlite/blob/9bb6dcd57c10a591377cf8e3a537e9292566d5b9/starlite/config/static_files.py#L32\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom functools import singledispatchmethod\nfrom typing import TYPE_CHECKING, Generic, Optional, TypeVar\n\nfrom sqlalchemy import Column, inspect, orm, sql\nfrom sqlalchemy.ext.associationproxy import AssociationProxy, AssociationProxyExtensionType\nfrom sqlalchemy.ext.hybrid import HybridExtensionType, hybrid_property\nfrom sqlalchemy.orm import (\n ColumnProperty,\n DeclarativeBase,\n InspectionAttr,\n Mapped,\n NotExtension,\n QueryableAttribute,\n RelationshipDirection,\n RelationshipProperty,\n)\n\nfrom litestar.dto.factory.abc import AbstractDTOFactory\nfrom litestar.dto.factory.data_structures import FieldDefinition\nfrom litestar.dto.factory.field import DTO_FIELD_META_KEY, DTOField, Mark\nfrom litestar.dto.factory.utils import get_model_type_hints\nfrom litestar.exceptions import ImproperlyConfiguredException\nfrom litestar.types.empty import Empty\nfrom litestar.typing import ParsedType\nfrom litestar.utils.helpers import get_fully_qualified_class_name\nfrom litestar.utils.signature import ParsedSignature\n\nif TYPE_CHECKING:\n from typing import Any, ClassVar, Collection, Generator\n\n from typing_extensions import TypeAlias\n\n__all__ = (\"SQLAlchemyDTO\",)\n\nT = TypeVar(\"T\", bound=\"DeclarativeBase | Collection[DeclarativeBase]\")\nElementType: TypeAlias = \"Column[Any] | RelationshipProperty[Any]\"\n\nSQLA_NS = {**vars(orm), **vars(sql)}\n\n\nclass SQLAlchemyDTO(AbstractDTOFactory[T], Generic[T]):\n \"\"\"Support for domain modelling with SQLAlchemy.\"\"\"\n\n __slots__ = ()\n\n model_type: ClassVar[type[DeclarativeBase]]\n\n @singledispatchmethod\n @classmethod\n def handle_orm_descriptor(\n cls,\n extension_type: NotExtension | AssociationProxyExtensionType | HybridExtensionType,\n orm_descriptor: InspectionAttr,\n key: str,\n model_type_hints: dict[str, ParsedType],\n model_name: str,\n ) -> list[FieldDefinition]:\n raise NotImplementedError(f\"Unsupported extension type: {extension_type}\")\n\n @handle_orm_descriptor.register(NotExtension)\n @classmethod\n def _(\n cls,\n extension_type: NotExtension,\n key: str,\n orm_descriptor: InspectionAttr,\n model_type_hints: dict[str, ParsedType],\n model_name: str,\n ) -> list[FieldDefinition]:\n if not isinstance(orm_descriptor, QueryableAttribute):\n raise NotImplementedError(f\"Unexpected descriptor type for '{extension_type}': '{orm_descriptor}'\")\n\n elem: ElementType\n if isinstance(orm_descriptor.property, ColumnProperty):\n if not isinstance(orm_descriptor.property.expression, Column):\n raise NotImplementedError(f\"Expected 'Column', got: '{orm_descriptor.property.expression}'\")\n elem = orm_descriptor.property.expression\n elif isinstance(orm_descriptor.property, RelationshipProperty):\n elem = orm_descriptor.property\n else:\n raise NotImplementedError(f\"Unhandled property type: '{orm_descriptor.property}'\")\n\n default, default_factory = _detect_defaults(elem)\n\n try:\n if (parsed_type := model_type_hints[key]).origin is Mapped:\n (parsed_type,) = parsed_type.inner_types\n else:\n raise NotImplementedError(f\"Expected 'Mapped' origin, got: '{parsed_type.origin}'\")\n except KeyError:\n parsed_type = parse_type_from_element(elem)\n\n return [\n FieldDefinition(\n name=key,\n default=default,\n parsed_type=parsed_type,\n default_factory=default_factory,\n dto_field=elem.info.get(DTO_FIELD_META_KEY, DTOField()),\n unique_model_name=model_name,\n dto_for=None,\n )\n ]\n\n @handle_orm_descriptor.register(AssociationProxyExtensionType)\n @classmethod\n def _(\n cls,\n extension_type: AssociationProxyExtensionType,\n key: str,\n orm_descriptor: InspectionAttr,\n model_type_hints: dict[str, ParsedType],\n model_name: str,\n ) -> list[FieldDefinition]:\n if not isinstance(orm_descriptor, AssociationProxy):\n raise NotImplementedError(f\"Unexpected descriptor type '{orm_descriptor}' for '{extension_type}'\")\n\n if (parsed_type := model_type_hints[key]).origin is AssociationProxy:\n (parsed_type,) = parsed_type.inner_types\n else:\n raise NotImplementedError(f\"Expected 'AssociationProxy' origin, got: '{parsed_type.origin}'\")\n\n return [\n FieldDefinition(\n name=key,\n default=Empty,\n parsed_type=parsed_type,\n default_factory=None,\n dto_field=orm_descriptor.info.get(DTO_FIELD_META_KEY, DTOField(mark=Mark.READ_ONLY)),\n unique_model_name=model_name,\n dto_for=None,\n )\n ]\n\n @handle_orm_descriptor.register(HybridExtensionType)\n @classmethod\n def _(\n cls,\n extension_type: HybridExtensionType,\n key: str,\n orm_descriptor: InspectionAttr,\n model_type_hints: dict[str, ParsedType],\n model_name: str,\n ) -> list[FieldDefinition]:\n if not isinstance(orm_descriptor, hybrid_property):\n raise NotImplementedError(f\"Unexpected descriptor type '{orm_descriptor}' for '{extension_type}'\")\n\n getter_sig = ParsedSignature.from_fn(orm_descriptor.fget, {})\n\n field_defs = [\n FieldDefinition(\n name=orm_descriptor.__name__,\n default=Empty,\n parsed_type=getter_sig.return_type,\n default_factory=None,\n dto_field=orm_descriptor.info.get(DTO_FIELD_META_KEY, DTOField(mark=Mark.READ_ONLY)),\n unique_model_name=model_name,\n dto_for=\"return\",\n )\n ]\n\n if orm_descriptor.fset is not None:\n setter_sig = ParsedSignature.from_fn(orm_descriptor.fset, {})\n field_defs.append(\n FieldDefinition(\n name=orm_descriptor.__name__,\n default=Empty,\n parsed_type=next(iter(setter_sig.parameters.values())).parsed_type,\n default_factory=None,\n dto_field=orm_descriptor.info.get(DTO_FIELD_META_KEY, DTOField(mark=Mark.WRITE_ONLY)),\n unique_model_name=model_name,\n dto_for=\"data\",\n )\n )\n\n return field_defs\n\n @classmethod\n def generate_field_definitions(cls, model_type: type[DeclarativeBase]) -> Generator[FieldDefinition, None, None]:\n if (mapper := inspect(model_type)) is None: # pragma: no cover\n raise RuntimeError(\"Unexpected `None` value for mapper.\")\n\n # includes SQLAlchemy names and other mapped class names in the forward reference resolution namespace\n namespace = {**SQLA_NS, **{m.class_.__name__: m.class_ for m in mapper.registry.mappers if m is not mapper}}\n model_type_hints = get_model_type_hints(model_type, namespace=namespace)\n model_name = get_fully_qualified_class_name(model_type)\n\n # the same hybrid property descriptor can be included in `all_orm_descriptors` multiple times, once\n # for each method name it is bound to. We only need to see it once, so track views of it here.\n seen_hybrid_descriptors: set[hybrid_property] = set()\n for key, orm_descriptor in mapper.all_orm_descriptors.items():\n if isinstance(orm_descriptor, hybrid_property):\n if orm_descriptor in seen_hybrid_descriptors:\n continue\n seen_hybrid_descriptors.add(orm_descriptor)\n\n yield from cls.handle_orm_descriptor(\n orm_descriptor.extension_type, key, orm_descriptor, model_type_hints, model_name\n )\n\n @classmethod\n def detect_nested_field(cls, parsed_type: ParsedType) -> bool:\n return parsed_type.is_subclass_of(DeclarativeBase)\n\n\ndef _detect_defaults(elem: ElementType) -> tuple[Any, Any]:\n default: Any = Empty\n default_factory: Any = None # pyright:ignore\n if sqla_default := getattr(elem, \"default\", None):\n if sqla_default.is_scalar:\n default = sqla_default.arg\n elif sqla_default.is_callable:\n\n def default_factory(d: Any = sqla_default) -> Any:\n return d.arg({})\n\n else:\n raise ValueError(\"Unexpected default type\")\n else:\n if (\n isinstance(elem, RelationshipProperty)\n and detect_nullable_relationship(elem)\n or getattr(elem, \"nullable\", False)\n ):\n default = None\n\n return default, default_factory\n\n\ndef parse_type_from_element(elem: ElementType) -> ParsedType:\n \"\"\"Parses a type from a SQLAlchemy element.\n\n Args:\n elem: The SQLAlchemy element to parse.\n\n Returns:\n ParsedType: The parsed type.\n\n Raises:\n ImproperlyConfiguredException: If the type cannot be parsed.\n \"\"\"\n\n if isinstance(elem, Column):\n if elem.nullable:\n return ParsedType(Optional[elem.type.python_type])\n return ParsedType(elem.type.python_type)\n\n if isinstance(elem, RelationshipProperty):\n if elem.direction in (RelationshipDirection.ONETOMANY, RelationshipDirection.MANYTOMANY):\n collection_type = ParsedType(elem.collection_class or list)\n return ParsedType(collection_type.safe_generic_origin[elem.mapper.class_])\n\n if detect_nullable_relationship(elem):\n return ParsedType(Optional[elem.mapper.class_])\n\n return ParsedType(elem.mapper.class_)\n\n raise ImproperlyConfiguredException(\n f\"Unable to parse type from element '{elem}'. Consider adding a type hint.\",\n )\n\n\ndef detect_nullable_relationship(elem: RelationshipProperty) -> bool:\n \"\"\"Detects if a relationship is nullable.\n\n This attempts to decide if we should allow a ``None`` default value for a relationship by looking at the\n foreign key fields. If all foreign key fields are nullable, then we allow a ``None`` default value.\n\n Args:\n elem: The relationship to check.\n\n Returns:\n bool: ``True`` if the relationship is nullable, ``False`` otherwise.\n \"\"\"\n return elem.direction == RelationshipDirection.MANYTOONE and all(c.nullable for c in elem.local_columns)\n", "path": "litestar/contrib/sqlalchemy/dto.py"}]}
| 3,583 | 147 |
gh_patches_debug_19793
|
rasdani/github-patches
|
git_diff
|
Flexget__Flexget-2512
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Notify (Pushbullet) Plugin Error.
Hi, since last week i have this error in my log. Up to this point everything worked without problems.
```
2019-11-13 10:30 ERROR notify_entry NexBox 'x-ratelimit-reset'
Traceback (most recent call last):
File "/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notify.py", line 104, in send_notification
send_notification(*args, **kwargs)
File "/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notification_framework.py", line 124, in send_notification
title, message, rendered_config
File "/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notifiers/pushbullet.py", line 89, in notify
self.send_push(key, title, message, config.get('url'), d, 'device_iden')
File "/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notifiers/pushbullet.py", line 130, in send_push
int(response.headers['X-Ratelimit-Reset'])
File "/usr/local/lib/python3.5/dist-packages/requests/structures.py", line 52, in __getitem__
return self._store[key.lower()][1]
KeyError: 'x-ratelimit-reset'
```
Flexget: 2.21.32
API: 1.5.0
Same with Flexget 3.0.8 and Python 3.8
Notify (Pushbullet) Plugin Error.
Hi, since last week i have this error in my log. Up to this point everything worked without problems.
```
2019-11-13 10:30 ERROR notify_entry NexBox 'x-ratelimit-reset'
Traceback (most recent call last):
File "/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notify.py", line 104, in send_notification
send_notification(*args, **kwargs)
File "/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notification_framework.py", line 124, in send_notification
title, message, rendered_config
File "/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notifiers/pushbullet.py", line 89, in notify
self.send_push(key, title, message, config.get('url'), d, 'device_iden')
File "/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notifiers/pushbullet.py", line 130, in send_push
int(response.headers['X-Ratelimit-Reset'])
File "/usr/local/lib/python3.5/dist-packages/requests/structures.py", line 52, in __getitem__
return self._store[key.lower()][1]
KeyError: 'x-ratelimit-reset'
```
Flexget: 2.21.32
API: 1.5.0
Same with Flexget 3.0.8 and Python 3.8
</issue>
<code>
[start of flexget/components/notify/notifiers/pushbullet.py]
1 import base64
2 import datetime
3 import logging
4
5 from requests.exceptions import RequestException
6
7 from flexget import plugin
8 from flexget.config_schema import one_or_more
9 from flexget.event import event
10 from flexget.plugin import PluginWarning
11 from flexget.utils.requests import Session as RequestSession
12 from flexget.utils.requests import TimedLimiter
13
14 plugin_name = 'pushbullet'
15 log = logging.getLogger(plugin_name)
16
17 PUSHBULLET_URL = 'https://api.pushbullet.com/v2/pushes'
18
19 requests = RequestSession(max_retries=3)
20 requests.add_domain_limiter(TimedLimiter('pushbullet.com', '5 seconds'))
21
22
23 class PushbulletNotifier:
24 """
25 Example::
26
27 notify:
28 entries:
29 via:
30 pushbullet:
31 apikey: <API_KEY>
32 [device: <DEVICE_IDEN> (can also be a list of device ids, or don't specify any ids to send to all devices)]
33 [email: <EMAIL_ADDRESS> (can also be a list of user email addresses)]
34 [channel: <CHANNEL_TAG> (you can only specify device / email or channel tag, cannot use both)]
35
36 Configuration parameters are also supported from entries (eg. through set).
37 """
38
39 schema = {
40 'type': 'object',
41 'properties': {
42 'api_key': one_or_more({'type': 'string'}),
43 'device': one_or_more({'type': 'string'}),
44 'email': one_or_more({'type': 'string', 'format': 'email'}),
45 'url': {'type': 'string'},
46 'channel': {'type': 'string'},
47 'file_template': {'type': 'string'},
48 },
49 'required': ['api_key'],
50 'oneOf': [
51 {'required': ['device']},
52 {'required': ['channel']},
53 {'required': ['email']},
54 {
55 'not': {
56 'anyOf': [
57 {'required': ['device']},
58 {'required': ['channel']},
59 {'required': ['email']},
60 ]
61 }
62 },
63 ],
64 'error_oneOf': 'One (and only one) of `email`, `device` or `channel` are allowed.',
65 'additionalProperties': False,
66 }
67
68 def notify(self, title, message, config):
69 """
70 Send a Pushbullet notification
71 """
72 if config.get('device') and not isinstance(config['device'], list):
73 config['device'] = [config['device']]
74
75 if config.get('email') and not isinstance(config['email'], list):
76 config['email'] = [config['email']]
77
78 if not isinstance(config['api_key'], list):
79 config['api_key'] = [config['api_key']]
80
81 for key in config['api_key']:
82 if config.get('channel'):
83 self.send_push(
84 key, title, message, config.get('url'), config.get('channel'), 'channel_tag'
85 )
86 elif config.get('device'):
87 for d in config['device']:
88 self.send_push(key, title, message, config.get('url'), d, 'device_iden')
89 elif config.get('email'):
90 for e in config['email']:
91 self.send_push(key, title, message, config.get('url'), e, 'email')
92 else:
93 self.send_push(key, title, message, config.get('url'))
94
95 def send_push(self, api_key, title, body, url=None, destination=None, destination_type=None):
96 push_type = 'link' if url else 'note'
97 notification = {'type': push_type, 'title': title, 'body': body}
98 if url:
99 notification['url'] = url
100 if destination:
101 notification[destination_type] = destination
102
103 # Make the request
104 headers = {
105 'Authorization': b'Basic ' + base64.b64encode(api_key.encode('ascii')),
106 'Content-Type': 'application/json',
107 'Accept': 'application/json',
108 'User-Agent': 'Flexget',
109 }
110 try:
111 response = requests.post(PUSHBULLET_URL, headers=headers, json=notification)
112 except RequestException as e:
113 if e.response is not None:
114 if e.response.status_code == 429:
115 reset_time = datetime.datetime.fromtimestamp(
116 int(e.response.headers['X-Ratelimit-Reset'])
117 ).strftime('%Y-%m-%d %H:%M:%S')
118 message = (
119 'Monthly Pushbullet database operations limit reached. Next reset: %s'
120 % reset_time
121 )
122 else:
123 message = e.response.json()['error']['message']
124 else:
125 message = str(e)
126 raise PluginWarning(message)
127
128 reset_time = datetime.datetime.fromtimestamp(
129 int(response.headers['X-Ratelimit-Reset'])
130 ).strftime('%Y-%m-%d %H:%M:%S')
131 remaining = response.headers['X-Ratelimit-Remaining']
132 log.debug(
133 'Pushbullet notification sent. Database operations remaining until next reset: %s. '
134 'Next reset at: %s',
135 remaining,
136 reset_time,
137 )
138
139
140 @event('plugin.register')
141 def register_plugin():
142 plugin.register(PushbulletNotifier, plugin_name, api_ver=2, interfaces=['notifiers'])
143
[end of flexget/components/notify/notifiers/pushbullet.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/flexget/components/notify/notifiers/pushbullet.py b/flexget/components/notify/notifiers/pushbullet.py
--- a/flexget/components/notify/notifiers/pushbullet.py
+++ b/flexget/components/notify/notifiers/pushbullet.py
@@ -112,13 +112,12 @@
except RequestException as e:
if e.response is not None:
if e.response.status_code == 429:
- reset_time = datetime.datetime.fromtimestamp(
- int(e.response.headers['X-Ratelimit-Reset'])
- ).strftime('%Y-%m-%d %H:%M:%S')
- message = (
- 'Monthly Pushbullet database operations limit reached. Next reset: %s'
- % reset_time
- )
+ reset_time = e.response.headers.get('X-Ratelimit-Reset')
+ if reset_time:
+ reset_time = datetime.datetime.fromtimestamp(int(reset_time)).strftime(
+ '%Y-%m-%d %H:%M:%S'
+ )
+ message = f'Monthly Pushbullet database operations limit reached. Next reset: {reset_time}'
else:
message = e.response.json()['error']['message']
else:
|
{"golden_diff": "diff --git a/flexget/components/notify/notifiers/pushbullet.py b/flexget/components/notify/notifiers/pushbullet.py\n--- a/flexget/components/notify/notifiers/pushbullet.py\n+++ b/flexget/components/notify/notifiers/pushbullet.py\n@@ -112,13 +112,12 @@\n except RequestException as e:\n if e.response is not None:\n if e.response.status_code == 429:\n- reset_time = datetime.datetime.fromtimestamp(\n- int(e.response.headers['X-Ratelimit-Reset'])\n- ).strftime('%Y-%m-%d %H:%M:%S')\n- message = (\n- 'Monthly Pushbullet database operations limit reached. Next reset: %s'\n- % reset_time\n- )\n+ reset_time = e.response.headers.get('X-Ratelimit-Reset')\n+ if reset_time:\n+ reset_time = datetime.datetime.fromtimestamp(int(reset_time)).strftime(\n+ '%Y-%m-%d %H:%M:%S'\n+ )\n+ message = f'Monthly Pushbullet database operations limit reached. Next reset: {reset_time}'\n else:\n message = e.response.json()['error']['message']\n else:\n", "issue": "Notify (Pushbullet) Plugin Error.\nHi, since last week i have this error in my log. Up to this point everything worked without problems.\r\n```\r\n2019-11-13 10:30 ERROR notify_entry NexBox 'x-ratelimit-reset'\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notify.py\", line 104, in send_notification\r\n send_notification(*args, **kwargs)\r\n File \"/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notification_framework.py\", line 124, in send_notification\r\n title, message, rendered_config\r\n File \"/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notifiers/pushbullet.py\", line 89, in notify\r\n self.send_push(key, title, message, config.get('url'), d, 'device_iden')\r\n File \"/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notifiers/pushbullet.py\", line 130, in send_push\r\n int(response.headers['X-Ratelimit-Reset'])\r\n File \"/usr/local/lib/python3.5/dist-packages/requests/structures.py\", line 52, in __getitem__\r\n return self._store[key.lower()][1]\r\nKeyError: 'x-ratelimit-reset'\r\n```\r\nFlexget: 2.21.32\r\nAPI: 1.5.0\r\n\r\nSame with Flexget 3.0.8 and Python 3.8\nNotify (Pushbullet) Plugin Error.\nHi, since last week i have this error in my log. Up to this point everything worked without problems.\r\n```\r\n2019-11-13 10:30 ERROR notify_entry NexBox 'x-ratelimit-reset'\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notify.py\", line 104, in send_notification\r\n send_notification(*args, **kwargs)\r\n File \"/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notification_framework.py\", line 124, in send_notification\r\n title, message, rendered_config\r\n File \"/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notifiers/pushbullet.py\", line 89, in notify\r\n self.send_push(key, title, message, config.get('url'), d, 'device_iden')\r\n File \"/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notifiers/pushbullet.py\", line 130, in send_push\r\n int(response.headers['X-Ratelimit-Reset'])\r\n File \"/usr/local/lib/python3.5/dist-packages/requests/structures.py\", line 52, in __getitem__\r\n return self._store[key.lower()][1]\r\nKeyError: 'x-ratelimit-reset'\r\n```\r\nFlexget: 2.21.32\r\nAPI: 1.5.0\r\n\r\nSame with Flexget 3.0.8 and Python 3.8\n", "before_files": [{"content": "import base64\nimport datetime\nimport logging\n\nfrom requests.exceptions import RequestException\n\nfrom flexget import plugin\nfrom flexget.config_schema import one_or_more\nfrom flexget.event import event\nfrom flexget.plugin import PluginWarning\nfrom flexget.utils.requests import Session as RequestSession\nfrom flexget.utils.requests import TimedLimiter\n\nplugin_name = 'pushbullet'\nlog = logging.getLogger(plugin_name)\n\nPUSHBULLET_URL = 'https://api.pushbullet.com/v2/pushes'\n\nrequests = RequestSession(max_retries=3)\nrequests.add_domain_limiter(TimedLimiter('pushbullet.com', '5 seconds'))\n\n\nclass PushbulletNotifier:\n \"\"\"\n Example::\n\n notify:\n entries:\n via:\n pushbullet:\n apikey: <API_KEY>\n [device: <DEVICE_IDEN> (can also be a list of device ids, or don't specify any ids to send to all devices)]\n [email: <EMAIL_ADDRESS> (can also be a list of user email addresses)]\n [channel: <CHANNEL_TAG> (you can only specify device / email or channel tag, cannot use both)]\n\n Configuration parameters are also supported from entries (eg. through set).\n \"\"\"\n\n schema = {\n 'type': 'object',\n 'properties': {\n 'api_key': one_or_more({'type': 'string'}),\n 'device': one_or_more({'type': 'string'}),\n 'email': one_or_more({'type': 'string', 'format': 'email'}),\n 'url': {'type': 'string'},\n 'channel': {'type': 'string'},\n 'file_template': {'type': 'string'},\n },\n 'required': ['api_key'],\n 'oneOf': [\n {'required': ['device']},\n {'required': ['channel']},\n {'required': ['email']},\n {\n 'not': {\n 'anyOf': [\n {'required': ['device']},\n {'required': ['channel']},\n {'required': ['email']},\n ]\n }\n },\n ],\n 'error_oneOf': 'One (and only one) of `email`, `device` or `channel` are allowed.',\n 'additionalProperties': False,\n }\n\n def notify(self, title, message, config):\n \"\"\"\n Send a Pushbullet notification\n \"\"\"\n if config.get('device') and not isinstance(config['device'], list):\n config['device'] = [config['device']]\n\n if config.get('email') and not isinstance(config['email'], list):\n config['email'] = [config['email']]\n\n if not isinstance(config['api_key'], list):\n config['api_key'] = [config['api_key']]\n\n for key in config['api_key']:\n if config.get('channel'):\n self.send_push(\n key, title, message, config.get('url'), config.get('channel'), 'channel_tag'\n )\n elif config.get('device'):\n for d in config['device']:\n self.send_push(key, title, message, config.get('url'), d, 'device_iden')\n elif config.get('email'):\n for e in config['email']:\n self.send_push(key, title, message, config.get('url'), e, 'email')\n else:\n self.send_push(key, title, message, config.get('url'))\n\n def send_push(self, api_key, title, body, url=None, destination=None, destination_type=None):\n push_type = 'link' if url else 'note'\n notification = {'type': push_type, 'title': title, 'body': body}\n if url:\n notification['url'] = url\n if destination:\n notification[destination_type] = destination\n\n # Make the request\n headers = {\n 'Authorization': b'Basic ' + base64.b64encode(api_key.encode('ascii')),\n 'Content-Type': 'application/json',\n 'Accept': 'application/json',\n 'User-Agent': 'Flexget',\n }\n try:\n response = requests.post(PUSHBULLET_URL, headers=headers, json=notification)\n except RequestException as e:\n if e.response is not None:\n if e.response.status_code == 429:\n reset_time = datetime.datetime.fromtimestamp(\n int(e.response.headers['X-Ratelimit-Reset'])\n ).strftime('%Y-%m-%d %H:%M:%S')\n message = (\n 'Monthly Pushbullet database operations limit reached. Next reset: %s'\n % reset_time\n )\n else:\n message = e.response.json()['error']['message']\n else:\n message = str(e)\n raise PluginWarning(message)\n\n reset_time = datetime.datetime.fromtimestamp(\n int(response.headers['X-Ratelimit-Reset'])\n ).strftime('%Y-%m-%d %H:%M:%S')\n remaining = response.headers['X-Ratelimit-Remaining']\n log.debug(\n 'Pushbullet notification sent. Database operations remaining until next reset: %s. '\n 'Next reset at: %s',\n remaining,\n reset_time,\n )\n\n\n@event('plugin.register')\ndef register_plugin():\n plugin.register(PushbulletNotifier, plugin_name, api_ver=2, interfaces=['notifiers'])\n", "path": "flexget/components/notify/notifiers/pushbullet.py"}]}
| 2,666 | 271 |
gh_patches_debug_6194
|
rasdani/github-patches
|
git_diff
|
cal-itp__benefits-1067
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Content Security Policy frame-src should not extend "none"
The default CSP `frame-src` setting [we configure is `["'none'"]`](https://github.com/cal-itp/benefits/blob/dev/benefits/settings.py#L275).
Then we `.extend()` that list with any additional allowed frame sources. But this is not correct in CSP, either `'none'` or a list of domains should be provided, not both.
We saw this with reCAPTCHA complaining in the console in `dev`:

## To Reproduce
Steps to reproduce the behavior:
1. Go to `dev`
2. Get to the Benefits selection page
3. Open the browser console
4. See error
## Expected behavior
A clear and concise description of what you expected to happen.
## Additional context
This _may_ be causing an issue where reCAPTCHA is allowing the form to submit even when required fields are not provided:

</issue>
<code>
[start of benefits/settings.py]
1 """
2 Django settings for benefits project.
3 """
4 import os
5 import benefits.logging
6
7
8 def _filter_empty(ls):
9 return [s for s in ls if s]
10
11
12 # Build paths inside the project like this: os.path.join(BASE_DIR, ...)
13 BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
14
15 # SECURITY WARNING: keep the secret key used in production secret!
16 SECRET_KEY = os.environ.get("DJANGO_SECRET_KEY", "secret")
17
18 # SECURITY WARNING: don't run with debug turned on in production!
19 DEBUG = os.environ.get("DJANGO_DEBUG", "False").lower() == "true"
20
21 ADMIN = os.environ.get("DJANGO_ADMIN", "False").lower() == "true"
22
23 ALLOWED_HOSTS = _filter_empty(os.environ.get("DJANGO_ALLOWED_HOSTS", "localhost,127.0.0.1").split(","))
24
25 # Application definition
26
27 INSTALLED_APPS = [
28 "django.contrib.messages",
29 "django.contrib.sessions",
30 "django.contrib.staticfiles",
31 "benefits.core",
32 "benefits.enrollment",
33 "benefits.eligibility",
34 "benefits.oauth",
35 ]
36
37 if ADMIN:
38 INSTALLED_APPS.extend(
39 [
40 "django.contrib.admin",
41 "django.contrib.auth",
42 "django.contrib.contenttypes",
43 ]
44 )
45
46 MIDDLEWARE = [
47 "django.middleware.security.SecurityMiddleware",
48 "django.contrib.sessions.middleware.SessionMiddleware",
49 "django.contrib.messages.middleware.MessageMiddleware",
50 "django.middleware.locale.LocaleMiddleware",
51 "benefits.core.middleware.Healthcheck",
52 "django.middleware.common.CommonMiddleware",
53 "django.middleware.csrf.CsrfViewMiddleware",
54 "django.middleware.clickjacking.XFrameOptionsMiddleware",
55 "csp.middleware.CSPMiddleware",
56 "benefits.core.middleware.ChangedLanguageEvent",
57 ]
58
59 if ADMIN:
60 MIDDLEWARE.extend(
61 [
62 "django.contrib.auth.middleware.AuthenticationMiddleware",
63 "django.contrib.messages.middleware.MessageMiddleware",
64 ]
65 )
66
67 if DEBUG:
68 MIDDLEWARE.append("benefits.core.middleware.DebugSession")
69
70
71 # Azure Insights
72 # https://docs.microsoft.com/en-us/azure/azure-monitor/app/opencensus-python-request#tracking-django-applications
73
74 ENABLE_AZURE_INSIGHTS = "APPLICATIONINSIGHTS_CONNECTION_STRING" in os.environ
75 print("ENABLE_AZURE_INSIGHTS: ", ENABLE_AZURE_INSIGHTS)
76 if ENABLE_AZURE_INSIGHTS:
77 MIDDLEWARE.extend(
78 [
79 "opencensus.ext.django.middleware.OpencensusMiddleware",
80 "benefits.core.middleware.LogErrorToAzure",
81 ]
82 )
83
84 # only used if enabled above
85 OPENCENSUS = {
86 "TRACE": {
87 "SAMPLER": "opencensus.trace.samplers.ProbabilitySampler(rate=1)",
88 "EXPORTER": "opencensus.ext.azure.trace_exporter.AzureExporter()",
89 }
90 }
91
92
93 CSRF_COOKIE_AGE = None
94 CSRF_COOKIE_SAMESITE = "Strict"
95 CSRF_COOKIE_HTTPONLY = True
96 CSRF_TRUSTED_ORIGINS = _filter_empty(os.environ.get("DJANGO_TRUSTED_ORIGINS", "http://localhost,http://127.0.0.1").split(","))
97
98 # With `Strict`, the user loses their Django session between leaving our app to
99 # sign in with OAuth, and coming back into our app from the OAuth redirect.
100 # This is because `Strict` disallows our cookie being sent from an external
101 # domain and so the session cookie is lost.
102 #
103 # `Lax` allows the cookie to travel with the user and be sent back to us by the
104 # OAuth server, as long as the request is "safe" i.e. GET
105 SESSION_COOKIE_SAMESITE = "Lax"
106 SESSION_ENGINE = "django.contrib.sessions.backends.signed_cookies"
107 SESSION_EXPIRE_AT_BROWSER_CLOSE = True
108 SESSION_COOKIE_NAME = "_benefitssessionid"
109
110 if not DEBUG:
111 CSRF_COOKIE_SECURE = True
112 CSRF_FAILURE_VIEW = "benefits.core.views.csrf_failure"
113 SESSION_COOKIE_SECURE = True
114
115 SECURE_BROWSER_XSS_FILTER = True
116
117 # required so that cross-origin pop-ups (like the enrollment overlay) have access to parent window context
118 # https://github.com/cal-itp/benefits/pull/793
119 SECURE_CROSS_ORIGIN_OPENER_POLICY = "same-origin-allow-popups"
120
121 # the NGINX reverse proxy sits in front of the application in deployed environments
122 # SSL terminates before getting to Django, and NGINX adds this header to indicate
123 # if the original request was secure or not
124 #
125 # See https://docs.djangoproject.com/en/4.0/ref/settings/#secure-proxy-ssl-header
126 if not DEBUG:
127 SECURE_PROXY_SSL_HEADER = ("HTTP_X_FORWARDED_PROTO", "https")
128
129 ROOT_URLCONF = "benefits.urls"
130
131 template_ctx_processors = [
132 "django.template.context_processors.request",
133 "django.contrib.messages.context_processors.messages",
134 "benefits.core.context_processors.analytics",
135 "benefits.core.context_processors.authentication",
136 "benefits.core.context_processors.recaptcha",
137 ]
138
139 if DEBUG:
140 template_ctx_processors.extend(
141 [
142 "django.template.context_processors.debug",
143 "benefits.core.context_processors.debug",
144 ]
145 )
146
147 if ADMIN:
148 template_ctx_processors.extend(
149 [
150 "django.contrib.auth.context_processors.auth",
151 "django.contrib.messages.context_processors.messages",
152 ]
153 )
154
155 TEMPLATES = [
156 {
157 "BACKEND": "django.template.backends.django.DjangoTemplates",
158 "DIRS": [os.path.join(BASE_DIR, "benefits", "templates")],
159 "APP_DIRS": True,
160 "OPTIONS": {
161 "context_processors": template_ctx_processors,
162 },
163 },
164 ]
165
166 WSGI_APPLICATION = "benefits.wsgi.application"
167
168 DATABASES = {
169 "default": {
170 "ENGINE": "django.db.backends.sqlite3",
171 "NAME": "django.db",
172 }
173 }
174
175 LOAD_SAMPLE_DATA = os.environ.get("DJANGO_LOAD_SAMPLE_DATA", "true").lower() != "false"
176
177 # Password validation
178
179 AUTH_PASSWORD_VALIDATORS = []
180
181 if ADMIN:
182 AUTH_PASSWORD_VALIDATORS.extend(
183 [
184 {
185 "NAME": "django.contrib.auth.password_validation.UserAttributeSimilarityValidator",
186 },
187 {
188 "NAME": "django.contrib.auth.password_validation.MinimumLengthValidator",
189 },
190 {
191 "NAME": "django.contrib.auth.password_validation.CommonPasswordValidator",
192 },
193 {
194 "NAME": "django.contrib.auth.password_validation.NumericPasswordValidator",
195 },
196 ]
197 )
198
199 # Internationalization
200
201 LANGUAGE_CODE = "en"
202
203 LANGUAGE_COOKIE_HTTPONLY = True
204 LANGUAGE_COOKIE_SAMESITE = "Strict"
205 LANGUAGE_COOKIE_SECURE = True
206
207 LANGUAGES = [("en", "English"), ("es", "Español")]
208
209 LOCALE_PATHS = [os.path.join(BASE_DIR, "benefits", "locale")]
210
211 USE_I18N = True
212 USE_L10N = True
213
214 TIME_ZONE = "UTC"
215 USE_TZ = True
216
217 # Static files (CSS, JavaScript, Images)
218
219 STATIC_URL = "/static/"
220 STATICFILES_DIRS = [os.path.join(BASE_DIR, "benefits", "static")]
221 # use Manifest Static Files Storage by default
222 STATICFILES_STORAGE = os.environ.get(
223 "DJANGO_STATICFILES_STORAGE", "django.contrib.staticfiles.storage.ManifestStaticFilesStorage"
224 )
225 STATIC_ROOT = os.path.join(BASE_DIR, "static")
226
227 # Logging configuration
228 LOG_LEVEL = os.environ.get("DJANGO_LOG_LEVEL", "DEBUG" if DEBUG else "WARNING")
229 LOGGING = benefits.logging.get_config(LOG_LEVEL, enable_azure=ENABLE_AZURE_INSIGHTS)
230
231 # Analytics configuration
232
233 ANALYTICS_KEY = os.environ.get("ANALYTICS_KEY")
234
235 # rate limit configuration
236
237 # number of requests allowed in the given period
238 RATE_LIMIT = int(os.environ.get("DJANGO_RATE_LIMIT", 5))
239
240 # HTTP request methods to rate limit
241 RATE_LIMIT_METHODS = os.environ.get("DJANGO_RATE_LIMIT_METHODS", "POST").upper().split(",")
242
243 # number of seconds before additional requests are denied
244 RATE_LIMIT_PERIOD = int(os.environ.get("DJANGO_RATE_LIMIT_PERIOD", 60))
245
246 # Rate Limit feature flag
247 RATE_LIMIT_ENABLED = all((RATE_LIMIT > 0, len(RATE_LIMIT_METHODS) > 0, RATE_LIMIT_PERIOD > 0))
248
249 # reCAPTCHA configuration
250
251 RECAPTCHA_API_URL = os.environ.get("DJANGO_RECAPTCHA_API_URL", "https://www.google.com/recaptcha/api.js")
252 RECAPTCHA_SITE_KEY = os.environ.get("DJANGO_RECAPTCHA_SITE_KEY")
253 RECAPTCHA_SECRET_KEY = os.environ.get("DJANGO_RECAPTCHA_SECRET_KEY")
254 RECAPTCHA_VERIFY_URL = os.environ.get("DJANGO_RECAPTCHA_VERIFY_URL", "https://www.google.com/recaptcha/api/siteverify")
255 RECAPTCHA_ENABLED = all((RECAPTCHA_API_URL, RECAPTCHA_SITE_KEY, RECAPTCHA_SECRET_KEY, RECAPTCHA_VERIFY_URL))
256
257 # Content Security Policy
258 # Configuration docs at https://django-csp.readthedocs.io/en/latest/configuration.html
259
260 # In particular, note that the inner single-quotes are required!
261 # https://django-csp.readthedocs.io/en/latest/configuration.html#policy-settings
262
263 CSP_DEFAULT_SRC = ["'self'"]
264
265 CSP_CONNECT_SRC = ["'self'", "https://api.amplitude.com/"]
266 env_connect_src = _filter_empty(os.environ.get("DJANGO_CSP_CONNECT_SRC", "").split(","))
267 CSP_CONNECT_SRC.extend(env_connect_src)
268
269 CSP_FONT_SRC = ["'self'", "https://california.azureedge.net/", "https://fonts.gstatic.com/"]
270 env_font_src = _filter_empty(os.environ.get("DJANGO_CSP_FONT_SRC", "").split(","))
271 CSP_FONT_SRC.extend(env_font_src)
272
273 CSP_FRAME_ANCESTORS = ["'none'"]
274
275 CSP_FRAME_SRC = ["'none'"]
276 env_frame_src = _filter_empty(os.environ.get("DJANGO_CSP_FRAME_SRC", "").split(","))
277 CSP_FRAME_SRC.extend(env_frame_src)
278 if RECAPTCHA_ENABLED:
279 CSP_FRAME_SRC.append("https://www.google.com")
280
281
282 CSP_SCRIPT_SRC = [
283 "'unsafe-inline'",
284 "https://california.azureedge.net/",
285 "https://cdn.amplitude.com/libs/",
286 "https://code.jquery.com/",
287 "*.littlepay.com",
288 ]
289 env_script_src = _filter_empty(os.environ.get("DJANGO_CSP_SCRIPT_SRC", "").split(","))
290 CSP_SCRIPT_SRC.extend(env_script_src)
291 if RECAPTCHA_ENABLED:
292 CSP_SCRIPT_SRC.extend(["https://www.google.com/recaptcha/", "https://www.gstatic.com/recaptcha/releases/"])
293
294 CSP_STYLE_SRC = [
295 "'self'",
296 "'unsafe-inline'",
297 "https://california.azureedge.net/",
298 "https://fonts.googleapis.com/css",
299 ]
300 env_style_src = _filter_empty(os.environ.get("DJANGO_CSP_STYLE_SRC", "").split(","))
301 CSP_STYLE_SRC.extend(env_style_src)
302
[end of benefits/settings.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/benefits/settings.py b/benefits/settings.py
--- a/benefits/settings.py
+++ b/benefits/settings.py
@@ -274,10 +274,10 @@
CSP_FRAME_SRC = ["'none'"]
env_frame_src = _filter_empty(os.environ.get("DJANGO_CSP_FRAME_SRC", "").split(","))
-CSP_FRAME_SRC.extend(env_frame_src)
if RECAPTCHA_ENABLED:
- CSP_FRAME_SRC.append("https://www.google.com")
-
+ env_frame_src.append("https://www.google.com")
+if len(env_frame_src) > 0:
+ CSP_FRAME_SRC = env_frame_src
CSP_SCRIPT_SRC = [
"'unsafe-inline'",
|
{"golden_diff": "diff --git a/benefits/settings.py b/benefits/settings.py\n--- a/benefits/settings.py\n+++ b/benefits/settings.py\n@@ -274,10 +274,10 @@\n \n CSP_FRAME_SRC = [\"'none'\"]\n env_frame_src = _filter_empty(os.environ.get(\"DJANGO_CSP_FRAME_SRC\", \"\").split(\",\"))\n-CSP_FRAME_SRC.extend(env_frame_src)\n if RECAPTCHA_ENABLED:\n- CSP_FRAME_SRC.append(\"https://www.google.com\")\n-\n+ env_frame_src.append(\"https://www.google.com\")\n+if len(env_frame_src) > 0:\n+ CSP_FRAME_SRC = env_frame_src\n \n CSP_SCRIPT_SRC = [\n \"'unsafe-inline'\",\n", "issue": "Content Security Policy frame-src should not extend \"none\"\nThe default CSP `frame-src` setting [we configure is `[\"'none'\"]`](https://github.com/cal-itp/benefits/blob/dev/benefits/settings.py#L275).\r\n\r\nThen we `.extend()` that list with any additional allowed frame sources. But this is not correct in CSP, either `'none'` or a list of domains should be provided, not both.\r\n\r\nWe saw this with reCAPTCHA complaining in the console in `dev`:\r\n\r\n\r\n\r\n## To Reproduce\r\n\r\nSteps to reproduce the behavior:\r\n\r\n1. Go to `dev`\r\n2. Get to the Benefits selection page\r\n3. Open the browser console\r\n4. See error\r\n\r\n## Expected behavior\r\n\r\nA clear and concise description of what you expected to happen.\r\n\r\n## Additional context\r\n\r\nThis _may_ be causing an issue where reCAPTCHA is allowing the form to submit even when required fields are not provided:\r\n\r\n\r\n\n", "before_files": [{"content": "\"\"\"\nDjango settings for benefits project.\n\"\"\"\nimport os\nimport benefits.logging\n\n\ndef _filter_empty(ls):\n return [s for s in ls if s]\n\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = os.environ.get(\"DJANGO_SECRET_KEY\", \"secret\")\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = os.environ.get(\"DJANGO_DEBUG\", \"False\").lower() == \"true\"\n\nADMIN = os.environ.get(\"DJANGO_ADMIN\", \"False\").lower() == \"true\"\n\nALLOWED_HOSTS = _filter_empty(os.environ.get(\"DJANGO_ALLOWED_HOSTS\", \"localhost,127.0.0.1\").split(\",\"))\n\n# Application definition\n\nINSTALLED_APPS = [\n \"django.contrib.messages\",\n \"django.contrib.sessions\",\n \"django.contrib.staticfiles\",\n \"benefits.core\",\n \"benefits.enrollment\",\n \"benefits.eligibility\",\n \"benefits.oauth\",\n]\n\nif ADMIN:\n INSTALLED_APPS.extend(\n [\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n ]\n )\n\nMIDDLEWARE = [\n \"django.middleware.security.SecurityMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.locale.LocaleMiddleware\",\n \"benefits.core.middleware.Healthcheck\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n \"csp.middleware.CSPMiddleware\",\n \"benefits.core.middleware.ChangedLanguageEvent\",\n]\n\nif ADMIN:\n MIDDLEWARE.extend(\n [\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n ]\n )\n\nif DEBUG:\n MIDDLEWARE.append(\"benefits.core.middleware.DebugSession\")\n\n\n# Azure Insights\n# https://docs.microsoft.com/en-us/azure/azure-monitor/app/opencensus-python-request#tracking-django-applications\n\nENABLE_AZURE_INSIGHTS = \"APPLICATIONINSIGHTS_CONNECTION_STRING\" in os.environ\nprint(\"ENABLE_AZURE_INSIGHTS: \", ENABLE_AZURE_INSIGHTS)\nif ENABLE_AZURE_INSIGHTS:\n MIDDLEWARE.extend(\n [\n \"opencensus.ext.django.middleware.OpencensusMiddleware\",\n \"benefits.core.middleware.LogErrorToAzure\",\n ]\n )\n\n# only used if enabled above\nOPENCENSUS = {\n \"TRACE\": {\n \"SAMPLER\": \"opencensus.trace.samplers.ProbabilitySampler(rate=1)\",\n \"EXPORTER\": \"opencensus.ext.azure.trace_exporter.AzureExporter()\",\n }\n}\n\n\nCSRF_COOKIE_AGE = None\nCSRF_COOKIE_SAMESITE = \"Strict\"\nCSRF_COOKIE_HTTPONLY = True\nCSRF_TRUSTED_ORIGINS = _filter_empty(os.environ.get(\"DJANGO_TRUSTED_ORIGINS\", \"http://localhost,http://127.0.0.1\").split(\",\"))\n\n# With `Strict`, the user loses their Django session between leaving our app to\n# sign in with OAuth, and coming back into our app from the OAuth redirect.\n# This is because `Strict` disallows our cookie being sent from an external\n# domain and so the session cookie is lost.\n#\n# `Lax` allows the cookie to travel with the user and be sent back to us by the\n# OAuth server, as long as the request is \"safe\" i.e. GET\nSESSION_COOKIE_SAMESITE = \"Lax\"\nSESSION_ENGINE = \"django.contrib.sessions.backends.signed_cookies\"\nSESSION_EXPIRE_AT_BROWSER_CLOSE = True\nSESSION_COOKIE_NAME = \"_benefitssessionid\"\n\nif not DEBUG:\n CSRF_COOKIE_SECURE = True\n CSRF_FAILURE_VIEW = \"benefits.core.views.csrf_failure\"\n SESSION_COOKIE_SECURE = True\n\nSECURE_BROWSER_XSS_FILTER = True\n\n# required so that cross-origin pop-ups (like the enrollment overlay) have access to parent window context\n# https://github.com/cal-itp/benefits/pull/793\nSECURE_CROSS_ORIGIN_OPENER_POLICY = \"same-origin-allow-popups\"\n\n# the NGINX reverse proxy sits in front of the application in deployed environments\n# SSL terminates before getting to Django, and NGINX adds this header to indicate\n# if the original request was secure or not\n#\n# See https://docs.djangoproject.com/en/4.0/ref/settings/#secure-proxy-ssl-header\nif not DEBUG:\n SECURE_PROXY_SSL_HEADER = (\"HTTP_X_FORWARDED_PROTO\", \"https\")\n\nROOT_URLCONF = \"benefits.urls\"\n\ntemplate_ctx_processors = [\n \"django.template.context_processors.request\",\n \"django.contrib.messages.context_processors.messages\",\n \"benefits.core.context_processors.analytics\",\n \"benefits.core.context_processors.authentication\",\n \"benefits.core.context_processors.recaptcha\",\n]\n\nif DEBUG:\n template_ctx_processors.extend(\n [\n \"django.template.context_processors.debug\",\n \"benefits.core.context_processors.debug\",\n ]\n )\n\nif ADMIN:\n template_ctx_processors.extend(\n [\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n ]\n )\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [os.path.join(BASE_DIR, \"benefits\", \"templates\")],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": template_ctx_processors,\n },\n },\n]\n\nWSGI_APPLICATION = \"benefits.wsgi.application\"\n\nDATABASES = {\n \"default\": {\n \"ENGINE\": \"django.db.backends.sqlite3\",\n \"NAME\": \"django.db\",\n }\n}\n\nLOAD_SAMPLE_DATA = os.environ.get(\"DJANGO_LOAD_SAMPLE_DATA\", \"true\").lower() != \"false\"\n\n# Password validation\n\nAUTH_PASSWORD_VALIDATORS = []\n\nif ADMIN:\n AUTH_PASSWORD_VALIDATORS.extend(\n [\n {\n \"NAME\": \"django.contrib.auth.password_validation.UserAttributeSimilarityValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.MinimumLengthValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.CommonPasswordValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.NumericPasswordValidator\",\n },\n ]\n )\n\n# Internationalization\n\nLANGUAGE_CODE = \"en\"\n\nLANGUAGE_COOKIE_HTTPONLY = True\nLANGUAGE_COOKIE_SAMESITE = \"Strict\"\nLANGUAGE_COOKIE_SECURE = True\n\nLANGUAGES = [(\"en\", \"English\"), (\"es\", \"Espa\u00f1ol\")]\n\nLOCALE_PATHS = [os.path.join(BASE_DIR, \"benefits\", \"locale\")]\n\nUSE_I18N = True\nUSE_L10N = True\n\nTIME_ZONE = \"UTC\"\nUSE_TZ = True\n\n# Static files (CSS, JavaScript, Images)\n\nSTATIC_URL = \"/static/\"\nSTATICFILES_DIRS = [os.path.join(BASE_DIR, \"benefits\", \"static\")]\n# use Manifest Static Files Storage by default\nSTATICFILES_STORAGE = os.environ.get(\n \"DJANGO_STATICFILES_STORAGE\", \"django.contrib.staticfiles.storage.ManifestStaticFilesStorage\"\n)\nSTATIC_ROOT = os.path.join(BASE_DIR, \"static\")\n\n# Logging configuration\nLOG_LEVEL = os.environ.get(\"DJANGO_LOG_LEVEL\", \"DEBUG\" if DEBUG else \"WARNING\")\nLOGGING = benefits.logging.get_config(LOG_LEVEL, enable_azure=ENABLE_AZURE_INSIGHTS)\n\n# Analytics configuration\n\nANALYTICS_KEY = os.environ.get(\"ANALYTICS_KEY\")\n\n# rate limit configuration\n\n# number of requests allowed in the given period\nRATE_LIMIT = int(os.environ.get(\"DJANGO_RATE_LIMIT\", 5))\n\n# HTTP request methods to rate limit\nRATE_LIMIT_METHODS = os.environ.get(\"DJANGO_RATE_LIMIT_METHODS\", \"POST\").upper().split(\",\")\n\n# number of seconds before additional requests are denied\nRATE_LIMIT_PERIOD = int(os.environ.get(\"DJANGO_RATE_LIMIT_PERIOD\", 60))\n\n# Rate Limit feature flag\nRATE_LIMIT_ENABLED = all((RATE_LIMIT > 0, len(RATE_LIMIT_METHODS) > 0, RATE_LIMIT_PERIOD > 0))\n\n# reCAPTCHA configuration\n\nRECAPTCHA_API_URL = os.environ.get(\"DJANGO_RECAPTCHA_API_URL\", \"https://www.google.com/recaptcha/api.js\")\nRECAPTCHA_SITE_KEY = os.environ.get(\"DJANGO_RECAPTCHA_SITE_KEY\")\nRECAPTCHA_SECRET_KEY = os.environ.get(\"DJANGO_RECAPTCHA_SECRET_KEY\")\nRECAPTCHA_VERIFY_URL = os.environ.get(\"DJANGO_RECAPTCHA_VERIFY_URL\", \"https://www.google.com/recaptcha/api/siteverify\")\nRECAPTCHA_ENABLED = all((RECAPTCHA_API_URL, RECAPTCHA_SITE_KEY, RECAPTCHA_SECRET_KEY, RECAPTCHA_VERIFY_URL))\n\n# Content Security Policy\n# Configuration docs at https://django-csp.readthedocs.io/en/latest/configuration.html\n\n# In particular, note that the inner single-quotes are required!\n# https://django-csp.readthedocs.io/en/latest/configuration.html#policy-settings\n\nCSP_DEFAULT_SRC = [\"'self'\"]\n\nCSP_CONNECT_SRC = [\"'self'\", \"https://api.amplitude.com/\"]\nenv_connect_src = _filter_empty(os.environ.get(\"DJANGO_CSP_CONNECT_SRC\", \"\").split(\",\"))\nCSP_CONNECT_SRC.extend(env_connect_src)\n\nCSP_FONT_SRC = [\"'self'\", \"https://california.azureedge.net/\", \"https://fonts.gstatic.com/\"]\nenv_font_src = _filter_empty(os.environ.get(\"DJANGO_CSP_FONT_SRC\", \"\").split(\",\"))\nCSP_FONT_SRC.extend(env_font_src)\n\nCSP_FRAME_ANCESTORS = [\"'none'\"]\n\nCSP_FRAME_SRC = [\"'none'\"]\nenv_frame_src = _filter_empty(os.environ.get(\"DJANGO_CSP_FRAME_SRC\", \"\").split(\",\"))\nCSP_FRAME_SRC.extend(env_frame_src)\nif RECAPTCHA_ENABLED:\n CSP_FRAME_SRC.append(\"https://www.google.com\")\n\n\nCSP_SCRIPT_SRC = [\n \"'unsafe-inline'\",\n \"https://california.azureedge.net/\",\n \"https://cdn.amplitude.com/libs/\",\n \"https://code.jquery.com/\",\n \"*.littlepay.com\",\n]\nenv_script_src = _filter_empty(os.environ.get(\"DJANGO_CSP_SCRIPT_SRC\", \"\").split(\",\"))\nCSP_SCRIPT_SRC.extend(env_script_src)\nif RECAPTCHA_ENABLED:\n CSP_SCRIPT_SRC.extend([\"https://www.google.com/recaptcha/\", \"https://www.gstatic.com/recaptcha/releases/\"])\n\nCSP_STYLE_SRC = [\n \"'self'\",\n \"'unsafe-inline'\",\n \"https://california.azureedge.net/\",\n \"https://fonts.googleapis.com/css\",\n]\nenv_style_src = _filter_empty(os.environ.get(\"DJANGO_CSP_STYLE_SRC\", \"\").split(\",\"))\nCSP_STYLE_SRC.extend(env_style_src)\n", "path": "benefits/settings.py"}]}
| 3,966 | 153 |
gh_patches_debug_20590
|
rasdani/github-patches
|
git_diff
|
e-valuation__EvaP-795
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove passwords from error messages
EvaP sends error messages to the admins when a server error occurs. Post data sent to the page where the error occurred will be included in the message, but passwords must not be included in these messages.
This currently happens e.g. when a user is logging in who has two accounts like described in #791.
Remove passwords from error messages
EvaP sends error messages to the admins when a server error occurs. Post data sent to the page where the error occurred will be included in the message, but passwords must not be included in these messages.
This currently happens e.g. when a user is logging in who has two accounts like described in #791.
</issue>
<code>
[start of evap/evaluation/views.py]
1 import logging
2
3 from django.conf import settings
4 from django.contrib import messages
5 from django.contrib.auth import login as auth_login
6 from django.contrib.auth.decorators import login_required
7 from django.core.mail import EmailMessage
8 from django.http import HttpResponse
9 from django.shortcuts import redirect, render
10 from django.utils.translation import ugettext as _
11 from django.core.urlresolvers import resolve, Resolver404
12 from django.views.decorators.http import require_POST
13
14 from evap.evaluation.forms import NewKeyForm, LoginUsernameForm
15 from evap.evaluation.models import UserProfile, FaqSection, EmailTemplate, Semester
16
17 logger = logging.getLogger(__name__)
18
19
20 def index(request):
21 """Main entry page into EvaP providing all the login options available. The username/password
22 login is thought to be used for internal users, e.g. by connecting to a LDAP directory.
23 The login key mechanism is meant to be used to include external participants, e.g. visiting
24 students or visiting contributors.
25 """
26
27 # parse the form data into the respective form
28 submit_type = request.POST.get("submit_type", "no_submit")
29 new_key_form = NewKeyForm(request.POST if submit_type == "new_key" else None)
30 login_username_form = LoginUsernameForm(request, request.POST if submit_type == "login_username" else None)
31
32 # process form data
33 if request.method == 'POST':
34 if new_key_form.is_valid():
35 # user wants a new login key
36 profile = new_key_form.get_user()
37 profile.generate_login_key()
38 profile.save()
39
40 EmailTemplate.send_login_url_to_user(new_key_form.get_user())
41
42 messages.success(request, _("We sent you an email with a one-time login URL. Please check your inbox."))
43 return redirect('evaluation:index')
44 elif login_username_form.is_valid():
45 # user would like to login with username and password and passed password test
46 auth_login(request, login_username_form.get_user())
47
48 # clean up our test cookie
49 if request.session.test_cookie_worked():
50 request.session.delete_test_cookie()
51
52 # if not logged in by now, render form
53 if not request.user.is_authenticated():
54 # set test cookie to verify whether they work in the next step
55 request.session.set_test_cookie()
56
57 template_data = dict(new_key_form=new_key_form, login_username_form=login_username_form)
58 return render(request, "index.html", template_data)
59 else:
60 user, __ = UserProfile.objects.get_or_create(username=request.user.username)
61
62 # check for redirect variable
63 redirect_to = request.GET.get("next", None)
64 if redirect_to is not None:
65 if redirect_to.startswith("/staff/"):
66 if request.user.is_staff:
67 return redirect(redirect_to)
68 elif redirect_to.startswith("/grades/"):
69 if request.user.is_grade_publisher:
70 return redirect(redirect_to)
71 elif redirect_to.startswith("/contributor/"):
72 if user.is_contributor:
73 return redirect(redirect_to)
74 elif redirect_to.startswith("/student/"):
75 if user.is_participant:
76 return redirect(redirect_to)
77 else:
78 try:
79 resolve(redirect_to)
80 except Resolver404:
81 pass
82 else:
83 return redirect(redirect_to)
84
85 # redirect user to appropriate start page
86 if request.user.is_staff:
87 return redirect('staff:index')
88 elif request.user.is_grade_publisher:
89 return redirect('grades:semester_view', Semester.active_semester().id)
90 elif user.is_student:
91 return redirect('student:index')
92 elif user.is_contributor_or_delegate:
93 return redirect('contributor:index')
94 elif user.is_participant:
95 return redirect('student:index')
96 else:
97 return redirect('results:index')
98
99
100 def faq(request):
101 return render(request, "faq.html", dict(sections=FaqSection.objects.all()))
102
103
104 def legal_notice(request):
105 return render(request, "legal_notice.html", dict())
106
107
108 @require_POST
109 @login_required
110 def feedback_send(request):
111 sender_email = request.user.email
112 message = request.POST.get("message")
113 subject = "Feedback from {}".format(sender_email)
114
115 if message:
116 mail = EmailMessage(
117 subject=subject,
118 body=message,
119 to=[settings.FEEDBACK_EMAIL])
120
121 try:
122 mail.send()
123 logger.info('Sent feedback email: \n{}\n'.format(mail.message()))
124 except Exception:
125 logger.exception('An exception occurred when sending the following feedback email:\n{}\n'.format(mail.message()))
126
127 return HttpResponse()
128
[end of evap/evaluation/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/evap/evaluation/views.py b/evap/evaluation/views.py
--- a/evap/evaluation/views.py
+++ b/evap/evaluation/views.py
@@ -10,6 +10,7 @@
from django.utils.translation import ugettext as _
from django.core.urlresolvers import resolve, Resolver404
from django.views.decorators.http import require_POST
+from django.views.decorators.debug import sensitive_post_parameters
from evap.evaluation.forms import NewKeyForm, LoginUsernameForm
from evap.evaluation.models import UserProfile, FaqSection, EmailTemplate, Semester
@@ -17,6 +18,7 @@
logger = logging.getLogger(__name__)
+@sensitive_post_parameters("password")
def index(request):
"""Main entry page into EvaP providing all the login options available. The username/password
login is thought to be used for internal users, e.g. by connecting to a LDAP directory.
|
{"golden_diff": "diff --git a/evap/evaluation/views.py b/evap/evaluation/views.py\n--- a/evap/evaluation/views.py\n+++ b/evap/evaluation/views.py\n@@ -10,6 +10,7 @@\n from django.utils.translation import ugettext as _\n from django.core.urlresolvers import resolve, Resolver404\n from django.views.decorators.http import require_POST\n+from django.views.decorators.debug import sensitive_post_parameters\n \n from evap.evaluation.forms import NewKeyForm, LoginUsernameForm\n from evap.evaluation.models import UserProfile, FaqSection, EmailTemplate, Semester\n@@ -17,6 +18,7 @@\n logger = logging.getLogger(__name__)\n \n \n+@sensitive_post_parameters(\"password\")\n def index(request):\n \"\"\"Main entry page into EvaP providing all the login options available. The username/password\n login is thought to be used for internal users, e.g. by connecting to a LDAP directory.\n", "issue": "Remove passwords from error messages\nEvaP sends error messages to the admins when a server error occurs. Post data sent to the page where the error occurred will be included in the message, but passwords must not be included in these messages.\nThis currently happens e.g. when a user is logging in who has two accounts like described in #791.\n\nRemove passwords from error messages\nEvaP sends error messages to the admins when a server error occurs. Post data sent to the page where the error occurred will be included in the message, but passwords must not be included in these messages.\nThis currently happens e.g. when a user is logging in who has two accounts like described in #791.\n\n", "before_files": [{"content": "import logging\n\nfrom django.conf import settings\nfrom django.contrib import messages\nfrom django.contrib.auth import login as auth_login\nfrom django.contrib.auth.decorators import login_required\nfrom django.core.mail import EmailMessage\nfrom django.http import HttpResponse\nfrom django.shortcuts import redirect, render\nfrom django.utils.translation import ugettext as _\nfrom django.core.urlresolvers import resolve, Resolver404\nfrom django.views.decorators.http import require_POST\n\nfrom evap.evaluation.forms import NewKeyForm, LoginUsernameForm\nfrom evap.evaluation.models import UserProfile, FaqSection, EmailTemplate, Semester\n\nlogger = logging.getLogger(__name__)\n\n\ndef index(request):\n \"\"\"Main entry page into EvaP providing all the login options available. The username/password\n login is thought to be used for internal users, e.g. by connecting to a LDAP directory.\n The login key mechanism is meant to be used to include external participants, e.g. visiting\n students or visiting contributors.\n \"\"\"\n\n # parse the form data into the respective form\n submit_type = request.POST.get(\"submit_type\", \"no_submit\")\n new_key_form = NewKeyForm(request.POST if submit_type == \"new_key\" else None)\n login_username_form = LoginUsernameForm(request, request.POST if submit_type == \"login_username\" else None)\n\n # process form data\n if request.method == 'POST':\n if new_key_form.is_valid():\n # user wants a new login key\n profile = new_key_form.get_user()\n profile.generate_login_key()\n profile.save()\n\n EmailTemplate.send_login_url_to_user(new_key_form.get_user())\n\n messages.success(request, _(\"We sent you an email with a one-time login URL. Please check your inbox.\"))\n return redirect('evaluation:index')\n elif login_username_form.is_valid():\n # user would like to login with username and password and passed password test\n auth_login(request, login_username_form.get_user())\n\n # clean up our test cookie\n if request.session.test_cookie_worked():\n request.session.delete_test_cookie()\n\n # if not logged in by now, render form\n if not request.user.is_authenticated():\n # set test cookie to verify whether they work in the next step\n request.session.set_test_cookie()\n\n template_data = dict(new_key_form=new_key_form, login_username_form=login_username_form)\n return render(request, \"index.html\", template_data)\n else:\n user, __ = UserProfile.objects.get_or_create(username=request.user.username)\n\n # check for redirect variable\n redirect_to = request.GET.get(\"next\", None)\n if redirect_to is not None:\n if redirect_to.startswith(\"/staff/\"):\n if request.user.is_staff:\n return redirect(redirect_to)\n elif redirect_to.startswith(\"/grades/\"):\n if request.user.is_grade_publisher:\n return redirect(redirect_to)\n elif redirect_to.startswith(\"/contributor/\"):\n if user.is_contributor:\n return redirect(redirect_to)\n elif redirect_to.startswith(\"/student/\"):\n if user.is_participant:\n return redirect(redirect_to)\n else:\n try:\n resolve(redirect_to)\n except Resolver404:\n pass\n else:\n return redirect(redirect_to)\n\n # redirect user to appropriate start page\n if request.user.is_staff:\n return redirect('staff:index')\n elif request.user.is_grade_publisher:\n return redirect('grades:semester_view', Semester.active_semester().id)\n elif user.is_student:\n return redirect('student:index')\n elif user.is_contributor_or_delegate:\n return redirect('contributor:index')\n elif user.is_participant:\n return redirect('student:index')\n else:\n return redirect('results:index')\n\n\ndef faq(request):\n return render(request, \"faq.html\", dict(sections=FaqSection.objects.all()))\n\n\ndef legal_notice(request):\n return render(request, \"legal_notice.html\", dict())\n\n\n@require_POST\n@login_required\ndef feedback_send(request):\n sender_email = request.user.email\n message = request.POST.get(\"message\")\n subject = \"Feedback from {}\".format(sender_email)\n\n if message:\n mail = EmailMessage(\n subject=subject,\n body=message,\n to=[settings.FEEDBACK_EMAIL])\n\n try:\n mail.send()\n logger.info('Sent feedback email: \\n{}\\n'.format(mail.message()))\n except Exception:\n logger.exception('An exception occurred when sending the following feedback email:\\n{}\\n'.format(mail.message()))\n\n return HttpResponse()\n", "path": "evap/evaluation/views.py"}]}
| 1,914 | 201 |
gh_patches_debug_4984
|
rasdani/github-patches
|
git_diff
|
zalando__patroni-2080
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
documentation build failure with sphinx-4.2.0
**Describe the bug**
On Debian unstable, patroni fails to build with the latest sphinx:
```
Running Sphinx v4.2.0
making output directory... done
Exception occurred:
File "/<<PKGBUILDDIR>>/docs/conf.py", line 207, in setup
app.add_stylesheet("custom.css")
AttributeError: 'Sphinx' object has no attribute 'add_stylesheet'
```
</issue>
<code>
[start of docs/conf.py]
1 #!/usr/bin/env python3
2 # -*- coding: utf-8 -*-
3 #
4 # Patroni documentation build configuration file, created by
5 # sphinx-quickstart on Mon Dec 19 16:54:09 2016.
6 #
7 # This file is execfile()d with the current directory set to its
8 # containing dir.
9 #
10 # Note that not all possible configuration values are present in this
11 # autogenerated file.
12 #
13 # All configuration values have a default; values that are commented out
14 # serve to show the default.
15
16 # If extensions (or modules to document with autodoc) are in another directory,
17 # add these directories to sys.path here. If the directory is relative to the
18 # documentation root, use os.path.abspath to make it absolute, like shown here.
19 #
20 import os
21
22 import sys
23 sys.path.insert(0, os.path.abspath('..'))
24
25 from patroni.version import __version__
26
27 # -- General configuration ------------------------------------------------
28
29 # If your documentation needs a minimal Sphinx version, state it here.
30 #
31 # needs_sphinx = '1.0'
32
33 # Add any Sphinx extension module names here, as strings. They can be
34 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
35 # ones.
36 extensions = ['sphinx.ext.intersphinx',
37 'sphinx.ext.todo',
38 'sphinx.ext.mathjax',
39 'sphinx.ext.ifconfig',
40 'sphinx.ext.viewcode']
41
42 # Add any paths that contain templates here, relative to this directory.
43 templates_path = ['_templates']
44
45 # The suffix(es) of source filenames.
46 # You can specify multiple suffix as a list of string:
47 #
48 # source_suffix = ['.rst', '.md']
49 source_suffix = '.rst'
50
51 # The master toctree document.
52 master_doc = 'index'
53
54 # General information about the project.
55 project = 'Patroni'
56 copyright = '2015 Compose, Zalando SE'
57 author = 'Zalando SE'
58
59 # The version info for the project you're documenting, acts as replacement for
60 # |version| and |release|, also used in various other places throughout the
61 # built documents.
62 #
63 # The short X.Y version.
64 version = __version__[:__version__.rfind('.')]
65 # The full version, including alpha/beta/rc tags.
66 release = __version__
67
68 # The language for content autogenerated by Sphinx. Refer to documentation
69 # for a list of supported languages.
70 #
71 # This is also used if you do content translation via gettext catalogs.
72 # Usually you set "language" from the command line for these cases.
73 language = None
74
75 # List of patterns, relative to source directory, that match files and
76 # directories to ignore when looking for source files.
77 # This patterns also effect to html_static_path and html_extra_path
78 exclude_patterns = []
79
80 # The name of the Pygments (syntax highlighting) style to use.
81 pygments_style = 'sphinx'
82
83 # If true, `todo` and `todoList` produce output, else they produce nothing.
84 todo_include_todos = True
85
86
87 # -- Options for HTML output ----------------------------------------------
88
89 # The theme to use for HTML and HTML Help pages. See the documentation for
90 # a list of builtin themes.
91 #
92
93 on_rtd = os.environ.get('READTHEDOCS', None) == 'True'
94 if not on_rtd: # only import and set the theme if we're building docs locally
95 import sphinx_rtd_theme
96 html_theme = 'sphinx_rtd_theme'
97 html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
98
99 # Theme options are theme-specific and customize the look and feel of a theme
100 # further. For a list of options available for each theme, see the
101 # documentation.
102 #
103 # html_theme_options = {}
104
105 # Add any paths that contain custom static files (such as style sheets) here,
106 # relative to this directory. They are copied after the builtin static files,
107 # so a file named "default.css" will overwrite the builtin "default.css".
108 html_static_path = ['_static']
109
110
111 # -- Options for HTMLHelp output ------------------------------------------
112
113 # Output file base name for HTML help builder.
114 htmlhelp_basename = 'Patronidoc'
115
116
117 # -- Options for LaTeX output ---------------------------------------------
118
119 latex_elements = {
120 # The paper size ('letterpaper' or 'a4paper').
121 #
122 # 'papersize': 'letterpaper',
123
124 # The font size ('10pt', '11pt' or '12pt').
125 #
126 # 'pointsize': '10pt',
127
128 # Additional stuff for the LaTeX preamble.
129 #
130 # 'preamble': '',
131
132 # Latex figure (float) alignment
133 #
134 # 'figure_align': 'htbp',
135 }
136
137 # Grouping the document tree into LaTeX files. List of tuples
138 # (source start file, target name, title,
139 # author, documentclass [howto, manual, or own class]).
140 latex_documents = [
141 (master_doc, 'Patroni.tex', 'Patroni Documentation',
142 'Zalando SE', 'manual'),
143 ]
144
145
146 # -- Options for manual page output ---------------------------------------
147
148 # One entry per manual page. List of tuples
149 # (source start file, name, description, authors, manual section).
150 man_pages = [
151 (master_doc, 'patroni', 'Patroni Documentation',
152 [author], 1)
153 ]
154
155
156 # -- Options for Texinfo output -------------------------------------------
157
158 # Grouping the document tree into Texinfo files. List of tuples
159 # (source start file, target name, title, author,
160 # dir menu entry, description, category)
161 texinfo_documents = [
162 (master_doc, 'Patroni', 'Patroni Documentation',
163 author, 'Patroni', 'One line description of project.',
164 'Miscellaneous'),
165 ]
166
167
168
169 # -- Options for Epub output ----------------------------------------------
170
171 # Bibliographic Dublin Core info.
172 epub_title = project
173 epub_author = author
174 epub_publisher = author
175 epub_copyright = copyright
176
177 # The unique identifier of the text. This can be a ISBN number
178 # or the project homepage.
179 #
180 # epub_identifier = ''
181
182 # A unique identification for the text.
183 #
184 # epub_uid = ''
185
186 # A list of files that should not be packed into the epub file.
187 epub_exclude_files = ['search.html']
188
189
190
191 # Example configuration for intersphinx: refer to the Python standard library.
192 intersphinx_mapping = {'https://docs.python.org/': None}
193
194 # A possibility to have an own stylesheet, to add new rules or override existing ones
195 # For the latter case, the CSS specificity of the rules should be higher than the default ones
196 def setup(app):
197 app.add_stylesheet("custom.css")
198
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -194,4 +194,7 @@
# A possibility to have an own stylesheet, to add new rules or override existing ones
# For the latter case, the CSS specificity of the rules should be higher than the default ones
def setup(app):
- app.add_stylesheet("custom.css")
+ if hasattr(app, 'add_css_file'):
+ app.add_css_file('custom.css')
+ else:
+ app.add_stylesheet('custom.css')
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -194,4 +194,7 @@\n # A possibility to have an own stylesheet, to add new rules or override existing ones\n # For the latter case, the CSS specificity of the rules should be higher than the default ones\n def setup(app):\n- app.add_stylesheet(\"custom.css\")\n+ if hasattr(app, 'add_css_file'):\n+ app.add_css_file('custom.css')\n+ else:\n+ app.add_stylesheet('custom.css')\n", "issue": "documentation build failure with sphinx-4.2.0\n**Describe the bug**\r\n\r\nOn Debian unstable, patroni fails to build with the latest sphinx:\r\n\r\n```\r\nRunning Sphinx v4.2.0\r\nmaking output directory... done\r\n\r\nException occurred:\r\n File \"/<<PKGBUILDDIR>>/docs/conf.py\", line 207, in setup\r\n app.add_stylesheet(\"custom.css\")\r\nAttributeError: 'Sphinx' object has no attribute 'add_stylesheet'\r\n```\n", "before_files": [{"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n#\n# Patroni documentation build configuration file, created by\n# sphinx-quickstart on Mon Dec 19 16:54:09 2016.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\n\nimport sys\nsys.path.insert(0, os.path.abspath('..'))\n\nfrom patroni.version import __version__\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = ['sphinx.ext.intersphinx',\n 'sphinx.ext.todo',\n 'sphinx.ext.mathjax',\n 'sphinx.ext.ifconfig',\n 'sphinx.ext.viewcode']\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = 'Patroni'\ncopyright = '2015 Compose, Zalando SE'\nauthor = 'Zalando SE'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = __version__[:__version__.rfind('.')]\n# The full version, including alpha/beta/rc tags.\nrelease = __version__\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = []\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = True\n\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\n\non_rtd = os.environ.get('READTHEDOCS', None) == 'True'\nif not on_rtd: # only import and set the theme if we're building docs locally\n import sphinx_rtd_theme\n html_theme = 'sphinx_rtd_theme'\n html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\n# html_theme_options = {}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n\n# -- Options for HTMLHelp output ------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'Patronidoc'\n\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'Patroni.tex', 'Patroni Documentation',\n 'Zalando SE', 'manual'),\n]\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'patroni', 'Patroni Documentation',\n [author], 1)\n]\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'Patroni', 'Patroni Documentation',\n author, 'Patroni', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n\n\n# -- Options for Epub output ----------------------------------------------\n\n# Bibliographic Dublin Core info.\nepub_title = project\nepub_author = author\nepub_publisher = author\nepub_copyright = copyright\n\n# The unique identifier of the text. This can be a ISBN number\n# or the project homepage.\n#\n# epub_identifier = ''\n\n# A unique identification for the text.\n#\n# epub_uid = ''\n\n# A list of files that should not be packed into the epub file.\nepub_exclude_files = ['search.html']\n\n\n\n# Example configuration for intersphinx: refer to the Python standard library.\nintersphinx_mapping = {'https://docs.python.org/': None}\n\n# A possibility to have an own stylesheet, to add new rules or override existing ones\n# For the latter case, the CSS specificity of the rules should be higher than the default ones\ndef setup(app):\n app.add_stylesheet(\"custom.css\")\n", "path": "docs/conf.py"}]}
| 2,562 | 123 |
gh_patches_debug_15446
|
rasdani/github-patches
|
git_diff
|
pretix__pretix-2983
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Migrate to celery 5
after #2056
</issue>
<code>
[start of src/setup.py]
1 #
2 # This file is part of pretix (Community Edition).
3 #
4 # Copyright (C) 2014-2020 Raphael Michel and contributors
5 # Copyright (C) 2020-2021 rami.io GmbH and contributors
6 #
7 # This program is free software: you can redistribute it and/or modify it under the terms of the GNU Affero General
8 # Public License as published by the Free Software Foundation in version 3 of the License.
9 #
10 # ADDITIONAL TERMS APPLY: Pursuant to Section 7 of the GNU Affero General Public License, additional terms are
11 # applicable granting you additional permissions and placing additional restrictions on your usage of this software.
12 # Please refer to the pretix LICENSE file to obtain the full terms applicable to this work. If you did not receive
13 # this file, see <https://pretix.eu/about/en/license>.
14 #
15 # This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied
16 # warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Affero General Public License for more
17 # details.
18 #
19 # You should have received a copy of the GNU Affero General Public License along with this program. If not, see
20 # <https://www.gnu.org/licenses/>.
21 #
22
23 # This file is based on an earlier version of pretix which was released under the Apache License 2.0. The full text of
24 # the Apache License 2.0 can be obtained at <http://www.apache.org/licenses/LICENSE-2.0>.
25 #
26 # This file may have since been changed and any changes are released under the terms of AGPLv3 as described above. A
27 # full history of changes and contributors is available at <https://github.com/pretix/pretix>.
28 #
29 # This file contains Apache-licensed contributions copyrighted by: Claudio Luck, FlaviaBastos, Katharina Bogad, Laura
30 # Klünder, Lukas Bockstaller, Matthew Emerson, Tobias Kunze, [email protected]
31 #
32 # Unless required by applicable law or agreed to in writing, software distributed under the Apache License 2.0 is
33 # distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
34 # License for the specific language governing permissions and limitations under the License.
35
36 import os
37 import subprocess
38 import sys
39 from codecs import open
40 from distutils.command.build import build
41 from distutils.command.build_ext import build_ext
42 from distutils.dir_util import copy_tree
43 from os import path
44
45 from setuptools import find_packages, setup
46
47 try:
48 from pretix import __version__
49 except:
50 if "PRETIX_DOCKER_BUILD" in os.environ:
51 __version__ = "0.0.0" # this is a hack to allow calling this file early in our docker build to make use of caching
52 else:
53 raise
54
55 CURRENT_PYTHON = sys.version_info[:2]
56 REQUIRED_PYTHON = (3, 6)
57 if CURRENT_PYTHON < REQUIRED_PYTHON:
58 sys.stderr.write("""
59 ==========================
60 Unsupported Python version
61 ==========================
62 This version of pretix requires Python {}.{}, but you're trying to
63 install it on Python {}.{}.
64 This may be because you are using a version of pip that doesn't
65 understand the python_requires classifier. Make sure you
66 have pip >= 9.0 and setuptools >= 24.2, then try again:
67 $ python -m pip install --upgrade pip setuptools
68 $ python -m pip install pretix
69 This will install the latest version of pretix which works on your
70 version of Python. If you can't upgrade your pip (or Python), request
71 an older version of pretix:
72 $ python -m pip install "pretix<2"
73 """.format(*(REQUIRED_PYTHON + CURRENT_PYTHON)))
74 sys.exit(1)
75
76 here = path.abspath(path.dirname(__file__))
77 npm_installed = False
78
79 # Get the long description from the relevant file
80 try:
81 with open(path.join(here, '../README.rst'), encoding='utf-8') as f:
82 long_description = f.read()
83 except:
84 long_description = ''
85
86
87 def npm_install():
88 global npm_installed
89
90 if not npm_installed:
91 # keep this in sync with Makefile!
92 node_prefix = os.path.join(here, 'pretix', 'static.dist', 'node_prefix')
93 os.makedirs(node_prefix, exist_ok=True)
94 copy_tree(os.path.join(here, 'pretix', 'static', 'npm_dir'), node_prefix)
95 subprocess.check_call('npm install', shell=True, cwd=node_prefix)
96 npm_installed = True
97
98
99 class CustomBuild(build):
100 def run(self):
101 if "PRETIX_DOCKER_BUILD" in os.environ:
102 return # this is a hack to allow calling this file early in our docker build to make use of caching
103 os.environ.setdefault("DJANGO_SETTINGS_MODULE", "pretix.settings")
104 os.environ.setdefault("PRETIX_IGNORE_CONFLICTS", "True")
105 import django
106 django.setup()
107 from django.conf import settings
108 from django.core import management
109
110 settings.COMPRESS_ENABLED = True
111 settings.COMPRESS_OFFLINE = True
112
113 npm_install()
114 management.call_command('compilemessages', verbosity=1)
115 management.call_command('compilejsi18n', verbosity=1)
116 management.call_command('collectstatic', verbosity=1, interactive=False)
117 management.call_command('compress', verbosity=1)
118
119 build.run(self)
120
121
122 class CustomBuildExt(build_ext):
123 def run(self):
124 if "PRETIX_DOCKER_BUILD" in os.environ:
125 return # this is a hack to allow calling this file early in our docker build to make use of caching
126 npm_install()
127 build_ext.run(self)
128
129
130 cmdclass = {
131 'build': CustomBuild,
132 'build_ext': CustomBuildExt,
133 }
134
135
136 setup(
137 name='pretix',
138 version=__version__,
139 python_requires='>={}.{}'.format(*REQUIRED_PYTHON),
140 description='Reinventing presales, one ticket at a time',
141 long_description=long_description,
142 url='https://pretix.eu',
143 author='Raphael Michel',
144 author_email='[email protected]',
145 license='GNU Affero General Public License v3 with Additional Terms',
146 classifiers=[
147 'Development Status :: 5 - Production/Stable',
148 'Intended Audience :: Developers',
149 'Intended Audience :: Other Audience',
150 'Topic :: Internet :: WWW/HTTP :: Dynamic Content',
151 'Environment :: Web Environment',
152 'License :: OSI Approved :: GNU Affero General Public License v3',
153 'Programming Language :: Python :: 3.7',
154 'Programming Language :: Python :: 3.8',
155 'Programming Language :: Python :: 3.9',
156 'Framework :: Django :: 3.2'
157 ],
158
159 keywords='tickets web shop ecommerce',
160 install_requires=[
161 'arabic-reshaper==2.1.4', # Support for Arabic in reportlab
162 'babel',
163 'BeautifulSoup4==4.11.*',
164 'bleach==5.0.*',
165 'celery==4.4.*',
166 'chardet==5.1.*',
167 'cryptography>=3.4.2',
168 'css-inline==0.8.*',
169 'defusedcsv>=1.1.0',
170 'dj-static',
171 'Django==3.2.*',
172 'django-bootstrap3==22.2.*',
173 'django-compressor==4.1.*',
174 'django-countries==7.5.*',
175 'django-filter==22.1',
176 'django-formset-js-improved==0.5.0.3',
177 'django-formtools==2.4',
178 'django-hierarkey==1.1.*',
179 'django-hijack==3.2.*',
180 'django-i18nfield==1.9.*,>=1.9.4',
181 'django-libsass==0.9',
182 'django-localflavor==3.1',
183 'django-markup',
184 'django-mysql',
185 'django-oauth-toolkit==1.2.*',
186 'django-otp==1.1.*',
187 'django-phonenumber-field==7.0.*',
188 'django-redis==5.2.*',
189 'django-scopes==1.2.*',
190 'django-statici18n==2.3.*',
191 'djangorestframework==3.14.*',
192 'dnspython<2.0', # do not upgrade, causes issues with eventlet / gunicorn 19 and we cannot upgrade gunicorn right now
193 'drf_ujson2==1.7.*',
194 'isoweek',
195 'jsonschema',
196 'kombu==4.6.*',
197 'libsass==0.22.*',
198 'lxml',
199 'markdown==3.3.4', # 3.3.5 requires importlib-metadata>=4.4, but django-bootstrap3 requires importlib-metadata<3.
200 # We can upgrade markdown again once django-bootstrap3 upgrades or once we drop Python 3.6 and 3.7
201 'mt-940==4.23.*',
202 'oauthlib==3.2.*',
203 'openpyxl==3.0.*',
204 'packaging',
205 'paypalrestsdk==1.13.*',
206 'paypal-checkout-serversdk==1.0.*',
207 'PyJWT==2.6.*',
208 'phonenumberslite==8.13.*',
209 'Pillow==9.3.*',
210 'protobuf==4.21.*',
211 'psycopg2-binary',
212 'pycountry',
213 'pycparser==2.21',
214 'pycryptodome==3.16.*',
215 'PyPDF2==2.11.*',
216 'python-bidi==0.4.*', # Support for Arabic in reportlab
217 'python-dateutil==2.8.*',
218 'python-u2flib-server==4.*',
219 'pytz',
220 'pyuca',
221 'redis==4.4.*',
222 'reportlab==3.6.*',
223 'requests==2.28.*',
224 'sentry-sdk==1.10.*', # when upgrading, check https://github.com/getsentry/sentry-python/issues/1700
225 'sepaxml==2.6.*',
226 'slimit',
227 'static3==0.7.*',
228 'stripe==5.0.*',
229 'text-unidecode==1.*',
230 'tlds>=2020041600',
231 'tqdm==4.*',
232 'vat_moss_forked==2020.3.20.0.11.0',
233 'vobject==0.9.*',
234 'webauthn==0.4.*',
235 'zeep==4.2.*'
236 ],
237 extras_require={
238 'dev': [
239 'coverage',
240 'coveralls',
241 'django-debug-toolbar==3.7.*',
242 'flake8==6.0.*',
243 'freezegun',
244 'isort==5.10.*',
245 'pep8-naming==0.12.*',
246 'potypo',
247 'pycodestyle==2.10.*',
248 'pyflakes==3.0.*',
249 'pytest-cache',
250 'pytest-cov',
251 'pytest-django==4.*',
252 'pytest-mock==3.10.*',
253 'pytest-rerunfailures==10.*',
254 'pytest-sugar',
255 'pytest-xdist==3.1.*',
256 'pytest==7.2.*',
257 'responses',
258 ],
259 'memcached': ['pylibmc'],
260 'mysql': ['mysqlclient'],
261 },
262 setup_requires=['setuptools-rust'],
263
264 packages=find_packages(exclude=['tests', 'tests.*']),
265 include_package_data=True,
266 cmdclass=cmdclass,
267 )
268
[end of src/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/setup.py b/src/setup.py
--- a/src/setup.py
+++ b/src/setup.py
@@ -162,7 +162,7 @@
'babel',
'BeautifulSoup4==4.11.*',
'bleach==5.0.*',
- 'celery==4.4.*',
+ 'celery==5.2.*',
'chardet==5.1.*',
'cryptography>=3.4.2',
'css-inline==0.8.*',
@@ -193,7 +193,7 @@
'drf_ujson2==1.7.*',
'isoweek',
'jsonschema',
- 'kombu==4.6.*',
+ 'kombu==5.2.*',
'libsass==0.22.*',
'lxml',
'markdown==3.3.4', # 3.3.5 requires importlib-metadata>=4.4, but django-bootstrap3 requires importlib-metadata<3.
|
{"golden_diff": "diff --git a/src/setup.py b/src/setup.py\n--- a/src/setup.py\n+++ b/src/setup.py\n@@ -162,7 +162,7 @@\n 'babel',\n 'BeautifulSoup4==4.11.*',\n 'bleach==5.0.*',\n- 'celery==4.4.*',\n+ 'celery==5.2.*',\n 'chardet==5.1.*',\n 'cryptography>=3.4.2',\n 'css-inline==0.8.*',\n@@ -193,7 +193,7 @@\n 'drf_ujson2==1.7.*',\n 'isoweek',\n 'jsonschema',\n- 'kombu==4.6.*',\n+ 'kombu==5.2.*',\n 'libsass==0.22.*',\n 'lxml',\n 'markdown==3.3.4', # 3.3.5 requires importlib-metadata>=4.4, but django-bootstrap3 requires importlib-metadata<3.\n", "issue": "Migrate to celery 5\nafter #2056 \n", "before_files": [{"content": "#\n# This file is part of pretix (Community Edition).\n#\n# Copyright (C) 2014-2020 Raphael Michel and contributors\n# Copyright (C) 2020-2021 rami.io GmbH and contributors\n#\n# This program is free software: you can redistribute it and/or modify it under the terms of the GNU Affero General\n# Public License as published by the Free Software Foundation in version 3 of the License.\n#\n# ADDITIONAL TERMS APPLY: Pursuant to Section 7 of the GNU Affero General Public License, additional terms are\n# applicable granting you additional permissions and placing additional restrictions on your usage of this software.\n# Please refer to the pretix LICENSE file to obtain the full terms applicable to this work. If you did not receive\n# this file, see <https://pretix.eu/about/en/license>.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied\n# warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Affero General Public License for more\n# details.\n#\n# You should have received a copy of the GNU Affero General Public License along with this program. If not, see\n# <https://www.gnu.org/licenses/>.\n#\n\n# This file is based on an earlier version of pretix which was released under the Apache License 2.0. The full text of\n# the Apache License 2.0 can be obtained at <http://www.apache.org/licenses/LICENSE-2.0>.\n#\n# This file may have since been changed and any changes are released under the terms of AGPLv3 as described above. A\n# full history of changes and contributors is available at <https://github.com/pretix/pretix>.\n#\n# This file contains Apache-licensed contributions copyrighted by: Claudio Luck, FlaviaBastos, Katharina Bogad, Laura\n# Kl\u00fcnder, Lukas Bockstaller, Matthew Emerson, Tobias Kunze, [email protected]\n#\n# Unless required by applicable law or agreed to in writing, software distributed under the Apache License 2.0 is\n# distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the\n# License for the specific language governing permissions and limitations under the License.\n\nimport os\nimport subprocess\nimport sys\nfrom codecs import open\nfrom distutils.command.build import build\nfrom distutils.command.build_ext import build_ext\nfrom distutils.dir_util import copy_tree\nfrom os import path\n\nfrom setuptools import find_packages, setup\n\ntry:\n from pretix import __version__\nexcept:\n if \"PRETIX_DOCKER_BUILD\" in os.environ:\n __version__ = \"0.0.0\" # this is a hack to allow calling this file early in our docker build to make use of caching\n else:\n raise\n\nCURRENT_PYTHON = sys.version_info[:2]\nREQUIRED_PYTHON = (3, 6)\nif CURRENT_PYTHON < REQUIRED_PYTHON:\n sys.stderr.write(\"\"\"\n==========================\nUnsupported Python version\n==========================\nThis version of pretix requires Python {}.{}, but you're trying to\ninstall it on Python {}.{}.\nThis may be because you are using a version of pip that doesn't\nunderstand the python_requires classifier. Make sure you\nhave pip >= 9.0 and setuptools >= 24.2, then try again:\n $ python -m pip install --upgrade pip setuptools\n $ python -m pip install pretix\nThis will install the latest version of pretix which works on your\nversion of Python. If you can't upgrade your pip (or Python), request\nan older version of pretix:\n $ python -m pip install \"pretix<2\"\n\"\"\".format(*(REQUIRED_PYTHON + CURRENT_PYTHON)))\n sys.exit(1)\n\nhere = path.abspath(path.dirname(__file__))\nnpm_installed = False\n\n# Get the long description from the relevant file\ntry:\n with open(path.join(here, '../README.rst'), encoding='utf-8') as f:\n long_description = f.read()\nexcept:\n long_description = ''\n\n\ndef npm_install():\n global npm_installed\n\n if not npm_installed:\n # keep this in sync with Makefile!\n node_prefix = os.path.join(here, 'pretix', 'static.dist', 'node_prefix')\n os.makedirs(node_prefix, exist_ok=True)\n copy_tree(os.path.join(here, 'pretix', 'static', 'npm_dir'), node_prefix)\n subprocess.check_call('npm install', shell=True, cwd=node_prefix)\n npm_installed = True\n\n\nclass CustomBuild(build):\n def run(self):\n if \"PRETIX_DOCKER_BUILD\" in os.environ:\n return # this is a hack to allow calling this file early in our docker build to make use of caching\n os.environ.setdefault(\"DJANGO_SETTINGS_MODULE\", \"pretix.settings\")\n os.environ.setdefault(\"PRETIX_IGNORE_CONFLICTS\", \"True\")\n import django\n django.setup()\n from django.conf import settings\n from django.core import management\n\n settings.COMPRESS_ENABLED = True\n settings.COMPRESS_OFFLINE = True\n\n npm_install()\n management.call_command('compilemessages', verbosity=1)\n management.call_command('compilejsi18n', verbosity=1)\n management.call_command('collectstatic', verbosity=1, interactive=False)\n management.call_command('compress', verbosity=1)\n\n build.run(self)\n\n\nclass CustomBuildExt(build_ext):\n def run(self):\n if \"PRETIX_DOCKER_BUILD\" in os.environ:\n return # this is a hack to allow calling this file early in our docker build to make use of caching\n npm_install()\n build_ext.run(self)\n\n\ncmdclass = {\n 'build': CustomBuild,\n 'build_ext': CustomBuildExt,\n}\n\n\nsetup(\n name='pretix',\n version=__version__,\n python_requires='>={}.{}'.format(*REQUIRED_PYTHON),\n description='Reinventing presales, one ticket at a time',\n long_description=long_description,\n url='https://pretix.eu',\n author='Raphael Michel',\n author_email='[email protected]',\n license='GNU Affero General Public License v3 with Additional Terms',\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Other Audience',\n 'Topic :: Internet :: WWW/HTTP :: Dynamic Content',\n 'Environment :: Web Environment',\n 'License :: OSI Approved :: GNU Affero General Public License v3',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n 'Framework :: Django :: 3.2'\n ],\n\n keywords='tickets web shop ecommerce',\n install_requires=[\n 'arabic-reshaper==2.1.4', # Support for Arabic in reportlab\n 'babel',\n 'BeautifulSoup4==4.11.*',\n 'bleach==5.0.*',\n 'celery==4.4.*',\n 'chardet==5.1.*',\n 'cryptography>=3.4.2',\n 'css-inline==0.8.*',\n 'defusedcsv>=1.1.0',\n 'dj-static',\n 'Django==3.2.*',\n 'django-bootstrap3==22.2.*',\n 'django-compressor==4.1.*',\n 'django-countries==7.5.*',\n 'django-filter==22.1',\n 'django-formset-js-improved==0.5.0.3',\n 'django-formtools==2.4',\n 'django-hierarkey==1.1.*',\n 'django-hijack==3.2.*',\n 'django-i18nfield==1.9.*,>=1.9.4',\n 'django-libsass==0.9',\n 'django-localflavor==3.1',\n 'django-markup',\n 'django-mysql',\n 'django-oauth-toolkit==1.2.*',\n 'django-otp==1.1.*',\n 'django-phonenumber-field==7.0.*',\n 'django-redis==5.2.*',\n 'django-scopes==1.2.*',\n 'django-statici18n==2.3.*',\n 'djangorestframework==3.14.*',\n 'dnspython<2.0', # do not upgrade, causes issues with eventlet / gunicorn 19 and we cannot upgrade gunicorn right now\n 'drf_ujson2==1.7.*',\n 'isoweek',\n 'jsonschema',\n 'kombu==4.6.*',\n 'libsass==0.22.*',\n 'lxml',\n 'markdown==3.3.4', # 3.3.5 requires importlib-metadata>=4.4, but django-bootstrap3 requires importlib-metadata<3.\n # We can upgrade markdown again once django-bootstrap3 upgrades or once we drop Python 3.6 and 3.7\n 'mt-940==4.23.*',\n 'oauthlib==3.2.*',\n 'openpyxl==3.0.*',\n 'packaging',\n 'paypalrestsdk==1.13.*',\n 'paypal-checkout-serversdk==1.0.*',\n 'PyJWT==2.6.*',\n 'phonenumberslite==8.13.*',\n 'Pillow==9.3.*',\n 'protobuf==4.21.*',\n 'psycopg2-binary',\n 'pycountry',\n 'pycparser==2.21',\n 'pycryptodome==3.16.*',\n 'PyPDF2==2.11.*',\n 'python-bidi==0.4.*', # Support for Arabic in reportlab\n 'python-dateutil==2.8.*',\n 'python-u2flib-server==4.*',\n 'pytz',\n 'pyuca',\n 'redis==4.4.*',\n 'reportlab==3.6.*',\n 'requests==2.28.*',\n 'sentry-sdk==1.10.*', # when upgrading, check https://github.com/getsentry/sentry-python/issues/1700\n 'sepaxml==2.6.*',\n 'slimit',\n 'static3==0.7.*',\n 'stripe==5.0.*',\n 'text-unidecode==1.*',\n 'tlds>=2020041600',\n 'tqdm==4.*',\n 'vat_moss_forked==2020.3.20.0.11.0',\n 'vobject==0.9.*',\n 'webauthn==0.4.*',\n 'zeep==4.2.*'\n ],\n extras_require={\n 'dev': [\n 'coverage',\n 'coveralls',\n 'django-debug-toolbar==3.7.*',\n 'flake8==6.0.*',\n 'freezegun',\n 'isort==5.10.*',\n 'pep8-naming==0.12.*',\n 'potypo',\n 'pycodestyle==2.10.*',\n 'pyflakes==3.0.*',\n 'pytest-cache',\n 'pytest-cov',\n 'pytest-django==4.*',\n 'pytest-mock==3.10.*',\n 'pytest-rerunfailures==10.*',\n 'pytest-sugar',\n 'pytest-xdist==3.1.*',\n 'pytest==7.2.*',\n 'responses',\n ],\n 'memcached': ['pylibmc'],\n 'mysql': ['mysqlclient'],\n },\n setup_requires=['setuptools-rust'],\n\n packages=find_packages(exclude=['tests', 'tests.*']),\n include_package_data=True,\n cmdclass=cmdclass,\n)\n", "path": "src/setup.py"}]}
| 3,862 | 234 |
gh_patches_debug_29476
|
rasdani/github-patches
|
git_diff
|
pytorch__ignite-1137
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Auto dataloader - ValueError: batch_size should be a positive integer value, but got batch_size=0
## 🐛 Bug description
The following code will brake if `batch_size` is smaller than world size :
```python
import torch
import ignite.distributed as idist
def foo(i):
data = torch.arange(100).reshape(25, 4)
data_loader = idist.auto_dataloader(data, batch_size=6, num_workers=12)
if __name__ == "__main__":
idist.spawn("gloo", foo, args=(), nproc_per_node=8)
```
```
ValueError: batch_size should be a positive integer value, but got batch_size=0
```
A fix can be:
- keep batch size as provided if smaller than world size
- same for `num_workers`
## Environment
- PyTorch Version (e.g., 1.4): 1.5.0
- Ignite Version (e.g., 0.3.0): master
- OS (e.g., Linux): linux
- How you installed Ignite (`conda`, `pip`, source):
- Python version: 3.7
- Any other relevant information:
@InCogNiTo124 would you like to fix this as you recently played around `auto_*` ?
</issue>
<code>
[start of ignite/distributed/auto.py]
1 import warnings
2
3 import torch
4 import torch.nn as nn
5 from torch.optim.optimizer import Optimizer
6 from torch.utils.data import DataLoader, Dataset
7 from torch.utils.data.distributed import DistributedSampler
8 from torch.utils.data.sampler import Sampler
9
10 from ignite.distributed import utils as idist
11 from ignite.distributed.comp_models import native as idist_native
12 from ignite.distributed.comp_models import xla as idist_xla
13 from ignite.utils import setup_logger
14
15 __all__ = ["auto_dataloader", "auto_model", "auto_optim", "DistributedProxySampler"]
16
17
18 def auto_dataloader(dataset, **kwargs):
19 """Helper method to create a dataloader adapted for non-distributed and distributed configurations (supporting
20 all available backends from :meth:`~ignite.distributed.utils.available_backends()`).
21
22 Internally, we create a dataloader with provided kwargs while applying the following updates:
23
24 - batch size is scaled by world size: ``batch_size / world_size``.
25 - number of workers is scaled by number of local processes: ``num_workers / nprocs``.
26 - if no sampler provided by user, `torch DistributedSampler` is setup.
27 - if a sampler is provided by user, it is wrapped by :class:`~ignite.distributed.auto.DistributedProxySampler`.
28 - if the default device is 'cuda', `pin_memory` is automatically set to `True`.
29
30 .. warning::
31
32 Custom batch sampler is not adapted for distributed configuration. Please, make sure that provided batch
33 sampler is compatible with distributed configuration.
34
35 Examples:
36
37 .. code-block:: python
38
39 import ignite.distribted as idist
40
41 train_loader = idist.auto_dataloader(
42 train_dataset,
43 batch_size=32,
44 num_workers=4,
45 shuffle=True,
46 pin_memory="cuda" in idist.device().type,
47 drop_last=True,
48 )
49
50 Args:
51 dataset (Dataset): input torch dataset
52 **kwargs: keyword arguments for `torch DataLoader`_.
53
54 Returns:
55 `torch DataLoader`_ or `XLA MpDeviceLoader`_ for XLA devices
56
57 .. _torch DataLoader: https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader
58 .. _XLA MpDeviceLoader: https://github.com/pytorch/xla/blob/master/torch_xla/distributed/parallel_loader.py#L178
59 .. _torch DistributedSampler:
60 https://pytorch.org/docs/stable/data.html#torch.utils.data.distributed.DistributedSampler
61 """
62 rank = idist.get_rank()
63 world_size = idist.get_world_size()
64
65 logger = setup_logger(__name__ + ".auto_dataloader")
66
67 if world_size > 1:
68 if "batch_size" in kwargs:
69 kwargs["batch_size"] //= world_size
70
71 if "num_workers" in kwargs:
72 nproc = idist.get_nproc_per_node()
73 kwargs["num_workers"] = (kwargs["num_workers"] + nproc - 1) // nproc
74
75 if "batch_sampler" not in kwargs:
76 if kwargs.get("sampler", None) is not None:
77 sampler = DistributedProxySampler(kwargs["sampler"], num_replicas=world_size, rank=rank)
78 else:
79 sampler = DistributedSampler(
80 dataset, num_replicas=world_size, rank=rank, shuffle=kwargs.get("shuffle", True)
81 )
82 # we need to remove "shuffle" from kwargs if sampler is used
83 if "shuffle" in kwargs:
84 del kwargs["shuffle"]
85
86 kwargs["sampler"] = sampler
87 else:
88 warnings.warn(
89 "Found batch_sampler in provided kwargs. Please, make sure that it is compatible "
90 "with distributed configuration"
91 )
92
93 if idist.has_xla_support and idist.backend() == idist_xla.XLA_TPU and kwargs.get("pin_memory", False):
94 # TODO: How about XLA GPU ?
95 warnings.warn(
96 "Found incompatible options: xla support and pin_memory args equal True. "
97 "Argument `pin_memory=False` will be used to construct data loader."
98 )
99 kwargs["pin_memory"] = False
100 else:
101 kwargs["pin_memory"] = kwargs.get("pin_memory", "cuda" in idist.device().type)
102
103 logger.info("Use data loader kwargs for dataset '{}': \n\t{}".format(repr(dataset)[:20].strip(), kwargs))
104 dataloader = DataLoader(dataset, **kwargs)
105
106 if idist.has_xla_support and idist.backend() == idist_xla.XLA_TPU and world_size > 1:
107
108 logger.info("DataLoader is wrapped by `MpDeviceLoader` on XLA")
109
110 mp_device_loader_cls = _MpDeviceLoader
111 try:
112 from torch_xla.distributed.parallel_loader import MpDeviceLoader
113
114 mp_device_loader_cls = MpDeviceLoader
115 except ImportError:
116 pass
117
118 sampler = dataloader.sampler
119 dataloader = mp_device_loader_cls(dataloader, idist.device())
120 dataloader.sampler = sampler
121
122 return dataloader
123
124
125 def auto_model(model: nn.Module) -> nn.Module:
126 """Helper method to adapt provided model for non-distributed and distributed configurations (supporting
127 all available backends from :meth:`~ignite.distributed.utils.available_backends()`).
128
129 Internally, we perform to following:
130
131 - send model to current :meth:`~ignite.distributed.utils.device()`.
132 - wrap the model to `torch DistributedDataParallel`_ for native torch distributed if world size is larger than 1
133 - wrap the model to `torch DataParallel`_ if no distributed context found and more than one CUDA devices available.
134
135 Examples:
136
137 .. code-block:: python
138
139 import ignite.distribted as idist
140
141 model = idist.auto_model(model)
142
143 Args:
144 model (torch.nn.Module): model to adapt.
145
146 Returns:
147 torch.nn.Module
148
149 .. _torch DistributedDataParallel: https://pytorch.org/docs/stable/nn.html#torch.nn.parallel.DistributedDataParallel
150 .. _torch DataParallel: https://pytorch.org/docs/stable/nn.html#torch.nn.DataParallel
151 """
152 logger = setup_logger(__name__ + ".auto_model")
153
154 model.to(idist.device())
155
156 # distributed data parallel model
157 if idist.get_world_size() > 1:
158 if idist.backend() == idist_native.NCCL:
159 lrank = idist.get_local_rank()
160 logger.info("Apply torch DistributedDataParallel on model, device id: {}".format(lrank))
161 model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[lrank,])
162 elif idist.backend() == idist_native.GLOO:
163 logger.info("Apply torch DistributedDataParallel on model")
164 model = torch.nn.parallel.DistributedDataParallel(model)
165
166 # not distributed but multiple GPUs reachable so data parallel model
167 elif torch.cuda.device_count() > 1 and "cuda" in idist.device().type:
168 logger.info("Apply torch DataParallel on model")
169 model = torch.nn.parallel.DataParallel(model)
170
171 return model
172
173
174 def auto_optim(optimizer: Optimizer) -> Optimizer:
175 """Helper method to adapt optimizer for non-distributed and distributed configurations (supporting
176 all available backends from :meth:`~ignite.distributed.utils.available_backends()`).
177
178 Internally, this method is no-op for non-distributed and torch native distributed configuration.
179 For XLA distributed configuration, we create a new class that inherits from provided optimizer.
180 The goal is to override the `step()` method with specific `xm.optimizer_step`_ implementation.
181
182 Examples:
183
184 .. code-block:: python
185
186 import ignite.distribted as idist
187
188 optimizer = idist.auto_optim(optimizer)
189
190
191 Args:
192 optimizer (Optimizer): input torch optimizer
193
194 Returns:
195 Optimizer
196
197 .. _xm.optimizer_step: http://pytorch.org/xla/release/1.5/index.html#torch_xla.core.xla_model.optimizer_step
198
199 """
200 if not (idist.has_xla_support and idist.backend() == idist_xla.XLA_TPU):
201 return optimizer
202
203 cls = type(optimizer.__class__.__name__, (optimizer.__class__,), dict(_XLADistributedOptimizer.__dict__))
204 return cls(optimizer)
205
206
207 class DistributedProxySampler(DistributedSampler):
208 """Distributed sampler proxy to adapt user's sampler for distributed data parallelism configuration.
209
210 Code is based on https://github.com/pytorch/pytorch/issues/23430#issuecomment-562350407
211
212
213 .. note::
214 Input sampler is assumed to have a constant size.
215
216 Args:
217 sampler (Sampler): Input torch data sampler.
218 num_replicas (int, optional): Number of processes participating in distributed training.
219 rank (int, optional): Rank of the current process within ``num_replicas``.
220
221 """
222
223 def __init__(self, sampler: Sampler, num_replicas=None, rank=None):
224
225 if not isinstance(sampler, Sampler):
226 raise TypeError("Argument sampler should be instance of torch Sampler, but given: {}".format(type(sampler)))
227
228 if not hasattr(sampler, "__len__"):
229 raise TypeError("Argument sampler should have length")
230
231 super(DistributedProxySampler, self).__init__(sampler, num_replicas=num_replicas, rank=rank, shuffle=False)
232 self.sampler = sampler
233
234 def __iter__(self):
235 # deterministically shuffle based on epoch
236 torch.manual_seed(self.epoch)
237
238 indices = []
239 while len(indices) < self.total_size:
240 indices += list(self.sampler)
241
242 if len(indices) != self.total_size:
243 raise RuntimeError("{} vs {}".format(len(indices), self.total_size))
244
245 # subsample
246 indices = indices[self.rank : self.total_size : self.num_replicas]
247 if len(indices) != self.num_samples:
248 raise RuntimeError("{} vs {}".format(len(indices), self.num_samples))
249
250 return iter(indices)
251
252
253 if idist.has_xla_support:
254
255 import torch_xla.core.xla_model as xm
256 from torch_xla.distributed.parallel_loader import ParallelLoader
257
258 class _MpDeviceLoader:
259 # https://github.com/pytorch/xla/pull/2117
260 # From pytorch/xla if `torch_xla.distributed.parallel_loader.MpDeviceLoader` is not available
261 def __init__(self, loader, device, **kwargs):
262 self._loader = loader
263 self._device = device
264 self._parallel_loader_kwargs = kwargs
265
266 def __iter__(self):
267 parallel_loader = ParallelLoader(self._loader, [self._device], **self._parallel_loader_kwargs)
268 return parallel_loader.per_device_loader(self._device)
269
270 def __len__(self):
271 return len(self._loader)
272
273 class _XLADistributedOptimizer(Optimizer):
274 def __init__(self, optimizer):
275 super(self.__class__, self).__init__(optimizer.param_groups)
276 self.wrapped_optimizer = optimizer
277
278 def step(self, closure=None):
279 xm.optimizer_step(self.wrapped_optimizer, barrier=True)
280
[end of ignite/distributed/auto.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ignite/distributed/auto.py b/ignite/distributed/auto.py
--- a/ignite/distributed/auto.py
+++ b/ignite/distributed/auto.py
@@ -21,8 +21,8 @@
Internally, we create a dataloader with provided kwargs while applying the following updates:
- - batch size is scaled by world size: ``batch_size / world_size``.
- - number of workers is scaled by number of local processes: ``num_workers / nprocs``.
+ - batch size is scaled by world size: ``batch_size / world_size`` if larger or equal world size.
+ - number of workers is scaled by number of local processes: ``num_workers / nprocs`` if larger or equal world size.
- if no sampler provided by user, `torch DistributedSampler` is setup.
- if a sampler is provided by user, it is wrapped by :class:`~ignite.distributed.auto.DistributedProxySampler`.
- if the default device is 'cuda', `pin_memory` is automatically set to `True`.
@@ -63,13 +63,12 @@
world_size = idist.get_world_size()
logger = setup_logger(__name__ + ".auto_dataloader")
-
if world_size > 1:
- if "batch_size" in kwargs:
+ if "batch_size" in kwargs and kwargs["batch_size"] >= world_size:
kwargs["batch_size"] //= world_size
- if "num_workers" in kwargs:
- nproc = idist.get_nproc_per_node()
+ nproc = idist.get_nproc_per_node()
+ if "num_workers" in kwargs and kwargs["num_workers"] >= nproc:
kwargs["num_workers"] = (kwargs["num_workers"] + nproc - 1) // nproc
if "batch_sampler" not in kwargs:
|
{"golden_diff": "diff --git a/ignite/distributed/auto.py b/ignite/distributed/auto.py\n--- a/ignite/distributed/auto.py\n+++ b/ignite/distributed/auto.py\n@@ -21,8 +21,8 @@\n \n Internally, we create a dataloader with provided kwargs while applying the following updates:\n \n- - batch size is scaled by world size: ``batch_size / world_size``.\n- - number of workers is scaled by number of local processes: ``num_workers / nprocs``.\n+ - batch size is scaled by world size: ``batch_size / world_size`` if larger or equal world size.\n+ - number of workers is scaled by number of local processes: ``num_workers / nprocs`` if larger or equal world size.\n - if no sampler provided by user, `torch DistributedSampler` is setup.\n - if a sampler is provided by user, it is wrapped by :class:`~ignite.distributed.auto.DistributedProxySampler`.\n - if the default device is 'cuda', `pin_memory` is automatically set to `True`.\n@@ -63,13 +63,12 @@\n world_size = idist.get_world_size()\n \n logger = setup_logger(__name__ + \".auto_dataloader\")\n-\n if world_size > 1:\n- if \"batch_size\" in kwargs:\n+ if \"batch_size\" in kwargs and kwargs[\"batch_size\"] >= world_size:\n kwargs[\"batch_size\"] //= world_size\n \n- if \"num_workers\" in kwargs:\n- nproc = idist.get_nproc_per_node()\n+ nproc = idist.get_nproc_per_node()\n+ if \"num_workers\" in kwargs and kwargs[\"num_workers\"] >= nproc:\n kwargs[\"num_workers\"] = (kwargs[\"num_workers\"] + nproc - 1) // nproc\n \n if \"batch_sampler\" not in kwargs:\n", "issue": "Auto dataloader - ValueError: batch_size should be a positive integer value, but got batch_size=0\n## \ud83d\udc1b Bug description\r\n\r\nThe following code will brake if `batch_size` is smaller than world size :\r\n```python\r\nimport torch\r\nimport ignite.distributed as idist\r\n\r\ndef foo(i):\r\n data = torch.arange(100).reshape(25, 4)\r\n data_loader = idist.auto_dataloader(data, batch_size=6, num_workers=12)\r\n\r\n\r\nif __name__ == \"__main__\":\r\n idist.spawn(\"gloo\", foo, args=(), nproc_per_node=8) \r\n```\r\n```\r\nValueError: batch_size should be a positive integer value, but got batch_size=0\r\n```\r\n\r\nA fix can be:\r\n- keep batch size as provided if smaller than world size\r\n- same for `num_workers`\r\n\r\n## Environment\r\n\r\n - PyTorch Version (e.g., 1.4): 1.5.0\r\n - Ignite Version (e.g., 0.3.0): master\r\n - OS (e.g., Linux): linux\r\n - How you installed Ignite (`conda`, `pip`, source):\r\n - Python version: 3.7\r\n - Any other relevant information:\r\n\r\n\r\n@InCogNiTo124 would you like to fix this as you recently played around `auto_*` ?\n", "before_files": [{"content": "import warnings\n\nimport torch\nimport torch.nn as nn\nfrom torch.optim.optimizer import Optimizer\nfrom torch.utils.data import DataLoader, Dataset\nfrom torch.utils.data.distributed import DistributedSampler\nfrom torch.utils.data.sampler import Sampler\n\nfrom ignite.distributed import utils as idist\nfrom ignite.distributed.comp_models import native as idist_native\nfrom ignite.distributed.comp_models import xla as idist_xla\nfrom ignite.utils import setup_logger\n\n__all__ = [\"auto_dataloader\", \"auto_model\", \"auto_optim\", \"DistributedProxySampler\"]\n\n\ndef auto_dataloader(dataset, **kwargs):\n \"\"\"Helper method to create a dataloader adapted for non-distributed and distributed configurations (supporting\n all available backends from :meth:`~ignite.distributed.utils.available_backends()`).\n\n Internally, we create a dataloader with provided kwargs while applying the following updates:\n\n - batch size is scaled by world size: ``batch_size / world_size``.\n - number of workers is scaled by number of local processes: ``num_workers / nprocs``.\n - if no sampler provided by user, `torch DistributedSampler` is setup.\n - if a sampler is provided by user, it is wrapped by :class:`~ignite.distributed.auto.DistributedProxySampler`.\n - if the default device is 'cuda', `pin_memory` is automatically set to `True`.\n\n .. warning::\n\n Custom batch sampler is not adapted for distributed configuration. Please, make sure that provided batch\n sampler is compatible with distributed configuration.\n\n Examples:\n\n .. code-block:: python\n\n import ignite.distribted as idist\n\n train_loader = idist.auto_dataloader(\n train_dataset,\n batch_size=32,\n num_workers=4,\n shuffle=True,\n pin_memory=\"cuda\" in idist.device().type,\n drop_last=True,\n )\n\n Args:\n dataset (Dataset): input torch dataset\n **kwargs: keyword arguments for `torch DataLoader`_.\n\n Returns:\n `torch DataLoader`_ or `XLA MpDeviceLoader`_ for XLA devices\n\n .. _torch DataLoader: https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader\n .. _XLA MpDeviceLoader: https://github.com/pytorch/xla/blob/master/torch_xla/distributed/parallel_loader.py#L178\n .. _torch DistributedSampler:\n https://pytorch.org/docs/stable/data.html#torch.utils.data.distributed.DistributedSampler\n \"\"\"\n rank = idist.get_rank()\n world_size = idist.get_world_size()\n\n logger = setup_logger(__name__ + \".auto_dataloader\")\n\n if world_size > 1:\n if \"batch_size\" in kwargs:\n kwargs[\"batch_size\"] //= world_size\n\n if \"num_workers\" in kwargs:\n nproc = idist.get_nproc_per_node()\n kwargs[\"num_workers\"] = (kwargs[\"num_workers\"] + nproc - 1) // nproc\n\n if \"batch_sampler\" not in kwargs:\n if kwargs.get(\"sampler\", None) is not None:\n sampler = DistributedProxySampler(kwargs[\"sampler\"], num_replicas=world_size, rank=rank)\n else:\n sampler = DistributedSampler(\n dataset, num_replicas=world_size, rank=rank, shuffle=kwargs.get(\"shuffle\", True)\n )\n # we need to remove \"shuffle\" from kwargs if sampler is used\n if \"shuffle\" in kwargs:\n del kwargs[\"shuffle\"]\n\n kwargs[\"sampler\"] = sampler\n else:\n warnings.warn(\n \"Found batch_sampler in provided kwargs. Please, make sure that it is compatible \"\n \"with distributed configuration\"\n )\n\n if idist.has_xla_support and idist.backend() == idist_xla.XLA_TPU and kwargs.get(\"pin_memory\", False):\n # TODO: How about XLA GPU ?\n warnings.warn(\n \"Found incompatible options: xla support and pin_memory args equal True. \"\n \"Argument `pin_memory=False` will be used to construct data loader.\"\n )\n kwargs[\"pin_memory\"] = False\n else:\n kwargs[\"pin_memory\"] = kwargs.get(\"pin_memory\", \"cuda\" in idist.device().type)\n\n logger.info(\"Use data loader kwargs for dataset '{}': \\n\\t{}\".format(repr(dataset)[:20].strip(), kwargs))\n dataloader = DataLoader(dataset, **kwargs)\n\n if idist.has_xla_support and idist.backend() == idist_xla.XLA_TPU and world_size > 1:\n\n logger.info(\"DataLoader is wrapped by `MpDeviceLoader` on XLA\")\n\n mp_device_loader_cls = _MpDeviceLoader\n try:\n from torch_xla.distributed.parallel_loader import MpDeviceLoader\n\n mp_device_loader_cls = MpDeviceLoader\n except ImportError:\n pass\n\n sampler = dataloader.sampler\n dataloader = mp_device_loader_cls(dataloader, idist.device())\n dataloader.sampler = sampler\n\n return dataloader\n\n\ndef auto_model(model: nn.Module) -> nn.Module:\n \"\"\"Helper method to adapt provided model for non-distributed and distributed configurations (supporting\n all available backends from :meth:`~ignite.distributed.utils.available_backends()`).\n\n Internally, we perform to following:\n\n - send model to current :meth:`~ignite.distributed.utils.device()`.\n - wrap the model to `torch DistributedDataParallel`_ for native torch distributed if world size is larger than 1\n - wrap the model to `torch DataParallel`_ if no distributed context found and more than one CUDA devices available.\n\n Examples:\n\n .. code-block:: python\n\n import ignite.distribted as idist\n\n model = idist.auto_model(model)\n\n Args:\n model (torch.nn.Module): model to adapt.\n\n Returns:\n torch.nn.Module\n\n .. _torch DistributedDataParallel: https://pytorch.org/docs/stable/nn.html#torch.nn.parallel.DistributedDataParallel\n .. _torch DataParallel: https://pytorch.org/docs/stable/nn.html#torch.nn.DataParallel\n \"\"\"\n logger = setup_logger(__name__ + \".auto_model\")\n\n model.to(idist.device())\n\n # distributed data parallel model\n if idist.get_world_size() > 1:\n if idist.backend() == idist_native.NCCL:\n lrank = idist.get_local_rank()\n logger.info(\"Apply torch DistributedDataParallel on model, device id: {}\".format(lrank))\n model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[lrank,])\n elif idist.backend() == idist_native.GLOO:\n logger.info(\"Apply torch DistributedDataParallel on model\")\n model = torch.nn.parallel.DistributedDataParallel(model)\n\n # not distributed but multiple GPUs reachable so data parallel model\n elif torch.cuda.device_count() > 1 and \"cuda\" in idist.device().type:\n logger.info(\"Apply torch DataParallel on model\")\n model = torch.nn.parallel.DataParallel(model)\n\n return model\n\n\ndef auto_optim(optimizer: Optimizer) -> Optimizer:\n \"\"\"Helper method to adapt optimizer for non-distributed and distributed configurations (supporting\n all available backends from :meth:`~ignite.distributed.utils.available_backends()`).\n\n Internally, this method is no-op for non-distributed and torch native distributed configuration.\n For XLA distributed configuration, we create a new class that inherits from provided optimizer.\n The goal is to override the `step()` method with specific `xm.optimizer_step`_ implementation.\n\n Examples:\n\n .. code-block:: python\n\n import ignite.distribted as idist\n\n optimizer = idist.auto_optim(optimizer)\n\n\n Args:\n optimizer (Optimizer): input torch optimizer\n\n Returns:\n Optimizer\n\n .. _xm.optimizer_step: http://pytorch.org/xla/release/1.5/index.html#torch_xla.core.xla_model.optimizer_step\n\n \"\"\"\n if not (idist.has_xla_support and idist.backend() == idist_xla.XLA_TPU):\n return optimizer\n\n cls = type(optimizer.__class__.__name__, (optimizer.__class__,), dict(_XLADistributedOptimizer.__dict__))\n return cls(optimizer)\n\n\nclass DistributedProxySampler(DistributedSampler):\n \"\"\"Distributed sampler proxy to adapt user's sampler for distributed data parallelism configuration.\n\n Code is based on https://github.com/pytorch/pytorch/issues/23430#issuecomment-562350407\n\n\n .. note::\n Input sampler is assumed to have a constant size.\n\n Args:\n sampler (Sampler): Input torch data sampler.\n num_replicas (int, optional): Number of processes participating in distributed training.\n rank (int, optional): Rank of the current process within ``num_replicas``.\n\n \"\"\"\n\n def __init__(self, sampler: Sampler, num_replicas=None, rank=None):\n\n if not isinstance(sampler, Sampler):\n raise TypeError(\"Argument sampler should be instance of torch Sampler, but given: {}\".format(type(sampler)))\n\n if not hasattr(sampler, \"__len__\"):\n raise TypeError(\"Argument sampler should have length\")\n\n super(DistributedProxySampler, self).__init__(sampler, num_replicas=num_replicas, rank=rank, shuffle=False)\n self.sampler = sampler\n\n def __iter__(self):\n # deterministically shuffle based on epoch\n torch.manual_seed(self.epoch)\n\n indices = []\n while len(indices) < self.total_size:\n indices += list(self.sampler)\n\n if len(indices) != self.total_size:\n raise RuntimeError(\"{} vs {}\".format(len(indices), self.total_size))\n\n # subsample\n indices = indices[self.rank : self.total_size : self.num_replicas]\n if len(indices) != self.num_samples:\n raise RuntimeError(\"{} vs {}\".format(len(indices), self.num_samples))\n\n return iter(indices)\n\n\nif idist.has_xla_support:\n\n import torch_xla.core.xla_model as xm\n from torch_xla.distributed.parallel_loader import ParallelLoader\n\n class _MpDeviceLoader:\n # https://github.com/pytorch/xla/pull/2117\n # From pytorch/xla if `torch_xla.distributed.parallel_loader.MpDeviceLoader` is not available\n def __init__(self, loader, device, **kwargs):\n self._loader = loader\n self._device = device\n self._parallel_loader_kwargs = kwargs\n\n def __iter__(self):\n parallel_loader = ParallelLoader(self._loader, [self._device], **self._parallel_loader_kwargs)\n return parallel_loader.per_device_loader(self._device)\n\n def __len__(self):\n return len(self._loader)\n\n class _XLADistributedOptimizer(Optimizer):\n def __init__(self, optimizer):\n super(self.__class__, self).__init__(optimizer.param_groups)\n self.wrapped_optimizer = optimizer\n\n def step(self, closure=None):\n xm.optimizer_step(self.wrapped_optimizer, barrier=True)\n", "path": "ignite/distributed/auto.py"}]}
| 3,970 | 403 |
gh_patches_debug_6190
|
rasdani/github-patches
|
git_diff
|
microsoft__torchgeo-626
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update README
Before blog: update verbiage and add pics from blog/paper.
After blog: add link to blog.
</issue>
<code>
[start of torchgeo/__init__.py]
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License.
3
4 """TorchGeo: datasets, transforms, and models for geospatial data.
5
6 This library is part of the `PyTorch <http://pytorch.org/>`_ project. PyTorch is an open
7 source machine learning framework.
8
9 The :mod:`torchgeo` package consists of popular datasets, model architectures, and
10 common image transformations for geospatial data.
11 """
12
13 __author__ = "Adam J. Stewart"
14 __version__ = "0.3.0.dev0"
15
[end of torchgeo/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/torchgeo/__init__.py b/torchgeo/__init__.py
--- a/torchgeo/__init__.py
+++ b/torchgeo/__init__.py
@@ -1,7 +1,7 @@
# Copyright (c) Microsoft Corporation. All rights reserved.
# Licensed under the MIT License.
-"""TorchGeo: datasets, transforms, and models for geospatial data.
+"""TorchGeo: datasets, samplers, transforms, and pre-trained models for geospatial data.
This library is part of the `PyTorch <http://pytorch.org/>`_ project. PyTorch is an open
source machine learning framework.
|
{"golden_diff": "diff --git a/torchgeo/__init__.py b/torchgeo/__init__.py\n--- a/torchgeo/__init__.py\n+++ b/torchgeo/__init__.py\n@@ -1,7 +1,7 @@\n # Copyright (c) Microsoft Corporation. All rights reserved.\n # Licensed under the MIT License.\n \n-\"\"\"TorchGeo: datasets, transforms, and models for geospatial data.\n+\"\"\"TorchGeo: datasets, samplers, transforms, and pre-trained models for geospatial data.\n \n This library is part of the `PyTorch <http://pytorch.org/>`_ project. PyTorch is an open\n source machine learning framework.\n", "issue": "Update README\nBefore blog: update verbiage and add pics from blog/paper. \n\nAfter blog: add link to blog.\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\n\n\"\"\"TorchGeo: datasets, transforms, and models for geospatial data.\n\nThis library is part of the `PyTorch <http://pytorch.org/>`_ project. PyTorch is an open\nsource machine learning framework.\n\nThe :mod:`torchgeo` package consists of popular datasets, model architectures, and\ncommon image transformations for geospatial data.\n\"\"\"\n\n__author__ = \"Adam J. Stewart\"\n__version__ = \"0.3.0.dev0\"\n", "path": "torchgeo/__init__.py"}]}
| 709 | 145 |
gh_patches_debug_34052
|
rasdani/github-patches
|
git_diff
|
ckan__ckan-5750
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Purging deleted packages does not delete associated filestore/datastore resources
**CKAN version**
2.9
**Describe the bug**
After deleting and purging dataset packages, the associated datastore/filestore resources are orphaned and not deleted.
**Steps to reproduce**
1. Delete datasets
2. Go to sysadmin/trash
3. Select "Purge All"
4. Check datastore and filestore. Associated resources are still there.
**Expected behavior**
Dataset resources in the filestore and the datastore are deleted when the associated package resources are purged.
**Additional details**
This is related to #4705 and a lot of work has been done on PRs #4867 and #4905, but neither have been merged.
</issue>
<code>
[start of ckanext/datastore/cli.py]
1 # encoding: utf-8
2
3 import logging
4 import os
5
6 import click
7
8 from ckan.model import parse_db_config
9 from ckan.common import config
10
11 import ckanext.datastore as datastore_module
12 from ckanext.datastore.backend.postgres import identifier
13 from ckanext.datastore.blueprint import DUMP_FORMATS, dump_to
14
15 log = logging.getLogger(__name__)
16
17
18 @click.group()
19 def datastore():
20 u'''Perform commands to set up the datastore.
21 '''
22
23
24 @datastore.command(
25 u'set-permissions',
26 short_help=u'Generate SQL for permission configuration.'
27 )
28 def set_permissions():
29 u'''Emit an SQL script that will set the permissions for the datastore
30 users as configured in your configuration file.'''
31
32 write_url = _parse_db_config(u'ckan.datastore.write_url')
33 read_url = _parse_db_config(u'ckan.datastore.read_url')
34 db_url = _parse_db_config(u'sqlalchemy.url')
35
36 # Basic validation that read and write URLs reference the same database.
37 # This obviously doesn't check they're the same database (the hosts/ports
38 # could be different), but it's better than nothing, I guess.
39
40 if write_url[u'db_name'] != read_url[u'db_name']:
41 click.secho(
42 u'The datastore write_url and read_url must refer to the same '
43 u'database!',
44 fg=u'red',
45 bold=True
46 )
47 raise click.Abort()
48
49 sql = permissions_sql(
50 maindb=db_url[u'db_name'],
51 datastoredb=write_url[u'db_name'],
52 mainuser=db_url[u'db_user'],
53 writeuser=write_url[u'db_user'],
54 readuser=read_url[u'db_user']
55 )
56
57 click.echo(sql)
58
59
60 def permissions_sql(maindb, datastoredb, mainuser, writeuser, readuser):
61 template_filename = os.path.join(
62 os.path.dirname(datastore_module.__file__), u'set_permissions.sql'
63 )
64 with open(template_filename) as fp:
65 template = fp.read()
66 return template.format(
67 maindb=identifier(maindb),
68 datastoredb=identifier(datastoredb),
69 mainuser=identifier(mainuser),
70 writeuser=identifier(writeuser),
71 readuser=identifier(readuser)
72 )
73
74
75 @datastore.command()
76 @click.argument(u'resource-id', nargs=1)
77 @click.argument(
78 u'output-file',
79 type=click.File(u'wb'),
80 default=click.get_binary_stream(u'stdout')
81 )
82 @click.option(u'--format', default=u'csv', type=click.Choice(DUMP_FORMATS))
83 @click.option(u'--offset', type=click.IntRange(0, None), default=0)
84 @click.option(u'--limit', type=click.IntRange(0))
85 @click.option(u'--bom', is_flag=True) # FIXME: options based on format
86 @click.pass_context
87 def dump(ctx, resource_id, output_file, format, offset, limit, bom):
88 u'''Dump a datastore resource.
89 '''
90 flask_app = ctx.meta['flask_app']
91 with flask_app.test_request_context():
92 dump_to(
93 resource_id,
94 output_file,
95 fmt=format,
96 offset=offset,
97 limit=limit,
98 options={u'bom': bom},
99 sort=u'_id',
100 search_params={}
101 )
102
103
104 def _parse_db_config(config_key=u'sqlalchemy.url'):
105 db_config = parse_db_config(config_key)
106 if not db_config:
107 click.secho(
108 u'Could not extract db details from url: %r' % config[config_key],
109 fg=u'red',
110 bold=True
111 )
112 raise click.Abort()
113 return db_config
114
[end of ckanext/datastore/cli.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ckanext/datastore/cli.py b/ckanext/datastore/cli.py
--- a/ckanext/datastore/cli.py
+++ b/ckanext/datastore/cli.py
@@ -7,6 +7,7 @@
from ckan.model import parse_db_config
from ckan.common import config
+import ckan.logic as logic
import ckanext.datastore as datastore_module
from ckanext.datastore.backend.postgres import identifier
@@ -111,3 +112,69 @@
)
raise click.Abort()
return db_config
+
+
[email protected](
+ u'purge',
+ short_help=u'purge orphaned resources from the datastore.'
+)
+def purge():
+ u'''Purge orphaned resources from the datastore using the datastore_delete
+ action, which drops tables when called without filters.'''
+
+ site_user = logic.get_action(u'get_site_user')({u'ignore_auth': True}, {})
+ context = {u'user': site_user[u'name']}
+
+ result = logic.get_action(u'datastore_search')(
+ context,
+ {u'resource_id': u'_table_metadata'}
+ )
+
+ resource_id_list = []
+ for record in result[u'records']:
+ try:
+ # ignore 'alias' records (views) as they are automatically
+ # deleted when the parent resource table is dropped
+ if record[u'alias_of']:
+ continue
+
+ # we need to do this to trigger resource_show auth function
+ site_user = logic.get_action(u'get_site_user')(
+ {u'ignore_auth': True}, {})
+ context = {u'user': site_user[u'name']}
+
+ logic.get_action(u'resource_show')(
+ context,
+ {u'id': record[u'name']}
+ )
+ except logic.NotFound:
+ resource_id_list.append(record[u'name'])
+ click.echo(u"Resource '%s' orphaned - queued for drop" %
+ record[u'name'])
+ except KeyError:
+ continue
+
+ orphaned_table_count = len(resource_id_list)
+ click.echo(u'%d orphaned tables found.' % orphaned_table_count)
+
+ if not orphaned_table_count:
+ return
+
+ click.confirm(u'Proceed with purge?', abort=True)
+
+ # Drop the orphaned datastore tables. When datastore_delete is called
+ # without filters, it does a drop table cascade
+ drop_count = 0
+ for resource_id in resource_id_list:
+ logic.get_action(u'datastore_delete')(
+ context,
+ {u'resource_id': resource_id, u'force': True}
+ )
+ click.echo(u"Table '%s' dropped)" % resource_id)
+ drop_count += 1
+
+ click.echo(u'Dropped %s tables' % drop_count)
+
+
+def get_commands():
+ return (set_permissions, dump, purge)
|
{"golden_diff": "diff --git a/ckanext/datastore/cli.py b/ckanext/datastore/cli.py\n--- a/ckanext/datastore/cli.py\n+++ b/ckanext/datastore/cli.py\n@@ -7,6 +7,7 @@\n \n from ckan.model import parse_db_config\n from ckan.common import config\n+import ckan.logic as logic\n \n import ckanext.datastore as datastore_module\n from ckanext.datastore.backend.postgres import identifier\n@@ -111,3 +112,69 @@\n )\n raise click.Abort()\n return db_config\n+\n+\[email protected](\n+ u'purge',\n+ short_help=u'purge orphaned resources from the datastore.'\n+)\n+def purge():\n+ u'''Purge orphaned resources from the datastore using the datastore_delete\n+ action, which drops tables when called without filters.'''\n+\n+ site_user = logic.get_action(u'get_site_user')({u'ignore_auth': True}, {})\n+ context = {u'user': site_user[u'name']}\n+\n+ result = logic.get_action(u'datastore_search')(\n+ context,\n+ {u'resource_id': u'_table_metadata'}\n+ )\n+\n+ resource_id_list = []\n+ for record in result[u'records']:\n+ try:\n+ # ignore 'alias' records (views) as they are automatically\n+ # deleted when the parent resource table is dropped\n+ if record[u'alias_of']:\n+ continue\n+\n+ # we need to do this to trigger resource_show auth function\n+ site_user = logic.get_action(u'get_site_user')(\n+ {u'ignore_auth': True}, {})\n+ context = {u'user': site_user[u'name']}\n+\n+ logic.get_action(u'resource_show')(\n+ context,\n+ {u'id': record[u'name']}\n+ )\n+ except logic.NotFound:\n+ resource_id_list.append(record[u'name'])\n+ click.echo(u\"Resource '%s' orphaned - queued for drop\" %\n+ record[u'name'])\n+ except KeyError:\n+ continue\n+\n+ orphaned_table_count = len(resource_id_list)\n+ click.echo(u'%d orphaned tables found.' % orphaned_table_count)\n+\n+ if not orphaned_table_count:\n+ return\n+\n+ click.confirm(u'Proceed with purge?', abort=True)\n+\n+ # Drop the orphaned datastore tables. When datastore_delete is called\n+ # without filters, it does a drop table cascade\n+ drop_count = 0\n+ for resource_id in resource_id_list:\n+ logic.get_action(u'datastore_delete')(\n+ context,\n+ {u'resource_id': resource_id, u'force': True}\n+ )\n+ click.echo(u\"Table '%s' dropped)\" % resource_id)\n+ drop_count += 1\n+\n+ click.echo(u'Dropped %s tables' % drop_count)\n+\n+\n+def get_commands():\n+ return (set_permissions, dump, purge)\n", "issue": "Purging deleted packages does not delete associated filestore/datastore resources\n**CKAN version**\r\n2.9\r\n\r\n**Describe the bug**\r\nAfter deleting and purging dataset packages, the associated datastore/filestore resources are orphaned and not deleted.\r\n\r\n**Steps to reproduce**\r\n\r\n1. Delete datasets\r\n2. Go to sysadmin/trash\r\n3. Select \"Purge All\"\r\n4. Check datastore and filestore. Associated resources are still there.\r\n\r\n**Expected behavior**\r\nDataset resources in the filestore and the datastore are deleted when the associated package resources are purged.\r\n\r\n**Additional details**\r\nThis is related to #4705 and a lot of work has been done on PRs #4867 and #4905, but neither have been merged.\r\n\n", "before_files": [{"content": "# encoding: utf-8\n\nimport logging\nimport os\n\nimport click\n\nfrom ckan.model import parse_db_config\nfrom ckan.common import config\n\nimport ckanext.datastore as datastore_module\nfrom ckanext.datastore.backend.postgres import identifier\nfrom ckanext.datastore.blueprint import DUMP_FORMATS, dump_to\n\nlog = logging.getLogger(__name__)\n\n\[email protected]()\ndef datastore():\n u'''Perform commands to set up the datastore.\n '''\n\n\[email protected](\n u'set-permissions',\n short_help=u'Generate SQL for permission configuration.'\n)\ndef set_permissions():\n u'''Emit an SQL script that will set the permissions for the datastore\n users as configured in your configuration file.'''\n\n write_url = _parse_db_config(u'ckan.datastore.write_url')\n read_url = _parse_db_config(u'ckan.datastore.read_url')\n db_url = _parse_db_config(u'sqlalchemy.url')\n\n # Basic validation that read and write URLs reference the same database.\n # This obviously doesn't check they're the same database (the hosts/ports\n # could be different), but it's better than nothing, I guess.\n\n if write_url[u'db_name'] != read_url[u'db_name']:\n click.secho(\n u'The datastore write_url and read_url must refer to the same '\n u'database!',\n fg=u'red',\n bold=True\n )\n raise click.Abort()\n\n sql = permissions_sql(\n maindb=db_url[u'db_name'],\n datastoredb=write_url[u'db_name'],\n mainuser=db_url[u'db_user'],\n writeuser=write_url[u'db_user'],\n readuser=read_url[u'db_user']\n )\n\n click.echo(sql)\n\n\ndef permissions_sql(maindb, datastoredb, mainuser, writeuser, readuser):\n template_filename = os.path.join(\n os.path.dirname(datastore_module.__file__), u'set_permissions.sql'\n )\n with open(template_filename) as fp:\n template = fp.read()\n return template.format(\n maindb=identifier(maindb),\n datastoredb=identifier(datastoredb),\n mainuser=identifier(mainuser),\n writeuser=identifier(writeuser),\n readuser=identifier(readuser)\n )\n\n\[email protected]()\[email protected](u'resource-id', nargs=1)\[email protected](\n u'output-file',\n type=click.File(u'wb'),\n default=click.get_binary_stream(u'stdout')\n)\[email protected](u'--format', default=u'csv', type=click.Choice(DUMP_FORMATS))\[email protected](u'--offset', type=click.IntRange(0, None), default=0)\[email protected](u'--limit', type=click.IntRange(0))\[email protected](u'--bom', is_flag=True) # FIXME: options based on format\[email protected]_context\ndef dump(ctx, resource_id, output_file, format, offset, limit, bom):\n u'''Dump a datastore resource.\n '''\n flask_app = ctx.meta['flask_app']\n with flask_app.test_request_context():\n dump_to(\n resource_id,\n output_file,\n fmt=format,\n offset=offset,\n limit=limit,\n options={u'bom': bom},\n sort=u'_id',\n search_params={}\n )\n\n\ndef _parse_db_config(config_key=u'sqlalchemy.url'):\n db_config = parse_db_config(config_key)\n if not db_config:\n click.secho(\n u'Could not extract db details from url: %r' % config[config_key],\n fg=u'red',\n bold=True\n )\n raise click.Abort()\n return db_config\n", "path": "ckanext/datastore/cli.py"}]}
| 1,743 | 664 |
gh_patches_debug_19386
|
rasdani/github-patches
|
git_diff
|
OCHA-DAP__hdx-ckan-1747
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Ebola Page: make millions and % smaller
About half the current height looks right.

</issue>
<code>
[start of ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py]
1 '''
2 Created on Nov 3, 2014
3
4 @author: alexandru-m-g
5 '''
6
7 import logging
8 import datetime as dt
9 import decimal
10
11 import pylons.config as config
12
13 import ckan.lib.base as base
14 import ckan.logic as logic
15 import ckan.model as model
16 import ckan.common as common
17 import ckan.lib.helpers as h
18
19 render = base.render
20 get_action = logic.get_action
21 c = common.c
22 request = common.request
23 _ = common._
24
25 Decimal = decimal.Decimal
26
27 log = logging.getLogger(__name__)
28
29
30 class CrisisController(base.BaseController):
31
32 def show(self):
33
34 context = {'model': model, 'session': model.Session,
35 'user': c.user or c.author, 'for_view': True,
36 'auth_user_obj': c.userobj}
37
38 datastore_resource_id = self._get_datastore_resource_id(
39 context, config.get('hdx.crisis.ebola_dataset', None), config.get('hdx.crisis.ebola_resource_title', None))
40 if datastore_resource_id:
41 c.top_line_items = self._get_top_line_items(
42 context, datastore_resource_id)
43
44 limit = 25
45 c.q = u'ebola'
46
47 page = int(request.params.get('page', 1))
48 data_dict = {'sort': u'metadata_modified desc',
49 'fq': '+dataset_type:dataset',
50 'rows': limit,
51 'q': c.q,
52 'start': (page - 1) * limit
53 }
54 query = get_action("package_search")(context, data_dict)
55
56 def pager_url(q=None, page=None):
57 return h.url_for('show_crisis', page=page)
58
59 c.page = h.Page(
60 collection=query['results'],
61 page=page,
62 url=pager_url,
63 item_count=query['count'],
64 items_per_page=limit
65 )
66 c.items = query['results']
67 c.item_count = query['count']
68
69 c.other_links = {}
70 c.other_links['show_more'] = h.url_for(
71 "search", **{'q': u'ebola', 'sort': u'metadata_modified desc',
72 'ext_indicator': '0'})
73
74 return render('crisis/crisis.html')
75
76 def _get_decimal_value(self, value):
77 decimal_value = Decimal(str(value)).quantize(
78 Decimal('.1'), rounding=decimal.ROUND_HALF_UP)
79 return decimal_value
80
81 def _format_results(self, result):
82 for r in result['records']:
83 d = dt.datetime.strptime(r[u'latest_date'], '%Y-%m-%dT%H:%M:%S')
84 r[u'latest_date'] = dt.datetime.strftime(d, '%b %d, %Y')
85
86 modified_value = r[u'value']
87 if r[u'units'] == 'ratio':
88 modified_value *= 100.0
89 elif r[u'units'] == 'million':
90 modified_value /= 1000000.0
91
92 int_value = int(modified_value)
93 if int_value == modified_value:
94 r[u'formatted_value'] = '{:,}'.format(int_value)
95 else:
96 if r[u'units'] == 'ratio':
97 r[u'formatted_value'] = '{:,.1f}%'.format(
98 self._get_decimal_value(modified_value))
99 elif r[u'units'] == 'million':
100 r[u'formatted_value'] = '{:,.1f} '.format(
101 self._get_decimal_value(modified_value))
102 r[u'formatted_value'] += ' ' + _('million')
103
104 def _get_top_line_items(self, context, datastore_resource_id):
105 modified_context = dict(context)
106 modified_context['ignore_auth'] = True
107 result = get_action('datastore_search')(
108 modified_context, {'resource_id': datastore_resource_id})
109 if 'records' in result:
110 self._format_results(result)
111 return result['records']
112 return []
113
114 def _get_datastore_resource_id(self, context, dataset_id, resource_name):
115 try:
116 modified_context = dict(context)
117 modified_context['ignore_auth'] = True
118 dataset = get_action('package_show')(
119 modified_context, {'id': dataset_id})
120
121 if 'resources' in dataset:
122 for r in dataset['resources']:
123 if 'datastore_active' in r and r['datastore_active'] \
124 and r['name'] == resource_name:
125 return r['id']
126 return None
127 except:
128 log.warning('No dataset with id ' + dataset_id)
129 return None
130
[end of ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py b/ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py
--- a/ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py
+++ b/ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py
@@ -94,12 +94,12 @@
r[u'formatted_value'] = '{:,}'.format(int_value)
else:
if r[u'units'] == 'ratio':
- r[u'formatted_value'] = '{:,.1f}%'.format(
+ r[u'formatted_value'] = '{:,.1f}'.format(
self._get_decimal_value(modified_value))
elif r[u'units'] == 'million':
- r[u'formatted_value'] = '{:,.1f} '.format(
+ r[u'formatted_value'] = '{:,.1f}'.format(
self._get_decimal_value(modified_value))
- r[u'formatted_value'] += ' ' + _('million')
+ #r[u'formatted_value'] += ' ' + _('million')
def _get_top_line_items(self, context, datastore_resource_id):
modified_context = dict(context)
|
{"golden_diff": "diff --git a/ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py b/ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py\n--- a/ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py\n+++ b/ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py\n@@ -94,12 +94,12 @@\n r[u'formatted_value'] = '{:,}'.format(int_value)\n else:\n if r[u'units'] == 'ratio':\n- r[u'formatted_value'] = '{:,.1f}%'.format(\n+ r[u'formatted_value'] = '{:,.1f}'.format(\n self._get_decimal_value(modified_value))\n elif r[u'units'] == 'million':\n- r[u'formatted_value'] = '{:,.1f} '.format(\n+ r[u'formatted_value'] = '{:,.1f}'.format(\n self._get_decimal_value(modified_value))\n- r[u'formatted_value'] += ' ' + _('million')\n+ #r[u'formatted_value'] += ' ' + _('million')\n \n def _get_top_line_items(self, context, datastore_resource_id):\n modified_context = dict(context)\n", "issue": "Ebola Page: make millions and % smaller\nAbout half the current height looks right.\n\n\n\n", "before_files": [{"content": "'''\nCreated on Nov 3, 2014\n\n@author: alexandru-m-g\n'''\n\nimport logging\nimport datetime as dt\nimport decimal\n\nimport pylons.config as config\n\nimport ckan.lib.base as base\nimport ckan.logic as logic\nimport ckan.model as model\nimport ckan.common as common\nimport ckan.lib.helpers as h\n\nrender = base.render\nget_action = logic.get_action\nc = common.c\nrequest = common.request\n_ = common._\n\nDecimal = decimal.Decimal\n\nlog = logging.getLogger(__name__)\n\n\nclass CrisisController(base.BaseController):\n\n def show(self):\n\n context = {'model': model, 'session': model.Session,\n 'user': c.user or c.author, 'for_view': True,\n 'auth_user_obj': c.userobj}\n\n datastore_resource_id = self._get_datastore_resource_id(\n context, config.get('hdx.crisis.ebola_dataset', None), config.get('hdx.crisis.ebola_resource_title', None))\n if datastore_resource_id:\n c.top_line_items = self._get_top_line_items(\n context, datastore_resource_id)\n\n limit = 25\n c.q = u'ebola'\n\n page = int(request.params.get('page', 1))\n data_dict = {'sort': u'metadata_modified desc',\n 'fq': '+dataset_type:dataset',\n 'rows': limit,\n 'q': c.q,\n 'start': (page - 1) * limit\n }\n query = get_action(\"package_search\")(context, data_dict)\n\n def pager_url(q=None, page=None):\n return h.url_for('show_crisis', page=page)\n\n c.page = h.Page(\n collection=query['results'],\n page=page,\n url=pager_url,\n item_count=query['count'],\n items_per_page=limit\n )\n c.items = query['results']\n c.item_count = query['count']\n\n c.other_links = {}\n c.other_links['show_more'] = h.url_for(\n \"search\", **{'q': u'ebola', 'sort': u'metadata_modified desc',\n 'ext_indicator': '0'})\n\n return render('crisis/crisis.html')\n\n def _get_decimal_value(self, value):\n decimal_value = Decimal(str(value)).quantize(\n Decimal('.1'), rounding=decimal.ROUND_HALF_UP)\n return decimal_value\n\n def _format_results(self, result):\n for r in result['records']:\n d = dt.datetime.strptime(r[u'latest_date'], '%Y-%m-%dT%H:%M:%S')\n r[u'latest_date'] = dt.datetime.strftime(d, '%b %d, %Y')\n\n modified_value = r[u'value']\n if r[u'units'] == 'ratio':\n modified_value *= 100.0\n elif r[u'units'] == 'million':\n modified_value /= 1000000.0\n\n int_value = int(modified_value)\n if int_value == modified_value:\n r[u'formatted_value'] = '{:,}'.format(int_value)\n else:\n if r[u'units'] == 'ratio':\n r[u'formatted_value'] = '{:,.1f}%'.format(\n self._get_decimal_value(modified_value))\n elif r[u'units'] == 'million':\n r[u'formatted_value'] = '{:,.1f} '.format(\n self._get_decimal_value(modified_value))\n r[u'formatted_value'] += ' ' + _('million')\n\n def _get_top_line_items(self, context, datastore_resource_id):\n modified_context = dict(context)\n modified_context['ignore_auth'] = True\n result = get_action('datastore_search')(\n modified_context, {'resource_id': datastore_resource_id})\n if 'records' in result:\n self._format_results(result)\n return result['records']\n return []\n\n def _get_datastore_resource_id(self, context, dataset_id, resource_name):\n try:\n modified_context = dict(context)\n modified_context['ignore_auth'] = True\n dataset = get_action('package_show')(\n modified_context, {'id': dataset_id})\n\n if 'resources' in dataset:\n for r in dataset['resources']:\n if 'datastore_active' in r and r['datastore_active'] \\\n and r['name'] == resource_name:\n return r['id']\n return None\n except:\n log.warning('No dataset with id ' + dataset_id)\n return None\n", "path": "ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py"}]}
| 1,928 | 306 |
gh_patches_debug_30258
|
rasdani/github-patches
|
git_diff
|
StackStorm__st2-2354
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
st2 key set in CLI doesn't allow one to set a TTL.
Reported by: psychopenguin on slack
</issue>
<code>
[start of st2client/st2client/commands/keyvalue.py]
1 # Licensed to the StackStorm, Inc ('StackStorm') under one or more
2 # contributor license agreements. See the NOTICE file distributed with
3 # this work for additional information regarding copyright ownership.
4 # The ASF licenses this file to You under the Apache License, Version 2.0
5 # (the "License"); you may not use this file except in compliance with
6 # the License. You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15
16 import os
17 import json
18 import logging
19 from os.path import join as pjoin
20
21 from st2client.commands import resource
22 from st2client.commands.noop import NoopCommand
23 from st2client.commands.resource import add_auth_token_to_kwargs_from_cli
24 from st2client.formatters import table
25 from st2client.models.keyvalue import KeyValuePair
26 from st2client.utils.date import format_isodate
27
28 LOG = logging.getLogger(__name__)
29
30
31 class KeyValuePairBranch(resource.ResourceBranch):
32
33 def __init__(self, description, app, subparsers, parent_parser=None):
34 super(KeyValuePairBranch, self).__init__(
35 KeyValuePair, description, app, subparsers,
36 parent_parser=parent_parser,
37 commands={
38 'list': KeyValuePairListCommand,
39 'get': KeyValuePairGetCommand,
40 'delete': KeyValuePairDeleteCommand,
41 'create': NoopCommand,
42 'update': NoopCommand
43 })
44
45 # Registers extended commands
46 self.commands['set'] = KeyValuePairSetCommand(self.resource, self.app,
47 self.subparsers)
48 self.commands['load'] = KeyValuePairLoadCommand(
49 self.resource, self.app, self.subparsers)
50 self.commands['delete_by_prefix'] = KeyValuePairDeleteByPrefixCommand(
51 self.resource, self.app, self.subparsers)
52
53 # Remove unsupported commands
54 # TODO: Refactor parent class and make it nicer
55 del self.commands['create']
56 del self.commands['update']
57
58
59 class KeyValuePairListCommand(resource.ResourceListCommand):
60 display_attributes = ['name', 'value', 'expire_timestamp']
61 attribute_transform_functions = {
62 'expire_timestamp': format_isodate,
63 }
64
65 def __init__(self, *args, **kwargs):
66 super(KeyValuePairListCommand, self).__init__(*args, **kwargs)
67
68 # Filter options
69 self.parser.add_argument('--prefix', help=('Only return values which name starts with the '
70 ' provided prefix.'))
71
72 def run_and_print(self, args, **kwargs):
73 if args.prefix:
74 kwargs['prefix'] = args.prefix
75
76 instances = self.run(args, **kwargs)
77 self.print_output(reversed(instances), table.MultiColumnTable,
78 attributes=args.attr, widths=args.width,
79 json=args.json,
80 attribute_transform_functions=self.attribute_transform_functions)
81
82
83 class KeyValuePairGetCommand(resource.ResourceGetCommand):
84 pk_argument_name = 'name'
85 display_attributes = ['name', 'value']
86
87
88 class KeyValuePairSetCommand(resource.ResourceCommand):
89 display_attributes = ['name', 'value']
90
91 def __init__(self, resource, *args, **kwargs):
92 super(KeyValuePairSetCommand, self).__init__(
93 resource, 'set',
94 'Set an existing %s.' % resource.get_display_name().lower(),
95 *args, **kwargs
96 )
97
98 self.parser.add_argument('name',
99 metavar='name',
100 help='Name of the key value pair.')
101 self.parser.add_argument('value', help='Value paired with the key.')
102
103 @add_auth_token_to_kwargs_from_cli
104 def run(self, args, **kwargs):
105 instance = KeyValuePair()
106 instance.id = args.name # TODO: refactor and get rid of id
107 instance.name = args.name
108 instance.value = args.value
109 return self.manager.update(instance, **kwargs)
110
111 def run_and_print(self, args, **kwargs):
112 instance = self.run(args, **kwargs)
113 self.print_output(instance, table.PropertyValueTable,
114 attributes=self.display_attributes, json=args.json)
115
116
117 class KeyValuePairDeleteCommand(resource.ResourceDeleteCommand):
118 pk_argument_name = 'name'
119
120 @add_auth_token_to_kwargs_from_cli
121 def run(self, args, **kwargs):
122 resource_id = getattr(args, self.pk_argument_name, None)
123 instance = self.get_resource(resource_id, **kwargs)
124
125 if not instance:
126 raise resource.ResourceNotFoundError('KeyValuePair with id "%s" not found', resource_id)
127
128 instance.id = resource_id # TODO: refactor and get rid of id
129 self.manager.delete(instance, **kwargs)
130
131
132 class KeyValuePairDeleteByPrefixCommand(resource.ResourceCommand):
133 """
134 Commands which delete all the key value pairs which match the provided
135 prefix.
136 """
137 def __init__(self, resource, *args, **kwargs):
138 super(KeyValuePairDeleteByPrefixCommand, self).__init__(resource, 'delete_by_prefix',
139 'Delete KeyValue pairs which match the provided prefix', *args, **kwargs)
140
141 self.parser.add_argument('-p', '--prefix', required=True,
142 help='Name prefix (e.g. twitter.TwitterSensor:)')
143
144 @add_auth_token_to_kwargs_from_cli
145 def run(self, args, **kwargs):
146 prefix = args.prefix
147 key_pairs = self.manager.get_all(prefix=prefix)
148
149 to_delete = []
150 for key_pair in key_pairs:
151 key_pair.id = key_pair.name
152 to_delete.append(key_pair)
153
154 deleted = []
155 for key_pair in to_delete:
156 self.manager.delete(instance=key_pair, **kwargs)
157 deleted.append(key_pair)
158
159 return deleted
160
161 def run_and_print(self, args, **kwargs):
162 # TODO: Need to use args, instead of kwargs (args=) because of bad API
163 # FIX ME
164 deleted = self.run(args, **kwargs)
165 key_ids = [key_pair.id for key_pair in deleted]
166
167 print('Deleted %s keys' % (len(deleted)))
168 print('Deleted key ids: %s' % (', '.join(key_ids)))
169
170
171 class KeyValuePairLoadCommand(resource.ResourceCommand):
172 pk_argument_name = 'name'
173 display_attributes = ['name', 'value']
174
175 def __init__(self, resource, *args, **kwargs):
176 help_text = ('Load a list of %s from file.' %
177 resource.get_plural_display_name().lower())
178 super(KeyValuePairLoadCommand, self).__init__(resource, 'load',
179 help_text, *args, **kwargs)
180
181 self.parser.add_argument(
182 'file', help=('JSON file containing the %s to create.'
183 % resource.get_plural_display_name().lower()))
184
185 @add_auth_token_to_kwargs_from_cli
186 def run(self, args, **kwargs):
187 file_path = os.path.normpath(pjoin(os.getcwd(), args.file))
188
189 if not os.path.exists(args.file):
190 raise ValueError('File "%s" doesn\'t exist' % (file_path))
191
192 if not os.path.isfile(args.file):
193 raise ValueError('"%s" is not a file' % (file_path))
194
195 with open(file_path, 'r') as f:
196 kvps = json.loads(f.read())
197
198 instances = []
199 for item in kvps:
200 name = item['name']
201 value = item['value']
202
203 instance = KeyValuePair()
204 instance.id = name # TODO: refactor and get rid of id
205 instance.name = name
206 instance.value = value
207
208 self.manager.update(instance, **kwargs)
209 instances.append(instance)
210 return instances
211
212 def run_and_print(self, args, **kwargs):
213 instances = self.run(args, **kwargs)
214 self.print_output(instances, table.MultiColumnTable,
215 attributes=['id', 'name', 'value'], json=args.json)
216
[end of st2client/st2client/commands/keyvalue.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/st2client/st2client/commands/keyvalue.py b/st2client/st2client/commands/keyvalue.py
--- a/st2client/st2client/commands/keyvalue.py
+++ b/st2client/st2client/commands/keyvalue.py
@@ -82,11 +82,11 @@
class KeyValuePairGetCommand(resource.ResourceGetCommand):
pk_argument_name = 'name'
- display_attributes = ['name', 'value']
+ display_attributes = ['name', 'value', 'expire_timestamp']
class KeyValuePairSetCommand(resource.ResourceCommand):
- display_attributes = ['name', 'value']
+ display_attributes = ['name', 'value', 'expire_timestamp']
def __init__(self, resource, *args, **kwargs):
super(KeyValuePairSetCommand, self).__init__(
@@ -99,6 +99,8 @@
metavar='name',
help='Name of the key value pair.')
self.parser.add_argument('value', help='Value paired with the key.')
+ self.parser.add_argument('-l', '--ttl', dest='ttl', type=int, default=None,
+ help='TTL (in seconds) for this value.')
@add_auth_token_to_kwargs_from_cli
def run(self, args, **kwargs):
@@ -106,6 +108,10 @@
instance.id = args.name # TODO: refactor and get rid of id
instance.name = args.name
instance.value = args.value
+
+ if args.ttl:
+ instance.ttl = args.ttl
+
return self.manager.update(instance, **kwargs)
def run_and_print(self, args, **kwargs):
|
{"golden_diff": "diff --git a/st2client/st2client/commands/keyvalue.py b/st2client/st2client/commands/keyvalue.py\n--- a/st2client/st2client/commands/keyvalue.py\n+++ b/st2client/st2client/commands/keyvalue.py\n@@ -82,11 +82,11 @@\n \n class KeyValuePairGetCommand(resource.ResourceGetCommand):\n pk_argument_name = 'name'\n- display_attributes = ['name', 'value']\n+ display_attributes = ['name', 'value', 'expire_timestamp']\n \n \n class KeyValuePairSetCommand(resource.ResourceCommand):\n- display_attributes = ['name', 'value']\n+ display_attributes = ['name', 'value', 'expire_timestamp']\n \n def __init__(self, resource, *args, **kwargs):\n super(KeyValuePairSetCommand, self).__init__(\n@@ -99,6 +99,8 @@\n metavar='name',\n help='Name of the key value pair.')\n self.parser.add_argument('value', help='Value paired with the key.')\n+ self.parser.add_argument('-l', '--ttl', dest='ttl', type=int, default=None,\n+ help='TTL (in seconds) for this value.')\n \n @add_auth_token_to_kwargs_from_cli\n def run(self, args, **kwargs):\n@@ -106,6 +108,10 @@\n instance.id = args.name # TODO: refactor and get rid of id\n instance.name = args.name\n instance.value = args.value\n+\n+ if args.ttl:\n+ instance.ttl = args.ttl\n+\n return self.manager.update(instance, **kwargs)\n \n def run_and_print(self, args, **kwargs):\n", "issue": "st2 key set in CLI doesn't allow one to set a TTL. \nReported by: psychopenguin on slack\n\n", "before_files": [{"content": "# Licensed to the StackStorm, Inc ('StackStorm') under one or more\n# contributor license agreements. See the NOTICE file distributed with\n# this work for additional information regarding copyright ownership.\n# The ASF licenses this file to You under the Apache License, Version 2.0\n# (the \"License\"); you may not use this file except in compliance with\n# the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport json\nimport logging\nfrom os.path import join as pjoin\n\nfrom st2client.commands import resource\nfrom st2client.commands.noop import NoopCommand\nfrom st2client.commands.resource import add_auth_token_to_kwargs_from_cli\nfrom st2client.formatters import table\nfrom st2client.models.keyvalue import KeyValuePair\nfrom st2client.utils.date import format_isodate\n\nLOG = logging.getLogger(__name__)\n\n\nclass KeyValuePairBranch(resource.ResourceBranch):\n\n def __init__(self, description, app, subparsers, parent_parser=None):\n super(KeyValuePairBranch, self).__init__(\n KeyValuePair, description, app, subparsers,\n parent_parser=parent_parser,\n commands={\n 'list': KeyValuePairListCommand,\n 'get': KeyValuePairGetCommand,\n 'delete': KeyValuePairDeleteCommand,\n 'create': NoopCommand,\n 'update': NoopCommand\n })\n\n # Registers extended commands\n self.commands['set'] = KeyValuePairSetCommand(self.resource, self.app,\n self.subparsers)\n self.commands['load'] = KeyValuePairLoadCommand(\n self.resource, self.app, self.subparsers)\n self.commands['delete_by_prefix'] = KeyValuePairDeleteByPrefixCommand(\n self.resource, self.app, self.subparsers)\n\n # Remove unsupported commands\n # TODO: Refactor parent class and make it nicer\n del self.commands['create']\n del self.commands['update']\n\n\nclass KeyValuePairListCommand(resource.ResourceListCommand):\n display_attributes = ['name', 'value', 'expire_timestamp']\n attribute_transform_functions = {\n 'expire_timestamp': format_isodate,\n }\n\n def __init__(self, *args, **kwargs):\n super(KeyValuePairListCommand, self).__init__(*args, **kwargs)\n\n # Filter options\n self.parser.add_argument('--prefix', help=('Only return values which name starts with the '\n ' provided prefix.'))\n\n def run_and_print(self, args, **kwargs):\n if args.prefix:\n kwargs['prefix'] = args.prefix\n\n instances = self.run(args, **kwargs)\n self.print_output(reversed(instances), table.MultiColumnTable,\n attributes=args.attr, widths=args.width,\n json=args.json,\n attribute_transform_functions=self.attribute_transform_functions)\n\n\nclass KeyValuePairGetCommand(resource.ResourceGetCommand):\n pk_argument_name = 'name'\n display_attributes = ['name', 'value']\n\n\nclass KeyValuePairSetCommand(resource.ResourceCommand):\n display_attributes = ['name', 'value']\n\n def __init__(self, resource, *args, **kwargs):\n super(KeyValuePairSetCommand, self).__init__(\n resource, 'set',\n 'Set an existing %s.' % resource.get_display_name().lower(),\n *args, **kwargs\n )\n\n self.parser.add_argument('name',\n metavar='name',\n help='Name of the key value pair.')\n self.parser.add_argument('value', help='Value paired with the key.')\n\n @add_auth_token_to_kwargs_from_cli\n def run(self, args, **kwargs):\n instance = KeyValuePair()\n instance.id = args.name # TODO: refactor and get rid of id\n instance.name = args.name\n instance.value = args.value\n return self.manager.update(instance, **kwargs)\n\n def run_and_print(self, args, **kwargs):\n instance = self.run(args, **kwargs)\n self.print_output(instance, table.PropertyValueTable,\n attributes=self.display_attributes, json=args.json)\n\n\nclass KeyValuePairDeleteCommand(resource.ResourceDeleteCommand):\n pk_argument_name = 'name'\n\n @add_auth_token_to_kwargs_from_cli\n def run(self, args, **kwargs):\n resource_id = getattr(args, self.pk_argument_name, None)\n instance = self.get_resource(resource_id, **kwargs)\n\n if not instance:\n raise resource.ResourceNotFoundError('KeyValuePair with id \"%s\" not found', resource_id)\n\n instance.id = resource_id # TODO: refactor and get rid of id\n self.manager.delete(instance, **kwargs)\n\n\nclass KeyValuePairDeleteByPrefixCommand(resource.ResourceCommand):\n \"\"\"\n Commands which delete all the key value pairs which match the provided\n prefix.\n \"\"\"\n def __init__(self, resource, *args, **kwargs):\n super(KeyValuePairDeleteByPrefixCommand, self).__init__(resource, 'delete_by_prefix',\n 'Delete KeyValue pairs which match the provided prefix', *args, **kwargs)\n\n self.parser.add_argument('-p', '--prefix', required=True,\n help='Name prefix (e.g. twitter.TwitterSensor:)')\n\n @add_auth_token_to_kwargs_from_cli\n def run(self, args, **kwargs):\n prefix = args.prefix\n key_pairs = self.manager.get_all(prefix=prefix)\n\n to_delete = []\n for key_pair in key_pairs:\n key_pair.id = key_pair.name\n to_delete.append(key_pair)\n\n deleted = []\n for key_pair in to_delete:\n self.manager.delete(instance=key_pair, **kwargs)\n deleted.append(key_pair)\n\n return deleted\n\n def run_and_print(self, args, **kwargs):\n # TODO: Need to use args, instead of kwargs (args=) because of bad API\n # FIX ME\n deleted = self.run(args, **kwargs)\n key_ids = [key_pair.id for key_pair in deleted]\n\n print('Deleted %s keys' % (len(deleted)))\n print('Deleted key ids: %s' % (', '.join(key_ids)))\n\n\nclass KeyValuePairLoadCommand(resource.ResourceCommand):\n pk_argument_name = 'name'\n display_attributes = ['name', 'value']\n\n def __init__(self, resource, *args, **kwargs):\n help_text = ('Load a list of %s from file.' %\n resource.get_plural_display_name().lower())\n super(KeyValuePairLoadCommand, self).__init__(resource, 'load',\n help_text, *args, **kwargs)\n\n self.parser.add_argument(\n 'file', help=('JSON file containing the %s to create.'\n % resource.get_plural_display_name().lower()))\n\n @add_auth_token_to_kwargs_from_cli\n def run(self, args, **kwargs):\n file_path = os.path.normpath(pjoin(os.getcwd(), args.file))\n\n if not os.path.exists(args.file):\n raise ValueError('File \"%s\" doesn\\'t exist' % (file_path))\n\n if not os.path.isfile(args.file):\n raise ValueError('\"%s\" is not a file' % (file_path))\n\n with open(file_path, 'r') as f:\n kvps = json.loads(f.read())\n\n instances = []\n for item in kvps:\n name = item['name']\n value = item['value']\n\n instance = KeyValuePair()\n instance.id = name # TODO: refactor and get rid of id\n instance.name = name\n instance.value = value\n\n self.manager.update(instance, **kwargs)\n instances.append(instance)\n return instances\n\n def run_and_print(self, args, **kwargs):\n instances = self.run(args, **kwargs)\n self.print_output(instances, table.MultiColumnTable,\n attributes=['id', 'name', 'value'], json=args.json)\n", "path": "st2client/st2client/commands/keyvalue.py"}]}
| 2,821 | 364 |
gh_patches_debug_26743
|
rasdani/github-patches
|
git_diff
|
sktime__sktime-533
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] plot_series inconsistent date/time index
**Describe the bug**
<!--
A clear and concise description of what the bug is.
-->
**To Reproduce**
```python
y = load_airline()
y = y[:48]
fh=np.arange(1, 13)
y_train, y_test = temporal_train_test_split(y, test_size=len(fh))
plot_series(y_train, y_test, labels=["y_train", "y_test"]);
print(y.shape, y_train.shape[0], y_test.shape[0])
print(y.index)
```
> (48,) 36 12
> PeriodIndex(['1949-01', '1949-02', '1949-03', '1949-04', '1949-05', '1949-06',
> '1949-07', '1949-08', '1949-09', '1949-10', '1949-11', '1949-12',
> '1950-01', '1950-02', '1950-03', '1950-04', '1950-05', '1950-06',
> '1950-07', '1950-08', '1950-09', '1950-10', '1950-11', '1950-12',
> '1951-01', '1951-02', '1951-03', '1951-04', '1951-05', '1951-06',
> '1951-07', '1951-08', '1951-09', '1951-10', '1951-11', '1951-12',
> '1952-01', '1952-02', '1952-03', '1952-04', '1952-05', '1952-06',
> '1952-07', '1952-08', '1952-09', '1952-10', '1952-11', '1952-12'],
> dtype='period[M]', name='Period', freq='M')
>
**Expected behavior**
The X-axis should go till end of 1952. The X-axis on the plot does not reflect the indices correctly. It should go till 1952, but shows values only till 1949
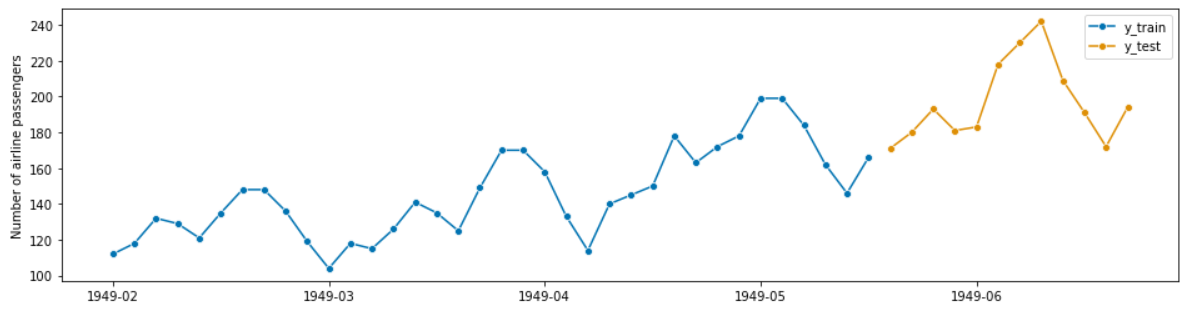
**Versions**
System:
python: 3.6.12 |Anaconda, Inc.| (default, Sep 9 2020, 00:29:25) [MSC v.1916 64 bit (AMD64)]
executable: C:\Users\xxxx\AppData\Local\Continuum\anaconda3\envs\sktime\python.exe
machine: Windows-10-10.0.18362-SP0
Python dependencies:
pip: 20.3
setuptools: 49.6.0
sklearn: 0.23.2
numpy: 1.19.2
scipy: 1.5.2
Cython: 0.29.17
pandas: 1.1.3
matplotlib: 3.3.2
joblib: 0.17.0
numba: None
pmdarima: 1.7.1
tsfresh: None
</issue>
<code>
[start of sktime/utils/plotting/__init__.py]
1 #!/usr/bin/env python3 -u
2 # -*- coding: utf-8 -*-
3 # copyright: sktime developers, BSD-3-Clause License (see LICENSE file)
4
5 __all__ = ["plot_series"]
6 __author__ = ["Markus Löning"]
7
8 import warnings
9
10 import numpy as np
11
12 from sktime.utils.check_imports import _check_soft_dependencies
13 from sktime.utils.validation.forecasting import check_y
14
15
16 def plot_series(*series, labels=None):
17 """Plot one or more time series
18
19 Parameters
20 ----------
21 series : pd.Series
22 One or more time series
23 labels : list, optional (default=None)
24 Names of series, will be displayed in figure legend
25
26 Returns
27 -------
28 fig : plt.Figure
29 ax : plt.Axis
30 """
31 _check_soft_dependencies("matplotlib", "seaborn")
32 import matplotlib.pyplot as plt
33 import seaborn as sns
34
35 n_series = len(series)
36 if labels is not None:
37 if n_series != len(labels):
38 raise ValueError(
39 "There must be one label for each time series, "
40 "but found inconsistent numbers of series and "
41 "labels."
42 )
43 legend = True
44 else:
45 labels = ["" for _ in range(n_series)]
46 legend = False
47
48 for y in series:
49 check_y(y)
50
51 # create combined index
52 index = series[0].index
53 for y in series[1:]:
54 # check types, note that isinstance() does not work here because index
55 # types inherit from each other, hence we check for type equality
56 if not type(index) is type(y.index): # noqa
57 raise TypeError("Found series with different index types.")
58 index = index.union(y.index)
59
60 # generate integer x-values
61 xs = [np.argwhere(index.isin(y.index)).ravel() for y in series]
62
63 # create figure
64 fig, ax = plt.subplots(1, figsize=plt.figaspect(0.25))
65 colors = sns.color_palette("colorblind", n_colors=n_series)
66
67 # plot series
68 for x, y, color, label in zip(xs, series, colors, labels):
69
70 # scatter if little data is available or index is not complete
71 if len(x) <= 3 or not np.array_equal(np.arange(x[0], x[-1] + 1), x):
72 plot_func = sns.scatterplot
73 else:
74 plot_func = sns.lineplot
75
76 plot_func(x=x, y=y, ax=ax, marker="o", label=label, color=color)
77
78 # set combined index as xticklabels, suppress matplotlib warning
79 with warnings.catch_warnings():
80 warnings.filterwarnings("ignore")
81 ax.set(xticklabels=index)
82
83 if legend:
84 ax.legend()
85
86 return fig, ax
87
[end of sktime/utils/plotting/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sktime/utils/plotting/__init__.py b/sktime/utils/plotting/__init__.py
--- a/sktime/utils/plotting/__init__.py
+++ b/sktime/utils/plotting/__init__.py
@@ -5,8 +5,6 @@
__all__ = ["plot_series"]
__author__ = ["Markus Löning"]
-import warnings
-
import numpy as np
from sktime.utils.check_imports import _check_soft_dependencies
@@ -30,6 +28,8 @@
"""
_check_soft_dependencies("matplotlib", "seaborn")
import matplotlib.pyplot as plt
+ from matplotlib.ticker import FuncFormatter, MaxNLocator
+ from matplotlib.cbook import flatten
import seaborn as sns
n_series = len(series)
@@ -75,10 +75,19 @@
plot_func(x=x, y=y, ax=ax, marker="o", label=label, color=color)
- # set combined index as xticklabels, suppress matplotlib warning
- with warnings.catch_warnings():
- warnings.filterwarnings("ignore")
- ax.set(xticklabels=index)
+ # combine data points for all series
+ xs_flat = list(flatten(xs))
+
+ # set x label of data point to the matching index
+ def format_fn(tick_val, tick_pos):
+ if int(tick_val) in xs_flat:
+ return index[int(tick_val)]
+ else:
+ return ""
+
+ # dynamically set x label ticks and spacing from index labels
+ ax.xaxis.set_major_formatter(FuncFormatter(format_fn))
+ ax.xaxis.set_major_locator(MaxNLocator(integer=True))
if legend:
ax.legend()
|
{"golden_diff": "diff --git a/sktime/utils/plotting/__init__.py b/sktime/utils/plotting/__init__.py\n--- a/sktime/utils/plotting/__init__.py\n+++ b/sktime/utils/plotting/__init__.py\n@@ -5,8 +5,6 @@\n __all__ = [\"plot_series\"]\n __author__ = [\"Markus L\u00f6ning\"]\n \n-import warnings\n-\n import numpy as np\n \n from sktime.utils.check_imports import _check_soft_dependencies\n@@ -30,6 +28,8 @@\n \"\"\"\n _check_soft_dependencies(\"matplotlib\", \"seaborn\")\n import matplotlib.pyplot as plt\n+ from matplotlib.ticker import FuncFormatter, MaxNLocator\n+ from matplotlib.cbook import flatten\n import seaborn as sns\n \n n_series = len(series)\n@@ -75,10 +75,19 @@\n \n plot_func(x=x, y=y, ax=ax, marker=\"o\", label=label, color=color)\n \n- # set combined index as xticklabels, suppress matplotlib warning\n- with warnings.catch_warnings():\n- warnings.filterwarnings(\"ignore\")\n- ax.set(xticklabels=index)\n+ # combine data points for all series\n+ xs_flat = list(flatten(xs))\n+\n+ # set x label of data point to the matching index\n+ def format_fn(tick_val, tick_pos):\n+ if int(tick_val) in xs_flat:\n+ return index[int(tick_val)]\n+ else:\n+ return \"\"\n+\n+ # dynamically set x label ticks and spacing from index labels\n+ ax.xaxis.set_major_formatter(FuncFormatter(format_fn))\n+ ax.xaxis.set_major_locator(MaxNLocator(integer=True))\n \n if legend:\n ax.legend()\n", "issue": "[BUG] plot_series inconsistent date/time index \n**Describe the bug**\r\n<!--\r\nA clear and concise description of what the bug is.\r\n-->\r\n\r\n**To Reproduce**\r\n\r\n```python\r\ny = load_airline()\r\ny = y[:48]\r\nfh=np.arange(1, 13)\r\n\r\ny_train, y_test = temporal_train_test_split(y, test_size=len(fh))\r\nplot_series(y_train, y_test, labels=[\"y_train\", \"y_test\"]);\r\nprint(y.shape, y_train.shape[0], y_test.shape[0])\r\nprint(y.index)\r\n```\r\n\r\n> (48,) 36 12\r\n> PeriodIndex(['1949-01', '1949-02', '1949-03', '1949-04', '1949-05', '1949-06',\r\n> '1949-07', '1949-08', '1949-09', '1949-10', '1949-11', '1949-12',\r\n> '1950-01', '1950-02', '1950-03', '1950-04', '1950-05', '1950-06',\r\n> '1950-07', '1950-08', '1950-09', '1950-10', '1950-11', '1950-12',\r\n> '1951-01', '1951-02', '1951-03', '1951-04', '1951-05', '1951-06',\r\n> '1951-07', '1951-08', '1951-09', '1951-10', '1951-11', '1951-12',\r\n> '1952-01', '1952-02', '1952-03', '1952-04', '1952-05', '1952-06',\r\n> '1952-07', '1952-08', '1952-09', '1952-10', '1952-11', '1952-12'],\r\n> dtype='period[M]', name='Period', freq='M')\r\n> \r\n\r\n**Expected behavior**\r\nThe X-axis should go till end of 1952. The X-axis on the plot does not reflect the indices correctly. It should go till 1952, but shows values only till 1949\r\n\r\n\r\n\r\n**Versions**\r\nSystem:\r\n python: 3.6.12 |Anaconda, Inc.| (default, Sep 9 2020, 00:29:25) [MSC v.1916 64 bit (AMD64)]\r\nexecutable: C:\\Users\\xxxx\\AppData\\Local\\Continuum\\anaconda3\\envs\\sktime\\python.exe\r\n machine: Windows-10-10.0.18362-SP0\r\n\r\nPython dependencies:\r\n pip: 20.3\r\n setuptools: 49.6.0\r\n sklearn: 0.23.2\r\n numpy: 1.19.2\r\n scipy: 1.5.2\r\n Cython: 0.29.17\r\n pandas: 1.1.3\r\n matplotlib: 3.3.2\r\n joblib: 0.17.0\r\n numba: None\r\n pmdarima: 1.7.1\r\n tsfresh: None\r\n\r\n\n", "before_files": [{"content": "#!/usr/bin/env python3 -u\n# -*- coding: utf-8 -*-\n# copyright: sktime developers, BSD-3-Clause License (see LICENSE file)\n\n__all__ = [\"plot_series\"]\n__author__ = [\"Markus L\u00f6ning\"]\n\nimport warnings\n\nimport numpy as np\n\nfrom sktime.utils.check_imports import _check_soft_dependencies\nfrom sktime.utils.validation.forecasting import check_y\n\n\ndef plot_series(*series, labels=None):\n \"\"\"Plot one or more time series\n\n Parameters\n ----------\n series : pd.Series\n One or more time series\n labels : list, optional (default=None)\n Names of series, will be displayed in figure legend\n\n Returns\n -------\n fig : plt.Figure\n ax : plt.Axis\n \"\"\"\n _check_soft_dependencies(\"matplotlib\", \"seaborn\")\n import matplotlib.pyplot as plt\n import seaborn as sns\n\n n_series = len(series)\n if labels is not None:\n if n_series != len(labels):\n raise ValueError(\n \"There must be one label for each time series, \"\n \"but found inconsistent numbers of series and \"\n \"labels.\"\n )\n legend = True\n else:\n labels = [\"\" for _ in range(n_series)]\n legend = False\n\n for y in series:\n check_y(y)\n\n # create combined index\n index = series[0].index\n for y in series[1:]:\n # check types, note that isinstance() does not work here because index\n # types inherit from each other, hence we check for type equality\n if not type(index) is type(y.index): # noqa\n raise TypeError(\"Found series with different index types.\")\n index = index.union(y.index)\n\n # generate integer x-values\n xs = [np.argwhere(index.isin(y.index)).ravel() for y in series]\n\n # create figure\n fig, ax = plt.subplots(1, figsize=plt.figaspect(0.25))\n colors = sns.color_palette(\"colorblind\", n_colors=n_series)\n\n # plot series\n for x, y, color, label in zip(xs, series, colors, labels):\n\n # scatter if little data is available or index is not complete\n if len(x) <= 3 or not np.array_equal(np.arange(x[0], x[-1] + 1), x):\n plot_func = sns.scatterplot\n else:\n plot_func = sns.lineplot\n\n plot_func(x=x, y=y, ax=ax, marker=\"o\", label=label, color=color)\n\n # set combined index as xticklabels, suppress matplotlib warning\n with warnings.catch_warnings():\n warnings.filterwarnings(\"ignore\")\n ax.set(xticklabels=index)\n\n if legend:\n ax.legend()\n\n return fig, ax\n", "path": "sktime/utils/plotting/__init__.py"}]}
| 2,271 | 379 |
gh_patches_debug_47805
|
rasdani/github-patches
|
git_diff
|
pypa__pip-7056
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add a documentation string to pip._internal.network.auth
Follow up to #7045
</issue>
<code>
[start of src/pip/_internal/network/__init__.py]
[end of src/pip/_internal/network/__init__.py]
[start of src/pip/_internal/network/auth.py]
1 import logging
2
3 from pip._vendor.requests.auth import AuthBase, HTTPBasicAuth
4 from pip._vendor.requests.utils import get_netrc_auth
5 from pip._vendor.six.moves.urllib import parse as urllib_parse
6
7 from pip._internal.utils.misc import (
8 ask,
9 ask_input,
10 ask_password,
11 remove_auth_from_url,
12 split_auth_netloc_from_url,
13 )
14 from pip._internal.utils.typing import MYPY_CHECK_RUNNING
15
16 if MYPY_CHECK_RUNNING:
17 from optparse import Values
18 from typing import Dict, Optional, Tuple
19
20 from pip._internal.vcs.versioncontrol import AuthInfo
21
22 Credentials = Tuple[str, str, str]
23
24 logger = logging.getLogger(__name__)
25
26 try:
27 import keyring # noqa
28 except ImportError:
29 keyring = None
30 except Exception as exc:
31 logger.warning(
32 "Keyring is skipped due to an exception: %s", str(exc),
33 )
34 keyring = None
35
36
37 def get_keyring_auth(url, username):
38 """Return the tuple auth for a given url from keyring."""
39 if not url or not keyring:
40 return None
41
42 try:
43 try:
44 get_credential = keyring.get_credential
45 except AttributeError:
46 pass
47 else:
48 logger.debug("Getting credentials from keyring for %s", url)
49 cred = get_credential(url, username)
50 if cred is not None:
51 return cred.username, cred.password
52 return None
53
54 if username:
55 logger.debug("Getting password from keyring for %s", url)
56 password = keyring.get_password(url, username)
57 if password:
58 return username, password
59
60 except Exception as exc:
61 logger.warning(
62 "Keyring is skipped due to an exception: %s", str(exc),
63 )
64
65
66 class MultiDomainBasicAuth(AuthBase):
67
68 def __init__(self, prompting=True, index_urls=None):
69 # type: (bool, Optional[Values]) -> None
70 self.prompting = prompting
71 self.index_urls = index_urls
72 self.passwords = {} # type: Dict[str, AuthInfo]
73 # When the user is prompted to enter credentials and keyring is
74 # available, we will offer to save them. If the user accepts,
75 # this value is set to the credentials they entered. After the
76 # request authenticates, the caller should call
77 # ``save_credentials`` to save these.
78 self._credentials_to_save = None # type: Optional[Credentials]
79
80 def _get_index_url(self, url):
81 """Return the original index URL matching the requested URL.
82
83 Cached or dynamically generated credentials may work against
84 the original index URL rather than just the netloc.
85
86 The provided url should have had its username and password
87 removed already. If the original index url had credentials then
88 they will be included in the return value.
89
90 Returns None if no matching index was found, or if --no-index
91 was specified by the user.
92 """
93 if not url or not self.index_urls:
94 return None
95
96 for u in self.index_urls:
97 prefix = remove_auth_from_url(u).rstrip("/") + "/"
98 if url.startswith(prefix):
99 return u
100
101 def _get_new_credentials(self, original_url, allow_netrc=True,
102 allow_keyring=True):
103 """Find and return credentials for the specified URL."""
104 # Split the credentials and netloc from the url.
105 url, netloc, url_user_password = split_auth_netloc_from_url(
106 original_url,
107 )
108
109 # Start with the credentials embedded in the url
110 username, password = url_user_password
111 if username is not None and password is not None:
112 logger.debug("Found credentials in url for %s", netloc)
113 return url_user_password
114
115 # Find a matching index url for this request
116 index_url = self._get_index_url(url)
117 if index_url:
118 # Split the credentials from the url.
119 index_info = split_auth_netloc_from_url(index_url)
120 if index_info:
121 index_url, _, index_url_user_password = index_info
122 logger.debug("Found index url %s", index_url)
123
124 # If an index URL was found, try its embedded credentials
125 if index_url and index_url_user_password[0] is not None:
126 username, password = index_url_user_password
127 if username is not None and password is not None:
128 logger.debug("Found credentials in index url for %s", netloc)
129 return index_url_user_password
130
131 # Get creds from netrc if we still don't have them
132 if allow_netrc:
133 netrc_auth = get_netrc_auth(original_url)
134 if netrc_auth:
135 logger.debug("Found credentials in netrc for %s", netloc)
136 return netrc_auth
137
138 # If we don't have a password and keyring is available, use it.
139 if allow_keyring:
140 # The index url is more specific than the netloc, so try it first
141 kr_auth = (
142 get_keyring_auth(index_url, username) or
143 get_keyring_auth(netloc, username)
144 )
145 if kr_auth:
146 logger.debug("Found credentials in keyring for %s", netloc)
147 return kr_auth
148
149 return username, password
150
151 def _get_url_and_credentials(self, original_url):
152 """Return the credentials to use for the provided URL.
153
154 If allowed, netrc and keyring may be used to obtain the
155 correct credentials.
156
157 Returns (url_without_credentials, username, password). Note
158 that even if the original URL contains credentials, this
159 function may return a different username and password.
160 """
161 url, netloc, _ = split_auth_netloc_from_url(original_url)
162
163 # Use any stored credentials that we have for this netloc
164 username, password = self.passwords.get(netloc, (None, None))
165
166 if username is None and password is None:
167 # No stored credentials. Acquire new credentials without prompting
168 # the user. (e.g. from netrc, keyring, or the URL itself)
169 username, password = self._get_new_credentials(original_url)
170
171 if username is not None or password is not None:
172 # Convert the username and password if they're None, so that
173 # this netloc will show up as "cached" in the conditional above.
174 # Further, HTTPBasicAuth doesn't accept None, so it makes sense to
175 # cache the value that is going to be used.
176 username = username or ""
177 password = password or ""
178
179 # Store any acquired credentials.
180 self.passwords[netloc] = (username, password)
181
182 assert (
183 # Credentials were found
184 (username is not None and password is not None) or
185 # Credentials were not found
186 (username is None and password is None)
187 ), "Could not load credentials from url: {}".format(original_url)
188
189 return url, username, password
190
191 def __call__(self, req):
192 # Get credentials for this request
193 url, username, password = self._get_url_and_credentials(req.url)
194
195 # Set the url of the request to the url without any credentials
196 req.url = url
197
198 if username is not None and password is not None:
199 # Send the basic auth with this request
200 req = HTTPBasicAuth(username, password)(req)
201
202 # Attach a hook to handle 401 responses
203 req.register_hook("response", self.handle_401)
204
205 return req
206
207 # Factored out to allow for easy patching in tests
208 def _prompt_for_password(self, netloc):
209 username = ask_input("User for %s: " % netloc)
210 if not username:
211 return None, None
212 auth = get_keyring_auth(netloc, username)
213 if auth:
214 return auth[0], auth[1], False
215 password = ask_password("Password: ")
216 return username, password, True
217
218 # Factored out to allow for easy patching in tests
219 def _should_save_password_to_keyring(self):
220 if not keyring:
221 return False
222 return ask("Save credentials to keyring [y/N]: ", ["y", "n"]) == "y"
223
224 def handle_401(self, resp, **kwargs):
225 # We only care about 401 responses, anything else we want to just
226 # pass through the actual response
227 if resp.status_code != 401:
228 return resp
229
230 # We are not able to prompt the user so simply return the response
231 if not self.prompting:
232 return resp
233
234 parsed = urllib_parse.urlparse(resp.url)
235
236 # Prompt the user for a new username and password
237 username, password, save = self._prompt_for_password(parsed.netloc)
238
239 # Store the new username and password to use for future requests
240 self._credentials_to_save = None
241 if username is not None and password is not None:
242 self.passwords[parsed.netloc] = (username, password)
243
244 # Prompt to save the password to keyring
245 if save and self._should_save_password_to_keyring():
246 self._credentials_to_save = (parsed.netloc, username, password)
247
248 # Consume content and release the original connection to allow our new
249 # request to reuse the same one.
250 resp.content
251 resp.raw.release_conn()
252
253 # Add our new username and password to the request
254 req = HTTPBasicAuth(username or "", password or "")(resp.request)
255 req.register_hook("response", self.warn_on_401)
256
257 # On successful request, save the credentials that were used to
258 # keyring. (Note that if the user responded "no" above, this member
259 # is not set and nothing will be saved.)
260 if self._credentials_to_save:
261 req.register_hook("response", self.save_credentials)
262
263 # Send our new request
264 new_resp = resp.connection.send(req, **kwargs)
265 new_resp.history.append(resp)
266
267 return new_resp
268
269 def warn_on_401(self, resp, **kwargs):
270 """Response callback to warn about incorrect credentials."""
271 if resp.status_code == 401:
272 logger.warning(
273 '401 Error, Credentials not correct for %s', resp.request.url,
274 )
275
276 def save_credentials(self, resp, **kwargs):
277 """Response callback to save credentials on success."""
278 assert keyring is not None, "should never reach here without keyring"
279 if not keyring:
280 return
281
282 creds = self._credentials_to_save
283 self._credentials_to_save = None
284 if creds and resp.status_code < 400:
285 try:
286 logger.info('Saving credentials to keyring')
287 keyring.set_password(*creds)
288 except Exception:
289 logger.exception('Failed to save credentials')
290
[end of src/pip/_internal/network/auth.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/pip/_internal/network/__init__.py b/src/pip/_internal/network/__init__.py
--- a/src/pip/_internal/network/__init__.py
+++ b/src/pip/_internal/network/__init__.py
@@ -0,0 +1,2 @@
+"""Contains purely network-related utilities.
+"""
diff --git a/src/pip/_internal/network/auth.py b/src/pip/_internal/network/auth.py
--- a/src/pip/_internal/network/auth.py
+++ b/src/pip/_internal/network/auth.py
@@ -1,3 +1,9 @@
+"""Network Authentication Helpers
+
+Contains interface (MultiDomainBasicAuth) and associated glue code for
+providing credentials in the context of network requests.
+"""
+
import logging
from pip._vendor.requests.auth import AuthBase, HTTPBasicAuth
|
{"golden_diff": "diff --git a/src/pip/_internal/network/__init__.py b/src/pip/_internal/network/__init__.py\n--- a/src/pip/_internal/network/__init__.py\n+++ b/src/pip/_internal/network/__init__.py\n@@ -0,0 +1,2 @@\n+\"\"\"Contains purely network-related utilities.\n+\"\"\"\ndiff --git a/src/pip/_internal/network/auth.py b/src/pip/_internal/network/auth.py\n--- a/src/pip/_internal/network/auth.py\n+++ b/src/pip/_internal/network/auth.py\n@@ -1,3 +1,9 @@\n+\"\"\"Network Authentication Helpers\n+\n+Contains interface (MultiDomainBasicAuth) and associated glue code for\n+providing credentials in the context of network requests.\n+\"\"\"\n+\n import logging\n \n from pip._vendor.requests.auth import AuthBase, HTTPBasicAuth\n", "issue": "Add a documentation string to pip._internal.network.auth\nFollow up to #7045\n", "before_files": [{"content": "", "path": "src/pip/_internal/network/__init__.py"}, {"content": "import logging\n\nfrom pip._vendor.requests.auth import AuthBase, HTTPBasicAuth\nfrom pip._vendor.requests.utils import get_netrc_auth\nfrom pip._vendor.six.moves.urllib import parse as urllib_parse\n\nfrom pip._internal.utils.misc import (\n ask,\n ask_input,\n ask_password,\n remove_auth_from_url,\n split_auth_netloc_from_url,\n)\nfrom pip._internal.utils.typing import MYPY_CHECK_RUNNING\n\nif MYPY_CHECK_RUNNING:\n from optparse import Values\n from typing import Dict, Optional, Tuple\n\n from pip._internal.vcs.versioncontrol import AuthInfo\n\n Credentials = Tuple[str, str, str]\n\nlogger = logging.getLogger(__name__)\n\ntry:\n import keyring # noqa\nexcept ImportError:\n keyring = None\nexcept Exception as exc:\n logger.warning(\n \"Keyring is skipped due to an exception: %s\", str(exc),\n )\n keyring = None\n\n\ndef get_keyring_auth(url, username):\n \"\"\"Return the tuple auth for a given url from keyring.\"\"\"\n if not url or not keyring:\n return None\n\n try:\n try:\n get_credential = keyring.get_credential\n except AttributeError:\n pass\n else:\n logger.debug(\"Getting credentials from keyring for %s\", url)\n cred = get_credential(url, username)\n if cred is not None:\n return cred.username, cred.password\n return None\n\n if username:\n logger.debug(\"Getting password from keyring for %s\", url)\n password = keyring.get_password(url, username)\n if password:\n return username, password\n\n except Exception as exc:\n logger.warning(\n \"Keyring is skipped due to an exception: %s\", str(exc),\n )\n\n\nclass MultiDomainBasicAuth(AuthBase):\n\n def __init__(self, prompting=True, index_urls=None):\n # type: (bool, Optional[Values]) -> None\n self.prompting = prompting\n self.index_urls = index_urls\n self.passwords = {} # type: Dict[str, AuthInfo]\n # When the user is prompted to enter credentials and keyring is\n # available, we will offer to save them. If the user accepts,\n # this value is set to the credentials they entered. After the\n # request authenticates, the caller should call\n # ``save_credentials`` to save these.\n self._credentials_to_save = None # type: Optional[Credentials]\n\n def _get_index_url(self, url):\n \"\"\"Return the original index URL matching the requested URL.\n\n Cached or dynamically generated credentials may work against\n the original index URL rather than just the netloc.\n\n The provided url should have had its username and password\n removed already. If the original index url had credentials then\n they will be included in the return value.\n\n Returns None if no matching index was found, or if --no-index\n was specified by the user.\n \"\"\"\n if not url or not self.index_urls:\n return None\n\n for u in self.index_urls:\n prefix = remove_auth_from_url(u).rstrip(\"/\") + \"/\"\n if url.startswith(prefix):\n return u\n\n def _get_new_credentials(self, original_url, allow_netrc=True,\n allow_keyring=True):\n \"\"\"Find and return credentials for the specified URL.\"\"\"\n # Split the credentials and netloc from the url.\n url, netloc, url_user_password = split_auth_netloc_from_url(\n original_url,\n )\n\n # Start with the credentials embedded in the url\n username, password = url_user_password\n if username is not None and password is not None:\n logger.debug(\"Found credentials in url for %s\", netloc)\n return url_user_password\n\n # Find a matching index url for this request\n index_url = self._get_index_url(url)\n if index_url:\n # Split the credentials from the url.\n index_info = split_auth_netloc_from_url(index_url)\n if index_info:\n index_url, _, index_url_user_password = index_info\n logger.debug(\"Found index url %s\", index_url)\n\n # If an index URL was found, try its embedded credentials\n if index_url and index_url_user_password[0] is not None:\n username, password = index_url_user_password\n if username is not None and password is not None:\n logger.debug(\"Found credentials in index url for %s\", netloc)\n return index_url_user_password\n\n # Get creds from netrc if we still don't have them\n if allow_netrc:\n netrc_auth = get_netrc_auth(original_url)\n if netrc_auth:\n logger.debug(\"Found credentials in netrc for %s\", netloc)\n return netrc_auth\n\n # If we don't have a password and keyring is available, use it.\n if allow_keyring:\n # The index url is more specific than the netloc, so try it first\n kr_auth = (\n get_keyring_auth(index_url, username) or\n get_keyring_auth(netloc, username)\n )\n if kr_auth:\n logger.debug(\"Found credentials in keyring for %s\", netloc)\n return kr_auth\n\n return username, password\n\n def _get_url_and_credentials(self, original_url):\n \"\"\"Return the credentials to use for the provided URL.\n\n If allowed, netrc and keyring may be used to obtain the\n correct credentials.\n\n Returns (url_without_credentials, username, password). Note\n that even if the original URL contains credentials, this\n function may return a different username and password.\n \"\"\"\n url, netloc, _ = split_auth_netloc_from_url(original_url)\n\n # Use any stored credentials that we have for this netloc\n username, password = self.passwords.get(netloc, (None, None))\n\n if username is None and password is None:\n # No stored credentials. Acquire new credentials without prompting\n # the user. (e.g. from netrc, keyring, or the URL itself)\n username, password = self._get_new_credentials(original_url)\n\n if username is not None or password is not None:\n # Convert the username and password if they're None, so that\n # this netloc will show up as \"cached\" in the conditional above.\n # Further, HTTPBasicAuth doesn't accept None, so it makes sense to\n # cache the value that is going to be used.\n username = username or \"\"\n password = password or \"\"\n\n # Store any acquired credentials.\n self.passwords[netloc] = (username, password)\n\n assert (\n # Credentials were found\n (username is not None and password is not None) or\n # Credentials were not found\n (username is None and password is None)\n ), \"Could not load credentials from url: {}\".format(original_url)\n\n return url, username, password\n\n def __call__(self, req):\n # Get credentials for this request\n url, username, password = self._get_url_and_credentials(req.url)\n\n # Set the url of the request to the url without any credentials\n req.url = url\n\n if username is not None and password is not None:\n # Send the basic auth with this request\n req = HTTPBasicAuth(username, password)(req)\n\n # Attach a hook to handle 401 responses\n req.register_hook(\"response\", self.handle_401)\n\n return req\n\n # Factored out to allow for easy patching in tests\n def _prompt_for_password(self, netloc):\n username = ask_input(\"User for %s: \" % netloc)\n if not username:\n return None, None\n auth = get_keyring_auth(netloc, username)\n if auth:\n return auth[0], auth[1], False\n password = ask_password(\"Password: \")\n return username, password, True\n\n # Factored out to allow for easy patching in tests\n def _should_save_password_to_keyring(self):\n if not keyring:\n return False\n return ask(\"Save credentials to keyring [y/N]: \", [\"y\", \"n\"]) == \"y\"\n\n def handle_401(self, resp, **kwargs):\n # We only care about 401 responses, anything else we want to just\n # pass through the actual response\n if resp.status_code != 401:\n return resp\n\n # We are not able to prompt the user so simply return the response\n if not self.prompting:\n return resp\n\n parsed = urllib_parse.urlparse(resp.url)\n\n # Prompt the user for a new username and password\n username, password, save = self._prompt_for_password(parsed.netloc)\n\n # Store the new username and password to use for future requests\n self._credentials_to_save = None\n if username is not None and password is not None:\n self.passwords[parsed.netloc] = (username, password)\n\n # Prompt to save the password to keyring\n if save and self._should_save_password_to_keyring():\n self._credentials_to_save = (parsed.netloc, username, password)\n\n # Consume content and release the original connection to allow our new\n # request to reuse the same one.\n resp.content\n resp.raw.release_conn()\n\n # Add our new username and password to the request\n req = HTTPBasicAuth(username or \"\", password or \"\")(resp.request)\n req.register_hook(\"response\", self.warn_on_401)\n\n # On successful request, save the credentials that were used to\n # keyring. (Note that if the user responded \"no\" above, this member\n # is not set and nothing will be saved.)\n if self._credentials_to_save:\n req.register_hook(\"response\", self.save_credentials)\n\n # Send our new request\n new_resp = resp.connection.send(req, **kwargs)\n new_resp.history.append(resp)\n\n return new_resp\n\n def warn_on_401(self, resp, **kwargs):\n \"\"\"Response callback to warn about incorrect credentials.\"\"\"\n if resp.status_code == 401:\n logger.warning(\n '401 Error, Credentials not correct for %s', resp.request.url,\n )\n\n def save_credentials(self, resp, **kwargs):\n \"\"\"Response callback to save credentials on success.\"\"\"\n assert keyring is not None, \"should never reach here without keyring\"\n if not keyring:\n return\n\n creds = self._credentials_to_save\n self._credentials_to_save = None\n if creds and resp.status_code < 400:\n try:\n logger.info('Saving credentials to keyring')\n keyring.set_password(*creds)\n except Exception:\n logger.exception('Failed to save credentials')\n", "path": "src/pip/_internal/network/auth.py"}]}
| 3,708 | 180 |
gh_patches_debug_18214
|
rasdani/github-patches
|
git_diff
|
python-poetry__poetry-1954
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
command to check lock file
<!-- Checked checkbox should look like this: [x] -->
- [X] I have searched the [issues](https://github.com/sdispater/poetry/issues) of this repo and believe that this is not a duplicate.
## Issue
Would it be possible to add a `poetry check` command (oh, I see you'e used that already, maybe the command could be extended or have a `poetry lock --check`?) that will return zero if the current poetry.lock is both correct w.r.t. the pyproject.toml (ie: packages match) *and* that it matches the output of `poetry lock`.
</issue>
<code>
[start of poetry/console/commands/lock.py]
1 from cleo.helpers import option
2
3 from .installer_command import InstallerCommand
4
5
6 class LockCommand(InstallerCommand):
7
8 name = "lock"
9 description = "Locks the project dependencies."
10
11 options = [
12 option(
13 "no-update", None, "Do not update locked versions, only refresh lock file."
14 ),
15 ]
16
17 help = """
18 The <info>lock</info> command reads the <comment>pyproject.toml</> file from the
19 current directory, processes it, and locks the dependencies in the <comment>poetry.lock</>
20 file.
21
22 <info>poetry lock</info>
23 """
24
25 loggers = ["poetry.repositories.pypi_repository"]
26
27 def handle(self) -> int:
28 self._installer.use_executor(
29 self.poetry.config.get("experimental.new-installer", False)
30 )
31
32 self._installer.lock(update=not self.option("no-update"))
33
34 return self._installer.run()
35
[end of poetry/console/commands/lock.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/poetry/console/commands/lock.py b/poetry/console/commands/lock.py
--- a/poetry/console/commands/lock.py
+++ b/poetry/console/commands/lock.py
@@ -12,6 +12,12 @@
option(
"no-update", None, "Do not update locked versions, only refresh lock file."
),
+ option(
+ "check",
+ None,
+ "Check that the <comment>poetry.lock</> file corresponds to the current version "
+ "of <comment>pyproject.toml</>.",
+ ),
]
help = """
@@ -29,6 +35,13 @@
self.poetry.config.get("experimental.new-installer", False)
)
+ if self.option("check"):
+ return (
+ 0
+ if self.poetry.locker.is_locked() and self.poetry.locker.is_fresh()
+ else 1
+ )
+
self._installer.lock(update=not self.option("no-update"))
return self._installer.run()
|
{"golden_diff": "diff --git a/poetry/console/commands/lock.py b/poetry/console/commands/lock.py\n--- a/poetry/console/commands/lock.py\n+++ b/poetry/console/commands/lock.py\n@@ -12,6 +12,12 @@\n option(\n \"no-update\", None, \"Do not update locked versions, only refresh lock file.\"\n ),\n+ option(\n+ \"check\",\n+ None,\n+ \"Check that the <comment>poetry.lock</> file corresponds to the current version \"\n+ \"of <comment>pyproject.toml</>.\",\n+ ),\n ]\n \n help = \"\"\"\n@@ -29,6 +35,13 @@\n self.poetry.config.get(\"experimental.new-installer\", False)\n )\n \n+ if self.option(\"check\"):\n+ return (\n+ 0\n+ if self.poetry.locker.is_locked() and self.poetry.locker.is_fresh()\n+ else 1\n+ )\n+\n self._installer.lock(update=not self.option(\"no-update\"))\n \n return self._installer.run()\n", "issue": "command to check lock file\n<!-- Checked checkbox should look like this: [x] -->\r\n- [X] I have searched the [issues](https://github.com/sdispater/poetry/issues) of this repo and believe that this is not a duplicate.\r\n\r\n## Issue\r\n\r\nWould it be possible to add a `poetry check` command (oh, I see you'e used that already, maybe the command could be extended or have a `poetry lock --check`?) that will return zero if the current poetry.lock is both correct w.r.t. the pyproject.toml (ie: packages match) *and* that it matches the output of `poetry lock`.\r\n\n", "before_files": [{"content": "from cleo.helpers import option\n\nfrom .installer_command import InstallerCommand\n\n\nclass LockCommand(InstallerCommand):\n\n name = \"lock\"\n description = \"Locks the project dependencies.\"\n\n options = [\n option(\n \"no-update\", None, \"Do not update locked versions, only refresh lock file.\"\n ),\n ]\n\n help = \"\"\"\nThe <info>lock</info> command reads the <comment>pyproject.toml</> file from the\ncurrent directory, processes it, and locks the dependencies in the <comment>poetry.lock</>\nfile.\n\n<info>poetry lock</info>\n\"\"\"\n\n loggers = [\"poetry.repositories.pypi_repository\"]\n\n def handle(self) -> int:\n self._installer.use_executor(\n self.poetry.config.get(\"experimental.new-installer\", False)\n )\n\n self._installer.lock(update=not self.option(\"no-update\"))\n\n return self._installer.run()\n", "path": "poetry/console/commands/lock.py"}]}
| 943 | 243 |
gh_patches_debug_39342
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-5564
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
VS generator not exporting for <Lib> tag in vcxproj
Need to add Conan-handled lib to be referenced in .vcxproj in <Lib> tags. Conan VS-generator is exporting only in <Link> tag.
</issue>
<code>
[start of conans/client/generators/visualstudio.py]
1 import os
2 import re
3
4 from conans.model import Generator
5 from conans.paths import BUILD_INFO_VISUAL_STUDIO
6 from conans.client.tools.files import VALID_LIB_EXTENSIONS
7
8
9 class VisualStudioGenerator(Generator):
10
11 template = '''<?xml version="1.0" encoding="utf-8"?>
12 <Project ToolsVersion="4.0" xmlns="http://schemas.microsoft.com/developer/msbuild/2003">
13 <ImportGroup Label="PropertySheets" />
14 <PropertyGroup Label="UserMacros" />
15 <PropertyGroup Label="Conan-RootDirs">{item_properties}
16 </PropertyGroup>
17 {properties}
18 <ItemGroup />
19 </Project>'''
20
21 properties_template = ''' <PropertyGroup Label="ConanVariables"{condition}>
22 <ConanBinaryDirectories>{bin_dirs};%(ConanBinaryDirectories)</ConanBinaryDirectories>
23 <ConanResourceDirectories>{res_dirs};%(ConanResourceDirectories)$(</ConanResourceDirectories>
24 </PropertyGroup>
25 <PropertyGroup{condition}>
26 <LocalDebuggerEnvironment>PATH=%PATH%;{bin_dirs}</LocalDebuggerEnvironment>
27 <DebuggerFlavor>WindowsLocalDebugger</DebuggerFlavor>
28 </PropertyGroup>
29 <ItemDefinitionGroup{condition}>
30 <ClCompile>
31 <AdditionalIncludeDirectories>{include_dirs}%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>
32 <PreprocessorDefinitions>{definitions}%(PreprocessorDefinitions)</PreprocessorDefinitions>
33 <AdditionalOptions>{compiler_flags} %(AdditionalOptions)</AdditionalOptions>
34 </ClCompile>
35 <Link>
36 <AdditionalLibraryDirectories>{lib_dirs}%(AdditionalLibraryDirectories)</AdditionalLibraryDirectories>
37 <AdditionalDependencies>{libs}%(AdditionalDependencies)</AdditionalDependencies>
38 <AdditionalOptions>{linker_flags} %(AdditionalOptions)</AdditionalOptions>
39 </Link>
40 <Midl>
41 <AdditionalIncludeDirectories>{include_dirs}%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>
42 </Midl>
43 <ResourceCompile>
44 <AdditionalIncludeDirectories>{include_dirs}%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>
45 <PreprocessorDefinitions>{definitions}%(PreprocessorDefinitions)</PreprocessorDefinitions>
46 <AdditionalOptions>{compiler_flags} %(AdditionalOptions)</AdditionalOptions>
47 </ResourceCompile>
48 </ItemDefinitionGroup>'''
49
50 item_template = '''
51 <Conan-{name}-Root>{root_dir}</Conan-{name}-Root>'''
52
53 def _format_items(self):
54 sections = []
55 for dep_name, cpp_info in self._deps_build_info.dependencies:
56 fields = {
57 'root_dir': cpp_info.rootpath,
58 'name': dep_name.replace(".", "-")
59 }
60 section = self.item_template.format(**fields)
61 sections.append(section)
62 return "".join(sections)
63
64 @property
65 def filename(self):
66 return BUILD_INFO_VISUAL_STUDIO
67
68 def _format_properties(self, build_info, condition):
69 def has_valid_ext(lib):
70 ext = os.path.splitext(lib)[1]
71 return ext in VALID_LIB_EXTENSIONS
72
73 fields = {
74 'condition': condition,
75 'bin_dirs': "".join("%s;" % p for p in build_info.bin_paths),
76 'res_dirs': "".join("%s;" % p for p in build_info.res_paths),
77 'include_dirs': "".join("%s;" % p for p in build_info.include_paths),
78 'lib_dirs': "".join("%s;" % p for p in build_info.lib_paths),
79 'libs': "".join(['%s.lib;' % lib if not has_valid_ext(lib)
80 else '%s;' % lib for lib in build_info.libs]),
81 'definitions': "".join("%s;" % d for d in build_info.defines),
82 'compiler_flags': " ".join(build_info.cxxflags + build_info.cflags),
83 'linker_flags': " ".join(build_info.sharedlinkflags),
84 'exe_flags': " ".join(build_info.exelinkflags)
85 }
86 formatted_template = self.properties_template.format(**fields)
87 return formatted_template
88
89 @property
90 def content(self):
91 per_item_props = self._format_items()
92
93 properties = [self._format_properties(self._deps_build_info, condition='')]
94 for config, cpp_info in self._deps_build_info.configs.items():
95 condition = " Condition=\"'$(Configuration)' == '%s'\"" % config
96 properties.append(self._format_properties(cpp_info, condition=condition))
97
98 fields = {
99 'item_properties': per_item_props,
100 'properties': '\n'.join(properties)
101 }
102 formatted_template = self.template.format(**fields)
103
104 userprofile = os.getenv("USERPROFILE")
105 if userprofile:
106 userprofile = userprofile.replace("\\", "\\\\")
107 formatted_template = re.sub(userprofile, "$(USERPROFILE)", formatted_template,
108 flags=re.I)
109 return formatted_template
110
[end of conans/client/generators/visualstudio.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/conans/client/generators/visualstudio.py b/conans/client/generators/visualstudio.py
--- a/conans/client/generators/visualstudio.py
+++ b/conans/client/generators/visualstudio.py
@@ -19,8 +19,12 @@
</Project>'''
properties_template = ''' <PropertyGroup Label="ConanVariables"{condition}>
- <ConanBinaryDirectories>{bin_dirs};%(ConanBinaryDirectories)</ConanBinaryDirectories>
- <ConanResourceDirectories>{res_dirs};%(ConanResourceDirectories)$(</ConanResourceDirectories>
+ <ConanCompilerFlags>{compiler_flags}</ConanCompilerFlags>
+ <ConanPreprocessorDefinitions>{definitions}</ConanPreprocessorDefinitions>
+ <ConanIncludeDirectories>{include_dirs}</ConanIncludeDirectories>
+ <ConanResourceDirectories>{res_dirs}</ConanResourceDirectories>
+ <ConanLibraryDirectories>{lib_dirs}</ConanLibraryDirectories>
+ <ConanBinaryDirectories>{bin_dirs}</ConanBinaryDirectories>
</PropertyGroup>
<PropertyGroup{condition}>
<LocalDebuggerEnvironment>PATH=%PATH%;{bin_dirs}</LocalDebuggerEnvironment>
@@ -28,22 +32,26 @@
</PropertyGroup>
<ItemDefinitionGroup{condition}>
<ClCompile>
- <AdditionalIncludeDirectories>{include_dirs}%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>
- <PreprocessorDefinitions>{definitions}%(PreprocessorDefinitions)</PreprocessorDefinitions>
- <AdditionalOptions>{compiler_flags} %(AdditionalOptions)</AdditionalOptions>
+ <AdditionalIncludeDirectories>$(ConanIncludeDirectories)%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>
+ <PreprocessorDefinitions>$(ConanPreprocessorDefinitions)%(PreprocessorDefinitions)</PreprocessorDefinitions>
+ <AdditionalOptions>$(ConanCompilerFlags) %(AdditionalOptions)</AdditionalOptions>
</ClCompile>
<Link>
- <AdditionalLibraryDirectories>{lib_dirs}%(AdditionalLibraryDirectories)</AdditionalLibraryDirectories>
+ <AdditionalLibraryDirectories>$(ConanLibraryDirectories)%(AdditionalLibraryDirectories)</AdditionalLibraryDirectories>
<AdditionalDependencies>{libs}%(AdditionalDependencies)</AdditionalDependencies>
<AdditionalOptions>{linker_flags} %(AdditionalOptions)</AdditionalOptions>
</Link>
+ <Lib>
+ <AdditionalLibraryDirectories>$(ConanLibraryDirectories)%(AdditionalLibraryDirectories)</AdditionalLibraryDirectories>
+ <AdditionalDependencies>{libs}%(AdditionalDependencies)</AdditionalDependencies>
+ </Lib>
<Midl>
- <AdditionalIncludeDirectories>{include_dirs}%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>
+ <AdditionalIncludeDirectories>$(ConanIncludeDirectories)%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>
</Midl>
<ResourceCompile>
- <AdditionalIncludeDirectories>{include_dirs}%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>
- <PreprocessorDefinitions>{definitions}%(PreprocessorDefinitions)</PreprocessorDefinitions>
- <AdditionalOptions>{compiler_flags} %(AdditionalOptions)</AdditionalOptions>
+ <AdditionalIncludeDirectories>$(ConanIncludeDirectories)%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>
+ <PreprocessorDefinitions>$(ConanPreprocessorDefinitions)%(PreprocessorDefinitions)</PreprocessorDefinitions>
+ <AdditionalOptions>$(ConanCompilerFlags) %(AdditionalOptions)</AdditionalOptions>
</ResourceCompile>
</ItemDefinitionGroup>'''
|
{"golden_diff": "diff --git a/conans/client/generators/visualstudio.py b/conans/client/generators/visualstudio.py\n--- a/conans/client/generators/visualstudio.py\n+++ b/conans/client/generators/visualstudio.py\n@@ -19,8 +19,12 @@\n </Project>'''\n \n properties_template = ''' <PropertyGroup Label=\"ConanVariables\"{condition}>\n- <ConanBinaryDirectories>{bin_dirs};%(ConanBinaryDirectories)</ConanBinaryDirectories>\n- <ConanResourceDirectories>{res_dirs};%(ConanResourceDirectories)$(</ConanResourceDirectories>\n+ <ConanCompilerFlags>{compiler_flags}</ConanCompilerFlags>\n+ <ConanPreprocessorDefinitions>{definitions}</ConanPreprocessorDefinitions>\n+ <ConanIncludeDirectories>{include_dirs}</ConanIncludeDirectories>\n+ <ConanResourceDirectories>{res_dirs}</ConanResourceDirectories>\n+ <ConanLibraryDirectories>{lib_dirs}</ConanLibraryDirectories>\n+ <ConanBinaryDirectories>{bin_dirs}</ConanBinaryDirectories>\n </PropertyGroup>\n <PropertyGroup{condition}>\n <LocalDebuggerEnvironment>PATH=%PATH%;{bin_dirs}</LocalDebuggerEnvironment>\n@@ -28,22 +32,26 @@\n </PropertyGroup>\n <ItemDefinitionGroup{condition}>\n <ClCompile>\n- <AdditionalIncludeDirectories>{include_dirs}%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>\n- <PreprocessorDefinitions>{definitions}%(PreprocessorDefinitions)</PreprocessorDefinitions>\n- <AdditionalOptions>{compiler_flags} %(AdditionalOptions)</AdditionalOptions>\n+ <AdditionalIncludeDirectories>$(ConanIncludeDirectories)%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>\n+ <PreprocessorDefinitions>$(ConanPreprocessorDefinitions)%(PreprocessorDefinitions)</PreprocessorDefinitions>\n+ <AdditionalOptions>$(ConanCompilerFlags) %(AdditionalOptions)</AdditionalOptions>\n </ClCompile>\n <Link>\n- <AdditionalLibraryDirectories>{lib_dirs}%(AdditionalLibraryDirectories)</AdditionalLibraryDirectories>\n+ <AdditionalLibraryDirectories>$(ConanLibraryDirectories)%(AdditionalLibraryDirectories)</AdditionalLibraryDirectories>\n <AdditionalDependencies>{libs}%(AdditionalDependencies)</AdditionalDependencies>\n <AdditionalOptions>{linker_flags} %(AdditionalOptions)</AdditionalOptions>\n </Link>\n+ <Lib>\n+ <AdditionalLibraryDirectories>$(ConanLibraryDirectories)%(AdditionalLibraryDirectories)</AdditionalLibraryDirectories>\n+ <AdditionalDependencies>{libs}%(AdditionalDependencies)</AdditionalDependencies>\n+ </Lib>\n <Midl>\n- <AdditionalIncludeDirectories>{include_dirs}%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>\n+ <AdditionalIncludeDirectories>$(ConanIncludeDirectories)%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>\n </Midl>\n <ResourceCompile>\n- <AdditionalIncludeDirectories>{include_dirs}%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>\n- <PreprocessorDefinitions>{definitions}%(PreprocessorDefinitions)</PreprocessorDefinitions>\n- <AdditionalOptions>{compiler_flags} %(AdditionalOptions)</AdditionalOptions>\n+ <AdditionalIncludeDirectories>$(ConanIncludeDirectories)%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>\n+ <PreprocessorDefinitions>$(ConanPreprocessorDefinitions)%(PreprocessorDefinitions)</PreprocessorDefinitions>\n+ <AdditionalOptions>$(ConanCompilerFlags) %(AdditionalOptions)</AdditionalOptions>\n </ResourceCompile>\n </ItemDefinitionGroup>'''\n", "issue": "VS generator not exporting for <Lib> tag in vcxproj\nNeed to add Conan-handled lib to be referenced in .vcxproj in <Lib> tags. Conan VS-generator is exporting only in <Link> tag. \r\n\n", "before_files": [{"content": "import os\nimport re\n\nfrom conans.model import Generator\nfrom conans.paths import BUILD_INFO_VISUAL_STUDIO\nfrom conans.client.tools.files import VALID_LIB_EXTENSIONS\n\n\nclass VisualStudioGenerator(Generator):\n\n template = '''<?xml version=\"1.0\" encoding=\"utf-8\"?>\n<Project ToolsVersion=\"4.0\" xmlns=\"http://schemas.microsoft.com/developer/msbuild/2003\">\n <ImportGroup Label=\"PropertySheets\" />\n <PropertyGroup Label=\"UserMacros\" />\n <PropertyGroup Label=\"Conan-RootDirs\">{item_properties}\n </PropertyGroup>\n {properties}\n <ItemGroup />\n</Project>'''\n\n properties_template = ''' <PropertyGroup Label=\"ConanVariables\"{condition}>\n <ConanBinaryDirectories>{bin_dirs};%(ConanBinaryDirectories)</ConanBinaryDirectories>\n <ConanResourceDirectories>{res_dirs};%(ConanResourceDirectories)$(</ConanResourceDirectories>\n </PropertyGroup>\n <PropertyGroup{condition}>\n <LocalDebuggerEnvironment>PATH=%PATH%;{bin_dirs}</LocalDebuggerEnvironment>\n <DebuggerFlavor>WindowsLocalDebugger</DebuggerFlavor>\n </PropertyGroup>\n <ItemDefinitionGroup{condition}>\n <ClCompile>\n <AdditionalIncludeDirectories>{include_dirs}%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>\n <PreprocessorDefinitions>{definitions}%(PreprocessorDefinitions)</PreprocessorDefinitions>\n <AdditionalOptions>{compiler_flags} %(AdditionalOptions)</AdditionalOptions>\n </ClCompile>\n <Link>\n <AdditionalLibraryDirectories>{lib_dirs}%(AdditionalLibraryDirectories)</AdditionalLibraryDirectories>\n <AdditionalDependencies>{libs}%(AdditionalDependencies)</AdditionalDependencies>\n <AdditionalOptions>{linker_flags} %(AdditionalOptions)</AdditionalOptions>\n </Link>\n <Midl>\n <AdditionalIncludeDirectories>{include_dirs}%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>\n </Midl>\n <ResourceCompile>\n <AdditionalIncludeDirectories>{include_dirs}%(AdditionalIncludeDirectories)</AdditionalIncludeDirectories>\n <PreprocessorDefinitions>{definitions}%(PreprocessorDefinitions)</PreprocessorDefinitions>\n <AdditionalOptions>{compiler_flags} %(AdditionalOptions)</AdditionalOptions>\n </ResourceCompile>\n </ItemDefinitionGroup>'''\n\n item_template = '''\n <Conan-{name}-Root>{root_dir}</Conan-{name}-Root>'''\n\n def _format_items(self):\n sections = []\n for dep_name, cpp_info in self._deps_build_info.dependencies:\n fields = {\n 'root_dir': cpp_info.rootpath,\n 'name': dep_name.replace(\".\", \"-\")\n }\n section = self.item_template.format(**fields)\n sections.append(section)\n return \"\".join(sections)\n\n @property\n def filename(self):\n return BUILD_INFO_VISUAL_STUDIO\n\n def _format_properties(self, build_info, condition):\n def has_valid_ext(lib):\n ext = os.path.splitext(lib)[1]\n return ext in VALID_LIB_EXTENSIONS\n\n fields = {\n 'condition': condition,\n 'bin_dirs': \"\".join(\"%s;\" % p for p in build_info.bin_paths),\n 'res_dirs': \"\".join(\"%s;\" % p for p in build_info.res_paths),\n 'include_dirs': \"\".join(\"%s;\" % p for p in build_info.include_paths),\n 'lib_dirs': \"\".join(\"%s;\" % p for p in build_info.lib_paths),\n 'libs': \"\".join(['%s.lib;' % lib if not has_valid_ext(lib)\n else '%s;' % lib for lib in build_info.libs]),\n 'definitions': \"\".join(\"%s;\" % d for d in build_info.defines),\n 'compiler_flags': \" \".join(build_info.cxxflags + build_info.cflags),\n 'linker_flags': \" \".join(build_info.sharedlinkflags),\n 'exe_flags': \" \".join(build_info.exelinkflags)\n }\n formatted_template = self.properties_template.format(**fields)\n return formatted_template\n\n @property\n def content(self):\n per_item_props = self._format_items()\n\n properties = [self._format_properties(self._deps_build_info, condition='')]\n for config, cpp_info in self._deps_build_info.configs.items():\n condition = \" Condition=\\\"'$(Configuration)' == '%s'\\\"\" % config\n properties.append(self._format_properties(cpp_info, condition=condition))\n\n fields = {\n 'item_properties': per_item_props,\n 'properties': '\\n'.join(properties)\n }\n formatted_template = self.template.format(**fields)\n\n userprofile = os.getenv(\"USERPROFILE\")\n if userprofile:\n userprofile = userprofile.replace(\"\\\\\", \"\\\\\\\\\")\n formatted_template = re.sub(userprofile, \"$(USERPROFILE)\", formatted_template,\n flags=re.I)\n return formatted_template\n", "path": "conans/client/generators/visualstudio.py"}]}
| 1,839 | 725 |
gh_patches_debug_9185
|
rasdani/github-patches
|
git_diff
|
fidals__shopelectro-729
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
502 error on category pages
We can reproduce it with code below.
Seems it's connected with https://github.com/fidals/shopelectro/issues/648, but it's not checked yet
```
import requests
BASE = 'https://www.shopelectro.ru'
broken_urls = []
for c in CategoryPage.objects.all():
response = requests.get(BASE + c.url)
if response.status_code != 200:
broken_urls += (response.status_code, response.url)
print('\n'.join((str(url) for url in broken_urls)))
---
# output:
502
https://www.shopelectro.ru/catalog/categories/batarei-saliutov-moshchnye/
502
https://www.shopelectro.ru/catalog/categories/khlopushki-pnevmaticheskie/
502
https://www.shopelectro.ru/catalog/categories/izmeritelnye-pribory-211/
502
https://www.shopelectro.ru/catalog/categories/dlia-tiporazmera-aaaaa/
502
https://www.shopelectro.ru/catalog/categories/tiporazmer-aa/
502
https://www.shopelectro.ru/catalog/categories/tiporazmer-6f22/
502
https://www.shopelectro.ru/catalog/categories/invertory/
502
https://www.shopelectro.ru/catalog/categories/palchikovye-aa-r6-lr6-fr6-316/
502
https://www.shopelectro.ru/catalog/categories/mizinchikovye-aaa-r03-lr03-fr03-286/
```
</issue>
<code>
[start of shopelectro/celery.py]
1 from __future__ import absolute_import, unicode_literals
2 from datetime import timedelta
3 import os
4
5 from celery import Celery
6 from kombu import Exchange, Queue
7
8 # set the default Django settings module for the 'celery' program.
9 os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'shopelectro.settings.local')
10
11 app = Celery('shopelectro')
12
13 # Exchanges
14 default_exchange = Exchange('default', type='direct')
15 utils_exchange = Exchange('utils', type='direct')
16
17 # http://docs.celeryproject.org/en/latest/userguide/tasks.html
18 task_queues = (
19 Queue(
20 name='default',
21 exchange=default_exchange,
22 routing_key='default',
23 ),
24 Queue(
25 name='mail',
26 exchange=utils_exchange,
27 routing_key='utils.mail',
28 ),
29 Queue(
30 name='command',
31 exchange=utils_exchange,
32 routing_key='utils.command',
33 )
34 )
35
36 # http://docs.celeryproject.org/en/latest/userguide/periodic-tasks.html
37 beat_schedule = {
38 'update-catalog': {
39 'task': 'shopelectro.tasks.update_catalog',
40 'schedule': timedelta(hours=2).total_seconds(),
41 },
42 'check-purchase': {
43 'task': 'shopelectro.tasks.check_purchase',
44 'schedule': timedelta(days=1).total_seconds(),
45 },
46 }
47
48 # http://docs.celeryproject.org/en/master/userguide/routing.html
49 task_routes = {
50 'shopelectro.tasks.update_catalog': {
51 'queue': 'command',
52 'routing_key': 'utils.command',
53 'priority': 30,
54 },
55 'shopelectro.tasks.check_purchase': {
56 'queue': 'command',
57 'routing_key': 'utils.command',
58 'priority': 20,
59 },
60 'ecommerce.tasks.send_mail': {
61 'queue': 'mail',
62 'routing_key': 'utils.mail',
63 'priority': 50,
64 },
65 }
66
67 # Using a string here means the worker don't have to serialize
68 # the configuration object to child processes.
69 # - namespace='CELERY' means all celery-related configuration keys
70 # should have a `CELERY_` prefix.
71 app.config_from_object('django.conf:settings', namespace='CELERY')
72
73 # http://docs.celeryproject.org/en/latest/userguide/configuration.html
74
75 BROCKER_URL = (
76 f'amqp://{os.environ["RABBITMQ_DEFAULT_USER"]}:{os.environ["RABBITMQ_DEFAULT_PASS"]}'
77 f'@{os.environ["RABBITMQ_URL"]}:{os.environ["RABBITMQ_PORT"]}/'
78 )
79 app.conf.update(
80 broker_url=BROCKER_URL,
81 broker_heartbeat=30,
82 task_acks_late=True,
83 task_default_queue='default',
84 task_default_exchange='default',
85 task_default_routing_key='default',
86 task_ignore_result=True,
87 worker_pool_restarts=1000,
88 task_routes=task_routes,
89 task_queues=task_queues,
90 beat_schedule=beat_schedule,
91 )
92
93 # Load task modules from all registered Django app configs.
94 app.autodiscover_tasks()
95
[end of shopelectro/celery.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/shopelectro/celery.py b/shopelectro/celery.py
--- a/shopelectro/celery.py
+++ b/shopelectro/celery.py
@@ -83,11 +83,11 @@
task_default_queue='default',
task_default_exchange='default',
task_default_routing_key='default',
- task_ignore_result=True,
- worker_pool_restarts=1000,
+ worker_pool_restarts=True,
task_routes=task_routes,
task_queues=task_queues,
beat_schedule=beat_schedule,
+ worker_max_memory_per_child=200000, # after 250MB will restart
)
# Load task modules from all registered Django app configs.
|
{"golden_diff": "diff --git a/shopelectro/celery.py b/shopelectro/celery.py\n--- a/shopelectro/celery.py\n+++ b/shopelectro/celery.py\n@@ -83,11 +83,11 @@\n task_default_queue='default',\n task_default_exchange='default',\n task_default_routing_key='default',\n- task_ignore_result=True,\n- worker_pool_restarts=1000,\n+ worker_pool_restarts=True,\n task_routes=task_routes,\n task_queues=task_queues,\n beat_schedule=beat_schedule,\n+ worker_max_memory_per_child=200000, # after 250MB will restart\n )\n \n # Load task modules from all registered Django app configs.\n", "issue": "502 error on category pages\nWe can reproduce it with code below.\r\n\r\nSeems it's connected with https://github.com/fidals/shopelectro/issues/648, but it's not checked yet\r\n\r\n```\r\nimport requests\r\n\r\nBASE = 'https://www.shopelectro.ru'\r\n\r\nbroken_urls = []\r\nfor c in CategoryPage.objects.all():\r\n\tresponse = requests.get(BASE + c.url)\r\n\tif response.status_code != 200:\r\n\t\tbroken_urls += (response.status_code, response.url)\r\n\r\nprint('\\n'.join((str(url) for url in broken_urls)))\r\n\r\n---\r\n\r\n# output:\r\n502\r\nhttps://www.shopelectro.ru/catalog/categories/batarei-saliutov-moshchnye/\r\n502\r\nhttps://www.shopelectro.ru/catalog/categories/khlopushki-pnevmaticheskie/\r\n502\r\nhttps://www.shopelectro.ru/catalog/categories/izmeritelnye-pribory-211/\r\n502\r\nhttps://www.shopelectro.ru/catalog/categories/dlia-tiporazmera-aaaaa/\r\n502\r\nhttps://www.shopelectro.ru/catalog/categories/tiporazmer-aa/\r\n502\r\nhttps://www.shopelectro.ru/catalog/categories/tiporazmer-6f22/\r\n502\r\nhttps://www.shopelectro.ru/catalog/categories/invertory/\r\n502\r\nhttps://www.shopelectro.ru/catalog/categories/palchikovye-aa-r6-lr6-fr6-316/\r\n502\r\nhttps://www.shopelectro.ru/catalog/categories/mizinchikovye-aaa-r03-lr03-fr03-286/\r\n```\n", "before_files": [{"content": "from __future__ import absolute_import, unicode_literals\nfrom datetime import timedelta\nimport os\n\nfrom celery import Celery\nfrom kombu import Exchange, Queue\n\n# set the default Django settings module for the 'celery' program.\nos.environ.setdefault('DJANGO_SETTINGS_MODULE', 'shopelectro.settings.local')\n\napp = Celery('shopelectro')\n\n# Exchanges\ndefault_exchange = Exchange('default', type='direct')\nutils_exchange = Exchange('utils', type='direct')\n\n# http://docs.celeryproject.org/en/latest/userguide/tasks.html\ntask_queues = (\n Queue(\n name='default',\n exchange=default_exchange,\n routing_key='default',\n ),\n Queue(\n name='mail',\n exchange=utils_exchange,\n routing_key='utils.mail',\n ),\n Queue(\n name='command',\n exchange=utils_exchange,\n routing_key='utils.command',\n )\n)\n\n# http://docs.celeryproject.org/en/latest/userguide/periodic-tasks.html\nbeat_schedule = {\n 'update-catalog': {\n 'task': 'shopelectro.tasks.update_catalog',\n 'schedule': timedelta(hours=2).total_seconds(),\n },\n 'check-purchase': {\n 'task': 'shopelectro.tasks.check_purchase',\n 'schedule': timedelta(days=1).total_seconds(),\n },\n}\n\n# http://docs.celeryproject.org/en/master/userguide/routing.html\ntask_routes = {\n 'shopelectro.tasks.update_catalog': {\n 'queue': 'command',\n 'routing_key': 'utils.command',\n 'priority': 30,\n },\n 'shopelectro.tasks.check_purchase': {\n 'queue': 'command',\n 'routing_key': 'utils.command',\n 'priority': 20,\n },\n 'ecommerce.tasks.send_mail': {\n 'queue': 'mail',\n 'routing_key': 'utils.mail',\n 'priority': 50,\n },\n}\n\n# Using a string here means the worker don't have to serialize\n# the configuration object to child processes.\n# - namespace='CELERY' means all celery-related configuration keys\n# should have a `CELERY_` prefix.\napp.config_from_object('django.conf:settings', namespace='CELERY')\n\n# http://docs.celeryproject.org/en/latest/userguide/configuration.html\n\nBROCKER_URL = (\n f'amqp://{os.environ[\"RABBITMQ_DEFAULT_USER\"]}:{os.environ[\"RABBITMQ_DEFAULT_PASS\"]}'\n f'@{os.environ[\"RABBITMQ_URL\"]}:{os.environ[\"RABBITMQ_PORT\"]}/'\n)\napp.conf.update(\n broker_url=BROCKER_URL,\n broker_heartbeat=30,\n task_acks_late=True,\n task_default_queue='default',\n task_default_exchange='default',\n task_default_routing_key='default',\n task_ignore_result=True,\n worker_pool_restarts=1000,\n task_routes=task_routes,\n task_queues=task_queues,\n beat_schedule=beat_schedule,\n)\n\n# Load task modules from all registered Django app configs.\napp.autodiscover_tasks()\n", "path": "shopelectro/celery.py"}]}
| 1,763 | 167 |
gh_patches_debug_18091
|
rasdani/github-patches
|
git_diff
|
nilearn__nilearn-2198
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Pip installing Nilearn 0.6.0a0 in Py2 envs
Not sure why, installing Nilearn 06.0a0 in a Python2environment does not raise an error. This is strange, since the wheels I build this time are not universal and I removed Python 2 tags. Maybe something was overlooked? Will look at this.
</issue>
<code>
[start of setup.py]
1 #! /usr/bin/env python
2
3 descr = """A set of python modules for neuroimaging..."""
4
5 import sys
6 import os
7
8 from setuptools import setup, find_packages
9
10
11 def load_version():
12 """Executes nilearn/version.py in a globals dictionary and return it.
13
14 Note: importing nilearn is not an option because there may be
15 dependencies like nibabel which are not installed and
16 setup.py is supposed to install them.
17 """
18 # load all vars into globals, otherwise
19 # the later function call using global vars doesn't work.
20 globals_dict = {}
21 with open(os.path.join('nilearn', 'version.py')) as fp:
22 exec(fp.read(), globals_dict)
23
24 return globals_dict
25
26
27 def is_installing():
28 # Allow command-lines such as "python setup.py build install"
29 install_commands = set(['install', 'develop'])
30 return install_commands.intersection(set(sys.argv))
31
32
33 # Make sources available using relative paths from this file's directory.
34 os.chdir(os.path.dirname(os.path.abspath(__file__)))
35
36 _VERSION_GLOBALS = load_version()
37 DISTNAME = 'nilearn'
38 DESCRIPTION = 'Statistical learning for neuroimaging in Python'
39 with open('README.rst') as fp:
40 LONG_DESCRIPTION = fp.read()
41 MAINTAINER = 'Gael Varoquaux'
42 MAINTAINER_EMAIL = '[email protected]'
43 URL = 'http://nilearn.github.io'
44 LICENSE = 'new BSD'
45 DOWNLOAD_URL = 'http://nilearn.github.io'
46 VERSION = _VERSION_GLOBALS['__version__']
47
48
49 if __name__ == "__main__":
50 if is_installing():
51 module_check_fn = _VERSION_GLOBALS['_check_module_dependencies']
52 module_check_fn(is_nilearn_installing=True)
53
54 install_requires = \
55 ['%s>=%s' % (mod, meta['min_version'])
56 for mod, meta in _VERSION_GLOBALS['REQUIRED_MODULE_METADATA']
57 if not meta['required_at_installation']]
58
59 setup(name=DISTNAME,
60 maintainer=MAINTAINER,
61 maintainer_email=MAINTAINER_EMAIL,
62 description=DESCRIPTION,
63 license=LICENSE,
64 url=URL,
65 version=VERSION,
66 download_url=DOWNLOAD_URL,
67 long_description=LONG_DESCRIPTION,
68 zip_safe=False, # the package can run out of an .egg file
69 classifiers=[
70 'Intended Audience :: Science/Research',
71 'Intended Audience :: Developers',
72 'License :: OSI Approved',
73 'Programming Language :: C',
74 'Programming Language :: Python',
75 'Topic :: Software Development',
76 'Topic :: Scientific/Engineering',
77 'Operating System :: Microsoft :: Windows',
78 'Operating System :: POSIX',
79 'Operating System :: Unix',
80 'Operating System :: MacOS',
81 'Programming Language :: Python :: 3.5',
82 'Programming Language :: Python :: 3.6',
83 'Programming Language :: Python :: 3.7',
84 ],
85 packages=find_packages(),
86 package_data={'nilearn.datasets.data': ['*.nii.gz', '*.csv', '*.txt'
87 ],
88 'nilearn.datasets.data.fsaverage5': ['*.gz'],
89 'nilearn.surface.data': ['*.csv'],
90 'nilearn.plotting.data.js': ['*.js'],
91 'nilearn.plotting.data.html': ['*.html'],
92 'nilearn.plotting.glass_brain_files': ['*.json'],
93 'nilearn.tests.data': ['*'],
94 'nilearn.image.tests.data': ['*.mgz'],
95 'nilearn.surface.tests.data': ['*.annot', '*.label'],
96 'nilearn.datasets.tests.data': ['*.*'],
97 'nilearn.datasets.description': ['*.rst'],
98 'nilearn.reporting.data.html': ['*.html']},
99 install_requires=install_requires,)
100
[end of setup.py]
[start of nilearn/version.py]
1 # *- encoding: utf-8 -*-
2 """
3 nilearn version, required package versions, and utilities for checking
4 """
5 # Author: Loic Esteve, Ben Cipollini
6 # License: simplified BSD
7
8 # PEP0440 compatible formatted version, see:
9 # https://www.python.org/dev/peps/pep-0440/
10 #
11 # Generic release markers:
12 # X.Y
13 # X.Y.Z # For bugfix releases
14 #
15 # Admissible pre-release markers:
16 # X.YaN # Alpha release
17 # X.YbN # Beta release
18 # X.YrcN # Release Candidate
19 # X.Y # Final release
20 #
21 # Dev branch marker is: 'X.Y.dev' or 'X.Y.devN' where N is an integer.
22 # 'X.Y.dev0' is the canonical version of 'X.Y.dev'
23 #
24 __version__ = '0.6.0a'
25
26 _NILEARN_INSTALL_MSG = 'See %s for installation information.' % (
27 'http://nilearn.github.io/introduction.html#installation')
28
29 # This is a tuple to preserve order, so that dependencies are checked
30 # in some meaningful order (more => less 'core').
31 REQUIRED_MODULE_METADATA = (
32 ('numpy', {
33 'min_version': '1.11',
34 'required_at_installation': True,
35 'install_info': _NILEARN_INSTALL_MSG}),
36 ('scipy', {
37 'min_version': '0.19',
38 'required_at_installation': True,
39 'install_info': _NILEARN_INSTALL_MSG}),
40 ('sklearn', {
41 'min_version': '0.19',
42 'required_at_installation': True,
43 'install_info': _NILEARN_INSTALL_MSG}),
44 ('joblib', {
45 'min_version': '0.11',
46 'required_at_installation': True,
47 'install_info': _NILEARN_INSTALL_MSG}),
48 ('nibabel', {
49 'min_version': '2.0.2',
50 'required_at_installation': False}))
51
52 OPTIONAL_MATPLOTLIB_MIN_VERSION = '2.0'
53
54
55 def _import_module_with_version_check(
56 module_name,
57 minimum_version,
58 install_info=None):
59 """Check that module is installed with a recent enough version
60 """
61 from distutils.version import LooseVersion
62
63 try:
64 module = __import__(module_name)
65 except ImportError as exc:
66 user_friendly_info = ('Module "{0}" could not be found. {1}').format(
67 module_name,
68 install_info or 'Please install it properly to use nilearn.')
69 exc.args += (user_friendly_info,)
70 # Necessary for Python 3 because the repr/str of ImportError
71 # objects was changed in Python 3
72 if hasattr(exc, 'msg'):
73 exc.msg += '. ' + user_friendly_info
74 raise
75
76 # Avoid choking on modules with no __version__ attribute
77 module_version = getattr(module, '__version__', '0.0.0')
78
79 version_too_old = (not LooseVersion(module_version) >=
80 LooseVersion(minimum_version))
81
82 if version_too_old:
83 message = (
84 'A {module_name} version of at least {minimum_version} '
85 'is required to use nilearn. {module_version} was found. '
86 'Please upgrade {module_name}').format(
87 module_name=module_name,
88 minimum_version=minimum_version,
89 module_version=module_version)
90
91 raise ImportError(message)
92
93 return module
94
95
96 def _check_module_dependencies(is_nilearn_installing=False):
97 """Throw an exception if nilearn dependencies are not installed.
98
99 Parameters
100 ----------
101 is_nilearn_installing: boolean
102 if True, only error on missing packages that cannot be auto-installed.
103 if False, error on any missing package.
104
105 Throws
106 -------
107 ImportError
108 """
109
110 for (module_name, module_metadata) in REQUIRED_MODULE_METADATA:
111 if not (is_nilearn_installing and
112 not module_metadata['required_at_installation']):
113 # Skip check only when installing and it's a module that
114 # will be auto-installed.
115 _import_module_with_version_check(
116 module_name=module_name,
117 minimum_version=module_metadata['min_version'],
118 install_info=module_metadata.get('install_info'))
119
[end of nilearn/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nilearn/version.py b/nilearn/version.py
--- a/nilearn/version.py
+++ b/nilearn/version.py
@@ -21,7 +21,7 @@
# Dev branch marker is: 'X.Y.dev' or 'X.Y.devN' where N is an integer.
# 'X.Y.dev0' is the canonical version of 'X.Y.dev'
#
-__version__ = '0.6.0a'
+__version__ = '0.6.0b'
_NILEARN_INSTALL_MSG = 'See %s for installation information.' % (
'http://nilearn.github.io/introduction.html#installation')
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -96,4 +96,6 @@
'nilearn.datasets.tests.data': ['*.*'],
'nilearn.datasets.description': ['*.rst'],
'nilearn.reporting.data.html': ['*.html']},
- install_requires=install_requires,)
+ install_requires=install_requires,
+ python_requires='>=3.5',
+ )
|
{"golden_diff": "diff --git a/nilearn/version.py b/nilearn/version.py\n--- a/nilearn/version.py\n+++ b/nilearn/version.py\n@@ -21,7 +21,7 @@\n # Dev branch marker is: 'X.Y.dev' or 'X.Y.devN' where N is an integer.\n # 'X.Y.dev0' is the canonical version of 'X.Y.dev'\n #\n-__version__ = '0.6.0a'\n+__version__ = '0.6.0b'\n \n _NILEARN_INSTALL_MSG = 'See %s for installation information.' % (\n 'http://nilearn.github.io/introduction.html#installation')\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -96,4 +96,6 @@\n 'nilearn.datasets.tests.data': ['*.*'],\n 'nilearn.datasets.description': ['*.rst'],\n 'nilearn.reporting.data.html': ['*.html']},\n- install_requires=install_requires,)\n+ install_requires=install_requires,\n+ python_requires='>=3.5',\n+ )\n", "issue": "Pip installing Nilearn 0.6.0a0 in Py2 envs\nNot sure why, installing Nilearn 06.0a0 in a Python2environment does not raise an error. This is strange, since the wheels I build this time are not universal and I removed Python 2 tags. Maybe something was overlooked? Will look at this.\n", "before_files": [{"content": "#! /usr/bin/env python\n\ndescr = \"\"\"A set of python modules for neuroimaging...\"\"\"\n\nimport sys\nimport os\n\nfrom setuptools import setup, find_packages\n\n\ndef load_version():\n \"\"\"Executes nilearn/version.py in a globals dictionary and return it.\n\n Note: importing nilearn is not an option because there may be\n dependencies like nibabel which are not installed and\n setup.py is supposed to install them.\n \"\"\"\n # load all vars into globals, otherwise\n # the later function call using global vars doesn't work.\n globals_dict = {}\n with open(os.path.join('nilearn', 'version.py')) as fp:\n exec(fp.read(), globals_dict)\n\n return globals_dict\n\n\ndef is_installing():\n # Allow command-lines such as \"python setup.py build install\"\n install_commands = set(['install', 'develop'])\n return install_commands.intersection(set(sys.argv))\n\n\n# Make sources available using relative paths from this file's directory.\nos.chdir(os.path.dirname(os.path.abspath(__file__)))\n\n_VERSION_GLOBALS = load_version()\nDISTNAME = 'nilearn'\nDESCRIPTION = 'Statistical learning for neuroimaging in Python'\nwith open('README.rst') as fp:\n LONG_DESCRIPTION = fp.read()\nMAINTAINER = 'Gael Varoquaux'\nMAINTAINER_EMAIL = '[email protected]'\nURL = 'http://nilearn.github.io'\nLICENSE = 'new BSD'\nDOWNLOAD_URL = 'http://nilearn.github.io'\nVERSION = _VERSION_GLOBALS['__version__']\n\n\nif __name__ == \"__main__\":\n if is_installing():\n module_check_fn = _VERSION_GLOBALS['_check_module_dependencies']\n module_check_fn(is_nilearn_installing=True)\n\n install_requires = \\\n ['%s>=%s' % (mod, meta['min_version'])\n for mod, meta in _VERSION_GLOBALS['REQUIRED_MODULE_METADATA']\n if not meta['required_at_installation']]\n\n setup(name=DISTNAME,\n maintainer=MAINTAINER,\n maintainer_email=MAINTAINER_EMAIL,\n description=DESCRIPTION,\n license=LICENSE,\n url=URL,\n version=VERSION,\n download_url=DOWNLOAD_URL,\n long_description=LONG_DESCRIPTION,\n zip_safe=False, # the package can run out of an .egg file\n classifiers=[\n 'Intended Audience :: Science/Research',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved',\n 'Programming Language :: C',\n 'Programming Language :: Python',\n 'Topic :: Software Development',\n 'Topic :: Scientific/Engineering',\n 'Operating System :: Microsoft :: Windows',\n 'Operating System :: POSIX',\n 'Operating System :: Unix',\n 'Operating System :: MacOS',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n ],\n packages=find_packages(),\n package_data={'nilearn.datasets.data': ['*.nii.gz', '*.csv', '*.txt'\n ],\n 'nilearn.datasets.data.fsaverage5': ['*.gz'],\n 'nilearn.surface.data': ['*.csv'],\n 'nilearn.plotting.data.js': ['*.js'],\n 'nilearn.plotting.data.html': ['*.html'],\n 'nilearn.plotting.glass_brain_files': ['*.json'],\n 'nilearn.tests.data': ['*'],\n 'nilearn.image.tests.data': ['*.mgz'],\n 'nilearn.surface.tests.data': ['*.annot', '*.label'],\n 'nilearn.datasets.tests.data': ['*.*'],\n 'nilearn.datasets.description': ['*.rst'],\n 'nilearn.reporting.data.html': ['*.html']},\n install_requires=install_requires,)\n", "path": "setup.py"}, {"content": "# *- encoding: utf-8 -*-\n\"\"\"\nnilearn version, required package versions, and utilities for checking\n\"\"\"\n# Author: Loic Esteve, Ben Cipollini\n# License: simplified BSD\n\n# PEP0440 compatible formatted version, see:\n# https://www.python.org/dev/peps/pep-0440/\n#\n# Generic release markers:\n# X.Y\n# X.Y.Z # For bugfix releases\n#\n# Admissible pre-release markers:\n# X.YaN # Alpha release\n# X.YbN # Beta release\n# X.YrcN # Release Candidate\n# X.Y # Final release\n#\n# Dev branch marker is: 'X.Y.dev' or 'X.Y.devN' where N is an integer.\n# 'X.Y.dev0' is the canonical version of 'X.Y.dev'\n#\n__version__ = '0.6.0a'\n\n_NILEARN_INSTALL_MSG = 'See %s for installation information.' % (\n 'http://nilearn.github.io/introduction.html#installation')\n\n# This is a tuple to preserve order, so that dependencies are checked\n# in some meaningful order (more => less 'core').\nREQUIRED_MODULE_METADATA = (\n ('numpy', {\n 'min_version': '1.11',\n 'required_at_installation': True,\n 'install_info': _NILEARN_INSTALL_MSG}),\n ('scipy', {\n 'min_version': '0.19',\n 'required_at_installation': True,\n 'install_info': _NILEARN_INSTALL_MSG}),\n ('sklearn', {\n 'min_version': '0.19',\n 'required_at_installation': True,\n 'install_info': _NILEARN_INSTALL_MSG}),\n ('joblib', {\n 'min_version': '0.11',\n 'required_at_installation': True,\n 'install_info': _NILEARN_INSTALL_MSG}),\n ('nibabel', {\n 'min_version': '2.0.2',\n 'required_at_installation': False}))\n\nOPTIONAL_MATPLOTLIB_MIN_VERSION = '2.0'\n\n\ndef _import_module_with_version_check(\n module_name,\n minimum_version,\n install_info=None):\n \"\"\"Check that module is installed with a recent enough version\n \"\"\"\n from distutils.version import LooseVersion\n\n try:\n module = __import__(module_name)\n except ImportError as exc:\n user_friendly_info = ('Module \"{0}\" could not be found. {1}').format(\n module_name,\n install_info or 'Please install it properly to use nilearn.')\n exc.args += (user_friendly_info,)\n # Necessary for Python 3 because the repr/str of ImportError\n # objects was changed in Python 3\n if hasattr(exc, 'msg'):\n exc.msg += '. ' + user_friendly_info\n raise\n\n # Avoid choking on modules with no __version__ attribute\n module_version = getattr(module, '__version__', '0.0.0')\n\n version_too_old = (not LooseVersion(module_version) >=\n LooseVersion(minimum_version))\n\n if version_too_old:\n message = (\n 'A {module_name} version of at least {minimum_version} '\n 'is required to use nilearn. {module_version} was found. '\n 'Please upgrade {module_name}').format(\n module_name=module_name,\n minimum_version=minimum_version,\n module_version=module_version)\n\n raise ImportError(message)\n\n return module\n\n\ndef _check_module_dependencies(is_nilearn_installing=False):\n \"\"\"Throw an exception if nilearn dependencies are not installed.\n\n Parameters\n ----------\n is_nilearn_installing: boolean\n if True, only error on missing packages that cannot be auto-installed.\n if False, error on any missing package.\n\n Throws\n -------\n ImportError\n \"\"\"\n\n for (module_name, module_metadata) in REQUIRED_MODULE_METADATA:\n if not (is_nilearn_installing and\n not module_metadata['required_at_installation']):\n # Skip check only when installing and it's a module that\n # will be auto-installed.\n _import_module_with_version_check(\n module_name=module_name,\n minimum_version=module_metadata['min_version'],\n install_info=module_metadata.get('install_info'))\n", "path": "nilearn/version.py"}]}
| 2,829 | 244 |
gh_patches_debug_5657
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-254
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`split_axis` fails when it splits the last axis of an array on py3
This code causes an error.
```
>>> x=chainer.Variable(chainer.cuda.to_gpu(numpy.array([1,2,3], numpy.float32)))
>>> chainer.functions.split_axis(x, [1], 0)
...
struct.error: required argument is not an integer
```
A return value of `numpy.prod(())` is `float`, and pycuda cannot pass a float value as an integer argument on py3 (on py2, it works).
https://github.com/pfnet/chainer/blob/master/chainer/functions/split_axis.py#L60
@ShigekiKarita reported this bug. Thanks!!
https://gist.github.com/ShigekiKarita/f27d1d149ccc3e3f381f
</issue>
<code>
[start of chainer/functions/split_axis.py]
1 import collections
2
3 import numpy
4
5 from chainer import cuda
6 from chainer import function
7 from chainer.utils import type_check
8
9
10 _args = 'float* y, float* x, int cdimy, int cdimx, int rdim, int coffset'
11 _preamble = '''
12 #define COPY(statement) \
13 int l = i / (rdim * cdimy); \
14 int c = i / rdim % cdimy + coffset; \
15 int r = i % rdim; \
16 int idx = r + rdim * (c + cdimx * l); \
17 statement;
18 '''
19
20
21 class SplitAxis(function.Function):
22
23 """Function that splits multiple arrays towards the specified axis."""
24
25 def __init__(self, indices_or_sections, axis):
26 if not isinstance(indices_or_sections, (int, collections.Iterable)):
27 raise TypeError('indices_or_sections must be integer or 1-D array')
28 self.indices_or_sections = indices_or_sections
29 self.axis = axis
30
31 def check_type_forward(self, in_types):
32 type_check.expect(in_types.size() == 1)
33 type_check.expect(in_types[0].ndim >= self.axis)
34
35 if isinstance(self.indices_or_sections, collections.Iterable):
36 max_index = type_check.Variable(
37 self.indices_or_sections[-1], 'max_index')
38 type_check.expect(in_types[0].shape[self.axis] > max_index)
39 else:
40 sections = type_check.Variable(
41 self.indices_or_sections, 'sections')
42 type_check.expect(in_types[0].shape[self.axis] % sections == 0)
43
44 def forward_cpu(self, x):
45 if isinstance(self.indices_or_sections, collections.Iterable):
46 cdimx = x[0].shape[self.axis]
47 ind = list(self.indices_or_sections)
48 ind.append(cdimx)
49 prev_i = 0
50 for i in ind:
51 cdimy = max(0, min(i, cdimx) - prev_i)
52 if cdimy == 0:
53 raise ValueError('Not support if shape contains 0')
54 prev_i = i
55 return tuple(numpy.split(x[0], self.indices_or_sections, self.axis))
56
57 def forward_gpu(self, x):
58 xshape = x[0].shape
59 self.cdimx = xshape[self.axis]
60 self.rdim = numpy.prod(xshape[self.axis + 1:])
61
62 if isinstance(self.indices_or_sections, collections.Iterable):
63 ind = list(self.indices_or_sections)
64 ind.append(self.cdimx)
65 else:
66 sec = self.indices_or_sections
67 if self.cdimx % sec:
68 raise ValueError(
69 'array split does not result in an equal division')
70 ind = numpy.arange(1, sec + 1) * (self.cdimx // sec)
71 ys = []
72 kernel = cuda.elementwise(
73 _args, 'COPY(y[i] = x[idx])', 'split_fwd', preamble=_preamble)
74 prev_i = 0
75 for i in ind:
76 cdimy = max(0, min(i, self.cdimx) - prev_i)
77 s = list(xshape)
78 s[self.axis] = cdimy
79 y = cuda.empty(s, dtype=x[0].dtype)
80 if cdimy == 0:
81 raise ValueError('Not support if shape contains 0')
82 kernel(y, x[0], cdimy, self.cdimx, self.rdim, prev_i)
83 prev_i = i
84 ys.append(y)
85 return tuple(ys)
86
87 def backward_cpu(self, x, gys):
88 return numpy.concatenate(gys, axis=self.axis),
89
90 def backward_gpu(self, x, gys):
91 gx = cuda.empty_like(x[0])
92 coffset = 0
93 kernel = cuda.elementwise(
94 _args, 'COPY(x[idx] = y[i])', 'split_bwd', preamble=_preamble)
95 for gy in gys:
96 cdimy = gy.shape[self.axis]
97 if cdimy != 0:
98 kernel(gy, gx, cdimy, self.cdimx, self.rdim, coffset)
99 coffset += cdimy
100 return gx,
101
102
103 def split_axis(x, indices_or_sections, axis):
104 """Splits given variables along an axis.
105
106 Args:
107 x (tuple of Variables): Variables to be split.
108 indices_or_sections (int or 1-D array): If this argument is an integer,
109 N, the array will be divided into N equal arrays along axis.
110 If it is a 1-D array of sorted integers, it
111 indicates the positions where the array is split.
112 axis (int): Axis that the input array is split along.
113
114 Returns:
115 ``tuple`` or ``Variable``: Tuple of :class:`~chainer.Variable` objects
116 if the number of outputs is more than 1 or
117 :class:`~chainer.Variable` otherwise.
118
119 .. note::
120 This function raises ``ValueError`` if at least
121 one of the outputs is splitted to zero-size
122 (i.e. `axis`-th value of its shape is zero).
123
124 """
125 return SplitAxis(indices_or_sections, axis)(x)
126
[end of chainer/functions/split_axis.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/chainer/functions/split_axis.py b/chainer/functions/split_axis.py
--- a/chainer/functions/split_axis.py
+++ b/chainer/functions/split_axis.py
@@ -57,7 +57,7 @@
def forward_gpu(self, x):
xshape = x[0].shape
self.cdimx = xshape[self.axis]
- self.rdim = numpy.prod(xshape[self.axis + 1:])
+ self.rdim = numpy.prod(xshape[self.axis + 1:], dtype=int)
if isinstance(self.indices_or_sections, collections.Iterable):
ind = list(self.indices_or_sections)
|
{"golden_diff": "diff --git a/chainer/functions/split_axis.py b/chainer/functions/split_axis.py\n--- a/chainer/functions/split_axis.py\n+++ b/chainer/functions/split_axis.py\n@@ -57,7 +57,7 @@\n def forward_gpu(self, x):\n xshape = x[0].shape\n self.cdimx = xshape[self.axis]\n- self.rdim = numpy.prod(xshape[self.axis + 1:])\n+ self.rdim = numpy.prod(xshape[self.axis + 1:], dtype=int)\n \n if isinstance(self.indices_or_sections, collections.Iterable):\n ind = list(self.indices_or_sections)\n", "issue": "`split_axis` fails when it splits the last axis of an array on py3\nThis code causes an error.\n\n```\n>>> x=chainer.Variable(chainer.cuda.to_gpu(numpy.array([1,2,3], numpy.float32)))\n>>> chainer.functions.split_axis(x, [1], 0)\n...\nstruct.error: required argument is not an integer\n```\n\nA return value of `numpy.prod(())` is `float`, and pycuda cannot pass a float value as an integer argument on py3 (on py2, it works).\nhttps://github.com/pfnet/chainer/blob/master/chainer/functions/split_axis.py#L60\n\n@ShigekiKarita reported this bug. Thanks!!\nhttps://gist.github.com/ShigekiKarita/f27d1d149ccc3e3f381f\n\n", "before_files": [{"content": "import collections\n\nimport numpy\n\nfrom chainer import cuda\nfrom chainer import function\nfrom chainer.utils import type_check\n\n\n_args = 'float* y, float* x, int cdimy, int cdimx, int rdim, int coffset'\n_preamble = '''\n#define COPY(statement) \\\n int l = i / (rdim * cdimy); \\\n int c = i / rdim % cdimy + coffset; \\\n int r = i % rdim; \\\n int idx = r + rdim * (c + cdimx * l); \\\n statement;\n'''\n\n\nclass SplitAxis(function.Function):\n\n \"\"\"Function that splits multiple arrays towards the specified axis.\"\"\"\n\n def __init__(self, indices_or_sections, axis):\n if not isinstance(indices_or_sections, (int, collections.Iterable)):\n raise TypeError('indices_or_sections must be integer or 1-D array')\n self.indices_or_sections = indices_or_sections\n self.axis = axis\n\n def check_type_forward(self, in_types):\n type_check.expect(in_types.size() == 1)\n type_check.expect(in_types[0].ndim >= self.axis)\n\n if isinstance(self.indices_or_sections, collections.Iterable):\n max_index = type_check.Variable(\n self.indices_or_sections[-1], 'max_index')\n type_check.expect(in_types[0].shape[self.axis] > max_index)\n else:\n sections = type_check.Variable(\n self.indices_or_sections, 'sections')\n type_check.expect(in_types[0].shape[self.axis] % sections == 0)\n\n def forward_cpu(self, x):\n if isinstance(self.indices_or_sections, collections.Iterable):\n cdimx = x[0].shape[self.axis]\n ind = list(self.indices_or_sections)\n ind.append(cdimx)\n prev_i = 0\n for i in ind:\n cdimy = max(0, min(i, cdimx) - prev_i)\n if cdimy == 0:\n raise ValueError('Not support if shape contains 0')\n prev_i = i\n return tuple(numpy.split(x[0], self.indices_or_sections, self.axis))\n\n def forward_gpu(self, x):\n xshape = x[0].shape\n self.cdimx = xshape[self.axis]\n self.rdim = numpy.prod(xshape[self.axis + 1:])\n\n if isinstance(self.indices_or_sections, collections.Iterable):\n ind = list(self.indices_or_sections)\n ind.append(self.cdimx)\n else:\n sec = self.indices_or_sections\n if self.cdimx % sec:\n raise ValueError(\n 'array split does not result in an equal division')\n ind = numpy.arange(1, sec + 1) * (self.cdimx // sec)\n ys = []\n kernel = cuda.elementwise(\n _args, 'COPY(y[i] = x[idx])', 'split_fwd', preamble=_preamble)\n prev_i = 0\n for i in ind:\n cdimy = max(0, min(i, self.cdimx) - prev_i)\n s = list(xshape)\n s[self.axis] = cdimy\n y = cuda.empty(s, dtype=x[0].dtype)\n if cdimy == 0:\n raise ValueError('Not support if shape contains 0')\n kernel(y, x[0], cdimy, self.cdimx, self.rdim, prev_i)\n prev_i = i\n ys.append(y)\n return tuple(ys)\n\n def backward_cpu(self, x, gys):\n return numpy.concatenate(gys, axis=self.axis),\n\n def backward_gpu(self, x, gys):\n gx = cuda.empty_like(x[0])\n coffset = 0\n kernel = cuda.elementwise(\n _args, 'COPY(x[idx] = y[i])', 'split_bwd', preamble=_preamble)\n for gy in gys:\n cdimy = gy.shape[self.axis]\n if cdimy != 0:\n kernel(gy, gx, cdimy, self.cdimx, self.rdim, coffset)\n coffset += cdimy\n return gx,\n\n\ndef split_axis(x, indices_or_sections, axis):\n \"\"\"Splits given variables along an axis.\n\n Args:\n x (tuple of Variables): Variables to be split.\n indices_or_sections (int or 1-D array): If this argument is an integer,\n N, the array will be divided into N equal arrays along axis.\n If it is a 1-D array of sorted integers, it\n indicates the positions where the array is split.\n axis (int): Axis that the input array is split along.\n\n Returns:\n ``tuple`` or ``Variable``: Tuple of :class:`~chainer.Variable` objects\n if the number of outputs is more than 1 or\n :class:`~chainer.Variable` otherwise.\n\n .. note::\n This function raises ``ValueError`` if at least\n one of the outputs is splitted to zero-size\n (i.e. `axis`-th value of its shape is zero).\n\n \"\"\"\n return SplitAxis(indices_or_sections, axis)(x)\n", "path": "chainer/functions/split_axis.py"}]}
| 2,124 | 138 |
gh_patches_debug_45615
|
rasdani/github-patches
|
git_diff
|
Flexget__Flexget-2628
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
AniList crashing with custom lists
### Expected behaviour:
Parse AniList by status, ignore custom lists since they are duplicate entries from status lists.
### Actual behaviour:
Trying to parse custom lists cause a crash
### Steps to reproduce:
- Step 1: Try to parse an AniList account with a custom list.
#### Config:
```yaml
Paste FULL config and remove any personal info if config is too long, attach the file to the ticket.
If issue is with a single task, you can get get resulting configuration by running:
flexget execute --task <NAME> --dump-config
Make sure to redact any personal information (passwords, api keys, etc) !
```
#### Log:
<details>
<summary>(click to expand)</summary>
```
2020-03-18 10:22:25 CRITICAL task_queue BUG: Unhandled exception during task queue run loop.
2020-03-18 10:22:25 DEBUG scheduler task finished executing: fill-anime-movies-list
Traceback (most recent call last):
File "github\flexget\flexget\task_queue.py", line 46, in run
self.current_task.execute()
File "github\flexget\flexget\task.py", line 80, in wrapper
return func(self, *args, **kw)
File "github\flexget\flexget\task.py", line 697, in execute
self._execute()
File "github\flexget\flexget\task.py", line 663, in _execute
self.__run_task_phase(phase)
File "github\flexget\flexget\task.py", line 492, in __run_task_phase
for e in response:
File "github\flexget\flexget\utils\cached_input.py", line 217, in __iter__
for item in self.iterable:
File "github\flexget\flexget\plugins\input\anilist.py", line 133, in on_task_input
entry['al_list_status'] = list_status['status'].capitalize()
AttributeError: 'NoneType' object has no attribute 'capitalize'
```
</details>
### Additional information:
- FlexGet version: 3.1.34
- Python version: 3.7
- Installation method: git
- Using daemon (yes/no): yes
- OS and version: Win10
- Link to crash log: N/A
</issue>
<code>
[start of flexget/plugins/input/anilist.py]
1 from loguru import logger
2
3 from flexget import plugin
4 from flexget.config_schema import one_or_more
5 from flexget.entry import Entry
6 from flexget.event import event
7 from flexget.utils.cached_input import cached
8 from flexget.utils.requests import RequestException
9
10 logger = logger.bind(name='anilist')
11
12 LIST_STATUS = ['current', 'planning', 'completed', 'dropped', 'paused', 'repeating']
13
14 RELEASE_STATUS = ['finished', 'releasing', 'not_yet_released', 'cancelled', 'all']
15
16 ANIME_FORMAT = ['tv', 'tv_short', 'movie', 'special', 'ova', 'ona', 'all']
17
18 TRAILER_SOURCE = {
19 'youtube': 'https://www.youtube.com/embed/',
20 'dailymotion': 'https://www.dailymotion.com/embed/video/',
21 }
22
23
24 class AniList(object):
25 """" Creates entries for series and movies from your AniList list
26
27 Syntax:
28 anilist:
29 username: <value>
30 status:
31 - <current|planning|completed|dropped|paused|repeating>
32 - <current|planning|completed|dropped|paused|repeating>
33 ...
34 release_status:
35 - <all|finished|releasing|not_yet_released|cancelled>
36 - <finished|releasing|not_yet_released|cancelled>
37 ...
38 format:
39 - <all|tv|tv_short|movie|special|ova|ona>
40 - <tv|tv_short|movie|special|ova|ona>
41 ...
42 """
43
44 schema = {
45 'oneOf': [
46 {'type': 'string'},
47 {
48 'type': 'object',
49 'properties': {
50 'username': {'type': 'string'},
51 'status': one_or_more(
52 {'type': 'string', 'enum': LIST_STATUS}, unique_items=True
53 ),
54 'release_status': one_or_more(
55 {'type': 'string', 'enum': RELEASE_STATUS}, unique_items=True
56 ),
57 'format': one_or_more(
58 {'type': 'string', 'enum': ANIME_FORMAT}, unique_items=True
59 ),
60 },
61 'required': ['username'],
62 'additionalProperties': False,
63 },
64 ]
65 }
66
67 @cached('anilist', persist='2 hours')
68 def on_task_input(self, task, config):
69 if isinstance(config, str):
70 config = {'username': config}
71 selected_list_status = config['status'] if 'status' in config else ['current', 'planning']
72 selected_release_status = (
73 config['release_status'] if 'release_status' in config else ['all']
74 )
75 selected_formats = config['format'] if 'format' in config else ['all']
76
77 if not isinstance(selected_list_status, list):
78 selected_list_status = [selected_list_status]
79
80 if not isinstance(selected_release_status, list):
81 selected_release_status = [selected_release_status]
82
83 if not isinstance(selected_formats, list):
84 selected_formats = [selected_formats]
85
86 logger.debug('Selected List Status: {}', selected_list_status)
87 logger.debug('Selected Release Status: {}', selected_release_status)
88 logger.debug('Selected Formats: {}', selected_formats)
89
90 req_variables = {'user': config['username']}
91 req_chunk = 1
92 req_fields = (
93 'status, title{ romaji, english }, synonyms, siteUrl, idMal, format, episodes, '
94 'trailer{ site, id }, coverImage{ large }, bannerImage, genres, tags{ name }, '
95 'externalLinks{ site, url }'
96 )
97 while req_chunk:
98 req_query = (
99 f'query ($user: String){{ collection: MediaListCollection(userName: $user, '
100 f'type: ANIME, perChunk: 500, chunk: {req_chunk}, status_in: '
101 f'[{", ".join([s.upper() for s in selected_list_status])}]) {{ hasNextChunk, '
102 f'statuses: lists{{ status, list: entries{{ anime: media{{ {req_fields} }}}}}}}}}}'
103 )
104
105 try:
106 list_response = task.requests.post(
107 'https://graphql.anilist.co',
108 json={'query': req_query, 'variables': req_variables},
109 )
110 except RequestException as e:
111 raise plugin.PluginError('Error reading list - {url}'.format(url=e))
112
113 try:
114 list_response = list_response.json()['data']
115 logger.debug('JSON output: {}', list_response)
116 for list_status in list_response['collection']['statuses']:
117 for anime in list_status['list']:
118 anime = anime['anime']
119 has_selected_release_status = (
120 anime['status'].lower() in selected_release_status
121 or 'all' in selected_release_status
122 )
123 has_selected_type = (
124 anime['format'].lower() in selected_formats
125 or 'all' in selected_formats
126 )
127 if has_selected_type and has_selected_release_status:
128 entry = Entry()
129 entry['title'] = anime['title']['romaji']
130 entry['al_title'] = anime['title']
131 entry['al_format'] = anime['format']
132 entry['al_release_status'] = anime['status'].capitalize()
133 entry['al_list_status'] = list_status['status'].capitalize()
134 entry['alternate_name'] = anime.get('synonyms', [])
135 if (
136 anime['title'].get('english')
137 and anime['title'].get('english') != anime['title']['romaji']
138 and anime['title'].get('english') not in entry['alternate_name']
139 ):
140 entry['alternate_name'].insert(0, anime['title']['english'])
141 entry['url'] = anime['siteUrl']
142 entry['al_idMal'] = anime['idMal']
143 entry['al_episodes'] = anime['episodes']
144 entry['al_trailer'] = (
145 TRAILER_SOURCE[anime['trailer']['site']] + anime['trailer']['id']
146 if anime['trailer']
147 else ''
148 )
149 entry['al_cover'] = anime['coverImage']['large']
150 entry['al_banner'] = anime['bannerImage']
151 entry['al_genres'] = anime['genres']
152 entry['al_tags'] = [t['name'] for t in anime['tags']]
153 entry['al_links'] = anime['externalLinks']
154 if entry.isvalid():
155 yield entry
156 req_chunk = req_chunk + 1 if list_response['collection']['hasNextChunk'] else False
157
158 except ValueError:
159 raise plugin.PluginError('Invalid JSON response')
160
161
162 @event('plugin.register')
163 def register_plugin():
164 plugin.register(AniList, 'anilist', api_ver=2)
165
[end of flexget/plugins/input/anilist.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/flexget/plugins/input/anilist.py b/flexget/plugins/input/anilist.py
--- a/flexget/plugins/input/anilist.py
+++ b/flexget/plugins/input/anilist.py
@@ -26,7 +26,7 @@
Syntax:
anilist:
- username: <value>
+ username: <string>
status:
- <current|planning|completed|dropped|paused|repeating>
- <current|planning|completed|dropped|paused|repeating>
@@ -39,6 +39,10 @@
- <all|tv|tv_short|movie|special|ova|ona>
- <tv|tv_short|movie|special|ova|ona>
...
+ list:
+ - <string>
+ - <string>
+ ...
"""
schema = {
@@ -57,6 +61,7 @@
'format': one_or_more(
{'type': 'string', 'enum': ANIME_FORMAT}, unique_items=True
),
+ 'list': one_or_more({'type': 'string'}),
},
'required': ['username'],
'additionalProperties': False,
@@ -68,11 +73,10 @@
def on_task_input(self, task, config):
if isinstance(config, str):
config = {'username': config}
- selected_list_status = config['status'] if 'status' in config else ['current', 'planning']
- selected_release_status = (
- config['release_status'] if 'release_status' in config else ['all']
- )
- selected_formats = config['format'] if 'format' in config else ['all']
+ selected_list_status = config.get('status', ['current', 'planning'])
+ selected_release_status = config.get('release_status', ['all'])
+ selected_formats = config.get('format', ['all'])
+ selected_list_name = config.get('list', [])
if not isinstance(selected_list_status, list):
selected_list_status = [selected_list_status]
@@ -83,6 +87,10 @@
if not isinstance(selected_formats, list):
selected_formats = [selected_formats]
+ if not isinstance(selected_list_name, list):
+ selected_list_name = [selected_list_name]
+ selected_list_name = [i.lower() for i in selected_list_name]
+
logger.debug('Selected List Status: {}', selected_list_status)
logger.debug('Selected Release Status: {}', selected_release_status)
logger.debug('Selected Formats: {}', selected_formats)
@@ -99,7 +107,8 @@
f'query ($user: String){{ collection: MediaListCollection(userName: $user, '
f'type: ANIME, perChunk: 500, chunk: {req_chunk}, status_in: '
f'[{", ".join([s.upper() for s in selected_list_status])}]) {{ hasNextChunk, '
- f'statuses: lists{{ status, list: entries{{ anime: media{{ {req_fields} }}}}}}}}}}'
+ f'statuses: lists{{ status, name, list: entries{{ anime: media{{ {req_fields}'
+ f' }}}}}}}}}}'
)
try:
@@ -114,6 +123,11 @@
list_response = list_response.json()['data']
logger.debug('JSON output: {}', list_response)
for list_status in list_response['collection']['statuses']:
+ if (
+ selected_list_name
+ and list_status['name'].lower() not in selected_list_name
+ ):
+ continue
for anime in list_status['list']:
anime = anime['anime']
has_selected_release_status = (
@@ -130,7 +144,12 @@
entry['al_title'] = anime['title']
entry['al_format'] = anime['format']
entry['al_release_status'] = anime['status'].capitalize()
- entry['al_list_status'] = list_status['status'].capitalize()
+ entry['al_list'] = list_status['name']
+ entry['al_list_status'] = (
+ list_status['status'].capitalize()
+ if list_status.get('status')
+ else ''
+ )
entry['alternate_name'] = anime.get('synonyms', [])
if (
anime['title'].get('english')
|
{"golden_diff": "diff --git a/flexget/plugins/input/anilist.py b/flexget/plugins/input/anilist.py\n--- a/flexget/plugins/input/anilist.py\n+++ b/flexget/plugins/input/anilist.py\n@@ -26,7 +26,7 @@\n \n Syntax:\n anilist:\n- username: <value>\n+ username: <string>\n status:\n - <current|planning|completed|dropped|paused|repeating>\n - <current|planning|completed|dropped|paused|repeating>\n@@ -39,6 +39,10 @@\n - <all|tv|tv_short|movie|special|ova|ona>\n - <tv|tv_short|movie|special|ova|ona>\n ...\n+ list:\n+ - <string>\n+ - <string>\n+ ...\n \"\"\"\n \n schema = {\n@@ -57,6 +61,7 @@\n 'format': one_or_more(\n {'type': 'string', 'enum': ANIME_FORMAT}, unique_items=True\n ),\n+ 'list': one_or_more({'type': 'string'}),\n },\n 'required': ['username'],\n 'additionalProperties': False,\n@@ -68,11 +73,10 @@\n def on_task_input(self, task, config):\n if isinstance(config, str):\n config = {'username': config}\n- selected_list_status = config['status'] if 'status' in config else ['current', 'planning']\n- selected_release_status = (\n- config['release_status'] if 'release_status' in config else ['all']\n- )\n- selected_formats = config['format'] if 'format' in config else ['all']\n+ selected_list_status = config.get('status', ['current', 'planning'])\n+ selected_release_status = config.get('release_status', ['all'])\n+ selected_formats = config.get('format', ['all'])\n+ selected_list_name = config.get('list', [])\n \n if not isinstance(selected_list_status, list):\n selected_list_status = [selected_list_status]\n@@ -83,6 +87,10 @@\n if not isinstance(selected_formats, list):\n selected_formats = [selected_formats]\n \n+ if not isinstance(selected_list_name, list):\n+ selected_list_name = [selected_list_name]\n+ selected_list_name = [i.lower() for i in selected_list_name]\n+\n logger.debug('Selected List Status: {}', selected_list_status)\n logger.debug('Selected Release Status: {}', selected_release_status)\n logger.debug('Selected Formats: {}', selected_formats)\n@@ -99,7 +107,8 @@\n f'query ($user: String){{ collection: MediaListCollection(userName: $user, '\n f'type: ANIME, perChunk: 500, chunk: {req_chunk}, status_in: '\n f'[{\", \".join([s.upper() for s in selected_list_status])}]) {{ hasNextChunk, '\n- f'statuses: lists{{ status, list: entries{{ anime: media{{ {req_fields} }}}}}}}}}}'\n+ f'statuses: lists{{ status, name, list: entries{{ anime: media{{ {req_fields}'\n+ f' }}}}}}}}}}'\n )\n \n try:\n@@ -114,6 +123,11 @@\n list_response = list_response.json()['data']\n logger.debug('JSON output: {}', list_response)\n for list_status in list_response['collection']['statuses']:\n+ if (\n+ selected_list_name\n+ and list_status['name'].lower() not in selected_list_name\n+ ):\n+ continue\n for anime in list_status['list']:\n anime = anime['anime']\n has_selected_release_status = (\n@@ -130,7 +144,12 @@\n entry['al_title'] = anime['title']\n entry['al_format'] = anime['format']\n entry['al_release_status'] = anime['status'].capitalize()\n- entry['al_list_status'] = list_status['status'].capitalize()\n+ entry['al_list'] = list_status['name']\n+ entry['al_list_status'] = (\n+ list_status['status'].capitalize()\n+ if list_status.get('status')\n+ else ''\n+ )\n entry['alternate_name'] = anime.get('synonyms', [])\n if (\n anime['title'].get('english')\n", "issue": "AniList crashing with custom lists\n### Expected behaviour:\r\nParse AniList by status, ignore custom lists since they are duplicate entries from status lists.\r\n\r\n### Actual behaviour:\r\nTrying to parse custom lists cause a crash\r\n### Steps to reproduce:\r\n- Step 1: Try to parse an AniList account with a custom list.\r\n\r\n#### Config:\r\n```yaml\r\nPaste FULL config and remove any personal info if config is too long, attach the file to the ticket.\r\nIf issue is with a single task, you can get get resulting configuration by running:\r\n flexget execute --task <NAME> --dump-config\r\nMake sure to redact any personal information (passwords, api keys, etc) !\r\n```\r\n \r\n#### Log:\r\n<details>\r\n <summary>(click to expand)</summary>\r\n\r\n```\r\n2020-03-18 10:22:25 CRITICAL task_queue BUG: Unhandled exception during task queue run loop.\r\n2020-03-18 10:22:25 DEBUG scheduler task finished executing: fill-anime-movies-list\r\nTraceback (most recent call last):\r\n File \"github\\flexget\\flexget\\task_queue.py\", line 46, in run\r\n self.current_task.execute()\r\n File \"github\\flexget\\flexget\\task.py\", line 80, in wrapper\r\n return func(self, *args, **kw)\r\n File \"github\\flexget\\flexget\\task.py\", line 697, in execute\r\n self._execute()\r\n File \"github\\flexget\\flexget\\task.py\", line 663, in _execute\r\n self.__run_task_phase(phase)\r\n File \"github\\flexget\\flexget\\task.py\", line 492, in __run_task_phase\r\n for e in response:\r\n File \"github\\flexget\\flexget\\utils\\cached_input.py\", line 217, in __iter__\r\n for item in self.iterable:\r\n File \"github\\flexget\\flexget\\plugins\\input\\anilist.py\", line 133, in on_task_input\r\n entry['al_list_status'] = list_status['status'].capitalize()\r\nAttributeError: 'NoneType' object has no attribute 'capitalize'\r\n```\r\n</details>\r\n\r\n### Additional information:\r\n\r\n- FlexGet version: 3.1.34\r\n- Python version: 3.7\r\n- Installation method: git\r\n- Using daemon (yes/no): yes\r\n- OS and version: Win10\r\n- Link to crash log: N/A\r\n\n", "before_files": [{"content": "from loguru import logger\n\nfrom flexget import plugin\nfrom flexget.config_schema import one_or_more\nfrom flexget.entry import Entry\nfrom flexget.event import event\nfrom flexget.utils.cached_input import cached\nfrom flexget.utils.requests import RequestException\n\nlogger = logger.bind(name='anilist')\n\nLIST_STATUS = ['current', 'planning', 'completed', 'dropped', 'paused', 'repeating']\n\nRELEASE_STATUS = ['finished', 'releasing', 'not_yet_released', 'cancelled', 'all']\n\nANIME_FORMAT = ['tv', 'tv_short', 'movie', 'special', 'ova', 'ona', 'all']\n\nTRAILER_SOURCE = {\n 'youtube': 'https://www.youtube.com/embed/',\n 'dailymotion': 'https://www.dailymotion.com/embed/video/',\n}\n\n\nclass AniList(object):\n \"\"\"\" Creates entries for series and movies from your AniList list\n\n Syntax:\n anilist:\n username: <value>\n status:\n - <current|planning|completed|dropped|paused|repeating>\n - <current|planning|completed|dropped|paused|repeating>\n ...\n release_status:\n - <all|finished|releasing|not_yet_released|cancelled>\n - <finished|releasing|not_yet_released|cancelled>\n ...\n format:\n - <all|tv|tv_short|movie|special|ova|ona>\n - <tv|tv_short|movie|special|ova|ona>\n ...\n \"\"\"\n\n schema = {\n 'oneOf': [\n {'type': 'string'},\n {\n 'type': 'object',\n 'properties': {\n 'username': {'type': 'string'},\n 'status': one_or_more(\n {'type': 'string', 'enum': LIST_STATUS}, unique_items=True\n ),\n 'release_status': one_or_more(\n {'type': 'string', 'enum': RELEASE_STATUS}, unique_items=True\n ),\n 'format': one_or_more(\n {'type': 'string', 'enum': ANIME_FORMAT}, unique_items=True\n ),\n },\n 'required': ['username'],\n 'additionalProperties': False,\n },\n ]\n }\n\n @cached('anilist', persist='2 hours')\n def on_task_input(self, task, config):\n if isinstance(config, str):\n config = {'username': config}\n selected_list_status = config['status'] if 'status' in config else ['current', 'planning']\n selected_release_status = (\n config['release_status'] if 'release_status' in config else ['all']\n )\n selected_formats = config['format'] if 'format' in config else ['all']\n\n if not isinstance(selected_list_status, list):\n selected_list_status = [selected_list_status]\n\n if not isinstance(selected_release_status, list):\n selected_release_status = [selected_release_status]\n\n if not isinstance(selected_formats, list):\n selected_formats = [selected_formats]\n\n logger.debug('Selected List Status: {}', selected_list_status)\n logger.debug('Selected Release Status: {}', selected_release_status)\n logger.debug('Selected Formats: {}', selected_formats)\n\n req_variables = {'user': config['username']}\n req_chunk = 1\n req_fields = (\n 'status, title{ romaji, english }, synonyms, siteUrl, idMal, format, episodes, '\n 'trailer{ site, id }, coverImage{ large }, bannerImage, genres, tags{ name }, '\n 'externalLinks{ site, url }'\n )\n while req_chunk:\n req_query = (\n f'query ($user: String){{ collection: MediaListCollection(userName: $user, '\n f'type: ANIME, perChunk: 500, chunk: {req_chunk}, status_in: '\n f'[{\", \".join([s.upper() for s in selected_list_status])}]) {{ hasNextChunk, '\n f'statuses: lists{{ status, list: entries{{ anime: media{{ {req_fields} }}}}}}}}}}'\n )\n\n try:\n list_response = task.requests.post(\n 'https://graphql.anilist.co',\n json={'query': req_query, 'variables': req_variables},\n )\n except RequestException as e:\n raise plugin.PluginError('Error reading list - {url}'.format(url=e))\n\n try:\n list_response = list_response.json()['data']\n logger.debug('JSON output: {}', list_response)\n for list_status in list_response['collection']['statuses']:\n for anime in list_status['list']:\n anime = anime['anime']\n has_selected_release_status = (\n anime['status'].lower() in selected_release_status\n or 'all' in selected_release_status\n )\n has_selected_type = (\n anime['format'].lower() in selected_formats\n or 'all' in selected_formats\n )\n if has_selected_type and has_selected_release_status:\n entry = Entry()\n entry['title'] = anime['title']['romaji']\n entry['al_title'] = anime['title']\n entry['al_format'] = anime['format']\n entry['al_release_status'] = anime['status'].capitalize()\n entry['al_list_status'] = list_status['status'].capitalize()\n entry['alternate_name'] = anime.get('synonyms', [])\n if (\n anime['title'].get('english')\n and anime['title'].get('english') != anime['title']['romaji']\n and anime['title'].get('english') not in entry['alternate_name']\n ):\n entry['alternate_name'].insert(0, anime['title']['english'])\n entry['url'] = anime['siteUrl']\n entry['al_idMal'] = anime['idMal']\n entry['al_episodes'] = anime['episodes']\n entry['al_trailer'] = (\n TRAILER_SOURCE[anime['trailer']['site']] + anime['trailer']['id']\n if anime['trailer']\n else ''\n )\n entry['al_cover'] = anime['coverImage']['large']\n entry['al_banner'] = anime['bannerImage']\n entry['al_genres'] = anime['genres']\n entry['al_tags'] = [t['name'] for t in anime['tags']]\n entry['al_links'] = anime['externalLinks']\n if entry.isvalid():\n yield entry\n req_chunk = req_chunk + 1 if list_response['collection']['hasNextChunk'] else False\n\n except ValueError:\n raise plugin.PluginError('Invalid JSON response')\n\n\n@event('plugin.register')\ndef register_plugin():\n plugin.register(AniList, 'anilist', api_ver=2)\n", "path": "flexget/plugins/input/anilist.py"}]}
| 2,932 | 967 |
gh_patches_debug_13030
|
rasdani/github-patches
|
git_diff
|
microsoft__AzureTRE-395
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Application Insights configuration for processor function broken
The `createNewWorkspace` function monitoring blade indicates that Application Insights integration is not enabled.

At a first glance, the config seems to be there in [processor_function/function.tf](https://github.com/microsoft/AzureTRE/blob/develop/templates/core/terraform/processor_function/function.tf#L24)
```plaintext
APP_INSIGHTS_INSTRUMENTATION_KEY = var.app_insights_instrumentation_key
```
however, the setting key name is incorrect.
Manually enabling the integration in the portal adds additional config keys:
`APPLICATIONINSIGHTS_CONNECTION_STRING`
`APPINSIGHTS_INSTRUMENTATIONKEY`
Need to add above keys with values to function app config.
[Reference](https://docs.microsoft.com/en-us/azure/azure-monitor/app/resource-manager-function-app)
</issue>
<code>
[start of processor_function/shared/logging.py]
1 import logging
2 import os
3
4 from opencensus.ext.azure.log_exporter import AzureLogHandler
5 from opencensus.trace import config_integration
6 from opencensus.trace.samplers import AlwaysOnSampler
7 from opencensus.trace.tracer import Tracer
8
9
10 def initialize_logging(logging_level: int, correlation_id: str) -> logging.LoggerAdapter:
11 """
12 Adds the Application Insights handler for the root logger and sets the given logging level.
13 Creates and returns a logger adapter that integrates the correlation ID, if given, to the log messages.
14
15 :param logging_level: The logging level to set e.g., logging.WARNING.
16 :param correlation_id: Optional. The correlation ID that is passed on to the operation_Id in App Insights.
17 :returns: A newly created logger adapter.
18 """
19 logger = logging.getLogger()
20 logger.addHandler(logging.StreamHandler()) # For logging into console
21 app_insights_instrumentation_key = os.getenv("APP_INSIGHTS_INSTRUMENTATION_KEY")
22
23 try:
24 logger.addHandler(AzureLogHandler(connection_string=f"InstrumentationKey={app_insights_instrumentation_key}"))
25 except ValueError as e:
26 logger.error(f"Failed to set Application Insights logger handler: {e}")
27
28 config_integration.trace_integrations(['logging'])
29 logging.basicConfig(level=logging_level, format='%(asctime)s traceId=%(traceId)s spanId=%(spanId)s %(message)s')
30 Tracer(sampler=AlwaysOnSampler())
31 logger.setLevel(logging_level)
32
33 extra = None
34
35 if correlation_id:
36 extra = {'traceId': correlation_id}
37
38 adapter = logging.LoggerAdapter(logger, extra)
39 adapter.debug(f"Logger adapter initialized with extra: {extra}")
40
41 return adapter
42
[end of processor_function/shared/logging.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/processor_function/shared/logging.py b/processor_function/shared/logging.py
--- a/processor_function/shared/logging.py
+++ b/processor_function/shared/logging.py
@@ -18,10 +18,10 @@
"""
logger = logging.getLogger()
logger.addHandler(logging.StreamHandler()) # For logging into console
- app_insights_instrumentation_key = os.getenv("APP_INSIGHTS_INSTRUMENTATION_KEY")
+ app_insights_connection_string = os.getenv("APPLICATIONINSIGHTS_CONNECTION_STRING")
try:
- logger.addHandler(AzureLogHandler(connection_string=f"InstrumentationKey={app_insights_instrumentation_key}"))
+ logger.addHandler(AzureLogHandler(connection_string=app_insights_connection_string))
except ValueError as e:
logger.error(f"Failed to set Application Insights logger handler: {e}")
|
{"golden_diff": "diff --git a/processor_function/shared/logging.py b/processor_function/shared/logging.py\n--- a/processor_function/shared/logging.py\n+++ b/processor_function/shared/logging.py\n@@ -18,10 +18,10 @@\n \"\"\"\n logger = logging.getLogger()\n logger.addHandler(logging.StreamHandler()) # For logging into console\n- app_insights_instrumentation_key = os.getenv(\"APP_INSIGHTS_INSTRUMENTATION_KEY\")\n+ app_insights_connection_string = os.getenv(\"APPLICATIONINSIGHTS_CONNECTION_STRING\")\n \n try:\n- logger.addHandler(AzureLogHandler(connection_string=f\"InstrumentationKey={app_insights_instrumentation_key}\"))\n+ logger.addHandler(AzureLogHandler(connection_string=app_insights_connection_string))\n except ValueError as e:\n logger.error(f\"Failed to set Application Insights logger handler: {e}\")\n", "issue": "Application Insights configuration for processor function broken\nThe `createNewWorkspace` function monitoring blade indicates that Application Insights integration is not enabled.\r\n\r\n\r\nAt a first glance, the config seems to be there in [processor_function/function.tf](https://github.com/microsoft/AzureTRE/blob/develop/templates/core/terraform/processor_function/function.tf#L24)\r\n```plaintext\r\n APP_INSIGHTS_INSTRUMENTATION_KEY = var.app_insights_instrumentation_key\r\n```\r\nhowever, the setting key name is incorrect.\r\n\r\nManually enabling the integration in the portal adds additional config keys:\r\n\r\n`APPLICATIONINSIGHTS_CONNECTION_STRING`\r\n`APPINSIGHTS_INSTRUMENTATIONKEY`\r\n\r\nNeed to add above keys with values to function app config.\r\n\r\n[Reference](https://docs.microsoft.com/en-us/azure/azure-monitor/app/resource-manager-function-app)\n", "before_files": [{"content": "import logging\nimport os\n\nfrom opencensus.ext.azure.log_exporter import AzureLogHandler\nfrom opencensus.trace import config_integration\nfrom opencensus.trace.samplers import AlwaysOnSampler\nfrom opencensus.trace.tracer import Tracer\n\n\ndef initialize_logging(logging_level: int, correlation_id: str) -> logging.LoggerAdapter:\n \"\"\"\n Adds the Application Insights handler for the root logger and sets the given logging level.\n Creates and returns a logger adapter that integrates the correlation ID, if given, to the log messages.\n\n :param logging_level: The logging level to set e.g., logging.WARNING.\n :param correlation_id: Optional. The correlation ID that is passed on to the operation_Id in App Insights.\n :returns: A newly created logger adapter.\n \"\"\"\n logger = logging.getLogger()\n logger.addHandler(logging.StreamHandler()) # For logging into console\n app_insights_instrumentation_key = os.getenv(\"APP_INSIGHTS_INSTRUMENTATION_KEY\")\n\n try:\n logger.addHandler(AzureLogHandler(connection_string=f\"InstrumentationKey={app_insights_instrumentation_key}\"))\n except ValueError as e:\n logger.error(f\"Failed to set Application Insights logger handler: {e}\")\n\n config_integration.trace_integrations(['logging'])\n logging.basicConfig(level=logging_level, format='%(asctime)s traceId=%(traceId)s spanId=%(spanId)s %(message)s')\n Tracer(sampler=AlwaysOnSampler())\n logger.setLevel(logging_level)\n\n extra = None\n\n if correlation_id:\n extra = {'traceId': correlation_id}\n\n adapter = logging.LoggerAdapter(logger, extra)\n adapter.debug(f\"Logger adapter initialized with extra: {extra}\")\n\n return adapter\n", "path": "processor_function/shared/logging.py"}]}
| 1,208 | 181 |
gh_patches_debug_15975
|
rasdani/github-patches
|
git_diff
|
pypa__pip-3031
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
--process-dependency-links not recognized in requirements.txt
</issue>
<code>
[start of pip/req/req_file.py]
1 """
2 Requirements file parsing
3 """
4
5 from __future__ import absolute_import
6
7 import os
8 import re
9 import shlex
10 import optparse
11 import warnings
12
13 from pip._vendor.six.moves.urllib import parse as urllib_parse
14 from pip._vendor.six.moves import filterfalse
15
16 import pip
17 from pip.download import get_file_content
18 from pip.req.req_install import InstallRequirement
19 from pip.exceptions import (RequirementsFileParseError)
20 from pip.utils.deprecation import RemovedInPip10Warning
21 from pip import cmdoptions
22
23 __all__ = ['parse_requirements']
24
25 SCHEME_RE = re.compile(r'^(http|https|file):', re.I)
26 COMMENT_RE = re.compile(r'(^|\s)+#.*$')
27
28 SUPPORTED_OPTIONS = [
29 cmdoptions.constraints,
30 cmdoptions.editable,
31 cmdoptions.requirements,
32 cmdoptions.no_index,
33 cmdoptions.index_url,
34 cmdoptions.find_links,
35 cmdoptions.extra_index_url,
36 cmdoptions.allow_external,
37 cmdoptions.allow_all_external,
38 cmdoptions.no_allow_external,
39 cmdoptions.allow_unsafe,
40 cmdoptions.no_allow_unsafe,
41 cmdoptions.use_wheel,
42 cmdoptions.no_use_wheel,
43 cmdoptions.always_unzip,
44 cmdoptions.no_binary,
45 cmdoptions.only_binary,
46 cmdoptions.trusted_host,
47 ]
48
49 # options to be passed to requirements
50 SUPPORTED_OPTIONS_REQ = [
51 cmdoptions.install_options,
52 cmdoptions.global_options
53 ]
54
55 # the 'dest' string values
56 SUPPORTED_OPTIONS_REQ_DEST = [o().dest for o in SUPPORTED_OPTIONS_REQ]
57
58
59 def parse_requirements(filename, finder=None, comes_from=None, options=None,
60 session=None, constraint=False, wheel_cache=None):
61 """Parse a requirements file and yield InstallRequirement instances.
62
63 :param filename: Path or url of requirements file.
64 :param finder: Instance of pip.index.PackageFinder.
65 :param comes_from: Origin description of requirements.
66 :param options: Global options.
67 :param session: Instance of pip.download.PipSession.
68 :param constraint: If true, parsing a constraint file rather than
69 requirements file.
70 :param wheel_cache: Instance of pip.wheel.WheelCache
71 """
72 if session is None:
73 raise TypeError(
74 "parse_requirements() missing 1 required keyword argument: "
75 "'session'"
76 )
77
78 _, content = get_file_content(
79 filename, comes_from=comes_from, session=session
80 )
81
82 lines = content.splitlines()
83 lines = ignore_comments(lines)
84 lines = join_lines(lines)
85 lines = skip_regex(lines, options)
86
87 for line_number, line in enumerate(lines, 1):
88 req_iter = process_line(line, filename, line_number, finder,
89 comes_from, options, session, wheel_cache,
90 constraint=constraint)
91 for req in req_iter:
92 yield req
93
94
95 def process_line(line, filename, line_number, finder=None, comes_from=None,
96 options=None, session=None, wheel_cache=None,
97 constraint=False):
98 """Process a single requirements line; This can result in creating/yielding
99 requirements, or updating the finder.
100
101 For lines that contain requirements, the only options that have an effect
102 are from SUPPORTED_OPTIONS_REQ, and they are scoped to the
103 requirement. Other options from SUPPORTED_OPTIONS may be present, but are
104 ignored.
105
106 For lines that do not contain requirements, the only options that have an
107 effect are from SUPPORTED_OPTIONS. Options from SUPPORTED_OPTIONS_REQ may
108 be present, but are ignored. These lines may contain multiple options
109 (although our docs imply only one is supported), and all our parsed and
110 affect the finder.
111
112 :param constraint: If True, parsing a constraints file.
113 """
114 parser = build_parser()
115 defaults = parser.get_default_values()
116 defaults.index_url = None
117 if finder:
118 # `finder.format_control` will be updated during parsing
119 defaults.format_control = finder.format_control
120 args_str, options_str = break_args_options(line)
121 opts, _ = parser.parse_args(shlex.split(options_str), defaults)
122
123 # preserve for the nested code path
124 line_comes_from = '%s %s (line %s)' % (
125 '-c' if constraint else '-r', filename, line_number)
126
127 # yield a line requirement
128 if args_str:
129 isolated = options.isolated_mode if options else False
130 if options:
131 cmdoptions.check_install_build_global(options, opts)
132 # get the options that apply to requirements
133 req_options = {}
134 for dest in SUPPORTED_OPTIONS_REQ_DEST:
135 if dest in opts.__dict__ and opts.__dict__[dest]:
136 req_options[dest] = opts.__dict__[dest]
137 yield InstallRequirement.from_line(
138 args_str, line_comes_from, constraint=constraint,
139 isolated=isolated, options=req_options, wheel_cache=wheel_cache
140 )
141
142 # yield an editable requirement
143 elif opts.editables:
144 isolated = options.isolated_mode if options else False
145 default_vcs = options.default_vcs if options else None
146 yield InstallRequirement.from_editable(
147 opts.editables[0], comes_from=line_comes_from,
148 constraint=constraint, default_vcs=default_vcs, isolated=isolated,
149 wheel_cache=wheel_cache
150 )
151
152 # parse a nested requirements file
153 elif opts.requirements or opts.constraints:
154 if opts.requirements:
155 req_path = opts.requirements[0]
156 nested_constraint = False
157 else:
158 req_path = opts.constraints[0]
159 nested_constraint = True
160 # original file is over http
161 if SCHEME_RE.search(filename):
162 # do a url join so relative paths work
163 req_path = urllib_parse.urljoin(filename, req_path)
164 # original file and nested file are paths
165 elif not SCHEME_RE.search(req_path):
166 # do a join so relative paths work
167 req_dir = os.path.dirname(filename)
168 req_path = os.path.join(os.path.dirname(filename), req_path)
169 # TODO: Why not use `comes_from='-r {} (line {})'` here as well?
170 parser = parse_requirements(
171 req_path, finder, comes_from, options, session,
172 constraint=nested_constraint, wheel_cache=wheel_cache
173 )
174 for req in parser:
175 yield req
176
177 # set finder options
178 elif finder:
179 if opts.allow_external:
180 warnings.warn(
181 "--allow-external has been deprecated and will be removed in "
182 "the future. Due to changes in the repository protocol, it no "
183 "longer has any effect.",
184 RemovedInPip10Warning,
185 )
186
187 if opts.allow_all_external:
188 warnings.warn(
189 "--allow-all-external has been deprecated and will be removed "
190 "in the future. Due to changes in the repository protocol, it "
191 "no longer has any effect.",
192 RemovedInPip10Warning,
193 )
194
195 if opts.allow_unverified:
196 warnings.warn(
197 "--allow-unverified has been deprecated and will be removed "
198 "in the future. Due to changes in the repository protocol, it "
199 "no longer has any effect.",
200 RemovedInPip10Warning,
201 )
202
203 if opts.index_url:
204 finder.index_urls = [opts.index_url]
205 if opts.use_wheel is False:
206 finder.use_wheel = False
207 pip.index.fmt_ctl_no_use_wheel(finder.format_control)
208 if opts.no_index is True:
209 finder.index_urls = []
210 if opts.extra_index_urls:
211 finder.index_urls.extend(opts.extra_index_urls)
212 if opts.find_links:
213 # FIXME: it would be nice to keep track of the source
214 # of the find_links: support a find-links local path
215 # relative to a requirements file.
216 value = opts.find_links[0]
217 req_dir = os.path.dirname(os.path.abspath(filename))
218 relative_to_reqs_file = os.path.join(req_dir, value)
219 if os.path.exists(relative_to_reqs_file):
220 value = relative_to_reqs_file
221 finder.find_links.append(value)
222 if opts.trusted_hosts:
223 finder.secure_origins.extend(
224 ("*", host, "*") for host in opts.trusted_hosts)
225
226
227 def break_args_options(line):
228 """Break up the line into an args and options string. We only want to shlex
229 (and then optparse) the options, not the args. args can contain markers
230 which are corrupted by shlex.
231 """
232 tokens = line.split(' ')
233 args = []
234 options = tokens[:]
235 for token in tokens:
236 if token.startswith('-') or token.startswith('--'):
237 break
238 else:
239 args.append(token)
240 options.pop(0)
241 return ' '.join(args), ' '.join(options)
242
243
244 def build_parser():
245 """
246 Return a parser for parsing requirement lines
247 """
248 parser = optparse.OptionParser(add_help_option=False)
249
250 option_factories = SUPPORTED_OPTIONS + SUPPORTED_OPTIONS_REQ
251 for option_factory in option_factories:
252 option = option_factory()
253 parser.add_option(option)
254
255 # By default optparse sys.exits on parsing errors. We want to wrap
256 # that in our own exception.
257 def parser_exit(self, msg):
258 raise RequirementsFileParseError(msg)
259 parser.exit = parser_exit
260
261 return parser
262
263
264 def join_lines(iterator):
265 """
266 Joins a line ending in '\' with the previous line.
267 """
268 lines = []
269 for line in iterator:
270 if not line.endswith('\\'):
271 if lines:
272 lines.append(line)
273 yield ''.join(lines)
274 lines = []
275 else:
276 yield line
277 else:
278 lines.append(line.strip('\\'))
279
280 # TODO: handle space after '\'.
281 # TODO: handle '\' on last line.
282
283
284 def ignore_comments(iterator):
285 """
286 Strips and filters empty or commented lines.
287 """
288 for line in iterator:
289 line = COMMENT_RE.sub('', line)
290 line = line.strip()
291 if line:
292 yield line
293
294
295 def skip_regex(lines, options):
296 """
297 Optionally exclude lines that match '--skip-requirements-regex'
298 """
299 skip_regex = options.skip_requirements_regex if options else None
300 if skip_regex:
301 lines = filterfalse(re.compile(skip_regex).search, lines)
302 return lines
303
[end of pip/req/req_file.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pip/req/req_file.py b/pip/req/req_file.py
--- a/pip/req/req_file.py
+++ b/pip/req/req_file.py
@@ -43,6 +43,7 @@
cmdoptions.always_unzip,
cmdoptions.no_binary,
cmdoptions.only_binary,
+ cmdoptions.process_dependency_links,
cmdoptions.trusted_host,
]
@@ -219,6 +220,8 @@
if os.path.exists(relative_to_reqs_file):
value = relative_to_reqs_file
finder.find_links.append(value)
+ if opts.process_dependency_links:
+ finder.process_dependency_links = True
if opts.trusted_hosts:
finder.secure_origins.extend(
("*", host, "*") for host in opts.trusted_hosts)
|
{"golden_diff": "diff --git a/pip/req/req_file.py b/pip/req/req_file.py\n--- a/pip/req/req_file.py\n+++ b/pip/req/req_file.py\n@@ -43,6 +43,7 @@\n cmdoptions.always_unzip,\n cmdoptions.no_binary,\n cmdoptions.only_binary,\n+ cmdoptions.process_dependency_links,\n cmdoptions.trusted_host,\n ]\n \n@@ -219,6 +220,8 @@\n if os.path.exists(relative_to_reqs_file):\n value = relative_to_reqs_file\n finder.find_links.append(value)\n+ if opts.process_dependency_links:\n+ finder.process_dependency_links = True\n if opts.trusted_hosts:\n finder.secure_origins.extend(\n (\"*\", host, \"*\") for host in opts.trusted_hosts)\n", "issue": "--process-dependency-links not recognized in requirements.txt\n\n", "before_files": [{"content": "\"\"\"\nRequirements file parsing\n\"\"\"\n\nfrom __future__ import absolute_import\n\nimport os\nimport re\nimport shlex\nimport optparse\nimport warnings\n\nfrom pip._vendor.six.moves.urllib import parse as urllib_parse\nfrom pip._vendor.six.moves import filterfalse\n\nimport pip\nfrom pip.download import get_file_content\nfrom pip.req.req_install import InstallRequirement\nfrom pip.exceptions import (RequirementsFileParseError)\nfrom pip.utils.deprecation import RemovedInPip10Warning\nfrom pip import cmdoptions\n\n__all__ = ['parse_requirements']\n\nSCHEME_RE = re.compile(r'^(http|https|file):', re.I)\nCOMMENT_RE = re.compile(r'(^|\\s)+#.*$')\n\nSUPPORTED_OPTIONS = [\n cmdoptions.constraints,\n cmdoptions.editable,\n cmdoptions.requirements,\n cmdoptions.no_index,\n cmdoptions.index_url,\n cmdoptions.find_links,\n cmdoptions.extra_index_url,\n cmdoptions.allow_external,\n cmdoptions.allow_all_external,\n cmdoptions.no_allow_external,\n cmdoptions.allow_unsafe,\n cmdoptions.no_allow_unsafe,\n cmdoptions.use_wheel,\n cmdoptions.no_use_wheel,\n cmdoptions.always_unzip,\n cmdoptions.no_binary,\n cmdoptions.only_binary,\n cmdoptions.trusted_host,\n]\n\n# options to be passed to requirements\nSUPPORTED_OPTIONS_REQ = [\n cmdoptions.install_options,\n cmdoptions.global_options\n]\n\n# the 'dest' string values\nSUPPORTED_OPTIONS_REQ_DEST = [o().dest for o in SUPPORTED_OPTIONS_REQ]\n\n\ndef parse_requirements(filename, finder=None, comes_from=None, options=None,\n session=None, constraint=False, wheel_cache=None):\n \"\"\"Parse a requirements file and yield InstallRequirement instances.\n\n :param filename: Path or url of requirements file.\n :param finder: Instance of pip.index.PackageFinder.\n :param comes_from: Origin description of requirements.\n :param options: Global options.\n :param session: Instance of pip.download.PipSession.\n :param constraint: If true, parsing a constraint file rather than\n requirements file.\n :param wheel_cache: Instance of pip.wheel.WheelCache\n \"\"\"\n if session is None:\n raise TypeError(\n \"parse_requirements() missing 1 required keyword argument: \"\n \"'session'\"\n )\n\n _, content = get_file_content(\n filename, comes_from=comes_from, session=session\n )\n\n lines = content.splitlines()\n lines = ignore_comments(lines)\n lines = join_lines(lines)\n lines = skip_regex(lines, options)\n\n for line_number, line in enumerate(lines, 1):\n req_iter = process_line(line, filename, line_number, finder,\n comes_from, options, session, wheel_cache,\n constraint=constraint)\n for req in req_iter:\n yield req\n\n\ndef process_line(line, filename, line_number, finder=None, comes_from=None,\n options=None, session=None, wheel_cache=None,\n constraint=False):\n \"\"\"Process a single requirements line; This can result in creating/yielding\n requirements, or updating the finder.\n\n For lines that contain requirements, the only options that have an effect\n are from SUPPORTED_OPTIONS_REQ, and they are scoped to the\n requirement. Other options from SUPPORTED_OPTIONS may be present, but are\n ignored.\n\n For lines that do not contain requirements, the only options that have an\n effect are from SUPPORTED_OPTIONS. Options from SUPPORTED_OPTIONS_REQ may\n be present, but are ignored. These lines may contain multiple options\n (although our docs imply only one is supported), and all our parsed and\n affect the finder.\n\n :param constraint: If True, parsing a constraints file.\n \"\"\"\n parser = build_parser()\n defaults = parser.get_default_values()\n defaults.index_url = None\n if finder:\n # `finder.format_control` will be updated during parsing\n defaults.format_control = finder.format_control\n args_str, options_str = break_args_options(line)\n opts, _ = parser.parse_args(shlex.split(options_str), defaults)\n\n # preserve for the nested code path\n line_comes_from = '%s %s (line %s)' % (\n '-c' if constraint else '-r', filename, line_number)\n\n # yield a line requirement\n if args_str:\n isolated = options.isolated_mode if options else False\n if options:\n cmdoptions.check_install_build_global(options, opts)\n # get the options that apply to requirements\n req_options = {}\n for dest in SUPPORTED_OPTIONS_REQ_DEST:\n if dest in opts.__dict__ and opts.__dict__[dest]:\n req_options[dest] = opts.__dict__[dest]\n yield InstallRequirement.from_line(\n args_str, line_comes_from, constraint=constraint,\n isolated=isolated, options=req_options, wheel_cache=wheel_cache\n )\n\n # yield an editable requirement\n elif opts.editables:\n isolated = options.isolated_mode if options else False\n default_vcs = options.default_vcs if options else None\n yield InstallRequirement.from_editable(\n opts.editables[0], comes_from=line_comes_from,\n constraint=constraint, default_vcs=default_vcs, isolated=isolated,\n wheel_cache=wheel_cache\n )\n\n # parse a nested requirements file\n elif opts.requirements or opts.constraints:\n if opts.requirements:\n req_path = opts.requirements[0]\n nested_constraint = False\n else:\n req_path = opts.constraints[0]\n nested_constraint = True\n # original file is over http\n if SCHEME_RE.search(filename):\n # do a url join so relative paths work\n req_path = urllib_parse.urljoin(filename, req_path)\n # original file and nested file are paths\n elif not SCHEME_RE.search(req_path):\n # do a join so relative paths work\n req_dir = os.path.dirname(filename)\n req_path = os.path.join(os.path.dirname(filename), req_path)\n # TODO: Why not use `comes_from='-r {} (line {})'` here as well?\n parser = parse_requirements(\n req_path, finder, comes_from, options, session,\n constraint=nested_constraint, wheel_cache=wheel_cache\n )\n for req in parser:\n yield req\n\n # set finder options\n elif finder:\n if opts.allow_external:\n warnings.warn(\n \"--allow-external has been deprecated and will be removed in \"\n \"the future. Due to changes in the repository protocol, it no \"\n \"longer has any effect.\",\n RemovedInPip10Warning,\n )\n\n if opts.allow_all_external:\n warnings.warn(\n \"--allow-all-external has been deprecated and will be removed \"\n \"in the future. Due to changes in the repository protocol, it \"\n \"no longer has any effect.\",\n RemovedInPip10Warning,\n )\n\n if opts.allow_unverified:\n warnings.warn(\n \"--allow-unverified has been deprecated and will be removed \"\n \"in the future. Due to changes in the repository protocol, it \"\n \"no longer has any effect.\",\n RemovedInPip10Warning,\n )\n\n if opts.index_url:\n finder.index_urls = [opts.index_url]\n if opts.use_wheel is False:\n finder.use_wheel = False\n pip.index.fmt_ctl_no_use_wheel(finder.format_control)\n if opts.no_index is True:\n finder.index_urls = []\n if opts.extra_index_urls:\n finder.index_urls.extend(opts.extra_index_urls)\n if opts.find_links:\n # FIXME: it would be nice to keep track of the source\n # of the find_links: support a find-links local path\n # relative to a requirements file.\n value = opts.find_links[0]\n req_dir = os.path.dirname(os.path.abspath(filename))\n relative_to_reqs_file = os.path.join(req_dir, value)\n if os.path.exists(relative_to_reqs_file):\n value = relative_to_reqs_file\n finder.find_links.append(value)\n if opts.trusted_hosts:\n finder.secure_origins.extend(\n (\"*\", host, \"*\") for host in opts.trusted_hosts)\n\n\ndef break_args_options(line):\n \"\"\"Break up the line into an args and options string. We only want to shlex\n (and then optparse) the options, not the args. args can contain markers\n which are corrupted by shlex.\n \"\"\"\n tokens = line.split(' ')\n args = []\n options = tokens[:]\n for token in tokens:\n if token.startswith('-') or token.startswith('--'):\n break\n else:\n args.append(token)\n options.pop(0)\n return ' '.join(args), ' '.join(options)\n\n\ndef build_parser():\n \"\"\"\n Return a parser for parsing requirement lines\n \"\"\"\n parser = optparse.OptionParser(add_help_option=False)\n\n option_factories = SUPPORTED_OPTIONS + SUPPORTED_OPTIONS_REQ\n for option_factory in option_factories:\n option = option_factory()\n parser.add_option(option)\n\n # By default optparse sys.exits on parsing errors. We want to wrap\n # that in our own exception.\n def parser_exit(self, msg):\n raise RequirementsFileParseError(msg)\n parser.exit = parser_exit\n\n return parser\n\n\ndef join_lines(iterator):\n \"\"\"\n Joins a line ending in '\\' with the previous line.\n \"\"\"\n lines = []\n for line in iterator:\n if not line.endswith('\\\\'):\n if lines:\n lines.append(line)\n yield ''.join(lines)\n lines = []\n else:\n yield line\n else:\n lines.append(line.strip('\\\\'))\n\n # TODO: handle space after '\\'.\n # TODO: handle '\\' on last line.\n\n\ndef ignore_comments(iterator):\n \"\"\"\n Strips and filters empty or commented lines.\n \"\"\"\n for line in iterator:\n line = COMMENT_RE.sub('', line)\n line = line.strip()\n if line:\n yield line\n\n\ndef skip_regex(lines, options):\n \"\"\"\n Optionally exclude lines that match '--skip-requirements-regex'\n \"\"\"\n skip_regex = options.skip_requirements_regex if options else None\n if skip_regex:\n lines = filterfalse(re.compile(skip_regex).search, lines)\n return lines\n", "path": "pip/req/req_file.py"}]}
| 3,566 | 181 |
gh_patches_debug_42415
|
rasdani/github-patches
|
git_diff
|
great-expectations__great_expectations-4502
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Use cleaner solution for non-truncating division in python 2
Prefer `from __future__ import division` to `1.*x/y`
</issue>
<code>
[start of assets/scripts/build_gallery.py]
1 import ast
2 import importlib
3 import json
4 import logging
5 import os
6 import sys
7 import traceback
8 from io import StringIO
9 from subprocess import CalledProcessError, CompletedProcess, run
10 from typing import Dict
11
12 import pkg_resources
13
14 logger = logging.getLogger(__name__)
15 chandler = logging.StreamHandler(stream=sys.stdout)
16 chandler.setLevel(logging.DEBUG)
17 chandler.setFormatter(
18 logging.Formatter("%(asctime)s - %(levelname)s - %(message)s", "%Y-%m-%dT%H:%M:%S")
19 )
20 logger.addHandler(chandler)
21 logger.setLevel(logging.DEBUG)
22
23
24 expectation_tracebacks = StringIO()
25 expectation_checklists = StringIO()
26
27
28 def execute_shell_command(command: str) -> int:
29 """
30 Wrap subprocess command in a try/except block to provide a convenient method for pip installing dependencies.
31
32 :param command: bash command -- as if typed in a shell/Terminal window
33 :return: status code -- 0 if successful; all other values (1 is the most common) indicate an error
34 """
35 cwd: str = os.getcwd()
36
37 path_env_var: str = os.pathsep.join([os.environ.get("PATH", os.defpath), cwd])
38 env: dict = dict(os.environ, PATH=path_env_var)
39
40 status_code: int = 0
41 try:
42 res: CompletedProcess = run(
43 args=["bash", "-c", command],
44 stdin=None,
45 input=None,
46 # stdout=None, # commenting out to prevent issues with `subprocess.run` in python <3.7.4
47 # stderr=None, # commenting out to prevent issues with `subprocess.run` in python <3.7.4
48 capture_output=True,
49 shell=False,
50 cwd=cwd,
51 timeout=None,
52 check=True,
53 encoding=None,
54 errors=None,
55 text=None,
56 env=env,
57 universal_newlines=True,
58 )
59 sh_out: str = res.stdout.strip()
60 logger.info(sh_out)
61 except CalledProcessError as cpe:
62 status_code = cpe.returncode
63 sys.stderr.write(cpe.output)
64 sys.stderr.flush()
65 exception_message: str = "A Sub-Process call Exception occurred.\n"
66 exception_traceback: str = traceback.format_exc()
67 exception_message += (
68 f'{type(cpe).__name__}: "{str(cpe)}". Traceback: "{exception_traceback}".'
69 )
70 logger.error(exception_message)
71
72 return status_code
73
74
75 def get_contrib_requirements(filepath: str) -> Dict:
76 """
77 Parse the python file from filepath to identify a "library_metadata" dictionary in any defined classes, and return a requirements_info object that includes a list of pip-installable requirements for each class that defines them.
78
79 Note, currently we are handling all dependencies at the module level. To support future expandability and detail, this method also returns per-class requirements in addition to the concatenated list.
80
81 Args:
82 filepath: the path to the file to parse and analyze
83
84 Returns:
85 A dictionary:
86 {
87 "requirements": [ all_requirements_found_in_any_library_metadata_in_file ],
88 class_name: [ requirements ]
89 }
90
91 """
92 with open(filepath) as file:
93 tree = ast.parse(file.read())
94
95 requirements_info = {"requirements": []}
96 for child in ast.iter_child_nodes(tree):
97 if not isinstance(child, ast.ClassDef):
98 continue
99 current_class = child.name
100 for node in ast.walk(child):
101 if isinstance(node, ast.Assign):
102 try:
103 target_ids = [target.id for target in node.targets]
104 except (ValueError, AttributeError):
105 # some assignment types assign to non-node objects (e.g. Tuple)
106 target_ids = []
107 if "library_metadata" in target_ids:
108 library_metadata = ast.literal_eval(node.value)
109 requirements = library_metadata.get("requirements", [])
110 requirements_info[current_class] = requirements
111 requirements_info["requirements"] += requirements
112
113 return requirements_info
114
115
116 def build_gallery(include_core: bool = True, include_contrib: bool = True) -> Dict:
117 """
118 Build the gallery object by running diagnostics for each Expectation and returning the resulting reports.
119
120 Args:
121 include_core: if true, include Expectations defined in the core module
122 include_contrib_experimental: if true, include Expectations defined in contrib_experimental:
123
124 Returns:
125 None
126
127 """
128 gallery_info = dict()
129 requirements_dict = {}
130 logger.info("Loading great_expectations library.")
131 installed_packages = pkg_resources.working_set
132 installed_packages_txt = sorted(f"{i.key}=={i.version}" for i in installed_packages)
133 logger.debug(f"Found the following packages: {installed_packages_txt}")
134
135 import great_expectations
136
137 if include_core:
138 print("\n\n\n=== (Core) ===")
139 logger.info("Getting base registered expectations list")
140 core_expectations = (
141 great_expectations.expectations.registry.list_registered_expectation_implementations()
142 )
143 logger.debug(f"Found the following expectations: {sorted(core_expectations)}")
144 for expectation in core_expectations:
145 requirements_dict[expectation] = {"group": "core"}
146
147 just_installed = set()
148
149 if include_contrib:
150 print("\n\n\n=== (Contrib) ===")
151 logger.info("Finding contrib modules")
152 skip_dirs = ("cli", "tests")
153 contrib_dir = os.path.join(
154 os.path.dirname(__file__),
155 "..",
156 "..",
157 "contrib",
158 )
159
160 for root, dirs, files in os.walk(contrib_dir):
161 for dirname in skip_dirs:
162 if dirname in dirs:
163 dirs.remove(dirname)
164 if "expectations" in dirs:
165 if root.endswith("great_expectations_experimental"):
166 sys.path.append(root)
167 else:
168 # A package in contrib that may contain more Expectations
169 sys.path.append(os.path.dirname(root))
170 for filename in files:
171 if filename.endswith(".py") and filename.startswith("expect_"):
172 logger.debug(f"Getting requirements for module {filename}")
173 contrib_subdir_name = os.path.basename(os.path.dirname(root))
174 requirements_dict[filename[:-3]] = get_contrib_requirements(
175 os.path.join(root, filename)
176 )
177 requirements_dict[filename[:-3]]["group"] = contrib_subdir_name
178
179 for expectation in sorted(requirements_dict):
180 group = requirements_dict[expectation]["group"]
181 print(f"\n\n\n=== {expectation} ({group}) ===")
182 requirements = requirements_dict[expectation].get("requirements", [])
183 parsed_requirements = pkg_resources.parse_requirements(requirements)
184 for req in parsed_requirements:
185 is_satisfied = any(
186 [installed_pkg in req for installed_pkg in installed_packages]
187 )
188 if is_satisfied or req in just_installed:
189 continue
190 logger.debug(f"Executing command: 'pip install \"{req}\"'")
191 status_code = execute_shell_command(f'pip install "{req}"')
192 if status_code == 0:
193 just_installed.add(req)
194 else:
195 expectation_tracebacks.write(
196 f"\n\n----------------\n{expectation} ({group})\n"
197 )
198 expectation_tracebacks.write(f"Failed to pip install {req}\n\n")
199
200 if group != "core":
201 logger.debug(f"Importing {expectation}")
202 try:
203 if group == "great_expectations_experimental":
204 importlib.import_module(f"expectations.{expectation}", group)
205 else:
206 importlib.import_module(f"{group}.expectations")
207 except ModuleNotFoundError as e:
208 logger.error(f"Failed to load expectation: {expectation}")
209 print(traceback.format_exc())
210 expectation_tracebacks.write(
211 f"\n\n----------------\n{expectation} ({group})\n"
212 )
213 expectation_tracebacks.write(traceback.format_exc())
214 continue
215
216 logger.debug(f"Running diagnostics for expectation: {expectation}")
217 impl = great_expectations.expectations.registry.get_expectation_impl(
218 expectation
219 )
220 try:
221 diagnostics = impl().run_diagnostics(return_only_gallery_examples=True)
222 checklist_string = diagnostics.generate_checklist()
223 expectation_checklists.write(
224 f"\n\n----------------\n{expectation} ({group})\n"
225 )
226 expectation_checklists.write(f"{checklist_string}\n")
227 gallery_info[expectation] = diagnostics.to_json_dict()
228 except Exception:
229 logger.error(f"Failed to run diagnostics for: {expectation}")
230 print(traceback.format_exc())
231 expectation_tracebacks.write(
232 f"\n\n----------------\n{expectation} ({group})\n"
233 )
234 expectation_tracebacks.write(traceback.format_exc())
235
236 if just_installed:
237 print("\n\n\n=== (Uninstalling) ===")
238 logger.info(
239 f"Uninstalling packages that were installed while running this script..."
240 )
241 for req in just_installed:
242 logger.debug(f"Executing command: 'pip uninstall -y \"{req}\"'")
243 execute_shell_command(f'pip uninstall -y "{req}"')
244
245 expectation_filenames_set = set(requirements_dict.keys())
246 registered_expectations_set = set(
247 great_expectations.expectations.registry.list_registered_expectation_implementations()
248 )
249 non_matched_filenames = expectation_filenames_set - registered_expectations_set
250 if non_matched_filenames:
251 expectation_tracebacks.write(f"\n\n----------------\n(Not a traceback)\n")
252 expectation_tracebacks.write(
253 "Expectation filenames that don't match their defined Expectation name:\n"
254 )
255 for fname in sorted(non_matched_filenames):
256 expectation_tracebacks.write(f"- {fname}\n")
257
258 bad_names = sorted(
259 list(registered_expectations_set - expectation_filenames_set)
260 )
261 expectation_tracebacks.write(
262 f"\nRegistered Expectation names that don't match:\n"
263 )
264 for exp_name in bad_names:
265 expectation_tracebacks.write(f"- {exp_name}\n")
266
267 if include_core:
268 core_dir = os.path.join(
269 os.path.dirname(__file__),
270 "..",
271 "..",
272 "great_expectations",
273 "expectations",
274 "core",
275 )
276 core_expectations_filename_set = set(
277 [
278 fname.rsplit(".", 1)[0]
279 for fname in os.listdir(core_dir)
280 if fname.startswith("expect_")
281 ]
282 )
283 core_expectations_not_in_gallery = core_expectations_filename_set - set(
284 core_expectations
285 )
286 if core_expectations_not_in_gallery:
287 expectation_tracebacks.write(f"\n\n----------------\n(Not a traceback)\n")
288 expectation_tracebacks.write(
289 f"Core Expectation files not included in core_expectations:\n"
290 )
291 for exp_name in sorted(core_expectations_not_in_gallery):
292 expectation_tracebacks.write(f"- {exp_name}\n")
293
294 return gallery_info
295
296
297 if __name__ == "__main__":
298 gallery_info = build_gallery(include_core=True, include_contrib=True)
299 tracebacks = expectation_tracebacks.getvalue()
300 checklists = expectation_checklists.getvalue()
301 if tracebacks != "":
302 print("\n\n\n" + "#" * 30 + " T R A C E B A C K S " + "#" * 30 + "\n")
303 print(tracebacks)
304 print(
305 "\n\n" + "#" * 30 + " E N D T R A C E B A C K S " + "#" * 30 + "\n\n"
306 )
307 with open("./gallery-errors.txt", "w") as outfile:
308 outfile.write(tracebacks)
309 if checklists != "":
310 print(checklists)
311 with open("./checklists.txt", "w") as outfile:
312 outfile.write(checklists)
313 with open("./expectation_library_v2.json", "w") as outfile:
314 json.dump(gallery_info, outfile)
315
[end of assets/scripts/build_gallery.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/assets/scripts/build_gallery.py b/assets/scripts/build_gallery.py
--- a/assets/scripts/build_gallery.py
+++ b/assets/scripts/build_gallery.py
@@ -3,6 +3,7 @@
import json
import logging
import os
+import re
import sys
import traceback
from io import StringIO
@@ -224,6 +225,10 @@
f"\n\n----------------\n{expectation} ({group})\n"
)
expectation_checklists.write(f"{checklist_string}\n")
+ if diagnostics["description"]["docstring"]:
+ diagnostics["description"]["docstring"] = format_docstring_to_markdown(
+ diagnostics["description"]["docstring"]
+ )
gallery_info[expectation] = diagnostics.to_json_dict()
except Exception:
logger.error(f"Failed to run diagnostics for: {expectation}")
@@ -294,6 +299,77 @@
return gallery_info
+def format_docstring_to_markdown(docstr: str) -> str:
+ """
+ Add markdown formatting to a provided docstring
+
+ Args:
+ docstr: the original docstring that needs to be converted to markdown.
+
+ Returns:
+ str of Docstring formatted as markdown
+
+ """
+ r = re.compile(r"\s\s+", re.MULTILINE)
+ clean_docstr_list = []
+ prev_line = None
+ in_code_block = False
+ in_param = False
+ first_code_indentation = None
+
+ # Parse each line to determine if it needs formatting
+ for original_line in docstr.split("\n"):
+ # Remove excess spaces from lines formed by concatenated docstring lines.
+ line = r.sub(" ", original_line)
+ # In some old docstrings, this indicates the start of an example block.
+ if line.strip() == "::":
+ in_code_block = True
+ clean_docstr_list.append("```")
+
+ # All of our parameter/arg/etc lists start after a line ending in ':'.
+ elif line.strip().endswith(":"):
+ in_param = True
+ # This adds a blank line before the header if one doesn't already exist.
+ if prev_line != "":
+ clean_docstr_list.append("")
+ # Turn the line into an H4 header
+ clean_docstr_list.append(f"#### {line.strip()}")
+ elif line.strip() == "" and prev_line != "::":
+ # All of our parameter groups end with a line break, but we don't want to exit a parameter block due to a
+ # line break in a code block. However, some code blocks start with a blank first line, so we want to make
+ # sure we aren't immediately exiting the code block (hence the test for '::' on the previous line.
+ in_param = False
+ # Add the markdown indicator to close a code block, since we aren't in one now.
+ if in_code_block:
+ clean_docstr_list.append("```")
+ in_code_block = False
+ first_code_indentation = None
+ clean_docstr_list.append(line)
+ else:
+ if in_code_block:
+ # Determine the number of spaces indenting the first line of code so they can be removed from all lines
+ # in the code block without wrecking the hierarchical indentation levels of future lines.
+ if first_code_indentation == None and line.strip() != "":
+ first_code_indentation = len(
+ re.match(r"\s*", original_line, re.UNICODE).group(0)
+ )
+ if line.strip() == "" and prev_line == "::":
+ # If the first line of the code block is a blank one, just skip it.
+ pass
+ else:
+ # Append the line of code, minus the extra indentation from being written in an indented docstring.
+ clean_docstr_list.append(original_line[first_code_indentation:])
+ elif ":" in line.replace(":ref:", "") and in_param:
+ # This indicates a parameter. arg. or other definition.
+ clean_docstr_list.append(f"- {line.strip()}")
+ else:
+ # This indicates a regular line of text.
+ clean_docstr_list.append(f"{line.strip()}")
+ prev_line = line.strip()
+ clean_docstr = "\n".join(clean_docstr_list)
+ return clean_docstr
+
+
if __name__ == "__main__":
gallery_info = build_gallery(include_core=True, include_contrib=True)
tracebacks = expectation_tracebacks.getvalue()
|
{"golden_diff": "diff --git a/assets/scripts/build_gallery.py b/assets/scripts/build_gallery.py\n--- a/assets/scripts/build_gallery.py\n+++ b/assets/scripts/build_gallery.py\n@@ -3,6 +3,7 @@\n import json\n import logging\n import os\n+import re\n import sys\n import traceback\n from io import StringIO\n@@ -224,6 +225,10 @@\n f\"\\n\\n----------------\\n{expectation} ({group})\\n\"\n )\n expectation_checklists.write(f\"{checklist_string}\\n\")\n+ if diagnostics[\"description\"][\"docstring\"]:\n+ diagnostics[\"description\"][\"docstring\"] = format_docstring_to_markdown(\n+ diagnostics[\"description\"][\"docstring\"]\n+ )\n gallery_info[expectation] = diagnostics.to_json_dict()\n except Exception:\n logger.error(f\"Failed to run diagnostics for: {expectation}\")\n@@ -294,6 +299,77 @@\n return gallery_info\n \n \n+def format_docstring_to_markdown(docstr: str) -> str:\n+ \"\"\"\n+ Add markdown formatting to a provided docstring\n+\n+ Args:\n+ docstr: the original docstring that needs to be converted to markdown.\n+\n+ Returns:\n+ str of Docstring formatted as markdown\n+\n+ \"\"\"\n+ r = re.compile(r\"\\s\\s+\", re.MULTILINE)\n+ clean_docstr_list = []\n+ prev_line = None\n+ in_code_block = False\n+ in_param = False\n+ first_code_indentation = None\n+\n+ # Parse each line to determine if it needs formatting\n+ for original_line in docstr.split(\"\\n\"):\n+ # Remove excess spaces from lines formed by concatenated docstring lines.\n+ line = r.sub(\" \", original_line)\n+ # In some old docstrings, this indicates the start of an example block.\n+ if line.strip() == \"::\":\n+ in_code_block = True\n+ clean_docstr_list.append(\"```\")\n+\n+ # All of our parameter/arg/etc lists start after a line ending in ':'.\n+ elif line.strip().endswith(\":\"):\n+ in_param = True\n+ # This adds a blank line before the header if one doesn't already exist.\n+ if prev_line != \"\":\n+ clean_docstr_list.append(\"\")\n+ # Turn the line into an H4 header\n+ clean_docstr_list.append(f\"#### {line.strip()}\")\n+ elif line.strip() == \"\" and prev_line != \"::\":\n+ # All of our parameter groups end with a line break, but we don't want to exit a parameter block due to a\n+ # line break in a code block. However, some code blocks start with a blank first line, so we want to make\n+ # sure we aren't immediately exiting the code block (hence the test for '::' on the previous line.\n+ in_param = False\n+ # Add the markdown indicator to close a code block, since we aren't in one now.\n+ if in_code_block:\n+ clean_docstr_list.append(\"```\")\n+ in_code_block = False\n+ first_code_indentation = None\n+ clean_docstr_list.append(line)\n+ else:\n+ if in_code_block:\n+ # Determine the number of spaces indenting the first line of code so they can be removed from all lines\n+ # in the code block without wrecking the hierarchical indentation levels of future lines.\n+ if first_code_indentation == None and line.strip() != \"\":\n+ first_code_indentation = len(\n+ re.match(r\"\\s*\", original_line, re.UNICODE).group(0)\n+ )\n+ if line.strip() == \"\" and prev_line == \"::\":\n+ # If the first line of the code block is a blank one, just skip it.\n+ pass\n+ else:\n+ # Append the line of code, minus the extra indentation from being written in an indented docstring.\n+ clean_docstr_list.append(original_line[first_code_indentation:])\n+ elif \":\" in line.replace(\":ref:\", \"\") and in_param:\n+ # This indicates a parameter. arg. or other definition.\n+ clean_docstr_list.append(f\"- {line.strip()}\")\n+ else:\n+ # This indicates a regular line of text.\n+ clean_docstr_list.append(f\"{line.strip()}\")\n+ prev_line = line.strip()\n+ clean_docstr = \"\\n\".join(clean_docstr_list)\n+ return clean_docstr\n+\n+\n if __name__ == \"__main__\":\n gallery_info = build_gallery(include_core=True, include_contrib=True)\n tracebacks = expectation_tracebacks.getvalue()\n", "issue": "Use cleaner solution for non-truncating division in python 2\nPrefer `from __future__ import division` to `1.*x/y`\n", "before_files": [{"content": "import ast\nimport importlib\nimport json\nimport logging\nimport os\nimport sys\nimport traceback\nfrom io import StringIO\nfrom subprocess import CalledProcessError, CompletedProcess, run\nfrom typing import Dict\n\nimport pkg_resources\n\nlogger = logging.getLogger(__name__)\nchandler = logging.StreamHandler(stream=sys.stdout)\nchandler.setLevel(logging.DEBUG)\nchandler.setFormatter(\n logging.Formatter(\"%(asctime)s - %(levelname)s - %(message)s\", \"%Y-%m-%dT%H:%M:%S\")\n)\nlogger.addHandler(chandler)\nlogger.setLevel(logging.DEBUG)\n\n\nexpectation_tracebacks = StringIO()\nexpectation_checklists = StringIO()\n\n\ndef execute_shell_command(command: str) -> int:\n \"\"\"\n Wrap subprocess command in a try/except block to provide a convenient method for pip installing dependencies.\n\n :param command: bash command -- as if typed in a shell/Terminal window\n :return: status code -- 0 if successful; all other values (1 is the most common) indicate an error\n \"\"\"\n cwd: str = os.getcwd()\n\n path_env_var: str = os.pathsep.join([os.environ.get(\"PATH\", os.defpath), cwd])\n env: dict = dict(os.environ, PATH=path_env_var)\n\n status_code: int = 0\n try:\n res: CompletedProcess = run(\n args=[\"bash\", \"-c\", command],\n stdin=None,\n input=None,\n # stdout=None, # commenting out to prevent issues with `subprocess.run` in python <3.7.4\n # stderr=None, # commenting out to prevent issues with `subprocess.run` in python <3.7.4\n capture_output=True,\n shell=False,\n cwd=cwd,\n timeout=None,\n check=True,\n encoding=None,\n errors=None,\n text=None,\n env=env,\n universal_newlines=True,\n )\n sh_out: str = res.stdout.strip()\n logger.info(sh_out)\n except CalledProcessError as cpe:\n status_code = cpe.returncode\n sys.stderr.write(cpe.output)\n sys.stderr.flush()\n exception_message: str = \"A Sub-Process call Exception occurred.\\n\"\n exception_traceback: str = traceback.format_exc()\n exception_message += (\n f'{type(cpe).__name__}: \"{str(cpe)}\". Traceback: \"{exception_traceback}\".'\n )\n logger.error(exception_message)\n\n return status_code\n\n\ndef get_contrib_requirements(filepath: str) -> Dict:\n \"\"\"\n Parse the python file from filepath to identify a \"library_metadata\" dictionary in any defined classes, and return a requirements_info object that includes a list of pip-installable requirements for each class that defines them.\n\n Note, currently we are handling all dependencies at the module level. To support future expandability and detail, this method also returns per-class requirements in addition to the concatenated list.\n\n Args:\n filepath: the path to the file to parse and analyze\n\n Returns:\n A dictionary:\n {\n \"requirements\": [ all_requirements_found_in_any_library_metadata_in_file ],\n class_name: [ requirements ]\n }\n\n \"\"\"\n with open(filepath) as file:\n tree = ast.parse(file.read())\n\n requirements_info = {\"requirements\": []}\n for child in ast.iter_child_nodes(tree):\n if not isinstance(child, ast.ClassDef):\n continue\n current_class = child.name\n for node in ast.walk(child):\n if isinstance(node, ast.Assign):\n try:\n target_ids = [target.id for target in node.targets]\n except (ValueError, AttributeError):\n # some assignment types assign to non-node objects (e.g. Tuple)\n target_ids = []\n if \"library_metadata\" in target_ids:\n library_metadata = ast.literal_eval(node.value)\n requirements = library_metadata.get(\"requirements\", [])\n requirements_info[current_class] = requirements\n requirements_info[\"requirements\"] += requirements\n\n return requirements_info\n\n\ndef build_gallery(include_core: bool = True, include_contrib: bool = True) -> Dict:\n \"\"\"\n Build the gallery object by running diagnostics for each Expectation and returning the resulting reports.\n\n Args:\n include_core: if true, include Expectations defined in the core module\n include_contrib_experimental: if true, include Expectations defined in contrib_experimental:\n\n Returns:\n None\n\n \"\"\"\n gallery_info = dict()\n requirements_dict = {}\n logger.info(\"Loading great_expectations library.\")\n installed_packages = pkg_resources.working_set\n installed_packages_txt = sorted(f\"{i.key}=={i.version}\" for i in installed_packages)\n logger.debug(f\"Found the following packages: {installed_packages_txt}\")\n\n import great_expectations\n\n if include_core:\n print(\"\\n\\n\\n=== (Core) ===\")\n logger.info(\"Getting base registered expectations list\")\n core_expectations = (\n great_expectations.expectations.registry.list_registered_expectation_implementations()\n )\n logger.debug(f\"Found the following expectations: {sorted(core_expectations)}\")\n for expectation in core_expectations:\n requirements_dict[expectation] = {\"group\": \"core\"}\n\n just_installed = set()\n\n if include_contrib:\n print(\"\\n\\n\\n=== (Contrib) ===\")\n logger.info(\"Finding contrib modules\")\n skip_dirs = (\"cli\", \"tests\")\n contrib_dir = os.path.join(\n os.path.dirname(__file__),\n \"..\",\n \"..\",\n \"contrib\",\n )\n\n for root, dirs, files in os.walk(contrib_dir):\n for dirname in skip_dirs:\n if dirname in dirs:\n dirs.remove(dirname)\n if \"expectations\" in dirs:\n if root.endswith(\"great_expectations_experimental\"):\n sys.path.append(root)\n else:\n # A package in contrib that may contain more Expectations\n sys.path.append(os.path.dirname(root))\n for filename in files:\n if filename.endswith(\".py\") and filename.startswith(\"expect_\"):\n logger.debug(f\"Getting requirements for module {filename}\")\n contrib_subdir_name = os.path.basename(os.path.dirname(root))\n requirements_dict[filename[:-3]] = get_contrib_requirements(\n os.path.join(root, filename)\n )\n requirements_dict[filename[:-3]][\"group\"] = contrib_subdir_name\n\n for expectation in sorted(requirements_dict):\n group = requirements_dict[expectation][\"group\"]\n print(f\"\\n\\n\\n=== {expectation} ({group}) ===\")\n requirements = requirements_dict[expectation].get(\"requirements\", [])\n parsed_requirements = pkg_resources.parse_requirements(requirements)\n for req in parsed_requirements:\n is_satisfied = any(\n [installed_pkg in req for installed_pkg in installed_packages]\n )\n if is_satisfied or req in just_installed:\n continue\n logger.debug(f\"Executing command: 'pip install \\\"{req}\\\"'\")\n status_code = execute_shell_command(f'pip install \"{req}\"')\n if status_code == 0:\n just_installed.add(req)\n else:\n expectation_tracebacks.write(\n f\"\\n\\n----------------\\n{expectation} ({group})\\n\"\n )\n expectation_tracebacks.write(f\"Failed to pip install {req}\\n\\n\")\n\n if group != \"core\":\n logger.debug(f\"Importing {expectation}\")\n try:\n if group == \"great_expectations_experimental\":\n importlib.import_module(f\"expectations.{expectation}\", group)\n else:\n importlib.import_module(f\"{group}.expectations\")\n except ModuleNotFoundError as e:\n logger.error(f\"Failed to load expectation: {expectation}\")\n print(traceback.format_exc())\n expectation_tracebacks.write(\n f\"\\n\\n----------------\\n{expectation} ({group})\\n\"\n )\n expectation_tracebacks.write(traceback.format_exc())\n continue\n\n logger.debug(f\"Running diagnostics for expectation: {expectation}\")\n impl = great_expectations.expectations.registry.get_expectation_impl(\n expectation\n )\n try:\n diagnostics = impl().run_diagnostics(return_only_gallery_examples=True)\n checklist_string = diagnostics.generate_checklist()\n expectation_checklists.write(\n f\"\\n\\n----------------\\n{expectation} ({group})\\n\"\n )\n expectation_checklists.write(f\"{checklist_string}\\n\")\n gallery_info[expectation] = diagnostics.to_json_dict()\n except Exception:\n logger.error(f\"Failed to run diagnostics for: {expectation}\")\n print(traceback.format_exc())\n expectation_tracebacks.write(\n f\"\\n\\n----------------\\n{expectation} ({group})\\n\"\n )\n expectation_tracebacks.write(traceback.format_exc())\n\n if just_installed:\n print(\"\\n\\n\\n=== (Uninstalling) ===\")\n logger.info(\n f\"Uninstalling packages that were installed while running this script...\"\n )\n for req in just_installed:\n logger.debug(f\"Executing command: 'pip uninstall -y \\\"{req}\\\"'\")\n execute_shell_command(f'pip uninstall -y \"{req}\"')\n\n expectation_filenames_set = set(requirements_dict.keys())\n registered_expectations_set = set(\n great_expectations.expectations.registry.list_registered_expectation_implementations()\n )\n non_matched_filenames = expectation_filenames_set - registered_expectations_set\n if non_matched_filenames:\n expectation_tracebacks.write(f\"\\n\\n----------------\\n(Not a traceback)\\n\")\n expectation_tracebacks.write(\n \"Expectation filenames that don't match their defined Expectation name:\\n\"\n )\n for fname in sorted(non_matched_filenames):\n expectation_tracebacks.write(f\"- {fname}\\n\")\n\n bad_names = sorted(\n list(registered_expectations_set - expectation_filenames_set)\n )\n expectation_tracebacks.write(\n f\"\\nRegistered Expectation names that don't match:\\n\"\n )\n for exp_name in bad_names:\n expectation_tracebacks.write(f\"- {exp_name}\\n\")\n\n if include_core:\n core_dir = os.path.join(\n os.path.dirname(__file__),\n \"..\",\n \"..\",\n \"great_expectations\",\n \"expectations\",\n \"core\",\n )\n core_expectations_filename_set = set(\n [\n fname.rsplit(\".\", 1)[0]\n for fname in os.listdir(core_dir)\n if fname.startswith(\"expect_\")\n ]\n )\n core_expectations_not_in_gallery = core_expectations_filename_set - set(\n core_expectations\n )\n if core_expectations_not_in_gallery:\n expectation_tracebacks.write(f\"\\n\\n----------------\\n(Not a traceback)\\n\")\n expectation_tracebacks.write(\n f\"Core Expectation files not included in core_expectations:\\n\"\n )\n for exp_name in sorted(core_expectations_not_in_gallery):\n expectation_tracebacks.write(f\"- {exp_name}\\n\")\n\n return gallery_info\n\n\nif __name__ == \"__main__\":\n gallery_info = build_gallery(include_core=True, include_contrib=True)\n tracebacks = expectation_tracebacks.getvalue()\n checklists = expectation_checklists.getvalue()\n if tracebacks != \"\":\n print(\"\\n\\n\\n\" + \"#\" * 30 + \" T R A C E B A C K S \" + \"#\" * 30 + \"\\n\")\n print(tracebacks)\n print(\n \"\\n\\n\" + \"#\" * 30 + \" E N D T R A C E B A C K S \" + \"#\" * 30 + \"\\n\\n\"\n )\n with open(\"./gallery-errors.txt\", \"w\") as outfile:\n outfile.write(tracebacks)\n if checklists != \"\":\n print(checklists)\n with open(\"./checklists.txt\", \"w\") as outfile:\n outfile.write(checklists)\n with open(\"./expectation_library_v2.json\", \"w\") as outfile:\n json.dump(gallery_info, outfile)\n", "path": "assets/scripts/build_gallery.py"}]}
| 3,911 | 1,004 |
gh_patches_debug_22772
|
rasdani/github-patches
|
git_diff
|
nilearn__nilearn-559
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Doc does not build
Am I the only one?
```
Exception occurred:
File "/home/aa013911/work/nilearn/doc/sphinxext/sphinxgallery/docs_resolv.py", line 348, in embed_code_links
gallery_dir = os.path.join(app.builder.srcdir, gallery_conf['gallery_dir'])
KeyError: 'gallery_dir'
The full traceback has been saved in /tmp/sphinx-err-sePU7r.log, if you want to report the issue to the developers.
Please also report this if it was a user error, so that a better error message can be provided next time.
```
</issue>
<code>
[start of doc/sphinxext/sphinxgallery/__init__.py]
1 """Sphinx Gallery
2 """
3 import os
4 __version__ = '0.0.8'
5
6 def path_static():
7 """Returns path to packaged static files"""
8 return os.path.abspath(os.path.dirname(__file__))+'/_static'
9
[end of doc/sphinxext/sphinxgallery/__init__.py]
[start of doc/sphinxext/sphinxgallery/gen_gallery.py]
1 # -*- coding: utf-8 -*-
2 # Author: Óscar Nájera
3 # License: 3-clause BSD
4
5 import os
6 from sphinxgallery.gen_rst import generate_dir_rst
7 from sphinxgallery.docs_resolv import embed_code_links
8
9
10 def generate_gallery_rst(app):
11 """Starts the gallery configuration and recursively scans the examples
12 directory in order to populate the examples gallery
13 """
14 try:
15 plot_gallery = eval(app.builder.config.plot_gallery)
16 except TypeError:
17 plot_gallery = bool(app.builder.config.plot_gallery)
18
19 if not plot_gallery:
20 return
21
22 gallery_conf.update(app.config.sphinxgallery_conf)
23
24 # this assures I can call the config in other places
25 app.config.sphinxgallery_conf = gallery_conf
26
27 examples_dir = os.path.join(app.builder.srcdir, gallery_conf['examples_dir'])
28 gallery_dir = os.path.join(app.builder.srcdir, gallery_conf['gallery_dir'])
29 mod_examples_dir = os.path.join(app.builder.srcdir, gallery_conf['mod_example_dir'])
30
31 for workdir in [examples_dir, gallery_dir, mod_examples_dir]:
32 if not os.path.exists(workdir):
33 os.makedirs(workdir)
34
35 # we create an index.rst with all examples
36 fhindex = open(os.path.join(gallery_dir, 'index.rst'), 'w')
37 fhindex.write("""
38
39 .. _examples-index:
40
41 Gallery of Examples
42 ===================
43
44 """)
45 # Here we don't use an os.walk, but we recurse only twice: flat is
46 # better than nested.
47 seen_backrefs = set()
48 generate_dir_rst('.', fhindex, examples_dir, gallery_dir, gallery_conf, plot_gallery, seen_backrefs)
49 for directory in sorted(os.listdir(examples_dir)):
50 if os.path.isdir(os.path.join(examples_dir, directory)):
51 generate_dir_rst(directory, fhindex, examples_dir, gallery_dir, gallery_conf, plot_gallery, seen_backrefs)
52 fhindex.flush()
53
54
55 gallery_conf = {
56 'examples_dir' : '../examples',
57 'gallery_dir' : 'auto_examples',
58 'mod_example_dir': 'modules/generated',
59 'doc_module' : (),
60 'reference_url' : {},
61 }
62
63 def setup(app):
64 app.add_config_value('plot_gallery', True, 'html')
65 app.add_config_value('sphinxgallery_conf', gallery_conf, 'html')
66 app.add_stylesheet('gallery.css')
67
68 app.connect('builder-inited', generate_gallery_rst)
69
70 app.connect('build-finished', embed_code_links)
71
72 # Sphinx hack: sphinx copies generated images to the build directory
73 # each time the docs are made. If the desired image name already
74 # exists, it appends a digit to prevent overwrites. The problem is,
75 # the directory is never cleared. This means that each time you build
76 # the docs, the number of images in the directory grows.
77 #
78 # This question has been asked on the sphinx development list, but there
79 # was no response: http://osdir.com/ml/sphinx-dev/2011-02/msg00123.html
80 #
81 # The following is a hack that prevents this behavior by clearing the
82 # image build directory each time the docs are built. If sphinx
83 # changes their layout between versions, this will not work (though
84 # it should probably not cause a crash). Tested successfully
85 # on Sphinx 1.0.7
86 build_image_dir = '_build/html/_images'
87 if os.path.exists(build_image_dir):
88 filelist = os.listdir(build_image_dir)
89 for filename in filelist:
90 if filename.endswith('png'):
91 os.remove(os.path.join(build_image_dir, filename))
92
93 def setup_module():
94 # HACK: Stop nosetests running setup() above
95 pass
96
[end of doc/sphinxext/sphinxgallery/gen_gallery.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/doc/sphinxext/sphinxgallery/__init__.py b/doc/sphinxext/sphinxgallery/__init__.py
--- a/doc/sphinxext/sphinxgallery/__init__.py
+++ b/doc/sphinxext/sphinxgallery/__init__.py
@@ -1,7 +1,7 @@
"""Sphinx Gallery
"""
import os
-__version__ = '0.0.8'
+__version__ = '0.0.9-dev'
def path_static():
"""Returns path to packaged static files"""
diff --git a/doc/sphinxext/sphinxgallery/gen_gallery.py b/doc/sphinxext/sphinxgallery/gen_gallery.py
--- a/doc/sphinxext/sphinxgallery/gen_gallery.py
+++ b/doc/sphinxext/sphinxgallery/gen_gallery.py
@@ -16,14 +16,14 @@
except TypeError:
plot_gallery = bool(app.builder.config.plot_gallery)
- if not plot_gallery:
- return
-
gallery_conf.update(app.config.sphinxgallery_conf)
# this assures I can call the config in other places
app.config.sphinxgallery_conf = gallery_conf
+ if not plot_gallery:
+ return
+
examples_dir = os.path.join(app.builder.srcdir, gallery_conf['examples_dir'])
gallery_dir = os.path.join(app.builder.srcdir, gallery_conf['gallery_dir'])
mod_examples_dir = os.path.join(app.builder.srcdir, gallery_conf['mod_example_dir'])
|
{"golden_diff": "diff --git a/doc/sphinxext/sphinxgallery/__init__.py b/doc/sphinxext/sphinxgallery/__init__.py\n--- a/doc/sphinxext/sphinxgallery/__init__.py\n+++ b/doc/sphinxext/sphinxgallery/__init__.py\n@@ -1,7 +1,7 @@\n \"\"\"Sphinx Gallery\n \"\"\"\n import os\n-__version__ = '0.0.8'\n+__version__ = '0.0.9-dev'\n \n def path_static():\n \"\"\"Returns path to packaged static files\"\"\"\ndiff --git a/doc/sphinxext/sphinxgallery/gen_gallery.py b/doc/sphinxext/sphinxgallery/gen_gallery.py\n--- a/doc/sphinxext/sphinxgallery/gen_gallery.py\n+++ b/doc/sphinxext/sphinxgallery/gen_gallery.py\n@@ -16,14 +16,14 @@\n except TypeError:\n plot_gallery = bool(app.builder.config.plot_gallery)\n \n- if not plot_gallery:\n- return\n-\n gallery_conf.update(app.config.sphinxgallery_conf)\n \n # this assures I can call the config in other places\n app.config.sphinxgallery_conf = gallery_conf\n \n+ if not plot_gallery:\n+ return\n+\n examples_dir = os.path.join(app.builder.srcdir, gallery_conf['examples_dir'])\n gallery_dir = os.path.join(app.builder.srcdir, gallery_conf['gallery_dir'])\n mod_examples_dir = os.path.join(app.builder.srcdir, gallery_conf['mod_example_dir'])\n", "issue": "Doc does not build\nAm I the only one?\n\n```\nException occurred:\n File \"/home/aa013911/work/nilearn/doc/sphinxext/sphinxgallery/docs_resolv.py\", line 348, in embed_code_links\n gallery_dir = os.path.join(app.builder.srcdir, gallery_conf['gallery_dir'])\nKeyError: 'gallery_dir'\nThe full traceback has been saved in /tmp/sphinx-err-sePU7r.log, if you want to report the issue to the developers.\nPlease also report this if it was a user error, so that a better error message can be provided next time.\n```\n\n", "before_files": [{"content": "\"\"\"Sphinx Gallery\n\"\"\"\nimport os\n__version__ = '0.0.8'\n\ndef path_static():\n \"\"\"Returns path to packaged static files\"\"\"\n return os.path.abspath(os.path.dirname(__file__))+'/_static'\n", "path": "doc/sphinxext/sphinxgallery/__init__.py"}, {"content": "# -*- coding: utf-8 -*-\n# Author: \u00d3scar N\u00e1jera\n# License: 3-clause BSD\n\nimport os\nfrom sphinxgallery.gen_rst import generate_dir_rst\nfrom sphinxgallery.docs_resolv import embed_code_links\n\n\ndef generate_gallery_rst(app):\n \"\"\"Starts the gallery configuration and recursively scans the examples\n directory in order to populate the examples gallery\n \"\"\"\n try:\n plot_gallery = eval(app.builder.config.plot_gallery)\n except TypeError:\n plot_gallery = bool(app.builder.config.plot_gallery)\n\n if not plot_gallery:\n return\n\n gallery_conf.update(app.config.sphinxgallery_conf)\n\n # this assures I can call the config in other places\n app.config.sphinxgallery_conf = gallery_conf\n\n examples_dir = os.path.join(app.builder.srcdir, gallery_conf['examples_dir'])\n gallery_dir = os.path.join(app.builder.srcdir, gallery_conf['gallery_dir'])\n mod_examples_dir = os.path.join(app.builder.srcdir, gallery_conf['mod_example_dir'])\n\n for workdir in [examples_dir, gallery_dir, mod_examples_dir]:\n if not os.path.exists(workdir):\n os.makedirs(workdir)\n\n # we create an index.rst with all examples\n fhindex = open(os.path.join(gallery_dir, 'index.rst'), 'w')\n fhindex.write(\"\"\"\n\n.. _examples-index:\n\nGallery of Examples\n===================\n\n\"\"\")\n # Here we don't use an os.walk, but we recurse only twice: flat is\n # better than nested.\n seen_backrefs = set()\n generate_dir_rst('.', fhindex, examples_dir, gallery_dir, gallery_conf, plot_gallery, seen_backrefs)\n for directory in sorted(os.listdir(examples_dir)):\n if os.path.isdir(os.path.join(examples_dir, directory)):\n generate_dir_rst(directory, fhindex, examples_dir, gallery_dir, gallery_conf, plot_gallery, seen_backrefs)\n fhindex.flush()\n\n\ngallery_conf = {\n 'examples_dir' : '../examples',\n 'gallery_dir' : 'auto_examples',\n 'mod_example_dir': 'modules/generated',\n 'doc_module' : (),\n 'reference_url' : {},\n}\n\ndef setup(app):\n app.add_config_value('plot_gallery', True, 'html')\n app.add_config_value('sphinxgallery_conf', gallery_conf, 'html')\n app.add_stylesheet('gallery.css')\n\n app.connect('builder-inited', generate_gallery_rst)\n\n app.connect('build-finished', embed_code_links)\n\n # Sphinx hack: sphinx copies generated images to the build directory\n # each time the docs are made. If the desired image name already\n # exists, it appends a digit to prevent overwrites. The problem is,\n # the directory is never cleared. This means that each time you build\n # the docs, the number of images in the directory grows.\n #\n # This question has been asked on the sphinx development list, but there\n # was no response: http://osdir.com/ml/sphinx-dev/2011-02/msg00123.html\n #\n # The following is a hack that prevents this behavior by clearing the\n # image build directory each time the docs are built. If sphinx\n # changes their layout between versions, this will not work (though\n # it should probably not cause a crash). Tested successfully\n # on Sphinx 1.0.7\n build_image_dir = '_build/html/_images'\n if os.path.exists(build_image_dir):\n filelist = os.listdir(build_image_dir)\n for filename in filelist:\n if filename.endswith('png'):\n os.remove(os.path.join(build_image_dir, filename))\n\ndef setup_module():\n # HACK: Stop nosetests running setup() above\n pass\n", "path": "doc/sphinxext/sphinxgallery/gen_gallery.py"}]}
| 1,792 | 312 |
gh_patches_debug_13397
|
rasdani/github-patches
|
git_diff
|
fossasia__open-event-server-940
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
If nested fields are null, show null instead of their structure
Take for example Sessions API. If `track` is None (not set), it shows
``` json
"title": "string",
"track": {
"id": null,
"name": null
},
"video": "string"
```
It would be better if it shows
``` json
"title": "string",
"track": null,
"video": "string"
```
@shivamMg @mariobehling What do you think ?
</issue>
<code>
[start of open_event/api/sessions.py]
1 from flask.ext.restplus import Resource, Namespace
2 from sqlalchemy.orm.collections import InstrumentedList
3
4 from open_event.models.session import Session as SessionModel
5 from open_event.models.track import Track as TrackModel
6 from open_event.models.microlocation import Microlocation as MicrolocationModel
7 from open_event.models.speaker import Speaker as SpeakerModel
8
9 from .helpers.helpers import get_paginated_list, requires_auth, \
10 save_db_model, get_object_in_event
11 from .helpers.utils import PAGINATED_MODEL, PaginatedResourceBase, ServiceDAO, \
12 PAGE_PARAMS, POST_RESPONSES, PUT_RESPONSES
13 from .helpers import custom_fields as fields
14 from .helpers.special_fields import SessionLanguageField, SessionStateField
15
16 api = Namespace('sessions', description='Sessions', path='/')
17
18 # Create models
19 SESSION_TRACK = api.model('SessionTrack', {
20 'id': fields.Integer(required=True),
21 'name': fields.String(),
22 })
23
24 SESSION_SPEAKER = api.model('SessionSpeaker', {
25 'id': fields.Integer(required=True),
26 'name': fields.String(),
27 'organisation': fields.String()
28 })
29
30 SESSION_MICROLOCATION = api.model('SessionMicrolocation', {
31 'id': fields.Integer(required=True),
32 'name': fields.String(),
33 })
34
35 SESSION = api.model('Session', {
36 'id': fields.Integer(required=True),
37 'title': fields.String(required=True),
38 'subtitle': fields.String(),
39 'short_abstract': fields.String(),
40 'long_abstract': fields.String(required=True),
41 'comments': fields.String(),
42 'start_time': fields.DateTime(required=True),
43 'end_time': fields.DateTime(required=True),
44 'track': fields.Nested(SESSION_TRACK),
45 'speakers': fields.List(fields.Nested(SESSION_SPEAKER)),
46 'language': SessionLanguageField(),
47 'microlocation': fields.Nested(SESSION_MICROLOCATION),
48 'slides': fields.String(),
49 'video': fields.String(),
50 'audio': fields.String(),
51 'signup_url': fields.Uri(),
52 'state': SessionStateField()
53 })
54
55 SESSION_PAGINATED = api.clone('SessionPaginated', PAGINATED_MODEL, {
56 'results': fields.List(fields.Nested(SESSION))
57 })
58
59 SESSION_POST = api.clone('SessionPost', SESSION, {
60 'track_id': fields.Integer(),
61 'speaker_ids': fields.List(fields.Integer()),
62 'microlocation_id': fields.Integer()
63 })
64 del SESSION_POST['id']
65 del SESSION_POST['track']
66 del SESSION_POST['speakers']
67 del SESSION_POST['microlocation']
68
69
70 # Create DAO
71 class SessionDAO(ServiceDAO):
72 def _delete_fields(self, data):
73 del data['speaker_ids']
74 del data['track_id']
75 del data['microlocation_id']
76 data['start_time'] = SESSION_POST['start_time'].from_str(
77 data['start_time'])
78 data['end_time'] = SESSION_POST['end_time'].from_str(data['end_time'])
79 return data
80
81 def get_object(self, model, sid, event_id):
82 """
83 returns object (model). Checks if object is in same event
84 """
85 if sid is None:
86 return None
87 return get_object_in_event(model, sid, event_id)
88
89 def fix_payload_post(self, event_id, data):
90 """
91 Fixes payload of POST request
92 """
93 data['track'] = self.get_object(TrackModel, data['track_id'], event_id)
94 data['microlocation'] = self.get_object(MicrolocationModel, data['microlocation_id'], event_id)
95 data['event_id'] = event_id
96 data['speakers'] = InstrumentedList(
97 SpeakerModel.query.get(_) for _ in data['speaker_ids']
98 if self.get_object(SpeakerModel, _, event_id) is not None
99 )
100 data = self._delete_fields(data)
101 return data
102
103 def update(self, event_id, service_id, data):
104 data = self.validate(data)
105 data_copy = data.copy()
106 data_copy = self.fix_payload_post(event_id, data_copy)
107 data = self._delete_fields(data)
108 obj = ServiceDAO.update(self, event_id, service_id, data)
109 obj.track = data_copy['track']
110 obj.microlocation = data_copy['microlocation']
111 obj.speakers = data_copy['speakers']
112 obj = save_db_model(obj, SessionModel.__name__, event_id)
113 return obj
114
115 def create(self, event_id, data, url):
116 data = self.validate(data)
117 payload = self.fix_payload_post(event_id, data)
118 return ServiceDAO.create(self, event_id, payload, url, validate=False)
119
120
121 DAO = SessionDAO(SessionModel, SESSION_POST)
122
123
124 @api.route('/events/<int:event_id>/sessions/<int:session_id>')
125 @api.response(404, 'Session not found')
126 @api.response(400, 'Session does not belong to event')
127 class Session(Resource):
128 @api.doc('get_session')
129 @api.marshal_with(SESSION)
130 def get(self, event_id, session_id):
131 """Fetch a session given its id"""
132 return DAO.get(event_id, session_id)
133
134 @requires_auth
135 @api.doc('delete_session')
136 @api.marshal_with(SESSION)
137 def delete(self, event_id, session_id):
138 """Delete a session given its id"""
139 return DAO.delete(event_id, session_id)
140
141 @requires_auth
142 @api.doc('update_session', responses=PUT_RESPONSES)
143 @api.marshal_with(SESSION)
144 @api.expect(SESSION_POST)
145 def put(self, event_id, session_id):
146 """Update a session given its id"""
147 return DAO.update(event_id, session_id, self.api.payload)
148
149
150 @api.route('/events/<int:event_id>/sessions')
151 class SessionList(Resource):
152 @api.doc('list_sessions')
153 @api.marshal_list_with(SESSION)
154 def get(self, event_id):
155 """List all sessions"""
156 return DAO.list(event_id)
157
158 @requires_auth
159 @api.doc('create_session', responses=POST_RESPONSES)
160 @api.marshal_with(SESSION)
161 @api.expect(SESSION_POST)
162 def post(self, event_id):
163 """Create a session"""
164 return DAO.create(
165 event_id,
166 self.api.payload,
167 self.api.url_for(self, event_id=event_id)
168 )
169
170
171 @api.route('/events/<int:event_id>/sessions/page')
172 class SessionListPaginated(Resource, PaginatedResourceBase):
173 @api.doc('list_sessions_paginated', params=PAGE_PARAMS)
174 @api.marshal_with(SESSION_PAGINATED)
175 def get(self, event_id):
176 """List sessions in a paginated manner"""
177 return get_paginated_list(
178 SessionModel,
179 self.api.url_for(self, event_id=event_id),
180 args=self.parser.parse_args(),
181 event_id=event_id
182 )
183
[end of open_event/api/sessions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/open_event/api/sessions.py b/open_event/api/sessions.py
--- a/open_event/api/sessions.py
+++ b/open_event/api/sessions.py
@@ -41,10 +41,10 @@
'comments': fields.String(),
'start_time': fields.DateTime(required=True),
'end_time': fields.DateTime(required=True),
- 'track': fields.Nested(SESSION_TRACK),
+ 'track': fields.Nested(SESSION_TRACK, allow_null=True),
'speakers': fields.List(fields.Nested(SESSION_SPEAKER)),
'language': SessionLanguageField(),
- 'microlocation': fields.Nested(SESSION_MICROLOCATION),
+ 'microlocation': fields.Nested(SESSION_MICROLOCATION, allow_null=True),
'slides': fields.String(),
'video': fields.String(),
'audio': fields.String(),
|
{"golden_diff": "diff --git a/open_event/api/sessions.py b/open_event/api/sessions.py\n--- a/open_event/api/sessions.py\n+++ b/open_event/api/sessions.py\n@@ -41,10 +41,10 @@\n 'comments': fields.String(),\n 'start_time': fields.DateTime(required=True),\n 'end_time': fields.DateTime(required=True),\n- 'track': fields.Nested(SESSION_TRACK),\n+ 'track': fields.Nested(SESSION_TRACK, allow_null=True),\n 'speakers': fields.List(fields.Nested(SESSION_SPEAKER)),\n 'language': SessionLanguageField(),\n- 'microlocation': fields.Nested(SESSION_MICROLOCATION),\n+ 'microlocation': fields.Nested(SESSION_MICROLOCATION, allow_null=True),\n 'slides': fields.String(),\n 'video': fields.String(),\n 'audio': fields.String(),\n", "issue": "If nested fields are null, show null instead of their structure\nTake for example Sessions API. If `track` is None (not set), it shows \n\n``` json\n \"title\": \"string\",\n \"track\": {\n \"id\": null,\n \"name\": null\n },\n \"video\": \"string\"\n```\n\nIt would be better if it shows \n\n``` json\n \"title\": \"string\",\n \"track\": null,\n \"video\": \"string\"\n```\n\n@shivamMg @mariobehling What do you think ?\n\n", "before_files": [{"content": "from flask.ext.restplus import Resource, Namespace\nfrom sqlalchemy.orm.collections import InstrumentedList\n\nfrom open_event.models.session import Session as SessionModel\nfrom open_event.models.track import Track as TrackModel\nfrom open_event.models.microlocation import Microlocation as MicrolocationModel\nfrom open_event.models.speaker import Speaker as SpeakerModel\n\nfrom .helpers.helpers import get_paginated_list, requires_auth, \\\n save_db_model, get_object_in_event\nfrom .helpers.utils import PAGINATED_MODEL, PaginatedResourceBase, ServiceDAO, \\\n PAGE_PARAMS, POST_RESPONSES, PUT_RESPONSES\nfrom .helpers import custom_fields as fields\nfrom .helpers.special_fields import SessionLanguageField, SessionStateField\n\napi = Namespace('sessions', description='Sessions', path='/')\n\n# Create models\nSESSION_TRACK = api.model('SessionTrack', {\n 'id': fields.Integer(required=True),\n 'name': fields.String(),\n})\n\nSESSION_SPEAKER = api.model('SessionSpeaker', {\n 'id': fields.Integer(required=True),\n 'name': fields.String(),\n 'organisation': fields.String()\n})\n\nSESSION_MICROLOCATION = api.model('SessionMicrolocation', {\n 'id': fields.Integer(required=True),\n 'name': fields.String(),\n})\n\nSESSION = api.model('Session', {\n 'id': fields.Integer(required=True),\n 'title': fields.String(required=True),\n 'subtitle': fields.String(),\n 'short_abstract': fields.String(),\n 'long_abstract': fields.String(required=True),\n 'comments': fields.String(),\n 'start_time': fields.DateTime(required=True),\n 'end_time': fields.DateTime(required=True),\n 'track': fields.Nested(SESSION_TRACK),\n 'speakers': fields.List(fields.Nested(SESSION_SPEAKER)),\n 'language': SessionLanguageField(),\n 'microlocation': fields.Nested(SESSION_MICROLOCATION),\n 'slides': fields.String(),\n 'video': fields.String(),\n 'audio': fields.String(),\n 'signup_url': fields.Uri(),\n 'state': SessionStateField()\n})\n\nSESSION_PAGINATED = api.clone('SessionPaginated', PAGINATED_MODEL, {\n 'results': fields.List(fields.Nested(SESSION))\n})\n\nSESSION_POST = api.clone('SessionPost', SESSION, {\n 'track_id': fields.Integer(),\n 'speaker_ids': fields.List(fields.Integer()),\n 'microlocation_id': fields.Integer()\n})\ndel SESSION_POST['id']\ndel SESSION_POST['track']\ndel SESSION_POST['speakers']\ndel SESSION_POST['microlocation']\n\n\n# Create DAO\nclass SessionDAO(ServiceDAO):\n def _delete_fields(self, data):\n del data['speaker_ids']\n del data['track_id']\n del data['microlocation_id']\n data['start_time'] = SESSION_POST['start_time'].from_str(\n data['start_time'])\n data['end_time'] = SESSION_POST['end_time'].from_str(data['end_time'])\n return data\n\n def get_object(self, model, sid, event_id):\n \"\"\"\n returns object (model). Checks if object is in same event\n \"\"\"\n if sid is None:\n return None\n return get_object_in_event(model, sid, event_id)\n\n def fix_payload_post(self, event_id, data):\n \"\"\"\n Fixes payload of POST request\n \"\"\"\n data['track'] = self.get_object(TrackModel, data['track_id'], event_id)\n data['microlocation'] = self.get_object(MicrolocationModel, data['microlocation_id'], event_id)\n data['event_id'] = event_id\n data['speakers'] = InstrumentedList(\n SpeakerModel.query.get(_) for _ in data['speaker_ids']\n if self.get_object(SpeakerModel, _, event_id) is not None\n )\n data = self._delete_fields(data)\n return data\n\n def update(self, event_id, service_id, data):\n data = self.validate(data)\n data_copy = data.copy()\n data_copy = self.fix_payload_post(event_id, data_copy)\n data = self._delete_fields(data)\n obj = ServiceDAO.update(self, event_id, service_id, data)\n obj.track = data_copy['track']\n obj.microlocation = data_copy['microlocation']\n obj.speakers = data_copy['speakers']\n obj = save_db_model(obj, SessionModel.__name__, event_id)\n return obj\n\n def create(self, event_id, data, url):\n data = self.validate(data)\n payload = self.fix_payload_post(event_id, data)\n return ServiceDAO.create(self, event_id, payload, url, validate=False)\n\n\nDAO = SessionDAO(SessionModel, SESSION_POST)\n\n\[email protected]('/events/<int:event_id>/sessions/<int:session_id>')\[email protected](404, 'Session not found')\[email protected](400, 'Session does not belong to event')\nclass Session(Resource):\n @api.doc('get_session')\n @api.marshal_with(SESSION)\n def get(self, event_id, session_id):\n \"\"\"Fetch a session given its id\"\"\"\n return DAO.get(event_id, session_id)\n\n @requires_auth\n @api.doc('delete_session')\n @api.marshal_with(SESSION)\n def delete(self, event_id, session_id):\n \"\"\"Delete a session given its id\"\"\"\n return DAO.delete(event_id, session_id)\n\n @requires_auth\n @api.doc('update_session', responses=PUT_RESPONSES)\n @api.marshal_with(SESSION)\n @api.expect(SESSION_POST)\n def put(self, event_id, session_id):\n \"\"\"Update a session given its id\"\"\"\n return DAO.update(event_id, session_id, self.api.payload)\n\n\[email protected]('/events/<int:event_id>/sessions')\nclass SessionList(Resource):\n @api.doc('list_sessions')\n @api.marshal_list_with(SESSION)\n def get(self, event_id):\n \"\"\"List all sessions\"\"\"\n return DAO.list(event_id)\n\n @requires_auth\n @api.doc('create_session', responses=POST_RESPONSES)\n @api.marshal_with(SESSION)\n @api.expect(SESSION_POST)\n def post(self, event_id):\n \"\"\"Create a session\"\"\"\n return DAO.create(\n event_id,\n self.api.payload,\n self.api.url_for(self, event_id=event_id)\n )\n\n\[email protected]('/events/<int:event_id>/sessions/page')\nclass SessionListPaginated(Resource, PaginatedResourceBase):\n @api.doc('list_sessions_paginated', params=PAGE_PARAMS)\n @api.marshal_with(SESSION_PAGINATED)\n def get(self, event_id):\n \"\"\"List sessions in a paginated manner\"\"\"\n return get_paginated_list(\n SessionModel,\n self.api.url_for(self, event_id=event_id),\n args=self.parser.parse_args(),\n event_id=event_id\n )\n", "path": "open_event/api/sessions.py"}]}
| 2,554 | 183 |
gh_patches_debug_5308
|
rasdani/github-patches
|
git_diff
|
beetbox__beets-1263
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Improve extractart to extract cover art of all albums for a query
The current `extractart` command of the `embedart` plugin is only able to extract the cover art of a single file. If the query the user specifies results in more than one item, only the art of the first one is extracted.
I would like to improve the command such the user queries for albums (like `ls -a` command) and one cover art is extracted per album and placed inside the album folder. The command should try all files of an album until an art is found. The command could be executed like `beet extractart -a <query>`.
</issue>
<code>
[start of beetsplug/embedart.py]
1 # This file is part of beets.
2 # Copyright 2015, Adrian Sampson.
3 #
4 # Permission is hereby granted, free of charge, to any person obtaining
5 # a copy of this software and associated documentation files (the
6 # "Software"), to deal in the Software without restriction, including
7 # without limitation the rights to use, copy, modify, merge, publish,
8 # distribute, sublicense, and/or sell copies of the Software, and to
9 # permit persons to whom the Software is furnished to do so, subject to
10 # the following conditions:
11 #
12 # The above copyright notice and this permission notice shall be
13 # included in all copies or substantial portions of the Software.
14
15 """Allows beets to embed album art into file metadata."""
16 import os.path
17 import imghdr
18 import subprocess
19 import platform
20 from tempfile import NamedTemporaryFile
21
22 from beets import logging
23 from beets.plugins import BeetsPlugin
24 from beets import mediafile
25 from beets import ui
26 from beets.ui import decargs
27 from beets.util import syspath, normpath, displayable_path
28 from beets.util.artresizer import ArtResizer
29 from beets import config
30
31
32 class EmbedCoverArtPlugin(BeetsPlugin):
33 """Allows albumart to be embedded into the actual files.
34 """
35 def __init__(self):
36 super(EmbedCoverArtPlugin, self).__init__()
37 self.config.add({
38 'maxwidth': 0,
39 'auto': True,
40 'compare_threshold': 0,
41 'ifempty': False,
42 })
43
44 if self.config['maxwidth'].get(int) and not ArtResizer.shared.local:
45 self.config['maxwidth'] = 0
46 self._log.warn(u"ImageMagick or PIL not found; "
47 u"'maxwidth' option ignored")
48 if self.config['compare_threshold'].get(int) and not \
49 ArtResizer.shared.can_compare:
50 self.config['compare_threshold'] = 0
51 self._log.warn(u"ImageMagick 6.8.7 or higher not installed; "
52 u"'compare_threshold' option ignored")
53
54 self.register_listener('album_imported', self.album_imported)
55
56 def commands(self):
57 # Embed command.
58 embed_cmd = ui.Subcommand(
59 'embedart', help='embed image files into file metadata'
60 )
61 embed_cmd.parser.add_option(
62 '-f', '--file', metavar='PATH', help='the image file to embed'
63 )
64 maxwidth = self.config['maxwidth'].get(int)
65 compare_threshold = self.config['compare_threshold'].get(int)
66 ifempty = self.config['ifempty'].get(bool)
67
68 def embed_func(lib, opts, args):
69 if opts.file:
70 imagepath = normpath(opts.file)
71 if not os.path.isfile(syspath(imagepath)):
72 raise ui.UserError(u'image file {0} not found'.format(
73 displayable_path(imagepath)
74 ))
75 for item in lib.items(decargs(args)):
76 self.embed_item(item, imagepath, maxwidth, None,
77 compare_threshold, ifempty)
78 else:
79 for album in lib.albums(decargs(args)):
80 self.embed_album(album, maxwidth)
81
82 embed_cmd.func = embed_func
83
84 # Extract command.
85 extract_cmd = ui.Subcommand('extractart',
86 help='extract an image from file metadata')
87 extract_cmd.parser.add_option('-o', dest='outpath',
88 help='image output file')
89
90 def extract_func(lib, opts, args):
91 outpath = normpath(opts.outpath or (config['art_filename'].get()
92 or 'cover'))
93 item = lib.items(decargs(args)).get()
94 self.extract(outpath, item)
95 extract_cmd.func = extract_func
96
97 # Clear command.
98 clear_cmd = ui.Subcommand('clearart',
99 help='remove images from file metadata')
100
101 def clear_func(lib, opts, args):
102 self.clear(lib, decargs(args))
103 clear_cmd.func = clear_func
104
105 return [embed_cmd, extract_cmd, clear_cmd]
106
107 def album_imported(self, lib, album):
108 """Automatically embed art into imported albums.
109 """
110 if album.artpath and self.config['auto']:
111 max_width = self.config['maxwidth'].get(int)
112 self.embed_album(album, max_width, True)
113
114 def embed_item(self, item, imagepath, maxwidth=None, itempath=None,
115 compare_threshold=0, ifempty=False, as_album=False):
116 """Embed an image into the item's media file.
117 """
118 if compare_threshold:
119 if not self.check_art_similarity(item, imagepath,
120 compare_threshold):
121 self._log.warn(u'Image not similar; skipping.')
122 return
123 if ifempty:
124 art = self.get_art(item)
125 if not art:
126 pass
127 else:
128 self._log.debug(u'media file contained art already {0}',
129 displayable_path(imagepath))
130 return
131 if maxwidth and not as_album:
132 imagepath = self.resize_image(imagepath, maxwidth)
133
134 try:
135 self._log.debug(u'embedding {0}', displayable_path(imagepath))
136 item['images'] = [self._mediafile_image(imagepath, maxwidth)]
137 except IOError as exc:
138 self._log.error(u'could not read image file: {0}', exc)
139 else:
140 # We don't want to store the image in the database.
141 item.try_write(itempath)
142 del item['images']
143
144 def embed_album(self, album, maxwidth=None, quiet=False):
145 """Embed album art into all of the album's items.
146 """
147 imagepath = album.artpath
148 if not imagepath:
149 self._log.info(u'No album art present: {0} - {1}',
150 album.albumartist, album.album)
151 return
152 if not os.path.isfile(syspath(imagepath)):
153 self._log.error(u'Album art not found at {0}',
154 displayable_path(imagepath))
155 return
156 if maxwidth:
157 imagepath = self.resize_image(imagepath, maxwidth)
158
159 self._log.log(
160 logging.DEBUG if quiet else logging.INFO,
161 u'Embedding album art into {0.albumartist} - {0.album}.', album
162 )
163
164 for item in album.items():
165 thresh = self.config['compare_threshold'].get(int)
166 ifempty = self.config['ifempty'].get(bool)
167 self.embed_item(item, imagepath, maxwidth, None,
168 thresh, ifempty, as_album=True)
169
170 def resize_image(self, imagepath, maxwidth):
171 """Returns path to an image resized to maxwidth.
172 """
173 self._log.info(u'Resizing album art to {0} pixels wide', maxwidth)
174 imagepath = ArtResizer.shared.resize(maxwidth, syspath(imagepath))
175 return imagepath
176
177 def check_art_similarity(self, item, imagepath, compare_threshold):
178 """A boolean indicating if an image is similar to embedded item art.
179 """
180 with NamedTemporaryFile(delete=True) as f:
181 art = self.extract(f.name, item)
182
183 if art:
184 is_windows = platform.system() == "Windows"
185
186 # Converting images to grayscale tends to minimize the weight
187 # of colors in the diff score.
188 convert_proc = subprocess.Popen(
189 ['convert', syspath(imagepath), syspath(art),
190 '-colorspace', 'gray', 'MIFF:-'],
191 stdout=subprocess.PIPE,
192 close_fds=not is_windows,
193 )
194 compare_proc = subprocess.Popen(
195 ['compare', '-metric', 'PHASH', '-', 'null:'],
196 stdin=convert_proc.stdout,
197 stdout=subprocess.PIPE,
198 stderr=subprocess.PIPE,
199 close_fds=not is_windows,
200 )
201 convert_proc.stdout.close()
202
203 stdout, stderr = compare_proc.communicate()
204 if compare_proc.returncode:
205 if compare_proc.returncode != 1:
206 self._log.debug(u'IM phashes compare failed for {0}, '
207 u'{1}', displayable_path(imagepath),
208 displayable_path(art))
209 return
210 out_str = stderr
211 else:
212 out_str = stdout
213
214 try:
215 phash_diff = float(out_str)
216 except ValueError:
217 self._log.debug(u'IM output is not a number: {0!r}',
218 out_str)
219 return
220
221 self._log.info(u'compare PHASH score is {0}', phash_diff)
222 if phash_diff > compare_threshold:
223 return False
224
225 return True
226
227 def _mediafile_image(self, image_path, maxwidth=None):
228 """Return a `mediafile.Image` object for the path.
229 """
230
231 with open(syspath(image_path), 'rb') as f:
232 data = f.read()
233 return mediafile.Image(data, type=mediafile.ImageType.front)
234
235 def get_art(self, item):
236 # Extract the art.
237 try:
238 mf = mediafile.MediaFile(syspath(item.path))
239 except mediafile.UnreadableFileError as exc:
240 self._log.error(u'Could not extract art from {0}: {1}',
241 displayable_path(item.path), exc)
242 return
243
244 return mf.art
245
246 # 'extractart' command.
247
248 def extract(self, outpath, item):
249 if not item:
250 self._log.error(u'No item matches query.')
251 return
252
253 art = self.get_art(item)
254
255 if not art:
256 self._log.error(u'No album art present in {0} - {1}.',
257 item.artist, item.title)
258 return
259
260 # Add an extension to the filename.
261 ext = imghdr.what(None, h=art)
262 if not ext:
263 self._log.error(u'Unknown image type.')
264 return
265 outpath += '.' + ext
266
267 self._log.info(u'Extracting album art from: {0.artist} - {0.title} '
268 u'to: {1}', item, displayable_path(outpath))
269 with open(syspath(outpath), 'wb') as f:
270 f.write(art)
271 return outpath
272
273 # 'clearart' command.
274 def clear(self, lib, query):
275 self._log.info(u'Clearing album art from items:')
276 for item in lib.items(query):
277 self._log.info(u'{0} - {1}', item.artist, item.title)
278 try:
279 mf = mediafile.MediaFile(syspath(item.path),
280 config['id3v23'].get(bool))
281 except mediafile.UnreadableFileError as exc:
282 self._log.error(u'Could not clear art from {0}: {1}',
283 displayable_path(item.path), exc)
284 continue
285 del mf.art
286 mf.save()
287
[end of beetsplug/embedart.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/beetsplug/embedart.py b/beetsplug/embedart.py
--- a/beetsplug/embedart.py
+++ b/beetsplug/embedart.py
@@ -89,8 +89,9 @@
def extract_func(lib, opts, args):
outpath = normpath(opts.outpath or 'cover')
- item = lib.items(decargs(args)).get()
- self.extract(outpath, item)
+ for item in lib.items(decargs(args)):
+ if self.extract(outpath, item):
+ return
extract_cmd.func = extract_func
# Clear command.
|
{"golden_diff": "diff --git a/beetsplug/embedart.py b/beetsplug/embedart.py\n--- a/beetsplug/embedart.py\n+++ b/beetsplug/embedart.py\n@@ -89,8 +89,9 @@\n \n def extract_func(lib, opts, args):\n outpath = normpath(opts.outpath or 'cover')\n- item = lib.items(decargs(args)).get()\n- self.extract(outpath, item)\n+ for item in lib.items(decargs(args)):\n+ if self.extract(outpath, item):\n+ return\n extract_cmd.func = extract_func\n \n # Clear command.\n", "issue": "Improve extractart to extract cover art of all albums for a query\nThe current `extractart` command of the `embedart` plugin is only able to extract the cover art of a single file. If the query the user specifies results in more than one item, only the art of the first one is extracted.\n\nI would like to improve the command such the user queries for albums (like `ls -a` command) and one cover art is extracted per album and placed inside the album folder. The command should try all files of an album until an art is found. The command could be executed like `beet extractart -a <query>`.\n\n", "before_files": [{"content": "# This file is part of beets.\n# Copyright 2015, Adrian Sampson.\n#\n# Permission is hereby granted, free of charge, to any person obtaining\n# a copy of this software and associated documentation files (the\n# \"Software\"), to deal in the Software without restriction, including\n# without limitation the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the Software, and to\n# permit persons to whom the Software is furnished to do so, subject to\n# the following conditions:\n#\n# The above copyright notice and this permission notice shall be\n# included in all copies or substantial portions of the Software.\n\n\"\"\"Allows beets to embed album art into file metadata.\"\"\"\nimport os.path\nimport imghdr\nimport subprocess\nimport platform\nfrom tempfile import NamedTemporaryFile\n\nfrom beets import logging\nfrom beets.plugins import BeetsPlugin\nfrom beets import mediafile\nfrom beets import ui\nfrom beets.ui import decargs\nfrom beets.util import syspath, normpath, displayable_path\nfrom beets.util.artresizer import ArtResizer\nfrom beets import config\n\n\nclass EmbedCoverArtPlugin(BeetsPlugin):\n \"\"\"Allows albumart to be embedded into the actual files.\n \"\"\"\n def __init__(self):\n super(EmbedCoverArtPlugin, self).__init__()\n self.config.add({\n 'maxwidth': 0,\n 'auto': True,\n 'compare_threshold': 0,\n 'ifempty': False,\n })\n\n if self.config['maxwidth'].get(int) and not ArtResizer.shared.local:\n self.config['maxwidth'] = 0\n self._log.warn(u\"ImageMagick or PIL not found; \"\n u\"'maxwidth' option ignored\")\n if self.config['compare_threshold'].get(int) and not \\\n ArtResizer.shared.can_compare:\n self.config['compare_threshold'] = 0\n self._log.warn(u\"ImageMagick 6.8.7 or higher not installed; \"\n u\"'compare_threshold' option ignored\")\n\n self.register_listener('album_imported', self.album_imported)\n\n def commands(self):\n # Embed command.\n embed_cmd = ui.Subcommand(\n 'embedart', help='embed image files into file metadata'\n )\n embed_cmd.parser.add_option(\n '-f', '--file', metavar='PATH', help='the image file to embed'\n )\n maxwidth = self.config['maxwidth'].get(int)\n compare_threshold = self.config['compare_threshold'].get(int)\n ifempty = self.config['ifempty'].get(bool)\n\n def embed_func(lib, opts, args):\n if opts.file:\n imagepath = normpath(opts.file)\n if not os.path.isfile(syspath(imagepath)):\n raise ui.UserError(u'image file {0} not found'.format(\n displayable_path(imagepath)\n ))\n for item in lib.items(decargs(args)):\n self.embed_item(item, imagepath, maxwidth, None,\n compare_threshold, ifempty)\n else:\n for album in lib.albums(decargs(args)):\n self.embed_album(album, maxwidth)\n\n embed_cmd.func = embed_func\n\n # Extract command.\n extract_cmd = ui.Subcommand('extractart',\n help='extract an image from file metadata')\n extract_cmd.parser.add_option('-o', dest='outpath',\n help='image output file')\n\n def extract_func(lib, opts, args):\n outpath = normpath(opts.outpath or (config['art_filename'].get()\n or 'cover'))\n item = lib.items(decargs(args)).get()\n self.extract(outpath, item)\n extract_cmd.func = extract_func\n\n # Clear command.\n clear_cmd = ui.Subcommand('clearart',\n help='remove images from file metadata')\n\n def clear_func(lib, opts, args):\n self.clear(lib, decargs(args))\n clear_cmd.func = clear_func\n\n return [embed_cmd, extract_cmd, clear_cmd]\n\n def album_imported(self, lib, album):\n \"\"\"Automatically embed art into imported albums.\n \"\"\"\n if album.artpath and self.config['auto']:\n max_width = self.config['maxwidth'].get(int)\n self.embed_album(album, max_width, True)\n\n def embed_item(self, item, imagepath, maxwidth=None, itempath=None,\n compare_threshold=0, ifempty=False, as_album=False):\n \"\"\"Embed an image into the item's media file.\n \"\"\"\n if compare_threshold:\n if not self.check_art_similarity(item, imagepath,\n compare_threshold):\n self._log.warn(u'Image not similar; skipping.')\n return\n if ifempty:\n art = self.get_art(item)\n if not art:\n pass\n else:\n self._log.debug(u'media file contained art already {0}',\n displayable_path(imagepath))\n return\n if maxwidth and not as_album:\n imagepath = self.resize_image(imagepath, maxwidth)\n\n try:\n self._log.debug(u'embedding {0}', displayable_path(imagepath))\n item['images'] = [self._mediafile_image(imagepath, maxwidth)]\n except IOError as exc:\n self._log.error(u'could not read image file: {0}', exc)\n else:\n # We don't want to store the image in the database.\n item.try_write(itempath)\n del item['images']\n\n def embed_album(self, album, maxwidth=None, quiet=False):\n \"\"\"Embed album art into all of the album's items.\n \"\"\"\n imagepath = album.artpath\n if not imagepath:\n self._log.info(u'No album art present: {0} - {1}',\n album.albumartist, album.album)\n return\n if not os.path.isfile(syspath(imagepath)):\n self._log.error(u'Album art not found at {0}',\n displayable_path(imagepath))\n return\n if maxwidth:\n imagepath = self.resize_image(imagepath, maxwidth)\n\n self._log.log(\n logging.DEBUG if quiet else logging.INFO,\n u'Embedding album art into {0.albumartist} - {0.album}.', album\n )\n\n for item in album.items():\n thresh = self.config['compare_threshold'].get(int)\n ifempty = self.config['ifempty'].get(bool)\n self.embed_item(item, imagepath, maxwidth, None,\n thresh, ifempty, as_album=True)\n\n def resize_image(self, imagepath, maxwidth):\n \"\"\"Returns path to an image resized to maxwidth.\n \"\"\"\n self._log.info(u'Resizing album art to {0} pixels wide', maxwidth)\n imagepath = ArtResizer.shared.resize(maxwidth, syspath(imagepath))\n return imagepath\n\n def check_art_similarity(self, item, imagepath, compare_threshold):\n \"\"\"A boolean indicating if an image is similar to embedded item art.\n \"\"\"\n with NamedTemporaryFile(delete=True) as f:\n art = self.extract(f.name, item)\n\n if art:\n is_windows = platform.system() == \"Windows\"\n\n # Converting images to grayscale tends to minimize the weight\n # of colors in the diff score.\n convert_proc = subprocess.Popen(\n ['convert', syspath(imagepath), syspath(art),\n '-colorspace', 'gray', 'MIFF:-'],\n stdout=subprocess.PIPE,\n close_fds=not is_windows,\n )\n compare_proc = subprocess.Popen(\n ['compare', '-metric', 'PHASH', '-', 'null:'],\n stdin=convert_proc.stdout,\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE,\n close_fds=not is_windows,\n )\n convert_proc.stdout.close()\n\n stdout, stderr = compare_proc.communicate()\n if compare_proc.returncode:\n if compare_proc.returncode != 1:\n self._log.debug(u'IM phashes compare failed for {0}, '\n u'{1}', displayable_path(imagepath),\n displayable_path(art))\n return\n out_str = stderr\n else:\n out_str = stdout\n\n try:\n phash_diff = float(out_str)\n except ValueError:\n self._log.debug(u'IM output is not a number: {0!r}',\n out_str)\n return\n\n self._log.info(u'compare PHASH score is {0}', phash_diff)\n if phash_diff > compare_threshold:\n return False\n\n return True\n\n def _mediafile_image(self, image_path, maxwidth=None):\n \"\"\"Return a `mediafile.Image` object for the path.\n \"\"\"\n\n with open(syspath(image_path), 'rb') as f:\n data = f.read()\n return mediafile.Image(data, type=mediafile.ImageType.front)\n\n def get_art(self, item):\n # Extract the art.\n try:\n mf = mediafile.MediaFile(syspath(item.path))\n except mediafile.UnreadableFileError as exc:\n self._log.error(u'Could not extract art from {0}: {1}',\n displayable_path(item.path), exc)\n return\n\n return mf.art\n\n # 'extractart' command.\n\n def extract(self, outpath, item):\n if not item:\n self._log.error(u'No item matches query.')\n return\n\n art = self.get_art(item)\n\n if not art:\n self._log.error(u'No album art present in {0} - {1}.',\n item.artist, item.title)\n return\n\n # Add an extension to the filename.\n ext = imghdr.what(None, h=art)\n if not ext:\n self._log.error(u'Unknown image type.')\n return\n outpath += '.' + ext\n\n self._log.info(u'Extracting album art from: {0.artist} - {0.title} '\n u'to: {1}', item, displayable_path(outpath))\n with open(syspath(outpath), 'wb') as f:\n f.write(art)\n return outpath\n\n # 'clearart' command.\n def clear(self, lib, query):\n self._log.info(u'Clearing album art from items:')\n for item in lib.items(query):\n self._log.info(u'{0} - {1}', item.artist, item.title)\n try:\n mf = mediafile.MediaFile(syspath(item.path),\n config['id3v23'].get(bool))\n except mediafile.UnreadableFileError as exc:\n self._log.error(u'Could not clear art from {0}: {1}',\n displayable_path(item.path), exc)\n continue\n del mf.art\n mf.save()\n", "path": "beetsplug/embedart.py"}]}
| 3,735 | 131 |
gh_patches_debug_22829
|
rasdani/github-patches
|
git_diff
|
pyodide__pyodide-891
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
JsProxy does not handle Error correctly
Example:
```python
from js import Error
e = Error.new("Hi")
raise e
```
Raises: `TypeError: exceptions must derive from BaseException`.
This came up in https://github.com/iodide-project/pyodide/pull/880#pullrequestreview-555341317. I will try to fix this.
</issue>
<code>
[start of src/pyodide-py/pyodide/__init__.py]
1 from ._base import open_url, eval_code, find_imports, as_nested_list
2 from .console import get_completions
3
4 __version__ = "0.15.0"
5
6 __all__ = ["open_url", "eval_code", "find_imports", "as_nested_list", "get_completions"]
7
[end of src/pyodide-py/pyodide/__init__.py]
[start of src/pyodide-py/pyodide/_base.py]
1 """
2 A library of helper utilities for connecting Python to the browser environment.
3 """
4
5 import ast
6 from io import StringIO
7 from textwrap import dedent
8 from typing import Dict, List, Any
9
10
11 def open_url(url: str) -> StringIO:
12 """
13 Fetches a given URL
14
15 Parameters
16 ----------
17 url
18 URL to fetch
19
20 Returns
21 -------
22 a io.StringIO object with the contents of the URL.
23 """
24 from js import XMLHttpRequest
25
26 req = XMLHttpRequest.new()
27 req.open("GET", url, False)
28 req.send(None)
29 return StringIO(req.response)
30
31
32 def eval_code(code: str, ns: Dict[str, Any]) -> None:
33 """Runs a code string
34
35 The last part of the provided code may be an expression.
36
37 Parameters
38 ----------
39 code
40 the Python code to run.
41 ns
42 `locals()` or `globals()` context where to execute code.
43
44 Returns
45 -------
46 None
47 """
48 # handle mis-indented input from multi-line strings
49 code = dedent(code)
50
51 mod = ast.parse(code)
52 if len(mod.body) == 0:
53 return None
54
55 expr: Any
56 if isinstance(mod.body[-1], ast.Expr):
57 expr = ast.Expression(mod.body[-1].value)
58 del mod.body[-1]
59 else:
60 expr = None
61
62 if len(mod.body):
63 exec(compile(mod, "<exec>", mode="exec"), ns, ns)
64 if expr is not None:
65 return eval(compile(expr, "<eval>", mode="eval"), ns, ns)
66 else:
67 return None
68
69
70 def find_imports(code: str) -> List[str]:
71 """
72 Finds the imports in a string of code
73
74 Parameters
75 ----------
76 code
77 the Python code to run.
78
79 Returns
80 -------
81 A list of module names that are imported in the code.
82
83 Examples
84 --------
85 >>> from pyodide import find_imports
86 >>> code = "import numpy as np; import scipy.stats"
87 >>> find_imports(code)
88 ['numpy', 'scipy']
89 """
90 # handle mis-indented input from multi-line strings
91 code = dedent(code)
92
93 mod = ast.parse(code)
94 imports = set()
95 for node in ast.walk(mod):
96 if isinstance(node, ast.Import):
97 for name in node.names:
98 node_name = name.name
99 imports.add(node_name.split(".")[0])
100 elif isinstance(node, ast.ImportFrom):
101 module_name = node.module
102 if module_name is None:
103 continue
104 imports.add(module_name.split(".")[0])
105 return list(sorted(imports))
106
107
108 def as_nested_list(obj) -> List:
109 """Convert a nested JS array to nested Python list.
110
111 Assumes a Javascript object is made of (possibly nested) arrays and
112 converts them to nested Python lists.
113
114 Parameters
115 ----------
116 obj
117 a Javscript object made of nested arrays.
118
119 Returns
120 -------
121 Python list, or a nested Python list
122 """
123 try:
124 it = iter(obj)
125 return [as_nested_list(x) for x in it]
126 except TypeError:
127 return obj
128
[end of src/pyodide-py/pyodide/_base.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/pyodide-py/pyodide/__init__.py b/src/pyodide-py/pyodide/__init__.py
--- a/src/pyodide-py/pyodide/__init__.py
+++ b/src/pyodide-py/pyodide/__init__.py
@@ -1,6 +1,13 @@
-from ._base import open_url, eval_code, find_imports, as_nested_list
+from ._base import open_url, eval_code, find_imports, as_nested_list, JsException
from .console import get_completions
__version__ = "0.15.0"
-__all__ = ["open_url", "eval_code", "find_imports", "as_nested_list", "get_completions"]
+__all__ = [
+ "open_url",
+ "eval_code",
+ "find_imports",
+ "as_nested_list",
+ "get_completions",
+ "JsException",
+]
diff --git a/src/pyodide-py/pyodide/_base.py b/src/pyodide-py/pyodide/_base.py
--- a/src/pyodide-py/pyodide/_base.py
+++ b/src/pyodide-py/pyodide/_base.py
@@ -1,6 +1,8 @@
"""
A library of helper utilities for connecting Python to the browser environment.
"""
+# Added by C:
+# JsException (from jsproxy.c)
import ast
from io import StringIO
@@ -8,6 +10,16 @@
from typing import Dict, List, Any
+class JsException(Exception):
+ """
+ A wrapper around a Javascript Error to allow the Error to be thrown in Python.
+ """
+
+ # This gets overwritten in jsproxy.c, it is just here for autodoc and humans
+ # reading this file.
+ pass
+
+
def open_url(url: str) -> StringIO:
"""
Fetches a given URL
|
{"golden_diff": "diff --git a/src/pyodide-py/pyodide/__init__.py b/src/pyodide-py/pyodide/__init__.py\n--- a/src/pyodide-py/pyodide/__init__.py\n+++ b/src/pyodide-py/pyodide/__init__.py\n@@ -1,6 +1,13 @@\n-from ._base import open_url, eval_code, find_imports, as_nested_list\n+from ._base import open_url, eval_code, find_imports, as_nested_list, JsException\n from .console import get_completions\n \n __version__ = \"0.15.0\"\n \n-__all__ = [\"open_url\", \"eval_code\", \"find_imports\", \"as_nested_list\", \"get_completions\"]\n+__all__ = [\n+ \"open_url\",\n+ \"eval_code\",\n+ \"find_imports\",\n+ \"as_nested_list\",\n+ \"get_completions\",\n+ \"JsException\",\n+]\ndiff --git a/src/pyodide-py/pyodide/_base.py b/src/pyodide-py/pyodide/_base.py\n--- a/src/pyodide-py/pyodide/_base.py\n+++ b/src/pyodide-py/pyodide/_base.py\n@@ -1,6 +1,8 @@\n \"\"\"\n A library of helper utilities for connecting Python to the browser environment.\n \"\"\"\n+# Added by C:\n+# JsException (from jsproxy.c)\n \n import ast\n from io import StringIO\n@@ -8,6 +10,16 @@\n from typing import Dict, List, Any\n \n \n+class JsException(Exception):\n+ \"\"\"\n+ A wrapper around a Javascript Error to allow the Error to be thrown in Python.\n+ \"\"\"\n+\n+ # This gets overwritten in jsproxy.c, it is just here for autodoc and humans\n+ # reading this file.\n+ pass\n+\n+\n def open_url(url: str) -> StringIO:\n \"\"\"\n Fetches a given URL\n", "issue": "JsProxy does not handle Error correctly\nExample:\r\n```python\r\nfrom js import Error\r\ne = Error.new(\"Hi\")\r\nraise e\r\n```\r\nRaises: `TypeError: exceptions must derive from BaseException`.\r\nThis came up in https://github.com/iodide-project/pyodide/pull/880#pullrequestreview-555341317. I will try to fix this.\n", "before_files": [{"content": "from ._base import open_url, eval_code, find_imports, as_nested_list\nfrom .console import get_completions\n\n__version__ = \"0.15.0\"\n\n__all__ = [\"open_url\", \"eval_code\", \"find_imports\", \"as_nested_list\", \"get_completions\"]\n", "path": "src/pyodide-py/pyodide/__init__.py"}, {"content": "\"\"\"\nA library of helper utilities for connecting Python to the browser environment.\n\"\"\"\n\nimport ast\nfrom io import StringIO\nfrom textwrap import dedent\nfrom typing import Dict, List, Any\n\n\ndef open_url(url: str) -> StringIO:\n \"\"\"\n Fetches a given URL\n\n Parameters\n ----------\n url\n URL to fetch\n\n Returns\n -------\n a io.StringIO object with the contents of the URL.\n \"\"\"\n from js import XMLHttpRequest\n\n req = XMLHttpRequest.new()\n req.open(\"GET\", url, False)\n req.send(None)\n return StringIO(req.response)\n\n\ndef eval_code(code: str, ns: Dict[str, Any]) -> None:\n \"\"\"Runs a code string\n\n The last part of the provided code may be an expression.\n\n Parameters\n ----------\n code\n the Python code to run.\n ns\n `locals()` or `globals()` context where to execute code.\n\n Returns\n -------\n None\n \"\"\"\n # handle mis-indented input from multi-line strings\n code = dedent(code)\n\n mod = ast.parse(code)\n if len(mod.body) == 0:\n return None\n\n expr: Any\n if isinstance(mod.body[-1], ast.Expr):\n expr = ast.Expression(mod.body[-1].value)\n del mod.body[-1]\n else:\n expr = None\n\n if len(mod.body):\n exec(compile(mod, \"<exec>\", mode=\"exec\"), ns, ns)\n if expr is not None:\n return eval(compile(expr, \"<eval>\", mode=\"eval\"), ns, ns)\n else:\n return None\n\n\ndef find_imports(code: str) -> List[str]:\n \"\"\"\n Finds the imports in a string of code\n\n Parameters\n ----------\n code\n the Python code to run.\n\n Returns\n -------\n A list of module names that are imported in the code.\n\n Examples\n --------\n >>> from pyodide import find_imports\n >>> code = \"import numpy as np; import scipy.stats\"\n >>> find_imports(code)\n ['numpy', 'scipy']\n \"\"\"\n # handle mis-indented input from multi-line strings\n code = dedent(code)\n\n mod = ast.parse(code)\n imports = set()\n for node in ast.walk(mod):\n if isinstance(node, ast.Import):\n for name in node.names:\n node_name = name.name\n imports.add(node_name.split(\".\")[0])\n elif isinstance(node, ast.ImportFrom):\n module_name = node.module\n if module_name is None:\n continue\n imports.add(module_name.split(\".\")[0])\n return list(sorted(imports))\n\n\ndef as_nested_list(obj) -> List:\n \"\"\"Convert a nested JS array to nested Python list.\n\n Assumes a Javascript object is made of (possibly nested) arrays and\n converts them to nested Python lists.\n\n Parameters\n ----------\n obj\n a Javscript object made of nested arrays.\n\n Returns\n -------\n Python list, or a nested Python list\n \"\"\"\n try:\n it = iter(obj)\n return [as_nested_list(x) for x in it]\n except TypeError:\n return obj\n", "path": "src/pyodide-py/pyodide/_base.py"}]}
| 1,714 | 429 |
gh_patches_debug_20992
|
rasdani/github-patches
|
git_diff
|
fossasia__open-event-server-4997
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Minor bug in export orders as CSV task
**Describe the bug**
Minor bug in exporting orders as CSV. Trying to decode string which throws a type error:
```python
if order.user and order.user.first_name else '',
str(order.user.last_name, 'utf-8')
```
**To Reproduce**
Steps to reproduce the behavior:
1. Start export orders as csv task
2. Make sure user is linked for that particular order
3. See the error
**Expected behavior**
It should work properly
**Stacktrace**
```sh
File "/home/mayank/OpenSource/open-event-server/app/api/helpers/tasks.py", line 238, in export_order_csv_task
content = export_orders_csv(orders)
File "/home/mayank/OpenSource/open-event-server/app/api/helpers/csv_jobs_util.py", line 13, in export_orders_csv
if order.user and order.user.first_name else '',
TypeError: decoding str is not supported
```
**Additional details (please complete the following information):**
- OS: Ubuntu 18.04
- Python Version 3.6
- `HEAD` Commit hash [e.g. `4629c62`]
</issue>
<code>
[start of app/api/helpers/csv_jobs_util.py]
1 def export_orders_csv(orders):
2 headers = ['Order#', 'Order Date', 'Status', 'Payment Type', 'Total Amount', 'Quantity',
3 'Discount Code', 'First Name', 'Last Name', 'Email']
4
5 rows = [headers]
6 for order in orders:
7 if order.status != "deleted":
8 column = [str(order.get_invoice_number()), str(order.created_at) if order.created_at else '',
9 str(order.status) if order.status else '', str(order.paid_via) if order.paid_via else '',
10 str(order.amount) if order.amount else '', str(order.get_tickets_count()),
11 str(order.discount_code.code) if order.discount_code else '',
12 str(order.user.first_name, 'utf-8')
13 if order.user and order.user.first_name else '',
14 str(order.user.last_name, 'utf-8')
15 if order.user and order.user.last_name else '',
16 str(order.user._email, 'utf-8') if order.user and order.user._email else '']
17 rows.append(column)
18
19 return rows
20
[end of app/api/helpers/csv_jobs_util.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/app/api/helpers/csv_jobs_util.py b/app/api/helpers/csv_jobs_util.py
--- a/app/api/helpers/csv_jobs_util.py
+++ b/app/api/helpers/csv_jobs_util.py
@@ -9,11 +9,11 @@
str(order.status) if order.status else '', str(order.paid_via) if order.paid_via else '',
str(order.amount) if order.amount else '', str(order.get_tickets_count()),
str(order.discount_code.code) if order.discount_code else '',
- str(order.user.first_name, 'utf-8')
+ str(order.user.first_name)
if order.user and order.user.first_name else '',
- str(order.user.last_name, 'utf-8')
+ str(order.user.last_name)
if order.user and order.user.last_name else '',
- str(order.user._email, 'utf-8') if order.user and order.user._email else '']
+ str(order.user.email) if order.user and order.user.email else '']
rows.append(column)
return rows
|
{"golden_diff": "diff --git a/app/api/helpers/csv_jobs_util.py b/app/api/helpers/csv_jobs_util.py\n--- a/app/api/helpers/csv_jobs_util.py\n+++ b/app/api/helpers/csv_jobs_util.py\n@@ -9,11 +9,11 @@\n str(order.status) if order.status else '', str(order.paid_via) if order.paid_via else '',\n str(order.amount) if order.amount else '', str(order.get_tickets_count()),\n str(order.discount_code.code) if order.discount_code else '',\n- str(order.user.first_name, 'utf-8')\n+ str(order.user.first_name)\n if order.user and order.user.first_name else '',\n- str(order.user.last_name, 'utf-8')\n+ str(order.user.last_name)\n if order.user and order.user.last_name else '',\n- str(order.user._email, 'utf-8') if order.user and order.user._email else '']\n+ str(order.user.email) if order.user and order.user.email else '']\n rows.append(column)\n \n return rows\n", "issue": "Minor bug in export orders as CSV task\n**Describe the bug**\r\nMinor bug in exporting orders as CSV. Trying to decode string which throws a type error:\r\n```python\r\n if order.user and order.user.first_name else '',\r\n str(order.user.last_name, 'utf-8')\r\n```\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Start export orders as csv task \r\n2. Make sure user is linked for that particular order\r\n3. See the error\r\n\r\n**Expected behavior**\r\nIt should work properly\r\n\r\n**Stacktrace**\r\n```sh\r\n File \"/home/mayank/OpenSource/open-event-server/app/api/helpers/tasks.py\", line 238, in export_order_csv_task\r\n content = export_orders_csv(orders)\r\n File \"/home/mayank/OpenSource/open-event-server/app/api/helpers/csv_jobs_util.py\", line 13, in export_orders_csv\r\n if order.user and order.user.first_name else '',\r\nTypeError: decoding str is not supported\r\n```\r\n**Additional details (please complete the following information):**\r\n - OS: Ubuntu 18.04\r\n - Python Version 3.6\r\n - `HEAD` Commit hash [e.g. `4629c62`]\n", "before_files": [{"content": "def export_orders_csv(orders):\n headers = ['Order#', 'Order Date', 'Status', 'Payment Type', 'Total Amount', 'Quantity',\n 'Discount Code', 'First Name', 'Last Name', 'Email']\n\n rows = [headers]\n for order in orders:\n if order.status != \"deleted\":\n column = [str(order.get_invoice_number()), str(order.created_at) if order.created_at else '',\n str(order.status) if order.status else '', str(order.paid_via) if order.paid_via else '',\n str(order.amount) if order.amount else '', str(order.get_tickets_count()),\n str(order.discount_code.code) if order.discount_code else '',\n str(order.user.first_name, 'utf-8')\n if order.user and order.user.first_name else '',\n str(order.user.last_name, 'utf-8')\n if order.user and order.user.last_name else '',\n str(order.user._email, 'utf-8') if order.user and order.user._email else '']\n rows.append(column)\n\n return rows\n", "path": "app/api/helpers/csv_jobs_util.py"}]}
| 1,045 | 219 |
gh_patches_debug_15044
|
rasdani/github-patches
|
git_diff
|
vyperlang__vyper-2077
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Arrays as default arguments do not properly copy to memory
### Version Information
* vyper Version: latest master
* OS: linux
* Python Version: 3.8.2
### What's your issue about?
When an array used as a default argument is copied to a memory variable, every item in the memory variable has the value of the first item in the array. For example:
```python
@public
@constant
def foo(a: int128[2] = [1, 2]) -> int128[2]:
b: int128[2] = a
return b
```
Calls to `foo` produce the following output:
```python
>>> x.foo()
(1, 1)
>>> x.foo([4, 6])
(4, 4)
```
* The same effect is observed with longer arrays and different types.
* Returning directly from calldata gives the expected result.
* Writing to storage gives the expected result.
</issue>
<code>
[start of vyper/parser/function_definitions/parse_external_function.py]
1 import ast
2 from typing import Any, List, Union
3
4 from vyper.exceptions import FunctionDeclarationException
5 from vyper.parser.arg_clamps import make_arg_clamper
6 from vyper.parser.context import Context, VariableRecord
7 from vyper.parser.expr import Expr
8 from vyper.parser.function_definitions.utils import (
9 get_default_names_to_set,
10 get_nonreentrant_lock,
11 get_sig_statements,
12 )
13 from vyper.parser.global_context import GlobalContext
14 from vyper.parser.lll_node import LLLnode
15 from vyper.parser.parser_utils import getpos, make_setter
16 from vyper.parser.stmt import parse_body
17 from vyper.signatures import sig_utils
18 from vyper.signatures.function_signature import FunctionSignature
19 from vyper.types.types import ByteArrayLike, get_size_of_type
20 from vyper.utils import MemoryPositions
21
22
23 def get_external_arg_copier(
24 total_size: int, memory_dest: int, offset: Union[int, List[Any]] = 4
25 ) -> List[Any]:
26 """
27 Generate argument copier.
28
29 :param total_size: total memory size to copy
30 :param memory_dest: base memory address to start from
31 :param offset: starting offset, used for ByteArrays
32 """
33 copier = ["calldatacopy", memory_dest, offset, total_size]
34 return copier
35
36
37 def validate_external_function(
38 code: ast.FunctionDef, sig: FunctionSignature, global_ctx: GlobalContext
39 ) -> None:
40 """ Validate external function definition. """
41
42 # __init__ function may not have defaults.
43 if sig.is_initializer() and sig.total_default_args > 0:
44 raise FunctionDeclarationException(
45 "__init__ function may not have default parameters.", code
46 )
47
48 # Check for duplicate variables with globals
49 for arg in sig.args:
50 if arg.name in global_ctx._globals:
51 raise FunctionDeclarationException(
52 "Variable name duplicated between " "function arguments and globals: " + arg.name,
53 code,
54 )
55
56
57 def parse_external_function(
58 code: ast.FunctionDef, sig: FunctionSignature, context: Context
59 ) -> LLLnode:
60 """
61 Parse a external function (FuncDef), and produce full function body.
62
63 :param sig: the FuntionSignature
64 :param code: ast of function
65 :return: full sig compare & function body
66 """
67
68 validate_external_function(code, sig, context.global_ctx)
69
70 # Get nonreentrant lock
71 nonreentrant_pre, nonreentrant_post = get_nonreentrant_lock(sig, context.global_ctx)
72
73 clampers = []
74
75 # Generate copiers
76 copier: List[Any] = ["pass"]
77 if not len(sig.base_args):
78 copier = ["pass"]
79 elif sig.name == "__init__":
80 copier = ["codecopy", MemoryPositions.RESERVED_MEMORY, "~codelen", sig.base_copy_size]
81 context.memory_allocator.increase_memory(sig.max_copy_size)
82 clampers.append(copier)
83
84 # Add asserts for payable and internal
85 if sig.mutability != "payable":
86 clampers.append(["assert", ["iszero", "callvalue"]])
87
88 # Fill variable positions
89 default_args_start_pos = len(sig.base_args)
90 for i, arg in enumerate(sig.args):
91 if i < len(sig.base_args):
92 clampers.append(
93 make_arg_clamper(
94 arg.pos,
95 context.memory_allocator.get_next_memory_position(),
96 arg.typ,
97 sig.name == "__init__",
98 )
99 )
100 if isinstance(arg.typ, ByteArrayLike):
101 mem_pos, _ = context.memory_allocator.increase_memory(32 * get_size_of_type(arg.typ))
102 context.vars[arg.name] = VariableRecord(arg.name, mem_pos, arg.typ, False)
103 else:
104 if sig.name == "__init__":
105 context.vars[arg.name] = VariableRecord(
106 arg.name, MemoryPositions.RESERVED_MEMORY + arg.pos, arg.typ, False,
107 )
108 elif i >= default_args_start_pos: # default args need to be allocated in memory.
109 default_arg_pos, _ = context.memory_allocator.increase_memory(32)
110 context.vars[arg.name] = VariableRecord(
111 name=arg.name, pos=default_arg_pos, typ=arg.typ, mutable=False,
112 )
113 else:
114 context.vars[arg.name] = VariableRecord(
115 name=arg.name, pos=4 + arg.pos, typ=arg.typ, mutable=False, location="calldata"
116 )
117
118 # Create "clampers" (input well-formedness checkers)
119 # Return function body
120 if sig.name == "__init__":
121 o = LLLnode.from_list(
122 ["seq"] + clampers + [parse_body(code.body, context)], # type: ignore
123 pos=getpos(code),
124 )
125 # Is default function.
126 elif sig.is_default_func():
127 if len(sig.args) > 0:
128 raise FunctionDeclarationException(
129 "Default function may not receive any arguments.", code
130 )
131 o = LLLnode.from_list(
132 ["seq"] + clampers + [parse_body(code.body, context)], # type: ignore
133 pos=getpos(code),
134 )
135 # Is a normal function.
136 else:
137 # Function with default parameters.
138 if sig.total_default_args > 0:
139 function_routine = f"{sig.name}_{sig.method_id}"
140 default_sigs = sig_utils.generate_default_arg_sigs(
141 code, context.sigs, context.global_ctx
142 )
143 sig_chain: List[Any] = ["seq"]
144
145 for default_sig in default_sigs:
146 sig_compare, _ = get_sig_statements(default_sig, getpos(code))
147
148 # Populate unset default variables
149 set_defaults = []
150 for arg_name in get_default_names_to_set(sig, default_sig):
151 value = Expr(sig.default_values[arg_name], context).lll_node
152 var = context.vars[arg_name]
153 left = LLLnode.from_list(
154 var.pos,
155 typ=var.typ,
156 location="memory",
157 pos=getpos(code),
158 mutable=var.mutable,
159 )
160 set_defaults.append(make_setter(left, value, "memory", pos=getpos(code)))
161
162 current_sig_arg_names = {x.name for x in default_sig.args}
163 base_arg_names = {arg.name for arg in sig.base_args}
164 copier_arg_count = len(default_sig.args) - len(sig.base_args)
165 copier_arg_names = list(current_sig_arg_names - base_arg_names)
166
167 # Order copier_arg_names, this is very important.
168 copier_arg_names = [x.name for x in default_sig.args if x.name in copier_arg_names]
169
170 # Variables to be populated from calldata/stack.
171 default_copiers: List[Any] = []
172 if copier_arg_count > 0:
173 # Get map of variables in calldata, with thier offsets
174 offset = 4
175 calldata_offset_map = {}
176 for arg in default_sig.args:
177 calldata_offset_map[arg.name] = offset
178 offset += (
179 32
180 if isinstance(arg.typ, ByteArrayLike)
181 else get_size_of_type(arg.typ) * 32
182 )
183
184 # Copy default parameters from calldata.
185 for arg_name in copier_arg_names:
186 var = context.vars[arg_name]
187 calldata_offset = calldata_offset_map[arg_name]
188
189 # Add clampers.
190 default_copiers.append(
191 make_arg_clamper(calldata_offset - 4, var.pos, var.typ,)
192 )
193 # Add copying code.
194 _offset: Union[int, List[Any]] = calldata_offset
195 if isinstance(var.typ, ByteArrayLike):
196 _offset = ["add", 4, ["calldataload", calldata_offset]]
197 default_copiers.append(
198 get_external_arg_copier(
199 memory_dest=var.pos, total_size=var.size * 32, offset=_offset,
200 )
201 )
202
203 default_copiers.append(0) # for over arching seq, POP
204
205 sig_chain.append(
206 [
207 "if",
208 sig_compare,
209 [
210 "seq",
211 ["seq"] + set_defaults if set_defaults else ["pass"],
212 ["seq_unchecked"] + default_copiers if default_copiers else ["pass"],
213 ["goto", function_routine],
214 ],
215 ]
216 )
217
218 # Function with default parameters.
219 o = LLLnode.from_list(
220 [
221 "seq",
222 sig_chain,
223 [
224 "if",
225 0, # can only be jumped into
226 [
227 "seq",
228 ["label", function_routine],
229 ["seq"]
230 + nonreentrant_pre
231 + clampers
232 + [parse_body(c, context) for c in code.body]
233 + nonreentrant_post
234 + [["stop"]],
235 ],
236 ],
237 ],
238 typ=None,
239 pos=getpos(code),
240 )
241
242 else:
243 # Function without default parameters.
244 sig_compare, _ = get_sig_statements(sig, getpos(code))
245 o = LLLnode.from_list(
246 [
247 "if",
248 sig_compare,
249 ["seq"]
250 + nonreentrant_pre
251 + clampers
252 + [parse_body(c, context) for c in code.body]
253 + nonreentrant_post
254 + [["stop"]],
255 ],
256 typ=None,
257 pos=getpos(code),
258 )
259 return o
260
[end of vyper/parser/function_definitions/parse_external_function.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/vyper/parser/function_definitions/parse_external_function.py b/vyper/parser/function_definitions/parse_external_function.py
--- a/vyper/parser/function_definitions/parse_external_function.py
+++ b/vyper/parser/function_definitions/parse_external_function.py
@@ -106,7 +106,8 @@
arg.name, MemoryPositions.RESERVED_MEMORY + arg.pos, arg.typ, False,
)
elif i >= default_args_start_pos: # default args need to be allocated in memory.
- default_arg_pos, _ = context.memory_allocator.increase_memory(32)
+ type_size = get_size_of_type(arg.typ) * 32
+ default_arg_pos, _ = context.memory_allocator.increase_memory(type_size)
context.vars[arg.name] = VariableRecord(
name=arg.name, pos=default_arg_pos, typ=arg.typ, mutable=False,
)
|
{"golden_diff": "diff --git a/vyper/parser/function_definitions/parse_external_function.py b/vyper/parser/function_definitions/parse_external_function.py\n--- a/vyper/parser/function_definitions/parse_external_function.py\n+++ b/vyper/parser/function_definitions/parse_external_function.py\n@@ -106,7 +106,8 @@\n arg.name, MemoryPositions.RESERVED_MEMORY + arg.pos, arg.typ, False,\n )\n elif i >= default_args_start_pos: # default args need to be allocated in memory.\n- default_arg_pos, _ = context.memory_allocator.increase_memory(32)\n+ type_size = get_size_of_type(arg.typ) * 32\n+ default_arg_pos, _ = context.memory_allocator.increase_memory(type_size)\n context.vars[arg.name] = VariableRecord(\n name=arg.name, pos=default_arg_pos, typ=arg.typ, mutable=False,\n )\n", "issue": "Arrays as default arguments do not properly copy to memory\n### Version Information\r\n\r\n* vyper Version: latest master\r\n* OS: linux\r\n* Python Version: 3.8.2\r\n\r\n### What's your issue about?\r\nWhen an array used as a default argument is copied to a memory variable, every item in the memory variable has the value of the first item in the array. For example:\r\n\r\n```python\r\n@public\r\n@constant\r\ndef foo(a: int128[2] = [1, 2]) -> int128[2]:\r\n b: int128[2] = a\r\n return b\r\n```\r\n\r\nCalls to `foo` produce the following output:\r\n\r\n```python\r\n>>> x.foo()\r\n(1, 1)\r\n>>> x.foo([4, 6])\r\n(4, 4)\r\n```\r\n\r\n* The same effect is observed with longer arrays and different types.\r\n* Returning directly from calldata gives the expected result.\r\n* Writing to storage gives the expected result.\r\n\n", "before_files": [{"content": "import ast\nfrom typing import Any, List, Union\n\nfrom vyper.exceptions import FunctionDeclarationException\nfrom vyper.parser.arg_clamps import make_arg_clamper\nfrom vyper.parser.context import Context, VariableRecord\nfrom vyper.parser.expr import Expr\nfrom vyper.parser.function_definitions.utils import (\n get_default_names_to_set,\n get_nonreentrant_lock,\n get_sig_statements,\n)\nfrom vyper.parser.global_context import GlobalContext\nfrom vyper.parser.lll_node import LLLnode\nfrom vyper.parser.parser_utils import getpos, make_setter\nfrom vyper.parser.stmt import parse_body\nfrom vyper.signatures import sig_utils\nfrom vyper.signatures.function_signature import FunctionSignature\nfrom vyper.types.types import ByteArrayLike, get_size_of_type\nfrom vyper.utils import MemoryPositions\n\n\ndef get_external_arg_copier(\n total_size: int, memory_dest: int, offset: Union[int, List[Any]] = 4\n) -> List[Any]:\n \"\"\"\n Generate argument copier.\n\n :param total_size: total memory size to copy\n :param memory_dest: base memory address to start from\n :param offset: starting offset, used for ByteArrays\n \"\"\"\n copier = [\"calldatacopy\", memory_dest, offset, total_size]\n return copier\n\n\ndef validate_external_function(\n code: ast.FunctionDef, sig: FunctionSignature, global_ctx: GlobalContext\n) -> None:\n \"\"\" Validate external function definition. \"\"\"\n\n # __init__ function may not have defaults.\n if sig.is_initializer() and sig.total_default_args > 0:\n raise FunctionDeclarationException(\n \"__init__ function may not have default parameters.\", code\n )\n\n # Check for duplicate variables with globals\n for arg in sig.args:\n if arg.name in global_ctx._globals:\n raise FunctionDeclarationException(\n \"Variable name duplicated between \" \"function arguments and globals: \" + arg.name,\n code,\n )\n\n\ndef parse_external_function(\n code: ast.FunctionDef, sig: FunctionSignature, context: Context\n) -> LLLnode:\n \"\"\"\n Parse a external function (FuncDef), and produce full function body.\n\n :param sig: the FuntionSignature\n :param code: ast of function\n :return: full sig compare & function body\n \"\"\"\n\n validate_external_function(code, sig, context.global_ctx)\n\n # Get nonreentrant lock\n nonreentrant_pre, nonreentrant_post = get_nonreentrant_lock(sig, context.global_ctx)\n\n clampers = []\n\n # Generate copiers\n copier: List[Any] = [\"pass\"]\n if not len(sig.base_args):\n copier = [\"pass\"]\n elif sig.name == \"__init__\":\n copier = [\"codecopy\", MemoryPositions.RESERVED_MEMORY, \"~codelen\", sig.base_copy_size]\n context.memory_allocator.increase_memory(sig.max_copy_size)\n clampers.append(copier)\n\n # Add asserts for payable and internal\n if sig.mutability != \"payable\":\n clampers.append([\"assert\", [\"iszero\", \"callvalue\"]])\n\n # Fill variable positions\n default_args_start_pos = len(sig.base_args)\n for i, arg in enumerate(sig.args):\n if i < len(sig.base_args):\n clampers.append(\n make_arg_clamper(\n arg.pos,\n context.memory_allocator.get_next_memory_position(),\n arg.typ,\n sig.name == \"__init__\",\n )\n )\n if isinstance(arg.typ, ByteArrayLike):\n mem_pos, _ = context.memory_allocator.increase_memory(32 * get_size_of_type(arg.typ))\n context.vars[arg.name] = VariableRecord(arg.name, mem_pos, arg.typ, False)\n else:\n if sig.name == \"__init__\":\n context.vars[arg.name] = VariableRecord(\n arg.name, MemoryPositions.RESERVED_MEMORY + arg.pos, arg.typ, False,\n )\n elif i >= default_args_start_pos: # default args need to be allocated in memory.\n default_arg_pos, _ = context.memory_allocator.increase_memory(32)\n context.vars[arg.name] = VariableRecord(\n name=arg.name, pos=default_arg_pos, typ=arg.typ, mutable=False,\n )\n else:\n context.vars[arg.name] = VariableRecord(\n name=arg.name, pos=4 + arg.pos, typ=arg.typ, mutable=False, location=\"calldata\"\n )\n\n # Create \"clampers\" (input well-formedness checkers)\n # Return function body\n if sig.name == \"__init__\":\n o = LLLnode.from_list(\n [\"seq\"] + clampers + [parse_body(code.body, context)], # type: ignore\n pos=getpos(code),\n )\n # Is default function.\n elif sig.is_default_func():\n if len(sig.args) > 0:\n raise FunctionDeclarationException(\n \"Default function may not receive any arguments.\", code\n )\n o = LLLnode.from_list(\n [\"seq\"] + clampers + [parse_body(code.body, context)], # type: ignore\n pos=getpos(code),\n )\n # Is a normal function.\n else:\n # Function with default parameters.\n if sig.total_default_args > 0:\n function_routine = f\"{sig.name}_{sig.method_id}\"\n default_sigs = sig_utils.generate_default_arg_sigs(\n code, context.sigs, context.global_ctx\n )\n sig_chain: List[Any] = [\"seq\"]\n\n for default_sig in default_sigs:\n sig_compare, _ = get_sig_statements(default_sig, getpos(code))\n\n # Populate unset default variables\n set_defaults = []\n for arg_name in get_default_names_to_set(sig, default_sig):\n value = Expr(sig.default_values[arg_name], context).lll_node\n var = context.vars[arg_name]\n left = LLLnode.from_list(\n var.pos,\n typ=var.typ,\n location=\"memory\",\n pos=getpos(code),\n mutable=var.mutable,\n )\n set_defaults.append(make_setter(left, value, \"memory\", pos=getpos(code)))\n\n current_sig_arg_names = {x.name for x in default_sig.args}\n base_arg_names = {arg.name for arg in sig.base_args}\n copier_arg_count = len(default_sig.args) - len(sig.base_args)\n copier_arg_names = list(current_sig_arg_names - base_arg_names)\n\n # Order copier_arg_names, this is very important.\n copier_arg_names = [x.name for x in default_sig.args if x.name in copier_arg_names]\n\n # Variables to be populated from calldata/stack.\n default_copiers: List[Any] = []\n if copier_arg_count > 0:\n # Get map of variables in calldata, with thier offsets\n offset = 4\n calldata_offset_map = {}\n for arg in default_sig.args:\n calldata_offset_map[arg.name] = offset\n offset += (\n 32\n if isinstance(arg.typ, ByteArrayLike)\n else get_size_of_type(arg.typ) * 32\n )\n\n # Copy default parameters from calldata.\n for arg_name in copier_arg_names:\n var = context.vars[arg_name]\n calldata_offset = calldata_offset_map[arg_name]\n\n # Add clampers.\n default_copiers.append(\n make_arg_clamper(calldata_offset - 4, var.pos, var.typ,)\n )\n # Add copying code.\n _offset: Union[int, List[Any]] = calldata_offset\n if isinstance(var.typ, ByteArrayLike):\n _offset = [\"add\", 4, [\"calldataload\", calldata_offset]]\n default_copiers.append(\n get_external_arg_copier(\n memory_dest=var.pos, total_size=var.size * 32, offset=_offset,\n )\n )\n\n default_copiers.append(0) # for over arching seq, POP\n\n sig_chain.append(\n [\n \"if\",\n sig_compare,\n [\n \"seq\",\n [\"seq\"] + set_defaults if set_defaults else [\"pass\"],\n [\"seq_unchecked\"] + default_copiers if default_copiers else [\"pass\"],\n [\"goto\", function_routine],\n ],\n ]\n )\n\n # Function with default parameters.\n o = LLLnode.from_list(\n [\n \"seq\",\n sig_chain,\n [\n \"if\",\n 0, # can only be jumped into\n [\n \"seq\",\n [\"label\", function_routine],\n [\"seq\"]\n + nonreentrant_pre\n + clampers\n + [parse_body(c, context) for c in code.body]\n + nonreentrant_post\n + [[\"stop\"]],\n ],\n ],\n ],\n typ=None,\n pos=getpos(code),\n )\n\n else:\n # Function without default parameters.\n sig_compare, _ = get_sig_statements(sig, getpos(code))\n o = LLLnode.from_list(\n [\n \"if\",\n sig_compare,\n [\"seq\"]\n + nonreentrant_pre\n + clampers\n + [parse_body(c, context) for c in code.body]\n + nonreentrant_post\n + [[\"stop\"]],\n ],\n typ=None,\n pos=getpos(code),\n )\n return o\n", "path": "vyper/parser/function_definitions/parse_external_function.py"}]}
| 3,447 | 189 |
gh_patches_debug_39511
|
rasdani/github-patches
|
git_diff
|
pytorch__vision-3330
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Utility to draw Semantic Segmentation Masks
## 🚀 Feature
We recently added utility to draw bounding boxes, which works really well with detection models. #2785 #2556
It might be nice to draw segmentation masks which we obtain from instance segmentation models.
## Motivation
Same as bounding box utils. It is very useful to have these. It reduces the dependence of users over other plotting libraries.
## Pitch
Our API should be compatible with segmentation models, so we should probably use Tensors.
I think most params remain as same as the previous util. This keeps consistency too.
```
@torch.no_grad()
def draw_segmentation_masks(image: torch.Tensor,
masks: torch.Tensor,
labels: Optional[List[str]] = None,
colors: Optional[List[Union[str, Tuple[int, int, int]]]] = None,
width: int = 1,
font: Optional[str] = None,
font_size: int = 10)
```
We might need to see a method using which we can draw with PIL.
We used `draw.rectangle()` to draw a box in utils, maybe there is some functionality in PIL that can help us draw shapes.
## Alternatives
Let's discuss further, how this API would work with our models.
Also, it would be nice if this works directly for instance segmentation model Mask RCNN.
</issue>
<code>
[start of torchvision/utils.py]
1 from typing import Union, Optional, List, Tuple, Text, BinaryIO
2 import pathlib
3 import torch
4 import math
5 import warnings
6 import numpy as np
7 from PIL import Image, ImageDraw, ImageFont, ImageColor
8
9 __all__ = ["make_grid", "save_image", "draw_bounding_boxes"]
10
11
12 @torch.no_grad()
13 def make_grid(
14 tensor: Union[torch.Tensor, List[torch.Tensor]],
15 nrow: int = 8,
16 padding: int = 2,
17 normalize: bool = False,
18 value_range: Optional[Tuple[int, int]] = None,
19 scale_each: bool = False,
20 pad_value: int = 0,
21 **kwargs
22 ) -> torch.Tensor:
23 """Make a grid of images.
24
25 Args:
26 tensor (Tensor or list): 4D mini-batch Tensor of shape (B x C x H x W)
27 or a list of images all of the same size.
28 nrow (int, optional): Number of images displayed in each row of the grid.
29 The final grid size is ``(B / nrow, nrow)``. Default: ``8``.
30 padding (int, optional): amount of padding. Default: ``2``.
31 normalize (bool, optional): If True, shift the image to the range (0, 1),
32 by the min and max values specified by :attr:`range`. Default: ``False``.
33 value_range (tuple, optional): tuple (min, max) where min and max are numbers,
34 then these numbers are used to normalize the image. By default, min and max
35 are computed from the tensor.
36 scale_each (bool, optional): If ``True``, scale each image in the batch of
37 images separately rather than the (min, max) over all images. Default: ``False``.
38 pad_value (float, optional): Value for the padded pixels. Default: ``0``.
39
40 Example:
41 See this notebook `here <https://gist.github.com/anonymous/bf16430f7750c023141c562f3e9f2a91>`_
42
43 """
44 if not (torch.is_tensor(tensor) or
45 (isinstance(tensor, list) and all(torch.is_tensor(t) for t in tensor))):
46 raise TypeError(f'tensor or list of tensors expected, got {type(tensor)}')
47
48 if "range" in kwargs.keys():
49 warning = "range will be deprecated, please use value_range instead."
50 warnings.warn(warning)
51 value_range = kwargs["range"]
52
53 # if list of tensors, convert to a 4D mini-batch Tensor
54 if isinstance(tensor, list):
55 tensor = torch.stack(tensor, dim=0)
56
57 if tensor.dim() == 2: # single image H x W
58 tensor = tensor.unsqueeze(0)
59 if tensor.dim() == 3: # single image
60 if tensor.size(0) == 1: # if single-channel, convert to 3-channel
61 tensor = torch.cat((tensor, tensor, tensor), 0)
62 tensor = tensor.unsqueeze(0)
63
64 if tensor.dim() == 4 and tensor.size(1) == 1: # single-channel images
65 tensor = torch.cat((tensor, tensor, tensor), 1)
66
67 if normalize is True:
68 tensor = tensor.clone() # avoid modifying tensor in-place
69 if value_range is not None:
70 assert isinstance(value_range, tuple), \
71 "value_range has to be a tuple (min, max) if specified. min and max are numbers"
72
73 def norm_ip(img, low, high):
74 img.clamp_(min=low, max=high)
75 img.sub_(low).div_(max(high - low, 1e-5))
76
77 def norm_range(t, value_range):
78 if value_range is not None:
79 norm_ip(t, value_range[0], value_range[1])
80 else:
81 norm_ip(t, float(t.min()), float(t.max()))
82
83 if scale_each is True:
84 for t in tensor: # loop over mini-batch dimension
85 norm_range(t, value_range)
86 else:
87 norm_range(tensor, value_range)
88
89 if tensor.size(0) == 1:
90 return tensor.squeeze(0)
91
92 # make the mini-batch of images into a grid
93 nmaps = tensor.size(0)
94 xmaps = min(nrow, nmaps)
95 ymaps = int(math.ceil(float(nmaps) / xmaps))
96 height, width = int(tensor.size(2) + padding), int(tensor.size(3) + padding)
97 num_channels = tensor.size(1)
98 grid = tensor.new_full((num_channels, height * ymaps + padding, width * xmaps + padding), pad_value)
99 k = 0
100 for y in range(ymaps):
101 for x in range(xmaps):
102 if k >= nmaps:
103 break
104 # Tensor.copy_() is a valid method but seems to be missing from the stubs
105 # https://pytorch.org/docs/stable/tensors.html#torch.Tensor.copy_
106 grid.narrow(1, y * height + padding, height - padding).narrow( # type: ignore[attr-defined]
107 2, x * width + padding, width - padding
108 ).copy_(tensor[k])
109 k = k + 1
110 return grid
111
112
113 @torch.no_grad()
114 def save_image(
115 tensor: Union[torch.Tensor, List[torch.Tensor]],
116 fp: Union[Text, pathlib.Path, BinaryIO],
117 format: Optional[str] = None,
118 **kwargs
119 ) -> None:
120 """Save a given Tensor into an image file.
121
122 Args:
123 tensor (Tensor or list): Image to be saved. If given a mini-batch tensor,
124 saves the tensor as a grid of images by calling ``make_grid``.
125 fp (string or file object): A filename or a file object
126 format(Optional): If omitted, the format to use is determined from the filename extension.
127 If a file object was used instead of a filename, this parameter should always be used.
128 **kwargs: Other arguments are documented in ``make_grid``.
129 """
130
131 grid = make_grid(tensor, **kwargs)
132 # Add 0.5 after unnormalizing to [0, 255] to round to nearest integer
133 ndarr = grid.mul(255).add_(0.5).clamp_(0, 255).permute(1, 2, 0).to('cpu', torch.uint8).numpy()
134 im = Image.fromarray(ndarr)
135 im.save(fp, format=format)
136
137
138 @torch.no_grad()
139 def draw_bounding_boxes(
140 image: torch.Tensor,
141 boxes: torch.Tensor,
142 labels: Optional[List[str]] = None,
143 colors: Optional[List[Union[str, Tuple[int, int, int]]]] = None,
144 fill: Optional[bool] = False,
145 width: int = 1,
146 font: Optional[str] = None,
147 font_size: int = 10
148 ) -> torch.Tensor:
149
150 """
151 Draws bounding boxes on given image.
152 The values of the input image should be uint8 between 0 and 255.
153 If filled, Resulting Tensor should be saved as PNG image.
154
155 Args:
156 image (Tensor): Tensor of shape (C x H x W)
157 boxes (Tensor): Tensor of size (N, 4) containing bounding boxes in (xmin, ymin, xmax, ymax) format. Note that
158 the boxes are absolute coordinates with respect to the image. In other words: `0 <= xmin < xmax < W` and
159 `0 <= ymin < ymax < H`.
160 labels (List[str]): List containing the labels of bounding boxes.
161 colors (List[Union[str, Tuple[int, int, int]]]): List containing the colors of bounding boxes. The colors can
162 be represented as `str` or `Tuple[int, int, int]`.
163 fill (bool): If `True` fills the bounding box with specified color.
164 width (int): Width of bounding box.
165 font (str): A filename containing a TrueType font. If the file is not found in this filename, the loader may
166 also search in other directories, such as the `fonts/` directory on Windows or `/Library/Fonts/`,
167 `/System/Library/Fonts/` and `~/Library/Fonts/` on macOS.
168 font_size (int): The requested font size in points.
169 """
170
171 if not isinstance(image, torch.Tensor):
172 raise TypeError(f"Tensor expected, got {type(image)}")
173 elif image.dtype != torch.uint8:
174 raise ValueError(f"Tensor uint8 expected, got {image.dtype}")
175 elif image.dim() != 3:
176 raise ValueError("Pass individual images, not batches")
177
178 ndarr = image.permute(1, 2, 0).numpy()
179 img_to_draw = Image.fromarray(ndarr)
180
181 img_boxes = boxes.to(torch.int64).tolist()
182
183 if fill:
184 draw = ImageDraw.Draw(img_to_draw, "RGBA")
185
186 else:
187 draw = ImageDraw.Draw(img_to_draw)
188
189 txt_font = ImageFont.load_default() if font is None else ImageFont.truetype(font=font, size=font_size)
190
191 for i, bbox in enumerate(img_boxes):
192 if colors is None:
193 color = None
194 else:
195 color = colors[i]
196
197 if fill:
198 if color is None:
199 fill_color = (255, 255, 255, 100)
200 elif isinstance(color, str):
201 # This will automatically raise Error if rgb cannot be parsed.
202 fill_color = ImageColor.getrgb(color) + (100,)
203 elif isinstance(color, tuple):
204 fill_color = color + (100,)
205 draw.rectangle(bbox, width=width, outline=color, fill=fill_color)
206 else:
207 draw.rectangle(bbox, width=width, outline=color)
208
209 if labels is not None:
210 draw.text((bbox[0], bbox[1]), labels[i], fill=color, font=txt_font)
211
212 return torch.from_numpy(np.array(img_to_draw)).permute(2, 0, 1)
213
[end of torchvision/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/torchvision/utils.py b/torchvision/utils.py
--- a/torchvision/utils.py
+++ b/torchvision/utils.py
@@ -6,7 +6,7 @@
import numpy as np
from PIL import Image, ImageDraw, ImageFont, ImageColor
-__all__ = ["make_grid", "save_image", "draw_bounding_boxes"]
+__all__ = ["make_grid", "save_image", "draw_bounding_boxes", "draw_segmentation_masks"]
@torch.no_grad()
@@ -153,7 +153,7 @@
If filled, Resulting Tensor should be saved as PNG image.
Args:
- image (Tensor): Tensor of shape (C x H x W)
+ image (Tensor): Tensor of shape (C x H x W) and dtype uint8.
boxes (Tensor): Tensor of size (N, 4) containing bounding boxes in (xmin, ymin, xmax, ymax) format. Note that
the boxes are absolute coordinates with respect to the image. In other words: `0 <= xmin < xmax < W` and
`0 <= ymin < ymax < H`.
@@ -210,3 +210,61 @@
draw.text((bbox[0], bbox[1]), labels[i], fill=color, font=txt_font)
return torch.from_numpy(np.array(img_to_draw)).permute(2, 0, 1)
+
+
[email protected]_grad()
+def draw_segmentation_masks(
+ image: torch.Tensor,
+ masks: torch.Tensor,
+ alpha: float = 0.2,
+ colors: Optional[List[Union[str, Tuple[int, int, int]]]] = None,
+) -> torch.Tensor:
+
+ """
+ Draws segmentation masks on given RGB image.
+ The values of the input image should be uint8 between 0 and 255.
+
+ Args:
+ image (Tensor): Tensor of shape (3 x H x W) and dtype uint8.
+ masks (Tensor): Tensor of shape (num_masks, H, W). Each containing probability of predicted class.
+ alpha (float): Float number between 0 and 1 denoting factor of transpaerency of masks.
+ colors (List[Union[str, Tuple[int, int, int]]]): List containing the colors of masks. The colors can
+ be represented as `str` or `Tuple[int, int, int]`.
+ """
+
+ if not isinstance(image, torch.Tensor):
+ raise TypeError(f"Tensor expected, got {type(image)}")
+ elif image.dtype != torch.uint8:
+ raise ValueError(f"Tensor uint8 expected, got {image.dtype}")
+ elif image.dim() != 3:
+ raise ValueError("Pass individual images, not batches")
+ elif image.size()[0] != 3:
+ raise ValueError("Pass an RGB image. Other Image formats are not supported")
+
+ num_masks = masks.size()[0]
+ masks = masks.argmax(0)
+
+ if colors is None:
+ palette = torch.tensor([2 ** 25 - 1, 2 ** 15 - 1, 2 ** 21 - 1])
+ colors_t = torch.as_tensor([i for i in range(num_masks)])[:, None] * palette
+ color_arr = (colors_t % 255).numpy().astype("uint8")
+ else:
+ color_list = []
+ for color in colors:
+ if isinstance(color, str):
+ # This will automatically raise Error if rgb cannot be parsed.
+ fill_color = ImageColor.getrgb(color)
+ color_list.append(fill_color)
+ elif isinstance(color, tuple):
+ color_list.append(color)
+
+ color_arr = np.array(color_list).astype("uint8")
+
+ _, h, w = image.size()
+ img_to_draw = Image.fromarray(masks.byte().cpu().numpy()).resize((w, h))
+ img_to_draw.putpalette(color_arr)
+
+ img_to_draw = torch.from_numpy(np.array(img_to_draw.convert('RGB')))
+ img_to_draw = img_to_draw.permute((2, 0, 1))
+
+ return (image.float() * alpha + img_to_draw.float() * (1.0 - alpha)).to(dtype=torch.uint8)
|
{"golden_diff": "diff --git a/torchvision/utils.py b/torchvision/utils.py\n--- a/torchvision/utils.py\n+++ b/torchvision/utils.py\n@@ -6,7 +6,7 @@\n import numpy as np\n from PIL import Image, ImageDraw, ImageFont, ImageColor\n \n-__all__ = [\"make_grid\", \"save_image\", \"draw_bounding_boxes\"]\n+__all__ = [\"make_grid\", \"save_image\", \"draw_bounding_boxes\", \"draw_segmentation_masks\"]\n \n \n @torch.no_grad()\n@@ -153,7 +153,7 @@\n If filled, Resulting Tensor should be saved as PNG image.\n \n Args:\n- image (Tensor): Tensor of shape (C x H x W)\n+ image (Tensor): Tensor of shape (C x H x W) and dtype uint8.\n boxes (Tensor): Tensor of size (N, 4) containing bounding boxes in (xmin, ymin, xmax, ymax) format. Note that\n the boxes are absolute coordinates with respect to the image. In other words: `0 <= xmin < xmax < W` and\n `0 <= ymin < ymax < H`.\n@@ -210,3 +210,61 @@\n draw.text((bbox[0], bbox[1]), labels[i], fill=color, font=txt_font)\n \n return torch.from_numpy(np.array(img_to_draw)).permute(2, 0, 1)\n+\n+\[email protected]_grad()\n+def draw_segmentation_masks(\n+ image: torch.Tensor,\n+ masks: torch.Tensor,\n+ alpha: float = 0.2,\n+ colors: Optional[List[Union[str, Tuple[int, int, int]]]] = None,\n+) -> torch.Tensor:\n+\n+ \"\"\"\n+ Draws segmentation masks on given RGB image.\n+ The values of the input image should be uint8 between 0 and 255.\n+\n+ Args:\n+ image (Tensor): Tensor of shape (3 x H x W) and dtype uint8.\n+ masks (Tensor): Tensor of shape (num_masks, H, W). Each containing probability of predicted class.\n+ alpha (float): Float number between 0 and 1 denoting factor of transpaerency of masks.\n+ colors (List[Union[str, Tuple[int, int, int]]]): List containing the colors of masks. The colors can\n+ be represented as `str` or `Tuple[int, int, int]`.\n+ \"\"\"\n+\n+ if not isinstance(image, torch.Tensor):\n+ raise TypeError(f\"Tensor expected, got {type(image)}\")\n+ elif image.dtype != torch.uint8:\n+ raise ValueError(f\"Tensor uint8 expected, got {image.dtype}\")\n+ elif image.dim() != 3:\n+ raise ValueError(\"Pass individual images, not batches\")\n+ elif image.size()[0] != 3:\n+ raise ValueError(\"Pass an RGB image. Other Image formats are not supported\")\n+\n+ num_masks = masks.size()[0]\n+ masks = masks.argmax(0)\n+\n+ if colors is None:\n+ palette = torch.tensor([2 ** 25 - 1, 2 ** 15 - 1, 2 ** 21 - 1])\n+ colors_t = torch.as_tensor([i for i in range(num_masks)])[:, None] * palette\n+ color_arr = (colors_t % 255).numpy().astype(\"uint8\")\n+ else:\n+ color_list = []\n+ for color in colors:\n+ if isinstance(color, str):\n+ # This will automatically raise Error if rgb cannot be parsed.\n+ fill_color = ImageColor.getrgb(color)\n+ color_list.append(fill_color)\n+ elif isinstance(color, tuple):\n+ color_list.append(color)\n+\n+ color_arr = np.array(color_list).astype(\"uint8\")\n+\n+ _, h, w = image.size()\n+ img_to_draw = Image.fromarray(masks.byte().cpu().numpy()).resize((w, h))\n+ img_to_draw.putpalette(color_arr)\n+\n+ img_to_draw = torch.from_numpy(np.array(img_to_draw.convert('RGB')))\n+ img_to_draw = img_to_draw.permute((2, 0, 1))\n+\n+ return (image.float() * alpha + img_to_draw.float() * (1.0 - alpha)).to(dtype=torch.uint8)\n", "issue": "Utility to draw Semantic Segmentation Masks\n## \ud83d\ude80 Feature\r\n\r\nWe recently added utility to draw bounding boxes, which works really well with detection models. #2785 #2556 \r\nIt might be nice to draw segmentation masks which we obtain from instance segmentation models.\r\n\r\n## Motivation\r\n\r\nSame as bounding box utils. It is very useful to have these. It reduces the dependence of users over other plotting libraries.\r\n\r\n## Pitch\r\n\r\nOur API should be compatible with segmentation models, so we should probably use Tensors.\r\nI think most params remain as same as the previous util. This keeps consistency too.\r\n\r\n```\r\[email protected]_grad()\r\ndef draw_segmentation_masks(image: torch.Tensor,\r\n masks: torch.Tensor,\r\n labels: Optional[List[str]] = None,\r\n colors: Optional[List[Union[str, Tuple[int, int, int]]]] = None,\r\n width: int = 1,\r\n font: Optional[str] = None,\r\n font_size: int = 10)\r\n```\r\n\r\nWe might need to see a method using which we can draw with PIL.\r\nWe used `draw.rectangle()` to draw a box in utils, maybe there is some functionality in PIL that can help us draw shapes.\r\n\r\n## Alternatives\r\n\r\nLet's discuss further, how this API would work with our models.\r\nAlso, it would be nice if this works directly for instance segmentation model Mask RCNN.\r\n\n", "before_files": [{"content": "from typing import Union, Optional, List, Tuple, Text, BinaryIO\nimport pathlib\nimport torch\nimport math\nimport warnings\nimport numpy as np\nfrom PIL import Image, ImageDraw, ImageFont, ImageColor\n\n__all__ = [\"make_grid\", \"save_image\", \"draw_bounding_boxes\"]\n\n\[email protected]_grad()\ndef make_grid(\n tensor: Union[torch.Tensor, List[torch.Tensor]],\n nrow: int = 8,\n padding: int = 2,\n normalize: bool = False,\n value_range: Optional[Tuple[int, int]] = None,\n scale_each: bool = False,\n pad_value: int = 0,\n **kwargs\n) -> torch.Tensor:\n \"\"\"Make a grid of images.\n\n Args:\n tensor (Tensor or list): 4D mini-batch Tensor of shape (B x C x H x W)\n or a list of images all of the same size.\n nrow (int, optional): Number of images displayed in each row of the grid.\n The final grid size is ``(B / nrow, nrow)``. Default: ``8``.\n padding (int, optional): amount of padding. Default: ``2``.\n normalize (bool, optional): If True, shift the image to the range (0, 1),\n by the min and max values specified by :attr:`range`. Default: ``False``.\n value_range (tuple, optional): tuple (min, max) where min and max are numbers,\n then these numbers are used to normalize the image. By default, min and max\n are computed from the tensor.\n scale_each (bool, optional): If ``True``, scale each image in the batch of\n images separately rather than the (min, max) over all images. Default: ``False``.\n pad_value (float, optional): Value for the padded pixels. Default: ``0``.\n\n Example:\n See this notebook `here <https://gist.github.com/anonymous/bf16430f7750c023141c562f3e9f2a91>`_\n\n \"\"\"\n if not (torch.is_tensor(tensor) or\n (isinstance(tensor, list) and all(torch.is_tensor(t) for t in tensor))):\n raise TypeError(f'tensor or list of tensors expected, got {type(tensor)}')\n\n if \"range\" in kwargs.keys():\n warning = \"range will be deprecated, please use value_range instead.\"\n warnings.warn(warning)\n value_range = kwargs[\"range\"]\n\n # if list of tensors, convert to a 4D mini-batch Tensor\n if isinstance(tensor, list):\n tensor = torch.stack(tensor, dim=0)\n\n if tensor.dim() == 2: # single image H x W\n tensor = tensor.unsqueeze(0)\n if tensor.dim() == 3: # single image\n if tensor.size(0) == 1: # if single-channel, convert to 3-channel\n tensor = torch.cat((tensor, tensor, tensor), 0)\n tensor = tensor.unsqueeze(0)\n\n if tensor.dim() == 4 and tensor.size(1) == 1: # single-channel images\n tensor = torch.cat((tensor, tensor, tensor), 1)\n\n if normalize is True:\n tensor = tensor.clone() # avoid modifying tensor in-place\n if value_range is not None:\n assert isinstance(value_range, tuple), \\\n \"value_range has to be a tuple (min, max) if specified. min and max are numbers\"\n\n def norm_ip(img, low, high):\n img.clamp_(min=low, max=high)\n img.sub_(low).div_(max(high - low, 1e-5))\n\n def norm_range(t, value_range):\n if value_range is not None:\n norm_ip(t, value_range[0], value_range[1])\n else:\n norm_ip(t, float(t.min()), float(t.max()))\n\n if scale_each is True:\n for t in tensor: # loop over mini-batch dimension\n norm_range(t, value_range)\n else:\n norm_range(tensor, value_range)\n\n if tensor.size(0) == 1:\n return tensor.squeeze(0)\n\n # make the mini-batch of images into a grid\n nmaps = tensor.size(0)\n xmaps = min(nrow, nmaps)\n ymaps = int(math.ceil(float(nmaps) / xmaps))\n height, width = int(tensor.size(2) + padding), int(tensor.size(3) + padding)\n num_channels = tensor.size(1)\n grid = tensor.new_full((num_channels, height * ymaps + padding, width * xmaps + padding), pad_value)\n k = 0\n for y in range(ymaps):\n for x in range(xmaps):\n if k >= nmaps:\n break\n # Tensor.copy_() is a valid method but seems to be missing from the stubs\n # https://pytorch.org/docs/stable/tensors.html#torch.Tensor.copy_\n grid.narrow(1, y * height + padding, height - padding).narrow( # type: ignore[attr-defined]\n 2, x * width + padding, width - padding\n ).copy_(tensor[k])\n k = k + 1\n return grid\n\n\[email protected]_grad()\ndef save_image(\n tensor: Union[torch.Tensor, List[torch.Tensor]],\n fp: Union[Text, pathlib.Path, BinaryIO],\n format: Optional[str] = None,\n **kwargs\n) -> None:\n \"\"\"Save a given Tensor into an image file.\n\n Args:\n tensor (Tensor or list): Image to be saved. If given a mini-batch tensor,\n saves the tensor as a grid of images by calling ``make_grid``.\n fp (string or file object): A filename or a file object\n format(Optional): If omitted, the format to use is determined from the filename extension.\n If a file object was used instead of a filename, this parameter should always be used.\n **kwargs: Other arguments are documented in ``make_grid``.\n \"\"\"\n\n grid = make_grid(tensor, **kwargs)\n # Add 0.5 after unnormalizing to [0, 255] to round to nearest integer\n ndarr = grid.mul(255).add_(0.5).clamp_(0, 255).permute(1, 2, 0).to('cpu', torch.uint8).numpy()\n im = Image.fromarray(ndarr)\n im.save(fp, format=format)\n\n\[email protected]_grad()\ndef draw_bounding_boxes(\n image: torch.Tensor,\n boxes: torch.Tensor,\n labels: Optional[List[str]] = None,\n colors: Optional[List[Union[str, Tuple[int, int, int]]]] = None,\n fill: Optional[bool] = False,\n width: int = 1,\n font: Optional[str] = None,\n font_size: int = 10\n) -> torch.Tensor:\n\n \"\"\"\n Draws bounding boxes on given image.\n The values of the input image should be uint8 between 0 and 255.\n If filled, Resulting Tensor should be saved as PNG image.\n\n Args:\n image (Tensor): Tensor of shape (C x H x W)\n boxes (Tensor): Tensor of size (N, 4) containing bounding boxes in (xmin, ymin, xmax, ymax) format. Note that\n the boxes are absolute coordinates with respect to the image. In other words: `0 <= xmin < xmax < W` and\n `0 <= ymin < ymax < H`.\n labels (List[str]): List containing the labels of bounding boxes.\n colors (List[Union[str, Tuple[int, int, int]]]): List containing the colors of bounding boxes. The colors can\n be represented as `str` or `Tuple[int, int, int]`.\n fill (bool): If `True` fills the bounding box with specified color.\n width (int): Width of bounding box.\n font (str): A filename containing a TrueType font. If the file is not found in this filename, the loader may\n also search in other directories, such as the `fonts/` directory on Windows or `/Library/Fonts/`,\n `/System/Library/Fonts/` and `~/Library/Fonts/` on macOS.\n font_size (int): The requested font size in points.\n \"\"\"\n\n if not isinstance(image, torch.Tensor):\n raise TypeError(f\"Tensor expected, got {type(image)}\")\n elif image.dtype != torch.uint8:\n raise ValueError(f\"Tensor uint8 expected, got {image.dtype}\")\n elif image.dim() != 3:\n raise ValueError(\"Pass individual images, not batches\")\n\n ndarr = image.permute(1, 2, 0).numpy()\n img_to_draw = Image.fromarray(ndarr)\n\n img_boxes = boxes.to(torch.int64).tolist()\n\n if fill:\n draw = ImageDraw.Draw(img_to_draw, \"RGBA\")\n\n else:\n draw = ImageDraw.Draw(img_to_draw)\n\n txt_font = ImageFont.load_default() if font is None else ImageFont.truetype(font=font, size=font_size)\n\n for i, bbox in enumerate(img_boxes):\n if colors is None:\n color = None\n else:\n color = colors[i]\n\n if fill:\n if color is None:\n fill_color = (255, 255, 255, 100)\n elif isinstance(color, str):\n # This will automatically raise Error if rgb cannot be parsed.\n fill_color = ImageColor.getrgb(color) + (100,)\n elif isinstance(color, tuple):\n fill_color = color + (100,)\n draw.rectangle(bbox, width=width, outline=color, fill=fill_color)\n else:\n draw.rectangle(bbox, width=width, outline=color)\n\n if labels is not None:\n draw.text((bbox[0], bbox[1]), labels[i], fill=color, font=txt_font)\n\n return torch.from_numpy(np.array(img_to_draw)).permute(2, 0, 1)\n", "path": "torchvision/utils.py"}]}
| 3,573 | 948 |
gh_patches_debug_56926
|
rasdani/github-patches
|
git_diff
|
kivy__python-for-android-615
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
OpenSSL 1.0.2e outdated (replaced by 1.0.2f)
A new version has been published today. The recipe no longer can download version 1.0.2e.
Does `disable-solver.patch` still apply?
</issue>
<code>
[start of pythonforandroid/recipes/openssl/__init__.py]
1 from functools import partial
2
3 from pythonforandroid.toolchain import Recipe, shprint, current_directory
4 import sh
5
6
7 class OpenSSLRecipe(Recipe):
8 version = '1.0.2e'
9 url = 'https://www.openssl.org/source/openssl-{version}.tar.gz'
10
11 def should_build(self, arch):
12 return not self.has_libs(arch, 'libssl.so', 'libcrypto.so')
13
14 def check_symbol(self, env, sofile, symbol):
15 nm = env.get('NM', 'nm')
16 syms = sh.sh('-c', "{} -gp {} | cut -d' ' -f3".format(
17 nm, sofile), _env=env).splitlines()
18 if symbol in syms:
19 return True
20 print('{} missing symbol {}; rebuilding'.format(sofile, symbol))
21 return False
22
23 def get_recipe_env(self, arch=None):
24 env = super(OpenSSLRecipe, self).get_recipe_env(arch)
25 env['CFLAGS'] += ' ' + env['LDFLAGS']
26 env['CC'] += ' ' + env['LDFLAGS']
27 return env
28
29 def select_build_arch(self, arch):
30 aname = arch.arch
31 if 'arm64' in aname:
32 return 'linux-aarch64'
33 if 'v7a' in aname:
34 return 'android-armv7'
35 if 'arm' in aname:
36 return 'android'
37 return 'linux-armv4'
38
39 def build_arch(self, arch):
40 env = self.get_recipe_env(arch)
41 with current_directory(self.get_build_dir(arch.arch)):
42 # sh fails with code 255 trying to execute ./Configure
43 # so instead we manually run perl passing in Configure
44 perl = sh.Command('perl')
45 buildarch = self.select_build_arch(arch)
46 shprint(perl, 'Configure', 'shared', 'no-dso', 'no-krb5', buildarch, _env=env)
47 self.apply_patch('disable-sover.patch', arch.arch)
48
49 check_crypto = partial(self.check_symbol, env, 'libcrypto.so')
50 # check_ssl = partial(self.check_symbol, env, 'libssl.so')
51 while True:
52 shprint(sh.make, 'build_libs', _env=env)
53 if all(map(check_crypto, ('SSLeay', 'MD5_Transform', 'MD4_Init'))):
54 break
55 shprint(sh.make, 'clean', _env=env)
56
57 self.install_libs(arch, 'libssl.so', 'libcrypto.so')
58
59 recipe = OpenSSLRecipe()
60
[end of pythonforandroid/recipes/openssl/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pythonforandroid/recipes/openssl/__init__.py b/pythonforandroid/recipes/openssl/__init__.py
--- a/pythonforandroid/recipes/openssl/__init__.py
+++ b/pythonforandroid/recipes/openssl/__init__.py
@@ -5,7 +5,7 @@
class OpenSSLRecipe(Recipe):
- version = '1.0.2e'
+ version = '1.0.2f'
url = 'https://www.openssl.org/source/openssl-{version}.tar.gz'
def should_build(self, arch):
|
{"golden_diff": "diff --git a/pythonforandroid/recipes/openssl/__init__.py b/pythonforandroid/recipes/openssl/__init__.py\n--- a/pythonforandroid/recipes/openssl/__init__.py\n+++ b/pythonforandroid/recipes/openssl/__init__.py\n@@ -5,7 +5,7 @@\n \n \n class OpenSSLRecipe(Recipe):\n- version = '1.0.2e'\n+ version = '1.0.2f'\n url = 'https://www.openssl.org/source/openssl-{version}.tar.gz'\n \n def should_build(self, arch):\n", "issue": "OpenSSL 1.0.2e outdated (replaced by 1.0.2f)\nA new version has been published today. The recipe no longer can download version 1.0.2e.\n\nDoes `disable-solver.patch` still apply?\n\n", "before_files": [{"content": "from functools import partial\n\nfrom pythonforandroid.toolchain import Recipe, shprint, current_directory\nimport sh\n\n\nclass OpenSSLRecipe(Recipe):\n version = '1.0.2e'\n url = 'https://www.openssl.org/source/openssl-{version}.tar.gz'\n\n def should_build(self, arch):\n return not self.has_libs(arch, 'libssl.so', 'libcrypto.so')\n\n def check_symbol(self, env, sofile, symbol):\n nm = env.get('NM', 'nm')\n syms = sh.sh('-c', \"{} -gp {} | cut -d' ' -f3\".format(\n nm, sofile), _env=env).splitlines()\n if symbol in syms:\n return True\n print('{} missing symbol {}; rebuilding'.format(sofile, symbol))\n return False\n\n def get_recipe_env(self, arch=None):\n env = super(OpenSSLRecipe, self).get_recipe_env(arch)\n env['CFLAGS'] += ' ' + env['LDFLAGS']\n env['CC'] += ' ' + env['LDFLAGS']\n return env\n\n def select_build_arch(self, arch):\n aname = arch.arch\n if 'arm64' in aname:\n return 'linux-aarch64'\n if 'v7a' in aname:\n return 'android-armv7'\n if 'arm' in aname:\n return 'android'\n return 'linux-armv4'\n\n def build_arch(self, arch):\n env = self.get_recipe_env(arch)\n with current_directory(self.get_build_dir(arch.arch)):\n # sh fails with code 255 trying to execute ./Configure\n # so instead we manually run perl passing in Configure\n perl = sh.Command('perl')\n buildarch = self.select_build_arch(arch)\n shprint(perl, 'Configure', 'shared', 'no-dso', 'no-krb5', buildarch, _env=env)\n self.apply_patch('disable-sover.patch', arch.arch)\n\n check_crypto = partial(self.check_symbol, env, 'libcrypto.so')\n # check_ssl = partial(self.check_symbol, env, 'libssl.so')\n while True:\n shprint(sh.make, 'build_libs', _env=env)\n if all(map(check_crypto, ('SSLeay', 'MD5_Transform', 'MD4_Init'))):\n break\n shprint(sh.make, 'clean', _env=env)\n\n self.install_libs(arch, 'libssl.so', 'libcrypto.so')\n\nrecipe = OpenSSLRecipe()\n", "path": "pythonforandroid/recipes/openssl/__init__.py"}]}
| 1,283 | 125 |
gh_patches_debug_520
|
rasdani/github-patches
|
git_diff
|
googleapis__google-api-python-client-303
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Suggest use of httplib2 v0.9.2 in readme if using python > 3
Python3.x implementations of the client, passes bytestring to httplib2 header encoding method. Httplib2 < 0.9.2 does not support this.
Documentation should make a note that implementations in python3 should explicitly install httplib2 0.9.2. PyPi index targets 0.8.0, which is no bueno for those unaware of this issue.
</issue>
<code>
[start of setup.py]
1 # Copyright 2014 Google Inc. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Setup script for Google API Python client.
16
17 Also installs included versions of third party libraries, if those libraries
18 are not already installed.
19 """
20 from __future__ import print_function
21
22 import sys
23
24 if sys.version_info < (2, 6):
25 print('google-api-python-client requires python version >= 2.6.',
26 file=sys.stderr)
27 sys.exit(1)
28 if (3, 1) <= sys.version_info < (3, 3):
29 print('google-api-python-client requires python3 version >= 3.3.',
30 file=sys.stderr)
31 sys.exit(1)
32
33 from setuptools import setup
34 import pkg_resources
35
36 def _DetectBadness():
37 import os
38 if 'SKIP_GOOGLEAPICLIENT_COMPAT_CHECK' in os.environ:
39 return
40 o2c_pkg = None
41 try:
42 o2c_pkg = pkg_resources.get_distribution('oauth2client')
43 except pkg_resources.DistributionNotFound:
44 pass
45 oauth2client = None
46 try:
47 import oauth2client
48 except ImportError:
49 pass
50 if o2c_pkg is None and oauth2client is not None:
51 raise RuntimeError(
52 'Previous version of google-api-python-client detected; due to a '
53 'packaging issue, we cannot perform an in-place upgrade. Please remove '
54 'the old version and re-install this package.'
55 )
56
57 _DetectBadness()
58
59 packages = [
60 'apiclient',
61 'googleapiclient',
62 'googleapiclient/discovery_cache',
63 ]
64
65 install_requires = [
66 'httplib2>=0.8,<1dev',
67 'oauth2client>=1.5.0,<5.0.0dev',
68 'six>=1.6.1,<2dev',
69 'uritemplate>=3.0.0,<4dev',
70 ]
71
72 if sys.version_info < (2, 7):
73 install_requires.append('argparse')
74
75 long_desc = """The Google API Client for Python is a client library for
76 accessing the Plus, Moderator, and many other Google APIs."""
77
78 import googleapiclient
79 version = googleapiclient.__version__
80
81 setup(
82 name="google-api-python-client",
83 version=version,
84 description="Google API Client Library for Python",
85 long_description=long_desc,
86 author="Google Inc.",
87 url="http://github.com/google/google-api-python-client/",
88 install_requires=install_requires,
89 packages=packages,
90 package_data={},
91 license="Apache 2.0",
92 keywords="google api client",
93 classifiers=[
94 'Programming Language :: Python :: 2',
95 'Programming Language :: Python :: 2.6',
96 'Programming Language :: Python :: 2.7',
97 'Programming Language :: Python :: 3',
98 'Programming Language :: Python :: 3.3',
99 'Programming Language :: Python :: 3.4',
100 'Development Status :: 5 - Production/Stable',
101 'Intended Audience :: Developers',
102 'License :: OSI Approved :: Apache Software License',
103 'Operating System :: OS Independent',
104 'Topic :: Internet :: WWW/HTTP',
105 ],
106 )
107
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -63,7 +63,7 @@
]
install_requires = [
- 'httplib2>=0.8,<1dev',
+ 'httplib2>=0.9.2,<1dev',
'oauth2client>=1.5.0,<5.0.0dev',
'six>=1.6.1,<2dev',
'uritemplate>=3.0.0,<4dev',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -63,7 +63,7 @@\n ]\n \n install_requires = [\n- 'httplib2>=0.8,<1dev',\n+ 'httplib2>=0.9.2,<1dev',\n 'oauth2client>=1.5.0,<5.0.0dev',\n 'six>=1.6.1,<2dev',\n 'uritemplate>=3.0.0,<4dev',\n", "issue": "Suggest use of httplib2 v0.9.2 in readme if using python > 3\nPython3.x implementations of the client, passes bytestring to httplib2 header encoding method. Httplib2 < 0.9.2 does not support this. \n\nDocumentation should make a note that implementations in python3 should explicitly install httplib2 0.9.2. PyPi index targets 0.8.0, which is no bueno for those unaware of this issue. \n\n", "before_files": [{"content": "# Copyright 2014 Google Inc. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Setup script for Google API Python client.\n\nAlso installs included versions of third party libraries, if those libraries\nare not already installed.\n\"\"\"\nfrom __future__ import print_function\n\nimport sys\n\nif sys.version_info < (2, 6):\n print('google-api-python-client requires python version >= 2.6.',\n file=sys.stderr)\n sys.exit(1)\nif (3, 1) <= sys.version_info < (3, 3):\n print('google-api-python-client requires python3 version >= 3.3.',\n file=sys.stderr)\n sys.exit(1)\n\nfrom setuptools import setup\nimport pkg_resources\n\ndef _DetectBadness():\n import os\n if 'SKIP_GOOGLEAPICLIENT_COMPAT_CHECK' in os.environ:\n return\n o2c_pkg = None\n try:\n o2c_pkg = pkg_resources.get_distribution('oauth2client')\n except pkg_resources.DistributionNotFound:\n pass\n oauth2client = None\n try:\n import oauth2client\n except ImportError:\n pass\n if o2c_pkg is None and oauth2client is not None:\n raise RuntimeError(\n 'Previous version of google-api-python-client detected; due to a '\n 'packaging issue, we cannot perform an in-place upgrade. Please remove '\n 'the old version and re-install this package.'\n )\n\n_DetectBadness()\n\npackages = [\n 'apiclient',\n 'googleapiclient',\n 'googleapiclient/discovery_cache',\n]\n\ninstall_requires = [\n 'httplib2>=0.8,<1dev',\n 'oauth2client>=1.5.0,<5.0.0dev',\n 'six>=1.6.1,<2dev',\n 'uritemplate>=3.0.0,<4dev',\n]\n\nif sys.version_info < (2, 7):\n install_requires.append('argparse')\n\nlong_desc = \"\"\"The Google API Client for Python is a client library for\naccessing the Plus, Moderator, and many other Google APIs.\"\"\"\n\nimport googleapiclient\nversion = googleapiclient.__version__\n\nsetup(\n name=\"google-api-python-client\",\n version=version,\n description=\"Google API Client Library for Python\",\n long_description=long_desc,\n author=\"Google Inc.\",\n url=\"http://github.com/google/google-api-python-client/\",\n install_requires=install_requires,\n packages=packages,\n package_data={},\n license=\"Apache 2.0\",\n keywords=\"google api client\",\n classifiers=[\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.6',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: Apache Software License',\n 'Operating System :: OS Independent',\n 'Topic :: Internet :: WWW/HTTP',\n ],\n)\n", "path": "setup.py"}]}
| 1,647 | 115 |
gh_patches_debug_504
|
rasdani/github-patches
|
git_diff
|
beetbox__beets-3702
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
"the" plugin uses incorrect regex
### Problem
Running this command:
```sh
~ ❯ beet move artist:trance -p
Moving 40 items.
M:\TET - Travailleur En Trance\[2008] Cobra Coded Escalation\01-01 - Cobra Reporting In.mp3
-> M:\‒ Travailleur En Trance, TET\[2008] Cobra Coded Escalation\01-01 - Cobra Reporting In.mp3
```
Led to this problem:
"TET" is recognized by the "the" plugin as something it should move. This is because the regex used in the.py, line 26, is
```
PATTERN_THE = u'^[the]{3}\\s'
```
which matches "TET". It should probably be:
```
PATTERN_THE = u'^the\\s'
```
### Setup
* OS: Windows 10 2004
* Python version: 3.8
* beets version: latest trunk
* Turning off plugins made problem go away (yes/no): obviously, if I disable 'the' it no longer does this
</issue>
<code>
[start of beetsplug/the.py]
1 # -*- coding: utf-8 -*-
2 # This file is part of beets.
3 # Copyright 2016, Blemjhoo Tezoulbr <[email protected]>.
4 #
5 # Permission is hereby granted, free of charge, to any person obtaining
6 # a copy of this software and associated documentation files (the
7 # "Software"), to deal in the Software without restriction, including
8 # without limitation the rights to use, copy, modify, merge, publish,
9 # distribute, sublicense, and/or sell copies of the Software, and to
10 # permit persons to whom the Software is furnished to do so, subject to
11 # the following conditions:
12 #
13 # The above copyright notice and this permission notice shall be
14 # included in all copies or substantial portions of the Software.
15
16 """Moves patterns in path formats (suitable for moving articles)."""
17
18 from __future__ import division, absolute_import, print_function
19
20 import re
21 from beets.plugins import BeetsPlugin
22
23 __author__ = '[email protected]'
24 __version__ = '1.1'
25
26 PATTERN_THE = u'^[the]{3}\\s'
27 PATTERN_A = u'^[a][n]?\\s'
28 FORMAT = u'{0}, {1}'
29
30
31 class ThePlugin(BeetsPlugin):
32
33 patterns = []
34
35 def __init__(self):
36 super(ThePlugin, self).__init__()
37
38 self.template_funcs['the'] = self.the_template_func
39
40 self.config.add({
41 'the': True,
42 'a': True,
43 'format': u'{0}, {1}',
44 'strip': False,
45 'patterns': [],
46 })
47
48 self.patterns = self.config['patterns'].as_str_seq()
49 for p in self.patterns:
50 if p:
51 try:
52 re.compile(p)
53 except re.error:
54 self._log.error(u'invalid pattern: {0}', p)
55 else:
56 if not (p.startswith('^') or p.endswith('$')):
57 self._log.warning(u'warning: \"{0}\" will not '
58 u'match string start/end', p)
59 if self.config['a']:
60 self.patterns = [PATTERN_A] + self.patterns
61 if self.config['the']:
62 self.patterns = [PATTERN_THE] + self.patterns
63 if not self.patterns:
64 self._log.warning(u'no patterns defined!')
65
66 def unthe(self, text, pattern):
67 """Moves pattern in the path format string or strips it
68
69 text -- text to handle
70 pattern -- regexp pattern (case ignore is already on)
71 strip -- if True, pattern will be removed
72 """
73 if text:
74 r = re.compile(pattern, flags=re.IGNORECASE)
75 try:
76 t = r.findall(text)[0]
77 except IndexError:
78 return text
79 else:
80 r = re.sub(r, '', text).strip()
81 if self.config['strip']:
82 return r
83 else:
84 fmt = self.config['format'].as_str()
85 return fmt.format(r, t.strip()).strip()
86 else:
87 return u''
88
89 def the_template_func(self, text):
90 if not self.patterns:
91 return text
92 if text:
93 for p in self.patterns:
94 r = self.unthe(text, p)
95 if r != text:
96 self._log.debug(u'\"{0}\" -> \"{1}\"', text, r)
97 break
98 return r
99 else:
100 return u''
101
[end of beetsplug/the.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/beetsplug/the.py b/beetsplug/the.py
--- a/beetsplug/the.py
+++ b/beetsplug/the.py
@@ -23,7 +23,7 @@
__author__ = '[email protected]'
__version__ = '1.1'
-PATTERN_THE = u'^[the]{3}\\s'
+PATTERN_THE = u'^the\\s'
PATTERN_A = u'^[a][n]?\\s'
FORMAT = u'{0}, {1}'
|
{"golden_diff": "diff --git a/beetsplug/the.py b/beetsplug/the.py\n--- a/beetsplug/the.py\n+++ b/beetsplug/the.py\n@@ -23,7 +23,7 @@\n __author__ = '[email protected]'\n __version__ = '1.1'\n \n-PATTERN_THE = u'^[the]{3}\\\\s'\n+PATTERN_THE = u'^the\\\\s'\n PATTERN_A = u'^[a][n]?\\\\s'\n FORMAT = u'{0}, {1}'\n", "issue": "\"the\" plugin uses incorrect regex\n### Problem\r\n\r\nRunning this command:\r\n\r\n```sh\r\n~ \u276f beet move artist:trance -p\r\nMoving 40 items.\r\nM:\\TET - Travailleur En Trance\\[2008] Cobra Coded Escalation\\01-01 - Cobra Reporting In.mp3\r\n -> M:\\\u2012 Travailleur En Trance, TET\\[2008] Cobra Coded Escalation\\01-01 - Cobra Reporting In.mp3\r\n```\r\n\r\nLed to this problem:\r\n\r\n\"TET\" is recognized by the \"the\" plugin as something it should move. This is because the regex used in the.py, line 26, is\r\n```\r\nPATTERN_THE = u'^[the]{3}\\\\s'\r\n```\r\nwhich matches \"TET\". It should probably be:\r\n```\r\nPATTERN_THE = u'^the\\\\s'\r\n```\r\n\r\n### Setup\r\n\r\n* OS: Windows 10 2004\r\n* Python version: 3.8\r\n* beets version: latest trunk\r\n* Turning off plugins made problem go away (yes/no): obviously, if I disable 'the' it no longer does this\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# This file is part of beets.\n# Copyright 2016, Blemjhoo Tezoulbr <[email protected]>.\n#\n# Permission is hereby granted, free of charge, to any person obtaining\n# a copy of this software and associated documentation files (the\n# \"Software\"), to deal in the Software without restriction, including\n# without limitation the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the Software, and to\n# permit persons to whom the Software is furnished to do so, subject to\n# the following conditions:\n#\n# The above copyright notice and this permission notice shall be\n# included in all copies or substantial portions of the Software.\n\n\"\"\"Moves patterns in path formats (suitable for moving articles).\"\"\"\n\nfrom __future__ import division, absolute_import, print_function\n\nimport re\nfrom beets.plugins import BeetsPlugin\n\n__author__ = '[email protected]'\n__version__ = '1.1'\n\nPATTERN_THE = u'^[the]{3}\\\\s'\nPATTERN_A = u'^[a][n]?\\\\s'\nFORMAT = u'{0}, {1}'\n\n\nclass ThePlugin(BeetsPlugin):\n\n patterns = []\n\n def __init__(self):\n super(ThePlugin, self).__init__()\n\n self.template_funcs['the'] = self.the_template_func\n\n self.config.add({\n 'the': True,\n 'a': True,\n 'format': u'{0}, {1}',\n 'strip': False,\n 'patterns': [],\n })\n\n self.patterns = self.config['patterns'].as_str_seq()\n for p in self.patterns:\n if p:\n try:\n re.compile(p)\n except re.error:\n self._log.error(u'invalid pattern: {0}', p)\n else:\n if not (p.startswith('^') or p.endswith('$')):\n self._log.warning(u'warning: \\\"{0}\\\" will not '\n u'match string start/end', p)\n if self.config['a']:\n self.patterns = [PATTERN_A] + self.patterns\n if self.config['the']:\n self.patterns = [PATTERN_THE] + self.patterns\n if not self.patterns:\n self._log.warning(u'no patterns defined!')\n\n def unthe(self, text, pattern):\n \"\"\"Moves pattern in the path format string or strips it\n\n text -- text to handle\n pattern -- regexp pattern (case ignore is already on)\n strip -- if True, pattern will be removed\n \"\"\"\n if text:\n r = re.compile(pattern, flags=re.IGNORECASE)\n try:\n t = r.findall(text)[0]\n except IndexError:\n return text\n else:\n r = re.sub(r, '', text).strip()\n if self.config['strip']:\n return r\n else:\n fmt = self.config['format'].as_str()\n return fmt.format(r, t.strip()).strip()\n else:\n return u''\n\n def the_template_func(self, text):\n if not self.patterns:\n return text\n if text:\n for p in self.patterns:\n r = self.unthe(text, p)\n if r != text:\n self._log.debug(u'\\\"{0}\\\" -> \\\"{1}\\\"', text, r)\n break\n return r\n else:\n return u''\n", "path": "beetsplug/the.py"}]}
| 1,730 | 115 |
gh_patches_debug_38490
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-modules-extras-68
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add support for "cpanm --mirror-only"
##### Issue Type:
Feature Idea
##### Ansible Version:
1.7.2
##### Environment:
Ubuntu, but this goes for any environment.
##### Summary:
It would be great if it was possible to specify `mirror_only=yes` in the cpanm module. This enable installs from [minicpan](https://metacpan.org/pod/CPAN::Mini) in a local environment where extra packages has been injected.
Example:
```
cpanm --mirror-only --mirror http://cpan.myinternal.net My::Custom::Module
```
Without "--mirror-only", cpanm will try to lookup My::Custom::Module in CPAN Meta DB.
##### Steps To Reproduce:
##### Expected Results:
##### Actual Results:
</issue>
<code>
[start of packaging/language/cpanm.py]
1 #!/usr/bin/python
2 # -*- coding: utf-8 -*-
3
4 # (c) 2012, Franck Cuny <[email protected]>
5 #
6 # This file is part of Ansible
7 #
8 # Ansible is free software: you can redistribute it and/or modify
9 # it under the terms of the GNU General Public License as published by
10 # the Free Software Foundation, either version 3 of the License, or
11 # (at your option) any later version.
12 #
13 # Ansible is distributed in the hope that it will be useful,
14 # but WITHOUT ANY WARRANTY; without even the implied warranty of
15 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
16 # GNU General Public License for more details.
17 #
18 # You should have received a copy of the GNU General Public License
19 # along with Ansible. If not, see <http://www.gnu.org/licenses/>.
20 #
21
22 DOCUMENTATION = '''
23 ---
24 module: cpanm
25 short_description: Manages Perl library dependencies.
26 description:
27 - Manage Perl library dependencies.
28 version_added: "1.6"
29 options:
30 name:
31 description:
32 - The name of the Perl library to install. You may use the "full distribution path", e.g. MIYAGAWA/Plack-0.99_05.tar.gz
33 required: false
34 default: null
35 aliases: ["pkg"]
36 from_path:
37 description:
38 - The local directory from where to install
39 required: false
40 default: null
41 notest:
42 description:
43 - Do not run unit tests
44 required: false
45 default: false
46 locallib:
47 description:
48 - Specify the install base to install modules
49 required: false
50 default: false
51 mirror:
52 description:
53 - Specifies the base URL for the CPAN mirror to use
54 required: false
55 default: false
56 examples:
57 - code: "cpanm: name=Dancer"
58 description: Install I(Dancer) perl package.
59 - code: "cpanm: name=MIYAGAWA/Plack-0.99_05.tar.gz"
60 description: Install version 0.99_05 of the I(Plack) perl package.
61 - code: "cpanm: name=Dancer locallib=/srv/webapps/my_app/extlib"
62 description: "Install I(Dancer) (U(http://perldancer.org/)) into the specified I(locallib)"
63 - code: "cpanm: from_path=/srv/webapps/my_app/src/"
64 description: Install perl dependencies from local directory.
65 - code: "cpanm: name=Dancer notest=True locallib=/srv/webapps/my_app/extlib"
66 description: Install I(Dancer) perl package without running the unit tests in indicated I(locallib).
67 - code: "cpanm: name=Dancer mirror=http://cpan.cpantesters.org/"
68 description: Install I(Dancer) perl package from a specific mirror
69 notes:
70 - Please note that U(http://search.cpan.org/dist/App-cpanminus/bin/cpanm, cpanm) must be installed on the remote host.
71 author: Franck Cuny
72 '''
73
74 def _is_package_installed(module, name, locallib, cpanm):
75 cmd = ""
76 if locallib:
77 os.environ["PERL5LIB"] = "%s/lib/perl5" % locallib
78 cmd = "%s perl -M%s -e '1'" % (cmd, name)
79 res, stdout, stderr = module.run_command(cmd, check_rc=False)
80 if res == 0:
81 return True
82 else:
83 return False
84
85 def _build_cmd_line(name, from_path, notest, locallib, mirror, cpanm):
86 # this code should use "%s" like everything else and just return early but not fixing all of it now.
87 # don't copy stuff like this
88 if from_path:
89 cmd = "{cpanm} {path}".format(cpanm=cpanm, path=from_path)
90 else:
91 cmd = "{cpanm} {name}".format(cpanm=cpanm, name=name)
92
93 if notest is True:
94 cmd = "{cmd} -n".format(cmd=cmd)
95
96 if locallib is not None:
97 cmd = "{cmd} -l {locallib}".format(cmd=cmd, locallib=locallib)
98
99 if mirror is not None:
100 cmd = "{cmd} --mirror {mirror}".format(cmd=cmd, mirror=mirror)
101
102 return cmd
103
104
105 def main():
106 arg_spec = dict(
107 name=dict(default=None, required=False, aliases=['pkg']),
108 from_path=dict(default=None, required=False),
109 notest=dict(default=False, type='bool'),
110 locallib=dict(default=None, required=False),
111 mirror=dict(default=None, required=False)
112 )
113
114 module = AnsibleModule(
115 argument_spec=arg_spec,
116 required_one_of=[['name', 'from_path']],
117 )
118
119 cpanm = module.get_bin_path('cpanm', True)
120 name = module.params['name']
121 from_path = module.params['from_path']
122 notest = module.boolean(module.params.get('notest', False))
123 locallib = module.params['locallib']
124 mirror = module.params['mirror']
125
126 changed = False
127
128 installed = _is_package_installed(module, name, locallib, cpanm)
129
130 if not installed:
131 out_cpanm = err_cpanm = ''
132 cmd = _build_cmd_line(name, from_path, notest, locallib, mirror, cpanm)
133
134 rc_cpanm, out_cpanm, err_cpanm = module.run_command(cmd, check_rc=False)
135
136 if rc_cpanm != 0:
137 module.fail_json(msg=err_cpanm, cmd=cmd)
138
139 if err_cpanm and 'is up to date' not in err_cpanm:
140 changed = True
141
142 module.exit_json(changed=changed, binary=cpanm, name=name)
143
144 # import module snippets
145 from ansible.module_utils.basic import *
146
147 main()
148
[end of packaging/language/cpanm.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/packaging/language/cpanm.py b/packaging/language/cpanm.py
--- a/packaging/language/cpanm.py
+++ b/packaging/language/cpanm.py
@@ -53,6 +53,11 @@
- Specifies the base URL for the CPAN mirror to use
required: false
default: false
+ mirror_only:
+ description:
+ - Use the mirror's index file instead of the CPAN Meta DB
+ required: false
+ default: false
examples:
- code: "cpanm: name=Dancer"
description: Install I(Dancer) perl package.
@@ -82,7 +87,7 @@
else:
return False
-def _build_cmd_line(name, from_path, notest, locallib, mirror, cpanm):
+def _build_cmd_line(name, from_path, notest, locallib, mirror, mirror_only, cpanm):
# this code should use "%s" like everything else and just return early but not fixing all of it now.
# don't copy stuff like this
if from_path:
@@ -99,6 +104,9 @@
if mirror is not None:
cmd = "{cmd} --mirror {mirror}".format(cmd=cmd, mirror=mirror)
+ if mirror_only is True:
+ cmd = "{cmd} --mirror-only".format(cmd=cmd)
+
return cmd
@@ -109,6 +117,7 @@
notest=dict(default=False, type='bool'),
locallib=dict(default=None, required=False),
mirror=dict(default=None, required=False)
+ mirror_only=dict(default=False, type='bool'),
)
module = AnsibleModule(
@@ -116,12 +125,13 @@
required_one_of=[['name', 'from_path']],
)
- cpanm = module.get_bin_path('cpanm', True)
- name = module.params['name']
- from_path = module.params['from_path']
- notest = module.boolean(module.params.get('notest', False))
- locallib = module.params['locallib']
- mirror = module.params['mirror']
+ cpanm = module.get_bin_path('cpanm', True)
+ name = module.params['name']
+ from_path = module.params['from_path']
+ notest = module.boolean(module.params.get('notest', False))
+ locallib = module.params['locallib']
+ mirror = module.params['mirror']
+ mirror_only = module.params['mirror_only']
changed = False
@@ -129,7 +139,7 @@
if not installed:
out_cpanm = err_cpanm = ''
- cmd = _build_cmd_line(name, from_path, notest, locallib, mirror, cpanm)
+ cmd = _build_cmd_line(name, from_path, notest, locallib, mirror, mirror_only, cpanm)
rc_cpanm, out_cpanm, err_cpanm = module.run_command(cmd, check_rc=False)
|
{"golden_diff": "diff --git a/packaging/language/cpanm.py b/packaging/language/cpanm.py\n--- a/packaging/language/cpanm.py\n+++ b/packaging/language/cpanm.py\n@@ -53,6 +53,11 @@\n - Specifies the base URL for the CPAN mirror to use\n required: false\n default: false\n+ mirror_only:\n+ description:\n+ - Use the mirror's index file instead of the CPAN Meta DB\n+ required: false\n+ default: false\n examples:\n - code: \"cpanm: name=Dancer\"\n description: Install I(Dancer) perl package.\n@@ -82,7 +87,7 @@\n else: \n return False\n \n-def _build_cmd_line(name, from_path, notest, locallib, mirror, cpanm):\n+def _build_cmd_line(name, from_path, notest, locallib, mirror, mirror_only, cpanm):\n # this code should use \"%s\" like everything else and just return early but not fixing all of it now.\n # don't copy stuff like this\n if from_path:\n@@ -99,6 +104,9 @@\n if mirror is not None:\n cmd = \"{cmd} --mirror {mirror}\".format(cmd=cmd, mirror=mirror)\n \n+ if mirror_only is True:\n+ cmd = \"{cmd} --mirror-only\".format(cmd=cmd)\n+\n return cmd\n \n \n@@ -109,6 +117,7 @@\n notest=dict(default=False, type='bool'),\n locallib=dict(default=None, required=False),\n mirror=dict(default=None, required=False)\n+ mirror_only=dict(default=False, type='bool'),\n )\n \n module = AnsibleModule(\n@@ -116,12 +125,13 @@\n required_one_of=[['name', 'from_path']],\n )\n \n- cpanm = module.get_bin_path('cpanm', True)\n- name = module.params['name']\n- from_path = module.params['from_path']\n- notest = module.boolean(module.params.get('notest', False))\n- locallib = module.params['locallib']\n- mirror = module.params['mirror']\n+ cpanm = module.get_bin_path('cpanm', True)\n+ name = module.params['name']\n+ from_path = module.params['from_path']\n+ notest = module.boolean(module.params.get('notest', False))\n+ locallib = module.params['locallib']\n+ mirror = module.params['mirror']\n+ mirror_only = module.params['mirror_only']\n \n changed = False\n \n@@ -129,7 +139,7 @@\n \n if not installed:\n out_cpanm = err_cpanm = ''\n- cmd = _build_cmd_line(name, from_path, notest, locallib, mirror, cpanm)\n+ cmd = _build_cmd_line(name, from_path, notest, locallib, mirror, mirror_only, cpanm)\n \n rc_cpanm, out_cpanm, err_cpanm = module.run_command(cmd, check_rc=False)\n", "issue": "Add support for \"cpanm --mirror-only\"\n##### Issue Type:\n\nFeature Idea\n##### Ansible Version:\n\n1.7.2\n##### Environment:\n\nUbuntu, but this goes for any environment.\n##### Summary:\n\nIt would be great if it was possible to specify `mirror_only=yes` in the cpanm module. This enable installs from [minicpan](https://metacpan.org/pod/CPAN::Mini) in a local environment where extra packages has been injected.\n\nExample:\n\n```\ncpanm --mirror-only --mirror http://cpan.myinternal.net My::Custom::Module\n```\n\nWithout \"--mirror-only\", cpanm will try to lookup My::Custom::Module in CPAN Meta DB.\n##### Steps To Reproduce:\n##### Expected Results:\n##### Actual Results:\n\n", "before_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# (c) 2012, Franck Cuny <[email protected]>\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n#\n\nDOCUMENTATION = '''\n---\nmodule: cpanm\nshort_description: Manages Perl library dependencies.\ndescription:\n - Manage Perl library dependencies.\nversion_added: \"1.6\"\noptions:\n name:\n description:\n - The name of the Perl library to install. You may use the \"full distribution path\", e.g. MIYAGAWA/Plack-0.99_05.tar.gz\n required: false\n default: null\n aliases: [\"pkg\"]\n from_path:\n description:\n - The local directory from where to install\n required: false\n default: null\n notest:\n description:\n - Do not run unit tests\n required: false\n default: false\n locallib:\n description:\n - Specify the install base to install modules\n required: false\n default: false\n mirror:\n description:\n - Specifies the base URL for the CPAN mirror to use\n required: false\n default: false\nexamples:\n - code: \"cpanm: name=Dancer\"\n description: Install I(Dancer) perl package.\n - code: \"cpanm: name=MIYAGAWA/Plack-0.99_05.tar.gz\"\n description: Install version 0.99_05 of the I(Plack) perl package.\n - code: \"cpanm: name=Dancer locallib=/srv/webapps/my_app/extlib\"\n description: \"Install I(Dancer) (U(http://perldancer.org/)) into the specified I(locallib)\"\n - code: \"cpanm: from_path=/srv/webapps/my_app/src/\"\n description: Install perl dependencies from local directory.\n - code: \"cpanm: name=Dancer notest=True locallib=/srv/webapps/my_app/extlib\"\n description: Install I(Dancer) perl package without running the unit tests in indicated I(locallib).\n - code: \"cpanm: name=Dancer mirror=http://cpan.cpantesters.org/\"\n description: Install I(Dancer) perl package from a specific mirror\nnotes:\n - Please note that U(http://search.cpan.org/dist/App-cpanminus/bin/cpanm, cpanm) must be installed on the remote host.\nauthor: Franck Cuny\n'''\n\ndef _is_package_installed(module, name, locallib, cpanm):\n cmd = \"\"\n if locallib:\n os.environ[\"PERL5LIB\"] = \"%s/lib/perl5\" % locallib\n cmd = \"%s perl -M%s -e '1'\" % (cmd, name)\n res, stdout, stderr = module.run_command(cmd, check_rc=False)\n if res == 0:\n return True\n else: \n return False\n\ndef _build_cmd_line(name, from_path, notest, locallib, mirror, cpanm):\n # this code should use \"%s\" like everything else and just return early but not fixing all of it now.\n # don't copy stuff like this\n if from_path:\n cmd = \"{cpanm} {path}\".format(cpanm=cpanm, path=from_path)\n else:\n cmd = \"{cpanm} {name}\".format(cpanm=cpanm, name=name)\n\n if notest is True:\n cmd = \"{cmd} -n\".format(cmd=cmd)\n\n if locallib is not None:\n cmd = \"{cmd} -l {locallib}\".format(cmd=cmd, locallib=locallib)\n\n if mirror is not None:\n cmd = \"{cmd} --mirror {mirror}\".format(cmd=cmd, mirror=mirror)\n\n return cmd\n\n\ndef main():\n arg_spec = dict(\n name=dict(default=None, required=False, aliases=['pkg']),\n from_path=dict(default=None, required=False),\n notest=dict(default=False, type='bool'),\n locallib=dict(default=None, required=False),\n mirror=dict(default=None, required=False)\n )\n\n module = AnsibleModule(\n argument_spec=arg_spec,\n required_one_of=[['name', 'from_path']],\n )\n\n cpanm = module.get_bin_path('cpanm', True)\n name = module.params['name']\n from_path = module.params['from_path']\n notest = module.boolean(module.params.get('notest', False))\n locallib = module.params['locallib']\n mirror = module.params['mirror']\n\n changed = False\n\n installed = _is_package_installed(module, name, locallib, cpanm)\n\n if not installed:\n out_cpanm = err_cpanm = ''\n cmd = _build_cmd_line(name, from_path, notest, locallib, mirror, cpanm)\n\n rc_cpanm, out_cpanm, err_cpanm = module.run_command(cmd, check_rc=False)\n\n if rc_cpanm != 0:\n module.fail_json(msg=err_cpanm, cmd=cmd)\n\n if err_cpanm and 'is up to date' not in err_cpanm:\n changed = True\n\n module.exit_json(changed=changed, binary=cpanm, name=name)\n\n# import module snippets\nfrom ansible.module_utils.basic import *\n\nmain()\n", "path": "packaging/language/cpanm.py"}]}
| 2,395 | 716 |
gh_patches_debug_777
|
rasdani/github-patches
|
git_diff
|
getmoto__moto-1840
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cryptography Package has a Security Vulnerability
Discovered using pipenv's security check feature that there's a vulnerability in the cryptography package versions<2.3.
> Checking installed package safety...
36351: cryptography >=1.9.0,<2.3 resolved (2.2.2 installed)!
python-cryptography versions >=1.9.0 and <2.3 did not enforce a minimum tag length for finalize_with_tag API. If a user did not validate the input length prior to passing it to finalize_with_tag an attacker could craft an invalid payload with a shortened tag (e.g. 1 byte) such that they would have a 1 in 256 chance of passing the MAC check. GCM tag forgeries can cause key leakage.
More details here: http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-10903
setup.py should be updated to require cryptography>=2.3.0.
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 from __future__ import unicode_literals
3 import setuptools
4 from setuptools import setup, find_packages
5 import sys
6
7
8 install_requires = [
9 "Jinja2>=2.7.3",
10 "boto>=2.36.0",
11 "boto3>=1.6.16,<1.8",
12 "botocore>=1.9.16,<1.11",
13 "cryptography>=2.0.0",
14 "requests>=2.5",
15 "xmltodict",
16 "six>1.9",
17 "werkzeug",
18 "pyaml",
19 "pytz",
20 "python-dateutil<3.0.0,>=2.1",
21 "python-jose<3.0.0",
22 "mock",
23 "docker>=2.5.1",
24 "jsondiff==1.1.1",
25 "aws-xray-sdk<0.96,>=0.93",
26 "responses>=0.9.0",
27 ]
28
29 extras_require = {
30 'server': ['flask'],
31 }
32
33 # https://hynek.me/articles/conditional-python-dependencies/
34 if int(setuptools.__version__.split(".", 1)[0]) < 18:
35 if sys.version_info[0:2] < (3, 3):
36 install_requires.append("backports.tempfile")
37 else:
38 extras_require[":python_version<'3.3'"] = ["backports.tempfile"]
39
40
41 setup(
42 name='moto',
43 version='1.3.6',
44 description='A library that allows your python tests to easily'
45 ' mock out the boto library',
46 author='Steve Pulec',
47 author_email='[email protected]',
48 url='https://github.com/spulec/moto',
49 entry_points={
50 'console_scripts': [
51 'moto_server = moto.server:main',
52 ],
53 },
54 packages=find_packages(exclude=("tests", "tests.*")),
55 install_requires=install_requires,
56 extras_require=extras_require,
57 include_package_data=True,
58 license="Apache",
59 test_suite="tests",
60 classifiers=[
61 "Programming Language :: Python :: 2",
62 "Programming Language :: Python :: 2.7",
63 "Programming Language :: Python :: 3",
64 "Programming Language :: Python :: 3.3",
65 "Programming Language :: Python :: 3.4",
66 "Programming Language :: Python :: 3.5",
67 "Programming Language :: Python :: 3.6",
68 "License :: OSI Approved :: Apache Software License",
69 "Topic :: Software Development :: Testing",
70 ],
71 )
72
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -10,7 +10,7 @@
"boto>=2.36.0",
"boto3>=1.6.16,<1.8",
"botocore>=1.9.16,<1.11",
- "cryptography>=2.0.0",
+ "cryptography>=2.3.0",
"requests>=2.5",
"xmltodict",
"six>1.9",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -10,7 +10,7 @@\n \"boto>=2.36.0\",\n \"boto3>=1.6.16,<1.8\",\n \"botocore>=1.9.16,<1.11\",\n- \"cryptography>=2.0.0\",\n+ \"cryptography>=2.3.0\",\n \"requests>=2.5\",\n \"xmltodict\",\n \"six>1.9\",\n", "issue": "Cryptography Package has a Security Vulnerability\nDiscovered using pipenv's security check feature that there's a vulnerability in the cryptography package versions<2.3.\r\n \r\n> Checking installed package safety...\r\n36351: cryptography >=1.9.0,<2.3 resolved (2.2.2 installed)!\r\npython-cryptography versions >=1.9.0 and <2.3 did not enforce a minimum tag length for finalize_with_tag API. If a user did not validate the input length prior to passing it to finalize_with_tag an attacker could craft an invalid payload with a shortened tag (e.g. 1 byte) such that they would have a 1 in 256 chance of passing the MAC check. GCM tag forgeries can cause key leakage.\r\n \r\nMore details here: http://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2018-10903\r\n\r\nsetup.py should be updated to require cryptography>=2.3.0.\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\nfrom __future__ import unicode_literals\nimport setuptools\nfrom setuptools import setup, find_packages\nimport sys\n\n\ninstall_requires = [\n \"Jinja2>=2.7.3\",\n \"boto>=2.36.0\",\n \"boto3>=1.6.16,<1.8\",\n \"botocore>=1.9.16,<1.11\",\n \"cryptography>=2.0.0\",\n \"requests>=2.5\",\n \"xmltodict\",\n \"six>1.9\",\n \"werkzeug\",\n \"pyaml\",\n \"pytz\",\n \"python-dateutil<3.0.0,>=2.1\",\n \"python-jose<3.0.0\",\n \"mock\",\n \"docker>=2.5.1\",\n \"jsondiff==1.1.1\",\n \"aws-xray-sdk<0.96,>=0.93\",\n \"responses>=0.9.0\",\n]\n\nextras_require = {\n 'server': ['flask'],\n}\n\n# https://hynek.me/articles/conditional-python-dependencies/\nif int(setuptools.__version__.split(\".\", 1)[0]) < 18:\n if sys.version_info[0:2] < (3, 3):\n install_requires.append(\"backports.tempfile\")\nelse:\n extras_require[\":python_version<'3.3'\"] = [\"backports.tempfile\"]\n\n\nsetup(\n name='moto',\n version='1.3.6',\n description='A library that allows your python tests to easily'\n ' mock out the boto library',\n author='Steve Pulec',\n author_email='[email protected]',\n url='https://github.com/spulec/moto',\n entry_points={\n 'console_scripts': [\n 'moto_server = moto.server:main',\n ],\n },\n packages=find_packages(exclude=(\"tests\", \"tests.*\")),\n install_requires=install_requires,\n extras_require=extras_require,\n include_package_data=True,\n license=\"Apache\",\n test_suite=\"tests\",\n classifiers=[\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.3\",\n \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Topic :: Software Development :: Testing\",\n ],\n)\n", "path": "setup.py"}]}
| 1,443 | 125 |
gh_patches_debug_31049
|
rasdani/github-patches
|
git_diff
|
freqtrade__freqtrade-1656
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Minimal ROI value is not really optional, Bot Crash if minimal_roi have no 0 value
## The problem:
### The "minimal_roi" configuration object is suposed to be optionnal as explained in the doc:
> Most of the strategy files already include the optimal minimal_roi value. This parameter is optional. If you use it in the configuration file, it will take over the minimal_roi value from the strategy file.
Exemple:
> minimal_roi = {
> "40": 0.0,
> "30": 0.01,
> "20": 0.02,
> "0": 0.04
> }
**However, If I remove this parameter in the strategy and config I get this error:**
> 2019-03-06 21:56:56,768 - freqtrade - ERROR - Fatal exception!
> Traceback (most recent call last):
> File "./freqtrade/main.py", line 45, in main
> freqtrade = FreqtradeBot(config)
> File "/home/axel/dev/shatta/framework-dev/private/freqtrade/freqtrade/freqtradebot.py", line 54, in __init__
> self.strategy: IStrategy = StrategyResolver(self.config).strategy
> File "/home/axel/dev/shatta/framework-dev/private/freqtrade/freqtrade/resolvers/strategy_resolver.py", line 77, in __init__
> {int(key): value for (key, value) in self.strategy.minimal_roi.items()}.items(),
> AttributeError: 'ShattaStrategy' object has no attribute 'minimal_roi'
**Also, If I remove the 0 value key like that:**
> minimal_roi = {
> "40": 0.0,
> "30": 0.01,
> "20": 0.02,
> }
**The bot start but crash when trying to check ROI with this error:**
> File "/freqtrade/freqtrade/freqtradebot.py", line 699, in check_sell
> should_sell = self.strategy.should_sell(trade, sell_rate, datetime.utcnow(), buy, sell)
> File "/framework-dev/private/freqtrade/freqtrade/strategy/interface.py", line 273, in should_sell
> if self.min_roi_reached(trade=trade, current_profit=current_profit, current_time=date):
> File "/framework-dev/private/freqtrade/freqtrade/strategy/**interface.py", line 349**, in min_roi_reached
> **roi_entry = max(list(filter(lambda x: trade_dur >= x, self.minimal_roi.keys())))**
### Standalone Python test to reproduce:
> minimal_roi_keys = [0, 20, 30, 40, 50] ## Remove the 0 to trigger error
> trade_dur = 0.3486263354619344
> roi_entry = max(list(filter(lambda x: trade_dur >= x, minimal_roi_keys)))
> print(str(roi_entry))
### Solutions
1. The quick easy solution to temporaly deal with that issue is to make the minimal_roi parameter mandatory and make the "min_roi_reached" work with missing 0. Users who don't want to use ROI can simply put an unrealistic hight value.
2. The other is to make this parameter truly optionnal.
Minimal ROI value is not really optional, Bot Crash if minimal_roi have no 0 value
## The problem:
### The "minimal_roi" configuration object is suposed to be optionnal as explained in the doc:
> Most of the strategy files already include the optimal minimal_roi value. This parameter is optional. If you use it in the configuration file, it will take over the minimal_roi value from the strategy file.
Exemple:
> minimal_roi = {
> "40": 0.0,
> "30": 0.01,
> "20": 0.02,
> "0": 0.04
> }
**However, If I remove this parameter in the strategy and config I get this error:**
> 2019-03-06 21:56:56,768 - freqtrade - ERROR - Fatal exception!
> Traceback (most recent call last):
> File "./freqtrade/main.py", line 45, in main
> freqtrade = FreqtradeBot(config)
> File "/home/axel/dev/shatta/framework-dev/private/freqtrade/freqtrade/freqtradebot.py", line 54, in __init__
> self.strategy: IStrategy = StrategyResolver(self.config).strategy
> File "/home/axel/dev/shatta/framework-dev/private/freqtrade/freqtrade/resolvers/strategy_resolver.py", line 77, in __init__
> {int(key): value for (key, value) in self.strategy.minimal_roi.items()}.items(),
> AttributeError: 'ShattaStrategy' object has no attribute 'minimal_roi'
**Also, If I remove the 0 value key like that:**
> minimal_roi = {
> "40": 0.0,
> "30": 0.01,
> "20": 0.02,
> }
**The bot start but crash when trying to check ROI with this error:**
> File "/freqtrade/freqtrade/freqtradebot.py", line 699, in check_sell
> should_sell = self.strategy.should_sell(trade, sell_rate, datetime.utcnow(), buy, sell)
> File "/framework-dev/private/freqtrade/freqtrade/strategy/interface.py", line 273, in should_sell
> if self.min_roi_reached(trade=trade, current_profit=current_profit, current_time=date):
> File "/framework-dev/private/freqtrade/freqtrade/strategy/**interface.py", line 349**, in min_roi_reached
> **roi_entry = max(list(filter(lambda x: trade_dur >= x, self.minimal_roi.keys())))**
### Standalone Python test to reproduce:
> minimal_roi_keys = [0, 20, 30, 40, 50] ## Remove the 0 to trigger error
> trade_dur = 0.3486263354619344
> roi_entry = max(list(filter(lambda x: trade_dur >= x, minimal_roi_keys)))
> print(str(roi_entry))
### Solutions
1. The quick easy solution to temporaly deal with that issue is to make the minimal_roi parameter mandatory and make the "min_roi_reached" work with missing 0. Users who don't want to use ROI can simply put an unrealistic hight value.
2. The other is to make this parameter truly optionnal.
</issue>
<code>
[start of freqtrade/resolvers/strategy_resolver.py]
1 # pragma pylint: disable=attribute-defined-outside-init
2
3 """
4 This module load custom strategies
5 """
6 import logging
7 import tempfile
8 from base64 import urlsafe_b64decode
9 from collections import OrderedDict
10 from inspect import getfullargspec
11 from pathlib import Path
12 from typing import Dict, Optional
13
14 from freqtrade import constants
15 from freqtrade.resolvers import IResolver
16 from freqtrade.strategy import import_strategy
17 from freqtrade.strategy.interface import IStrategy
18
19 logger = logging.getLogger(__name__)
20
21
22 class StrategyResolver(IResolver):
23 """
24 This class contains all the logic to load custom strategy class
25 """
26
27 __slots__ = ['strategy']
28
29 def __init__(self, config: Optional[Dict] = None) -> None:
30 """
31 Load the custom class from config parameter
32 :param config: configuration dictionary or None
33 """
34 config = config or {}
35
36 # Verify the strategy is in the configuration, otherwise fallback to the default strategy
37 strategy_name = config.get('strategy') or constants.DEFAULT_STRATEGY
38 self.strategy: IStrategy = self._load_strategy(strategy_name,
39 config=config,
40 extra_dir=config.get('strategy_path'))
41
42 # make sure experimental dict is available
43 if 'experimental' not in config:
44 config['experimental'] = {}
45
46 # Set attributes
47 # Check if we need to override configuration
48 # (Attribute name, default, experimental)
49 attributes = [("minimal_roi", None, False),
50 ("ticker_interval", None, False),
51 ("stoploss", None, False),
52 ("trailing_stop", None, False),
53 ("trailing_stop_positive", None, False),
54 ("trailing_stop_positive_offset", 0.0, False),
55 ("process_only_new_candles", None, False),
56 ("order_types", None, False),
57 ("order_time_in_force", None, False),
58 ("use_sell_signal", False, True),
59 ("sell_profit_only", False, True),
60 ("ignore_roi_if_buy_signal", False, True),
61 ]
62 for attribute, default, experimental in attributes:
63 if experimental:
64 self._override_attribute_helper(config['experimental'], attribute, default)
65 else:
66 self._override_attribute_helper(config, attribute, default)
67
68 # Loop this list again to have output combined
69 for attribute, _, exp in attributes:
70 if exp and attribute in config['experimental']:
71 logger.info("Strategy using %s: %s", attribute, config['experimental'][attribute])
72 elif attribute in config:
73 logger.info("Strategy using %s: %s", attribute, config[attribute])
74
75 # Sort and apply type conversions
76 self.strategy.minimal_roi = OrderedDict(sorted(
77 {int(key): value for (key, value) in self.strategy.minimal_roi.items()}.items(),
78 key=lambda t: t[0]))
79 self.strategy.stoploss = float(self.strategy.stoploss)
80
81 self._strategy_sanity_validations()
82
83 def _override_attribute_helper(self, config, attribute: str, default):
84 """
85 Override attributes in the strategy.
86 Prevalence:
87 - Configuration
88 - Strategy
89 - default (if not None)
90 """
91 if attribute in config:
92 setattr(self.strategy, attribute, config[attribute])
93 logger.info("Override strategy '%s' with value in config file: %s.",
94 attribute, config[attribute])
95 elif hasattr(self.strategy, attribute):
96 config[attribute] = getattr(self.strategy, attribute)
97 # Explicitly check for None here as other "falsy" values are possible
98 elif default is not None:
99 setattr(self.strategy, attribute, default)
100 config[attribute] = default
101
102 def _strategy_sanity_validations(self):
103 if not all(k in self.strategy.order_types for k in constants.REQUIRED_ORDERTYPES):
104 raise ImportError(f"Impossible to load Strategy '{self.strategy.__class__.__name__}'. "
105 f"Order-types mapping is incomplete.")
106
107 if not all(k in self.strategy.order_time_in_force for k in constants.REQUIRED_ORDERTIF):
108 raise ImportError(f"Impossible to load Strategy '{self.strategy.__class__.__name__}'. "
109 f"Order-time-in-force mapping is incomplete.")
110
111 def _load_strategy(
112 self, strategy_name: str, config: dict, extra_dir: Optional[str] = None) -> IStrategy:
113 """
114 Search and loads the specified strategy.
115 :param strategy_name: name of the module to import
116 :param config: configuration for the strategy
117 :param extra_dir: additional directory to search for the given strategy
118 :return: Strategy instance or None
119 """
120 current_path = Path(__file__).parent.parent.joinpath('strategy').resolve()
121
122 abs_paths = [
123 Path.cwd().joinpath('user_data/strategies'),
124 current_path,
125 ]
126
127 if extra_dir:
128 # Add extra strategy directory on top of search paths
129 abs_paths.insert(0, Path(extra_dir).resolve())
130
131 if ":" in strategy_name:
132 logger.info("loading base64 endocded strategy")
133 strat = strategy_name.split(":")
134
135 if len(strat) == 2:
136 temp = Path(tempfile.mkdtemp("freq", "strategy"))
137 name = strat[0] + ".py"
138
139 temp.joinpath(name).write_text(urlsafe_b64decode(strat[1]).decode('utf-8'))
140 temp.joinpath("__init__.py").touch()
141
142 strategy_name = strat[0]
143
144 # register temp path with the bot
145 abs_paths.insert(0, temp.resolve())
146
147 for _path in abs_paths:
148 try:
149 strategy = self._search_object(directory=_path, object_type=IStrategy,
150 object_name=strategy_name, kwargs={'config': config})
151 if strategy:
152 logger.info("Using resolved strategy %s from '%s'", strategy_name, _path)
153 strategy._populate_fun_len = len(
154 getfullargspec(strategy.populate_indicators).args)
155 strategy._buy_fun_len = len(getfullargspec(strategy.populate_buy_trend).args)
156 strategy._sell_fun_len = len(getfullargspec(strategy.populate_sell_trend).args)
157
158 return import_strategy(strategy, config=config)
159 except FileNotFoundError:
160 logger.warning('Path "%s" does not exist', _path.relative_to(Path.cwd()))
161
162 raise ImportError(
163 "Impossible to load Strategy '{}'. This class does not exist"
164 " or contains Python code errors".format(strategy_name)
165 )
166
[end of freqtrade/resolvers/strategy_resolver.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/freqtrade/resolvers/strategy_resolver.py b/freqtrade/resolvers/strategy_resolver.py
--- a/freqtrade/resolvers/strategy_resolver.py
+++ b/freqtrade/resolvers/strategy_resolver.py
@@ -46,18 +46,18 @@
# Set attributes
# Check if we need to override configuration
# (Attribute name, default, experimental)
- attributes = [("minimal_roi", None, False),
- ("ticker_interval", None, False),
- ("stoploss", None, False),
- ("trailing_stop", None, False),
- ("trailing_stop_positive", None, False),
- ("trailing_stop_positive_offset", 0.0, False),
- ("process_only_new_candles", None, False),
- ("order_types", None, False),
- ("order_time_in_force", None, False),
- ("use_sell_signal", False, True),
- ("sell_profit_only", False, True),
- ("ignore_roi_if_buy_signal", False, True),
+ attributes = [("minimal_roi", {"0": 10.0}, False),
+ ("ticker_interval", None, False),
+ ("stoploss", None, False),
+ ("trailing_stop", None, False),
+ ("trailing_stop_positive", None, False),
+ ("trailing_stop_positive_offset", 0.0, False),
+ ("process_only_new_candles", None, False),
+ ("order_types", None, False),
+ ("order_time_in_force", None, False),
+ ("use_sell_signal", False, True),
+ ("sell_profit_only", False, True),
+ ("ignore_roi_if_buy_signal", False, True),
]
for attribute, default, experimental in attributes:
if experimental:
|
{"golden_diff": "diff --git a/freqtrade/resolvers/strategy_resolver.py b/freqtrade/resolvers/strategy_resolver.py\n--- a/freqtrade/resolvers/strategy_resolver.py\n+++ b/freqtrade/resolvers/strategy_resolver.py\n@@ -46,18 +46,18 @@\n # Set attributes\n # Check if we need to override configuration\n # (Attribute name, default, experimental)\n- attributes = [(\"minimal_roi\", None, False),\n- (\"ticker_interval\", None, False),\n- (\"stoploss\", None, False),\n- (\"trailing_stop\", None, False),\n- (\"trailing_stop_positive\", None, False),\n- (\"trailing_stop_positive_offset\", 0.0, False),\n- (\"process_only_new_candles\", None, False),\n- (\"order_types\", None, False),\n- (\"order_time_in_force\", None, False),\n- (\"use_sell_signal\", False, True),\n- (\"sell_profit_only\", False, True),\n- (\"ignore_roi_if_buy_signal\", False, True),\n+ attributes = [(\"minimal_roi\", {\"0\": 10.0}, False),\n+ (\"ticker_interval\", None, False),\n+ (\"stoploss\", None, False),\n+ (\"trailing_stop\", None, False),\n+ (\"trailing_stop_positive\", None, False),\n+ (\"trailing_stop_positive_offset\", 0.0, False),\n+ (\"process_only_new_candles\", None, False),\n+ (\"order_types\", None, False),\n+ (\"order_time_in_force\", None, False),\n+ (\"use_sell_signal\", False, True),\n+ (\"sell_profit_only\", False, True),\n+ (\"ignore_roi_if_buy_signal\", False, True),\n ]\n for attribute, default, experimental in attributes:\n if experimental:\n", "issue": "Minimal ROI value is not really optional, Bot Crash if minimal_roi have no 0 value\n## The problem:\r\n### The \"minimal_roi\" configuration object is suposed to be optionnal as explained in the doc:\r\n\r\n> Most of the strategy files already include the optimal minimal_roi value. This parameter is optional. If you use it in the configuration file, it will take over the minimal_roi value from the strategy file.\r\n\r\nExemple:\r\n\r\n> minimal_roi = {\r\n> \"40\": 0.0,\r\n> \"30\": 0.01,\r\n> \"20\": 0.02,\r\n> \"0\": 0.04\r\n> }\r\n\r\n**However, If I remove this parameter in the strategy and config I get this error:**\r\n\r\n> 2019-03-06 21:56:56,768 - freqtrade - ERROR - Fatal exception!\r\n> Traceback (most recent call last):\r\n> File \"./freqtrade/main.py\", line 45, in main\r\n> freqtrade = FreqtradeBot(config)\r\n> File \"/home/axel/dev/shatta/framework-dev/private/freqtrade/freqtrade/freqtradebot.py\", line 54, in __init__\r\n> self.strategy: IStrategy = StrategyResolver(self.config).strategy\r\n> File \"/home/axel/dev/shatta/framework-dev/private/freqtrade/freqtrade/resolvers/strategy_resolver.py\", line 77, in __init__\r\n> {int(key): value for (key, value) in self.strategy.minimal_roi.items()}.items(),\r\n> AttributeError: 'ShattaStrategy' object has no attribute 'minimal_roi'\r\n\r\n **Also, If I remove the 0 value key like that:**\r\n\r\n> minimal_roi = {\r\n> \"40\": 0.0,\r\n> \"30\": 0.01,\r\n> \"20\": 0.02,\r\n> }\r\n\r\n**The bot start but crash when trying to check ROI with this error:**\r\n> File \"/freqtrade/freqtrade/freqtradebot.py\", line 699, in check_sell\r\n> should_sell = self.strategy.should_sell(trade, sell_rate, datetime.utcnow(), buy, sell)\r\n> File \"/framework-dev/private/freqtrade/freqtrade/strategy/interface.py\", line 273, in should_sell\r\n> if self.min_roi_reached(trade=trade, current_profit=current_profit, current_time=date):\r\n> File \"/framework-dev/private/freqtrade/freqtrade/strategy/**interface.py\", line 349**, in min_roi_reached\r\n> **roi_entry = max(list(filter(lambda x: trade_dur >= x, self.minimal_roi.keys())))**\r\n\r\n### Standalone Python test to reproduce:\r\n\r\n> minimal_roi_keys = [0, 20, 30, 40, 50] ## Remove the 0 to trigger error\r\n> trade_dur = 0.3486263354619344\r\n> roi_entry = max(list(filter(lambda x: trade_dur >= x, minimal_roi_keys)))\r\n> print(str(roi_entry))\r\n\r\n\r\n### Solutions\r\n\r\n1. The quick easy solution to temporaly deal with that issue is to make the minimal_roi parameter mandatory and make the \"min_roi_reached\" work with missing 0. Users who don't want to use ROI can simply put an unrealistic hight value.\r\n\r\n2. The other is to make this parameter truly optionnal.\r\n\r\n\nMinimal ROI value is not really optional, Bot Crash if minimal_roi have no 0 value\n## The problem:\r\n### The \"minimal_roi\" configuration object is suposed to be optionnal as explained in the doc:\r\n\r\n> Most of the strategy files already include the optimal minimal_roi value. This parameter is optional. If you use it in the configuration file, it will take over the minimal_roi value from the strategy file.\r\n\r\nExemple:\r\n\r\n> minimal_roi = {\r\n> \"40\": 0.0,\r\n> \"30\": 0.01,\r\n> \"20\": 0.02,\r\n> \"0\": 0.04\r\n> }\r\n\r\n**However, If I remove this parameter in the strategy and config I get this error:**\r\n\r\n> 2019-03-06 21:56:56,768 - freqtrade - ERROR - Fatal exception!\r\n> Traceback (most recent call last):\r\n> File \"./freqtrade/main.py\", line 45, in main\r\n> freqtrade = FreqtradeBot(config)\r\n> File \"/home/axel/dev/shatta/framework-dev/private/freqtrade/freqtrade/freqtradebot.py\", line 54, in __init__\r\n> self.strategy: IStrategy = StrategyResolver(self.config).strategy\r\n> File \"/home/axel/dev/shatta/framework-dev/private/freqtrade/freqtrade/resolvers/strategy_resolver.py\", line 77, in __init__\r\n> {int(key): value for (key, value) in self.strategy.minimal_roi.items()}.items(),\r\n> AttributeError: 'ShattaStrategy' object has no attribute 'minimal_roi'\r\n\r\n **Also, If I remove the 0 value key like that:**\r\n\r\n> minimal_roi = {\r\n> \"40\": 0.0,\r\n> \"30\": 0.01,\r\n> \"20\": 0.02,\r\n> }\r\n\r\n**The bot start but crash when trying to check ROI with this error:**\r\n> File \"/freqtrade/freqtrade/freqtradebot.py\", line 699, in check_sell\r\n> should_sell = self.strategy.should_sell(trade, sell_rate, datetime.utcnow(), buy, sell)\r\n> File \"/framework-dev/private/freqtrade/freqtrade/strategy/interface.py\", line 273, in should_sell\r\n> if self.min_roi_reached(trade=trade, current_profit=current_profit, current_time=date):\r\n> File \"/framework-dev/private/freqtrade/freqtrade/strategy/**interface.py\", line 349**, in min_roi_reached\r\n> **roi_entry = max(list(filter(lambda x: trade_dur >= x, self.minimal_roi.keys())))**\r\n\r\n### Standalone Python test to reproduce:\r\n\r\n> minimal_roi_keys = [0, 20, 30, 40, 50] ## Remove the 0 to trigger error\r\n> trade_dur = 0.3486263354619344\r\n> roi_entry = max(list(filter(lambda x: trade_dur >= x, minimal_roi_keys)))\r\n> print(str(roi_entry))\r\n\r\n\r\n### Solutions\r\n\r\n1. The quick easy solution to temporaly deal with that issue is to make the minimal_roi parameter mandatory and make the \"min_roi_reached\" work with missing 0. Users who don't want to use ROI can simply put an unrealistic hight value.\r\n\r\n2. The other is to make this parameter truly optionnal.\r\n\r\n\n", "before_files": [{"content": "# pragma pylint: disable=attribute-defined-outside-init\n\n\"\"\"\nThis module load custom strategies\n\"\"\"\nimport logging\nimport tempfile\nfrom base64 import urlsafe_b64decode\nfrom collections import OrderedDict\nfrom inspect import getfullargspec\nfrom pathlib import Path\nfrom typing import Dict, Optional\n\nfrom freqtrade import constants\nfrom freqtrade.resolvers import IResolver\nfrom freqtrade.strategy import import_strategy\nfrom freqtrade.strategy.interface import IStrategy\n\nlogger = logging.getLogger(__name__)\n\n\nclass StrategyResolver(IResolver):\n \"\"\"\n This class contains all the logic to load custom strategy class\n \"\"\"\n\n __slots__ = ['strategy']\n\n def __init__(self, config: Optional[Dict] = None) -> None:\n \"\"\"\n Load the custom class from config parameter\n :param config: configuration dictionary or None\n \"\"\"\n config = config or {}\n\n # Verify the strategy is in the configuration, otherwise fallback to the default strategy\n strategy_name = config.get('strategy') or constants.DEFAULT_STRATEGY\n self.strategy: IStrategy = self._load_strategy(strategy_name,\n config=config,\n extra_dir=config.get('strategy_path'))\n\n # make sure experimental dict is available\n if 'experimental' not in config:\n config['experimental'] = {}\n\n # Set attributes\n # Check if we need to override configuration\n # (Attribute name, default, experimental)\n attributes = [(\"minimal_roi\", None, False),\n (\"ticker_interval\", None, False),\n (\"stoploss\", None, False),\n (\"trailing_stop\", None, False),\n (\"trailing_stop_positive\", None, False),\n (\"trailing_stop_positive_offset\", 0.0, False),\n (\"process_only_new_candles\", None, False),\n (\"order_types\", None, False),\n (\"order_time_in_force\", None, False),\n (\"use_sell_signal\", False, True),\n (\"sell_profit_only\", False, True),\n (\"ignore_roi_if_buy_signal\", False, True),\n ]\n for attribute, default, experimental in attributes:\n if experimental:\n self._override_attribute_helper(config['experimental'], attribute, default)\n else:\n self._override_attribute_helper(config, attribute, default)\n\n # Loop this list again to have output combined\n for attribute, _, exp in attributes:\n if exp and attribute in config['experimental']:\n logger.info(\"Strategy using %s: %s\", attribute, config['experimental'][attribute])\n elif attribute in config:\n logger.info(\"Strategy using %s: %s\", attribute, config[attribute])\n\n # Sort and apply type conversions\n self.strategy.minimal_roi = OrderedDict(sorted(\n {int(key): value for (key, value) in self.strategy.minimal_roi.items()}.items(),\n key=lambda t: t[0]))\n self.strategy.stoploss = float(self.strategy.stoploss)\n\n self._strategy_sanity_validations()\n\n def _override_attribute_helper(self, config, attribute: str, default):\n \"\"\"\n Override attributes in the strategy.\n Prevalence:\n - Configuration\n - Strategy\n - default (if not None)\n \"\"\"\n if attribute in config:\n setattr(self.strategy, attribute, config[attribute])\n logger.info(\"Override strategy '%s' with value in config file: %s.\",\n attribute, config[attribute])\n elif hasattr(self.strategy, attribute):\n config[attribute] = getattr(self.strategy, attribute)\n # Explicitly check for None here as other \"falsy\" values are possible\n elif default is not None:\n setattr(self.strategy, attribute, default)\n config[attribute] = default\n\n def _strategy_sanity_validations(self):\n if not all(k in self.strategy.order_types for k in constants.REQUIRED_ORDERTYPES):\n raise ImportError(f\"Impossible to load Strategy '{self.strategy.__class__.__name__}'. \"\n f\"Order-types mapping is incomplete.\")\n\n if not all(k in self.strategy.order_time_in_force for k in constants.REQUIRED_ORDERTIF):\n raise ImportError(f\"Impossible to load Strategy '{self.strategy.__class__.__name__}'. \"\n f\"Order-time-in-force mapping is incomplete.\")\n\n def _load_strategy(\n self, strategy_name: str, config: dict, extra_dir: Optional[str] = None) -> IStrategy:\n \"\"\"\n Search and loads the specified strategy.\n :param strategy_name: name of the module to import\n :param config: configuration for the strategy\n :param extra_dir: additional directory to search for the given strategy\n :return: Strategy instance or None\n \"\"\"\n current_path = Path(__file__).parent.parent.joinpath('strategy').resolve()\n\n abs_paths = [\n Path.cwd().joinpath('user_data/strategies'),\n current_path,\n ]\n\n if extra_dir:\n # Add extra strategy directory on top of search paths\n abs_paths.insert(0, Path(extra_dir).resolve())\n\n if \":\" in strategy_name:\n logger.info(\"loading base64 endocded strategy\")\n strat = strategy_name.split(\":\")\n\n if len(strat) == 2:\n temp = Path(tempfile.mkdtemp(\"freq\", \"strategy\"))\n name = strat[0] + \".py\"\n\n temp.joinpath(name).write_text(urlsafe_b64decode(strat[1]).decode('utf-8'))\n temp.joinpath(\"__init__.py\").touch()\n\n strategy_name = strat[0]\n\n # register temp path with the bot\n abs_paths.insert(0, temp.resolve())\n\n for _path in abs_paths:\n try:\n strategy = self._search_object(directory=_path, object_type=IStrategy,\n object_name=strategy_name, kwargs={'config': config})\n if strategy:\n logger.info(\"Using resolved strategy %s from '%s'\", strategy_name, _path)\n strategy._populate_fun_len = len(\n getfullargspec(strategy.populate_indicators).args)\n strategy._buy_fun_len = len(getfullargspec(strategy.populate_buy_trend).args)\n strategy._sell_fun_len = len(getfullargspec(strategy.populate_sell_trend).args)\n\n return import_strategy(strategy, config=config)\n except FileNotFoundError:\n logger.warning('Path \"%s\" does not exist', _path.relative_to(Path.cwd()))\n\n raise ImportError(\n \"Impossible to load Strategy '{}'. This class does not exist\"\n \" or contains Python code errors\".format(strategy_name)\n )\n", "path": "freqtrade/resolvers/strategy_resolver.py"}]}
| 3,830 | 438 |
gh_patches_debug_49499
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-1896
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Release 2.1.104
On the docket:
+ [x] Pull in Pip fixes. #1805
+ [x] pex fails to overwrite zipapp pex with loose pex #1879
+ [x] Make lock update sensitive to artifacts. #1887
+ [x] PEXBuilder is not robust to ephemeral .pyc compiles. #1889
</issue>
<code>
[start of pex/version.py]
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = "2.1.103"
5
[end of pex/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = "2.1.103"
+__version__ = "2.1.104"
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = \"2.1.103\"\n+__version__ = \"2.1.104\"\n", "issue": "Release 2.1.104\nOn the docket:\r\n+ [x] Pull in Pip fixes. #1805\r\n+ [x] pex fails to overwrite zipapp pex with loose pex #1879\r\n+ [x] Make lock update sensitive to artifacts. #1887 \r\n+ [x] PEXBuilder is not robust to ephemeral .pyc compiles. #1889 \n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.103\"\n", "path": "pex/version.py"}]}
| 678 | 98 |
gh_patches_debug_15256
|
rasdani/github-patches
|
git_diff
|
bookwyrm-social__bookwyrm-1645
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Previews not loading correctly when using local image storage
**Describe the bug**
Previews not loading correctly when using local image storage
**To Reproduce**
In status update previews are not shown, for example:
https://ziurkes.group.lt/user/athinkingmeat/quotation/167#anchor-167
https://ziurkes.group.lt/user/athinkingmeat/review/166#anchor-166
**Expected behavior**
they work for books though:
https://ziurkes.group.lt/book/7
**Examples**
https://twitter.com/DievaiDemonai/status/1459865136781578243
**Instance**
https://ziurkes.group.lt/
**Additional context**
Using cloudflare and also caddy instead of nginx to serve files, but it seems that the variable is not generated in template itself, not that the file is not being served.
</issue>
<code>
[start of bookwyrm/views/feed.py]
1 """ non-interactive pages """
2 from django.contrib.auth.decorators import login_required
3 from django.core.paginator import Paginator
4 from django.db.models import Q
5 from django.http import HttpResponseNotFound, Http404
6 from django.shortcuts import get_object_or_404
7 from django.template.response import TemplateResponse
8 from django.utils import timezone
9 from django.utils.decorators import method_decorator
10 from django.views import View
11
12 from bookwyrm import activitystreams, forms, models
13 from bookwyrm.models.user import FeedFilterChoices
14 from bookwyrm.activitypub import ActivitypubResponse
15 from bookwyrm.settings import PAGE_LENGTH, STREAMS
16 from bookwyrm.suggested_users import suggested_users
17 from .helpers import filter_stream_by_status_type, get_user_from_username
18 from .helpers import is_api_request, is_bookwyrm_request
19
20
21 # pylint: disable= no-self-use
22 @method_decorator(login_required, name="dispatch")
23 class Feed(View):
24 """activity stream"""
25
26 def post(self, request, tab):
27 """save feed settings form, with a silent validation fail"""
28 settings_saved = False
29 form = forms.FeedStatusTypesForm(request.POST, instance=request.user)
30 if form.is_valid():
31 form.save()
32 settings_saved = True
33
34 return self.get(request, tab, settings_saved)
35
36 def get(self, request, tab, settings_saved=False):
37 """user's homepage with activity feed"""
38 tab = [s for s in STREAMS if s["key"] == tab]
39 tab = tab[0] if tab else STREAMS[0]
40
41 activities = activitystreams.streams[tab["key"]].get_activity_stream(
42 request.user
43 )
44 filtered_activities = filter_stream_by_status_type(
45 activities,
46 allowed_types=request.user.feed_status_types,
47 )
48 paginated = Paginator(filtered_activities, PAGE_LENGTH)
49
50 suggestions = suggested_users.get_suggestions(request.user)
51
52 data = {
53 **feed_page_data(request.user),
54 **{
55 "user": request.user,
56 "activities": paginated.get_page(request.GET.get("page")),
57 "suggested_users": suggestions,
58 "tab": tab,
59 "streams": STREAMS,
60 "goal_form": forms.GoalForm(),
61 "feed_status_types_options": FeedFilterChoices,
62 "allowed_status_types": request.user.feed_status_types,
63 "settings_saved": settings_saved,
64 "path": f"/{tab['key']}",
65 },
66 }
67 return TemplateResponse(request, "feed/feed.html", data)
68
69
70 @method_decorator(login_required, name="dispatch")
71 class DirectMessage(View):
72 """dm view"""
73
74 def get(self, request, username=None):
75 """like a feed but for dms only"""
76 # remove fancy subclasses of status, keep just good ol' notes
77 activities = (
78 models.Status.privacy_filter(request.user, privacy_levels=["direct"])
79 .filter(
80 review__isnull=True,
81 comment__isnull=True,
82 quotation__isnull=True,
83 generatednote__isnull=True,
84 )
85 .order_by("-published_date")
86 )
87
88 user = None
89 if username:
90 try:
91 user = get_user_from_username(request.user, username)
92 except Http404:
93 pass
94 if user:
95 activities = activities.filter(Q(user=user) | Q(mention_users=user))
96
97 paginated = Paginator(activities, PAGE_LENGTH)
98 data = {
99 **feed_page_data(request.user),
100 **{
101 "user": request.user,
102 "partner": user,
103 "activities": paginated.get_page(request.GET.get("page")),
104 "path": "/direct-messages",
105 },
106 }
107 return TemplateResponse(request, "feed/direct_messages.html", data)
108
109
110 class Status(View):
111 """get posting"""
112
113 def get(self, request, username, status_id):
114 """display a particular status (and replies, etc)"""
115 user = get_user_from_username(request.user, username)
116 status = get_object_or_404(
117 models.Status.objects.select_subclasses(),
118 user=user,
119 id=status_id,
120 deleted=False,
121 )
122 # make sure the user is authorized to see the status
123 status.raise_visible_to_user(request.user)
124
125 if is_api_request(request):
126 return ActivitypubResponse(
127 status.to_activity(pure=not is_bookwyrm_request(request))
128 )
129
130 visible_thread = (
131 models.Status.privacy_filter(request.user)
132 .filter(thread_id=status.thread_id)
133 .values_list("id", flat=True)
134 )
135 visible_thread = list(visible_thread)
136
137 ancestors = models.Status.objects.select_subclasses().raw(
138 """
139 WITH RECURSIVE get_thread(depth, id, path) AS (
140
141 SELECT 1, st.id, ARRAY[st.id]
142 FROM bookwyrm_status st
143 WHERE id = '%s' AND id = ANY(%s)
144
145 UNION
146
147 SELECT (gt.depth + 1), st.reply_parent_id, path || st.id
148 FROM get_thread gt, bookwyrm_status st
149
150 WHERE st.id = gt.id AND depth < 5 AND st.id = ANY(%s)
151
152 )
153
154 SELECT * FROM get_thread ORDER BY path DESC;
155 """,
156 params=[status.reply_parent_id or 0, visible_thread, visible_thread],
157 )
158 children = models.Status.objects.select_subclasses().raw(
159 """
160 WITH RECURSIVE get_thread(depth, id, path) AS (
161
162 SELECT 1, st.id, ARRAY[st.id]
163 FROM bookwyrm_status st
164 WHERE reply_parent_id = '%s' AND id = ANY(%s)
165
166 UNION
167
168 SELECT (gt.depth + 1), st.id, path || st.id
169 FROM get_thread gt, bookwyrm_status st
170
171 WHERE st.reply_parent_id = gt.id AND depth < 5 AND st.id = ANY(%s)
172
173 )
174
175 SELECT * FROM get_thread ORDER BY path;
176 """,
177 params=[status.id, visible_thread, visible_thread],
178 )
179
180 data = {
181 **feed_page_data(request.user),
182 **{
183 "status": status,
184 "children": children,
185 "ancestors": ancestors,
186 },
187 }
188 return TemplateResponse(request, "feed/status.html", data)
189
190
191 class Replies(View):
192 """replies page (a json view of status)"""
193
194 def get(self, request, username, status_id):
195 """ordered collection of replies to a status"""
196 # the html view is the same as Status
197 if not is_api_request(request):
198 status_view = Status.as_view()
199 return status_view(request, username, status_id)
200
201 # the json view is different than Status
202 status = models.Status.objects.get(id=status_id)
203 if status.user.localname != username:
204 return HttpResponseNotFound()
205 status.raise_visible_to_user(request.user)
206
207 return ActivitypubResponse(status.to_replies(**request.GET))
208
209
210 def feed_page_data(user):
211 """info we need for every feed page"""
212 if not user.is_authenticated:
213 return {}
214
215 goal = models.AnnualGoal.objects.filter(user=user, year=timezone.now().year).first()
216 return {
217 "suggested_books": get_suggested_books(user),
218 "goal": goal,
219 "goal_form": forms.GoalForm(),
220 }
221
222
223 def get_suggested_books(user, max_books=5):
224 """helper to get a user's recent books"""
225 book_count = 0
226 preset_shelves = [("reading", max_books), ("read", 2), ("to-read", max_books)]
227 suggested_books = []
228 for (preset, shelf_max) in preset_shelves:
229 limit = (
230 shelf_max
231 if shelf_max < (max_books - book_count)
232 else max_books - book_count
233 )
234 shelf = user.shelf_set.get(identifier=preset)
235 if not shelf.books.exists():
236 continue
237
238 shelf_preview = {
239 "name": shelf.name,
240 "identifier": shelf.identifier,
241 "books": models.Edition.viewer_aware_objects(user)
242 .filter(
243 shelfbook__shelf=shelf,
244 )
245 .order_by("-shelfbook__shelved_date")
246 .prefetch_related("authors")[:limit],
247 }
248 suggested_books.append(shelf_preview)
249 book_count += len(shelf_preview["books"])
250 return suggested_books
251
[end of bookwyrm/views/feed.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bookwyrm/views/feed.py b/bookwyrm/views/feed.py
--- a/bookwyrm/views/feed.py
+++ b/bookwyrm/views/feed.py
@@ -177,12 +177,19 @@
params=[status.id, visible_thread, visible_thread],
)
+ preview = None
+ if hasattr(status, "book"):
+ preview = status.book.preview_image
+ elif status.mention_books.exists():
+ preview = status.mention_books.first().preview_image
+
data = {
**feed_page_data(request.user),
**{
"status": status,
"children": children,
"ancestors": ancestors,
+ "preview": preview,
},
}
return TemplateResponse(request, "feed/status.html", data)
|
{"golden_diff": "diff --git a/bookwyrm/views/feed.py b/bookwyrm/views/feed.py\n--- a/bookwyrm/views/feed.py\n+++ b/bookwyrm/views/feed.py\n@@ -177,12 +177,19 @@\n params=[status.id, visible_thread, visible_thread],\n )\n \n+ preview = None\n+ if hasattr(status, \"book\"):\n+ preview = status.book.preview_image\n+ elif status.mention_books.exists():\n+ preview = status.mention_books.first().preview_image\n+\n data = {\n **feed_page_data(request.user),\n **{\n \"status\": status,\n \"children\": children,\n \"ancestors\": ancestors,\n+ \"preview\": preview,\n },\n }\n return TemplateResponse(request, \"feed/status.html\", data)\n", "issue": "Previews not loading correctly when using local image storage \n**Describe the bug**\r\nPreviews not loading correctly when using local image storage \r\n\r\n**To Reproduce**\r\nIn status update previews are not shown, for example:\r\nhttps://ziurkes.group.lt/user/athinkingmeat/quotation/167#anchor-167\r\nhttps://ziurkes.group.lt/user/athinkingmeat/review/166#anchor-166\r\n\r\n**Expected behavior**\r\nthey work for books though:\r\nhttps://ziurkes.group.lt/book/7\r\n\r\n**Examples**\r\nhttps://twitter.com/DievaiDemonai/status/1459865136781578243\r\n\r\n**Instance**\r\nhttps://ziurkes.group.lt/\r\n\r\n**Additional context**\r\nUsing cloudflare and also caddy instead of nginx to serve files, but it seems that the variable is not generated in template itself, not that the file is not being served.\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "\"\"\" non-interactive pages \"\"\"\nfrom django.contrib.auth.decorators import login_required\nfrom django.core.paginator import Paginator\nfrom django.db.models import Q\nfrom django.http import HttpResponseNotFound, Http404\nfrom django.shortcuts import get_object_or_404\nfrom django.template.response import TemplateResponse\nfrom django.utils import timezone\nfrom django.utils.decorators import method_decorator\nfrom django.views import View\n\nfrom bookwyrm import activitystreams, forms, models\nfrom bookwyrm.models.user import FeedFilterChoices\nfrom bookwyrm.activitypub import ActivitypubResponse\nfrom bookwyrm.settings import PAGE_LENGTH, STREAMS\nfrom bookwyrm.suggested_users import suggested_users\nfrom .helpers import filter_stream_by_status_type, get_user_from_username\nfrom .helpers import is_api_request, is_bookwyrm_request\n\n\n# pylint: disable= no-self-use\n@method_decorator(login_required, name=\"dispatch\")\nclass Feed(View):\n \"\"\"activity stream\"\"\"\n\n def post(self, request, tab):\n \"\"\"save feed settings form, with a silent validation fail\"\"\"\n settings_saved = False\n form = forms.FeedStatusTypesForm(request.POST, instance=request.user)\n if form.is_valid():\n form.save()\n settings_saved = True\n\n return self.get(request, tab, settings_saved)\n\n def get(self, request, tab, settings_saved=False):\n \"\"\"user's homepage with activity feed\"\"\"\n tab = [s for s in STREAMS if s[\"key\"] == tab]\n tab = tab[0] if tab else STREAMS[0]\n\n activities = activitystreams.streams[tab[\"key\"]].get_activity_stream(\n request.user\n )\n filtered_activities = filter_stream_by_status_type(\n activities,\n allowed_types=request.user.feed_status_types,\n )\n paginated = Paginator(filtered_activities, PAGE_LENGTH)\n\n suggestions = suggested_users.get_suggestions(request.user)\n\n data = {\n **feed_page_data(request.user),\n **{\n \"user\": request.user,\n \"activities\": paginated.get_page(request.GET.get(\"page\")),\n \"suggested_users\": suggestions,\n \"tab\": tab,\n \"streams\": STREAMS,\n \"goal_form\": forms.GoalForm(),\n \"feed_status_types_options\": FeedFilterChoices,\n \"allowed_status_types\": request.user.feed_status_types,\n \"settings_saved\": settings_saved,\n \"path\": f\"/{tab['key']}\",\n },\n }\n return TemplateResponse(request, \"feed/feed.html\", data)\n\n\n@method_decorator(login_required, name=\"dispatch\")\nclass DirectMessage(View):\n \"\"\"dm view\"\"\"\n\n def get(self, request, username=None):\n \"\"\"like a feed but for dms only\"\"\"\n # remove fancy subclasses of status, keep just good ol' notes\n activities = (\n models.Status.privacy_filter(request.user, privacy_levels=[\"direct\"])\n .filter(\n review__isnull=True,\n comment__isnull=True,\n quotation__isnull=True,\n generatednote__isnull=True,\n )\n .order_by(\"-published_date\")\n )\n\n user = None\n if username:\n try:\n user = get_user_from_username(request.user, username)\n except Http404:\n pass\n if user:\n activities = activities.filter(Q(user=user) | Q(mention_users=user))\n\n paginated = Paginator(activities, PAGE_LENGTH)\n data = {\n **feed_page_data(request.user),\n **{\n \"user\": request.user,\n \"partner\": user,\n \"activities\": paginated.get_page(request.GET.get(\"page\")),\n \"path\": \"/direct-messages\",\n },\n }\n return TemplateResponse(request, \"feed/direct_messages.html\", data)\n\n\nclass Status(View):\n \"\"\"get posting\"\"\"\n\n def get(self, request, username, status_id):\n \"\"\"display a particular status (and replies, etc)\"\"\"\n user = get_user_from_username(request.user, username)\n status = get_object_or_404(\n models.Status.objects.select_subclasses(),\n user=user,\n id=status_id,\n deleted=False,\n )\n # make sure the user is authorized to see the status\n status.raise_visible_to_user(request.user)\n\n if is_api_request(request):\n return ActivitypubResponse(\n status.to_activity(pure=not is_bookwyrm_request(request))\n )\n\n visible_thread = (\n models.Status.privacy_filter(request.user)\n .filter(thread_id=status.thread_id)\n .values_list(\"id\", flat=True)\n )\n visible_thread = list(visible_thread)\n\n ancestors = models.Status.objects.select_subclasses().raw(\n \"\"\"\n WITH RECURSIVE get_thread(depth, id, path) AS (\n\n SELECT 1, st.id, ARRAY[st.id]\n FROM bookwyrm_status st\n WHERE id = '%s' AND id = ANY(%s)\n\n UNION\n\n SELECT (gt.depth + 1), st.reply_parent_id, path || st.id\n FROM get_thread gt, bookwyrm_status st\n\n WHERE st.id = gt.id AND depth < 5 AND st.id = ANY(%s)\n\n )\n\n SELECT * FROM get_thread ORDER BY path DESC;\n \"\"\",\n params=[status.reply_parent_id or 0, visible_thread, visible_thread],\n )\n children = models.Status.objects.select_subclasses().raw(\n \"\"\"\n WITH RECURSIVE get_thread(depth, id, path) AS (\n\n SELECT 1, st.id, ARRAY[st.id]\n FROM bookwyrm_status st\n WHERE reply_parent_id = '%s' AND id = ANY(%s)\n\n UNION\n\n SELECT (gt.depth + 1), st.id, path || st.id\n FROM get_thread gt, bookwyrm_status st\n\n WHERE st.reply_parent_id = gt.id AND depth < 5 AND st.id = ANY(%s)\n\n )\n\n SELECT * FROM get_thread ORDER BY path;\n \"\"\",\n params=[status.id, visible_thread, visible_thread],\n )\n\n data = {\n **feed_page_data(request.user),\n **{\n \"status\": status,\n \"children\": children,\n \"ancestors\": ancestors,\n },\n }\n return TemplateResponse(request, \"feed/status.html\", data)\n\n\nclass Replies(View):\n \"\"\"replies page (a json view of status)\"\"\"\n\n def get(self, request, username, status_id):\n \"\"\"ordered collection of replies to a status\"\"\"\n # the html view is the same as Status\n if not is_api_request(request):\n status_view = Status.as_view()\n return status_view(request, username, status_id)\n\n # the json view is different than Status\n status = models.Status.objects.get(id=status_id)\n if status.user.localname != username:\n return HttpResponseNotFound()\n status.raise_visible_to_user(request.user)\n\n return ActivitypubResponse(status.to_replies(**request.GET))\n\n\ndef feed_page_data(user):\n \"\"\"info we need for every feed page\"\"\"\n if not user.is_authenticated:\n return {}\n\n goal = models.AnnualGoal.objects.filter(user=user, year=timezone.now().year).first()\n return {\n \"suggested_books\": get_suggested_books(user),\n \"goal\": goal,\n \"goal_form\": forms.GoalForm(),\n }\n\n\ndef get_suggested_books(user, max_books=5):\n \"\"\"helper to get a user's recent books\"\"\"\n book_count = 0\n preset_shelves = [(\"reading\", max_books), (\"read\", 2), (\"to-read\", max_books)]\n suggested_books = []\n for (preset, shelf_max) in preset_shelves:\n limit = (\n shelf_max\n if shelf_max < (max_books - book_count)\n else max_books - book_count\n )\n shelf = user.shelf_set.get(identifier=preset)\n if not shelf.books.exists():\n continue\n\n shelf_preview = {\n \"name\": shelf.name,\n \"identifier\": shelf.identifier,\n \"books\": models.Edition.viewer_aware_objects(user)\n .filter(\n shelfbook__shelf=shelf,\n )\n .order_by(\"-shelfbook__shelved_date\")\n .prefetch_related(\"authors\")[:limit],\n }\n suggested_books.append(shelf_preview)\n book_count += len(shelf_preview[\"books\"])\n return suggested_books\n", "path": "bookwyrm/views/feed.py"}]}
| 3,165 | 173 |
gh_patches_debug_25518
|
rasdani/github-patches
|
git_diff
|
microsoft__torchgeo-1072
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
EuroSAT Dataset URL not being secure anymore
### Description
As `url = "https://madm.dfki.de/files/sentinel/EuroSATallBands.zip"` is not secure anymore, downloading the EuroSat dataset is blocked by default by certify.
We might need to either change the zip source or remove the `https`
### Steps to reproduce
Load the EuroSAT dataset
```python
from torchgeo.datasets import EuroSAT
eurosat_train = EuroSAT(download=True)
```
### Version
0.4.0
</issue>
<code>
[start of torchgeo/datasets/eurosat.py]
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License.
3
4 """EuroSAT dataset."""
5
6 import os
7 from typing import Callable, Dict, Optional, Sequence, cast
8
9 import matplotlib.pyplot as plt
10 import numpy as np
11 import torch
12 from torch import Tensor
13
14 from .geo import NonGeoClassificationDataset
15 from .utils import check_integrity, download_url, extract_archive, rasterio_loader
16
17
18 class EuroSAT(NonGeoClassificationDataset):
19 """EuroSAT dataset.
20
21 The `EuroSAT <https://github.com/phelber/EuroSAT>`__ dataset is based on Sentinel-2
22 satellite images covering 13 spectral bands and consists of 10 target classes with
23 a total of 27,000 labeled and geo-referenced images.
24
25 Dataset format:
26
27 * rasters are 13-channel GeoTiffs
28 * labels are values in the range [0,9]
29
30 Dataset classes:
31
32 * Industrial Buildings
33 * Residential Buildings
34 * Annual Crop
35 * Permanent Crop
36 * River
37 * Sea and Lake
38 * Herbaceous Vegetation
39 * Highway
40 * Pasture
41 * Forest
42
43 This dataset uses the train/val/test splits defined in the "In-domain representation
44 learning for remote sensing" paper:
45
46 * https://arxiv.org/abs/1911.06721
47
48 If you use this dataset in your research, please cite the following papers:
49
50 * https://ieeexplore.ieee.org/document/8736785
51 * https://ieeexplore.ieee.org/document/8519248
52 """
53
54 # TODO: Change to https after https://github.com/phelber/EuroSAT/issues/10 is
55 # resolved
56 url = "http://madm.dfki.de/files/sentinel/EuroSATallBands.zip" # 2.0 GB download
57 filename = "EuroSATallBands.zip"
58 md5 = "5ac12b3b2557aa56e1826e981e8e200e"
59
60 # For some reason the class directories are actually nested in this directory
61 base_dir = os.path.join(
62 "ds", "images", "remote_sensing", "otherDatasets", "sentinel_2", "tif"
63 )
64
65 splits = ["train", "val", "test"]
66 split_urls = {
67 "train": "https://storage.googleapis.com/remote_sensing_representations/eurosat-train.txt", # noqa: E501
68 "val": "https://storage.googleapis.com/remote_sensing_representations/eurosat-val.txt", # noqa: E501
69 "test": "https://storage.googleapis.com/remote_sensing_representations/eurosat-test.txt", # noqa: E501
70 }
71 split_md5s = {
72 "train": "908f142e73d6acdf3f482c5e80d851b1",
73 "val": "95de90f2aa998f70a3b2416bfe0687b4",
74 "test": "7ae5ab94471417b6e315763121e67c5f",
75 }
76 classes = [
77 "Industrial Buildings",
78 "Residential Buildings",
79 "Annual Crop",
80 "Permanent Crop",
81 "River",
82 "Sea and Lake",
83 "Herbaceous Vegetation",
84 "Highway",
85 "Pasture",
86 "Forest",
87 ]
88
89 all_band_names = (
90 "B01",
91 "B02",
92 "B03",
93 "B04",
94 "B05",
95 "B06",
96 "B07",
97 "B08",
98 "B08A",
99 "B09",
100 "B10",
101 "B11",
102 "B12",
103 )
104
105 rgb_bands = ("B04", "B03", "B02")
106
107 BAND_SETS = {"all": all_band_names, "rgb": rgb_bands}
108
109 # TODO: reset checksum to False after https://github.com/phelber/EuroSAT/issues/10
110 # is resolved
111 def __init__(
112 self,
113 root: str = "data",
114 split: str = "train",
115 bands: Sequence[str] = BAND_SETS["all"],
116 transforms: Optional[Callable[[Dict[str, Tensor]], Dict[str, Tensor]]] = None,
117 download: bool = False,
118 checksum: bool = True,
119 ) -> None:
120 """Initialize a new EuroSAT dataset instance.
121
122 Args:
123 root: root directory where dataset can be found
124 split: one of "train", "val", or "test"
125 bands: a sequence of band names to load
126 transforms: a function/transform that takes input sample and its target as
127 entry and returns a transformed version
128 download: if True, download dataset and store it in the root directory
129 checksum: if True, check the MD5 of the downloaded files (may be slow)
130
131 Raises:
132 AssertionError: if ``split`` argument is invalid
133 RuntimeError: if ``download=False`` and data is not found, or checksums
134 don't match
135
136 .. versionadded:: 0.3
137 The *bands* parameter.
138 """
139 self.root = root
140 self.transforms = transforms
141 self.download = download
142 self.checksum = checksum
143
144 assert split in ["train", "val", "test"]
145
146 self._validate_bands(bands)
147 self.bands = bands
148 self.band_indices = Tensor(
149 [self.all_band_names.index(b) for b in bands if b in self.all_band_names]
150 ).long()
151
152 self._verify()
153
154 valid_fns = set()
155 with open(os.path.join(self.root, f"eurosat-{split}.txt")) as f:
156 for fn in f:
157 valid_fns.add(fn.strip().replace(".jpg", ".tif"))
158 is_in_split: Callable[[str], bool] = lambda x: os.path.basename(x) in valid_fns
159
160 super().__init__(
161 root=os.path.join(root, self.base_dir),
162 transforms=transforms,
163 loader=rasterio_loader,
164 is_valid_file=is_in_split,
165 )
166
167 def __getitem__(self, index: int) -> Dict[str, Tensor]:
168 """Return an index within the dataset.
169
170 Args:
171 index: index to return
172 Returns:
173 data and label at that index
174 """
175 image, label = self._load_image(index)
176
177 image = torch.index_select(image, dim=0, index=self.band_indices).float()
178 sample = {"image": image, "label": label}
179
180 if self.transforms is not None:
181 sample = self.transforms(sample)
182
183 return sample
184
185 def _check_integrity(self) -> bool:
186 """Check integrity of dataset.
187
188 Returns:
189 True if dataset files are found and/or MD5s match, else False
190 """
191 integrity: bool = check_integrity(
192 os.path.join(self.root, self.filename), self.md5 if self.checksum else None
193 )
194 return integrity
195
196 def _verify(self) -> None:
197 """Verify the integrity of the dataset.
198
199 Raises:
200 RuntimeError: if ``download=False`` but dataset is missing or checksum fails
201 """
202 # Check if the files already exist
203 filepath = os.path.join(self.root, self.base_dir)
204 if os.path.exists(filepath):
205 return
206
207 # Check if zip file already exists (if so then extract)
208 if self._check_integrity():
209 self._extract()
210 return
211
212 # Check if the user requested to download the dataset
213 if not self.download:
214 raise RuntimeError(
215 "Dataset not found in `root` directory and `download=False`, "
216 "either specify a different `root` directory or use `download=True` "
217 "to automatically download the dataset."
218 )
219
220 # Download and extract the dataset
221 self._download()
222 self._extract()
223
224 def _download(self) -> None:
225 """Download the dataset."""
226 download_url(
227 self.url,
228 self.root,
229 filename=self.filename,
230 md5=self.md5 if self.checksum else None,
231 )
232 for split in self.splits:
233 download_url(
234 self.split_urls[split],
235 self.root,
236 filename=f"eurosat-{split}.txt",
237 md5=self.split_md5s[split] if self.checksum else None,
238 )
239
240 def _extract(self) -> None:
241 """Extract the dataset."""
242 filepath = os.path.join(self.root, self.filename)
243 extract_archive(filepath)
244
245 def _validate_bands(self, bands: Sequence[str]) -> None:
246 """Validate list of bands.
247
248 Args:
249 bands: user-provided sequence of bands to load
250
251 Raises:
252 AssertionError: if ``bands`` is not a sequence
253 ValueError: if an invalid band name is provided
254
255 .. versionadded:: 0.3
256 """
257 assert isinstance(bands, Sequence), "'bands' must be a sequence"
258 for band in bands:
259 if band not in self.all_band_names:
260 raise ValueError(f"'{band}' is an invalid band name.")
261
262 def plot(
263 self,
264 sample: Dict[str, Tensor],
265 show_titles: bool = True,
266 suptitle: Optional[str] = None,
267 ) -> plt.Figure:
268 """Plot a sample from the dataset.
269
270 Args:
271 sample: a sample returned by :meth:`NonGeoClassificationDataset.__getitem__`
272 show_titles: flag indicating whether to show titles above each panel
273 suptitle: optional string to use as a suptitle
274
275 Returns:
276 a matplotlib Figure with the rendered sample
277
278 Raises:
279 ValueError: if RGB bands are not found in dataset
280
281 .. versionadded:: 0.2
282 """
283 rgb_indices = []
284 for band in self.rgb_bands:
285 if band in self.bands:
286 rgb_indices.append(self.bands.index(band))
287 else:
288 raise ValueError("Dataset doesn't contain some of the RGB bands")
289
290 image = np.take(sample["image"].numpy(), indices=rgb_indices, axis=0)
291 image = np.rollaxis(image, 0, 3)
292 image = np.clip(image / 3000, 0, 1)
293
294 label = cast(int, sample["label"].item())
295 label_class = self.classes[label]
296
297 showing_predictions = "prediction" in sample
298 if showing_predictions:
299 prediction = cast(int, sample["prediction"].item())
300 prediction_class = self.classes[prediction]
301
302 fig, ax = plt.subplots(figsize=(4, 4))
303 ax.imshow(image)
304 ax.axis("off")
305 if show_titles:
306 title = f"Label: {label_class}"
307 if showing_predictions:
308 title += f"\nPrediction: {prediction_class}"
309 ax.set_title(title)
310
311 if suptitle is not None:
312 plt.suptitle(suptitle)
313 return fig
314
[end of torchgeo/datasets/eurosat.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/torchgeo/datasets/eurosat.py b/torchgeo/datasets/eurosat.py
--- a/torchgeo/datasets/eurosat.py
+++ b/torchgeo/datasets/eurosat.py
@@ -51,9 +51,7 @@
* https://ieeexplore.ieee.org/document/8519248
"""
- # TODO: Change to https after https://github.com/phelber/EuroSAT/issues/10 is
- # resolved
- url = "http://madm.dfki.de/files/sentinel/EuroSATallBands.zip" # 2.0 GB download
+ url = "https://huggingface.co/datasets/torchgeo/eurosat/resolve/main/EuroSATallBands.zip" # noqa: E501
filename = "EuroSATallBands.zip"
md5 = "5ac12b3b2557aa56e1826e981e8e200e"
@@ -106,8 +104,6 @@
BAND_SETS = {"all": all_band_names, "rgb": rgb_bands}
- # TODO: reset checksum to False after https://github.com/phelber/EuroSAT/issues/10
- # is resolved
def __init__(
self,
root: str = "data",
@@ -115,7 +111,7 @@
bands: Sequence[str] = BAND_SETS["all"],
transforms: Optional[Callable[[Dict[str, Tensor]], Dict[str, Tensor]]] = None,
download: bool = False,
- checksum: bool = True,
+ checksum: bool = False,
) -> None:
"""Initialize a new EuroSAT dataset instance.
|
{"golden_diff": "diff --git a/torchgeo/datasets/eurosat.py b/torchgeo/datasets/eurosat.py\n--- a/torchgeo/datasets/eurosat.py\n+++ b/torchgeo/datasets/eurosat.py\n@@ -51,9 +51,7 @@\n * https://ieeexplore.ieee.org/document/8519248\n \"\"\"\n \n- # TODO: Change to https after https://github.com/phelber/EuroSAT/issues/10 is\n- # resolved\n- url = \"http://madm.dfki.de/files/sentinel/EuroSATallBands.zip\" # 2.0 GB download\n+ url = \"https://huggingface.co/datasets/torchgeo/eurosat/resolve/main/EuroSATallBands.zip\" # noqa: E501\n filename = \"EuroSATallBands.zip\"\n md5 = \"5ac12b3b2557aa56e1826e981e8e200e\"\n \n@@ -106,8 +104,6 @@\n \n BAND_SETS = {\"all\": all_band_names, \"rgb\": rgb_bands}\n \n- # TODO: reset checksum to False after https://github.com/phelber/EuroSAT/issues/10\n- # is resolved\n def __init__(\n self,\n root: str = \"data\",\n@@ -115,7 +111,7 @@\n bands: Sequence[str] = BAND_SETS[\"all\"],\n transforms: Optional[Callable[[Dict[str, Tensor]], Dict[str, Tensor]]] = None,\n download: bool = False,\n- checksum: bool = True,\n+ checksum: bool = False,\n ) -> None:\n \"\"\"Initialize a new EuroSAT dataset instance.\n", "issue": "EuroSAT Dataset URL not being secure anymore\n### Description\r\n\r\nAs `url = \"https://madm.dfki.de/files/sentinel/EuroSATallBands.zip\"` is not secure anymore, downloading the EuroSat dataset is blocked by default by certify.\r\n\r\nWe might need to either change the zip source or remove the `https`\r\n\r\n### Steps to reproduce\r\n\r\nLoad the EuroSAT dataset\r\n```python\r\nfrom torchgeo.datasets import EuroSAT\r\neurosat_train = EuroSAT(download=True)\r\n```\r\n\r\n### Version\r\n\r\n0.4.0\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\n\n\"\"\"EuroSAT dataset.\"\"\"\n\nimport os\nfrom typing import Callable, Dict, Optional, Sequence, cast\n\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport torch\nfrom torch import Tensor\n\nfrom .geo import NonGeoClassificationDataset\nfrom .utils import check_integrity, download_url, extract_archive, rasterio_loader\n\n\nclass EuroSAT(NonGeoClassificationDataset):\n \"\"\"EuroSAT dataset.\n\n The `EuroSAT <https://github.com/phelber/EuroSAT>`__ dataset is based on Sentinel-2\n satellite images covering 13 spectral bands and consists of 10 target classes with\n a total of 27,000 labeled and geo-referenced images.\n\n Dataset format:\n\n * rasters are 13-channel GeoTiffs\n * labels are values in the range [0,9]\n\n Dataset classes:\n\n * Industrial Buildings\n * Residential Buildings\n * Annual Crop\n * Permanent Crop\n * River\n * Sea and Lake\n * Herbaceous Vegetation\n * Highway\n * Pasture\n * Forest\n\n This dataset uses the train/val/test splits defined in the \"In-domain representation\n learning for remote sensing\" paper:\n\n * https://arxiv.org/abs/1911.06721\n\n If you use this dataset in your research, please cite the following papers:\n\n * https://ieeexplore.ieee.org/document/8736785\n * https://ieeexplore.ieee.org/document/8519248\n \"\"\"\n\n # TODO: Change to https after https://github.com/phelber/EuroSAT/issues/10 is\n # resolved\n url = \"http://madm.dfki.de/files/sentinel/EuroSATallBands.zip\" # 2.0 GB download\n filename = \"EuroSATallBands.zip\"\n md5 = \"5ac12b3b2557aa56e1826e981e8e200e\"\n\n # For some reason the class directories are actually nested in this directory\n base_dir = os.path.join(\n \"ds\", \"images\", \"remote_sensing\", \"otherDatasets\", \"sentinel_2\", \"tif\"\n )\n\n splits = [\"train\", \"val\", \"test\"]\n split_urls = {\n \"train\": \"https://storage.googleapis.com/remote_sensing_representations/eurosat-train.txt\", # noqa: E501\n \"val\": \"https://storage.googleapis.com/remote_sensing_representations/eurosat-val.txt\", # noqa: E501\n \"test\": \"https://storage.googleapis.com/remote_sensing_representations/eurosat-test.txt\", # noqa: E501\n }\n split_md5s = {\n \"train\": \"908f142e73d6acdf3f482c5e80d851b1\",\n \"val\": \"95de90f2aa998f70a3b2416bfe0687b4\",\n \"test\": \"7ae5ab94471417b6e315763121e67c5f\",\n }\n classes = [\n \"Industrial Buildings\",\n \"Residential Buildings\",\n \"Annual Crop\",\n \"Permanent Crop\",\n \"River\",\n \"Sea and Lake\",\n \"Herbaceous Vegetation\",\n \"Highway\",\n \"Pasture\",\n \"Forest\",\n ]\n\n all_band_names = (\n \"B01\",\n \"B02\",\n \"B03\",\n \"B04\",\n \"B05\",\n \"B06\",\n \"B07\",\n \"B08\",\n \"B08A\",\n \"B09\",\n \"B10\",\n \"B11\",\n \"B12\",\n )\n\n rgb_bands = (\"B04\", \"B03\", \"B02\")\n\n BAND_SETS = {\"all\": all_band_names, \"rgb\": rgb_bands}\n\n # TODO: reset checksum to False after https://github.com/phelber/EuroSAT/issues/10\n # is resolved\n def __init__(\n self,\n root: str = \"data\",\n split: str = \"train\",\n bands: Sequence[str] = BAND_SETS[\"all\"],\n transforms: Optional[Callable[[Dict[str, Tensor]], Dict[str, Tensor]]] = None,\n download: bool = False,\n checksum: bool = True,\n ) -> None:\n \"\"\"Initialize a new EuroSAT dataset instance.\n\n Args:\n root: root directory where dataset can be found\n split: one of \"train\", \"val\", or \"test\"\n bands: a sequence of band names to load\n transforms: a function/transform that takes input sample and its target as\n entry and returns a transformed version\n download: if True, download dataset and store it in the root directory\n checksum: if True, check the MD5 of the downloaded files (may be slow)\n\n Raises:\n AssertionError: if ``split`` argument is invalid\n RuntimeError: if ``download=False`` and data is not found, or checksums\n don't match\n\n .. versionadded:: 0.3\n The *bands* parameter.\n \"\"\"\n self.root = root\n self.transforms = transforms\n self.download = download\n self.checksum = checksum\n\n assert split in [\"train\", \"val\", \"test\"]\n\n self._validate_bands(bands)\n self.bands = bands\n self.band_indices = Tensor(\n [self.all_band_names.index(b) for b in bands if b in self.all_band_names]\n ).long()\n\n self._verify()\n\n valid_fns = set()\n with open(os.path.join(self.root, f\"eurosat-{split}.txt\")) as f:\n for fn in f:\n valid_fns.add(fn.strip().replace(\".jpg\", \".tif\"))\n is_in_split: Callable[[str], bool] = lambda x: os.path.basename(x) in valid_fns\n\n super().__init__(\n root=os.path.join(root, self.base_dir),\n transforms=transforms,\n loader=rasterio_loader,\n is_valid_file=is_in_split,\n )\n\n def __getitem__(self, index: int) -> Dict[str, Tensor]:\n \"\"\"Return an index within the dataset.\n\n Args:\n index: index to return\n Returns:\n data and label at that index\n \"\"\"\n image, label = self._load_image(index)\n\n image = torch.index_select(image, dim=0, index=self.band_indices).float()\n sample = {\"image\": image, \"label\": label}\n\n if self.transforms is not None:\n sample = self.transforms(sample)\n\n return sample\n\n def _check_integrity(self) -> bool:\n \"\"\"Check integrity of dataset.\n\n Returns:\n True if dataset files are found and/or MD5s match, else False\n \"\"\"\n integrity: bool = check_integrity(\n os.path.join(self.root, self.filename), self.md5 if self.checksum else None\n )\n return integrity\n\n def _verify(self) -> None:\n \"\"\"Verify the integrity of the dataset.\n\n Raises:\n RuntimeError: if ``download=False`` but dataset is missing or checksum fails\n \"\"\"\n # Check if the files already exist\n filepath = os.path.join(self.root, self.base_dir)\n if os.path.exists(filepath):\n return\n\n # Check if zip file already exists (if so then extract)\n if self._check_integrity():\n self._extract()\n return\n\n # Check if the user requested to download the dataset\n if not self.download:\n raise RuntimeError(\n \"Dataset not found in `root` directory and `download=False`, \"\n \"either specify a different `root` directory or use `download=True` \"\n \"to automatically download the dataset.\"\n )\n\n # Download and extract the dataset\n self._download()\n self._extract()\n\n def _download(self) -> None:\n \"\"\"Download the dataset.\"\"\"\n download_url(\n self.url,\n self.root,\n filename=self.filename,\n md5=self.md5 if self.checksum else None,\n )\n for split in self.splits:\n download_url(\n self.split_urls[split],\n self.root,\n filename=f\"eurosat-{split}.txt\",\n md5=self.split_md5s[split] if self.checksum else None,\n )\n\n def _extract(self) -> None:\n \"\"\"Extract the dataset.\"\"\"\n filepath = os.path.join(self.root, self.filename)\n extract_archive(filepath)\n\n def _validate_bands(self, bands: Sequence[str]) -> None:\n \"\"\"Validate list of bands.\n\n Args:\n bands: user-provided sequence of bands to load\n\n Raises:\n AssertionError: if ``bands`` is not a sequence\n ValueError: if an invalid band name is provided\n\n .. versionadded:: 0.3\n \"\"\"\n assert isinstance(bands, Sequence), \"'bands' must be a sequence\"\n for band in bands:\n if band not in self.all_band_names:\n raise ValueError(f\"'{band}' is an invalid band name.\")\n\n def plot(\n self,\n sample: Dict[str, Tensor],\n show_titles: bool = True,\n suptitle: Optional[str] = None,\n ) -> plt.Figure:\n \"\"\"Plot a sample from the dataset.\n\n Args:\n sample: a sample returned by :meth:`NonGeoClassificationDataset.__getitem__`\n show_titles: flag indicating whether to show titles above each panel\n suptitle: optional string to use as a suptitle\n\n Returns:\n a matplotlib Figure with the rendered sample\n\n Raises:\n ValueError: if RGB bands are not found in dataset\n\n .. versionadded:: 0.2\n \"\"\"\n rgb_indices = []\n for band in self.rgb_bands:\n if band in self.bands:\n rgb_indices.append(self.bands.index(band))\n else:\n raise ValueError(\"Dataset doesn't contain some of the RGB bands\")\n\n image = np.take(sample[\"image\"].numpy(), indices=rgb_indices, axis=0)\n image = np.rollaxis(image, 0, 3)\n image = np.clip(image / 3000, 0, 1)\n\n label = cast(int, sample[\"label\"].item())\n label_class = self.classes[label]\n\n showing_predictions = \"prediction\" in sample\n if showing_predictions:\n prediction = cast(int, sample[\"prediction\"].item())\n prediction_class = self.classes[prediction]\n\n fig, ax = plt.subplots(figsize=(4, 4))\n ax.imshow(image)\n ax.axis(\"off\")\n if show_titles:\n title = f\"Label: {label_class}\"\n if showing_predictions:\n title += f\"\\nPrediction: {prediction_class}\"\n ax.set_title(title)\n\n if suptitle is not None:\n plt.suptitle(suptitle)\n return fig\n", "path": "torchgeo/datasets/eurosat.py"}]}
| 3,964 | 404 |
gh_patches_debug_2793
|
rasdani/github-patches
|
git_diff
|
kornia__kornia-579
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Backslash not showing in equation for Tversky Loss
## 📚 Documentation
The backslashs in the denominator of the Tversky loss equation is not rendered correctly with MathJax. As shown in this screenshot it only inserts a little space between P and G and thus does not correctly render the equation.

<!-- A clear and concise description of what content in https://kornia.readthedocs.io is an issue. If this has to do with the general https://kornia.org website, please file an issue at https://github.com/kornia/kornia.github.io/issues/new/choose instead. If this has to do with https://kornia.org/tutorials, please file an issue at https://github.com/kornia/tutorials/issues/new -->
</issue>
<code>
[start of kornia/losses/tversky.py]
1 from typing import Optional
2
3 import torch
4 import torch.nn as nn
5 import torch.nn.functional as F
6
7 from kornia.utils import one_hot
8
9 # based on:
10 # https://github.com/kevinzakka/pytorch-goodies/blob/master/losses.py
11
12
13 def tversky_loss(input: torch.Tensor, target: torch.Tensor,
14 alpha: float, beta: float, eps: float = 1e-8) -> torch.Tensor:
15 r"""Function that computes Tversky loss.
16
17 See :class:`~kornia.losses.TverskyLoss` for details.
18 """
19 if not torch.is_tensor(input):
20 raise TypeError("Input type is not a torch.Tensor. Got {}"
21 .format(type(input)))
22
23 if not len(input.shape) == 4:
24 raise ValueError("Invalid input shape, we expect BxNxHxW. Got: {}"
25 .format(input.shape))
26
27 if not input.shape[-2:] == target.shape[-2:]:
28 raise ValueError("input and target shapes must be the same. Got: {} and {}"
29 .format(input.shape, input.shape))
30
31 if not input.device == target.device:
32 raise ValueError(
33 "input and target must be in the same device. Got: {} and {}" .format(
34 input.device, target.device))
35
36 # compute softmax over the classes axis
37 input_soft: torch.Tensor = F.softmax(input, dim=1)
38
39 # create the labels one hot tensor
40 target_one_hot: torch.Tensor = one_hot(
41 target, num_classes=input.shape[1],
42 device=input.device, dtype=input.dtype)
43
44 # compute the actual dice score
45 dims = (1, 2, 3)
46 intersection = torch.sum(input_soft * target_one_hot, dims)
47 fps = torch.sum(input_soft * (-target_one_hot + 1.), dims)
48 fns = torch.sum((-input_soft + 1.) * target_one_hot, dims)
49
50 numerator = intersection
51 denominator = intersection + alpha * fps + beta * fns
52 tversky_loss = numerator / (denominator + eps)
53 return torch.mean(-tversky_loss + 1.)
54
55
56 class TverskyLoss(nn.Module):
57 r"""Criterion that computes Tversky Coeficient loss.
58
59 According to [1], we compute the Tversky Coefficient as follows:
60
61 .. math::
62
63 \text{S}(P, G, \alpha; \beta) =
64 \frac{|PG|}{|PG| + \alpha |P \ G| + \beta |G \ P|}
65
66 where:
67 - :math:`P` and :math:`G` are the predicted and ground truth binary
68 labels.
69 - :math:`\alpha` and :math:`\beta` control the magnitude of the
70 penalties for FPs and FNs, respectively.
71
72 Notes:
73 - :math:`\alpha = \beta = 0.5` => dice coeff
74 - :math:`\alpha = \beta = 1` => tanimoto coeff
75 - :math:`\alpha + \beta = 1` => F beta coeff
76
77 Shape:
78 - Input: :math:`(N, C, H, W)` where C = number of classes.
79 - Target: :math:`(N, H, W)` where each value is
80 :math:`0 ≤ targets[i] ≤ C−1`.
81
82 Examples:
83 >>> N = 5 # num_classes
84 >>> loss = kornia.losses.TverskyLoss(alpha=0.5, beta=0.5)
85 >>> input = torch.randn(1, N, 3, 5, requires_grad=True)
86 >>> target = torch.empty(1, 3, 5, dtype=torch.long).random_(N)
87 >>> output = loss(input, target)
88 >>> output.backward()
89
90 References:
91 [1]: https://arxiv.org/abs/1706.05721
92 """
93
94 def __init__(self, alpha: float, beta: float, eps: float = 1e-8) -> None:
95 super(TverskyLoss, self).__init__()
96 self.alpha: float = alpha
97 self.beta: float = beta
98 self.eps: float = eps
99
100 def forward( # type: ignore
101 self,
102 input: torch.Tensor,
103 target: torch.Tensor) -> torch.Tensor:
104 return tversky_loss(input, target, self.alpha, self.beta, self.eps)
105
[end of kornia/losses/tversky.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kornia/losses/tversky.py b/kornia/losses/tversky.py
--- a/kornia/losses/tversky.py
+++ b/kornia/losses/tversky.py
@@ -61,7 +61,7 @@
.. math::
\text{S}(P, G, \alpha; \beta) =
- \frac{|PG|}{|PG| + \alpha |P \ G| + \beta |G \ P|}
+ \frac{|PG|}{|PG| + \alpha |P \setminus G| + \beta |G \setminus P|}
where:
- :math:`P` and :math:`G` are the predicted and ground truth binary
|
{"golden_diff": "diff --git a/kornia/losses/tversky.py b/kornia/losses/tversky.py\n--- a/kornia/losses/tversky.py\n+++ b/kornia/losses/tversky.py\n@@ -61,7 +61,7 @@\n .. math::\n \n \\text{S}(P, G, \\alpha; \\beta) =\n- \\frac{|PG|}{|PG| + \\alpha |P \\ G| + \\beta |G \\ P|}\n+ \\frac{|PG|}{|PG| + \\alpha |P \\setminus G| + \\beta |G \\setminus P|}\n \n where:\n - :math:`P` and :math:`G` are the predicted and ground truth binary\n", "issue": "Backslash not showing in equation for Tversky Loss\n## \ud83d\udcda Documentation\r\n\r\nThe backslashs in the denominator of the Tversky loss equation is not rendered correctly with MathJax. As shown in this screenshot it only inserts a little space between P and G and thus does not correctly render the equation.\r\n\r\n\r\n\r\n\r\n<!-- A clear and concise description of what content in https://kornia.readthedocs.io is an issue. If this has to do with the general https://kornia.org website, please file an issue at https://github.com/kornia/kornia.github.io/issues/new/choose instead. If this has to do with https://kornia.org/tutorials, please file an issue at https://github.com/kornia/tutorials/issues/new -->\r\n\r\n\n", "before_files": [{"content": "from typing import Optional\n\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\n\nfrom kornia.utils import one_hot\n\n# based on:\n# https://github.com/kevinzakka/pytorch-goodies/blob/master/losses.py\n\n\ndef tversky_loss(input: torch.Tensor, target: torch.Tensor,\n alpha: float, beta: float, eps: float = 1e-8) -> torch.Tensor:\n r\"\"\"Function that computes Tversky loss.\n\n See :class:`~kornia.losses.TverskyLoss` for details.\n \"\"\"\n if not torch.is_tensor(input):\n raise TypeError(\"Input type is not a torch.Tensor. Got {}\"\n .format(type(input)))\n\n if not len(input.shape) == 4:\n raise ValueError(\"Invalid input shape, we expect BxNxHxW. Got: {}\"\n .format(input.shape))\n\n if not input.shape[-2:] == target.shape[-2:]:\n raise ValueError(\"input and target shapes must be the same. Got: {} and {}\"\n .format(input.shape, input.shape))\n\n if not input.device == target.device:\n raise ValueError(\n \"input and target must be in the same device. Got: {} and {}\" .format(\n input.device, target.device))\n\n # compute softmax over the classes axis\n input_soft: torch.Tensor = F.softmax(input, dim=1)\n\n # create the labels one hot tensor\n target_one_hot: torch.Tensor = one_hot(\n target, num_classes=input.shape[1],\n device=input.device, dtype=input.dtype)\n\n # compute the actual dice score\n dims = (1, 2, 3)\n intersection = torch.sum(input_soft * target_one_hot, dims)\n fps = torch.sum(input_soft * (-target_one_hot + 1.), dims)\n fns = torch.sum((-input_soft + 1.) * target_one_hot, dims)\n\n numerator = intersection\n denominator = intersection + alpha * fps + beta * fns\n tversky_loss = numerator / (denominator + eps)\n return torch.mean(-tversky_loss + 1.)\n\n\nclass TverskyLoss(nn.Module):\n r\"\"\"Criterion that computes Tversky Coeficient loss.\n\n According to [1], we compute the Tversky Coefficient as follows:\n\n .. math::\n\n \\text{S}(P, G, \\alpha; \\beta) =\n \\frac{|PG|}{|PG| + \\alpha |P \\ G| + \\beta |G \\ P|}\n\n where:\n - :math:`P` and :math:`G` are the predicted and ground truth binary\n labels.\n - :math:`\\alpha` and :math:`\\beta` control the magnitude of the\n penalties for FPs and FNs, respectively.\n\n Notes:\n - :math:`\\alpha = \\beta = 0.5` => dice coeff\n - :math:`\\alpha = \\beta = 1` => tanimoto coeff\n - :math:`\\alpha + \\beta = 1` => F beta coeff\n\n Shape:\n - Input: :math:`(N, C, H, W)` where C = number of classes.\n - Target: :math:`(N, H, W)` where each value is\n :math:`0 \u2264 targets[i] \u2264 C\u22121`.\n\n Examples:\n >>> N = 5 # num_classes\n >>> loss = kornia.losses.TverskyLoss(alpha=0.5, beta=0.5)\n >>> input = torch.randn(1, N, 3, 5, requires_grad=True)\n >>> target = torch.empty(1, 3, 5, dtype=torch.long).random_(N)\n >>> output = loss(input, target)\n >>> output.backward()\n\n References:\n [1]: https://arxiv.org/abs/1706.05721\n \"\"\"\n\n def __init__(self, alpha: float, beta: float, eps: float = 1e-8) -> None:\n super(TverskyLoss, self).__init__()\n self.alpha: float = alpha\n self.beta: float = beta\n self.eps: float = eps\n\n def forward( # type: ignore\n self,\n input: torch.Tensor,\n target: torch.Tensor) -> torch.Tensor:\n return tversky_loss(input, target, self.alpha, self.beta, self.eps)\n", "path": "kornia/losses/tversky.py"}]}
| 1,958 | 169 |
gh_patches_debug_18960
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-9119
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Locked pages report renders all users in "locked_by" filter
### Issue Summary
Currently, the select-field for the "locked_by" filter on the "Locked pages"-report renders all users unfiltered from the user table.
This breaks the view for one of our projects, which tries to list all 500k users...
Actually, only the users which have locked a page should be listed.
I will try to make a PR for that, in the meantime this quickfix works for us (with wagtail 4.0, django 3.2):
```python
# in one of our apps.py
from django.apps import AppConfig
class BaseConfig(AppConfig):
name = "base"
def ready(self):
patch_locked_pages_filter()
def patch_locked_pages_filter():
import django_filters
from django.contrib.auth import get_user_model
from wagtail.admin.views.reports.locked_pages import LockedPagesView, LockedPagesReportFilterSet
def get_users_for_filter():
User = get_user_model()
return User.objects.filter(locked_pages__isnull=False).order_by(User.USERNAME_FIELD)
class PatchedLockedPagesReportFilterSet(LockedPagesReportFilterSet):
locked_by = django_filters.ModelChoiceFilter(
field_name="locked_by", queryset=lambda request: get_users_for_filter()
)
LockedPagesView.filterset_class = PatchedLockedPagesReportFilterSet
```
### Steps to Reproduce
1. Start a new project with `wagtail start myproject`
2. Create many users, no matter if they have access to the CMS or not
3. Open `/admin/reports/locked/` and find all those users in the "locked_by" dropdown on the right
- I have confirmed that this issue can be reproduced as described on a fresh Wagtail project: yes
### Technical details
- Python version: 3.10
- Django version: 3.2
- Wagtail version: 4.0, 2.15,... (according to the git history seems to be there from the beginning)
</issue>
<code>
[start of wagtail/admin/views/reports/locked_pages.py]
1 import datetime
2
3 import django_filters
4 from django.conf import settings
5 from django.core.exceptions import PermissionDenied
6 from django.utils.translation import gettext_lazy as _
7
8 from wagtail.admin.filters import DateRangePickerWidget, WagtailFilterSet
9 from wagtail.models import Page, UserPagePermissionsProxy
10
11 from .base import PageReportView
12
13
14 class LockedPagesReportFilterSet(WagtailFilterSet):
15 locked_at = django_filters.DateFromToRangeFilter(widget=DateRangePickerWidget)
16
17 class Meta:
18 model = Page
19 fields = ["locked_by", "locked_at", "live"]
20
21
22 class LockedPagesView(PageReportView):
23 template_name = "wagtailadmin/reports/locked_pages.html"
24 title = _("Locked pages")
25 header_icon = "lock"
26 list_export = PageReportView.list_export + [
27 "locked_at",
28 "locked_by",
29 ]
30 filterset_class = LockedPagesReportFilterSet
31
32 def get_filename(self):
33 return "locked-pages-report-{}".format(
34 datetime.datetime.today().strftime("%Y-%m-%d")
35 )
36
37 def get_queryset(self):
38 pages = (
39 (
40 UserPagePermissionsProxy(self.request.user).editable_pages()
41 | Page.objects.filter(locked_by=self.request.user)
42 )
43 .filter(locked=True)
44 .specific(defer=True)
45 )
46
47 if getattr(settings, "WAGTAIL_I18N_ENABLED", False):
48 pages = pages.select_related("locale")
49
50 self.queryset = pages
51 return super().get_queryset()
52
53 def dispatch(self, request, *args, **kwargs):
54 if not UserPagePermissionsProxy(request.user).can_remove_locks():
55 raise PermissionDenied
56 return super().dispatch(request, *args, **kwargs)
57
[end of wagtail/admin/views/reports/locked_pages.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/wagtail/admin/views/reports/locked_pages.py b/wagtail/admin/views/reports/locked_pages.py
--- a/wagtail/admin/views/reports/locked_pages.py
+++ b/wagtail/admin/views/reports/locked_pages.py
@@ -2,6 +2,7 @@
import django_filters
from django.conf import settings
+from django.contrib.auth import get_user_model
from django.core.exceptions import PermissionDenied
from django.utils.translation import gettext_lazy as _
@@ -11,8 +12,16 @@
from .base import PageReportView
+def get_users_for_filter():
+ User = get_user_model()
+ return User.objects.filter(locked_pages__isnull=False).order_by(User.USERNAME_FIELD)
+
+
class LockedPagesReportFilterSet(WagtailFilterSet):
locked_at = django_filters.DateFromToRangeFilter(widget=DateRangePickerWidget)
+ locked_by = django_filters.ModelChoiceFilter(
+ field_name="locked_by", queryset=lambda request: get_users_for_filter()
+ )
class Meta:
model = Page
|
{"golden_diff": "diff --git a/wagtail/admin/views/reports/locked_pages.py b/wagtail/admin/views/reports/locked_pages.py\n--- a/wagtail/admin/views/reports/locked_pages.py\n+++ b/wagtail/admin/views/reports/locked_pages.py\n@@ -2,6 +2,7 @@\n \n import django_filters\n from django.conf import settings\n+from django.contrib.auth import get_user_model\n from django.core.exceptions import PermissionDenied\n from django.utils.translation import gettext_lazy as _\n \n@@ -11,8 +12,16 @@\n from .base import PageReportView\n \n \n+def get_users_for_filter():\n+ User = get_user_model()\n+ return User.objects.filter(locked_pages__isnull=False).order_by(User.USERNAME_FIELD)\n+\n+\n class LockedPagesReportFilterSet(WagtailFilterSet):\n locked_at = django_filters.DateFromToRangeFilter(widget=DateRangePickerWidget)\n+ locked_by = django_filters.ModelChoiceFilter(\n+ field_name=\"locked_by\", queryset=lambda request: get_users_for_filter()\n+ )\n \n class Meta:\n model = Page\n", "issue": "Locked pages report renders all users in \"locked_by\" filter\n### Issue Summary\r\n\r\nCurrently, the select-field for the \"locked_by\" filter on the \"Locked pages\"-report renders all users unfiltered from the user table.\r\nThis breaks the view for one of our projects, which tries to list all 500k users...\r\nActually, only the users which have locked a page should be listed.\r\n\r\nI will try to make a PR for that, in the meantime this quickfix works for us (with wagtail 4.0, django 3.2):\r\n```python\r\n# in one of our apps.py\r\nfrom django.apps import AppConfig\r\n\r\nclass BaseConfig(AppConfig):\r\n name = \"base\"\r\n\r\n def ready(self):\r\n patch_locked_pages_filter()\r\n\r\ndef patch_locked_pages_filter():\r\n import django_filters\r\n from django.contrib.auth import get_user_model\r\n\r\n from wagtail.admin.views.reports.locked_pages import LockedPagesView, LockedPagesReportFilterSet\r\n\r\n def get_users_for_filter():\r\n User = get_user_model()\r\n return User.objects.filter(locked_pages__isnull=False).order_by(User.USERNAME_FIELD)\r\n\r\n class PatchedLockedPagesReportFilterSet(LockedPagesReportFilterSet):\r\n locked_by = django_filters.ModelChoiceFilter(\r\n field_name=\"locked_by\", queryset=lambda request: get_users_for_filter()\r\n )\r\n\r\n LockedPagesView.filterset_class = PatchedLockedPagesReportFilterSet\r\n\r\n```\r\n\r\n### Steps to Reproduce\r\n\r\n1. Start a new project with `wagtail start myproject`\r\n2. Create many users, no matter if they have access to the CMS or not\r\n3. Open `/admin/reports/locked/` and find all those users in the \"locked_by\" dropdown on the right\r\n\r\n- I have confirmed that this issue can be reproduced as described on a fresh Wagtail project: yes\r\n\r\n### Technical details\r\n\r\n- Python version: 3.10\r\n- Django version: 3.2\r\n- Wagtail version: 4.0, 2.15,... (according to the git history seems to be there from the beginning)\r\n\n", "before_files": [{"content": "import datetime\n\nimport django_filters\nfrom django.conf import settings\nfrom django.core.exceptions import PermissionDenied\nfrom django.utils.translation import gettext_lazy as _\n\nfrom wagtail.admin.filters import DateRangePickerWidget, WagtailFilterSet\nfrom wagtail.models import Page, UserPagePermissionsProxy\n\nfrom .base import PageReportView\n\n\nclass LockedPagesReportFilterSet(WagtailFilterSet):\n locked_at = django_filters.DateFromToRangeFilter(widget=DateRangePickerWidget)\n\n class Meta:\n model = Page\n fields = [\"locked_by\", \"locked_at\", \"live\"]\n\n\nclass LockedPagesView(PageReportView):\n template_name = \"wagtailadmin/reports/locked_pages.html\"\n title = _(\"Locked pages\")\n header_icon = \"lock\"\n list_export = PageReportView.list_export + [\n \"locked_at\",\n \"locked_by\",\n ]\n filterset_class = LockedPagesReportFilterSet\n\n def get_filename(self):\n return \"locked-pages-report-{}\".format(\n datetime.datetime.today().strftime(\"%Y-%m-%d\")\n )\n\n def get_queryset(self):\n pages = (\n (\n UserPagePermissionsProxy(self.request.user).editable_pages()\n | Page.objects.filter(locked_by=self.request.user)\n )\n .filter(locked=True)\n .specific(defer=True)\n )\n\n if getattr(settings, \"WAGTAIL_I18N_ENABLED\", False):\n pages = pages.select_related(\"locale\")\n\n self.queryset = pages\n return super().get_queryset()\n\n def dispatch(self, request, *args, **kwargs):\n if not UserPagePermissionsProxy(request.user).can_remove_locks():\n raise PermissionDenied\n return super().dispatch(request, *args, **kwargs)\n", "path": "wagtail/admin/views/reports/locked_pages.py"}]}
| 1,466 | 236 |
gh_patches_debug_207
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-239
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add type check to Identity Function
Related to #123
</issue>
<code>
[start of chainer/functions/identity.py]
1 from chainer import function
2
3
4 class Identity(function.Function):
5
6 """Identity function."""
7
8 def forward(self, xs):
9 return xs
10
11 def backward(self, xs, gys):
12 return gys
13
14
15 def identity(*inputs):
16 """Just returns input variables."""
17 return Identity()(*inputs)
18
[end of chainer/functions/identity.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/chainer/functions/identity.py b/chainer/functions/identity.py
--- a/chainer/functions/identity.py
+++ b/chainer/functions/identity.py
@@ -5,6 +5,9 @@
"""Identity function."""
+ def check_type_forward(self, in_types):
+ pass
+
def forward(self, xs):
return xs
|
{"golden_diff": "diff --git a/chainer/functions/identity.py b/chainer/functions/identity.py\n--- a/chainer/functions/identity.py\n+++ b/chainer/functions/identity.py\n@@ -5,6 +5,9 @@\n \n \"\"\"Identity function.\"\"\"\n \n+ def check_type_forward(self, in_types):\n+ pass\n+\n def forward(self, xs):\n return xs\n", "issue": "Add type check to Identity Function\nRelated to #123\n\n", "before_files": [{"content": "from chainer import function\n\n\nclass Identity(function.Function):\n\n \"\"\"Identity function.\"\"\"\n\n def forward(self, xs):\n return xs\n\n def backward(self, xs, gys):\n return gys\n\n\ndef identity(*inputs):\n \"\"\"Just returns input variables.\"\"\"\n return Identity()(*inputs)\n", "path": "chainer/functions/identity.py"}]}
| 646 | 80 |
gh_patches_debug_44307
|
rasdani/github-patches
|
git_diff
|
qutip__qutip-285
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add progressbar for propatgator?
It is really great to use qutip 3.0 in iPython notebook with the HTMLProgressbar, especially when using mesolve or essolve. Unfortunately there is no progressbar when using the propagator function.
Would it be possible to implement this, for propagator (and/or possible other functions), since it calls mesolve, which already has it implemented?
Thanks
</issue>
<code>
[start of qutip/propagator.py]
1 # This file is part of QuTiP: Quantum Toolbox in Python.
2 #
3 # Copyright (c) 2011 and later, Paul D. Nation and Robert J. Johansson.
4 # All rights reserved.
5 #
6 # Redistribution and use in source and binary forms, with or without
7 # modification, are permitted provided that the following conditions are
8 # met:
9 #
10 # 1. Redistributions of source code must retain the above copyright notice,
11 # this list of conditions and the following disclaimer.
12 #
13 # 2. Redistributions in binary form must reproduce the above copyright
14 # notice, this list of conditions and the following disclaimer in the
15 # documentation and/or other materials provided with the distribution.
16 #
17 # 3. Neither the name of the QuTiP: Quantum Toolbox in Python nor the names
18 # of its contributors may be used to endorse or promote products derived
19 # from this software without specific prior written permission.
20 #
21 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
22 # "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
23 # LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A
24 # PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
25 # HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
26 # SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
27 # LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
28 # DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
29 # THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
30 # (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
31 # OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
32 ###############################################################################
33
34 __all__ = ['propagator', 'propagator_steadystate']
35
36 import types
37 import numpy as np
38 import scipy.linalg as la
39 import functools
40
41 from qutip.qobj import Qobj
42 from qutip.rhs_generate import rhs_clear
43 from qutip.superoperator import (vec2mat, mat2vec,
44 vector_to_operator, operator_to_vector)
45 from qutip.mesolve import mesolve
46 from qutip.sesolve import sesolve
47 from qutip.states import basis
48 from qutip.solver import Options
49
50
51 def propagator(H, t, c_op_list, args=None, options=None, sparse=False):
52 """
53 Calculate the propagator U(t) for the density matrix or wave function such
54 that :math:`\psi(t) = U(t)\psi(0)` or
55 :math:`\\rho_{\mathrm vec}(t) = U(t) \\rho_{\mathrm vec}(0)`
56 where :math:`\\rho_{\mathrm vec}` is the vector representation of the
57 density matrix.
58
59 Parameters
60 ----------
61 H : qobj or list
62 Hamiltonian as a Qobj instance of a nested list of Qobjs and
63 coefficients in the list-string or list-function format for
64 time-dependent Hamiltonians (see description in :func:`qutip.mesolve`).
65
66 t : float or array-like
67 Time or list of times for which to evaluate the propagator.
68
69 c_op_list : list
70 List of qobj collapse operators.
71
72 args : list/array/dictionary
73 Parameters to callback functions for time-dependent Hamiltonians and
74 collapse operators.
75
76 options : :class:`qutip.Options`
77 with options for the ODE solver.
78
79 Returns
80 -------
81 a : qobj
82 Instance representing the propagator :math:`U(t)`.
83
84 """
85
86 if options is None:
87 options = Options()
88 options.rhs_reuse = True
89 rhs_clear()
90
91 if isinstance(t, (int, float, np.integer, np.floating)):
92 tlist = [0, t]
93 else:
94 tlist = t
95
96 if isinstance(H, (types.FunctionType, types.BuiltinFunctionType,
97 functools.partial)):
98 H0 = H(0.0, args)
99 elif isinstance(H, list):
100 H0 = H[0][0] if isinstance(H[0], list) else H[0]
101 else:
102 H0 = H
103
104 if len(c_op_list) == 0 and H0.isoper:
105 # calculate propagator for the wave function
106
107 N = H0.shape[0]
108 dims = H0.dims
109 u = np.zeros([N, N, len(tlist)], dtype=complex)
110
111 for n in range(0, N):
112 psi0 = basis(N, n)
113 output = sesolve(H, psi0, tlist, [], args, options)
114 for k, t in enumerate(tlist):
115 u[:, n, k] = output.states[k].full().T
116
117 # todo: evolving a batch of wave functions:
118 # psi_0_list = [basis(N, n) for n in range(N)]
119 # psi_t_list = mesolve(H, psi_0_list, [0, t], [], [], args, options)
120 # for n in range(0, N):
121 # u[:,n] = psi_t_list[n][1].full().T
122
123 elif len(c_op_list) == 0 and H0.issuper:
124 # calculate the propagator for the vector representation of the
125 # density matrix (a superoperator propagator)
126
127 N = H0.shape[0]
128 dims = H0.dims
129
130 u = np.zeros([N, N, len(tlist)], dtype=complex)
131
132 for n in range(0, N):
133 psi0 = basis(N, n)
134 rho0 = Qobj(vec2mat(psi0.full()))
135 output = mesolve(H, rho0, tlist, [], [], args, options)
136 for k, t in enumerate(tlist):
137 u[:, n, k] = mat2vec(output.states[k].full()).T
138
139 else:
140 # calculate the propagator for the vector representation of the
141 # density matrix (a superoperator propagator)
142
143 N = H0.shape[0]
144 dims = [H0.dims, H0.dims]
145
146 u = np.zeros([N * N, N * N, len(tlist)], dtype=complex)
147
148 if sparse:
149 for n in range(N * N):
150 psi0 = basis(N * N, n)
151 psi0.dims = [dims[0], 1]
152 rho0 = vector_to_operator(psi0)
153 output = mesolve(H, rho0, tlist, c_op_list, [], args, options)
154 for k, t in enumerate(tlist):
155 u[:, n, k] = operator_to_vector(
156 output.states[k]).full(squeeze=True)
157
158 else:
159 for n in range(N * N):
160 psi0 = basis(N * N, n)
161 rho0 = Qobj(vec2mat(psi0.full()))
162 output = mesolve(H, rho0, tlist, c_op_list, [], args, options)
163 for k, t in enumerate(tlist):
164 u[:, n, k] = mat2vec(output.states[k].full()).T
165
166 if len(tlist) == 2:
167 return Qobj(u[:, :, 1], dims=dims)
168 else:
169 return [Qobj(u[:, :, k], dims=dims) for k in range(len(tlist))]
170
171
172 def _get_min_and_index(lst):
173 """
174 Private function for obtaining min and max indicies.
175 """
176 minval, minidx = lst[0], 0
177 for i, v in enumerate(lst[1:]):
178 if v < minval:
179 minval, minidx = v, i + 1
180 return minval, minidx
181
182
183 def propagator_steadystate(U):
184 """Find the steady state for successive applications of the propagator
185 :math:`U`.
186
187 Parameters
188 ----------
189 U : qobj
190 Operator representing the propagator.
191
192 Returns
193 -------
194 a : qobj
195 Instance representing the steady-state density matrix.
196
197 """
198
199 evals, evecs = la.eig(U.full())
200
201 ev_min, ev_idx = _get_min_and_index(abs(evals - 1.0))
202
203 evecs = evecs.T
204 rho = Qobj(vec2mat(evecs[ev_idx]), dims=U.dims[0])
205 rho = rho * (1.0 / rho.tr())
206 rho = 0.5 * (rho + rho.dag()) # make sure rho is herm
207 return rho
208
[end of qutip/propagator.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/qutip/propagator.py b/qutip/propagator.py
--- a/qutip/propagator.py
+++ b/qutip/propagator.py
@@ -46,9 +46,10 @@
from qutip.sesolve import sesolve
from qutip.states import basis
from qutip.solver import Options
+from qutip.ui.progressbar import BaseProgressBar, TextProgressBar
-
-def propagator(H, t, c_op_list, args=None, options=None, sparse=False):
+def propagator(H, t, c_op_list, args=None, options=None, sparse=False,
+ progress_bar=None):
"""
Calculate the propagator U(t) for the density matrix or wave function such
that :math:`\psi(t) = U(t)\psi(0)` or
@@ -76,6 +77,11 @@
options : :class:`qutip.Options`
with options for the ODE solver.
+ progress_bar: BaseProgressBar
+ Optional instance of BaseProgressBar, or a subclass thereof, for
+ showing the progress of the simulation. By default no progress bar
+ is used, and if set to True a TextProgressBar will be used.
+
Returns
-------
a : qobj
@@ -83,6 +89,11 @@
"""
+ if progress_bar is None:
+ progress_bar = BaseProgressBar()
+ elif progress_bar is True:
+ progress_bar = TextProgressBar()
+
if options is None:
options = Options()
options.rhs_reuse = True
@@ -108,11 +119,14 @@
dims = H0.dims
u = np.zeros([N, N, len(tlist)], dtype=complex)
+ progress_bar.start(N)
for n in range(0, N):
+ progress_bar.update(n)
psi0 = basis(N, n)
output = sesolve(H, psi0, tlist, [], args, options)
for k, t in enumerate(tlist):
u[:, n, k] = output.states[k].full().T
+ progress_bar.finished()
# todo: evolving a batch of wave functions:
# psi_0_list = [basis(N, n) for n in range(N)]
@@ -129,12 +143,15 @@
u = np.zeros([N, N, len(tlist)], dtype=complex)
+ progress_bar.start(N)
for n in range(0, N):
+ progress_bar.update(n)
psi0 = basis(N, n)
rho0 = Qobj(vec2mat(psi0.full()))
output = mesolve(H, rho0, tlist, [], [], args, options)
for k, t in enumerate(tlist):
u[:, n, k] = mat2vec(output.states[k].full()).T
+ progress_bar.finished()
else:
# calculate the propagator for the vector representation of the
@@ -146,7 +163,9 @@
u = np.zeros([N * N, N * N, len(tlist)], dtype=complex)
if sparse:
+ progress_bar.start(N * N)
for n in range(N * N):
+ progress_bar.update(n)
psi0 = basis(N * N, n)
psi0.dims = [dims[0], 1]
rho0 = vector_to_operator(psi0)
@@ -154,14 +173,18 @@
for k, t in enumerate(tlist):
u[:, n, k] = operator_to_vector(
output.states[k]).full(squeeze=True)
+ progress_bar.finished()
else:
+ progress_bar.start(N * N)
for n in range(N * N):
+ progress_bar.update(n)
psi0 = basis(N * N, n)
rho0 = Qobj(vec2mat(psi0.full()))
output = mesolve(H, rho0, tlist, c_op_list, [], args, options)
for k, t in enumerate(tlist):
u[:, n, k] = mat2vec(output.states[k].full()).T
+ progress_bar.finished()
if len(tlist) == 2:
return Qobj(u[:, :, 1], dims=dims)
|
{"golden_diff": "diff --git a/qutip/propagator.py b/qutip/propagator.py\n--- a/qutip/propagator.py\n+++ b/qutip/propagator.py\n@@ -46,9 +46,10 @@\n from qutip.sesolve import sesolve\n from qutip.states import basis\n from qutip.solver import Options\n+from qutip.ui.progressbar import BaseProgressBar, TextProgressBar\n \n-\n-def propagator(H, t, c_op_list, args=None, options=None, sparse=False):\n+def propagator(H, t, c_op_list, args=None, options=None, sparse=False,\n+ progress_bar=None):\n \"\"\"\n Calculate the propagator U(t) for the density matrix or wave function such\n that :math:`\\psi(t) = U(t)\\psi(0)` or\n@@ -76,6 +77,11 @@\n options : :class:`qutip.Options`\n with options for the ODE solver.\n \n+ progress_bar: BaseProgressBar\n+ Optional instance of BaseProgressBar, or a subclass thereof, for\n+ showing the progress of the simulation. By default no progress bar\n+ is used, and if set to True a TextProgressBar will be used.\n+\n Returns\n -------\n a : qobj\n@@ -83,6 +89,11 @@\n \n \"\"\"\n \n+ if progress_bar is None:\n+ progress_bar = BaseProgressBar()\n+ elif progress_bar is True:\n+ progress_bar = TextProgressBar()\n+\n if options is None:\n options = Options()\n options.rhs_reuse = True\n@@ -108,11 +119,14 @@\n dims = H0.dims\n u = np.zeros([N, N, len(tlist)], dtype=complex)\n \n+ progress_bar.start(N)\n for n in range(0, N):\n+ progress_bar.update(n)\n psi0 = basis(N, n)\n output = sesolve(H, psi0, tlist, [], args, options)\n for k, t in enumerate(tlist):\n u[:, n, k] = output.states[k].full().T\n+ progress_bar.finished()\n \n # todo: evolving a batch of wave functions:\n # psi_0_list = [basis(N, n) for n in range(N)]\n@@ -129,12 +143,15 @@\n \n u = np.zeros([N, N, len(tlist)], dtype=complex)\n \n+ progress_bar.start(N)\n for n in range(0, N):\n+ progress_bar.update(n)\n psi0 = basis(N, n)\n rho0 = Qobj(vec2mat(psi0.full()))\n output = mesolve(H, rho0, tlist, [], [], args, options)\n for k, t in enumerate(tlist):\n u[:, n, k] = mat2vec(output.states[k].full()).T\n+ progress_bar.finished()\n \n else:\n # calculate the propagator for the vector representation of the\n@@ -146,7 +163,9 @@\n u = np.zeros([N * N, N * N, len(tlist)], dtype=complex)\n \n if sparse:\n+ progress_bar.start(N * N)\n for n in range(N * N):\n+ progress_bar.update(n)\n psi0 = basis(N * N, n)\n psi0.dims = [dims[0], 1]\n rho0 = vector_to_operator(psi0)\n@@ -154,14 +173,18 @@\n for k, t in enumerate(tlist):\n u[:, n, k] = operator_to_vector(\n output.states[k]).full(squeeze=True)\n+ progress_bar.finished()\n \n else:\n+ progress_bar.start(N * N)\n for n in range(N * N):\n+ progress_bar.update(n)\n psi0 = basis(N * N, n)\n rho0 = Qobj(vec2mat(psi0.full()))\n output = mesolve(H, rho0, tlist, c_op_list, [], args, options)\n for k, t in enumerate(tlist):\n u[:, n, k] = mat2vec(output.states[k].full()).T\n+ progress_bar.finished()\n \n if len(tlist) == 2:\n return Qobj(u[:, :, 1], dims=dims)\n", "issue": "Add progressbar for propatgator?\nIt is really great to use qutip 3.0 in iPython notebook with the HTMLProgressbar, especially when using mesolve or essolve. Unfortunately there is no progressbar when using the propagator function.\n\nWould it be possible to implement this, for propagator (and/or possible other functions), since it calls mesolve, which already has it implemented?\n\nThanks\n\n", "before_files": [{"content": "# This file is part of QuTiP: Quantum Toolbox in Python.\n#\n# Copyright (c) 2011 and later, Paul D. Nation and Robert J. Johansson.\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are\n# met:\n#\n# 1. Redistributions of source code must retain the above copyright notice,\n# this list of conditions and the following disclaimer.\n#\n# 2. Redistributions in binary form must reproduce the above copyright\n# notice, this list of conditions and the following disclaimer in the\n# documentation and/or other materials provided with the distribution.\n#\n# 3. Neither the name of the QuTiP: Quantum Toolbox in Python nor the names\n# of its contributors may be used to endorse or promote products derived\n# from this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS\n# \"AS IS\" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT\n# LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A\n# PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT\n# HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,\n# SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT\n# LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,\n# DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY\n# THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT\n# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n###############################################################################\n\n__all__ = ['propagator', 'propagator_steadystate']\n\nimport types\nimport numpy as np\nimport scipy.linalg as la\nimport functools\n\nfrom qutip.qobj import Qobj\nfrom qutip.rhs_generate import rhs_clear\nfrom qutip.superoperator import (vec2mat, mat2vec,\n vector_to_operator, operator_to_vector)\nfrom qutip.mesolve import mesolve\nfrom qutip.sesolve import sesolve\nfrom qutip.states import basis\nfrom qutip.solver import Options\n\n\ndef propagator(H, t, c_op_list, args=None, options=None, sparse=False):\n \"\"\"\n Calculate the propagator U(t) for the density matrix or wave function such\n that :math:`\\psi(t) = U(t)\\psi(0)` or\n :math:`\\\\rho_{\\mathrm vec}(t) = U(t) \\\\rho_{\\mathrm vec}(0)`\n where :math:`\\\\rho_{\\mathrm vec}` is the vector representation of the\n density matrix.\n\n Parameters\n ----------\n H : qobj or list\n Hamiltonian as a Qobj instance of a nested list of Qobjs and\n coefficients in the list-string or list-function format for\n time-dependent Hamiltonians (see description in :func:`qutip.mesolve`).\n\n t : float or array-like\n Time or list of times for which to evaluate the propagator.\n\n c_op_list : list\n List of qobj collapse operators.\n\n args : list/array/dictionary\n Parameters to callback functions for time-dependent Hamiltonians and\n collapse operators.\n\n options : :class:`qutip.Options`\n with options for the ODE solver.\n\n Returns\n -------\n a : qobj\n Instance representing the propagator :math:`U(t)`.\n\n \"\"\"\n\n if options is None:\n options = Options()\n options.rhs_reuse = True\n rhs_clear()\n\n if isinstance(t, (int, float, np.integer, np.floating)):\n tlist = [0, t]\n else:\n tlist = t\n\n if isinstance(H, (types.FunctionType, types.BuiltinFunctionType,\n functools.partial)):\n H0 = H(0.0, args)\n elif isinstance(H, list):\n H0 = H[0][0] if isinstance(H[0], list) else H[0]\n else:\n H0 = H\n\n if len(c_op_list) == 0 and H0.isoper:\n # calculate propagator for the wave function\n\n N = H0.shape[0]\n dims = H0.dims\n u = np.zeros([N, N, len(tlist)], dtype=complex)\n\n for n in range(0, N):\n psi0 = basis(N, n)\n output = sesolve(H, psi0, tlist, [], args, options)\n for k, t in enumerate(tlist):\n u[:, n, k] = output.states[k].full().T\n\n # todo: evolving a batch of wave functions:\n # psi_0_list = [basis(N, n) for n in range(N)]\n # psi_t_list = mesolve(H, psi_0_list, [0, t], [], [], args, options)\n # for n in range(0, N):\n # u[:,n] = psi_t_list[n][1].full().T\n\n elif len(c_op_list) == 0 and H0.issuper:\n # calculate the propagator for the vector representation of the\n # density matrix (a superoperator propagator)\n\n N = H0.shape[0]\n dims = H0.dims\n\n u = np.zeros([N, N, len(tlist)], dtype=complex)\n\n for n in range(0, N):\n psi0 = basis(N, n)\n rho0 = Qobj(vec2mat(psi0.full()))\n output = mesolve(H, rho0, tlist, [], [], args, options)\n for k, t in enumerate(tlist):\n u[:, n, k] = mat2vec(output.states[k].full()).T\n\n else:\n # calculate the propagator for the vector representation of the\n # density matrix (a superoperator propagator)\n\n N = H0.shape[0]\n dims = [H0.dims, H0.dims]\n\n u = np.zeros([N * N, N * N, len(tlist)], dtype=complex)\n\n if sparse:\n for n in range(N * N):\n psi0 = basis(N * N, n)\n psi0.dims = [dims[0], 1]\n rho0 = vector_to_operator(psi0)\n output = mesolve(H, rho0, tlist, c_op_list, [], args, options)\n for k, t in enumerate(tlist):\n u[:, n, k] = operator_to_vector(\n output.states[k]).full(squeeze=True)\n\n else:\n for n in range(N * N):\n psi0 = basis(N * N, n)\n rho0 = Qobj(vec2mat(psi0.full()))\n output = mesolve(H, rho0, tlist, c_op_list, [], args, options)\n for k, t in enumerate(tlist):\n u[:, n, k] = mat2vec(output.states[k].full()).T\n\n if len(tlist) == 2:\n return Qobj(u[:, :, 1], dims=dims)\n else:\n return [Qobj(u[:, :, k], dims=dims) for k in range(len(tlist))]\n\n\ndef _get_min_and_index(lst):\n \"\"\"\n Private function for obtaining min and max indicies.\n \"\"\"\n minval, minidx = lst[0], 0\n for i, v in enumerate(lst[1:]):\n if v < minval:\n minval, minidx = v, i + 1\n return minval, minidx\n\n\ndef propagator_steadystate(U):\n \"\"\"Find the steady state for successive applications of the propagator\n :math:`U`.\n\n Parameters\n ----------\n U : qobj\n Operator representing the propagator.\n\n Returns\n -------\n a : qobj\n Instance representing the steady-state density matrix.\n\n \"\"\"\n\n evals, evecs = la.eig(U.full())\n\n ev_min, ev_idx = _get_min_and_index(abs(evals - 1.0))\n\n evecs = evecs.T\n rho = Qobj(vec2mat(evecs[ev_idx]), dims=U.dims[0])\n rho = rho * (1.0 / rho.tr())\n rho = 0.5 * (rho + rho.dag()) # make sure rho is herm\n return rho\n", "path": "qutip/propagator.py"}]}
| 3,012 | 960 |
gh_patches_debug_1215
|
rasdani/github-patches
|
git_diff
|
TabbycatDebate__tabbycat-2348
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Crash when generating QF draw (WS)
**Running:** a1ca1a390866199e1884db12c215ddaa867a98dc
When generating the draw for the first elimination round in a WS tournament, I encountered this exception:
```python
[2023-07-09 12:01:47,564] ERROR django.request: Internal Server Error: /xxx-yyz/admin/draw/round/7/create/
Traceback (most recent call last):
File "/usr/local/lib/python3.9/site-packages/django/core/handlers/exception.py", line 56, in inner
response = get_response(request)
File "/usr/local/lib/python3.9/site-packages/django/core/handlers/base.py", line 197, in _get_response
response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "/usr/local/lib/python3.9/site-packages/django/views/generic/base.py", line 103, in view
return self.dispatch(request, *args, **kwargs)
File "/usr/local/lib/python3.9/site-packages/django/contrib/auth/mixins.py", line 135, in dispatch
return super().dispatch(request, *args, **kwargs)
File "/tcd/tabbycat/tournaments/mixins.py", line 125, in dispatch
return super().dispatch(request, *args, **kwargs)
File "/usr/local/lib/python3.9/site-packages/django/views/generic/base.py", line 142, in dispatch
return handler(request, *args, **kwargs)
File "/tcd/tabbycat/draw/views.py", line 664, in post
manager.create()
File "/tcd/tabbycat/draw/manager.py", line 157, in create
drawer = DrawGenerator(self.teams_in_debate, generator_type, teams,
File "/tcd/tabbycat/draw/generator/__init__.py", line 93, in DrawGenerator
return klass(teams, results, rrseq, **kwargs)
File "/tcd/tabbycat/draw/generator/common.py", line 182, in __init__
super().__init__(teams, results, rrseq, **kwargs)
File "/tcd/tabbycat/draw/generator/common.py", line 73, in __init__
raise ValueError("Unrecognised options: " + ", ".join(unrecognised))
ValueError: Unrecognised options: avoid_conflicts
```
I quickly patched around it like so and we manually confirmed the draw was correct:
```diff
diff --git a/tabbycat/draw/generator/common.py b/tabbycat/draw/generator/common.py
index 2a61de6ea..3d7167aa1 100644
--- a/tabbycat/draw/generator/common.py
+++ b/tabbycat/draw/generator/common.py
@@ -68,9 +68,10 @@ class BaseDrawGenerator:
# Compute the full dictionary of default options
self.options = self.BASE_DEFAULT_OPTIONS.copy()
self.options.update(self.DEFAULT_OPTIONS)
+ print(self.__class__)
unrecognised = [key for key in kwargs if key not in self.options]
- if unrecognised:
- raise ValueError("Unrecognised options: " + ", ".join(unrecognised))
+# if unrecognised:
+# raise ValueError("Unrecognised options: " + ", ".join(unrecognised))
self.options.update(kwargs)
def generate(self):
```
Of course, this is not a fix for the problem, just avoiding the symptoms. **I intend to find the cause of this issue and fix it in the following days**, bu I'm dropping an issue here so I don't forget
</issue>
<code>
[start of tabbycat/draw/generator/common.py]
1 import logging
2
3 from django.utils.translation import gettext as _
4
5 logger = logging.getLogger(__name__)
6
7
8 class BaseDrawError(Exception):
9 pass
10
11
12 class DrawUserError(BaseDrawError):
13 """DrawUserError is raised by any DrawGenerator class when a problem that
14 would appear to be user error prevents a draw from being produced.
15 DrawUserErrors are caught by the view class and shown to the user as an
16 error message.
17
18 Because DrawUserErrors expected and rectifier, the strings that go into them
19 should be internationalised (marked for translation)."""
20 pass
21
22
23 class DrawFatalError(BaseDrawError):
24 """DrawAlgorithmError is raised by any DrawGenerator class when a problem
25 that is an error condition that should never (ever) happen prevents a draw
26 from being produced. DrawAlgorithmError are also caught by the view class
27 and shown to the user as an error message. However, because they should
28 never happen, their messages are not internationalised, since that just
29 creates unnecessary work for translators."""
30 pass
31
32
33 class BaseDrawGenerator:
34 """Base class for generators for all draw types, for both two-team and BP.
35 """
36
37 # Subclasses must define BASE_DEFAULT_OPTIONS
38
39 requires_even_teams = True
40 requires_prev_results = False
41 requires_rrseq = False
42
43 def __init__(self, teams, results=None, rrseq=None, **kwargs):
44 self.teams = teams
45 self.team_flags = dict()
46 self.results = results
47 self.rrseq = rrseq
48
49 if self.requires_even_teams:
50 if not len(self.teams) % self.TEAMS_PER_DEBATE == 0:
51 raise DrawUserError(_("The number of teams presented for the draw was not "
52 "a multiple of %(num)d.") % {'num': self.TEAMS_PER_DEBATE})
53 if not self.teams:
54 raise DrawUserError(_("There were no teams for the draw."))
55
56 if results is None and self.requires_prev_results:
57 raise TypeError("'results' is required for draw of type {0:s}".format(
58 self.__class__.__name__))
59
60 if results is not None and not self.requires_prev_results:
61 logger.warning("'results' not required for draw of type %s, will probably be ignored",
62 self.__class__.__name__)
63
64 if rrseq is None and self.requires_rrseq:
65 raise TypeError("'rrseq' (round robin sequence) is required for draw of type {0:s}".format(
66 self.__class__.__name__))
67
68 # Compute the full dictionary of default options
69 self.options = self.BASE_DEFAULT_OPTIONS.copy()
70 self.options.update(self.DEFAULT_OPTIONS)
71 unrecognised = [key for key in kwargs if key not in self.options]
72 if unrecognised:
73 raise ValueError("Unrecognised options: " + ", ".join(unrecognised))
74 self.options.update(kwargs)
75
76 def generate(self):
77 """Abstract method."""
78 raise NotImplementedError
79
80 def get_option_function(self, option_name, option_dict):
81 option = self.options[option_name]
82 if callable(option):
83 return option
84 try:
85 return getattr(self, option_dict[option])
86 except KeyError:
87 raise ValueError("Invalid option for {1}: {0}".format(option, option_name))
88
89 def add_team_flag(self, team, flag):
90 """Attaches a flag to a team.
91 Child classes may use this when flags should follow teams, but
92 eventually be attached to pairings."""
93 flags = self.team_flags.setdefault(team, list())
94 flags.append(flag)
95
96 def annotate_team_flags(self, pairings):
97 """Applies the team flags to the pairings given.
98 Child classes that use team flags should call this method as the last
99 thing before the draw is returned."""
100 for pairing in pairings:
101 for team in pairing.teams:
102 if team in self.team_flags:
103 pairing.add_team_flags(team, self.team_flags[team])
104
105 @classmethod
106 def available_options(cls):
107 keys = set(cls.BASE_DEFAULT_OPTIONS.keys())
108 keys |= set(cls.DEFAULT_OPTIONS.keys())
109 return sorted(list(keys))
110
111 def check_teams_for_attribute(self, name, choices=None, checkfunc=None):
112 """Checks that all teams have the specified attribute, and raises a
113 DrawFatalError if they don't. This should be called during the
114 constructor. Note: Whether to run this check will sometimes be
115 conditional on options supplied to the DrawGenerator. 'name' is the name
116 of the attribute. 'choices', if specified, is a list of allowed values
117 for the attribute.
118 """
119 has_attribute = [hasattr(x, name) for x in self.teams]
120 if not all(has_attribute):
121 offending_teams = has_attribute.count(False)
122 raise DrawFatalError("{0} out of {1} teams don't have a '{name}' attribute.".format(
123 offending_teams, len(self.teams), name=name))
124
125 if choices:
126 attribute_value_valid = [getattr(x, name) in choices for x in self.teams]
127 elif checkfunc:
128 attribute_value_valid = [checkfunc(getattr(x, name)) for x in self.teams]
129 else:
130 return
131
132 if not all(attribute_value_valid):
133 offending_teams = attribute_value_valid.count(False)
134 message = "{0} out of {1} teams have an invalid '{name}' attribute.".format(offending_teams, len(self.teams), name=name)
135 if choices:
136 message += " Valid choices: " + ", ".join(map(repr, choices))
137 raise DrawFatalError(message)
138
139
140 class BasePairDrawGenerator(BaseDrawGenerator):
141 """Base class for generators for all draw types.
142 Options:
143 "side_allocations" - Side allocation method, one of:
144 "balance" - the team that has affirmed less in prior rounds affirms,
145 or randomly if both teams have affirmed the same number of times.
146 If used, team objects must have an `side_history` attribute.
147 "preallocated" - teams were pre-allocated sides. If used, teams must
148 have an 'allocated_side' attribute.
149 "none" - leave sides as they were when the pairings were drawn.
150 (This is almost never desirable.)
151 "random" - allocate randomly.
152 "avoid_history" - if True, draw tries to avoid pairing teams that have
153 seen each other before, and tries harder if they've seen each other
154 multiple times.
155 "history_penalty" -
156 "avoid_institution" - if True, draw tries to avoid pairing teams that
157 are from the same institution.
158 "side_penalty" - A penalty to apply when optimizing with side balance
159 """
160
161 BASE_DEFAULT_OPTIONS = {
162 "side_allocations" : "balance",
163 "avoid_history" : True,
164 "avoid_institution" : True,
165 "history_penalty" : 1e3,
166 "institution_penalty" : 1,
167 "side_penalty" : 0,
168 "pullup_debates_penalty": 0,
169 "pairing_penalty" : 0,
170 }
171
172 TEAMS_PER_DEBATE = 2
173
174 requires_even_teams = True
175 requires_prev_results = False
176 requires_rrseq = False
177
178 # All subclasses must define this with any options that may exist.
179 DEFAULT_OPTIONS = {}
180
181 def __init__(self, teams, results=None, rrseq=None, **kwargs):
182 super().__init__(teams, results, rrseq, **kwargs)
183
184 # Check for required team attributes. Subclasses might do more.
185 if self.options["avoid_history"]:
186 self.check_teams_for_attribute("seen", checkfunc=callable)
187 if self.options["avoid_institution"]:
188 self.check_teams_for_attribute("institution")
189
190 def allocate_sides(self, pairings):
191 if self.options["side_allocations"] == "balance":
192 for pairing in pairings:
193 pairing.balance_sides()
194 elif self.options["side_allocations"] == "random":
195 for pairing in pairings:
196 pairing.shuffle_sides()
197 elif self.options["side_allocations"] not in ["none", "preallocated"]:
198 raise ValueError("side_allocations setting not recognized: {0!r}".format(self.options["side_allocations"]))
199
200
201 class BaseBPDrawGenerator(BaseDrawGenerator):
202 BASE_DEFAULT_OPTIONS = {}
203 TEAMS_PER_DEBATE = 4
204
205
206 class EliminationDrawMixin:
207 """Mixin for elimination draws."""
208
209 def generate(self):
210 pairings = self.make_pairings()
211 self.shuffle_sides(pairings)
212 return pairings
213
214 def shuffle_sides(self, pairings):
215 for pairing in pairings:
216 pairing.shuffle_sides()
217
218 def make_pairings(self):
219 raise NotImplementedError
220
221
222 class ManualDrawGenerator(BaseDrawGenerator):
223 """Returns an empty draw.
224 Since this doesn't really do anything, it works for both two-team and BP.
225 """
226 DEFAULT_OPTIONS = {}
227 BASE_DEFAULT_OPTIONS = {}
228 requires_even_teams = False
229 requires_prev_results = False
230
231 def generate(self):
232 return []
233
[end of tabbycat/draw/generator/common.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/tabbycat/draw/generator/common.py b/tabbycat/draw/generator/common.py
--- a/tabbycat/draw/generator/common.py
+++ b/tabbycat/draw/generator/common.py
@@ -167,6 +167,7 @@
"side_penalty" : 0,
"pullup_debates_penalty": 0,
"pairing_penalty" : 0,
+ "avoid_conflicts" : "off",
}
TEAMS_PER_DEBATE = 2
|
{"golden_diff": "diff --git a/tabbycat/draw/generator/common.py b/tabbycat/draw/generator/common.py\n--- a/tabbycat/draw/generator/common.py\n+++ b/tabbycat/draw/generator/common.py\n@@ -167,6 +167,7 @@\n \"side_penalty\" : 0,\n \"pullup_debates_penalty\": 0,\n \"pairing_penalty\" : 0,\n+ \"avoid_conflicts\" : \"off\",\n }\n \n TEAMS_PER_DEBATE = 2\n", "issue": "Crash when generating QF draw (WS)\n**Running:** a1ca1a390866199e1884db12c215ddaa867a98dc\r\n\r\nWhen generating the draw for the first elimination round in a WS tournament, I encountered this exception:\r\n\r\n```python\r\n[2023-07-09 12:01:47,564] ERROR django.request: Internal Server Error: /xxx-yyz/admin/draw/round/7/create/\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.9/site-packages/django/core/handlers/exception.py\", line 56, in inner\r\n response = get_response(request)\r\n File \"/usr/local/lib/python3.9/site-packages/django/core/handlers/base.py\", line 197, in _get_response\r\n response = wrapped_callback(request, *callback_args, **callback_kwargs)\r\n File \"/usr/local/lib/python3.9/site-packages/django/views/generic/base.py\", line 103, in view\r\n return self.dispatch(request, *args, **kwargs)\r\n File \"/usr/local/lib/python3.9/site-packages/django/contrib/auth/mixins.py\", line 135, in dispatch\r\n return super().dispatch(request, *args, **kwargs)\r\n File \"/tcd/tabbycat/tournaments/mixins.py\", line 125, in dispatch\r\n return super().dispatch(request, *args, **kwargs)\r\n File \"/usr/local/lib/python3.9/site-packages/django/views/generic/base.py\", line 142, in dispatch\r\n return handler(request, *args, **kwargs)\r\n File \"/tcd/tabbycat/draw/views.py\", line 664, in post\r\n manager.create()\r\n File \"/tcd/tabbycat/draw/manager.py\", line 157, in create\r\n drawer = DrawGenerator(self.teams_in_debate, generator_type, teams,\r\n File \"/tcd/tabbycat/draw/generator/__init__.py\", line 93, in DrawGenerator\r\n return klass(teams, results, rrseq, **kwargs)\r\n File \"/tcd/tabbycat/draw/generator/common.py\", line 182, in __init__\r\n super().__init__(teams, results, rrseq, **kwargs)\r\n File \"/tcd/tabbycat/draw/generator/common.py\", line 73, in __init__\r\n raise ValueError(\"Unrecognised options: \" + \", \".join(unrecognised))\r\nValueError: Unrecognised options: avoid_conflicts\r\n```\r\n\r\nI quickly patched around it like so and we manually confirmed the draw was correct:\r\n\r\n```diff\r\ndiff --git a/tabbycat/draw/generator/common.py b/tabbycat/draw/generator/common.py\r\nindex 2a61de6ea..3d7167aa1 100644\r\n--- a/tabbycat/draw/generator/common.py\r\n+++ b/tabbycat/draw/generator/common.py\r\n@@ -68,9 +68,10 @@ class BaseDrawGenerator:\r\n # Compute the full dictionary of default options\r\n self.options = self.BASE_DEFAULT_OPTIONS.copy()\r\n self.options.update(self.DEFAULT_OPTIONS)\r\n+ print(self.__class__)\r\n unrecognised = [key for key in kwargs if key not in self.options]\r\n- if unrecognised:\r\n- raise ValueError(\"Unrecognised options: \" + \", \".join(unrecognised))\r\n+# if unrecognised:\r\n+# raise ValueError(\"Unrecognised options: \" + \", \".join(unrecognised))\r\n self.options.update(kwargs)\r\n \r\n def generate(self):\r\n```\r\n\r\nOf course, this is not a fix for the problem, just avoiding the symptoms. **I intend to find the cause of this issue and fix it in the following days**, bu I'm dropping an issue here so I don't forget\n", "before_files": [{"content": "import logging\n\nfrom django.utils.translation import gettext as _\n\nlogger = logging.getLogger(__name__)\n\n\nclass BaseDrawError(Exception):\n pass\n\n\nclass DrawUserError(BaseDrawError):\n \"\"\"DrawUserError is raised by any DrawGenerator class when a problem that\n would appear to be user error prevents a draw from being produced.\n DrawUserErrors are caught by the view class and shown to the user as an\n error message.\n\n Because DrawUserErrors expected and rectifier, the strings that go into them\n should be internationalised (marked for translation).\"\"\"\n pass\n\n\nclass DrawFatalError(BaseDrawError):\n \"\"\"DrawAlgorithmError is raised by any DrawGenerator class when a problem\n that is an error condition that should never (ever) happen prevents a draw\n from being produced. DrawAlgorithmError are also caught by the view class\n and shown to the user as an error message. However, because they should\n never happen, their messages are not internationalised, since that just\n creates unnecessary work for translators.\"\"\"\n pass\n\n\nclass BaseDrawGenerator:\n \"\"\"Base class for generators for all draw types, for both two-team and BP.\n \"\"\"\n\n # Subclasses must define BASE_DEFAULT_OPTIONS\n\n requires_even_teams = True\n requires_prev_results = False\n requires_rrseq = False\n\n def __init__(self, teams, results=None, rrseq=None, **kwargs):\n self.teams = teams\n self.team_flags = dict()\n self.results = results\n self.rrseq = rrseq\n\n if self.requires_even_teams:\n if not len(self.teams) % self.TEAMS_PER_DEBATE == 0:\n raise DrawUserError(_(\"The number of teams presented for the draw was not \"\n \"a multiple of %(num)d.\") % {'num': self.TEAMS_PER_DEBATE})\n if not self.teams:\n raise DrawUserError(_(\"There were no teams for the draw.\"))\n\n if results is None and self.requires_prev_results:\n raise TypeError(\"'results' is required for draw of type {0:s}\".format(\n self.__class__.__name__))\n\n if results is not None and not self.requires_prev_results:\n logger.warning(\"'results' not required for draw of type %s, will probably be ignored\",\n self.__class__.__name__)\n\n if rrseq is None and self.requires_rrseq:\n raise TypeError(\"'rrseq' (round robin sequence) is required for draw of type {0:s}\".format(\n self.__class__.__name__))\n\n # Compute the full dictionary of default options\n self.options = self.BASE_DEFAULT_OPTIONS.copy()\n self.options.update(self.DEFAULT_OPTIONS)\n unrecognised = [key for key in kwargs if key not in self.options]\n if unrecognised:\n raise ValueError(\"Unrecognised options: \" + \", \".join(unrecognised))\n self.options.update(kwargs)\n\n def generate(self):\n \"\"\"Abstract method.\"\"\"\n raise NotImplementedError\n\n def get_option_function(self, option_name, option_dict):\n option = self.options[option_name]\n if callable(option):\n return option\n try:\n return getattr(self, option_dict[option])\n except KeyError:\n raise ValueError(\"Invalid option for {1}: {0}\".format(option, option_name))\n\n def add_team_flag(self, team, flag):\n \"\"\"Attaches a flag to a team.\n Child classes may use this when flags should follow teams, but\n eventually be attached to pairings.\"\"\"\n flags = self.team_flags.setdefault(team, list())\n flags.append(flag)\n\n def annotate_team_flags(self, pairings):\n \"\"\"Applies the team flags to the pairings given.\n Child classes that use team flags should call this method as the last\n thing before the draw is returned.\"\"\"\n for pairing in pairings:\n for team in pairing.teams:\n if team in self.team_flags:\n pairing.add_team_flags(team, self.team_flags[team])\n\n @classmethod\n def available_options(cls):\n keys = set(cls.BASE_DEFAULT_OPTIONS.keys())\n keys |= set(cls.DEFAULT_OPTIONS.keys())\n return sorted(list(keys))\n\n def check_teams_for_attribute(self, name, choices=None, checkfunc=None):\n \"\"\"Checks that all teams have the specified attribute, and raises a\n DrawFatalError if they don't. This should be called during the\n constructor. Note: Whether to run this check will sometimes be\n conditional on options supplied to the DrawGenerator. 'name' is the name\n of the attribute. 'choices', if specified, is a list of allowed values\n for the attribute.\n \"\"\"\n has_attribute = [hasattr(x, name) for x in self.teams]\n if not all(has_attribute):\n offending_teams = has_attribute.count(False)\n raise DrawFatalError(\"{0} out of {1} teams don't have a '{name}' attribute.\".format(\n offending_teams, len(self.teams), name=name))\n\n if choices:\n attribute_value_valid = [getattr(x, name) in choices for x in self.teams]\n elif checkfunc:\n attribute_value_valid = [checkfunc(getattr(x, name)) for x in self.teams]\n else:\n return\n\n if not all(attribute_value_valid):\n offending_teams = attribute_value_valid.count(False)\n message = \"{0} out of {1} teams have an invalid '{name}' attribute.\".format(offending_teams, len(self.teams), name=name)\n if choices:\n message += \" Valid choices: \" + \", \".join(map(repr, choices))\n raise DrawFatalError(message)\n\n\nclass BasePairDrawGenerator(BaseDrawGenerator):\n \"\"\"Base class for generators for all draw types.\n Options:\n \"side_allocations\" - Side allocation method, one of:\n \"balance\" - the team that has affirmed less in prior rounds affirms,\n or randomly if both teams have affirmed the same number of times.\n If used, team objects must have an `side_history` attribute.\n \"preallocated\" - teams were pre-allocated sides. If used, teams must\n have an 'allocated_side' attribute.\n \"none\" - leave sides as they were when the pairings were drawn.\n (This is almost never desirable.)\n \"random\" - allocate randomly.\n \"avoid_history\" - if True, draw tries to avoid pairing teams that have\n seen each other before, and tries harder if they've seen each other\n multiple times.\n \"history_penalty\" -\n \"avoid_institution\" - if True, draw tries to avoid pairing teams that\n are from the same institution.\n \"side_penalty\" - A penalty to apply when optimizing with side balance\n \"\"\"\n\n BASE_DEFAULT_OPTIONS = {\n \"side_allocations\" : \"balance\",\n \"avoid_history\" : True,\n \"avoid_institution\" : True,\n \"history_penalty\" : 1e3,\n \"institution_penalty\" : 1,\n \"side_penalty\" : 0,\n \"pullup_debates_penalty\": 0,\n \"pairing_penalty\" : 0,\n }\n\n TEAMS_PER_DEBATE = 2\n\n requires_even_teams = True\n requires_prev_results = False\n requires_rrseq = False\n\n # All subclasses must define this with any options that may exist.\n DEFAULT_OPTIONS = {}\n\n def __init__(self, teams, results=None, rrseq=None, **kwargs):\n super().__init__(teams, results, rrseq, **kwargs)\n\n # Check for required team attributes. Subclasses might do more.\n if self.options[\"avoid_history\"]:\n self.check_teams_for_attribute(\"seen\", checkfunc=callable)\n if self.options[\"avoid_institution\"]:\n self.check_teams_for_attribute(\"institution\")\n\n def allocate_sides(self, pairings):\n if self.options[\"side_allocations\"] == \"balance\":\n for pairing in pairings:\n pairing.balance_sides()\n elif self.options[\"side_allocations\"] == \"random\":\n for pairing in pairings:\n pairing.shuffle_sides()\n elif self.options[\"side_allocations\"] not in [\"none\", \"preallocated\"]:\n raise ValueError(\"side_allocations setting not recognized: {0!r}\".format(self.options[\"side_allocations\"]))\n\n\nclass BaseBPDrawGenerator(BaseDrawGenerator):\n BASE_DEFAULT_OPTIONS = {}\n TEAMS_PER_DEBATE = 4\n\n\nclass EliminationDrawMixin:\n \"\"\"Mixin for elimination draws.\"\"\"\n\n def generate(self):\n pairings = self.make_pairings()\n self.shuffle_sides(pairings)\n return pairings\n\n def shuffle_sides(self, pairings):\n for pairing in pairings:\n pairing.shuffle_sides()\n\n def make_pairings(self):\n raise NotImplementedError\n\n\nclass ManualDrawGenerator(BaseDrawGenerator):\n \"\"\"Returns an empty draw.\n Since this doesn't really do anything, it works for both two-team and BP.\n \"\"\"\n DEFAULT_OPTIONS = {}\n BASE_DEFAULT_OPTIONS = {}\n requires_even_teams = False\n requires_prev_results = False\n\n def generate(self):\n return []\n", "path": "tabbycat/draw/generator/common.py"}]}
| 3,943 | 121 |
gh_patches_debug_28839
|
rasdani/github-patches
|
git_diff
|
urllib3__urllib3-2070
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[v2] Detect unsupported Python versions and raise a helpful ImportError
We'll need to ensure our `urllib3/__init__.py` is still Python 2.x compatible for early urllib3 v2.x releases. If we detect an unsupported Python version we raise a helpful error message recommending pinning to `urllib3<2`
</issue>
<code>
[start of noxfile.py]
1 import os
2 import shutil
3 import subprocess
4
5 import nox
6
7 # Whenever type-hints are completed on a file it should be added here so that
8 # this file will continue to be checked by mypy. Errors from other files are
9 # ignored.
10 TYPED_FILES = {
11 "src/urllib3/contrib/__init__.py",
12 "src/urllib3/exceptions.py",
13 "src/urllib3/fields.py",
14 "src/urllib3/filepost.py",
15 "src/urllib3/packages/__init__.py",
16 "src/urllib3/packages/six.py",
17 "src/urllib3/packages/ssl_match_hostname/__init__.py",
18 "src/urllib3/packages/ssl_match_hostname/_implementation.py",
19 "src/urllib3/util/queue.py",
20 "src/urllib3/util/url.py",
21 }
22 SOURCE_FILES = [
23 "docs/",
24 "dummyserver/",
25 "src/",
26 "test/",
27 "noxfile.py",
28 "setup.py",
29 ]
30
31
32 def tests_impl(session, extras="socks,secure,brotli"):
33 # Install deps and the package itself.
34 session.install("-r", "dev-requirements.txt")
35 session.install(f".[{extras}]")
36
37 # Show the pip version.
38 session.run("pip", "--version")
39 # Print the Python version and bytesize.
40 session.run("python", "--version")
41 session.run("python", "-c", "import struct; print(struct.calcsize('P') * 8)")
42 # Print OpenSSL information.
43 session.run("python", "-m", "OpenSSL.debug")
44
45 # Inspired from https://github.com/pyca/cryptography
46 # We use parallel mode and then combine here so that coverage.py will take
47 # the paths like .tox/pyXY/lib/pythonX.Y/site-packages/urllib3/__init__.py
48 # and collapse them into src/urllib3/__init__.py.
49
50 session.run(
51 "coverage",
52 "run",
53 "--parallel-mode",
54 "-m",
55 "pytest",
56 "-r",
57 "a",
58 "--tb=native",
59 "--no-success-flaky-report",
60 *(session.posargs or ("test/",)),
61 env={"PYTHONWARNINGS": "always::DeprecationWarning"},
62 )
63 session.run("coverage", "combine")
64 session.run("coverage", "report", "-m")
65 session.run("coverage", "xml")
66
67
68 @nox.session(python=["3.6", "3.7", "3.8", "3.9", "3.10", "pypy"])
69 def test(session):
70 tests_impl(session)
71
72
73 @nox.session(python=["3"])
74 def google_brotli(session):
75 # https://pypi.org/project/Brotli/ is the Google version of brotli, so
76 # install it separately and don't install our brotli extra (which installs
77 # brotlipy).
78 session.install("brotli")
79 tests_impl(session, extras="socks,secure")
80
81
82 @nox.session()
83 def format(session):
84 """Run code formatters."""
85 session.install("black", "isort")
86 session.run("black", *SOURCE_FILES)
87 session.run("isort", *SOURCE_FILES)
88
89 lint(session)
90
91
92 @nox.session
93 def lint(session):
94 session.install("flake8", "flake8-2020", "black", "isort", "mypy")
95 session.run("flake8", "--version")
96 session.run("black", "--version")
97 session.run("isort", "--version")
98 session.run("mypy", "--version")
99 session.run("black", "--check", *SOURCE_FILES)
100 session.run("isort", "--check", *SOURCE_FILES)
101 session.run("flake8", *SOURCE_FILES)
102
103 session.log("mypy --strict src/urllib3")
104 all_errors, errors = [], []
105 process = subprocess.run(
106 ["mypy", "--strict", "src/urllib3"],
107 env=session.env,
108 text=True,
109 stdout=subprocess.PIPE,
110 stderr=subprocess.STDOUT,
111 )
112 # Ensure that mypy itself ran successfully
113 assert process.returncode in (0, 1)
114
115 for line in process.stdout.split("\n"):
116 all_errors.append(line)
117 filepath = line.partition(":")[0]
118 if filepath.replace(".pyi", ".py") in TYPED_FILES:
119 errors.append(line)
120 session.log(f"all errors count: {len(all_errors)}")
121 if errors:
122 session.error("\n" + "\n".join(sorted(set(errors))))
123
124
125 @nox.session
126 def docs(session):
127 session.install("-r", "docs/requirements.txt")
128 session.install(".[socks,secure,brotli]")
129
130 session.chdir("docs")
131 if os.path.exists("_build"):
132 shutil.rmtree("_build")
133 session.run("sphinx-build", "-b", "html", "-W", ".", "_build/html")
134
[end of noxfile.py]
[start of setup.py]
1 #!/usr/bin/env python
2 # This file is protected via CODEOWNERS
3
4 import codecs
5 import os
6 import re
7
8 from setuptools import setup
9
10 base_path = os.path.dirname(__file__)
11
12 # Get the version (borrowed from SQLAlchemy)
13 with open(os.path.join(base_path, "src", "urllib3", "_version.py")) as fp:
14 VERSION = (
15 re.compile(r""".*__version__ = ["'](.*?)['"]""", re.S).match(fp.read()).group(1)
16 )
17
18
19 with codecs.open("README.rst", encoding="utf-8") as fp:
20 # Remove reST raw directive from README as they're not allowed on PyPI
21 # Those blocks start with a newline and continue until the next newline
22 mode = None
23 lines = []
24 for line in fp:
25 if line.startswith(".. raw::"):
26 mode = "ignore_nl"
27 elif line == "\n":
28 mode = "wait_nl" if mode == "ignore_nl" else None
29
30 if mode is None:
31 lines.append(line)
32 readme = "".join(lines)
33
34 with codecs.open("CHANGES.rst", encoding="utf-8") as fp:
35 changes = fp.read()
36
37 version = VERSION
38
39 setup(
40 name="urllib3",
41 version=version,
42 description="HTTP library with thread-safe connection pooling, file post, and more.",
43 long_description="\n\n".join([readme, changes]),
44 long_description_content_type="text/x-rst",
45 classifiers=[
46 "Environment :: Web Environment",
47 "Intended Audience :: Developers",
48 "License :: OSI Approved :: MIT License",
49 "Operating System :: OS Independent",
50 "Programming Language :: Python",
51 "Programming Language :: Python :: 3",
52 "Programming Language :: Python :: 3.6",
53 "Programming Language :: Python :: 3.7",
54 "Programming Language :: Python :: 3.8",
55 "Programming Language :: Python :: 3.9",
56 "Programming Language :: Python :: 3 :: Only",
57 "Programming Language :: Python :: Implementation :: CPython",
58 "Programming Language :: Python :: Implementation :: PyPy",
59 "Topic :: Internet :: WWW/HTTP",
60 "Topic :: Software Development :: Libraries",
61 ],
62 keywords="urllib httplib threadsafe filepost http https ssl pooling",
63 author="Andrey Petrov",
64 author_email="[email protected]",
65 url="https://urllib3.readthedocs.io/",
66 project_urls={
67 "Documentation": "https://urllib3.readthedocs.io/",
68 "Code": "https://github.com/urllib3/urllib3",
69 "Issue tracker": "https://github.com/urllib3/urllib3/issues",
70 },
71 license="MIT",
72 packages=[
73 "urllib3",
74 "urllib3.packages",
75 "urllib3.packages.ssl_match_hostname",
76 "urllib3.packages.backports",
77 "urllib3.contrib",
78 "urllib3.contrib._securetransport",
79 "urllib3.util",
80 ],
81 package_dir={"": "src"},
82 requires=[],
83 python_requires=">=3.6, <4",
84 extras_require={
85 "brotli": ["brotlipy>=0.6.0"],
86 "secure": [
87 "pyOpenSSL>=0.14",
88 "cryptography>=1.3.4",
89 "idna>=2.0.0",
90 "certifi",
91 ],
92 "socks": ["PySocks>=1.5.6,<2.0,!=1.5.7"],
93 },
94 )
95
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/noxfile.py b/noxfile.py
--- a/noxfile.py
+++ b/noxfile.py
@@ -70,6 +70,20 @@
tests_impl(session)
[email protected](python=["2.7"])
+def unsupported_python2(session):
+ # Can't check both returncode and output with session.run
+ process = subprocess.run(
+ ["python", "setup.py", "install"],
+ env={**session.env},
+ text=True,
+ capture_output=True,
+ )
+ assert process.returncode == 1
+ print(process.stderr)
+ assert "Unsupported Python version" in process.stderr
+
+
@nox.session(python=["3"])
def google_brotli(session):
# https://pypi.org/project/Brotli/ is the Google version of brotli, so
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -4,9 +4,38 @@
import codecs
import os
import re
+import sys
from setuptools import setup
+CURRENT_PYTHON = sys.version_info[:2]
+REQUIRED_PYTHON = (3, 6)
+
+# This check and everything above must remain compatible with Python 2.7.
+if CURRENT_PYTHON < REQUIRED_PYTHON:
+ sys.stderr.write(
+ """
+==========================
+Unsupported Python version
+==========================
+This version of urllib3 requires Python {}.{}, but you're trying to
+install it on Python {}.{}.
+This may be because you are using a version of pip that doesn't
+understand the python_requires classifier. Make sure you
+have pip >= 9.0 and setuptools >= 24.2, then try again:
+ $ python -m pip install --upgrade pip setuptools
+ $ python -m pip install urllib3
+This will install the latest version of urllib3 which works on your
+version of Python. If you can't upgrade your pip (or Python), request
+an older version of urllib3:
+ $ python -m pip install "urllib3<2"
+""".format(
+ *(REQUIRED_PYTHON + CURRENT_PYTHON)
+ )
+ )
+ sys.exit(1)
+
+
base_path = os.path.dirname(__file__)
# Get the version (borrowed from SQLAlchemy)
|
{"golden_diff": "diff --git a/noxfile.py b/noxfile.py\n--- a/noxfile.py\n+++ b/noxfile.py\n@@ -70,6 +70,20 @@\n tests_impl(session)\n \n \[email protected](python=[\"2.7\"])\n+def unsupported_python2(session):\n+ # Can't check both returncode and output with session.run\n+ process = subprocess.run(\n+ [\"python\", \"setup.py\", \"install\"],\n+ env={**session.env},\n+ text=True,\n+ capture_output=True,\n+ )\n+ assert process.returncode == 1\n+ print(process.stderr)\n+ assert \"Unsupported Python version\" in process.stderr\n+\n+\n @nox.session(python=[\"3\"])\n def google_brotli(session):\n # https://pypi.org/project/Brotli/ is the Google version of brotli, so\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -4,9 +4,38 @@\n import codecs\n import os\n import re\n+import sys\n \n from setuptools import setup\n \n+CURRENT_PYTHON = sys.version_info[:2]\n+REQUIRED_PYTHON = (3, 6)\n+\n+# This check and everything above must remain compatible with Python 2.7.\n+if CURRENT_PYTHON < REQUIRED_PYTHON:\n+ sys.stderr.write(\n+ \"\"\"\n+==========================\n+Unsupported Python version\n+==========================\n+This version of urllib3 requires Python {}.{}, but you're trying to\n+install it on Python {}.{}.\n+This may be because you are using a version of pip that doesn't\n+understand the python_requires classifier. Make sure you\n+have pip >= 9.0 and setuptools >= 24.2, then try again:\n+ $ python -m pip install --upgrade pip setuptools\n+ $ python -m pip install urllib3\n+This will install the latest version of urllib3 which works on your\n+version of Python. If you can't upgrade your pip (or Python), request\n+an older version of urllib3:\n+ $ python -m pip install \"urllib3<2\"\n+\"\"\".format(\n+ *(REQUIRED_PYTHON + CURRENT_PYTHON)\n+ )\n+ )\n+ sys.exit(1)\n+\n+\n base_path = os.path.dirname(__file__)\n \n # Get the version (borrowed from SQLAlchemy)\n", "issue": "[v2] Detect unsupported Python versions and raise a helpful ImportError\nWe'll need to ensure our `urllib3/__init__.py` is still Python 2.x compatible for early urllib3 v2.x releases. If we detect an unsupported Python version we raise a helpful error message recommending pinning to `urllib3<2`\n", "before_files": [{"content": "import os\nimport shutil\nimport subprocess\n\nimport nox\n\n# Whenever type-hints are completed on a file it should be added here so that\n# this file will continue to be checked by mypy. Errors from other files are\n# ignored.\nTYPED_FILES = {\n \"src/urllib3/contrib/__init__.py\",\n \"src/urllib3/exceptions.py\",\n \"src/urllib3/fields.py\",\n \"src/urllib3/filepost.py\",\n \"src/urllib3/packages/__init__.py\",\n \"src/urllib3/packages/six.py\",\n \"src/urllib3/packages/ssl_match_hostname/__init__.py\",\n \"src/urllib3/packages/ssl_match_hostname/_implementation.py\",\n \"src/urllib3/util/queue.py\",\n \"src/urllib3/util/url.py\",\n}\nSOURCE_FILES = [\n \"docs/\",\n \"dummyserver/\",\n \"src/\",\n \"test/\",\n \"noxfile.py\",\n \"setup.py\",\n]\n\n\ndef tests_impl(session, extras=\"socks,secure,brotli\"):\n # Install deps and the package itself.\n session.install(\"-r\", \"dev-requirements.txt\")\n session.install(f\".[{extras}]\")\n\n # Show the pip version.\n session.run(\"pip\", \"--version\")\n # Print the Python version and bytesize.\n session.run(\"python\", \"--version\")\n session.run(\"python\", \"-c\", \"import struct; print(struct.calcsize('P') * 8)\")\n # Print OpenSSL information.\n session.run(\"python\", \"-m\", \"OpenSSL.debug\")\n\n # Inspired from https://github.com/pyca/cryptography\n # We use parallel mode and then combine here so that coverage.py will take\n # the paths like .tox/pyXY/lib/pythonX.Y/site-packages/urllib3/__init__.py\n # and collapse them into src/urllib3/__init__.py.\n\n session.run(\n \"coverage\",\n \"run\",\n \"--parallel-mode\",\n \"-m\",\n \"pytest\",\n \"-r\",\n \"a\",\n \"--tb=native\",\n \"--no-success-flaky-report\",\n *(session.posargs or (\"test/\",)),\n env={\"PYTHONWARNINGS\": \"always::DeprecationWarning\"},\n )\n session.run(\"coverage\", \"combine\")\n session.run(\"coverage\", \"report\", \"-m\")\n session.run(\"coverage\", \"xml\")\n\n\[email protected](python=[\"3.6\", \"3.7\", \"3.8\", \"3.9\", \"3.10\", \"pypy\"])\ndef test(session):\n tests_impl(session)\n\n\[email protected](python=[\"3\"])\ndef google_brotli(session):\n # https://pypi.org/project/Brotli/ is the Google version of brotli, so\n # install it separately and don't install our brotli extra (which installs\n # brotlipy).\n session.install(\"brotli\")\n tests_impl(session, extras=\"socks,secure\")\n\n\[email protected]()\ndef format(session):\n \"\"\"Run code formatters.\"\"\"\n session.install(\"black\", \"isort\")\n session.run(\"black\", *SOURCE_FILES)\n session.run(\"isort\", *SOURCE_FILES)\n\n lint(session)\n\n\[email protected]\ndef lint(session):\n session.install(\"flake8\", \"flake8-2020\", \"black\", \"isort\", \"mypy\")\n session.run(\"flake8\", \"--version\")\n session.run(\"black\", \"--version\")\n session.run(\"isort\", \"--version\")\n session.run(\"mypy\", \"--version\")\n session.run(\"black\", \"--check\", *SOURCE_FILES)\n session.run(\"isort\", \"--check\", *SOURCE_FILES)\n session.run(\"flake8\", *SOURCE_FILES)\n\n session.log(\"mypy --strict src/urllib3\")\n all_errors, errors = [], []\n process = subprocess.run(\n [\"mypy\", \"--strict\", \"src/urllib3\"],\n env=session.env,\n text=True,\n stdout=subprocess.PIPE,\n stderr=subprocess.STDOUT,\n )\n # Ensure that mypy itself ran successfully\n assert process.returncode in (0, 1)\n\n for line in process.stdout.split(\"\\n\"):\n all_errors.append(line)\n filepath = line.partition(\":\")[0]\n if filepath.replace(\".pyi\", \".py\") in TYPED_FILES:\n errors.append(line)\n session.log(f\"all errors count: {len(all_errors)}\")\n if errors:\n session.error(\"\\n\" + \"\\n\".join(sorted(set(errors))))\n\n\[email protected]\ndef docs(session):\n session.install(\"-r\", \"docs/requirements.txt\")\n session.install(\".[socks,secure,brotli]\")\n\n session.chdir(\"docs\")\n if os.path.exists(\"_build\"):\n shutil.rmtree(\"_build\")\n session.run(\"sphinx-build\", \"-b\", \"html\", \"-W\", \".\", \"_build/html\")\n", "path": "noxfile.py"}, {"content": "#!/usr/bin/env python\n# This file is protected via CODEOWNERS\n\nimport codecs\nimport os\nimport re\n\nfrom setuptools import setup\n\nbase_path = os.path.dirname(__file__)\n\n# Get the version (borrowed from SQLAlchemy)\nwith open(os.path.join(base_path, \"src\", \"urllib3\", \"_version.py\")) as fp:\n VERSION = (\n re.compile(r\"\"\".*__version__ = [\"'](.*?)['\"]\"\"\", re.S).match(fp.read()).group(1)\n )\n\n\nwith codecs.open(\"README.rst\", encoding=\"utf-8\") as fp:\n # Remove reST raw directive from README as they're not allowed on PyPI\n # Those blocks start with a newline and continue until the next newline\n mode = None\n lines = []\n for line in fp:\n if line.startswith(\".. raw::\"):\n mode = \"ignore_nl\"\n elif line == \"\\n\":\n mode = \"wait_nl\" if mode == \"ignore_nl\" else None\n\n if mode is None:\n lines.append(line)\n readme = \"\".join(lines)\n\nwith codecs.open(\"CHANGES.rst\", encoding=\"utf-8\") as fp:\n changes = fp.read()\n\nversion = VERSION\n\nsetup(\n name=\"urllib3\",\n version=version,\n description=\"HTTP library with thread-safe connection pooling, file post, and more.\",\n long_description=\"\\n\\n\".join([readme, changes]),\n long_description_content_type=\"text/x-rst\",\n classifiers=[\n \"Environment :: Web Environment\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: MIT License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3 :: Only\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n \"Topic :: Internet :: WWW/HTTP\",\n \"Topic :: Software Development :: Libraries\",\n ],\n keywords=\"urllib httplib threadsafe filepost http https ssl pooling\",\n author=\"Andrey Petrov\",\n author_email=\"[email protected]\",\n url=\"https://urllib3.readthedocs.io/\",\n project_urls={\n \"Documentation\": \"https://urllib3.readthedocs.io/\",\n \"Code\": \"https://github.com/urllib3/urllib3\",\n \"Issue tracker\": \"https://github.com/urllib3/urllib3/issues\",\n },\n license=\"MIT\",\n packages=[\n \"urllib3\",\n \"urllib3.packages\",\n \"urllib3.packages.ssl_match_hostname\",\n \"urllib3.packages.backports\",\n \"urllib3.contrib\",\n \"urllib3.contrib._securetransport\",\n \"urllib3.util\",\n ],\n package_dir={\"\": \"src\"},\n requires=[],\n python_requires=\">=3.6, <4\",\n extras_require={\n \"brotli\": [\"brotlipy>=0.6.0\"],\n \"secure\": [\n \"pyOpenSSL>=0.14\",\n \"cryptography>=1.3.4\",\n \"idna>=2.0.0\",\n \"certifi\",\n ],\n \"socks\": [\"PySocks>=1.5.6,<2.0,!=1.5.7\"],\n },\n)\n", "path": "setup.py"}]}
| 2,941 | 511 |
gh_patches_debug_1010
|
rasdani/github-patches
|
git_diff
|
cornellius-gp__gpytorch-871
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug] SumBatchLazyTensor size is inconsistent with indices
# 🐛 Bug
I want to do a KroneckerProductLazyTensor on a batch of lazyTensor `x` times, then SumBatchLazyTensor and then get a specific row and finally evaluate. The code works if I first do an evaluation on the `sum_a` then retrieve the row (which is inefficient) but gives `size is inconsistent with indices` error if I retrieve the row first and then wants to evaluate.
Interestingly, If I use the same number for the dimension -1 and -2, there would be no error then.
## To reproduce
** Code snippet to reproduce **
```python
import gpytorch
x = 3
a = torch.rand((x, 5, 2, 3))
lazy_a = gpytorch.lazy.NonLazyTensor(a)
assert lazy_a.shape == torch.Size([3, 5, 2, 3])
prod_a = gpytorch.lazy.KroneckerProductLazyTensor(*lazy_a)
assert prod_a.shape == torch.Size([5, 8, 27])
sum_a = gpytorch.lazy.SumBatchLazyTensor(prod_a)
assert sum_a.shape == torch.Size([8, 27])
assert sum_a.evaluate()[0].shape == torch.Size([27])
assert sum_a[0].evaluate().shape == torch.Size([27]) # gives error in here
```
** Stack trace/error message **
```
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-251-7cce10ce99d3> in <module>()
8 assert sum_a.shape == torch.Size([8, 27])
9 assert sum_a.evaluate()[0].shape == torch.Size([27])
---> 10 assert sum_a[0].evaluate().shape == torch.Size([27])
11
9 frames
/usr/local/lib/python3.6/dist-packages/gpytorch/lazy/lazy_tensor.py in __getitem__(self, index)
1703 # with the appropriate shape
1704 if (squeeze_row or squeeze_col or row_col_are_absorbed):
-> 1705 res = delazify(res)
1706 if squeeze_row:
1707 res = res.squeeze(-2)
/usr/local/lib/python3.6/dist-packages/gpytorch/lazy/lazy_tensor.py in delazify(obj)
1753 return obj
1754 elif isinstance(obj, LazyTensor):
-> 1755 return obj.evaluate()
1756 else:
1757 raise TypeError("object of class {} cannot be made into a Tensor".format(obj.__class__.__name__))
/usr/local/lib/python3.6/dist-packages/gpytorch/utils/memoize.py in g(self, *args, **kwargs)
32 cache_name = name if name is not None else method
33 if not is_in_cache(self, cache_name):
---> 34 add_to_cache(self, cache_name, method(self, *args, **kwargs))
35 return get_from_cache(self, cache_name)
36
/usr/local/lib/python3.6/dist-packages/gpytorch/lazy/lazy_tensor.py in evaluate(self)
858 eye = torch.eye(num_rows, dtype=self.dtype, device=self.device)
859 eye = eye.expand(*self.batch_shape, num_rows, num_rows)
--> 860 res = self.transpose(-1, -2).matmul(eye).transpose(-1, -2).contiguous()
861 else:
862 eye = torch.eye(num_cols, dtype=self.dtype, device=self.device)
/usr/local/lib/python3.6/dist-packages/gpytorch/lazy/lazy_tensor.py in matmul(self, other)
1093
1094 func = Matmul()
-> 1095 return func.apply(self.representation_tree(), other, *self.representation())
1096
1097 @property
/usr/local/lib/python3.6/dist-packages/gpytorch/functions/_matmul.py in forward(ctx, representation_tree, rhs, *matrix_args)
18
19 lazy_tsr = ctx.representation_tree(*matrix_args)
---> 20 res = lazy_tsr._matmul(rhs)
21
22 to_save = [orig_rhs] + list(matrix_args)
/usr/local/lib/python3.6/dist-packages/gpytorch/lazy/block_lazy_tensor.py in _matmul(self, rhs)
64
65 rhs = self._add_batch_dim(rhs)
---> 66 res = self.base_lazy_tensor._matmul(rhs)
67 res = self._remove_batch_dim(res)
68
/usr/local/lib/python3.6/dist-packages/gpytorch/lazy/interpolated_lazy_tensor.py in _matmul(self, rhs)
157 def _matmul(self, rhs):
158 # Get sparse tensor representations of left/right interp matrices
--> 159 left_interp_t = self._sparse_left_interp_t(self.left_interp_indices, self.left_interp_values)
160 right_interp_t = self._sparse_right_interp_t(self.right_interp_indices, self.right_interp_values)
161
/usr/local/lib/python3.6/dist-packages/gpytorch/lazy/interpolated_lazy_tensor.py in _sparse_left_interp_t(self, left_interp_indices_tensor, left_interp_values_tensor)
309
310 left_interp_t = sparse.make_sparse_from_indices_and_values(
--> 311 left_interp_indices_tensor, left_interp_values_tensor, self.base_lazy_tensor.size()[-1]
312 )
313 self._left_interp_indices_memo = left_interp_indices_tensor
/usr/local/lib/python3.6/dist-packages/gpytorch/utils/sparse.py in make_sparse_from_indices_and_values(interp_indices, interp_values, num_rows)
59 else:
60 cls = getattr(torch.sparse, type_name)
---> 61 res = cls(index_tensor, value_tensor, interp_size)
62
63 # Wrap things as a variable, if necessary
RuntimeError: size is inconsistent with indices: for dim 1, size is 8 but found index 26
```
## Expected Behavior
Expected to pass the tests.
## System information
**Please complete the following information:**
- GPyTorch Version 0.3.5
- PyTorch Version 1.2.0
- Ubuntu 18.04.3 LTS
</issue>
<code>
[start of gpytorch/lazy/sum_batch_lazy_tensor.py]
1 #!/usr/bin/env python3
2
3 import torch
4 from .block_lazy_tensor import BlockLazyTensor
5 from ..utils.broadcasting import _pad_with_singletons
6 from ..utils.getitem import _noop_index
7
8
9 class SumBatchLazyTensor(BlockLazyTensor):
10 """
11 Represents a lazy tensor that is actually the sum of several lazy tensors blocks.
12 The :attr:`block_dim` attribute specifies which dimension of the base LazyTensor
13 specifies the blocks.
14 For example, (with `block_dim=-3` a `k x n x n` tensor represents `k` `n x n` blocks (a `n x n` matrix).
15 A `b x k x n x n` tensor represents `k` `b x n x n` blocks (a `b x n x n` batch matrix).
16
17 Args:
18 :attr:`base_lazy_tensor` (LazyTensor):
19 A `k x n x n` LazyTensor, or a `b x k x n x n` LazyTensor.
20 :attr:`block_dim` (int):
21 The dimension that specifies the blocks.
22 """
23 def _add_batch_dim(self, other):
24 shape = list(other.shape)
25 expand_shape = list(other.shape)
26 shape.insert(-2, 1)
27 expand_shape.insert(-2, self.base_lazy_tensor.size(-3))
28 other = other.reshape(*shape).expand(*expand_shape)
29 return other
30
31 def _get_indices(self, row_index, col_index, *batch_indices):
32 # Create an extra index for the summed dimension
33 sum_index = torch.arange(0, self.base_lazy_tensor.size(-3), device=self.device)
34 sum_index = _pad_with_singletons(sum_index, row_index.dim(), 0)
35 row_index = row_index.unsqueeze(-1)
36 col_index = col_index.unsqueeze(-1)
37 batch_indices = [index.unsqueeze(-1) for index in batch_indices]
38
39 res = self.base_lazy_tensor._get_indices(row_index, col_index, *batch_indices, sum_index)
40 return res.sum(-1)
41
42 def _getitem(self, row_index, col_index, *batch_indices):
43 res = self.base_lazy_tensor._getitem(row_index, col_index, *batch_indices, _noop_index)
44 return self.__class__(res, **self._kwargs)
45
46 def _remove_batch_dim(self, other):
47 return other.sum(-3)
48
49 def _size(self):
50 shape = list(self.base_lazy_tensor.shape)
51 del shape[-3]
52 return torch.Size(shape)
53
54 def diag(self):
55 diag = self.base_lazy_tensor.diag().sum(-2)
56 return diag
57
[end of gpytorch/lazy/sum_batch_lazy_tensor.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/gpytorch/lazy/sum_batch_lazy_tensor.py b/gpytorch/lazy/sum_batch_lazy_tensor.py
--- a/gpytorch/lazy/sum_batch_lazy_tensor.py
+++ b/gpytorch/lazy/sum_batch_lazy_tensor.py
@@ -54,3 +54,6 @@
def diag(self):
diag = self.base_lazy_tensor.diag().sum(-2)
return diag
+
+ def evaluate(self):
+ return self.base_lazy_tensor.evaluate().sum(dim=-3) # BlockLazyTensors always use dim3 for the block_dim
|
{"golden_diff": "diff --git a/gpytorch/lazy/sum_batch_lazy_tensor.py b/gpytorch/lazy/sum_batch_lazy_tensor.py\n--- a/gpytorch/lazy/sum_batch_lazy_tensor.py\n+++ b/gpytorch/lazy/sum_batch_lazy_tensor.py\n@@ -54,3 +54,6 @@\n def diag(self):\n diag = self.base_lazy_tensor.diag().sum(-2)\n return diag\n+\n+ def evaluate(self):\n+ return self.base_lazy_tensor.evaluate().sum(dim=-3) # BlockLazyTensors always use dim3 for the block_dim\n", "issue": "[Bug] SumBatchLazyTensor size is inconsistent with indices\n# \ud83d\udc1b Bug\r\n\r\nI want to do a KroneckerProductLazyTensor on a batch of lazyTensor `x` times, then SumBatchLazyTensor and then get a specific row and finally evaluate. The code works if I first do an evaluation on the `sum_a` then retrieve the row (which is inefficient) but gives `size is inconsistent with indices` error if I retrieve the row first and then wants to evaluate.\r\n\r\nInterestingly, If I use the same number for the dimension -1 and -2, there would be no error then.\r\n\r\n## To reproduce\r\n\r\n** Code snippet to reproduce **\r\n```python\r\nimport gpytorch\r\nx = 3\r\na = torch.rand((x, 5, 2, 3))\r\nlazy_a = gpytorch.lazy.NonLazyTensor(a)\r\nassert lazy_a.shape == torch.Size([3, 5, 2, 3])\r\nprod_a = gpytorch.lazy.KroneckerProductLazyTensor(*lazy_a)\r\nassert prod_a.shape == torch.Size([5, 8, 27])\r\nsum_a = gpytorch.lazy.SumBatchLazyTensor(prod_a)\r\nassert sum_a.shape == torch.Size([8, 27])\r\nassert sum_a.evaluate()[0].shape == torch.Size([27])\r\nassert sum_a[0].evaluate().shape == torch.Size([27]) # gives error in here\r\n```\r\n\r\n** Stack trace/error message **\r\n```\r\n---------------------------------------------------------------------------\r\nRuntimeError Traceback (most recent call last)\r\n<ipython-input-251-7cce10ce99d3> in <module>()\r\n 8 assert sum_a.shape == torch.Size([8, 27])\r\n 9 assert sum_a.evaluate()[0].shape == torch.Size([27])\r\n---> 10 assert sum_a[0].evaluate().shape == torch.Size([27])\r\n 11 \r\n\r\n9 frames\r\n/usr/local/lib/python3.6/dist-packages/gpytorch/lazy/lazy_tensor.py in __getitem__(self, index)\r\n 1703 # with the appropriate shape\r\n 1704 if (squeeze_row or squeeze_col or row_col_are_absorbed):\r\n-> 1705 res = delazify(res)\r\n 1706 if squeeze_row:\r\n 1707 res = res.squeeze(-2)\r\n\r\n/usr/local/lib/python3.6/dist-packages/gpytorch/lazy/lazy_tensor.py in delazify(obj)\r\n 1753 return obj\r\n 1754 elif isinstance(obj, LazyTensor):\r\n-> 1755 return obj.evaluate()\r\n 1756 else:\r\n 1757 raise TypeError(\"object of class {} cannot be made into a Tensor\".format(obj.__class__.__name__))\r\n\r\n/usr/local/lib/python3.6/dist-packages/gpytorch/utils/memoize.py in g(self, *args, **kwargs)\r\n 32 cache_name = name if name is not None else method\r\n 33 if not is_in_cache(self, cache_name):\r\n---> 34 add_to_cache(self, cache_name, method(self, *args, **kwargs))\r\n 35 return get_from_cache(self, cache_name)\r\n 36 \r\n\r\n/usr/local/lib/python3.6/dist-packages/gpytorch/lazy/lazy_tensor.py in evaluate(self)\r\n 858 eye = torch.eye(num_rows, dtype=self.dtype, device=self.device)\r\n 859 eye = eye.expand(*self.batch_shape, num_rows, num_rows)\r\n--> 860 res = self.transpose(-1, -2).matmul(eye).transpose(-1, -2).contiguous()\r\n 861 else:\r\n 862 eye = torch.eye(num_cols, dtype=self.dtype, device=self.device)\r\n\r\n/usr/local/lib/python3.6/dist-packages/gpytorch/lazy/lazy_tensor.py in matmul(self, other)\r\n 1093 \r\n 1094 func = Matmul()\r\n-> 1095 return func.apply(self.representation_tree(), other, *self.representation())\r\n 1096 \r\n 1097 @property\r\n\r\n/usr/local/lib/python3.6/dist-packages/gpytorch/functions/_matmul.py in forward(ctx, representation_tree, rhs, *matrix_args)\r\n 18 \r\n 19 lazy_tsr = ctx.representation_tree(*matrix_args)\r\n---> 20 res = lazy_tsr._matmul(rhs)\r\n 21 \r\n 22 to_save = [orig_rhs] + list(matrix_args)\r\n\r\n/usr/local/lib/python3.6/dist-packages/gpytorch/lazy/block_lazy_tensor.py in _matmul(self, rhs)\r\n 64 \r\n 65 rhs = self._add_batch_dim(rhs)\r\n---> 66 res = self.base_lazy_tensor._matmul(rhs)\r\n 67 res = self._remove_batch_dim(res)\r\n 68 \r\n\r\n/usr/local/lib/python3.6/dist-packages/gpytorch/lazy/interpolated_lazy_tensor.py in _matmul(self, rhs)\r\n 157 def _matmul(self, rhs):\r\n 158 # Get sparse tensor representations of left/right interp matrices\r\n--> 159 left_interp_t = self._sparse_left_interp_t(self.left_interp_indices, self.left_interp_values)\r\n 160 right_interp_t = self._sparse_right_interp_t(self.right_interp_indices, self.right_interp_values)\r\n 161 \r\n\r\n/usr/local/lib/python3.6/dist-packages/gpytorch/lazy/interpolated_lazy_tensor.py in _sparse_left_interp_t(self, left_interp_indices_tensor, left_interp_values_tensor)\r\n 309 \r\n 310 left_interp_t = sparse.make_sparse_from_indices_and_values(\r\n--> 311 left_interp_indices_tensor, left_interp_values_tensor, self.base_lazy_tensor.size()[-1]\r\n 312 )\r\n 313 self._left_interp_indices_memo = left_interp_indices_tensor\r\n\r\n/usr/local/lib/python3.6/dist-packages/gpytorch/utils/sparse.py in make_sparse_from_indices_and_values(interp_indices, interp_values, num_rows)\r\n 59 else:\r\n 60 cls = getattr(torch.sparse, type_name)\r\n---> 61 res = cls(index_tensor, value_tensor, interp_size)\r\n 62 \r\n 63 # Wrap things as a variable, if necessary\r\n\r\nRuntimeError: size is inconsistent with indices: for dim 1, size is 8 but found index 26\r\n```\r\n\r\n## Expected Behavior\r\n\r\nExpected to pass the tests.\r\n\r\n## System information\r\n\r\n**Please complete the following information:**\r\n- GPyTorch Version 0.3.5\r\n- PyTorch Version 1.2.0\r\n- Ubuntu 18.04.3 LTS\r\n\r\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nimport torch\nfrom .block_lazy_tensor import BlockLazyTensor\nfrom ..utils.broadcasting import _pad_with_singletons\nfrom ..utils.getitem import _noop_index\n\n\nclass SumBatchLazyTensor(BlockLazyTensor):\n \"\"\"\n Represents a lazy tensor that is actually the sum of several lazy tensors blocks.\n The :attr:`block_dim` attribute specifies which dimension of the base LazyTensor\n specifies the blocks.\n For example, (with `block_dim=-3` a `k x n x n` tensor represents `k` `n x n` blocks (a `n x n` matrix).\n A `b x k x n x n` tensor represents `k` `b x n x n` blocks (a `b x n x n` batch matrix).\n\n Args:\n :attr:`base_lazy_tensor` (LazyTensor):\n A `k x n x n` LazyTensor, or a `b x k x n x n` LazyTensor.\n :attr:`block_dim` (int):\n The dimension that specifies the blocks.\n \"\"\"\n def _add_batch_dim(self, other):\n shape = list(other.shape)\n expand_shape = list(other.shape)\n shape.insert(-2, 1)\n expand_shape.insert(-2, self.base_lazy_tensor.size(-3))\n other = other.reshape(*shape).expand(*expand_shape)\n return other\n\n def _get_indices(self, row_index, col_index, *batch_indices):\n # Create an extra index for the summed dimension\n sum_index = torch.arange(0, self.base_lazy_tensor.size(-3), device=self.device)\n sum_index = _pad_with_singletons(sum_index, row_index.dim(), 0)\n row_index = row_index.unsqueeze(-1)\n col_index = col_index.unsqueeze(-1)\n batch_indices = [index.unsqueeze(-1) for index in batch_indices]\n\n res = self.base_lazy_tensor._get_indices(row_index, col_index, *batch_indices, sum_index)\n return res.sum(-1)\n\n def _getitem(self, row_index, col_index, *batch_indices):\n res = self.base_lazy_tensor._getitem(row_index, col_index, *batch_indices, _noop_index)\n return self.__class__(res, **self._kwargs)\n\n def _remove_batch_dim(self, other):\n return other.sum(-3)\n\n def _size(self):\n shape = list(self.base_lazy_tensor.shape)\n del shape[-3]\n return torch.Size(shape)\n\n def diag(self):\n diag = self.base_lazy_tensor.diag().sum(-2)\n return diag\n", "path": "gpytorch/lazy/sum_batch_lazy_tensor.py"}]}
| 2,706 | 126 |
gh_patches_debug_40380
|
rasdani/github-patches
|
git_diff
|
aio-libs__aiohttp-7198
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
StreamResponse write() does not raise an exception if client disconnects
### Describe the bug
Hi!
I have an application that uses a `StreamResponse` to continuously write data to the client by calling the `write()` method. The server stops sending data when the client disconnects. In version 3.8.1 the `write()` method raises an exception when the client disconnects, but in later version it does not. The commit that introduces the bug is 20c93656d18b50c17c85b7a1e234276fb1444f27.
I've tested on Python 3.7, 3.8 and 3.10.
### To Reproduce
Add later if really needed.
### Expected behavior
An exception is raised when the client disconnects.
### Logs/tracebacks
```python-traceback
-
```
### Python Version
```console
$ python --version
Python 3.10.7
```
### aiohttp Version
```console
$ python -m pip show aiohttp
Name: aiohttp
Version: 3.8.3
...
```
### multidict Version
```console
-
```
### yarl Version
```console
-
```
### OS
Linux
### Related component
Server
### Additional context
_No response_
### Code of Conduct
- [X] I agree to follow the aio-libs Code of Conduct
</issue>
<code>
[start of aiohttp/base_protocol.py]
1 import asyncio
2 from typing import Optional, cast
3
4 from .tcp_helpers import tcp_nodelay
5
6
7 class BaseProtocol(asyncio.Protocol):
8 __slots__ = (
9 "_loop",
10 "_paused",
11 "_drain_waiter",
12 "_connection_lost",
13 "_reading_paused",
14 "transport",
15 )
16
17 def __init__(self, loop: asyncio.AbstractEventLoop) -> None:
18 self._loop: asyncio.AbstractEventLoop = loop
19 self._paused = False
20 self._drain_waiter: Optional[asyncio.Future[None]] = None
21 self._connection_lost = False
22 self._reading_paused = False
23
24 self.transport: Optional[asyncio.Transport] = None
25
26 def pause_writing(self) -> None:
27 assert not self._paused
28 self._paused = True
29
30 def resume_writing(self) -> None:
31 assert self._paused
32 self._paused = False
33
34 waiter = self._drain_waiter
35 if waiter is not None:
36 self._drain_waiter = None
37 if not waiter.done():
38 waiter.set_result(None)
39
40 def pause_reading(self) -> None:
41 if not self._reading_paused and self.transport is not None:
42 try:
43 self.transport.pause_reading()
44 except (AttributeError, NotImplementedError, RuntimeError):
45 pass
46 self._reading_paused = True
47
48 def resume_reading(self) -> None:
49 if self._reading_paused and self.transport is not None:
50 try:
51 self.transport.resume_reading()
52 except (AttributeError, NotImplementedError, RuntimeError):
53 pass
54 self._reading_paused = False
55
56 def connection_made(self, transport: asyncio.BaseTransport) -> None:
57 tr = cast(asyncio.Transport, transport)
58 tcp_nodelay(tr, True)
59 self.transport = tr
60
61 def connection_lost(self, exc: Optional[BaseException]) -> None:
62 self._connection_lost = True
63 # Wake up the writer if currently paused.
64 self.transport = None
65 if not self._paused:
66 return
67 waiter = self._drain_waiter
68 if waiter is None:
69 return
70 self._drain_waiter = None
71 if waiter.done():
72 return
73 if exc is None:
74 waiter.set_result(None)
75 else:
76 waiter.set_exception(exc)
77
78 async def _drain_helper(self) -> None:
79 if self._connection_lost:
80 raise ConnectionResetError("Connection lost")
81 if not self._paused:
82 return
83 waiter = self._drain_waiter
84 if waiter is None:
85 waiter = self._loop.create_future()
86 self._drain_waiter = waiter
87 await asyncio.shield(waiter)
88
[end of aiohttp/base_protocol.py]
[start of aiohttp/http_writer.py]
1 """Http related parsers and protocol."""
2
3 import asyncio
4 import zlib
5 from typing import Any, Awaitable, Callable, NamedTuple, Optional, Union # noqa
6
7 from multidict import CIMultiDict
8
9 from .abc import AbstractStreamWriter
10 from .base_protocol import BaseProtocol
11 from .helpers import NO_EXTENSIONS
12
13 __all__ = ("StreamWriter", "HttpVersion", "HttpVersion10", "HttpVersion11")
14
15
16 class HttpVersion(NamedTuple):
17 major: int
18 minor: int
19
20
21 HttpVersion10 = HttpVersion(1, 0)
22 HttpVersion11 = HttpVersion(1, 1)
23
24
25 _T_OnChunkSent = Optional[Callable[[bytes], Awaitable[None]]]
26 _T_OnHeadersSent = Optional[Callable[["CIMultiDict[str]"], Awaitable[None]]]
27
28
29 class StreamWriter(AbstractStreamWriter):
30 def __init__(
31 self,
32 protocol: BaseProtocol,
33 loop: asyncio.AbstractEventLoop,
34 on_chunk_sent: _T_OnChunkSent = None,
35 on_headers_sent: _T_OnHeadersSent = None,
36 ) -> None:
37 self._protocol = protocol
38 self._transport = protocol.transport
39
40 self.loop = loop
41 self.length = None
42 self.chunked = False
43 self.buffer_size = 0
44 self.output_size = 0
45
46 self._eof = False
47 self._compress: Any = None
48 self._drain_waiter = None
49
50 self._on_chunk_sent: _T_OnChunkSent = on_chunk_sent
51 self._on_headers_sent: _T_OnHeadersSent = on_headers_sent
52
53 @property
54 def transport(self) -> Optional[asyncio.Transport]:
55 return self._transport
56
57 @property
58 def protocol(self) -> BaseProtocol:
59 return self._protocol
60
61 def enable_chunking(self) -> None:
62 self.chunked = True
63
64 def enable_compression(
65 self, encoding: str = "deflate", strategy: int = zlib.Z_DEFAULT_STRATEGY
66 ) -> None:
67 zlib_mode = 16 + zlib.MAX_WBITS if encoding == "gzip" else zlib.MAX_WBITS
68 self._compress = zlib.compressobj(wbits=zlib_mode, strategy=strategy)
69
70 def _write(self, chunk: bytes) -> None:
71 size = len(chunk)
72 self.buffer_size += size
73 self.output_size += size
74
75 if self._transport is None or self._transport.is_closing():
76 raise ConnectionResetError("Cannot write to closing transport")
77 self._transport.write(chunk)
78
79 async def write(
80 self, chunk: bytes, *, drain: bool = True, LIMIT: int = 0x10000
81 ) -> None:
82 """Writes chunk of data to a stream.
83
84 write_eof() indicates end of stream.
85 writer can't be used after write_eof() method being called.
86 write() return drain future.
87 """
88 if self._on_chunk_sent is not None:
89 await self._on_chunk_sent(chunk)
90
91 if isinstance(chunk, memoryview):
92 if chunk.nbytes != len(chunk):
93 # just reshape it
94 chunk = chunk.cast("c")
95
96 if self._compress is not None:
97 chunk = self._compress.compress(chunk)
98 if not chunk:
99 return
100
101 if self.length is not None:
102 chunk_len = len(chunk)
103 if self.length >= chunk_len:
104 self.length = self.length - chunk_len
105 else:
106 chunk = chunk[: self.length]
107 self.length = 0
108 if not chunk:
109 return
110
111 if chunk:
112 if self.chunked:
113 chunk_len_pre = ("%x\r\n" % len(chunk)).encode("ascii")
114 chunk = chunk_len_pre + chunk + b"\r\n"
115
116 self._write(chunk)
117
118 if self.buffer_size > LIMIT and drain:
119 self.buffer_size = 0
120 await self.drain()
121
122 async def write_headers(
123 self, status_line: str, headers: "CIMultiDict[str]"
124 ) -> None:
125 """Write request/response status and headers."""
126 if self._on_headers_sent is not None:
127 await self._on_headers_sent(headers)
128
129 # status + headers
130 buf = _serialize_headers(status_line, headers)
131 self._write(buf)
132
133 async def write_eof(self, chunk: bytes = b"") -> None:
134 if self._eof:
135 return
136
137 if chunk and self._on_chunk_sent is not None:
138 await self._on_chunk_sent(chunk)
139
140 if self._compress:
141 if chunk:
142 chunk = self._compress.compress(chunk)
143
144 chunk = chunk + self._compress.flush()
145 if chunk and self.chunked:
146 chunk_len = ("%x\r\n" % len(chunk)).encode("ascii")
147 chunk = chunk_len + chunk + b"\r\n0\r\n\r\n"
148 else:
149 if self.chunked:
150 if chunk:
151 chunk_len = ("%x\r\n" % len(chunk)).encode("ascii")
152 chunk = chunk_len + chunk + b"\r\n0\r\n\r\n"
153 else:
154 chunk = b"0\r\n\r\n"
155
156 if chunk:
157 self._write(chunk)
158
159 await self.drain()
160
161 self._eof = True
162 self._transport = None
163
164 async def drain(self) -> None:
165 """Flush the write buffer.
166
167 The intended use is to write
168
169 await w.write(data)
170 await w.drain()
171 """
172 if self._protocol.transport is not None:
173 await self._protocol._drain_helper()
174
175
176 def _safe_header(string: str) -> str:
177 if "\r" in string or "\n" in string:
178 raise ValueError(
179 "Newline or carriage return detected in headers. "
180 "Potential header injection attack."
181 )
182 return string
183
184
185 def _py_serialize_headers(status_line: str, headers: "CIMultiDict[str]") -> bytes:
186 headers_gen = (_safe_header(k) + ": " + _safe_header(v) for k, v in headers.items())
187 line = status_line + "\r\n" + "\r\n".join(headers_gen) + "\r\n\r\n"
188 return line.encode("utf-8")
189
190
191 _serialize_headers = _py_serialize_headers
192
193 try:
194 import aiohttp._http_writer as _http_writer # type: ignore[import]
195
196 _c_serialize_headers = _http_writer._serialize_headers
197 if not NO_EXTENSIONS:
198 _serialize_headers = _c_serialize_headers
199 except ImportError:
200 pass
201
[end of aiohttp/http_writer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/aiohttp/base_protocol.py b/aiohttp/base_protocol.py
--- a/aiohttp/base_protocol.py
+++ b/aiohttp/base_protocol.py
@@ -18,11 +18,15 @@
self._loop: asyncio.AbstractEventLoop = loop
self._paused = False
self._drain_waiter: Optional[asyncio.Future[None]] = None
- self._connection_lost = False
self._reading_paused = False
self.transport: Optional[asyncio.Transport] = None
+ @property
+ def connected(self) -> bool:
+ """Return True if the connection is open."""
+ return self.transport is not None
+
def pause_writing(self) -> None:
assert not self._paused
self._paused = True
@@ -59,7 +63,6 @@
self.transport = tr
def connection_lost(self, exc: Optional[BaseException]) -> None:
- self._connection_lost = True
# Wake up the writer if currently paused.
self.transport = None
if not self._paused:
@@ -76,7 +79,7 @@
waiter.set_exception(exc)
async def _drain_helper(self) -> None:
- if self._connection_lost:
+ if not self.connected:
raise ConnectionResetError("Connection lost")
if not self._paused:
return
diff --git a/aiohttp/http_writer.py b/aiohttp/http_writer.py
--- a/aiohttp/http_writer.py
+++ b/aiohttp/http_writer.py
@@ -35,7 +35,6 @@
on_headers_sent: _T_OnHeadersSent = None,
) -> None:
self._protocol = protocol
- self._transport = protocol.transport
self.loop = loop
self.length = None
@@ -52,7 +51,7 @@
@property
def transport(self) -> Optional[asyncio.Transport]:
- return self._transport
+ return self._protocol.transport
@property
def protocol(self) -> BaseProtocol:
@@ -71,10 +70,10 @@
size = len(chunk)
self.buffer_size += size
self.output_size += size
-
- if self._transport is None or self._transport.is_closing():
+ transport = self.transport
+ if not self._protocol.connected or transport is None or transport.is_closing():
raise ConnectionResetError("Cannot write to closing transport")
- self._transport.write(chunk)
+ transport.write(chunk)
async def write(
self, chunk: bytes, *, drain: bool = True, LIMIT: int = 0x10000
@@ -159,7 +158,6 @@
await self.drain()
self._eof = True
- self._transport = None
async def drain(self) -> None:
"""Flush the write buffer.
|
{"golden_diff": "diff --git a/aiohttp/base_protocol.py b/aiohttp/base_protocol.py\n--- a/aiohttp/base_protocol.py\n+++ b/aiohttp/base_protocol.py\n@@ -18,11 +18,15 @@\n self._loop: asyncio.AbstractEventLoop = loop\n self._paused = False\n self._drain_waiter: Optional[asyncio.Future[None]] = None\n- self._connection_lost = False\n self._reading_paused = False\n \n self.transport: Optional[asyncio.Transport] = None\n \n+ @property\n+ def connected(self) -> bool:\n+ \"\"\"Return True if the connection is open.\"\"\"\n+ return self.transport is not None\n+\n def pause_writing(self) -> None:\n assert not self._paused\n self._paused = True\n@@ -59,7 +63,6 @@\n self.transport = tr\n \n def connection_lost(self, exc: Optional[BaseException]) -> None:\n- self._connection_lost = True\n # Wake up the writer if currently paused.\n self.transport = None\n if not self._paused:\n@@ -76,7 +79,7 @@\n waiter.set_exception(exc)\n \n async def _drain_helper(self) -> None:\n- if self._connection_lost:\n+ if not self.connected:\n raise ConnectionResetError(\"Connection lost\")\n if not self._paused:\n return\ndiff --git a/aiohttp/http_writer.py b/aiohttp/http_writer.py\n--- a/aiohttp/http_writer.py\n+++ b/aiohttp/http_writer.py\n@@ -35,7 +35,6 @@\n on_headers_sent: _T_OnHeadersSent = None,\n ) -> None:\n self._protocol = protocol\n- self._transport = protocol.transport\n \n self.loop = loop\n self.length = None\n@@ -52,7 +51,7 @@\n \n @property\n def transport(self) -> Optional[asyncio.Transport]:\n- return self._transport\n+ return self._protocol.transport\n \n @property\n def protocol(self) -> BaseProtocol:\n@@ -71,10 +70,10 @@\n size = len(chunk)\n self.buffer_size += size\n self.output_size += size\n-\n- if self._transport is None or self._transport.is_closing():\n+ transport = self.transport\n+ if not self._protocol.connected or transport is None or transport.is_closing():\n raise ConnectionResetError(\"Cannot write to closing transport\")\n- self._transport.write(chunk)\n+ transport.write(chunk)\n \n async def write(\n self, chunk: bytes, *, drain: bool = True, LIMIT: int = 0x10000\n@@ -159,7 +158,6 @@\n await self.drain()\n \n self._eof = True\n- self._transport = None\n \n async def drain(self) -> None:\n \"\"\"Flush the write buffer.\n", "issue": "StreamResponse write() does not raise an exception if client disconnects\n### Describe the bug\n\nHi!\r\n\r\nI have an application that uses a `StreamResponse` to continuously write data to the client by calling the `write()` method. The server stops sending data when the client disconnects. In version 3.8.1 the `write()` method raises an exception when the client disconnects, but in later version it does not. The commit that introduces the bug is 20c93656d18b50c17c85b7a1e234276fb1444f27.\r\n\r\nI've tested on Python 3.7, 3.8 and 3.10.\n\n### To Reproduce\n\nAdd later if really needed.\n\n### Expected behavior\n\nAn exception is raised when the client disconnects.\n\n### Logs/tracebacks\n\n```python-traceback\n-\n```\n\n\n### Python Version\n\n```console\n$ python --version\r\nPython 3.10.7\n```\n\n\n### aiohttp Version\n\n```console\n$ python -m pip show aiohttp\r\nName: aiohttp\r\nVersion: 3.8.3\r\n...\n```\n\n\n### multidict Version\n\n```console\n-\n```\n\n\n### yarl Version\n\n```console\n-\n```\n\n\n### OS\n\nLinux\n\n### Related component\n\nServer\n\n### Additional context\n\n_No response_\n\n### Code of Conduct\n\n- [X] I agree to follow the aio-libs Code of Conduct\n", "before_files": [{"content": "import asyncio\nfrom typing import Optional, cast\n\nfrom .tcp_helpers import tcp_nodelay\n\n\nclass BaseProtocol(asyncio.Protocol):\n __slots__ = (\n \"_loop\",\n \"_paused\",\n \"_drain_waiter\",\n \"_connection_lost\",\n \"_reading_paused\",\n \"transport\",\n )\n\n def __init__(self, loop: asyncio.AbstractEventLoop) -> None:\n self._loop: asyncio.AbstractEventLoop = loop\n self._paused = False\n self._drain_waiter: Optional[asyncio.Future[None]] = None\n self._connection_lost = False\n self._reading_paused = False\n\n self.transport: Optional[asyncio.Transport] = None\n\n def pause_writing(self) -> None:\n assert not self._paused\n self._paused = True\n\n def resume_writing(self) -> None:\n assert self._paused\n self._paused = False\n\n waiter = self._drain_waiter\n if waiter is not None:\n self._drain_waiter = None\n if not waiter.done():\n waiter.set_result(None)\n\n def pause_reading(self) -> None:\n if not self._reading_paused and self.transport is not None:\n try:\n self.transport.pause_reading()\n except (AttributeError, NotImplementedError, RuntimeError):\n pass\n self._reading_paused = True\n\n def resume_reading(self) -> None:\n if self._reading_paused and self.transport is not None:\n try:\n self.transport.resume_reading()\n except (AttributeError, NotImplementedError, RuntimeError):\n pass\n self._reading_paused = False\n\n def connection_made(self, transport: asyncio.BaseTransport) -> None:\n tr = cast(asyncio.Transport, transport)\n tcp_nodelay(tr, True)\n self.transport = tr\n\n def connection_lost(self, exc: Optional[BaseException]) -> None:\n self._connection_lost = True\n # Wake up the writer if currently paused.\n self.transport = None\n if not self._paused:\n return\n waiter = self._drain_waiter\n if waiter is None:\n return\n self._drain_waiter = None\n if waiter.done():\n return\n if exc is None:\n waiter.set_result(None)\n else:\n waiter.set_exception(exc)\n\n async def _drain_helper(self) -> None:\n if self._connection_lost:\n raise ConnectionResetError(\"Connection lost\")\n if not self._paused:\n return\n waiter = self._drain_waiter\n if waiter is None:\n waiter = self._loop.create_future()\n self._drain_waiter = waiter\n await asyncio.shield(waiter)\n", "path": "aiohttp/base_protocol.py"}, {"content": "\"\"\"Http related parsers and protocol.\"\"\"\n\nimport asyncio\nimport zlib\nfrom typing import Any, Awaitable, Callable, NamedTuple, Optional, Union # noqa\n\nfrom multidict import CIMultiDict\n\nfrom .abc import AbstractStreamWriter\nfrom .base_protocol import BaseProtocol\nfrom .helpers import NO_EXTENSIONS\n\n__all__ = (\"StreamWriter\", \"HttpVersion\", \"HttpVersion10\", \"HttpVersion11\")\n\n\nclass HttpVersion(NamedTuple):\n major: int\n minor: int\n\n\nHttpVersion10 = HttpVersion(1, 0)\nHttpVersion11 = HttpVersion(1, 1)\n\n\n_T_OnChunkSent = Optional[Callable[[bytes], Awaitable[None]]]\n_T_OnHeadersSent = Optional[Callable[[\"CIMultiDict[str]\"], Awaitable[None]]]\n\n\nclass StreamWriter(AbstractStreamWriter):\n def __init__(\n self,\n protocol: BaseProtocol,\n loop: asyncio.AbstractEventLoop,\n on_chunk_sent: _T_OnChunkSent = None,\n on_headers_sent: _T_OnHeadersSent = None,\n ) -> None:\n self._protocol = protocol\n self._transport = protocol.transport\n\n self.loop = loop\n self.length = None\n self.chunked = False\n self.buffer_size = 0\n self.output_size = 0\n\n self._eof = False\n self._compress: Any = None\n self._drain_waiter = None\n\n self._on_chunk_sent: _T_OnChunkSent = on_chunk_sent\n self._on_headers_sent: _T_OnHeadersSent = on_headers_sent\n\n @property\n def transport(self) -> Optional[asyncio.Transport]:\n return self._transport\n\n @property\n def protocol(self) -> BaseProtocol:\n return self._protocol\n\n def enable_chunking(self) -> None:\n self.chunked = True\n\n def enable_compression(\n self, encoding: str = \"deflate\", strategy: int = zlib.Z_DEFAULT_STRATEGY\n ) -> None:\n zlib_mode = 16 + zlib.MAX_WBITS if encoding == \"gzip\" else zlib.MAX_WBITS\n self._compress = zlib.compressobj(wbits=zlib_mode, strategy=strategy)\n\n def _write(self, chunk: bytes) -> None:\n size = len(chunk)\n self.buffer_size += size\n self.output_size += size\n\n if self._transport is None or self._transport.is_closing():\n raise ConnectionResetError(\"Cannot write to closing transport\")\n self._transport.write(chunk)\n\n async def write(\n self, chunk: bytes, *, drain: bool = True, LIMIT: int = 0x10000\n ) -> None:\n \"\"\"Writes chunk of data to a stream.\n\n write_eof() indicates end of stream.\n writer can't be used after write_eof() method being called.\n write() return drain future.\n \"\"\"\n if self._on_chunk_sent is not None:\n await self._on_chunk_sent(chunk)\n\n if isinstance(chunk, memoryview):\n if chunk.nbytes != len(chunk):\n # just reshape it\n chunk = chunk.cast(\"c\")\n\n if self._compress is not None:\n chunk = self._compress.compress(chunk)\n if not chunk:\n return\n\n if self.length is not None:\n chunk_len = len(chunk)\n if self.length >= chunk_len:\n self.length = self.length - chunk_len\n else:\n chunk = chunk[: self.length]\n self.length = 0\n if not chunk:\n return\n\n if chunk:\n if self.chunked:\n chunk_len_pre = (\"%x\\r\\n\" % len(chunk)).encode(\"ascii\")\n chunk = chunk_len_pre + chunk + b\"\\r\\n\"\n\n self._write(chunk)\n\n if self.buffer_size > LIMIT and drain:\n self.buffer_size = 0\n await self.drain()\n\n async def write_headers(\n self, status_line: str, headers: \"CIMultiDict[str]\"\n ) -> None:\n \"\"\"Write request/response status and headers.\"\"\"\n if self._on_headers_sent is not None:\n await self._on_headers_sent(headers)\n\n # status + headers\n buf = _serialize_headers(status_line, headers)\n self._write(buf)\n\n async def write_eof(self, chunk: bytes = b\"\") -> None:\n if self._eof:\n return\n\n if chunk and self._on_chunk_sent is not None:\n await self._on_chunk_sent(chunk)\n\n if self._compress:\n if chunk:\n chunk = self._compress.compress(chunk)\n\n chunk = chunk + self._compress.flush()\n if chunk and self.chunked:\n chunk_len = (\"%x\\r\\n\" % len(chunk)).encode(\"ascii\")\n chunk = chunk_len + chunk + b\"\\r\\n0\\r\\n\\r\\n\"\n else:\n if self.chunked:\n if chunk:\n chunk_len = (\"%x\\r\\n\" % len(chunk)).encode(\"ascii\")\n chunk = chunk_len + chunk + b\"\\r\\n0\\r\\n\\r\\n\"\n else:\n chunk = b\"0\\r\\n\\r\\n\"\n\n if chunk:\n self._write(chunk)\n\n await self.drain()\n\n self._eof = True\n self._transport = None\n\n async def drain(self) -> None:\n \"\"\"Flush the write buffer.\n\n The intended use is to write\n\n await w.write(data)\n await w.drain()\n \"\"\"\n if self._protocol.transport is not None:\n await self._protocol._drain_helper()\n\n\ndef _safe_header(string: str) -> str:\n if \"\\r\" in string or \"\\n\" in string:\n raise ValueError(\n \"Newline or carriage return detected in headers. \"\n \"Potential header injection attack.\"\n )\n return string\n\n\ndef _py_serialize_headers(status_line: str, headers: \"CIMultiDict[str]\") -> bytes:\n headers_gen = (_safe_header(k) + \": \" + _safe_header(v) for k, v in headers.items())\n line = status_line + \"\\r\\n\" + \"\\r\\n\".join(headers_gen) + \"\\r\\n\\r\\n\"\n return line.encode(\"utf-8\")\n\n\n_serialize_headers = _py_serialize_headers\n\ntry:\n import aiohttp._http_writer as _http_writer # type: ignore[import]\n\n _c_serialize_headers = _http_writer._serialize_headers\n if not NO_EXTENSIONS:\n _serialize_headers = _c_serialize_headers\nexcept ImportError:\n pass\n", "path": "aiohttp/http_writer.py"}]}
| 3,544 | 647 |
gh_patches_debug_4580
|
rasdani/github-patches
|
git_diff
|
pypa__pip-5136
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Name normalization issue in 10.0.0b1 yields false-positive installation warnings
* Pip version: 10.0.0b1
* Python version: 2.7.14
* Operating system: Linux
### Description:
The new pip check mode used during installation wrongly reports that packages are not being installed. This only happens for package containing a `.` (dot) in the name.
### What I've run:
```
pip install pyramid
Collecting pyramid
Using cached pyramid-1.9.1-py2.py3-none-any.whl
Collecting zope.interface>=3.8.0 (from pyramid)
Using cached zope.interface-4.4.3-cp36-cp36m-manylinux1_x86_64.whl
Collecting hupper (from pyramid)
Using cached hupper-1.1-py2.py3-none-any.whl
Collecting zope.deprecation>=3.5.0 (from pyramid)
Using cached zope.deprecation-4.3.0-py2.py3-none-any.whl
Collecting translationstring>=0.4 (from pyramid)
Using cached translationstring-1.3-py2.py3-none-any.whl
Requirement already satisfied: setuptools in ./venv-ex/lib/python3.6/site-packages (from pyramid) (39.0.1)
Collecting WebOb>=1.7.0rc2 (from pyramid)
Using cached WebOb-1.8.0rc1-py2.py3-none-any.whl
Collecting venusian>=1.0a3 (from pyramid)
Using cached venusian-1.1.0-py2.py3-none-any.whl
Collecting repoze.lru>=0.4 (from pyramid)
Using cached repoze.lru-0.7-py3-none-any.whl
Collecting plaster-pastedeploy (from pyramid)
Using cached plaster_pastedeploy-0.5-py2.py3-none-any.whl
Collecting PasteDeploy>=1.5.0 (from pyramid)
Using cached PasteDeploy-1.5.2-py2.py3-none-any.whl
Collecting plaster (from pyramid)
Using cached plaster-1.0-py2.py3-none-any.whl
pyramid 1.9.1 requires repoze.lru>=0.4, which is not installed.
pyramid 1.9.1 requires zope.deprecation>=3.5.0, which is not installed.
pyramid 1.9.1 requires zope.interface>=3.8.0, which is not installed.
Installing collected packages: zope.interface, hupper, zope.deprecation, translationstring, WebOb, venusian, repoze.lru, PasteDeploy, plaster, plaster-pastedeploy, pyramid
Successfully installed PasteDeploy-1.5.2 WebOb-1.8.0rc1 hupper-1.1 plaster-1.0 plaster-pastedeploy-0.5 pyramid-1.9.1 repoze.lru-0.7 translationstring-1.3 venusian-1.1.0 zope.deprecation-4.3.0 zope.interface-4.4.3
```
</issue>
<code>
[start of src/pip/_internal/operations/check.py]
1 """Validation of dependencies of packages
2 """
3
4 from collections import namedtuple
5
6 from pip._vendor.packaging.utils import canonicalize_name
7
8 from pip._internal.operations.prepare import make_abstract_dist
9
10 from pip._internal.utils.misc import get_installed_distributions
11 from pip._internal.utils.typing import MYPY_CHECK_RUNNING
12
13 if MYPY_CHECK_RUNNING:
14 from pip._internal.req.req_install import InstallRequirement
15 from typing import Any, Dict, Iterator, Set, Tuple, List
16
17 # Shorthands
18 PackageSet = Dict[str, 'PackageDetails']
19 Missing = Tuple[str, Any]
20 Conflicting = Tuple[str, str, Any]
21
22 MissingDict = Dict[str, List[Missing]]
23 ConflictingDict = Dict[str, List[Conflicting]]
24 CheckResult = Tuple[MissingDict, ConflictingDict]
25
26 PackageDetails = namedtuple('PackageDetails', ['version', 'requires'])
27
28
29 def create_package_set_from_installed(**kwargs):
30 # type: (**Any) -> PackageSet
31 """Converts a list of distributions into a PackageSet.
32 """
33 retval = {}
34 for dist in get_installed_distributions(**kwargs):
35 name = canonicalize_name(dist.project_name)
36 retval[name] = PackageDetails(dist.version, dist.requires())
37 return retval
38
39
40 def check_package_set(package_set):
41 # type: (PackageSet) -> CheckResult
42 """Check if a package set is consistent
43 """
44 missing = dict()
45 conflicting = dict()
46
47 for package_name in package_set:
48 # Info about dependencies of package_name
49 missing_deps = set() # type: Set[Missing]
50 conflicting_deps = set() # type: Set[Conflicting]
51
52 for req in package_set[package_name].requires:
53 name = canonicalize_name(req.project_name) # type: str
54
55 # Check if it's missing
56 if name not in package_set:
57 missed = True
58 if req.marker is not None:
59 missed = req.marker.evaluate()
60 if missed:
61 missing_deps.add((name, req))
62 continue
63
64 # Check if there's a conflict
65 version = package_set[name].version # type: str
66 if version not in req.specifier:
67 conflicting_deps.add((name, version, req))
68
69 def str_key(x):
70 return str(x)
71
72 if missing_deps:
73 missing[package_name] = sorted(missing_deps, key=str_key)
74 if conflicting_deps:
75 conflicting[package_name] = sorted(conflicting_deps, key=str_key)
76
77 return missing, conflicting
78
79
80 def check_install_conflicts(to_install):
81 # type: (List[InstallRequirement]) -> Tuple[PackageSet, CheckResult]
82 """For checking if the dependency graph would be consistent after \
83 installing given requirements
84 """
85 # Start from the current state
86 state = create_package_set_from_installed()
87 _simulate_installation_of(to_install, state)
88 return state, check_package_set(state)
89
90
91 # NOTE from @pradyunsg
92 # This required a minor update in dependency link handling logic over at
93 # operations.prepare.IsSDist.dist() to get it working
94 def _simulate_installation_of(to_install, state):
95 # type: (List[InstallRequirement], PackageSet) -> None
96 """Computes the version of packages after installing to_install.
97 """
98
99 # Modify it as installing requirement_set would (assuming no errors)
100 for inst_req in to_install:
101 dist = make_abstract_dist(inst_req).dist(finder=None)
102 state[dist.key] = PackageDetails(dist.version, dist.requires())
103
[end of src/pip/_internal/operations/check.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/pip/_internal/operations/check.py b/src/pip/_internal/operations/check.py
--- a/src/pip/_internal/operations/check.py
+++ b/src/pip/_internal/operations/check.py
@@ -99,4 +99,5 @@
# Modify it as installing requirement_set would (assuming no errors)
for inst_req in to_install:
dist = make_abstract_dist(inst_req).dist(finder=None)
- state[dist.key] = PackageDetails(dist.version, dist.requires())
+ name = canonicalize_name(dist.key)
+ state[name] = PackageDetails(dist.version, dist.requires())
|
{"golden_diff": "diff --git a/src/pip/_internal/operations/check.py b/src/pip/_internal/operations/check.py\n--- a/src/pip/_internal/operations/check.py\n+++ b/src/pip/_internal/operations/check.py\n@@ -99,4 +99,5 @@\n # Modify it as installing requirement_set would (assuming no errors)\n for inst_req in to_install:\n dist = make_abstract_dist(inst_req).dist(finder=None)\n- state[dist.key] = PackageDetails(dist.version, dist.requires())\n+ name = canonicalize_name(dist.key)\n+ state[name] = PackageDetails(dist.version, dist.requires())\n", "issue": "Name normalization issue in 10.0.0b1 yields false-positive installation warnings\n* Pip version: 10.0.0b1\r\n* Python version: 2.7.14\r\n* Operating system: Linux\r\n\r\n### Description:\r\n\r\nThe new pip check mode used during installation wrongly reports that packages are not being installed. This only happens for package containing a `.` (dot) in the name.\r\n\r\n### What I've run:\r\n\r\n```\r\npip install pyramid\r\nCollecting pyramid\r\n Using cached pyramid-1.9.1-py2.py3-none-any.whl\r\nCollecting zope.interface>=3.8.0 (from pyramid)\r\n Using cached zope.interface-4.4.3-cp36-cp36m-manylinux1_x86_64.whl\r\nCollecting hupper (from pyramid)\r\n Using cached hupper-1.1-py2.py3-none-any.whl\r\nCollecting zope.deprecation>=3.5.0 (from pyramid)\r\n Using cached zope.deprecation-4.3.0-py2.py3-none-any.whl\r\nCollecting translationstring>=0.4 (from pyramid)\r\n Using cached translationstring-1.3-py2.py3-none-any.whl\r\nRequirement already satisfied: setuptools in ./venv-ex/lib/python3.6/site-packages (from pyramid) (39.0.1)\r\nCollecting WebOb>=1.7.0rc2 (from pyramid)\r\n Using cached WebOb-1.8.0rc1-py2.py3-none-any.whl\r\nCollecting venusian>=1.0a3 (from pyramid)\r\n Using cached venusian-1.1.0-py2.py3-none-any.whl\r\nCollecting repoze.lru>=0.4 (from pyramid)\r\n Using cached repoze.lru-0.7-py3-none-any.whl\r\nCollecting plaster-pastedeploy (from pyramid)\r\n Using cached plaster_pastedeploy-0.5-py2.py3-none-any.whl\r\nCollecting PasteDeploy>=1.5.0 (from pyramid)\r\n Using cached PasteDeploy-1.5.2-py2.py3-none-any.whl\r\nCollecting plaster (from pyramid)\r\n Using cached plaster-1.0-py2.py3-none-any.whl\r\npyramid 1.9.1 requires repoze.lru>=0.4, which is not installed.\r\npyramid 1.9.1 requires zope.deprecation>=3.5.0, which is not installed.\r\npyramid 1.9.1 requires zope.interface>=3.8.0, which is not installed.\r\nInstalling collected packages: zope.interface, hupper, zope.deprecation, translationstring, WebOb, venusian, repoze.lru, PasteDeploy, plaster, plaster-pastedeploy, pyramid\r\nSuccessfully installed PasteDeploy-1.5.2 WebOb-1.8.0rc1 hupper-1.1 plaster-1.0 plaster-pastedeploy-0.5 pyramid-1.9.1 repoze.lru-0.7 translationstring-1.3 venusian-1.1.0 zope.deprecation-4.3.0 zope.interface-4.4.3\r\n```\r\n\n", "before_files": [{"content": "\"\"\"Validation of dependencies of packages\n\"\"\"\n\nfrom collections import namedtuple\n\nfrom pip._vendor.packaging.utils import canonicalize_name\n\nfrom pip._internal.operations.prepare import make_abstract_dist\n\nfrom pip._internal.utils.misc import get_installed_distributions\nfrom pip._internal.utils.typing import MYPY_CHECK_RUNNING\n\nif MYPY_CHECK_RUNNING:\n from pip._internal.req.req_install import InstallRequirement\n from typing import Any, Dict, Iterator, Set, Tuple, List\n\n # Shorthands\n PackageSet = Dict[str, 'PackageDetails']\n Missing = Tuple[str, Any]\n Conflicting = Tuple[str, str, Any]\n\n MissingDict = Dict[str, List[Missing]]\n ConflictingDict = Dict[str, List[Conflicting]]\n CheckResult = Tuple[MissingDict, ConflictingDict]\n\nPackageDetails = namedtuple('PackageDetails', ['version', 'requires'])\n\n\ndef create_package_set_from_installed(**kwargs):\n # type: (**Any) -> PackageSet\n \"\"\"Converts a list of distributions into a PackageSet.\n \"\"\"\n retval = {}\n for dist in get_installed_distributions(**kwargs):\n name = canonicalize_name(dist.project_name)\n retval[name] = PackageDetails(dist.version, dist.requires())\n return retval\n\n\ndef check_package_set(package_set):\n # type: (PackageSet) -> CheckResult\n \"\"\"Check if a package set is consistent\n \"\"\"\n missing = dict()\n conflicting = dict()\n\n for package_name in package_set:\n # Info about dependencies of package_name\n missing_deps = set() # type: Set[Missing]\n conflicting_deps = set() # type: Set[Conflicting]\n\n for req in package_set[package_name].requires:\n name = canonicalize_name(req.project_name) # type: str\n\n # Check if it's missing\n if name not in package_set:\n missed = True\n if req.marker is not None:\n missed = req.marker.evaluate()\n if missed:\n missing_deps.add((name, req))\n continue\n\n # Check if there's a conflict\n version = package_set[name].version # type: str\n if version not in req.specifier:\n conflicting_deps.add((name, version, req))\n\n def str_key(x):\n return str(x)\n\n if missing_deps:\n missing[package_name] = sorted(missing_deps, key=str_key)\n if conflicting_deps:\n conflicting[package_name] = sorted(conflicting_deps, key=str_key)\n\n return missing, conflicting\n\n\ndef check_install_conflicts(to_install):\n # type: (List[InstallRequirement]) -> Tuple[PackageSet, CheckResult]\n \"\"\"For checking if the dependency graph would be consistent after \\\n installing given requirements\n \"\"\"\n # Start from the current state\n state = create_package_set_from_installed()\n _simulate_installation_of(to_install, state)\n return state, check_package_set(state)\n\n\n# NOTE from @pradyunsg\n# This required a minor update in dependency link handling logic over at\n# operations.prepare.IsSDist.dist() to get it working\ndef _simulate_installation_of(to_install, state):\n # type: (List[InstallRequirement], PackageSet) -> None\n \"\"\"Computes the version of packages after installing to_install.\n \"\"\"\n\n # Modify it as installing requirement_set would (assuming no errors)\n for inst_req in to_install:\n dist = make_abstract_dist(inst_req).dist(finder=None)\n state[dist.key] = PackageDetails(dist.version, dist.requires())\n", "path": "src/pip/_internal/operations/check.py"}]}
| 2,219 | 136 |
gh_patches_debug_33145
|
rasdani/github-patches
|
git_diff
|
inventree__InvenTree-3538
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[FR]Unit test for Schema allowance
**Is your feature request the result of a bug?**
#3414 #3411
**Problem**
Custom schema settings are not e2e or unit-tested in the API.
**Suggested solution**
Add tests
**Describe alternatives you've considered**
N/A
**Examples of other systems**
N/A
**Do you want to develop this?**
Yes
</issue>
<code>
[start of InvenTree/InvenTree/fields.py]
1 """Custom fields used in InvenTree."""
2
3 import sys
4 from decimal import Decimal
5
6 from django import forms
7 from django.core import validators
8 from django.db import models as models
9 from django.utils.translation import gettext_lazy as _
10
11 from djmoney.forms.fields import MoneyField
12 from djmoney.models.fields import MoneyField as ModelMoneyField
13 from djmoney.models.validators import MinMoneyValidator
14 from rest_framework.fields import URLField as RestURLField
15
16 import InvenTree.helpers
17
18 from .validators import allowable_url_schemes
19
20
21 class InvenTreeRestURLField(RestURLField):
22 """Custom field for DRF with custom scheme vaildators."""
23 def __init__(self, **kwargs):
24 """Update schemes."""
25
26 # Enforce 'max length' parameter in form validation
27 if 'max_length' not in kwargs:
28 kwargs['max_length'] = 200
29
30 super().__init__(**kwargs)
31 self.validators[-1].schemes = allowable_url_schemes()
32
33
34 class InvenTreeURLField(models.URLField):
35 """Custom URL field which has custom scheme validators."""
36
37 default_validators = [validators.URLValidator(schemes=allowable_url_schemes())]
38
39 def __init__(self, **kwargs):
40 """Initialization method for InvenTreeURLField"""
41
42 # Max length for InvenTreeURLField defaults to 200
43 if 'max_length' not in kwargs:
44 kwargs['max_length'] = 200
45
46 super().__init__(**kwargs)
47
48
49 def money_kwargs():
50 """Returns the database settings for MoneyFields."""
51 from common.settings import currency_code_default, currency_code_mappings
52
53 kwargs = {}
54 kwargs['currency_choices'] = currency_code_mappings()
55 kwargs['default_currency'] = currency_code_default()
56 return kwargs
57
58
59 class InvenTreeModelMoneyField(ModelMoneyField):
60 """Custom MoneyField for clean migrations while using dynamic currency settings."""
61
62 def __init__(self, **kwargs):
63 """Overwrite default values and validators."""
64 # detect if creating migration
65 if 'migrate' in sys.argv or 'makemigrations' in sys.argv:
66 # remove currency information for a clean migration
67 kwargs['default_currency'] = ''
68 kwargs['currency_choices'] = []
69 else:
70 # set defaults
71 kwargs.update(money_kwargs())
72
73 # Set a minimum value validator
74 validators = kwargs.get('validators', [])
75
76 allow_negative = kwargs.pop('allow_negative', False)
77
78 # If no validators are provided, add some "standard" ones
79 if len(validators) == 0:
80
81 if not allow_negative:
82 validators.append(
83 MinMoneyValidator(0),
84 )
85
86 kwargs['validators'] = validators
87
88 super().__init__(**kwargs)
89
90 def formfield(self, **kwargs):
91 """Override form class to use own function."""
92 kwargs['form_class'] = InvenTreeMoneyField
93 return super().formfield(**kwargs)
94
95
96 class InvenTreeMoneyField(MoneyField):
97 """Custom MoneyField for clean migrations while using dynamic currency settings."""
98 def __init__(self, *args, **kwargs):
99 """Override initial values with the real info from database."""
100 kwargs.update(money_kwargs())
101 super().__init__(*args, **kwargs)
102
103
104 class DatePickerFormField(forms.DateField):
105 """Custom date-picker field."""
106
107 def __init__(self, **kwargs):
108 """Set up custom values."""
109 help_text = kwargs.get('help_text', _('Enter date'))
110 label = kwargs.get('label', None)
111 required = kwargs.get('required', False)
112 initial = kwargs.get('initial', None)
113
114 widget = forms.DateInput(
115 attrs={
116 'type': 'date',
117 }
118 )
119
120 forms.DateField.__init__(
121 self,
122 required=required,
123 initial=initial,
124 help_text=help_text,
125 widget=widget,
126 label=label
127 )
128
129
130 def round_decimal(value, places):
131 """Round value to the specified number of places."""
132 if value is not None:
133 # see https://docs.python.org/2/library/decimal.html#decimal.Decimal.quantize for options
134 return value.quantize(Decimal(10) ** -places)
135 return value
136
137
138 class RoundingDecimalFormField(forms.DecimalField):
139 """Custom FormField that automatically rounds inputs."""
140
141 def to_python(self, value):
142 """Convert value to python type."""
143 value = super().to_python(value)
144 value = round_decimal(value, self.decimal_places)
145 return value
146
147 def prepare_value(self, value):
148 """Override the 'prepare_value' method, to remove trailing zeros when displaying.
149
150 Why? It looks nice!
151 """
152 if type(value) == Decimal:
153 return InvenTree.helpers.normalize(value)
154 else:
155 return value
156
157
158 class RoundingDecimalField(models.DecimalField):
159 """Custom Field that automatically rounds inputs."""
160
161 def to_python(self, value):
162 """Convert value to python type."""
163 value = super().to_python(value)
164 return round_decimal(value, self.decimal_places)
165
166 def formfield(self, **kwargs):
167 """Return a Field instance for this field."""
168
169 kwargs['form_class'] = RoundingDecimalFormField
170
171 return super().formfield(**kwargs)
172
173
174 class InvenTreeNotesField(models.TextField):
175 """Custom implementation of a 'notes' field"""
176
177 # Maximum character limit for the various 'notes' fields
178 NOTES_MAX_LENGTH = 50000
179
180 def __init__(self, **kwargs):
181 """Configure default initial values for this field"""
182 kwargs['max_length'] = self.NOTES_MAX_LENGTH
183 kwargs['verbose_name'] = _('Notes')
184 kwargs['blank'] = True
185 kwargs['null'] = True
186
187 super().__init__(**kwargs)
188
[end of InvenTree/InvenTree/fields.py]
[start of InvenTree/InvenTree/validators.py]
1 """Custom field validators for InvenTree."""
2
3 import re
4 from decimal import Decimal, InvalidOperation
5
6 from django.conf import settings
7 from django.core.exceptions import FieldDoesNotExist, ValidationError
8 from django.utils.translation import gettext_lazy as _
9
10 from moneyed import CURRENCIES
11
12 import common.models
13
14
15 def validate_currency_code(code):
16 """Check that a given code is a valid currency code."""
17 if code not in CURRENCIES:
18 raise ValidationError(_('Not a valid currency code'))
19
20
21 def allowable_url_schemes():
22 """Return the list of allowable URL schemes.
23
24 In addition to the default schemes allowed by Django,
25 the install configuration file (config.yaml) can specify
26 extra schemas
27 """
28 # Default schemes
29 schemes = ['http', 'https', 'ftp', 'ftps']
30
31 extra = settings.EXTRA_URL_SCHEMES
32
33 for e in extra:
34 if e.lower() not in schemes:
35 schemes.append(e.lower())
36
37 return schemes
38
39
40 def validate_part_name(value):
41 """Prevent some illegal characters in part names."""
42 for c in ['|', '#', '$', '{', '}']:
43 if c in str(value):
44 raise ValidationError(
45 _('Invalid character in part name')
46 )
47
48
49 def validate_part_ipn(value):
50 """Validate the Part IPN against regex rule."""
51 pattern = common.models.InvenTreeSetting.get_setting('PART_IPN_REGEX')
52
53 if pattern:
54 match = re.search(pattern, value)
55
56 if match is None:
57 raise ValidationError(_('IPN must match regex pattern {pat}').format(pat=pattern))
58
59
60 def validate_purchase_order_reference(value):
61 """Validate the 'reference' field of a PurchaseOrder."""
62 pattern = common.models.InvenTreeSetting.get_setting('PURCHASEORDER_REFERENCE_REGEX')
63
64 if pattern:
65 match = re.search(pattern, value)
66
67 if match is None:
68 raise ValidationError(_('Reference must match pattern {pattern}').format(pattern=pattern))
69
70
71 def validate_sales_order_reference(value):
72 """Validate the 'reference' field of a SalesOrder."""
73 pattern = common.models.InvenTreeSetting.get_setting('SALESORDER_REFERENCE_REGEX')
74
75 if pattern:
76 match = re.search(pattern, value)
77
78 if match is None:
79 raise ValidationError(_('Reference must match pattern {pattern}').format(pattern=pattern))
80
81
82 def validate_tree_name(value):
83 """Placeholder for legacy function used in migrations."""
84
85
86 def validate_overage(value):
87 """Validate that a BOM overage string is properly formatted.
88
89 An overage string can look like:
90
91 - An integer number ('1' / 3 / 4)
92 - A decimal number ('0.123')
93 - A percentage ('5%' / '10 %')
94 """
95 value = str(value).lower().strip()
96
97 # First look for a simple numerical value
98 try:
99 i = Decimal(value)
100
101 if i < 0:
102 raise ValidationError(_("Overage value must not be negative"))
103
104 # Looks like a number
105 return True
106 except (ValueError, InvalidOperation):
107 pass
108
109 # Now look for a percentage value
110 if value.endswith('%'):
111 v = value[:-1].strip()
112
113 # Does it look like a number?
114 try:
115 f = float(v)
116
117 if f < 0:
118 raise ValidationError(_("Overage value must not be negative"))
119 elif f > 100:
120 raise ValidationError(_("Overage must not exceed 100%"))
121
122 return True
123 except ValueError:
124 pass
125
126 raise ValidationError(
127 _("Invalid value for overage")
128 )
129
130
131 def validate_part_name_format(self):
132 """Validate part name format.
133
134 Make sure that each template container has a field of Part Model
135 """
136 jinja_template_regex = re.compile('{{.*?}}')
137 field_name_regex = re.compile('(?<=part\\.)[A-z]+')
138 for jinja_template in jinja_template_regex.findall(str(self)):
139 # make sure at least one and only one field is present inside the parser
140 field_names = field_name_regex.findall(jinja_template)
141 if len(field_names) < 1:
142 raise ValidationError({
143 'value': 'At least one field must be present inside a jinja template container i.e {{}}'
144 })
145
146 # Make sure that the field_name exists in Part model
147 from part.models import Part
148
149 for field_name in field_names:
150 try:
151 Part._meta.get_field(field_name)
152 except FieldDoesNotExist:
153 raise ValidationError({
154 'value': f'{field_name} does not exist in Part Model'
155 })
156
157 return True
158
[end of InvenTree/InvenTree/validators.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/InvenTree/InvenTree/fields.py b/InvenTree/InvenTree/fields.py
--- a/InvenTree/InvenTree/fields.py
+++ b/InvenTree/InvenTree/fields.py
@@ -4,7 +4,6 @@
from decimal import Decimal
from django import forms
-from django.core import validators
from django.db import models as models
from django.utils.translation import gettext_lazy as _
@@ -15,7 +14,7 @@
import InvenTree.helpers
-from .validators import allowable_url_schemes
+from .validators import AllowedURLValidator, allowable_url_schemes
class InvenTreeRestURLField(RestURLField):
@@ -34,7 +33,7 @@
class InvenTreeURLField(models.URLField):
"""Custom URL field which has custom scheme validators."""
- default_validators = [validators.URLValidator(schemes=allowable_url_schemes())]
+ default_validators = [AllowedURLValidator()]
def __init__(self, **kwargs):
"""Initialization method for InvenTreeURLField"""
diff --git a/InvenTree/InvenTree/validators.py b/InvenTree/InvenTree/validators.py
--- a/InvenTree/InvenTree/validators.py
+++ b/InvenTree/InvenTree/validators.py
@@ -4,6 +4,7 @@
from decimal import Decimal, InvalidOperation
from django.conf import settings
+from django.core import validators
from django.core.exceptions import FieldDoesNotExist, ValidationError
from django.utils.translation import gettext_lazy as _
@@ -37,6 +38,14 @@
return schemes
+class AllowedURLValidator(validators.URLValidator):
+ """Custom URL validator to allow for custom schemes."""
+ def __call__(self, value):
+ """Validate the URL."""
+ self.schemes = allowable_url_schemes()
+ super().__call__(value)
+
+
def validate_part_name(value):
"""Prevent some illegal characters in part names."""
for c in ['|', '#', '$', '{', '}']:
|
{"golden_diff": "diff --git a/InvenTree/InvenTree/fields.py b/InvenTree/InvenTree/fields.py\n--- a/InvenTree/InvenTree/fields.py\n+++ b/InvenTree/InvenTree/fields.py\n@@ -4,7 +4,6 @@\n from decimal import Decimal\n \n from django import forms\n-from django.core import validators\n from django.db import models as models\n from django.utils.translation import gettext_lazy as _\n \n@@ -15,7 +14,7 @@\n \n import InvenTree.helpers\n \n-from .validators import allowable_url_schemes\n+from .validators import AllowedURLValidator, allowable_url_schemes\n \n \n class InvenTreeRestURLField(RestURLField):\n@@ -34,7 +33,7 @@\n class InvenTreeURLField(models.URLField):\n \"\"\"Custom URL field which has custom scheme validators.\"\"\"\n \n- default_validators = [validators.URLValidator(schemes=allowable_url_schemes())]\n+ default_validators = [AllowedURLValidator()]\n \n def __init__(self, **kwargs):\n \"\"\"Initialization method for InvenTreeURLField\"\"\"\ndiff --git a/InvenTree/InvenTree/validators.py b/InvenTree/InvenTree/validators.py\n--- a/InvenTree/InvenTree/validators.py\n+++ b/InvenTree/InvenTree/validators.py\n@@ -4,6 +4,7 @@\n from decimal import Decimal, InvalidOperation\n \n from django.conf import settings\n+from django.core import validators\n from django.core.exceptions import FieldDoesNotExist, ValidationError\n from django.utils.translation import gettext_lazy as _\n \n@@ -37,6 +38,14 @@\n return schemes\n \n \n+class AllowedURLValidator(validators.URLValidator):\n+ \"\"\"Custom URL validator to allow for custom schemes.\"\"\"\n+ def __call__(self, value):\n+ \"\"\"Validate the URL.\"\"\"\n+ self.schemes = allowable_url_schemes()\n+ super().__call__(value)\n+\n+\n def validate_part_name(value):\n \"\"\"Prevent some illegal characters in part names.\"\"\"\n for c in ['|', '#', '$', '{', '}']:\n", "issue": "[FR]Unit test for Schema allowance\n**Is your feature request the result of a bug?**\r\n#3414 #3411\r\n\r\n**Problem**\r\nCustom schema settings are not e2e or unit-tested in the API.\r\n\r\n**Suggested solution**\r\nAdd tests\r\n\r\n**Describe alternatives you've considered**\r\nN/A\r\n\r\n**Examples of other systems**\r\nN/A\r\n\r\n**Do you want to develop this?**\r\nYes\r\n\n", "before_files": [{"content": "\"\"\"Custom fields used in InvenTree.\"\"\"\n\nimport sys\nfrom decimal import Decimal\n\nfrom django import forms\nfrom django.core import validators\nfrom django.db import models as models\nfrom django.utils.translation import gettext_lazy as _\n\nfrom djmoney.forms.fields import MoneyField\nfrom djmoney.models.fields import MoneyField as ModelMoneyField\nfrom djmoney.models.validators import MinMoneyValidator\nfrom rest_framework.fields import URLField as RestURLField\n\nimport InvenTree.helpers\n\nfrom .validators import allowable_url_schemes\n\n\nclass InvenTreeRestURLField(RestURLField):\n \"\"\"Custom field for DRF with custom scheme vaildators.\"\"\"\n def __init__(self, **kwargs):\n \"\"\"Update schemes.\"\"\"\n\n # Enforce 'max length' parameter in form validation\n if 'max_length' not in kwargs:\n kwargs['max_length'] = 200\n\n super().__init__(**kwargs)\n self.validators[-1].schemes = allowable_url_schemes()\n\n\nclass InvenTreeURLField(models.URLField):\n \"\"\"Custom URL field which has custom scheme validators.\"\"\"\n\n default_validators = [validators.URLValidator(schemes=allowable_url_schemes())]\n\n def __init__(self, **kwargs):\n \"\"\"Initialization method for InvenTreeURLField\"\"\"\n\n # Max length for InvenTreeURLField defaults to 200\n if 'max_length' not in kwargs:\n kwargs['max_length'] = 200\n\n super().__init__(**kwargs)\n\n\ndef money_kwargs():\n \"\"\"Returns the database settings for MoneyFields.\"\"\"\n from common.settings import currency_code_default, currency_code_mappings\n\n kwargs = {}\n kwargs['currency_choices'] = currency_code_mappings()\n kwargs['default_currency'] = currency_code_default()\n return kwargs\n\n\nclass InvenTreeModelMoneyField(ModelMoneyField):\n \"\"\"Custom MoneyField for clean migrations while using dynamic currency settings.\"\"\"\n\n def __init__(self, **kwargs):\n \"\"\"Overwrite default values and validators.\"\"\"\n # detect if creating migration\n if 'migrate' in sys.argv or 'makemigrations' in sys.argv:\n # remove currency information for a clean migration\n kwargs['default_currency'] = ''\n kwargs['currency_choices'] = []\n else:\n # set defaults\n kwargs.update(money_kwargs())\n\n # Set a minimum value validator\n validators = kwargs.get('validators', [])\n\n allow_negative = kwargs.pop('allow_negative', False)\n\n # If no validators are provided, add some \"standard\" ones\n if len(validators) == 0:\n\n if not allow_negative:\n validators.append(\n MinMoneyValidator(0),\n )\n\n kwargs['validators'] = validators\n\n super().__init__(**kwargs)\n\n def formfield(self, **kwargs):\n \"\"\"Override form class to use own function.\"\"\"\n kwargs['form_class'] = InvenTreeMoneyField\n return super().formfield(**kwargs)\n\n\nclass InvenTreeMoneyField(MoneyField):\n \"\"\"Custom MoneyField for clean migrations while using dynamic currency settings.\"\"\"\n def __init__(self, *args, **kwargs):\n \"\"\"Override initial values with the real info from database.\"\"\"\n kwargs.update(money_kwargs())\n super().__init__(*args, **kwargs)\n\n\nclass DatePickerFormField(forms.DateField):\n \"\"\"Custom date-picker field.\"\"\"\n\n def __init__(self, **kwargs):\n \"\"\"Set up custom values.\"\"\"\n help_text = kwargs.get('help_text', _('Enter date'))\n label = kwargs.get('label', None)\n required = kwargs.get('required', False)\n initial = kwargs.get('initial', None)\n\n widget = forms.DateInput(\n attrs={\n 'type': 'date',\n }\n )\n\n forms.DateField.__init__(\n self,\n required=required,\n initial=initial,\n help_text=help_text,\n widget=widget,\n label=label\n )\n\n\ndef round_decimal(value, places):\n \"\"\"Round value to the specified number of places.\"\"\"\n if value is not None:\n # see https://docs.python.org/2/library/decimal.html#decimal.Decimal.quantize for options\n return value.quantize(Decimal(10) ** -places)\n return value\n\n\nclass RoundingDecimalFormField(forms.DecimalField):\n \"\"\"Custom FormField that automatically rounds inputs.\"\"\"\n\n def to_python(self, value):\n \"\"\"Convert value to python type.\"\"\"\n value = super().to_python(value)\n value = round_decimal(value, self.decimal_places)\n return value\n\n def prepare_value(self, value):\n \"\"\"Override the 'prepare_value' method, to remove trailing zeros when displaying.\n\n Why? It looks nice!\n \"\"\"\n if type(value) == Decimal:\n return InvenTree.helpers.normalize(value)\n else:\n return value\n\n\nclass RoundingDecimalField(models.DecimalField):\n \"\"\"Custom Field that automatically rounds inputs.\"\"\"\n\n def to_python(self, value):\n \"\"\"Convert value to python type.\"\"\"\n value = super().to_python(value)\n return round_decimal(value, self.decimal_places)\n\n def formfield(self, **kwargs):\n \"\"\"Return a Field instance for this field.\"\"\"\n\n kwargs['form_class'] = RoundingDecimalFormField\n\n return super().formfield(**kwargs)\n\n\nclass InvenTreeNotesField(models.TextField):\n \"\"\"Custom implementation of a 'notes' field\"\"\"\n\n # Maximum character limit for the various 'notes' fields\n NOTES_MAX_LENGTH = 50000\n\n def __init__(self, **kwargs):\n \"\"\"Configure default initial values for this field\"\"\"\n kwargs['max_length'] = self.NOTES_MAX_LENGTH\n kwargs['verbose_name'] = _('Notes')\n kwargs['blank'] = True\n kwargs['null'] = True\n\n super().__init__(**kwargs)\n", "path": "InvenTree/InvenTree/fields.py"}, {"content": "\"\"\"Custom field validators for InvenTree.\"\"\"\n\nimport re\nfrom decimal import Decimal, InvalidOperation\n\nfrom django.conf import settings\nfrom django.core.exceptions import FieldDoesNotExist, ValidationError\nfrom django.utils.translation import gettext_lazy as _\n\nfrom moneyed import CURRENCIES\n\nimport common.models\n\n\ndef validate_currency_code(code):\n \"\"\"Check that a given code is a valid currency code.\"\"\"\n if code not in CURRENCIES:\n raise ValidationError(_('Not a valid currency code'))\n\n\ndef allowable_url_schemes():\n \"\"\"Return the list of allowable URL schemes.\n\n In addition to the default schemes allowed by Django,\n the install configuration file (config.yaml) can specify\n extra schemas\n \"\"\"\n # Default schemes\n schemes = ['http', 'https', 'ftp', 'ftps']\n\n extra = settings.EXTRA_URL_SCHEMES\n\n for e in extra:\n if e.lower() not in schemes:\n schemes.append(e.lower())\n\n return schemes\n\n\ndef validate_part_name(value):\n \"\"\"Prevent some illegal characters in part names.\"\"\"\n for c in ['|', '#', '$', '{', '}']:\n if c in str(value):\n raise ValidationError(\n _('Invalid character in part name')\n )\n\n\ndef validate_part_ipn(value):\n \"\"\"Validate the Part IPN against regex rule.\"\"\"\n pattern = common.models.InvenTreeSetting.get_setting('PART_IPN_REGEX')\n\n if pattern:\n match = re.search(pattern, value)\n\n if match is None:\n raise ValidationError(_('IPN must match regex pattern {pat}').format(pat=pattern))\n\n\ndef validate_purchase_order_reference(value):\n \"\"\"Validate the 'reference' field of a PurchaseOrder.\"\"\"\n pattern = common.models.InvenTreeSetting.get_setting('PURCHASEORDER_REFERENCE_REGEX')\n\n if pattern:\n match = re.search(pattern, value)\n\n if match is None:\n raise ValidationError(_('Reference must match pattern {pattern}').format(pattern=pattern))\n\n\ndef validate_sales_order_reference(value):\n \"\"\"Validate the 'reference' field of a SalesOrder.\"\"\"\n pattern = common.models.InvenTreeSetting.get_setting('SALESORDER_REFERENCE_REGEX')\n\n if pattern:\n match = re.search(pattern, value)\n\n if match is None:\n raise ValidationError(_('Reference must match pattern {pattern}').format(pattern=pattern))\n\n\ndef validate_tree_name(value):\n \"\"\"Placeholder for legacy function used in migrations.\"\"\"\n\n\ndef validate_overage(value):\n \"\"\"Validate that a BOM overage string is properly formatted.\n\n An overage string can look like:\n\n - An integer number ('1' / 3 / 4)\n - A decimal number ('0.123')\n - A percentage ('5%' / '10 %')\n \"\"\"\n value = str(value).lower().strip()\n\n # First look for a simple numerical value\n try:\n i = Decimal(value)\n\n if i < 0:\n raise ValidationError(_(\"Overage value must not be negative\"))\n\n # Looks like a number\n return True\n except (ValueError, InvalidOperation):\n pass\n\n # Now look for a percentage value\n if value.endswith('%'):\n v = value[:-1].strip()\n\n # Does it look like a number?\n try:\n f = float(v)\n\n if f < 0:\n raise ValidationError(_(\"Overage value must not be negative\"))\n elif f > 100:\n raise ValidationError(_(\"Overage must not exceed 100%\"))\n\n return True\n except ValueError:\n pass\n\n raise ValidationError(\n _(\"Invalid value for overage\")\n )\n\n\ndef validate_part_name_format(self):\n \"\"\"Validate part name format.\n\n Make sure that each template container has a field of Part Model\n \"\"\"\n jinja_template_regex = re.compile('{{.*?}}')\n field_name_regex = re.compile('(?<=part\\\\.)[A-z]+')\n for jinja_template in jinja_template_regex.findall(str(self)):\n # make sure at least one and only one field is present inside the parser\n field_names = field_name_regex.findall(jinja_template)\n if len(field_names) < 1:\n raise ValidationError({\n 'value': 'At least one field must be present inside a jinja template container i.e {{}}'\n })\n\n # Make sure that the field_name exists in Part model\n from part.models import Part\n\n for field_name in field_names:\n try:\n Part._meta.get_field(field_name)\n except FieldDoesNotExist:\n raise ValidationError({\n 'value': f'{field_name} does not exist in Part Model'\n })\n\n return True\n", "path": "InvenTree/InvenTree/validators.py"}]}
| 3,733 | 460 |
gh_patches_debug_4138
|
rasdani/github-patches
|
git_diff
|
google__turbinia-793
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
path_spec.parent is None exception
```
FsstatTask Task failed with exception: ['NoneType' object has no attribute 'type_indicator']
Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/turbinia-20210208.4.dev19+g7c02e5e-py3.6.egg/turbinia/workers/__init__.py", line 881, in run_wrapper
self.evidence_setup(evidence)
File "/usr/local/lib/python3.6/dist-packages/turbinia-20210208.4.dev19+g7c02e5e-py3.6.egg/turbinia/workers/__init__.py", line 499, in evidence_setup
evidence.preprocess(self.tmp_dir, required_states=self.REQUIRED_STATES)
File "/usr/local/lib/python3.6/dist-packages/turbinia-20210208.4.dev19+g7c02e5e-py3.6.egg/turbinia/evidence.py", line 341, in preprocess
self._preprocess(tmp_dir, required_states)
File "/usr/local/lib/python3.6/dist-packages/turbinia-20210208.4.dev19+g7c02e5e-py3.6.egg/turbinia/evidence.py", line 575, in _preprocess
encryption_type = partitions.GetPartitionEncryptionType(path_spec)
File "/usr/local/lib/python3.6/dist-packages/turbinia-20210208.4.dev19+g7c02e5e-py3.6.egg/turbinia/processors/partitions.py", line 66, in GetPartitionEncryptionType
if path_spec.parent.type_indicator == dfvfs_definitions.TYPE_INDICATOR_BDE:
AttributeError: 'NoneType' object has no attribute 'type_indicator'
No state_manager initialized, not updating Task info
Trying last ditch attempt to close result
Task Result was auto-closed from task executor on turbinia-worker-6eaf93e7aee7c9cf-0 likely due to previous failures. Previous status: [FsstatTask Task failed with exception: ['NoneType' object has no attribute 'type_indicator']]
Task Result was auto-closed from task executor on turbinia-worker-6eaf93e7aee7c9cf-0 likely due to previous failures. Previous status: [FsstatTask Task failed with exception: ['NoneType' object has no attribute 'type_indicator']]
```
</issue>
<code>
[start of turbinia/processors/partitions.py]
1 # -*- coding: utf-8 -*-
2 # Copyright 2021 Google LLC
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # https://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 """Evidence processor to enumerate partitions."""
16
17 import logging
18
19 from dfvfs.helpers import volume_scanner
20 from dfvfs.lib import definitions as dfvfs_definitions
21 from dfvfs.lib import errors as dfvfs_errors
22
23 from turbinia.lib.dfvfs_classes import UnattendedVolumeScannerMediator
24 from turbinia import TurbiniaException
25
26 log = logging.getLogger('turbinia')
27
28
29 def Enumerate(evidence):
30 """Uses dfVFS to enumerate partitions in a disk / image.
31
32 Args:
33 evidence: Evidence object to be scanned.
34
35 Raises:
36 TurbiniaException if source evidence can't be scanned.
37
38 Returns:
39 list[dfVFS.path_spec]: path specs for identified partitions
40 """
41 dfvfs_definitions.PREFERRED_GPT_BACK_END = (
42 dfvfs_definitions.TYPE_INDICATOR_GPT)
43 mediator = UnattendedVolumeScannerMediator()
44 mediator.credentials = evidence.credentials
45 path_specs = []
46 try:
47 scanner = volume_scanner.VolumeScanner(mediator=mediator)
48 path_specs = scanner.GetBasePathSpecs(evidence.local_path)
49 except dfvfs_errors.ScannerError as e:
50 raise TurbiniaException(
51 'Could not enumerate partitions [{0!s}]: {1!s}'.format(
52 evidence.local_path, e))
53
54 return path_specs
55
56
57 def GetPartitionEncryptionType(path_spec):
58 """Checks a partition for encryption.
59
60 Args:
61 path_spec (dfVFS.path_spec): Partition path_spec.
62
63 Returns:
64 String representing the type of encryption, or None.
65 """
66 encryption_type = None
67 if path_spec.parent.type_indicator == dfvfs_definitions.TYPE_INDICATOR_BDE:
68 encryption_type = 'BDE'
69 return encryption_type
70
71
72 def GetPathSpecByLocation(path_specs, location):
73 """Finds a path_spec from a list of path_specs for a given location.
74
75 Args:
76 path_specs (list[dfVFS.path_spec]): List of path_specs from volume scanner.
77 location (str): dfVFS location to search for.
78
79 Returns:
80 dfVFS.path_spec for the given location or None if not found.
81 """
82 for path_spec in path_specs:
83 child_path_spec = path_spec
84 fs_location = getattr(path_spec, 'location', None)
85 while path_spec.HasParent():
86 type_indicator = path_spec.type_indicator
87 if type_indicator in (dfvfs_definitions.TYPE_INDICATOR_TSK_PARTITION,
88 dfvfs_definitions.TYPE_INDICATOR_GPT):
89 if fs_location in ('\\', '/'):
90 fs_location = getattr(path_spec, 'location', None)
91 break
92 path_spec = path_spec.parent
93 if fs_location == location:
94 return child_path_spec
95 return None
96
[end of turbinia/processors/partitions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/turbinia/processors/partitions.py b/turbinia/processors/partitions.py
--- a/turbinia/processors/partitions.py
+++ b/turbinia/processors/partitions.py
@@ -64,6 +64,10 @@
String representing the type of encryption, or None.
"""
encryption_type = None
+
+ if not path_spec.HasParent():
+ return None
+
if path_spec.parent.type_indicator == dfvfs_definitions.TYPE_INDICATOR_BDE:
encryption_type = 'BDE'
return encryption_type
|
{"golden_diff": "diff --git a/turbinia/processors/partitions.py b/turbinia/processors/partitions.py\n--- a/turbinia/processors/partitions.py\n+++ b/turbinia/processors/partitions.py\n@@ -64,6 +64,10 @@\n String representing the type of encryption, or None.\n \"\"\"\n encryption_type = None\n+\n+ if not path_spec.HasParent():\n+ return None\n+\n if path_spec.parent.type_indicator == dfvfs_definitions.TYPE_INDICATOR_BDE:\n encryption_type = 'BDE'\n return encryption_type\n", "issue": "path_spec.parent is None exception\n```\r\nFsstatTask Task failed with exception: ['NoneType' object has no attribute 'type_indicator']\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.6/dist-packages/turbinia-20210208.4.dev19+g7c02e5e-py3.6.egg/turbinia/workers/__init__.py\", line 881, in run_wrapper\r\n self.evidence_setup(evidence)\r\n File \"/usr/local/lib/python3.6/dist-packages/turbinia-20210208.4.dev19+g7c02e5e-py3.6.egg/turbinia/workers/__init__.py\", line 499, in evidence_setup\r\n evidence.preprocess(self.tmp_dir, required_states=self.REQUIRED_STATES)\r\n File \"/usr/local/lib/python3.6/dist-packages/turbinia-20210208.4.dev19+g7c02e5e-py3.6.egg/turbinia/evidence.py\", line 341, in preprocess\r\n self._preprocess(tmp_dir, required_states)\r\n File \"/usr/local/lib/python3.6/dist-packages/turbinia-20210208.4.dev19+g7c02e5e-py3.6.egg/turbinia/evidence.py\", line 575, in _preprocess\r\n encryption_type = partitions.GetPartitionEncryptionType(path_spec)\r\n File \"/usr/local/lib/python3.6/dist-packages/turbinia-20210208.4.dev19+g7c02e5e-py3.6.egg/turbinia/processors/partitions.py\", line 66, in GetPartitionEncryptionType\r\n if path_spec.parent.type_indicator == dfvfs_definitions.TYPE_INDICATOR_BDE:\r\nAttributeError: 'NoneType' object has no attribute 'type_indicator'\r\n\r\nNo state_manager initialized, not updating Task info\r\nTrying last ditch attempt to close result\r\nTask Result was auto-closed from task executor on turbinia-worker-6eaf93e7aee7c9cf-0 likely due to previous failures. Previous status: [FsstatTask Task failed with exception: ['NoneType' object has no attribute 'type_indicator']]\r\nTask Result was auto-closed from task executor on turbinia-worker-6eaf93e7aee7c9cf-0 likely due to previous failures. Previous status: [FsstatTask Task failed with exception: ['NoneType' object has no attribute 'type_indicator']]\r\n```\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright 2021 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Evidence processor to enumerate partitions.\"\"\"\n\nimport logging\n\nfrom dfvfs.helpers import volume_scanner\nfrom dfvfs.lib import definitions as dfvfs_definitions\nfrom dfvfs.lib import errors as dfvfs_errors\n\nfrom turbinia.lib.dfvfs_classes import UnattendedVolumeScannerMediator\nfrom turbinia import TurbiniaException\n\nlog = logging.getLogger('turbinia')\n\n\ndef Enumerate(evidence):\n \"\"\"Uses dfVFS to enumerate partitions in a disk / image.\n\n Args:\n evidence: Evidence object to be scanned.\n\n Raises:\n TurbiniaException if source evidence can't be scanned.\n\n Returns:\n list[dfVFS.path_spec]: path specs for identified partitions\n \"\"\"\n dfvfs_definitions.PREFERRED_GPT_BACK_END = (\n dfvfs_definitions.TYPE_INDICATOR_GPT)\n mediator = UnattendedVolumeScannerMediator()\n mediator.credentials = evidence.credentials\n path_specs = []\n try:\n scanner = volume_scanner.VolumeScanner(mediator=mediator)\n path_specs = scanner.GetBasePathSpecs(evidence.local_path)\n except dfvfs_errors.ScannerError as e:\n raise TurbiniaException(\n 'Could not enumerate partitions [{0!s}]: {1!s}'.format(\n evidence.local_path, e))\n\n return path_specs\n\n\ndef GetPartitionEncryptionType(path_spec):\n \"\"\"Checks a partition for encryption.\n\n Args:\n path_spec (dfVFS.path_spec): Partition path_spec.\n\n Returns:\n String representing the type of encryption, or None.\n \"\"\"\n encryption_type = None\n if path_spec.parent.type_indicator == dfvfs_definitions.TYPE_INDICATOR_BDE:\n encryption_type = 'BDE'\n return encryption_type\n\n\ndef GetPathSpecByLocation(path_specs, location):\n \"\"\"Finds a path_spec from a list of path_specs for a given location.\n\n Args:\n path_specs (list[dfVFS.path_spec]): List of path_specs from volume scanner.\n location (str): dfVFS location to search for.\n\n Returns:\n dfVFS.path_spec for the given location or None if not found.\n \"\"\"\n for path_spec in path_specs:\n child_path_spec = path_spec\n fs_location = getattr(path_spec, 'location', None)\n while path_spec.HasParent():\n type_indicator = path_spec.type_indicator\n if type_indicator in (dfvfs_definitions.TYPE_INDICATOR_TSK_PARTITION,\n dfvfs_definitions.TYPE_INDICATOR_GPT):\n if fs_location in ('\\\\', '/'):\n fs_location = getattr(path_spec, 'location', None)\n break\n path_spec = path_spec.parent\n if fs_location == location:\n return child_path_spec\n return None\n", "path": "turbinia/processors/partitions.py"}]}
| 2,032 | 127 |
gh_patches_debug_40735
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-2087
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Parsing error scanning terraform plan output
**Describe the bug**
Receiving a parsing error when scanning terraform plan output. parsing error is in the cloudformation scan results. the file being scanned contains no cloudformation code. the terraform_plan scan results are reporting well
**To Reproduce**
Steps to reproduce the behavior:
1. Go to a folder which contains the output of a terraform plan piped into a tf.json file
2. Run cli command checkov -f .\tf.json
3. See error in attached scanlog.txt
**Expected behavior**
Expect to be able to scan terraform plan output without encountering a parsing error
**Screenshots**
scanlog.txt
[scanlog.txt](https://github.com/bridgecrewio/checkov/files/7464351/scanlog.txt)
ts.json - terraform plan output being scanned
[tf.json.txt](https://github.com/bridgecrewio/checkov/files/7464354/tf.json.txt)
**Desktop (please complete the following information):**
- OS: Windows 10
- Checkov Version 2.0.536
**Additional context**
Add any other context about the problem here (e.g. code snippets).
</issue>
<code>
[start of checkov/cloudformation/parser/cfn_yaml.py]
1 """
2 Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.
3 SPDX-License-Identifier: MIT-0
4 """
5 import logging
6 from yaml import MappingNode
7 from yaml import ScalarNode
8 from yaml import SequenceNode
9 from yaml.composer import Composer
10 from yaml.constructor import ConstructorError
11 from yaml.constructor import SafeConstructor
12 from yaml.reader import Reader
13 from yaml.resolver import Resolver
14 from yaml.scanner import Scanner
15
16 from checkov.common.parsers.node import StrNode, DictNode, ListNode
17
18 try:
19 from yaml.cyaml import CParser as Parser # pylint: disable=ungrouped-imports
20
21 cyaml = True
22 except ImportError:
23 from yaml.parser import Parser # pylint: disable=ungrouped-imports
24
25 cyaml = False
26
27 UNCONVERTED_SUFFIXES = ['Ref', 'Condition']
28 FN_PREFIX = 'Fn::'
29
30 LOGGER = logging.getLogger(__name__)
31
32
33 class CfnParseError(ConstructorError):
34 """
35 Error thrown when the template contains Cfn Error
36 """
37
38 def __init__(self, filename, message, line_number, column_number, key=' '):
39 # Call the base class constructor with the parameters it needs
40 super(CfnParseError, self).__init__(message)
41
42 # Now for your custom code...
43 self.filename = filename
44 self.line_number = line_number
45 self.column_number = column_number
46 self.message = message
47
48
49 class NodeConstructor(SafeConstructor):
50 """
51 Node Constructors for loading different types in Yaml
52 """
53
54 def __init__(self, filename):
55 # Call the base class constructor
56 super(NodeConstructor, self).__init__()
57
58 self.filename = filename
59
60 # To support lazy loading, the original constructors first yield
61 # an empty object, then fill them in when iterated. Due to
62 # laziness we omit this behaviour (and will only do "deep
63 # construction") by first exhausting iterators, then yielding
64 # copies.
65 def construct_yaml_map(self, node):
66
67 # Check for duplicate keys on the current level, this is not desirable
68 # because a dict does not support this. It overwrites it with the last
69 # occurance, which can give unexpected results
70 mapping = {}
71 self.flatten_mapping(node)
72 for key_node, value_node in node.value:
73 key = self.construct_object(key_node, False)
74 value = self.construct_object(value_node, False)
75
76 if key in mapping:
77 raise CfnParseError(
78 self.filename,
79 'Duplicate resource found "{}" (line {})'.format(
80 key, key_node.start_mark.line + 1),
81 key_node.start_mark.line, key_node.start_mark.column, key)
82 mapping[key] = value
83
84 obj, = SafeConstructor.construct_yaml_map(self, node)
85 return DictNode(obj, node.start_mark, node.end_mark)
86
87 def construct_yaml_str(self, node):
88 obj = SafeConstructor.construct_yaml_str(self, node)
89 assert isinstance(obj, str) # nosec
90 return StrNode(obj, node.start_mark, node.end_mark)
91
92 def construct_yaml_seq(self, node):
93 obj, = SafeConstructor.construct_yaml_seq(self, node)
94 assert isinstance(obj, list) # nosec
95 return ListNode(obj, node.start_mark, node.end_mark) # nosec
96
97 def construct_yaml_null_error(self, node):
98 """Throw a null error"""
99 raise CfnParseError(
100 self.filename,
101 'Null value at line {0} column {1}'.format(
102 node.start_mark.line + 1, node.start_mark.column + 1),
103 node.start_mark.line, node.start_mark.column, ' ')
104
105
106 NodeConstructor.add_constructor(
107 u'tag:yaml.org,2002:map',
108 NodeConstructor.construct_yaml_map)
109
110 NodeConstructor.add_constructor(
111 u'tag:yaml.org,2002:str',
112 NodeConstructor.construct_yaml_str)
113
114 NodeConstructor.add_constructor(
115 u'tag:yaml.org,2002:seq',
116 NodeConstructor.construct_yaml_seq)
117
118 NodeConstructor.add_constructor(
119 u'tag:yaml.org,2002:null',
120 NodeConstructor.construct_yaml_null_error)
121
122
123 class MarkedLoader(Reader, Scanner, Parser, Composer, NodeConstructor, Resolver):
124 """
125 Class for marked loading YAML
126 """
127
128 # pylint: disable=non-parent-init-called,super-init-not-called
129
130 def __init__(self, stream, filename):
131 Reader.__init__(self, stream)
132 Scanner.__init__(self)
133 if cyaml:
134 Parser.__init__(self, stream)
135 else:
136 Parser.__init__(self)
137 Composer.__init__(self)
138 SafeConstructor.__init__(self)
139 Resolver.__init__(self)
140 NodeConstructor.__init__(self, filename)
141
142 def construct_mapping(self, node, deep=False):
143 mapping = super(MarkedLoader, self).construct_mapping(node, deep=deep)
144 # Add 1 so line numbering starts at 1
145 # mapping['__line__'] = node.start_mark.line + 1
146 mapping['__startline__'] = node.start_mark.line + 1
147 mapping['__endline__'] = node.end_mark.line + 1
148 return mapping
149
150
151 def multi_constructor(loader, tag_suffix, node):
152 """
153 Deal with !Ref style function format
154 """
155
156 if tag_suffix not in UNCONVERTED_SUFFIXES:
157 tag_suffix = '{}{}'.format(FN_PREFIX, tag_suffix)
158
159 constructor = None
160 if tag_suffix == 'Fn::GetAtt':
161 constructor = construct_getatt
162 elif isinstance(node, ScalarNode):
163 constructor = loader.construct_scalar
164 elif isinstance(node, SequenceNode):
165 constructor = loader.construct_sequence
166 elif isinstance(node, MappingNode):
167 constructor = loader.construct_mapping
168 else:
169 raise 'Bad tag: !{}'.format(tag_suffix)
170
171 return DictNode({tag_suffix: constructor(node)}, node.start_mark, node.end_mark)
172
173
174 def construct_getatt(node):
175 """
176 Reconstruct !GetAtt into a list
177 """
178
179 if isinstance(node.value, str):
180 return ListNode(node.value.split('.'), node.start_mark, node.end_mark)
181 if isinstance(node.value, list):
182 return ListNode([s.value for s in node.value], node.start_mark, node.end_mark)
183
184 raise ValueError('Unexpected node type: {}'.format(type(node.value)))
185
186
187 def loads(yaml_string, fname=None):
188 """
189 Load the given YAML string
190 """
191 loader = MarkedLoader(yaml_string, fname)
192 loader.add_multi_constructor('!', multi_constructor)
193
194 template = loader.get_single_data()
195 # Convert an empty file to an empty dict
196 if template is None:
197 template = {}
198
199 return template
200
201
202 def load(filename):
203 """
204 Load the given YAML file
205 """
206
207 content = ''
208
209 with open(filename) as fp:
210 content = fp.read()
211 fp.seek(0)
212 file_lines = [(ind + 1, line) for (ind, line) in
213 list(enumerate(fp.readlines()))]
214
215 return (loads(content, filename), file_lines)
216
[end of checkov/cloudformation/parser/cfn_yaml.py]
[start of checkov/cloudformation/parser/__init__.py]
1 import logging
2 from typing import Tuple, List, Union, Dict
3
4 from checkov.cloudformation.parser import cfn_yaml
5 from checkov.common.parsers.json import parse as json_parse
6 from checkov.common.parsers.node import DictNode
7 from checkov.cloudformation.parser.cfn_keywords import TemplateSections
8 from yaml.parser import ScannerError
9 from yaml import YAMLError
10
11 LOGGER = logging.getLogger(__name__)
12
13
14 def parse(filename: str, out_parsing_errors: Dict[str, str] = {}) -> Union[Tuple[DictNode, List[Tuple[int, str]]], Tuple[None, None]]:
15 """
16 Decode filename into an object
17 """
18 template = None
19 template_lines = None
20 error = None
21 try:
22 (template, template_lines) = cfn_yaml.load(filename)
23 except IOError as err:
24 if err.errno == 2:
25 error = f"Template file not found: {filename} - {err}"
26 LOGGER.error(error)
27 elif err.errno == 21:
28 error = f"Template references a directory, not a file: {filename} - {err}"
29 LOGGER.error(error)
30 elif err.errno == 13:
31 error = f"Permission denied when accessing template file: {filename} - {err}"
32 LOGGER.error(error)
33 except UnicodeDecodeError as err:
34 error = f"Cannot read file contents: {filename} - {err}"
35 LOGGER.error(error)
36 except cfn_yaml.CfnParseError as err:
37 error = f"Parsing error in file: {filename} - {err}"
38 LOGGER.info(error)
39 except ValueError as err:
40 error = f"Parsing error in file: {filename} - {err}"
41 LOGGER.info(error)
42 except ScannerError as err:
43 if err.problem in ["found character '\\t' that cannot start any token", "found unknown escape character"]:
44 try:
45 (template, template_lines) = json_parse(filename, allow_nulls=False)
46 except Exception as json_err: # pylint: disable=W0703
47 error = f"Template {filename} is malformed: {err.problem}. Tried to parse {filename} as JSON but got error: {json_err}"
48 LOGGER.info(error)
49 except YAMLError as err:
50 error = f"Parsing error in file: {filename} - {err}"
51 LOGGER.info(error)
52
53 if error:
54 out_parsing_errors[filename] = error
55
56 if isinstance(template, dict):
57 resources = template.get(TemplateSections.RESOURCES.value, None)
58 if resources:
59 if '__startline__' in resources:
60 del resources['__startline__']
61 if '__endline__' in resources:
62 del resources['__endline__']
63 return template, template_lines
64
[end of checkov/cloudformation/parser/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/checkov/cloudformation/parser/__init__.py b/checkov/cloudformation/parser/__init__.py
--- a/checkov/cloudformation/parser/__init__.py
+++ b/checkov/cloudformation/parser/__init__.py
@@ -1,5 +1,5 @@
import logging
-from typing import Tuple, List, Union, Dict
+from typing import Tuple, List, Union, Dict, Optional
from checkov.cloudformation.parser import cfn_yaml
from checkov.common.parsers.json import parse as json_parse
@@ -11,13 +11,19 @@
LOGGER = logging.getLogger(__name__)
-def parse(filename: str, out_parsing_errors: Dict[str, str] = {}) -> Union[Tuple[DictNode, List[Tuple[int, str]]], Tuple[None, None]]:
+def parse(
+ filename: str, out_parsing_errors: Optional[Dict[str, str]] = None
+) -> Union[Tuple[DictNode, List[Tuple[int, str]]], Tuple[None, None]]:
"""
- Decode filename into an object
+ Decode filename into an object
"""
template = None
template_lines = None
error = None
+
+ if out_parsing_errors is None:
+ out_parsing_errors = {}
+
try:
(template, template_lines) = cfn_yaml.load(filename)
except IOError as err:
@@ -34,6 +40,10 @@
error = f"Cannot read file contents: {filename} - {err}"
LOGGER.error(error)
except cfn_yaml.CfnParseError as err:
+ if "Null value at" in err.message:
+ LOGGER.info(f"Null values do not exist in CFN templates: {filename} - {err}")
+ return None, None
+
error = f"Parsing error in file: {filename} - {err}"
LOGGER.info(error)
except ValueError as err:
@@ -56,8 +66,8 @@
if isinstance(template, dict):
resources = template.get(TemplateSections.RESOURCES.value, None)
if resources:
- if '__startline__' in resources:
- del resources['__startline__']
- if '__endline__' in resources:
- del resources['__endline__']
+ if "__startline__" in resources:
+ del resources["__startline__"]
+ if "__endline__" in resources:
+ del resources["__endline__"]
return template, template_lines
diff --git a/checkov/cloudformation/parser/cfn_yaml.py b/checkov/cloudformation/parser/cfn_yaml.py
--- a/checkov/cloudformation/parser/cfn_yaml.py
+++ b/checkov/cloudformation/parser/cfn_yaml.py
@@ -3,6 +3,9 @@
SPDX-License-Identifier: MIT-0
"""
import logging
+from pathlib import Path
+from typing import List, Tuple
+
from yaml import MappingNode
from yaml import ScalarNode
from yaml import SequenceNode
@@ -199,17 +202,13 @@
return template
-def load(filename):
+def load(filename: str) -> Tuple[DictNode, List[Tuple[int, str]]]:
"""
Load the given YAML file
"""
- content = ''
-
- with open(filename) as fp:
- content = fp.read()
- fp.seek(0)
- file_lines = [(ind + 1, line) for (ind, line) in
- list(enumerate(fp.readlines()))]
+ file_path = Path(filename)
+ content = file_path.read_text()
+ file_lines = [(idx + 1, line) for idx, line in enumerate(content.splitlines(keepends=True))]
return (loads(content, filename), file_lines)
|
{"golden_diff": "diff --git a/checkov/cloudformation/parser/__init__.py b/checkov/cloudformation/parser/__init__.py\n--- a/checkov/cloudformation/parser/__init__.py\n+++ b/checkov/cloudformation/parser/__init__.py\n@@ -1,5 +1,5 @@\n import logging\n-from typing import Tuple, List, Union, Dict\n+from typing import Tuple, List, Union, Dict, Optional\n \n from checkov.cloudformation.parser import cfn_yaml\n from checkov.common.parsers.json import parse as json_parse\n@@ -11,13 +11,19 @@\n LOGGER = logging.getLogger(__name__)\n \n \n-def parse(filename: str, out_parsing_errors: Dict[str, str] = {}) -> Union[Tuple[DictNode, List[Tuple[int, str]]], Tuple[None, None]]:\n+def parse(\n+ filename: str, out_parsing_errors: Optional[Dict[str, str]] = None\n+) -> Union[Tuple[DictNode, List[Tuple[int, str]]], Tuple[None, None]]:\n \"\"\"\n- Decode filename into an object\n+ Decode filename into an object\n \"\"\"\n template = None\n template_lines = None\n error = None\n+\n+ if out_parsing_errors is None:\n+ out_parsing_errors = {}\n+\n try:\n (template, template_lines) = cfn_yaml.load(filename)\n except IOError as err:\n@@ -34,6 +40,10 @@\n error = f\"Cannot read file contents: {filename} - {err}\"\n LOGGER.error(error)\n except cfn_yaml.CfnParseError as err:\n+ if \"Null value at\" in err.message:\n+ LOGGER.info(f\"Null values do not exist in CFN templates: {filename} - {err}\")\n+ return None, None\n+\n error = f\"Parsing error in file: {filename} - {err}\"\n LOGGER.info(error)\n except ValueError as err:\n@@ -56,8 +66,8 @@\n if isinstance(template, dict):\n resources = template.get(TemplateSections.RESOURCES.value, None)\n if resources:\n- if '__startline__' in resources:\n- del resources['__startline__']\n- if '__endline__' in resources:\n- del resources['__endline__']\n+ if \"__startline__\" in resources:\n+ del resources[\"__startline__\"]\n+ if \"__endline__\" in resources:\n+ del resources[\"__endline__\"]\n return template, template_lines\ndiff --git a/checkov/cloudformation/parser/cfn_yaml.py b/checkov/cloudformation/parser/cfn_yaml.py\n--- a/checkov/cloudformation/parser/cfn_yaml.py\n+++ b/checkov/cloudformation/parser/cfn_yaml.py\n@@ -3,6 +3,9 @@\n SPDX-License-Identifier: MIT-0\n \"\"\"\n import logging\n+from pathlib import Path\n+from typing import List, Tuple\n+\n from yaml import MappingNode\n from yaml import ScalarNode\n from yaml import SequenceNode\n@@ -199,17 +202,13 @@\n return template\n \n \n-def load(filename):\n+def load(filename: str) -> Tuple[DictNode, List[Tuple[int, str]]]:\n \"\"\"\n Load the given YAML file\n \"\"\"\n \n- content = ''\n-\n- with open(filename) as fp:\n- content = fp.read()\n- fp.seek(0)\n- file_lines = [(ind + 1, line) for (ind, line) in\n- list(enumerate(fp.readlines()))]\n+ file_path = Path(filename)\n+ content = file_path.read_text()\n+ file_lines = [(idx + 1, line) for idx, line in enumerate(content.splitlines(keepends=True))]\n \n return (loads(content, filename), file_lines)\n", "issue": "Parsing error scanning terraform plan output\n**Describe the bug**\r\nReceiving a parsing error when scanning terraform plan output. parsing error is in the cloudformation scan results. the file being scanned contains no cloudformation code. the terraform_plan scan results are reporting well\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Go to a folder which contains the output of a terraform plan piped into a tf.json file\r\n2. Run cli command checkov -f .\\tf.json\r\n3. See error in attached scanlog.txt\r\n\r\n**Expected behavior**\r\nExpect to be able to scan terraform plan output without encountering a parsing error\r\n\r\n**Screenshots**\r\nscanlog.txt\r\n[scanlog.txt](https://github.com/bridgecrewio/checkov/files/7464351/scanlog.txt)\r\n\r\nts.json - terraform plan output being scanned\r\n[tf.json.txt](https://github.com/bridgecrewio/checkov/files/7464354/tf.json.txt)\r\n\r\n\r\n**Desktop (please complete the following information):**\r\n - OS: Windows 10\r\n - Checkov Version 2.0.536\r\n\r\n**Additional context**\r\nAdd any other context about the problem here (e.g. code snippets).\r\n\n", "before_files": [{"content": "\"\"\"\nCopyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport logging\nfrom yaml import MappingNode\nfrom yaml import ScalarNode\nfrom yaml import SequenceNode\nfrom yaml.composer import Composer\nfrom yaml.constructor import ConstructorError\nfrom yaml.constructor import SafeConstructor\nfrom yaml.reader import Reader\nfrom yaml.resolver import Resolver\nfrom yaml.scanner import Scanner\n\nfrom checkov.common.parsers.node import StrNode, DictNode, ListNode\n\ntry:\n from yaml.cyaml import CParser as Parser # pylint: disable=ungrouped-imports\n\n cyaml = True\nexcept ImportError:\n from yaml.parser import Parser # pylint: disable=ungrouped-imports\n\n cyaml = False\n\nUNCONVERTED_SUFFIXES = ['Ref', 'Condition']\nFN_PREFIX = 'Fn::'\n\nLOGGER = logging.getLogger(__name__)\n\n\nclass CfnParseError(ConstructorError):\n \"\"\"\n Error thrown when the template contains Cfn Error\n \"\"\"\n\n def __init__(self, filename, message, line_number, column_number, key=' '):\n # Call the base class constructor with the parameters it needs\n super(CfnParseError, self).__init__(message)\n\n # Now for your custom code...\n self.filename = filename\n self.line_number = line_number\n self.column_number = column_number\n self.message = message\n\n\nclass NodeConstructor(SafeConstructor):\n \"\"\"\n Node Constructors for loading different types in Yaml\n \"\"\"\n\n def __init__(self, filename):\n # Call the base class constructor\n super(NodeConstructor, self).__init__()\n\n self.filename = filename\n\n # To support lazy loading, the original constructors first yield\n # an empty object, then fill them in when iterated. Due to\n # laziness we omit this behaviour (and will only do \"deep\n # construction\") by first exhausting iterators, then yielding\n # copies.\n def construct_yaml_map(self, node):\n\n # Check for duplicate keys on the current level, this is not desirable\n # because a dict does not support this. It overwrites it with the last\n # occurance, which can give unexpected results\n mapping = {}\n self.flatten_mapping(node)\n for key_node, value_node in node.value:\n key = self.construct_object(key_node, False)\n value = self.construct_object(value_node, False)\n\n if key in mapping:\n raise CfnParseError(\n self.filename,\n 'Duplicate resource found \"{}\" (line {})'.format(\n key, key_node.start_mark.line + 1),\n key_node.start_mark.line, key_node.start_mark.column, key)\n mapping[key] = value\n\n obj, = SafeConstructor.construct_yaml_map(self, node)\n return DictNode(obj, node.start_mark, node.end_mark)\n\n def construct_yaml_str(self, node):\n obj = SafeConstructor.construct_yaml_str(self, node)\n assert isinstance(obj, str) # nosec\n return StrNode(obj, node.start_mark, node.end_mark)\n\n def construct_yaml_seq(self, node):\n obj, = SafeConstructor.construct_yaml_seq(self, node)\n assert isinstance(obj, list) # nosec\n return ListNode(obj, node.start_mark, node.end_mark) # nosec\n\n def construct_yaml_null_error(self, node):\n \"\"\"Throw a null error\"\"\"\n raise CfnParseError(\n self.filename,\n 'Null value at line {0} column {1}'.format(\n node.start_mark.line + 1, node.start_mark.column + 1),\n node.start_mark.line, node.start_mark.column, ' ')\n\n\nNodeConstructor.add_constructor(\n u'tag:yaml.org,2002:map',\n NodeConstructor.construct_yaml_map)\n\nNodeConstructor.add_constructor(\n u'tag:yaml.org,2002:str',\n NodeConstructor.construct_yaml_str)\n\nNodeConstructor.add_constructor(\n u'tag:yaml.org,2002:seq',\n NodeConstructor.construct_yaml_seq)\n\nNodeConstructor.add_constructor(\n u'tag:yaml.org,2002:null',\n NodeConstructor.construct_yaml_null_error)\n\n\nclass MarkedLoader(Reader, Scanner, Parser, Composer, NodeConstructor, Resolver):\n \"\"\"\n Class for marked loading YAML\n \"\"\"\n\n # pylint: disable=non-parent-init-called,super-init-not-called\n\n def __init__(self, stream, filename):\n Reader.__init__(self, stream)\n Scanner.__init__(self)\n if cyaml:\n Parser.__init__(self, stream)\n else:\n Parser.__init__(self)\n Composer.__init__(self)\n SafeConstructor.__init__(self)\n Resolver.__init__(self)\n NodeConstructor.__init__(self, filename)\n\n def construct_mapping(self, node, deep=False):\n mapping = super(MarkedLoader, self).construct_mapping(node, deep=deep)\n # Add 1 so line numbering starts at 1\n # mapping['__line__'] = node.start_mark.line + 1\n mapping['__startline__'] = node.start_mark.line + 1\n mapping['__endline__'] = node.end_mark.line + 1\n return mapping\n\n\ndef multi_constructor(loader, tag_suffix, node):\n \"\"\"\n Deal with !Ref style function format\n \"\"\"\n\n if tag_suffix not in UNCONVERTED_SUFFIXES:\n tag_suffix = '{}{}'.format(FN_PREFIX, tag_suffix)\n\n constructor = None\n if tag_suffix == 'Fn::GetAtt':\n constructor = construct_getatt\n elif isinstance(node, ScalarNode):\n constructor = loader.construct_scalar\n elif isinstance(node, SequenceNode):\n constructor = loader.construct_sequence\n elif isinstance(node, MappingNode):\n constructor = loader.construct_mapping\n else:\n raise 'Bad tag: !{}'.format(tag_suffix)\n\n return DictNode({tag_suffix: constructor(node)}, node.start_mark, node.end_mark)\n\n\ndef construct_getatt(node):\n \"\"\"\n Reconstruct !GetAtt into a list\n \"\"\"\n\n if isinstance(node.value, str):\n return ListNode(node.value.split('.'), node.start_mark, node.end_mark)\n if isinstance(node.value, list):\n return ListNode([s.value for s in node.value], node.start_mark, node.end_mark)\n\n raise ValueError('Unexpected node type: {}'.format(type(node.value)))\n\n\ndef loads(yaml_string, fname=None):\n \"\"\"\n Load the given YAML string\n \"\"\"\n loader = MarkedLoader(yaml_string, fname)\n loader.add_multi_constructor('!', multi_constructor)\n\n template = loader.get_single_data()\n # Convert an empty file to an empty dict\n if template is None:\n template = {}\n\n return template\n\n\ndef load(filename):\n \"\"\"\n Load the given YAML file\n \"\"\"\n\n content = ''\n\n with open(filename) as fp:\n content = fp.read()\n fp.seek(0)\n file_lines = [(ind + 1, line) for (ind, line) in\n list(enumerate(fp.readlines()))]\n\n return (loads(content, filename), file_lines)\n", "path": "checkov/cloudformation/parser/cfn_yaml.py"}, {"content": "import logging\nfrom typing import Tuple, List, Union, Dict\n\nfrom checkov.cloudformation.parser import cfn_yaml\nfrom checkov.common.parsers.json import parse as json_parse\nfrom checkov.common.parsers.node import DictNode\nfrom checkov.cloudformation.parser.cfn_keywords import TemplateSections\nfrom yaml.parser import ScannerError\nfrom yaml import YAMLError\n\nLOGGER = logging.getLogger(__name__)\n\n\ndef parse(filename: str, out_parsing_errors: Dict[str, str] = {}) -> Union[Tuple[DictNode, List[Tuple[int, str]]], Tuple[None, None]]:\n \"\"\"\n Decode filename into an object\n \"\"\"\n template = None\n template_lines = None\n error = None\n try:\n (template, template_lines) = cfn_yaml.load(filename)\n except IOError as err:\n if err.errno == 2:\n error = f\"Template file not found: {filename} - {err}\"\n LOGGER.error(error)\n elif err.errno == 21:\n error = f\"Template references a directory, not a file: {filename} - {err}\"\n LOGGER.error(error)\n elif err.errno == 13:\n error = f\"Permission denied when accessing template file: {filename} - {err}\"\n LOGGER.error(error)\n except UnicodeDecodeError as err:\n error = f\"Cannot read file contents: {filename} - {err}\"\n LOGGER.error(error)\n except cfn_yaml.CfnParseError as err:\n error = f\"Parsing error in file: {filename} - {err}\"\n LOGGER.info(error)\n except ValueError as err:\n error = f\"Parsing error in file: {filename} - {err}\"\n LOGGER.info(error)\n except ScannerError as err:\n if err.problem in [\"found character '\\\\t' that cannot start any token\", \"found unknown escape character\"]:\n try:\n (template, template_lines) = json_parse(filename, allow_nulls=False)\n except Exception as json_err: # pylint: disable=W0703\n error = f\"Template {filename} is malformed: {err.problem}. Tried to parse {filename} as JSON but got error: {json_err}\"\n LOGGER.info(error)\n except YAMLError as err:\n error = f\"Parsing error in file: {filename} - {err}\"\n LOGGER.info(error)\n\n if error:\n out_parsing_errors[filename] = error\n\n if isinstance(template, dict):\n resources = template.get(TemplateSections.RESOURCES.value, None)\n if resources:\n if '__startline__' in resources:\n del resources['__startline__']\n if '__endline__' in resources:\n del resources['__endline__']\n return template, template_lines\n", "path": "checkov/cloudformation/parser/__init__.py"}]}
| 3,616 | 818 |
gh_patches_debug_10545
|
rasdani/github-patches
|
git_diff
|
hpcaitech__ColossalAI-4889
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[tensor] fix some unittests
[tensor] fix some unittests
[tensor] fix some unittests
</issue>
<code>
[start of colossalai/nn/optimizer/cpu_adam.py]
1 import math
2 from typing import Optional
3
4 import torch
5
6 from colossalai.kernel.op_builder import CPUAdamBuilder
7
8 from .nvme_optimizer import NVMeOptimizer
9
10
11 class CPUAdam(NVMeOptimizer):
12 """Implements Adam algorithm.
13
14 Supports parameters updating on both GPU and CPU, depending on the device of parameters.
15 But the parameters and gradients should on the same device:
16 * Parameters on CPU and gradients on CPU is allowed.
17 * Parameters on GPU and gradients on GPU is allowed.
18 * Parameters on GPU and gradients on CPU is **not** allowed.
19
20 `CPUAdam` requires CUDA extensions which can be built during installation or runtime.
21
22 This version of CPU Adam accelerates parameters updating on CPU with SIMD.
23 Support of AVX2 or AVX512 is required.
24
25 The GPU part is implemented in an naive way.
26
27 CPU Adam also supports the hybrid precision calculation, eg. fp32 parameters and fp16 gradients.
28
29 :class:`colossalai.nn.optimizer.CPUAdam` may be used as a drop-in replacement for ``torch.optim.AdamW``,
30 or ``torch.optim.Adam`` with ``adamw_mode=False``
31
32 Adam was been proposed in `Adam: A Method for Stochastic Optimization`_.
33
34 Arguments:
35 model_params (iterable): iterable of parameters of dicts defining
36 parameter groups.
37 lr (float, optional): learning rate. (default: 1e-3)
38 betas (Tuple[float, float], optional): coefficients used for computing
39 running averages of gradient and its square. (default: (0.9, 0.999))
40 eps (float, optional): term added to the denominator to improve
41 numerical stability. (default: 1e-8)
42 weight_decay (float, optional): weight decay (L2 penalty) (default: 0)
43 amsgrad (boolean, optional): whether to use the AMSGrad variant of this
44 algorithm from the paper `On the Convergence of Adam and Beyond`_
45 (default: False) NOT SUPPORTED yet in CPUAdam!
46 adamw_mode (boolean, optional): Apply L2 regularization or weight decay
47 True for decoupled weight decay(also known as AdamW) (default: True)
48 simd_log (boolean, optional): whether to show if you are using SIMD to
49 accelerate. (default: False)
50 nvme_offload_fraction (float, optional): Fraction of optimizer states to be offloaded to NVMe. Defaults to 0.0.
51 nvme_offload_dir (Optional[str], optional): Directory to save NVMe offload files.
52 If it's ``None``, a random temporary directory will be used. Defaults to None.
53
54 .. _Adam\: A Method for Stochastic Optimization:
55 https://arxiv.org/abs/1412.6980
56 .. _On the Convergence of Adam and Beyond:
57 https://openreview.net/forum?id=ryQu7f-RZ
58 """
59
60 # Number of fp32 shards for per parameter
61 # Param weight, grad, momentum and variance
62 num_fp32_shards_per_param = 4
63
64 def __init__(
65 self,
66 model_params,
67 lr=1e-3,
68 bias_correction=True,
69 betas=(0.9, 0.999),
70 eps=1e-8,
71 weight_decay=0,
72 adamw_mode=True,
73 nvme_offload_fraction: float = 0.0,
74 nvme_offload_dir: Optional[str] = None,
75 ):
76 default_args = dict(lr=lr, betas=betas, eps=eps, weight_decay=weight_decay, bias_correction=bias_correction)
77 super(CPUAdam, self).__init__(model_params, default_args, nvme_offload_fraction, nvme_offload_dir)
78 self.adamw_mode = adamw_mode
79 cpu_adam = CPUAdamBuilder().load()
80 self.cpu_adam_op = cpu_adam.CPUAdamOptimizer(lr, betas[0], betas[1], eps, weight_decay, adamw_mode)
81
82 def torch_adam_update(
83 self,
84 data,
85 grad,
86 exp_avg,
87 exp_avg_sq,
88 lr,
89 beta1,
90 beta2,
91 eps,
92 weight_decay,
93 bias_correction1,
94 bias_correction2,
95 use_adamw=False,
96 ):
97 grad = grad.to(data.dtype)
98
99 if weight_decay != 0:
100 if use_adamw:
101 data.mul_(1 - lr * weight_decay)
102 else:
103 grad = grad.add(data, alpha=weight_decay)
104
105 # Decay the first and second moment running average coefficient
106 exp_avg.mul_(beta1).add_(grad, alpha=1 - beta1)
107 exp_avg_sq.mul_(beta2).addcmul_(grad, grad, value=1 - beta2)
108
109 # TODO(jiaruifang) dose not support amsgrad
110 denom = (exp_avg_sq.sqrt() / math.sqrt(bias_correction2)).add_(eps)
111
112 step_size = lr / bias_correction1
113
114 data.addcdiv_(exp_avg, denom, value=-step_size)
115
116 @torch.no_grad()
117 def step(self, closure=None, div_scale: float = -1):
118 loss = None
119 if closure is not None:
120 with torch.enable_grad():
121 loss = closure()
122
123 self._pre_step("exp_avg", "exp_avg_sq")
124 for _, group in enumerate(self.param_groups):
125 for _, p in enumerate(group["params"]):
126 if p.grad is None:
127 continue
128
129 state = self.state[p]
130
131 target_device = p.device
132 if len(state) == 0:
133 state["step"] = 0
134
135 # FIXME(ver217): CPU adam kernel only supports fp32 states now
136 assert p.dtype is torch.float, "CPUAdam only support fp32 parameters"
137 # gradient momentums
138 state["exp_avg"] = torch.zeros_like(p, device=target_device)
139 # gradient variances
140 state["exp_avg_sq"] = torch.zeros_like(p, device=target_device)
141 self._post_state_init(p)
142
143 state["step"] += 1
144 beta1, beta2 = group["betas"]
145
146 if target_device.type == "cpu":
147 assert p.data.numel() == p.grad.data.numel(), "parameter and gradient should have the same size"
148 assert state["exp_avg"].device.type == "cpu", "exp_avg should stay on cpu"
149 assert state["exp_avg_sq"].device.type == "cpu", "exp_avg should stay on cpu"
150 self._pre_update(p, "exp_avg", "exp_avg_sq")
151 if p.grad.dtype is torch.bfloat16:
152 # cpu adam kernel does not support bf16 now
153 bias_correction1 = 1 - beta1 ** state["step"]
154 bias_correction2 = 1 - beta2 ** state["step"]
155 self.torch_adam_update(
156 p.data,
157 p.grad.data,
158 state["exp_avg"],
159 state["exp_avg_sq"],
160 group["lr"],
161 beta1,
162 beta2,
163 group["eps"],
164 group["weight_decay"],
165 bias_correction1,
166 bias_correction2,
167 self.adamw_mode,
168 )
169 else:
170 self.cpu_adam_op.step(
171 state["step"],
172 group["lr"],
173 beta1,
174 beta2,
175 group["eps"],
176 group["weight_decay"],
177 group["bias_correction"],
178 p.data,
179 p.grad.data,
180 state["exp_avg"],
181 state["exp_avg_sq"],
182 div_scale,
183 )
184 self._post_update(p, "exp_avg", "exp_avg_sq")
185 elif target_device.type == "cuda":
186 assert div_scale == -1, "div_scale should remain default"
187 assert state["exp_avg"].device.type == "cuda", "exp_avg should stay on cuda"
188 assert state["exp_avg_sq"].device.type == "cuda", "exp_avg should stay on cuda"
189
190 bias_correction1 = 1 - beta1 ** state["step"]
191 bias_correction2 = 1 - beta2 ** state["step"]
192
193 # adam on cuda
194 self.torch_adam_update(
195 p.data,
196 p.grad.data,
197 state["exp_avg"],
198 state["exp_avg_sq"],
199 group["lr"],
200 beta1,
201 beta2,
202 group["eps"],
203 group["weight_decay"],
204 bias_correction1,
205 bias_correction2,
206 self.adamw_mode,
207 )
208 else:
209 raise RuntimeError
210 self._post_step()
211 return loss
212
[end of colossalai/nn/optimizer/cpu_adam.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/colossalai/nn/optimizer/cpu_adam.py b/colossalai/nn/optimizer/cpu_adam.py
--- a/colossalai/nn/optimizer/cpu_adam.py
+++ b/colossalai/nn/optimizer/cpu_adam.py
@@ -77,6 +77,7 @@
super(CPUAdam, self).__init__(model_params, default_args, nvme_offload_fraction, nvme_offload_dir)
self.adamw_mode = adamw_mode
cpu_adam = CPUAdamBuilder().load()
+ # if you find yourself stuck here, make sure that you install colossalai with CUDA_EXT=1 specification
self.cpu_adam_op = cpu_adam.CPUAdamOptimizer(lr, betas[0], betas[1], eps, weight_decay, adamw_mode)
def torch_adam_update(
|
{"golden_diff": "diff --git a/colossalai/nn/optimizer/cpu_adam.py b/colossalai/nn/optimizer/cpu_adam.py\n--- a/colossalai/nn/optimizer/cpu_adam.py\n+++ b/colossalai/nn/optimizer/cpu_adam.py\n@@ -77,6 +77,7 @@\n super(CPUAdam, self).__init__(model_params, default_args, nvme_offload_fraction, nvme_offload_dir)\n self.adamw_mode = adamw_mode\n cpu_adam = CPUAdamBuilder().load()\n+ # if you find yourself stuck here, make sure that you install colossalai with CUDA_EXT=1 specification\n self.cpu_adam_op = cpu_adam.CPUAdamOptimizer(lr, betas[0], betas[1], eps, weight_decay, adamw_mode)\n \n def torch_adam_update(\n", "issue": "[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n", "before_files": [{"content": "import math\nfrom typing import Optional\n\nimport torch\n\nfrom colossalai.kernel.op_builder import CPUAdamBuilder\n\nfrom .nvme_optimizer import NVMeOptimizer\n\n\nclass CPUAdam(NVMeOptimizer):\n \"\"\"Implements Adam algorithm.\n\n Supports parameters updating on both GPU and CPU, depending on the device of parameters.\n But the parameters and gradients should on the same device:\n * Parameters on CPU and gradients on CPU is allowed.\n * Parameters on GPU and gradients on GPU is allowed.\n * Parameters on GPU and gradients on CPU is **not** allowed.\n\n `CPUAdam` requires CUDA extensions which can be built during installation or runtime.\n\n This version of CPU Adam accelerates parameters updating on CPU with SIMD.\n Support of AVX2 or AVX512 is required.\n\n The GPU part is implemented in an naive way.\n\n CPU Adam also supports the hybrid precision calculation, eg. fp32 parameters and fp16 gradients.\n\n :class:`colossalai.nn.optimizer.CPUAdam` may be used as a drop-in replacement for ``torch.optim.AdamW``,\n or ``torch.optim.Adam`` with ``adamw_mode=False``\n\n Adam was been proposed in `Adam: A Method for Stochastic Optimization`_.\n\n Arguments:\n model_params (iterable): iterable of parameters of dicts defining\n parameter groups.\n lr (float, optional): learning rate. (default: 1e-3)\n betas (Tuple[float, float], optional): coefficients used for computing\n running averages of gradient and its square. (default: (0.9, 0.999))\n eps (float, optional): term added to the denominator to improve\n numerical stability. (default: 1e-8)\n weight_decay (float, optional): weight decay (L2 penalty) (default: 0)\n amsgrad (boolean, optional): whether to use the AMSGrad variant of this\n algorithm from the paper `On the Convergence of Adam and Beyond`_\n (default: False) NOT SUPPORTED yet in CPUAdam!\n adamw_mode (boolean, optional): Apply L2 regularization or weight decay\n True for decoupled weight decay(also known as AdamW) (default: True)\n simd_log (boolean, optional): whether to show if you are using SIMD to\n accelerate. (default: False)\n nvme_offload_fraction (float, optional): Fraction of optimizer states to be offloaded to NVMe. Defaults to 0.0.\n nvme_offload_dir (Optional[str], optional): Directory to save NVMe offload files.\n If it's ``None``, a random temporary directory will be used. Defaults to None.\n\n .. _Adam\\: A Method for Stochastic Optimization:\n https://arxiv.org/abs/1412.6980\n .. _On the Convergence of Adam and Beyond:\n https://openreview.net/forum?id=ryQu7f-RZ\n \"\"\"\n\n # Number of fp32 shards for per parameter\n # Param weight, grad, momentum and variance\n num_fp32_shards_per_param = 4\n\n def __init__(\n self,\n model_params,\n lr=1e-3,\n bias_correction=True,\n betas=(0.9, 0.999),\n eps=1e-8,\n weight_decay=0,\n adamw_mode=True,\n nvme_offload_fraction: float = 0.0,\n nvme_offload_dir: Optional[str] = None,\n ):\n default_args = dict(lr=lr, betas=betas, eps=eps, weight_decay=weight_decay, bias_correction=bias_correction)\n super(CPUAdam, self).__init__(model_params, default_args, nvme_offload_fraction, nvme_offload_dir)\n self.adamw_mode = adamw_mode\n cpu_adam = CPUAdamBuilder().load()\n self.cpu_adam_op = cpu_adam.CPUAdamOptimizer(lr, betas[0], betas[1], eps, weight_decay, adamw_mode)\n\n def torch_adam_update(\n self,\n data,\n grad,\n exp_avg,\n exp_avg_sq,\n lr,\n beta1,\n beta2,\n eps,\n weight_decay,\n bias_correction1,\n bias_correction2,\n use_adamw=False,\n ):\n grad = grad.to(data.dtype)\n\n if weight_decay != 0:\n if use_adamw:\n data.mul_(1 - lr * weight_decay)\n else:\n grad = grad.add(data, alpha=weight_decay)\n\n # Decay the first and second moment running average coefficient\n exp_avg.mul_(beta1).add_(grad, alpha=1 - beta1)\n exp_avg_sq.mul_(beta2).addcmul_(grad, grad, value=1 - beta2)\n\n # TODO(jiaruifang) dose not support amsgrad\n denom = (exp_avg_sq.sqrt() / math.sqrt(bias_correction2)).add_(eps)\n\n step_size = lr / bias_correction1\n\n data.addcdiv_(exp_avg, denom, value=-step_size)\n\n @torch.no_grad()\n def step(self, closure=None, div_scale: float = -1):\n loss = None\n if closure is not None:\n with torch.enable_grad():\n loss = closure()\n\n self._pre_step(\"exp_avg\", \"exp_avg_sq\")\n for _, group in enumerate(self.param_groups):\n for _, p in enumerate(group[\"params\"]):\n if p.grad is None:\n continue\n\n state = self.state[p]\n\n target_device = p.device\n if len(state) == 0:\n state[\"step\"] = 0\n\n # FIXME(ver217): CPU adam kernel only supports fp32 states now\n assert p.dtype is torch.float, \"CPUAdam only support fp32 parameters\"\n # gradient momentums\n state[\"exp_avg\"] = torch.zeros_like(p, device=target_device)\n # gradient variances\n state[\"exp_avg_sq\"] = torch.zeros_like(p, device=target_device)\n self._post_state_init(p)\n\n state[\"step\"] += 1\n beta1, beta2 = group[\"betas\"]\n\n if target_device.type == \"cpu\":\n assert p.data.numel() == p.grad.data.numel(), \"parameter and gradient should have the same size\"\n assert state[\"exp_avg\"].device.type == \"cpu\", \"exp_avg should stay on cpu\"\n assert state[\"exp_avg_sq\"].device.type == \"cpu\", \"exp_avg should stay on cpu\"\n self._pre_update(p, \"exp_avg\", \"exp_avg_sq\")\n if p.grad.dtype is torch.bfloat16:\n # cpu adam kernel does not support bf16 now\n bias_correction1 = 1 - beta1 ** state[\"step\"]\n bias_correction2 = 1 - beta2 ** state[\"step\"]\n self.torch_adam_update(\n p.data,\n p.grad.data,\n state[\"exp_avg\"],\n state[\"exp_avg_sq\"],\n group[\"lr\"],\n beta1,\n beta2,\n group[\"eps\"],\n group[\"weight_decay\"],\n bias_correction1,\n bias_correction2,\n self.adamw_mode,\n )\n else:\n self.cpu_adam_op.step(\n state[\"step\"],\n group[\"lr\"],\n beta1,\n beta2,\n group[\"eps\"],\n group[\"weight_decay\"],\n group[\"bias_correction\"],\n p.data,\n p.grad.data,\n state[\"exp_avg\"],\n state[\"exp_avg_sq\"],\n div_scale,\n )\n self._post_update(p, \"exp_avg\", \"exp_avg_sq\")\n elif target_device.type == \"cuda\":\n assert div_scale == -1, \"div_scale should remain default\"\n assert state[\"exp_avg\"].device.type == \"cuda\", \"exp_avg should stay on cuda\"\n assert state[\"exp_avg_sq\"].device.type == \"cuda\", \"exp_avg should stay on cuda\"\n\n bias_correction1 = 1 - beta1 ** state[\"step\"]\n bias_correction2 = 1 - beta2 ** state[\"step\"]\n\n # adam on cuda\n self.torch_adam_update(\n p.data,\n p.grad.data,\n state[\"exp_avg\"],\n state[\"exp_avg_sq\"],\n group[\"lr\"],\n beta1,\n beta2,\n group[\"eps\"],\n group[\"weight_decay\"],\n bias_correction1,\n bias_correction2,\n self.adamw_mode,\n )\n else:\n raise RuntimeError\n self._post_step()\n return loss\n", "path": "colossalai/nn/optimizer/cpu_adam.py"}]}
| 2,961 | 189 |
gh_patches_debug_49337
|
rasdani/github-patches
|
git_diff
|
ckan__ckan-4249
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
'_Globals' has no attribute 'user' : exception when using an IAuthenticator on CKAN 2.8.0
I'm putting together a new deployment based on the new CKAN v2.8.0 release. I'm using ckanext-ldap as an authenticator, though it looks like this bug would apply to any authenticator plugin.
This exact setup worked fine on CKAN v2.7.3.
### CKAN Version if known (or site URL)
CKAN v 2.8.0
ckanext-ldap @ `ckan-upgrade-2.8.0a`
### Please describe the expected behaviour
If the IAuthenticator plugin cannot authenticate the user, it does not set `g.user`, and CKAN should run the default authenticator.
### Please describe the actual behaviour
If the IAuthenticator plugin cannot authenticate the user, it does not set `g.user`, and CKAN tries to lookup `g.user` and crashes with traceback:
```
Traceback (most recent call last):
File "/usr/lib/ckan/venv/local/lib/python2.7/site-packages/flask/app.py", line 1982, in wsgi_app
response = self.full_dispatch_request()
File "/usr/lib/ckan/venv/local/lib/python2.7/site-packages/flask/app.py", line 1614, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/usr/lib/ckan/venv/local/lib/python2.7/site-packages/flask/app.py", line 1517, in handle_user_exception
reraise(exc_type, exc_value, tb)
File "/usr/lib/ckan/venv/local/lib/python2.7/site-packages/flask/app.py", line 1610, in full_dispatch_request
rv = self.preprocess_request()
File "/usr/lib/ckan/venv/local/lib/python2.7/site-packages/flask/app.py", line 1831, in preprocess_request
rv = func()
File "/usr/lib/ckan/venv/src/ckan/ckan/config/middleware/flask_app.py", line 281, in ckan_before_request
identify_user()
File "/usr/lib/ckan/venv/src/ckan/ckan/views/__init__.py", line 101, in identify_user
if g.user:
File "/usr/lib/ckan/venv/local/lib/python2.7/site-packages/werkzeug/local.py", line 347, in __getattr__
return getattr(self._get_current_object(), name)
File "/usr/lib/ckan/venv/local/lib/python2.7/site-packages/werkzeug/local.py", line 347, in __getattr__
return getattr(self._get_current_object(), name)
File "/usr/lib/ckan/venv/src/ckan/ckan/config/middleware/flask_app.py", line 334, in __getattr__
return getattr(app_globals.app_globals, name)
AttributeError: '_Globals' object has no attribute 'user'
```
### What steps can be taken to reproduce the issue?
* Install CKAN v2.8.0 as per documented instructions
* Install a plugin that implements IAuthenticator (In this case I am using the ckanext-ldap plugin in the 2.8.0 branch), that may not be able to authenticate the user, so may not set `g.user`.
* Run CKAN normally
* Attempt to load any page.
What is odd is that this section of code at `identify_user` in `ckan/views/__init__.py` has not changed between v2.7.3 and v2.8.0. And the way the authenticator plugin handles/sets `g.user` has not changed either. I'm guessing this is caused by a change in the way the _Globals object behaves when it cannot find an attribute.
</issue>
<code>
[start of ckan/views/__init__.py]
1 # encoding: utf-8
2
3 from paste.deploy.converters import asbool
4 from six import text_type
5
6 import ckan.model as model
7 from ckan.common import g, request, config, session
8 from ckan.lib.helpers import redirect_to as redirect
9 import ckan.plugins as p
10
11 import logging
12 log = logging.getLogger(__name__)
13
14 APIKEY_HEADER_NAME_KEY = u'apikey_header_name'
15 APIKEY_HEADER_NAME_DEFAULT = u'X-CKAN-API-Key'
16
17
18 def check_session_cookie(response):
19 u'''
20 The cookies for auth (auth_tkt) and session (ckan) are separate. This
21 checks whether a user is logged in, and determines the validity of the
22 session cookie, removing it if necessary.
23 '''
24 for cookie in request.cookies:
25 # Remove the ckan session cookie if logged out.
26 if cookie == u'ckan' and not getattr(g, u'user', None):
27 # Check session for valid data (including flash messages)
28 is_valid_cookie_data = False
29 for key, value in session.items():
30 if not key.startswith(u'_') and value:
31 is_valid_cookie_data = True
32 break
33 if not is_valid_cookie_data:
34 if session.id:
35 log.debug(u'No valid session data - deleting session')
36 log.debug(u'Session: %r', session.items())
37 session.delete()
38 else:
39 log.debug(u'No session id - deleting session cookie')
40 response.delete_cookie(cookie)
41 # Remove auth_tkt repoze.who cookie if user not logged in.
42 elif cookie == u'auth_tkt' and not session.id:
43 response.delete_cookie(cookie)
44
45 return response
46
47
48 def set_cors_headers_for_response(response):
49 u'''
50 Set up Access Control Allow headers if either origin_allow_all is True, or
51 the request Origin is in the origin_whitelist.
52 '''
53 if config.get(u'ckan.cors.origin_allow_all') \
54 and request.headers.get(u'Origin'):
55
56 cors_origin_allowed = None
57 if asbool(config.get(u'ckan.cors.origin_allow_all')):
58 cors_origin_allowed = b'*'
59 elif config.get(u'ckan.cors.origin_whitelist') and \
60 request.headers.get(u'Origin') \
61 in config[u'ckan.cors.origin_whitelist'].split(u' '):
62 # set var to the origin to allow it.
63 cors_origin_allowed = request.headers.get(u'Origin')
64
65 if cors_origin_allowed is not None:
66 response.headers[b'Access-Control-Allow-Origin'] = \
67 cors_origin_allowed
68 response.headers[b'Access-Control-Allow-Methods'] = \
69 b'POST, PUT, GET, DELETE, OPTIONS'
70 response.headers[b'Access-Control-Allow-Headers'] = \
71 b'X-CKAN-API-KEY, Authorization, Content-Type'
72
73 return response
74
75
76 def identify_user():
77 u'''Try to identify the user
78 If the user is identified then:
79 g.user = user name (unicode)
80 g.userobj = user object
81 g.author = user name
82 otherwise:
83 g.user = None
84 g.userobj = None
85 g.author = user's IP address (unicode)
86
87 Note: Remember, when running under Pylons, `g` is the Pylons `c` object
88 '''
89 # see if it was proxied first
90 g.remote_addr = request.environ.get(u'HTTP_X_FORWARDED_FOR', u'')
91 if not g.remote_addr:
92 g.remote_addr = request.environ.get(u'REMOTE_ADDR',
93 u'Unknown IP Address')
94
95 # Authentication plugins get a chance to run here break as soon as a user
96 # is identified.
97 authenticators = p.PluginImplementations(p.IAuthenticator)
98 if authenticators:
99 for item in authenticators:
100 item.identify()
101 if g.user:
102 break
103
104 # We haven't identified the user so try the default methods
105 if not getattr(g, u'user', None):
106 _identify_user_default()
107
108 # If we have a user but not the userobj let's get the userobj. This means
109 # that IAuthenticator extensions do not need to access the user model
110 # directly.
111 if g.user and not getattr(g, u'userobj', None):
112 g.userobj = model.User.by_name(g.user)
113
114 # general settings
115 if g.user:
116 g.author = g.user
117 else:
118 g.author = g.remote_addr
119 g.author = text_type(g.author)
120
121
122 def _identify_user_default():
123 u'''
124 Identifies the user using two methods:
125 a) If they logged into the web interface then repoze.who will
126 set REMOTE_USER.
127 b) For API calls they may set a header with an API key.
128 '''
129
130 # environ['REMOTE_USER'] is set by repoze.who if it authenticates a
131 # user's cookie. But repoze.who doesn't check the user (still) exists
132 # in our database - we need to do that here. (Another way would be
133 # with an userid_checker, but that would mean another db access.
134 # See: http://docs.repoze.org/who/1.0/narr.html#module-repoze.who\
135 # .plugins.sql )
136 g.user = request.environ.get(u'REMOTE_USER', u'')
137 if g.user:
138 g.user = g.user.decode(u'utf8')
139 g.userobj = model.User.by_name(g.user)
140
141 if g.userobj is None or not g.userobj.is_active():
142
143 # This occurs when a user that was still logged in is deleted, or
144 # when you are logged in, clean db and then restart (or when you
145 # change your username). There is no user object, so even though
146 # repoze thinks you are logged in and your cookie has
147 # ckan_display_name, we need to force user to logout and login
148 # again to get the User object.
149
150 ev = request.environ
151 if u'repoze.who.plugins' in ev:
152 pth = getattr(ev[u'repoze.who.plugins'][u'friendlyform'],
153 u'logout_handler_path')
154 redirect(pth)
155 else:
156 g.userobj = _get_user_for_apikey()
157 if g.userobj is not None:
158 g.user = g.userobj.name
159
160
161 def _get_user_for_apikey():
162 apikey_header_name = config.get(APIKEY_HEADER_NAME_KEY,
163 APIKEY_HEADER_NAME_DEFAULT)
164 apikey = request.headers.get(apikey_header_name, u'')
165 if not apikey:
166 apikey = request.environ.get(apikey_header_name, u'')
167 if not apikey:
168 # For misunderstanding old documentation (now fixed).
169 apikey = request.environ.get(u'HTTP_AUTHORIZATION', u'')
170 if not apikey:
171 apikey = request.environ.get(u'Authorization', u'')
172 # Forget HTTP Auth credentials (they have spaces).
173 if u' ' in apikey:
174 apikey = u''
175 if not apikey:
176 return None
177 apikey = apikey.decode(u'utf8', u'ignore')
178 log.debug(u'Received API Key: %s' % apikey)
179 query = model.Session.query(model.User)
180 user = query.filter_by(apikey=apikey).first()
181 return user
182
[end of ckan/views/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ckan/views/__init__.py b/ckan/views/__init__.py
--- a/ckan/views/__init__.py
+++ b/ckan/views/__init__.py
@@ -98,8 +98,11 @@
if authenticators:
for item in authenticators:
item.identify()
- if g.user:
- break
+ try:
+ if g.user:
+ break
+ except AttributeError:
+ continue
# We haven't identified the user so try the default methods
if not getattr(g, u'user', None):
|
{"golden_diff": "diff --git a/ckan/views/__init__.py b/ckan/views/__init__.py\n--- a/ckan/views/__init__.py\n+++ b/ckan/views/__init__.py\n@@ -98,8 +98,11 @@\n if authenticators:\n for item in authenticators:\n item.identify()\n- if g.user:\n- break\n+ try:\n+ if g.user:\n+ break\n+ except AttributeError:\n+ continue\n \n # We haven't identified the user so try the default methods\n if not getattr(g, u'user', None):\n", "issue": "'_Globals' has no attribute 'user' : exception when using an IAuthenticator on CKAN 2.8.0\nI'm putting together a new deployment based on the new CKAN v2.8.0 release. I'm using ckanext-ldap as an authenticator, though it looks like this bug would apply to any authenticator plugin.\r\nThis exact setup worked fine on CKAN v2.7.3.\r\n\r\n### CKAN Version if known (or site URL)\r\nCKAN v 2.8.0\r\nckanext-ldap @ `ckan-upgrade-2.8.0a`\r\n\r\n### Please describe the expected behaviour\r\nIf the IAuthenticator plugin cannot authenticate the user, it does not set `g.user`, and CKAN should run the default authenticator.\r\n\r\n### Please describe the actual behaviour\r\nIf the IAuthenticator plugin cannot authenticate the user, it does not set `g.user`, and CKAN tries to lookup `g.user` and crashes with traceback:\r\n```\r\nTraceback (most recent call last):\r\n File \"/usr/lib/ckan/venv/local/lib/python2.7/site-packages/flask/app.py\", line 1982, in wsgi_app\r\n response = self.full_dispatch_request()\r\n File \"/usr/lib/ckan/venv/local/lib/python2.7/site-packages/flask/app.py\", line 1614, in full_dispatch_request\r\n rv = self.handle_user_exception(e)\r\n File \"/usr/lib/ckan/venv/local/lib/python2.7/site-packages/flask/app.py\", line 1517, in handle_user_exception\r\n reraise(exc_type, exc_value, tb)\r\n File \"/usr/lib/ckan/venv/local/lib/python2.7/site-packages/flask/app.py\", line 1610, in full_dispatch_request\r\n rv = self.preprocess_request()\r\n File \"/usr/lib/ckan/venv/local/lib/python2.7/site-packages/flask/app.py\", line 1831, in preprocess_request\r\n rv = func()\r\n File \"/usr/lib/ckan/venv/src/ckan/ckan/config/middleware/flask_app.py\", line 281, in ckan_before_request\r\n identify_user()\r\n File \"/usr/lib/ckan/venv/src/ckan/ckan/views/__init__.py\", line 101, in identify_user\r\n if g.user:\r\n File \"/usr/lib/ckan/venv/local/lib/python2.7/site-packages/werkzeug/local.py\", line 347, in __getattr__\r\n return getattr(self._get_current_object(), name)\r\n File \"/usr/lib/ckan/venv/local/lib/python2.7/site-packages/werkzeug/local.py\", line 347, in __getattr__\r\n return getattr(self._get_current_object(), name)\r\n File \"/usr/lib/ckan/venv/src/ckan/ckan/config/middleware/flask_app.py\", line 334, in __getattr__\r\n return getattr(app_globals.app_globals, name)\r\nAttributeError: '_Globals' object has no attribute 'user'\r\n```\r\n### What steps can be taken to reproduce the issue? \r\n* Install CKAN v2.8.0 as per documented instructions\r\n* Install a plugin that implements IAuthenticator (In this case I am using the ckanext-ldap plugin in the 2.8.0 branch), that may not be able to authenticate the user, so may not set `g.user`.\r\n* Run CKAN normally\r\n* Attempt to load any page. \r\n\r\nWhat is odd is that this section of code at `identify_user` in `ckan/views/__init__.py` has not changed between v2.7.3 and v2.8.0. And the way the authenticator plugin handles/sets `g.user` has not changed either. I'm guessing this is caused by a change in the way the _Globals object behaves when it cannot find an attribute.\n", "before_files": [{"content": "# encoding: utf-8\n\nfrom paste.deploy.converters import asbool\nfrom six import text_type\n\nimport ckan.model as model\nfrom ckan.common import g, request, config, session\nfrom ckan.lib.helpers import redirect_to as redirect\nimport ckan.plugins as p\n\nimport logging\nlog = logging.getLogger(__name__)\n\nAPIKEY_HEADER_NAME_KEY = u'apikey_header_name'\nAPIKEY_HEADER_NAME_DEFAULT = u'X-CKAN-API-Key'\n\n\ndef check_session_cookie(response):\n u'''\n The cookies for auth (auth_tkt) and session (ckan) are separate. This\n checks whether a user is logged in, and determines the validity of the\n session cookie, removing it if necessary.\n '''\n for cookie in request.cookies:\n # Remove the ckan session cookie if logged out.\n if cookie == u'ckan' and not getattr(g, u'user', None):\n # Check session for valid data (including flash messages)\n is_valid_cookie_data = False\n for key, value in session.items():\n if not key.startswith(u'_') and value:\n is_valid_cookie_data = True\n break\n if not is_valid_cookie_data:\n if session.id:\n log.debug(u'No valid session data - deleting session')\n log.debug(u'Session: %r', session.items())\n session.delete()\n else:\n log.debug(u'No session id - deleting session cookie')\n response.delete_cookie(cookie)\n # Remove auth_tkt repoze.who cookie if user not logged in.\n elif cookie == u'auth_tkt' and not session.id:\n response.delete_cookie(cookie)\n\n return response\n\n\ndef set_cors_headers_for_response(response):\n u'''\n Set up Access Control Allow headers if either origin_allow_all is True, or\n the request Origin is in the origin_whitelist.\n '''\n if config.get(u'ckan.cors.origin_allow_all') \\\n and request.headers.get(u'Origin'):\n\n cors_origin_allowed = None\n if asbool(config.get(u'ckan.cors.origin_allow_all')):\n cors_origin_allowed = b'*'\n elif config.get(u'ckan.cors.origin_whitelist') and \\\n request.headers.get(u'Origin') \\\n in config[u'ckan.cors.origin_whitelist'].split(u' '):\n # set var to the origin to allow it.\n cors_origin_allowed = request.headers.get(u'Origin')\n\n if cors_origin_allowed is not None:\n response.headers[b'Access-Control-Allow-Origin'] = \\\n cors_origin_allowed\n response.headers[b'Access-Control-Allow-Methods'] = \\\n b'POST, PUT, GET, DELETE, OPTIONS'\n response.headers[b'Access-Control-Allow-Headers'] = \\\n b'X-CKAN-API-KEY, Authorization, Content-Type'\n\n return response\n\n\ndef identify_user():\n u'''Try to identify the user\n If the user is identified then:\n g.user = user name (unicode)\n g.userobj = user object\n g.author = user name\n otherwise:\n g.user = None\n g.userobj = None\n g.author = user's IP address (unicode)\n\n Note: Remember, when running under Pylons, `g` is the Pylons `c` object\n '''\n # see if it was proxied first\n g.remote_addr = request.environ.get(u'HTTP_X_FORWARDED_FOR', u'')\n if not g.remote_addr:\n g.remote_addr = request.environ.get(u'REMOTE_ADDR',\n u'Unknown IP Address')\n\n # Authentication plugins get a chance to run here break as soon as a user\n # is identified.\n authenticators = p.PluginImplementations(p.IAuthenticator)\n if authenticators:\n for item in authenticators:\n item.identify()\n if g.user:\n break\n\n # We haven't identified the user so try the default methods\n if not getattr(g, u'user', None):\n _identify_user_default()\n\n # If we have a user but not the userobj let's get the userobj. This means\n # that IAuthenticator extensions do not need to access the user model\n # directly.\n if g.user and not getattr(g, u'userobj', None):\n g.userobj = model.User.by_name(g.user)\n\n # general settings\n if g.user:\n g.author = g.user\n else:\n g.author = g.remote_addr\n g.author = text_type(g.author)\n\n\ndef _identify_user_default():\n u'''\n Identifies the user using two methods:\n a) If they logged into the web interface then repoze.who will\n set REMOTE_USER.\n b) For API calls they may set a header with an API key.\n '''\n\n # environ['REMOTE_USER'] is set by repoze.who if it authenticates a\n # user's cookie. But repoze.who doesn't check the user (still) exists\n # in our database - we need to do that here. (Another way would be\n # with an userid_checker, but that would mean another db access.\n # See: http://docs.repoze.org/who/1.0/narr.html#module-repoze.who\\\n # .plugins.sql )\n g.user = request.environ.get(u'REMOTE_USER', u'')\n if g.user:\n g.user = g.user.decode(u'utf8')\n g.userobj = model.User.by_name(g.user)\n\n if g.userobj is None or not g.userobj.is_active():\n\n # This occurs when a user that was still logged in is deleted, or\n # when you are logged in, clean db and then restart (or when you\n # change your username). There is no user object, so even though\n # repoze thinks you are logged in and your cookie has\n # ckan_display_name, we need to force user to logout and login\n # again to get the User object.\n\n ev = request.environ\n if u'repoze.who.plugins' in ev:\n pth = getattr(ev[u'repoze.who.plugins'][u'friendlyform'],\n u'logout_handler_path')\n redirect(pth)\n else:\n g.userobj = _get_user_for_apikey()\n if g.userobj is not None:\n g.user = g.userobj.name\n\n\ndef _get_user_for_apikey():\n apikey_header_name = config.get(APIKEY_HEADER_NAME_KEY,\n APIKEY_HEADER_NAME_DEFAULT)\n apikey = request.headers.get(apikey_header_name, u'')\n if not apikey:\n apikey = request.environ.get(apikey_header_name, u'')\n if not apikey:\n # For misunderstanding old documentation (now fixed).\n apikey = request.environ.get(u'HTTP_AUTHORIZATION', u'')\n if not apikey:\n apikey = request.environ.get(u'Authorization', u'')\n # Forget HTTP Auth credentials (they have spaces).\n if u' ' in apikey:\n apikey = u''\n if not apikey:\n return None\n apikey = apikey.decode(u'utf8', u'ignore')\n log.debug(u'Received API Key: %s' % apikey)\n query = model.Session.query(model.User)\n user = query.filter_by(apikey=apikey).first()\n return user\n", "path": "ckan/views/__init__.py"}]}
| 3,414 | 132 |
gh_patches_debug_6803
|
rasdani/github-patches
|
git_diff
|
xorbitsai__inference-510
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
FEAT: support Mistral-7B-Instruct
### Is your feature request related to a problem? Please describe
https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1
</issue>
<code>
[start of xinference/model/llm/ggml/ctransformers.py]
1 # Copyright 2022-2023 XProbe Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import logging
16 import os
17 from typing import TYPE_CHECKING, Iterator, Optional, Sequence, TypedDict, Union
18
19 if TYPE_CHECKING:
20 from ctransformers import AutoConfig
21
22 from ....types import Completion, CompletionChunk
23 from ..core import LLM
24 from ..llm_family import LLMFamilyV1, LLMSpecV1
25 from .ctransformers_util import generate_stream
26
27 logger = logging.getLogger(__name__)
28
29 # all supported models for Ctransformers with their model type.
30 # Please Strictly follows this name format when inputting new model to model_family.
31 MODEL_TYPE_FOR_CTRANSFORMERS = {
32 "gpt-2": "gpt2",
33 "gpt-j": "gptj",
34 "gpt4all-j": "gptj",
35 "gpt-neox": "gpt_neox",
36 "stablelm": "gpt_neox",
37 "llama": "llama",
38 "llama-2": "llama",
39 "mpt": "mpt",
40 "dolly-v2": "dolly-v2",
41 "replit": "replit",
42 "starcoder": "starcoder",
43 "starchat": "starcoder",
44 "falcon": "falcon",
45 }
46
47 # these two constants subjects to change for future development and ctransformers updates.
48 CTRANSFORMERS_SUPPORTED_MODEL = ["starcoder", "gpt-2"]
49
50 CTRANSFORMERS_GPU_SUPPORT = ["llama", "llama-2", "mpt", "falcon"]
51
52 SIZE_TO_GPU_LAYERS = {
53 3: 26,
54 7: 32,
55 13: 40,
56 30: 60,
57 65: 80,
58 }
59
60
61 class CtransformersModelConfig(TypedDict, total=False):
62 n_ctx: int
63 n_gpu_layers: int
64
65
66 class CtransformersGenerateConfig(TypedDict, total=False):
67 max_tokens: Optional[int]
68 top_k: Optional[int]
69 top_p: Optional[float]
70 temperature: Optional[float]
71 repetition_penalty: Optional[float]
72 last_n_tokens: Optional[int]
73 seed: Optional[int]
74 batch_size: Optional[int]
75 threads: Optional[int]
76 stop: Optional[Sequence[str]]
77 stream: Optional[bool]
78 reset: Optional[bool]
79
80
81 class CtransformersModel(LLM):
82 def __init__(
83 self,
84 model_uid: str,
85 model_family: "LLMFamilyV1",
86 model_spec: "LLMSpecV1",
87 quantization: str,
88 model_path: str,
89 ctransformers_model_config: Optional[CtransformersModelConfig],
90 ):
91 super().__init__(model_uid, model_family, model_spec, quantization, model_path)
92
93 self._model_type = None
94 closest_size = min(
95 SIZE_TO_GPU_LAYERS.keys(),
96 key=lambda x: abs(x - model_spec.model_size_in_billions),
97 )
98
99 self._model_family = model_family
100 self._model_uid = model_uid
101 self._llm = None
102
103 self._gpu_layers = SIZE_TO_GPU_LAYERS[closest_size]
104 self._ctransformer_model_config = self._sanitize_model_config(
105 model_path, ctransformers_model_config
106 )
107
108 def _sanitize_model_config(
109 self, model_path, ctransformers_model_config: Optional[CtransformersModelConfig]
110 ) -> "AutoConfig":
111 try:
112 from ctransformers import AutoConfig, Config
113 except ImportError:
114 error_message = (
115 "Failed to import module 'ctransformers - AutoConfig and Config'"
116 )
117
118 installation_guide = [
119 f"Please make sure 'ctransformers' is installed.",
120 f"You can install it by checking out the repository for command:"
121 f"https://github.com/marella/ctransformers",
122 ]
123
124 raise ImportError(f"{error_message}\n\n{''.join(installation_guide)}")
125
126 # if the model have customized config, we update it.
127 model_config_ret = Config()
128 potential_gpu_layers = None
129 if ctransformers_model_config:
130 potential_context_length = ctransformers_model_config.pop("n_ctx", None)
131 potential_gpu_layers = ctransformers_model_config.pop("n_gpu_layers", None)
132
133 model_config_ret.context_length = potential_context_length
134 model_config_ret.gpu_layers = potential_gpu_layers
135
136 # if user does not define gpu layers, we have to set it with our system if applicable.
137 if potential_gpu_layers is None:
138 if self._model_family.model_name not in CTRANSFORMERS_GPU_SUPPORT:
139 model_config_ret.gpu_layers = -1
140 elif self._is_darwin_and_apple_silicon():
141 model_config_ret.gpu_layers = 1
142 elif self._has_cuda_device():
143 model_config_ret.gpu_layers = self._gpu_layers
144
145 return AutoConfig(model_config_ret)
146
147 def _sanitize_generate_config(
148 self,
149 ctransformers_generate_config: Optional[CtransformersGenerateConfig],
150 ) -> CtransformersGenerateConfig:
151 # if the input config is not None, we try to copy the selected attributes to the ctransformersGenerateConfig.
152 if ctransformers_generate_config is None:
153 ctransformers_generate_config = CtransformersGenerateConfig()
154
155 # for our system, the threads will have to be set to 4
156 # all other parameters, if not specified, will be set to default when generate.
157 ctransformers_generate_config.setdefault("threads", 4)
158
159 return ctransformers_generate_config
160
161 def load(self):
162 try:
163 from ctransformers import AutoModelForCausalLM
164 except ImportError:
165 error_message = "Failed to import module 'ctransformers'"
166
167 installation_guide = [
168 f"Please make sure 'ctransformers' is installed.",
169 f"You can install it by checking out the repository for command."
170 f"https://github.com/marella/ctransformers",
171 ]
172
173 raise ImportError(f"{error_message}\n\n{''.join(installation_guide)}")
174
175 model_path = os.path.join(
176 self.model_path,
177 self.model_spec.model_file_name_template.format(
178 quantization=self.quantization
179 ),
180 )
181
182 self._model_type = self._determine_model_type()
183 self._llm = AutoModelForCausalLM.from_pretrained(
184 model_path_or_repo_id=model_path,
185 model_type=self._model_type,
186 config=self._ctransformer_model_config,
187 )
188
189 @classmethod
190 def match(
191 cls, llm_family: LLMFamilyV1, llm_spec: LLMSpecV1, quantization: str
192 ) -> bool:
193 if llm_spec.model_format != "ggmlv3":
194 return False
195 if llm_family.model_name not in CTRANSFORMERS_SUPPORTED_MODEL:
196 return False
197 if "generate" not in llm_family.model_ability:
198 return False
199 return True
200
201 def _determine_model_type(self):
202 if self._model_family.model_name not in MODEL_TYPE_FOR_CTRANSFORMERS:
203 raise ValueError(
204 f"The current model {self._model_family.model_name} is not supported, check your model name. "
205 )
206 return MODEL_TYPE_FOR_CTRANSFORMERS[self._model_family.model_name]
207
208 def generate(
209 self, prompt: str, generate_config_raw: CtransformersGenerateConfig
210 ) -> Union[Completion, Iterator[CompletionChunk]]:
211 def generator_wrapper(
212 _prompt: str,
213 _max_new_tokens: Union[int, None],
214 _generate_config: CtransformersGenerateConfig,
215 ) -> Iterator[CompletionChunk]:
216 assert self._model_uid is not None
217 for _completion_chunk, _ in generate_stream(
218 model=self._model_uid,
219 model_ref=self._llm,
220 prompt=_prompt,
221 max_new_tokens=_max_new_tokens,
222 **_generate_config,
223 ):
224 yield _completion_chunk
225
226 generate_config = self._sanitize_generate_config(generate_config_raw)
227
228 logger.debug(
229 "Enter generate, prompt: %s, generate config: %s", prompt, generate_config
230 )
231
232 max_new_tokens = generate_config.pop("max_tokens", None)
233
234 stream_or_not = generate_config.get("stream", False)
235 if stream_or_not:
236 return generator_wrapper(
237 _prompt=prompt,
238 _max_new_tokens=max_new_tokens,
239 _generate_config=generate_config,
240 )
241 else:
242 assert self.model_uid is not None
243 completion_chunk = None
244 completion_usage = None
245 for completion_chunk, completion_usage in generate_stream(
246 model=self.model_uid,
247 model_ref=self._llm,
248 prompt=prompt,
249 max_new_tokens=max_new_tokens,
250 **generate_config,
251 ):
252 pass
253
254 assert completion_chunk is not None
255 assert completion_usage is not None
256
257 completion = Completion(
258 id=completion_chunk["id"],
259 object=completion_chunk["object"],
260 created=completion_chunk["created"],
261 model=completion_chunk["model"],
262 choices=completion_chunk["choices"],
263 usage=completion_usage,
264 )
265
266 logger.debug(
267 "Generated, completion: %s, generate config: %s",
268 completion,
269 generate_config,
270 )
271
272 return completion
273
[end of xinference/model/llm/ggml/ctransformers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/xinference/model/llm/ggml/ctransformers.py b/xinference/model/llm/ggml/ctransformers.py
--- a/xinference/model/llm/ggml/ctransformers.py
+++ b/xinference/model/llm/ggml/ctransformers.py
@@ -190,7 +190,7 @@
def match(
cls, llm_family: LLMFamilyV1, llm_spec: LLMSpecV1, quantization: str
) -> bool:
- if llm_spec.model_format != "ggmlv3":
+ if llm_spec.model_format != "ggmlv3" and llm_spec.model_format != "ggufv2":
return False
if llm_family.model_name not in CTRANSFORMERS_SUPPORTED_MODEL:
return False
|
{"golden_diff": "diff --git a/xinference/model/llm/ggml/ctransformers.py b/xinference/model/llm/ggml/ctransformers.py\n--- a/xinference/model/llm/ggml/ctransformers.py\n+++ b/xinference/model/llm/ggml/ctransformers.py\n@@ -190,7 +190,7 @@\n def match(\n cls, llm_family: LLMFamilyV1, llm_spec: LLMSpecV1, quantization: str\n ) -> bool:\n- if llm_spec.model_format != \"ggmlv3\":\n+ if llm_spec.model_format != \"ggmlv3\" and llm_spec.model_format != \"ggufv2\":\n return False\n if llm_family.model_name not in CTRANSFORMERS_SUPPORTED_MODEL:\n return False\n", "issue": "FEAT: support Mistral-7B-Instruct\n### Is your feature request related to a problem? Please describe\r\nhttps://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1\r\n\r\n\n", "before_files": [{"content": "# Copyright 2022-2023 XProbe Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nimport os\nfrom typing import TYPE_CHECKING, Iterator, Optional, Sequence, TypedDict, Union\n\nif TYPE_CHECKING:\n from ctransformers import AutoConfig\n\nfrom ....types import Completion, CompletionChunk\nfrom ..core import LLM\nfrom ..llm_family import LLMFamilyV1, LLMSpecV1\nfrom .ctransformers_util import generate_stream\n\nlogger = logging.getLogger(__name__)\n\n# all supported models for Ctransformers with their model type.\n# Please Strictly follows this name format when inputting new model to model_family.\nMODEL_TYPE_FOR_CTRANSFORMERS = {\n \"gpt-2\": \"gpt2\",\n \"gpt-j\": \"gptj\",\n \"gpt4all-j\": \"gptj\",\n \"gpt-neox\": \"gpt_neox\",\n \"stablelm\": \"gpt_neox\",\n \"llama\": \"llama\",\n \"llama-2\": \"llama\",\n \"mpt\": \"mpt\",\n \"dolly-v2\": \"dolly-v2\",\n \"replit\": \"replit\",\n \"starcoder\": \"starcoder\",\n \"starchat\": \"starcoder\",\n \"falcon\": \"falcon\",\n}\n\n# these two constants subjects to change for future development and ctransformers updates.\nCTRANSFORMERS_SUPPORTED_MODEL = [\"starcoder\", \"gpt-2\"]\n\nCTRANSFORMERS_GPU_SUPPORT = [\"llama\", \"llama-2\", \"mpt\", \"falcon\"]\n\nSIZE_TO_GPU_LAYERS = {\n 3: 26,\n 7: 32,\n 13: 40,\n 30: 60,\n 65: 80,\n}\n\n\nclass CtransformersModelConfig(TypedDict, total=False):\n n_ctx: int\n n_gpu_layers: int\n\n\nclass CtransformersGenerateConfig(TypedDict, total=False):\n max_tokens: Optional[int]\n top_k: Optional[int]\n top_p: Optional[float]\n temperature: Optional[float]\n repetition_penalty: Optional[float]\n last_n_tokens: Optional[int]\n seed: Optional[int]\n batch_size: Optional[int]\n threads: Optional[int]\n stop: Optional[Sequence[str]]\n stream: Optional[bool]\n reset: Optional[bool]\n\n\nclass CtransformersModel(LLM):\n def __init__(\n self,\n model_uid: str,\n model_family: \"LLMFamilyV1\",\n model_spec: \"LLMSpecV1\",\n quantization: str,\n model_path: str,\n ctransformers_model_config: Optional[CtransformersModelConfig],\n ):\n super().__init__(model_uid, model_family, model_spec, quantization, model_path)\n\n self._model_type = None\n closest_size = min(\n SIZE_TO_GPU_LAYERS.keys(),\n key=lambda x: abs(x - model_spec.model_size_in_billions),\n )\n\n self._model_family = model_family\n self._model_uid = model_uid\n self._llm = None\n\n self._gpu_layers = SIZE_TO_GPU_LAYERS[closest_size]\n self._ctransformer_model_config = self._sanitize_model_config(\n model_path, ctransformers_model_config\n )\n\n def _sanitize_model_config(\n self, model_path, ctransformers_model_config: Optional[CtransformersModelConfig]\n ) -> \"AutoConfig\":\n try:\n from ctransformers import AutoConfig, Config\n except ImportError:\n error_message = (\n \"Failed to import module 'ctransformers - AutoConfig and Config'\"\n )\n\n installation_guide = [\n f\"Please make sure 'ctransformers' is installed.\",\n f\"You can install it by checking out the repository for command:\"\n f\"https://github.com/marella/ctransformers\",\n ]\n\n raise ImportError(f\"{error_message}\\n\\n{''.join(installation_guide)}\")\n\n # if the model have customized config, we update it.\n model_config_ret = Config()\n potential_gpu_layers = None\n if ctransformers_model_config:\n potential_context_length = ctransformers_model_config.pop(\"n_ctx\", None)\n potential_gpu_layers = ctransformers_model_config.pop(\"n_gpu_layers\", None)\n\n model_config_ret.context_length = potential_context_length\n model_config_ret.gpu_layers = potential_gpu_layers\n\n # if user does not define gpu layers, we have to set it with our system if applicable.\n if potential_gpu_layers is None:\n if self._model_family.model_name not in CTRANSFORMERS_GPU_SUPPORT:\n model_config_ret.gpu_layers = -1\n elif self._is_darwin_and_apple_silicon():\n model_config_ret.gpu_layers = 1\n elif self._has_cuda_device():\n model_config_ret.gpu_layers = self._gpu_layers\n\n return AutoConfig(model_config_ret)\n\n def _sanitize_generate_config(\n self,\n ctransformers_generate_config: Optional[CtransformersGenerateConfig],\n ) -> CtransformersGenerateConfig:\n # if the input config is not None, we try to copy the selected attributes to the ctransformersGenerateConfig.\n if ctransformers_generate_config is None:\n ctransformers_generate_config = CtransformersGenerateConfig()\n\n # for our system, the threads will have to be set to 4\n # all other parameters, if not specified, will be set to default when generate.\n ctransformers_generate_config.setdefault(\"threads\", 4)\n\n return ctransformers_generate_config\n\n def load(self):\n try:\n from ctransformers import AutoModelForCausalLM\n except ImportError:\n error_message = \"Failed to import module 'ctransformers'\"\n\n installation_guide = [\n f\"Please make sure 'ctransformers' is installed.\",\n f\"You can install it by checking out the repository for command.\"\n f\"https://github.com/marella/ctransformers\",\n ]\n\n raise ImportError(f\"{error_message}\\n\\n{''.join(installation_guide)}\")\n\n model_path = os.path.join(\n self.model_path,\n self.model_spec.model_file_name_template.format(\n quantization=self.quantization\n ),\n )\n\n self._model_type = self._determine_model_type()\n self._llm = AutoModelForCausalLM.from_pretrained(\n model_path_or_repo_id=model_path,\n model_type=self._model_type,\n config=self._ctransformer_model_config,\n )\n\n @classmethod\n def match(\n cls, llm_family: LLMFamilyV1, llm_spec: LLMSpecV1, quantization: str\n ) -> bool:\n if llm_spec.model_format != \"ggmlv3\":\n return False\n if llm_family.model_name not in CTRANSFORMERS_SUPPORTED_MODEL:\n return False\n if \"generate\" not in llm_family.model_ability:\n return False\n return True\n\n def _determine_model_type(self):\n if self._model_family.model_name not in MODEL_TYPE_FOR_CTRANSFORMERS:\n raise ValueError(\n f\"The current model {self._model_family.model_name} is not supported, check your model name. \"\n )\n return MODEL_TYPE_FOR_CTRANSFORMERS[self._model_family.model_name]\n\n def generate(\n self, prompt: str, generate_config_raw: CtransformersGenerateConfig\n ) -> Union[Completion, Iterator[CompletionChunk]]:\n def generator_wrapper(\n _prompt: str,\n _max_new_tokens: Union[int, None],\n _generate_config: CtransformersGenerateConfig,\n ) -> Iterator[CompletionChunk]:\n assert self._model_uid is not None\n for _completion_chunk, _ in generate_stream(\n model=self._model_uid,\n model_ref=self._llm,\n prompt=_prompt,\n max_new_tokens=_max_new_tokens,\n **_generate_config,\n ):\n yield _completion_chunk\n\n generate_config = self._sanitize_generate_config(generate_config_raw)\n\n logger.debug(\n \"Enter generate, prompt: %s, generate config: %s\", prompt, generate_config\n )\n\n max_new_tokens = generate_config.pop(\"max_tokens\", None)\n\n stream_or_not = generate_config.get(\"stream\", False)\n if stream_or_not:\n return generator_wrapper(\n _prompt=prompt,\n _max_new_tokens=max_new_tokens,\n _generate_config=generate_config,\n )\n else:\n assert self.model_uid is not None\n completion_chunk = None\n completion_usage = None\n for completion_chunk, completion_usage in generate_stream(\n model=self.model_uid,\n model_ref=self._llm,\n prompt=prompt,\n max_new_tokens=max_new_tokens,\n **generate_config,\n ):\n pass\n\n assert completion_chunk is not None\n assert completion_usage is not None\n\n completion = Completion(\n id=completion_chunk[\"id\"],\n object=completion_chunk[\"object\"],\n created=completion_chunk[\"created\"],\n model=completion_chunk[\"model\"],\n choices=completion_chunk[\"choices\"],\n usage=completion_usage,\n )\n\n logger.debug(\n \"Generated, completion: %s, generate config: %s\",\n completion,\n generate_config,\n )\n\n return completion\n", "path": "xinference/model/llm/ggml/ctransformers.py"}]}
| 3,474 | 194 |
gh_patches_debug_27171
|
rasdani/github-patches
|
git_diff
|
projectmesa__mesa-339
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Advanced tutorial chart
I have been unable to get the chart showing the gini coefficient to open up in the advanced tutorial to open up. Everything else is working, the chart just does not appear. Please advise,
Thank you.
Tom
</issue>
<code>
[start of mesa/visualization/ModularVisualization.py]
1 # -*- coding: utf-8 -*-
2 """
3 ModularServer
4 =============
5
6 A visualization server which renders a model via one or more elements.
7
8 The concept for the modular visualization server as follows:
9 A visualization is composed of VisualizationElements, each of which defines how
10 to generate some visualization from a model instance and render it on the
11 client. VisualizationElements may be anything from a simple text display to
12 a multilayered HTML5 canvas.
13
14 The actual server is launched with one or more VisualizationElements;
15 it runs the model object through each of them, generating data to be sent to
16 the client. The client page is also generated based on the JavaScript code
17 provided by each element.
18
19 This file consists of the following classes:
20
21 VisualizationElement: Parent class for all other visualization elements, with
22 the minimal necessary options.
23 PageHandler: The handler for the visualization page, generated from a template
24 and built from the various visualization elements.
25 SocketHandler: Handles the websocket connection between the client page and
26 the server.
27 ModularServer: The overall visualization application class which stores and
28 controls the model and visualization instance.
29
30
31 ModularServer should *not* need to be subclassed on a model-by-model basis; it
32 should be primarily a pass-through for VisualizationElement subclasses, which
33 define the actual visualization specifics.
34
35 For example, suppose we have created two visualization elements for our model,
36 called canvasvis and graphvis; we would launch a server with:
37
38 server = ModularServer(MyModel, [canvasvis, graphvis], name="My Model")
39 server.launch()
40
41 The client keeps track of what step it is showing. Clicking the Step button in
42 the browser sends a message requesting the viz_state corresponding to the next
43 step position, which is then sent back to the client via the websocket.
44
45 The websocket protocol is as follows:
46 Each message is a JSON object, with a "type" property which defines the rest of
47 the structure.
48
49 Server -> Client:
50 Send over the model state to visualize.
51 Model state is a list, with each element corresponding to a div; each div
52 is expected to have a render function associated with it, which knows how
53 to render that particular data. The example below includes two elements:
54 the first is data for a CanvasGrid, the second for a raw text display.
55
56 {
57 "type": "viz_state",
58 "data": [{0:[ {"Shape": "circle", "x": 0, "y": 0, "r": 0.5,
59 "Color": "#AAAAAA", "Filled": "true", "Layer": 0,
60 "text": 'A', "text_color": "white" }]},
61 "Shape Count: 1"]
62 }
63
64 Informs the client that the model is over.
65 {"type": "end"}
66
67 Client -> Server:
68 Reset the model.
69 TODO: Allow this to come with parameters
70 {
71 "type": "reset"
72 }
73
74 Get a given state.
75 {
76 "type": "get_step",
77 "step:" index of the step to get.
78 }
79
80 """
81 import os
82
83 import tornado.ioloop
84 import tornado.web
85 import tornado.websocket
86 import tornado.escape
87 import tornado.gen
88
89 import webbrowser
90
91 # Suppress several pylint warnings for this file.
92 # Attributes being defined outside of init is a Tornado feature.
93 # pylint: disable=attribute-defined-outside-init
94
95
96 class VisualizationElement:
97 """
98 Defines an element of the visualization.
99
100 Attributes:
101 package_includes: A list of external JavaScript files to include that
102 are part of the Mesa packages.
103 local_includes: A list of JavaScript files that are local to the
104 directory that the server is being run in.
105 js_code: A JavaScript code string to instantiate the element.
106
107 Methods:
108 render: Takes a model object, and produces JSON data which can be sent
109 to the client.
110
111 """
112
113 package_includes = []
114 local_includes = []
115 js_code = ''
116 render_args = {}
117
118 def __init__(self):
119 pass
120
121 def render(self, model):
122 """ Build visualization data from a model object.
123
124 Args:
125 model: A model object
126
127 Returns:
128 A JSON-ready object.
129
130 """
131 return "<b>VisualizationElement goes here</b>."
132
133 # =============================================================================
134 # Actual Tornado code starts here:
135
136
137 class PageHandler(tornado.web.RequestHandler):
138 """ Handler for the HTML template which holds the visualization. """
139
140 def get(self):
141 elements = self.application.visualization_elements
142 for i, element in enumerate(elements):
143 element.index = i
144 self.render("modular_template.html", port=self.application.port,
145 model_name=self.application.model_name,
146 package_includes=self.application.package_includes,
147 local_includes=self.application.local_includes,
148 scripts=self.application.js_code)
149
150
151 class SocketHandler(tornado.websocket.WebSocketHandler):
152 """ Handler for websocket. """
153 def open(self):
154 if self.application.verbose:
155 print("Socket opened!")
156
157 def check_origin(self, origin):
158 return True
159
160 def on_message(self, message):
161 """ Receiving a message from the websocket, parse, and act accordingly.
162
163 """
164 if self.application.verbose:
165 print(message)
166 msg = tornado.escape.json_decode(message)
167
168 if msg["type"] == "get_step":
169 self.application.model.step()
170 self.write_message({"type": "viz_state",
171 "data": self.application.render_model()})
172
173 elif msg["type"] == "reset":
174 self.application.reset_model()
175 self.write_message({"type": "viz_state",
176 "data": self.application.render_model()})
177
178 else:
179 if self.application.verbose:
180 print("Unexpected message!")
181
182
183 class ModularServer(tornado.web.Application):
184 """ Main visualization application. """
185 verbose = True
186
187 model_name = "Mesa Model"
188 model_cls = None # A model class
189 portrayal_method = None
190 port = 8521 # Default port to listen on
191 canvas_width = 500
192 canvas_height = 500
193 grid_height = 0
194 grid_width = 0
195
196 max_steps = 100000
197
198 model_args = ()
199 model_kwargs = {}
200
201 # Handlers and other globals:
202 page_handler = (r'/', PageHandler)
203 socket_handler = (r'/ws', SocketHandler)
204 static_handler = (r'/static/(.*)', tornado.web.StaticFileHandler,
205 {"path": os.path.dirname(__file__) + "/templates"})
206 local_handler = (r'/local/(.*)', tornado.web.StaticFileHandler,
207 {"path": ''})
208
209 handlers = [page_handler, socket_handler, static_handler, local_handler]
210
211 settings = {"debug": True,
212 "template_path": os.path.dirname(__file__) + "/templates"}
213
214 def __init__(self, model_cls, visualization_elements, name="Mesa Model",
215 *args, **kwargs):
216 """ Create a new visualization server with the given elements. """
217 # Prep visualization elements:
218 self.visualization_elements = visualization_elements
219 self.package_includes = set()
220 self.local_includes = set()
221 self.js_code = []
222 for element in self.visualization_elements:
223 for include_file in element.package_includes:
224 self.package_includes.add(include_file)
225 for include_file in element.local_includes:
226 self.local_includes.add(include_file)
227 self.js_code.append(element.js_code)
228
229 # Initializing the model
230 self.model_name = name
231 self.model_cls = model_cls
232
233 self.model_args = args
234 self.model_kwargs = kwargs
235 self.reset_model()
236
237 # Initializing the application itself:
238 super().__init__(self.handlers, **self.settings)
239
240 def reset_model(self):
241 """ Reinstantiate the model object, using the current parameters. """
242 self.model = self.model_cls(*self.model_args, **self.model_kwargs)
243
244 def render_model(self):
245 """ Turn the current state of the model into a dictionary of
246 visualizations
247
248 """
249 visualization_state = []
250 for element in self.visualization_elements:
251 element_state = element.render(self.model)
252 visualization_state.append(element_state)
253 return visualization_state
254
255 def launch(self, port=None):
256 """ Run the app. """
257 if port is not None:
258 self.port = port
259 url = 'http://127.0.0.1:{PORT}'.format(PORT=self.port)
260 print('Interface starting at {url}'.format(url=url))
261 self.listen(self.port)
262 webbrowser.open(url)
263 tornado.ioloop.IOLoop.instance().start()
264
[end of mesa/visualization/ModularVisualization.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mesa/visualization/ModularVisualization.py b/mesa/visualization/ModularVisualization.py
--- a/mesa/visualization/ModularVisualization.py
+++ b/mesa/visualization/ModularVisualization.py
@@ -80,6 +80,7 @@
"""
import os
+import tornado.autoreload
import tornado.ioloop
import tornado.web
import tornado.websocket
@@ -209,6 +210,7 @@
handlers = [page_handler, socket_handler, static_handler, local_handler]
settings = {"debug": True,
+ "autoreload": False,
"template_path": os.path.dirname(__file__) + "/templates"}
def __init__(self, model_cls, visualization_elements, name="Mesa Model",
@@ -254,10 +256,13 @@
def launch(self, port=None):
""" Run the app. """
+ startLoop = not tornado.ioloop.IOLoop.initialized()
if port is not None:
self.port = port
url = 'http://127.0.0.1:{PORT}'.format(PORT=self.port)
print('Interface starting at {url}'.format(url=url))
self.listen(self.port)
webbrowser.open(url)
- tornado.ioloop.IOLoop.instance().start()
+ tornado.autoreload.start()
+ if startLoop:
+ tornado.ioloop.IOLoop.instance().start()
|
{"golden_diff": "diff --git a/mesa/visualization/ModularVisualization.py b/mesa/visualization/ModularVisualization.py\n--- a/mesa/visualization/ModularVisualization.py\n+++ b/mesa/visualization/ModularVisualization.py\n@@ -80,6 +80,7 @@\n \"\"\"\n import os\n \n+import tornado.autoreload\n import tornado.ioloop\n import tornado.web\n import tornado.websocket\n@@ -209,6 +210,7 @@\n handlers = [page_handler, socket_handler, static_handler, local_handler]\n \n settings = {\"debug\": True,\n+ \"autoreload\": False,\n \"template_path\": os.path.dirname(__file__) + \"/templates\"}\n \n def __init__(self, model_cls, visualization_elements, name=\"Mesa Model\",\n@@ -254,10 +256,13 @@\n \n def launch(self, port=None):\n \"\"\" Run the app. \"\"\"\n+ startLoop = not tornado.ioloop.IOLoop.initialized()\n if port is not None:\n self.port = port\n url = 'http://127.0.0.1:{PORT}'.format(PORT=self.port)\n print('Interface starting at {url}'.format(url=url))\n self.listen(self.port)\n webbrowser.open(url)\n- tornado.ioloop.IOLoop.instance().start()\n+ tornado.autoreload.start()\n+ if startLoop:\n+ tornado.ioloop.IOLoop.instance().start()\n", "issue": "Advanced tutorial chart\nI have been unable to get the chart showing the gini coefficient to open up in the advanced tutorial to open up. Everything else is working, the chart just does not appear. Please advise, \r\n\r\nThank you.\r\n\r\nTom \n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nModularServer\n=============\n\nA visualization server which renders a model via one or more elements.\n\nThe concept for the modular visualization server as follows:\nA visualization is composed of VisualizationElements, each of which defines how\nto generate some visualization from a model instance and render it on the\nclient. VisualizationElements may be anything from a simple text display to\na multilayered HTML5 canvas.\n\nThe actual server is launched with one or more VisualizationElements;\nit runs the model object through each of them, generating data to be sent to\nthe client. The client page is also generated based on the JavaScript code\nprovided by each element.\n\nThis file consists of the following classes:\n\nVisualizationElement: Parent class for all other visualization elements, with\n the minimal necessary options.\nPageHandler: The handler for the visualization page, generated from a template\n and built from the various visualization elements.\nSocketHandler: Handles the websocket connection between the client page and\n the server.\nModularServer: The overall visualization application class which stores and\n controls the model and visualization instance.\n\n\nModularServer should *not* need to be subclassed on a model-by-model basis; it\nshould be primarily a pass-through for VisualizationElement subclasses, which\ndefine the actual visualization specifics.\n\nFor example, suppose we have created two visualization elements for our model,\ncalled canvasvis and graphvis; we would launch a server with:\n\n server = ModularServer(MyModel, [canvasvis, graphvis], name=\"My Model\")\n server.launch()\n\nThe client keeps track of what step it is showing. Clicking the Step button in\nthe browser sends a message requesting the viz_state corresponding to the next\nstep position, which is then sent back to the client via the websocket.\n\nThe websocket protocol is as follows:\nEach message is a JSON object, with a \"type\" property which defines the rest of\nthe structure.\n\nServer -> Client:\n Send over the model state to visualize.\n Model state is a list, with each element corresponding to a div; each div\n is expected to have a render function associated with it, which knows how\n to render that particular data. The example below includes two elements:\n the first is data for a CanvasGrid, the second for a raw text display.\n\n {\n \"type\": \"viz_state\",\n \"data\": [{0:[ {\"Shape\": \"circle\", \"x\": 0, \"y\": 0, \"r\": 0.5,\n \"Color\": \"#AAAAAA\", \"Filled\": \"true\", \"Layer\": 0,\n \"text\": 'A', \"text_color\": \"white\" }]},\n \"Shape Count: 1\"]\n }\n\n Informs the client that the model is over.\n {\"type\": \"end\"}\n\nClient -> Server:\n Reset the model.\n TODO: Allow this to come with parameters\n {\n \"type\": \"reset\"\n }\n\n Get a given state.\n {\n \"type\": \"get_step\",\n \"step:\" index of the step to get.\n }\n\n\"\"\"\nimport os\n\nimport tornado.ioloop\nimport tornado.web\nimport tornado.websocket\nimport tornado.escape\nimport tornado.gen\n\nimport webbrowser\n\n# Suppress several pylint warnings for this file.\n# Attributes being defined outside of init is a Tornado feature.\n# pylint: disable=attribute-defined-outside-init\n\n\nclass VisualizationElement:\n \"\"\"\n Defines an element of the visualization.\n\n Attributes:\n package_includes: A list of external JavaScript files to include that\n are part of the Mesa packages.\n local_includes: A list of JavaScript files that are local to the\n directory that the server is being run in.\n js_code: A JavaScript code string to instantiate the element.\n\n Methods:\n render: Takes a model object, and produces JSON data which can be sent\n to the client.\n\n \"\"\"\n\n package_includes = []\n local_includes = []\n js_code = ''\n render_args = {}\n\n def __init__(self):\n pass\n\n def render(self, model):\n \"\"\" Build visualization data from a model object.\n\n Args:\n model: A model object\n\n Returns:\n A JSON-ready object.\n\n \"\"\"\n return \"<b>VisualizationElement goes here</b>.\"\n\n# =============================================================================\n# Actual Tornado code starts here:\n\n\nclass PageHandler(tornado.web.RequestHandler):\n \"\"\" Handler for the HTML template which holds the visualization. \"\"\"\n\n def get(self):\n elements = self.application.visualization_elements\n for i, element in enumerate(elements):\n element.index = i\n self.render(\"modular_template.html\", port=self.application.port,\n model_name=self.application.model_name,\n package_includes=self.application.package_includes,\n local_includes=self.application.local_includes,\n scripts=self.application.js_code)\n\n\nclass SocketHandler(tornado.websocket.WebSocketHandler):\n \"\"\" Handler for websocket. \"\"\"\n def open(self):\n if self.application.verbose:\n print(\"Socket opened!\")\n\n def check_origin(self, origin):\n return True\n\n def on_message(self, message):\n \"\"\" Receiving a message from the websocket, parse, and act accordingly.\n\n \"\"\"\n if self.application.verbose:\n print(message)\n msg = tornado.escape.json_decode(message)\n\n if msg[\"type\"] == \"get_step\":\n self.application.model.step()\n self.write_message({\"type\": \"viz_state\",\n \"data\": self.application.render_model()})\n\n elif msg[\"type\"] == \"reset\":\n self.application.reset_model()\n self.write_message({\"type\": \"viz_state\",\n \"data\": self.application.render_model()})\n\n else:\n if self.application.verbose:\n print(\"Unexpected message!\")\n\n\nclass ModularServer(tornado.web.Application):\n \"\"\" Main visualization application. \"\"\"\n verbose = True\n\n model_name = \"Mesa Model\"\n model_cls = None # A model class\n portrayal_method = None\n port = 8521 # Default port to listen on\n canvas_width = 500\n canvas_height = 500\n grid_height = 0\n grid_width = 0\n\n max_steps = 100000\n\n model_args = ()\n model_kwargs = {}\n\n # Handlers and other globals:\n page_handler = (r'/', PageHandler)\n socket_handler = (r'/ws', SocketHandler)\n static_handler = (r'/static/(.*)', tornado.web.StaticFileHandler,\n {\"path\": os.path.dirname(__file__) + \"/templates\"})\n local_handler = (r'/local/(.*)', tornado.web.StaticFileHandler,\n {\"path\": ''})\n\n handlers = [page_handler, socket_handler, static_handler, local_handler]\n\n settings = {\"debug\": True,\n \"template_path\": os.path.dirname(__file__) + \"/templates\"}\n\n def __init__(self, model_cls, visualization_elements, name=\"Mesa Model\",\n *args, **kwargs):\n \"\"\" Create a new visualization server with the given elements. \"\"\"\n # Prep visualization elements:\n self.visualization_elements = visualization_elements\n self.package_includes = set()\n self.local_includes = set()\n self.js_code = []\n for element in self.visualization_elements:\n for include_file in element.package_includes:\n self.package_includes.add(include_file)\n for include_file in element.local_includes:\n self.local_includes.add(include_file)\n self.js_code.append(element.js_code)\n\n # Initializing the model\n self.model_name = name\n self.model_cls = model_cls\n\n self.model_args = args\n self.model_kwargs = kwargs\n self.reset_model()\n\n # Initializing the application itself:\n super().__init__(self.handlers, **self.settings)\n\n def reset_model(self):\n \"\"\" Reinstantiate the model object, using the current parameters. \"\"\"\n self.model = self.model_cls(*self.model_args, **self.model_kwargs)\n\n def render_model(self):\n \"\"\" Turn the current state of the model into a dictionary of\n visualizations\n\n \"\"\"\n visualization_state = []\n for element in self.visualization_elements:\n element_state = element.render(self.model)\n visualization_state.append(element_state)\n return visualization_state\n\n def launch(self, port=None):\n \"\"\" Run the app. \"\"\"\n if port is not None:\n self.port = port\n url = 'http://127.0.0.1:{PORT}'.format(PORT=self.port)\n print('Interface starting at {url}'.format(url=url))\n self.listen(self.port)\n webbrowser.open(url)\n tornado.ioloop.IOLoop.instance().start()\n", "path": "mesa/visualization/ModularVisualization.py"}]}
| 3,124 | 317 |
gh_patches_debug_23548
|
rasdani/github-patches
|
git_diff
|
facebookresearch__ParlAI-1595
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Empty training examples throwing runtime error
I'm getting an error with the OpenSubtitles (2009 and 2018) and the Cornell Movie datasets with length 0 examples being loaded. My guess is that there are empty messages in the datasets, which could easily be removed with some preprocessing or a flag to avoid such examples. However, I'm having trouble finding such a flag and would appreciate any help you can provide. I do not have this issue arise on other datasets that I have explored so far.
I'm a bit puzzled as to why others haven't seemed to run into this problem and was hoping you could help point me in the right direction, especially if I'm missing an easy fix. Thanks.
**Error:**
```
Traceback (most recent call last):
File "examples/train_model.py", line 16, in <module>
TrainLoop(opt).train()
File "/data/odemasi/packages/ParlAI/parlai/scripts/train_model.py", line 523, in train
world.parley()
File "/data/odemasi/packages/ParlAI/parlai/core/worlds.py", line 654, in parley
batch_act = self.batch_act(agent_idx, batch_observations[agent_idx])
File "/data/odemasi/packages/ParlAI/parlai/core/worlds.py", line 627, in batch_act
batch_actions = a.batch_act(batch_observation)
File "/data/odemasi/packages/ParlAI/parlai/core/torch_agent.py", line 1206, in batch_act
output = self.train_step(batch)
File "/data/odemasi/packages/ParlAI/parlai/core/torch_generator_agent.py", line 478, in train_step
raise e
File "/data/odemasi/packages/ParlAI/parlai/core/torch_generator_agent.py", line 454, in train_step
scores, preds, _ = self.model(batch.text_vec, batch.label_vec)
File "/data/odemasi/anaconda3/envs/parlai_venv/lib/python3.7/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/data/odemasi/packages/ParlAI/parlai/core/torch_generator_agent.py", line 214, in forward
encoder_states = prev_enc if prev_enc is not None else self.encoder(xs)
File "/data/odemasi/anaconda3/envs/parlai_venv/lib/python3.7/site-packages/torch/nn/modules/module.py", line 489, in __call__
result = self.forward(*input, **kwargs)
File "/data/odemasi/packages/ParlAI/parlai/agents/seq2seq/modules.py", line 226, in forward
xes = pack_padded_sequence(xes, x_lens, batch_first=True)
File "/data/odemasi/anaconda3/envs/parlai_venv/lib/python3.7/site-packages/torch/nn/utils/rnn.py", line 148, in pack_padded_sequence
return PackedSequence(torch._C._VariableFunctions._pack_padded_sequence(input, lengths, batch_first))
RuntimeError: Length of all samples has to be greater than 0, but found an element in 'lengths' that is <= 0
```
**Resulted from:**
python examples/train_model.py \
-t cornell_movie \
-bs 32 \
--hiddensize 1024 \
--dict-minfreq 2 \
--dict-lower True \
--dict-file cornell_dict \
-m seq2seq \
-mf cornell_seq2seq
</issue>
<code>
[start of parlai/agents/seq2seq/seq2seq.py]
1 #!/usr/bin/env python3
2
3 # Copyright (c) Facebook, Inc. and its affiliates.
4 # This source code is licensed under the MIT license found in the
5 # LICENSE file in the root directory of this source tree.
6
7 from parlai.core.torch_generator_agent import TorchGeneratorAgent
8 from .modules import Seq2seq, opt_to_kwargs
9
10 import torch
11 import torch.nn as nn
12
13 import json
14
15
16 class Seq2seqAgent(TorchGeneratorAgent):
17 """Agent which takes an input sequence and produces an output sequence.
18
19 This model supports encoding the input and decoding the output via one of
20 several flavors of RNN. It then uses a linear layer (whose weights can
21 be shared with the embedding layer) to convert RNN output states into
22 output tokens. This model supports greedy decoding, selecting the
23 highest probability token at each time step, as well as beam
24 search.
25
26 For more information, see the following papers:
27 - Neural Machine Translation by Jointly Learning to Align and Translate
28 `(Bahdanau et al. 2014) <arxiv.org/abs/1409.0473>`_
29 - Sequence to Sequence Learning with Neural Networks
30 `(Sutskever et al. 2014) <arxiv.org/abs/1409.3215>`_
31 - Effective Approaches to Attention-based Neural Machine Translation
32 `(Luong et al. 2015) <arxiv.org/abs/1508.04025>`_
33 """
34
35 @classmethod
36 def add_cmdline_args(cls, argparser):
37 """Add command-line arguments specifically for this agent."""
38 agent = argparser.add_argument_group('Seq2Seq Arguments')
39 agent.add_argument('-hs', '--hiddensize', type=int, default=128,
40 help='size of the hidden layers')
41 agent.add_argument('-esz', '--embeddingsize', type=int, default=128,
42 help='size of the token embeddings')
43 agent.add_argument('-nl', '--numlayers', type=int, default=2,
44 help='number of hidden layers')
45 agent.add_argument('-dr', '--dropout', type=float, default=0.1,
46 help='dropout rate')
47 agent.add_argument('-bi', '--bidirectional', type='bool',
48 default=False,
49 help='whether to encode the context with a '
50 'bidirectional rnn')
51 agent.add_argument('-att', '--attention', default='none',
52 choices=['none', 'concat', 'general', 'dot',
53 'local'],
54 help='Choices: none, concat, general, local. '
55 'If set local, also set attention-length. '
56 '(see arxiv.org/abs/1508.04025)')
57 agent.add_argument('-attl', '--attention-length', default=48, type=int,
58 help='Length of local attention.')
59 agent.add_argument('--attention-time', default='post',
60 choices=['pre', 'post'],
61 help='Whether to apply attention before or after '
62 'decoding.')
63 agent.add_argument('-rnn', '--rnn-class', default='lstm',
64 choices=Seq2seq.RNN_OPTS.keys(),
65 help='Choose between different types of RNNs.')
66 agent.add_argument('-dec', '--decoder', default='same',
67 choices=['same', 'shared'],
68 help='Choose between different decoder modules. '
69 'Default "same" uses same class as encoder, '
70 'while "shared" also uses the same weights. '
71 'Note that shared disabled some encoder '
72 'options--in particular, bidirectionality.')
73 agent.add_argument('-lt', '--lookuptable', default='unique',
74 choices=['unique', 'enc_dec', 'dec_out', 'all'],
75 help='The encoder, decoder, and output modules can '
76 'share weights, or not. '
77 'Unique has independent embeddings for each. '
78 'Enc_dec shares the embedding for the encoder '
79 'and decoder. '
80 'Dec_out shares decoder embedding and output '
81 'weights. '
82 'All shares all three weights.')
83 agent.add_argument('-soft', '--numsoftmax', default=1, type=int,
84 help='default 1, if greater then uses mixture of '
85 'softmax (see arxiv.org/abs/1711.03953).')
86 agent.add_argument('-idr', '--input-dropout', type=float, default=0.0,
87 help='Probability of replacing tokens with UNK in training.')
88
89 super(Seq2seqAgent, cls).add_cmdline_args(argparser)
90 return agent
91
92 @staticmethod
93 def model_version():
94 """Return current version of this model, counting up from 0.
95
96 Models may not be backwards-compatible with older versions.
97 Version 1 split from version 0 on Aug 29, 2018.
98 Version 2 split from version 1 on Nov 13, 2018
99 To use version 0, use --model legacy:seq2seq:0
100 To use version 1, use --model legacy:seq2seq:1
101 (legacy agent code is located in parlai/agents/legacy_agents).
102 """
103 return 2
104
105 def __init__(self, opt, shared=None):
106 """Set up model."""
107 super().__init__(opt, shared)
108 self.id = 'Seq2Seq'
109
110 def build_model(self, states=None):
111 """Initialize model, override to change model setup."""
112 opt = self.opt
113 if not states:
114 states = {}
115
116 kwargs = opt_to_kwargs(opt)
117 self.model = Seq2seq(
118 len(self.dict), opt['embeddingsize'], opt['hiddensize'],
119 padding_idx=self.NULL_IDX, start_idx=self.START_IDX,
120 end_idx=self.END_IDX, unknown_idx=self.dict[self.dict.unk_token],
121 longest_label=states.get('longest_label', 1),
122 **kwargs)
123
124 if (opt.get('dict_tokenizer') == 'bpe' and
125 opt['embedding_type'] != 'random'):
126 print('skipping preinitialization of embeddings for bpe')
127 elif not states and opt['embedding_type'] != 'random':
128 # `not states`: only set up embeddings if not loading model
129 self._copy_embeddings(self.model.decoder.lt.weight,
130 opt['embedding_type'])
131 if opt['lookuptable'] in ['unique', 'dec_out']:
132 # also set encoder lt, since it's not shared
133 self._copy_embeddings(self.model.encoder.lt.weight,
134 opt['embedding_type'], log=False)
135
136 if states:
137 # set loaded states if applicable
138 self.model.load_state_dict(states['model'])
139
140 if self.use_cuda:
141 self.model.cuda()
142
143 if opt['embedding_type'].endswith('fixed'):
144 print('Seq2seq: fixing embedding weights.')
145 self.model.decoder.lt.weight.requires_grad = False
146 self.model.encoder.lt.weight.requires_grad = False
147 if opt['lookuptable'] in ['dec_out', 'all']:
148 self.model.decoder.e2s.weight.requires_grad = False
149
150 if self.use_cuda:
151 self.model.cuda()
152
153 return self.model
154
155 def build_criterion(self):
156 # set up criteria
157 if self.opt.get('numsoftmax', 1) > 1:
158 self.criterion = nn.NLLLoss(
159 ignore_index=self.NULL_IDX, size_average=False)
160 else:
161 self.criterion = nn.CrossEntropyLoss(
162 ignore_index=self.NULL_IDX, size_average=False)
163
164 if self.use_cuda:
165 self.criterion.cuda()
166
167 def batchify(self, *args, **kwargs):
168 """Override batchify options for seq2seq."""
169 kwargs['sort'] = True # need sorted for pack_padded
170 return super().batchify(*args, **kwargs)
171
172 def save(self, path=None):
173 """Save model parameters if model_file is set."""
174 path = self.opt.get('model_file', None) if path is None else path
175
176 if path and hasattr(self, 'model'):
177 model = {}
178 if hasattr(self.model, 'module'):
179 model['model'] = self.model.module.state_dict()
180 model['longest_label'] = self.model.module.longest_label
181 else:
182 model['model'] = self.model.state_dict()
183 model['longest_label'] = self.model.longest_label
184 model['optimizer'] = self.optimizer.state_dict()
185 model['optimizer_type'] = self.opt['optimizer']
186
187 with open(path, 'wb') as write:
188 torch.save(model, write)
189
190 # save opt file
191 with open(path + '.opt', 'w') as handle:
192 # save version string
193 self.opt['model_version'] = self.model_version()
194 json.dump(self.opt, handle)
195
196 def load(self, path):
197 """Return opt and model states."""
198 states = torch.load(path, map_location=lambda cpu, _: cpu)
199 # set loaded states if applicable
200 self.model.load_state_dict(states['model'])
201 if 'longest_label' in states:
202 self.model.longest_label = states['longest_label']
203 return states
204
[end of parlai/agents/seq2seq/seq2seq.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/parlai/agents/seq2seq/seq2seq.py b/parlai/agents/seq2seq/seq2seq.py
--- a/parlai/agents/seq2seq/seq2seq.py
+++ b/parlai/agents/seq2seq/seq2seq.py
@@ -5,6 +5,7 @@
# LICENSE file in the root directory of this source tree.
from parlai.core.torch_generator_agent import TorchGeneratorAgent
+from parlai.core.utils import warn_once
from .modules import Seq2seq, opt_to_kwargs
import torch
@@ -201,3 +202,22 @@
if 'longest_label' in states:
self.model.longest_label = states['longest_label']
return states
+
+ def is_valid(self, obs):
+ normally_valid = super().is_valid(obs)
+ if not normally_valid:
+ # shortcut boolean evaluation
+ return normally_valid
+ contains_empties = obs['text_vec'].shape[0] == 0
+ if self.is_training and contains_empties:
+ warn_once(
+ 'seq2seq got an empty input sequence (text_vec) during training. '
+ 'Skipping this example, but you should check your dataset and '
+ 'preprocessing.'
+ )
+ elif not self.is_training and contains_empties:
+ warn_once(
+ 'seq2seq got an empty input sequence (text_vec) in an '
+ 'evaluation example! This may affect your metrics!'
+ )
+ return not contains_empties
|
{"golden_diff": "diff --git a/parlai/agents/seq2seq/seq2seq.py b/parlai/agents/seq2seq/seq2seq.py\n--- a/parlai/agents/seq2seq/seq2seq.py\n+++ b/parlai/agents/seq2seq/seq2seq.py\n@@ -5,6 +5,7 @@\n # LICENSE file in the root directory of this source tree.\n \n from parlai.core.torch_generator_agent import TorchGeneratorAgent\n+from parlai.core.utils import warn_once\n from .modules import Seq2seq, opt_to_kwargs\n \n import torch\n@@ -201,3 +202,22 @@\n if 'longest_label' in states:\n self.model.longest_label = states['longest_label']\n return states\n+\n+ def is_valid(self, obs):\n+ normally_valid = super().is_valid(obs)\n+ if not normally_valid:\n+ # shortcut boolean evaluation\n+ return normally_valid\n+ contains_empties = obs['text_vec'].shape[0] == 0\n+ if self.is_training and contains_empties:\n+ warn_once(\n+ 'seq2seq got an empty input sequence (text_vec) during training. '\n+ 'Skipping this example, but you should check your dataset and '\n+ 'preprocessing.'\n+ )\n+ elif not self.is_training and contains_empties:\n+ warn_once(\n+ 'seq2seq got an empty input sequence (text_vec) in an '\n+ 'evaluation example! This may affect your metrics!'\n+ )\n+ return not contains_empties\n", "issue": "Empty training examples throwing runtime error\nI'm getting an error with the OpenSubtitles (2009 and 2018) and the Cornell Movie datasets with length 0 examples being loaded. My guess is that there are empty messages in the datasets, which could easily be removed with some preprocessing or a flag to avoid such examples. However, I'm having trouble finding such a flag and would appreciate any help you can provide. I do not have this issue arise on other datasets that I have explored so far. \r\n\r\nI'm a bit puzzled as to why others haven't seemed to run into this problem and was hoping you could help point me in the right direction, especially if I'm missing an easy fix. Thanks.\r\n\r\n**Error:**\r\n```\r\nTraceback (most recent call last):\r\n File \"examples/train_model.py\", line 16, in <module>\r\n TrainLoop(opt).train()\r\n File \"/data/odemasi/packages/ParlAI/parlai/scripts/train_model.py\", line 523, in train\r\n world.parley()\r\n File \"/data/odemasi/packages/ParlAI/parlai/core/worlds.py\", line 654, in parley\r\n batch_act = self.batch_act(agent_idx, batch_observations[agent_idx])\r\n File \"/data/odemasi/packages/ParlAI/parlai/core/worlds.py\", line 627, in batch_act\r\n batch_actions = a.batch_act(batch_observation)\r\n File \"/data/odemasi/packages/ParlAI/parlai/core/torch_agent.py\", line 1206, in batch_act\r\n output = self.train_step(batch)\r\n File \"/data/odemasi/packages/ParlAI/parlai/core/torch_generator_agent.py\", line 478, in train_step\r\n raise e\r\n File \"/data/odemasi/packages/ParlAI/parlai/core/torch_generator_agent.py\", line 454, in train_step\r\n scores, preds, _ = self.model(batch.text_vec, batch.label_vec)\r\n File \"/data/odemasi/anaconda3/envs/parlai_venv/lib/python3.7/site-packages/torch/nn/modules/module.py\", line 489, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/data/odemasi/packages/ParlAI/parlai/core/torch_generator_agent.py\", line 214, in forward\r\n encoder_states = prev_enc if prev_enc is not None else self.encoder(xs)\r\n File \"/data/odemasi/anaconda3/envs/parlai_venv/lib/python3.7/site-packages/torch/nn/modules/module.py\", line 489, in __call__\r\n result = self.forward(*input, **kwargs)\r\n File \"/data/odemasi/packages/ParlAI/parlai/agents/seq2seq/modules.py\", line 226, in forward\r\n xes = pack_padded_sequence(xes, x_lens, batch_first=True)\r\n File \"/data/odemasi/anaconda3/envs/parlai_venv/lib/python3.7/site-packages/torch/nn/utils/rnn.py\", line 148, in pack_padded_sequence\r\n return PackedSequence(torch._C._VariableFunctions._pack_padded_sequence(input, lengths, batch_first))\r\nRuntimeError: Length of all samples has to be greater than 0, but found an element in 'lengths' that is <= 0\r\n```\r\n\r\n\r\n**Resulted from:**\r\npython examples/train_model.py \\\r\n-t cornell_movie \\\r\n-bs 32 \\\r\n--hiddensize 1024 \\\r\n--dict-minfreq 2 \\\r\n--dict-lower True \\\r\n--dict-file cornell_dict \\\r\n-m seq2seq \\\r\n-mf cornell_seq2seq \n", "before_files": [{"content": "#!/usr/bin/env python3\n\n# Copyright (c) Facebook, Inc. and its affiliates.\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\nfrom parlai.core.torch_generator_agent import TorchGeneratorAgent\nfrom .modules import Seq2seq, opt_to_kwargs\n\nimport torch\nimport torch.nn as nn\n\nimport json\n\n\nclass Seq2seqAgent(TorchGeneratorAgent):\n \"\"\"Agent which takes an input sequence and produces an output sequence.\n\n This model supports encoding the input and decoding the output via one of\n several flavors of RNN. It then uses a linear layer (whose weights can\n be shared with the embedding layer) to convert RNN output states into\n output tokens. This model supports greedy decoding, selecting the\n highest probability token at each time step, as well as beam\n search.\n\n For more information, see the following papers:\n - Neural Machine Translation by Jointly Learning to Align and Translate\n `(Bahdanau et al. 2014) <arxiv.org/abs/1409.0473>`_\n - Sequence to Sequence Learning with Neural Networks\n `(Sutskever et al. 2014) <arxiv.org/abs/1409.3215>`_\n - Effective Approaches to Attention-based Neural Machine Translation\n `(Luong et al. 2015) <arxiv.org/abs/1508.04025>`_\n \"\"\"\n\n @classmethod\n def add_cmdline_args(cls, argparser):\n \"\"\"Add command-line arguments specifically for this agent.\"\"\"\n agent = argparser.add_argument_group('Seq2Seq Arguments')\n agent.add_argument('-hs', '--hiddensize', type=int, default=128,\n help='size of the hidden layers')\n agent.add_argument('-esz', '--embeddingsize', type=int, default=128,\n help='size of the token embeddings')\n agent.add_argument('-nl', '--numlayers', type=int, default=2,\n help='number of hidden layers')\n agent.add_argument('-dr', '--dropout', type=float, default=0.1,\n help='dropout rate')\n agent.add_argument('-bi', '--bidirectional', type='bool',\n default=False,\n help='whether to encode the context with a '\n 'bidirectional rnn')\n agent.add_argument('-att', '--attention', default='none',\n choices=['none', 'concat', 'general', 'dot',\n 'local'],\n help='Choices: none, concat, general, local. '\n 'If set local, also set attention-length. '\n '(see arxiv.org/abs/1508.04025)')\n agent.add_argument('-attl', '--attention-length', default=48, type=int,\n help='Length of local attention.')\n agent.add_argument('--attention-time', default='post',\n choices=['pre', 'post'],\n help='Whether to apply attention before or after '\n 'decoding.')\n agent.add_argument('-rnn', '--rnn-class', default='lstm',\n choices=Seq2seq.RNN_OPTS.keys(),\n help='Choose between different types of RNNs.')\n agent.add_argument('-dec', '--decoder', default='same',\n choices=['same', 'shared'],\n help='Choose between different decoder modules. '\n 'Default \"same\" uses same class as encoder, '\n 'while \"shared\" also uses the same weights. '\n 'Note that shared disabled some encoder '\n 'options--in particular, bidirectionality.')\n agent.add_argument('-lt', '--lookuptable', default='unique',\n choices=['unique', 'enc_dec', 'dec_out', 'all'],\n help='The encoder, decoder, and output modules can '\n 'share weights, or not. '\n 'Unique has independent embeddings for each. '\n 'Enc_dec shares the embedding for the encoder '\n 'and decoder. '\n 'Dec_out shares decoder embedding and output '\n 'weights. '\n 'All shares all three weights.')\n agent.add_argument('-soft', '--numsoftmax', default=1, type=int,\n help='default 1, if greater then uses mixture of '\n 'softmax (see arxiv.org/abs/1711.03953).')\n agent.add_argument('-idr', '--input-dropout', type=float, default=0.0,\n help='Probability of replacing tokens with UNK in training.')\n\n super(Seq2seqAgent, cls).add_cmdline_args(argparser)\n return agent\n\n @staticmethod\n def model_version():\n \"\"\"Return current version of this model, counting up from 0.\n\n Models may not be backwards-compatible with older versions.\n Version 1 split from version 0 on Aug 29, 2018.\n Version 2 split from version 1 on Nov 13, 2018\n To use version 0, use --model legacy:seq2seq:0\n To use version 1, use --model legacy:seq2seq:1\n (legacy agent code is located in parlai/agents/legacy_agents).\n \"\"\"\n return 2\n\n def __init__(self, opt, shared=None):\n \"\"\"Set up model.\"\"\"\n super().__init__(opt, shared)\n self.id = 'Seq2Seq'\n\n def build_model(self, states=None):\n \"\"\"Initialize model, override to change model setup.\"\"\"\n opt = self.opt\n if not states:\n states = {}\n\n kwargs = opt_to_kwargs(opt)\n self.model = Seq2seq(\n len(self.dict), opt['embeddingsize'], opt['hiddensize'],\n padding_idx=self.NULL_IDX, start_idx=self.START_IDX,\n end_idx=self.END_IDX, unknown_idx=self.dict[self.dict.unk_token],\n longest_label=states.get('longest_label', 1),\n **kwargs)\n\n if (opt.get('dict_tokenizer') == 'bpe' and\n opt['embedding_type'] != 'random'):\n print('skipping preinitialization of embeddings for bpe')\n elif not states and opt['embedding_type'] != 'random':\n # `not states`: only set up embeddings if not loading model\n self._copy_embeddings(self.model.decoder.lt.weight,\n opt['embedding_type'])\n if opt['lookuptable'] in ['unique', 'dec_out']:\n # also set encoder lt, since it's not shared\n self._copy_embeddings(self.model.encoder.lt.weight,\n opt['embedding_type'], log=False)\n\n if states:\n # set loaded states if applicable\n self.model.load_state_dict(states['model'])\n\n if self.use_cuda:\n self.model.cuda()\n\n if opt['embedding_type'].endswith('fixed'):\n print('Seq2seq: fixing embedding weights.')\n self.model.decoder.lt.weight.requires_grad = False\n self.model.encoder.lt.weight.requires_grad = False\n if opt['lookuptable'] in ['dec_out', 'all']:\n self.model.decoder.e2s.weight.requires_grad = False\n\n if self.use_cuda:\n self.model.cuda()\n\n return self.model\n\n def build_criterion(self):\n # set up criteria\n if self.opt.get('numsoftmax', 1) > 1:\n self.criterion = nn.NLLLoss(\n ignore_index=self.NULL_IDX, size_average=False)\n else:\n self.criterion = nn.CrossEntropyLoss(\n ignore_index=self.NULL_IDX, size_average=False)\n\n if self.use_cuda:\n self.criterion.cuda()\n\n def batchify(self, *args, **kwargs):\n \"\"\"Override batchify options for seq2seq.\"\"\"\n kwargs['sort'] = True # need sorted for pack_padded\n return super().batchify(*args, **kwargs)\n\n def save(self, path=None):\n \"\"\"Save model parameters if model_file is set.\"\"\"\n path = self.opt.get('model_file', None) if path is None else path\n\n if path and hasattr(self, 'model'):\n model = {}\n if hasattr(self.model, 'module'):\n model['model'] = self.model.module.state_dict()\n model['longest_label'] = self.model.module.longest_label\n else:\n model['model'] = self.model.state_dict()\n model['longest_label'] = self.model.longest_label\n model['optimizer'] = self.optimizer.state_dict()\n model['optimizer_type'] = self.opt['optimizer']\n\n with open(path, 'wb') as write:\n torch.save(model, write)\n\n # save opt file\n with open(path + '.opt', 'w') as handle:\n # save version string\n self.opt['model_version'] = self.model_version()\n json.dump(self.opt, handle)\n\n def load(self, path):\n \"\"\"Return opt and model states.\"\"\"\n states = torch.load(path, map_location=lambda cpu, _: cpu)\n # set loaded states if applicable\n self.model.load_state_dict(states['model'])\n if 'longest_label' in states:\n self.model.longest_label = states['longest_label']\n return states\n", "path": "parlai/agents/seq2seq/seq2seq.py"}]}
| 3,850 | 356 |
gh_patches_debug_24707
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-3714
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Adding new dimension name to indicator should propagate to children
Adding dimension names to indicators after an import should update the child indicators and add the corresponding indicator dimension names to the children too.
</issue>
<code>
[start of akvo/rsr/models/result/indicator.py]
1 # -*- coding: utf-8 -*-
2
3 # Akvo RSR is covered by the GNU Affero General Public License.
4 # See more details in the license.txt file located at the root folder of the Akvo RSR module.
5 # For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
6
7 from akvo.codelists.models import IndicatorMeasure
8 from akvo.codelists.store.default_codelists import INDICATOR_MEASURE as IM
9 from akvo.rsr.fields import ValidXMLCharField
10 from akvo.utils import codelist_choices, codelist_value
11
12 from django.core.exceptions import ValidationError
13 from django.db import models
14 from django.utils.translation import ugettext_lazy as _
15 from django.db.models.signals import post_save
16 from django.dispatch import receiver
17
18 from .indicator_period import IndicatorPeriod
19 from .indicator_label import IndicatorLabel
20 from .result import Result
21 from .utils import PERCENTAGE_MEASURE, QUALITATIVE, QUANTITATIVE
22
23 # Currently we support only Unit, Percentage measures. Qualitative is
24 # implemented as a different Indicator type, and hence we drop that from the
25 # measure list. We also drop nominal and ordinal since we don't support those.
26 INDICATOR_MEASURE = IM[:3]
27
28
29 class Indicator(models.Model):
30 project_relation = 'results__indicators__in'
31
32 INDICATOR_TYPES = (
33 (QUANTITATIVE, _('Quantitative')),
34 (QUALITATIVE, _('Qualitative')),
35 )
36
37 result = models.ForeignKey('Result', verbose_name=_(u'result'), related_name='indicators')
38 parent_indicator = models.ForeignKey(
39 'self', blank=True, null=True, default=None,
40 verbose_name=_(u'parent indicator'), related_name='child_indicators'
41 )
42 title = ValidXMLCharField(
43 _(u'indicator title'), blank=True, max_length=500,
44 help_text=_(u'Within each result indicators can be defined. Indicators should be items '
45 u'that can be counted and evaluated as the project continues and is completed.')
46 )
47 # NOTE: type and measure should probably only be one field measure, wit the values Unit,
48 # Percentage and Qualitative. However since the project editor design splits the choice we use
49 # two fields, type and measure to simplify the interaction between front and back end.
50 type = models.PositiveSmallIntegerField(
51 _('indicator type'), choices=INDICATOR_TYPES, default=QUANTITATIVE
52 )
53 measure = ValidXMLCharField(
54 _(u'indicator measure'), blank=True, max_length=1,
55 choices=codelist_choices(INDICATOR_MEASURE),
56 help_text=_(u'Choose how the indicator will be measured (in percentage or units).')
57 )
58 ascending = models.NullBooleanField(
59 _(u'ascending'), blank=True,
60 help_text=_(u'Choose ascending if the target value of the indicator is higher than the '
61 u'baseline value (eg. people with access to sanitation). Choose descending if '
62 u'the target value of the indicator is lower than the baseline value '
63 u'(eg. people with diarrhea).'))
64 description = ValidXMLCharField(
65 _(u'indicator description'), blank=True, max_length=2000,
66 help_text=_(u'You can provide further information of the indicator here.')
67 )
68 baseline_year = models.PositiveIntegerField(
69 _(u'baseline year'), blank=True, null=True,
70 help_text=_(u'The year the baseline value was taken.')
71 )
72 baseline_value = ValidXMLCharField(
73 _(u'baseline value'), blank=True, max_length=200,
74 help_text=_(u'The value of the baseline at the start of the project.')
75 )
76 baseline_comment = ValidXMLCharField(
77 _(u'baseline comment'), blank=True, max_length=2000,
78 help_text=_(u'Here you can provide extra information on the baseline value, if needed.')
79 )
80 order = models.PositiveSmallIntegerField(_(u'indicator order'), null=True, blank=True)
81 default_periods = models.NullBooleanField(
82 _(u'default indicator periods'), default=False, blank=True,
83 help_text=_(u'Determines whether periods of indicator are used by default.')
84 )
85 export_to_iati = models.BooleanField(
86 _(u'Include indicator in IATI exports'), default=True,
87 help_text=_(u'Choose whether this indicator will be included in IATI exports. '
88 u'If you are not exporting to IATI, you may ignore this option.')
89 )
90 dimension_names = models.ManyToManyField('IndicatorDimensionName', related_name=u'indicators')
91
92 def __unicode__(self):
93 indicator_unicode = self.title if self.title else u'%s' % _(u'No indicator title')
94
95 if self.periods.all():
96 indicator_unicode += u' - %s %s' % (unicode(self.periods.count()),
97 _(u'period(s)'))
98
99 indicator_unicode += u' - %s' % dict(self.INDICATOR_TYPES)[self.type]
100
101 return indicator_unicode
102
103 def save(self, *args, **kwargs):
104 """Update the values of child indicators, if a parent indicator is updated."""
105
106 new_indicator = not self.pk
107
108 if new_indicator and Indicator.objects.filter(result_id=self.result.id).exists():
109 prev_indicator = Indicator.objects.filter(result_id=self.result.id).reverse()[0]
110 if prev_indicator.order:
111 self.order = prev_indicator.order + 1
112
113 # HACK: Delete IndicatorLabels on non-qualitative indicators
114 if new_indicator and self.type != QUALITATIVE:
115 IndicatorLabel.objects.filter(indicator=self).delete()
116
117 super(Indicator, self).save(*args, **kwargs)
118
119 for child_result in self.result.child_results.all():
120 if new_indicator:
121 child_result.project.copy_indicator(child_result, self, set_parent=True)
122 else:
123 child_result.project.update_indicator(child_result, self)
124
125 def clean(self):
126 validation_errors = {}
127
128 if self.pk and self.is_child_indicator():
129 orig_indicator = Indicator.objects.get(pk=self.pk)
130
131 # Don't allow some values to be changed when it is a child indicator
132 if self.result != orig_indicator.result:
133 validation_errors['result'] = u'%s' % \
134 _(u'It is not possible to update the result of this indicator, '
135 u'because it is linked to a parent result.')
136 if self.title != orig_indicator.title:
137 validation_errors['title'] = u'%s' % \
138 _(u'It is not possible to update the title of this indicator, '
139 u'because it is linked to a parent result.')
140 if self.measure != orig_indicator.measure:
141 validation_errors['measure'] = u'%s' % \
142 _(u'It is not possible to update the measure of this indicator, '
143 u'because it is linked to a parent result.')
144 if self.ascending != orig_indicator.ascending:
145 validation_errors['ascending'] = u'%s' % \
146 _(u'It is not possible to update the ascending value of this indicator, '
147 u'because it is linked to a parent result.')
148
149 if validation_errors:
150 raise ValidationError(validation_errors)
151
152 def delete(self, *args, **kwargs):
153 """
154 Check if indicator is ordered manually, and cascade following indicators if needed
155 """
156 if self.order:
157 sibling_indicators = Indicator.objects.filter(result_id=self.result.id)
158
159 if not self == sibling_indicators.reverse()[0]:
160 for ind in range(self.order + 1, len(sibling_indicators)):
161 sibling_indicators[ind].order -= 1
162 sibling_indicators[ind].save()
163
164 super(Indicator, self).delete(*args, **kwargs)
165
166 def iati_measure(self):
167 return codelist_value(IndicatorMeasure, self, 'measure')
168
169 def iati_measure_unicode(self):
170 return str(self.iati_measure())
171
172 def is_calculated(self):
173 return self.result.project.is_impact_project
174
175 def is_child_indicator(self):
176 """
177 Indicates whether this indicator is linked to a parent indicator.
178 """
179 return bool(self.parent_indicator)
180
181 def is_parent_indicator(self):
182 """
183 Indicates whether this indicator has children.
184 """
185 return self.child_indicators.count() > 0
186
187 @property
188 def children_aggregate_percentage(self):
189 """
190 Returns True if this indicator has percentage as a measure and has children that aggregate
191 to this indicator.
192 """
193 if self.measure == PERCENTAGE_MEASURE and self.is_parent_indicator() and \
194 self.result.project.aggregate_children and \
195 any(self.child_indicators.values_list('result__project__aggregate_to_parent', flat=True)):
196 return True
197 return False
198
199 class Meta:
200 app_label = 'rsr'
201 ordering = ['order', 'id']
202 verbose_name = _(u'indicator')
203 verbose_name_plural = _(u'indicators')
204 unique_together = ('result', 'parent_indicator')
205
206
207 # Add default indicator periods if necessary
208 @receiver(post_save, sender=Indicator, dispatch_uid='add_default_periods')
209 def add_default_periods(sender, instance, created, **kwargs):
210 if created:
211 project = instance.result.project
212 results = Result.objects.filter(project_id=project)
213 default_indicator = Indicator.objects.filter(result_id__in=results,
214 default_periods=True).first()
215
216 if default_indicator:
217 default_periods = IndicatorPeriod.objects.filter(indicator_id=default_indicator)
218
219 for period in default_periods:
220 period.pk = None
221
222 # Blank all values except id and locked status
223 period.target_value = ''
224 period.target_comment = ''
225 period.actual_value = ''
226 period.actual_comment = ''
227
228 period.indicator_id = instance.id
229 period.save()
230
[end of akvo/rsr/models/result/indicator.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/akvo/rsr/models/result/indicator.py b/akvo/rsr/models/result/indicator.py
--- a/akvo/rsr/models/result/indicator.py
+++ b/akvo/rsr/models/result/indicator.py
@@ -12,7 +12,7 @@
from django.core.exceptions import ValidationError
from django.db import models
from django.utils.translation import ugettext_lazy as _
-from django.db.models.signals import post_save
+from django.db.models.signals import post_save, m2m_changed
from django.dispatch import receiver
from .indicator_period import IndicatorPeriod
@@ -227,3 +227,25 @@
period.indicator_id = instance.id
period.save()
+
+
+@receiver(m2m_changed, sender=Indicator.dimension_names.through)
+def add_dimension_names_to_children(sender, instance, action, **kwargs):
+ if not action.startswith('post_'):
+ return
+
+ if not instance.child_indicators.exists():
+ return
+
+ dimension_name = kwargs['model'].objects.filter(id__in=kwargs['pk_set']).first()
+ for indicator in instance.child_indicators.all():
+ child_dimension_name, _ = dimension_name.child_dimension_names.get_or_create(
+ name=dimension_name.name,
+ parent_dimension_name=dimension_name,
+ project=indicator.result.project)
+
+ if action == 'post_add':
+ indicator.dimension_names.add(child_dimension_name)
+
+ elif action == 'post_remove':
+ indicator.dimension_names.remove(child_dimension_name)
|
{"golden_diff": "diff --git a/akvo/rsr/models/result/indicator.py b/akvo/rsr/models/result/indicator.py\n--- a/akvo/rsr/models/result/indicator.py\n+++ b/akvo/rsr/models/result/indicator.py\n@@ -12,7 +12,7 @@\n from django.core.exceptions import ValidationError\n from django.db import models\n from django.utils.translation import ugettext_lazy as _\n-from django.db.models.signals import post_save\n+from django.db.models.signals import post_save, m2m_changed\n from django.dispatch import receiver\n \n from .indicator_period import IndicatorPeriod\n@@ -227,3 +227,25 @@\n \n period.indicator_id = instance.id\n period.save()\n+\n+\n+@receiver(m2m_changed, sender=Indicator.dimension_names.through)\n+def add_dimension_names_to_children(sender, instance, action, **kwargs):\n+ if not action.startswith('post_'):\n+ return\n+\n+ if not instance.child_indicators.exists():\n+ return\n+\n+ dimension_name = kwargs['model'].objects.filter(id__in=kwargs['pk_set']).first()\n+ for indicator in instance.child_indicators.all():\n+ child_dimension_name, _ = dimension_name.child_dimension_names.get_or_create(\n+ name=dimension_name.name,\n+ parent_dimension_name=dimension_name,\n+ project=indicator.result.project)\n+\n+ if action == 'post_add':\n+ indicator.dimension_names.add(child_dimension_name)\n+\n+ elif action == 'post_remove':\n+ indicator.dimension_names.remove(child_dimension_name)\n", "issue": "Adding new dimension name to indicator should propagate to children\nAdding dimension names to indicators after an import should update the child indicators and add the corresponding indicator dimension names to the children too. \n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\nfrom akvo.codelists.models import IndicatorMeasure\nfrom akvo.codelists.store.default_codelists import INDICATOR_MEASURE as IM\nfrom akvo.rsr.fields import ValidXMLCharField\nfrom akvo.utils import codelist_choices, codelist_value\n\nfrom django.core.exceptions import ValidationError\nfrom django.db import models\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.db.models.signals import post_save\nfrom django.dispatch import receiver\n\nfrom .indicator_period import IndicatorPeriod\nfrom .indicator_label import IndicatorLabel\nfrom .result import Result\nfrom .utils import PERCENTAGE_MEASURE, QUALITATIVE, QUANTITATIVE\n\n# Currently we support only Unit, Percentage measures. Qualitative is\n# implemented as a different Indicator type, and hence we drop that from the\n# measure list. We also drop nominal and ordinal since we don't support those.\nINDICATOR_MEASURE = IM[:3]\n\n\nclass Indicator(models.Model):\n project_relation = 'results__indicators__in'\n\n INDICATOR_TYPES = (\n (QUANTITATIVE, _('Quantitative')),\n (QUALITATIVE, _('Qualitative')),\n )\n\n result = models.ForeignKey('Result', verbose_name=_(u'result'), related_name='indicators')\n parent_indicator = models.ForeignKey(\n 'self', blank=True, null=True, default=None,\n verbose_name=_(u'parent indicator'), related_name='child_indicators'\n )\n title = ValidXMLCharField(\n _(u'indicator title'), blank=True, max_length=500,\n help_text=_(u'Within each result indicators can be defined. Indicators should be items '\n u'that can be counted and evaluated as the project continues and is completed.')\n )\n # NOTE: type and measure should probably only be one field measure, wit the values Unit,\n # Percentage and Qualitative. However since the project editor design splits the choice we use\n # two fields, type and measure to simplify the interaction between front and back end.\n type = models.PositiveSmallIntegerField(\n _('indicator type'), choices=INDICATOR_TYPES, default=QUANTITATIVE\n )\n measure = ValidXMLCharField(\n _(u'indicator measure'), blank=True, max_length=1,\n choices=codelist_choices(INDICATOR_MEASURE),\n help_text=_(u'Choose how the indicator will be measured (in percentage or units).')\n )\n ascending = models.NullBooleanField(\n _(u'ascending'), blank=True,\n help_text=_(u'Choose ascending if the target value of the indicator is higher than the '\n u'baseline value (eg. people with access to sanitation). Choose descending if '\n u'the target value of the indicator is lower than the baseline value '\n u'(eg. people with diarrhea).'))\n description = ValidXMLCharField(\n _(u'indicator description'), blank=True, max_length=2000,\n help_text=_(u'You can provide further information of the indicator here.')\n )\n baseline_year = models.PositiveIntegerField(\n _(u'baseline year'), blank=True, null=True,\n help_text=_(u'The year the baseline value was taken.')\n )\n baseline_value = ValidXMLCharField(\n _(u'baseline value'), blank=True, max_length=200,\n help_text=_(u'The value of the baseline at the start of the project.')\n )\n baseline_comment = ValidXMLCharField(\n _(u'baseline comment'), blank=True, max_length=2000,\n help_text=_(u'Here you can provide extra information on the baseline value, if needed.')\n )\n order = models.PositiveSmallIntegerField(_(u'indicator order'), null=True, blank=True)\n default_periods = models.NullBooleanField(\n _(u'default indicator periods'), default=False, blank=True,\n help_text=_(u'Determines whether periods of indicator are used by default.')\n )\n export_to_iati = models.BooleanField(\n _(u'Include indicator in IATI exports'), default=True,\n help_text=_(u'Choose whether this indicator will be included in IATI exports. '\n u'If you are not exporting to IATI, you may ignore this option.')\n )\n dimension_names = models.ManyToManyField('IndicatorDimensionName', related_name=u'indicators')\n\n def __unicode__(self):\n indicator_unicode = self.title if self.title else u'%s' % _(u'No indicator title')\n\n if self.periods.all():\n indicator_unicode += u' - %s %s' % (unicode(self.periods.count()),\n _(u'period(s)'))\n\n indicator_unicode += u' - %s' % dict(self.INDICATOR_TYPES)[self.type]\n\n return indicator_unicode\n\n def save(self, *args, **kwargs):\n \"\"\"Update the values of child indicators, if a parent indicator is updated.\"\"\"\n\n new_indicator = not self.pk\n\n if new_indicator and Indicator.objects.filter(result_id=self.result.id).exists():\n prev_indicator = Indicator.objects.filter(result_id=self.result.id).reverse()[0]\n if prev_indicator.order:\n self.order = prev_indicator.order + 1\n\n # HACK: Delete IndicatorLabels on non-qualitative indicators\n if new_indicator and self.type != QUALITATIVE:\n IndicatorLabel.objects.filter(indicator=self).delete()\n\n super(Indicator, self).save(*args, **kwargs)\n\n for child_result in self.result.child_results.all():\n if new_indicator:\n child_result.project.copy_indicator(child_result, self, set_parent=True)\n else:\n child_result.project.update_indicator(child_result, self)\n\n def clean(self):\n validation_errors = {}\n\n if self.pk and self.is_child_indicator():\n orig_indicator = Indicator.objects.get(pk=self.pk)\n\n # Don't allow some values to be changed when it is a child indicator\n if self.result != orig_indicator.result:\n validation_errors['result'] = u'%s' % \\\n _(u'It is not possible to update the result of this indicator, '\n u'because it is linked to a parent result.')\n if self.title != orig_indicator.title:\n validation_errors['title'] = u'%s' % \\\n _(u'It is not possible to update the title of this indicator, '\n u'because it is linked to a parent result.')\n if self.measure != orig_indicator.measure:\n validation_errors['measure'] = u'%s' % \\\n _(u'It is not possible to update the measure of this indicator, '\n u'because it is linked to a parent result.')\n if self.ascending != orig_indicator.ascending:\n validation_errors['ascending'] = u'%s' % \\\n _(u'It is not possible to update the ascending value of this indicator, '\n u'because it is linked to a parent result.')\n\n if validation_errors:\n raise ValidationError(validation_errors)\n\n def delete(self, *args, **kwargs):\n \"\"\"\n Check if indicator is ordered manually, and cascade following indicators if needed\n \"\"\"\n if self.order:\n sibling_indicators = Indicator.objects.filter(result_id=self.result.id)\n\n if not self == sibling_indicators.reverse()[0]:\n for ind in range(self.order + 1, len(sibling_indicators)):\n sibling_indicators[ind].order -= 1\n sibling_indicators[ind].save()\n\n super(Indicator, self).delete(*args, **kwargs)\n\n def iati_measure(self):\n return codelist_value(IndicatorMeasure, self, 'measure')\n\n def iati_measure_unicode(self):\n return str(self.iati_measure())\n\n def is_calculated(self):\n return self.result.project.is_impact_project\n\n def is_child_indicator(self):\n \"\"\"\n Indicates whether this indicator is linked to a parent indicator.\n \"\"\"\n return bool(self.parent_indicator)\n\n def is_parent_indicator(self):\n \"\"\"\n Indicates whether this indicator has children.\n \"\"\"\n return self.child_indicators.count() > 0\n\n @property\n def children_aggregate_percentage(self):\n \"\"\"\n Returns True if this indicator has percentage as a measure and has children that aggregate\n to this indicator.\n \"\"\"\n if self.measure == PERCENTAGE_MEASURE and self.is_parent_indicator() and \\\n self.result.project.aggregate_children and \\\n any(self.child_indicators.values_list('result__project__aggregate_to_parent', flat=True)):\n return True\n return False\n\n class Meta:\n app_label = 'rsr'\n ordering = ['order', 'id']\n verbose_name = _(u'indicator')\n verbose_name_plural = _(u'indicators')\n unique_together = ('result', 'parent_indicator')\n\n\n# Add default indicator periods if necessary\n@receiver(post_save, sender=Indicator, dispatch_uid='add_default_periods')\ndef add_default_periods(sender, instance, created, **kwargs):\n if created:\n project = instance.result.project\n results = Result.objects.filter(project_id=project)\n default_indicator = Indicator.objects.filter(result_id__in=results,\n default_periods=True).first()\n\n if default_indicator:\n default_periods = IndicatorPeriod.objects.filter(indicator_id=default_indicator)\n\n for period in default_periods:\n period.pk = None\n\n # Blank all values except id and locked status\n period.target_value = ''\n period.target_comment = ''\n period.actual_value = ''\n period.actual_comment = ''\n\n period.indicator_id = instance.id\n period.save()\n", "path": "akvo/rsr/models/result/indicator.py"}]}
| 3,252 | 333 |
gh_patches_debug_10351
|
rasdani/github-patches
|
git_diff
|
liqd__a4-meinberlin-3993
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
In Bplans required field (start-date & end-date) for publication is not marked as such
**URL:** https://meinberlin-dev.liqd.net/dashboard/projects/sabinas-bebauungsplan/bplan/
**user:** A Bplan initiator
**expected behaviour:** As a Bplan initiator, I want the form to tell me which fields are required so that I can publish
**behaviour:** Because the start- and enddate are not marked as required for publication, it's unclear that not filling these in is hindering publication
**important screensize:** any
**device & browser:** ubuntu chrome
**Comment/Question:**
These are just missing red the exclamation point icons. It's a simple fix in forms.py
Screenshot?

</issue>
<code>
[start of meinberlin/apps/bplan/forms.py]
1 from django import forms
2
3 from meinberlin.apps.extprojects.forms import ExternalProjectCreateForm
4 from meinberlin.apps.extprojects.forms import ExternalProjectForm
5
6 from . import models
7
8
9 class StatementForm(forms.ModelForm):
10 class Meta:
11 model = models.Statement
12 fields = ['name', 'email', 'statement',
13 'street_number', 'postal_code_city']
14
15
16 class BplanProjectCreateForm(ExternalProjectCreateForm):
17
18 class Meta:
19 model = models.Bplan
20 fields = ['name', 'description', 'tile_image', 'tile_image_copyright']
21
22
23 class BplanProjectForm(ExternalProjectForm):
24
25 class Meta:
26 model = models.Bplan
27 fields = ['name', 'identifier', 'url', 'description', 'tile_image',
28 'tile_image_copyright', 'is_archived', 'office_worker_email',
29 'start_date', 'end_date']
30 required_for_project_publish = ['name', 'url', 'description',
31 'office_worker_email']
32
33 def __init__(self, *args, **kwargs):
34 super().__init__(*args, **kwargs)
35 self.fields['name'].widget.attrs.update({
36 'autocomplete': 'off', 'autofill': 'off'
37 })
38
[end of meinberlin/apps/bplan/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/meinberlin/apps/bplan/forms.py b/meinberlin/apps/bplan/forms.py
--- a/meinberlin/apps/bplan/forms.py
+++ b/meinberlin/apps/bplan/forms.py
@@ -28,7 +28,8 @@
'tile_image_copyright', 'is_archived', 'office_worker_email',
'start_date', 'end_date']
required_for_project_publish = ['name', 'url', 'description',
- 'office_worker_email']
+ 'office_worker_email',
+ 'start_date', 'end_date']
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
|
{"golden_diff": "diff --git a/meinberlin/apps/bplan/forms.py b/meinberlin/apps/bplan/forms.py\n--- a/meinberlin/apps/bplan/forms.py\n+++ b/meinberlin/apps/bplan/forms.py\n@@ -28,7 +28,8 @@\n 'tile_image_copyright', 'is_archived', 'office_worker_email',\n 'start_date', 'end_date']\n required_for_project_publish = ['name', 'url', 'description',\n- 'office_worker_email']\n+ 'office_worker_email',\n+ 'start_date', 'end_date']\n \n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n", "issue": "In Bplans required field (start-date & end-date) for publication is not marked as such\n**URL:** https://meinberlin-dev.liqd.net/dashboard/projects/sabinas-bebauungsplan/bplan/\r\n**user:** A Bplan initiator\r\n**expected behaviour:** As a Bplan initiator, I want the form to tell me which fields are required so that I can publish\r\n**behaviour:** Because the start- and enddate are not marked as required for publication, it's unclear that not filling these in is hindering publication\r\n**important screensize:** any\r\n**device & browser:** ubuntu chrome\r\n**Comment/Question:**\r\nThese are just missing red the exclamation point icons. It's a simple fix in forms.py\r\n\r\nScreenshot?\r\n\r\n\r\n\n", "before_files": [{"content": "from django import forms\n\nfrom meinberlin.apps.extprojects.forms import ExternalProjectCreateForm\nfrom meinberlin.apps.extprojects.forms import ExternalProjectForm\n\nfrom . import models\n\n\nclass StatementForm(forms.ModelForm):\n class Meta:\n model = models.Statement\n fields = ['name', 'email', 'statement',\n 'street_number', 'postal_code_city']\n\n\nclass BplanProjectCreateForm(ExternalProjectCreateForm):\n\n class Meta:\n model = models.Bplan\n fields = ['name', 'description', 'tile_image', 'tile_image_copyright']\n\n\nclass BplanProjectForm(ExternalProjectForm):\n\n class Meta:\n model = models.Bplan\n fields = ['name', 'identifier', 'url', 'description', 'tile_image',\n 'tile_image_copyright', 'is_archived', 'office_worker_email',\n 'start_date', 'end_date']\n required_for_project_publish = ['name', 'url', 'description',\n 'office_worker_email']\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.fields['name'].widget.attrs.update({\n 'autocomplete': 'off', 'autofill': 'off'\n })\n", "path": "meinberlin/apps/bplan/forms.py"}]}
| 1,092 | 149 |
gh_patches_debug_12785
|
rasdani/github-patches
|
git_diff
|
learningequality__kolibri-8076
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Catch ValueError during network discovery for when JSON parsing fails
<!--
Instructions:
* Fill out the sections below, replace …'s with information about your issue
* Use the 'preview' function above this text box to verify formatting before submitting
-->
### Observed behavior
<!--
Description of the behavior that was observed, including screenshots or other references when applicable
-->
When trying to import content channels (from local network or internet), no error message is produced even though the connection isn't established. (The "trying to connect" message stays on forever) This happens when there is a typo in the address. (I used kolibri-demo.learningequality.omg) When there's no internet, an error message DOES get produced.
### Expected behavior
<!--
Description of what behavior was expected but did not occur
-->
An error message should've been produced.
### User-facing consequences
<!--
Implications and real-world consequences for learners, coaches, admins, and other users of the application
-->
The user will not know how long they have to wait to see if the connection is being established.
### Errors and logs
<!--
Relevant logs from:
* the command line
* ~/.kolibri/logs/kolibri.txt
* the browser console
Please wrap errors in triple backticks for clean formatting like this:
```
01:10 info: something happened
01:12 error: something bad happened
```
-->
…
### Steps to reproduce
<!--
Precise steps that someone else can follow in order to see this behavior
-->
Import content channels from local network or internet >input "kolibri-demo.learningequality.omg" or something else with a typo in it.
### Context
<!--
Tell us about your environment, including:
* Kolibri version
* Operating system
* Browser
-->
Kolibri version: 0.14.3
Operating system: Android 5.1
Browser: Android App
Device: BLU Advance 5.0
</issue>
<code>
[start of kolibri/core/discovery/utils/network/client.py]
1 import logging
2
3 import requests
4 from six.moves.urllib.parse import urljoin
5
6 from . import errors
7 from .urls import get_normalized_url_variations
8
9 logger = logging.getLogger(__name__)
10
11
12 class NetworkClient(object):
13 DEFAULT_TIMEOUT_IN_SECS = 5
14
15 def __init__(self, base_url=None, address=None, timeout=None, **kwargs):
16 """If an explicit base_url is already known, provide that. If a vague address is provided, we can try to infer the base_url"""
17 if not base_url and not address:
18 raise Exception(
19 "You must provide either a `base_url` or `address` argument"
20 )
21 self.timeout = timeout or self.DEFAULT_TIMEOUT_IN_SECS
22 self.session = requests.Session(**kwargs)
23 if base_url:
24 self.base_url = self._attempt_connections([base_url])
25 else:
26 # normalize the URL and try a number of variations until we find one that's able to connect
27 logger.info(
28 "Attempting connections to variations of the URL: {}".format(address)
29 )
30 self.base_url = self._attempt_connections(
31 get_normalized_url_variations(address)
32 )
33
34 def _attempt_connections(self, urls):
35 # try each of the URLs in turn, returning the first one that succeeds
36 for url in urls:
37 try:
38 logger.info("Attempting connection to: {}".format(url))
39 response = self.get(
40 "/api/public/info/",
41 base_url=url,
42 timeout=self.timeout,
43 allow_redirects=True,
44 )
45 # check that we successfully connected, and if we were redirected that it's still the right endpoint
46 if response.status_code == 200 and response.url.rstrip("/").endswith(
47 "/api/public/info"
48 ):
49 self.info = response.json()
50 if self.info["application"] not in ["studio", "kolibri"]:
51 raise requests.RequestException(
52 "Server is not running Kolibri or Studio"
53 )
54 logger.info("Success! We connected to: {}".format(response.url))
55 return response.url.rstrip("/").replace("api/public/info", "")
56 except (requests.RequestException) as e:
57 logger.info("Unable to connect: {}".format(e))
58
59 # we weren't able to connect to any of the URL variations, so all we can do is throw
60 raise errors.NetworkLocationNotFound()
61
62 def get(self, path, **kwargs):
63 return self.request("get", path, **kwargs)
64
65 def head(self, path, **kwargs):
66 return self.request("head", path, **kwargs)
67
68 def request(self, method, path, base_url=None, **kwargs):
69 base_url = base_url or self.base_url
70 url = urljoin(base_url, path)
71 response = getattr(self.session, method)(url, **kwargs)
72 response.raise_for_status()
73 return response
74
[end of kolibri/core/discovery/utils/network/client.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kolibri/core/discovery/utils/network/client.py b/kolibri/core/discovery/utils/network/client.py
--- a/kolibri/core/discovery/utils/network/client.py
+++ b/kolibri/core/discovery/utils/network/client.py
@@ -55,6 +55,10 @@
return response.url.rstrip("/").replace("api/public/info", "")
except (requests.RequestException) as e:
logger.info("Unable to connect: {}".format(e))
+ except ValueError:
+ logger.info(
+ "Invalid JSON returned when attempting to connect to a remote server"
+ )
# we weren't able to connect to any of the URL variations, so all we can do is throw
raise errors.NetworkLocationNotFound()
|
{"golden_diff": "diff --git a/kolibri/core/discovery/utils/network/client.py b/kolibri/core/discovery/utils/network/client.py\n--- a/kolibri/core/discovery/utils/network/client.py\n+++ b/kolibri/core/discovery/utils/network/client.py\n@@ -55,6 +55,10 @@\n return response.url.rstrip(\"/\").replace(\"api/public/info\", \"\")\n except (requests.RequestException) as e:\n logger.info(\"Unable to connect: {}\".format(e))\n+ except ValueError:\n+ logger.info(\n+ \"Invalid JSON returned when attempting to connect to a remote server\"\n+ )\n \n # we weren't able to connect to any of the URL variations, so all we can do is throw\n raise errors.NetworkLocationNotFound()\n", "issue": "Catch ValueError during network discovery for when JSON parsing fails\n<!--\r\nInstructions:\r\n * Fill out the sections below, replace \u2026's with information about your issue\r\n * Use the 'preview' function above this text box to verify formatting before submitting\r\n-->\r\n\r\n### Observed behavior\r\n<!--\r\nDescription of the behavior that was observed, including screenshots or other references when applicable\r\n-->\r\n\r\nWhen trying to import content channels (from local network or internet), no error message is produced even though the connection isn't established. (The \"trying to connect\" message stays on forever) This happens when there is a typo in the address. (I used kolibri-demo.learningequality.omg) When there's no internet, an error message DOES get produced. \r\n\r\n### Expected behavior\r\n<!--\r\nDescription of what behavior was expected but did not occur\r\n-->\r\n\r\nAn error message should've been produced.\r\n\r\n### User-facing consequences\r\n<!--\r\nImplications and real-world consequences for learners, coaches, admins, and other users of the application\r\n-->\r\n\r\nThe user will not know how long they have to wait to see if the connection is being established.\r\n\r\n### Errors and logs\r\n<!--\r\nRelevant logs from:\r\n * the command line\r\n * ~/.kolibri/logs/kolibri.txt\r\n * the browser console\r\n\r\nPlease wrap errors in triple backticks for clean formatting like this:\r\n```\r\n01:10 info: something happened\r\n01:12 error: something bad happened\r\n```\r\n-->\r\n\r\n\u2026\r\n\r\n### Steps to reproduce\r\n<!--\r\nPrecise steps that someone else can follow in order to see this behavior\r\n-->\r\n\r\nImport content channels from local network or internet >input \"kolibri-demo.learningequality.omg\" or something else with a typo in it.\r\n\r\n### Context\r\n<!--\r\nTell us about your environment, including:\r\n * Kolibri version\r\n * Operating system\r\n * Browser\r\n-->\r\n\r\nKolibri version: 0.14.3\r\nOperating system: Android 5.1\r\nBrowser: Android App\r\nDevice: BLU Advance 5.0\r\n\n", "before_files": [{"content": "import logging\n\nimport requests\nfrom six.moves.urllib.parse import urljoin\n\nfrom . import errors\nfrom .urls import get_normalized_url_variations\n\nlogger = logging.getLogger(__name__)\n\n\nclass NetworkClient(object):\n DEFAULT_TIMEOUT_IN_SECS = 5\n\n def __init__(self, base_url=None, address=None, timeout=None, **kwargs):\n \"\"\"If an explicit base_url is already known, provide that. If a vague address is provided, we can try to infer the base_url\"\"\"\n if not base_url and not address:\n raise Exception(\n \"You must provide either a `base_url` or `address` argument\"\n )\n self.timeout = timeout or self.DEFAULT_TIMEOUT_IN_SECS\n self.session = requests.Session(**kwargs)\n if base_url:\n self.base_url = self._attempt_connections([base_url])\n else:\n # normalize the URL and try a number of variations until we find one that's able to connect\n logger.info(\n \"Attempting connections to variations of the URL: {}\".format(address)\n )\n self.base_url = self._attempt_connections(\n get_normalized_url_variations(address)\n )\n\n def _attempt_connections(self, urls):\n # try each of the URLs in turn, returning the first one that succeeds\n for url in urls:\n try:\n logger.info(\"Attempting connection to: {}\".format(url))\n response = self.get(\n \"/api/public/info/\",\n base_url=url,\n timeout=self.timeout,\n allow_redirects=True,\n )\n # check that we successfully connected, and if we were redirected that it's still the right endpoint\n if response.status_code == 200 and response.url.rstrip(\"/\").endswith(\n \"/api/public/info\"\n ):\n self.info = response.json()\n if self.info[\"application\"] not in [\"studio\", \"kolibri\"]:\n raise requests.RequestException(\n \"Server is not running Kolibri or Studio\"\n )\n logger.info(\"Success! We connected to: {}\".format(response.url))\n return response.url.rstrip(\"/\").replace(\"api/public/info\", \"\")\n except (requests.RequestException) as e:\n logger.info(\"Unable to connect: {}\".format(e))\n\n # we weren't able to connect to any of the URL variations, so all we can do is throw\n raise errors.NetworkLocationNotFound()\n\n def get(self, path, **kwargs):\n return self.request(\"get\", path, **kwargs)\n\n def head(self, path, **kwargs):\n return self.request(\"head\", path, **kwargs)\n\n def request(self, method, path, base_url=None, **kwargs):\n base_url = base_url or self.base_url\n url = urljoin(base_url, path)\n response = getattr(self.session, method)(url, **kwargs)\n response.raise_for_status()\n return response\n", "path": "kolibri/core/discovery/utils/network/client.py"}]}
| 1,701 | 160 |
gh_patches_debug_12113
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-trace-py-1465
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
gRPC server interceptor raises AttributeError
When a gRPC service is not found, the Datadog interceptor raises an AttributeError:
```
ERROR grpc._server:_server.py:732 Exception servicing handler: 'NoneType' object has no attribute '_pin'
...
File "/src/ddtrace/contrib/grpc/server_interceptor.py", line 153, in intercept_service
return self._fn(continuation, handler_call_details)
File "/src/ddtrace/contrib/grpc/server_interceptor.py", line 22, in interceptor_function
return _TracedRpcMethodHandler(pin, handler_call_details, rpc_method_handler)
File "/src/ddtrace/contrib/grpc/server_interceptor.py", line 58, in __init__
self._pin = pin
AttributeError: 'NoneType' object has no attribute '_pin'
```
The gRPC documentation [points](https://grpc.github.io/grpc/python/grpc.html#grpc.ServerInterceptor.intercept_service) out that `continuation()` in a server-side interceptor can return a `None`, which is not handled by the Datadog interceptor.
This applies to `ddtrace>=0.28.0` when the server interceptor was added.
</issue>
<code>
[start of ddtrace/contrib/grpc/server_interceptor.py]
1 import grpc
2 from ddtrace.vendor import wrapt
3
4 from ddtrace import config
5 from ddtrace.ext import errors
6 from ddtrace.compat import to_unicode
7
8 from ...constants import ANALYTICS_SAMPLE_RATE_KEY, SPAN_MEASURED_KEY
9 from ...ext import SpanTypes
10 from ...propagation.http import HTTPPropagator
11 from . import constants
12 from .utils import parse_method_path
13
14
15 def create_server_interceptor(pin):
16 def interceptor_function(continuation, handler_call_details):
17 if not pin.enabled:
18 return continuation(handler_call_details)
19
20 rpc_method_handler = continuation(handler_call_details)
21 return _TracedRpcMethodHandler(pin, handler_call_details, rpc_method_handler)
22
23 return _ServerInterceptor(interceptor_function)
24
25
26 def _handle_server_exception(server_context, span):
27 if server_context is not None and \
28 hasattr(server_context, '_state') and \
29 server_context._state is not None:
30 code = to_unicode(server_context._state.code)
31 details = to_unicode(server_context._state.details)
32 span.error = 1
33 span.set_tag(errors.ERROR_MSG, details)
34 span.set_tag(errors.ERROR_TYPE, code)
35
36
37 def _wrap_response_iterator(response_iterator, server_context, span):
38 try:
39 for response in response_iterator:
40 yield response
41 except Exception:
42 span.set_traceback()
43 _handle_server_exception(server_context, span)
44 raise
45 finally:
46 span.finish()
47
48
49 class _TracedRpcMethodHandler(wrapt.ObjectProxy):
50 def __init__(self, pin, handler_call_details, wrapped):
51 super(_TracedRpcMethodHandler, self).__init__(wrapped)
52 self._pin = pin
53 self._handler_call_details = handler_call_details
54
55 def _fn(self, method_kind, behavior, args, kwargs):
56 if config.grpc_server.distributed_tracing_enabled:
57 headers = dict(self._handler_call_details.invocation_metadata)
58 propagator = HTTPPropagator()
59 context = propagator.extract(headers)
60
61 if context.trace_id:
62 self._pin.tracer.context_provider.activate(context)
63
64 tracer = self._pin.tracer
65
66 span = tracer.trace(
67 'grpc',
68 span_type=SpanTypes.GRPC,
69 service=self._pin.service,
70 resource=self._handler_call_details.method,
71 )
72 span.set_tag(SPAN_MEASURED_KEY)
73
74 method_path = self._handler_call_details.method
75 method_package, method_service, method_name = parse_method_path(method_path)
76 span.set_tag(constants.GRPC_METHOD_PATH_KEY, method_path)
77 span.set_tag(constants.GRPC_METHOD_PACKAGE_KEY, method_package)
78 span.set_tag(constants.GRPC_METHOD_SERVICE_KEY, method_service)
79 span.set_tag(constants.GRPC_METHOD_NAME_KEY, method_name)
80 span.set_tag(constants.GRPC_METHOD_KIND_KEY, method_kind)
81 span.set_tag(constants.GRPC_SPAN_KIND_KEY, constants.GRPC_SPAN_KIND_VALUE_SERVER)
82
83 sample_rate = config.grpc_server.get_analytics_sample_rate()
84 if sample_rate is not None:
85 span.set_tag(ANALYTICS_SAMPLE_RATE_KEY, sample_rate)
86
87 # access server context by taking second argument as server context
88 # if not found, skip using context to tag span with server state information
89 server_context = args[1] if isinstance(args[1], grpc.ServicerContext) else None
90
91 if self._pin.tags:
92 span.set_tags(self._pin.tags)
93
94 try:
95 response_or_iterator = behavior(*args, **kwargs)
96
97 if self.__wrapped__.response_streaming:
98 response_or_iterator = _wrap_response_iterator(response_or_iterator, server_context, span)
99 except Exception:
100 span.set_traceback()
101 _handle_server_exception(server_context, span)
102 raise
103 finally:
104 if not self.__wrapped__.response_streaming:
105 span.finish()
106
107 return response_or_iterator
108
109 def unary_unary(self, *args, **kwargs):
110 return self._fn(
111 constants.GRPC_METHOD_KIND_UNARY,
112 self.__wrapped__.unary_unary,
113 args,
114 kwargs
115 )
116
117 def unary_stream(self, *args, **kwargs):
118 return self._fn(
119 constants.GRPC_METHOD_KIND_SERVER_STREAMING,
120 self.__wrapped__.unary_stream,
121 args,
122 kwargs
123 )
124
125 def stream_unary(self, *args, **kwargs):
126 return self._fn(
127 constants.GRPC_METHOD_KIND_CLIENT_STREAMING,
128 self.__wrapped__.stream_unary,
129 args,
130 kwargs
131 )
132
133 def stream_stream(self, *args, **kwargs):
134 return self._fn(
135 constants.GRPC_METHOD_KIND_BIDI_STREAMING,
136 self.__wrapped__.stream_stream,
137 args,
138 kwargs
139 )
140
141
142 class _ServerInterceptor(grpc.ServerInterceptor):
143 def __init__(self, interceptor_function):
144 self._fn = interceptor_function
145
146 def intercept_service(self, continuation, handler_call_details):
147 return self._fn(continuation, handler_call_details)
148
[end of ddtrace/contrib/grpc/server_interceptor.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ddtrace/contrib/grpc/server_interceptor.py b/ddtrace/contrib/grpc/server_interceptor.py
--- a/ddtrace/contrib/grpc/server_interceptor.py
+++ b/ddtrace/contrib/grpc/server_interceptor.py
@@ -18,7 +18,15 @@
return continuation(handler_call_details)
rpc_method_handler = continuation(handler_call_details)
- return _TracedRpcMethodHandler(pin, handler_call_details, rpc_method_handler)
+
+ # continuation returns an RpcMethodHandler instance if the RPC is
+ # considered serviced, or None otherwise
+ # https://grpc.github.io/grpc/python/grpc.html#grpc.ServerInterceptor.intercept_service
+
+ if rpc_method_handler:
+ return _TracedRpcMethodHandler(pin, handler_call_details, rpc_method_handler)
+
+ return rpc_method_handler
return _ServerInterceptor(interceptor_function)
|
{"golden_diff": "diff --git a/ddtrace/contrib/grpc/server_interceptor.py b/ddtrace/contrib/grpc/server_interceptor.py\n--- a/ddtrace/contrib/grpc/server_interceptor.py\n+++ b/ddtrace/contrib/grpc/server_interceptor.py\n@@ -18,7 +18,15 @@\n return continuation(handler_call_details)\n \n rpc_method_handler = continuation(handler_call_details)\n- return _TracedRpcMethodHandler(pin, handler_call_details, rpc_method_handler)\n+\n+ # continuation returns an RpcMethodHandler instance if the RPC is\n+ # considered serviced, or None otherwise\n+ # https://grpc.github.io/grpc/python/grpc.html#grpc.ServerInterceptor.intercept_service\n+\n+ if rpc_method_handler:\n+ return _TracedRpcMethodHandler(pin, handler_call_details, rpc_method_handler)\n+\n+ return rpc_method_handler\n \n return _ServerInterceptor(interceptor_function)\n", "issue": "gRPC server interceptor raises AttributeError\nWhen a gRPC service is not found, the Datadog interceptor raises an AttributeError:\r\n\r\n```\r\nERROR grpc._server:_server.py:732 Exception servicing handler: 'NoneType' object has no attribute '_pin'\r\n...\r\n File \"/src/ddtrace/contrib/grpc/server_interceptor.py\", line 153, in intercept_service\r\n return self._fn(continuation, handler_call_details)\r\n File \"/src/ddtrace/contrib/grpc/server_interceptor.py\", line 22, in interceptor_function\r\n return _TracedRpcMethodHandler(pin, handler_call_details, rpc_method_handler)\r\n File \"/src/ddtrace/contrib/grpc/server_interceptor.py\", line 58, in __init__\r\n self._pin = pin\r\nAttributeError: 'NoneType' object has no attribute '_pin'\r\n```\r\n\r\nThe gRPC documentation [points](https://grpc.github.io/grpc/python/grpc.html#grpc.ServerInterceptor.intercept_service) out that `continuation()` in a server-side interceptor can return a `None`, which is not handled by the Datadog interceptor.\r\n\r\nThis applies to `ddtrace>=0.28.0` when the server interceptor was added.\n", "before_files": [{"content": "import grpc\nfrom ddtrace.vendor import wrapt\n\nfrom ddtrace import config\nfrom ddtrace.ext import errors\nfrom ddtrace.compat import to_unicode\n\nfrom ...constants import ANALYTICS_SAMPLE_RATE_KEY, SPAN_MEASURED_KEY\nfrom ...ext import SpanTypes\nfrom ...propagation.http import HTTPPropagator\nfrom . import constants\nfrom .utils import parse_method_path\n\n\ndef create_server_interceptor(pin):\n def interceptor_function(continuation, handler_call_details):\n if not pin.enabled:\n return continuation(handler_call_details)\n\n rpc_method_handler = continuation(handler_call_details)\n return _TracedRpcMethodHandler(pin, handler_call_details, rpc_method_handler)\n\n return _ServerInterceptor(interceptor_function)\n\n\ndef _handle_server_exception(server_context, span):\n if server_context is not None and \\\n hasattr(server_context, '_state') and \\\n server_context._state is not None:\n code = to_unicode(server_context._state.code)\n details = to_unicode(server_context._state.details)\n span.error = 1\n span.set_tag(errors.ERROR_MSG, details)\n span.set_tag(errors.ERROR_TYPE, code)\n\n\ndef _wrap_response_iterator(response_iterator, server_context, span):\n try:\n for response in response_iterator:\n yield response\n except Exception:\n span.set_traceback()\n _handle_server_exception(server_context, span)\n raise\n finally:\n span.finish()\n\n\nclass _TracedRpcMethodHandler(wrapt.ObjectProxy):\n def __init__(self, pin, handler_call_details, wrapped):\n super(_TracedRpcMethodHandler, self).__init__(wrapped)\n self._pin = pin\n self._handler_call_details = handler_call_details\n\n def _fn(self, method_kind, behavior, args, kwargs):\n if config.grpc_server.distributed_tracing_enabled:\n headers = dict(self._handler_call_details.invocation_metadata)\n propagator = HTTPPropagator()\n context = propagator.extract(headers)\n\n if context.trace_id:\n self._pin.tracer.context_provider.activate(context)\n\n tracer = self._pin.tracer\n\n span = tracer.trace(\n 'grpc',\n span_type=SpanTypes.GRPC,\n service=self._pin.service,\n resource=self._handler_call_details.method,\n )\n span.set_tag(SPAN_MEASURED_KEY)\n\n method_path = self._handler_call_details.method\n method_package, method_service, method_name = parse_method_path(method_path)\n span.set_tag(constants.GRPC_METHOD_PATH_KEY, method_path)\n span.set_tag(constants.GRPC_METHOD_PACKAGE_KEY, method_package)\n span.set_tag(constants.GRPC_METHOD_SERVICE_KEY, method_service)\n span.set_tag(constants.GRPC_METHOD_NAME_KEY, method_name)\n span.set_tag(constants.GRPC_METHOD_KIND_KEY, method_kind)\n span.set_tag(constants.GRPC_SPAN_KIND_KEY, constants.GRPC_SPAN_KIND_VALUE_SERVER)\n\n sample_rate = config.grpc_server.get_analytics_sample_rate()\n if sample_rate is not None:\n span.set_tag(ANALYTICS_SAMPLE_RATE_KEY, sample_rate)\n\n # access server context by taking second argument as server context\n # if not found, skip using context to tag span with server state information\n server_context = args[1] if isinstance(args[1], grpc.ServicerContext) else None\n\n if self._pin.tags:\n span.set_tags(self._pin.tags)\n\n try:\n response_or_iterator = behavior(*args, **kwargs)\n\n if self.__wrapped__.response_streaming:\n response_or_iterator = _wrap_response_iterator(response_or_iterator, server_context, span)\n except Exception:\n span.set_traceback()\n _handle_server_exception(server_context, span)\n raise\n finally:\n if not self.__wrapped__.response_streaming:\n span.finish()\n\n return response_or_iterator\n\n def unary_unary(self, *args, **kwargs):\n return self._fn(\n constants.GRPC_METHOD_KIND_UNARY,\n self.__wrapped__.unary_unary,\n args,\n kwargs\n )\n\n def unary_stream(self, *args, **kwargs):\n return self._fn(\n constants.GRPC_METHOD_KIND_SERVER_STREAMING,\n self.__wrapped__.unary_stream,\n args,\n kwargs\n )\n\n def stream_unary(self, *args, **kwargs):\n return self._fn(\n constants.GRPC_METHOD_KIND_CLIENT_STREAMING,\n self.__wrapped__.stream_unary,\n args,\n kwargs\n )\n\n def stream_stream(self, *args, **kwargs):\n return self._fn(\n constants.GRPC_METHOD_KIND_BIDI_STREAMING,\n self.__wrapped__.stream_stream,\n args,\n kwargs\n )\n\n\nclass _ServerInterceptor(grpc.ServerInterceptor):\n def __init__(self, interceptor_function):\n self._fn = interceptor_function\n\n def intercept_service(self, continuation, handler_call_details):\n return self._fn(continuation, handler_call_details)\n", "path": "ddtrace/contrib/grpc/server_interceptor.py"}]}
| 2,194 | 188 |
gh_patches_debug_18834
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-3308
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Spider kopps is broken
During the global build at 2021-06-16-14-42-20, spider **kopps** failed with **0 features** and **1 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-06-16-14-42-20/logs/kopps.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-06-16-14-42-20/output/kopps.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-06-16-14-42-20/output/kopps.geojson))
</issue>
<code>
[start of locations/spiders/kopps.py]
1 import scrapy
2 import re
3 from locations.items import GeojsonPointItem
4
5 DAY_MAPPING = {
6 "Mon": "Mo",
7 "Tues": "Tu",
8 "Wed": "We",
9 "Thur": "Th",
10 "Fri": "Fr",
11 "Sat": "Sa",
12 "Sun": "Su"
13 }
14 class KoppsSpider(scrapy.Spider):
15 name = "kopps"
16 item_attributes = { 'brand': "Kopps" }
17 allowed_domains = ["www.kopps.com"]
18 download_delay = 1.5
19 start_urls = (
20 'https://www.kopps.com/',
21 )
22
23 def parse_day(self, day):
24 if re.search('-', day):
25 days = day.split('-')
26 osm_days = []
27 if len(days) == 2:
28 for day in days:
29 osm_day = DAY_MAPPING[day.strip()]
30 osm_days.append(osm_day)
31 return "-".join(osm_days)
32
33 def parse_times(self, times):
34 if times.strip() == 'Open 24 hours':
35 return '24/7'
36 hours_to = [x.strip() for x in times.split('-')]
37 cleaned_times = []
38
39 for hour in hours_to:
40 if re.search('pm$', hour):
41 hour = re.sub('pm', '', hour).strip()
42 hour_min = hour.split(":")
43 if int(hour_min[0]) < 12:
44 hour_min[0] = str(12 + int(hour_min[0]))
45 cleaned_times.append(":".join(hour_min))
46
47 if re.search('am$', hour):
48 hour = re.sub('am', '', hour).strip()
49 hour_min = hour.split(":")
50 if len(hour_min[0]) <2:
51 hour_min[0] = hour_min[0].zfill(2)
52 else:
53 hour_min[0] = str( int(hour_min[0]))
54
55 cleaned_times.append(":".join(hour_min))
56 return "-".join(cleaned_times)
57
58 def parse_hours(self, lis):
59 hours = []
60 for li in lis:
61 day_times = li.xpath('normalize-space(./text())').extract_first()
62 day = re.findall(r"^[a-zA-Z-]+" , day_times)
63 if(len(day)>0):
64 day = day[0]
65 else:
66 day = 'Mon-Sun'
67 times = re.findall(r"[0-9]{2}:[0-9]{2}[a|p]m - [0-9]{2}:[0-9]{2}[a|p]m" ,day_times)
68 times = times[0]
69 if times and day:
70 parsed_time = self.parse_times(times)
71 parsed_day = self.parse_day(day)
72 hours.append(parsed_day + ' ' + parsed_time)
73
74 return "; ".join(hours)
75
76
77 def parse(self, response):
78 locations = response.xpath('//div[@id="locations"]/div/div')
79
80 for location in locations:
81 properties = {
82 'addr_full': location.xpath('normalize-space(./div/address/a/text())').extract_first(),
83 'phone': location.xpath('normalize-space(./div/ul/li/span/a/text())').extract_first(),
84 'city': location.xpath('./div/address/a/text()').extract()[1].replace(' ' ,'').split(',')[0].replace('\r\n' ,''),
85 'state': location.xpath('./div/address/a/text()').extract()[1].lstrip().split(',')[1].split(' ')[1],
86 'postcode': location.xpath('./div/address/a/text()').extract()[1].lstrip().split(',')[1].split(' ')[2].replace('\r\n' ,''),
87 'ref': location.xpath('normalize-space(./div/address/a/@href)').extract_first(),
88 'website': response.url,
89 'lat':re.findall(r"\/[0-9]{2}[^(\/)]+z",location.xpath('normalize-space(./div/address/a/@href)').extract_first())[0][1:].split(',')[0],
90 'lon': re.findall(r"\/[0-9]{2}[^(\/)]+z",location.xpath('normalize-space(./div/address/a/@href)').extract_first())[0][1:].split(',')[1],
91 }
92
93 hours = self.parse_hours(location.xpath('./div/ul/li[3]/span'))
94 if hours:
95 properties['opening_hours'] = hours
96
97 yield GeojsonPointItem(**properties)
[end of locations/spiders/kopps.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/locations/spiders/kopps.py b/locations/spiders/kopps.py
--- a/locations/spiders/kopps.py
+++ b/locations/spiders/kopps.py
@@ -26,8 +26,9 @@
osm_days = []
if len(days) == 2:
for day in days:
- osm_day = DAY_MAPPING[day.strip()]
- osm_days.append(osm_day)
+ if day.strip() in DAY_MAPPING:
+ osm_day = DAY_MAPPING[day.strip()]
+ osm_days.append(osm_day)
return "-".join(osm_days)
def parse_times(self, times):
@@ -69,7 +70,8 @@
if times and day:
parsed_time = self.parse_times(times)
parsed_day = self.parse_day(day)
- hours.append(parsed_day + ' ' + parsed_time)
+ if parsed_day and parsed_time:
+ hours.append(parsed_day + ' ' + parsed_time)
return "; ".join(hours)
|
{"golden_diff": "diff --git a/locations/spiders/kopps.py b/locations/spiders/kopps.py\n--- a/locations/spiders/kopps.py\n+++ b/locations/spiders/kopps.py\n@@ -26,8 +26,9 @@\n osm_days = []\n if len(days) == 2:\n for day in days:\n- osm_day = DAY_MAPPING[day.strip()]\n- osm_days.append(osm_day)\n+ if day.strip() in DAY_MAPPING:\n+ osm_day = DAY_MAPPING[day.strip()]\n+ osm_days.append(osm_day)\n return \"-\".join(osm_days)\n \n def parse_times(self, times):\n@@ -69,7 +70,8 @@\n if times and day:\n parsed_time = self.parse_times(times)\n parsed_day = self.parse_day(day)\n- hours.append(parsed_day + ' ' + parsed_time)\n+ if parsed_day and parsed_time:\n+ hours.append(parsed_day + ' ' + parsed_time)\n \n return \"; \".join(hours)\n", "issue": "Spider kopps is broken\nDuring the global build at 2021-06-16-14-42-20, spider **kopps** failed with **0 features** and **1 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-06-16-14-42-20/logs/kopps.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-06-16-14-42-20/output/kopps.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-06-16-14-42-20/output/kopps.geojson))\n", "before_files": [{"content": "import scrapy\nimport re\nfrom locations.items import GeojsonPointItem\n\nDAY_MAPPING = {\n \"Mon\": \"Mo\",\n \"Tues\": \"Tu\",\n \"Wed\": \"We\",\n \"Thur\": \"Th\",\n \"Fri\": \"Fr\",\n \"Sat\": \"Sa\",\n \"Sun\": \"Su\"\n}\nclass KoppsSpider(scrapy.Spider):\n name = \"kopps\"\n item_attributes = { 'brand': \"Kopps\" }\n allowed_domains = [\"www.kopps.com\"]\n download_delay = 1.5\n start_urls = (\n 'https://www.kopps.com/',\n )\n\n def parse_day(self, day):\n if re.search('-', day):\n days = day.split('-')\n osm_days = []\n if len(days) == 2:\n for day in days:\n osm_day = DAY_MAPPING[day.strip()]\n osm_days.append(osm_day)\n return \"-\".join(osm_days)\n\n def parse_times(self, times):\n if times.strip() == 'Open 24 hours':\n return '24/7'\n hours_to = [x.strip() for x in times.split('-')]\n cleaned_times = []\n\n for hour in hours_to:\n if re.search('pm$', hour):\n hour = re.sub('pm', '', hour).strip()\n hour_min = hour.split(\":\")\n if int(hour_min[0]) < 12:\n hour_min[0] = str(12 + int(hour_min[0]))\n cleaned_times.append(\":\".join(hour_min))\n\n if re.search('am$', hour):\n hour = re.sub('am', '', hour).strip()\n hour_min = hour.split(\":\")\n if len(hour_min[0]) <2:\n hour_min[0] = hour_min[0].zfill(2)\n else:\n hour_min[0] = str( int(hour_min[0]))\n\n cleaned_times.append(\":\".join(hour_min))\n return \"-\".join(cleaned_times)\n\n def parse_hours(self, lis):\n hours = []\n for li in lis:\n day_times = li.xpath('normalize-space(./text())').extract_first()\n day = re.findall(r\"^[a-zA-Z-]+\" , day_times)\n if(len(day)>0):\n day = day[0]\n else:\n day = 'Mon-Sun'\n times = re.findall(r\"[0-9]{2}:[0-9]{2}[a|p]m - [0-9]{2}:[0-9]{2}[a|p]m\" ,day_times)\n times = times[0]\n if times and day:\n parsed_time = self.parse_times(times)\n parsed_day = self.parse_day(day)\n hours.append(parsed_day + ' ' + parsed_time)\n\n return \"; \".join(hours)\n\n\n def parse(self, response):\n locations = response.xpath('//div[@id=\"locations\"]/div/div')\n\n for location in locations:\n properties = {\n 'addr_full': location.xpath('normalize-space(./div/address/a/text())').extract_first(),\n 'phone': location.xpath('normalize-space(./div/ul/li/span/a/text())').extract_first(),\n 'city': location.xpath('./div/address/a/text()').extract()[1].replace(' ' ,'').split(',')[0].replace('\\r\\n' ,''),\n 'state': location.xpath('./div/address/a/text()').extract()[1].lstrip().split(',')[1].split(' ')[1],\n 'postcode': location.xpath('./div/address/a/text()').extract()[1].lstrip().split(',')[1].split(' ')[2].replace('\\r\\n' ,''),\n 'ref': location.xpath('normalize-space(./div/address/a/@href)').extract_first(),\n 'website': response.url,\n 'lat':re.findall(r\"\\/[0-9]{2}[^(\\/)]+z\",location.xpath('normalize-space(./div/address/a/@href)').extract_first())[0][1:].split(',')[0],\n 'lon': re.findall(r\"\\/[0-9]{2}[^(\\/)]+z\",location.xpath('normalize-space(./div/address/a/@href)').extract_first())[0][1:].split(',')[1],\n }\n\n hours = self.parse_hours(location.xpath('./div/ul/li[3]/span'))\n if hours:\n properties['opening_hours'] = hours\n\n yield GeojsonPointItem(**properties)", "path": "locations/spiders/kopps.py"}]}
| 1,866 | 228 |
gh_patches_debug_1434
|
rasdani/github-patches
|
git_diff
|
Textualize__rich-2642
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] export_html leaks style into the page
**Describe the bug**
Following discussion https://github.com/Textualize/rich/discussions/2640
Injecting HTML generated with Rich's `Console.export_html()` method seems to leak some style into the page.

The page is built with MkDocs + Material for MkDocs. The dark theme is activated.
The light theme is less impacted, I just see extra "bars" (like an empty code line) in-between block elements:

Code used to generate the HTML:
```python
import os
from rich.console import Console
report = """$ griffe check griffe -ssrc -b0.24.0 -a0.23.0
[bold]src/griffe/loader.py[/]:156: GriffeLoader.resolve_aliases([blue]only_exported[/]): [yellow]Parameter kind was changed[/]: positional or keyword -> keyword-only
etc.
"""
with open(os.devnull, "w") as devnull:
console = Console(record=True, width=150, file=devnull)
console.print(report, markup=True, highlight=False)
print(console.export_html(inline_styles=True))
```
Both `inline_styles=True` and `inline_styles=False` give the same result.
**Platform**
<details>
<summary>Click to expand</summary>
Linux
```console
$ python -m rich.diagnose
╭───────────────────────── <class 'rich.console.Console'> ─────────────────────────╮
│ A high level console interface. │
│ │
│ ╭──────────────────────────────────────────────────────────────────────────────╮ │
│ │ <console width=239 ColorSystem.TRUECOLOR> │ │
│ ╰──────────────────────────────────────────────────────────────────────────────╯ │
│ │
│ color_system = 'truecolor' │
│ encoding = 'utf-8' │
│ file = <_io.TextIOWrapper name='<stdout>' mode='w' encoding='utf-8'> │
│ height = 58 │
│ is_alt_screen = False │
│ is_dumb_terminal = False │
│ is_interactive = True │
│ is_jupyter = False │
│ is_terminal = True │
│ legacy_windows = False │
│ no_color = False │
│ options = ConsoleOptions( │
│ size=ConsoleDimensions(width=239, height=58), │
│ legacy_windows=False, │
│ min_width=1, │
│ max_width=239, │
│ is_terminal=True, │
│ encoding='utf-8', │
│ max_height=58, │
│ justify=None, │
│ overflow=None, │
│ no_wrap=False, │
│ highlight=None, │
│ markup=None, │
│ height=None │
│ ) │
│ quiet = False │
│ record = False │
│ safe_box = True │
│ size = ConsoleDimensions(width=239, height=58) │
│ soft_wrap = False │
│ stderr = False │
│ style = None │
│ tab_size = 8 │
│ width = 239 │
╰──────────────────────────────────────────────────────────────────────────────────╯
╭─── <class 'rich._windows.WindowsConsoleFeatures'> ────╮
│ Windows features available. │
│ │
│ ╭───────────────────────────────────────────────────╮ │
│ │ WindowsConsoleFeatures(vt=False, truecolor=False) │ │
│ ╰───────────────────────────────────────────────────╯ │
│ │
│ truecolor = False │
│ vt = False │
╰───────────────────────────────────────────────────────╯
╭────── Environment Variables ───────╮
│ { │
│ 'TERM': 'xterm-256color', │
│ 'COLORTERM': 'truecolor', │
│ 'CLICOLOR': None, │
│ 'NO_COLOR': None, │
│ 'TERM_PROGRAM': None, │
│ 'COLUMNS': None, │
│ 'LINES': None, │
│ 'JUPYTER_COLUMNS': None, │
│ 'JUPYTER_LINES': None, │
│ 'JPY_PARENT_PID': None, │
│ 'VSCODE_VERBOSE_LOGGING': None │
│ } │
╰────────────────────────────────────╯
platform="Linux"
```
```console
% pdm list --freeze | grep rich
rich==12.6.0
```
</details>
</issue>
<code>
[start of rich/_export_format.py]
1 CONSOLE_HTML_FORMAT = """\
2 <!DOCTYPE html>
3 <head>
4 <meta charset="UTF-8">
5 <style>
6 {stylesheet}
7 body {{
8 color: {foreground};
9 background-color: {background};
10 }}
11 </style>
12 </head>
13 <html>
14 <body>
15 <code>
16 <pre style="font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace">{code}</pre>
17 </code>
18 </body>
19 </html>
20 """
21
22 CONSOLE_SVG_FORMAT = """\
23 <svg class="rich-terminal" viewBox="0 0 {width} {height}" xmlns="http://www.w3.org/2000/svg">
24 <!-- Generated with Rich https://www.textualize.io -->
25 <style>
26
27 @font-face {{
28 font-family: "Fira Code";
29 src: local("FiraCode-Regular"),
30 url("https://cdnjs.cloudflare.com/ajax/libs/firacode/6.2.0/woff2/FiraCode-Regular.woff2") format("woff2"),
31 url("https://cdnjs.cloudflare.com/ajax/libs/firacode/6.2.0/woff/FiraCode-Regular.woff") format("woff");
32 font-style: normal;
33 font-weight: 400;
34 }}
35 @font-face {{
36 font-family: "Fira Code";
37 src: local("FiraCode-Bold"),
38 url("https://cdnjs.cloudflare.com/ajax/libs/firacode/6.2.0/woff2/FiraCode-Bold.woff2") format("woff2"),
39 url("https://cdnjs.cloudflare.com/ajax/libs/firacode/6.2.0/woff/FiraCode-Bold.woff") format("woff");
40 font-style: bold;
41 font-weight: 700;
42 }}
43
44 .{unique_id}-matrix {{
45 font-family: Fira Code, monospace;
46 font-size: {char_height}px;
47 line-height: {line_height}px;
48 font-variant-east-asian: full-width;
49 }}
50
51 .{unique_id}-title {{
52 font-size: 18px;
53 font-weight: bold;
54 font-family: arial;
55 }}
56
57 {styles}
58 </style>
59
60 <defs>
61 <clipPath id="{unique_id}-clip-terminal">
62 <rect x="0" y="0" width="{terminal_width}" height="{terminal_height}" />
63 </clipPath>
64 {lines}
65 </defs>
66
67 {chrome}
68 <g transform="translate({terminal_x}, {terminal_y})" clip-path="url(#{unique_id}-clip-terminal)">
69 {backgrounds}
70 <g class="{unique_id}-matrix">
71 {matrix}
72 </g>
73 </g>
74 </svg>
75 """
76
77 _SVG_FONT_FAMILY = "Rich Fira Code"
78 _SVG_CLASSES_PREFIX = "rich-svg"
79
[end of rich/_export_format.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/rich/_export_format.py b/rich/_export_format.py
--- a/rich/_export_format.py
+++ b/rich/_export_format.py
@@ -12,9 +12,9 @@
</head>
<html>
<body>
- <code>
- <pre style="font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace">{code}</pre>
- </code>
+ <pre style="font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace">
+ <code>{code}</code>
+ </pre>
</body>
</html>
"""
|
{"golden_diff": "diff --git a/rich/_export_format.py b/rich/_export_format.py\n--- a/rich/_export_format.py\n+++ b/rich/_export_format.py\n@@ -12,9 +12,9 @@\n </head>\n <html>\n <body>\n- <code>\n- <pre style=\"font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace\">{code}</pre>\n- </code>\n+ <pre style=\"font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace\">\n+ <code>{code}</code>\n+ </pre>\n </body>\n </html>\n \"\"\"\n", "issue": "[BUG] export_html leaks style into the page\n**Describe the bug**\r\n\r\nFollowing discussion https://github.com/Textualize/rich/discussions/2640\r\nInjecting HTML generated with Rich's `Console.export_html()` method seems to leak some style into the page.\r\n\r\n\r\n\r\nThe page is built with MkDocs + Material for MkDocs. The dark theme is activated.\r\nThe light theme is less impacted, I just see extra \"bars\" (like an empty code line) in-between block elements:\r\n\r\n\r\n\r\nCode used to generate the HTML:\r\n\r\n```python\r\nimport os\r\n\r\nfrom rich.console import Console\r\n\r\nreport = \"\"\"$ griffe check griffe -ssrc -b0.24.0 -a0.23.0\r\n[bold]src/griffe/loader.py[/]:156: GriffeLoader.resolve_aliases([blue]only_exported[/]): [yellow]Parameter kind was changed[/]: positional or keyword -> keyword-only\r\netc.\r\n\"\"\"\r\n\r\nwith open(os.devnull, \"w\") as devnull:\r\n console = Console(record=True, width=150, file=devnull)\r\n console.print(report, markup=True, highlight=False)\r\nprint(console.export_html(inline_styles=True))\r\n```\r\n\r\nBoth `inline_styles=True` and `inline_styles=False` give the same result.\r\n\r\n**Platform**\r\n<details>\r\n<summary>Click to expand</summary>\r\n\r\nLinux\r\n\r\n```console\r\n$ python -m rich.diagnose\r\n\u256d\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500 <class 'rich.console.Console'> \u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u256e\r\n\u2502 A high level console interface. \u2502\r\n\u2502 \u2502\r\n\u2502 \u256d\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u256e \u2502\r\n\u2502 \u2502 <console width=239 ColorSystem.TRUECOLOR> \u2502 \u2502\r\n\u2502 \u2570\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u256f \u2502\r\n\u2502 \u2502\r\n\u2502 color_system = 'truecolor' \u2502\r\n\u2502 encoding = 'utf-8' \u2502\r\n\u2502 file = <_io.TextIOWrapper name='<stdout>' mode='w' encoding='utf-8'> \u2502\r\n\u2502 height = 58 \u2502\r\n\u2502 is_alt_screen = False \u2502\r\n\u2502 is_dumb_terminal = False \u2502\r\n\u2502 is_interactive = True \u2502\r\n\u2502 is_jupyter = False \u2502\r\n\u2502 is_terminal = True \u2502\r\n\u2502 legacy_windows = False \u2502\r\n\u2502 no_color = False \u2502\r\n\u2502 options = ConsoleOptions( \u2502\r\n\u2502 size=ConsoleDimensions(width=239, height=58), \u2502\r\n\u2502 legacy_windows=False, \u2502\r\n\u2502 min_width=1, \u2502\r\n\u2502 max_width=239, \u2502\r\n\u2502 is_terminal=True, \u2502\r\n\u2502 encoding='utf-8', \u2502\r\n\u2502 max_height=58, \u2502\r\n\u2502 justify=None, \u2502\r\n\u2502 overflow=None, \u2502\r\n\u2502 no_wrap=False, \u2502\r\n\u2502 highlight=None, \u2502\r\n\u2502 markup=None, \u2502\r\n\u2502 height=None \u2502\r\n\u2502 ) \u2502\r\n\u2502 quiet = False \u2502\r\n\u2502 record = False \u2502\r\n\u2502 safe_box = True \u2502\r\n\u2502 size = ConsoleDimensions(width=239, height=58) \u2502\r\n\u2502 soft_wrap = False \u2502\r\n\u2502 stderr = False \u2502\r\n\u2502 style = None \u2502\r\n\u2502 tab_size = 8 \u2502\r\n\u2502 width = 239 \u2502\r\n\u2570\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u256f\r\n\u256d\u2500\u2500\u2500 <class 'rich._windows.WindowsConsoleFeatures'> \u2500\u2500\u2500\u2500\u256e\r\n\u2502 Windows features available. \u2502\r\n\u2502 \u2502\r\n\u2502 \u256d\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u256e \u2502\r\n\u2502 \u2502 WindowsConsoleFeatures(vt=False, truecolor=False) \u2502 \u2502\r\n\u2502 \u2570\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u256f \u2502\r\n\u2502 \u2502\r\n\u2502 truecolor = False \u2502\r\n\u2502 vt = False \u2502\r\n\u2570\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u256f\r\n\u256d\u2500\u2500\u2500\u2500\u2500\u2500 Environment Variables \u2500\u2500\u2500\u2500\u2500\u2500\u2500\u256e\r\n\u2502 { \u2502\r\n\u2502 'TERM': 'xterm-256color', \u2502\r\n\u2502 'COLORTERM': 'truecolor', \u2502\r\n\u2502 'CLICOLOR': None, \u2502\r\n\u2502 'NO_COLOR': None, \u2502\r\n\u2502 'TERM_PROGRAM': None, \u2502\r\n\u2502 'COLUMNS': None, \u2502\r\n\u2502 'LINES': None, \u2502\r\n\u2502 'JUPYTER_COLUMNS': None, \u2502\r\n\u2502 'JUPYTER_LINES': None, \u2502\r\n\u2502 'JPY_PARENT_PID': None, \u2502\r\n\u2502 'VSCODE_VERBOSE_LOGGING': None \u2502\r\n\u2502 } \u2502\r\n\u2570\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u256f\r\nplatform=\"Linux\"\r\n```\r\n\r\n```console\r\n% pdm list --freeze | grep rich\r\nrich==12.6.0\r\n```\r\n\r\n</details>\r\n\n", "before_files": [{"content": "CONSOLE_HTML_FORMAT = \"\"\"\\\n<!DOCTYPE html>\n<head>\n<meta charset=\"UTF-8\">\n<style>\n{stylesheet}\nbody {{\n color: {foreground};\n background-color: {background};\n}}\n</style>\n</head>\n<html>\n<body>\n <code>\n <pre style=\"font-family:Menlo,'DejaVu Sans Mono',consolas,'Courier New',monospace\">{code}</pre>\n </code>\n</body>\n</html>\n\"\"\"\n\nCONSOLE_SVG_FORMAT = \"\"\"\\\n<svg class=\"rich-terminal\" viewBox=\"0 0 {width} {height}\" xmlns=\"http://www.w3.org/2000/svg\">\n <!-- Generated with Rich https://www.textualize.io -->\n <style>\n\n @font-face {{\n font-family: \"Fira Code\";\n src: local(\"FiraCode-Regular\"),\n url(\"https://cdnjs.cloudflare.com/ajax/libs/firacode/6.2.0/woff2/FiraCode-Regular.woff2\") format(\"woff2\"),\n url(\"https://cdnjs.cloudflare.com/ajax/libs/firacode/6.2.0/woff/FiraCode-Regular.woff\") format(\"woff\");\n font-style: normal;\n font-weight: 400;\n }}\n @font-face {{\n font-family: \"Fira Code\";\n src: local(\"FiraCode-Bold\"),\n url(\"https://cdnjs.cloudflare.com/ajax/libs/firacode/6.2.0/woff2/FiraCode-Bold.woff2\") format(\"woff2\"),\n url(\"https://cdnjs.cloudflare.com/ajax/libs/firacode/6.2.0/woff/FiraCode-Bold.woff\") format(\"woff\");\n font-style: bold;\n font-weight: 700;\n }}\n\n .{unique_id}-matrix {{\n font-family: Fira Code, monospace;\n font-size: {char_height}px;\n line-height: {line_height}px;\n font-variant-east-asian: full-width;\n }}\n\n .{unique_id}-title {{\n font-size: 18px;\n font-weight: bold;\n font-family: arial;\n }}\n\n {styles}\n </style>\n\n <defs>\n <clipPath id=\"{unique_id}-clip-terminal\">\n <rect x=\"0\" y=\"0\" width=\"{terminal_width}\" height=\"{terminal_height}\" />\n </clipPath>\n {lines}\n </defs>\n\n {chrome}\n <g transform=\"translate({terminal_x}, {terminal_y})\" clip-path=\"url(#{unique_id}-clip-terminal)\">\n {backgrounds}\n <g class=\"{unique_id}-matrix\">\n {matrix}\n </g>\n </g>\n</svg>\n\"\"\"\n\n_SVG_FONT_FAMILY = \"Rich Fira Code\"\n_SVG_CLASSES_PREFIX = \"rich-svg\"\n", "path": "rich/_export_format.py"}]}
| 2,498 | 146 |
gh_patches_debug_12705
|
rasdani/github-patches
|
git_diff
|
Lightning-Universe__lightning-bolts-315
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
add caching for used dataset
## 🚀 Feature
atm for each CI run the datasets are downloaded (seems so as I observed som downloading failers)
### Motivation
Speed-up runs and avoids random connection failers
</issue>
<code>
[start of pl_bolts/models/mnist_module.py]
1 import os
2 from argparse import ArgumentParser
3 from warnings import warn
4
5 import torch
6 from pytorch_lightning import LightningModule, Trainer
7 from torch.nn import functional as F
8 from torch.utils.data import DataLoader, random_split
9
10 try:
11 from torchvision import transforms
12 from torchvision.datasets import MNIST
13 except ModuleNotFoundError:
14 warn('You want to use `torchvision` which is not installed yet,' # pragma: no-cover
15 ' install it with `pip install torchvision`.')
16
17
18 class LitMNIST(LightningModule):
19 def __init__(self, hidden_dim=128, learning_rate=1e-3, batch_size=32, num_workers=4, data_dir='', **kwargs):
20 super().__init__()
21 self.save_hyperparameters()
22
23 self.l1 = torch.nn.Linear(28 * 28, self.hparams.hidden_dim)
24 self.l2 = torch.nn.Linear(self.hparams.hidden_dim, 10)
25
26 self.mnist_train = None
27 self.mnist_val = None
28
29 def forward(self, x):
30 x = x.view(x.size(0), -1)
31 x = torch.relu(self.l1(x))
32 x = torch.relu(self.l2(x))
33 return x
34
35 def training_step(self, batch, batch_idx):
36 x, y = batch
37 y_hat = self(x)
38 loss = F.cross_entropy(y_hat, y)
39 self.log('train_loss', loss)
40 return loss
41
42 def validation_step(self, batch, batch_idx):
43 x, y = batch
44 y_hat = self(x)
45 loss = F.cross_entropy(y_hat, y)
46 self.log('val_loss', loss)
47
48 def test_step(self, batch, batch_idx):
49 x, y = batch
50 y_hat = self(x)
51 loss = F.cross_entropy(y_hat, y)
52 self.log('test_loss', loss)
53
54 def configure_optimizers(self):
55 return torch.optim.Adam(self.parameters(), lr=self.hparams.learning_rate)
56
57 def prepare_data(self):
58 MNIST(self.hparams.data_dir, train=True, download=True, transform=transforms.ToTensor())
59
60 def train_dataloader(self):
61 dataset = MNIST(self.hparams.data_dir, train=True, download=False, transform=transforms.ToTensor())
62 mnist_train, _ = random_split(dataset, [55000, 5000])
63 loader = DataLoader(mnist_train, batch_size=self.hparams.batch_size, num_workers=self.hparams.num_workers)
64 return loader
65
66 def val_dataloader(self):
67 dataset = MNIST(self.hparams.data_dir, train=True, download=False, transform=transforms.ToTensor())
68 _, mnist_val = random_split(dataset, [55000, 5000])
69 loader = DataLoader(mnist_val, batch_size=self.hparams.batch_size, num_workers=self.hparams.num_workers)
70 return loader
71
72 def test_dataloader(self):
73 test_dataset = MNIST(os.getcwd(), train=False, download=True, transform=transforms.ToTensor())
74 loader = DataLoader(test_dataset, batch_size=self.hparams.batch_size, num_workers=self.hparams.num_workers)
75 return loader
76
77 @staticmethod
78 def add_model_specific_args(parent_parser):
79 parser = ArgumentParser(parents=[parent_parser], add_help=False)
80 parser.add_argument('--batch_size', type=int, default=32)
81 parser.add_argument('--num_workers', type=int, default=4)
82 parser.add_argument('--hidden_dim', type=int, default=128)
83 parser.add_argument('--data_dir', type=str, default='')
84 parser.add_argument('--learning_rate', type=float, default=0.0001)
85 return parser
86
87
88 def cli_main():
89 # args
90 parser = ArgumentParser()
91 parser = Trainer.add_argparse_args(parser)
92 parser = LitMNIST.add_model_specific_args(parser)
93 args = parser.parse_args()
94
95 # model
96 model = LitMNIST(**vars(args))
97
98 # training
99 trainer = Trainer.from_argparse_args(args)
100 trainer.fit(model)
101
102
103 if __name__ == '__main__': # pragma: no cover
104 cli_main()
105
[end of pl_bolts/models/mnist_module.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pl_bolts/models/mnist_module.py b/pl_bolts/models/mnist_module.py
--- a/pl_bolts/models/mnist_module.py
+++ b/pl_bolts/models/mnist_module.py
@@ -1,4 +1,3 @@
-import os
from argparse import ArgumentParser
from warnings import warn
@@ -70,7 +69,7 @@
return loader
def test_dataloader(self):
- test_dataset = MNIST(os.getcwd(), train=False, download=True, transform=transforms.ToTensor())
+ test_dataset = MNIST(self.hparams.data_dir, train=False, download=True, transform=transforms.ToTensor())
loader = DataLoader(test_dataset, batch_size=self.hparams.batch_size, num_workers=self.hparams.num_workers)
return loader
|
{"golden_diff": "diff --git a/pl_bolts/models/mnist_module.py b/pl_bolts/models/mnist_module.py\n--- a/pl_bolts/models/mnist_module.py\n+++ b/pl_bolts/models/mnist_module.py\n@@ -1,4 +1,3 @@\n-import os\n from argparse import ArgumentParser\n from warnings import warn\n \n@@ -70,7 +69,7 @@\n return loader\n \n def test_dataloader(self):\n- test_dataset = MNIST(os.getcwd(), train=False, download=True, transform=transforms.ToTensor())\n+ test_dataset = MNIST(self.hparams.data_dir, train=False, download=True, transform=transforms.ToTensor())\n loader = DataLoader(test_dataset, batch_size=self.hparams.batch_size, num_workers=self.hparams.num_workers)\n return loader\n", "issue": "add caching for used dataset\n## \ud83d\ude80 Feature\r\n\r\natm for each CI run the datasets are downloaded (seems so as I observed som downloading failers)\r\n\r\n### Motivation\r\n\r\nSpeed-up runs and avoids random connection failers\r\n\n", "before_files": [{"content": "import os\nfrom argparse import ArgumentParser\nfrom warnings import warn\n\nimport torch\nfrom pytorch_lightning import LightningModule, Trainer\nfrom torch.nn import functional as F\nfrom torch.utils.data import DataLoader, random_split\n\ntry:\n from torchvision import transforms\n from torchvision.datasets import MNIST\nexcept ModuleNotFoundError:\n warn('You want to use `torchvision` which is not installed yet,' # pragma: no-cover\n ' install it with `pip install torchvision`.')\n\n\nclass LitMNIST(LightningModule):\n def __init__(self, hidden_dim=128, learning_rate=1e-3, batch_size=32, num_workers=4, data_dir='', **kwargs):\n super().__init__()\n self.save_hyperparameters()\n\n self.l1 = torch.nn.Linear(28 * 28, self.hparams.hidden_dim)\n self.l2 = torch.nn.Linear(self.hparams.hidden_dim, 10)\n\n self.mnist_train = None\n self.mnist_val = None\n\n def forward(self, x):\n x = x.view(x.size(0), -1)\n x = torch.relu(self.l1(x))\n x = torch.relu(self.l2(x))\n return x\n\n def training_step(self, batch, batch_idx):\n x, y = batch\n y_hat = self(x)\n loss = F.cross_entropy(y_hat, y)\n self.log('train_loss', loss)\n return loss\n\n def validation_step(self, batch, batch_idx):\n x, y = batch\n y_hat = self(x)\n loss = F.cross_entropy(y_hat, y)\n self.log('val_loss', loss)\n\n def test_step(self, batch, batch_idx):\n x, y = batch\n y_hat = self(x)\n loss = F.cross_entropy(y_hat, y)\n self.log('test_loss', loss)\n\n def configure_optimizers(self):\n return torch.optim.Adam(self.parameters(), lr=self.hparams.learning_rate)\n\n def prepare_data(self):\n MNIST(self.hparams.data_dir, train=True, download=True, transform=transforms.ToTensor())\n\n def train_dataloader(self):\n dataset = MNIST(self.hparams.data_dir, train=True, download=False, transform=transforms.ToTensor())\n mnist_train, _ = random_split(dataset, [55000, 5000])\n loader = DataLoader(mnist_train, batch_size=self.hparams.batch_size, num_workers=self.hparams.num_workers)\n return loader\n\n def val_dataloader(self):\n dataset = MNIST(self.hparams.data_dir, train=True, download=False, transform=transforms.ToTensor())\n _, mnist_val = random_split(dataset, [55000, 5000])\n loader = DataLoader(mnist_val, batch_size=self.hparams.batch_size, num_workers=self.hparams.num_workers)\n return loader\n\n def test_dataloader(self):\n test_dataset = MNIST(os.getcwd(), train=False, download=True, transform=transforms.ToTensor())\n loader = DataLoader(test_dataset, batch_size=self.hparams.batch_size, num_workers=self.hparams.num_workers)\n return loader\n\n @staticmethod\n def add_model_specific_args(parent_parser):\n parser = ArgumentParser(parents=[parent_parser], add_help=False)\n parser.add_argument('--batch_size', type=int, default=32)\n parser.add_argument('--num_workers', type=int, default=4)\n parser.add_argument('--hidden_dim', type=int, default=128)\n parser.add_argument('--data_dir', type=str, default='')\n parser.add_argument('--learning_rate', type=float, default=0.0001)\n return parser\n\n\ndef cli_main():\n # args\n parser = ArgumentParser()\n parser = Trainer.add_argparse_args(parser)\n parser = LitMNIST.add_model_specific_args(parser)\n args = parser.parse_args()\n\n # model\n model = LitMNIST(**vars(args))\n\n # training\n trainer = Trainer.from_argparse_args(args)\n trainer.fit(model)\n\n\nif __name__ == '__main__': # pragma: no cover\n cli_main()\n", "path": "pl_bolts/models/mnist_module.py"}]}
| 1,695 | 169 |
gh_patches_debug_5031
|
rasdani/github-patches
|
git_diff
|
svthalia__concrexit-2190
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Visual quirk in the login failure message
### Describe the bug
When you fail to log in on desktop (or probably any wider screen) the message saying this shows up on the left and the login fields are offset to the right. I would expect the message to appear on top, while the login fields were to stay in the same horizontal position.
### How to reproduce
Steps to reproduce the behaviour:
1. Go to the login page
2. Enter invalid credentials
### Expected behaviour
The login fields do not move to the right. The error message is either shown above the login fields or next to them.
### Screenshots

### Additional context
Not sure in what other situations these message boxes are used, but it may occur in other places too. Haven't checked.
</issue>
<code>
[start of website/thaliawebsite/templatetags/alert.py]
1 from django import template
2
3 register = template.Library()
4
5
6 @register.inclusion_tag("includes/alert.html")
7 def alert(alert_type="info", message=None, dismissible=False, extra_classes=""):
8 if dismissible:
9 extra_classes += " alert-dimissable"
10 return {
11 "type": alert_type,
12 "message": message,
13 "dismissible": dismissible,
14 "extra_classes": extra_classes,
15 }
16
[end of website/thaliawebsite/templatetags/alert.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/website/thaliawebsite/templatetags/alert.py b/website/thaliawebsite/templatetags/alert.py
--- a/website/thaliawebsite/templatetags/alert.py
+++ b/website/thaliawebsite/templatetags/alert.py
@@ -6,7 +6,7 @@
@register.inclusion_tag("includes/alert.html")
def alert(alert_type="info", message=None, dismissible=False, extra_classes=""):
if dismissible:
- extra_classes += " alert-dimissable"
+ extra_classes += " alert-dismissible"
return {
"type": alert_type,
"message": message,
|
{"golden_diff": "diff --git a/website/thaliawebsite/templatetags/alert.py b/website/thaliawebsite/templatetags/alert.py\n--- a/website/thaliawebsite/templatetags/alert.py\n+++ b/website/thaliawebsite/templatetags/alert.py\n@@ -6,7 +6,7 @@\n @register.inclusion_tag(\"includes/alert.html\")\n def alert(alert_type=\"info\", message=None, dismissible=False, extra_classes=\"\"):\n if dismissible:\n- extra_classes += \" alert-dimissable\"\n+ extra_classes += \" alert-dismissible\"\n return {\n \"type\": alert_type,\n \"message\": message,\n", "issue": "Visual quirk in the login failure message\n### Describe the bug\r\nWhen you fail to log in on desktop (or probably any wider screen) the message saying this shows up on the left and the login fields are offset to the right. I would expect the message to appear on top, while the login fields were to stay in the same horizontal position.\r\n\r\n### How to reproduce\r\nSteps to reproduce the behaviour:\r\n1. Go to the login page\r\n2. Enter invalid credentials\r\n\r\n### Expected behaviour\r\nThe login fields do not move to the right. The error message is either shown above the login fields or next to them.\r\n\r\n### Screenshots\r\n\r\n\r\n\r\n### Additional context\r\nNot sure in what other situations these message boxes are used, but it may occur in other places too. Haven't checked.\r\n\n", "before_files": [{"content": "from django import template\n\nregister = template.Library()\n\n\[email protected]_tag(\"includes/alert.html\")\ndef alert(alert_type=\"info\", message=None, dismissible=False, extra_classes=\"\"):\n if dismissible:\n extra_classes += \" alert-dimissable\"\n return {\n \"type\": alert_type,\n \"message\": message,\n \"dismissible\": dismissible,\n \"extra_classes\": extra_classes,\n }\n", "path": "website/thaliawebsite/templatetags/alert.py"}]}
| 904 | 144 |
gh_patches_debug_25902
|
rasdani/github-patches
|
git_diff
|
psychopy__psychopy-4533
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
uninstall: cannot change path
Hello,
the current uninst.exe is fixed to the path C:\Program Files\PsychoPy3,
which makes it impossible to uninstall an old version in another fold or disk.
Best
PJ
</issue>
<code>
[start of psychopy/__init__.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3
4 # Part of the PsychoPy library
5 # Copyright (C) 2002-2018 Jonathan Peirce (C) 2019-2021 Open Science Tools Ltd.
6 # Distributed under the terms of the GNU General Public License (GPL).
7
8 # --------------------------------------------------------------------------
9 # This file is automatically generated during build (do not edit directly).
10 # --------------------------------------------------------------------------
11
12 import os
13 import sys
14
15 __version__ = '2022.1.0rc5'
16 __license__ = 'GNU GPLv3 (or more recent equivalent)'
17 __author__ = 'Jonathan Peirce'
18 __author_email__ = '[email protected]'
19 __maintainer_email__ = '[email protected]'
20 __url__ = 'https://www.psychopy.org/'
21 __download_url__ = 'https://github.com/psychopy/psychopy/releases/'
22 __git_sha__ = 'n/a'
23 __build_platform__ = 'n/a'
24
25 __all__ = ["gui", "misc", "visual", "core",
26 "event", "data", "sound", "microphone"]
27
28 # for developers the following allows access to the current git sha from
29 # their repository
30 if __git_sha__ == 'n/a':
31 from subprocess import check_output, PIPE
32 # see if we're in a git repo and fetch from there
33 try:
34 thisFileLoc = os.path.split(__file__)[0]
35 output = check_output(['git', 'rev-parse', '--short', 'HEAD'],
36 cwd=thisFileLoc, stderr=PIPE)
37 except Exception:
38 output = False
39 if output:
40 __git_sha__ = output.strip() # remove final linefeed
41
42 # update preferences and the user paths
43 if 'installing' not in locals():
44 from psychopy.preferences import prefs
45 for pathName in prefs.general['paths']:
46 sys.path.append(pathName)
47
48 from psychopy.tools.versionchooser import useVersion, ensureMinimal
49
50 if sys.version_info.major < 3:
51 raise ImportError("psychopy does not support Python2 installations. "
52 "The last version to support Python2.7 was PsychoPy "
53 "2021.2.x")
54
55 # import readline here to get around an issue with sounddevice
56 # issues GH-2230 GH-2344 GH-2662
57 try:
58 import readline
59 except ImportError:
60 pass # all that will happen is the stderr/stdout might get redirected
61
62
[end of psychopy/__init__.py]
[start of setupApp.py]
1 #!/usr/bin/env python
2 ################
3 # see notes at bottom for requirements
4
5 import glob
6 import os
7 import sys
8 from sys import platform
9 from distutils.core import setup
10 from pkg_resources import parse_version
11 # import versioneer
12 import psychopy
13 version = psychopy.__version__
14
15 # regenerate __init__.py only if we're in the source repos (not in a zip file)
16 try:
17 from building import createInitFile # won't exist in a sdist.zip
18 writeNewInit=True
19 except:
20 writeNewInit=False
21 if writeNewInit:
22 vStr = createInitFile.createInitFile(dist='bdist')
23
24 #define the extensions to compile if necess
25 packageData = []
26 requires = []
27
28 if platform != 'darwin':
29 raise RuntimeError("setupApp.py is only for building Mac Standalone bundle")
30
31 import bdist_mpkg
32 import py2app
33 resources = glob.glob('psychopy/app/Resources/*')
34 frameworks = [ # these installed using homebrew
35 "/usr/local/opt/libevent/lib/libevent.dylib",
36 "/usr/local/opt/lame/lib/libmp3lame.0.dylib",
37 "/usr/local/opt/libffi/lib/libffi.dylib",
38 "/usr/local/opt/libglfw/lib/libglfw.3.2.dylib",
39 ]
40 opencvLibs = glob.glob(os.path.join(sys.exec_prefix, 'lib', 'libopencv*.2.4.dylib'))
41 frameworks.extend(opencvLibs)
42
43 import macholib
44 #print("~"*60 + "macholib version: "+macholib.__version__)
45
46 if parse_version(macholib.__version__) <= parse_version('1.7'):
47 print("Applying macholib patch...")
48 import macholib.dyld
49 import macholib.MachOGraph
50 dyld_find_1_7 = macholib.dyld.dyld_find
51 def dyld_find(name, loader=None, **kwargs):
52 #print("~"*60 + "calling alternate dyld_find")
53 if loader is not None:
54 kwargs['loader_path'] = loader
55 return dyld_find_1_7(name, **kwargs)
56 macholib.MachOGraph.dyld_find = dyld_find
57
58 includes = ['Tkinter', 'tkFileDialog',
59 'imp', 'subprocess', 'shlex',
60 'shelve', # for scipy.io
61 '_elementtree', 'pyexpat', # for openpyxl
62 'hid',
63 'pyo', 'greenlet', 'zmq', 'tornado',
64 'psutil', # for iohub
65 'tobii_research', # need tobii_research file and tobiiresearch pkg
66 'pysoundcard', 'soundfile', 'sounddevice', 'readline',
67 'hid',
68 'xlwt', # writes excel files for pandas
69 'vlc', # install with pip install python-vlc
70 'msgpack_numpy',
71 'configparser',
72 ]
73 packages = ['wx', 'psychopy',
74 'pyglet', 'pytz', 'OpenGL', 'glfw',
75 'scipy', 'matplotlib', 'openpyxl',
76 'xml', 'xmlschema', 'elementpath',
77 'moviepy', 'imageio', 'imageio_ffmpeg',
78 '_sounddevice_data', '_soundfile_data',
79 'cffi', 'pycparser',
80 'PIL', # 'Image',
81 'objc', 'Quartz', 'AppKit', 'QTKit', 'Cocoa',
82 'Foundation', 'CoreFoundation',
83 'pkg_resources', # needed for objc
84 'pyo',
85 'requests', 'certifi', 'cryptography',
86 # for unit testing
87 'coverage',
88 # handy external science libs
89 'serial',
90 'egi', 'pylink', 'tobiiresearch',
91 'pyxid2', 'ftd2xx', # ftd2xx is used by cedrus
92 'pandas', 'tables', # 'cython',
93 'msgpack', 'yaml', 'gevent', # for ioHub
94 # these aren't needed, but liked
95 'bidi', 'arabic_reshaper', # for right-left language conversions
96 # for Py3 compatibility
97 'ujson', # faster than built-in json
98 'json_tricks', # allows saving arrays/dates in json
99 'git', 'gitlab',
100 'astunparse', 'esprima', # for translating/adapting py/JS
101 'pylsl', 'pygaze',
102 'smite', # https://github.com/marcus-nystrom/SMITE (not pypi!)
103 'cv2',
104 'badapted', 'darc_toolbox', # adaptive methods from Ben Vincent
105 'questplus',
106 'metapensiero.pj', 'dukpy', 'macropy',
107 'jedi', 'parso',
108 'psychtoolbox',
109 'freetype', 'h5py',
110 'markdown_it',
111 'speech_recognition', 'googleapiclient', 'pocketsphinx',
112 'six', # needed by configobj
113 'PyQt5',
114 ]
115
116 setup(
117 app=['psychopy/app/psychopyApp.py'],
118 options=dict(py2app=dict(
119 includes=includes,
120 packages=packages,
121 excludes=['bsddb', 'jinja2', 'IPython','ipython_genutils','nbconvert',
122 'libsz.2.dylib', 'pygame',
123 # 'stringprep',
124 'functools32',
125 ], # anything we need to forcibly exclude?
126 resources=resources,
127 argv_emulation=False, # must be False or app bundle pauses (py2app 0.21 and 0.24 tested)
128 site_packages=True,
129 frameworks=frameworks,
130 iconfile='psychopy/app/Resources/psychopy.icns',
131 plist=dict(
132 CFBundleIconFile='psychopy.icns',
133 CFBundleName = "PsychoPy",
134 CFBundleShortVersionString = version, # must be in X.X.X format
135 CFBundleVersion = version,
136 CFBundleExecutable = "PsychoPy",
137 CFBundleIdentifier = "org.opensciencetools.psychopy",
138 CFBundleLicense = "GNU GPLv3+",
139 NSHumanReadableCopyright = "Open Science Tools Limited",
140 CFBundleDocumentTypes=[dict(CFBundleTypeExtensions=['*'],
141 CFBundleTypeRole='Editor')],
142 LSEnvironment=dict(PATH="/usr/local/git/bin:/usr/local/bin:"
143 "/usr/local:/usr/bin:/usr/sbin"),
144 ),
145 )) # end of the options dict
146 )
147
148
149 # ugly hack for opencv2:
150 # As of opencv 2.4.5 the cv2.so binary used rpath to a fixed
151 # location to find libs and even more annoyingly it then appended
152 # 'lib' to the rpath as well. These were fine for the packaged
153 # framework python but the libs in an app bundle are different.
154 # So, create symlinks so they appear in the same place as in framework python
155 rpath = "dist/PsychoPy.app/Contents/Resources/"
156 for libPath in opencvLibs:
157 libname = os.path.split(libPath)[-1]
158 realPath = "../../Frameworks/"+libname # relative path (w.r.t. the fake)
159 fakePath = os.path.join(rpath, "lib", libname)
160 os.symlink(realPath, fakePath)
161 # they even did this for Python lib itself, which is in diff location
162 realPath = "../Frameworks/Python.framework/Python" # relative to the fake path
163 fakePath = os.path.join(rpath, "Python")
164 os.symlink(realPath, fakePath)
165
166 if writeNewInit:
167 # remove unwanted info about this system post-build
168 createInitFile.createInitFile(dist=None)
169
[end of setupApp.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/psychopy/__init__.py b/psychopy/__init__.py
--- a/psychopy/__init__.py
+++ b/psychopy/__init__.py
@@ -12,7 +12,7 @@
import os
import sys
-__version__ = '2022.1.0rc5'
+__version__ = '2022.1.0rc7'
__license__ = 'GNU GPLv3 (or more recent equivalent)'
__author__ = 'Jonathan Peirce'
__author_email__ = '[email protected]'
diff --git a/setupApp.py b/setupApp.py
--- a/setupApp.py
+++ b/setupApp.py
@@ -6,9 +6,12 @@
import os
import sys
from sys import platform
+import setuptools # noqa: setuptools complains if it isn't implicitly imported before distutils
from distutils.core import setup
from pkg_resources import parse_version
-# import versioneer
+import bdist_mpkg # noqa: needed to build bdist, even though not explicitly used here
+import py2app # noqa: needed to build app bundle, even though not explicitly used here
+
import psychopy
version = psychopy.__version__
@@ -28,8 +31,6 @@
if platform != 'darwin':
raise RuntimeError("setupApp.py is only for building Mac Standalone bundle")
-import bdist_mpkg
-import py2app
resources = glob.glob('psychopy/app/Resources/*')
frameworks = [ # these installed using homebrew
"/usr/local/opt/libevent/lib/libevent.dylib",
|
{"golden_diff": "diff --git a/psychopy/__init__.py b/psychopy/__init__.py\n--- a/psychopy/__init__.py\n+++ b/psychopy/__init__.py\n@@ -12,7 +12,7 @@\n import os\n import sys\n \n-__version__ = '2022.1.0rc5'\n+__version__ = '2022.1.0rc7'\n __license__ = 'GNU GPLv3 (or more recent equivalent)'\n __author__ = 'Jonathan Peirce'\n __author_email__ = '[email protected]'\ndiff --git a/setupApp.py b/setupApp.py\n--- a/setupApp.py\n+++ b/setupApp.py\n@@ -6,9 +6,12 @@\n import os\n import sys\n from sys import platform\n+import setuptools # noqa: setuptools complains if it isn't implicitly imported before distutils\n from distutils.core import setup\n from pkg_resources import parse_version\n-# import versioneer\n+import bdist_mpkg # noqa: needed to build bdist, even though not explicitly used here\n+import py2app # noqa: needed to build app bundle, even though not explicitly used here\n+\n import psychopy\n version = psychopy.__version__\n \n@@ -28,8 +31,6 @@\n if platform != 'darwin':\n raise RuntimeError(\"setupApp.py is only for building Mac Standalone bundle\")\n \n-import bdist_mpkg\n-import py2app\n resources = glob.glob('psychopy/app/Resources/*')\n frameworks = [ # these installed using homebrew\n \"/usr/local/opt/libevent/lib/libevent.dylib\",\n", "issue": "uninstall: cannot change path\nHello,\r\nthe current uninst.exe is fixed to the path C:\\Program Files\\PsychoPy3,\r\nwhich makes it impossible to uninstall an old version in another fold or disk.\r\nBest\r\nPJ\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n# Part of the PsychoPy library\n# Copyright (C) 2002-2018 Jonathan Peirce (C) 2019-2021 Open Science Tools Ltd.\n# Distributed under the terms of the GNU General Public License (GPL).\n\n# --------------------------------------------------------------------------\n# This file is automatically generated during build (do not edit directly).\n# --------------------------------------------------------------------------\n\nimport os\nimport sys\n\n__version__ = '2022.1.0rc5'\n__license__ = 'GNU GPLv3 (or more recent equivalent)'\n__author__ = 'Jonathan Peirce'\n__author_email__ = '[email protected]'\n__maintainer_email__ = '[email protected]'\n__url__ = 'https://www.psychopy.org/'\n__download_url__ = 'https://github.com/psychopy/psychopy/releases/'\n__git_sha__ = 'n/a'\n__build_platform__ = 'n/a'\n\n__all__ = [\"gui\", \"misc\", \"visual\", \"core\",\n \"event\", \"data\", \"sound\", \"microphone\"]\n\n# for developers the following allows access to the current git sha from\n# their repository\nif __git_sha__ == 'n/a':\n from subprocess import check_output, PIPE\n # see if we're in a git repo and fetch from there\n try:\n thisFileLoc = os.path.split(__file__)[0]\n output = check_output(['git', 'rev-parse', '--short', 'HEAD'],\n cwd=thisFileLoc, stderr=PIPE)\n except Exception:\n output = False\n if output:\n __git_sha__ = output.strip() # remove final linefeed\n\n# update preferences and the user paths\nif 'installing' not in locals():\n from psychopy.preferences import prefs\n for pathName in prefs.general['paths']:\n sys.path.append(pathName)\n\n from psychopy.tools.versionchooser import useVersion, ensureMinimal\n\nif sys.version_info.major < 3:\n raise ImportError(\"psychopy does not support Python2 installations. \"\n \"The last version to support Python2.7 was PsychoPy \"\n \"2021.2.x\")\n\n# import readline here to get around an issue with sounddevice\n# issues GH-2230 GH-2344 GH-2662\ntry:\n import readline\nexcept ImportError:\n pass # all that will happen is the stderr/stdout might get redirected\n\n", "path": "psychopy/__init__.py"}, {"content": "#!/usr/bin/env python\n################\n# see notes at bottom for requirements\n\nimport glob\nimport os\nimport sys\nfrom sys import platform\nfrom distutils.core import setup\nfrom pkg_resources import parse_version\n# import versioneer\nimport psychopy\nversion = psychopy.__version__\n\n# regenerate __init__.py only if we're in the source repos (not in a zip file)\ntry:\n from building import createInitFile # won't exist in a sdist.zip\n writeNewInit=True\nexcept:\n writeNewInit=False\nif writeNewInit:\n vStr = createInitFile.createInitFile(dist='bdist')\n\n#define the extensions to compile if necess\npackageData = []\nrequires = []\n\nif platform != 'darwin':\n raise RuntimeError(\"setupApp.py is only for building Mac Standalone bundle\")\n\nimport bdist_mpkg\nimport py2app\nresources = glob.glob('psychopy/app/Resources/*')\nframeworks = [ # these installed using homebrew\n \"/usr/local/opt/libevent/lib/libevent.dylib\", \n \"/usr/local/opt/lame/lib/libmp3lame.0.dylib\",\n \"/usr/local/opt/libffi/lib/libffi.dylib\",\n \"/usr/local/opt/libglfw/lib/libglfw.3.2.dylib\",\n ]\nopencvLibs = glob.glob(os.path.join(sys.exec_prefix, 'lib', 'libopencv*.2.4.dylib'))\nframeworks.extend(opencvLibs)\n\nimport macholib\n#print(\"~\"*60 + \"macholib version: \"+macholib.__version__)\n\nif parse_version(macholib.__version__) <= parse_version('1.7'):\n print(\"Applying macholib patch...\")\n import macholib.dyld\n import macholib.MachOGraph\n dyld_find_1_7 = macholib.dyld.dyld_find\n def dyld_find(name, loader=None, **kwargs):\n #print(\"~\"*60 + \"calling alternate dyld_find\")\n if loader is not None:\n kwargs['loader_path'] = loader\n return dyld_find_1_7(name, **kwargs)\n macholib.MachOGraph.dyld_find = dyld_find\n\nincludes = ['Tkinter', 'tkFileDialog',\n 'imp', 'subprocess', 'shlex',\n 'shelve', # for scipy.io\n '_elementtree', 'pyexpat', # for openpyxl\n 'hid',\n 'pyo', 'greenlet', 'zmq', 'tornado',\n 'psutil', # for iohub\n 'tobii_research', # need tobii_research file and tobiiresearch pkg\n 'pysoundcard', 'soundfile', 'sounddevice', 'readline',\n 'hid',\n 'xlwt', # writes excel files for pandas\n 'vlc', # install with pip install python-vlc\n 'msgpack_numpy',\n 'configparser',\n ]\npackages = ['wx', 'psychopy',\n 'pyglet', 'pytz', 'OpenGL', 'glfw',\n 'scipy', 'matplotlib', 'openpyxl',\n 'xml', 'xmlschema', 'elementpath',\n 'moviepy', 'imageio', 'imageio_ffmpeg',\n '_sounddevice_data', '_soundfile_data',\n 'cffi', 'pycparser',\n 'PIL', # 'Image',\n 'objc', 'Quartz', 'AppKit', 'QTKit', 'Cocoa',\n 'Foundation', 'CoreFoundation',\n 'pkg_resources', # needed for objc\n 'pyo',\n 'requests', 'certifi', 'cryptography',\n # for unit testing\n 'coverage',\n # handy external science libs\n 'serial',\n 'egi', 'pylink', 'tobiiresearch',\n 'pyxid2', 'ftd2xx', # ftd2xx is used by cedrus\n 'pandas', 'tables', # 'cython',\n 'msgpack', 'yaml', 'gevent', # for ioHub\n # these aren't needed, but liked\n 'bidi', 'arabic_reshaper', # for right-left language conversions\n # for Py3 compatibility\n 'ujson', # faster than built-in json\n 'json_tricks', # allows saving arrays/dates in json\n 'git', 'gitlab',\n 'astunparse', 'esprima', # for translating/adapting py/JS\n 'pylsl', 'pygaze',\n 'smite', # https://github.com/marcus-nystrom/SMITE (not pypi!)\n 'cv2',\n 'badapted', 'darc_toolbox', # adaptive methods from Ben Vincent\n 'questplus',\n 'metapensiero.pj', 'dukpy', 'macropy',\n 'jedi', 'parso',\n 'psychtoolbox',\n 'freetype', 'h5py',\n 'markdown_it',\n 'speech_recognition', 'googleapiclient', 'pocketsphinx',\n 'six', # needed by configobj\n 'PyQt5',\n ]\n\nsetup(\n app=['psychopy/app/psychopyApp.py'],\n options=dict(py2app=dict(\n includes=includes,\n packages=packages,\n excludes=['bsddb', 'jinja2', 'IPython','ipython_genutils','nbconvert',\n 'libsz.2.dylib', 'pygame',\n # 'stringprep',\n 'functools32',\n ], # anything we need to forcibly exclude?\n resources=resources,\n argv_emulation=False, # must be False or app bundle pauses (py2app 0.21 and 0.24 tested)\n site_packages=True,\n frameworks=frameworks,\n iconfile='psychopy/app/Resources/psychopy.icns',\n plist=dict(\n CFBundleIconFile='psychopy.icns',\n CFBundleName = \"PsychoPy\",\n CFBundleShortVersionString = version, # must be in X.X.X format\n CFBundleVersion = version,\n CFBundleExecutable = \"PsychoPy\",\n CFBundleIdentifier = \"org.opensciencetools.psychopy\",\n CFBundleLicense = \"GNU GPLv3+\",\n NSHumanReadableCopyright = \"Open Science Tools Limited\",\n CFBundleDocumentTypes=[dict(CFBundleTypeExtensions=['*'],\n CFBundleTypeRole='Editor')],\n LSEnvironment=dict(PATH=\"/usr/local/git/bin:/usr/local/bin:\"\n \"/usr/local:/usr/bin:/usr/sbin\"),\n ),\n )) # end of the options dict\n)\n\n\n# ugly hack for opencv2:\n# As of opencv 2.4.5 the cv2.so binary used rpath to a fixed\n# location to find libs and even more annoyingly it then appended\n# 'lib' to the rpath as well. These were fine for the packaged\n# framework python but the libs in an app bundle are different.\n# So, create symlinks so they appear in the same place as in framework python\nrpath = \"dist/PsychoPy.app/Contents/Resources/\"\nfor libPath in opencvLibs:\n libname = os.path.split(libPath)[-1]\n realPath = \"../../Frameworks/\"+libname # relative path (w.r.t. the fake)\n fakePath = os.path.join(rpath, \"lib\", libname)\n os.symlink(realPath, fakePath)\n# they even did this for Python lib itself, which is in diff location\nrealPath = \"../Frameworks/Python.framework/Python\" # relative to the fake path\nfakePath = os.path.join(rpath, \"Python\")\nos.symlink(realPath, fakePath)\n\nif writeNewInit:\n # remove unwanted info about this system post-build\n createInitFile.createInitFile(dist=None)\n", "path": "setupApp.py"}]}
| 3,363 | 351 |
gh_patches_debug_31883
|
rasdani/github-patches
|
git_diff
|
sql-machine-learning__elasticdl-1385
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[PS-1] RPC service `push_model` implementation
</issue>
<code>
[start of elasticdl/python/ps/parameters.py]
1 import tensorflow as tf
2
3 from elasticdl.python.common.ndarray import tensor_to_ndarray
4 from elasticdl.python.ps.embedding_table import create_embedding_table
5
6
7 class Parameters(object):
8 """
9 There are two kinds of parameters:
10
11 1. non-embedding parameters, or dense tensor parameters. We save it
12 in a hashmap `non-embedding_params`, the key is the parameter name,
13 the value is a tf.Variable` object.
14 2. embedding parameters, or row-sparse parameters. We save it in a
15 hashmap `embedding_params`, the key is the embedding layer name,
16 the value is an `EmbeddingTable` object.
17
18 """
19
20 def __init__(self):
21 self.init_status = False
22 self.non_embedding_params = {}
23 self.embedding_params = {}
24
25 def get_embedding_param(self, name, indices):
26 if name not in self.embedding_params:
27 raise ValueError(
28 "Please initialize embedding param %s first!", name
29 )
30 return self.embedding_params[name].get(indices)
31
32 def set_embedding_param(self, name, indices, values):
33 if name not in self.embedding_params:
34 raise ValueError(
35 "Please initialize embedding param %s first!", name
36 )
37 self.embedding_params[name].set(indices, values)
38
39 def init_from_model_pb(self, model_pb):
40 if not self.init_status:
41 tensors_pb = model_pb.param
42 embeddings_pb = model_pb.embedding_table_info
43 self._init_non_embedding_params(tensors_pb)
44 self._init_embedding_params(embeddings_pb)
45 self.init_status = True
46
47 def _init_non_embedding_params(self, tensors_pb):
48 for pb in tensors_pb:
49 name = pb.name
50 arr = tensor_to_ndarray(pb)
51 var = tf.Variable(name=name, initial_value=arr, trainable=True)
52 self.non_embedding_params[name] = var
53
54 def _init_embedding_params(self, embeddings_pb):
55 for pb in embeddings_pb:
56 self.embedding_params[pb.name] = create_embedding_table(pb)
57
[end of elasticdl/python/ps/parameters.py]
[start of elasticdl/python/ps/servicer.py]
1 from google.protobuf import empty_pb2
2
3 from elasticdl.proto import elasticdl_pb2, elasticdl_pb2_grpc
4
5
6 class PserverServicer(elasticdl_pb2_grpc.PserverServicer):
7 """PS service implementation"""
8
9 def __init__(
10 self,
11 parameters,
12 grads_to_wait,
13 optimizer,
14 lr_staleness_modulation=False,
15 use_async=False,
16 ):
17 self._parameters = parameters
18 self._grads_to_wait = grads_to_wait
19 self._optimizer = optimizer
20 self._lr_staleness_modulation = lr_staleness_modulation
21 self._use_async = use_async
22 self._version = 0
23
24 def pull_variable(self, request, _):
25 # TODO: implement this RPC service
26 return elasticdl_pb2.PullVariableResponse()
27
28 def pull_embedding_vector(self, request, _):
29 # TODO: implement this RPC service
30 return elasticdl_pb2.Tensor()
31
32 def push_model(self, request, _):
33 # TODO: implement this RPC service
34 return empty_pb2.Empty()
35
36 def push_gradient(self, request, _):
37 # TODO: implement this RPC service
38 return elasticdl_pb2.PushGradientResponse()
39
[end of elasticdl/python/ps/servicer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/elasticdl/python/ps/parameters.py b/elasticdl/python/ps/parameters.py
--- a/elasticdl/python/ps/parameters.py
+++ b/elasticdl/python/ps/parameters.py
@@ -18,6 +18,7 @@
"""
def __init__(self):
+ self.version = 0
self.init_status = False
self.non_embedding_params = {}
self.embedding_params = {}
@@ -42,6 +43,7 @@
embeddings_pb = model_pb.embedding_table_info
self._init_non_embedding_params(tensors_pb)
self._init_embedding_params(embeddings_pb)
+ self.version = model_pb.version
self.init_status = True
def _init_non_embedding_params(self, tensors_pb):
diff --git a/elasticdl/python/ps/servicer.py b/elasticdl/python/ps/servicer.py
--- a/elasticdl/python/ps/servicer.py
+++ b/elasticdl/python/ps/servicer.py
@@ -1,3 +1,5 @@
+import threading
+
from google.protobuf import empty_pb2
from elasticdl.proto import elasticdl_pb2, elasticdl_pb2_grpc
@@ -20,6 +22,7 @@
self._lr_staleness_modulation = lr_staleness_modulation
self._use_async = use_async
self._version = 0
+ self._lock = threading.Lock()
def pull_variable(self, request, _):
# TODO: implement this RPC service
@@ -30,7 +33,8 @@
return elasticdl_pb2.Tensor()
def push_model(self, request, _):
- # TODO: implement this RPC service
+ with self._lock:
+ self._parameters.init_from_model_pb(request)
return empty_pb2.Empty()
def push_gradient(self, request, _):
|
{"golden_diff": "diff --git a/elasticdl/python/ps/parameters.py b/elasticdl/python/ps/parameters.py\n--- a/elasticdl/python/ps/parameters.py\n+++ b/elasticdl/python/ps/parameters.py\n@@ -18,6 +18,7 @@\n \"\"\"\n \n def __init__(self):\n+ self.version = 0\n self.init_status = False\n self.non_embedding_params = {}\n self.embedding_params = {}\n@@ -42,6 +43,7 @@\n embeddings_pb = model_pb.embedding_table_info\n self._init_non_embedding_params(tensors_pb)\n self._init_embedding_params(embeddings_pb)\n+ self.version = model_pb.version\n self.init_status = True\n \n def _init_non_embedding_params(self, tensors_pb):\ndiff --git a/elasticdl/python/ps/servicer.py b/elasticdl/python/ps/servicer.py\n--- a/elasticdl/python/ps/servicer.py\n+++ b/elasticdl/python/ps/servicer.py\n@@ -1,3 +1,5 @@\n+import threading\n+\n from google.protobuf import empty_pb2\n \n from elasticdl.proto import elasticdl_pb2, elasticdl_pb2_grpc\n@@ -20,6 +22,7 @@\n self._lr_staleness_modulation = lr_staleness_modulation\n self._use_async = use_async\n self._version = 0\n+ self._lock = threading.Lock()\n \n def pull_variable(self, request, _):\n # TODO: implement this RPC service\n@@ -30,7 +33,8 @@\n return elasticdl_pb2.Tensor()\n \n def push_model(self, request, _):\n- # TODO: implement this RPC service\n+ with self._lock:\n+ self._parameters.init_from_model_pb(request)\n return empty_pb2.Empty()\n \n def push_gradient(self, request, _):\n", "issue": "[PS-1] RPC service `push_model` implementation\n\n", "before_files": [{"content": "import tensorflow as tf\n\nfrom elasticdl.python.common.ndarray import tensor_to_ndarray\nfrom elasticdl.python.ps.embedding_table import create_embedding_table\n\n\nclass Parameters(object):\n \"\"\"\n There are two kinds of parameters:\n\n 1. non-embedding parameters, or dense tensor parameters. We save it\n in a hashmap `non-embedding_params`, the key is the parameter name,\n the value is a tf.Variable` object.\n 2. embedding parameters, or row-sparse parameters. We save it in a\n hashmap `embedding_params`, the key is the embedding layer name,\n the value is an `EmbeddingTable` object.\n\n \"\"\"\n\n def __init__(self):\n self.init_status = False\n self.non_embedding_params = {}\n self.embedding_params = {}\n\n def get_embedding_param(self, name, indices):\n if name not in self.embedding_params:\n raise ValueError(\n \"Please initialize embedding param %s first!\", name\n )\n return self.embedding_params[name].get(indices)\n\n def set_embedding_param(self, name, indices, values):\n if name not in self.embedding_params:\n raise ValueError(\n \"Please initialize embedding param %s first!\", name\n )\n self.embedding_params[name].set(indices, values)\n\n def init_from_model_pb(self, model_pb):\n if not self.init_status:\n tensors_pb = model_pb.param\n embeddings_pb = model_pb.embedding_table_info\n self._init_non_embedding_params(tensors_pb)\n self._init_embedding_params(embeddings_pb)\n self.init_status = True\n\n def _init_non_embedding_params(self, tensors_pb):\n for pb in tensors_pb:\n name = pb.name\n arr = tensor_to_ndarray(pb)\n var = tf.Variable(name=name, initial_value=arr, trainable=True)\n self.non_embedding_params[name] = var\n\n def _init_embedding_params(self, embeddings_pb):\n for pb in embeddings_pb:\n self.embedding_params[pb.name] = create_embedding_table(pb)\n", "path": "elasticdl/python/ps/parameters.py"}, {"content": "from google.protobuf import empty_pb2\n\nfrom elasticdl.proto import elasticdl_pb2, elasticdl_pb2_grpc\n\n\nclass PserverServicer(elasticdl_pb2_grpc.PserverServicer):\n \"\"\"PS service implementation\"\"\"\n\n def __init__(\n self,\n parameters,\n grads_to_wait,\n optimizer,\n lr_staleness_modulation=False,\n use_async=False,\n ):\n self._parameters = parameters\n self._grads_to_wait = grads_to_wait\n self._optimizer = optimizer\n self._lr_staleness_modulation = lr_staleness_modulation\n self._use_async = use_async\n self._version = 0\n\n def pull_variable(self, request, _):\n # TODO: implement this RPC service\n return elasticdl_pb2.PullVariableResponse()\n\n def pull_embedding_vector(self, request, _):\n # TODO: implement this RPC service\n return elasticdl_pb2.Tensor()\n\n def push_model(self, request, _):\n # TODO: implement this RPC service\n return empty_pb2.Empty()\n\n def push_gradient(self, request, _):\n # TODO: implement this RPC service\n return elasticdl_pb2.PushGradientResponse()\n", "path": "elasticdl/python/ps/servicer.py"}]}
| 1,444 | 413 |
gh_patches_debug_37394
|
rasdani/github-patches
|
git_diff
|
great-expectations__great_expectations-7139
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
SQLAlchemy warning when not using SQL
**Describe the bug**
I'm using Azure Blob Storage as a backend and getting the following warning in the new version of ge 0.15.4. Don't think this warning showed up in versions prior to 0.15.
`WARNING:great_expectations.data_context.util:Something went wrong when trying to use SQLAlchemy to obfuscate URL: Could not parse rfc1738 URL from string 'BlobEndpoint=xxxxxx'`
**Expected behavior**
No warning of this is type should show when TupleAzureBlobStoreBackend backend is used.
**Environment (please complete the following information):**
- System: Azure
- Great Expectations Version: 0.15.4
</issue>
<code>
[start of great_expectations/data_context/util.py]
1 import copy
2 import inspect
3 import logging
4 import pathlib
5 import warnings
6 from typing import Any, Optional
7 from urllib.parse import urlparse
8
9 import pyparsing as pp
10
11 from great_expectations.alias_types import PathStr # noqa: TCH001
12 from great_expectations.types import safe_deep_copy
13 from great_expectations.util import load_class, verify_dynamic_loading_support
14
15 try:
16 import sqlalchemy as sa
17 except ImportError:
18 sa = None
19
20 logger = logging.getLogger(__name__)
21
22
23 # TODO: Rename config to constructor_kwargs and config_defaults -> constructor_kwarg_default
24 # TODO: Improve error messages in this method. Since so much of our workflow is config-driven, this will be a *super* important part of DX.
25 def instantiate_class_from_config(config, runtime_environment, config_defaults=None):
26 """Build a GX class from configuration dictionaries."""
27
28 if config_defaults is None:
29 config_defaults = {}
30
31 config = copy.deepcopy(config)
32
33 module_name = config.pop("module_name", None)
34 if module_name is None:
35 try:
36 module_name = config_defaults.pop("module_name")
37 except KeyError:
38 raise KeyError(
39 "Neither config : {} nor config_defaults : {} contains a module_name key.".format(
40 config,
41 config_defaults,
42 )
43 )
44 else:
45 # Pop the value without using it, to avoid sending an unwanted value to the config_class
46 config_defaults.pop("module_name", None)
47
48 logger.debug(f"(instantiate_class_from_config) module_name -> {module_name}")
49 verify_dynamic_loading_support(module_name=module_name)
50
51 class_name = config.pop("class_name", None)
52 if class_name is None:
53 logger.warning(
54 "Instantiating class from config without an explicit class_name is dangerous. Consider adding "
55 f"an explicit class_name for {config.get('name')}"
56 )
57 try:
58 class_name = config_defaults.pop("class_name")
59 except KeyError:
60 raise KeyError(
61 "Neither config : {} nor config_defaults : {} contains a class_name key.".format(
62 config,
63 config_defaults,
64 )
65 )
66 else:
67 # Pop the value without using it, to avoid sending an unwanted value to the config_class
68 config_defaults.pop("class_name", None)
69
70 class_ = load_class(class_name=class_name, module_name=module_name)
71
72 config_with_defaults = copy.deepcopy(config_defaults)
73 config_with_defaults.update(config)
74 if runtime_environment is not None:
75 # If there are additional kwargs available in the runtime_environment requested by a
76 # class to be instantiated, provide them
77 argspec = inspect.getfullargspec(class_.__init__)[0][1:]
78
79 missing_args = set(argspec) - set(config_with_defaults.keys())
80 config_with_defaults.update(
81 {
82 missing_arg: runtime_environment[missing_arg]
83 for missing_arg in missing_args
84 if missing_arg in runtime_environment
85 }
86 )
87 # Add the entire runtime_environment as well if it's requested
88 if "runtime_environment" in missing_args:
89 config_with_defaults.update({"runtime_environment": runtime_environment})
90
91 try:
92 class_instance = class_(**config_with_defaults)
93 except TypeError as e:
94 raise TypeError(
95 "Couldn't instantiate class: {} with config: \n\t{}\n \n".format(
96 class_name, format_dict_for_error_message(config_with_defaults)
97 )
98 + str(e)
99 )
100
101 return class_instance
102
103
104 def format_dict_for_error_message(dict_):
105 # TODO : Tidy this up a bit. Indentation isn't fully consistent.
106
107 return "\n\t".join("\t\t".join((str(key), str(dict_[key]))) for key in dict_)
108
109
110 def file_relative_path(
111 source_path: PathStr,
112 relative_path: PathStr,
113 strict: bool = True,
114 ) -> str:
115 """
116 This function is useful when one needs to load a file that is
117 relative to the position of the current file. (Such as when
118 you encode a configuration file path in source file and want
119 in runnable in any current working directory)
120
121 It is meant to be used like the following:
122 file_relative_path(__file__, 'path/relative/to/file')
123
124 This has been modified from Dagster's utils:
125 H/T https://github.com/dagster-io/dagster/blob/8a250e9619a49e8bff8e9aa7435df89c2d2ea039/python_modules/dagster/dagster/utils/__init__.py#L34
126 """
127 dir_path = pathlib.Path(source_path).parent
128 abs_path = dir_path.joinpath(relative_path).resolve(strict=strict)
129 return str(abs_path)
130
131
132 def parse_substitution_variable(substitution_variable: str) -> Optional[str]:
133 """
134 Parse and check whether the string contains a substitution variable of the case insensitive form ${SOME_VAR} or $SOME_VAR
135 Args:
136 substitution_variable: string to be parsed
137
138 Returns:
139 string of variable name e.g. SOME_VAR or None if not parsable. If there are multiple substitution variables this currently returns the first e.g. $SOME_$TRING -> $SOME_
140 """
141 substitution_variable_name = pp.Word(pp.alphanums + "_").setResultsName(
142 "substitution_variable_name"
143 )
144 curly_brace_parser = "${" + substitution_variable_name + "}"
145 non_curly_brace_parser = "$" + substitution_variable_name
146 both_parser = curly_brace_parser | non_curly_brace_parser
147 try:
148 parsed_substitution_variable = both_parser.parseString(substitution_variable)
149 return parsed_substitution_variable.substitution_variable_name
150 except pp.ParseException:
151 return None
152
153
154 class PasswordMasker:
155 """
156 Used to mask passwords in Datasources. Does not mask sqlite urls.
157
158 Example usage
159 masked_db_url = PasswordMasker.mask_db_url(url)
160 where url = "postgresql+psycopg2://username:password@host:65432/database"
161 and masked_url = "postgresql+psycopg2://username:***@host:65432/database"
162
163 """
164
165 MASKED_PASSWORD_STRING = "***"
166
167 # values with the following keys will be processed with cls.mask_db_url:
168 URL_KEYS = {"connection_string", "url"}
169
170 # values with these keys will be directly replaced with cls.MASKED_PASSWORD_STRING:
171 PASSWORD_KEYS = {"access_token", "password"}
172
173 @classmethod
174 def mask_db_url(cls, url: str, use_urlparse: bool = False, **kwargs) -> str:
175 """
176 Mask password in database url.
177 Uses sqlalchemy engine parsing if sqlalchemy is installed, otherwise defaults to using urlparse from the stdlib which does not handle kwargs.
178 Args:
179 url: Database url e.g. "postgresql+psycopg2://username:password@host:65432/database"
180 use_urlparse: Skip trying to parse url with sqlalchemy and use urlparse
181 **kwargs: passed to create_engine()
182
183 Returns:
184 url with password masked e.g. "postgresql+psycopg2://username:***@host:65432/database"
185 """
186 if sa is not None and use_urlparse is False:
187 try:
188 engine = sa.create_engine(url, **kwargs)
189 return engine.url.__repr__()
190 # Account for the edge case where we have SQLAlchemy in our env but haven't installed the appropriate dialect to match the input URL
191 except Exception as e:
192 logger.warning(
193 f"Something went wrong when trying to use SQLAlchemy to obfuscate URL: {e}"
194 )
195 else:
196 warnings.warn(
197 "SQLAlchemy is not installed, using urlparse to mask database url password which ignores **kwargs."
198 )
199 return cls._mask_db_url_no_sa(url=url)
200
201 @classmethod
202 def _mask_db_url_no_sa(cls, url: str) -> str:
203 # oracle+cx_oracle does not parse well using urlparse, parse as oracle then swap back
204 replace_prefix = None
205 if url.startswith("oracle+cx_oracle"):
206 replace_prefix = {"original": "oracle+cx_oracle", "temporary": "oracle"}
207 url = url.replace(replace_prefix["original"], replace_prefix["temporary"])
208
209 parsed_url = urlparse(url)
210
211 # Do not parse sqlite
212 if parsed_url.scheme == "sqlite":
213 return url
214
215 colon = ":" if parsed_url.port is not None else ""
216 masked_url = (
217 f"{parsed_url.scheme}://{parsed_url.username}:{cls.MASKED_PASSWORD_STRING}"
218 f"@{parsed_url.hostname}{colon}{parsed_url.port or ''}{parsed_url.path or ''}"
219 )
220
221 if replace_prefix is not None:
222 masked_url = masked_url.replace(
223 replace_prefix["temporary"], replace_prefix["original"]
224 )
225
226 return masked_url
227
228 @classmethod
229 def sanitize_config(cls, config: dict) -> dict:
230 """
231 Mask sensitive fields in a Dict.
232 """
233
234 # be defensive, since it would be logical to expect this method works with DataContextConfig
235 if not isinstance(config, dict):
236 raise TypeError(
237 "PasswordMasker.sanitize_config expects param `config` "
238 + f"to be of type Dict, not of type {type(config)}"
239 )
240
241 config_copy = safe_deep_copy(config) # be immutable
242
243 def recursive_cleaner_method(config: Any) -> None:
244 if isinstance(config, dict):
245 for key, val in config.items():
246 if not isinstance(val, str):
247 recursive_cleaner_method(val)
248 elif key in cls.URL_KEYS:
249 config[key] = cls.mask_db_url(val)
250 elif key in cls.PASSWORD_KEYS:
251 config[key] = cls.MASKED_PASSWORD_STRING
252 else:
253 pass # this string is not sensitive
254 elif isinstance(config, list):
255 for val in config:
256 recursive_cleaner_method(val)
257
258 recursive_cleaner_method(config_copy) # Perform anonymization in place
259
260 return config_copy
261
[end of great_expectations/data_context/util.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/great_expectations/data_context/util.py b/great_expectations/data_context/util.py
--- a/great_expectations/data_context/util.py
+++ b/great_expectations/data_context/util.py
@@ -1,7 +1,10 @@
+from __future__ import annotations
+
import copy
import inspect
import logging
import pathlib
+import re
import warnings
from typing import Any, Optional
from urllib.parse import urlparse
@@ -9,6 +12,7 @@
import pyparsing as pp
from great_expectations.alias_types import PathStr # noqa: TCH001
+from great_expectations.exceptions import StoreConfigurationError
from great_expectations.types import safe_deep_copy
from great_expectations.util import load_class, verify_dynamic_loading_support
@@ -183,7 +187,9 @@
Returns:
url with password masked e.g. "postgresql+psycopg2://username:***@host:65432/database"
"""
- if sa is not None and use_urlparse is False:
+ if url.startswith("DefaultEndpointsProtocol"):
+ return cls._obfuscate_azure_blobstore_connection_string(url)
+ elif sa is not None and use_urlparse is False:
try:
engine = sa.create_engine(url, **kwargs)
return engine.url.__repr__()
@@ -198,6 +204,25 @@
)
return cls._mask_db_url_no_sa(url=url)
+ @classmethod
+ def _obfuscate_azure_blobstore_connection_string(cls, url: str) -> str:
+ # Parse Azure Connection Strings
+ azure_conn_str_re = re.compile(
+ "(DefaultEndpointsProtocol=(http|https));(AccountName=([a-zA-Z0-9]+));(AccountKey=)(.+);(EndpointSuffix=([a-zA-Z\\.]+))"
+ )
+ try:
+ matched: re.Match[str] | None = azure_conn_str_re.match(url)
+ if not matched:
+ raise StoreConfigurationError(
+ f"The URL for the Azure connection-string, was not configured properly. Please check and try again: {url} "
+ )
+ res = f"DefaultEndpointsProtocol={matched.group(2)};AccountName={matched.group(4)};AccountKey=***;EndpointSuffix={matched.group(8)}"
+ return res
+ except Exception as e:
+ raise StoreConfigurationError(
+ f"Something went wrong when trying to obfuscate URL for Azure connection-string. Please check your configuration: {e}"
+ )
+
@classmethod
def _mask_db_url_no_sa(cls, url: str) -> str:
# oracle+cx_oracle does not parse well using urlparse, parse as oracle then swap back
|
{"golden_diff": "diff --git a/great_expectations/data_context/util.py b/great_expectations/data_context/util.py\n--- a/great_expectations/data_context/util.py\n+++ b/great_expectations/data_context/util.py\n@@ -1,7 +1,10 @@\n+from __future__ import annotations\n+\n import copy\n import inspect\n import logging\n import pathlib\n+import re\n import warnings\n from typing import Any, Optional\n from urllib.parse import urlparse\n@@ -9,6 +12,7 @@\n import pyparsing as pp\n \n from great_expectations.alias_types import PathStr # noqa: TCH001\n+from great_expectations.exceptions import StoreConfigurationError\n from great_expectations.types import safe_deep_copy\n from great_expectations.util import load_class, verify_dynamic_loading_support\n \n@@ -183,7 +187,9 @@\n Returns:\n url with password masked e.g. \"postgresql+psycopg2://username:***@host:65432/database\"\n \"\"\"\n- if sa is not None and use_urlparse is False:\n+ if url.startswith(\"DefaultEndpointsProtocol\"):\n+ return cls._obfuscate_azure_blobstore_connection_string(url)\n+ elif sa is not None and use_urlparse is False:\n try:\n engine = sa.create_engine(url, **kwargs)\n return engine.url.__repr__()\n@@ -198,6 +204,25 @@\n )\n return cls._mask_db_url_no_sa(url=url)\n \n+ @classmethod\n+ def _obfuscate_azure_blobstore_connection_string(cls, url: str) -> str:\n+ # Parse Azure Connection Strings\n+ azure_conn_str_re = re.compile(\n+ \"(DefaultEndpointsProtocol=(http|https));(AccountName=([a-zA-Z0-9]+));(AccountKey=)(.+);(EndpointSuffix=([a-zA-Z\\\\.]+))\"\n+ )\n+ try:\n+ matched: re.Match[str] | None = azure_conn_str_re.match(url)\n+ if not matched:\n+ raise StoreConfigurationError(\n+ f\"The URL for the Azure connection-string, was not configured properly. Please check and try again: {url} \"\n+ )\n+ res = f\"DefaultEndpointsProtocol={matched.group(2)};AccountName={matched.group(4)};AccountKey=***;EndpointSuffix={matched.group(8)}\"\n+ return res\n+ except Exception as e:\n+ raise StoreConfigurationError(\n+ f\"Something went wrong when trying to obfuscate URL for Azure connection-string. Please check your configuration: {e}\"\n+ )\n+\n @classmethod\n def _mask_db_url_no_sa(cls, url: str) -> str:\n # oracle+cx_oracle does not parse well using urlparse, parse as oracle then swap back\n", "issue": "SQLAlchemy warning when not using SQL\n**Describe the bug**\r\nI'm using Azure Blob Storage as a backend and getting the following warning in the new version of ge 0.15.4. Don't think this warning showed up in versions prior to 0.15.\r\n\r\n`WARNING:great_expectations.data_context.util:Something went wrong when trying to use SQLAlchemy to obfuscate URL: Could not parse rfc1738 URL from string 'BlobEndpoint=xxxxxx'`\r\n\r\n**Expected behavior**\r\nNo warning of this is type should show when TupleAzureBlobStoreBackend backend is used.\r\n\r\n**Environment (please complete the following information):**\r\n - System: Azure\r\n - Great Expectations Version: 0.15.4\r\n\r\n\n", "before_files": [{"content": "import copy\nimport inspect\nimport logging\nimport pathlib\nimport warnings\nfrom typing import Any, Optional\nfrom urllib.parse import urlparse\n\nimport pyparsing as pp\n\nfrom great_expectations.alias_types import PathStr # noqa: TCH001\nfrom great_expectations.types import safe_deep_copy\nfrom great_expectations.util import load_class, verify_dynamic_loading_support\n\ntry:\n import sqlalchemy as sa\nexcept ImportError:\n sa = None\n\nlogger = logging.getLogger(__name__)\n\n\n# TODO: Rename config to constructor_kwargs and config_defaults -> constructor_kwarg_default\n# TODO: Improve error messages in this method. Since so much of our workflow is config-driven, this will be a *super* important part of DX.\ndef instantiate_class_from_config(config, runtime_environment, config_defaults=None):\n \"\"\"Build a GX class from configuration dictionaries.\"\"\"\n\n if config_defaults is None:\n config_defaults = {}\n\n config = copy.deepcopy(config)\n\n module_name = config.pop(\"module_name\", None)\n if module_name is None:\n try:\n module_name = config_defaults.pop(\"module_name\")\n except KeyError:\n raise KeyError(\n \"Neither config : {} nor config_defaults : {} contains a module_name key.\".format(\n config,\n config_defaults,\n )\n )\n else:\n # Pop the value without using it, to avoid sending an unwanted value to the config_class\n config_defaults.pop(\"module_name\", None)\n\n logger.debug(f\"(instantiate_class_from_config) module_name -> {module_name}\")\n verify_dynamic_loading_support(module_name=module_name)\n\n class_name = config.pop(\"class_name\", None)\n if class_name is None:\n logger.warning(\n \"Instantiating class from config without an explicit class_name is dangerous. Consider adding \"\n f\"an explicit class_name for {config.get('name')}\"\n )\n try:\n class_name = config_defaults.pop(\"class_name\")\n except KeyError:\n raise KeyError(\n \"Neither config : {} nor config_defaults : {} contains a class_name key.\".format(\n config,\n config_defaults,\n )\n )\n else:\n # Pop the value without using it, to avoid sending an unwanted value to the config_class\n config_defaults.pop(\"class_name\", None)\n\n class_ = load_class(class_name=class_name, module_name=module_name)\n\n config_with_defaults = copy.deepcopy(config_defaults)\n config_with_defaults.update(config)\n if runtime_environment is not None:\n # If there are additional kwargs available in the runtime_environment requested by a\n # class to be instantiated, provide them\n argspec = inspect.getfullargspec(class_.__init__)[0][1:]\n\n missing_args = set(argspec) - set(config_with_defaults.keys())\n config_with_defaults.update(\n {\n missing_arg: runtime_environment[missing_arg]\n for missing_arg in missing_args\n if missing_arg in runtime_environment\n }\n )\n # Add the entire runtime_environment as well if it's requested\n if \"runtime_environment\" in missing_args:\n config_with_defaults.update({\"runtime_environment\": runtime_environment})\n\n try:\n class_instance = class_(**config_with_defaults)\n except TypeError as e:\n raise TypeError(\n \"Couldn't instantiate class: {} with config: \\n\\t{}\\n \\n\".format(\n class_name, format_dict_for_error_message(config_with_defaults)\n )\n + str(e)\n )\n\n return class_instance\n\n\ndef format_dict_for_error_message(dict_):\n # TODO : Tidy this up a bit. Indentation isn't fully consistent.\n\n return \"\\n\\t\".join(\"\\t\\t\".join((str(key), str(dict_[key]))) for key in dict_)\n\n\ndef file_relative_path(\n source_path: PathStr,\n relative_path: PathStr,\n strict: bool = True,\n) -> str:\n \"\"\"\n This function is useful when one needs to load a file that is\n relative to the position of the current file. (Such as when\n you encode a configuration file path in source file and want\n in runnable in any current working directory)\n\n It is meant to be used like the following:\n file_relative_path(__file__, 'path/relative/to/file')\n\n This has been modified from Dagster's utils:\n H/T https://github.com/dagster-io/dagster/blob/8a250e9619a49e8bff8e9aa7435df89c2d2ea039/python_modules/dagster/dagster/utils/__init__.py#L34\n \"\"\"\n dir_path = pathlib.Path(source_path).parent\n abs_path = dir_path.joinpath(relative_path).resolve(strict=strict)\n return str(abs_path)\n\n\ndef parse_substitution_variable(substitution_variable: str) -> Optional[str]:\n \"\"\"\n Parse and check whether the string contains a substitution variable of the case insensitive form ${SOME_VAR} or $SOME_VAR\n Args:\n substitution_variable: string to be parsed\n\n Returns:\n string of variable name e.g. SOME_VAR or None if not parsable. If there are multiple substitution variables this currently returns the first e.g. $SOME_$TRING -> $SOME_\n \"\"\"\n substitution_variable_name = pp.Word(pp.alphanums + \"_\").setResultsName(\n \"substitution_variable_name\"\n )\n curly_brace_parser = \"${\" + substitution_variable_name + \"}\"\n non_curly_brace_parser = \"$\" + substitution_variable_name\n both_parser = curly_brace_parser | non_curly_brace_parser\n try:\n parsed_substitution_variable = both_parser.parseString(substitution_variable)\n return parsed_substitution_variable.substitution_variable_name\n except pp.ParseException:\n return None\n\n\nclass PasswordMasker:\n \"\"\"\n Used to mask passwords in Datasources. Does not mask sqlite urls.\n\n Example usage\n masked_db_url = PasswordMasker.mask_db_url(url)\n where url = \"postgresql+psycopg2://username:password@host:65432/database\"\n and masked_url = \"postgresql+psycopg2://username:***@host:65432/database\"\n\n \"\"\"\n\n MASKED_PASSWORD_STRING = \"***\"\n\n # values with the following keys will be processed with cls.mask_db_url:\n URL_KEYS = {\"connection_string\", \"url\"}\n\n # values with these keys will be directly replaced with cls.MASKED_PASSWORD_STRING:\n PASSWORD_KEYS = {\"access_token\", \"password\"}\n\n @classmethod\n def mask_db_url(cls, url: str, use_urlparse: bool = False, **kwargs) -> str:\n \"\"\"\n Mask password in database url.\n Uses sqlalchemy engine parsing if sqlalchemy is installed, otherwise defaults to using urlparse from the stdlib which does not handle kwargs.\n Args:\n url: Database url e.g. \"postgresql+psycopg2://username:password@host:65432/database\"\n use_urlparse: Skip trying to parse url with sqlalchemy and use urlparse\n **kwargs: passed to create_engine()\n\n Returns:\n url with password masked e.g. \"postgresql+psycopg2://username:***@host:65432/database\"\n \"\"\"\n if sa is not None and use_urlparse is False:\n try:\n engine = sa.create_engine(url, **kwargs)\n return engine.url.__repr__()\n # Account for the edge case where we have SQLAlchemy in our env but haven't installed the appropriate dialect to match the input URL\n except Exception as e:\n logger.warning(\n f\"Something went wrong when trying to use SQLAlchemy to obfuscate URL: {e}\"\n )\n else:\n warnings.warn(\n \"SQLAlchemy is not installed, using urlparse to mask database url password which ignores **kwargs.\"\n )\n return cls._mask_db_url_no_sa(url=url)\n\n @classmethod\n def _mask_db_url_no_sa(cls, url: str) -> str:\n # oracle+cx_oracle does not parse well using urlparse, parse as oracle then swap back\n replace_prefix = None\n if url.startswith(\"oracle+cx_oracle\"):\n replace_prefix = {\"original\": \"oracle+cx_oracle\", \"temporary\": \"oracle\"}\n url = url.replace(replace_prefix[\"original\"], replace_prefix[\"temporary\"])\n\n parsed_url = urlparse(url)\n\n # Do not parse sqlite\n if parsed_url.scheme == \"sqlite\":\n return url\n\n colon = \":\" if parsed_url.port is not None else \"\"\n masked_url = (\n f\"{parsed_url.scheme}://{parsed_url.username}:{cls.MASKED_PASSWORD_STRING}\"\n f\"@{parsed_url.hostname}{colon}{parsed_url.port or ''}{parsed_url.path or ''}\"\n )\n\n if replace_prefix is not None:\n masked_url = masked_url.replace(\n replace_prefix[\"temporary\"], replace_prefix[\"original\"]\n )\n\n return masked_url\n\n @classmethod\n def sanitize_config(cls, config: dict) -> dict:\n \"\"\"\n Mask sensitive fields in a Dict.\n \"\"\"\n\n # be defensive, since it would be logical to expect this method works with DataContextConfig\n if not isinstance(config, dict):\n raise TypeError(\n \"PasswordMasker.sanitize_config expects param `config` \"\n + f\"to be of type Dict, not of type {type(config)}\"\n )\n\n config_copy = safe_deep_copy(config) # be immutable\n\n def recursive_cleaner_method(config: Any) -> None:\n if isinstance(config, dict):\n for key, val in config.items():\n if not isinstance(val, str):\n recursive_cleaner_method(val)\n elif key in cls.URL_KEYS:\n config[key] = cls.mask_db_url(val)\n elif key in cls.PASSWORD_KEYS:\n config[key] = cls.MASKED_PASSWORD_STRING\n else:\n pass # this string is not sensitive\n elif isinstance(config, list):\n for val in config:\n recursive_cleaner_method(val)\n\n recursive_cleaner_method(config_copy) # Perform anonymization in place\n\n return config_copy\n", "path": "great_expectations/data_context/util.py"}]}
| 3,529 | 604 |
gh_patches_debug_6
|
rasdani/github-patches
|
git_diff
|
cookiecutter__cookiecutter-1273
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
PEP257 docstrings for file "./docs/__init__.py"
Cover `./docs/__init__.py` file with docstrings and follow [PEP257](https://www.python.org/dev/peps/pep-0257/). We use [pydocstyle](https://pypi.org/project/pydocstyle/) for validation.
Current validation log:
```
./docs/__init__.py:1 at module level:
D104: Missing docstring in public package
```
Subtask for #742
</issue>
<code>
[start of docs/__init__.py]
[end of docs/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/__init__.py b/docs/__init__.py
--- a/docs/__init__.py
+++ b/docs/__init__.py
@@ -0,0 +1,3 @@
+# -*- coding: utf-8 -*-
+
+"""Main package for docs."""
|
{"golden_diff": "diff --git a/docs/__init__.py b/docs/__init__.py\n--- a/docs/__init__.py\n+++ b/docs/__init__.py\n@@ -0,0 +1,3 @@\n+# -*- coding: utf-8 -*-\n+\n+\"\"\"Main package for docs.\"\"\"\n", "issue": "PEP257 docstrings for file \"./docs/__init__.py\"\nCover `./docs/__init__.py` file with docstrings and follow [PEP257](https://www.python.org/dev/peps/pep-0257/). We use [pydocstyle](https://pypi.org/project/pydocstyle/) for validation.\r\n\r\nCurrent validation log:\r\n\r\n```\r\n./docs/__init__.py:1 at module level:\r\n D104: Missing docstring in public package\r\n```\r\n\r\nSubtask for #742 \n", "before_files": [{"content": "", "path": "docs/__init__.py"}]}
| 652 | 58 |
gh_patches_debug_13173
|
rasdani/github-patches
|
git_diff
|
ros__ros_comm-187
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
roslaunch --files prints error if multiple anon nodes have same id
When running:
```
roslaunch --files package_name launch_file.launch
```
I get the following error:
```
roslaunch file contains multiple nodes named [/$(anon foo)].
Please check all <node> 'name' attributes to make sure they are unique.
Also check that $(anon id) use different ids.
```
Note that when actually launching the launch file, this will not be a problem because the anonymous node names will be expanded with unique suffixes. Also, the list of files does not relate to the expansion of anonymous node names, so the file list should be printable regardless.
This is similar in spirit to bugs #94 and #65, both of which suffer because roslaunch simply prints an error and quits when it finds non-unique node names instead of doing as much as possible to help you find your error.
</issue>
<code>
[start of tools/roslaunch/src/roslaunch/rlutil.py]
1 # Software License Agreement (BSD License)
2 #
3 # Copyright (c) 2009, Willow Garage, Inc.
4 # All rights reserved.
5 #
6 # Redistribution and use in source and binary forms, with or without
7 # modification, are permitted provided that the following conditions
8 # are met:
9 #
10 # * Redistributions of source code must retain the above copyright
11 # notice, this list of conditions and the following disclaimer.
12 # * Redistributions in binary form must reproduce the above
13 # copyright notice, this list of conditions and the following
14 # disclaimer in the documentation and/or other materials provided
15 # with the distribution.
16 # * Neither the name of Willow Garage, Inc. nor the names of its
17 # contributors may be used to endorse or promote products derived
18 # from this software without specific prior written permission.
19 #
20 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
21 # "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
22 # LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS
23 # FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE
24 # COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT,
25 # INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,
26 # BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
27 # LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
28 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT
29 # LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN
30 # ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
31 # POSSIBILITY OF SUCH DAMAGE.
32
33 """
34 Uncategorized utility routines for roslaunch.
35
36 This API should not be considered stable.
37 """
38
39 from __future__ import print_function
40
41 import os
42 import sys
43 import time
44
45 import roslib.packages
46
47 import rosclean
48 import rospkg
49 import rosgraph
50
51 import roslaunch.core
52 import roslaunch.config
53 import roslaunch.depends
54 from rosmaster import DEFAULT_MASTER_PORT
55
56 def check_log_disk_usage():
57 """
58 Check size of log directory. If high, print warning to user
59 """
60 try:
61 d = rospkg.get_log_dir()
62 roslaunch.core.printlog("Checking log directory for disk usage. This may take awhile.\nPress Ctrl-C to interrupt")
63 disk_usage = rosclean.get_disk_usage(d)
64 # warn if over a gig
65 if disk_usage > 1073741824:
66 roslaunch.core.printerrlog("WARNING: disk usage in log directory [%s] is over 1GB.\nIt's recommended that you use the 'rosclean' command."%d)
67 else:
68 roslaunch.core.printlog("Done checking log file disk usage. Usage is <1GB.")
69 except:
70 pass
71
72 def resolve_launch_arguments(args):
73 """
74 Resolve command-line args to roslaunch filenames.
75
76 :returns: resolved filenames, ``[str]``
77 """
78
79 # strip remapping args for processing
80 args = rosgraph.myargv(args)
81
82 # user can either specify:
83 # - filename + launch args
84 # - package + relative-filename + launch args
85 if not args:
86 return args
87 resolved_args = None
88 top = args[0]
89 if os.path.isfile(top):
90 resolved_args = [top] + args[1:]
91 elif len(args) == 1:
92 raise roslaunch.core.RLException("[%s] does not exist. please specify a package and launch file"%(top))
93 else:
94 try:
95 resolved = roslib.packages.find_resource(top, args[1])
96 if len(resolved) == 1:
97 resolved = resolved[0]
98 elif len(resolved) > 1:
99 raise roslaunch.core.RLException("multiple files named [%s] in package [%s]:%s\nPlease specify full path instead" % (args[1], top, ''.join(['\n- %s' % r for r in resolved])))
100 except rospkg.ResourceNotFound as e:
101 raise roslaunch.core.RLException("[%s] is not a package or launch file name"%top)
102 if not resolved:
103 raise roslaunch.core.RLException("cannot locate [%s] in package [%s]"%(args[1], top))
104 else:
105 resolved_args = [resolved] + args[2:]
106 return resolved_args
107
108 def _wait_for_master():
109 """
110 Block until ROS Master is online
111
112 :raise: :exc:`RuntimeError` If unexpected error occurs
113 """
114 m = roslaunch.core.Master() # get a handle to the default master
115 is_running = m.is_running()
116 if not is_running:
117 roslaunch.core.printlog("roscore/master is not yet running, will wait for it to start")
118 while not is_running:
119 time.sleep(0.1)
120 is_running = m.is_running()
121 if is_running:
122 roslaunch.core.printlog("master has started, initiating launch")
123 else:
124 raise RuntimeError("unknown error waiting for master to start")
125
126 _terminal_name = None
127
128 def _set_terminal(s):
129 import platform
130 if platform.system() in ['FreeBSD', 'Linux', 'Darwin', 'Unix']:
131 try:
132 print('\033]2;%s\007'%(s))
133 except:
134 pass
135
136 def update_terminal_name(ros_master_uri):
137 """
138 append master URI to the terminal name
139 """
140 if _terminal_name:
141 _set_terminal(_terminal_name + ' ' + ros_master_uri)
142
143 def change_terminal_name(args, is_core):
144 """
145 use echo (where available) to change the name of the terminal window
146 """
147 global _terminal_name
148 _terminal_name = 'roscore' if is_core else ','.join(args)
149 _set_terminal(_terminal_name)
150
151 def get_or_generate_uuid(options_runid, options_wait_for_master):
152 """
153 :param options_runid: run_id value from command-line or ``None``, ``str``
154 :param options_wait_for_master: the wait_for_master command
155 option. If this is True, it means that we must retrieve the
156 value from the parameter server and need to avoid any race
157 conditions with the roscore being initialized. ``bool``
158 """
159
160 # Three possible sources of the run_id:
161 #
162 # - if we're a child process, we get it from options_runid
163 # - if there's already a roscore running, read from the param server
164 # - generate one if we're running the roscore
165 if options_runid:
166 return options_runid
167
168 # #773: Generate a run_id to use if we launch a master
169 # process. If a master is already running, we'll get the
170 # run_id from it instead
171 param_server = rosgraph.Master('/roslaunch')
172 val = None
173 while val is None:
174 try:
175 val = param_server.getParam('/run_id')
176 except:
177 if not options_wait_for_master:
178 val = roslaunch.core.generate_run_id()
179 return val
180
181 def check_roslaunch(f):
182 """
183 Check roslaunch file for errors, returning error message if check fails. This routine
184 is mainly to support rostest's roslaunch_check.
185
186 :param f: roslaunch file name, ``str``
187 :returns: error message or ``None``
188 """
189 try:
190 rl_config = roslaunch.config.load_config_default([f], DEFAULT_MASTER_PORT, verbose=False)
191 except roslaunch.core.RLException as e:
192 return str(e)
193
194 errors = []
195 # check for missing deps
196 base_pkg, file_deps, missing = roslaunch.depends.roslaunch_deps([f])
197 for pkg, miss in missing.iteritems():
198 if miss:
199 errors.append("Missing manifest dependencies: %s/manifest.xml: %s"%(pkg, ', '.join(miss)))
200
201 # load all node defs
202 nodes = []
203 for filename, rldeps in file_deps.iteritems():
204 nodes.extend(rldeps.nodes)
205
206 # check for missing packages
207 rospack = rospkg.RosPack()
208 for pkg, node_type in nodes:
209 try:
210 rospack.get_path(pkg)
211 except:
212 errors.append("cannot find package [%s] for node [%s]"%(pkg, node_type))
213
214 # check for missing nodes
215 for pkg, node_type in nodes:
216 try:
217 if not roslib.packages.find_node(pkg, node_type):
218 errors.append("cannot find node [%s] in package [%s]"%(node_type, pkg))
219 except Exception as e:
220 errors.append("unable to find node [%s/%s]: %s"%(pkg, node_type, str(e)))
221
222 # Check for configuration errors, #2889
223 for err in rl_config.config_errors:
224 errors.append('ROSLaunch config error: %s' % err)
225
226 if errors:
227 return '\n'.join(errors)
228
229 def print_file_list(roslaunch_files):
230 """
231 :param roslaunch_files: list of launch files to load, ``str``
232
233 :returns: list of files involved in processing roslaunch_files, including the files themselves.
234 """
235 from roslaunch.config import load_config_default, get_roscore_filename
236 import roslaunch.xmlloader
237 try:
238 loader = roslaunch.xmlloader.XmlLoader(resolve_anon=False)
239 config = load_config_default(roslaunch_files, None, loader=loader, verbose=False, assign_machines=False)
240 files = [os.path.abspath(x) for x in set(config.roslaunch_files) - set([get_roscore_filename()])]
241 print('\n'.join(files))
242 except roslaunch.core.RLException as e:
243 print(str(e), file=sys.stderr)
244 sys.exit(1)
245
246
[end of tools/roslaunch/src/roslaunch/rlutil.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/tools/roslaunch/src/roslaunch/rlutil.py b/tools/roslaunch/src/roslaunch/rlutil.py
--- a/tools/roslaunch/src/roslaunch/rlutil.py
+++ b/tools/roslaunch/src/roslaunch/rlutil.py
@@ -235,7 +235,7 @@
from roslaunch.config import load_config_default, get_roscore_filename
import roslaunch.xmlloader
try:
- loader = roslaunch.xmlloader.XmlLoader(resolve_anon=False)
+ loader = roslaunch.xmlloader.XmlLoader(resolve_anon=True)
config = load_config_default(roslaunch_files, None, loader=loader, verbose=False, assign_machines=False)
files = [os.path.abspath(x) for x in set(config.roslaunch_files) - set([get_roscore_filename()])]
print('\n'.join(files))
|
{"golden_diff": "diff --git a/tools/roslaunch/src/roslaunch/rlutil.py b/tools/roslaunch/src/roslaunch/rlutil.py\n--- a/tools/roslaunch/src/roslaunch/rlutil.py\n+++ b/tools/roslaunch/src/roslaunch/rlutil.py\n@@ -235,7 +235,7 @@\n from roslaunch.config import load_config_default, get_roscore_filename\n import roslaunch.xmlloader\n try:\n- loader = roslaunch.xmlloader.XmlLoader(resolve_anon=False)\n+ loader = roslaunch.xmlloader.XmlLoader(resolve_anon=True)\n config = load_config_default(roslaunch_files, None, loader=loader, verbose=False, assign_machines=False)\n files = [os.path.abspath(x) for x in set(config.roslaunch_files) - set([get_roscore_filename()])]\n print('\\n'.join(files))\n", "issue": "roslaunch --files prints error if multiple anon nodes have same id\nWhen running:\n\n```\nroslaunch --files package_name launch_file.launch\n```\n\nI get the following error:\n\n```\nroslaunch file contains multiple nodes named [/$(anon foo)].\nPlease check all <node> 'name' attributes to make sure they are unique.\nAlso check that $(anon id) use different ids.\n```\n\nNote that when actually launching the launch file, this will not be a problem because the anonymous node names will be expanded with unique suffixes. Also, the list of files does not relate to the expansion of anonymous node names, so the file list should be printable regardless.\n\nThis is similar in spirit to bugs #94 and #65, both of which suffer because roslaunch simply prints an error and quits when it finds non-unique node names instead of doing as much as possible to help you find your error.\n\n", "before_files": [{"content": "# Software License Agreement (BSD License)\n#\n# Copyright (c) 2009, Willow Garage, Inc.\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions\n# are met:\n#\n# * Redistributions of source code must retain the above copyright\n# notice, this list of conditions and the following disclaimer.\n# * Redistributions in binary form must reproduce the above\n# copyright notice, this list of conditions and the following\n# disclaimer in the documentation and/or other materials provided\n# with the distribution.\n# * Neither the name of Willow Garage, Inc. nor the names of its\n# contributors may be used to endorse or promote products derived\n# from this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS\n# \"AS IS\" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT\n# LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS\n# FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE\n# COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT,\n# INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING,\n# BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;\n# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT\n# LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN\n# ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE\n# POSSIBILITY OF SUCH DAMAGE.\n\n\"\"\"\nUncategorized utility routines for roslaunch.\n\nThis API should not be considered stable.\n\"\"\"\n\nfrom __future__ import print_function\n\nimport os\nimport sys\nimport time\n\nimport roslib.packages\n\nimport rosclean\nimport rospkg\nimport rosgraph\n\nimport roslaunch.core\nimport roslaunch.config\nimport roslaunch.depends\nfrom rosmaster import DEFAULT_MASTER_PORT\n\ndef check_log_disk_usage():\n \"\"\"\n Check size of log directory. If high, print warning to user\n \"\"\"\n try:\n d = rospkg.get_log_dir()\n roslaunch.core.printlog(\"Checking log directory for disk usage. This may take awhile.\\nPress Ctrl-C to interrupt\") \n disk_usage = rosclean.get_disk_usage(d)\n # warn if over a gig\n if disk_usage > 1073741824:\n roslaunch.core.printerrlog(\"WARNING: disk usage in log directory [%s] is over 1GB.\\nIt's recommended that you use the 'rosclean' command.\"%d)\n else:\n roslaunch.core.printlog(\"Done checking log file disk usage. Usage is <1GB.\") \n except:\n pass\n\ndef resolve_launch_arguments(args):\n \"\"\"\n Resolve command-line args to roslaunch filenames.\n\n :returns: resolved filenames, ``[str]``\n \"\"\"\n\n # strip remapping args for processing\n args = rosgraph.myargv(args)\n \n # user can either specify:\n # - filename + launch args\n # - package + relative-filename + launch args\n if not args:\n return args\n resolved_args = None\n top = args[0]\n if os.path.isfile(top):\n resolved_args = [top] + args[1:]\n elif len(args) == 1:\n raise roslaunch.core.RLException(\"[%s] does not exist. please specify a package and launch file\"%(top))\n else:\n try:\n resolved = roslib.packages.find_resource(top, args[1])\n if len(resolved) == 1:\n resolved = resolved[0]\n elif len(resolved) > 1:\n raise roslaunch.core.RLException(\"multiple files named [%s] in package [%s]:%s\\nPlease specify full path instead\" % (args[1], top, ''.join(['\\n- %s' % r for r in resolved])))\n except rospkg.ResourceNotFound as e:\n raise roslaunch.core.RLException(\"[%s] is not a package or launch file name\"%top)\n if not resolved:\n raise roslaunch.core.RLException(\"cannot locate [%s] in package [%s]\"%(args[1], top))\n else:\n resolved_args = [resolved] + args[2:]\n return resolved_args\n\ndef _wait_for_master():\n \"\"\"\n Block until ROS Master is online\n \n :raise: :exc:`RuntimeError` If unexpected error occurs\n \"\"\"\n m = roslaunch.core.Master() # get a handle to the default master\n is_running = m.is_running()\n if not is_running:\n roslaunch.core.printlog(\"roscore/master is not yet running, will wait for it to start\")\n while not is_running:\n time.sleep(0.1)\n is_running = m.is_running()\n if is_running:\n roslaunch.core.printlog(\"master has started, initiating launch\")\n else:\n raise RuntimeError(\"unknown error waiting for master to start\")\n\n_terminal_name = None\n\ndef _set_terminal(s):\n import platform\n if platform.system() in ['FreeBSD', 'Linux', 'Darwin', 'Unix']:\n try:\n print('\\033]2;%s\\007'%(s))\n except:\n pass\n \ndef update_terminal_name(ros_master_uri):\n \"\"\"\n append master URI to the terminal name\n \"\"\"\n if _terminal_name:\n _set_terminal(_terminal_name + ' ' + ros_master_uri)\n\ndef change_terminal_name(args, is_core):\n \"\"\"\n use echo (where available) to change the name of the terminal window\n \"\"\"\n global _terminal_name\n _terminal_name = 'roscore' if is_core else ','.join(args)\n _set_terminal(_terminal_name)\n\ndef get_or_generate_uuid(options_runid, options_wait_for_master):\n \"\"\"\n :param options_runid: run_id value from command-line or ``None``, ``str``\n :param options_wait_for_master: the wait_for_master command\n option. If this is True, it means that we must retrieve the\n value from the parameter server and need to avoid any race\n conditions with the roscore being initialized. ``bool``\n \"\"\"\n\n # Three possible sources of the run_id:\n #\n # - if we're a child process, we get it from options_runid\n # - if there's already a roscore running, read from the param server\n # - generate one if we're running the roscore\n if options_runid:\n return options_runid\n\n # #773: Generate a run_id to use if we launch a master\n # process. If a master is already running, we'll get the\n # run_id from it instead\n param_server = rosgraph.Master('/roslaunch')\n val = None\n while val is None:\n try:\n val = param_server.getParam('/run_id')\n except:\n if not options_wait_for_master:\n val = roslaunch.core.generate_run_id()\n return val\n \ndef check_roslaunch(f):\n \"\"\"\n Check roslaunch file for errors, returning error message if check fails. This routine\n is mainly to support rostest's roslaunch_check.\n\n :param f: roslaunch file name, ``str``\n :returns: error message or ``None``\n \"\"\"\n try:\n rl_config = roslaunch.config.load_config_default([f], DEFAULT_MASTER_PORT, verbose=False)\n except roslaunch.core.RLException as e:\n return str(e)\n \n errors = []\n # check for missing deps\n base_pkg, file_deps, missing = roslaunch.depends.roslaunch_deps([f])\n for pkg, miss in missing.iteritems():\n if miss:\n errors.append(\"Missing manifest dependencies: %s/manifest.xml: %s\"%(pkg, ', '.join(miss)))\n \n # load all node defs\n nodes = []\n for filename, rldeps in file_deps.iteritems():\n nodes.extend(rldeps.nodes)\n\n # check for missing packages\n rospack = rospkg.RosPack()\n for pkg, node_type in nodes:\n try:\n rospack.get_path(pkg)\n except:\n errors.append(\"cannot find package [%s] for node [%s]\"%(pkg, node_type))\n\n # check for missing nodes\n for pkg, node_type in nodes:\n try:\n if not roslib.packages.find_node(pkg, node_type):\n errors.append(\"cannot find node [%s] in package [%s]\"%(node_type, pkg))\n except Exception as e:\n errors.append(\"unable to find node [%s/%s]: %s\"%(pkg, node_type, str(e)))\n \n # Check for configuration errors, #2889\n for err in rl_config.config_errors:\n errors.append('ROSLaunch config error: %s' % err)\n\n if errors:\n return '\\n'.join(errors)\n \ndef print_file_list(roslaunch_files):\n \"\"\"\n :param roslaunch_files: list of launch files to load, ``str``\n\n :returns: list of files involved in processing roslaunch_files, including the files themselves.\n \"\"\"\n from roslaunch.config import load_config_default, get_roscore_filename\n import roslaunch.xmlloader\n try:\n loader = roslaunch.xmlloader.XmlLoader(resolve_anon=False)\n config = load_config_default(roslaunch_files, None, loader=loader, verbose=False, assign_machines=False)\n files = [os.path.abspath(x) for x in set(config.roslaunch_files) - set([get_roscore_filename()])]\n print('\\n'.join(files))\n except roslaunch.core.RLException as e:\n print(str(e), file=sys.stderr)\n sys.exit(1)\n\n", "path": "tools/roslaunch/src/roslaunch/rlutil.py"}]}
| 3,516 | 202 |
gh_patches_debug_9186
|
rasdani/github-patches
|
git_diff
|
fidals__shopelectro-199
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
SE Iterate tags in templates
[trello origin](https://trello.com/c/zulRj7lF/294-se-iterate-tags-in-templates)
[seo templates doc](https://docs.google.com/document/d/18DFBsuh6NT8hjyihOJ2bxw9zEe8z_070MBQrbAq0kvE/edit#)
**Проблема**
Сеошники после некоторых применений мультисв-в обнаружили заголовок *Блоки питания для ноутбуков устанавливает пользователь и от сети 220 В* [по этому линку](https://www.shopelectro.ru/catalog/categories/bloki-pitaniia-288/tags/ustanavlivaet-polzovatel-and-ot-seti-220-v/)
Получилось нехорошо. Предлагают сделать заголовок таким:
*Блоки питания для ноутбуков от сети 220 В, выбор выходного напряжения - устанавливает пользователь*
**Решение**
Чтобы переделать заголовок, нам нужно добавить в шаблон возможность указывать имя одного конкретного тега.
А решить это можно так: добавляем полноценный tags в seo-шаблоны.
Сейчас у нас только обрезанный tags.titles
</issue>
<code>
[start of shopelectro/views/catalog.py]
1 from functools import partial
2
3 from django.conf import settings
4 from django.http import HttpResponse, HttpResponseForbidden
5 from django.shortcuts import render, get_object_or_404
6 from django.views.decorators.http import require_POST
7 from django.urls import reverse
8 from django_user_agents.utils import get_user_agent
9
10 from catalog.views import catalog
11 from images.models import Image
12 from pages import views as pages_views
13
14 from shopelectro import config
15 from shopelectro import models
16 from shopelectro.views.helpers import set_csrf_cookie
17
18 PRODUCTS_ON_PAGE_PC = 48
19 PRODUCTS_ON_PAGE_MOB = 10
20
21
22 def get_products_count(request):
23 """Get Products count for response context depends on the `user_agent`."""
24 mobile_view = get_user_agent(request).is_mobile
25 return PRODUCTS_ON_PAGE_MOB if mobile_view else PRODUCTS_ON_PAGE_PC
26
27
28 # CATALOG VIEWS
29 class CategoryTree(catalog.CategoryTree):
30 category_model = models.Category
31
32
33 @set_csrf_cookie
34 class ProductPage(catalog.ProductPage):
35 pk_url_kwarg = None
36 slug_url_kwarg = 'product_vendor_code'
37 slug_field = 'vendor_code'
38
39 queryset = (
40 models.Product.objects
41 .filter(category__isnull=False)
42 .prefetch_related('product_feedbacks', 'page__images')
43 .select_related('page')
44 )
45
46 def get_context_data(self, **kwargs):
47 context = super(ProductPage, self).get_context_data(**kwargs)
48
49 group_tags_pairs = (
50 models.Tag.objects
51 .filter(products=self.object)
52 .get_group_tags_pairs()
53 )
54
55 return {
56 **context,
57 'price_bounds': config.PRICE_BOUNDS,
58 'group_tags_pairs': group_tags_pairs
59 }
60
61
62 # SHOPELECTRO-SPECIFIC VIEWS
63 @set_csrf_cookie
64 class IndexPage(pages_views.CustomPageView):
65
66 def get_context_data(self, **kwargs):
67 """Extended method. Add product's images to context."""
68 context = super(IndexPage, self).get_context_data(**kwargs)
69 mobile_view = get_user_agent(self.request).is_mobile
70
71 top_products = (
72 models.Product.objects
73 .filter(id__in=settings.TOP_PRODUCTS)
74 .prefetch_related('category')
75 .select_related('page')
76 )
77
78 images = Image.objects.get_main_images_by_pages(
79 models.ProductPage.objects.filter(
80 shopelectro_product__in=top_products
81 )
82 )
83
84 categories = models.Category.objects.get_root_categories_by_products(
85 top_products)
86
87 prepared_top_products = []
88 if not mobile_view:
89 prepared_top_products = [
90 (product, images.get(product.page), categories.get(product))
91 for product in top_products
92 ]
93
94 return {
95 **context,
96 'category_tile': config.MAIN_PAGE_TILE,
97 'prepared_top_products': prepared_top_products,
98 }
99
100
101 def merge_products_and_images(products):
102 images = Image.objects.get_main_images_by_pages(
103 models.ProductPage.objects.filter(shopelectro_product__in=products)
104 )
105
106 return [
107 (product, images.get(product.page))
108 for product in products
109 ]
110
111
112 @set_csrf_cookie
113 class CategoryPage(catalog.CategoryPage):
114
115 def get_context_data(self, **kwargs):
116 """Add sorting options and view_types in context."""
117 context = super(CategoryPage, self).get_context_data(**kwargs)
118 products_on_page = get_products_count(self.request)
119
120 # tile is default view_type
121 view_type = self.request.session.get('view_type', 'tile')
122
123 category = context['category']
124
125 sorting = int(self.kwargs.get('sorting', 0))
126 sorting_option = config.category_sorting(sorting)
127
128 all_products = (
129 models.Product.objects
130 .prefetch_related('page__images')
131 .select_related('page')
132 .get_by_category(category, ordering=(sorting_option, ))
133 )
134
135 group_tags_pairs = (
136 models.Tag.objects
137 .filter(products__in=all_products)
138 .get_group_tags_pairs()
139 )
140
141 tags = self.kwargs.get('tags')
142 tags_metadata = {
143 'titles': '',
144 }
145
146 if tags:
147 slugs = models.Tag.parse_url_tags(tags)
148 tags = models.Tag.objects.filter(slug__in=slugs)
149
150 all_products = (
151 all_products
152 .filter(tags__in=tags)
153 # Use distinct because filtering by QuerySet tags,
154 # that related with products by many-to-many relation.
155 .distinct(sorting_option.lstrip('-'))
156 )
157
158 tags_titles = models.Tag.serialize_title_tags(
159 tags.get_group_tags_pairs()
160 )
161
162 tags_metadata['titles'] = tags_titles
163
164 def template_context(page, tags):
165 return {
166 'page': page,
167 'tags': tags,
168 }
169
170 page = context['page']
171 page.get_template_render_context = partial(
172 template_context, page, tags_metadata)
173
174 products = all_products.get_offset(0, products_on_page)
175
176 return {
177 **context,
178 'product_image_pairs': merge_products_and_images(products),
179 'group_tags_pairs': group_tags_pairs,
180 'total_products': all_products.count(),
181 'sorting_options': config.category_sorting(),
182 'sort': sorting,
183 'tags': tags,
184 'view_type': view_type,
185 'tags_metadata': tags_metadata,
186 'skip_canonical': bool(tags),
187 }
188
189
190 def load_more(request, category_slug, offset=0, sorting=0, tags=None):
191 """
192 Load more products of a given category.
193
194 :param sorting: preferred sorting index from CATEGORY_SORTING tuple
195 :param request: HttpRequest object
196 :param category_slug: Slug for a given category
197 :param offset: used for slicing QuerySet.
198 :return:
199 """
200 products_on_page = get_products_count(request)
201
202 category = get_object_or_404(models.CategoryPage, slug=category_slug).model
203 sorting_option = config.category_sorting(int(sorting))
204
205 products = (
206 models.Product.objects
207 .prefetch_related('page__images')
208 .select_related('page')
209 .get_by_category(category, ordering=(sorting_option,))
210 )
211
212 if tags:
213 tag_entities = models.Tag.objects.filter(
214 slug__in=models.Tag.parse_url_tags(tags)
215 )
216
217 products = (
218 products
219 .filter(tags__in=tag_entities)
220 # Use distinct because filtering by QuerySet tags,
221 # that related with products by many-to-many relation.
222 .distinct(sorting_option.lstrip('-'))
223 )
224
225 products = products.get_offset(int(offset), products_on_page)
226 view = request.session.get('view_type', 'tile')
227
228 return render(request, 'catalog/category_products.html', {
229 'product_image_pairs': merge_products_and_images(products),
230 'view_type': view,
231 'prods': products_on_page,
232 })
233
234
235 @require_POST
236 def save_feedback(request):
237 def get_keys_from_post(*args):
238 return {arg: request.POST.get(arg, '') for arg in args}
239
240 product_id = request.POST.get('id')
241 product = models.Product.objects.filter(id=product_id).first()
242 if not (product_id and product):
243 return HttpResponse(status=422)
244
245 fields = ['rating', 'name', 'dignities', 'limitations', 'general']
246 feedback_data = get_keys_from_post(*fields)
247
248 models.ProductFeedback.objects.create(product=product, **feedback_data)
249 return HttpResponse('ok')
250
251
252 @require_POST
253 def delete_feedback(request):
254 if not request.user.is_authenticated:
255 return HttpResponseForbidden('Not today, sly guy...')
256
257 feedback_id = request.POST.get('id')
258 feedback = models.ProductFeedback.objects.filter(id=feedback_id).first()
259 if not (feedback_id and feedback):
260 return HttpResponse(status=422)
261
262 feedback.delete()
263 return HttpResponse('Feedback with id={} was deleted.'.format(feedback_id))
264
265
266 class ProductsWithoutImages(catalog.ProductsWithoutImages):
267 model = models.Product
268
269
270 class ProductsWithoutText(catalog.ProductsWithoutText):
271 model = models.Product
272
[end of shopelectro/views/catalog.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/shopelectro/views/catalog.py b/shopelectro/views/catalog.py
--- a/shopelectro/views/catalog.py
+++ b/shopelectro/views/catalog.py
@@ -141,6 +141,7 @@
tags = self.kwargs.get('tags')
tags_metadata = {
'titles': '',
+ 'raw': [],
}
if tags:
@@ -160,6 +161,7 @@
)
tags_metadata['titles'] = tags_titles
+ tags_metadata['raw'] = tags
def template_context(page, tags):
return {
|
{"golden_diff": "diff --git a/shopelectro/views/catalog.py b/shopelectro/views/catalog.py\n--- a/shopelectro/views/catalog.py\n+++ b/shopelectro/views/catalog.py\n@@ -141,6 +141,7 @@\n tags = self.kwargs.get('tags')\n tags_metadata = {\n 'titles': '',\n+ 'raw': [],\n }\n \n if tags:\n@@ -160,6 +161,7 @@\n )\n \n tags_metadata['titles'] = tags_titles\n+ tags_metadata['raw'] = tags\n \n def template_context(page, tags):\n return {\n", "issue": "SE Iterate tags in templates\n[trello origin](https://trello.com/c/zulRj7lF/294-se-iterate-tags-in-templates)\r\n[seo templates doc](https://docs.google.com/document/d/18DFBsuh6NT8hjyihOJ2bxw9zEe8z_070MBQrbAq0kvE/edit#)\r\n\r\n**\u041f\u0440\u043e\u0431\u043b\u0435\u043c\u0430**\r\n\u0421\u0435\u043e\u0448\u043d\u0438\u043a\u0438 \u043f\u043e\u0441\u043b\u0435 \u043d\u0435\u043a\u043e\u0442\u043e\u0440\u044b\u0445 \u043f\u0440\u0438\u043c\u0435\u043d\u0435\u043d\u0438\u0439 \u043c\u0443\u043b\u044c\u0442\u0438\u0441\u0432-\u0432 \u043e\u0431\u043d\u0430\u0440\u0443\u0436\u0438\u043b\u0438 \u0437\u0430\u0433\u043e\u043b\u043e\u0432\u043e\u043a *\u0411\u043b\u043e\u043a\u0438 \u043f\u0438\u0442\u0430\u043d\u0438\u044f \u0434\u043b\u044f \u043d\u043e\u0443\u0442\u0431\u0443\u043a\u043e\u0432 \u0443\u0441\u0442\u0430\u043d\u0430\u0432\u043b\u0438\u0432\u0430\u0435\u0442 \u043f\u043e\u043b\u044c\u0437\u043e\u0432\u0430\u0442\u0435\u043b\u044c \u0438 \u043e\u0442 \u0441\u0435\u0442\u0438 220 \u0412* [\u043f\u043e \u044d\u0442\u043e\u043c\u0443 \u043b\u0438\u043d\u043a\u0443](https://www.shopelectro.ru/catalog/categories/bloki-pitaniia-288/tags/ustanavlivaet-polzovatel-and-ot-seti-220-v/)\r\n\r\n\u041f\u043e\u043b\u0443\u0447\u0438\u043b\u043e\u0441\u044c \u043d\u0435\u0445\u043e\u0440\u043e\u0448\u043e. \u041f\u0440\u0435\u0434\u043b\u0430\u0433\u0430\u044e\u0442 \u0441\u0434\u0435\u043b\u0430\u0442\u044c \u0437\u0430\u0433\u043e\u043b\u043e\u0432\u043e\u043a \u0442\u0430\u043a\u0438\u043c:\r\n*\u0411\u043b\u043e\u043a\u0438 \u043f\u0438\u0442\u0430\u043d\u0438\u044f \u0434\u043b\u044f \u043d\u043e\u0443\u0442\u0431\u0443\u043a\u043e\u0432 \u043e\u0442 \u0441\u0435\u0442\u0438 220 \u0412, \u0432\u044b\u0431\u043e\u0440 \u0432\u044b\u0445\u043e\u0434\u043d\u043e\u0433\u043e \u043d\u0430\u043f\u0440\u044f\u0436\u0435\u043d\u0438\u044f - \u0443\u0441\u0442\u0430\u043d\u0430\u0432\u043b\u0438\u0432\u0430\u0435\u0442 \u043f\u043e\u043b\u044c\u0437\u043e\u0432\u0430\u0442\u0435\u043b\u044c*\r\n\r\n\r\n**\u0420\u0435\u0448\u0435\u043d\u0438\u0435**\r\n\u0427\u0442\u043e\u0431\u044b \u043f\u0435\u0440\u0435\u0434\u0435\u043b\u0430\u0442\u044c \u0437\u0430\u0433\u043e\u043b\u043e\u0432\u043e\u043a, \u043d\u0430\u043c \u043d\u0443\u0436\u043d\u043e \u0434\u043e\u0431\u0430\u0432\u0438\u0442\u044c \u0432 \u0448\u0430\u0431\u043b\u043e\u043d \u0432\u043e\u0437\u043c\u043e\u0436\u043d\u043e\u0441\u0442\u044c \u0443\u043a\u0430\u0437\u044b\u0432\u0430\u0442\u044c \u0438\u043c\u044f \u043e\u0434\u043d\u043e\u0433\u043e \u043a\u043e\u043d\u043a\u0440\u0435\u0442\u043d\u043e\u0433\u043e \u0442\u0435\u0433\u0430.\r\n\r\n\u0410 \u0440\u0435\u0448\u0438\u0442\u044c \u044d\u0442\u043e \u043c\u043e\u0436\u043d\u043e \u0442\u0430\u043a: \u0434\u043e\u0431\u0430\u0432\u043b\u044f\u0435\u043c \u043f\u043e\u043b\u043d\u043e\u0446\u0435\u043d\u043d\u044b\u0439 tags \u0432 seo-\u0448\u0430\u0431\u043b\u043e\u043d\u044b.\r\n\u0421\u0435\u0439\u0447\u0430\u0441 \u0443 \u043d\u0430\u0441 \u0442\u043e\u043b\u044c\u043a\u043e \u043e\u0431\u0440\u0435\u0437\u0430\u043d\u043d\u044b\u0439 tags.titles\n", "before_files": [{"content": "from functools import partial\n\nfrom django.conf import settings\nfrom django.http import HttpResponse, HttpResponseForbidden\nfrom django.shortcuts import render, get_object_or_404\nfrom django.views.decorators.http import require_POST\nfrom django.urls import reverse\nfrom django_user_agents.utils import get_user_agent\n\nfrom catalog.views import catalog\nfrom images.models import Image\nfrom pages import views as pages_views\n\nfrom shopelectro import config\nfrom shopelectro import models\nfrom shopelectro.views.helpers import set_csrf_cookie\n\nPRODUCTS_ON_PAGE_PC = 48\nPRODUCTS_ON_PAGE_MOB = 10\n\n\ndef get_products_count(request):\n \"\"\"Get Products count for response context depends on the `user_agent`.\"\"\"\n mobile_view = get_user_agent(request).is_mobile\n return PRODUCTS_ON_PAGE_MOB if mobile_view else PRODUCTS_ON_PAGE_PC\n\n\n# CATALOG VIEWS\nclass CategoryTree(catalog.CategoryTree):\n category_model = models.Category\n\n\n@set_csrf_cookie\nclass ProductPage(catalog.ProductPage):\n pk_url_kwarg = None\n slug_url_kwarg = 'product_vendor_code'\n slug_field = 'vendor_code'\n\n queryset = (\n models.Product.objects\n .filter(category__isnull=False)\n .prefetch_related('product_feedbacks', 'page__images')\n .select_related('page')\n )\n\n def get_context_data(self, **kwargs):\n context = super(ProductPage, self).get_context_data(**kwargs)\n\n group_tags_pairs = (\n models.Tag.objects\n .filter(products=self.object)\n .get_group_tags_pairs()\n )\n\n return {\n **context,\n 'price_bounds': config.PRICE_BOUNDS,\n 'group_tags_pairs': group_tags_pairs\n }\n\n\n# SHOPELECTRO-SPECIFIC VIEWS\n@set_csrf_cookie\nclass IndexPage(pages_views.CustomPageView):\n\n def get_context_data(self, **kwargs):\n \"\"\"Extended method. Add product's images to context.\"\"\"\n context = super(IndexPage, self).get_context_data(**kwargs)\n mobile_view = get_user_agent(self.request).is_mobile\n\n top_products = (\n models.Product.objects\n .filter(id__in=settings.TOP_PRODUCTS)\n .prefetch_related('category')\n .select_related('page')\n )\n\n images = Image.objects.get_main_images_by_pages(\n models.ProductPage.objects.filter(\n shopelectro_product__in=top_products\n )\n )\n\n categories = models.Category.objects.get_root_categories_by_products(\n top_products)\n\n prepared_top_products = []\n if not mobile_view:\n prepared_top_products = [\n (product, images.get(product.page), categories.get(product))\n for product in top_products\n ]\n\n return {\n **context,\n 'category_tile': config.MAIN_PAGE_TILE,\n 'prepared_top_products': prepared_top_products,\n }\n\n\ndef merge_products_and_images(products):\n images = Image.objects.get_main_images_by_pages(\n models.ProductPage.objects.filter(shopelectro_product__in=products)\n )\n\n return [\n (product, images.get(product.page))\n for product in products\n ]\n\n\n@set_csrf_cookie\nclass CategoryPage(catalog.CategoryPage):\n\n def get_context_data(self, **kwargs):\n \"\"\"Add sorting options and view_types in context.\"\"\"\n context = super(CategoryPage, self).get_context_data(**kwargs)\n products_on_page = get_products_count(self.request)\n\n # tile is default view_type\n view_type = self.request.session.get('view_type', 'tile')\n\n category = context['category']\n\n sorting = int(self.kwargs.get('sorting', 0))\n sorting_option = config.category_sorting(sorting)\n\n all_products = (\n models.Product.objects\n .prefetch_related('page__images')\n .select_related('page')\n .get_by_category(category, ordering=(sorting_option, ))\n )\n\n group_tags_pairs = (\n models.Tag.objects\n .filter(products__in=all_products)\n .get_group_tags_pairs()\n )\n\n tags = self.kwargs.get('tags')\n tags_metadata = {\n 'titles': '',\n }\n\n if tags:\n slugs = models.Tag.parse_url_tags(tags)\n tags = models.Tag.objects.filter(slug__in=slugs)\n\n all_products = (\n all_products\n .filter(tags__in=tags)\n # Use distinct because filtering by QuerySet tags,\n # that related with products by many-to-many relation.\n .distinct(sorting_option.lstrip('-'))\n )\n\n tags_titles = models.Tag.serialize_title_tags(\n tags.get_group_tags_pairs()\n )\n\n tags_metadata['titles'] = tags_titles\n\n def template_context(page, tags):\n return {\n 'page': page,\n 'tags': tags,\n }\n\n page = context['page']\n page.get_template_render_context = partial(\n template_context, page, tags_metadata)\n\n products = all_products.get_offset(0, products_on_page)\n\n return {\n **context,\n 'product_image_pairs': merge_products_and_images(products),\n 'group_tags_pairs': group_tags_pairs,\n 'total_products': all_products.count(),\n 'sorting_options': config.category_sorting(),\n 'sort': sorting,\n 'tags': tags,\n 'view_type': view_type,\n 'tags_metadata': tags_metadata,\n 'skip_canonical': bool(tags),\n }\n\n\ndef load_more(request, category_slug, offset=0, sorting=0, tags=None):\n \"\"\"\n Load more products of a given category.\n\n :param sorting: preferred sorting index from CATEGORY_SORTING tuple\n :param request: HttpRequest object\n :param category_slug: Slug for a given category\n :param offset: used for slicing QuerySet.\n :return:\n \"\"\"\n products_on_page = get_products_count(request)\n\n category = get_object_or_404(models.CategoryPage, slug=category_slug).model\n sorting_option = config.category_sorting(int(sorting))\n\n products = (\n models.Product.objects\n .prefetch_related('page__images')\n .select_related('page')\n .get_by_category(category, ordering=(sorting_option,))\n )\n\n if tags:\n tag_entities = models.Tag.objects.filter(\n slug__in=models.Tag.parse_url_tags(tags)\n )\n\n products = (\n products\n .filter(tags__in=tag_entities)\n # Use distinct because filtering by QuerySet tags,\n # that related with products by many-to-many relation.\n .distinct(sorting_option.lstrip('-'))\n )\n\n products = products.get_offset(int(offset), products_on_page)\n view = request.session.get('view_type', 'tile')\n\n return render(request, 'catalog/category_products.html', {\n 'product_image_pairs': merge_products_and_images(products),\n 'view_type': view,\n 'prods': products_on_page,\n })\n\n\n@require_POST\ndef save_feedback(request):\n def get_keys_from_post(*args):\n return {arg: request.POST.get(arg, '') for arg in args}\n\n product_id = request.POST.get('id')\n product = models.Product.objects.filter(id=product_id).first()\n if not (product_id and product):\n return HttpResponse(status=422)\n\n fields = ['rating', 'name', 'dignities', 'limitations', 'general']\n feedback_data = get_keys_from_post(*fields)\n\n models.ProductFeedback.objects.create(product=product, **feedback_data)\n return HttpResponse('ok')\n\n\n@require_POST\ndef delete_feedback(request):\n if not request.user.is_authenticated:\n return HttpResponseForbidden('Not today, sly guy...')\n\n feedback_id = request.POST.get('id')\n feedback = models.ProductFeedback.objects.filter(id=feedback_id).first()\n if not (feedback_id and feedback):\n return HttpResponse(status=422)\n\n feedback.delete()\n return HttpResponse('Feedback with id={} was deleted.'.format(feedback_id))\n\n\nclass ProductsWithoutImages(catalog.ProductsWithoutImages):\n model = models.Product\n\n\nclass ProductsWithoutText(catalog.ProductsWithoutText):\n model = models.Product\n", "path": "shopelectro/views/catalog.py"}]}
| 3,305 | 134 |
gh_patches_debug_17994
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-6938
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Anthropologie spider produces transposed coordinates
https://www.alltheplaces.xyz/map/#7.69/-75.171/39.95

The cause is the upstream data:
https://www.anthropologie.com/stores/rittenhouse-square-philadelphia

It might be worth doing any of the following:
- Suspend the lat/long from the parser for now
- Contact the company (I'll probably do that shortly) about the bug
- Any kind of high level validations that can check the expected bounds for a scraper, vs the results?
</issue>
<code>
[start of locations/spiders/anthropologie.py]
1 from scrapy.spiders import SitemapSpider
2
3 from locations.structured_data_spider import StructuredDataSpider
4
5
6 class AnthropologieSpider(SitemapSpider, StructuredDataSpider):
7 name = "anthropologie"
8 item_attributes = {"brand": "Anthropologie", "brand_wikidata": "Q4773903"}
9 allowed_domains = ["anthropologie.com"]
10 sitemap_urls = ["https://www.anthropologie.com/store_sitemap.xml"]
11 sitemap_rules = [("/stores/", "parse_sd")]
12 requires_proxy = True
13
[end of locations/spiders/anthropologie.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/locations/spiders/anthropologie.py b/locations/spiders/anthropologie.py
--- a/locations/spiders/anthropologie.py
+++ b/locations/spiders/anthropologie.py
@@ -1,5 +1,6 @@
from scrapy.spiders import SitemapSpider
+from locations.items import set_closed
from locations.structured_data_spider import StructuredDataSpider
@@ -10,3 +11,17 @@
sitemap_urls = ["https://www.anthropologie.com/store_sitemap.xml"]
sitemap_rules = [("/stores/", "parse_sd")]
requires_proxy = True
+
+ def pre_process_data(self, ld_data, **kwargs):
+ ld_data["geo"]["latitude"], ld_data["geo"]["longitude"] = (
+ ld_data["geo"]["longitude"],
+ ld_data["geo"]["latitude"],
+ )
+
+ def post_process_item(self, item, response, ld_data, **kwargs):
+ item["branch"] = item.pop("name").removeprefix(" - Anthropologie Store")
+
+ if item["branch"].startswith("Closed - ") or item["branch"].endswith(" - Closed"):
+ set_closed(item)
+
+ yield item
|
{"golden_diff": "diff --git a/locations/spiders/anthropologie.py b/locations/spiders/anthropologie.py\n--- a/locations/spiders/anthropologie.py\n+++ b/locations/spiders/anthropologie.py\n@@ -1,5 +1,6 @@\n from scrapy.spiders import SitemapSpider\n \n+from locations.items import set_closed\n from locations.structured_data_spider import StructuredDataSpider\n \n \n@@ -10,3 +11,17 @@\n sitemap_urls = [\"https://www.anthropologie.com/store_sitemap.xml\"]\n sitemap_rules = [(\"/stores/\", \"parse_sd\")]\n requires_proxy = True\n+\n+ def pre_process_data(self, ld_data, **kwargs):\n+ ld_data[\"geo\"][\"latitude\"], ld_data[\"geo\"][\"longitude\"] = (\n+ ld_data[\"geo\"][\"longitude\"],\n+ ld_data[\"geo\"][\"latitude\"],\n+ )\n+\n+ def post_process_item(self, item, response, ld_data, **kwargs):\n+ item[\"branch\"] = item.pop(\"name\").removeprefix(\" - Anthropologie Store\")\n+\n+ if item[\"branch\"].startswith(\"Closed - \") or item[\"branch\"].endswith(\" - Closed\"):\n+ set_closed(item)\n+\n+ yield item\n", "issue": "Anthropologie spider produces transposed coordinates\nhttps://www.alltheplaces.xyz/map/#7.69/-75.171/39.95\r\n\r\n\r\n\r\nThe cause is the upstream data:\r\n\r\nhttps://www.anthropologie.com/stores/rittenhouse-square-philadelphia\r\n\r\n\r\nIt might be worth doing any of the following:\r\n\r\n- Suspend the lat/long from the parser for now\r\n- Contact the company (I'll probably do that shortly) about the bug\r\n- Any kind of high level validations that can check the expected bounds for a scraper, vs the results?\r\n\r\n\n", "before_files": [{"content": "from scrapy.spiders import SitemapSpider\n\nfrom locations.structured_data_spider import StructuredDataSpider\n\n\nclass AnthropologieSpider(SitemapSpider, StructuredDataSpider):\n name = \"anthropologie\"\n item_attributes = {\"brand\": \"Anthropologie\", \"brand_wikidata\": \"Q4773903\"}\n allowed_domains = [\"anthropologie.com\"]\n sitemap_urls = [\"https://www.anthropologie.com/store_sitemap.xml\"]\n sitemap_rules = [(\"/stores/\", \"parse_sd\")]\n requires_proxy = True\n", "path": "locations/spiders/anthropologie.py"}]}
| 909 | 268 |
gh_patches_debug_29189
|
rasdani/github-patches
|
git_diff
|
pytorch__pytorch-53822
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Problems in TensorPipeRpcBackendOptions device mapping documentation?
## 📚 Documentation
The new release of PyTorch 1.8 introduces CUDA-support in RPC.
I've referred to the RPC documentation, and the only reference for the CUDA-support I could find is under [`TensorPipeRpcBackendOptions`](https://pytorch.org/docs/1.8.0/rpc.html#torch.distributed.rpc.TensorPipeRpcBackendOptions) and [`set_device_map`](https://pytorch.org/docs/1.8.0/rpc.html#torch.distributed.rpc.TensorPipeRpcBackendOptions.set_device_map).
Seems like setting up CUDA-support is simply done by supplying a device mapping in the `TensorPipeRpcBackendOptions`, pretty cool.
However, I find the documentation for the `device_maps`/`device_map` to be unclear. It seems that `TensorPipeRpcBackendOptions`'s `device_maps` is a dictionary where the keys are worker names, but I'm not exactly sure what the structure of the dictionary's values should be like? Supposedly each value should be some sort of dictionary (as indicated by the parameter's type - `Dict[str, Dict]`), yet the example code provides a set: `device_maps={"worker1": {0, 1}}`. I don't really understand how does this "map worker0's cuda:0 to worker1's cuda:1"?
Same for `set_device_map`'s `device_map`, the parameter's type also indicates it's a dictionary (`(Dict of python:int, str, or torch.device)`), but doesn't quite explain its structure. And again, the example code provides a set: `options.set_device_map("worker1", {1, 2})`.
It is also not explained how to define a GPU->CPU mapping (or vice versa).
Apart for this, there are 2 obvious errors in the example code provided in that documentation:
1. There is a missing comma in the following part:
```python
>>> rpc.init_rpc(
>>> "worker0",
>>> rank=0,
>>> world_size=2 # <-- missing comma
>>> backend=rpc.BackendType.TENSORPIPE,
>>> rpc_backend_options=options
>>> )
```
2. I don't see how it is possible that those two `print`s will give different results. I'm guessing that the second line should read `print(rets[1])`?
```python
>>> print(rets[0]) # tensor([2., 2.], device='cuda:0')
>>> print(rets[0]) # tensor([2., 2.], device='cuda:1')
```
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @gqchen @aazzolini @rohan-varma @jjlilley @osalpekar @jiayisuse @mrzzd @agolynski @SciPioneer @H-Huang @cbalioglu
</issue>
<code>
[start of torch/distributed/rpc/options.py]
1 from torch._C._distributed_rpc import _TensorPipeRpcBackendOptionsBase
2 from . import constants as rpc_contants
3
4 import torch
5
6 from typing import Dict, List
7
8
9 class TensorPipeRpcBackendOptions(_TensorPipeRpcBackendOptionsBase):
10 r"""
11 The backend options for
12 :class:`~torch.distributed.rpc.TensorPipeAgent`, derived from
13 :class:`~torch.distributed.rpc.RpcBackendOptions`.
14
15 Args:
16 num_worker_threads (int, optional): The number of threads in the
17 thread-pool used by
18 :class:`~torch.distributed.rpc.TensorPipeAgent` to execute
19 requests (default: 16).
20 rpc_timeout (float, optional): The default timeout, in seconds,
21 for RPC requests (default: 60 seconds). If the RPC has not
22 completed in this timeframe, an exception indicating so will
23 be raised. Callers can override this timeout for individual
24 RPCs in :meth:`~torch.distributed.rpc.rpc_sync` and
25 :meth:`~torch.distributed.rpc.rpc_async` if necessary.
26 init_method (str, optional): The URL to initialize the distributed
27 store used for rendezvous. It takes any value accepted for the
28 same argument of :meth:`~torch.distributed.init_process_group`
29 (default: ``env://``).
30 device_maps (Dict[str, Dict]): Device placement mappings from this
31 worker to the callee. Key is the callee worker name and value the
32 dictionary (``Dict`` of ``int``, ``str``, or ``torch.device``) that
33 maps this worker's devices to the callee worker's devices.
34 (default: ``None``)
35 """
36 def __init__(
37 self,
38 *,
39 num_worker_threads: int = rpc_contants.DEFAULT_NUM_WORKER_THREADS,
40 rpc_timeout: float = rpc_contants.DEFAULT_RPC_TIMEOUT_SEC,
41 init_method: str = rpc_contants.DEFAULT_INIT_METHOD,
42 device_maps: Dict = None,
43 _transports: List = None,
44 _channels: List = None,
45 ):
46 super().__init__(
47 num_worker_threads,
48 _transports,
49 _channels,
50 rpc_timeout,
51 init_method,
52 device_maps if device_maps else {}
53 )
54
55 def set_device_map(self, to: str, device_map: Dict):
56 r"""
57 Set device mapping between each RPC caller and callee pair. This
58 function can be called multiple times to incrementally add
59 device placement configurations.
60
61 Args:
62 worker_name (str): Callee name.
63 device_map (Dict of int, str, or torch.device): Device placement
64 mappings from this worker to the callee. This map must be
65 invertible.
66
67 Example::
68 >>> # both workers
69 >>> def add(x, y):
70 >>> print(x) # tensor([1., 1.], device='cuda:1')
71 >>> return x + y, (x + y).to(2)
72 >>>
73 >>> # on worker 0
74 >>> options = TensorPipeRpcBackendOptions(
75 >>> num_worker_threads=8,
76 >>> device_maps={"worker1": {0, 1}}
77 >>> # maps worker0's cuda:0 to worker1's cuda:1
78 >>> )
79 >>> options.set_device_map("worker1", {1, 2})
80 >>> # maps worker0's cuda:1 to worker1's cuda:2
81 >>>
82 >>> rpc.init_rpc(
83 >>> "worker0",
84 >>> rank=0,
85 >>> world_size=2
86 >>> backend=rpc.BackendType.TENSORPIPE,
87 >>> rpc_backend_options=options
88 >>> )
89 >>>
90 >>> x = torch.ones(2)
91 >>> rets = rpc.rpc_sync("worker1", add, args=(x.to(0), 1))
92 >>> # The first argument will be moved to cuda:1 on worker1. When
93 >>> # sending the return value back, it will follow the invert of
94 >>> # the device map, and hence will be moved back to cuda:0 and
95 >>> # cuda:1 on worker0
96 >>> print(rets[0]) # tensor([2., 2.], device='cuda:0')
97 >>> print(rets[0]) # tensor([2., 2.], device='cuda:1')
98 """
99 device_index_map = {}
100 curr_device_maps = super().device_maps
101 for k in device_map:
102 v = device_map[k]
103 k, v = torch.device(k), torch.device(v)
104 if k.type != 'cuda' or v.type != 'cuda':
105 raise ValueError(
106 "`set_device_map` only supports CUDA devices, "
107 f"but got device pair {k}: {v}"
108
109 )
110 if to in curr_device_maps and k.index in curr_device_maps[to]:
111 curr_v = super().device_maps[to][k.index]
112 if curr_v != v.index:
113 raise ValueError(
114 "`set_device_map` only supports 1-to-1 mapping, "
115 f"trying to map {k} to {v} and {curr_v}"
116 )
117 device_index_map[k.index] = v.index
118 super().set_device_map(to, device_index_map)
119
[end of torch/distributed/rpc/options.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/torch/distributed/rpc/options.py b/torch/distributed/rpc/options.py
--- a/torch/distributed/rpc/options.py
+++ b/torch/distributed/rpc/options.py
@@ -73,16 +73,16 @@
>>> # on worker 0
>>> options = TensorPipeRpcBackendOptions(
>>> num_worker_threads=8,
- >>> device_maps={"worker1": {0, 1}}
+ >>> device_maps={"worker1": {0: 1}}
>>> # maps worker0's cuda:0 to worker1's cuda:1
>>> )
- >>> options.set_device_map("worker1", {1, 2})
+ >>> options.set_device_map("worker1", {1: 2})
>>> # maps worker0's cuda:1 to worker1's cuda:2
>>>
>>> rpc.init_rpc(
>>> "worker0",
>>> rank=0,
- >>> world_size=2
+ >>> world_size=2,
>>> backend=rpc.BackendType.TENSORPIPE,
>>> rpc_backend_options=options
>>> )
@@ -94,7 +94,7 @@
>>> # the device map, and hence will be moved back to cuda:0 and
>>> # cuda:1 on worker0
>>> print(rets[0]) # tensor([2., 2.], device='cuda:0')
- >>> print(rets[0]) # tensor([2., 2.], device='cuda:1')
+ >>> print(rets[1]) # tensor([2., 2.], device='cuda:1')
"""
device_index_map = {}
curr_device_maps = super().device_maps
|
{"golden_diff": "diff --git a/torch/distributed/rpc/options.py b/torch/distributed/rpc/options.py\n--- a/torch/distributed/rpc/options.py\n+++ b/torch/distributed/rpc/options.py\n@@ -73,16 +73,16 @@\n >>> # on worker 0\n >>> options = TensorPipeRpcBackendOptions(\n >>> num_worker_threads=8,\n- >>> device_maps={\"worker1\": {0, 1}}\n+ >>> device_maps={\"worker1\": {0: 1}}\n >>> # maps worker0's cuda:0 to worker1's cuda:1\n >>> )\n- >>> options.set_device_map(\"worker1\", {1, 2})\n+ >>> options.set_device_map(\"worker1\", {1: 2})\n >>> # maps worker0's cuda:1 to worker1's cuda:2\n >>>\n >>> rpc.init_rpc(\n >>> \"worker0\",\n >>> rank=0,\n- >>> world_size=2\n+ >>> world_size=2,\n >>> backend=rpc.BackendType.TENSORPIPE,\n >>> rpc_backend_options=options\n >>> )\n@@ -94,7 +94,7 @@\n >>> # the device map, and hence will be moved back to cuda:0 and\n >>> # cuda:1 on worker0\n >>> print(rets[0]) # tensor([2., 2.], device='cuda:0')\n- >>> print(rets[0]) # tensor([2., 2.], device='cuda:1')\n+ >>> print(rets[1]) # tensor([2., 2.], device='cuda:1')\n \"\"\"\n device_index_map = {}\n curr_device_maps = super().device_maps\n", "issue": "Problems in TensorPipeRpcBackendOptions device mapping documentation?\n## \ud83d\udcda Documentation\r\n\r\nThe new release of PyTorch 1.8 introduces CUDA-support in RPC.\r\nI've referred to the RPC documentation, and the only reference for the CUDA-support I could find is under [`TensorPipeRpcBackendOptions`](https://pytorch.org/docs/1.8.0/rpc.html#torch.distributed.rpc.TensorPipeRpcBackendOptions) and [`set_device_map`](https://pytorch.org/docs/1.8.0/rpc.html#torch.distributed.rpc.TensorPipeRpcBackendOptions.set_device_map).\r\nSeems like setting up CUDA-support is simply done by supplying a device mapping in the `TensorPipeRpcBackendOptions`, pretty cool.\r\n\r\nHowever, I find the documentation for the `device_maps`/`device_map` to be unclear. It seems that `TensorPipeRpcBackendOptions`'s `device_maps` is a dictionary where the keys are worker names, but I'm not exactly sure what the structure of the dictionary's values should be like? Supposedly each value should be some sort of dictionary (as indicated by the parameter's type - `Dict[str, Dict]`), yet the example code provides a set: `device_maps={\"worker1\": {0, 1}}`. I don't really understand how does this \"map worker0's cuda:0 to worker1's cuda:1\"?\r\n\r\nSame for `set_device_map`'s `device_map`, the parameter's type also indicates it's a dictionary (`(Dict of python:int, str, or torch.device)`), but doesn't quite explain its structure. And again, the example code provides a set: `options.set_device_map(\"worker1\", {1, 2})`.\r\n\r\nIt is also not explained how to define a GPU->CPU mapping (or vice versa).\r\n\r\nApart for this, there are 2 obvious errors in the example code provided in that documentation:\r\n\r\n1. There is a missing comma in the following part:\r\n```python\r\n>>> rpc.init_rpc(\r\n>>> \"worker0\",\r\n>>> rank=0,\r\n>>> world_size=2 # <-- missing comma\r\n>>> backend=rpc.BackendType.TENSORPIPE,\r\n>>> rpc_backend_options=options\r\n>>> )\r\n```\r\n2. I don't see how it is possible that those two `print`s will give different results. I'm guessing that the second line should read `print(rets[1])`?\r\n```python\r\n>>> print(rets[0]) # tensor([2., 2.], device='cuda:0')\r\n>>> print(rets[0]) # tensor([2., 2.], device='cuda:1')\r\n```\n\ncc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @gqchen @aazzolini @rohan-varma @jjlilley @osalpekar @jiayisuse @mrzzd @agolynski @SciPioneer @H-Huang @cbalioglu\n", "before_files": [{"content": "from torch._C._distributed_rpc import _TensorPipeRpcBackendOptionsBase\nfrom . import constants as rpc_contants\n\nimport torch\n\nfrom typing import Dict, List\n\n\nclass TensorPipeRpcBackendOptions(_TensorPipeRpcBackendOptionsBase):\n r\"\"\"\n The backend options for\n :class:`~torch.distributed.rpc.TensorPipeAgent`, derived from\n :class:`~torch.distributed.rpc.RpcBackendOptions`.\n\n Args:\n num_worker_threads (int, optional): The number of threads in the\n thread-pool used by\n :class:`~torch.distributed.rpc.TensorPipeAgent` to execute\n requests (default: 16).\n rpc_timeout (float, optional): The default timeout, in seconds,\n for RPC requests (default: 60 seconds). If the RPC has not\n completed in this timeframe, an exception indicating so will\n be raised. Callers can override this timeout for individual\n RPCs in :meth:`~torch.distributed.rpc.rpc_sync` and\n :meth:`~torch.distributed.rpc.rpc_async` if necessary.\n init_method (str, optional): The URL to initialize the distributed\n store used for rendezvous. It takes any value accepted for the\n same argument of :meth:`~torch.distributed.init_process_group`\n (default: ``env://``).\n device_maps (Dict[str, Dict]): Device placement mappings from this\n worker to the callee. Key is the callee worker name and value the\n dictionary (``Dict`` of ``int``, ``str``, or ``torch.device``) that\n maps this worker's devices to the callee worker's devices.\n (default: ``None``)\n \"\"\"\n def __init__(\n self,\n *,\n num_worker_threads: int = rpc_contants.DEFAULT_NUM_WORKER_THREADS,\n rpc_timeout: float = rpc_contants.DEFAULT_RPC_TIMEOUT_SEC,\n init_method: str = rpc_contants.DEFAULT_INIT_METHOD,\n device_maps: Dict = None,\n _transports: List = None,\n _channels: List = None,\n ):\n super().__init__(\n num_worker_threads,\n _transports,\n _channels,\n rpc_timeout,\n init_method,\n device_maps if device_maps else {}\n )\n\n def set_device_map(self, to: str, device_map: Dict):\n r\"\"\"\n Set device mapping between each RPC caller and callee pair. This\n function can be called multiple times to incrementally add\n device placement configurations.\n\n Args:\n worker_name (str): Callee name.\n device_map (Dict of int, str, or torch.device): Device placement\n mappings from this worker to the callee. This map must be\n invertible.\n\n Example::\n >>> # both workers\n >>> def add(x, y):\n >>> print(x) # tensor([1., 1.], device='cuda:1')\n >>> return x + y, (x + y).to(2)\n >>>\n >>> # on worker 0\n >>> options = TensorPipeRpcBackendOptions(\n >>> num_worker_threads=8,\n >>> device_maps={\"worker1\": {0, 1}}\n >>> # maps worker0's cuda:0 to worker1's cuda:1\n >>> )\n >>> options.set_device_map(\"worker1\", {1, 2})\n >>> # maps worker0's cuda:1 to worker1's cuda:2\n >>>\n >>> rpc.init_rpc(\n >>> \"worker0\",\n >>> rank=0,\n >>> world_size=2\n >>> backend=rpc.BackendType.TENSORPIPE,\n >>> rpc_backend_options=options\n >>> )\n >>>\n >>> x = torch.ones(2)\n >>> rets = rpc.rpc_sync(\"worker1\", add, args=(x.to(0), 1))\n >>> # The first argument will be moved to cuda:1 on worker1. When\n >>> # sending the return value back, it will follow the invert of\n >>> # the device map, and hence will be moved back to cuda:0 and\n >>> # cuda:1 on worker0\n >>> print(rets[0]) # tensor([2., 2.], device='cuda:0')\n >>> print(rets[0]) # tensor([2., 2.], device='cuda:1')\n \"\"\"\n device_index_map = {}\n curr_device_maps = super().device_maps\n for k in device_map:\n v = device_map[k]\n k, v = torch.device(k), torch.device(v)\n if k.type != 'cuda' or v.type != 'cuda':\n raise ValueError(\n \"`set_device_map` only supports CUDA devices, \"\n f\"but got device pair {k}: {v}\"\n\n )\n if to in curr_device_maps and k.index in curr_device_maps[to]:\n curr_v = super().device_maps[to][k.index]\n if curr_v != v.index:\n raise ValueError(\n \"`set_device_map` only supports 1-to-1 mapping, \"\n f\"trying to map {k} to {v} and {curr_v}\"\n )\n device_index_map[k.index] = v.index\n super().set_device_map(to, device_index_map)\n", "path": "torch/distributed/rpc/options.py"}]}
| 2,551 | 389 |
gh_patches_debug_4009
|
rasdani/github-patches
|
git_diff
|
easybuilders__easybuild-easyblocks-2889
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
New sanity check commands for netCDF break build of older netCDF
This one took me a while to chase down. It might be a wontfix due to old software, but maybe this issue can at least serve as an FFR.
N.b. the easybuild and netCDF tag numbers are very similar here.
[In easybuild v4.6.2 some `nc-config` and `ncgen` sanity check commands were added to the netCDF easyblock](https://github.com/easybuilders/easybuild-easyblocks/commit/d8aa9420be572ab4df2c5993c5a3cdf370623404).
The command `ncgen -h`, in particular, should show the help text for `ncgen`. However, up until netCDF v4.6.1, `ncgen -h` meant running `ncgen` in 'header-only" mode, while `-H` was used for help. These flags were switched in [this commit](https://github.com/Unidata/netcdf-c/commit/2ea1cf5f1bc2a7352e3f66721f5181e26e556011#diff-6f23c24b125838dbee16fd3fd9edf84acc7a0492bd223c5ed03e9095cd50b15e) which first appeared in netCDF v4.6.2.
The problem is that when `ncgen` is run without any other args, or similarly, in "header-only" mode, it waits for stdin until an EOF. This causes the `ncgen` sanity check in the new easyblock to fail.
I think the fix would be to check `ncgen -H` instead of `ncgen -h` for netCDF older than v4.6.2.
</issue>
<code>
[start of easybuild/easyblocks/n/netcdf.py]
1 ##
2 # Copyright 2009-2023 Ghent University
3 #
4 # This file is part of EasyBuild,
5 # originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),
6 # with support of Ghent University (http://ugent.be/hpc),
7 # the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),
8 # Flemish Research Foundation (FWO) (http://www.fwo.be/en)
9 # and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).
10 #
11 # https://github.com/easybuilders/easybuild
12 #
13 # EasyBuild is free software: you can redistribute it and/or modify
14 # it under the terms of the GNU General Public License as published by
15 # the Free Software Foundation v2.
16 #
17 # EasyBuild is distributed in the hope that it will be useful,
18 # but WITHOUT ANY WARRANTY; without even the implied warranty of
19 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
20 # GNU General Public License for more details.
21 #
22 # You should have received a copy of the GNU General Public License
23 # along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.
24 ##
25 """
26 EasyBuild support for building and installing netCDF, implemented as an easyblock
27
28 @author: Stijn De Weirdt (Ghent University)
29 @author: Dries Verdegem (Ghent University)
30 @author: Kenneth Hoste (Ghent University)
31 @author: Pieter De Baets (Ghent University)
32 @author: Jens Timmerman (Ghent University)
33 """
34
35 import os
36 from distutils.version import LooseVersion
37
38 import easybuild.tools.environment as env
39 import easybuild.tools.toolchain as toolchain
40 from easybuild.easyblocks.generic.cmakemake import CMakeMake
41 from easybuild.easyblocks.generic.configuremake import ConfigureMake
42 from easybuild.tools.build_log import EasyBuildError
43 from easybuild.tools.modules import get_software_root, get_software_version, get_software_libdir
44 from easybuild.tools.systemtools import get_shared_lib_ext
45
46
47 class EB_netCDF(CMakeMake):
48 """Support for building/installing netCDF"""
49
50 @staticmethod
51 def extra_options():
52 extra_vars = CMakeMake.extra_options()
53 extra_vars['separate_build_dir'][0] = True
54 return extra_vars
55
56 def configure_step(self):
57 """Configure build: set config options and configure"""
58
59 shlib_ext = get_shared_lib_ext()
60
61 if LooseVersion(self.version) < LooseVersion("4.3"):
62 self.cfg.update('configopts', "--enable-shared")
63
64 if self.toolchain.options['pic']:
65 self.cfg.update('configopts', '--with-pic')
66
67 tup = (os.getenv('FFLAGS'), os.getenv('MPICC'), os.getenv('F90'))
68 self.cfg.update('configopts', 'FCFLAGS="%s" CC="%s" FC="%s"' % tup)
69
70 # add -DgFortran to CPPFLAGS when building with GCC
71 if self.toolchain.comp_family() == toolchain.GCC: # @UndefinedVariable
72 self.cfg.update('configopts', 'CPPFLAGS="%s -DgFortran"' % os.getenv('CPPFLAGS'))
73
74 ConfigureMake.configure_step(self)
75
76 else:
77 for (dep, libname) in [('cURL', 'curl'), ('HDF5', 'hdf5'), ('Szip', 'sz'), ('zlib', 'z'),
78 ('PnetCDF', 'pnetcdf')]:
79 dep_root = get_software_root(dep)
80 dep_libdir = get_software_libdir(dep)
81
82 if dep_root:
83 incdir = os.path.join(dep_root, 'include')
84 self.cfg.update('configopts', '-D%s_INCLUDE_DIR=%s ' % (dep.upper(), incdir))
85
86 if dep == 'HDF5':
87 env.setvar('HDF5_ROOT', dep_root)
88 self.cfg.update('configopts', '-DUSE_HDF5=ON')
89
90 hdf5cmvars = {
91 # library name: (cmake option suffix in netcdf<4.4, cmake option suffix in netcfd>=4.4)
92 'hdf5': ('LIB', 'C_LIBRARY'),
93 'hdf5_hl': ('HL_LIB', 'HL_LIBRARY'),
94 }
95
96 for libname in hdf5cmvars:
97 if LooseVersion(self.version) < LooseVersion("4.4"):
98 cmvar = hdf5cmvars[libname][0]
99 else:
100 cmvar = hdf5cmvars[libname][1]
101 libhdf5 = os.path.join(dep_root, dep_libdir, 'lib%s.%s' % (libname, shlib_ext))
102 self.cfg.update('configopts', '-DHDF5_%s=%s ' % (cmvar, libhdf5))
103 # 4.4 forgot to set HDF5_<lang>_LIBRARIES
104 if LooseVersion(self.version) == LooseVersion("4.4.0"):
105 lang = 'HL' if cmvar[0] == 'H' else 'C'
106 self.cfg.update('configopts', '-DHDF5_%s_LIBRARIES=%s ' % (lang, libhdf5))
107
108 elif dep == 'PnetCDF':
109 self.cfg.update('configopts', '-DENABLE_PNETCDF=ON')
110
111 else:
112 libso = os.path.join(dep_root, dep_libdir, 'lib%s.%s' % (libname, shlib_ext))
113 self.cfg.update('configopts', '-D%s_LIBRARY=%s ' % (dep.upper(), libso))
114
115 CMakeMake.configure_step(self)
116
117 def sanity_check_step(self):
118 """
119 Custom sanity check for netCDF
120 """
121
122 shlib_ext = get_shared_lib_ext()
123
124 incs = ["netcdf.h"]
125 libs = ["libnetcdf.%s" % shlib_ext, "libnetcdf.a"]
126 # since v4.2, the non-C libraries have been split off in seperate extensions_step
127 # see netCDF-Fortran and netCDF-C++
128 if LooseVersion(self.version) < LooseVersion("4.2"):
129 incs += ["netcdf%s" % x for x in ["cpp.h", ".hh", ".inc", ".mod"]]
130 incs += ["ncvalues.h", "typesizes.mod"]
131 libs += ["libnetcdf_c++.%s" % shlib_ext, "libnetcdff.%s" % shlib_ext,
132 "libnetcdf_c++.a", "libnetcdff.a"]
133 binaries = ["nc%s" % x for x in ["-config", "copy", "dump", "gen", "gen3"]]
134
135 custom_paths = {
136 'files': (
137 [os.path.join("bin", x) for x in binaries] +
138 [os.path.join("lib", x) for x in libs] +
139 [os.path.join("include", x) for x in incs]
140 ),
141 'dirs': []
142 }
143
144 custom_commands = [
145 "nc-config --help",
146 "ncgen -h",
147 ]
148
149 super(EB_netCDF, self).sanity_check_step(custom_commands=custom_commands, custom_paths=custom_paths)
150
151
152 def set_netcdf_env_vars(log):
153 """Set netCDF environment variables used by other software."""
154
155 netcdf = get_software_root('netCDF')
156 if not netcdf:
157 raise EasyBuildError("netCDF module not loaded?")
158 else:
159 env.setvar('NETCDF', netcdf)
160 log.debug("Set NETCDF to %s" % netcdf)
161 netcdff = get_software_root('netCDF-Fortran')
162 netcdf_ver = get_software_version('netCDF')
163 if not netcdff:
164 if LooseVersion(netcdf_ver) >= LooseVersion("4.2"):
165 raise EasyBuildError("netCDF v4.2 no longer supplies Fortran library, also need netCDF-Fortran")
166 else:
167 env.setvar('NETCDFF', netcdff)
168 log.debug("Set NETCDFF to %s" % netcdff)
169
[end of easybuild/easyblocks/n/netcdf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/easybuild/easyblocks/n/netcdf.py b/easybuild/easyblocks/n/netcdf.py
--- a/easybuild/easyblocks/n/netcdf.py
+++ b/easybuild/easyblocks/n/netcdf.py
@@ -143,7 +143,7 @@
custom_commands = [
"nc-config --help",
- "ncgen -h",
+ "ncgen -h" if LooseVersion(self.version) > LooseVersion("4.6.1") else "ncgen -H",
]
super(EB_netCDF, self).sanity_check_step(custom_commands=custom_commands, custom_paths=custom_paths)
|
{"golden_diff": "diff --git a/easybuild/easyblocks/n/netcdf.py b/easybuild/easyblocks/n/netcdf.py\n--- a/easybuild/easyblocks/n/netcdf.py\n+++ b/easybuild/easyblocks/n/netcdf.py\n@@ -143,7 +143,7 @@\n \n custom_commands = [\n \"nc-config --help\",\n- \"ncgen -h\",\n+ \"ncgen -h\" if LooseVersion(self.version) > LooseVersion(\"4.6.1\") else \"ncgen -H\",\n ]\n \n super(EB_netCDF, self).sanity_check_step(custom_commands=custom_commands, custom_paths=custom_paths)\n", "issue": "New sanity check commands for netCDF break build of older netCDF\nThis one took me a while to chase down. It might be a wontfix due to old software, but maybe this issue can at least serve as an FFR.\r\n\r\nN.b. the easybuild and netCDF tag numbers are very similar here.\r\n\r\n[In easybuild v4.6.2 some `nc-config` and `ncgen` sanity check commands were added to the netCDF easyblock](https://github.com/easybuilders/easybuild-easyblocks/commit/d8aa9420be572ab4df2c5993c5a3cdf370623404).\r\n\r\nThe command `ncgen -h`, in particular, should show the help text for `ncgen`. However, up until netCDF v4.6.1, `ncgen -h` meant running `ncgen` in 'header-only\" mode, while `-H` was used for help. These flags were switched in [this commit](https://github.com/Unidata/netcdf-c/commit/2ea1cf5f1bc2a7352e3f66721f5181e26e556011#diff-6f23c24b125838dbee16fd3fd9edf84acc7a0492bd223c5ed03e9095cd50b15e) which first appeared in netCDF v4.6.2.\r\n\r\nThe problem is that when `ncgen` is run without any other args, or similarly, in \"header-only\" mode, it waits for stdin until an EOF. This causes the `ncgen` sanity check in the new easyblock to fail.\r\n\r\nI think the fix would be to check `ncgen -H` instead of `ncgen -h` for netCDF older than v4.6.2.\n", "before_files": [{"content": "##\n# Copyright 2009-2023 Ghent University\n#\n# This file is part of EasyBuild,\n# originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),\n# with support of Ghent University (http://ugent.be/hpc),\n# the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),\n# Flemish Research Foundation (FWO) (http://www.fwo.be/en)\n# and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).\n#\n# https://github.com/easybuilders/easybuild\n#\n# EasyBuild is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation v2.\n#\n# EasyBuild is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.\n##\n\"\"\"\nEasyBuild support for building and installing netCDF, implemented as an easyblock\n\n@author: Stijn De Weirdt (Ghent University)\n@author: Dries Verdegem (Ghent University)\n@author: Kenneth Hoste (Ghent University)\n@author: Pieter De Baets (Ghent University)\n@author: Jens Timmerman (Ghent University)\n\"\"\"\n\nimport os\nfrom distutils.version import LooseVersion\n\nimport easybuild.tools.environment as env\nimport easybuild.tools.toolchain as toolchain\nfrom easybuild.easyblocks.generic.cmakemake import CMakeMake\nfrom easybuild.easyblocks.generic.configuremake import ConfigureMake\nfrom easybuild.tools.build_log import EasyBuildError\nfrom easybuild.tools.modules import get_software_root, get_software_version, get_software_libdir\nfrom easybuild.tools.systemtools import get_shared_lib_ext\n\n\nclass EB_netCDF(CMakeMake):\n \"\"\"Support for building/installing netCDF\"\"\"\n\n @staticmethod\n def extra_options():\n extra_vars = CMakeMake.extra_options()\n extra_vars['separate_build_dir'][0] = True\n return extra_vars\n\n def configure_step(self):\n \"\"\"Configure build: set config options and configure\"\"\"\n\n shlib_ext = get_shared_lib_ext()\n\n if LooseVersion(self.version) < LooseVersion(\"4.3\"):\n self.cfg.update('configopts', \"--enable-shared\")\n\n if self.toolchain.options['pic']:\n self.cfg.update('configopts', '--with-pic')\n\n tup = (os.getenv('FFLAGS'), os.getenv('MPICC'), os.getenv('F90'))\n self.cfg.update('configopts', 'FCFLAGS=\"%s\" CC=\"%s\" FC=\"%s\"' % tup)\n\n # add -DgFortran to CPPFLAGS when building with GCC\n if self.toolchain.comp_family() == toolchain.GCC: # @UndefinedVariable\n self.cfg.update('configopts', 'CPPFLAGS=\"%s -DgFortran\"' % os.getenv('CPPFLAGS'))\n\n ConfigureMake.configure_step(self)\n\n else:\n for (dep, libname) in [('cURL', 'curl'), ('HDF5', 'hdf5'), ('Szip', 'sz'), ('zlib', 'z'),\n ('PnetCDF', 'pnetcdf')]:\n dep_root = get_software_root(dep)\n dep_libdir = get_software_libdir(dep)\n\n if dep_root:\n incdir = os.path.join(dep_root, 'include')\n self.cfg.update('configopts', '-D%s_INCLUDE_DIR=%s ' % (dep.upper(), incdir))\n\n if dep == 'HDF5':\n env.setvar('HDF5_ROOT', dep_root)\n self.cfg.update('configopts', '-DUSE_HDF5=ON')\n\n hdf5cmvars = {\n # library name: (cmake option suffix in netcdf<4.4, cmake option suffix in netcfd>=4.4)\n 'hdf5': ('LIB', 'C_LIBRARY'),\n 'hdf5_hl': ('HL_LIB', 'HL_LIBRARY'),\n }\n\n for libname in hdf5cmvars:\n if LooseVersion(self.version) < LooseVersion(\"4.4\"):\n cmvar = hdf5cmvars[libname][0]\n else:\n cmvar = hdf5cmvars[libname][1]\n libhdf5 = os.path.join(dep_root, dep_libdir, 'lib%s.%s' % (libname, shlib_ext))\n self.cfg.update('configopts', '-DHDF5_%s=%s ' % (cmvar, libhdf5))\n # 4.4 forgot to set HDF5_<lang>_LIBRARIES\n if LooseVersion(self.version) == LooseVersion(\"4.4.0\"):\n lang = 'HL' if cmvar[0] == 'H' else 'C'\n self.cfg.update('configopts', '-DHDF5_%s_LIBRARIES=%s ' % (lang, libhdf5))\n\n elif dep == 'PnetCDF':\n self.cfg.update('configopts', '-DENABLE_PNETCDF=ON')\n\n else:\n libso = os.path.join(dep_root, dep_libdir, 'lib%s.%s' % (libname, shlib_ext))\n self.cfg.update('configopts', '-D%s_LIBRARY=%s ' % (dep.upper(), libso))\n\n CMakeMake.configure_step(self)\n\n def sanity_check_step(self):\n \"\"\"\n Custom sanity check for netCDF\n \"\"\"\n\n shlib_ext = get_shared_lib_ext()\n\n incs = [\"netcdf.h\"]\n libs = [\"libnetcdf.%s\" % shlib_ext, \"libnetcdf.a\"]\n # since v4.2, the non-C libraries have been split off in seperate extensions_step\n # see netCDF-Fortran and netCDF-C++\n if LooseVersion(self.version) < LooseVersion(\"4.2\"):\n incs += [\"netcdf%s\" % x for x in [\"cpp.h\", \".hh\", \".inc\", \".mod\"]]\n incs += [\"ncvalues.h\", \"typesizes.mod\"]\n libs += [\"libnetcdf_c++.%s\" % shlib_ext, \"libnetcdff.%s\" % shlib_ext,\n \"libnetcdf_c++.a\", \"libnetcdff.a\"]\n binaries = [\"nc%s\" % x for x in [\"-config\", \"copy\", \"dump\", \"gen\", \"gen3\"]]\n\n custom_paths = {\n 'files': (\n [os.path.join(\"bin\", x) for x in binaries] +\n [os.path.join(\"lib\", x) for x in libs] +\n [os.path.join(\"include\", x) for x in incs]\n ),\n 'dirs': []\n }\n\n custom_commands = [\n \"nc-config --help\",\n \"ncgen -h\",\n ]\n\n super(EB_netCDF, self).sanity_check_step(custom_commands=custom_commands, custom_paths=custom_paths)\n\n\ndef set_netcdf_env_vars(log):\n \"\"\"Set netCDF environment variables used by other software.\"\"\"\n\n netcdf = get_software_root('netCDF')\n if not netcdf:\n raise EasyBuildError(\"netCDF module not loaded?\")\n else:\n env.setvar('NETCDF', netcdf)\n log.debug(\"Set NETCDF to %s\" % netcdf)\n netcdff = get_software_root('netCDF-Fortran')\n netcdf_ver = get_software_version('netCDF')\n if not netcdff:\n if LooseVersion(netcdf_ver) >= LooseVersion(\"4.2\"):\n raise EasyBuildError(\"netCDF v4.2 no longer supplies Fortran library, also need netCDF-Fortran\")\n else:\n env.setvar('NETCDFF', netcdff)\n log.debug(\"Set NETCDFF to %s\" % netcdff)\n", "path": "easybuild/easyblocks/n/netcdf.py"}]}
| 3,142 | 146 |
gh_patches_debug_25775
|
rasdani/github-patches
|
git_diff
|
apache__tvm-2759
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[TEST][FLAKY] test_dlpack
Both #2749 and #2353 encountered seg fault error at test_dlpack.
http://ci.tvm.ai:8080/blue/organizations/jenkins/tvm/detail/PR-2749/2/pipeline
http://ci.tvm.ai:8080/blue/organizations/jenkins/tvm/detail/PR-2353/48/pipeline
cc @eqy , could you help look at this?
</issue>
<code>
[start of python/tvm/_ffi/_ctypes/ndarray.py]
1 # pylint: disable=invalid-name
2 """Runtime NDArray api"""
3 from __future__ import absolute_import
4
5 import ctypes
6 from ..base import _LIB, check_call, c_str
7 from ..runtime_ctypes import TVMArrayHandle, TVMNDArrayContainerHandle
8 from .types import RETURN_SWITCH, C_TO_PY_ARG_SWITCH, _wrap_arg_func, _return_handle
9
10
11 TVMPyCapsuleDestructor = ctypes.CFUNCTYPE(None, ctypes.c_void_p)
12 _c_str_dltensor = c_str('dltensor')
13 _c_str_used_dltensor = c_str('used_dltensor')
14
15
16 # used for PyCapsule manipulation
17 if hasattr(ctypes, 'pythonapi'):
18 ctypes.pythonapi.PyCapsule_GetName.restype = ctypes.c_char_p
19 ctypes.pythonapi.PyCapsule_GetPointer.restype = ctypes.c_void_p
20 ctypes.pythonapi.PyCapsule_New.restype = ctypes.py_object
21
22
23 def _from_dlpack(dltensor):
24 dltensor = ctypes.py_object(dltensor)
25 if ctypes.pythonapi.PyCapsule_IsValid(dltensor, _c_str_dltensor):
26 ptr = ctypes.pythonapi.PyCapsule_GetPointer(dltensor, _c_str_dltensor)
27 handle = TVMArrayHandle()
28 check_call(_LIB.TVMArrayFromDLPack(ptr, ctypes.byref(handle)))
29 ctypes.pythonapi.PyCapsule_SetName(dltensor, _c_str_used_dltensor)
30 ctypes.pythonapi.PyCapsule_SetDestructor(dltensor, TVMPyCapsuleDestructor(0))
31 return _make_array(handle, False, False)
32 raise ValueError("Expect a dltensor field, PyCapsule can only be consumed once")
33
34
35 def _dlpack_deleter(pycapsule):
36 pycapsule = ctypes.cast(pycapsule, ctypes.py_object)
37 if ctypes.pythonapi.PyCapsule_IsValid(pycapsule, _c_str_dltensor):
38 ptr = ctypes.pythonapi.PyCapsule_GetPointer(pycapsule, _c_str_dltensor)
39 _LIB.TVMDLManagedTensorCallDeleter(ptr)
40 ctypes.pythonapi.PyCapsule_SetDestructor(dltensor, TVMPyCapsuleDestructor(0))
41
42 _c_dlpack_deleter = TVMPyCapsuleDestructor(_dlpack_deleter)
43
44
45 class NDArrayBase(object):
46 """A simple Device/CPU Array object in runtime."""
47 __slots__ = ["handle", "is_view"]
48 # pylint: disable=no-member
49 def __init__(self, handle, is_view=False):
50 """Initialize the function with handle
51
52 Parameters
53 ----------
54 handle : TVMArrayHandle
55 the handle to the underlying C++ TVMArray
56 """
57 self.handle = handle
58 self.is_view = is_view
59
60 def __del__(self):
61 if not self.is_view and _LIB:
62 check_call(_LIB.TVMArrayFree(self.handle))
63
64 @property
65 def _tvm_handle(self):
66 return ctypes.cast(self.handle, ctypes.c_void_p).value
67
68 def to_dlpack(self):
69 """Produce an array from a DLPack Tensor without copying memory
70
71 Returns
72 -------
73 dlpack : DLPack tensor view of the array data
74 """
75 handle = ctypes.c_void_p()
76 check_call(_LIB.TVMArrayToDLPack(self.handle, ctypes.byref(handle)))
77 return ctypes.pythonapi.PyCapsule_New(handle, _c_str_dltensor, _c_dlpack_deleter)
78
79
80 def _make_array(handle, is_view, is_container):
81 global _TVM_ND_CLS
82 handle = ctypes.cast(handle, TVMArrayHandle)
83 fcreate = _CLASS_NDARRAY
84 if is_container and _TVM_ND_CLS:
85 array_type_info = ctypes.cast(handle, TVMNDArrayContainerHandle).array_type_info.value
86 if array_type_info > 0:
87 fcreate = _TVM_ND_CLS[array_type_info]
88 return fcreate(handle, is_view)
89
90 _TVM_COMPATS = ()
91
92 def _reg_extension(cls, fcreate):
93 global _TVM_COMPATS
94 _TVM_COMPATS += (cls,)
95 if fcreate:
96 fret = lambda x: fcreate(_return_handle(x))
97 RETURN_SWITCH[cls._tvm_tcode] = fret
98 C_TO_PY_ARG_SWITCH[cls._tvm_tcode] = _wrap_arg_func(fret, cls._tvm_tcode)
99
100 _TVM_ND_CLS = {}
101
102 def _reg_ndarray(cls, fcreate):
103 global _TVM_ND_CLS
104 _TVM_ND_CLS[cls._array_type_code] = fcreate
105
106 _CLASS_NDARRAY = None
107
108 def _set_class_ndarray(cls):
109 global _CLASS_NDARRAY
110 _CLASS_NDARRAY = cls
111
[end of python/tvm/_ffi/_ctypes/ndarray.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/python/tvm/_ffi/_ctypes/ndarray.py b/python/tvm/_ffi/_ctypes/ndarray.py
--- a/python/tvm/_ffi/_ctypes/ndarray.py
+++ b/python/tvm/_ffi/_ctypes/ndarray.py
@@ -24,6 +24,8 @@
dltensor = ctypes.py_object(dltensor)
if ctypes.pythonapi.PyCapsule_IsValid(dltensor, _c_str_dltensor):
ptr = ctypes.pythonapi.PyCapsule_GetPointer(dltensor, _c_str_dltensor)
+ # enforce type to make sure it works for all ctypes
+ ptr = ctypes.cast(ptr, ctypes.c_void_p)
handle = TVMArrayHandle()
check_call(_LIB.TVMArrayFromDLPack(ptr, ctypes.byref(handle)))
ctypes.pythonapi.PyCapsule_SetName(dltensor, _c_str_used_dltensor)
@@ -36,6 +38,8 @@
pycapsule = ctypes.cast(pycapsule, ctypes.py_object)
if ctypes.pythonapi.PyCapsule_IsValid(pycapsule, _c_str_dltensor):
ptr = ctypes.pythonapi.PyCapsule_GetPointer(pycapsule, _c_str_dltensor)
+ # enforce type to make sure it works for all ctypes
+ ptr = ctypes.cast(ctypes.c_void_p, ptr)
_LIB.TVMDLManagedTensorCallDeleter(ptr)
ctypes.pythonapi.PyCapsule_SetDestructor(dltensor, TVMPyCapsuleDestructor(0))
|
{"golden_diff": "diff --git a/python/tvm/_ffi/_ctypes/ndarray.py b/python/tvm/_ffi/_ctypes/ndarray.py\n--- a/python/tvm/_ffi/_ctypes/ndarray.py\n+++ b/python/tvm/_ffi/_ctypes/ndarray.py\n@@ -24,6 +24,8 @@\n dltensor = ctypes.py_object(dltensor)\n if ctypes.pythonapi.PyCapsule_IsValid(dltensor, _c_str_dltensor):\n ptr = ctypes.pythonapi.PyCapsule_GetPointer(dltensor, _c_str_dltensor)\n+ # enforce type to make sure it works for all ctypes\n+ ptr = ctypes.cast(ptr, ctypes.c_void_p)\n handle = TVMArrayHandle()\n check_call(_LIB.TVMArrayFromDLPack(ptr, ctypes.byref(handle)))\n ctypes.pythonapi.PyCapsule_SetName(dltensor, _c_str_used_dltensor)\n@@ -36,6 +38,8 @@\n pycapsule = ctypes.cast(pycapsule, ctypes.py_object)\n if ctypes.pythonapi.PyCapsule_IsValid(pycapsule, _c_str_dltensor):\n ptr = ctypes.pythonapi.PyCapsule_GetPointer(pycapsule, _c_str_dltensor)\n+ # enforce type to make sure it works for all ctypes\n+ ptr = ctypes.cast(ctypes.c_void_p, ptr)\n _LIB.TVMDLManagedTensorCallDeleter(ptr)\n ctypes.pythonapi.PyCapsule_SetDestructor(dltensor, TVMPyCapsuleDestructor(0))\n", "issue": "[TEST][FLAKY] test_dlpack\nBoth #2749 and #2353 encountered seg fault error at test_dlpack.\r\nhttp://ci.tvm.ai:8080/blue/organizations/jenkins/tvm/detail/PR-2749/2/pipeline\r\nhttp://ci.tvm.ai:8080/blue/organizations/jenkins/tvm/detail/PR-2353/48/pipeline\r\n\r\ncc @eqy , could you help look at this?\n", "before_files": [{"content": "# pylint: disable=invalid-name\n\"\"\"Runtime NDArray api\"\"\"\nfrom __future__ import absolute_import\n\nimport ctypes\nfrom ..base import _LIB, check_call, c_str\nfrom ..runtime_ctypes import TVMArrayHandle, TVMNDArrayContainerHandle\nfrom .types import RETURN_SWITCH, C_TO_PY_ARG_SWITCH, _wrap_arg_func, _return_handle\n\n\nTVMPyCapsuleDestructor = ctypes.CFUNCTYPE(None, ctypes.c_void_p)\n_c_str_dltensor = c_str('dltensor')\n_c_str_used_dltensor = c_str('used_dltensor')\n\n\n# used for PyCapsule manipulation\nif hasattr(ctypes, 'pythonapi'):\n ctypes.pythonapi.PyCapsule_GetName.restype = ctypes.c_char_p\n ctypes.pythonapi.PyCapsule_GetPointer.restype = ctypes.c_void_p\n ctypes.pythonapi.PyCapsule_New.restype = ctypes.py_object\n\n\ndef _from_dlpack(dltensor):\n dltensor = ctypes.py_object(dltensor)\n if ctypes.pythonapi.PyCapsule_IsValid(dltensor, _c_str_dltensor):\n ptr = ctypes.pythonapi.PyCapsule_GetPointer(dltensor, _c_str_dltensor)\n handle = TVMArrayHandle()\n check_call(_LIB.TVMArrayFromDLPack(ptr, ctypes.byref(handle)))\n ctypes.pythonapi.PyCapsule_SetName(dltensor, _c_str_used_dltensor)\n ctypes.pythonapi.PyCapsule_SetDestructor(dltensor, TVMPyCapsuleDestructor(0))\n return _make_array(handle, False, False)\n raise ValueError(\"Expect a dltensor field, PyCapsule can only be consumed once\")\n\n\ndef _dlpack_deleter(pycapsule):\n pycapsule = ctypes.cast(pycapsule, ctypes.py_object)\n if ctypes.pythonapi.PyCapsule_IsValid(pycapsule, _c_str_dltensor):\n ptr = ctypes.pythonapi.PyCapsule_GetPointer(pycapsule, _c_str_dltensor)\n _LIB.TVMDLManagedTensorCallDeleter(ptr)\n ctypes.pythonapi.PyCapsule_SetDestructor(dltensor, TVMPyCapsuleDestructor(0))\n\n_c_dlpack_deleter = TVMPyCapsuleDestructor(_dlpack_deleter)\n\n\nclass NDArrayBase(object):\n \"\"\"A simple Device/CPU Array object in runtime.\"\"\"\n __slots__ = [\"handle\", \"is_view\"]\n # pylint: disable=no-member\n def __init__(self, handle, is_view=False):\n \"\"\"Initialize the function with handle\n\n Parameters\n ----------\n handle : TVMArrayHandle\n the handle to the underlying C++ TVMArray\n \"\"\"\n self.handle = handle\n self.is_view = is_view\n\n def __del__(self):\n if not self.is_view and _LIB:\n check_call(_LIB.TVMArrayFree(self.handle))\n\n @property\n def _tvm_handle(self):\n return ctypes.cast(self.handle, ctypes.c_void_p).value\n\n def to_dlpack(self):\n \"\"\"Produce an array from a DLPack Tensor without copying memory\n\n Returns\n -------\n dlpack : DLPack tensor view of the array data\n \"\"\"\n handle = ctypes.c_void_p()\n check_call(_LIB.TVMArrayToDLPack(self.handle, ctypes.byref(handle)))\n return ctypes.pythonapi.PyCapsule_New(handle, _c_str_dltensor, _c_dlpack_deleter)\n\n\ndef _make_array(handle, is_view, is_container):\n global _TVM_ND_CLS\n handle = ctypes.cast(handle, TVMArrayHandle)\n fcreate = _CLASS_NDARRAY\n if is_container and _TVM_ND_CLS:\n array_type_info = ctypes.cast(handle, TVMNDArrayContainerHandle).array_type_info.value\n if array_type_info > 0:\n fcreate = _TVM_ND_CLS[array_type_info]\n return fcreate(handle, is_view)\n\n_TVM_COMPATS = ()\n\ndef _reg_extension(cls, fcreate):\n global _TVM_COMPATS\n _TVM_COMPATS += (cls,)\n if fcreate:\n fret = lambda x: fcreate(_return_handle(x))\n RETURN_SWITCH[cls._tvm_tcode] = fret\n C_TO_PY_ARG_SWITCH[cls._tvm_tcode] = _wrap_arg_func(fret, cls._tvm_tcode)\n\n_TVM_ND_CLS = {}\n\ndef _reg_ndarray(cls, fcreate):\n global _TVM_ND_CLS\n _TVM_ND_CLS[cls._array_type_code] = fcreate\n\n_CLASS_NDARRAY = None\n\ndef _set_class_ndarray(cls):\n global _CLASS_NDARRAY\n _CLASS_NDARRAY = cls\n", "path": "python/tvm/_ffi/_ctypes/ndarray.py"}]}
| 1,946 | 347 |
gh_patches_debug_4541
|
rasdani/github-patches
|
git_diff
|
holoviz__panel-2109
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Video widget appears to be broken in 0.11.x?
#### ALL software version info
Python 3.8.3 x64
Output of `pip list` in the virtualenv I tested this in:
```
Package Version
------------------- ---------
argon2-cffi 20.1.0
async-generator 1.10
attrs 20.3.0
backcall 0.2.0
bleach 3.3.0
bokeh 2.3.0
certifi 2020.12.5
cffi 1.14.5
chardet 4.0.0
colorama 0.4.4
decorator 4.4.2
defusedxml 0.7.1
entrypoints 0.3
idna 2.10
ipykernel 5.5.0
ipython 7.21.0
ipython-genutils 0.2.0
ipywidgets 7.6.3
jedi 0.18.0
Jinja2 2.11.3
jsonschema 3.2.0
jupyter 1.0.0
jupyter-client 6.1.12
jupyter-console 6.3.0
jupyter-core 4.7.1
jupyterlab-pygments 0.1.2
jupyterlab-widgets 1.0.0
Markdown 3.3.4
MarkupSafe 1.1.1
mistune 0.8.4
nbclient 0.5.3
nbconvert 6.0.7
nbformat 5.1.2
nest-asyncio 1.5.1
notebook 6.1.0
numpy 1.20.1
packaging 20.9
pandocfilters 1.4.3
panel 0.11.1
param 1.10.1
parso 0.8.1
pickleshare 0.7.5
Pillow 8.1.2
pip 20.1.1
prometheus-client 0.9.0
prompt-toolkit 3.0.17
pycparser 2.20
pyct 0.4.8
Pygments 2.8.1
pyparsing 2.4.7
pyrsistent 0.17.3
python-dateutil 2.8.1
pyviz-comms 2.0.1
pywin32 300
pywinpty 0.5.7
PyYAML 5.4.1
pyzmq 22.0.3
qtconsole 5.0.3
QtPy 1.9.0
requests 2.25.1
Send2Trash 1.5.0
setuptools 46.4.0
six 1.15.0
terminado 0.9.3
testpath 0.4.4
tornado 6.1
tqdm 4.59.0
traitlets 5.0.5
typing-extensions 3.7.4.3
urllib3 1.26.4
wcwidth 0.2.5
webencodings 0.5.1
wheel 0.34.2
widgetsnbextension 3.5.1
```
Tested on recent versions of Firefox and Chrome, Win10 and Linux.
The problem occurs on both 0.11.0 and 0.11.1, but does not happen if I simply downgrade to 0.10.3.
#### Description of expected behavior and the observed behavior
Initially noticed this trying to play other videos, but it happens with the reference [Video pane example notebook](https://raw.githubusercontent.com/holoviz/panel/master/examples/reference/panes/Video.ipynb). When the cell creating the widget is executed, the video never loads. Checking the generated HTML reveals that the src attribute is empty:
```
<video height="360" width="640" controls="" src="" loop="" style="object-fit: fill; min-width: 100%; min-height: 100%;"></video>
```
compared to the working version from 0.10.3:
```
<video height="360" width="640" controls="" src="https://file-examples-com.github.io/uploads/2017/04/file_example_MP4_640_3MG.mp4" loop="" style="object-fit: fill; min-width: 100%; min-height: 100%;"></video>
```
#### Complete, minimal, self-contained example code that reproduces the issue
Just run the reference [Video.ipynb notebook](https://raw.githubusercontent.com/holoviz/panel/master/examples/reference/panes/Video.ipynb).
#### Stack traceback and/or browser JavaScript console output
There don't seem to be any obvious errors in the JS console or the jupyter server output. A sample log from the JS console when restarting and then running the notebook:
```
kernel.js:106 Kernel: kernel_restarting (28828522-1f07-401a-bb70-0aaa5f7fbf15)
kernel.js:106 Kernel: kernel_created (28828522-1f07-401a-bb70-0aaa5f7fbf15)
kernel.js:463 Starting WebSockets: ws://localhost:8888/api/kernels/28828522-1f07-401a-bb70-0aaa5f7fbf15
kernel.js:106 Kernel: kernel_connected (28828522-1f07-401a-bb70-0aaa5f7fbf15)
kernel.js:106 Kernel: kernel_starting (28828522-1f07-401a-bb70-0aaa5f7fbf15)
kernel.js:106 Kernel: kernel_ready (28828522-1f07-401a-bb70-0aaa5f7fbf15)
kernel.js:106 Kernel: kernel_ready (28828522-1f07-401a-bb70-0aaa5f7fbf15)
bokeh-2.3.0.min.js:184 [bokeh] setting log level to: 'info'
bokeh-2.3.0.min.js:165 [bokeh] document idle at 14 ms
```
#### Screenshots or screencasts of the bug in action
How the video widget appears in both Chrome and Firefox:


</issue>
<code>
[start of panel/pane/media.py]
1 """
2 Contains Media panes including renderers for Audio and Video content.
3 """
4 import os
5
6 from base64 import b64encode
7 from io import BytesIO
8 from six import string_types
9
10 import numpy as np
11 import param
12
13 from ..models import Audio as _BkAudio, Video as _BkVideo
14 from ..util import isfile, isurl
15 from .base import PaneBase
16
17
18 class _MediaBase(PaneBase):
19
20 loop = param.Boolean(default=False, doc="""
21 Whether the meida should loop""")
22
23 time = param.Number(default=0, doc="""
24 The current timestamp""")
25
26 throttle = param.Integer(default=250, doc="""
27 How frequently to sample the current playback time in milliseconds""")
28
29 paused = param.Boolean(default=True, doc="""
30 Whether the media is currently paused""")
31
32 object = param.String(default='', allow_None=True, doc="""
33 The media file either local or remote.""")
34
35 volume = param.Number(default=None, bounds=(0, 100), doc="""
36 The volume of the media player.""")
37
38 _default_mime = None
39
40 _formats = []
41
42 _media_type = None
43
44 _rename = {'name': None, 'sample_rate': None, 'object': 'value'}
45
46 _updates = True
47
48 __abstract = True
49
50 @classmethod
51 def applies(cls, obj):
52 if isinstance(obj, string_types):
53 if isfile(obj) and any(obj.endswith('.'+fmt) for fmt in cls._formats):
54 return True
55 if isurl(obj, cls._formats):
56 return True
57 if hasattr(obj, 'read'): # Check for file like object
58 return True
59 return False
60
61 def _get_model(self, doc, root=None, parent=None, comm=None):
62 props = self._process_param_change(self._init_params())
63 model = self._bokeh_model(**props)
64 if root is None:
65 root = model
66 self._models[root.ref['id']] = (model, parent)
67 self._link_props(model, list(model.properties()), doc, root, comm)
68 return model
69
70 def _from_numpy(self, data):
71 from scipy.io import wavfile
72 buffer = BytesIO()
73 wavfile.write(buffer, self.sample_rate, data)
74 return buffer
75
76 def _process_param_change(self, msg):
77 msg = super()._process_param_change(msg)
78 if 'value' in msg:
79 value = msg['value']
80 if isinstance(value, np.ndarray):
81 fmt = 'wav'
82 buffer = self._from_numpy(value)
83 data = b64encode(buffer.getvalue())
84 elif os.path.isfile(value):
85 fmt = value.split('.')[-1]
86 with open(value, 'rb') as f:
87 data = f.read()
88 data = b64encode(data)
89 elif value.lower().startswith('http'):
90 return msg
91 elif not value:
92 data, fmt = b'', self._default_mime
93 else:
94 raise ValueError('Object should be either path to a sound file or numpy array')
95 template = 'data:audio/{mime};base64,{data}'
96 msg['value'] = template.format(data=data.decode('utf-8'),
97 mime=fmt)
98
99 return msg
100
101
102 class Audio(_MediaBase):
103
104 object = param.ClassSelector(default='', class_=(string_types + (np.ndarray,)),
105 allow_None=True, doc="""
106 The audio file either local or remote.""")
107
108 sample_rate = param.Integer(default=44100, doc="""
109 The sample_rate of the audio when given a NumPy array.""")
110
111 _bokeh_model = _BkAudio
112
113 _default_mime = 'wav'
114
115 _formats = ['mp3', 'wav', 'ogg']
116
117 _media_type = 'audio'
118
119 @classmethod
120 def applies(cls, obj):
121 return (super().applies(obj) or
122 (isinstance(obj, np.ndarray) and obj.ndim==1 and obj.dtype in [np.int16, np.uint16]))
123
124
125 class Video(_MediaBase):
126
127 _bokeh_model = _BkVideo
128
129 _default_mime = 'mp4'
130
131 _formats = ['mp4', 'webm', 'ogg']
132
133 _media_type = 'video'
134
135
[end of panel/pane/media.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/panel/pane/media.py b/panel/pane/media.py
--- a/panel/pane/media.py
+++ b/panel/pane/media.py
@@ -60,6 +60,8 @@
def _get_model(self, doc, root=None, parent=None, comm=None):
props = self._process_param_change(self._init_params())
+ if self.object is not None:
+ props['value'] = self.object
model = self._bokeh_model(**props)
if root is None:
root = model
|
{"golden_diff": "diff --git a/panel/pane/media.py b/panel/pane/media.py\n--- a/panel/pane/media.py\n+++ b/panel/pane/media.py\n@@ -60,6 +60,8 @@\n \n def _get_model(self, doc, root=None, parent=None, comm=None):\n props = self._process_param_change(self._init_params())\n+ if self.object is not None:\n+ props['value'] = self.object\n model = self._bokeh_model(**props)\n if root is None:\n root = model\n", "issue": "Video widget appears to be broken in 0.11.x?\n#### ALL software version info\r\nPython 3.8.3 x64\r\n\r\nOutput of `pip list` in the virtualenv I tested this in:\r\n```\r\nPackage Version\r\n------------------- ---------\r\nargon2-cffi 20.1.0\r\nasync-generator 1.10\r\nattrs 20.3.0\r\nbackcall 0.2.0\r\nbleach 3.3.0\r\nbokeh 2.3.0\r\ncertifi 2020.12.5\r\ncffi 1.14.5\r\nchardet 4.0.0\r\ncolorama 0.4.4\r\ndecorator 4.4.2\r\ndefusedxml 0.7.1\r\nentrypoints 0.3\r\nidna 2.10\r\nipykernel 5.5.0\r\nipython 7.21.0\r\nipython-genutils 0.2.0\r\nipywidgets 7.6.3\r\njedi 0.18.0\r\nJinja2 2.11.3\r\njsonschema 3.2.0\r\njupyter 1.0.0\r\njupyter-client 6.1.12\r\njupyter-console 6.3.0\r\njupyter-core 4.7.1\r\njupyterlab-pygments 0.1.2\r\njupyterlab-widgets 1.0.0\r\nMarkdown 3.3.4\r\nMarkupSafe 1.1.1\r\nmistune 0.8.4\r\nnbclient 0.5.3\r\nnbconvert 6.0.7\r\nnbformat 5.1.2\r\nnest-asyncio 1.5.1\r\nnotebook 6.1.0\r\nnumpy 1.20.1\r\npackaging 20.9\r\npandocfilters 1.4.3\r\npanel 0.11.1\r\nparam 1.10.1\r\nparso 0.8.1\r\npickleshare 0.7.5\r\nPillow 8.1.2\r\npip 20.1.1\r\nprometheus-client 0.9.0\r\nprompt-toolkit 3.0.17\r\npycparser 2.20\r\npyct 0.4.8\r\nPygments 2.8.1\r\npyparsing 2.4.7\r\npyrsistent 0.17.3\r\npython-dateutil 2.8.1\r\npyviz-comms 2.0.1\r\npywin32 300\r\npywinpty 0.5.7\r\nPyYAML 5.4.1\r\npyzmq 22.0.3\r\nqtconsole 5.0.3\r\nQtPy 1.9.0\r\nrequests 2.25.1\r\nSend2Trash 1.5.0\r\nsetuptools 46.4.0\r\nsix 1.15.0\r\nterminado 0.9.3\r\ntestpath 0.4.4\r\ntornado 6.1\r\ntqdm 4.59.0\r\ntraitlets 5.0.5\r\ntyping-extensions 3.7.4.3\r\nurllib3 1.26.4\r\nwcwidth 0.2.5\r\nwebencodings 0.5.1\r\nwheel 0.34.2\r\nwidgetsnbextension 3.5.1\r\n```\r\nTested on recent versions of Firefox and Chrome, Win10 and Linux. \r\n\r\nThe problem occurs on both 0.11.0 and 0.11.1, but does not happen if I simply downgrade to 0.10.3. \r\n\r\n#### Description of expected behavior and the observed behavior\r\n\r\nInitially noticed this trying to play other videos, but it happens with the reference [Video pane example notebook](https://raw.githubusercontent.com/holoviz/panel/master/examples/reference/panes/Video.ipynb). When the cell creating the widget is executed, the video never loads. Checking the generated HTML reveals that the src attribute is empty:\r\n\r\n```\r\n<video height=\"360\" width=\"640\" controls=\"\" src=\"\" loop=\"\" style=\"object-fit: fill; min-width: 100%; min-height: 100%;\"></video>\r\n```\r\ncompared to the working version from 0.10.3:\r\n```\r\n<video height=\"360\" width=\"640\" controls=\"\" src=\"https://file-examples-com.github.io/uploads/2017/04/file_example_MP4_640_3MG.mp4\" loop=\"\" style=\"object-fit: fill; min-width: 100%; min-height: 100%;\"></video>\r\n```\r\n\r\n#### Complete, minimal, self-contained example code that reproduces the issue\r\n\r\nJust run the reference [Video.ipynb notebook](https://raw.githubusercontent.com/holoviz/panel/master/examples/reference/panes/Video.ipynb). \r\n\r\n#### Stack traceback and/or browser JavaScript console output\r\n\r\nThere don't seem to be any obvious errors in the JS console or the jupyter server output. A sample log from the JS console when restarting and then running the notebook:\r\n\r\n```\r\nkernel.js:106 Kernel: kernel_restarting (28828522-1f07-401a-bb70-0aaa5f7fbf15)\r\nkernel.js:106 Kernel: kernel_created (28828522-1f07-401a-bb70-0aaa5f7fbf15)\r\nkernel.js:463 Starting WebSockets: ws://localhost:8888/api/kernels/28828522-1f07-401a-bb70-0aaa5f7fbf15\r\nkernel.js:106 Kernel: kernel_connected (28828522-1f07-401a-bb70-0aaa5f7fbf15)\r\nkernel.js:106 Kernel: kernel_starting (28828522-1f07-401a-bb70-0aaa5f7fbf15)\r\nkernel.js:106 Kernel: kernel_ready (28828522-1f07-401a-bb70-0aaa5f7fbf15)\r\nkernel.js:106 Kernel: kernel_ready (28828522-1f07-401a-bb70-0aaa5f7fbf15)\r\nbokeh-2.3.0.min.js:184 [bokeh] setting log level to: 'info'\r\nbokeh-2.3.0.min.js:165 [bokeh] document idle at 14 ms\r\n```\r\n\r\n#### Screenshots or screencasts of the bug in action\r\n\r\nHow the video widget appears in both Chrome and Firefox: \r\n\r\n\r\n\r\n\n", "before_files": [{"content": "\"\"\"\nContains Media panes including renderers for Audio and Video content.\n\"\"\"\nimport os\n\nfrom base64 import b64encode\nfrom io import BytesIO\nfrom six import string_types\n\nimport numpy as np\nimport param\n\nfrom ..models import Audio as _BkAudio, Video as _BkVideo\nfrom ..util import isfile, isurl\nfrom .base import PaneBase\n\n\nclass _MediaBase(PaneBase):\n\n loop = param.Boolean(default=False, doc=\"\"\"\n Whether the meida should loop\"\"\")\n\n time = param.Number(default=0, doc=\"\"\"\n The current timestamp\"\"\")\n\n throttle = param.Integer(default=250, doc=\"\"\"\n How frequently to sample the current playback time in milliseconds\"\"\")\n\n paused = param.Boolean(default=True, doc=\"\"\"\n Whether the media is currently paused\"\"\")\n\n object = param.String(default='', allow_None=True, doc=\"\"\"\n The media file either local or remote.\"\"\")\n\n volume = param.Number(default=None, bounds=(0, 100), doc=\"\"\"\n The volume of the media player.\"\"\")\n\n _default_mime = None\n\n _formats = []\n\n _media_type = None\n\n _rename = {'name': None, 'sample_rate': None, 'object': 'value'}\n\n _updates = True\n\n __abstract = True\n\n @classmethod\n def applies(cls, obj):\n if isinstance(obj, string_types):\n if isfile(obj) and any(obj.endswith('.'+fmt) for fmt in cls._formats):\n return True\n if isurl(obj, cls._formats):\n return True\n if hasattr(obj, 'read'): # Check for file like object\n return True\n return False\n\n def _get_model(self, doc, root=None, parent=None, comm=None):\n props = self._process_param_change(self._init_params())\n model = self._bokeh_model(**props)\n if root is None:\n root = model\n self._models[root.ref['id']] = (model, parent)\n self._link_props(model, list(model.properties()), doc, root, comm)\n return model\n\n def _from_numpy(self, data):\n from scipy.io import wavfile\n buffer = BytesIO()\n wavfile.write(buffer, self.sample_rate, data)\n return buffer\n\n def _process_param_change(self, msg):\n msg = super()._process_param_change(msg)\n if 'value' in msg:\n value = msg['value']\n if isinstance(value, np.ndarray):\n fmt = 'wav'\n buffer = self._from_numpy(value)\n data = b64encode(buffer.getvalue())\n elif os.path.isfile(value):\n fmt = value.split('.')[-1]\n with open(value, 'rb') as f:\n data = f.read()\n data = b64encode(data)\n elif value.lower().startswith('http'):\n return msg\n elif not value:\n data, fmt = b'', self._default_mime\n else:\n raise ValueError('Object should be either path to a sound file or numpy array')\n template = 'data:audio/{mime};base64,{data}'\n msg['value'] = template.format(data=data.decode('utf-8'),\n mime=fmt)\n \n return msg\n\n\nclass Audio(_MediaBase):\n\n object = param.ClassSelector(default='', class_=(string_types + (np.ndarray,)),\n allow_None=True, doc=\"\"\"\n The audio file either local or remote.\"\"\")\n\n sample_rate = param.Integer(default=44100, doc=\"\"\"\n The sample_rate of the audio when given a NumPy array.\"\"\")\n\n _bokeh_model = _BkAudio\n\n _default_mime = 'wav'\n\n _formats = ['mp3', 'wav', 'ogg']\n\n _media_type = 'audio'\n\n @classmethod\n def applies(cls, obj):\n return (super().applies(obj) or \n (isinstance(obj, np.ndarray) and obj.ndim==1 and obj.dtype in [np.int16, np.uint16]))\n\n\nclass Video(_MediaBase):\n\n _bokeh_model = _BkVideo\n\n _default_mime = 'mp4'\n\n _formats = ['mp4', 'webm', 'ogg']\n\n _media_type = 'video'\n\n", "path": "panel/pane/media.py"}]}
| 3,532 | 121 |
gh_patches_debug_15795
|
rasdani/github-patches
|
git_diff
|
zestedesavoir__zds-site-6544
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Faciliter la programmation des Unes en modifiant le type de la date de publication.
À ce jour, quand on créer une Unes il faut remplir le champ "Date de publication" avec un format texte de style "2023/08/21 10:00". C'est assez désagréable à remplir.

Les propositions sont des Unes que j'ai déjà faite.
En ajoutant le type "datetime-local" à cette input on pourrait accèder aux interfaces natives des navigateurs/OS pour ce genre d'input.

</issue>
<code>
[start of zds/featured/forms.py]
1 from crispy_forms.bootstrap import StrictButton
2 from crispy_forms.helper import FormHelper
3 from crispy_forms.layout import Layout, Field, ButtonHolder
4 from django import forms
5 from django.urls import reverse
6 from django.utils.translation import gettext_lazy as _
7
8 from zds.featured.models import FeaturedResource, FeaturedMessage
9
10
11 class FeaturedResourceForm(forms.ModelForm):
12 class Meta:
13 model = FeaturedResource
14
15 fields = ["title", "type", "authors", "image_url", "url"]
16
17 widgets = {
18 "title": forms.TextInput(attrs={"placeholder": _("Titre de la Une")}),
19 "type": forms.TextInput(attrs={"placeholder": _("ex: Un projet, Un article, Un tutoriel...")}),
20 "authors": forms.TextInput(attrs={"placeholder": _("Des auteurs (ou pas) ?")}),
21 "image_url": forms.URLInput(
22 attrs={"placeholder": _("Lien vers l'image de la Une (dimensions: 228x228px).")}
23 ),
24 "url": forms.URLInput(attrs={"placeholder": _("Lien vers la ressource.")}),
25 }
26
27 major_update = forms.BooleanField(
28 label=_("Mise à jour majeure (fera passer la Une en première position lors d'un changement)"),
29 initial=False,
30 required=False,
31 )
32
33 pubdate = forms.DateTimeField(
34 label=_("Date de publication (exemple: 25/12/2015 15:00 ou 2015-12-25T15:00)"),
35 input_formats=[
36 "%d/%m/%Y %H:%M:%S",
37 "%Y-%m-%d %H:%M:%S", # full format with second
38 "%Y-%m-%dT%H:%M", # datetime field format
39 "%Y-%m-%d %H:%M",
40 "%d/%m/%Y %H:%M", # without second
41 "%Y-%m-%d",
42 "%d/%m/%Y", # day only
43 ],
44 widget=forms.DateTimeInput(
45 attrs={"placeholder": _("Exemple : 25/12/2016 10:00"), "type": "text"},
46 format="%d/%m/%Y %H:%M", # datetime field format
47 ),
48 )
49
50 request = forms.IntegerField(widget=forms.HiddenInput(), required=False)
51
52 def __init__(self, *args, **kwargs):
53 hide_major_update_field = kwargs.pop("hide_major_update_field", False)
54
55 super().__init__(*args, **kwargs)
56 self.helper = FormHelper()
57 self.helper.form_class = "content-wrapper"
58 self.helper.form_method = "post"
59 self.helper.form_action = reverse("featured:resource-create")
60
61 fields = [Field("request"), Field("title"), Field("type"), Field("authors"), Field("image_url"), Field("url")]
62
63 if not hide_major_update_field:
64 fields.append(Field("major_update"))
65
66 fields.extend(
67 [
68 Field("pubdate"),
69 ButtonHolder(
70 StrictButton(_("Enregistrer"), type="submit"),
71 ),
72 ]
73 )
74
75 self.helper.layout = Layout(*fields)
76
77
78 class FeaturedMessageForm(forms.ModelForm):
79 class Meta:
80 model = FeaturedMessage
81
82 fields = ["hook", "message", "url"]
83
84 widgets = {
85 "hook": forms.TextInput(attrs={"placeholder": _('Mot d\'accroche court ("Nouveau !")')}),
86 "message": forms.TextInput(attrs={"placeholder": _("Message à afficher")}),
87 "url": forms.URLInput(attrs={"placeholder": _("Lien vers la description de la ressource")}),
88 }
89
90 def __init__(self, *args, **kwargs):
91 super().__init__(*args, **kwargs)
92 self.helper = FormHelper()
93 self.helper.form_class = "content-wrapper"
94 self.helper.form_method = "post"
95 self.helper.form_action = reverse("featured:message-create")
96
97 self.helper.layout = Layout(
98 Field("hook"),
99 Field("message"),
100 Field("url"),
101 ButtonHolder(
102 StrictButton(_("Enregistrer"), type="submit"),
103 ),
104 )
105
[end of zds/featured/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/zds/featured/forms.py b/zds/featured/forms.py
--- a/zds/featured/forms.py
+++ b/zds/featured/forms.py
@@ -31,20 +31,8 @@
)
pubdate = forms.DateTimeField(
- label=_("Date de publication (exemple: 25/12/2015 15:00 ou 2015-12-25T15:00)"),
- input_formats=[
- "%d/%m/%Y %H:%M:%S",
- "%Y-%m-%d %H:%M:%S", # full format with second
- "%Y-%m-%dT%H:%M", # datetime field format
- "%Y-%m-%d %H:%M",
- "%d/%m/%Y %H:%M", # without second
- "%Y-%m-%d",
- "%d/%m/%Y", # day only
- ],
- widget=forms.DateTimeInput(
- attrs={"placeholder": _("Exemple : 25/12/2016 10:00"), "type": "text"},
- format="%d/%m/%Y %H:%M", # datetime field format
- ),
+ label=_("Date de publication (exemple: 25/12/2015 15:00)"),
+ widget=forms.DateTimeInput(attrs={"type": "datetime-local"}),
)
request = forms.IntegerField(widget=forms.HiddenInput(), required=False)
|
{"golden_diff": "diff --git a/zds/featured/forms.py b/zds/featured/forms.py\n--- a/zds/featured/forms.py\n+++ b/zds/featured/forms.py\n@@ -31,20 +31,8 @@\n )\n \n pubdate = forms.DateTimeField(\n- label=_(\"Date de publication (exemple: 25/12/2015 15:00 ou 2015-12-25T15:00)\"),\n- input_formats=[\n- \"%d/%m/%Y %H:%M:%S\",\n- \"%Y-%m-%d %H:%M:%S\", # full format with second\n- \"%Y-%m-%dT%H:%M\", # datetime field format\n- \"%Y-%m-%d %H:%M\",\n- \"%d/%m/%Y %H:%M\", # without second\n- \"%Y-%m-%d\",\n- \"%d/%m/%Y\", # day only\n- ],\n- widget=forms.DateTimeInput(\n- attrs={\"placeholder\": _(\"Exemple : 25/12/2016 10:00\"), \"type\": \"text\"},\n- format=\"%d/%m/%Y %H:%M\", # datetime field format\n- ),\n+ label=_(\"Date de publication (exemple: 25/12/2015 15:00)\"),\n+ widget=forms.DateTimeInput(attrs={\"type\": \"datetime-local\"}),\n )\n \n request = forms.IntegerField(widget=forms.HiddenInput(), required=False)\n", "issue": "Faciliter la programmation des Unes en modifiant le type de la date de publication.\n\u00c0 ce jour, quand on cr\u00e9er une Unes il faut remplir le champ \"Date de publication\" avec un format texte de style \"2023/08/21 10:00\". C'est assez d\u00e9sagr\u00e9able \u00e0 remplir. \r\n\r\n\r\nLes propositions sont des Unes que j'ai d\u00e9j\u00e0 faite.\r\n\r\nEn ajoutant le type \"datetime-local\" \u00e0 cette input on pourrait acc\u00e8der aux interfaces natives des navigateurs/OS pour ce genre d'input.\r\n\r\n\n", "before_files": [{"content": "from crispy_forms.bootstrap import StrictButton\nfrom crispy_forms.helper import FormHelper\nfrom crispy_forms.layout import Layout, Field, ButtonHolder\nfrom django import forms\nfrom django.urls import reverse\nfrom django.utils.translation import gettext_lazy as _\n\nfrom zds.featured.models import FeaturedResource, FeaturedMessage\n\n\nclass FeaturedResourceForm(forms.ModelForm):\n class Meta:\n model = FeaturedResource\n\n fields = [\"title\", \"type\", \"authors\", \"image_url\", \"url\"]\n\n widgets = {\n \"title\": forms.TextInput(attrs={\"placeholder\": _(\"Titre de la Une\")}),\n \"type\": forms.TextInput(attrs={\"placeholder\": _(\"ex: Un projet, Un article, Un tutoriel...\")}),\n \"authors\": forms.TextInput(attrs={\"placeholder\": _(\"Des auteurs (ou pas)\u00a0?\")}),\n \"image_url\": forms.URLInput(\n attrs={\"placeholder\": _(\"Lien vers l'image de la Une (dimensions: 228x228px).\")}\n ),\n \"url\": forms.URLInput(attrs={\"placeholder\": _(\"Lien vers la ressource.\")}),\n }\n\n major_update = forms.BooleanField(\n label=_(\"Mise \u00e0 jour majeure (fera passer la Une en premi\u00e8re position lors d'un changement)\"),\n initial=False,\n required=False,\n )\n\n pubdate = forms.DateTimeField(\n label=_(\"Date de publication (exemple: 25/12/2015 15:00 ou 2015-12-25T15:00)\"),\n input_formats=[\n \"%d/%m/%Y %H:%M:%S\",\n \"%Y-%m-%d %H:%M:%S\", # full format with second\n \"%Y-%m-%dT%H:%M\", # datetime field format\n \"%Y-%m-%d %H:%M\",\n \"%d/%m/%Y %H:%M\", # without second\n \"%Y-%m-%d\",\n \"%d/%m/%Y\", # day only\n ],\n widget=forms.DateTimeInput(\n attrs={\"placeholder\": _(\"Exemple : 25/12/2016 10:00\"), \"type\": \"text\"},\n format=\"%d/%m/%Y %H:%M\", # datetime field format\n ),\n )\n\n request = forms.IntegerField(widget=forms.HiddenInput(), required=False)\n\n def __init__(self, *args, **kwargs):\n hide_major_update_field = kwargs.pop(\"hide_major_update_field\", False)\n\n super().__init__(*args, **kwargs)\n self.helper = FormHelper()\n self.helper.form_class = \"content-wrapper\"\n self.helper.form_method = \"post\"\n self.helper.form_action = reverse(\"featured:resource-create\")\n\n fields = [Field(\"request\"), Field(\"title\"), Field(\"type\"), Field(\"authors\"), Field(\"image_url\"), Field(\"url\")]\n\n if not hide_major_update_field:\n fields.append(Field(\"major_update\"))\n\n fields.extend(\n [\n Field(\"pubdate\"),\n ButtonHolder(\n StrictButton(_(\"Enregistrer\"), type=\"submit\"),\n ),\n ]\n )\n\n self.helper.layout = Layout(*fields)\n\n\nclass FeaturedMessageForm(forms.ModelForm):\n class Meta:\n model = FeaturedMessage\n\n fields = [\"hook\", \"message\", \"url\"]\n\n widgets = {\n \"hook\": forms.TextInput(attrs={\"placeholder\": _('Mot d\\'accroche court (\"Nouveau\u00a0!\")')}),\n \"message\": forms.TextInput(attrs={\"placeholder\": _(\"Message \u00e0 afficher\")}),\n \"url\": forms.URLInput(attrs={\"placeholder\": _(\"Lien vers la description de la ressource\")}),\n }\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.helper = FormHelper()\n self.helper.form_class = \"content-wrapper\"\n self.helper.form_method = \"post\"\n self.helper.form_action = reverse(\"featured:message-create\")\n\n self.helper.layout = Layout(\n Field(\"hook\"),\n Field(\"message\"),\n Field(\"url\"),\n ButtonHolder(\n StrictButton(_(\"Enregistrer\"), type=\"submit\"),\n ),\n )\n", "path": "zds/featured/forms.py"}]}
| 1,882 | 346 |
gh_patches_debug_8191
|
rasdani/github-patches
|
git_diff
|
TheAlgorithms__Python-10361
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
missing_number algorithm dosen't work as intended (bit_manipulation/missing_number.py)
### Repository commit
d0c54acd75cedf14cff353869482a0487fea1697
### Python version (python --version)
Python 3.12.0
### Dependencies version (pip freeze)
setuptools==68.2.2
wheel==0.41.2
### Expected behavior
for array [1,3,4,5,6] the output should be 2
### Actual behavior
the output got is 4
</issue>
<code>
[start of bit_manipulation/missing_number.py]
1 def find_missing_number(nums: list[int]) -> int:
2 """
3 Finds the missing number in a list of consecutive integers.
4
5 Args:
6 nums: A list of integers.
7
8 Returns:
9 The missing number.
10
11 Example:
12 >>> find_missing_number([0, 1, 3, 4])
13 2
14 """
15 n = len(nums)
16 missing_number = n
17
18 for i in range(n):
19 missing_number ^= i ^ nums[i]
20
21 return missing_number
22
[end of bit_manipulation/missing_number.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bit_manipulation/missing_number.py b/bit_manipulation/missing_number.py
--- a/bit_manipulation/missing_number.py
+++ b/bit_manipulation/missing_number.py
@@ -11,11 +11,18 @@
Example:
>>> find_missing_number([0, 1, 3, 4])
2
+ >>> find_missing_number([1, 3, 4, 5, 6])
+ 2
+ >>> find_missing_number([6, 5, 4, 2, 1])
+ 3
+ >>> find_missing_number([6, 1, 5, 3, 4])
+ 2
"""
- n = len(nums)
- missing_number = n
+ low = min(nums)
+ high = max(nums)
+ missing_number = high
- for i in range(n):
- missing_number ^= i ^ nums[i]
+ for i in range(low, high):
+ missing_number ^= i ^ nums[i - low]
return missing_number
|
{"golden_diff": "diff --git a/bit_manipulation/missing_number.py b/bit_manipulation/missing_number.py\n--- a/bit_manipulation/missing_number.py\n+++ b/bit_manipulation/missing_number.py\n@@ -11,11 +11,18 @@\n Example:\n >>> find_missing_number([0, 1, 3, 4])\n 2\n+ >>> find_missing_number([1, 3, 4, 5, 6])\n+ 2\n+ >>> find_missing_number([6, 5, 4, 2, 1])\n+ 3\n+ >>> find_missing_number([6, 1, 5, 3, 4])\n+ 2\n \"\"\"\n- n = len(nums)\n- missing_number = n\n+ low = min(nums)\n+ high = max(nums)\n+ missing_number = high\n \n- for i in range(n):\n- missing_number ^= i ^ nums[i]\n+ for i in range(low, high):\n+ missing_number ^= i ^ nums[i - low]\n \n return missing_number\n", "issue": "missing_number algorithm dosen't work as intended (bit_manipulation/missing_number.py)\n### Repository commit\n\nd0c54acd75cedf14cff353869482a0487fea1697\n\n### Python version (python --version)\n\nPython 3.12.0\n\n### Dependencies version (pip freeze)\n\nsetuptools==68.2.2\r\nwheel==0.41.2\n\n### Expected behavior\n\nfor array [1,3,4,5,6] the output should be 2\n\n### Actual behavior\n\nthe output got is 4\n", "before_files": [{"content": "def find_missing_number(nums: list[int]) -> int:\n \"\"\"\n Finds the missing number in a list of consecutive integers.\n\n Args:\n nums: A list of integers.\n\n Returns:\n The missing number.\n\n Example:\n >>> find_missing_number([0, 1, 3, 4])\n 2\n \"\"\"\n n = len(nums)\n missing_number = n\n\n for i in range(n):\n missing_number ^= i ^ nums[i]\n\n return missing_number\n", "path": "bit_manipulation/missing_number.py"}]}
| 819 | 243 |
gh_patches_debug_15727
|
rasdani/github-patches
|
git_diff
|
crytic__slither-561
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
AssertionError when obtaining address of library
```solidity
library UnsafeMath {
function add(uint a, uint b) external returns (uint) {
return a + b;
}
}
contract Test {
function getUnsafeMathAddr() public view returns (address) {
return address(UnsafeMath);
}
}
```
https://solidity.readthedocs.io/en/latest/contracts.html#libraries:~:text=It%20is%20possible%20to%20obtain%20the%20address%20of%20a%20library
</issue>
<code>
[start of slither/slithir/operations/type_conversion.py]
1 from slither.core.solidity_types.type import Type
2 from slither.slithir.operations.lvalue import OperationWithLValue
3 from slither.slithir.utils.utils import is_valid_lvalue, is_valid_rvalue
4
5
6 class TypeConversion(OperationWithLValue):
7
8 def __init__(self, result, variable, variable_type):
9 super().__init__()
10 assert is_valid_rvalue(variable)
11 assert is_valid_lvalue(result)
12 assert isinstance(variable_type, Type)
13
14 self._variable = variable
15 self._type = variable_type
16 self._lvalue = result
17
18
19 @property
20 def variable(self):
21 return self._variable
22
23 @property
24 def type(self):
25 return self._type
26
27 @property
28 def read(self):
29 return [self.variable]
30
31 def __str__(self):
32 return str(self.lvalue) +' = CONVERT {} to {}'.format(self.variable, self.type)
33
[end of slither/slithir/operations/type_conversion.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/slither/slithir/operations/type_conversion.py b/slither/slithir/operations/type_conversion.py
--- a/slither/slithir/operations/type_conversion.py
+++ b/slither/slithir/operations/type_conversion.py
@@ -1,3 +1,4 @@
+from slither.core.declarations import Contract
from slither.core.solidity_types.type import Type
from slither.slithir.operations.lvalue import OperationWithLValue
from slither.slithir.utils.utils import is_valid_lvalue, is_valid_rvalue
@@ -7,7 +8,7 @@
def __init__(self, result, variable, variable_type):
super().__init__()
- assert is_valid_rvalue(variable)
+ assert is_valid_rvalue(variable) or isinstance(variable, Contract)
assert is_valid_lvalue(result)
assert isinstance(variable_type, Type)
|
{"golden_diff": "diff --git a/slither/slithir/operations/type_conversion.py b/slither/slithir/operations/type_conversion.py\n--- a/slither/slithir/operations/type_conversion.py\n+++ b/slither/slithir/operations/type_conversion.py\n@@ -1,3 +1,4 @@\n+from slither.core.declarations import Contract\n from slither.core.solidity_types.type import Type\n from slither.slithir.operations.lvalue import OperationWithLValue\n from slither.slithir.utils.utils import is_valid_lvalue, is_valid_rvalue\n@@ -7,7 +8,7 @@\n \n def __init__(self, result, variable, variable_type):\n super().__init__()\n- assert is_valid_rvalue(variable)\n+ assert is_valid_rvalue(variable) or isinstance(variable, Contract)\n assert is_valid_lvalue(result)\n assert isinstance(variable_type, Type)\n", "issue": "AssertionError when obtaining address of library\n```solidity\r\nlibrary UnsafeMath {\r\n function add(uint a, uint b) external returns (uint) {\r\n return a + b;\r\n }\r\n}\r\n\r\ncontract Test {\r\n function getUnsafeMathAddr() public view returns (address) {\r\n return address(UnsafeMath);\r\n }\r\n}\r\n```\r\n\r\nhttps://solidity.readthedocs.io/en/latest/contracts.html#libraries:~:text=It%20is%20possible%20to%20obtain%20the%20address%20of%20a%20library\n", "before_files": [{"content": "from slither.core.solidity_types.type import Type\nfrom slither.slithir.operations.lvalue import OperationWithLValue\nfrom slither.slithir.utils.utils import is_valid_lvalue, is_valid_rvalue\n\n\nclass TypeConversion(OperationWithLValue):\n\n def __init__(self, result, variable, variable_type):\n super().__init__()\n assert is_valid_rvalue(variable)\n assert is_valid_lvalue(result)\n assert isinstance(variable_type, Type)\n\n self._variable = variable\n self._type = variable_type\n self._lvalue = result\n \n\n @property\n def variable(self):\n return self._variable\n\n @property\n def type(self):\n return self._type\n\n @property\n def read(self):\n return [self.variable]\n\n def __str__(self):\n return str(self.lvalue) +' = CONVERT {} to {}'.format(self.variable, self.type)\n", "path": "slither/slithir/operations/type_conversion.py"}]}
| 931 | 188 |
gh_patches_debug_35196
|
rasdani/github-patches
|
git_diff
|
facebookresearch__CompilerGym-692
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add support for loading URLs to CompilerEnvStateReader.read_paths()
## 🚀 Feature
Extend [CompilerEnvStateReader.read_paths()](https://github.com/facebookresearch/CompilerGym/blob/de07d4867e0bb0b47f6fa4bce5e262ea8f014c3e/tests/compiler_env_state_test.py#L212-L335) so that any combination of file path or URL can be loaded.
</issue>
<code>
[start of compiler_gym/compiler_env_state.py]
1 # Copyright (c) Facebook, Inc. and its affiliates.
2 #
3 # This source code is licensed under the MIT license found in the
4 # LICENSE file in the root directory of this source tree.
5 """This module defines a class to represent a compiler environment state."""
6 import csv
7 import sys
8 from typing import Iterable, List, Optional, TextIO
9
10 from pydantic import BaseModel, Field, validator
11
12 from compiler_gym.datasets.uri import BenchmarkUri
13 from compiler_gym.util.truncate import truncate
14
15
16 class CompilerEnvState(BaseModel):
17 """The representation of a compiler environment state.
18
19 The state of an environment is defined as a benchmark and a sequence of
20 actions that has been applied to it. For a given environment, the state
21 contains the information required to reproduce the result.
22 """
23
24 benchmark: str = Field(
25 allow_mutation=False,
26 examples=[
27 "benchmark://cbench-v1/crc32",
28 "generator://csmith-v0/0",
29 ],
30 )
31 """The URI of the benchmark used for this episode."""
32
33 commandline: str
34 """The list of actions that produced this state, as a commandline."""
35
36 walltime: float
37 """The walltime of the episode in seconds. Must be non-negative."""
38
39 reward: Optional[float] = Field(
40 required=False,
41 default=None,
42 allow_mutation=True,
43 )
44 """The cumulative reward for this episode. Optional."""
45
46 @validator("walltime")
47 def walltime_nonnegative(cls, v):
48 if v is not None:
49 assert v >= 0, "Walltime cannot be negative"
50 return v
51
52 @validator("benchmark", pre=True)
53 def validate_benchmark(cls, value):
54 if isinstance(value, BenchmarkUri):
55 return str(value)
56 return value
57
58 @property
59 def has_reward(self) -> bool:
60 """Return whether the state has a reward value."""
61 return self.reward is not None
62
63 def __eq__(self, rhs) -> bool:
64 if not isinstance(rhs, CompilerEnvState):
65 return False
66 epsilon = 1e-5
67 # Only compare reward if both states have it.
68 if not (self.has_reward and rhs.has_reward):
69 reward_equal = True
70 else:
71 reward_equal = abs(self.reward - rhs.reward) < epsilon
72 # Note that walltime is excluded from equivalence checks as two states
73 # are equivalent if they define the same point in the optimization space
74 # irrespective of how long it took to get there.
75 return (
76 self.benchmark == rhs.benchmark
77 and reward_equal
78 and self.commandline == rhs.commandline
79 )
80
81 def __ne__(self, rhs) -> bool:
82 return not self == rhs
83
84 class Config:
85 validate_assignment = True
86
87
88 class CompilerEnvStateWriter:
89 """Serialize compiler environment states to CSV.
90
91 Example use:
92
93 >>> with CompilerEnvStateWriter(open("results.csv", "wb")) as writer:
94 ... writer.write_state(env.state)
95 """
96
97 def __init__(self, f: TextIO, header: bool = True):
98 """Constructor.
99
100 :param f: The file to write to.
101 :param header: Whether to include a header row.
102 """
103 self.f = f
104 self.writer = csv.writer(self.f, lineterminator="\n")
105 self.header = header
106
107 def write_state(self, state: CompilerEnvState, flush: bool = False) -> None:
108 """Write the state to file.
109
110 :param state: A compiler environment state.
111
112 :param flush: Write to file immediately.
113 """
114 if self.header:
115 self.writer.writerow(("benchmark", "reward", "walltime", "commandline"))
116 self.header = False
117 self.writer.writerow(
118 (state.benchmark, state.reward, state.walltime, state.commandline)
119 )
120 if flush:
121 self.f.flush()
122
123 def __enter__(self):
124 """Support with-statement for the writer."""
125 return self
126
127 def __exit__(self, *args):
128 """Support with-statement for the writer."""
129 self.f.close()
130
131
132 class CompilerEnvStateReader:
133 """Read states from a CSV file.
134
135 Example usage:
136
137 >>> with CompilerEnvStateReader(open("results.csv", "rb")) as reader:
138 ... for state in reader:
139 ... print(state)
140 """
141
142 def __init__(self, f: TextIO):
143 """Constructor.
144
145 :param f: The file to read.
146 """
147 self.f = f
148 self.reader = csv.reader(self.f)
149
150 def __iter__(self) -> Iterable[CompilerEnvState]:
151 """Read the states from the file."""
152 columns_in_order = ["benchmark", "reward", "walltime", "commandline"]
153 # Read the CSV and coerce the columns into the expected order.
154 for (
155 benchmark,
156 reward,
157 walltime,
158 commandline,
159 ) in self._iterate_columns_in_order(self.reader, columns_in_order):
160 yield CompilerEnvState(
161 benchmark=benchmark,
162 reward=None if reward == "" else float(reward),
163 walltime=0 if walltime == "" else float(walltime),
164 commandline=commandline,
165 )
166
167 @staticmethod
168 def _iterate_columns_in_order(
169 reader: csv.reader, columns: List[str]
170 ) -> Iterable[List[str]]:
171 """Read the input CSV and return each row in the given column order.
172
173 Supports CSVs both with and without a header. If no header, columns are
174 expected to be in the correct order. Else the header row is used to
175 determine column order.
176
177 Header row detection is case insensitive.
178
179 :param reader: The CSV file to read.
180
181 :param columns: A list of column names in the order that they are
182 expected.
183
184 :return: An iterator over rows.
185 """
186 try:
187 row = next(reader)
188 except StopIteration:
189 # Empty file.
190 return
191
192 if len(row) != len(columns):
193 raise ValueError(
194 f"Expected {len(columns)} columns in the first row of CSV: {truncate(row)}"
195 )
196
197 # Convert the maybe-header columns to lowercase for case-insensitive
198 # comparison.
199 maybe_header = [v.lower() for v in row]
200 if set(maybe_header) == set(columns):
201 # The first row matches the expected columns names, so use it to
202 # determine the column order.
203 column_order = [maybe_header.index(v) for v in columns]
204 yield from ([row[v] for v in column_order] for row in reader)
205 else:
206 # The first row isn't a header, so assume that all rows are in
207 # expected column order.
208 yield row
209 yield from reader
210
211 def __enter__(self):
212 """Support with-statement for the reader."""
213 return self
214
215 def __exit__(self, *args):
216 """Support with-statement for the reader."""
217 self.f.close()
218
219 @staticmethod
220 def read_paths(paths: Iterable[str]) -> Iterable[CompilerEnvState]:
221 """Read a states from a list of file paths.
222
223 Read states from stdin using a special path :code:`"-"`.
224
225 :param: A list of paths.
226
227 :return: A generator of compiler env states.
228 """
229 for path in paths:
230 if path == "-":
231 yield from iter(CompilerEnvStateReader(sys.stdin))
232 else:
233 with open(path) as f:
234 yield from iter(CompilerEnvStateReader(f))
235
[end of compiler_gym/compiler_env_state.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/compiler_gym/compiler_env_state.py b/compiler_gym/compiler_env_state.py
--- a/compiler_gym/compiler_env_state.py
+++ b/compiler_gym/compiler_env_state.py
@@ -4,9 +4,12 @@
# LICENSE file in the root directory of this source tree.
"""This module defines a class to represent a compiler environment state."""
import csv
+import re
import sys
+from io import StringIO
from typing import Iterable, List, Optional, TextIO
+import requests
from pydantic import BaseModel, Field, validator
from compiler_gym.datasets.uri import BenchmarkUri
@@ -23,10 +26,7 @@
benchmark: str = Field(
allow_mutation=False,
- examples=[
- "benchmark://cbench-v1/crc32",
- "generator://csmith-v0/0",
- ],
+ examples=["benchmark://cbench-v1/crc32", "generator://csmith-v0/0",],
)
"""The URI of the benchmark used for this episode."""
@@ -37,9 +37,7 @@
"""The walltime of the episode in seconds. Must be non-negative."""
reward: Optional[float] = Field(
- required=False,
- default=None,
- allow_mutation=True,
+ required=False, default=None, allow_mutation=True,
)
"""The cumulative reward for this episode. Optional."""
@@ -229,6 +227,16 @@
for path in paths:
if path == "-":
yield from iter(CompilerEnvStateReader(sys.stdin))
+ elif (
+ re.match(r"^(http|https)://[a-zA-Z0-9.-_/]+(\.csv)$", path) is not None
+ ):
+ response: requests.Response = requests.get(path)
+ if response.status_code == 200:
+ yield from iter(CompilerEnvStateReader(StringIO(response.text)))
+ else:
+ raise requests.exceptions.InvalidURL(
+ f"Url {path} content could not be obtained"
+ )
else:
with open(path) as f:
yield from iter(CompilerEnvStateReader(f))
|
{"golden_diff": "diff --git a/compiler_gym/compiler_env_state.py b/compiler_gym/compiler_env_state.py\n--- a/compiler_gym/compiler_env_state.py\n+++ b/compiler_gym/compiler_env_state.py\n@@ -4,9 +4,12 @@\n # LICENSE file in the root directory of this source tree.\n \"\"\"This module defines a class to represent a compiler environment state.\"\"\"\n import csv\n+import re\n import sys\n+from io import StringIO\n from typing import Iterable, List, Optional, TextIO\n \n+import requests\n from pydantic import BaseModel, Field, validator\n \n from compiler_gym.datasets.uri import BenchmarkUri\n@@ -23,10 +26,7 @@\n \n benchmark: str = Field(\n allow_mutation=False,\n- examples=[\n- \"benchmark://cbench-v1/crc32\",\n- \"generator://csmith-v0/0\",\n- ],\n+ examples=[\"benchmark://cbench-v1/crc32\", \"generator://csmith-v0/0\",],\n )\n \"\"\"The URI of the benchmark used for this episode.\"\"\"\n \n@@ -37,9 +37,7 @@\n \"\"\"The walltime of the episode in seconds. Must be non-negative.\"\"\"\n \n reward: Optional[float] = Field(\n- required=False,\n- default=None,\n- allow_mutation=True,\n+ required=False, default=None, allow_mutation=True,\n )\n \"\"\"The cumulative reward for this episode. Optional.\"\"\"\n \n@@ -229,6 +227,16 @@\n for path in paths:\n if path == \"-\":\n yield from iter(CompilerEnvStateReader(sys.stdin))\n+ elif (\n+ re.match(r\"^(http|https)://[a-zA-Z0-9.-_/]+(\\.csv)$\", path) is not None\n+ ):\n+ response: requests.Response = requests.get(path)\n+ if response.status_code == 200:\n+ yield from iter(CompilerEnvStateReader(StringIO(response.text)))\n+ else:\n+ raise requests.exceptions.InvalidURL(\n+ f\"Url {path} content could not be obtained\"\n+ )\n else:\n with open(path) as f:\n yield from iter(CompilerEnvStateReader(f))\n", "issue": "Add support for loading URLs to CompilerEnvStateReader.read_paths()\n## \ud83d\ude80 Feature\r\n\r\nExtend [CompilerEnvStateReader.read_paths()](https://github.com/facebookresearch/CompilerGym/blob/de07d4867e0bb0b47f6fa4bce5e262ea8f014c3e/tests/compiler_env_state_test.py#L212-L335) so that any combination of file path or URL can be loaded.\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\"\"\"This module defines a class to represent a compiler environment state.\"\"\"\nimport csv\nimport sys\nfrom typing import Iterable, List, Optional, TextIO\n\nfrom pydantic import BaseModel, Field, validator\n\nfrom compiler_gym.datasets.uri import BenchmarkUri\nfrom compiler_gym.util.truncate import truncate\n\n\nclass CompilerEnvState(BaseModel):\n \"\"\"The representation of a compiler environment state.\n\n The state of an environment is defined as a benchmark and a sequence of\n actions that has been applied to it. For a given environment, the state\n contains the information required to reproduce the result.\n \"\"\"\n\n benchmark: str = Field(\n allow_mutation=False,\n examples=[\n \"benchmark://cbench-v1/crc32\",\n \"generator://csmith-v0/0\",\n ],\n )\n \"\"\"The URI of the benchmark used for this episode.\"\"\"\n\n commandline: str\n \"\"\"The list of actions that produced this state, as a commandline.\"\"\"\n\n walltime: float\n \"\"\"The walltime of the episode in seconds. Must be non-negative.\"\"\"\n\n reward: Optional[float] = Field(\n required=False,\n default=None,\n allow_mutation=True,\n )\n \"\"\"The cumulative reward for this episode. Optional.\"\"\"\n\n @validator(\"walltime\")\n def walltime_nonnegative(cls, v):\n if v is not None:\n assert v >= 0, \"Walltime cannot be negative\"\n return v\n\n @validator(\"benchmark\", pre=True)\n def validate_benchmark(cls, value):\n if isinstance(value, BenchmarkUri):\n return str(value)\n return value\n\n @property\n def has_reward(self) -> bool:\n \"\"\"Return whether the state has a reward value.\"\"\"\n return self.reward is not None\n\n def __eq__(self, rhs) -> bool:\n if not isinstance(rhs, CompilerEnvState):\n return False\n epsilon = 1e-5\n # Only compare reward if both states have it.\n if not (self.has_reward and rhs.has_reward):\n reward_equal = True\n else:\n reward_equal = abs(self.reward - rhs.reward) < epsilon\n # Note that walltime is excluded from equivalence checks as two states\n # are equivalent if they define the same point in the optimization space\n # irrespective of how long it took to get there.\n return (\n self.benchmark == rhs.benchmark\n and reward_equal\n and self.commandline == rhs.commandline\n )\n\n def __ne__(self, rhs) -> bool:\n return not self == rhs\n\n class Config:\n validate_assignment = True\n\n\nclass CompilerEnvStateWriter:\n \"\"\"Serialize compiler environment states to CSV.\n\n Example use:\n\n >>> with CompilerEnvStateWriter(open(\"results.csv\", \"wb\")) as writer:\n ... writer.write_state(env.state)\n \"\"\"\n\n def __init__(self, f: TextIO, header: bool = True):\n \"\"\"Constructor.\n\n :param f: The file to write to.\n :param header: Whether to include a header row.\n \"\"\"\n self.f = f\n self.writer = csv.writer(self.f, lineterminator=\"\\n\")\n self.header = header\n\n def write_state(self, state: CompilerEnvState, flush: bool = False) -> None:\n \"\"\"Write the state to file.\n\n :param state: A compiler environment state.\n\n :param flush: Write to file immediately.\n \"\"\"\n if self.header:\n self.writer.writerow((\"benchmark\", \"reward\", \"walltime\", \"commandline\"))\n self.header = False\n self.writer.writerow(\n (state.benchmark, state.reward, state.walltime, state.commandline)\n )\n if flush:\n self.f.flush()\n\n def __enter__(self):\n \"\"\"Support with-statement for the writer.\"\"\"\n return self\n\n def __exit__(self, *args):\n \"\"\"Support with-statement for the writer.\"\"\"\n self.f.close()\n\n\nclass CompilerEnvStateReader:\n \"\"\"Read states from a CSV file.\n\n Example usage:\n\n >>> with CompilerEnvStateReader(open(\"results.csv\", \"rb\")) as reader:\n ... for state in reader:\n ... print(state)\n \"\"\"\n\n def __init__(self, f: TextIO):\n \"\"\"Constructor.\n\n :param f: The file to read.\n \"\"\"\n self.f = f\n self.reader = csv.reader(self.f)\n\n def __iter__(self) -> Iterable[CompilerEnvState]:\n \"\"\"Read the states from the file.\"\"\"\n columns_in_order = [\"benchmark\", \"reward\", \"walltime\", \"commandline\"]\n # Read the CSV and coerce the columns into the expected order.\n for (\n benchmark,\n reward,\n walltime,\n commandline,\n ) in self._iterate_columns_in_order(self.reader, columns_in_order):\n yield CompilerEnvState(\n benchmark=benchmark,\n reward=None if reward == \"\" else float(reward),\n walltime=0 if walltime == \"\" else float(walltime),\n commandline=commandline,\n )\n\n @staticmethod\n def _iterate_columns_in_order(\n reader: csv.reader, columns: List[str]\n ) -> Iterable[List[str]]:\n \"\"\"Read the input CSV and return each row in the given column order.\n\n Supports CSVs both with and without a header. If no header, columns are\n expected to be in the correct order. Else the header row is used to\n determine column order.\n\n Header row detection is case insensitive.\n\n :param reader: The CSV file to read.\n\n :param columns: A list of column names in the order that they are\n expected.\n\n :return: An iterator over rows.\n \"\"\"\n try:\n row = next(reader)\n except StopIteration:\n # Empty file.\n return\n\n if len(row) != len(columns):\n raise ValueError(\n f\"Expected {len(columns)} columns in the first row of CSV: {truncate(row)}\"\n )\n\n # Convert the maybe-header columns to lowercase for case-insensitive\n # comparison.\n maybe_header = [v.lower() for v in row]\n if set(maybe_header) == set(columns):\n # The first row matches the expected columns names, so use it to\n # determine the column order.\n column_order = [maybe_header.index(v) for v in columns]\n yield from ([row[v] for v in column_order] for row in reader)\n else:\n # The first row isn't a header, so assume that all rows are in\n # expected column order.\n yield row\n yield from reader\n\n def __enter__(self):\n \"\"\"Support with-statement for the reader.\"\"\"\n return self\n\n def __exit__(self, *args):\n \"\"\"Support with-statement for the reader.\"\"\"\n self.f.close()\n\n @staticmethod\n def read_paths(paths: Iterable[str]) -> Iterable[CompilerEnvState]:\n \"\"\"Read a states from a list of file paths.\n\n Read states from stdin using a special path :code:`\"-\"`.\n\n :param: A list of paths.\n\n :return: A generator of compiler env states.\n \"\"\"\n for path in paths:\n if path == \"-\":\n yield from iter(CompilerEnvStateReader(sys.stdin))\n else:\n with open(path) as f:\n yield from iter(CompilerEnvStateReader(f))\n", "path": "compiler_gym/compiler_env_state.py"}]}
| 2,879 | 480 |
gh_patches_debug_26253
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-5551
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
plugins.Pluto: Freezes at commercials and plays no audio on TV Shows
### Checklist
- [X] This is a [plugin issue](https://streamlink.github.io/plugins.html) and not [a different kind of issue](https://github.com/streamlink/streamlink/issues/new/choose)
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [x] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
Latest build from the master branch
### Description
Hello! Pluto TV plugin have problems. The plugin plays fine, but it freezes at commercials and some TV shows don't have commercials, it plays no audio because it thinks it at a commercial. This happens on all Pluto TV channels.
### Debug log
```text
C:\Windows\system32>streamlink -l debug https://pluto.tv/live-tv/forever-kids best
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.11.5
[cli][debug] Streamlink: 6.1.0
[cli][debug] Dependencies:
[cli][debug] certifi: 2023.7.22
[cli][debug] isodate: 0.6.1
[cli][debug] lxml: 4.9.3
[cli][debug] pycountry: 22.3.5
[cli][debug] pycryptodome: 3.18.0
[cli][debug] PySocks: 1.7.1
[cli][debug] requests: 2.31.0
[cli][debug] trio: 0.22.2
[cli][debug] trio-websocket: 0.10.3
[cli][debug] typing-extensions: 4.7.1
[cli][debug] urllib3: 2.0.4
[cli][debug] websocket-client: 1.6.1
[cli][debug] Arguments:
[cli][debug] url=https://pluto.tv/live-tv/forever-kids
[cli][debug] stream=['best']
[cli][debug] --loglevel=debug
[cli][debug] --ffmpeg-ffmpeg=C:\Program Files (x86)\Streamlink\ffmpeg\ffmpeg.exe
[cli][info] Found matching plugin pluto for URL https://pluto.tv/live-tv/forever-kids
[plugins.pluto][debug] slug=forever-kids
[plugins.pluto][debug] app_version=7.7.0-18f7ab32608969ea5bcbce8d0e23b9d0e1b24717
[stream.hls][warning] Encountered a stream discontinuity. This is unsupported and will result in incoherent output data.
```
</issue>
<code>
[start of src/streamlink/plugins/pluto.py]
1 """
2 $description Live TV and video on-demand service owned by Paramount Streaming.
3 $url pluto.tv
4 $type live, vod
5 $metadata id
6 $metadata author
7 $metadata category
8 $metadata title
9 """
10
11 import logging
12 import re
13 from urllib.parse import parse_qs, urljoin
14 from uuid import uuid4
15
16 from streamlink.plugin import Plugin, pluginmatcher
17 from streamlink.plugin.api import validate
18 from streamlink.stream.hls import HLSStream, HLSStreamReader, HLSStreamWriter
19 from streamlink.utils.url import update_qsd
20
21
22 log = logging.getLogger(__name__)
23
24
25 class PlutoHLSStreamWriter(HLSStreamWriter):
26 ad_re = re.compile(r"_ad/creative/|dai\.google\.com|Pluto_TV_OandO/.*Bumper")
27
28 def should_filter_sequence(self, sequence):
29 return self.ad_re.search(sequence.segment.uri) is not None or super().should_filter_sequence(sequence)
30
31
32 class PlutoHLSStreamReader(HLSStreamReader):
33 __writer__ = PlutoHLSStreamWriter
34
35
36 class PlutoHLSStream(HLSStream):
37 __shortname__ = "hls-pluto"
38 __reader__ = PlutoHLSStreamReader
39
40
41 @pluginmatcher(re.compile(r"""
42 https?://(?:www\.)?pluto\.tv/(?:\w{2}/)?(?:
43 live-tv/(?P<slug_live>[^/]+)
44 |
45 on-demand/series/(?P<slug_series>[^/]+)(?:/season/\d+)?/episode/(?P<slug_episode>[^/]+)
46 |
47 on-demand/movies/(?P<slug_movies>[^/]+)
48 )/?$
49 """, re.VERBOSE))
50 class Pluto(Plugin):
51 def _get_api_data(self, kind, slug, slugfilter=None):
52 log.debug(f"slug={slug}")
53 app_version = self.session.http.get(self.url, schema=validate.Schema(
54 validate.parse_html(),
55 validate.xml_xpath_string(".//head/meta[@name='appVersion']/@content"),
56 validate.any(None, str),
57 ))
58 if not app_version:
59 return
60
61 log.debug(f"app_version={app_version}")
62
63 return self.session.http.get(
64 "https://boot.pluto.tv/v4/start",
65 params={
66 "appName": "web",
67 "appVersion": app_version,
68 "deviceVersion": "94.0.0",
69 "deviceModel": "web",
70 "deviceMake": "firefox",
71 "deviceType": "web",
72 "clientID": str(uuid4()),
73 "clientModelNumber": "1.0",
74 kind: slug,
75 },
76 schema=validate.Schema(
77 validate.parse_json(), {
78 "servers": {
79 "stitcher": validate.url(),
80 },
81 validate.optional("EPG"): [{
82 "name": str,
83 "id": str,
84 "slug": str,
85 "stitched": {
86 "path": str,
87 },
88 }],
89 validate.optional("VOD"): [{
90 "name": str,
91 "id": str,
92 "slug": str,
93 "genre": str,
94 "stitched": {
95 "path": str,
96 },
97 validate.optional("seasons"): [{
98 "episodes": validate.all(
99 [{
100 "name": str,
101 "_id": str,
102 "slug": str,
103 "stitched": {
104 "path": str,
105 },
106 }],
107 validate.filter(lambda k: slugfilter and k["slug"] == slugfilter),
108 ),
109 }],
110 }],
111 "sessionToken": str,
112 "stitcherParams": str,
113 },
114 ),
115 )
116
117 def _get_playlist(self, host, path, params, token):
118 qs = parse_qs(params)
119 qs["jwt"] = token
120 yield from PlutoHLSStream.parse_variant_playlist(self.session, update_qsd(urljoin(host, path), qs)).items()
121
122 @staticmethod
123 def _get_media_data(data, key, slug):
124 media = data.get(key)
125 if media and media[0]["slug"] == slug:
126 return media[0]
127
128 def _get_streams(self):
129 m = self.match.groupdict()
130 if m["slug_live"]:
131 data = self._get_api_data("channelSlug", m["slug_live"])
132 media = self._get_media_data(data, "EPG", m["slug_live"])
133 if not media:
134 return
135
136 self.id = media["id"]
137 self.title = media["name"]
138 path = media["stitched"]["path"]
139
140 elif m["slug_series"] and m["slug_episode"]:
141 data = self._get_api_data("episodeSlugs", m["slug_series"], slugfilter=m["slug_episode"])
142 media = self._get_media_data(data, "VOD", m["slug_series"])
143 if not media or "seasons" not in media:
144 return
145
146 for season in media["seasons"]:
147 if season["episodes"]:
148 episode = season["episodes"][0]
149 if episode["slug"] == m["slug_episode"]:
150 break
151 else:
152 return
153
154 self.author = media["name"]
155 self.category = media["genre"]
156 self.id = episode["_id"]
157 self.title = episode["name"]
158 path = episode["stitched"]["path"]
159
160 elif m["slug_movies"]:
161 data = self._get_api_data("episodeSlugs", m["slug_movies"])
162 media = self._get_media_data(data, "VOD", m["slug_movies"])
163 if not media:
164 return
165
166 self.category = media["genre"]
167 self.id = media["id"]
168 self.title = media["name"]
169 path = media["stitched"]["path"]
170
171 else:
172 return
173
174 log.trace(f"data={data!r}")
175 log.debug(f"path={path}")
176
177 return self._get_playlist(
178 data["servers"]["stitcher"],
179 path,
180 data["stitcherParams"],
181 data["sessionToken"],
182 )
183
184
185 __plugin__ = Pluto
186
[end of src/streamlink/plugins/pluto.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/streamlink/plugins/pluto.py b/src/streamlink/plugins/pluto.py
--- a/src/streamlink/plugins/pluto.py
+++ b/src/streamlink/plugins/pluto.py
@@ -10,7 +10,7 @@
import logging
import re
-from urllib.parse import parse_qs, urljoin
+from urllib.parse import parse_qsl, urljoin
from uuid import uuid4
from streamlink.plugin import Plugin, pluginmatcher
@@ -23,7 +23,7 @@
class PlutoHLSStreamWriter(HLSStreamWriter):
- ad_re = re.compile(r"_ad/creative/|dai\.google\.com|Pluto_TV_OandO/.*Bumper")
+ ad_re = re.compile(r"_ad/creative/|dai\.google\.com|Pluto_TV_OandO/.*(Bumper|plutotv_filler)")
def should_filter_sequence(self, sequence):
return self.ad_re.search(sequence.segment.uri) is not None or super().should_filter_sequence(sequence)
@@ -115,9 +115,13 @@
)
def _get_playlist(self, host, path, params, token):
- qs = parse_qs(params)
- qs["jwt"] = token
- yield from PlutoHLSStream.parse_variant_playlist(self.session, update_qsd(urljoin(host, path), qs)).items()
+ qsd = dict(parse_qsl(params))
+ qsd["jwt"] = token
+
+ url = urljoin(host, path)
+ url = update_qsd(url, qsd)
+
+ return PlutoHLSStream.parse_variant_playlist(self.session, url)
@staticmethod
def _get_media_data(data, key, slug):
|
{"golden_diff": "diff --git a/src/streamlink/plugins/pluto.py b/src/streamlink/plugins/pluto.py\n--- a/src/streamlink/plugins/pluto.py\n+++ b/src/streamlink/plugins/pluto.py\n@@ -10,7 +10,7 @@\n \n import logging\n import re\n-from urllib.parse import parse_qs, urljoin\n+from urllib.parse import parse_qsl, urljoin\n from uuid import uuid4\n \n from streamlink.plugin import Plugin, pluginmatcher\n@@ -23,7 +23,7 @@\n \n \n class PlutoHLSStreamWriter(HLSStreamWriter):\n- ad_re = re.compile(r\"_ad/creative/|dai\\.google\\.com|Pluto_TV_OandO/.*Bumper\")\n+ ad_re = re.compile(r\"_ad/creative/|dai\\.google\\.com|Pluto_TV_OandO/.*(Bumper|plutotv_filler)\")\n \n def should_filter_sequence(self, sequence):\n return self.ad_re.search(sequence.segment.uri) is not None or super().should_filter_sequence(sequence)\n@@ -115,9 +115,13 @@\n )\n \n def _get_playlist(self, host, path, params, token):\n- qs = parse_qs(params)\n- qs[\"jwt\"] = token\n- yield from PlutoHLSStream.parse_variant_playlist(self.session, update_qsd(urljoin(host, path), qs)).items()\n+ qsd = dict(parse_qsl(params))\n+ qsd[\"jwt\"] = token\n+\n+ url = urljoin(host, path)\n+ url = update_qsd(url, qsd)\n+\n+ return PlutoHLSStream.parse_variant_playlist(self.session, url)\n \n @staticmethod\n def _get_media_data(data, key, slug):\n", "issue": "plugins.Pluto: Freezes at commercials and plays no audio on TV Shows\n### Checklist\n\n- [X] This is a [plugin issue](https://streamlink.github.io/plugins.html) and not [a different kind of issue](https://github.com/streamlink/streamlink/issues/new/choose)\n- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)\n- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)\n- [x] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)\n\n### Streamlink version\n\nLatest build from the master branch\n\n### Description\n\nHello! Pluto TV plugin have problems. The plugin plays fine, but it freezes at commercials and some TV shows don't have commercials, it plays no audio because it thinks it at a commercial. This happens on all Pluto TV channels.\n\n### Debug log\n\n```text\nC:\\Windows\\system32>streamlink -l debug https://pluto.tv/live-tv/forever-kids best\r\n[cli][debug] OS: Windows 10\r\n[cli][debug] Python: 3.11.5\r\n[cli][debug] Streamlink: 6.1.0\r\n[cli][debug] Dependencies:\r\n[cli][debug] certifi: 2023.7.22\r\n[cli][debug] isodate: 0.6.1\r\n[cli][debug] lxml: 4.9.3\r\n[cli][debug] pycountry: 22.3.5\r\n[cli][debug] pycryptodome: 3.18.0\r\n[cli][debug] PySocks: 1.7.1\r\n[cli][debug] requests: 2.31.0\r\n[cli][debug] trio: 0.22.2\r\n[cli][debug] trio-websocket: 0.10.3\r\n[cli][debug] typing-extensions: 4.7.1\r\n[cli][debug] urllib3: 2.0.4\r\n[cli][debug] websocket-client: 1.6.1\r\n[cli][debug] Arguments:\r\n[cli][debug] url=https://pluto.tv/live-tv/forever-kids\r\n[cli][debug] stream=['best']\r\n[cli][debug] --loglevel=debug\r\n[cli][debug] --ffmpeg-ffmpeg=C:\\Program Files (x86)\\Streamlink\\ffmpeg\\ffmpeg.exe\r\n[cli][info] Found matching plugin pluto for URL https://pluto.tv/live-tv/forever-kids\r\n[plugins.pluto][debug] slug=forever-kids\r\n[plugins.pluto][debug] app_version=7.7.0-18f7ab32608969ea5bcbce8d0e23b9d0e1b24717\r\n[stream.hls][warning] Encountered a stream discontinuity. This is unsupported and will result in incoherent output data.\n```\n\n", "before_files": [{"content": "\"\"\"\n$description Live TV and video on-demand service owned by Paramount Streaming.\n$url pluto.tv\n$type live, vod\n$metadata id\n$metadata author\n$metadata category\n$metadata title\n\"\"\"\n\nimport logging\nimport re\nfrom urllib.parse import parse_qs, urljoin\nfrom uuid import uuid4\n\nfrom streamlink.plugin import Plugin, pluginmatcher\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream.hls import HLSStream, HLSStreamReader, HLSStreamWriter\nfrom streamlink.utils.url import update_qsd\n\n\nlog = logging.getLogger(__name__)\n\n\nclass PlutoHLSStreamWriter(HLSStreamWriter):\n ad_re = re.compile(r\"_ad/creative/|dai\\.google\\.com|Pluto_TV_OandO/.*Bumper\")\n\n def should_filter_sequence(self, sequence):\n return self.ad_re.search(sequence.segment.uri) is not None or super().should_filter_sequence(sequence)\n\n\nclass PlutoHLSStreamReader(HLSStreamReader):\n __writer__ = PlutoHLSStreamWriter\n\n\nclass PlutoHLSStream(HLSStream):\n __shortname__ = \"hls-pluto\"\n __reader__ = PlutoHLSStreamReader\n\n\n@pluginmatcher(re.compile(r\"\"\"\n https?://(?:www\\.)?pluto\\.tv/(?:\\w{2}/)?(?:\n live-tv/(?P<slug_live>[^/]+)\n |\n on-demand/series/(?P<slug_series>[^/]+)(?:/season/\\d+)?/episode/(?P<slug_episode>[^/]+)\n |\n on-demand/movies/(?P<slug_movies>[^/]+)\n )/?$\n\"\"\", re.VERBOSE))\nclass Pluto(Plugin):\n def _get_api_data(self, kind, slug, slugfilter=None):\n log.debug(f\"slug={slug}\")\n app_version = self.session.http.get(self.url, schema=validate.Schema(\n validate.parse_html(),\n validate.xml_xpath_string(\".//head/meta[@name='appVersion']/@content\"),\n validate.any(None, str),\n ))\n if not app_version:\n return\n\n log.debug(f\"app_version={app_version}\")\n\n return self.session.http.get(\n \"https://boot.pluto.tv/v4/start\",\n params={\n \"appName\": \"web\",\n \"appVersion\": app_version,\n \"deviceVersion\": \"94.0.0\",\n \"deviceModel\": \"web\",\n \"deviceMake\": \"firefox\",\n \"deviceType\": \"web\",\n \"clientID\": str(uuid4()),\n \"clientModelNumber\": \"1.0\",\n kind: slug,\n },\n schema=validate.Schema(\n validate.parse_json(), {\n \"servers\": {\n \"stitcher\": validate.url(),\n },\n validate.optional(\"EPG\"): [{\n \"name\": str,\n \"id\": str,\n \"slug\": str,\n \"stitched\": {\n \"path\": str,\n },\n }],\n validate.optional(\"VOD\"): [{\n \"name\": str,\n \"id\": str,\n \"slug\": str,\n \"genre\": str,\n \"stitched\": {\n \"path\": str,\n },\n validate.optional(\"seasons\"): [{\n \"episodes\": validate.all(\n [{\n \"name\": str,\n \"_id\": str,\n \"slug\": str,\n \"stitched\": {\n \"path\": str,\n },\n }],\n validate.filter(lambda k: slugfilter and k[\"slug\"] == slugfilter),\n ),\n }],\n }],\n \"sessionToken\": str,\n \"stitcherParams\": str,\n },\n ),\n )\n\n def _get_playlist(self, host, path, params, token):\n qs = parse_qs(params)\n qs[\"jwt\"] = token\n yield from PlutoHLSStream.parse_variant_playlist(self.session, update_qsd(urljoin(host, path), qs)).items()\n\n @staticmethod\n def _get_media_data(data, key, slug):\n media = data.get(key)\n if media and media[0][\"slug\"] == slug:\n return media[0]\n\n def _get_streams(self):\n m = self.match.groupdict()\n if m[\"slug_live\"]:\n data = self._get_api_data(\"channelSlug\", m[\"slug_live\"])\n media = self._get_media_data(data, \"EPG\", m[\"slug_live\"])\n if not media:\n return\n\n self.id = media[\"id\"]\n self.title = media[\"name\"]\n path = media[\"stitched\"][\"path\"]\n\n elif m[\"slug_series\"] and m[\"slug_episode\"]:\n data = self._get_api_data(\"episodeSlugs\", m[\"slug_series\"], slugfilter=m[\"slug_episode\"])\n media = self._get_media_data(data, \"VOD\", m[\"slug_series\"])\n if not media or \"seasons\" not in media:\n return\n\n for season in media[\"seasons\"]:\n if season[\"episodes\"]:\n episode = season[\"episodes\"][0]\n if episode[\"slug\"] == m[\"slug_episode\"]:\n break\n else:\n return\n\n self.author = media[\"name\"]\n self.category = media[\"genre\"]\n self.id = episode[\"_id\"]\n self.title = episode[\"name\"]\n path = episode[\"stitched\"][\"path\"]\n\n elif m[\"slug_movies\"]:\n data = self._get_api_data(\"episodeSlugs\", m[\"slug_movies\"])\n media = self._get_media_data(data, \"VOD\", m[\"slug_movies\"])\n if not media:\n return\n\n self.category = media[\"genre\"]\n self.id = media[\"id\"]\n self.title = media[\"name\"]\n path = media[\"stitched\"][\"path\"]\n\n else:\n return\n\n log.trace(f\"data={data!r}\")\n log.debug(f\"path={path}\")\n\n return self._get_playlist(\n data[\"servers\"][\"stitcher\"],\n path,\n data[\"stitcherParams\"],\n data[\"sessionToken\"],\n )\n\n\n__plugin__ = Pluto\n", "path": "src/streamlink/plugins/pluto.py"}]}
| 3,003 | 375 |
gh_patches_debug_22747
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-2275
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Idea: warn users when trying to use TextResponse functionality with plain Response
Currently, if we try to use TextResponse functionality like response.text or css()/xpath() methods with a plain Response (e.g. in case of binary content), we get an AttributeError:
```
>>> response.css
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-1-7d6e256164d4> in <module>()
----> 1 response.css
AttributeError: 'Response' object has no attribute 'css'
>>> response.xpath
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-2-4f61f6e9fc6e> in <module>()
----> 1 response.xpath
AttributeError: 'Response' object has no attribute 'xpath'
>>> response.text
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-3-be6a4a00df5e> in <module>()
----> 1 response.text
AttributeError: 'Response' object has no attribute 'text'
```
Would it make sense to add a few methods/properties to explain what's going on for new users?
I was thinking instead of AttributeError, a better behavior could be a ValueError with a message giving a bit more context.
So, in plain `Response`, we could have:
```
def css(self, *args, **kw):
raise ValueError('Response content is not text')
def xpath(self, *args, **kw):
raise ValueError('Response content is not text')
@property
def text(self, *args, **kw):
raise ValueError('Response content is not text')
```
This would be nice, because we'd had to explain fewer things when teaching people about responses and also about using `.css` and `.xpath` methods.
What do you think?
</issue>
<code>
[start of scrapy/http/response/__init__.py]
1 """
2 This module implements the Response class which is used to represent HTTP
3 responses in Scrapy.
4
5 See documentation in docs/topics/request-response.rst
6 """
7 from six.moves.urllib.parse import urljoin
8
9 from scrapy.http.headers import Headers
10 from scrapy.utils.trackref import object_ref
11 from scrapy.http.common import obsolete_setter
12
13 class Response(object_ref):
14
15 def __init__(self, url, status=200, headers=None, body=b'', flags=None, request=None):
16 self.headers = Headers(headers or {})
17 self.status = int(status)
18 self._set_body(body)
19 self._set_url(url)
20 self.request = request
21 self.flags = [] if flags is None else list(flags)
22
23 @property
24 def meta(self):
25 try:
26 return self.request.meta
27 except AttributeError:
28 raise AttributeError(
29 "Response.meta not available, this response "
30 "is not tied to any request"
31 )
32
33 def _get_url(self):
34 return self._url
35
36 def _set_url(self, url):
37 if isinstance(url, str):
38 self._url = url
39 else:
40 raise TypeError('%s url must be str, got %s:' % (type(self).__name__,
41 type(url).__name__))
42
43 url = property(_get_url, obsolete_setter(_set_url, 'url'))
44
45 def _get_body(self):
46 return self._body
47
48 def _set_body(self, body):
49 if body is None:
50 self._body = b''
51 elif not isinstance(body, bytes):
52 raise TypeError(
53 "Response body must be bytes. "
54 "If you want to pass unicode body use TextResponse "
55 "or HtmlResponse.")
56 else:
57 self._body = body
58
59 body = property(_get_body, obsolete_setter(_set_body, 'body'))
60
61 def __str__(self):
62 return "<%d %s>" % (self.status, self.url)
63
64 __repr__ = __str__
65
66 def copy(self):
67 """Return a copy of this Response"""
68 return self.replace()
69
70 def replace(self, *args, **kwargs):
71 """Create a new Response with the same attributes except for those
72 given new values.
73 """
74 for x in ['url', 'status', 'headers', 'body', 'request', 'flags']:
75 kwargs.setdefault(x, getattr(self, x))
76 cls = kwargs.pop('cls', self.__class__)
77 return cls(*args, **kwargs)
78
79 def urljoin(self, url):
80 """Join this Response's url with a possible relative url to form an
81 absolute interpretation of the latter."""
82 return urljoin(self.url, url)
83
[end of scrapy/http/response/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scrapy/http/response/__init__.py b/scrapy/http/response/__init__.py
--- a/scrapy/http/response/__init__.py
+++ b/scrapy/http/response/__init__.py
@@ -9,6 +9,8 @@
from scrapy.http.headers import Headers
from scrapy.utils.trackref import object_ref
from scrapy.http.common import obsolete_setter
+from scrapy.exceptions import NotSupported
+
class Response(object_ref):
@@ -80,3 +82,22 @@
"""Join this Response's url with a possible relative url to form an
absolute interpretation of the latter."""
return urljoin(self.url, url)
+
+ @property
+ def text(self):
+ """For subclasses of TextResponse, this will return the body
+ as text (unicode object in Python 2 and str in Python 3)
+ """
+ raise AttributeError("Response content isn't text")
+
+ def css(self, *a, **kw):
+ """Shortcut method implemented only by responses whose content
+ is text (subclasses of TextResponse).
+ """
+ raise NotSupported("Response content isn't text")
+
+ def xpath(self, *a, **kw):
+ """Shortcut method implemented only by responses whose content
+ is text (subclasses of TextResponse).
+ """
+ raise NotSupported("Response content isn't text")
|
{"golden_diff": "diff --git a/scrapy/http/response/__init__.py b/scrapy/http/response/__init__.py\n--- a/scrapy/http/response/__init__.py\n+++ b/scrapy/http/response/__init__.py\n@@ -9,6 +9,8 @@\n from scrapy.http.headers import Headers\n from scrapy.utils.trackref import object_ref\n from scrapy.http.common import obsolete_setter\n+from scrapy.exceptions import NotSupported\n+\n \n class Response(object_ref):\n \n@@ -80,3 +82,22 @@\n \"\"\"Join this Response's url with a possible relative url to form an\n absolute interpretation of the latter.\"\"\"\n return urljoin(self.url, url)\n+\n+ @property\n+ def text(self):\n+ \"\"\"For subclasses of TextResponse, this will return the body\n+ as text (unicode object in Python 2 and str in Python 3)\n+ \"\"\"\n+ raise AttributeError(\"Response content isn't text\")\n+\n+ def css(self, *a, **kw):\n+ \"\"\"Shortcut method implemented only by responses whose content\n+ is text (subclasses of TextResponse).\n+ \"\"\"\n+ raise NotSupported(\"Response content isn't text\")\n+\n+ def xpath(self, *a, **kw):\n+ \"\"\"Shortcut method implemented only by responses whose content\n+ is text (subclasses of TextResponse).\n+ \"\"\"\n+ raise NotSupported(\"Response content isn't text\")\n", "issue": "Idea: warn users when trying to use TextResponse functionality with plain Response\nCurrently, if we try to use TextResponse functionality like response.text or css()/xpath() methods with a plain Response (e.g. in case of binary content), we get an AttributeError:\n\n```\n>>> response.css\n---------------------------------------------------------------------------\nAttributeError Traceback (most recent call last)\n<ipython-input-1-7d6e256164d4> in <module>()\n----> 1 response.css\n\nAttributeError: 'Response' object has no attribute 'css'\n>>> response.xpath\n---------------------------------------------------------------------------\nAttributeError Traceback (most recent call last)\n<ipython-input-2-4f61f6e9fc6e> in <module>()\n----> 1 response.xpath\n\nAttributeError: 'Response' object has no attribute 'xpath'\n>>> response.text\n---------------------------------------------------------------------------\nAttributeError Traceback (most recent call last)\n<ipython-input-3-be6a4a00df5e> in <module>()\n----> 1 response.text\n\nAttributeError: 'Response' object has no attribute 'text'\n```\n\nWould it make sense to add a few methods/properties to explain what's going on for new users?\n\nI was thinking instead of AttributeError, a better behavior could be a ValueError with a message giving a bit more context.\n\nSo, in plain `Response`, we could have:\n\n```\ndef css(self, *args, **kw):\n raise ValueError('Response content is not text')\n\ndef xpath(self, *args, **kw):\n raise ValueError('Response content is not text')\n\n@property\ndef text(self, *args, **kw):\n raise ValueError('Response content is not text')\n```\n\nThis would be nice, because we'd had to explain fewer things when teaching people about responses and also about using `.css` and `.xpath` methods.\n\nWhat do you think?\n\n", "before_files": [{"content": "\"\"\"\nThis module implements the Response class which is used to represent HTTP\nresponses in Scrapy.\n\nSee documentation in docs/topics/request-response.rst\n\"\"\"\nfrom six.moves.urllib.parse import urljoin\n\nfrom scrapy.http.headers import Headers\nfrom scrapy.utils.trackref import object_ref\nfrom scrapy.http.common import obsolete_setter\n\nclass Response(object_ref):\n\n def __init__(self, url, status=200, headers=None, body=b'', flags=None, request=None):\n self.headers = Headers(headers or {})\n self.status = int(status)\n self._set_body(body)\n self._set_url(url)\n self.request = request\n self.flags = [] if flags is None else list(flags)\n\n @property\n def meta(self):\n try:\n return self.request.meta\n except AttributeError:\n raise AttributeError(\n \"Response.meta not available, this response \"\n \"is not tied to any request\"\n )\n\n def _get_url(self):\n return self._url\n\n def _set_url(self, url):\n if isinstance(url, str):\n self._url = url\n else:\n raise TypeError('%s url must be str, got %s:' % (type(self).__name__,\n type(url).__name__))\n\n url = property(_get_url, obsolete_setter(_set_url, 'url'))\n\n def _get_body(self):\n return self._body\n\n def _set_body(self, body):\n if body is None:\n self._body = b''\n elif not isinstance(body, bytes):\n raise TypeError(\n \"Response body must be bytes. \"\n \"If you want to pass unicode body use TextResponse \"\n \"or HtmlResponse.\")\n else:\n self._body = body\n\n body = property(_get_body, obsolete_setter(_set_body, 'body'))\n\n def __str__(self):\n return \"<%d %s>\" % (self.status, self.url)\n\n __repr__ = __str__\n\n def copy(self):\n \"\"\"Return a copy of this Response\"\"\"\n return self.replace()\n\n def replace(self, *args, **kwargs):\n \"\"\"Create a new Response with the same attributes except for those\n given new values.\n \"\"\"\n for x in ['url', 'status', 'headers', 'body', 'request', 'flags']:\n kwargs.setdefault(x, getattr(self, x))\n cls = kwargs.pop('cls', self.__class__)\n return cls(*args, **kwargs)\n\n def urljoin(self, url):\n \"\"\"Join this Response's url with a possible relative url to form an\n absolute interpretation of the latter.\"\"\"\n return urljoin(self.url, url)\n", "path": "scrapy/http/response/__init__.py"}]}
| 1,660 | 301 |
gh_patches_debug_36105
|
rasdani/github-patches
|
git_diff
|
dbt-labs__dbt-core-2056
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Partial parsing: duplicate resource error
### Describe the bug
When the `--partial-parse` flag is enable, dbt can fail with an errant compilation error:
```
$ dbt --partial-parse compile
Running with dbt=0.15.0
Encountered an error:
Compilation Error
dbt found two resources with the name "adwords_ad_performance_adapter". Since these resources have the same name,
dbt will be unable to find the correct resource when ref("adwords_ad_performance_adapter") is used. To fix this,
change the name of one of these resources:
- model.adwords.adwords_ad_performance_adapter (models/router/adapter/criteria/adwords_ad_performance_adapter.sql)
- model.adwords.adwords_ad_performance_adapter (models/router/adapter/criteria/adwords_ad_performance_adapter.sql)
```
dbt is reporting the same model twice. Interestingly, there actually _are_ two instances of models named `adwords_ad_performance_adapter` in the [adwords package](https://github.com/fishtown-analytics/adwords):
- https://github.com/fishtown-analytics/adwords/blob/master/models/router/adapter/criteria/adwords_ad_performance_adapter.sql
- https://github.com/fishtown-analytics/adwords/blob/master/models/router/adapter/url/adwords_ad_performance_adapter.sql
These models are conditionally enabled using a variable, `adapter_value`, defined in the `dbt_project.yml` file.
It's not yet clear to me if dbt is failing because it's finding both of these models and reporting an errant error message, or if dbt really is picking up the same model twice somehow.
### Steps To Reproduce
Add the following to `packages.yml`:
```
packages:
- package: fishtown-analytics/adwords
version: 0.2.9
```
Add the following to `dbt_project.yml`:
```
models:
adwords:
vars:
adapter_value: criteria
```
Create a model called `adwords_criteria_performance.sql` with the contents:
```
select 1 as id
```
```
# Succeeds
$ dbt compile
# Fails with duplicate model error
$ dbt --partial-parse compile
```
### Expected behavior
dbt should compile and run this project successfully.
**The output of `dbt --version`:**
```
dbt v0.15.0
```
</issue>
<code>
[start of core/dbt/parser/results.py]
1 from dataclasses import dataclass, field
2 from typing import TypeVar, MutableMapping, Mapping, Union, List
3
4 from hologram import JsonSchemaMixin
5
6 from dbt.contracts.graph.manifest import SourceFile, RemoteFile, FileHash
7 from dbt.contracts.graph.parsed import (
8 ParsedNode, HasUniqueID, ParsedMacro, ParsedDocumentation, ParsedNodePatch,
9 ParsedSourceDefinition, ParsedAnalysisNode, ParsedHookNode, ParsedRPCNode,
10 ParsedModelNode, ParsedSeedNode, ParsedTestNode, ParsedSnapshotNode,
11 )
12 from dbt.contracts.util import Writable, Replaceable
13 from dbt.exceptions import (
14 raise_duplicate_resource_name, raise_duplicate_patch_name,
15 CompilationException, InternalException
16 )
17 from dbt.version import __version__
18
19
20 # Parsers can return anything as long as it's a unique ID
21 ParsedValueType = TypeVar('ParsedValueType', bound=HasUniqueID)
22
23
24 def _check_duplicates(
25 value: HasUniqueID, src: Mapping[str, HasUniqueID]
26 ):
27 if value.unique_id in src:
28 raise_duplicate_resource_name(value, src[value.unique_id])
29
30
31 ManifestNodes = Union[
32 ParsedAnalysisNode,
33 ParsedHookNode,
34 ParsedModelNode,
35 ParsedSeedNode,
36 ParsedTestNode,
37 ParsedSnapshotNode,
38 ParsedRPCNode,
39 ]
40
41
42 def dict_field():
43 return field(default_factory=dict)
44
45
46 @dataclass
47 class ParseResult(JsonSchemaMixin, Writable, Replaceable):
48 vars_hash: FileHash
49 profile_hash: FileHash
50 project_hashes: MutableMapping[str, FileHash]
51 nodes: MutableMapping[str, ManifestNodes] = dict_field()
52 sources: MutableMapping[str, ParsedSourceDefinition] = dict_field()
53 docs: MutableMapping[str, ParsedDocumentation] = dict_field()
54 macros: MutableMapping[str, ParsedMacro] = dict_field()
55 patches: MutableMapping[str, ParsedNodePatch] = dict_field()
56 files: MutableMapping[str, SourceFile] = dict_field()
57 disabled: MutableMapping[str, List[ParsedNode]] = dict_field()
58 dbt_version: str = __version__
59
60 def get_file(self, source_file: SourceFile) -> SourceFile:
61 key = source_file.search_key
62 if key is None:
63 return source_file
64 if key not in self.files:
65 self.files[key] = source_file
66 return self.files[key]
67
68 def add_source(
69 self, source_file: SourceFile, node: ParsedSourceDefinition
70 ):
71 # nodes can't be overwritten!
72 _check_duplicates(node, self.sources)
73 self.sources[node.unique_id] = node
74 self.get_file(source_file).sources.append(node.unique_id)
75
76 def add_node(self, source_file: SourceFile, node: ManifestNodes):
77 # nodes can't be overwritten!
78 _check_duplicates(node, self.nodes)
79 self.nodes[node.unique_id] = node
80 self.get_file(source_file).nodes.append(node.unique_id)
81
82 def add_disabled(self, source_file: SourceFile, node: ParsedNode):
83 if node.unique_id in self.disabled:
84 self.disabled[node.unique_id].append(node)
85 else:
86 self.disabled[node.unique_id] = [node]
87 self.get_file(source_file).nodes.append(node.unique_id)
88
89 def add_macro(self, source_file: SourceFile, macro: ParsedMacro):
90 # macros can be overwritten (should they be?)
91 self.macros[macro.unique_id] = macro
92 self.get_file(source_file).macros.append(macro.unique_id)
93
94 def add_doc(self, source_file: SourceFile, doc: ParsedDocumentation):
95 # Docs also can be overwritten (should they be?)
96 self.docs[doc.unique_id] = doc
97 self.get_file(source_file).docs.append(doc.unique_id)
98
99 def add_patch(self, source_file: SourceFile, patch: ParsedNodePatch):
100 # matches can't be overwritten
101 if patch.name in self.patches:
102 raise_duplicate_patch_name(patch.name, patch,
103 self.patches[patch.name])
104 self.patches[patch.name] = patch
105 self.get_file(source_file).patches.append(patch.name)
106
107 def _get_disabled(
108 self, unique_id: str, match_file: SourceFile
109 ) -> List[ParsedNode]:
110 if unique_id not in self.disabled:
111 raise InternalException(
112 'called _get_disabled with id={}, but it does not exist'
113 .format(unique_id)
114 )
115 return [
116 n for n in self.disabled[unique_id]
117 if n.original_file_path == match_file.path.original_file_path
118 ]
119
120 def sanitized_update(
121 self, source_file: SourceFile, old_result: 'ParseResult',
122 ) -> bool:
123 """Perform a santized update. If the file can't be updated, invalidate
124 it and return false.
125 """
126 if isinstance(source_file.path, RemoteFile):
127 return False
128
129 old_file = old_result.get_file(source_file)
130 for doc_id in old_file.docs:
131 doc = _expect_value(doc_id, old_result.docs, old_file, "docs")
132 self.add_doc(source_file, doc)
133
134 for macro_id in old_file.macros:
135 macro = _expect_value(
136 macro_id, old_result.macros, old_file, "macros"
137 )
138 self.add_macro(source_file, macro)
139
140 for source_id in old_file.sources:
141 source = _expect_value(
142 source_id, old_result.sources, old_file, "sources"
143 )
144 self.add_source(source_file, source)
145
146 # because we know this is how we _parsed_ the node, we can safely
147 # assume if it's disabled it was done by the project or file, and
148 # we can keep our old data
149 for node_id in old_file.nodes:
150 if node_id in old_result.nodes:
151 node = old_result.nodes[node_id]
152 self.add_node(source_file, node)
153 elif node_id in old_result.disabled:
154 matches = old_result._get_disabled(node_id, source_file)
155 for match in matches:
156 self.add_disabled(source_file, match)
157 else:
158 raise CompilationException(
159 'Expected to find "{}" in cached "manifest.nodes" or '
160 '"manifest.disabled" based on cached file information: {}!'
161 .format(node_id, old_file)
162 )
163
164 for name in old_file.patches:
165 patch = _expect_value(
166 name, old_result.patches, old_file, "patches"
167 )
168 self.add_patch(source_file, patch)
169
170 return True
171
172 def has_file(self, source_file: SourceFile) -> bool:
173 key = source_file.search_key
174 if key is None:
175 return False
176 if key not in self.files:
177 return False
178 my_checksum = self.files[key].checksum
179 return my_checksum == source_file.checksum
180
181 @classmethod
182 def rpc(cls):
183 # ugh!
184 return cls(FileHash.empty(), FileHash.empty(), {})
185
186
187 T = TypeVar('T')
188
189
190 def _expect_value(
191 key: str, src: Mapping[str, T], old_file: SourceFile, name: str
192 ) -> T:
193 if key not in src:
194 raise CompilationException(
195 'Expected to find "{}" in cached "result.{}" based '
196 'on cached file information: {}!'
197 .format(key, name, old_file)
198 )
199 return src[key]
200
[end of core/dbt/parser/results.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/core/dbt/parser/results.py b/core/dbt/parser/results.py
--- a/core/dbt/parser/results.py
+++ b/core/dbt/parser/results.py
@@ -117,6 +117,37 @@
if n.original_file_path == match_file.path.original_file_path
]
+ def _process_node(
+ self,
+ node_id: str,
+ source_file: SourceFile,
+ old_file: SourceFile,
+ old_result: 'ParseResult',
+ ) -> None:
+ """Nodes are a special kind of complicated - there can be multiple
+ with the same name, as long as all but one are disabled.
+ """
+ source_path = source_file.path.original_file_path
+ found: bool = False
+ if node_id in old_result.nodes:
+ old_node = old_result.nodes[node_id]
+ if old_node.original_file_path == source_path:
+ self.add_node(source_file, old_node)
+ found = True
+
+ if node_id in old_result.disabled:
+ matches = old_result._get_disabled(node_id, source_file)
+ for match in matches:
+ self.add_disabled(source_file, match)
+ found = True
+
+ if not found:
+ raise CompilationException(
+ 'Expected to find "{}" in cached "manifest.nodes" or '
+ '"manifest.disabled" based on cached file information: {}!'
+ .format(node_id, old_file)
+ )
+
def sanitized_update(
self, source_file: SourceFile, old_result: 'ParseResult',
) -> bool:
@@ -146,20 +177,10 @@
# because we know this is how we _parsed_ the node, we can safely
# assume if it's disabled it was done by the project or file, and
# we can keep our old data
+ # the node ID could be in old_result.disabled AND in old_result.nodes.
+ # In that case, we have to make sure the path also matches.
for node_id in old_file.nodes:
- if node_id in old_result.nodes:
- node = old_result.nodes[node_id]
- self.add_node(source_file, node)
- elif node_id in old_result.disabled:
- matches = old_result._get_disabled(node_id, source_file)
- for match in matches:
- self.add_disabled(source_file, match)
- else:
- raise CompilationException(
- 'Expected to find "{}" in cached "manifest.nodes" or '
- '"manifest.disabled" based on cached file information: {}!'
- .format(node_id, old_file)
- )
+ self._process_node(node_id, source_file, old_file, old_result)
for name in old_file.patches:
patch = _expect_value(
|
{"golden_diff": "diff --git a/core/dbt/parser/results.py b/core/dbt/parser/results.py\n--- a/core/dbt/parser/results.py\n+++ b/core/dbt/parser/results.py\n@@ -117,6 +117,37 @@\n if n.original_file_path == match_file.path.original_file_path\n ]\n \n+ def _process_node(\n+ self,\n+ node_id: str,\n+ source_file: SourceFile,\n+ old_file: SourceFile,\n+ old_result: 'ParseResult',\n+ ) -> None:\n+ \"\"\"Nodes are a special kind of complicated - there can be multiple\n+ with the same name, as long as all but one are disabled.\n+ \"\"\"\n+ source_path = source_file.path.original_file_path\n+ found: bool = False\n+ if node_id in old_result.nodes:\n+ old_node = old_result.nodes[node_id]\n+ if old_node.original_file_path == source_path:\n+ self.add_node(source_file, old_node)\n+ found = True\n+\n+ if node_id in old_result.disabled:\n+ matches = old_result._get_disabled(node_id, source_file)\n+ for match in matches:\n+ self.add_disabled(source_file, match)\n+ found = True\n+\n+ if not found:\n+ raise CompilationException(\n+ 'Expected to find \"{}\" in cached \"manifest.nodes\" or '\n+ '\"manifest.disabled\" based on cached file information: {}!'\n+ .format(node_id, old_file)\n+ )\n+\n def sanitized_update(\n self, source_file: SourceFile, old_result: 'ParseResult',\n ) -> bool:\n@@ -146,20 +177,10 @@\n # because we know this is how we _parsed_ the node, we can safely\n # assume if it's disabled it was done by the project or file, and\n # we can keep our old data\n+ # the node ID could be in old_result.disabled AND in old_result.nodes.\n+ # In that case, we have to make sure the path also matches.\n for node_id in old_file.nodes:\n- if node_id in old_result.nodes:\n- node = old_result.nodes[node_id]\n- self.add_node(source_file, node)\n- elif node_id in old_result.disabled:\n- matches = old_result._get_disabled(node_id, source_file)\n- for match in matches:\n- self.add_disabled(source_file, match)\n- else:\n- raise CompilationException(\n- 'Expected to find \"{}\" in cached \"manifest.nodes\" or '\n- '\"manifest.disabled\" based on cached file information: {}!'\n- .format(node_id, old_file)\n- )\n+ self._process_node(node_id, source_file, old_file, old_result)\n \n for name in old_file.patches:\n patch = _expect_value(\n", "issue": "Partial parsing: duplicate resource error\n### Describe the bug\r\nWhen the `--partial-parse` flag is enable, dbt can fail with an errant compilation error:\r\n\r\n```\r\n$ dbt --partial-parse compile\r\nRunning with dbt=0.15.0\r\nEncountered an error:\r\nCompilation Error\r\n dbt found two resources with the name \"adwords_ad_performance_adapter\". Since these resources have the same name,\r\n dbt will be unable to find the correct resource when ref(\"adwords_ad_performance_adapter\") is used. To fix this,\r\n change the name of one of these resources:\r\n - model.adwords.adwords_ad_performance_adapter (models/router/adapter/criteria/adwords_ad_performance_adapter.sql)\r\n - model.adwords.adwords_ad_performance_adapter (models/router/adapter/criteria/adwords_ad_performance_adapter.sql)\r\n```\r\n\r\ndbt is reporting the same model twice. Interestingly, there actually _are_ two instances of models named `adwords_ad_performance_adapter` in the [adwords package](https://github.com/fishtown-analytics/adwords):\r\n - https://github.com/fishtown-analytics/adwords/blob/master/models/router/adapter/criteria/adwords_ad_performance_adapter.sql\r\n - https://github.com/fishtown-analytics/adwords/blob/master/models/router/adapter/url/adwords_ad_performance_adapter.sql\r\n\r\nThese models are conditionally enabled using a variable, `adapter_value`, defined in the `dbt_project.yml` file.\r\n\r\nIt's not yet clear to me if dbt is failing because it's finding both of these models and reporting an errant error message, or if dbt really is picking up the same model twice somehow.\r\n\r\n### Steps To Reproduce\r\n\r\nAdd the following to `packages.yml`:\r\n```\r\npackages:\r\n - package: fishtown-analytics/adwords\r\n version: 0.2.9\r\n```\r\n\r\nAdd the following to `dbt_project.yml`:\r\n```\r\nmodels:\r\n adwords:\r\n vars:\r\n adapter_value: criteria\r\n```\r\n\r\nCreate a model called `adwords_criteria_performance.sql` with the contents:\r\n```\r\nselect 1 as id\r\n```\r\n\r\n```\r\n# Succeeds\r\n$ dbt compile\r\n\r\n# Fails with duplicate model error\r\n$ dbt --partial-parse compile\r\n```\r\n\r\n### Expected behavior\r\ndbt should compile and run this project successfully.\r\n\r\n**The output of `dbt --version`:**\r\n```\r\ndbt v0.15.0\r\n```\n", "before_files": [{"content": "from dataclasses import dataclass, field\nfrom typing import TypeVar, MutableMapping, Mapping, Union, List\n\nfrom hologram import JsonSchemaMixin\n\nfrom dbt.contracts.graph.manifest import SourceFile, RemoteFile, FileHash\nfrom dbt.contracts.graph.parsed import (\n ParsedNode, HasUniqueID, ParsedMacro, ParsedDocumentation, ParsedNodePatch,\n ParsedSourceDefinition, ParsedAnalysisNode, ParsedHookNode, ParsedRPCNode,\n ParsedModelNode, ParsedSeedNode, ParsedTestNode, ParsedSnapshotNode,\n)\nfrom dbt.contracts.util import Writable, Replaceable\nfrom dbt.exceptions import (\n raise_duplicate_resource_name, raise_duplicate_patch_name,\n CompilationException, InternalException\n)\nfrom dbt.version import __version__\n\n\n# Parsers can return anything as long as it's a unique ID\nParsedValueType = TypeVar('ParsedValueType', bound=HasUniqueID)\n\n\ndef _check_duplicates(\n value: HasUniqueID, src: Mapping[str, HasUniqueID]\n):\n if value.unique_id in src:\n raise_duplicate_resource_name(value, src[value.unique_id])\n\n\nManifestNodes = Union[\n ParsedAnalysisNode,\n ParsedHookNode,\n ParsedModelNode,\n ParsedSeedNode,\n ParsedTestNode,\n ParsedSnapshotNode,\n ParsedRPCNode,\n]\n\n\ndef dict_field():\n return field(default_factory=dict)\n\n\n@dataclass\nclass ParseResult(JsonSchemaMixin, Writable, Replaceable):\n vars_hash: FileHash\n profile_hash: FileHash\n project_hashes: MutableMapping[str, FileHash]\n nodes: MutableMapping[str, ManifestNodes] = dict_field()\n sources: MutableMapping[str, ParsedSourceDefinition] = dict_field()\n docs: MutableMapping[str, ParsedDocumentation] = dict_field()\n macros: MutableMapping[str, ParsedMacro] = dict_field()\n patches: MutableMapping[str, ParsedNodePatch] = dict_field()\n files: MutableMapping[str, SourceFile] = dict_field()\n disabled: MutableMapping[str, List[ParsedNode]] = dict_field()\n dbt_version: str = __version__\n\n def get_file(self, source_file: SourceFile) -> SourceFile:\n key = source_file.search_key\n if key is None:\n return source_file\n if key not in self.files:\n self.files[key] = source_file\n return self.files[key]\n\n def add_source(\n self, source_file: SourceFile, node: ParsedSourceDefinition\n ):\n # nodes can't be overwritten!\n _check_duplicates(node, self.sources)\n self.sources[node.unique_id] = node\n self.get_file(source_file).sources.append(node.unique_id)\n\n def add_node(self, source_file: SourceFile, node: ManifestNodes):\n # nodes can't be overwritten!\n _check_duplicates(node, self.nodes)\n self.nodes[node.unique_id] = node\n self.get_file(source_file).nodes.append(node.unique_id)\n\n def add_disabled(self, source_file: SourceFile, node: ParsedNode):\n if node.unique_id in self.disabled:\n self.disabled[node.unique_id].append(node)\n else:\n self.disabled[node.unique_id] = [node]\n self.get_file(source_file).nodes.append(node.unique_id)\n\n def add_macro(self, source_file: SourceFile, macro: ParsedMacro):\n # macros can be overwritten (should they be?)\n self.macros[macro.unique_id] = macro\n self.get_file(source_file).macros.append(macro.unique_id)\n\n def add_doc(self, source_file: SourceFile, doc: ParsedDocumentation):\n # Docs also can be overwritten (should they be?)\n self.docs[doc.unique_id] = doc\n self.get_file(source_file).docs.append(doc.unique_id)\n\n def add_patch(self, source_file: SourceFile, patch: ParsedNodePatch):\n # matches can't be overwritten\n if patch.name in self.patches:\n raise_duplicate_patch_name(patch.name, patch,\n self.patches[patch.name])\n self.patches[patch.name] = patch\n self.get_file(source_file).patches.append(patch.name)\n\n def _get_disabled(\n self, unique_id: str, match_file: SourceFile\n ) -> List[ParsedNode]:\n if unique_id not in self.disabled:\n raise InternalException(\n 'called _get_disabled with id={}, but it does not exist'\n .format(unique_id)\n )\n return [\n n for n in self.disabled[unique_id]\n if n.original_file_path == match_file.path.original_file_path\n ]\n\n def sanitized_update(\n self, source_file: SourceFile, old_result: 'ParseResult',\n ) -> bool:\n \"\"\"Perform a santized update. If the file can't be updated, invalidate\n it and return false.\n \"\"\"\n if isinstance(source_file.path, RemoteFile):\n return False\n\n old_file = old_result.get_file(source_file)\n for doc_id in old_file.docs:\n doc = _expect_value(doc_id, old_result.docs, old_file, \"docs\")\n self.add_doc(source_file, doc)\n\n for macro_id in old_file.macros:\n macro = _expect_value(\n macro_id, old_result.macros, old_file, \"macros\"\n )\n self.add_macro(source_file, macro)\n\n for source_id in old_file.sources:\n source = _expect_value(\n source_id, old_result.sources, old_file, \"sources\"\n )\n self.add_source(source_file, source)\n\n # because we know this is how we _parsed_ the node, we can safely\n # assume if it's disabled it was done by the project or file, and\n # we can keep our old data\n for node_id in old_file.nodes:\n if node_id in old_result.nodes:\n node = old_result.nodes[node_id]\n self.add_node(source_file, node)\n elif node_id in old_result.disabled:\n matches = old_result._get_disabled(node_id, source_file)\n for match in matches:\n self.add_disabled(source_file, match)\n else:\n raise CompilationException(\n 'Expected to find \"{}\" in cached \"manifest.nodes\" or '\n '\"manifest.disabled\" based on cached file information: {}!'\n .format(node_id, old_file)\n )\n\n for name in old_file.patches:\n patch = _expect_value(\n name, old_result.patches, old_file, \"patches\"\n )\n self.add_patch(source_file, patch)\n\n return True\n\n def has_file(self, source_file: SourceFile) -> bool:\n key = source_file.search_key\n if key is None:\n return False\n if key not in self.files:\n return False\n my_checksum = self.files[key].checksum\n return my_checksum == source_file.checksum\n\n @classmethod\n def rpc(cls):\n # ugh!\n return cls(FileHash.empty(), FileHash.empty(), {})\n\n\nT = TypeVar('T')\n\n\ndef _expect_value(\n key: str, src: Mapping[str, T], old_file: SourceFile, name: str\n) -> T:\n if key not in src:\n raise CompilationException(\n 'Expected to find \"{}\" in cached \"result.{}\" based '\n 'on cached file information: {}!'\n .format(key, name, old_file)\n )\n return src[key]\n", "path": "core/dbt/parser/results.py"}]}
| 3,148 | 620 |
gh_patches_debug_66309
|
rasdani/github-patches
|
git_diff
|
sql-machine-learning__elasticdl-1463
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
No module named 'elasticdl.python.elasticdl.layers' on master
```
Traceback (most recent call last):
File "/usr/local/lib/python3.7/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/usr/local/lib/python3.7/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/elasticdl/python/master/main.py", line 28, in <module>
from elasticdl.python.elasticdl.layers.embedding import Embedding
ModuleNotFoundError: No module named 'elasticdl.python.elasticdl.layers'
```
Seems `layers` directory is not installed to `/usr/local/lib/python3.7/site-packages/elasticdl-develop-py3.7.egg/elasticdl/python/elasticdl` after running `python setup.py install`
Steps to reproduce:
1. In a Python Docker container, clone ElasticDL and run `python setup.py install`
1. remove the cloned source
1. execute a demo job by: `elasticdl train ...`
</issue>
<code>
[start of elasticdl/python/elasticdl/__init__.py]
[end of elasticdl/python/elasticdl/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/elasticdl/python/elasticdl/__init__.py b/elasticdl/python/elasticdl/__init__.py
--- a/elasticdl/python/elasticdl/__init__.py
+++ b/elasticdl/python/elasticdl/__init__.py
@@ -0,0 +1 @@
+from elasticdl.python.elasticdl import layers # noqa: F401
|
{"golden_diff": "diff --git a/elasticdl/python/elasticdl/__init__.py b/elasticdl/python/elasticdl/__init__.py\n--- a/elasticdl/python/elasticdl/__init__.py\n+++ b/elasticdl/python/elasticdl/__init__.py\n@@ -0,0 +1 @@\n+from elasticdl.python.elasticdl import layers # noqa: F401\n", "issue": "No module named 'elasticdl.python.elasticdl.layers' on master\n```\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.7/runpy.py\", line 193, in _run_module_as_main\r\n \"__main__\", mod_spec)\r\n File \"/usr/local/lib/python3.7/runpy.py\", line 85, in _run_code\r\n exec(code, run_globals)\r\n File \"/elasticdl/python/master/main.py\", line 28, in <module>\r\n from elasticdl.python.elasticdl.layers.embedding import Embedding\r\nModuleNotFoundError: No module named 'elasticdl.python.elasticdl.layers'\r\n```\r\n\r\nSeems `layers` directory is not installed to `/usr/local/lib/python3.7/site-packages/elasticdl-develop-py3.7.egg/elasticdl/python/elasticdl` after running `python setup.py install`\r\n\r\nSteps to reproduce:\r\n\r\n1. In a Python Docker container, clone ElasticDL and run `python setup.py install`\r\n1. remove the cloned source\r\n1. execute a demo job by: `elasticdl train ...`\n", "before_files": [{"content": "", "path": "elasticdl/python/elasticdl/__init__.py"}]}
| 777 | 83 |
gh_patches_debug_30901
|
rasdani/github-patches
|
git_diff
|
lk-geimfari__mimesis-677
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Auto add builtin provider to Generic based on passed locale
# Feature request
An idea is very simple:
```python
generic = Generic('ru', auto_add_builtin=True)
generic.russia_provider.inn()
```
Instead of this:
```python
from mimesis import Generic
from mimesis.builtins import RussiaSpecProvider
generic = Generic('ru')
generic.add_provider(RussiaSpecProvider)
generic.russia_provider.inn()
```
Optionally we can make builtin's name customizable:
```python
generic = Generic('ru', auto_add_builtin=True, builtin_custom_name='russia')
generic.russia.inn()
```
</issue>
<code>
[start of mimesis/providers/generic.py]
1 # -*- coding: utf-8 -*-
2
3 """Provides all at one."""
4
5 import inspect
6 from typing import Any, List, Type
7
8 from mimesis.providers.address import Address
9 from mimesis.providers.base import BaseDataProvider, BaseProvider
10 from mimesis.providers.business import Business
11 from mimesis.providers.choice import Choice
12 from mimesis.providers.clothing import Clothing
13 from mimesis.providers.code import Code
14 from mimesis.providers.cryptographic import Cryptographic
15 from mimesis.providers.date import Datetime
16 from mimesis.providers.development import Development
17 from mimesis.providers.file import File
18 from mimesis.providers.food import Food
19 from mimesis.providers.hardware import Hardware
20 from mimesis.providers.internet import Internet
21 from mimesis.providers.numbers import Numbers
22 from mimesis.providers.path import Path
23 from mimesis.providers.payment import Payment
24 from mimesis.providers.person import Person
25 from mimesis.providers.science import Science
26 from mimesis.providers.structure import Structure
27 from mimesis.providers.text import Text
28 from mimesis.providers.transport import Transport
29 from mimesis.providers.units import UnitSystem
30
31 __all__ = ['Generic']
32
33
34 class Generic(BaseDataProvider):
35 """Class which contain all providers at one."""
36
37 def __init__(self, *args, **kwargs) -> None:
38 """Initialize attributes lazily.
39
40 :param args: Arguments.
41 :param kwargs: Keyword arguments.
42 """
43 super().__init__(*args, **kwargs)
44 self._person = Person
45 self._address = Address
46 self._datetime = Datetime
47 self._business = Business
48 self._text = Text
49 self._food = Food
50 self._science = Science
51 self.transport = Transport(seed=self.seed)
52 self.code = Code(seed=self.seed)
53 self.unit_system = UnitSystem(seed=self.seed)
54 self.file = File(seed=self.seed)
55 self.numbers = Numbers(seed=self.seed)
56 self.development = Development(seed=self.seed)
57 self.hardware = Hardware(seed=self.seed)
58 self.clothing = Clothing(seed=self.seed)
59 self.internet = Internet(seed=self.seed)
60 self.path = Path(seed=self.seed)
61 self.payment = Payment(seed=self.seed)
62 self.cryptographic = Cryptographic(seed=self.seed)
63 self.structure = Structure(seed=self.seed)
64 self.choice = Choice(seed=self.seed)
65
66 class Meta:
67 """Class for metadata."""
68
69 name = 'generic'
70
71 def __getattr__(self, attrname: str) -> Any:
72 """Get attribute without underscore.
73
74 :param attrname: Attribute name.
75 :return: An attribute.
76 """
77 attribute = object.__getattribute__(
78 self, '_' + attrname)
79 if attribute and callable(attribute):
80 self.__dict__[attrname] = attribute(
81 self.locale,
82 self.seed,
83 )
84 return self.__dict__[attrname]
85
86 def __dir__(self) -> List[str]:
87 """Available data providers.
88
89 The list of result will be used in AbstractField to
90 determine method's class.
91
92 :return: List of attributes.
93 """
94 attributes = []
95 exclude = BaseDataProvider().__dict__.keys()
96
97 for a in self.__dict__:
98 if a not in exclude:
99 if a.startswith('_'):
100 attribute = a.replace('_', '', 1)
101 attributes.append(attribute)
102 else:
103 attributes.append(a)
104 return attributes
105
106 def add_provider(self, cls: Type[BaseProvider]) -> None:
107 """Add a custom provider to Generic() object.
108
109 :param cls: Custom provider.
110 :return: None
111 :raises TypeError: if cls is not class.
112 """
113 if inspect.isclass(cls):
114 if not issubclass(cls, BaseProvider):
115 raise TypeError('The provider must be a '
116 'subclass of BaseProvider')
117 try:
118 meta = getattr(cls, 'Meta')
119 name = getattr(meta, 'name')
120 except AttributeError:
121 name = cls.__name__.lower()
122 setattr(self, name, cls(seed=self.seed))
123 else:
124 raise TypeError('The provider must be a class')
125
126 def add_providers(self, *providers: Type[BaseProvider]) -> None:
127 """Add a lot of custom providers to Generic() object.
128
129 :param providers: Custom providers.
130 :return: None
131 """
132 for provider in providers:
133 self.add_provider(provider)
134
[end of mimesis/providers/generic.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mimesis/providers/generic.py b/mimesis/providers/generic.py
--- a/mimesis/providers/generic.py
+++ b/mimesis/providers/generic.py
@@ -5,6 +5,17 @@
import inspect
from typing import Any, List, Type
+from mimesis.builtins import (
+ BrazilSpecProvider,
+ DenmarkSpecProvider,
+ GermanySpecProvider,
+ ItalySpecProvider,
+ NetherlandsSpecProvider,
+ PolandSpecProvider,
+ RussiaSpecProvider,
+ UkraineSpecProvider,
+ USASpecProvider,
+)
from mimesis.providers.address import Address
from mimesis.providers.base import BaseDataProvider, BaseProvider
from mimesis.providers.business import Business
@@ -48,6 +59,21 @@
self._text = Text
self._food = Food
self._science = Science
+
+ _spec_providers = {
+ 'de': DenmarkSpecProvider,
+ 'ge': GermanySpecProvider,
+ 'en': USASpecProvider,
+ 'it': ItalySpecProvider,
+ 'nl': NetherlandsSpecProvider,
+ 'pl': PolandSpecProvider,
+ 'pt-br': BrazilSpecProvider,
+ 'ru': RussiaSpecProvider,
+ 'uk': UkraineSpecProvider,
+ }
+ if self.locale in _spec_providers:
+ self.add_provider(_spec_providers[self.locale])
+
self.transport = Transport(seed=self.seed)
self.code = Code(seed=self.seed)
self.unit_system = UnitSystem(seed=self.seed)
@@ -108,7 +134,8 @@
:param cls: Custom provider.
:return: None
- :raises TypeError: if cls is not class.
+ :raises TypeError: if cls is not class or is not a subclass
+ of BaseProvider.
"""
if inspect.isclass(cls):
if not issubclass(cls, BaseProvider):
|
{"golden_diff": "diff --git a/mimesis/providers/generic.py b/mimesis/providers/generic.py\n--- a/mimesis/providers/generic.py\n+++ b/mimesis/providers/generic.py\n@@ -5,6 +5,17 @@\n import inspect\n from typing import Any, List, Type\n \n+from mimesis.builtins import (\n+ BrazilSpecProvider,\n+ DenmarkSpecProvider,\n+ GermanySpecProvider,\n+ ItalySpecProvider,\n+ NetherlandsSpecProvider,\n+ PolandSpecProvider,\n+ RussiaSpecProvider,\n+ UkraineSpecProvider,\n+ USASpecProvider,\n+)\n from mimesis.providers.address import Address\n from mimesis.providers.base import BaseDataProvider, BaseProvider\n from mimesis.providers.business import Business\n@@ -48,6 +59,21 @@\n self._text = Text\n self._food = Food\n self._science = Science\n+\n+ _spec_providers = {\n+ 'de': DenmarkSpecProvider,\n+ 'ge': GermanySpecProvider,\n+ 'en': USASpecProvider,\n+ 'it': ItalySpecProvider,\n+ 'nl': NetherlandsSpecProvider,\n+ 'pl': PolandSpecProvider,\n+ 'pt-br': BrazilSpecProvider,\n+ 'ru': RussiaSpecProvider,\n+ 'uk': UkraineSpecProvider,\n+ }\n+ if self.locale in _spec_providers:\n+ self.add_provider(_spec_providers[self.locale])\n+\n self.transport = Transport(seed=self.seed)\n self.code = Code(seed=self.seed)\n self.unit_system = UnitSystem(seed=self.seed)\n@@ -108,7 +134,8 @@\n \n :param cls: Custom provider.\n :return: None\n- :raises TypeError: if cls is not class.\n+ :raises TypeError: if cls is not class or is not a subclass\n+ of BaseProvider.\n \"\"\"\n if inspect.isclass(cls):\n if not issubclass(cls, BaseProvider):\n", "issue": "Auto add builtin provider to Generic based on passed locale\n# Feature request\r\n\r\nAn idea is very simple:\r\n\r\n```python\r\ngeneric = Generic('ru', auto_add_builtin=True)\r\ngeneric.russia_provider.inn()\r\n```\r\n\r\nInstead of this:\r\n\r\n```python\r\nfrom mimesis import Generic\r\nfrom mimesis.builtins import RussiaSpecProvider\r\n\r\ngeneric = Generic('ru')\r\ngeneric.add_provider(RussiaSpecProvider)\r\ngeneric.russia_provider.inn()\r\n```\r\n\r\nOptionally we can make builtin's name customizable: \r\n\r\n```python\r\ngeneric = Generic('ru', auto_add_builtin=True, builtin_custom_name='russia')\r\ngeneric.russia.inn()\r\n```\r\n\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Provides all at one.\"\"\"\n\nimport inspect\nfrom typing import Any, List, Type\n\nfrom mimesis.providers.address import Address\nfrom mimesis.providers.base import BaseDataProvider, BaseProvider\nfrom mimesis.providers.business import Business\nfrom mimesis.providers.choice import Choice\nfrom mimesis.providers.clothing import Clothing\nfrom mimesis.providers.code import Code\nfrom mimesis.providers.cryptographic import Cryptographic\nfrom mimesis.providers.date import Datetime\nfrom mimesis.providers.development import Development\nfrom mimesis.providers.file import File\nfrom mimesis.providers.food import Food\nfrom mimesis.providers.hardware import Hardware\nfrom mimesis.providers.internet import Internet\nfrom mimesis.providers.numbers import Numbers\nfrom mimesis.providers.path import Path\nfrom mimesis.providers.payment import Payment\nfrom mimesis.providers.person import Person\nfrom mimesis.providers.science import Science\nfrom mimesis.providers.structure import Structure\nfrom mimesis.providers.text import Text\nfrom mimesis.providers.transport import Transport\nfrom mimesis.providers.units import UnitSystem\n\n__all__ = ['Generic']\n\n\nclass Generic(BaseDataProvider):\n \"\"\"Class which contain all providers at one.\"\"\"\n\n def __init__(self, *args, **kwargs) -> None:\n \"\"\"Initialize attributes lazily.\n\n :param args: Arguments.\n :param kwargs: Keyword arguments.\n \"\"\"\n super().__init__(*args, **kwargs)\n self._person = Person\n self._address = Address\n self._datetime = Datetime\n self._business = Business\n self._text = Text\n self._food = Food\n self._science = Science\n self.transport = Transport(seed=self.seed)\n self.code = Code(seed=self.seed)\n self.unit_system = UnitSystem(seed=self.seed)\n self.file = File(seed=self.seed)\n self.numbers = Numbers(seed=self.seed)\n self.development = Development(seed=self.seed)\n self.hardware = Hardware(seed=self.seed)\n self.clothing = Clothing(seed=self.seed)\n self.internet = Internet(seed=self.seed)\n self.path = Path(seed=self.seed)\n self.payment = Payment(seed=self.seed)\n self.cryptographic = Cryptographic(seed=self.seed)\n self.structure = Structure(seed=self.seed)\n self.choice = Choice(seed=self.seed)\n\n class Meta:\n \"\"\"Class for metadata.\"\"\"\n\n name = 'generic'\n\n def __getattr__(self, attrname: str) -> Any:\n \"\"\"Get attribute without underscore.\n\n :param attrname: Attribute name.\n :return: An attribute.\n \"\"\"\n attribute = object.__getattribute__(\n self, '_' + attrname)\n if attribute and callable(attribute):\n self.__dict__[attrname] = attribute(\n self.locale,\n self.seed,\n )\n return self.__dict__[attrname]\n\n def __dir__(self) -> List[str]:\n \"\"\"Available data providers.\n\n The list of result will be used in AbstractField to\n determine method's class.\n\n :return: List of attributes.\n \"\"\"\n attributes = []\n exclude = BaseDataProvider().__dict__.keys()\n\n for a in self.__dict__:\n if a not in exclude:\n if a.startswith('_'):\n attribute = a.replace('_', '', 1)\n attributes.append(attribute)\n else:\n attributes.append(a)\n return attributes\n\n def add_provider(self, cls: Type[BaseProvider]) -> None:\n \"\"\"Add a custom provider to Generic() object.\n\n :param cls: Custom provider.\n :return: None\n :raises TypeError: if cls is not class.\n \"\"\"\n if inspect.isclass(cls):\n if not issubclass(cls, BaseProvider):\n raise TypeError('The provider must be a '\n 'subclass of BaseProvider')\n try:\n meta = getattr(cls, 'Meta')\n name = getattr(meta, 'name')\n except AttributeError:\n name = cls.__name__.lower()\n setattr(self, name, cls(seed=self.seed))\n else:\n raise TypeError('The provider must be a class')\n\n def add_providers(self, *providers: Type[BaseProvider]) -> None:\n \"\"\"Add a lot of custom providers to Generic() object.\n\n :param providers: Custom providers.\n :return: None\n \"\"\"\n for provider in providers:\n self.add_provider(provider)\n", "path": "mimesis/providers/generic.py"}]}
| 1,907 | 426 |
gh_patches_debug_10035
|
rasdani/github-patches
|
git_diff
|
comic__grand-challenge.org-1433
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Helptext for supported file formats is not up-to-date
</issue>
<code>
[start of app/grandchallenge/cases/forms.py]
1 from typing import List
2
3 from crispy_forms.helper import FormHelper
4 from crispy_forms.layout import Submit
5 from django import forms
6 from django.conf import settings
7 from django.core.exceptions import ValidationError
8
9 from grandchallenge.cases.models import RawImageFile, RawImageUploadSession
10 from grandchallenge.jqfileupload.widgets import uploader
11 from grandchallenge.jqfileupload.widgets.uploader import (
12 StagedAjaxFile,
13 UploadedAjaxFileList,
14 )
15
16
17 class UploadRawImagesForm(forms.ModelForm):
18 files = UploadedAjaxFileList(
19 widget=uploader.AjaxUploadWidget(multifile=True, auto_commit=False),
20 label="Image files",
21 help_text=(
22 "The total size of all files uploaded in a single session "
23 "cannot exceed 10 GB.<br>"
24 "The following file formats are supported: "
25 ".mha, .mhd, .raw, .zraw, .dcm, .tiff, .png, .jpeg and .jpg."
26 ),
27 )
28
29 def __init__(self, *args, user, linked_task=None, **kwargs):
30 super().__init__(*args, **kwargs)
31 self.helper = FormHelper()
32 self.helper.add_input(Submit("save", "Submit"))
33 self.fields["files"].widget.user = user
34 self._linked_task = linked_task
35
36 def clean_files(self):
37 files = self.cleaned_data["files"]
38
39 if len({f.name for f in files}) != len(files):
40 raise ValidationError("Filenames must be unique.")
41
42 if sum([f.size for f in files]) > settings.UPLOAD_SESSION_MAX_BYTES:
43 raise ValidationError(
44 "Total size of all files exceeds the upload limit."
45 )
46
47 return files
48
49 def save(self, commit=True):
50 instance = super().save(commit=False) # type: RawImageUploadSession
51
52 # Create links between the created session and all uploaded files
53 uploaded_files = self.cleaned_data[
54 "files"
55 ] # type: List[StagedAjaxFile]
56
57 raw_files = [
58 RawImageFile(
59 upload_session=instance,
60 filename=uploaded_file.name,
61 staged_file_id=uploaded_file.uuid,
62 )
63 for uploaded_file in uploaded_files
64 ]
65
66 if commit:
67 instance.save()
68 RawImageFile.objects.bulk_create(raw_files)
69 instance.process_images(linked_task=self._linked_task)
70
71 return instance
72
73 class Meta:
74 model = RawImageUploadSession
75 fields = ["files"]
76
[end of app/grandchallenge/cases/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/app/grandchallenge/cases/forms.py b/app/grandchallenge/cases/forms.py
--- a/app/grandchallenge/cases/forms.py
+++ b/app/grandchallenge/cases/forms.py
@@ -22,7 +22,10 @@
"The total size of all files uploaded in a single session "
"cannot exceed 10 GB.<br>"
"The following file formats are supported: "
- ".mha, .mhd, .raw, .zraw, .dcm, .tiff, .png, .jpeg and .jpg."
+ ".mha, .mhd, .raw, .zraw, .dcm, .tiff, .png, .jpeg and .jpg.<br>"
+ "The following file formats can be uploaded and will be converted to "
+ "tif: Aperio(.svs), Hamamatsu(.vms, .vmu, .ndpi), Leica(.scn), MIRAX"
+ "(.mrxs) and Ventana(.bif)."
),
)
|
{"golden_diff": "diff --git a/app/grandchallenge/cases/forms.py b/app/grandchallenge/cases/forms.py\n--- a/app/grandchallenge/cases/forms.py\n+++ b/app/grandchallenge/cases/forms.py\n@@ -22,7 +22,10 @@\n \"The total size of all files uploaded in a single session \"\n \"cannot exceed 10 GB.<br>\"\n \"The following file formats are supported: \"\n- \".mha, .mhd, .raw, .zraw, .dcm, .tiff, .png, .jpeg and .jpg.\"\n+ \".mha, .mhd, .raw, .zraw, .dcm, .tiff, .png, .jpeg and .jpg.<br>\"\n+ \"The following file formats can be uploaded and will be converted to \"\n+ \"tif: Aperio(.svs), Hamamatsu(.vms, .vmu, .ndpi), Leica(.scn), MIRAX\"\n+ \"(.mrxs) and Ventana(.bif).\"\n ),\n )\n", "issue": "Helptext for supported file formats is not up-to-date\n\n", "before_files": [{"content": "from typing import List\n\nfrom crispy_forms.helper import FormHelper\nfrom crispy_forms.layout import Submit\nfrom django import forms\nfrom django.conf import settings\nfrom django.core.exceptions import ValidationError\n\nfrom grandchallenge.cases.models import RawImageFile, RawImageUploadSession\nfrom grandchallenge.jqfileupload.widgets import uploader\nfrom grandchallenge.jqfileupload.widgets.uploader import (\n StagedAjaxFile,\n UploadedAjaxFileList,\n)\n\n\nclass UploadRawImagesForm(forms.ModelForm):\n files = UploadedAjaxFileList(\n widget=uploader.AjaxUploadWidget(multifile=True, auto_commit=False),\n label=\"Image files\",\n help_text=(\n \"The total size of all files uploaded in a single session \"\n \"cannot exceed 10 GB.<br>\"\n \"The following file formats are supported: \"\n \".mha, .mhd, .raw, .zraw, .dcm, .tiff, .png, .jpeg and .jpg.\"\n ),\n )\n\n def __init__(self, *args, user, linked_task=None, **kwargs):\n super().__init__(*args, **kwargs)\n self.helper = FormHelper()\n self.helper.add_input(Submit(\"save\", \"Submit\"))\n self.fields[\"files\"].widget.user = user\n self._linked_task = linked_task\n\n def clean_files(self):\n files = self.cleaned_data[\"files\"]\n\n if len({f.name for f in files}) != len(files):\n raise ValidationError(\"Filenames must be unique.\")\n\n if sum([f.size for f in files]) > settings.UPLOAD_SESSION_MAX_BYTES:\n raise ValidationError(\n \"Total size of all files exceeds the upload limit.\"\n )\n\n return files\n\n def save(self, commit=True):\n instance = super().save(commit=False) # type: RawImageUploadSession\n\n # Create links between the created session and all uploaded files\n uploaded_files = self.cleaned_data[\n \"files\"\n ] # type: List[StagedAjaxFile]\n\n raw_files = [\n RawImageFile(\n upload_session=instance,\n filename=uploaded_file.name,\n staged_file_id=uploaded_file.uuid,\n )\n for uploaded_file in uploaded_files\n ]\n\n if commit:\n instance.save()\n RawImageFile.objects.bulk_create(raw_files)\n instance.process_images(linked_task=self._linked_task)\n\n return instance\n\n class Meta:\n model = RawImageUploadSession\n fields = [\"files\"]\n", "path": "app/grandchallenge/cases/forms.py"}]}
| 1,228 | 235 |
gh_patches_debug_16908
|
rasdani/github-patches
|
git_diff
|
conda__conda-build-1548
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
patching issue with test_api_skeleton.py
Hi,
I am having issued with tests/test_api_skeleton.py.
On the first failure:
```bash
============================= test session starts ==============================
platform linux -- Python 3.5.2, pytest-2.9.2, py-1.4.31, pluggy-0.3.1
rootdir: <...>/conda-build, inifile: setup.cfg
plugins: capturelog-0.7, cov-2.3.1
collected 11 items
tests/test_api_skeleton.py F
generated xml file: <...>/conda-build/junit.xml
=================================== FAILURES ===================================
__________________________ test_repo[-pypi-pip-8.1.2] __________________________
Traceback (most recent call last):
File "<...>/conda-build/tests/test_api_skeleton.py", line 21, in test_repo
api.skeletonize(package, repo, version=version, output_dir=testing_workdir, config=test_config)
File "<...>/conda-build/conda_build/api.py", line 193, in skeletonize
recursive=recursive, config=config, **kwargs)
File "<...>/conda-build/conda_build/skeletons/pypi.py", line 406, in skeletonize
noprompt, packages, config=config, setup_options=setup_options)
File "<...>/conda-build/conda_build/skeletons/pypi.py", line 664, in get_package_metadata
config=config)
File "<...>/conda-build/conda_build/skeletons/pypi.py", line 924, in get_pkginfo
run_setuppy(src_dir, tempdir, python_version, config=config, setup_options=setup_options)
File "<...>/conda-build/conda_build/skeletons/pypi.py", line 983, in run_setuppy
apply_patch(join(stdlib_dir, 'distutils'), patch, config=config)
File "<...>/conda-build/conda_build/source.py", line 483, in apply_patch
check_call_env([patch] + patch_args, cwd=src_dir)
File "<...>/conda-build/conda_build/utils.py", line 552, in check_call_env
return _func_defaulting_env_to_os_environ(subprocess.check_call, *popenargs, **kwargs)
File "<...>/conda-build/conda_build/utils.py", line 548, in _func_defaulting_env_to_os_environ
return func(_args, **kwargs)
File "<...>/lib/python3.5/subprocess.py", line 581, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command '['/usr/bin/patch', '-p0', '-i', '/tmp/tmp3rh8k2j4conda_skeleton_pip-8.1.2.tar.gz/pypi-distutils.patch']' returned non-zero exit status 1
----------------------------- Captured stdout call -----------------------------
Using url https://pypi.python.org/packages/e7/a8/7556133689add8d1a54c0b14aeff0acb03c64707ce100ecd53934da1aa13/pip-8.1.2.tar.gz (1.1 MB) for pip.
Downloading pip
Unpacking pip...
done
working in /tmp/tmp3rh8k2j4conda_skeleton_pip-8.1.2.tar.gz
updating index in: /tmp/pytest-of-<...>/pytest-7/test_repo__pypi_pip_8_1_2_0/linux-64
updating index in: /tmp/pytest-of-<...>/pytest-7/test_repo__pypi_pip_8_1_2_0/noarch
The following NEW packages will be INSTALLED:
openssl: 1.0.2j-0 (soft-link)
pip: 8.1.2-py35_0 (soft-link)
python: 3.5.2-0 (soft-link)
pyyaml: 3.12-py35_0 (soft-link)
readline: 6.2-2 (soft-link)
setuptools: 27.2.0-py35_0 (soft-link)
sqlite: 3.13.0-0 (soft-link)
tk: 8.5.18-0 (soft-link)
wheel: 0.29.0-py35_0 (soft-link)
xz: 5.2.2-0 (soft-link)
yaml: 0.1.6-0 (soft-link)
zlib: 1.2.8-3 (soft-link)
Applying patch: '/tmp/tmp3rh8k2j4conda_skeleton_pip-8.1.2.tar.gz/pypi-distutils.patch' in /tmp/pytest-of-<...>/pytest-7/test_repo__pypi_pip_8_1_2_0/skeleton_1478167437529/_b_env_placehold_<...>/lib/python3.5/distutils
File core.py is not a regular file -- refusing to patch
1 out of 1 hunk ignored -- saving rejects to file core.py.rej
```
patching fails because core.py is a symlink ...
A temporary fix would be adding --follow-symlinks in the patch command, but this is ugly
**source.py l.480 in apply_patch**
```python
patch_args = ['-p%d' % patch_strip_level, '-i', path, '--follow-symlinks']
```
</issue>
<code>
[start of conda_build/conda_interface.py]
1 # -*- coding: utf-8 -*-
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 from functools import partial
5 from pkg_resources import parse_version
6
7 import conda
8 from conda import compat, plan # NOQA
9 from conda.api import get_index # NOQA
10 from conda.cli.common import (Completer, InstalledPackages, add_parser_channels, add_parser_prefix, # NOQA
11 specs_from_args, spec_from_line, specs_from_url) # NOQA
12 from conda.cli.conda_argparse import ArgumentParser # NOQA
13 from conda.compat import (PY3, StringIO, configparser, input, iteritems, lchmod, string_types, # NOQA
14 text_type, TemporaryDirectory) # NOQA
15 from conda.connection import CondaSession # NOQA
16 from conda.fetch import TmpDownload, download, fetch_index, handle_proxy_407 # NOQA
17 from conda.install import (delete_trash, is_linked, linked, linked_data, prefix_placeholder, # NOQA
18 rm_rf, symlink_conda, rm_fetched, package_cache) # NOQA
19 from conda.lock import Locked # NOQA
20 from conda.misc import untracked, walk_prefix # NOQA
21 from conda.resolve import MatchSpec, NoPackagesFound, Resolve, Unsatisfiable, normalized_version # NOQA
22 from conda.signature import KEYS, KEYS_DIR, hash_file, verify # NOQA
23 from conda.utils import human_bytes, hashsum_file, md5_file, memoized, unix_path_to_win, win_path_to_unix, url_path # NOQA
24 import conda.config as cc # NOQA
25 from conda.config import rc_path # NOQA
26 from conda.version import VersionOrder # NOQA
27
28 if parse_version(conda.__version__) >= parse_version("4.2"):
29 # conda 4.2.x
30 import conda.base.context
31 import conda.exceptions
32 from conda.base.context import get_prefix as context_get_prefix, non_x86_linux_machines # NOQA
33
34 from conda.base.constants import DEFAULT_CHANNELS # NOQA
35 get_prefix = partial(context_get_prefix, conda.base.context.context)
36 get_default_urls = lambda: DEFAULT_CHANNELS
37
38 arch_name = conda.base.context.context.arch_name
39 binstar_upload = conda.base.context.context.binstar_upload
40 bits = conda.base.context.context.bits
41 default_prefix = conda.base.context.context.default_prefix
42 default_python = conda.base.context.context.default_python
43 envs_dirs = conda.base.context.context.envs_dirs
44 pkgs_dirs = conda.base.context.context.pkgs_dirs
45 platform = conda.base.context.context.platform
46 root_dir = conda.base.context.context.root_dir
47 root_writable = conda.base.context.context.root_writable
48 subdir = conda.base.context.context.subdir
49 from conda.models.channel import get_conda_build_local_url
50 get_rc_urls = lambda: list(conda.base.context.context.channels)
51 get_local_urls = lambda: list(get_conda_build_local_url()) or []
52 load_condarc = lambda fn: conda.base.context.reset_context([fn])
53 PaddingError = conda.exceptions.PaddingError
54 LinkError = conda.exceptions.LinkError
55 NoPackagesFoundError = conda.exceptions.NoPackagesFoundError
56 CondaValueError = conda.exceptions.CondaValueError
57
58 else:
59 from conda.config import get_default_urls, non_x86_linux_machines, load_condarc # NOQA
60 from conda.cli.common import get_prefix # NOQA
61
62 arch_name = cc.arch_name
63 binstar_upload = cc.binstar_upload
64 bits = cc.bits
65 default_prefix = cc.default_prefix
66 default_python = cc.default_python
67 envs_dirs = cc.envs_dirs
68 pkgs_dirs = cc.pkgs_dirs
69 platform = cc.platform
70 root_dir = cc.root_dir
71 root_writable = cc.root_writable
72 subdir = cc.subdir
73
74 get_rc_urls = cc.get_rc_urls
75 get_local_urls = cc.get_local_urls
76
77 class PaddingError(Exception):
78 pass
79
80 class LinkError(Exception):
81 pass
82
83 class NoPackagesFoundError(Exception):
84 pass
85
86 class CondaValueError(Exception):
87 pass
88
89
90 class SignatureError(Exception):
91 pass
92
93
94 def which_package(path):
95 """
96 given the path (of a (presumably) conda installed file) iterate over
97 the conda packages the file came from. Usually the iteration yields
98 only one package.
99 """
100 from os.path import abspath, join
101 path = abspath(path)
102 prefix = which_prefix(path)
103 if prefix is None:
104 raise RuntimeError("could not determine conda prefix from: %s" % path)
105 for dist in linked(prefix):
106 meta = is_linked(prefix, dist)
107 if any(abspath(join(prefix, f)) == path for f in meta['files']):
108 yield dist
109
110
111 def which_prefix(path):
112 """
113 given the path (to a (presumably) conda installed file) return the
114 environment prefix in which the file in located
115 """
116 from os.path import abspath, join, isdir, dirname
117 prefix = abspath(path)
118 while True:
119 if isdir(join(prefix, 'conda-meta')):
120 # we found the it, so let's return it
121 return prefix
122 if prefix == dirname(prefix):
123 # we cannot chop off any more directories, so we didn't find it
124 return None
125 prefix = dirname(prefix)
126
[end of conda_build/conda_interface.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/conda_build/conda_interface.py b/conda_build/conda_interface.py
--- a/conda_build/conda_interface.py
+++ b/conda_build/conda_interface.py
@@ -55,6 +55,9 @@
NoPackagesFoundError = conda.exceptions.NoPackagesFoundError
CondaValueError = conda.exceptions.CondaValueError
+ # disallow softlinks. This avoids a lot of dumb issues, at the potential cost of disk space.
+ conda.base.context.context.allow_softlinks = False
+
else:
from conda.config import get_default_urls, non_x86_linux_machines, load_condarc # NOQA
from conda.cli.common import get_prefix # NOQA
@@ -74,6 +77,8 @@
get_rc_urls = cc.get_rc_urls
get_local_urls = cc.get_local_urls
+ cc.allow_softlinks = False
+
class PaddingError(Exception):
pass
|
{"golden_diff": "diff --git a/conda_build/conda_interface.py b/conda_build/conda_interface.py\n--- a/conda_build/conda_interface.py\n+++ b/conda_build/conda_interface.py\n@@ -55,6 +55,9 @@\n NoPackagesFoundError = conda.exceptions.NoPackagesFoundError\n CondaValueError = conda.exceptions.CondaValueError\n \n+ # disallow softlinks. This avoids a lot of dumb issues, at the potential cost of disk space.\n+ conda.base.context.context.allow_softlinks = False\n+\n else:\n from conda.config import get_default_urls, non_x86_linux_machines, load_condarc # NOQA\n from conda.cli.common import get_prefix # NOQA\n@@ -74,6 +77,8 @@\n get_rc_urls = cc.get_rc_urls\n get_local_urls = cc.get_local_urls\n \n+ cc.allow_softlinks = False\n+\n class PaddingError(Exception):\n pass\n", "issue": "patching issue with test_api_skeleton.py\nHi, \r\n\r\nI am having issued with tests/test_api_skeleton.py.\r\n\r\nOn the first failure:\r\n\r\n```bash\r\n============================= test session starts ==============================\r\nplatform linux -- Python 3.5.2, pytest-2.9.2, py-1.4.31, pluggy-0.3.1\r\nrootdir: <...>/conda-build, inifile: setup.cfg\r\nplugins: capturelog-0.7, cov-2.3.1\r\ncollected 11 items\r\n\r\ntests/test_api_skeleton.py F\r\n\r\n generated xml file: <...>/conda-build/junit.xml \r\n=================================== FAILURES ===================================\r\n__________________________ test_repo[-pypi-pip-8.1.2] __________________________\r\nTraceback (most recent call last):\r\n File \"<...>/conda-build/tests/test_api_skeleton.py\", line 21, in test_repo\r\n api.skeletonize(package, repo, version=version, output_dir=testing_workdir, config=test_config)\r\n File \"<...>/conda-build/conda_build/api.py\", line 193, in skeletonize\r\n recursive=recursive, config=config, **kwargs)\r\n File \"<...>/conda-build/conda_build/skeletons/pypi.py\", line 406, in skeletonize\r\n noprompt, packages, config=config, setup_options=setup_options)\r\n File \"<...>/conda-build/conda_build/skeletons/pypi.py\", line 664, in get_package_metadata\r\n config=config)\r\n File \"<...>/conda-build/conda_build/skeletons/pypi.py\", line 924, in get_pkginfo\r\n run_setuppy(src_dir, tempdir, python_version, config=config, setup_options=setup_options)\r\n File \"<...>/conda-build/conda_build/skeletons/pypi.py\", line 983, in run_setuppy\r\n apply_patch(join(stdlib_dir, 'distutils'), patch, config=config)\r\n File \"<...>/conda-build/conda_build/source.py\", line 483, in apply_patch\r\n check_call_env([patch] + patch_args, cwd=src_dir)\r\n File \"<...>/conda-build/conda_build/utils.py\", line 552, in check_call_env\r\n return _func_defaulting_env_to_os_environ(subprocess.check_call, *popenargs, **kwargs)\r\n File \"<...>/conda-build/conda_build/utils.py\", line 548, in _func_defaulting_env_to_os_environ\r\n return func(_args, **kwargs)\r\n File \"<...>/lib/python3.5/subprocess.py\", line 581, in check_call\r\n raise CalledProcessError(retcode, cmd)\r\nsubprocess.CalledProcessError: Command '['/usr/bin/patch', '-p0', '-i', '/tmp/tmp3rh8k2j4conda_skeleton_pip-8.1.2.tar.gz/pypi-distutils.patch']' returned non-zero exit status 1\r\n----------------------------- Captured stdout call -----------------------------\r\nUsing url https://pypi.python.org/packages/e7/a8/7556133689add8d1a54c0b14aeff0acb03c64707ce100ecd53934da1aa13/pip-8.1.2.tar.gz (1.1 MB) for pip.\r\nDownloading pip\r\nUnpacking pip...\r\ndone\r\nworking in /tmp/tmp3rh8k2j4conda_skeleton_pip-8.1.2.tar.gz\r\nupdating index in: /tmp/pytest-of-<...>/pytest-7/test_repo__pypi_pip_8_1_2_0/linux-64\r\nupdating index in: /tmp/pytest-of-<...>/pytest-7/test_repo__pypi_pip_8_1_2_0/noarch\r\n\r\nThe following NEW packages will be INSTALLED:\r\n\r\n openssl: 1.0.2j-0 (soft-link)\r\n pip: 8.1.2-py35_0 (soft-link)\r\n python: 3.5.2-0 (soft-link)\r\n pyyaml: 3.12-py35_0 (soft-link)\r\n readline: 6.2-2 (soft-link)\r\n setuptools: 27.2.0-py35_0 (soft-link)\r\n sqlite: 3.13.0-0 (soft-link)\r\n tk: 8.5.18-0 (soft-link)\r\n wheel: 0.29.0-py35_0 (soft-link)\r\n xz: 5.2.2-0 (soft-link)\r\n yaml: 0.1.6-0 (soft-link)\r\n zlib: 1.2.8-3 (soft-link)\r\n\r\nApplying patch: '/tmp/tmp3rh8k2j4conda_skeleton_pip-8.1.2.tar.gz/pypi-distutils.patch' in /tmp/pytest-of-<...>/pytest-7/test_repo__pypi_pip_8_1_2_0/skeleton_1478167437529/_b_env_placehold_<...>/lib/python3.5/distutils\r\nFile core.py is not a regular file -- refusing to patch\r\n1 out of 1 hunk ignored -- saving rejects to file core.py.rej\r\n```\r\n\r\npatching fails because core.py is a symlink ...\r\n\r\nA temporary fix would be adding --follow-symlinks in the patch command, but this is ugly\r\n**source.py l.480 in apply_patch**\r\n```python\r\npatch_args = ['-p%d' % patch_strip_level, '-i', path, '--follow-symlinks']\r\n``` \n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom functools import partial\nfrom pkg_resources import parse_version\n\nimport conda\nfrom conda import compat, plan # NOQA\nfrom conda.api import get_index # NOQA\nfrom conda.cli.common import (Completer, InstalledPackages, add_parser_channels, add_parser_prefix, # NOQA\n specs_from_args, spec_from_line, specs_from_url) # NOQA\nfrom conda.cli.conda_argparse import ArgumentParser # NOQA\nfrom conda.compat import (PY3, StringIO, configparser, input, iteritems, lchmod, string_types, # NOQA\n text_type, TemporaryDirectory) # NOQA\nfrom conda.connection import CondaSession # NOQA\nfrom conda.fetch import TmpDownload, download, fetch_index, handle_proxy_407 # NOQA\nfrom conda.install import (delete_trash, is_linked, linked, linked_data, prefix_placeholder, # NOQA\n rm_rf, symlink_conda, rm_fetched, package_cache) # NOQA\nfrom conda.lock import Locked # NOQA\nfrom conda.misc import untracked, walk_prefix # NOQA\nfrom conda.resolve import MatchSpec, NoPackagesFound, Resolve, Unsatisfiable, normalized_version # NOQA\nfrom conda.signature import KEYS, KEYS_DIR, hash_file, verify # NOQA\nfrom conda.utils import human_bytes, hashsum_file, md5_file, memoized, unix_path_to_win, win_path_to_unix, url_path # NOQA\nimport conda.config as cc # NOQA\nfrom conda.config import rc_path # NOQA\nfrom conda.version import VersionOrder # NOQA\n\nif parse_version(conda.__version__) >= parse_version(\"4.2\"):\n # conda 4.2.x\n import conda.base.context\n import conda.exceptions\n from conda.base.context import get_prefix as context_get_prefix, non_x86_linux_machines # NOQA\n\n from conda.base.constants import DEFAULT_CHANNELS # NOQA\n get_prefix = partial(context_get_prefix, conda.base.context.context)\n get_default_urls = lambda: DEFAULT_CHANNELS\n\n arch_name = conda.base.context.context.arch_name\n binstar_upload = conda.base.context.context.binstar_upload\n bits = conda.base.context.context.bits\n default_prefix = conda.base.context.context.default_prefix\n default_python = conda.base.context.context.default_python\n envs_dirs = conda.base.context.context.envs_dirs\n pkgs_dirs = conda.base.context.context.pkgs_dirs\n platform = conda.base.context.context.platform\n root_dir = conda.base.context.context.root_dir\n root_writable = conda.base.context.context.root_writable\n subdir = conda.base.context.context.subdir\n from conda.models.channel import get_conda_build_local_url\n get_rc_urls = lambda: list(conda.base.context.context.channels)\n get_local_urls = lambda: list(get_conda_build_local_url()) or []\n load_condarc = lambda fn: conda.base.context.reset_context([fn])\n PaddingError = conda.exceptions.PaddingError\n LinkError = conda.exceptions.LinkError\n NoPackagesFoundError = conda.exceptions.NoPackagesFoundError\n CondaValueError = conda.exceptions.CondaValueError\n\nelse:\n from conda.config import get_default_urls, non_x86_linux_machines, load_condarc # NOQA\n from conda.cli.common import get_prefix # NOQA\n\n arch_name = cc.arch_name\n binstar_upload = cc.binstar_upload\n bits = cc.bits\n default_prefix = cc.default_prefix\n default_python = cc.default_python\n envs_dirs = cc.envs_dirs\n pkgs_dirs = cc.pkgs_dirs\n platform = cc.platform\n root_dir = cc.root_dir\n root_writable = cc.root_writable\n subdir = cc.subdir\n\n get_rc_urls = cc.get_rc_urls\n get_local_urls = cc.get_local_urls\n\n class PaddingError(Exception):\n pass\n\n class LinkError(Exception):\n pass\n\n class NoPackagesFoundError(Exception):\n pass\n\n class CondaValueError(Exception):\n pass\n\n\nclass SignatureError(Exception):\n pass\n\n\ndef which_package(path):\n \"\"\"\n given the path (of a (presumably) conda installed file) iterate over\n the conda packages the file came from. Usually the iteration yields\n only one package.\n \"\"\"\n from os.path import abspath, join\n path = abspath(path)\n prefix = which_prefix(path)\n if prefix is None:\n raise RuntimeError(\"could not determine conda prefix from: %s\" % path)\n for dist in linked(prefix):\n meta = is_linked(prefix, dist)\n if any(abspath(join(prefix, f)) == path for f in meta['files']):\n yield dist\n\n\ndef which_prefix(path):\n \"\"\"\n given the path (to a (presumably) conda installed file) return the\n environment prefix in which the file in located\n \"\"\"\n from os.path import abspath, join, isdir, dirname\n prefix = abspath(path)\n while True:\n if isdir(join(prefix, 'conda-meta')):\n # we found the it, so let's return it\n return prefix\n if prefix == dirname(prefix):\n # we cannot chop off any more directories, so we didn't find it\n return None\n prefix = dirname(prefix)\n", "path": "conda_build/conda_interface.py"}]}
| 3,306 | 212 |
gh_patches_debug_58053
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-3312
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Spider upsstore is broken
During the global build at 2021-10-13-14-42-23, spider **upsstore** failed with **5176 features** and **5 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-10-13-14-42-23/logs/upsstore.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-10-13-14-42-23/output/upsstore.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-10-13-14-42-23/output/upsstore.geojson))
</issue>
<code>
[start of locations/spiders/upsstore.py]
1 import scrapy
2 import json
3 import re
4 from locations.items import GeojsonPointItem
5 from locations.hours import OpeningHours
6
7 DAY_MAPPING = {
8 "MONDAY": "Mo",
9 "TUESDAY": "Tu",
10 "WEDNESDAY": "We",
11 "THURSDAY": "Th",
12 "FRIDAY": "Fr",
13 "SATURDAY": "Sa",
14 "SUNDAY": "Su"
15 }
16
17
18 class UpsStoreSpider(scrapy.Spider):
19 name = "upsstore"
20 item_attributes = { 'brand': "UPS Store" }
21 allowed_domains = ["theupsstore.com"]
22 download_delay = 0.1
23 start_urls = (
24 'https://locations.theupsstore.com/',
25 )
26
27 def parse_hours(self, hours):
28 """
29 :param hours:
30 :return:
31 """
32 hours = json.loads(hours)
33 o = OpeningHours()
34
35 for day in hours["hours"]["days"]:
36 if not day["isClosed"]:
37 interval = day["intervals"][0]
38
39 o.add_range(DAY_MAPPING[day["day"]],
40 open_time=str(interval["start"]),
41 close_time=str(interval["end"]),
42 time_format="%H%M")
43 return o.as_opening_hours()
44
45 def parse_store(self, response):
46 ref = response.xpath('//input[@id="store_id"]/@value').extract_first()
47 if not ref:
48 ref = re.search(r'store(\d+)@theupsstore.com',
49 response.xpath('//a[@itemprop="email"]/text()').extract_first()).groups()
50
51 properties = {
52 'name': response.xpath('//span[@class="LocationName-geo"]/text()').extract_first(),
53 'phone': response.xpath('//span[@itemprop="telephone"]/text()').extract_first(),
54 'addr_full': response.xpath('//meta[@itemprop="streetAddress"]/@content').extract_first(),
55 'city': response.xpath('//meta[@itemprop="addressLocality"]/@content').extract_first(),
56 'state': response.xpath('//abbr[@itemprop="addressRegion"]/text()').extract_first(),
57 'country': response.xpath('//abbr[@itemprop="addressCountry"]/text()').extract_first(),
58 'postcode': response.xpath('//span[@itemprop="postalCode"]/text()').extract_first(),
59 'ref': ref,
60 'website': response.url,
61 'lat': float(response.xpath('//meta[@itemprop="latitude"]/@content').extract_first()),
62 'lon': float(response.xpath('//meta[@itemprop="longitude"]/@content').extract_first()),
63 }
64
65 hours = response.xpath('//script[@id="location_info_hours"]/text()').extract_first()
66 try:
67 hours = self.parse_hours(hours)
68 if hours:
69 properties['opening_hours'] = hours
70 except:
71 pass
72
73 yield GeojsonPointItem(**properties)
74
75 def parse(self, response):
76 urls = response.xpath('//a[@class="Directory-listLink"]/@href').extract()
77
78 if urls:
79 for url in urls:
80 if len(url.split('/')) == 3:
81 callback = self.parse_store
82 else:
83 callback = self.parse
84
85 yield scrapy.Request(
86 response.urljoin(url),
87 callback=callback,
88 )
89
90 else:
91 urls = response.xpath('//a[@class="Link"]/@href').extract()
92 for url in urls:
93 yield scrapy.Request(
94 response.urljoin(url),
95 callback=self.parse_store,
96 )
[end of locations/spiders/upsstore.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/locations/spiders/upsstore.py b/locations/spiders/upsstore.py
--- a/locations/spiders/upsstore.py
+++ b/locations/spiders/upsstore.py
@@ -43,6 +43,9 @@
return o.as_opening_hours()
def parse_store(self, response):
+ if "Permanently Closed" in response.text:
+ return
+
ref = response.xpath('//input[@id="store_id"]/@value').extract_first()
if not ref:
ref = re.search(r'store(\d+)@theupsstore.com',
|
{"golden_diff": "diff --git a/locations/spiders/upsstore.py b/locations/spiders/upsstore.py\n--- a/locations/spiders/upsstore.py\n+++ b/locations/spiders/upsstore.py\n@@ -43,6 +43,9 @@\n return o.as_opening_hours()\n \n def parse_store(self, response):\n+ if \"Permanently Closed\" in response.text:\n+ return\n+\n ref = response.xpath('//input[@id=\"store_id\"]/@value').extract_first()\n if not ref:\n ref = re.search(r'store(\\d+)@theupsstore.com',\n", "issue": "Spider upsstore is broken\nDuring the global build at 2021-10-13-14-42-23, spider **upsstore** failed with **5176 features** and **5 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-10-13-14-42-23/logs/upsstore.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-10-13-14-42-23/output/upsstore.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-10-13-14-42-23/output/upsstore.geojson))\n", "before_files": [{"content": "import scrapy\nimport json\nimport re\nfrom locations.items import GeojsonPointItem\nfrom locations.hours import OpeningHours\n\nDAY_MAPPING = {\n \"MONDAY\": \"Mo\",\n \"TUESDAY\": \"Tu\",\n \"WEDNESDAY\": \"We\",\n \"THURSDAY\": \"Th\",\n \"FRIDAY\": \"Fr\",\n \"SATURDAY\": \"Sa\",\n \"SUNDAY\": \"Su\"\n}\n\n\nclass UpsStoreSpider(scrapy.Spider):\n name = \"upsstore\"\n item_attributes = { 'brand': \"UPS Store\" }\n allowed_domains = [\"theupsstore.com\"]\n download_delay = 0.1\n start_urls = (\n 'https://locations.theupsstore.com/',\n )\n\n def parse_hours(self, hours):\n \"\"\"\n :param hours:\n :return:\n \"\"\"\n hours = json.loads(hours)\n o = OpeningHours()\n\n for day in hours[\"hours\"][\"days\"]:\n if not day[\"isClosed\"]:\n interval = day[\"intervals\"][0]\n\n o.add_range(DAY_MAPPING[day[\"day\"]],\n open_time=str(interval[\"start\"]),\n close_time=str(interval[\"end\"]),\n time_format=\"%H%M\")\n return o.as_opening_hours()\n\n def parse_store(self, response):\n ref = response.xpath('//input[@id=\"store_id\"]/@value').extract_first()\n if not ref:\n ref = re.search(r'store(\\d+)@theupsstore.com',\n response.xpath('//a[@itemprop=\"email\"]/text()').extract_first()).groups()\n\n properties = {\n 'name': response.xpath('//span[@class=\"LocationName-geo\"]/text()').extract_first(),\n 'phone': response.xpath('//span[@itemprop=\"telephone\"]/text()').extract_first(),\n 'addr_full': response.xpath('//meta[@itemprop=\"streetAddress\"]/@content').extract_first(),\n 'city': response.xpath('//meta[@itemprop=\"addressLocality\"]/@content').extract_first(),\n 'state': response.xpath('//abbr[@itemprop=\"addressRegion\"]/text()').extract_first(),\n 'country': response.xpath('//abbr[@itemprop=\"addressCountry\"]/text()').extract_first(),\n 'postcode': response.xpath('//span[@itemprop=\"postalCode\"]/text()').extract_first(),\n 'ref': ref,\n 'website': response.url,\n 'lat': float(response.xpath('//meta[@itemprop=\"latitude\"]/@content').extract_first()),\n 'lon': float(response.xpath('//meta[@itemprop=\"longitude\"]/@content').extract_first()),\n }\n\n hours = response.xpath('//script[@id=\"location_info_hours\"]/text()').extract_first()\n try:\n hours = self.parse_hours(hours)\n if hours:\n properties['opening_hours'] = hours\n except:\n pass\n\n yield GeojsonPointItem(**properties)\n\n def parse(self, response):\n urls = response.xpath('//a[@class=\"Directory-listLink\"]/@href').extract()\n\n if urls:\n for url in urls:\n if len(url.split('/')) == 3:\n callback = self.parse_store\n else:\n callback = self.parse\n\n yield scrapy.Request(\n response.urljoin(url),\n callback=callback,\n )\n\n else:\n urls = response.xpath('//a[@class=\"Link\"]/@href').extract()\n for url in urls:\n yield scrapy.Request(\n response.urljoin(url),\n callback=self.parse_store,\n )", "path": "locations/spiders/upsstore.py"}]}
| 1,649 | 133 |
gh_patches_debug_40290
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmengine-764
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unexpected weight initialization
Thanks for your error report and we appreciate it a lot.
**Checklist**
1. I have searched related issues but cannot get the expected help.
2. I have read the [FAQ documentation](https://mmengine.readthedocs.io/en/latest/faq.html) but cannot get the expected help.
3. The bug has not been fixed in the latest version.
**Describe the bug**
When using `Pretrained` init_cfg to init a model, the outside init_cfg will **disable all submodules' init_weights**.
If the outside model's pretrained weight does not strictly match, e.g. different num_classes, the mismatched submodule's weight will initialize **by pytorch's default init weight logic**, instead of the submodule's init_cfg.
This lead's to some unacceptable results, e.g. a huge classification loss due to the failed initialization of the classification head when finetuning a model.
**Reproduction**
In mmdet, finetuning rtmdet_l_8xb32-300e_coco
```python
_base_ = './rtmdet_l_8xb32-300e_coco.py'
checkpoint = 'work_dir/rtmdet/rtmdet_l_8xb32-300e_coco/epoch_300.pth'
model = dict(bbox_head=dict(num_classes=1), init_cfg=dict(type='Pretrained', checkpoint=checkpoint))
```
</issue>
<code>
[start of mmengine/model/base_module.py]
1 # Copyright (c) OpenMMLab. All rights reserved.
2 import copy
3 import logging
4 import warnings
5 from abc import ABCMeta
6 from collections import defaultdict
7 from logging import FileHandler
8 from typing import Iterable, Optional
9
10 import torch.nn as nn
11
12 from mmengine.dist import master_only
13 from mmengine.logging import MMLogger, print_log
14 from .weight_init import initialize, update_init_info
15
16
17 class BaseModule(nn.Module, metaclass=ABCMeta):
18 """Base module for all modules in openmmlab. ``BaseModule`` is a wrapper of
19 ``torch.nn.Module`` with additional functionality of parameter
20 initialization. Compared with ``torch.nn.Module``, ``BaseModule`` mainly
21 adds three attributes.
22
23 - ``init_cfg``: the config to control the initialization.
24 - ``init_weights``: The function of parameter initialization and recording
25 initialization information.
26 - ``_params_init_info``: Used to track the parameter initialization
27 information. This attribute only exists during executing the
28 ``init_weights``.
29 Args:
30 init_cfg (dict, optional): Initialization config dict.
31 """
32
33 def __init__(self, init_cfg=None):
34 """Initialize BaseModule, inherited from `torch.nn.Module`"""
35
36 # NOTE init_cfg can be defined in different levels, but init_cfg
37 # in low levels has a higher priority.
38
39 super().__init__()
40 # define default value of init_cfg instead of hard code
41 # in init_weights() function
42 self._is_init = False
43
44 self.init_cfg = copy.deepcopy(init_cfg)
45
46 # Backward compatibility in derived classes
47 # if pretrained is not None:
48 # warnings.warn('DeprecationWarning: pretrained is a deprecated \
49 # key, please consider using init_cfg')
50 # self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)
51
52 @property
53 def is_init(self):
54 return self._is_init
55
56 def init_weights(self):
57 """Initialize the weights."""
58
59 is_top_level_module = False
60 # check if it is top-level module
61 if not hasattr(self, '_params_init_info'):
62 # The `_params_init_info` is used to record the initialization
63 # information of the parameters
64 # the key should be the obj:`nn.Parameter` of model and the value
65 # should be a dict containing
66 # - init_info (str): The string that describes the initialization.
67 # - tmp_mean_value (FloatTensor): The mean of the parameter,
68 # which indicates whether the parameter has been modified.
69 # this attribute would be deleted after all parameters
70 # is initialized.
71 self._params_init_info = defaultdict(dict)
72 is_top_level_module = True
73
74 # Initialize the `_params_init_info`,
75 # When detecting the `tmp_mean_value` of
76 # the corresponding parameter is changed, update related
77 # initialization information
78 for name, param in self.named_parameters():
79 self._params_init_info[param][
80 'init_info'] = f'The value is the same before and ' \
81 f'after calling `init_weights` ' \
82 f'of {self.__class__.__name__} '
83 self._params_init_info[param][
84 'tmp_mean_value'] = param.data.mean().cpu()
85
86 # pass `params_init_info` to all submodules
87 # All submodules share the same `params_init_info`,
88 # so it will be updated when parameters are
89 # modified at any level of the model.
90 for sub_module in self.modules():
91 sub_module._params_init_info = self._params_init_info
92
93 logger = MMLogger.get_current_instance()
94 logger_name = logger.instance_name
95
96 module_name = self.__class__.__name__
97 if not self._is_init:
98 if self.init_cfg:
99 print_log(
100 f'initialize {module_name} with init_cfg {self.init_cfg}',
101 logger=logger_name,
102 level=logging.DEBUG)
103 initialize(self, self.init_cfg)
104 if isinstance(self.init_cfg, dict):
105 # prevent the parameters of
106 # the pre-trained model
107 # from being overwritten by
108 # the `init_weights`
109 if self.init_cfg['type'] == 'Pretrained':
110 return
111
112 for m in self.children():
113 if hasattr(m, 'init_weights'):
114 m.init_weights()
115 # users may overload the `init_weights`
116 update_init_info(
117 m,
118 init_info=f'Initialized by '
119 f'user-defined `init_weights`'
120 f' in {m.__class__.__name__} ')
121
122 self._is_init = True
123 else:
124 warnings.warn(f'init_weights of {self.__class__.__name__} has '
125 f'been called more than once.')
126
127 if is_top_level_module:
128 # self._dump_init_info(logger_name)
129 self._dump_init_info()
130
131 for sub_module in self.modules():
132 del sub_module._params_init_info
133
134 @master_only
135 def _dump_init_info(self):
136 """Dump the initialization information to a file named
137 `initialization.log.json` in workdir.
138
139 Args:
140 logger_name (str): The name of logger.
141 """
142
143 logger = MMLogger.get_current_instance()
144 logger_name = logger.instance_name
145 with_file_handler = False
146 # dump the information to the logger file if there is a `FileHandler`
147 for handler in logger.handlers:
148 if isinstance(handler, FileHandler):
149 handler.stream.write(
150 'Name of parameter - Initialization information\n')
151 for name, param in self.named_parameters():
152 handler.stream.write(
153 f'\n{name} - {param.shape}: '
154 f"\n{self._params_init_info[param]['init_info']} \n")
155 handler.stream.flush()
156 with_file_handler = True
157 if not with_file_handler:
158 for name, param in self.named_parameters():
159 print_log(
160 f'\n{name} - {param.shape}: '
161 f"\n{self._params_init_info[param]['init_info']} \n ",
162 logger=logger_name)
163
164 def __repr__(self):
165 s = super().__repr__()
166 if self.init_cfg:
167 s += f'\ninit_cfg={self.init_cfg}'
168 return s
169
170
171 class Sequential(BaseModule, nn.Sequential):
172 """Sequential module in openmmlab.
173
174 Ensures that all modules in ``Sequential`` have a different initialization
175 strategy than the outer model
176
177 Args:
178 init_cfg (dict, optional): Initialization config dict.
179 """
180
181 def __init__(self, *args, init_cfg: Optional[dict] = None):
182 BaseModule.__init__(self, init_cfg)
183 nn.Sequential.__init__(self, *args)
184
185
186 class ModuleList(BaseModule, nn.ModuleList):
187 """ModuleList in openmmlab.
188
189 Ensures that all modules in ``ModuleList`` have a different initialization
190 strategy than the outer model
191
192 Args:
193 modules (iterable, optional): An iterable of modules to add.
194 init_cfg (dict, optional): Initialization config dict.
195 """
196
197 def __init__(self,
198 modules: Optional[Iterable] = None,
199 init_cfg: Optional[dict] = None):
200 BaseModule.__init__(self, init_cfg)
201 nn.ModuleList.__init__(self, modules)
202
203
204 class ModuleDict(BaseModule, nn.ModuleDict):
205 """ModuleDict in openmmlab.
206
207 Ensures that all modules in ``ModuleDict`` have a different initialization
208 strategy than the outer model
209
210 Args:
211 modules (dict, optional): A mapping (dictionary) of (string: module)
212 or an iterable of key-value pairs of type (string, module).
213 init_cfg (dict, optional): Initialization config dict.
214 """
215
216 def __init__(self,
217 modules: Optional[dict] = None,
218 init_cfg: Optional[dict] = None):
219 BaseModule.__init__(self, init_cfg)
220 nn.ModuleDict.__init__(self, modules)
221
[end of mmengine/model/base_module.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mmengine/model/base_module.py b/mmengine/model/base_module.py
--- a/mmengine/model/base_module.py
+++ b/mmengine/model/base_module.py
@@ -5,7 +5,7 @@
from abc import ABCMeta
from collections import defaultdict
from logging import FileHandler
-from typing import Iterable, Optional
+from typing import Iterable, List, Optional, Union
import torch.nn as nn
@@ -26,11 +26,17 @@
- ``_params_init_info``: Used to track the parameter initialization
information. This attribute only exists during executing the
``init_weights``.
+
+ Note:
+ :obj:`PretrainedInit` has a higher priority than any other
+ initializer. The loaded pretrained weights will overwrite
+ the previous initialized weights.
+
Args:
- init_cfg (dict, optional): Initialization config dict.
+ init_cfg (dict or List[dict], optional): Initialization config dict.
"""
- def __init__(self, init_cfg=None):
+ def __init__(self, init_cfg: Union[dict, List[dict], None] = None):
"""Initialize BaseModule, inherited from `torch.nn.Module`"""
# NOTE init_cfg can be defined in different levels, but init_cfg
@@ -100,14 +106,25 @@
f'initialize {module_name} with init_cfg {self.init_cfg}',
logger=logger_name,
level=logging.DEBUG)
- initialize(self, self.init_cfg)
+
+ init_cfgs = self.init_cfg
if isinstance(self.init_cfg, dict):
- # prevent the parameters of
- # the pre-trained model
- # from being overwritten by
- # the `init_weights`
- if self.init_cfg['type'] == 'Pretrained':
- return
+ init_cfgs = [self.init_cfg]
+
+ # PretrainedInit has higher priority than any other init_cfg.
+ # Therefore we initialize `pretrained_cfg` last to overwrite
+ # the previous initialized weights.
+ # See details in https://github.com/open-mmlab/mmengine/issues/691 # noqa E501
+ other_cfgs = []
+ pretrained_cfg = []
+ for init_cfg in init_cfgs:
+ assert isinstance(init_cfg, dict)
+ if init_cfg['type'] == 'Pretrained':
+ pretrained_cfg.append(init_cfg)
+ else:
+ other_cfgs.append(init_cfg)
+
+ initialize(self, other_cfgs)
for m in self.children():
if hasattr(m, 'init_weights'):
@@ -118,7 +135,8 @@
init_info=f'Initialized by '
f'user-defined `init_weights`'
f' in {m.__class__.__name__} ')
-
+ if self.init_cfg and pretrained_cfg:
+ initialize(self, pretrained_cfg)
self._is_init = True
else:
warnings.warn(f'init_weights of {self.__class__.__name__} has '
|
{"golden_diff": "diff --git a/mmengine/model/base_module.py b/mmengine/model/base_module.py\n--- a/mmengine/model/base_module.py\n+++ b/mmengine/model/base_module.py\n@@ -5,7 +5,7 @@\n from abc import ABCMeta\n from collections import defaultdict\n from logging import FileHandler\n-from typing import Iterable, Optional\n+from typing import Iterable, List, Optional, Union\n \n import torch.nn as nn\n \n@@ -26,11 +26,17 @@\n - ``_params_init_info``: Used to track the parameter initialization\n information. This attribute only exists during executing the\n ``init_weights``.\n+\n+ Note:\n+ :obj:`PretrainedInit` has a higher priority than any other\n+ initializer. The loaded pretrained weights will overwrite\n+ the previous initialized weights.\n+\n Args:\n- init_cfg (dict, optional): Initialization config dict.\n+ init_cfg (dict or List[dict], optional): Initialization config dict.\n \"\"\"\n \n- def __init__(self, init_cfg=None):\n+ def __init__(self, init_cfg: Union[dict, List[dict], None] = None):\n \"\"\"Initialize BaseModule, inherited from `torch.nn.Module`\"\"\"\n \n # NOTE init_cfg can be defined in different levels, but init_cfg\n@@ -100,14 +106,25 @@\n f'initialize {module_name} with init_cfg {self.init_cfg}',\n logger=logger_name,\n level=logging.DEBUG)\n- initialize(self, self.init_cfg)\n+\n+ init_cfgs = self.init_cfg\n if isinstance(self.init_cfg, dict):\n- # prevent the parameters of\n- # the pre-trained model\n- # from being overwritten by\n- # the `init_weights`\n- if self.init_cfg['type'] == 'Pretrained':\n- return\n+ init_cfgs = [self.init_cfg]\n+\n+ # PretrainedInit has higher priority than any other init_cfg.\n+ # Therefore we initialize `pretrained_cfg` last to overwrite\n+ # the previous initialized weights.\n+ # See details in https://github.com/open-mmlab/mmengine/issues/691 # noqa E501\n+ other_cfgs = []\n+ pretrained_cfg = []\n+ for init_cfg in init_cfgs:\n+ assert isinstance(init_cfg, dict)\n+ if init_cfg['type'] == 'Pretrained':\n+ pretrained_cfg.append(init_cfg)\n+ else:\n+ other_cfgs.append(init_cfg)\n+\n+ initialize(self, other_cfgs)\n \n for m in self.children():\n if hasattr(m, 'init_weights'):\n@@ -118,7 +135,8 @@\n init_info=f'Initialized by '\n f'user-defined `init_weights`'\n f' in {m.__class__.__name__} ')\n-\n+ if self.init_cfg and pretrained_cfg:\n+ initialize(self, pretrained_cfg)\n self._is_init = True\n else:\n warnings.warn(f'init_weights of {self.__class__.__name__} has '\n", "issue": "Unexpected weight initialization\nThanks for your error report and we appreciate it a lot.\r\n\r\n**Checklist**\r\n\r\n1. I have searched related issues but cannot get the expected help.\r\n2. I have read the [FAQ documentation](https://mmengine.readthedocs.io/en/latest/faq.html) but cannot get the expected help.\r\n3. The bug has not been fixed in the latest version.\r\n\r\n**Describe the bug**\r\n\r\nWhen using `Pretrained` init_cfg to init a model, the outside init_cfg will **disable all submodules' init_weights**.\r\n\r\nIf the outside model's pretrained weight does not strictly match, e.g. different num_classes, the mismatched submodule's weight will initialize **by pytorch's default init weight logic**, instead of the submodule's init_cfg. \r\n\r\nThis lead's to some unacceptable results, e.g. a huge classification loss due to the failed initialization of the classification head when finetuning a model.\r\n\r\n\r\n**Reproduction**\r\n\r\nIn mmdet, finetuning rtmdet_l_8xb32-300e_coco\r\n\r\n```python\r\n_base_ = './rtmdet_l_8xb32-300e_coco.py'\r\n\r\ncheckpoint = 'work_dir/rtmdet/rtmdet_l_8xb32-300e_coco/epoch_300.pth'\r\nmodel = dict(bbox_head=dict(num_classes=1), init_cfg=dict(type='Pretrained', checkpoint=checkpoint))\r\n```\r\n\r\n\n", "before_files": [{"content": "# Copyright (c) OpenMMLab. All rights reserved.\nimport copy\nimport logging\nimport warnings\nfrom abc import ABCMeta\nfrom collections import defaultdict\nfrom logging import FileHandler\nfrom typing import Iterable, Optional\n\nimport torch.nn as nn\n\nfrom mmengine.dist import master_only\nfrom mmengine.logging import MMLogger, print_log\nfrom .weight_init import initialize, update_init_info\n\n\nclass BaseModule(nn.Module, metaclass=ABCMeta):\n \"\"\"Base module for all modules in openmmlab. ``BaseModule`` is a wrapper of\n ``torch.nn.Module`` with additional functionality of parameter\n initialization. Compared with ``torch.nn.Module``, ``BaseModule`` mainly\n adds three attributes.\n\n - ``init_cfg``: the config to control the initialization.\n - ``init_weights``: The function of parameter initialization and recording\n initialization information.\n - ``_params_init_info``: Used to track the parameter initialization\n information. This attribute only exists during executing the\n ``init_weights``.\n Args:\n init_cfg (dict, optional): Initialization config dict.\n \"\"\"\n\n def __init__(self, init_cfg=None):\n \"\"\"Initialize BaseModule, inherited from `torch.nn.Module`\"\"\"\n\n # NOTE init_cfg can be defined in different levels, but init_cfg\n # in low levels has a higher priority.\n\n super().__init__()\n # define default value of init_cfg instead of hard code\n # in init_weights() function\n self._is_init = False\n\n self.init_cfg = copy.deepcopy(init_cfg)\n\n # Backward compatibility in derived classes\n # if pretrained is not None:\n # warnings.warn('DeprecationWarning: pretrained is a deprecated \\\n # key, please consider using init_cfg')\n # self.init_cfg = dict(type='Pretrained', checkpoint=pretrained)\n\n @property\n def is_init(self):\n return self._is_init\n\n def init_weights(self):\n \"\"\"Initialize the weights.\"\"\"\n\n is_top_level_module = False\n # check if it is top-level module\n if not hasattr(self, '_params_init_info'):\n # The `_params_init_info` is used to record the initialization\n # information of the parameters\n # the key should be the obj:`nn.Parameter` of model and the value\n # should be a dict containing\n # - init_info (str): The string that describes the initialization.\n # - tmp_mean_value (FloatTensor): The mean of the parameter,\n # which indicates whether the parameter has been modified.\n # this attribute would be deleted after all parameters\n # is initialized.\n self._params_init_info = defaultdict(dict)\n is_top_level_module = True\n\n # Initialize the `_params_init_info`,\n # When detecting the `tmp_mean_value` of\n # the corresponding parameter is changed, update related\n # initialization information\n for name, param in self.named_parameters():\n self._params_init_info[param][\n 'init_info'] = f'The value is the same before and ' \\\n f'after calling `init_weights` ' \\\n f'of {self.__class__.__name__} '\n self._params_init_info[param][\n 'tmp_mean_value'] = param.data.mean().cpu()\n\n # pass `params_init_info` to all submodules\n # All submodules share the same `params_init_info`,\n # so it will be updated when parameters are\n # modified at any level of the model.\n for sub_module in self.modules():\n sub_module._params_init_info = self._params_init_info\n\n logger = MMLogger.get_current_instance()\n logger_name = logger.instance_name\n\n module_name = self.__class__.__name__\n if not self._is_init:\n if self.init_cfg:\n print_log(\n f'initialize {module_name} with init_cfg {self.init_cfg}',\n logger=logger_name,\n level=logging.DEBUG)\n initialize(self, self.init_cfg)\n if isinstance(self.init_cfg, dict):\n # prevent the parameters of\n # the pre-trained model\n # from being overwritten by\n # the `init_weights`\n if self.init_cfg['type'] == 'Pretrained':\n return\n\n for m in self.children():\n if hasattr(m, 'init_weights'):\n m.init_weights()\n # users may overload the `init_weights`\n update_init_info(\n m,\n init_info=f'Initialized by '\n f'user-defined `init_weights`'\n f' in {m.__class__.__name__} ')\n\n self._is_init = True\n else:\n warnings.warn(f'init_weights of {self.__class__.__name__} has '\n f'been called more than once.')\n\n if is_top_level_module:\n # self._dump_init_info(logger_name)\n self._dump_init_info()\n\n for sub_module in self.modules():\n del sub_module._params_init_info\n\n @master_only\n def _dump_init_info(self):\n \"\"\"Dump the initialization information to a file named\n `initialization.log.json` in workdir.\n\n Args:\n logger_name (str): The name of logger.\n \"\"\"\n\n logger = MMLogger.get_current_instance()\n logger_name = logger.instance_name\n with_file_handler = False\n # dump the information to the logger file if there is a `FileHandler`\n for handler in logger.handlers:\n if isinstance(handler, FileHandler):\n handler.stream.write(\n 'Name of parameter - Initialization information\\n')\n for name, param in self.named_parameters():\n handler.stream.write(\n f'\\n{name} - {param.shape}: '\n f\"\\n{self._params_init_info[param]['init_info']} \\n\")\n handler.stream.flush()\n with_file_handler = True\n if not with_file_handler:\n for name, param in self.named_parameters():\n print_log(\n f'\\n{name} - {param.shape}: '\n f\"\\n{self._params_init_info[param]['init_info']} \\n \",\n logger=logger_name)\n\n def __repr__(self):\n s = super().__repr__()\n if self.init_cfg:\n s += f'\\ninit_cfg={self.init_cfg}'\n return s\n\n\nclass Sequential(BaseModule, nn.Sequential):\n \"\"\"Sequential module in openmmlab.\n\n Ensures that all modules in ``Sequential`` have a different initialization\n strategy than the outer model\n\n Args:\n init_cfg (dict, optional): Initialization config dict.\n \"\"\"\n\n def __init__(self, *args, init_cfg: Optional[dict] = None):\n BaseModule.__init__(self, init_cfg)\n nn.Sequential.__init__(self, *args)\n\n\nclass ModuleList(BaseModule, nn.ModuleList):\n \"\"\"ModuleList in openmmlab.\n\n Ensures that all modules in ``ModuleList`` have a different initialization\n strategy than the outer model\n\n Args:\n modules (iterable, optional): An iterable of modules to add.\n init_cfg (dict, optional): Initialization config dict.\n \"\"\"\n\n def __init__(self,\n modules: Optional[Iterable] = None,\n init_cfg: Optional[dict] = None):\n BaseModule.__init__(self, init_cfg)\n nn.ModuleList.__init__(self, modules)\n\n\nclass ModuleDict(BaseModule, nn.ModuleDict):\n \"\"\"ModuleDict in openmmlab.\n\n Ensures that all modules in ``ModuleDict`` have a different initialization\n strategy than the outer model\n\n Args:\n modules (dict, optional): A mapping (dictionary) of (string: module)\n or an iterable of key-value pairs of type (string, module).\n init_cfg (dict, optional): Initialization config dict.\n \"\"\"\n\n def __init__(self,\n modules: Optional[dict] = None,\n init_cfg: Optional[dict] = None):\n BaseModule.__init__(self, init_cfg)\n nn.ModuleDict.__init__(self, modules)\n", "path": "mmengine/model/base_module.py"}]}
| 3,122 | 664 |
gh_patches_debug_55717
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-5622
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
plugins.dlive: Failed to fetch segment | 403 Client Error
### Checklist
- [X] This is a [plugin issue](https://streamlink.github.io/plugins.html) and not [a different kind of issue](https://github.com/streamlink/streamlink/issues/new/choose)
- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)
- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)
- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)
### Streamlink version
[cli][info] Your Streamlink version (6.2.1) is up to date!
### Description
I navigate to the folder where streamlink.exe is located and enter the command "streamlink.exe https://dlive.tv/cryptokaprika best". It doesn't matter which channel is specified, the same error comes up for all of them as of late.
Here is the complete output that is shown to me in the command line:
C:\Program Files\Streamlink\bin>streamlink.exe https://dlive.tv/cryptokaprika best
[cli][info] Found matching plugin dlive for URL https://dlive.tv/cryptokaprika
[cli][info] Available streams: src (worst, best)
[cli][info] Opening stream: src (hls)
[cli][info] Starting player: C:\Program Files\VideoLAN\VLC\vlc.exe
[stream.hls][error] Failed to fetch segment 79790: Unable to open URL: https://videos.prd.dlivecdn.com/dlive/0000079790.ts (403 Client Error: Forbidden for url: https://videos.prd.dlivecdn.com/dlive/0000079790.ts)
[stream.hls][error] Failed to fetch segment 79791: Unable to open URL: https://videos.prd.dlivecdn.com/dlive/0000079791.ts (403 Client Error: Forbidden for url: https://videos.prd.dlivecdn.com/dlive/0000079791.ts)
[cli][info] Stream ended
[cli][info] Closing currently open stream...
The VLC Media Player also starts, but I only get the following picture and am referred to the homepage: [https://imgur.com/a/NpuAHQ3](https://imgur.com/a/NpuAHQ3)
### Debug log
```text
C:\Program Files\Streamlink\bin>streamlink.exe --loglevel=debug https://dlive.tv/cryptokaprika best
[cli][debug] OS: Windows 10
[cli][debug] Python: 3.11.5
[cli][debug] OpenSSL: OpenSSL 3.0.9 30 May 2023
[cli][debug] Streamlink: 6.2.1
[cli][debug] Dependencies:
[cli][debug] certifi: 2023.7.22
[cli][debug] isodate: 0.6.1
[cli][debug] lxml: 4.9.3
[cli][debug] pycountry: 22.3.5
[cli][debug] pycryptodome: 3.19.0
[cli][debug] PySocks: 1.7.1
[cli][debug] requests: 2.31.0
[cli][debug] trio: 0.22.2
[cli][debug] trio-websocket: 0.11.1
[cli][debug] typing-extensions: 4.8.0
[cli][debug] urllib3: 2.0.6
[cli][debug] websocket-client: 1.6.3
[cli][debug] Arguments:
[cli][debug] url=https://dlive.tv/cryptokaprika
[cli][debug] stream=['best']
[cli][debug] --loglevel=debug
[cli][debug] --ffmpeg-ffmpeg=C:\Program Files\Streamlink\ffmpeg\ffmpeg.exe
[cli][info] Found matching plugin dlive for URL https://dlive.tv/cryptokaprika
[plugins.dlive][debug] Getting live HLS streams for cryptokaprika
[utils.l10n][debug] Language code: en_US
[cli][info] Available streams: src (worst, best)
[cli][info] Opening stream: src (hls)
[cli][info] Starting player: C:\Program Files\VideoLAN\VLC\vlc.exe
[stream.hls][debug] Reloading playlist
[cli][debug] Pre-buffering 8192 bytes
[stream.hls][debug] First Sequence: 79786; Last Sequence: 79791
[stream.hls][debug] Start offset: 0; Duration: None; Start Sequence: 79786; End Sequence: 79791
[stream.hls][debug] Adding segment 79786 to queue
[stream.hls][debug] Adding segment 79787 to queue
[stream.hls][debug] Adding segment 79788 to queue
[stream.hls][debug] Adding segment 79789 to queue
[stream.hls][debug] Adding segment 79790 to queue
[stream.hls][debug] Adding segment 79791 to queue
[stream.segmented][debug] Closing worker thread
[stream.hls][debug] Writing segment 79786 to output
[stream.hls][debug] Segment 79786 complete
[cli.output][debug] Opening subprocess: ['C:\\Program Files\\VideoLAN\\VLC\\vlc.exe', '--input-title-format', 'https://dlive.tv/cryptokaprika', '-']
[stream.hls][debug] Writing segment 79787 to output
[stream.hls][debug] Segment 79787 complete
[stream.hls][debug] Writing segment 79788 to output
[stream.hls][debug] Segment 79788 complete
[stream.hls][debug] Writing segment 79789 to output
[stream.hls][debug] Segment 79789 complete
[cli][debug] Writing stream to output
[stream.hls][error] Failed to fetch segment 79790: Unable to open URL: https://videos.prd.dlivecdn.com/dlive/0000079790.ts (403 Client Error: Forbidden for url: https://videos.prd.dlivecdn.com/dlive/0000079790.ts)
[stream.hls][error] Failed to fetch segment 79791: Unable to open URL: https://videos.prd.dlivecdn.com/dlive/0000079791.ts (403 Client Error: Forbidden for url: https://videos.prd.dlivecdn.com/dlive/0000079791.ts)
[stream.segmented][debug] Closing writer thread
[cli][info] Stream ended
[cli][info] Closing currently open stream...
```
</issue>
<code>
[start of src/streamlink/plugins/dlive.py]
1 """
2 $description Global live-streaming platform owned by BitTorrent, Inc.
3 $url dlive.tv
4 $type live, vod
5 $metadata author
6 $metadata title
7 """
8
9 import logging
10 import re
11 from urllib.parse import unquote_plus
12
13 from streamlink.plugin import Plugin, pluginmatcher
14 from streamlink.plugin.api import validate
15 from streamlink.stream.hls import HLSStream
16
17
18 log = logging.getLogger(__name__)
19
20
21 @pluginmatcher(re.compile(r"""
22 https?://(?:www\.)?dlive\.tv/
23 (?:
24 p/(?P<video>[^/]+)
25 |
26 (?P<channel>[^/]+)
27 )
28 """, re.VERBOSE))
29 class DLive(Plugin):
30 URL_LIVE = "https://live.prd.dlive.tv/hls/live/{username}.m3u8"
31
32 QUALITY_WEIGHTS = {
33 "src": 1080,
34 }
35
36 @classmethod
37 def stream_weight(cls, key):
38 weight = cls.QUALITY_WEIGHTS.get(key)
39 if weight:
40 return weight, "dlive"
41
42 return super().stream_weight(key)
43
44 def _get_streams_video(self, video):
45 log.debug(f"Getting video HLS streams for {video}")
46 hls_url = self.session.http.get(self.url, schema=validate.Schema(
47 validate.regex(re.compile(r'"playbackUrl"\s*:\s*"([^"]+\.m3u8)"')),
48 validate.get(1),
49 validate.transform(unquote_plus),
50 validate.transform(lambda url: bytes(url, "utf-8").decode("unicode_escape")),
51 validate.url(),
52 ))
53
54 return HLSStream.parse_variant_playlist(self.session, hls_url)
55
56 def _get_streams_live(self, channel):
57 log.debug(f"Getting live HLS streams for {channel}")
58 query = f"""query {{
59 userByDisplayName(displayname:"{channel}") {{
60 livestream {{
61 title
62 }}
63 username
64 }}
65 }}"""
66 livestream, username = self.session.http.post(
67 "https://graphigo.prd.dlive.tv/",
68 json={"query": query},
69 schema=validate.Schema(
70 validate.parse_json(),
71 {
72 "data": {
73 "userByDisplayName": {
74 "livestream": {
75 "title": str,
76 },
77 "username": str,
78 },
79 },
80 },
81 validate.get(("data", "userByDisplayName")),
82 validate.union_get("livestream", "username"),
83 ),
84 )
85
86 self.author = channel
87 self.title = livestream["title"]
88
89 return HLSStream.parse_variant_playlist(self.session, self.URL_LIVE.format(username=username))
90
91 def _get_streams(self):
92 video = self.match.group("video")
93 channel = self.match.group("channel")
94
95 if video:
96 return self._get_streams_video(video)
97 elif channel:
98 return self._get_streams_live(channel)
99
100
101 __plugin__ = DLive
102
[end of src/streamlink/plugins/dlive.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/streamlink/plugins/dlive.py b/src/streamlink/plugins/dlive.py
--- a/src/streamlink/plugins/dlive.py
+++ b/src/streamlink/plugins/dlive.py
@@ -86,7 +86,7 @@
self.author = channel
self.title = livestream["title"]
- return HLSStream.parse_variant_playlist(self.session, self.URL_LIVE.format(username=username))
+ return HLSStream.parse_variant_playlist(self.session, self.URL_LIVE.format(username=username), headers={"Referer": "https://dlive.tv/"})
def _get_streams(self):
video = self.match.group("video")
|
{"golden_diff": "diff --git a/src/streamlink/plugins/dlive.py b/src/streamlink/plugins/dlive.py\n--- a/src/streamlink/plugins/dlive.py\n+++ b/src/streamlink/plugins/dlive.py\n@@ -86,7 +86,7 @@\n self.author = channel\n self.title = livestream[\"title\"]\n \n- return HLSStream.parse_variant_playlist(self.session, self.URL_LIVE.format(username=username))\n+ return HLSStream.parse_variant_playlist(self.session, self.URL_LIVE.format(username=username), headers={\"Referer\": \"https://dlive.tv/\"})\n \n def _get_streams(self):\n video = self.match.group(\"video\")\n", "issue": "plugins.dlive: Failed to fetch segment | 403 Client Error\n### Checklist\n\n- [X] This is a [plugin issue](https://streamlink.github.io/plugins.html) and not [a different kind of issue](https://github.com/streamlink/streamlink/issues/new/choose)\n- [X] [I have read the contribution guidelines](https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink)\n- [X] [I have checked the list of open and recently closed plugin issues](https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22)\n- [X] [I have checked the commit log of the master branch](https://github.com/streamlink/streamlink/commits/master)\n\n### Streamlink version\n\n[cli][info] Your Streamlink version (6.2.1) is up to date!\n\n### Description\n\nI navigate to the folder where streamlink.exe is located and enter the command \"streamlink.exe https://dlive.tv/cryptokaprika best\". It doesn't matter which channel is specified, the same error comes up for all of them as of late.\r\n\r\n\r\nHere is the complete output that is shown to me in the command line:\r\n\r\n\r\nC:\\Program Files\\Streamlink\\bin>streamlink.exe https://dlive.tv/cryptokaprika best\r\n\r\n[cli][info] Found matching plugin dlive for URL https://dlive.tv/cryptokaprika\r\n\r\n[cli][info] Available streams: src (worst, best)\r\n\r\n[cli][info] Opening stream: src (hls)\r\n\r\n[cli][info] Starting player: C:\\Program Files\\VideoLAN\\VLC\\vlc.exe\r\n\r\n[stream.hls][error] Failed to fetch segment 79790: Unable to open URL: https://videos.prd.dlivecdn.com/dlive/0000079790.ts (403 Client Error: Forbidden for url: https://videos.prd.dlivecdn.com/dlive/0000079790.ts)\r\n\r\n[stream.hls][error] Failed to fetch segment 79791: Unable to open URL: https://videos.prd.dlivecdn.com/dlive/0000079791.ts (403 Client Error: Forbidden for url: https://videos.prd.dlivecdn.com/dlive/0000079791.ts)\r\n\r\n[cli][info] Stream ended\r\n\r\n[cli][info] Closing currently open stream...\r\n\r\n\r\nThe VLC Media Player also starts, but I only get the following picture and am referred to the homepage: [https://imgur.com/a/NpuAHQ3](https://imgur.com/a/NpuAHQ3)\n\n### Debug log\n\n```text\nC:\\Program Files\\Streamlink\\bin>streamlink.exe --loglevel=debug https://dlive.tv/cryptokaprika best\r\n[cli][debug] OS: Windows 10\r\n[cli][debug] Python: 3.11.5\r\n[cli][debug] OpenSSL: OpenSSL 3.0.9 30 May 2023\r\n[cli][debug] Streamlink: 6.2.1\r\n[cli][debug] Dependencies:\r\n[cli][debug] certifi: 2023.7.22\r\n[cli][debug] isodate: 0.6.1\r\n[cli][debug] lxml: 4.9.3\r\n[cli][debug] pycountry: 22.3.5\r\n[cli][debug] pycryptodome: 3.19.0\r\n[cli][debug] PySocks: 1.7.1\r\n[cli][debug] requests: 2.31.0\r\n[cli][debug] trio: 0.22.2\r\n[cli][debug] trio-websocket: 0.11.1\r\n[cli][debug] typing-extensions: 4.8.0\r\n[cli][debug] urllib3: 2.0.6\r\n[cli][debug] websocket-client: 1.6.3\r\n[cli][debug] Arguments:\r\n[cli][debug] url=https://dlive.tv/cryptokaprika\r\n[cli][debug] stream=['best']\r\n[cli][debug] --loglevel=debug\r\n[cli][debug] --ffmpeg-ffmpeg=C:\\Program Files\\Streamlink\\ffmpeg\\ffmpeg.exe\r\n[cli][info] Found matching plugin dlive for URL https://dlive.tv/cryptokaprika\r\n[plugins.dlive][debug] Getting live HLS streams for cryptokaprika\r\n[utils.l10n][debug] Language code: en_US\r\n[cli][info] Available streams: src (worst, best)\r\n[cli][info] Opening stream: src (hls)\r\n[cli][info] Starting player: C:\\Program Files\\VideoLAN\\VLC\\vlc.exe\r\n[stream.hls][debug] Reloading playlist\r\n[cli][debug] Pre-buffering 8192 bytes\r\n[stream.hls][debug] First Sequence: 79786; Last Sequence: 79791\r\n[stream.hls][debug] Start offset: 0; Duration: None; Start Sequence: 79786; End Sequence: 79791\r\n[stream.hls][debug] Adding segment 79786 to queue\r\n[stream.hls][debug] Adding segment 79787 to queue\r\n[stream.hls][debug] Adding segment 79788 to queue\r\n[stream.hls][debug] Adding segment 79789 to queue\r\n[stream.hls][debug] Adding segment 79790 to queue\r\n[stream.hls][debug] Adding segment 79791 to queue\r\n[stream.segmented][debug] Closing worker thread\r\n[stream.hls][debug] Writing segment 79786 to output\r\n[stream.hls][debug] Segment 79786 complete\r\n[cli.output][debug] Opening subprocess: ['C:\\\\Program Files\\\\VideoLAN\\\\VLC\\\\vlc.exe', '--input-title-format', 'https://dlive.tv/cryptokaprika', '-']\r\n[stream.hls][debug] Writing segment 79787 to output\r\n[stream.hls][debug] Segment 79787 complete\r\n[stream.hls][debug] Writing segment 79788 to output\r\n[stream.hls][debug] Segment 79788 complete\r\n[stream.hls][debug] Writing segment 79789 to output\r\n[stream.hls][debug] Segment 79789 complete\r\n[cli][debug] Writing stream to output\r\n[stream.hls][error] Failed to fetch segment 79790: Unable to open URL: https://videos.prd.dlivecdn.com/dlive/0000079790.ts (403 Client Error: Forbidden for url: https://videos.prd.dlivecdn.com/dlive/0000079790.ts)\r\n[stream.hls][error] Failed to fetch segment 79791: Unable to open URL: https://videos.prd.dlivecdn.com/dlive/0000079791.ts (403 Client Error: Forbidden for url: https://videos.prd.dlivecdn.com/dlive/0000079791.ts)\r\n[stream.segmented][debug] Closing writer thread\r\n[cli][info] Stream ended\r\n[cli][info] Closing currently open stream...\n```\n\n", "before_files": [{"content": "\"\"\"\n$description Global live-streaming platform owned by BitTorrent, Inc.\n$url dlive.tv\n$type live, vod\n$metadata author\n$metadata title\n\"\"\"\n\nimport logging\nimport re\nfrom urllib.parse import unquote_plus\n\nfrom streamlink.plugin import Plugin, pluginmatcher\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream.hls import HLSStream\n\n\nlog = logging.getLogger(__name__)\n\n\n@pluginmatcher(re.compile(r\"\"\"\n https?://(?:www\\.)?dlive\\.tv/\n (?:\n p/(?P<video>[^/]+)\n |\n (?P<channel>[^/]+)\n )\n\"\"\", re.VERBOSE))\nclass DLive(Plugin):\n URL_LIVE = \"https://live.prd.dlive.tv/hls/live/{username}.m3u8\"\n\n QUALITY_WEIGHTS = {\n \"src\": 1080,\n }\n\n @classmethod\n def stream_weight(cls, key):\n weight = cls.QUALITY_WEIGHTS.get(key)\n if weight:\n return weight, \"dlive\"\n\n return super().stream_weight(key)\n\n def _get_streams_video(self, video):\n log.debug(f\"Getting video HLS streams for {video}\")\n hls_url = self.session.http.get(self.url, schema=validate.Schema(\n validate.regex(re.compile(r'\"playbackUrl\"\\s*:\\s*\"([^\"]+\\.m3u8)\"')),\n validate.get(1),\n validate.transform(unquote_plus),\n validate.transform(lambda url: bytes(url, \"utf-8\").decode(\"unicode_escape\")),\n validate.url(),\n ))\n\n return HLSStream.parse_variant_playlist(self.session, hls_url)\n\n def _get_streams_live(self, channel):\n log.debug(f\"Getting live HLS streams for {channel}\")\n query = f\"\"\"query {{\n userByDisplayName(displayname:\"{channel}\") {{\n livestream {{\n title\n }}\n username\n }}\n }}\"\"\"\n livestream, username = self.session.http.post(\n \"https://graphigo.prd.dlive.tv/\",\n json={\"query\": query},\n schema=validate.Schema(\n validate.parse_json(),\n {\n \"data\": {\n \"userByDisplayName\": {\n \"livestream\": {\n \"title\": str,\n },\n \"username\": str,\n },\n },\n },\n validate.get((\"data\", \"userByDisplayName\")),\n validate.union_get(\"livestream\", \"username\"),\n ),\n )\n\n self.author = channel\n self.title = livestream[\"title\"]\n\n return HLSStream.parse_variant_playlist(self.session, self.URL_LIVE.format(username=username))\n\n def _get_streams(self):\n video = self.match.group(\"video\")\n channel = self.match.group(\"channel\")\n\n if video:\n return self._get_streams_video(video)\n elif channel:\n return self._get_streams_live(channel)\n\n\n__plugin__ = DLive\n", "path": "src/streamlink/plugins/dlive.py"}]}
| 3,046 | 136 |
gh_patches_debug_40324
|
rasdani/github-patches
|
git_diff
|
pantsbuild__pants-15841
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix Scala using `add_dependencies_on_all_siblings=True`
After dependency inference was improved for Scala, `add_dependencies_on_all_siblings` was not removed:
https://github.com/pantsbuild/pants/blob/c2f6404c1ed5fd11a6a37eac8682a5d337bf22aa/src/python/pants/backend/scala/target_types.py#L233 This means that we are overly coarsening Scala (all BUILD targets end up compiled together).
We should fix this (or drive it via an option), but it will definitely impact compilation success rates, and might also impact performance. We should test out the impact in our testbed repositories.
</issue>
<code>
[start of src/python/pants/backend/scala/target_types.py]
1 # Copyright 2020 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 from __future__ import annotations
5
6 from dataclasses import dataclass
7
8 from pants.engine.rules import collect_rules, rule
9 from pants.engine.target import (
10 COMMON_TARGET_FIELDS,
11 AsyncFieldMixin,
12 Dependencies,
13 FieldSet,
14 MultipleSourcesField,
15 SingleSourceField,
16 StringField,
17 StringSequenceField,
18 Target,
19 TargetFilesGenerator,
20 TargetFilesGeneratorSettings,
21 TargetFilesGeneratorSettingsRequest,
22 generate_multiple_sources_field_help_message,
23 )
24 from pants.engine.unions import UnionRule
25 from pants.jvm.target_types import (
26 JunitTestSourceField,
27 JvmJdkField,
28 JvmProvidesTypesField,
29 JvmResolveField,
30 )
31 from pants.util.strutil import softwrap
32
33
34 class ScalaSettingsRequest(TargetFilesGeneratorSettingsRequest):
35 pass
36
37
38 @rule
39 def scala_settings_request(_: ScalaSettingsRequest) -> TargetFilesGeneratorSettings:
40 # TODO: See https://github.com/pantsbuild/pants/issues/14382.
41 return TargetFilesGeneratorSettings(add_dependencies_on_all_siblings=True)
42
43
44 class ScalaSourceField(SingleSourceField):
45 expected_file_extensions = (".scala",)
46
47
48 class ScalaGeneratorSourcesField(MultipleSourcesField):
49 expected_file_extensions = (".scala",)
50
51
52 class ScalaDependenciesField(Dependencies):
53 pass
54
55
56 class ScalaConsumedPluginNamesField(StringSequenceField):
57 help = softwrap(
58 """
59 The names of Scala plugins that this source file requires.
60
61 The plugin must be defined by a corresponding `scalac_plugin` AND `jvm_artifact` target,
62 and must be present in this target's resolve's lockfile.
63
64 If not specified, this will default to the plugins specified in
65 `[scalac].plugins_for_resolve` for this target's resolve.
66 """
67 )
68
69 alias = "scalac_plugins"
70 required = False
71
72
73 @dataclass(frozen=True)
74 class ScalaFieldSet(FieldSet):
75 required_fields = (ScalaSourceField,)
76
77 sources: ScalaSourceField
78
79
80 @dataclass(frozen=True)
81 class ScalaGeneratorFieldSet(FieldSet):
82 required_fields = (ScalaGeneratorSourcesField,)
83
84 sources: ScalaGeneratorSourcesField
85
86
87 # -----------------------------------------------------------------------------------------------
88 # `scalatest_tests`
89 # -----------------------------------------------------------------------------------------------
90
91
92 class ScalatestTestSourceField(ScalaSourceField):
93 pass
94
95
96 class ScalatestTestTarget(Target):
97 alias = "scalatest_test"
98 core_fields = (
99 *COMMON_TARGET_FIELDS,
100 ScalaDependenciesField,
101 ScalatestTestSourceField,
102 ScalaConsumedPluginNamesField,
103 JvmResolveField,
104 JvmProvidesTypesField,
105 JvmJdkField,
106 )
107 help = "A single Scala test, run with Scalatest."
108
109
110 class ScalatestTestsGeneratorSourcesField(ScalaGeneratorSourcesField):
111 default = ("*Spec.scala", "*Suite.scala")
112 help = generate_multiple_sources_field_help_message(
113 "Example: `sources=['*Spec.scala', '!SuiteIgnore.scala']`"
114 )
115
116
117 class ScalatestTestsGeneratorTarget(TargetFilesGenerator):
118 alias = "scalatest_tests"
119 core_fields = (
120 *COMMON_TARGET_FIELDS,
121 ScalatestTestsGeneratorSourcesField,
122 )
123 generated_target_cls = ScalatestTestTarget
124 copied_fields = COMMON_TARGET_FIELDS
125 moved_fields = (
126 ScalaDependenciesField,
127 ScalaConsumedPluginNamesField,
128 JvmJdkField,
129 JvmProvidesTypesField,
130 JvmResolveField,
131 )
132 settings_request_cls = ScalaSettingsRequest
133 help = softwrap(
134 f"""
135 Generate a `scalatest_test` target for each file in the `sources` field (defaults to
136 all files in the directory matching {ScalatestTestsGeneratorSourcesField.default}).
137 """
138 )
139
140
141 # -----------------------------------------------------------------------------------------------
142 # `scala_junit_tests`
143 # -----------------------------------------------------------------------------------------------
144
145
146 class ScalaJunitTestSourceField(ScalaSourceField, JunitTestSourceField):
147 pass
148
149
150 class ScalaJunitTestTarget(Target):
151 alias = "scala_junit_test"
152 core_fields = (
153 *COMMON_TARGET_FIELDS,
154 ScalaDependenciesField,
155 ScalaJunitTestSourceField,
156 ScalaConsumedPluginNamesField,
157 JvmResolveField,
158 JvmProvidesTypesField,
159 JvmJdkField,
160 )
161 help = "A single Scala test, run with JUnit."
162
163
164 class ScalaJunitTestsGeneratorSourcesField(ScalaGeneratorSourcesField):
165 default = ("*Test.scala",)
166 help = generate_multiple_sources_field_help_message(
167 "Example: `sources=['*Test.scala', '!TestIgnore.scala']`"
168 )
169
170
171 class ScalaJunitTestsGeneratorTarget(TargetFilesGenerator):
172 alias = "scala_junit_tests"
173 core_fields = (
174 *COMMON_TARGET_FIELDS,
175 ScalaJunitTestsGeneratorSourcesField,
176 )
177 generated_target_cls = ScalaJunitTestTarget
178 copied_fields = COMMON_TARGET_FIELDS
179 moved_fields = (
180 ScalaDependenciesField,
181 ScalaConsumedPluginNamesField,
182 JvmJdkField,
183 JvmProvidesTypesField,
184 JvmResolveField,
185 )
186 settings_request_cls = ScalaSettingsRequest
187 help = "Generate a `scala_junit_test` target for each file in the `sources` field."
188
189
190 # -----------------------------------------------------------------------------------------------
191 # `scala_source` target
192 # -----------------------------------------------------------------------------------------------
193
194
195 class ScalaSourceTarget(Target):
196 alias = "scala_source"
197 core_fields = (
198 *COMMON_TARGET_FIELDS,
199 ScalaDependenciesField,
200 ScalaSourceField,
201 ScalaConsumedPluginNamesField,
202 JvmResolveField,
203 JvmProvidesTypesField,
204 JvmJdkField,
205 )
206 help = "A single Scala source file containing application or library code."
207
208
209 # -----------------------------------------------------------------------------------------------
210 # `scala_sources` target generator
211 # -----------------------------------------------------------------------------------------------
212
213
214 class ScalaSourcesGeneratorSourcesField(ScalaGeneratorSourcesField):
215 default = (
216 "*.scala",
217 *(f"!{pat}" for pat in (ScalaJunitTestsGeneratorSourcesField.default)),
218 *(f"!{pat}" for pat in (ScalatestTestsGeneratorSourcesField.default)),
219 )
220 help = generate_multiple_sources_field_help_message(
221 "Example: `sources=['Example.scala', 'New*.scala', '!OldIgnore.scala']`"
222 )
223
224
225 class ScalaSourcesGeneratorTarget(TargetFilesGenerator):
226 alias = "scala_sources"
227 core_fields = (
228 *COMMON_TARGET_FIELDS,
229 ScalaSourcesGeneratorSourcesField,
230 )
231 generated_target_cls = ScalaSourceTarget
232 copied_fields = COMMON_TARGET_FIELDS
233 moved_fields = (
234 ScalaDependenciesField,
235 ScalaConsumedPluginNamesField,
236 JvmResolveField,
237 JvmJdkField,
238 JvmProvidesTypesField,
239 )
240 settings_request_cls = ScalaSettingsRequest
241 help = "Generate a `scala_source` target for each file in the `sources` field."
242
243
244 # -----------------------------------------------------------------------------------------------
245 # `scalac_plugin` target
246 # -----------------------------------------------------------------------------------------------
247
248
249 class ScalacPluginArtifactField(StringField, AsyncFieldMixin):
250 alias = "artifact"
251 required = True
252 value: str
253 help = "The address of a `jvm_artifact` that defines a plugin for `scalac`."
254
255
256 class ScalacPluginNameField(StringField):
257 alias = "plugin_name"
258 help = softwrap(
259 """
260 The name that `scalac` should use to load the plugin.
261
262 If not set, the plugin name defaults to the target name.
263 """
264 )
265
266
267 class ScalacPluginTarget(Target):
268 alias = "scalac_plugin"
269 core_fields = (
270 *COMMON_TARGET_FIELDS,
271 ScalacPluginArtifactField,
272 ScalacPluginNameField,
273 )
274 help = softwrap(
275 """
276 A plugin for `scalac`.
277
278 Currently only thirdparty plugins are supported. To enable a plugin, define this
279 target type, and set the `artifact=` field to the address of a `jvm_artifact` that
280 provides the plugin.
281
282 If the `scalac`-loaded name of the plugin does not match the target's name,
283 additionally set the `plugin_name=` field.
284 """
285 )
286
287
288 def rules():
289 return (
290 *collect_rules(),
291 UnionRule(TargetFilesGeneratorSettingsRequest, ScalaSettingsRequest),
292 )
293
[end of src/python/pants/backend/scala/target_types.py]
[start of src/python/pants/backend/scala/subsystems/scala_infer.py]
1 # Copyright 2021 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 from pants.option.option_types import BoolOption
5 from pants.option.subsystem import Subsystem
6
7
8 class ScalaInferSubsystem(Subsystem):
9 options_scope = "scala-infer"
10 help = "Options controlling which dependencies will be inferred for Scala targets."
11
12 imports = BoolOption(
13 "--imports",
14 default=True,
15 help="Infer a target's dependencies by parsing import statements from sources.",
16 )
17 consumed_types = BoolOption(
18 "--consumed-types",
19 default=True,
20 help="Infer a target's dependencies by parsing consumed types from sources.",
21 )
22
[end of src/python/pants/backend/scala/subsystems/scala_infer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/python/pants/backend/scala/subsystems/scala_infer.py b/src/python/pants/backend/scala/subsystems/scala_infer.py
--- a/src/python/pants/backend/scala/subsystems/scala_infer.py
+++ b/src/python/pants/backend/scala/subsystems/scala_infer.py
@@ -3,6 +3,7 @@
from pants.option.option_types import BoolOption
from pants.option.subsystem import Subsystem
+from pants.util.strutil import softwrap
class ScalaInferSubsystem(Subsystem):
@@ -19,3 +20,18 @@
default=True,
help="Infer a target's dependencies by parsing consumed types from sources.",
)
+ force_add_siblings_as_dependencies = BoolOption(
+ "--force-add-siblings-as-dependencies",
+ default=True,
+ help=softwrap(
+ """
+ If true, add a dependency on all scala_source targets generated by the same scala_sources target generator.
+ If false, the dependencies will only be added if [scala-infer].imports is also set to false.
+
+ Setting this option to true reduces the precision of dependency information.
+ That means that you may end up compiling more than is necessary for a particular task,
+ and that compilation will be invalidated more frequently than actually necessary.
+ However, setting to true may be helpful if compilation fails due to missing dependencies.
+ """
+ ),
+ )
diff --git a/src/python/pants/backend/scala/target_types.py b/src/python/pants/backend/scala/target_types.py
--- a/src/python/pants/backend/scala/target_types.py
+++ b/src/python/pants/backend/scala/target_types.py
@@ -5,6 +5,8 @@
from dataclasses import dataclass
+from pants.backend.scala.subsystems.scala_infer import ScalaInferSubsystem
+from pants.base.deprecated import warn_or_error
from pants.engine.rules import collect_rules, rule
from pants.engine.target import (
COMMON_TARGET_FIELDS,
@@ -36,9 +38,35 @@
@rule
-def scala_settings_request(_: ScalaSettingsRequest) -> TargetFilesGeneratorSettings:
- # TODO: See https://github.com/pantsbuild/pants/issues/14382.
- return TargetFilesGeneratorSettings(add_dependencies_on_all_siblings=True)
+def scala_settings_request(
+ scala_infer_subsystem: ScalaInferSubsystem, _: ScalaSettingsRequest
+) -> TargetFilesGeneratorSettings:
+ if scala_infer_subsystem.options.is_default("force_add_siblings_as_dependencies"):
+ warn_or_error(
+ removal_version="2.14.0.dev0",
+ entity="`force_add_siblings_as_dependencies` defaulting to True",
+ hint=softwrap(
+ """
+ Setting this option to true reduces the precision of dependency information.
+ That means that you may end up compiling more than is necessary for a particular task,
+ and that compilation will be invalidated more frequently than actually necessary.
+ However, setting to true may be helpful if compilation fails due to missing dependencies.
+
+ We have made several improvements to Pants's Scala dependency inference,
+ where we no longer think it's necessary to adding dependencies on sibling targets.
+ If you have compilation failures after disabling this option, please consider opening an issue at
+ https://github.com/pantsbuild/pants/issues/new so that we can continue to improve Pants's dependency inference.
+
+ To opt into the new default early, set `force_add_siblings_as_dependencies = false` in the `[scala_infer]`
+ section in `pants.toml`. Otherwise, set to `true` to silence this warning.
+ """
+ ),
+ )
+
+ return TargetFilesGeneratorSettings(
+ add_dependencies_on_all_siblings=scala_infer_subsystem.force_add_siblings_as_dependencies
+ or not scala_infer_subsystem.imports
+ )
class ScalaSourceField(SingleSourceField):
|
{"golden_diff": "diff --git a/src/python/pants/backend/scala/subsystems/scala_infer.py b/src/python/pants/backend/scala/subsystems/scala_infer.py\n--- a/src/python/pants/backend/scala/subsystems/scala_infer.py\n+++ b/src/python/pants/backend/scala/subsystems/scala_infer.py\n@@ -3,6 +3,7 @@\n \n from pants.option.option_types import BoolOption\n from pants.option.subsystem import Subsystem\n+from pants.util.strutil import softwrap\n \n \n class ScalaInferSubsystem(Subsystem):\n@@ -19,3 +20,18 @@\n default=True,\n help=\"Infer a target's dependencies by parsing consumed types from sources.\",\n )\n+ force_add_siblings_as_dependencies = BoolOption(\n+ \"--force-add-siblings-as-dependencies\",\n+ default=True,\n+ help=softwrap(\n+ \"\"\"\n+ If true, add a dependency on all scala_source targets generated by the same scala_sources target generator.\n+ If false, the dependencies will only be added if [scala-infer].imports is also set to false.\n+\n+ Setting this option to true reduces the precision of dependency information.\n+ That means that you may end up compiling more than is necessary for a particular task,\n+ and that compilation will be invalidated more frequently than actually necessary.\n+ However, setting to true may be helpful if compilation fails due to missing dependencies.\n+ \"\"\"\n+ ),\n+ )\ndiff --git a/src/python/pants/backend/scala/target_types.py b/src/python/pants/backend/scala/target_types.py\n--- a/src/python/pants/backend/scala/target_types.py\n+++ b/src/python/pants/backend/scala/target_types.py\n@@ -5,6 +5,8 @@\n \n from dataclasses import dataclass\n \n+from pants.backend.scala.subsystems.scala_infer import ScalaInferSubsystem\n+from pants.base.deprecated import warn_or_error\n from pants.engine.rules import collect_rules, rule\n from pants.engine.target import (\n COMMON_TARGET_FIELDS,\n@@ -36,9 +38,35 @@\n \n \n @rule\n-def scala_settings_request(_: ScalaSettingsRequest) -> TargetFilesGeneratorSettings:\n- # TODO: See https://github.com/pantsbuild/pants/issues/14382.\n- return TargetFilesGeneratorSettings(add_dependencies_on_all_siblings=True)\n+def scala_settings_request(\n+ scala_infer_subsystem: ScalaInferSubsystem, _: ScalaSettingsRequest\n+) -> TargetFilesGeneratorSettings:\n+ if scala_infer_subsystem.options.is_default(\"force_add_siblings_as_dependencies\"):\n+ warn_or_error(\n+ removal_version=\"2.14.0.dev0\",\n+ entity=\"`force_add_siblings_as_dependencies` defaulting to True\",\n+ hint=softwrap(\n+ \"\"\"\n+ Setting this option to true reduces the precision of dependency information.\n+ That means that you may end up compiling more than is necessary for a particular task,\n+ and that compilation will be invalidated more frequently than actually necessary.\n+ However, setting to true may be helpful if compilation fails due to missing dependencies.\n+\n+ We have made several improvements to Pants's Scala dependency inference,\n+ where we no longer think it's necessary to adding dependencies on sibling targets.\n+ If you have compilation failures after disabling this option, please consider opening an issue at\n+ https://github.com/pantsbuild/pants/issues/new so that we can continue to improve Pants's dependency inference.\n+\n+ To opt into the new default early, set `force_add_siblings_as_dependencies = false` in the `[scala_infer]`\n+ section in `pants.toml`. Otherwise, set to `true` to silence this warning.\n+ \"\"\"\n+ ),\n+ )\n+\n+ return TargetFilesGeneratorSettings(\n+ add_dependencies_on_all_siblings=scala_infer_subsystem.force_add_siblings_as_dependencies\n+ or not scala_infer_subsystem.imports\n+ )\n \n \n class ScalaSourceField(SingleSourceField):\n", "issue": "Fix Scala using `add_dependencies_on_all_siblings=True`\nAfter dependency inference was improved for Scala, `add_dependencies_on_all_siblings` was not removed:\r\nhttps://github.com/pantsbuild/pants/blob/c2f6404c1ed5fd11a6a37eac8682a5d337bf22aa/src/python/pants/backend/scala/target_types.py#L233 This means that we are overly coarsening Scala (all BUILD targets end up compiled together).\r\n\r\nWe should fix this (or drive it via an option), but it will definitely impact compilation success rates, and might also impact performance. We should test out the impact in our testbed repositories.\n", "before_files": [{"content": "# Copyright 2020 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom __future__ import annotations\n\nfrom dataclasses import dataclass\n\nfrom pants.engine.rules import collect_rules, rule\nfrom pants.engine.target import (\n COMMON_TARGET_FIELDS,\n AsyncFieldMixin,\n Dependencies,\n FieldSet,\n MultipleSourcesField,\n SingleSourceField,\n StringField,\n StringSequenceField,\n Target,\n TargetFilesGenerator,\n TargetFilesGeneratorSettings,\n TargetFilesGeneratorSettingsRequest,\n generate_multiple_sources_field_help_message,\n)\nfrom pants.engine.unions import UnionRule\nfrom pants.jvm.target_types import (\n JunitTestSourceField,\n JvmJdkField,\n JvmProvidesTypesField,\n JvmResolveField,\n)\nfrom pants.util.strutil import softwrap\n\n\nclass ScalaSettingsRequest(TargetFilesGeneratorSettingsRequest):\n pass\n\n\n@rule\ndef scala_settings_request(_: ScalaSettingsRequest) -> TargetFilesGeneratorSettings:\n # TODO: See https://github.com/pantsbuild/pants/issues/14382.\n return TargetFilesGeneratorSettings(add_dependencies_on_all_siblings=True)\n\n\nclass ScalaSourceField(SingleSourceField):\n expected_file_extensions = (\".scala\",)\n\n\nclass ScalaGeneratorSourcesField(MultipleSourcesField):\n expected_file_extensions = (\".scala\",)\n\n\nclass ScalaDependenciesField(Dependencies):\n pass\n\n\nclass ScalaConsumedPluginNamesField(StringSequenceField):\n help = softwrap(\n \"\"\"\n The names of Scala plugins that this source file requires.\n\n The plugin must be defined by a corresponding `scalac_plugin` AND `jvm_artifact` target,\n and must be present in this target's resolve's lockfile.\n\n If not specified, this will default to the plugins specified in\n `[scalac].plugins_for_resolve` for this target's resolve.\n \"\"\"\n )\n\n alias = \"scalac_plugins\"\n required = False\n\n\n@dataclass(frozen=True)\nclass ScalaFieldSet(FieldSet):\n required_fields = (ScalaSourceField,)\n\n sources: ScalaSourceField\n\n\n@dataclass(frozen=True)\nclass ScalaGeneratorFieldSet(FieldSet):\n required_fields = (ScalaGeneratorSourcesField,)\n\n sources: ScalaGeneratorSourcesField\n\n\n# -----------------------------------------------------------------------------------------------\n# `scalatest_tests`\n# -----------------------------------------------------------------------------------------------\n\n\nclass ScalatestTestSourceField(ScalaSourceField):\n pass\n\n\nclass ScalatestTestTarget(Target):\n alias = \"scalatest_test\"\n core_fields = (\n *COMMON_TARGET_FIELDS,\n ScalaDependenciesField,\n ScalatestTestSourceField,\n ScalaConsumedPluginNamesField,\n JvmResolveField,\n JvmProvidesTypesField,\n JvmJdkField,\n )\n help = \"A single Scala test, run with Scalatest.\"\n\n\nclass ScalatestTestsGeneratorSourcesField(ScalaGeneratorSourcesField):\n default = (\"*Spec.scala\", \"*Suite.scala\")\n help = generate_multiple_sources_field_help_message(\n \"Example: `sources=['*Spec.scala', '!SuiteIgnore.scala']`\"\n )\n\n\nclass ScalatestTestsGeneratorTarget(TargetFilesGenerator):\n alias = \"scalatest_tests\"\n core_fields = (\n *COMMON_TARGET_FIELDS,\n ScalatestTestsGeneratorSourcesField,\n )\n generated_target_cls = ScalatestTestTarget\n copied_fields = COMMON_TARGET_FIELDS\n moved_fields = (\n ScalaDependenciesField,\n ScalaConsumedPluginNamesField,\n JvmJdkField,\n JvmProvidesTypesField,\n JvmResolveField,\n )\n settings_request_cls = ScalaSettingsRequest\n help = softwrap(\n f\"\"\"\n Generate a `scalatest_test` target for each file in the `sources` field (defaults to\n all files in the directory matching {ScalatestTestsGeneratorSourcesField.default}).\n \"\"\"\n )\n\n\n# -----------------------------------------------------------------------------------------------\n# `scala_junit_tests`\n# -----------------------------------------------------------------------------------------------\n\n\nclass ScalaJunitTestSourceField(ScalaSourceField, JunitTestSourceField):\n pass\n\n\nclass ScalaJunitTestTarget(Target):\n alias = \"scala_junit_test\"\n core_fields = (\n *COMMON_TARGET_FIELDS,\n ScalaDependenciesField,\n ScalaJunitTestSourceField,\n ScalaConsumedPluginNamesField,\n JvmResolveField,\n JvmProvidesTypesField,\n JvmJdkField,\n )\n help = \"A single Scala test, run with JUnit.\"\n\n\nclass ScalaJunitTestsGeneratorSourcesField(ScalaGeneratorSourcesField):\n default = (\"*Test.scala\",)\n help = generate_multiple_sources_field_help_message(\n \"Example: `sources=['*Test.scala', '!TestIgnore.scala']`\"\n )\n\n\nclass ScalaJunitTestsGeneratorTarget(TargetFilesGenerator):\n alias = \"scala_junit_tests\"\n core_fields = (\n *COMMON_TARGET_FIELDS,\n ScalaJunitTestsGeneratorSourcesField,\n )\n generated_target_cls = ScalaJunitTestTarget\n copied_fields = COMMON_TARGET_FIELDS\n moved_fields = (\n ScalaDependenciesField,\n ScalaConsumedPluginNamesField,\n JvmJdkField,\n JvmProvidesTypesField,\n JvmResolveField,\n )\n settings_request_cls = ScalaSettingsRequest\n help = \"Generate a `scala_junit_test` target for each file in the `sources` field.\"\n\n\n# -----------------------------------------------------------------------------------------------\n# `scala_source` target\n# -----------------------------------------------------------------------------------------------\n\n\nclass ScalaSourceTarget(Target):\n alias = \"scala_source\"\n core_fields = (\n *COMMON_TARGET_FIELDS,\n ScalaDependenciesField,\n ScalaSourceField,\n ScalaConsumedPluginNamesField,\n JvmResolveField,\n JvmProvidesTypesField,\n JvmJdkField,\n )\n help = \"A single Scala source file containing application or library code.\"\n\n\n# -----------------------------------------------------------------------------------------------\n# `scala_sources` target generator\n# -----------------------------------------------------------------------------------------------\n\n\nclass ScalaSourcesGeneratorSourcesField(ScalaGeneratorSourcesField):\n default = (\n \"*.scala\",\n *(f\"!{pat}\" for pat in (ScalaJunitTestsGeneratorSourcesField.default)),\n *(f\"!{pat}\" for pat in (ScalatestTestsGeneratorSourcesField.default)),\n )\n help = generate_multiple_sources_field_help_message(\n \"Example: `sources=['Example.scala', 'New*.scala', '!OldIgnore.scala']`\"\n )\n\n\nclass ScalaSourcesGeneratorTarget(TargetFilesGenerator):\n alias = \"scala_sources\"\n core_fields = (\n *COMMON_TARGET_FIELDS,\n ScalaSourcesGeneratorSourcesField,\n )\n generated_target_cls = ScalaSourceTarget\n copied_fields = COMMON_TARGET_FIELDS\n moved_fields = (\n ScalaDependenciesField,\n ScalaConsumedPluginNamesField,\n JvmResolveField,\n JvmJdkField,\n JvmProvidesTypesField,\n )\n settings_request_cls = ScalaSettingsRequest\n help = \"Generate a `scala_source` target for each file in the `sources` field.\"\n\n\n# -----------------------------------------------------------------------------------------------\n# `scalac_plugin` target\n# -----------------------------------------------------------------------------------------------\n\n\nclass ScalacPluginArtifactField(StringField, AsyncFieldMixin):\n alias = \"artifact\"\n required = True\n value: str\n help = \"The address of a `jvm_artifact` that defines a plugin for `scalac`.\"\n\n\nclass ScalacPluginNameField(StringField):\n alias = \"plugin_name\"\n help = softwrap(\n \"\"\"\n The name that `scalac` should use to load the plugin.\n\n If not set, the plugin name defaults to the target name.\n \"\"\"\n )\n\n\nclass ScalacPluginTarget(Target):\n alias = \"scalac_plugin\"\n core_fields = (\n *COMMON_TARGET_FIELDS,\n ScalacPluginArtifactField,\n ScalacPluginNameField,\n )\n help = softwrap(\n \"\"\"\n A plugin for `scalac`.\n\n Currently only thirdparty plugins are supported. To enable a plugin, define this\n target type, and set the `artifact=` field to the address of a `jvm_artifact` that\n provides the plugin.\n\n If the `scalac`-loaded name of the plugin does not match the target's name,\n additionally set the `plugin_name=` field.\n \"\"\"\n )\n\n\ndef rules():\n return (\n *collect_rules(),\n UnionRule(TargetFilesGeneratorSettingsRequest, ScalaSettingsRequest),\n )\n", "path": "src/python/pants/backend/scala/target_types.py"}, {"content": "# Copyright 2021 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom pants.option.option_types import BoolOption\nfrom pants.option.subsystem import Subsystem\n\n\nclass ScalaInferSubsystem(Subsystem):\n options_scope = \"scala-infer\"\n help = \"Options controlling which dependencies will be inferred for Scala targets.\"\n\n imports = BoolOption(\n \"--imports\",\n default=True,\n help=\"Infer a target's dependencies by parsing import statements from sources.\",\n )\n consumed_types = BoolOption(\n \"--consumed-types\",\n default=True,\n help=\"Infer a target's dependencies by parsing consumed types from sources.\",\n )\n", "path": "src/python/pants/backend/scala/subsystems/scala_infer.py"}]}
| 3,483 | 851 |
gh_patches_debug_309
|
rasdani/github-patches
|
git_diff
|
wemake-services__wemake-python-styleguide-195
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix documentation main page's header
The header is gone:
<img width="1032" alt="2018-10-03 0 18 01" src="https://user-images.githubusercontent.com/4660275/46377643-d0ce1080-c6a1-11e8-950b-d2d0c515dee1.png">
</issue>
<code>
[start of wemake_python_styleguide/visitors/ast/numbers.py]
1 # -*- coding: utf-8 -*-
2
3 import ast
4 from typing import Optional
5
6 from wemake_python_styleguide.constants import MAGIC_NUMBERS_WHITELIST
7 from wemake_python_styleguide.violations.best_practices import (
8 MagicNumberViolation,
9 )
10 from wemake_python_styleguide.visitors.base import BaseNodeVisitor
11
12
13 class MagicNumberVisitor(BaseNodeVisitor):
14 """Checks magic numbers used in the code."""
15
16 _ALLOWED_PARENTS = (
17 ast.Assign,
18
19 # Constructor usages:
20 ast.FunctionDef,
21 ast.arguments,
22
23 # Primitives:
24 ast.List,
25 ast.Dict,
26 ast.Set,
27 ast.Tuple,
28 )
29
30 _PROXY_PARENTS = (
31 ast.UnaryOp,
32 )
33
34 def _get_real_parent(self, node: Optional[ast.AST]) -> Optional[ast.AST]:
35 """
36 Returns real number's parent.
37
38 What can go wrong?
39
40 1. Number can be negative: ``x = -1``,
41 so ``1`` has ``UnaryOp`` as parent, but should return ``Assign``
42
43 """
44 parent = getattr(node, 'parent', None)
45 if isinstance(parent, self._PROXY_PARENTS):
46 return self._get_real_parent(parent)
47 return parent
48
49 def _check_is_magic(self, node: ast.Num) -> None:
50 parent = self._get_real_parent(node)
51 if isinstance(parent, self._ALLOWED_PARENTS):
52 return
53
54 if node.n in MAGIC_NUMBERS_WHITELIST:
55 return
56
57 if isinstance(node.n, int) and node.n <= 10:
58 return
59
60 self.add_violation(MagicNumberViolation(node, text=str(node.n)))
61
62 def visit_Num(self, node: ast.Num) -> None:
63 """
64 Checks numbers not to be magic constants inside the code.
65
66 Raises:
67 MagicNumberViolation
68
69 """
70 self._check_is_magic(node)
71 self.generic_visit(node)
72
[end of wemake_python_styleguide/visitors/ast/numbers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/wemake_python_styleguide/visitors/ast/numbers.py b/wemake_python_styleguide/visitors/ast/numbers.py
--- a/wemake_python_styleguide/visitors/ast/numbers.py
+++ b/wemake_python_styleguide/visitors/ast/numbers.py
@@ -27,6 +27,7 @@
ast.Tuple,
)
+ # TODO: make consistent naming rules for class attributes:
_PROXY_PARENTS = (
ast.UnaryOp,
)
|
{"golden_diff": "diff --git a/wemake_python_styleguide/visitors/ast/numbers.py b/wemake_python_styleguide/visitors/ast/numbers.py\n--- a/wemake_python_styleguide/visitors/ast/numbers.py\n+++ b/wemake_python_styleguide/visitors/ast/numbers.py\n@@ -27,6 +27,7 @@\n ast.Tuple,\n )\n \n+ # TODO: make consistent naming rules for class attributes:\n _PROXY_PARENTS = (\n ast.UnaryOp,\n )\n", "issue": "Fix documentation main page's header\nThe header is gone:\r\n<img width=\"1032\" alt=\"2018-10-03 0 18 01\" src=\"https://user-images.githubusercontent.com/4660275/46377643-d0ce1080-c6a1-11e8-950b-d2d0c515dee1.png\">\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport ast\nfrom typing import Optional\n\nfrom wemake_python_styleguide.constants import MAGIC_NUMBERS_WHITELIST\nfrom wemake_python_styleguide.violations.best_practices import (\n MagicNumberViolation,\n)\nfrom wemake_python_styleguide.visitors.base import BaseNodeVisitor\n\n\nclass MagicNumberVisitor(BaseNodeVisitor):\n \"\"\"Checks magic numbers used in the code.\"\"\"\n\n _ALLOWED_PARENTS = (\n ast.Assign,\n\n # Constructor usages:\n ast.FunctionDef,\n ast.arguments,\n\n # Primitives:\n ast.List,\n ast.Dict,\n ast.Set,\n ast.Tuple,\n )\n\n _PROXY_PARENTS = (\n ast.UnaryOp,\n )\n\n def _get_real_parent(self, node: Optional[ast.AST]) -> Optional[ast.AST]:\n \"\"\"\n Returns real number's parent.\n\n What can go wrong?\n\n 1. Number can be negative: ``x = -1``,\n so ``1`` has ``UnaryOp`` as parent, but should return ``Assign``\n\n \"\"\"\n parent = getattr(node, 'parent', None)\n if isinstance(parent, self._PROXY_PARENTS):\n return self._get_real_parent(parent)\n return parent\n\n def _check_is_magic(self, node: ast.Num) -> None:\n parent = self._get_real_parent(node)\n if isinstance(parent, self._ALLOWED_PARENTS):\n return\n\n if node.n in MAGIC_NUMBERS_WHITELIST:\n return\n\n if isinstance(node.n, int) and node.n <= 10:\n return\n\n self.add_violation(MagicNumberViolation(node, text=str(node.n)))\n\n def visit_Num(self, node: ast.Num) -> None:\n \"\"\"\n Checks numbers not to be magic constants inside the code.\n\n Raises:\n MagicNumberViolation\n\n \"\"\"\n self._check_is_magic(node)\n self.generic_visit(node)\n", "path": "wemake_python_styleguide/visitors/ast/numbers.py"}]}
| 1,218 | 117 |
gh_patches_debug_20210
|
rasdani/github-patches
|
git_diff
|
learningequality__kolibri-11001
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add custom user-agent to `NetworkClient` and external API calls
<!--
Instructions:
* Fill out the sections below, replace …'s with information about your issue
* Use the 'preview' function above this text box to verify formatting before submitting
-->
## Observed behavior
<!--
Description of the behavior that was observed, including screenshots or other references when applicable
-->
The user agent for API calls made with python `requests` do not clearly identify the device as Kolibri
## Errors and logs
<!--
Relevant logs from:
* the command line
* ~/.kolibri/logs/kolibri.txt
* the browser console
Please wrap errors in triple backticks for clean formatting like this:
```
01:10 info: something happened
01:12 error: something bad happened
```
-->
Perhaps connected with errors like the following although these are not the primary reason to customize the user-agent:
```
http.client.RemoteDisconnected: Remote end closed connection without response
```
## Expected behavior
<!--
Description of what behavior was expected but did not occur
-->
It's recommended that we clearly identify the application making API calls, to differentiate it from potential scripting. According to MDN, it should have the format:
```
User-Agent: <product> / <product-version> <comment>
```
So for Kolibri 0.16.0:
```
User-Agent: kolibri/0.16.0 python-requests/2.28.2
```
## User-facing consequences
<!--
Implications and real-world consequences for learners, coaches, admins, and other users of the application
-->
Web application firewalls may take more aggressive action against clients making many requests if it appears to be purely something scripted.
## Context
<!--
Tell us about your environment, including:
* Kolibri version
* Operating system
* Browser
-->
Kolibri 0.15+
</issue>
<code>
[start of kolibri/core/discovery/utils/network/client.py]
1 import logging
2
3 import requests
4 from six import raise_from
5 from six.moves.urllib.parse import urlparse
6
7 from . import errors
8 from .urls import get_normalized_url_variations
9 from .urls import HTTP_PORTS
10 from .urls import HTTPS_PORTS
11 from kolibri.core.discovery.models import ConnectionStatus
12 from kolibri.core.tasks.utils import get_current_job
13 from kolibri.core.utils.urls import join_url
14 from kolibri.utils.server import get_urls
15
16 logger = logging.getLogger(__name__)
17
18 device_info_defaults = {
19 "subset_of_users_device": False,
20 }
21
22 DEFAULT_CONNECT_TIMEOUT = 5
23 DEFAULT_READ_TIMEOUT = 60
24 # default read timeout when within a job
25 DEFAULT_ASYNC_READ_TIMEOUT = 30
26 # when the network client tries variations of a url, that means the overall length of time it takes
27 # is multiplied by the number of variations, so for synchronous operations (in a HTTP request) we
28 # make the overall timeout ~= the DEFAULT_READ_TIMEOUT
29 DEFAULT_SYNC_READ_TIMEOUT = DEFAULT_READ_TIMEOUT / (len(HTTP_PORTS) + len(HTTPS_PORTS))
30
31
32 class NetworkClient(requests.Session):
33 __slots__ = ("base_url", "timeout", "session", "device_info", "remote_ip")
34
35 def __init__(self, base_url, timeout=None):
36 """
37 If an explicit base_url is already known, provide that. If only a vague address is known,
38 `build_from_address` can build a client to determine the actual `base_url`
39 :param base_url: The fully composed URL for a network location, without path
40 :param timeout: A timeout value in seconds or tuple for (connect, read)
41 :type timeout: float|tuple
42 """
43 super(NetworkClient, self).__init__()
44
45 self.base_url = base_url
46 self.timeout = timeout or (DEFAULT_CONNECT_TIMEOUT, DEFAULT_READ_TIMEOUT)
47 self.session = None
48 self.device_info = None
49 self.remote_ip = None
50
51 @classmethod
52 def build_for_address(cls, address, timeout=None):
53 """
54 Normalizes the address URL and tries a number of variations until we find one
55 that's able to connect
56
57 :param address: The address of which to try variations of
58 :param timeout: A timeout value in seconds or tuple for (connect, read)
59 :return: A NetworkClient with a verified connection
60 :rtype: NetworkClient
61 """
62 logger.info(
63 "Attempting connections to variations of the URL: {}".format(address)
64 )
65 if timeout is None:
66 if get_current_job() is not None:
67 # when we're within a job, then we can use longer timeouts
68 timeout = (DEFAULT_CONNECT_TIMEOUT, DEFAULT_ASYNC_READ_TIMEOUT)
69 else:
70 # if we're within a request thread, then we limit it for an overall time
71 timeout = (DEFAULT_CONNECT_TIMEOUT, DEFAULT_SYNC_READ_TIMEOUT)
72 _, self_urls = get_urls()
73 for url in get_normalized_url_variations(address):
74 if url in self_urls:
75 continue # exclude our own URLs
76 with NetworkClient(url, timeout=timeout) as client:
77 if client.connect(raise_if_unavailable=False):
78 return client
79 # we weren't able to connect to any of the URL variations, so all we can do is throw
80 raise errors.NetworkLocationNotFound()
81
82 @classmethod
83 def build_from_network_location(cls, network_location, timeout=None):
84 """
85 Creates a NetworkClient for a NetworkLocation, and validates the connection if the status
86 isn't already 'Okay'
87 :param network_location: The network location model
88 :type network_location: kolibri.core.discovery.models.NetworkLocation
89 :param timeout: A timeout value in seconds or tuple for (connect, read)
90 :return: A NetworkClient with a verified connection
91 :rtype: NetworkClient
92 """
93 # expect that static network locations have an exact base_url, and only try different
94 # variations if we haven't already
95 if (
96 network_location.dynamic
97 and network_location.connection_status == ConnectionStatus.Unknown
98 ):
99 return NetworkClient.build_for_address(
100 network_location.base_url, timeout=timeout
101 )
102 return NetworkClient(network_location.base_url, timeout=timeout)
103
104 def head(self, path, **kwargs):
105 return self.request("HEAD", path, **kwargs)
106
107 def get(self, path, **kwargs):
108 return self.request("GET", path, **kwargs)
109
110 def post(self, path, **kwargs):
111 return self.request("POST", path, **kwargs)
112
113 def request(self, method, path, **kwargs):
114 response = None
115 if "timeout" not in kwargs:
116 kwargs.update(timeout=self.timeout)
117
118 url = join_url(self.base_url, path)
119 try:
120 with super(NetworkClient, self).request(
121 method, url, stream=True, **kwargs
122 ) as response:
123 if response.raw._connection.sock is None:
124 raise requests.exceptions.ConnectionError("No socket available")
125
126 # capture the remote IP address, which requires `stream=True` and before consumed
127 self.remote_ip = response.raw._connection.sock.getpeername()[0]
128 # now consume content, see how `Session.send` does this when `stream=False`
129 response.content
130
131 response.raise_for_status()
132 return response
133 except (
134 requests.exceptions.ConnectionError,
135 requests.exceptions.SSLError,
136 requests.exceptions.ConnectTimeout,
137 requests.exceptions.URLRequired,
138 requests.exceptions.MissingSchema,
139 requests.exceptions.InvalidSchema,
140 requests.exceptions.InvalidURL,
141 requests.exceptions.InvalidHeader,
142 requests.exceptions.InvalidJSONError,
143 ) as e:
144 raise_from(
145 errors.NetworkLocationConnectionFailure(
146 "Unable to connect: {}".format(url)
147 ),
148 e,
149 )
150 except (
151 requests.exceptions.ReadTimeout,
152 requests.exceptions.TooManyRedirects,
153 ) as e:
154 raise_from(
155 errors.NetworkLocationResponseTimeout(
156 "Response timeout: {}".format(url)
157 ),
158 e,
159 )
160 except (
161 requests.exceptions.HTTPError,
162 requests.exceptions.ContentDecodingError,
163 requests.exceptions.ChunkedEncodingError,
164 requests.exceptions.RequestException,
165 ) as e:
166 raise_from(
167 errors.NetworkLocationResponseFailure(
168 "Response failure: {}".format(url), response=response
169 ),
170 e,
171 )
172
173 def connect(self, raise_if_unavailable=True): # noqa: C901
174 """
175 Attempts a connection to the instance and caches its device information if successful
176 :param raise_if_unavailable: Raises an error if connection fails and this value is True
177 :return: A boolean determining success, never False if `raise_if_unavailable=True`
178 """
179
180 from kolibri.core.device.utils import DEVICE_INFO_VERSION
181 from kolibri.core.device.utils import device_info_keys
182
183 # don't reconnect if client has already done so
184 if self.device_info is not None:
185 return True
186
187 try:
188 logger.info("Attempting connection to: {}".format(self.base_url))
189 response = self.get(
190 "api/public/info/",
191 allow_redirects=True,
192 params={"v": DEVICE_INFO_VERSION},
193 timeout=(DEFAULT_CONNECT_TIMEOUT, 5),
194 )
195 except errors.NetworkClientError as e:
196 logger.info(e)
197 if raise_if_unavailable:
198 raise e
199 return False
200
201 # check that we successfully connected, and if we were redirected that it's still
202 # the right endpoint
203 parsed_url = urlparse(response.url)
204 if response.status_code != 200:
205 if raise_if_unavailable:
206 raise errors.NetworkLocationInvalidResponse(
207 "Response status {}".format(response.status_code)
208 )
209 return False
210 if not parsed_url.path.rstrip("/").endswith("/api/public/info"):
211 if raise_if_unavailable:
212 raise errors.NetworkLocationInvalidResponse(
213 "Request redirected to {}".format(parsed_url.path)
214 )
215 return False
216
217 try:
218 info = response.json()
219 self.device_info = {}
220 for key in device_info_keys.get(DEVICE_INFO_VERSION, []):
221 self.device_info[key] = info.get(key, device_info_defaults.get(key))
222 if self.device_info["application"] not in ["studio", "kolibri"]:
223 raise errors.NetworkLocationInvalidResponse(
224 "Server is not running Kolibri or Studio"
225 )
226 logger.info("Success! We connected to: {}".format(response.url))
227
228 self.base_url = "{}://{}{}".format(
229 parsed_url.scheme,
230 parsed_url.netloc,
231 parsed_url.path.rstrip("/").replace("api/public/info", ""),
232 )
233 except (requests.exceptions.JSONDecodeError, ValueError) as e:
234 logger.info(
235 "Invalid JSON returned when attempting to connect to a remote server"
236 )
237 if raise_if_unavailable:
238 raise_from(
239 errors.NetworkLocationInvalidResponse("Invalid JSON returned"), e
240 )
241 return False
242
243 return True
244
[end of kolibri/core/discovery/utils/network/client.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kolibri/core/discovery/utils/network/client.py b/kolibri/core/discovery/utils/network/client.py
--- a/kolibri/core/discovery/utils/network/client.py
+++ b/kolibri/core/discovery/utils/network/client.py
@@ -4,6 +4,7 @@
from six import raise_from
from six.moves.urllib.parse import urlparse
+import kolibri
from . import errors
from .urls import get_normalized_url_variations
from .urls import HTTP_PORTS
@@ -47,6 +48,11 @@
self.session = None
self.device_info = None
self.remote_ip = None
+ self.headers.update(
+ {
+ "User-Agent": get_user_agent(),
+ }
+ )
@classmethod
def build_for_address(cls, address, timeout=None):
@@ -241,3 +247,9 @@
return False
return True
+
+
+def get_user_agent():
+ return "Kolibri/{0} python-requests/{1}".format(
+ kolibri.__version__, requests.__version__
+ )
|
{"golden_diff": "diff --git a/kolibri/core/discovery/utils/network/client.py b/kolibri/core/discovery/utils/network/client.py\n--- a/kolibri/core/discovery/utils/network/client.py\n+++ b/kolibri/core/discovery/utils/network/client.py\n@@ -4,6 +4,7 @@\n from six import raise_from\n from six.moves.urllib.parse import urlparse\n \n+import kolibri\n from . import errors\n from .urls import get_normalized_url_variations\n from .urls import HTTP_PORTS\n@@ -47,6 +48,11 @@\n self.session = None\n self.device_info = None\n self.remote_ip = None\n+ self.headers.update(\n+ {\n+ \"User-Agent\": get_user_agent(),\n+ }\n+ )\n \n @classmethod\n def build_for_address(cls, address, timeout=None):\n@@ -241,3 +247,9 @@\n return False\n \n return True\n+\n+\n+def get_user_agent():\n+ return \"Kolibri/{0} python-requests/{1}\".format(\n+ kolibri.__version__, requests.__version__\n+ )\n", "issue": "Add custom user-agent to `NetworkClient` and external API calls\n<!--\r\nInstructions:\r\n * Fill out the sections below, replace \u2026's with information about your issue\r\n * Use the 'preview' function above this text box to verify formatting before submitting\r\n-->\r\n\r\n## Observed behavior\r\n<!--\r\nDescription of the behavior that was observed, including screenshots or other references when applicable\r\n-->\r\nThe user agent for API calls made with python `requests` do not clearly identify the device as Kolibri\r\n\r\n## Errors and logs\r\n<!--\r\nRelevant logs from:\r\n * the command line\r\n * ~/.kolibri/logs/kolibri.txt\r\n * the browser console\r\n\r\nPlease wrap errors in triple backticks for clean formatting like this:\r\n```\r\n01:10 info: something happened\r\n01:12 error: something bad happened\r\n```\r\n-->\r\nPerhaps connected with errors like the following although these are not the primary reason to customize the user-agent:\r\n```\r\nhttp.client.RemoteDisconnected: Remote end closed connection without response\r\n```\r\n\r\n## Expected behavior\r\n<!--\r\nDescription of what behavior was expected but did not occur\r\n-->\r\nIt's recommended that we clearly identify the application making API calls, to differentiate it from potential scripting. According to MDN, it should have the format:\r\n```\r\nUser-Agent: <product> / <product-version> <comment>\r\n```\r\nSo for Kolibri 0.16.0:\r\n```\r\nUser-Agent: kolibri/0.16.0 python-requests/2.28.2\r\n```\r\n\r\n## User-facing consequences\r\n<!--\r\nImplications and real-world consequences for learners, coaches, admins, and other users of the application\r\n-->\r\nWeb application firewalls may take more aggressive action against clients making many requests if it appears to be purely something scripted.\r\n\r\n\r\n## Context\r\n<!--\r\nTell us about your environment, including:\r\n * Kolibri version\r\n * Operating system\r\n * Browser\r\n-->\r\nKolibri 0.15+\r\n\n", "before_files": [{"content": "import logging\n\nimport requests\nfrom six import raise_from\nfrom six.moves.urllib.parse import urlparse\n\nfrom . import errors\nfrom .urls import get_normalized_url_variations\nfrom .urls import HTTP_PORTS\nfrom .urls import HTTPS_PORTS\nfrom kolibri.core.discovery.models import ConnectionStatus\nfrom kolibri.core.tasks.utils import get_current_job\nfrom kolibri.core.utils.urls import join_url\nfrom kolibri.utils.server import get_urls\n\nlogger = logging.getLogger(__name__)\n\ndevice_info_defaults = {\n \"subset_of_users_device\": False,\n}\n\nDEFAULT_CONNECT_TIMEOUT = 5\nDEFAULT_READ_TIMEOUT = 60\n# default read timeout when within a job\nDEFAULT_ASYNC_READ_TIMEOUT = 30\n# when the network client tries variations of a url, that means the overall length of time it takes\n# is multiplied by the number of variations, so for synchronous operations (in a HTTP request) we\n# make the overall timeout ~= the DEFAULT_READ_TIMEOUT\nDEFAULT_SYNC_READ_TIMEOUT = DEFAULT_READ_TIMEOUT / (len(HTTP_PORTS) + len(HTTPS_PORTS))\n\n\nclass NetworkClient(requests.Session):\n __slots__ = (\"base_url\", \"timeout\", \"session\", \"device_info\", \"remote_ip\")\n\n def __init__(self, base_url, timeout=None):\n \"\"\"\n If an explicit base_url is already known, provide that. If only a vague address is known,\n `build_from_address` can build a client to determine the actual `base_url`\n :param base_url: The fully composed URL for a network location, without path\n :param timeout: A timeout value in seconds or tuple for (connect, read)\n :type timeout: float|tuple\n \"\"\"\n super(NetworkClient, self).__init__()\n\n self.base_url = base_url\n self.timeout = timeout or (DEFAULT_CONNECT_TIMEOUT, DEFAULT_READ_TIMEOUT)\n self.session = None\n self.device_info = None\n self.remote_ip = None\n\n @classmethod\n def build_for_address(cls, address, timeout=None):\n \"\"\"\n Normalizes the address URL and tries a number of variations until we find one\n that's able to connect\n\n :param address: The address of which to try variations of\n :param timeout: A timeout value in seconds or tuple for (connect, read)\n :return: A NetworkClient with a verified connection\n :rtype: NetworkClient\n \"\"\"\n logger.info(\n \"Attempting connections to variations of the URL: {}\".format(address)\n )\n if timeout is None:\n if get_current_job() is not None:\n # when we're within a job, then we can use longer timeouts\n timeout = (DEFAULT_CONNECT_TIMEOUT, DEFAULT_ASYNC_READ_TIMEOUT)\n else:\n # if we're within a request thread, then we limit it for an overall time\n timeout = (DEFAULT_CONNECT_TIMEOUT, DEFAULT_SYNC_READ_TIMEOUT)\n _, self_urls = get_urls()\n for url in get_normalized_url_variations(address):\n if url in self_urls:\n continue # exclude our own URLs\n with NetworkClient(url, timeout=timeout) as client:\n if client.connect(raise_if_unavailable=False):\n return client\n # we weren't able to connect to any of the URL variations, so all we can do is throw\n raise errors.NetworkLocationNotFound()\n\n @classmethod\n def build_from_network_location(cls, network_location, timeout=None):\n \"\"\"\n Creates a NetworkClient for a NetworkLocation, and validates the connection if the status\n isn't already 'Okay'\n :param network_location: The network location model\n :type network_location: kolibri.core.discovery.models.NetworkLocation\n :param timeout: A timeout value in seconds or tuple for (connect, read)\n :return: A NetworkClient with a verified connection\n :rtype: NetworkClient\n \"\"\"\n # expect that static network locations have an exact base_url, and only try different\n # variations if we haven't already\n if (\n network_location.dynamic\n and network_location.connection_status == ConnectionStatus.Unknown\n ):\n return NetworkClient.build_for_address(\n network_location.base_url, timeout=timeout\n )\n return NetworkClient(network_location.base_url, timeout=timeout)\n\n def head(self, path, **kwargs):\n return self.request(\"HEAD\", path, **kwargs)\n\n def get(self, path, **kwargs):\n return self.request(\"GET\", path, **kwargs)\n\n def post(self, path, **kwargs):\n return self.request(\"POST\", path, **kwargs)\n\n def request(self, method, path, **kwargs):\n response = None\n if \"timeout\" not in kwargs:\n kwargs.update(timeout=self.timeout)\n\n url = join_url(self.base_url, path)\n try:\n with super(NetworkClient, self).request(\n method, url, stream=True, **kwargs\n ) as response:\n if response.raw._connection.sock is None:\n raise requests.exceptions.ConnectionError(\"No socket available\")\n\n # capture the remote IP address, which requires `stream=True` and before consumed\n self.remote_ip = response.raw._connection.sock.getpeername()[0]\n # now consume content, see how `Session.send` does this when `stream=False`\n response.content\n\n response.raise_for_status()\n return response\n except (\n requests.exceptions.ConnectionError,\n requests.exceptions.SSLError,\n requests.exceptions.ConnectTimeout,\n requests.exceptions.URLRequired,\n requests.exceptions.MissingSchema,\n requests.exceptions.InvalidSchema,\n requests.exceptions.InvalidURL,\n requests.exceptions.InvalidHeader,\n requests.exceptions.InvalidJSONError,\n ) as e:\n raise_from(\n errors.NetworkLocationConnectionFailure(\n \"Unable to connect: {}\".format(url)\n ),\n e,\n )\n except (\n requests.exceptions.ReadTimeout,\n requests.exceptions.TooManyRedirects,\n ) as e:\n raise_from(\n errors.NetworkLocationResponseTimeout(\n \"Response timeout: {}\".format(url)\n ),\n e,\n )\n except (\n requests.exceptions.HTTPError,\n requests.exceptions.ContentDecodingError,\n requests.exceptions.ChunkedEncodingError,\n requests.exceptions.RequestException,\n ) as e:\n raise_from(\n errors.NetworkLocationResponseFailure(\n \"Response failure: {}\".format(url), response=response\n ),\n e,\n )\n\n def connect(self, raise_if_unavailable=True): # noqa: C901\n \"\"\"\n Attempts a connection to the instance and caches its device information if successful\n :param raise_if_unavailable: Raises an error if connection fails and this value is True\n :return: A boolean determining success, never False if `raise_if_unavailable=True`\n \"\"\"\n\n from kolibri.core.device.utils import DEVICE_INFO_VERSION\n from kolibri.core.device.utils import device_info_keys\n\n # don't reconnect if client has already done so\n if self.device_info is not None:\n return True\n\n try:\n logger.info(\"Attempting connection to: {}\".format(self.base_url))\n response = self.get(\n \"api/public/info/\",\n allow_redirects=True,\n params={\"v\": DEVICE_INFO_VERSION},\n timeout=(DEFAULT_CONNECT_TIMEOUT, 5),\n )\n except errors.NetworkClientError as e:\n logger.info(e)\n if raise_if_unavailable:\n raise e\n return False\n\n # check that we successfully connected, and if we were redirected that it's still\n # the right endpoint\n parsed_url = urlparse(response.url)\n if response.status_code != 200:\n if raise_if_unavailable:\n raise errors.NetworkLocationInvalidResponse(\n \"Response status {}\".format(response.status_code)\n )\n return False\n if not parsed_url.path.rstrip(\"/\").endswith(\"/api/public/info\"):\n if raise_if_unavailable:\n raise errors.NetworkLocationInvalidResponse(\n \"Request redirected to {}\".format(parsed_url.path)\n )\n return False\n\n try:\n info = response.json()\n self.device_info = {}\n for key in device_info_keys.get(DEVICE_INFO_VERSION, []):\n self.device_info[key] = info.get(key, device_info_defaults.get(key))\n if self.device_info[\"application\"] not in [\"studio\", \"kolibri\"]:\n raise errors.NetworkLocationInvalidResponse(\n \"Server is not running Kolibri or Studio\"\n )\n logger.info(\"Success! We connected to: {}\".format(response.url))\n\n self.base_url = \"{}://{}{}\".format(\n parsed_url.scheme,\n parsed_url.netloc,\n parsed_url.path.rstrip(\"/\").replace(\"api/public/info\", \"\"),\n )\n except (requests.exceptions.JSONDecodeError, ValueError) as e:\n logger.info(\n \"Invalid JSON returned when attempting to connect to a remote server\"\n )\n if raise_if_unavailable:\n raise_from(\n errors.NetworkLocationInvalidResponse(\"Invalid JSON returned\"), e\n )\n return False\n\n return True\n", "path": "kolibri/core/discovery/utils/network/client.py"}]}
| 3,454 | 241 |
gh_patches_debug_32176
|
rasdani/github-patches
|
git_diff
|
Qiskit__qiskit-2288
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Error when number of qubits is of type numpy.int64
<!-- ⚠️ If you do not respect this template, your issue will be closed -->
<!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. -->
### What is the expected enhancement?
In `qiskit/validation/base.py`, function `check_types`: currently, if `n_qubits` or `memory_slots` are of type `numpy.int64`, then an error is triggered, because type `int` is expected.
I find it too strict. Especially considering that if the number of qubits is originated in a `numpy` array, then its default type is `numpy.int64`. Terra can allow additional types, or convert the type internally.
</issue>
<code>
[start of qiskit/circuit/register.py]
1 # -*- coding: utf-8 -*-
2
3 # This code is part of Qiskit.
4 #
5 # (C) Copyright IBM 2017.
6 #
7 # This code is licensed under the Apache License, Version 2.0. You may
8 # obtain a copy of this license in the LICENSE.txt file in the root directory
9 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
10 #
11 # Any modifications or derivative works of this code must retain this
12 # copyright notice, and modified files need to carry a notice indicating
13 # that they have been altered from the originals.
14
15 """
16 Base register reference object.
17 """
18 import re
19 import logging
20 import itertools
21
22 from qiskit.exceptions import QiskitError, QiskitIndexError
23
24 logger = logging.getLogger(__name__)
25
26
27 class Register:
28 """Implement a generic register."""
29
30 # Counter for the number of instances in this class.
31 instances_counter = itertools.count()
32 # Prefix to use for auto naming.
33 prefix = 'reg'
34
35 def __init__(self, size, name=None):
36 """Create a new generic register.
37 """
38
39 if name is None:
40 name = '%s%i' % (self.prefix, next(self.instances_counter))
41
42 if not isinstance(name, str):
43 raise QiskitError("The circuit name should be a string "
44 "(or None for autogenerate a name).")
45
46 test = re.compile('[a-z][a-zA-Z0-9_]*')
47 if test.match(name) is None:
48 raise QiskitError("%s is an invalid OPENQASM register name." % name)
49
50 self.name = name
51 self.size = size
52 if size <= 0:
53 raise QiskitError("register size must be positive")
54
55 def __repr__(self):
56 """Return the official string representing the register."""
57 return "%s(%d, '%s')" % (self.__class__.__qualname__,
58 self.size, self.name)
59
60 def __len__(self):
61 """Return register size"""
62 return self.size
63
64 def check_range(self, j):
65 """Check that j is a valid index into self."""
66 if isinstance(j, int):
67 if j < 0 or j >= self.size:
68 raise QiskitIndexError("register index out of range")
69 elif isinstance(j, slice):
70 if j.start < 0 or j.stop >= self.size or (j.step is not None and
71 j.step <= 0):
72 raise QiskitIndexError("register index slice out of range")
73
74 def __getitem__(self, key):
75 """
76 Arg:
77 key (int|slice|list): index of the bit/qubit to be retrieved.
78
79 Returns:
80 tuple[Register, int]: a tuple in the form `(self, key)` if key is int.
81 If key is a slice, return a `list((self,key))`.
82
83 Raises:
84 QiskitError: if the `key` is not an integer.
85 QiskitIndexError: if the `key` is not in the range
86 `(0, self.size)`.
87 """
88 if not isinstance(key, (int, slice, list)):
89 raise QiskitError("expected integer or slice index into register")
90 if isinstance(key, int) and key < 0:
91 key = self.size + key
92 self.check_range(key)
93 if isinstance(key, slice):
94 return [(self, ind) for ind in range(*key.indices(len(self)))]
95 elif isinstance(key, list): # list of qubit indices
96 if max(key) < len(self):
97 return [(self, ind) for ind in key]
98 else:
99 raise QiskitError('register index out of range')
100 else:
101 return self, key
102
103 def __iter__(self):
104 """
105 Returns:
106 iterator: an iterator over the bits/qubits of the register, in the
107 form `tuple (Register, int)`.
108 """
109 return zip([self]*self.size, range(self.size))
110
111 def __eq__(self, other):
112 """Two Registers are the same if they are of the same type
113 (i.e. quantum/classical), and have the same name and size.
114
115 Args:
116 other (Register): other Register
117
118 Returns:
119 bool: are self and other equal.
120 """
121 res = False
122 if type(self) is type(other) and \
123 self.name == other.name and \
124 self.size == other.size:
125 res = True
126 return res
127
128 def __hash__(self):
129 """Make object hashable, based on the name and size to hash."""
130 return hash((type(self), self.name, self.size))
131
[end of qiskit/circuit/register.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/qiskit/circuit/register.py b/qiskit/circuit/register.py
--- a/qiskit/circuit/register.py
+++ b/qiskit/circuit/register.py
@@ -36,21 +36,29 @@
"""Create a new generic register.
"""
+ # validate (or cast) size
+ try:
+ size = int(size)
+ except Exception:
+ raise QiskitError("size needs to be castable to an int")
+ if size <= 0:
+ raise QiskitError("register size must be positive")
+
+ # validate (or cast) name
if name is None:
name = '%s%i' % (self.prefix, next(self.instances_counter))
-
- if not isinstance(name, str):
- raise QiskitError("The circuit name should be a string "
- "(or None for autogenerate a name).")
-
- test = re.compile('[a-z][a-zA-Z0-9_]*')
- if test.match(name) is None:
- raise QiskitError("%s is an invalid OPENQASM register name." % name)
+ else:
+ try:
+ name = str(name)
+ except Exception:
+ raise QiskitError("The circuit name should be castable to a string "
+ "(or None for autogenerate a name).")
+ name_format = re.compile('[a-z][a-zA-Z0-9_]*')
+ if name_format.match(name) is None:
+ raise QiskitError("%s is an invalid OPENQASM register name." % name)
self.name = name
self.size = size
- if size <= 0:
- raise QiskitError("register size must be positive")
def __repr__(self):
"""Return the official string representing the register."""
@@ -106,7 +114,7 @@
iterator: an iterator over the bits/qubits of the register, in the
form `tuple (Register, int)`.
"""
- return zip([self]*self.size, range(self.size))
+ return zip([self] * self.size, range(self.size))
def __eq__(self, other):
"""Two Registers are the same if they are of the same type
|
{"golden_diff": "diff --git a/qiskit/circuit/register.py b/qiskit/circuit/register.py\n--- a/qiskit/circuit/register.py\n+++ b/qiskit/circuit/register.py\n@@ -36,21 +36,29 @@\n \"\"\"Create a new generic register.\n \"\"\"\n \n+ # validate (or cast) size\n+ try:\n+ size = int(size)\n+ except Exception:\n+ raise QiskitError(\"size needs to be castable to an int\")\n+ if size <= 0:\n+ raise QiskitError(\"register size must be positive\")\n+\n+ # validate (or cast) name\n if name is None:\n name = '%s%i' % (self.prefix, next(self.instances_counter))\n-\n- if not isinstance(name, str):\n- raise QiskitError(\"The circuit name should be a string \"\n- \"(or None for autogenerate a name).\")\n-\n- test = re.compile('[a-z][a-zA-Z0-9_]*')\n- if test.match(name) is None:\n- raise QiskitError(\"%s is an invalid OPENQASM register name.\" % name)\n+ else:\n+ try:\n+ name = str(name)\n+ except Exception:\n+ raise QiskitError(\"The circuit name should be castable to a string \"\n+ \"(or None for autogenerate a name).\")\n+ name_format = re.compile('[a-z][a-zA-Z0-9_]*')\n+ if name_format.match(name) is None:\n+ raise QiskitError(\"%s is an invalid OPENQASM register name.\" % name)\n \n self.name = name\n self.size = size\n- if size <= 0:\n- raise QiskitError(\"register size must be positive\")\n \n def __repr__(self):\n \"\"\"Return the official string representing the register.\"\"\"\n@@ -106,7 +114,7 @@\n iterator: an iterator over the bits/qubits of the register, in the\n form `tuple (Register, int)`.\n \"\"\"\n- return zip([self]*self.size, range(self.size))\n+ return zip([self] * self.size, range(self.size))\n \n def __eq__(self, other):\n \"\"\"Two Registers are the same if they are of the same type\n", "issue": "Error when number of qubits is of type numpy.int64\n<!-- \u26a0\ufe0f If you do not respect this template, your issue will be closed -->\r\n<!-- \u26a0\ufe0f Make sure to browse the opened and closed issues to confirm this idea does not exist. -->\r\n\r\n### What is the expected enhancement?\r\n\r\nIn `qiskit/validation/base.py`, function `check_types`: currently, if `n_qubits` or `memory_slots` are of type `numpy.int64`, then an error is triggered, because type `int` is expected.\r\n\r\nI find it too strict. Especially considering that if the number of qubits is originated in a `numpy` array, then its default type is `numpy.int64`. Terra can allow additional types, or convert the type internally.\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n\"\"\"\nBase register reference object.\n\"\"\"\nimport re\nimport logging\nimport itertools\n\nfrom qiskit.exceptions import QiskitError, QiskitIndexError\n\nlogger = logging.getLogger(__name__)\n\n\nclass Register:\n \"\"\"Implement a generic register.\"\"\"\n\n # Counter for the number of instances in this class.\n instances_counter = itertools.count()\n # Prefix to use for auto naming.\n prefix = 'reg'\n\n def __init__(self, size, name=None):\n \"\"\"Create a new generic register.\n \"\"\"\n\n if name is None:\n name = '%s%i' % (self.prefix, next(self.instances_counter))\n\n if not isinstance(name, str):\n raise QiskitError(\"The circuit name should be a string \"\n \"(or None for autogenerate a name).\")\n\n test = re.compile('[a-z][a-zA-Z0-9_]*')\n if test.match(name) is None:\n raise QiskitError(\"%s is an invalid OPENQASM register name.\" % name)\n\n self.name = name\n self.size = size\n if size <= 0:\n raise QiskitError(\"register size must be positive\")\n\n def __repr__(self):\n \"\"\"Return the official string representing the register.\"\"\"\n return \"%s(%d, '%s')\" % (self.__class__.__qualname__,\n self.size, self.name)\n\n def __len__(self):\n \"\"\"Return register size\"\"\"\n return self.size\n\n def check_range(self, j):\n \"\"\"Check that j is a valid index into self.\"\"\"\n if isinstance(j, int):\n if j < 0 or j >= self.size:\n raise QiskitIndexError(\"register index out of range\")\n elif isinstance(j, slice):\n if j.start < 0 or j.stop >= self.size or (j.step is not None and\n j.step <= 0):\n raise QiskitIndexError(\"register index slice out of range\")\n\n def __getitem__(self, key):\n \"\"\"\n Arg:\n key (int|slice|list): index of the bit/qubit to be retrieved.\n\n Returns:\n tuple[Register, int]: a tuple in the form `(self, key)` if key is int.\n If key is a slice, return a `list((self,key))`.\n\n Raises:\n QiskitError: if the `key` is not an integer.\n QiskitIndexError: if the `key` is not in the range\n `(0, self.size)`.\n \"\"\"\n if not isinstance(key, (int, slice, list)):\n raise QiskitError(\"expected integer or slice index into register\")\n if isinstance(key, int) and key < 0:\n key = self.size + key\n self.check_range(key)\n if isinstance(key, slice):\n return [(self, ind) for ind in range(*key.indices(len(self)))]\n elif isinstance(key, list): # list of qubit indices\n if max(key) < len(self):\n return [(self, ind) for ind in key]\n else:\n raise QiskitError('register index out of range')\n else:\n return self, key\n\n def __iter__(self):\n \"\"\"\n Returns:\n iterator: an iterator over the bits/qubits of the register, in the\n form `tuple (Register, int)`.\n \"\"\"\n return zip([self]*self.size, range(self.size))\n\n def __eq__(self, other):\n \"\"\"Two Registers are the same if they are of the same type\n (i.e. quantum/classical), and have the same name and size.\n\n Args:\n other (Register): other Register\n\n Returns:\n bool: are self and other equal.\n \"\"\"\n res = False\n if type(self) is type(other) and \\\n self.name == other.name and \\\n self.size == other.size:\n res = True\n return res\n\n def __hash__(self):\n \"\"\"Make object hashable, based on the name and size to hash.\"\"\"\n return hash((type(self), self.name, self.size))\n", "path": "qiskit/circuit/register.py"}]}
| 2,001 | 509 |
gh_patches_debug_40866
|
rasdani/github-patches
|
git_diff
|
hpcaitech__ColossalAI-5273
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[tensor] fix some unittests
[tensor] fix some unittests
[tensor] fix some unittests
</issue>
<code>
[start of colossalai/kernel/triton/kvcache_copy.py]
1 import torch
2 import triton
3 import triton.language as tl
4
5
6 # Triton 2.1.0
7 @triton.jit
8 def _copy_to_kvcache_seqlen1_kernel(
9 KV, # K or V
10 KVCache, # KCache or VCache
11 BLOCK_TABLES,
12 context_lengths,
13 stride_kt,
14 stride_kh,
15 stride_kd,
16 stride_cacheb,
17 stride_cacheh,
18 stride_cached,
19 stride_cachebs,
20 stride_bts,
21 stride_btb,
22 block_size,
23 HEAD_DIM: tl.constexpr,
24 ):
25 cur_seq_idx = tl.program_id(0)
26 cur_kv_head_idx = tl.program_id(1)
27
28 cur_kv_seq_len = tl.load(context_lengths + cur_seq_idx)
29 last_bt_block_idx = cur_kv_seq_len // block_size
30 block_table_ptr = BLOCK_TABLES + cur_seq_idx * stride_bts
31 block_id = tl.load(block_table_ptr + last_bt_block_idx * stride_btb)
32 offsets_in_last_block = (cur_kv_seq_len % block_size) * stride_cachebs
33 offsets_dmodel = tl.arange(0, HEAD_DIM)
34 offsets_kv = cur_seq_idx * stride_kt + cur_kv_head_idx * stride_kh + offsets_dmodel * stride_kd
35 kv = tl.load(KV + offsets_kv)
36 offsets_kvcache = (
37 block_id * stride_cacheb
38 + cur_kv_head_idx * stride_cacheh
39 + offsets_dmodel * stride_cached
40 + offsets_in_last_block
41 )
42 tl.store(KVCache + offsets_kvcache, kv)
43 return
44
45
46 # Used with blocked kv cache.
47 # Copy k or v to block k/v cache during decoding stage
48 def copy_kv_to_blocked_cache(
49 k: torch.Tensor, # [bsz, 1, num_kv_heads, head_dim], k or v during decoding stage
50 k_cache: torch.Tensor, # [num_blocks, num_kv_heads, head_dim, block_size], blocked k or v cache (for now, the shapes of them are the same)
51 context_lengths: torch.Tensor, # [bsz], past kv seq len (not incorporating the current kv of length 1)
52 block_tables: torch.Tensor, # [bsz, max_blocks_per_sequence]
53 ):
54 assert k.dim() == 4, "Unsupported shape of k (supposed to be used for decoding stage)"
55 assert k.size(1) == 1, "Unsupported kv seq len (supposed to be used for decoding stage)"
56 assert k.size(-1) == k_cache.size(-2), "Incompatible head dim"
57 assert k.dtype == k_cache.dtype, "Expected consistent dtype for tensor and cache."
58 bsz, _, num_kv_heads, head_dim = k.shape
59 assert context_lengths.shape[0] == block_tables.shape[0] == bsz, (
60 f"Got incompatible batch size (number of seqs):\n"
61 f" Conext lengths bsz {context_lengths.shape[0]}, Block tables bsz {block_tables.shape[0]}, "
62 f"batch size {bsz}"
63 )
64
65 # Modify if the shape of kv cahce is changed.
66 block_size = k_cache.size(-1)
67 # [bsz, 1, num_kv_heads, head_dim] -> [bsz, num_kv_heads, head_dim]
68 k = k.squeeze(dim=1)
69
70 num_warps = 8 if head_dim > 128 else 4
71
72 grid = (bsz, num_kv_heads)
73 _copy_to_kvcache_seqlen1_kernel[grid](
74 k,
75 k_cache,
76 block_tables,
77 context_lengths,
78 k.stride(0),
79 k.stride(1),
80 k.stride(2),
81 k_cache.stride(0),
82 k_cache.stride(1),
83 k_cache.stride(2),
84 k_cache.stride(3),
85 block_tables.stride(0),
86 block_tables.stride(1),
87 block_size,
88 HEAD_DIM=head_dim,
89 num_warps=num_warps,
90 )
91
[end of colossalai/kernel/triton/kvcache_copy.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/colossalai/kernel/triton/kvcache_copy.py b/colossalai/kernel/triton/kvcache_copy.py
--- a/colossalai/kernel/triton/kvcache_copy.py
+++ b/colossalai/kernel/triton/kvcache_copy.py
@@ -25,11 +25,11 @@
cur_seq_idx = tl.program_id(0)
cur_kv_head_idx = tl.program_id(1)
- cur_kv_seq_len = tl.load(context_lengths + cur_seq_idx)
- last_bt_block_idx = cur_kv_seq_len // block_size
+ past_kv_seq_len = tl.load(context_lengths + cur_seq_idx) - 1
+ last_bt_block_idx = past_kv_seq_len // block_size
block_table_ptr = BLOCK_TABLES + cur_seq_idx * stride_bts
block_id = tl.load(block_table_ptr + last_bt_block_idx * stride_btb)
- offsets_in_last_block = (cur_kv_seq_len % block_size) * stride_cachebs
+ offsets_in_last_block = (past_kv_seq_len % block_size) * stride_cachebs
offsets_dmodel = tl.arange(0, HEAD_DIM)
offsets_kv = cur_seq_idx * stride_kt + cur_kv_head_idx * stride_kh + offsets_dmodel * stride_kd
kv = tl.load(KV + offsets_kv)
@@ -43,23 +43,30 @@
return
-# Used with blocked kv cache.
-# Copy k or v to block k/v cache during decoding stage
def copy_kv_to_blocked_cache(
- k: torch.Tensor, # [bsz, 1, num_kv_heads, head_dim], k or v during decoding stage
- k_cache: torch.Tensor, # [num_blocks, num_kv_heads, head_dim, block_size], blocked k or v cache (for now, the shapes of them are the same)
- context_lengths: torch.Tensor, # [bsz], past kv seq len (not incorporating the current kv of length 1)
- block_tables: torch.Tensor, # [bsz, max_blocks_per_sequence]
+ k: torch.Tensor,
+ k_cache: torch.Tensor,
+ kv_lengths: torch.Tensor,
+ block_tables: torch.Tensor,
):
+ """
+ Copy keys or values to the blocked key/value cache during decoding stage.
+
+ Parameters:
+ - k (torch.Tensor): [bsz, 1, num_kv_heads, head_dim] - Keys or values during decoding with seq len 1.
+ - k_cache (torch.Tensor): [num_blocks, num_kv_heads, head_dim, block_size] - Blocked key or value cache.
+ - kv_lengths (torch.Tensor): [bsz] - Past key/value sequence lengths plus current sequence length for each sequence.
+ - block_tables (torch.Tensor): [bsz, max_blocks_per_sequence] - Block tables for each sequence.
+ """
assert k.dim() == 4, "Unsupported shape of k (supposed to be used for decoding stage)"
assert k.size(1) == 1, "Unsupported kv seq len (supposed to be used for decoding stage)"
assert k.size(-1) == k_cache.size(-2), "Incompatible head dim"
assert k.dtype == k_cache.dtype, "Expected consistent dtype for tensor and cache."
bsz, _, num_kv_heads, head_dim = k.shape
- assert context_lengths.shape[0] == block_tables.shape[0] == bsz, (
+ assert kv_lengths.shape[0] == block_tables.shape[0] == bsz, (
f"Got incompatible batch size (number of seqs):\n"
- f" Conext lengths bsz {context_lengths.shape[0]}, Block tables bsz {block_tables.shape[0]}, "
- f"batch size {bsz}"
+ f" Past kv sequence lengths bsz {kv_lengths.shape[0]}; "
+ f" block tables bsz {block_tables.shape[0]}, input k batch size {bsz}"
)
# Modify if the shape of kv cahce is changed.
@@ -74,7 +81,7 @@
k,
k_cache,
block_tables,
- context_lengths,
+ kv_lengths,
k.stride(0),
k.stride(1),
k.stride(2),
|
{"golden_diff": "diff --git a/colossalai/kernel/triton/kvcache_copy.py b/colossalai/kernel/triton/kvcache_copy.py\n--- a/colossalai/kernel/triton/kvcache_copy.py\n+++ b/colossalai/kernel/triton/kvcache_copy.py\n@@ -25,11 +25,11 @@\n cur_seq_idx = tl.program_id(0)\n cur_kv_head_idx = tl.program_id(1)\n \n- cur_kv_seq_len = tl.load(context_lengths + cur_seq_idx)\n- last_bt_block_idx = cur_kv_seq_len // block_size\n+ past_kv_seq_len = tl.load(context_lengths + cur_seq_idx) - 1\n+ last_bt_block_idx = past_kv_seq_len // block_size\n block_table_ptr = BLOCK_TABLES + cur_seq_idx * stride_bts\n block_id = tl.load(block_table_ptr + last_bt_block_idx * stride_btb)\n- offsets_in_last_block = (cur_kv_seq_len % block_size) * stride_cachebs\n+ offsets_in_last_block = (past_kv_seq_len % block_size) * stride_cachebs\n offsets_dmodel = tl.arange(0, HEAD_DIM)\n offsets_kv = cur_seq_idx * stride_kt + cur_kv_head_idx * stride_kh + offsets_dmodel * stride_kd\n kv = tl.load(KV + offsets_kv)\n@@ -43,23 +43,30 @@\n return\n \n \n-# Used with blocked kv cache.\n-# Copy k or v to block k/v cache during decoding stage\n def copy_kv_to_blocked_cache(\n- k: torch.Tensor, # [bsz, 1, num_kv_heads, head_dim], k or v during decoding stage\n- k_cache: torch.Tensor, # [num_blocks, num_kv_heads, head_dim, block_size], blocked k or v cache (for now, the shapes of them are the same)\n- context_lengths: torch.Tensor, # [bsz], past kv seq len (not incorporating the current kv of length 1)\n- block_tables: torch.Tensor, # [bsz, max_blocks_per_sequence]\n+ k: torch.Tensor,\n+ k_cache: torch.Tensor,\n+ kv_lengths: torch.Tensor,\n+ block_tables: torch.Tensor,\n ):\n+ \"\"\"\n+ Copy keys or values to the blocked key/value cache during decoding stage.\n+\n+ Parameters:\n+ - k (torch.Tensor): [bsz, 1, num_kv_heads, head_dim] - Keys or values during decoding with seq len 1.\n+ - k_cache (torch.Tensor): [num_blocks, num_kv_heads, head_dim, block_size] - Blocked key or value cache.\n+ - kv_lengths (torch.Tensor): [bsz] - Past key/value sequence lengths plus current sequence length for each sequence.\n+ - block_tables (torch.Tensor): [bsz, max_blocks_per_sequence] - Block tables for each sequence.\n+ \"\"\"\n assert k.dim() == 4, \"Unsupported shape of k (supposed to be used for decoding stage)\"\n assert k.size(1) == 1, \"Unsupported kv seq len (supposed to be used for decoding stage)\"\n assert k.size(-1) == k_cache.size(-2), \"Incompatible head dim\"\n assert k.dtype == k_cache.dtype, \"Expected consistent dtype for tensor and cache.\"\n bsz, _, num_kv_heads, head_dim = k.shape\n- assert context_lengths.shape[0] == block_tables.shape[0] == bsz, (\n+ assert kv_lengths.shape[0] == block_tables.shape[0] == bsz, (\n f\"Got incompatible batch size (number of seqs):\\n\"\n- f\" Conext lengths bsz {context_lengths.shape[0]}, Block tables bsz {block_tables.shape[0]}, \"\n- f\"batch size {bsz}\"\n+ f\" Past kv sequence lengths bsz {kv_lengths.shape[0]}; \"\n+ f\" block tables bsz {block_tables.shape[0]}, input k batch size {bsz}\"\n )\n \n # Modify if the shape of kv cahce is changed.\n@@ -74,7 +81,7 @@\n k,\n k_cache,\n block_tables,\n- context_lengths,\n+ kv_lengths,\n k.stride(0),\n k.stride(1),\n k.stride(2),\n", "issue": "[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n", "before_files": [{"content": "import torch\nimport triton\nimport triton.language as tl\n\n\n# Triton 2.1.0\[email protected]\ndef _copy_to_kvcache_seqlen1_kernel(\n KV, # K or V\n KVCache, # KCache or VCache\n BLOCK_TABLES,\n context_lengths,\n stride_kt,\n stride_kh,\n stride_kd,\n stride_cacheb,\n stride_cacheh,\n stride_cached,\n stride_cachebs,\n stride_bts,\n stride_btb,\n block_size,\n HEAD_DIM: tl.constexpr,\n):\n cur_seq_idx = tl.program_id(0)\n cur_kv_head_idx = tl.program_id(1)\n\n cur_kv_seq_len = tl.load(context_lengths + cur_seq_idx)\n last_bt_block_idx = cur_kv_seq_len // block_size\n block_table_ptr = BLOCK_TABLES + cur_seq_idx * stride_bts\n block_id = tl.load(block_table_ptr + last_bt_block_idx * stride_btb)\n offsets_in_last_block = (cur_kv_seq_len % block_size) * stride_cachebs\n offsets_dmodel = tl.arange(0, HEAD_DIM)\n offsets_kv = cur_seq_idx * stride_kt + cur_kv_head_idx * stride_kh + offsets_dmodel * stride_kd\n kv = tl.load(KV + offsets_kv)\n offsets_kvcache = (\n block_id * stride_cacheb\n + cur_kv_head_idx * stride_cacheh\n + offsets_dmodel * stride_cached\n + offsets_in_last_block\n )\n tl.store(KVCache + offsets_kvcache, kv)\n return\n\n\n# Used with blocked kv cache.\n# Copy k or v to block k/v cache during decoding stage\ndef copy_kv_to_blocked_cache(\n k: torch.Tensor, # [bsz, 1, num_kv_heads, head_dim], k or v during decoding stage\n k_cache: torch.Tensor, # [num_blocks, num_kv_heads, head_dim, block_size], blocked k or v cache (for now, the shapes of them are the same)\n context_lengths: torch.Tensor, # [bsz], past kv seq len (not incorporating the current kv of length 1)\n block_tables: torch.Tensor, # [bsz, max_blocks_per_sequence]\n):\n assert k.dim() == 4, \"Unsupported shape of k (supposed to be used for decoding stage)\"\n assert k.size(1) == 1, \"Unsupported kv seq len (supposed to be used for decoding stage)\"\n assert k.size(-1) == k_cache.size(-2), \"Incompatible head dim\"\n assert k.dtype == k_cache.dtype, \"Expected consistent dtype for tensor and cache.\"\n bsz, _, num_kv_heads, head_dim = k.shape\n assert context_lengths.shape[0] == block_tables.shape[0] == bsz, (\n f\"Got incompatible batch size (number of seqs):\\n\"\n f\" Conext lengths bsz {context_lengths.shape[0]}, Block tables bsz {block_tables.shape[0]}, \"\n f\"batch size {bsz}\"\n )\n\n # Modify if the shape of kv cahce is changed.\n block_size = k_cache.size(-1)\n # [bsz, 1, num_kv_heads, head_dim] -> [bsz, num_kv_heads, head_dim]\n k = k.squeeze(dim=1)\n\n num_warps = 8 if head_dim > 128 else 4\n\n grid = (bsz, num_kv_heads)\n _copy_to_kvcache_seqlen1_kernel[grid](\n k,\n k_cache,\n block_tables,\n context_lengths,\n k.stride(0),\n k.stride(1),\n k.stride(2),\n k_cache.stride(0),\n k_cache.stride(1),\n k_cache.stride(2),\n k_cache.stride(3),\n block_tables.stride(0),\n block_tables.stride(1),\n block_size,\n HEAD_DIM=head_dim,\n num_warps=num_warps,\n )\n", "path": "colossalai/kernel/triton/kvcache_copy.py"}]}
| 1,625 | 948 |
gh_patches_debug_20577
|
rasdani/github-patches
|
git_diff
|
great-expectations__great_expectations-3194
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Use cleaner solution for non-truncating division in python 2
Prefer `from __future__ import division` to `1.*x/y`
</issue>
<code>
[start of great_expectations/datasource/data_connector/configured_asset_s3_data_connector.py]
1 import logging
2 import os
3 from typing import List, Optional
4
5 try:
6 import boto3
7 except ImportError:
8 boto3 = None
9
10 from great_expectations.core.batch import BatchDefinition
11 from great_expectations.core.batch_spec import PathBatchSpec, S3BatchSpec
12 from great_expectations.datasource.data_connector import (
13 ConfiguredAssetFilePathDataConnector,
14 )
15 from great_expectations.datasource.data_connector.asset import Asset
16 from great_expectations.datasource.data_connector.util import list_s3_keys
17 from great_expectations.execution_engine import ExecutionEngine
18
19 logger = logging.getLogger(__name__)
20
21
22 class ConfiguredAssetS3DataConnector(ConfiguredAssetFilePathDataConnector):
23 """
24 Extension of ConfiguredAssetFilePathDataConnector used to connect to S3
25
26 DataConnectors produce identifying information, called "batch_spec" that ExecutionEngines
27 can use to get individual batches of data. They add flexibility in how to obtain data
28 such as with time-based partitioning, downsampling, or other techniques appropriate
29 for the Datasource.
30
31 The ConfiguredAssetS3DataConnector is one of two classes (InferredAssetS3DataConnector being the
32 other one) designed for connecting to data on S3.
33
34 A ConfiguredAssetS3DataConnector requires an explicit listing of each DataAsset you want to connect to.
35 This allows more fine-tuning, but also requires more setup.
36 """
37
38 def __init__(
39 self,
40 name: str,
41 datasource_name: str,
42 bucket: str,
43 assets: dict,
44 execution_engine: Optional[ExecutionEngine] = None,
45 default_regex: Optional[dict] = None,
46 sorters: Optional[list] = None,
47 prefix: Optional[str] = "",
48 delimiter: Optional[str] = "/",
49 max_keys: Optional[int] = 1000,
50 boto3_options: Optional[dict] = None,
51 batch_spec_passthrough: Optional[dict] = None,
52 ):
53 """
54 ConfiguredAssetDataConnector for connecting to S3.
55
56 Args:
57 name (str): required name for DataConnector
58 datasource_name (str): required name for datasource
59 bucket (str): bucket for S3
60 assets (dict): dict of asset configuration (required for ConfiguredAssetDataConnector)
61 execution_engine (ExecutionEngine): optional reference to ExecutionEngine
62 default_regex (dict): optional regex configuration for filtering data_references
63 sorters (list): optional list of sorters for sorting data_references
64 prefix (str): S3 prefix
65 delimiter (str): S3 delimiter
66 max_keys (int): S3 max_keys (default is 1000)
67 boto3_options (dict): optional boto3 options
68 batch_spec_passthrough (dict): dictionary with keys that will be added directly to batch_spec
69 """
70 logger.debug(f'Constructing ConfiguredAssetS3DataConnector "{name}".')
71
72 super().__init__(
73 name=name,
74 datasource_name=datasource_name,
75 execution_engine=execution_engine,
76 assets=assets,
77 default_regex=default_regex,
78 sorters=sorters,
79 batch_spec_passthrough=batch_spec_passthrough,
80 )
81 self._bucket = bucket
82 self._prefix = os.path.join(prefix, "")
83 self._delimiter = delimiter
84 self._max_keys = max_keys
85
86 if boto3_options is None:
87 boto3_options = {}
88
89 try:
90 self._s3 = boto3.client("s3", **boto3_options)
91 except (TypeError, AttributeError):
92 raise ImportError(
93 "Unable to load boto3 (it is required for ConfiguredAssetS3DataConnector)."
94 )
95
96 def build_batch_spec(self, batch_definition: BatchDefinition) -> S3BatchSpec:
97 """
98 Build BatchSpec from batch_definition by calling DataConnector's build_batch_spec function.
99
100 Args:
101 batch_definition (BatchDefinition): to be used to build batch_spec
102
103 Returns:
104 BatchSpec built from batch_definition
105 """
106 batch_spec: PathBatchSpec = super().build_batch_spec(
107 batch_definition=batch_definition
108 )
109 return S3BatchSpec(batch_spec)
110
111 def _get_data_reference_list_for_asset(self, asset: Optional[Asset]) -> List[str]:
112 query_options: dict = {
113 "Bucket": self._bucket,
114 "Prefix": self._prefix,
115 "Delimiter": self._delimiter,
116 "MaxKeys": self._max_keys,
117 }
118 if asset is not None:
119 if asset.bucket:
120 query_options["Bucket"] = asset.bucket
121 if asset.prefix:
122 query_options["Prefix"] = asset.prefix
123 if asset.delimiter:
124 query_options["Delimiter"] = asset.delimiter
125 if asset.max_keys:
126 query_options["MaxKeys"] = asset.max_keys
127
128 path_list: List[str] = [
129 key
130 for key in list_s3_keys(
131 s3=self._s3,
132 query_options=query_options,
133 iterator_dict={},
134 recursive=False,
135 )
136 ]
137 return path_list
138
139 def _get_full_file_path(
140 self,
141 path: str,
142 data_asset_name: Optional[str] = None,
143 ) -> str:
144 # data_assert_name isn't used in this method.
145 # It's only kept for compatibility with parent methods.
146 return f"s3a://{os.path.join(self._bucket, path)}"
147
[end of great_expectations/datasource/data_connector/configured_asset_s3_data_connector.py]
[start of great_expectations/datasource/data_connector/inferred_asset_s3_data_connector.py]
1 import logging
2 import os
3 from typing import List, Optional
4
5 from great_expectations.core.batch import BatchDefinition
6 from great_expectations.core.batch_spec import PathBatchSpec, S3BatchSpec
7 from great_expectations.exceptions.exceptions import ParserError
8
9 try:
10 import boto3
11 except ImportError:
12 boto3 = None
13
14 from great_expectations.datasource.data_connector import (
15 InferredAssetFilePathDataConnector,
16 )
17 from great_expectations.datasource.data_connector.util import list_s3_keys
18 from great_expectations.execution_engine import ExecutionEngine
19
20 logger = logging.getLogger(__name__)
21
22 INVALID_S3_CHARS = ["*"]
23
24
25 class InferredAssetS3DataConnector(InferredAssetFilePathDataConnector):
26 """
27 Extension of InferredAssetFilePathDataConnector used to connect to S3
28
29 The InferredAssetS3DataConnector is one of two classes (ConfiguredAssetS3DataConnector being the
30 other one) designed for connecting to filesystem-like data, more specifically files on S3. It connects to assets
31 inferred from bucket, prefix, and file name by default_regex.
32
33 InferredAssetS3DataConnector that operates on S3 buckets and determines
34 the data_asset_name implicitly (e.g., through the combination of the regular expressions pattern and group names)
35
36 """
37
38 def __init__(
39 self,
40 name: str,
41 datasource_name: str,
42 bucket: str,
43 execution_engine: Optional[ExecutionEngine] = None,
44 default_regex: Optional[dict] = None,
45 sorters: Optional[list] = None,
46 prefix: Optional[str] = "",
47 delimiter: Optional[str] = "/",
48 max_keys: Optional[int] = 1000,
49 boto3_options: Optional[dict] = None,
50 batch_spec_passthrough: Optional[dict] = None,
51 ):
52 """
53 InferredAssetS3DataConnector for connecting to S3.
54
55 Args:
56 name (str): required name for data_connector
57 datasource_name (str): required name for datasource
58 bucket (str): bucket for S3
59 execution_engine (ExecutionEngine): optional reference to ExecutionEngine
60 default_regex (dict): optional regex configuration for filtering data_references
61 sorters (list): optional list of sorters for sorting data_references
62 prefix (str): S3 prefix
63 delimiter (str): S3 delimiter
64 max_keys (int): S3 max_keys (default is 1000)
65 boto3_options (dict): optional boto3 options
66 batch_spec_passthrough (dict): dictionary with keys that will be added directly to batch_spec
67 """
68 logger.debug(f'Constructing InferredAssetS3DataConnector "{name}".')
69
70 super().__init__(
71 name=name,
72 datasource_name=datasource_name,
73 execution_engine=execution_engine,
74 default_regex=default_regex,
75 sorters=sorters,
76 batch_spec_passthrough=batch_spec_passthrough,
77 )
78
79 self._bucket = bucket
80 self._prefix = os.path.join(prefix, "")
81 self._delimiter = delimiter
82 self._max_keys = max_keys
83
84 if boto3_options is None:
85 boto3_options = {}
86
87 try:
88 self._s3 = boto3.client("s3", **boto3_options)
89 except (TypeError, AttributeError):
90 raise ImportError(
91 "Unable to load boto3 (it is required for InferredAssetS3DataConnector)."
92 )
93
94 def build_batch_spec(self, batch_definition: BatchDefinition) -> S3BatchSpec:
95 """
96 Build BatchSpec from batch_definition by calling DataConnector's build_batch_spec function.
97
98 Args:
99 batch_definition (BatchDefinition): to be used to build batch_spec
100
101 Returns:
102 BatchSpec built from batch_definition
103 """
104 batch_spec: PathBatchSpec = super().build_batch_spec(
105 batch_definition=batch_definition
106 )
107 return S3BatchSpec(batch_spec)
108
109 def _get_data_reference_list(
110 self, data_asset_name: Optional[str] = None
111 ) -> List[str]:
112 """
113 List objects in the underlying data store to create a list of data_references.
114
115 This method is used to refresh the cache.
116 """
117 query_options: dict = {
118 "Bucket": self._bucket,
119 "Prefix": self._prefix,
120 "Delimiter": self._delimiter,
121 "MaxKeys": self._max_keys,
122 }
123
124 path_list: List[str] = [
125 key
126 for key in list_s3_keys(
127 s3=self._s3,
128 query_options=query_options,
129 iterator_dict={},
130 recursive=True,
131 )
132 ]
133 return path_list
134
135 def _get_full_file_path(
136 self,
137 path: str,
138 data_asset_name: Optional[str] = None,
139 ) -> str:
140 # data_assert_name isn't used in this method.
141 # It's only kept for compatibility with parent methods.
142 _check_valid_s3_path(path)
143 return f"s3a://{os.path.join(self._bucket, path)}"
144
145
146 def _check_valid_s3_path(
147 path: str,
148 ) -> None:
149 """Performs a basic check for validity of the S3 path"""
150 bad_chars = [c for c in INVALID_S3_CHARS if c in path]
151 if len(bad_chars) > 0:
152 msg = (
153 f"The parsed S3 path={path} contains the invalid characters {bad_chars}."
154 "Please make sure your regex is correct and characters are escaped."
155 )
156 if "*" in bad_chars:
157 msg += "Note: `*` is internally used to replace the regex for `.`."
158 raise ParserError(msg)
159
[end of great_expectations/datasource/data_connector/inferred_asset_s3_data_connector.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/great_expectations/datasource/data_connector/configured_asset_s3_data_connector.py b/great_expectations/datasource/data_connector/configured_asset_s3_data_connector.py
--- a/great_expectations/datasource/data_connector/configured_asset_s3_data_connector.py
+++ b/great_expectations/datasource/data_connector/configured_asset_s3_data_connector.py
@@ -141,6 +141,6 @@
path: str,
data_asset_name: Optional[str] = None,
) -> str:
- # data_assert_name isn't used in this method.
+ # data_asset_name isn't used in this method.
# It's only kept for compatibility with parent methods.
return f"s3a://{os.path.join(self._bucket, path)}"
diff --git a/great_expectations/datasource/data_connector/inferred_asset_s3_data_connector.py b/great_expectations/datasource/data_connector/inferred_asset_s3_data_connector.py
--- a/great_expectations/datasource/data_connector/inferred_asset_s3_data_connector.py
+++ b/great_expectations/datasource/data_connector/inferred_asset_s3_data_connector.py
@@ -137,7 +137,7 @@
path: str,
data_asset_name: Optional[str] = None,
) -> str:
- # data_assert_name isn't used in this method.
+ # data_asset_name isn't used in this method.
# It's only kept for compatibility with parent methods.
_check_valid_s3_path(path)
return f"s3a://{os.path.join(self._bucket, path)}"
|
{"golden_diff": "diff --git a/great_expectations/datasource/data_connector/configured_asset_s3_data_connector.py b/great_expectations/datasource/data_connector/configured_asset_s3_data_connector.py\n--- a/great_expectations/datasource/data_connector/configured_asset_s3_data_connector.py\n+++ b/great_expectations/datasource/data_connector/configured_asset_s3_data_connector.py\n@@ -141,6 +141,6 @@\n path: str,\n data_asset_name: Optional[str] = None,\n ) -> str:\n- # data_assert_name isn't used in this method.\n+ # data_asset_name isn't used in this method.\n # It's only kept for compatibility with parent methods.\n return f\"s3a://{os.path.join(self._bucket, path)}\"\ndiff --git a/great_expectations/datasource/data_connector/inferred_asset_s3_data_connector.py b/great_expectations/datasource/data_connector/inferred_asset_s3_data_connector.py\n--- a/great_expectations/datasource/data_connector/inferred_asset_s3_data_connector.py\n+++ b/great_expectations/datasource/data_connector/inferred_asset_s3_data_connector.py\n@@ -137,7 +137,7 @@\n path: str,\n data_asset_name: Optional[str] = None,\n ) -> str:\n- # data_assert_name isn't used in this method.\n+ # data_asset_name isn't used in this method.\n # It's only kept for compatibility with parent methods.\n _check_valid_s3_path(path)\n return f\"s3a://{os.path.join(self._bucket, path)}\"\n", "issue": "Use cleaner solution for non-truncating division in python 2\nPrefer `from __future__ import division` to `1.*x/y`\n", "before_files": [{"content": "import logging\nimport os\nfrom typing import List, Optional\n\ntry:\n import boto3\nexcept ImportError:\n boto3 = None\n\nfrom great_expectations.core.batch import BatchDefinition\nfrom great_expectations.core.batch_spec import PathBatchSpec, S3BatchSpec\nfrom great_expectations.datasource.data_connector import (\n ConfiguredAssetFilePathDataConnector,\n)\nfrom great_expectations.datasource.data_connector.asset import Asset\nfrom great_expectations.datasource.data_connector.util import list_s3_keys\nfrom great_expectations.execution_engine import ExecutionEngine\n\nlogger = logging.getLogger(__name__)\n\n\nclass ConfiguredAssetS3DataConnector(ConfiguredAssetFilePathDataConnector):\n \"\"\"\n Extension of ConfiguredAssetFilePathDataConnector used to connect to S3\n\n DataConnectors produce identifying information, called \"batch_spec\" that ExecutionEngines\n can use to get individual batches of data. They add flexibility in how to obtain data\n such as with time-based partitioning, downsampling, or other techniques appropriate\n for the Datasource.\n\n The ConfiguredAssetS3DataConnector is one of two classes (InferredAssetS3DataConnector being the\n other one) designed for connecting to data on S3.\n\n A ConfiguredAssetS3DataConnector requires an explicit listing of each DataAsset you want to connect to.\n This allows more fine-tuning, but also requires more setup.\n \"\"\"\n\n def __init__(\n self,\n name: str,\n datasource_name: str,\n bucket: str,\n assets: dict,\n execution_engine: Optional[ExecutionEngine] = None,\n default_regex: Optional[dict] = None,\n sorters: Optional[list] = None,\n prefix: Optional[str] = \"\",\n delimiter: Optional[str] = \"/\",\n max_keys: Optional[int] = 1000,\n boto3_options: Optional[dict] = None,\n batch_spec_passthrough: Optional[dict] = None,\n ):\n \"\"\"\n ConfiguredAssetDataConnector for connecting to S3.\n\n Args:\n name (str): required name for DataConnector\n datasource_name (str): required name for datasource\n bucket (str): bucket for S3\n assets (dict): dict of asset configuration (required for ConfiguredAssetDataConnector)\n execution_engine (ExecutionEngine): optional reference to ExecutionEngine\n default_regex (dict): optional regex configuration for filtering data_references\n sorters (list): optional list of sorters for sorting data_references\n prefix (str): S3 prefix\n delimiter (str): S3 delimiter\n max_keys (int): S3 max_keys (default is 1000)\n boto3_options (dict): optional boto3 options\n batch_spec_passthrough (dict): dictionary with keys that will be added directly to batch_spec\n \"\"\"\n logger.debug(f'Constructing ConfiguredAssetS3DataConnector \"{name}\".')\n\n super().__init__(\n name=name,\n datasource_name=datasource_name,\n execution_engine=execution_engine,\n assets=assets,\n default_regex=default_regex,\n sorters=sorters,\n batch_spec_passthrough=batch_spec_passthrough,\n )\n self._bucket = bucket\n self._prefix = os.path.join(prefix, \"\")\n self._delimiter = delimiter\n self._max_keys = max_keys\n\n if boto3_options is None:\n boto3_options = {}\n\n try:\n self._s3 = boto3.client(\"s3\", **boto3_options)\n except (TypeError, AttributeError):\n raise ImportError(\n \"Unable to load boto3 (it is required for ConfiguredAssetS3DataConnector).\"\n )\n\n def build_batch_spec(self, batch_definition: BatchDefinition) -> S3BatchSpec:\n \"\"\"\n Build BatchSpec from batch_definition by calling DataConnector's build_batch_spec function.\n\n Args:\n batch_definition (BatchDefinition): to be used to build batch_spec\n\n Returns:\n BatchSpec built from batch_definition\n \"\"\"\n batch_spec: PathBatchSpec = super().build_batch_spec(\n batch_definition=batch_definition\n )\n return S3BatchSpec(batch_spec)\n\n def _get_data_reference_list_for_asset(self, asset: Optional[Asset]) -> List[str]:\n query_options: dict = {\n \"Bucket\": self._bucket,\n \"Prefix\": self._prefix,\n \"Delimiter\": self._delimiter,\n \"MaxKeys\": self._max_keys,\n }\n if asset is not None:\n if asset.bucket:\n query_options[\"Bucket\"] = asset.bucket\n if asset.prefix:\n query_options[\"Prefix\"] = asset.prefix\n if asset.delimiter:\n query_options[\"Delimiter\"] = asset.delimiter\n if asset.max_keys:\n query_options[\"MaxKeys\"] = asset.max_keys\n\n path_list: List[str] = [\n key\n for key in list_s3_keys(\n s3=self._s3,\n query_options=query_options,\n iterator_dict={},\n recursive=False,\n )\n ]\n return path_list\n\n def _get_full_file_path(\n self,\n path: str,\n data_asset_name: Optional[str] = None,\n ) -> str:\n # data_assert_name isn't used in this method.\n # It's only kept for compatibility with parent methods.\n return f\"s3a://{os.path.join(self._bucket, path)}\"\n", "path": "great_expectations/datasource/data_connector/configured_asset_s3_data_connector.py"}, {"content": "import logging\nimport os\nfrom typing import List, Optional\n\nfrom great_expectations.core.batch import BatchDefinition\nfrom great_expectations.core.batch_spec import PathBatchSpec, S3BatchSpec\nfrom great_expectations.exceptions.exceptions import ParserError\n\ntry:\n import boto3\nexcept ImportError:\n boto3 = None\n\nfrom great_expectations.datasource.data_connector import (\n InferredAssetFilePathDataConnector,\n)\nfrom great_expectations.datasource.data_connector.util import list_s3_keys\nfrom great_expectations.execution_engine import ExecutionEngine\n\nlogger = logging.getLogger(__name__)\n\nINVALID_S3_CHARS = [\"*\"]\n\n\nclass InferredAssetS3DataConnector(InferredAssetFilePathDataConnector):\n \"\"\"\n Extension of InferredAssetFilePathDataConnector used to connect to S3\n\n The InferredAssetS3DataConnector is one of two classes (ConfiguredAssetS3DataConnector being the\n other one) designed for connecting to filesystem-like data, more specifically files on S3. It connects to assets\n inferred from bucket, prefix, and file name by default_regex.\n\n InferredAssetS3DataConnector that operates on S3 buckets and determines\n the data_asset_name implicitly (e.g., through the combination of the regular expressions pattern and group names)\n\n \"\"\"\n\n def __init__(\n self,\n name: str,\n datasource_name: str,\n bucket: str,\n execution_engine: Optional[ExecutionEngine] = None,\n default_regex: Optional[dict] = None,\n sorters: Optional[list] = None,\n prefix: Optional[str] = \"\",\n delimiter: Optional[str] = \"/\",\n max_keys: Optional[int] = 1000,\n boto3_options: Optional[dict] = None,\n batch_spec_passthrough: Optional[dict] = None,\n ):\n \"\"\"\n InferredAssetS3DataConnector for connecting to S3.\n\n Args:\n name (str): required name for data_connector\n datasource_name (str): required name for datasource\n bucket (str): bucket for S3\n execution_engine (ExecutionEngine): optional reference to ExecutionEngine\n default_regex (dict): optional regex configuration for filtering data_references\n sorters (list): optional list of sorters for sorting data_references\n prefix (str): S3 prefix\n delimiter (str): S3 delimiter\n max_keys (int): S3 max_keys (default is 1000)\n boto3_options (dict): optional boto3 options\n batch_spec_passthrough (dict): dictionary with keys that will be added directly to batch_spec\n \"\"\"\n logger.debug(f'Constructing InferredAssetS3DataConnector \"{name}\".')\n\n super().__init__(\n name=name,\n datasource_name=datasource_name,\n execution_engine=execution_engine,\n default_regex=default_regex,\n sorters=sorters,\n batch_spec_passthrough=batch_spec_passthrough,\n )\n\n self._bucket = bucket\n self._prefix = os.path.join(prefix, \"\")\n self._delimiter = delimiter\n self._max_keys = max_keys\n\n if boto3_options is None:\n boto3_options = {}\n\n try:\n self._s3 = boto3.client(\"s3\", **boto3_options)\n except (TypeError, AttributeError):\n raise ImportError(\n \"Unable to load boto3 (it is required for InferredAssetS3DataConnector).\"\n )\n\n def build_batch_spec(self, batch_definition: BatchDefinition) -> S3BatchSpec:\n \"\"\"\n Build BatchSpec from batch_definition by calling DataConnector's build_batch_spec function.\n\n Args:\n batch_definition (BatchDefinition): to be used to build batch_spec\n\n Returns:\n BatchSpec built from batch_definition\n \"\"\"\n batch_spec: PathBatchSpec = super().build_batch_spec(\n batch_definition=batch_definition\n )\n return S3BatchSpec(batch_spec)\n\n def _get_data_reference_list(\n self, data_asset_name: Optional[str] = None\n ) -> List[str]:\n \"\"\"\n List objects in the underlying data store to create a list of data_references.\n\n This method is used to refresh the cache.\n \"\"\"\n query_options: dict = {\n \"Bucket\": self._bucket,\n \"Prefix\": self._prefix,\n \"Delimiter\": self._delimiter,\n \"MaxKeys\": self._max_keys,\n }\n\n path_list: List[str] = [\n key\n for key in list_s3_keys(\n s3=self._s3,\n query_options=query_options,\n iterator_dict={},\n recursive=True,\n )\n ]\n return path_list\n\n def _get_full_file_path(\n self,\n path: str,\n data_asset_name: Optional[str] = None,\n ) -> str:\n # data_assert_name isn't used in this method.\n # It's only kept for compatibility with parent methods.\n _check_valid_s3_path(path)\n return f\"s3a://{os.path.join(self._bucket, path)}\"\n\n\ndef _check_valid_s3_path(\n path: str,\n) -> None:\n \"\"\"Performs a basic check for validity of the S3 path\"\"\"\n bad_chars = [c for c in INVALID_S3_CHARS if c in path]\n if len(bad_chars) > 0:\n msg = (\n f\"The parsed S3 path={path} contains the invalid characters {bad_chars}.\"\n \"Please make sure your regex is correct and characters are escaped.\"\n )\n if \"*\" in bad_chars:\n msg += \"Note: `*` is internally used to replace the regex for `.`.\"\n raise ParserError(msg)\n", "path": "great_expectations/datasource/data_connector/inferred_asset_s3_data_connector.py"}]}
| 3,676 | 347 |
gh_patches_debug_14637
|
rasdani/github-patches
|
git_diff
|
googleapis__google-auth-library-python-124
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add public properties to google.oauth2.credentials.Credentials
Resolves #124
</issue>
<code>
[start of google/oauth2/credentials.py]
1 # Copyright 2016 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """OAuth 2.0 Credentials.
16
17 This module provides credentials based on OAuth 2.0 access and refresh tokens.
18 These credentials usually access resources on behalf of a user (resource
19 owner).
20
21 Specifically, this is intended to use access tokens acquired using the
22 `Authorization Code grant`_ and can refresh those tokens using a
23 optional `refresh token`_.
24
25 Obtaining the initial access and refresh token is outside of the scope of this
26 module. Consult `rfc6749 section 4.1`_ for complete details on the
27 Authorization Code grant flow.
28
29 .. _Authorization Code grant: https://tools.ietf.org/html/rfc6749#section-1.3.1
30 .. _refresh token: https://tools.ietf.org/html/rfc6749#section-6
31 .. _rfc6749 section 4.1: https://tools.ietf.org/html/rfc6749#section-4.1
32 """
33
34 from google.auth import _helpers
35 from google.auth import credentials
36 from google.oauth2 import _client
37
38
39 class Credentials(credentials.Scoped, credentials.Credentials):
40 """Credentials using OAuth 2.0 access and refresh tokens."""
41
42 def __init__(self, token, refresh_token=None, token_uri=None,
43 client_id=None, client_secret=None, scopes=None):
44 """
45 Args:
46 token (Optional(str)): The OAuth 2.0 access token. Can be None
47 if refresh information is provided.
48 refresh_token (str): The OAuth 2.0 refresh token. If specified,
49 credentials can be refreshed.
50 token_uri (str): The OAuth 2.0 authorization server's token
51 endpoint URI. Must be specified for refresh, can be left as
52 None if the token can not be refreshed.
53 client_id (str): The OAuth 2.0 client ID. Must be specified for
54 refresh, can be left as None if the token can not be refreshed.
55 client_secret(str): The OAuth 2.0 client secret. Must be specified
56 for refresh, can be left as None if the token can not be
57 refreshed.
58 scopes (Sequence[str]): The scopes that were originally used
59 to obtain authorization. This is a purely informative parameter
60 that can be used by :meth:`has_scopes`. OAuth 2.0 credentials
61 can not request additional scopes after authorization.
62 """
63 super(Credentials, self).__init__()
64 self.token = token
65 self._refresh_token = refresh_token
66 self._scopes = scopes
67 self._token_uri = token_uri
68 self._client_id = client_id
69 self._client_secret = client_secret
70
71 @property
72 def requires_scopes(self):
73 """False: OAuth 2.0 credentials have their scopes set when
74 the initial token is requested and can not be changed."""
75 return False
76
77 def with_scopes(self, scopes):
78 """Unavailable, OAuth 2.0 credentials can not be re-scoped.
79
80 OAuth 2.0 credentials have their scopes set when the initial token is
81 requested and can not be changed.
82 """
83 raise NotImplementedError(
84 'OAuth 2.0 Credentials can not modify their scopes.')
85
86 @_helpers.copy_docstring(credentials.Credentials)
87 def refresh(self, request):
88 access_token, refresh_token, expiry, _ = _client.refresh_grant(
89 request, self._token_uri, self._refresh_token, self._client_id,
90 self._client_secret)
91
92 self.token = access_token
93 self.expiry = expiry
94 self._refresh_token = refresh_token
95
[end of google/oauth2/credentials.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/google/oauth2/credentials.py b/google/oauth2/credentials.py
--- a/google/oauth2/credentials.py
+++ b/google/oauth2/credentials.py
@@ -68,6 +68,27 @@
self._client_id = client_id
self._client_secret = client_secret
+ @property
+ def refresh_token(self):
+ """Optional[str]: The OAuth 2.0 refresh token."""
+ return self._refresh_token
+
+ @property
+ def token_uri(self):
+ """Optional[str]: The OAuth 2.0 authorization server's token endpoint
+ URI."""
+ return self._token_uri
+
+ @property
+ def client_id(self):
+ """Optional[str]: The OAuth 2.0 client ID."""
+ return self._client_id
+
+ @property
+ def client_secret(self):
+ """Optional[str]: The OAuth 2.0 client secret."""
+ return self._client_secret
+
@property
def requires_scopes(self):
"""False: OAuth 2.0 credentials have their scopes set when
|
{"golden_diff": "diff --git a/google/oauth2/credentials.py b/google/oauth2/credentials.py\n--- a/google/oauth2/credentials.py\n+++ b/google/oauth2/credentials.py\n@@ -68,6 +68,27 @@\n self._client_id = client_id\n self._client_secret = client_secret\n \n+ @property\n+ def refresh_token(self):\n+ \"\"\"Optional[str]: The OAuth 2.0 refresh token.\"\"\"\n+ return self._refresh_token\n+\n+ @property\n+ def token_uri(self):\n+ \"\"\"Optional[str]: The OAuth 2.0 authorization server's token endpoint\n+ URI.\"\"\"\n+ return self._token_uri\n+\n+ @property\n+ def client_id(self):\n+ \"\"\"Optional[str]: The OAuth 2.0 client ID.\"\"\"\n+ return self._client_id\n+\n+ @property\n+ def client_secret(self):\n+ \"\"\"Optional[str]: The OAuth 2.0 client secret.\"\"\"\n+ return self._client_secret\n+\n @property\n def requires_scopes(self):\n \"\"\"False: OAuth 2.0 credentials have their scopes set when\n", "issue": "Add public properties to google.oauth2.credentials.Credentials\nResolves #124 \n", "before_files": [{"content": "# Copyright 2016 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"OAuth 2.0 Credentials.\n\nThis module provides credentials based on OAuth 2.0 access and refresh tokens.\nThese credentials usually access resources on behalf of a user (resource\nowner).\n\nSpecifically, this is intended to use access tokens acquired using the\n`Authorization Code grant`_ and can refresh those tokens using a\noptional `refresh token`_.\n\nObtaining the initial access and refresh token is outside of the scope of this\nmodule. Consult `rfc6749 section 4.1`_ for complete details on the\nAuthorization Code grant flow.\n\n.. _Authorization Code grant: https://tools.ietf.org/html/rfc6749#section-1.3.1\n.. _refresh token: https://tools.ietf.org/html/rfc6749#section-6\n.. _rfc6749 section 4.1: https://tools.ietf.org/html/rfc6749#section-4.1\n\"\"\"\n\nfrom google.auth import _helpers\nfrom google.auth import credentials\nfrom google.oauth2 import _client\n\n\nclass Credentials(credentials.Scoped, credentials.Credentials):\n \"\"\"Credentials using OAuth 2.0 access and refresh tokens.\"\"\"\n\n def __init__(self, token, refresh_token=None, token_uri=None,\n client_id=None, client_secret=None, scopes=None):\n \"\"\"\n Args:\n token (Optional(str)): The OAuth 2.0 access token. Can be None\n if refresh information is provided.\n refresh_token (str): The OAuth 2.0 refresh token. If specified,\n credentials can be refreshed.\n token_uri (str): The OAuth 2.0 authorization server's token\n endpoint URI. Must be specified for refresh, can be left as\n None if the token can not be refreshed.\n client_id (str): The OAuth 2.0 client ID. Must be specified for\n refresh, can be left as None if the token can not be refreshed.\n client_secret(str): The OAuth 2.0 client secret. Must be specified\n for refresh, can be left as None if the token can not be\n refreshed.\n scopes (Sequence[str]): The scopes that were originally used\n to obtain authorization. This is a purely informative parameter\n that can be used by :meth:`has_scopes`. OAuth 2.0 credentials\n can not request additional scopes after authorization.\n \"\"\"\n super(Credentials, self).__init__()\n self.token = token\n self._refresh_token = refresh_token\n self._scopes = scopes\n self._token_uri = token_uri\n self._client_id = client_id\n self._client_secret = client_secret\n\n @property\n def requires_scopes(self):\n \"\"\"False: OAuth 2.0 credentials have their scopes set when\n the initial token is requested and can not be changed.\"\"\"\n return False\n\n def with_scopes(self, scopes):\n \"\"\"Unavailable, OAuth 2.0 credentials can not be re-scoped.\n\n OAuth 2.0 credentials have their scopes set when the initial token is\n requested and can not be changed.\n \"\"\"\n raise NotImplementedError(\n 'OAuth 2.0 Credentials can not modify their scopes.')\n\n @_helpers.copy_docstring(credentials.Credentials)\n def refresh(self, request):\n access_token, refresh_token, expiry, _ = _client.refresh_grant(\n request, self._token_uri, self._refresh_token, self._client_id,\n self._client_secret)\n\n self.token = access_token\n self.expiry = expiry\n self._refresh_token = refresh_token\n", "path": "google/oauth2/credentials.py"}]}
| 1,633 | 245 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.