
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
18.9k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 465
23.6k
| num_tokens_prompt
int64 556
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_21757
|
rasdani/github-patches
|
git_diff
|
zestedesavoir__zds-site-3209
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Les derniers sujets suivis cette semaine ne le sont pas forcément.
A l'heure ou je poste cette issue, on est lundi et dans mes sujets suivis j'ai des sujets suivis de :
- aujourd'hui : normal
- hier (dimanche) : normal
- cette semaine : il y'a un problème de vocable ici. Car "cette semaine" à commencée en fait aujourd'hui. Le code lui veut plutôt parler des "7 derniers jours".
Donc j'ignore la bonne façon de faire ici ? renommer le "cette semaine" ou modifier le comportement pour n'avoir que ce qui s'est passé cette semaine ?
Mais dans tout les cas l'affichage ne correspond pas à la réalité. Au vu du code, le problème est aussi présent pour "Ce mois" qui devrait plutôt s'appeler "Les 30 derniers jours" pour être cohérent avec la réalité.
</issue>
<code>
[start of zds/utils/templatetags/interventions.py]
1 # coding: utf-8
2
3 from datetime import datetime, timedelta
4 import time
5
6 from django import template
7 from django.db.models import F
8
9 from zds.forum.models import TopicFollowed, never_read as never_read_topic, Post, TopicRead
10 from zds.mp.models import PrivateTopic
11
12 from zds.utils.models import Alert
13 from zds.tutorialv2.models.models_database import ContentRead, ContentReaction
14
15 register = template.Library()
16
17
18 @register.filter('is_read')
19 def is_read(topic):
20 if never_read_topic(topic):
21 return False
22 else:
23 return True
24
25
26 @register.filter('humane_delta')
27 def humane_delta(value):
28 # mapping between label day and key
29 const = {1: "Aujourd'hui", 2: "Hier", 3: "Cette semaine", 4: "Ce mois-ci", 5: "Cette année"}
30
31 return const[value]
32
33
34 @register.filter('followed_topics')
35 def followed_topics(user):
36 topicsfollowed = TopicFollowed.objects.select_related("topic").filter(user=user)\
37 .order_by('-topic__last_message__pubdate')[:10]
38 # This period is a map for link a moment (Today, yesterday, this week, this month, etc.) with
39 # the number of days for which we can say we're still in the period
40 # for exemple, the tuple (2, 1) means for the period "2" corresponding to "Yesterday" according
41 # to humane_delta, means if your pubdate hasn't exceeded one day, we are always at "Yesterday"
42 # Number is use for index for sort map easily
43 periods = ((1, 0), (2, 1), (3, 7), (4, 30), (5, 360))
44 topics = {}
45 for tfollowed in topicsfollowed:
46 for period in periods:
47 if tfollowed.topic.last_message.pubdate.date() >= (datetime.now() - timedelta(days=int(period[1]),
48 hours=0,
49 minutes=0,
50 seconds=0)).date():
51 if period[0] in topics:
52 topics[period[0]].append(tfollowed.topic)
53 else:
54 topics[period[0]] = [tfollowed.topic]
55 break
56 return topics
57
58
59 def comp(dated_element1, dated_element2):
60 version1 = int(time.mktime(dated_element1['pubdate'].timetuple()))
61 version2 = int(time.mktime(dated_element2['pubdate'].timetuple()))
62 if version1 > version2:
63 return -1
64 elif version1 < version2:
65 return 1
66 else:
67 return 0
68
69
70 @register.filter('interventions_topics')
71 def interventions_topics(user):
72 topicsfollowed = TopicFollowed.objects.filter(user=user).values("topic").distinct().all()
73
74 topics_never_read = TopicRead.objects\
75 .filter(user=user)\
76 .filter(topic__in=topicsfollowed)\
77 .select_related("topic")\
78 .exclude(post=F('topic__last_message')).all()
79
80 content_followed_pk = ContentReaction.objects\
81 .filter(author=user, related_content__public_version__isnull=False)\
82 .values_list('related_content__pk', flat=True)
83
84 content_to_read = ContentRead.objects\
85 .select_related('note')\
86 .select_related('note__author')\
87 .select_related('content')\
88 .select_related('note__related_content__public_version')\
89 .filter(user=user)\
90 .exclude(note__pk=F('content__last_note__pk')).all()
91
92 posts_unread = []
93
94 for top in topics_never_read:
95 content = top.topic.first_unread_post()
96 if content is None:
97 content = top.topic.last_message
98 posts_unread.append({'pubdate': content.pubdate,
99 'author': content.author,
100 'title': top.topic.title,
101 'url': content.get_absolute_url()})
102
103 for content_read in content_to_read:
104 content = content_read.content
105 if content.pk not in content_followed_pk and user not in content.authors.all():
106 continue
107 reaction = content.first_unread_note()
108 if reaction is None:
109 reaction = content.first_note()
110 if reaction is None:
111 continue
112 posts_unread.append({'pubdate': reaction.pubdate,
113 'author': reaction.author,
114 'title': content.title,
115 'url': reaction.get_absolute_url()})
116
117 posts_unread.sort(cmp=comp)
118
119 return posts_unread
120
121
122 @register.filter('interventions_privatetopics')
123 def interventions_privatetopics(user):
124
125 # Raw query because ORM doesn't seems to allow this kind of "left outer join" clauses.
126 # Parameters = list with 3x the same ID because SQLite backend doesn't allow map parameters.
127 privatetopics_unread = PrivateTopic.objects.raw(
128 '''
129 select distinct t.*
130 from mp_privatetopic t
131 left outer join mp_privatetopic_participants p on p.privatetopic_id = t.id
132 left outer join mp_privatetopicread r on r.user_id = %s and r.privatepost_id = t.last_message_id
133 where (t.author_id = %s or p.user_id = %s)
134 and r.id is null
135 order by t.pubdate desc''',
136 [user.id, user.id, user.id])
137
138 # "total" re-do the query, but there is no other way to get the length as __len__ is not available on raw queries.
139 topics = list(privatetopics_unread)
140 return {'unread': topics, 'total': len(topics)}
141
142
143 @register.filter(name='alerts_list')
144 def alerts_list(user):
145 total = []
146 alerts = Alert.objects.select_related('author', 'comment').all().order_by('-pubdate')[:10]
147 nb_alerts = Alert.objects.count()
148 for alert in alerts:
149 if alert.scope == Alert.FORUM:
150 post = Post.objects.select_related('topic').get(pk=alert.comment.pk)
151 total.append({'title': post.topic.title,
152 'url': post.get_absolute_url(),
153 'pubdate': alert.pubdate,
154 'author': alert.author,
155 'text': alert.text})
156
157 elif alert.scope == Alert.CONTENT:
158 note = ContentReaction.objects.select_related('related_content').get(pk=alert.comment.pk)
159 total.append({'title': note.related_content.title,
160 'url': note.get_absolute_url(),
161 'pubdate': alert.pubdate,
162 'author': alert.author,
163 'text': alert.text})
164
165 return {'alerts': total, 'nb_alerts': nb_alerts}
166
[end of zds/utils/templatetags/interventions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/zds/utils/templatetags/interventions.py b/zds/utils/templatetags/interventions.py
--- a/zds/utils/templatetags/interventions.py
+++ b/zds/utils/templatetags/interventions.py
@@ -5,10 +5,10 @@
from django import template
from django.db.models import F
+from django.utils.translation import ugettext_lazy as _
from zds.forum.models import TopicFollowed, never_read as never_read_topic, Post, TopicRead
from zds.mp.models import PrivateTopic
-
from zds.utils.models import Alert
from zds.tutorialv2.models.models_database import ContentRead, ContentReaction
@@ -25,8 +25,19 @@
@register.filter('humane_delta')
def humane_delta(value):
- # mapping between label day and key
- const = {1: "Aujourd'hui", 2: "Hier", 3: "Cette semaine", 4: "Ce mois-ci", 5: "Cette année"}
+ """
+ Mapping between label day and key
+
+ :param int value:
+ :return: string
+ """
+ const = {
+ 1: _("Aujourd'hui"),
+ 2: _("Hier"),
+ 3: _("Les 7 derniers jours"),
+ 4: _("Les 30 derniers jours"),
+ 5: _("Plus ancien")
+ }
return const[value]
|
{"golden_diff": "diff --git a/zds/utils/templatetags/interventions.py b/zds/utils/templatetags/interventions.py\n--- a/zds/utils/templatetags/interventions.py\n+++ b/zds/utils/templatetags/interventions.py\n@@ -5,10 +5,10 @@\n \n from django import template\n from django.db.models import F\n+from django.utils.translation import ugettext_lazy as _\n \n from zds.forum.models import TopicFollowed, never_read as never_read_topic, Post, TopicRead\n from zds.mp.models import PrivateTopic\n-\n from zds.utils.models import Alert\n from zds.tutorialv2.models.models_database import ContentRead, ContentReaction\n \n@@ -25,8 +25,19 @@\n \n @register.filter('humane_delta')\n def humane_delta(value):\n- # mapping between label day and key\n- const = {1: \"Aujourd'hui\", 2: \"Hier\", 3: \"Cette semaine\", 4: \"Ce mois-ci\", 5: \"Cette ann\u00e9e\"}\n+ \"\"\"\n+ Mapping between label day and key\n+\n+ :param int value:\n+ :return: string\n+ \"\"\"\n+ const = {\n+ 1: _(\"Aujourd'hui\"),\n+ 2: _(\"Hier\"),\n+ 3: _(\"Les 7 derniers jours\"),\n+ 4: _(\"Les 30 derniers jours\"),\n+ 5: _(\"Plus ancien\")\n+ }\n \n return const[value]\n", "issue": "Les derniers sujets suivis cette semaine ne le sont pas forc\u00e9ment.\nA l'heure ou je poste cette issue, on est lundi et dans mes sujets suivis j'ai des sujets suivis de : \n- aujourd'hui : normal\n- hier (dimanche) : normal\n- cette semaine : il y'a un probl\u00e8me de vocable ici. Car \"cette semaine\" \u00e0 commenc\u00e9e en fait aujourd'hui. Le code lui veut plut\u00f4t parler des \"7 derniers jours\".\n\nDonc j'ignore la bonne fa\u00e7on de faire ici ? renommer le \"cette semaine\" ou modifier le comportement pour n'avoir que ce qui s'est pass\u00e9 cette semaine ?\n\nMais dans tout les cas l'affichage ne correspond pas \u00e0 la r\u00e9alit\u00e9. Au vu du code, le probl\u00e8me est aussi pr\u00e9sent pour \"Ce mois\" qui devrait plut\u00f4t s'appeler \"Les 30 derniers jours\" pour \u00eatre coh\u00e9rent avec la r\u00e9alit\u00e9.\n\n", "before_files": [{"content": "# coding: utf-8\n\nfrom datetime import datetime, timedelta\nimport time\n\nfrom django import template\nfrom django.db.models import F\n\nfrom zds.forum.models import TopicFollowed, never_read as never_read_topic, Post, TopicRead\nfrom zds.mp.models import PrivateTopic\n\nfrom zds.utils.models import Alert\nfrom zds.tutorialv2.models.models_database import ContentRead, ContentReaction\n\nregister = template.Library()\n\n\[email protected]('is_read')\ndef is_read(topic):\n if never_read_topic(topic):\n return False\n else:\n return True\n\n\[email protected]('humane_delta')\ndef humane_delta(value):\n # mapping between label day and key\n const = {1: \"Aujourd'hui\", 2: \"Hier\", 3: \"Cette semaine\", 4: \"Ce mois-ci\", 5: \"Cette ann\u00e9e\"}\n\n return const[value]\n\n\[email protected]('followed_topics')\ndef followed_topics(user):\n topicsfollowed = TopicFollowed.objects.select_related(\"topic\").filter(user=user)\\\n .order_by('-topic__last_message__pubdate')[:10]\n # This period is a map for link a moment (Today, yesterday, this week, this month, etc.) with\n # the number of days for which we can say we're still in the period\n # for exemple, the tuple (2, 1) means for the period \"2\" corresponding to \"Yesterday\" according\n # to humane_delta, means if your pubdate hasn't exceeded one day, we are always at \"Yesterday\"\n # Number is use for index for sort map easily\n periods = ((1, 0), (2, 1), (3, 7), (4, 30), (5, 360))\n topics = {}\n for tfollowed in topicsfollowed:\n for period in periods:\n if tfollowed.topic.last_message.pubdate.date() >= (datetime.now() - timedelta(days=int(period[1]),\n hours=0,\n minutes=0,\n seconds=0)).date():\n if period[0] in topics:\n topics[period[0]].append(tfollowed.topic)\n else:\n topics[period[0]] = [tfollowed.topic]\n break\n return topics\n\n\ndef comp(dated_element1, dated_element2):\n version1 = int(time.mktime(dated_element1['pubdate'].timetuple()))\n version2 = int(time.mktime(dated_element2['pubdate'].timetuple()))\n if version1 > version2:\n return -1\n elif version1 < version2:\n return 1\n else:\n return 0\n\n\[email protected]('interventions_topics')\ndef interventions_topics(user):\n topicsfollowed = TopicFollowed.objects.filter(user=user).values(\"topic\").distinct().all()\n\n topics_never_read = TopicRead.objects\\\n .filter(user=user)\\\n .filter(topic__in=topicsfollowed)\\\n .select_related(\"topic\")\\\n .exclude(post=F('topic__last_message')).all()\n\n content_followed_pk = ContentReaction.objects\\\n .filter(author=user, related_content__public_version__isnull=False)\\\n .values_list('related_content__pk', flat=True)\n\n content_to_read = ContentRead.objects\\\n .select_related('note')\\\n .select_related('note__author')\\\n .select_related('content')\\\n .select_related('note__related_content__public_version')\\\n .filter(user=user)\\\n .exclude(note__pk=F('content__last_note__pk')).all()\n\n posts_unread = []\n\n for top in topics_never_read:\n content = top.topic.first_unread_post()\n if content is None:\n content = top.topic.last_message\n posts_unread.append({'pubdate': content.pubdate,\n 'author': content.author,\n 'title': top.topic.title,\n 'url': content.get_absolute_url()})\n\n for content_read in content_to_read:\n content = content_read.content\n if content.pk not in content_followed_pk and user not in content.authors.all():\n continue\n reaction = content.first_unread_note()\n if reaction is None:\n reaction = content.first_note()\n if reaction is None:\n continue\n posts_unread.append({'pubdate': reaction.pubdate,\n 'author': reaction.author,\n 'title': content.title,\n 'url': reaction.get_absolute_url()})\n\n posts_unread.sort(cmp=comp)\n\n return posts_unread\n\n\[email protected]('interventions_privatetopics')\ndef interventions_privatetopics(user):\n\n # Raw query because ORM doesn't seems to allow this kind of \"left outer join\" clauses.\n # Parameters = list with 3x the same ID because SQLite backend doesn't allow map parameters.\n privatetopics_unread = PrivateTopic.objects.raw(\n '''\n select distinct t.*\n from mp_privatetopic t\n left outer join mp_privatetopic_participants p on p.privatetopic_id = t.id\n left outer join mp_privatetopicread r on r.user_id = %s and r.privatepost_id = t.last_message_id\n where (t.author_id = %s or p.user_id = %s)\n and r.id is null\n order by t.pubdate desc''',\n [user.id, user.id, user.id])\n\n # \"total\" re-do the query, but there is no other way to get the length as __len__ is not available on raw queries.\n topics = list(privatetopics_unread)\n return {'unread': topics, 'total': len(topics)}\n\n\[email protected](name='alerts_list')\ndef alerts_list(user):\n total = []\n alerts = Alert.objects.select_related('author', 'comment').all().order_by('-pubdate')[:10]\n nb_alerts = Alert.objects.count()\n for alert in alerts:\n if alert.scope == Alert.FORUM:\n post = Post.objects.select_related('topic').get(pk=alert.comment.pk)\n total.append({'title': post.topic.title,\n 'url': post.get_absolute_url(),\n 'pubdate': alert.pubdate,\n 'author': alert.author,\n 'text': alert.text})\n\n elif alert.scope == Alert.CONTENT:\n note = ContentReaction.objects.select_related('related_content').get(pk=alert.comment.pk)\n total.append({'title': note.related_content.title,\n 'url': note.get_absolute_url(),\n 'pubdate': alert.pubdate,\n 'author': alert.author,\n 'text': alert.text})\n\n return {'alerts': total, 'nb_alerts': nb_alerts}\n", "path": "zds/utils/templatetags/interventions.py"}]}
| 2,591 | 333 |
gh_patches_debug_16231
|
rasdani/github-patches
|
git_diff
|
ytdl-org__youtube-dl-28074
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
urplay
<!--
######################################################################
WARNING!
IGNORING THE FOLLOWING TEMPLATE WILL RESULT IN ISSUE CLOSED AS INCOMPLETE
######################################################################
-->
## Checklist
<!--
Carefully read and work through this check list in order to prevent the most common mistakes and misuse of youtube-dl:
- First of, make sure you are using the latest version of youtube-dl. Run `youtube-dl --version` and ensure your version is 2021.02.04.1. If it's not, see https://yt-dl.org/update on how to update. Issues with outdated version will be REJECTED.
- Make sure that all provided video/audio/playlist URLs (if any) are alive and playable in a browser.
- Make sure that all URLs and arguments with special characters are properly quoted or escaped as explained in http://yt-dl.org/escape.
- Search the bugtracker for similar issues: http://yt-dl.org/search-issues. DO NOT post duplicates.
- Finally, put x into all relevant boxes (like this [x])
-->
- [x] I'm reporting a broken site support
- [x] I've verified that I'm running youtube-dl version **2021.02.04.1**
- [x] I've checked that all provided URLs are alive and playable in a browser
- [x] I've checked that all URLs and arguments with special characters are properly quoted or escaped
- [x] I've searched the bugtracker for similar issues including closed ones
## Verbose log
<!--
Provide the complete verbose output of youtube-dl that clearly demonstrates the problem.
Add the `-v` flag to your command line you run youtube-dl with (`youtube-dl -v <your command line>`), copy the WHOLE output and insert it below. It should look similar to this:
[debug] System config: []
[debug] User config: []
[debug] Command-line args: [u'-v', u'http://www.youtube.com/watch?v=BaW_jenozKcj']
[debug] Encodings: locale cp1251, fs mbcs, out cp866, pref cp1251
[debug] youtube-dl version 2021.02.04.1
[debug] Python version 2.7.11 - Windows-2003Server-5.2.3790-SP2
[debug] exe versions: ffmpeg N-75573-g1d0487f, ffprobe N-75573-g1d0487f, rtmpdump 2.4
[debug] Proxy map: {}
<more lines>
-->
```
[debug] System config: []
[debug] User config: []
[debug] Custom config: []
[debug] Command-line args: ['--proxy', 'https://127.0.0.1:10809', '-J', 'https://urplay.se/program/220659-seniorsurfarskolan-social-pa-distans?autostart=true', '-v']
[debug] Encodings: locale cp936, fs mbcs, out cp936, pref cp936
[debug] youtube-dl version 2021.02.04.1
[debug] Python version 3.4.4 (CPython) - Windows-7-6.1.7601-SP1
[debug] exe versions: none
[debug] Proxy map: {'http': 'https://127.0.0.1:10809', 'https': 'https://127.0.0.1:10809'}
ERROR: Unable to download webpage: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:600)> (caused by URLError(SSLError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:600)'),))
File "C:\Users\dst\AppData\Roaming\Build archive\youtube-dl\ytdl-org\tmpgi7ngq0n\build\youtube_dl\extractor\common.py", line 632, in _request_webpage
File "C:\Users\dst\AppData\Roaming\Build archive\youtube-dl\ytdl-org\tmpgi7ngq0n\build\youtube_dl\YoutubeDL.py", line 2275, in urlopen
File "C:\Python\Python34\lib\urllib\request.py", line 464, in open
File "C:\Python\Python34\lib\urllib\request.py", line 482, in _open
File "C:\Python\Python34\lib\urllib\request.py", line 442, in _call_chain
File "C:\Users\dst\AppData\Roaming\Build archive\youtube-dl\ytdl-org\tmpgi7ngq0n\build\youtube_dl\utils.py", line 2736, in https_open
File "C:\Python\Python34\lib\urllib\request.py", line 1185, in do_open
```
## Description
<!--
Provide an explanation of your issue in an arbitrary form. Provide any additional information, suggested solution and as much context and examples as possible.
If work on your issue requires account credentials please provide them or explain how one can obtain them.
-->
This problem is exsactly same as #26815, but I saw that issue is closed, now the problem is still there, hope you guys can fix it!
</issue>
<code>
[start of youtube_dl/extractor/urplay.py]
1 # coding: utf-8
2 from __future__ import unicode_literals
3
4 from .common import InfoExtractor
5 from ..utils import (
6 dict_get,
7 int_or_none,
8 unified_timestamp,
9 )
10
11
12 class URPlayIE(InfoExtractor):
13 _VALID_URL = r'https?://(?:www\.)?ur(?:play|skola)\.se/(?:program|Produkter)/(?P<id>[0-9]+)'
14 _TESTS = [{
15 'url': 'https://urplay.se/program/203704-ur-samtiden-livet-universum-och-rymdens-markliga-musik-om-vetenskap-kritiskt-tankande-och-motstand',
16 'md5': 'ff5b0c89928f8083c74bbd5099c9292d',
17 'info_dict': {
18 'id': '203704',
19 'ext': 'mp4',
20 'title': 'UR Samtiden - Livet, universum och rymdens märkliga musik : Om vetenskap, kritiskt tänkande och motstånd',
21 'description': 'md5:5344508a52aa78c1ced6c1b8b9e44e9a',
22 'timestamp': 1513292400,
23 'upload_date': '20171214',
24 },
25 }, {
26 'url': 'https://urskola.se/Produkter/190031-Tripp-Trapp-Trad-Sovkudde',
27 'info_dict': {
28 'id': '190031',
29 'ext': 'mp4',
30 'title': 'Tripp, Trapp, Träd : Sovkudde',
31 'description': 'md5:b86bffdae04a7e9379d1d7e5947df1d1',
32 'timestamp': 1440086400,
33 'upload_date': '20150820',
34 },
35 }, {
36 'url': 'http://urskola.se/Produkter/155794-Smasagor-meankieli-Grodan-i-vida-varlden',
37 'only_matching': True,
38 }]
39
40 def _real_extract(self, url):
41 video_id = self._match_id(url)
42 url = url.replace('skola.se/Produkter', 'play.se/program')
43 webpage = self._download_webpage(url, video_id)
44 urplayer_data = self._parse_json(self._html_search_regex(
45 r'data-react-class="components/Player/Player"[^>]+data-react-props="({.+?})"',
46 webpage, 'urplayer data'), video_id)['currentProduct']
47 episode = urplayer_data['title']
48 raw_streaming_info = urplayer_data['streamingInfo']['raw']
49 host = self._download_json(
50 'http://streaming-loadbalancer.ur.se/loadbalancer.json',
51 video_id)['redirect']
52
53 formats = []
54 for k, v in raw_streaming_info.items():
55 if not (k in ('sd', 'hd') and isinstance(v, dict)):
56 continue
57 file_http = v.get('location')
58 if file_http:
59 formats.extend(self._extract_wowza_formats(
60 'http://%s/%splaylist.m3u8' % (host, file_http),
61 video_id, skip_protocols=['f4m', 'rtmp', 'rtsp']))
62 self._sort_formats(formats)
63
64 image = urplayer_data.get('image') or {}
65 thumbnails = []
66 for k, v in image.items():
67 t = {
68 'id': k,
69 'url': v,
70 }
71 wh = k.split('x')
72 if len(wh) == 2:
73 t.update({
74 'width': int_or_none(wh[0]),
75 'height': int_or_none(wh[1]),
76 })
77 thumbnails.append(t)
78
79 series = urplayer_data.get('series') or {}
80 series_title = dict_get(series, ('seriesTitle', 'title')) or dict_get(urplayer_data, ('seriesTitle', 'mainTitle'))
81
82 return {
83 'id': video_id,
84 'title': '%s : %s' % (series_title, episode) if series_title else episode,
85 'description': urplayer_data.get('description'),
86 'thumbnails': thumbnails,
87 'timestamp': unified_timestamp(urplayer_data.get('publishedAt')),
88 'series': series_title,
89 'formats': formats,
90 'duration': int_or_none(urplayer_data.get('duration')),
91 'categories': urplayer_data.get('categories'),
92 'tags': urplayer_data.get('keywords'),
93 'season': series.get('label'),
94 'episode': episode,
95 'episode_number': int_or_none(urplayer_data.get('episodeNumber')),
96 }
97
[end of youtube_dl/extractor/urplay.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/youtube_dl/extractor/urplay.py b/youtube_dl/extractor/urplay.py
--- a/youtube_dl/extractor/urplay.py
+++ b/youtube_dl/extractor/urplay.py
@@ -42,8 +42,8 @@
url = url.replace('skola.se/Produkter', 'play.se/program')
webpage = self._download_webpage(url, video_id)
urplayer_data = self._parse_json(self._html_search_regex(
- r'data-react-class="components/Player/Player"[^>]+data-react-props="({.+?})"',
- webpage, 'urplayer data'), video_id)['currentProduct']
+ r'data-react-class="routes/Product/components/ProgramContainer/ProgramContainer"[^>]+data-react-props="({.+?})"',
+ webpage, 'urplayer data'), video_id)['accessibleEpisodes'][0]
episode = urplayer_data['title']
raw_streaming_info = urplayer_data['streamingInfo']['raw']
host = self._download_json(
|
{"golden_diff": "diff --git a/youtube_dl/extractor/urplay.py b/youtube_dl/extractor/urplay.py\n--- a/youtube_dl/extractor/urplay.py\n+++ b/youtube_dl/extractor/urplay.py\n@@ -42,8 +42,8 @@\n url = url.replace('skola.se/Produkter', 'play.se/program')\n webpage = self._download_webpage(url, video_id)\n urplayer_data = self._parse_json(self._html_search_regex(\n- r'data-react-class=\"components/Player/Player\"[^>]+data-react-props=\"({.+?})\"',\n- webpage, 'urplayer data'), video_id)['currentProduct']\n+ r'data-react-class=\"routes/Product/components/ProgramContainer/ProgramContainer\"[^>]+data-react-props=\"({.+?})\"',\n+ webpage, 'urplayer data'), video_id)['accessibleEpisodes'][0]\n episode = urplayer_data['title']\n raw_streaming_info = urplayer_data['streamingInfo']['raw']\n host = self._download_json(\n", "issue": "urplay\n<!--\r\n\r\n######################################################################\r\n WARNING!\r\n IGNORING THE FOLLOWING TEMPLATE WILL RESULT IN ISSUE CLOSED AS INCOMPLETE\r\n######################################################################\r\n\r\n-->\r\n\r\n\r\n## Checklist\r\n\r\n<!--\r\nCarefully read and work through this check list in order to prevent the most common mistakes and misuse of youtube-dl:\r\n- First of, make sure you are using the latest version of youtube-dl. Run `youtube-dl --version` and ensure your version is 2021.02.04.1. If it's not, see https://yt-dl.org/update on how to update. Issues with outdated version will be REJECTED.\r\n- Make sure that all provided video/audio/playlist URLs (if any) are alive and playable in a browser.\r\n- Make sure that all URLs and arguments with special characters are properly quoted or escaped as explained in http://yt-dl.org/escape.\r\n- Search the bugtracker for similar issues: http://yt-dl.org/search-issues. DO NOT post duplicates.\r\n- Finally, put x into all relevant boxes (like this [x])\r\n-->\r\n\r\n- [x] I'm reporting a broken site support\r\n- [x] I've verified that I'm running youtube-dl version **2021.02.04.1**\r\n- [x] I've checked that all provided URLs are alive and playable in a browser\r\n- [x] I've checked that all URLs and arguments with special characters are properly quoted or escaped\r\n- [x] I've searched the bugtracker for similar issues including closed ones\r\n\r\n\r\n## Verbose log\r\n\r\n<!--\r\nProvide the complete verbose output of youtube-dl that clearly demonstrates the problem.\r\nAdd the `-v` flag to your command line you run youtube-dl with (`youtube-dl -v <your command line>`), copy the WHOLE output and insert it below. It should look similar to this:\r\n [debug] System config: []\r\n [debug] User config: []\r\n [debug] Command-line args: [u'-v', u'http://www.youtube.com/watch?v=BaW_jenozKcj']\r\n [debug] Encodings: locale cp1251, fs mbcs, out cp866, pref cp1251\r\n [debug] youtube-dl version 2021.02.04.1\r\n [debug] Python version 2.7.11 - Windows-2003Server-5.2.3790-SP2\r\n [debug] exe versions: ffmpeg N-75573-g1d0487f, ffprobe N-75573-g1d0487f, rtmpdump 2.4\r\n [debug] Proxy map: {}\r\n <more lines>\r\n-->\r\n\r\n```\r\n[debug] System config: []\r\n[debug] User config: []\r\n[debug] Custom config: []\r\n[debug] Command-line args: ['--proxy', 'https://127.0.0.1:10809', '-J', 'https://urplay.se/program/220659-seniorsurfarskolan-social-pa-distans?autostart=true', '-v']\r\n[debug] Encodings: locale cp936, fs mbcs, out cp936, pref cp936\r\n[debug] youtube-dl version 2021.02.04.1\r\n[debug] Python version 3.4.4 (CPython) - Windows-7-6.1.7601-SP1\r\n[debug] exe versions: none\r\n[debug] Proxy map: {'http': 'https://127.0.0.1:10809', 'https': 'https://127.0.0.1:10809'}\r\nERROR: Unable to download webpage: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:600)> (caused by URLError(SSLError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:600)'),))\r\n File \"C:\\Users\\dst\\AppData\\Roaming\\Build archive\\youtube-dl\\ytdl-org\\tmpgi7ngq0n\\build\\youtube_dl\\extractor\\common.py\", line 632, in _request_webpage\r\n File \"C:\\Users\\dst\\AppData\\Roaming\\Build archive\\youtube-dl\\ytdl-org\\tmpgi7ngq0n\\build\\youtube_dl\\YoutubeDL.py\", line 2275, in urlopen\r\n File \"C:\\Python\\Python34\\lib\\urllib\\request.py\", line 464, in open\r\n File \"C:\\Python\\Python34\\lib\\urllib\\request.py\", line 482, in _open\r\n File \"C:\\Python\\Python34\\lib\\urllib\\request.py\", line 442, in _call_chain\r\n File \"C:\\Users\\dst\\AppData\\Roaming\\Build archive\\youtube-dl\\ytdl-org\\tmpgi7ngq0n\\build\\youtube_dl\\utils.py\", line 2736, in https_open\r\n File \"C:\\Python\\Python34\\lib\\urllib\\request.py\", line 1185, in do_open\r\n```\r\n\r\n\r\n## Description\r\n\r\n<!--\r\nProvide an explanation of your issue in an arbitrary form. Provide any additional information, suggested solution and as much context and examples as possible.\r\nIf work on your issue requires account credentials please provide them or explain how one can obtain them.\r\n-->\r\n\r\n This problem is exsactly same as #26815, but I saw that issue is closed, now the problem is still there, hope you guys can fix it!\r\n\n", "before_files": [{"content": "# coding: utf-8\nfrom __future__ import unicode_literals\n\nfrom .common import InfoExtractor\nfrom ..utils import (\n dict_get,\n int_or_none,\n unified_timestamp,\n)\n\n\nclass URPlayIE(InfoExtractor):\n _VALID_URL = r'https?://(?:www\\.)?ur(?:play|skola)\\.se/(?:program|Produkter)/(?P<id>[0-9]+)'\n _TESTS = [{\n 'url': 'https://urplay.se/program/203704-ur-samtiden-livet-universum-och-rymdens-markliga-musik-om-vetenskap-kritiskt-tankande-och-motstand',\n 'md5': 'ff5b0c89928f8083c74bbd5099c9292d',\n 'info_dict': {\n 'id': '203704',\n 'ext': 'mp4',\n 'title': 'UR Samtiden - Livet, universum och rymdens m\u00e4rkliga musik : Om vetenskap, kritiskt t\u00e4nkande och motst\u00e5nd',\n 'description': 'md5:5344508a52aa78c1ced6c1b8b9e44e9a',\n 'timestamp': 1513292400,\n 'upload_date': '20171214',\n },\n }, {\n 'url': 'https://urskola.se/Produkter/190031-Tripp-Trapp-Trad-Sovkudde',\n 'info_dict': {\n 'id': '190031',\n 'ext': 'mp4',\n 'title': 'Tripp, Trapp, Tr\u00e4d : Sovkudde',\n 'description': 'md5:b86bffdae04a7e9379d1d7e5947df1d1',\n 'timestamp': 1440086400,\n 'upload_date': '20150820',\n },\n }, {\n 'url': 'http://urskola.se/Produkter/155794-Smasagor-meankieli-Grodan-i-vida-varlden',\n 'only_matching': True,\n }]\n\n def _real_extract(self, url):\n video_id = self._match_id(url)\n url = url.replace('skola.se/Produkter', 'play.se/program')\n webpage = self._download_webpage(url, video_id)\n urplayer_data = self._parse_json(self._html_search_regex(\n r'data-react-class=\"components/Player/Player\"[^>]+data-react-props=\"({.+?})\"',\n webpage, 'urplayer data'), video_id)['currentProduct']\n episode = urplayer_data['title']\n raw_streaming_info = urplayer_data['streamingInfo']['raw']\n host = self._download_json(\n 'http://streaming-loadbalancer.ur.se/loadbalancer.json',\n video_id)['redirect']\n\n formats = []\n for k, v in raw_streaming_info.items():\n if not (k in ('sd', 'hd') and isinstance(v, dict)):\n continue\n file_http = v.get('location')\n if file_http:\n formats.extend(self._extract_wowza_formats(\n 'http://%s/%splaylist.m3u8' % (host, file_http),\n video_id, skip_protocols=['f4m', 'rtmp', 'rtsp']))\n self._sort_formats(formats)\n\n image = urplayer_data.get('image') or {}\n thumbnails = []\n for k, v in image.items():\n t = {\n 'id': k,\n 'url': v,\n }\n wh = k.split('x')\n if len(wh) == 2:\n t.update({\n 'width': int_or_none(wh[0]),\n 'height': int_or_none(wh[1]),\n })\n thumbnails.append(t)\n\n series = urplayer_data.get('series') or {}\n series_title = dict_get(series, ('seriesTitle', 'title')) or dict_get(urplayer_data, ('seriesTitle', 'mainTitle'))\n\n return {\n 'id': video_id,\n 'title': '%s : %s' % (series_title, episode) if series_title else episode,\n 'description': urplayer_data.get('description'),\n 'thumbnails': thumbnails,\n 'timestamp': unified_timestamp(urplayer_data.get('publishedAt')),\n 'series': series_title,\n 'formats': formats,\n 'duration': int_or_none(urplayer_data.get('duration')),\n 'categories': urplayer_data.get('categories'),\n 'tags': urplayer_data.get('keywords'),\n 'season': series.get('label'),\n 'episode': episode,\n 'episode_number': int_or_none(urplayer_data.get('episodeNumber')),\n }\n", "path": "youtube_dl/extractor/urplay.py"}]}
| 3,070 | 236 |
gh_patches_debug_42286
|
rasdani/github-patches
|
git_diff
|
ethereum__web3.py-785
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Better error message on failed encoding
* Version: 4.1.0
### What was wrong?
A field of type `HexBytes` slipped through the pythonic middleware and the web3 provider tried to encode it with json. The only error message was:
> TypeError: Object of type 'HexBytes' is not JSON serializable
### How can it be fixed?
Catch type errors in:
```
~/web3/providers/base.py in encode_rpc_request(self, method, params)
65 "method": method,
---> 66 "params": params or [],
67 "id": next(self.request_counter),
68 }))
69
```
In case of a `TypeError`, inspect `params` and raise another `TypeError` saying which parameter index was failing to json encode, and (if applicable) which key in the `dict` at that index.
</issue>
<code>
[start of web3/utils/encoding.py]
1 # String encodings and numeric representations
2 import re
3
4 from eth_utils import (
5 add_0x_prefix,
6 big_endian_to_int,
7 decode_hex,
8 encode_hex,
9 int_to_big_endian,
10 is_boolean,
11 is_bytes,
12 is_hex,
13 is_integer,
14 remove_0x_prefix,
15 to_hex,
16 )
17
18 from web3.utils.abi import (
19 is_address_type,
20 is_array_type,
21 is_bool_type,
22 is_bytes_type,
23 is_int_type,
24 is_string_type,
25 is_uint_type,
26 size_of_type,
27 sub_type_of_array_type,
28 )
29 from web3.utils.toolz import (
30 curry,
31 )
32 from web3.utils.validation import (
33 assert_one_val,
34 validate_abi_type,
35 validate_abi_value,
36 )
37
38
39 def hex_encode_abi_type(abi_type, value, force_size=None):
40 """
41 Encodes value into a hex string in format of abi_type
42 """
43 validate_abi_type(abi_type)
44 validate_abi_value(abi_type, value)
45
46 data_size = force_size or size_of_type(abi_type)
47 if is_array_type(abi_type):
48 sub_type = sub_type_of_array_type(abi_type)
49 return "".join([remove_0x_prefix(hex_encode_abi_type(sub_type, v, 256)) for v in value])
50 elif is_bool_type(abi_type):
51 return to_hex_with_size(value, data_size)
52 elif is_uint_type(abi_type):
53 return to_hex_with_size(value, data_size)
54 elif is_int_type(abi_type):
55 return to_hex_twos_compliment(value, data_size)
56 elif is_address_type(abi_type):
57 return pad_hex(value, data_size)
58 elif is_bytes_type(abi_type):
59 if is_bytes(value):
60 return encode_hex(value)
61 else:
62 return value
63 elif is_string_type(abi_type):
64 return to_hex(text=value)
65 else:
66 raise ValueError(
67 "Unsupported ABI type: {0}".format(abi_type)
68 )
69
70
71 def to_hex_twos_compliment(value, bit_size):
72 """
73 Converts integer value to twos compliment hex representation with given bit_size
74 """
75 if value >= 0:
76 return to_hex_with_size(value, bit_size)
77
78 value = (1 << bit_size) + value
79 hex_value = hex(value)
80 hex_value = hex_value.rstrip("L")
81 return hex_value
82
83
84 def to_hex_with_size(value, bit_size):
85 """
86 Converts a value to hex with given bit_size:
87 """
88 return pad_hex(to_hex(value), bit_size)
89
90
91 def pad_hex(value, bit_size):
92 """
93 Pads a hex string up to the given bit_size
94 """
95 value = remove_0x_prefix(value)
96 return add_0x_prefix(value.zfill(int(bit_size / 4)))
97
98
99 def trim_hex(hexstr):
100 if hexstr.startswith('0x0'):
101 hexstr = re.sub('^0x0+', '0x', hexstr)
102 if hexstr == '0x':
103 hexstr = '0x0'
104 return hexstr
105
106
107 def to_int(value=None, hexstr=None, text=None):
108 """
109 Converts value to it's integer representation.
110
111 Values are converted this way:
112
113 * value:
114 * bytes: big-endian integer
115 * bool: True => 1, False => 0
116 * hexstr: interpret hex as integer
117 * text: interpret as string of digits, like '12' => 12
118 """
119 assert_one_val(value, hexstr=hexstr, text=text)
120
121 if hexstr is not None:
122 return int(hexstr, 16)
123 elif text is not None:
124 return int(text)
125 elif isinstance(value, bytes):
126 return big_endian_to_int(value)
127 elif isinstance(value, str):
128 raise TypeError("Pass in strings with keyword hexstr or text")
129 else:
130 return int(value)
131
132
133 @curry
134 def pad_bytes(fill_with, num_bytes, unpadded):
135 return unpadded.rjust(num_bytes, fill_with)
136
137
138 zpad_bytes = pad_bytes(b'\0')
139
140
141 def to_bytes(primitive=None, hexstr=None, text=None):
142 assert_one_val(primitive, hexstr=hexstr, text=text)
143
144 if is_boolean(primitive):
145 return b'\x01' if primitive else b'\x00'
146 elif isinstance(primitive, bytes):
147 return primitive
148 elif is_integer(primitive):
149 return to_bytes(hexstr=to_hex(primitive))
150 elif hexstr is not None:
151 if len(hexstr) % 2:
152 hexstr = '0x0' + remove_0x_prefix(hexstr)
153 return decode_hex(hexstr)
154 elif text is not None:
155 return text.encode('utf-8')
156 raise TypeError("expected an int in first arg, or keyword of hexstr or text")
157
158
159 def to_text(primitive=None, hexstr=None, text=None):
160 assert_one_val(primitive, hexstr=hexstr, text=text)
161
162 if hexstr is not None:
163 return to_bytes(hexstr=hexstr).decode('utf-8')
164 elif text is not None:
165 return text
166 elif isinstance(primitive, str):
167 return to_text(hexstr=primitive)
168 elif isinstance(primitive, bytes):
169 return primitive.decode('utf-8')
170 elif is_integer(primitive):
171 byte_encoding = int_to_big_endian(primitive)
172 return to_text(byte_encoding)
173 raise TypeError("Expected an int, bytes or hexstr.")
174
175
176 @curry
177 def text_if_str(to_type, text_or_primitive):
178 '''
179 Convert to a type, assuming that strings can be only unicode text (not a hexstr)
180
181 @param to_type is a function that takes the arguments (primitive, hexstr=hexstr, text=text),
182 eg~ to_bytes, to_text, to_hex, to_int, etc
183 @param hexstr_or_primitive in bytes, str, or int.
184 '''
185 if isinstance(text_or_primitive, str):
186 (primitive, text) = (None, text_or_primitive)
187 else:
188 (primitive, text) = (text_or_primitive, None)
189 return to_type(primitive, text=text)
190
191
192 @curry
193 def hexstr_if_str(to_type, hexstr_or_primitive):
194 '''
195 Convert to a type, assuming that strings can be only hexstr (not unicode text)
196
197 @param to_type is a function that takes the arguments (primitive, hexstr=hexstr, text=text),
198 eg~ to_bytes, to_text, to_hex, to_int, etc
199 @param text_or_primitive in bytes, str, or int.
200 '''
201 if isinstance(hexstr_or_primitive, str):
202 (primitive, hexstr) = (None, hexstr_or_primitive)
203 if remove_0x_prefix(hexstr) and not is_hex(hexstr):
204 raise ValueError(
205 "when sending a str, it must be a hex string. Got: {0!r}".format(
206 hexstr_or_primitive,
207 )
208 )
209 else:
210 (primitive, hexstr) = (hexstr_or_primitive, None)
211 return to_type(primitive, hexstr=hexstr)
212
[end of web3/utils/encoding.py]
[start of web3/providers/__init__.py]
1 from .base import ( # noqa: F401
2 BaseProvider,
3 )
4 from .rpc import HTTPProvider # noqa: F401
5 from .ipc import IPCProvider # noqa: F401
6 from .websocket import WebsocketProvider # noqa: F401
7 from .auto import AutoProvider # noqa: F401
8
[end of web3/providers/__init__.py]
[start of web3/providers/base.py]
1 import itertools
2 import json
3
4 from eth_utils import (
5 to_bytes,
6 to_text,
7 )
8
9 from web3.middleware import (
10 combine_middlewares,
11 )
12
13
14 class BaseProvider:
15 _middlewares = ()
16 _request_func_cache = (None, None) # a tuple of (all_middlewares, request_func)
17
18 @property
19 def middlewares(self):
20 return self._middlewares
21
22 @middlewares.setter
23 def middlewares(self, values):
24 self._middlewares = tuple(values)
25
26 def request_func(self, web3, outer_middlewares):
27 '''
28 @param outer_middlewares is an iterable of middlewares, ordered by first to execute
29 @returns a function that calls all the middleware and eventually self.make_request()
30 '''
31 all_middlewares = tuple(outer_middlewares) + tuple(self.middlewares)
32
33 cache_key = self._request_func_cache[0]
34 if cache_key is None or cache_key != all_middlewares:
35 self._request_func_cache = (
36 all_middlewares,
37 self._generate_request_func(web3, all_middlewares)
38 )
39 return self._request_func_cache[-1]
40
41 def _generate_request_func(self, web3, middlewares):
42 return combine_middlewares(
43 middlewares=middlewares,
44 web3=web3,
45 provider_request_fn=self.make_request,
46 )
47
48 def make_request(self, method, params):
49 raise NotImplementedError("Providers must implement this method")
50
51 def isConnected(self):
52 raise NotImplementedError("Providers must implement this method")
53
54
55 class JSONBaseProvider(BaseProvider):
56 def __init__(self):
57 self.request_counter = itertools.count()
58
59 def decode_rpc_response(self, response):
60 return json.loads(to_text(response))
61
62 def encode_rpc_request(self, method, params):
63 return to_bytes(text=json.dumps({
64 "jsonrpc": "2.0",
65 "method": method,
66 "params": params or [],
67 "id": next(self.request_counter),
68 }))
69
70 def isConnected(self):
71 try:
72 response = self.make_request('web3_clientVersion', [])
73 except IOError:
74 return False
75 else:
76 assert response['jsonrpc'] == '2.0'
77 assert 'error' not in response
78 return True
79 assert False
80
[end of web3/providers/base.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/web3/providers/__init__.py b/web3/providers/__init__.py
--- a/web3/providers/__init__.py
+++ b/web3/providers/__init__.py
@@ -1,6 +1,8 @@
from .base import ( # noqa: F401
BaseProvider,
+ JSONBaseProvider,
)
+
from .rpc import HTTPProvider # noqa: F401
from .ipc import IPCProvider # noqa: F401
from .websocket import WebsocketProvider # noqa: F401
diff --git a/web3/providers/base.py b/web3/providers/base.py
--- a/web3/providers/base.py
+++ b/web3/providers/base.py
@@ -1,5 +1,4 @@
import itertools
-import json
from eth_utils import (
to_bytes,
@@ -9,6 +8,9 @@
from web3.middleware import (
combine_middlewares,
)
+from web3.utils.encoding import (
+ FriendlyJsonSerde,
+)
class BaseProvider:
@@ -57,15 +59,18 @@
self.request_counter = itertools.count()
def decode_rpc_response(self, response):
- return json.loads(to_text(response))
+ text_response = to_text(response)
+ return FriendlyJsonSerde().json_decode(text_response)
def encode_rpc_request(self, method, params):
- return to_bytes(text=json.dumps({
+ rpc_dict = {
"jsonrpc": "2.0",
"method": method,
"params": params or [],
"id": next(self.request_counter),
- }))
+ }
+ encoded = FriendlyJsonSerde().json_encode(rpc_dict)
+ return to_bytes(text=encoded)
def isConnected(self):
try:
diff --git a/web3/utils/encoding.py b/web3/utils/encoding.py
--- a/web3/utils/encoding.py
+++ b/web3/utils/encoding.py
@@ -1,4 +1,5 @@
# String encodings and numeric representations
+import json
import re
from eth_utils import (
@@ -11,6 +12,7 @@
is_bytes,
is_hex,
is_integer,
+ is_list_like,
remove_0x_prefix,
to_hex,
)
@@ -209,3 +211,54 @@
else:
(primitive, hexstr) = (hexstr_or_primitive, None)
return to_type(primitive, hexstr=hexstr)
+
+
+class FriendlyJsonSerde:
+ '''
+ Friendly JSON serializer & deserializer
+
+ When encoding or decoding fails, this class collects
+ information on which fields failed, to show more
+ helpful information in the raised error messages.
+ '''
+ def _json_mapping_errors(self, mapping):
+ for key, val in mapping.items():
+ try:
+ self._friendly_json_encode(val)
+ except TypeError as exc:
+ yield "%r: because (%s)" % (key, exc)
+
+ def _json_list_errors(self, iterable):
+ for index, element in enumerate(iterable):
+ try:
+ self._friendly_json_encode(element)
+ except TypeError as exc:
+ yield "%d: because (%s)" % (index, exc)
+
+ def _friendly_json_encode(self, obj):
+ try:
+ encoded = json.dumps(obj)
+ return encoded
+ except TypeError as full_exception:
+ if hasattr(obj, 'items'):
+ item_errors = '; '.join(self._json_mapping_errors(obj))
+ raise TypeError("dict had unencodable value at keys: {{{}}}".format(item_errors))
+ elif is_list_like(obj):
+ element_errors = '; '.join(self._json_list_errors(obj))
+ raise TypeError("list had unencodable value at index: [{}]".format(element_errors))
+ else:
+ raise full_exception
+
+ def json_decode(self, json_str):
+ try:
+ decoded = json.loads(json_str)
+ return decoded
+ except json.decoder.JSONDecodeError as exc:
+ err_msg = 'Could not decode {} because of {}.'.format(repr(json_str), exc)
+ raise ValueError(err_msg)
+
+ def json_encode(self, obj):
+ try:
+ return self._friendly_json_encode(obj)
+ except TypeError as exc:
+ raise TypeError("Could not encode to JSON: {}".format(exc))
|
{"golden_diff": "diff --git a/web3/providers/__init__.py b/web3/providers/__init__.py\n--- a/web3/providers/__init__.py\n+++ b/web3/providers/__init__.py\n@@ -1,6 +1,8 @@\n from .base import ( # noqa: F401\n BaseProvider,\n+ JSONBaseProvider,\n )\n+\n from .rpc import HTTPProvider # noqa: F401\n from .ipc import IPCProvider # noqa: F401\n from .websocket import WebsocketProvider # noqa: F401\ndiff --git a/web3/providers/base.py b/web3/providers/base.py\n--- a/web3/providers/base.py\n+++ b/web3/providers/base.py\n@@ -1,5 +1,4 @@\n import itertools\n-import json\n \n from eth_utils import (\n to_bytes,\n@@ -9,6 +8,9 @@\n from web3.middleware import (\n combine_middlewares,\n )\n+from web3.utils.encoding import (\n+ FriendlyJsonSerde,\n+)\n \n \n class BaseProvider:\n@@ -57,15 +59,18 @@\n self.request_counter = itertools.count()\n \n def decode_rpc_response(self, response):\n- return json.loads(to_text(response))\n+ text_response = to_text(response)\n+ return FriendlyJsonSerde().json_decode(text_response)\n \n def encode_rpc_request(self, method, params):\n- return to_bytes(text=json.dumps({\n+ rpc_dict = {\n \"jsonrpc\": \"2.0\",\n \"method\": method,\n \"params\": params or [],\n \"id\": next(self.request_counter),\n- }))\n+ }\n+ encoded = FriendlyJsonSerde().json_encode(rpc_dict)\n+ return to_bytes(text=encoded)\n \n def isConnected(self):\n try:\ndiff --git a/web3/utils/encoding.py b/web3/utils/encoding.py\n--- a/web3/utils/encoding.py\n+++ b/web3/utils/encoding.py\n@@ -1,4 +1,5 @@\n # String encodings and numeric representations\n+import json\n import re\n \n from eth_utils import (\n@@ -11,6 +12,7 @@\n is_bytes,\n is_hex,\n is_integer,\n+ is_list_like,\n remove_0x_prefix,\n to_hex,\n )\n@@ -209,3 +211,54 @@\n else:\n (primitive, hexstr) = (hexstr_or_primitive, None)\n return to_type(primitive, hexstr=hexstr)\n+\n+\n+class FriendlyJsonSerde:\n+ '''\n+ Friendly JSON serializer & deserializer\n+\n+ When encoding or decoding fails, this class collects\n+ information on which fields failed, to show more\n+ helpful information in the raised error messages.\n+ '''\n+ def _json_mapping_errors(self, mapping):\n+ for key, val in mapping.items():\n+ try:\n+ self._friendly_json_encode(val)\n+ except TypeError as exc:\n+ yield \"%r: because (%s)\" % (key, exc)\n+\n+ def _json_list_errors(self, iterable):\n+ for index, element in enumerate(iterable):\n+ try:\n+ self._friendly_json_encode(element)\n+ except TypeError as exc:\n+ yield \"%d: because (%s)\" % (index, exc)\n+\n+ def _friendly_json_encode(self, obj):\n+ try:\n+ encoded = json.dumps(obj)\n+ return encoded\n+ except TypeError as full_exception:\n+ if hasattr(obj, 'items'):\n+ item_errors = '; '.join(self._json_mapping_errors(obj))\n+ raise TypeError(\"dict had unencodable value at keys: {{{}}}\".format(item_errors))\n+ elif is_list_like(obj):\n+ element_errors = '; '.join(self._json_list_errors(obj))\n+ raise TypeError(\"list had unencodable value at index: [{}]\".format(element_errors))\n+ else:\n+ raise full_exception\n+\n+ def json_decode(self, json_str):\n+ try:\n+ decoded = json.loads(json_str)\n+ return decoded\n+ except json.decoder.JSONDecodeError as exc:\n+ err_msg = 'Could not decode {} because of {}.'.format(repr(json_str), exc)\n+ raise ValueError(err_msg)\n+\n+ def json_encode(self, obj):\n+ try:\n+ return self._friendly_json_encode(obj)\n+ except TypeError as exc:\n+ raise TypeError(\"Could not encode to JSON: {}\".format(exc))\n", "issue": "Better error message on failed encoding\n* Version: 4.1.0\r\n\r\n### What was wrong?\r\n\r\nA field of type `HexBytes` slipped through the pythonic middleware and the web3 provider tried to encode it with json. The only error message was:\r\n\r\n> TypeError: Object of type 'HexBytes' is not JSON serializable\r\n\r\n\r\n### How can it be fixed?\r\n\r\nCatch type errors in:\r\n\r\n```\r\n~/web3/providers/base.py in encode_rpc_request(self, method, params)\r\n 65 \"method\": method,\r\n---> 66 \"params\": params or [],\r\n 67 \"id\": next(self.request_counter),\r\n 68 }))\r\n 69\r\n```\r\nIn case of a `TypeError`, inspect `params` and raise another `TypeError` saying which parameter index was failing to json encode, and (if applicable) which key in the `dict` at that index.\n", "before_files": [{"content": "# String encodings and numeric representations\nimport re\n\nfrom eth_utils import (\n add_0x_prefix,\n big_endian_to_int,\n decode_hex,\n encode_hex,\n int_to_big_endian,\n is_boolean,\n is_bytes,\n is_hex,\n is_integer,\n remove_0x_prefix,\n to_hex,\n)\n\nfrom web3.utils.abi import (\n is_address_type,\n is_array_type,\n is_bool_type,\n is_bytes_type,\n is_int_type,\n is_string_type,\n is_uint_type,\n size_of_type,\n sub_type_of_array_type,\n)\nfrom web3.utils.toolz import (\n curry,\n)\nfrom web3.utils.validation import (\n assert_one_val,\n validate_abi_type,\n validate_abi_value,\n)\n\n\ndef hex_encode_abi_type(abi_type, value, force_size=None):\n \"\"\"\n Encodes value into a hex string in format of abi_type\n \"\"\"\n validate_abi_type(abi_type)\n validate_abi_value(abi_type, value)\n\n data_size = force_size or size_of_type(abi_type)\n if is_array_type(abi_type):\n sub_type = sub_type_of_array_type(abi_type)\n return \"\".join([remove_0x_prefix(hex_encode_abi_type(sub_type, v, 256)) for v in value])\n elif is_bool_type(abi_type):\n return to_hex_with_size(value, data_size)\n elif is_uint_type(abi_type):\n return to_hex_with_size(value, data_size)\n elif is_int_type(abi_type):\n return to_hex_twos_compliment(value, data_size)\n elif is_address_type(abi_type):\n return pad_hex(value, data_size)\n elif is_bytes_type(abi_type):\n if is_bytes(value):\n return encode_hex(value)\n else:\n return value\n elif is_string_type(abi_type):\n return to_hex(text=value)\n else:\n raise ValueError(\n \"Unsupported ABI type: {0}\".format(abi_type)\n )\n\n\ndef to_hex_twos_compliment(value, bit_size):\n \"\"\"\n Converts integer value to twos compliment hex representation with given bit_size\n \"\"\"\n if value >= 0:\n return to_hex_with_size(value, bit_size)\n\n value = (1 << bit_size) + value\n hex_value = hex(value)\n hex_value = hex_value.rstrip(\"L\")\n return hex_value\n\n\ndef to_hex_with_size(value, bit_size):\n \"\"\"\n Converts a value to hex with given bit_size:\n \"\"\"\n return pad_hex(to_hex(value), bit_size)\n\n\ndef pad_hex(value, bit_size):\n \"\"\"\n Pads a hex string up to the given bit_size\n \"\"\"\n value = remove_0x_prefix(value)\n return add_0x_prefix(value.zfill(int(bit_size / 4)))\n\n\ndef trim_hex(hexstr):\n if hexstr.startswith('0x0'):\n hexstr = re.sub('^0x0+', '0x', hexstr)\n if hexstr == '0x':\n hexstr = '0x0'\n return hexstr\n\n\ndef to_int(value=None, hexstr=None, text=None):\n \"\"\"\n Converts value to it's integer representation.\n\n Values are converted this way:\n\n * value:\n * bytes: big-endian integer\n * bool: True => 1, False => 0\n * hexstr: interpret hex as integer\n * text: interpret as string of digits, like '12' => 12\n \"\"\"\n assert_one_val(value, hexstr=hexstr, text=text)\n\n if hexstr is not None:\n return int(hexstr, 16)\n elif text is not None:\n return int(text)\n elif isinstance(value, bytes):\n return big_endian_to_int(value)\n elif isinstance(value, str):\n raise TypeError(\"Pass in strings with keyword hexstr or text\")\n else:\n return int(value)\n\n\n@curry\ndef pad_bytes(fill_with, num_bytes, unpadded):\n return unpadded.rjust(num_bytes, fill_with)\n\n\nzpad_bytes = pad_bytes(b'\\0')\n\n\ndef to_bytes(primitive=None, hexstr=None, text=None):\n assert_one_val(primitive, hexstr=hexstr, text=text)\n\n if is_boolean(primitive):\n return b'\\x01' if primitive else b'\\x00'\n elif isinstance(primitive, bytes):\n return primitive\n elif is_integer(primitive):\n return to_bytes(hexstr=to_hex(primitive))\n elif hexstr is not None:\n if len(hexstr) % 2:\n hexstr = '0x0' + remove_0x_prefix(hexstr)\n return decode_hex(hexstr)\n elif text is not None:\n return text.encode('utf-8')\n raise TypeError(\"expected an int in first arg, or keyword of hexstr or text\")\n\n\ndef to_text(primitive=None, hexstr=None, text=None):\n assert_one_val(primitive, hexstr=hexstr, text=text)\n\n if hexstr is not None:\n return to_bytes(hexstr=hexstr).decode('utf-8')\n elif text is not None:\n return text\n elif isinstance(primitive, str):\n return to_text(hexstr=primitive)\n elif isinstance(primitive, bytes):\n return primitive.decode('utf-8')\n elif is_integer(primitive):\n byte_encoding = int_to_big_endian(primitive)\n return to_text(byte_encoding)\n raise TypeError(\"Expected an int, bytes or hexstr.\")\n\n\n@curry\ndef text_if_str(to_type, text_or_primitive):\n '''\n Convert to a type, assuming that strings can be only unicode text (not a hexstr)\n\n @param to_type is a function that takes the arguments (primitive, hexstr=hexstr, text=text),\n eg~ to_bytes, to_text, to_hex, to_int, etc\n @param hexstr_or_primitive in bytes, str, or int.\n '''\n if isinstance(text_or_primitive, str):\n (primitive, text) = (None, text_or_primitive)\n else:\n (primitive, text) = (text_or_primitive, None)\n return to_type(primitive, text=text)\n\n\n@curry\ndef hexstr_if_str(to_type, hexstr_or_primitive):\n '''\n Convert to a type, assuming that strings can be only hexstr (not unicode text)\n\n @param to_type is a function that takes the arguments (primitive, hexstr=hexstr, text=text),\n eg~ to_bytes, to_text, to_hex, to_int, etc\n @param text_or_primitive in bytes, str, or int.\n '''\n if isinstance(hexstr_or_primitive, str):\n (primitive, hexstr) = (None, hexstr_or_primitive)\n if remove_0x_prefix(hexstr) and not is_hex(hexstr):\n raise ValueError(\n \"when sending a str, it must be a hex string. Got: {0!r}\".format(\n hexstr_or_primitive,\n )\n )\n else:\n (primitive, hexstr) = (hexstr_or_primitive, None)\n return to_type(primitive, hexstr=hexstr)\n", "path": "web3/utils/encoding.py"}, {"content": "from .base import ( # noqa: F401\n BaseProvider,\n)\nfrom .rpc import HTTPProvider # noqa: F401\nfrom .ipc import IPCProvider # noqa: F401\nfrom .websocket import WebsocketProvider # noqa: F401\nfrom .auto import AutoProvider # noqa: F401\n", "path": "web3/providers/__init__.py"}, {"content": "import itertools\nimport json\n\nfrom eth_utils import (\n to_bytes,\n to_text,\n)\n\nfrom web3.middleware import (\n combine_middlewares,\n)\n\n\nclass BaseProvider:\n _middlewares = ()\n _request_func_cache = (None, None) # a tuple of (all_middlewares, request_func)\n\n @property\n def middlewares(self):\n return self._middlewares\n\n @middlewares.setter\n def middlewares(self, values):\n self._middlewares = tuple(values)\n\n def request_func(self, web3, outer_middlewares):\n '''\n @param outer_middlewares is an iterable of middlewares, ordered by first to execute\n @returns a function that calls all the middleware and eventually self.make_request()\n '''\n all_middlewares = tuple(outer_middlewares) + tuple(self.middlewares)\n\n cache_key = self._request_func_cache[0]\n if cache_key is None or cache_key != all_middlewares:\n self._request_func_cache = (\n all_middlewares,\n self._generate_request_func(web3, all_middlewares)\n )\n return self._request_func_cache[-1]\n\n def _generate_request_func(self, web3, middlewares):\n return combine_middlewares(\n middlewares=middlewares,\n web3=web3,\n provider_request_fn=self.make_request,\n )\n\n def make_request(self, method, params):\n raise NotImplementedError(\"Providers must implement this method\")\n\n def isConnected(self):\n raise NotImplementedError(\"Providers must implement this method\")\n\n\nclass JSONBaseProvider(BaseProvider):\n def __init__(self):\n self.request_counter = itertools.count()\n\n def decode_rpc_response(self, response):\n return json.loads(to_text(response))\n\n def encode_rpc_request(self, method, params):\n return to_bytes(text=json.dumps({\n \"jsonrpc\": \"2.0\",\n \"method\": method,\n \"params\": params or [],\n \"id\": next(self.request_counter),\n }))\n\n def isConnected(self):\n try:\n response = self.make_request('web3_clientVersion', [])\n except IOError:\n return False\n else:\n assert response['jsonrpc'] == '2.0'\n assert 'error' not in response\n return True\n assert False\n", "path": "web3/providers/base.py"}]}
| 3,584 | 965 |
gh_patches_debug_36645
|
rasdani/github-patches
|
git_diff
|
scikit-hep__awkward-2029
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Checking isinstance of a Protocol is slow
### Version of Awkward Array
2.0.2
### Description and code to reproduce
In a profiling run of a coffea processor with awkward2 (eager mode) I found that 20% of the time was spent in the following line:
https://github.com/scikit-hep/awkward/blob/7e6f504c3cb0310cdbe0be7b5d662722ee73aaa7/src/awkward/contents/content.py#L94

This instance check would normally be very fast but I suspect because the type is a `@runtime_checkable` protocol, it is doing more work.
https://github.com/scikit-hep/awkward/blob/7e6f504c3cb0310cdbe0be7b5d662722ee73aaa7/src/awkward/_backends.py#L42-L45
Perhaps there is a way to have it first check the class `__mro__` and then fall back to the protocol?
If this time is removed from the profile, the remaining time is in line with what I get running the same processor in awkward 1.
</issue>
<code>
[start of src/awkward/_backends.py]
1 from __future__ import annotations
2
3 from abc import abstractmethod
4
5 import awkward_cpp
6
7 import awkward as ak
8 from awkward._nplikes import (
9 Cupy,
10 CupyKernel,
11 Jax,
12 JaxKernel,
13 Numpy,
14 NumpyKernel,
15 NumpyLike,
16 NumpyMetadata,
17 Singleton,
18 nplike_of,
19 )
20 from awkward._typetracer import NoKernel, TypeTracer
21 from awkward.typing import (
22 Any,
23 Callable,
24 Final,
25 Protocol,
26 Self,
27 Tuple,
28 TypeAlias,
29 TypeVar,
30 Unpack,
31 runtime_checkable,
32 )
33
34 np = NumpyMetadata.instance()
35
36
37 T = TypeVar("T", covariant=True)
38 KernelKeyType: TypeAlias = Tuple[str, Unpack[Tuple[np.dtype, ...]]]
39 KernelType: TypeAlias = Callable[..., None]
40
41
42 @runtime_checkable
43 class Backend(Protocol[T]):
44 name: str
45
46 @property
47 @abstractmethod
48 def nplike(self) -> NumpyLike:
49 raise ak._errors.wrap_error(NotImplementedError)
50
51 @property
52 @abstractmethod
53 def index_nplike(self) -> NumpyLike:
54 raise ak._errors.wrap_error(NotImplementedError)
55
56 @classmethod
57 @abstractmethod
58 def instance(cls) -> Self:
59 raise ak._errors.wrap_error(NotImplementedError)
60
61 def __getitem__(self, key: KernelKeyType) -> KernelType:
62 raise ak._errors.wrap_error(NotImplementedError)
63
64
65 class NumpyBackend(Singleton, Backend[Any]):
66 name: Final[str] = "cpu"
67
68 _numpy: Numpy
69
70 @property
71 def nplike(self) -> Numpy:
72 return self._numpy
73
74 @property
75 def index_nplike(self) -> Numpy:
76 return self._numpy
77
78 def __init__(self):
79 self._numpy = Numpy.instance()
80
81 def __getitem__(self, index: KernelKeyType) -> NumpyKernel:
82 return NumpyKernel(awkward_cpp.cpu_kernels.kernel[index], index)
83
84
85 class CupyBackend(Singleton, Backend[Any]):
86 name: Final[str] = "cuda"
87
88 _cupy: Cupy
89
90 @property
91 def nplike(self) -> Cupy:
92 return self._cupy
93
94 @property
95 def index_nplike(self) -> Cupy:
96 return self._cupy
97
98 def __init__(self):
99 self._cupy = Cupy.instance()
100
101 def __getitem__(self, index: KernelKeyType) -> CupyKernel | NumpyKernel:
102 from awkward._connect import cuda
103
104 cupy = cuda.import_cupy("Awkward Arrays with CUDA")
105 _cuda_kernels = cuda.initialize_cuda_kernels(cupy)
106 func = _cuda_kernels[index]
107 if func is not None:
108 return CupyKernel(func, index)
109 else:
110 raise ak._errors.wrap_error(
111 AssertionError(f"CuPyKernel not found: {index!r}")
112 )
113
114
115 class JaxBackend(Singleton, Backend[Any]):
116 name: Final[str] = "jax"
117
118 _jax: Jax
119 _numpy: Numpy
120
121 @property
122 def nplike(self) -> Jax:
123 return self._jax
124
125 @property
126 def index_nplike(self) -> Numpy:
127 return self._numpy
128
129 def __init__(self):
130 self._jax = Jax.instance()
131 self._numpy = Numpy.instance()
132
133 def __getitem__(self, index: KernelKeyType) -> JaxKernel:
134 # JAX uses Awkward's C++ kernels for index-only operations
135 return JaxKernel(awkward_cpp.cpu_kernels.kernel[index], index)
136
137
138 class TypeTracerBackend(Singleton, Backend[Any]):
139 name: Final[str] = "typetracer"
140
141 _typetracer: TypeTracer
142
143 @property
144 def nplike(self) -> TypeTracer:
145 return self._typetracer
146
147 @property
148 def index_nplike(self) -> TypeTracer:
149 return self._typetracer
150
151 def __init__(self):
152 self._typetracer = TypeTracer.instance()
153
154 def __getitem__(self, index: KernelKeyType) -> NoKernel:
155 return NoKernel(index)
156
157
158 def _backend_for_nplike(nplike: ak._nplikes.NumpyLike) -> Backend:
159 # Currently there exists a one-to-one relationship between the nplike
160 # and the backend. In future, this might need refactoring
161 if isinstance(nplike, Numpy):
162 return NumpyBackend.instance()
163 elif isinstance(nplike, Cupy):
164 return CupyBackend.instance()
165 elif isinstance(nplike, Jax):
166 return JaxBackend.instance()
167 elif isinstance(nplike, TypeTracer):
168 return TypeTracerBackend.instance()
169 else:
170 raise ak._errors.wrap_error(ValueError("unrecognised nplike", nplike))
171
172
173 _UNSET = object()
174 D = TypeVar("D")
175
176
177 def backend_of(*objects, default: D = _UNSET) -> Backend | D:
178 """
179 Args:
180 objects: objects for which to find a suitable backend
181 default: value to return if no backend is found.
182
183 Return the most suitable backend for the given objects (e.g. arrays, layouts). If no
184 suitable backend is found, return the `default` value, or raise a `ValueError` if
185 no default is given.
186 """
187 nplike = nplike_of(*objects, default=None)
188 if nplike is not None:
189 return _backend_for_nplike(nplike)
190 elif default is _UNSET:
191 raise ak._errors.wrap_error(ValueError("could not find backend for", objects))
192 else:
193 return default
194
195
196 _backends: Final[dict[str, type[Backend]]] = {
197 b.name: b for b in (NumpyBackend, CupyBackend, JaxBackend, TypeTracerBackend)
198 }
199
200
201 def regularize_backend(backend: str | Backend) -> Backend:
202 if isinstance(backend, Backend):
203 return backend
204 elif backend in _backends:
205 return _backends[backend].instance()
206 else:
207 raise ak._errors.wrap_error(ValueError(f"No such backend {backend!r} exists."))
208
[end of src/awkward/_backends.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/awkward/_backends.py b/src/awkward/_backends.py
--- a/src/awkward/_backends.py
+++ b/src/awkward/_backends.py
@@ -1,6 +1,6 @@
from __future__ import annotations
-from abc import abstractmethod
+from abc import ABC, abstractmethod
import awkward_cpp
@@ -18,18 +18,7 @@
nplike_of,
)
from awkward._typetracer import NoKernel, TypeTracer
-from awkward.typing import (
- Any,
- Callable,
- Final,
- Protocol,
- Self,
- Tuple,
- TypeAlias,
- TypeVar,
- Unpack,
- runtime_checkable,
-)
+from awkward.typing import Callable, Final, Tuple, TypeAlias, TypeVar, Unpack
np = NumpyMetadata.instance()
@@ -39,8 +28,7 @@
KernelType: TypeAlias = Callable[..., None]
-@runtime_checkable
-class Backend(Protocol[T]):
+class Backend(Singleton, ABC):
name: str
@property
@@ -53,16 +41,11 @@
def index_nplike(self) -> NumpyLike:
raise ak._errors.wrap_error(NotImplementedError)
- @classmethod
- @abstractmethod
- def instance(cls) -> Self:
- raise ak._errors.wrap_error(NotImplementedError)
-
def __getitem__(self, key: KernelKeyType) -> KernelType:
raise ak._errors.wrap_error(NotImplementedError)
-class NumpyBackend(Singleton, Backend[Any]):
+class NumpyBackend(Backend):
name: Final[str] = "cpu"
_numpy: Numpy
@@ -82,7 +65,7 @@
return NumpyKernel(awkward_cpp.cpu_kernels.kernel[index], index)
-class CupyBackend(Singleton, Backend[Any]):
+class CupyBackend(Backend):
name: Final[str] = "cuda"
_cupy: Cupy
@@ -112,7 +95,7 @@
)
-class JaxBackend(Singleton, Backend[Any]):
+class JaxBackend(Backend):
name: Final[str] = "jax"
_jax: Jax
@@ -135,7 +118,7 @@
return JaxKernel(awkward_cpp.cpu_kernels.kernel[index], index)
-class TypeTracerBackend(Singleton, Backend[Any]):
+class TypeTracerBackend(Backend):
name: Final[str] = "typetracer"
_typetracer: TypeTracer
|
{"golden_diff": "diff --git a/src/awkward/_backends.py b/src/awkward/_backends.py\n--- a/src/awkward/_backends.py\n+++ b/src/awkward/_backends.py\n@@ -1,6 +1,6 @@\n from __future__ import annotations\n \n-from abc import abstractmethod\n+from abc import ABC, abstractmethod\n \n import awkward_cpp\n \n@@ -18,18 +18,7 @@\n nplike_of,\n )\n from awkward._typetracer import NoKernel, TypeTracer\n-from awkward.typing import (\n- Any,\n- Callable,\n- Final,\n- Protocol,\n- Self,\n- Tuple,\n- TypeAlias,\n- TypeVar,\n- Unpack,\n- runtime_checkable,\n-)\n+from awkward.typing import Callable, Final, Tuple, TypeAlias, TypeVar, Unpack\n \n np = NumpyMetadata.instance()\n \n@@ -39,8 +28,7 @@\n KernelType: TypeAlias = Callable[..., None]\n \n \n-@runtime_checkable\n-class Backend(Protocol[T]):\n+class Backend(Singleton, ABC):\n name: str\n \n @property\n@@ -53,16 +41,11 @@\n def index_nplike(self) -> NumpyLike:\n raise ak._errors.wrap_error(NotImplementedError)\n \n- @classmethod\n- @abstractmethod\n- def instance(cls) -> Self:\n- raise ak._errors.wrap_error(NotImplementedError)\n-\n def __getitem__(self, key: KernelKeyType) -> KernelType:\n raise ak._errors.wrap_error(NotImplementedError)\n \n \n-class NumpyBackend(Singleton, Backend[Any]):\n+class NumpyBackend(Backend):\n name: Final[str] = \"cpu\"\n \n _numpy: Numpy\n@@ -82,7 +65,7 @@\n return NumpyKernel(awkward_cpp.cpu_kernels.kernel[index], index)\n \n \n-class CupyBackend(Singleton, Backend[Any]):\n+class CupyBackend(Backend):\n name: Final[str] = \"cuda\"\n \n _cupy: Cupy\n@@ -112,7 +95,7 @@\n )\n \n \n-class JaxBackend(Singleton, Backend[Any]):\n+class JaxBackend(Backend):\n name: Final[str] = \"jax\"\n \n _jax: Jax\n@@ -135,7 +118,7 @@\n return JaxKernel(awkward_cpp.cpu_kernels.kernel[index], index)\n \n \n-class TypeTracerBackend(Singleton, Backend[Any]):\n+class TypeTracerBackend(Backend):\n name: Final[str] = \"typetracer\"\n \n _typetracer: TypeTracer\n", "issue": "Checking isinstance of a Protocol is slow\n### Version of Awkward Array\n\n2.0.2\n\n### Description and code to reproduce\n\nIn a profiling run of a coffea processor with awkward2 (eager mode) I found that 20% of the time was spent in the following line:\r\nhttps://github.com/scikit-hep/awkward/blob/7e6f504c3cb0310cdbe0be7b5d662722ee73aaa7/src/awkward/contents/content.py#L94\r\n\r\nThis instance check would normally be very fast but I suspect because the type is a `@runtime_checkable` protocol, it is doing more work.\r\nhttps://github.com/scikit-hep/awkward/blob/7e6f504c3cb0310cdbe0be7b5d662722ee73aaa7/src/awkward/_backends.py#L42-L45\r\n\r\nPerhaps there is a way to have it first check the class `__mro__` and then fall back to the protocol?\r\n\r\nIf this time is removed from the profile, the remaining time is in line with what I get running the same processor in awkward 1.\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom abc import abstractmethod\n\nimport awkward_cpp\n\nimport awkward as ak\nfrom awkward._nplikes import (\n Cupy,\n CupyKernel,\n Jax,\n JaxKernel,\n Numpy,\n NumpyKernel,\n NumpyLike,\n NumpyMetadata,\n Singleton,\n nplike_of,\n)\nfrom awkward._typetracer import NoKernel, TypeTracer\nfrom awkward.typing import (\n Any,\n Callable,\n Final,\n Protocol,\n Self,\n Tuple,\n TypeAlias,\n TypeVar,\n Unpack,\n runtime_checkable,\n)\n\nnp = NumpyMetadata.instance()\n\n\nT = TypeVar(\"T\", covariant=True)\nKernelKeyType: TypeAlias = Tuple[str, Unpack[Tuple[np.dtype, ...]]]\nKernelType: TypeAlias = Callable[..., None]\n\n\n@runtime_checkable\nclass Backend(Protocol[T]):\n name: str\n\n @property\n @abstractmethod\n def nplike(self) -> NumpyLike:\n raise ak._errors.wrap_error(NotImplementedError)\n\n @property\n @abstractmethod\n def index_nplike(self) -> NumpyLike:\n raise ak._errors.wrap_error(NotImplementedError)\n\n @classmethod\n @abstractmethod\n def instance(cls) -> Self:\n raise ak._errors.wrap_error(NotImplementedError)\n\n def __getitem__(self, key: KernelKeyType) -> KernelType:\n raise ak._errors.wrap_error(NotImplementedError)\n\n\nclass NumpyBackend(Singleton, Backend[Any]):\n name: Final[str] = \"cpu\"\n\n _numpy: Numpy\n\n @property\n def nplike(self) -> Numpy:\n return self._numpy\n\n @property\n def index_nplike(self) -> Numpy:\n return self._numpy\n\n def __init__(self):\n self._numpy = Numpy.instance()\n\n def __getitem__(self, index: KernelKeyType) -> NumpyKernel:\n return NumpyKernel(awkward_cpp.cpu_kernels.kernel[index], index)\n\n\nclass CupyBackend(Singleton, Backend[Any]):\n name: Final[str] = \"cuda\"\n\n _cupy: Cupy\n\n @property\n def nplike(self) -> Cupy:\n return self._cupy\n\n @property\n def index_nplike(self) -> Cupy:\n return self._cupy\n\n def __init__(self):\n self._cupy = Cupy.instance()\n\n def __getitem__(self, index: KernelKeyType) -> CupyKernel | NumpyKernel:\n from awkward._connect import cuda\n\n cupy = cuda.import_cupy(\"Awkward Arrays with CUDA\")\n _cuda_kernels = cuda.initialize_cuda_kernels(cupy)\n func = _cuda_kernels[index]\n if func is not None:\n return CupyKernel(func, index)\n else:\n raise ak._errors.wrap_error(\n AssertionError(f\"CuPyKernel not found: {index!r}\")\n )\n\n\nclass JaxBackend(Singleton, Backend[Any]):\n name: Final[str] = \"jax\"\n\n _jax: Jax\n _numpy: Numpy\n\n @property\n def nplike(self) -> Jax:\n return self._jax\n\n @property\n def index_nplike(self) -> Numpy:\n return self._numpy\n\n def __init__(self):\n self._jax = Jax.instance()\n self._numpy = Numpy.instance()\n\n def __getitem__(self, index: KernelKeyType) -> JaxKernel:\n # JAX uses Awkward's C++ kernels for index-only operations\n return JaxKernel(awkward_cpp.cpu_kernels.kernel[index], index)\n\n\nclass TypeTracerBackend(Singleton, Backend[Any]):\n name: Final[str] = \"typetracer\"\n\n _typetracer: TypeTracer\n\n @property\n def nplike(self) -> TypeTracer:\n return self._typetracer\n\n @property\n def index_nplike(self) -> TypeTracer:\n return self._typetracer\n\n def __init__(self):\n self._typetracer = TypeTracer.instance()\n\n def __getitem__(self, index: KernelKeyType) -> NoKernel:\n return NoKernel(index)\n\n\ndef _backend_for_nplike(nplike: ak._nplikes.NumpyLike) -> Backend:\n # Currently there exists a one-to-one relationship between the nplike\n # and the backend. In future, this might need refactoring\n if isinstance(nplike, Numpy):\n return NumpyBackend.instance()\n elif isinstance(nplike, Cupy):\n return CupyBackend.instance()\n elif isinstance(nplike, Jax):\n return JaxBackend.instance()\n elif isinstance(nplike, TypeTracer):\n return TypeTracerBackend.instance()\n else:\n raise ak._errors.wrap_error(ValueError(\"unrecognised nplike\", nplike))\n\n\n_UNSET = object()\nD = TypeVar(\"D\")\n\n\ndef backend_of(*objects, default: D = _UNSET) -> Backend | D:\n \"\"\"\n Args:\n objects: objects for which to find a suitable backend\n default: value to return if no backend is found.\n\n Return the most suitable backend for the given objects (e.g. arrays, layouts). If no\n suitable backend is found, return the `default` value, or raise a `ValueError` if\n no default is given.\n \"\"\"\n nplike = nplike_of(*objects, default=None)\n if nplike is not None:\n return _backend_for_nplike(nplike)\n elif default is _UNSET:\n raise ak._errors.wrap_error(ValueError(\"could not find backend for\", objects))\n else:\n return default\n\n\n_backends: Final[dict[str, type[Backend]]] = {\n b.name: b for b in (NumpyBackend, CupyBackend, JaxBackend, TypeTracerBackend)\n}\n\n\ndef regularize_backend(backend: str | Backend) -> Backend:\n if isinstance(backend, Backend):\n return backend\n elif backend in _backends:\n return _backends[backend].instance()\n else:\n raise ak._errors.wrap_error(ValueError(f\"No such backend {backend!r} exists.\"))\n", "path": "src/awkward/_backends.py"}]}
| 2,791 | 580 |
gh_patches_debug_16434
|
rasdani/github-patches
|
git_diff
|
lightly-ai__lightly-655
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Did cifar10 dataset need gaussian blur
In the https://github.com/lightly-ai/lightly/blob/master/lightly/data/collate.py, class SimCLRCollateFunction() presents a n example for using it,
collate_fn = SimCLRCollateFunction(
>>> input_size=32,
>>> gaussian_blur=0.,
>>> )
but in https://docs.lightly.ai/examples/simclr.html
collate_fn = SimCLRCollateFunction(input_size=32)
so I wonder which one is the one you suggested?
</issue>
<code>
[start of examples/pytorch/simclr.py]
1 import torch
2 from torch import nn
3 import torchvision
4
5 from lightly.data import LightlyDataset
6 from lightly.data import SimCLRCollateFunction
7 from lightly.loss import NTXentLoss
8 from lightly.models.modules import SimCLRProjectionHead
9
10
11 class SimCLR(nn.Module):
12 def __init__(self, backbone):
13 super().__init__()
14 self.backbone = backbone
15 self.projection_head = SimCLRProjectionHead(512, 512, 128)
16
17 def forward(self, x):
18 x = self.backbone(x).flatten(start_dim=1)
19 z = self.projection_head(x)
20 return z
21
22
23 resnet = torchvision.models.resnet18()
24 backbone = nn.Sequential(*list(resnet.children())[:-1])
25 model = SimCLR(backbone)
26
27 device = "cuda" if torch.cuda.is_available() else "cpu"
28 model.to(device)
29
30 cifar10 = torchvision.datasets.CIFAR10("datasets/cifar10", download=True)
31 dataset = LightlyDataset.from_torch_dataset(cifar10)
32 # or create a dataset from a folder containing images or videos:
33 # dataset = LightlyDataset("path/to/folder")
34
35 collate_fn = SimCLRCollateFunction(input_size=32)
36
37 dataloader = torch.utils.data.DataLoader(
38 dataset,
39 batch_size=256,
40 collate_fn=collate_fn,
41 shuffle=True,
42 drop_last=True,
43 num_workers=8,
44 )
45
46 criterion = NTXentLoss()
47 optimizer = torch.optim.SGD(model.parameters(), lr=0.06)
48
49 print("Starting Training")
50 for epoch in range(10):
51 total_loss = 0
52 for (x0, x1), _, _ in dataloader:
53 x0 = x0.to(device)
54 x1 = x1.to(device)
55 z0 = model(x0)
56 z1 = model(x1)
57 loss = criterion(z0, z1)
58 total_loss += loss.detach()
59 loss.backward()
60 optimizer.step()
61 optimizer.zero_grad()
62 avg_loss = total_loss / len(dataloader)
63 print(f"epoch: {epoch:>02}, loss: {avg_loss:.5f}")
64
[end of examples/pytorch/simclr.py]
[start of examples/pytorch_lightning/simclr.py]
1 import torch
2 from torch import nn
3 import torchvision
4 import pytorch_lightning as pl
5
6 from lightly.data import LightlyDataset
7 from lightly.data import SimCLRCollateFunction
8 from lightly.loss import NTXentLoss
9 from lightly.models.modules import SimCLRProjectionHead
10
11
12 class SimCLR(pl.LightningModule):
13 def __init__(self):
14 super().__init__()
15 resnet = torchvision.models.resnet18()
16 self.backbone = nn.Sequential(*list(resnet.children())[:-1])
17 self.projection_head = SimCLRProjectionHead(512, 2048, 2048)
18 self.criterion = NTXentLoss()
19
20 def forward(self, x):
21 x = self.backbone(x).flatten(start_dim=1)
22 z = self.projection_head(x)
23 return z
24
25 def training_step(self, batch, batch_index):
26 (x0, x1), _, _ = batch
27 z0 = self.forward(x0)
28 z1 = self.forward(x1)
29 loss = self.criterion(z0, z1)
30 return loss
31
32 def configure_optimizers(self):
33 optim = torch.optim.SGD(self.parameters(), lr=0.06)
34 return optim
35
36
37 model = SimCLR()
38
39 cifar10 = torchvision.datasets.CIFAR10("datasets/cifar10", download=True)
40 dataset = LightlyDataset.from_torch_dataset(cifar10)
41 # or create a dataset from a folder containing images or videos:
42 # dataset = LightlyDataset("path/to/folder")
43
44 collate_fn = SimCLRCollateFunction(input_size=32)
45
46 dataloader = torch.utils.data.DataLoader(
47 dataset,
48 batch_size=256,
49 collate_fn=collate_fn,
50 shuffle=True,
51 drop_last=True,
52 num_workers=8,
53 )
54
55 gpus = 1 if torch.cuda.is_available() else 0
56
57 trainer = pl.Trainer(max_epochs=10, gpus=gpus)
58 trainer.fit(model=model, train_dataloaders=dataloader)
59
[end of examples/pytorch_lightning/simclr.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/pytorch/simclr.py b/examples/pytorch/simclr.py
--- a/examples/pytorch/simclr.py
+++ b/examples/pytorch/simclr.py
@@ -32,7 +32,10 @@
# or create a dataset from a folder containing images or videos:
# dataset = LightlyDataset("path/to/folder")
-collate_fn = SimCLRCollateFunction(input_size=32)
+collate_fn = SimCLRCollateFunction(
+ input_size=32,
+ gaussian_blur=0.,
+)
dataloader = torch.utils.data.DataLoader(
dataset,
diff --git a/examples/pytorch_lightning/simclr.py b/examples/pytorch_lightning/simclr.py
--- a/examples/pytorch_lightning/simclr.py
+++ b/examples/pytorch_lightning/simclr.py
@@ -41,7 +41,10 @@
# or create a dataset from a folder containing images or videos:
# dataset = LightlyDataset("path/to/folder")
-collate_fn = SimCLRCollateFunction(input_size=32)
+collate_fn = SimCLRCollateFunction(
+ input_size=32,
+ gaussian_blur=0.,
+)
dataloader = torch.utils.data.DataLoader(
dataset,
|
{"golden_diff": "diff --git a/examples/pytorch/simclr.py b/examples/pytorch/simclr.py\n--- a/examples/pytorch/simclr.py\n+++ b/examples/pytorch/simclr.py\n@@ -32,7 +32,10 @@\n # or create a dataset from a folder containing images or videos:\n # dataset = LightlyDataset(\"path/to/folder\")\n \n-collate_fn = SimCLRCollateFunction(input_size=32)\n+collate_fn = SimCLRCollateFunction(\n+ input_size=32,\n+ gaussian_blur=0.,\n+)\n \n dataloader = torch.utils.data.DataLoader(\n dataset,\ndiff --git a/examples/pytorch_lightning/simclr.py b/examples/pytorch_lightning/simclr.py\n--- a/examples/pytorch_lightning/simclr.py\n+++ b/examples/pytorch_lightning/simclr.py\n@@ -41,7 +41,10 @@\n # or create a dataset from a folder containing images or videos:\n # dataset = LightlyDataset(\"path/to/folder\")\n \n-collate_fn = SimCLRCollateFunction(input_size=32)\n+collate_fn = SimCLRCollateFunction(\n+ input_size=32,\n+ gaussian_blur=0.,\n+)\n \n dataloader = torch.utils.data.DataLoader(\n dataset,\n", "issue": "Did cifar10 dataset need gaussian blur\nIn the https://github.com/lightly-ai/lightly/blob/master/lightly/data/collate.py, class SimCLRCollateFunction() presents a n example for using it,\r\ncollate_fn = SimCLRCollateFunction(\r\n >>> input_size=32,\r\n >>> gaussian_blur=0.,\r\n >>> )\r\nbut in https://docs.lightly.ai/examples/simclr.html\r\ncollate_fn = SimCLRCollateFunction(input_size=32)\r\nso I wonder which one is the one you suggested?\n", "before_files": [{"content": "import torch\nfrom torch import nn\nimport torchvision\n\nfrom lightly.data import LightlyDataset\nfrom lightly.data import SimCLRCollateFunction\nfrom lightly.loss import NTXentLoss\nfrom lightly.models.modules import SimCLRProjectionHead\n\n\nclass SimCLR(nn.Module):\n def __init__(self, backbone):\n super().__init__()\n self.backbone = backbone\n self.projection_head = SimCLRProjectionHead(512, 512, 128)\n\n def forward(self, x):\n x = self.backbone(x).flatten(start_dim=1)\n z = self.projection_head(x)\n return z\n\n\nresnet = torchvision.models.resnet18()\nbackbone = nn.Sequential(*list(resnet.children())[:-1])\nmodel = SimCLR(backbone)\n\ndevice = \"cuda\" if torch.cuda.is_available() else \"cpu\"\nmodel.to(device)\n\ncifar10 = torchvision.datasets.CIFAR10(\"datasets/cifar10\", download=True)\ndataset = LightlyDataset.from_torch_dataset(cifar10)\n# or create a dataset from a folder containing images or videos:\n# dataset = LightlyDataset(\"path/to/folder\")\n\ncollate_fn = SimCLRCollateFunction(input_size=32)\n\ndataloader = torch.utils.data.DataLoader(\n dataset,\n batch_size=256,\n collate_fn=collate_fn,\n shuffle=True,\n drop_last=True,\n num_workers=8,\n)\n\ncriterion = NTXentLoss()\noptimizer = torch.optim.SGD(model.parameters(), lr=0.06)\n\nprint(\"Starting Training\")\nfor epoch in range(10):\n total_loss = 0\n for (x0, x1), _, _ in dataloader:\n x0 = x0.to(device)\n x1 = x1.to(device)\n z0 = model(x0)\n z1 = model(x1)\n loss = criterion(z0, z1)\n total_loss += loss.detach()\n loss.backward()\n optimizer.step()\n optimizer.zero_grad()\n avg_loss = total_loss / len(dataloader)\n print(f\"epoch: {epoch:>02}, loss: {avg_loss:.5f}\")\n", "path": "examples/pytorch/simclr.py"}, {"content": "import torch\nfrom torch import nn\nimport torchvision\nimport pytorch_lightning as pl\n\nfrom lightly.data import LightlyDataset\nfrom lightly.data import SimCLRCollateFunction\nfrom lightly.loss import NTXentLoss\nfrom lightly.models.modules import SimCLRProjectionHead\n\n\nclass SimCLR(pl.LightningModule):\n def __init__(self):\n super().__init__()\n resnet = torchvision.models.resnet18()\n self.backbone = nn.Sequential(*list(resnet.children())[:-1])\n self.projection_head = SimCLRProjectionHead(512, 2048, 2048)\n self.criterion = NTXentLoss()\n\n def forward(self, x):\n x = self.backbone(x).flatten(start_dim=1)\n z = self.projection_head(x)\n return z\n\n def training_step(self, batch, batch_index):\n (x0, x1), _, _ = batch\n z0 = self.forward(x0)\n z1 = self.forward(x1)\n loss = self.criterion(z0, z1)\n return loss\n\n def configure_optimizers(self):\n optim = torch.optim.SGD(self.parameters(), lr=0.06)\n return optim\n\n\nmodel = SimCLR()\n\ncifar10 = torchvision.datasets.CIFAR10(\"datasets/cifar10\", download=True)\ndataset = LightlyDataset.from_torch_dataset(cifar10)\n# or create a dataset from a folder containing images or videos:\n# dataset = LightlyDataset(\"path/to/folder\")\n\ncollate_fn = SimCLRCollateFunction(input_size=32)\n\ndataloader = torch.utils.data.DataLoader(\n dataset,\n batch_size=256,\n collate_fn=collate_fn,\n shuffle=True,\n drop_last=True,\n num_workers=8,\n)\n\ngpus = 1 if torch.cuda.is_available() else 0\n\ntrainer = pl.Trainer(max_epochs=10, gpus=gpus)\ntrainer.fit(model=model, train_dataloaders=dataloader)\n", "path": "examples/pytorch_lightning/simclr.py"}]}
| 1,836 | 288 |
gh_patches_debug_18351
|
rasdani/github-patches
|
git_diff
|
microsoft__torchgeo-2087
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
AgriFieldNet missing filename glob
### Description
The filename glob is missing from the AgriFieldNet dataset.
### Steps to reproduce
1. Check line 76 in torchgeo/datasets/agrifieldnet.py
### Version
main
</issue>
<code>
[start of torchgeo/datasets/agrifieldnet.py]
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License.
3
4 """AgriFieldNet India Challenge dataset."""
5
6 import os
7 import re
8 from collections.abc import Callable, Iterable, Sequence
9 from typing import Any, cast
10
11 import matplotlib.pyplot as plt
12 import torch
13 from matplotlib.figure import Figure
14 from rasterio.crs import CRS
15 from torch import Tensor
16
17 from .errors import RGBBandsMissingError
18 from .geo import RasterDataset
19 from .utils import BoundingBox
20
21
22 class AgriFieldNet(RasterDataset):
23 """AgriFieldNet India Challenge dataset.
24
25 The `AgriFieldNet India Challenge
26 <https://zindi.africa/competitions/agrifieldnet-india-challenge>`__ dataset
27 includes satellite imagery from Sentinel-2 cloud free composites
28 (single snapshot) and labels for crop type that were collected by ground survey.
29 The Sentinel-2 data are then matched with corresponding labels.
30 The dataset contains 7081 fields, which have been split into training and
31 test sets (5551 fields in the train and 1530 fields in the test).
32 Satellite imagery and labels are tiled into 256x256 chips adding up to 1217 tiles.
33 The fields are distributed across all chips, some chips may only have train or
34 test fields and some may have both. Since the labels are derived from data
35 collected on the ground, not all the pixels are labeled in each chip.
36 If the field ID for a pixel is set to 0 it means that pixel is not included in
37 either of the train or test set (and correspondingly the crop label
38 will be 0 as well). For this challenge train and test sets have slightly
39 different crop type distributions. The train set follows the distribution
40 of ground reference data which is a skewed distribution with a few dominant
41 crops being over represented. The test set was drawn randomly from an area
42 weighted field list that ensured that fields with less common crop types
43 were better represented in the test set. The original dataset can be
44 downloaded from `Source Cooperative <https://beta.source.coop/
45 radiantearth/agrifieldnet-competition/>`__.
46
47 Dataset format:
48
49 * images are 12-band Sentinel-2 data
50 * masks are tiff images with unique values representing the class and field id
51
52 Dataset classes:
53
54 0 - No-Data
55 1 - Wheat
56 2 - Mustard
57 3 - Lentil
58 4 - No Crop/Fallow
59 5 - Green pea
60 6 - Sugarcane
61 8 - Garlic
62 9 - Maize
63 13 - Gram
64 14 - Coriander
65 15 - Potato
66 16 - Berseem
67 36 - Rice
68
69 If you use this dataset in your research, please cite the following dataset:
70
71 * https://doi.org/10.34911/rdnt.wu92p1
72
73 .. versionadded:: 0.6
74 """
75
76 filename_regex = r"""
77 ^ref_agrifieldnet_competition_v1_source_
78 (?P<unique_folder_id>[a-z0-9]{5})
79 _(?P<band>B[0-9A-Z]{2})_10m
80 """
81
82 rgb_bands = ['B04', 'B03', 'B02']
83 all_bands = [
84 'B01',
85 'B02',
86 'B03',
87 'B04',
88 'B05',
89 'B06',
90 'B07',
91 'B08',
92 'B8A',
93 'B09',
94 'B11',
95 'B12',
96 ]
97
98 cmap = {
99 0: (0, 0, 0, 255),
100 1: (255, 211, 0, 255),
101 2: (255, 37, 37, 255),
102 3: (0, 168, 226, 255),
103 4: (255, 158, 9, 255),
104 5: (37, 111, 0, 255),
105 6: (255, 255, 0, 255),
106 8: (111, 166, 0, 255),
107 9: (0, 175, 73, 255),
108 13: (222, 166, 9, 255),
109 14: (222, 166, 9, 255),
110 15: (124, 211, 255, 255),
111 16: (226, 0, 124, 255),
112 36: (137, 96, 83, 255),
113 }
114
115 def __init__(
116 self,
117 paths: str | Iterable[str] = 'data',
118 crs: CRS | None = None,
119 classes: list[int] = list(cmap.keys()),
120 bands: Sequence[str] = all_bands,
121 transforms: Callable[[dict[str, Tensor]], dict[str, Tensor]] | None = None,
122 cache: bool = True,
123 ) -> None:
124 """Initialize a new AgriFieldNet dataset instance.
125
126 Args:
127 paths: one or more root directories to search for files to load
128 crs: :term:`coordinate reference system (CRS)` to warp to
129 (defaults to the CRS of the first file found)
130 classes: list of classes to include, the rest will be mapped to 0
131 (defaults to all classes)
132 bands: the subset of bands to load
133 transforms: a function/transform that takes input sample and its target as
134 entry and returns a transformed version
135 cache: if True, cache the dataset in memory
136
137 Raises:
138 DatasetNotFoundError: If dataset is not found.
139 """
140 assert (
141 set(classes) <= self.cmap.keys()
142 ), f'Only the following classes are valid: {list(self.cmap.keys())}.'
143 assert 0 in classes, 'Classes must include the background class: 0'
144
145 self.paths = paths
146 self.classes = classes
147 self.ordinal_map = torch.zeros(max(self.cmap.keys()) + 1, dtype=self.dtype)
148 self.ordinal_cmap = torch.zeros((len(self.classes), 4), dtype=torch.uint8)
149
150 super().__init__(
151 paths=paths, crs=crs, bands=bands, transforms=transforms, cache=cache
152 )
153
154 # Map chosen classes to ordinal numbers, all others mapped to background class
155 for v, k in enumerate(self.classes):
156 self.ordinal_map[k] = v
157 self.ordinal_cmap[v] = torch.tensor(self.cmap[k])
158
159 def __getitem__(self, query: BoundingBox) -> dict[str, Any]:
160 """Return an index within the dataset.
161
162 Args:
163 query: (minx, maxx, miny, maxy, mint, maxt) coordinates to index
164
165 Returns:
166 data, label, and field ids at that index
167 """
168 assert isinstance(self.paths, str)
169
170 hits = self.index.intersection(tuple(query), objects=True)
171 filepaths = cast(list[str], [hit.object for hit in hits])
172
173 if not filepaths:
174 raise IndexError(
175 f'query: {query} not found in index with bounds: {self.bounds}'
176 )
177
178 data_list: list[Tensor] = []
179 filename_regex = re.compile(self.filename_regex, re.VERBOSE)
180 for band in self.bands:
181 band_filepaths = []
182 for filepath in filepaths:
183 filename = os.path.basename(filepath)
184 directory = os.path.dirname(filepath)
185 match = re.match(filename_regex, filename)
186 if match:
187 if 'band' in match.groupdict():
188 start = match.start('band')
189 end = match.end('band')
190 filename = filename[:start] + band + filename[end:]
191 filepath = os.path.join(directory, filename)
192 band_filepaths.append(filepath)
193 data_list.append(self._merge_files(band_filepaths, query))
194 image = torch.cat(data_list)
195
196 mask_filepaths = []
197 for root, dirs, files in os.walk(os.path.join(self.paths, 'train_labels')):
198 for file in files:
199 if not file.endswith('_field_ids.tif') and file.endswith('.tif'):
200 file_path = os.path.join(root, file)
201 mask_filepaths.append(file_path)
202
203 mask = self._merge_files(mask_filepaths, query)
204 mask = self.ordinal_map[mask.squeeze().long()]
205
206 sample = {
207 'crs': self.crs,
208 'bbox': query,
209 'image': image.float(),
210 'mask': mask.long(),
211 }
212
213 if self.transforms is not None:
214 sample = self.transforms(sample)
215
216 return sample
217
218 def plot(
219 self,
220 sample: dict[str, Tensor],
221 show_titles: bool = True,
222 suptitle: str | None = None,
223 ) -> Figure:
224 """Plot a sample from the dataset.
225
226 Args:
227 sample: a sample returned by :meth:`__getitem__`
228 show_titles: flag indicating whether to show titles above each panel
229 suptitle: optional string to use as a suptitle
230
231 Returns:
232 a matplotlib Figure with the rendered sample
233
234 Raises:
235 RGBBandsMissingError: If *bands* does not include all RGB bands.
236 """
237 rgb_indices = []
238 for band in self.rgb_bands:
239 if band in self.bands:
240 rgb_indices.append(self.bands.index(band))
241 else:
242 raise RGBBandsMissingError()
243
244 image = sample['image'][rgb_indices].permute(1, 2, 0)
245 image = (image - image.min()) / (image.max() - image.min())
246
247 mask = sample['mask'].squeeze()
248 ncols = 2
249
250 showing_prediction = 'prediction' in sample
251 if showing_prediction:
252 pred = sample['prediction'].squeeze()
253 ncols += 1
254
255 fig, axs = plt.subplots(nrows=1, ncols=ncols, figsize=(ncols * 4, 4))
256 axs[0].imshow(image)
257 axs[0].axis('off')
258 axs[1].imshow(self.ordinal_cmap[mask], interpolation='none')
259 axs[1].axis('off')
260 if show_titles:
261 axs[0].set_title('Image')
262 axs[1].set_title('Mask')
263
264 if showing_prediction:
265 axs[2].imshow(self.ordinal_cmap[pred], interpolation='none')
266 axs[2].axis('off')
267 if show_titles:
268 axs[2].set_title('Prediction')
269
270 if suptitle is not None:
271 plt.suptitle(suptitle)
272
273 return fig
274
[end of torchgeo/datasets/agrifieldnet.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/torchgeo/datasets/agrifieldnet.py b/torchgeo/datasets/agrifieldnet.py
--- a/torchgeo/datasets/agrifieldnet.py
+++ b/torchgeo/datasets/agrifieldnet.py
@@ -73,6 +73,7 @@
.. versionadded:: 0.6
"""
+ filename_glob = 'ref_agrifieldnet_competition_v1_source_*_{}_10m.*'
filename_regex = r"""
^ref_agrifieldnet_competition_v1_source_
(?P<unique_folder_id>[a-z0-9]{5})
@@ -146,6 +147,7 @@
self.classes = classes
self.ordinal_map = torch.zeros(max(self.cmap.keys()) + 1, dtype=self.dtype)
self.ordinal_cmap = torch.zeros((len(self.classes), 4), dtype=torch.uint8)
+ self.filename_glob = self.filename_glob.format(bands[0])
super().__init__(
paths=paths, crs=crs, bands=bands, transforms=transforms, cache=cache
|
{"golden_diff": "diff --git a/torchgeo/datasets/agrifieldnet.py b/torchgeo/datasets/agrifieldnet.py\n--- a/torchgeo/datasets/agrifieldnet.py\n+++ b/torchgeo/datasets/agrifieldnet.py\n@@ -73,6 +73,7 @@\n .. versionadded:: 0.6\n \"\"\"\n \n+ filename_glob = 'ref_agrifieldnet_competition_v1_source_*_{}_10m.*'\n filename_regex = r\"\"\"\n ^ref_agrifieldnet_competition_v1_source_\n (?P<unique_folder_id>[a-z0-9]{5})\n@@ -146,6 +147,7 @@\n self.classes = classes\n self.ordinal_map = torch.zeros(max(self.cmap.keys()) + 1, dtype=self.dtype)\n self.ordinal_cmap = torch.zeros((len(self.classes), 4), dtype=torch.uint8)\n+ self.filename_glob = self.filename_glob.format(bands[0])\n \n super().__init__(\n paths=paths, crs=crs, bands=bands, transforms=transforms, cache=cache\n", "issue": "AgriFieldNet missing filename glob\n### Description\n\nThe filename glob is missing from the AgriFieldNet dataset.\n\n### Steps to reproduce\n\n1. Check line 76 in torchgeo/datasets/agrifieldnet.py\n\n### Version\n\nmain\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\n\n\"\"\"AgriFieldNet India Challenge dataset.\"\"\"\n\nimport os\nimport re\nfrom collections.abc import Callable, Iterable, Sequence\nfrom typing import Any, cast\n\nimport matplotlib.pyplot as plt\nimport torch\nfrom matplotlib.figure import Figure\nfrom rasterio.crs import CRS\nfrom torch import Tensor\n\nfrom .errors import RGBBandsMissingError\nfrom .geo import RasterDataset\nfrom .utils import BoundingBox\n\n\nclass AgriFieldNet(RasterDataset):\n \"\"\"AgriFieldNet India Challenge dataset.\n\n The `AgriFieldNet India Challenge\n <https://zindi.africa/competitions/agrifieldnet-india-challenge>`__ dataset\n includes satellite imagery from Sentinel-2 cloud free composites\n (single snapshot) and labels for crop type that were collected by ground survey.\n The Sentinel-2 data are then matched with corresponding labels.\n The dataset contains 7081 fields, which have been split into training and\n test sets (5551 fields in the train and 1530 fields in the test).\n Satellite imagery and labels are tiled into 256x256 chips adding up to 1217 tiles.\n The fields are distributed across all chips, some chips may only have train or\n test fields and some may have both. Since the labels are derived from data\n collected on the ground, not all the pixels are labeled in each chip.\n If the field ID for a pixel is set to 0 it means that pixel is not included in\n either of the train or test set (and correspondingly the crop label\n will be 0 as well). For this challenge train and test sets have slightly\n different crop type distributions. The train set follows the distribution\n of ground reference data which is a skewed distribution with a few dominant\n crops being over represented. The test set was drawn randomly from an area\n weighted field list that ensured that fields with less common crop types\n were better represented in the test set. The original dataset can be\n downloaded from `Source Cooperative <https://beta.source.coop/\n radiantearth/agrifieldnet-competition/>`__.\n\n Dataset format:\n\n * images are 12-band Sentinel-2 data\n * masks are tiff images with unique values representing the class and field id\n\n Dataset classes:\n\n 0 - No-Data\n 1 - Wheat\n 2 - Mustard\n 3 - Lentil\n 4 - No Crop/Fallow\n 5 - Green pea\n 6 - Sugarcane\n 8 - Garlic\n 9 - Maize\n 13 - Gram\n 14 - Coriander\n 15 - Potato\n 16 - Berseem\n 36 - Rice\n\n If you use this dataset in your research, please cite the following dataset:\n\n * https://doi.org/10.34911/rdnt.wu92p1\n\n .. versionadded:: 0.6\n \"\"\"\n\n filename_regex = r\"\"\"\n ^ref_agrifieldnet_competition_v1_source_\n (?P<unique_folder_id>[a-z0-9]{5})\n _(?P<band>B[0-9A-Z]{2})_10m\n \"\"\"\n\n rgb_bands = ['B04', 'B03', 'B02']\n all_bands = [\n 'B01',\n 'B02',\n 'B03',\n 'B04',\n 'B05',\n 'B06',\n 'B07',\n 'B08',\n 'B8A',\n 'B09',\n 'B11',\n 'B12',\n ]\n\n cmap = {\n 0: (0, 0, 0, 255),\n 1: (255, 211, 0, 255),\n 2: (255, 37, 37, 255),\n 3: (0, 168, 226, 255),\n 4: (255, 158, 9, 255),\n 5: (37, 111, 0, 255),\n 6: (255, 255, 0, 255),\n 8: (111, 166, 0, 255),\n 9: (0, 175, 73, 255),\n 13: (222, 166, 9, 255),\n 14: (222, 166, 9, 255),\n 15: (124, 211, 255, 255),\n 16: (226, 0, 124, 255),\n 36: (137, 96, 83, 255),\n }\n\n def __init__(\n self,\n paths: str | Iterable[str] = 'data',\n crs: CRS | None = None,\n classes: list[int] = list(cmap.keys()),\n bands: Sequence[str] = all_bands,\n transforms: Callable[[dict[str, Tensor]], dict[str, Tensor]] | None = None,\n cache: bool = True,\n ) -> None:\n \"\"\"Initialize a new AgriFieldNet dataset instance.\n\n Args:\n paths: one or more root directories to search for files to load\n crs: :term:`coordinate reference system (CRS)` to warp to\n (defaults to the CRS of the first file found)\n classes: list of classes to include, the rest will be mapped to 0\n (defaults to all classes)\n bands: the subset of bands to load\n transforms: a function/transform that takes input sample and its target as\n entry and returns a transformed version\n cache: if True, cache the dataset in memory\n\n Raises:\n DatasetNotFoundError: If dataset is not found.\n \"\"\"\n assert (\n set(classes) <= self.cmap.keys()\n ), f'Only the following classes are valid: {list(self.cmap.keys())}.'\n assert 0 in classes, 'Classes must include the background class: 0'\n\n self.paths = paths\n self.classes = classes\n self.ordinal_map = torch.zeros(max(self.cmap.keys()) + 1, dtype=self.dtype)\n self.ordinal_cmap = torch.zeros((len(self.classes), 4), dtype=torch.uint8)\n\n super().__init__(\n paths=paths, crs=crs, bands=bands, transforms=transforms, cache=cache\n )\n\n # Map chosen classes to ordinal numbers, all others mapped to background class\n for v, k in enumerate(self.classes):\n self.ordinal_map[k] = v\n self.ordinal_cmap[v] = torch.tensor(self.cmap[k])\n\n def __getitem__(self, query: BoundingBox) -> dict[str, Any]:\n \"\"\"Return an index within the dataset.\n\n Args:\n query: (minx, maxx, miny, maxy, mint, maxt) coordinates to index\n\n Returns:\n data, label, and field ids at that index\n \"\"\"\n assert isinstance(self.paths, str)\n\n hits = self.index.intersection(tuple(query), objects=True)\n filepaths = cast(list[str], [hit.object for hit in hits])\n\n if not filepaths:\n raise IndexError(\n f'query: {query} not found in index with bounds: {self.bounds}'\n )\n\n data_list: list[Tensor] = []\n filename_regex = re.compile(self.filename_regex, re.VERBOSE)\n for band in self.bands:\n band_filepaths = []\n for filepath in filepaths:\n filename = os.path.basename(filepath)\n directory = os.path.dirname(filepath)\n match = re.match(filename_regex, filename)\n if match:\n if 'band' in match.groupdict():\n start = match.start('band')\n end = match.end('band')\n filename = filename[:start] + band + filename[end:]\n filepath = os.path.join(directory, filename)\n band_filepaths.append(filepath)\n data_list.append(self._merge_files(band_filepaths, query))\n image = torch.cat(data_list)\n\n mask_filepaths = []\n for root, dirs, files in os.walk(os.path.join(self.paths, 'train_labels')):\n for file in files:\n if not file.endswith('_field_ids.tif') and file.endswith('.tif'):\n file_path = os.path.join(root, file)\n mask_filepaths.append(file_path)\n\n mask = self._merge_files(mask_filepaths, query)\n mask = self.ordinal_map[mask.squeeze().long()]\n\n sample = {\n 'crs': self.crs,\n 'bbox': query,\n 'image': image.float(),\n 'mask': mask.long(),\n }\n\n if self.transforms is not None:\n sample = self.transforms(sample)\n\n return sample\n\n def plot(\n self,\n sample: dict[str, Tensor],\n show_titles: bool = True,\n suptitle: str | None = None,\n ) -> Figure:\n \"\"\"Plot a sample from the dataset.\n\n Args:\n sample: a sample returned by :meth:`__getitem__`\n show_titles: flag indicating whether to show titles above each panel\n suptitle: optional string to use as a suptitle\n\n Returns:\n a matplotlib Figure with the rendered sample\n\n Raises:\n RGBBandsMissingError: If *bands* does not include all RGB bands.\n \"\"\"\n rgb_indices = []\n for band in self.rgb_bands:\n if band in self.bands:\n rgb_indices.append(self.bands.index(band))\n else:\n raise RGBBandsMissingError()\n\n image = sample['image'][rgb_indices].permute(1, 2, 0)\n image = (image - image.min()) / (image.max() - image.min())\n\n mask = sample['mask'].squeeze()\n ncols = 2\n\n showing_prediction = 'prediction' in sample\n if showing_prediction:\n pred = sample['prediction'].squeeze()\n ncols += 1\n\n fig, axs = plt.subplots(nrows=1, ncols=ncols, figsize=(ncols * 4, 4))\n axs[0].imshow(image)\n axs[0].axis('off')\n axs[1].imshow(self.ordinal_cmap[mask], interpolation='none')\n axs[1].axis('off')\n if show_titles:\n axs[0].set_title('Image')\n axs[1].set_title('Mask')\n\n if showing_prediction:\n axs[2].imshow(self.ordinal_cmap[pred], interpolation='none')\n axs[2].axis('off')\n if show_titles:\n axs[2].set_title('Prediction')\n\n if suptitle is not None:\n plt.suptitle(suptitle)\n\n return fig\n", "path": "torchgeo/datasets/agrifieldnet.py"}]}
| 3,770 | 242 |
gh_patches_debug_41582
|
rasdani/github-patches
|
git_diff
|
emissary-ingress__emissary-238
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
imagePullPolicy is set to Always
We should have a more sensible setup for our default YAML
</issue>
<code>
[start of end-to-end/demotest.py]
1 #!/usr/bin/env python
2
3 import sys
4
5 import json
6 import os
7 import requests
8 import time
9 import yaml
10
11 # Yes, it's a terrible idea to use skip cert verification for TLS.
12 # We really don't care for this test though.
13 import urllib3
14 urllib3.disable_warnings()
15
16 def call(url, headers=None, iterations=1):
17 got = {}
18
19 for x in range(iterations):
20 # Yes, it's a terrible idea to use skip cert verification for TLS.
21 # We really don't care for this test though.
22 result = requests.get(url, headers=headers, verify=False)
23 version = 'unknown'
24
25 sys.stdout.write('.')
26 sys.stdout.flush()
27
28 if result.status_code != 200:
29 version='failure %d' % result.status_code
30 elif result.text.startswith('VERSION '):
31 version=result.text[len('VERSION '):]
32 else:
33 version='unknown %s' % result.text
34
35 got.setdefault(version, 0)
36 got[version] += 1
37
38 sys.stdout.write("\n")
39 sys.stdout.flush()
40
41 return got
42
43 def test_demo(base, v2_wanted):
44 url = "%s/demo/" % base
45
46 attempts = 3
47
48 while attempts > 0:
49 print("2.0.0: attempts left %d" % attempts)
50 got = call(url, iterations=1000)
51
52 print(got)
53 v2_seen = ((got.get('2.0.0', 0) + 5) // 10)
54 delta = abs(v2_seen - v2_wanted)
55 rc = (delta <= 2)
56
57 print("2.0.0: wanted %d, got %d (delta %d) => %s" %
58 (v2_wanted, v2_seen, delta, "pass" if rc else "FAIL"))
59
60 if rc:
61 return rc
62
63 attempts -= 1
64 print("waiting for retry")
65 time.sleep(5)
66
67 return False
68
69 def test_from_yaml(base, yaml_path):
70 spec = yaml.safe_load(open(yaml_path, "r"))
71
72 url = spec['url'].replace('{BASE}', base)
73
74 test_num = 0
75 rc = True
76
77 for test in spec['tests']:
78 test_num += 1
79 name = test.get('name', "%s.%d" % (os.path.basename(yaml_path), test_num))
80
81 headers = test.get('headers', None)
82 host = test.get('host', None)
83 versions = test.get('versions', None)
84 iterations = test.get('iterations', 100)
85
86 if not versions:
87 print("missing versions in %s?" % name)
88 print("%s" % yaml.safe_dump(test))
89 return False
90
91 if host:
92 if not headers:
93 headers = {}
94
95 headers['Host'] = host
96
97 attempts = 3
98
99 while attempts > 0:
100 print("%s: attempts left %d" % (name, attempts))
101 print("%s: headers %s" % (name, headers))
102
103 got = call(url, headers=headers, iterations=iterations)
104
105 print("%s: %s" % (name, json.dumps(got)))
106
107 test_ok = True
108
109 for version, wanted_count in versions.items():
110 got_count = got.get(version, 0)
111 delta = abs(got_count - wanted_count)
112
113 print("%s %s: wanted %d, got %d (delta %d)" %
114 (name, version, wanted_count, got_count, delta))
115
116 if delta > 2:
117 test_ok = False
118
119 if test_ok:
120 print("%s: passed" % name)
121 break
122 else:
123 attempts -= 1
124
125 if attempts <= 0:
126 print("%s: FAILED" % name)
127 rc = False
128
129 return rc
130
131 if __name__ == "__main__":
132 base = sys.argv[1]
133
134 if not (base.startswith("http://") or base.startswith("https://")):
135 base = "http://%s" % base
136
137 v2_percent = None
138
139 try:
140 v2_percent = int(sys.argv[2])
141 except ValueError:
142 pass
143
144 if v2_percent != None:
145 rc = test_demo(base, v2_percent)
146 else:
147 rc = test_from_yaml(base, sys.argv[2])
148
149 if rc:
150 sys.exit(0)
151 else:
152 print("FAILED")
153 sys.exit(1)
154
[end of end-to-end/demotest.py]
[start of ambassador/ambassador/mapping.py]
1 import hashlib
2
3 from .utils import SourcedDict
4
5 class Mapping (object):
6 @classmethod
7 def group_id(klass, method, prefix, headers):
8 # Yes, we're using a cryptographic hash here. Cope. [ :) ]
9
10 h = hashlib.new('sha1')
11 h.update(method.encode('utf-8'))
12 h.update(prefix.encode('utf-8'))
13
14 for hdr in headers:
15 h.update(hdr['name'].encode('utf-8'))
16
17 if 'value' in hdr:
18 h.update(hdr['value'].encode('utf-8'))
19
20 return h.hexdigest()
21
22 @classmethod
23 def route_weight(klass, route):
24 prefix = route['prefix']
25 method = route.get('method', 'GET')
26 headers = route.get('headers', [])
27
28 weight = [ len(prefix) + len(headers), prefix, method ]
29 weight += [ hdr['name'] + '-' + hdr.get('value', '*') for hdr in headers ]
30
31 return tuple(weight)
32
33 TransparentRouteKeys = {
34 "host_redirect": True,
35 "path_redirect": True,
36 "host_rewrite": True,
37 "auto_host_rewrite": True,
38 "case_sensitive": True,
39 "use_websocket": True,
40 "timeout_ms": True,
41 "priority": True,
42 }
43
44 def __init__(self, _source="--internal--", _from=None, **kwargs):
45 # Save the raw input...
46 self.attrs = dict(**kwargs)
47
48 if _from and ('_source' in _from):
49 self.attrs['_source'] = _from['_source']
50 else:
51 self.attrs['_source'] = _source
52
53 # ...and cache some useful first-class stuff.
54 self.name = self['name']
55 self.kind = self['kind']
56 self.prefix = self['prefix']
57 self.method = self.get('method', 'GET')
58
59 # Next up, build up the headers. We do this unconditionally at init
60 # time because we need the headers to work out the group ID.
61 self.headers = []
62
63 for name, value in self.get('headers', {}).items():
64 if value == True:
65 self.headers.append({ "name": name })
66 else:
67 self.headers.append({ "name": name, "value": value, "regex": False })
68
69 for name, value in self.get('regex_headers', []):
70 self.headers.append({ "name": name, "value": value, "regex": True })
71
72 if 'host' in self.attrs:
73 self.headers.append({
74 "name": ":authority",
75 "value": self['host'],
76 "regex": self.get('host_regex', False)
77 })
78
79 if 'method' in self.attrs:
80 self.headers.append({
81 "name": ":method",
82 "value": self['method'],
83 "regex": self.get('method_regex', False)
84 })
85
86 # OK. After all that we can compute the group ID.
87 self.group_id = Mapping.group_id(self.method, self.prefix, self.headers)
88
89 def __getitem__(self, key):
90 return self.attrs[key]
91
92 def get(self, key, *args):
93 if len(args) > 0:
94 return self.attrs.get(key, args[0])
95 else:
96 return self.attrs.get(key)
97
98 def new_route(self, cluster_name):
99 route = SourcedDict(
100 _source=self['_source'],
101 _group_id=self.group_id,
102 prefix=self.prefix,
103 prefix_rewrite=self.get('rewrite', '/'),
104 clusters=[ { "name": cluster_name,
105 "weight": self.get("weight", None) } ]
106 )
107
108 if self.headers:
109 route['headers'] = self.headers
110
111 # Even though we don't use it for generating the Envoy config, go ahead
112 # and make sure that any ':method' header match gets saved under the
113 # route's '_method' key -- diag uses it to make life easier.
114
115 route['_method'] = self.method
116
117 # We refer to this route, of course.
118 route._mark_referenced_by(self['_source'])
119
120 # There's a slew of things we'll just copy over transparently; handle
121 # those.
122
123 for key, value in self.attrs.items():
124 if key in Mapping.TransparentRouteKeys:
125 route[key] = value
126
127 # Done!
128 return route
129
130 if __name__ == "__main__":
131 import sys
132
133 import json
134 import os
135
136 import yaml
137
138 for path in sys.argv[1:]:
139 try:
140 # XXX This is a bit of a hack -- yaml.safe_load_all returns a
141 # generator, and if we don't use list() here, any exception
142 # dealing with the actual object gets deferred
143 objects = list(yaml.safe_load_all(open(path, "r")))
144 except Exception as e:
145 print("%s: could not parse YAML: %s" % (path, e))
146 continue
147
148 ocount = 0
149 for obj in objects:
150 ocount += 1
151 srckey = "%s.%d" % (path, ocount)
152
153 if obj['kind'] == 'Mapping':
154 m = Mapping(srckey, **obj)
155
156 print("%s: %s" % (m.name, m.group_id))
157
158 print(json.dumps(m.new_route("test_cluster"), indent=4, sort_keys=True))
159
[end of ambassador/ambassador/mapping.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ambassador/ambassador/mapping.py b/ambassador/ambassador/mapping.py
--- a/ambassador/ambassador/mapping.py
+++ b/ambassador/ambassador/mapping.py
@@ -31,14 +31,14 @@
return tuple(weight)
TransparentRouteKeys = {
- "host_redirect": True,
- "path_redirect": True,
- "host_rewrite": True,
"auto_host_rewrite": True,
"case_sensitive": True,
- "use_websocket": True,
- "timeout_ms": True,
+ "host_redirect": True,
+ "host_rewrite": True,
+ "path_redirect": True,
"priority": True,
+ "timeout_ms": True,
+ "use_websocket": True,
}
def __init__(self, _source="--internal--", _from=None, **kwargs):
@@ -108,6 +108,12 @@
if self.headers:
route['headers'] = self.headers
+ add_request_headers = self.get('add_request_headers')
+ if add_request_headers:
+ route['request_headers_to_add'] = []
+ for key, value in add_request_headers.items():
+ route['request_headers_to_add'].append({"key": key, "value": value})
+
# Even though we don't use it for generating the Envoy config, go ahead
# and make sure that any ':method' header match gets saved under the
# route's '_method' key -- diag uses it to make life easier.
diff --git a/end-to-end/demotest.py b/end-to-end/demotest.py
--- a/end-to-end/demotest.py
+++ b/end-to-end/demotest.py
@@ -8,6 +8,8 @@
import time
import yaml
+DEFAULT_ITERATIONS=500
+
# Yes, it's a terrible idea to use skip cert verification for TLS.
# We really don't care for this test though.
import urllib3
@@ -40,17 +42,22 @@
return got
+def to_percentage(count, iterations):
+ bias = iterations // 2
+ return ((count * 100) + bias) // iterations
+
def test_demo(base, v2_wanted):
url = "%s/demo/" % base
attempts = 3
+ iterations = DEFAULT_ITERATIONS
while attempts > 0:
print("2.0.0: attempts left %d" % attempts)
- got = call(url, iterations=1000)
+ got = call(url, iterations=iterations)
print(got)
- v2_seen = ((got.get('2.0.0', 0) + 5) // 10)
+ v2_seen = to_percentage(got.get('2.0.0', 0), iterations)
delta = abs(v2_seen - v2_wanted)
rc = (delta <= 2)
@@ -81,7 +88,7 @@
headers = test.get('headers', None)
host = test.get('host', None)
versions = test.get('versions', None)
- iterations = test.get('iterations', 100)
+ iterations = test.get('iterations', DEFAULT_ITERATIONS)
if not versions:
print("missing versions in %s?" % name)
@@ -107,7 +114,8 @@
test_ok = True
for version, wanted_count in versions.items():
- got_count = got.get(version, 0)
+ # Convert iterations to percent.
+ got_count = to_percentage(got.get(version, 0), iterations)
delta = abs(got_count - wanted_count)
print("%s %s: wanted %d, got %d (delta %d)" %
|
{"golden_diff": "diff --git a/ambassador/ambassador/mapping.py b/ambassador/ambassador/mapping.py\n--- a/ambassador/ambassador/mapping.py\n+++ b/ambassador/ambassador/mapping.py\n@@ -31,14 +31,14 @@\n return tuple(weight)\n \n TransparentRouteKeys = {\n- \"host_redirect\": True,\n- \"path_redirect\": True,\n- \"host_rewrite\": True,\n \"auto_host_rewrite\": True,\n \"case_sensitive\": True,\n- \"use_websocket\": True,\n- \"timeout_ms\": True,\n+ \"host_redirect\": True,\n+ \"host_rewrite\": True,\n+ \"path_redirect\": True,\n \"priority\": True,\n+ \"timeout_ms\": True,\n+ \"use_websocket\": True,\n }\n \n def __init__(self, _source=\"--internal--\", _from=None, **kwargs):\n@@ -108,6 +108,12 @@\n if self.headers:\n route['headers'] = self.headers\n \n+ add_request_headers = self.get('add_request_headers')\n+ if add_request_headers:\n+ route['request_headers_to_add'] = []\n+ for key, value in add_request_headers.items():\n+ route['request_headers_to_add'].append({\"key\": key, \"value\": value})\n+\n # Even though we don't use it for generating the Envoy config, go ahead\n # and make sure that any ':method' header match gets saved under the\n # route's '_method' key -- diag uses it to make life easier.\ndiff --git a/end-to-end/demotest.py b/end-to-end/demotest.py\n--- a/end-to-end/demotest.py\n+++ b/end-to-end/demotest.py\n@@ -8,6 +8,8 @@\n import time\n import yaml\n \n+DEFAULT_ITERATIONS=500\n+\n # Yes, it's a terrible idea to use skip cert verification for TLS.\n # We really don't care for this test though.\n import urllib3\n@@ -40,17 +42,22 @@\n \n return got\n \n+def to_percentage(count, iterations):\n+ bias = iterations // 2\n+ return ((count * 100) + bias) // iterations\n+\n def test_demo(base, v2_wanted):\n url = \"%s/demo/\" % base\n \n attempts = 3\n+ iterations = DEFAULT_ITERATIONS\n \n while attempts > 0:\n print(\"2.0.0: attempts left %d\" % attempts)\n- got = call(url, iterations=1000)\n+ got = call(url, iterations=iterations)\n \n print(got)\n- v2_seen = ((got.get('2.0.0', 0) + 5) // 10)\n+ v2_seen = to_percentage(got.get('2.0.0', 0), iterations)\n delta = abs(v2_seen - v2_wanted)\n rc = (delta <= 2)\n \n@@ -81,7 +88,7 @@\n headers = test.get('headers', None)\n host = test.get('host', None)\n versions = test.get('versions', None)\n- iterations = test.get('iterations', 100)\n+ iterations = test.get('iterations', DEFAULT_ITERATIONS)\n \n if not versions:\n print(\"missing versions in %s?\" % name)\n@@ -107,7 +114,8 @@\n test_ok = True\n \n for version, wanted_count in versions.items():\n- got_count = got.get(version, 0)\n+ # Convert iterations to percent.\n+ got_count = to_percentage(got.get(version, 0), iterations)\n delta = abs(got_count - wanted_count)\n \n print(\"%s %s: wanted %d, got %d (delta %d)\" %\n", "issue": "imagePullPolicy is set to Always\nWe should have a more sensible setup for our default YAML\n", "before_files": [{"content": "#!/usr/bin/env python\n\nimport sys\n\nimport json\nimport os\nimport requests\nimport time\nimport yaml\n\n# Yes, it's a terrible idea to use skip cert verification for TLS.\n# We really don't care for this test though.\nimport urllib3\nurllib3.disable_warnings()\n\ndef call(url, headers=None, iterations=1):\n got = {}\n\n for x in range(iterations):\n # Yes, it's a terrible idea to use skip cert verification for TLS.\n # We really don't care for this test though.\n result = requests.get(url, headers=headers, verify=False)\n version = 'unknown'\n\n sys.stdout.write('.')\n sys.stdout.flush()\n\n if result.status_code != 200:\n version='failure %d' % result.status_code\n elif result.text.startswith('VERSION '):\n version=result.text[len('VERSION '):]\n else:\n version='unknown %s' % result.text\n\n got.setdefault(version, 0)\n got[version] += 1\n\n sys.stdout.write(\"\\n\")\n sys.stdout.flush()\n \n return got\n\ndef test_demo(base, v2_wanted):\n url = \"%s/demo/\" % base\n\n attempts = 3\n\n while attempts > 0:\n print(\"2.0.0: attempts left %d\" % attempts)\n got = call(url, iterations=1000)\n\n print(got)\n v2_seen = ((got.get('2.0.0', 0) + 5) // 10)\n delta = abs(v2_seen - v2_wanted)\n rc = (delta <= 2)\n\n print(\"2.0.0: wanted %d, got %d (delta %d) => %s\" % \n (v2_wanted, v2_seen, delta, \"pass\" if rc else \"FAIL\"))\n\n if rc:\n return rc\n\n attempts -= 1\n print(\"waiting for retry\")\n time.sleep(5)\n\n return False\n\ndef test_from_yaml(base, yaml_path):\n spec = yaml.safe_load(open(yaml_path, \"r\"))\n\n url = spec['url'].replace('{BASE}', base)\n\n test_num = 0\n rc = True\n\n for test in spec['tests']:\n test_num += 1\n name = test.get('name', \"%s.%d\" % (os.path.basename(yaml_path), test_num))\n\n headers = test.get('headers', None)\n host = test.get('host', None)\n versions = test.get('versions', None)\n iterations = test.get('iterations', 100)\n\n if not versions:\n print(\"missing versions in %s?\" % name)\n print(\"%s\" % yaml.safe_dump(test))\n return False\n\n if host:\n if not headers:\n headers = {}\n\n headers['Host'] = host\n\n attempts = 3\n\n while attempts > 0:\n print(\"%s: attempts left %d\" % (name, attempts))\n print(\"%s: headers %s\" % (name, headers))\n\n got = call(url, headers=headers, iterations=iterations)\n\n print(\"%s: %s\" % (name, json.dumps(got)))\n\n test_ok = True\n\n for version, wanted_count in versions.items():\n got_count = got.get(version, 0)\n delta = abs(got_count - wanted_count)\n\n print(\"%s %s: wanted %d, got %d (delta %d)\" % \n (name, version, wanted_count, got_count, delta))\n\n if delta > 2:\n test_ok = False\n\n if test_ok:\n print(\"%s: passed\" % name)\n break\n else:\n attempts -= 1\n\n if attempts <= 0:\n print(\"%s: FAILED\" % name)\n rc = False\n\n return rc\n\nif __name__ == \"__main__\":\n base = sys.argv[1]\n\n if not (base.startswith(\"http://\") or base.startswith(\"https://\")):\n base = \"http://%s\" % base\n\n v2_percent = None\n\n try:\n v2_percent = int(sys.argv[2])\n except ValueError:\n pass\n\n if v2_percent != None:\n rc = test_demo(base, v2_percent)\n else:\n rc = test_from_yaml(base, sys.argv[2])\n\n if rc:\n sys.exit(0)\n else:\n print(\"FAILED\")\n sys.exit(1)\n", "path": "end-to-end/demotest.py"}, {"content": "import hashlib\n\nfrom .utils import SourcedDict\n\nclass Mapping (object):\n @classmethod\n def group_id(klass, method, prefix, headers):\n # Yes, we're using a cryptographic hash here. Cope. [ :) ]\n\n h = hashlib.new('sha1')\n h.update(method.encode('utf-8'))\n h.update(prefix.encode('utf-8'))\n\n for hdr in headers:\n h.update(hdr['name'].encode('utf-8'))\n\n if 'value' in hdr:\n h.update(hdr['value'].encode('utf-8'))\n\n return h.hexdigest()\n\n @classmethod\n def route_weight(klass, route):\n prefix = route['prefix']\n method = route.get('method', 'GET')\n headers = route.get('headers', [])\n\n weight = [ len(prefix) + len(headers), prefix, method ]\n weight += [ hdr['name'] + '-' + hdr.get('value', '*') for hdr in headers ]\n\n return tuple(weight)\n\n TransparentRouteKeys = {\n \"host_redirect\": True,\n \"path_redirect\": True,\n \"host_rewrite\": True,\n \"auto_host_rewrite\": True,\n \"case_sensitive\": True,\n \"use_websocket\": True,\n \"timeout_ms\": True,\n \"priority\": True,\n }\n\n def __init__(self, _source=\"--internal--\", _from=None, **kwargs):\n # Save the raw input...\n self.attrs = dict(**kwargs)\n\n if _from and ('_source' in _from):\n self.attrs['_source'] = _from['_source']\n else:\n self.attrs['_source'] = _source\n\n # ...and cache some useful first-class stuff.\n self.name = self['name']\n self.kind = self['kind']\n self.prefix = self['prefix']\n self.method = self.get('method', 'GET')\n\n # Next up, build up the headers. We do this unconditionally at init\n # time because we need the headers to work out the group ID.\n self.headers = []\n\n for name, value in self.get('headers', {}).items():\n if value == True:\n self.headers.append({ \"name\": name })\n else:\n self.headers.append({ \"name\": name, \"value\": value, \"regex\": False })\n\n for name, value in self.get('regex_headers', []):\n self.headers.append({ \"name\": name, \"value\": value, \"regex\": True })\n\n if 'host' in self.attrs:\n self.headers.append({\n \"name\": \":authority\",\n \"value\": self['host'],\n \"regex\": self.get('host_regex', False)\n })\n\n if 'method' in self.attrs:\n self.headers.append({\n \"name\": \":method\",\n \"value\": self['method'],\n \"regex\": self.get('method_regex', False)\n })\n\n # OK. After all that we can compute the group ID.\n self.group_id = Mapping.group_id(self.method, self.prefix, self.headers)\n\n def __getitem__(self, key):\n return self.attrs[key]\n\n def get(self, key, *args):\n if len(args) > 0:\n return self.attrs.get(key, args[0])\n else:\n return self.attrs.get(key)\n\n def new_route(self, cluster_name):\n route = SourcedDict(\n _source=self['_source'],\n _group_id=self.group_id,\n prefix=self.prefix,\n prefix_rewrite=self.get('rewrite', '/'),\n clusters=[ { \"name\": cluster_name,\n \"weight\": self.get(\"weight\", None) } ]\n )\n\n if self.headers:\n route['headers'] = self.headers\n\n # Even though we don't use it for generating the Envoy config, go ahead\n # and make sure that any ':method' header match gets saved under the\n # route's '_method' key -- diag uses it to make life easier.\n\n route['_method'] = self.method\n\n # We refer to this route, of course.\n route._mark_referenced_by(self['_source'])\n\n # There's a slew of things we'll just copy over transparently; handle\n # those.\n\n for key, value in self.attrs.items():\n if key in Mapping.TransparentRouteKeys:\n route[key] = value\n\n # Done!\n return route\n\nif __name__ == \"__main__\":\n import sys\n\n import json\n import os\n\n import yaml\n\n for path in sys.argv[1:]:\n try:\n # XXX This is a bit of a hack -- yaml.safe_load_all returns a\n # generator, and if we don't use list() here, any exception\n # dealing with the actual object gets deferred \n objects = list(yaml.safe_load_all(open(path, \"r\")))\n except Exception as e:\n print(\"%s: could not parse YAML: %s\" % (path, e))\n continue\n\n ocount = 0\n for obj in objects:\n ocount += 1\n srckey = \"%s.%d\" % (path, ocount)\n\n if obj['kind'] == 'Mapping':\n m = Mapping(srckey, **obj)\n\n print(\"%s: %s\" % (m.name, m.group_id))\n\n print(json.dumps(m.new_route(\"test_cluster\"), indent=4, sort_keys=True))\n", "path": "ambassador/ambassador/mapping.py"}]}
| 3,475 | 850 |
gh_patches_debug_32201
|
rasdani/github-patches
|
git_diff
|
Pyomo__pyomo-2366
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
assert_units_consistent fails when model has reference to unindexed Var
## Summary
Running `assert_units_consistent` on a model with a `Reference` to an unindexed variable results in an error.
### Steps to reproduce the issue
```console
import pyomo.environ as pyo
from pyomo.util.check_units import assert_units_consistent
m = pyo.ConcreteModel()
m.x = pyo.Var(initialize=1, units=pyo.units.m)
m.y = pyo.Var(initialize=1, units=pyo.units.m)
m.z = pyo.Reference(m.x)
m.expr = pyo.Expression(expr=(m.x+m.z[None]))
assert_units_consistent(m)
```
### Error Message
> Traceback (most recent call last):
>
> File ~\Work\assert_units_consistent_fail.py:10 in <module>
> assert_units_consistent(m)
>
> File ~\miniconda3\envs\idaes-new\lib\site-packages\pyomo\util\check_units.py:236 in assert_units_consistent
> handler(obj)
>
> File ~\miniconda3\envs\idaes-new\lib\site-packages\pyomo\util\check_units.py:164 in _assert_units_consistent_block
> assert_units_consistent(component)
>
> File ~\miniconda3\envs\idaes-new\lib\site-packages\pyomo\util\check_units.py:219 in assert_units_consistent
> raise TypeError("Units checking not supported for object of type {}.".format(obj.ctype))
>
> TypeError: Units checking not supported for object of type <class 'pyomo.core.base.set.SetOf'>.
### Information on your system
Pyomo version: 6.4.0
Python version: 3.9
Operating system: Windows 11
How Pyomo was installed: Through IDAES install (I think the script uses pip?)
</issue>
<code>
[start of pyomo/util/check_units.py]
1 # ___________________________________________________________________________
2 #
3 # Pyomo: Python Optimization Modeling Objects
4 # Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC
5 # Under the terms of Contract DE-NA0003525 with National Technology and
6 # Engineering Solutions of Sandia, LLC, the U.S. Government retains certain
7 # rights in this software.
8 # This software is distributed under the 3-clause BSD License.
9 # __________________________________________________________________________
10 #
11 #
12 """ Pyomo Units Checking Module
13 This module has some helpful methods to support checking units on Pyomo
14 module objects.
15 """
16 from pyomo.core.base.units_container import units, UnitsError
17 from pyomo.core.base import (Objective, Constraint, Var, Param,
18 Suffix, Set, RangeSet, Block,
19 ExternalFunction, Expression,
20 value, BooleanVar)
21 from pyomo.dae import ContinuousSet, DerivativeVar
22 from pyomo.network import Port, Arc
23 from pyomo.mpec import Complementarity
24 from pyomo.gdp import Disjunct, Disjunction
25 from pyomo.core.expr.template_expr import IndexTemplate
26 from pyomo.core.expr.numvalue import native_types
27 from pyomo.util.components import iter_component
28
29 def check_units_equivalent(*args):
30 """
31 Returns True if the units associated with each of the
32 expressions passed as arguments are all equivalent (and False
33 otherwise).
34
35 Note that this method will raise an exception if the units are
36 inconsistent within an expression (since the units for that
37 expression are not valid).
38
39 Parameters
40 ----------
41 args : an argument list of Pyomo expressions
42
43 Returns
44 -------
45 bool : True if all the expressions passed as argments have the same units
46 """
47 try:
48 assert_units_equivalent(*args)
49 return True
50 except UnitsError:
51 return False
52
53 def assert_units_equivalent(*args):
54 """
55 Raise an exception if the units are inconsistent within an
56 expression, or not equivalent across all the passed
57 expressions.
58
59 Parameters
60 ----------
61 args : an argument list of Pyomo expressions
62 The Pyomo expressions to test
63
64 Raises
65 ------
66 :py:class:`pyomo.core.base.units_container.UnitsError`, :py:class:`pyomo.core.base.units_container.InconsistentUnitsError`
67 """
68 # this call will raise an exception if an inconsistency is found
69 pint_units = [units._get_pint_units(arg) for arg in args]
70 pint_unit_compare = pint_units[0]
71 for pint_unit in pint_units:
72 if not units._equivalent_pint_units(pint_unit_compare, pint_unit):
73 raise UnitsError(
74 "Units between {} and {} are not consistent.".format(
75 str(pint_unit_compare), str(pint_unit)))
76
77 def _assert_units_consistent_constraint_data(condata):
78 """
79 Raise an exception if the any units in lower, body, upper on a
80 ConstraintData object are not consistent or are not equivalent
81 with each other.
82 """
83 # Pyomo can rearrange expressions, resulting in a value
84 # of 0 for upper or lower that does not have units associated
85 # Therefore, if the lower and/or upper is 0, we allow it to be unitless
86 # and check the consistency of the body only
87 args = list()
88 if condata.lower is not None and value(condata.lower) != 0.0:
89 args.append(condata.lower)
90
91 args.append(condata.body)
92
93 if condata.upper is not None and value(condata.upper) != 0.0:
94 args.append(condata.upper)
95
96 if len(args) == 1:
97 assert_units_consistent(*args)
98 else:
99 assert_units_equivalent(*args)
100
101 def _assert_units_consistent_arc_data(arcdata):
102 """
103 Raise an exception if the any units do not match for the connected ports
104 """
105 sport = arcdata.source
106 dport = arcdata.destination
107 if sport is None or dport is None:
108 # nothing to check
109 return
110
111 # both sport and dport are not None
112 # iterate over the vars in one and check against the other
113 for key in sport.vars:
114 svar = sport.vars[key]
115 dvar = dport.vars[key]
116
117 if svar.is_indexed():
118 for k in svar:
119 svardata = svar[k]
120 dvardata = dvar[k]
121 assert_units_equivalent(svardata, dvardata)
122 else:
123 assert_units_equivalent(svar, dvar)
124
125 def _assert_units_consistent_property_expr(obj):
126 """
127 Check the .expr property of the object and raise
128 an exception if the units are not consistent
129 """
130 _assert_units_consistent_expression(obj.expr)
131
132 def _assert_units_consistent_expression(expr):
133 """
134 Raise an exception if any units in expr are inconsistent.
135 """
136 # this will raise an exception if the units are not consistent
137 # in the expression
138 pint_unit = units._get_pint_units(expr)
139 # pyomo_unit = units.get_units(expr)
140
141 # Complementarities that are not in standard form do not
142 # current work with the checking code. The Units container
143 # should be modified to allow sum and relationals with zero
144 # terms (e.g., unitless). Then this code can be enabled.
145 #def _assert_units_complementarity(cdata):
146 # """
147 # Raise an exception if any units in either of the complementarity
148 # expressions are inconsistent, and also check the standard block
149 # methods.
150 # """
151 # if cdata._args[0] is not None:
152 # pyomo_unit, pint_unit = units._get_units_tuple(cdata._args[0])
153 # if cdata._args[1] is not None:
154 # pyomo_unit, pint_unit = units._get_units_tuple(cdata._args[1])
155 # _assert_units_consistent_block(cdata)
156
157 def _assert_units_consistent_block(obj):
158 """
159 This method gets all the components from the block
160 and checks if the units are consistent on each of them
161 """
162 # check all the component objects
163 for component in obj.component_objects(descend_into=False, active=True):
164 assert_units_consistent(component)
165
166 _component_data_handlers = {
167 Objective: _assert_units_consistent_property_expr,
168 Constraint: _assert_units_consistent_constraint_data,
169 Var: _assert_units_consistent_expression,
170 DerivativeVar: _assert_units_consistent_expression,
171 Port: None,
172 Arc: _assert_units_consistent_arc_data,
173 Expression: _assert_units_consistent_property_expr,
174 Suffix: None,
175 Param: _assert_units_consistent_expression,
176 Set: None,
177 RangeSet: None,
178 Disjunct: _assert_units_consistent_block,
179 Disjunction: None,
180 BooleanVar: None,
181 Block: _assert_units_consistent_block,
182 ExternalFunction: None,
183 ContinuousSet: None, # ToDo: change this when continuous sets have units assigned
184 # complementarities that are not in normal form are not working yet
185 # see comment in test_check_units
186 # Complementarity: _assert_units_complementarity
187 }
188
189 def assert_units_consistent(obj):
190 """
191 This method raises an exception if the units are not
192 consistent on the passed in object. Argument obj can be one
193 of the following components: Pyomo Block (or Model),
194 Constraint, Objective, Expression, or it can be a Pyomo
195 expression object
196
197 Parameters
198 ----------
199 obj : Pyomo component (e.g., Block, Model, Constraint, Objective, or Expression) or Pyomo expression
200 The object or expression to test
201
202 Raises
203 ------
204 :py:class:`pyomo.core.base.units_container.UnitsError`, :py:class:`pyomo.core.base.units_container.InconsistentUnitsError`
205 """
206 objtype = type(obj)
207 if objtype in native_types:
208 return
209 elif obj.is_expression_type() or objtype is IndexTemplate:
210 try:
211 _assert_units_consistent_expression(obj)
212 except UnitsError:
213 print('Units problem with expression {}'.format(obj))
214 raise
215 return
216
217 # if object is not in our component handler, raise an exception
218 if obj.ctype not in _component_data_handlers:
219 raise TypeError("Units checking not supported for object of type {}.".format(obj.ctype))
220
221 # get the function form the list of handlers
222 handler = _component_data_handlers[obj.ctype]
223 if handler is None:
224 return
225
226 if obj.is_indexed():
227 # check all the component data objects
228 for cdata in obj.values():
229 try:
230 handler(cdata)
231 except UnitsError:
232 print('Error in units when checking {}'.format(cdata))
233 raise
234 else:
235 try:
236 handler(obj)
237 except UnitsError:
238 print('Error in units when checking {}'.format(obj))
239 raise
240
241
[end of pyomo/util/check_units.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pyomo/util/check_units.py b/pyomo/util/check_units.py
--- a/pyomo/util/check_units.py
+++ b/pyomo/util/check_units.py
@@ -15,9 +15,9 @@
"""
from pyomo.core.base.units_container import units, UnitsError
from pyomo.core.base import (Objective, Constraint, Var, Param,
- Suffix, Set, RangeSet, Block,
+ Suffix, Set, SetOf, RangeSet, Block,
ExternalFunction, Expression,
- value, BooleanVar)
+ value, BooleanVar, BuildAction, BuildCheck)
from pyomo.dae import ContinuousSet, DerivativeVar
from pyomo.network import Port, Arc
from pyomo.mpec import Complementarity
@@ -173,17 +173,24 @@
Expression: _assert_units_consistent_property_expr,
Suffix: None,
Param: _assert_units_consistent_expression,
- Set: None,
- RangeSet: None,
Disjunct: _assert_units_consistent_block,
Disjunction: None,
BooleanVar: None,
Block: _assert_units_consistent_block,
ExternalFunction: None,
- ContinuousSet: None, # ToDo: change this when continuous sets have units assigned
+ # TODO: change this when Sets / ContinuousSets sets have units:
+ ContinuousSet: None,
+ Set: None,
+ SetOf: None,
+ RangeSet: None,
+ # TODO: Piecewise: _assert_units_consistent_piecewise,
+ # TODO: SOSConstraint: _assert_units_consistent_sos,
+ # TODO: LogicalConstriant: _assert_units_consistent_logical,
+ BuildAction: None,
+ BuildCheck: None,
# complementarities that are not in normal form are not working yet
# see comment in test_check_units
- # Complementarity: _assert_units_complementarity
+ # TODO: Complementarity: _assert_units_complementarity
}
def assert_units_consistent(obj):
|
{"golden_diff": "diff --git a/pyomo/util/check_units.py b/pyomo/util/check_units.py\n--- a/pyomo/util/check_units.py\n+++ b/pyomo/util/check_units.py\n@@ -15,9 +15,9 @@\n \"\"\"\n from pyomo.core.base.units_container import units, UnitsError\n from pyomo.core.base import (Objective, Constraint, Var, Param,\n- Suffix, Set, RangeSet, Block,\n+ Suffix, Set, SetOf, RangeSet, Block,\n ExternalFunction, Expression,\n- value, BooleanVar)\n+ value, BooleanVar, BuildAction, BuildCheck)\n from pyomo.dae import ContinuousSet, DerivativeVar\n from pyomo.network import Port, Arc\n from pyomo.mpec import Complementarity\n@@ -173,17 +173,24 @@\n Expression: _assert_units_consistent_property_expr,\n Suffix: None,\n Param: _assert_units_consistent_expression,\n- Set: None,\n- RangeSet: None,\n Disjunct: _assert_units_consistent_block,\n Disjunction: None,\n BooleanVar: None,\n Block: _assert_units_consistent_block,\n ExternalFunction: None,\n- ContinuousSet: None, # ToDo: change this when continuous sets have units assigned\n+ # TODO: change this when Sets / ContinuousSets sets have units:\n+ ContinuousSet: None,\n+ Set: None,\n+ SetOf: None,\n+ RangeSet: None,\n+ # TODO: Piecewise: _assert_units_consistent_piecewise,\n+ # TODO: SOSConstraint: _assert_units_consistent_sos,\n+ # TODO: LogicalConstriant: _assert_units_consistent_logical,\n+ BuildAction: None,\n+ BuildCheck: None,\n # complementarities that are not in normal form are not working yet\n # see comment in test_check_units\n- # Complementarity: _assert_units_complementarity\n+ # TODO: Complementarity: _assert_units_complementarity\n }\n \n def assert_units_consistent(obj):\n", "issue": "assert_units_consistent fails when model has reference to unindexed Var\n## Summary\r\n\r\nRunning `assert_units_consistent` on a model with a `Reference` to an unindexed variable results in an error.\r\n\r\n### Steps to reproduce the issue\r\n\r\n```console\r\nimport pyomo.environ as pyo\r\nfrom pyomo.util.check_units import assert_units_consistent\r\n\r\nm = pyo.ConcreteModel()\r\n\r\nm.x = pyo.Var(initialize=1, units=pyo.units.m)\r\nm.y = pyo.Var(initialize=1, units=pyo.units.m)\r\nm.z = pyo.Reference(m.x)\r\nm.expr = pyo.Expression(expr=(m.x+m.z[None]))\r\nassert_units_consistent(m)\r\n```\r\n\r\n### Error Message\r\n\r\n> Traceback (most recent call last):\r\n> \r\n> File ~\\Work\\assert_units_consistent_fail.py:10 in <module>\r\n> assert_units_consistent(m)\r\n> \r\n> File ~\\miniconda3\\envs\\idaes-new\\lib\\site-packages\\pyomo\\util\\check_units.py:236 in assert_units_consistent\r\n> handler(obj)\r\n> \r\n> File ~\\miniconda3\\envs\\idaes-new\\lib\\site-packages\\pyomo\\util\\check_units.py:164 in _assert_units_consistent_block\r\n> assert_units_consistent(component)\r\n> \r\n> File ~\\miniconda3\\envs\\idaes-new\\lib\\site-packages\\pyomo\\util\\check_units.py:219 in assert_units_consistent\r\n> raise TypeError(\"Units checking not supported for object of type {}.\".format(obj.ctype))\r\n> \r\n> TypeError: Units checking not supported for object of type <class 'pyomo.core.base.set.SetOf'>.\r\n\r\n### Information on your system\r\n\r\nPyomo version: 6.4.0\r\nPython version: 3.9\r\nOperating system: Windows 11\r\nHow Pyomo was installed: Through IDAES install (I think the script uses pip?)\r\n\n", "before_files": [{"content": "# ___________________________________________________________________________\n#\n# Pyomo: Python Optimization Modeling Objects\n# Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC\n# Under the terms of Contract DE-NA0003525 with National Technology and\n# Engineering Solutions of Sandia, LLC, the U.S. Government retains certain\n# rights in this software.\n# This software is distributed under the 3-clause BSD License.\n# __________________________________________________________________________\n#\n#\n\"\"\" Pyomo Units Checking Module\nThis module has some helpful methods to support checking units on Pyomo\nmodule objects.\n\"\"\"\nfrom pyomo.core.base.units_container import units, UnitsError\nfrom pyomo.core.base import (Objective, Constraint, Var, Param,\n Suffix, Set, RangeSet, Block,\n ExternalFunction, Expression,\n value, BooleanVar)\nfrom pyomo.dae import ContinuousSet, DerivativeVar\nfrom pyomo.network import Port, Arc\nfrom pyomo.mpec import Complementarity\nfrom pyomo.gdp import Disjunct, Disjunction\nfrom pyomo.core.expr.template_expr import IndexTemplate\nfrom pyomo.core.expr.numvalue import native_types\nfrom pyomo.util.components import iter_component\n\ndef check_units_equivalent(*args):\n \"\"\"\n Returns True if the units associated with each of the\n expressions passed as arguments are all equivalent (and False\n otherwise).\n\n Note that this method will raise an exception if the units are\n inconsistent within an expression (since the units for that\n expression are not valid).\n\n Parameters\n ----------\n args : an argument list of Pyomo expressions\n\n Returns\n -------\n bool : True if all the expressions passed as argments have the same units\n \"\"\"\n try:\n assert_units_equivalent(*args)\n return True\n except UnitsError:\n return False\n\ndef assert_units_equivalent(*args):\n \"\"\"\n Raise an exception if the units are inconsistent within an\n expression, or not equivalent across all the passed\n expressions.\n\n Parameters\n ----------\n args : an argument list of Pyomo expressions\n The Pyomo expressions to test\n\n Raises\n ------\n :py:class:`pyomo.core.base.units_container.UnitsError`, :py:class:`pyomo.core.base.units_container.InconsistentUnitsError`\n \"\"\"\n # this call will raise an exception if an inconsistency is found\n pint_units = [units._get_pint_units(arg) for arg in args]\n pint_unit_compare = pint_units[0]\n for pint_unit in pint_units:\n if not units._equivalent_pint_units(pint_unit_compare, pint_unit):\n raise UnitsError(\n \"Units between {} and {} are not consistent.\".format(\n str(pint_unit_compare), str(pint_unit)))\n\ndef _assert_units_consistent_constraint_data(condata):\n \"\"\"\n Raise an exception if the any units in lower, body, upper on a\n ConstraintData object are not consistent or are not equivalent\n with each other.\n \"\"\"\n # Pyomo can rearrange expressions, resulting in a value\n # of 0 for upper or lower that does not have units associated\n # Therefore, if the lower and/or upper is 0, we allow it to be unitless\n # and check the consistency of the body only\n args = list()\n if condata.lower is not None and value(condata.lower) != 0.0:\n args.append(condata.lower)\n\n args.append(condata.body)\n\n if condata.upper is not None and value(condata.upper) != 0.0:\n args.append(condata.upper)\n\n if len(args) == 1:\n assert_units_consistent(*args)\n else:\n assert_units_equivalent(*args)\n\ndef _assert_units_consistent_arc_data(arcdata):\n \"\"\"\n Raise an exception if the any units do not match for the connected ports\n \"\"\"\n sport = arcdata.source\n dport = arcdata.destination\n if sport is None or dport is None:\n # nothing to check\n return\n\n # both sport and dport are not None\n # iterate over the vars in one and check against the other\n for key in sport.vars:\n svar = sport.vars[key]\n dvar = dport.vars[key]\n\n if svar.is_indexed():\n for k in svar:\n svardata = svar[k]\n dvardata = dvar[k]\n assert_units_equivalent(svardata, dvardata)\n else:\n assert_units_equivalent(svar, dvar)\n\ndef _assert_units_consistent_property_expr(obj):\n \"\"\"\n Check the .expr property of the object and raise\n an exception if the units are not consistent\n \"\"\"\n _assert_units_consistent_expression(obj.expr)\n\ndef _assert_units_consistent_expression(expr):\n \"\"\"\n Raise an exception if any units in expr are inconsistent.\n \"\"\"\n # this will raise an exception if the units are not consistent\n # in the expression\n pint_unit = units._get_pint_units(expr)\n # pyomo_unit = units.get_units(expr)\n\n# Complementarities that are not in standard form do not\n# current work with the checking code. The Units container\n# should be modified to allow sum and relationals with zero\n# terms (e.g., unitless). Then this code can be enabled.\n#def _assert_units_complementarity(cdata):\n# \"\"\"\n# Raise an exception if any units in either of the complementarity\n# expressions are inconsistent, and also check the standard block\n# methods.\n# \"\"\"\n# if cdata._args[0] is not None:\n# pyomo_unit, pint_unit = units._get_units_tuple(cdata._args[0])\n# if cdata._args[1] is not None:\n# pyomo_unit, pint_unit = units._get_units_tuple(cdata._args[1])\n# _assert_units_consistent_block(cdata)\n\ndef _assert_units_consistent_block(obj):\n \"\"\"\n This method gets all the components from the block\n and checks if the units are consistent on each of them\n \"\"\"\n # check all the component objects\n for component in obj.component_objects(descend_into=False, active=True):\n assert_units_consistent(component)\n\n_component_data_handlers = {\n Objective: _assert_units_consistent_property_expr,\n Constraint: _assert_units_consistent_constraint_data,\n Var: _assert_units_consistent_expression,\n DerivativeVar: _assert_units_consistent_expression,\n Port: None,\n Arc: _assert_units_consistent_arc_data,\n Expression: _assert_units_consistent_property_expr,\n Suffix: None,\n Param: _assert_units_consistent_expression,\n Set: None,\n RangeSet: None,\n Disjunct: _assert_units_consistent_block,\n Disjunction: None,\n BooleanVar: None,\n Block: _assert_units_consistent_block,\n ExternalFunction: None,\n ContinuousSet: None, # ToDo: change this when continuous sets have units assigned\n # complementarities that are not in normal form are not working yet\n # see comment in test_check_units\n # Complementarity: _assert_units_complementarity\n }\n\ndef assert_units_consistent(obj):\n \"\"\"\n This method raises an exception if the units are not\n consistent on the passed in object. Argument obj can be one\n of the following components: Pyomo Block (or Model),\n Constraint, Objective, Expression, or it can be a Pyomo\n expression object\n\n Parameters\n ----------\n obj : Pyomo component (e.g., Block, Model, Constraint, Objective, or Expression) or Pyomo expression\n The object or expression to test\n\n Raises\n ------\n :py:class:`pyomo.core.base.units_container.UnitsError`, :py:class:`pyomo.core.base.units_container.InconsistentUnitsError`\n \"\"\"\n objtype = type(obj)\n if objtype in native_types:\n return\n elif obj.is_expression_type() or objtype is IndexTemplate:\n try:\n _assert_units_consistent_expression(obj)\n except UnitsError:\n print('Units problem with expression {}'.format(obj))\n raise\n return\n\n # if object is not in our component handler, raise an exception\n if obj.ctype not in _component_data_handlers:\n raise TypeError(\"Units checking not supported for object of type {}.\".format(obj.ctype))\n\n # get the function form the list of handlers\n handler = _component_data_handlers[obj.ctype]\n if handler is None:\n return\n\n if obj.is_indexed():\n # check all the component data objects\n for cdata in obj.values():\n try:\n handler(cdata)\n except UnitsError:\n print('Error in units when checking {}'.format(cdata))\n raise\n else:\n try:\n handler(obj)\n except UnitsError:\n print('Error in units when checking {}'.format(obj))\n raise\n \n", "path": "pyomo/util/check_units.py"}]}
| 3,517 | 448 |
gh_patches_debug_55301
|
rasdani/github-patches
|
git_diff
|
elastic__apm-agent-python-1618
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
enabling sniff_on_start in elasticsearch() breaks elasticserach instrumentation
**Describe the bug**:
sniff_on_start in elasticsearch with apm enabled fails the request due to a null span object
```python
ERROR File /opt/venv/lib/python3.9/site-packages/django/utils/log.py, line 224, Internal Server Error: /api/test_view
Traceback (most recent call last):
File "/opt/venv/lib/python3.9/site-packages/django/core/handlers/exception.py", line 47, in inner
response = get_response(request)
File "/opt/venv/lib/python3.9/site-packages/django/core/handlers/base.py", line 181, in _get_response
response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "/usr/local/lib/python3.9/contextlib.py", line 79, in inner
return func(*args, **kwds)
File "/opt/venv/lib/python3.9/site-packages/django/views/generic/base.py", line 70, in view
return self.dispatch(request, *args, **kwargs)
File "/opt/venv/lib/python3.9/site-packages/django/views/generic/base.py", line 98, in dispatch
return handler(request, *args, **kwargs)
File "/app/api/views.py", line 592, in get
es = Elasticsearch(hosts=["elasticsearch"],sniff_on_start=True)
File "/opt/venv/lib/python3.9/site-packages/elasticsearch/client/__init__.py", line 205, in __init__
self.transport = transport_class(_normalize_hosts(hosts), **kwargs)
File "/opt/venv/lib/python3.9/site-packages/elasticsearch/transport.py", line 200, in __init__
self.sniff_hosts(True)
File "/opt/venv/lib/python3.9/site-packages/elasticsearch/transport.py", line 365, in sniff_hosts
node_info = self._get_sniff_data(initial)
File "/opt/venv/lib/python3.9/site-packages/elasticsearch/transport.py", line 308, in _get_sniff_data
_, headers, node_info = c.perform_request(
File "/opt/venv/lib/python3.9/site-packages/elasticapm/instrumentation/packages/base.py", line 210, in call_if_sampling
return self.call(module, method, wrapped, instance, args, kwargs)
File "/opt/venv/lib/python3.9/site-packages/elasticapm/instrumentation/packages/elasticsearch.py", line 58, in call
self._update_context_by_request_data(span.context, instance, args, kwargs)
AttributeError: 'NoneType' object has no attribute 'context'
```
**To Reproduce**
1. setup an elasticsearch instance or a cluser and a django app
2. create test view to create elasticsearch connection instance
```python
from elasticsearch import Elasticsearch
from django.http import HttpResponse
from django.views import View
class TestView(View):
def get(self, request, *args, **kwargs):
es = Elasticsearch(hosts=["elasticsearch"],sniff_on_start=True)
return HttpResponse("Success !")
```
4. curl that view
**Environment**
- OS: debian buster docker
- Python version: 3.9
- Framework and version : django 3.2.15
- elasticserach-py: 7.17.14
- elasticsearch: 7.15.3
- APM Server version: 7.10.2
- Agent version: 6.10.1
</issue>
<code>
[start of elasticapm/instrumentation/packages/elasticsearch.py]
1 # BSD 3-Clause License
2 #
3 # Copyright (c) 2019, Elasticsearch BV
4 # All rights reserved.
5 #
6 # Redistribution and use in source and binary forms, with or without
7 # modification, are permitted provided that the following conditions are met:
8 #
9 # * Redistributions of source code must retain the above copyright notice, this
10 # list of conditions and the following disclaimer.
11 #
12 # * Redistributions in binary form must reproduce the above copyright notice,
13 # this list of conditions and the following disclaimer in the documentation
14 # and/or other materials provided with the distribution.
15 #
16 # * Neither the name of the copyright holder nor the names of its
17 # contributors may be used to endorse or promote products derived from
18 # this software without specific prior written permission.
19 #
20 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
21 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
22 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
23 # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
24 # FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
25 # DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
26 # SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
27 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
28 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
29 # OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
30
31 from __future__ import absolute_import
32
33 import re
34
35 import elasticapm
36 from elasticapm.instrumentation.packages.base import AbstractInstrumentedModule
37 from elasticapm.traces import DroppedSpan, execution_context
38 from elasticapm.utils.logging import get_logger
39
40 logger = get_logger("elasticapm.instrument")
41
42 should_capture_body_re = re.compile("/(_search|_msearch|_count|_async_search|_sql|_eql)(/|$)")
43
44
45 class ElasticsearchConnectionInstrumentation(AbstractInstrumentedModule):
46 name = "elasticsearch_connection"
47
48 instrument_list = [
49 ("elasticsearch.connection.http_urllib3", "Urllib3HttpConnection.perform_request"),
50 ("elasticsearch.connection.http_requests", "RequestsHttpConnection.perform_request"),
51 ]
52
53 def call(self, module, method, wrapped, instance, args, kwargs):
54 span = execution_context.get_span()
55 if isinstance(span, DroppedSpan):
56 return wrapped(*args, **kwargs)
57
58 self._update_context_by_request_data(span.context, instance, args, kwargs)
59
60 status_code, headers, raw_data = wrapped(*args, **kwargs)
61
62 span.context["http"] = {"status_code": status_code}
63
64 return status_code, headers, raw_data
65
66 def _update_context_by_request_data(self, context, instance, args, kwargs):
67 args_len = len(args)
68 url = args[1] if args_len > 1 else kwargs.get("url")
69 params = args[2] if args_len > 2 else kwargs.get("params")
70 body_serialized = args[3] if args_len > 3 else kwargs.get("body")
71
72 should_capture_body = bool(should_capture_body_re.search(url))
73
74 context["db"] = {"type": "elasticsearch"}
75 if should_capture_body:
76 query = []
77 # using both q AND body is allowed in some API endpoints / ES versions,
78 # but not in others. We simply capture both if they are there so the
79 # user can see it.
80 if params and "q" in params:
81 # 'q' is already encoded to a byte string at this point
82 # we assume utf8, which is the default
83 query.append("q=" + params["q"].decode("utf-8", errors="replace"))
84 if body_serialized:
85 if isinstance(body_serialized, bytes):
86 query.append(body_serialized.decode("utf-8", errors="replace"))
87 else:
88 query.append(body_serialized)
89 if query:
90 context["db"]["statement"] = "\n\n".join(query)
91
92 context["destination"] = {
93 "address": instance.host,
94 }
95
96
97 class ElasticsearchTransportInstrumentation(AbstractInstrumentedModule):
98 name = "elasticsearch_connection"
99
100 instrument_list = [
101 ("elasticsearch.transport", "Transport.perform_request"),
102 ]
103
104 def call(self, module, method, wrapped, instance, args, kwargs):
105 with elasticapm.capture_span(
106 self._get_signature(args, kwargs),
107 span_type="db",
108 span_subtype="elasticsearch",
109 span_action="query",
110 extra={},
111 skip_frames=2,
112 leaf=True,
113 ) as span:
114 result_data = wrapped(*args, **kwargs)
115
116 try:
117 span.context["db"]["rows_affected"] = result_data["hits"]["total"]["value"]
118 except (KeyError, TypeError):
119 pass
120
121 return result_data
122
123 def _get_signature(self, args, kwargs):
124 args_len = len(args)
125 http_method = args[0] if args_len else kwargs.get("method")
126 http_path = args[1] if args_len > 1 else kwargs.get("url")
127
128 return "ES %s %s" % (http_method, http_path)
129
[end of elasticapm/instrumentation/packages/elasticsearch.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/elasticapm/instrumentation/packages/elasticsearch.py b/elasticapm/instrumentation/packages/elasticsearch.py
--- a/elasticapm/instrumentation/packages/elasticsearch.py
+++ b/elasticapm/instrumentation/packages/elasticsearch.py
@@ -52,7 +52,7 @@
def call(self, module, method, wrapped, instance, args, kwargs):
span = execution_context.get_span()
- if isinstance(span, DroppedSpan):
+ if not span or isinstance(span, DroppedSpan):
return wrapped(*args, **kwargs)
self._update_context_by_request_data(span.context, instance, args, kwargs)
|
{"golden_diff": "diff --git a/elasticapm/instrumentation/packages/elasticsearch.py b/elasticapm/instrumentation/packages/elasticsearch.py\n--- a/elasticapm/instrumentation/packages/elasticsearch.py\n+++ b/elasticapm/instrumentation/packages/elasticsearch.py\n@@ -52,7 +52,7 @@\n \n def call(self, module, method, wrapped, instance, args, kwargs):\n span = execution_context.get_span()\n- if isinstance(span, DroppedSpan):\n+ if not span or isinstance(span, DroppedSpan):\n return wrapped(*args, **kwargs)\n \n self._update_context_by_request_data(span.context, instance, args, kwargs)\n", "issue": "enabling sniff_on_start in elasticsearch() breaks elasticserach instrumentation\n**Describe the bug**:\r\nsniff_on_start in elasticsearch with apm enabled fails the request due to a null span object\r\n```python\r\nERROR File /opt/venv/lib/python3.9/site-packages/django/utils/log.py, line 224, Internal Server Error: /api/test_view\r\nTraceback (most recent call last):\r\n File \"/opt/venv/lib/python3.9/site-packages/django/core/handlers/exception.py\", line 47, in inner\r\n response = get_response(request)\r\n File \"/opt/venv/lib/python3.9/site-packages/django/core/handlers/base.py\", line 181, in _get_response\r\n response = wrapped_callback(request, *callback_args, **callback_kwargs)\r\n File \"/usr/local/lib/python3.9/contextlib.py\", line 79, in inner\r\n return func(*args, **kwds)\r\n File \"/opt/venv/lib/python3.9/site-packages/django/views/generic/base.py\", line 70, in view\r\n return self.dispatch(request, *args, **kwargs)\r\n File \"/opt/venv/lib/python3.9/site-packages/django/views/generic/base.py\", line 98, in dispatch\r\n return handler(request, *args, **kwargs)\r\n File \"/app/api/views.py\", line 592, in get\r\n es = Elasticsearch(hosts=[\"elasticsearch\"],sniff_on_start=True)\r\n File \"/opt/venv/lib/python3.9/site-packages/elasticsearch/client/__init__.py\", line 205, in __init__\r\n self.transport = transport_class(_normalize_hosts(hosts), **kwargs)\r\n File \"/opt/venv/lib/python3.9/site-packages/elasticsearch/transport.py\", line 200, in __init__\r\n self.sniff_hosts(True)\r\n File \"/opt/venv/lib/python3.9/site-packages/elasticsearch/transport.py\", line 365, in sniff_hosts\r\n node_info = self._get_sniff_data(initial)\r\n File \"/opt/venv/lib/python3.9/site-packages/elasticsearch/transport.py\", line 308, in _get_sniff_data\r\n _, headers, node_info = c.perform_request(\r\n File \"/opt/venv/lib/python3.9/site-packages/elasticapm/instrumentation/packages/base.py\", line 210, in call_if_sampling\r\n return self.call(module, method, wrapped, instance, args, kwargs)\r\n File \"/opt/venv/lib/python3.9/site-packages/elasticapm/instrumentation/packages/elasticsearch.py\", line 58, in call\r\n self._update_context_by_request_data(span.context, instance, args, kwargs)\r\nAttributeError: 'NoneType' object has no attribute 'context'\r\n\r\n```\r\n\r\n\r\n**To Reproduce**\r\n\r\n1. setup an elasticsearch instance or a cluser and a django app\r\n2. create test view to create elasticsearch connection instance\r\n ```python\r\nfrom elasticsearch import Elasticsearch\r\nfrom django.http import HttpResponse\r\nfrom django.views import View\r\n\r\nclass TestView(View):\r\n def get(self, request, *args, **kwargs):\r\n es = Elasticsearch(hosts=[\"elasticsearch\"],sniff_on_start=True)\r\n return HttpResponse(\"Success !\")\r\n```\r\n4. curl that view \r\n\r\n**Environment**\r\n- OS: debian buster docker\r\n- Python version: 3.9\r\n- Framework and version : django 3.2.15\r\n- elasticserach-py: 7.17.14\r\n- elasticsearch: 7.15.3\r\n- APM Server version: 7.10.2\r\n- Agent version: 6.10.1\r\n\r\n\r\n\n", "before_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\nfrom __future__ import absolute_import\n\nimport re\n\nimport elasticapm\nfrom elasticapm.instrumentation.packages.base import AbstractInstrumentedModule\nfrom elasticapm.traces import DroppedSpan, execution_context\nfrom elasticapm.utils.logging import get_logger\n\nlogger = get_logger(\"elasticapm.instrument\")\n\nshould_capture_body_re = re.compile(\"/(_search|_msearch|_count|_async_search|_sql|_eql)(/|$)\")\n\n\nclass ElasticsearchConnectionInstrumentation(AbstractInstrumentedModule):\n name = \"elasticsearch_connection\"\n\n instrument_list = [\n (\"elasticsearch.connection.http_urllib3\", \"Urllib3HttpConnection.perform_request\"),\n (\"elasticsearch.connection.http_requests\", \"RequestsHttpConnection.perform_request\"),\n ]\n\n def call(self, module, method, wrapped, instance, args, kwargs):\n span = execution_context.get_span()\n if isinstance(span, DroppedSpan):\n return wrapped(*args, **kwargs)\n\n self._update_context_by_request_data(span.context, instance, args, kwargs)\n\n status_code, headers, raw_data = wrapped(*args, **kwargs)\n\n span.context[\"http\"] = {\"status_code\": status_code}\n\n return status_code, headers, raw_data\n\n def _update_context_by_request_data(self, context, instance, args, kwargs):\n args_len = len(args)\n url = args[1] if args_len > 1 else kwargs.get(\"url\")\n params = args[2] if args_len > 2 else kwargs.get(\"params\")\n body_serialized = args[3] if args_len > 3 else kwargs.get(\"body\")\n\n should_capture_body = bool(should_capture_body_re.search(url))\n\n context[\"db\"] = {\"type\": \"elasticsearch\"}\n if should_capture_body:\n query = []\n # using both q AND body is allowed in some API endpoints / ES versions,\n # but not in others. We simply capture both if they are there so the\n # user can see it.\n if params and \"q\" in params:\n # 'q' is already encoded to a byte string at this point\n # we assume utf8, which is the default\n query.append(\"q=\" + params[\"q\"].decode(\"utf-8\", errors=\"replace\"))\n if body_serialized:\n if isinstance(body_serialized, bytes):\n query.append(body_serialized.decode(\"utf-8\", errors=\"replace\"))\n else:\n query.append(body_serialized)\n if query:\n context[\"db\"][\"statement\"] = \"\\n\\n\".join(query)\n\n context[\"destination\"] = {\n \"address\": instance.host,\n }\n\n\nclass ElasticsearchTransportInstrumentation(AbstractInstrumentedModule):\n name = \"elasticsearch_connection\"\n\n instrument_list = [\n (\"elasticsearch.transport\", \"Transport.perform_request\"),\n ]\n\n def call(self, module, method, wrapped, instance, args, kwargs):\n with elasticapm.capture_span(\n self._get_signature(args, kwargs),\n span_type=\"db\",\n span_subtype=\"elasticsearch\",\n span_action=\"query\",\n extra={},\n skip_frames=2,\n leaf=True,\n ) as span:\n result_data = wrapped(*args, **kwargs)\n\n try:\n span.context[\"db\"][\"rows_affected\"] = result_data[\"hits\"][\"total\"][\"value\"]\n except (KeyError, TypeError):\n pass\n\n return result_data\n\n def _get_signature(self, args, kwargs):\n args_len = len(args)\n http_method = args[0] if args_len else kwargs.get(\"method\")\n http_path = args[1] if args_len > 1 else kwargs.get(\"url\")\n\n return \"ES %s %s\" % (http_method, http_path)\n", "path": "elasticapm/instrumentation/packages/elasticsearch.py"}]}
| 2,779 | 144 |
gh_patches_debug_39737
|
rasdani/github-patches
|
git_diff
|
xorbitsai__inference-282
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
FEAT: PyTorch model embeddings
</issue>
<code>
[start of xinference/model/llm/pytorch/core.py]
1 # Copyright 2022-2023 XProbe Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import logging
16 from typing import Iterator, List, Optional, TypedDict, Union
17
18 from ....constants import XINFERENCE_CACHE_DIR
19 from ....types import (
20 ChatCompletion,
21 ChatCompletionChunk,
22 ChatCompletionMessage,
23 Completion,
24 CompletionChunk,
25 Embedding,
26 )
27 from ..core import LLM
28 from ..llm_family import LLMFamilyV1, LLMSpecV1
29 from ..utils import ChatModelMixin
30
31 logger = logging.getLogger(__name__)
32
33
34 class PytorchGenerateConfig(TypedDict, total=False):
35 temperature: float
36 repetition_penalty: float
37 top_p: float
38 top_k: int
39 stream: bool
40 max_new_tokens: int
41 echo: bool
42 stop: Optional[Union[str, List[str]]]
43 stop_token_ids: Optional[Union[int, List[int]]]
44 stream_interval: int
45 model: Optional[str]
46
47
48 class PytorchModelConfig(TypedDict, total=False):
49 revision: str
50 device: str
51 gpus: Optional[str]
52 num_gpus: int
53 max_gpu_memory: str
54 gptq_ckpt: Optional[str]
55 gptq_wbits: int
56 gptq_groupsize: int
57 gptq_act_order: bool
58
59
60 class PytorchModel(LLM):
61 def __init__(
62 self,
63 model_uid: str,
64 model_family: "LLMFamilyV1",
65 model_spec: "LLMSpecV1",
66 quantization: str,
67 model_path: str,
68 pytorch_model_config: Optional[PytorchModelConfig] = None,
69 ):
70 super().__init__(model_uid, model_family, model_spec, quantization, model_path)
71 self._use_fast_tokenizer = True
72 self._pytorch_model_config: PytorchModelConfig = self._sanitize_model_config(
73 pytorch_model_config
74 )
75
76 def _sanitize_model_config(
77 self, pytorch_model_config: Optional[PytorchModelConfig]
78 ) -> PytorchModelConfig:
79 if pytorch_model_config is None:
80 pytorch_model_config = PytorchModelConfig()
81 pytorch_model_config.setdefault("revision", "main")
82 pytorch_model_config.setdefault("gpus", None)
83 pytorch_model_config.setdefault("num_gpus", 1)
84 pytorch_model_config.setdefault("gptq_ckpt", None)
85 pytorch_model_config.setdefault("gptq_wbits", 16)
86 pytorch_model_config.setdefault("gptq_groupsize", -1)
87 pytorch_model_config.setdefault("gptq_act_order", False)
88 if self._is_darwin_and_apple_silicon():
89 pytorch_model_config.setdefault("device", "mps")
90 else:
91 pytorch_model_config.setdefault("device", "cuda")
92 return pytorch_model_config
93
94 def _sanitize_generate_config(
95 self,
96 pytorch_generate_config: Optional[PytorchGenerateConfig],
97 ) -> PytorchGenerateConfig:
98 if pytorch_generate_config is None:
99 pytorch_generate_config = PytorchGenerateConfig()
100 pytorch_generate_config.setdefault("temperature", 0.7)
101 pytorch_generate_config.setdefault("repetition_penalty", 1.0)
102 pytorch_generate_config.setdefault("max_new_tokens", 512)
103 pytorch_generate_config.setdefault("stream_interval", 2)
104 pytorch_generate_config["model"] = self.model_uid
105 return pytorch_generate_config
106
107 def _load_model(self, kwargs: dict):
108 try:
109 from transformers import AutoModelForCausalLM, AutoTokenizer
110 except ImportError:
111 error_message = "Failed to import module 'transformers'"
112 installation_guide = [
113 "Please make sure 'transformers' is installed. ",
114 "You can install it by `pip install transformers`\n",
115 ]
116
117 raise ImportError(f"{error_message}\n\n{''.join(installation_guide)}")
118
119 tokenizer = AutoTokenizer.from_pretrained(
120 self.model_path,
121 use_fast=self._use_fast_tokenizer,
122 revision=kwargs["revision"],
123 cache_dir=XINFERENCE_CACHE_DIR,
124 )
125 model = AutoModelForCausalLM.from_pretrained(
126 self.model_path,
127 low_cpu_mem_usage=True,
128 cache_dir=XINFERENCE_CACHE_DIR,
129 **kwargs,
130 )
131 return model, tokenizer
132
133 def load(self):
134 try:
135 import torch
136 except ImportError:
137 raise ImportError(
138 f"Failed to import module 'torch'. Please make sure 'torch' is installed.\n\n"
139 )
140 from .compression import load_compress_model
141
142 quantization = self.quantization
143 num_gpus = self._pytorch_model_config.get("num_gpus", 1)
144 if self._is_darwin_and_apple_silicon():
145 device = self._pytorch_model_config.get("device", "mps")
146 else:
147 device = self._pytorch_model_config.get("device", "cuda")
148
149 if device == "cpu":
150 kwargs = {"torch_dtype": torch.float32}
151 elif device == "cuda":
152 kwargs = {"torch_dtype": torch.float16}
153 elif device == "mps":
154 kwargs = {"torch_dtype": torch.float16}
155 else:
156 raise ValueError(f"Device {device} is not supported in temporary")
157 kwargs["revision"] = self._pytorch_model_config.get("revision", "main")
158
159 if quantization != "none":
160 if device == "cuda" and self._is_linux():
161 kwargs["device_map"] = "auto"
162 if quantization == "4-bit":
163 kwargs["load_in_4bit"] = True
164 elif quantization == "8-bit":
165 kwargs["load_in_8bit"] = True
166 else:
167 raise ValueError(
168 f"Quantization {quantization} is not supported in temporary"
169 )
170 else:
171 if num_gpus != 1:
172 raise ValueError(f"Quantization is not supported for multi-gpu")
173 elif quantization != "8-bit":
174 raise ValueError(
175 f"Only 8-bit quantization is supported if it is not linux system or cuda device"
176 )
177 else:
178 self._model, self._tokenizer = load_compress_model(
179 model_path=self.model_path,
180 device=device,
181 torch_dtype=kwargs["torch_dtype"],
182 use_fast=self._use_fast_tokenizer,
183 revision=kwargs["revision"],
184 )
185 logger.debug(f"Model Memory: {self._model.get_memory_footprint()}")
186 return
187
188 self._model, self._tokenizer = self._load_model(kwargs)
189
190 if (
191 device == "cuda" and num_gpus == 1 and quantization == "none"
192 ) or device == "mps":
193 self._model.to(device)
194 logger.debug(f"Model Memory: {self._model.get_memory_footprint()}")
195
196 @classmethod
197 def match(cls, llm_family: "LLMFamilyV1", llm_spec: "LLMSpecV1") -> bool:
198 if llm_spec.model_format != "pytorch":
199 return False
200 if "baichuan" in llm_family.model_name:
201 return False
202 if "generate" not in llm_family.model_ability:
203 return False
204 return True
205
206 def generate(
207 self, prompt: str, generate_config: Optional[PytorchGenerateConfig] = None
208 ) -> Union[Completion, Iterator[CompletionChunk]]:
209 from .utils import generate_stream
210
211 def generator_wrapper(
212 prompt: str, device: str, generate_config: PytorchGenerateConfig
213 ) -> Iterator[CompletionChunk]:
214 for completion_chunk, _ in generate_stream(
215 self._model, self._tokenizer, prompt, device, generate_config
216 ):
217 yield completion_chunk
218
219 logger.debug(
220 "Enter generate, prompt: %s, generate config: %s", prompt, generate_config
221 )
222
223 generate_config = self._sanitize_generate_config(generate_config)
224
225 assert self._model is not None
226 assert self._tokenizer is not None
227
228 stream = generate_config.get("stream", False)
229 if self._is_darwin_and_apple_silicon():
230 device = self._pytorch_model_config.get("device", "mps")
231 else:
232 device = self._pytorch_model_config.get("device", "cuda")
233 if not stream:
234 for completion_chunk, completion_usage in generate_stream(
235 self._model, self._tokenizer, prompt, device, generate_config
236 ):
237 pass
238 completion = Completion(
239 id=completion_chunk["id"],
240 object=completion_chunk["object"],
241 created=completion_chunk["created"],
242 model=completion_chunk["model"],
243 choices=completion_chunk["choices"],
244 usage=completion_usage,
245 )
246 return completion
247 else:
248 return generator_wrapper(prompt, device, generate_config)
249
250 def create_embedding(self, input: Union[str, List[str]]) -> Embedding:
251 raise NotImplementedError
252
253
254 class PytorchChatModel(PytorchModel, ChatModelMixin):
255 def __init__(
256 self,
257 model_uid: str,
258 model_family: "LLMFamilyV1",
259 model_spec: "LLMSpecV1",
260 quantization: str,
261 model_path: str,
262 pytorch_model_config: Optional[PytorchModelConfig] = None,
263 ):
264 super().__init__(
265 model_uid,
266 model_family,
267 model_spec,
268 quantization,
269 model_path,
270 pytorch_model_config,
271 )
272
273 def _sanitize_generate_config(
274 self,
275 pytorch_generate_config: Optional[PytorchGenerateConfig],
276 ) -> PytorchGenerateConfig:
277 pytorch_generate_config = super()._sanitize_generate_config(
278 pytorch_generate_config
279 )
280 if (
281 "stop" not in pytorch_generate_config
282 and self.model_family.prompt_style
283 and self.model_family.prompt_style.stop
284 ):
285 pytorch_generate_config["stop"] = self.model_family.prompt_style.stop
286 if (
287 "stop_token_ids" not in pytorch_generate_config
288 and self.model_family.prompt_style
289 and self.model_family.prompt_style.stop_token_ids
290 ):
291 pytorch_generate_config[
292 "stop_token_ids"
293 ] = self.model_family.prompt_style.stop_token_ids
294
295 return pytorch_generate_config
296
297 @classmethod
298 def match(cls, llm_family: "LLMFamilyV1", llm_spec: "LLMSpecV1") -> bool:
299 if llm_spec.model_format != "pytorch":
300 return False
301 if "baichuan" in llm_family.model_name:
302 return False
303 if "chat" not in llm_family.model_ability:
304 return False
305 return True
306
307 def chat(
308 self,
309 prompt: str,
310 system_prompt: Optional[str] = None,
311 chat_history: Optional[List[ChatCompletionMessage]] = None,
312 generate_config: Optional[PytorchGenerateConfig] = None,
313 ) -> Union[ChatCompletion, Iterator[ChatCompletionChunk]]:
314 assert self.model_family.prompt_style is not None
315 prompt_style = self.model_family.prompt_style.copy()
316 if system_prompt:
317 prompt_style.system_prompt = system_prompt
318 chat_history = chat_history or []
319 full_prompt = self.get_prompt(prompt, chat_history, prompt_style)
320
321 generate_config = self._sanitize_generate_config(generate_config)
322
323 stream = generate_config.get("stream", False)
324 if stream:
325 it = self.generate(full_prompt, generate_config)
326 assert isinstance(it, Iterator)
327 return self._convert_chat_completion_chunks_to_chat(it)
328 else:
329 c = self.generate(full_prompt, generate_config)
330 assert not isinstance(c, Iterator)
331 return self._convert_text_completion_to_chat(c)
332
[end of xinference/model/llm/pytorch/core.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/xinference/model/llm/pytorch/core.py b/xinference/model/llm/pytorch/core.py
--- a/xinference/model/llm/pytorch/core.py
+++ b/xinference/model/llm/pytorch/core.py
@@ -23,6 +23,8 @@
Completion,
CompletionChunk,
Embedding,
+ EmbeddingData,
+ EmbeddingUsage,
)
from ..core import LLM
from ..llm_family import LLMFamilyV1, LLMSpecV1
@@ -248,7 +250,85 @@
return generator_wrapper(prompt, device, generate_config)
def create_embedding(self, input: Union[str, List[str]]) -> Embedding:
- raise NotImplementedError
+ try:
+ import torch
+ import torch.nn.functional as F
+ except ImportError as e:
+ raise ImportError(
+ "Could not import torch. Please install it with `pip install torch`."
+ ) from e
+
+ if self._is_darwin_and_apple_silicon():
+ device = self._pytorch_model_config.get("device", "mps")
+ else:
+ device = self._pytorch_model_config.get("device", "cuda")
+
+ if isinstance(input, str):
+ inputs = [input]
+ else:
+ inputs = input
+
+ tokenizer = self._tokenizer
+ is_llama = "llama" in str(type(self._model)) # llama supports batch inference
+ is_chatglm = "chatglm" in str(type(self._model))
+ if is_llama:
+ encoding = tokenizer.batch_encode_plus(
+ inputs, padding=True, return_tensors="pt"
+ )
+ input_ids = encoding["input_ids"].to(device)
+ attention_mask = encoding["attention_mask"].to(device)
+ model_output = self._model(
+ input_ids, attention_mask, output_hidden_states=True
+ )
+ data = model_output.hidden_states[-1]
+ mask = attention_mask.unsqueeze(-1).expand(data.size()).float()
+ masked_embeddings = data * mask
+ sum_embeddings = torch.sum(masked_embeddings, dim=1)
+ seq_length = torch.sum(mask, dim=1)
+ embedding = sum_embeddings / seq_length
+ normalized_embeddings = F.normalize(embedding, p=2, dim=1)
+ normalized_embeddings = normalized_embeddings.tolist()
+ token_num = torch.sum(attention_mask).item()
+
+ embedding_list = []
+ for index, data in enumerate(normalized_embeddings):
+ embedding_list.append(
+ EmbeddingData(index=index, object="embedding", embedding=data)
+ )
+
+ usage = EmbeddingUsage(prompt_tokens=token_num, total_tokens=token_num)
+
+ ret = Embedding(
+ object="list",
+ model=self.model_uid,
+ data=embedding_list,
+ usage=usage,
+ )
+
+ else:
+ embedding = []
+ token_num = 0
+ for index, text in enumerate(inputs):
+ input_ids = tokenizer.encode(text, return_tensors="pt").to(device)
+ model_output = self._model(input_ids, output_hidden_states=True)
+ if is_chatglm:
+ data = (model_output.hidden_states[-1].transpose(0, 1))[0]
+ else:
+ data = model_output.hidden_states[-1][0]
+ data = F.normalize(torch.mean(data, dim=0), p=2, dim=0)
+ data = data.tolist()
+
+ embedding.append(
+ EmbeddingData(index=index, object="embedding", embedding=data)
+ )
+ token_num += len(input_ids[0])
+
+ usage = EmbeddingUsage(prompt_tokens=token_num, total_tokens=token_num)
+ ret = Embedding(
+ object="list", model=self.model_uid, data=embedding, usage=usage
+ )
+
+ return ret
class PytorchChatModel(PytorchModel, ChatModelMixin):
|
{"golden_diff": "diff --git a/xinference/model/llm/pytorch/core.py b/xinference/model/llm/pytorch/core.py\n--- a/xinference/model/llm/pytorch/core.py\n+++ b/xinference/model/llm/pytorch/core.py\n@@ -23,6 +23,8 @@\n Completion,\n CompletionChunk,\n Embedding,\n+ EmbeddingData,\n+ EmbeddingUsage,\n )\n from ..core import LLM\n from ..llm_family import LLMFamilyV1, LLMSpecV1\n@@ -248,7 +250,85 @@\n return generator_wrapper(prompt, device, generate_config)\n \n def create_embedding(self, input: Union[str, List[str]]) -> Embedding:\n- raise NotImplementedError\n+ try:\n+ import torch\n+ import torch.nn.functional as F\n+ except ImportError as e:\n+ raise ImportError(\n+ \"Could not import torch. Please install it with `pip install torch`.\"\n+ ) from e\n+\n+ if self._is_darwin_and_apple_silicon():\n+ device = self._pytorch_model_config.get(\"device\", \"mps\")\n+ else:\n+ device = self._pytorch_model_config.get(\"device\", \"cuda\")\n+\n+ if isinstance(input, str):\n+ inputs = [input]\n+ else:\n+ inputs = input\n+\n+ tokenizer = self._tokenizer\n+ is_llama = \"llama\" in str(type(self._model)) # llama supports batch inference\n+ is_chatglm = \"chatglm\" in str(type(self._model))\n+ if is_llama:\n+ encoding = tokenizer.batch_encode_plus(\n+ inputs, padding=True, return_tensors=\"pt\"\n+ )\n+ input_ids = encoding[\"input_ids\"].to(device)\n+ attention_mask = encoding[\"attention_mask\"].to(device)\n+ model_output = self._model(\n+ input_ids, attention_mask, output_hidden_states=True\n+ )\n+ data = model_output.hidden_states[-1]\n+ mask = attention_mask.unsqueeze(-1).expand(data.size()).float()\n+ masked_embeddings = data * mask\n+ sum_embeddings = torch.sum(masked_embeddings, dim=1)\n+ seq_length = torch.sum(mask, dim=1)\n+ embedding = sum_embeddings / seq_length\n+ normalized_embeddings = F.normalize(embedding, p=2, dim=1)\n+ normalized_embeddings = normalized_embeddings.tolist()\n+ token_num = torch.sum(attention_mask).item()\n+\n+ embedding_list = []\n+ for index, data in enumerate(normalized_embeddings):\n+ embedding_list.append(\n+ EmbeddingData(index=index, object=\"embedding\", embedding=data)\n+ )\n+\n+ usage = EmbeddingUsage(prompt_tokens=token_num, total_tokens=token_num)\n+\n+ ret = Embedding(\n+ object=\"list\",\n+ model=self.model_uid,\n+ data=embedding_list,\n+ usage=usage,\n+ )\n+\n+ else:\n+ embedding = []\n+ token_num = 0\n+ for index, text in enumerate(inputs):\n+ input_ids = tokenizer.encode(text, return_tensors=\"pt\").to(device)\n+ model_output = self._model(input_ids, output_hidden_states=True)\n+ if is_chatglm:\n+ data = (model_output.hidden_states[-1].transpose(0, 1))[0]\n+ else:\n+ data = model_output.hidden_states[-1][0]\n+ data = F.normalize(torch.mean(data, dim=0), p=2, dim=0)\n+ data = data.tolist()\n+\n+ embedding.append(\n+ EmbeddingData(index=index, object=\"embedding\", embedding=data)\n+ )\n+ token_num += len(input_ids[0])\n+\n+ usage = EmbeddingUsage(prompt_tokens=token_num, total_tokens=token_num)\n+ ret = Embedding(\n+ object=\"list\", model=self.model_uid, data=embedding, usage=usage\n+ )\n+\n+ return ret\n \n \n class PytorchChatModel(PytorchModel, ChatModelMixin):\n", "issue": "FEAT: PyTorch model embeddings\n\n", "before_files": [{"content": "# Copyright 2022-2023 XProbe Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nfrom typing import Iterator, List, Optional, TypedDict, Union\n\nfrom ....constants import XINFERENCE_CACHE_DIR\nfrom ....types import (\n ChatCompletion,\n ChatCompletionChunk,\n ChatCompletionMessage,\n Completion,\n CompletionChunk,\n Embedding,\n)\nfrom ..core import LLM\nfrom ..llm_family import LLMFamilyV1, LLMSpecV1\nfrom ..utils import ChatModelMixin\n\nlogger = logging.getLogger(__name__)\n\n\nclass PytorchGenerateConfig(TypedDict, total=False):\n temperature: float\n repetition_penalty: float\n top_p: float\n top_k: int\n stream: bool\n max_new_tokens: int\n echo: bool\n stop: Optional[Union[str, List[str]]]\n stop_token_ids: Optional[Union[int, List[int]]]\n stream_interval: int\n model: Optional[str]\n\n\nclass PytorchModelConfig(TypedDict, total=False):\n revision: str\n device: str\n gpus: Optional[str]\n num_gpus: int\n max_gpu_memory: str\n gptq_ckpt: Optional[str]\n gptq_wbits: int\n gptq_groupsize: int\n gptq_act_order: bool\n\n\nclass PytorchModel(LLM):\n def __init__(\n self,\n model_uid: str,\n model_family: \"LLMFamilyV1\",\n model_spec: \"LLMSpecV1\",\n quantization: str,\n model_path: str,\n pytorch_model_config: Optional[PytorchModelConfig] = None,\n ):\n super().__init__(model_uid, model_family, model_spec, quantization, model_path)\n self._use_fast_tokenizer = True\n self._pytorch_model_config: PytorchModelConfig = self._sanitize_model_config(\n pytorch_model_config\n )\n\n def _sanitize_model_config(\n self, pytorch_model_config: Optional[PytorchModelConfig]\n ) -> PytorchModelConfig:\n if pytorch_model_config is None:\n pytorch_model_config = PytorchModelConfig()\n pytorch_model_config.setdefault(\"revision\", \"main\")\n pytorch_model_config.setdefault(\"gpus\", None)\n pytorch_model_config.setdefault(\"num_gpus\", 1)\n pytorch_model_config.setdefault(\"gptq_ckpt\", None)\n pytorch_model_config.setdefault(\"gptq_wbits\", 16)\n pytorch_model_config.setdefault(\"gptq_groupsize\", -1)\n pytorch_model_config.setdefault(\"gptq_act_order\", False)\n if self._is_darwin_and_apple_silicon():\n pytorch_model_config.setdefault(\"device\", \"mps\")\n else:\n pytorch_model_config.setdefault(\"device\", \"cuda\")\n return pytorch_model_config\n\n def _sanitize_generate_config(\n self,\n pytorch_generate_config: Optional[PytorchGenerateConfig],\n ) -> PytorchGenerateConfig:\n if pytorch_generate_config is None:\n pytorch_generate_config = PytorchGenerateConfig()\n pytorch_generate_config.setdefault(\"temperature\", 0.7)\n pytorch_generate_config.setdefault(\"repetition_penalty\", 1.0)\n pytorch_generate_config.setdefault(\"max_new_tokens\", 512)\n pytorch_generate_config.setdefault(\"stream_interval\", 2)\n pytorch_generate_config[\"model\"] = self.model_uid\n return pytorch_generate_config\n\n def _load_model(self, kwargs: dict):\n try:\n from transformers import AutoModelForCausalLM, AutoTokenizer\n except ImportError:\n error_message = \"Failed to import module 'transformers'\"\n installation_guide = [\n \"Please make sure 'transformers' is installed. \",\n \"You can install it by `pip install transformers`\\n\",\n ]\n\n raise ImportError(f\"{error_message}\\n\\n{''.join(installation_guide)}\")\n\n tokenizer = AutoTokenizer.from_pretrained(\n self.model_path,\n use_fast=self._use_fast_tokenizer,\n revision=kwargs[\"revision\"],\n cache_dir=XINFERENCE_CACHE_DIR,\n )\n model = AutoModelForCausalLM.from_pretrained(\n self.model_path,\n low_cpu_mem_usage=True,\n cache_dir=XINFERENCE_CACHE_DIR,\n **kwargs,\n )\n return model, tokenizer\n\n def load(self):\n try:\n import torch\n except ImportError:\n raise ImportError(\n f\"Failed to import module 'torch'. Please make sure 'torch' is installed.\\n\\n\"\n )\n from .compression import load_compress_model\n\n quantization = self.quantization\n num_gpus = self._pytorch_model_config.get(\"num_gpus\", 1)\n if self._is_darwin_and_apple_silicon():\n device = self._pytorch_model_config.get(\"device\", \"mps\")\n else:\n device = self._pytorch_model_config.get(\"device\", \"cuda\")\n\n if device == \"cpu\":\n kwargs = {\"torch_dtype\": torch.float32}\n elif device == \"cuda\":\n kwargs = {\"torch_dtype\": torch.float16}\n elif device == \"mps\":\n kwargs = {\"torch_dtype\": torch.float16}\n else:\n raise ValueError(f\"Device {device} is not supported in temporary\")\n kwargs[\"revision\"] = self._pytorch_model_config.get(\"revision\", \"main\")\n\n if quantization != \"none\":\n if device == \"cuda\" and self._is_linux():\n kwargs[\"device_map\"] = \"auto\"\n if quantization == \"4-bit\":\n kwargs[\"load_in_4bit\"] = True\n elif quantization == \"8-bit\":\n kwargs[\"load_in_8bit\"] = True\n else:\n raise ValueError(\n f\"Quantization {quantization} is not supported in temporary\"\n )\n else:\n if num_gpus != 1:\n raise ValueError(f\"Quantization is not supported for multi-gpu\")\n elif quantization != \"8-bit\":\n raise ValueError(\n f\"Only 8-bit quantization is supported if it is not linux system or cuda device\"\n )\n else:\n self._model, self._tokenizer = load_compress_model(\n model_path=self.model_path,\n device=device,\n torch_dtype=kwargs[\"torch_dtype\"],\n use_fast=self._use_fast_tokenizer,\n revision=kwargs[\"revision\"],\n )\n logger.debug(f\"Model Memory: {self._model.get_memory_footprint()}\")\n return\n\n self._model, self._tokenizer = self._load_model(kwargs)\n\n if (\n device == \"cuda\" and num_gpus == 1 and quantization == \"none\"\n ) or device == \"mps\":\n self._model.to(device)\n logger.debug(f\"Model Memory: {self._model.get_memory_footprint()}\")\n\n @classmethod\n def match(cls, llm_family: \"LLMFamilyV1\", llm_spec: \"LLMSpecV1\") -> bool:\n if llm_spec.model_format != \"pytorch\":\n return False\n if \"baichuan\" in llm_family.model_name:\n return False\n if \"generate\" not in llm_family.model_ability:\n return False\n return True\n\n def generate(\n self, prompt: str, generate_config: Optional[PytorchGenerateConfig] = None\n ) -> Union[Completion, Iterator[CompletionChunk]]:\n from .utils import generate_stream\n\n def generator_wrapper(\n prompt: str, device: str, generate_config: PytorchGenerateConfig\n ) -> Iterator[CompletionChunk]:\n for completion_chunk, _ in generate_stream(\n self._model, self._tokenizer, prompt, device, generate_config\n ):\n yield completion_chunk\n\n logger.debug(\n \"Enter generate, prompt: %s, generate config: %s\", prompt, generate_config\n )\n\n generate_config = self._sanitize_generate_config(generate_config)\n\n assert self._model is not None\n assert self._tokenizer is not None\n\n stream = generate_config.get(\"stream\", False)\n if self._is_darwin_and_apple_silicon():\n device = self._pytorch_model_config.get(\"device\", \"mps\")\n else:\n device = self._pytorch_model_config.get(\"device\", \"cuda\")\n if not stream:\n for completion_chunk, completion_usage in generate_stream(\n self._model, self._tokenizer, prompt, device, generate_config\n ):\n pass\n completion = Completion(\n id=completion_chunk[\"id\"],\n object=completion_chunk[\"object\"],\n created=completion_chunk[\"created\"],\n model=completion_chunk[\"model\"],\n choices=completion_chunk[\"choices\"],\n usage=completion_usage,\n )\n return completion\n else:\n return generator_wrapper(prompt, device, generate_config)\n\n def create_embedding(self, input: Union[str, List[str]]) -> Embedding:\n raise NotImplementedError\n\n\nclass PytorchChatModel(PytorchModel, ChatModelMixin):\n def __init__(\n self,\n model_uid: str,\n model_family: \"LLMFamilyV1\",\n model_spec: \"LLMSpecV1\",\n quantization: str,\n model_path: str,\n pytorch_model_config: Optional[PytorchModelConfig] = None,\n ):\n super().__init__(\n model_uid,\n model_family,\n model_spec,\n quantization,\n model_path,\n pytorch_model_config,\n )\n\n def _sanitize_generate_config(\n self,\n pytorch_generate_config: Optional[PytorchGenerateConfig],\n ) -> PytorchGenerateConfig:\n pytorch_generate_config = super()._sanitize_generate_config(\n pytorch_generate_config\n )\n if (\n \"stop\" not in pytorch_generate_config\n and self.model_family.prompt_style\n and self.model_family.prompt_style.stop\n ):\n pytorch_generate_config[\"stop\"] = self.model_family.prompt_style.stop\n if (\n \"stop_token_ids\" not in pytorch_generate_config\n and self.model_family.prompt_style\n and self.model_family.prompt_style.stop_token_ids\n ):\n pytorch_generate_config[\n \"stop_token_ids\"\n ] = self.model_family.prompt_style.stop_token_ids\n\n return pytorch_generate_config\n\n @classmethod\n def match(cls, llm_family: \"LLMFamilyV1\", llm_spec: \"LLMSpecV1\") -> bool:\n if llm_spec.model_format != \"pytorch\":\n return False\n if \"baichuan\" in llm_family.model_name:\n return False\n if \"chat\" not in llm_family.model_ability:\n return False\n return True\n\n def chat(\n self,\n prompt: str,\n system_prompt: Optional[str] = None,\n chat_history: Optional[List[ChatCompletionMessage]] = None,\n generate_config: Optional[PytorchGenerateConfig] = None,\n ) -> Union[ChatCompletion, Iterator[ChatCompletionChunk]]:\n assert self.model_family.prompt_style is not None\n prompt_style = self.model_family.prompt_style.copy()\n if system_prompt:\n prompt_style.system_prompt = system_prompt\n chat_history = chat_history or []\n full_prompt = self.get_prompt(prompt, chat_history, prompt_style)\n\n generate_config = self._sanitize_generate_config(generate_config)\n\n stream = generate_config.get(\"stream\", False)\n if stream:\n it = self.generate(full_prompt, generate_config)\n assert isinstance(it, Iterator)\n return self._convert_chat_completion_chunks_to_chat(it)\n else:\n c = self.generate(full_prompt, generate_config)\n assert not isinstance(c, Iterator)\n return self._convert_text_completion_to_chat(c)\n", "path": "xinference/model/llm/pytorch/core.py"}]}
| 4,090 | 887 |
gh_patches_debug_34268
|
rasdani/github-patches
|
git_diff
|
AUTOMATIC1111__stable-diffusion-webui-9513
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug]: UnidentifiedImageError when using "Batch Process" in "Extras"
### Is there an existing issue for this?
- [X] I have searched the existing issues and checked the recent builds/commits
### What happened?
Hello,
I'm trying to upscale a bunch of images in the "Extras" Tab. When I pick an image in the "Single Image" tab it works perfectly fine. But when I pick the exact same imagefile in the "Batch Process" and hit "Generate" I instantly get this error message in the UI:
UnidentifiedImageError: cannot identify image file <tempfile._TemporaryFileWrapper object at 0x000001F589DBF1F0>
Time taken: 0.00sTorch active/reserved: 1/2 MiB, Sys VRAM: 1277/4096 MiB (31.18%)
In the CMD it looks like this:
Error completing request
Arguments: (1, <PIL.Image.Image image mode=RGB size=960x1200 at 0x1F589DBF160>, [<tempfile._TemporaryFileWrapper object at 0x000001F589DBF1F0>], '', '', True, 0, 4, 512, 512, True, 'SwinIR_4x', 'None', 0, 0, 0, 0) {}
Traceback (most recent call last):
File "C:\AI\stable-diffusion-webui\modules\call_queue.py", line 56, in f
res = list(func(*args, **kwargs))
File "C:\AI\stable-diffusion-webui\modules\call_queue.py", line 37, in f
res = func(*args, **kwargs)
File "C:\AI\stable-diffusion-webui\modules\postprocessing.py", line 21, in run_postprocessing
image = Image.open(img)
File "C:\AI\stable-diffusion-webui\venv\lib\site-packages\PIL\Image.py", line 3283, in open
raise UnidentifiedImageError(msg)
PIL.UnidentifiedImageError: cannot identify image file <tempfile._TemporaryFileWrapper object at 0x000001F589DBF1F0>
### Steps to reproduce the problem
1. Go to .... Extras, Batch Process
2. Press .... Import to add the image, and press Generate
### What should have happened?
It should create the upscaled image, just like in the Single Image tab.
### Commit where the problem happens
a0d07fb5
### What platforms do you use to access the UI ?
Windows
### What browsers do you use to access the UI ?
Google Chrome
### Command Line Arguments
```Shell
git pull
pause
--xformers --medvram
```
### List of extensions
no
### Console logs
```Shell
C:\AI\stable-diffusion-webui>git pull
Already up to date.
C:\AI\stable-diffusion-webui>pause
Drücken Sie eine beliebige Taste . . .
venv "C:\AI\stable-diffusion-webui\venv\Scripts\Python.exe"
Python 3.10.10 (tags/v3.10.10:aad5f6a, Feb 7 2023, 17:20:36) [MSC v.1929 64 bit (AMD64)]
Commit hash: a0d07fb5807ad55c8ccfdfc9a6d9ae3c62b9d211
Installing requirements for Web UI
Launching Web UI with arguments: --xformers --medvram
Loading weights [cc6cb27103] from C:\AI\stable-diffusion-webui\models\Stable-diffusion\model.ckpt
Creating model from config: C:\AI\stable-diffusion-webui\configs\v1-inference.yaml
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
Applying cross attention optimization (Doggettx).
Textual inversion embeddings loaded(0):
Model loaded in 3.2s (load weights from disk: 1.6s, create model: 0.5s, apply weights to model: 0.5s, apply half(): 0.6s).
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
Startup time: 12.3s (import torch: 2.7s, import gradio: 1.5s, import ldm: 0.4s, other imports: 1.3s, setup codeformer: 0.1s, load scripts: 2.2s, load SD checkpoint: 3.5s, create ui: 0.3s, gradio launch: 0.1s).
Error completing request
Arguments: (1, None, [<tempfile._TemporaryFileWrapper object at 0x000001E5841F11E0>], '', '', True, 0, 4, 512, 512, True, 'None', 'None', 0, 0, 0, 0) {}
Traceback (most recent call last):
File "C:\AI\stable-diffusion-webui\modules\call_queue.py", line 56, in f
res = list(func(*args, **kwargs))
File "C:\AI\stable-diffusion-webui\modules\call_queue.py", line 37, in f
res = func(*args, **kwargs)
File "C:\AI\stable-diffusion-webui\modules\postprocessing.py", line 21, in run_postprocessing
image = Image.open(img)
File "C:\AI\stable-diffusion-webui\venv\lib\site-packages\PIL\Image.py", line 3283, in open
raise UnidentifiedImageError(msg)
PIL.UnidentifiedImageError: cannot identify image file <tempfile._TemporaryFileWrapper object at 0x000001E5841F11E0>
```
### Additional information
_No response_
</issue>
<code>
[start of modules/ui_postprocessing.py]
1 import gradio as gr
2 from modules import scripts_postprocessing, scripts, shared, gfpgan_model, codeformer_model, ui_common, postprocessing, call_queue
3 import modules.generation_parameters_copypaste as parameters_copypaste
4
5
6 def create_ui():
7 tab_index = gr.State(value=0)
8
9 with gr.Row().style(equal_height=False, variant='compact'):
10 with gr.Column(variant='compact'):
11 with gr.Tabs(elem_id="mode_extras"):
12 with gr.TabItem('Single Image', elem_id="extras_single_tab") as tab_single:
13 extras_image = gr.Image(label="Source", source="upload", interactive=True, type="pil", elem_id="extras_image")
14
15 with gr.TabItem('Batch Process', elem_id="extras_batch_process_tab") as tab_batch:
16 image_batch = gr.File(label="Batch Process", file_count="multiple", interactive=True, type="file", elem_id="extras_image_batch")
17
18 with gr.TabItem('Batch from Directory', elem_id="extras_batch_directory_tab") as tab_batch_dir:
19 extras_batch_input_dir = gr.Textbox(label="Input directory", **shared.hide_dirs, placeholder="A directory on the same machine where the server is running.", elem_id="extras_batch_input_dir")
20 extras_batch_output_dir = gr.Textbox(label="Output directory", **shared.hide_dirs, placeholder="Leave blank to save images to the default path.", elem_id="extras_batch_output_dir")
21 show_extras_results = gr.Checkbox(label='Show result images', value=True, elem_id="extras_show_extras_results")
22
23 submit = gr.Button('Generate', elem_id="extras_generate", variant='primary')
24
25 script_inputs = scripts.scripts_postproc.setup_ui()
26
27 with gr.Column():
28 result_images, html_info_x, html_info, html_log = ui_common.create_output_panel("extras", shared.opts.outdir_extras_samples)
29
30 tab_single.select(fn=lambda: 0, inputs=[], outputs=[tab_index])
31 tab_batch.select(fn=lambda: 1, inputs=[], outputs=[tab_index])
32 tab_batch_dir.select(fn=lambda: 2, inputs=[], outputs=[tab_index])
33
34 submit.click(
35 fn=call_queue.wrap_gradio_gpu_call(postprocessing.run_postprocessing, extra_outputs=[None, '']),
36 inputs=[
37 tab_index,
38 extras_image,
39 image_batch,
40 extras_batch_input_dir,
41 extras_batch_output_dir,
42 show_extras_results,
43 *script_inputs
44 ],
45 outputs=[
46 result_images,
47 html_info_x,
48 html_info,
49 ]
50 )
51
52 parameters_copypaste.add_paste_fields("extras", extras_image, None)
53
54 extras_image.change(
55 fn=scripts.scripts_postproc.image_changed,
56 inputs=[], outputs=[]
57 )
58
[end of modules/ui_postprocessing.py]
[start of modules/postprocessing.py]
1 import os
2
3 from PIL import Image
4
5 from modules import shared, images, devices, scripts, scripts_postprocessing, ui_common, generation_parameters_copypaste
6 from modules.shared import opts
7
8
9 def run_postprocessing(extras_mode, image, image_folder, input_dir, output_dir, show_extras_results, *args, save_output: bool = True):
10 devices.torch_gc()
11
12 shared.state.begin()
13 shared.state.job = 'extras'
14
15 image_data = []
16 image_names = []
17 outputs = []
18
19 if extras_mode == 1:
20 for img in image_folder:
21 if isinstance(img, Image.Image):
22 image = img
23 fn = ''
24 else:
25 image = Image.open(img)
26 fn = os.path.splitext(img.orig_name)[0]
27
28 image_data.append(image)
29 image_names.append(fn)
30 elif extras_mode == 2:
31 assert not shared.cmd_opts.hide_ui_dir_config, '--hide-ui-dir-config option must be disabled'
32 assert input_dir, 'input directory not selected'
33
34 image_list = shared.listfiles(input_dir)
35 for filename in image_list:
36 try:
37 image = Image.open(filename)
38 except Exception:
39 continue
40 image_data.append(image)
41 image_names.append(filename)
42 else:
43 assert image, 'image not selected'
44
45 image_data.append(image)
46 image_names.append(None)
47
48 if extras_mode == 2 and output_dir != '':
49 outpath = output_dir
50 else:
51 outpath = opts.outdir_samples or opts.outdir_extras_samples
52
53 infotext = ''
54
55 for image, name in zip(image_data, image_names):
56 shared.state.textinfo = name
57
58 existing_pnginfo = image.info or {}
59
60 pp = scripts_postprocessing.PostprocessedImage(image.convert("RGB"))
61
62 scripts.scripts_postproc.run(pp, args)
63
64 if opts.use_original_name_batch and name is not None:
65 basename = os.path.splitext(os.path.basename(name))[0]
66 else:
67 basename = ''
68
69 infotext = ", ".join([k if k == v else f'{k}: {generation_parameters_copypaste.quote(v)}' for k, v in pp.info.items() if v is not None])
70
71 if opts.enable_pnginfo:
72 pp.image.info = existing_pnginfo
73 pp.image.info["postprocessing"] = infotext
74
75 if save_output:
76 images.save_image(pp.image, path=outpath, basename=basename, seed=None, prompt=None, extension=opts.samples_format, info=infotext, short_filename=True, no_prompt=True, grid=False, pnginfo_section_name="extras", existing_info=existing_pnginfo, forced_filename=None)
77
78 if extras_mode != 2 or show_extras_results:
79 outputs.append(pp.image)
80
81 devices.torch_gc()
82
83 return outputs, ui_common.plaintext_to_html(infotext), ''
84
85
86 def run_extras(extras_mode, resize_mode, image, image_folder, input_dir, output_dir, show_extras_results, gfpgan_visibility, codeformer_visibility, codeformer_weight, upscaling_resize, upscaling_resize_w, upscaling_resize_h, upscaling_crop, extras_upscaler_1, extras_upscaler_2, extras_upscaler_2_visibility, upscale_first: bool, save_output: bool = True):
87 """old handler for API"""
88
89 args = scripts.scripts_postproc.create_args_for_run({
90 "Upscale": {
91 "upscale_mode": resize_mode,
92 "upscale_by": upscaling_resize,
93 "upscale_to_width": upscaling_resize_w,
94 "upscale_to_height": upscaling_resize_h,
95 "upscale_crop": upscaling_crop,
96 "upscaler_1_name": extras_upscaler_1,
97 "upscaler_2_name": extras_upscaler_2,
98 "upscaler_2_visibility": extras_upscaler_2_visibility,
99 },
100 "GFPGAN": {
101 "gfpgan_visibility": gfpgan_visibility,
102 },
103 "CodeFormer": {
104 "codeformer_visibility": codeformer_visibility,
105 "codeformer_weight": codeformer_weight,
106 },
107 })
108
109 return run_postprocessing(extras_mode, image, image_folder, input_dir, output_dir, show_extras_results, *args, save_output=save_output)
110
[end of modules/postprocessing.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/modules/postprocessing.py b/modules/postprocessing.py
--- a/modules/postprocessing.py
+++ b/modules/postprocessing.py
@@ -1,4 +1,6 @@
import os
+import tempfile
+from typing import List
from PIL import Image
@@ -6,7 +8,7 @@
from modules.shared import opts
-def run_postprocessing(extras_mode, image, image_folder, input_dir, output_dir, show_extras_results, *args, save_output: bool = True):
+def run_postprocessing(extras_mode, image, image_folder: List[tempfile.NamedTemporaryFile], input_dir, output_dir, show_extras_results, *args, save_output: bool = True):
devices.torch_gc()
shared.state.begin()
@@ -22,7 +24,7 @@
image = img
fn = ''
else:
- image = Image.open(img)
+ image = Image.open(os.path.abspath(img.name))
fn = os.path.splitext(img.orig_name)[0]
image_data.append(image)
diff --git a/modules/ui_postprocessing.py b/modules/ui_postprocessing.py
--- a/modules/ui_postprocessing.py
+++ b/modules/ui_postprocessing.py
@@ -13,7 +13,7 @@
extras_image = gr.Image(label="Source", source="upload", interactive=True, type="pil", elem_id="extras_image")
with gr.TabItem('Batch Process', elem_id="extras_batch_process_tab") as tab_batch:
- image_batch = gr.File(label="Batch Process", file_count="multiple", interactive=True, type="file", elem_id="extras_image_batch")
+ image_batch = gr.Files(label="Batch Process", interactive=True, elem_id="extras_image_batch")
with gr.TabItem('Batch from Directory', elem_id="extras_batch_directory_tab") as tab_batch_dir:
extras_batch_input_dir = gr.Textbox(label="Input directory", **shared.hide_dirs, placeholder="A directory on the same machine where the server is running.", elem_id="extras_batch_input_dir")
|
{"golden_diff": "diff --git a/modules/postprocessing.py b/modules/postprocessing.py\n--- a/modules/postprocessing.py\n+++ b/modules/postprocessing.py\n@@ -1,4 +1,6 @@\n import os\r\n+import tempfile\r\n+from typing import List\r\n \r\n from PIL import Image\r\n \r\n@@ -6,7 +8,7 @@\n from modules.shared import opts\r\n \r\n \r\n-def run_postprocessing(extras_mode, image, image_folder, input_dir, output_dir, show_extras_results, *args, save_output: bool = True):\r\n+def run_postprocessing(extras_mode, image, image_folder: List[tempfile.NamedTemporaryFile], input_dir, output_dir, show_extras_results, *args, save_output: bool = True):\r\n devices.torch_gc()\r\n \r\n shared.state.begin()\r\n@@ -22,7 +24,7 @@\n image = img\r\n fn = ''\r\n else:\r\n- image = Image.open(img)\r\n+ image = Image.open(os.path.abspath(img.name))\r\n fn = os.path.splitext(img.orig_name)[0]\r\n \r\n image_data.append(image)\r\ndiff --git a/modules/ui_postprocessing.py b/modules/ui_postprocessing.py\n--- a/modules/ui_postprocessing.py\n+++ b/modules/ui_postprocessing.py\n@@ -13,7 +13,7 @@\n extras_image = gr.Image(label=\"Source\", source=\"upload\", interactive=True, type=\"pil\", elem_id=\"extras_image\")\r\n \r\n with gr.TabItem('Batch Process', elem_id=\"extras_batch_process_tab\") as tab_batch:\r\n- image_batch = gr.File(label=\"Batch Process\", file_count=\"multiple\", interactive=True, type=\"file\", elem_id=\"extras_image_batch\")\r\n+ image_batch = gr.Files(label=\"Batch Process\", interactive=True, elem_id=\"extras_image_batch\")\r\n \r\n with gr.TabItem('Batch from Directory', elem_id=\"extras_batch_directory_tab\") as tab_batch_dir:\r\n extras_batch_input_dir = gr.Textbox(label=\"Input directory\", **shared.hide_dirs, placeholder=\"A directory on the same machine where the server is running.\", elem_id=\"extras_batch_input_dir\")\n", "issue": "[Bug]: UnidentifiedImageError when using \"Batch Process\" in \"Extras\"\n### Is there an existing issue for this?\n\n- [X] I have searched the existing issues and checked the recent builds/commits\n\n### What happened?\n\nHello,\r\n\r\nI'm trying to upscale a bunch of images in the \"Extras\" Tab. When I pick an image in the \"Single Image\" tab it works perfectly fine. But when I pick the exact same imagefile in the \"Batch Process\" and hit \"Generate\" I instantly get this error message in the UI:\r\n\r\nUnidentifiedImageError: cannot identify image file <tempfile._TemporaryFileWrapper object at 0x000001F589DBF1F0>\r\nTime taken: 0.00sTorch active/reserved: 1/2 MiB, Sys VRAM: 1277/4096 MiB (31.18%)\r\n\r\nIn the CMD it looks like this:\r\nError completing request\r\nArguments: (1, <PIL.Image.Image image mode=RGB size=960x1200 at 0x1F589DBF160>, [<tempfile._TemporaryFileWrapper object at 0x000001F589DBF1F0>], '', '', True, 0, 4, 512, 512, True, 'SwinIR_4x', 'None', 0, 0, 0, 0) {}\r\nTraceback (most recent call last):\r\n File \"C:\\AI\\stable-diffusion-webui\\modules\\call_queue.py\", line 56, in f\r\n res = list(func(*args, **kwargs))\r\n File \"C:\\AI\\stable-diffusion-webui\\modules\\call_queue.py\", line 37, in f\r\n res = func(*args, **kwargs)\r\n File \"C:\\AI\\stable-diffusion-webui\\modules\\postprocessing.py\", line 21, in run_postprocessing\r\n image = Image.open(img)\r\n File \"C:\\AI\\stable-diffusion-webui\\venv\\lib\\site-packages\\PIL\\Image.py\", line 3283, in open\r\n raise UnidentifiedImageError(msg)\r\nPIL.UnidentifiedImageError: cannot identify image file <tempfile._TemporaryFileWrapper object at 0x000001F589DBF1F0>\r\n\r\n\r\n\n\n### Steps to reproduce the problem\n\n1. Go to .... Extras, Batch Process\r\n2. Press .... Import to add the image, and press Generate\r\n\n\n### What should have happened?\n\nIt should create the upscaled image, just like in the Single Image tab.\n\n### Commit where the problem happens\n\na0d07fb5\n\n### What platforms do you use to access the UI ?\n\nWindows\n\n### What browsers do you use to access the UI ?\n\nGoogle Chrome\n\n### Command Line Arguments\n\n```Shell\ngit pull\r\npause \r\n\r\n --xformers --medvram\n```\n\n\n### List of extensions\n\nno\n\n### Console logs\n\n```Shell\nC:\\AI\\stable-diffusion-webui>git pull\r\nAlready up to date.\r\n\r\nC:\\AI\\stable-diffusion-webui>pause\r\nDr\u00fccken Sie eine beliebige Taste . . .\r\nvenv \"C:\\AI\\stable-diffusion-webui\\venv\\Scripts\\Python.exe\"\r\nPython 3.10.10 (tags/v3.10.10:aad5f6a, Feb 7 2023, 17:20:36) [MSC v.1929 64 bit (AMD64)]\r\nCommit hash: a0d07fb5807ad55c8ccfdfc9a6d9ae3c62b9d211\r\nInstalling requirements for Web UI\r\nLaunching Web UI with arguments: --xformers --medvram\r\nLoading weights [cc6cb27103] from C:\\AI\\stable-diffusion-webui\\models\\Stable-diffusion\\model.ckpt\r\nCreating model from config: C:\\AI\\stable-diffusion-webui\\configs\\v1-inference.yaml\r\nLatentDiffusion: Running in eps-prediction mode\r\nDiffusionWrapper has 859.52 M params.\r\nApplying cross attention optimization (Doggettx).\r\nTextual inversion embeddings loaded(0):\r\nModel loaded in 3.2s (load weights from disk: 1.6s, create model: 0.5s, apply weights to model: 0.5s, apply half(): 0.6s).\r\nRunning on local URL: http://127.0.0.1:7860\r\n\r\nTo create a public link, set `share=True` in `launch()`.\r\nStartup time: 12.3s (import torch: 2.7s, import gradio: 1.5s, import ldm: 0.4s, other imports: 1.3s, setup codeformer: 0.1s, load scripts: 2.2s, load SD checkpoint: 3.5s, create ui: 0.3s, gradio launch: 0.1s).\r\nError completing request\r\nArguments: (1, None, [<tempfile._TemporaryFileWrapper object at 0x000001E5841F11E0>], '', '', True, 0, 4, 512, 512, True, 'None', 'None', 0, 0, 0, 0) {}\r\nTraceback (most recent call last):\r\n File \"C:\\AI\\stable-diffusion-webui\\modules\\call_queue.py\", line 56, in f\r\n res = list(func(*args, **kwargs))\r\n File \"C:\\AI\\stable-diffusion-webui\\modules\\call_queue.py\", line 37, in f\r\n res = func(*args, **kwargs)\r\n File \"C:\\AI\\stable-diffusion-webui\\modules\\postprocessing.py\", line 21, in run_postprocessing\r\n image = Image.open(img)\r\n File \"C:\\AI\\stable-diffusion-webui\\venv\\lib\\site-packages\\PIL\\Image.py\", line 3283, in open\r\n raise UnidentifiedImageError(msg)\r\nPIL.UnidentifiedImageError: cannot identify image file <tempfile._TemporaryFileWrapper object at 0x000001E5841F11E0>\n```\n\n\n### Additional information\n\n_No response_\n", "before_files": [{"content": "import gradio as gr\r\nfrom modules import scripts_postprocessing, scripts, shared, gfpgan_model, codeformer_model, ui_common, postprocessing, call_queue\r\nimport modules.generation_parameters_copypaste as parameters_copypaste\r\n\r\n\r\ndef create_ui():\r\n tab_index = gr.State(value=0)\r\n\r\n with gr.Row().style(equal_height=False, variant='compact'):\r\n with gr.Column(variant='compact'):\r\n with gr.Tabs(elem_id=\"mode_extras\"):\r\n with gr.TabItem('Single Image', elem_id=\"extras_single_tab\") as tab_single:\r\n extras_image = gr.Image(label=\"Source\", source=\"upload\", interactive=True, type=\"pil\", elem_id=\"extras_image\")\r\n\r\n with gr.TabItem('Batch Process', elem_id=\"extras_batch_process_tab\") as tab_batch:\r\n image_batch = gr.File(label=\"Batch Process\", file_count=\"multiple\", interactive=True, type=\"file\", elem_id=\"extras_image_batch\")\r\n\r\n with gr.TabItem('Batch from Directory', elem_id=\"extras_batch_directory_tab\") as tab_batch_dir:\r\n extras_batch_input_dir = gr.Textbox(label=\"Input directory\", **shared.hide_dirs, placeholder=\"A directory on the same machine where the server is running.\", elem_id=\"extras_batch_input_dir\")\r\n extras_batch_output_dir = gr.Textbox(label=\"Output directory\", **shared.hide_dirs, placeholder=\"Leave blank to save images to the default path.\", elem_id=\"extras_batch_output_dir\")\r\n show_extras_results = gr.Checkbox(label='Show result images', value=True, elem_id=\"extras_show_extras_results\")\r\n\r\n submit = gr.Button('Generate', elem_id=\"extras_generate\", variant='primary')\r\n\r\n script_inputs = scripts.scripts_postproc.setup_ui()\r\n\r\n with gr.Column():\r\n result_images, html_info_x, html_info, html_log = ui_common.create_output_panel(\"extras\", shared.opts.outdir_extras_samples)\r\n\r\n tab_single.select(fn=lambda: 0, inputs=[], outputs=[tab_index])\r\n tab_batch.select(fn=lambda: 1, inputs=[], outputs=[tab_index])\r\n tab_batch_dir.select(fn=lambda: 2, inputs=[], outputs=[tab_index])\r\n\r\n submit.click(\r\n fn=call_queue.wrap_gradio_gpu_call(postprocessing.run_postprocessing, extra_outputs=[None, '']),\r\n inputs=[\r\n tab_index,\r\n extras_image,\r\n image_batch,\r\n extras_batch_input_dir,\r\n extras_batch_output_dir,\r\n show_extras_results,\r\n *script_inputs\r\n ],\r\n outputs=[\r\n result_images,\r\n html_info_x,\r\n html_info,\r\n ]\r\n )\r\n\r\n parameters_copypaste.add_paste_fields(\"extras\", extras_image, None)\r\n\r\n extras_image.change(\r\n fn=scripts.scripts_postproc.image_changed,\r\n inputs=[], outputs=[]\r\n )\r\n", "path": "modules/ui_postprocessing.py"}, {"content": "import os\r\n\r\nfrom PIL import Image\r\n\r\nfrom modules import shared, images, devices, scripts, scripts_postprocessing, ui_common, generation_parameters_copypaste\r\nfrom modules.shared import opts\r\n\r\n\r\ndef run_postprocessing(extras_mode, image, image_folder, input_dir, output_dir, show_extras_results, *args, save_output: bool = True):\r\n devices.torch_gc()\r\n\r\n shared.state.begin()\r\n shared.state.job = 'extras'\r\n\r\n image_data = []\r\n image_names = []\r\n outputs = []\r\n\r\n if extras_mode == 1:\r\n for img in image_folder:\r\n if isinstance(img, Image.Image):\r\n image = img\r\n fn = ''\r\n else:\r\n image = Image.open(img)\r\n fn = os.path.splitext(img.orig_name)[0]\r\n\r\n image_data.append(image)\r\n image_names.append(fn)\r\n elif extras_mode == 2:\r\n assert not shared.cmd_opts.hide_ui_dir_config, '--hide-ui-dir-config option must be disabled'\r\n assert input_dir, 'input directory not selected'\r\n\r\n image_list = shared.listfiles(input_dir)\r\n for filename in image_list:\r\n try:\r\n image = Image.open(filename)\r\n except Exception:\r\n continue\r\n image_data.append(image)\r\n image_names.append(filename)\r\n else:\r\n assert image, 'image not selected'\r\n\r\n image_data.append(image)\r\n image_names.append(None)\r\n\r\n if extras_mode == 2 and output_dir != '':\r\n outpath = output_dir\r\n else:\r\n outpath = opts.outdir_samples or opts.outdir_extras_samples\r\n\r\n infotext = ''\r\n\r\n for image, name in zip(image_data, image_names):\r\n shared.state.textinfo = name\r\n\r\n existing_pnginfo = image.info or {}\r\n\r\n pp = scripts_postprocessing.PostprocessedImage(image.convert(\"RGB\"))\r\n\r\n scripts.scripts_postproc.run(pp, args)\r\n\r\n if opts.use_original_name_batch and name is not None:\r\n basename = os.path.splitext(os.path.basename(name))[0]\r\n else:\r\n basename = ''\r\n\r\n infotext = \", \".join([k if k == v else f'{k}: {generation_parameters_copypaste.quote(v)}' for k, v in pp.info.items() if v is not None])\r\n\r\n if opts.enable_pnginfo:\r\n pp.image.info = existing_pnginfo\r\n pp.image.info[\"postprocessing\"] = infotext\r\n\r\n if save_output:\r\n images.save_image(pp.image, path=outpath, basename=basename, seed=None, prompt=None, extension=opts.samples_format, info=infotext, short_filename=True, no_prompt=True, grid=False, pnginfo_section_name=\"extras\", existing_info=existing_pnginfo, forced_filename=None)\r\n\r\n if extras_mode != 2 or show_extras_results:\r\n outputs.append(pp.image)\r\n\r\n devices.torch_gc()\r\n\r\n return outputs, ui_common.plaintext_to_html(infotext), ''\r\n\r\n\r\ndef run_extras(extras_mode, resize_mode, image, image_folder, input_dir, output_dir, show_extras_results, gfpgan_visibility, codeformer_visibility, codeformer_weight, upscaling_resize, upscaling_resize_w, upscaling_resize_h, upscaling_crop, extras_upscaler_1, extras_upscaler_2, extras_upscaler_2_visibility, upscale_first: bool, save_output: bool = True):\r\n \"\"\"old handler for API\"\"\"\r\n\r\n args = scripts.scripts_postproc.create_args_for_run({\r\n \"Upscale\": {\r\n \"upscale_mode\": resize_mode,\r\n \"upscale_by\": upscaling_resize,\r\n \"upscale_to_width\": upscaling_resize_w,\r\n \"upscale_to_height\": upscaling_resize_h,\r\n \"upscale_crop\": upscaling_crop,\r\n \"upscaler_1_name\": extras_upscaler_1,\r\n \"upscaler_2_name\": extras_upscaler_2,\r\n \"upscaler_2_visibility\": extras_upscaler_2_visibility,\r\n },\r\n \"GFPGAN\": {\r\n \"gfpgan_visibility\": gfpgan_visibility,\r\n },\r\n \"CodeFormer\": {\r\n \"codeformer_visibility\": codeformer_visibility,\r\n \"codeformer_weight\": codeformer_weight,\r\n },\r\n })\r\n\r\n return run_postprocessing(extras_mode, image, image_folder, input_dir, output_dir, show_extras_results, *args, save_output=save_output)\r\n", "path": "modules/postprocessing.py"}]}
| 3,828 | 438 |
gh_patches_debug_25652
|
rasdani/github-patches
|
git_diff
|
pytorch__ignite-2335
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[docs] Add doctests for metrics
### 📚 Documentation
Following #2230 , I listed the metrics places (suggested by @sdesrozis) where doctests can be added.
#### Metrics
- [x] Average (#2332)
- [x] GeometricAverage (#2332)
- [x] VariableAccumulation (This class is an helper, no test needed)
- [x] Accuracy (#2345)
- [x] ConfusionMatrix (#2336)
- [x] ClassificationReport (#2346)
- [x] DiceCoefficient (#2336)
- [x] JaccardIndex (#2336)
- [x] IoU (#2336)
- [x] mIoU (#2336)
- [x] EpochMetric (#2351)
- [x] Fbeta (#2340)
- [x] Loss (#2335)
- [x] MeanAbsoluteError (#2280)
- [x] MeanPairwiseDistance (#2307)
- [x] MeanSquaredError (#2280)
- [x] MetricsLambda (#2352)
- [x] MultiLabelConfusionMatrix (#2347)
- [x] Precision (#2340)
- [x] PSNR (#2311)
- [x] Recall (#2340)
- [x] RootMeanSquaredError (#2307)
- [x] RunningAverage (#2348)
- [x] SSIM (#2241)
- [x] TopKCategoricalAccuracy (#2284)
- [x] Bleu (#2317)
- [x] Rouge (#2317)
- [x] RougeL (#2317)
- [x] RougeN (#2317)
- [x] InceptionScore (#2349)
- [x] FID (#2349)
#### Contrib Metrics
- [x] AveragePrecision (#2341)
- [x] CohenKappa (#2321)
- [x] PrecisionRecallCurve (#2341)
- [x] ROC_AUC (#2341)
- [x] RocCurve (#2341)
- [x] CanberraMetric (#2323)
- [x] FractionalAbsoluteError (#2323)
- [x] FractionalBias (#2323)
- [x] GeometricMeanAbsoluteError (#2323)
- [x] GeometricMeanRelativeAbsoluteError (#2324)
- [x] ManhattanDistance (#2324)
- [x] MaximumAbsoluteError (#2324)
- [x] MeanAbsoluteRelativeError (#2324)
- [x] MeanError (#2324)
- [x] MeanNormalizedBias (#2324)
- [x] MedianAbsoluteError (#2324)
- [x] MedianAbsolutePercentageError (#2324)
- [x] MedianRelativeAbsoluteError (#2324)
- [x] R2Score (#2324)
- [x] WaveHedgesDistance (#2324)
This is a great issue for first comers and those who want to learn more about Sphinx. This issue is the community effort.
If you want to contribute, please comment on this issue with the metric you want to add doctest (one by one).
Example on how to add doctest, see #2241
Thanks!
</issue>
<code>
[start of ignite/metrics/loss.py]
1 from typing import Callable, Dict, Sequence, Tuple, Union, cast
2
3 import torch
4
5 from ignite.exceptions import NotComputableError
6 from ignite.metrics.metric import Metric, reinit__is_reduced, sync_all_reduce
7
8 __all__ = ["Loss"]
9
10
11 class Loss(Metric):
12 """
13 Calculates the average loss according to the passed loss_fn.
14
15 Args:
16 loss_fn: a callable taking a prediction tensor, a target
17 tensor, optionally other arguments, and returns the average loss
18 over all observations in the batch.
19 output_transform: a callable that is used to transform the
20 :class:`~ignite.engine.engine.Engine`'s ``process_function``'s output into the
21 form expected by the metric.
22 This can be useful if, for example, you have a multi-output model and
23 you want to compute the metric with respect to one of the outputs.
24 The output is expected to be a tuple `(prediction, target)` or
25 (prediction, target, kwargs) where kwargs is a dictionary of extra
26 keywords arguments. If extra keywords arguments are provided they are passed to `loss_fn`.
27 batch_size: a callable taking a target tensor that returns the
28 first dimension size (usually the batch size).
29 device: specifies which device updates are accumulated on. Setting the
30 metric's device to be the same as your ``update`` arguments ensures the ``update`` method is
31 non-blocking. By default, CPU.
32
33 Attributes:
34 required_output_keys: dictionary defines required keys to be found in ``engine.state.output`` if the
35 latter is a dictionary. Default, ``("y_pred", "y", "criterion_kwargs")``. This is useful when the
36 criterion function requires additional arguments, which can be passed using ``criterion_kwargs``.
37 See an example below.
38
39 Examples:
40 Let's implement a Loss metric that requires ``x``, ``y_pred``, ``y`` and ``criterion_kwargs`` as input
41 for ``criterion`` function. In the example below we show how to setup standard metric like Accuracy
42 and the Loss metric using an ``evaluator`` created with
43 :meth:`~ignite.engine.create_supervised_evaluator` method.
44
45 .. code-block:: python
46
47 import torch
48 import torch.nn as nn
49 from torch.nn.functional import nll_loss
50
51 from ignite.metrics import Accuracy, Loss
52 from ignite.engine import create_supervised_evaluator
53
54 model = ...
55
56 criterion = nll_loss
57
58 metrics = {
59 "Accuracy": Accuracy(),
60 "Loss": Loss(criterion)
61 }
62
63 # global criterion kwargs
64 criterion_kwargs = {...}
65
66 evaluator = create_supervised_evaluator(
67 model,
68 metrics=metrics,
69 output_transform=lambda x, y, y_pred: {
70 "x": x, "y": y, "y_pred": y_pred, "criterion_kwargs": criterion_kwargs}
71 )
72
73 res = evaluator.run(data)
74
75 """
76
77 required_output_keys = ("y_pred", "y", "criterion_kwargs")
78
79 def __init__(
80 self,
81 loss_fn: Callable,
82 output_transform: Callable = lambda x: x,
83 batch_size: Callable = len,
84 device: Union[str, torch.device] = torch.device("cpu"),
85 ):
86 super(Loss, self).__init__(output_transform, device=device)
87 self._loss_fn = loss_fn
88 self._batch_size = batch_size
89
90 @reinit__is_reduced
91 def reset(self) -> None:
92 self._sum = torch.tensor(0.0, device=self._device)
93 self._num_examples = 0
94
95 @reinit__is_reduced
96 def update(self, output: Sequence[Union[torch.Tensor, Dict]]) -> None:
97 if len(output) == 2:
98 y_pred, y = cast(Tuple[torch.Tensor, torch.Tensor], output)
99 kwargs = {} # type: Dict
100 else:
101 y_pred, y, kwargs = cast(Tuple[torch.Tensor, torch.Tensor, Dict], output)
102 average_loss = self._loss_fn(y_pred, y, **kwargs).detach()
103
104 if len(average_loss.shape) != 0:
105 raise ValueError("loss_fn did not return the average loss.")
106
107 n = self._batch_size(y)
108 self._sum += average_loss.to(self._device) * n
109 self._num_examples += n
110
111 @sync_all_reduce("_sum", "_num_examples")
112 def compute(self) -> float:
113 if self._num_examples == 0:
114 raise NotComputableError("Loss must have at least one example before it can be computed.")
115 return self._sum.item() / self._num_examples
116
[end of ignite/metrics/loss.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ignite/metrics/loss.py b/ignite/metrics/loss.py
--- a/ignite/metrics/loss.py
+++ b/ignite/metrics/loss.py
@@ -42,35 +42,24 @@
and the Loss metric using an ``evaluator`` created with
:meth:`~ignite.engine.create_supervised_evaluator` method.
- .. code-block:: python
+ .. testsetup:: *
- import torch
- import torch.nn as nn
- from torch.nn.functional import nll_loss
+ default_trainer = get_default_trainer()
- from ignite.metrics import Accuracy, Loss
- from ignite.engine import create_supervised_evaluator
+ .. testcode::
- model = ...
+ model = default_model
+ criterion = nn.NLLLoss()
+ metric = Loss(criterion)
+ metric.attach(default_evaluator, 'loss')
+ y_pred = torch.tensor([[0.1, 0.4, 0.5], [0.1, 0.7, 0.2]])
+ y_true = torch.tensor([2, 2]).long()
+ state = default_evaluator.run([[y_pred, y_true]])
+ print(state.metrics['loss'])
- criterion = nll_loss
+ .. testoutput::
- metrics = {
- "Accuracy": Accuracy(),
- "Loss": Loss(criterion)
- }
-
- # global criterion kwargs
- criterion_kwargs = {...}
-
- evaluator = create_supervised_evaluator(
- model,
- metrics=metrics,
- output_transform=lambda x, y, y_pred: {
- "x": x, "y": y, "y_pred": y_pred, "criterion_kwargs": criterion_kwargs}
- )
-
- res = evaluator.run(data)
+ -0.3499999...
"""
|
{"golden_diff": "diff --git a/ignite/metrics/loss.py b/ignite/metrics/loss.py\n--- a/ignite/metrics/loss.py\n+++ b/ignite/metrics/loss.py\n@@ -42,35 +42,24 @@\n and the Loss metric using an ``evaluator`` created with\n :meth:`~ignite.engine.create_supervised_evaluator` method.\n \n- .. code-block:: python\n+ .. testsetup:: *\n \n- import torch\n- import torch.nn as nn\n- from torch.nn.functional import nll_loss\n+ default_trainer = get_default_trainer()\n \n- from ignite.metrics import Accuracy, Loss\n- from ignite.engine import create_supervised_evaluator\n+ .. testcode::\n \n- model = ...\n+ model = default_model\n+ criterion = nn.NLLLoss()\n+ metric = Loss(criterion)\n+ metric.attach(default_evaluator, 'loss')\n+ y_pred = torch.tensor([[0.1, 0.4, 0.5], [0.1, 0.7, 0.2]])\n+ y_true = torch.tensor([2, 2]).long()\n+ state = default_evaluator.run([[y_pred, y_true]])\n+ print(state.metrics['loss'])\n \n- criterion = nll_loss\n+ .. testoutput::\n \n- metrics = {\n- \"Accuracy\": Accuracy(),\n- \"Loss\": Loss(criterion)\n- }\n-\n- # global criterion kwargs\n- criterion_kwargs = {...}\n-\n- evaluator = create_supervised_evaluator(\n- model,\n- metrics=metrics,\n- output_transform=lambda x, y, y_pred: {\n- \"x\": x, \"y\": y, \"y_pred\": y_pred, \"criterion_kwargs\": criterion_kwargs}\n- )\n-\n- res = evaluator.run(data)\n+ -0.3499999...\n \n \"\"\"\n", "issue": "[docs] Add doctests for metrics\n### \ud83d\udcda Documentation\r\n\r\nFollowing #2230 , I listed the metrics places (suggested by @sdesrozis) where doctests can be added.\r\n\r\n#### Metrics\r\n\r\n- [x] Average (#2332)\r\n- [x] GeometricAverage (#2332)\r\n- [x] VariableAccumulation (This class is an helper, no test needed)\r\n- [x] Accuracy (#2345)\r\n- [x] ConfusionMatrix (#2336)\r\n- [x] ClassificationReport (#2346)\r\n- [x] DiceCoefficient (#2336)\r\n- [x] JaccardIndex (#2336)\r\n- [x] IoU (#2336)\r\n- [x] mIoU (#2336)\r\n- [x] EpochMetric (#2351)\r\n- [x] Fbeta (#2340)\r\n- [x] Loss (#2335)\r\n- [x] MeanAbsoluteError (#2280)\r\n- [x] MeanPairwiseDistance (#2307)\r\n- [x] MeanSquaredError (#2280)\r\n- [x] MetricsLambda (#2352)\r\n- [x] MultiLabelConfusionMatrix (#2347)\r\n- [x] Precision (#2340)\r\n- [x] PSNR (#2311)\r\n- [x] Recall (#2340)\r\n- [x] RootMeanSquaredError (#2307)\r\n- [x] RunningAverage (#2348)\r\n- [x] SSIM (#2241)\r\n- [x] TopKCategoricalAccuracy (#2284)\r\n- [x] Bleu (#2317)\r\n- [x] Rouge (#2317)\r\n- [x] RougeL (#2317)\r\n- [x] RougeN (#2317)\r\n- [x] InceptionScore (#2349)\r\n- [x] FID (#2349)\r\n\r\n#### Contrib Metrics\r\n\r\n- [x] AveragePrecision (#2341)\r\n- [x] CohenKappa (#2321)\r\n- [x] PrecisionRecallCurve (#2341)\r\n- [x] ROC_AUC (#2341)\r\n- [x] RocCurve (#2341)\r\n- [x] CanberraMetric (#2323)\r\n- [x] FractionalAbsoluteError (#2323)\r\n- [x] FractionalBias (#2323)\r\n- [x] GeometricMeanAbsoluteError (#2323)\r\n- [x] GeometricMeanRelativeAbsoluteError (#2324)\r\n- [x] ManhattanDistance (#2324)\r\n- [x] MaximumAbsoluteError (#2324)\r\n- [x] MeanAbsoluteRelativeError (#2324)\r\n- [x] MeanError (#2324)\r\n- [x] MeanNormalizedBias (#2324)\r\n- [x] MedianAbsoluteError (#2324)\r\n- [x] MedianAbsolutePercentageError (#2324) \r\n- [x] MedianRelativeAbsoluteError (#2324)\r\n- [x] R2Score (#2324)\r\n- [x] WaveHedgesDistance (#2324) \r\n\r\nThis is a great issue for first comers and those who want to learn more about Sphinx. This issue is the community effort.\r\nIf you want to contribute, please comment on this issue with the metric you want to add doctest (one by one).\r\n\r\nExample on how to add doctest, see #2241 \r\n\r\nThanks!\n", "before_files": [{"content": "from typing import Callable, Dict, Sequence, Tuple, Union, cast\n\nimport torch\n\nfrom ignite.exceptions import NotComputableError\nfrom ignite.metrics.metric import Metric, reinit__is_reduced, sync_all_reduce\n\n__all__ = [\"Loss\"]\n\n\nclass Loss(Metric):\n \"\"\"\n Calculates the average loss according to the passed loss_fn.\n\n Args:\n loss_fn: a callable taking a prediction tensor, a target\n tensor, optionally other arguments, and returns the average loss\n over all observations in the batch.\n output_transform: a callable that is used to transform the\n :class:`~ignite.engine.engine.Engine`'s ``process_function``'s output into the\n form expected by the metric.\n This can be useful if, for example, you have a multi-output model and\n you want to compute the metric with respect to one of the outputs.\n The output is expected to be a tuple `(prediction, target)` or\n (prediction, target, kwargs) where kwargs is a dictionary of extra\n keywords arguments. If extra keywords arguments are provided they are passed to `loss_fn`.\n batch_size: a callable taking a target tensor that returns the\n first dimension size (usually the batch size).\n device: specifies which device updates are accumulated on. Setting the\n metric's device to be the same as your ``update`` arguments ensures the ``update`` method is\n non-blocking. By default, CPU.\n\n Attributes:\n required_output_keys: dictionary defines required keys to be found in ``engine.state.output`` if the\n latter is a dictionary. Default, ``(\"y_pred\", \"y\", \"criterion_kwargs\")``. This is useful when the\n criterion function requires additional arguments, which can be passed using ``criterion_kwargs``.\n See an example below.\n\n Examples:\n Let's implement a Loss metric that requires ``x``, ``y_pred``, ``y`` and ``criterion_kwargs`` as input\n for ``criterion`` function. In the example below we show how to setup standard metric like Accuracy\n and the Loss metric using an ``evaluator`` created with\n :meth:`~ignite.engine.create_supervised_evaluator` method.\n\n .. code-block:: python\n\n import torch\n import torch.nn as nn\n from torch.nn.functional import nll_loss\n\n from ignite.metrics import Accuracy, Loss\n from ignite.engine import create_supervised_evaluator\n\n model = ...\n\n criterion = nll_loss\n\n metrics = {\n \"Accuracy\": Accuracy(),\n \"Loss\": Loss(criterion)\n }\n\n # global criterion kwargs\n criterion_kwargs = {...}\n\n evaluator = create_supervised_evaluator(\n model,\n metrics=metrics,\n output_transform=lambda x, y, y_pred: {\n \"x\": x, \"y\": y, \"y_pred\": y_pred, \"criterion_kwargs\": criterion_kwargs}\n )\n\n res = evaluator.run(data)\n\n \"\"\"\n\n required_output_keys = (\"y_pred\", \"y\", \"criterion_kwargs\")\n\n def __init__(\n self,\n loss_fn: Callable,\n output_transform: Callable = lambda x: x,\n batch_size: Callable = len,\n device: Union[str, torch.device] = torch.device(\"cpu\"),\n ):\n super(Loss, self).__init__(output_transform, device=device)\n self._loss_fn = loss_fn\n self._batch_size = batch_size\n\n @reinit__is_reduced\n def reset(self) -> None:\n self._sum = torch.tensor(0.0, device=self._device)\n self._num_examples = 0\n\n @reinit__is_reduced\n def update(self, output: Sequence[Union[torch.Tensor, Dict]]) -> None:\n if len(output) == 2:\n y_pred, y = cast(Tuple[torch.Tensor, torch.Tensor], output)\n kwargs = {} # type: Dict\n else:\n y_pred, y, kwargs = cast(Tuple[torch.Tensor, torch.Tensor, Dict], output)\n average_loss = self._loss_fn(y_pred, y, **kwargs).detach()\n\n if len(average_loss.shape) != 0:\n raise ValueError(\"loss_fn did not return the average loss.\")\n\n n = self._batch_size(y)\n self._sum += average_loss.to(self._device) * n\n self._num_examples += n\n\n @sync_all_reduce(\"_sum\", \"_num_examples\")\n def compute(self) -> float:\n if self._num_examples == 0:\n raise NotComputableError(\"Loss must have at least one example before it can be computed.\")\n return self._sum.item() / self._num_examples\n", "path": "ignite/metrics/loss.py"}]}
| 2,570 | 423 |
gh_patches_debug_40648
|
rasdani/github-patches
|
git_diff
|
microsoft__AzureTRE-241
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] ResourceTemplates have properties - should be parameters
Rename properties to parameters
</issue>
<code>
[start of management_api_app/models/domain/resource_template.py]
1 from typing import List, Optional, Any
2
3 from pydantic import Field
4
5 from models.domain.azuretremodel import AzureTREModel
6 from models.domain.resource import ResourceType
7
8
9 class Parameter(AzureTREModel):
10 name: str = Field(title="Parameter name")
11 type: str = Field(title="Parameter type")
12 default: Any = Field(title="Default value for the parameter")
13 applyTo: str = Field("All Actions", title="The actions that the parameter applies to e.g. install, delete etc")
14 description: Optional[str] = Field(title="Parameter description")
15 required: bool = Field(False, title="Is the parameter required")
16
17
18 class ResourceTemplate(AzureTREModel):
19 id: str
20 name: str = Field(title="Unique template name")
21 description: str = Field(title="Template description")
22 version: str = Field(title="Template version")
23 properties: List[dict] = Field(title="Template parameters")
24 resourceType: ResourceType = Field(title="Type of resource this template is for (workspace/service)")
25 current: bool = Field(title="Is this the current version of this template")
26
[end of management_api_app/models/domain/resource_template.py]
[start of management_api_app/models/schemas/workspace_template.py]
1 from typing import List
2 from pydantic import BaseModel, Field
3
4 from models.domain.resource import ResourceType
5 from models.domain.resource_template import ResourceTemplate, Parameter
6
7
8 def get_sample_workspace_template_object(template_name: str = "tre-workspace-vanilla") -> ResourceTemplate:
9 return ResourceTemplate(
10 id="a7a7a7bd-7f4e-4a4e-b970-dc86a6b31dfb",
11 name=template_name,
12 description="vanilla workspace bundle",
13 version="0.1.0",
14 properties=[
15 Parameter(name="azure_location", type="string"),
16 Parameter(name="tre_id", type="string"),
17 Parameter(name="workspace_id", type="string"),
18 Parameter(name="address_space", type="string", default="10.2.1.0/24", description="VNet address space for the workspace services")
19 ],
20 resourceType=ResourceType.Workspace,
21 current=True,
22 )
23
24
25 def get_sample_workspace_template() -> dict:
26 return get_sample_workspace_template_object().dict()
27
28
29 class WorkspaceTemplateNamesInList(BaseModel):
30 templateNames: List[str]
31
32 class Config:
33 schema_extra = {
34 "example": {
35 "templateNames": ["tre-workspace-vanilla", "tre-workspace-base"]
36 }
37 }
38
39
40 class WorkspaceTemplateInCreate(BaseModel):
41
42 name: str = Field(title="Name of workspace template")
43 version: str = Field(title="Version of workspace template")
44 description: str = Field(title=" Description of workspace template")
45 properties: List[dict] = Field([{}], title="Workspace template properties",
46 description="Values for the properties required by the workspace template")
47 resourceType: str = Field(title="Type of workspace template")
48 current: bool = Field(title="Mark this version as current")
49
50 class Config:
51 schema_extra = {
52 "example": {
53 "name": "my-tre-workspace",
54 "version": "0.0.1",
55 "description": "workspace template for great product",
56 "properties": [{
57 "name": "azure_location",
58 "type": "string"
59 }],
60 "resourceType": "workspace",
61 "current": "true"
62 }
63 }
64
65
66 class WorkspaceTemplateInResponse(BaseModel):
67 workspaceTemplate: ResourceTemplate
68
69 class Config:
70 schema_extra = {
71 "example": {
72 "resourceTemplateId": "49a7445c-aae6-41ec-a539-30dfa90ab1ae",
73 "workspaceTemplate": get_sample_workspace_template()
74 }
75 }
76
[end of management_api_app/models/schemas/workspace_template.py]
[start of management_api_app/db/repositories/workspace_templates.py]
1 import uuid
2 from typing import List
3
4 from azure.cosmos import CosmosClient
5
6 from core import config
7 from db.errors import EntityDoesNotExist
8 from db.repositories.base import BaseRepository
9 from models.domain.resource_template import ResourceTemplate
10 from models.schemas.workspace_template import WorkspaceTemplateInCreate
11
12
13 class WorkspaceTemplateRepository(BaseRepository):
14 def __init__(self, client: CosmosClient):
15 super().__init__(client, config.STATE_STORE_RESOURCE_TEMPLATES_CONTAINER)
16
17 @staticmethod
18 def _workspace_template_by_name_query(name: str) -> str:
19 return f'SELECT * FROM c WHERE c.resourceType = "workspace" AND c.name = "{name}"'
20
21 def get_workspace_templates_by_name(self, name: str) -> List[ResourceTemplate]:
22 query = self._workspace_template_by_name_query(name)
23 return self.query(query=query)
24
25 def get_current_workspace_template_by_name(self, name: str) -> ResourceTemplate:
26 query = self._workspace_template_by_name_query(name) + ' AND c.current = true'
27 workspace_templates = self.query(query=query)
28 if len(workspace_templates) != 1:
29 raise EntityDoesNotExist
30 return workspace_templates[0]
31
32 def get_workspace_template_by_name_and_version(self, name: str, version: str) -> ResourceTemplate:
33 query = self._workspace_template_by_name_query(name) + f' AND c.version = "{version}"'
34 workspace_templates = self.query(query=query)
35 if len(workspace_templates) != 1:
36 raise EntityDoesNotExist
37 return workspace_templates[0]
38
39 def get_workspace_template_names(self) -> List[str]:
40 query = 'SELECT c.name FROM c'
41 workspace_templates = self.query(query=query)
42 print(workspace_templates)
43 workspace_template_names = [template["name"] for template in workspace_templates]
44 return list(set(workspace_template_names))
45
46 def create_workspace_template_item(self, workspace_template_create: WorkspaceTemplateInCreate):
47 item_id = str(uuid.uuid4())
48 resource_template = ResourceTemplate(
49 id=item_id,
50 name=workspace_template_create.name,
51 description=workspace_template_create.description,
52 version=workspace_template_create.version,
53 properties=workspace_template_create.properties,
54 resourceType=workspace_template_create.resourceType,
55 current=workspace_template_create.current
56 )
57 self.create_item(resource_template)
58 return resource_template
59
60 def update_item(self, resource_template: ResourceTemplate):
61 self.container.upsert_item(resource_template)
62
[end of management_api_app/db/repositories/workspace_templates.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/management_api_app/db/repositories/workspace_templates.py b/management_api_app/db/repositories/workspace_templates.py
--- a/management_api_app/db/repositories/workspace_templates.py
+++ b/management_api_app/db/repositories/workspace_templates.py
@@ -50,7 +50,7 @@
name=workspace_template_create.name,
description=workspace_template_create.description,
version=workspace_template_create.version,
- properties=workspace_template_create.properties,
+ parameters=workspace_template_create.parameters,
resourceType=workspace_template_create.resourceType,
current=workspace_template_create.current
)
diff --git a/management_api_app/models/domain/resource_template.py b/management_api_app/models/domain/resource_template.py
--- a/management_api_app/models/domain/resource_template.py
+++ b/management_api_app/models/domain/resource_template.py
@@ -20,6 +20,6 @@
name: str = Field(title="Unique template name")
description: str = Field(title="Template description")
version: str = Field(title="Template version")
- properties: List[dict] = Field(title="Template parameters")
+ parameters: List[dict] = Field(title="Template parameters")
resourceType: ResourceType = Field(title="Type of resource this template is for (workspace/service)")
current: bool = Field(title="Is this the current version of this template")
diff --git a/management_api_app/models/schemas/workspace_template.py b/management_api_app/models/schemas/workspace_template.py
--- a/management_api_app/models/schemas/workspace_template.py
+++ b/management_api_app/models/schemas/workspace_template.py
@@ -11,7 +11,7 @@
name=template_name,
description="vanilla workspace bundle",
version="0.1.0",
- properties=[
+ parameters=[
Parameter(name="azure_location", type="string"),
Parameter(name="tre_id", type="string"),
Parameter(name="workspace_id", type="string"),
@@ -42,8 +42,8 @@
name: str = Field(title="Name of workspace template")
version: str = Field(title="Version of workspace template")
description: str = Field(title=" Description of workspace template")
- properties: List[dict] = Field([{}], title="Workspace template properties",
- description="Values for the properties required by the workspace template")
+ parameters: List[dict] = Field([{}], title="Workspace template parameters",
+ description="Values for the parameters required by the workspace template")
resourceType: str = Field(title="Type of workspace template")
current: bool = Field(title="Mark this version as current")
@@ -53,7 +53,7 @@
"name": "my-tre-workspace",
"version": "0.0.1",
"description": "workspace template for great product",
- "properties": [{
+ "parameters": [{
"name": "azure_location",
"type": "string"
}],
|
{"golden_diff": "diff --git a/management_api_app/db/repositories/workspace_templates.py b/management_api_app/db/repositories/workspace_templates.py\n--- a/management_api_app/db/repositories/workspace_templates.py\n+++ b/management_api_app/db/repositories/workspace_templates.py\n@@ -50,7 +50,7 @@\n name=workspace_template_create.name,\n description=workspace_template_create.description,\n version=workspace_template_create.version,\n- properties=workspace_template_create.properties,\n+ parameters=workspace_template_create.parameters,\n resourceType=workspace_template_create.resourceType,\n current=workspace_template_create.current\n )\ndiff --git a/management_api_app/models/domain/resource_template.py b/management_api_app/models/domain/resource_template.py\n--- a/management_api_app/models/domain/resource_template.py\n+++ b/management_api_app/models/domain/resource_template.py\n@@ -20,6 +20,6 @@\n name: str = Field(title=\"Unique template name\")\n description: str = Field(title=\"Template description\")\n version: str = Field(title=\"Template version\")\n- properties: List[dict] = Field(title=\"Template parameters\")\n+ parameters: List[dict] = Field(title=\"Template parameters\")\n resourceType: ResourceType = Field(title=\"Type of resource this template is for (workspace/service)\")\n current: bool = Field(title=\"Is this the current version of this template\")\ndiff --git a/management_api_app/models/schemas/workspace_template.py b/management_api_app/models/schemas/workspace_template.py\n--- a/management_api_app/models/schemas/workspace_template.py\n+++ b/management_api_app/models/schemas/workspace_template.py\n@@ -11,7 +11,7 @@\n name=template_name,\n description=\"vanilla workspace bundle\",\n version=\"0.1.0\",\n- properties=[\n+ parameters=[\n Parameter(name=\"azure_location\", type=\"string\"),\n Parameter(name=\"tre_id\", type=\"string\"),\n Parameter(name=\"workspace_id\", type=\"string\"),\n@@ -42,8 +42,8 @@\n name: str = Field(title=\"Name of workspace template\")\n version: str = Field(title=\"Version of workspace template\")\n description: str = Field(title=\" Description of workspace template\")\n- properties: List[dict] = Field([{}], title=\"Workspace template properties\",\n- description=\"Values for the properties required by the workspace template\")\n+ parameters: List[dict] = Field([{}], title=\"Workspace template parameters\",\n+ description=\"Values for the parameters required by the workspace template\")\n resourceType: str = Field(title=\"Type of workspace template\")\n current: bool = Field(title=\"Mark this version as current\")\n \n@@ -53,7 +53,7 @@\n \"name\": \"my-tre-workspace\",\n \"version\": \"0.0.1\",\n \"description\": \"workspace template for great product\",\n- \"properties\": [{\n+ \"parameters\": [{\n \"name\": \"azure_location\",\n \"type\": \"string\"\n }],\n", "issue": "[BUG] ResourceTemplates have properties - should be parameters\nRename properties to parameters\r\n\n", "before_files": [{"content": "from typing import List, Optional, Any\n\nfrom pydantic import Field\n\nfrom models.domain.azuretremodel import AzureTREModel\nfrom models.domain.resource import ResourceType\n\n\nclass Parameter(AzureTREModel):\n name: str = Field(title=\"Parameter name\")\n type: str = Field(title=\"Parameter type\")\n default: Any = Field(title=\"Default value for the parameter\")\n applyTo: str = Field(\"All Actions\", title=\"The actions that the parameter applies to e.g. install, delete etc\")\n description: Optional[str] = Field(title=\"Parameter description\")\n required: bool = Field(False, title=\"Is the parameter required\")\n\n\nclass ResourceTemplate(AzureTREModel):\n id: str\n name: str = Field(title=\"Unique template name\")\n description: str = Field(title=\"Template description\")\n version: str = Field(title=\"Template version\")\n properties: List[dict] = Field(title=\"Template parameters\")\n resourceType: ResourceType = Field(title=\"Type of resource this template is for (workspace/service)\")\n current: bool = Field(title=\"Is this the current version of this template\")\n", "path": "management_api_app/models/domain/resource_template.py"}, {"content": "from typing import List\nfrom pydantic import BaseModel, Field\n\nfrom models.domain.resource import ResourceType\nfrom models.domain.resource_template import ResourceTemplate, Parameter\n\n\ndef get_sample_workspace_template_object(template_name: str = \"tre-workspace-vanilla\") -> ResourceTemplate:\n return ResourceTemplate(\n id=\"a7a7a7bd-7f4e-4a4e-b970-dc86a6b31dfb\",\n name=template_name,\n description=\"vanilla workspace bundle\",\n version=\"0.1.0\",\n properties=[\n Parameter(name=\"azure_location\", type=\"string\"),\n Parameter(name=\"tre_id\", type=\"string\"),\n Parameter(name=\"workspace_id\", type=\"string\"),\n Parameter(name=\"address_space\", type=\"string\", default=\"10.2.1.0/24\", description=\"VNet address space for the workspace services\")\n ],\n resourceType=ResourceType.Workspace,\n current=True,\n )\n\n\ndef get_sample_workspace_template() -> dict:\n return get_sample_workspace_template_object().dict()\n\n\nclass WorkspaceTemplateNamesInList(BaseModel):\n templateNames: List[str]\n\n class Config:\n schema_extra = {\n \"example\": {\n \"templateNames\": [\"tre-workspace-vanilla\", \"tre-workspace-base\"]\n }\n }\n\n\nclass WorkspaceTemplateInCreate(BaseModel):\n\n name: str = Field(title=\"Name of workspace template\")\n version: str = Field(title=\"Version of workspace template\")\n description: str = Field(title=\" Description of workspace template\")\n properties: List[dict] = Field([{}], title=\"Workspace template properties\",\n description=\"Values for the properties required by the workspace template\")\n resourceType: str = Field(title=\"Type of workspace template\")\n current: bool = Field(title=\"Mark this version as current\")\n\n class Config:\n schema_extra = {\n \"example\": {\n \"name\": \"my-tre-workspace\",\n \"version\": \"0.0.1\",\n \"description\": \"workspace template for great product\",\n \"properties\": [{\n \"name\": \"azure_location\",\n \"type\": \"string\"\n }],\n \"resourceType\": \"workspace\",\n \"current\": \"true\"\n }\n }\n\n\nclass WorkspaceTemplateInResponse(BaseModel):\n workspaceTemplate: ResourceTemplate\n\n class Config:\n schema_extra = {\n \"example\": {\n \"resourceTemplateId\": \"49a7445c-aae6-41ec-a539-30dfa90ab1ae\",\n \"workspaceTemplate\": get_sample_workspace_template()\n }\n }\n", "path": "management_api_app/models/schemas/workspace_template.py"}, {"content": "import uuid\nfrom typing import List\n\nfrom azure.cosmos import CosmosClient\n\nfrom core import config\nfrom db.errors import EntityDoesNotExist\nfrom db.repositories.base import BaseRepository\nfrom models.domain.resource_template import ResourceTemplate\nfrom models.schemas.workspace_template import WorkspaceTemplateInCreate\n\n\nclass WorkspaceTemplateRepository(BaseRepository):\n def __init__(self, client: CosmosClient):\n super().__init__(client, config.STATE_STORE_RESOURCE_TEMPLATES_CONTAINER)\n\n @staticmethod\n def _workspace_template_by_name_query(name: str) -> str:\n return f'SELECT * FROM c WHERE c.resourceType = \"workspace\" AND c.name = \"{name}\"'\n\n def get_workspace_templates_by_name(self, name: str) -> List[ResourceTemplate]:\n query = self._workspace_template_by_name_query(name)\n return self.query(query=query)\n\n def get_current_workspace_template_by_name(self, name: str) -> ResourceTemplate:\n query = self._workspace_template_by_name_query(name) + ' AND c.current = true'\n workspace_templates = self.query(query=query)\n if len(workspace_templates) != 1:\n raise EntityDoesNotExist\n return workspace_templates[0]\n\n def get_workspace_template_by_name_and_version(self, name: str, version: str) -> ResourceTemplate:\n query = self._workspace_template_by_name_query(name) + f' AND c.version = \"{version}\"'\n workspace_templates = self.query(query=query)\n if len(workspace_templates) != 1:\n raise EntityDoesNotExist\n return workspace_templates[0]\n\n def get_workspace_template_names(self) -> List[str]:\n query = 'SELECT c.name FROM c'\n workspace_templates = self.query(query=query)\n print(workspace_templates)\n workspace_template_names = [template[\"name\"] for template in workspace_templates]\n return list(set(workspace_template_names))\n\n def create_workspace_template_item(self, workspace_template_create: WorkspaceTemplateInCreate):\n item_id = str(uuid.uuid4())\n resource_template = ResourceTemplate(\n id=item_id,\n name=workspace_template_create.name,\n description=workspace_template_create.description,\n version=workspace_template_create.version,\n properties=workspace_template_create.properties,\n resourceType=workspace_template_create.resourceType,\n current=workspace_template_create.current\n )\n self.create_item(resource_template)\n return resource_template\n\n def update_item(self, resource_template: ResourceTemplate):\n self.container.upsert_item(resource_template)\n", "path": "management_api_app/db/repositories/workspace_templates.py"}]}
| 2,237 | 635 |
gh_patches_debug_10154
|
rasdani/github-patches
|
git_diff
|
cal-itp__benefits-1611
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
MultiValueDictKeyError: 'language'
Sentry Issue: (https://sentry.calitp.org/organizations/sentry/issues/69523/?referrer=github_integration)
```
KeyError: 'language'
File "django/utils/datastructures.py", line 84, in __getitem__
list_ = super().__getitem__(key)
MultiValueDictKeyError: 'language'
File "benefits/core/middleware.py", line 157, in process_view
new_lang = request.POST["language"]
```
</issue>
<code>
[start of benefits/core/middleware.py]
1 """
2 The core application: middleware definitions for request/response cycle.
3 """
4 import logging
5
6 from django.conf import settings
7 from django.http import HttpResponse
8 from django.shortcuts import redirect
9 from django.template.response import TemplateResponse
10 from django.urls import reverse
11 from django.utils.decorators import decorator_from_middleware
12 from django.utils.deprecation import MiddlewareMixin
13 from django.views import i18n
14
15 from . import analytics, recaptcha, session
16
17
18 logger = logging.getLogger(__name__)
19
20 HEALTHCHECK_PATH = "/healthcheck"
21 ROUTE_INDEX = "core:index"
22 TEMPLATE_USER_ERROR = "200-user-error.html"
23
24
25 def user_error(request):
26 return TemplateResponse(request, TEMPLATE_USER_ERROR)
27
28
29 class AgencySessionRequired(MiddlewareMixin):
30 """Middleware raises an exception for sessions lacking an agency configuration."""
31
32 def process_request(self, request):
33 if session.active_agency(request):
34 logger.debug("Session configured with agency")
35 return None
36 else:
37 logger.debug("Session not configured with agency")
38 return user_error(request)
39
40
41 class EligibleSessionRequired(MiddlewareMixin):
42 """Middleware raises an exception for sessions lacking confirmed eligibility."""
43
44 def process_request(self, request):
45 if session.eligible(request):
46 logger.debug("Session has confirmed eligibility")
47 return None
48 else:
49 logger.debug("Session has no confirmed eligibility")
50 return user_error(request)
51
52
53 class DebugSession(MiddlewareMixin):
54 """Middleware to configure debug context in the request session."""
55
56 def process_request(self, request):
57 session.update(request, debug=settings.DEBUG)
58 return None
59
60
61 class Healthcheck:
62 """Middleware intercepts and accepts /healthcheck requests."""
63
64 def __init__(self, get_response):
65 self.get_response = get_response
66
67 def __call__(self, request):
68 if request.path == HEALTHCHECK_PATH:
69 return HttpResponse("Healthy", content_type="text/plain")
70 return self.get_response(request)
71
72
73 class HealthcheckUserAgents(MiddlewareMixin):
74 """Middleware to return healthcheck for user agents specified in HEALTHCHECK_USER_AGENTS."""
75
76 def process_request(self, request):
77 if hasattr(request, "META"):
78 user_agent = request.META.get("HTTP_USER_AGENT", "")
79 if user_agent in settings.HEALTHCHECK_USER_AGENTS:
80 return HttpResponse("Healthy", content_type="text/plain")
81
82 return self.get_response(request)
83
84
85 class VerifierSessionRequired(MiddlewareMixin):
86 """Middleware raises an exception for sessions lacking an eligibility verifier configuration."""
87
88 def process_request(self, request):
89 if session.verifier(request):
90 logger.debug("Session configured with eligibility verifier")
91 return None
92 else:
93 logger.debug("Session not configured with eligibility verifier")
94 return user_error(request)
95
96
97 class ViewedPageEvent(MiddlewareMixin):
98 """Middleware sends an analytics event for page views."""
99
100 def process_response(self, request, response):
101 event = analytics.ViewedPageEvent(request)
102 try:
103 analytics.send_event(event)
104 except Exception:
105 logger.warning(f"Failed to send event: {event}")
106 finally:
107 return response
108
109
110 pageview_decorator = decorator_from_middleware(ViewedPageEvent)
111
112
113 class ChangedLanguageEvent(MiddlewareMixin):
114 """Middleware hooks into django.views.i18n.set_language to send an analytics event."""
115
116 def process_view(self, request, view_func, view_args, view_kwargs):
117 if view_func == i18n.set_language:
118 new_lang = request.POST["language"]
119 event = analytics.ChangedLanguageEvent(request, new_lang)
120 analytics.send_event(event)
121 return None
122
123
124 class LoginRequired(MiddlewareMixin):
125 """Middleware that checks whether a user is logged in."""
126
127 def process_view(self, request, view_func, view_args, view_kwargs):
128 # only require login if verifier requires it
129 verifier = session.verifier(request)
130 if not verifier or not verifier.is_auth_required or session.logged_in(request):
131 # pass through
132 return None
133
134 return redirect("oauth:login")
135
136
137 class RecaptchaEnabled(MiddlewareMixin):
138 """Middleware configures the request with required reCAPTCHA settings."""
139
140 def process_request(self, request):
141 if settings.RECAPTCHA_ENABLED:
142 request.recaptcha = {
143 "data_field": recaptcha.DATA_FIELD,
144 "script_api": settings.RECAPTCHA_API_KEY_URL,
145 "site_key": settings.RECAPTCHA_SITE_KEY,
146 }
147 return None
148
149
150 class IndexOrAgencyIndexOrigin(MiddlewareMixin):
151 """Middleware sets the session.origin to either the core:index or core:agency_index depending on agency config."""
152
153 def process_request(self, request):
154 if session.active_agency(request):
155 session.update(request, origin=session.agency(request).index_url)
156 else:
157 session.update(request, origin=reverse(ROUTE_INDEX))
158 return None
159
160
161 index_or_agencyindex_origin_decorator = decorator_from_middleware(IndexOrAgencyIndexOrigin)
162
[end of benefits/core/middleware.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/benefits/core/middleware.py b/benefits/core/middleware.py
--- a/benefits/core/middleware.py
+++ b/benefits/core/middleware.py
@@ -115,9 +115,12 @@
def process_view(self, request, view_func, view_args, view_kwargs):
if view_func == i18n.set_language:
- new_lang = request.POST["language"]
- event = analytics.ChangedLanguageEvent(request, new_lang)
- analytics.send_event(event)
+ new_lang = request.POST.get("language")
+ if new_lang:
+ event = analytics.ChangedLanguageEvent(request, new_lang)
+ analytics.send_event(event)
+ else:
+ logger.warning("i18n.set_language POST without language")
return None
|
{"golden_diff": "diff --git a/benefits/core/middleware.py b/benefits/core/middleware.py\n--- a/benefits/core/middleware.py\n+++ b/benefits/core/middleware.py\n@@ -115,9 +115,12 @@\n \n def process_view(self, request, view_func, view_args, view_kwargs):\n if view_func == i18n.set_language:\n- new_lang = request.POST[\"language\"]\n- event = analytics.ChangedLanguageEvent(request, new_lang)\n- analytics.send_event(event)\n+ new_lang = request.POST.get(\"language\")\n+ if new_lang:\n+ event = analytics.ChangedLanguageEvent(request, new_lang)\n+ analytics.send_event(event)\n+ else:\n+ logger.warning(\"i18n.set_language POST without language\")\n return None\n", "issue": "MultiValueDictKeyError: 'language'\nSentry Issue: (https://sentry.calitp.org/organizations/sentry/issues/69523/?referrer=github_integration)\n\n```\nKeyError: 'language'\n File \"django/utils/datastructures.py\", line 84, in __getitem__\n list_ = super().__getitem__(key)\n\nMultiValueDictKeyError: 'language'\n File \"benefits/core/middleware.py\", line 157, in process_view\n new_lang = request.POST[\"language\"]\n```\n", "before_files": [{"content": "\"\"\"\nThe core application: middleware definitions for request/response cycle.\n\"\"\"\nimport logging\n\nfrom django.conf import settings\nfrom django.http import HttpResponse\nfrom django.shortcuts import redirect\nfrom django.template.response import TemplateResponse\nfrom django.urls import reverse\nfrom django.utils.decorators import decorator_from_middleware\nfrom django.utils.deprecation import MiddlewareMixin\nfrom django.views import i18n\n\nfrom . import analytics, recaptcha, session\n\n\nlogger = logging.getLogger(__name__)\n\nHEALTHCHECK_PATH = \"/healthcheck\"\nROUTE_INDEX = \"core:index\"\nTEMPLATE_USER_ERROR = \"200-user-error.html\"\n\n\ndef user_error(request):\n return TemplateResponse(request, TEMPLATE_USER_ERROR)\n\n\nclass AgencySessionRequired(MiddlewareMixin):\n \"\"\"Middleware raises an exception for sessions lacking an agency configuration.\"\"\"\n\n def process_request(self, request):\n if session.active_agency(request):\n logger.debug(\"Session configured with agency\")\n return None\n else:\n logger.debug(\"Session not configured with agency\")\n return user_error(request)\n\n\nclass EligibleSessionRequired(MiddlewareMixin):\n \"\"\"Middleware raises an exception for sessions lacking confirmed eligibility.\"\"\"\n\n def process_request(self, request):\n if session.eligible(request):\n logger.debug(\"Session has confirmed eligibility\")\n return None\n else:\n logger.debug(\"Session has no confirmed eligibility\")\n return user_error(request)\n\n\nclass DebugSession(MiddlewareMixin):\n \"\"\"Middleware to configure debug context in the request session.\"\"\"\n\n def process_request(self, request):\n session.update(request, debug=settings.DEBUG)\n return None\n\n\nclass Healthcheck:\n \"\"\"Middleware intercepts and accepts /healthcheck requests.\"\"\"\n\n def __init__(self, get_response):\n self.get_response = get_response\n\n def __call__(self, request):\n if request.path == HEALTHCHECK_PATH:\n return HttpResponse(\"Healthy\", content_type=\"text/plain\")\n return self.get_response(request)\n\n\nclass HealthcheckUserAgents(MiddlewareMixin):\n \"\"\"Middleware to return healthcheck for user agents specified in HEALTHCHECK_USER_AGENTS.\"\"\"\n\n def process_request(self, request):\n if hasattr(request, \"META\"):\n user_agent = request.META.get(\"HTTP_USER_AGENT\", \"\")\n if user_agent in settings.HEALTHCHECK_USER_AGENTS:\n return HttpResponse(\"Healthy\", content_type=\"text/plain\")\n\n return self.get_response(request)\n\n\nclass VerifierSessionRequired(MiddlewareMixin):\n \"\"\"Middleware raises an exception for sessions lacking an eligibility verifier configuration.\"\"\"\n\n def process_request(self, request):\n if session.verifier(request):\n logger.debug(\"Session configured with eligibility verifier\")\n return None\n else:\n logger.debug(\"Session not configured with eligibility verifier\")\n return user_error(request)\n\n\nclass ViewedPageEvent(MiddlewareMixin):\n \"\"\"Middleware sends an analytics event for page views.\"\"\"\n\n def process_response(self, request, response):\n event = analytics.ViewedPageEvent(request)\n try:\n analytics.send_event(event)\n except Exception:\n logger.warning(f\"Failed to send event: {event}\")\n finally:\n return response\n\n\npageview_decorator = decorator_from_middleware(ViewedPageEvent)\n\n\nclass ChangedLanguageEvent(MiddlewareMixin):\n \"\"\"Middleware hooks into django.views.i18n.set_language to send an analytics event.\"\"\"\n\n def process_view(self, request, view_func, view_args, view_kwargs):\n if view_func == i18n.set_language:\n new_lang = request.POST[\"language\"]\n event = analytics.ChangedLanguageEvent(request, new_lang)\n analytics.send_event(event)\n return None\n\n\nclass LoginRequired(MiddlewareMixin):\n \"\"\"Middleware that checks whether a user is logged in.\"\"\"\n\n def process_view(self, request, view_func, view_args, view_kwargs):\n # only require login if verifier requires it\n verifier = session.verifier(request)\n if not verifier or not verifier.is_auth_required or session.logged_in(request):\n # pass through\n return None\n\n return redirect(\"oauth:login\")\n\n\nclass RecaptchaEnabled(MiddlewareMixin):\n \"\"\"Middleware configures the request with required reCAPTCHA settings.\"\"\"\n\n def process_request(self, request):\n if settings.RECAPTCHA_ENABLED:\n request.recaptcha = {\n \"data_field\": recaptcha.DATA_FIELD,\n \"script_api\": settings.RECAPTCHA_API_KEY_URL,\n \"site_key\": settings.RECAPTCHA_SITE_KEY,\n }\n return None\n\n\nclass IndexOrAgencyIndexOrigin(MiddlewareMixin):\n \"\"\"Middleware sets the session.origin to either the core:index or core:agency_index depending on agency config.\"\"\"\n\n def process_request(self, request):\n if session.active_agency(request):\n session.update(request, origin=session.agency(request).index_url)\n else:\n session.update(request, origin=reverse(ROUTE_INDEX))\n return None\n\n\nindex_or_agencyindex_origin_decorator = decorator_from_middleware(IndexOrAgencyIndexOrigin)\n", "path": "benefits/core/middleware.py"}]}
| 2,066 | 177 |
gh_patches_debug_3496
|
rasdani/github-patches
|
git_diff
|
strawberry-graphql__strawberry-858
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
from_pydantic() converts False values to None
When calling `from_pydantic()`, values consistent with `bool(value) == False` may be replaced with None.
This recreates the issue:
```
from pydantic import BaseModel
import strawberry
class PydanticClass(BaseModel):
str1: str
str2: str
bool1: bool
bool2: bool
@strawberry.experimental.pydantic.type(
model=PydanticClass,
fields=['str1', 'str2', 'bool1', 'bool2']
)
class StrawberryClass:
pass
str1 = 'nonempty'
str2 = ''
bool1 = True
bool2 = False
myobj = PydanticClass(
str1=str1,
str2=str2,
bool1=bool1,
bool2=bool2
)
print('pydantic obj:', myobj)
converted = StrawberryClass.from_pydantic(myobj)
print('converted:', converted)
```
The output:
```
pydantic obj: str1='nonempty' str2='' bool1=True bool2=False
converted obj: StrawberryClass(str1='nonempty', str2=None, bool1=True, bool2=None)
```
Both str2 and bool2 were converted to None.
Location of the bug: https://github.com/strawberry-graphql/strawberry/blob/main/strawberry/experimental/pydantic/conversion.py#L10
</issue>
<code>
[start of strawberry/experimental/pydantic/conversion.py]
1 from typing import cast
2
3 from strawberry.field import StrawberryField
4 from strawberry.scalars import is_scalar
5
6
7 def _convert_from_pydantic_to_strawberry_field(
8 field: StrawberryField, data_from_model=None, extra=None
9 ):
10 data = data_from_model or extra
11
12 if field.is_list:
13 assert field.child is not None
14
15 items = [None for _ in data]
16
17 for index, item in enumerate(data):
18 items[index] = _convert_from_pydantic_to_strawberry_field(
19 field.child,
20 data_from_model=item,
21 extra=extra[index] if extra else None,
22 )
23
24 return items
25 elif is_scalar(field.type): # type: ignore
26 return data
27 else:
28 return convert_pydantic_model_to_strawberry_class(
29 field.type, model_instance=data_from_model, extra=extra
30 )
31
32
33 def convert_pydantic_model_to_strawberry_class(cls, *, model_instance=None, extra=None):
34 extra = extra or {}
35 kwargs = {}
36
37 for field in cls._type_definition.fields:
38 field = cast(StrawberryField, field)
39 python_name = field.python_name
40
41 data_from_extra = extra.get(python_name, None)
42 data_from_model = (
43 getattr(model_instance, python_name, None) if model_instance else None
44 )
45 kwargs[python_name] = _convert_from_pydantic_to_strawberry_field(
46 field, data_from_model, extra=data_from_extra
47 )
48
49 return cls(**kwargs)
50
[end of strawberry/experimental/pydantic/conversion.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/strawberry/experimental/pydantic/conversion.py b/strawberry/experimental/pydantic/conversion.py
--- a/strawberry/experimental/pydantic/conversion.py
+++ b/strawberry/experimental/pydantic/conversion.py
@@ -7,7 +7,7 @@
def _convert_from_pydantic_to_strawberry_field(
field: StrawberryField, data_from_model=None, extra=None
):
- data = data_from_model or extra
+ data = data_from_model if data_from_model is not None else extra
if field.is_list:
assert field.child is not None
|
{"golden_diff": "diff --git a/strawberry/experimental/pydantic/conversion.py b/strawberry/experimental/pydantic/conversion.py\n--- a/strawberry/experimental/pydantic/conversion.py\n+++ b/strawberry/experimental/pydantic/conversion.py\n@@ -7,7 +7,7 @@\n def _convert_from_pydantic_to_strawberry_field(\n field: StrawberryField, data_from_model=None, extra=None\n ):\n- data = data_from_model or extra\n+ data = data_from_model if data_from_model is not None else extra\n \n if field.is_list:\n assert field.child is not None\n", "issue": "from_pydantic() converts False values to None\nWhen calling `from_pydantic()`, values consistent with `bool(value) == False` may be replaced with None. \r\n\r\nThis recreates the issue:\r\n```\r\nfrom pydantic import BaseModel\r\nimport strawberry\r\n\r\nclass PydanticClass(BaseModel):\r\n str1: str\r\n str2: str\r\n bool1: bool\r\n bool2: bool\r\n\r\[email protected](\r\n model=PydanticClass,\r\n fields=['str1', 'str2', 'bool1', 'bool2']\r\n)\r\nclass StrawberryClass:\r\n pass\r\n\r\nstr1 = 'nonempty'\r\nstr2 = ''\r\nbool1 = True\r\nbool2 = False\r\n\r\nmyobj = PydanticClass(\r\n str1=str1,\r\n str2=str2,\r\n bool1=bool1,\r\n bool2=bool2\r\n)\r\nprint('pydantic obj:', myobj)\r\n\r\nconverted = StrawberryClass.from_pydantic(myobj)\r\nprint('converted:', converted)\r\n```\r\n\r\nThe output:\r\n```\r\npydantic obj: str1='nonempty' str2='' bool1=True bool2=False\r\nconverted obj: StrawberryClass(str1='nonempty', str2=None, bool1=True, bool2=None)\r\n```\r\nBoth str2 and bool2 were converted to None.\r\n\r\nLocation of the bug: https://github.com/strawberry-graphql/strawberry/blob/main/strawberry/experimental/pydantic/conversion.py#L10\r\n\r\n\n", "before_files": [{"content": "from typing import cast\n\nfrom strawberry.field import StrawberryField\nfrom strawberry.scalars import is_scalar\n\n\ndef _convert_from_pydantic_to_strawberry_field(\n field: StrawberryField, data_from_model=None, extra=None\n):\n data = data_from_model or extra\n\n if field.is_list:\n assert field.child is not None\n\n items = [None for _ in data]\n\n for index, item in enumerate(data):\n items[index] = _convert_from_pydantic_to_strawberry_field(\n field.child,\n data_from_model=item,\n extra=extra[index] if extra else None,\n )\n\n return items\n elif is_scalar(field.type): # type: ignore\n return data\n else:\n return convert_pydantic_model_to_strawberry_class(\n field.type, model_instance=data_from_model, extra=extra\n )\n\n\ndef convert_pydantic_model_to_strawberry_class(cls, *, model_instance=None, extra=None):\n extra = extra or {}\n kwargs = {}\n\n for field in cls._type_definition.fields:\n field = cast(StrawberryField, field)\n python_name = field.python_name\n\n data_from_extra = extra.get(python_name, None)\n data_from_model = (\n getattr(model_instance, python_name, None) if model_instance else None\n )\n kwargs[python_name] = _convert_from_pydantic_to_strawberry_field(\n field, data_from_model, extra=data_from_extra\n )\n\n return cls(**kwargs)\n", "path": "strawberry/experimental/pydantic/conversion.py"}]}
| 1,281 | 139 |
gh_patches_debug_24313
|
rasdani/github-patches
|
git_diff
|
microsoft__ptvsd-111
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Pip Installing PTVSD fails
* Python2.7
* Pip install ptvsd from local source fails with the following error:
```
running build_ext
building 'ptvsd.pydevd._pydevd_bundle.pydevd_cython' extension
error: Microsoft Visual C++ 9.0 is required. Get it from http://aka.ms/vcpython27
```
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2
3 # Copyright (c) Microsoft Corporation. All rights reserved.
4 # Licensed under the MIT License. See LICENSE in the project root
5 # for license information.
6
7 import os
8 import os.path
9 from setuptools import setup, Extension
10
11 ROOT = os.path.dirname(os.path.abspath(__file__))
12
13 # Add pydevd files as data files for this package. They are not treated as a package of their own,
14 # because we don't actually want to provide pydevd - just use our own copy internally.
15 def get_pydevd_package_data():
16 ptvsd_prefix = os.path.join(ROOT, 'ptvsd')
17 pydevd_prefix = os.path.join(ptvsd_prefix, 'pydevd')
18 for root, dirs, files in os.walk(pydevd_prefix):
19 # From the root of pydevd repo, we want only scripts and subdirectories that
20 # constitute the package itself (not helper scripts, tests etc). But when
21 # walking down into those subdirectories, we want everything below.
22 if os.path.normcase(root) == os.path.normcase(pydevd_prefix):
23 dirs[:] = [d for d in dirs if d.startswith('pydev') or d.startswith('_pydev')]
24 files[:] = [f for f in files if f.endswith('.py') and 'pydev' in f]
25 for f in files:
26 yield os.path.join(root[len(ptvsd_prefix) + 1:], f)
27
28 setup(name='ptvsd',
29 version='4.0.0a1',
30 description='Visual Studio remote debugging server for Python',
31 license='MIT',
32 author='Microsoft Corporation',
33 author_email='[email protected]',
34 url='https://aka.ms/ptvs',
35 classifiers=[
36 'Development Status :: 3 - Alpha',
37 'Programming Language :: Python',
38 'Programming Language :: Python :: 2',
39 'Programming Language :: Python :: 3',
40 'License :: OSI Approved :: MIT License'],
41 packages=['ptvsd'],
42 package_data={'ptvsd': list(get_pydevd_package_data()) + ['ThirdPartyNotices.txt']},
43 ext_modules=[Extension('ptvsd.pydevd._pydevd_bundle.pydevd_cython',
44 ['ptvsd/pydevd/_pydevd_bundle/pydevd_cython.c'],
45 optional=True)],
46 )
47
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -6,6 +6,7 @@
import os
import os.path
+import sys
from setuptools import setup, Extension
ROOT = os.path.dirname(os.path.abspath(__file__))
@@ -25,6 +26,18 @@
for f in files:
yield os.path.join(root[len(ptvsd_prefix) + 1:], f)
+cmdclass = {}
+
+if sys.version_info[0] == 2:
+ from setuptools.command.build_ext import build_ext
+ class build_optional_ext(build_ext):
+ def build_extension(self, ext):
+ try:
+ super(build_optional_ext, self).build_extension(ext)
+ except:
+ pass
+ cmdclass = { 'build_ext': build_optional_ext }
+
setup(name='ptvsd',
version='4.0.0a1',
description='Visual Studio remote debugging server for Python',
@@ -43,4 +56,5 @@
ext_modules=[Extension('ptvsd.pydevd._pydevd_bundle.pydevd_cython',
['ptvsd/pydevd/_pydevd_bundle/pydevd_cython.c'],
optional=True)],
+ cmdclass=cmdclass,
)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -6,6 +6,7 @@\n \n import os\n import os.path\n+import sys\n from setuptools import setup, Extension\n \n ROOT = os.path.dirname(os.path.abspath(__file__))\n@@ -25,6 +26,18 @@\n for f in files:\n yield os.path.join(root[len(ptvsd_prefix) + 1:], f)\n \n+cmdclass = {}\n+\n+if sys.version_info[0] == 2:\n+ from setuptools.command.build_ext import build_ext\n+ class build_optional_ext(build_ext):\n+ def build_extension(self, ext):\n+ try:\n+ super(build_optional_ext, self).build_extension(ext)\n+ except:\n+ pass\n+ cmdclass = { 'build_ext': build_optional_ext }\n+\n setup(name='ptvsd',\n version='4.0.0a1',\n description='Visual Studio remote debugging server for Python',\n@@ -43,4 +56,5 @@\n ext_modules=[Extension('ptvsd.pydevd._pydevd_bundle.pydevd_cython',\n ['ptvsd/pydevd/_pydevd_bundle/pydevd_cython.c'],\n optional=True)],\n+ cmdclass=cmdclass,\n )\n", "issue": "Pip Installing PTVSD fails \n* Python2.7\r\n* Pip install ptvsd from local source fails with the following error:\r\n```\r\nrunning build_ext\r\n building 'ptvsd.pydevd._pydevd_bundle.pydevd_cython' extension\r\n error: Microsoft Visual C++ 9.0 is required. Get it from http://aka.ms/vcpython27\r\n```\n", "before_files": [{"content": "#!/usr/bin/env python\n\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See LICENSE in the project root\n# for license information.\n\nimport os\nimport os.path\nfrom setuptools import setup, Extension\n\nROOT = os.path.dirname(os.path.abspath(__file__))\n\n# Add pydevd files as data files for this package. They are not treated as a package of their own,\n# because we don't actually want to provide pydevd - just use our own copy internally.\ndef get_pydevd_package_data():\n ptvsd_prefix = os.path.join(ROOT, 'ptvsd')\n pydevd_prefix = os.path.join(ptvsd_prefix, 'pydevd')\n for root, dirs, files in os.walk(pydevd_prefix):\n # From the root of pydevd repo, we want only scripts and subdirectories that\n # constitute the package itself (not helper scripts, tests etc). But when\n # walking down into those subdirectories, we want everything below.\n if os.path.normcase(root) == os.path.normcase(pydevd_prefix):\n dirs[:] = [d for d in dirs if d.startswith('pydev') or d.startswith('_pydev')]\n files[:] = [f for f in files if f.endswith('.py') and 'pydev' in f]\n for f in files:\n yield os.path.join(root[len(ptvsd_prefix) + 1:], f)\n\nsetup(name='ptvsd',\n version='4.0.0a1',\n description='Visual Studio remote debugging server for Python',\n license='MIT',\n author='Microsoft Corporation',\n author_email='[email protected]',\n url='https://aka.ms/ptvs',\n classifiers=[\n 'Development Status :: 3 - Alpha',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 3',\n 'License :: OSI Approved :: MIT License'],\n packages=['ptvsd'],\n package_data={'ptvsd': list(get_pydevd_package_data()) + ['ThirdPartyNotices.txt']},\n ext_modules=[Extension('ptvsd.pydevd._pydevd_bundle.pydevd_cython',\n ['ptvsd/pydevd/_pydevd_bundle/pydevd_cython.c'],\n optional=True)],\n )\n", "path": "setup.py"}]}
| 1,204 | 283 |
gh_patches_debug_19118
|
rasdani/github-patches
|
git_diff
|
pfnet__pytorch-pfn-extras-788
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix nightly CPU test failures
https://github.com/pfnet/pytorch-pfn-extras/actions/workflows/nightly-test-cpu.yml
</issue>
<code>
[start of pytorch_pfn_extras/distributed/_distributed_validation_sampler.py]
1 from typing import Iterator, Optional, Sized, TypeVar
2
3 import numpy as np
4 import torch
5 import torch.distributed as dist
6
7 T_co = TypeVar("T_co", covariant=True)
8
9
10 class DistributedValidationSampler(torch.utils.data.Sampler):
11 """Distributed sampler without duplication
12
13 This sampler splits the input dataset to each worker process in distributed setup
14 without allowing repetition.
15 It is for evaluation purpose such as :class:`~DistributedEvaluator`.
16 This does not guarantee each worker to get the same number of samples,
17 so for training do not use this sampler (use PyTorch DistributedSampler instead).
18 """
19
20 def __init__(
21 self,
22 dataset: Sized,
23 num_replicas: Optional[int] = None,
24 rank: Optional[int] = None,
25 shuffle: bool = True,
26 seed: int = 0,
27 ) -> None:
28 if num_replicas is None:
29 if not dist.is_available(): # type: ignore[no-untyped-call]
30 raise RuntimeError(
31 "Requires distributed package to be available"
32 )
33 num_replicas = dist.get_world_size() # type: ignore[no-untyped-call]
34 if rank is None:
35 if not dist.is_available(): # type: ignore[no-untyped-call]
36 raise RuntimeError(
37 "Requires distributed package to be available"
38 )
39 rank = dist.get_rank() # type: ignore[no-untyped-call]
40 if rank >= num_replicas or rank < 0:
41 raise ValueError(
42 "Invalid rank {}, rank should be in the interval"
43 " [0, {}]".format(rank, num_replicas - 1)
44 )
45 self.dataset = dataset
46 self.num_replicas = num_replicas
47 self.rank = rank
48 self.shuffle = shuffle
49 self.seed = seed
50
51 self.dataset_len = len(dataset)
52 self.num_samples = len(
53 np.array_split(range(self.dataset_len), num_replicas)[rank]
54 )
55
56 def __iter__(self) -> Iterator[T_co]:
57 if self.shuffle:
58 # deterministically shuffle based on epoch and seed
59 g = torch.Generator()
60 g.manual_seed(self.seed)
61 indices = torch.randperm(self.dataset_len, generator=g).tolist()
62 else:
63 indices = list(range(self.dataset_len))
64
65 return iter(np.array_split(indices, self.num_replicas)[self.rank])
66
67 def __len__(self) -> int:
68 return self.num_samples
69
[end of pytorch_pfn_extras/distributed/_distributed_validation_sampler.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pytorch_pfn_extras/distributed/_distributed_validation_sampler.py b/pytorch_pfn_extras/distributed/_distributed_validation_sampler.py
--- a/pytorch_pfn_extras/distributed/_distributed_validation_sampler.py
+++ b/pytorch_pfn_extras/distributed/_distributed_validation_sampler.py
@@ -26,13 +26,13 @@
seed: int = 0,
) -> None:
if num_replicas is None:
- if not dist.is_available(): # type: ignore[no-untyped-call]
+ if not dist.is_available() or not dist.is_initialized(): # type: ignore[no-untyped-call]
raise RuntimeError(
"Requires distributed package to be available"
)
num_replicas = dist.get_world_size() # type: ignore[no-untyped-call]
if rank is None:
- if not dist.is_available(): # type: ignore[no-untyped-call]
+ if not dist.is_available() or not dist.is_initialized(): # type: ignore[no-untyped-call]
raise RuntimeError(
"Requires distributed package to be available"
)
|
{"golden_diff": "diff --git a/pytorch_pfn_extras/distributed/_distributed_validation_sampler.py b/pytorch_pfn_extras/distributed/_distributed_validation_sampler.py\n--- a/pytorch_pfn_extras/distributed/_distributed_validation_sampler.py\n+++ b/pytorch_pfn_extras/distributed/_distributed_validation_sampler.py\n@@ -26,13 +26,13 @@\n seed: int = 0,\n ) -> None:\n if num_replicas is None:\n- if not dist.is_available(): # type: ignore[no-untyped-call]\n+ if not dist.is_available() or not dist.is_initialized(): # type: ignore[no-untyped-call]\n raise RuntimeError(\n \"Requires distributed package to be available\"\n )\n num_replicas = dist.get_world_size() # type: ignore[no-untyped-call]\n if rank is None:\n- if not dist.is_available(): # type: ignore[no-untyped-call]\n+ if not dist.is_available() or not dist.is_initialized(): # type: ignore[no-untyped-call]\n raise RuntimeError(\n \"Requires distributed package to be available\"\n )\n", "issue": "Fix nightly CPU test failures\nhttps://github.com/pfnet/pytorch-pfn-extras/actions/workflows/nightly-test-cpu.yml\n", "before_files": [{"content": "from typing import Iterator, Optional, Sized, TypeVar\n\nimport numpy as np\nimport torch\nimport torch.distributed as dist\n\nT_co = TypeVar(\"T_co\", covariant=True)\n\n\nclass DistributedValidationSampler(torch.utils.data.Sampler):\n \"\"\"Distributed sampler without duplication\n\n This sampler splits the input dataset to each worker process in distributed setup\n without allowing repetition.\n It is for evaluation purpose such as :class:`~DistributedEvaluator`.\n This does not guarantee each worker to get the same number of samples,\n so for training do not use this sampler (use PyTorch DistributedSampler instead).\n \"\"\"\n\n def __init__(\n self,\n dataset: Sized,\n num_replicas: Optional[int] = None,\n rank: Optional[int] = None,\n shuffle: bool = True,\n seed: int = 0,\n ) -> None:\n if num_replicas is None:\n if not dist.is_available(): # type: ignore[no-untyped-call]\n raise RuntimeError(\n \"Requires distributed package to be available\"\n )\n num_replicas = dist.get_world_size() # type: ignore[no-untyped-call]\n if rank is None:\n if not dist.is_available(): # type: ignore[no-untyped-call]\n raise RuntimeError(\n \"Requires distributed package to be available\"\n )\n rank = dist.get_rank() # type: ignore[no-untyped-call]\n if rank >= num_replicas or rank < 0:\n raise ValueError(\n \"Invalid rank {}, rank should be in the interval\"\n \" [0, {}]\".format(rank, num_replicas - 1)\n )\n self.dataset = dataset\n self.num_replicas = num_replicas\n self.rank = rank\n self.shuffle = shuffle\n self.seed = seed\n\n self.dataset_len = len(dataset)\n self.num_samples = len(\n np.array_split(range(self.dataset_len), num_replicas)[rank]\n )\n\n def __iter__(self) -> Iterator[T_co]:\n if self.shuffle:\n # deterministically shuffle based on epoch and seed\n g = torch.Generator()\n g.manual_seed(self.seed)\n indices = torch.randperm(self.dataset_len, generator=g).tolist()\n else:\n indices = list(range(self.dataset_len))\n\n return iter(np.array_split(indices, self.num_replicas)[self.rank])\n\n def __len__(self) -> int:\n return self.num_samples\n", "path": "pytorch_pfn_extras/distributed/_distributed_validation_sampler.py"}]}
| 1,236 | 244 |
gh_patches_debug_5714
|
rasdani/github-patches
|
git_diff
|
pytorch__ignite-1145
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ProgressBar does not close the bar on Colab if every is used
## 🐛 Bug description
Progress bar is set with `common.setup_common_training_handlers(... log_every_iters=15, ...)` and it does not close itself as being not terminated ...
<img width="451" alt="Screen Shot 2020-06-09 at 16 34 53" src="https://user-images.githubusercontent.com/2459423/84161178-48effa80-aa6f-11ea-9fd1-5b6c673c940f.png">
## Environment
- PyTorch Version (e.g., 1.4):
- Ignite Version (e.g., 0.3.0):
- OS (e.g., Linux):
- How you installed Ignite (`conda`, `pip`, source):
- Python version:
- Any other relevant information:
</issue>
<code>
[start of ignite/contrib/handlers/tqdm_logger.py]
1 # -*- coding: utf-8 -*-
2 import warnings
3 from typing import Any, Mapping
4
5 import torch
6
7 from ignite.contrib.handlers.base_logger import BaseLogger, BaseOutputHandler
8 from ignite.engine import Engine, Events
9 from ignite.engine.events import CallableEventWithFilter
10
11
12 class _OutputHandler(BaseOutputHandler):
13 """Helper handler to log engine's output and/or metrics
14
15 Args:
16 description (str): progress bar description.
17 metric_names (list of str, optional): list of metric names to plot or a string "all" to plot all available
18 metrics.
19 output_transform (callable, optional): output transform function to prepare `engine.state.output` as a number.
20 For example, `output_transform = lambda output: output`
21 This function can also return a dictionary, e.g `{'loss': loss1, 'another_loss': loss2}` to label the plot
22 with corresponding keys.
23 closing_event_name: event's name on which the progress bar is closed. Valid events are from
24 :class:`~ignite.engine.events.Events` or any `event_name` added by
25 :meth:`~ignite.engine.engine.Engine.register_events`.
26
27 """
28
29 def __init__(
30 self, description, metric_names=None, output_transform=None, closing_event_name=Events.EPOCH_COMPLETED
31 ):
32 if metric_names is None and output_transform is None:
33 # This helps to avoid 'Either metric_names or output_transform should be defined' of BaseOutputHandler
34 metric_names = []
35 super(_OutputHandler, self).__init__(description, metric_names, output_transform, global_step_transform=None)
36 self.closing_event_name = closing_event_name
37
38 @staticmethod
39 def get_max_number_events(event_name, engine):
40 if event_name in (Events.ITERATION_STARTED, Events.ITERATION_COMPLETED):
41 return engine.state.epoch_length
42 if event_name in (Events.EPOCH_STARTED, Events.EPOCH_COMPLETED):
43 return engine.state.max_epochs
44 return 1
45
46 def __call__(self, engine, logger, event_name):
47
48 pbar_total = self.get_max_number_events(event_name, engine)
49 if logger.pbar is None:
50 logger._reset(pbar_total=pbar_total)
51
52 desc = self.tag
53 max_num_of_closing_events = self.get_max_number_events(self.closing_event_name, engine)
54 if max_num_of_closing_events > 1:
55 global_step = engine.state.get_event_attrib_value(self.closing_event_name)
56 desc += " [{}/{}]".format(global_step, max_num_of_closing_events)
57 logger.pbar.set_description(desc)
58
59 metrics = self._setup_output_metrics(engine)
60
61 rendered_metrics = {}
62 for key, value in metrics.items():
63 if isinstance(value, torch.Tensor):
64 if value.ndimension() == 0:
65 rendered_metrics[key] = value.item()
66 elif value.ndimension() == 1:
67 for i, v in enumerate(value):
68 k = "{}_{}".format(key, i)
69 rendered_metrics[k] = v.item()
70 else:
71 warnings.warn("ProgressBar can not log " "tensor with {} dimensions".format(value.ndimension()))
72 else:
73 rendered_metrics[key] = value
74
75 if rendered_metrics:
76 logger.pbar.set_postfix(**rendered_metrics)
77
78 global_step = engine.state.get_event_attrib_value(event_name)
79 if pbar_total is not None:
80 global_step = (global_step - 1) % pbar_total + 1
81 logger.pbar.update(global_step - logger.pbar.n)
82
83
84 class ProgressBar(BaseLogger):
85 """
86 TQDM progress bar handler to log training progress and computed metrics.
87
88 Args:
89 persist (bool, optional): set to ``True`` to persist the progress bar after completion (default = ``False``)
90 bar_format (str, optional): Specify a custom bar string formatting. May impact performance.
91 [default: '{desc}[{n_fmt}/{total_fmt}] {percentage:3.0f}%|{bar}{postfix} [{elapsed}<{remaining}]'].
92 Set to ``None`` to use ``tqdm`` default bar formatting: '{l_bar}{bar}{r_bar}', where
93 l_bar='{desc}: {percentage:3.0f}%|' and
94 r_bar='| {n_fmt}/{total_fmt} [{elapsed}<{remaining}, {rate_fmt}{postfix}]'. For more details on the
95 formatting, see `tqdm docs <https://tqdm.github.io/docs/tqdm/>`_.
96 **tqdm_kwargs: kwargs passed to tqdm progress bar.
97 By default, progress bar description displays "Epoch [5/10]" where 5 is the current epoch and 10 is the
98 number of epochs. If tqdm_kwargs defines `desc`, e.g. "Predictions", than the description is
99 "Predictions [5/10]" if number of epochs is more than one otherwise it is simply "Predictions".
100
101 Examples:
102
103 Simple progress bar
104
105 .. code-block:: python
106
107 trainer = create_supervised_trainer(model, optimizer, loss)
108
109 pbar = ProgressBar()
110 pbar.attach(trainer)
111
112 # Progress bar will looks like
113 # Epoch [2/50]: [64/128] 50%|█████ [06:17<12:34]
114
115 Log output to a file instead of stderr (tqdm's default output)
116
117 .. code-block:: python
118
119 trainer = create_supervised_trainer(model, optimizer, loss)
120
121 log_file = open("output.log", "w")
122 pbar = ProgressBar(file=log_file)
123 pbar.attach(trainer)
124
125 Attach metrics that already have been computed at :attr:`~ignite.engine.events.Events.ITERATION_COMPLETED`
126 (such as :class:`~ignite.metrics.RunningAverage`)
127
128 .. code-block:: python
129
130 trainer = create_supervised_trainer(model, optimizer, loss)
131
132 RunningAverage(output_transform=lambda x: x).attach(trainer, 'loss')
133
134 pbar = ProgressBar()
135 pbar.attach(trainer, ['loss'])
136
137 # Progress bar will looks like
138 # Epoch [2/50]: [64/128] 50%|█████ , loss=0.123 [06:17<12:34]
139
140 Directly attach the engine's output
141
142 .. code-block:: python
143
144 trainer = create_supervised_trainer(model, optimizer, loss)
145
146 pbar = ProgressBar()
147 pbar.attach(trainer, output_transform=lambda x: {'loss': x})
148
149 # Progress bar will looks like
150 # Epoch [2/50]: [64/128] 50%|█████ , loss=0.123 [06:17<12:34]
151
152 Note:
153 When adding attaching the progress bar to an engine, it is recommend that you replace
154 every print operation in the engine's handlers triggered every iteration with
155 ``pbar.log_message`` to guarantee the correct format of the stdout.
156
157 Note:
158 When using inside jupyter notebook, `ProgressBar` automatically uses `tqdm_notebook`. For correct rendering,
159 please install `ipywidgets <https://ipywidgets.readthedocs.io/en/stable/user_install.html#installation>`_.
160 Due to `tqdm notebook bugs <https://github.com/tqdm/tqdm/issues/594>`_, bar format may be needed to be set
161 to an empty string value.
162
163 """
164
165 _events_order = [
166 Events.STARTED,
167 Events.EPOCH_STARTED,
168 Events.ITERATION_STARTED,
169 Events.ITERATION_COMPLETED,
170 Events.EPOCH_COMPLETED,
171 Events.COMPLETED,
172 ]
173
174 def __init__(
175 self,
176 persist=False,
177 bar_format="{desc}[{n_fmt}/{total_fmt}] {percentage:3.0f}%|{bar}{postfix} [{elapsed}<{remaining}]",
178 **tqdm_kwargs
179 ):
180
181 try:
182 from tqdm.autonotebook import tqdm
183 except ImportError:
184 raise RuntimeError(
185 "This contrib module requires tqdm to be installed. "
186 "Please install it with command: \n pip install tqdm"
187 )
188
189 self.pbar_cls = tqdm
190 self.pbar = None
191 self.persist = persist
192 self.bar_format = bar_format
193 self.tqdm_kwargs = tqdm_kwargs
194
195 def _reset(self, pbar_total):
196 self.pbar = self.pbar_cls(
197 total=pbar_total, leave=self.persist, bar_format=self.bar_format, initial=1, **self.tqdm_kwargs
198 )
199
200 def _close(self, engine):
201 if self.pbar is not None:
202 self.pbar.close()
203 self.pbar = None
204
205 @staticmethod
206 def _compare_lt(event1, event2):
207 i1 = ProgressBar._events_order.index(event1)
208 i2 = ProgressBar._events_order.index(event2)
209 return i1 < i2
210
211 def log_message(self, message):
212 """
213 Logs a message, preserving the progress bar correct output format.
214
215 Args:
216 message (str): string you wish to log.
217 """
218 from tqdm import tqdm
219
220 tqdm.write(message, file=self.tqdm_kwargs.get("file", None))
221
222 def attach(
223 self,
224 engine,
225 metric_names=None,
226 output_transform=None,
227 event_name=Events.ITERATION_COMPLETED,
228 closing_event_name=Events.EPOCH_COMPLETED,
229 ):
230 """
231 Attaches the progress bar to an engine object.
232
233 Args:
234 engine (Engine): engine object.
235 metric_names (list of str, optional): list of metric names to plot or a string "all" to plot all available
236 metrics.
237 output_transform (callable, optional): a function to select what you want to print from the engine's
238 output. This function may return either a dictionary with entries in the format of ``{name: value}``,
239 or a single scalar, which will be displayed with the default name `output`.
240 event_name: event's name on which the progress bar advances. Valid events are from
241 :class:`~ignite.engine.events.Events`.
242 closing_event_name: event's name on which the progress bar is closed. Valid events are from
243 :class:`~ignite.engine.events.Events`.
244
245 Note: accepted output value types are numbers, 0d and 1d torch tensors and strings
246
247 """
248 desc = self.tqdm_kwargs.get("desc", "Epoch")
249
250 if event_name not in engine._allowed_events:
251 raise ValueError("Logging event {} is not in allowed events for this engine".format(event_name.name))
252
253 if isinstance(closing_event_name, CallableEventWithFilter):
254 if closing_event_name.filter != CallableEventWithFilter.default_event_filter:
255 raise ValueError("Closing Event should not be a filtered event")
256
257 if not self._compare_lt(event_name, closing_event_name):
258 raise ValueError(
259 "Logging event {} should be called before closing event {}".format(event_name, closing_event_name)
260 )
261
262 log_handler = _OutputHandler(desc, metric_names, output_transform, closing_event_name=closing_event_name)
263
264 super(ProgressBar, self).attach(engine, log_handler, event_name)
265 engine.add_event_handler(closing_event_name, self._close)
266
267 def attach_opt_params_handler(self, engine: Engine, event_name: str, *args: Any, **kwargs: Mapping):
268 """Intentionally empty"""
269 pass
270
271 def _create_output_handler(self, *args, **kwargs):
272 return _OutputHandler(*args, **kwargs)
273
274 def _create_opt_params_handler(self, *args, **kwargs):
275 """Intentionally empty"""
276 pass
277
[end of ignite/contrib/handlers/tqdm_logger.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ignite/contrib/handlers/tqdm_logger.py b/ignite/contrib/handlers/tqdm_logger.py
--- a/ignite/contrib/handlers/tqdm_logger.py
+++ b/ignite/contrib/handlers/tqdm_logger.py
@@ -199,6 +199,11 @@
def _close(self, engine):
if self.pbar is not None:
+ # https://github.com/tqdm/notebook.py#L240-L250
+ # issue #1115 : notebook backend of tqdm checks if n < total (error or KeyboardInterrupt)
+ # and the bar persists in 'danger' mode
+ if self.pbar.total is not None:
+ self.pbar.n = self.pbar.total
self.pbar.close()
self.pbar = None
|
{"golden_diff": "diff --git a/ignite/contrib/handlers/tqdm_logger.py b/ignite/contrib/handlers/tqdm_logger.py\n--- a/ignite/contrib/handlers/tqdm_logger.py\n+++ b/ignite/contrib/handlers/tqdm_logger.py\n@@ -199,6 +199,11 @@\n \n def _close(self, engine):\n if self.pbar is not None:\n+ # https://github.com/tqdm/notebook.py#L240-L250\n+ # issue #1115 : notebook backend of tqdm checks if n < total (error or KeyboardInterrupt)\n+ # and the bar persists in 'danger' mode\n+ if self.pbar.total is not None:\n+ self.pbar.n = self.pbar.total\n self.pbar.close()\n self.pbar = None\n", "issue": "ProgressBar does not close the bar on Colab if every is used\n## \ud83d\udc1b Bug description\r\n\r\nProgress bar is set with `common.setup_common_training_handlers(... log_every_iters=15, ...)` and it does not close itself as being not terminated ...\r\n\r\n<img width=\"451\" alt=\"Screen Shot 2020-06-09 at 16 34 53\" src=\"https://user-images.githubusercontent.com/2459423/84161178-48effa80-aa6f-11ea-9fd1-5b6c673c940f.png\">\r\n\r\n## Environment\r\n\r\n - PyTorch Version (e.g., 1.4): \r\n - Ignite Version (e.g., 0.3.0):\r\n - OS (e.g., Linux):\r\n - How you installed Ignite (`conda`, `pip`, source):\r\n - Python version:\r\n - Any other relevant information:\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport warnings\nfrom typing import Any, Mapping\n\nimport torch\n\nfrom ignite.contrib.handlers.base_logger import BaseLogger, BaseOutputHandler\nfrom ignite.engine import Engine, Events\nfrom ignite.engine.events import CallableEventWithFilter\n\n\nclass _OutputHandler(BaseOutputHandler):\n \"\"\"Helper handler to log engine's output and/or metrics\n\n Args:\n description (str): progress bar description.\n metric_names (list of str, optional): list of metric names to plot or a string \"all\" to plot all available\n metrics.\n output_transform (callable, optional): output transform function to prepare `engine.state.output` as a number.\n For example, `output_transform = lambda output: output`\n This function can also return a dictionary, e.g `{'loss': loss1, 'another_loss': loss2}` to label the plot\n with corresponding keys.\n closing_event_name: event's name on which the progress bar is closed. Valid events are from\n :class:`~ignite.engine.events.Events` or any `event_name` added by\n :meth:`~ignite.engine.engine.Engine.register_events`.\n\n \"\"\"\n\n def __init__(\n self, description, metric_names=None, output_transform=None, closing_event_name=Events.EPOCH_COMPLETED\n ):\n if metric_names is None and output_transform is None:\n # This helps to avoid 'Either metric_names or output_transform should be defined' of BaseOutputHandler\n metric_names = []\n super(_OutputHandler, self).__init__(description, metric_names, output_transform, global_step_transform=None)\n self.closing_event_name = closing_event_name\n\n @staticmethod\n def get_max_number_events(event_name, engine):\n if event_name in (Events.ITERATION_STARTED, Events.ITERATION_COMPLETED):\n return engine.state.epoch_length\n if event_name in (Events.EPOCH_STARTED, Events.EPOCH_COMPLETED):\n return engine.state.max_epochs\n return 1\n\n def __call__(self, engine, logger, event_name):\n\n pbar_total = self.get_max_number_events(event_name, engine)\n if logger.pbar is None:\n logger._reset(pbar_total=pbar_total)\n\n desc = self.tag\n max_num_of_closing_events = self.get_max_number_events(self.closing_event_name, engine)\n if max_num_of_closing_events > 1:\n global_step = engine.state.get_event_attrib_value(self.closing_event_name)\n desc += \" [{}/{}]\".format(global_step, max_num_of_closing_events)\n logger.pbar.set_description(desc)\n\n metrics = self._setup_output_metrics(engine)\n\n rendered_metrics = {}\n for key, value in metrics.items():\n if isinstance(value, torch.Tensor):\n if value.ndimension() == 0:\n rendered_metrics[key] = value.item()\n elif value.ndimension() == 1:\n for i, v in enumerate(value):\n k = \"{}_{}\".format(key, i)\n rendered_metrics[k] = v.item()\n else:\n warnings.warn(\"ProgressBar can not log \" \"tensor with {} dimensions\".format(value.ndimension()))\n else:\n rendered_metrics[key] = value\n\n if rendered_metrics:\n logger.pbar.set_postfix(**rendered_metrics)\n\n global_step = engine.state.get_event_attrib_value(event_name)\n if pbar_total is not None:\n global_step = (global_step - 1) % pbar_total + 1\n logger.pbar.update(global_step - logger.pbar.n)\n\n\nclass ProgressBar(BaseLogger):\n \"\"\"\n TQDM progress bar handler to log training progress and computed metrics.\n\n Args:\n persist (bool, optional): set to ``True`` to persist the progress bar after completion (default = ``False``)\n bar_format (str, optional): Specify a custom bar string formatting. May impact performance.\n [default: '{desc}[{n_fmt}/{total_fmt}] {percentage:3.0f}%|{bar}{postfix} [{elapsed}<{remaining}]'].\n Set to ``None`` to use ``tqdm`` default bar formatting: '{l_bar}{bar}{r_bar}', where\n l_bar='{desc}: {percentage:3.0f}%|' and\n r_bar='| {n_fmt}/{total_fmt} [{elapsed}<{remaining}, {rate_fmt}{postfix}]'. For more details on the\n formatting, see `tqdm docs <https://tqdm.github.io/docs/tqdm/>`_.\n **tqdm_kwargs: kwargs passed to tqdm progress bar.\n By default, progress bar description displays \"Epoch [5/10]\" where 5 is the current epoch and 10 is the\n number of epochs. If tqdm_kwargs defines `desc`, e.g. \"Predictions\", than the description is\n \"Predictions [5/10]\" if number of epochs is more than one otherwise it is simply \"Predictions\".\n\n Examples:\n\n Simple progress bar\n\n .. code-block:: python\n\n trainer = create_supervised_trainer(model, optimizer, loss)\n\n pbar = ProgressBar()\n pbar.attach(trainer)\n\n # Progress bar will looks like\n # Epoch [2/50]: [64/128] 50%|\u2588\u2588\u2588\u2588\u2588 [06:17<12:34]\n\n Log output to a file instead of stderr (tqdm's default output)\n\n .. code-block:: python\n\n trainer = create_supervised_trainer(model, optimizer, loss)\n\n log_file = open(\"output.log\", \"w\")\n pbar = ProgressBar(file=log_file)\n pbar.attach(trainer)\n\n Attach metrics that already have been computed at :attr:`~ignite.engine.events.Events.ITERATION_COMPLETED`\n (such as :class:`~ignite.metrics.RunningAverage`)\n\n .. code-block:: python\n\n trainer = create_supervised_trainer(model, optimizer, loss)\n\n RunningAverage(output_transform=lambda x: x).attach(trainer, 'loss')\n\n pbar = ProgressBar()\n pbar.attach(trainer, ['loss'])\n\n # Progress bar will looks like\n # Epoch [2/50]: [64/128] 50%|\u2588\u2588\u2588\u2588\u2588 , loss=0.123 [06:17<12:34]\n\n Directly attach the engine's output\n\n .. code-block:: python\n\n trainer = create_supervised_trainer(model, optimizer, loss)\n\n pbar = ProgressBar()\n pbar.attach(trainer, output_transform=lambda x: {'loss': x})\n\n # Progress bar will looks like\n # Epoch [2/50]: [64/128] 50%|\u2588\u2588\u2588\u2588\u2588 , loss=0.123 [06:17<12:34]\n\n Note:\n When adding attaching the progress bar to an engine, it is recommend that you replace\n every print operation in the engine's handlers triggered every iteration with\n ``pbar.log_message`` to guarantee the correct format of the stdout.\n\n Note:\n When using inside jupyter notebook, `ProgressBar` automatically uses `tqdm_notebook`. For correct rendering,\n please install `ipywidgets <https://ipywidgets.readthedocs.io/en/stable/user_install.html#installation>`_.\n Due to `tqdm notebook bugs <https://github.com/tqdm/tqdm/issues/594>`_, bar format may be needed to be set\n to an empty string value.\n\n \"\"\"\n\n _events_order = [\n Events.STARTED,\n Events.EPOCH_STARTED,\n Events.ITERATION_STARTED,\n Events.ITERATION_COMPLETED,\n Events.EPOCH_COMPLETED,\n Events.COMPLETED,\n ]\n\n def __init__(\n self,\n persist=False,\n bar_format=\"{desc}[{n_fmt}/{total_fmt}] {percentage:3.0f}%|{bar}{postfix} [{elapsed}<{remaining}]\",\n **tqdm_kwargs\n ):\n\n try:\n from tqdm.autonotebook import tqdm\n except ImportError:\n raise RuntimeError(\n \"This contrib module requires tqdm to be installed. \"\n \"Please install it with command: \\n pip install tqdm\"\n )\n\n self.pbar_cls = tqdm\n self.pbar = None\n self.persist = persist\n self.bar_format = bar_format\n self.tqdm_kwargs = tqdm_kwargs\n\n def _reset(self, pbar_total):\n self.pbar = self.pbar_cls(\n total=pbar_total, leave=self.persist, bar_format=self.bar_format, initial=1, **self.tqdm_kwargs\n )\n\n def _close(self, engine):\n if self.pbar is not None:\n self.pbar.close()\n self.pbar = None\n\n @staticmethod\n def _compare_lt(event1, event2):\n i1 = ProgressBar._events_order.index(event1)\n i2 = ProgressBar._events_order.index(event2)\n return i1 < i2\n\n def log_message(self, message):\n \"\"\"\n Logs a message, preserving the progress bar correct output format.\n\n Args:\n message (str): string you wish to log.\n \"\"\"\n from tqdm import tqdm\n\n tqdm.write(message, file=self.tqdm_kwargs.get(\"file\", None))\n\n def attach(\n self,\n engine,\n metric_names=None,\n output_transform=None,\n event_name=Events.ITERATION_COMPLETED,\n closing_event_name=Events.EPOCH_COMPLETED,\n ):\n \"\"\"\n Attaches the progress bar to an engine object.\n\n Args:\n engine (Engine): engine object.\n metric_names (list of str, optional): list of metric names to plot or a string \"all\" to plot all available\n metrics.\n output_transform (callable, optional): a function to select what you want to print from the engine's\n output. This function may return either a dictionary with entries in the format of ``{name: value}``,\n or a single scalar, which will be displayed with the default name `output`.\n event_name: event's name on which the progress bar advances. Valid events are from\n :class:`~ignite.engine.events.Events`.\n closing_event_name: event's name on which the progress bar is closed. Valid events are from\n :class:`~ignite.engine.events.Events`.\n\n Note: accepted output value types are numbers, 0d and 1d torch tensors and strings\n\n \"\"\"\n desc = self.tqdm_kwargs.get(\"desc\", \"Epoch\")\n\n if event_name not in engine._allowed_events:\n raise ValueError(\"Logging event {} is not in allowed events for this engine\".format(event_name.name))\n\n if isinstance(closing_event_name, CallableEventWithFilter):\n if closing_event_name.filter != CallableEventWithFilter.default_event_filter:\n raise ValueError(\"Closing Event should not be a filtered event\")\n\n if not self._compare_lt(event_name, closing_event_name):\n raise ValueError(\n \"Logging event {} should be called before closing event {}\".format(event_name, closing_event_name)\n )\n\n log_handler = _OutputHandler(desc, metric_names, output_transform, closing_event_name=closing_event_name)\n\n super(ProgressBar, self).attach(engine, log_handler, event_name)\n engine.add_event_handler(closing_event_name, self._close)\n\n def attach_opt_params_handler(self, engine: Engine, event_name: str, *args: Any, **kwargs: Mapping):\n \"\"\"Intentionally empty\"\"\"\n pass\n\n def _create_output_handler(self, *args, **kwargs):\n return _OutputHandler(*args, **kwargs)\n\n def _create_opt_params_handler(self, *args, **kwargs):\n \"\"\"Intentionally empty\"\"\"\n pass\n", "path": "ignite/contrib/handlers/tqdm_logger.py"}]}
| 4,024 | 190 |
gh_patches_debug_35465
|
rasdani/github-patches
|
git_diff
|
python-discord__bot-817
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Write unit tests for `bot/cogs/moderation/utils.py`
Write unit tests for [`bot/cogs/moderation/utils.py`](../blob/master/bot/cogs/moderation/utils.py).
## Implementation details
Please make sure to read the general information in the [meta issue](553) and the [testing README](../blob/master/tests/README.md). We are aiming for a 100% [branch coverage](https://coverage.readthedocs.io/en/stable/branch.html) for this file, but if you think that is not possible, please discuss that in this issue.
## Additional information
If you want to work on this issue, **please make sure that you get assigned to it** by one of the core devs before starting to work on it. We would like to prevent the situation that multiple people are working on the same issue. To get assigned, leave a comment showing your interesting in tackling this issue.
</issue>
<code>
[start of bot/exts/moderation/infraction/_utils.py]
1 import logging
2 import textwrap
3 import typing as t
4 from datetime import datetime
5
6 import discord
7 from discord.ext.commands import Context
8
9 from bot.api import ResponseCodeError
10 from bot.constants import Colours, Icons
11
12 log = logging.getLogger(__name__)
13
14 # apply icon, pardon icon
15 INFRACTION_ICONS = {
16 "ban": (Icons.user_ban, Icons.user_unban),
17 "kick": (Icons.sign_out, None),
18 "mute": (Icons.user_mute, Icons.user_unmute),
19 "note": (Icons.user_warn, None),
20 "superstar": (Icons.superstarify, Icons.unsuperstarify),
21 "warning": (Icons.user_warn, None),
22 }
23 RULES_URL = "https://pythondiscord.com/pages/rules"
24 APPEALABLE_INFRACTIONS = ("ban", "mute")
25
26 # Type aliases
27 UserObject = t.Union[discord.Member, discord.User]
28 UserSnowflake = t.Union[UserObject, discord.Object]
29 Infraction = t.Dict[str, t.Union[str, int, bool]]
30
31
32 async def post_user(ctx: Context, user: UserSnowflake) -> t.Optional[dict]:
33 """
34 Create a new user in the database.
35
36 Used when an infraction needs to be applied on a user absent in the guild.
37 """
38 log.trace(f"Attempting to add user {user.id} to the database.")
39
40 if not isinstance(user, (discord.Member, discord.User)):
41 log.debug("The user being added to the DB is not a Member or User object.")
42
43 payload = {
44 'discriminator': int(getattr(user, 'discriminator', 0)),
45 'id': user.id,
46 'in_guild': False,
47 'name': getattr(user, 'name', 'Name unknown'),
48 'roles': []
49 }
50
51 try:
52 response = await ctx.bot.api_client.post('bot/users', json=payload)
53 log.info(f"User {user.id} added to the DB.")
54 return response
55 except ResponseCodeError as e:
56 log.error(f"Failed to add user {user.id} to the DB. {e}")
57 await ctx.send(f":x: The attempt to add the user to the DB failed: status {e.status}")
58
59
60 async def post_infraction(
61 ctx: Context,
62 user: UserSnowflake,
63 infr_type: str,
64 reason: str,
65 expires_at: datetime = None,
66 hidden: bool = False,
67 active: bool = True
68 ) -> t.Optional[dict]:
69 """Posts an infraction to the API."""
70 log.trace(f"Posting {infr_type} infraction for {user} to the API.")
71
72 payload = {
73 "actor": ctx.author.id, # Don't use ctx.message.author; antispam only patches ctx.author.
74 "hidden": hidden,
75 "reason": reason,
76 "type": infr_type,
77 "user": user.id,
78 "active": active
79 }
80 if expires_at:
81 payload['expires_at'] = expires_at.isoformat()
82
83 # Try to apply the infraction. If it fails because the user doesn't exist, try to add it.
84 for should_post_user in (True, False):
85 try:
86 response = await ctx.bot.api_client.post('bot/infractions', json=payload)
87 return response
88 except ResponseCodeError as e:
89 if e.status == 400 and 'user' in e.response_json:
90 # Only one attempt to add the user to the database, not two:
91 if not should_post_user or await post_user(ctx, user) is None:
92 return
93 else:
94 log.exception(f"Unexpected error while adding an infraction for {user}:")
95 await ctx.send(f":x: There was an error adding the infraction: status {e.status}.")
96 return
97
98
99 async def get_active_infraction(
100 ctx: Context,
101 user: UserSnowflake,
102 infr_type: str,
103 send_msg: bool = True
104 ) -> t.Optional[dict]:
105 """
106 Retrieves an active infraction of the given type for the user.
107
108 If `send_msg` is True and the user has an active infraction matching the `infr_type` parameter,
109 then a message for the moderator will be sent to the context channel letting them know.
110 Otherwise, no message will be sent.
111 """
112 log.trace(f"Checking if {user} has active infractions of type {infr_type}.")
113
114 active_infractions = await ctx.bot.api_client.get(
115 'bot/infractions',
116 params={
117 'active': 'true',
118 'type': infr_type,
119 'user__id': str(user.id)
120 }
121 )
122 if active_infractions:
123 # Checks to see if the moderator should be told there is an active infraction
124 if send_msg:
125 log.trace(f"{user} has active infractions of type {infr_type}.")
126 await ctx.send(
127 f":x: According to my records, this user already has a {infr_type} infraction. "
128 f"See infraction **#{active_infractions[0]['id']}**."
129 )
130 return active_infractions[0]
131 else:
132 log.trace(f"{user} does not have active infractions of type {infr_type}.")
133
134
135 async def notify_infraction(
136 user: UserObject,
137 infr_type: str,
138 expires_at: t.Optional[str] = None,
139 reason: t.Optional[str] = None,
140 icon_url: str = Icons.token_removed
141 ) -> bool:
142 """DM a user about their new infraction and return True if the DM is successful."""
143 log.trace(f"Sending {user} a DM about their {infr_type} infraction.")
144
145 text = textwrap.dedent(f"""
146 **Type:** {infr_type.capitalize()}
147 **Expires:** {expires_at or "N/A"}
148 **Reason:** {reason or "No reason provided."}
149 """)
150
151 embed = discord.Embed(
152 description=textwrap.shorten(text, width=2048, placeholder="..."),
153 colour=Colours.soft_red
154 )
155
156 embed.set_author(name="Infraction information", icon_url=icon_url, url=RULES_URL)
157 embed.title = f"Please review our rules over at {RULES_URL}"
158 embed.url = RULES_URL
159
160 if infr_type in APPEALABLE_INFRACTIONS:
161 embed.set_footer(
162 text="To appeal this infraction, send an e-mail to [email protected]"
163 )
164
165 return await send_private_embed(user, embed)
166
167
168 async def notify_pardon(
169 user: UserObject,
170 title: str,
171 content: str,
172 icon_url: str = Icons.user_verified
173 ) -> bool:
174 """DM a user about their pardoned infraction and return True if the DM is successful."""
175 log.trace(f"Sending {user} a DM about their pardoned infraction.")
176
177 embed = discord.Embed(
178 description=content,
179 colour=Colours.soft_green
180 )
181
182 embed.set_author(name=title, icon_url=icon_url)
183
184 return await send_private_embed(user, embed)
185
186
187 async def send_private_embed(user: UserObject, embed: discord.Embed) -> bool:
188 """
189 A helper method for sending an embed to a user's DMs.
190
191 Returns a boolean indicator of DM success.
192 """
193 try:
194 await user.send(embed=embed)
195 return True
196 except (discord.HTTPException, discord.Forbidden, discord.NotFound):
197 log.debug(
198 f"Infraction-related information could not be sent to user {user} ({user.id}). "
199 "The user either could not be retrieved or probably disabled their DMs."
200 )
201 return False
202
[end of bot/exts/moderation/infraction/_utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bot/exts/moderation/infraction/_utils.py b/bot/exts/moderation/infraction/_utils.py
--- a/bot/exts/moderation/infraction/_utils.py
+++ b/bot/exts/moderation/infraction/_utils.py
@@ -1,5 +1,4 @@
import logging
-import textwrap
import typing as t
from datetime import datetime
@@ -28,6 +27,18 @@
UserSnowflake = t.Union[UserObject, discord.Object]
Infraction = t.Dict[str, t.Union[str, int, bool]]
+APPEAL_EMAIL = "[email protected]"
+
+INFRACTION_TITLE = f"Please review our rules over at {RULES_URL}"
+INFRACTION_APPEAL_FOOTER = f"To appeal this infraction, send an e-mail to {APPEAL_EMAIL}"
+INFRACTION_AUTHOR_NAME = "Infraction information"
+
+INFRACTION_DESCRIPTION_TEMPLATE = (
+ "**Type:** {type}\n"
+ "**Expires:** {expires}\n"
+ "**Reason:** {reason}\n"
+)
+
async def post_user(ctx: Context, user: UserSnowflake) -> t.Optional[dict]:
"""
@@ -142,25 +153,27 @@
"""DM a user about their new infraction and return True if the DM is successful."""
log.trace(f"Sending {user} a DM about their {infr_type} infraction.")
- text = textwrap.dedent(f"""
- **Type:** {infr_type.capitalize()}
- **Expires:** {expires_at or "N/A"}
- **Reason:** {reason or "No reason provided."}
- """)
+ text = INFRACTION_DESCRIPTION_TEMPLATE.format(
+ type=infr_type.capitalize(),
+ expires=expires_at or "N/A",
+ reason=reason or "No reason provided."
+ )
+
+ # For case when other fields than reason is too long and this reach limit, then force-shorten string
+ if len(text) > 2048:
+ text = f"{text[:2045]}..."
embed = discord.Embed(
- description=textwrap.shorten(text, width=2048, placeholder="..."),
+ description=text,
colour=Colours.soft_red
)
- embed.set_author(name="Infraction information", icon_url=icon_url, url=RULES_URL)
- embed.title = f"Please review our rules over at {RULES_URL}"
+ embed.set_author(name=INFRACTION_AUTHOR_NAME, icon_url=icon_url, url=RULES_URL)
+ embed.title = INFRACTION_TITLE
embed.url = RULES_URL
if infr_type in APPEALABLE_INFRACTIONS:
- embed.set_footer(
- text="To appeal this infraction, send an e-mail to [email protected]"
- )
+ embed.set_footer(text=INFRACTION_APPEAL_FOOTER)
return await send_private_embed(user, embed)
|
{"golden_diff": "diff --git a/bot/exts/moderation/infraction/_utils.py b/bot/exts/moderation/infraction/_utils.py\n--- a/bot/exts/moderation/infraction/_utils.py\n+++ b/bot/exts/moderation/infraction/_utils.py\n@@ -1,5 +1,4 @@\n import logging\n-import textwrap\n import typing as t\n from datetime import datetime\n \n@@ -28,6 +27,18 @@\n UserSnowflake = t.Union[UserObject, discord.Object]\n Infraction = t.Dict[str, t.Union[str, int, bool]]\n \n+APPEAL_EMAIL = \"[email protected]\"\n+\n+INFRACTION_TITLE = f\"Please review our rules over at {RULES_URL}\"\n+INFRACTION_APPEAL_FOOTER = f\"To appeal this infraction, send an e-mail to {APPEAL_EMAIL}\"\n+INFRACTION_AUTHOR_NAME = \"Infraction information\"\n+\n+INFRACTION_DESCRIPTION_TEMPLATE = (\n+ \"**Type:** {type}\\n\"\n+ \"**Expires:** {expires}\\n\"\n+ \"**Reason:** {reason}\\n\"\n+)\n+\n \n async def post_user(ctx: Context, user: UserSnowflake) -> t.Optional[dict]:\n \"\"\"\n@@ -142,25 +153,27 @@\n \"\"\"DM a user about their new infraction and return True if the DM is successful.\"\"\"\n log.trace(f\"Sending {user} a DM about their {infr_type} infraction.\")\n \n- text = textwrap.dedent(f\"\"\"\n- **Type:** {infr_type.capitalize()}\n- **Expires:** {expires_at or \"N/A\"}\n- **Reason:** {reason or \"No reason provided.\"}\n- \"\"\")\n+ text = INFRACTION_DESCRIPTION_TEMPLATE.format(\n+ type=infr_type.capitalize(),\n+ expires=expires_at or \"N/A\",\n+ reason=reason or \"No reason provided.\"\n+ )\n+\n+ # For case when other fields than reason is too long and this reach limit, then force-shorten string\n+ if len(text) > 2048:\n+ text = f\"{text[:2045]}...\"\n \n embed = discord.Embed(\n- description=textwrap.shorten(text, width=2048, placeholder=\"...\"),\n+ description=text,\n colour=Colours.soft_red\n )\n \n- embed.set_author(name=\"Infraction information\", icon_url=icon_url, url=RULES_URL)\n- embed.title = f\"Please review our rules over at {RULES_URL}\"\n+ embed.set_author(name=INFRACTION_AUTHOR_NAME, icon_url=icon_url, url=RULES_URL)\n+ embed.title = INFRACTION_TITLE\n embed.url = RULES_URL\n \n if infr_type in APPEALABLE_INFRACTIONS:\n- embed.set_footer(\n- text=\"To appeal this infraction, send an e-mail to [email protected]\"\n- )\n+ embed.set_footer(text=INFRACTION_APPEAL_FOOTER)\n \n return await send_private_embed(user, embed)\n", "issue": "Write unit tests for `bot/cogs/moderation/utils.py`\nWrite unit tests for [`bot/cogs/moderation/utils.py`](../blob/master/bot/cogs/moderation/utils.py).\n\n## Implementation details\nPlease make sure to read the general information in the [meta issue](553) and the [testing README](../blob/master/tests/README.md). We are aiming for a 100% [branch coverage](https://coverage.readthedocs.io/en/stable/branch.html) for this file, but if you think that is not possible, please discuss that in this issue.\n\n## Additional information\nIf you want to work on this issue, **please make sure that you get assigned to it** by one of the core devs before starting to work on it. We would like to prevent the situation that multiple people are working on the same issue. To get assigned, leave a comment showing your interesting in tackling this issue.\n\n", "before_files": [{"content": "import logging\nimport textwrap\nimport typing as t\nfrom datetime import datetime\n\nimport discord\nfrom discord.ext.commands import Context\n\nfrom bot.api import ResponseCodeError\nfrom bot.constants import Colours, Icons\n\nlog = logging.getLogger(__name__)\n\n# apply icon, pardon icon\nINFRACTION_ICONS = {\n \"ban\": (Icons.user_ban, Icons.user_unban),\n \"kick\": (Icons.sign_out, None),\n \"mute\": (Icons.user_mute, Icons.user_unmute),\n \"note\": (Icons.user_warn, None),\n \"superstar\": (Icons.superstarify, Icons.unsuperstarify),\n \"warning\": (Icons.user_warn, None),\n}\nRULES_URL = \"https://pythondiscord.com/pages/rules\"\nAPPEALABLE_INFRACTIONS = (\"ban\", \"mute\")\n\n# Type aliases\nUserObject = t.Union[discord.Member, discord.User]\nUserSnowflake = t.Union[UserObject, discord.Object]\nInfraction = t.Dict[str, t.Union[str, int, bool]]\n\n\nasync def post_user(ctx: Context, user: UserSnowflake) -> t.Optional[dict]:\n \"\"\"\n Create a new user in the database.\n\n Used when an infraction needs to be applied on a user absent in the guild.\n \"\"\"\n log.trace(f\"Attempting to add user {user.id} to the database.\")\n\n if not isinstance(user, (discord.Member, discord.User)):\n log.debug(\"The user being added to the DB is not a Member or User object.\")\n\n payload = {\n 'discriminator': int(getattr(user, 'discriminator', 0)),\n 'id': user.id,\n 'in_guild': False,\n 'name': getattr(user, 'name', 'Name unknown'),\n 'roles': []\n }\n\n try:\n response = await ctx.bot.api_client.post('bot/users', json=payload)\n log.info(f\"User {user.id} added to the DB.\")\n return response\n except ResponseCodeError as e:\n log.error(f\"Failed to add user {user.id} to the DB. {e}\")\n await ctx.send(f\":x: The attempt to add the user to the DB failed: status {e.status}\")\n\n\nasync def post_infraction(\n ctx: Context,\n user: UserSnowflake,\n infr_type: str,\n reason: str,\n expires_at: datetime = None,\n hidden: bool = False,\n active: bool = True\n) -> t.Optional[dict]:\n \"\"\"Posts an infraction to the API.\"\"\"\n log.trace(f\"Posting {infr_type} infraction for {user} to the API.\")\n\n payload = {\n \"actor\": ctx.author.id, # Don't use ctx.message.author; antispam only patches ctx.author.\n \"hidden\": hidden,\n \"reason\": reason,\n \"type\": infr_type,\n \"user\": user.id,\n \"active\": active\n }\n if expires_at:\n payload['expires_at'] = expires_at.isoformat()\n\n # Try to apply the infraction. If it fails because the user doesn't exist, try to add it.\n for should_post_user in (True, False):\n try:\n response = await ctx.bot.api_client.post('bot/infractions', json=payload)\n return response\n except ResponseCodeError as e:\n if e.status == 400 and 'user' in e.response_json:\n # Only one attempt to add the user to the database, not two:\n if not should_post_user or await post_user(ctx, user) is None:\n return\n else:\n log.exception(f\"Unexpected error while adding an infraction for {user}:\")\n await ctx.send(f\":x: There was an error adding the infraction: status {e.status}.\")\n return\n\n\nasync def get_active_infraction(\n ctx: Context,\n user: UserSnowflake,\n infr_type: str,\n send_msg: bool = True\n) -> t.Optional[dict]:\n \"\"\"\n Retrieves an active infraction of the given type for the user.\n\n If `send_msg` is True and the user has an active infraction matching the `infr_type` parameter,\n then a message for the moderator will be sent to the context channel letting them know.\n Otherwise, no message will be sent.\n \"\"\"\n log.trace(f\"Checking if {user} has active infractions of type {infr_type}.\")\n\n active_infractions = await ctx.bot.api_client.get(\n 'bot/infractions',\n params={\n 'active': 'true',\n 'type': infr_type,\n 'user__id': str(user.id)\n }\n )\n if active_infractions:\n # Checks to see if the moderator should be told there is an active infraction\n if send_msg:\n log.trace(f\"{user} has active infractions of type {infr_type}.\")\n await ctx.send(\n f\":x: According to my records, this user already has a {infr_type} infraction. \"\n f\"See infraction **#{active_infractions[0]['id']}**.\"\n )\n return active_infractions[0]\n else:\n log.trace(f\"{user} does not have active infractions of type {infr_type}.\")\n\n\nasync def notify_infraction(\n user: UserObject,\n infr_type: str,\n expires_at: t.Optional[str] = None,\n reason: t.Optional[str] = None,\n icon_url: str = Icons.token_removed\n) -> bool:\n \"\"\"DM a user about their new infraction and return True if the DM is successful.\"\"\"\n log.trace(f\"Sending {user} a DM about their {infr_type} infraction.\")\n\n text = textwrap.dedent(f\"\"\"\n **Type:** {infr_type.capitalize()}\n **Expires:** {expires_at or \"N/A\"}\n **Reason:** {reason or \"No reason provided.\"}\n \"\"\")\n\n embed = discord.Embed(\n description=textwrap.shorten(text, width=2048, placeholder=\"...\"),\n colour=Colours.soft_red\n )\n\n embed.set_author(name=\"Infraction information\", icon_url=icon_url, url=RULES_URL)\n embed.title = f\"Please review our rules over at {RULES_URL}\"\n embed.url = RULES_URL\n\n if infr_type in APPEALABLE_INFRACTIONS:\n embed.set_footer(\n text=\"To appeal this infraction, send an e-mail to [email protected]\"\n )\n\n return await send_private_embed(user, embed)\n\n\nasync def notify_pardon(\n user: UserObject,\n title: str,\n content: str,\n icon_url: str = Icons.user_verified\n) -> bool:\n \"\"\"DM a user about their pardoned infraction and return True if the DM is successful.\"\"\"\n log.trace(f\"Sending {user} a DM about their pardoned infraction.\")\n\n embed = discord.Embed(\n description=content,\n colour=Colours.soft_green\n )\n\n embed.set_author(name=title, icon_url=icon_url)\n\n return await send_private_embed(user, embed)\n\n\nasync def send_private_embed(user: UserObject, embed: discord.Embed) -> bool:\n \"\"\"\n A helper method for sending an embed to a user's DMs.\n\n Returns a boolean indicator of DM success.\n \"\"\"\n try:\n await user.send(embed=embed)\n return True\n except (discord.HTTPException, discord.Forbidden, discord.NotFound):\n log.debug(\n f\"Infraction-related information could not be sent to user {user} ({user.id}). \"\n \"The user either could not be retrieved or probably disabled their DMs.\"\n )\n return False\n", "path": "bot/exts/moderation/infraction/_utils.py"}]}
| 2,910 | 681 |
gh_patches_debug_32661
|
rasdani/github-patches
|
git_diff
|
SeldonIO__MLServer-1169
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
500 Error on MacOS
I'm running MLServer on MacOS (arm). I was following [Serving XGBoost models](https://mlserver.readthedocs.io/en/latest/examples/xgboost/README.html) example. I receive a 500 error when requesting a model with url `http://localhost:8080/v2/models/mushroom-xgboost/versions/v0.1.0/infer`.
MLServer throws an error
```
...
File "/opt/homebrew/Cellar/[email protected]/3.10.9/Frameworks/Python.framework/Versions/3.10/lib/python3.10/multiprocessing/queues.py", line 126, in qsize
return self._maxsize - self._sem._semlock._get_value()
NotImplementedError
```
Developers of `queues.py` left a comment that this is broken on MacOS 😬
```python
def qsize(self):
# Raises NotImplementedError on Mac OSX because of broken sem_getvalue()
return self._maxsize - self._sem._semlock._get_value()
```
Is it possible to get around this when running models with MLServer?
Thanks!
</issue>
<code>
[start of mlserver/parallel/dispatcher.py]
1 import asyncio
2
3 from typing import Dict, List, Tuple
4 from itertools import cycle
5 from multiprocessing import Queue
6 from concurrent.futures import ThreadPoolExecutor
7 from asyncio import Future
8
9 from ..utils import schedule_with_callback, generate_uuid
10 from ..metrics import REGISTRY
11
12 from .worker import Worker
13 from .logging import logger
14 from .utils import END_OF_QUEUE, cancel_task
15 from .messages import (
16 Message,
17 ModelUpdateMessage,
18 ModelRequestMessage,
19 ModelResponseMessage,
20 )
21 from prometheus_client import Histogram
22
23 QUEUE_METRIC_NAME = "parallel_request_queue"
24
25
26 class Dispatcher:
27 def __init__(self, workers: Dict[int, Worker], responses: Queue):
28 self._responses = responses
29 self._workers = workers
30 self._workers_round_robin = cycle(self._workers.keys())
31 self._active = False
32 self._process_responses_task = None
33 self._executor = ThreadPoolExecutor()
34 self._async_responses: Dict[str, Future[ModelResponseMessage]] = {}
35 self.parallel_request_queue_size = self._get_or_create_metric()
36
37 def _get_or_create_metric(self) -> Histogram:
38 if QUEUE_METRIC_NAME in REGISTRY:
39 return REGISTRY[QUEUE_METRIC_NAME] # type: ignore
40
41 return Histogram(
42 QUEUE_METRIC_NAME,
43 "counter of request queue size for workers",
44 ["workerpid"],
45 registry=REGISTRY,
46 )
47
48 def start(self):
49 self._active = True
50 self._process_responses_task = schedule_with_callback(
51 self._process_responses(), self._process_responses_cb
52 )
53
54 def _process_responses_cb(self, process_responses):
55 try:
56 process_responses.result()
57 except asyncio.CancelledError:
58 # NOTE: The response loop was cancelled from the outside, so don't
59 # restart
60 return
61 except Exception:
62 logger.exception("Response processing loop crashed. Restarting the loop...")
63 # If process loop crashed, restart it
64 self.start()
65
66 async def _process_responses(self):
67 logger.debug("Starting response processing loop...")
68 loop = asyncio.get_event_loop()
69 while self._active:
70 response = await loop.run_in_executor(self._executor, self._responses.get)
71
72 # If the queue gets terminated, detect the "sentinel value" and
73 # stop reading
74 if response is END_OF_QUEUE:
75 return
76
77 await self._process_response(response)
78
79 async def _process_response(self, response: ModelResponseMessage):
80 internal_id = response.id
81
82 async_response = self._async_responses[internal_id]
83
84 # NOTE: Use call_soon_threadsafe to cover cases where `model.predict()`
85 # (or other methods) get called from a separate thread (and a separate
86 # AsyncIO loop)
87 response_loop = async_response.get_loop()
88 if response.exception:
89 response_loop.call_soon_threadsafe(
90 async_response.set_exception, response.exception
91 )
92 else:
93 response_loop.call_soon_threadsafe(async_response.set_result, response)
94
95 async def dispatch_request(
96 self, request_message: ModelRequestMessage
97 ) -> ModelResponseMessage:
98 worker, wpid = self._get_worker()
99 self._workers_queue_monitor(worker, wpid)
100 worker.send_request(request_message)
101
102 return await self._dispatch(request_message)
103
104 def _get_worker(self) -> Tuple[Worker, int]:
105 """
106 Get next available worker.
107 By default, this is just a round-robin through all the workers.
108 """
109 worker_pid = next(self._workers_round_robin)
110 return self._workers[worker_pid], worker_pid
111
112 def _workers_queue_monitor(self, worker: Worker, worker_pid: int):
113 """Get metrics from every worker request queue"""
114 queue_size = worker._requests.qsize()
115
116 self.parallel_request_queue_size.labels(workerpid=str(worker_pid)).observe(
117 float(queue_size)
118 )
119
120 async def dispatch_update(
121 self, model_update: ModelUpdateMessage
122 ) -> List[ModelResponseMessage]:
123 return await asyncio.gather(
124 *[
125 self._dispatch_update(worker, model_update)
126 for worker in self._workers.values()
127 ]
128 )
129
130 async def _dispatch_update(
131 self, worker: Worker, model_update: ModelUpdateMessage
132 ) -> ModelResponseMessage:
133 # NOTE: Need to rewrite the UUID to ensure each worker sends back a
134 # unique result
135 worker_update = model_update.copy()
136 worker_update.id = generate_uuid()
137 worker.send_update(worker_update)
138 return await self._dispatch(worker_update)
139
140 async def _dispatch(self, message: Message) -> ModelResponseMessage:
141 loop = asyncio.get_running_loop()
142 async_response = loop.create_future()
143 internal_id = message.id
144 self._async_responses[internal_id] = async_response
145
146 return await self._wait_response(internal_id)
147
148 async def _wait_response(self, internal_id: str) -> ModelResponseMessage:
149 async_response = self._async_responses[internal_id]
150
151 try:
152 inference_response = await async_response
153 return inference_response
154 finally:
155 del self._async_responses[internal_id]
156
157 async def stop(self):
158 self._executor.shutdown()
159 if self._process_responses_task is not None:
160 await cancel_task(self._process_responses_task)
161
[end of mlserver/parallel/dispatcher.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mlserver/parallel/dispatcher.py b/mlserver/parallel/dispatcher.py
--- a/mlserver/parallel/dispatcher.py
+++ b/mlserver/parallel/dispatcher.py
@@ -41,7 +41,6 @@
return Histogram(
QUEUE_METRIC_NAME,
"counter of request queue size for workers",
- ["workerpid"],
registry=REGISTRY,
)
@@ -96,7 +95,6 @@
self, request_message: ModelRequestMessage
) -> ModelResponseMessage:
worker, wpid = self._get_worker()
- self._workers_queue_monitor(worker, wpid)
worker.send_request(request_message)
return await self._dispatch(request_message)
@@ -109,14 +107,6 @@
worker_pid = next(self._workers_round_robin)
return self._workers[worker_pid], worker_pid
- def _workers_queue_monitor(self, worker: Worker, worker_pid: int):
- """Get metrics from every worker request queue"""
- queue_size = worker._requests.qsize()
-
- self.parallel_request_queue_size.labels(workerpid=str(worker_pid)).observe(
- float(queue_size)
- )
-
async def dispatch_update(
self, model_update: ModelUpdateMessage
) -> List[ModelResponseMessage]:
@@ -143,6 +133,8 @@
internal_id = message.id
self._async_responses[internal_id] = async_response
+ # Monitor current in-flight requests
+ self.parallel_request_queue_size.observe(len(self._async_responses))
return await self._wait_response(internal_id)
async def _wait_response(self, internal_id: str) -> ModelResponseMessage:
|
{"golden_diff": "diff --git a/mlserver/parallel/dispatcher.py b/mlserver/parallel/dispatcher.py\n--- a/mlserver/parallel/dispatcher.py\n+++ b/mlserver/parallel/dispatcher.py\n@@ -41,7 +41,6 @@\n return Histogram(\n QUEUE_METRIC_NAME,\n \"counter of request queue size for workers\",\n- [\"workerpid\"],\n registry=REGISTRY,\n )\n \n@@ -96,7 +95,6 @@\n self, request_message: ModelRequestMessage\n ) -> ModelResponseMessage:\n worker, wpid = self._get_worker()\n- self._workers_queue_monitor(worker, wpid)\n worker.send_request(request_message)\n \n return await self._dispatch(request_message)\n@@ -109,14 +107,6 @@\n worker_pid = next(self._workers_round_robin)\n return self._workers[worker_pid], worker_pid\n \n- def _workers_queue_monitor(self, worker: Worker, worker_pid: int):\n- \"\"\"Get metrics from every worker request queue\"\"\"\n- queue_size = worker._requests.qsize()\n-\n- self.parallel_request_queue_size.labels(workerpid=str(worker_pid)).observe(\n- float(queue_size)\n- )\n-\n async def dispatch_update(\n self, model_update: ModelUpdateMessage\n ) -> List[ModelResponseMessage]:\n@@ -143,6 +133,8 @@\n internal_id = message.id\n self._async_responses[internal_id] = async_response\n \n+ # Monitor current in-flight requests\n+ self.parallel_request_queue_size.observe(len(self._async_responses))\n return await self._wait_response(internal_id)\n \n async def _wait_response(self, internal_id: str) -> ModelResponseMessage:\n", "issue": "500 Error on MacOS\nI'm running MLServer on MacOS (arm). I was following [Serving XGBoost models](https://mlserver.readthedocs.io/en/latest/examples/xgboost/README.html) example. I receive a 500 error when requesting a model with url `http://localhost:8080/v2/models/mushroom-xgboost/versions/v0.1.0/infer`.\r\n\r\nMLServer throws an error\r\n\r\n```\r\n...\r\n File \"/opt/homebrew/Cellar/[email protected]/3.10.9/Frameworks/Python.framework/Versions/3.10/lib/python3.10/multiprocessing/queues.py\", line 126, in qsize\r\n return self._maxsize - self._sem._semlock._get_value()\r\nNotImplementedError\r\n```\r\n\r\nDevelopers of `queues.py` left a comment that this is broken on MacOS \ud83d\ude2c \r\n\r\n```python\r\n def qsize(self):\r\n # Raises NotImplementedError on Mac OSX because of broken sem_getvalue()\r\n return self._maxsize - self._sem._semlock._get_value()\r\n```\r\n\r\nIs it possible to get around this when running models with MLServer?\r\nThanks!\n", "before_files": [{"content": "import asyncio\n\nfrom typing import Dict, List, Tuple\nfrom itertools import cycle\nfrom multiprocessing import Queue\nfrom concurrent.futures import ThreadPoolExecutor\nfrom asyncio import Future\n\nfrom ..utils import schedule_with_callback, generate_uuid\nfrom ..metrics import REGISTRY\n\nfrom .worker import Worker\nfrom .logging import logger\nfrom .utils import END_OF_QUEUE, cancel_task\nfrom .messages import (\n Message,\n ModelUpdateMessage,\n ModelRequestMessage,\n ModelResponseMessage,\n)\nfrom prometheus_client import Histogram\n\nQUEUE_METRIC_NAME = \"parallel_request_queue\"\n\n\nclass Dispatcher:\n def __init__(self, workers: Dict[int, Worker], responses: Queue):\n self._responses = responses\n self._workers = workers\n self._workers_round_robin = cycle(self._workers.keys())\n self._active = False\n self._process_responses_task = None\n self._executor = ThreadPoolExecutor()\n self._async_responses: Dict[str, Future[ModelResponseMessage]] = {}\n self.parallel_request_queue_size = self._get_or_create_metric()\n\n def _get_or_create_metric(self) -> Histogram:\n if QUEUE_METRIC_NAME in REGISTRY:\n return REGISTRY[QUEUE_METRIC_NAME] # type: ignore\n\n return Histogram(\n QUEUE_METRIC_NAME,\n \"counter of request queue size for workers\",\n [\"workerpid\"],\n registry=REGISTRY,\n )\n\n def start(self):\n self._active = True\n self._process_responses_task = schedule_with_callback(\n self._process_responses(), self._process_responses_cb\n )\n\n def _process_responses_cb(self, process_responses):\n try:\n process_responses.result()\n except asyncio.CancelledError:\n # NOTE: The response loop was cancelled from the outside, so don't\n # restart\n return\n except Exception:\n logger.exception(\"Response processing loop crashed. Restarting the loop...\")\n # If process loop crashed, restart it\n self.start()\n\n async def _process_responses(self):\n logger.debug(\"Starting response processing loop...\")\n loop = asyncio.get_event_loop()\n while self._active:\n response = await loop.run_in_executor(self._executor, self._responses.get)\n\n # If the queue gets terminated, detect the \"sentinel value\" and\n # stop reading\n if response is END_OF_QUEUE:\n return\n\n await self._process_response(response)\n\n async def _process_response(self, response: ModelResponseMessage):\n internal_id = response.id\n\n async_response = self._async_responses[internal_id]\n\n # NOTE: Use call_soon_threadsafe to cover cases where `model.predict()`\n # (or other methods) get called from a separate thread (and a separate\n # AsyncIO loop)\n response_loop = async_response.get_loop()\n if response.exception:\n response_loop.call_soon_threadsafe(\n async_response.set_exception, response.exception\n )\n else:\n response_loop.call_soon_threadsafe(async_response.set_result, response)\n\n async def dispatch_request(\n self, request_message: ModelRequestMessage\n ) -> ModelResponseMessage:\n worker, wpid = self._get_worker()\n self._workers_queue_monitor(worker, wpid)\n worker.send_request(request_message)\n\n return await self._dispatch(request_message)\n\n def _get_worker(self) -> Tuple[Worker, int]:\n \"\"\"\n Get next available worker.\n By default, this is just a round-robin through all the workers.\n \"\"\"\n worker_pid = next(self._workers_round_robin)\n return self._workers[worker_pid], worker_pid\n\n def _workers_queue_monitor(self, worker: Worker, worker_pid: int):\n \"\"\"Get metrics from every worker request queue\"\"\"\n queue_size = worker._requests.qsize()\n\n self.parallel_request_queue_size.labels(workerpid=str(worker_pid)).observe(\n float(queue_size)\n )\n\n async def dispatch_update(\n self, model_update: ModelUpdateMessage\n ) -> List[ModelResponseMessage]:\n return await asyncio.gather(\n *[\n self._dispatch_update(worker, model_update)\n for worker in self._workers.values()\n ]\n )\n\n async def _dispatch_update(\n self, worker: Worker, model_update: ModelUpdateMessage\n ) -> ModelResponseMessage:\n # NOTE: Need to rewrite the UUID to ensure each worker sends back a\n # unique result\n worker_update = model_update.copy()\n worker_update.id = generate_uuid()\n worker.send_update(worker_update)\n return await self._dispatch(worker_update)\n\n async def _dispatch(self, message: Message) -> ModelResponseMessage:\n loop = asyncio.get_running_loop()\n async_response = loop.create_future()\n internal_id = message.id\n self._async_responses[internal_id] = async_response\n\n return await self._wait_response(internal_id)\n\n async def _wait_response(self, internal_id: str) -> ModelResponseMessage:\n async_response = self._async_responses[internal_id]\n\n try:\n inference_response = await async_response\n return inference_response\n finally:\n del self._async_responses[internal_id]\n\n async def stop(self):\n self._executor.shutdown()\n if self._process_responses_task is not None:\n await cancel_task(self._process_responses_task)\n", "path": "mlserver/parallel/dispatcher.py"}]}
| 2,308 | 377 |
gh_patches_debug_11912
|
rasdani/github-patches
|
git_diff
|
ibis-project__ibis-2558
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
link to documentation on http://ibis-project.org/ is broken
Everything under /docs/ (including the tutorial) 404's as of 2020-12-02.
</issue>
<code>
[start of ibis/backends/impala/__init__.py]
1 """Impala backend"""
2 import ibis.common.exceptions as com
3 import ibis.config
4 from ibis.config import options
5
6 # these objects are exposed in the public API and are not used in the module
7 from .client import ( # noqa: F401
8 ImpalaClient,
9 ImpalaConnection,
10 ImpalaDatabase,
11 ImpalaTable,
12 )
13 from .compiler import dialect # noqa: F401
14 from .hdfs import HDFS, WebHDFS, hdfs_connect # noqa: F401
15 from .udf import * # noqa: F401,F403
16
17 with ibis.config.config_prefix('impala'):
18 ibis.config.register_option(
19 'temp_db',
20 '__ibis_tmp',
21 'Database to use for temporary tables, views. functions, etc.',
22 )
23 ibis.config.register_option(
24 'temp_hdfs_path',
25 '/tmp/ibis',
26 'HDFS path for storage of temporary data',
27 )
28
29
30 def compile(expr, params=None):
31 """Force compilation of expression.
32
33 Returns
34 -------
35 str
36
37 """
38 from .compiler import to_sql
39
40 return to_sql(expr, dialect.make_context(params=params))
41
42
43 def verify(expr, params=None):
44 """
45 Determine if expression can be successfully translated to execute on Impala
46 """
47 try:
48 compile(expr, params=params)
49 return True
50 except com.TranslationError:
51 return False
52
53
54 def connect(
55 host='localhost',
56 port=21050,
57 database='default',
58 timeout=45,
59 use_ssl=False,
60 ca_cert=None,
61 user=None,
62 password=None,
63 auth_mechanism='NOSASL',
64 kerberos_service_name='impala',
65 pool_size=8,
66 hdfs_client=None,
67 ):
68 """Create an ImpalaClient for use with Ibis.
69
70 Parameters
71 ----------
72 host : str, optional
73 Host name of the impalad or HiveServer2 in Hive
74 port : int, optional
75 Impala's HiveServer2 port
76 database : str, optional
77 Default database when obtaining new cursors
78 timeout : int, optional
79 Connection timeout in seconds when communicating with HiveServer2
80 use_ssl : bool, optional
81 Use SSL when connecting to HiveServer2
82 ca_cert : str, optional
83 Local path to 3rd party CA certificate or copy of server certificate
84 for self-signed certificates. If SSL is enabled, but this argument is
85 ``None``, then certificate validation is skipped.
86 user : str, optional
87 LDAP user to authenticate
88 password : str, optional
89 LDAP password to authenticate
90 auth_mechanism : str, optional
91 {'NOSASL' <- default, 'PLAIN', 'GSSAPI', 'LDAP'}.
92 Use NOSASL for non-secured Impala connections. Use PLAIN for
93 non-secured Hive clusters. Use LDAP for LDAP authenticated
94 connections. Use GSSAPI for Kerberos-secured clusters.
95 kerberos_service_name : str, optional
96 Specify particular impalad service principal.
97
98 Examples
99 --------
100 >>> import ibis
101 >>> import os
102 >>> hdfs_host = os.environ.get('IBIS_TEST_NN_HOST', 'localhost')
103 >>> hdfs_port = int(os.environ.get('IBIS_TEST_NN_PORT', 50070))
104 >>> impala_host = os.environ.get('IBIS_TEST_IMPALA_HOST', 'localhost')
105 >>> impala_port = int(os.environ.get('IBIS_TEST_IMPALA_PORT', 21050))
106 >>> hdfs = ibis.hdfs_connect(host=hdfs_host, port=hdfs_port)
107 >>> hdfs # doctest: +ELLIPSIS
108 <ibis.filesystems.WebHDFS object at 0x...>
109 >>> client = ibis.impala.connect(
110 ... host=impala_host,
111 ... port=impala_port,
112 ... hdfs_client=hdfs,
113 ... )
114 >>> client # doctest: +ELLIPSIS
115 <ibis.impala.client.ImpalaClient object at 0x...>
116
117 Returns
118 -------
119 ImpalaClient
120 """
121 params = {
122 'host': host,
123 'port': port,
124 'database': database,
125 'timeout': timeout,
126 'use_ssl': use_ssl,
127 'ca_cert': ca_cert,
128 'user': user,
129 'password': password,
130 'auth_mechanism': auth_mechanism,
131 'kerberos_service_name': kerberos_service_name,
132 }
133
134 con = ImpalaConnection(pool_size=pool_size, **params)
135 try:
136 client = ImpalaClient(con, hdfs_client=hdfs_client)
137 except Exception:
138 con.close()
139 raise
140 else:
141 if options.default_backend is None:
142 options.default_backend = client
143
144 return client
145
[end of ibis/backends/impala/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ibis/backends/impala/__init__.py b/ibis/backends/impala/__init__.py
--- a/ibis/backends/impala/__init__.py
+++ b/ibis/backends/impala/__init__.py
@@ -103,7 +103,7 @@
>>> hdfs_port = int(os.environ.get('IBIS_TEST_NN_PORT', 50070))
>>> impala_host = os.environ.get('IBIS_TEST_IMPALA_HOST', 'localhost')
>>> impala_port = int(os.environ.get('IBIS_TEST_IMPALA_PORT', 21050))
- >>> hdfs = ibis.hdfs_connect(host=hdfs_host, port=hdfs_port)
+ >>> hdfs = ibis.impala.hdfs_connect(host=hdfs_host, port=hdfs_port)
>>> hdfs # doctest: +ELLIPSIS
<ibis.filesystems.WebHDFS object at 0x...>
>>> client = ibis.impala.connect(
|
{"golden_diff": "diff --git a/ibis/backends/impala/__init__.py b/ibis/backends/impala/__init__.py\n--- a/ibis/backends/impala/__init__.py\n+++ b/ibis/backends/impala/__init__.py\n@@ -103,7 +103,7 @@\n >>> hdfs_port = int(os.environ.get('IBIS_TEST_NN_PORT', 50070))\n >>> impala_host = os.environ.get('IBIS_TEST_IMPALA_HOST', 'localhost')\n >>> impala_port = int(os.environ.get('IBIS_TEST_IMPALA_PORT', 21050))\n- >>> hdfs = ibis.hdfs_connect(host=hdfs_host, port=hdfs_port)\n+ >>> hdfs = ibis.impala.hdfs_connect(host=hdfs_host, port=hdfs_port)\n >>> hdfs # doctest: +ELLIPSIS\n <ibis.filesystems.WebHDFS object at 0x...>\n >>> client = ibis.impala.connect(\n", "issue": "link to documentation on http://ibis-project.org/ is broken\nEverything under /docs/ (including the tutorial) 404's as of 2020-12-02.\n", "before_files": [{"content": "\"\"\"Impala backend\"\"\"\nimport ibis.common.exceptions as com\nimport ibis.config\nfrom ibis.config import options\n\n# these objects are exposed in the public API and are not used in the module\nfrom .client import ( # noqa: F401\n ImpalaClient,\n ImpalaConnection,\n ImpalaDatabase,\n ImpalaTable,\n)\nfrom .compiler import dialect # noqa: F401\nfrom .hdfs import HDFS, WebHDFS, hdfs_connect # noqa: F401\nfrom .udf import * # noqa: F401,F403\n\nwith ibis.config.config_prefix('impala'):\n ibis.config.register_option(\n 'temp_db',\n '__ibis_tmp',\n 'Database to use for temporary tables, views. functions, etc.',\n )\n ibis.config.register_option(\n 'temp_hdfs_path',\n '/tmp/ibis',\n 'HDFS path for storage of temporary data',\n )\n\n\ndef compile(expr, params=None):\n \"\"\"Force compilation of expression.\n\n Returns\n -------\n str\n\n \"\"\"\n from .compiler import to_sql\n\n return to_sql(expr, dialect.make_context(params=params))\n\n\ndef verify(expr, params=None):\n \"\"\"\n Determine if expression can be successfully translated to execute on Impala\n \"\"\"\n try:\n compile(expr, params=params)\n return True\n except com.TranslationError:\n return False\n\n\ndef connect(\n host='localhost',\n port=21050,\n database='default',\n timeout=45,\n use_ssl=False,\n ca_cert=None,\n user=None,\n password=None,\n auth_mechanism='NOSASL',\n kerberos_service_name='impala',\n pool_size=8,\n hdfs_client=None,\n):\n \"\"\"Create an ImpalaClient for use with Ibis.\n\n Parameters\n ----------\n host : str, optional\n Host name of the impalad or HiveServer2 in Hive\n port : int, optional\n Impala's HiveServer2 port\n database : str, optional\n Default database when obtaining new cursors\n timeout : int, optional\n Connection timeout in seconds when communicating with HiveServer2\n use_ssl : bool, optional\n Use SSL when connecting to HiveServer2\n ca_cert : str, optional\n Local path to 3rd party CA certificate or copy of server certificate\n for self-signed certificates. If SSL is enabled, but this argument is\n ``None``, then certificate validation is skipped.\n user : str, optional\n LDAP user to authenticate\n password : str, optional\n LDAP password to authenticate\n auth_mechanism : str, optional\n {'NOSASL' <- default, 'PLAIN', 'GSSAPI', 'LDAP'}.\n Use NOSASL for non-secured Impala connections. Use PLAIN for\n non-secured Hive clusters. Use LDAP for LDAP authenticated\n connections. Use GSSAPI for Kerberos-secured clusters.\n kerberos_service_name : str, optional\n Specify particular impalad service principal.\n\n Examples\n --------\n >>> import ibis\n >>> import os\n >>> hdfs_host = os.environ.get('IBIS_TEST_NN_HOST', 'localhost')\n >>> hdfs_port = int(os.environ.get('IBIS_TEST_NN_PORT', 50070))\n >>> impala_host = os.environ.get('IBIS_TEST_IMPALA_HOST', 'localhost')\n >>> impala_port = int(os.environ.get('IBIS_TEST_IMPALA_PORT', 21050))\n >>> hdfs = ibis.hdfs_connect(host=hdfs_host, port=hdfs_port)\n >>> hdfs # doctest: +ELLIPSIS\n <ibis.filesystems.WebHDFS object at 0x...>\n >>> client = ibis.impala.connect(\n ... host=impala_host,\n ... port=impala_port,\n ... hdfs_client=hdfs,\n ... )\n >>> client # doctest: +ELLIPSIS\n <ibis.impala.client.ImpalaClient object at 0x...>\n\n Returns\n -------\n ImpalaClient\n \"\"\"\n params = {\n 'host': host,\n 'port': port,\n 'database': database,\n 'timeout': timeout,\n 'use_ssl': use_ssl,\n 'ca_cert': ca_cert,\n 'user': user,\n 'password': password,\n 'auth_mechanism': auth_mechanism,\n 'kerberos_service_name': kerberos_service_name,\n }\n\n con = ImpalaConnection(pool_size=pool_size, **params)\n try:\n client = ImpalaClient(con, hdfs_client=hdfs_client)\n except Exception:\n con.close()\n raise\n else:\n if options.default_backend is None:\n options.default_backend = client\n\n return client\n", "path": "ibis/backends/impala/__init__.py"}]}
| 1,992 | 230 |
gh_patches_debug_38030
|
rasdani/github-patches
|
git_diff
|
aio-libs__aiohttp-2573
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pytest-aiohttp: compatibility with pytest v3.3.0
## Long story short
https://github.com/pytest-dev/pytest/issues/2959
Fixture parameters are now immutable, [pytest_plugin.py](https://github.com/aio-libs/aiohttp/blob/master/aiohttp/pytest_plugin.py#L195-L200) need to be updated
pytest-aiohttp: compatibility with pytest v3.3.0
## Long story short
https://github.com/pytest-dev/pytest/issues/2959
Fixture parameters are now immutable, [pytest_plugin.py](https://github.com/aio-libs/aiohttp/blob/master/aiohttp/pytest_plugin.py#L195-L200) need to be updated
</issue>
<code>
[start of aiohttp/pytest_plugin.py]
1 import asyncio
2 import collections
3 import contextlib
4 import tempfile
5 import warnings
6
7 import pytest
8 from py import path
9
10 from aiohttp.helpers import isasyncgenfunction
11 from aiohttp.web import Application
12
13 from .test_utils import unused_port as _unused_port
14 from .test_utils import (BaseTestServer, RawTestServer, TestClient, TestServer,
15 loop_context, setup_test_loop, teardown_test_loop)
16
17
18 try:
19 import uvloop
20 except: # pragma: no cover
21 uvloop = None
22
23 try:
24 import tokio
25 except: # pragma: no cover
26 tokio = None
27
28
29 def pytest_addoption(parser):
30 parser.addoption(
31 '--fast', action='store_true', default=False,
32 help='run tests faster by disabling extra checks')
33 parser.addoption(
34 '--loop', action='store', default='pyloop',
35 help='run tests with specific loop: pyloop, uvloop, tokio or all')
36 parser.addoption(
37 '--enable-loop-debug', action='store_true', default=False,
38 help='enable event loop debug mode')
39
40
41 def pytest_fixture_setup(fixturedef, request):
42 """
43 Allow fixtures to be coroutines. Run coroutine fixtures in an event loop.
44 """
45 func = fixturedef.func
46
47 if isasyncgenfunction(func):
48 # async generator fixture
49 is_async_gen = True
50 elif asyncio.iscoroutinefunction(func):
51 # regular async fixture
52 is_async_gen = False
53 else:
54 # not an async fixture, nothing to do
55 return
56
57 strip_request = False
58 if 'request' not in fixturedef.argnames:
59 fixturedef.argnames += ('request',)
60 strip_request = True
61
62 def wrapper(*args, **kwargs):
63 request = kwargs['request']
64 if strip_request:
65 del kwargs['request']
66
67 # if neither the fixture nor the test use the 'loop' fixture,
68 # 'getfixturevalue' will fail because the test is not parameterized
69 # (this can be removed someday if 'loop' is no longer parameterized)
70 if 'loop' not in request.fixturenames:
71 raise Exception(
72 "Asynchronous fixtures must depend on the 'loop' fixture or "
73 "be used in tests depending from it."
74 )
75
76 _loop = request.getfixturevalue('loop')
77
78 if is_async_gen:
79 # for async generators, we need to advance the generator once,
80 # then advance it again in a finalizer
81 gen = func(*args, **kwargs)
82
83 def finalizer():
84 try:
85 return _loop.run_until_complete(gen.__anext__())
86 except StopAsyncIteration: # NOQA
87 pass
88
89 request.addfinalizer(finalizer)
90 return _loop.run_until_complete(gen.__anext__())
91 else:
92 return _loop.run_until_complete(func(*args, **kwargs))
93
94 fixturedef.func = wrapper
95
96
97 @pytest.fixture
98 def fast(request):
99 """ --fast config option """
100 return request.config.getoption('--fast') # pragma: no cover
101
102
103 @contextlib.contextmanager
104 def _runtime_warning_context():
105 """
106 Context manager which checks for RuntimeWarnings, specifically to
107 avoid "coroutine 'X' was never awaited" warnings being missed.
108
109 If RuntimeWarnings occur in the context a RuntimeError is raised.
110 """
111 with warnings.catch_warnings(record=True) as _warnings:
112 yield
113 rw = ['{w.filename}:{w.lineno}:{w.message}'.format(w=w)
114 for w in _warnings if w.category == RuntimeWarning]
115 if rw:
116 raise RuntimeError('{} Runtime Warning{},\n{}'.format(
117 len(rw),
118 '' if len(rw) == 1 else 's',
119 '\n'.join(rw)
120 ))
121
122
123 @contextlib.contextmanager
124 def _passthrough_loop_context(loop, fast=False):
125 """
126 setups and tears down a loop unless one is passed in via the loop
127 argument when it's passed straight through.
128 """
129 if loop:
130 # loop already exists, pass it straight through
131 yield loop
132 else:
133 # this shadows loop_context's standard behavior
134 loop = setup_test_loop()
135 yield loop
136 teardown_test_loop(loop, fast=fast)
137
138
139 def pytest_pycollect_makeitem(collector, name, obj):
140 """
141 Fix pytest collecting for coroutines.
142 """
143 if collector.funcnamefilter(name) and asyncio.iscoroutinefunction(obj):
144 return list(collector._genfunctions(name, obj))
145
146
147 def pytest_pyfunc_call(pyfuncitem):
148 """
149 Run coroutines in an event loop instead of a normal function call.
150 """
151 fast = pyfuncitem.config.getoption("--fast")
152 if asyncio.iscoroutinefunction(pyfuncitem.function):
153 existing_loop = pyfuncitem.funcargs.get('loop', None)
154 with _runtime_warning_context():
155 with _passthrough_loop_context(existing_loop, fast=fast) as _loop:
156 testargs = {arg: pyfuncitem.funcargs[arg]
157 for arg in pyfuncitem._fixtureinfo.argnames}
158
159 task = _loop.create_task(pyfuncitem.obj(**testargs))
160 _loop.run_until_complete(task)
161
162 return True
163
164
165 def pytest_configure(config):
166 loops = config.getoption('--loop')
167
168 factories = {'pyloop': asyncio.new_event_loop}
169
170 if uvloop is not None: # pragma: no cover
171 factories['uvloop'] = uvloop.new_event_loop
172
173 if tokio is not None: # pragma: no cover
174 factories['tokio'] = tokio.new_event_loop
175
176 LOOP_FACTORIES.clear()
177 LOOP_FACTORY_IDS.clear()
178
179 if loops == 'all':
180 loops = 'pyloop,uvloop?,tokio?'
181
182 for name in loops.split(','):
183 required = not name.endswith('?')
184 name = name.strip(' ?')
185 if name in factories:
186 LOOP_FACTORIES.append(factories[name])
187 LOOP_FACTORY_IDS.append(name)
188 elif required:
189 raise ValueError(
190 "Unknown loop '%s', available loops: %s" % (
191 name, list(factories.keys())))
192 asyncio.set_event_loop(None)
193
194
195 LOOP_FACTORIES = []
196 LOOP_FACTORY_IDS = []
197
198
199 @pytest.fixture(params=LOOP_FACTORIES, ids=LOOP_FACTORY_IDS)
200 def loop(request):
201 """Return an instance of the event loop."""
202 fast = request.config.getoption('--fast')
203 debug = request.config.getoption('--enable-loop-debug')
204
205 with loop_context(request.param, fast=fast) as _loop:
206 if debug:
207 _loop.set_debug(True) # pragma: no cover
208 yield _loop
209
210
211 @pytest.fixture
212 def unused_port():
213 """Return a port that is unused on the current host."""
214 return _unused_port
215
216
217 @pytest.yield_fixture
218 def test_server(loop):
219 """Factory to create a TestServer instance, given an app.
220
221 test_server(app, **kwargs)
222 """
223 servers = []
224
225 @asyncio.coroutine
226 def go(app, **kwargs):
227 server = TestServer(app)
228 yield from server.start_server(loop=loop, **kwargs)
229 servers.append(server)
230 return server
231
232 yield go
233
234 @asyncio.coroutine
235 def finalize():
236 while servers:
237 yield from servers.pop().close()
238
239 loop.run_until_complete(finalize())
240
241
242 @pytest.yield_fixture
243 def raw_test_server(loop):
244 """Factory to create a RawTestServer instance, given a web handler.
245
246 raw_test_server(handler, **kwargs)
247 """
248 servers = []
249
250 @asyncio.coroutine
251 def go(handler, **kwargs):
252 server = RawTestServer(handler)
253 yield from server.start_server(loop=loop, **kwargs)
254 servers.append(server)
255 return server
256
257 yield go
258
259 @asyncio.coroutine
260 def finalize():
261 while servers:
262 yield from servers.pop().close()
263
264 loop.run_until_complete(finalize())
265
266
267 @pytest.yield_fixture
268 def test_client(loop):
269 """Factory to create a TestClient instance.
270
271 test_client(app, **kwargs)
272 test_client(server, **kwargs)
273 test_client(raw_server, **kwargs)
274 """
275 clients = []
276
277 @asyncio.coroutine
278 def go(__param, *args, server_kwargs=None, **kwargs):
279
280 if isinstance(__param, collections.Callable) and \
281 not isinstance(__param, (Application, BaseTestServer)):
282 __param = __param(loop, *args, **kwargs)
283 kwargs = {}
284 else:
285 assert not args, "args should be empty"
286
287 if isinstance(__param, Application):
288 server_kwargs = server_kwargs or {}
289 server = TestServer(__param, loop=loop, **server_kwargs)
290 client = TestClient(server, loop=loop, **kwargs)
291 elif isinstance(__param, BaseTestServer):
292 client = TestClient(__param, loop=loop, **kwargs)
293 else:
294 raise ValueError("Unknown argument type: %r" % type(__param))
295
296 yield from client.start_server()
297 clients.append(client)
298 return client
299
300 yield go
301
302 @asyncio.coroutine
303 def finalize():
304 while clients:
305 yield from clients.pop().close()
306
307 loop.run_until_complete(finalize())
308
309
310 @pytest.fixture
311 def shorttmpdir():
312 """Provides a temporary directory with a shorter file system path than the
313 tmpdir fixture.
314 """
315 tmpdir = path.local(tempfile.mkdtemp())
316 yield tmpdir
317 tmpdir.remove(rec=1)
318
[end of aiohttp/pytest_plugin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/aiohttp/pytest_plugin.py b/aiohttp/pytest_plugin.py
--- a/aiohttp/pytest_plugin.py
+++ b/aiohttp/pytest_plugin.py
@@ -96,8 +96,14 @@
@pytest.fixture
def fast(request):
- """ --fast config option """
- return request.config.getoption('--fast') # pragma: no cover
+ """--fast config option"""
+ return request.config.getoption('--fast')
+
+
[email protected]
+def loop_debug(request):
+ """--enable-loop-debug config option"""
+ return request.config.getoption('--enable-loop-debug')
@contextlib.contextmanager
@@ -162,50 +168,47 @@
return True
-def pytest_configure(config):
- loops = config.getoption('--loop')
+def pytest_generate_tests(metafunc):
+ if 'loop_factory' not in metafunc.fixturenames:
+ return
- factories = {'pyloop': asyncio.new_event_loop}
+ loops = metafunc.config.option.loop
+ avail_factories = {'pyloop': asyncio.new_event_loop}
if uvloop is not None: # pragma: no cover
- factories['uvloop'] = uvloop.new_event_loop
+ avail_factories['uvloop'] = uvloop.new_event_loop
if tokio is not None: # pragma: no cover
- factories['tokio'] = tokio.new_event_loop
-
- LOOP_FACTORIES.clear()
- LOOP_FACTORY_IDS.clear()
+ avail_factories['tokio'] = tokio.new_event_loop
if loops == 'all':
loops = 'pyloop,uvloop?,tokio?'
+ factories = {}
for name in loops.split(','):
required = not name.endswith('?')
name = name.strip(' ?')
- if name in factories:
- LOOP_FACTORIES.append(factories[name])
- LOOP_FACTORY_IDS.append(name)
- elif required:
- raise ValueError(
- "Unknown loop '%s', available loops: %s" % (
- name, list(factories.keys())))
- asyncio.set_event_loop(None)
+ if name not in avail_factories: # pragma: no cover
+ if required:
+ raise ValueError(
+ "Unknown loop '%s', available loops: %s" % (
+ name, list(factories.keys())))
+ else:
+ continue
+ factories[name] = avail_factories[name]
+ metafunc.parametrize("loop_factory",
+ list(factories.values()),
+ ids=list(factories.keys()))
-LOOP_FACTORIES = []
-LOOP_FACTORY_IDS = []
-
-
[email protected](params=LOOP_FACTORIES, ids=LOOP_FACTORY_IDS)
-def loop(request):
[email protected]
+def loop(loop_factory, fast, loop_debug):
"""Return an instance of the event loop."""
- fast = request.config.getoption('--fast')
- debug = request.config.getoption('--enable-loop-debug')
-
- with loop_context(request.param, fast=fast) as _loop:
- if debug:
+ with loop_context(loop_factory, fast=fast) as _loop:
+ if loop_debug:
_loop.set_debug(True) # pragma: no cover
yield _loop
+ asyncio.set_event_loop(None)
@pytest.fixture
|
{"golden_diff": "diff --git a/aiohttp/pytest_plugin.py b/aiohttp/pytest_plugin.py\n--- a/aiohttp/pytest_plugin.py\n+++ b/aiohttp/pytest_plugin.py\n@@ -96,8 +96,14 @@\n \n @pytest.fixture\n def fast(request):\n- \"\"\" --fast config option \"\"\"\n- return request.config.getoption('--fast') # pragma: no cover\n+ \"\"\"--fast config option\"\"\"\n+ return request.config.getoption('--fast')\n+\n+\[email protected]\n+def loop_debug(request):\n+ \"\"\"--enable-loop-debug config option\"\"\"\n+ return request.config.getoption('--enable-loop-debug')\n \n \n @contextlib.contextmanager\n@@ -162,50 +168,47 @@\n return True\n \n \n-def pytest_configure(config):\n- loops = config.getoption('--loop')\n+def pytest_generate_tests(metafunc):\n+ if 'loop_factory' not in metafunc.fixturenames:\n+ return\n \n- factories = {'pyloop': asyncio.new_event_loop}\n+ loops = metafunc.config.option.loop\n+ avail_factories = {'pyloop': asyncio.new_event_loop}\n \n if uvloop is not None: # pragma: no cover\n- factories['uvloop'] = uvloop.new_event_loop\n+ avail_factories['uvloop'] = uvloop.new_event_loop\n \n if tokio is not None: # pragma: no cover\n- factories['tokio'] = tokio.new_event_loop\n-\n- LOOP_FACTORIES.clear()\n- LOOP_FACTORY_IDS.clear()\n+ avail_factories['tokio'] = tokio.new_event_loop\n \n if loops == 'all':\n loops = 'pyloop,uvloop?,tokio?'\n \n+ factories = {}\n for name in loops.split(','):\n required = not name.endswith('?')\n name = name.strip(' ?')\n- if name in factories:\n- LOOP_FACTORIES.append(factories[name])\n- LOOP_FACTORY_IDS.append(name)\n- elif required:\n- raise ValueError(\n- \"Unknown loop '%s', available loops: %s\" % (\n- name, list(factories.keys())))\n- asyncio.set_event_loop(None)\n+ if name not in avail_factories: # pragma: no cover\n+ if required:\n+ raise ValueError(\n+ \"Unknown loop '%s', available loops: %s\" % (\n+ name, list(factories.keys())))\n+ else:\n+ continue\n+ factories[name] = avail_factories[name]\n+ metafunc.parametrize(\"loop_factory\",\n+ list(factories.values()),\n+ ids=list(factories.keys()))\n \n \n-LOOP_FACTORIES = []\n-LOOP_FACTORY_IDS = []\n-\n-\[email protected](params=LOOP_FACTORIES, ids=LOOP_FACTORY_IDS)\n-def loop(request):\[email protected]\n+def loop(loop_factory, fast, loop_debug):\n \"\"\"Return an instance of the event loop.\"\"\"\n- fast = request.config.getoption('--fast')\n- debug = request.config.getoption('--enable-loop-debug')\n-\n- with loop_context(request.param, fast=fast) as _loop:\n- if debug:\n+ with loop_context(loop_factory, fast=fast) as _loop:\n+ if loop_debug:\n _loop.set_debug(True) # pragma: no cover\n yield _loop\n+ asyncio.set_event_loop(None)\n \n \n @pytest.fixture\n", "issue": "pytest-aiohttp: compatibility with pytest v3.3.0\n## Long story short\r\n\r\nhttps://github.com/pytest-dev/pytest/issues/2959\r\nFixture parameters are now immutable, [pytest_plugin.py](https://github.com/aio-libs/aiohttp/blob/master/aiohttp/pytest_plugin.py#L195-L200) need to be updated\r\n\npytest-aiohttp: compatibility with pytest v3.3.0\n## Long story short\r\n\r\nhttps://github.com/pytest-dev/pytest/issues/2959\r\nFixture parameters are now immutable, [pytest_plugin.py](https://github.com/aio-libs/aiohttp/blob/master/aiohttp/pytest_plugin.py#L195-L200) need to be updated\r\n\n", "before_files": [{"content": "import asyncio\nimport collections\nimport contextlib\nimport tempfile\nimport warnings\n\nimport pytest\nfrom py import path\n\nfrom aiohttp.helpers import isasyncgenfunction\nfrom aiohttp.web import Application\n\nfrom .test_utils import unused_port as _unused_port\nfrom .test_utils import (BaseTestServer, RawTestServer, TestClient, TestServer,\n loop_context, setup_test_loop, teardown_test_loop)\n\n\ntry:\n import uvloop\nexcept: # pragma: no cover\n uvloop = None\n\ntry:\n import tokio\nexcept: # pragma: no cover\n tokio = None\n\n\ndef pytest_addoption(parser):\n parser.addoption(\n '--fast', action='store_true', default=False,\n help='run tests faster by disabling extra checks')\n parser.addoption(\n '--loop', action='store', default='pyloop',\n help='run tests with specific loop: pyloop, uvloop, tokio or all')\n parser.addoption(\n '--enable-loop-debug', action='store_true', default=False,\n help='enable event loop debug mode')\n\n\ndef pytest_fixture_setup(fixturedef, request):\n \"\"\"\n Allow fixtures to be coroutines. Run coroutine fixtures in an event loop.\n \"\"\"\n func = fixturedef.func\n\n if isasyncgenfunction(func):\n # async generator fixture\n is_async_gen = True\n elif asyncio.iscoroutinefunction(func):\n # regular async fixture\n is_async_gen = False\n else:\n # not an async fixture, nothing to do\n return\n\n strip_request = False\n if 'request' not in fixturedef.argnames:\n fixturedef.argnames += ('request',)\n strip_request = True\n\n def wrapper(*args, **kwargs):\n request = kwargs['request']\n if strip_request:\n del kwargs['request']\n\n # if neither the fixture nor the test use the 'loop' fixture,\n # 'getfixturevalue' will fail because the test is not parameterized\n # (this can be removed someday if 'loop' is no longer parameterized)\n if 'loop' not in request.fixturenames:\n raise Exception(\n \"Asynchronous fixtures must depend on the 'loop' fixture or \"\n \"be used in tests depending from it.\"\n )\n\n _loop = request.getfixturevalue('loop')\n\n if is_async_gen:\n # for async generators, we need to advance the generator once,\n # then advance it again in a finalizer\n gen = func(*args, **kwargs)\n\n def finalizer():\n try:\n return _loop.run_until_complete(gen.__anext__())\n except StopAsyncIteration: # NOQA\n pass\n\n request.addfinalizer(finalizer)\n return _loop.run_until_complete(gen.__anext__())\n else:\n return _loop.run_until_complete(func(*args, **kwargs))\n\n fixturedef.func = wrapper\n\n\[email protected]\ndef fast(request):\n \"\"\" --fast config option \"\"\"\n return request.config.getoption('--fast') # pragma: no cover\n\n\[email protected]\ndef _runtime_warning_context():\n \"\"\"\n Context manager which checks for RuntimeWarnings, specifically to\n avoid \"coroutine 'X' was never awaited\" warnings being missed.\n\n If RuntimeWarnings occur in the context a RuntimeError is raised.\n \"\"\"\n with warnings.catch_warnings(record=True) as _warnings:\n yield\n rw = ['{w.filename}:{w.lineno}:{w.message}'.format(w=w)\n for w in _warnings if w.category == RuntimeWarning]\n if rw:\n raise RuntimeError('{} Runtime Warning{},\\n{}'.format(\n len(rw),\n '' if len(rw) == 1 else 's',\n '\\n'.join(rw)\n ))\n\n\[email protected]\ndef _passthrough_loop_context(loop, fast=False):\n \"\"\"\n setups and tears down a loop unless one is passed in via the loop\n argument when it's passed straight through.\n \"\"\"\n if loop:\n # loop already exists, pass it straight through\n yield loop\n else:\n # this shadows loop_context's standard behavior\n loop = setup_test_loop()\n yield loop\n teardown_test_loop(loop, fast=fast)\n\n\ndef pytest_pycollect_makeitem(collector, name, obj):\n \"\"\"\n Fix pytest collecting for coroutines.\n \"\"\"\n if collector.funcnamefilter(name) and asyncio.iscoroutinefunction(obj):\n return list(collector._genfunctions(name, obj))\n\n\ndef pytest_pyfunc_call(pyfuncitem):\n \"\"\"\n Run coroutines in an event loop instead of a normal function call.\n \"\"\"\n fast = pyfuncitem.config.getoption(\"--fast\")\n if asyncio.iscoroutinefunction(pyfuncitem.function):\n existing_loop = pyfuncitem.funcargs.get('loop', None)\n with _runtime_warning_context():\n with _passthrough_loop_context(existing_loop, fast=fast) as _loop:\n testargs = {arg: pyfuncitem.funcargs[arg]\n for arg in pyfuncitem._fixtureinfo.argnames}\n\n task = _loop.create_task(pyfuncitem.obj(**testargs))\n _loop.run_until_complete(task)\n\n return True\n\n\ndef pytest_configure(config):\n loops = config.getoption('--loop')\n\n factories = {'pyloop': asyncio.new_event_loop}\n\n if uvloop is not None: # pragma: no cover\n factories['uvloop'] = uvloop.new_event_loop\n\n if tokio is not None: # pragma: no cover\n factories['tokio'] = tokio.new_event_loop\n\n LOOP_FACTORIES.clear()\n LOOP_FACTORY_IDS.clear()\n\n if loops == 'all':\n loops = 'pyloop,uvloop?,tokio?'\n\n for name in loops.split(','):\n required = not name.endswith('?')\n name = name.strip(' ?')\n if name in factories:\n LOOP_FACTORIES.append(factories[name])\n LOOP_FACTORY_IDS.append(name)\n elif required:\n raise ValueError(\n \"Unknown loop '%s', available loops: %s\" % (\n name, list(factories.keys())))\n asyncio.set_event_loop(None)\n\n\nLOOP_FACTORIES = []\nLOOP_FACTORY_IDS = []\n\n\[email protected](params=LOOP_FACTORIES, ids=LOOP_FACTORY_IDS)\ndef loop(request):\n \"\"\"Return an instance of the event loop.\"\"\"\n fast = request.config.getoption('--fast')\n debug = request.config.getoption('--enable-loop-debug')\n\n with loop_context(request.param, fast=fast) as _loop:\n if debug:\n _loop.set_debug(True) # pragma: no cover\n yield _loop\n\n\[email protected]\ndef unused_port():\n \"\"\"Return a port that is unused on the current host.\"\"\"\n return _unused_port\n\n\[email protected]_fixture\ndef test_server(loop):\n \"\"\"Factory to create a TestServer instance, given an app.\n\n test_server(app, **kwargs)\n \"\"\"\n servers = []\n\n @asyncio.coroutine\n def go(app, **kwargs):\n server = TestServer(app)\n yield from server.start_server(loop=loop, **kwargs)\n servers.append(server)\n return server\n\n yield go\n\n @asyncio.coroutine\n def finalize():\n while servers:\n yield from servers.pop().close()\n\n loop.run_until_complete(finalize())\n\n\[email protected]_fixture\ndef raw_test_server(loop):\n \"\"\"Factory to create a RawTestServer instance, given a web handler.\n\n raw_test_server(handler, **kwargs)\n \"\"\"\n servers = []\n\n @asyncio.coroutine\n def go(handler, **kwargs):\n server = RawTestServer(handler)\n yield from server.start_server(loop=loop, **kwargs)\n servers.append(server)\n return server\n\n yield go\n\n @asyncio.coroutine\n def finalize():\n while servers:\n yield from servers.pop().close()\n\n loop.run_until_complete(finalize())\n\n\[email protected]_fixture\ndef test_client(loop):\n \"\"\"Factory to create a TestClient instance.\n\n test_client(app, **kwargs)\n test_client(server, **kwargs)\n test_client(raw_server, **kwargs)\n \"\"\"\n clients = []\n\n @asyncio.coroutine\n def go(__param, *args, server_kwargs=None, **kwargs):\n\n if isinstance(__param, collections.Callable) and \\\n not isinstance(__param, (Application, BaseTestServer)):\n __param = __param(loop, *args, **kwargs)\n kwargs = {}\n else:\n assert not args, \"args should be empty\"\n\n if isinstance(__param, Application):\n server_kwargs = server_kwargs or {}\n server = TestServer(__param, loop=loop, **server_kwargs)\n client = TestClient(server, loop=loop, **kwargs)\n elif isinstance(__param, BaseTestServer):\n client = TestClient(__param, loop=loop, **kwargs)\n else:\n raise ValueError(\"Unknown argument type: %r\" % type(__param))\n\n yield from client.start_server()\n clients.append(client)\n return client\n\n yield go\n\n @asyncio.coroutine\n def finalize():\n while clients:\n yield from clients.pop().close()\n\n loop.run_until_complete(finalize())\n\n\[email protected]\ndef shorttmpdir():\n \"\"\"Provides a temporary directory with a shorter file system path than the\n tmpdir fixture.\n \"\"\"\n tmpdir = path.local(tempfile.mkdtemp())\n yield tmpdir\n tmpdir.remove(rec=1)\n", "path": "aiohttp/pytest_plugin.py"}]}
| 3,604 | 728 |
gh_patches_debug_29627
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-2649
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ValueError: list.remove(x): x not in list
### CloudFormation Lint Version
0.76.0
### What operating system are you using?
macOS
### Describe the bug
We run latest `cfn-lint` on all templates in the [AWS SAM repository](https://github.com/aws/serverless-application-model/); looks like 0.76.0 introduced a bug.
Since today, `cfn-lint` fails with:
```text
Traceback (most recent call last):
File "/Users/rehnc/Desktop/tmp/serverless-application-model/.venv_cfn_lint/bin/cfn-lint", line 8, in <module>
sys.exit(main())
File "/Users/rehnc/Desktop/tmp/serverless-application-model/.venv_cfn_lint/lib/python3.10/site-packages/cfnlint/__main__.py", line 39, in main
matches = list(cfnlint.core.get_matches(filenames, args))
File "/Users/rehnc/Desktop/tmp/serverless-application-model/.venv_cfn_lint/lib/python3.10/site-packages/cfnlint/core.py", line 173, in get_matches
matches = run_cli(
File "/Users/rehnc/Desktop/tmp/serverless-application-model/.venv_cfn_lint/lib/python3.10/site-packages/cfnlint/core.py", line 78, in run_cli
return run_checks(filename, template, rules, regions, mandatory_rules)
File "/Users/rehnc/Desktop/tmp/serverless-application-model/.venv_cfn_lint/lib/python3.10/site-packages/cfnlint/core.py", line 334, in run_checks
runner = cfnlint.runner.Runner(
File "/Users/rehnc/Desktop/tmp/serverless-application-model/.venv_cfn_lint/lib/python3.10/site-packages/cfnlint/runner.py", line 32, in __init__
self.cfn = Template(filename, template, regions)
File "/Users/rehnc/Desktop/tmp/serverless-application-model/.venv_cfn_lint/lib/python3.10/site-packages/cfnlint/template/template.py", line 44, in __init__
self.conditions = cfnlint.conditions.Conditions(self)
File "/Users/rehnc/Desktop/tmp/serverless-application-model/.venv_cfn_lint/lib/python3.10/site-packages/cfnlint/conditions/conditions.py", line 34, in __init__
self._cnf, self._solver_params = self._build_cnf(list(self._conditions.keys()))
File "/Users/rehnc/Desktop/tmp/serverless-application-model/.venv_cfn_lint/lib/python3.10/site-packages/cfnlint/conditions/conditions.py", line 118, in _build_cnf
allowed_values[param.hash].remove(get_hash(equal_1.left))
ValueError: list.remove(x): x not in list
```
### Expected behavior
Expected it not to fail, or to fail like a template violation would.
### Reproduction template
Not sure yet which one is causing the issue, but this reproduces it:
```bash
git clone https://github.com/aws/serverless-application-model.git --depth 1
cd serverless-application-model
python3 -m venv .venv
.venv/bin/python -m pip install cfn-lint==0.76.0
.venv/bin/cfn-lint
```
However, if you try with `.venv/bin/python -m pip install cfn-lint==0.75.0`, it succeeds.
</issue>
<code>
[start of src/cfnlint/conditions/conditions.py]
1 """
2 Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.
3 SPDX-License-Identifier: MIT-0
4 """
5 import itertools
6 import logging
7 import traceback
8 from typing import Any, Dict, Iterator, List, Tuple
9
10 from sympy import And, Implies, Not, Symbol
11 from sympy.assumptions.cnf import EncodedCNF
12 from sympy.logic.boolalg import BooleanFalse, BooleanTrue
13 from sympy.logic.inference import satisfiable
14
15 from cfnlint.conditions._utils import get_hash
16 from cfnlint.conditions.condition import ConditionNamed
17 from cfnlint.conditions.equals import Equal
18
19 LOGGER = logging.getLogger(__name__)
20
21
22 class Conditions:
23 """Conditions provides the logic for relating individual condition together"""
24
25 _conditions: Dict[str, ConditionNamed]
26 _parameters: Dict[str, List[str]] # Dict of parameters with AllowedValues hashed
27 _max_scenarios: int = 128 # equivalent to 2^7
28
29 def __init__(self, cfn):
30 self._conditions = {}
31 self._parameters = {}
32 self._init_conditions(cfn=cfn)
33 self._init_parameters(cfn=cfn)
34 self._cnf, self._solver_params = self._build_cnf(list(self._conditions.keys()))
35
36 def _init_conditions(self, cfn):
37 conditions = cfn.template.get("Conditions")
38 if isinstance(conditions, dict):
39 for k, _ in conditions.items():
40 try:
41 self._conditions[k] = ConditionNamed(k, conditions)
42 except ValueError as e:
43 LOGGER.debug(
44 "Captured error while building condition %s: %s", k, str(e)
45 )
46 except Exception as e: # pylint: disable=broad-exception-caught
47 if LOGGER.getEffectiveLevel() == logging.DEBUG:
48 error_message = traceback.format_exc()
49 else:
50 error_message = str(e)
51 LOGGER.debug(
52 "Captured unknown error while building condition %s: %s",
53 k,
54 error_message,
55 )
56
57 def _init_parameters(self, cfn: Any) -> None:
58 parameters = cfn.template.get("Parameters")
59 if not isinstance(parameters, dict):
60 return
61 for parameter_name, parameter in parameters.items():
62 if not isinstance(parameter, dict):
63 continue
64 allowed_values = parameter.get("AllowedValues")
65 if not allowed_values or not isinstance(allowed_values, list):
66 continue
67
68 param_hash = get_hash({"Ref": parameter_name})
69 self._parameters[param_hash] = []
70 for allowed_value in allowed_values:
71 if isinstance(allowed_value, (str, int, float, bool)):
72 self._parameters[param_hash].append(get_hash(str(allowed_value)))
73
74 def _build_cnf(
75 self, condition_names: List[str]
76 ) -> Tuple[EncodedCNF, Dict[str, Any]]:
77 cnf = EncodedCNF()
78
79 # build parameters and equals into solver
80 equal_vars: Dict[str, Symbol] = {}
81
82 equals: Dict[str, Equal] = {}
83 for condition_name in condition_names:
84 c_equals = self._conditions[condition_name].equals
85 for c_equal in c_equals:
86 # check to see if equals already matches another one
87 if c_equal.hash in equal_vars:
88 continue
89
90 if c_equal.is_static is not None:
91 if c_equal.is_static:
92 equal_vars[c_equal.hash] = BooleanTrue()
93 else:
94 equal_vars[c_equal.hash] = BooleanFalse()
95 else:
96 equal_vars[c_equal.hash] = Symbol(c_equal.hash)
97 # See if parameter in this equals is the same as another equals
98 for param in c_equal.parameters:
99 for e_hash, e_equals in equals.items():
100 if param in e_equals.parameters:
101 # equivalent to NAND logic. We want to make sure that both equals
102 # are not both True at the same time
103 cnf.add_prop(
104 ~(equal_vars[c_equal.hash] & equal_vars[e_hash])
105 )
106 equals[c_equal.hash] = c_equal
107
108 # Determine if a set of conditions can never be all false
109 allowed_values = self._parameters.copy()
110 if allowed_values:
111 # iteration 1 cleans up all the hash values from allowed_values to know if we
112 # used them all
113 for _, equal_1 in equals.items():
114 for param in equal_1.parameters:
115 if param.hash not in allowed_values:
116 continue
117 if isinstance(equal_1.left, str):
118 allowed_values[param.hash].remove(get_hash(equal_1.left))
119 if isinstance(equal_1.right, str):
120 allowed_values[param.hash].remove(get_hash(equal_1.right))
121
122 # iteration 2 builds the cnf formulas to make sure any empty lists
123 # are now full not equals
124 for allowed_hash, allowed_value in allowed_values.items():
125 # means the list is empty and all allowed values are validated
126 # so not all equals can be false
127 if not allowed_value:
128 prop = None
129 for _, equal_1 in equals.items():
130 for param in equal_1.parameters:
131 if allowed_hash == param.hash:
132 if prop is None:
133 prop = Not(equal_vars[equal_1.hash])
134 else:
135 prop = prop & Not(equal_vars[equal_1.hash])
136 # Need to make sure they aren't all False
137 # So Not(Not(Equal1) & Not(Equal2))
138 # When Equal1 False and Equal2 False
139 # Not(True & True) = False allowing this not to happen
140 if prop is not None:
141 cnf.add_prop(Not(prop))
142
143 return (cnf, equal_vars)
144
145 def build_scenarios(self, condition_names: List[str]) -> Iterator[Dict[str, bool]]:
146 """Given a list of condition names this function will yield scenarios that represent
147 those conditions and there result (True/False)
148
149 Args:
150 condition_names (List[str]): A list of condition names
151
152 Returns:
153 Iterator[Dict[str, bool]]: yield dict objects of {ConditionName: True/False}
154 """
155 # nothing to yield if there are no conditions
156 if len(condition_names) == 0:
157 return
158
159 # if only one condition we will assume its True/False
160 if len(condition_names) == 1:
161 yield {condition_names[0]: True}
162 yield {condition_names[0]: False}
163 return
164
165 try:
166 # build a large matric of True/False options based on the provided conditions
167 scenarios_returned = 0
168 for p in itertools.product([True, False], repeat=len(condition_names)):
169 cnf = self._cnf.copy()
170 params = dict(zip(condition_names, p))
171 for condition_name, opt in params.items():
172 if opt:
173 cnf.add_prop(
174 self._conditions[condition_name].build_true_cnf(
175 self._solver_params
176 )
177 )
178 else:
179 cnf.add_prop(
180 self._conditions[condition_name].build_false_cnf(
181 self._solver_params
182 )
183 )
184
185 # if the scenario can be satisfied then return it
186 if satisfiable(cnf):
187 yield params
188 scenarios_returned += 1
189
190 # On occassions people will use a lot of non-related conditions
191 # this is fail safe to limit the maximum number of responses
192 if scenarios_returned >= self._max_scenarios:
193 return
194 except KeyError:
195 # KeyError is because the listed condition doesn't exist because of bad
196 # formatting or just the wrong condition name
197 return
198
199 def check_implies(self, scenarios: Dict[str, bool], implies: str) -> bool:
200 """Based on a bunch of scenario conditions and their Truth/False value
201 determine if implies condition is True any time the scenarios are satisfied
202 solver, solver_params = self._build_solver(list(scenarios.keys()) + [implies])
203
204 Args:
205 scenarios (Dict[str, bool]): A list of condition names and if they are True or False
206 implies: the condition name that we are implying will also be True
207
208 Returns:
209 bool: if the implied condition will be True if the scenario is True
210 """
211 try:
212 cnf = self._cnf.copy()
213 # if the implies condition has to be false in the scenarios we
214 # know it can never be true
215 if not scenarios.get(implies, True):
216 return False
217
218 conditions = []
219 for condition_name, opt in scenarios.items():
220 if opt:
221 conditions.append(
222 self._conditions[condition_name].build_true_cnf(
223 self._solver_params
224 )
225 )
226 else:
227 conditions.append(
228 self._conditions[condition_name].build_false_cnf(
229 self._solver_params
230 )
231 )
232
233 implies_condition = self._conditions[implies].build_true_cnf(
234 self._solver_params
235 )
236
237 and_condition = And(*conditions)
238 cnf.add_prop(and_condition)
239
240 # if the implies condition has to be true already then we don't
241 # need to imply it
242 if not scenarios.get(implies):
243 cnf.add_prop(Not(Implies(and_condition, implies_condition)))
244 if satisfiable(cnf):
245 return True
246
247 return False
248 except KeyError:
249 # KeyError is because the listed condition doesn't exist because of bad
250 # formatting or just the wrong condition name
251 return True
252
[end of src/cfnlint/conditions/conditions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cfnlint/conditions/conditions.py b/src/cfnlint/conditions/conditions.py
--- a/src/cfnlint/conditions/conditions.py
+++ b/src/cfnlint/conditions/conditions.py
@@ -115,9 +115,15 @@
if param.hash not in allowed_values:
continue
if isinstance(equal_1.left, str):
- allowed_values[param.hash].remove(get_hash(equal_1.left))
+ if get_hash(equal_1.left) in allowed_values[param.hash]:
+ allowed_values[param.hash].remove(get_hash(equal_1.left))
+ else:
+ equal_vars[equal_1.hash] = BooleanFalse()
if isinstance(equal_1.right, str):
- allowed_values[param.hash].remove(get_hash(equal_1.right))
+ if get_hash(equal_1.right) in allowed_values[param.hash]:
+ allowed_values[param.hash].remove(get_hash(equal_1.right))
+ else:
+ equal_vars[equal_1.hash] = BooleanFalse()
# iteration 2 builds the cnf formulas to make sure any empty lists
# are now full not equals
@@ -157,10 +163,10 @@
return
# if only one condition we will assume its True/False
- if len(condition_names) == 1:
- yield {condition_names[0]: True}
- yield {condition_names[0]: False}
- return
+ # if len(condition_names) == 1:
+ # yield {condition_names[0]: True}
+ # yield {condition_names[0]: False}
+ # return
try:
# build a large matric of True/False options based on the provided conditions
|
{"golden_diff": "diff --git a/src/cfnlint/conditions/conditions.py b/src/cfnlint/conditions/conditions.py\n--- a/src/cfnlint/conditions/conditions.py\n+++ b/src/cfnlint/conditions/conditions.py\n@@ -115,9 +115,15 @@\n if param.hash not in allowed_values:\n continue\n if isinstance(equal_1.left, str):\n- allowed_values[param.hash].remove(get_hash(equal_1.left))\n+ if get_hash(equal_1.left) in allowed_values[param.hash]:\n+ allowed_values[param.hash].remove(get_hash(equal_1.left))\n+ else:\n+ equal_vars[equal_1.hash] = BooleanFalse()\n if isinstance(equal_1.right, str):\n- allowed_values[param.hash].remove(get_hash(equal_1.right))\n+ if get_hash(equal_1.right) in allowed_values[param.hash]:\n+ allowed_values[param.hash].remove(get_hash(equal_1.right))\n+ else:\n+ equal_vars[equal_1.hash] = BooleanFalse()\n \n # iteration 2 builds the cnf formulas to make sure any empty lists\n # are now full not equals\n@@ -157,10 +163,10 @@\n return\n \n # if only one condition we will assume its True/False\n- if len(condition_names) == 1:\n- yield {condition_names[0]: True}\n- yield {condition_names[0]: False}\n- return\n+ # if len(condition_names) == 1:\n+ # yield {condition_names[0]: True}\n+ # yield {condition_names[0]: False}\n+ # return\n \n try:\n # build a large matric of True/False options based on the provided conditions\n", "issue": "ValueError: list.remove(x): x not in list\n### CloudFormation Lint Version\r\n\r\n0.76.0\r\n\r\n### What operating system are you using?\r\n\r\nmacOS\r\n\r\n### Describe the bug\r\n\r\nWe run latest `cfn-lint` on all templates in the [AWS SAM repository](https://github.com/aws/serverless-application-model/); looks like 0.76.0 introduced a bug.\r\n\r\nSince today, `cfn-lint` fails with:\r\n\r\n```text\r\nTraceback (most recent call last):\r\n File \"/Users/rehnc/Desktop/tmp/serverless-application-model/.venv_cfn_lint/bin/cfn-lint\", line 8, in <module>\r\n sys.exit(main())\r\n File \"/Users/rehnc/Desktop/tmp/serverless-application-model/.venv_cfn_lint/lib/python3.10/site-packages/cfnlint/__main__.py\", line 39, in main\r\n matches = list(cfnlint.core.get_matches(filenames, args))\r\n File \"/Users/rehnc/Desktop/tmp/serverless-application-model/.venv_cfn_lint/lib/python3.10/site-packages/cfnlint/core.py\", line 173, in get_matches\r\n matches = run_cli(\r\n File \"/Users/rehnc/Desktop/tmp/serverless-application-model/.venv_cfn_lint/lib/python3.10/site-packages/cfnlint/core.py\", line 78, in run_cli\r\n return run_checks(filename, template, rules, regions, mandatory_rules)\r\n File \"/Users/rehnc/Desktop/tmp/serverless-application-model/.venv_cfn_lint/lib/python3.10/site-packages/cfnlint/core.py\", line 334, in run_checks\r\n runner = cfnlint.runner.Runner(\r\n File \"/Users/rehnc/Desktop/tmp/serverless-application-model/.venv_cfn_lint/lib/python3.10/site-packages/cfnlint/runner.py\", line 32, in __init__\r\n self.cfn = Template(filename, template, regions)\r\n File \"/Users/rehnc/Desktop/tmp/serverless-application-model/.venv_cfn_lint/lib/python3.10/site-packages/cfnlint/template/template.py\", line 44, in __init__\r\n self.conditions = cfnlint.conditions.Conditions(self)\r\n File \"/Users/rehnc/Desktop/tmp/serverless-application-model/.venv_cfn_lint/lib/python3.10/site-packages/cfnlint/conditions/conditions.py\", line 34, in __init__\r\n self._cnf, self._solver_params = self._build_cnf(list(self._conditions.keys()))\r\n File \"/Users/rehnc/Desktop/tmp/serverless-application-model/.venv_cfn_lint/lib/python3.10/site-packages/cfnlint/conditions/conditions.py\", line 118, in _build_cnf\r\n allowed_values[param.hash].remove(get_hash(equal_1.left))\r\nValueError: list.remove(x): x not in list\r\n```\r\n\r\n### Expected behavior\r\n\r\nExpected it not to fail, or to fail like a template violation would.\r\n\r\n### Reproduction template\r\n\r\nNot sure yet which one is causing the issue, but this reproduces it:\r\n\r\n```bash\r\ngit clone https://github.com/aws/serverless-application-model.git --depth 1\r\ncd serverless-application-model\r\npython3 -m venv .venv\r\n.venv/bin/python -m pip install cfn-lint==0.76.0\r\n.venv/bin/cfn-lint\r\n```\r\n\r\nHowever, if you try with `.venv/bin/python -m pip install cfn-lint==0.75.0`, it succeeds.\n", "before_files": [{"content": "\"\"\"\nCopyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport itertools\nimport logging\nimport traceback\nfrom typing import Any, Dict, Iterator, List, Tuple\n\nfrom sympy import And, Implies, Not, Symbol\nfrom sympy.assumptions.cnf import EncodedCNF\nfrom sympy.logic.boolalg import BooleanFalse, BooleanTrue\nfrom sympy.logic.inference import satisfiable\n\nfrom cfnlint.conditions._utils import get_hash\nfrom cfnlint.conditions.condition import ConditionNamed\nfrom cfnlint.conditions.equals import Equal\n\nLOGGER = logging.getLogger(__name__)\n\n\nclass Conditions:\n \"\"\"Conditions provides the logic for relating individual condition together\"\"\"\n\n _conditions: Dict[str, ConditionNamed]\n _parameters: Dict[str, List[str]] # Dict of parameters with AllowedValues hashed\n _max_scenarios: int = 128 # equivalent to 2^7\n\n def __init__(self, cfn):\n self._conditions = {}\n self._parameters = {}\n self._init_conditions(cfn=cfn)\n self._init_parameters(cfn=cfn)\n self._cnf, self._solver_params = self._build_cnf(list(self._conditions.keys()))\n\n def _init_conditions(self, cfn):\n conditions = cfn.template.get(\"Conditions\")\n if isinstance(conditions, dict):\n for k, _ in conditions.items():\n try:\n self._conditions[k] = ConditionNamed(k, conditions)\n except ValueError as e:\n LOGGER.debug(\n \"Captured error while building condition %s: %s\", k, str(e)\n )\n except Exception as e: # pylint: disable=broad-exception-caught\n if LOGGER.getEffectiveLevel() == logging.DEBUG:\n error_message = traceback.format_exc()\n else:\n error_message = str(e)\n LOGGER.debug(\n \"Captured unknown error while building condition %s: %s\",\n k,\n error_message,\n )\n\n def _init_parameters(self, cfn: Any) -> None:\n parameters = cfn.template.get(\"Parameters\")\n if not isinstance(parameters, dict):\n return\n for parameter_name, parameter in parameters.items():\n if not isinstance(parameter, dict):\n continue\n allowed_values = parameter.get(\"AllowedValues\")\n if not allowed_values or not isinstance(allowed_values, list):\n continue\n\n param_hash = get_hash({\"Ref\": parameter_name})\n self._parameters[param_hash] = []\n for allowed_value in allowed_values:\n if isinstance(allowed_value, (str, int, float, bool)):\n self._parameters[param_hash].append(get_hash(str(allowed_value)))\n\n def _build_cnf(\n self, condition_names: List[str]\n ) -> Tuple[EncodedCNF, Dict[str, Any]]:\n cnf = EncodedCNF()\n\n # build parameters and equals into solver\n equal_vars: Dict[str, Symbol] = {}\n\n equals: Dict[str, Equal] = {}\n for condition_name in condition_names:\n c_equals = self._conditions[condition_name].equals\n for c_equal in c_equals:\n # check to see if equals already matches another one\n if c_equal.hash in equal_vars:\n continue\n\n if c_equal.is_static is not None:\n if c_equal.is_static:\n equal_vars[c_equal.hash] = BooleanTrue()\n else:\n equal_vars[c_equal.hash] = BooleanFalse()\n else:\n equal_vars[c_equal.hash] = Symbol(c_equal.hash)\n # See if parameter in this equals is the same as another equals\n for param in c_equal.parameters:\n for e_hash, e_equals in equals.items():\n if param in e_equals.parameters:\n # equivalent to NAND logic. We want to make sure that both equals\n # are not both True at the same time\n cnf.add_prop(\n ~(equal_vars[c_equal.hash] & equal_vars[e_hash])\n )\n equals[c_equal.hash] = c_equal\n\n # Determine if a set of conditions can never be all false\n allowed_values = self._parameters.copy()\n if allowed_values:\n # iteration 1 cleans up all the hash values from allowed_values to know if we\n # used them all\n for _, equal_1 in equals.items():\n for param in equal_1.parameters:\n if param.hash not in allowed_values:\n continue\n if isinstance(equal_1.left, str):\n allowed_values[param.hash].remove(get_hash(equal_1.left))\n if isinstance(equal_1.right, str):\n allowed_values[param.hash].remove(get_hash(equal_1.right))\n\n # iteration 2 builds the cnf formulas to make sure any empty lists\n # are now full not equals\n for allowed_hash, allowed_value in allowed_values.items():\n # means the list is empty and all allowed values are validated\n # so not all equals can be false\n if not allowed_value:\n prop = None\n for _, equal_1 in equals.items():\n for param in equal_1.parameters:\n if allowed_hash == param.hash:\n if prop is None:\n prop = Not(equal_vars[equal_1.hash])\n else:\n prop = prop & Not(equal_vars[equal_1.hash])\n # Need to make sure they aren't all False\n # So Not(Not(Equal1) & Not(Equal2))\n # When Equal1 False and Equal2 False\n # Not(True & True) = False allowing this not to happen\n if prop is not None:\n cnf.add_prop(Not(prop))\n\n return (cnf, equal_vars)\n\n def build_scenarios(self, condition_names: List[str]) -> Iterator[Dict[str, bool]]:\n \"\"\"Given a list of condition names this function will yield scenarios that represent\n those conditions and there result (True/False)\n\n Args:\n condition_names (List[str]): A list of condition names\n\n Returns:\n Iterator[Dict[str, bool]]: yield dict objects of {ConditionName: True/False}\n \"\"\"\n # nothing to yield if there are no conditions\n if len(condition_names) == 0:\n return\n\n # if only one condition we will assume its True/False\n if len(condition_names) == 1:\n yield {condition_names[0]: True}\n yield {condition_names[0]: False}\n return\n\n try:\n # build a large matric of True/False options based on the provided conditions\n scenarios_returned = 0\n for p in itertools.product([True, False], repeat=len(condition_names)):\n cnf = self._cnf.copy()\n params = dict(zip(condition_names, p))\n for condition_name, opt in params.items():\n if opt:\n cnf.add_prop(\n self._conditions[condition_name].build_true_cnf(\n self._solver_params\n )\n )\n else:\n cnf.add_prop(\n self._conditions[condition_name].build_false_cnf(\n self._solver_params\n )\n )\n\n # if the scenario can be satisfied then return it\n if satisfiable(cnf):\n yield params\n scenarios_returned += 1\n\n # On occassions people will use a lot of non-related conditions\n # this is fail safe to limit the maximum number of responses\n if scenarios_returned >= self._max_scenarios:\n return\n except KeyError:\n # KeyError is because the listed condition doesn't exist because of bad\n # formatting or just the wrong condition name\n return\n\n def check_implies(self, scenarios: Dict[str, bool], implies: str) -> bool:\n \"\"\"Based on a bunch of scenario conditions and their Truth/False value\n determine if implies condition is True any time the scenarios are satisfied\n solver, solver_params = self._build_solver(list(scenarios.keys()) + [implies])\n\n Args:\n scenarios (Dict[str, bool]): A list of condition names and if they are True or False\n implies: the condition name that we are implying will also be True\n\n Returns:\n bool: if the implied condition will be True if the scenario is True\n \"\"\"\n try:\n cnf = self._cnf.copy()\n # if the implies condition has to be false in the scenarios we\n # know it can never be true\n if not scenarios.get(implies, True):\n return False\n\n conditions = []\n for condition_name, opt in scenarios.items():\n if opt:\n conditions.append(\n self._conditions[condition_name].build_true_cnf(\n self._solver_params\n )\n )\n else:\n conditions.append(\n self._conditions[condition_name].build_false_cnf(\n self._solver_params\n )\n )\n\n implies_condition = self._conditions[implies].build_true_cnf(\n self._solver_params\n )\n\n and_condition = And(*conditions)\n cnf.add_prop(and_condition)\n\n # if the implies condition has to be true already then we don't\n # need to imply it\n if not scenarios.get(implies):\n cnf.add_prop(Not(Implies(and_condition, implies_condition)))\n if satisfiable(cnf):\n return True\n\n return False\n except KeyError:\n # KeyError is because the listed condition doesn't exist because of bad\n # formatting or just the wrong condition name\n return True\n", "path": "src/cfnlint/conditions/conditions.py"}]}
| 3,988 | 384 |
gh_patches_debug_24109
|
rasdani/github-patches
|
git_diff
|
sublimelsp__LSP-2356
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
The Go To on a cloned view is enabled on the first view, instead of the current one
Copied from: https://github.com/SublimeTextIssues/Core/issues/1482 (The Go To on a cloned view is enabled on the first view, instead of the current one)
```patch
diff --git a/plugin/definition.py b/plugin/definition.py
index 7e77681..a84899c 100644
--- a/plugin/definition.py
+++ b/plugin/definition.py
@@ -42,12 +42,17 @@ class LspSymbolDefinitionCommand(LspTextCommand):
# save to jump back history
get_jump_history_for_view(self.view).push_selection(self.view)
+ # https://github.com/SublimeTextIssues/Core/issues/1482
+ group, view_index = window.get_view_index(self.view)
+ window.set_view_index(self.view, group, 0)
+
location = response if isinstance(response, dict) else response[0]
file_path = uri_to_filename(location.get("uri"))
start = Point.from_lsp(location['range']['start'])
file_location = "{}:{}:{}".format(file_path, start.row + 1, start.col + 1)
log(2, "opening location %s <%s>", location, file_location)
window.open_file(file_location, sublime.ENCODED_POSITION)
+ window.set_view_index(self.view, group, view_index)
# TODO: can add region here.
else:
window.run_command("goto_definition")
```
</issue>
<code>
[start of plugin/core/open.py]
1 from .logging import exception_log
2 from .promise import Promise
3 from .promise import ResolveFunc
4 from .protocol import DocumentUri
5 from .protocol import Range
6 from .protocol import UINT_MAX
7 from .typing import Dict, Tuple, Optional
8 from .typing import cast
9 from .url import parse_uri
10 from .views import range_to_region
11 from urllib.parse import unquote, urlparse
12 import os
13 import re
14 import sublime
15 import sublime_plugin
16 import subprocess
17 import webbrowser
18
19
20 opening_files = {} # type: Dict[str, Tuple[Promise[Optional[sublime.View]], ResolveFunc[Optional[sublime.View]]]]
21 FRAGMENT_PATTERN = re.compile(r'^L?(\d+)(?:,(\d+))?(?:-L?(\d+)(?:,(\d+))?)?')
22
23
24 def lsp_range_from_uri_fragment(fragment: str) -> Optional[Range]:
25 match = FRAGMENT_PATTERN.match(fragment)
26 if match:
27 selection = {'start': {'line': 0, 'character': 0}, 'end': {'line': 0, 'character': 0}} # type: Range
28 # Line and column numbers in the fragment are assumed to be 1-based and need to be converted to 0-based
29 # numbers for the LSP Position structure.
30 start_line, start_column, end_line, end_column = [max(0, int(g) - 1) if g else None for g in match.groups()]
31 if start_line:
32 selection['start']['line'] = start_line
33 selection['end']['line'] = start_line
34 if start_column:
35 selection['start']['character'] = start_column
36 selection['end']['character'] = start_column
37 if end_line:
38 selection['end']['line'] = end_line
39 selection['end']['character'] = UINT_MAX
40 if end_column is not None:
41 selection['end']['character'] = end_column
42 return selection
43 return None
44
45
46 def open_file_uri(
47 window: sublime.Window, uri: DocumentUri, flags: int = 0, group: int = -1
48 ) -> Promise[Optional[sublime.View]]:
49
50 decoded_uri = unquote(uri) # decode percent-encoded characters
51 parsed = urlparse(decoded_uri)
52 open_promise = open_file(window, decoded_uri, flags, group)
53 if parsed.fragment:
54 selection = lsp_range_from_uri_fragment(parsed.fragment)
55 if selection:
56 return open_promise.then(lambda view: _select_and_center(view, cast(Range, selection)))
57 return open_promise
58
59
60 def _select_and_center(view: Optional[sublime.View], r: Range) -> Optional[sublime.View]:
61 if view:
62 return center_selection(view, r)
63 return None
64
65
66 def _return_existing_view(flags: int, existing_view_group: int, active_group: int, specified_group: int) -> bool:
67 if specified_group > -1:
68 return existing_view_group == specified_group
69 if bool(flags & (sublime.ADD_TO_SELECTION | sublime.REPLACE_MRU)):
70 return False
71 if existing_view_group == active_group:
72 return True
73 return not bool(flags & sublime.FORCE_GROUP)
74
75
76 def open_file(
77 window: sublime.Window, uri: DocumentUri, flags: int = 0, group: int = -1
78 ) -> Promise[Optional[sublime.View]]:
79 """
80 Open a file asynchronously.
81 It is only safe to call this function from the UI thread.
82 The provided uri MUST be a file URI
83 """
84 file = parse_uri(uri)[1]
85 # window.open_file brings the file to focus if it's already opened, which we don't want (unless it's supposed
86 # to open as a separate view).
87 view = window.find_open_file(file)
88 if view and _return_existing_view(flags, window.get_view_index(view)[0], window.active_group(), group):
89 return Promise.resolve(view)
90
91 was_already_open = view is not None
92 view = window.open_file(file, flags, group)
93 if not view.is_loading():
94 if was_already_open and (flags & sublime.SEMI_TRANSIENT):
95 # workaround bug https://github.com/sublimehq/sublime_text/issues/2411 where transient view might not get
96 # its view listeners initialized.
97 sublime_plugin.check_view_event_listeners(view) # type: ignore
98 # It's already loaded. Possibly already open in a tab.
99 return Promise.resolve(view)
100
101 # Is the view opening right now? Then return the associated unresolved promise
102 for fn, value in opening_files.items():
103 if fn == file or os.path.samefile(fn, file):
104 # Return the unresolved promise. A future on_load event will resolve the promise.
105 return value[0]
106
107 # Prepare a new promise to be resolved by a future on_load event (see the event listener in main.py)
108 def fullfill(resolve: ResolveFunc[Optional[sublime.View]]) -> None:
109 global opening_files
110 # Save the promise in the first element of the tuple -- except we cannot yet do that here
111 opening_files[file] = (None, resolve) # type: ignore
112
113 promise = Promise(fullfill)
114 tup = opening_files[file]
115 # Save the promise in the first element of the tuple so that the for-loop above can return it
116 opening_files[file] = (promise, tup[1])
117 return promise
118
119
120 def center_selection(v: sublime.View, r: Range) -> sublime.View:
121 selection = range_to_region(r, v)
122 v.run_command("lsp_selection_set", {"regions": [(selection.a, selection.a)]})
123 window = v.window()
124 if window:
125 window.focus_view(v)
126 if int(sublime.version()) >= 4124:
127 v.show_at_center(selection.begin(), animate=False)
128 else:
129 # TODO: remove later when a stable build lands
130 v.show_at_center(selection.begin()) # type: ignore
131 return v
132
133
134 def open_in_browser(uri: str) -> None:
135 # NOTE: Remove this check when on py3.8.
136 if not uri.lower().startswith(("http://", "https://")):
137 uri = "https://" + uri
138 if not webbrowser.open(uri):
139 sublime.status_message("failed to open: " + uri)
140
141
142 def open_externally(uri: str, take_focus: bool) -> bool:
143 """
144 A blocking function that invokes the OS's "open with default extension"
145 """
146 try:
147 # TODO: handle take_focus
148 if sublime.platform() == "windows":
149 os.startfile(uri) # type: ignore
150 elif sublime.platform() == "osx":
151 subprocess.check_call(("/usr/bin/open", uri))
152 else: # linux
153 subprocess.check_call(("xdg-open", uri))
154 return True
155 except Exception as ex:
156 exception_log("Failed to open {}".format(uri), ex)
157 return False
158
[end of plugin/core/open.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugin/core/open.py b/plugin/core/open.py
--- a/plugin/core/open.py
+++ b/plugin/core/open.py
@@ -73,6 +73,15 @@
return not bool(flags & sublime.FORCE_GROUP)
+def _find_open_file(window: sublime.Window, fname: str, group: int = -1) -> Optional[sublime.View]:
+ """A replacement for Window.find_open_file that prefers the active view instead of the leftmost one."""
+ _group = window.active_group() if group == -1 else group
+ view = window.active_view_in_group(_group)
+ if fname == view.file_name():
+ return view
+ return window.find_open_file(fname, group)
+
+
def open_file(
window: sublime.Window, uri: DocumentUri, flags: int = 0, group: int = -1
) -> Promise[Optional[sublime.View]]:
@@ -84,7 +93,7 @@
file = parse_uri(uri)[1]
# window.open_file brings the file to focus if it's already opened, which we don't want (unless it's supposed
# to open as a separate view).
- view = window.find_open_file(file)
+ view = _find_open_file(window, file)
if view and _return_existing_view(flags, window.get_view_index(view)[0], window.active_group(), group):
return Promise.resolve(view)
|
{"golden_diff": "diff --git a/plugin/core/open.py b/plugin/core/open.py\n--- a/plugin/core/open.py\n+++ b/plugin/core/open.py\n@@ -73,6 +73,15 @@\n return not bool(flags & sublime.FORCE_GROUP)\n \n \n+def _find_open_file(window: sublime.Window, fname: str, group: int = -1) -> Optional[sublime.View]:\n+ \"\"\"A replacement for Window.find_open_file that prefers the active view instead of the leftmost one.\"\"\"\n+ _group = window.active_group() if group == -1 else group\n+ view = window.active_view_in_group(_group)\n+ if fname == view.file_name():\n+ return view\n+ return window.find_open_file(fname, group)\n+\n+\n def open_file(\n window: sublime.Window, uri: DocumentUri, flags: int = 0, group: int = -1\n ) -> Promise[Optional[sublime.View]]:\n@@ -84,7 +93,7 @@\n file = parse_uri(uri)[1]\n # window.open_file brings the file to focus if it's already opened, which we don't want (unless it's supposed\n # to open as a separate view).\n- view = window.find_open_file(file)\n+ view = _find_open_file(window, file)\n if view and _return_existing_view(flags, window.get_view_index(view)[0], window.active_group(), group):\n return Promise.resolve(view)\n", "issue": "The Go To on a cloned view is enabled on the first view, instead of the current one\nCopied from: https://github.com/SublimeTextIssues/Core/issues/1482 (The Go To on a cloned view is enabled on the first view, instead of the current one)\r\n\r\n```patch\r\ndiff --git a/plugin/definition.py b/plugin/definition.py\r\nindex 7e77681..a84899c 100644\r\n--- a/plugin/definition.py\r\n+++ b/plugin/definition.py\r\n@@ -42,12 +42,17 @@ class LspSymbolDefinitionCommand(LspTextCommand):\r\n # save to jump back history\r\n get_jump_history_for_view(self.view).push_selection(self.view)\r\n \r\n+ # https://github.com/SublimeTextIssues/Core/issues/1482\r\n+ group, view_index = window.get_view_index(self.view)\r\n+ window.set_view_index(self.view, group, 0)\r\n+\r\n location = response if isinstance(response, dict) else response[0]\r\n file_path = uri_to_filename(location.get(\"uri\"))\r\n start = Point.from_lsp(location['range']['start'])\r\n file_location = \"{}:{}:{}\".format(file_path, start.row + 1, start.col + 1)\r\n log(2, \"opening location %s <%s>\", location, file_location)\r\n window.open_file(file_location, sublime.ENCODED_POSITION)\r\n+ window.set_view_index(self.view, group, view_index)\r\n # TODO: can add region here.\r\n else:\r\n window.run_command(\"goto_definition\")\r\n```\n", "before_files": [{"content": "from .logging import exception_log\nfrom .promise import Promise\nfrom .promise import ResolveFunc\nfrom .protocol import DocumentUri\nfrom .protocol import Range\nfrom .protocol import UINT_MAX\nfrom .typing import Dict, Tuple, Optional\nfrom .typing import cast\nfrom .url import parse_uri\nfrom .views import range_to_region\nfrom urllib.parse import unquote, urlparse\nimport os\nimport re\nimport sublime\nimport sublime_plugin\nimport subprocess\nimport webbrowser\n\n\nopening_files = {} # type: Dict[str, Tuple[Promise[Optional[sublime.View]], ResolveFunc[Optional[sublime.View]]]]\nFRAGMENT_PATTERN = re.compile(r'^L?(\\d+)(?:,(\\d+))?(?:-L?(\\d+)(?:,(\\d+))?)?')\n\n\ndef lsp_range_from_uri_fragment(fragment: str) -> Optional[Range]:\n match = FRAGMENT_PATTERN.match(fragment)\n if match:\n selection = {'start': {'line': 0, 'character': 0}, 'end': {'line': 0, 'character': 0}} # type: Range\n # Line and column numbers in the fragment are assumed to be 1-based and need to be converted to 0-based\n # numbers for the LSP Position structure.\n start_line, start_column, end_line, end_column = [max(0, int(g) - 1) if g else None for g in match.groups()]\n if start_line:\n selection['start']['line'] = start_line\n selection['end']['line'] = start_line\n if start_column:\n selection['start']['character'] = start_column\n selection['end']['character'] = start_column\n if end_line:\n selection['end']['line'] = end_line\n selection['end']['character'] = UINT_MAX\n if end_column is not None:\n selection['end']['character'] = end_column\n return selection\n return None\n\n\ndef open_file_uri(\n window: sublime.Window, uri: DocumentUri, flags: int = 0, group: int = -1\n) -> Promise[Optional[sublime.View]]:\n\n decoded_uri = unquote(uri) # decode percent-encoded characters\n parsed = urlparse(decoded_uri)\n open_promise = open_file(window, decoded_uri, flags, group)\n if parsed.fragment:\n selection = lsp_range_from_uri_fragment(parsed.fragment)\n if selection:\n return open_promise.then(lambda view: _select_and_center(view, cast(Range, selection)))\n return open_promise\n\n\ndef _select_and_center(view: Optional[sublime.View], r: Range) -> Optional[sublime.View]:\n if view:\n return center_selection(view, r)\n return None\n\n\ndef _return_existing_view(flags: int, existing_view_group: int, active_group: int, specified_group: int) -> bool:\n if specified_group > -1:\n return existing_view_group == specified_group\n if bool(flags & (sublime.ADD_TO_SELECTION | sublime.REPLACE_MRU)):\n return False\n if existing_view_group == active_group:\n return True\n return not bool(flags & sublime.FORCE_GROUP)\n\n\ndef open_file(\n window: sublime.Window, uri: DocumentUri, flags: int = 0, group: int = -1\n) -> Promise[Optional[sublime.View]]:\n \"\"\"\n Open a file asynchronously.\n It is only safe to call this function from the UI thread.\n The provided uri MUST be a file URI\n \"\"\"\n file = parse_uri(uri)[1]\n # window.open_file brings the file to focus if it's already opened, which we don't want (unless it's supposed\n # to open as a separate view).\n view = window.find_open_file(file)\n if view and _return_existing_view(flags, window.get_view_index(view)[0], window.active_group(), group):\n return Promise.resolve(view)\n\n was_already_open = view is not None\n view = window.open_file(file, flags, group)\n if not view.is_loading():\n if was_already_open and (flags & sublime.SEMI_TRANSIENT):\n # workaround bug https://github.com/sublimehq/sublime_text/issues/2411 where transient view might not get\n # its view listeners initialized.\n sublime_plugin.check_view_event_listeners(view) # type: ignore\n # It's already loaded. Possibly already open in a tab.\n return Promise.resolve(view)\n\n # Is the view opening right now? Then return the associated unresolved promise\n for fn, value in opening_files.items():\n if fn == file or os.path.samefile(fn, file):\n # Return the unresolved promise. A future on_load event will resolve the promise.\n return value[0]\n\n # Prepare a new promise to be resolved by a future on_load event (see the event listener in main.py)\n def fullfill(resolve: ResolveFunc[Optional[sublime.View]]) -> None:\n global opening_files\n # Save the promise in the first element of the tuple -- except we cannot yet do that here\n opening_files[file] = (None, resolve) # type: ignore\n\n promise = Promise(fullfill)\n tup = opening_files[file]\n # Save the promise in the first element of the tuple so that the for-loop above can return it\n opening_files[file] = (promise, tup[1])\n return promise\n\n\ndef center_selection(v: sublime.View, r: Range) -> sublime.View:\n selection = range_to_region(r, v)\n v.run_command(\"lsp_selection_set\", {\"regions\": [(selection.a, selection.a)]})\n window = v.window()\n if window:\n window.focus_view(v)\n if int(sublime.version()) >= 4124:\n v.show_at_center(selection.begin(), animate=False)\n else:\n # TODO: remove later when a stable build lands\n v.show_at_center(selection.begin()) # type: ignore\n return v\n\n\ndef open_in_browser(uri: str) -> None:\n # NOTE: Remove this check when on py3.8.\n if not uri.lower().startswith((\"http://\", \"https://\")):\n uri = \"https://\" + uri\n if not webbrowser.open(uri):\n sublime.status_message(\"failed to open: \" + uri)\n\n\ndef open_externally(uri: str, take_focus: bool) -> bool:\n \"\"\"\n A blocking function that invokes the OS's \"open with default extension\"\n \"\"\"\n try:\n # TODO: handle take_focus\n if sublime.platform() == \"windows\":\n os.startfile(uri) # type: ignore\n elif sublime.platform() == \"osx\":\n subprocess.check_call((\"/usr/bin/open\", uri))\n else: # linux\n subprocess.check_call((\"xdg-open\", uri))\n return True\n except Exception as ex:\n exception_log(\"Failed to open {}\".format(uri), ex)\n return False\n", "path": "plugin/core/open.py"}]}
| 2,731 | 307 |
gh_patches_debug_26835
|
rasdani/github-patches
|
git_diff
|
azavea__raster-vision-536
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Avoid error when working with subtypes for SemanticSegmentationRasterSource
Here: https://github.com/azavea/raster-vision/blob/f6ea64a37fd4d09375da1838cd679e6cbce5b35b/rastervision/data/label_source/semantic_segmentation_raster_source_config.py#L123
We check for the type explicitly. We should use `isinstance` instead to allow for subclasses to pass this check - or figure out a more general way of not having other types and allowing them to bypass having to set the rgb class map.
</issue>
<code>
[start of rastervision/data/label_source/semantic_segmentation_raster_source_config.py]
1 from copy import deepcopy
2
3 import rastervision as rv
4 from rastervision.core.class_map import ClassMap
5 from rastervision.data.label_source import (LabelSourceConfig,
6 LabelSourceConfigBuilder,
7 SemanticSegmentationRasterSource)
8 from rastervision.protos.label_source_pb2 import LabelSourceConfig as LabelSourceConfigMsg
9 from rastervision.data.raster_source import RasterSourceConfig, GeoJSONSourceConfig
10
11
12 class SemanticSegmentationRasterSourceConfig(LabelSourceConfig):
13 def __init__(self, source, rgb_class_map=None):
14 super().__init__(source_type=rv.SEMANTIC_SEGMENTATION_RASTER)
15 self.source = source
16 self.rgb_class_map = rgb_class_map
17
18 def to_proto(self):
19 msg = super().to_proto()
20
21 rgb_class_items = None
22 if self.rgb_class_map is not None:
23 rgb_class_items = self.rgb_class_map.to_proto()
24 opts = LabelSourceConfigMsg.SemanticSegmentationRasterSource(
25 source=self.source.to_proto(), rgb_class_items=rgb_class_items)
26 msg.semantic_segmentation_raster_source.CopyFrom(opts)
27 return msg
28
29 def create_source(self, task_config, extent, crs_transformer, tmp_dir):
30 return SemanticSegmentationRasterSource(
31 self.source.create_source(tmp_dir, extent, crs_transformer),
32 self.rgb_class_map)
33
34 def update_for_command(self, command_type, experiment_config, context=[]):
35 if context is None:
36 context = []
37 context = context + [self]
38 io_def = rv.core.CommandIODefinition()
39
40 b = self.to_builder()
41
42 (new_raster_source, sub_io_def) = self.source.update_for_command(
43 command_type, experiment_config, context)
44
45 io_def.merge(sub_io_def)
46 b = b.with_raster_source(new_raster_source)
47
48 return (b.build(), io_def)
49
50
51 class SemanticSegmentationRasterSourceConfigBuilder(LabelSourceConfigBuilder):
52 def __init__(self, prev=None):
53 config = {}
54 if prev:
55 config = {
56 'source': prev.source,
57 'rgb_class_map': prev.rgb_class_map
58 }
59
60 super().__init__(SemanticSegmentationRasterSourceConfig, config)
61
62 def from_proto(self, msg):
63 b = SemanticSegmentationRasterSourceConfigBuilder()
64
65 raster_source_config = rv.RasterSourceConfig.from_proto(
66 msg.semantic_segmentation_raster_source.source)
67
68 b = b.with_raster_source(raster_source_config)
69 rgb_class_items = msg.semantic_segmentation_raster_source.rgb_class_items
70 if rgb_class_items:
71 b = b.with_rgb_class_map(
72 ClassMap.construct_from(list(rgb_class_items)))
73
74 return b
75
76 def with_raster_source(self, source, channel_order=None):
77 """Set raster_source.
78
79 Args:
80 source: (RasterSourceConfig) A RasterSource assumed to have RGB values that
81 are mapped to class_ids using the rgb_class_map.
82
83 Returns:
84 SemanticSegmentationRasterSourceConfigBuilder
85 """
86 b = deepcopy(self)
87 if isinstance(source, RasterSourceConfig):
88 b.config['source'] = source
89 elif isinstance(source, str):
90 provider = rv._registry.get_raster_source_default_provider(source)
91 source = provider.construct(source, channel_order=channel_order)
92 b.config['source'] = source
93 else:
94 raise rv.ConfigError(
95 'source must be either string or RasterSourceConfig, '
96 ' not {}'.format(str(type(source))))
97
98 return b
99
100 def with_rgb_class_map(self, rgb_class_map):
101 """Set rgb_class_map.
102
103 Args:
104 rgb_class_map: (something accepted by ClassMap.construct_from) a class
105 map with color values used to map RGB values to class ids
106
107 Returns:
108 SemanticSegmentationRasterSourceConfigBuilder
109 """
110 b = deepcopy(self)
111 b.config['rgb_class_map'] = ClassMap.construct_from(rgb_class_map)
112 return b
113
114 def validate(self):
115 source = self.config.get('source')
116 rgb_class_map = self.config.get('rgb_class_map')
117
118 if source is None:
119 raise rv.ConfigError(
120 'You must set the source for SemanticSegmentationRasterSourceConfig'
121 ' Use "with_raster_source".')
122
123 if type(source) != GeoJSONSourceConfig and rgb_class_map is None:
124 raise rv.ConfigError(
125 'You must set the rgb_class_map for '
126 'SemanticSegmentationRasterSourceConfig. Use "with_rgb_class_map".'
127 )
128
[end of rastervision/data/label_source/semantic_segmentation_raster_source_config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/rastervision/data/label_source/semantic_segmentation_raster_source_config.py b/rastervision/data/label_source/semantic_segmentation_raster_source_config.py
--- a/rastervision/data/label_source/semantic_segmentation_raster_source_config.py
+++ b/rastervision/data/label_source/semantic_segmentation_raster_source_config.py
@@ -6,7 +6,7 @@
LabelSourceConfigBuilder,
SemanticSegmentationRasterSource)
from rastervision.protos.label_source_pb2 import LabelSourceConfig as LabelSourceConfigMsg
-from rastervision.data.raster_source import RasterSourceConfig, GeoJSONSourceConfig
+from rastervision.data.raster_source import RasterSourceConfig
class SemanticSegmentationRasterSourceConfig(LabelSourceConfig):
@@ -113,15 +113,8 @@
def validate(self):
source = self.config.get('source')
- rgb_class_map = self.config.get('rgb_class_map')
if source is None:
raise rv.ConfigError(
'You must set the source for SemanticSegmentationRasterSourceConfig'
' Use "with_raster_source".')
-
- if type(source) != GeoJSONSourceConfig and rgb_class_map is None:
- raise rv.ConfigError(
- 'You must set the rgb_class_map for '
- 'SemanticSegmentationRasterSourceConfig. Use "with_rgb_class_map".'
- )
|
{"golden_diff": "diff --git a/rastervision/data/label_source/semantic_segmentation_raster_source_config.py b/rastervision/data/label_source/semantic_segmentation_raster_source_config.py\n--- a/rastervision/data/label_source/semantic_segmentation_raster_source_config.py\n+++ b/rastervision/data/label_source/semantic_segmentation_raster_source_config.py\n@@ -6,7 +6,7 @@\n LabelSourceConfigBuilder,\n SemanticSegmentationRasterSource)\n from rastervision.protos.label_source_pb2 import LabelSourceConfig as LabelSourceConfigMsg\n-from rastervision.data.raster_source import RasterSourceConfig, GeoJSONSourceConfig\n+from rastervision.data.raster_source import RasterSourceConfig\n \n \n class SemanticSegmentationRasterSourceConfig(LabelSourceConfig):\n@@ -113,15 +113,8 @@\n \n def validate(self):\n source = self.config.get('source')\n- rgb_class_map = self.config.get('rgb_class_map')\n \n if source is None:\n raise rv.ConfigError(\n 'You must set the source for SemanticSegmentationRasterSourceConfig'\n ' Use \"with_raster_source\".')\n-\n- if type(source) != GeoJSONSourceConfig and rgb_class_map is None:\n- raise rv.ConfigError(\n- 'You must set the rgb_class_map for '\n- 'SemanticSegmentationRasterSourceConfig. Use \"with_rgb_class_map\".'\n- )\n", "issue": "Avoid error when working with subtypes for SemanticSegmentationRasterSource\nHere: https://github.com/azavea/raster-vision/blob/f6ea64a37fd4d09375da1838cd679e6cbce5b35b/rastervision/data/label_source/semantic_segmentation_raster_source_config.py#L123\r\n\r\nWe check for the type explicitly. We should use `isinstance` instead to allow for subclasses to pass this check - or figure out a more general way of not having other types and allowing them to bypass having to set the rgb class map.\n", "before_files": [{"content": "from copy import deepcopy\n\nimport rastervision as rv\nfrom rastervision.core.class_map import ClassMap\nfrom rastervision.data.label_source import (LabelSourceConfig,\n LabelSourceConfigBuilder,\n SemanticSegmentationRasterSource)\nfrom rastervision.protos.label_source_pb2 import LabelSourceConfig as LabelSourceConfigMsg\nfrom rastervision.data.raster_source import RasterSourceConfig, GeoJSONSourceConfig\n\n\nclass SemanticSegmentationRasterSourceConfig(LabelSourceConfig):\n def __init__(self, source, rgb_class_map=None):\n super().__init__(source_type=rv.SEMANTIC_SEGMENTATION_RASTER)\n self.source = source\n self.rgb_class_map = rgb_class_map\n\n def to_proto(self):\n msg = super().to_proto()\n\n rgb_class_items = None\n if self.rgb_class_map is not None:\n rgb_class_items = self.rgb_class_map.to_proto()\n opts = LabelSourceConfigMsg.SemanticSegmentationRasterSource(\n source=self.source.to_proto(), rgb_class_items=rgb_class_items)\n msg.semantic_segmentation_raster_source.CopyFrom(opts)\n return msg\n\n def create_source(self, task_config, extent, crs_transformer, tmp_dir):\n return SemanticSegmentationRasterSource(\n self.source.create_source(tmp_dir, extent, crs_transformer),\n self.rgb_class_map)\n\n def update_for_command(self, command_type, experiment_config, context=[]):\n if context is None:\n context = []\n context = context + [self]\n io_def = rv.core.CommandIODefinition()\n\n b = self.to_builder()\n\n (new_raster_source, sub_io_def) = self.source.update_for_command(\n command_type, experiment_config, context)\n\n io_def.merge(sub_io_def)\n b = b.with_raster_source(new_raster_source)\n\n return (b.build(), io_def)\n\n\nclass SemanticSegmentationRasterSourceConfigBuilder(LabelSourceConfigBuilder):\n def __init__(self, prev=None):\n config = {}\n if prev:\n config = {\n 'source': prev.source,\n 'rgb_class_map': prev.rgb_class_map\n }\n\n super().__init__(SemanticSegmentationRasterSourceConfig, config)\n\n def from_proto(self, msg):\n b = SemanticSegmentationRasterSourceConfigBuilder()\n\n raster_source_config = rv.RasterSourceConfig.from_proto(\n msg.semantic_segmentation_raster_source.source)\n\n b = b.with_raster_source(raster_source_config)\n rgb_class_items = msg.semantic_segmentation_raster_source.rgb_class_items\n if rgb_class_items:\n b = b.with_rgb_class_map(\n ClassMap.construct_from(list(rgb_class_items)))\n\n return b\n\n def with_raster_source(self, source, channel_order=None):\n \"\"\"Set raster_source.\n\n Args:\n source: (RasterSourceConfig) A RasterSource assumed to have RGB values that\n are mapped to class_ids using the rgb_class_map.\n\n Returns:\n SemanticSegmentationRasterSourceConfigBuilder\n \"\"\"\n b = deepcopy(self)\n if isinstance(source, RasterSourceConfig):\n b.config['source'] = source\n elif isinstance(source, str):\n provider = rv._registry.get_raster_source_default_provider(source)\n source = provider.construct(source, channel_order=channel_order)\n b.config['source'] = source\n else:\n raise rv.ConfigError(\n 'source must be either string or RasterSourceConfig, '\n ' not {}'.format(str(type(source))))\n\n return b\n\n def with_rgb_class_map(self, rgb_class_map):\n \"\"\"Set rgb_class_map.\n\n Args:\n rgb_class_map: (something accepted by ClassMap.construct_from) a class\n map with color values used to map RGB values to class ids\n\n Returns:\n SemanticSegmentationRasterSourceConfigBuilder\n \"\"\"\n b = deepcopy(self)\n b.config['rgb_class_map'] = ClassMap.construct_from(rgb_class_map)\n return b\n\n def validate(self):\n source = self.config.get('source')\n rgb_class_map = self.config.get('rgb_class_map')\n\n if source is None:\n raise rv.ConfigError(\n 'You must set the source for SemanticSegmentationRasterSourceConfig'\n ' Use \"with_raster_source\".')\n\n if type(source) != GeoJSONSourceConfig and rgb_class_map is None:\n raise rv.ConfigError(\n 'You must set the rgb_class_map for '\n 'SemanticSegmentationRasterSourceConfig. Use \"with_rgb_class_map\".'\n )\n", "path": "rastervision/data/label_source/semantic_segmentation_raster_source_config.py"}]}
| 1,948 | 313 |
gh_patches_debug_28879
|
rasdani/github-patches
|
git_diff
|
python-geeks__Automation-scripts-885
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
yaml_to_json add command line interface
**Describe the bug**
yaml_to_json currently only allow to enter filename. It is not convenient and cannot be used with bash autocomplete
**To Reproduce**
**Expected behavior**
Application should accept command line arguments with filenames
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Additional context**
Add any other context about the problem here.
</issue>
<code>
[start of yaml_to_json/yaml_to_json.py]
1 from ruyaml import YAML
2 import json
3
4
5 def get_yaml_data():
6 yaml_name = input("Enter the yaml file name: ")
7
8 try:
9 with open(yaml_name, "r+") as f:
10 yaml_data = YAML().load(f)
11 return yaml_data
12 except: # noqa
13 print("Invalid input enter a valid yaml file name e.g. example.yaml")
14 yaml_data = get_yaml_data()
15
16
17 def convert_to_json(yaml_data):
18 json_name = input("Enter the name of output json file: ")
19
20 try:
21 with open(json_name, "w+") as o:
22 o.write(json.dumps(yaml_data))
23 except: # noqa
24 print("Invalid input enter a valid json file name e.g. example.json")
25 convert_to_json(yaml_data)
26
27
28 yaml_data = get_yaml_data()
29 convert_to_json(yaml_data)
30
31 print("Your yaml file has been converted and saved as json")
32
[end of yaml_to_json/yaml_to_json.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/yaml_to_json/yaml_to_json.py b/yaml_to_json/yaml_to_json.py
--- a/yaml_to_json/yaml_to_json.py
+++ b/yaml_to_json/yaml_to_json.py
@@ -1,9 +1,11 @@
from ruyaml import YAML
+import argparse
import json
-def get_yaml_data():
- yaml_name = input("Enter the yaml file name: ")
+def get_yaml_data(yaml_name=None):
+ if not yaml_name:
+ yaml_name = input("Enter the yaml file name: ")
try:
with open(yaml_name, "r+") as f:
@@ -14,18 +16,34 @@
yaml_data = get_yaml_data()
-def convert_to_json(yaml_data):
- json_name = input("Enter the name of output json file: ")
+def convert_to_json(yaml_data, json_name=None, intent=None):
+ if not json_name:
+ json_name = input("Enter the name of output json file: ")
try:
with open(json_name, "w+") as o:
- o.write(json.dumps(yaml_data))
+ o.write(json.dumps(yaml_data, indent=intent))
except: # noqa
print("Invalid input enter a valid json file name e.g. example.json")
convert_to_json(yaml_data)
-yaml_data = get_yaml_data()
-convert_to_json(yaml_data)
+def main():
+ parser = argparse.ArgumentParser(description='Convert YAML file to JSON')
+ parser.add_argument('--yaml', type=str, help='YAML filename')
+ parser.add_argument('--json', type=str, help='JSON filename')
+ parser.add_argument('--intent', type=int, help="intent value for JSON")
+ args = parser.parse_args()
-print("Your yaml file has been converted and saved as json")
+ yaml_name = args.yaml
+ json_name = args.json
+ intent = args.intent
+
+ yaml_data = get_yaml_data(yaml_name)
+ convert_to_json(yaml_data, json_name, intent=intent)
+
+ print("Your yaml file has been converted and saved as json")
+
+
+if __name__ == "__main__":
+ main()
|
{"golden_diff": "diff --git a/yaml_to_json/yaml_to_json.py b/yaml_to_json/yaml_to_json.py\n--- a/yaml_to_json/yaml_to_json.py\n+++ b/yaml_to_json/yaml_to_json.py\n@@ -1,9 +1,11 @@\n from ruyaml import YAML\n+import argparse\n import json\n \n \n-def get_yaml_data():\n- yaml_name = input(\"Enter the yaml file name: \")\n+def get_yaml_data(yaml_name=None):\n+ if not yaml_name:\n+ yaml_name = input(\"Enter the yaml file name: \")\n \n try:\n with open(yaml_name, \"r+\") as f:\n@@ -14,18 +16,34 @@\n yaml_data = get_yaml_data()\n \n \n-def convert_to_json(yaml_data):\n- json_name = input(\"Enter the name of output json file: \")\n+def convert_to_json(yaml_data, json_name=None, intent=None):\n+ if not json_name:\n+ json_name = input(\"Enter the name of output json file: \")\n \n try:\n with open(json_name, \"w+\") as o:\n- o.write(json.dumps(yaml_data))\n+ o.write(json.dumps(yaml_data, indent=intent))\n except: # noqa\n print(\"Invalid input enter a valid json file name e.g. example.json\")\n convert_to_json(yaml_data)\n \n \n-yaml_data = get_yaml_data()\n-convert_to_json(yaml_data)\n+def main():\n+ parser = argparse.ArgumentParser(description='Convert YAML file to JSON')\n+ parser.add_argument('--yaml', type=str, help='YAML filename')\n+ parser.add_argument('--json', type=str, help='JSON filename')\n+ parser.add_argument('--intent', type=int, help=\"intent value for JSON\")\n+ args = parser.parse_args()\n \n-print(\"Your yaml file has been converted and saved as json\")\n+ yaml_name = args.yaml\n+ json_name = args.json\n+ intent = args.intent\n+\n+ yaml_data = get_yaml_data(yaml_name)\n+ convert_to_json(yaml_data, json_name, intent=intent)\n+\n+ print(\"Your yaml file has been converted and saved as json\")\n+\n+\n+if __name__ == \"__main__\":\n+ main()\n", "issue": "yaml_to_json add command line interface\n**Describe the bug**\r\nyaml_to_json currently only allow to enter filename. It is not convenient and cannot be used with bash autocomplete \r\n\r\n**To Reproduce**\r\n\r\n**Expected behavior**\r\nApplication should accept command line arguments with filenames\r\n\r\n**Screenshots**\r\nIf applicable, add screenshots to help explain your problem.\r\n\r\n**Additional context**\r\nAdd any other context about the problem here.\n", "before_files": [{"content": "from ruyaml import YAML\nimport json\n\n\ndef get_yaml_data():\n yaml_name = input(\"Enter the yaml file name: \")\n\n try:\n with open(yaml_name, \"r+\") as f:\n yaml_data = YAML().load(f)\n return yaml_data\n except: # noqa\n print(\"Invalid input enter a valid yaml file name e.g. example.yaml\")\n yaml_data = get_yaml_data()\n\n\ndef convert_to_json(yaml_data):\n json_name = input(\"Enter the name of output json file: \")\n\n try:\n with open(json_name, \"w+\") as o:\n o.write(json.dumps(yaml_data))\n except: # noqa\n print(\"Invalid input enter a valid json file name e.g. example.json\")\n convert_to_json(yaml_data)\n\n\nyaml_data = get_yaml_data()\nconvert_to_json(yaml_data)\n\nprint(\"Your yaml file has been converted and saved as json\")\n", "path": "yaml_to_json/yaml_to_json.py"}]}
| 883 | 490 |
gh_patches_debug_5937
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-5497
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Command parse unhandled error :AttributeError: 'NoneType' object has no attribute 'start_requests'
Scrapy version :1.5.0
When i run the command **scrapy parse http://www.baidu.com**, and the url www.baidu.com dosn't have spider matched , then i got the error:
> 2018-03-11 16:23:35 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: DouTu)
> 2018-03-11 16:23:35 [scrapy.utils.log] INFO: Versions: lxml 4.2.1.0, libxml2 2.9.8, cssselect 1.0.3, parsel 1.4.0, w3lib 1.19.0, Twisted 17.9.0, Python 2.7.12 (default, Dec 4 2017, 14:50:18) - [GCC 5.4.0 20160609], pyOpenSSL 17.5.0 (OpenSSL 1.1.0h 27 Mar 2018), cryptography 2.2.2, Platform Linux-4.13.0-38-generic-x86_64-with-Ubuntu-16.04-xenial
> 2018-05-18 16:23:35 [scrapy.commands.parse] ERROR: Unable to find spider for: http://www.baidu.com
> Traceback (most recent call last):
> File "/home/wangsir/code/sourceWorkSpace/scrapy/cmdline.py", line 239, in <module>
> execute(['scrapy','parse','http://www.baidu.com'])
> File "/home/wangsir/code/sourceWorkSpace/scrapy/cmdline.py", line 168, in execute
> _run_print_help(parser, _run_command, cmd, args, opts)
> File "/home/wangsir/code/sourceWorkSpace/scrapy/cmdline.py", line 98, in _run_print_help
> func(*a, **kw)
> File "/home/wangsir/code/sourceWorkSpace/scrapy/cmdline.py", line 176, in _run_command
> cmd.run(args, opts)
> File "/home/wangsir/code/sourceWorkSpace/scrapy/commands/parse.py", line 250, in run
> self.set_spidercls(url, opts)
> File "/home/wangsir/code/sourceWorkSpace/scrapy/commands/parse.py", line 151, in set_spidercls
> self.spidercls.start_requests = _start_requests
> AttributeError: 'NoneType' object has no attribute 'start_requests'.
The failed reason should be follwing code(scrapy/commands/parse.py line 151):
**`self.spidercls.start_requests = _start_requests`**
because the url www.baidu.com dosn't have spider matched,so self.spidercls is none,so self.spidercls.start_requests throw the error.
Fix command parse unhandled error :AttributeError: 'NoneType' object has no attribute 'start_requests'(#3264)
Reopening @wangrenlei's PR
Fixes #3264
</issue>
<code>
[start of scrapy/commands/parse.py]
1 import json
2 import logging
3 from typing import Dict
4
5 from itemadapter import is_item, ItemAdapter
6 from w3lib.url import is_url
7
8 from scrapy.commands import BaseRunSpiderCommand
9 from scrapy.http import Request
10 from scrapy.utils import display
11 from scrapy.utils.spider import iterate_spider_output, spidercls_for_request
12 from scrapy.exceptions import UsageError
13
14
15 logger = logging.getLogger(__name__)
16
17
18 class Command(BaseRunSpiderCommand):
19 requires_project = True
20
21 spider = None
22 items: Dict[int, list] = {}
23 requests: Dict[int, list] = {}
24
25 first_response = None
26
27 def syntax(self):
28 return "[options] <url>"
29
30 def short_desc(self):
31 return "Parse URL (using its spider) and print the results"
32
33 def add_options(self, parser):
34 BaseRunSpiderCommand.add_options(self, parser)
35 parser.add_argument("--spider", dest="spider", default=None,
36 help="use this spider without looking for one")
37 parser.add_argument("--pipelines", action="store_true",
38 help="process items through pipelines")
39 parser.add_argument("--nolinks", dest="nolinks", action="store_true",
40 help="don't show links to follow (extracted requests)")
41 parser.add_argument("--noitems", dest="noitems", action="store_true",
42 help="don't show scraped items")
43 parser.add_argument("--nocolour", dest="nocolour", action="store_true",
44 help="avoid using pygments to colorize the output")
45 parser.add_argument("-r", "--rules", dest="rules", action="store_true",
46 help="use CrawlSpider rules to discover the callback")
47 parser.add_argument("-c", "--callback", dest="callback",
48 help="use this callback for parsing, instead looking for a callback")
49 parser.add_argument("-m", "--meta", dest="meta",
50 help="inject extra meta into the Request, it must be a valid raw json string")
51 parser.add_argument("--cbkwargs", dest="cbkwargs",
52 help="inject extra callback kwargs into the Request, it must be a valid raw json string")
53 parser.add_argument("-d", "--depth", dest="depth", type=int, default=1,
54 help="maximum depth for parsing requests [default: %default]")
55 parser.add_argument("-v", "--verbose", dest="verbose", action="store_true",
56 help="print each depth level one by one")
57
58 @property
59 def max_level(self):
60 max_items, max_requests = 0, 0
61 if self.items:
62 max_items = max(self.items)
63 if self.requests:
64 max_requests = max(self.requests)
65 return max(max_items, max_requests)
66
67 def add_items(self, lvl, new_items):
68 old_items = self.items.get(lvl, [])
69 self.items[lvl] = old_items + new_items
70
71 def add_requests(self, lvl, new_reqs):
72 old_reqs = self.requests.get(lvl, [])
73 self.requests[lvl] = old_reqs + new_reqs
74
75 def print_items(self, lvl=None, colour=True):
76 if lvl is None:
77 items = [item for lst in self.items.values() for item in lst]
78 else:
79 items = self.items.get(lvl, [])
80
81 print("# Scraped Items ", "-" * 60)
82 display.pprint([ItemAdapter(x).asdict() for x in items], colorize=colour)
83
84 def print_requests(self, lvl=None, colour=True):
85 if lvl is None:
86 if self.requests:
87 requests = self.requests[max(self.requests)]
88 else:
89 requests = []
90 else:
91 requests = self.requests.get(lvl, [])
92
93 print("# Requests ", "-" * 65)
94 display.pprint(requests, colorize=colour)
95
96 def print_results(self, opts):
97 colour = not opts.nocolour
98
99 if opts.verbose:
100 for level in range(1, self.max_level + 1):
101 print(f'\n>>> DEPTH LEVEL: {level} <<<')
102 if not opts.noitems:
103 self.print_items(level, colour)
104 if not opts.nolinks:
105 self.print_requests(level, colour)
106 else:
107 print(f'\n>>> STATUS DEPTH LEVEL {self.max_level} <<<')
108 if not opts.noitems:
109 self.print_items(colour=colour)
110 if not opts.nolinks:
111 self.print_requests(colour=colour)
112
113 def run_callback(self, response, callback, cb_kwargs=None):
114 cb_kwargs = cb_kwargs or {}
115 items, requests = [], []
116
117 for x in iterate_spider_output(callback(response, **cb_kwargs)):
118 if is_item(x):
119 items.append(x)
120 elif isinstance(x, Request):
121 requests.append(x)
122 return items, requests
123
124 def get_callback_from_rules(self, spider, response):
125 if getattr(spider, 'rules', None):
126 for rule in spider.rules:
127 if rule.link_extractor.matches(response.url):
128 return rule.callback or "parse"
129 else:
130 logger.error('No CrawlSpider rules found in spider %(spider)r, '
131 'please specify a callback to use for parsing',
132 {'spider': spider.name})
133
134 def set_spidercls(self, url, opts):
135 spider_loader = self.crawler_process.spider_loader
136 if opts.spider:
137 try:
138 self.spidercls = spider_loader.load(opts.spider)
139 except KeyError:
140 logger.error('Unable to find spider: %(spider)s',
141 {'spider': opts.spider})
142 else:
143 self.spidercls = spidercls_for_request(spider_loader, Request(url))
144 if not self.spidercls:
145 logger.error('Unable to find spider for: %(url)s', {'url': url})
146
147 def _start_requests(spider):
148 yield self.prepare_request(spider, Request(url), opts)
149 self.spidercls.start_requests = _start_requests
150
151 def start_parsing(self, url, opts):
152 self.crawler_process.crawl(self.spidercls, **opts.spargs)
153 self.pcrawler = list(self.crawler_process.crawlers)[0]
154 self.crawler_process.start()
155
156 if not self.first_response:
157 logger.error('No response downloaded for: %(url)s',
158 {'url': url})
159
160 def prepare_request(self, spider, request, opts):
161 def callback(response, **cb_kwargs):
162 # memorize first request
163 if not self.first_response:
164 self.first_response = response
165
166 # determine real callback
167 cb = response.meta['_callback']
168 if not cb:
169 if opts.callback:
170 cb = opts.callback
171 elif opts.rules and self.first_response == response:
172 cb = self.get_callback_from_rules(spider, response)
173
174 if not cb:
175 logger.error('Cannot find a rule that matches %(url)r in spider: %(spider)s',
176 {'url': response.url, 'spider': spider.name})
177 return
178 else:
179 cb = 'parse'
180
181 if not callable(cb):
182 cb_method = getattr(spider, cb, None)
183 if callable(cb_method):
184 cb = cb_method
185 else:
186 logger.error('Cannot find callback %(callback)r in spider: %(spider)s',
187 {'callback': cb, 'spider': spider.name})
188 return
189
190 # parse items and requests
191 depth = response.meta['_depth']
192
193 items, requests = self.run_callback(response, cb, cb_kwargs)
194 if opts.pipelines:
195 itemproc = self.pcrawler.engine.scraper.itemproc
196 for item in items:
197 itemproc.process_item(item, spider)
198 self.add_items(depth, items)
199 self.add_requests(depth, requests)
200
201 scraped_data = items if opts.output else []
202 if depth < opts.depth:
203 for req in requests:
204 req.meta['_depth'] = depth + 1
205 req.meta['_callback'] = req.callback
206 req.callback = callback
207 scraped_data += requests
208
209 return scraped_data
210
211 # update request meta if any extra meta was passed through the --meta/-m opts.
212 if opts.meta:
213 request.meta.update(opts.meta)
214
215 # update cb_kwargs if any extra values were was passed through the --cbkwargs option.
216 if opts.cbkwargs:
217 request.cb_kwargs.update(opts.cbkwargs)
218
219 request.meta['_depth'] = 1
220 request.meta['_callback'] = request.callback
221 request.callback = callback
222 return request
223
224 def process_options(self, args, opts):
225 BaseRunSpiderCommand.process_options(self, args, opts)
226
227 self.process_request_meta(opts)
228 self.process_request_cb_kwargs(opts)
229
230 def process_request_meta(self, opts):
231 if opts.meta:
232 try:
233 opts.meta = json.loads(opts.meta)
234 except ValueError:
235 raise UsageError("Invalid -m/--meta value, pass a valid json string to -m or --meta. "
236 "Example: --meta='{\"foo\" : \"bar\"}'", print_help=False)
237
238 def process_request_cb_kwargs(self, opts):
239 if opts.cbkwargs:
240 try:
241 opts.cbkwargs = json.loads(opts.cbkwargs)
242 except ValueError:
243 raise UsageError("Invalid --cbkwargs value, pass a valid json string to --cbkwargs. "
244 "Example: --cbkwargs='{\"foo\" : \"bar\"}'", print_help=False)
245
246 def run(self, args, opts):
247 # parse arguments
248 if not len(args) == 1 or not is_url(args[0]):
249 raise UsageError()
250 else:
251 url = args[0]
252
253 # prepare spidercls
254 self.set_spidercls(url, opts)
255
256 if self.spidercls and opts.depth > 0:
257 self.start_parsing(url, opts)
258 self.print_results(opts)
259
[end of scrapy/commands/parse.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scrapy/commands/parse.py b/scrapy/commands/parse.py
--- a/scrapy/commands/parse.py
+++ b/scrapy/commands/parse.py
@@ -146,7 +146,8 @@
def _start_requests(spider):
yield self.prepare_request(spider, Request(url), opts)
- self.spidercls.start_requests = _start_requests
+ if self.spidercls:
+ self.spidercls.start_requests = _start_requests
def start_parsing(self, url, opts):
self.crawler_process.crawl(self.spidercls, **opts.spargs)
|
{"golden_diff": "diff --git a/scrapy/commands/parse.py b/scrapy/commands/parse.py\n--- a/scrapy/commands/parse.py\n+++ b/scrapy/commands/parse.py\n@@ -146,7 +146,8 @@\n \n def _start_requests(spider):\n yield self.prepare_request(spider, Request(url), opts)\n- self.spidercls.start_requests = _start_requests\n+ if self.spidercls:\n+ self.spidercls.start_requests = _start_requests\n \n def start_parsing(self, url, opts):\n self.crawler_process.crawl(self.spidercls, **opts.spargs)\n", "issue": "Command parse unhandled error :AttributeError: 'NoneType' object has no attribute 'start_requests'\nScrapy version :1.5.0\r\nWhen i run the command **scrapy parse http://www.baidu.com**, and the url www.baidu.com dosn't have spider matched , then i got the error:\r\n\r\n> 2018-03-11 16:23:35 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: DouTu)\r\n> 2018-03-11 16:23:35 [scrapy.utils.log] INFO: Versions: lxml 4.2.1.0, libxml2 2.9.8, cssselect 1.0.3, parsel 1.4.0, w3lib 1.19.0, Twisted 17.9.0, Python 2.7.12 (default, Dec 4 2017, 14:50:18) - [GCC 5.4.0 20160609], pyOpenSSL 17.5.0 (OpenSSL 1.1.0h 27 Mar 2018), cryptography 2.2.2, Platform Linux-4.13.0-38-generic-x86_64-with-Ubuntu-16.04-xenial\r\n> 2018-05-18 16:23:35 [scrapy.commands.parse] ERROR: Unable to find spider for: http://www.baidu.com\r\n> Traceback (most recent call last):\r\n> File \"/home/wangsir/code/sourceWorkSpace/scrapy/cmdline.py\", line 239, in <module>\r\n> execute(['scrapy','parse','http://www.baidu.com'])\r\n> File \"/home/wangsir/code/sourceWorkSpace/scrapy/cmdline.py\", line 168, in execute\r\n> _run_print_help(parser, _run_command, cmd, args, opts)\r\n> File \"/home/wangsir/code/sourceWorkSpace/scrapy/cmdline.py\", line 98, in _run_print_help\r\n> func(*a, **kw)\r\n> File \"/home/wangsir/code/sourceWorkSpace/scrapy/cmdline.py\", line 176, in _run_command\r\n> cmd.run(args, opts)\r\n> File \"/home/wangsir/code/sourceWorkSpace/scrapy/commands/parse.py\", line 250, in run\r\n> self.set_spidercls(url, opts)\r\n> File \"/home/wangsir/code/sourceWorkSpace/scrapy/commands/parse.py\", line 151, in set_spidercls\r\n> self.spidercls.start_requests = _start_requests\r\n> AttributeError: 'NoneType' object has no attribute 'start_requests'.\r\n\r\nThe failed reason should be follwing code(scrapy/commands/parse.py line 151):\r\n **`self.spidercls.start_requests = _start_requests`**\r\nbecause the url www.baidu.com dosn't have spider matched,so self.spidercls is none,so self.spidercls.start_requests throw the error.\nFix command parse unhandled error :AttributeError: 'NoneType' object has no attribute 'start_requests'(#3264)\nReopening @wangrenlei's PR \r\nFixes #3264\n", "before_files": [{"content": "import json\nimport logging\nfrom typing import Dict\n\nfrom itemadapter import is_item, ItemAdapter\nfrom w3lib.url import is_url\n\nfrom scrapy.commands import BaseRunSpiderCommand\nfrom scrapy.http import Request\nfrom scrapy.utils import display\nfrom scrapy.utils.spider import iterate_spider_output, spidercls_for_request\nfrom scrapy.exceptions import UsageError\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass Command(BaseRunSpiderCommand):\n requires_project = True\n\n spider = None\n items: Dict[int, list] = {}\n requests: Dict[int, list] = {}\n\n first_response = None\n\n def syntax(self):\n return \"[options] <url>\"\n\n def short_desc(self):\n return \"Parse URL (using its spider) and print the results\"\n\n def add_options(self, parser):\n BaseRunSpiderCommand.add_options(self, parser)\n parser.add_argument(\"--spider\", dest=\"spider\", default=None,\n help=\"use this spider without looking for one\")\n parser.add_argument(\"--pipelines\", action=\"store_true\",\n help=\"process items through pipelines\")\n parser.add_argument(\"--nolinks\", dest=\"nolinks\", action=\"store_true\",\n help=\"don't show links to follow (extracted requests)\")\n parser.add_argument(\"--noitems\", dest=\"noitems\", action=\"store_true\",\n help=\"don't show scraped items\")\n parser.add_argument(\"--nocolour\", dest=\"nocolour\", action=\"store_true\",\n help=\"avoid using pygments to colorize the output\")\n parser.add_argument(\"-r\", \"--rules\", dest=\"rules\", action=\"store_true\",\n help=\"use CrawlSpider rules to discover the callback\")\n parser.add_argument(\"-c\", \"--callback\", dest=\"callback\",\n help=\"use this callback for parsing, instead looking for a callback\")\n parser.add_argument(\"-m\", \"--meta\", dest=\"meta\",\n help=\"inject extra meta into the Request, it must be a valid raw json string\")\n parser.add_argument(\"--cbkwargs\", dest=\"cbkwargs\",\n help=\"inject extra callback kwargs into the Request, it must be a valid raw json string\")\n parser.add_argument(\"-d\", \"--depth\", dest=\"depth\", type=int, default=1,\n help=\"maximum depth for parsing requests [default: %default]\")\n parser.add_argument(\"-v\", \"--verbose\", dest=\"verbose\", action=\"store_true\",\n help=\"print each depth level one by one\")\n\n @property\n def max_level(self):\n max_items, max_requests = 0, 0\n if self.items:\n max_items = max(self.items)\n if self.requests:\n max_requests = max(self.requests)\n return max(max_items, max_requests)\n\n def add_items(self, lvl, new_items):\n old_items = self.items.get(lvl, [])\n self.items[lvl] = old_items + new_items\n\n def add_requests(self, lvl, new_reqs):\n old_reqs = self.requests.get(lvl, [])\n self.requests[lvl] = old_reqs + new_reqs\n\n def print_items(self, lvl=None, colour=True):\n if lvl is None:\n items = [item for lst in self.items.values() for item in lst]\n else:\n items = self.items.get(lvl, [])\n\n print(\"# Scraped Items \", \"-\" * 60)\n display.pprint([ItemAdapter(x).asdict() for x in items], colorize=colour)\n\n def print_requests(self, lvl=None, colour=True):\n if lvl is None:\n if self.requests:\n requests = self.requests[max(self.requests)]\n else:\n requests = []\n else:\n requests = self.requests.get(lvl, [])\n\n print(\"# Requests \", \"-\" * 65)\n display.pprint(requests, colorize=colour)\n\n def print_results(self, opts):\n colour = not opts.nocolour\n\n if opts.verbose:\n for level in range(1, self.max_level + 1):\n print(f'\\n>>> DEPTH LEVEL: {level} <<<')\n if not opts.noitems:\n self.print_items(level, colour)\n if not opts.nolinks:\n self.print_requests(level, colour)\n else:\n print(f'\\n>>> STATUS DEPTH LEVEL {self.max_level} <<<')\n if not opts.noitems:\n self.print_items(colour=colour)\n if not opts.nolinks:\n self.print_requests(colour=colour)\n\n def run_callback(self, response, callback, cb_kwargs=None):\n cb_kwargs = cb_kwargs or {}\n items, requests = [], []\n\n for x in iterate_spider_output(callback(response, **cb_kwargs)):\n if is_item(x):\n items.append(x)\n elif isinstance(x, Request):\n requests.append(x)\n return items, requests\n\n def get_callback_from_rules(self, spider, response):\n if getattr(spider, 'rules', None):\n for rule in spider.rules:\n if rule.link_extractor.matches(response.url):\n return rule.callback or \"parse\"\n else:\n logger.error('No CrawlSpider rules found in spider %(spider)r, '\n 'please specify a callback to use for parsing',\n {'spider': spider.name})\n\n def set_spidercls(self, url, opts):\n spider_loader = self.crawler_process.spider_loader\n if opts.spider:\n try:\n self.spidercls = spider_loader.load(opts.spider)\n except KeyError:\n logger.error('Unable to find spider: %(spider)s',\n {'spider': opts.spider})\n else:\n self.spidercls = spidercls_for_request(spider_loader, Request(url))\n if not self.spidercls:\n logger.error('Unable to find spider for: %(url)s', {'url': url})\n\n def _start_requests(spider):\n yield self.prepare_request(spider, Request(url), opts)\n self.spidercls.start_requests = _start_requests\n\n def start_parsing(self, url, opts):\n self.crawler_process.crawl(self.spidercls, **opts.spargs)\n self.pcrawler = list(self.crawler_process.crawlers)[0]\n self.crawler_process.start()\n\n if not self.first_response:\n logger.error('No response downloaded for: %(url)s',\n {'url': url})\n\n def prepare_request(self, spider, request, opts):\n def callback(response, **cb_kwargs):\n # memorize first request\n if not self.first_response:\n self.first_response = response\n\n # determine real callback\n cb = response.meta['_callback']\n if not cb:\n if opts.callback:\n cb = opts.callback\n elif opts.rules and self.first_response == response:\n cb = self.get_callback_from_rules(spider, response)\n\n if not cb:\n logger.error('Cannot find a rule that matches %(url)r in spider: %(spider)s',\n {'url': response.url, 'spider': spider.name})\n return\n else:\n cb = 'parse'\n\n if not callable(cb):\n cb_method = getattr(spider, cb, None)\n if callable(cb_method):\n cb = cb_method\n else:\n logger.error('Cannot find callback %(callback)r in spider: %(spider)s',\n {'callback': cb, 'spider': spider.name})\n return\n\n # parse items and requests\n depth = response.meta['_depth']\n\n items, requests = self.run_callback(response, cb, cb_kwargs)\n if opts.pipelines:\n itemproc = self.pcrawler.engine.scraper.itemproc\n for item in items:\n itemproc.process_item(item, spider)\n self.add_items(depth, items)\n self.add_requests(depth, requests)\n\n scraped_data = items if opts.output else []\n if depth < opts.depth:\n for req in requests:\n req.meta['_depth'] = depth + 1\n req.meta['_callback'] = req.callback\n req.callback = callback\n scraped_data += requests\n\n return scraped_data\n\n # update request meta if any extra meta was passed through the --meta/-m opts.\n if opts.meta:\n request.meta.update(opts.meta)\n\n # update cb_kwargs if any extra values were was passed through the --cbkwargs option.\n if opts.cbkwargs:\n request.cb_kwargs.update(opts.cbkwargs)\n\n request.meta['_depth'] = 1\n request.meta['_callback'] = request.callback\n request.callback = callback\n return request\n\n def process_options(self, args, opts):\n BaseRunSpiderCommand.process_options(self, args, opts)\n\n self.process_request_meta(opts)\n self.process_request_cb_kwargs(opts)\n\n def process_request_meta(self, opts):\n if opts.meta:\n try:\n opts.meta = json.loads(opts.meta)\n except ValueError:\n raise UsageError(\"Invalid -m/--meta value, pass a valid json string to -m or --meta. \"\n \"Example: --meta='{\\\"foo\\\" : \\\"bar\\\"}'\", print_help=False)\n\n def process_request_cb_kwargs(self, opts):\n if opts.cbkwargs:\n try:\n opts.cbkwargs = json.loads(opts.cbkwargs)\n except ValueError:\n raise UsageError(\"Invalid --cbkwargs value, pass a valid json string to --cbkwargs. \"\n \"Example: --cbkwargs='{\\\"foo\\\" : \\\"bar\\\"}'\", print_help=False)\n\n def run(self, args, opts):\n # parse arguments\n if not len(args) == 1 or not is_url(args[0]):\n raise UsageError()\n else:\n url = args[0]\n\n # prepare spidercls\n self.set_spidercls(url, opts)\n\n if self.spidercls and opts.depth > 0:\n self.start_parsing(url, opts)\n self.print_results(opts)\n", "path": "scrapy/commands/parse.py"}]}
| 4,059 | 138 |
gh_patches_debug_7306
|
rasdani/github-patches
|
git_diff
|
ESMCI__cime-1391
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
env_mach_pes.xml not being locked properly
I ran into this problem while doing testing on cheyenne. I was able to make changes in env_mach_pes.xml and submit to the queue without any error messages.
I was also able to change env_mach_pes.xml, then do a rebuild and submit without redoing case.setup.
</issue>
<code>
[start of scripts/lib/CIME/check_lockedfiles.py]
1 """
2 API for checking locked files
3 """
4
5 from CIME.XML.standard_module_setup import *
6 from CIME.XML.env_build import EnvBuild
7 from CIME.XML.env_case import EnvCase
8 from CIME.XML.env_mach_pes import EnvMachPes
9 from CIME.XML.env_batch import EnvBatch
10 from CIME.utils import run_cmd_no_fail
11
12 logger = logging.getLogger(__name__)
13
14 import glob, shutil
15
16 LOCKED_DIR = "LockedFiles"
17
18 def lock_file(filename, caseroot=None, newname=None):
19 expect("/" not in filename, "Please just provide basename of locked file")
20 caseroot = os.getcwd() if caseroot is None else caseroot
21 newname = filename if newname is None else newname
22 fulllockdir = os.path.join(caseroot, LOCKED_DIR)
23 if not os.path.exists(fulllockdir):
24 os.mkdir(fulllockdir)
25 logging.debug("Locking file %s to %s"%(filename, newname))
26 shutil.copyfile(os.path.join(caseroot, filename), os.path.join(fulllockdir, newname))
27
28 def unlock_file(filename, caseroot=None):
29 expect("/" not in filename, "Please just provide basename of locked file")
30 caseroot = os.getcwd() if caseroot is None else caseroot
31 locked_path = os.path.join(caseroot, LOCKED_DIR, filename)
32 if os.path.exists(locked_path):
33 os.remove(locked_path)
34
35 def is_locked(filename, caseroot=None):
36 expect("/" not in filename, "Please just provide basename of locked file")
37 caseroot = os.getcwd() if caseroot is None else caseroot
38 return os.path.exists(os.path.join(caseroot, LOCKED_DIR, filename))
39
40 def restore(filename, caseroot=None, newname=None):
41 """
42 Restore the locked version of filename into main case dir
43 """
44 expect("/" not in filename, "Please just provide basename of locked file")
45 caseroot = os.getcwd() if caseroot is None else caseroot
46 newname = filename if newname is None else newname
47 shutil.copyfile(os.path.join(caseroot, LOCKED_DIR, filename), os.path.join(caseroot, newname))
48 # relock the restored file if names diffs
49 if newname != filename:
50 lock_file(newname, caseroot)
51
52 def check_pelayouts_require_rebuild(case, models):
53 """
54 Create if we require a rebuild, expects cwd is caseroot
55 """
56 locked_pes = os.path.join(LOCKED_DIR, "env_mach_pes.xml")
57 if os.path.exists(locked_pes):
58 # Look to see if $comp_PE_CHANGE_REQUIRES_REBUILD is defined
59 # for any component
60 env_mach_pes_locked = EnvMachPes(infile=locked_pes, components=case.get_values("COMP_CLASSES"))
61 for comp in models:
62 if case.get_value("%s_PE_CHANGE_REQUIRES_REBUILD" % comp):
63 # Changing these values in env_mach_pes.xml will force
64 # you to clean the corresponding component
65 old_tasks = env_mach_pes_locked.get_value("NTASKS_%s" % comp)
66 old_threads = env_mach_pes_locked.get_value("NTHRDS_%s" % comp)
67 old_inst = env_mach_pes_locked.get_value("NINST_%s" % comp)
68
69 new_tasks = case.get_value("NTASKS_%s" % comp)
70 new_threads = case.get_value("NTHRDS_%s" % comp)
71 new_inst = case.get_value("NINST_%s" % comp)
72
73 if old_tasks != new_tasks or old_threads != new_threads or old_inst != new_inst:
74 logging.warn("%s pe change requires clean build %s %s" % (comp, old_tasks, new_tasks))
75 cleanflag = comp.lower()
76 run_cmd_no_fail("./case.build --clean %s" % cleanflag)
77
78 unlock_file("env_mach_pes.xml", case.get_value("CASEROOT"))
79
80 def check_lockedfiles(caseroot=None):
81 """
82 Check that all lockedfiles match what's in case
83
84 If caseroot is not specified, it is set to the current working directory
85 """
86 caseroot = os.getcwd() if caseroot is None else caseroot
87 lockedfiles = glob.glob(os.path.join(caseroot, "LockedFiles", "*.xml"))
88 for lfile in lockedfiles:
89 fpart = os.path.basename(lfile)
90 # ignore files used for tests such as env_mach_pes.ERP1.xml by looking for extra dots in the name
91 if lfile.count('.') > 1:
92 continue
93 cfile = os.path.join(caseroot, fpart)
94 if os.path.isfile(cfile):
95 objname = fpart.split('.')[0]
96 if objname == "env_build":
97 f1obj = EnvBuild(caseroot, cfile)
98 f2obj = EnvBuild(caseroot, lfile)
99 elif objname == "env_mach_pes":
100 f1obj = EnvMachPes(caseroot, cfile)
101 f2obj = EnvMachPes(caseroot, lfile)
102 elif objname == "env_case":
103 f1obj = EnvCase(caseroot, cfile)
104 f2obj = EnvCase(caseroot, lfile)
105 elif objname == "env_batch":
106 f1obj = EnvBatch(caseroot, cfile)
107 f2obj = EnvBatch(caseroot, lfile)
108 else:
109 logging.warn("Locked XML file '%s' is not current being handled" % fpart)
110 continue
111 diffs = f1obj.compare_xml(f2obj)
112 if diffs:
113 logging.warn("File %s has been modified"%lfile)
114 for key in diffs.keys():
115 print(" found difference in %s : case %s locked %s" %
116 (key, repr(diffs[key][0]), repr(diffs[key][1])))
117
118 if objname == "env_mach_pes":
119 expect(False, "Invoke case.setup --reset ")
120 elif objname == "env_case":
121 expect(False, "Cannot change file env_case.xml, please"
122 " recover the original copy from LockedFiles")
123 elif objname == "env_build":
124 logging.warn("Setting build complete to False")
125 f1obj.set_value("BUILD_COMPLETE", False)
126 if "PIO_VERSION" in diffs.keys():
127 f1obj.set_value("BUILD_STATUS", 2)
128 f1obj.write()
129 logging.critical("Changing PIO_VERSION requires running "
130 "case.build --clean-all and rebuilding")
131 else:
132 f1obj.set_value("BUILD_STATUS", 1)
133 f1obj.write()
134 elif objname == "env_batch":
135 expect(False, "Batch configuration has changed, please run case.setup --reset")
136 else:
137 expect(False, "'%s' diff was not handled" % objname)
138
[end of scripts/lib/CIME/check_lockedfiles.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scripts/lib/CIME/check_lockedfiles.py b/scripts/lib/CIME/check_lockedfiles.py
--- a/scripts/lib/CIME/check_lockedfiles.py
+++ b/scripts/lib/CIME/check_lockedfiles.py
@@ -88,7 +88,7 @@
for lfile in lockedfiles:
fpart = os.path.basename(lfile)
# ignore files used for tests such as env_mach_pes.ERP1.xml by looking for extra dots in the name
- if lfile.count('.') > 1:
+ if fpart.count('.') > 1:
continue
cfile = os.path.join(caseroot, fpart)
if os.path.isfile(cfile):
|
{"golden_diff": "diff --git a/scripts/lib/CIME/check_lockedfiles.py b/scripts/lib/CIME/check_lockedfiles.py\n--- a/scripts/lib/CIME/check_lockedfiles.py\n+++ b/scripts/lib/CIME/check_lockedfiles.py\n@@ -88,7 +88,7 @@\n for lfile in lockedfiles:\n fpart = os.path.basename(lfile)\n # ignore files used for tests such as env_mach_pes.ERP1.xml by looking for extra dots in the name\n- if lfile.count('.') > 1:\n+ if fpart.count('.') > 1:\n continue\n cfile = os.path.join(caseroot, fpart)\n if os.path.isfile(cfile):\n", "issue": "env_mach_pes.xml not being locked properly\nI ran into this problem while doing testing on cheyenne. I was able to make changes in env_mach_pes.xml and submit to the queue without any error messages. \r\n\r\nI was also able to change env_mach_pes.xml, then do a rebuild and submit without redoing case.setup.\n", "before_files": [{"content": "\"\"\"\nAPI for checking locked files\n\"\"\"\n\nfrom CIME.XML.standard_module_setup import *\nfrom CIME.XML.env_build import EnvBuild\nfrom CIME.XML.env_case import EnvCase\nfrom CIME.XML.env_mach_pes import EnvMachPes\nfrom CIME.XML.env_batch import EnvBatch\nfrom CIME.utils import run_cmd_no_fail\n\nlogger = logging.getLogger(__name__)\n\nimport glob, shutil\n\nLOCKED_DIR = \"LockedFiles\"\n\ndef lock_file(filename, caseroot=None, newname=None):\n expect(\"/\" not in filename, \"Please just provide basename of locked file\")\n caseroot = os.getcwd() if caseroot is None else caseroot\n newname = filename if newname is None else newname\n fulllockdir = os.path.join(caseroot, LOCKED_DIR)\n if not os.path.exists(fulllockdir):\n os.mkdir(fulllockdir)\n logging.debug(\"Locking file %s to %s\"%(filename, newname))\n shutil.copyfile(os.path.join(caseroot, filename), os.path.join(fulllockdir, newname))\n\ndef unlock_file(filename, caseroot=None):\n expect(\"/\" not in filename, \"Please just provide basename of locked file\")\n caseroot = os.getcwd() if caseroot is None else caseroot\n locked_path = os.path.join(caseroot, LOCKED_DIR, filename)\n if os.path.exists(locked_path):\n os.remove(locked_path)\n\ndef is_locked(filename, caseroot=None):\n expect(\"/\" not in filename, \"Please just provide basename of locked file\")\n caseroot = os.getcwd() if caseroot is None else caseroot\n return os.path.exists(os.path.join(caseroot, LOCKED_DIR, filename))\n\ndef restore(filename, caseroot=None, newname=None):\n \"\"\"\n Restore the locked version of filename into main case dir\n \"\"\"\n expect(\"/\" not in filename, \"Please just provide basename of locked file\")\n caseroot = os.getcwd() if caseroot is None else caseroot\n newname = filename if newname is None else newname\n shutil.copyfile(os.path.join(caseroot, LOCKED_DIR, filename), os.path.join(caseroot, newname))\n # relock the restored file if names diffs\n if newname != filename:\n lock_file(newname, caseroot)\n\ndef check_pelayouts_require_rebuild(case, models):\n \"\"\"\n Create if we require a rebuild, expects cwd is caseroot\n \"\"\"\n locked_pes = os.path.join(LOCKED_DIR, \"env_mach_pes.xml\")\n if os.path.exists(locked_pes):\n # Look to see if $comp_PE_CHANGE_REQUIRES_REBUILD is defined\n # for any component\n env_mach_pes_locked = EnvMachPes(infile=locked_pes, components=case.get_values(\"COMP_CLASSES\"))\n for comp in models:\n if case.get_value(\"%s_PE_CHANGE_REQUIRES_REBUILD\" % comp):\n # Changing these values in env_mach_pes.xml will force\n # you to clean the corresponding component\n old_tasks = env_mach_pes_locked.get_value(\"NTASKS_%s\" % comp)\n old_threads = env_mach_pes_locked.get_value(\"NTHRDS_%s\" % comp)\n old_inst = env_mach_pes_locked.get_value(\"NINST_%s\" % comp)\n\n new_tasks = case.get_value(\"NTASKS_%s\" % comp)\n new_threads = case.get_value(\"NTHRDS_%s\" % comp)\n new_inst = case.get_value(\"NINST_%s\" % comp)\n\n if old_tasks != new_tasks or old_threads != new_threads or old_inst != new_inst:\n logging.warn(\"%s pe change requires clean build %s %s\" % (comp, old_tasks, new_tasks))\n cleanflag = comp.lower()\n run_cmd_no_fail(\"./case.build --clean %s\" % cleanflag)\n\n unlock_file(\"env_mach_pes.xml\", case.get_value(\"CASEROOT\"))\n\ndef check_lockedfiles(caseroot=None):\n \"\"\"\n Check that all lockedfiles match what's in case\n\n If caseroot is not specified, it is set to the current working directory\n \"\"\"\n caseroot = os.getcwd() if caseroot is None else caseroot\n lockedfiles = glob.glob(os.path.join(caseroot, \"LockedFiles\", \"*.xml\"))\n for lfile in lockedfiles:\n fpart = os.path.basename(lfile)\n # ignore files used for tests such as env_mach_pes.ERP1.xml by looking for extra dots in the name\n if lfile.count('.') > 1:\n continue\n cfile = os.path.join(caseroot, fpart)\n if os.path.isfile(cfile):\n objname = fpart.split('.')[0]\n if objname == \"env_build\":\n f1obj = EnvBuild(caseroot, cfile)\n f2obj = EnvBuild(caseroot, lfile)\n elif objname == \"env_mach_pes\":\n f1obj = EnvMachPes(caseroot, cfile)\n f2obj = EnvMachPes(caseroot, lfile)\n elif objname == \"env_case\":\n f1obj = EnvCase(caseroot, cfile)\n f2obj = EnvCase(caseroot, lfile)\n elif objname == \"env_batch\":\n f1obj = EnvBatch(caseroot, cfile)\n f2obj = EnvBatch(caseroot, lfile)\n else:\n logging.warn(\"Locked XML file '%s' is not current being handled\" % fpart)\n continue\n diffs = f1obj.compare_xml(f2obj)\n if diffs:\n logging.warn(\"File %s has been modified\"%lfile)\n for key in diffs.keys():\n print(\" found difference in %s : case %s locked %s\" %\n (key, repr(diffs[key][0]), repr(diffs[key][1])))\n\n if objname == \"env_mach_pes\":\n expect(False, \"Invoke case.setup --reset \")\n elif objname == \"env_case\":\n expect(False, \"Cannot change file env_case.xml, please\"\n \" recover the original copy from LockedFiles\")\n elif objname == \"env_build\":\n logging.warn(\"Setting build complete to False\")\n f1obj.set_value(\"BUILD_COMPLETE\", False)\n if \"PIO_VERSION\" in diffs.keys():\n f1obj.set_value(\"BUILD_STATUS\", 2)\n f1obj.write()\n logging.critical(\"Changing PIO_VERSION requires running \"\n \"case.build --clean-all and rebuilding\")\n else:\n f1obj.set_value(\"BUILD_STATUS\", 1)\n f1obj.write()\n elif objname == \"env_batch\":\n expect(False, \"Batch configuration has changed, please run case.setup --reset\")\n else:\n expect(False, \"'%s' diff was not handled\" % objname)\n", "path": "scripts/lib/CIME/check_lockedfiles.py"}]}
| 2,423 | 147 |
gh_patches_debug_12937
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-1973
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[package] xorg/system: Can you add support for dnf package manager?
<!--
Please don't forget to update the issue title.
Include all applicable information to help us reproduce your problem.
-->
Fedora uses the dnf package manager instead of yum, although yum exists in Fedora too. Also, dnf uses the same package names as yum, so maybe you could change line 42 like this:
```python
elif tools.os_info.with_yum or tools.os_info.with_dnf:
...
```
In addition, could you also add support for `FreeBSD pkg`? I think in `pkg` this package name is just `xorg`.
### Package and Environment Details (include every applicable attribute)
* Package Name/Version: **xorg/system**
* Operating System+version: **Fedora 32**
* Compiler+version: **GCC 10**
* Conan version: **conan 1.26.0**
* Python version: **Python 3.8.3**
### Conan profile (output of `conan profile show default` or `conan profile show <profile>` if custom profile is in use)
```
arch=x86_64
arch_build=x86_64
build_type=Release
compiler=gcc
compiler.libcxx=libstdc++
compiler.version=10
os=Linux
os_build=Linux
```
### Steps to reproduce (Include if Applicable)
When I try to install xorg/system
`conan install xorg/system@ --build missing`
### Logs (Include/Attach if Applicable)
<details><summary>Click to expand log</summary>
```
Configuration:
[settings]
arch=x86_64
arch_build=x86_64
build_type=Release
compiler=gcc
compiler.libcxx=libstdc++
compiler.version=10
os=Linux
os_build=Linux
[options]
[build_requires]
[env]
Installing package: xorg/system
Requirements
xorg/system from 'conan-center' - Cache
Packages
xorg/system:5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9 - Cache
Installing (downloading, building) binaries...
xorg/system: Already installed!
ERROR: xorg/system: Error in package_info() method, line 57
self._fill_cppinfo_from_pkgconfig(name)
while calling '_fill_cppinfo_from_pkgconfig', line 18
if not pkg_config.provides:
ConanException: pkg-config command ['pkg-config', '--print-provides', 'sm', '--print-errors'] failed with error: Command 'pkg-config --print-provides sm --print-errors' returned non-zero exit status 1.
Package sm was not found in the pkg-config search path.
Perhaps you should add the directory containing `sm.pc'
to the PKG_CONFIG_PATH environment variable
Package 'sm', required by 'virtual:world', not found
```
</details>
</issue>
<code>
[start of recipes/xorg/all/conanfile.py]
1 from conans import ConanFile, tools
2 from conans.errors import ConanException
3
4
5 class ConanXOrg(ConanFile):
6 name = "xorg"
7 url = "https://github.com/conan-io/conan-center-index"
8 license = "MIT"
9 homepage = "https://www.x.org/wiki/"
10 description = "The X.Org project provides an open source implementation of the X Window System."
11 settings = {"os": "Linux"}
12
13 def package_id(self):
14 self.info.header_only()
15
16 def _fill_cppinfo_from_pkgconfig(self, name):
17 pkg_config = tools.PkgConfig(name)
18 if not pkg_config.provides:
19 raise ConanException("OpenGL development files aren't available, give up")
20 libs = [lib[2:] for lib in pkg_config.libs_only_l]
21 lib_dirs = [lib[2:] for lib in pkg_config.libs_only_L]
22 ldflags = [flag for flag in pkg_config.libs_only_other]
23 include_dirs = [include[2:] for include in pkg_config.cflags_only_I]
24 cflags = [flag for flag in pkg_config.cflags_only_other if not flag.startswith("-D")]
25 defines = [flag[2:] for flag in pkg_config.cflags_only_other if flag.startswith("-D")]
26
27 self.cpp_info.system_libs.extend(libs)
28 self.cpp_info.libdirs.extend(lib_dirs)
29 self.cpp_info.sharedlinkflags.extend(ldflags)
30 self.cpp_info.exelinkflags.extend(ldflags)
31 self.cpp_info.defines.extend(defines)
32 self.cpp_info.includedirs.extend(include_dirs)
33 self.cpp_info.cflags.extend(cflags)
34 self.cpp_info.cxxflags.extend(cflags)
35
36
37 def system_requirements(self):
38 if tools.os_info.is_linux and self.settings.os == "Linux":
39 package_tool = tools.SystemPackageTool(conanfile=self, default_mode="verify")
40 if tools.os_info.with_apt:
41 packages = ["xorg-dev", "libx11-xcb-dev", "libxcb-render0-dev", "libxcb-render-util0-dev"]
42 elif tools.os_info.with_yum:
43 packages = ["xorg-x11-server-devel"]
44 elif tools.os_info.with_pacman:
45 packages = ["xorg-server-devel"]
46 elif tools.os_info.with_zypper:
47 packages = ["Xorg-x11-devel"]
48 else:
49 self.output.warn("Do not know how to install 'xorg' for {}.".format(tools.os_info.linux_distro))
50 for p in packages:
51 package_tool.install(update=True, packages=p)
52
53 def package_info(self):
54 for name in ["x11", "x11-xcb", "dmx", "fontenc", "libfs", "ice", "sm", "xau", "xaw7",
55 "xcomposite","xcursor", "xdamage", "xdmcp", "xext", "xfixes", "xft", "xi",
56 "xinerama", "xkbfile", "xmu", "xmuu", "xpm", "xrandr", "xrender", "xres",
57 "xscrnsaver", "xt", "xtst", "xv", "xvmc", "xxf86dga", "xxf86vm", "xtrans"]:
58 self._fill_cppinfo_from_pkgconfig(name)
59
[end of recipes/xorg/all/conanfile.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/recipes/xorg/all/conanfile.py b/recipes/xorg/all/conanfile.py
--- a/recipes/xorg/all/conanfile.py
+++ b/recipes/xorg/all/conanfile.py
@@ -39,7 +39,7 @@
package_tool = tools.SystemPackageTool(conanfile=self, default_mode="verify")
if tools.os_info.with_apt:
packages = ["xorg-dev", "libx11-xcb-dev", "libxcb-render0-dev", "libxcb-render-util0-dev"]
- elif tools.os_info.with_yum:
+ elif tools.os_info.with_yum or tools.os_info.with_dnf:
packages = ["xorg-x11-server-devel"]
elif tools.os_info.with_pacman:
packages = ["xorg-server-devel"]
|
{"golden_diff": "diff --git a/recipes/xorg/all/conanfile.py b/recipes/xorg/all/conanfile.py\n--- a/recipes/xorg/all/conanfile.py\n+++ b/recipes/xorg/all/conanfile.py\n@@ -39,7 +39,7 @@\n package_tool = tools.SystemPackageTool(conanfile=self, default_mode=\"verify\")\n if tools.os_info.with_apt:\n packages = [\"xorg-dev\", \"libx11-xcb-dev\", \"libxcb-render0-dev\", \"libxcb-render-util0-dev\"]\n- elif tools.os_info.with_yum:\n+ elif tools.os_info.with_yum or tools.os_info.with_dnf:\n packages = [\"xorg-x11-server-devel\"]\n elif tools.os_info.with_pacman:\n packages = [\"xorg-server-devel\"]\n", "issue": "[package] xorg/system: Can you add support for dnf package manager?\n<!-- \r\n Please don't forget to update the issue title.\r\n Include all applicable information to help us reproduce your problem.\r\n-->\r\n\r\nFedora uses the dnf package manager instead of yum, although yum exists in Fedora too. Also, dnf uses the same package names as yum, so maybe you could change line 42 like this:\r\n```python\r\nelif tools.os_info.with_yum or tools.os_info.with_dnf:\r\n ...\r\n```\r\nIn addition, could you also add support for `FreeBSD pkg`? I think in `pkg` this package name is just `xorg`.\r\n\r\n### Package and Environment Details (include every applicable attribute)\r\n * Package Name/Version: **xorg/system**\r\n * Operating System+version: **Fedora 32**\r\n * Compiler+version: **GCC 10**\r\n * Conan version: **conan 1.26.0**\r\n * Python version: **Python 3.8.3**\r\n\r\n\r\n### Conan profile (output of `conan profile show default` or `conan profile show <profile>` if custom profile is in use)\r\n```\r\narch=x86_64\r\narch_build=x86_64\r\nbuild_type=Release\r\ncompiler=gcc\r\ncompiler.libcxx=libstdc++\r\ncompiler.version=10\r\nos=Linux\r\nos_build=Linux\r\n```\r\n\r\n\r\n### Steps to reproduce (Include if Applicable)\r\nWhen I try to install xorg/system\r\n`conan install xorg/system@ --build missing`\r\n\r\n\r\n### Logs (Include/Attach if Applicable)\r\n<details><summary>Click to expand log</summary>\r\n\r\n```\r\nConfiguration:\r\n[settings]\r\narch=x86_64\r\narch_build=x86_64\r\nbuild_type=Release\r\ncompiler=gcc\r\ncompiler.libcxx=libstdc++\r\ncompiler.version=10\r\nos=Linux\r\nos_build=Linux\r\n[options]\r\n[build_requires]\r\n[env]\r\n\r\nInstalling package: xorg/system\r\nRequirements\r\n xorg/system from 'conan-center' - Cache\r\nPackages\r\n xorg/system:5ab84d6acfe1f23c4fae0ab88f26e3a396351ac9 - Cache\r\n\r\nInstalling (downloading, building) binaries...\r\nxorg/system: Already installed!\r\nERROR: xorg/system: Error in package_info() method, line 57\r\n\tself._fill_cppinfo_from_pkgconfig(name)\r\nwhile calling '_fill_cppinfo_from_pkgconfig', line 18\r\n\tif not pkg_config.provides:\r\n\tConanException: pkg-config command ['pkg-config', '--print-provides', 'sm', '--print-errors'] failed with error: Command 'pkg-config --print-provides sm --print-errors' returned non-zero exit status 1.\r\nPackage sm was not found in the pkg-config search path.\r\nPerhaps you should add the directory containing `sm.pc'\r\nto the PKG_CONFIG_PATH environment variable\r\nPackage 'sm', required by 'virtual:world', not found\r\n```\r\n\r\n</details>\r\n\n", "before_files": [{"content": "from conans import ConanFile, tools\nfrom conans.errors import ConanException\n\n\nclass ConanXOrg(ConanFile):\n name = \"xorg\"\n url = \"https://github.com/conan-io/conan-center-index\"\n license = \"MIT\"\n homepage = \"https://www.x.org/wiki/\"\n description = \"The X.Org project provides an open source implementation of the X Window System.\"\n settings = {\"os\": \"Linux\"}\n\n def package_id(self):\n self.info.header_only()\n\n def _fill_cppinfo_from_pkgconfig(self, name):\n pkg_config = tools.PkgConfig(name)\n if not pkg_config.provides:\n raise ConanException(\"OpenGL development files aren't available, give up\")\n libs = [lib[2:] for lib in pkg_config.libs_only_l]\n lib_dirs = [lib[2:] for lib in pkg_config.libs_only_L]\n ldflags = [flag for flag in pkg_config.libs_only_other]\n include_dirs = [include[2:] for include in pkg_config.cflags_only_I]\n cflags = [flag for flag in pkg_config.cflags_only_other if not flag.startswith(\"-D\")]\n defines = [flag[2:] for flag in pkg_config.cflags_only_other if flag.startswith(\"-D\")]\n\n self.cpp_info.system_libs.extend(libs)\n self.cpp_info.libdirs.extend(lib_dirs)\n self.cpp_info.sharedlinkflags.extend(ldflags)\n self.cpp_info.exelinkflags.extend(ldflags)\n self.cpp_info.defines.extend(defines)\n self.cpp_info.includedirs.extend(include_dirs)\n self.cpp_info.cflags.extend(cflags)\n self.cpp_info.cxxflags.extend(cflags)\n\n\n def system_requirements(self):\n if tools.os_info.is_linux and self.settings.os == \"Linux\":\n package_tool = tools.SystemPackageTool(conanfile=self, default_mode=\"verify\")\n if tools.os_info.with_apt:\n packages = [\"xorg-dev\", \"libx11-xcb-dev\", \"libxcb-render0-dev\", \"libxcb-render-util0-dev\"]\n elif tools.os_info.with_yum:\n packages = [\"xorg-x11-server-devel\"]\n elif tools.os_info.with_pacman:\n packages = [\"xorg-server-devel\"]\n elif tools.os_info.with_zypper:\n packages = [\"Xorg-x11-devel\"]\n else:\n self.output.warn(\"Do not know how to install 'xorg' for {}.\".format(tools.os_info.linux_distro))\n for p in packages:\n package_tool.install(update=True, packages=p)\n\n def package_info(self):\n for name in [\"x11\", \"x11-xcb\", \"dmx\", \"fontenc\", \"libfs\", \"ice\", \"sm\", \"xau\", \"xaw7\",\n \"xcomposite\",\"xcursor\", \"xdamage\", \"xdmcp\", \"xext\", \"xfixes\", \"xft\", \"xi\",\n \"xinerama\", \"xkbfile\", \"xmu\", \"xmuu\", \"xpm\", \"xrandr\", \"xrender\", \"xres\",\n \"xscrnsaver\", \"xt\", \"xtst\", \"xv\", \"xvmc\", \"xxf86dga\", \"xxf86vm\", \"xtrans\"]:\n self._fill_cppinfo_from_pkgconfig(name)\n", "path": "recipes/xorg/all/conanfile.py"}]}
| 2,027 | 176 |
gh_patches_debug_23490
|
rasdani/github-patches
|
git_diff
|
numba__numba-1801
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add erff and erfc to CUDA Targets
The erff and erfc family of functions are missing from the CUDA target.
Originally posted on the google-groups.
https://groups.google.com/a/continuum.io/forum/#!topic/numba-users/2wupabM4vJ4
</issue>
<code>
[start of numba/cuda/libdevice.py]
1 from __future__ import print_function, absolute_import, division
2 import sys
3 import math
4 from llvmlite.llvmpy.core import Type
5 from numba import cgutils, types
6 from numba.targets.imputils import Registry
7
8 registry = Registry()
9 lower = registry.lower
10
11 float_set = types.float32, types.float64
12
13
14 def bool_implement(nvname, ty):
15 def core(context, builder, sig, args):
16 assert sig.return_type == types.boolean, nvname
17 fty = context.get_value_type(ty)
18 lmod = builder.module
19 fnty = Type.function(Type.int(), [fty])
20 fn = lmod.get_or_insert_function(fnty, name=nvname)
21 result = builder.call(fn, args)
22 return context.cast(builder, result, types.int32, types.boolean)
23
24 return core
25
26
27
28 def unary_implement(nvname, ty):
29 def core(context, builder, sig, args):
30 fty = context.get_value_type(ty)
31 lmod = builder.module
32 fnty = Type.function(fty, [fty])
33 fn = lmod.get_or_insert_function(fnty, name=nvname)
34 return builder.call(fn, args)
35
36 return core
37
38
39 def binary_implement(nvname, ty):
40 def core(context, builder, sig, args):
41 fty = context.get_value_type(ty)
42 lmod = builder.module
43 fnty = Type.function(fty, [fty, fty])
44 fn = lmod.get_or_insert_function(fnty, name=nvname)
45 return builder.call(fn, args)
46
47 return core
48
49
50 def powi_implement(nvname):
51 def core(context, builder, sig, args):
52 [base, pow] = args
53 [basety, powty] = sig.args
54 lmod = builder.module
55 fty = context.get_value_type(basety)
56 ity = context.get_value_type(types.int32)
57 fnty = Type.function(fty, [fty, ity])
58 fn = lmod.get_or_insert_function(fnty, name=nvname)
59 return builder.call(fn, [base, pow])
60
61
62 return core
63
64
65 lower(math.pow, types.float32, types.int32)(powi_implement('__nv_powif'))
66 lower(math.pow, types.float64, types.int32)(powi_implement('__nv_powi'))
67
68
69 booleans = []
70 booleans += [('__nv_isnand', '__nv_isnanf', math.isnan)]
71 booleans += [('__nv_isinfd', '__nv_isinff', math.isinf)]
72
73 unarys = []
74 unarys += [('__nv_ceil', '__nv_ceilf', math.ceil)]
75 unarys += [('__nv_floor', '__nv_floorf', math.floor)]
76 unarys += [('__nv_fabs', '__nv_fabsf', math.fabs)]
77 unarys += [('__nv_exp', '__nv_expf', math.exp)]
78 unarys += [('__nv_expm1', '__nv_expm1f', math.expm1)]
79 unarys += [('__nv_sqrt', '__nv_sqrtf', math.sqrt)]
80 unarys += [('__nv_log', '__nv_logf', math.log)]
81 unarys += [('__nv_log10', '__nv_log10f', math.log10)]
82 unarys += [('__nv_log1p', '__nv_log1pf', math.log1p)]
83 unarys += [('__nv_acosh', '__nv_acoshf', math.acosh)]
84 unarys += [('__nv_acos', '__nv_acosf', math.acos)]
85 unarys += [('__nv_cos', '__nv_cosf', math.cos)]
86 unarys += [('__nv_cosh', '__nv_coshf', math.cosh)]
87 unarys += [('__nv_asinh', '__nv_asinhf', math.asinh)]
88 unarys += [('__nv_asin', '__nv_asinf', math.asin)]
89 unarys += [('__nv_sin', '__nv_sinf', math.sin)]
90 unarys += [('__nv_sinh', '__nv_sinhf', math.sinh)]
91 unarys += [('__nv_atan', '__nv_atanf', math.atan)]
92 unarys += [('__nv_atanh', '__nv_atanhf', math.atanh)]
93 unarys += [('__nv_tan', '__nv_tanf', math.tan)]
94 unarys += [('__nv_tanh', '__nv_tanhf', math.tanh)]
95
96 binarys = []
97 binarys += [('__nv_copysign', '__nv_copysignf', math.copysign)]
98 binarys += [('__nv_atan2', '__nv_atan2f', math.atan2)]
99 binarys += [('__nv_pow', '__nv_powf', math.pow)]
100 binarys += [('__nv_fmod', '__nv_fmodf', math.fmod)]
101 binarys += [('__nv_hypot', '__nv_hypotf', math.hypot)]
102
103
104 for name64, name32, key in booleans:
105 impl64 = bool_implement(name64, types.float64)
106 lower(key, types.float64)(impl64)
107 impl32 = bool_implement(name32, types.float32)
108 lower(key, types.float32)(impl32)
109
110
111 for name64, name32, key in unarys:
112 impl64 = unary_implement(name64, types.float64)
113 lower(key, types.float64)(impl64)
114 impl32 = unary_implement(name32, types.float32)
115 lower(key, types.float32)(impl32)
116
117 for name64, name32, key in binarys:
118 impl64 = binary_implement(name64, types.float64)
119 lower(key, types.float64, types.float64)(impl64)
120 impl32 = binary_implement(name32, types.float32)
121 lower(key, types.float32, types.float32)(impl32)
122
[end of numba/cuda/libdevice.py]
[start of numba/cuda/cudamath.py]
1 from __future__ import print_function, absolute_import, division
2 import math
3 from numba import types, utils
4 from numba.typing.templates import (AttributeTemplate, ConcreteTemplate,
5 signature, Registry)
6
7 registry = Registry()
8 infer_global = registry.register_global
9
10
11 @infer_global(math.acos)
12 @infer_global(math.acosh)
13 @infer_global(math.asin)
14 @infer_global(math.asinh)
15 @infer_global(math.atan)
16 @infer_global(math.atanh)
17 @infer_global(math.ceil)
18 @infer_global(math.cos)
19 @infer_global(math.cosh)
20 @infer_global(math.degrees)
21 @infer_global(math.exp)
22 @infer_global(math.expm1)
23 @infer_global(math.fabs)
24 @infer_global(math.floor)
25 @infer_global(math.log)
26 @infer_global(math.log10)
27 @infer_global(math.log1p)
28 @infer_global(math.radians)
29 @infer_global(math.sin)
30 @infer_global(math.sinh)
31 @infer_global(math.sqrt)
32 @infer_global(math.tan)
33 @infer_global(math.tanh)
34 @infer_global(math.trunc)
35 class Math_unary(ConcreteTemplate):
36 cases = [
37 signature(types.float64, types.int64),
38 signature(types.float64, types.uint64),
39 signature(types.float32, types.float32),
40 signature(types.float64, types.float64),
41 ]
42
43
44 @infer_global(math.atan2)
45 class Math_atan2(ConcreteTemplate):
46 key = math.atan2
47 cases = [
48 signature(types.float64, types.int64, types.int64),
49 signature(types.float64, types.uint64, types.uint64),
50 signature(types.float32, types.float32, types.float32),
51 signature(types.float64, types.float64, types.float64),
52 ]
53
54
55 @infer_global(math.hypot)
56 class Math_hypot(ConcreteTemplate):
57 key = math.hypot
58 cases = [
59 signature(types.float64, types.int64, types.int64),
60 signature(types.float64, types.uint64, types.uint64),
61 signature(types.float32, types.float32, types.float32),
62 signature(types.float64, types.float64, types.float64),
63 ]
64
65
66 @infer_global(math.copysign)
67 @infer_global(math.fmod)
68 class Math_binary(ConcreteTemplate):
69 cases = [
70 signature(types.float32, types.float32, types.float32),
71 signature(types.float64, types.float64, types.float64),
72 ]
73
74
75 @infer_global(math.pow)
76 class Math_pow(ConcreteTemplate):
77 cases = [
78 signature(types.float32, types.float32, types.float32),
79 signature(types.float64, types.float64, types.float64),
80 signature(types.float32, types.float32, types.int32),
81 signature(types.float64, types.float64, types.int32),
82 ]
83
84
85 @infer_global(math.isinf)
86 @infer_global(math.isnan)
87 class Math_isnan(ConcreteTemplate):
88 cases = [
89 signature(types.boolean, types.int64),
90 signature(types.boolean, types.uint64),
91 signature(types.boolean, types.float32),
92 signature(types.boolean, types.float64),
93 ]
94
[end of numba/cuda/cudamath.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/numba/cuda/cudamath.py b/numba/cuda/cudamath.py
--- a/numba/cuda/cudamath.py
+++ b/numba/cuda/cudamath.py
@@ -18,10 +18,14 @@
@infer_global(math.cos)
@infer_global(math.cosh)
@infer_global(math.degrees)
+@infer_global(math.erf)
+@infer_global(math.erfc)
@infer_global(math.exp)
@infer_global(math.expm1)
@infer_global(math.fabs)
@infer_global(math.floor)
+@infer_global(math.gamma)
+@infer_global(math.lgamma)
@infer_global(math.log)
@infer_global(math.log10)
@infer_global(math.log1p)
diff --git a/numba/cuda/libdevice.py b/numba/cuda/libdevice.py
--- a/numba/cuda/libdevice.py
+++ b/numba/cuda/libdevice.py
@@ -76,6 +76,10 @@
unarys += [('__nv_fabs', '__nv_fabsf', math.fabs)]
unarys += [('__nv_exp', '__nv_expf', math.exp)]
unarys += [('__nv_expm1', '__nv_expm1f', math.expm1)]
+unarys += [('__nv_erf', '__nv_erff', math.erf)]
+unarys += [('__nv_erfc', '__nv_erfcf', math.erfc)]
+unarys += [('__nv_tgamma', '__nv_tgammaf', math.gamma)]
+unarys += [('__nv_lgamma', '__nv_lgammaf', math.lgamma)]
unarys += [('__nv_sqrt', '__nv_sqrtf', math.sqrt)]
unarys += [('__nv_log', '__nv_logf', math.log)]
unarys += [('__nv_log10', '__nv_log10f', math.log10)]
|
{"golden_diff": "diff --git a/numba/cuda/cudamath.py b/numba/cuda/cudamath.py\n--- a/numba/cuda/cudamath.py\n+++ b/numba/cuda/cudamath.py\n@@ -18,10 +18,14 @@\n @infer_global(math.cos)\n @infer_global(math.cosh)\n @infer_global(math.degrees)\n+@infer_global(math.erf)\n+@infer_global(math.erfc)\n @infer_global(math.exp)\n @infer_global(math.expm1)\n @infer_global(math.fabs)\n @infer_global(math.floor)\n+@infer_global(math.gamma)\n+@infer_global(math.lgamma)\n @infer_global(math.log)\n @infer_global(math.log10)\n @infer_global(math.log1p)\ndiff --git a/numba/cuda/libdevice.py b/numba/cuda/libdevice.py\n--- a/numba/cuda/libdevice.py\n+++ b/numba/cuda/libdevice.py\n@@ -76,6 +76,10 @@\n unarys += [('__nv_fabs', '__nv_fabsf', math.fabs)]\n unarys += [('__nv_exp', '__nv_expf', math.exp)]\n unarys += [('__nv_expm1', '__nv_expm1f', math.expm1)]\n+unarys += [('__nv_erf', '__nv_erff', math.erf)]\n+unarys += [('__nv_erfc', '__nv_erfcf', math.erfc)]\n+unarys += [('__nv_tgamma', '__nv_tgammaf', math.gamma)]\n+unarys += [('__nv_lgamma', '__nv_lgammaf', math.lgamma)]\n unarys += [('__nv_sqrt', '__nv_sqrtf', math.sqrt)]\n unarys += [('__nv_log', '__nv_logf', math.log)]\n unarys += [('__nv_log10', '__nv_log10f', math.log10)]\n", "issue": "Add erff and erfc to CUDA Targets\nThe erff and erfc family of functions are missing from the CUDA target.\nOriginally posted on the google-groups.\nhttps://groups.google.com/a/continuum.io/forum/#!topic/numba-users/2wupabM4vJ4\n\n", "before_files": [{"content": "from __future__ import print_function, absolute_import, division\nimport sys\nimport math\nfrom llvmlite.llvmpy.core import Type\nfrom numba import cgutils, types\nfrom numba.targets.imputils import Registry\n\nregistry = Registry()\nlower = registry.lower\n\nfloat_set = types.float32, types.float64\n\n\ndef bool_implement(nvname, ty):\n def core(context, builder, sig, args):\n assert sig.return_type == types.boolean, nvname\n fty = context.get_value_type(ty)\n lmod = builder.module\n fnty = Type.function(Type.int(), [fty])\n fn = lmod.get_or_insert_function(fnty, name=nvname)\n result = builder.call(fn, args)\n return context.cast(builder, result, types.int32, types.boolean)\n\n return core\n\n\n\ndef unary_implement(nvname, ty):\n def core(context, builder, sig, args):\n fty = context.get_value_type(ty)\n lmod = builder.module\n fnty = Type.function(fty, [fty])\n fn = lmod.get_or_insert_function(fnty, name=nvname)\n return builder.call(fn, args)\n\n return core\n\n\ndef binary_implement(nvname, ty):\n def core(context, builder, sig, args):\n fty = context.get_value_type(ty)\n lmod = builder.module\n fnty = Type.function(fty, [fty, fty])\n fn = lmod.get_or_insert_function(fnty, name=nvname)\n return builder.call(fn, args)\n\n return core\n\n\ndef powi_implement(nvname):\n def core(context, builder, sig, args):\n [base, pow] = args\n [basety, powty] = sig.args\n lmod = builder.module\n fty = context.get_value_type(basety)\n ity = context.get_value_type(types.int32)\n fnty = Type.function(fty, [fty, ity])\n fn = lmod.get_or_insert_function(fnty, name=nvname)\n return builder.call(fn, [base, pow])\n\n\n return core\n\n\nlower(math.pow, types.float32, types.int32)(powi_implement('__nv_powif'))\nlower(math.pow, types.float64, types.int32)(powi_implement('__nv_powi'))\n\n\nbooleans = []\nbooleans += [('__nv_isnand', '__nv_isnanf', math.isnan)]\nbooleans += [('__nv_isinfd', '__nv_isinff', math.isinf)]\n\nunarys = []\nunarys += [('__nv_ceil', '__nv_ceilf', math.ceil)]\nunarys += [('__nv_floor', '__nv_floorf', math.floor)]\nunarys += [('__nv_fabs', '__nv_fabsf', math.fabs)]\nunarys += [('__nv_exp', '__nv_expf', math.exp)]\nunarys += [('__nv_expm1', '__nv_expm1f', math.expm1)]\nunarys += [('__nv_sqrt', '__nv_sqrtf', math.sqrt)]\nunarys += [('__nv_log', '__nv_logf', math.log)]\nunarys += [('__nv_log10', '__nv_log10f', math.log10)]\nunarys += [('__nv_log1p', '__nv_log1pf', math.log1p)]\nunarys += [('__nv_acosh', '__nv_acoshf', math.acosh)]\nunarys += [('__nv_acos', '__nv_acosf', math.acos)]\nunarys += [('__nv_cos', '__nv_cosf', math.cos)]\nunarys += [('__nv_cosh', '__nv_coshf', math.cosh)]\nunarys += [('__nv_asinh', '__nv_asinhf', math.asinh)]\nunarys += [('__nv_asin', '__nv_asinf', math.asin)]\nunarys += [('__nv_sin', '__nv_sinf', math.sin)]\nunarys += [('__nv_sinh', '__nv_sinhf', math.sinh)]\nunarys += [('__nv_atan', '__nv_atanf', math.atan)]\nunarys += [('__nv_atanh', '__nv_atanhf', math.atanh)]\nunarys += [('__nv_tan', '__nv_tanf', math.tan)]\nunarys += [('__nv_tanh', '__nv_tanhf', math.tanh)]\n\nbinarys = []\nbinarys += [('__nv_copysign', '__nv_copysignf', math.copysign)]\nbinarys += [('__nv_atan2', '__nv_atan2f', math.atan2)]\nbinarys += [('__nv_pow', '__nv_powf', math.pow)]\nbinarys += [('__nv_fmod', '__nv_fmodf', math.fmod)]\nbinarys += [('__nv_hypot', '__nv_hypotf', math.hypot)]\n\n\nfor name64, name32, key in booleans:\n impl64 = bool_implement(name64, types.float64)\n lower(key, types.float64)(impl64)\n impl32 = bool_implement(name32, types.float32)\n lower(key, types.float32)(impl32)\n\n\nfor name64, name32, key in unarys:\n impl64 = unary_implement(name64, types.float64)\n lower(key, types.float64)(impl64)\n impl32 = unary_implement(name32, types.float32)\n lower(key, types.float32)(impl32)\n\nfor name64, name32, key in binarys:\n impl64 = binary_implement(name64, types.float64)\n lower(key, types.float64, types.float64)(impl64)\n impl32 = binary_implement(name32, types.float32)\n lower(key, types.float32, types.float32)(impl32)\n", "path": "numba/cuda/libdevice.py"}, {"content": "from __future__ import print_function, absolute_import, division\nimport math\nfrom numba import types, utils\nfrom numba.typing.templates import (AttributeTemplate, ConcreteTemplate,\n signature, Registry)\n\nregistry = Registry()\ninfer_global = registry.register_global\n\n\n@infer_global(math.acos)\n@infer_global(math.acosh)\n@infer_global(math.asin)\n@infer_global(math.asinh)\n@infer_global(math.atan)\n@infer_global(math.atanh)\n@infer_global(math.ceil)\n@infer_global(math.cos)\n@infer_global(math.cosh)\n@infer_global(math.degrees)\n@infer_global(math.exp)\n@infer_global(math.expm1)\n@infer_global(math.fabs)\n@infer_global(math.floor)\n@infer_global(math.log)\n@infer_global(math.log10)\n@infer_global(math.log1p)\n@infer_global(math.radians)\n@infer_global(math.sin)\n@infer_global(math.sinh)\n@infer_global(math.sqrt)\n@infer_global(math.tan)\n@infer_global(math.tanh)\n@infer_global(math.trunc)\nclass Math_unary(ConcreteTemplate):\n cases = [\n signature(types.float64, types.int64),\n signature(types.float64, types.uint64),\n signature(types.float32, types.float32),\n signature(types.float64, types.float64),\n ]\n\n\n@infer_global(math.atan2)\nclass Math_atan2(ConcreteTemplate):\n key = math.atan2\n cases = [\n signature(types.float64, types.int64, types.int64),\n signature(types.float64, types.uint64, types.uint64),\n signature(types.float32, types.float32, types.float32),\n signature(types.float64, types.float64, types.float64),\n ]\n\n\n@infer_global(math.hypot)\nclass Math_hypot(ConcreteTemplate):\n key = math.hypot\n cases = [\n signature(types.float64, types.int64, types.int64),\n signature(types.float64, types.uint64, types.uint64),\n signature(types.float32, types.float32, types.float32),\n signature(types.float64, types.float64, types.float64),\n ]\n\n\n@infer_global(math.copysign)\n@infer_global(math.fmod)\nclass Math_binary(ConcreteTemplate):\n cases = [\n signature(types.float32, types.float32, types.float32),\n signature(types.float64, types.float64, types.float64),\n ]\n\n\n@infer_global(math.pow)\nclass Math_pow(ConcreteTemplate):\n cases = [\n signature(types.float32, types.float32, types.float32),\n signature(types.float64, types.float64, types.float64),\n signature(types.float32, types.float32, types.int32),\n signature(types.float64, types.float64, types.int32),\n ]\n\n\n@infer_global(math.isinf)\n@infer_global(math.isnan)\nclass Math_isnan(ConcreteTemplate):\n cases = [\n signature(types.boolean, types.int64),\n signature(types.boolean, types.uint64),\n signature(types.boolean, types.float32),\n signature(types.boolean, types.float64),\n ]\n", "path": "numba/cuda/cudamath.py"}]}
| 3,077 | 416 |
gh_patches_debug_12110
|
rasdani/github-patches
|
git_diff
|
getnikola__nikola-492
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Only render the last index page
The render_indexes plugin only renders the last index page.
To reproduce, set the 'use_in_feed' parameter to True in more than one directory of posts.
I provide the patch in a pull request (it's a little identation modification)
</issue>
<code>
[start of nikola/plugins/task_indexes.py]
1 # Copyright (c) 2012 Roberto Alsina y otros.
2
3 # Permission is hereby granted, free of charge, to any
4 # person obtaining a copy of this software and associated
5 # documentation files (the "Software"), to deal in the
6 # Software without restriction, including without limitation
7 # the rights to use, copy, modify, merge, publish,
8 # distribute, sublicense, and/or sell copies of the
9 # Software, and to permit persons to whom the Software is
10 # furnished to do so, subject to the following conditions:
11 #
12 # The above copyright notice and this permission notice
13 # shall be included in all copies or substantial portions of
14 # the Software.
15 #
16 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY
17 # KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
18 # WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
19 # PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS
20 # OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR
21 # OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
22 # OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
23 # SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
24
25 from __future__ import unicode_literals
26 import glob
27 import os
28
29 from nikola.plugin_categories import Task
30 from nikola.utils import config_changed
31
32
33 class Indexes(Task):
34 """Render the blog indexes."""
35
36 name = "render_indexes"
37
38 def gen_tasks(self):
39 self.site.scan_posts()
40
41 kw = {
42 "translations": self.site.config['TRANSLATIONS'],
43 "index_display_post_count":
44 self.site.config['INDEX_DISPLAY_POST_COUNT'],
45 "messages": self.site.MESSAGES,
46 "index_teasers": self.site.config['INDEX_TEASERS'],
47 "output_folder": self.site.config['OUTPUT_FOLDER'],
48 "filters": self.site.config['FILTERS'],
49 "hide_untranslated_posts": self.site.config['HIDE_UNTRANSLATED_POSTS'],
50 "indexes_title": self.site.config['INDEXES_TITLE'],
51 "indexes_pages": self.site.config['INDEXES_PAGES'],
52 "blog_title": self.site.config["BLOG_TITLE"],
53 }
54
55 template_name = "index.tmpl"
56 posts = [x for x in self.site.timeline if x.use_in_feeds]
57 if not posts:
58 yield {'basename': 'render_indexes', 'actions': []}
59 for lang in kw["translations"]:
60 # Split in smaller lists
61 lists = []
62 if kw["hide_untranslated_posts"]:
63 filtered_posts = [x for x in posts if x.is_translation_available(lang)]
64 else:
65 filtered_posts = posts
66 while filtered_posts:
67 lists.append(filtered_posts[:kw["index_display_post_count"]])
68 filtered_posts = filtered_posts[kw["index_display_post_count"]:]
69 num_pages = len(lists)
70 for i, post_list in enumerate(lists):
71 context = {}
72 indexes_title = kw['indexes_title'] or kw['blog_title']
73 if not i:
74 context["title"] = indexes_title
75 else:
76 if kw["indexes_pages"]:
77 indexes_pages = kw["indexes_pages"] % i
78 else:
79 indexes_pages = " (" + \
80 kw["messages"][lang]["old posts page %d"] % i + ")"
81 context["title"] = indexes_title + indexes_pages
82 context["prevlink"] = None
83 context["nextlink"] = None
84 context['index_teasers'] = kw['index_teasers']
85 if i > 1:
86 context["prevlink"] = "index-{0}.html".format(i - 1)
87 if i == 1:
88 context["prevlink"] = self.site.config["INDEX_FILE"]
89 if i < num_pages - 1:
90 context["nextlink"] = "index-{0}.html".format(i + 1)
91 context["permalink"] = self.site.link("index", i, lang)
92 output_name = os.path.join(
93 kw['output_folder'], self.site.path("index", i,
94 lang))
95 task = self.site.generic_post_list_renderer(
96 lang,
97 post_list,
98 output_name,
99 template_name,
100 kw['filters'],
101 context,
102 )
103 task_cfg = {1: task['uptodate'][0].config, 2: kw}
104 task['uptodate'] = [config_changed(task_cfg)]
105 task['basename'] = 'render_indexes'
106 yield task
107
108 if not self.site.config["STORY_INDEX"]:
109 return
110 kw = {
111 "translations": self.site.config['TRANSLATIONS'],
112 "post_pages": self.site.config["post_pages"],
113 "output_folder": self.site.config['OUTPUT_FOLDER'],
114 "filters": self.site.config['FILTERS'],
115 }
116 template_name = "list.tmpl"
117 for lang in kw["translations"]:
118 for wildcard, dest, _, is_post in kw["post_pages"]:
119 if is_post:
120 continue
121 context = {}
122 # vim/pyflakes thinks it's unused
123 # src_dir = os.path.dirname(wildcard)
124 files = glob.glob(wildcard)
125 post_list = [self.site.global_data[os.path.splitext(p)[0]] for
126 p in files]
127 output_name = os.path.join(kw["output_folder"],
128 self.site.path("post_path",
129 wildcard,
130 lang)).encode('utf8')
131 context["items"] = [(post.title(lang), post.permalink(lang))
132 for post in post_list]
133 task = self.site.generic_post_list_renderer(lang, post_list,
134 output_name,
135 template_name,
136 kw['filters'],
137 context)
138 task_cfg = {1: task['uptodate'][0].config, 2: kw}
139 task['uptodate'] = [config_changed(task_cfg)]
140 task['basename'] = self.name
141 yield task
142
[end of nikola/plugins/task_indexes.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nikola/plugins/task_indexes.py b/nikola/plugins/task_indexes.py
--- a/nikola/plugins/task_indexes.py
+++ b/nikola/plugins/task_indexes.py
@@ -135,7 +135,7 @@
template_name,
kw['filters'],
context)
- task_cfg = {1: task['uptodate'][0].config, 2: kw}
- task['uptodate'] = [config_changed(task_cfg)]
- task['basename'] = self.name
- yield task
+ task_cfg = {1: task['uptodate'][0].config, 2: kw}
+ task['uptodate'] = [config_changed(task_cfg)]
+ task['basename'] = self.name
+ yield task
|
{"golden_diff": "diff --git a/nikola/plugins/task_indexes.py b/nikola/plugins/task_indexes.py\n--- a/nikola/plugins/task_indexes.py\n+++ b/nikola/plugins/task_indexes.py\n@@ -135,7 +135,7 @@\n template_name,\n kw['filters'],\n context)\n- task_cfg = {1: task['uptodate'][0].config, 2: kw}\n- task['uptodate'] = [config_changed(task_cfg)]\n- task['basename'] = self.name\n- yield task\n+ task_cfg = {1: task['uptodate'][0].config, 2: kw}\n+ task['uptodate'] = [config_changed(task_cfg)]\n+ task['basename'] = self.name\n+ yield task\n", "issue": "Only render the last index page\nThe render_indexes plugin only renders the last index page.\n\nTo reproduce, set the 'use_in_feed' parameter to True in more than one directory of posts.\n\nI provide the patch in a pull request (it's a little identation modification)\n\n", "before_files": [{"content": "# Copyright (c) 2012 Roberto Alsina y otros.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\nfrom __future__ import unicode_literals\nimport glob\nimport os\n\nfrom nikola.plugin_categories import Task\nfrom nikola.utils import config_changed\n\n\nclass Indexes(Task):\n \"\"\"Render the blog indexes.\"\"\"\n\n name = \"render_indexes\"\n\n def gen_tasks(self):\n self.site.scan_posts()\n\n kw = {\n \"translations\": self.site.config['TRANSLATIONS'],\n \"index_display_post_count\":\n self.site.config['INDEX_DISPLAY_POST_COUNT'],\n \"messages\": self.site.MESSAGES,\n \"index_teasers\": self.site.config['INDEX_TEASERS'],\n \"output_folder\": self.site.config['OUTPUT_FOLDER'],\n \"filters\": self.site.config['FILTERS'],\n \"hide_untranslated_posts\": self.site.config['HIDE_UNTRANSLATED_POSTS'],\n \"indexes_title\": self.site.config['INDEXES_TITLE'],\n \"indexes_pages\": self.site.config['INDEXES_PAGES'],\n \"blog_title\": self.site.config[\"BLOG_TITLE\"],\n }\n\n template_name = \"index.tmpl\"\n posts = [x for x in self.site.timeline if x.use_in_feeds]\n if not posts:\n yield {'basename': 'render_indexes', 'actions': []}\n for lang in kw[\"translations\"]:\n # Split in smaller lists\n lists = []\n if kw[\"hide_untranslated_posts\"]:\n filtered_posts = [x for x in posts if x.is_translation_available(lang)]\n else:\n filtered_posts = posts\n while filtered_posts:\n lists.append(filtered_posts[:kw[\"index_display_post_count\"]])\n filtered_posts = filtered_posts[kw[\"index_display_post_count\"]:]\n num_pages = len(lists)\n for i, post_list in enumerate(lists):\n context = {}\n indexes_title = kw['indexes_title'] or kw['blog_title']\n if not i:\n context[\"title\"] = indexes_title\n else:\n if kw[\"indexes_pages\"]:\n indexes_pages = kw[\"indexes_pages\"] % i\n else:\n indexes_pages = \" (\" + \\\n kw[\"messages\"][lang][\"old posts page %d\"] % i + \")\"\n context[\"title\"] = indexes_title + indexes_pages\n context[\"prevlink\"] = None\n context[\"nextlink\"] = None\n context['index_teasers'] = kw['index_teasers']\n if i > 1:\n context[\"prevlink\"] = \"index-{0}.html\".format(i - 1)\n if i == 1:\n context[\"prevlink\"] = self.site.config[\"INDEX_FILE\"]\n if i < num_pages - 1:\n context[\"nextlink\"] = \"index-{0}.html\".format(i + 1)\n context[\"permalink\"] = self.site.link(\"index\", i, lang)\n output_name = os.path.join(\n kw['output_folder'], self.site.path(\"index\", i,\n lang))\n task = self.site.generic_post_list_renderer(\n lang,\n post_list,\n output_name,\n template_name,\n kw['filters'],\n context,\n )\n task_cfg = {1: task['uptodate'][0].config, 2: kw}\n task['uptodate'] = [config_changed(task_cfg)]\n task['basename'] = 'render_indexes'\n yield task\n\n if not self.site.config[\"STORY_INDEX\"]:\n return\n kw = {\n \"translations\": self.site.config['TRANSLATIONS'],\n \"post_pages\": self.site.config[\"post_pages\"],\n \"output_folder\": self.site.config['OUTPUT_FOLDER'],\n \"filters\": self.site.config['FILTERS'],\n }\n template_name = \"list.tmpl\"\n for lang in kw[\"translations\"]:\n for wildcard, dest, _, is_post in kw[\"post_pages\"]:\n if is_post:\n continue\n context = {}\n # vim/pyflakes thinks it's unused\n # src_dir = os.path.dirname(wildcard)\n files = glob.glob(wildcard)\n post_list = [self.site.global_data[os.path.splitext(p)[0]] for\n p in files]\n output_name = os.path.join(kw[\"output_folder\"],\n self.site.path(\"post_path\",\n wildcard,\n lang)).encode('utf8')\n context[\"items\"] = [(post.title(lang), post.permalink(lang))\n for post in post_list]\n task = self.site.generic_post_list_renderer(lang, post_list,\n output_name,\n template_name,\n kw['filters'],\n context)\n task_cfg = {1: task['uptodate'][0].config, 2: kw}\n task['uptodate'] = [config_changed(task_cfg)]\n task['basename'] = self.name\n yield task\n", "path": "nikola/plugins/task_indexes.py"}]}
| 2,148 | 168 |
gh_patches_debug_29497
|
rasdani/github-patches
|
git_diff
|
python__peps-2533
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Waste less vertical space at top of rendered PEP
This is about usability of peps rendered on peps.python.org.
At the top of a PEP (e.g. https://peps.python.org/pep-0687/) there's a table with metadata. Most of that I ignore or is even duplicate (the title). I usually have to scroll right past that to the Abstract. Maybe the metadata could be collapsed, like the ToC? Or moved to the sidebar, like the ToC?
</issue>
<code>
[start of pep_sphinx_extensions/pep_processor/transforms/pep_title.py]
1 from pathlib import Path
2
3 from docutils import nodes
4 from docutils import transforms
5 from docutils import utils
6 from docutils.parsers.rst import roles
7 from docutils.parsers.rst import states
8
9
10 class PEPTitle(transforms.Transform):
11 """Add PEP title and organise document hierarchy."""
12
13 # needs to run before docutils.transforms.frontmatter.DocInfo and after
14 # pep_processor.transforms.pep_title.PEPTitle
15 default_priority = 335
16
17 def apply(self) -> None:
18 if not Path(self.document["source"]).match("pep-*"):
19 return # not a PEP file, exit early
20
21 # Directory to hold the PEP's RFC2822 header details, to extract a title string
22 pep_header_details = {}
23
24 # Iterate through the header fields, which are the first section of the document
25 for field in self.document[0]:
26 # Hold details of the attribute's tag against its details
27 row_attributes = {sub.tagname: sub.rawsource for sub in field}
28 pep_header_details[row_attributes["field_name"]] = row_attributes["field_body"]
29
30 # We only need the PEP number and title
31 if pep_header_details.keys() >= {"PEP", "Title"}:
32 break
33
34 # Create the title string for the PEP
35 pep_number = int(pep_header_details["PEP"])
36 pep_title = pep_header_details["Title"]
37 pep_title_string = f"PEP {pep_number} -- {pep_title}" # double hyphen for en dash
38
39 # Generate the title section node and its properties
40 title_nodes = _line_to_nodes(pep_title_string)
41 pep_title_node = nodes.section("", nodes.title("", "", *title_nodes, classes=["page-title"]), names=["pep-content"])
42
43 # Insert the title node as the root element, move children down
44 document_children = self.document.children
45 self.document.children = [pep_title_node]
46 pep_title_node.extend(document_children)
47 self.document.note_implicit_target(pep_title_node, pep_title_node)
48
49
50 def _line_to_nodes(text: str) -> list[nodes.Node]:
51 """Parse RST string to nodes."""
52 document = utils.new_document("<inline-rst>")
53 document.settings.pep_references = document.settings.rfc_references = False # patch settings
54 states.RSTStateMachine(state_classes=states.state_classes, initial_state="Body").run([text], document) # do parsing
55 roles._roles.pop("", None) # restore the "default" default role after parsing a document
56 return document[0].children
57
[end of pep_sphinx_extensions/pep_processor/transforms/pep_title.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pep_sphinx_extensions/pep_processor/transforms/pep_title.py b/pep_sphinx_extensions/pep_processor/transforms/pep_title.py
--- a/pep_sphinx_extensions/pep_processor/transforms/pep_title.py
+++ b/pep_sphinx_extensions/pep_processor/transforms/pep_title.py
@@ -22,13 +22,19 @@
pep_header_details = {}
# Iterate through the header fields, which are the first section of the document
+ desired_fields = {"PEP", "Title"}
+ fields_to_remove = []
for field in self.document[0]:
# Hold details of the attribute's tag against its details
row_attributes = {sub.tagname: sub.rawsource for sub in field}
pep_header_details[row_attributes["field_name"]] = row_attributes["field_body"]
+ # Store the redundant fields in the table for removal
+ if row_attributes["field_name"] in desired_fields:
+ fields_to_remove.append(field)
+
# We only need the PEP number and title
- if pep_header_details.keys() >= {"PEP", "Title"}:
+ if pep_header_details.keys() >= desired_fields:
break
# Create the title string for the PEP
@@ -46,6 +52,10 @@
pep_title_node.extend(document_children)
self.document.note_implicit_target(pep_title_node, pep_title_node)
+ # Remove the now-redundant fields
+ for field in fields_to_remove:
+ field.parent.remove(field)
+
def _line_to_nodes(text: str) -> list[nodes.Node]:
"""Parse RST string to nodes."""
|
{"golden_diff": "diff --git a/pep_sphinx_extensions/pep_processor/transforms/pep_title.py b/pep_sphinx_extensions/pep_processor/transforms/pep_title.py\n--- a/pep_sphinx_extensions/pep_processor/transforms/pep_title.py\n+++ b/pep_sphinx_extensions/pep_processor/transforms/pep_title.py\n@@ -22,13 +22,19 @@\n pep_header_details = {}\n \n # Iterate through the header fields, which are the first section of the document\n+ desired_fields = {\"PEP\", \"Title\"}\n+ fields_to_remove = []\n for field in self.document[0]:\n # Hold details of the attribute's tag against its details\n row_attributes = {sub.tagname: sub.rawsource for sub in field}\n pep_header_details[row_attributes[\"field_name\"]] = row_attributes[\"field_body\"]\n \n+ # Store the redundant fields in the table for removal\n+ if row_attributes[\"field_name\"] in desired_fields:\n+ fields_to_remove.append(field)\n+\n # We only need the PEP number and title\n- if pep_header_details.keys() >= {\"PEP\", \"Title\"}:\n+ if pep_header_details.keys() >= desired_fields:\n break\n \n # Create the title string for the PEP\n@@ -46,6 +52,10 @@\n pep_title_node.extend(document_children)\n self.document.note_implicit_target(pep_title_node, pep_title_node)\n \n+ # Remove the now-redundant fields\n+ for field in fields_to_remove:\n+ field.parent.remove(field)\n+\n \n def _line_to_nodes(text: str) -> list[nodes.Node]:\n \"\"\"Parse RST string to nodes.\"\"\"\n", "issue": "Waste less vertical space at top of rendered PEP\nThis is about usability of peps rendered on peps.python.org.\r\n\r\nAt the top of a PEP (e.g. https://peps.python.org/pep-0687/) there's a table with metadata. Most of that I ignore or is even duplicate (the title). I usually have to scroll right past that to the Abstract. Maybe the metadata could be collapsed, like the ToC? Or moved to the sidebar, like the ToC?\n", "before_files": [{"content": "from pathlib import Path\n\nfrom docutils import nodes\nfrom docutils import transforms\nfrom docutils import utils\nfrom docutils.parsers.rst import roles\nfrom docutils.parsers.rst import states\n\n\nclass PEPTitle(transforms.Transform):\n \"\"\"Add PEP title and organise document hierarchy.\"\"\"\n\n # needs to run before docutils.transforms.frontmatter.DocInfo and after\n # pep_processor.transforms.pep_title.PEPTitle\n default_priority = 335\n\n def apply(self) -> None:\n if not Path(self.document[\"source\"]).match(\"pep-*\"):\n return # not a PEP file, exit early\n\n # Directory to hold the PEP's RFC2822 header details, to extract a title string\n pep_header_details = {}\n\n # Iterate through the header fields, which are the first section of the document\n for field in self.document[0]:\n # Hold details of the attribute's tag against its details\n row_attributes = {sub.tagname: sub.rawsource for sub in field}\n pep_header_details[row_attributes[\"field_name\"]] = row_attributes[\"field_body\"]\n\n # We only need the PEP number and title\n if pep_header_details.keys() >= {\"PEP\", \"Title\"}:\n break\n\n # Create the title string for the PEP\n pep_number = int(pep_header_details[\"PEP\"])\n pep_title = pep_header_details[\"Title\"]\n pep_title_string = f\"PEP {pep_number} -- {pep_title}\" # double hyphen for en dash\n\n # Generate the title section node and its properties\n title_nodes = _line_to_nodes(pep_title_string)\n pep_title_node = nodes.section(\"\", nodes.title(\"\", \"\", *title_nodes, classes=[\"page-title\"]), names=[\"pep-content\"])\n\n # Insert the title node as the root element, move children down\n document_children = self.document.children\n self.document.children = [pep_title_node]\n pep_title_node.extend(document_children)\n self.document.note_implicit_target(pep_title_node, pep_title_node)\n\n\ndef _line_to_nodes(text: str) -> list[nodes.Node]:\n \"\"\"Parse RST string to nodes.\"\"\"\n document = utils.new_document(\"<inline-rst>\")\n document.settings.pep_references = document.settings.rfc_references = False # patch settings\n states.RSTStateMachine(state_classes=states.state_classes, initial_state=\"Body\").run([text], document) # do parsing\n roles._roles.pop(\"\", None) # restore the \"default\" default role after parsing a document\n return document[0].children\n", "path": "pep_sphinx_extensions/pep_processor/transforms/pep_title.py"}]}
| 1,331 | 376 |
gh_patches_debug_13421
|
rasdani/github-patches
|
git_diff
|
napari__napari-2413
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Points layer allows panning when in Add mode
## 🐛 Bug
When in the `Add Points` mode on a points layer panning is not prevented. This can make it tricky to label a point as you have to hold the mouse perfectly still.

In contrast the `pick` mode of a labels layer prevents panning.
## To Reproduce
1. Open napari
2. Add a points layer
3. Move mouse around and then click
Alternatively:
`python examples/nD_points.py`
## Expected behavior
Clicking when in `Add Points` mode will not allow panning, the same as when when in `Pick` mode for a labels layer.
## Environment
```
napari: 0.4.7.dev14+gc473058
Platform: Linux-5.8.0-7630-generic-x86_64-with-glibc2.31
System: Pop!_OS 20.04 LTS
Python: 3.9.1 | packaged by conda-forge | (default, Jan 26 2021, 01:34:10) [GCC 9.3.0]
Qt: 5.15.2
PyQt5: 5.15.2
NumPy: 1.19.5
SciPy: 1.6.0
Dask: 2021.01.1
VisPy: 0.6.6
OpenGL:
- GL version: 4.6 (Compatibility Profile) Mesa 20.2.6
- MAX_TEXTURE_SIZE: 16384
Screens:
- screen 1: resolution 1920x1080, scale 1.0
Plugins:
- console: 0.0.3
- svg: 0.1.4
```
## Additional context
<!-- Add any other context about the problem here. -->
</issue>
<code>
[start of napari/layers/points/_points_mouse_bindings.py]
1 import numpy as np
2
3 from ._points_utils import points_in_box
4
5
6 def select(layer, event):
7 """Select points.
8
9 Clicking on a point will select that point. If holding shift while clicking
10 that point will be added to or removed from the existing selection
11 depending on whether it is selected or not.
12
13 Clicking and dragging a point that is already selected will drag all the
14 currently selected points.
15
16 Clicking and dragging on an empty part of the canvas (i.e. not on a point)
17 will create a drag box that will select all points inside it when finished.
18 Holding shift throughout the entirety of this process will add those points
19 to any existing selection, otherwise these will become the only selected
20 points.
21 """
22 # on press
23 modify_selection = (
24 'Shift' in event.modifiers or 'Control' in event.modifiers
25 )
26
27 # Get value under the cursor, for points, this is the index of the highlighted
28 # if any, or None.
29 value = layer.get_value(event.position, world=True)
30 # if modifying selection add / remove any from existing selection
31 if modify_selection:
32 if value is not None:
33 layer.selected_data = _toggle_selected(layer.selected_data, value)
34 else:
35 if value is not None:
36 # If the current index is not in the current list make it the only
37 # index selected, otherwise don't change the selection so that
38 # the current selection can be dragged together.
39 if value not in layer.selected_data:
40 layer.selected_data = {value}
41 else:
42 layer.selected_data = set()
43 layer._set_highlight()
44
45 yield
46
47 # on move
48 while event.type == 'mouse_move':
49 coordinates = layer.world_to_data(event.position)
50 # If not holding modifying selection and points selected then drag them
51 if not modify_selection and len(layer.selected_data) > 0:
52 layer._move(layer.selected_data, coordinates)
53 else:
54 coord = [coordinates[i] for i in layer._dims_displayed]
55 layer._is_selecting = True
56 if layer._drag_start is None:
57 layer._drag_start = coord
58 layer._drag_box = np.array([layer._drag_start, coord])
59 layer._set_highlight()
60 yield
61
62 # on release
63 layer._drag_start = None
64 if layer._is_selecting:
65 layer._is_selecting = False
66 if len(layer._view_data) > 0:
67 selection = points_in_box(
68 layer._drag_box, layer._view_data, layer._view_size
69 )
70 # If shift combine drag selection with existing selected ones
71 if modify_selection:
72 new_selected = layer._indices_view[selection]
73 target = set(layer.selected_data).symmetric_difference(
74 set(new_selected)
75 )
76 layer.selected_data = list(target)
77 else:
78 layer.selected_data = layer._indices_view[selection]
79 else:
80 layer.selected_data = set()
81 layer._set_highlight(force=True)
82
83
84 def add(layer, event):
85 """Add a new point at the clicked position."""
86 # on press
87 dragged = False
88 yield
89
90 # on move
91 while event.type == 'mouse_move':
92 dragged = True
93 yield
94
95 # on release
96 if not dragged:
97 coordinates = layer.world_to_data(event.position)
98 layer.add(coordinates)
99
100
101 def highlight(layer, event):
102 """Highlight hovered points."""
103 layer._set_highlight()
104
105
106 def _toggle_selected(selected_data, value):
107 """Add or remove value from the selected data set.
108
109 Parameters
110 ----------
111 selected_data : set
112 Set of selected data points to be modified.
113 value : int
114 Index of point to add or remove from selected data set.
115
116 Returns
117 -------
118 set
119 Modified selected_data set.
120 """
121 if value in selected_data:
122 selected_data.remove(value)
123 else:
124 selected_data.add(value)
125
126 return selected_data
127
[end of napari/layers/points/_points_mouse_bindings.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/napari/layers/points/_points_mouse_bindings.py b/napari/layers/points/_points_mouse_bindings.py
--- a/napari/layers/points/_points_mouse_bindings.py
+++ b/napari/layers/points/_points_mouse_bindings.py
@@ -81,19 +81,20 @@
layer._set_highlight(force=True)
+DRAG_DIST_THRESHOLD = 5
+
+
def add(layer, event):
"""Add a new point at the clicked position."""
- # on press
- dragged = False
- yield
- # on move
- while event.type == 'mouse_move':
- dragged = True
+ if event.type == 'mouse_press':
+ start_pos = event.pos
+
+ while event.type != 'mouse_release':
yield
- # on release
- if not dragged:
+ dist = np.linalg.norm(start_pos - event.pos)
+ if dist < DRAG_DIST_THRESHOLD:
coordinates = layer.world_to_data(event.position)
layer.add(coordinates)
|
{"golden_diff": "diff --git a/napari/layers/points/_points_mouse_bindings.py b/napari/layers/points/_points_mouse_bindings.py\n--- a/napari/layers/points/_points_mouse_bindings.py\n+++ b/napari/layers/points/_points_mouse_bindings.py\n@@ -81,19 +81,20 @@\n layer._set_highlight(force=True)\n \n \n+DRAG_DIST_THRESHOLD = 5\n+\n+\n def add(layer, event):\n \"\"\"Add a new point at the clicked position.\"\"\"\n- # on press\n- dragged = False\n- yield\n \n- # on move\n- while event.type == 'mouse_move':\n- dragged = True\n+ if event.type == 'mouse_press':\n+ start_pos = event.pos\n+\n+ while event.type != 'mouse_release':\n yield\n \n- # on release\n- if not dragged:\n+ dist = np.linalg.norm(start_pos - event.pos)\n+ if dist < DRAG_DIST_THRESHOLD:\n coordinates = layer.world_to_data(event.position)\n layer.add(coordinates)\n", "issue": "Points layer allows panning when in Add mode\n## \ud83d\udc1b Bug\r\nWhen in the `Add Points` mode on a points layer panning is not prevented. This can make it tricky to label a point as you have to hold the mouse perfectly still.\r\n\r\n\r\n\r\nIn contrast the `pick` mode of a labels layer prevents panning.\r\n\r\n## To Reproduce\r\n1. Open napari\r\n2. Add a points layer\r\n3. Move mouse around and then click\r\n\r\nAlternatively:\r\n`python examples/nD_points.py`\r\n\r\n## Expected behavior\r\nClicking when in `Add Points` mode will not allow panning, the same as when when in `Pick` mode for a labels layer.\r\n\r\n\r\n## Environment\r\n\r\n```\r\nnapari: 0.4.7.dev14+gc473058\r\nPlatform: Linux-5.8.0-7630-generic-x86_64-with-glibc2.31\r\nSystem: Pop!_OS 20.04 LTS\r\nPython: 3.9.1 | packaged by conda-forge | (default, Jan 26 2021, 01:34:10) [GCC 9.3.0]\r\nQt: 5.15.2\r\nPyQt5: 5.15.2\r\nNumPy: 1.19.5\r\nSciPy: 1.6.0\r\nDask: 2021.01.1\r\nVisPy: 0.6.6\r\n\r\nOpenGL:\r\n- GL version: 4.6 (Compatibility Profile) Mesa 20.2.6\r\n- MAX_TEXTURE_SIZE: 16384\r\n\r\nScreens:\r\n- screen 1: resolution 1920x1080, scale 1.0\r\n\r\nPlugins:\r\n- console: 0.0.3\r\n- svg: 0.1.4\r\n```\r\n\r\n## Additional context\r\n\r\n<!-- Add any other context about the problem here. -->\r\n\n", "before_files": [{"content": "import numpy as np\n\nfrom ._points_utils import points_in_box\n\n\ndef select(layer, event):\n \"\"\"Select points.\n\n Clicking on a point will select that point. If holding shift while clicking\n that point will be added to or removed from the existing selection\n depending on whether it is selected or not.\n\n Clicking and dragging a point that is already selected will drag all the\n currently selected points.\n\n Clicking and dragging on an empty part of the canvas (i.e. not on a point)\n will create a drag box that will select all points inside it when finished.\n Holding shift throughout the entirety of this process will add those points\n to any existing selection, otherwise these will become the only selected\n points.\n \"\"\"\n # on press\n modify_selection = (\n 'Shift' in event.modifiers or 'Control' in event.modifiers\n )\n\n # Get value under the cursor, for points, this is the index of the highlighted\n # if any, or None.\n value = layer.get_value(event.position, world=True)\n # if modifying selection add / remove any from existing selection\n if modify_selection:\n if value is not None:\n layer.selected_data = _toggle_selected(layer.selected_data, value)\n else:\n if value is not None:\n # If the current index is not in the current list make it the only\n # index selected, otherwise don't change the selection so that\n # the current selection can be dragged together.\n if value not in layer.selected_data:\n layer.selected_data = {value}\n else:\n layer.selected_data = set()\n layer._set_highlight()\n\n yield\n\n # on move\n while event.type == 'mouse_move':\n coordinates = layer.world_to_data(event.position)\n # If not holding modifying selection and points selected then drag them\n if not modify_selection and len(layer.selected_data) > 0:\n layer._move(layer.selected_data, coordinates)\n else:\n coord = [coordinates[i] for i in layer._dims_displayed]\n layer._is_selecting = True\n if layer._drag_start is None:\n layer._drag_start = coord\n layer._drag_box = np.array([layer._drag_start, coord])\n layer._set_highlight()\n yield\n\n # on release\n layer._drag_start = None\n if layer._is_selecting:\n layer._is_selecting = False\n if len(layer._view_data) > 0:\n selection = points_in_box(\n layer._drag_box, layer._view_data, layer._view_size\n )\n # If shift combine drag selection with existing selected ones\n if modify_selection:\n new_selected = layer._indices_view[selection]\n target = set(layer.selected_data).symmetric_difference(\n set(new_selected)\n )\n layer.selected_data = list(target)\n else:\n layer.selected_data = layer._indices_view[selection]\n else:\n layer.selected_data = set()\n layer._set_highlight(force=True)\n\n\ndef add(layer, event):\n \"\"\"Add a new point at the clicked position.\"\"\"\n # on press\n dragged = False\n yield\n\n # on move\n while event.type == 'mouse_move':\n dragged = True\n yield\n\n # on release\n if not dragged:\n coordinates = layer.world_to_data(event.position)\n layer.add(coordinates)\n\n\ndef highlight(layer, event):\n \"\"\"Highlight hovered points.\"\"\"\n layer._set_highlight()\n\n\ndef _toggle_selected(selected_data, value):\n \"\"\"Add or remove value from the selected data set.\n\n Parameters\n ----------\n selected_data : set\n Set of selected data points to be modified.\n value : int\n Index of point to add or remove from selected data set.\n\n Returns\n -------\n set\n Modified selected_data set.\n \"\"\"\n if value in selected_data:\n selected_data.remove(value)\n else:\n selected_data.add(value)\n\n return selected_data\n", "path": "napari/layers/points/_points_mouse_bindings.py"}]}
| 2,186 | 231 |
gh_patches_debug_37663
|
rasdani/github-patches
|
git_diff
|
rotki__rotki-2172
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Importing IOTA trades from bitcoin.de throw errors
## Problem Definition
On importing exchange data from bitcoin.de an error is thrown:
"Query trades of bitcoinde exchange died with exception: Unknown asset IOT provided.. Check the logs for more details"
This is probably the same issue as in https://github.com/rotki/rotki/issues/299 -> IOT needs to be mapped to IOTA
## Logs
The log is empty.
### System Description
Operating system:
Rotki version: 1.12.2
</issue>
<code>
[start of rotkehlchen/exchanges/bitcoinde.py]
1 import hashlib
2 import hmac
3 import logging
4 import time
5 from json.decoder import JSONDecodeError
6 from typing import TYPE_CHECKING, Any, Dict, List, Optional, Tuple
7 from urllib.parse import urlencode
8
9 import requests
10 from typing_extensions import Literal
11
12 from rotkehlchen.assets.asset import Asset
13 from rotkehlchen.errors import RemoteError
14 from rotkehlchen.exchanges.data_structures import (
15 AssetMovement,
16 Location,
17 MarginPosition,
18 Price,
19 Trade,
20 TradePair,
21 )
22 from rotkehlchen.exchanges.exchange import ExchangeInterface
23 from rotkehlchen.inquirer import Inquirer
24 from rotkehlchen.logging import RotkehlchenLogsAdapter
25 from rotkehlchen.serialization.deserialize import (
26 deserialize_fee,
27 deserialize_timestamp_from_date,
28 deserialize_trade_type,
29 )
30 from rotkehlchen.typing import ApiKey, ApiSecret, AssetAmount, FVal, Timestamp
31 from rotkehlchen.user_messages import MessagesAggregator
32 from rotkehlchen.utils.misc import iso8601ts_to_timestamp
33 from rotkehlchen.utils.serialization import rlk_jsonloads
34
35 if TYPE_CHECKING:
36 from rotkehlchen.db.dbhandler import DBHandler
37
38 logger = logging.getLogger(__name__)
39 log = RotkehlchenLogsAdapter(logger)
40
41 # This corresponds to md5('') and is used in signature generation
42 MD5_EMPTY_STR = 'd41d8cd98f00b204e9800998ecf8427e'
43
44 # Pairs can be found in Basic API doc: https://www.bitcoin.de/de/api/marketplace
45 BITCOINDE_TRADING_PAIRS = (
46 'btceur',
47 'bcheur',
48 'btgeur',
49 'etheur',
50 'bsveur',
51 'ltceur',
52 )
53
54
55 def bitcoinde_asset(asset: str) -> Asset:
56 return Asset(asset.upper())
57
58
59 def bitcoinde_pair_to_world(pair: str) -> Tuple[Asset, Asset]:
60 tx_asset = bitcoinde_asset(pair[:3])
61 native_asset = bitcoinde_asset(pair[3:])
62 return tx_asset, native_asset
63
64
65 def trade_from_bitcoinde(raw_trade: Dict) -> Trade:
66
67 try:
68 timestamp = deserialize_timestamp_from_date(
69 raw_trade['successfully_finished_at'],
70 'iso8601',
71 'bitcoinde',
72 )
73 except KeyError:
74 # For very old trades (2013) bitcoin.de does not return 'successfully_finished_at'
75 timestamp = deserialize_timestamp_from_date(
76 raw_trade['trade_marked_as_paid_at'],
77 'iso8601',
78 'bitcoinde',
79 )
80
81 trade_type = deserialize_trade_type(raw_trade['type'])
82 tx_amount = AssetAmount(FVal(raw_trade['amount_currency_to_trade']))
83 native_amount = FVal(raw_trade['volume_currency_to_pay'])
84 tx_asset, native_asset = bitcoinde_pair_to_world(raw_trade['trading_pair'])
85 pair = TradePair(f'{tx_asset.identifier}_{native_asset.identifier}')
86 amount = tx_amount
87 rate = Price(native_amount / tx_amount)
88 fee_amount = deserialize_fee(raw_trade['fee_currency_to_pay'])
89 fee_asset = Asset('EUR')
90
91 return Trade(
92 timestamp=timestamp,
93 location=Location.BITCOINDE,
94 pair=pair,
95 trade_type=trade_type,
96 amount=amount,
97 rate=rate,
98 fee=fee_amount,
99 fee_currency=fee_asset,
100 link=str(raw_trade['trade_id']),
101 )
102
103
104 class Bitcoinde(ExchangeInterface): # lgtm[py/missing-call-to-init]
105 def __init__(
106 self,
107 api_key: ApiKey,
108 secret: ApiSecret,
109 database: 'DBHandler',
110 msg_aggregator: MessagesAggregator,
111 ):
112 super().__init__('bitcoinde', api_key, secret, database)
113 self.uri = 'https://api.bitcoin.de'
114 self.session.headers.update({'x-api-key': api_key})
115 self.msg_aggregator = msg_aggregator
116
117 def _generate_signature(self, request_type: str, url: str, nonce: str) -> str:
118 signed_data = '#'.join([request_type, url, self.api_key, nonce, MD5_EMPTY_STR]).encode()
119 signature = hmac.new(
120 self.secret,
121 signed_data,
122 hashlib.sha256,
123 ).hexdigest()
124 self.session.headers.update({
125 'x-api-signature': signature,
126 })
127 return signature
128
129 def _api_query(
130 self,
131 verb: Literal['get', 'post'],
132 path: str,
133 options: Optional[Dict] = None,
134 ) -> Dict:
135 """
136 Queries Bitcoin.de with the given verb for the given path and options
137 """
138 assert verb in ('get', 'post'), (
139 'Given verb {} is not a valid HTTP verb'.format(verb)
140 )
141
142 request_path_no_args = '/v4/' + path
143
144 data = ''
145 if not options:
146 request_path = request_path_no_args
147 else:
148 request_path = request_path_no_args + '?' + urlencode(options)
149
150 nonce = str(int(time.time() * 1000))
151 request_url = self.uri + request_path
152
153 self._generate_signature(
154 request_type=verb.upper(),
155 url=request_url,
156 nonce=nonce,
157 )
158
159 headers = {
160 'x-api-nonce': nonce,
161 }
162 if data != '':
163 headers.update({
164 'Content-Type': 'application/json',
165 'Content-Length': str(len(data)),
166 })
167
168 log.debug('Bitcoin.de API Query', verb=verb, request_url=request_url)
169
170 try:
171 response = getattr(self.session, verb)(request_url, data=data, headers=headers)
172 except requests.exceptions.RequestException as e:
173 raise RemoteError(f'Bitcoin.de API request failed due to {str(e)}') from e
174
175 try:
176 json_ret = rlk_jsonloads(response.text)
177 except JSONDecodeError as exc:
178 raise RemoteError('Bitcoin.de returned invalid JSON response') from exc
179
180 if response.status_code not in (200, 401):
181 if isinstance(json_ret, dict) and 'errors' in json_ret:
182 for error in json_ret['errors']:
183 if error.get('field') == 'X-API-KEY' and error.get('code') == 1:
184 raise RemoteError('Provided API Key is in invalid Format')
185
186 if error.get('code') == 3:
187 raise RemoteError('Provided API Key is invalid')
188
189 raise RemoteError(json_ret['errors'])
190
191 raise RemoteError(
192 'Bitcoin.de api request for {} failed with HTTP status code {}'.format(
193 response.url,
194 response.status_code,
195 ),
196 )
197
198 if not isinstance(json_ret, dict):
199 raise RemoteError('Bitcoin.de returned invalid non-dict response')
200
201 return json_ret
202
203 def validate_api_key(self) -> Tuple[bool, str]:
204 """
205 Validates that the Bitcoin.de API key is good for usage in Rotki
206 """
207
208 try:
209 self._api_query('get', 'account')
210 return True, ""
211
212 except RemoteError as e:
213 return False, str(e)
214
215 def query_balances(self, **kwargs: Any) -> Tuple[Optional[Dict[Asset, Dict[str, Any]]], str]:
216 balances = {}
217 try:
218 resp_info = self._api_query('get', 'account')
219 except RemoteError as e:
220 msg = (
221 'Bitcoin.de request failed. Could not reach bitcoin.de due '
222 'to {}'.format(e)
223 )
224 log.error(msg)
225 return None, msg
226
227 for currency, balance in resp_info['data']['balances'].items():
228 asset = bitcoinde_asset(currency)
229 try:
230 usd_price = Inquirer().find_usd_price(asset=asset)
231 except RemoteError as e:
232 self.msg_aggregator.add_error(
233 f'Error processing Bitcoin.de balance entry due to inability to '
234 f'query USD price: {str(e)}. Skipping balance entry',
235 )
236 continue
237
238 balances[asset] = {
239 'amount': balance['total_amount'],
240 'usd_value': balance['total_amount'] * usd_price,
241 }
242
243 return balances, ''
244
245 def query_online_trade_history(
246 self,
247 start_ts: Timestamp,
248 end_ts: Timestamp,
249 ) -> List[Trade]:
250
251 page = 1
252 resp_trades = []
253
254 while True:
255 resp = self._api_query('get', 'trades', {'state': 1, 'page': page})
256 resp_trades.extend(resp['trades'])
257
258 if 'page' not in resp:
259 break
260
261 if resp['page']['current'] >= resp['page']['last']:
262 break
263
264 page = resp['page']['current'] + 1
265
266 log.debug('Bitcoin.de trade history query', results_num=len(resp_trades))
267
268 trades = []
269 for tx in resp_trades:
270 try:
271 timestamp = iso8601ts_to_timestamp(tx['successfully_finished_at'])
272 except KeyError:
273 # For very old trades (2013) bitcoin.de does not return 'successfully_finished_at'
274 timestamp = iso8601ts_to_timestamp(tx['trade_marked_as_paid_at'])
275
276 if tx['state'] != 1:
277 continue
278 if timestamp < start_ts or timestamp > end_ts:
279 continue
280 trades.append(trade_from_bitcoinde(tx))
281
282 return trades
283
284 def query_online_deposits_withdrawals(
285 self, # pylint: disable=no-self-use
286 start_ts: Timestamp, # pylint: disable=unused-argument
287 end_ts: Timestamp, # pylint: disable=unused-argument
288 ) -> List[AssetMovement]:
289 return [] # noop for bitcoinde
290
291 def query_online_margin_history(
292 self, # pylint: disable=no-self-use
293 start_ts: Timestamp, # pylint: disable=unused-argument
294 end_ts: Timestamp, # pylint: disable=unused-argument
295 ) -> List[MarginPosition]:
296 return [] # noop for bitcoinde
297
[end of rotkehlchen/exchanges/bitcoinde.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/rotkehlchen/exchanges/bitcoinde.py b/rotkehlchen/exchanges/bitcoinde.py
--- a/rotkehlchen/exchanges/bitcoinde.py
+++ b/rotkehlchen/exchanges/bitcoinde.py
@@ -10,7 +10,7 @@
from typing_extensions import Literal
from rotkehlchen.assets.asset import Asset
-from rotkehlchen.errors import RemoteError
+from rotkehlchen.errors import DeserializationError, RemoteError, UnknownAsset
from rotkehlchen.exchanges.data_structures import (
AssetMovement,
Location,
@@ -41,7 +41,8 @@
# This corresponds to md5('') and is used in signature generation
MD5_EMPTY_STR = 'd41d8cd98f00b204e9800998ecf8427e'
-# Pairs can be found in Basic API doc: https://www.bitcoin.de/de/api/marketplace
+# Pairs can be found in Basic API doc:
+# https://www.bitcoin.de/en/api/tapi/v4/docu#handelspaarliste_c2f
BITCOINDE_TRADING_PAIRS = (
'btceur',
'bcheur',
@@ -49,6 +50,10 @@
'etheur',
'bsveur',
'ltceur',
+ 'iotabtc',
+ 'dashbtc',
+ 'gntbtc',
+ 'ltcbtc',
)
@@ -57,8 +62,14 @@
def bitcoinde_pair_to_world(pair: str) -> Tuple[Asset, Asset]:
- tx_asset = bitcoinde_asset(pair[:3])
- native_asset = bitcoinde_asset(pair[3:])
+ if len(pair) == 6:
+ tx_asset = bitcoinde_asset(pair[:3])
+ native_asset = bitcoinde_asset(pair[3:])
+ elif len(pair) in (7, 8):
+ tx_asset = bitcoinde_asset(pair[:4])
+ native_asset = bitcoinde_asset(pair[4:])
+ else:
+ raise DeserializationError(f'Could not parse pair: {pair}')
return tx_asset, native_asset
@@ -277,7 +288,28 @@
continue
if timestamp < start_ts or timestamp > end_ts:
continue
- trades.append(trade_from_bitcoinde(tx))
+ try:
+ trades.append(trade_from_bitcoinde(tx))
+ except UnknownAsset as e:
+ self.msg_aggregator.add_warning(
+ f'Found bitcoin.de trade with unknown asset '
+ f'{e.asset_name}. Ignoring it.',
+ )
+ continue
+ except (DeserializationError, KeyError) as e:
+ msg = str(e)
+ if isinstance(e, KeyError):
+ msg = f'Missing key entry for {msg}.'
+ self.msg_aggregator.add_error(
+ 'Error processing a Bitcoin.de trade. Check logs '
+ 'for details. Ignoring it.',
+ )
+ log.error(
+ 'Error processing a Bitcoin.de trade',
+ trade=tx,
+ error=msg,
+ )
+ continue
return trades
|
{"golden_diff": "diff --git a/rotkehlchen/exchanges/bitcoinde.py b/rotkehlchen/exchanges/bitcoinde.py\n--- a/rotkehlchen/exchanges/bitcoinde.py\n+++ b/rotkehlchen/exchanges/bitcoinde.py\n@@ -10,7 +10,7 @@\n from typing_extensions import Literal\n \n from rotkehlchen.assets.asset import Asset\n-from rotkehlchen.errors import RemoteError\n+from rotkehlchen.errors import DeserializationError, RemoteError, UnknownAsset\n from rotkehlchen.exchanges.data_structures import (\n AssetMovement,\n Location,\n@@ -41,7 +41,8 @@\n # This corresponds to md5('') and is used in signature generation\n MD5_EMPTY_STR = 'd41d8cd98f00b204e9800998ecf8427e'\n \n-# Pairs can be found in Basic API doc: https://www.bitcoin.de/de/api/marketplace\n+# Pairs can be found in Basic API doc:\n+# https://www.bitcoin.de/en/api/tapi/v4/docu#handelspaarliste_c2f\n BITCOINDE_TRADING_PAIRS = (\n 'btceur',\n 'bcheur',\n@@ -49,6 +50,10 @@\n 'etheur',\n 'bsveur',\n 'ltceur',\n+ 'iotabtc',\n+ 'dashbtc',\n+ 'gntbtc',\n+ 'ltcbtc',\n )\n \n \n@@ -57,8 +62,14 @@\n \n \n def bitcoinde_pair_to_world(pair: str) -> Tuple[Asset, Asset]:\n- tx_asset = bitcoinde_asset(pair[:3])\n- native_asset = bitcoinde_asset(pair[3:])\n+ if len(pair) == 6:\n+ tx_asset = bitcoinde_asset(pair[:3])\n+ native_asset = bitcoinde_asset(pair[3:])\n+ elif len(pair) in (7, 8):\n+ tx_asset = bitcoinde_asset(pair[:4])\n+ native_asset = bitcoinde_asset(pair[4:])\n+ else:\n+ raise DeserializationError(f'Could not parse pair: {pair}')\n return tx_asset, native_asset\n \n \n@@ -277,7 +288,28 @@\n continue\n if timestamp < start_ts or timestamp > end_ts:\n continue\n- trades.append(trade_from_bitcoinde(tx))\n+ try:\n+ trades.append(trade_from_bitcoinde(tx))\n+ except UnknownAsset as e:\n+ self.msg_aggregator.add_warning(\n+ f'Found bitcoin.de trade with unknown asset '\n+ f'{e.asset_name}. Ignoring it.',\n+ )\n+ continue\n+ except (DeserializationError, KeyError) as e:\n+ msg = str(e)\n+ if isinstance(e, KeyError):\n+ msg = f'Missing key entry for {msg}.'\n+ self.msg_aggregator.add_error(\n+ 'Error processing a Bitcoin.de trade. Check logs '\n+ 'for details. Ignoring it.',\n+ )\n+ log.error(\n+ 'Error processing a Bitcoin.de trade',\n+ trade=tx,\n+ error=msg,\n+ )\n+ continue\n \n return trades\n", "issue": "Importing IOTA trades from bitcoin.de throw errors\n## Problem Definition\r\n\r\nOn importing exchange data from bitcoin.de an error is thrown:\r\n\"Query trades of bitcoinde exchange died with exception: Unknown asset IOT provided.. Check the logs for more details\"\r\nThis is probably the same issue as in https://github.com/rotki/rotki/issues/299 -> IOT needs to be mapped to IOTA\r\n\r\n## Logs\r\n\r\nThe log is empty.\r\n\r\n\r\n### System Description\r\n\r\n\r\nOperating system: \r\nRotki version: 1.12.2\r\n\n", "before_files": [{"content": "import hashlib\nimport hmac\nimport logging\nimport time\nfrom json.decoder import JSONDecodeError\nfrom typing import TYPE_CHECKING, Any, Dict, List, Optional, Tuple\nfrom urllib.parse import urlencode\n\nimport requests\nfrom typing_extensions import Literal\n\nfrom rotkehlchen.assets.asset import Asset\nfrom rotkehlchen.errors import RemoteError\nfrom rotkehlchen.exchanges.data_structures import (\n AssetMovement,\n Location,\n MarginPosition,\n Price,\n Trade,\n TradePair,\n)\nfrom rotkehlchen.exchanges.exchange import ExchangeInterface\nfrom rotkehlchen.inquirer import Inquirer\nfrom rotkehlchen.logging import RotkehlchenLogsAdapter\nfrom rotkehlchen.serialization.deserialize import (\n deserialize_fee,\n deserialize_timestamp_from_date,\n deserialize_trade_type,\n)\nfrom rotkehlchen.typing import ApiKey, ApiSecret, AssetAmount, FVal, Timestamp\nfrom rotkehlchen.user_messages import MessagesAggregator\nfrom rotkehlchen.utils.misc import iso8601ts_to_timestamp\nfrom rotkehlchen.utils.serialization import rlk_jsonloads\n\nif TYPE_CHECKING:\n from rotkehlchen.db.dbhandler import DBHandler\n\nlogger = logging.getLogger(__name__)\nlog = RotkehlchenLogsAdapter(logger)\n\n# This corresponds to md5('') and is used in signature generation\nMD5_EMPTY_STR = 'd41d8cd98f00b204e9800998ecf8427e'\n\n# Pairs can be found in Basic API doc: https://www.bitcoin.de/de/api/marketplace\nBITCOINDE_TRADING_PAIRS = (\n 'btceur',\n 'bcheur',\n 'btgeur',\n 'etheur',\n 'bsveur',\n 'ltceur',\n)\n\n\ndef bitcoinde_asset(asset: str) -> Asset:\n return Asset(asset.upper())\n\n\ndef bitcoinde_pair_to_world(pair: str) -> Tuple[Asset, Asset]:\n tx_asset = bitcoinde_asset(pair[:3])\n native_asset = bitcoinde_asset(pair[3:])\n return tx_asset, native_asset\n\n\ndef trade_from_bitcoinde(raw_trade: Dict) -> Trade:\n\n try:\n timestamp = deserialize_timestamp_from_date(\n raw_trade['successfully_finished_at'],\n 'iso8601',\n 'bitcoinde',\n )\n except KeyError:\n # For very old trades (2013) bitcoin.de does not return 'successfully_finished_at'\n timestamp = deserialize_timestamp_from_date(\n raw_trade['trade_marked_as_paid_at'],\n 'iso8601',\n 'bitcoinde',\n )\n\n trade_type = deserialize_trade_type(raw_trade['type'])\n tx_amount = AssetAmount(FVal(raw_trade['amount_currency_to_trade']))\n native_amount = FVal(raw_trade['volume_currency_to_pay'])\n tx_asset, native_asset = bitcoinde_pair_to_world(raw_trade['trading_pair'])\n pair = TradePair(f'{tx_asset.identifier}_{native_asset.identifier}')\n amount = tx_amount\n rate = Price(native_amount / tx_amount)\n fee_amount = deserialize_fee(raw_trade['fee_currency_to_pay'])\n fee_asset = Asset('EUR')\n\n return Trade(\n timestamp=timestamp,\n location=Location.BITCOINDE,\n pair=pair,\n trade_type=trade_type,\n amount=amount,\n rate=rate,\n fee=fee_amount,\n fee_currency=fee_asset,\n link=str(raw_trade['trade_id']),\n )\n\n\nclass Bitcoinde(ExchangeInterface): # lgtm[py/missing-call-to-init]\n def __init__(\n self,\n api_key: ApiKey,\n secret: ApiSecret,\n database: 'DBHandler',\n msg_aggregator: MessagesAggregator,\n ):\n super().__init__('bitcoinde', api_key, secret, database)\n self.uri = 'https://api.bitcoin.de'\n self.session.headers.update({'x-api-key': api_key})\n self.msg_aggregator = msg_aggregator\n\n def _generate_signature(self, request_type: str, url: str, nonce: str) -> str:\n signed_data = '#'.join([request_type, url, self.api_key, nonce, MD5_EMPTY_STR]).encode()\n signature = hmac.new(\n self.secret,\n signed_data,\n hashlib.sha256,\n ).hexdigest()\n self.session.headers.update({\n 'x-api-signature': signature,\n })\n return signature\n\n def _api_query(\n self,\n verb: Literal['get', 'post'],\n path: str,\n options: Optional[Dict] = None,\n ) -> Dict:\n \"\"\"\n Queries Bitcoin.de with the given verb for the given path and options\n \"\"\"\n assert verb in ('get', 'post'), (\n 'Given verb {} is not a valid HTTP verb'.format(verb)\n )\n\n request_path_no_args = '/v4/' + path\n\n data = ''\n if not options:\n request_path = request_path_no_args\n else:\n request_path = request_path_no_args + '?' + urlencode(options)\n\n nonce = str(int(time.time() * 1000))\n request_url = self.uri + request_path\n\n self._generate_signature(\n request_type=verb.upper(),\n url=request_url,\n nonce=nonce,\n )\n\n headers = {\n 'x-api-nonce': nonce,\n }\n if data != '':\n headers.update({\n 'Content-Type': 'application/json',\n 'Content-Length': str(len(data)),\n })\n\n log.debug('Bitcoin.de API Query', verb=verb, request_url=request_url)\n\n try:\n response = getattr(self.session, verb)(request_url, data=data, headers=headers)\n except requests.exceptions.RequestException as e:\n raise RemoteError(f'Bitcoin.de API request failed due to {str(e)}') from e\n\n try:\n json_ret = rlk_jsonloads(response.text)\n except JSONDecodeError as exc:\n raise RemoteError('Bitcoin.de returned invalid JSON response') from exc\n\n if response.status_code not in (200, 401):\n if isinstance(json_ret, dict) and 'errors' in json_ret:\n for error in json_ret['errors']:\n if error.get('field') == 'X-API-KEY' and error.get('code') == 1:\n raise RemoteError('Provided API Key is in invalid Format')\n\n if error.get('code') == 3:\n raise RemoteError('Provided API Key is invalid')\n\n raise RemoteError(json_ret['errors'])\n\n raise RemoteError(\n 'Bitcoin.de api request for {} failed with HTTP status code {}'.format(\n response.url,\n response.status_code,\n ),\n )\n\n if not isinstance(json_ret, dict):\n raise RemoteError('Bitcoin.de returned invalid non-dict response')\n\n return json_ret\n\n def validate_api_key(self) -> Tuple[bool, str]:\n \"\"\"\n Validates that the Bitcoin.de API key is good for usage in Rotki\n \"\"\"\n\n try:\n self._api_query('get', 'account')\n return True, \"\"\n\n except RemoteError as e:\n return False, str(e)\n\n def query_balances(self, **kwargs: Any) -> Tuple[Optional[Dict[Asset, Dict[str, Any]]], str]:\n balances = {}\n try:\n resp_info = self._api_query('get', 'account')\n except RemoteError as e:\n msg = (\n 'Bitcoin.de request failed. Could not reach bitcoin.de due '\n 'to {}'.format(e)\n )\n log.error(msg)\n return None, msg\n\n for currency, balance in resp_info['data']['balances'].items():\n asset = bitcoinde_asset(currency)\n try:\n usd_price = Inquirer().find_usd_price(asset=asset)\n except RemoteError as e:\n self.msg_aggregator.add_error(\n f'Error processing Bitcoin.de balance entry due to inability to '\n f'query USD price: {str(e)}. Skipping balance entry',\n )\n continue\n\n balances[asset] = {\n 'amount': balance['total_amount'],\n 'usd_value': balance['total_amount'] * usd_price,\n }\n\n return balances, ''\n\n def query_online_trade_history(\n self,\n start_ts: Timestamp,\n end_ts: Timestamp,\n ) -> List[Trade]:\n\n page = 1\n resp_trades = []\n\n while True:\n resp = self._api_query('get', 'trades', {'state': 1, 'page': page})\n resp_trades.extend(resp['trades'])\n\n if 'page' not in resp:\n break\n\n if resp['page']['current'] >= resp['page']['last']:\n break\n\n page = resp['page']['current'] + 1\n\n log.debug('Bitcoin.de trade history query', results_num=len(resp_trades))\n\n trades = []\n for tx in resp_trades:\n try:\n timestamp = iso8601ts_to_timestamp(tx['successfully_finished_at'])\n except KeyError:\n # For very old trades (2013) bitcoin.de does not return 'successfully_finished_at'\n timestamp = iso8601ts_to_timestamp(tx['trade_marked_as_paid_at'])\n\n if tx['state'] != 1:\n continue\n if timestamp < start_ts or timestamp > end_ts:\n continue\n trades.append(trade_from_bitcoinde(tx))\n\n return trades\n\n def query_online_deposits_withdrawals(\n self, # pylint: disable=no-self-use\n start_ts: Timestamp, # pylint: disable=unused-argument\n end_ts: Timestamp, # pylint: disable=unused-argument\n ) -> List[AssetMovement]:\n return [] # noop for bitcoinde\n\n def query_online_margin_history(\n self, # pylint: disable=no-self-use\n start_ts: Timestamp, # pylint: disable=unused-argument\n end_ts: Timestamp, # pylint: disable=unused-argument\n ) -> List[MarginPosition]:\n return [] # noop for bitcoinde\n", "path": "rotkehlchen/exchanges/bitcoinde.py"}]}
| 3,643 | 715 |
gh_patches_debug_4941
|
rasdani/github-patches
|
git_diff
|
Parsl__parsl-1156
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Monitoring should be an optional extra
We should push this out as 0.8.1. This is needed by the nersc DESC stack.
</issue>
<code>
[start of setup.py]
1 from setuptools import setup, find_packages
2
3 with open('parsl/version.py') as f:
4 exec(f.read())
5
6 with open('requirements.txt') as f:
7 install_requires = f.readlines()
8
9 extras_require = {
10 'aws' : ['boto3'],
11 'kubernetes' : ['kubernetes'],
12 'oauth_ssh' : ['oauth-ssh>=0.9'],
13 'extreme_scale' : ['mpi4py'],
14 'docs' : ['nbsphinx', 'sphinx_rtd_theme'],
15 'google_cloud' : ['google-auth', 'google-api-python-client'],
16 'gssapi' : ['python-gssapi'],
17 'azure' : ['azure', 'msrestazure'],
18 'workqueue': ['work_queue'],
19 }
20 extras_require['all'] = sum(extras_require.values(), [])
21
22 setup(
23 name='parsl',
24 version=VERSION,
25 description='Simple data dependent workflows in Python',
26 long_description='Simple parallel workflows system for Python',
27 url='https://github.com/Parsl/parsl',
28 author='The Parsl Team',
29 author_email='[email protected]',
30 license='Apache 2.0',
31 download_url='https://github.com/Parsl/parsl/archive/{}.tar.gz'.format(VERSION),
32 include_package_data=True,
33 packages=find_packages(),
34 install_requires=install_requires,
35 scripts = ['parsl/executors/high_throughput/process_worker_pool.py',
36 'parsl/executors/extreme_scale/mpi_worker_pool.py',
37 'parsl/executors/low_latency/lowlatency_worker.py',
38 'parsl/executors/workqueue/workqueue_worker.py',
39 ],
40
41 extras_require=extras_require,
42 classifiers=[
43 # Maturity
44 'Development Status :: 3 - Alpha',
45 # Intended audience
46 'Intended Audience :: Developers',
47 # Licence, must match with licence above
48 'License :: OSI Approved :: Apache Software License',
49 # Python versions supported
50 'Programming Language :: Python :: 3.5',
51 'Programming Language :: Python :: 3.6',
52 ],
53 keywords=['Workflows', 'Scientific computing'],
54 entry_points={'console_scripts':
55 [
56 'parsl-globus-auth=parsl.data_provider.globus:cli_run',
57 'parsl-visualize=parsl.monitoring.visualization.app:cli_run',
58 ]}
59 )
60
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -7,6 +7,17 @@
install_requires = f.readlines()
extras_require = {
+ 'monitoring' : [
+ 'sqlalchemy>=1.3.0,!=1.3.4',
+ 'sqlalchemy_utils',
+ 'pydot',
+ 'networkx',
+ 'Flask>=1.0.2',
+ 'flask_sqlalchemy',
+ 'pandas',
+ 'plotly',
+ 'python-daemon'
+ ],
'aws' : ['boto3'],
'kubernetes' : ['kubernetes'],
'oauth_ssh' : ['oauth-ssh>=0.9'],
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -7,6 +7,17 @@\n install_requires = f.readlines()\n \n extras_require = {\n+ 'monitoring' : [\n+ 'sqlalchemy>=1.3.0,!=1.3.4',\n+ 'sqlalchemy_utils',\n+ 'pydot',\n+ 'networkx',\n+ 'Flask>=1.0.2',\n+ 'flask_sqlalchemy',\n+ 'pandas',\n+ 'plotly',\n+ 'python-daemon'\n+ ],\n 'aws' : ['boto3'],\n 'kubernetes' : ['kubernetes'],\n 'oauth_ssh' : ['oauth-ssh>=0.9'],\n", "issue": "Monitoring should be an optional extra\nWe should push this out as 0.8.1. This is needed by the nersc DESC stack.\n", "before_files": [{"content": "from setuptools import setup, find_packages\n\nwith open('parsl/version.py') as f:\n exec(f.read())\n\nwith open('requirements.txt') as f:\n install_requires = f.readlines()\n\nextras_require = {\n 'aws' : ['boto3'],\n 'kubernetes' : ['kubernetes'],\n 'oauth_ssh' : ['oauth-ssh>=0.9'],\n 'extreme_scale' : ['mpi4py'],\n 'docs' : ['nbsphinx', 'sphinx_rtd_theme'],\n 'google_cloud' : ['google-auth', 'google-api-python-client'],\n 'gssapi' : ['python-gssapi'],\n 'azure' : ['azure', 'msrestazure'],\n 'workqueue': ['work_queue'],\n}\nextras_require['all'] = sum(extras_require.values(), [])\n\nsetup(\n name='parsl',\n version=VERSION,\n description='Simple data dependent workflows in Python',\n long_description='Simple parallel workflows system for Python',\n url='https://github.com/Parsl/parsl',\n author='The Parsl Team',\n author_email='[email protected]',\n license='Apache 2.0',\n download_url='https://github.com/Parsl/parsl/archive/{}.tar.gz'.format(VERSION),\n include_package_data=True,\n packages=find_packages(),\n install_requires=install_requires,\n scripts = ['parsl/executors/high_throughput/process_worker_pool.py',\n 'parsl/executors/extreme_scale/mpi_worker_pool.py',\n 'parsl/executors/low_latency/lowlatency_worker.py',\n 'parsl/executors/workqueue/workqueue_worker.py',\n ],\n\n extras_require=extras_require,\n classifiers=[\n # Maturity\n 'Development Status :: 3 - Alpha',\n # Intended audience\n 'Intended Audience :: Developers',\n # Licence, must match with licence above\n 'License :: OSI Approved :: Apache Software License',\n # Python versions supported\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n ],\n keywords=['Workflows', 'Scientific computing'],\n entry_points={'console_scripts':\n [\n 'parsl-globus-auth=parsl.data_provider.globus:cli_run',\n 'parsl-visualize=parsl.monitoring.visualization.app:cli_run',\n ]}\n)\n", "path": "setup.py"}]}
| 1,182 | 166 |
gh_patches_debug_2799
|
rasdani/github-patches
|
git_diff
|
kartoza__prj.app-199
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Atom feed gets a 500 error
See http://sentry.kartoza.com/kartoza/projecta-live/group/5846/
Problem is cause by models/entry.py get_absolute_url() method which still uses old slug system to resolve path to an entry.
</issue>
<code>
[start of django_project/changes/models/entry.py]
1 # coding=utf-8
2 """Models for changelog entries."""
3 from django.core.urlresolvers import reverse
4 from django.utils.text import slugify
5 import os
6 import logging
7 from core.settings.contrib import STOP_WORDS
8 from django.conf.global_settings import MEDIA_ROOT
9 from django.db import models
10 from embed_video.fields import EmbedVideoField
11 from django.contrib.auth.models import User
12
13 logger = logging.getLogger(__name__)
14
15
16 class ApprovedEntryManager(models.Manager):
17 """Custom entry manager that shows only approved records."""
18
19 def get_queryset(self):
20 """Query set generator"""
21 return super(
22 ApprovedEntryManager, self).get_queryset().filter(
23 approved=True)
24
25
26 class UnapprovedEntryManager(models.Manager):
27 """Custom entry manager that shows only unapproved records."""
28
29 def get_queryset(self):
30 """Query set generator"""
31 return super(
32 UnapprovedEntryManager, self).get_queryset().filter(
33 approved=False)
34
35
36 class Entry(models.Model):
37 """An entry is the basic unit of a changelog."""
38 title = models.CharField(
39 help_text='Feature title for this changelog entry.',
40 max_length=255,
41 null=False,
42 blank=False,
43 unique=False) # Unique together rule applies in meta class
44
45 description = models.TextField(
46 null=True,
47 blank=True,
48 help_text='Describe the new feature. Markdown is supported.')
49
50 image_file = models.ImageField(
51 help_text=(
52 'A image that is related to this visual changelog entry. '
53 'Most browsers support dragging the image directly on to the '
54 '"Choose File" button above.'),
55 upload_to=os.path.join(MEDIA_ROOT, 'images/entries'),
56 blank=True)
57
58 image_credits = models.CharField(
59 help_text='Who should be credited for this image?',
60 max_length=255,
61 null=True,
62 blank=True)
63
64 video = EmbedVideoField(
65 verbose_name='Youtube video',
66 help_text='Paste your youtube video link',
67 null=True,
68 blank=True)
69
70 funded_by = models.CharField(
71 help_text='Input the funder name.',
72 max_length=255,
73 null=True,
74 blank=True)
75
76 funder_url = models.CharField(
77 help_text='Input the funder URL.',
78 max_length=255,
79 null=True,
80 blank=True)
81
82 developed_by = models.CharField(
83 help_text='Input the developer name.',
84 max_length=255,
85 null=True,
86 blank=True)
87
88 developer_url = models.CharField(
89 help_text='Input the developer URL.',
90 max_length=255,
91 null=True,
92 blank=True)
93
94 approved = models.BooleanField(
95 help_text=(
96 'Whether this entry has been approved for use by the '
97 'project owner.'),
98 default=False
99 )
100 author = models.ForeignKey(User)
101 slug = models.SlugField()
102 # noinspection PyUnresolvedReferences
103 version = models.ForeignKey('Version')
104 # noinspection PyUnresolvedReferences
105 category = models.ForeignKey('Category')
106 objects = models.Manager()
107 approved_objects = ApprovedEntryManager()
108 unapproved_objects = UnapprovedEntryManager()
109
110 # noinspection PyClassicStyleClass
111 class Meta:
112 """Meta options for the version class."""
113 unique_together = (
114 ('title', 'version', 'category'),
115 ('version', 'slug'),
116 )
117 app_label = 'changes'
118
119 def save(self, *args, **kwargs):
120 if not self.pk:
121 words = self.title.split()
122 filtered_words = [t for t in words if t.lower() not in STOP_WORDS]
123 new_list = ' '.join(filtered_words)
124 self.slug = slugify(new_list)[:50]
125 super(Entry, self).save(*args, **kwargs)
126
127 def __unicode__(self):
128 return u'%s' % self.title
129
130 def get_absolute_url(self):
131 return reverse('entry-detail', kwargs={
132 'slug': self.slug,
133 'version_slug': self.version.slug,
134 'project_slug': self.version.project.slug
135 })
136
137 def funder_info_html(self):
138 string = ""
139 if self.funded_by and self.funder_url is None:
140 string = ""
141 return string
142 elif self.funded_by and not self.funder_url:
143 string = "This feature was funded by %s " % self.funded_by
144 return string
145 elif self.funder_url and not self.funded_by:
146 string = "This feature was funded by [%s](%s)" % (
147 self.funder_url, self.funder_url)
148 return string
149 elif self.funded_by and self.funder_url:
150 string = "This feature was funded by [%s](%s)" % (
151 self.funded_by, self.funder_url)
152 return string
153 else:
154 return string
155
156 def developer_info_html(self):
157 string = ""
158 if self.developed_by and self.developer_url is None:
159 string = ""
160 return string
161 elif self.developed_by and not self.developer_url:
162 string = "This feature was developed by %s " % self.developed_by
163 return string
164 elif self.developer_url and not self.developed_by:
165 string = "This feature was developed by [%s](%s)" % (
166 self.developer_url, self.developer_url)
167 return string
168 elif self.developed_by and self.developer_url:
169 string = "This feature was developed by [%s](%s)" % (
170 self.developed_by, self.developer_url)
171 return string
172 else:
173 return string
174
[end of django_project/changes/models/entry.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/django_project/changes/models/entry.py b/django_project/changes/models/entry.py
--- a/django_project/changes/models/entry.py
+++ b/django_project/changes/models/entry.py
@@ -129,9 +129,7 @@
def get_absolute_url(self):
return reverse('entry-detail', kwargs={
- 'slug': self.slug,
- 'version_slug': self.version.slug,
- 'project_slug': self.version.project.slug
+ 'pk': self.id
})
def funder_info_html(self):
|
{"golden_diff": "diff --git a/django_project/changes/models/entry.py b/django_project/changes/models/entry.py\n--- a/django_project/changes/models/entry.py\n+++ b/django_project/changes/models/entry.py\n@@ -129,9 +129,7 @@\n \n def get_absolute_url(self):\n return reverse('entry-detail', kwargs={\n- 'slug': self.slug,\n- 'version_slug': self.version.slug,\n- 'project_slug': self.version.project.slug\n+ 'pk': self.id\n })\n \n def funder_info_html(self):\n", "issue": "Atom feed gets a 500 error\nSee http://sentry.kartoza.com/kartoza/projecta-live/group/5846/\n\nProblem is cause by models/entry.py get_absolute_url() method which still uses old slug system to resolve path to an entry.\n\n", "before_files": [{"content": "# coding=utf-8\n\"\"\"Models for changelog entries.\"\"\"\nfrom django.core.urlresolvers import reverse\nfrom django.utils.text import slugify\nimport os\nimport logging\nfrom core.settings.contrib import STOP_WORDS\nfrom django.conf.global_settings import MEDIA_ROOT\nfrom django.db import models\nfrom embed_video.fields import EmbedVideoField\nfrom django.contrib.auth.models import User\n\nlogger = logging.getLogger(__name__)\n\n\nclass ApprovedEntryManager(models.Manager):\n \"\"\"Custom entry manager that shows only approved records.\"\"\"\n\n def get_queryset(self):\n \"\"\"Query set generator\"\"\"\n return super(\n ApprovedEntryManager, self).get_queryset().filter(\n approved=True)\n\n\nclass UnapprovedEntryManager(models.Manager):\n \"\"\"Custom entry manager that shows only unapproved records.\"\"\"\n\n def get_queryset(self):\n \"\"\"Query set generator\"\"\"\n return super(\n UnapprovedEntryManager, self).get_queryset().filter(\n approved=False)\n\n\nclass Entry(models.Model):\n \"\"\"An entry is the basic unit of a changelog.\"\"\"\n title = models.CharField(\n help_text='Feature title for this changelog entry.',\n max_length=255,\n null=False,\n blank=False,\n unique=False) # Unique together rule applies in meta class\n\n description = models.TextField(\n null=True,\n blank=True,\n help_text='Describe the new feature. Markdown is supported.')\n\n image_file = models.ImageField(\n help_text=(\n 'A image that is related to this visual changelog entry. '\n 'Most browsers support dragging the image directly on to the '\n '\"Choose File\" button above.'),\n upload_to=os.path.join(MEDIA_ROOT, 'images/entries'),\n blank=True)\n\n image_credits = models.CharField(\n help_text='Who should be credited for this image?',\n max_length=255,\n null=True,\n blank=True)\n\n video = EmbedVideoField(\n verbose_name='Youtube video',\n help_text='Paste your youtube video link',\n null=True,\n blank=True)\n\n funded_by = models.CharField(\n help_text='Input the funder name.',\n max_length=255,\n null=True,\n blank=True)\n\n funder_url = models.CharField(\n help_text='Input the funder URL.',\n max_length=255,\n null=True,\n blank=True)\n\n developed_by = models.CharField(\n help_text='Input the developer name.',\n max_length=255,\n null=True,\n blank=True)\n\n developer_url = models.CharField(\n help_text='Input the developer URL.',\n max_length=255,\n null=True,\n blank=True)\n\n approved = models.BooleanField(\n help_text=(\n 'Whether this entry has been approved for use by the '\n 'project owner.'),\n default=False\n )\n author = models.ForeignKey(User)\n slug = models.SlugField()\n # noinspection PyUnresolvedReferences\n version = models.ForeignKey('Version')\n # noinspection PyUnresolvedReferences\n category = models.ForeignKey('Category')\n objects = models.Manager()\n approved_objects = ApprovedEntryManager()\n unapproved_objects = UnapprovedEntryManager()\n\n # noinspection PyClassicStyleClass\n class Meta:\n \"\"\"Meta options for the version class.\"\"\"\n unique_together = (\n ('title', 'version', 'category'),\n ('version', 'slug'),\n )\n app_label = 'changes'\n\n def save(self, *args, **kwargs):\n if not self.pk:\n words = self.title.split()\n filtered_words = [t for t in words if t.lower() not in STOP_WORDS]\n new_list = ' '.join(filtered_words)\n self.slug = slugify(new_list)[:50]\n super(Entry, self).save(*args, **kwargs)\n\n def __unicode__(self):\n return u'%s' % self.title\n\n def get_absolute_url(self):\n return reverse('entry-detail', kwargs={\n 'slug': self.slug,\n 'version_slug': self.version.slug,\n 'project_slug': self.version.project.slug\n })\n\n def funder_info_html(self):\n string = \"\"\n if self.funded_by and self.funder_url is None:\n string = \"\"\n return string\n elif self.funded_by and not self.funder_url:\n string = \"This feature was funded by %s \" % self.funded_by\n return string\n elif self.funder_url and not self.funded_by:\n string = \"This feature was funded by [%s](%s)\" % (\n self.funder_url, self.funder_url)\n return string\n elif self.funded_by and self.funder_url:\n string = \"This feature was funded by [%s](%s)\" % (\n self.funded_by, self.funder_url)\n return string\n else:\n return string\n\n def developer_info_html(self):\n string = \"\"\n if self.developed_by and self.developer_url is None:\n string = \"\"\n return string\n elif self.developed_by and not self.developer_url:\n string = \"This feature was developed by %s \" % self.developed_by\n return string\n elif self.developer_url and not self.developed_by:\n string = \"This feature was developed by [%s](%s)\" % (\n self.developer_url, self.developer_url)\n return string\n elif self.developed_by and self.developer_url:\n string = \"This feature was developed by [%s](%s)\" % (\n self.developed_by, self.developer_url)\n return string\n else:\n return string\n", "path": "django_project/changes/models/entry.py"}]}
| 2,217 | 127 |
gh_patches_debug_490
|
rasdani/github-patches
|
git_diff
|
scikit-hep__awkward-2009
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`ak.type` does not accept "anything `ak.to_layout` recognizes"
### Version of Awkward Array
main
### Description and code to reproduce
```python
>>> import awkward as ak
>>> ak.type([1,2,3])
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[12], line 1
----> 1 ak.type([1,2,3])
File /lib/python3.10/site-packages/awkward/operations/ak_type.py:77, in type(array)
15 """
16 Args:
17 array: Array-like data (anything #ak.to_layout recognizes).
(...)
71 to the language.)
72 """
73 with ak._errors.OperationErrorContext(
74 "ak.type",
75 dict(array=array),
76 ):
---> 77 return _impl(array)
File /lib/python3.10/site-packages/awkward/operations/ak_type.py:144, in _impl(array)
141 return array.form.type
143 else:
--> 144 raise ak._errors.wrap_error(TypeError(f"unrecognized array type: {array!r}"))
TypeError: while calling
ak.type(
array = [1, 2, 3]
)
Error details: unrecognized array type: [1, 2, 3]
```
</issue>
<code>
[start of src/awkward/operations/ak_type.py]
1 # BSD 3-Clause License; see https://github.com/scikit-hep/awkward-1.0/blob/main/LICENSE
2
3 import builtins
4 import numbers
5 from datetime import datetime, timedelta
6
7 from awkward_cpp.lib import _ext
8
9 import awkward as ak
10
11 np = ak._nplikes.NumpyMetadata.instance()
12
13
14 def type(array):
15 """
16 Args:
17 array: Array-like data (anything #ak.to_layout recognizes).
18
19 The high-level type of an `array` (many types supported, including all
20 Awkward Arrays and Records) as #ak.types.Type objects.
21
22 The high-level type ignores layout differences like
23 #ak.contents.ListArray versus #ak.contents.ListOffsetArray, but
24 not differences like "regular-sized lists" (i.e.
25 #ak.contents.RegularArray) versus "variable-sized lists" (i.e.
26 #ak.contents.ListArray and similar).
27
28 Types are rendered as [Datashape](https://datashape.readthedocs.io/)
29 strings, which makes the same distinctions.
30
31 For example,
32
33 >>> array = ak.Array([[{"x": 1.1, "y": [1]}, {"x": 2.2, "y": [2, 2]}],
34 ... [],
35 ... [{"x": 3.3, "y": [3, 3, 3]}]])
36
37 has type
38
39 >>> ak.type(array).show()
40 3 * var * {
41 x: float64,
42 y: var * int64
43 }
44
45 but
46
47 >>> array = ak.Array(np.arange(2*3*5).reshape(2, 3, 5))
48
49 has type
50
51 >>> ak.type(array).show()
52 2 * 3 * 5 * int64
53
54 Some cases, like heterogeneous data, require [extensions beyond the
55 Datashape specification](https://github.com/blaze/datashape/issues/237).
56 For example,
57
58 >>> array = ak.Array([1, "two", [3, 3, 3]])
59
60 has type
61
62 >>> ak.type(array).show()
63 3 * union[
64 int64,
65 string,
66 var * int64
67 ]
68
69 but "union" is not a Datashape type-constructor. (Its syntax is
70 similar to existing type-constructors, so it's a plausible addition
71 to the language.)
72 """
73 with ak._errors.OperationErrorContext(
74 "ak.type",
75 dict(array=array),
76 ):
77 return _impl(array)
78
79
80 def _impl(array):
81 if array is None:
82 return ak.types.UnknownType()
83
84 elif isinstance(array, np.dtype):
85 return ak.types.NumpyType(ak.types.numpytype.dtype_to_primitive(array))
86
87 elif (
88 isinstance(array, np.generic)
89 or isinstance(array, builtins.type)
90 and issubclass(array, np.generic)
91 ):
92 primitive = ak.types.numpytype.dtype_to_primitive(np.dtype(array))
93 return ak.types.NumpyType(primitive)
94
95 elif isinstance(array, bool): # np.bool_ in np.generic (above)
96 return ak.types.NumpyType("bool")
97
98 elif isinstance(array, numbers.Integral):
99 return ak.types.NumpyType("int64")
100
101 elif isinstance(array, numbers.Real):
102 return ak.types.NumpyType("float64")
103
104 elif isinstance(array, numbers.Complex):
105 return ak.types.NumpyType("complex128")
106
107 elif isinstance(array, datetime): # np.datetime64 in np.generic (above)
108 return ak.types.NumpyType("datetime64")
109
110 elif isinstance(array, timedelta): # np.timedelta64 in np.generic (above)
111 return ak.types.NumpyType("timedelta")
112
113 elif isinstance(
114 array,
115 (
116 ak.highlevel.Array,
117 ak.highlevel.Record,
118 ak.highlevel.ArrayBuilder,
119 ),
120 ):
121 return array.type
122
123 elif isinstance(array, np.ndarray):
124 if len(array.shape) == 0:
125 return _impl(array.reshape((1,))[0])
126 else:
127 primitive = ak.types.numpytype.dtype_to_primitive(array.dtype)
128 out = ak.types.NumpyType(primitive)
129 for x in array.shape[-1:0:-1]:
130 out = ak.types.RegularType(out, x)
131 return ak.types.ArrayType(out, array.shape[0])
132
133 elif isinstance(array, _ext.ArrayBuilder):
134 form = ak.forms.from_json(array.form())
135 return ak.types.ArrayType(form.type_from_behavior(None), len(array))
136
137 elif isinstance(array, ak.record.Record):
138 return array.array.form.type
139
140 elif isinstance(array, ak.contents.Content):
141 return array.form.type
142
143 else:
144 raise ak._errors.wrap_error(TypeError(f"unrecognized array type: {array!r}"))
145
[end of src/awkward/operations/ak_type.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/awkward/operations/ak_type.py b/src/awkward/operations/ak_type.py
--- a/src/awkward/operations/ak_type.py
+++ b/src/awkward/operations/ak_type.py
@@ -141,4 +141,5 @@
return array.form.type
else:
- raise ak._errors.wrap_error(TypeError(f"unrecognized array type: {array!r}"))
+ layout = ak.to_layout(array, allow_other=False)
+ return _impl(ak._util.wrap(layout))
|
{"golden_diff": "diff --git a/src/awkward/operations/ak_type.py b/src/awkward/operations/ak_type.py\n--- a/src/awkward/operations/ak_type.py\n+++ b/src/awkward/operations/ak_type.py\n@@ -141,4 +141,5 @@\n return array.form.type\n \n else:\n- raise ak._errors.wrap_error(TypeError(f\"unrecognized array type: {array!r}\"))\n+ layout = ak.to_layout(array, allow_other=False)\n+ return _impl(ak._util.wrap(layout))\n", "issue": "`ak.type` does not accept \"anything `ak.to_layout` recognizes\"\n### Version of Awkward Array\n\nmain\n\n### Description and code to reproduce\n\n```python\r\n>>> import awkward as ak\r\n>>> ak.type([1,2,3])\r\n\r\n---------------------------------------------------------------------------\r\nTypeError Traceback (most recent call last)\r\nCell In[12], line 1\r\n----> 1 ak.type([1,2,3])\r\n\r\nFile /lib/python3.10/site-packages/awkward/operations/ak_type.py:77, in type(array)\r\n 15 \"\"\"\r\n 16 Args:\r\n 17 array: Array-like data (anything #ak.to_layout recognizes).\r\n (...)\r\n 71 to the language.)\r\n 72 \"\"\"\r\n 73 with ak._errors.OperationErrorContext(\r\n 74 \"ak.type\",\r\n 75 dict(array=array),\r\n 76 ):\r\n---> 77 return _impl(array)\r\n\r\nFile /lib/python3.10/site-packages/awkward/operations/ak_type.py:144, in _impl(array)\r\n 141 return array.form.type\r\n 143 else:\r\n--> 144 raise ak._errors.wrap_error(TypeError(f\"unrecognized array type: {array!r}\"))\r\n\r\nTypeError: while calling\r\n\r\n ak.type(\r\n array = [1, 2, 3]\r\n )\r\n\r\nError details: unrecognized array type: [1, 2, 3]\r\n```\n", "before_files": [{"content": "# BSD 3-Clause License; see https://github.com/scikit-hep/awkward-1.0/blob/main/LICENSE\n\nimport builtins\nimport numbers\nfrom datetime import datetime, timedelta\n\nfrom awkward_cpp.lib import _ext\n\nimport awkward as ak\n\nnp = ak._nplikes.NumpyMetadata.instance()\n\n\ndef type(array):\n \"\"\"\n Args:\n array: Array-like data (anything #ak.to_layout recognizes).\n\n The high-level type of an `array` (many types supported, including all\n Awkward Arrays and Records) as #ak.types.Type objects.\n\n The high-level type ignores layout differences like\n #ak.contents.ListArray versus #ak.contents.ListOffsetArray, but\n not differences like \"regular-sized lists\" (i.e.\n #ak.contents.RegularArray) versus \"variable-sized lists\" (i.e.\n #ak.contents.ListArray and similar).\n\n Types are rendered as [Datashape](https://datashape.readthedocs.io/)\n strings, which makes the same distinctions.\n\n For example,\n\n >>> array = ak.Array([[{\"x\": 1.1, \"y\": [1]}, {\"x\": 2.2, \"y\": [2, 2]}],\n ... [],\n ... [{\"x\": 3.3, \"y\": [3, 3, 3]}]])\n\n has type\n\n >>> ak.type(array).show()\n 3 * var * {\n x: float64,\n y: var * int64\n }\n\n but\n\n >>> array = ak.Array(np.arange(2*3*5).reshape(2, 3, 5))\n\n has type\n\n >>> ak.type(array).show()\n 2 * 3 * 5 * int64\n\n Some cases, like heterogeneous data, require [extensions beyond the\n Datashape specification](https://github.com/blaze/datashape/issues/237).\n For example,\n\n >>> array = ak.Array([1, \"two\", [3, 3, 3]])\n\n has type\n\n >>> ak.type(array).show()\n 3 * union[\n int64,\n string,\n var * int64\n ]\n\n but \"union\" is not a Datashape type-constructor. (Its syntax is\n similar to existing type-constructors, so it's a plausible addition\n to the language.)\n \"\"\"\n with ak._errors.OperationErrorContext(\n \"ak.type\",\n dict(array=array),\n ):\n return _impl(array)\n\n\ndef _impl(array):\n if array is None:\n return ak.types.UnknownType()\n\n elif isinstance(array, np.dtype):\n return ak.types.NumpyType(ak.types.numpytype.dtype_to_primitive(array))\n\n elif (\n isinstance(array, np.generic)\n or isinstance(array, builtins.type)\n and issubclass(array, np.generic)\n ):\n primitive = ak.types.numpytype.dtype_to_primitive(np.dtype(array))\n return ak.types.NumpyType(primitive)\n\n elif isinstance(array, bool): # np.bool_ in np.generic (above)\n return ak.types.NumpyType(\"bool\")\n\n elif isinstance(array, numbers.Integral):\n return ak.types.NumpyType(\"int64\")\n\n elif isinstance(array, numbers.Real):\n return ak.types.NumpyType(\"float64\")\n\n elif isinstance(array, numbers.Complex):\n return ak.types.NumpyType(\"complex128\")\n\n elif isinstance(array, datetime): # np.datetime64 in np.generic (above)\n return ak.types.NumpyType(\"datetime64\")\n\n elif isinstance(array, timedelta): # np.timedelta64 in np.generic (above)\n return ak.types.NumpyType(\"timedelta\")\n\n elif isinstance(\n array,\n (\n ak.highlevel.Array,\n ak.highlevel.Record,\n ak.highlevel.ArrayBuilder,\n ),\n ):\n return array.type\n\n elif isinstance(array, np.ndarray):\n if len(array.shape) == 0:\n return _impl(array.reshape((1,))[0])\n else:\n primitive = ak.types.numpytype.dtype_to_primitive(array.dtype)\n out = ak.types.NumpyType(primitive)\n for x in array.shape[-1:0:-1]:\n out = ak.types.RegularType(out, x)\n return ak.types.ArrayType(out, array.shape[0])\n\n elif isinstance(array, _ext.ArrayBuilder):\n form = ak.forms.from_json(array.form())\n return ak.types.ArrayType(form.type_from_behavior(None), len(array))\n\n elif isinstance(array, ak.record.Record):\n return array.array.form.type\n\n elif isinstance(array, ak.contents.Content):\n return array.form.type\n\n else:\n raise ak._errors.wrap_error(TypeError(f\"unrecognized array type: {array!r}\"))\n", "path": "src/awkward/operations/ak_type.py"}]}
| 2,245 | 122 |
gh_patches_debug_23185
|
rasdani/github-patches
|
git_diff
|
angr__angr-3508
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
TypeError angr 9.2.16 and PyPy 7.3.9 (CPython 3.9)
<!--
*Disclaimer:
The angr suite is maintained by a small team of volunteers.
While we cannot guarantee any timeliness for fixes and enhancements, we will do our best.
For more real-time help with angr, from us and the community, join our [Slack.](https://angr.io/invite/)*
-->
---
**Describe the bug.**
<!--
Please include a clear and concise description of what the bug is.
-->
The latest version of angr appears to have issues when ran with the latest version of PyPy (I haven't tested with CPython). This issue affects all angr versions newer than 9.2.11:
```text
$ python --version
Python 3.9.12 (05fbe3aa5b0845e6c37239768aa455451aa5faba, Mar 29 2022, 08:15:34)
[PyPy 7.3.9 with GCC 10.2.1 20210130 (Red Hat 10.2.1-11)]
$ python -c "import angr; p = angr.Project('/bin/ls')"
WARNING | 2022-08-31 09:52:12,054 | cle.loader | The main binary is a position-independent executable. It is being loaded with a base address of 0x400000.
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/home/carter/env/lib/pypy3.9/site-packages/angr/project.py", line 230, in __init__
self.simos.configure_project()
File "/home/carter/env/lib/pypy3.9/site-packages/angr/simos/linux.py", line 161, in configure_project
super(SimLinux, self).configure_project(syscall_abis)
File "/home/carter/env/lib/pypy3.9/site-packages/angr/simos/userland.py", line 49, in configure_project
super().configure_project()
File "/home/carter/env/lib/pypy3.9/site-packages/angr/simos/simos.py", line 82, in configure_project
self.project.loader.perform_irelative_relocs(irelative_resolver)
File "/home/carter/env/lib/pypy3.9/site-packages/cle/loader.py", line 601, in perform_irelative_relocs
val = resolver_func(resolver)
File "/home/carter/env/lib/pypy3.9/site-packages/angr/simos/simos.py", line 72, in irelative_resolver
val = resolver()
File "/home/carter/env/lib/pypy3.9/site-packages/angr/callable.py", line 55, in __call__
self.perform_call(*args, prototype=prototype)
File "/home/carter/env/lib/pypy3.9/site-packages/angr/callable.py", line 78, in perform_call
caller = self._project.factory.simulation_manager(state)
File "/home/carter/env/lib/pypy3.9/site-packages/angr/factory.py", line 181, in simulation_manager
return SimulationManager(self.project, active_states=thing, **kwargs)
File "/home/carter/env/lib/pypy3.9/site-packages/angr/sim_manager.py", line 94, in __init__
self._hierarchy = StateHierarchy() if hierarchy is None else hierarchy
File "/home/carter/env/lib/pypy3.9/site-packages/angr/state_hierarchy.py", line 31, in __init__
self._lock = PicklableRLock()
File "/home/carter/env/lib/pypy3.9/site-packages/angr/misc/picklable_lock.py", line 11, in __init__
self._lock = self._LOCK(*args, **kwargs) # pylint: disable=too-many-function-args
File "/home/carter/pypy3.9/lib/pypy3.9/threading.py", line 93, in RLock
return _CRLock(*args, **kwargs)
TypeError: __new__() takes 1 positional argument but 2 were given
```
**Environment Information.**
<!--
Many common issues are caused by problems with the local Python environment.
Before submitting, double-check that your versions of all modules in the angr suite (angr, cle, pyvex, ...) are up to date.
Please include the output of `python -m angr.misc.bug_report` here.
-->
* Affects angr versions 9.2.12 through 9.2.16
* PyPy version 7.3.9 (latest release at time of writing)
* Debian Bullseye
**To Reproduce.**
<!--
Please include *both a script to reproduce the crash, and attach the binary used, if possible*
-->
1. Install latest PyPy release
2. Install angr version 9.2.16
3. Run: `python -c "import angr; p = angr.Project('/bin/ls')`
</issue>
<code>
[start of angr/misc/picklable_lock.py]
1 import threading
2
3 class PicklableLock:
4 """
5 Normal thread-locks are not pickleable. This provides a pickleable lock by mandating that the lock is unlocked
6 during serialization.
7 """
8 _LOCK = threading.Lock
9
10 def __init__(self, *args, **kwargs):
11 self._lock = self._LOCK(*args, **kwargs) # pylint: disable=too-many-function-args
12
13 def __enter__(self):
14 return self._lock.__enter__()
15
16 def __exit__(self, exc_type, exc_val, exc_tb):
17 return self._lock.__exit__(exc_type, exc_val, exc_tb)
18
19 def acquire(self, *args, **kwargs):
20 return self._lock.acquire(*args, **kwargs)
21
22 def locked(self):
23 return self._lock.locked()
24
25 def release(self):
26 return self._lock.release()
27
28 def __reduce__(self):
29 if self.locked():
30 raise TypeError("Why are you pickling a locked lock")
31 return type(self), ()
32
33 class PicklableRLock(PicklableLock):
34 """
35 Same as above, but uses RLock instead of Lock for locking. Note that RLock does not provide an interface to tell
36 whether is it presently held by any thread, and thus this class will lie about whether it is locked.
37 """
38 _LOCK = threading.RLock
39
40 def locked(self):
41 return False # ummmmmmmmmmmmmmmm
42
[end of angr/misc/picklable_lock.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/angr/misc/picklable_lock.py b/angr/misc/picklable_lock.py
--- a/angr/misc/picklable_lock.py
+++ b/angr/misc/picklable_lock.py
@@ -1,5 +1,6 @@
import threading
+
class PicklableLock:
"""
Normal thread-locks are not pickleable. This provides a pickleable lock by mandating that the lock is unlocked
@@ -8,7 +9,7 @@
_LOCK = threading.Lock
def __init__(self, *args, **kwargs):
- self._lock = self._LOCK(*args, **kwargs) # pylint: disable=too-many-function-args
+ self._lock = self.__class__._LOCK(*args, **kwargs) # pylint: disable=too-many-function-args
def __enter__(self):
return self._lock.__enter__()
@@ -30,6 +31,7 @@
raise TypeError("Why are you pickling a locked lock")
return type(self), ()
+
class PicklableRLock(PicklableLock):
"""
Same as above, but uses RLock instead of Lock for locking. Note that RLock does not provide an interface to tell
|
{"golden_diff": "diff --git a/angr/misc/picklable_lock.py b/angr/misc/picklable_lock.py\n--- a/angr/misc/picklable_lock.py\n+++ b/angr/misc/picklable_lock.py\n@@ -1,5 +1,6 @@\n import threading\n \n+\n class PicklableLock:\n \"\"\"\n Normal thread-locks are not pickleable. This provides a pickleable lock by mandating that the lock is unlocked\n@@ -8,7 +9,7 @@\n _LOCK = threading.Lock\n \n def __init__(self, *args, **kwargs):\n- self._lock = self._LOCK(*args, **kwargs) # pylint: disable=too-many-function-args\n+ self._lock = self.__class__._LOCK(*args, **kwargs) # pylint: disable=too-many-function-args\n \n def __enter__(self):\n return self._lock.__enter__()\n@@ -30,6 +31,7 @@\n raise TypeError(\"Why are you pickling a locked lock\")\n return type(self), ()\n \n+\n class PicklableRLock(PicklableLock):\n \"\"\"\n Same as above, but uses RLock instead of Lock for locking. Note that RLock does not provide an interface to tell\n", "issue": "TypeError angr 9.2.16 and PyPy 7.3.9 (CPython 3.9)\n<!--\r\n*Disclaimer:\r\nThe angr suite is maintained by a small team of volunteers.\r\nWhile we cannot guarantee any timeliness for fixes and enhancements, we will do our best.\r\nFor more real-time help with angr, from us and the community, join our [Slack.](https://angr.io/invite/)*\r\n-->\r\n---\r\n\r\n**Describe the bug.**\r\n<!--\r\nPlease include a clear and concise description of what the bug is.\r\n-->\r\n\r\nThe latest version of angr appears to have issues when ran with the latest version of PyPy (I haven't tested with CPython). This issue affects all angr versions newer than 9.2.11:\r\n\r\n```text\r\n$ python --version\r\nPython 3.9.12 (05fbe3aa5b0845e6c37239768aa455451aa5faba, Mar 29 2022, 08:15:34)\r\n[PyPy 7.3.9 with GCC 10.2.1 20210130 (Red Hat 10.2.1-11)]\r\n$ python -c \"import angr; p = angr.Project('/bin/ls')\"\r\nWARNING | 2022-08-31 09:52:12,054 | cle.loader | The main binary is a position-independent executable. It is being loaded with a base address of 0x400000.\r\nTraceback (most recent call last):\r\n File \"<string>\", line 1, in <module>\r\n File \"/home/carter/env/lib/pypy3.9/site-packages/angr/project.py\", line 230, in __init__\r\n self.simos.configure_project()\r\n File \"/home/carter/env/lib/pypy3.9/site-packages/angr/simos/linux.py\", line 161, in configure_project\r\n super(SimLinux, self).configure_project(syscall_abis)\r\n File \"/home/carter/env/lib/pypy3.9/site-packages/angr/simos/userland.py\", line 49, in configure_project\r\n super().configure_project()\r\n File \"/home/carter/env/lib/pypy3.9/site-packages/angr/simos/simos.py\", line 82, in configure_project\r\n self.project.loader.perform_irelative_relocs(irelative_resolver)\r\n File \"/home/carter/env/lib/pypy3.9/site-packages/cle/loader.py\", line 601, in perform_irelative_relocs\r\n val = resolver_func(resolver)\r\n File \"/home/carter/env/lib/pypy3.9/site-packages/angr/simos/simos.py\", line 72, in irelative_resolver\r\n val = resolver()\r\n File \"/home/carter/env/lib/pypy3.9/site-packages/angr/callable.py\", line 55, in __call__\r\n self.perform_call(*args, prototype=prototype)\r\n File \"/home/carter/env/lib/pypy3.9/site-packages/angr/callable.py\", line 78, in perform_call\r\n caller = self._project.factory.simulation_manager(state)\r\n File \"/home/carter/env/lib/pypy3.9/site-packages/angr/factory.py\", line 181, in simulation_manager\r\n return SimulationManager(self.project, active_states=thing, **kwargs)\r\n File \"/home/carter/env/lib/pypy3.9/site-packages/angr/sim_manager.py\", line 94, in __init__\r\n self._hierarchy = StateHierarchy() if hierarchy is None else hierarchy\r\n File \"/home/carter/env/lib/pypy3.9/site-packages/angr/state_hierarchy.py\", line 31, in __init__\r\n self._lock = PicklableRLock()\r\n File \"/home/carter/env/lib/pypy3.9/site-packages/angr/misc/picklable_lock.py\", line 11, in __init__\r\n self._lock = self._LOCK(*args, **kwargs) # pylint: disable=too-many-function-args\r\n File \"/home/carter/pypy3.9/lib/pypy3.9/threading.py\", line 93, in RLock\r\n return _CRLock(*args, **kwargs)\r\nTypeError: __new__() takes 1 positional argument but 2 were given\r\n```\r\n\r\n**Environment Information.**\r\n<!--\r\nMany common issues are caused by problems with the local Python environment.\r\nBefore submitting, double-check that your versions of all modules in the angr suite (angr, cle, pyvex, ...) are up to date.\r\nPlease include the output of `python -m angr.misc.bug_report` here.\r\n-->\r\n\r\n* Affects angr versions 9.2.12 through 9.2.16\r\n* PyPy version 7.3.9 (latest release at time of writing)\r\n* Debian Bullseye\r\n\r\n**To Reproduce.**\r\n<!--\r\nPlease include *both a script to reproduce the crash, and attach the binary used, if possible*\r\n-->\r\n\r\n1. Install latest PyPy release\r\n2. Install angr version 9.2.16\r\n3. Run: `python -c \"import angr; p = angr.Project('/bin/ls')`\n", "before_files": [{"content": "import threading\n\nclass PicklableLock:\n \"\"\"\n Normal thread-locks are not pickleable. This provides a pickleable lock by mandating that the lock is unlocked\n during serialization.\n \"\"\"\n _LOCK = threading.Lock\n\n def __init__(self, *args, **kwargs):\n self._lock = self._LOCK(*args, **kwargs) # pylint: disable=too-many-function-args\n\n def __enter__(self):\n return self._lock.__enter__()\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n return self._lock.__exit__(exc_type, exc_val, exc_tb)\n\n def acquire(self, *args, **kwargs):\n return self._lock.acquire(*args, **kwargs)\n\n def locked(self):\n return self._lock.locked()\n\n def release(self):\n return self._lock.release()\n\n def __reduce__(self):\n if self.locked():\n raise TypeError(\"Why are you pickling a locked lock\")\n return type(self), ()\n\nclass PicklableRLock(PicklableLock):\n \"\"\"\n Same as above, but uses RLock instead of Lock for locking. Note that RLock does not provide an interface to tell\n whether is it presently held by any thread, and thus this class will lie about whether it is locked.\n \"\"\"\n _LOCK = threading.RLock\n\n def locked(self):\n return False # ummmmmmmmmmmmmmmm\n", "path": "angr/misc/picklable_lock.py"}]}
| 2,110 | 275 |
gh_patches_debug_36603
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-59486
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
User avatars don't show in emails
At least for comment notifications, the avatar of the user who commented is just a blue box with a question mark regardless of whether they have a custom avatar or the default gravatar. We should check if this is happening for other notifications or if it's just the comment workflow email.
</issue>
<code>
[start of src/sentry/notifications/utils/avatar.py]
1 from __future__ import annotations
2
3 from django.urls import reverse
4 from django.utils.html import format_html
5 from django.utils.safestring import SafeString
6
7 from sentry.models.avatars.user_avatar import UserAvatar
8 from sentry.models.user import User
9 from sentry.services.hybrid_cloud.user import RpcUser
10 from sentry.utils.assets import get_asset_url
11 from sentry.utils.avatar import get_email_avatar
12 from sentry.utils.http import absolute_uri
13
14
15 def get_user_avatar_url(user: User | RpcUser, size: int = 20) -> str:
16 ident: str
17 if isinstance(user, User):
18 try:
19 avatar = UserAvatar.objects.get(user=user)
20 ident = avatar.ident
21 except UserAvatar.DoesNotExist:
22 return ""
23 elif user.avatar:
24 if user.avatar is None:
25 return ""
26 ident = user.avatar.ident
27 else:
28 return ""
29
30 url = reverse("sentry-user-avatar-url", args=[ident])
31 if size:
32 url = f"{url}?s={int(size)}"
33 return str(absolute_uri(url))
34
35
36 def get_sentry_avatar_url() -> str:
37 url = "/images/sentry-email-avatar.png"
38 return str(absolute_uri(get_asset_url("sentry", url)))
39
40
41 def avatar_as_html(user: User | RpcUser) -> SafeString:
42 if not user:
43 return format_html(
44 '<img class="avatar" src="{}" width="20px" height="20px" />', get_sentry_avatar_url()
45 )
46 avatar_type = user.get_avatar_type()
47 if avatar_type == "upload":
48 return format_html('<img class="avatar" src="{}" />', get_user_avatar_url(user))
49 elif avatar_type == "letter_avatar":
50 return get_email_avatar(user.get_display_name(), user.get_label(), 20, False)
51 else:
52 return get_email_avatar(user.get_display_name(), user.get_label(), 20, True)
53
[end of src/sentry/notifications/utils/avatar.py]
[start of src/sentry/notifications/notifications/activity/note.py]
1 from __future__ import annotations
2
3 from typing import Any, Mapping, Optional
4
5 from sentry.services.hybrid_cloud.actor import RpcActor
6 from sentry.types.integrations import ExternalProviders
7
8 from .base import GroupActivityNotification
9
10
11 class NoteActivityNotification(GroupActivityNotification):
12 message_builder = "SlackNotificationsMessageBuilder"
13 metrics_key = "note_activity"
14 template_path = "sentry/emails/activity/note"
15
16 def get_description(self) -> tuple[str, Optional[str], Mapping[str, Any]]:
17 # Notes may contain {} characters so we should escape them.
18 text = str(self.activity.data["text"]).replace("{", "{{").replace("}", "}}")
19 return text, None, {}
20
21 @property
22 def title(self) -> str:
23 if self.user:
24 author = self.user.get_display_name()
25 else:
26 author = "Unknown"
27 return f"New comment by {author}"
28
29 def get_notification_title(
30 self, provider: ExternalProviders, context: Mapping[str, Any] | None = None
31 ) -> str:
32 return self.title
33
34 def get_message_description(self, recipient: RpcActor, provider: ExternalProviders) -> Any:
35 return self.get_context()["text_description"]
36
[end of src/sentry/notifications/notifications/activity/note.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/sentry/notifications/notifications/activity/note.py b/src/sentry/notifications/notifications/activity/note.py
--- a/src/sentry/notifications/notifications/activity/note.py
+++ b/src/sentry/notifications/notifications/activity/note.py
@@ -2,6 +2,10 @@
from typing import Any, Mapping, Optional
+from django.utils.html import format_html
+from django.utils.safestring import SafeString
+
+from sentry.notifications.utils.avatar import avatar_as_html
from sentry.services.hybrid_cloud.actor import RpcActor
from sentry.types.integrations import ExternalProviders
@@ -33,3 +37,15 @@
def get_message_description(self, recipient: RpcActor, provider: ExternalProviders) -> Any:
return self.get_context()["text_description"]
+
+ def description_as_html(self, description: str, params: Mapping[str, Any]) -> SafeString:
+ """Note emails are formatted differently from almost all other activity emails.
+ Rather than passing the `description` as a string to be formatted into HTML with
+ `author` and `an_issue` (see base definition and resolved.py's `get_description`
+ as an example) we are simply passed the comment as a string that needs no formatting,
+ and want the avatar on it's own rather than bundled with the author's display name
+ because the display name is already shown in the notification title."""
+ fmt = '<span class="avatar-container">{}</span>'
+ if self.user:
+ return format_html(fmt, avatar_as_html(self.user, 48))
+ return format_html(description)
diff --git a/src/sentry/notifications/utils/avatar.py b/src/sentry/notifications/utils/avatar.py
--- a/src/sentry/notifications/utils/avatar.py
+++ b/src/sentry/notifications/utils/avatar.py
@@ -38,15 +38,18 @@
return str(absolute_uri(get_asset_url("sentry", url)))
-def avatar_as_html(user: User | RpcUser) -> SafeString:
+def avatar_as_html(user: User | RpcUser, size: int = 20) -> SafeString:
if not user:
return format_html(
- '<img class="avatar" src="{}" width="20px" height="20px" />', get_sentry_avatar_url()
+ '<img class="avatar" src="{}" width="{}px" height="{}px" />',
+ get_sentry_avatar_url(),
+ size,
+ size,
)
avatar_type = user.get_avatar_type()
if avatar_type == "upload":
return format_html('<img class="avatar" src="{}" />', get_user_avatar_url(user))
elif avatar_type == "letter_avatar":
- return get_email_avatar(user.get_display_name(), user.get_label(), 20, False)
+ return get_email_avatar(user.get_display_name(), user.get_label(), size, False)
else:
- return get_email_avatar(user.get_display_name(), user.get_label(), 20, True)
+ return get_email_avatar(user.get_display_name(), user.get_label(), size, True)
|
{"golden_diff": "diff --git a/src/sentry/notifications/notifications/activity/note.py b/src/sentry/notifications/notifications/activity/note.py\n--- a/src/sentry/notifications/notifications/activity/note.py\n+++ b/src/sentry/notifications/notifications/activity/note.py\n@@ -2,6 +2,10 @@\n \n from typing import Any, Mapping, Optional\n \n+from django.utils.html import format_html\n+from django.utils.safestring import SafeString\n+\n+from sentry.notifications.utils.avatar import avatar_as_html\n from sentry.services.hybrid_cloud.actor import RpcActor\n from sentry.types.integrations import ExternalProviders\n \n@@ -33,3 +37,15 @@\n \n def get_message_description(self, recipient: RpcActor, provider: ExternalProviders) -> Any:\n return self.get_context()[\"text_description\"]\n+\n+ def description_as_html(self, description: str, params: Mapping[str, Any]) -> SafeString:\n+ \"\"\"Note emails are formatted differently from almost all other activity emails.\n+ Rather than passing the `description` as a string to be formatted into HTML with\n+ `author` and `an_issue` (see base definition and resolved.py's `get_description`\n+ as an example) we are simply passed the comment as a string that needs no formatting,\n+ and want the avatar on it's own rather than bundled with the author's display name\n+ because the display name is already shown in the notification title.\"\"\"\n+ fmt = '<span class=\"avatar-container\">{}</span>'\n+ if self.user:\n+ return format_html(fmt, avatar_as_html(self.user, 48))\n+ return format_html(description)\ndiff --git a/src/sentry/notifications/utils/avatar.py b/src/sentry/notifications/utils/avatar.py\n--- a/src/sentry/notifications/utils/avatar.py\n+++ b/src/sentry/notifications/utils/avatar.py\n@@ -38,15 +38,18 @@\n return str(absolute_uri(get_asset_url(\"sentry\", url)))\n \n \n-def avatar_as_html(user: User | RpcUser) -> SafeString:\n+def avatar_as_html(user: User | RpcUser, size: int = 20) -> SafeString:\n if not user:\n return format_html(\n- '<img class=\"avatar\" src=\"{}\" width=\"20px\" height=\"20px\" />', get_sentry_avatar_url()\n+ '<img class=\"avatar\" src=\"{}\" width=\"{}px\" height=\"{}px\" />',\n+ get_sentry_avatar_url(),\n+ size,\n+ size,\n )\n avatar_type = user.get_avatar_type()\n if avatar_type == \"upload\":\n return format_html('<img class=\"avatar\" src=\"{}\" />', get_user_avatar_url(user))\n elif avatar_type == \"letter_avatar\":\n- return get_email_avatar(user.get_display_name(), user.get_label(), 20, False)\n+ return get_email_avatar(user.get_display_name(), user.get_label(), size, False)\n else:\n- return get_email_avatar(user.get_display_name(), user.get_label(), 20, True)\n+ return get_email_avatar(user.get_display_name(), user.get_label(), size, True)\n", "issue": "User avatars don't show in emails\nAt least for comment notifications, the avatar of the user who commented is just a blue box with a question mark regardless of whether they have a custom avatar or the default gravatar. We should check if this is happening for other notifications or if it's just the comment workflow email.\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom django.urls import reverse\nfrom django.utils.html import format_html\nfrom django.utils.safestring import SafeString\n\nfrom sentry.models.avatars.user_avatar import UserAvatar\nfrom sentry.models.user import User\nfrom sentry.services.hybrid_cloud.user import RpcUser\nfrom sentry.utils.assets import get_asset_url\nfrom sentry.utils.avatar import get_email_avatar\nfrom sentry.utils.http import absolute_uri\n\n\ndef get_user_avatar_url(user: User | RpcUser, size: int = 20) -> str:\n ident: str\n if isinstance(user, User):\n try:\n avatar = UserAvatar.objects.get(user=user)\n ident = avatar.ident\n except UserAvatar.DoesNotExist:\n return \"\"\n elif user.avatar:\n if user.avatar is None:\n return \"\"\n ident = user.avatar.ident\n else:\n return \"\"\n\n url = reverse(\"sentry-user-avatar-url\", args=[ident])\n if size:\n url = f\"{url}?s={int(size)}\"\n return str(absolute_uri(url))\n\n\ndef get_sentry_avatar_url() -> str:\n url = \"/images/sentry-email-avatar.png\"\n return str(absolute_uri(get_asset_url(\"sentry\", url)))\n\n\ndef avatar_as_html(user: User | RpcUser) -> SafeString:\n if not user:\n return format_html(\n '<img class=\"avatar\" src=\"{}\" width=\"20px\" height=\"20px\" />', get_sentry_avatar_url()\n )\n avatar_type = user.get_avatar_type()\n if avatar_type == \"upload\":\n return format_html('<img class=\"avatar\" src=\"{}\" />', get_user_avatar_url(user))\n elif avatar_type == \"letter_avatar\":\n return get_email_avatar(user.get_display_name(), user.get_label(), 20, False)\n else:\n return get_email_avatar(user.get_display_name(), user.get_label(), 20, True)\n", "path": "src/sentry/notifications/utils/avatar.py"}, {"content": "from __future__ import annotations\n\nfrom typing import Any, Mapping, Optional\n\nfrom sentry.services.hybrid_cloud.actor import RpcActor\nfrom sentry.types.integrations import ExternalProviders\n\nfrom .base import GroupActivityNotification\n\n\nclass NoteActivityNotification(GroupActivityNotification):\n message_builder = \"SlackNotificationsMessageBuilder\"\n metrics_key = \"note_activity\"\n template_path = \"sentry/emails/activity/note\"\n\n def get_description(self) -> tuple[str, Optional[str], Mapping[str, Any]]:\n # Notes may contain {} characters so we should escape them.\n text = str(self.activity.data[\"text\"]).replace(\"{\", \"{{\").replace(\"}\", \"}}\")\n return text, None, {}\n\n @property\n def title(self) -> str:\n if self.user:\n author = self.user.get_display_name()\n else:\n author = \"Unknown\"\n return f\"New comment by {author}\"\n\n def get_notification_title(\n self, provider: ExternalProviders, context: Mapping[str, Any] | None = None\n ) -> str:\n return self.title\n\n def get_message_description(self, recipient: RpcActor, provider: ExternalProviders) -> Any:\n return self.get_context()[\"text_description\"]\n", "path": "src/sentry/notifications/notifications/activity/note.py"}]}
| 1,476 | 682 |
gh_patches_debug_34973
|
rasdani/github-patches
|
git_diff
|
facebookresearch__hydra-1273
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug] hydra.job.id and hydra.job.num are not properly transferred to jobs in multirun
</issue>
<code>
[start of hydra/core/utils.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2 import copy
3 import logging
4 import os
5 import re
6 import sys
7 import warnings
8 from contextlib import contextmanager
9 from dataclasses import dataclass
10 from os.path import basename, dirname, splitext
11 from pathlib import Path
12 from time import localtime, strftime
13 from typing import Any, Dict, Optional, Sequence, Tuple, Union, cast
14
15 from omegaconf import DictConfig, OmegaConf, open_dict, read_write
16
17 from hydra.core.hydra_config import HydraConfig
18 from hydra.core.singleton import Singleton
19 from hydra.types import TaskFunction
20
21 log = logging.getLogger(__name__)
22
23
24 def simple_stdout_log_config(level: int = logging.INFO) -> None:
25 root = logging.getLogger()
26 root.setLevel(level)
27 handler = logging.StreamHandler(sys.stdout)
28 formatter = logging.Formatter("%(message)s")
29 handler.setFormatter(formatter)
30 root.addHandler(handler)
31
32
33 def configure_log(
34 log_config: DictConfig, verbose_config: Union[bool, str, Sequence[str]]
35 ) -> None:
36 assert isinstance(verbose_config, (bool, str)) or OmegaConf.is_list(verbose_config)
37 if log_config is not None:
38 conf: Dict[str, Any] = OmegaConf.to_container( # type: ignore
39 log_config, resolve=True
40 )
41 logging.config.dictConfig(conf)
42 else:
43 # default logging to stdout
44 root = logging.getLogger()
45 root.setLevel(logging.INFO)
46 handler = logging.StreamHandler(sys.stdout)
47 formatter = logging.Formatter(
48 "[%(asctime)s][%(name)s][%(levelname)s] - %(message)s"
49 )
50 handler.setFormatter(formatter)
51 root.addHandler(handler)
52 if isinstance(verbose_config, bool):
53 if verbose_config:
54 logging.getLogger().setLevel(logging.DEBUG)
55 else:
56 if isinstance(verbose_config, str):
57 verbose_list = OmegaConf.create([verbose_config])
58 elif OmegaConf.is_list(verbose_config):
59 verbose_list = verbose_config # type: ignore
60 else:
61 assert False
62
63 for logger in verbose_list:
64 logging.getLogger(logger).setLevel(logging.DEBUG)
65
66
67 def _save_config(cfg: DictConfig, filename: str, output_dir: Path) -> None:
68 output_dir.mkdir(parents=True, exist_ok=True)
69 with open(str(output_dir / filename), "w") as file:
70 file.write(OmegaConf.to_yaml(cfg))
71
72
73 def filter_overrides(overrides: Sequence[str]) -> Sequence[str]:
74 """
75 :param overrides: overrides list
76 :return: returning a new overrides list with all the keys starting with hydra. filtered.
77 """
78 return [x for x in overrides if not x.startswith("hydra.")]
79
80
81 def run_job(
82 config: DictConfig,
83 task_function: TaskFunction,
84 job_dir_key: str,
85 job_subdir_key: Optional[str],
86 configure_logging: bool = True,
87 ) -> "JobReturn":
88 old_cwd = os.getcwd()
89 working_dir = str(OmegaConf.select(config, job_dir_key))
90 if job_subdir_key is not None:
91 # evaluate job_subdir_key lazily.
92 # this is running on the client side in sweep and contains things such as job:id which
93 # are only available there.
94 subdir = str(OmegaConf.select(config, job_subdir_key))
95 working_dir = os.path.join(working_dir, subdir)
96 try:
97 ret = JobReturn()
98 ret.working_dir = working_dir
99 task_cfg = copy.deepcopy(config)
100 with read_write(task_cfg):
101 with open_dict(task_cfg):
102 del task_cfg["hydra"]
103 ret.cfg = task_cfg
104 ret.hydra_cfg = OmegaConf.create({"hydra": HydraConfig.get()})
105 overrides = OmegaConf.to_container(config.hydra.overrides.task)
106 assert isinstance(overrides, list)
107 ret.overrides = overrides
108 # handle output directories here
109 Path(str(working_dir)).mkdir(parents=True, exist_ok=True)
110 os.chdir(working_dir)
111
112 if configure_logging:
113 configure_log(config.hydra.job_logging, config.hydra.verbose)
114
115 hydra_cfg = OmegaConf.masked_copy(config, "hydra")
116 assert isinstance(hydra_cfg, DictConfig)
117
118 if config.hydra.output_subdir is not None:
119 hydra_output = Path(config.hydra.output_subdir)
120 _save_config(task_cfg, "config.yaml", hydra_output)
121 _save_config(hydra_cfg, "hydra.yaml", hydra_output)
122 _save_config(config.hydra.overrides.task, "overrides.yaml", hydra_output)
123
124 with env_override(hydra_cfg.hydra.job.env_set):
125 ret.return_value = task_function(task_cfg)
126 ret.task_name = JobRuntime.instance().get("name")
127
128 _flush_loggers()
129
130 return ret
131 finally:
132 os.chdir(old_cwd)
133
134
135 def get_valid_filename(s: str) -> str:
136 s = str(s).strip().replace(" ", "_")
137 return re.sub(r"(?u)[^-\w.]", "", s)
138
139
140 def setup_globals() -> None:
141 def register(name: str, f: Any) -> None:
142 try:
143 OmegaConf.register_resolver(name, f)
144 except AssertionError:
145 # calling it again in no_workers mode will throw. safe to ignore.
146 pass
147
148 # please add documentation when you add a new resolver
149 register("now", lambda pattern: strftime(pattern, localtime()))
150 register(
151 "hydra",
152 lambda path: OmegaConf.select(cast(DictConfig, HydraConfig.get()), path),
153 )
154
155 vi = sys.version_info
156 version_dict = {
157 "major": f"{vi[0]}",
158 "minor": f"{vi[0]}.{vi[1]}",
159 "micro": f"{vi[0]}.{vi[1]}.{vi[2]}",
160 }
161 register("python_version", lambda level="minor": version_dict.get(level))
162
163
164 @dataclass
165 class JobReturn:
166 overrides: Optional[Sequence[str]] = None
167 return_value: Any = None
168 cfg: Optional[DictConfig] = None
169 hydra_cfg: Optional[DictConfig] = None
170 working_dir: Optional[str] = None
171 task_name: Optional[str] = None
172
173
174 class JobRuntime(metaclass=Singleton):
175 def __init__(self) -> None:
176 self.conf: DictConfig = OmegaConf.create()
177 self.set("name", "UNKNOWN_NAME")
178
179 def get(self, key: str) -> Any:
180 ret = OmegaConf.select(self.conf, key)
181 if ret is None:
182 raise KeyError(f"Key not found in {type(self).__name__}: {key}")
183 return ret
184
185 def set(self, key: str, value: Any) -> None:
186 log.debug(f"Setting {type(self).__name__}:{key}={value}")
187 self.conf[key] = value
188
189
190 def split_config_path(
191 config_path: Optional[str], config_name: Optional[str]
192 ) -> Tuple[Optional[str], Optional[str]]:
193 if config_path is None or config_path == "":
194 return None, config_name
195 split_file = splitext(config_path)
196 if split_file[1] in (".yaml", ".yml"):
197 # assuming dir/config.yaml form
198 config_file: Optional[str] = basename(config_path)
199 config_dir: Optional[str] = dirname(config_path)
200 msg = (
201 "\nUsing config_path to specify the config name is deprecated, specify the config name via config_name"
202 "\nSee https://hydra.cc/docs/next/upgrades/0.11_to_1.0/config_path_changes"
203 )
204 warnings.warn(category=UserWarning, message=msg)
205 else:
206 # assuming dir form without a config file.
207 config_file = None
208 config_dir = config_path
209
210 if config_dir == "":
211 config_dir = None
212
213 if config_file == "":
214 config_file = None
215
216 if config_file is not None:
217 if config_name is not None:
218 raise ValueError(
219 "Config name should be specified in either normalized_config_path or config_name, but not both"
220 )
221 config_name = config_file
222
223 return config_dir, config_name
224
225
226 @contextmanager
227 def env_override(env: Dict[str, str]) -> Any:
228 """Temporarily set environment variables inside the context manager and
229 fully restore previous environment afterwards
230 """
231 original_env = {key: os.getenv(key) for key in env}
232 os.environ.update(env)
233 try:
234 yield
235 finally:
236 for key, value in original_env.items():
237 if value is None:
238 del os.environ[key]
239 else:
240 os.environ[key] = value
241
242
243 def _flush_loggers() -> None:
244 # Python logging does not have an official API to flush all loggers.
245 # This will have to do.
246 for h_weak_ref in logging._handlerList: # type: ignore
247 try:
248 h_weak_ref().flush()
249 except Exception:
250 # ignore exceptions thrown during flushing
251 pass
252
[end of hydra/core/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/hydra/core/utils.py b/hydra/core/utils.py
--- a/hydra/core/utils.py
+++ b/hydra/core/utils.py
@@ -87,6 +87,7 @@
) -> "JobReturn":
old_cwd = os.getcwd()
working_dir = str(OmegaConf.select(config, job_dir_key))
+ orig_hydra_cfg = HydraConfig.instance().cfg
if job_subdir_key is not None:
# evaluate job_subdir_key lazily.
# this is running on the client side in sweep and contains things such as job:id which
@@ -97,11 +98,16 @@
ret = JobReturn()
ret.working_dir = working_dir
task_cfg = copy.deepcopy(config)
+ hydra_cfg = OmegaConf.masked_copy(task_cfg, "hydra")
+ # maintain parent to preserve interpolation links from hydra_cfg to job_cfg
+ hydra_cfg._set_parent(task_cfg)
with read_write(task_cfg):
with open_dict(task_cfg):
del task_cfg["hydra"]
+ HydraConfig.instance().cfg = hydra_cfg # type: ignore
+
ret.cfg = task_cfg
- ret.hydra_cfg = OmegaConf.create({"hydra": HydraConfig.get()})
+ ret.hydra_cfg = hydra_cfg
overrides = OmegaConf.to_container(config.hydra.overrides.task)
assert isinstance(overrides, list)
ret.overrides = overrides
@@ -112,9 +118,6 @@
if configure_logging:
configure_log(config.hydra.job_logging, config.hydra.verbose)
- hydra_cfg = OmegaConf.masked_copy(config, "hydra")
- assert isinstance(hydra_cfg, DictConfig)
-
if config.hydra.output_subdir is not None:
hydra_output = Path(config.hydra.output_subdir)
_save_config(task_cfg, "config.yaml", hydra_output)
@@ -129,6 +132,7 @@
return ret
finally:
+ HydraConfig.instance().cfg = orig_hydra_cfg
os.chdir(old_cwd)
|
{"golden_diff": "diff --git a/hydra/core/utils.py b/hydra/core/utils.py\n--- a/hydra/core/utils.py\n+++ b/hydra/core/utils.py\n@@ -87,6 +87,7 @@\n ) -> \"JobReturn\":\n old_cwd = os.getcwd()\n working_dir = str(OmegaConf.select(config, job_dir_key))\n+ orig_hydra_cfg = HydraConfig.instance().cfg\n if job_subdir_key is not None:\n # evaluate job_subdir_key lazily.\n # this is running on the client side in sweep and contains things such as job:id which\n@@ -97,11 +98,16 @@\n ret = JobReturn()\n ret.working_dir = working_dir\n task_cfg = copy.deepcopy(config)\n+ hydra_cfg = OmegaConf.masked_copy(task_cfg, \"hydra\")\n+ # maintain parent to preserve interpolation links from hydra_cfg to job_cfg\n+ hydra_cfg._set_parent(task_cfg)\n with read_write(task_cfg):\n with open_dict(task_cfg):\n del task_cfg[\"hydra\"]\n+ HydraConfig.instance().cfg = hydra_cfg # type: ignore\n+\n ret.cfg = task_cfg\n- ret.hydra_cfg = OmegaConf.create({\"hydra\": HydraConfig.get()})\n+ ret.hydra_cfg = hydra_cfg\n overrides = OmegaConf.to_container(config.hydra.overrides.task)\n assert isinstance(overrides, list)\n ret.overrides = overrides\n@@ -112,9 +118,6 @@\n if configure_logging:\n configure_log(config.hydra.job_logging, config.hydra.verbose)\n \n- hydra_cfg = OmegaConf.masked_copy(config, \"hydra\")\n- assert isinstance(hydra_cfg, DictConfig)\n-\n if config.hydra.output_subdir is not None:\n hydra_output = Path(config.hydra.output_subdir)\n _save_config(task_cfg, \"config.yaml\", hydra_output)\n@@ -129,6 +132,7 @@\n \n return ret\n finally:\n+ HydraConfig.instance().cfg = orig_hydra_cfg\n os.chdir(old_cwd)\n", "issue": "[Bug] hydra.job.id and hydra.job.num are not properly transferred to jobs in multirun\n\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\nimport copy\nimport logging\nimport os\nimport re\nimport sys\nimport warnings\nfrom contextlib import contextmanager\nfrom dataclasses import dataclass\nfrom os.path import basename, dirname, splitext\nfrom pathlib import Path\nfrom time import localtime, strftime\nfrom typing import Any, Dict, Optional, Sequence, Tuple, Union, cast\n\nfrom omegaconf import DictConfig, OmegaConf, open_dict, read_write\n\nfrom hydra.core.hydra_config import HydraConfig\nfrom hydra.core.singleton import Singleton\nfrom hydra.types import TaskFunction\n\nlog = logging.getLogger(__name__)\n\n\ndef simple_stdout_log_config(level: int = logging.INFO) -> None:\n root = logging.getLogger()\n root.setLevel(level)\n handler = logging.StreamHandler(sys.stdout)\n formatter = logging.Formatter(\"%(message)s\")\n handler.setFormatter(formatter)\n root.addHandler(handler)\n\n\ndef configure_log(\n log_config: DictConfig, verbose_config: Union[bool, str, Sequence[str]]\n) -> None:\n assert isinstance(verbose_config, (bool, str)) or OmegaConf.is_list(verbose_config)\n if log_config is not None:\n conf: Dict[str, Any] = OmegaConf.to_container( # type: ignore\n log_config, resolve=True\n )\n logging.config.dictConfig(conf)\n else:\n # default logging to stdout\n root = logging.getLogger()\n root.setLevel(logging.INFO)\n handler = logging.StreamHandler(sys.stdout)\n formatter = logging.Formatter(\n \"[%(asctime)s][%(name)s][%(levelname)s] - %(message)s\"\n )\n handler.setFormatter(formatter)\n root.addHandler(handler)\n if isinstance(verbose_config, bool):\n if verbose_config:\n logging.getLogger().setLevel(logging.DEBUG)\n else:\n if isinstance(verbose_config, str):\n verbose_list = OmegaConf.create([verbose_config])\n elif OmegaConf.is_list(verbose_config):\n verbose_list = verbose_config # type: ignore\n else:\n assert False\n\n for logger in verbose_list:\n logging.getLogger(logger).setLevel(logging.DEBUG)\n\n\ndef _save_config(cfg: DictConfig, filename: str, output_dir: Path) -> None:\n output_dir.mkdir(parents=True, exist_ok=True)\n with open(str(output_dir / filename), \"w\") as file:\n file.write(OmegaConf.to_yaml(cfg))\n\n\ndef filter_overrides(overrides: Sequence[str]) -> Sequence[str]:\n \"\"\"\n :param overrides: overrides list\n :return: returning a new overrides list with all the keys starting with hydra. filtered.\n \"\"\"\n return [x for x in overrides if not x.startswith(\"hydra.\")]\n\n\ndef run_job(\n config: DictConfig,\n task_function: TaskFunction,\n job_dir_key: str,\n job_subdir_key: Optional[str],\n configure_logging: bool = True,\n) -> \"JobReturn\":\n old_cwd = os.getcwd()\n working_dir = str(OmegaConf.select(config, job_dir_key))\n if job_subdir_key is not None:\n # evaluate job_subdir_key lazily.\n # this is running on the client side in sweep and contains things such as job:id which\n # are only available there.\n subdir = str(OmegaConf.select(config, job_subdir_key))\n working_dir = os.path.join(working_dir, subdir)\n try:\n ret = JobReturn()\n ret.working_dir = working_dir\n task_cfg = copy.deepcopy(config)\n with read_write(task_cfg):\n with open_dict(task_cfg):\n del task_cfg[\"hydra\"]\n ret.cfg = task_cfg\n ret.hydra_cfg = OmegaConf.create({\"hydra\": HydraConfig.get()})\n overrides = OmegaConf.to_container(config.hydra.overrides.task)\n assert isinstance(overrides, list)\n ret.overrides = overrides\n # handle output directories here\n Path(str(working_dir)).mkdir(parents=True, exist_ok=True)\n os.chdir(working_dir)\n\n if configure_logging:\n configure_log(config.hydra.job_logging, config.hydra.verbose)\n\n hydra_cfg = OmegaConf.masked_copy(config, \"hydra\")\n assert isinstance(hydra_cfg, DictConfig)\n\n if config.hydra.output_subdir is not None:\n hydra_output = Path(config.hydra.output_subdir)\n _save_config(task_cfg, \"config.yaml\", hydra_output)\n _save_config(hydra_cfg, \"hydra.yaml\", hydra_output)\n _save_config(config.hydra.overrides.task, \"overrides.yaml\", hydra_output)\n\n with env_override(hydra_cfg.hydra.job.env_set):\n ret.return_value = task_function(task_cfg)\n ret.task_name = JobRuntime.instance().get(\"name\")\n\n _flush_loggers()\n\n return ret\n finally:\n os.chdir(old_cwd)\n\n\ndef get_valid_filename(s: str) -> str:\n s = str(s).strip().replace(\" \", \"_\")\n return re.sub(r\"(?u)[^-\\w.]\", \"\", s)\n\n\ndef setup_globals() -> None:\n def register(name: str, f: Any) -> None:\n try:\n OmegaConf.register_resolver(name, f)\n except AssertionError:\n # calling it again in no_workers mode will throw. safe to ignore.\n pass\n\n # please add documentation when you add a new resolver\n register(\"now\", lambda pattern: strftime(pattern, localtime()))\n register(\n \"hydra\",\n lambda path: OmegaConf.select(cast(DictConfig, HydraConfig.get()), path),\n )\n\n vi = sys.version_info\n version_dict = {\n \"major\": f\"{vi[0]}\",\n \"minor\": f\"{vi[0]}.{vi[1]}\",\n \"micro\": f\"{vi[0]}.{vi[1]}.{vi[2]}\",\n }\n register(\"python_version\", lambda level=\"minor\": version_dict.get(level))\n\n\n@dataclass\nclass JobReturn:\n overrides: Optional[Sequence[str]] = None\n return_value: Any = None\n cfg: Optional[DictConfig] = None\n hydra_cfg: Optional[DictConfig] = None\n working_dir: Optional[str] = None\n task_name: Optional[str] = None\n\n\nclass JobRuntime(metaclass=Singleton):\n def __init__(self) -> None:\n self.conf: DictConfig = OmegaConf.create()\n self.set(\"name\", \"UNKNOWN_NAME\")\n\n def get(self, key: str) -> Any:\n ret = OmegaConf.select(self.conf, key)\n if ret is None:\n raise KeyError(f\"Key not found in {type(self).__name__}: {key}\")\n return ret\n\n def set(self, key: str, value: Any) -> None:\n log.debug(f\"Setting {type(self).__name__}:{key}={value}\")\n self.conf[key] = value\n\n\ndef split_config_path(\n config_path: Optional[str], config_name: Optional[str]\n) -> Tuple[Optional[str], Optional[str]]:\n if config_path is None or config_path == \"\":\n return None, config_name\n split_file = splitext(config_path)\n if split_file[1] in (\".yaml\", \".yml\"):\n # assuming dir/config.yaml form\n config_file: Optional[str] = basename(config_path)\n config_dir: Optional[str] = dirname(config_path)\n msg = (\n \"\\nUsing config_path to specify the config name is deprecated, specify the config name via config_name\"\n \"\\nSee https://hydra.cc/docs/next/upgrades/0.11_to_1.0/config_path_changes\"\n )\n warnings.warn(category=UserWarning, message=msg)\n else:\n # assuming dir form without a config file.\n config_file = None\n config_dir = config_path\n\n if config_dir == \"\":\n config_dir = None\n\n if config_file == \"\":\n config_file = None\n\n if config_file is not None:\n if config_name is not None:\n raise ValueError(\n \"Config name should be specified in either normalized_config_path or config_name, but not both\"\n )\n config_name = config_file\n\n return config_dir, config_name\n\n\n@contextmanager\ndef env_override(env: Dict[str, str]) -> Any:\n \"\"\"Temporarily set environment variables inside the context manager and\n fully restore previous environment afterwards\n \"\"\"\n original_env = {key: os.getenv(key) for key in env}\n os.environ.update(env)\n try:\n yield\n finally:\n for key, value in original_env.items():\n if value is None:\n del os.environ[key]\n else:\n os.environ[key] = value\n\n\ndef _flush_loggers() -> None:\n # Python logging does not have an official API to flush all loggers.\n # This will have to do.\n for h_weak_ref in logging._handlerList: # type: ignore\n try:\n h_weak_ref().flush()\n except Exception:\n # ignore exceptions thrown during flushing\n pass\n", "path": "hydra/core/utils.py"}]}
| 3,155 | 466 |
gh_patches_debug_14921
|
rasdani/github-patches
|
git_diff
|
dotkom__onlineweb4-457
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
OnlineUser.year tests
We really should write some tests to verify that the year attribute actually produces a correct value.
Make sure to include:
- Any date in August should produce a correct value for year. Especially important if "now" is august
- Masters degrees are registered differently in the user object now, many field_of_study entries will be eligible for 4th and 5th year.
- What happens to a user that started in january?
</issue>
<code>
[start of apps/authentication/models.py]
1 # -*- coding: utf-8 -*-
2
3 import datetime
4
5 from django.conf import settings
6 from django.contrib.auth.models import AbstractUser
7 from django.db import models
8 from django.utils.translation import ugettext as _
9 from django.utils import timezone
10
11
12 # If this list is changed, remember to check that the year property on
13 # OnlineUser is still correct!
14 FIELD_OF_STUDY_CHOICES = [
15 (0, _(u'Gjest')),
16 (1, _(u'Bachelor i Informatikk (BIT)')),
17 # master degrees take up the interval [10,30]
18 (10, _(u'Software (SW)')),
19 (11, _(u'Informasjonsforvaltning (DIF)')),
20 (12, _(u'Komplekse Datasystemer (KDS)')),
21 (13, _(u'Spillteknologi (SPT)')),
22 (14, _(u'Intelligente Systemer (IRS)')),
23 (15, _(u'Helseinformatikk (MSMEDTEK)')),
24 (30, _(u'Annen mastergrad')),
25 (80, _(u'PhD')),
26 (90, _(u'International')),
27 (100, _(u'Annet Onlinemedlem')),
28 ]
29
30 class OnlineUser(AbstractUser):
31
32 IMAGE_FOLDER = "images/profiles"
33 IMAGE_EXTENSIONS = ['.jpg', '.jpeg', '.gif', '.png']
34
35 # Online related fields
36 field_of_study = models.SmallIntegerField(_(u"studieretning"), choices=FIELD_OF_STUDY_CHOICES, default=0)
37 started_date = models.DateField(_(u"startet studie"), default=timezone.now().date())
38 compiled = models.BooleanField(_(u"kompilert"), default=False)
39
40 # Email
41 infomail = models.BooleanField(_(u"vil ha infomail"), default=True)
42
43 # Address
44 phone_number = models.CharField(_(u"telefonnummer"), max_length=20, blank=True, null=True)
45 address = models.CharField(_(u"adresse"), max_length=30, blank=True, null=True)
46 zip_code = models.CharField(_(u"postnummer"), max_length=4, blank=True, null=True)
47
48 # Other
49 allergies = models.TextField(_(u"allergier"), blank=True, null=True)
50 mark_rules = models.BooleanField(_(u"godtatt prikkeregler"), default=False)
51 rfid = models.CharField(_(u"RFID"), max_length=50, blank=True, null=True)
52 nickname = models.CharField(_(u"nickname"), max_length=50, blank=True, null=True)
53 website = models.URLField(_(u"hjemmeside"), blank=True, null=True)
54
55
56 image = models.ImageField(_(u"bilde"), max_length=200, upload_to=IMAGE_FOLDER, blank=True, null=True,
57 default=settings.DEFAULT_PROFILE_PICTURE_URL)
58
59 # NTNU credentials
60 ntnu_username = models.CharField(_(u"NTNU-brukernavn"), max_length=10, blank=True, null=True)
61
62 # TODO checkbox for forwarding of @online.ntnu.no mail
63
64 @property
65 def is_member(self):
66 """
67 Returns true if the User object is associated with Online.
68 """
69 if AllowedUsername.objects.filter(username=self.ntnu_username).filter(expiration_date__gte=timezone.now()).count() > 0:
70 return True
71 return False
72
73 def get_full_name(self):
74 """
75 Returns the first_name plus the last_name, with a space in between.
76 """
77 full_name = u'%s %s' % (self.first_name, self.last_name)
78 return full_name.strip()
79
80 def get_email(self):
81 return self.get_emails().filter(primary = True)[0]
82
83 def get_emails(self):
84 return Email.objects.all().filter(user = self)
85
86 @property
87 def year(self):
88 today = timezone.now().date()
89 started = self.started_date
90
91 # We say that a year is 360 days incase we are a bit slower to
92 # add users one year.
93 year = ((today - started).days / 360) + 1
94
95 if self.field_of_study == 0 or self.field_of_study == 100: # others
96 return 0
97 # dont return a bachelor student as 4th or 5th grade
98 elif self.field_of_study == 1: # bachelor
99 if year > 3:
100 return 3
101 return year
102 elif 9 < self.field_of_study < 30: # 10-29 is considered master
103 if year >= 2:
104 return 5
105 return 4
106 elif self.field_of_study == 80: # phd
107 return year + 5
108 elif self.field_of_study == 90: # international
109 if year == 1:
110 return 1
111 return 4
112
113 def __unicode__(self):
114 return self.get_full_name()
115
116 class Meta:
117 ordering = ['first_name', 'last_name']
118 verbose_name = _(u"brukerprofil")
119 verbose_name_plural = _(u"brukerprofiler")
120
121
122 class Email(models.Model):
123 user = models.ForeignKey(OnlineUser, related_name="email_user")
124 email = models.EmailField(_(u"epostadresse"), unique=True)
125 primary = models.BooleanField(_(u"aktiv"), default=False)
126 verified = models.BooleanField(_(u"verifisert"), default=False)
127
128 def __unicode__(self):
129 return self.email
130
131 class Meta:
132 verbose_name = _(u"epostadresse")
133 verbose_name_plural = _(u"epostadresser")
134
135
136 class RegisterToken(models.Model):
137 user = models.ForeignKey(OnlineUser, related_name="register_user")
138 email = models.EmailField(_(u"epost"), max_length=254)
139 token = models.CharField(_(u"token"), max_length=32)
140 created = models.DateTimeField(_(u"opprettet dato"), editable=False, auto_now_add=True)
141
142 @property
143 def is_valid(self):
144 valid_period = datetime.timedelta(days=1)
145 now = timezone.now()
146 return now < self.created + valid_period
147
148
149 class AllowedUsername(models.Model):
150 """
151 Holds usernames that are considered valid members of Online and the time they expire.
152 """
153 username = models.CharField(_(u"brukernavn"), max_length=10)
154 registered = models.DateField(_(u"registrert"))
155 note = models.CharField(_(u"notat"), max_length=100)
156 description = models.TextField(_(u"beskrivelse"), blank=True, null=True)
157 expiration_date = models.DateField(_(u"utløpsdato"))
158
159 @property
160 def is_active(self):
161 return timezone.now().date() < self.expiration_date
162
163 def __unicode__(self):
164 return self.username
165
166 class Meta:
167 verbose_name = _(u"tillatt brukernavn")
168 verbose_name_plural = _(u"tillatte brukernavn")
169 ordering = (u"username",)
170
171
[end of apps/authentication/models.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/apps/authentication/models.py b/apps/authentication/models.py
--- a/apps/authentication/models.py
+++ b/apps/authentication/models.py
@@ -99,7 +99,7 @@
if year > 3:
return 3
return year
- elif 9 < self.field_of_study < 30: # 10-29 is considered master
+ elif 10 <= self.field_of_study <= 30: # 10-29 is considered master
if year >= 2:
return 5
return 4
@@ -109,6 +109,9 @@
if year == 1:
return 1
return 4
+ # If user's field of study is not matched by any of these tests, return -1
+ else:
+ return -1
def __unicode__(self):
return self.get_full_name()
|
{"golden_diff": "diff --git a/apps/authentication/models.py b/apps/authentication/models.py\n--- a/apps/authentication/models.py\n+++ b/apps/authentication/models.py\n@@ -99,7 +99,7 @@\n if year > 3:\n return 3\n return year\n- elif 9 < self.field_of_study < 30: # 10-29 is considered master\n+ elif 10 <= self.field_of_study <= 30: # 10-29 is considered master\n if year >= 2:\n return 5\n return 4\n@@ -109,6 +109,9 @@\n if year == 1:\n return 1\n return 4\n+ # If user's field of study is not matched by any of these tests, return -1\n+ else:\n+ return -1\n \n def __unicode__(self):\n return self.get_full_name()\n", "issue": "OnlineUser.year tests\nWe really should write some tests to verify that the year attribute actually produces a correct value.\n\nMake sure to include:\n- Any date in August should produce a correct value for year. Especially important if \"now\" is august\n- Masters degrees are registered differently in the user object now, many field_of_study entries will be eligible for 4th and 5th year.\n- What happens to a user that started in january?\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport datetime\n\nfrom django.conf import settings\nfrom django.contrib.auth.models import AbstractUser\nfrom django.db import models\nfrom django.utils.translation import ugettext as _\nfrom django.utils import timezone\n\n\n# If this list is changed, remember to check that the year property on\n# OnlineUser is still correct!\nFIELD_OF_STUDY_CHOICES = [\n (0, _(u'Gjest')),\n (1, _(u'Bachelor i Informatikk (BIT)')),\n # master degrees take up the interval [10,30]\n (10, _(u'Software (SW)')),\n (11, _(u'Informasjonsforvaltning (DIF)')),\n (12, _(u'Komplekse Datasystemer (KDS)')),\n (13, _(u'Spillteknologi (SPT)')),\n (14, _(u'Intelligente Systemer (IRS)')),\n (15, _(u'Helseinformatikk (MSMEDTEK)')),\n (30, _(u'Annen mastergrad')),\n (80, _(u'PhD')),\n (90, _(u'International')),\n (100, _(u'Annet Onlinemedlem')),\n]\n\nclass OnlineUser(AbstractUser):\n\n IMAGE_FOLDER = \"images/profiles\"\n IMAGE_EXTENSIONS = ['.jpg', '.jpeg', '.gif', '.png']\n \n # Online related fields\n field_of_study = models.SmallIntegerField(_(u\"studieretning\"), choices=FIELD_OF_STUDY_CHOICES, default=0)\n started_date = models.DateField(_(u\"startet studie\"), default=timezone.now().date())\n compiled = models.BooleanField(_(u\"kompilert\"), default=False)\n\n # Email\n infomail = models.BooleanField(_(u\"vil ha infomail\"), default=True)\n\n # Address\n phone_number = models.CharField(_(u\"telefonnummer\"), max_length=20, blank=True, null=True)\n address = models.CharField(_(u\"adresse\"), max_length=30, blank=True, null=True)\n zip_code = models.CharField(_(u\"postnummer\"), max_length=4, blank=True, null=True)\n\n # Other\n allergies = models.TextField(_(u\"allergier\"), blank=True, null=True)\n mark_rules = models.BooleanField(_(u\"godtatt prikkeregler\"), default=False)\n rfid = models.CharField(_(u\"RFID\"), max_length=50, blank=True, null=True)\n nickname = models.CharField(_(u\"nickname\"), max_length=50, blank=True, null=True)\n website = models.URLField(_(u\"hjemmeside\"), blank=True, null=True)\n\n\n image = models.ImageField(_(u\"bilde\"), max_length=200, upload_to=IMAGE_FOLDER, blank=True, null=True,\n default=settings.DEFAULT_PROFILE_PICTURE_URL)\n\n # NTNU credentials\n ntnu_username = models.CharField(_(u\"NTNU-brukernavn\"), max_length=10, blank=True, null=True)\n\n # TODO checkbox for forwarding of @online.ntnu.no mail\n \n @property\n def is_member(self):\n \"\"\"\n Returns true if the User object is associated with Online.\n \"\"\"\n if AllowedUsername.objects.filter(username=self.ntnu_username).filter(expiration_date__gte=timezone.now()).count() > 0:\n return True\n return False\n\n def get_full_name(self):\n \"\"\"\n Returns the first_name plus the last_name, with a space in between.\n \"\"\"\n full_name = u'%s %s' % (self.first_name, self.last_name)\n return full_name.strip()\n\n def get_email(self):\n return self.get_emails().filter(primary = True)[0]\n\n def get_emails(self):\n return Email.objects.all().filter(user = self)\n\n @property\n def year(self):\n today = timezone.now().date()\n started = self.started_date\n\n # We say that a year is 360 days incase we are a bit slower to\n # add users one year.\n year = ((today - started).days / 360) + 1\n\n if self.field_of_study == 0 or self.field_of_study == 100: # others\n return 0\n # dont return a bachelor student as 4th or 5th grade\n elif self.field_of_study == 1: # bachelor\n if year > 3:\n return 3\n return year\n elif 9 < self.field_of_study < 30: # 10-29 is considered master\n if year >= 2:\n return 5\n return 4\n elif self.field_of_study == 80: # phd\n return year + 5\n elif self.field_of_study == 90: # international\n if year == 1:\n return 1\n return 4\n\n def __unicode__(self):\n return self.get_full_name()\n\n class Meta:\n ordering = ['first_name', 'last_name']\n verbose_name = _(u\"brukerprofil\")\n verbose_name_plural = _(u\"brukerprofiler\")\n\n\nclass Email(models.Model):\n user = models.ForeignKey(OnlineUser, related_name=\"email_user\")\n email = models.EmailField(_(u\"epostadresse\"), unique=True)\n primary = models.BooleanField(_(u\"aktiv\"), default=False)\n verified = models.BooleanField(_(u\"verifisert\"), default=False)\n\n def __unicode__(self):\n return self.email\n\n class Meta:\n verbose_name = _(u\"epostadresse\")\n verbose_name_plural = _(u\"epostadresser\")\n\n\nclass RegisterToken(models.Model):\n user = models.ForeignKey(OnlineUser, related_name=\"register_user\")\n email = models.EmailField(_(u\"epost\"), max_length=254)\n token = models.CharField(_(u\"token\"), max_length=32)\n created = models.DateTimeField(_(u\"opprettet dato\"), editable=False, auto_now_add=True)\n\n @property\n def is_valid(self):\n valid_period = datetime.timedelta(days=1)\n now = timezone.now()\n return now < self.created + valid_period \n\n\nclass AllowedUsername(models.Model):\n \"\"\"\n Holds usernames that are considered valid members of Online and the time they expire.\n \"\"\"\n username = models.CharField(_(u\"brukernavn\"), max_length=10)\n registered = models.DateField(_(u\"registrert\"))\n note = models.CharField(_(u\"notat\"), max_length=100)\n description = models.TextField(_(u\"beskrivelse\"), blank=True, null=True)\n expiration_date = models.DateField(_(u\"utl\u00f8psdato\"))\n\n @property\n def is_active(self):\n return timezone.now().date() < self.expiration_date\n\n def __unicode__(self):\n return self.username\n\n class Meta:\n verbose_name = _(u\"tillatt brukernavn\")\n verbose_name_plural = _(u\"tillatte brukernavn\")\n ordering = (u\"username\",)\n\n", "path": "apps/authentication/models.py"}]}
| 2,619 | 205 |
gh_patches_debug_34555
|
rasdani/github-patches
|
git_diff
|
Parsl__parsl-2977
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Newly frequent WorkQueueTaskFailure in CI
**Describe the bug**
I'm seeing this WorkQueueExecutor heisenbug happen in CI a lot recently: I'm not clear what has changed to make it happen more - for example in https://github.com/Parsl/parsl/actions/runs/6518865549/job/17704749713
```
ERROR parsl.dataflow.dflow:dflow.py:350 Task 207 failed after 0 retry attempts
Traceback (most recent call last):
File "/home/runner/work/parsl/parsl/parsl/dataflow/dflow.py", line 301, in handle_exec_update
res = self._unwrap_remote_exception_wrapper(future)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/runner/work/parsl/parsl/parsl/dataflow/dflow.py", line 571, in _unwrap_remote_exception_wrapper
result = future.result()
^^^^^^^^^^^^^^^
File "/opt/hostedtoolcache/Python/3.11.5/x64/lib/python3.11/concurrent/futures/_base.py", line 449, in result
return self.__get_result()
^^^^^^^^^^^^^^^^^^^
File "/opt/hostedtoolcache/Python/3.11.5/x64/lib/python3.11/concurrent/futures/_base.py", line 401, in __get_result
raise self._exception
parsl.executors.workqueue.errors.WorkQueueTaskFailure: ('work queue result: The result file was not transfered from the worker.\nThis usually means that there is a problem with the python setup,\nor the wrapper that executes the function.\nTrace:\n', FileNotFoundError(2, 'No such file or directory'))
INFO parsl.dataflow.dflow:dflow.py:1390 Standard output for task 207 available at std.out
```
I'm don't have any immediate strong ideas about what is going on - I've had a little poke but can't see anything that sticks out right away.
I've opened:
* PR #2912 to try a newer cctools
* draft PR #2910 to try to capture more FileNotFoundError information in output - there is more stuff in that FileNotFoundError (such as the actual filename) that isn't rendered by the above error reporting
I haven't been successful in recreating this on my laptop. However I have seen a related error on perlmutter under certain high load / high concurrency conditions which is a bit more recreatable and maybe I can debug from there.
cc @dthain
</issue>
<code>
[start of parsl/executors/workqueue/parsl_coprocess.py]
1 #! /usr/bin/env python3
2
3 import sys
4 from parsl.app.errors import RemoteExceptionWrapper
5
6 import socket
7 import json
8 import os
9 import sys
10 import threading
11 import queue
12 def remote_execute(func):
13 def remote_wrapper(event, q=None):
14 if q:
15 event = json.loads(event)
16 kwargs = event["fn_kwargs"]
17 args = event["fn_args"]
18 try:
19 response = {
20 "Result": func(*args, **kwargs),
21 "StatusCode": 200
22 }
23 except Exception as e:
24 response = {
25 "Result": str(e),
26 "StatusCode": 500
27 }
28 if not q:
29 return response
30 q.put(response)
31 return remote_wrapper
32
33 read, write = os.pipe()
34 def send_configuration(config):
35 config_string = json.dumps(config)
36 config_cmd = f"{len(config_string) + 1}\n{config_string}\n"
37 sys.stdout.write(config_cmd)
38 sys.stdout.flush()
39 def main():
40 s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
41 try:
42 # modify the port argument to be 0 to listen on an arbitrary port
43 s.bind(('localhost', 0))
44 except Exception as e:
45 s.close()
46 print(e)
47 exit(1)
48 # information to print to stdout for worker
49 config = {
50 "name": name(),
51 "port": s.getsockname()[1],
52 }
53 send_configuration(config)
54 while True:
55 s.listen()
56 conn, addr = s.accept()
57 print('Network function: connection from {}'.format(addr), file=sys.stderr)
58 while True:
59 # peek at message to find newline to get the size
60 event_size = None
61 line = conn.recv(100, socket.MSG_PEEK)
62 eol = line.find(b'\n')
63 if eol >= 0:
64 size = eol+1
65 # actually read the size of the event
66 input_spec = conn.recv(size).decode('utf-8').split()
67 function_name = input_spec[0]
68 task_id = int(input_spec[1])
69 event_size = int(input_spec[2])
70 try:
71 if event_size:
72 # receive the bytes containing the event and turn it into a string
73 event_str = conn.recv(event_size).decode("utf-8")
74 # turn the event into a python dictionary
75 event = json.loads(event_str)
76 # see if the user specified an execution method
77 exec_method = event.get("remote_task_exec_method", None)
78 print('Network function: recieved event: {}'.format(event), file=sys.stderr)
79 os.chdir(f"t.{task_id}")
80 if exec_method == "thread":
81 # create a forked process for function handler
82 q = queue.Queue()
83 p = threading.Thread(target=globals()[function_name], args=(event_str, q))
84 p.start()
85 p.join()
86 response = json.dumps(q.get()).encode("utf-8")
87 elif exec_method == "direct":
88 response = json.dumps(globals()[function_name](event)).encode("utf-8")
89 else:
90 p = os.fork()
91 if p == 0:
92 response =globals()[function_name](event)
93 os.write(write, json.dumps(response).encode("utf-8"))
94 os._exit(0)
95 elif p < 0:
96 print('Network function: unable to fork', file=sys.stderr)
97 response = {
98 "Result": "unable to fork",
99 "StatusCode": 500
100 }
101 else:
102 chunk = os.read(read, 65536).decode("utf-8")
103 all_chunks = [chunk]
104 while (len(chunk) >= 65536):
105 chunk = os.read(read, 65536).decode("utf-8")
106 all_chunks.append(chunk)
107 response = "".join(all_chunks).encode("utf-8")
108 os.waitid(os.P_PID, p, os.WEXITED)
109 response_size = len(response)
110 size_msg = "{}\n".format(response_size)
111 # send the size of response
112 conn.sendall(size_msg.encode('utf-8'))
113 # send response
114 conn.sendall(response)
115 os.chdir("..")
116 break
117 except Exception as e:
118 print("Network function encountered exception ", str(e), file=sys.stderr)
119 return 0
120 def name():
121 return 'parsl_coprocess'
122 @remote_execute
123 def run_parsl_task(a, b, c):
124 import parsl.executors.workqueue.exec_parsl_function as epf
125 try:
126 map_file, function_file, result_file = (a, b, c)
127 try:
128 namespace, function_code, result_name = epf.load_function(map_file, function_file)
129 except Exception:
130 raise
131 try:
132 result = epf.execute_function(namespace, function_code, result_name)
133 except Exception:
134 raise
135 except Exception:
136 result = RemoteExceptionWrapper(*sys.exc_info())
137 epf.dump_result_to_file(result_file, result)
138 return None
139 if __name__ == "__main__":
140 main()
141
142
[end of parsl/executors/workqueue/parsl_coprocess.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/parsl/executors/workqueue/parsl_coprocess.py b/parsl/executors/workqueue/parsl_coprocess.py
--- a/parsl/executors/workqueue/parsl_coprocess.py
+++ b/parsl/executors/workqueue/parsl_coprocess.py
@@ -51,6 +51,7 @@
"port": s.getsockname()[1],
}
send_configuration(config)
+ abs_working_dir = os.getcwd()
while True:
s.listen()
conn, addr = s.accept()
@@ -76,7 +77,7 @@
# see if the user specified an execution method
exec_method = event.get("remote_task_exec_method", None)
print('Network function: recieved event: {}'.format(event), file=sys.stderr)
- os.chdir(f"t.{task_id}")
+ os.chdir(os.path.join(abs_working_dir, f't.{task_id}'))
if exec_method == "thread":
# create a forked process for function handler
q = queue.Queue()
@@ -112,10 +113,22 @@
conn.sendall(size_msg.encode('utf-8'))
# send response
conn.sendall(response)
- os.chdir("..")
break
except Exception as e:
print("Network function encountered exception ", str(e), file=sys.stderr)
+ response = {
+ 'Result': f'network function encountered exception {e}',
+ 'Status Code': 500
+ }
+ response = json.dumps(response).encode('utf-8')
+ response_size = len(response)
+ size_msg = "{}\n".format(response_size)
+ # send the size of response
+ conn.sendall(size_msg.encode('utf-8'))
+ # send response
+ conn.sendall(response)
+ finally:
+ os.chdir(abs_working_dir)
return 0
def name():
return 'parsl_coprocess'
|
{"golden_diff": "diff --git a/parsl/executors/workqueue/parsl_coprocess.py b/parsl/executors/workqueue/parsl_coprocess.py\n--- a/parsl/executors/workqueue/parsl_coprocess.py\n+++ b/parsl/executors/workqueue/parsl_coprocess.py\n@@ -51,6 +51,7 @@\n \"port\": s.getsockname()[1],\n }\n send_configuration(config)\n+ abs_working_dir = os.getcwd()\n while True:\n s.listen()\n conn, addr = s.accept()\n@@ -76,7 +77,7 @@\n # see if the user specified an execution method\n exec_method = event.get(\"remote_task_exec_method\", None)\n print('Network function: recieved event: {}'.format(event), file=sys.stderr)\n- os.chdir(f\"t.{task_id}\")\n+ os.chdir(os.path.join(abs_working_dir, f't.{task_id}'))\n if exec_method == \"thread\":\n # create a forked process for function handler\n q = queue.Queue()\n@@ -112,10 +113,22 @@\n conn.sendall(size_msg.encode('utf-8'))\n # send response\n conn.sendall(response)\n- os.chdir(\"..\")\n break\n except Exception as e:\n print(\"Network function encountered exception \", str(e), file=sys.stderr)\n+ response = {\n+ 'Result': f'network function encountered exception {e}',\n+ 'Status Code': 500\n+ }\n+ response = json.dumps(response).encode('utf-8')\n+ response_size = len(response)\n+ size_msg = \"{}\\n\".format(response_size)\n+ # send the size of response\n+ conn.sendall(size_msg.encode('utf-8'))\n+ # send response\n+ conn.sendall(response)\n+ finally:\n+ os.chdir(abs_working_dir)\n return 0\n def name():\n return 'parsl_coprocess'\n", "issue": "Newly frequent WorkQueueTaskFailure in CI\n**Describe the bug**\r\n\r\nI'm seeing this WorkQueueExecutor heisenbug happen in CI a lot recently: I'm not clear what has changed to make it happen more - for example in https://github.com/Parsl/parsl/actions/runs/6518865549/job/17704749713\r\n\r\n```\r\nERROR parsl.dataflow.dflow:dflow.py:350 Task 207 failed after 0 retry attempts\r\nTraceback (most recent call last):\r\n File \"/home/runner/work/parsl/parsl/parsl/dataflow/dflow.py\", line 301, in handle_exec_update\r\n res = self._unwrap_remote_exception_wrapper(future)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/home/runner/work/parsl/parsl/parsl/dataflow/dflow.py\", line 571, in _unwrap_remote_exception_wrapper\r\n result = future.result()\r\n ^^^^^^^^^^^^^^^\r\n File \"/opt/hostedtoolcache/Python/3.11.5/x64/lib/python3.11/concurrent/futures/_base.py\", line 449, in result\r\n return self.__get_result()\r\n ^^^^^^^^^^^^^^^^^^^\r\n File \"/opt/hostedtoolcache/Python/3.11.5/x64/lib/python3.11/concurrent/futures/_base.py\", line 401, in __get_result\r\n raise self._exception\r\nparsl.executors.workqueue.errors.WorkQueueTaskFailure: ('work queue result: The result file was not transfered from the worker.\\nThis usually means that there is a problem with the python setup,\\nor the wrapper that executes the function.\\nTrace:\\n', FileNotFoundError(2, 'No such file or directory'))\r\nINFO parsl.dataflow.dflow:dflow.py:1390 Standard output for task 207 available at std.out\r\n```\r\n\r\nI'm don't have any immediate strong ideas about what is going on - I've had a little poke but can't see anything that sticks out right away.\r\n\r\nI've opened:\r\n* PR #2912 to try a newer cctools\r\n* draft PR #2910 to try to capture more FileNotFoundError information in output - there is more stuff in that FileNotFoundError (such as the actual filename) that isn't rendered by the above error reporting\r\n\r\nI haven't been successful in recreating this on my laptop. However I have seen a related error on perlmutter under certain high load / high concurrency conditions which is a bit more recreatable and maybe I can debug from there.\r\n\r\ncc @dthain\n", "before_files": [{"content": "#! /usr/bin/env python3\n\nimport sys\nfrom parsl.app.errors import RemoteExceptionWrapper\n\nimport socket\nimport json\nimport os\nimport sys\nimport threading\nimport queue\ndef remote_execute(func):\n def remote_wrapper(event, q=None):\n if q:\n event = json.loads(event)\n kwargs = event[\"fn_kwargs\"]\n args = event[\"fn_args\"]\n try:\n response = {\n \"Result\": func(*args, **kwargs),\n \"StatusCode\": 200\n }\n except Exception as e:\n response = { \n \"Result\": str(e),\n \"StatusCode\": 500 \n }\n if not q:\n return response\n q.put(response)\n return remote_wrapper\n \nread, write = os.pipe() \ndef send_configuration(config):\n config_string = json.dumps(config)\n config_cmd = f\"{len(config_string) + 1}\\n{config_string}\\n\"\n sys.stdout.write(config_cmd)\n sys.stdout.flush()\ndef main():\n s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n try:\n # modify the port argument to be 0 to listen on an arbitrary port\n s.bind(('localhost', 0))\n except Exception as e:\n s.close()\n print(e)\n exit(1)\n # information to print to stdout for worker\n config = {\n \"name\": name(),\n \"port\": s.getsockname()[1],\n }\n send_configuration(config)\n while True:\n s.listen()\n conn, addr = s.accept()\n print('Network function: connection from {}'.format(addr), file=sys.stderr)\n while True:\n # peek at message to find newline to get the size\n event_size = None\n line = conn.recv(100, socket.MSG_PEEK)\n eol = line.find(b'\\n')\n if eol >= 0:\n size = eol+1\n # actually read the size of the event\n input_spec = conn.recv(size).decode('utf-8').split()\n function_name = input_spec[0]\n task_id = int(input_spec[1])\n event_size = int(input_spec[2])\n try:\n if event_size:\n # receive the bytes containing the event and turn it into a string\n event_str = conn.recv(event_size).decode(\"utf-8\")\n # turn the event into a python dictionary\n event = json.loads(event_str)\n # see if the user specified an execution method\n exec_method = event.get(\"remote_task_exec_method\", None)\n print('Network function: recieved event: {}'.format(event), file=sys.stderr)\n os.chdir(f\"t.{task_id}\")\n if exec_method == \"thread\":\n # create a forked process for function handler\n q = queue.Queue()\n p = threading.Thread(target=globals()[function_name], args=(event_str, q))\n p.start()\n p.join()\n response = json.dumps(q.get()).encode(\"utf-8\")\n elif exec_method == \"direct\":\n response = json.dumps(globals()[function_name](event)).encode(\"utf-8\")\n else:\n p = os.fork()\n if p == 0:\n response =globals()[function_name](event)\n os.write(write, json.dumps(response).encode(\"utf-8\"))\n os._exit(0)\n elif p < 0:\n print('Network function: unable to fork', file=sys.stderr)\n response = { \n \"Result\": \"unable to fork\",\n \"StatusCode\": 500 \n }\n else:\n chunk = os.read(read, 65536).decode(\"utf-8\")\n all_chunks = [chunk]\n while (len(chunk) >= 65536):\n chunk = os.read(read, 65536).decode(\"utf-8\")\n all_chunks.append(chunk)\n response = \"\".join(all_chunks).encode(\"utf-8\")\n os.waitid(os.P_PID, p, os.WEXITED)\n response_size = len(response)\n size_msg = \"{}\\n\".format(response_size)\n # send the size of response\n conn.sendall(size_msg.encode('utf-8'))\n # send response\n conn.sendall(response)\n os.chdir(\"..\")\n break\n except Exception as e:\n print(\"Network function encountered exception \", str(e), file=sys.stderr)\n return 0\ndef name():\n return 'parsl_coprocess'\n@remote_execute\ndef run_parsl_task(a, b, c):\n import parsl.executors.workqueue.exec_parsl_function as epf\n try:\n map_file, function_file, result_file = (a, b, c)\n try:\n namespace, function_code, result_name = epf.load_function(map_file, function_file)\n except Exception:\n raise\n try:\n result = epf.execute_function(namespace, function_code, result_name)\n except Exception:\n raise\n except Exception:\n result = RemoteExceptionWrapper(*sys.exc_info())\n epf.dump_result_to_file(result_file, result)\n return None\nif __name__ == \"__main__\":\n\tmain()\n\n", "path": "parsl/executors/workqueue/parsl_coprocess.py"}]}
| 2,557 | 432 |
gh_patches_debug_19243
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-2204
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
API crashes when a non-valid date is entered
E.g. `http://rsr.akvo.org/rest/v1/project_update_extra/?created_at__gt=2015-07`
</issue>
<code>
[start of akvo/rest/views/project_update.py]
1 # -*- coding: utf-8 -*-
2 """Akvo RSR is covered by the GNU Affero General Public License.
3
4 See more details in the license.txt file located at the root folder of the Akvo RSR module.
5 For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
6 """
7
8 from akvo.rsr.models import ProjectUpdate
9
10 from ..serializers import ProjectUpdateSerializer, ProjectUpdateExtraSerializer
11 from ..viewsets import PublicProjectViewSet
12
13 from rest_framework.decorators import api_view, permission_classes
14 from rest_framework.permissions import IsAuthenticated
15 from rest_framework.response import Response
16 from rest_framework.exceptions import ParseError
17 from re import match
18
19
20 class ProjectUpdateViewSet(PublicProjectViewSet):
21
22 """."""
23 queryset = ProjectUpdate.objects.select_related('project',
24 'user').prefetch_related('locations')
25 serializer_class = ProjectUpdateSerializer
26
27 paginate_by_param = 'limit'
28 max_paginate_by = 1000
29
30 def get_queryset(self):
31 """
32 Allow simple filtering on selected fields.
33 We don't use the default filter_fields, because Up filters on
34 datetime for last_modified_at, and they only support a date, not datetime.
35 """
36 created_at__gt = validate_date(self.request.QUERY_PARAMS.get('created_at__gt', None))
37 if created_at__gt is not None:
38 self.queryset = self.queryset.filter(created_at__gt=created_at__gt)
39 created_at__lt = validate_date(self.request.QUERY_PARAMS.get('created_at__lt', None))
40 if created_at__lt is not None:
41 self.queryset = self.queryset.filter(created_at__lt=created_at__lt)
42 last_modified_at__gt = validate_date(self.request.QUERY_PARAMS.get('last_modified_at__gt', None))
43 if last_modified_at__gt is not None:
44 self.queryset = self.queryset.filter(last_modified_at__gt=last_modified_at__gt)
45 last_modified_at__lt = validate_date(self.request.QUERY_PARAMS.get('last_modified_at__lt', None))
46 if last_modified_at__lt is not None:
47 self.queryset = self.queryset.filter(last_modified_at__lt=last_modified_at__lt)
48 # Get updates per organisation
49 project__partners = self.request.QUERY_PARAMS.get('project__partners', None)
50 if project__partners:
51 self.queryset = self.queryset.filter(project__partners=project__partners)
52 user__organisations = self.request.QUERY_PARAMS.get('user__organisations', None)
53 if user__organisations:
54 self.queryset = self.queryset.filter(user__organisations=user__organisations)
55 return super(ProjectUpdateViewSet, self).get_queryset()
56
57
58 class ProjectUpdateExtraViewSet(PublicProjectViewSet):
59
60 """Project update extra resource."""
61
62 max_paginate_by = 30
63 paginate_by = 10
64
65 queryset = ProjectUpdate.objects.select_related(
66 'primary_location',
67 'primary_location__location_target',
68 'primary_location__location_target__project',
69 'primary_location__location_target__user',
70 'primary_location__location_target__primary_location',
71 'primary_location__location_target__country',
72 'project',
73 'user',
74 'user__organisation',
75 'user__organisation__primary_location',
76 'user__organisation__primary_location__country',
77 'user__organisation__primary_location__location_target',
78 'user__organisation__primary_location__location_target__internal_org_ids',
79
80 ).prefetch_related(
81 'user__organisations',
82 'user__organisations__primary_location',
83 'user__organisations__primary_location__country',
84 'user__organisations__primary_location__location_target')
85 serializer_class = ProjectUpdateExtraSerializer
86
87 def get_queryset(self):
88 """
89 Allow simple filtering on selected fields.
90 We don't use the default filter_fields, because Up filters on
91 datetime for last_modified_at, and they only support a date, not datetime.
92 """
93 created_at__gt = validate_date(self.request.QUERY_PARAMS.get('created_at__gt', None))
94 if created_at__gt is not None:
95 self.queryset = self.queryset.filter(created_at__gt=created_at__gt)
96 created_at__lt = validate_date(self.request.QUERY_PARAMS.get('created_at__lt', None))
97 if created_at__lt is not None:
98 self.queryset = self.queryset.filter(created_at__lt=created_at__lt)
99 last_modified_at__gt = validate_date(self.request.QUERY_PARAMS.get('last_modified_at__gt', None))
100 if last_modified_at__gt is not None:
101 self.queryset = self.queryset.filter(last_modified_at__gt=last_modified_at__gt)
102 last_modified_at__lt = validate_date(self.request.QUERY_PARAMS.get('last_modified_at__lt', None))
103 if last_modified_at__lt is not None:
104 self.queryset = self.queryset.filter(last_modified_at__lt=last_modified_at__lt)
105 # Get updates per organisation
106 project__partners = self.request.QUERY_PARAMS.get('project__partners', None)
107 if project__partners:
108 self.queryset = self.queryset.filter(project__partners=project__partners)
109 user__organisations = self.request.QUERY_PARAMS.get('user__organisations', None)
110 if user__organisations:
111 self.queryset = self.queryset.filter(user__organisations=user__organisations)
112 return super(ProjectUpdateExtraViewSet, self).get_queryset()
113
114
115 # validate date strings from URL
116 def validate_date(date):
117
118 if date is None:
119 return None
120 # if yyyy-mm-dd
121 elif match('^\d{4}\-(0?[1-9]|1[012])\-(0?[1-9]|[12][0-9]|3[01])$', date) is not None:
122 return date
123 # if yyyy-mm
124 elif match('^\d{4}\-(0?[1-9]|1[012])$', date) is not None:
125 return date + '-01'
126 else:
127 raise ParseError('created_at and last_modified_at dates must be in format: yyyy-mm-dd')
128
129
130 @api_view(['POST'])
131 @permission_classes((IsAuthenticated, ))
132 def upload_indicator_update_photo(request, pk=None):
133 update = ProjectUpdate.objects.get(pk=pk)
134 user = request.user
135
136 # TODO: permissions
137
138 files = request.FILES
139
140 if 'photo' in files.keys():
141 update.photo = files['photo']
142 update.save(update_fields=['photo'])
143
144 return Response(ProjectUpdateExtraSerializer(update).data)
145
[end of akvo/rest/views/project_update.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/akvo/rest/views/project_update.py b/akvo/rest/views/project_update.py
--- a/akvo/rest/views/project_update.py
+++ b/akvo/rest/views/project_update.py
@@ -117,6 +117,11 @@
if date is None:
return None
+ # if yyyy-mm-ddThh:mm:ss
+ elif match(
+ '^\d{4}\-(0?[1-9]|1[012])\-(0?[1-9]|[12][0-9]|3[01])T[0-2]\d{1}:[0-5]\d{1}:[0-5]\d{1}$',
+ date) is not None:
+ return date
# if yyyy-mm-dd
elif match('^\d{4}\-(0?[1-9]|1[012])\-(0?[1-9]|[12][0-9]|3[01])$', date) is not None:
return date
@@ -124,7 +129,10 @@
elif match('^\d{4}\-(0?[1-9]|1[012])$', date) is not None:
return date + '-01'
else:
- raise ParseError('created_at and last_modified_at dates must be in format: yyyy-mm-dd')
+ raise ParseError(
+ 'Invalid date: created_at and last_modified_at dates must be in one of the following '
+ 'formats: yyyy-mm, yyyy-mm-dd or yyyy-mm-ddThh:mm:ss'
+ )
@api_view(['POST'])
|
{"golden_diff": "diff --git a/akvo/rest/views/project_update.py b/akvo/rest/views/project_update.py\n--- a/akvo/rest/views/project_update.py\n+++ b/akvo/rest/views/project_update.py\n@@ -117,6 +117,11 @@\n \n if date is None:\n return None\n+ # if yyyy-mm-ddThh:mm:ss\n+ elif match(\n+ '^\\d{4}\\-(0?[1-9]|1[012])\\-(0?[1-9]|[12][0-9]|3[01])T[0-2]\\d{1}:[0-5]\\d{1}:[0-5]\\d{1}$',\n+ date) is not None:\n+ return date\n # if yyyy-mm-dd\n elif match('^\\d{4}\\-(0?[1-9]|1[012])\\-(0?[1-9]|[12][0-9]|3[01])$', date) is not None:\n return date\n@@ -124,7 +129,10 @@\n elif match('^\\d{4}\\-(0?[1-9]|1[012])$', date) is not None:\n return date + '-01'\n else:\n- raise ParseError('created_at and last_modified_at dates must be in format: yyyy-mm-dd')\n+ raise ParseError(\n+ 'Invalid date: created_at and last_modified_at dates must be in one of the following '\n+ 'formats: yyyy-mm, yyyy-mm-dd or yyyy-mm-ddThh:mm:ss'\n+ )\n \n \n @api_view(['POST'])\n", "issue": "API crashes when a non-valid date is entered\nE.g. `http://rsr.akvo.org/rest/v1/project_update_extra/?created_at__gt=2015-07`\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"Akvo RSR is covered by the GNU Affero General Public License.\n\nSee more details in the license.txt file located at the root folder of the Akvo RSR module.\nFor additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\"\"\"\n\nfrom akvo.rsr.models import ProjectUpdate\n\nfrom ..serializers import ProjectUpdateSerializer, ProjectUpdateExtraSerializer\nfrom ..viewsets import PublicProjectViewSet\n\nfrom rest_framework.decorators import api_view, permission_classes\nfrom rest_framework.permissions import IsAuthenticated\nfrom rest_framework.response import Response\nfrom rest_framework.exceptions import ParseError\nfrom re import match\n\n\nclass ProjectUpdateViewSet(PublicProjectViewSet):\n\n \"\"\".\"\"\"\n queryset = ProjectUpdate.objects.select_related('project',\n 'user').prefetch_related('locations')\n serializer_class = ProjectUpdateSerializer\n\n paginate_by_param = 'limit'\n max_paginate_by = 1000\n\n def get_queryset(self):\n \"\"\"\n Allow simple filtering on selected fields.\n We don't use the default filter_fields, because Up filters on\n datetime for last_modified_at, and they only support a date, not datetime.\n \"\"\"\n created_at__gt = validate_date(self.request.QUERY_PARAMS.get('created_at__gt', None))\n if created_at__gt is not None:\n self.queryset = self.queryset.filter(created_at__gt=created_at__gt)\n created_at__lt = validate_date(self.request.QUERY_PARAMS.get('created_at__lt', None))\n if created_at__lt is not None:\n self.queryset = self.queryset.filter(created_at__lt=created_at__lt)\n last_modified_at__gt = validate_date(self.request.QUERY_PARAMS.get('last_modified_at__gt', None))\n if last_modified_at__gt is not None:\n self.queryset = self.queryset.filter(last_modified_at__gt=last_modified_at__gt)\n last_modified_at__lt = validate_date(self.request.QUERY_PARAMS.get('last_modified_at__lt', None))\n if last_modified_at__lt is not None:\n self.queryset = self.queryset.filter(last_modified_at__lt=last_modified_at__lt)\n # Get updates per organisation\n project__partners = self.request.QUERY_PARAMS.get('project__partners', None)\n if project__partners:\n self.queryset = self.queryset.filter(project__partners=project__partners)\n user__organisations = self.request.QUERY_PARAMS.get('user__organisations', None)\n if user__organisations:\n self.queryset = self.queryset.filter(user__organisations=user__organisations)\n return super(ProjectUpdateViewSet, self).get_queryset()\n\n\nclass ProjectUpdateExtraViewSet(PublicProjectViewSet):\n\n \"\"\"Project update extra resource.\"\"\"\n\n max_paginate_by = 30\n paginate_by = 10\n\n queryset = ProjectUpdate.objects.select_related(\n 'primary_location',\n 'primary_location__location_target',\n 'primary_location__location_target__project',\n 'primary_location__location_target__user',\n 'primary_location__location_target__primary_location',\n 'primary_location__location_target__country',\n 'project',\n 'user',\n 'user__organisation',\n 'user__organisation__primary_location',\n 'user__organisation__primary_location__country',\n 'user__organisation__primary_location__location_target',\n 'user__organisation__primary_location__location_target__internal_org_ids',\n\n ).prefetch_related(\n 'user__organisations',\n 'user__organisations__primary_location',\n 'user__organisations__primary_location__country',\n 'user__organisations__primary_location__location_target')\n serializer_class = ProjectUpdateExtraSerializer\n\n def get_queryset(self):\n \"\"\"\n Allow simple filtering on selected fields.\n We don't use the default filter_fields, because Up filters on\n datetime for last_modified_at, and they only support a date, not datetime.\n \"\"\"\n created_at__gt = validate_date(self.request.QUERY_PARAMS.get('created_at__gt', None))\n if created_at__gt is not None:\n self.queryset = self.queryset.filter(created_at__gt=created_at__gt)\n created_at__lt = validate_date(self.request.QUERY_PARAMS.get('created_at__lt', None))\n if created_at__lt is not None:\n self.queryset = self.queryset.filter(created_at__lt=created_at__lt)\n last_modified_at__gt = validate_date(self.request.QUERY_PARAMS.get('last_modified_at__gt', None))\n if last_modified_at__gt is not None:\n self.queryset = self.queryset.filter(last_modified_at__gt=last_modified_at__gt)\n last_modified_at__lt = validate_date(self.request.QUERY_PARAMS.get('last_modified_at__lt', None))\n if last_modified_at__lt is not None:\n self.queryset = self.queryset.filter(last_modified_at__lt=last_modified_at__lt)\n # Get updates per organisation\n project__partners = self.request.QUERY_PARAMS.get('project__partners', None)\n if project__partners:\n self.queryset = self.queryset.filter(project__partners=project__partners)\n user__organisations = self.request.QUERY_PARAMS.get('user__organisations', None)\n if user__organisations:\n self.queryset = self.queryset.filter(user__organisations=user__organisations)\n return super(ProjectUpdateExtraViewSet, self).get_queryset()\n\n\n# validate date strings from URL\ndef validate_date(date):\n\n if date is None:\n return None\n # if yyyy-mm-dd\n elif match('^\\d{4}\\-(0?[1-9]|1[012])\\-(0?[1-9]|[12][0-9]|3[01])$', date) is not None:\n return date\n # if yyyy-mm\n elif match('^\\d{4}\\-(0?[1-9]|1[012])$', date) is not None:\n return date + '-01'\n else:\n raise ParseError('created_at and last_modified_at dates must be in format: yyyy-mm-dd')\n\n\n@api_view(['POST'])\n@permission_classes((IsAuthenticated, ))\ndef upload_indicator_update_photo(request, pk=None):\n update = ProjectUpdate.objects.get(pk=pk)\n user = request.user\n\n # TODO: permissions\n\n files = request.FILES\n\n if 'photo' in files.keys():\n update.photo = files['photo']\n update.save(update_fields=['photo'])\n\n return Response(ProjectUpdateExtraSerializer(update).data)\n", "path": "akvo/rest/views/project_update.py"}]}
| 2,325 | 364 |
gh_patches_debug_7838
|
rasdani/github-patches
|
git_diff
|
facebookresearch__hydra-472
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug] setuptools finds and installs tests/ as a top-level package in site-packages/
</issue>
<code>
[start of setup.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2 # type: ignore
3 import codecs
4 import os
5 import pathlib
6 import re
7 import shutil
8 from distutils import cmd
9 from os.path import exists, isdir, join
10 from typing import Any, List
11
12 import pkg_resources
13 from setuptools import find_packages, setup
14
15 here = os.path.abspath(os.path.dirname(__file__))
16
17
18 def read(*parts):
19 with codecs.open(os.path.join(here, *parts), "r") as fp:
20 return fp.read()
21
22
23 def find_version(*file_paths):
24 version_file = read(*file_paths)
25 version_match = re.search(r"^__version__ = ['\"]([^'\"]*)['\"]", version_file, re.M)
26 if version_match:
27 return version_match.group(1)
28 raise RuntimeError("Unable to find version string.")
29
30
31 with pathlib.Path("requirements/requirements.txt").open() as requirements_txt:
32 install_requires = [
33 str(requirement)
34 for requirement in pkg_resources.parse_requirements(requirements_txt)
35 ]
36
37
38 class CleanCommand(cmd.Command):
39 """
40 Our custom command to clean out junk files.
41 """
42
43 description = "Cleans out junk files we don't want in the repo"
44 user_options: List[Any] = []
45
46 def initialize_options(self):
47 pass
48
49 def finalize_options(self):
50 pass
51
52 @staticmethod
53 def find(root, includes, excludes=[]):
54 res = []
55 for parent, dirs, files in os.walk(root):
56 for f in dirs + files:
57 add = list()
58 for include in includes:
59 if re.findall(include, f):
60 add.append(join(parent, f))
61 res.extend(add)
62 final_list = []
63 # Exclude things that matches an exclude pattern
64 for ex in excludes:
65 for file in res:
66 if not re.findall(ex, file):
67 final_list.append(file)
68 return final_list
69
70 def run(self):
71 delete_patterns = [
72 ".eggs",
73 ".egg-info",
74 ".pytest_cache",
75 "build",
76 "dist",
77 "__pycache__",
78 ".pyc",
79 ]
80 deletion_list = CleanCommand.find(
81 ".", includes=delete_patterns, excludes=["\\.nox/.*"]
82 )
83
84 for f in deletion_list:
85 if exists(f):
86 if isdir(f):
87 shutil.rmtree(f, ignore_errors=True)
88 else:
89 os.unlink(f)
90
91
92 with open("README.md", "r") as fh:
93 LONG_DESC = fh.read()
94 setup(
95 cmdclass={"clean": CleanCommand},
96 name="hydra-core",
97 version=find_version("hydra", "__init__.py"),
98 author="Omry Yadan",
99 author_email="[email protected]",
100 description="A framework for elegantly configuring complex applications",
101 long_description=LONG_DESC,
102 long_description_content_type="text/markdown",
103 url="https://github.com/facebookresearch/hydra",
104 keywords="command-line configuration yaml tab-completion",
105 packages=find_packages(),
106 include_package_data=True,
107 classifiers=[
108 "License :: OSI Approved :: MIT License",
109 "Development Status :: 4 - Beta",
110 "Programming Language :: Python :: 3.6",
111 "Programming Language :: Python :: 3.7",
112 "Programming Language :: Python :: 3.8",
113 "Operating System :: POSIX :: Linux",
114 "Operating System :: MacOS",
115 "Operating System :: Microsoft :: Windows",
116 ],
117 install_requires=install_requires,
118 # Install development dependencies with
119 # pip install -r requirements/dev.txt -e .
120 )
121
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -102,7 +102,7 @@
long_description_content_type="text/markdown",
url="https://github.com/facebookresearch/hydra",
keywords="command-line configuration yaml tab-completion",
- packages=find_packages(),
+ packages=find_packages(include=["hydra"]),
include_package_data=True,
classifiers=[
"License :: OSI Approved :: MIT License",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -102,7 +102,7 @@\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/facebookresearch/hydra\",\n keywords=\"command-line configuration yaml tab-completion\",\n- packages=find_packages(),\n+ packages=find_packages(include=[\"hydra\"]),\n include_package_data=True,\n classifiers=[\n \"License :: OSI Approved :: MIT License\",\n", "issue": "[Bug] setuptools finds and installs tests/ as a top-level package in site-packages/\n\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n# type: ignore\nimport codecs\nimport os\nimport pathlib\nimport re\nimport shutil\nfrom distutils import cmd\nfrom os.path import exists, isdir, join\nfrom typing import Any, List\n\nimport pkg_resources\nfrom setuptools import find_packages, setup\n\nhere = os.path.abspath(os.path.dirname(__file__))\n\n\ndef read(*parts):\n with codecs.open(os.path.join(here, *parts), \"r\") as fp:\n return fp.read()\n\n\ndef find_version(*file_paths):\n version_file = read(*file_paths)\n version_match = re.search(r\"^__version__ = ['\\\"]([^'\\\"]*)['\\\"]\", version_file, re.M)\n if version_match:\n return version_match.group(1)\n raise RuntimeError(\"Unable to find version string.\")\n\n\nwith pathlib.Path(\"requirements/requirements.txt\").open() as requirements_txt:\n install_requires = [\n str(requirement)\n for requirement in pkg_resources.parse_requirements(requirements_txt)\n ]\n\n\nclass CleanCommand(cmd.Command):\n \"\"\"\n Our custom command to clean out junk files.\n \"\"\"\n\n description = \"Cleans out junk files we don't want in the repo\"\n user_options: List[Any] = []\n\n def initialize_options(self):\n pass\n\n def finalize_options(self):\n pass\n\n @staticmethod\n def find(root, includes, excludes=[]):\n res = []\n for parent, dirs, files in os.walk(root):\n for f in dirs + files:\n add = list()\n for include in includes:\n if re.findall(include, f):\n add.append(join(parent, f))\n res.extend(add)\n final_list = []\n # Exclude things that matches an exclude pattern\n for ex in excludes:\n for file in res:\n if not re.findall(ex, file):\n final_list.append(file)\n return final_list\n\n def run(self):\n delete_patterns = [\n \".eggs\",\n \".egg-info\",\n \".pytest_cache\",\n \"build\",\n \"dist\",\n \"__pycache__\",\n \".pyc\",\n ]\n deletion_list = CleanCommand.find(\n \".\", includes=delete_patterns, excludes=[\"\\\\.nox/.*\"]\n )\n\n for f in deletion_list:\n if exists(f):\n if isdir(f):\n shutil.rmtree(f, ignore_errors=True)\n else:\n os.unlink(f)\n\n\nwith open(\"README.md\", \"r\") as fh:\n LONG_DESC = fh.read()\n setup(\n cmdclass={\"clean\": CleanCommand},\n name=\"hydra-core\",\n version=find_version(\"hydra\", \"__init__.py\"),\n author=\"Omry Yadan\",\n author_email=\"[email protected]\",\n description=\"A framework for elegantly configuring complex applications\",\n long_description=LONG_DESC,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/facebookresearch/hydra\",\n keywords=\"command-line configuration yaml tab-completion\",\n packages=find_packages(),\n include_package_data=True,\n classifiers=[\n \"License :: OSI Approved :: MIT License\",\n \"Development Status :: 4 - Beta\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Operating System :: POSIX :: Linux\",\n \"Operating System :: MacOS\",\n \"Operating System :: Microsoft :: Windows\",\n ],\n install_requires=install_requires,\n # Install development dependencies with\n # pip install -r requirements/dev.txt -e .\n )\n", "path": "setup.py"}]}
| 1,571 | 103 |
gh_patches_debug_26381
|
rasdani/github-patches
|
git_diff
|
pretix__pretix-2436
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Internal Server Error: KeyError: 'payment_stripe_secret_key'
when entering "*****" as secret key into the stripe payment plugin I get this internal server error:
```
ERROR 2022-01-29 19:52:01,164 django.request log Internal Server Error: /control/event/test/test/settings/payment/stripe_settings
Traceback (most recent call last):
File "/var/pretix/venv/lib/python3.8/site-packages/django/core/handlers/exception.py", line 47, in inner
response = get_response(request)
File "/var/pretix/venv/lib/python3.8/site-packages/django/core/handlers/base.py", line 181, in _get_response
response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "/var/pretix/venv/lib/python3.8/site-packages/pretix/control/permissions.py", line 69, in wrapper
return function(request, *args, **kw)
File "/var/pretix/venv/lib/python3.8/site-packages/django/views/generic/base.py", line 70, in view
return self.dispatch(request, *args, **kwargs)
File "/var/pretix/venv/lib/python3.8/site-packages/pretix/control/views/event.py", line 431, in dispatch
return super().dispatch(request, *args, **kwargs)
File "/var/pretix/venv/lib/python3.8/site-packages/django/views/generic/base.py", line 98, in dispatch
return handler(request, *args, **kwargs)
File "/usr/lib/python3.8/contextlib.py", line 75, in inner
return func(*args, **kwds)
File "/var/pretix/venv/lib/python3.8/site-packages/pretix/control/views/event.py", line 453, in post
self.form.save()
File "/var/pretix/venv/lib/python3.8/site-packages/pretix/base/forms/__init__.py", line 118, in save
self.cleaned_data[k] = self.initial[k]
KeyError: 'payment_stripe_secret_key'
```
</issue>
<code>
[start of src/pretix/base/forms/__init__.py]
1 #
2 # This file is part of pretix (Community Edition).
3 #
4 # Copyright (C) 2014-2020 Raphael Michel and contributors
5 # Copyright (C) 2020-2021 rami.io GmbH and contributors
6 #
7 # This program is free software: you can redistribute it and/or modify it under the terms of the GNU Affero General
8 # Public License as published by the Free Software Foundation in version 3 of the License.
9 #
10 # ADDITIONAL TERMS APPLY: Pursuant to Section 7 of the GNU Affero General Public License, additional terms are
11 # applicable granting you additional permissions and placing additional restrictions on your usage of this software.
12 # Please refer to the pretix LICENSE file to obtain the full terms applicable to this work. If you did not receive
13 # this file, see <https://pretix.eu/about/en/license>.
14 #
15 # This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied
16 # warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Affero General Public License for more
17 # details.
18 #
19 # You should have received a copy of the GNU Affero General Public License along with this program. If not, see
20 # <https://www.gnu.org/licenses/>.
21 #
22
23 # This file is based on an earlier version of pretix which was released under the Apache License 2.0. The full text of
24 # the Apache License 2.0 can be obtained at <http://www.apache.org/licenses/LICENSE-2.0>.
25 #
26 # This file may have since been changed and any changes are released under the terms of AGPLv3 as described above. A
27 # full history of changes and contributors is available at <https://github.com/pretix/pretix>.
28 #
29 # This file contains Apache-licensed contributions copyrighted by: Alexey Kislitsin, Tobias Kunze
30 #
31 # Unless required by applicable law or agreed to in writing, software distributed under the Apache License 2.0 is
32 # distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
33 # License for the specific language governing permissions and limitations under the License.
34
35 import logging
36
37 import i18nfield.forms
38 from django import forms
39 from django.forms.models import ModelFormMetaclass
40 from django.utils.crypto import get_random_string
41 from formtools.wizard.views import SessionWizardView
42 from hierarkey.forms import HierarkeyForm
43
44 from pretix.base.reldate import RelativeDateField, RelativeDateTimeField
45
46 from .validators import PlaceholderValidator # NOQA
47
48 logger = logging.getLogger(__name__)
49
50
51 class BaseI18nModelForm(i18nfield.forms.BaseI18nModelForm):
52 # compatibility shim for django-i18nfield library
53
54 def __init__(self, *args, **kwargs):
55 self.event = kwargs.pop('event', None)
56 if self.event:
57 kwargs['locales'] = self.event.settings.get('locales')
58 super().__init__(*args, **kwargs)
59
60
61 class I18nModelForm(BaseI18nModelForm, metaclass=ModelFormMetaclass):
62 pass
63
64
65 class I18nFormSet(i18nfield.forms.I18nModelFormSet):
66 # compatibility shim for django-i18nfield library
67
68 def __init__(self, *args, **kwargs):
69 self.event = kwargs.pop('event', None)
70 if self.event:
71 kwargs['locales'] = self.event.settings.get('locales')
72 super().__init__(*args, **kwargs)
73
74
75 class I18nInlineFormSet(i18nfield.forms.I18nInlineFormSet):
76 # compatibility shim for django-i18nfield library
77
78 def __init__(self, *args, **kwargs):
79 event = kwargs.pop('event', None)
80 if event:
81 kwargs['locales'] = event.settings.get('locales')
82 super().__init__(*args, **kwargs)
83
84
85 SECRET_REDACTED = '*****'
86
87
88 class SettingsForm(i18nfield.forms.I18nFormMixin, HierarkeyForm):
89 auto_fields = []
90
91 def __init__(self, *args, **kwargs):
92 from pretix.base.settings import DEFAULTS
93
94 self.obj = kwargs.get('obj', None)
95 self.locales = self.obj.settings.get('locales') if self.obj else kwargs.pop('locales', None)
96 kwargs['attribute_name'] = 'settings'
97 kwargs['locales'] = self.locales
98 kwargs['initial'] = self.obj.settings.freeze()
99 super().__init__(*args, **kwargs)
100 for fname in self.auto_fields:
101 kwargs = DEFAULTS[fname].get('form_kwargs', {})
102 if callable(kwargs):
103 kwargs = kwargs()
104 kwargs.setdefault('required', False)
105 field = DEFAULTS[fname]['form_class'](
106 **kwargs
107 )
108 if isinstance(field, i18nfield.forms.I18nFormField):
109 field.widget.enabled_locales = self.locales
110 self.fields[fname] = field
111 for k, f in self.fields.items():
112 if isinstance(f, (RelativeDateTimeField, RelativeDateField)):
113 f.set_event(self.obj)
114
115 def save(self):
116 for k, v in self.cleaned_data.items():
117 if isinstance(self.fields.get(k), SecretKeySettingsField) and self.cleaned_data.get(k) == SECRET_REDACTED:
118 self.cleaned_data[k] = self.initial[k]
119 return super().save()
120
121 def clean(self):
122 d = super().clean()
123
124 # There is logic in HierarkeyForm.save() to only persist fields that changed. HierarkeyForm determines if
125 # something changed by comparing `self._s.get(name)` to `value`. This leaves an edge case open for multi-lingual
126 # text fields. On the very first load, the initial value in `self._s.get(name)` will be a LazyGettextProxy-based
127 # string. However, only some of the languages are usually visible, so even if the user does not change anything
128 # at all, it will be considered a changed value and stored. We do not want that, as it makes it very hard to add
129 # languages to an organizer/event later on. So we trick it and make sure nothing gets changed in that situation.
130 for name, field in self.fields.items():
131 if isinstance(field, i18nfield.forms.I18nFormField):
132 value = d.get(name)
133 if not value:
134 continue
135
136 current = self._s.get(name, as_type=type(value))
137 if name not in self.changed_data:
138 d[name] = current
139
140 return d
141
142 def get_new_filename(self, name: str) -> str:
143 from pretix.base.models import Event
144
145 nonce = get_random_string(length=8)
146 if isinstance(self.obj, Event):
147 fname = '%s/%s/%s.%s.%s' % (
148 self.obj.organizer.slug, self.obj.slug, name, nonce, name.split('.')[-1]
149 )
150 else:
151 fname = '%s/%s.%s.%s' % (self.obj.slug, name, nonce, name.split('.')[-1])
152 # TODO: make sure pub is always correct
153 return 'pub/' + fname
154
155
156 class PrefixForm(forms.Form):
157 prefix = forms.CharField(widget=forms.HiddenInput)
158
159
160 class SafeSessionWizardView(SessionWizardView):
161 def get_prefix(self, request, *args, **kwargs):
162 if hasattr(request, '_session_wizard_prefix'):
163 return request._session_wizard_prefix
164 prefix_form = PrefixForm(self.request.POST, prefix=super().get_prefix(request, *args, **kwargs))
165 if not prefix_form.is_valid():
166 request._session_wizard_prefix = get_random_string(length=24)
167 else:
168 request._session_wizard_prefix = prefix_form.cleaned_data['prefix']
169 return request._session_wizard_prefix
170
171 def get_context_data(self, form, **kwargs):
172 context = super().get_context_data(form=form, **kwargs)
173 context['wizard']['prefix_form'] = PrefixForm(
174 prefix=super().get_prefix(self.request),
175 initial={
176 'prefix': self.get_prefix(self.request)
177 }
178 )
179 return context
180
181
182 class SecretKeySettingsWidget(forms.TextInput):
183 def __init__(self, attrs=None):
184 if attrs is None:
185 attrs = {}
186 attrs.update({
187 'autocomplete': 'new-password' # see https://bugs.chromium.org/p/chromium/issues/detail?id=370363#c7
188 })
189 super().__init__(attrs)
190
191 def get_context(self, name, value, attrs):
192 if value:
193 value = SECRET_REDACTED
194 return super().get_context(name, value, attrs)
195
196
197 class SecretKeySettingsField(forms.CharField):
198 widget = SecretKeySettingsWidget
199
200 def has_changed(self, initial, data):
201 if data == SECRET_REDACTED:
202 return False
203 return super().has_changed(initial, data)
204
205 def run_validators(self, value):
206 if value == SECRET_REDACTED:
207 return
208 return super().run_validators(value)
209
[end of src/pretix/base/forms/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/pretix/base/forms/__init__.py b/src/pretix/base/forms/__init__.py
--- a/src/pretix/base/forms/__init__.py
+++ b/src/pretix/base/forms/__init__.py
@@ -38,6 +38,7 @@
from django import forms
from django.forms.models import ModelFormMetaclass
from django.utils.crypto import get_random_string
+from django.utils.translation import gettext_lazy as _
from formtools.wizard.views import SessionWizardView
from hierarkey.forms import HierarkeyForm
@@ -128,6 +129,12 @@
# at all, it will be considered a changed value and stored. We do not want that, as it makes it very hard to add
# languages to an organizer/event later on. So we trick it and make sure nothing gets changed in that situation.
for name, field in self.fields.items():
+ if isinstance(field, SecretKeySettingsField) and d.get(name) == SECRET_REDACTED and not self.initial.get(name):
+ self.add_error(
+ name,
+ _('Due to technical reasons you cannot set inputs, that need to be masked (e.g. passwords), to %(value)s.') % {'value': SECRET_REDACTED}
+ )
+
if isinstance(field, i18nfield.forms.I18nFormField):
value = d.get(name)
if not value:
|
{"golden_diff": "diff --git a/src/pretix/base/forms/__init__.py b/src/pretix/base/forms/__init__.py\n--- a/src/pretix/base/forms/__init__.py\n+++ b/src/pretix/base/forms/__init__.py\n@@ -38,6 +38,7 @@\n from django import forms\n from django.forms.models import ModelFormMetaclass\n from django.utils.crypto import get_random_string\n+from django.utils.translation import gettext_lazy as _\n from formtools.wizard.views import SessionWizardView\n from hierarkey.forms import HierarkeyForm\n \n@@ -128,6 +129,12 @@\n # at all, it will be considered a changed value and stored. We do not want that, as it makes it very hard to add\n # languages to an organizer/event later on. So we trick it and make sure nothing gets changed in that situation.\n for name, field in self.fields.items():\n+ if isinstance(field, SecretKeySettingsField) and d.get(name) == SECRET_REDACTED and not self.initial.get(name):\n+ self.add_error(\n+ name,\n+ _('Due to technical reasons you cannot set inputs, that need to be masked (e.g. passwords), to %(value)s.') % {'value': SECRET_REDACTED}\n+ )\n+\n if isinstance(field, i18nfield.forms.I18nFormField):\n value = d.get(name)\n if not value:\n", "issue": "Internal Server Error: KeyError: 'payment_stripe_secret_key'\nwhen entering \"*****\" as secret key into the stripe payment plugin I get this internal server error:\r\n\r\n```\r\nERROR 2022-01-29 19:52:01,164 django.request log Internal Server Error: /control/event/test/test/settings/payment/stripe_settings\r\nTraceback (most recent call last):\r\n File \"/var/pretix/venv/lib/python3.8/site-packages/django/core/handlers/exception.py\", line 47, in inner\r\n response = get_response(request)\r\n File \"/var/pretix/venv/lib/python3.8/site-packages/django/core/handlers/base.py\", line 181, in _get_response\r\n response = wrapped_callback(request, *callback_args, **callback_kwargs)\r\n File \"/var/pretix/venv/lib/python3.8/site-packages/pretix/control/permissions.py\", line 69, in wrapper\r\n return function(request, *args, **kw)\r\n File \"/var/pretix/venv/lib/python3.8/site-packages/django/views/generic/base.py\", line 70, in view\r\n return self.dispatch(request, *args, **kwargs)\r\n File \"/var/pretix/venv/lib/python3.8/site-packages/pretix/control/views/event.py\", line 431, in dispatch\r\n return super().dispatch(request, *args, **kwargs)\r\n File \"/var/pretix/venv/lib/python3.8/site-packages/django/views/generic/base.py\", line 98, in dispatch\r\n return handler(request, *args, **kwargs)\r\n File \"/usr/lib/python3.8/contextlib.py\", line 75, in inner\r\n return func(*args, **kwds)\r\n File \"/var/pretix/venv/lib/python3.8/site-packages/pretix/control/views/event.py\", line 453, in post\r\n self.form.save()\r\n File \"/var/pretix/venv/lib/python3.8/site-packages/pretix/base/forms/__init__.py\", line 118, in save\r\n self.cleaned_data[k] = self.initial[k]\r\nKeyError: 'payment_stripe_secret_key'\r\n```\n", "before_files": [{"content": "#\n# This file is part of pretix (Community Edition).\n#\n# Copyright (C) 2014-2020 Raphael Michel and contributors\n# Copyright (C) 2020-2021 rami.io GmbH and contributors\n#\n# This program is free software: you can redistribute it and/or modify it under the terms of the GNU Affero General\n# Public License as published by the Free Software Foundation in version 3 of the License.\n#\n# ADDITIONAL TERMS APPLY: Pursuant to Section 7 of the GNU Affero General Public License, additional terms are\n# applicable granting you additional permissions and placing additional restrictions on your usage of this software.\n# Please refer to the pretix LICENSE file to obtain the full terms applicable to this work. If you did not receive\n# this file, see <https://pretix.eu/about/en/license>.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied\n# warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Affero General Public License for more\n# details.\n#\n# You should have received a copy of the GNU Affero General Public License along with this program. If not, see\n# <https://www.gnu.org/licenses/>.\n#\n\n# This file is based on an earlier version of pretix which was released under the Apache License 2.0. The full text of\n# the Apache License 2.0 can be obtained at <http://www.apache.org/licenses/LICENSE-2.0>.\n#\n# This file may have since been changed and any changes are released under the terms of AGPLv3 as described above. A\n# full history of changes and contributors is available at <https://github.com/pretix/pretix>.\n#\n# This file contains Apache-licensed contributions copyrighted by: Alexey Kislitsin, Tobias Kunze\n#\n# Unless required by applicable law or agreed to in writing, software distributed under the Apache License 2.0 is\n# distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the\n# License for the specific language governing permissions and limitations under the License.\n\nimport logging\n\nimport i18nfield.forms\nfrom django import forms\nfrom django.forms.models import ModelFormMetaclass\nfrom django.utils.crypto import get_random_string\nfrom formtools.wizard.views import SessionWizardView\nfrom hierarkey.forms import HierarkeyForm\n\nfrom pretix.base.reldate import RelativeDateField, RelativeDateTimeField\n\nfrom .validators import PlaceholderValidator # NOQA\n\nlogger = logging.getLogger(__name__)\n\n\nclass BaseI18nModelForm(i18nfield.forms.BaseI18nModelForm):\n # compatibility shim for django-i18nfield library\n\n def __init__(self, *args, **kwargs):\n self.event = kwargs.pop('event', None)\n if self.event:\n kwargs['locales'] = self.event.settings.get('locales')\n super().__init__(*args, **kwargs)\n\n\nclass I18nModelForm(BaseI18nModelForm, metaclass=ModelFormMetaclass):\n pass\n\n\nclass I18nFormSet(i18nfield.forms.I18nModelFormSet):\n # compatibility shim for django-i18nfield library\n\n def __init__(self, *args, **kwargs):\n self.event = kwargs.pop('event', None)\n if self.event:\n kwargs['locales'] = self.event.settings.get('locales')\n super().__init__(*args, **kwargs)\n\n\nclass I18nInlineFormSet(i18nfield.forms.I18nInlineFormSet):\n # compatibility shim for django-i18nfield library\n\n def __init__(self, *args, **kwargs):\n event = kwargs.pop('event', None)\n if event:\n kwargs['locales'] = event.settings.get('locales')\n super().__init__(*args, **kwargs)\n\n\nSECRET_REDACTED = '*****'\n\n\nclass SettingsForm(i18nfield.forms.I18nFormMixin, HierarkeyForm):\n auto_fields = []\n\n def __init__(self, *args, **kwargs):\n from pretix.base.settings import DEFAULTS\n\n self.obj = kwargs.get('obj', None)\n self.locales = self.obj.settings.get('locales') if self.obj else kwargs.pop('locales', None)\n kwargs['attribute_name'] = 'settings'\n kwargs['locales'] = self.locales\n kwargs['initial'] = self.obj.settings.freeze()\n super().__init__(*args, **kwargs)\n for fname in self.auto_fields:\n kwargs = DEFAULTS[fname].get('form_kwargs', {})\n if callable(kwargs):\n kwargs = kwargs()\n kwargs.setdefault('required', False)\n field = DEFAULTS[fname]['form_class'](\n **kwargs\n )\n if isinstance(field, i18nfield.forms.I18nFormField):\n field.widget.enabled_locales = self.locales\n self.fields[fname] = field\n for k, f in self.fields.items():\n if isinstance(f, (RelativeDateTimeField, RelativeDateField)):\n f.set_event(self.obj)\n\n def save(self):\n for k, v in self.cleaned_data.items():\n if isinstance(self.fields.get(k), SecretKeySettingsField) and self.cleaned_data.get(k) == SECRET_REDACTED:\n self.cleaned_data[k] = self.initial[k]\n return super().save()\n\n def clean(self):\n d = super().clean()\n\n # There is logic in HierarkeyForm.save() to only persist fields that changed. HierarkeyForm determines if\n # something changed by comparing `self._s.get(name)` to `value`. This leaves an edge case open for multi-lingual\n # text fields. On the very first load, the initial value in `self._s.get(name)` will be a LazyGettextProxy-based\n # string. However, only some of the languages are usually visible, so even if the user does not change anything\n # at all, it will be considered a changed value and stored. We do not want that, as it makes it very hard to add\n # languages to an organizer/event later on. So we trick it and make sure nothing gets changed in that situation.\n for name, field in self.fields.items():\n if isinstance(field, i18nfield.forms.I18nFormField):\n value = d.get(name)\n if not value:\n continue\n\n current = self._s.get(name, as_type=type(value))\n if name not in self.changed_data:\n d[name] = current\n\n return d\n\n def get_new_filename(self, name: str) -> str:\n from pretix.base.models import Event\n\n nonce = get_random_string(length=8)\n if isinstance(self.obj, Event):\n fname = '%s/%s/%s.%s.%s' % (\n self.obj.organizer.slug, self.obj.slug, name, nonce, name.split('.')[-1]\n )\n else:\n fname = '%s/%s.%s.%s' % (self.obj.slug, name, nonce, name.split('.')[-1])\n # TODO: make sure pub is always correct\n return 'pub/' + fname\n\n\nclass PrefixForm(forms.Form):\n prefix = forms.CharField(widget=forms.HiddenInput)\n\n\nclass SafeSessionWizardView(SessionWizardView):\n def get_prefix(self, request, *args, **kwargs):\n if hasattr(request, '_session_wizard_prefix'):\n return request._session_wizard_prefix\n prefix_form = PrefixForm(self.request.POST, prefix=super().get_prefix(request, *args, **kwargs))\n if not prefix_form.is_valid():\n request._session_wizard_prefix = get_random_string(length=24)\n else:\n request._session_wizard_prefix = prefix_form.cleaned_data['prefix']\n return request._session_wizard_prefix\n\n def get_context_data(self, form, **kwargs):\n context = super().get_context_data(form=form, **kwargs)\n context['wizard']['prefix_form'] = PrefixForm(\n prefix=super().get_prefix(self.request),\n initial={\n 'prefix': self.get_prefix(self.request)\n }\n )\n return context\n\n\nclass SecretKeySettingsWidget(forms.TextInput):\n def __init__(self, attrs=None):\n if attrs is None:\n attrs = {}\n attrs.update({\n 'autocomplete': 'new-password' # see https://bugs.chromium.org/p/chromium/issues/detail?id=370363#c7\n })\n super().__init__(attrs)\n\n def get_context(self, name, value, attrs):\n if value:\n value = SECRET_REDACTED\n return super().get_context(name, value, attrs)\n\n\nclass SecretKeySettingsField(forms.CharField):\n widget = SecretKeySettingsWidget\n\n def has_changed(self, initial, data):\n if data == SECRET_REDACTED:\n return False\n return super().has_changed(initial, data)\n\n def run_validators(self, value):\n if value == SECRET_REDACTED:\n return\n return super().run_validators(value)\n", "path": "src/pretix/base/forms/__init__.py"}]}
| 3,526 | 309 |
gh_patches_debug_31026
|
rasdani/github-patches
|
git_diff
|
comic__grand-challenge.org-1282
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add a check for browser on reader study session detail
Don't use internet explorer or an old version of chrome.
</issue>
<code>
[start of app/grandchallenge/workstations/views.py]
1 from datetime import timedelta
2
3 from dal import autocomplete
4 from django.conf import settings
5 from django.contrib.auth import get_user_model
6 from django.contrib.auth.mixins import (
7 PermissionRequiredMixin,
8 UserPassesTestMixin,
9 )
10 from django.contrib.messages.views import SuccessMessageMixin
11 from django.core.exceptions import PermissionDenied
12 from django.http import HttpResponse
13 from django.shortcuts import get_object_or_404
14 from django.utils._os import safe_join
15 from django.utils.timezone import now
16 from django.views.generic import (
17 CreateView,
18 DetailView,
19 FormView,
20 ListView,
21 RedirectView,
22 UpdateView,
23 )
24 from guardian.mixins import (
25 LoginRequiredMixin,
26 PermissionListMixin,
27 PermissionRequiredMixin as ObjectPermissionRequiredMixin,
28 )
29 from rest_framework.decorators import action
30 from rest_framework.response import Response
31 from rest_framework.status import HTTP_400_BAD_REQUEST
32 from rest_framework.viewsets import ReadOnlyModelViewSet
33 from rest_framework_guardian.filters import ObjectPermissionsFilter
34
35 from grandchallenge.core.permissions.rest_framework import (
36 DjangoObjectOnlyPermissions,
37 )
38 from grandchallenge.workstations.forms import (
39 EditorsForm,
40 UsersForm,
41 WorkstationForm,
42 WorkstationImageForm,
43 )
44 from grandchallenge.workstations.models import (
45 Session,
46 Workstation,
47 WorkstationImage,
48 )
49 from grandchallenge.workstations.serializers import SessionSerializer
50 from grandchallenge.workstations.utils import (
51 get_or_create_active_session,
52 get_workstation_image_or_404,
53 )
54
55
56 class SessionViewSet(ReadOnlyModelViewSet):
57 queryset = Session.objects.all()
58 serializer_class = SessionSerializer
59 permission_classes = (DjangoObjectOnlyPermissions,)
60 filter_backends = (ObjectPermissionsFilter,)
61
62 @action(detail=True, methods=["patch"])
63 def keep_alive(self, *_, **__):
64 """Increase the maximum duration of the session, up to the limit."""
65 session = self.get_object()
66
67 new_duration = now() + timedelta(minutes=5) - session.created
68 duration_limit = timedelta(
69 seconds=settings.WORKSTATIONS_SESSION_DURATION_LIMIT
70 )
71
72 if new_duration < duration_limit:
73 session.maximum_duration = new_duration
74 session.save()
75 return Response({"status": "session extended"})
76 else:
77 session.maximum_duration = duration_limit
78 session.save()
79 return Response(
80 {"status": "session duration limit reached"},
81 status=HTTP_400_BAD_REQUEST,
82 )
83
84
85 class WorkstationList(LoginRequiredMixin, PermissionListMixin, ListView):
86 model = Workstation
87 permission_required = (
88 f"{Workstation._meta.app_label}.view_{Workstation._meta.model_name}"
89 )
90
91
92 class WorkstationCreate(
93 LoginRequiredMixin, PermissionRequiredMixin, CreateView
94 ):
95 model = Workstation
96 form_class = WorkstationForm
97 permission_required = (
98 f"{Workstation._meta.app_label}.add_{Workstation._meta.model_name}"
99 )
100
101 def form_valid(self, form):
102 response = super().form_valid(form)
103 self.object.add_editor(user=self.request.user)
104 return response
105
106
107 class WorkstationDetail(
108 LoginRequiredMixin, ObjectPermissionRequiredMixin, DetailView
109 ):
110 model = Workstation
111 permission_required = (
112 f"{Workstation._meta.app_label}.view_{Workstation._meta.model_name}"
113 )
114 raise_exception = True
115
116
117 class WorkstationUpdate(
118 LoginRequiredMixin, ObjectPermissionRequiredMixin, UpdateView
119 ):
120 model = Workstation
121 form_class = WorkstationForm
122 permission_required = (
123 f"{Workstation._meta.app_label}.change_{Workstation._meta.model_name}"
124 )
125 raise_exception = True
126
127
128 class WorkstationUsersAutocomplete(
129 LoginRequiredMixin, UserPassesTestMixin, autocomplete.Select2QuerySetView
130 ):
131 def test_func(self):
132 group_pks = (
133 Workstation.objects.all()
134 .select_related("editors_group")
135 .values_list("editors_group__pk", flat=True)
136 )
137 return (
138 self.request.user.is_superuser
139 or self.request.user.groups.filter(pk__in=group_pks).exists()
140 )
141
142 def get_queryset(self):
143 qs = (
144 get_user_model()
145 .objects.all()
146 .order_by("username")
147 .exclude(username=settings.ANONYMOUS_USER_NAME)
148 )
149
150 if self.q:
151 qs = qs.filter(username__istartswith=self.q)
152
153 return qs
154
155
156 class WorkstationGroupUpdateMixin(
157 LoginRequiredMixin,
158 ObjectPermissionRequiredMixin,
159 SuccessMessageMixin,
160 FormView,
161 ):
162 template_name = "workstations/workstation_user_groups_form.html"
163 permission_required = (
164 f"{Workstation._meta.app_label}.change_{Workstation._meta.model_name}"
165 )
166 raise_exception = True
167
168 def get_permission_object(self):
169 return self.workstation
170
171 @property
172 def workstation(self):
173 return get_object_or_404(Workstation, slug=self.kwargs["slug"])
174
175 def get_context_data(self, **kwargs):
176 context = super().get_context_data(**kwargs)
177 context.update(
178 {"object": self.workstation, "role": self.get_form().role}
179 )
180 return context
181
182 def get_success_url(self):
183 return self.workstation.get_absolute_url()
184
185 def form_valid(self, form):
186 form.add_or_remove_user(workstation=self.workstation)
187 return super().form_valid(form)
188
189
190 class WorkstationEditorsUpdate(WorkstationGroupUpdateMixin):
191 form_class = EditorsForm
192 success_message = "Editors successfully updated"
193
194
195 class WorkstationUsersUpdate(WorkstationGroupUpdateMixin):
196 form_class = UsersForm
197 success_message = "Users successfully updated"
198
199
200 class WorkstationImageCreate(
201 LoginRequiredMixin, ObjectPermissionRequiredMixin, CreateView
202 ):
203 model = WorkstationImage
204 form_class = WorkstationImageForm
205 permission_required = (
206 f"{Workstation._meta.app_label}.change_{Workstation._meta.model_name}"
207 )
208 raise_exception = True
209
210 def get_context_data(self, **kwargs):
211 context = super().get_context_data(**kwargs)
212 context.update({"workstation": self.workstation})
213 return context
214
215 def get_form_kwargs(self):
216 kwargs = super().get_form_kwargs()
217 kwargs.update({"user": self.request.user})
218 return kwargs
219
220 @property
221 def workstation(self):
222 return get_object_or_404(Workstation, slug=self.kwargs["slug"])
223
224 def get_permission_object(self):
225 return self.workstation
226
227 def form_valid(self, form):
228 form.instance.creator = self.request.user
229 form.instance.workstation = self.workstation
230
231 uploaded_file = form.cleaned_data["chunked_upload"][0]
232 form.instance.staged_image_uuid = uploaded_file.uuid
233
234 return super().form_valid(form)
235
236
237 class WorkstationImageDetail(
238 LoginRequiredMixin, ObjectPermissionRequiredMixin, DetailView
239 ):
240 model = WorkstationImage
241 permission_required = f"{WorkstationImage._meta.app_label}.view_{WorkstationImage._meta.model_name}"
242 raise_exception = True
243
244
245 class WorkstationImageUpdate(
246 LoginRequiredMixin, ObjectPermissionRequiredMixin, UpdateView
247 ):
248 model = WorkstationImage
249 fields = ("initial_path", "http_port", "websocket_port")
250 template_name_suffix = "_update"
251 permission_required = f"{WorkstationImage._meta.app_label}.change_{WorkstationImage._meta.model_name}"
252 raise_exception = True
253
254
255 class SessionRedirectView(
256 LoginRequiredMixin, ObjectPermissionRequiredMixin, RedirectView
257 ):
258 permanent = False
259 permission_required = (
260 f"{Workstation._meta.app_label}.view_{Workstation._meta.model_name}"
261 )
262 raise_exception = True
263
264 def get_permission_object(self):
265 return get_workstation_image_or_404(**self.kwargs).workstation
266
267 def get_redirect_url(self, *args, **kwargs):
268 workstation_image = get_workstation_image_or_404(**kwargs)
269 session = get_or_create_active_session(
270 user=self.request.user, workstation_image=workstation_image
271 )
272
273 url = session.get_absolute_url()
274
275 qs = self.request.META.get("QUERY_STRING", "")
276 if qs:
277 url = f"{url}?{qs}"
278
279 return url
280
281
282 class SessionCreate(
283 LoginRequiredMixin, ObjectPermissionRequiredMixin, CreateView
284 ):
285 model = Session
286 fields = []
287 permission_required = (
288 f"{Workstation._meta.app_label}.view_{Workstation._meta.model_name}"
289 )
290 raise_exception = True
291
292 @property
293 def workstation(self):
294 return get_object_or_404(Workstation, slug=self.kwargs["slug"])
295
296 def get_permission_object(self):
297 return self.workstation
298
299 def form_valid(self, form):
300 form.instance.creator = self.request.user
301 form.instance.workstation_image = self.workstation.latest_ready_image
302 return super().form_valid(form)
303
304
305 class SessionUpdate(
306 LoginRequiredMixin, ObjectPermissionRequiredMixin, UpdateView
307 ):
308 model = Session
309 fields = ["user_finished"]
310 permission_required = (
311 f"{Session._meta.app_label}.change_{Session._meta.model_name}"
312 )
313 raise_exception = True
314
315
316 class SessionDetail(
317 LoginRequiredMixin, ObjectPermissionRequiredMixin, DetailView
318 ):
319 model = Session
320 permission_required = (
321 f"{Session._meta.app_label}.view_{Session._meta.model_name}"
322 )
323 raise_exception = True
324
325
326 def session_proxy(request, *, pk, path, **_):
327 """Return an internal redirect to the session instance if authorised."""
328 session = get_object_or_404(Session, pk=pk)
329 path = safe_join(f"/workstation-proxy/{session.hostname}", path)
330
331 user = request.user
332 if session.creator != user:
333 raise PermissionDenied
334
335 response = HttpResponse()
336 response["X-Accel-Redirect"] = path
337
338 return response
339
[end of app/grandchallenge/workstations/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/app/grandchallenge/workstations/views.py b/app/grandchallenge/workstations/views.py
--- a/app/grandchallenge/workstations/views.py
+++ b/app/grandchallenge/workstations/views.py
@@ -31,6 +31,7 @@
from rest_framework.status import HTTP_400_BAD_REQUEST
from rest_framework.viewsets import ReadOnlyModelViewSet
from rest_framework_guardian.filters import ObjectPermissionsFilter
+from ua_parser.user_agent_parser import ParseUserAgent
from grandchallenge.core.permissions.rest_framework import (
DjangoObjectOnlyPermissions,
@@ -322,6 +323,45 @@
)
raise_exception = True
+ def _get_unsupported_browser_message(self):
+ user_agent = ParseUserAgent(
+ self.request.META.get("HTTP_USER_AGENT", "")
+ )
+
+ unsupported_browser = user_agent["family"].lower() not in [
+ "firefox",
+ "chrome",
+ ]
+
+ unsupported_chrome_version = (
+ user_agent["family"].lower() == "chrome"
+ and int(user_agent["major"]) < 79
+ )
+
+ if unsupported_browser:
+ unsupported_browser_message = (
+ "Unfortunately your browser is not supported. "
+ "Please try again with the latest version of Firefox or Chrome."
+ )
+ elif unsupported_chrome_version:
+ unsupported_browser_message = (
+ "Unfortunately your version of Chrome is not supported. "
+ "Please update to the latest version and try again."
+ )
+ else:
+ unsupported_browser_message = None
+
+ return unsupported_browser_message
+
+ def get_context_data(self, **kwargs):
+ context = super().get_context_data(**kwargs)
+ context.update(
+ {
+ "unsupported_browser_message": self._get_unsupported_browser_message()
+ }
+ )
+ return context
+
def session_proxy(request, *, pk, path, **_):
"""Return an internal redirect to the session instance if authorised."""
|
{"golden_diff": "diff --git a/app/grandchallenge/workstations/views.py b/app/grandchallenge/workstations/views.py\n--- a/app/grandchallenge/workstations/views.py\n+++ b/app/grandchallenge/workstations/views.py\n@@ -31,6 +31,7 @@\n from rest_framework.status import HTTP_400_BAD_REQUEST\n from rest_framework.viewsets import ReadOnlyModelViewSet\n from rest_framework_guardian.filters import ObjectPermissionsFilter\n+from ua_parser.user_agent_parser import ParseUserAgent\n \n from grandchallenge.core.permissions.rest_framework import (\n DjangoObjectOnlyPermissions,\n@@ -322,6 +323,45 @@\n )\n raise_exception = True\n \n+ def _get_unsupported_browser_message(self):\n+ user_agent = ParseUserAgent(\n+ self.request.META.get(\"HTTP_USER_AGENT\", \"\")\n+ )\n+\n+ unsupported_browser = user_agent[\"family\"].lower() not in [\n+ \"firefox\",\n+ \"chrome\",\n+ ]\n+\n+ unsupported_chrome_version = (\n+ user_agent[\"family\"].lower() == \"chrome\"\n+ and int(user_agent[\"major\"]) < 79\n+ )\n+\n+ if unsupported_browser:\n+ unsupported_browser_message = (\n+ \"Unfortunately your browser is not supported. \"\n+ \"Please try again with the latest version of Firefox or Chrome.\"\n+ )\n+ elif unsupported_chrome_version:\n+ unsupported_browser_message = (\n+ \"Unfortunately your version of Chrome is not supported. \"\n+ \"Please update to the latest version and try again.\"\n+ )\n+ else:\n+ unsupported_browser_message = None\n+\n+ return unsupported_browser_message\n+\n+ def get_context_data(self, **kwargs):\n+ context = super().get_context_data(**kwargs)\n+ context.update(\n+ {\n+ \"unsupported_browser_message\": self._get_unsupported_browser_message()\n+ }\n+ )\n+ return context\n+\n \n def session_proxy(request, *, pk, path, **_):\n \"\"\"Return an internal redirect to the session instance if authorised.\"\"\"\n", "issue": "Add a check for browser on reader study session detail\nDon't use internet explorer or an old version of chrome.\n", "before_files": [{"content": "from datetime import timedelta\n\nfrom dal import autocomplete\nfrom django.conf import settings\nfrom django.contrib.auth import get_user_model\nfrom django.contrib.auth.mixins import (\n PermissionRequiredMixin,\n UserPassesTestMixin,\n)\nfrom django.contrib.messages.views import SuccessMessageMixin\nfrom django.core.exceptions import PermissionDenied\nfrom django.http import HttpResponse\nfrom django.shortcuts import get_object_or_404\nfrom django.utils._os import safe_join\nfrom django.utils.timezone import now\nfrom django.views.generic import (\n CreateView,\n DetailView,\n FormView,\n ListView,\n RedirectView,\n UpdateView,\n)\nfrom guardian.mixins import (\n LoginRequiredMixin,\n PermissionListMixin,\n PermissionRequiredMixin as ObjectPermissionRequiredMixin,\n)\nfrom rest_framework.decorators import action\nfrom rest_framework.response import Response\nfrom rest_framework.status import HTTP_400_BAD_REQUEST\nfrom rest_framework.viewsets import ReadOnlyModelViewSet\nfrom rest_framework_guardian.filters import ObjectPermissionsFilter\n\nfrom grandchallenge.core.permissions.rest_framework import (\n DjangoObjectOnlyPermissions,\n)\nfrom grandchallenge.workstations.forms import (\n EditorsForm,\n UsersForm,\n WorkstationForm,\n WorkstationImageForm,\n)\nfrom grandchallenge.workstations.models import (\n Session,\n Workstation,\n WorkstationImage,\n)\nfrom grandchallenge.workstations.serializers import SessionSerializer\nfrom grandchallenge.workstations.utils import (\n get_or_create_active_session,\n get_workstation_image_or_404,\n)\n\n\nclass SessionViewSet(ReadOnlyModelViewSet):\n queryset = Session.objects.all()\n serializer_class = SessionSerializer\n permission_classes = (DjangoObjectOnlyPermissions,)\n filter_backends = (ObjectPermissionsFilter,)\n\n @action(detail=True, methods=[\"patch\"])\n def keep_alive(self, *_, **__):\n \"\"\"Increase the maximum duration of the session, up to the limit.\"\"\"\n session = self.get_object()\n\n new_duration = now() + timedelta(minutes=5) - session.created\n duration_limit = timedelta(\n seconds=settings.WORKSTATIONS_SESSION_DURATION_LIMIT\n )\n\n if new_duration < duration_limit:\n session.maximum_duration = new_duration\n session.save()\n return Response({\"status\": \"session extended\"})\n else:\n session.maximum_duration = duration_limit\n session.save()\n return Response(\n {\"status\": \"session duration limit reached\"},\n status=HTTP_400_BAD_REQUEST,\n )\n\n\nclass WorkstationList(LoginRequiredMixin, PermissionListMixin, ListView):\n model = Workstation\n permission_required = (\n f\"{Workstation._meta.app_label}.view_{Workstation._meta.model_name}\"\n )\n\n\nclass WorkstationCreate(\n LoginRequiredMixin, PermissionRequiredMixin, CreateView\n):\n model = Workstation\n form_class = WorkstationForm\n permission_required = (\n f\"{Workstation._meta.app_label}.add_{Workstation._meta.model_name}\"\n )\n\n def form_valid(self, form):\n response = super().form_valid(form)\n self.object.add_editor(user=self.request.user)\n return response\n\n\nclass WorkstationDetail(\n LoginRequiredMixin, ObjectPermissionRequiredMixin, DetailView\n):\n model = Workstation\n permission_required = (\n f\"{Workstation._meta.app_label}.view_{Workstation._meta.model_name}\"\n )\n raise_exception = True\n\n\nclass WorkstationUpdate(\n LoginRequiredMixin, ObjectPermissionRequiredMixin, UpdateView\n):\n model = Workstation\n form_class = WorkstationForm\n permission_required = (\n f\"{Workstation._meta.app_label}.change_{Workstation._meta.model_name}\"\n )\n raise_exception = True\n\n\nclass WorkstationUsersAutocomplete(\n LoginRequiredMixin, UserPassesTestMixin, autocomplete.Select2QuerySetView\n):\n def test_func(self):\n group_pks = (\n Workstation.objects.all()\n .select_related(\"editors_group\")\n .values_list(\"editors_group__pk\", flat=True)\n )\n return (\n self.request.user.is_superuser\n or self.request.user.groups.filter(pk__in=group_pks).exists()\n )\n\n def get_queryset(self):\n qs = (\n get_user_model()\n .objects.all()\n .order_by(\"username\")\n .exclude(username=settings.ANONYMOUS_USER_NAME)\n )\n\n if self.q:\n qs = qs.filter(username__istartswith=self.q)\n\n return qs\n\n\nclass WorkstationGroupUpdateMixin(\n LoginRequiredMixin,\n ObjectPermissionRequiredMixin,\n SuccessMessageMixin,\n FormView,\n):\n template_name = \"workstations/workstation_user_groups_form.html\"\n permission_required = (\n f\"{Workstation._meta.app_label}.change_{Workstation._meta.model_name}\"\n )\n raise_exception = True\n\n def get_permission_object(self):\n return self.workstation\n\n @property\n def workstation(self):\n return get_object_or_404(Workstation, slug=self.kwargs[\"slug\"])\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context.update(\n {\"object\": self.workstation, \"role\": self.get_form().role}\n )\n return context\n\n def get_success_url(self):\n return self.workstation.get_absolute_url()\n\n def form_valid(self, form):\n form.add_or_remove_user(workstation=self.workstation)\n return super().form_valid(form)\n\n\nclass WorkstationEditorsUpdate(WorkstationGroupUpdateMixin):\n form_class = EditorsForm\n success_message = \"Editors successfully updated\"\n\n\nclass WorkstationUsersUpdate(WorkstationGroupUpdateMixin):\n form_class = UsersForm\n success_message = \"Users successfully updated\"\n\n\nclass WorkstationImageCreate(\n LoginRequiredMixin, ObjectPermissionRequiredMixin, CreateView\n):\n model = WorkstationImage\n form_class = WorkstationImageForm\n permission_required = (\n f\"{Workstation._meta.app_label}.change_{Workstation._meta.model_name}\"\n )\n raise_exception = True\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context.update({\"workstation\": self.workstation})\n return context\n\n def get_form_kwargs(self):\n kwargs = super().get_form_kwargs()\n kwargs.update({\"user\": self.request.user})\n return kwargs\n\n @property\n def workstation(self):\n return get_object_or_404(Workstation, slug=self.kwargs[\"slug\"])\n\n def get_permission_object(self):\n return self.workstation\n\n def form_valid(self, form):\n form.instance.creator = self.request.user\n form.instance.workstation = self.workstation\n\n uploaded_file = form.cleaned_data[\"chunked_upload\"][0]\n form.instance.staged_image_uuid = uploaded_file.uuid\n\n return super().form_valid(form)\n\n\nclass WorkstationImageDetail(\n LoginRequiredMixin, ObjectPermissionRequiredMixin, DetailView\n):\n model = WorkstationImage\n permission_required = f\"{WorkstationImage._meta.app_label}.view_{WorkstationImage._meta.model_name}\"\n raise_exception = True\n\n\nclass WorkstationImageUpdate(\n LoginRequiredMixin, ObjectPermissionRequiredMixin, UpdateView\n):\n model = WorkstationImage\n fields = (\"initial_path\", \"http_port\", \"websocket_port\")\n template_name_suffix = \"_update\"\n permission_required = f\"{WorkstationImage._meta.app_label}.change_{WorkstationImage._meta.model_name}\"\n raise_exception = True\n\n\nclass SessionRedirectView(\n LoginRequiredMixin, ObjectPermissionRequiredMixin, RedirectView\n):\n permanent = False\n permission_required = (\n f\"{Workstation._meta.app_label}.view_{Workstation._meta.model_name}\"\n )\n raise_exception = True\n\n def get_permission_object(self):\n return get_workstation_image_or_404(**self.kwargs).workstation\n\n def get_redirect_url(self, *args, **kwargs):\n workstation_image = get_workstation_image_or_404(**kwargs)\n session = get_or_create_active_session(\n user=self.request.user, workstation_image=workstation_image\n )\n\n url = session.get_absolute_url()\n\n qs = self.request.META.get(\"QUERY_STRING\", \"\")\n if qs:\n url = f\"{url}?{qs}\"\n\n return url\n\n\nclass SessionCreate(\n LoginRequiredMixin, ObjectPermissionRequiredMixin, CreateView\n):\n model = Session\n fields = []\n permission_required = (\n f\"{Workstation._meta.app_label}.view_{Workstation._meta.model_name}\"\n )\n raise_exception = True\n\n @property\n def workstation(self):\n return get_object_or_404(Workstation, slug=self.kwargs[\"slug\"])\n\n def get_permission_object(self):\n return self.workstation\n\n def form_valid(self, form):\n form.instance.creator = self.request.user\n form.instance.workstation_image = self.workstation.latest_ready_image\n return super().form_valid(form)\n\n\nclass SessionUpdate(\n LoginRequiredMixin, ObjectPermissionRequiredMixin, UpdateView\n):\n model = Session\n fields = [\"user_finished\"]\n permission_required = (\n f\"{Session._meta.app_label}.change_{Session._meta.model_name}\"\n )\n raise_exception = True\n\n\nclass SessionDetail(\n LoginRequiredMixin, ObjectPermissionRequiredMixin, DetailView\n):\n model = Session\n permission_required = (\n f\"{Session._meta.app_label}.view_{Session._meta.model_name}\"\n )\n raise_exception = True\n\n\ndef session_proxy(request, *, pk, path, **_):\n \"\"\"Return an internal redirect to the session instance if authorised.\"\"\"\n session = get_object_or_404(Session, pk=pk)\n path = safe_join(f\"/workstation-proxy/{session.hostname}\", path)\n\n user = request.user\n if session.creator != user:\n raise PermissionDenied\n\n response = HttpResponse()\n response[\"X-Accel-Redirect\"] = path\n\n return response\n", "path": "app/grandchallenge/workstations/views.py"}]}
| 3,587 | 437 |
gh_patches_debug_7197
|
rasdani/github-patches
|
git_diff
|
wemake-services__wemake-python-styleguide-677
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Incorrect error message when over-using empty string
# Bug report
<!--
Hi, thanks for submitting a bug. We appreciate that.
But, we will need some information about what's wrong to help you.
-->
## What's wrong
Right now:
> hooks/post_gen_project.py:0:1: Z226 Found string constant over-use:
## How is that should be
> hooks/post_gen_project.py:0:1: Z226 Found string constant over-use: ''
I am using `0.10`
</issue>
<code>
[start of wemake_python_styleguide/visitors/ast/builtins.py]
1 # -*- coding: utf-8 -*-
2
3 import ast
4 from collections import Counter, defaultdict
5 from typing import ClassVar, DefaultDict, Iterable, List, Mapping
6
7 import astor
8 from typing_extensions import final
9
10 from wemake_python_styleguide import constants
11 from wemake_python_styleguide.logic.operators import (
12 count_unary_operator,
13 get_parent_ignoring_unary,
14 unwrap_unary_node,
15 )
16 from wemake_python_styleguide.types import AnyNodes, AnyUnaryOp
17 from wemake_python_styleguide.violations.best_practices import (
18 MagicNumberViolation,
19 MultipleAssignmentsViolation,
20 NonUniqueItemsInSetViolation,
21 WrongUnpackingViolation,
22 )
23 from wemake_python_styleguide.violations.complexity import (
24 OverusedStringViolation,
25 )
26 from wemake_python_styleguide.violations.consistency import (
27 FormattedStringViolation,
28 UselessOperatorsViolation,
29 )
30 from wemake_python_styleguide.visitors.base import BaseNodeVisitor
31
32
33 @final
34 class WrongStringVisitor(BaseNodeVisitor):
35 """Restricts several string usages."""
36
37 def __init__(self, *args, **kwargs) -> None:
38 """Inits the counter for constants."""
39 super().__init__(*args, **kwargs)
40 self._string_constants: DefaultDict[str, int] = defaultdict(int)
41
42 def _check_string_constant(self, node: ast.Str) -> None:
43 self._string_constants[node.s] += 1
44
45 def _post_visit(self) -> None:
46 for string, usage_count in self._string_constants.items():
47 if usage_count > self.options.max_string_usages:
48 self.add_violation(OverusedStringViolation(text=string))
49
50 def visit_Str(self, node: ast.Str) -> None:
51 """
52 Restricts to over-use string constants.
53
54 Raises:
55 OverusedStringViolation
56
57 """
58 self._check_string_constant(node)
59 self.generic_visit(node)
60
61 def visit_JoinedStr(self, node: ast.JoinedStr) -> None:
62 """
63 Restricts to use ``f`` strings.
64
65 Raises:
66 FormattedStringViolation
67
68 """
69 self.add_violation(FormattedStringViolation(node))
70 self.generic_visit(node)
71
72
73 @final
74 class MagicNumberVisitor(BaseNodeVisitor):
75 """Checks magic numbers used in the code."""
76
77 _allowed_parents: ClassVar[AnyNodes] = (
78 ast.Assign,
79 ast.AnnAssign,
80
81 # Constructor usages:
82 ast.FunctionDef,
83 ast.AsyncFunctionDef,
84 ast.arguments,
85
86 # Primitives:
87 ast.List,
88 ast.Dict,
89 ast.Set,
90 ast.Tuple,
91 )
92
93 def _check_is_magic(self, node: ast.Num) -> None:
94 parent = get_parent_ignoring_unary(node)
95 if isinstance(parent, self._allowed_parents):
96 return
97
98 if node.n in constants.MAGIC_NUMBERS_WHITELIST:
99 return
100
101 if isinstance(node.n, int) and node.n <= constants.NON_MAGIC_MODULO:
102 return
103
104 self.add_violation(MagicNumberViolation(node, text=str(node.n)))
105
106 def visit_Num(self, node: ast.Num) -> None:
107 """
108 Checks numbers not to be magic constants inside the code.
109
110 Raises:
111 MagicNumberViolation
112
113 """
114 self._check_is_magic(node)
115 self.generic_visit(node)
116
117
118 @final
119 class UselessOperatorsVisitor(BaseNodeVisitor):
120 """Checks operators used in the code."""
121
122 _limits: ClassVar[Mapping[AnyUnaryOp, int]] = {
123 ast.UAdd: 0,
124 ast.Invert: 1,
125 ast.Not: 1,
126 ast.USub: 1,
127 }
128
129 def _check_operator_count(self, node: ast.Num) -> None:
130 for node_type, limit in self._limits.items():
131 if count_unary_operator(node, node_type) > limit:
132 self.add_violation(
133 UselessOperatorsViolation(node, text=str(node.n)),
134 )
135
136 def visit_Num(self, node: ast.Num) -> None:
137 """
138 Checks numbers unnecessary operators inside the code.
139
140 Raises:
141 UselessOperatorsViolation
142
143 """
144 self._check_operator_count(node)
145 self.generic_visit(node)
146
147
148 @final
149 class WrongAssignmentVisitor(BaseNodeVisitor):
150 """Visits all assign nodes."""
151
152 def _check_assign_targets(self, node: ast.Assign) -> None:
153 if len(node.targets) > 1:
154 self.add_violation(MultipleAssignmentsViolation(node))
155
156 def _check_unpacking_targets(
157 self,
158 node: ast.AST,
159 targets: Iterable[ast.AST],
160 ) -> None:
161 for target in targets:
162 if isinstance(target, ast.Starred):
163 target = target.value
164 if not isinstance(target, ast.Name):
165 self.add_violation(WrongUnpackingViolation(node))
166
167 def visit_With(self, node: ast.With) -> None:
168 """
169 Checks assignments inside context managers to be correct.
170
171 Raises:
172 WrongUnpackingViolation
173
174 """
175 for withitem in node.items:
176 if isinstance(withitem.optional_vars, ast.Tuple):
177 self._check_unpacking_targets(
178 node, withitem.optional_vars.elts,
179 )
180 self.generic_visit(node)
181
182 def visit_For(self, node: ast.For) -> None:
183 """
184 Checks assignments inside ``for`` loops to be correct.
185
186 Raises:
187 WrongUnpackingViolation
188
189 """
190 if isinstance(node.target, ast.Tuple):
191 self._check_unpacking_targets(node, node.target.elts)
192 self.generic_visit(node)
193
194 def visit_Assign(self, node: ast.Assign) -> None:
195 """
196 Checks assignments to be correct.
197
198 Raises:
199 MultipleAssignmentsViolation
200 WrongUnpackingViolation
201
202 """
203 self._check_assign_targets(node)
204 if isinstance(node.targets[0], ast.Tuple):
205 self._check_unpacking_targets(node, node.targets[0].elts)
206 self.generic_visit(node)
207
208
209 @final
210 class WrongCollectionVisitor(BaseNodeVisitor):
211 """Ensures that collection definitions are correct."""
212
213 _elements_in_sets: ClassVar[AnyNodes] = (
214 ast.Str,
215 ast.Bytes,
216 ast.Num,
217 ast.NameConstant,
218 ast.Name,
219 )
220
221 def _report_set_elements(self, node: ast.Set, elements: List[str]) -> None:
222 for element, count in Counter(elements).items():
223 if count > 1:
224 self.add_violation(
225 NonUniqueItemsInSetViolation(node, text=element),
226 )
227
228 def _check_set_elements(self, node: ast.Set) -> None:
229 elements: List[str] = []
230 for set_item in node.elts:
231 real_set_item = unwrap_unary_node(set_item)
232 if isinstance(real_set_item, self._elements_in_sets):
233 source = astor.to_source(set_item)
234 elements.append(source.strip().strip('(').strip(')'))
235 self._report_set_elements(node, elements)
236
237 def visit_Set(self, node: ast.Set) -> None:
238 """
239 Ensures that set literals do not have any duplicate items.
240
241 Raises:
242 NonUniqueItemsInSetViolation
243
244 """
245 self._check_set_elements(node)
246 self.generic_visit(node)
247
[end of wemake_python_styleguide/visitors/ast/builtins.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/wemake_python_styleguide/visitors/ast/builtins.py b/wemake_python_styleguide/visitors/ast/builtins.py
--- a/wemake_python_styleguide/visitors/ast/builtins.py
+++ b/wemake_python_styleguide/visitors/ast/builtins.py
@@ -45,7 +45,7 @@
def _post_visit(self) -> None:
for string, usage_count in self._string_constants.items():
if usage_count > self.options.max_string_usages:
- self.add_violation(OverusedStringViolation(text=string))
+ self.add_violation(OverusedStringViolation(text=string or "''"))
def visit_Str(self, node: ast.Str) -> None:
"""
|
{"golden_diff": "diff --git a/wemake_python_styleguide/visitors/ast/builtins.py b/wemake_python_styleguide/visitors/ast/builtins.py\n--- a/wemake_python_styleguide/visitors/ast/builtins.py\n+++ b/wemake_python_styleguide/visitors/ast/builtins.py\n@@ -45,7 +45,7 @@\n def _post_visit(self) -> None:\n for string, usage_count in self._string_constants.items():\n if usage_count > self.options.max_string_usages:\n- self.add_violation(OverusedStringViolation(text=string))\n+ self.add_violation(OverusedStringViolation(text=string or \"''\"))\n \n def visit_Str(self, node: ast.Str) -> None:\n \"\"\"\n", "issue": "Incorrect error message when over-using empty string\n# Bug report\r\n\r\n<!--\r\nHi, thanks for submitting a bug. We appreciate that.\r\n\r\nBut, we will need some information about what's wrong to help you.\r\n-->\r\n\r\n## What's wrong\r\n\r\nRight now:\r\n\r\n> hooks/post_gen_project.py:0:1: Z226 Found string constant over-use: \r\n\r\n## How is that should be\r\n\r\n> hooks/post_gen_project.py:0:1: Z226 Found string constant over-use: ''\r\n\r\nI am using `0.10`\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport ast\nfrom collections import Counter, defaultdict\nfrom typing import ClassVar, DefaultDict, Iterable, List, Mapping\n\nimport astor\nfrom typing_extensions import final\n\nfrom wemake_python_styleguide import constants\nfrom wemake_python_styleguide.logic.operators import (\n count_unary_operator,\n get_parent_ignoring_unary,\n unwrap_unary_node,\n)\nfrom wemake_python_styleguide.types import AnyNodes, AnyUnaryOp\nfrom wemake_python_styleguide.violations.best_practices import (\n MagicNumberViolation,\n MultipleAssignmentsViolation,\n NonUniqueItemsInSetViolation,\n WrongUnpackingViolation,\n)\nfrom wemake_python_styleguide.violations.complexity import (\n OverusedStringViolation,\n)\nfrom wemake_python_styleguide.violations.consistency import (\n FormattedStringViolation,\n UselessOperatorsViolation,\n)\nfrom wemake_python_styleguide.visitors.base import BaseNodeVisitor\n\n\n@final\nclass WrongStringVisitor(BaseNodeVisitor):\n \"\"\"Restricts several string usages.\"\"\"\n\n def __init__(self, *args, **kwargs) -> None:\n \"\"\"Inits the counter for constants.\"\"\"\n super().__init__(*args, **kwargs)\n self._string_constants: DefaultDict[str, int] = defaultdict(int)\n\n def _check_string_constant(self, node: ast.Str) -> None:\n self._string_constants[node.s] += 1\n\n def _post_visit(self) -> None:\n for string, usage_count in self._string_constants.items():\n if usage_count > self.options.max_string_usages:\n self.add_violation(OverusedStringViolation(text=string))\n\n def visit_Str(self, node: ast.Str) -> None:\n \"\"\"\n Restricts to over-use string constants.\n\n Raises:\n OverusedStringViolation\n\n \"\"\"\n self._check_string_constant(node)\n self.generic_visit(node)\n\n def visit_JoinedStr(self, node: ast.JoinedStr) -> None:\n \"\"\"\n Restricts to use ``f`` strings.\n\n Raises:\n FormattedStringViolation\n\n \"\"\"\n self.add_violation(FormattedStringViolation(node))\n self.generic_visit(node)\n\n\n@final\nclass MagicNumberVisitor(BaseNodeVisitor):\n \"\"\"Checks magic numbers used in the code.\"\"\"\n\n _allowed_parents: ClassVar[AnyNodes] = (\n ast.Assign,\n ast.AnnAssign,\n\n # Constructor usages:\n ast.FunctionDef,\n ast.AsyncFunctionDef,\n ast.arguments,\n\n # Primitives:\n ast.List,\n ast.Dict,\n ast.Set,\n ast.Tuple,\n )\n\n def _check_is_magic(self, node: ast.Num) -> None:\n parent = get_parent_ignoring_unary(node)\n if isinstance(parent, self._allowed_parents):\n return\n\n if node.n in constants.MAGIC_NUMBERS_WHITELIST:\n return\n\n if isinstance(node.n, int) and node.n <= constants.NON_MAGIC_MODULO:\n return\n\n self.add_violation(MagicNumberViolation(node, text=str(node.n)))\n\n def visit_Num(self, node: ast.Num) -> None:\n \"\"\"\n Checks numbers not to be magic constants inside the code.\n\n Raises:\n MagicNumberViolation\n\n \"\"\"\n self._check_is_magic(node)\n self.generic_visit(node)\n\n\n@final\nclass UselessOperatorsVisitor(BaseNodeVisitor):\n \"\"\"Checks operators used in the code.\"\"\"\n\n _limits: ClassVar[Mapping[AnyUnaryOp, int]] = {\n ast.UAdd: 0,\n ast.Invert: 1,\n ast.Not: 1,\n ast.USub: 1,\n }\n\n def _check_operator_count(self, node: ast.Num) -> None:\n for node_type, limit in self._limits.items():\n if count_unary_operator(node, node_type) > limit:\n self.add_violation(\n UselessOperatorsViolation(node, text=str(node.n)),\n )\n\n def visit_Num(self, node: ast.Num) -> None:\n \"\"\"\n Checks numbers unnecessary operators inside the code.\n\n Raises:\n UselessOperatorsViolation\n\n \"\"\"\n self._check_operator_count(node)\n self.generic_visit(node)\n\n\n@final\nclass WrongAssignmentVisitor(BaseNodeVisitor):\n \"\"\"Visits all assign nodes.\"\"\"\n\n def _check_assign_targets(self, node: ast.Assign) -> None:\n if len(node.targets) > 1:\n self.add_violation(MultipleAssignmentsViolation(node))\n\n def _check_unpacking_targets(\n self,\n node: ast.AST,\n targets: Iterable[ast.AST],\n ) -> None:\n for target in targets:\n if isinstance(target, ast.Starred):\n target = target.value\n if not isinstance(target, ast.Name):\n self.add_violation(WrongUnpackingViolation(node))\n\n def visit_With(self, node: ast.With) -> None:\n \"\"\"\n Checks assignments inside context managers to be correct.\n\n Raises:\n WrongUnpackingViolation\n\n \"\"\"\n for withitem in node.items:\n if isinstance(withitem.optional_vars, ast.Tuple):\n self._check_unpacking_targets(\n node, withitem.optional_vars.elts,\n )\n self.generic_visit(node)\n\n def visit_For(self, node: ast.For) -> None:\n \"\"\"\n Checks assignments inside ``for`` loops to be correct.\n\n Raises:\n WrongUnpackingViolation\n\n \"\"\"\n if isinstance(node.target, ast.Tuple):\n self._check_unpacking_targets(node, node.target.elts)\n self.generic_visit(node)\n\n def visit_Assign(self, node: ast.Assign) -> None:\n \"\"\"\n Checks assignments to be correct.\n\n Raises:\n MultipleAssignmentsViolation\n WrongUnpackingViolation\n\n \"\"\"\n self._check_assign_targets(node)\n if isinstance(node.targets[0], ast.Tuple):\n self._check_unpacking_targets(node, node.targets[0].elts)\n self.generic_visit(node)\n\n\n@final\nclass WrongCollectionVisitor(BaseNodeVisitor):\n \"\"\"Ensures that collection definitions are correct.\"\"\"\n\n _elements_in_sets: ClassVar[AnyNodes] = (\n ast.Str,\n ast.Bytes,\n ast.Num,\n ast.NameConstant,\n ast.Name,\n )\n\n def _report_set_elements(self, node: ast.Set, elements: List[str]) -> None:\n for element, count in Counter(elements).items():\n if count > 1:\n self.add_violation(\n NonUniqueItemsInSetViolation(node, text=element),\n )\n\n def _check_set_elements(self, node: ast.Set) -> None:\n elements: List[str] = []\n for set_item in node.elts:\n real_set_item = unwrap_unary_node(set_item)\n if isinstance(real_set_item, self._elements_in_sets):\n source = astor.to_source(set_item)\n elements.append(source.strip().strip('(').strip(')'))\n self._report_set_elements(node, elements)\n\n def visit_Set(self, node: ast.Set) -> None:\n \"\"\"\n Ensures that set literals do not have any duplicate items.\n\n Raises:\n NonUniqueItemsInSetViolation\n\n \"\"\"\n self._check_set_elements(node)\n self.generic_visit(node)\n", "path": "wemake_python_styleguide/visitors/ast/builtins.py"}]}
| 2,877 | 171 |
gh_patches_debug_39108
|
rasdani/github-patches
|
git_diff
|
google__fuzzbench-1898
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Only trigger experiments when a comment starts with `/gcbrun`
Currently, a `GCB` experiment will be triggered if our comment **_mentions_** `/gcbrun`.
This is problematic because experiments will be launched unintendedly (e.g., when we quote previous `/gcb` commands, or even when we mention `/gcb` in any form).
## Root cause
1. `GCB` trigger simply [checks for `/gcb` without any constraints](https://pantheon.corp.google.com/cloud-build/triggers/edit/fff67372-9e94-4eeb-ab8c-4566ca73badf?project=fuzzbench).
2. Our `gcbrun_experiment.py` [iterates all previous comments](https://github.com/google/fuzzbench/blob/56caa83e81bc59a1389367c6bd29d46fd35d03e6/service/gcbrun_experiment.py#L57) to find the latest valid `/gcb` command, which might have already been run.
## Proofs
1. [This example](https://github.com/google/fuzzbench/pull/1893#issuecomment-1716770892) quotes an old command and modifies its experiment name. However, it triggers an experiment with the old name, indicating we launch the latest valid experiment command.
2. [This example](https://github.com/google/fuzzbench/pull/1893#issuecomment-1716780709) includes a random `/gcb` command in the middle of the sentence. It also triggers the same old experiment, confirming the same conclusion.
## Propose fix
Change https://github.com/google/fuzzbench/blob/56caa83e81bc59a1389367c6bd29d46fd35d03e6/service/gcbrun_experiment.py#L56-L57
to
```python
if not body.startswith(RUN_EXPERIMENT_COMMAND_STR):
return None
```
## Justification
1. Based on our setting on Google Cloud, all `/gcb` commands will immediately trigger an experiment, there is no need to search back in history for an old command.
2. If we need to run an old command, we can always add a new comment for it.
@jonathanmetzman: Did I miss anything?
If it looks good to you, I will implement the fix proposed above.
Only trigger experiments when a comment starts with `/gcbrun`
Currently, a `GCB` experiment will be triggered if our comment **_mentions_** `/gcbrun`.
This is problematic because experiments will be launched unintendedly (e.g., when we quote previous `/gcb` commands, or even when we mention `/gcb` in any form).
## Root cause
1. `GCB` trigger simply [checks for `/gcb` without any constraints](https://pantheon.corp.google.com/cloud-build/triggers/edit/fff67372-9e94-4eeb-ab8c-4566ca73badf?project=fuzzbench).
2. Our `gcbrun_experiment.py` [iterates all previous comments](https://github.com/google/fuzzbench/blob/56caa83e81bc59a1389367c6bd29d46fd35d03e6/service/gcbrun_experiment.py#L57) to find the latest valid `/gcb` command, which might have already been run.
## Proofs
1. [This example](https://github.com/google/fuzzbench/pull/1893#issuecomment-1716770892) quotes an old command and modifies its experiment name. However, it triggers an experiment with the old name, indicating we launch the latest valid experiment command.
2. [This example](https://github.com/google/fuzzbench/pull/1893#issuecomment-1716780709) includes a random `/gcb` command in the middle of the sentence. It also triggers the same old experiment, confirming the same conclusion.
## Propose fix
Change https://github.com/google/fuzzbench/blob/56caa83e81bc59a1389367c6bd29d46fd35d03e6/service/gcbrun_experiment.py#L56-L57
to
```python
if not body.startswith(RUN_EXPERIMENT_COMMAND_STR):
return None
```
## Justification
1. Based on our setting on Google Cloud, all `/gcb` commands will immediately trigger an experiment, there is no need to search back in history for an old command.
2. If we need to run an old command, we can always add a new comment for it.
@jonathanmetzman: Did I miss anything?
If it looks good to you, I will implement the fix proposed above.
</issue>
<code>
[start of service/gcbrun_experiment.py]
1 # Copyright 2023 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 #
15 ################################################################################
16 """Entrypoint for gcbrun into run_experiment. This script will get the command
17 from the last PR comment containing "/gcbrun" and pass it to run_experiment.py
18 which will run an experiment."""
19
20 import logging
21 import os
22 import sys
23
24 # pytype: disable=import-error
25 import github # pylint: disable=import-error
26
27 from experiment import run_experiment
28
29 TRIGGER_COMMAND = '/gcbrun'
30 RUN_EXPERIMENT_COMMAND_STR = f'{TRIGGER_COMMAND} run_experiment.py '
31 SKIP_COMMAND_STR = f'{TRIGGER_COMMAND} skip'
32
33
34 def get_comments(pull_request_number):
35 """Returns comments on the GitHub Pull request referenced by
36 |pull_request_number|."""
37 github_obj = github.Github()
38 repo = github_obj.get_repo('google/fuzzbench')
39 pull = repo.get_pull(pull_request_number)
40 pull_comments = list(pull.get_comments())
41 issue = repo.get_issue(pull_request_number)
42 issue_comments = list(issue.get_comments())
43 # Github only returns comments if from the pull object when a pull request
44 # is open. If it is a draft, it will only return comments from the issue
45 # object.
46 return pull_comments + issue_comments
47
48
49 def get_latest_gcbrun_command(comments):
50 """Gets the last /gcbrun comment from comments."""
51 for comment in reversed(comments):
52 # This seems to get comments on code too.
53 body = comment.body
54 if body.startswith(SKIP_COMMAND_STR):
55 return None
56 if not body.startswith(RUN_EXPERIMENT_COMMAND_STR):
57 continue
58 if len(body) == len(RUN_EXPERIMENT_COMMAND_STR):
59 return None
60 command = body[len(RUN_EXPERIMENT_COMMAND_STR):].strip().split(' ')
61 # Items that only contain space are redundant and will confuse
62 # `run_experiment_main()` in `experiment/run_experiment.py`
63 return [word for word in command if word.strip()]
64 return None
65
66
67 def exec_command_from_github(pull_request_number):
68 """Executes the gcbrun command for run_experiment.py in the most recent
69 command on |pull_request_number|."""
70 comments = get_comments(pull_request_number)
71 print(comments)
72 command = get_latest_gcbrun_command(comments)
73 if command is None:
74 logging.info('Experiment not requested.')
75 return None
76 print(command)
77 logging.info('Command: %s.', command)
78 return run_experiment.run_experiment_main(command)
79
80
81 def main():
82 """Entrypoint for GitHub CI into run_experiment.py"""
83 logging.basicConfig(level=logging.INFO)
84 pull_request_number = int(os.environ['PULL_REQUEST_NUMBER'])
85 result = exec_command_from_github(pull_request_number)
86 print('result', result)
87 if not result:
88 return 0
89 return 1
90
91
92 if __name__ == '__main__':
93 sys.exit(main())
94
[end of service/gcbrun_experiment.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/service/gcbrun_experiment.py b/service/gcbrun_experiment.py
--- a/service/gcbrun_experiment.py
+++ b/service/gcbrun_experiment.py
@@ -23,7 +23,6 @@
# pytype: disable=import-error
import github # pylint: disable=import-error
-
from experiment import run_experiment
TRIGGER_COMMAND = '/gcbrun'
@@ -38,38 +37,41 @@
repo = github_obj.get_repo('google/fuzzbench')
pull = repo.get_pull(pull_request_number)
pull_comments = list(pull.get_comments())
+ last_pull_comment = pull_comments[-1] if pull_comments else None
issue = repo.get_issue(pull_request_number)
issue_comments = list(issue.get_comments())
+ last_issue_comment = issue_comments[-1] if issue_comments else None
# Github only returns comments if from the pull object when a pull request
# is open. If it is a draft, it will only return comments from the issue
# object.
- return pull_comments + issue_comments
+ return last_pull_comment, last_issue_comment
-def get_latest_gcbrun_command(comments):
+def get_latest_gcbrun_command(comment):
"""Gets the last /gcbrun comment from comments."""
- for comment in reversed(comments):
- # This seems to get comments on code too.
- body = comment.body
- if body.startswith(SKIP_COMMAND_STR):
- return None
- if not body.startswith(RUN_EXPERIMENT_COMMAND_STR):
- continue
- if len(body) == len(RUN_EXPERIMENT_COMMAND_STR):
- return None
- command = body[len(RUN_EXPERIMENT_COMMAND_STR):].strip().split(' ')
- # Items that only contain space are redundant and will confuse
- # `run_experiment_main()` in `experiment/run_experiment.py`
- return [word for word in command if word.strip()]
- return None
+ # This seems to get comments on code too.
+ if comment is None:
+ return None
+ body = comment.body
+ if body.startswith(SKIP_COMMAND_STR):
+ return None
+ if not body.startswith(RUN_EXPERIMENT_COMMAND_STR):
+ return None
+ if len(body) == len(RUN_EXPERIMENT_COMMAND_STR):
+ return None
+ command = body[len(RUN_EXPERIMENT_COMMAND_STR):].strip().split(' ')
+ # Items that only contain space are redundant and will confuse
+ # `run_experiment_main()` in `experiment/run_experiment.py`
+ return [word for word in command if word.strip()]
def exec_command_from_github(pull_request_number):
"""Executes the gcbrun command for run_experiment.py in the most recent
command on |pull_request_number|."""
- comments = get_comments(pull_request_number)
- print(comments)
- command = get_latest_gcbrun_command(comments)
+ pull_cmt, issue_cmt = get_comments(pull_request_number)
+ print(f'Pull comment: {pull_cmt}\nIssue comment: {issue_cmt}')
+ command = (get_latest_gcbrun_command(pull_cmt) or
+ get_latest_gcbrun_command(issue_cmt))
if command is None:
logging.info('Experiment not requested.')
return None
|
{"golden_diff": "diff --git a/service/gcbrun_experiment.py b/service/gcbrun_experiment.py\n--- a/service/gcbrun_experiment.py\n+++ b/service/gcbrun_experiment.py\n@@ -23,7 +23,6 @@\n \n # pytype: disable=import-error\n import github # pylint: disable=import-error\n-\n from experiment import run_experiment\n \n TRIGGER_COMMAND = '/gcbrun'\n@@ -38,38 +37,41 @@\n repo = github_obj.get_repo('google/fuzzbench')\n pull = repo.get_pull(pull_request_number)\n pull_comments = list(pull.get_comments())\n+ last_pull_comment = pull_comments[-1] if pull_comments else None\n issue = repo.get_issue(pull_request_number)\n issue_comments = list(issue.get_comments())\n+ last_issue_comment = issue_comments[-1] if issue_comments else None\n # Github only returns comments if from the pull object when a pull request\n # is open. If it is a draft, it will only return comments from the issue\n # object.\n- return pull_comments + issue_comments\n+ return last_pull_comment, last_issue_comment\n \n \n-def get_latest_gcbrun_command(comments):\n+def get_latest_gcbrun_command(comment):\n \"\"\"Gets the last /gcbrun comment from comments.\"\"\"\n- for comment in reversed(comments):\n- # This seems to get comments on code too.\n- body = comment.body\n- if body.startswith(SKIP_COMMAND_STR):\n- return None\n- if not body.startswith(RUN_EXPERIMENT_COMMAND_STR):\n- continue\n- if len(body) == len(RUN_EXPERIMENT_COMMAND_STR):\n- return None\n- command = body[len(RUN_EXPERIMENT_COMMAND_STR):].strip().split(' ')\n- # Items that only contain space are redundant and will confuse\n- # `run_experiment_main()` in `experiment/run_experiment.py`\n- return [word for word in command if word.strip()]\n- return None\n+ # This seems to get comments on code too.\n+ if comment is None:\n+ return None\n+ body = comment.body\n+ if body.startswith(SKIP_COMMAND_STR):\n+ return None\n+ if not body.startswith(RUN_EXPERIMENT_COMMAND_STR):\n+ return None\n+ if len(body) == len(RUN_EXPERIMENT_COMMAND_STR):\n+ return None\n+ command = body[len(RUN_EXPERIMENT_COMMAND_STR):].strip().split(' ')\n+ # Items that only contain space are redundant and will confuse\n+ # `run_experiment_main()` in `experiment/run_experiment.py`\n+ return [word for word in command if word.strip()]\n \n \n def exec_command_from_github(pull_request_number):\n \"\"\"Executes the gcbrun command for run_experiment.py in the most recent\n command on |pull_request_number|.\"\"\"\n- comments = get_comments(pull_request_number)\n- print(comments)\n- command = get_latest_gcbrun_command(comments)\n+ pull_cmt, issue_cmt = get_comments(pull_request_number)\n+ print(f'Pull comment: {pull_cmt}\\nIssue comment: {issue_cmt}')\n+ command = (get_latest_gcbrun_command(pull_cmt) or\n+ get_latest_gcbrun_command(issue_cmt))\n if command is None:\n logging.info('Experiment not requested.')\n return None\n", "issue": "Only trigger experiments when a comment starts with `/gcbrun`\nCurrently, a `GCB` experiment will be triggered if our comment **_mentions_** `/gcbrun`.\r\n\r\nThis is problematic because experiments will be launched unintendedly (e.g., when we quote previous `/gcb` commands, or even when we mention `/gcb` in any form).\r\n\r\n## Root cause\r\n1. `GCB` trigger simply [checks for `/gcb` without any constraints](https://pantheon.corp.google.com/cloud-build/triggers/edit/fff67372-9e94-4eeb-ab8c-4566ca73badf?project=fuzzbench). \r\n2. Our `gcbrun_experiment.py` [iterates all previous comments](https://github.com/google/fuzzbench/blob/56caa83e81bc59a1389367c6bd29d46fd35d03e6/service/gcbrun_experiment.py#L57) to find the latest valid `/gcb` command, which might have already been run.\r\n\r\n## Proofs\r\n1. [This example](https://github.com/google/fuzzbench/pull/1893#issuecomment-1716770892) quotes an old command and modifies its experiment name. However, it triggers an experiment with the old name, indicating we launch the latest valid experiment command.\r\n2. [This example](https://github.com/google/fuzzbench/pull/1893#issuecomment-1716780709) includes a random `/gcb` command in the middle of the sentence. It also triggers the same old experiment, confirming the same conclusion.\r\n\r\n## Propose fix\r\nChange https://github.com/google/fuzzbench/blob/56caa83e81bc59a1389367c6bd29d46fd35d03e6/service/gcbrun_experiment.py#L56-L57\r\nto\r\n```python\r\n if not body.startswith(RUN_EXPERIMENT_COMMAND_STR): \r\n return None \r\n```\r\n\r\n## Justification\r\n1. Based on our setting on Google Cloud, all `/gcb` commands will immediately trigger an experiment, there is no need to search back in history for an old command.\r\n2. If we need to run an old command, we can always add a new comment for it.\r\n\r\n@jonathanmetzman: Did I miss anything?\r\nIf it looks good to you, I will implement the fix proposed above.\nOnly trigger experiments when a comment starts with `/gcbrun`\nCurrently, a `GCB` experiment will be triggered if our comment **_mentions_** `/gcbrun`.\r\n\r\nThis is problematic because experiments will be launched unintendedly (e.g., when we quote previous `/gcb` commands, or even when we mention `/gcb` in any form).\r\n\r\n## Root cause\r\n1. `GCB` trigger simply [checks for `/gcb` without any constraints](https://pantheon.corp.google.com/cloud-build/triggers/edit/fff67372-9e94-4eeb-ab8c-4566ca73badf?project=fuzzbench). \r\n2. Our `gcbrun_experiment.py` [iterates all previous comments](https://github.com/google/fuzzbench/blob/56caa83e81bc59a1389367c6bd29d46fd35d03e6/service/gcbrun_experiment.py#L57) to find the latest valid `/gcb` command, which might have already been run.\r\n\r\n## Proofs\r\n1. [This example](https://github.com/google/fuzzbench/pull/1893#issuecomment-1716770892) quotes an old command and modifies its experiment name. However, it triggers an experiment with the old name, indicating we launch the latest valid experiment command.\r\n2. [This example](https://github.com/google/fuzzbench/pull/1893#issuecomment-1716780709) includes a random `/gcb` command in the middle of the sentence. It also triggers the same old experiment, confirming the same conclusion.\r\n\r\n## Propose fix\r\nChange https://github.com/google/fuzzbench/blob/56caa83e81bc59a1389367c6bd29d46fd35d03e6/service/gcbrun_experiment.py#L56-L57\r\nto\r\n```python\r\n if not body.startswith(RUN_EXPERIMENT_COMMAND_STR): \r\n return None \r\n```\r\n\r\n## Justification\r\n1. Based on our setting on Google Cloud, all `/gcb` commands will immediately trigger an experiment, there is no need to search back in history for an old command.\r\n2. If we need to run an old command, we can always add a new comment for it.\r\n\r\n@jonathanmetzman: Did I miss anything?\r\nIf it looks good to you, I will implement the fix proposed above.\n", "before_files": [{"content": "# Copyright 2023 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n################################################################################\n\"\"\"Entrypoint for gcbrun into run_experiment. This script will get the command\nfrom the last PR comment containing \"/gcbrun\" and pass it to run_experiment.py\nwhich will run an experiment.\"\"\"\n\nimport logging\nimport os\nimport sys\n\n# pytype: disable=import-error\nimport github # pylint: disable=import-error\n\nfrom experiment import run_experiment\n\nTRIGGER_COMMAND = '/gcbrun'\nRUN_EXPERIMENT_COMMAND_STR = f'{TRIGGER_COMMAND} run_experiment.py '\nSKIP_COMMAND_STR = f'{TRIGGER_COMMAND} skip'\n\n\ndef get_comments(pull_request_number):\n \"\"\"Returns comments on the GitHub Pull request referenced by\n |pull_request_number|.\"\"\"\n github_obj = github.Github()\n repo = github_obj.get_repo('google/fuzzbench')\n pull = repo.get_pull(pull_request_number)\n pull_comments = list(pull.get_comments())\n issue = repo.get_issue(pull_request_number)\n issue_comments = list(issue.get_comments())\n # Github only returns comments if from the pull object when a pull request\n # is open. If it is a draft, it will only return comments from the issue\n # object.\n return pull_comments + issue_comments\n\n\ndef get_latest_gcbrun_command(comments):\n \"\"\"Gets the last /gcbrun comment from comments.\"\"\"\n for comment in reversed(comments):\n # This seems to get comments on code too.\n body = comment.body\n if body.startswith(SKIP_COMMAND_STR):\n return None\n if not body.startswith(RUN_EXPERIMENT_COMMAND_STR):\n continue\n if len(body) == len(RUN_EXPERIMENT_COMMAND_STR):\n return None\n command = body[len(RUN_EXPERIMENT_COMMAND_STR):].strip().split(' ')\n # Items that only contain space are redundant and will confuse\n # `run_experiment_main()` in `experiment/run_experiment.py`\n return [word for word in command if word.strip()]\n return None\n\n\ndef exec_command_from_github(pull_request_number):\n \"\"\"Executes the gcbrun command for run_experiment.py in the most recent\n command on |pull_request_number|.\"\"\"\n comments = get_comments(pull_request_number)\n print(comments)\n command = get_latest_gcbrun_command(comments)\n if command is None:\n logging.info('Experiment not requested.')\n return None\n print(command)\n logging.info('Command: %s.', command)\n return run_experiment.run_experiment_main(command)\n\n\ndef main():\n \"\"\"Entrypoint for GitHub CI into run_experiment.py\"\"\"\n logging.basicConfig(level=logging.INFO)\n pull_request_number = int(os.environ['PULL_REQUEST_NUMBER'])\n result = exec_command_from_github(pull_request_number)\n print('result', result)\n if not result:\n return 0\n return 1\n\n\nif __name__ == '__main__':\n sys.exit(main())\n", "path": "service/gcbrun_experiment.py"}]}
| 2,571 | 738 |
gh_patches_debug_2075
|
rasdani/github-patches
|
git_diff
|
litestar-org__litestar-2433
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug: `2.2.0` does not have `[full]` group
### Description
The move from `poetry` to `pdm` in 2.2.0 has a regression for the `[full]` group.
### URL to code causing the issue
_No response_
### MCVE
```python
pip install litestar[full]==2.2.0 && pip show pydantic
```
### Steps to reproduce
- `pip install litestar[full]`
- Observe no `[full]` group is available, and `pip show $package` does not show expected pacakges
### Screenshots
_No response_
### Logs
_No response_
### Litestar Version
2.2.0
### Platform
- [ ] Linux
- [ ] Mac
- [ ] Windows
- [X] Other (Please specify in the description above)
<!-- POLAR PLEDGE BADGE START -->
> [!NOTE]
> Check out all issues funded or available for funding here: https://polar.sh/litestar-org
> * If you would like to see an issue prioritized, make a pledge towards it!
> * We receive the pledge once the issue is completed & verified
<a href="https://polar.sh/litestar-org/litestar/issues/2434">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://polar.sh/api/github/litestar-org/litestar/issues/2434/pledge.svg?darkmode=1">
<img alt="Fund with Polar" src="https://polar.sh/api/github/litestar-org/litestar/issues/2434/pledge.svg">
</picture>
</a>
<!-- POLAR PLEDGE BADGE END -->
</issue>
<code>
[start of litestar/types/internal_types.py]
1 from __future__ import annotations
2
3 from typing import TYPE_CHECKING, Any, Callable, Literal, NamedTuple
4
5 from litestar.utils.deprecation import warn_deprecation
6
7 __all__ = (
8 "ControllerRouterHandler",
9 "PathParameterDefinition",
10 "PathParameterDefinition",
11 "ReservedKwargs",
12 "ResponseType",
13 "RouteHandlerMapItem",
14 "RouteHandlerType",
15 )
16
17 if TYPE_CHECKING:
18 from typing_extensions import TypeAlias
19
20 from litestar.app import Litestar
21 from litestar.controller import Controller
22 from litestar.handlers.asgi_handlers import ASGIRouteHandler
23 from litestar.handlers.http_handlers import HTTPRouteHandler
24 from litestar.handlers.websocket_handlers import WebsocketRouteHandler
25 from litestar.response import Response
26 from litestar.router import Router
27 from litestar.types import Method
28
29 ReservedKwargs: TypeAlias = Literal["request", "socket", "headers", "query", "cookies", "state", "data"]
30 RouteHandlerType: TypeAlias = "HTTPRouteHandler | WebsocketRouteHandler | ASGIRouteHandler"
31 ResponseType: TypeAlias = "type[Response]"
32 ControllerRouterHandler: TypeAlias = "type[Controller] | RouteHandlerType | Router | Callable[..., Any]"
33 RouteHandlerMapItem: TypeAlias = 'dict[Method | Literal["websocket", "asgi"], RouteHandlerType]'
34
35 # deprecated
36 _LitestarType: TypeAlias = "Litestar"
37
38
39 class PathParameterDefinition(NamedTuple):
40 """Path parameter tuple."""
41
42 name: str
43 full: str
44 type: type
45 parser: Callable[[str], Any] | None
46
47
48 def __getattr__(name: str) -> Any:
49 if name == "LitestarType":
50 warn_deprecation(
51 "2.3.0",
52 "LitestarType",
53 "import",
54 removal_in="3.0.0",
55 alternative="Litestar",
56 )
57 return _LitestarType
58 raise AttributeError(f"module {__name__!r} has no attribute {name!r}")
59
[end of litestar/types/internal_types.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/litestar/types/internal_types.py b/litestar/types/internal_types.py
--- a/litestar/types/internal_types.py
+++ b/litestar/types/internal_types.py
@@ -48,7 +48,7 @@
def __getattr__(name: str) -> Any:
if name == "LitestarType":
warn_deprecation(
- "2.3.0",
+ "2.2.1",
"LitestarType",
"import",
removal_in="3.0.0",
|
{"golden_diff": "diff --git a/litestar/types/internal_types.py b/litestar/types/internal_types.py\n--- a/litestar/types/internal_types.py\n+++ b/litestar/types/internal_types.py\n@@ -48,7 +48,7 @@\n def __getattr__(name: str) -> Any:\n if name == \"LitestarType\":\n warn_deprecation(\n- \"2.3.0\",\n+ \"2.2.1\",\n \"LitestarType\",\n \"import\",\n removal_in=\"3.0.0\",\n", "issue": "Bug: `2.2.0` does not have `[full]` group\n### Description\r\n\r\nThe move from `poetry` to `pdm` in 2.2.0 has a regression for the `[full]` group.\r\n\r\n### URL to code causing the issue\r\n\r\n_No response_\r\n\r\n### MCVE\r\n\r\n```python\r\npip install litestar[full]==2.2.0 && pip show pydantic\r\n```\r\n\r\n\r\n### Steps to reproduce\r\n\r\n- `pip install litestar[full]`\r\n- Observe no `[full]` group is available, and `pip show $package` does not show expected pacakges\r\n\r\n\r\n### Screenshots\r\n\r\n_No response_\r\n\r\n### Logs\r\n\r\n_No response_\r\n\r\n### Litestar Version\r\n\r\n2.2.0\r\n\r\n### Platform\r\n\r\n- [ ] Linux\r\n- [ ] Mac\r\n- [ ] Windows\r\n- [X] Other (Please specify in the description above)\r\n\r\n<!-- POLAR PLEDGE BADGE START -->\r\n> [!NOTE] \r\n> Check out all issues funded or available for funding here: https://polar.sh/litestar-org\r\n> * If you would like to see an issue prioritized, make a pledge towards it!\r\n> * We receive the pledge once the issue is completed & verified\r\n\r\n<a href=\"https://polar.sh/litestar-org/litestar/issues/2434\">\r\n<picture>\r\n <source media=\"(prefers-color-scheme: dark)\" srcset=\"https://polar.sh/api/github/litestar-org/litestar/issues/2434/pledge.svg?darkmode=1\">\r\n <img alt=\"Fund with Polar\" src=\"https://polar.sh/api/github/litestar-org/litestar/issues/2434/pledge.svg\">\r\n</picture>\r\n</a>\r\n<!-- POLAR PLEDGE BADGE END -->\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING, Any, Callable, Literal, NamedTuple\n\nfrom litestar.utils.deprecation import warn_deprecation\n\n__all__ = (\n \"ControllerRouterHandler\",\n \"PathParameterDefinition\",\n \"PathParameterDefinition\",\n \"ReservedKwargs\",\n \"ResponseType\",\n \"RouteHandlerMapItem\",\n \"RouteHandlerType\",\n)\n\nif TYPE_CHECKING:\n from typing_extensions import TypeAlias\n\n from litestar.app import Litestar\n from litestar.controller import Controller\n from litestar.handlers.asgi_handlers import ASGIRouteHandler\n from litestar.handlers.http_handlers import HTTPRouteHandler\n from litestar.handlers.websocket_handlers import WebsocketRouteHandler\n from litestar.response import Response\n from litestar.router import Router\n from litestar.types import Method\n\nReservedKwargs: TypeAlias = Literal[\"request\", \"socket\", \"headers\", \"query\", \"cookies\", \"state\", \"data\"]\nRouteHandlerType: TypeAlias = \"HTTPRouteHandler | WebsocketRouteHandler | ASGIRouteHandler\"\nResponseType: TypeAlias = \"type[Response]\"\nControllerRouterHandler: TypeAlias = \"type[Controller] | RouteHandlerType | Router | Callable[..., Any]\"\nRouteHandlerMapItem: TypeAlias = 'dict[Method | Literal[\"websocket\", \"asgi\"], RouteHandlerType]'\n\n# deprecated\n_LitestarType: TypeAlias = \"Litestar\"\n\n\nclass PathParameterDefinition(NamedTuple):\n \"\"\"Path parameter tuple.\"\"\"\n\n name: str\n full: str\n type: type\n parser: Callable[[str], Any] | None\n\n\ndef __getattr__(name: str) -> Any:\n if name == \"LitestarType\":\n warn_deprecation(\n \"2.3.0\",\n \"LitestarType\",\n \"import\",\n removal_in=\"3.0.0\",\n alternative=\"Litestar\",\n )\n return _LitestarType\n raise AttributeError(f\"module {__name__!r} has no attribute {name!r}\")\n", "path": "litestar/types/internal_types.py"}]}
| 1,472 | 115 |
gh_patches_debug_32626
|
rasdani/github-patches
|
git_diff
|
uccser__cs-unplugged-147
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Store custom Kordac templates
The custom Kordac templates for Markdown conversion need to be stored within the repository.
Gut instinct is to store these within the `templates` directory under `markdown_templates` and then exclude this folder from the Django template loader (to avoid loading unused templates in serving webpages).
These can then be loaded for Kordac (possibly a Django loader would do the job).
</issue>
<code>
[start of csunplugged/utils/BaseLoader.py]
1 import yaml
2 import mdx_math
3 import abc
4 import sys
5 from kordac import Kordac
6 from .check_converter_required_files import check_required_files
7
8
9 class BaseLoader():
10 """Base loader class for individual loaders"""
11
12 def __init__(self, BASE_PATH='', load_log=[]):
13 if load_log:
14 self.load_log = load_log
15 else:
16 self.load_log = list(load_log)
17 self.BASE_PATH = BASE_PATH
18 self.setup_md_to_html_converter()
19
20 def setup_md_to_html_converter(self):
21 """Create Kordac converter with custom processors, html templates,
22 and extensions.
23 """
24 templates = dict()
25 templates['scratch'] = '<div><object data="{% autoescape false -%}{{ "{% get_static_prefix %}" }}img/scratch-blocks-{{ hash }}.svg{%- endautoescape %}" type="image/svg+xml" /></div>' # noqa: E501 Fixed in #77
26 templates['iframe'] = '<iframe allowtransparency="true" width="485" height="402" src="{{ link }}" frameborder="0" allowfullscreen="true"></iframe>' # noqa: E501 Fixed in #77
27 templates['heading'] = '<{{ heading_type }} id="{{ title_slug }}">{{ title }}</{{ heading_type }}>' # noqa: E501 Fixed in #77
28 extensions = [
29 'markdown.extensions.fenced_code',
30 'markdown.extensions.codehilite',
31 'markdown.extensions.sane_lists',
32 'markdown.extensions.tables',
33 mdx_math.MathExtension(enable_dollar_delimiter=True)
34 ]
35 self.converter = Kordac(html_templates=templates, extensions=extensions)
36 custom_processors = self.converter.processor_defaults()
37 custom_processors.add('remove-title')
38 self.converter.update_processors(custom_processors)
39
40 def convert_md_file(self, md_file_path):
41 """Returns the Kordac object for a given Markdown file
42
43 Args:
44 file_path: location of md file to convert
45
46 Returns:
47 Kordac result object
48 """
49 content = open(md_file_path, encoding='UTF-8').read()
50 result = self.converter.convert(content)
51 check_required_files(result.required_files)
52 return result
53
54 def log(self, log_message, indent_amount=0):
55 """Adds the log message to the load log with the specified indent"""
56 self.load_log.append((log_message, indent_amount))
57
58 def print_load_log(self):
59 """Output log messages from loader to console"""
60 for (log, indent_amount) in self.load_log:
61 indent = ' ' * indent_amount
62 sys.stdout.write('{indent}{text}\n'.format(indent=indent, text=log))
63 sys.stdout.write('\n')
64 self.load_log = []
65
66 def load_yaml_file(self, yaml_file_path):
67 """Loads and reads yaml file
68
69 Args:
70 file_path: location of yaml file to read
71
72 Returns:
73 Either list or string, depending on structure of given yaml file
74 """
75 yaml_file = open(yaml_file_path, encoding='UTF-8').read()
76 return yaml.load(yaml_file)
77
78 @abc.abstractmethod
79 def load(self):
80 raise NotImplementedError('subclass does not implement this method')
81
[end of csunplugged/utils/BaseLoader.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/csunplugged/utils/BaseLoader.py b/csunplugged/utils/BaseLoader.py
--- a/csunplugged/utils/BaseLoader.py
+++ b/csunplugged/utils/BaseLoader.py
@@ -2,6 +2,9 @@
import mdx_math
import abc
import sys
+import re
+import os.path
+from os import listdir
from kordac import Kordac
from .check_converter_required_files import check_required_files
@@ -21,10 +24,7 @@
"""Create Kordac converter with custom processors, html templates,
and extensions.
"""
- templates = dict()
- templates['scratch'] = '<div><object data="{% autoescape false -%}{{ "{% get_static_prefix %}" }}img/scratch-blocks-{{ hash }}.svg{%- endautoescape %}" type="image/svg+xml" /></div>' # noqa: E501 Fixed in #77
- templates['iframe'] = '<iframe allowtransparency="true" width="485" height="402" src="{{ link }}" frameborder="0" allowfullscreen="true"></iframe>' # noqa: E501 Fixed in #77
- templates['heading'] = '<{{ heading_type }} id="{{ title_slug }}">{{ title }}</{{ heading_type }}>' # noqa: E501 Fixed in #77
+ templates = self.load_template_files()
extensions = [
'markdown.extensions.fenced_code',
'markdown.extensions.codehilite',
@@ -75,6 +75,19 @@
yaml_file = open(yaml_file_path, encoding='UTF-8').read()
return yaml.load(yaml_file)
+ def load_template_files(self):
+ templates = dict()
+ template_path = os.path.join(
+ os.path.dirname(__file__),
+ 'custom_converter_templates/'
+ )
+ for file in listdir(template_path):
+ template_file = re.search(r'(.*?).html$', file)
+ if template_file:
+ template_name = template_file.groups()[0]
+ templates[template_name] = open(template_path + file).read()
+ return templates
+
@abc.abstractmethod
def load(self):
raise NotImplementedError('subclass does not implement this method')
|
{"golden_diff": "diff --git a/csunplugged/utils/BaseLoader.py b/csunplugged/utils/BaseLoader.py\n--- a/csunplugged/utils/BaseLoader.py\n+++ b/csunplugged/utils/BaseLoader.py\n@@ -2,6 +2,9 @@\n import mdx_math\n import abc\n import sys\n+import re\n+import os.path\n+from os import listdir\n from kordac import Kordac\n from .check_converter_required_files import check_required_files\n \n@@ -21,10 +24,7 @@\n \"\"\"Create Kordac converter with custom processors, html templates,\n and extensions.\n \"\"\"\n- templates = dict()\n- templates['scratch'] = '<div><object data=\"{% autoescape false -%}{{ \"{% get_static_prefix %}\" }}img/scratch-blocks-{{ hash }}.svg{%- endautoescape %}\" type=\"image/svg+xml\" /></div>' # noqa: E501 Fixed in #77\n- templates['iframe'] = '<iframe allowtransparency=\"true\" width=\"485\" height=\"402\" src=\"{{ link }}\" frameborder=\"0\" allowfullscreen=\"true\"></iframe>' # noqa: E501 Fixed in #77\n- templates['heading'] = '<{{ heading_type }} id=\"{{ title_slug }}\">{{ title }}</{{ heading_type }}>' # noqa: E501 Fixed in #77\n+ templates = self.load_template_files()\n extensions = [\n 'markdown.extensions.fenced_code',\n 'markdown.extensions.codehilite',\n@@ -75,6 +75,19 @@\n yaml_file = open(yaml_file_path, encoding='UTF-8').read()\n return yaml.load(yaml_file)\n \n+ def load_template_files(self):\n+ templates = dict()\n+ template_path = os.path.join(\n+ os.path.dirname(__file__),\n+ 'custom_converter_templates/'\n+ )\n+ for file in listdir(template_path):\n+ template_file = re.search(r'(.*?).html$', file)\n+ if template_file:\n+ template_name = template_file.groups()[0]\n+ templates[template_name] = open(template_path + file).read()\n+ return templates\n+\n @abc.abstractmethod\n def load(self):\n raise NotImplementedError('subclass does not implement this method')\n", "issue": "Store custom Kordac templates\nThe custom Kordac templates for Markdown conversion need to be stored within the repository.\r\nGut instinct is to store these within the `templates` directory under `markdown_templates` and then exclude this folder from the Django template loader (to avoid loading unused templates in serving webpages).\r\n\r\nThese can then be loaded for Kordac (possibly a Django loader would do the job).\n", "before_files": [{"content": "import yaml\nimport mdx_math\nimport abc\nimport sys\nfrom kordac import Kordac\nfrom .check_converter_required_files import check_required_files\n\n\nclass BaseLoader():\n \"\"\"Base loader class for individual loaders\"\"\"\n\n def __init__(self, BASE_PATH='', load_log=[]):\n if load_log:\n self.load_log = load_log\n else:\n self.load_log = list(load_log)\n self.BASE_PATH = BASE_PATH\n self.setup_md_to_html_converter()\n\n def setup_md_to_html_converter(self):\n \"\"\"Create Kordac converter with custom processors, html templates,\n and extensions.\n \"\"\"\n templates = dict()\n templates['scratch'] = '<div><object data=\"{% autoescape false -%}{{ \"{% get_static_prefix %}\" }}img/scratch-blocks-{{ hash }}.svg{%- endautoescape %}\" type=\"image/svg+xml\" /></div>' # noqa: E501 Fixed in #77\n templates['iframe'] = '<iframe allowtransparency=\"true\" width=\"485\" height=\"402\" src=\"{{ link }}\" frameborder=\"0\" allowfullscreen=\"true\"></iframe>' # noqa: E501 Fixed in #77\n templates['heading'] = '<{{ heading_type }} id=\"{{ title_slug }}\">{{ title }}</{{ heading_type }}>' # noqa: E501 Fixed in #77\n extensions = [\n 'markdown.extensions.fenced_code',\n 'markdown.extensions.codehilite',\n 'markdown.extensions.sane_lists',\n 'markdown.extensions.tables',\n mdx_math.MathExtension(enable_dollar_delimiter=True)\n ]\n self.converter = Kordac(html_templates=templates, extensions=extensions)\n custom_processors = self.converter.processor_defaults()\n custom_processors.add('remove-title')\n self.converter.update_processors(custom_processors)\n\n def convert_md_file(self, md_file_path):\n \"\"\"Returns the Kordac object for a given Markdown file\n\n Args:\n file_path: location of md file to convert\n\n Returns:\n Kordac result object\n \"\"\"\n content = open(md_file_path, encoding='UTF-8').read()\n result = self.converter.convert(content)\n check_required_files(result.required_files)\n return result\n\n def log(self, log_message, indent_amount=0):\n \"\"\"Adds the log message to the load log with the specified indent\"\"\"\n self.load_log.append((log_message, indent_amount))\n\n def print_load_log(self):\n \"\"\"Output log messages from loader to console\"\"\"\n for (log, indent_amount) in self.load_log:\n indent = ' ' * indent_amount\n sys.stdout.write('{indent}{text}\\n'.format(indent=indent, text=log))\n sys.stdout.write('\\n')\n self.load_log = []\n\n def load_yaml_file(self, yaml_file_path):\n \"\"\"Loads and reads yaml file\n\n Args:\n file_path: location of yaml file to read\n\n Returns:\n Either list or string, depending on structure of given yaml file\n \"\"\"\n yaml_file = open(yaml_file_path, encoding='UTF-8').read()\n return yaml.load(yaml_file)\n\n @abc.abstractmethod\n def load(self):\n raise NotImplementedError('subclass does not implement this method')\n", "path": "csunplugged/utils/BaseLoader.py"}]}
| 1,476 | 501 |
gh_patches_debug_2679
|
rasdani/github-patches
|
git_diff
|
TileDB-Inc__TileDB-Py-501
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Four components should be three components?
In the recently created example "writing_dense_rgb.py" there is this fragment:
https://github.com/TileDB-Inc/TileDB-Py/blob/75ddcf56ed80ba5e1a1237b7e527ec4fbd87abb9/examples/writing_dense_rgb.py#L56-L57
It says four int32 components where it seems like it should be three int32 components. After all the values of the attribute are RGB and not RGBA.
</issue>
<code>
[start of examples/writing_dense_rgb.py]
1 # writing_dense_rgb.py
2 #
3 # LICENSE
4 #
5 # The MIT License
6 #
7 # Copyright (c) 2021 TileDB, Inc.
8 #
9 # Permission is hereby granted, free of charge, to any person obtaining a copy
10 # of this software and associated documentation files (the "Software"), to deal
11 # in the Software without restriction, including without limitation the rights
12 # to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
13 # copies of the Software, and to permit persons to whom the Software is
14 # furnished to do so, subject to the following conditions:
15 #
16 # The above copyright notice and this permission notice shall be included in
17 # all copies or substantial portions of the Software.
18 #
19 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
20 # IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
21 # FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
22 # AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
23 # LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
24 # OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
25 # THE SOFTWARE.
26 #
27 # DESCRIPTION
28 #
29 # Please see the TileDB documentation for more information:
30 # https://docs.tiledb.com/main/solutions/tiledb-embedded/api-usage/writing-arrays/writing-in-dense-subarrays
31 #
32 # When run, this program will create a 2D+1 multi-component (eg RGB) dense array, write some
33 # data to it, and read the entire array data.
34
35 import tiledb, numpy as np
36
37 img_shape = (100, 224, 224)
38 img_uri = "writing_dense_rgb"
39
40 image_data = np.random.randint(low=0, high=100, size=(*img_shape, 3), dtype=np.int32)
41
42
43 def create_array():
44 domain = tiledb.Domain(
45 tiledb.Dim(
46 name="image_id", domain=(0, img_shape[0] - 1), tile=4, dtype=np.int32
47 ),
48 tiledb.Dim(
49 name="x", domain=(0, img_shape[1] - 1), tile=img_shape[1], dtype=np.int32
50 ),
51 tiledb.Dim(
52 name="y", domain=(0, img_shape[2] - 1), tile=img_shape[2], dtype=np.int32
53 ),
54 )
55
56 # create multi-component attribute with four int32 components
57 attr = tiledb.Attr(dtype=np.dtype("i4, i4, i4"))
58
59 schema = tiledb.ArraySchema(domain=domain, sparse=False, attrs=[attr])
60
61 tiledb.Array.create(img_uri, schema)
62
63 image_data_rgb = image_data.view(np.dtype("i4, i4, i4"))
64
65 with tiledb.open(img_uri, "w") as A:
66 # write data to 1st image_id slot
67 A[:] = image_data_rgb
68
69
70 def read_array():
71 with tiledb.open(img_uri) as A:
72 print(A[:].shape)
73
74
75 if __name__ == "__main__":
76 create_array()
77 read_array()
78
[end of examples/writing_dense_rgb.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/writing_dense_rgb.py b/examples/writing_dense_rgb.py
--- a/examples/writing_dense_rgb.py
+++ b/examples/writing_dense_rgb.py
@@ -53,7 +53,7 @@
),
)
- # create multi-component attribute with four int32 components
+ # create multi-component attribute with three int32 components
attr = tiledb.Attr(dtype=np.dtype("i4, i4, i4"))
schema = tiledb.ArraySchema(domain=domain, sparse=False, attrs=[attr])
|
{"golden_diff": "diff --git a/examples/writing_dense_rgb.py b/examples/writing_dense_rgb.py\n--- a/examples/writing_dense_rgb.py\n+++ b/examples/writing_dense_rgb.py\n@@ -53,7 +53,7 @@\n ),\n )\n \n- # create multi-component attribute with four int32 components\n+ # create multi-component attribute with three int32 components\n attr = tiledb.Attr(dtype=np.dtype(\"i4, i4, i4\"))\n \n schema = tiledb.ArraySchema(domain=domain, sparse=False, attrs=[attr])\n", "issue": "Four components should be three components?\nIn the recently created example \"writing_dense_rgb.py\" there is this fragment:\r\nhttps://github.com/TileDB-Inc/TileDB-Py/blob/75ddcf56ed80ba5e1a1237b7e527ec4fbd87abb9/examples/writing_dense_rgb.py#L56-L57\r\n\r\nIt says four int32 components where it seems like it should be three int32 components. After all the values of the attribute are RGB and not RGBA.\n", "before_files": [{"content": "# writing_dense_rgb.py\n#\n# LICENSE\n#\n# The MIT License\n#\n# Copyright (c) 2021 TileDB, Inc.\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN\n# THE SOFTWARE.\n#\n# DESCRIPTION\n#\n# Please see the TileDB documentation for more information:\n# https://docs.tiledb.com/main/solutions/tiledb-embedded/api-usage/writing-arrays/writing-in-dense-subarrays\n#\n# When run, this program will create a 2D+1 multi-component (eg RGB) dense array, write some\n# data to it, and read the entire array data.\n\nimport tiledb, numpy as np\n\nimg_shape = (100, 224, 224)\nimg_uri = \"writing_dense_rgb\"\n\nimage_data = np.random.randint(low=0, high=100, size=(*img_shape, 3), dtype=np.int32)\n\n\ndef create_array():\n domain = tiledb.Domain(\n tiledb.Dim(\n name=\"image_id\", domain=(0, img_shape[0] - 1), tile=4, dtype=np.int32\n ),\n tiledb.Dim(\n name=\"x\", domain=(0, img_shape[1] - 1), tile=img_shape[1], dtype=np.int32\n ),\n tiledb.Dim(\n name=\"y\", domain=(0, img_shape[2] - 1), tile=img_shape[2], dtype=np.int32\n ),\n )\n\n # create multi-component attribute with four int32 components\n attr = tiledb.Attr(dtype=np.dtype(\"i4, i4, i4\"))\n\n schema = tiledb.ArraySchema(domain=domain, sparse=False, attrs=[attr])\n\n tiledb.Array.create(img_uri, schema)\n\n image_data_rgb = image_data.view(np.dtype(\"i4, i4, i4\"))\n\n with tiledb.open(img_uri, \"w\") as A:\n # write data to 1st image_id slot\n A[:] = image_data_rgb\n\n\ndef read_array():\n with tiledb.open(img_uri) as A:\n print(A[:].shape)\n\n\nif __name__ == \"__main__\":\n create_array()\n read_array()\n", "path": "examples/writing_dense_rgb.py"}]}
| 1,498 | 120 |
gh_patches_debug_27645
|
rasdani/github-patches
|
git_diff
|
hpcaitech__ColossalAI-4514
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[tensor] fix some unittests
[tensor] fix some unittests
[tensor] fix some unittests
</issue>
<code>
[start of colossalai/shardformer/policies/opt.py]
1 import warnings
2 from functools import partial
3 from typing import Callable, Dict, List
4
5 import torch.nn as nn
6 from torch import Tensor, nn
7
8 from colossalai.shardformer.layer import FusedLayerNorm, Linear1D_Col, Linear1D_Row, VocabParallelEmbedding1D
9
10 from .._utils import getattr_
11 from ..modeling.jit import get_jit_fused_dropout_add_func
12 from ..modeling.opt import OPTPipelineForwards, get_jit_fused_opt_decoder_layer_forward, get_opt_flash_attention_forward
13 from .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription
14
15 __all__ = [
16 'OPTPolicy', 'OPTModelPolicy', 'OPTForCausalLMPolicy', 'OPTForSequenceClassificationPolicy',
17 'OPTForQuestionAnsweringPolicy'
18 ]
19
20
21 class OPTPolicy(Policy):
22
23 def config_sanity_check(self):
24 pass
25
26 def preprocess(self):
27 # reshape the embedding layer
28 r"""
29 Reshape the Embedding layer to make the embedding dimension divisible by world_size
30 """
31 if self.shard_config.enable_tensor_parallelism:
32 vocab_size = self.model.config.vocab_size
33 world_size = self.shard_config.tensor_parallel_size
34 if vocab_size % world_size != 0:
35 new_vocab_size = vocab_size + world_size - vocab_size % world_size
36 self.model.resize_token_embeddings(new_vocab_size)
37 return self.model
38
39 def module_policy(self):
40 from transformers.models.opt.modeling_opt import OPTAttention, OPTDecoder, OPTDecoderLayer
41
42 policy = {}
43 if self.shard_config.enable_sequence_parallelism:
44 self.shard_config.enable_sequence_parallelism = False
45 warnings.warn("OPT dosen't support sequence parallelism now, will ignore the sequence parallelism flag.")
46
47 if self.shard_config.enable_tensor_parallelism:
48 policy[OPTDecoder] = ModulePolicyDescription(sub_module_replacement=[
49 SubModuleReplacementDescription(
50 suffix="embed_tokens",
51 target_module=VocabParallelEmbedding1D,
52 )
53 ])
54 policy[OPTDecoderLayer] = ModulePolicyDescription(sub_module_replacement=[
55 SubModuleReplacementDescription(
56 suffix="fc1",
57 target_module=Linear1D_Col,
58 ),
59 SubModuleReplacementDescription(
60 suffix="fc2",
61 target_module=Linear1D_Row,
62 )
63 ])
64
65 policy[OPTAttention] = ModulePolicyDescription(attribute_replacement={
66 "embed_dim": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,
67 "num_heads": self.model.config.num_attention_heads // self.shard_config.tensor_parallel_size
68 },
69 sub_module_replacement=[
70 SubModuleReplacementDescription(
71 suffix="q_proj",
72 target_module=Linear1D_Col,
73 ),
74 SubModuleReplacementDescription(
75 suffix="k_proj",
76 target_module=Linear1D_Col,
77 ),
78 SubModuleReplacementDescription(
79 suffix="v_proj",
80 target_module=Linear1D_Col,
81 ),
82 SubModuleReplacementDescription(
83 suffix="out_proj",
84 target_module=Linear1D_Row,
85 ),
86 ])
87
88 # optimization configuration
89 if self.shard_config.enable_fused_normalization:
90 self.append_or_create_submodule_replacement(description=SubModuleReplacementDescription(
91 suffix="final_layer_norm", target_module=FusedLayerNorm, ignore_if_not_exist=True),
92 policy=policy,
93 target_key=OPTDecoder)
94 self.append_or_create_submodule_replacement(description=[
95 SubModuleReplacementDescription(suffix="self_attn_layer_norm",
96 target_module=FusedLayerNorm,
97 ignore_if_not_exist=True),
98 SubModuleReplacementDescription(suffix="final_layer_norm",
99 target_module=FusedLayerNorm,
100 ignore_if_not_exist=True)
101 ],
102 policy=policy,
103 target_key=OPTDecoderLayer)
104
105 # use flash attention
106 if self.shard_config.enable_flash_attention:
107 self.append_or_create_method_replacement(description={
108 'forward': get_opt_flash_attention_forward(),
109 },
110 policy=policy,
111 target_key=OPTAttention)
112
113 # use jit fused operator
114 if self.shard_config.enable_jit_fused:
115 self.append_or_create_method_replacement(description={
116 'forward': get_jit_fused_opt_decoder_layer_forward(),
117 'dropout_add': get_jit_fused_dropout_add_func(),
118 },
119 policy=policy,
120 target_key=OPTDecoderLayer)
121
122 return policy
123
124 def postprocess(self):
125 return self.model
126
127 def get_held_layers(self) -> List[nn.Module]:
128 """Get pipeline layers for current stage."""
129 assert self.pipeline_stage_manager is not None
130
131 if self.model.__class__.__name__ == 'OPTModel':
132 module = self.model.decoder
133 else:
134 module = self.model.model.decoder
135 stage_manager = self.pipeline_stage_manager
136
137 held_layers = []
138 layers_per_stage = self.distribute_layers(len(module.layers), stage_manager.num_stages)
139 if stage_manager.is_first_stage():
140 held_layers.append(module.embed_tokens)
141 held_layers.append(module.embed_positions)
142 held_layers.append(module.project_in)
143 start_idx, end_idx = self.get_stage_index(layers_per_stage, stage_manager.stage)
144 held_layers.extend(module.layers[start_idx:end_idx])
145 if stage_manager.is_last_stage():
146 held_layers.append(module.final_layer_norm)
147 held_layers.append(module.project_out)
148 return held_layers
149
150 def set_pipeline_forward(self, model_cls: nn.Module, new_forward: Callable, policy: Dict) -> None:
151 """If under pipeline parallel setting, replacing the original forward method of huggingface
152 to customized forward method, and add this changing to policy."""
153 if self.pipeline_stage_manager:
154 stage_manager = self.pipeline_stage_manager
155 if self.model.__class__.__name__ == 'OPTModel':
156 module = self.model.decoder
157 else:
158 module = self.model.model.decoder
159
160 layers_per_stage = Policy.distribute_layers(len(module.layers), stage_manager.num_stages)
161 stage_index = Policy.get_stage_index(layers_per_stage, stage_manager.stage)
162 method_replacement = {'forward': partial(new_forward, stage_manager=stage_manager, stage_index=stage_index)}
163 self.append_or_create_method_replacement(description=method_replacement,
164 policy=policy,
165 target_key=model_cls)
166
167
168 class OPTModelPolicy(OPTPolicy):
169
170 def __init__(self) -> None:
171 super().__init__()
172
173 def module_policy(self):
174 from transformers.models.opt.modeling_opt import OPTModel
175
176 policy = super().module_policy()
177 if self.pipeline_stage_manager:
178 self.set_pipeline_forward(model_cls=OPTModel,
179 new_forward=OPTPipelineForwards.opt_model_forward,
180 policy=policy)
181 return policy
182
183 def get_held_layers(self) -> List[nn.Module]:
184 return super().get_held_layers()
185
186 def get_shared_params(self) -> List[Dict[int, Tensor]]:
187 """No shared params in OPTModel."""
188 return []
189
190
191 class OPTForCausalLMPolicy(OPTPolicy):
192
193 def module_policy(self):
194 from transformers.models.opt.modeling_opt import OPTForCausalLM
195
196 policy = super().module_policy()
197 if self.shard_config.enable_tensor_parallelism:
198 self.append_or_create_submodule_replacement(description=SubModuleReplacementDescription(
199 suffix="lm_head", target_module=Linear1D_Col, kwargs=dict(gather_output=True)),
200 policy=policy,
201 target_key=OPTForCausalLM)
202 if self.pipeline_stage_manager:
203 self.set_pipeline_forward(model_cls=OPTForCausalLM,
204 new_forward=OPTPipelineForwards.opt_for_causal_lm_forward,
205 policy=policy)
206
207 return policy
208
209 def get_held_layers(self) -> List[nn.Module]:
210 held_layers = super().get_held_layers()
211 if self.pipeline_stage_manager.is_last_stage():
212 held_layers.append(self.model.lm_head)
213 return held_layers
214
215 def get_shared_params(self) -> List[Dict[int, Tensor]]:
216 opt_model = self.model
217 if self.pipeline_stage_manager and self.pipeline_stage_manager.num_stages > 1:
218 num_stages = self.pipeline_stage_manager.num_stages
219 if id(opt_model.model.decoder.embed_tokens.weight) == id(opt_model.lm_head.weight):
220 return [{0: opt_model.model.decoder.embed_tokens.weight, num_stages - 1: opt_model.lm_head.weight}]
221 return []
222
223 def postprocess(self):
224 if self.shard_config.enable_tensor_parallelism and self.pipeline_stage_manager is None:
225 binding_map = {
226 'model.decoder.embed_tokens': 'lm_head',
227 }
228
229 for k, v in binding_map.items():
230 src_mod = getattr_(self.model, k)
231 dst_mod = getattr_(self.model, v)
232 dst_mod.weight = src_mod.weight
233
234 return self.model
235
236
237 class OPTForSequenceClassificationPolicy(OPTPolicy):
238
239 def __init__(self) -> None:
240 super().__init__()
241
242 def module_policy(self):
243 from transformers.models.opt.modeling_opt import OPTForSequenceClassification
244
245 policy = super().module_policy()
246 if self.pipeline_stage_manager:
247 self.set_pipeline_forward(model_cls=OPTForSequenceClassification,
248 new_forward=OPTPipelineForwards.opt_for_sequence_classification_forward,
249 policy=policy)
250
251 return policy
252
253 def get_held_layers(self) -> List[nn.Module]:
254 held_layers = super().get_held_layers()
255 if self.pipeline_stage_manager.is_last_stage():
256 held_layers.append(self.model.score)
257 return held_layers
258
259 def get_shared_params(self) -> List[Dict[int, Tensor]]:
260 "no shared params in OPTForSequenceClassification"
261 return []
262
263
264 class OPTForQuestionAnsweringPolicy(OPTPolicy):
265
266 def __init__(self) -> None:
267 super().__init__()
268
269 def module_policy(self):
270 from transformers.models.opt.modeling_opt import OPTForQuestionAnswering
271
272 policy = super().module_policy()
273 if self.pipeline_stage_manager:
274 self.set_pipeline_forward(model_cls=OPTForQuestionAnswering,
275 new_forward=OPTPipelineForwards.opt_for_question_answering_forward,
276 policy=policy)
277
278 return policy
279
280 def get_held_layers(self) -> List[nn.Module]:
281 held_layers = super().get_held_layers()
282 if self.pipeline_stage_manager.is_last_stage():
283 held_layers.append(self.model.qa_outputs)
284 return held_layers
285
286 def get_shared_params(self) -> List[Dict[int, Tensor]]:
287 "no shared params in OPTForSequenceClassification"
288 return []
289
[end of colossalai/shardformer/policies/opt.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/colossalai/shardformer/policies/opt.py b/colossalai/shardformer/policies/opt.py
--- a/colossalai/shardformer/policies/opt.py
+++ b/colossalai/shardformer/policies/opt.py
@@ -103,21 +103,21 @@
target_key=OPTDecoderLayer)
# use flash attention
- if self.shard_config.enable_flash_attention:
- self.append_or_create_method_replacement(description={
- 'forward': get_opt_flash_attention_forward(),
- },
- policy=policy,
- target_key=OPTAttention)
+ # if self.shard_config.enable_flash_attention:
+ # self.append_or_create_method_replacement(description={
+ # 'forward': get_opt_flash_attention_forward(),
+ # },
+ # policy=policy,
+ # target_key=OPTAttention)
# use jit fused operator
- if self.shard_config.enable_jit_fused:
- self.append_or_create_method_replacement(description={
- 'forward': get_jit_fused_opt_decoder_layer_forward(),
- 'dropout_add': get_jit_fused_dropout_add_func(),
- },
- policy=policy,
- target_key=OPTDecoderLayer)
+ # if self.shard_config.enable_jit_fused:
+ # self.append_or_create_method_replacement(description={
+ # 'forward': get_jit_fused_opt_decoder_layer_forward(),
+ # 'dropout_add': get_jit_fused_dropout_add_func(),
+ # },
+ # policy=policy,
+ # target_key=OPTDecoderLayer)
return policy
|
{"golden_diff": "diff --git a/colossalai/shardformer/policies/opt.py b/colossalai/shardformer/policies/opt.py\n--- a/colossalai/shardformer/policies/opt.py\n+++ b/colossalai/shardformer/policies/opt.py\n@@ -103,21 +103,21 @@\n target_key=OPTDecoderLayer)\n \n # use flash attention\n- if self.shard_config.enable_flash_attention:\n- self.append_or_create_method_replacement(description={\n- 'forward': get_opt_flash_attention_forward(),\n- },\n- policy=policy,\n- target_key=OPTAttention)\n+ # if self.shard_config.enable_flash_attention:\n+ # self.append_or_create_method_replacement(description={\n+ # 'forward': get_opt_flash_attention_forward(),\n+ # },\n+ # policy=policy,\n+ # target_key=OPTAttention)\n \n # use jit fused operator\n- if self.shard_config.enable_jit_fused:\n- self.append_or_create_method_replacement(description={\n- 'forward': get_jit_fused_opt_decoder_layer_forward(),\n- 'dropout_add': get_jit_fused_dropout_add_func(),\n- },\n- policy=policy,\n- target_key=OPTDecoderLayer)\n+ # if self.shard_config.enable_jit_fused:\n+ # self.append_or_create_method_replacement(description={\n+ # 'forward': get_jit_fused_opt_decoder_layer_forward(),\n+ # 'dropout_add': get_jit_fused_dropout_add_func(),\n+ # },\n+ # policy=policy,\n+ # target_key=OPTDecoderLayer)\n \n return policy\n", "issue": "[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n", "before_files": [{"content": "import warnings\nfrom functools import partial\nfrom typing import Callable, Dict, List\n\nimport torch.nn as nn\nfrom torch import Tensor, nn\n\nfrom colossalai.shardformer.layer import FusedLayerNorm, Linear1D_Col, Linear1D_Row, VocabParallelEmbedding1D\n\nfrom .._utils import getattr_\nfrom ..modeling.jit import get_jit_fused_dropout_add_func\nfrom ..modeling.opt import OPTPipelineForwards, get_jit_fused_opt_decoder_layer_forward, get_opt_flash_attention_forward\nfrom .base_policy import ModulePolicyDescription, Policy, SubModuleReplacementDescription\n\n__all__ = [\n 'OPTPolicy', 'OPTModelPolicy', 'OPTForCausalLMPolicy', 'OPTForSequenceClassificationPolicy',\n 'OPTForQuestionAnsweringPolicy'\n]\n\n\nclass OPTPolicy(Policy):\n\n def config_sanity_check(self):\n pass\n\n def preprocess(self):\n # reshape the embedding layer\n r\"\"\"\n Reshape the Embedding layer to make the embedding dimension divisible by world_size\n \"\"\"\n if self.shard_config.enable_tensor_parallelism:\n vocab_size = self.model.config.vocab_size\n world_size = self.shard_config.tensor_parallel_size\n if vocab_size % world_size != 0:\n new_vocab_size = vocab_size + world_size - vocab_size % world_size\n self.model.resize_token_embeddings(new_vocab_size)\n return self.model\n\n def module_policy(self):\n from transformers.models.opt.modeling_opt import OPTAttention, OPTDecoder, OPTDecoderLayer\n\n policy = {}\n if self.shard_config.enable_sequence_parallelism:\n self.shard_config.enable_sequence_parallelism = False\n warnings.warn(\"OPT dosen't support sequence parallelism now, will ignore the sequence parallelism flag.\")\n\n if self.shard_config.enable_tensor_parallelism:\n policy[OPTDecoder] = ModulePolicyDescription(sub_module_replacement=[\n SubModuleReplacementDescription(\n suffix=\"embed_tokens\",\n target_module=VocabParallelEmbedding1D,\n )\n ])\n policy[OPTDecoderLayer] = ModulePolicyDescription(sub_module_replacement=[\n SubModuleReplacementDescription(\n suffix=\"fc1\",\n target_module=Linear1D_Col,\n ),\n SubModuleReplacementDescription(\n suffix=\"fc2\",\n target_module=Linear1D_Row,\n )\n ])\n\n policy[OPTAttention] = ModulePolicyDescription(attribute_replacement={\n \"embed_dim\": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,\n \"num_heads\": self.model.config.num_attention_heads // self.shard_config.tensor_parallel_size\n },\n sub_module_replacement=[\n SubModuleReplacementDescription(\n suffix=\"q_proj\",\n target_module=Linear1D_Col,\n ),\n SubModuleReplacementDescription(\n suffix=\"k_proj\",\n target_module=Linear1D_Col,\n ),\n SubModuleReplacementDescription(\n suffix=\"v_proj\",\n target_module=Linear1D_Col,\n ),\n SubModuleReplacementDescription(\n suffix=\"out_proj\",\n target_module=Linear1D_Row,\n ),\n ])\n\n # optimization configuration\n if self.shard_config.enable_fused_normalization:\n self.append_or_create_submodule_replacement(description=SubModuleReplacementDescription(\n suffix=\"final_layer_norm\", target_module=FusedLayerNorm, ignore_if_not_exist=True),\n policy=policy,\n target_key=OPTDecoder)\n self.append_or_create_submodule_replacement(description=[\n SubModuleReplacementDescription(suffix=\"self_attn_layer_norm\",\n target_module=FusedLayerNorm,\n ignore_if_not_exist=True),\n SubModuleReplacementDescription(suffix=\"final_layer_norm\",\n target_module=FusedLayerNorm,\n ignore_if_not_exist=True)\n ],\n policy=policy,\n target_key=OPTDecoderLayer)\n\n # use flash attention\n if self.shard_config.enable_flash_attention:\n self.append_or_create_method_replacement(description={\n 'forward': get_opt_flash_attention_forward(),\n },\n policy=policy,\n target_key=OPTAttention)\n\n # use jit fused operator\n if self.shard_config.enable_jit_fused:\n self.append_or_create_method_replacement(description={\n 'forward': get_jit_fused_opt_decoder_layer_forward(),\n 'dropout_add': get_jit_fused_dropout_add_func(),\n },\n policy=policy,\n target_key=OPTDecoderLayer)\n\n return policy\n\n def postprocess(self):\n return self.model\n\n def get_held_layers(self) -> List[nn.Module]:\n \"\"\"Get pipeline layers for current stage.\"\"\"\n assert self.pipeline_stage_manager is not None\n\n if self.model.__class__.__name__ == 'OPTModel':\n module = self.model.decoder\n else:\n module = self.model.model.decoder\n stage_manager = self.pipeline_stage_manager\n\n held_layers = []\n layers_per_stage = self.distribute_layers(len(module.layers), stage_manager.num_stages)\n if stage_manager.is_first_stage():\n held_layers.append(module.embed_tokens)\n held_layers.append(module.embed_positions)\n held_layers.append(module.project_in)\n start_idx, end_idx = self.get_stage_index(layers_per_stage, stage_manager.stage)\n held_layers.extend(module.layers[start_idx:end_idx])\n if stage_manager.is_last_stage():\n held_layers.append(module.final_layer_norm)\n held_layers.append(module.project_out)\n return held_layers\n\n def set_pipeline_forward(self, model_cls: nn.Module, new_forward: Callable, policy: Dict) -> None:\n \"\"\"If under pipeline parallel setting, replacing the original forward method of huggingface\n to customized forward method, and add this changing to policy.\"\"\"\n if self.pipeline_stage_manager:\n stage_manager = self.pipeline_stage_manager\n if self.model.__class__.__name__ == 'OPTModel':\n module = self.model.decoder\n else:\n module = self.model.model.decoder\n\n layers_per_stage = Policy.distribute_layers(len(module.layers), stage_manager.num_stages)\n stage_index = Policy.get_stage_index(layers_per_stage, stage_manager.stage)\n method_replacement = {'forward': partial(new_forward, stage_manager=stage_manager, stage_index=stage_index)}\n self.append_or_create_method_replacement(description=method_replacement,\n policy=policy,\n target_key=model_cls)\n\n\nclass OPTModelPolicy(OPTPolicy):\n\n def __init__(self) -> None:\n super().__init__()\n\n def module_policy(self):\n from transformers.models.opt.modeling_opt import OPTModel\n\n policy = super().module_policy()\n if self.pipeline_stage_manager:\n self.set_pipeline_forward(model_cls=OPTModel,\n new_forward=OPTPipelineForwards.opt_model_forward,\n policy=policy)\n return policy\n\n def get_held_layers(self) -> List[nn.Module]:\n return super().get_held_layers()\n\n def get_shared_params(self) -> List[Dict[int, Tensor]]:\n \"\"\"No shared params in OPTModel.\"\"\"\n return []\n\n\nclass OPTForCausalLMPolicy(OPTPolicy):\n\n def module_policy(self):\n from transformers.models.opt.modeling_opt import OPTForCausalLM\n\n policy = super().module_policy()\n if self.shard_config.enable_tensor_parallelism:\n self.append_or_create_submodule_replacement(description=SubModuleReplacementDescription(\n suffix=\"lm_head\", target_module=Linear1D_Col, kwargs=dict(gather_output=True)),\n policy=policy,\n target_key=OPTForCausalLM)\n if self.pipeline_stage_manager:\n self.set_pipeline_forward(model_cls=OPTForCausalLM,\n new_forward=OPTPipelineForwards.opt_for_causal_lm_forward,\n policy=policy)\n\n return policy\n\n def get_held_layers(self) -> List[nn.Module]:\n held_layers = super().get_held_layers()\n if self.pipeline_stage_manager.is_last_stage():\n held_layers.append(self.model.lm_head)\n return held_layers\n\n def get_shared_params(self) -> List[Dict[int, Tensor]]:\n opt_model = self.model\n if self.pipeline_stage_manager and self.pipeline_stage_manager.num_stages > 1:\n num_stages = self.pipeline_stage_manager.num_stages\n if id(opt_model.model.decoder.embed_tokens.weight) == id(opt_model.lm_head.weight):\n return [{0: opt_model.model.decoder.embed_tokens.weight, num_stages - 1: opt_model.lm_head.weight}]\n return []\n\n def postprocess(self):\n if self.shard_config.enable_tensor_parallelism and self.pipeline_stage_manager is None:\n binding_map = {\n 'model.decoder.embed_tokens': 'lm_head',\n }\n\n for k, v in binding_map.items():\n src_mod = getattr_(self.model, k)\n dst_mod = getattr_(self.model, v)\n dst_mod.weight = src_mod.weight\n\n return self.model\n\n\nclass OPTForSequenceClassificationPolicy(OPTPolicy):\n\n def __init__(self) -> None:\n super().__init__()\n\n def module_policy(self):\n from transformers.models.opt.modeling_opt import OPTForSequenceClassification\n\n policy = super().module_policy()\n if self.pipeline_stage_manager:\n self.set_pipeline_forward(model_cls=OPTForSequenceClassification,\n new_forward=OPTPipelineForwards.opt_for_sequence_classification_forward,\n policy=policy)\n\n return policy\n\n def get_held_layers(self) -> List[nn.Module]:\n held_layers = super().get_held_layers()\n if self.pipeline_stage_manager.is_last_stage():\n held_layers.append(self.model.score)\n return held_layers\n\n def get_shared_params(self) -> List[Dict[int, Tensor]]:\n \"no shared params in OPTForSequenceClassification\"\n return []\n\n\nclass OPTForQuestionAnsweringPolicy(OPTPolicy):\n\n def __init__(self) -> None:\n super().__init__()\n\n def module_policy(self):\n from transformers.models.opt.modeling_opt import OPTForQuestionAnswering\n\n policy = super().module_policy()\n if self.pipeline_stage_manager:\n self.set_pipeline_forward(model_cls=OPTForQuestionAnswering,\n new_forward=OPTPipelineForwards.opt_for_question_answering_forward,\n policy=policy)\n\n return policy\n\n def get_held_layers(self) -> List[nn.Module]:\n held_layers = super().get_held_layers()\n if self.pipeline_stage_manager.is_last_stage():\n held_layers.append(self.model.qa_outputs)\n return held_layers\n\n def get_shared_params(self) -> List[Dict[int, Tensor]]:\n \"no shared params in OPTForSequenceClassification\"\n return []\n", "path": "colossalai/shardformer/policies/opt.py"}]}
| 3,570 | 368 |
gh_patches_debug_15860
|
rasdani/github-patches
|
git_diff
|
spotify__luigi-2593
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
AttributeError during logging setup with Python 2.7
Hi,
I upgraded to luigi 2.8.0 and experience an `AttributeError` that occurs within the new `setup_logging.py`. Here is the important part of the stack trace:
```
File ".../lib/python2.7/site-packages/luigi/cmdline.py", line 9, in luigi_run
run_with_retcodes(argv)
File ".../lib/python2.7/site-packages/luigi/retcodes.py", line 81, in run_with_retcodes
InterfaceLogging.setup(env_params)
File ".../lib/python2.7/site-packages/luigi/setup_logging.py", line 74, in setup
configured = cls._section(opts)
File ".../lib/python2.7/site-packages/luigi/setup_logging.py", line 42, in _section
logging_config = cls.config['logging']
AttributeError: LuigiConfigParser instance has no attribute '__getitem__'
```
`cls.config` is a `ConfigParser` instance which does not implement `__getitem__` in Python 2.7 (which I'm forced to use -.-). This could be fixed by using `cls.config.options('logging')` instead. I checked, and this is the only place where items are used.
https://github.com/spotify/luigi/blob/0a098f6f99da0bad03af56a057b9a15254d1a957/luigi/setup_logging.py#L42
Adding @orsinium here who is maybe faster to fix this. I could create a PR on Friday.
</issue>
<code>
[start of luigi/setup_logging.py]
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright 2018 Vote Inc.
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16 #
17 """
18 This module contains helper classes for configuring logging for luigid and
19 workers via command line arguments and options from config files.
20 """
21
22 import logging
23 import logging.config
24 import os.path
25 from luigi.configuration import get_config
26
27 # In python3 ConfigParser was renamed
28 # https://stackoverflow.com/a/41202010
29 try:
30 from ConfigParser import NoSectionError
31 except ImportError:
32 from configparser import NoSectionError
33
34
35 class BaseLogging(object):
36 config = get_config()
37
38 @classmethod
39 def _section(cls, opts):
40 """Get logging settings from config file section "logging"."""
41 try:
42 logging_config = cls.config['logging']
43 except (TypeError, KeyError, NoSectionError):
44 return False
45 logging.config.dictConfig(logging_config)
46 return True
47
48 @classmethod
49 def setup(cls, opts):
50 """Setup logging via CLI params and config."""
51 logger = logging.getLogger('luigi')
52
53 if cls._configured:
54 logger.info('logging already configured')
55 return False
56 cls._configured = True
57
58 if cls.config.getboolean('core', 'no_configure_logging', False):
59 logger.info('logging disabled in settings')
60 return False
61
62 configured = cls._cli(opts)
63 if configured:
64 logger = logging.getLogger('luigi')
65 logger.info('logging configured via special settings')
66 return True
67
68 configured = cls._conf(opts)
69 if configured:
70 logger = logging.getLogger('luigi')
71 logger.info('logging configured via *.conf file')
72 return True
73
74 configured = cls._section(opts)
75 if configured:
76 logger = logging.getLogger('luigi')
77 logger.info('logging configured via config section')
78 return True
79
80 configured = cls._default(opts)
81 if configured:
82 logger = logging.getLogger('luigi')
83 logger.info('logging configured by default settings')
84 return configured
85
86
87 class DaemonLogging(BaseLogging):
88 """Configure logging for luigid
89 """
90 _configured = False
91 _log_format = "%(asctime)s %(name)s[%(process)s] %(levelname)s: %(message)s"
92
93 @classmethod
94 def _cli(cls, opts):
95 """Setup logging via CLI options
96
97 If `--background` -- set INFO level for root logger.
98 If `--logdir` -- set logging with next params:
99 default Luigi's formatter,
100 INFO level,
101 output in logdir in `luigi-server.log` file
102 """
103 if opts.background:
104 logging.getLogger().setLevel(logging.INFO)
105 return True
106
107 if opts.logdir:
108 logging.basicConfig(
109 level=logging.INFO,
110 format=cls._log_format,
111 filename=os.path.join(opts.logdir, "luigi-server.log"))
112 return True
113
114 return False
115
116 @classmethod
117 def _conf(cls, opts):
118 """Setup logging via ini-file from logging_conf_file option."""
119 logging_conf = cls.config.get('core', 'logging_conf_file', None)
120 if logging_conf is None:
121 return False
122
123 if not os.path.exists(logging_conf):
124 # FileNotFoundError added only in Python 3.3
125 # https://docs.python.org/3/whatsnew/3.3.html#pep-3151-reworking-the-os-and-io-exception-hierarchy
126 raise OSError("Error: Unable to locate specified logging configuration file!")
127
128 logging.config.fileConfig(logging_conf)
129 return True
130
131 @classmethod
132 def _default(cls, opts):
133 """Setup default logger"""
134 logging.basicConfig(level=logging.INFO, format=cls._log_format)
135 return True
136
137
138 # Part of this logic taken for dropped function "setup_interface_logging"
139 class InterfaceLogging(BaseLogging):
140 """Configure logging for worker"""
141 _configured = False
142
143 @classmethod
144 def _cli(cls, opts):
145 return False
146
147 @classmethod
148 def _conf(cls, opts):
149 """Setup logging via ini-file from logging_conf_file option."""
150 if not opts.logging_conf_file:
151 return False
152
153 if not os.path.exists(opts.logging_conf_file):
154 # FileNotFoundError added only in Python 3.3
155 # https://docs.python.org/3/whatsnew/3.3.html#pep-3151-reworking-the-os-and-io-exception-hierarchy
156 raise OSError("Error: Unable to locate specified logging configuration file!")
157
158 logging.config.fileConfig(opts.logging_conf_file, disable_existing_loggers=False)
159 return True
160
161 @classmethod
162 def _default(cls, opts):
163 """Setup default logger"""
164 level = getattr(logging, opts.log_level, logging.DEBUG)
165
166 logger = logging.getLogger('luigi-interface')
167 logger.setLevel(level)
168
169 stream_handler = logging.StreamHandler()
170 stream_handler.setLevel(level)
171
172 formatter = logging.Formatter('%(levelname)s: %(message)s')
173 stream_handler.setFormatter(formatter)
174
175 logger.addHandler(stream_handler)
176 return True
177
[end of luigi/setup_logging.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/luigi/setup_logging.py b/luigi/setup_logging.py
--- a/luigi/setup_logging.py
+++ b/luigi/setup_logging.py
@@ -22,7 +22,7 @@
import logging
import logging.config
import os.path
-from luigi.configuration import get_config
+from luigi.configuration import get_config, LuigiConfigParser
# In python3 ConfigParser was renamed
# https://stackoverflow.com/a/41202010
@@ -38,6 +38,8 @@
@classmethod
def _section(cls, opts):
"""Get logging settings from config file section "logging"."""
+ if isinstance(cls.config, LuigiConfigParser):
+ return False
try:
logging_config = cls.config['logging']
except (TypeError, KeyError, NoSectionError):
|
{"golden_diff": "diff --git a/luigi/setup_logging.py b/luigi/setup_logging.py\n--- a/luigi/setup_logging.py\n+++ b/luigi/setup_logging.py\n@@ -22,7 +22,7 @@\n import logging\n import logging.config\n import os.path\n-from luigi.configuration import get_config\n+from luigi.configuration import get_config, LuigiConfigParser\n \n # In python3 ConfigParser was renamed\n # https://stackoverflow.com/a/41202010\n@@ -38,6 +38,8 @@\n @classmethod\n def _section(cls, opts):\n \"\"\"Get logging settings from config file section \"logging\".\"\"\"\n+ if isinstance(cls.config, LuigiConfigParser):\n+ return False\n try:\n logging_config = cls.config['logging']\n except (TypeError, KeyError, NoSectionError):\n", "issue": "AttributeError during logging setup with Python 2.7\nHi,\r\n\r\nI upgraded to luigi 2.8.0 and experience an `AttributeError` that occurs within the new `setup_logging.py`. Here is the important part of the stack trace:\r\n\r\n```\r\n File \".../lib/python2.7/site-packages/luigi/cmdline.py\", line 9, in luigi_run\r\n run_with_retcodes(argv)\r\n File \".../lib/python2.7/site-packages/luigi/retcodes.py\", line 81, in run_with_retcodes\r\n InterfaceLogging.setup(env_params)\r\n File \".../lib/python2.7/site-packages/luigi/setup_logging.py\", line 74, in setup\r\n configured = cls._section(opts)\r\n File \".../lib/python2.7/site-packages/luigi/setup_logging.py\", line 42, in _section\r\n logging_config = cls.config['logging']\r\nAttributeError: LuigiConfigParser instance has no attribute '__getitem__'\r\n```\r\n\r\n`cls.config` is a `ConfigParser` instance which does not implement `__getitem__` in Python 2.7 (which I'm forced to use -.-). This could be fixed by using `cls.config.options('logging')` instead. I checked, and this is the only place where items are used.\r\n\r\nhttps://github.com/spotify/luigi/blob/0a098f6f99da0bad03af56a057b9a15254d1a957/luigi/setup_logging.py#L42\r\n\r\nAdding @orsinium here who is maybe faster to fix this. I could create a PR on Friday.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright 2018 Vote Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\"\"\"\nThis module contains helper classes for configuring logging for luigid and\nworkers via command line arguments and options from config files.\n\"\"\"\n\nimport logging\nimport logging.config\nimport os.path\nfrom luigi.configuration import get_config\n\n# In python3 ConfigParser was renamed\n# https://stackoverflow.com/a/41202010\ntry:\n from ConfigParser import NoSectionError\nexcept ImportError:\n from configparser import NoSectionError\n\n\nclass BaseLogging(object):\n config = get_config()\n\n @classmethod\n def _section(cls, opts):\n \"\"\"Get logging settings from config file section \"logging\".\"\"\"\n try:\n logging_config = cls.config['logging']\n except (TypeError, KeyError, NoSectionError):\n return False\n logging.config.dictConfig(logging_config)\n return True\n\n @classmethod\n def setup(cls, opts):\n \"\"\"Setup logging via CLI params and config.\"\"\"\n logger = logging.getLogger('luigi')\n\n if cls._configured:\n logger.info('logging already configured')\n return False\n cls._configured = True\n\n if cls.config.getboolean('core', 'no_configure_logging', False):\n logger.info('logging disabled in settings')\n return False\n\n configured = cls._cli(opts)\n if configured:\n logger = logging.getLogger('luigi')\n logger.info('logging configured via special settings')\n return True\n\n configured = cls._conf(opts)\n if configured:\n logger = logging.getLogger('luigi')\n logger.info('logging configured via *.conf file')\n return True\n\n configured = cls._section(opts)\n if configured:\n logger = logging.getLogger('luigi')\n logger.info('logging configured via config section')\n return True\n\n configured = cls._default(opts)\n if configured:\n logger = logging.getLogger('luigi')\n logger.info('logging configured by default settings')\n return configured\n\n\nclass DaemonLogging(BaseLogging):\n \"\"\"Configure logging for luigid\n \"\"\"\n _configured = False\n _log_format = \"%(asctime)s %(name)s[%(process)s] %(levelname)s: %(message)s\"\n\n @classmethod\n def _cli(cls, opts):\n \"\"\"Setup logging via CLI options\n\n If `--background` -- set INFO level for root logger.\n If `--logdir` -- set logging with next params:\n default Luigi's formatter,\n INFO level,\n output in logdir in `luigi-server.log` file\n \"\"\"\n if opts.background:\n logging.getLogger().setLevel(logging.INFO)\n return True\n\n if opts.logdir:\n logging.basicConfig(\n level=logging.INFO,\n format=cls._log_format,\n filename=os.path.join(opts.logdir, \"luigi-server.log\"))\n return True\n\n return False\n\n @classmethod\n def _conf(cls, opts):\n \"\"\"Setup logging via ini-file from logging_conf_file option.\"\"\"\n logging_conf = cls.config.get('core', 'logging_conf_file', None)\n if logging_conf is None:\n return False\n\n if not os.path.exists(logging_conf):\n # FileNotFoundError added only in Python 3.3\n # https://docs.python.org/3/whatsnew/3.3.html#pep-3151-reworking-the-os-and-io-exception-hierarchy\n raise OSError(\"Error: Unable to locate specified logging configuration file!\")\n\n logging.config.fileConfig(logging_conf)\n return True\n\n @classmethod\n def _default(cls, opts):\n \"\"\"Setup default logger\"\"\"\n logging.basicConfig(level=logging.INFO, format=cls._log_format)\n return True\n\n\n# Part of this logic taken for dropped function \"setup_interface_logging\"\nclass InterfaceLogging(BaseLogging):\n \"\"\"Configure logging for worker\"\"\"\n _configured = False\n\n @classmethod\n def _cli(cls, opts):\n return False\n\n @classmethod\n def _conf(cls, opts):\n \"\"\"Setup logging via ini-file from logging_conf_file option.\"\"\"\n if not opts.logging_conf_file:\n return False\n\n if not os.path.exists(opts.logging_conf_file):\n # FileNotFoundError added only in Python 3.3\n # https://docs.python.org/3/whatsnew/3.3.html#pep-3151-reworking-the-os-and-io-exception-hierarchy\n raise OSError(\"Error: Unable to locate specified logging configuration file!\")\n\n logging.config.fileConfig(opts.logging_conf_file, disable_existing_loggers=False)\n return True\n\n @classmethod\n def _default(cls, opts):\n \"\"\"Setup default logger\"\"\"\n level = getattr(logging, opts.log_level, logging.DEBUG)\n\n logger = logging.getLogger('luigi-interface')\n logger.setLevel(level)\n\n stream_handler = logging.StreamHandler()\n stream_handler.setLevel(level)\n\n formatter = logging.Formatter('%(levelname)s: %(message)s')\n stream_handler.setFormatter(formatter)\n\n logger.addHandler(stream_handler)\n return True\n", "path": "luigi/setup_logging.py"}]}
| 2,509 | 181 |
gh_patches_debug_7792
|
rasdani/github-patches
|
git_diff
|
locustio__locust-401
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
requests.exceptions.ConnectionError: ('Connection aborted.', ResponseNotReady('Request-sent',))
I wanted to offer this up not as an issue, but as a solution to one that I found today.
I had a test that when run on a specific server would always fail with this unhelpful message:
requests.exceptions.ConnectionError: ('Connection aborted.', ResponseNotReady('Request-sent',))
The test had multiple requests to the same client within a single task and a colleague suspected it was something to do with the connection from the first request not being properly closed.
After a lot of playing around with timeouts and attempting to close out the first connection before the next one was sent (both of which did not solve the issue), I found a stackoverflow article with the same issue:
http://stackoverflow.com/questions/30033516/single-session-multiple-post-get-in-python-requests
The quick and dirty solution was to update to requests 2.7.0. At the time of getting this error I was on 2.6.2. I also noticed that the default version for locust is on 2.4. If you are experiencing this issue, simply update to 2.7 and you should be good!
</issue>
<code>
[start of setup.py]
1 # encoding: utf-8
2
3 from setuptools import setup, find_packages, Command
4 import sys, os
5
6 version = '0.7.3'
7
8
9 class Unit2Discover(Command):
10 user_options = []
11
12 def initialize_options(self):
13 pass
14
15 def finalize_options(self):
16 pass
17
18 def run(self):
19 import sys, subprocess
20 basecmd = ['unit2', 'discover']
21 errno = subprocess.call(basecmd)
22 raise SystemExit(errno)
23
24
25 setup(
26 name='locustio',
27 version=version,
28 description="Website load testing framework",
29 long_description="""Locust is a python utility for doing easy, distributed load testing of a web site""",
30 classifiers=[
31 "Topic :: Software Development :: Testing :: Traffic Generation",
32 "Development Status :: 4 - Beta",
33 "License :: OSI Approved :: MIT License",
34 "Operating System :: OS Independent",
35 "Programming Language :: Python",
36 "Programming Language :: Python :: 2",
37 "Programming Language :: Python :: 2.6",
38 "Programming Language :: Python :: 2.7",
39 "Intended Audience :: Developers",
40 "Intended Audience :: System Administrators",
41 ],
42 keywords='',
43 author='Jonatan Heyman, Carl Bystrom, Joakim Hamrén, Hugo Heyman',
44 author_email='',
45 url='http://locust.io',
46 license='MIT',
47 packages=find_packages(exclude=['ez_setup', 'examples', 'tests']),
48 include_package_data=True,
49 zip_safe=False,
50 install_requires=["gevent==1.0.1", "flask>=0.10.1", "requests>=2.4.1", "msgpack-python>=0.4.2"],
51 tests_require=['unittest2', 'mock', 'pyzmq'],
52 entry_points={
53 'console_scripts': [
54 'locust = locust.main:main',
55 ]
56 },
57 test_suite='unittest2.collector',
58 )
59
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -47,7 +47,7 @@
packages=find_packages(exclude=['ez_setup', 'examples', 'tests']),
include_package_data=True,
zip_safe=False,
- install_requires=["gevent==1.0.1", "flask>=0.10.1", "requests>=2.4.1", "msgpack-python>=0.4.2"],
+ install_requires=["gevent==1.0.1", "flask>=0.10.1", "requests>=2.9.1", "msgpack-python>=0.4.2"],
tests_require=['unittest2', 'mock', 'pyzmq'],
entry_points={
'console_scripts': [
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -47,7 +47,7 @@\n packages=find_packages(exclude=['ez_setup', 'examples', 'tests']),\n include_package_data=True,\n zip_safe=False,\n- install_requires=[\"gevent==1.0.1\", \"flask>=0.10.1\", \"requests>=2.4.1\", \"msgpack-python>=0.4.2\"],\n+ install_requires=[\"gevent==1.0.1\", \"flask>=0.10.1\", \"requests>=2.9.1\", \"msgpack-python>=0.4.2\"],\n tests_require=['unittest2', 'mock', 'pyzmq'],\n entry_points={\n 'console_scripts': [\n", "issue": "requests.exceptions.ConnectionError: ('Connection aborted.', ResponseNotReady('Request-sent',))\nI wanted to offer this up not as an issue, but as a solution to one that I found today.\n\nI had a test that when run on a specific server would always fail with this unhelpful message:\nrequests.exceptions.ConnectionError: ('Connection aborted.', ResponseNotReady('Request-sent',))\n\nThe test had multiple requests to the same client within a single task and a colleague suspected it was something to do with the connection from the first request not being properly closed.\n\nAfter a lot of playing around with timeouts and attempting to close out the first connection before the next one was sent (both of which did not solve the issue), I found a stackoverflow article with the same issue:\nhttp://stackoverflow.com/questions/30033516/single-session-multiple-post-get-in-python-requests\n\nThe quick and dirty solution was to update to requests 2.7.0. At the time of getting this error I was on 2.6.2. I also noticed that the default version for locust is on 2.4. If you are experiencing this issue, simply update to 2.7 and you should be good!\n\n", "before_files": [{"content": "# encoding: utf-8\n\nfrom setuptools import setup, find_packages, Command\nimport sys, os\n\nversion = '0.7.3'\n\n\nclass Unit2Discover(Command):\n user_options = []\n\n def initialize_options(self):\n pass\n\n def finalize_options(self):\n pass\n\n def run(self):\n import sys, subprocess\n basecmd = ['unit2', 'discover']\n errno = subprocess.call(basecmd)\n raise SystemExit(errno)\n\n\nsetup(\n name='locustio',\n version=version,\n description=\"Website load testing framework\",\n long_description=\"\"\"Locust is a python utility for doing easy, distributed load testing of a web site\"\"\",\n classifiers=[\n \"Topic :: Software Development :: Testing :: Traffic Generation\",\n \"Development Status :: 4 - Beta\",\n \"License :: OSI Approved :: MIT License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.6\",\n \"Programming Language :: Python :: 2.7\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: System Administrators\",\n ],\n keywords='',\n author='Jonatan Heyman, Carl Bystrom, Joakim Hamr\u00e9n, Hugo Heyman',\n author_email='',\n url='http://locust.io',\n license='MIT',\n packages=find_packages(exclude=['ez_setup', 'examples', 'tests']),\n include_package_data=True,\n zip_safe=False,\n install_requires=[\"gevent==1.0.1\", \"flask>=0.10.1\", \"requests>=2.4.1\", \"msgpack-python>=0.4.2\"],\n tests_require=['unittest2', 'mock', 'pyzmq'],\n entry_points={\n 'console_scripts': [\n 'locust = locust.main:main',\n ]\n },\n test_suite='unittest2.collector',\n)\n", "path": "setup.py"}]}
| 1,309 | 174 |
gh_patches_debug_34594
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-4746
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[WIP] fix xmliter namespace on selected node
This PR was triggered by [scrapy-users](https://groups.google.com/forum/#!topic/scrapy-users/VN6409UHexQ)
Actually `xmliter` populates a `Selector` with everything from the position 0 to the tag start, so if we had 100mb before the tag we want to iter it copy those 100mb across all the `Selector` objects. Also it just extract this info for the first tag and embed the rest on that, this can cause info crossing.
In this PR I kept the regex stuff even tho I think we should use something like [`iterparse`](https://docs.python.org/2/library/xml.etree.elementtree.html#xml.etree.ElementTree.iterparse).
Currently `xmliter_lxml` tests are failing due to it has a different API.
</issue>
<code>
[start of scrapy/utils/iterators.py]
1 import csv
2 import logging
3 import re
4 from io import StringIO
5
6 from scrapy.http import TextResponse, Response
7 from scrapy.selector import Selector
8 from scrapy.utils.python import re_rsearch, to_unicode
9
10
11 logger = logging.getLogger(__name__)
12
13
14 def xmliter(obj, nodename):
15 """Return a iterator of Selector's over all nodes of a XML document,
16 given the name of the node to iterate. Useful for parsing XML feeds.
17
18 obj can be:
19 - a Response object
20 - a unicode string
21 - a string encoded as utf-8
22 """
23 nodename_patt = re.escape(nodename)
24
25 HEADER_START_RE = re.compile(fr'^(.*?)<\s*{nodename_patt}(?:\s|>)', re.S)
26 HEADER_END_RE = re.compile(fr'<\s*/{nodename_patt}\s*>', re.S)
27 text = _body_or_str(obj)
28
29 header_start = re.search(HEADER_START_RE, text)
30 header_start = header_start.group(1).strip() if header_start else ''
31 header_end = re_rsearch(HEADER_END_RE, text)
32 header_end = text[header_end[1]:].strip() if header_end else ''
33
34 r = re.compile(fr'<{nodename_patt}[\s>].*?</{nodename_patt}>', re.DOTALL)
35 for match in r.finditer(text):
36 nodetext = header_start + match.group() + header_end
37 yield Selector(text=nodetext, type='xml').xpath('//' + nodename)[0]
38
39
40 def xmliter_lxml(obj, nodename, namespace=None, prefix='x'):
41 from lxml import etree
42 reader = _StreamReader(obj)
43 tag = f'{{{namespace}}}{nodename}'if namespace else nodename
44 iterable = etree.iterparse(reader, tag=tag, encoding=reader.encoding)
45 selxpath = '//' + (f'{prefix}:{nodename}' if namespace else nodename)
46 for _, node in iterable:
47 nodetext = etree.tostring(node, encoding='unicode')
48 node.clear()
49 xs = Selector(text=nodetext, type='xml')
50 if namespace:
51 xs.register_namespace(prefix, namespace)
52 yield xs.xpath(selxpath)[0]
53
54
55 class _StreamReader:
56
57 def __init__(self, obj):
58 self._ptr = 0
59 if isinstance(obj, Response):
60 self._text, self.encoding = obj.body, obj.encoding
61 else:
62 self._text, self.encoding = obj, 'utf-8'
63 self._is_unicode = isinstance(self._text, str)
64
65 def read(self, n=65535):
66 self.read = self._read_unicode if self._is_unicode else self._read_string
67 return self.read(n).lstrip()
68
69 def _read_string(self, n=65535):
70 s, e = self._ptr, self._ptr + n
71 self._ptr = e
72 return self._text[s:e]
73
74 def _read_unicode(self, n=65535):
75 s, e = self._ptr, self._ptr + n
76 self._ptr = e
77 return self._text[s:e].encode('utf-8')
78
79
80 def csviter(obj, delimiter=None, headers=None, encoding=None, quotechar=None):
81 """ Returns an iterator of dictionaries from the given csv object
82
83 obj can be:
84 - a Response object
85 - a unicode string
86 - a string encoded as utf-8
87
88 delimiter is the character used to separate fields on the given obj.
89
90 headers is an iterable that when provided offers the keys
91 for the returned dictionaries, if not the first row is used.
92
93 quotechar is the character used to enclosure fields on the given obj.
94 """
95
96 encoding = obj.encoding if isinstance(obj, TextResponse) else encoding or 'utf-8'
97
98 def row_to_unicode(row_):
99 return [to_unicode(field, encoding) for field in row_]
100
101 lines = StringIO(_body_or_str(obj, unicode=True))
102
103 kwargs = {}
104 if delimiter:
105 kwargs["delimiter"] = delimiter
106 if quotechar:
107 kwargs["quotechar"] = quotechar
108 csv_r = csv.reader(lines, **kwargs)
109
110 if not headers:
111 try:
112 row = next(csv_r)
113 except StopIteration:
114 return
115 headers = row_to_unicode(row)
116
117 for row in csv_r:
118 row = row_to_unicode(row)
119 if len(row) != len(headers):
120 logger.warning("ignoring row %(csvlnum)d (length: %(csvrow)d, "
121 "should be: %(csvheader)d)",
122 {'csvlnum': csv_r.line_num, 'csvrow': len(row),
123 'csvheader': len(headers)})
124 continue
125 else:
126 yield dict(zip(headers, row))
127
128
129 def _body_or_str(obj, unicode=True):
130 expected_types = (Response, str, bytes)
131 if not isinstance(obj, expected_types):
132 expected_types_str = " or ".join(t.__name__ for t in expected_types)
133 raise TypeError(
134 f"Object {obj!r} must be {expected_types_str}, not {type(obj).__name__}"
135 )
136 if isinstance(obj, Response):
137 if not unicode:
138 return obj.body
139 elif isinstance(obj, TextResponse):
140 return obj.text
141 else:
142 return obj.body.decode('utf-8')
143 elif isinstance(obj, str):
144 return obj if unicode else obj.encode('utf-8')
145 else:
146 return obj.decode('utf-8') if unicode else obj
147
[end of scrapy/utils/iterators.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scrapy/utils/iterators.py b/scrapy/utils/iterators.py
--- a/scrapy/utils/iterators.py
+++ b/scrapy/utils/iterators.py
@@ -22,25 +22,41 @@
"""
nodename_patt = re.escape(nodename)
- HEADER_START_RE = re.compile(fr'^(.*?)<\s*{nodename_patt}(?:\s|>)', re.S)
+ DOCUMENT_HEADER_RE = re.compile(r'<\?xml[^>]+>\s*', re.S)
HEADER_END_RE = re.compile(fr'<\s*/{nodename_patt}\s*>', re.S)
+ END_TAG_RE = re.compile(r'<\s*/([^\s>]+)\s*>', re.S)
+ NAMESPACE_RE = re.compile(r'((xmlns[:A-Za-z]*)=[^>\s]+)', re.S)
text = _body_or_str(obj)
- header_start = re.search(HEADER_START_RE, text)
- header_start = header_start.group(1).strip() if header_start else ''
- header_end = re_rsearch(HEADER_END_RE, text)
- header_end = text[header_end[1]:].strip() if header_end else ''
+ document_header = re.search(DOCUMENT_HEADER_RE, text)
+ document_header = document_header.group().strip() if document_header else ''
+ header_end_idx = re_rsearch(HEADER_END_RE, text)
+ header_end = text[header_end_idx[1]:].strip() if header_end_idx else ''
+ namespaces = {}
+ if header_end:
+ for tagname in reversed(re.findall(END_TAG_RE, header_end)):
+ tag = re.search(fr'<\s*{tagname}.*?xmlns[:=][^>]*>', text[:header_end_idx[1]], re.S)
+ if tag:
+ namespaces.update(reversed(x) for x in re.findall(NAMESPACE_RE, tag.group()))
r = re.compile(fr'<{nodename_patt}[\s>].*?</{nodename_patt}>', re.DOTALL)
for match in r.finditer(text):
- nodetext = header_start + match.group() + header_end
- yield Selector(text=nodetext, type='xml').xpath('//' + nodename)[0]
+ nodetext = (
+ document_header
+ + match.group().replace(
+ nodename,
+ f'{nodename} {" ".join(namespaces.values())}',
+ 1
+ )
+ + header_end
+ )
+ yield Selector(text=nodetext, type='xml')
def xmliter_lxml(obj, nodename, namespace=None, prefix='x'):
from lxml import etree
reader = _StreamReader(obj)
- tag = f'{{{namespace}}}{nodename}'if namespace else nodename
+ tag = f'{{{namespace}}}{nodename}' if namespace else nodename
iterable = etree.iterparse(reader, tag=tag, encoding=reader.encoding)
selxpath = '//' + (f'{prefix}:{nodename}' if namespace else nodename)
for _, node in iterable:
|
{"golden_diff": "diff --git a/scrapy/utils/iterators.py b/scrapy/utils/iterators.py\n--- a/scrapy/utils/iterators.py\n+++ b/scrapy/utils/iterators.py\n@@ -22,25 +22,41 @@\n \"\"\"\n nodename_patt = re.escape(nodename)\n \n- HEADER_START_RE = re.compile(fr'^(.*?)<\\s*{nodename_patt}(?:\\s|>)', re.S)\n+ DOCUMENT_HEADER_RE = re.compile(r'<\\?xml[^>]+>\\s*', re.S)\n HEADER_END_RE = re.compile(fr'<\\s*/{nodename_patt}\\s*>', re.S)\n+ END_TAG_RE = re.compile(r'<\\s*/([^\\s>]+)\\s*>', re.S)\n+ NAMESPACE_RE = re.compile(r'((xmlns[:A-Za-z]*)=[^>\\s]+)', re.S)\n text = _body_or_str(obj)\n \n- header_start = re.search(HEADER_START_RE, text)\n- header_start = header_start.group(1).strip() if header_start else ''\n- header_end = re_rsearch(HEADER_END_RE, text)\n- header_end = text[header_end[1]:].strip() if header_end else ''\n+ document_header = re.search(DOCUMENT_HEADER_RE, text)\n+ document_header = document_header.group().strip() if document_header else ''\n+ header_end_idx = re_rsearch(HEADER_END_RE, text)\n+ header_end = text[header_end_idx[1]:].strip() if header_end_idx else ''\n+ namespaces = {}\n+ if header_end:\n+ for tagname in reversed(re.findall(END_TAG_RE, header_end)):\n+ tag = re.search(fr'<\\s*{tagname}.*?xmlns[:=][^>]*>', text[:header_end_idx[1]], re.S)\n+ if tag:\n+ namespaces.update(reversed(x) for x in re.findall(NAMESPACE_RE, tag.group()))\n \n r = re.compile(fr'<{nodename_patt}[\\s>].*?</{nodename_patt}>', re.DOTALL)\n for match in r.finditer(text):\n- nodetext = header_start + match.group() + header_end\n- yield Selector(text=nodetext, type='xml').xpath('//' + nodename)[0]\n+ nodetext = (\n+ document_header\n+ + match.group().replace(\n+ nodename,\n+ f'{nodename} {\" \".join(namespaces.values())}',\n+ 1\n+ )\n+ + header_end\n+ )\n+ yield Selector(text=nodetext, type='xml')\n \n \n def xmliter_lxml(obj, nodename, namespace=None, prefix='x'):\n from lxml import etree\n reader = _StreamReader(obj)\n- tag = f'{{{namespace}}}{nodename}'if namespace else nodename\n+ tag = f'{{{namespace}}}{nodename}' if namespace else nodename\n iterable = etree.iterparse(reader, tag=tag, encoding=reader.encoding)\n selxpath = '//' + (f'{prefix}:{nodename}' if namespace else nodename)\n for _, node in iterable:\n", "issue": "[WIP] fix xmliter namespace on selected node\nThis PR was triggered by [scrapy-users](https://groups.google.com/forum/#!topic/scrapy-users/VN6409UHexQ)\n\nActually `xmliter` populates a `Selector` with everything from the position 0 to the tag start, so if we had 100mb before the tag we want to iter it copy those 100mb across all the `Selector` objects. Also it just extract this info for the first tag and embed the rest on that, this can cause info crossing.\n\nIn this PR I kept the regex stuff even tho I think we should use something like [`iterparse`](https://docs.python.org/2/library/xml.etree.elementtree.html#xml.etree.ElementTree.iterparse).\n\nCurrently `xmliter_lxml` tests are failing due to it has a different API.\n\n", "before_files": [{"content": "import csv\nimport logging\nimport re\nfrom io import StringIO\n\nfrom scrapy.http import TextResponse, Response\nfrom scrapy.selector import Selector\nfrom scrapy.utils.python import re_rsearch, to_unicode\n\n\nlogger = logging.getLogger(__name__)\n\n\ndef xmliter(obj, nodename):\n \"\"\"Return a iterator of Selector's over all nodes of a XML document,\n given the name of the node to iterate. Useful for parsing XML feeds.\n\n obj can be:\n - a Response object\n - a unicode string\n - a string encoded as utf-8\n \"\"\"\n nodename_patt = re.escape(nodename)\n\n HEADER_START_RE = re.compile(fr'^(.*?)<\\s*{nodename_patt}(?:\\s|>)', re.S)\n HEADER_END_RE = re.compile(fr'<\\s*/{nodename_patt}\\s*>', re.S)\n text = _body_or_str(obj)\n\n header_start = re.search(HEADER_START_RE, text)\n header_start = header_start.group(1).strip() if header_start else ''\n header_end = re_rsearch(HEADER_END_RE, text)\n header_end = text[header_end[1]:].strip() if header_end else ''\n\n r = re.compile(fr'<{nodename_patt}[\\s>].*?</{nodename_patt}>', re.DOTALL)\n for match in r.finditer(text):\n nodetext = header_start + match.group() + header_end\n yield Selector(text=nodetext, type='xml').xpath('//' + nodename)[0]\n\n\ndef xmliter_lxml(obj, nodename, namespace=None, prefix='x'):\n from lxml import etree\n reader = _StreamReader(obj)\n tag = f'{{{namespace}}}{nodename}'if namespace else nodename\n iterable = etree.iterparse(reader, tag=tag, encoding=reader.encoding)\n selxpath = '//' + (f'{prefix}:{nodename}' if namespace else nodename)\n for _, node in iterable:\n nodetext = etree.tostring(node, encoding='unicode')\n node.clear()\n xs = Selector(text=nodetext, type='xml')\n if namespace:\n xs.register_namespace(prefix, namespace)\n yield xs.xpath(selxpath)[0]\n\n\nclass _StreamReader:\n\n def __init__(self, obj):\n self._ptr = 0\n if isinstance(obj, Response):\n self._text, self.encoding = obj.body, obj.encoding\n else:\n self._text, self.encoding = obj, 'utf-8'\n self._is_unicode = isinstance(self._text, str)\n\n def read(self, n=65535):\n self.read = self._read_unicode if self._is_unicode else self._read_string\n return self.read(n).lstrip()\n\n def _read_string(self, n=65535):\n s, e = self._ptr, self._ptr + n\n self._ptr = e\n return self._text[s:e]\n\n def _read_unicode(self, n=65535):\n s, e = self._ptr, self._ptr + n\n self._ptr = e\n return self._text[s:e].encode('utf-8')\n\n\ndef csviter(obj, delimiter=None, headers=None, encoding=None, quotechar=None):\n \"\"\" Returns an iterator of dictionaries from the given csv object\n\n obj can be:\n - a Response object\n - a unicode string\n - a string encoded as utf-8\n\n delimiter is the character used to separate fields on the given obj.\n\n headers is an iterable that when provided offers the keys\n for the returned dictionaries, if not the first row is used.\n\n quotechar is the character used to enclosure fields on the given obj.\n \"\"\"\n\n encoding = obj.encoding if isinstance(obj, TextResponse) else encoding or 'utf-8'\n\n def row_to_unicode(row_):\n return [to_unicode(field, encoding) for field in row_]\n\n lines = StringIO(_body_or_str(obj, unicode=True))\n\n kwargs = {}\n if delimiter:\n kwargs[\"delimiter\"] = delimiter\n if quotechar:\n kwargs[\"quotechar\"] = quotechar\n csv_r = csv.reader(lines, **kwargs)\n\n if not headers:\n try:\n row = next(csv_r)\n except StopIteration:\n return\n headers = row_to_unicode(row)\n\n for row in csv_r:\n row = row_to_unicode(row)\n if len(row) != len(headers):\n logger.warning(\"ignoring row %(csvlnum)d (length: %(csvrow)d, \"\n \"should be: %(csvheader)d)\",\n {'csvlnum': csv_r.line_num, 'csvrow': len(row),\n 'csvheader': len(headers)})\n continue\n else:\n yield dict(zip(headers, row))\n\n\ndef _body_or_str(obj, unicode=True):\n expected_types = (Response, str, bytes)\n if not isinstance(obj, expected_types):\n expected_types_str = \" or \".join(t.__name__ for t in expected_types)\n raise TypeError(\n f\"Object {obj!r} must be {expected_types_str}, not {type(obj).__name__}\"\n )\n if isinstance(obj, Response):\n if not unicode:\n return obj.body\n elif isinstance(obj, TextResponse):\n return obj.text\n else:\n return obj.body.decode('utf-8')\n elif isinstance(obj, str):\n return obj if unicode else obj.encode('utf-8')\n else:\n return obj.decode('utf-8') if unicode else obj\n", "path": "scrapy/utils/iterators.py"}]}
| 2,270 | 695 |
gh_patches_debug_35304
|
rasdani/github-patches
|
git_diff
|
vaexio__vaex-757
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bool values get flipped when converting Arrow table to DataFrame
Using the latest version:
`vaex==2.6.1`
Just realised that when converting an Arrow table to a DataFrame, bool columns get flipped and converted to integers:
```python
import vaex
from pyarrow import feather
bool_array = [False, True, True, False]
pdf = pd.DataFrame({"col1": bool_array})
pdf.to_feather("test_data.feather")
arrow_table = feather.read_table("test_data.feather")
vaex.from_arrow_table(arrow_table)
```
```
# | col1
-- | --
0 | 1
1 | 0
2 | 0
3 | 1
```
</issue>
<code>
[start of packages/vaex-arrow/vaex_arrow/convert.py]
1 """Convert between arrow and vaex/numpy columns/arrays without doing memory copies."""
2 import pyarrow
3 import numpy as np
4 from vaex.column import ColumnStringArrow
5
6 def arrow_array_from_numpy_array(array):
7 dtype = array.dtype
8 mask = None
9 if np.ma.isMaskedArray(array):
10 mask = array.mask
11 # arrow 0.16 behaves weird in this case https://github.com/vaexio/vaex/pull/639
12 if mask is np.False_:
13 mask = None
14 elif mask is np.True_:
15 raise ValueError('not sure what pyarrow does with mask=True')
16 array = array.data
17 if dtype.kind == 'S':
18 type = pyarrow.binary(dtype.itemsize)
19 arrow_array = pyarrow.array(array, type, mask=mask)
20 else:
21 if not dtype.isnative:
22 array = array.astype(dtype.newbyteorder('='))
23 arrow_array = pyarrow.Array.from_pandas(array, mask=mask)
24 return arrow_array
25
26 from vaex.dataframe import Column
27
28
29 def column_from_arrow_array(arrow_array):
30 arrow_type = arrow_array.type
31 buffers = arrow_array.buffers()
32 if len(buffers) == 2:
33 return numpy_array_from_arrow_array(arrow_array)
34 elif len(buffers) == 3 and isinstance(arrow_array.type, type(pyarrow.string())):
35 bitmap_buffer, offsets, string_bytes = arrow_array.buffers()
36 if arrow_array.null_count == 0:
37 null_bitmap = None # we drop any null_bitmap when there are no null counts
38 else:
39 null_bitmap = np.frombuffer(bitmap_buffer, 'uint8', len(bitmap_buffer))
40 offsets = np.frombuffer(offsets, np.int32, len(offsets)//4)
41 if string_bytes is None:
42 string_bytes = np.array([], dtype='S1')
43 else:
44 string_bytes = np.frombuffer(string_bytes, 'S1', len(string_bytes))
45 column = ColumnStringArrow(offsets, string_bytes, len(arrow_array), null_bitmap=null_bitmap)
46 return column
47 else:
48 raise TypeError('type unsupported: %r' % arrow_type)
49
50
51 def numpy_array_from_arrow_array(arrow_array):
52 arrow_type = arrow_array.type
53 buffers = arrow_array.buffers()
54 assert len(buffers) == 2
55 bitmap_buffer, data_buffer = buffers
56 if isinstance(arrow_type, type(pyarrow.binary(1))): # todo, is there a better way to typecheck?
57 # mimics python/pyarrow/array.pxi::Array::to_numpy
58 assert len(buffers) == 2
59 dtype = "S" + str(arrow_type.byte_width)
60 # arrow seems to do padding, check if it is all ok
61 expected_length = arrow_type.byte_width * len(arrow_array)
62 actual_length = len(buffers[-1])
63 if actual_length < expected_length:
64 raise ValueError('buffer is smaller (%d) than expected (%d)' % (actual_length, expected_length))
65 array = np.frombuffer(buffers[-1], dtype, len(arrow_array))# TODO: deal with offset ? [arrow_array.offset:arrow_array.offset + len(arrow_array)]
66 else:
67 dtype = arrow_array.type.to_pandas_dtype()
68 if np.bool_ == dtype:
69 # TODO: this will also be a copy, we probably want to support bitmasks as well
70 bitmap = np.frombuffer(data_buffer, np.uint8, len(data_buffer))
71 array = numpy_mask_from_arrow_mask(bitmap, len(arrow_array))
72 else:
73 array = np.frombuffer(data_buffer, dtype, len(arrow_array))
74
75 if bitmap_buffer is not None:
76 bitmap = np.frombuffer(bitmap_buffer, np.uint8, len(bitmap_buffer))
77 mask = numpy_mask_from_arrow_mask(bitmap, len(arrow_array))
78 array = np.ma.MaskedArray(array, mask=mask)
79 return array
80
81 def numpy_mask_from_arrow_mask(bitmap, length):
82 # arrow uses a bitmap https://github.com/apache/arrow/blob/master/format/Layout.md
83 # we do have to change the ordering of the bits
84 return 1-np.unpackbits(bitmap).reshape((len(bitmap),8))[:,::-1].reshape(-1)[:length]
85
86
87
88 def arrow_table_from_vaex_df(ds, column_names=None, selection=None, strings=True, virtual=False):
89 """Implementation of Dataset.to_arrow_table"""
90 names = []
91 arrays = []
92 for name, array in ds.to_items(column_names=column_names, selection=selection, strings=strings, virtual=virtual):
93 names.append(name)
94 arrays.append(arrow_array_from_numpy_array(array))
95 return pyarrow.Table.from_arrays(arrays, names)
96
97 def vaex_df_from_arrow_table(table):
98 from .dataset import DatasetArrow
99 return DatasetArrow(table=table)
100
[end of packages/vaex-arrow/vaex_arrow/convert.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/packages/vaex-arrow/vaex_arrow/convert.py b/packages/vaex-arrow/vaex_arrow/convert.py
--- a/packages/vaex-arrow/vaex_arrow/convert.py
+++ b/packages/vaex-arrow/vaex_arrow/convert.py
@@ -53,6 +53,7 @@
buffers = arrow_array.buffers()
assert len(buffers) == 2
bitmap_buffer, data_buffer = buffers
+ offset = arrow_array.offset
if isinstance(arrow_type, type(pyarrow.binary(1))): # todo, is there a better way to typecheck?
# mimics python/pyarrow/array.pxi::Array::to_numpy
assert len(buffers) == 2
@@ -68,13 +69,13 @@
if np.bool_ == dtype:
# TODO: this will also be a copy, we probably want to support bitmasks as well
bitmap = np.frombuffer(data_buffer, np.uint8, len(data_buffer))
- array = numpy_mask_from_arrow_mask(bitmap, len(arrow_array))
+ array = numpy_bool_from_arrow_bitmap(bitmap, len(arrow_array) + offset)[offset:]
else:
- array = np.frombuffer(data_buffer, dtype, len(arrow_array))
+ array = np.frombuffer(data_buffer, dtype, len(arrow_array) + offset)[offset:]
if bitmap_buffer is not None:
bitmap = np.frombuffer(bitmap_buffer, np.uint8, len(bitmap_buffer))
- mask = numpy_mask_from_arrow_mask(bitmap, len(arrow_array))
+ mask = numpy_mask_from_arrow_mask(bitmap, len(arrow_array) + offset)[offset:]
array = np.ma.MaskedArray(array, mask=mask)
return array
@@ -83,7 +84,10 @@
# we do have to change the ordering of the bits
return 1-np.unpackbits(bitmap).reshape((len(bitmap),8))[:,::-1].reshape(-1)[:length]
-
+def numpy_bool_from_arrow_bitmap(bitmap, length):
+ # arrow uses a bitmap https://github.com/apache/arrow/blob/master/format/Layout.md
+ # we do have to change the ordering of the bits
+ return np.unpackbits(bitmap).reshape((len(bitmap),8))[:,::-1].reshape(-1)[:length].view(np.bool_)
def arrow_table_from_vaex_df(ds, column_names=None, selection=None, strings=True, virtual=False):
"""Implementation of Dataset.to_arrow_table"""
|
{"golden_diff": "diff --git a/packages/vaex-arrow/vaex_arrow/convert.py b/packages/vaex-arrow/vaex_arrow/convert.py\n--- a/packages/vaex-arrow/vaex_arrow/convert.py\n+++ b/packages/vaex-arrow/vaex_arrow/convert.py\n@@ -53,6 +53,7 @@\n buffers = arrow_array.buffers()\n assert len(buffers) == 2\n bitmap_buffer, data_buffer = buffers\n+ offset = arrow_array.offset\n if isinstance(arrow_type, type(pyarrow.binary(1))): # todo, is there a better way to typecheck?\n # mimics python/pyarrow/array.pxi::Array::to_numpy\n assert len(buffers) == 2\n@@ -68,13 +69,13 @@\n if np.bool_ == dtype:\n # TODO: this will also be a copy, we probably want to support bitmasks as well\n bitmap = np.frombuffer(data_buffer, np.uint8, len(data_buffer))\n- array = numpy_mask_from_arrow_mask(bitmap, len(arrow_array))\n+ array = numpy_bool_from_arrow_bitmap(bitmap, len(arrow_array) + offset)[offset:]\n else:\n- array = np.frombuffer(data_buffer, dtype, len(arrow_array))\n+ array = np.frombuffer(data_buffer, dtype, len(arrow_array) + offset)[offset:]\n \n if bitmap_buffer is not None:\n bitmap = np.frombuffer(bitmap_buffer, np.uint8, len(bitmap_buffer))\n- mask = numpy_mask_from_arrow_mask(bitmap, len(arrow_array))\n+ mask = numpy_mask_from_arrow_mask(bitmap, len(arrow_array) + offset)[offset:]\n array = np.ma.MaskedArray(array, mask=mask)\n return array\n \n@@ -83,7 +84,10 @@\n # we do have to change the ordering of the bits\n return 1-np.unpackbits(bitmap).reshape((len(bitmap),8))[:,::-1].reshape(-1)[:length]\n \n-\n+def numpy_bool_from_arrow_bitmap(bitmap, length):\n+ # arrow uses a bitmap https://github.com/apache/arrow/blob/master/format/Layout.md\n+ # we do have to change the ordering of the bits\n+ return np.unpackbits(bitmap).reshape((len(bitmap),8))[:,::-1].reshape(-1)[:length].view(np.bool_)\n \n def arrow_table_from_vaex_df(ds, column_names=None, selection=None, strings=True, virtual=False):\n \"\"\"Implementation of Dataset.to_arrow_table\"\"\"\n", "issue": "Bool values get flipped when converting Arrow table to DataFrame\nUsing the latest version:\r\n`vaex==2.6.1`\r\n\r\nJust realised that when converting an Arrow table to a DataFrame, bool columns get flipped and converted to integers:\r\n\r\n```python\r\nimport vaex\r\nfrom pyarrow import feather\r\n\r\nbool_array = [False, True, True, False]\r\npdf = pd.DataFrame({\"col1\": bool_array})\r\npdf.to_feather(\"test_data.feather\")\r\narrow_table = feather.read_table(\"test_data.feather\")\r\nvaex.from_arrow_table(arrow_table)\r\n```\r\n\r\n```\r\n# | col1\r\n-- | --\r\n0 | 1\r\n1 | 0\r\n2 | 0\r\n3 | 1\r\n```\n", "before_files": [{"content": "\"\"\"Convert between arrow and vaex/numpy columns/arrays without doing memory copies.\"\"\"\nimport pyarrow\nimport numpy as np\nfrom vaex.column import ColumnStringArrow\n\ndef arrow_array_from_numpy_array(array):\n dtype = array.dtype\n mask = None\n if np.ma.isMaskedArray(array):\n mask = array.mask\n # arrow 0.16 behaves weird in this case https://github.com/vaexio/vaex/pull/639\n if mask is np.False_:\n mask = None\n elif mask is np.True_:\n raise ValueError('not sure what pyarrow does with mask=True')\n array = array.data\n if dtype.kind == 'S':\n type = pyarrow.binary(dtype.itemsize)\n arrow_array = pyarrow.array(array, type, mask=mask)\n else:\n if not dtype.isnative:\n array = array.astype(dtype.newbyteorder('='))\n arrow_array = pyarrow.Array.from_pandas(array, mask=mask)\n return arrow_array\n\nfrom vaex.dataframe import Column\n\n\ndef column_from_arrow_array(arrow_array):\n arrow_type = arrow_array.type\n buffers = arrow_array.buffers()\n if len(buffers) == 2:\n return numpy_array_from_arrow_array(arrow_array)\n elif len(buffers) == 3 and isinstance(arrow_array.type, type(pyarrow.string())):\n bitmap_buffer, offsets, string_bytes = arrow_array.buffers()\n if arrow_array.null_count == 0:\n null_bitmap = None # we drop any null_bitmap when there are no null counts\n else:\n null_bitmap = np.frombuffer(bitmap_buffer, 'uint8', len(bitmap_buffer))\n offsets = np.frombuffer(offsets, np.int32, len(offsets)//4)\n if string_bytes is None:\n string_bytes = np.array([], dtype='S1')\n else:\n string_bytes = np.frombuffer(string_bytes, 'S1', len(string_bytes))\n column = ColumnStringArrow(offsets, string_bytes, len(arrow_array), null_bitmap=null_bitmap)\n return column\n else:\n raise TypeError('type unsupported: %r' % arrow_type)\n\n\ndef numpy_array_from_arrow_array(arrow_array):\n arrow_type = arrow_array.type\n buffers = arrow_array.buffers()\n assert len(buffers) == 2\n bitmap_buffer, data_buffer = buffers\n if isinstance(arrow_type, type(pyarrow.binary(1))): # todo, is there a better way to typecheck?\n # mimics python/pyarrow/array.pxi::Array::to_numpy\n assert len(buffers) == 2\n dtype = \"S\" + str(arrow_type.byte_width)\n # arrow seems to do padding, check if it is all ok\n expected_length = arrow_type.byte_width * len(arrow_array)\n actual_length = len(buffers[-1])\n if actual_length < expected_length:\n raise ValueError('buffer is smaller (%d) than expected (%d)' % (actual_length, expected_length))\n array = np.frombuffer(buffers[-1], dtype, len(arrow_array))# TODO: deal with offset ? [arrow_array.offset:arrow_array.offset + len(arrow_array)]\n else:\n dtype = arrow_array.type.to_pandas_dtype()\n if np.bool_ == dtype:\n # TODO: this will also be a copy, we probably want to support bitmasks as well\n bitmap = np.frombuffer(data_buffer, np.uint8, len(data_buffer))\n array = numpy_mask_from_arrow_mask(bitmap, len(arrow_array))\n else:\n array = np.frombuffer(data_buffer, dtype, len(arrow_array))\n\n if bitmap_buffer is not None:\n bitmap = np.frombuffer(bitmap_buffer, np.uint8, len(bitmap_buffer))\n mask = numpy_mask_from_arrow_mask(bitmap, len(arrow_array))\n array = np.ma.MaskedArray(array, mask=mask)\n return array\n\ndef numpy_mask_from_arrow_mask(bitmap, length):\n # arrow uses a bitmap https://github.com/apache/arrow/blob/master/format/Layout.md\n # we do have to change the ordering of the bits\n return 1-np.unpackbits(bitmap).reshape((len(bitmap),8))[:,::-1].reshape(-1)[:length]\n\n\n\ndef arrow_table_from_vaex_df(ds, column_names=None, selection=None, strings=True, virtual=False):\n \"\"\"Implementation of Dataset.to_arrow_table\"\"\"\n names = []\n arrays = []\n for name, array in ds.to_items(column_names=column_names, selection=selection, strings=strings, virtual=virtual):\n names.append(name)\n arrays.append(arrow_array_from_numpy_array(array))\n return pyarrow.Table.from_arrays(arrays, names)\n\ndef vaex_df_from_arrow_table(table):\n from .dataset import DatasetArrow\n return DatasetArrow(table=table)\n", "path": "packages/vaex-arrow/vaex_arrow/convert.py"}]}
| 1,932 | 543 |
gh_patches_debug_32162
|
rasdani/github-patches
|
git_diff
|
wright-group__WrightTools-117
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
workup.panda docstring description
</issue>
<code>
[start of WrightTools/tuning/workup.py]
1 '''
2 Methods for processing OPA 800 tuning data.
3 '''
4
5
6 ### import ####################################################################
7
8
9 from __future__ import absolute_import, division, print_function, unicode_literals
10
11 import os
12 import re
13 import sys
14 import imp
15 import ast
16 import time
17 import copy
18 import inspect
19 import collections
20 import subprocess
21 import glob
22
23 try:
24 import configparser as _ConfigParser # python 3
25 except ImportError:
26 import ConfigParser as _ConfigParser # python 2'
27
28 import matplotlib
29 import matplotlib.pyplot as plt
30
31 import numpy as np
32 from numpy import sin, cos
33
34 import scipy
35 from scipy.interpolate import griddata, interp1d, interp2d, UnivariateSpline
36 import scipy.integrate as integrate
37 from scipy.optimize import leastsq
38
39 from pylab import *
40
41 from . import curve as wt_curve
42 from .. import artists as wt_artists
43 from .. import data as wt_data
44 from .. import fit as wt_fit
45 from .. import kit as wt_kit
46 from .. import units as wt_units
47
48
49 ### define ####################################################################
50
51
52 cmap = wt_artists.colormaps['default']
53 cmap.set_bad([0.75] * 3, 1.)
54 cmap.set_under([0.75] * 3)
55
56 ### processing methods ########################################################
57
58
59 def intensity(data, curve, channel_name, level=False, cutoff_factor=0.1,
60 autosave=True, save_directory=None):
61 '''
62 Parameters
63 ----------
64 data : wt.data.Data objeect
65 should be in (setpoint, motor)
66
67 Returns
68 -------
69 curve
70 New curve object.
71 '''
72 # TODO: documentation
73 data.transpose()
74 channel_index = data.channel_names.index(channel_name)
75 tune_points = curve.colors
76 # process data ------------------------------------------------------------
77 if level:
78 data.level(channel_index, 0, -3)
79 # cutoff
80 channel = data.channels[channel_index]
81 cutoff = np.nanmax(channel.values) * cutoff_factor
82 channel.values[channel.values < cutoff] = np.nan
83 # get centers through expectation value
84 motor_axis_name = data.axes[0].name
85 function = wt_fit.Moments()
86 function.subtract_baseline = False
87 fitter = wt_fit.Fitter(function, data, motor_axis_name, verbose=False)
88 outs = fitter.run(channel_index, verbose=False)
89 offsets = outs.one.values
90 # pass offsets through spline
91 spline = wt_kit.Spline(tune_points, offsets)
92 offsets_splined = spline(tune_points)
93 # make curve --------------------------------------------------------------
94 old_curve = curve.copy()
95 motors = []
96 for motor_index, motor_name in enumerate([m.name for m in old_curve.motors]):
97 if motor_name == motor_axis_name.split('_')[-1]:
98 positions = data.axes[0].centers + offsets_splined
99 motor = wt_curve.Motor(positions, motor_name)
100 motors.append(motor)
101 tuned_motor_index = motor_index
102 else:
103 motors.append(old_curve.motors[motor_index])
104 kind = old_curve.kind
105 interaction = old_curve.interaction
106 curve = wt_curve.Curve(tune_points, 'wn', motors,
107 name=old_curve.name.split('-')[0],
108 kind=kind, interaction=interaction)
109 curve.map_colors(old_curve.colors)
110 # plot --------------------------------------------------------------------
111 fig, gs = wt_artists.create_figure(nrows=2, default_aspect=0.5, cols=[1, 'cbar'])
112 # curves
113 ax = plt.subplot(gs[0, 0])
114 xi = old_curve.colors
115 yi = old_curve.motors[tuned_motor_index].positions
116 ax.plot(xi, yi, c='k', lw=1)
117 xi = curve.colors
118 yi = curve.motors[tuned_motor_index].positions
119 ax.plot(xi, yi, c='k', lw=5, alpha=0.5)
120 ax.grid()
121 ax.set_xlim(tune_points.min(), tune_points.max())
122 ax.set_ylabel(curve.motor_names[tuned_motor_index], fontsize=18)
123 plt.setp(ax.get_xticklabels(), visible=False)
124 # heatmap
125 ax = plt.subplot(gs[1, 0])
126 xi = data.axes[1].points
127 yi = data.axes[0].points
128 zi = data.channels[channel_index].values
129 X, Y, Z = wt_artists.pcolor_helper(xi, yi, zi)
130 ax.pcolor(X, Y, Z, vmin=0, vmax=np.nanmax(zi), cmap=cmap)
131 ax.set_xlim(xi.min(), xi.max())
132 ax.set_ylim(yi.min(), yi.max())
133 ax.grid()
134 ax.axhline(c='k', lw=1)
135 xi = curve.colors
136 yi = offsets
137 ax.plot(xi, yi, c='grey', lw=5, alpha=0.5)
138 xi = curve.colors
139 yi = offsets_splined
140 ax.plot(xi, yi, c='k', lw=5, alpha=0.5)
141 units_string = '$\mathsf{(' + wt_units.color_symbols[curve.units] + ')}$'
142 ax.set_xlabel(' '.join(['setpoint', units_string]), fontsize=18)
143 ax.set_ylabel(
144 ' '.join(['$\mathsf{\Delta}$', curve.motor_names[tuned_motor_index]]), fontsize=18)
145 # colorbar
146 cax = plt.subplot(gs[1, -1])
147 label = channel_name
148 ticks = np.linspace(0, np.nanmax(zi), 7)
149 wt_artists.plot_colorbar(cax=cax, cmap=cmap, label=label, ticks=ticks)
150 # finish ------------------------------------------------------------------
151 if autosave:
152 if save_directory is None:
153 save_directory = os.getcwd()
154 curve.save(save_directory=save_directory, full=True)
155 p = os.path.join(save_directory, 'intensity.png')
156 wt_artists.savefig(p, fig=fig)
157 return curve
158
159
160 def tune_test(data, curve, channel_name, level=False, cutoff_factor=0.01,
161 autosave=True, save_directory=None):
162 """
163
164 Parameters
165 ----------
166 data : wt.data.Data object
167 should be in (setpoint, detuning)
168 curve : wt.curve object
169 tuning curve used to do tune_test
170 channel_nam : str
171 name of the signal chanel to evalute
172 level : bool (optional)
173 does nothing, default is False
174 cutoff_factor : float (optoinal)
175 minimum value for datapoint/max(datapoints) for point to be included
176 in the fitting procedure, default is 0.01
177 autosave : bool (optional)
178 saves output curve if True, default is True
179 save_directory : str
180 directory to save new curve, default is None which uses the data source
181 directory
182
183 Returns
184 -------
185 curve
186 New curve object.
187 """
188 # make data object
189 data = data.copy()
190 data.bring_to_front(channel_name)
191 data.transpose()
192 # process data ------------------------------------------------------------
193 # cutoff
194 channel_index = data.channel_names.index(channel_name)
195 channel = data.channels[channel_index]
196 cutoff = np.nanmax(channel.values) * cutoff_factor
197 channel.values[channel.values < cutoff] = np.nan
198 # fit
199 gauss_function = wt_fit.Gaussian()
200 g_fitter = wt_fit.Fitter(gauss_function, data, data.axes[0].name)
201 outs = g_fitter.run()
202 # spline
203 xi = outs.axes[0].points
204 yi = outs.mean.values
205 spline = wt_kit.Spline(xi, yi)
206 offsets_splined = spline(xi) # wn
207 # make curve --------------------------------------------------------------
208 curve = curve.copy()
209 curve_native_units = curve.units
210 curve.convert('wn')
211 points = curve.colors.copy()
212 curve.colors += offsets_splined
213 curve.map_colors(points, units='wn')
214 curve.convert(curve_native_units)
215 # plot --------------------------------------------------------------------
216 data.axes[1].convert(curve_native_units)
217 fig, gs = wt_artists.create_figure(default_aspect=0.5, cols=[1, 'cbar'])
218 # heatmap
219 ax = plt.subplot(gs[0, 0])
220 xi = data.axes[1].points
221 yi = data.axes[0].points
222 zi = data.channels[channel_index].values
223 X, Y, Z = wt_artists.pcolor_helper(xi, yi, zi)
224 ax.pcolor(X, Y, Z, vmin=0, vmax=np.nanmax(zi), cmap=cmap)
225 ax.set_xlim(xi.min(), xi.max())
226 ax.set_ylim(yi.min(), yi.max())
227 # lines
228 outs.convert(curve_native_units)
229 xi = outs.axes[0].points
230 yi = outs.mean.values
231 ax.plot(xi, yi, c='grey', lw=5, alpha=0.5)
232 ax.plot(xi, offsets_splined, c='k', lw=5, alpha=0.5)
233 ax.axhline(c='k', lw=1)
234 ax.grid()
235 units_string = '$\mathsf{(' + wt_units.color_symbols[curve.units] + ')}$'
236 ax.set_xlabel(r' '.join(['setpoint', units_string]), fontsize=18)
237 ax.set_ylabel(r'$\mathsf{\Delta' + wt_units.color_symbols['wn'] + '}$', fontsize=18)
238 # colorbar
239 cax = plt.subplot(gs[:, -1])
240 label = channel_name
241 ticks = np.linspace(0, np.nanmax(zi), 7)
242 wt_artists.plot_colorbar(cax=cax, cmap=cmap, label=label, ticks=ticks)
243 # finish ------------------------------------------------------------------
244 if autosave:
245 if save_directory is None:
246 save_directory = os.path.dirname(data.source)
247 curve.save(save_directory=save_directory, full=True)
248 p = os.path.join(save_directory, 'tune test.png')
249 wt_artists.savefig(p, fig=fig)
250 return curve
251
252
253 def panda(data, curve, channel_name, level=False, cutoff_factor=0.01,
254 autosave=True, save_directory=None):
255 """
256
257 Parameters
258 ----------
259 data : wt.data.Data object
260 should be in (setpoint, detuning)
261 curve : wt.curve object
262 tuning curve used to do tune_test
263 channel_nam : str
264 name of the signal chanel to evalute
265 level : bool (optional)
266 does nothing, default is False
267 cutoff_factor : float (optoinal)
268 minimum value for datapoint/max(datapoints) for point to be included
269 in the fitting procedure, default is 0.01
270 autosave : bool (optional)
271 saves output curve if True, default is True
272 save_directory : str
273 directory to save new curve, default is None which uses the data source
274 directory
275
276 Returns
277 -------
278 curve
279 New curve object.
280 """
281 # make data object
282 data.bring_to_front(channel_name)
283 data.transpose()
284 # process data ------------------------------------------------------------
285 # cutoff
286 channel_index = data.channel_names.index(channel_name)
287 channel = data.channels[channel_index]
288 cutoff = np.nanmax(channel.values) * cutoff_factor
289 channel.values[channel.values < cutoff] = np.nan
290 # fit
291 # TODO: evaluate suggested edits to fit section
292 function = wt_fit.Moments()
293 fitter = wt_fit.Fitter(function, data, data.axes[0].name)
294 outs = fitter.run()
295 gauss_function = wt_fit.Gaussian()
296 g_fitter = wt_fit.Fitter(gauss_function, data, data.axes[0].name)
297 gauss_outs = g_fitter.run()
298 return gauss_outs
299
[end of WrightTools/tuning/workup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/WrightTools/tuning/workup.py b/WrightTools/tuning/workup.py
--- a/WrightTools/tuning/workup.py
+++ b/WrightTools/tuning/workup.py
@@ -36,8 +36,6 @@
import scipy.integrate as integrate
from scipy.optimize import leastsq
-from pylab import *
-
from . import curve as wt_curve
from .. import artists as wt_artists
from .. import data as wt_data
@@ -248,51 +246,3 @@
p = os.path.join(save_directory, 'tune test.png')
wt_artists.savefig(p, fig=fig)
return curve
-
-
-def panda(data, curve, channel_name, level=False, cutoff_factor=0.01,
- autosave=True, save_directory=None):
- """
-
- Parameters
- ----------
- data : wt.data.Data object
- should be in (setpoint, detuning)
- curve : wt.curve object
- tuning curve used to do tune_test
- channel_nam : str
- name of the signal chanel to evalute
- level : bool (optional)
- does nothing, default is False
- cutoff_factor : float (optoinal)
- minimum value for datapoint/max(datapoints) for point to be included
- in the fitting procedure, default is 0.01
- autosave : bool (optional)
- saves output curve if True, default is True
- save_directory : str
- directory to save new curve, default is None which uses the data source
- directory
-
- Returns
- -------
- curve
- New curve object.
- """
- # make data object
- data.bring_to_front(channel_name)
- data.transpose()
- # process data ------------------------------------------------------------
- # cutoff
- channel_index = data.channel_names.index(channel_name)
- channel = data.channels[channel_index]
- cutoff = np.nanmax(channel.values) * cutoff_factor
- channel.values[channel.values < cutoff] = np.nan
- # fit
- # TODO: evaluate suggested edits to fit section
- function = wt_fit.Moments()
- fitter = wt_fit.Fitter(function, data, data.axes[0].name)
- outs = fitter.run()
- gauss_function = wt_fit.Gaussian()
- g_fitter = wt_fit.Fitter(gauss_function, data, data.axes[0].name)
- gauss_outs = g_fitter.run()
- return gauss_outs
|
{"golden_diff": "diff --git a/WrightTools/tuning/workup.py b/WrightTools/tuning/workup.py\n--- a/WrightTools/tuning/workup.py\n+++ b/WrightTools/tuning/workup.py\n@@ -36,8 +36,6 @@\n import scipy.integrate as integrate\n from scipy.optimize import leastsq\n \n-from pylab import *\n-\n from . import curve as wt_curve\n from .. import artists as wt_artists\n from .. import data as wt_data\n@@ -248,51 +246,3 @@\n p = os.path.join(save_directory, 'tune test.png')\n wt_artists.savefig(p, fig=fig)\n return curve\n-\n-\n-def panda(data, curve, channel_name, level=False, cutoff_factor=0.01,\n- autosave=True, save_directory=None):\n- \"\"\"\n-\n- Parameters\n- ----------\n- data : wt.data.Data object\n- should be in (setpoint, detuning)\n- curve : wt.curve object\n- tuning curve used to do tune_test\n- channel_nam : str\n- name of the signal chanel to evalute\n- level : bool (optional)\n- does nothing, default is False\n- cutoff_factor : float (optoinal)\n- minimum value for datapoint/max(datapoints) for point to be included\n- in the fitting procedure, default is 0.01\n- autosave : bool (optional)\n- saves output curve if True, default is True\n- save_directory : str\n- directory to save new curve, default is None which uses the data source\n- directory\n-\n- Returns\n- -------\n- curve\n- New curve object.\n- \"\"\"\n- # make data object\n- data.bring_to_front(channel_name)\n- data.transpose()\n- # process data ------------------------------------------------------------\n- # cutoff\n- channel_index = data.channel_names.index(channel_name)\n- channel = data.channels[channel_index]\n- cutoff = np.nanmax(channel.values) * cutoff_factor\n- channel.values[channel.values < cutoff] = np.nan\n- # fit\n- # TODO: evaluate suggested edits to fit section\n- function = wt_fit.Moments()\n- fitter = wt_fit.Fitter(function, data, data.axes[0].name)\n- outs = fitter.run()\n- gauss_function = wt_fit.Gaussian()\n- g_fitter = wt_fit.Fitter(gauss_function, data, data.axes[0].name)\n- gauss_outs = g_fitter.run()\n- return gauss_outs\n", "issue": "workup.panda docstring description\n\n", "before_files": [{"content": "'''\nMethods for processing OPA 800 tuning data.\n'''\n\n\n### import ####################################################################\n\n\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport os\nimport re\nimport sys\nimport imp\nimport ast\nimport time\nimport copy\nimport inspect\nimport collections\nimport subprocess\nimport glob\n\ntry:\n import configparser as _ConfigParser # python 3\nexcept ImportError:\n import ConfigParser as _ConfigParser # python 2'\n\nimport matplotlib\nimport matplotlib.pyplot as plt\n\nimport numpy as np\nfrom numpy import sin, cos\n\nimport scipy\nfrom scipy.interpolate import griddata, interp1d, interp2d, UnivariateSpline\nimport scipy.integrate as integrate\nfrom scipy.optimize import leastsq\n\nfrom pylab import *\n\nfrom . import curve as wt_curve\nfrom .. import artists as wt_artists\nfrom .. import data as wt_data\nfrom .. import fit as wt_fit\nfrom .. import kit as wt_kit\nfrom .. import units as wt_units\n\n\n### define ####################################################################\n\n\ncmap = wt_artists.colormaps['default']\ncmap.set_bad([0.75] * 3, 1.)\ncmap.set_under([0.75] * 3)\n\n### processing methods ########################################################\n\n\ndef intensity(data, curve, channel_name, level=False, cutoff_factor=0.1,\n autosave=True, save_directory=None):\n '''\n Parameters\n ----------\n data : wt.data.Data objeect\n should be in (setpoint, motor)\n\n Returns\n -------\n curve\n New curve object.\n '''\n # TODO: documentation\n data.transpose()\n channel_index = data.channel_names.index(channel_name)\n tune_points = curve.colors\n # process data ------------------------------------------------------------\n if level:\n data.level(channel_index, 0, -3)\n # cutoff\n channel = data.channels[channel_index]\n cutoff = np.nanmax(channel.values) * cutoff_factor\n channel.values[channel.values < cutoff] = np.nan\n # get centers through expectation value\n motor_axis_name = data.axes[0].name\n function = wt_fit.Moments()\n function.subtract_baseline = False\n fitter = wt_fit.Fitter(function, data, motor_axis_name, verbose=False)\n outs = fitter.run(channel_index, verbose=False)\n offsets = outs.one.values\n # pass offsets through spline\n spline = wt_kit.Spline(tune_points, offsets)\n offsets_splined = spline(tune_points)\n # make curve --------------------------------------------------------------\n old_curve = curve.copy()\n motors = []\n for motor_index, motor_name in enumerate([m.name for m in old_curve.motors]):\n if motor_name == motor_axis_name.split('_')[-1]:\n positions = data.axes[0].centers + offsets_splined\n motor = wt_curve.Motor(positions, motor_name)\n motors.append(motor)\n tuned_motor_index = motor_index\n else:\n motors.append(old_curve.motors[motor_index])\n kind = old_curve.kind\n interaction = old_curve.interaction\n curve = wt_curve.Curve(tune_points, 'wn', motors,\n name=old_curve.name.split('-')[0],\n kind=kind, interaction=interaction)\n curve.map_colors(old_curve.colors)\n # plot --------------------------------------------------------------------\n fig, gs = wt_artists.create_figure(nrows=2, default_aspect=0.5, cols=[1, 'cbar'])\n # curves\n ax = plt.subplot(gs[0, 0])\n xi = old_curve.colors\n yi = old_curve.motors[tuned_motor_index].positions\n ax.plot(xi, yi, c='k', lw=1)\n xi = curve.colors\n yi = curve.motors[tuned_motor_index].positions\n ax.plot(xi, yi, c='k', lw=5, alpha=0.5)\n ax.grid()\n ax.set_xlim(tune_points.min(), tune_points.max())\n ax.set_ylabel(curve.motor_names[tuned_motor_index], fontsize=18)\n plt.setp(ax.get_xticklabels(), visible=False)\n # heatmap\n ax = plt.subplot(gs[1, 0])\n xi = data.axes[1].points\n yi = data.axes[0].points\n zi = data.channels[channel_index].values\n X, Y, Z = wt_artists.pcolor_helper(xi, yi, zi)\n ax.pcolor(X, Y, Z, vmin=0, vmax=np.nanmax(zi), cmap=cmap)\n ax.set_xlim(xi.min(), xi.max())\n ax.set_ylim(yi.min(), yi.max())\n ax.grid()\n ax.axhline(c='k', lw=1)\n xi = curve.colors\n yi = offsets\n ax.plot(xi, yi, c='grey', lw=5, alpha=0.5)\n xi = curve.colors\n yi = offsets_splined\n ax.plot(xi, yi, c='k', lw=5, alpha=0.5)\n units_string = '$\\mathsf{(' + wt_units.color_symbols[curve.units] + ')}$'\n ax.set_xlabel(' '.join(['setpoint', units_string]), fontsize=18)\n ax.set_ylabel(\n ' '.join(['$\\mathsf{\\Delta}$', curve.motor_names[tuned_motor_index]]), fontsize=18)\n # colorbar\n cax = plt.subplot(gs[1, -1])\n label = channel_name\n ticks = np.linspace(0, np.nanmax(zi), 7)\n wt_artists.plot_colorbar(cax=cax, cmap=cmap, label=label, ticks=ticks)\n # finish ------------------------------------------------------------------\n if autosave:\n if save_directory is None:\n save_directory = os.getcwd()\n curve.save(save_directory=save_directory, full=True)\n p = os.path.join(save_directory, 'intensity.png')\n wt_artists.savefig(p, fig=fig)\n return curve\n\n\ndef tune_test(data, curve, channel_name, level=False, cutoff_factor=0.01,\n autosave=True, save_directory=None):\n \"\"\"\n\n Parameters\n ----------\n data : wt.data.Data object\n should be in (setpoint, detuning)\n curve : wt.curve object\n tuning curve used to do tune_test\n channel_nam : str\n name of the signal chanel to evalute\n level : bool (optional)\n does nothing, default is False\n cutoff_factor : float (optoinal)\n minimum value for datapoint/max(datapoints) for point to be included\n in the fitting procedure, default is 0.01\n autosave : bool (optional)\n saves output curve if True, default is True\n save_directory : str\n directory to save new curve, default is None which uses the data source\n directory\n\n Returns\n -------\n curve\n New curve object.\n \"\"\"\n # make data object\n data = data.copy()\n data.bring_to_front(channel_name)\n data.transpose()\n # process data ------------------------------------------------------------\n # cutoff\n channel_index = data.channel_names.index(channel_name)\n channel = data.channels[channel_index]\n cutoff = np.nanmax(channel.values) * cutoff_factor\n channel.values[channel.values < cutoff] = np.nan\n # fit\n gauss_function = wt_fit.Gaussian()\n g_fitter = wt_fit.Fitter(gauss_function, data, data.axes[0].name)\n outs = g_fitter.run()\n # spline\n xi = outs.axes[0].points\n yi = outs.mean.values\n spline = wt_kit.Spline(xi, yi)\n offsets_splined = spline(xi) # wn\n # make curve --------------------------------------------------------------\n curve = curve.copy()\n curve_native_units = curve.units\n curve.convert('wn')\n points = curve.colors.copy()\n curve.colors += offsets_splined\n curve.map_colors(points, units='wn')\n curve.convert(curve_native_units)\n # plot --------------------------------------------------------------------\n data.axes[1].convert(curve_native_units)\n fig, gs = wt_artists.create_figure(default_aspect=0.5, cols=[1, 'cbar'])\n # heatmap\n ax = plt.subplot(gs[0, 0])\n xi = data.axes[1].points\n yi = data.axes[0].points\n zi = data.channels[channel_index].values\n X, Y, Z = wt_artists.pcolor_helper(xi, yi, zi)\n ax.pcolor(X, Y, Z, vmin=0, vmax=np.nanmax(zi), cmap=cmap)\n ax.set_xlim(xi.min(), xi.max())\n ax.set_ylim(yi.min(), yi.max())\n # lines\n outs.convert(curve_native_units)\n xi = outs.axes[0].points\n yi = outs.mean.values\n ax.plot(xi, yi, c='grey', lw=5, alpha=0.5)\n ax.plot(xi, offsets_splined, c='k', lw=5, alpha=0.5)\n ax.axhline(c='k', lw=1)\n ax.grid()\n units_string = '$\\mathsf{(' + wt_units.color_symbols[curve.units] + ')}$'\n ax.set_xlabel(r' '.join(['setpoint', units_string]), fontsize=18)\n ax.set_ylabel(r'$\\mathsf{\\Delta' + wt_units.color_symbols['wn'] + '}$', fontsize=18)\n # colorbar\n cax = plt.subplot(gs[:, -1])\n label = channel_name\n ticks = np.linspace(0, np.nanmax(zi), 7)\n wt_artists.plot_colorbar(cax=cax, cmap=cmap, label=label, ticks=ticks)\n # finish ------------------------------------------------------------------\n if autosave:\n if save_directory is None:\n save_directory = os.path.dirname(data.source)\n curve.save(save_directory=save_directory, full=True)\n p = os.path.join(save_directory, 'tune test.png')\n wt_artists.savefig(p, fig=fig)\n return curve\n\n\ndef panda(data, curve, channel_name, level=False, cutoff_factor=0.01,\n autosave=True, save_directory=None):\n \"\"\"\n\n Parameters\n ----------\n data : wt.data.Data object\n should be in (setpoint, detuning)\n curve : wt.curve object\n tuning curve used to do tune_test\n channel_nam : str\n name of the signal chanel to evalute\n level : bool (optional)\n does nothing, default is False\n cutoff_factor : float (optoinal)\n minimum value for datapoint/max(datapoints) for point to be included\n in the fitting procedure, default is 0.01\n autosave : bool (optional)\n saves output curve if True, default is True\n save_directory : str\n directory to save new curve, default is None which uses the data source\n directory\n\n Returns\n -------\n curve\n New curve object.\n \"\"\"\n # make data object\n data.bring_to_front(channel_name)\n data.transpose()\n # process data ------------------------------------------------------------\n # cutoff\n channel_index = data.channel_names.index(channel_name)\n channel = data.channels[channel_index]\n cutoff = np.nanmax(channel.values) * cutoff_factor\n channel.values[channel.values < cutoff] = np.nan\n # fit\n # TODO: evaluate suggested edits to fit section\n function = wt_fit.Moments()\n fitter = wt_fit.Fitter(function, data, data.axes[0].name)\n outs = fitter.run()\n gauss_function = wt_fit.Gaussian()\n g_fitter = wt_fit.Fitter(gauss_function, data, data.axes[0].name)\n gauss_outs = g_fitter.run()\n return gauss_outs\n", "path": "WrightTools/tuning/workup.py"}]}
| 3,887 | 566 |
gh_patches_debug_26668
|
rasdani/github-patches
|
git_diff
|
facebookresearch__hydra-1098
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug] Joblib launcher plugin doesn't properly convert some joblib arguments to integers
# 🐛 Bug
## Description
The following `joblib.Parallel` arguments are currently provided as strings to joblib when they should be integers:
* `pre_dispatch`
* `batch_size`
* `max_nbytes`
## Checklist
- [X] I checked on the latest version of Hydra
- [X] I created a minimal repro
## To reproduce
** Minimal Code/Config snippet to reproduce **
```bash
wget https://raw.githubusercontent.com/facebookresearch/hydra/master/examples/tutorials/basic/your_first_hydra_app/1_simple_cli/my_app.py
python my_app.py hydra.launcher.batch_size=1 hydra/launcher=joblib -m
```
** Stack trace/error message **
```
[2020-10-27 18:20:48,363][HYDRA] Joblib.Parallel(n_jobs=-1,backend=loky,prefer=processes,require=None,verbose=0,timeout=None,pre_dispatch=2*n_jobs,batch_size=1,temp_folder=None,max_nbytes=None,mmap_mode=r) is launching 1 jobs
[2020-10-27 18:20:48,363][HYDRA] Launching jobs, sweep output dir : multirun/2020-10-27/18-20-48
[2020-10-27 18:20:48,363][HYDRA] #0 :
Traceback (most recent call last):
File "/Users/odelalleau/src/hydra/hydra/_internal/utils.py", line 207, in run_and_report
return func()
File "/Users/odelalleau/src/hydra/hydra/_internal/utils.py", line 364, in <lambda>
lambda: hydra.multirun(
File "/Users/odelalleau/src/hydra/hydra/_internal/hydra.py", line 136, in multirun
return sweeper.sweep(arguments=task_overrides)
File "/Users/odelalleau/src/hydra/hydra/_internal/core_plugins/basic_sweeper.py", line 154, in sweep
results = self.launcher.launch(batch, initial_job_idx=initial_job_idx)
File "/Users/odelalleau/src/hydra/plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/joblib_launcher.py", line 45, in launch
return _core.launch(
File "/Users/odelalleau/src/hydra/plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/_core.py", line 89, in launch
runs = Parallel(**joblib_cfg)(
File "/Users/odelalleau/.local/lib/python3.8/site-packages/joblib/parallel.py", line 715, in __init__
raise ValueError(
ValueError: batch_size must be 'auto' or a positive integer, got: '1'
```
(with `max_nbytes` it also crashes due to the string issue, `pre_dispatch` actually runs but not sure what happens exactly since it's given as a string)
## Expected Behavior
Running without error, providing appropriate integer arguments to `joblib.Parallel` when they should be integers (obviously there are situations where they should remain strings).
## System information
- **Hydra Version** : master
- **Python version** : 3.8.5
- **Virtual environment type and version** : conda 4.8.5
- **Operating system** : MacOS
</issue>
<code>
[start of plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/config.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2 from dataclasses import dataclass
3 from typing import Optional
4
5 from hydra.core.config_store import ConfigStore
6
7
8 @dataclass
9 class JobLibLauncherConf:
10 _target_: str = "hydra_plugins.hydra_joblib_launcher.joblib_launcher.JoblibLauncher"
11
12 # maximum number of concurrently running jobs. if -1, all CPUs are used
13 n_jobs: int = -1
14
15 # allows to hard-code backend, otherwise inferred based on prefer and require
16 backend: Optional[str] = None
17
18 # processes or threads, soft hint to choose backend
19 prefer: str = "processes"
20
21 # null or sharedmem, sharedmem will select thread-based backend
22 require: Optional[str] = None
23
24 # if greater than zero, prints progress messages
25 verbose: int = 0
26
27 # timeout limit for each task
28 timeout: Optional[int] = None
29
30 # number of batches to be pre-dispatched
31 pre_dispatch: str = "2*n_jobs"
32
33 # number of atomic tasks to dispatch at once to each worker
34 batch_size: str = "auto"
35
36 # path used for memmapping large arrays for sharing memory with workers
37 temp_folder: Optional[str] = None
38
39 # thresholds size of arrays that triggers automated memmapping
40 max_nbytes: Optional[str] = None
41
42 # memmapping mode for numpy arrays passed to workers
43 mmap_mode: str = "r"
44
45
46 ConfigStore.instance().store(
47 group="hydra/launcher",
48 name="joblib",
49 node=JobLibLauncherConf,
50 provider="joblib_launcher",
51 )
52
[end of plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/config.py]
[start of plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/_core.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2 import logging
3 from pathlib import Path
4 from typing import Any, Dict, List, Sequence
5
6 from hydra.core.config_loader import ConfigLoader
7 from hydra.core.hydra_config import HydraConfig
8 from hydra.core.singleton import Singleton
9 from hydra.core.utils import (
10 JobReturn,
11 configure_log,
12 filter_overrides,
13 run_job,
14 setup_globals,
15 )
16 from hydra.types import TaskFunction
17 from joblib import Parallel, delayed # type: ignore
18 from omegaconf import DictConfig, open_dict
19
20 from .joblib_launcher import JoblibLauncher
21
22 log = logging.getLogger(__name__)
23
24
25 def execute_job(
26 idx: int,
27 overrides: Sequence[str],
28 config_loader: ConfigLoader,
29 config: DictConfig,
30 task_function: TaskFunction,
31 singleton_state: Dict[Any, Any],
32 ) -> JobReturn:
33 """Calls `run_job` in parallel"""
34 setup_globals()
35 Singleton.set_state(singleton_state)
36
37 sweep_config = config_loader.load_sweep_config(config, list(overrides))
38 with open_dict(sweep_config):
39 sweep_config.hydra.job.id = "{}_{}".format(sweep_config.hydra.job.name, idx)
40 sweep_config.hydra.job.num = idx
41 HydraConfig.instance().set_config(sweep_config)
42
43 ret = run_job(
44 config=sweep_config,
45 task_function=task_function,
46 job_dir_key="hydra.sweep.dir",
47 job_subdir_key="hydra.sweep.subdir",
48 )
49
50 return ret
51
52
53 def launch(
54 launcher: JoblibLauncher,
55 job_overrides: Sequence[Sequence[str]],
56 initial_job_idx: int,
57 ) -> Sequence[JobReturn]:
58 """
59 :param job_overrides: a List of List<String>, where each inner list is the arguments for one job run.
60 :param initial_job_idx: Initial job idx in batch.
61 :return: an array of return values from run_job with indexes corresponding to the input list indexes.
62 """
63 setup_globals()
64 assert launcher.config is not None
65 assert launcher.config_loader is not None
66 assert launcher.task_function is not None
67
68 configure_log(launcher.config.hydra.hydra_logging, launcher.config.hydra.verbose)
69 sweep_dir = Path(str(launcher.config.hydra.sweep.dir))
70 sweep_dir.mkdir(parents=True, exist_ok=True)
71
72 # Joblib's backend is hard-coded to loky since the threading
73 # backend is incompatible with Hydra
74 joblib_cfg = launcher.joblib
75 joblib_cfg["backend"] = "loky"
76
77 log.info(
78 "Joblib.Parallel({}) is launching {} jobs".format(
79 ",".join([f"{k}={v}" for k, v in joblib_cfg.items()]),
80 len(job_overrides),
81 )
82 )
83 log.info("Launching jobs, sweep output dir : {}".format(sweep_dir))
84 for idx, overrides in enumerate(job_overrides):
85 log.info("\t#{} : {}".format(idx, " ".join(filter_overrides(overrides))))
86
87 singleton_state = Singleton.get_state()
88
89 runs = Parallel(**joblib_cfg)(
90 delayed(execute_job)(
91 initial_job_idx + idx,
92 overrides,
93 launcher.config_loader,
94 launcher.config,
95 launcher.task_function,
96 singleton_state,
97 )
98 for idx, overrides in enumerate(job_overrides)
99 )
100
101 assert isinstance(runs, List)
102 for run in runs:
103 assert isinstance(run, JobReturn)
104 return runs
105
[end of plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/_core.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/_core.py b/plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/_core.py
--- a/plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/_core.py
+++ b/plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/_core.py
@@ -50,6 +50,17 @@
return ret
+def process_joblib_cfg(joblib_cfg: Dict[str, Any]) -> None:
+ for k in ["pre_dispatch", "batch_size", "max_nbytes"]:
+ if k in joblib_cfg.keys():
+ try:
+ val = joblib_cfg.get(k)
+ if val:
+ joblib_cfg[k] = int(val)
+ except ValueError:
+ pass
+
+
def launch(
launcher: JoblibLauncher,
job_overrides: Sequence[Sequence[str]],
@@ -73,6 +84,7 @@
# backend is incompatible with Hydra
joblib_cfg = launcher.joblib
joblib_cfg["backend"] = "loky"
+ process_joblib_cfg(joblib_cfg)
log.info(
"Joblib.Parallel({}) is launching {} jobs".format(
diff --git a/plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/config.py b/plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/config.py
--- a/plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/config.py
+++ b/plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/config.py
@@ -24,8 +24,8 @@
# if greater than zero, prints progress messages
verbose: int = 0
- # timeout limit for each task
- timeout: Optional[int] = None
+ # timeout limit for each task. Unit dependent on backend implementation; miliseconds for loky.
+ timeout: Optional[float] = None
# number of batches to be pre-dispatched
pre_dispatch: str = "2*n_jobs"
|
{"golden_diff": "diff --git a/plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/_core.py b/plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/_core.py\n--- a/plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/_core.py\n+++ b/plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/_core.py\n@@ -50,6 +50,17 @@\n return ret\n \n \n+def process_joblib_cfg(joblib_cfg: Dict[str, Any]) -> None:\n+ for k in [\"pre_dispatch\", \"batch_size\", \"max_nbytes\"]:\n+ if k in joblib_cfg.keys():\n+ try:\n+ val = joblib_cfg.get(k)\n+ if val:\n+ joblib_cfg[k] = int(val)\n+ except ValueError:\n+ pass\n+\n+\n def launch(\n launcher: JoblibLauncher,\n job_overrides: Sequence[Sequence[str]],\n@@ -73,6 +84,7 @@\n # backend is incompatible with Hydra\n joblib_cfg = launcher.joblib\n joblib_cfg[\"backend\"] = \"loky\"\n+ process_joblib_cfg(joblib_cfg)\n \n log.info(\n \"Joblib.Parallel({}) is launching {} jobs\".format(\ndiff --git a/plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/config.py b/plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/config.py\n--- a/plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/config.py\n+++ b/plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/config.py\n@@ -24,8 +24,8 @@\n # if greater than zero, prints progress messages\n verbose: int = 0\n \n- # timeout limit for each task\n- timeout: Optional[int] = None\n+ # timeout limit for each task. Unit dependent on backend implementation; miliseconds for loky.\n+ timeout: Optional[float] = None\n \n # number of batches to be pre-dispatched\n pre_dispatch: str = \"2*n_jobs\"\n", "issue": "[Bug] Joblib launcher plugin doesn't properly convert some joblib arguments to integers\n# \ud83d\udc1b Bug\r\n## Description\r\n\r\nThe following `joblib.Parallel` arguments are currently provided as strings to joblib when they should be integers:\r\n* `pre_dispatch`\r\n* `batch_size`\r\n* `max_nbytes`\r\n\r\n## Checklist\r\n- [X] I checked on the latest version of Hydra\r\n- [X] I created a minimal repro\r\n\r\n## To reproduce\r\n\r\n** Minimal Code/Config snippet to reproduce **\r\n\r\n```bash\r\nwget https://raw.githubusercontent.com/facebookresearch/hydra/master/examples/tutorials/basic/your_first_hydra_app/1_simple_cli/my_app.py\r\npython my_app.py hydra.launcher.batch_size=1 hydra/launcher=joblib -m\r\n```\r\n\r\n** Stack trace/error message **\r\n```\r\n[2020-10-27 18:20:48,363][HYDRA] Joblib.Parallel(n_jobs=-1,backend=loky,prefer=processes,require=None,verbose=0,timeout=None,pre_dispatch=2*n_jobs,batch_size=1,temp_folder=None,max_nbytes=None,mmap_mode=r) is launching 1 jobs\r\n[2020-10-27 18:20:48,363][HYDRA] Launching jobs, sweep output dir : multirun/2020-10-27/18-20-48\r\n[2020-10-27 18:20:48,363][HYDRA] #0 :\r\nTraceback (most recent call last):\r\n File \"/Users/odelalleau/src/hydra/hydra/_internal/utils.py\", line 207, in run_and_report\r\n return func()\r\n File \"/Users/odelalleau/src/hydra/hydra/_internal/utils.py\", line 364, in <lambda>\r\n lambda: hydra.multirun(\r\n File \"/Users/odelalleau/src/hydra/hydra/_internal/hydra.py\", line 136, in multirun\r\n return sweeper.sweep(arguments=task_overrides)\r\n File \"/Users/odelalleau/src/hydra/hydra/_internal/core_plugins/basic_sweeper.py\", line 154, in sweep\r\n results = self.launcher.launch(batch, initial_job_idx=initial_job_idx)\r\n File \"/Users/odelalleau/src/hydra/plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/joblib_launcher.py\", line 45, in launch\r\n return _core.launch(\r\n File \"/Users/odelalleau/src/hydra/plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/_core.py\", line 89, in launch\r\n runs = Parallel(**joblib_cfg)(\r\n File \"/Users/odelalleau/.local/lib/python3.8/site-packages/joblib/parallel.py\", line 715, in __init__\r\n raise ValueError(\r\nValueError: batch_size must be 'auto' or a positive integer, got: '1'\r\n```\r\n\r\n(with `max_nbytes` it also crashes due to the string issue, `pre_dispatch` actually runs but not sure what happens exactly since it's given as a string)\r\n\r\n## Expected Behavior\r\n\r\nRunning without error, providing appropriate integer arguments to `joblib.Parallel` when they should be integers (obviously there are situations where they should remain strings).\r\n\r\n## System information\r\n- **Hydra Version** : master\r\n- **Python version** : 3.8.5\r\n- **Virtual environment type and version** : conda 4.8.5\r\n- **Operating system** : MacOS\r\n\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\nfrom dataclasses import dataclass\nfrom typing import Optional\n\nfrom hydra.core.config_store import ConfigStore\n\n\n@dataclass\nclass JobLibLauncherConf:\n _target_: str = \"hydra_plugins.hydra_joblib_launcher.joblib_launcher.JoblibLauncher\"\n\n # maximum number of concurrently running jobs. if -1, all CPUs are used\n n_jobs: int = -1\n\n # allows to hard-code backend, otherwise inferred based on prefer and require\n backend: Optional[str] = None\n\n # processes or threads, soft hint to choose backend\n prefer: str = \"processes\"\n\n # null or sharedmem, sharedmem will select thread-based backend\n require: Optional[str] = None\n\n # if greater than zero, prints progress messages\n verbose: int = 0\n\n # timeout limit for each task\n timeout: Optional[int] = None\n\n # number of batches to be pre-dispatched\n pre_dispatch: str = \"2*n_jobs\"\n\n # number of atomic tasks to dispatch at once to each worker\n batch_size: str = \"auto\"\n\n # path used for memmapping large arrays for sharing memory with workers\n temp_folder: Optional[str] = None\n\n # thresholds size of arrays that triggers automated memmapping\n max_nbytes: Optional[str] = None\n\n # memmapping mode for numpy arrays passed to workers\n mmap_mode: str = \"r\"\n\n\nConfigStore.instance().store(\n group=\"hydra/launcher\",\n name=\"joblib\",\n node=JobLibLauncherConf,\n provider=\"joblib_launcher\",\n)\n", "path": "plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/config.py"}, {"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\nimport logging\nfrom pathlib import Path\nfrom typing import Any, Dict, List, Sequence\n\nfrom hydra.core.config_loader import ConfigLoader\nfrom hydra.core.hydra_config import HydraConfig\nfrom hydra.core.singleton import Singleton\nfrom hydra.core.utils import (\n JobReturn,\n configure_log,\n filter_overrides,\n run_job,\n setup_globals,\n)\nfrom hydra.types import TaskFunction\nfrom joblib import Parallel, delayed # type: ignore\nfrom omegaconf import DictConfig, open_dict\n\nfrom .joblib_launcher import JoblibLauncher\n\nlog = logging.getLogger(__name__)\n\n\ndef execute_job(\n idx: int,\n overrides: Sequence[str],\n config_loader: ConfigLoader,\n config: DictConfig,\n task_function: TaskFunction,\n singleton_state: Dict[Any, Any],\n) -> JobReturn:\n \"\"\"Calls `run_job` in parallel\"\"\"\n setup_globals()\n Singleton.set_state(singleton_state)\n\n sweep_config = config_loader.load_sweep_config(config, list(overrides))\n with open_dict(sweep_config):\n sweep_config.hydra.job.id = \"{}_{}\".format(sweep_config.hydra.job.name, idx)\n sweep_config.hydra.job.num = idx\n HydraConfig.instance().set_config(sweep_config)\n\n ret = run_job(\n config=sweep_config,\n task_function=task_function,\n job_dir_key=\"hydra.sweep.dir\",\n job_subdir_key=\"hydra.sweep.subdir\",\n )\n\n return ret\n\n\ndef launch(\n launcher: JoblibLauncher,\n job_overrides: Sequence[Sequence[str]],\n initial_job_idx: int,\n) -> Sequence[JobReturn]:\n \"\"\"\n :param job_overrides: a List of List<String>, where each inner list is the arguments for one job run.\n :param initial_job_idx: Initial job idx in batch.\n :return: an array of return values from run_job with indexes corresponding to the input list indexes.\n \"\"\"\n setup_globals()\n assert launcher.config is not None\n assert launcher.config_loader is not None\n assert launcher.task_function is not None\n\n configure_log(launcher.config.hydra.hydra_logging, launcher.config.hydra.verbose)\n sweep_dir = Path(str(launcher.config.hydra.sweep.dir))\n sweep_dir.mkdir(parents=True, exist_ok=True)\n\n # Joblib's backend is hard-coded to loky since the threading\n # backend is incompatible with Hydra\n joblib_cfg = launcher.joblib\n joblib_cfg[\"backend\"] = \"loky\"\n\n log.info(\n \"Joblib.Parallel({}) is launching {} jobs\".format(\n \",\".join([f\"{k}={v}\" for k, v in joblib_cfg.items()]),\n len(job_overrides),\n )\n )\n log.info(\"Launching jobs, sweep output dir : {}\".format(sweep_dir))\n for idx, overrides in enumerate(job_overrides):\n log.info(\"\\t#{} : {}\".format(idx, \" \".join(filter_overrides(overrides))))\n\n singleton_state = Singleton.get_state()\n\n runs = Parallel(**joblib_cfg)(\n delayed(execute_job)(\n initial_job_idx + idx,\n overrides,\n launcher.config_loader,\n launcher.config,\n launcher.task_function,\n singleton_state,\n )\n for idx, overrides in enumerate(job_overrides)\n )\n\n assert isinstance(runs, List)\n for run in runs:\n assert isinstance(run, JobReturn)\n return runs\n", "path": "plugins/hydra_joblib_launcher/hydra_plugins/hydra_joblib_launcher/_core.py"}]}
| 2,857 | 480 |
gh_patches_debug_64467
|
rasdani/github-patches
|
git_diff
|
liqd__a4-meinberlin-3019
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
testing 2958: bplan verification mail
**URL:** mail
**user:** administration staff working via imperia
**expected behaviour:** /
**behaviour:** wording changed, see below
**important screensize:**/
**device & browser:** /
**Comment/Question:**
- cross out the word "Betreff" in e-mail-subject
- correct "Projektü**n**ersicht" to "Projektübersicht"
- can you write "Uhr" behind date and time?
- I already know that it is complicated to separate date and time via comma, I guess this hasn't changed?
- the word "identifier" shouldn't be there but I guess it is only there because you entered it into the field together with the identifier itself, right?
Screenshot?
<img width="707" alt="Bildschirmfoto 2020-07-02 um 12 25 14" src="https://user-images.githubusercontent.com/35491681/86348098-7ccdd280-bc5f-11ea-9fb7-010f71c1a1a9.png">
</issue>
<code>
[start of meinberlin/apps/bplan/signals.py]
1 from django.db.models.signals import post_save
2 from django.dispatch import receiver
3
4 from . import emails
5 from . import tasks
6 from .models import Bplan
7 from .models import Statement
8
9
10 @receiver(post_save, sender=Bplan)
11 def get_location(sender, instance, update_fields, **kwargs):
12 if instance.identifier and (not update_fields or
13 'point' not in update_fields):
14 tasks.get_location_information(instance.pk)
15
16
17 @receiver(post_save, sender=Statement)
18 def send_notification(sender, instance, created, **kwargs):
19 if created:
20 emails.OfficeWorkerNotification.send(instance)
21
22 if instance.email:
23 emails.SubmitterConfirmation.send(instance)
24
25
26 @receiver(post_save, sender=Bplan)
27 def send_update(sender, instance, update_fields, **kwargs):
28 if update_fields:
29 emails.OfficeWorkerUpdateConfirmation.send(instance)
30
[end of meinberlin/apps/bplan/signals.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/meinberlin/apps/bplan/signals.py b/meinberlin/apps/bplan/signals.py
--- a/meinberlin/apps/bplan/signals.py
+++ b/meinberlin/apps/bplan/signals.py
@@ -25,5 +25,5 @@
@receiver(post_save, sender=Bplan)
def send_update(sender, instance, update_fields, **kwargs):
- if update_fields:
+ if not update_fields or 'point' not in update_fields:
emails.OfficeWorkerUpdateConfirmation.send(instance)
|
{"golden_diff": "diff --git a/meinberlin/apps/bplan/signals.py b/meinberlin/apps/bplan/signals.py\n--- a/meinberlin/apps/bplan/signals.py\n+++ b/meinberlin/apps/bplan/signals.py\n@@ -25,5 +25,5 @@\n \n @receiver(post_save, sender=Bplan)\n def send_update(sender, instance, update_fields, **kwargs):\n- if update_fields:\n+ if not update_fields or 'point' not in update_fields:\n emails.OfficeWorkerUpdateConfirmation.send(instance)\n", "issue": "testing 2958: bplan verification mail\n**URL:** mail\r\n**user:** administration staff working via imperia\r\n**expected behaviour:** /\r\n**behaviour:** wording changed, see below\r\n**important screensize:**/\r\n**device & browser:** /\r\n**Comment/Question:**\r\n\r\n- cross out the word \"Betreff\" in e-mail-subject\r\n\r\n- correct \"Projekt\u00fc**n**ersicht\" to \"Projekt\u00fcbersicht\"\r\n\r\n- can you write \"Uhr\" behind date and time?\r\n\r\n- I already know that it is complicated to separate date and time via comma, I guess this hasn't changed?\r\n\r\n- the word \"identifier\" shouldn't be there but I guess it is only there because you entered it into the field together with the identifier itself, right?\r\n\r\nScreenshot?\r\n<img width=\"707\" alt=\"Bildschirmfoto 2020-07-02 um 12 25 14\" src=\"https://user-images.githubusercontent.com/35491681/86348098-7ccdd280-bc5f-11ea-9fb7-010f71c1a1a9.png\">\r\n\r\n\r\n\n", "before_files": [{"content": "from django.db.models.signals import post_save\nfrom django.dispatch import receiver\n\nfrom . import emails\nfrom . import tasks\nfrom .models import Bplan\nfrom .models import Statement\n\n\n@receiver(post_save, sender=Bplan)\ndef get_location(sender, instance, update_fields, **kwargs):\n if instance.identifier and (not update_fields or\n 'point' not in update_fields):\n tasks.get_location_information(instance.pk)\n\n\n@receiver(post_save, sender=Statement)\ndef send_notification(sender, instance, created, **kwargs):\n if created:\n emails.OfficeWorkerNotification.send(instance)\n\n if instance.email:\n emails.SubmitterConfirmation.send(instance)\n\n\n@receiver(post_save, sender=Bplan)\ndef send_update(sender, instance, update_fields, **kwargs):\n if update_fields:\n emails.OfficeWorkerUpdateConfirmation.send(instance)\n", "path": "meinberlin/apps/bplan/signals.py"}]}
| 1,041 | 117 |
gh_patches_debug_23033
|
rasdani/github-patches
|
git_diff
|
litestar-org__litestar-2509
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug: Wrong OpenAPI `examples` format and nesting
### Description
For examples to show up on SwaggerUI, the `examples` array should be an object and nested on the same level as `schema`, not under it.
Wrong definition:
```json
{
"parameters": [
{
"schema": {
"type": "string",
"examples": [
{
"summary": "example summary",
"value": "example value"
}
]
}
}
]
}
````
Correct definition:
```json
{
"parameters": [
{
"schema": {
"type": "string"
},
"examples": {
"example1": {
"summary": "example summary"
"value": "example value"
}
}
}
]
}
```
### MCVE
```python
from litestar import Litestar, get
from litestar.openapi import OpenAPIConfig
from litestar.openapi.spec.example import Example
from litestar.params import Parameter
from typing import Annotated
@get(path="/")
async def index(
text: Annotated[
str,
Parameter(
examples=[Example(value="example value", summary="example summary")]
)
]
) -> str:
return text
app = Litestar(
route_handlers=[
index
],
openapi_config=OpenAPIConfig(
title="Test API",
version="1.0.0"
)
)
```
### Steps to reproduce
```bash
1. Go to the SwaggerUI docs.
2. Click on the `index` GET method.
3. See that there are no examples under the `text` query parameter.
```
### Screenshots

### Litestar Version
2.1.1
### Platform
- [ ] Linux
- [ ] Mac
- [X] Windows
- [ ] Other (Please specify in the description above)
<!-- POLAR PLEDGE BADGE START -->
---
> [!NOTE]
> While we are open for sponsoring on [GitHub Sponsors](https://github.com/sponsors/litestar-org/) and
> [OpenCollective](https://opencollective.com/litestar), we also utilize [Polar.sh](https://polar.sh/) to engage in pledge-based sponsorship.
>
> Check out all issues funded or available for funding [on our Polar.sh Litestar dashboard](https://polar.sh/litestar-org)
> * If you would like to see an issue prioritized, make a pledge towards it!
> * We receive the pledge once the issue is completed & verified
> * This, along with engagement in the community, helps us know which features are a priority to our users.
<a href="https://polar.sh/litestar-org/litestar/issues/2494">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://polar.sh/api/github/litestar-org/litestar/issues/2494/pledge.svg?darkmode=1">
<img alt="Fund with Polar" src="https://polar.sh/api/github/litestar-org/litestar/issues/2494/pledge.svg">
</picture>
</a>
<!-- POLAR PLEDGE BADGE END -->
</issue>
<code>
[start of litestar/_openapi/parameters.py]
1 from __future__ import annotations
2
3 from typing import TYPE_CHECKING
4
5 from litestar.constants import RESERVED_KWARGS
6 from litestar.enums import ParamType
7 from litestar.exceptions import ImproperlyConfiguredException
8 from litestar.openapi.spec.parameter import Parameter
9 from litestar.openapi.spec.schema import Schema
10 from litestar.params import DependencyKwarg, ParameterKwarg
11 from litestar.types import Empty
12
13 __all__ = ("create_parameter_for_handler",)
14
15 from litestar.typing import FieldDefinition
16
17 if TYPE_CHECKING:
18 from litestar._openapi.schema_generation import SchemaCreator
19 from litestar.di import Provide
20 from litestar.handlers.base import BaseRouteHandler
21 from litestar.openapi.spec import Reference
22 from litestar.types.internal_types import PathParameterDefinition
23
24
25 class ParameterCollection:
26 """Facilitates conditional deduplication of parameters.
27
28 If multiple parameters with the same name are produced for a handler, the condition is ignored if the two
29 ``Parameter`` instances are the same (the first is retained and any duplicates are ignored). If the ``Parameter``
30 instances are not the same, an exception is raised.
31 """
32
33 def __init__(self, route_handler: BaseRouteHandler) -> None:
34 """Initialize ``ParameterCollection``.
35
36 Args:
37 route_handler: Associated route handler
38 """
39 self.route_handler = route_handler
40 self._parameters: dict[str, Parameter] = {}
41
42 def add(self, parameter: Parameter) -> None:
43 """Add a ``Parameter`` to the collection.
44
45 If an existing parameter with the same name and type already exists, the
46 parameter is ignored.
47
48 If an existing parameter with the same name but different type exists, raises
49 ``ImproperlyConfiguredException``.
50 """
51
52 if parameter.name not in self._parameters:
53 # because we are defining routes as unique per path, we have to handle here a situation when there is an optional
54 # path parameter. e.g. get(path=["/", "/{param:str}"]). When parsing the parameter for path, the route handler
55 # would still have a kwarg called param:
56 # def handler(param: str | None) -> ...
57 if parameter.param_in != ParamType.QUERY or all(
58 "{" + parameter.name + ":" not in path for path in self.route_handler.paths
59 ):
60 self._parameters[parameter.name] = parameter
61 return
62
63 pre_existing = self._parameters[parameter.name]
64 if parameter == pre_existing:
65 return
66
67 raise ImproperlyConfiguredException(
68 f"OpenAPI schema generation for handler `{self.route_handler}` detected multiple parameters named "
69 f"'{parameter.name}' with different types."
70 )
71
72 def list(self) -> list[Parameter]:
73 """Return a list of all ``Parameter``'s in the collection."""
74 return list(self._parameters.values())
75
76
77 def create_parameter(
78 field_definition: FieldDefinition,
79 parameter_name: str,
80 path_parameters: tuple[PathParameterDefinition, ...],
81 schema_creator: SchemaCreator,
82 ) -> Parameter:
83 """Create an OpenAPI Parameter instance."""
84
85 result: Schema | Reference | None = None
86 kwarg_definition = (
87 field_definition.kwarg_definition if isinstance(field_definition.kwarg_definition, ParameterKwarg) else None
88 )
89
90 if any(path_param.name == parameter_name for path_param in path_parameters):
91 param_in = ParamType.PATH
92 is_required = True
93 result = schema_creator.for_field_definition(field_definition)
94 elif kwarg_definition and kwarg_definition.header:
95 parameter_name = kwarg_definition.header
96 param_in = ParamType.HEADER
97 is_required = field_definition.is_required
98 elif kwarg_definition and kwarg_definition.cookie:
99 parameter_name = kwarg_definition.cookie
100 param_in = ParamType.COOKIE
101 is_required = field_definition.is_required
102 else:
103 is_required = field_definition.is_required
104 param_in = ParamType.QUERY
105 parameter_name = kwarg_definition.query if kwarg_definition and kwarg_definition.query else parameter_name
106
107 if not result:
108 result = schema_creator.for_field_definition(field_definition)
109
110 schema = result if isinstance(result, Schema) else schema_creator.schemas[result.value]
111
112 return Parameter(
113 description=schema.description,
114 name=parameter_name,
115 param_in=param_in,
116 required=is_required,
117 schema=result,
118 )
119
120
121 def get_recursive_handler_parameters(
122 field_name: str,
123 field_definition: FieldDefinition,
124 dependency_providers: dict[str, Provide],
125 route_handler: BaseRouteHandler,
126 path_parameters: tuple[PathParameterDefinition, ...],
127 schema_creator: SchemaCreator,
128 ) -> list[Parameter]:
129 """Create and return parameters for a handler.
130
131 If the provided field is not a dependency, a normal parameter is created and returned as a list, otherwise
132 `create_parameter_for_handler()` is called to generate parameters for the dependency.
133 """
134
135 if field_name not in dependency_providers:
136 return [
137 create_parameter(
138 field_definition=field_definition,
139 parameter_name=field_name,
140 path_parameters=path_parameters,
141 schema_creator=schema_creator,
142 )
143 ]
144
145 dependency_fields = dependency_providers[field_name].signature_model._fields
146 return create_parameter_for_handler(
147 route_handler=route_handler,
148 handler_fields=dependency_fields,
149 path_parameters=path_parameters,
150 schema_creator=schema_creator,
151 )
152
153
154 def get_layered_parameter(
155 field_name: str,
156 field_definition: FieldDefinition,
157 layered_parameters: dict[str, FieldDefinition],
158 path_parameters: tuple[PathParameterDefinition, ...],
159 schema_creator: SchemaCreator,
160 ) -> Parameter:
161 """Create a layered parameter for a given signature model field.
162
163 Layer info is extracted from the provided ``layered_parameters`` dict and set as the field's ``field_info`` attribute.
164 """
165 layer_field = layered_parameters[field_name]
166
167 field = field_definition if field_definition.is_parameter_field else layer_field
168 default = layer_field.default if field_definition.has_default else field_definition.default
169 annotation = field_definition.annotation if field_definition is not Empty else layer_field.annotation
170
171 parameter_name = field_name
172 if isinstance(field.kwarg_definition, ParameterKwarg):
173 parameter_name = (
174 field.kwarg_definition.query or field.kwarg_definition.header or field.kwarg_definition.cookie or field_name
175 )
176
177 field_definition = FieldDefinition.from_kwarg(
178 inner_types=field.inner_types,
179 default=default,
180 extra=field.extra,
181 annotation=annotation,
182 kwarg_definition=field.kwarg_definition,
183 name=field_name,
184 )
185 return create_parameter(
186 field_definition=field_definition,
187 parameter_name=parameter_name,
188 path_parameters=path_parameters,
189 schema_creator=schema_creator,
190 )
191
192
193 def create_parameter_for_handler(
194 route_handler: BaseRouteHandler,
195 handler_fields: dict[str, FieldDefinition],
196 path_parameters: tuple[PathParameterDefinition, ...],
197 schema_creator: SchemaCreator,
198 ) -> list[Parameter]:
199 """Create a list of path/query/header Parameter models for the given PathHandler."""
200 parameters = ParameterCollection(route_handler=route_handler)
201 dependency_providers = route_handler.resolve_dependencies()
202 layered_parameters = route_handler.resolve_layered_parameters()
203
204 unique_handler_fields = tuple(
205 (k, v) for k, v in handler_fields.items() if k not in RESERVED_KWARGS and k not in layered_parameters
206 )
207 unique_layered_fields = tuple(
208 (k, v) for k, v in layered_parameters.items() if k not in RESERVED_KWARGS and k not in handler_fields
209 )
210 intersection_fields = tuple(
211 (k, v) for k, v in handler_fields.items() if k not in RESERVED_KWARGS and k in layered_parameters
212 )
213
214 for field_name, field_definition in unique_handler_fields:
215 if isinstance(field_definition.kwarg_definition, DependencyKwarg) and field_name not in dependency_providers:
216 # never document explicit dependencies
217 continue
218
219 for parameter in get_recursive_handler_parameters(
220 field_name=field_name,
221 field_definition=field_definition,
222 dependency_providers=dependency_providers,
223 route_handler=route_handler,
224 path_parameters=path_parameters,
225 schema_creator=schema_creator,
226 ):
227 parameters.add(parameter)
228
229 for field_name, field_definition in unique_layered_fields:
230 parameters.add(
231 create_parameter(
232 field_definition=field_definition,
233 parameter_name=field_name,
234 path_parameters=path_parameters,
235 schema_creator=schema_creator,
236 )
237 )
238
239 for field_name, field_definition in intersection_fields:
240 parameters.add(
241 get_layered_parameter(
242 field_name=field_name,
243 field_definition=field_definition,
244 layered_parameters=layered_parameters,
245 path_parameters=path_parameters,
246 schema_creator=schema_creator,
247 )
248 )
249
250 return parameters.list()
251
[end of litestar/_openapi/parameters.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/litestar/_openapi/parameters.py b/litestar/_openapi/parameters.py
--- a/litestar/_openapi/parameters.py
+++ b/litestar/_openapi/parameters.py
@@ -18,7 +18,7 @@
from litestar._openapi.schema_generation import SchemaCreator
from litestar.di import Provide
from litestar.handlers.base import BaseRouteHandler
- from litestar.openapi.spec import Reference
+ from litestar.openapi.spec import Example, Reference
from litestar.types.internal_types import PathParameterDefinition
@@ -109,12 +109,17 @@
schema = result if isinstance(result, Schema) else schema_creator.schemas[result.value]
+ examples: dict[str, Example | Reference] = {}
+ for i, example in enumerate(kwarg_definition.examples or [] if kwarg_definition else []):
+ examples[f"{field_definition.name}-example-{i}"] = example
+
return Parameter(
description=schema.description,
name=parameter_name,
param_in=param_in,
required=is_required,
schema=result,
+ examples=examples or None,
)
|
{"golden_diff": "diff --git a/litestar/_openapi/parameters.py b/litestar/_openapi/parameters.py\n--- a/litestar/_openapi/parameters.py\n+++ b/litestar/_openapi/parameters.py\n@@ -18,7 +18,7 @@\n from litestar._openapi.schema_generation import SchemaCreator\n from litestar.di import Provide\n from litestar.handlers.base import BaseRouteHandler\n- from litestar.openapi.spec import Reference\n+ from litestar.openapi.spec import Example, Reference\n from litestar.types.internal_types import PathParameterDefinition\n \n \n@@ -109,12 +109,17 @@\n \n schema = result if isinstance(result, Schema) else schema_creator.schemas[result.value]\n \n+ examples: dict[str, Example | Reference] = {}\n+ for i, example in enumerate(kwarg_definition.examples or [] if kwarg_definition else []):\n+ examples[f\"{field_definition.name}-example-{i}\"] = example\n+\n return Parameter(\n description=schema.description,\n name=parameter_name,\n param_in=param_in,\n required=is_required,\n schema=result,\n+ examples=examples or None,\n )\n", "issue": "Bug: Wrong OpenAPI `examples` format and nesting\n### Description\r\n\r\nFor examples to show up on SwaggerUI, the `examples` array should be an object and nested on the same level as `schema`, not under it.\r\n\r\nWrong definition:\r\n```json\r\n{\r\n \"parameters\": [\r\n {\r\n \"schema\": {\r\n \"type\": \"string\",\r\n \"examples\": [\r\n {\r\n \"summary\": \"example summary\",\r\n \"value\": \"example value\"\r\n }\r\n ]\r\n }\r\n }\r\n ]\r\n}\r\n````\r\n\r\nCorrect definition:\r\n```json\r\n{\r\n \"parameters\": [\r\n {\r\n \"schema\": {\r\n \"type\": \"string\"\r\n },\r\n\t \"examples\": {\r\n \"example1\": {\r\n \"summary\": \"example summary\"\r\n \"value\": \"example value\"\r\n }\r\n }\r\n }\r\n ]\r\n}\r\n```\r\n\r\n### MCVE\r\n\r\n```python\r\nfrom litestar import Litestar, get\r\nfrom litestar.openapi import OpenAPIConfig\r\nfrom litestar.openapi.spec.example import Example\r\nfrom litestar.params import Parameter\r\n\r\nfrom typing import Annotated\r\n\r\n\r\n@get(path=\"/\")\r\nasync def index(\r\n text: Annotated[\r\n str,\r\n Parameter(\r\n examples=[Example(value=\"example value\", summary=\"example summary\")]\r\n )\r\n ]\r\n) -> str:\r\n return text\r\n\r\napp = Litestar(\r\n route_handlers=[\r\n index\r\n ],\r\n openapi_config=OpenAPIConfig(\r\n title=\"Test API\",\r\n version=\"1.0.0\"\r\n )\r\n)\r\n```\r\n\r\n\r\n### Steps to reproduce\r\n\r\n```bash\r\n1. Go to the SwaggerUI docs.\r\n2. Click on the `index` GET method.\r\n3. See that there are no examples under the `text` query parameter.\r\n```\r\n\r\n\r\n### Screenshots\r\n\r\n\r\n\r\n### Litestar Version\r\n\r\n2.1.1\r\n\r\n### Platform\r\n\r\n- [ ] Linux\r\n- [ ] Mac\r\n- [X] Windows\r\n- [ ] Other (Please specify in the description above)\r\n\r\n<!-- POLAR PLEDGE BADGE START -->\r\n---\r\n> [!NOTE] \r\n> While we are open for sponsoring on [GitHub Sponsors](https://github.com/sponsors/litestar-org/) and \r\n> [OpenCollective](https://opencollective.com/litestar), we also utilize [Polar.sh](https://polar.sh/) to engage in pledge-based sponsorship.\r\n>\r\n> Check out all issues funded or available for funding [on our Polar.sh Litestar dashboard](https://polar.sh/litestar-org)\r\n> * If you would like to see an issue prioritized, make a pledge towards it!\r\n> * We receive the pledge once the issue is completed & verified\r\n> * This, along with engagement in the community, helps us know which features are a priority to our users.\r\n\r\n<a href=\"https://polar.sh/litestar-org/litestar/issues/2494\">\r\n<picture>\r\n <source media=\"(prefers-color-scheme: dark)\" srcset=\"https://polar.sh/api/github/litestar-org/litestar/issues/2494/pledge.svg?darkmode=1\">\r\n <img alt=\"Fund with Polar\" src=\"https://polar.sh/api/github/litestar-org/litestar/issues/2494/pledge.svg\">\r\n</picture>\r\n</a>\r\n<!-- POLAR PLEDGE BADGE END -->\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING\n\nfrom litestar.constants import RESERVED_KWARGS\nfrom litestar.enums import ParamType\nfrom litestar.exceptions import ImproperlyConfiguredException\nfrom litestar.openapi.spec.parameter import Parameter\nfrom litestar.openapi.spec.schema import Schema\nfrom litestar.params import DependencyKwarg, ParameterKwarg\nfrom litestar.types import Empty\n\n__all__ = (\"create_parameter_for_handler\",)\n\nfrom litestar.typing import FieldDefinition\n\nif TYPE_CHECKING:\n from litestar._openapi.schema_generation import SchemaCreator\n from litestar.di import Provide\n from litestar.handlers.base import BaseRouteHandler\n from litestar.openapi.spec import Reference\n from litestar.types.internal_types import PathParameterDefinition\n\n\nclass ParameterCollection:\n \"\"\"Facilitates conditional deduplication of parameters.\n\n If multiple parameters with the same name are produced for a handler, the condition is ignored if the two\n ``Parameter`` instances are the same (the first is retained and any duplicates are ignored). If the ``Parameter``\n instances are not the same, an exception is raised.\n \"\"\"\n\n def __init__(self, route_handler: BaseRouteHandler) -> None:\n \"\"\"Initialize ``ParameterCollection``.\n\n Args:\n route_handler: Associated route handler\n \"\"\"\n self.route_handler = route_handler\n self._parameters: dict[str, Parameter] = {}\n\n def add(self, parameter: Parameter) -> None:\n \"\"\"Add a ``Parameter`` to the collection.\n\n If an existing parameter with the same name and type already exists, the\n parameter is ignored.\n\n If an existing parameter with the same name but different type exists, raises\n ``ImproperlyConfiguredException``.\n \"\"\"\n\n if parameter.name not in self._parameters:\n # because we are defining routes as unique per path, we have to handle here a situation when there is an optional\n # path parameter. e.g. get(path=[\"/\", \"/{param:str}\"]). When parsing the parameter for path, the route handler\n # would still have a kwarg called param:\n # def handler(param: str | None) -> ...\n if parameter.param_in != ParamType.QUERY or all(\n \"{\" + parameter.name + \":\" not in path for path in self.route_handler.paths\n ):\n self._parameters[parameter.name] = parameter\n return\n\n pre_existing = self._parameters[parameter.name]\n if parameter == pre_existing:\n return\n\n raise ImproperlyConfiguredException(\n f\"OpenAPI schema generation for handler `{self.route_handler}` detected multiple parameters named \"\n f\"'{parameter.name}' with different types.\"\n )\n\n def list(self) -> list[Parameter]:\n \"\"\"Return a list of all ``Parameter``'s in the collection.\"\"\"\n return list(self._parameters.values())\n\n\ndef create_parameter(\n field_definition: FieldDefinition,\n parameter_name: str,\n path_parameters: tuple[PathParameterDefinition, ...],\n schema_creator: SchemaCreator,\n) -> Parameter:\n \"\"\"Create an OpenAPI Parameter instance.\"\"\"\n\n result: Schema | Reference | None = None\n kwarg_definition = (\n field_definition.kwarg_definition if isinstance(field_definition.kwarg_definition, ParameterKwarg) else None\n )\n\n if any(path_param.name == parameter_name for path_param in path_parameters):\n param_in = ParamType.PATH\n is_required = True\n result = schema_creator.for_field_definition(field_definition)\n elif kwarg_definition and kwarg_definition.header:\n parameter_name = kwarg_definition.header\n param_in = ParamType.HEADER\n is_required = field_definition.is_required\n elif kwarg_definition and kwarg_definition.cookie:\n parameter_name = kwarg_definition.cookie\n param_in = ParamType.COOKIE\n is_required = field_definition.is_required\n else:\n is_required = field_definition.is_required\n param_in = ParamType.QUERY\n parameter_name = kwarg_definition.query if kwarg_definition and kwarg_definition.query else parameter_name\n\n if not result:\n result = schema_creator.for_field_definition(field_definition)\n\n schema = result if isinstance(result, Schema) else schema_creator.schemas[result.value]\n\n return Parameter(\n description=schema.description,\n name=parameter_name,\n param_in=param_in,\n required=is_required,\n schema=result,\n )\n\n\ndef get_recursive_handler_parameters(\n field_name: str,\n field_definition: FieldDefinition,\n dependency_providers: dict[str, Provide],\n route_handler: BaseRouteHandler,\n path_parameters: tuple[PathParameterDefinition, ...],\n schema_creator: SchemaCreator,\n) -> list[Parameter]:\n \"\"\"Create and return parameters for a handler.\n\n If the provided field is not a dependency, a normal parameter is created and returned as a list, otherwise\n `create_parameter_for_handler()` is called to generate parameters for the dependency.\n \"\"\"\n\n if field_name not in dependency_providers:\n return [\n create_parameter(\n field_definition=field_definition,\n parameter_name=field_name,\n path_parameters=path_parameters,\n schema_creator=schema_creator,\n )\n ]\n\n dependency_fields = dependency_providers[field_name].signature_model._fields\n return create_parameter_for_handler(\n route_handler=route_handler,\n handler_fields=dependency_fields,\n path_parameters=path_parameters,\n schema_creator=schema_creator,\n )\n\n\ndef get_layered_parameter(\n field_name: str,\n field_definition: FieldDefinition,\n layered_parameters: dict[str, FieldDefinition],\n path_parameters: tuple[PathParameterDefinition, ...],\n schema_creator: SchemaCreator,\n) -> Parameter:\n \"\"\"Create a layered parameter for a given signature model field.\n\n Layer info is extracted from the provided ``layered_parameters`` dict and set as the field's ``field_info`` attribute.\n \"\"\"\n layer_field = layered_parameters[field_name]\n\n field = field_definition if field_definition.is_parameter_field else layer_field\n default = layer_field.default if field_definition.has_default else field_definition.default\n annotation = field_definition.annotation if field_definition is not Empty else layer_field.annotation\n\n parameter_name = field_name\n if isinstance(field.kwarg_definition, ParameterKwarg):\n parameter_name = (\n field.kwarg_definition.query or field.kwarg_definition.header or field.kwarg_definition.cookie or field_name\n )\n\n field_definition = FieldDefinition.from_kwarg(\n inner_types=field.inner_types,\n default=default,\n extra=field.extra,\n annotation=annotation,\n kwarg_definition=field.kwarg_definition,\n name=field_name,\n )\n return create_parameter(\n field_definition=field_definition,\n parameter_name=parameter_name,\n path_parameters=path_parameters,\n schema_creator=schema_creator,\n )\n\n\ndef create_parameter_for_handler(\n route_handler: BaseRouteHandler,\n handler_fields: dict[str, FieldDefinition],\n path_parameters: tuple[PathParameterDefinition, ...],\n schema_creator: SchemaCreator,\n) -> list[Parameter]:\n \"\"\"Create a list of path/query/header Parameter models for the given PathHandler.\"\"\"\n parameters = ParameterCollection(route_handler=route_handler)\n dependency_providers = route_handler.resolve_dependencies()\n layered_parameters = route_handler.resolve_layered_parameters()\n\n unique_handler_fields = tuple(\n (k, v) for k, v in handler_fields.items() if k not in RESERVED_KWARGS and k not in layered_parameters\n )\n unique_layered_fields = tuple(\n (k, v) for k, v in layered_parameters.items() if k not in RESERVED_KWARGS and k not in handler_fields\n )\n intersection_fields = tuple(\n (k, v) for k, v in handler_fields.items() if k not in RESERVED_KWARGS and k in layered_parameters\n )\n\n for field_name, field_definition in unique_handler_fields:\n if isinstance(field_definition.kwarg_definition, DependencyKwarg) and field_name not in dependency_providers:\n # never document explicit dependencies\n continue\n\n for parameter in get_recursive_handler_parameters(\n field_name=field_name,\n field_definition=field_definition,\n dependency_providers=dependency_providers,\n route_handler=route_handler,\n path_parameters=path_parameters,\n schema_creator=schema_creator,\n ):\n parameters.add(parameter)\n\n for field_name, field_definition in unique_layered_fields:\n parameters.add(\n create_parameter(\n field_definition=field_definition,\n parameter_name=field_name,\n path_parameters=path_parameters,\n schema_creator=schema_creator,\n )\n )\n\n for field_name, field_definition in intersection_fields:\n parameters.add(\n get_layered_parameter(\n field_name=field_name,\n field_definition=field_definition,\n layered_parameters=layered_parameters,\n path_parameters=path_parameters,\n schema_creator=schema_creator,\n )\n )\n\n return parameters.list()\n", "path": "litestar/_openapi/parameters.py"}]}
| 3,842 | 258 |
gh_patches_debug_8947
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-2762
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
AttributeError: 'NonRecordingSpan' object has no attribute 'parent'
[Environment]
------------------------------------------
python==3.7.1
opentelemetry-api==1.7.1
opentelemetry-exporter-jaeger==1.7.1
opentelemetry-propagator-jaeger==1.7.1
opentelemetry-sdk==1.7.1
OTEL_TRACES_SAMPLER=traceidratio
OTEL_TRACES_SAMPLER_ARG=0
My Code :

[Issue]
------------------------------------------
0 rate for TraceIdRatioBased sampler to create the NonRecordingSpan, which with no `parent` attribute.
Then I try to inject carrier with Jaeger Propagator. Following exception happened:
`
'NonRecordingSpan' object has no attribute 'parent'
File "/usr/local/lib/python3.7/dist-packages/opentelemetry/propagators/jaeger/__init__.py", line 84, in inject
span_parent_id = span.parent.span_id if span.parent else 0
`
[expected behavior]
----------------------------------
It should return with empty carrier without any exception.
AttributeError: 'NonRecordingSpan' object has no attribute 'parent'
[Environment]
------------------------------------------
python==3.7.1
opentelemetry-api==1.7.1
opentelemetry-exporter-jaeger==1.7.1
opentelemetry-propagator-jaeger==1.7.1
opentelemetry-sdk==1.7.1
OTEL_TRACES_SAMPLER=traceidratio
OTEL_TRACES_SAMPLER_ARG=0
My Code :

[Issue]
------------------------------------------
0 rate for TraceIdRatioBased sampler to create the NonRecordingSpan, which with no `parent` attribute.
Then I try to inject carrier with Jaeger Propagator. Following exception happened:
`
'NonRecordingSpan' object has no attribute 'parent'
File "/usr/local/lib/python3.7/dist-packages/opentelemetry/propagators/jaeger/__init__.py", line 84, in inject
span_parent_id = span.parent.span_id if span.parent else 0
`
[expected behavior]
----------------------------------
It should return with empty carrier without any exception.
</issue>
<code>
[start of propagator/opentelemetry-propagator-jaeger/src/opentelemetry/propagators/jaeger/__init__.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import typing
16 import urllib.parse
17
18 from opentelemetry import baggage, trace
19 from opentelemetry.context import Context
20 from opentelemetry.propagators.textmap import (
21 CarrierT,
22 Getter,
23 Setter,
24 TextMapPropagator,
25 default_getter,
26 default_setter,
27 )
28 from opentelemetry.trace import format_span_id, format_trace_id
29
30
31 class JaegerPropagator(TextMapPropagator):
32 """Propagator for the Jaeger format.
33
34 See: https://www.jaegertracing.io/docs/1.19/client-libraries/#propagation-format
35 """
36
37 TRACE_ID_KEY = "uber-trace-id"
38 BAGGAGE_PREFIX = "uberctx-"
39 DEBUG_FLAG = 0x02
40
41 def extract(
42 self,
43 carrier: CarrierT,
44 context: typing.Optional[Context] = None,
45 getter: Getter = default_getter,
46 ) -> Context:
47
48 if context is None:
49 context = Context()
50 header = getter.get(carrier, self.TRACE_ID_KEY)
51 if not header:
52 return context
53
54 context = self._extract_baggage(getter, carrier, context)
55
56 trace_id, span_id, flags = _parse_trace_id_header(header)
57 if (
58 trace_id == trace.INVALID_TRACE_ID
59 or span_id == trace.INVALID_SPAN_ID
60 ):
61 return context
62
63 span = trace.NonRecordingSpan(
64 trace.SpanContext(
65 trace_id=trace_id,
66 span_id=span_id,
67 is_remote=True,
68 trace_flags=trace.TraceFlags(flags & trace.TraceFlags.SAMPLED),
69 )
70 )
71 return trace.set_span_in_context(span, context)
72
73 def inject(
74 self,
75 carrier: CarrierT,
76 context: typing.Optional[Context] = None,
77 setter: Setter = default_setter,
78 ) -> None:
79 span = trace.get_current_span(context=context)
80 span_context = span.get_span_context()
81 if span_context == trace.INVALID_SPAN_CONTEXT:
82 return
83
84 span_parent_id = span.parent.span_id if span.parent else 0
85 trace_flags = span_context.trace_flags
86 if trace_flags.sampled:
87 trace_flags |= self.DEBUG_FLAG
88
89 # set span identity
90 setter.set(
91 carrier,
92 self.TRACE_ID_KEY,
93 _format_uber_trace_id(
94 span_context.trace_id,
95 span_context.span_id,
96 span_parent_id,
97 trace_flags,
98 ),
99 )
100
101 # set span baggage, if any
102 baggage_entries = baggage.get_all(context=context)
103 if not baggage_entries:
104 return
105 for key, value in baggage_entries.items():
106 baggage_key = self.BAGGAGE_PREFIX + key
107 setter.set(carrier, baggage_key, urllib.parse.quote(str(value)))
108
109 @property
110 def fields(self) -> typing.Set[str]:
111 return {self.TRACE_ID_KEY}
112
113 def _extract_baggage(self, getter, carrier, context):
114 baggage_keys = [
115 key
116 for key in getter.keys(carrier)
117 if key.startswith(self.BAGGAGE_PREFIX)
118 ]
119 for key in baggage_keys:
120 value = _extract_first_element(getter.get(carrier, key))
121 context = baggage.set_baggage(
122 key.replace(self.BAGGAGE_PREFIX, ""),
123 urllib.parse.unquote(value).strip(),
124 context=context,
125 )
126 return context
127
128
129 def _format_uber_trace_id(trace_id, span_id, parent_span_id, flags):
130 return f"{format_trace_id(trace_id)}:{format_span_id(span_id)}:{format_span_id(parent_span_id)}:{flags:02x}"
131
132
133 def _extract_first_element(
134 items: typing.Iterable[CarrierT],
135 ) -> typing.Optional[CarrierT]:
136 if items is None:
137 return None
138 return next(iter(items), None)
139
140
141 def _parse_trace_id_header(
142 items: typing.Iterable[CarrierT],
143 ) -> typing.Tuple[int]:
144 invalid_header_result = (trace.INVALID_TRACE_ID, trace.INVALID_SPAN_ID, 0)
145
146 header = _extract_first_element(items)
147 if header is None:
148 return invalid_header_result
149
150 fields = header.split(":")
151 if len(fields) != 4:
152 return invalid_header_result
153
154 trace_id_str, span_id_str, _parent_id_str, flags_str = fields
155 flags = _int_from_hex_str(flags_str, None)
156 if flags is None:
157 return invalid_header_result
158
159 trace_id = _int_from_hex_str(trace_id_str, trace.INVALID_TRACE_ID)
160 span_id = _int_from_hex_str(span_id_str, trace.INVALID_SPAN_ID)
161 return trace_id, span_id, flags
162
163
164 def _int_from_hex_str(
165 identifier: str, default: typing.Optional[int]
166 ) -> typing.Optional[int]:
167 try:
168 return int(identifier, 16)
169 except ValueError:
170 return default
171
[end of propagator/opentelemetry-propagator-jaeger/src/opentelemetry/propagators/jaeger/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/propagator/opentelemetry-propagator-jaeger/src/opentelemetry/propagators/jaeger/__init__.py b/propagator/opentelemetry-propagator-jaeger/src/opentelemetry/propagators/jaeger/__init__.py
--- a/propagator/opentelemetry-propagator-jaeger/src/opentelemetry/propagators/jaeger/__init__.py
+++ b/propagator/opentelemetry-propagator-jaeger/src/opentelemetry/propagators/jaeger/__init__.py
@@ -81,7 +81,10 @@
if span_context == trace.INVALID_SPAN_CONTEXT:
return
- span_parent_id = span.parent.span_id if span.parent else 0
+ # Non-recording spans do not have a parent
+ span_parent_id = (
+ span.parent.span_id if span.is_recording() and span.parent else 0
+ )
trace_flags = span_context.trace_flags
if trace_flags.sampled:
trace_flags |= self.DEBUG_FLAG
|
{"golden_diff": "diff --git a/propagator/opentelemetry-propagator-jaeger/src/opentelemetry/propagators/jaeger/__init__.py b/propagator/opentelemetry-propagator-jaeger/src/opentelemetry/propagators/jaeger/__init__.py\n--- a/propagator/opentelemetry-propagator-jaeger/src/opentelemetry/propagators/jaeger/__init__.py\n+++ b/propagator/opentelemetry-propagator-jaeger/src/opentelemetry/propagators/jaeger/__init__.py\n@@ -81,7 +81,10 @@\n if span_context == trace.INVALID_SPAN_CONTEXT:\n return\n \n- span_parent_id = span.parent.span_id if span.parent else 0\n+ # Non-recording spans do not have a parent\n+ span_parent_id = (\n+ span.parent.span_id if span.is_recording() and span.parent else 0\n+ )\n trace_flags = span_context.trace_flags\n if trace_flags.sampled:\n trace_flags |= self.DEBUG_FLAG\n", "issue": "AttributeError: 'NonRecordingSpan' object has no attribute 'parent'\n[Environment]\r\n------------------------------------------\r\npython==3.7.1\r\nopentelemetry-api==1.7.1\r\nopentelemetry-exporter-jaeger==1.7.1\r\nopentelemetry-propagator-jaeger==1.7.1\r\nopentelemetry-sdk==1.7.1\r\n\r\nOTEL_TRACES_SAMPLER=traceidratio\r\nOTEL_TRACES_SAMPLER_ARG=0\r\n\r\nMy Code :\r\n\r\n\r\n\r\n[Issue]\r\n------------------------------------------\r\n0 rate for TraceIdRatioBased sampler to create the NonRecordingSpan, which with no `parent` attribute. \r\nThen I try to inject carrier with Jaeger Propagator. Following exception happened:\r\n`\r\n'NonRecordingSpan' object has no attribute 'parent'\r\n File \"/usr/local/lib/python3.7/dist-packages/opentelemetry/propagators/jaeger/__init__.py\", line 84, in inject\r\n span_parent_id = span.parent.span_id if span.parent else 0\r\n`\r\n\r\n[expected behavior]\r\n----------------------------------\r\nIt should return with empty carrier without any exception.\r\n\nAttributeError: 'NonRecordingSpan' object has no attribute 'parent'\n[Environment]\r\n------------------------------------------\r\npython==3.7.1\r\nopentelemetry-api==1.7.1\r\nopentelemetry-exporter-jaeger==1.7.1\r\nopentelemetry-propagator-jaeger==1.7.1\r\nopentelemetry-sdk==1.7.1\r\n\r\nOTEL_TRACES_SAMPLER=traceidratio\r\nOTEL_TRACES_SAMPLER_ARG=0\r\n\r\nMy Code :\r\n\r\n\r\n\r\n[Issue]\r\n------------------------------------------\r\n0 rate for TraceIdRatioBased sampler to create the NonRecordingSpan, which with no `parent` attribute. \r\nThen I try to inject carrier with Jaeger Propagator. Following exception happened:\r\n`\r\n'NonRecordingSpan' object has no attribute 'parent'\r\n File \"/usr/local/lib/python3.7/dist-packages/opentelemetry/propagators/jaeger/__init__.py\", line 84, in inject\r\n span_parent_id = span.parent.span_id if span.parent else 0\r\n`\r\n\r\n[expected behavior]\r\n----------------------------------\r\nIt should return with empty carrier without any exception.\r\n\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport typing\nimport urllib.parse\n\nfrom opentelemetry import baggage, trace\nfrom opentelemetry.context import Context\nfrom opentelemetry.propagators.textmap import (\n CarrierT,\n Getter,\n Setter,\n TextMapPropagator,\n default_getter,\n default_setter,\n)\nfrom opentelemetry.trace import format_span_id, format_trace_id\n\n\nclass JaegerPropagator(TextMapPropagator):\n \"\"\"Propagator for the Jaeger format.\n\n See: https://www.jaegertracing.io/docs/1.19/client-libraries/#propagation-format\n \"\"\"\n\n TRACE_ID_KEY = \"uber-trace-id\"\n BAGGAGE_PREFIX = \"uberctx-\"\n DEBUG_FLAG = 0x02\n\n def extract(\n self,\n carrier: CarrierT,\n context: typing.Optional[Context] = None,\n getter: Getter = default_getter,\n ) -> Context:\n\n if context is None:\n context = Context()\n header = getter.get(carrier, self.TRACE_ID_KEY)\n if not header:\n return context\n\n context = self._extract_baggage(getter, carrier, context)\n\n trace_id, span_id, flags = _parse_trace_id_header(header)\n if (\n trace_id == trace.INVALID_TRACE_ID\n or span_id == trace.INVALID_SPAN_ID\n ):\n return context\n\n span = trace.NonRecordingSpan(\n trace.SpanContext(\n trace_id=trace_id,\n span_id=span_id,\n is_remote=True,\n trace_flags=trace.TraceFlags(flags & trace.TraceFlags.SAMPLED),\n )\n )\n return trace.set_span_in_context(span, context)\n\n def inject(\n self,\n carrier: CarrierT,\n context: typing.Optional[Context] = None,\n setter: Setter = default_setter,\n ) -> None:\n span = trace.get_current_span(context=context)\n span_context = span.get_span_context()\n if span_context == trace.INVALID_SPAN_CONTEXT:\n return\n\n span_parent_id = span.parent.span_id if span.parent else 0\n trace_flags = span_context.trace_flags\n if trace_flags.sampled:\n trace_flags |= self.DEBUG_FLAG\n\n # set span identity\n setter.set(\n carrier,\n self.TRACE_ID_KEY,\n _format_uber_trace_id(\n span_context.trace_id,\n span_context.span_id,\n span_parent_id,\n trace_flags,\n ),\n )\n\n # set span baggage, if any\n baggage_entries = baggage.get_all(context=context)\n if not baggage_entries:\n return\n for key, value in baggage_entries.items():\n baggage_key = self.BAGGAGE_PREFIX + key\n setter.set(carrier, baggage_key, urllib.parse.quote(str(value)))\n\n @property\n def fields(self) -> typing.Set[str]:\n return {self.TRACE_ID_KEY}\n\n def _extract_baggage(self, getter, carrier, context):\n baggage_keys = [\n key\n for key in getter.keys(carrier)\n if key.startswith(self.BAGGAGE_PREFIX)\n ]\n for key in baggage_keys:\n value = _extract_first_element(getter.get(carrier, key))\n context = baggage.set_baggage(\n key.replace(self.BAGGAGE_PREFIX, \"\"),\n urllib.parse.unquote(value).strip(),\n context=context,\n )\n return context\n\n\ndef _format_uber_trace_id(trace_id, span_id, parent_span_id, flags):\n return f\"{format_trace_id(trace_id)}:{format_span_id(span_id)}:{format_span_id(parent_span_id)}:{flags:02x}\"\n\n\ndef _extract_first_element(\n items: typing.Iterable[CarrierT],\n) -> typing.Optional[CarrierT]:\n if items is None:\n return None\n return next(iter(items), None)\n\n\ndef _parse_trace_id_header(\n items: typing.Iterable[CarrierT],\n) -> typing.Tuple[int]:\n invalid_header_result = (trace.INVALID_TRACE_ID, trace.INVALID_SPAN_ID, 0)\n\n header = _extract_first_element(items)\n if header is None:\n return invalid_header_result\n\n fields = header.split(\":\")\n if len(fields) != 4:\n return invalid_header_result\n\n trace_id_str, span_id_str, _parent_id_str, flags_str = fields\n flags = _int_from_hex_str(flags_str, None)\n if flags is None:\n return invalid_header_result\n\n trace_id = _int_from_hex_str(trace_id_str, trace.INVALID_TRACE_ID)\n span_id = _int_from_hex_str(span_id_str, trace.INVALID_SPAN_ID)\n return trace_id, span_id, flags\n\n\ndef _int_from_hex_str(\n identifier: str, default: typing.Optional[int]\n) -> typing.Optional[int]:\n try:\n return int(identifier, 16)\n except ValueError:\n return default\n", "path": "propagator/opentelemetry-propagator-jaeger/src/opentelemetry/propagators/jaeger/__init__.py"}]}
| 2,760 | 234 |
gh_patches_debug_17228
|
rasdani/github-patches
|
git_diff
|
easybuilders__easybuild-easyblocks-2512
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ESMF sanity check
Hi, There is a newer release version of EMSF available 8.1.1.
The current `sanity_check_step` in `/easybuild/easyblocks/e/esmf.py` (line 120 or so) will not work since the filenames for the binaries have been changed in 8.1.1 (the current `esmf.py` checks for `ESMF_Info` but since the 8.1.0 it's acutally `EMSF_PrintInfo`, same with `ESMF_InfoC` and `ESMF_PrintInfoC`).
Also, it seems that the `ESMF-6.1.1_libopts.patch` is no longer needed in the `easyconfig`
And source url + the naming scheme have changed:
```
source_urls = ['https://github.com/esmf-org/esmf/archive/refs/tags/']
sources = ['%%(name)s_%s.tar.gz' % '_'.join(version.split('.'))]
```
</issue>
<code>
[start of easybuild/easyblocks/e/esmf.py]
1 ##
2 # Copyright 2013-2021 Ghent University
3 #
4 # This file is part of EasyBuild,
5 # originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),
6 # with support of Ghent University (http://ugent.be/hpc),
7 # the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),
8 # Flemish Research Foundation (FWO) (http://www.fwo.be/en)
9 # and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).
10 #
11 # https://github.com/easybuilders/easybuild
12 #
13 # EasyBuild is free software: you can redistribute it and/or modify
14 # it under the terms of the GNU General Public License as published by
15 # the Free Software Foundation v2.
16 #
17 # EasyBuild is distributed in the hope that it will be useful,
18 # but WITHOUT ANY WARRANTY; without even the implied warranty of
19 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
20 # GNU General Public License for more details.
21 #
22 # You should have received a copy of the GNU General Public License
23 # along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.
24 ##
25 """
26 EasyBuild support for building and installing ESMF, implemented as an easyblock
27
28 @author: Kenneth Hoste (Ghent University)
29 @author: Damian Alvarez (Forschungszentrum Juelich GmbH)
30 """
31 import os
32 from distutils.version import LooseVersion
33
34 import easybuild.tools.environment as env
35 import easybuild.tools.toolchain as toolchain
36 from easybuild.easyblocks.generic.configuremake import ConfigureMake
37 from easybuild.tools.build_log import EasyBuildError
38 from easybuild.tools.modules import get_software_root
39 from easybuild.tools.run import run_cmd
40 from easybuild.tools.systemtools import get_shared_lib_ext
41
42
43 class EB_ESMF(ConfigureMake):
44 """Support for building/installing ESMF."""
45
46 def configure_step(self):
47 """Custom configuration procedure for ESMF through environment variables."""
48
49 env.setvar('ESMF_DIR', self.cfg['start_dir'])
50 env.setvar('ESMF_INSTALL_PREFIX', self.installdir)
51 env.setvar('ESMF_INSTALL_BINDIR', 'bin')
52 env.setvar('ESMF_INSTALL_LIBDIR', 'lib')
53 env.setvar('ESMF_INSTALL_MODDIR', 'mod')
54
55 # specify compiler
56 comp_family = self.toolchain.comp_family()
57 if comp_family in [toolchain.GCC]:
58 compiler = 'gfortran'
59 else:
60 compiler = comp_family.lower()
61 env.setvar('ESMF_COMPILER', compiler)
62
63 env.setvar('ESMF_F90COMPILEOPTS', os.getenv('F90FLAGS'))
64 env.setvar('ESMF_CXXCOMPILEOPTS', os.getenv('CXXFLAGS'))
65
66 # specify MPI communications library
67 comm = None
68 mpi_family = self.toolchain.mpi_family()
69 if mpi_family in [toolchain.MPICH, toolchain.QLOGICMPI]:
70 # MPICH family for MPICH v3.x, which is MPICH2 compatible
71 comm = 'mpich2'
72 else:
73 comm = mpi_family.lower()
74 env.setvar('ESMF_COMM', comm)
75
76 # specify decent LAPACK lib
77 env.setvar('ESMF_LAPACK', 'user')
78 ldflags = os.getenv('LDFLAGS')
79 liblapack = os.getenv('LIBLAPACK_MT') or os.getenv('LIBLAPACK')
80 if liblapack is None:
81 raise EasyBuildError("$LIBLAPACK(_MT) not defined, no BLAS/LAPACK in %s toolchain?", self.toolchain.name)
82 else:
83 env.setvar('ESMF_LAPACK_LIBS', ldflags + ' ' + liblapack)
84
85 # specify netCDF
86 netcdf = get_software_root('netCDF')
87 if netcdf:
88 if LooseVersion(self.version) >= LooseVersion('7.1.0'):
89 env.setvar('ESMF_NETCDF', 'nc-config')
90 else:
91 env.setvar('ESMF_NETCDF', 'user')
92 netcdf_libs = ['-L%s/lib' % netcdf, '-lnetcdf']
93
94 # Fortran
95 netcdff = get_software_root('netCDF-Fortran')
96 if netcdff:
97 netcdf_libs = ["-L%s/lib" % netcdff] + netcdf_libs + ["-lnetcdff"]
98 else:
99 netcdf_libs.append('-lnetcdff')
100
101 # C++
102 netcdfcxx = get_software_root('netCDF-C++')
103 if netcdfcxx:
104 netcdf_libs = ["-L%s/lib" % netcdfcxx] + netcdf_libs + ["-lnetcdf_c++"]
105 else:
106 netcdfcxx = get_software_root('netCDF-C++4')
107 if netcdfcxx:
108 netcdf_libs = ["-L%s/lib" % netcdfcxx] + netcdf_libs + ["-lnetcdf_c++4"]
109 else:
110 netcdf_libs.append('-lnetcdf_c++')
111 env.setvar('ESMF_NETCDF_LIBS', ' '.join(netcdf_libs))
112
113 # 'make info' provides useful debug info
114 cmd = "make info"
115 run_cmd(cmd, log_all=True, simple=True, log_ok=True)
116
117 def sanity_check_step(self):
118 """Custom sanity check for ESMF."""
119
120 binaries = ['ESMF_Info', 'ESMF_InfoC', 'ESMF_RegridWeightGen', 'ESMF_WebServController']
121 libs = ['libesmf.a', 'libesmf.%s' % get_shared_lib_ext()]
122 custom_paths = {
123 'files': [os.path.join('bin', x) for x in binaries] + [os.path.join('lib', x) for x in libs],
124 'dirs': ['include', 'mod'],
125 }
126
127 super(EB_ESMF, self).sanity_check_step(custom_paths=custom_paths)
128
[end of easybuild/easyblocks/e/esmf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/easybuild/easyblocks/e/esmf.py b/easybuild/easyblocks/e/esmf.py
--- a/easybuild/easyblocks/e/esmf.py
+++ b/easybuild/easyblocks/e/esmf.py
@@ -117,7 +117,13 @@
def sanity_check_step(self):
"""Custom sanity check for ESMF."""
- binaries = ['ESMF_Info', 'ESMF_InfoC', 'ESMF_RegridWeightGen', 'ESMF_WebServController']
+ if LooseVersion(self.version) < LooseVersion('8.1.0'):
+ binaries = ['ESMF_Info', 'ESMF_InfoC', 'ESMF_Regrid', 'ESMF_RegridWeightGen',
+ 'ESMF_Scrip2Unstruct', 'ESMF_WebServController']
+ else:
+ binaries = ['ESMF_PrintInfo', 'ESMF_PrintInfoC', 'ESMF_Regrid', 'ESMF_RegridWeightGen',
+ 'ESMF_Scrip2Unstruct', 'ESMF_WebServController']
+
libs = ['libesmf.a', 'libesmf.%s' % get_shared_lib_ext()]
custom_paths = {
'files': [os.path.join('bin', x) for x in binaries] + [os.path.join('lib', x) for x in libs],
|
{"golden_diff": "diff --git a/easybuild/easyblocks/e/esmf.py b/easybuild/easyblocks/e/esmf.py\n--- a/easybuild/easyblocks/e/esmf.py\n+++ b/easybuild/easyblocks/e/esmf.py\n@@ -117,7 +117,13 @@\n def sanity_check_step(self):\n \"\"\"Custom sanity check for ESMF.\"\"\"\n \n- binaries = ['ESMF_Info', 'ESMF_InfoC', 'ESMF_RegridWeightGen', 'ESMF_WebServController']\n+ if LooseVersion(self.version) < LooseVersion('8.1.0'):\n+ binaries = ['ESMF_Info', 'ESMF_InfoC', 'ESMF_Regrid', 'ESMF_RegridWeightGen',\n+ 'ESMF_Scrip2Unstruct', 'ESMF_WebServController']\n+ else:\n+ binaries = ['ESMF_PrintInfo', 'ESMF_PrintInfoC', 'ESMF_Regrid', 'ESMF_RegridWeightGen',\n+ 'ESMF_Scrip2Unstruct', 'ESMF_WebServController']\n+\n libs = ['libesmf.a', 'libesmf.%s' % get_shared_lib_ext()]\n custom_paths = {\n 'files': [os.path.join('bin', x) for x in binaries] + [os.path.join('lib', x) for x in libs],\n", "issue": "ESMF sanity check\nHi, There is a newer release version of EMSF available 8.1.1.\r\nThe current `sanity_check_step` in `/easybuild/easyblocks/e/esmf.py` (line 120 or so) will not work since the filenames for the binaries have been changed in 8.1.1 (the current `esmf.py` checks for `ESMF_Info` but since the 8.1.0 it's acutally `EMSF_PrintInfo`, same with `ESMF_InfoC` and `ESMF_PrintInfoC`). \r\n\r\nAlso, it seems that the `ESMF-6.1.1_libopts.patch` is no longer needed in the `easyconfig`\r\n\r\nAnd source url + the naming scheme have changed:\r\n```\r\nsource_urls = ['https://github.com/esmf-org/esmf/archive/refs/tags/']\r\nsources = ['%%(name)s_%s.tar.gz' % '_'.join(version.split('.'))]\r\n```\r\n\n", "before_files": [{"content": "##\n# Copyright 2013-2021 Ghent University\n#\n# This file is part of EasyBuild,\n# originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),\n# with support of Ghent University (http://ugent.be/hpc),\n# the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),\n# Flemish Research Foundation (FWO) (http://www.fwo.be/en)\n# and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).\n#\n# https://github.com/easybuilders/easybuild\n#\n# EasyBuild is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation v2.\n#\n# EasyBuild is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.\n##\n\"\"\"\nEasyBuild support for building and installing ESMF, implemented as an easyblock\n\n@author: Kenneth Hoste (Ghent University)\n@author: Damian Alvarez (Forschungszentrum Juelich GmbH)\n\"\"\"\nimport os\nfrom distutils.version import LooseVersion\n\nimport easybuild.tools.environment as env\nimport easybuild.tools.toolchain as toolchain\nfrom easybuild.easyblocks.generic.configuremake import ConfigureMake\nfrom easybuild.tools.build_log import EasyBuildError\nfrom easybuild.tools.modules import get_software_root\nfrom easybuild.tools.run import run_cmd\nfrom easybuild.tools.systemtools import get_shared_lib_ext\n\n\nclass EB_ESMF(ConfigureMake):\n \"\"\"Support for building/installing ESMF.\"\"\"\n\n def configure_step(self):\n \"\"\"Custom configuration procedure for ESMF through environment variables.\"\"\"\n\n env.setvar('ESMF_DIR', self.cfg['start_dir'])\n env.setvar('ESMF_INSTALL_PREFIX', self.installdir)\n env.setvar('ESMF_INSTALL_BINDIR', 'bin')\n env.setvar('ESMF_INSTALL_LIBDIR', 'lib')\n env.setvar('ESMF_INSTALL_MODDIR', 'mod')\n\n # specify compiler\n comp_family = self.toolchain.comp_family()\n if comp_family in [toolchain.GCC]:\n compiler = 'gfortran'\n else:\n compiler = comp_family.lower()\n env.setvar('ESMF_COMPILER', compiler)\n\n env.setvar('ESMF_F90COMPILEOPTS', os.getenv('F90FLAGS'))\n env.setvar('ESMF_CXXCOMPILEOPTS', os.getenv('CXXFLAGS'))\n\n # specify MPI communications library\n comm = None\n mpi_family = self.toolchain.mpi_family()\n if mpi_family in [toolchain.MPICH, toolchain.QLOGICMPI]:\n # MPICH family for MPICH v3.x, which is MPICH2 compatible\n comm = 'mpich2'\n else:\n comm = mpi_family.lower()\n env.setvar('ESMF_COMM', comm)\n\n # specify decent LAPACK lib\n env.setvar('ESMF_LAPACK', 'user')\n ldflags = os.getenv('LDFLAGS')\n liblapack = os.getenv('LIBLAPACK_MT') or os.getenv('LIBLAPACK')\n if liblapack is None:\n raise EasyBuildError(\"$LIBLAPACK(_MT) not defined, no BLAS/LAPACK in %s toolchain?\", self.toolchain.name)\n else:\n env.setvar('ESMF_LAPACK_LIBS', ldflags + ' ' + liblapack)\n\n # specify netCDF\n netcdf = get_software_root('netCDF')\n if netcdf:\n if LooseVersion(self.version) >= LooseVersion('7.1.0'):\n env.setvar('ESMF_NETCDF', 'nc-config')\n else:\n env.setvar('ESMF_NETCDF', 'user')\n netcdf_libs = ['-L%s/lib' % netcdf, '-lnetcdf']\n\n # Fortran\n netcdff = get_software_root('netCDF-Fortran')\n if netcdff:\n netcdf_libs = [\"-L%s/lib\" % netcdff] + netcdf_libs + [\"-lnetcdff\"]\n else:\n netcdf_libs.append('-lnetcdff')\n\n # C++\n netcdfcxx = get_software_root('netCDF-C++')\n if netcdfcxx:\n netcdf_libs = [\"-L%s/lib\" % netcdfcxx] + netcdf_libs + [\"-lnetcdf_c++\"]\n else:\n netcdfcxx = get_software_root('netCDF-C++4')\n if netcdfcxx:\n netcdf_libs = [\"-L%s/lib\" % netcdfcxx] + netcdf_libs + [\"-lnetcdf_c++4\"]\n else:\n netcdf_libs.append('-lnetcdf_c++')\n env.setvar('ESMF_NETCDF_LIBS', ' '.join(netcdf_libs))\n\n # 'make info' provides useful debug info\n cmd = \"make info\"\n run_cmd(cmd, log_all=True, simple=True, log_ok=True)\n\n def sanity_check_step(self):\n \"\"\"Custom sanity check for ESMF.\"\"\"\n\n binaries = ['ESMF_Info', 'ESMF_InfoC', 'ESMF_RegridWeightGen', 'ESMF_WebServController']\n libs = ['libesmf.a', 'libesmf.%s' % get_shared_lib_ext()]\n custom_paths = {\n 'files': [os.path.join('bin', x) for x in binaries] + [os.path.join('lib', x) for x in libs],\n 'dirs': ['include', 'mod'],\n }\n\n super(EB_ESMF, self).sanity_check_step(custom_paths=custom_paths)\n", "path": "easybuild/easyblocks/e/esmf.py"}]}
| 2,355 | 299 |
gh_patches_debug_11254
|
rasdani/github-patches
|
git_diff
|
nipy__nipype-3007
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
mne.WatershedBEM creates incorrect command line
### Summary
The mne.WatershedBEM interface `_cmd` do not correspond to the behavior of the stable release of mne [see documentation](https://martinos.org/mne/stable/generated/commands.html#create-bem-surfaces-using-the-watershed-algorithm-included-with-freesurfer)
[This line](https://github.com/nipy/nipype/blob/f79581edc042ed38064f48e85b6dcc38bc30a084/nipype/interfaces/mne/base.py#L97) `_cmd = 'mne_watershed_bem'` should be `_cmd = 'mne watershed_bem'`
mne.WatershedBEM creates incorrect command line
### Summary
The mne.WatershedBEM interface `_cmd` do not correspond to the behavior of the stable release of mne [see documentation](https://martinos.org/mne/stable/generated/commands.html#create-bem-surfaces-using-the-watershed-algorithm-included-with-freesurfer)
[This line](https://github.com/nipy/nipype/blob/f79581edc042ed38064f48e85b6dcc38bc30a084/nipype/interfaces/mne/base.py#L97) `_cmd = 'mne_watershed_bem'` should be `_cmd = 'mne watershed_bem'`
</issue>
<code>
[start of nipype/interfaces/mne/base.py]
1 # -*- coding: utf-8 -*-
2 from __future__ import (print_function, division, unicode_literals,
3 absolute_import)
4 from builtins import str, bytes
5
6 import os.path as op
7 import glob
8
9 from ... import logging
10 from ...utils.filemanip import simplify_list
11 from ..base import (traits, File, Directory, TraitedSpec, OutputMultiPath)
12 from ..freesurfer.base import FSCommand, FSTraitedSpec
13
14 iflogger = logging.getLogger('nipype.interface')
15
16
17 class WatershedBEMInputSpec(FSTraitedSpec):
18 subject_id = traits.Str(
19 argstr='--subject %s',
20 mandatory=True,
21 desc='Subject ID (must have a complete Freesurfer directory)')
22 subjects_dir = Directory(
23 exists=True,
24 mandatory=True,
25 usedefault=True,
26 desc='Path to Freesurfer subjects directory')
27 volume = traits.Enum(
28 'T1',
29 'aparc+aseg',
30 'aseg',
31 'brain',
32 'orig',
33 'brainmask',
34 'ribbon',
35 argstr='--volume %s',
36 usedefault=True,
37 desc='The volume from the "mri" directory to use (defaults to T1)')
38 overwrite = traits.Bool(
39 True,
40 usedefault=True,
41 argstr='--overwrite',
42 desc='Overwrites the existing files')
43 atlas_mode = traits.Bool(
44 argstr='--atlas',
45 desc='Use atlas mode for registration (default: no rigid alignment)')
46
47
48 class WatershedBEMOutputSpec(TraitedSpec):
49 mesh_files = OutputMultiPath(
50 File(exists=True),
51 desc=('Paths to the output meshes (brain, inner '
52 'skull, outer skull, outer skin)'))
53 brain_surface = File(
54 exists=True,
55 loc='bem/watershed',
56 desc='Brain surface (in Freesurfer format)')
57 inner_skull_surface = File(
58 exists=True,
59 loc='bem/watershed',
60 desc='Inner skull surface (in Freesurfer format)')
61 outer_skull_surface = File(
62 exists=True,
63 loc='bem/watershed',
64 desc='Outer skull surface (in Freesurfer format)')
65 outer_skin_surface = File(
66 exists=True,
67 loc='bem/watershed',
68 desc='Outer skin surface (in Freesurfer format)')
69 fif_file = File(
70 exists=True,
71 loc='bem',
72 altkey='fif',
73 desc='"fif" format file for EEG processing in MNE')
74 cor_files = OutputMultiPath(
75 File(exists=True),
76 loc='bem/watershed/ws',
77 altkey='COR',
78 desc='"COR" format files')
79
80
81 class WatershedBEM(FSCommand):
82 """Uses mne_watershed_bem to get information from dicom directories
83
84 Examples
85 --------
86
87 >>> from nipype.interfaces.mne import WatershedBEM
88 >>> bem = WatershedBEM()
89 >>> bem.inputs.subject_id = 'subj1'
90 >>> bem.inputs.subjects_dir = '.'
91 >>> bem.cmdline
92 'mne_watershed_bem --overwrite --subject subj1 --volume T1'
93 >>> bem.run() # doctest: +SKIP
94
95 """
96
97 _cmd = 'mne_watershed_bem'
98 input_spec = WatershedBEMInputSpec
99 output_spec = WatershedBEMOutputSpec
100 _additional_metadata = ['loc', 'altkey']
101
102 def _get_files(self, path, key, dirval, altkey=None):
103 globsuffix = '*'
104 globprefix = '*'
105 keydir = op.join(path, dirval)
106 if altkey:
107 key = altkey
108 globpattern = op.join(keydir, ''.join((globprefix, key, globsuffix)))
109 return glob.glob(globpattern)
110
111 def _list_outputs(self):
112 outputs = self.output_spec().get()
113 subjects_dir = self.inputs.subjects_dir
114 subject_path = op.join(subjects_dir, self.inputs.subject_id)
115 output_traits = self._outputs()
116 mesh_paths = []
117 for k in list(outputs.keys()):
118 if k != 'mesh_files':
119 val = self._get_files(subject_path, k,
120 output_traits.traits()[k].loc,
121 output_traits.traits()[k].altkey)
122 if val:
123 value_list = simplify_list(val)
124 if isinstance(value_list, list):
125 out_files = []
126 for value in value_list:
127 out_files.append(op.abspath(value))
128 elif isinstance(value_list, (str, bytes)):
129 out_files = op.abspath(value_list)
130 else:
131 raise TypeError
132 outputs[k] = out_files
133 if not k.rfind('surface') == -1:
134 mesh_paths.append(out_files)
135 outputs['mesh_files'] = mesh_paths
136 return outputs
137
[end of nipype/interfaces/mne/base.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nipype/interfaces/mne/base.py b/nipype/interfaces/mne/base.py
--- a/nipype/interfaces/mne/base.py
+++ b/nipype/interfaces/mne/base.py
@@ -89,12 +89,12 @@
>>> bem.inputs.subject_id = 'subj1'
>>> bem.inputs.subjects_dir = '.'
>>> bem.cmdline
- 'mne_watershed_bem --overwrite --subject subj1 --volume T1'
+ 'mne watershed_bem --overwrite --subject subj1 --volume T1'
>>> bem.run() # doctest: +SKIP
"""
- _cmd = 'mne_watershed_bem'
+ _cmd = 'mne watershed_bem'
input_spec = WatershedBEMInputSpec
output_spec = WatershedBEMOutputSpec
_additional_metadata = ['loc', 'altkey']
|
{"golden_diff": "diff --git a/nipype/interfaces/mne/base.py b/nipype/interfaces/mne/base.py\n--- a/nipype/interfaces/mne/base.py\n+++ b/nipype/interfaces/mne/base.py\n@@ -89,12 +89,12 @@\n >>> bem.inputs.subject_id = 'subj1'\n >>> bem.inputs.subjects_dir = '.'\n >>> bem.cmdline\n- 'mne_watershed_bem --overwrite --subject subj1 --volume T1'\n+ 'mne watershed_bem --overwrite --subject subj1 --volume T1'\n >>> bem.run() \t\t\t\t# doctest: +SKIP\n \n \"\"\"\n \n- _cmd = 'mne_watershed_bem'\n+ _cmd = 'mne watershed_bem'\n input_spec = WatershedBEMInputSpec\n output_spec = WatershedBEMOutputSpec\n _additional_metadata = ['loc', 'altkey']\n", "issue": "mne.WatershedBEM creates incorrect command line\n### Summary\r\nThe mne.WatershedBEM interface `_cmd` do not correspond to the behavior of the stable release of mne [see documentation](https://martinos.org/mne/stable/generated/commands.html#create-bem-surfaces-using-the-watershed-algorithm-included-with-freesurfer)\r\n [This line](https://github.com/nipy/nipype/blob/f79581edc042ed38064f48e85b6dcc38bc30a084/nipype/interfaces/mne/base.py#L97) `_cmd = 'mne_watershed_bem'` should be `_cmd = 'mne watershed_bem'`\nmne.WatershedBEM creates incorrect command line\n### Summary\r\nThe mne.WatershedBEM interface `_cmd` do not correspond to the behavior of the stable release of mne [see documentation](https://martinos.org/mne/stable/generated/commands.html#create-bem-surfaces-using-the-watershed-algorithm-included-with-freesurfer)\r\n [This line](https://github.com/nipy/nipype/blob/f79581edc042ed38064f48e85b6dcc38bc30a084/nipype/interfaces/mne/base.py#L97) `_cmd = 'mne_watershed_bem'` should be `_cmd = 'mne watershed_bem'`\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import (print_function, division, unicode_literals,\n absolute_import)\nfrom builtins import str, bytes\n\nimport os.path as op\nimport glob\n\nfrom ... import logging\nfrom ...utils.filemanip import simplify_list\nfrom ..base import (traits, File, Directory, TraitedSpec, OutputMultiPath)\nfrom ..freesurfer.base import FSCommand, FSTraitedSpec\n\niflogger = logging.getLogger('nipype.interface')\n\n\nclass WatershedBEMInputSpec(FSTraitedSpec):\n subject_id = traits.Str(\n argstr='--subject %s',\n mandatory=True,\n desc='Subject ID (must have a complete Freesurfer directory)')\n subjects_dir = Directory(\n exists=True,\n mandatory=True,\n usedefault=True,\n desc='Path to Freesurfer subjects directory')\n volume = traits.Enum(\n 'T1',\n 'aparc+aseg',\n 'aseg',\n 'brain',\n 'orig',\n 'brainmask',\n 'ribbon',\n argstr='--volume %s',\n usedefault=True,\n desc='The volume from the \"mri\" directory to use (defaults to T1)')\n overwrite = traits.Bool(\n True,\n usedefault=True,\n argstr='--overwrite',\n desc='Overwrites the existing files')\n atlas_mode = traits.Bool(\n argstr='--atlas',\n desc='Use atlas mode for registration (default: no rigid alignment)')\n\n\nclass WatershedBEMOutputSpec(TraitedSpec):\n mesh_files = OutputMultiPath(\n File(exists=True),\n desc=('Paths to the output meshes (brain, inner '\n 'skull, outer skull, outer skin)'))\n brain_surface = File(\n exists=True,\n loc='bem/watershed',\n desc='Brain surface (in Freesurfer format)')\n inner_skull_surface = File(\n exists=True,\n loc='bem/watershed',\n desc='Inner skull surface (in Freesurfer format)')\n outer_skull_surface = File(\n exists=True,\n loc='bem/watershed',\n desc='Outer skull surface (in Freesurfer format)')\n outer_skin_surface = File(\n exists=True,\n loc='bem/watershed',\n desc='Outer skin surface (in Freesurfer format)')\n fif_file = File(\n exists=True,\n loc='bem',\n altkey='fif',\n desc='\"fif\" format file for EEG processing in MNE')\n cor_files = OutputMultiPath(\n File(exists=True),\n loc='bem/watershed/ws',\n altkey='COR',\n desc='\"COR\" format files')\n\n\nclass WatershedBEM(FSCommand):\n \"\"\"Uses mne_watershed_bem to get information from dicom directories\n\n Examples\n --------\n\n >>> from nipype.interfaces.mne import WatershedBEM\n >>> bem = WatershedBEM()\n >>> bem.inputs.subject_id = 'subj1'\n >>> bem.inputs.subjects_dir = '.'\n >>> bem.cmdline\n 'mne_watershed_bem --overwrite --subject subj1 --volume T1'\n >>> bem.run() \t\t\t\t# doctest: +SKIP\n\n \"\"\"\n\n _cmd = 'mne_watershed_bem'\n input_spec = WatershedBEMInputSpec\n output_spec = WatershedBEMOutputSpec\n _additional_metadata = ['loc', 'altkey']\n\n def _get_files(self, path, key, dirval, altkey=None):\n globsuffix = '*'\n globprefix = '*'\n keydir = op.join(path, dirval)\n if altkey:\n key = altkey\n globpattern = op.join(keydir, ''.join((globprefix, key, globsuffix)))\n return glob.glob(globpattern)\n\n def _list_outputs(self):\n outputs = self.output_spec().get()\n subjects_dir = self.inputs.subjects_dir\n subject_path = op.join(subjects_dir, self.inputs.subject_id)\n output_traits = self._outputs()\n mesh_paths = []\n for k in list(outputs.keys()):\n if k != 'mesh_files':\n val = self._get_files(subject_path, k,\n output_traits.traits()[k].loc,\n output_traits.traits()[k].altkey)\n if val:\n value_list = simplify_list(val)\n if isinstance(value_list, list):\n out_files = []\n for value in value_list:\n out_files.append(op.abspath(value))\n elif isinstance(value_list, (str, bytes)):\n out_files = op.abspath(value_list)\n else:\n raise TypeError\n outputs[k] = out_files\n if not k.rfind('surface') == -1:\n mesh_paths.append(out_files)\n outputs['mesh_files'] = mesh_paths\n return outputs\n", "path": "nipype/interfaces/mne/base.py"}]}
| 2,230 | 202 |
gh_patches_debug_2177
|
rasdani/github-patches
|
git_diff
|
yt-project__yt-2259
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Index Error updating from YT-3.4.0 to YT-3.5.1
<!--To help us understand and resolve your issue, please fill out the form to
the best of your ability.-->
<!--You can feel free to delete the sections that do not apply.-->
### Bug report
**Bug summary**
Index error after yt upgrade
**Code for reproduction**
<!--A minimum code snippet required to reproduce the bug, also minimizing the
number of dependencies required.-->
<!-- If you need to use a data file to trigger the issue you're having, consider
using one of the datasets from the yt data hub (http://yt-project.org/data). If
your issue cannot be triggered using a public dataset, you can use the yt
curldrop (https://docs.hub.yt/services.html#curldrop) to share data
files. Please include a link to the dataset in the issue if you use the
curldrop.-->
```
import yt
from yt.units import kpc
import matplotlib.pyplot as plt
import numpy as np
np.set_printoptions(threshold=1500)
filename="/lunarc/nobackup/users/samvad/FINAL-50-0.5/output/output_00018/info_00018.txt"
ds=yt.load(filename)
for i in sorted(ds.derived_field_list):
print(i)
```
**Actual outcome**
<!--The output produced by the above code, which may be a screenshot, console
output, etc.-->
```
File "fields.py", line 10, in <module>
for i in sorted(ds.derived_field_list):
File "yt/data_objects/static_output.py", line 216, in ireq
self.index
File "yt/data_objects/static_output.py", line 509, in index
self, dataset_type=self.dataset_type)
File "yt/frontends/ramses/data_structures.py", line 236, in __init__
super(RAMSESIndex, self).__init__(ds, dataset_type)
File "yt/geometry/geometry_handler.py", line 50, in __init__
self._setup_geometry()
File "yt/geometry/oct_geometry_handler.py", line 25, in _setup_geometry
self._initialize_oct_handler()
File "yt/frontends/ramses/data_structures.py", line 245, in _initialize_oct_handler
for i in cpu_list]
File "yt/frontends/ramses/data_structures.py", line 245, in <listcomp>
for i in cpu_list]
File "yt/frontends/ramses/data_structures.py", line 82, in __init__
self._read_amr_header()
File "yt/frontends/ramses/data_structures.py", line 141, in _read_amr_header
hvals.update(f.read_attrs(header))
File "yt/utilities/cython_fortran_utils.pyx", line 223, in yt.utilities.cython_fortran_utils.FortranFile.read_attrs
IndexError: index 0 is out of bounds for axis 0 with size 0
```
**Expected outcome**
has to print the fields in the data. Was working with yt 3.4.0
**Version Information**
<!--Please specify your platform and versions of the relevant libraries you are
using:-->
* Operating System: Mac
* Python Version: 3.6
* yt version: 3.5.1
* Other Libraries (if applicable):
installed Anaconda separately and then did conda installation of YT using 'forge'
<!--Please tell us how you installed yt and python e.g., from source,
pip, conda. If you installed from conda, please specify which channel you used
if not the default-->
</issue>
<code>
[start of yt/frontends/ramses/definitions.py]
1 """
2 Definitions for RAMSES files
3
4
5
6
7 """
8
9 #-----------------------------------------------------------------------------
10 # Copyright (c) 2013, yt Development Team.
11 #
12 # Distributed under the terms of the Modified BSD License.
13 #
14 # The full license is in the file COPYING.txt, distributed with this software.
15 #-----------------------------------------------------------------------------
16
17 # These functions are RAMSES-specific
18 from yt.config import ytcfg
19 from yt.funcs import mylog
20 import re
21
22 def ramses_header(hvals):
23 header = ( ('ncpu', 1, 'i'),
24 ('ndim', 1, 'i'),
25 ('nx', 3, 'i'),
26 ('nlevelmax', 1, 'i'),
27 ('ngridmax', 1, 'i'),
28 ('nboundary', 1, 'i'),
29 ('ngrid_current', 1, 'i'),
30 ('boxlen', 1, 'd'),
31 ('nout', 3, 'i')
32 )
33 yield header
34 # TODO: REMOVE
35 noutput, iout, ifout = hvals['nout']
36 next_set = ( ('tout', noutput, 'd'),
37 ('aout', noutput, 'd'),
38 ('t', 1, 'd'),
39 ('dtold', hvals['nlevelmax'], 'd'),
40 ('dtnew', hvals['nlevelmax'], 'd'),
41 ('nstep', 2, 'i'),
42 ('stat', 3, 'd'),
43 ('cosm', 7, 'd'),
44 ('timing', 5, 'd'),
45 ('mass_sph', 1, 'd') )
46 yield next_set
47
48 field_aliases = {
49 'standard_five': ('Density',
50 'x-velocity',
51 'y-velocity',
52 'z-velocity',
53 'Pressure'),
54 'standard_six': ('Density',
55 'x-velocity',
56 'y-velocity',
57 'z-velocity',
58 'Pressure',
59 'Metallicity'),
60
61 }
62
63 ## Regular expressions used to parse file descriptors
64 VERSION_RE = re.compile(r'# version: *(\d+)')
65 # This will match comma-separated strings, discarding whitespaces
66 # on the left hand side
67 VAR_DESC_RE = re.compile(r'\s*([^\s]+),\s*([^\s]+),\s*([^\s]+)')
68
69
70 ## Configure family mapping
71 particle_families = {
72 'DM': 1,
73 'star': 2,
74 'cloud': 3,
75 'dust': 4,
76 'star_tracer': -2,
77 'cloud_tracer': -3,
78 'dust_tracer': -4,
79 'gas_tracer': 0
80 }
81
82 if ytcfg.has_section('ramses-families'):
83 for key in particle_families.keys():
84 val = ytcfg.getint('ramses-families', key, fallback=None)
85 if val is not None:
86 mylog.info('Changing family %s from %s to %s' % (key, particle_families[key], val))
87 particle_families[key] = val
88
[end of yt/frontends/ramses/definitions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/yt/frontends/ramses/definitions.py b/yt/frontends/ramses/definitions.py
--- a/yt/frontends/ramses/definitions.py
+++ b/yt/frontends/ramses/definitions.py
@@ -42,7 +42,8 @@
('stat', 3, 'd'),
('cosm', 7, 'd'),
('timing', 5, 'd'),
- ('mass_sph', 1, 'd') )
+ ('mass_sph', 1, 'd', True)
+ )
yield next_set
field_aliases = {
|
{"golden_diff": "diff --git a/yt/frontends/ramses/definitions.py b/yt/frontends/ramses/definitions.py\n--- a/yt/frontends/ramses/definitions.py\n+++ b/yt/frontends/ramses/definitions.py\n@@ -42,7 +42,8 @@\n ('stat', 3, 'd'),\n ('cosm', 7, 'd'),\n ('timing', 5, 'd'),\n- ('mass_sph', 1, 'd') )\n+ ('mass_sph', 1, 'd', True)\n+ )\n yield next_set\n \n field_aliases = {\n", "issue": "Index Error updating from YT-3.4.0 to YT-3.5.1\n<!--To help us understand and resolve your issue, please fill out the form to\r\nthe best of your ability.-->\r\n<!--You can feel free to delete the sections that do not apply.-->\r\n\r\n### Bug report\r\n\r\n**Bug summary**\r\n\r\nIndex error after yt upgrade \r\n\r\n**Code for reproduction**\r\n\r\n<!--A minimum code snippet required to reproduce the bug, also minimizing the\r\nnumber of dependencies required.-->\r\n\r\n<!-- If you need to use a data file to trigger the issue you're having, consider\r\nusing one of the datasets from the yt data hub (http://yt-project.org/data). If\r\nyour issue cannot be triggered using a public dataset, you can use the yt\r\ncurldrop (https://docs.hub.yt/services.html#curldrop) to share data\r\nfiles. Please include a link to the dataset in the issue if you use the\r\ncurldrop.-->\r\n\r\n```\r\nimport yt\r\nfrom yt.units import kpc\r\nimport matplotlib.pyplot as plt\r\nimport numpy as np\r\nnp.set_printoptions(threshold=1500)\r\nfilename=\"/lunarc/nobackup/users/samvad/FINAL-50-0.5/output/output_00018/info_00018.txt\"\r\nds=yt.load(filename)\r\n\r\nfor i in sorted(ds.derived_field_list):\r\n print(i)\r\n```\r\n\r\n**Actual outcome**\r\n\r\n<!--The output produced by the above code, which may be a screenshot, console\r\noutput, etc.-->\r\n\r\n```\r\nFile \"fields.py\", line 10, in <module>\r\n for i in sorted(ds.derived_field_list):\r\n File \"yt/data_objects/static_output.py\", line 216, in ireq\r\n self.index\r\n File \"yt/data_objects/static_output.py\", line 509, in index\r\n self, dataset_type=self.dataset_type)\r\n File \"yt/frontends/ramses/data_structures.py\", line 236, in __init__\r\n super(RAMSESIndex, self).__init__(ds, dataset_type)\r\n File \"yt/geometry/geometry_handler.py\", line 50, in __init__\r\n self._setup_geometry()\r\n File \"yt/geometry/oct_geometry_handler.py\", line 25, in _setup_geometry\r\n self._initialize_oct_handler()\r\n File \"yt/frontends/ramses/data_structures.py\", line 245, in _initialize_oct_handler\r\n for i in cpu_list]\r\n File \"yt/frontends/ramses/data_structures.py\", line 245, in <listcomp>\r\n for i in cpu_list]\r\n File \"yt/frontends/ramses/data_structures.py\", line 82, in __init__\r\n self._read_amr_header()\r\n File \"yt/frontends/ramses/data_structures.py\", line 141, in _read_amr_header\r\n hvals.update(f.read_attrs(header))\r\n File \"yt/utilities/cython_fortran_utils.pyx\", line 223, in yt.utilities.cython_fortran_utils.FortranFile.read_attrs\r\nIndexError: index 0 is out of bounds for axis 0 with size 0\r\n```\r\n\r\n**Expected outcome**\r\n\r\nhas to print the fields in the data. Was working with yt 3.4.0\r\n\r\n**Version Information**\r\n<!--Please specify your platform and versions of the relevant libraries you are\r\nusing:-->\r\n * Operating System: Mac\r\n * Python Version: 3.6\r\n * yt version: 3.5.1\r\n * Other Libraries (if applicable): \r\n\r\ninstalled Anaconda separately and then did conda installation of YT using 'forge'\r\n<!--Please tell us how you installed yt and python e.g., from source,\r\npip, conda. If you installed from conda, please specify which channel you used\r\nif not the default-->\r\n\n", "before_files": [{"content": "\"\"\"\nDefinitions for RAMSES files\n\n\n\n\n\"\"\"\n\n#-----------------------------------------------------------------------------\n# Copyright (c) 2013, yt Development Team.\n#\n# Distributed under the terms of the Modified BSD License.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#-----------------------------------------------------------------------------\n\n# These functions are RAMSES-specific\nfrom yt.config import ytcfg\nfrom yt.funcs import mylog\nimport re\n\ndef ramses_header(hvals):\n header = ( ('ncpu', 1, 'i'),\n ('ndim', 1, 'i'),\n ('nx', 3, 'i'),\n ('nlevelmax', 1, 'i'),\n ('ngridmax', 1, 'i'),\n ('nboundary', 1, 'i'),\n ('ngrid_current', 1, 'i'),\n ('boxlen', 1, 'd'),\n ('nout', 3, 'i')\n )\n yield header\n # TODO: REMOVE\n noutput, iout, ifout = hvals['nout']\n next_set = ( ('tout', noutput, 'd'),\n ('aout', noutput, 'd'),\n ('t', 1, 'd'),\n ('dtold', hvals['nlevelmax'], 'd'),\n ('dtnew', hvals['nlevelmax'], 'd'),\n ('nstep', 2, 'i'),\n ('stat', 3, 'd'),\n ('cosm', 7, 'd'),\n ('timing', 5, 'd'),\n ('mass_sph', 1, 'd') )\n yield next_set\n\nfield_aliases = {\n 'standard_five': ('Density',\n 'x-velocity',\n 'y-velocity',\n 'z-velocity',\n 'Pressure'),\n 'standard_six': ('Density',\n 'x-velocity',\n 'y-velocity',\n 'z-velocity',\n 'Pressure',\n 'Metallicity'),\n\n}\n\n## Regular expressions used to parse file descriptors\nVERSION_RE = re.compile(r'# version: *(\\d+)')\n# This will match comma-separated strings, discarding whitespaces\n# on the left hand side\nVAR_DESC_RE = re.compile(r'\\s*([^\\s]+),\\s*([^\\s]+),\\s*([^\\s]+)')\n\n\n## Configure family mapping\nparticle_families = {\n 'DM': 1,\n 'star': 2,\n 'cloud': 3,\n 'dust': 4,\n 'star_tracer': -2,\n 'cloud_tracer': -3,\n 'dust_tracer': -4,\n 'gas_tracer': 0\n}\n\nif ytcfg.has_section('ramses-families'):\n for key in particle_families.keys():\n val = ytcfg.getint('ramses-families', key, fallback=None)\n if val is not None:\n mylog.info('Changing family %s from %s to %s' % (key, particle_families[key], val))\n particle_families[key] = val\n", "path": "yt/frontends/ramses/definitions.py"}]}
| 2,210 | 136 |
gh_patches_debug_28179
|
rasdani/github-patches
|
git_diff
|
pallets__click-1135
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Incorrect OSError raised when redirecting to NUL on Windows
Reproducible for both Python 3.6 and 3.7. I did not test against older versions.
Tested on the Click 6.x series. Windows 10, Build 17134.
Steps to reproduce:
```python
# t.py
import click
@click.command()
def main():
click.echo('run')
if __name__ == '__main__':
main()
```
```
> python t.py
run
> python t.py >NUL
Traceback (most recent call last):
File "t.py", line 10, in <module>
main()
File ".venv\lib\site-packages\click\core.py", line 722, in __call__
return self.main(*args, **kwargs)
File ".venv\lib\site-packages\click\core.py", line 697, in main
rv = self.invoke(ctx)
File ".venv\lib\site-packages\click\core.py", line 895, in invoke
return ctx.invoke(self.callback, **ctx.params)
File ".venv\lib\site-packages\click\core.py", line 535, in invoke
return callback(*args, **kwargs)
File "t.py", line 6, in main
click.echo('run')
File ".venv\lib\site-packages\click\utils.py", line 259, in echo
file.write(message)
File ".venv\lib\site-packages\click\_winconsole.py", line 180, in write
return self._text_stream.write(x)
File ".venv\lib\site-packages\click\_winconsole.py", line 164, in write
raise OSError(self._get_error_message(GetLastError()))
OSError: Windows error 1
```
I believe the problem is that Click tries to be helpful, and raises an error when there are not bytes written when there should be. This is, however, exactly what is expected to happen when you redirect things to `NUL` on Windows.
Curiously, however, Windows seems to act a little differently for stderr. `2>NUL` works as expected.
</issue>
<code>
[start of click/_winconsole.py]
1 # -*- coding: utf-8 -*-
2 # This module is based on the excellent work by Adam Bartoš who
3 # provided a lot of what went into the implementation here in
4 # the discussion to issue1602 in the Python bug tracker.
5 #
6 # There are some general differences in regards to how this works
7 # compared to the original patches as we do not need to patch
8 # the entire interpreter but just work in our little world of
9 # echo and prmopt.
10
11 import io
12 import os
13 import sys
14 import zlib
15 import time
16 import ctypes
17 import msvcrt
18 from ._compat import _NonClosingTextIOWrapper, text_type, PY2
19 from ctypes import byref, POINTER, c_int, c_char, c_char_p, \
20 c_void_p, py_object, c_ssize_t, c_ulong, windll, WINFUNCTYPE
21 try:
22 from ctypes import pythonapi
23 PyObject_GetBuffer = pythonapi.PyObject_GetBuffer
24 PyBuffer_Release = pythonapi.PyBuffer_Release
25 except ImportError:
26 pythonapi = None
27 from ctypes.wintypes import LPWSTR, LPCWSTR, HANDLE
28
29
30 c_ssize_p = POINTER(c_ssize_t)
31
32 kernel32 = windll.kernel32
33 GetStdHandle = kernel32.GetStdHandle
34 ReadConsoleW = kernel32.ReadConsoleW
35 WriteConsoleW = kernel32.WriteConsoleW
36 GetLastError = kernel32.GetLastError
37 GetCommandLineW = WINFUNCTYPE(LPWSTR)(
38 ('GetCommandLineW', windll.kernel32))
39 CommandLineToArgvW = WINFUNCTYPE(
40 POINTER(LPWSTR), LPCWSTR, POINTER(c_int))(
41 ('CommandLineToArgvW', windll.shell32))
42
43
44 STDIN_HANDLE = GetStdHandle(-10)
45 STDOUT_HANDLE = GetStdHandle(-11)
46 STDERR_HANDLE = GetStdHandle(-12)
47
48
49 PyBUF_SIMPLE = 0
50 PyBUF_WRITABLE = 1
51
52 ERROR_SUCCESS = 0
53 ERROR_NOT_ENOUGH_MEMORY = 8
54 ERROR_OPERATION_ABORTED = 995
55
56 STDIN_FILENO = 0
57 STDOUT_FILENO = 1
58 STDERR_FILENO = 2
59
60 EOF = b'\x1a'
61 MAX_BYTES_WRITTEN = 32767
62
63
64 class Py_buffer(ctypes.Structure):
65 _fields_ = [
66 ('buf', c_void_p),
67 ('obj', py_object),
68 ('len', c_ssize_t),
69 ('itemsize', c_ssize_t),
70 ('readonly', c_int),
71 ('ndim', c_int),
72 ('format', c_char_p),
73 ('shape', c_ssize_p),
74 ('strides', c_ssize_p),
75 ('suboffsets', c_ssize_p),
76 ('internal', c_void_p)
77 ]
78
79 if PY2:
80 _fields_.insert(-1, ('smalltable', c_ssize_t * 2))
81
82
83 # On PyPy we cannot get buffers so our ability to operate here is
84 # serverly limited.
85 if pythonapi is None:
86 get_buffer = None
87 else:
88 def get_buffer(obj, writable=False):
89 buf = Py_buffer()
90 flags = PyBUF_WRITABLE if writable else PyBUF_SIMPLE
91 PyObject_GetBuffer(py_object(obj), byref(buf), flags)
92 try:
93 buffer_type = c_char * buf.len
94 return buffer_type.from_address(buf.buf)
95 finally:
96 PyBuffer_Release(byref(buf))
97
98
99 class _WindowsConsoleRawIOBase(io.RawIOBase):
100
101 def __init__(self, handle):
102 self.handle = handle
103
104 def isatty(self):
105 io.RawIOBase.isatty(self)
106 return True
107
108
109 class _WindowsConsoleReader(_WindowsConsoleRawIOBase):
110
111 def readable(self):
112 return True
113
114 def readinto(self, b):
115 bytes_to_be_read = len(b)
116 if not bytes_to_be_read:
117 return 0
118 elif bytes_to_be_read % 2:
119 raise ValueError('cannot read odd number of bytes from '
120 'UTF-16-LE encoded console')
121
122 buffer = get_buffer(b, writable=True)
123 code_units_to_be_read = bytes_to_be_read // 2
124 code_units_read = c_ulong()
125
126 rv = ReadConsoleW(HANDLE(self.handle), buffer, code_units_to_be_read,
127 byref(code_units_read), None)
128 if GetLastError() == ERROR_OPERATION_ABORTED:
129 # wait for KeyboardInterrupt
130 time.sleep(0.1)
131 if not rv:
132 raise OSError('Windows error: %s' % GetLastError())
133
134 if buffer[0] == EOF:
135 return 0
136 return 2 * code_units_read.value
137
138
139 class _WindowsConsoleWriter(_WindowsConsoleRawIOBase):
140
141 def writable(self):
142 return True
143
144 @staticmethod
145 def _get_error_message(errno):
146 if errno == ERROR_SUCCESS:
147 return 'ERROR_SUCCESS'
148 elif errno == ERROR_NOT_ENOUGH_MEMORY:
149 return 'ERROR_NOT_ENOUGH_MEMORY'
150 return 'Windows error %s' % errno
151
152 def write(self, b):
153 bytes_to_be_written = len(b)
154 buf = get_buffer(b)
155 code_units_to_be_written = min(bytes_to_be_written,
156 MAX_BYTES_WRITTEN) // 2
157 code_units_written = c_ulong()
158
159 WriteConsoleW(HANDLE(self.handle), buf, code_units_to_be_written,
160 byref(code_units_written), None)
161 bytes_written = 2 * code_units_written.value
162
163 if bytes_written == 0 and bytes_to_be_written > 0:
164 raise OSError(self._get_error_message(GetLastError()))
165 return bytes_written
166
167
168 class ConsoleStream(object):
169
170 def __init__(self, text_stream, byte_stream):
171 self._text_stream = text_stream
172 self.buffer = byte_stream
173
174 @property
175 def name(self):
176 return self.buffer.name
177
178 def write(self, x):
179 if isinstance(x, text_type):
180 return self._text_stream.write(x)
181 try:
182 self.flush()
183 except Exception:
184 pass
185 return self.buffer.write(x)
186
187 def writelines(self, lines):
188 for line in lines:
189 self.write(line)
190
191 def __getattr__(self, name):
192 return getattr(self._text_stream, name)
193
194 def isatty(self):
195 return self.buffer.isatty()
196
197 def __repr__(self):
198 return '<ConsoleStream name=%r encoding=%r>' % (
199 self.name,
200 self.encoding,
201 )
202
203
204 class WindowsChunkedWriter(object):
205 """
206 Wraps a stream (such as stdout), acting as a transparent proxy for all
207 attribute access apart from method 'write()' which we wrap to write in
208 limited chunks due to a Windows limitation on binary console streams.
209 """
210 def __init__(self, wrapped):
211 # double-underscore everything to prevent clashes with names of
212 # attributes on the wrapped stream object.
213 self.__wrapped = wrapped
214
215 def __getattr__(self, name):
216 return getattr(self.__wrapped, name)
217
218 def write(self, text):
219 total_to_write = len(text)
220 written = 0
221
222 while written < total_to_write:
223 to_write = min(total_to_write - written, MAX_BYTES_WRITTEN)
224 self.__wrapped.write(text[written:written+to_write])
225 written += to_write
226
227
228 _wrapped_std_streams = set()
229
230
231 def _wrap_std_stream(name):
232 # Python 2 & Windows 7 and below
233 if PY2 and sys.getwindowsversion()[:2] <= (6, 1) and name not in _wrapped_std_streams:
234 setattr(sys, name, WindowsChunkedWriter(getattr(sys, name)))
235 _wrapped_std_streams.add(name)
236
237
238 def _get_text_stdin(buffer_stream):
239 text_stream = _NonClosingTextIOWrapper(
240 io.BufferedReader(_WindowsConsoleReader(STDIN_HANDLE)),
241 'utf-16-le', 'strict', line_buffering=True)
242 return ConsoleStream(text_stream, buffer_stream)
243
244
245 def _get_text_stdout(buffer_stream):
246 text_stream = _NonClosingTextIOWrapper(
247 io.BufferedWriter(_WindowsConsoleWriter(STDOUT_HANDLE)),
248 'utf-16-le', 'strict', line_buffering=True)
249 return ConsoleStream(text_stream, buffer_stream)
250
251
252 def _get_text_stderr(buffer_stream):
253 text_stream = _NonClosingTextIOWrapper(
254 io.BufferedWriter(_WindowsConsoleWriter(STDERR_HANDLE)),
255 'utf-16-le', 'strict', line_buffering=True)
256 return ConsoleStream(text_stream, buffer_stream)
257
258
259 if PY2:
260 def _hash_py_argv():
261 return zlib.crc32('\x00'.join(sys.argv[1:]))
262
263 _initial_argv_hash = _hash_py_argv()
264
265 def _get_windows_argv():
266 argc = c_int(0)
267 argv_unicode = CommandLineToArgvW(GetCommandLineW(), byref(argc))
268 argv = [argv_unicode[i] for i in range(0, argc.value)]
269
270 if not hasattr(sys, 'frozen'):
271 argv = argv[1:]
272 while len(argv) > 0:
273 arg = argv[0]
274 if not arg.startswith('-') or arg == '-':
275 break
276 argv = argv[1:]
277 if arg.startswith(('-c', '-m')):
278 break
279
280 return argv[1:]
281
282
283 _stream_factories = {
284 0: _get_text_stdin,
285 1: _get_text_stdout,
286 2: _get_text_stderr,
287 }
288
289
290 def _get_windows_console_stream(f, encoding, errors):
291 if get_buffer is not None and \
292 encoding in ('utf-16-le', None) \
293 and errors in ('strict', None) and \
294 hasattr(f, 'isatty') and f.isatty():
295 func = _stream_factories.get(f.fileno())
296 if func is not None:
297 if not PY2:
298 f = getattr(f, 'buffer', None)
299 if f is None:
300 return None
301 else:
302 # If we are on Python 2 we need to set the stream that we
303 # deal with to binary mode as otherwise the exercise if a
304 # bit moot. The same problems apply as for
305 # get_binary_stdin and friends from _compat.
306 msvcrt.setmode(f.fileno(), os.O_BINARY)
307 return func(f)
308
[end of click/_winconsole.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/click/_winconsole.py b/click/_winconsole.py
--- a/click/_winconsole.py
+++ b/click/_winconsole.py
@@ -24,7 +24,7 @@
PyBuffer_Release = pythonapi.PyBuffer_Release
except ImportError:
pythonapi = None
-from ctypes.wintypes import LPWSTR, LPCWSTR, HANDLE
+from ctypes.wintypes import DWORD, LPWSTR, LPCWSTR, HANDLE
c_ssize_p = POINTER(c_ssize_t)
@@ -33,6 +33,7 @@
GetStdHandle = kernel32.GetStdHandle
ReadConsoleW = kernel32.ReadConsoleW
WriteConsoleW = kernel32.WriteConsoleW
+GetConsoleMode = kernel32.GetConsoleMode
GetLastError = kernel32.GetLastError
GetCommandLineW = WINFUNCTYPE(LPWSTR)(
('GetCommandLineW', windll.kernel32))
@@ -287,11 +288,24 @@
}
+def _is_console(f):
+ if not hasattr(f, 'fileno'):
+ return False
+
+ try:
+ fileno = f.fileno()
+ except OSError:
+ return False
+
+ handle = msvcrt.get_osfhandle(fileno)
+ return bool(GetConsoleMode(handle, byref(DWORD())))
+
+
def _get_windows_console_stream(f, encoding, errors):
if get_buffer is not None and \
encoding in ('utf-16-le', None) \
and errors in ('strict', None) and \
- hasattr(f, 'isatty') and f.isatty():
+ _is_console(f):
func = _stream_factories.get(f.fileno())
if func is not None:
if not PY2:
|
{"golden_diff": "diff --git a/click/_winconsole.py b/click/_winconsole.py\n--- a/click/_winconsole.py\n+++ b/click/_winconsole.py\n@@ -24,7 +24,7 @@\n PyBuffer_Release = pythonapi.PyBuffer_Release\n except ImportError:\n pythonapi = None\n-from ctypes.wintypes import LPWSTR, LPCWSTR, HANDLE\n+from ctypes.wintypes import DWORD, LPWSTR, LPCWSTR, HANDLE\n \n \n c_ssize_p = POINTER(c_ssize_t)\n@@ -33,6 +33,7 @@\n GetStdHandle = kernel32.GetStdHandle\n ReadConsoleW = kernel32.ReadConsoleW\n WriteConsoleW = kernel32.WriteConsoleW\n+GetConsoleMode = kernel32.GetConsoleMode\n GetLastError = kernel32.GetLastError\n GetCommandLineW = WINFUNCTYPE(LPWSTR)(\n ('GetCommandLineW', windll.kernel32))\n@@ -287,11 +288,24 @@\n }\n \n \n+def _is_console(f):\n+ if not hasattr(f, 'fileno'):\n+ return False\n+\n+ try:\n+ fileno = f.fileno()\n+ except OSError:\n+ return False\n+\n+ handle = msvcrt.get_osfhandle(fileno)\n+ return bool(GetConsoleMode(handle, byref(DWORD())))\n+\n+\n def _get_windows_console_stream(f, encoding, errors):\n if get_buffer is not None and \\\n encoding in ('utf-16-le', None) \\\n and errors in ('strict', None) and \\\n- hasattr(f, 'isatty') and f.isatty():\n+ _is_console(f):\n func = _stream_factories.get(f.fileno())\n if func is not None:\n if not PY2:\n", "issue": "Incorrect OSError raised when redirecting to NUL on Windows\nReproducible for both Python 3.6 and 3.7. I did not test against older versions.\r\n\r\nTested on the Click 6.x series. Windows 10, Build 17134.\r\n\r\nSteps to reproduce:\r\n\r\n```python\r\n# t.py\r\nimport click\r\n\r\[email protected]()\r\ndef main():\r\n click.echo('run')\r\n\r\nif __name__ == '__main__':\r\n main()\r\n```\r\n\r\n```\r\n> python t.py\r\nrun\r\n\r\n> python t.py >NUL\r\nTraceback (most recent call last):\r\n File \"t.py\", line 10, in <module>\r\n main()\r\n File \".venv\\lib\\site-packages\\click\\core.py\", line 722, in __call__\r\n return self.main(*args, **kwargs)\r\n File \".venv\\lib\\site-packages\\click\\core.py\", line 697, in main\r\n rv = self.invoke(ctx)\r\n File \".venv\\lib\\site-packages\\click\\core.py\", line 895, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \".venv\\lib\\site-packages\\click\\core.py\", line 535, in invoke\r\n return callback(*args, **kwargs)\r\n File \"t.py\", line 6, in main\r\n click.echo('run')\r\n File \".venv\\lib\\site-packages\\click\\utils.py\", line 259, in echo\r\n file.write(message)\r\n File \".venv\\lib\\site-packages\\click\\_winconsole.py\", line 180, in write\r\n return self._text_stream.write(x)\r\n File \".venv\\lib\\site-packages\\click\\_winconsole.py\", line 164, in write\r\n raise OSError(self._get_error_message(GetLastError()))\r\nOSError: Windows error 1\r\n```\r\n\r\nI believe the problem is that Click tries to be helpful, and raises an error when there are not bytes written when there should be. This is, however, exactly what is expected to happen when you redirect things to `NUL` on Windows.\r\n\r\nCuriously, however, Windows seems to act a little differently for stderr. `2>NUL` works as expected.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# This module is based on the excellent work by Adam Barto\u0161 who\n# provided a lot of what went into the implementation here in\n# the discussion to issue1602 in the Python bug tracker.\n#\n# There are some general differences in regards to how this works\n# compared to the original patches as we do not need to patch\n# the entire interpreter but just work in our little world of\n# echo and prmopt.\n\nimport io\nimport os\nimport sys\nimport zlib\nimport time\nimport ctypes\nimport msvcrt\nfrom ._compat import _NonClosingTextIOWrapper, text_type, PY2\nfrom ctypes import byref, POINTER, c_int, c_char, c_char_p, \\\n c_void_p, py_object, c_ssize_t, c_ulong, windll, WINFUNCTYPE\ntry:\n from ctypes import pythonapi\n PyObject_GetBuffer = pythonapi.PyObject_GetBuffer\n PyBuffer_Release = pythonapi.PyBuffer_Release\nexcept ImportError:\n pythonapi = None\nfrom ctypes.wintypes import LPWSTR, LPCWSTR, HANDLE\n\n\nc_ssize_p = POINTER(c_ssize_t)\n\nkernel32 = windll.kernel32\nGetStdHandle = kernel32.GetStdHandle\nReadConsoleW = kernel32.ReadConsoleW\nWriteConsoleW = kernel32.WriteConsoleW\nGetLastError = kernel32.GetLastError\nGetCommandLineW = WINFUNCTYPE(LPWSTR)(\n ('GetCommandLineW', windll.kernel32))\nCommandLineToArgvW = WINFUNCTYPE(\n POINTER(LPWSTR), LPCWSTR, POINTER(c_int))(\n ('CommandLineToArgvW', windll.shell32))\n\n\nSTDIN_HANDLE = GetStdHandle(-10)\nSTDOUT_HANDLE = GetStdHandle(-11)\nSTDERR_HANDLE = GetStdHandle(-12)\n\n\nPyBUF_SIMPLE = 0\nPyBUF_WRITABLE = 1\n\nERROR_SUCCESS = 0\nERROR_NOT_ENOUGH_MEMORY = 8\nERROR_OPERATION_ABORTED = 995\n\nSTDIN_FILENO = 0\nSTDOUT_FILENO = 1\nSTDERR_FILENO = 2\n\nEOF = b'\\x1a'\nMAX_BYTES_WRITTEN = 32767\n\n\nclass Py_buffer(ctypes.Structure):\n _fields_ = [\n ('buf', c_void_p),\n ('obj', py_object),\n ('len', c_ssize_t),\n ('itemsize', c_ssize_t),\n ('readonly', c_int),\n ('ndim', c_int),\n ('format', c_char_p),\n ('shape', c_ssize_p),\n ('strides', c_ssize_p),\n ('suboffsets', c_ssize_p),\n ('internal', c_void_p)\n ]\n\n if PY2:\n _fields_.insert(-1, ('smalltable', c_ssize_t * 2))\n\n\n# On PyPy we cannot get buffers so our ability to operate here is\n# serverly limited.\nif pythonapi is None:\n get_buffer = None\nelse:\n def get_buffer(obj, writable=False):\n buf = Py_buffer()\n flags = PyBUF_WRITABLE if writable else PyBUF_SIMPLE\n PyObject_GetBuffer(py_object(obj), byref(buf), flags)\n try:\n buffer_type = c_char * buf.len\n return buffer_type.from_address(buf.buf)\n finally:\n PyBuffer_Release(byref(buf))\n\n\nclass _WindowsConsoleRawIOBase(io.RawIOBase):\n\n def __init__(self, handle):\n self.handle = handle\n\n def isatty(self):\n io.RawIOBase.isatty(self)\n return True\n\n\nclass _WindowsConsoleReader(_WindowsConsoleRawIOBase):\n\n def readable(self):\n return True\n\n def readinto(self, b):\n bytes_to_be_read = len(b)\n if not bytes_to_be_read:\n return 0\n elif bytes_to_be_read % 2:\n raise ValueError('cannot read odd number of bytes from '\n 'UTF-16-LE encoded console')\n\n buffer = get_buffer(b, writable=True)\n code_units_to_be_read = bytes_to_be_read // 2\n code_units_read = c_ulong()\n\n rv = ReadConsoleW(HANDLE(self.handle), buffer, code_units_to_be_read,\n byref(code_units_read), None)\n if GetLastError() == ERROR_OPERATION_ABORTED:\n # wait for KeyboardInterrupt\n time.sleep(0.1)\n if not rv:\n raise OSError('Windows error: %s' % GetLastError())\n\n if buffer[0] == EOF:\n return 0\n return 2 * code_units_read.value\n\n\nclass _WindowsConsoleWriter(_WindowsConsoleRawIOBase):\n\n def writable(self):\n return True\n\n @staticmethod\n def _get_error_message(errno):\n if errno == ERROR_SUCCESS:\n return 'ERROR_SUCCESS'\n elif errno == ERROR_NOT_ENOUGH_MEMORY:\n return 'ERROR_NOT_ENOUGH_MEMORY'\n return 'Windows error %s' % errno\n\n def write(self, b):\n bytes_to_be_written = len(b)\n buf = get_buffer(b)\n code_units_to_be_written = min(bytes_to_be_written,\n MAX_BYTES_WRITTEN) // 2\n code_units_written = c_ulong()\n\n WriteConsoleW(HANDLE(self.handle), buf, code_units_to_be_written,\n byref(code_units_written), None)\n bytes_written = 2 * code_units_written.value\n\n if bytes_written == 0 and bytes_to_be_written > 0:\n raise OSError(self._get_error_message(GetLastError()))\n return bytes_written\n\n\nclass ConsoleStream(object):\n\n def __init__(self, text_stream, byte_stream):\n self._text_stream = text_stream\n self.buffer = byte_stream\n\n @property\n def name(self):\n return self.buffer.name\n\n def write(self, x):\n if isinstance(x, text_type):\n return self._text_stream.write(x)\n try:\n self.flush()\n except Exception:\n pass\n return self.buffer.write(x)\n\n def writelines(self, lines):\n for line in lines:\n self.write(line)\n\n def __getattr__(self, name):\n return getattr(self._text_stream, name)\n\n def isatty(self):\n return self.buffer.isatty()\n\n def __repr__(self):\n return '<ConsoleStream name=%r encoding=%r>' % (\n self.name,\n self.encoding,\n )\n\n\nclass WindowsChunkedWriter(object):\n \"\"\"\n Wraps a stream (such as stdout), acting as a transparent proxy for all\n attribute access apart from method 'write()' which we wrap to write in\n limited chunks due to a Windows limitation on binary console streams.\n \"\"\"\n def __init__(self, wrapped):\n # double-underscore everything to prevent clashes with names of\n # attributes on the wrapped stream object.\n self.__wrapped = wrapped\n\n def __getattr__(self, name):\n return getattr(self.__wrapped, name)\n\n def write(self, text):\n total_to_write = len(text)\n written = 0\n\n while written < total_to_write:\n to_write = min(total_to_write - written, MAX_BYTES_WRITTEN)\n self.__wrapped.write(text[written:written+to_write])\n written += to_write\n\n\n_wrapped_std_streams = set()\n\n\ndef _wrap_std_stream(name):\n # Python 2 & Windows 7 and below\n if PY2 and sys.getwindowsversion()[:2] <= (6, 1) and name not in _wrapped_std_streams:\n setattr(sys, name, WindowsChunkedWriter(getattr(sys, name)))\n _wrapped_std_streams.add(name)\n\n\ndef _get_text_stdin(buffer_stream):\n text_stream = _NonClosingTextIOWrapper(\n io.BufferedReader(_WindowsConsoleReader(STDIN_HANDLE)),\n 'utf-16-le', 'strict', line_buffering=True)\n return ConsoleStream(text_stream, buffer_stream)\n\n\ndef _get_text_stdout(buffer_stream):\n text_stream = _NonClosingTextIOWrapper(\n io.BufferedWriter(_WindowsConsoleWriter(STDOUT_HANDLE)),\n 'utf-16-le', 'strict', line_buffering=True)\n return ConsoleStream(text_stream, buffer_stream)\n\n\ndef _get_text_stderr(buffer_stream):\n text_stream = _NonClosingTextIOWrapper(\n io.BufferedWriter(_WindowsConsoleWriter(STDERR_HANDLE)),\n 'utf-16-le', 'strict', line_buffering=True)\n return ConsoleStream(text_stream, buffer_stream)\n\n\nif PY2:\n def _hash_py_argv():\n return zlib.crc32('\\x00'.join(sys.argv[1:]))\n\n _initial_argv_hash = _hash_py_argv()\n\n def _get_windows_argv():\n argc = c_int(0)\n argv_unicode = CommandLineToArgvW(GetCommandLineW(), byref(argc))\n argv = [argv_unicode[i] for i in range(0, argc.value)]\n\n if not hasattr(sys, 'frozen'):\n argv = argv[1:]\n while len(argv) > 0:\n arg = argv[0]\n if not arg.startswith('-') or arg == '-':\n break\n argv = argv[1:]\n if arg.startswith(('-c', '-m')):\n break\n\n return argv[1:]\n\n\n_stream_factories = {\n 0: _get_text_stdin,\n 1: _get_text_stdout,\n 2: _get_text_stderr,\n}\n\n\ndef _get_windows_console_stream(f, encoding, errors):\n if get_buffer is not None and \\\n encoding in ('utf-16-le', None) \\\n and errors in ('strict', None) and \\\n hasattr(f, 'isatty') and f.isatty():\n func = _stream_factories.get(f.fileno())\n if func is not None:\n if not PY2:\n f = getattr(f, 'buffer', None)\n if f is None:\n return None\n else:\n # If we are on Python 2 we need to set the stream that we\n # deal with to binary mode as otherwise the exercise if a\n # bit moot. The same problems apply as for\n # get_binary_stdin and friends from _compat.\n msvcrt.setmode(f.fileno(), os.O_BINARY)\n return func(f)\n", "path": "click/_winconsole.py"}]}
| 4,070 | 385 |
gh_patches_debug_28484
|
rasdani/github-patches
|
git_diff
|
pytorch__TensorRT-2198
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unclear comparisons in conditional operator implementation
<!-- Edit the body of your new issue then click the ✓ "Create Issue" button in the top right of the editor. The first line will be the issue title. Assignees and Labels follow after a blank
line. Leave an empty line before beginning the body of the issue. -->
https://github.com/pytorch/TensorRT/blob/918e9832207d462c2a3aa42f9e7d3ab7aa7415aa/py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py#L68
https://github.com/pytorch/TensorRT/blob/918e9832207d462c2a3aa42f9e7d3ab7aa7415aa/py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py#L75-L76
https://github.com/pytorch/TensorRT/blob/918e9832207d462c2a3aa42f9e7d3ab7aa7415aa/py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py
The above lines are being flagged by mypy as the following:
```sh
py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py:68: error: Non-overlapping equality check (left operand type: "list[Any]", right operand type: "int") [comparison-overlap]
py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py:76: error: Non-overlapping equality check (left operand type: "list[Any]", right operand type: "int") [comparison-overlap]
py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py:98: error: Non-overlapping equality check (left operand type: "list[Any]", right operand type: "int") [comparison-overlap]
```
I cant really figure out what is being checked here but it is likely a bug.
</issue>
<code>
[start of py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py]
1 from typing import Optional
2
3 import torch
4 from torch.fx.node import Target
5 from torch_tensorrt.dynamo._SourceIR import SourceIR
6 from torch_tensorrt.dynamo.conversion.converter_utils import broadcastable
7 from torch_tensorrt.dynamo.conversion.impl.slice import expand
8 from torch_tensorrt.fx.converters.converter_utils import (
9 broadcast,
10 get_trt_tensor,
11 set_layer_name,
12 )
13 from torch_tensorrt.fx.types import TRTNetwork, TRTTensor
14
15 import tensorrt as trt
16
17
18 def where(
19 network: TRTNetwork,
20 target: Target,
21 source_ir: Optional[SourceIR],
22 name: str,
23 input: TRTTensor,
24 other: TRTTensor,
25 condition: TRTTensor,
26 ) -> TRTTensor:
27 input_dim = len(tuple(input.shape))
28 other_dim = len(tuple(other.shape))
29 condition_dim = len(tuple(condition.shape))
30
31 if type(input) != TRTTensor:
32 assert type(input) is torch.Tensor, f"value {input} is not torch.Tensor!"
33
34 if type(other) != TRTTensor:
35 assert type(other) is torch.Tensor, f"value {other} is not torch.Tensor!"
36
37 if not (broadcastable(input, other)):
38 assert "The two torch tensors should be broadcastable"
39
40 # get output shape
41 # purpose of this is to bring input and other rank same as
42 # output_shape to input it to the add_expand operation
43 # condition will have dimension of either input or other
44 input, other = broadcast(network, input, other, f"{name}_x", f"{name}_y")
45 if len(tuple(condition.shape)) != len(tuple(input.shape)):
46 condition, input = broadcast(
47 network, condition, input, f"{name}_condition", f"{name}_x"
48 )
49
50 x_shape = list(input.shape)
51 y_shape = list(other.shape)
52 condition_shape = list(condition.shape)
53 output_shape = list(torch.broadcast_shapes(condition_shape, x_shape, y_shape))
54
55 # expand shape
56 if type(condition) != TRTTensor:
57 assert condition.dtype == torch.bool, "condition dtype is not bool"
58 if condition_shape != output_shape:
59 condition.expand(output_shape)
60 condition = condition.to(torch.int32)
61 condition_const = get_trt_tensor(network, condition, f"{name}_condition")
62 condition_layer = network.add_identity(condition_const)
63 condition_layer.set_output_type(0, trt.bool)
64 set_layer_name(condition_layer, target, f"{name}_condition")
65 condition_val = condition_layer.get_output(0)
66 else:
67 assert condition.dtype == trt.bool, "mask dtype is not bool!"
68 if condition_shape != condition_dim: # TODO: What is this checking?
69 condition_val = expand(
70 network, target, source_ir, f"{name}_expand", condition, output_shape
71 )
72 else:
73 condition_val = condition
74
75 if type(input) != TRTTensor:
76 if x_shape != input_dim: # TODO: What is this checking?
77 # special case where 1 element in input
78 if len(input.shape) == 0:
79 input = input.unsqueeze(0)
80 input = input.expand(output_shape)
81 x_val = get_trt_tensor(network, input, f"{name}_x")
82 else:
83 x_val = input
84 if x_shape != output_shape:
85 x_val = expand(
86 network, target, source_ir, f"{name}_x_expand", input, output_shape
87 )
88
89 if type(other) != TRTTensor:
90 if y_shape != output_shape:
91 # special case where 1 element in other
92 if len(other.shape) == 0:
93 other = other.unsqueeze(0)
94 other = other.expand(output_shape)
95 y_val = get_trt_tensor(network, other, f"{name}_y")
96 else:
97 y_val = other
98 if y_shape != other_dim: # TODO: What is this checking?
99 y_val = expand(
100 network, target, source_ir, f"{name}_y_expand", y_val, output_shape
101 )
102
103 select_layer = network.add_select(condition_val, x_val, y_val)
104
105 set_layer_name(select_layer, target, f"{name}_select")
106
107 return select_layer.get_output(0)
108
[end of py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py b/py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py
--- a/py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py
+++ b/py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py
@@ -65,7 +65,7 @@
condition_val = condition_layer.get_output(0)
else:
assert condition.dtype == trt.bool, "mask dtype is not bool!"
- if condition_shape != condition_dim: # TODO: What is this checking?
+ if len(condition_shape) != condition_dim:
condition_val = expand(
network, target, source_ir, f"{name}_expand", condition, output_shape
)
@@ -73,7 +73,7 @@
condition_val = condition
if type(input) != TRTTensor:
- if x_shape != input_dim: # TODO: What is this checking?
+ if x_shape != output_shape:
# special case where 1 element in input
if len(input.shape) == 0:
input = input.unsqueeze(0)
@@ -95,7 +95,7 @@
y_val = get_trt_tensor(network, other, f"{name}_y")
else:
y_val = other
- if y_shape != other_dim: # TODO: What is this checking?
+ if y_shape != output_shape:
y_val = expand(
network, target, source_ir, f"{name}_y_expand", y_val, output_shape
)
|
{"golden_diff": "diff --git a/py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py b/py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py\n--- a/py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py\n+++ b/py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py\n@@ -65,7 +65,7 @@\n condition_val = condition_layer.get_output(0)\n else:\n assert condition.dtype == trt.bool, \"mask dtype is not bool!\"\n- if condition_shape != condition_dim: # TODO: What is this checking?\n+ if len(condition_shape) != condition_dim:\n condition_val = expand(\n network, target, source_ir, f\"{name}_expand\", condition, output_shape\n )\n@@ -73,7 +73,7 @@\n condition_val = condition\n \n if type(input) != TRTTensor:\n- if x_shape != input_dim: # TODO: What is this checking?\n+ if x_shape != output_shape:\n # special case where 1 element in input\n if len(input.shape) == 0:\n input = input.unsqueeze(0)\n@@ -95,7 +95,7 @@\n y_val = get_trt_tensor(network, other, f\"{name}_y\")\n else:\n y_val = other\n- if y_shape != other_dim: # TODO: What is this checking?\n+ if y_shape != output_shape:\n y_val = expand(\n network, target, source_ir, f\"{name}_y_expand\", y_val, output_shape\n )\n", "issue": "Unclear comparisons in conditional operator implementation\n<!-- Edit the body of your new issue then click the \u2713 \"Create Issue\" button in the top right of the editor. The first line will be the issue title. Assignees and Labels follow after a blank\nline. Leave an empty line before beginning the body of the issue. -->\n\nhttps://github.com/pytorch/TensorRT/blob/918e9832207d462c2a3aa42f9e7d3ab7aa7415aa/py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py#L68\nhttps://github.com/pytorch/TensorRT/blob/918e9832207d462c2a3aa42f9e7d3ab7aa7415aa/py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py#L75-L76\nhttps://github.com/pytorch/TensorRT/blob/918e9832207d462c2a3aa42f9e7d3ab7aa7415aa/py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py\n\nThe above lines are being flagged by mypy as the following:\n\n```sh\npy/torch_tensorrt/dynamo/conversion/impl/condition/ops.py:68: error: Non-overlapping equality check (left operand type: \"list[Any]\", right operand type: \"int\") [comparison-overlap]\npy/torch_tensorrt/dynamo/conversion/impl/condition/ops.py:76: error: Non-overlapping equality check (left operand type: \"list[Any]\", right operand type: \"int\") [comparison-overlap]\npy/torch_tensorrt/dynamo/conversion/impl/condition/ops.py:98: error: Non-overlapping equality check (left operand type: \"list[Any]\", right operand type: \"int\") [comparison-overlap]\n```\n\nI cant really figure out what is being checked here but it is likely a bug.\n", "before_files": [{"content": "from typing import Optional\n\nimport torch\nfrom torch.fx.node import Target\nfrom torch_tensorrt.dynamo._SourceIR import SourceIR\nfrom torch_tensorrt.dynamo.conversion.converter_utils import broadcastable\nfrom torch_tensorrt.dynamo.conversion.impl.slice import expand\nfrom torch_tensorrt.fx.converters.converter_utils import (\n broadcast,\n get_trt_tensor,\n set_layer_name,\n)\nfrom torch_tensorrt.fx.types import TRTNetwork, TRTTensor\n\nimport tensorrt as trt\n\n\ndef where(\n network: TRTNetwork,\n target: Target,\n source_ir: Optional[SourceIR],\n name: str,\n input: TRTTensor,\n other: TRTTensor,\n condition: TRTTensor,\n) -> TRTTensor:\n input_dim = len(tuple(input.shape))\n other_dim = len(tuple(other.shape))\n condition_dim = len(tuple(condition.shape))\n\n if type(input) != TRTTensor:\n assert type(input) is torch.Tensor, f\"value {input} is not torch.Tensor!\"\n\n if type(other) != TRTTensor:\n assert type(other) is torch.Tensor, f\"value {other} is not torch.Tensor!\"\n\n if not (broadcastable(input, other)):\n assert \"The two torch tensors should be broadcastable\"\n\n # get output shape\n # purpose of this is to bring input and other rank same as\n # output_shape to input it to the add_expand operation\n # condition will have dimension of either input or other\n input, other = broadcast(network, input, other, f\"{name}_x\", f\"{name}_y\")\n if len(tuple(condition.shape)) != len(tuple(input.shape)):\n condition, input = broadcast(\n network, condition, input, f\"{name}_condition\", f\"{name}_x\"\n )\n\n x_shape = list(input.shape)\n y_shape = list(other.shape)\n condition_shape = list(condition.shape)\n output_shape = list(torch.broadcast_shapes(condition_shape, x_shape, y_shape))\n\n # expand shape\n if type(condition) != TRTTensor:\n assert condition.dtype == torch.bool, \"condition dtype is not bool\"\n if condition_shape != output_shape:\n condition.expand(output_shape)\n condition = condition.to(torch.int32)\n condition_const = get_trt_tensor(network, condition, f\"{name}_condition\")\n condition_layer = network.add_identity(condition_const)\n condition_layer.set_output_type(0, trt.bool)\n set_layer_name(condition_layer, target, f\"{name}_condition\")\n condition_val = condition_layer.get_output(0)\n else:\n assert condition.dtype == trt.bool, \"mask dtype is not bool!\"\n if condition_shape != condition_dim: # TODO: What is this checking?\n condition_val = expand(\n network, target, source_ir, f\"{name}_expand\", condition, output_shape\n )\n else:\n condition_val = condition\n\n if type(input) != TRTTensor:\n if x_shape != input_dim: # TODO: What is this checking?\n # special case where 1 element in input\n if len(input.shape) == 0:\n input = input.unsqueeze(0)\n input = input.expand(output_shape)\n x_val = get_trt_tensor(network, input, f\"{name}_x\")\n else:\n x_val = input\n if x_shape != output_shape:\n x_val = expand(\n network, target, source_ir, f\"{name}_x_expand\", input, output_shape\n )\n\n if type(other) != TRTTensor:\n if y_shape != output_shape:\n # special case where 1 element in other\n if len(other.shape) == 0:\n other = other.unsqueeze(0)\n other = other.expand(output_shape)\n y_val = get_trt_tensor(network, other, f\"{name}_y\")\n else:\n y_val = other\n if y_shape != other_dim: # TODO: What is this checking?\n y_val = expand(\n network, target, source_ir, f\"{name}_y_expand\", y_val, output_shape\n )\n\n select_layer = network.add_select(condition_val, x_val, y_val)\n\n set_layer_name(select_layer, target, f\"{name}_select\")\n\n return select_layer.get_output(0)\n", "path": "py/torch_tensorrt/dynamo/conversion/impl/condition/ops.py"}]}
| 2,145 | 353 |
gh_patches_debug_13787
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-2851
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Creating empty order draft causes API to explode
### What I'm trying to achieve
To get order draft details from API.
### Steps to reproduce the problem
Execute this query
```
{
orders {
edges {
node {
id
userEmail
}
}
}
}
```
### What I expected to happen
Definitely not to throw an error.
</issue>
<code>
[start of saleor/graphql/order/types.py]
1 import graphene
2 from graphene import relay
3
4 from ...order import OrderEvents, models
5 from ..account.types import User
6 from ..core.types.common import CountableDjangoObjectType
7 from ..core.types.money import Money, TaxedMoney
8 from decimal import Decimal
9
10 OrderEventsEnum = graphene.Enum.from_enum(OrderEvents)
11
12
13 class OrderEvent(CountableDjangoObjectType):
14 date = graphene.types.datetime.DateTime(
15 description='Date when event happened at in ISO 8601 format.')
16 type = OrderEventsEnum(description='Order event type')
17 user = graphene.Field(
18 User, id=graphene.Argument(graphene.ID),
19 description='User who performed the action.')
20 message = graphene.String(
21 description='Content of a note added to the order.')
22 email = graphene.String(description='Email of the customer')
23 email_type = graphene.String(
24 description='Type of an email sent to the customer')
25 amount = graphene.Float(description='Amount of money.')
26 quantity = graphene.Int(description='Number of items.')
27 composed_id = graphene.String(
28 description='Composed id of the Fulfillment.')
29
30 class Meta:
31 description = 'History log of the order.'
32 model = models.OrderEvent
33 interfaces = [relay.Node]
34 exclude_fields = ['order', 'parameters']
35
36 def resolve_email(self, info):
37 return self.parameters.get('email', None)
38
39 def resolve_email_type(self, info):
40 return self.parameters.get('email_type', None)
41
42 def resolve_amount(self, info):
43 amount = self.parameters.get('amount', None)
44 return Decimal(amount) if amount else None
45
46 def resolve_quantity(self, info):
47 quantity = self.parameters.get('quantity', None)
48 return int(quantity) if quantity else None
49
50 def resolve_message(self, info):
51 return self.parameters.get('message', None)
52
53 def resolve_composed_id(self, info):
54 return self.parameters.get('composed_id', None)
55
56
57 class Fulfillment(CountableDjangoObjectType):
58 status_display = graphene.String(
59 description='User-friendly fulfillment status.')
60
61 class Meta:
62 description = 'Represents order fulfillment.'
63 interfaces = [relay.Node]
64 model = models.Fulfillment
65 exclude_fields = ['order']
66
67 def resolve_status_display(self, info):
68 return self.get_status_display()
69
70
71 class FulfillmentLine(CountableDjangoObjectType):
72 class Meta:
73 description = 'Represents line of the fulfillment.'
74 interfaces = [relay.Node]
75 model = models.FulfillmentLine
76 exclude_fields = ['fulfillment']
77
78
79 class Order(CountableDjangoObjectType):
80 fulfillments = graphene.List(
81 Fulfillment,
82 required=True,
83 description='List of shipments for the order.')
84 is_paid = graphene.Boolean(
85 description='Informs if an order is fully paid.')
86 number = graphene.String(description='User-friendly number of an order.')
87 payment_status = graphene.String(description='Internal payment status.')
88 payment_status_display = graphene.String(
89 description='User-friendly payment status.')
90 subtotal = graphene.Field(
91 TaxedMoney,
92 description='The sum of line prices not including shipping.')
93 status_display = graphene.String(description='User-friendly order status.')
94 total_authorized = graphene.Field(
95 Money, description='Amount authorized for the order.')
96 total_captured = graphene.Field(
97 Money, description='Amount captured by payment.')
98 events = graphene.List(
99 OrderEvent,
100 description='List of events associated with the order.')
101
102 class Meta:
103 description = 'Represents an order in the shop.'
104 interfaces = [relay.Node]
105 model = models.Order
106 exclude_fields = [
107 'shipping_price_gross', 'shipping_price_net', 'total_gross',
108 'total_net']
109
110 @staticmethod
111 def resolve_subtotal(obj, info):
112 return obj.get_subtotal()
113
114 @staticmethod
115 def resolve_total_authorized(obj, info):
116 payment = obj.get_last_payment()
117 if payment:
118 return payment.get_total_price().gross
119
120 @staticmethod
121 def resolve_total_captured(obj, info):
122 payment = obj.get_last_payment()
123 if payment:
124 return payment.get_captured_price()
125
126 @staticmethod
127 def resolve_fulfillments(obj, info):
128 return obj.fulfillments.all()
129
130 @staticmethod
131 def resolve_events(obj, info):
132 return obj.events.all()
133
134 @staticmethod
135 def resolve_is_paid(obj, info):
136 return obj.is_fully_paid()
137
138 @staticmethod
139 def resolve_number(obj, info):
140 return str(obj.pk)
141
142 @staticmethod
143 def resolve_payment_status(obj, info):
144 return obj.get_last_payment_status()
145
146 @staticmethod
147 def resolve_payment_status_display(obj, info):
148 return obj.get_last_payment_status_display()
149
150 @staticmethod
151 def resolve_status_display(obj, info):
152 return obj.get_status_display()
153
154 @staticmethod
155 def resolve_user_email(obj, info):
156 if obj.user_email:
157 return obj.user_email
158 if obj.user_id:
159 return obj.user.email
160
161
162 class OrderLine(CountableDjangoObjectType):
163 class Meta:
164 description = 'Represents order line of particular order.'
165 model = models.OrderLine
166 interfaces = [relay.Node]
167 exclude_fields = [
168 'order', 'unit_price_gross', 'unit_price_net', 'variant']
169
[end of saleor/graphql/order/types.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/saleor/graphql/order/types.py b/saleor/graphql/order/types.py
--- a/saleor/graphql/order/types.py
+++ b/saleor/graphql/order/types.py
@@ -98,6 +98,8 @@
events = graphene.List(
OrderEvent,
description='List of events associated with the order.')
+ user_email = graphene.String(
+ required=False, description='Email address of the customer.')
class Meta:
description = 'Represents an order in the shop.'
@@ -157,6 +159,7 @@
return obj.user_email
if obj.user_id:
return obj.user.email
+ return None
class OrderLine(CountableDjangoObjectType):
|
{"golden_diff": "diff --git a/saleor/graphql/order/types.py b/saleor/graphql/order/types.py\n--- a/saleor/graphql/order/types.py\n+++ b/saleor/graphql/order/types.py\n@@ -98,6 +98,8 @@\n events = graphene.List(\n OrderEvent,\n description='List of events associated with the order.')\n+ user_email = graphene.String(\n+ required=False, description='Email address of the customer.')\n \n class Meta:\n description = 'Represents an order in the shop.'\n@@ -157,6 +159,7 @@\n return obj.user_email\n if obj.user_id:\n return obj.user.email\n+ return None\n \n \n class OrderLine(CountableDjangoObjectType):\n", "issue": "Creating empty order draft causes API to explode\n### What I'm trying to achieve\r\nTo get order draft details from API.\r\n\r\n### Steps to reproduce the problem\r\nExecute this query\r\n```\r\n{\r\n orders {\r\n edges {\r\n node {\r\n id\r\n userEmail\r\n }\r\n }\r\n }\r\n}\r\n```\r\n\r\n### What I expected to happen\r\nDefinitely not to throw an error.\n", "before_files": [{"content": "import graphene\nfrom graphene import relay\n\nfrom ...order import OrderEvents, models\nfrom ..account.types import User\nfrom ..core.types.common import CountableDjangoObjectType\nfrom ..core.types.money import Money, TaxedMoney\nfrom decimal import Decimal\n\nOrderEventsEnum = graphene.Enum.from_enum(OrderEvents)\n\n\nclass OrderEvent(CountableDjangoObjectType):\n date = graphene.types.datetime.DateTime(\n description='Date when event happened at in ISO 8601 format.')\n type = OrderEventsEnum(description='Order event type')\n user = graphene.Field(\n User, id=graphene.Argument(graphene.ID),\n description='User who performed the action.')\n message = graphene.String(\n description='Content of a note added to the order.')\n email = graphene.String(description='Email of the customer')\n email_type = graphene.String(\n description='Type of an email sent to the customer')\n amount = graphene.Float(description='Amount of money.')\n quantity = graphene.Int(description='Number of items.')\n composed_id = graphene.String(\n description='Composed id of the Fulfillment.')\n\n class Meta:\n description = 'History log of the order.'\n model = models.OrderEvent\n interfaces = [relay.Node]\n exclude_fields = ['order', 'parameters']\n\n def resolve_email(self, info):\n return self.parameters.get('email', None)\n\n def resolve_email_type(self, info):\n return self.parameters.get('email_type', None)\n\n def resolve_amount(self, info):\n amount = self.parameters.get('amount', None)\n return Decimal(amount) if amount else None\n\n def resolve_quantity(self, info):\n quantity = self.parameters.get('quantity', None)\n return int(quantity) if quantity else None\n\n def resolve_message(self, info):\n return self.parameters.get('message', None)\n\n def resolve_composed_id(self, info):\n return self.parameters.get('composed_id', None)\n\n\nclass Fulfillment(CountableDjangoObjectType):\n status_display = graphene.String(\n description='User-friendly fulfillment status.')\n\n class Meta:\n description = 'Represents order fulfillment.'\n interfaces = [relay.Node]\n model = models.Fulfillment\n exclude_fields = ['order']\n\n def resolve_status_display(self, info):\n return self.get_status_display()\n\n\nclass FulfillmentLine(CountableDjangoObjectType):\n class Meta:\n description = 'Represents line of the fulfillment.'\n interfaces = [relay.Node]\n model = models.FulfillmentLine\n exclude_fields = ['fulfillment']\n\n\nclass Order(CountableDjangoObjectType):\n fulfillments = graphene.List(\n Fulfillment,\n required=True,\n description='List of shipments for the order.')\n is_paid = graphene.Boolean(\n description='Informs if an order is fully paid.')\n number = graphene.String(description='User-friendly number of an order.')\n payment_status = graphene.String(description='Internal payment status.')\n payment_status_display = graphene.String(\n description='User-friendly payment status.')\n subtotal = graphene.Field(\n TaxedMoney,\n description='The sum of line prices not including shipping.')\n status_display = graphene.String(description='User-friendly order status.')\n total_authorized = graphene.Field(\n Money, description='Amount authorized for the order.')\n total_captured = graphene.Field(\n Money, description='Amount captured by payment.')\n events = graphene.List(\n OrderEvent,\n description='List of events associated with the order.')\n\n class Meta:\n description = 'Represents an order in the shop.'\n interfaces = [relay.Node]\n model = models.Order\n exclude_fields = [\n 'shipping_price_gross', 'shipping_price_net', 'total_gross',\n 'total_net']\n\n @staticmethod\n def resolve_subtotal(obj, info):\n return obj.get_subtotal()\n\n @staticmethod\n def resolve_total_authorized(obj, info):\n payment = obj.get_last_payment()\n if payment:\n return payment.get_total_price().gross\n\n @staticmethod\n def resolve_total_captured(obj, info):\n payment = obj.get_last_payment()\n if payment:\n return payment.get_captured_price()\n\n @staticmethod\n def resolve_fulfillments(obj, info):\n return obj.fulfillments.all()\n\n @staticmethod\n def resolve_events(obj, info):\n return obj.events.all()\n\n @staticmethod\n def resolve_is_paid(obj, info):\n return obj.is_fully_paid()\n\n @staticmethod\n def resolve_number(obj, info):\n return str(obj.pk)\n\n @staticmethod\n def resolve_payment_status(obj, info):\n return obj.get_last_payment_status()\n\n @staticmethod\n def resolve_payment_status_display(obj, info):\n return obj.get_last_payment_status_display()\n\n @staticmethod\n def resolve_status_display(obj, info):\n return obj.get_status_display()\n\n @staticmethod\n def resolve_user_email(obj, info):\n if obj.user_email:\n return obj.user_email\n if obj.user_id:\n return obj.user.email\n\n\nclass OrderLine(CountableDjangoObjectType):\n class Meta:\n description = 'Represents order line of particular order.'\n model = models.OrderLine\n interfaces = [relay.Node]\n exclude_fields = [\n 'order', 'unit_price_gross', 'unit_price_net', 'variant']\n", "path": "saleor/graphql/order/types.py"}]}
| 2,155 | 159 |
gh_patches_debug_61112
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-933
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pre-commit autoupdate fails when config is empty
Running `pre-commit autoupdate` with an empty `.pre-commit-config.yaml` results in the below error:
```An unexpected error has occurred: IndexError: list index out of range
Traceback (most recent call last):
File "/usr/local/Cellar/pre-commit/1.14.2/libexec/lib/python3.7/site-packages/pre_commit/error_handler.py", line 46, in error_handler
yield
File "/usr/local/Cellar/pre-commit/1.14.2/libexec/lib/python3.7/site-packages/pre_commit/main.py", line 286, in main
repos=args.repos,
File "/usr/local/Cellar/pre-commit/1.14.2/libexec/lib/python3.7/site-packages/pre_commit/commands/autoupdate.py", line 117, in autoupdate
migrate_config(config_file, quiet=True)
File "/usr/local/Cellar/pre-commit/1.14.2/libexec/lib/python3.7/site-packages/pre_commit/commands/migrate_config.py", line 52, in migrate_config
contents = _migrate_map(contents)
File "/usr/local/Cellar/pre-commit/1.14.2/libexec/lib/python3.7/site-packages/pre_commit/commands/migrate_config.py", line 24, in _migrate_map
while _is_header_line(lines[i]):
IndexError: list index out of range
```
</issue>
<code>
[start of pre_commit/commands/migrate_config.py]
1 from __future__ import print_function
2 from __future__ import unicode_literals
3
4 import io
5 import re
6
7 import yaml
8 from aspy.yaml import ordered_load
9
10
11 def _indent(s):
12 lines = s.splitlines(True)
13 return ''.join(' ' * 4 + line if line.strip() else line for line in lines)
14
15
16 def _is_header_line(line):
17 return (line.startswith(('#', '---')) or not line.strip())
18
19
20 def _migrate_map(contents):
21 # Find the first non-header line
22 lines = contents.splitlines(True)
23 i = 0
24 while _is_header_line(lines[i]):
25 i += 1
26
27 header = ''.join(lines[:i])
28 rest = ''.join(lines[i:])
29
30 if isinstance(ordered_load(contents), list):
31 # If they are using the "default" flow style of yaml, this operation
32 # will yield a valid configuration
33 try:
34 trial_contents = header + 'repos:\n' + rest
35 ordered_load(trial_contents)
36 contents = trial_contents
37 except yaml.YAMLError:
38 contents = header + 'repos:\n' + _indent(rest)
39
40 return contents
41
42
43 def _migrate_sha_to_rev(contents):
44 reg = re.compile(r'(\n\s+)sha:')
45 return reg.sub(r'\1rev:', contents)
46
47
48 def migrate_config(config_file, quiet=False):
49 with io.open(config_file) as f:
50 orig_contents = contents = f.read()
51
52 contents = _migrate_map(contents)
53 contents = _migrate_sha_to_rev(contents)
54
55 if contents != orig_contents:
56 with io.open(config_file, 'w') as f:
57 f.write(contents)
58
59 print('Configuration has been migrated.')
60 elif not quiet:
61 print('Configuration is already migrated.')
62
[end of pre_commit/commands/migrate_config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pre_commit/commands/migrate_config.py b/pre_commit/commands/migrate_config.py
--- a/pre_commit/commands/migrate_config.py
+++ b/pre_commit/commands/migrate_config.py
@@ -21,7 +21,8 @@
# Find the first non-header line
lines = contents.splitlines(True)
i = 0
- while _is_header_line(lines[i]):
+ # Only loop on non empty configuration file
+ while i < len(lines) and _is_header_line(lines[i]):
i += 1
header = ''.join(lines[:i])
|
{"golden_diff": "diff --git a/pre_commit/commands/migrate_config.py b/pre_commit/commands/migrate_config.py\n--- a/pre_commit/commands/migrate_config.py\n+++ b/pre_commit/commands/migrate_config.py\n@@ -21,7 +21,8 @@\n # Find the first non-header line\n lines = contents.splitlines(True)\n i = 0\n- while _is_header_line(lines[i]):\n+ # Only loop on non empty configuration file\n+ while i < len(lines) and _is_header_line(lines[i]):\n i += 1\n \n header = ''.join(lines[:i])\n", "issue": "pre-commit autoupdate fails when config is empty\nRunning `pre-commit autoupdate` with an empty `.pre-commit-config.yaml` results in the below error:\r\n```An unexpected error has occurred: IndexError: list index out of range\r\nTraceback (most recent call last):\r\n File \"/usr/local/Cellar/pre-commit/1.14.2/libexec/lib/python3.7/site-packages/pre_commit/error_handler.py\", line 46, in error_handler\r\n yield\r\n File \"/usr/local/Cellar/pre-commit/1.14.2/libexec/lib/python3.7/site-packages/pre_commit/main.py\", line 286, in main\r\n repos=args.repos,\r\n File \"/usr/local/Cellar/pre-commit/1.14.2/libexec/lib/python3.7/site-packages/pre_commit/commands/autoupdate.py\", line 117, in autoupdate\r\n migrate_config(config_file, quiet=True)\r\n File \"/usr/local/Cellar/pre-commit/1.14.2/libexec/lib/python3.7/site-packages/pre_commit/commands/migrate_config.py\", line 52, in migrate_config\r\n contents = _migrate_map(contents)\r\n File \"/usr/local/Cellar/pre-commit/1.14.2/libexec/lib/python3.7/site-packages/pre_commit/commands/migrate_config.py\", line 24, in _migrate_map\r\n while _is_header_line(lines[i]):\r\nIndexError: list index out of range\r\n```\n", "before_files": [{"content": "from __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport io\nimport re\n\nimport yaml\nfrom aspy.yaml import ordered_load\n\n\ndef _indent(s):\n lines = s.splitlines(True)\n return ''.join(' ' * 4 + line if line.strip() else line for line in lines)\n\n\ndef _is_header_line(line):\n return (line.startswith(('#', '---')) or not line.strip())\n\n\ndef _migrate_map(contents):\n # Find the first non-header line\n lines = contents.splitlines(True)\n i = 0\n while _is_header_line(lines[i]):\n i += 1\n\n header = ''.join(lines[:i])\n rest = ''.join(lines[i:])\n\n if isinstance(ordered_load(contents), list):\n # If they are using the \"default\" flow style of yaml, this operation\n # will yield a valid configuration\n try:\n trial_contents = header + 'repos:\\n' + rest\n ordered_load(trial_contents)\n contents = trial_contents\n except yaml.YAMLError:\n contents = header + 'repos:\\n' + _indent(rest)\n\n return contents\n\n\ndef _migrate_sha_to_rev(contents):\n reg = re.compile(r'(\\n\\s+)sha:')\n return reg.sub(r'\\1rev:', contents)\n\n\ndef migrate_config(config_file, quiet=False):\n with io.open(config_file) as f:\n orig_contents = contents = f.read()\n\n contents = _migrate_map(contents)\n contents = _migrate_sha_to_rev(contents)\n\n if contents != orig_contents:\n with io.open(config_file, 'w') as f:\n f.write(contents)\n\n print('Configuration has been migrated.')\n elif not quiet:\n print('Configuration is already migrated.')\n", "path": "pre_commit/commands/migrate_config.py"}]}
| 1,368 | 131 |
gh_patches_debug_18466
|
rasdani/github-patches
|
git_diff
|
vyperlang__vyper-2399
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Can't import interface using structs
### Version Information
* vyper Version (output of `vyper --version`): 0.2.12+commit.2c6842c
* OS: linux
* Python Version (output of `python --version`): 3.8.5
* Environment (output of `pip freeze`):
```
asttokens==2.0.4
pycryptodome==3.10.1
semantic-version==2.8.5
six==1.15.0
vyper==0.2.12
```
### What's your issue about?
Can't import an interface if it uses structs. Simple example:
foo.vy:
```
struct Widget:
name: String[8]
count: uint256
widget: Widget
@external
def show() -> (String[8], uint256):
return (self.widget.name, self.widget.count)
@external
def __init__():
self.widget = Widget({
name: "thing",
count: 1
})
```
bar.vy
```
import foo as Foo
@external
def __init__():
pass
```
Throw both in the same dir.
`vyper foo.vy` results in a successful compilation
`vyper bar.vy` results in:
```
Error compiling: bar.vy
vyper.exceptions.InvalidType: Invalid base type: Widget
contract "Foo", line 5:8
4
---> 5 widget: Widget
---------------^
6
```
### How can it be fixed?
Haven't spent time fixing yet
</issue>
<code>
[start of vyper/ast/signatures/interface.py]
1 # TODO does this module not get imported?
2
3 import importlib
4 import pkgutil
5
6 import vyper.builtin_interfaces
7 from vyper import ast as vy_ast
8 from vyper.ast.signatures import sig_utils
9 from vyper.ast.signatures.function_signature import FunctionSignature
10 from vyper.exceptions import StructureException
11 from vyper.old_codegen.global_context import GlobalContext
12
13
14 # Populate built-in interfaces.
15 def get_builtin_interfaces():
16 interface_names = [x.name for x in pkgutil.iter_modules(vyper.builtin_interfaces.__path__)]
17 return {
18 name: extract_sigs(
19 {
20 "type": "vyper",
21 "code": importlib.import_module(f"vyper.builtin_interfaces.{name}",).interface_code,
22 },
23 name,
24 )
25 for name in interface_names
26 }
27
28
29 def abi_type_to_ast(atype, expected_size):
30 if atype in ("int128", "uint256", "bool", "address", "bytes32"):
31 return vy_ast.Name(id=atype)
32 elif atype == "fixed168x10":
33 return vy_ast.Name(id="decimal")
34 elif atype in ("bytes", "string"):
35 # expected_size is the maximum length for inputs, minimum length for outputs
36 return vy_ast.Subscript(
37 value=vy_ast.Name(id=atype.capitalize()),
38 slice=vy_ast.Index(value=vy_ast.Int(value=expected_size)),
39 )
40 else:
41 raise StructureException(f"Type {atype} not supported by vyper.")
42
43
44 # Vyper defines a maximum length for bytes and string types, but Solidity does not.
45 # To maximize interoperability, we internally considers these types to have a
46 # a length of 1Mb (1024 * 1024 * 1 byte) for inputs, and 1 for outputs.
47 # Ths approach solves the issue because Vyper allows for an implicit casting
48 # from a lower length into a higher one. (@iamdefinitelyahuman)
49 def mk_full_signature_from_json(abi):
50 funcs = [func for func in abi if func["type"] == "function"]
51 sigs = []
52
53 for func in funcs:
54 args = []
55 returns = None
56 for a in func["inputs"]:
57 arg = vy_ast.arg(
58 arg=a["name"],
59 annotation=abi_type_to_ast(a["type"], 1048576),
60 lineno=0,
61 col_offset=0,
62 )
63 args.append(arg)
64
65 if len(func["outputs"]) == 1:
66 returns = abi_type_to_ast(func["outputs"][0]["type"], 1)
67 elif len(func["outputs"]) > 1:
68 returns = vy_ast.Tuple(
69 elements=[abi_type_to_ast(a["type"], 1) for a in func["outputs"]]
70 )
71
72 decorator_list = [vy_ast.Name(id="external")]
73 # Handle either constant/payable or stateMutability field
74 if ("constant" in func and func["constant"]) or (
75 "stateMutability" in func and func["stateMutability"] == "view"
76 ):
77 decorator_list.append(vy_ast.Name(id="view"))
78 if ("payable" in func and func["payable"]) or (
79 "stateMutability" in func and func["stateMutability"] == "payable"
80 ):
81 decorator_list.append(vy_ast.Name(id="payable"))
82
83 sig = FunctionSignature.from_definition(
84 code=vy_ast.FunctionDef(
85 name=func["name"],
86 args=vy_ast.arguments(args=args),
87 decorator_list=decorator_list,
88 returns=returns,
89 ),
90 custom_structs=dict(),
91 is_from_json=True,
92 )
93 sigs.append(sig)
94 return sigs
95
96
97 def extract_sigs(sig_code, interface_name=None):
98 if sig_code["type"] == "vyper":
99 interface_ast = [
100 i
101 for i in vy_ast.parse_to_ast(sig_code["code"], contract_name=interface_name)
102 if isinstance(i, vy_ast.FunctionDef)
103 or isinstance(i, vy_ast.EventDef)
104 or (isinstance(i, vy_ast.AnnAssign) and i.target.id != "implements")
105 ]
106 global_ctx = GlobalContext.get_global_context(interface_ast)
107 return sig_utils.mk_full_signature(global_ctx, sig_formatter=lambda x: x)
108 elif sig_code["type"] == "json":
109 return mk_full_signature_from_json(sig_code["code"])
110 else:
111 raise Exception(
112 (
113 f"Unknown interface signature type '{sig_code['type']}' supplied. "
114 "'vyper' & 'json' are supported"
115 )
116 )
117
[end of vyper/ast/signatures/interface.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/vyper/ast/signatures/interface.py b/vyper/ast/signatures/interface.py
--- a/vyper/ast/signatures/interface.py
+++ b/vyper/ast/signatures/interface.py
@@ -99,8 +99,20 @@
interface_ast = [
i
for i in vy_ast.parse_to_ast(sig_code["code"], contract_name=interface_name)
- if isinstance(i, vy_ast.FunctionDef)
- or isinstance(i, vy_ast.EventDef)
+ # all the nodes visited by ModuleNodeVisitor.
+ if isinstance(
+ i,
+ (
+ vy_ast.FunctionDef,
+ vy_ast.EventDef,
+ vy_ast.StructDef,
+ vy_ast.InterfaceDef,
+ # parsing import statements at this stage
+ # causes issues with recursive imports
+ # vy_ast.Import,
+ # vy_ast.ImportFrom,
+ ),
+ )
or (isinstance(i, vy_ast.AnnAssign) and i.target.id != "implements")
]
global_ctx = GlobalContext.get_global_context(interface_ast)
|
{"golden_diff": "diff --git a/vyper/ast/signatures/interface.py b/vyper/ast/signatures/interface.py\n--- a/vyper/ast/signatures/interface.py\n+++ b/vyper/ast/signatures/interface.py\n@@ -99,8 +99,20 @@\n interface_ast = [\n i\n for i in vy_ast.parse_to_ast(sig_code[\"code\"], contract_name=interface_name)\n- if isinstance(i, vy_ast.FunctionDef)\n- or isinstance(i, vy_ast.EventDef)\n+ # all the nodes visited by ModuleNodeVisitor.\n+ if isinstance(\n+ i,\n+ (\n+ vy_ast.FunctionDef,\n+ vy_ast.EventDef,\n+ vy_ast.StructDef,\n+ vy_ast.InterfaceDef,\n+ # parsing import statements at this stage\n+ # causes issues with recursive imports\n+ # vy_ast.Import,\n+ # vy_ast.ImportFrom,\n+ ),\n+ )\n or (isinstance(i, vy_ast.AnnAssign) and i.target.id != \"implements\")\n ]\n global_ctx = GlobalContext.get_global_context(interface_ast)\n", "issue": "Can't import interface using structs\n### Version Information\r\n\r\n* vyper Version (output of `vyper --version`): 0.2.12+commit.2c6842c\r\n* OS: linux\r\n* Python Version (output of `python --version`): 3.8.5\r\n* Environment (output of `pip freeze`):\r\n```\r\nasttokens==2.0.4\r\npycryptodome==3.10.1\r\nsemantic-version==2.8.5\r\nsix==1.15.0\r\nvyper==0.2.12\r\n```\r\n\r\n### What's your issue about?\r\n\r\nCan't import an interface if it uses structs. Simple example:\r\n\r\nfoo.vy:\r\n```\r\nstruct Widget:\r\n name: String[8]\r\n count: uint256\r\n\r\nwidget: Widget\r\n\r\n@external\r\ndef show() -> (String[8], uint256):\r\n return (self.widget.name, self.widget.count)\r\n\r\n@external\r\ndef __init__():\r\n self.widget = Widget({\r\n name: \"thing\",\r\n count: 1\r\n })\r\n```\r\nbar.vy\r\n```\r\nimport foo as Foo\r\n\r\n@external\r\ndef __init__():\r\n pass\r\n```\r\n\r\nThrow both in the same dir.\r\n\r\n`vyper foo.vy` results in a successful compilation\r\n\r\n`vyper bar.vy` results in:\r\n```\r\nError compiling: bar.vy\r\nvyper.exceptions.InvalidType: Invalid base type: Widget\r\n contract \"Foo\", line 5:8 \r\n 4\r\n ---> 5 widget: Widget\r\n ---------------^\r\n 6\r\n```\r\n\r\n### How can it be fixed?\r\n\r\nHaven't spent time fixing yet\n", "before_files": [{"content": "# TODO does this module not get imported?\n\nimport importlib\nimport pkgutil\n\nimport vyper.builtin_interfaces\nfrom vyper import ast as vy_ast\nfrom vyper.ast.signatures import sig_utils\nfrom vyper.ast.signatures.function_signature import FunctionSignature\nfrom vyper.exceptions import StructureException\nfrom vyper.old_codegen.global_context import GlobalContext\n\n\n# Populate built-in interfaces.\ndef get_builtin_interfaces():\n interface_names = [x.name for x in pkgutil.iter_modules(vyper.builtin_interfaces.__path__)]\n return {\n name: extract_sigs(\n {\n \"type\": \"vyper\",\n \"code\": importlib.import_module(f\"vyper.builtin_interfaces.{name}\",).interface_code,\n },\n name,\n )\n for name in interface_names\n }\n\n\ndef abi_type_to_ast(atype, expected_size):\n if atype in (\"int128\", \"uint256\", \"bool\", \"address\", \"bytes32\"):\n return vy_ast.Name(id=atype)\n elif atype == \"fixed168x10\":\n return vy_ast.Name(id=\"decimal\")\n elif atype in (\"bytes\", \"string\"):\n # expected_size is the maximum length for inputs, minimum length for outputs\n return vy_ast.Subscript(\n value=vy_ast.Name(id=atype.capitalize()),\n slice=vy_ast.Index(value=vy_ast.Int(value=expected_size)),\n )\n else:\n raise StructureException(f\"Type {atype} not supported by vyper.\")\n\n\n# Vyper defines a maximum length for bytes and string types, but Solidity does not.\n# To maximize interoperability, we internally considers these types to have a\n# a length of 1Mb (1024 * 1024 * 1 byte) for inputs, and 1 for outputs.\n# Ths approach solves the issue because Vyper allows for an implicit casting\n# from a lower length into a higher one. (@iamdefinitelyahuman)\ndef mk_full_signature_from_json(abi):\n funcs = [func for func in abi if func[\"type\"] == \"function\"]\n sigs = []\n\n for func in funcs:\n args = []\n returns = None\n for a in func[\"inputs\"]:\n arg = vy_ast.arg(\n arg=a[\"name\"],\n annotation=abi_type_to_ast(a[\"type\"], 1048576),\n lineno=0,\n col_offset=0,\n )\n args.append(arg)\n\n if len(func[\"outputs\"]) == 1:\n returns = abi_type_to_ast(func[\"outputs\"][0][\"type\"], 1)\n elif len(func[\"outputs\"]) > 1:\n returns = vy_ast.Tuple(\n elements=[abi_type_to_ast(a[\"type\"], 1) for a in func[\"outputs\"]]\n )\n\n decorator_list = [vy_ast.Name(id=\"external\")]\n # Handle either constant/payable or stateMutability field\n if (\"constant\" in func and func[\"constant\"]) or (\n \"stateMutability\" in func and func[\"stateMutability\"] == \"view\"\n ):\n decorator_list.append(vy_ast.Name(id=\"view\"))\n if (\"payable\" in func and func[\"payable\"]) or (\n \"stateMutability\" in func and func[\"stateMutability\"] == \"payable\"\n ):\n decorator_list.append(vy_ast.Name(id=\"payable\"))\n\n sig = FunctionSignature.from_definition(\n code=vy_ast.FunctionDef(\n name=func[\"name\"],\n args=vy_ast.arguments(args=args),\n decorator_list=decorator_list,\n returns=returns,\n ),\n custom_structs=dict(),\n is_from_json=True,\n )\n sigs.append(sig)\n return sigs\n\n\ndef extract_sigs(sig_code, interface_name=None):\n if sig_code[\"type\"] == \"vyper\":\n interface_ast = [\n i\n for i in vy_ast.parse_to_ast(sig_code[\"code\"], contract_name=interface_name)\n if isinstance(i, vy_ast.FunctionDef)\n or isinstance(i, vy_ast.EventDef)\n or (isinstance(i, vy_ast.AnnAssign) and i.target.id != \"implements\")\n ]\n global_ctx = GlobalContext.get_global_context(interface_ast)\n return sig_utils.mk_full_signature(global_ctx, sig_formatter=lambda x: x)\n elif sig_code[\"type\"] == \"json\":\n return mk_full_signature_from_json(sig_code[\"code\"])\n else:\n raise Exception(\n (\n f\"Unknown interface signature type '{sig_code['type']}' supplied. \"\n \"'vyper' & 'json' are supported\"\n )\n )\n", "path": "vyper/ast/signatures/interface.py"}]}
| 2,138 | 234 |
gh_patches_debug_51094
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-19536
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix paddle_math.test_paddle_conj
| | |
|---|---|
|numpy|<a href="https://github.com/unifyai/ivy/actions/runs/6197499538/job/16826154279"><img src=https://img.shields.io/badge/-failure-red></a>
|jax|<a href="https://github.com/unifyai/ivy/actions/runs/6197499538/job/16826154279"><img src=https://img.shields.io/badge/-failure-red></a>
|tensorflow|<a href="https://github.com/unifyai/ivy/actions/runs/6197499538/job/16826154279"><img src=https://img.shields.io/badge/-failure-red></a>
|torch|<a href="https://github.com/unifyai/ivy/actions/runs/6197499538/job/16826154279"><img src=https://img.shields.io/badge/-failure-red></a>
|paddle|<a href="https://github.com/unifyai/ivy/actions/runs/6197499538/job/16826154279"><img src=https://img.shields.io/badge/-success-success></a>
</issue>
<code>
[start of ivy/functional/backends/numpy/experimental/elementwise.py]
1 from typing import Optional, Union, Tuple, List
2 import numpy as np
3 import numpy.typing as npt
4
5 import ivy
6 from ivy import promote_types_of_inputs
7 from ivy.functional.backends.numpy.helpers import _scalar_output_to_0d_array
8 from ivy.func_wrapper import with_unsupported_dtypes
9 from . import backend_version
10
11
12 @_scalar_output_to_0d_array
13 @with_unsupported_dtypes({"1.25.1 and below": ("bfloat16",)}, backend_version)
14 def sinc(x: np.ndarray, /, *, out: Optional[np.ndarray] = None) -> np.ndarray:
15 return np.sinc(x).astype(x.dtype)
16
17
18 @_scalar_output_to_0d_array
19 def fmax(
20 x1: np.ndarray,
21 x2: np.ndarray,
22 /,
23 *,
24 out: Optional[np.ndarray] = None,
25 ) -> np.ndarray:
26 x1, x2 = promote_types_of_inputs(x1, x2)
27 return np.fmax(
28 x1,
29 x2,
30 out=None,
31 where=True,
32 casting="same_kind",
33 order="K",
34 dtype=None,
35 subok=True,
36 )
37
38
39 fmax.support_native_out = True
40
41
42 @_scalar_output_to_0d_array
43 def float_power(
44 x1: Union[np.ndarray, float, list, tuple],
45 x2: Union[np.ndarray, float, list, tuple],
46 /,
47 *,
48 out: Optional[np.ndarray] = None,
49 ) -> np.ndarray:
50 x1, x2 = promote_types_of_inputs(x1, x2)
51 return np.float_power(x1, x2, out=out)
52
53
54 float_power.support_native_out = True
55
56
57 @_scalar_output_to_0d_array
58 def copysign(
59 x1: npt.ArrayLike,
60 x2: npt.ArrayLike,
61 /,
62 *,
63 out: Optional[np.ndarray] = None,
64 ) -> np.ndarray:
65 x1, x2 = promote_types_of_inputs(x1, x2)
66 if not ivy.is_float_dtype(x1):
67 x1 = x1.astype(ivy.default_float_dtype(as_native=True))
68 x2 = x2.astype(ivy.default_float_dtype(as_native=True))
69 return np.copysign(x1, x2, out=out)
70
71
72 copysign.support_native_out = True
73
74
75 @_scalar_output_to_0d_array
76 def count_nonzero(
77 a: np.ndarray,
78 /,
79 *,
80 axis: Optional[Union[int, Tuple[int, ...]]] = None,
81 keepdims: bool = False,
82 dtype: Optional[np.dtype] = None,
83 out: Optional[np.ndarray] = None,
84 ) -> np.ndarray:
85 if isinstance(axis, list):
86 axis = tuple(axis)
87 ret = np.count_nonzero(a, axis=axis, keepdims=keepdims)
88 if np.isscalar(ret):
89 return np.array(ret, dtype=dtype)
90 return ret.astype(dtype)
91
92
93 count_nonzero.support_native_out = False
94
95
96 def nansum(
97 x: np.ndarray,
98 /,
99 *,
100 axis: Optional[Union[Tuple[int, ...], int]] = None,
101 dtype: Optional[np.dtype] = None,
102 keepdims: bool = False,
103 out: Optional[np.ndarray] = None,
104 ) -> np.ndarray:
105 if isinstance(axis, list):
106 axis = tuple(axis)
107 return np.nansum(x, axis=axis, dtype=dtype, keepdims=keepdims, out=out)
108
109
110 nansum.support_native_out = True
111
112
113 def isclose(
114 a: np.ndarray,
115 b: np.ndarray,
116 /,
117 *,
118 rtol: float = 1e-05,
119 atol: float = 1e-08,
120 equal_nan: bool = False,
121 out: Optional[np.ndarray] = None,
122 ) -> np.ndarray:
123 ret = np.isclose(a, b, rtol=rtol, atol=atol, equal_nan=equal_nan)
124 if np.isscalar(ret):
125 return np.array(ret, dtype="bool")
126 return ret
127
128
129 isclose.support_native_out = False
130
131
132 def signbit(
133 x: Union[np.ndarray, float, int, list, tuple],
134 /,
135 *,
136 out: Optional[np.ndarray] = None,
137 ) -> np.ndarray:
138 return np.signbit(x, out=out)
139
140
141 signbit.support_native_out = True
142
143
144 def hypot(
145 x1: np.ndarray,
146 x2: np.ndarray,
147 /,
148 *,
149 out: Optional[np.ndarray] = None,
150 ) -> np.ndarray:
151 return np.hypot(x1, x2)
152
153
154 def diff(
155 x: Union[np.ndarray, list, tuple],
156 /,
157 *,
158 n: int = 1,
159 axis: int = -1,
160 prepend: Optional[Union[np.ndarray, int, float, list, tuple]] = None,
161 append: Optional[Union[np.ndarray, int, float, list, tuple]] = None,
162 out: Optional[np.ndarray] = None,
163 ) -> np.ndarray:
164 prepend = prepend if prepend is not None else np._NoValue
165 append = append if append is not None else np._NoValue
166 return np.diff(x, n=n, axis=axis, prepend=prepend, append=append)
167
168
169 diff.support_native_out = False
170
171
172 @_scalar_output_to_0d_array
173 def allclose(
174 x1: np.ndarray,
175 x2: np.ndarray,
176 /,
177 *,
178 rtol: float = 1e-05,
179 atol: float = 1e-08,
180 equal_nan: bool = False,
181 out: Optional[np.ndarray] = None,
182 ) -> bool:
183 return np.allclose(x1, x2, rtol=rtol, atol=atol, equal_nan=equal_nan)
184
185
186 allclose.support_native_out = False
187
188
189 def fix(
190 x: np.ndarray,
191 /,
192 *,
193 out: Optional[np.ndarray] = None,
194 ) -> np.ndarray:
195 return np.fix(x, out=out)
196
197
198 fix.support_native_out = True
199
200
201 def nextafter(
202 x1: np.ndarray,
203 x2: np.ndarray,
204 /,
205 *,
206 out: Optional[np.ndarray] = None,
207 ) -> np.ndarray:
208 return np.nextafter(x1, x2)
209
210
211 nextafter.support_natvie_out = True
212
213
214 def zeta(
215 x: np.ndarray,
216 q: np.ndarray,
217 /,
218 *,
219 out: Optional[np.ndarray] = None,
220 ) -> np.ndarray:
221 temp = np.logical_and(np.greater(x, 0), np.equal(np.remainder(x, 2), 0))
222 temp = np.logical_and(temp, np.less_equal(q, 0))
223 temp = np.logical_and(temp, np.equal(np.remainder(q, 1), 0))
224 inf_indices = np.logical_or(temp, np.equal(x, 1))
225 temp = np.logical_and(np.not_equal(np.remainder(x, 2), 0), np.greater(x, 1))
226 temp = np.logical_and(temp, np.less_equal(q, 0))
227 nan_indices = np.logical_or(temp, np.less(x, 1))
228 n, res = 1, 1 / q**x
229 while n < 10000:
230 term = 1 / (q + n) ** x
231 n, res = n + 1, res + term
232 ret = np.round(res, decimals=4)
233 ret[nan_indices] = np.nan
234 ret[inf_indices] = np.inf
235 return ret
236
237
238 zeta.support_native_out = False
239
240
241 def gradient(
242 x: np.ndarray,
243 /,
244 *,
245 spacing: Union[int, list, tuple] = 1,
246 axis: Optional[Union[int, list, tuple]] = None,
247 edge_order: int = 1,
248 ) -> Union[np.ndarray, List[np.ndarray]]:
249 if type(spacing) in (int, float):
250 return np.gradient(x, spacing, axis=axis, edge_order=edge_order)
251 return np.gradient(x, *spacing, axis=axis, edge_order=edge_order)
252
253
254 def xlogy(
255 x: np.ndarray, y: np.ndarray, /, *, out: Optional[np.ndarray] = None
256 ) -> np.ndarray:
257 x, y = promote_types_of_inputs(x, y)
258 if (x == 0).all():
259 return 0.0
260 else:
261 return x * np.log(y)
262
263
264 def conj(
265 x: np.ndarray,
266 /,
267 *,
268 out: Optional[np.ndarray] = None,
269 ) -> np.ndarray:
270 ret = np.conj(x, out=out)
271 if x.dtype == np.bool:
272 return ret.astype("bool")
273 return ret
274
275
276 def ldexp(
277 x1: np.ndarray,
278 x2: Union[np.ndarray, int, list, tuple],
279 /,
280 *,
281 out: Optional[np.ndarray] = None,
282 ) -> np.ndarray:
283 return np.ldexp(x1, x2, out=out)
284
285
286 def frexp(
287 x: np.ndarray, /, *, out: Optional[Tuple[np.ndarray, np.ndarray]] = None
288 ) -> Tuple[np.ndarray, np.ndarray]:
289 if out is None:
290 return np.frexp(x, out=(None, None))
291 else:
292 return np.frexp(x, out=out)
293
294
295 def modf(
296 x: np.ndarray,
297 /,
298 *,
299 out: Optional[np.ndarray] = None,
300 ) -> np.ndarray:
301 return np.modf(x, out=out)
302
[end of ivy/functional/backends/numpy/experimental/elementwise.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ivy/functional/backends/numpy/experimental/elementwise.py b/ivy/functional/backends/numpy/experimental/elementwise.py
--- a/ivy/functional/backends/numpy/experimental/elementwise.py
+++ b/ivy/functional/backends/numpy/experimental/elementwise.py
@@ -268,7 +268,7 @@
out: Optional[np.ndarray] = None,
) -> np.ndarray:
ret = np.conj(x, out=out)
- if x.dtype == np.bool:
+ if x.dtype == bool:
return ret.astype("bool")
return ret
|
{"golden_diff": "diff --git a/ivy/functional/backends/numpy/experimental/elementwise.py b/ivy/functional/backends/numpy/experimental/elementwise.py\n--- a/ivy/functional/backends/numpy/experimental/elementwise.py\n+++ b/ivy/functional/backends/numpy/experimental/elementwise.py\n@@ -268,7 +268,7 @@\n out: Optional[np.ndarray] = None,\n ) -> np.ndarray:\n ret = np.conj(x, out=out)\n- if x.dtype == np.bool:\n+ if x.dtype == bool:\n return ret.astype(\"bool\")\n return ret\n", "issue": "Fix paddle_math.test_paddle_conj\n| | |\r\n|---|---|\r\n|numpy|<a href=\"https://github.com/unifyai/ivy/actions/runs/6197499538/job/16826154279\"><img src=https://img.shields.io/badge/-failure-red></a>\r\n|jax|<a href=\"https://github.com/unifyai/ivy/actions/runs/6197499538/job/16826154279\"><img src=https://img.shields.io/badge/-failure-red></a>\r\n|tensorflow|<a href=\"https://github.com/unifyai/ivy/actions/runs/6197499538/job/16826154279\"><img src=https://img.shields.io/badge/-failure-red></a>\r\n|torch|<a href=\"https://github.com/unifyai/ivy/actions/runs/6197499538/job/16826154279\"><img src=https://img.shields.io/badge/-failure-red></a>\r\n|paddle|<a href=\"https://github.com/unifyai/ivy/actions/runs/6197499538/job/16826154279\"><img src=https://img.shields.io/badge/-success-success></a>\r\n\n", "before_files": [{"content": "from typing import Optional, Union, Tuple, List\nimport numpy as np\nimport numpy.typing as npt\n\nimport ivy\nfrom ivy import promote_types_of_inputs\nfrom ivy.functional.backends.numpy.helpers import _scalar_output_to_0d_array\nfrom ivy.func_wrapper import with_unsupported_dtypes\nfrom . import backend_version\n\n\n@_scalar_output_to_0d_array\n@with_unsupported_dtypes({\"1.25.1 and below\": (\"bfloat16\",)}, backend_version)\ndef sinc(x: np.ndarray, /, *, out: Optional[np.ndarray] = None) -> np.ndarray:\n return np.sinc(x).astype(x.dtype)\n\n\n@_scalar_output_to_0d_array\ndef fmax(\n x1: np.ndarray,\n x2: np.ndarray,\n /,\n *,\n out: Optional[np.ndarray] = None,\n) -> np.ndarray:\n x1, x2 = promote_types_of_inputs(x1, x2)\n return np.fmax(\n x1,\n x2,\n out=None,\n where=True,\n casting=\"same_kind\",\n order=\"K\",\n dtype=None,\n subok=True,\n )\n\n\nfmax.support_native_out = True\n\n\n@_scalar_output_to_0d_array\ndef float_power(\n x1: Union[np.ndarray, float, list, tuple],\n x2: Union[np.ndarray, float, list, tuple],\n /,\n *,\n out: Optional[np.ndarray] = None,\n) -> np.ndarray:\n x1, x2 = promote_types_of_inputs(x1, x2)\n return np.float_power(x1, x2, out=out)\n\n\nfloat_power.support_native_out = True\n\n\n@_scalar_output_to_0d_array\ndef copysign(\n x1: npt.ArrayLike,\n x2: npt.ArrayLike,\n /,\n *,\n out: Optional[np.ndarray] = None,\n) -> np.ndarray:\n x1, x2 = promote_types_of_inputs(x1, x2)\n if not ivy.is_float_dtype(x1):\n x1 = x1.astype(ivy.default_float_dtype(as_native=True))\n x2 = x2.astype(ivy.default_float_dtype(as_native=True))\n return np.copysign(x1, x2, out=out)\n\n\ncopysign.support_native_out = True\n\n\n@_scalar_output_to_0d_array\ndef count_nonzero(\n a: np.ndarray,\n /,\n *,\n axis: Optional[Union[int, Tuple[int, ...]]] = None,\n keepdims: bool = False,\n dtype: Optional[np.dtype] = None,\n out: Optional[np.ndarray] = None,\n) -> np.ndarray:\n if isinstance(axis, list):\n axis = tuple(axis)\n ret = np.count_nonzero(a, axis=axis, keepdims=keepdims)\n if np.isscalar(ret):\n return np.array(ret, dtype=dtype)\n return ret.astype(dtype)\n\n\ncount_nonzero.support_native_out = False\n\n\ndef nansum(\n x: np.ndarray,\n /,\n *,\n axis: Optional[Union[Tuple[int, ...], int]] = None,\n dtype: Optional[np.dtype] = None,\n keepdims: bool = False,\n out: Optional[np.ndarray] = None,\n) -> np.ndarray:\n if isinstance(axis, list):\n axis = tuple(axis)\n return np.nansum(x, axis=axis, dtype=dtype, keepdims=keepdims, out=out)\n\n\nnansum.support_native_out = True\n\n\ndef isclose(\n a: np.ndarray,\n b: np.ndarray,\n /,\n *,\n rtol: float = 1e-05,\n atol: float = 1e-08,\n equal_nan: bool = False,\n out: Optional[np.ndarray] = None,\n) -> np.ndarray:\n ret = np.isclose(a, b, rtol=rtol, atol=atol, equal_nan=equal_nan)\n if np.isscalar(ret):\n return np.array(ret, dtype=\"bool\")\n return ret\n\n\nisclose.support_native_out = False\n\n\ndef signbit(\n x: Union[np.ndarray, float, int, list, tuple],\n /,\n *,\n out: Optional[np.ndarray] = None,\n) -> np.ndarray:\n return np.signbit(x, out=out)\n\n\nsignbit.support_native_out = True\n\n\ndef hypot(\n x1: np.ndarray,\n x2: np.ndarray,\n /,\n *,\n out: Optional[np.ndarray] = None,\n) -> np.ndarray:\n return np.hypot(x1, x2)\n\n\ndef diff(\n x: Union[np.ndarray, list, tuple],\n /,\n *,\n n: int = 1,\n axis: int = -1,\n prepend: Optional[Union[np.ndarray, int, float, list, tuple]] = None,\n append: Optional[Union[np.ndarray, int, float, list, tuple]] = None,\n out: Optional[np.ndarray] = None,\n) -> np.ndarray:\n prepend = prepend if prepend is not None else np._NoValue\n append = append if append is not None else np._NoValue\n return np.diff(x, n=n, axis=axis, prepend=prepend, append=append)\n\n\ndiff.support_native_out = False\n\n\n@_scalar_output_to_0d_array\ndef allclose(\n x1: np.ndarray,\n x2: np.ndarray,\n /,\n *,\n rtol: float = 1e-05,\n atol: float = 1e-08,\n equal_nan: bool = False,\n out: Optional[np.ndarray] = None,\n) -> bool:\n return np.allclose(x1, x2, rtol=rtol, atol=atol, equal_nan=equal_nan)\n\n\nallclose.support_native_out = False\n\n\ndef fix(\n x: np.ndarray,\n /,\n *,\n out: Optional[np.ndarray] = None,\n) -> np.ndarray:\n return np.fix(x, out=out)\n\n\nfix.support_native_out = True\n\n\ndef nextafter(\n x1: np.ndarray,\n x2: np.ndarray,\n /,\n *,\n out: Optional[np.ndarray] = None,\n) -> np.ndarray:\n return np.nextafter(x1, x2)\n\n\nnextafter.support_natvie_out = True\n\n\ndef zeta(\n x: np.ndarray,\n q: np.ndarray,\n /,\n *,\n out: Optional[np.ndarray] = None,\n) -> np.ndarray:\n temp = np.logical_and(np.greater(x, 0), np.equal(np.remainder(x, 2), 0))\n temp = np.logical_and(temp, np.less_equal(q, 0))\n temp = np.logical_and(temp, np.equal(np.remainder(q, 1), 0))\n inf_indices = np.logical_or(temp, np.equal(x, 1))\n temp = np.logical_and(np.not_equal(np.remainder(x, 2), 0), np.greater(x, 1))\n temp = np.logical_and(temp, np.less_equal(q, 0))\n nan_indices = np.logical_or(temp, np.less(x, 1))\n n, res = 1, 1 / q**x\n while n < 10000:\n term = 1 / (q + n) ** x\n n, res = n + 1, res + term\n ret = np.round(res, decimals=4)\n ret[nan_indices] = np.nan\n ret[inf_indices] = np.inf\n return ret\n\n\nzeta.support_native_out = False\n\n\ndef gradient(\n x: np.ndarray,\n /,\n *,\n spacing: Union[int, list, tuple] = 1,\n axis: Optional[Union[int, list, tuple]] = None,\n edge_order: int = 1,\n) -> Union[np.ndarray, List[np.ndarray]]:\n if type(spacing) in (int, float):\n return np.gradient(x, spacing, axis=axis, edge_order=edge_order)\n return np.gradient(x, *spacing, axis=axis, edge_order=edge_order)\n\n\ndef xlogy(\n x: np.ndarray, y: np.ndarray, /, *, out: Optional[np.ndarray] = None\n) -> np.ndarray:\n x, y = promote_types_of_inputs(x, y)\n if (x == 0).all():\n return 0.0\n else:\n return x * np.log(y)\n\n\ndef conj(\n x: np.ndarray,\n /,\n *,\n out: Optional[np.ndarray] = None,\n) -> np.ndarray:\n ret = np.conj(x, out=out)\n if x.dtype == np.bool:\n return ret.astype(\"bool\")\n return ret\n\n\ndef ldexp(\n x1: np.ndarray,\n x2: Union[np.ndarray, int, list, tuple],\n /,\n *,\n out: Optional[np.ndarray] = None,\n) -> np.ndarray:\n return np.ldexp(x1, x2, out=out)\n\n\ndef frexp(\n x: np.ndarray, /, *, out: Optional[Tuple[np.ndarray, np.ndarray]] = None\n) -> Tuple[np.ndarray, np.ndarray]:\n if out is None:\n return np.frexp(x, out=(None, None))\n else:\n return np.frexp(x, out=out)\n\n\ndef modf(\n x: np.ndarray,\n /,\n *,\n out: Optional[np.ndarray] = None,\n) -> np.ndarray:\n return np.modf(x, out=out)\n", "path": "ivy/functional/backends/numpy/experimental/elementwise.py"}]}
| 3,768 | 136 |
gh_patches_debug_6385
|
rasdani/github-patches
|
git_diff
|
goauthentik__authentik-5183
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Inactive user can't pass identification stage
**Describe the bug**
I hope I'm not completely wrong, but inactive users should also be able to pass an identification stage.
In my case it should be possible to request a password reset even with an inactive user account.
Like in the default-recovery-flow which is delivered as a blueprint example with Authentik and looks like this:
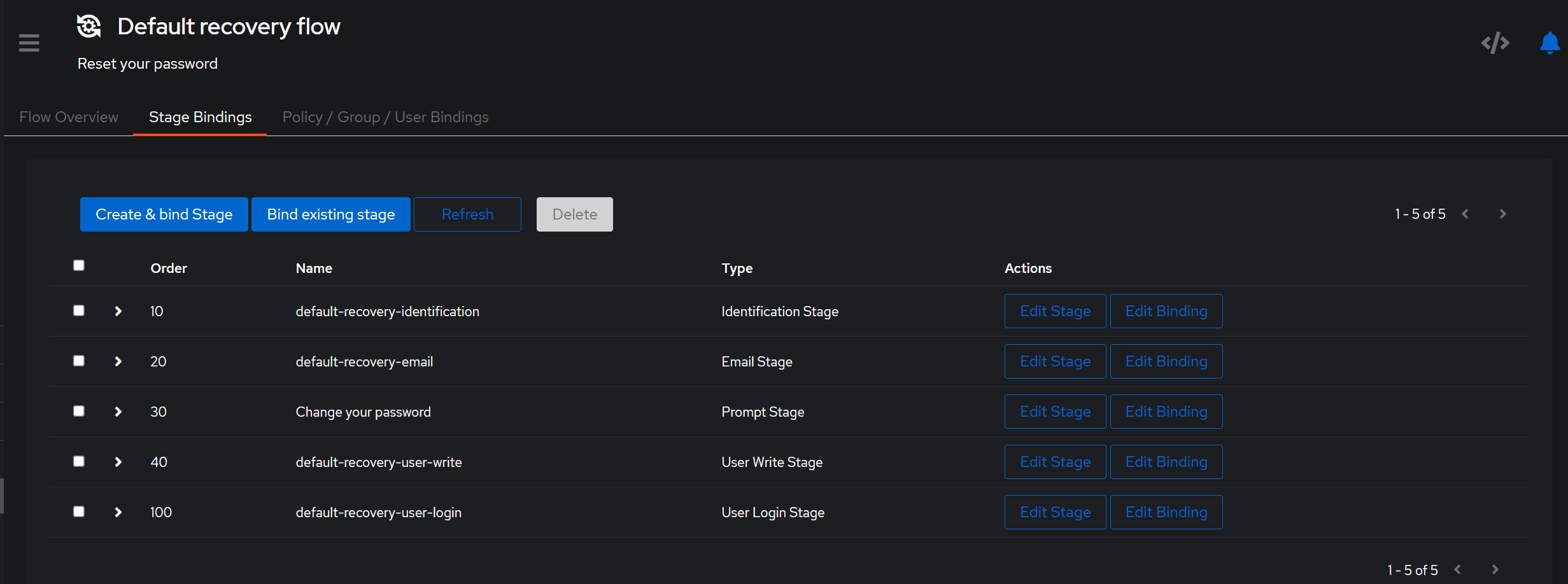
The "default-recovery-email" also has an option to activate inactive users with a normal password reset:
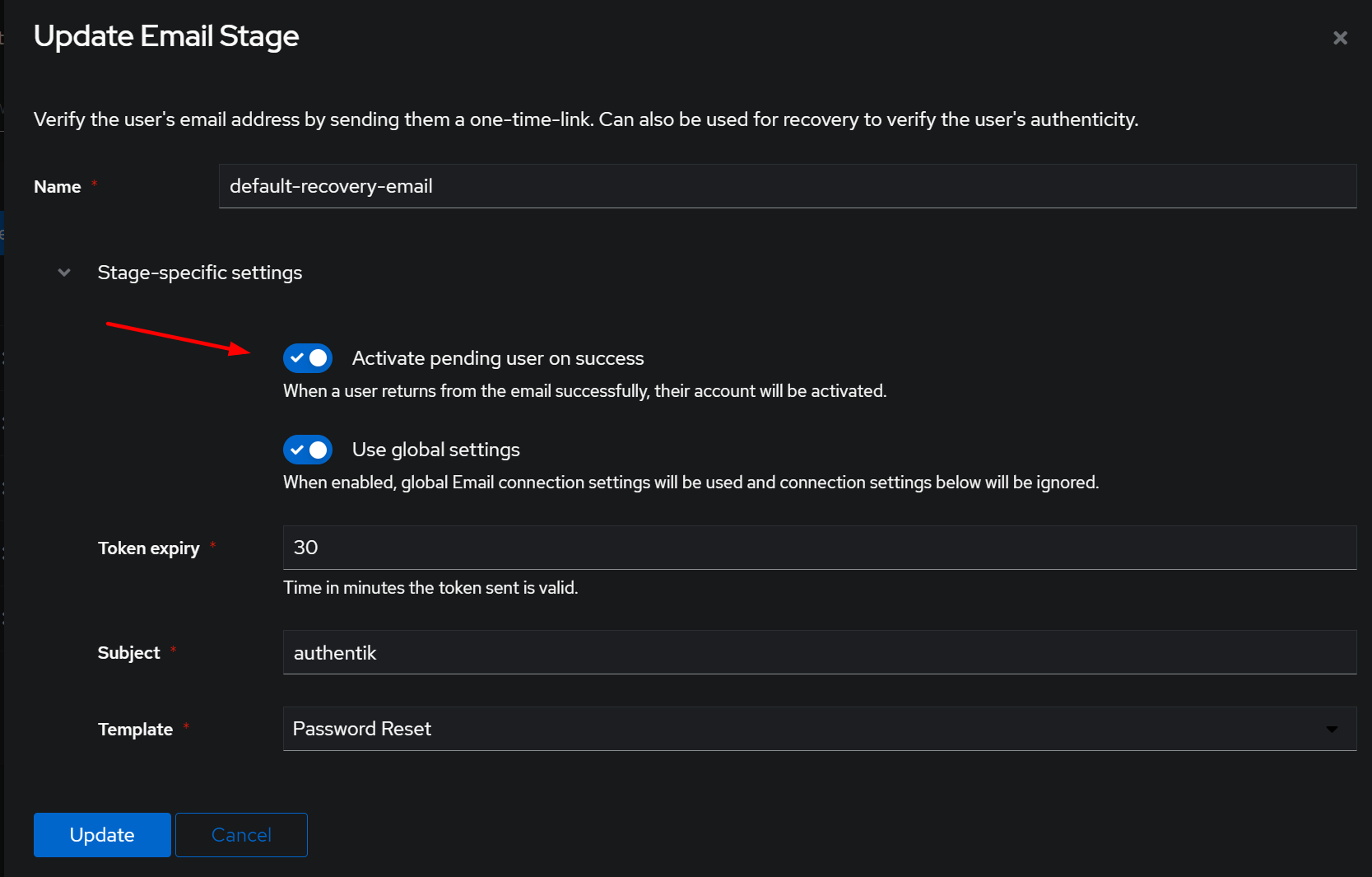
However, in my opinion, this interferes with the following query, which I have adapted for my purposes:
/authentics/authentics/stages/identification/stage.py
changed line 175:
user = User.objects.filter(query, is_active=True).first()
to
user = User.objects.filter(query).first()
Now even inactive users are able to pass the Identification Stage and get to the EMail Stage.
Please let me know if this customization is a safety issue or if it can be done this way.
**To Reproduce**
Steps to reproduce the behavior:
1. fresh Authentik installation
2. created a normal user and set it to inactive
3. created a new Blueprint instance from examples/flows-recovery-email-verification.yaml
4. executed the blueprint instance
5. now I have my recovery flow "default-recovery-flow"
6. to make the flow work I made a small correction to on of the expressions "default-recoery-skip-if-restored" as stated in this Github post: https://github.com/goauthentik/authentik/issues/3297
7. after that I deleted the flow cache and opened the flow in an incognito tab: "/if/flow/default-recovery-flow"
8. try to trigger the passwort reset function
**Expected behavior**
Also an inactive user should be able pass the identification stage to reach the email stage.
**Version and Deployment (please complete the following information):**
- authentik version: 2023.1.2
- Deployment: docker-compose
</issue>
<code>
[start of authentik/stages/identification/stage.py]
1 """Identification stage logic"""
2 from dataclasses import asdict
3 from random import SystemRandom
4 from time import sleep
5 from typing import Any, Optional
6
7 from django.core.exceptions import PermissionDenied
8 from django.db.models import Q
9 from django.http import HttpResponse
10 from django.utils.translation import gettext as _
11 from drf_spectacular.utils import PolymorphicProxySerializer, extend_schema_field
12 from rest_framework.fields import BooleanField, CharField, DictField, ListField
13 from rest_framework.serializers import ValidationError
14 from sentry_sdk.hub import Hub
15
16 from authentik.core.api.utils import PassiveSerializer
17 from authentik.core.models import Application, Source, User
18 from authentik.events.utils import sanitize_item
19 from authentik.flows.challenge import (
20 Challenge,
21 ChallengeResponse,
22 ChallengeTypes,
23 RedirectChallenge,
24 )
25 from authentik.flows.models import FlowDesignation
26 from authentik.flows.planner import PLAN_CONTEXT_PENDING_USER
27 from authentik.flows.stage import PLAN_CONTEXT_PENDING_USER_IDENTIFIER, ChallengeStageView
28 from authentik.flows.views.executor import SESSION_KEY_APPLICATION_PRE, SESSION_KEY_GET
29 from authentik.lib.utils.http import get_client_ip
30 from authentik.lib.utils.urls import reverse_with_qs
31 from authentik.sources.oauth.types.apple import AppleLoginChallenge
32 from authentik.sources.plex.models import PlexAuthenticationChallenge
33 from authentik.stages.identification.models import IdentificationStage
34 from authentik.stages.identification.signals import identification_failed
35 from authentik.stages.password.stage import authenticate
36
37
38 @extend_schema_field(
39 PolymorphicProxySerializer(
40 component_name="LoginChallengeTypes",
41 serializers={
42 RedirectChallenge().fields["component"].default: RedirectChallenge,
43 PlexAuthenticationChallenge().fields["component"].default: PlexAuthenticationChallenge,
44 AppleLoginChallenge().fields["component"].default: AppleLoginChallenge,
45 },
46 resource_type_field_name="component",
47 )
48 )
49 class ChallengeDictWrapper(DictField):
50 """Wrapper around DictField that annotates itself as challenge proxy"""
51
52
53 class LoginSourceSerializer(PassiveSerializer):
54 """Serializer for Login buttons of sources"""
55
56 name = CharField()
57 icon_url = CharField(required=False, allow_null=True)
58
59 challenge = ChallengeDictWrapper()
60
61
62 class IdentificationChallenge(Challenge):
63 """Identification challenges with all UI elements"""
64
65 user_fields = ListField(child=CharField(), allow_empty=True, allow_null=True)
66 password_fields = BooleanField()
67 application_pre = CharField(required=False)
68
69 enroll_url = CharField(required=False)
70 recovery_url = CharField(required=False)
71 passwordless_url = CharField(required=False)
72 primary_action = CharField()
73 sources = LoginSourceSerializer(many=True, required=False)
74 show_source_labels = BooleanField()
75
76 component = CharField(default="ak-stage-identification")
77
78
79 class IdentificationChallengeResponse(ChallengeResponse):
80 """Identification challenge"""
81
82 uid_field = CharField()
83 password = CharField(required=False, allow_blank=True, allow_null=True)
84 component = CharField(default="ak-stage-identification")
85
86 pre_user: Optional[User] = None
87
88 def validate(self, attrs: dict[str, Any]) -> dict[str, Any]:
89 """Validate that user exists, and optionally their password"""
90 uid_field = attrs["uid_field"]
91 current_stage: IdentificationStage = self.stage.executor.current_stage
92
93 pre_user = self.stage.get_user(uid_field)
94 if not pre_user:
95 with Hub.current.start_span(
96 op="authentik.stages.identification.validate_invalid_wait",
97 description="Sleep random time on invalid user identifier",
98 ):
99 # Sleep a random time (between 90 and 210ms) to "prevent" user enumeration attacks
100 sleep(0.030 * SystemRandom().randint(3, 7))
101 # Log in a similar format to Event.new(), but we don't want to create an event here
102 # as this stage is mostly used by unauthenticated users with very high rate limits
103 self.stage.logger.info(
104 "invalid_login",
105 identifier=uid_field,
106 client_ip=get_client_ip(self.stage.request),
107 action="invalid_identifier",
108 context={
109 "stage": sanitize_item(self.stage),
110 },
111 )
112 identification_failed.send(sender=self, request=self.stage.request, uid_field=uid_field)
113 # We set the pending_user even on failure so it's part of the context, even
114 # when the input is invalid
115 # This is so its part of the current flow plan, and on flow restart can be kept, and
116 # policies can be applied.
117 self.stage.executor.plan.context[PLAN_CONTEXT_PENDING_USER] = User(
118 username=uid_field,
119 email=uid_field,
120 )
121 if not current_stage.show_matched_user:
122 self.stage.executor.plan.context[PLAN_CONTEXT_PENDING_USER_IDENTIFIER] = uid_field
123 raise ValidationError("Failed to authenticate.")
124 self.pre_user = pre_user
125 if not current_stage.password_stage:
126 # No password stage select, don't validate the password
127 return attrs
128
129 password = attrs.get("password", None)
130 if not password:
131 self.stage.logger.warning("Password not set for ident+auth attempt")
132 try:
133 with Hub.current.start_span(
134 op="authentik.stages.identification.authenticate",
135 description="User authenticate call (combo stage)",
136 ):
137 user = authenticate(
138 self.stage.request,
139 current_stage.password_stage.backends,
140 current_stage,
141 username=self.pre_user.username,
142 password=password,
143 )
144 if not user:
145 raise ValidationError("Failed to authenticate.")
146 self.pre_user = user
147 except PermissionDenied as exc:
148 raise ValidationError(str(exc)) from exc
149 return attrs
150
151
152 class IdentificationStageView(ChallengeStageView):
153 """Form to identify the user"""
154
155 response_class = IdentificationChallengeResponse
156
157 def get_user(self, uid_value: str) -> Optional[User]:
158 """Find user instance. Returns None if no user was found."""
159 current_stage: IdentificationStage = self.executor.current_stage
160 query = Q()
161 for search_field in current_stage.user_fields:
162 model_field = {
163 "email": "email",
164 "username": "username",
165 "upn": "attributes__upn",
166 }[search_field]
167 if current_stage.case_insensitive_matching:
168 model_field += "__iexact"
169 else:
170 model_field += "__exact"
171 query |= Q(**{model_field: uid_value})
172 if not query:
173 self.logger.debug("Empty user query", query=query)
174 return None
175 user = User.objects.filter(query, is_active=True).first()
176 if user:
177 self.logger.debug("Found user", user=user.username, query=query)
178 return user
179 return None
180
181 def get_primary_action(self) -> str:
182 """Get the primary action label for this stage"""
183 if self.executor.flow.designation == FlowDesignation.AUTHENTICATION:
184 return _("Log in")
185 return _("Continue")
186
187 def get_challenge(self) -> Challenge:
188 current_stage: IdentificationStage = self.executor.current_stage
189 challenge = IdentificationChallenge(
190 data={
191 "type": ChallengeTypes.NATIVE.value,
192 "primary_action": self.get_primary_action(),
193 "component": "ak-stage-identification",
194 "user_fields": current_stage.user_fields,
195 "password_fields": bool(current_stage.password_stage),
196 "show_source_labels": current_stage.show_source_labels,
197 }
198 )
199 # If the user has been redirected to us whilst trying to access an
200 # application, SESSION_KEY_APPLICATION_PRE is set in the session
201 if SESSION_KEY_APPLICATION_PRE in self.request.session:
202 challenge.initial_data["application_pre"] = self.request.session.get(
203 SESSION_KEY_APPLICATION_PRE, Application()
204 ).name
205 get_qs = self.request.session.get(SESSION_KEY_GET, self.request.GET)
206 # Check for related enrollment and recovery flow, add URL to view
207 if current_stage.enrollment_flow:
208 challenge.initial_data["enroll_url"] = reverse_with_qs(
209 "authentik_core:if-flow",
210 query=get_qs,
211 kwargs={"flow_slug": current_stage.enrollment_flow.slug},
212 )
213 if current_stage.recovery_flow:
214 challenge.initial_data["recovery_url"] = reverse_with_qs(
215 "authentik_core:if-flow",
216 query=get_qs,
217 kwargs={"flow_slug": current_stage.recovery_flow.slug},
218 )
219 if current_stage.passwordless_flow:
220 challenge.initial_data["passwordless_url"] = reverse_with_qs(
221 "authentik_core:if-flow",
222 query=get_qs,
223 kwargs={"flow_slug": current_stage.passwordless_flow.slug},
224 )
225
226 # Check all enabled source, add them if they have a UI Login button.
227 ui_sources = []
228 sources: list[Source] = (
229 current_stage.sources.filter(enabled=True).order_by("name").select_subclasses()
230 )
231 for source in sources:
232 ui_login_button = source.ui_login_button(self.request)
233 if ui_login_button:
234 button = asdict(ui_login_button)
235 button["challenge"] = ui_login_button.challenge.data
236 ui_sources.append(button)
237 challenge.initial_data["sources"] = ui_sources
238 return challenge
239
240 def challenge_valid(self, response: IdentificationChallengeResponse) -> HttpResponse:
241 self.executor.plan.context[PLAN_CONTEXT_PENDING_USER] = response.pre_user
242 current_stage: IdentificationStage = self.executor.current_stage
243 if not current_stage.show_matched_user:
244 self.executor.plan.context[
245 PLAN_CONTEXT_PENDING_USER_IDENTIFIER
246 ] = response.validated_data.get("uid_field")
247 return self.executor.stage_ok()
248
[end of authentik/stages/identification/stage.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/authentik/stages/identification/stage.py b/authentik/stages/identification/stage.py
--- a/authentik/stages/identification/stage.py
+++ b/authentik/stages/identification/stage.py
@@ -172,7 +172,7 @@
if not query:
self.logger.debug("Empty user query", query=query)
return None
- user = User.objects.filter(query, is_active=True).first()
+ user = User.objects.filter(query).first()
if user:
self.logger.debug("Found user", user=user.username, query=query)
return user
|
{"golden_diff": "diff --git a/authentik/stages/identification/stage.py b/authentik/stages/identification/stage.py\n--- a/authentik/stages/identification/stage.py\n+++ b/authentik/stages/identification/stage.py\n@@ -172,7 +172,7 @@\n if not query:\n self.logger.debug(\"Empty user query\", query=query)\n return None\n- user = User.objects.filter(query, is_active=True).first()\n+ user = User.objects.filter(query).first()\n if user:\n self.logger.debug(\"Found user\", user=user.username, query=query)\n return user\n", "issue": "Inactive user can't pass identification stage\n**Describe the bug**\r\nI hope I'm not completely wrong, but inactive users should also be able to pass an identification stage.\r\nIn my case it should be possible to request a password reset even with an inactive user account. \r\n\r\nLike in the default-recovery-flow which is delivered as a blueprint example with Authentik and looks like this:\r\n\r\n\r\n\r\nThe \"default-recovery-email\" also has an option to activate inactive users with a normal password reset:\r\n\r\n\r\n\r\nHowever, in my opinion, this interferes with the following query, which I have adapted for my purposes:\r\n\r\n/authentics/authentics/stages/identification/stage.py\r\n\r\nchanged line 175:\r\n user = User.objects.filter(query, is_active=True).first()\r\nto \r\n user = User.objects.filter(query).first()\r\n\r\nNow even inactive users are able to pass the Identification Stage and get to the EMail Stage.\r\nPlease let me know if this customization is a safety issue or if it can be done this way.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. fresh Authentik installation\r\n2. created a normal user and set it to inactive\r\n3. created a new Blueprint instance from examples/flows-recovery-email-verification.yaml\r\n4. executed the blueprint instance\r\n5. now I have my recovery flow \"default-recovery-flow\"\r\n6. to make the flow work I made a small correction to on of the expressions \"default-recoery-skip-if-restored\" as stated in this Github post: https://github.com/goauthentik/authentik/issues/3297\r\n7. after that I deleted the flow cache and opened the flow in an incognito tab: \"/if/flow/default-recovery-flow\"\r\n8. try to trigger the passwort reset function\r\n\r\n**Expected behavior**\r\nAlso an inactive user should be able pass the identification stage to reach the email stage.\r\n\r\n**Version and Deployment (please complete the following information):**\r\n - authentik version: 2023.1.2\r\n - Deployment: docker-compose\n", "before_files": [{"content": "\"\"\"Identification stage logic\"\"\"\nfrom dataclasses import asdict\nfrom random import SystemRandom\nfrom time import sleep\nfrom typing import Any, Optional\n\nfrom django.core.exceptions import PermissionDenied\nfrom django.db.models import Q\nfrom django.http import HttpResponse\nfrom django.utils.translation import gettext as _\nfrom drf_spectacular.utils import PolymorphicProxySerializer, extend_schema_field\nfrom rest_framework.fields import BooleanField, CharField, DictField, ListField\nfrom rest_framework.serializers import ValidationError\nfrom sentry_sdk.hub import Hub\n\nfrom authentik.core.api.utils import PassiveSerializer\nfrom authentik.core.models import Application, Source, User\nfrom authentik.events.utils import sanitize_item\nfrom authentik.flows.challenge import (\n Challenge,\n ChallengeResponse,\n ChallengeTypes,\n RedirectChallenge,\n)\nfrom authentik.flows.models import FlowDesignation\nfrom authentik.flows.planner import PLAN_CONTEXT_PENDING_USER\nfrom authentik.flows.stage import PLAN_CONTEXT_PENDING_USER_IDENTIFIER, ChallengeStageView\nfrom authentik.flows.views.executor import SESSION_KEY_APPLICATION_PRE, SESSION_KEY_GET\nfrom authentik.lib.utils.http import get_client_ip\nfrom authentik.lib.utils.urls import reverse_with_qs\nfrom authentik.sources.oauth.types.apple import AppleLoginChallenge\nfrom authentik.sources.plex.models import PlexAuthenticationChallenge\nfrom authentik.stages.identification.models import IdentificationStage\nfrom authentik.stages.identification.signals import identification_failed\nfrom authentik.stages.password.stage import authenticate\n\n\n@extend_schema_field(\n PolymorphicProxySerializer(\n component_name=\"LoginChallengeTypes\",\n serializers={\n RedirectChallenge().fields[\"component\"].default: RedirectChallenge,\n PlexAuthenticationChallenge().fields[\"component\"].default: PlexAuthenticationChallenge,\n AppleLoginChallenge().fields[\"component\"].default: AppleLoginChallenge,\n },\n resource_type_field_name=\"component\",\n )\n)\nclass ChallengeDictWrapper(DictField):\n \"\"\"Wrapper around DictField that annotates itself as challenge proxy\"\"\"\n\n\nclass LoginSourceSerializer(PassiveSerializer):\n \"\"\"Serializer for Login buttons of sources\"\"\"\n\n name = CharField()\n icon_url = CharField(required=False, allow_null=True)\n\n challenge = ChallengeDictWrapper()\n\n\nclass IdentificationChallenge(Challenge):\n \"\"\"Identification challenges with all UI elements\"\"\"\n\n user_fields = ListField(child=CharField(), allow_empty=True, allow_null=True)\n password_fields = BooleanField()\n application_pre = CharField(required=False)\n\n enroll_url = CharField(required=False)\n recovery_url = CharField(required=False)\n passwordless_url = CharField(required=False)\n primary_action = CharField()\n sources = LoginSourceSerializer(many=True, required=False)\n show_source_labels = BooleanField()\n\n component = CharField(default=\"ak-stage-identification\")\n\n\nclass IdentificationChallengeResponse(ChallengeResponse):\n \"\"\"Identification challenge\"\"\"\n\n uid_field = CharField()\n password = CharField(required=False, allow_blank=True, allow_null=True)\n component = CharField(default=\"ak-stage-identification\")\n\n pre_user: Optional[User] = None\n\n def validate(self, attrs: dict[str, Any]) -> dict[str, Any]:\n \"\"\"Validate that user exists, and optionally their password\"\"\"\n uid_field = attrs[\"uid_field\"]\n current_stage: IdentificationStage = self.stage.executor.current_stage\n\n pre_user = self.stage.get_user(uid_field)\n if not pre_user:\n with Hub.current.start_span(\n op=\"authentik.stages.identification.validate_invalid_wait\",\n description=\"Sleep random time on invalid user identifier\",\n ):\n # Sleep a random time (between 90 and 210ms) to \"prevent\" user enumeration attacks\n sleep(0.030 * SystemRandom().randint(3, 7))\n # Log in a similar format to Event.new(), but we don't want to create an event here\n # as this stage is mostly used by unauthenticated users with very high rate limits\n self.stage.logger.info(\n \"invalid_login\",\n identifier=uid_field,\n client_ip=get_client_ip(self.stage.request),\n action=\"invalid_identifier\",\n context={\n \"stage\": sanitize_item(self.stage),\n },\n )\n identification_failed.send(sender=self, request=self.stage.request, uid_field=uid_field)\n # We set the pending_user even on failure so it's part of the context, even\n # when the input is invalid\n # This is so its part of the current flow plan, and on flow restart can be kept, and\n # policies can be applied.\n self.stage.executor.plan.context[PLAN_CONTEXT_PENDING_USER] = User(\n username=uid_field,\n email=uid_field,\n )\n if not current_stage.show_matched_user:\n self.stage.executor.plan.context[PLAN_CONTEXT_PENDING_USER_IDENTIFIER] = uid_field\n raise ValidationError(\"Failed to authenticate.\")\n self.pre_user = pre_user\n if not current_stage.password_stage:\n # No password stage select, don't validate the password\n return attrs\n\n password = attrs.get(\"password\", None)\n if not password:\n self.stage.logger.warning(\"Password not set for ident+auth attempt\")\n try:\n with Hub.current.start_span(\n op=\"authentik.stages.identification.authenticate\",\n description=\"User authenticate call (combo stage)\",\n ):\n user = authenticate(\n self.stage.request,\n current_stage.password_stage.backends,\n current_stage,\n username=self.pre_user.username,\n password=password,\n )\n if not user:\n raise ValidationError(\"Failed to authenticate.\")\n self.pre_user = user\n except PermissionDenied as exc:\n raise ValidationError(str(exc)) from exc\n return attrs\n\n\nclass IdentificationStageView(ChallengeStageView):\n \"\"\"Form to identify the user\"\"\"\n\n response_class = IdentificationChallengeResponse\n\n def get_user(self, uid_value: str) -> Optional[User]:\n \"\"\"Find user instance. Returns None if no user was found.\"\"\"\n current_stage: IdentificationStage = self.executor.current_stage\n query = Q()\n for search_field in current_stage.user_fields:\n model_field = {\n \"email\": \"email\",\n \"username\": \"username\",\n \"upn\": \"attributes__upn\",\n }[search_field]\n if current_stage.case_insensitive_matching:\n model_field += \"__iexact\"\n else:\n model_field += \"__exact\"\n query |= Q(**{model_field: uid_value})\n if not query:\n self.logger.debug(\"Empty user query\", query=query)\n return None\n user = User.objects.filter(query, is_active=True).first()\n if user:\n self.logger.debug(\"Found user\", user=user.username, query=query)\n return user\n return None\n\n def get_primary_action(self) -> str:\n \"\"\"Get the primary action label for this stage\"\"\"\n if self.executor.flow.designation == FlowDesignation.AUTHENTICATION:\n return _(\"Log in\")\n return _(\"Continue\")\n\n def get_challenge(self) -> Challenge:\n current_stage: IdentificationStage = self.executor.current_stage\n challenge = IdentificationChallenge(\n data={\n \"type\": ChallengeTypes.NATIVE.value,\n \"primary_action\": self.get_primary_action(),\n \"component\": \"ak-stage-identification\",\n \"user_fields\": current_stage.user_fields,\n \"password_fields\": bool(current_stage.password_stage),\n \"show_source_labels\": current_stage.show_source_labels,\n }\n )\n # If the user has been redirected to us whilst trying to access an\n # application, SESSION_KEY_APPLICATION_PRE is set in the session\n if SESSION_KEY_APPLICATION_PRE in self.request.session:\n challenge.initial_data[\"application_pre\"] = self.request.session.get(\n SESSION_KEY_APPLICATION_PRE, Application()\n ).name\n get_qs = self.request.session.get(SESSION_KEY_GET, self.request.GET)\n # Check for related enrollment and recovery flow, add URL to view\n if current_stage.enrollment_flow:\n challenge.initial_data[\"enroll_url\"] = reverse_with_qs(\n \"authentik_core:if-flow\",\n query=get_qs,\n kwargs={\"flow_slug\": current_stage.enrollment_flow.slug},\n )\n if current_stage.recovery_flow:\n challenge.initial_data[\"recovery_url\"] = reverse_with_qs(\n \"authentik_core:if-flow\",\n query=get_qs,\n kwargs={\"flow_slug\": current_stage.recovery_flow.slug},\n )\n if current_stage.passwordless_flow:\n challenge.initial_data[\"passwordless_url\"] = reverse_with_qs(\n \"authentik_core:if-flow\",\n query=get_qs,\n kwargs={\"flow_slug\": current_stage.passwordless_flow.slug},\n )\n\n # Check all enabled source, add them if they have a UI Login button.\n ui_sources = []\n sources: list[Source] = (\n current_stage.sources.filter(enabled=True).order_by(\"name\").select_subclasses()\n )\n for source in sources:\n ui_login_button = source.ui_login_button(self.request)\n if ui_login_button:\n button = asdict(ui_login_button)\n button[\"challenge\"] = ui_login_button.challenge.data\n ui_sources.append(button)\n challenge.initial_data[\"sources\"] = ui_sources\n return challenge\n\n def challenge_valid(self, response: IdentificationChallengeResponse) -> HttpResponse:\n self.executor.plan.context[PLAN_CONTEXT_PENDING_USER] = response.pre_user\n current_stage: IdentificationStage = self.executor.current_stage\n if not current_stage.show_matched_user:\n self.executor.plan.context[\n PLAN_CONTEXT_PENDING_USER_IDENTIFIER\n ] = response.validated_data.get(\"uid_field\")\n return self.executor.stage_ok()\n", "path": "authentik/stages/identification/stage.py"}]}
| 3,768 | 136 |
gh_patches_debug_8989
|
rasdani/github-patches
|
git_diff
|
certbot__certbot-4248
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
returned non-string (type Error)
Hey there, I installed certbot as per the doc's from letsencrypt on Debian Jessie and certbot in manual mode returns:
certbot certonly --manual -d mydomain.com
```
An unexpected error occurred:
TypeError: __str__ returned non-string (type Error)
```
```
pip2 list
acme (0.9.3)
...
certbot (0.9.3)
cryptography (1.5.3)
...
pyOpenSSL (16.0.0)
```
Anyone seen this before and can offer a solution? Thanks
</issue>
<code>
[start of acme/setup.py]
1 import sys
2
3 from setuptools import setup
4 from setuptools import find_packages
5
6
7 version = '0.12.0.dev0'
8
9 # Please update tox.ini when modifying dependency version requirements
10 install_requires = [
11 # load_pem_private/public_key (>=0.6)
12 # rsa_recover_prime_factors (>=0.8)
13 'cryptography>=0.8',
14 # Connection.set_tlsext_host_name (>=0.13)
15 'PyOpenSSL>=0.13',
16 'pyrfc3339',
17 'pytz',
18 'requests[security]>=2.4.1', # security extras added in 2.4.1
19 # For pkg_resources. >=1.0 so pip resolves it to a version cryptography
20 # will tolerate; see #2599:
21 'setuptools>=1.0',
22 'six',
23 ]
24
25 # env markers in extras_require cause problems with older pip: #517
26 # Keep in sync with conditional_requirements.py.
27 if sys.version_info < (2, 7):
28 install_requires.extend([
29 # only some distros recognize stdlib argparse as already satisfying
30 'argparse',
31 'mock<1.1.0',
32 ])
33 else:
34 install_requires.append('mock')
35
36 dev_extras = [
37 'nose',
38 'tox',
39 ]
40
41 docs_extras = [
42 'Sphinx>=1.0', # autodoc_member_order = 'bysource', autodoc_default_flags
43 'sphinx_rtd_theme',
44 ]
45
46
47 setup(
48 name='acme',
49 version=version,
50 description='ACME protocol implementation in Python',
51 url='https://github.com/letsencrypt/letsencrypt',
52 author="Certbot Project",
53 author_email='[email protected]',
54 license='Apache License 2.0',
55 classifiers=[
56 'Development Status :: 3 - Alpha',
57 'Intended Audience :: Developers',
58 'License :: OSI Approved :: Apache Software License',
59 'Programming Language :: Python',
60 'Programming Language :: Python :: 2',
61 'Programming Language :: Python :: 2.6',
62 'Programming Language :: Python :: 2.7',
63 'Programming Language :: Python :: 3',
64 'Programming Language :: Python :: 3.3',
65 'Programming Language :: Python :: 3.4',
66 'Programming Language :: Python :: 3.5',
67 'Topic :: Internet :: WWW/HTTP',
68 'Topic :: Security',
69 ],
70
71 packages=find_packages(),
72 include_package_data=True,
73 install_requires=install_requires,
74 extras_require={
75 'dev': dev_extras,
76 'docs': docs_extras,
77 },
78 entry_points={
79 'console_scripts': [
80 'jws = acme.jose.jws:CLI.run',
81 ],
82 },
83 test_suite='acme',
84 )
85
[end of acme/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/acme/setup.py b/acme/setup.py
--- a/acme/setup.py
+++ b/acme/setup.py
@@ -15,7 +15,11 @@
'PyOpenSSL>=0.13',
'pyrfc3339',
'pytz',
- 'requests[security]>=2.4.1', # security extras added in 2.4.1
+ # requests>=2.10 is required to fix
+ # https://github.com/shazow/urllib3/issues/556. This requirement can be
+ # relaxed to 'requests[security]>=2.4.1', however, less useful errors
+ # will be raised for some network/SSL errors.
+ 'requests[security]>=2.10',
# For pkg_resources. >=1.0 so pip resolves it to a version cryptography
# will tolerate; see #2599:
'setuptools>=1.0',
|
{"golden_diff": "diff --git a/acme/setup.py b/acme/setup.py\n--- a/acme/setup.py\n+++ b/acme/setup.py\n@@ -15,7 +15,11 @@\n 'PyOpenSSL>=0.13',\n 'pyrfc3339',\n 'pytz',\n- 'requests[security]>=2.4.1', # security extras added in 2.4.1\n+ # requests>=2.10 is required to fix\n+ # https://github.com/shazow/urllib3/issues/556. This requirement can be\n+ # relaxed to 'requests[security]>=2.4.1', however, less useful errors\n+ # will be raised for some network/SSL errors.\n+ 'requests[security]>=2.10',\n # For pkg_resources. >=1.0 so pip resolves it to a version cryptography\n # will tolerate; see #2599:\n 'setuptools>=1.0',\n", "issue": "returned non-string (type Error)\nHey there, I installed certbot as per the doc's from letsencrypt on Debian Jessie and certbot in manual mode returns:\r\n\r\ncertbot certonly --manual -d mydomain.com\r\n\r\n```\r\nAn unexpected error occurred:\r\nTypeError: __str__ returned non-string (type Error)\r\n```\r\n\r\n```\r\npip2 list\r\nacme (0.9.3)\r\n...\r\ncertbot (0.9.3)\r\ncryptography (1.5.3)\r\n...\r\npyOpenSSL (16.0.0)\r\n```\r\n\r\nAnyone seen this before and can offer a solution? Thanks\r\n\n", "before_files": [{"content": "import sys\n\nfrom setuptools import setup\nfrom setuptools import find_packages\n\n\nversion = '0.12.0.dev0'\n\n# Please update tox.ini when modifying dependency version requirements\ninstall_requires = [\n # load_pem_private/public_key (>=0.6)\n # rsa_recover_prime_factors (>=0.8)\n 'cryptography>=0.8',\n # Connection.set_tlsext_host_name (>=0.13)\n 'PyOpenSSL>=0.13',\n 'pyrfc3339',\n 'pytz',\n 'requests[security]>=2.4.1', # security extras added in 2.4.1\n # For pkg_resources. >=1.0 so pip resolves it to a version cryptography\n # will tolerate; see #2599:\n 'setuptools>=1.0',\n 'six',\n]\n\n# env markers in extras_require cause problems with older pip: #517\n# Keep in sync with conditional_requirements.py.\nif sys.version_info < (2, 7):\n install_requires.extend([\n # only some distros recognize stdlib argparse as already satisfying\n 'argparse',\n 'mock<1.1.0',\n ])\nelse:\n install_requires.append('mock')\n\ndev_extras = [\n 'nose',\n 'tox',\n]\n\ndocs_extras = [\n 'Sphinx>=1.0', # autodoc_member_order = 'bysource', autodoc_default_flags\n 'sphinx_rtd_theme',\n]\n\n\nsetup(\n name='acme',\n version=version,\n description='ACME protocol implementation in Python',\n url='https://github.com/letsencrypt/letsencrypt',\n author=\"Certbot Project\",\n author_email='[email protected]',\n license='Apache License 2.0',\n classifiers=[\n 'Development Status :: 3 - Alpha',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.6',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Topic :: Internet :: WWW/HTTP',\n 'Topic :: Security',\n ],\n\n packages=find_packages(),\n include_package_data=True,\n install_requires=install_requires,\n extras_require={\n 'dev': dev_extras,\n 'docs': docs_extras,\n },\n entry_points={\n 'console_scripts': [\n 'jws = acme.jose.jws:CLI.run',\n ],\n },\n test_suite='acme',\n)\n", "path": "acme/setup.py"}]}
| 1,439 | 219 |
gh_patches_debug_16335
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-1029
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Crash batch list of request has trailing comma
```
echo '{
"requests": [
{"path": "/buckets/default/collections/test1/records"},
{"path": "/buckets/default/collections/test2/records"},
]
}' | http POST :8888/v1/batch --auth a:a
```
```
2017-01-18 16:45:58,968 ERROR [kinto.core.views.errors][waitress] "POST /v1/batch" ? (? ms) '_null' object has no attribute 'get' agent=HTTPie/0.9.2 authn_type=None errno=None exception=Traceback (most recent call last):
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/tweens.py", line 22, in excview_tween
response = handler(request)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid_tm/__init__.py", line 119, in tm_tween
reraise(*exc_info)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid_tm/__init__.py", line 98, in tm_tween
response = handler(request)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/router.py", line 158, in handle_request
view_name
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/view.py", line 547, in _call_view
response = view_callable(context, request)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/config/views.py", line 182,
, in __call__
return view(context, request)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/viewderivers.py", line 393, in attr_view
return view(context, request)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/viewderivers.py", line 371, in predicate_wrapper
return view(context, request)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/viewderivers.py", line 442, in rendered_view
result = view(context, request)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/viewderivers.py", line 147, in _requestonly_view
response = view(request)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/cornice/service.py", line 484, in wrapper
validator(request, **args)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/cornice/validators/_colander.py", line 73, in validator
deserialized = schema.deserialize(cstruct)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/colander/__init__.py", line 2058, in deserialize
appstruct = self.typ.deserialize(self, cstruct)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/colander/__init__.py", line 719, in deserialize
return self._impl(node, cstruct, callback)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/colander/__init__.py", line 678, in _impl
sub_result = callback(subnode, subval)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/colander/__init__.py", line 717, in callback
return subnode.deserialize(subcstruct)
File "/home/mathieu/Code/Mozilla/kinto/kinto/core/views/batch.py", line 57, in deserialize
defaults = cstruct.get('defaults')
AttributeError: '_null' object has no attribute 'get' lang=None uid=None
2017-01-18 16:45:58,969 INFO [kinto.core.initialization][waitress] "POST /v1/batch" 500 (5 ms) request.summary agent=HTTPie/0.9.2 authn_type=None errno=999 lang=None time=2017-01-18T16:45:58 uid=None
```
Crash batch list of request has trailing comma
```
echo '{
"requests": [
{"path": "/buckets/default/collections/test1/records"},
{"path": "/buckets/default/collections/test2/records"},
]
}' | http POST :8888/v1/batch --auth a:a
```
```
2017-01-18 16:45:58,968 ERROR [kinto.core.views.errors][waitress] "POST /v1/batch" ? (? ms) '_null' object has no attribute 'get' agent=HTTPie/0.9.2 authn_type=None errno=None exception=Traceback (most recent call last):
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/tweens.py", line 22, in excview_tween
response = handler(request)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid_tm/__init__.py", line 119, in tm_tween
reraise(*exc_info)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid_tm/__init__.py", line 98, in tm_tween
response = handler(request)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/router.py", line 158, in handle_request
view_name
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/view.py", line 547, in _call_view
response = view_callable(context, request)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/config/views.py", line 182,
, in __call__
return view(context, request)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/viewderivers.py", line 393, in attr_view
return view(context, request)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/viewderivers.py", line 371, in predicate_wrapper
return view(context, request)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/viewderivers.py", line 442, in rendered_view
result = view(context, request)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/viewderivers.py", line 147, in _requestonly_view
response = view(request)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/cornice/service.py", line 484, in wrapper
validator(request, **args)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/cornice/validators/_colander.py", line 73, in validator
deserialized = schema.deserialize(cstruct)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/colander/__init__.py", line 2058, in deserialize
appstruct = self.typ.deserialize(self, cstruct)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/colander/__init__.py", line 719, in deserialize
return self._impl(node, cstruct, callback)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/colander/__init__.py", line 678, in _impl
sub_result = callback(subnode, subval)
File "/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/colander/__init__.py", line 717, in callback
return subnode.deserialize(subcstruct)
File "/home/mathieu/Code/Mozilla/kinto/kinto/core/views/batch.py", line 57, in deserialize
defaults = cstruct.get('defaults')
AttributeError: '_null' object has no attribute 'get' lang=None uid=None
2017-01-18 16:45:58,969 INFO [kinto.core.initialization][waitress] "POST /v1/batch" 500 (5 ms) request.summary agent=HTTPie/0.9.2 authn_type=None errno=999 lang=None time=2017-01-18T16:45:58 uid=None
```
</issue>
<code>
[start of kinto/core/views/batch.py]
1 import colander
2 import six
3
4 from cornice.validators import colander_validator
5 from pyramid import httpexceptions
6 from pyramid.security import NO_PERMISSION_REQUIRED
7
8 from kinto.core import errors
9 from kinto.core import logger
10 from kinto.core import Service
11 from kinto.core.utils import merge_dicts, build_request, build_response
12
13
14 valid_http_method = colander.OneOf(('GET', 'HEAD', 'DELETE', 'TRACE',
15 'POST', 'PUT', 'PATCH'))
16
17
18 def string_values(node, cstruct):
19 """Validate that a ``colander.Mapping`` only has strings in its values.
20
21 .. warning::
22
23 Should be associated to a ``colander.Mapping`` schema node.
24 """
25 are_strings = [isinstance(v, six.string_types) for v in cstruct.values()]
26 if not all(are_strings):
27 error_msg = '%s contains non string value' % cstruct
28 raise colander.Invalid(node, error_msg)
29
30
31 class BatchRequestSchema(colander.MappingSchema):
32 method = colander.SchemaNode(colander.String(),
33 validator=valid_http_method,
34 missing=colander.drop)
35 path = colander.SchemaNode(colander.String(),
36 validator=colander.Regex('^/'))
37 headers = colander.SchemaNode(colander.Mapping(unknown='preserve'),
38 validator=string_values,
39 missing=colander.drop)
40 body = colander.SchemaNode(colander.Mapping(unknown='preserve'),
41 missing=colander.drop)
42
43
44 class BatchPayloadSchema(colander.MappingSchema):
45 defaults = BatchRequestSchema(missing=colander.drop).clone()
46 requests = colander.SchemaNode(colander.Sequence(),
47 BatchRequestSchema())
48
49 def __init__(self, *args, **kwargs):
50 super(BatchPayloadSchema, self).__init__(*args, **kwargs)
51 # On defaults, path is not mandatory.
52 self.get('defaults').get('path').missing = colander.drop
53
54 def deserialize(self, cstruct=colander.null):
55 """Preprocess received data to carefully merge defaults.
56 """
57 defaults = cstruct.get('defaults')
58 requests = cstruct.get('requests')
59 if isinstance(defaults, dict) and isinstance(requests, list):
60 for request in requests:
61 if isinstance(request, dict):
62 merge_dicts(request, defaults)
63 return super(BatchPayloadSchema, self).deserialize(cstruct)
64
65
66 class BatchRequest(colander.MappingSchema):
67 body = BatchPayloadSchema()
68
69
70 batch = Service(name="batch", path='/batch',
71 description="Batch operations")
72
73
74 @batch.post(schema=BatchRequest,
75 validators=(colander_validator,),
76 permission=NO_PERMISSION_REQUIRED)
77 def post_batch(request):
78 requests = request.validated['body']['requests']
79 batch_size = len(requests)
80
81 limit = request.registry.settings['batch_max_requests']
82 if limit and len(requests) > int(limit):
83 error_msg = 'Number of requests is limited to %s' % limit
84 request.errors.add('body', 'requests', error_msg)
85 return
86
87 if any([batch.path in req['path'] for req in requests]):
88 error_msg = 'Recursive call on %s endpoint is forbidden.' % batch.path
89 request.errors.add('body', 'requests', error_msg)
90 return
91
92 responses = []
93
94 sublogger = logger.new()
95
96 for subrequest_spec in requests:
97 subrequest = build_request(request, subrequest_spec)
98
99 sublogger.bind(path=subrequest.path,
100 method=subrequest.method)
101 try:
102 # Invoke subrequest without individual transaction.
103 resp, subrequest = request.follow_subrequest(subrequest,
104 use_tweens=False)
105 except httpexceptions.HTTPException as e:
106 if e.content_type == 'application/json':
107 resp = e
108 else:
109 # JSONify raw Pyramid errors.
110 resp = errors.http_error(e)
111
112 sublogger.bind(code=resp.status_code)
113 sublogger.info('subrequest.summary')
114
115 dict_resp = build_response(resp, subrequest)
116 responses.append(dict_resp)
117
118 # Rebing batch request for summary
119 logger.bind(path=batch.path,
120 method=request.method,
121 batch_size=batch_size,
122 agent=request.headers.get('User-Agent'),)
123
124 return {
125 'responses': responses
126 }
127
[end of kinto/core/views/batch.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kinto/core/views/batch.py b/kinto/core/views/batch.py
--- a/kinto/core/views/batch.py
+++ b/kinto/core/views/batch.py
@@ -54,12 +54,13 @@
def deserialize(self, cstruct=colander.null):
"""Preprocess received data to carefully merge defaults.
"""
- defaults = cstruct.get('defaults')
- requests = cstruct.get('requests')
- if isinstance(defaults, dict) and isinstance(requests, list):
- for request in requests:
- if isinstance(request, dict):
- merge_dicts(request, defaults)
+ if cstruct is not colander.null:
+ defaults = cstruct.get('defaults')
+ requests = cstruct.get('requests')
+ if isinstance(defaults, dict) and isinstance(requests, list):
+ for request in requests:
+ if isinstance(request, dict):
+ merge_dicts(request, defaults)
return super(BatchPayloadSchema, self).deserialize(cstruct)
|
{"golden_diff": "diff --git a/kinto/core/views/batch.py b/kinto/core/views/batch.py\n--- a/kinto/core/views/batch.py\n+++ b/kinto/core/views/batch.py\n@@ -54,12 +54,13 @@\n def deserialize(self, cstruct=colander.null):\n \"\"\"Preprocess received data to carefully merge defaults.\n \"\"\"\n- defaults = cstruct.get('defaults')\n- requests = cstruct.get('requests')\n- if isinstance(defaults, dict) and isinstance(requests, list):\n- for request in requests:\n- if isinstance(request, dict):\n- merge_dicts(request, defaults)\n+ if cstruct is not colander.null:\n+ defaults = cstruct.get('defaults')\n+ requests = cstruct.get('requests')\n+ if isinstance(defaults, dict) and isinstance(requests, list):\n+ for request in requests:\n+ if isinstance(request, dict):\n+ merge_dicts(request, defaults)\n return super(BatchPayloadSchema, self).deserialize(cstruct)\n", "issue": "Crash batch list of request has trailing comma\n```\r\necho '{\r\n \"requests\": [\r\n {\"path\": \"/buckets/default/collections/test1/records\"},\r\n {\"path\": \"/buckets/default/collections/test2/records\"},\r\n ]\r\n}' | http POST :8888/v1/batch --auth a:a\r\n```\r\n\r\n\r\n```\r\n2017-01-18 16:45:58,968 ERROR [kinto.core.views.errors][waitress] \"POST /v1/batch\" ? (? ms) '_null' object has no attribute 'get' agent=HTTPie/0.9.2 authn_type=None errno=None exception=Traceback (most recent call last):\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/tweens.py\", line 22, in excview_tween\r\n response = handler(request)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid_tm/__init__.py\", line 119, in tm_tween\r\n reraise(*exc_info)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid_tm/__init__.py\", line 98, in tm_tween\r\n response = handler(request)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/router.py\", line 158, in handle_request\r\n view_name\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/view.py\", line 547, in _call_view\r\n response = view_callable(context, request)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/config/views.py\", line 182,\r\n, in __call__\r\n return view(context, request)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/viewderivers.py\", line 393, in attr_view\r\n return view(context, request)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/viewderivers.py\", line 371, in predicate_wrapper\r\n return view(context, request)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/viewderivers.py\", line 442, in rendered_view\r\n result = view(context, request)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/viewderivers.py\", line 147, in _requestonly_view\r\n response = view(request)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/cornice/service.py\", line 484, in wrapper\r\n validator(request, **args)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/cornice/validators/_colander.py\", line 73, in validator\r\n deserialized = schema.deserialize(cstruct)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/colander/__init__.py\", line 2058, in deserialize\r\n appstruct = self.typ.deserialize(self, cstruct)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/colander/__init__.py\", line 719, in deserialize\r\n return self._impl(node, cstruct, callback)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/colander/__init__.py\", line 678, in _impl\r\n sub_result = callback(subnode, subval)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/colander/__init__.py\", line 717, in callback\r\n return subnode.deserialize(subcstruct)\r\n File \"/home/mathieu/Code/Mozilla/kinto/kinto/core/views/batch.py\", line 57, in deserialize\r\n defaults = cstruct.get('defaults')\r\nAttributeError: '_null' object has no attribute 'get' lang=None uid=None\r\n2017-01-18 16:45:58,969 INFO [kinto.core.initialization][waitress] \"POST /v1/batch\" 500 (5 ms) request.summary agent=HTTPie/0.9.2 authn_type=None errno=999 lang=None time=2017-01-18T16:45:58 uid=None\r\n\r\n```\nCrash batch list of request has trailing comma\n```\r\necho '{\r\n \"requests\": [\r\n {\"path\": \"/buckets/default/collections/test1/records\"},\r\n {\"path\": \"/buckets/default/collections/test2/records\"},\r\n ]\r\n}' | http POST :8888/v1/batch --auth a:a\r\n```\r\n\r\n\r\n```\r\n2017-01-18 16:45:58,968 ERROR [kinto.core.views.errors][waitress] \"POST /v1/batch\" ? (? ms) '_null' object has no attribute 'get' agent=HTTPie/0.9.2 authn_type=None errno=None exception=Traceback (most recent call last):\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/tweens.py\", line 22, in excview_tween\r\n response = handler(request)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid_tm/__init__.py\", line 119, in tm_tween\r\n reraise(*exc_info)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid_tm/__init__.py\", line 98, in tm_tween\r\n response = handler(request)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/router.py\", line 158, in handle_request\r\n view_name\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/view.py\", line 547, in _call_view\r\n response = view_callable(context, request)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/config/views.py\", line 182,\r\n, in __call__\r\n return view(context, request)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/viewderivers.py\", line 393, in attr_view\r\n return view(context, request)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/viewderivers.py\", line 371, in predicate_wrapper\r\n return view(context, request)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/viewderivers.py\", line 442, in rendered_view\r\n result = view(context, request)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/pyramid/viewderivers.py\", line 147, in _requestonly_view\r\n response = view(request)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/cornice/service.py\", line 484, in wrapper\r\n validator(request, **args)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/cornice/validators/_colander.py\", line 73, in validator\r\n deserialized = schema.deserialize(cstruct)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/colander/__init__.py\", line 2058, in deserialize\r\n appstruct = self.typ.deserialize(self, cstruct)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/colander/__init__.py\", line 719, in deserialize\r\n return self._impl(node, cstruct, callback)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/colander/__init__.py\", line 678, in _impl\r\n sub_result = callback(subnode, subval)\r\n File \"/home/mathieu/Code/Mozilla/kinto/.venv/local/lib/python2.7/site-packages/colander/__init__.py\", line 717, in callback\r\n return subnode.deserialize(subcstruct)\r\n File \"/home/mathieu/Code/Mozilla/kinto/kinto/core/views/batch.py\", line 57, in deserialize\r\n defaults = cstruct.get('defaults')\r\nAttributeError: '_null' object has no attribute 'get' lang=None uid=None\r\n2017-01-18 16:45:58,969 INFO [kinto.core.initialization][waitress] \"POST /v1/batch\" 500 (5 ms) request.summary agent=HTTPie/0.9.2 authn_type=None errno=999 lang=None time=2017-01-18T16:45:58 uid=None\r\n\r\n```\n", "before_files": [{"content": "import colander\nimport six\n\nfrom cornice.validators import colander_validator\nfrom pyramid import httpexceptions\nfrom pyramid.security import NO_PERMISSION_REQUIRED\n\nfrom kinto.core import errors\nfrom kinto.core import logger\nfrom kinto.core import Service\nfrom kinto.core.utils import merge_dicts, build_request, build_response\n\n\nvalid_http_method = colander.OneOf(('GET', 'HEAD', 'DELETE', 'TRACE',\n 'POST', 'PUT', 'PATCH'))\n\n\ndef string_values(node, cstruct):\n \"\"\"Validate that a ``colander.Mapping`` only has strings in its values.\n\n .. warning::\n\n Should be associated to a ``colander.Mapping`` schema node.\n \"\"\"\n are_strings = [isinstance(v, six.string_types) for v in cstruct.values()]\n if not all(are_strings):\n error_msg = '%s contains non string value' % cstruct\n raise colander.Invalid(node, error_msg)\n\n\nclass BatchRequestSchema(colander.MappingSchema):\n method = colander.SchemaNode(colander.String(),\n validator=valid_http_method,\n missing=colander.drop)\n path = colander.SchemaNode(colander.String(),\n validator=colander.Regex('^/'))\n headers = colander.SchemaNode(colander.Mapping(unknown='preserve'),\n validator=string_values,\n missing=colander.drop)\n body = colander.SchemaNode(colander.Mapping(unknown='preserve'),\n missing=colander.drop)\n\n\nclass BatchPayloadSchema(colander.MappingSchema):\n defaults = BatchRequestSchema(missing=colander.drop).clone()\n requests = colander.SchemaNode(colander.Sequence(),\n BatchRequestSchema())\n\n def __init__(self, *args, **kwargs):\n super(BatchPayloadSchema, self).__init__(*args, **kwargs)\n # On defaults, path is not mandatory.\n self.get('defaults').get('path').missing = colander.drop\n\n def deserialize(self, cstruct=colander.null):\n \"\"\"Preprocess received data to carefully merge defaults.\n \"\"\"\n defaults = cstruct.get('defaults')\n requests = cstruct.get('requests')\n if isinstance(defaults, dict) and isinstance(requests, list):\n for request in requests:\n if isinstance(request, dict):\n merge_dicts(request, defaults)\n return super(BatchPayloadSchema, self).deserialize(cstruct)\n\n\nclass BatchRequest(colander.MappingSchema):\n body = BatchPayloadSchema()\n\n\nbatch = Service(name=\"batch\", path='/batch',\n description=\"Batch operations\")\n\n\[email protected](schema=BatchRequest,\n validators=(colander_validator,),\n permission=NO_PERMISSION_REQUIRED)\ndef post_batch(request):\n requests = request.validated['body']['requests']\n batch_size = len(requests)\n\n limit = request.registry.settings['batch_max_requests']\n if limit and len(requests) > int(limit):\n error_msg = 'Number of requests is limited to %s' % limit\n request.errors.add('body', 'requests', error_msg)\n return\n\n if any([batch.path in req['path'] for req in requests]):\n error_msg = 'Recursive call on %s endpoint is forbidden.' % batch.path\n request.errors.add('body', 'requests', error_msg)\n return\n\n responses = []\n\n sublogger = logger.new()\n\n for subrequest_spec in requests:\n subrequest = build_request(request, subrequest_spec)\n\n sublogger.bind(path=subrequest.path,\n method=subrequest.method)\n try:\n # Invoke subrequest without individual transaction.\n resp, subrequest = request.follow_subrequest(subrequest,\n use_tweens=False)\n except httpexceptions.HTTPException as e:\n if e.content_type == 'application/json':\n resp = e\n else:\n # JSONify raw Pyramid errors.\n resp = errors.http_error(e)\n\n sublogger.bind(code=resp.status_code)\n sublogger.info('subrequest.summary')\n\n dict_resp = build_response(resp, subrequest)\n responses.append(dict_resp)\n\n # Rebing batch request for summary\n logger.bind(path=batch.path,\n method=request.method,\n batch_size=batch_size,\n agent=request.headers.get('User-Agent'),)\n\n return {\n 'responses': responses\n }\n", "path": "kinto/core/views/batch.py"}]}
| 3,883 | 222 |
gh_patches_debug_41520
|
rasdani/github-patches
|
git_diff
|
sublimelsp__LSP-2153
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
LSP-rust-analyzer inlay hints appear on multiple lines
**Describe the bug**
inlay hints in `LSP-rust-analyzer` appear on multiple lines since https://github.com/rust-lang/rust-analyzer/pull/13699
**To Reproduce**
Steps to reproduce the behavior:
1. use the rust source file:
```rs
fn main() {
let v = vec![
"1".to_string(),
"1".to_string(),
"1".to_string(),
"1".to_string(),
"1".to_string(),
];
dbg!(&v);
}
```
2. settings files:
```js
// User/LSP.sublime-settings
// Settings in here override those in "LSP/LSP.sublime-settings"
{
"show_inlay_hints": true,
}
```
```js
// User/LSP-rust-analyzer.sublime-settings
// Settings in here override those in "LSP-rust-analyzer/LSP-rust-analyzer.sublime-settings"
{
"command": ["rust-analyzer-2022-12-26"],
"settings": {
// default: true
"rust-analyzer.inlayHints.locationLinks": true,
},
}
```
3. see the inlay hints broken down in multiple lines

**Expected behavior**
the inlay hints should be on one line
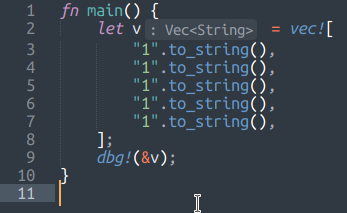
**Environment (please complete the following information):**
- OS: Debian 11.6
- Sublime Text version: 4143
- LSP version: v1.20.0
- Language servers used: LSP-rust-analyzer v1.1.0
```
> rust-analyzer-2022-12-26 --version
rust-analyzer 0.3.1334-standalone
```
**Additional context**
the `"rust-analyzer.inlayHints.locationLinks": false` setting (default: `true`) makes them appear again on one line
LSP panel output:
**rust-analyzer-2022-12-19**
```py
:: --> rust-analyzer textDocument/inlayHint(19): {'textDocument': {'uri': 'file:///home/it/Desktop/asd/src/main.rs'}, 'range': {'end': {'character': 0, 'line': 10}, 'start': {'character': 0, 'line': 0}}}
:: <<< rust-analyzer 19: [
{
'kind': 1,
'tooltip': ': Vec<String>',
'paddingRight': False,
'label': ': Vec<String>',
'paddingLeft': False,
'position': {'character': 6, 'line': 1},
'data': {
'text_document': {'uri': 'file:///home/it/Desktop/asd/src/main.rs', 'version': 24},
'position': {'end': {'character': 6, 'line': 1}, 'start': {'character': 5, 'line': 1}},
},
}
]
```
**rust-analyzer-2022-12-26**
```py
:: --> rust-analyzer textDocument/inlayHint(40): {'textDocument': {'uri': 'file:///home/it/Desktop/asd/src/main.rs'}, 'range': {'end': {'character': 0, 'line': 11}, 'start': {'character': 0, 'line': 0}}}
:: <<< rust-analyzer 40: [
{
'kind': 1,
'tooltip': ': Vec<String>',
'paddingRight': False,
'label': [
{'value': ': '},
{
'value': 'Vec',
'location': {
'uri': 'file:///home/it/.local/lib/rustup/toolchains/stable-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/alloc/src/vec/mod.rs',
'range': {'end': {'character': 14, 'line': 399}, 'start': {'character': 11, 'line': 399}},
},
},
{'value': '<'},
{
'value': 'String',
'location': {
'uri': 'file:///home/it/.local/lib/rustup/toolchains/stable-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/alloc/src/string.rs',
'range': {'end': {'character': 17, 'line': 366}, 'start': {'character': 11, 'line': 366}},
},
},
{'value': '>'},
],
'paddingLeft': False,
'position': {'character': 6, 'line': 1},
'data': {
'text_document': {'uri': 'file:///home/it/Desktop/asd/src/main.rs', 'version': 8},
'position': {'end': {'character': 6, 'line': 1}, 'start': {'character': 5, 'line': 1}},
},
}
]
```
</issue>
<code>
[start of plugin/inlay_hint.py]
1 from .core.protocol import InlayHintLabelPart, MarkupContent, Point, InlayHint, Request
2 from .core.registry import LspTextCommand
3 from .core.sessions import Session
4 from .core.typing import Optional, Union
5 from .core.views import point_to_offset
6 from .formatting import apply_text_edits_to_view
7 import html
8 import sublime
9 import uuid
10
11
12 class LspInlayHintClickCommand(LspTextCommand):
13 capability = 'inlayHintProvider'
14
15 def run(self, _edit: sublime.Edit, session_name: str, inlay_hint: InlayHint, phantom_uuid: str,
16 event: Optional[dict] = None, label_part: Optional[InlayHintLabelPart] = None) -> None:
17 # Insert textEdits for the given inlay hint.
18 # If a InlayHintLabelPart was clicked, label_part will be passed as an argument to the LspInlayHintClickCommand
19 # and InlayHintLabelPart.command will be executed.
20 session = self.session_by_name(session_name, 'inlayHintProvider')
21 if session and session.has_capability('inlayHintProvider.resolveProvider'):
22 request = Request.resolveInlayHint(inlay_hint, self.view)
23 session.send_request_async(
24 request,
25 lambda response: self.handle(session_name, response, phantom_uuid, label_part))
26 return
27 self.handle(session_name, inlay_hint, phantom_uuid, label_part)
28
29 def handle(self, session_name: str, inlay_hint: InlayHint, phantom_uuid: str,
30 label_part: Optional[InlayHintLabelPart] = None) -> None:
31 self.handle_inlay_hint_text_edits(session_name, inlay_hint, phantom_uuid)
32 self.handle_label_part_command(session_name, label_part)
33
34 def handle_inlay_hint_text_edits(self, session_name: str, inlay_hint: InlayHint, phantom_uuid: str) -> None:
35 session = self.session_by_name(session_name, 'inlayHintProvider')
36 if not session:
37 return
38 text_edits = inlay_hint.get('textEdits')
39 if not text_edits:
40 return
41 for sb in session.session_buffers_async():
42 sb.remove_inlay_hint_phantom(phantom_uuid)
43 apply_text_edits_to_view(text_edits, self.view)
44
45 def handle_label_part_command(self, session_name: str, label_part: Optional[InlayHintLabelPart] = None) -> None:
46 if not label_part:
47 return
48 command = label_part.get('command')
49 if not command:
50 return
51 args = {
52 "session_name": session_name,
53 "command_name": command["command"],
54 "command_args": command.get("arguments")
55 }
56 self.view.run_command("lsp_execute", args)
57
58
59 def inlay_hint_to_phantom(view: sublime.View, inlay_hint: InlayHint, session: Session) -> sublime.Phantom:
60 position = inlay_hint["position"] # type: ignore
61 region = sublime.Region(point_to_offset(Point.from_lsp(position), view))
62 phantom_uuid = str(uuid.uuid4())
63 content = get_inlay_hint_html(view, inlay_hint, session, phantom_uuid)
64 p = sublime.Phantom(region, content, sublime.LAYOUT_INLINE)
65 setattr(p, 'lsp_uuid', phantom_uuid)
66 return p
67
68
69 def get_inlay_hint_html(view: sublime.View, inlay_hint: InlayHint, session: Session, phantom_uuid: str) -> str:
70 tooltip = format_inlay_hint_tooltip(inlay_hint.get("tooltip"))
71 label = format_inlay_hint_label(inlay_hint, session, phantom_uuid)
72 font = view.settings().get('font_face') or "monospace"
73 html = """
74 <body id="lsp-inlay-hint">
75 <style>
76 .inlay-hint {{
77 color: color(var(--foreground) alpha(0.6));
78 background-color: color(var(--foreground) alpha(0.08));
79 border-radius: 4px;
80 padding: 0.05em 4px;
81 font-size: 0.9em;
82 font-family: {font};
83 }}
84
85 .inlay-hint a {{
86 color: color(var(--foreground) alpha(0.6));
87 text-decoration: none;
88 }}
89 </style>
90 <div class="inlay-hint" title="{tooltip}">
91 {label}
92 </div>
93 </body>
94 """.format(
95 tooltip=tooltip,
96 font=font,
97 label=label
98 )
99 return html
100
101
102 def format_inlay_hint_tooltip(tooltip: Optional[Union[str, MarkupContent]]) -> str:
103 if isinstance(tooltip, str):
104 return html.escape(tooltip)
105 if isinstance(tooltip, dict): # MarkupContent
106 return html.escape(tooltip.get('value') or "")
107 return ""
108
109
110 def format_inlay_hint_label(inlay_hint: InlayHint, session: Session, phantom_uuid: str) -> str:
111 result = ""
112 can_resolve_inlay_hint = session.has_capability('inlayHintProvider.resolveProvider')
113 label = inlay_hint['label'] # type: ignore
114 is_clickable = bool(inlay_hint.get('textEdits')) or can_resolve_inlay_hint
115 if isinstance(label, str):
116 if is_clickable:
117 inlay_hint_click_command = sublime.command_url('lsp_inlay_hint_click', {
118 'session_name': session.config.name,
119 'inlay_hint': inlay_hint,
120 'phantom_uuid': phantom_uuid
121 })
122 result += '<a href="{command}">'.format(command=inlay_hint_click_command)
123 result += html.escape(label)
124 if is_clickable:
125 result += "</a>"
126 return result
127
128 for label_part in label:
129 value = ""
130 is_clickable = is_clickable or bool(label_part.get('command'))
131 if is_clickable:
132 inlay_hint_click_command = sublime.command_url('lsp_inlay_hint_click', {
133 'session_name': session.config.name,
134 'inlay_hint': inlay_hint,
135 'phantom_uuid': phantom_uuid,
136 'label_part': label_part
137 })
138 value += '<a href="{command}">'.format(command=inlay_hint_click_command)
139 value += html.escape(label_part['value'])
140 if is_clickable:
141 value += "</a>"
142 # InlayHintLabelPart.location is not supported
143 result += "<div title=\"{tooltip}\">{value}</div>".format(
144 tooltip=format_inlay_hint_tooltip(label_part.get("tooltip")),
145 value=value
146 )
147 return result
148
[end of plugin/inlay_hint.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugin/inlay_hint.py b/plugin/inlay_hint.py
--- a/plugin/inlay_hint.py
+++ b/plugin/inlay_hint.py
@@ -1,7 +1,7 @@
from .core.protocol import InlayHintLabelPart, MarkupContent, Point, InlayHint, Request
from .core.registry import LspTextCommand
from .core.sessions import Session
-from .core.typing import Optional, Union
+from .core.typing import cast, Optional, Union
from .core.views import point_to_offset
from .formatting import apply_text_edits_to_view
import html
@@ -57,7 +57,7 @@
def inlay_hint_to_phantom(view: sublime.View, inlay_hint: InlayHint, session: Session) -> sublime.Phantom:
- position = inlay_hint["position"] # type: ignore
+ position = inlay_hint["position"]
region = sublime.Region(point_to_offset(Point.from_lsp(position), view))
phantom_uuid = str(uuid.uuid4())
content = get_inlay_hint_html(view, inlay_hint, session, phantom_uuid)
@@ -110,13 +110,13 @@
def format_inlay_hint_label(inlay_hint: InlayHint, session: Session, phantom_uuid: str) -> str:
result = ""
can_resolve_inlay_hint = session.has_capability('inlayHintProvider.resolveProvider')
- label = inlay_hint['label'] # type: ignore
+ label = inlay_hint['label']
is_clickable = bool(inlay_hint.get('textEdits')) or can_resolve_inlay_hint
if isinstance(label, str):
if is_clickable:
inlay_hint_click_command = sublime.command_url('lsp_inlay_hint_click', {
'session_name': session.config.name,
- 'inlay_hint': inlay_hint,
+ 'inlay_hint': cast(dict, inlay_hint),
'phantom_uuid': phantom_uuid
})
result += '<a href="{command}">'.format(command=inlay_hint_click_command)
@@ -131,16 +131,16 @@
if is_clickable:
inlay_hint_click_command = sublime.command_url('lsp_inlay_hint_click', {
'session_name': session.config.name,
- 'inlay_hint': inlay_hint,
+ 'inlay_hint': cast(dict, inlay_hint),
'phantom_uuid': phantom_uuid,
- 'label_part': label_part
+ 'label_part': cast(dict, label_part)
})
value += '<a href="{command}">'.format(command=inlay_hint_click_command)
value += html.escape(label_part['value'])
if is_clickable:
value += "</a>"
# InlayHintLabelPart.location is not supported
- result += "<div title=\"{tooltip}\">{value}</div>".format(
+ result += "<span title=\"{tooltip}\">{value}</span>".format(
tooltip=format_inlay_hint_tooltip(label_part.get("tooltip")),
value=value
)
|
{"golden_diff": "diff --git a/plugin/inlay_hint.py b/plugin/inlay_hint.py\n--- a/plugin/inlay_hint.py\n+++ b/plugin/inlay_hint.py\n@@ -1,7 +1,7 @@\n from .core.protocol import InlayHintLabelPart, MarkupContent, Point, InlayHint, Request\n from .core.registry import LspTextCommand\n from .core.sessions import Session\n-from .core.typing import Optional, Union\n+from .core.typing import cast, Optional, Union\n from .core.views import point_to_offset\n from .formatting import apply_text_edits_to_view\n import html\n@@ -57,7 +57,7 @@\n \n \n def inlay_hint_to_phantom(view: sublime.View, inlay_hint: InlayHint, session: Session) -> sublime.Phantom:\n- position = inlay_hint[\"position\"] # type: ignore\n+ position = inlay_hint[\"position\"]\n region = sublime.Region(point_to_offset(Point.from_lsp(position), view))\n phantom_uuid = str(uuid.uuid4())\n content = get_inlay_hint_html(view, inlay_hint, session, phantom_uuid)\n@@ -110,13 +110,13 @@\n def format_inlay_hint_label(inlay_hint: InlayHint, session: Session, phantom_uuid: str) -> str:\n result = \"\"\n can_resolve_inlay_hint = session.has_capability('inlayHintProvider.resolveProvider')\n- label = inlay_hint['label'] # type: ignore\n+ label = inlay_hint['label']\n is_clickable = bool(inlay_hint.get('textEdits')) or can_resolve_inlay_hint\n if isinstance(label, str):\n if is_clickable:\n inlay_hint_click_command = sublime.command_url('lsp_inlay_hint_click', {\n 'session_name': session.config.name,\n- 'inlay_hint': inlay_hint,\n+ 'inlay_hint': cast(dict, inlay_hint),\n 'phantom_uuid': phantom_uuid\n })\n result += '<a href=\"{command}\">'.format(command=inlay_hint_click_command)\n@@ -131,16 +131,16 @@\n if is_clickable:\n inlay_hint_click_command = sublime.command_url('lsp_inlay_hint_click', {\n 'session_name': session.config.name,\n- 'inlay_hint': inlay_hint,\n+ 'inlay_hint': cast(dict, inlay_hint),\n 'phantom_uuid': phantom_uuid,\n- 'label_part': label_part\n+ 'label_part': cast(dict, label_part)\n })\n value += '<a href=\"{command}\">'.format(command=inlay_hint_click_command)\n value += html.escape(label_part['value'])\n if is_clickable:\n value += \"</a>\"\n # InlayHintLabelPart.location is not supported\n- result += \"<div title=\\\"{tooltip}\\\">{value}</div>\".format(\n+ result += \"<span title=\\\"{tooltip}\\\">{value}</span>\".format(\n tooltip=format_inlay_hint_tooltip(label_part.get(\"tooltip\")),\n value=value\n )\n", "issue": "LSP-rust-analyzer inlay hints appear on multiple lines\n**Describe the bug**\r\ninlay hints in `LSP-rust-analyzer` appear on multiple lines since https://github.com/rust-lang/rust-analyzer/pull/13699\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n\r\n1. use the rust source file:\r\n\r\n```rs\r\nfn main() {\r\n\tlet v = vec![\r\n\t\t\"1\".to_string(),\r\n\t\t\"1\".to_string(),\r\n\t\t\"1\".to_string(),\r\n\t\t\"1\".to_string(),\r\n\t\t\"1\".to_string(),\r\n\t];\r\n\tdbg!(&v);\r\n}\r\n```\r\n\r\n2. settings files:\r\n\r\n```js\r\n// User/LSP.sublime-settings\r\n// Settings in here override those in \"LSP/LSP.sublime-settings\"\r\n{\r\n\t\"show_inlay_hints\": true,\r\n}\r\n```\r\n\r\n```js\r\n// User/LSP-rust-analyzer.sublime-settings\r\n// Settings in here override those in \"LSP-rust-analyzer/LSP-rust-analyzer.sublime-settings\"\r\n{\r\n\t\"command\": [\"rust-analyzer-2022-12-26\"],\r\n\t\"settings\": {\r\n\t\t// default: true\r\n\t\t\"rust-analyzer.inlayHints.locationLinks\": true,\r\n\t},\r\n}\r\n\r\n```\r\n\r\n3. see the inlay hints broken down in multiple lines\r\n\r\n\r\n\r\n**Expected behavior**\r\n\r\nthe inlay hints should be on one line\r\n\r\n\r\n\r\n**Environment (please complete the following information):**\r\n- OS: Debian 11.6\r\n- Sublime Text version: 4143\r\n- LSP version: v1.20.0\r\n- Language servers used: LSP-rust-analyzer v1.1.0\r\n\r\n```\r\n> rust-analyzer-2022-12-26 --version\r\nrust-analyzer 0.3.1334-standalone\r\n```\r\n\r\n**Additional context**\r\n\r\nthe `\"rust-analyzer.inlayHints.locationLinks\": false` setting (default: `true`) makes them appear again on one line\r\n\r\nLSP panel output:\r\n\r\n**rust-analyzer-2022-12-19**\r\n\r\n```py\r\n:: --> rust-analyzer textDocument/inlayHint(19): {'textDocument': {'uri': 'file:///home/it/Desktop/asd/src/main.rs'}, 'range': {'end': {'character': 0, 'line': 10}, 'start': {'character': 0, 'line': 0}}}\r\n:: <<< rust-analyzer 19: [\r\n {\r\n 'kind': 1,\r\n 'tooltip': ': Vec<String>',\r\n 'paddingRight': False,\r\n 'label': ': Vec<String>',\r\n 'paddingLeft': False,\r\n 'position': {'character': 6, 'line': 1},\r\n 'data': {\r\n 'text_document': {'uri': 'file:///home/it/Desktop/asd/src/main.rs', 'version': 24},\r\n 'position': {'end': {'character': 6, 'line': 1}, 'start': {'character': 5, 'line': 1}},\r\n },\r\n }\r\n]\r\n```\r\n\r\n**rust-analyzer-2022-12-26**\r\n\r\n```py\r\n:: --> rust-analyzer textDocument/inlayHint(40): {'textDocument': {'uri': 'file:///home/it/Desktop/asd/src/main.rs'}, 'range': {'end': {'character': 0, 'line': 11}, 'start': {'character': 0, 'line': 0}}}\r\n:: <<< rust-analyzer 40: [\r\n {\r\n 'kind': 1,\r\n 'tooltip': ': Vec<String>',\r\n 'paddingRight': False,\r\n 'label': [\r\n {'value': ': '},\r\n {\r\n 'value': 'Vec',\r\n 'location': {\r\n 'uri': 'file:///home/it/.local/lib/rustup/toolchains/stable-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/alloc/src/vec/mod.rs',\r\n 'range': {'end': {'character': 14, 'line': 399}, 'start': {'character': 11, 'line': 399}},\r\n },\r\n },\r\n {'value': '<'},\r\n {\r\n 'value': 'String',\r\n 'location': {\r\n 'uri': 'file:///home/it/.local/lib/rustup/toolchains/stable-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/alloc/src/string.rs',\r\n 'range': {'end': {'character': 17, 'line': 366}, 'start': {'character': 11, 'line': 366}},\r\n },\r\n },\r\n {'value': '>'},\r\n ],\r\n 'paddingLeft': False,\r\n 'position': {'character': 6, 'line': 1},\r\n 'data': {\r\n 'text_document': {'uri': 'file:///home/it/Desktop/asd/src/main.rs', 'version': 8},\r\n 'position': {'end': {'character': 6, 'line': 1}, 'start': {'character': 5, 'line': 1}},\r\n },\r\n }\r\n]\r\n```\r\n\r\n\r\n\n", "before_files": [{"content": "from .core.protocol import InlayHintLabelPart, MarkupContent, Point, InlayHint, Request\nfrom .core.registry import LspTextCommand\nfrom .core.sessions import Session\nfrom .core.typing import Optional, Union\nfrom .core.views import point_to_offset\nfrom .formatting import apply_text_edits_to_view\nimport html\nimport sublime\nimport uuid\n\n\nclass LspInlayHintClickCommand(LspTextCommand):\n capability = 'inlayHintProvider'\n\n def run(self, _edit: sublime.Edit, session_name: str, inlay_hint: InlayHint, phantom_uuid: str,\n event: Optional[dict] = None, label_part: Optional[InlayHintLabelPart] = None) -> None:\n # Insert textEdits for the given inlay hint.\n # If a InlayHintLabelPart was clicked, label_part will be passed as an argument to the LspInlayHintClickCommand\n # and InlayHintLabelPart.command will be executed.\n session = self.session_by_name(session_name, 'inlayHintProvider')\n if session and session.has_capability('inlayHintProvider.resolveProvider'):\n request = Request.resolveInlayHint(inlay_hint, self.view)\n session.send_request_async(\n request,\n lambda response: self.handle(session_name, response, phantom_uuid, label_part))\n return\n self.handle(session_name, inlay_hint, phantom_uuid, label_part)\n\n def handle(self, session_name: str, inlay_hint: InlayHint, phantom_uuid: str,\n label_part: Optional[InlayHintLabelPart] = None) -> None:\n self.handle_inlay_hint_text_edits(session_name, inlay_hint, phantom_uuid)\n self.handle_label_part_command(session_name, label_part)\n\n def handle_inlay_hint_text_edits(self, session_name: str, inlay_hint: InlayHint, phantom_uuid: str) -> None:\n session = self.session_by_name(session_name, 'inlayHintProvider')\n if not session:\n return\n text_edits = inlay_hint.get('textEdits')\n if not text_edits:\n return\n for sb in session.session_buffers_async():\n sb.remove_inlay_hint_phantom(phantom_uuid)\n apply_text_edits_to_view(text_edits, self.view)\n\n def handle_label_part_command(self, session_name: str, label_part: Optional[InlayHintLabelPart] = None) -> None:\n if not label_part:\n return\n command = label_part.get('command')\n if not command:\n return\n args = {\n \"session_name\": session_name,\n \"command_name\": command[\"command\"],\n \"command_args\": command.get(\"arguments\")\n }\n self.view.run_command(\"lsp_execute\", args)\n\n\ndef inlay_hint_to_phantom(view: sublime.View, inlay_hint: InlayHint, session: Session) -> sublime.Phantom:\n position = inlay_hint[\"position\"] # type: ignore\n region = sublime.Region(point_to_offset(Point.from_lsp(position), view))\n phantom_uuid = str(uuid.uuid4())\n content = get_inlay_hint_html(view, inlay_hint, session, phantom_uuid)\n p = sublime.Phantom(region, content, sublime.LAYOUT_INLINE)\n setattr(p, 'lsp_uuid', phantom_uuid)\n return p\n\n\ndef get_inlay_hint_html(view: sublime.View, inlay_hint: InlayHint, session: Session, phantom_uuid: str) -> str:\n tooltip = format_inlay_hint_tooltip(inlay_hint.get(\"tooltip\"))\n label = format_inlay_hint_label(inlay_hint, session, phantom_uuid)\n font = view.settings().get('font_face') or \"monospace\"\n html = \"\"\"\n <body id=\"lsp-inlay-hint\">\n <style>\n .inlay-hint {{\n color: color(var(--foreground) alpha(0.6));\n background-color: color(var(--foreground) alpha(0.08));\n border-radius: 4px;\n padding: 0.05em 4px;\n font-size: 0.9em;\n font-family: {font};\n }}\n\n .inlay-hint a {{\n color: color(var(--foreground) alpha(0.6));\n text-decoration: none;\n }}\n </style>\n <div class=\"inlay-hint\" title=\"{tooltip}\">\n {label}\n </div>\n </body>\n \"\"\".format(\n tooltip=tooltip,\n font=font,\n label=label\n )\n return html\n\n\ndef format_inlay_hint_tooltip(tooltip: Optional[Union[str, MarkupContent]]) -> str:\n if isinstance(tooltip, str):\n return html.escape(tooltip)\n if isinstance(tooltip, dict): # MarkupContent\n return html.escape(tooltip.get('value') or \"\")\n return \"\"\n\n\ndef format_inlay_hint_label(inlay_hint: InlayHint, session: Session, phantom_uuid: str) -> str:\n result = \"\"\n can_resolve_inlay_hint = session.has_capability('inlayHintProvider.resolveProvider')\n label = inlay_hint['label'] # type: ignore\n is_clickable = bool(inlay_hint.get('textEdits')) or can_resolve_inlay_hint\n if isinstance(label, str):\n if is_clickable:\n inlay_hint_click_command = sublime.command_url('lsp_inlay_hint_click', {\n 'session_name': session.config.name,\n 'inlay_hint': inlay_hint,\n 'phantom_uuid': phantom_uuid\n })\n result += '<a href=\"{command}\">'.format(command=inlay_hint_click_command)\n result += html.escape(label)\n if is_clickable:\n result += \"</a>\"\n return result\n\n for label_part in label:\n value = \"\"\n is_clickable = is_clickable or bool(label_part.get('command'))\n if is_clickable:\n inlay_hint_click_command = sublime.command_url('lsp_inlay_hint_click', {\n 'session_name': session.config.name,\n 'inlay_hint': inlay_hint,\n 'phantom_uuid': phantom_uuid,\n 'label_part': label_part\n })\n value += '<a href=\"{command}\">'.format(command=inlay_hint_click_command)\n value += html.escape(label_part['value'])\n if is_clickable:\n value += \"</a>\"\n # InlayHintLabelPart.location is not supported\n result += \"<div title=\\\"{tooltip}\\\">{value}</div>\".format(\n tooltip=format_inlay_hint_tooltip(label_part.get(\"tooltip\")),\n value=value\n )\n return result\n", "path": "plugin/inlay_hint.py"}]}
| 3,545 | 661 |
gh_patches_debug_13762
|
rasdani/github-patches
|
git_diff
|
CTFd__CTFd-1876
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
The REST API for deleting files does not remove the file's directory and does not update the Media Library list
**Environment**:
- CTFd Version/Commit: 3.2.1
- Operating System: Docker (`python:3.6-slim-buster`)
- Web Browser and Version: NA
**What happened?**
I am using the REST API for deleting files (e.g. `"DELETE /api/v1/files/41 HTTP/1.1"`) and it seems to work fine. The file is removed. However, two things do go wrong I think (at least to my expectation).
1. The file's directory (which has a hash based name) is not deleted. This means, after a while there will be a lot of empty directories.
1. The list of files used by the Media Library is not updated (i.e. file is removed from the list) which means the list grows constantly. The result is a list with many non-existing files as they are deleted.
The REST API returns a successful `200` code which seems to match with the expected behaviour.
**What did you expect to happen?**
When a file is deleted using the REST API, I expect the directory (the hash-based name) to be deleted and that the list used by the Media Library is updated accordingly.
**How to reproduce your issue**
1. Upload a file (e.g. via the web interface or REST API).
1. Use the REST API to delete this file.
1. Check the `upload/` folder and the Media Library for the behaviour described above.
**Any associated stack traces or error logs**
None
</issue>
<code>
[start of CTFd/utils/uploads/uploaders.py]
1 import os
2 import posixpath
3 import string
4 from shutil import copyfileobj
5
6 import boto3
7 from flask import current_app, redirect, send_file
8 from flask.helpers import safe_join
9 from werkzeug.utils import secure_filename
10
11 from CTFd.utils import get_app_config
12 from CTFd.utils.encoding import hexencode
13
14
15 class BaseUploader(object):
16 def __init__(self):
17 raise NotImplementedError
18
19 def store(self, fileobj, filename):
20 raise NotImplementedError
21
22 def upload(self, file_obj, filename):
23 raise NotImplementedError
24
25 def download(self, filename):
26 raise NotImplementedError
27
28 def delete(self, filename):
29 raise NotImplementedError
30
31 def sync(self):
32 raise NotImplementedError
33
34
35 class FilesystemUploader(BaseUploader):
36 def __init__(self, base_path=None):
37 super(BaseUploader, self).__init__()
38 self.base_path = base_path or current_app.config.get("UPLOAD_FOLDER")
39
40 def store(self, fileobj, filename):
41 location = os.path.join(self.base_path, filename)
42 directory = os.path.dirname(location)
43
44 if not os.path.exists(directory):
45 os.makedirs(directory)
46
47 with open(location, "wb") as dst:
48 copyfileobj(fileobj, dst, 16384)
49
50 return filename
51
52 def upload(self, file_obj, filename):
53 if len(filename) == 0:
54 raise Exception("Empty filenames cannot be used")
55
56 filename = secure_filename(filename)
57 md5hash = hexencode(os.urandom(16))
58 file_path = posixpath.join(md5hash, filename)
59
60 return self.store(file_obj, file_path)
61
62 def download(self, filename):
63 return send_file(safe_join(self.base_path, filename), as_attachment=True)
64
65 def delete(self, filename):
66 if os.path.exists(os.path.join(self.base_path, filename)):
67 os.unlink(os.path.join(self.base_path, filename))
68 return True
69 return False
70
71 def sync(self):
72 pass
73
74
75 class S3Uploader(BaseUploader):
76 def __init__(self):
77 super(BaseUploader, self).__init__()
78 self.s3 = self._get_s3_connection()
79 self.bucket = get_app_config("AWS_S3_BUCKET")
80
81 def _get_s3_connection(self):
82 access_key = get_app_config("AWS_ACCESS_KEY_ID")
83 secret_key = get_app_config("AWS_SECRET_ACCESS_KEY")
84 endpoint = get_app_config("AWS_S3_ENDPOINT_URL")
85 client = boto3.client(
86 "s3",
87 aws_access_key_id=access_key,
88 aws_secret_access_key=secret_key,
89 endpoint_url=endpoint,
90 )
91 return client
92
93 def _clean_filename(self, c):
94 if c in string.ascii_letters + string.digits + "-" + "_" + ".":
95 return True
96
97 def store(self, fileobj, filename):
98 self.s3.upload_fileobj(fileobj, self.bucket, filename)
99 return filename
100
101 def upload(self, file_obj, filename):
102 filename = filter(
103 self._clean_filename, secure_filename(filename).replace(" ", "_")
104 )
105 filename = "".join(filename)
106 if len(filename) <= 0:
107 return False
108
109 md5hash = hexencode(os.urandom(16))
110
111 dst = md5hash + "/" + filename
112 self.s3.upload_fileobj(file_obj, self.bucket, dst)
113 return dst
114
115 def download(self, filename):
116 key = filename
117 filename = filename.split("/").pop()
118 url = self.s3.generate_presigned_url(
119 "get_object",
120 Params={
121 "Bucket": self.bucket,
122 "Key": key,
123 "ResponseContentDisposition": "attachment; filename={}".format(
124 filename
125 ),
126 },
127 )
128 return redirect(url)
129
130 def delete(self, filename):
131 self.s3.delete_object(Bucket=self.bucket, Key=filename)
132 return True
133
134 def sync(self):
135 local_folder = current_app.config.get("UPLOAD_FOLDER")
136 # If the bucket is empty then Contents will not be in the response
137 bucket_list = self.s3.list_objects(Bucket=self.bucket).get("Contents", [])
138
139 for s3_key in bucket_list:
140 s3_object = s3_key["Key"]
141 # We don't want to download any directories
142 if s3_object.endswith("/") is False:
143 local_path = os.path.join(local_folder, s3_object)
144 directory = os.path.dirname(local_path)
145 if not os.path.exists(directory):
146 os.makedirs(directory)
147
148 self.s3.download_file(self.bucket, s3_object, local_path)
149
[end of CTFd/utils/uploads/uploaders.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/CTFd/utils/uploads/uploaders.py b/CTFd/utils/uploads/uploaders.py
--- a/CTFd/utils/uploads/uploaders.py
+++ b/CTFd/utils/uploads/uploaders.py
@@ -1,7 +1,8 @@
import os
import posixpath
import string
-from shutil import copyfileobj
+from pathlib import PurePath
+from shutil import copyfileobj, rmtree
import boto3
from flask import current_app, redirect, send_file
@@ -64,7 +65,8 @@
def delete(self, filename):
if os.path.exists(os.path.join(self.base_path, filename)):
- os.unlink(os.path.join(self.base_path, filename))
+ file_path = PurePath(filename).parts[0]
+ rmtree(os.path.join(self.base_path, file_path))
return True
return False
|
{"golden_diff": "diff --git a/CTFd/utils/uploads/uploaders.py b/CTFd/utils/uploads/uploaders.py\n--- a/CTFd/utils/uploads/uploaders.py\n+++ b/CTFd/utils/uploads/uploaders.py\n@@ -1,7 +1,8 @@\n import os\n import posixpath\n import string\n-from shutil import copyfileobj\n+from pathlib import PurePath\n+from shutil import copyfileobj, rmtree\n \n import boto3\n from flask import current_app, redirect, send_file\n@@ -64,7 +65,8 @@\n \n def delete(self, filename):\n if os.path.exists(os.path.join(self.base_path, filename)):\n- os.unlink(os.path.join(self.base_path, filename))\n+ file_path = PurePath(filename).parts[0]\n+ rmtree(os.path.join(self.base_path, file_path))\n return True\n return False\n", "issue": "The REST API for deleting files does not remove the file's directory and does not update the Media Library list\n**Environment**: \r\n\r\n- CTFd Version/Commit: 3.2.1\r\n- Operating System: Docker (`python:3.6-slim-buster`)\r\n- Web Browser and Version: NA\r\n\r\n**What happened?**\r\n\r\nI am using the REST API for deleting files (e.g. `\"DELETE /api/v1/files/41 HTTP/1.1\"`) and it seems to work fine. The file is removed. However, two things do go wrong I think (at least to my expectation).\r\n\r\n1. The file's directory (which has a hash based name) is not deleted. This means, after a while there will be a lot of empty directories.\r\n1. The list of files used by the Media Library is not updated (i.e. file is removed from the list) which means the list grows constantly. The result is a list with many non-existing files as they are deleted.\r\n\r\nThe REST API returns a successful `200` code which seems to match with the expected behaviour.\r\n\r\n**What did you expect to happen?**\r\n\r\nWhen a file is deleted using the REST API, I expect the directory (the hash-based name) to be deleted and that the list used by the Media Library is updated accordingly.\r\n\r\n**How to reproduce your issue**\r\n\r\n1. Upload a file (e.g. via the web interface or REST API). \r\n1. Use the REST API to delete this file.\r\n1. Check the `upload/` folder and the Media Library for the behaviour described above.\r\n\r\n**Any associated stack traces or error logs**\r\n\r\nNone\r\n\n", "before_files": [{"content": "import os\nimport posixpath\nimport string\nfrom shutil import copyfileobj\n\nimport boto3\nfrom flask import current_app, redirect, send_file\nfrom flask.helpers import safe_join\nfrom werkzeug.utils import secure_filename\n\nfrom CTFd.utils import get_app_config\nfrom CTFd.utils.encoding import hexencode\n\n\nclass BaseUploader(object):\n def __init__(self):\n raise NotImplementedError\n\n def store(self, fileobj, filename):\n raise NotImplementedError\n\n def upload(self, file_obj, filename):\n raise NotImplementedError\n\n def download(self, filename):\n raise NotImplementedError\n\n def delete(self, filename):\n raise NotImplementedError\n\n def sync(self):\n raise NotImplementedError\n\n\nclass FilesystemUploader(BaseUploader):\n def __init__(self, base_path=None):\n super(BaseUploader, self).__init__()\n self.base_path = base_path or current_app.config.get(\"UPLOAD_FOLDER\")\n\n def store(self, fileobj, filename):\n location = os.path.join(self.base_path, filename)\n directory = os.path.dirname(location)\n\n if not os.path.exists(directory):\n os.makedirs(directory)\n\n with open(location, \"wb\") as dst:\n copyfileobj(fileobj, dst, 16384)\n\n return filename\n\n def upload(self, file_obj, filename):\n if len(filename) == 0:\n raise Exception(\"Empty filenames cannot be used\")\n\n filename = secure_filename(filename)\n md5hash = hexencode(os.urandom(16))\n file_path = posixpath.join(md5hash, filename)\n\n return self.store(file_obj, file_path)\n\n def download(self, filename):\n return send_file(safe_join(self.base_path, filename), as_attachment=True)\n\n def delete(self, filename):\n if os.path.exists(os.path.join(self.base_path, filename)):\n os.unlink(os.path.join(self.base_path, filename))\n return True\n return False\n\n def sync(self):\n pass\n\n\nclass S3Uploader(BaseUploader):\n def __init__(self):\n super(BaseUploader, self).__init__()\n self.s3 = self._get_s3_connection()\n self.bucket = get_app_config(\"AWS_S3_BUCKET\")\n\n def _get_s3_connection(self):\n access_key = get_app_config(\"AWS_ACCESS_KEY_ID\")\n secret_key = get_app_config(\"AWS_SECRET_ACCESS_KEY\")\n endpoint = get_app_config(\"AWS_S3_ENDPOINT_URL\")\n client = boto3.client(\n \"s3\",\n aws_access_key_id=access_key,\n aws_secret_access_key=secret_key,\n endpoint_url=endpoint,\n )\n return client\n\n def _clean_filename(self, c):\n if c in string.ascii_letters + string.digits + \"-\" + \"_\" + \".\":\n return True\n\n def store(self, fileobj, filename):\n self.s3.upload_fileobj(fileobj, self.bucket, filename)\n return filename\n\n def upload(self, file_obj, filename):\n filename = filter(\n self._clean_filename, secure_filename(filename).replace(\" \", \"_\")\n )\n filename = \"\".join(filename)\n if len(filename) <= 0:\n return False\n\n md5hash = hexencode(os.urandom(16))\n\n dst = md5hash + \"/\" + filename\n self.s3.upload_fileobj(file_obj, self.bucket, dst)\n return dst\n\n def download(self, filename):\n key = filename\n filename = filename.split(\"/\").pop()\n url = self.s3.generate_presigned_url(\n \"get_object\",\n Params={\n \"Bucket\": self.bucket,\n \"Key\": key,\n \"ResponseContentDisposition\": \"attachment; filename={}\".format(\n filename\n ),\n },\n )\n return redirect(url)\n\n def delete(self, filename):\n self.s3.delete_object(Bucket=self.bucket, Key=filename)\n return True\n\n def sync(self):\n local_folder = current_app.config.get(\"UPLOAD_FOLDER\")\n # If the bucket is empty then Contents will not be in the response\n bucket_list = self.s3.list_objects(Bucket=self.bucket).get(\"Contents\", [])\n\n for s3_key in bucket_list:\n s3_object = s3_key[\"Key\"]\n # We don't want to download any directories\n if s3_object.endswith(\"/\") is False:\n local_path = os.path.join(local_folder, s3_object)\n directory = os.path.dirname(local_path)\n if not os.path.exists(directory):\n os.makedirs(directory)\n\n self.s3.download_file(self.bucket, s3_object, local_path)\n", "path": "CTFd/utils/uploads/uploaders.py"}]}
| 2,212 | 186 |
gh_patches_debug_38748
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-2769
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cryptography 1.2.2 on OS X causing TypeError with AES-GCM cipher
Found this in unit tests we've been working on for our system. Reduced the problem down to the following example code, which causes a TypeError, sometimes 1 in 3 runs cause the failure, sometimes fails every time, you may have to run a few times to hit the problem.
``` python
from cryptography.hazmat.backends import default_backend
from cryptography.hazmat.primitives.ciphers import Cipher, algorithms, modes
cek = [0] * 32
iv = [0] * 12
tag = [0] * 16
cipher = Cipher(algorithms.AES(cek), modes.GCM(iv, tag), backend=default_backend())
decryptor = cipher.decryptor()
```
as follows:
``` python
Traceback (most recent call last):
File "fail.py", line 13, in <module>
decryptor = cipher.decryptor()
File "/Users/collis/.virtualenvs/jwt/lib/python3.5/site-packages/cryptography/hazmat/primitives/ciphers/base.py", line 115, in decryptor
self.algorithm, self.mode
File "/Users/collis/.virtualenvs/jwt/lib/python3.5/site-packages/cryptography/hazmat/backends/multibackend.py", line 59, in create_symmetric_decryption_ctx
return b.create_symmetric_decryption_ctx(cipher, mode)
File "/Users/collis/.virtualenvs/jwt/lib/python3.5/site-packages/cryptography/hazmat/backends/openssl/backend.py", line 875, in create_symmetric_decryption_ctx
return _CipherContext(self, cipher, mode, _CipherContext._DECRYPT)
File "/Users/collis/.virtualenvs/jwt/lib/python3.5/site-packages/cryptography/hazmat/backends/openssl/ciphers.py", line 86, in __init__
len(mode.tag), mode.tag
TypeError: initializer for ctype 'void *' must be a cdata pointer, not list
```
I printed the values being passed to "self._backend._lib.EVP_CIPHER_CTX_ctrl()" above on error it gives:
``` python
<cdata 'EVP_CIPHER_CTX *' 0x7fa4fd83d980>, 17, 16, [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
```
Note the [0, 0, 0...] is just the tag, changing the value changes this. I've tried this with actual values from our test case which found the problem e.g.
``` python
cek = [177, 161, 244, 128, 84, 143, 225, 115, 63, 180, 3, 255, 107, 154, 212, 246, 138, 7, 110, 91, 112, 46, 34, 105, 47, 130, 203, 46, 122, 234, 64, 252]
iv = [227, 197, 117, 252, 2, 219, 233, 68, 180, 225, 77, 219]
tag = [92, 80, 104, 49, 133, 25, 161, 215, 173, 101, 219, 211, 136, 91, 210, 145]
```
Same result...
- OSX 10.11.2
- Python 3.5.1
- Cryptography 1.2.2
Tried Cryptography 1.1, 1.1.1, 1.1.2, 1.2, 1.2.1, 1.2.2, same problem.
Sometimes get the same error in a different location:
``` python
Traceback (most recent call last):
File "fail.py", line 13, in <module>
decryptor = cipher.decryptor()
File "/Users/collis/.virtualenvs/jwt/lib/python3.5/site-packages/cryptography/hazmat/primitives/ciphers/base.py", line 115, in decryptor
self.algorithm, self.mode
File "/Users/collis/.virtualenvs/jwt/lib/python3.5/site-packages/cryptography/hazmat/backends/multibackend.py", line 59, in create_symmetric_decryption_ctx
return b.create_symmetric_decryption_ctx(cipher, mode)
File "/Users/collis/.virtualenvs/jwt/lib/python3.5/site-packages/cryptography/hazmat/backends/commoncrypto/backend.py", line 120, in create_symmetric_decryption_ctx
self, cipher, mode, self._lib.kCCDecrypt
File "/Users/collis/.virtualenvs/jwt/lib/python3.5/site-packages/cryptography/hazmat/backends/commoncrypto/ciphers.py", line 137, in __init__
self._backend._ffi.NULL, 0, 0, 0, self._ctx)
TypeError: initializer for ctype 'void *' must be a cdata pointer, not list
```
Looks like something going on in OpenSSL/cffi?
</issue>
<code>
[start of src/cryptography/hazmat/primitives/ciphers/modes.py]
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5 from __future__ import absolute_import, division, print_function
6
7 import abc
8
9 import six
10
11 from cryptography import utils
12
13
14 @six.add_metaclass(abc.ABCMeta)
15 class Mode(object):
16 @abc.abstractproperty
17 def name(self):
18 """
19 A string naming this mode (e.g. "ECB", "CBC").
20 """
21
22 @abc.abstractmethod
23 def validate_for_algorithm(self, algorithm):
24 """
25 Checks that all the necessary invariants of this (mode, algorithm)
26 combination are met.
27 """
28
29
30 @six.add_metaclass(abc.ABCMeta)
31 class ModeWithInitializationVector(object):
32 @abc.abstractproperty
33 def initialization_vector(self):
34 """
35 The value of the initialization vector for this mode as bytes.
36 """
37
38
39 @six.add_metaclass(abc.ABCMeta)
40 class ModeWithNonce(object):
41 @abc.abstractproperty
42 def nonce(self):
43 """
44 The value of the nonce for this mode as bytes.
45 """
46
47
48 @six.add_metaclass(abc.ABCMeta)
49 class ModeWithAuthenticationTag(object):
50 @abc.abstractproperty
51 def tag(self):
52 """
53 The value of the tag supplied to the constructor of this mode.
54 """
55
56
57 def _check_iv_length(self, algorithm):
58 if len(self.initialization_vector) * 8 != algorithm.block_size:
59 raise ValueError("Invalid IV size ({0}) for {1}.".format(
60 len(self.initialization_vector), self.name
61 ))
62
63
64 @utils.register_interface(Mode)
65 @utils.register_interface(ModeWithInitializationVector)
66 class CBC(object):
67 name = "CBC"
68
69 def __init__(self, initialization_vector):
70 self._initialization_vector = initialization_vector
71
72 initialization_vector = utils.read_only_property("_initialization_vector")
73 validate_for_algorithm = _check_iv_length
74
75
76 @utils.register_interface(Mode)
77 class ECB(object):
78 name = "ECB"
79
80 def validate_for_algorithm(self, algorithm):
81 pass
82
83
84 @utils.register_interface(Mode)
85 @utils.register_interface(ModeWithInitializationVector)
86 class OFB(object):
87 name = "OFB"
88
89 def __init__(self, initialization_vector):
90 self._initialization_vector = initialization_vector
91
92 initialization_vector = utils.read_only_property("_initialization_vector")
93 validate_for_algorithm = _check_iv_length
94
95
96 @utils.register_interface(Mode)
97 @utils.register_interface(ModeWithInitializationVector)
98 class CFB(object):
99 name = "CFB"
100
101 def __init__(self, initialization_vector):
102 self._initialization_vector = initialization_vector
103
104 initialization_vector = utils.read_only_property("_initialization_vector")
105 validate_for_algorithm = _check_iv_length
106
107
108 @utils.register_interface(Mode)
109 @utils.register_interface(ModeWithInitializationVector)
110 class CFB8(object):
111 name = "CFB8"
112
113 def __init__(self, initialization_vector):
114 self._initialization_vector = initialization_vector
115
116 initialization_vector = utils.read_only_property("_initialization_vector")
117 validate_for_algorithm = _check_iv_length
118
119
120 @utils.register_interface(Mode)
121 @utils.register_interface(ModeWithNonce)
122 class CTR(object):
123 name = "CTR"
124
125 def __init__(self, nonce):
126 self._nonce = nonce
127
128 nonce = utils.read_only_property("_nonce")
129
130 def validate_for_algorithm(self, algorithm):
131 if len(self.nonce) * 8 != algorithm.block_size:
132 raise ValueError("Invalid nonce size ({0}) for {1}.".format(
133 len(self.nonce), self.name
134 ))
135
136
137 @utils.register_interface(Mode)
138 @utils.register_interface(ModeWithInitializationVector)
139 @utils.register_interface(ModeWithAuthenticationTag)
140 class GCM(object):
141 name = "GCM"
142 _MAX_ENCRYPTED_BYTES = (2 ** 39 - 256) // 8
143 _MAX_AAD_BYTES = (2 ** 64) // 8
144
145 def __init__(self, initialization_vector, tag=None, min_tag_length=16):
146 # len(initialization_vector) must in [1, 2 ** 64), but it's impossible
147 # to actually construct a bytes object that large, so we don't check
148 # for it
149 if min_tag_length < 4:
150 raise ValueError("min_tag_length must be >= 4")
151 if tag is not None and len(tag) < min_tag_length:
152 raise ValueError(
153 "Authentication tag must be {0} bytes or longer.".format(
154 min_tag_length)
155 )
156
157 self._initialization_vector = initialization_vector
158 self._tag = tag
159
160 tag = utils.read_only_property("_tag")
161 initialization_vector = utils.read_only_property("_initialization_vector")
162
163 def validate_for_algorithm(self, algorithm):
164 pass
165
[end of src/cryptography/hazmat/primitives/ciphers/modes.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cryptography/hazmat/primitives/ciphers/modes.py b/src/cryptography/hazmat/primitives/ciphers/modes.py
--- a/src/cryptography/hazmat/primitives/ciphers/modes.py
+++ b/src/cryptography/hazmat/primitives/ciphers/modes.py
@@ -67,6 +67,9 @@
name = "CBC"
def __init__(self, initialization_vector):
+ if not isinstance(initialization_vector, bytes):
+ raise TypeError("initialization_vector must be bytes")
+
self._initialization_vector = initialization_vector
initialization_vector = utils.read_only_property("_initialization_vector")
@@ -87,6 +90,9 @@
name = "OFB"
def __init__(self, initialization_vector):
+ if not isinstance(initialization_vector, bytes):
+ raise TypeError("initialization_vector must be bytes")
+
self._initialization_vector = initialization_vector
initialization_vector = utils.read_only_property("_initialization_vector")
@@ -99,6 +105,9 @@
name = "CFB"
def __init__(self, initialization_vector):
+ if not isinstance(initialization_vector, bytes):
+ raise TypeError("initialization_vector must be bytes")
+
self._initialization_vector = initialization_vector
initialization_vector = utils.read_only_property("_initialization_vector")
@@ -111,6 +120,9 @@
name = "CFB8"
def __init__(self, initialization_vector):
+ if not isinstance(initialization_vector, bytes):
+ raise TypeError("initialization_vector must be bytes")
+
self._initialization_vector = initialization_vector
initialization_vector = utils.read_only_property("_initialization_vector")
@@ -123,6 +135,9 @@
name = "CTR"
def __init__(self, nonce):
+ if not isinstance(nonce, bytes):
+ raise TypeError("nonce must be bytes")
+
self._nonce = nonce
nonce = utils.read_only_property("_nonce")
@@ -154,6 +169,12 @@
min_tag_length)
)
+ if not isinstance(initialization_vector, bytes):
+ raise TypeError("initialization_vector must be bytes")
+
+ if tag is not None and not isinstance(tag, bytes):
+ raise TypeError("tag must be bytes or None")
+
self._initialization_vector = initialization_vector
self._tag = tag
|
{"golden_diff": "diff --git a/src/cryptography/hazmat/primitives/ciphers/modes.py b/src/cryptography/hazmat/primitives/ciphers/modes.py\n--- a/src/cryptography/hazmat/primitives/ciphers/modes.py\n+++ b/src/cryptography/hazmat/primitives/ciphers/modes.py\n@@ -67,6 +67,9 @@\n name = \"CBC\"\n \n def __init__(self, initialization_vector):\n+ if not isinstance(initialization_vector, bytes):\n+ raise TypeError(\"initialization_vector must be bytes\")\n+\n self._initialization_vector = initialization_vector\n \n initialization_vector = utils.read_only_property(\"_initialization_vector\")\n@@ -87,6 +90,9 @@\n name = \"OFB\"\n \n def __init__(self, initialization_vector):\n+ if not isinstance(initialization_vector, bytes):\n+ raise TypeError(\"initialization_vector must be bytes\")\n+\n self._initialization_vector = initialization_vector\n \n initialization_vector = utils.read_only_property(\"_initialization_vector\")\n@@ -99,6 +105,9 @@\n name = \"CFB\"\n \n def __init__(self, initialization_vector):\n+ if not isinstance(initialization_vector, bytes):\n+ raise TypeError(\"initialization_vector must be bytes\")\n+\n self._initialization_vector = initialization_vector\n \n initialization_vector = utils.read_only_property(\"_initialization_vector\")\n@@ -111,6 +120,9 @@\n name = \"CFB8\"\n \n def __init__(self, initialization_vector):\n+ if not isinstance(initialization_vector, bytes):\n+ raise TypeError(\"initialization_vector must be bytes\")\n+\n self._initialization_vector = initialization_vector\n \n initialization_vector = utils.read_only_property(\"_initialization_vector\")\n@@ -123,6 +135,9 @@\n name = \"CTR\"\n \n def __init__(self, nonce):\n+ if not isinstance(nonce, bytes):\n+ raise TypeError(\"nonce must be bytes\")\n+\n self._nonce = nonce\n \n nonce = utils.read_only_property(\"_nonce\")\n@@ -154,6 +169,12 @@\n min_tag_length)\n )\n \n+ if not isinstance(initialization_vector, bytes):\n+ raise TypeError(\"initialization_vector must be bytes\")\n+\n+ if tag is not None and not isinstance(tag, bytes):\n+ raise TypeError(\"tag must be bytes or None\")\n+\n self._initialization_vector = initialization_vector\n self._tag = tag\n", "issue": "Cryptography 1.2.2 on OS X causing TypeError with AES-GCM cipher\nFound this in unit tests we've been working on for our system. Reduced the problem down to the following example code, which causes a TypeError, sometimes 1 in 3 runs cause the failure, sometimes fails every time, you may have to run a few times to hit the problem.\n\n``` python\nfrom cryptography.hazmat.backends import default_backend\nfrom cryptography.hazmat.primitives.ciphers import Cipher, algorithms, modes\n\ncek = [0] * 32\niv = [0] * 12\ntag = [0] * 16 \n\ncipher = Cipher(algorithms.AES(cek), modes.GCM(iv, tag), backend=default_backend())\ndecryptor = cipher.decryptor()\n```\n\nas follows:\n\n``` python\nTraceback (most recent call last):\n File \"fail.py\", line 13, in <module>\n decryptor = cipher.decryptor()\n File \"/Users/collis/.virtualenvs/jwt/lib/python3.5/site-packages/cryptography/hazmat/primitives/ciphers/base.py\", line 115, in decryptor\n self.algorithm, self.mode\n File \"/Users/collis/.virtualenvs/jwt/lib/python3.5/site-packages/cryptography/hazmat/backends/multibackend.py\", line 59, in create_symmetric_decryption_ctx\n return b.create_symmetric_decryption_ctx(cipher, mode)\n File \"/Users/collis/.virtualenvs/jwt/lib/python3.5/site-packages/cryptography/hazmat/backends/openssl/backend.py\", line 875, in create_symmetric_decryption_ctx\n return _CipherContext(self, cipher, mode, _CipherContext._DECRYPT)\n File \"/Users/collis/.virtualenvs/jwt/lib/python3.5/site-packages/cryptography/hazmat/backends/openssl/ciphers.py\", line 86, in __init__\n len(mode.tag), mode.tag\nTypeError: initializer for ctype 'void *' must be a cdata pointer, not list\n```\n\nI printed the values being passed to \"self._backend._lib.EVP_CIPHER_CTX_ctrl()\" above on error it gives:\n\n``` python\n<cdata 'EVP_CIPHER_CTX *' 0x7fa4fd83d980>, 17, 16, [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]\n```\n\nNote the [0, 0, 0...] is just the tag, changing the value changes this. I've tried this with actual values from our test case which found the problem e.g.\n\n``` python\ncek = [177, 161, 244, 128, 84, 143, 225, 115, 63, 180, 3, 255, 107, 154, 212, 246, 138, 7, 110, 91, 112, 46, 34, 105, 47, 130, 203, 46, 122, 234, 64, 252]\niv = [227, 197, 117, 252, 2, 219, 233, 68, 180, 225, 77, 219]\ntag = [92, 80, 104, 49, 133, 25, 161, 215, 173, 101, 219, 211, 136, 91, 210, 145]\n```\n\nSame result...\n- OSX 10.11.2\n- Python 3.5.1\n- Cryptography 1.2.2\n\nTried Cryptography 1.1, 1.1.1, 1.1.2, 1.2, 1.2.1, 1.2.2, same problem.\n\nSometimes get the same error in a different location:\n\n``` python\nTraceback (most recent call last):\n File \"fail.py\", line 13, in <module>\n decryptor = cipher.decryptor()\n File \"/Users/collis/.virtualenvs/jwt/lib/python3.5/site-packages/cryptography/hazmat/primitives/ciphers/base.py\", line 115, in decryptor\n self.algorithm, self.mode\n File \"/Users/collis/.virtualenvs/jwt/lib/python3.5/site-packages/cryptography/hazmat/backends/multibackend.py\", line 59, in create_symmetric_decryption_ctx\n return b.create_symmetric_decryption_ctx(cipher, mode)\n File \"/Users/collis/.virtualenvs/jwt/lib/python3.5/site-packages/cryptography/hazmat/backends/commoncrypto/backend.py\", line 120, in create_symmetric_decryption_ctx\n self, cipher, mode, self._lib.kCCDecrypt\n File \"/Users/collis/.virtualenvs/jwt/lib/python3.5/site-packages/cryptography/hazmat/backends/commoncrypto/ciphers.py\", line 137, in __init__\n self._backend._ffi.NULL, 0, 0, 0, self._ctx)\nTypeError: initializer for ctype 'void *' must be a cdata pointer, not list\n```\n\nLooks like something going on in OpenSSL/cffi?\n\n", "before_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport abc\n\nimport six\n\nfrom cryptography import utils\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass Mode(object):\n @abc.abstractproperty\n def name(self):\n \"\"\"\n A string naming this mode (e.g. \"ECB\", \"CBC\").\n \"\"\"\n\n @abc.abstractmethod\n def validate_for_algorithm(self, algorithm):\n \"\"\"\n Checks that all the necessary invariants of this (mode, algorithm)\n combination are met.\n \"\"\"\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass ModeWithInitializationVector(object):\n @abc.abstractproperty\n def initialization_vector(self):\n \"\"\"\n The value of the initialization vector for this mode as bytes.\n \"\"\"\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass ModeWithNonce(object):\n @abc.abstractproperty\n def nonce(self):\n \"\"\"\n The value of the nonce for this mode as bytes.\n \"\"\"\n\n\[email protected]_metaclass(abc.ABCMeta)\nclass ModeWithAuthenticationTag(object):\n @abc.abstractproperty\n def tag(self):\n \"\"\"\n The value of the tag supplied to the constructor of this mode.\n \"\"\"\n\n\ndef _check_iv_length(self, algorithm):\n if len(self.initialization_vector) * 8 != algorithm.block_size:\n raise ValueError(\"Invalid IV size ({0}) for {1}.\".format(\n len(self.initialization_vector), self.name\n ))\n\n\[email protected]_interface(Mode)\[email protected]_interface(ModeWithInitializationVector)\nclass CBC(object):\n name = \"CBC\"\n\n def __init__(self, initialization_vector):\n self._initialization_vector = initialization_vector\n\n initialization_vector = utils.read_only_property(\"_initialization_vector\")\n validate_for_algorithm = _check_iv_length\n\n\[email protected]_interface(Mode)\nclass ECB(object):\n name = \"ECB\"\n\n def validate_for_algorithm(self, algorithm):\n pass\n\n\[email protected]_interface(Mode)\[email protected]_interface(ModeWithInitializationVector)\nclass OFB(object):\n name = \"OFB\"\n\n def __init__(self, initialization_vector):\n self._initialization_vector = initialization_vector\n\n initialization_vector = utils.read_only_property(\"_initialization_vector\")\n validate_for_algorithm = _check_iv_length\n\n\[email protected]_interface(Mode)\[email protected]_interface(ModeWithInitializationVector)\nclass CFB(object):\n name = \"CFB\"\n\n def __init__(self, initialization_vector):\n self._initialization_vector = initialization_vector\n\n initialization_vector = utils.read_only_property(\"_initialization_vector\")\n validate_for_algorithm = _check_iv_length\n\n\[email protected]_interface(Mode)\[email protected]_interface(ModeWithInitializationVector)\nclass CFB8(object):\n name = \"CFB8\"\n\n def __init__(self, initialization_vector):\n self._initialization_vector = initialization_vector\n\n initialization_vector = utils.read_only_property(\"_initialization_vector\")\n validate_for_algorithm = _check_iv_length\n\n\[email protected]_interface(Mode)\[email protected]_interface(ModeWithNonce)\nclass CTR(object):\n name = \"CTR\"\n\n def __init__(self, nonce):\n self._nonce = nonce\n\n nonce = utils.read_only_property(\"_nonce\")\n\n def validate_for_algorithm(self, algorithm):\n if len(self.nonce) * 8 != algorithm.block_size:\n raise ValueError(\"Invalid nonce size ({0}) for {1}.\".format(\n len(self.nonce), self.name\n ))\n\n\[email protected]_interface(Mode)\[email protected]_interface(ModeWithInitializationVector)\[email protected]_interface(ModeWithAuthenticationTag)\nclass GCM(object):\n name = \"GCM\"\n _MAX_ENCRYPTED_BYTES = (2 ** 39 - 256) // 8\n _MAX_AAD_BYTES = (2 ** 64) // 8\n\n def __init__(self, initialization_vector, tag=None, min_tag_length=16):\n # len(initialization_vector) must in [1, 2 ** 64), but it's impossible\n # to actually construct a bytes object that large, so we don't check\n # for it\n if min_tag_length < 4:\n raise ValueError(\"min_tag_length must be >= 4\")\n if tag is not None and len(tag) < min_tag_length:\n raise ValueError(\n \"Authentication tag must be {0} bytes or longer.\".format(\n min_tag_length)\n )\n\n self._initialization_vector = initialization_vector\n self._tag = tag\n\n tag = utils.read_only_property(\"_tag\")\n initialization_vector = utils.read_only_property(\"_initialization_vector\")\n\n def validate_for_algorithm(self, algorithm):\n pass\n", "path": "src/cryptography/hazmat/primitives/ciphers/modes.py"}]}
| 3,288 | 534 |
gh_patches_debug_21404
|
rasdani/github-patches
|
git_diff
|
matrix-org__synapse-6578
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fatal 'Failed to upgrade database' error on startup
As of Synapse 1.7.0, when I start synapse with an old database version, I get this rather cryptic error.
</issue>
<code>
[start of synapse/storage/engines/sqlite.py]
1 # -*- coding: utf-8 -*-
2 # Copyright 2015, 2016 OpenMarket Ltd
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15
16 import struct
17 import threading
18
19 from synapse.storage.prepare_database import prepare_database
20
21
22 class Sqlite3Engine(object):
23 single_threaded = True
24
25 def __init__(self, database_module, database_config):
26 self.module = database_module
27
28 # The current max state_group, or None if we haven't looked
29 # in the DB yet.
30 self._current_state_group_id = None
31 self._current_state_group_id_lock = threading.Lock()
32
33 @property
34 def can_native_upsert(self):
35 """
36 Do we support native UPSERTs? This requires SQLite3 3.24+, plus some
37 more work we haven't done yet to tell what was inserted vs updated.
38 """
39 return self.module.sqlite_version_info >= (3, 24, 0)
40
41 @property
42 def supports_tuple_comparison(self):
43 """
44 Do we support comparing tuples, i.e. `(a, b) > (c, d)`? This requires
45 SQLite 3.15+.
46 """
47 return self.module.sqlite_version_info >= (3, 15, 0)
48
49 @property
50 def supports_using_any_list(self):
51 """Do we support using `a = ANY(?)` and passing a list
52 """
53 return False
54
55 def check_database(self, txn):
56 pass
57
58 def convert_param_style(self, sql):
59 return sql
60
61 def on_new_connection(self, db_conn):
62 prepare_database(db_conn, self, config=None)
63 db_conn.create_function("rank", 1, _rank)
64
65 def is_deadlock(self, error):
66 return False
67
68 def is_connection_closed(self, conn):
69 return False
70
71 def lock_table(self, txn, table):
72 return
73
74 def get_next_state_group_id(self, txn):
75 """Returns an int that can be used as a new state_group ID
76 """
77 # We do application locking here since if we're using sqlite then
78 # we are a single process synapse.
79 with self._current_state_group_id_lock:
80 if self._current_state_group_id is None:
81 txn.execute("SELECT COALESCE(max(id), 0) FROM state_groups")
82 self._current_state_group_id = txn.fetchone()[0]
83
84 self._current_state_group_id += 1
85 return self._current_state_group_id
86
87 @property
88 def server_version(self):
89 """Gets a string giving the server version. For example: '3.22.0'
90
91 Returns:
92 string
93 """
94 return "%i.%i.%i" % self.module.sqlite_version_info
95
96
97 # Following functions taken from: https://github.com/coleifer/peewee
98
99
100 def _parse_match_info(buf):
101 bufsize = len(buf)
102 return [struct.unpack("@I", buf[i : i + 4])[0] for i in range(0, bufsize, 4)]
103
104
105 def _rank(raw_match_info):
106 """Handle match_info called w/default args 'pcx' - based on the example rank
107 function http://sqlite.org/fts3.html#appendix_a
108 """
109 match_info = _parse_match_info(raw_match_info)
110 score = 0.0
111 p, c = match_info[:2]
112 for phrase_num in range(p):
113 phrase_info_idx = 2 + (phrase_num * c * 3)
114 for col_num in range(c):
115 col_idx = phrase_info_idx + (col_num * 3)
116 x1, x2 = match_info[col_idx : col_idx + 2]
117 if x1 > 0:
118 score += float(x1) / x2
119 return score
120
[end of synapse/storage/engines/sqlite.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/synapse/storage/engines/sqlite.py b/synapse/storage/engines/sqlite.py
--- a/synapse/storage/engines/sqlite.py
+++ b/synapse/storage/engines/sqlite.py
@@ -25,6 +25,9 @@
def __init__(self, database_module, database_config):
self.module = database_module
+ database = database_config.get("args", {}).get("database")
+ self._is_in_memory = database in (None, ":memory:",)
+
# The current max state_group, or None if we haven't looked
# in the DB yet.
self._current_state_group_id = None
@@ -59,7 +62,12 @@
return sql
def on_new_connection(self, db_conn):
- prepare_database(db_conn, self, config=None)
+ if self._is_in_memory:
+ # In memory databases need to be rebuilt each time. Ideally we'd
+ # reuse the same connection as we do when starting up, but that
+ # would involve using adbapi before we have started the reactor.
+ prepare_database(db_conn, self, config=None)
+
db_conn.create_function("rank", 1, _rank)
def is_deadlock(self, error):
|
{"golden_diff": "diff --git a/synapse/storage/engines/sqlite.py b/synapse/storage/engines/sqlite.py\n--- a/synapse/storage/engines/sqlite.py\n+++ b/synapse/storage/engines/sqlite.py\n@@ -25,6 +25,9 @@\n def __init__(self, database_module, database_config):\n self.module = database_module\n \n+ database = database_config.get(\"args\", {}).get(\"database\")\n+ self._is_in_memory = database in (None, \":memory:\",)\n+\n # The current max state_group, or None if we haven't looked\n # in the DB yet.\n self._current_state_group_id = None\n@@ -59,7 +62,12 @@\n return sql\n \n def on_new_connection(self, db_conn):\n- prepare_database(db_conn, self, config=None)\n+ if self._is_in_memory:\n+ # In memory databases need to be rebuilt each time. Ideally we'd\n+ # reuse the same connection as we do when starting up, but that\n+ # would involve using adbapi before we have started the reactor.\n+ prepare_database(db_conn, self, config=None)\n+\n db_conn.create_function(\"rank\", 1, _rank)\n \n def is_deadlock(self, error):\n", "issue": "Fatal 'Failed to upgrade database' error on startup\nAs of Synapse 1.7.0, when I start synapse with an old database version, I get this rather cryptic error.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright 2015, 2016 OpenMarket Ltd\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport struct\nimport threading\n\nfrom synapse.storage.prepare_database import prepare_database\n\n\nclass Sqlite3Engine(object):\n single_threaded = True\n\n def __init__(self, database_module, database_config):\n self.module = database_module\n\n # The current max state_group, or None if we haven't looked\n # in the DB yet.\n self._current_state_group_id = None\n self._current_state_group_id_lock = threading.Lock()\n\n @property\n def can_native_upsert(self):\n \"\"\"\n Do we support native UPSERTs? This requires SQLite3 3.24+, plus some\n more work we haven't done yet to tell what was inserted vs updated.\n \"\"\"\n return self.module.sqlite_version_info >= (3, 24, 0)\n\n @property\n def supports_tuple_comparison(self):\n \"\"\"\n Do we support comparing tuples, i.e. `(a, b) > (c, d)`? This requires\n SQLite 3.15+.\n \"\"\"\n return self.module.sqlite_version_info >= (3, 15, 0)\n\n @property\n def supports_using_any_list(self):\n \"\"\"Do we support using `a = ANY(?)` and passing a list\n \"\"\"\n return False\n\n def check_database(self, txn):\n pass\n\n def convert_param_style(self, sql):\n return sql\n\n def on_new_connection(self, db_conn):\n prepare_database(db_conn, self, config=None)\n db_conn.create_function(\"rank\", 1, _rank)\n\n def is_deadlock(self, error):\n return False\n\n def is_connection_closed(self, conn):\n return False\n\n def lock_table(self, txn, table):\n return\n\n def get_next_state_group_id(self, txn):\n \"\"\"Returns an int that can be used as a new state_group ID\n \"\"\"\n # We do application locking here since if we're using sqlite then\n # we are a single process synapse.\n with self._current_state_group_id_lock:\n if self._current_state_group_id is None:\n txn.execute(\"SELECT COALESCE(max(id), 0) FROM state_groups\")\n self._current_state_group_id = txn.fetchone()[0]\n\n self._current_state_group_id += 1\n return self._current_state_group_id\n\n @property\n def server_version(self):\n \"\"\"Gets a string giving the server version. For example: '3.22.0'\n\n Returns:\n string\n \"\"\"\n return \"%i.%i.%i\" % self.module.sqlite_version_info\n\n\n# Following functions taken from: https://github.com/coleifer/peewee\n\n\ndef _parse_match_info(buf):\n bufsize = len(buf)\n return [struct.unpack(\"@I\", buf[i : i + 4])[0] for i in range(0, bufsize, 4)]\n\n\ndef _rank(raw_match_info):\n \"\"\"Handle match_info called w/default args 'pcx' - based on the example rank\n function http://sqlite.org/fts3.html#appendix_a\n \"\"\"\n match_info = _parse_match_info(raw_match_info)\n score = 0.0\n p, c = match_info[:2]\n for phrase_num in range(p):\n phrase_info_idx = 2 + (phrase_num * c * 3)\n for col_num in range(c):\n col_idx = phrase_info_idx + (col_num * 3)\n x1, x2 = match_info[col_idx : col_idx + 2]\n if x1 > 0:\n score += float(x1) / x2\n return score\n", "path": "synapse/storage/engines/sqlite.py"}]}
| 1,779 | 284 |
gh_patches_debug_39466
|
rasdani/github-patches
|
git_diff
|
yt-dlp__yt-dlp-1877
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
RedTube DL don't work any more
### Checklist
- [X] I'm reporting a broken site
- [X] I've verified that I'm running yt-dlp version **2021.11.10.1**. ([update instructions](https://github.com/yt-dlp/yt-dlp#update))
- [X] I've checked that all provided URLs are alive and playable in a browser
- [X] I've checked that all URLs and arguments with special characters are [properly quoted or escaped](https://github.com/ytdl-org/youtube-dl#video-url-contains-an-ampersand-and-im-getting-some-strange-output-1-2839-or-v-is-not-recognized-as-an-internal-or-external-command)
- [X] I've searched the [bugtracker](https://github.com/yt-dlp/yt-dlp/issues?q=) for similar issues including closed ones. DO NOT post duplicates
- [X] I've read the [guidelines for opening an issue](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#opening-an-issue)
- [X] I've read about [sharing account credentials](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#are-you-willing-to-share-account-details-if-needed) and I'm willing to share it if required
### Region
_No response_
### Description
only downloaded a small file (893 btyes) which is obviously not the real video file...
sample url:
https://www.redtube.com/39016781
### Verbose log
```shell
Download Log for url: https://www.redtube.com/39016781
Waiting
[RedTube] 39016781: Downloading webpage
[RedTube] 39016781: Downloading m3u8 information
[info] 39016781: Downloading 1 format(s): 1
[download] Destination: C:\Users\Sony\xxx\Youtube-Dl\Cute Asian is fucked & creampied!-39016781.mp4
[download] 893.00B at 436.07KiB/s (00:02)
[download] 100% of 893.00B in 00:02
Download Worker Finished.
```
</issue>
<code>
[start of yt_dlp/extractor/redtube.py]
1 from __future__ import unicode_literals
2
3 import re
4
5 from .common import InfoExtractor
6 from ..utils import (
7 determine_ext,
8 ExtractorError,
9 int_or_none,
10 merge_dicts,
11 str_to_int,
12 unified_strdate,
13 url_or_none,
14 )
15
16
17 class RedTubeIE(InfoExtractor):
18 _VALID_URL = r'https?://(?:(?:\w+\.)?redtube\.com/|embed\.redtube\.com/\?.*?\bid=)(?P<id>[0-9]+)'
19 _TESTS = [{
20 'url': 'http://www.redtube.com/66418',
21 'md5': 'fc08071233725f26b8f014dba9590005',
22 'info_dict': {
23 'id': '66418',
24 'ext': 'mp4',
25 'title': 'Sucked on a toilet',
26 'upload_date': '20110811',
27 'duration': 596,
28 'view_count': int,
29 'age_limit': 18,
30 }
31 }, {
32 'url': 'http://embed.redtube.com/?bgcolor=000000&id=1443286',
33 'only_matching': True,
34 }, {
35 'url': 'http://it.redtube.com/66418',
36 'only_matching': True,
37 }]
38
39 @staticmethod
40 def _extract_urls(webpage):
41 return re.findall(
42 r'<iframe[^>]+?src=["\'](?P<url>(?:https?:)?//embed\.redtube\.com/\?.*?\bid=\d+)',
43 webpage)
44
45 def _real_extract(self, url):
46 video_id = self._match_id(url)
47 webpage = self._download_webpage(
48 'http://www.redtube.com/%s' % video_id, video_id)
49
50 ERRORS = (
51 (('video-deleted-info', '>This video has been removed'), 'has been removed'),
52 (('private_video_text', '>This video is private', '>Send a friend request to its owner to be able to view it'), 'is private'),
53 )
54
55 for patterns, message in ERRORS:
56 if any(p in webpage for p in patterns):
57 raise ExtractorError(
58 'Video %s %s' % (video_id, message), expected=True)
59
60 info = self._search_json_ld(webpage, video_id, default={})
61
62 if not info.get('title'):
63 info['title'] = self._html_search_regex(
64 (r'<h(\d)[^>]+class="(?:video_title_text|videoTitle|video_title)[^"]*">(?P<title>(?:(?!\1).)+)</h\1>',
65 r'(?:videoTitle|title)\s*:\s*(["\'])(?P<title>(?:(?!\1).)+)\1',),
66 webpage, 'title', group='title',
67 default=None) or self._og_search_title(webpage)
68
69 formats = []
70 sources = self._parse_json(
71 self._search_regex(
72 r'sources\s*:\s*({.+?})', webpage, 'source', default='{}'),
73 video_id, fatal=False)
74 if sources and isinstance(sources, dict):
75 for format_id, format_url in sources.items():
76 if format_url:
77 formats.append({
78 'url': format_url,
79 'format_id': format_id,
80 'height': int_or_none(format_id),
81 })
82 medias = self._parse_json(
83 self._search_regex(
84 r'mediaDefinition["\']?\s*:\s*(\[.+?}\s*\])', webpage,
85 'media definitions', default='{}'),
86 video_id, fatal=False)
87 if medias and isinstance(medias, list):
88 for media in medias:
89 format_url = url_or_none(media.get('videoUrl'))
90 if not format_url:
91 continue
92 if media.get('format') == 'hls' or determine_ext(format_url) == 'm3u8':
93 formats.extend(self._extract_m3u8_formats(
94 format_url, video_id, 'mp4',
95 entry_protocol='m3u8_native', m3u8_id='hls',
96 fatal=False))
97 continue
98 format_id = media.get('quality')
99 formats.append({
100 'url': format_url,
101 'ext': 'mp4',
102 'format_id': format_id,
103 'height': int_or_none(format_id),
104 })
105 if not formats:
106 video_url = self._html_search_regex(
107 r'<source src="(.+?)" type="video/mp4">', webpage, 'video URL')
108 formats.append({'url': video_url, 'ext': 'mp4'})
109 self._sort_formats(formats)
110
111 thumbnail = self._og_search_thumbnail(webpage)
112 upload_date = unified_strdate(self._search_regex(
113 r'<span[^>]+>(?:ADDED|Published on) ([^<]+)<',
114 webpage, 'upload date', default=None))
115 duration = int_or_none(self._og_search_property(
116 'video:duration', webpage, default=None) or self._search_regex(
117 r'videoDuration\s*:\s*(\d+)', webpage, 'duration', default=None))
118 view_count = str_to_int(self._search_regex(
119 (r'<div[^>]*>Views</div>\s*<div[^>]*>\s*([\d,.]+)',
120 r'<span[^>]*>VIEWS</span>\s*</td>\s*<td>\s*([\d,.]+)',
121 r'<span[^>]+\bclass=["\']video_view_count[^>]*>\s*([\d,.]+)'),
122 webpage, 'view count', default=None))
123
124 # No self-labeling, but they describe themselves as
125 # "Home of Videos Porno"
126 age_limit = 18
127
128 return merge_dicts(info, {
129 'id': video_id,
130 'ext': 'mp4',
131 'thumbnail': thumbnail,
132 'upload_date': upload_date,
133 'duration': duration,
134 'view_count': view_count,
135 'age_limit': age_limit,
136 'formats': formats,
137 })
138
[end of yt_dlp/extractor/redtube.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/yt_dlp/extractor/redtube.py b/yt_dlp/extractor/redtube.py
--- a/yt_dlp/extractor/redtube.py
+++ b/yt_dlp/extractor/redtube.py
@@ -17,17 +17,20 @@
class RedTubeIE(InfoExtractor):
_VALID_URL = r'https?://(?:(?:\w+\.)?redtube\.com/|embed\.redtube\.com/\?.*?\bid=)(?P<id>[0-9]+)'
_TESTS = [{
- 'url': 'http://www.redtube.com/66418',
- 'md5': 'fc08071233725f26b8f014dba9590005',
+ 'url': 'https://www.redtube.com/38864951',
+ 'md5': '4fba70cbca3aefd25767ab4b523c9878',
'info_dict': {
- 'id': '66418',
+ 'id': '38864951',
'ext': 'mp4',
- 'title': 'Sucked on a toilet',
- 'upload_date': '20110811',
- 'duration': 596,
+ 'title': 'Public Sex on the Balcony in Freezing Paris! Amateur Couple LeoLulu',
+ 'description': 'Watch video Public Sex on the Balcony in Freezing Paris! Amateur Couple LeoLulu on Redtube, home of free Blowjob porn videos and Blonde sex movies online. Video length: (10:46) - Uploaded by leolulu - Verified User - Starring Pornstar: Leolulu',
+ 'upload_date': '20210111',
+ 'timestamp': 1610343109,
+ 'duration': 646,
'view_count': int,
'age_limit': 18,
- }
+ 'thumbnail': r're:https://\wi-ph\.rdtcdn\.com/videos/.+/.+\.jpg',
+ },
}, {
'url': 'http://embed.redtube.com/?bgcolor=000000&id=1443286',
'only_matching': True,
@@ -84,15 +87,25 @@
r'mediaDefinition["\']?\s*:\s*(\[.+?}\s*\])', webpage,
'media definitions', default='{}'),
video_id, fatal=False)
- if medias and isinstance(medias, list):
- for media in medias:
+ for media in medias if isinstance(medias, list) else []:
+ format_url = url_or_none(media.get('videoUrl'))
+ if not format_url:
+ continue
+ format_id = media.get('format')
+ quality = media.get('quality')
+ if format_id == 'hls' or (format_id == 'mp4' and not quality):
+ more_media = self._download_json(format_url, video_id, fatal=False)
+ else:
+ more_media = [media]
+ for media in more_media if isinstance(more_media, list) else []:
format_url = url_or_none(media.get('videoUrl'))
if not format_url:
continue
- if media.get('format') == 'hls' or determine_ext(format_url) == 'm3u8':
+ format_id = media.get('format')
+ if format_id == 'hls' or determine_ext(format_url) == 'm3u8':
formats.extend(self._extract_m3u8_formats(
format_url, video_id, 'mp4',
- entry_protocol='m3u8_native', m3u8_id='hls',
+ entry_protocol='m3u8_native', m3u8_id=format_id or 'hls',
fatal=False))
continue
format_id = media.get('quality')
|
{"golden_diff": "diff --git a/yt_dlp/extractor/redtube.py b/yt_dlp/extractor/redtube.py\n--- a/yt_dlp/extractor/redtube.py\n+++ b/yt_dlp/extractor/redtube.py\n@@ -17,17 +17,20 @@\n class RedTubeIE(InfoExtractor):\n _VALID_URL = r'https?://(?:(?:\\w+\\.)?redtube\\.com/|embed\\.redtube\\.com/\\?.*?\\bid=)(?P<id>[0-9]+)'\n _TESTS = [{\n- 'url': 'http://www.redtube.com/66418',\n- 'md5': 'fc08071233725f26b8f014dba9590005',\n+ 'url': 'https://www.redtube.com/38864951',\n+ 'md5': '4fba70cbca3aefd25767ab4b523c9878',\n 'info_dict': {\n- 'id': '66418',\n+ 'id': '38864951',\n 'ext': 'mp4',\n- 'title': 'Sucked on a toilet',\n- 'upload_date': '20110811',\n- 'duration': 596,\n+ 'title': 'Public Sex on the Balcony in Freezing Paris! Amateur Couple LeoLulu',\n+ 'description': 'Watch video Public Sex on the Balcony in Freezing Paris! Amateur Couple LeoLulu on Redtube, home of free Blowjob porn videos and Blonde sex movies online. Video length: (10:46) - Uploaded by leolulu - Verified User - Starring Pornstar: Leolulu',\n+ 'upload_date': '20210111',\n+ 'timestamp': 1610343109,\n+ 'duration': 646,\n 'view_count': int,\n 'age_limit': 18,\n- }\n+ 'thumbnail': r're:https://\\wi-ph\\.rdtcdn\\.com/videos/.+/.+\\.jpg',\n+ },\n }, {\n 'url': 'http://embed.redtube.com/?bgcolor=000000&id=1443286',\n 'only_matching': True,\n@@ -84,15 +87,25 @@\n r'mediaDefinition[\"\\']?\\s*:\\s*(\\[.+?}\\s*\\])', webpage,\n 'media definitions', default='{}'),\n video_id, fatal=False)\n- if medias and isinstance(medias, list):\n- for media in medias:\n+ for media in medias if isinstance(medias, list) else []:\n+ format_url = url_or_none(media.get('videoUrl'))\n+ if not format_url:\n+ continue\n+ format_id = media.get('format')\n+ quality = media.get('quality')\n+ if format_id == 'hls' or (format_id == 'mp4' and not quality):\n+ more_media = self._download_json(format_url, video_id, fatal=False)\n+ else:\n+ more_media = [media]\n+ for media in more_media if isinstance(more_media, list) else []:\n format_url = url_or_none(media.get('videoUrl'))\n if not format_url:\n continue\n- if media.get('format') == 'hls' or determine_ext(format_url) == 'm3u8':\n+ format_id = media.get('format')\n+ if format_id == 'hls' or determine_ext(format_url) == 'm3u8':\n formats.extend(self._extract_m3u8_formats(\n format_url, video_id, 'mp4',\n- entry_protocol='m3u8_native', m3u8_id='hls',\n+ entry_protocol='m3u8_native', m3u8_id=format_id or 'hls',\n fatal=False))\n continue\n format_id = media.get('quality')\n", "issue": "RedTube DL don't work any more\n### Checklist\n\n- [X] I'm reporting a broken site\n- [X] I've verified that I'm running yt-dlp version **2021.11.10.1**. ([update instructions](https://github.com/yt-dlp/yt-dlp#update))\n- [X] I've checked that all provided URLs are alive and playable in a browser\n- [X] I've checked that all URLs and arguments with special characters are [properly quoted or escaped](https://github.com/ytdl-org/youtube-dl#video-url-contains-an-ampersand-and-im-getting-some-strange-output-1-2839-or-v-is-not-recognized-as-an-internal-or-external-command)\n- [X] I've searched the [bugtracker](https://github.com/yt-dlp/yt-dlp/issues?q=) for similar issues including closed ones. DO NOT post duplicates\n- [X] I've read the [guidelines for opening an issue](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#opening-an-issue)\n- [X] I've read about [sharing account credentials](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#are-you-willing-to-share-account-details-if-needed) and I'm willing to share it if required\n\n### Region\n\n_No response_\n\n### Description\n\nonly downloaded a small file (893 btyes) which is obviously not the real video file...\r\nsample url:\r\nhttps://www.redtube.com/39016781\n\n### Verbose log\n\n```shell\nDownload Log for url: https://www.redtube.com/39016781\r\n\r\nWaiting\r\n[RedTube] 39016781: Downloading webpage\r\n[RedTube] 39016781: Downloading m3u8 information\r\n[info] 39016781: Downloading 1 format(s): 1\r\n[download] Destination: C:\\Users\\Sony\\xxx\\Youtube-Dl\\Cute Asian is fucked & creampied!-39016781.mp4\r\n[download] 893.00B at 436.07KiB/s (00:02)\r\n[download] 100% of 893.00B in 00:02\r\nDownload Worker Finished.\n```\n\n", "before_files": [{"content": "from __future__ import unicode_literals\n\nimport re\n\nfrom .common import InfoExtractor\nfrom ..utils import (\n determine_ext,\n ExtractorError,\n int_or_none,\n merge_dicts,\n str_to_int,\n unified_strdate,\n url_or_none,\n)\n\n\nclass RedTubeIE(InfoExtractor):\n _VALID_URL = r'https?://(?:(?:\\w+\\.)?redtube\\.com/|embed\\.redtube\\.com/\\?.*?\\bid=)(?P<id>[0-9]+)'\n _TESTS = [{\n 'url': 'http://www.redtube.com/66418',\n 'md5': 'fc08071233725f26b8f014dba9590005',\n 'info_dict': {\n 'id': '66418',\n 'ext': 'mp4',\n 'title': 'Sucked on a toilet',\n 'upload_date': '20110811',\n 'duration': 596,\n 'view_count': int,\n 'age_limit': 18,\n }\n }, {\n 'url': 'http://embed.redtube.com/?bgcolor=000000&id=1443286',\n 'only_matching': True,\n }, {\n 'url': 'http://it.redtube.com/66418',\n 'only_matching': True,\n }]\n\n @staticmethod\n def _extract_urls(webpage):\n return re.findall(\n r'<iframe[^>]+?src=[\"\\'](?P<url>(?:https?:)?//embed\\.redtube\\.com/\\?.*?\\bid=\\d+)',\n webpage)\n\n def _real_extract(self, url):\n video_id = self._match_id(url)\n webpage = self._download_webpage(\n 'http://www.redtube.com/%s' % video_id, video_id)\n\n ERRORS = (\n (('video-deleted-info', '>This video has been removed'), 'has been removed'),\n (('private_video_text', '>This video is private', '>Send a friend request to its owner to be able to view it'), 'is private'),\n )\n\n for patterns, message in ERRORS:\n if any(p in webpage for p in patterns):\n raise ExtractorError(\n 'Video %s %s' % (video_id, message), expected=True)\n\n info = self._search_json_ld(webpage, video_id, default={})\n\n if not info.get('title'):\n info['title'] = self._html_search_regex(\n (r'<h(\\d)[^>]+class=\"(?:video_title_text|videoTitle|video_title)[^\"]*\">(?P<title>(?:(?!\\1).)+)</h\\1>',\n r'(?:videoTitle|title)\\s*:\\s*([\"\\'])(?P<title>(?:(?!\\1).)+)\\1',),\n webpage, 'title', group='title',\n default=None) or self._og_search_title(webpage)\n\n formats = []\n sources = self._parse_json(\n self._search_regex(\n r'sources\\s*:\\s*({.+?})', webpage, 'source', default='{}'),\n video_id, fatal=False)\n if sources and isinstance(sources, dict):\n for format_id, format_url in sources.items():\n if format_url:\n formats.append({\n 'url': format_url,\n 'format_id': format_id,\n 'height': int_or_none(format_id),\n })\n medias = self._parse_json(\n self._search_regex(\n r'mediaDefinition[\"\\']?\\s*:\\s*(\\[.+?}\\s*\\])', webpage,\n 'media definitions', default='{}'),\n video_id, fatal=False)\n if medias and isinstance(medias, list):\n for media in medias:\n format_url = url_or_none(media.get('videoUrl'))\n if not format_url:\n continue\n if media.get('format') == 'hls' or determine_ext(format_url) == 'm3u8':\n formats.extend(self._extract_m3u8_formats(\n format_url, video_id, 'mp4',\n entry_protocol='m3u8_native', m3u8_id='hls',\n fatal=False))\n continue\n format_id = media.get('quality')\n formats.append({\n 'url': format_url,\n 'ext': 'mp4',\n 'format_id': format_id,\n 'height': int_or_none(format_id),\n })\n if not formats:\n video_url = self._html_search_regex(\n r'<source src=\"(.+?)\" type=\"video/mp4\">', webpage, 'video URL')\n formats.append({'url': video_url, 'ext': 'mp4'})\n self._sort_formats(formats)\n\n thumbnail = self._og_search_thumbnail(webpage)\n upload_date = unified_strdate(self._search_regex(\n r'<span[^>]+>(?:ADDED|Published on) ([^<]+)<',\n webpage, 'upload date', default=None))\n duration = int_or_none(self._og_search_property(\n 'video:duration', webpage, default=None) or self._search_regex(\n r'videoDuration\\s*:\\s*(\\d+)', webpage, 'duration', default=None))\n view_count = str_to_int(self._search_regex(\n (r'<div[^>]*>Views</div>\\s*<div[^>]*>\\s*([\\d,.]+)',\n r'<span[^>]*>VIEWS</span>\\s*</td>\\s*<td>\\s*([\\d,.]+)',\n r'<span[^>]+\\bclass=[\"\\']video_view_count[^>]*>\\s*([\\d,.]+)'),\n webpage, 'view count', default=None))\n\n # No self-labeling, but they describe themselves as\n # \"Home of Videos Porno\"\n age_limit = 18\n\n return merge_dicts(info, {\n 'id': video_id,\n 'ext': 'mp4',\n 'thumbnail': thumbnail,\n 'upload_date': upload_date,\n 'duration': duration,\n 'view_count': view_count,\n 'age_limit': age_limit,\n 'formats': formats,\n })\n", "path": "yt_dlp/extractor/redtube.py"}]}
| 2,757 | 910 |
gh_patches_debug_19514
|
rasdani/github-patches
|
git_diff
|
pymedusa__Medusa-5684
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Growl not registering
2018-11-10 08:21:42 INFO CHECKVERSION :: [0c0a735] Checking for updates using GIT
**What you did: Input ip:port to register gowl
**What happened: Nothing!
**What you expected: Successful registration.
**Logs:**
2018-11-10 08:22:04 WARNING Thread_1 :: [0c0a735] GROWL: Unable to send growl to 192.168.1.4:23053 - u"error b'encode() takes exactly 1 argument (2 given)'"
2018-11-10 08:22:04 WARNING Thread_1 :: [0c0a735] GROWL: Unable to send growl to 192.168.1.4:23053 - u"error b'encode() takes exactly 1 argument (2 given)'"
Same IP:port work perfectly in rage/chill.
</issue>
<code>
[start of medusa/notifiers/growl.py]
1 # coding=utf-8
2
3 from __future__ import print_function
4 from __future__ import unicode_literals
5
6 import logging
7 import socket
8 from builtins import object
9
10 import gntp.core
11
12 from medusa import app, common
13 from medusa.helper.exceptions import ex
14 from medusa.logger.adapters.style import BraceAdapter
15
16 log = BraceAdapter(logging.getLogger(__name__))
17 log.logger.addHandler(logging.NullHandler())
18
19
20 class Notifier(object):
21 def test_notify(self, host, password):
22 self._sendRegistration(host, password)
23 return self._sendGrowl('Test Growl', 'Testing Growl settings from Medusa', 'Test', host, password,
24 force=True)
25
26 def notify_snatch(self, title, message):
27 if app.GROWL_NOTIFY_ONSNATCH:
28 self._sendGrowl(title, message)
29
30 def notify_download(self, ep_obj):
31 if app.GROWL_NOTIFY_ONDOWNLOAD:
32 self._sendGrowl(common.notifyStrings[common.NOTIFY_DOWNLOAD], ep_obj.pretty_name_with_quality())
33
34 def notify_subtitle_download(self, ep_obj, lang):
35 if app.GROWL_NOTIFY_ONSUBTITLEDOWNLOAD:
36 self._sendGrowl(common.notifyStrings[common.NOTIFY_SUBTITLE_DOWNLOAD], ep_obj.pretty_name() + ': ' + lang)
37
38 def notify_git_update(self, new_version='??'):
39 update_text = common.notifyStrings[common.NOTIFY_GIT_UPDATE_TEXT]
40 title = common.notifyStrings[common.NOTIFY_GIT_UPDATE]
41 self._sendGrowl(title, update_text + new_version)
42
43 def notify_login(self, ipaddress=''):
44 update_text = common.notifyStrings[common.NOTIFY_LOGIN_TEXT]
45 title = common.notifyStrings[common.NOTIFY_LOGIN]
46 self._sendGrowl(title, update_text.format(ipaddress))
47
48 def _send_growl(self, options, message=None):
49
50 # Initialize Notification
51 notice = gntp.core.GNTPNotice(
52 app=options['app'],
53 name=options['name'],
54 title=options['title'],
55 password=options['password'],
56 )
57
58 # Optional
59 if options['sticky']:
60 notice.add_header('Notification-Sticky', options['sticky'])
61 if options['priority']:
62 notice.add_header('Notification-Priority', options['priority'])
63 if options['icon']:
64 notice.add_header('Notification-Icon', app.LOGO_URL)
65
66 if message:
67 notice.add_header('Notification-Text', message)
68
69 response = self._send(options['host'], options['port'], notice.encode('utf-8'), options['debug'])
70 return True if isinstance(response, gntp.core.GNTPOK) else False
71
72 @staticmethod
73 def _send(host, port, data, debug=False):
74 if debug:
75 print('<Sending>\n', data, '\n</Sending>')
76
77 s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
78 s.connect((host, port))
79 s.send(data)
80 response = gntp.core.parse_gntp(s.recv(1024))
81 s.close()
82
83 if debug:
84 print('<Received>\n', response, '\n</Received>')
85
86 return response
87
88 def _sendGrowl(self, title='Medusa Notification', message=None, name=None, host=None, password=None,
89 force=False):
90 if not app.USE_GROWL and not force:
91 return False
92
93 if name is None:
94 name = title
95
96 if host is None:
97 hostParts = app.GROWL_HOST.split(':')
98 else:
99 hostParts = host.split(':')
100
101 if len(hostParts) != 2 or hostParts[1] == '':
102 port = 23053
103 else:
104 port = int(hostParts[1])
105
106 growlHosts = [(hostParts[0], port)]
107
108 opts = {
109 'name': name,
110 'title': title,
111 'app': 'Medusa',
112 'sticky': None,
113 'priority': None,
114 'debug': False
115 }
116
117 if password is None:
118 opts['password'] = app.GROWL_PASSWORD
119 else:
120 opts['password'] = password
121
122 opts['icon'] = True
123
124 for pc in growlHosts:
125 opts['host'] = pc[0]
126 opts['port'] = pc[1]
127 log.debug(
128 u'GROWL: Sending growl to {host}:{port} - {msg!r}',
129 {'msg': message, 'host': opts['host'], 'port': opts['port']}
130 )
131 try:
132 if self._send_growl(opts, message):
133 return True
134 else:
135 if self._sendRegistration(host, password):
136 return self._send_growl(opts, message)
137 else:
138 return False
139 except Exception as error:
140 log.warning(
141 u'GROWL: Unable to send growl to {host}:{port} - {msg!r}',
142 {'msg': ex(error), 'host': opts['host'], 'port': opts['port']}
143 )
144 return False
145
146 def _sendRegistration(self, host=None, password=None):
147 opts = {}
148
149 if host is None:
150 hostParts = app.GROWL_HOST.split(':')
151 else:
152 hostParts = host.split(':')
153
154 if len(hostParts) != 2 or hostParts[1] == '':
155 port = 23053
156 else:
157 port = int(hostParts[1])
158
159 opts['host'] = hostParts[0]
160 opts['port'] = port
161
162 if password is None:
163 opts['password'] = app.GROWL_PASSWORD
164 else:
165 opts['password'] = password
166
167 opts['app'] = 'Medusa'
168 opts['debug'] = False
169
170 # Send Registration
171 register = gntp.core.GNTPRegister()
172 register.add_header('Application-Name', opts['app'])
173 register.add_header('Application-Icon', app.LOGO_URL)
174
175 register.add_notification('Test', True)
176 register.add_notification(common.notifyStrings[common.NOTIFY_SNATCH], True)
177 register.add_notification(common.notifyStrings[common.NOTIFY_DOWNLOAD], True)
178 register.add_notification(common.notifyStrings[common.NOTIFY_GIT_UPDATE], True)
179
180 if opts['password']:
181 register.set_password(opts['password'])
182
183 try:
184 return self._send(opts['host'], opts['port'], register.encode('utf-8'), opts['debug'])
185 except Exception as error:
186 log.warning(
187 u'GROWL: Unable to send growl to {host}:{port} - {msg!r}',
188 {'msg': ex(error), 'host': opts['host'], 'port': opts['port']}
189 )
190 return False
191
[end of medusa/notifiers/growl.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/medusa/notifiers/growl.py b/medusa/notifiers/growl.py
--- a/medusa/notifiers/growl.py
+++ b/medusa/notifiers/growl.py
@@ -66,7 +66,7 @@
if message:
notice.add_header('Notification-Text', message)
- response = self._send(options['host'], options['port'], notice.encode('utf-8'), options['debug'])
+ response = self._send(options['host'], options['port'], notice.encode(), options['debug'])
return True if isinstance(response, gntp.core.GNTPOK) else False
@staticmethod
@@ -181,7 +181,7 @@
register.set_password(opts['password'])
try:
- return self._send(opts['host'], opts['port'], register.encode('utf-8'), opts['debug'])
+ return self._send(opts['host'], opts['port'], register.encode(), opts['debug'])
except Exception as error:
log.warning(
u'GROWL: Unable to send growl to {host}:{port} - {msg!r}',
|
{"golden_diff": "diff --git a/medusa/notifiers/growl.py b/medusa/notifiers/growl.py\n--- a/medusa/notifiers/growl.py\n+++ b/medusa/notifiers/growl.py\n@@ -66,7 +66,7 @@\n if message:\n notice.add_header('Notification-Text', message)\n \n- response = self._send(options['host'], options['port'], notice.encode('utf-8'), options['debug'])\n+ response = self._send(options['host'], options['port'], notice.encode(), options['debug'])\n return True if isinstance(response, gntp.core.GNTPOK) else False\n \n @staticmethod\n@@ -181,7 +181,7 @@\n register.set_password(opts['password'])\n \n try:\n- return self._send(opts['host'], opts['port'], register.encode('utf-8'), opts['debug'])\n+ return self._send(opts['host'], opts['port'], register.encode(), opts['debug'])\n except Exception as error:\n log.warning(\n u'GROWL: Unable to send growl to {host}:{port} - {msg!r}',\n", "issue": "Growl not registering\n2018-11-10 08:21:42 INFO CHECKVERSION :: [0c0a735] Checking for updates using GIT\r\n\r\n**What you did: Input ip:port to register gowl\r\n**What happened: Nothing!\r\n**What you expected: Successful registration.\r\n\r\n**Logs:**\r\n2018-11-10 08:22:04 WARNING Thread_1 :: [0c0a735] GROWL: Unable to send growl to 192.168.1.4:23053 - u\"error b'encode() takes exactly 1 argument (2 given)'\"\r\n2018-11-10 08:22:04 WARNING Thread_1 :: [0c0a735] GROWL: Unable to send growl to 192.168.1.4:23053 - u\"error b'encode() takes exactly 1 argument (2 given)'\"\r\n\r\nSame IP:port work perfectly in rage/chill.\r\n\n", "before_files": [{"content": "# coding=utf-8\n\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport logging\nimport socket\nfrom builtins import object\n\nimport gntp.core\n\nfrom medusa import app, common\nfrom medusa.helper.exceptions import ex\nfrom medusa.logger.adapters.style import BraceAdapter\n\nlog = BraceAdapter(logging.getLogger(__name__))\nlog.logger.addHandler(logging.NullHandler())\n\n\nclass Notifier(object):\n def test_notify(self, host, password):\n self._sendRegistration(host, password)\n return self._sendGrowl('Test Growl', 'Testing Growl settings from Medusa', 'Test', host, password,\n force=True)\n\n def notify_snatch(self, title, message):\n if app.GROWL_NOTIFY_ONSNATCH:\n self._sendGrowl(title, message)\n\n def notify_download(self, ep_obj):\n if app.GROWL_NOTIFY_ONDOWNLOAD:\n self._sendGrowl(common.notifyStrings[common.NOTIFY_DOWNLOAD], ep_obj.pretty_name_with_quality())\n\n def notify_subtitle_download(self, ep_obj, lang):\n if app.GROWL_NOTIFY_ONSUBTITLEDOWNLOAD:\n self._sendGrowl(common.notifyStrings[common.NOTIFY_SUBTITLE_DOWNLOAD], ep_obj.pretty_name() + ': ' + lang)\n\n def notify_git_update(self, new_version='??'):\n update_text = common.notifyStrings[common.NOTIFY_GIT_UPDATE_TEXT]\n title = common.notifyStrings[common.NOTIFY_GIT_UPDATE]\n self._sendGrowl(title, update_text + new_version)\n\n def notify_login(self, ipaddress=''):\n update_text = common.notifyStrings[common.NOTIFY_LOGIN_TEXT]\n title = common.notifyStrings[common.NOTIFY_LOGIN]\n self._sendGrowl(title, update_text.format(ipaddress))\n\n def _send_growl(self, options, message=None):\n\n # Initialize Notification\n notice = gntp.core.GNTPNotice(\n app=options['app'],\n name=options['name'],\n title=options['title'],\n password=options['password'],\n )\n\n # Optional\n if options['sticky']:\n notice.add_header('Notification-Sticky', options['sticky'])\n if options['priority']:\n notice.add_header('Notification-Priority', options['priority'])\n if options['icon']:\n notice.add_header('Notification-Icon', app.LOGO_URL)\n\n if message:\n notice.add_header('Notification-Text', message)\n\n response = self._send(options['host'], options['port'], notice.encode('utf-8'), options['debug'])\n return True if isinstance(response, gntp.core.GNTPOK) else False\n\n @staticmethod\n def _send(host, port, data, debug=False):\n if debug:\n print('<Sending>\\n', data, '\\n</Sending>')\n\n s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n s.connect((host, port))\n s.send(data)\n response = gntp.core.parse_gntp(s.recv(1024))\n s.close()\n\n if debug:\n print('<Received>\\n', response, '\\n</Received>')\n\n return response\n\n def _sendGrowl(self, title='Medusa Notification', message=None, name=None, host=None, password=None,\n force=False):\n if not app.USE_GROWL and not force:\n return False\n\n if name is None:\n name = title\n\n if host is None:\n hostParts = app.GROWL_HOST.split(':')\n else:\n hostParts = host.split(':')\n\n if len(hostParts) != 2 or hostParts[1] == '':\n port = 23053\n else:\n port = int(hostParts[1])\n\n growlHosts = [(hostParts[0], port)]\n\n opts = {\n 'name': name,\n 'title': title,\n 'app': 'Medusa',\n 'sticky': None,\n 'priority': None,\n 'debug': False\n }\n\n if password is None:\n opts['password'] = app.GROWL_PASSWORD\n else:\n opts['password'] = password\n\n opts['icon'] = True\n\n for pc in growlHosts:\n opts['host'] = pc[0]\n opts['port'] = pc[1]\n log.debug(\n u'GROWL: Sending growl to {host}:{port} - {msg!r}',\n {'msg': message, 'host': opts['host'], 'port': opts['port']}\n )\n try:\n if self._send_growl(opts, message):\n return True\n else:\n if self._sendRegistration(host, password):\n return self._send_growl(opts, message)\n else:\n return False\n except Exception as error:\n log.warning(\n u'GROWL: Unable to send growl to {host}:{port} - {msg!r}',\n {'msg': ex(error), 'host': opts['host'], 'port': opts['port']}\n )\n return False\n\n def _sendRegistration(self, host=None, password=None):\n opts = {}\n\n if host is None:\n hostParts = app.GROWL_HOST.split(':')\n else:\n hostParts = host.split(':')\n\n if len(hostParts) != 2 or hostParts[1] == '':\n port = 23053\n else:\n port = int(hostParts[1])\n\n opts['host'] = hostParts[0]\n opts['port'] = port\n\n if password is None:\n opts['password'] = app.GROWL_PASSWORD\n else:\n opts['password'] = password\n\n opts['app'] = 'Medusa'\n opts['debug'] = False\n\n # Send Registration\n register = gntp.core.GNTPRegister()\n register.add_header('Application-Name', opts['app'])\n register.add_header('Application-Icon', app.LOGO_URL)\n\n register.add_notification('Test', True)\n register.add_notification(common.notifyStrings[common.NOTIFY_SNATCH], True)\n register.add_notification(common.notifyStrings[common.NOTIFY_DOWNLOAD], True)\n register.add_notification(common.notifyStrings[common.NOTIFY_GIT_UPDATE], True)\n\n if opts['password']:\n register.set_password(opts['password'])\n\n try:\n return self._send(opts['host'], opts['port'], register.encode('utf-8'), opts['debug'])\n except Exception as error:\n log.warning(\n u'GROWL: Unable to send growl to {host}:{port} - {msg!r}',\n {'msg': ex(error), 'host': opts['host'], 'port': opts['port']}\n )\n return False\n", "path": "medusa/notifiers/growl.py"}]}
| 2,707 | 252 |
gh_patches_debug_29624
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-trace-py-826
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
nginx-opentracing + libdd_opentracing_plugin: SpanContextCorruptedException: failed to extract span context
I'm trying to set up an integration of nginx + nginx-opentracing module + DataDog tracer plugin + sample python app in order to get working multi-span traces in a manner when an app uses propagated context.
I'm getting the following error on every call:
```
ERROR:root:trace extract failed: failed to extract span context
Traceback (most recent call last):
File "/usr/local/lib/python2.7/dist-packages/opentracing_instrumentation/http_server.py", line 75, in before_request
format=Format.HTTP_HEADERS, carrier=carrier
File "/usr/local/lib/python2.7/dist-packages/ddtrace-0.20.4-py2.7.egg/ddtrace/opentracer/tracer.py", line 294, in extract
ot_span_ctx = propagator.extract(carrier)
File "/usr/local/lib/python2.7/dist-packages/ddtrace-0.20.4-py2.7.egg/ddtrace/opentracer/propagation/http.py", line 73, in extract
raise SpanContextCorruptedException('failed to extract span context')
SpanContextCorruptedException: failed to extract span context
```
Components used:
- nginx/1.15.7
- nginx-opentracing:
https://github.com/opentracing-contrib/nginx-opentracing/releases/tag/v0.8.0
- DataDog tracer plugin: https://github.com/DataDog/dd-opentracing-cpp/releases/download/v0.4.2/linux-amd64-libdd_opentracing_plugin.so.gz
nginx configuration:
```
# configuration file /etc/nginx/nginx.conf:
load_module modules/ngx_http_opentracing_module.so;
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log debug;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for" $request_id';
access_log /var/log/nginx/access.log main;
sendfile on;
keepalive_timeout 65;
opentracing_load_tracer /etc/nginx/linux-amd64-libdd_opentracing_plugin.so /etc/nginx/dd-config.json;
opentracing on;
opentracing_trace_locations off;
opentracing_tag http_user_agent $http_user_agent;
opentracing_tag http_uri $request_uri;
opentracing_tag http_request_id $request_id;
include /etc/nginx/conf.d/*.conf;
}
# configuration file /etc/nginx/conf.d/default.conf:
upstream u {
server 62.210.92.35:80;
keepalive 20;
zone u 128k;
}
upstream upload-app {
server 127.0.0.1:8080;
}
server {
listen 80 default_server;
server_name localhost;
opentracing_operation_name $uri;
location / {
opentracing_propagate_context;
proxy_set_header Host nginx.org;
proxy_set_header Connection "";
proxy_http_version 1.1;
proxy_pass http://u;
}
location /upload/ {
opentracing_propagate_context;
proxy_pass http://upload-app;
client_max_body_size 256m;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/share/nginx/html;
}
}
```
DataDog tracer configuration (/etc/nginx/dd-config.json):
```
{
"service": "nginx",
"operation_name_override": "nginx.handle",
"agent_host": "localhost",
"agent_port": 8126
}
```
DataDog agent version, OS used:
```
# dpkg -s datadog-agent
Package: datadog-agent
Status: install ok installed
Priority: extra
Section: utils
Installed-Size: 390206
Maintainer: Datadog Packages <[email protected]>
Architecture: amd64
Version: 1:6.9.0-1
Description: Datadog Monitoring Agent
The Datadog Monitoring Agent is a lightweight process that monitors system
processes and services, and sends information back to your Datadog account.
.
This package installs and runs the advanced Agent daemon, which queues and
forwards metrics from your applications as well as system services.
.
See http://www.datadoghq.com/ for more information
License: Apache License Version 2.0
Vendor: Datadog <[email protected]>
Homepage: http://www.datadoghq.com
# lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 18.04.1 LTS
Release: 18.04
Codename: bionic
```
App itself:
```
#!/usr/bin/env python
import logging
import hashlib
from flask import Flask
from flask import request
from werkzeug.debug import get_current_traceback
from opentracing_instrumentation import http_server
from opentracing_instrumentation import config
import opentracing
from ddtrace.opentracer import Tracer
from random import randint
application = Flask(__name__)
tracer = None
def init_dd_tracer(service_name='upload-app'):
print "INIT DATADOG TRACER"
return Tracer(service_name=service_name, config={})
@application.before_request
def before_request():
global tracer
request.stderr = request.environ['wsgi.errors'] if 'wsgi.errors' in request.environ else stderr
headers_summary = "HEADERS:\n\n" + "\n".join(["{0}: {1}".format(k, request.headers[k]) for k in sorted(request.headers.keys())]) + "\n"
request.stderr.write(headers_summary)
request.full_url = request.url
request.remote_ip = request.remote_addr
request.remote_port = request.environ['REMOTE_PORT']
request.caller_name = "n/a"
request.operation = request.method
if not tracer:
tracer = init_dd_tracer()
request.span = http_server.before_request(request=request, tracer=tracer)
@application.route("/", methods=['GET', 'POST'])
def default():
try:
environ_summary = "ENVIRON:\n\n" + "\n".join(["{0}: {1}".format(k, request.environ[k]) for k in sorted(request.environ.keys())]) + "\n"
args = "REQUEST ARGS: %s" % request.args
body = "REQUETS BODY: %s" % request.data
return "%s\n%s\n%s\n" % (args, body, environ_summary)
except Exception, e:
track = get_current_traceback(skip=1, show_hidden_frames=True, ignore_system_exceptions=False)
track.log()
abort(500)
@application.route("/upload/", methods=['GET', 'POST'])
@application.route("/upload-http/", methods=['GET', 'POST'])
def upload():
global tracer
with tracer.start_span('ProcessUpload', child_of=request.span) as span:
span.log_kv({'ProcessUpload': 'started'})
span.set_tag('payload-size', int(request.headers.get('Content-Length')) if 'Content-Length' in request.headers else 0)
if 'Content-Length' in request.headers and int(request.headers.get('Content-Length')):
body = request.stream.read()
for x in range(1, randint(2, 10)):
with tracer.start_span('SubPart%02d' % x, child_of=span) as subpart_span:
subpart_span.log_kv({'subpart_iteration': x, 'action': 'begin'})
m = hashlib.md5()
m.update(body)
response_body = "%d:%s\n" % (len(body), m.hexdigest())
subpart_span.log_kv({'subpart_iteration': x, 'action': 'end'})
request.stderr.write('ProcessUpload finished with %d iterations\n' % x)
else:
response_body = 'no data was uploaded'
try:
span.set_tag('iterations', x)
except NameError:
pass
span.log_kv({'ProcessUpload': 'finished'})
return response_body
@application.errorhandler(500)
def internal_error(error):
return "500 error"
if __name__ == "__main__":
application.debug = True
application.config['PROPAGATE_EXCEPTIONS'] = True
application.run(host='127.0.0.1', port=8080)
```
</issue>
<code>
[start of ddtrace/propagation/http.py]
1 import logging
2
3 from ..context import Context
4
5 from .utils import get_wsgi_header
6
7 log = logging.getLogger(__name__)
8
9 # HTTP headers one should set for distributed tracing.
10 # These are cross-language (eg: Python, Go and other implementations should honor these)
11 HTTP_HEADER_TRACE_ID = "x-datadog-trace-id"
12 HTTP_HEADER_PARENT_ID = "x-datadog-parent-id"
13 HTTP_HEADER_SAMPLING_PRIORITY = "x-datadog-sampling-priority"
14
15
16 # Note that due to WSGI spec we have to also check for uppercased and prefixed
17 # versions of these headers
18 POSSIBLE_HTTP_HEADER_TRACE_IDS = frozenset(
19 [HTTP_HEADER_TRACE_ID, get_wsgi_header(HTTP_HEADER_TRACE_ID)]
20 )
21 POSSIBLE_HTTP_HEADER_PARENT_IDS = frozenset(
22 [HTTP_HEADER_PARENT_ID, get_wsgi_header(HTTP_HEADER_PARENT_ID)]
23 )
24 POSSIBLE_HTTP_HEADER_SAMPLING_PRIORITIES = frozenset(
25 [HTTP_HEADER_SAMPLING_PRIORITY, get_wsgi_header(HTTP_HEADER_SAMPLING_PRIORITY)]
26 )
27
28
29 class HTTPPropagator(object):
30 """A HTTP Propagator using HTTP headers as carrier."""
31
32 def inject(self, span_context, headers):
33 """Inject Context attributes that have to be propagated as HTTP headers.
34
35 Here is an example using `requests`::
36
37 import requests
38 from ddtrace.propagation.http import HTTPPropagator
39
40 def parent_call():
41 with tracer.trace("parent_span") as span:
42 headers = {}
43 propagator = HTTPPropagator()
44 propagator.inject(span.context, headers)
45 url = "<some RPC endpoint>"
46 r = requests.get(url, headers=headers)
47
48 :param Context span_context: Span context to propagate.
49 :param dict headers: HTTP headers to extend with tracing attributes.
50 """
51 headers[HTTP_HEADER_TRACE_ID] = str(span_context.trace_id)
52 headers[HTTP_HEADER_PARENT_ID] = str(span_context.span_id)
53 sampling_priority = span_context.sampling_priority
54 # Propagate priority only if defined
55 if sampling_priority is not None:
56 headers[HTTP_HEADER_SAMPLING_PRIORITY] = str(span_context.sampling_priority)
57
58 @staticmethod
59 def extract_trace_id(headers):
60 trace_id = 0
61
62 for key in POSSIBLE_HTTP_HEADER_TRACE_IDS:
63 if key in headers:
64 trace_id = headers.get(key)
65
66 return int(trace_id)
67
68 @staticmethod
69 def extract_parent_span_id(headers):
70 parent_span_id = 0
71
72 for key in POSSIBLE_HTTP_HEADER_PARENT_IDS:
73 if key in headers:
74 parent_span_id = headers.get(key)
75
76 return int(parent_span_id)
77
78 @staticmethod
79 def extract_sampling_priority(headers):
80 sampling_priority = None
81
82 for key in POSSIBLE_HTTP_HEADER_SAMPLING_PRIORITIES:
83 if key in headers:
84 sampling_priority = headers.get(key)
85
86 return sampling_priority
87
88 def extract(self, headers):
89 """Extract a Context from HTTP headers into a new Context.
90
91 Here is an example from a web endpoint::
92
93 from ddtrace.propagation.http import HTTPPropagator
94
95 def my_controller(url, headers):
96 propagator = HTTPPropagator()
97 context = propagator.extract(headers)
98 tracer.context_provider.activate(context)
99
100 with tracer.trace("my_controller") as span:
101 span.set_meta('http.url', url)
102
103 :param dict headers: HTTP headers to extract tracing attributes.
104 :return: New `Context` with propagated attributes.
105 """
106 if not headers:
107 return Context()
108
109 try:
110 trace_id = HTTPPropagator.extract_trace_id(headers)
111 parent_span_id = HTTPPropagator.extract_parent_span_id(headers)
112 sampling_priority = HTTPPropagator.extract_sampling_priority(headers)
113
114 if sampling_priority is not None:
115 sampling_priority = int(sampling_priority)
116
117 return Context(
118 trace_id=trace_id,
119 span_id=parent_span_id,
120 sampling_priority=sampling_priority,
121 )
122 # If headers are invalid and cannot be parsed, return a new context and log the issue.
123 except Exception as error:
124 try:
125 log.debug(
126 "invalid x-datadog-* headers, trace-id: %s, parent-id: %s, priority: %s, error: %s",
127 headers.get(HTTP_HEADER_TRACE_ID, 0),
128 headers.get(HTTP_HEADER_PARENT_ID, 0),
129 headers.get(HTTP_HEADER_SAMPLING_PRIORITY),
130 error,
131 )
132 # We might fail on string formatting errors ; in that case only format the first error
133 except Exception:
134 log.debug(error)
135 return Context()
136
[end of ddtrace/propagation/http.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ddtrace/propagation/http.py b/ddtrace/propagation/http.py
--- a/ddtrace/propagation/http.py
+++ b/ddtrace/propagation/http.py
@@ -56,34 +56,35 @@
headers[HTTP_HEADER_SAMPLING_PRIORITY] = str(span_context.sampling_priority)
@staticmethod
- def extract_trace_id(headers):
- trace_id = 0
+ def extract_header_value(possible_header_names, headers, default=None):
+ for header, value in headers.items():
+ for header_name in possible_header_names:
+ if header.lower() == header_name.lower():
+ return value
- for key in POSSIBLE_HTTP_HEADER_TRACE_IDS:
- if key in headers:
- trace_id = headers.get(key)
+ return default
- return int(trace_id)
+ @staticmethod
+ def extract_trace_id(headers):
+ return int(
+ HTTPPropagator.extract_header_value(
+ POSSIBLE_HTTP_HEADER_TRACE_IDS, headers, default=0,
+ )
+ )
@staticmethod
def extract_parent_span_id(headers):
- parent_span_id = 0
-
- for key in POSSIBLE_HTTP_HEADER_PARENT_IDS:
- if key in headers:
- parent_span_id = headers.get(key)
-
- return int(parent_span_id)
+ return int(
+ HTTPPropagator.extract_header_value(
+ POSSIBLE_HTTP_HEADER_PARENT_IDS, headers, default=0,
+ )
+ )
@staticmethod
def extract_sampling_priority(headers):
- sampling_priority = None
-
- for key in POSSIBLE_HTTP_HEADER_SAMPLING_PRIORITIES:
- if key in headers:
- sampling_priority = headers.get(key)
-
- return sampling_priority
+ return HTTPPropagator.extract_header_value(
+ POSSIBLE_HTTP_HEADER_SAMPLING_PRIORITIES, headers,
+ )
def extract(self, headers):
"""Extract a Context from HTTP headers into a new Context.
|
{"golden_diff": "diff --git a/ddtrace/propagation/http.py b/ddtrace/propagation/http.py\n--- a/ddtrace/propagation/http.py\n+++ b/ddtrace/propagation/http.py\n@@ -56,34 +56,35 @@\n headers[HTTP_HEADER_SAMPLING_PRIORITY] = str(span_context.sampling_priority)\n \n @staticmethod\n- def extract_trace_id(headers):\n- trace_id = 0\n+ def extract_header_value(possible_header_names, headers, default=None):\n+ for header, value in headers.items():\n+ for header_name in possible_header_names:\n+ if header.lower() == header_name.lower():\n+ return value\n \n- for key in POSSIBLE_HTTP_HEADER_TRACE_IDS:\n- if key in headers:\n- trace_id = headers.get(key)\n+ return default\n \n- return int(trace_id)\n+ @staticmethod\n+ def extract_trace_id(headers):\n+ return int(\n+ HTTPPropagator.extract_header_value(\n+ POSSIBLE_HTTP_HEADER_TRACE_IDS, headers, default=0,\n+ )\n+ )\n \n @staticmethod\n def extract_parent_span_id(headers):\n- parent_span_id = 0\n-\n- for key in POSSIBLE_HTTP_HEADER_PARENT_IDS:\n- if key in headers:\n- parent_span_id = headers.get(key)\n-\n- return int(parent_span_id)\n+ return int(\n+ HTTPPropagator.extract_header_value(\n+ POSSIBLE_HTTP_HEADER_PARENT_IDS, headers, default=0,\n+ )\n+ )\n \n @staticmethod\n def extract_sampling_priority(headers):\n- sampling_priority = None\n-\n- for key in POSSIBLE_HTTP_HEADER_SAMPLING_PRIORITIES:\n- if key in headers:\n- sampling_priority = headers.get(key)\n-\n- return sampling_priority\n+ return HTTPPropagator.extract_header_value(\n+ POSSIBLE_HTTP_HEADER_SAMPLING_PRIORITIES, headers,\n+ )\n \n def extract(self, headers):\n \"\"\"Extract a Context from HTTP headers into a new Context.\n", "issue": "nginx-opentracing + libdd_opentracing_plugin: SpanContextCorruptedException: failed to extract span context\nI'm trying to set up an integration of nginx + nginx-opentracing module + DataDog tracer plugin + sample python app in order to get working multi-span traces in a manner when an app uses propagated context.\r\n\r\nI'm getting the following error on every call:\r\n\r\n```\r\nERROR:root:trace extract failed: failed to extract span context\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python2.7/dist-packages/opentracing_instrumentation/http_server.py\", line 75, in before_request\r\n format=Format.HTTP_HEADERS, carrier=carrier\r\n File \"/usr/local/lib/python2.7/dist-packages/ddtrace-0.20.4-py2.7.egg/ddtrace/opentracer/tracer.py\", line 294, in extract\r\n ot_span_ctx = propagator.extract(carrier)\r\n File \"/usr/local/lib/python2.7/dist-packages/ddtrace-0.20.4-py2.7.egg/ddtrace/opentracer/propagation/http.py\", line 73, in extract\r\n raise SpanContextCorruptedException('failed to extract span context')\r\nSpanContextCorruptedException: failed to extract span context\r\n```\r\n\r\nComponents used:\r\n - nginx/1.15.7\r\n - nginx-opentracing: \r\nhttps://github.com/opentracing-contrib/nginx-opentracing/releases/tag/v0.8.0\r\n - DataDog tracer plugin: https://github.com/DataDog/dd-opentracing-cpp/releases/download/v0.4.2/linux-amd64-libdd_opentracing_plugin.so.gz\r\n\r\nnginx configuration:\r\n\r\n```\r\n# configuration file /etc/nginx/nginx.conf:\r\nload_module modules/ngx_http_opentracing_module.so;\r\n\r\nuser nginx;\r\nworker_processes auto;\r\n\r\nerror_log /var/log/nginx/error.log debug;\r\npid /var/run/nginx.pid;\r\n\r\nevents {\r\n worker_connections 1024;\r\n}\r\n\r\nhttp {\r\n log_format main '$remote_addr - $remote_user [$time_local] \"$request\" '\r\n '$status $body_bytes_sent \"$http_referer\" '\r\n '\"$http_user_agent\" \"$http_x_forwarded_for\" $request_id';\r\n\r\n access_log /var/log/nginx/access.log main;\r\n\r\n sendfile on;\r\n\r\n keepalive_timeout 65;\r\n\r\n opentracing_load_tracer /etc/nginx/linux-amd64-libdd_opentracing_plugin.so /etc/nginx/dd-config.json;\r\n opentracing on;\r\n opentracing_trace_locations off;\r\n opentracing_tag http_user_agent $http_user_agent;\r\n opentracing_tag http_uri $request_uri;\r\n opentracing_tag http_request_id $request_id;\r\n\r\n include /etc/nginx/conf.d/*.conf;\r\n}\r\n\r\n# configuration file /etc/nginx/conf.d/default.conf:\r\nupstream u {\r\n server 62.210.92.35:80;\r\n keepalive 20;\r\n zone u 128k;\r\n}\r\n\r\nupstream upload-app {\r\n server 127.0.0.1:8080;\r\n}\r\n\r\nserver {\r\n listen 80 default_server;\r\n server_name localhost;\r\n\r\n opentracing_operation_name $uri;\r\n\r\n location / {\r\n opentracing_propagate_context;\r\n proxy_set_header Host nginx.org;\r\n proxy_set_header Connection \"\";\r\n proxy_http_version 1.1;\r\n proxy_pass http://u;\r\n }\r\n\r\n location /upload/ {\r\n opentracing_propagate_context;\r\n proxy_pass http://upload-app;\r\n client_max_body_size 256m;\r\n }\r\n\r\n error_page 500 502 503 504 /50x.html;\r\n location = /50x.html {\r\n root /usr/share/nginx/html;\r\n }\r\n}\r\n```\r\n\r\nDataDog tracer configuration (/etc/nginx/dd-config.json):\r\n\r\n```\r\n{\r\n \"service\": \"nginx\",\r\n \"operation_name_override\": \"nginx.handle\",\r\n \"agent_host\": \"localhost\",\r\n \"agent_port\": 8126\r\n}\r\n```\r\n\r\nDataDog agent version, OS used:\r\n\r\n```\r\n# dpkg -s datadog-agent\r\nPackage: datadog-agent\r\nStatus: install ok installed\r\nPriority: extra\r\nSection: utils\r\nInstalled-Size: 390206\r\nMaintainer: Datadog Packages <[email protected]>\r\nArchitecture: amd64\r\nVersion: 1:6.9.0-1\r\nDescription: Datadog Monitoring Agent\r\n The Datadog Monitoring Agent is a lightweight process that monitors system\r\n processes and services, and sends information back to your Datadog account.\r\n .\r\n This package installs and runs the advanced Agent daemon, which queues and\r\n forwards metrics from your applications as well as system services.\r\n .\r\n See http://www.datadoghq.com/ for more information\r\nLicense: Apache License Version 2.0\r\nVendor: Datadog <[email protected]>\r\nHomepage: http://www.datadoghq.com\r\n\r\n# lsb_release -a\r\nNo LSB modules are available.\r\nDistributor ID:\tUbuntu\r\nDescription:\tUbuntu 18.04.1 LTS\r\nRelease:\t18.04\r\nCodename:\tbionic\r\n```\r\n\r\nApp itself:\r\n\r\n```\r\n#!/usr/bin/env python\r\n\r\nimport logging\r\nimport hashlib\r\nfrom flask import Flask\r\nfrom flask import request\r\nfrom werkzeug.debug import get_current_traceback\r\nfrom opentracing_instrumentation import http_server\r\nfrom opentracing_instrumentation import config\r\nimport opentracing\r\nfrom ddtrace.opentracer import Tracer\r\nfrom random import randint\r\n\r\napplication = Flask(__name__)\r\ntracer = None \r\n\r\ndef init_dd_tracer(service_name='upload-app'):\r\n print \"INIT DATADOG TRACER\"\r\n return Tracer(service_name=service_name, config={})\r\n\r\[email protected]_request\r\ndef before_request():\r\n global tracer\r\n request.stderr = request.environ['wsgi.errors'] if 'wsgi.errors' in request.environ else stderr\r\n headers_summary = \"HEADERS:\\n\\n\" + \"\\n\".join([\"{0}: {1}\".format(k, request.headers[k]) for k in sorted(request.headers.keys())]) + \"\\n\"\r\n request.stderr.write(headers_summary)\r\n\r\n request.full_url = request.url\r\n request.remote_ip = request.remote_addr\r\n request.remote_port = request.environ['REMOTE_PORT']\r\n request.caller_name = \"n/a\"\r\n request.operation = request.method\r\n\r\n if not tracer:\r\n tracer = init_dd_tracer()\r\n\r\n request.span = http_server.before_request(request=request, tracer=tracer)\r\n\r\[email protected](\"/\", methods=['GET', 'POST'])\r\ndef default():\r\n try:\r\n environ_summary = \"ENVIRON:\\n\\n\" + \"\\n\".join([\"{0}: {1}\".format(k, request.environ[k]) for k in sorted(request.environ.keys())]) + \"\\n\"\r\n args = \"REQUEST ARGS: %s\" % request.args\r\n body = \"REQUETS BODY: %s\" % request.data\r\n return \"%s\\n%s\\n%s\\n\" % (args, body, environ_summary)\r\n except Exception, e:\r\n track = get_current_traceback(skip=1, show_hidden_frames=True, ignore_system_exceptions=False)\r\n track.log()\r\n abort(500)\r\n\r\[email protected](\"/upload/\", methods=['GET', 'POST'])\r\[email protected](\"/upload-http/\", methods=['GET', 'POST'])\r\ndef upload():\r\n global tracer\r\n with tracer.start_span('ProcessUpload', child_of=request.span) as span:\r\n span.log_kv({'ProcessUpload': 'started'})\r\n span.set_tag('payload-size', int(request.headers.get('Content-Length')) if 'Content-Length' in request.headers else 0)\r\n\r\n if 'Content-Length' in request.headers and int(request.headers.get('Content-Length')):\r\n body = request.stream.read()\r\n for x in range(1, randint(2, 10)):\r\n with tracer.start_span('SubPart%02d' % x, child_of=span) as subpart_span:\r\n subpart_span.log_kv({'subpart_iteration': x, 'action': 'begin'})\r\n m = hashlib.md5()\r\n m.update(body)\r\n response_body = \"%d:%s\\n\" % (len(body), m.hexdigest())\r\n subpart_span.log_kv({'subpart_iteration': x, 'action': 'end'})\r\n request.stderr.write('ProcessUpload finished with %d iterations\\n' % x)\r\n\r\n else:\r\n response_body = 'no data was uploaded'\r\n\r\n try:\r\n span.set_tag('iterations', x)\r\n except NameError:\r\n pass\r\n\r\n span.log_kv({'ProcessUpload': 'finished'})\r\n\r\n return response_body\r\n\r\[email protected](500)\r\ndef internal_error(error):\r\n return \"500 error\"\r\n\r\nif __name__ == \"__main__\":\r\n application.debug = True\r\n application.config['PROPAGATE_EXCEPTIONS'] = True\r\n application.run(host='127.0.0.1', port=8080)\r\n```\r\n\n", "before_files": [{"content": "import logging\n\nfrom ..context import Context\n\nfrom .utils import get_wsgi_header\n\nlog = logging.getLogger(__name__)\n\n# HTTP headers one should set for distributed tracing.\n# These are cross-language (eg: Python, Go and other implementations should honor these)\nHTTP_HEADER_TRACE_ID = \"x-datadog-trace-id\"\nHTTP_HEADER_PARENT_ID = \"x-datadog-parent-id\"\nHTTP_HEADER_SAMPLING_PRIORITY = \"x-datadog-sampling-priority\"\n\n\n# Note that due to WSGI spec we have to also check for uppercased and prefixed\n# versions of these headers\nPOSSIBLE_HTTP_HEADER_TRACE_IDS = frozenset(\n [HTTP_HEADER_TRACE_ID, get_wsgi_header(HTTP_HEADER_TRACE_ID)]\n)\nPOSSIBLE_HTTP_HEADER_PARENT_IDS = frozenset(\n [HTTP_HEADER_PARENT_ID, get_wsgi_header(HTTP_HEADER_PARENT_ID)]\n)\nPOSSIBLE_HTTP_HEADER_SAMPLING_PRIORITIES = frozenset(\n [HTTP_HEADER_SAMPLING_PRIORITY, get_wsgi_header(HTTP_HEADER_SAMPLING_PRIORITY)]\n)\n\n\nclass HTTPPropagator(object):\n \"\"\"A HTTP Propagator using HTTP headers as carrier.\"\"\"\n\n def inject(self, span_context, headers):\n \"\"\"Inject Context attributes that have to be propagated as HTTP headers.\n\n Here is an example using `requests`::\n\n import requests\n from ddtrace.propagation.http import HTTPPropagator\n\n def parent_call():\n with tracer.trace(\"parent_span\") as span:\n headers = {}\n propagator = HTTPPropagator()\n propagator.inject(span.context, headers)\n url = \"<some RPC endpoint>\"\n r = requests.get(url, headers=headers)\n\n :param Context span_context: Span context to propagate.\n :param dict headers: HTTP headers to extend with tracing attributes.\n \"\"\"\n headers[HTTP_HEADER_TRACE_ID] = str(span_context.trace_id)\n headers[HTTP_HEADER_PARENT_ID] = str(span_context.span_id)\n sampling_priority = span_context.sampling_priority\n # Propagate priority only if defined\n if sampling_priority is not None:\n headers[HTTP_HEADER_SAMPLING_PRIORITY] = str(span_context.sampling_priority)\n\n @staticmethod\n def extract_trace_id(headers):\n trace_id = 0\n\n for key in POSSIBLE_HTTP_HEADER_TRACE_IDS:\n if key in headers:\n trace_id = headers.get(key)\n\n return int(trace_id)\n\n @staticmethod\n def extract_parent_span_id(headers):\n parent_span_id = 0\n\n for key in POSSIBLE_HTTP_HEADER_PARENT_IDS:\n if key in headers:\n parent_span_id = headers.get(key)\n\n return int(parent_span_id)\n\n @staticmethod\n def extract_sampling_priority(headers):\n sampling_priority = None\n\n for key in POSSIBLE_HTTP_HEADER_SAMPLING_PRIORITIES:\n if key in headers:\n sampling_priority = headers.get(key)\n\n return sampling_priority\n\n def extract(self, headers):\n \"\"\"Extract a Context from HTTP headers into a new Context.\n\n Here is an example from a web endpoint::\n\n from ddtrace.propagation.http import HTTPPropagator\n\n def my_controller(url, headers):\n propagator = HTTPPropagator()\n context = propagator.extract(headers)\n tracer.context_provider.activate(context)\n\n with tracer.trace(\"my_controller\") as span:\n span.set_meta('http.url', url)\n\n :param dict headers: HTTP headers to extract tracing attributes.\n :return: New `Context` with propagated attributes.\n \"\"\"\n if not headers:\n return Context()\n\n try:\n trace_id = HTTPPropagator.extract_trace_id(headers)\n parent_span_id = HTTPPropagator.extract_parent_span_id(headers)\n sampling_priority = HTTPPropagator.extract_sampling_priority(headers)\n\n if sampling_priority is not None:\n sampling_priority = int(sampling_priority)\n\n return Context(\n trace_id=trace_id,\n span_id=parent_span_id,\n sampling_priority=sampling_priority,\n )\n # If headers are invalid and cannot be parsed, return a new context and log the issue.\n except Exception as error:\n try:\n log.debug(\n \"invalid x-datadog-* headers, trace-id: %s, parent-id: %s, priority: %s, error: %s\",\n headers.get(HTTP_HEADER_TRACE_ID, 0),\n headers.get(HTTP_HEADER_PARENT_ID, 0),\n headers.get(HTTP_HEADER_SAMPLING_PRIORITY),\n error,\n )\n # We might fail on string formatting errors ; in that case only format the first error\n except Exception:\n log.debug(error)\n return Context()\n", "path": "ddtrace/propagation/http.py"}]}
| 3,758 | 437 |
gh_patches_debug_17006
|
rasdani/github-patches
|
git_diff
|
sublimelsp__LSP-1950
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Side by side option for symbol action links in hover popup doesn't work if location is in same file
**Describe the bug**
The side by side icon link for "Definition" / "Type Definition" / "Declaration" from the hover popup doesn't work if the location of the definition/declaration is in the same file.
**To Reproduce**
Steps to reproduce the behavior:
1. Have `"show_symbol_action_links": true` in the settings (this is the default value)
2. Hover over symbol (e.g. function call) which has a definition in the same file
3. Click on ◨ next to "Definition", or use <kbd>Ctrl</kbd> + click on the text link
4. See that the view scrolls to the location, instead of opening the location in a new tab to the right
**Expected behavior**
LSP should open the definition in a new new to the right, similar to how the built-in definitions popup from ST does
**Environment (please complete the following information):**
- OS: Win 10
- LSP version: main
**Additional context**
Seems like the `flags` argument which includes the "side_by_side" information is lost/ignored here:
https://github.com/sublimelsp/LSP/blob/1bcd518102c1516c9d808c974b7d2a5eba7d0b80/plugin/core/open.py#L30-L31
</issue>
<code>
[start of plugin/core/open.py]
1 from .logging import exception_log
2 from .promise import Promise
3 from .promise import ResolveFunc
4 from .protocol import DocumentUri
5 from .protocol import Range
6 from .protocol import RangeLsp
7 from .typing import Dict, Tuple, Optional
8 from .url import parse_uri
9 from .views import range_to_region
10 import os
11 import sublime
12 import subprocess
13
14
15 opening_files = {} # type: Dict[str, Tuple[Promise[Optional[sublime.View]], ResolveFunc[Optional[sublime.View]]]]
16
17
18 def open_file(
19 window: sublime.Window, uri: DocumentUri, flags: int = 0, group: int = -1
20 ) -> Promise[Optional[sublime.View]]:
21 """
22 Open a file asynchronously.
23 It is only safe to call this function from the UI thread.
24 The provided uri MUST be a file URI
25 """
26 file = parse_uri(uri)[1]
27 # window.open_file brings the file to focus if it's already opened, which we don't want.
28 # So we first check if there's already a view for that file.
29 view = window.find_open_file(file)
30 if view:
31 return Promise.resolve(view)
32
33 view = window.open_file(file, flags, group)
34 if not view.is_loading():
35 # It's already loaded. Possibly already open in a tab.
36 return Promise.resolve(view)
37
38 # Is the view opening right now? Then return the associated unresolved promise
39 for fn, value in opening_files.items():
40 if fn == file or os.path.samefile(fn, file):
41 # Return the unresolved promise. A future on_load event will resolve the promise.
42 return value[0]
43
44 # Prepare a new promise to be resolved by a future on_load event (see the event listener in main.py)
45 def fullfill(resolve: ResolveFunc[Optional[sublime.View]]) -> None:
46 global opening_files
47 # Save the promise in the first element of the tuple -- except we cannot yet do that here
48 opening_files[file] = (None, resolve) # type: ignore
49
50 promise = Promise(fullfill)
51 tup = opening_files[file]
52 # Save the promise in the first element of the tuple so that the for-loop above can return it
53 opening_files[file] = (promise, tup[1])
54 return promise
55
56
57 def center_selection(v: sublime.View, r: RangeLsp) -> sublime.View:
58 selection = range_to_region(Range.from_lsp(r), v)
59 v.run_command("lsp_selection_set", {"regions": [(selection.a, selection.a)]})
60 window = v.window()
61 if window:
62 window.focus_view(v)
63 if int(sublime.version()) >= 4124:
64 v.show_at_center(selection, animate=False)
65 else:
66 # TODO: remove later when a stable build lands
67 v.show_at_center(selection) # type: ignore
68 return v
69
70
71 def open_externally(uri: str, take_focus: bool) -> bool:
72 """
73 A blocking function that invokes the OS's "open with default extension"
74 """
75 try:
76 # TODO: handle take_focus
77 if sublime.platform() == "windows":
78 os.startfile(uri) # type: ignore
79 elif sublime.platform() == "osx":
80 subprocess.check_call(("/usr/bin/open", uri))
81 else: # linux
82 subprocess.check_call(("xdg-open", uri))
83 return True
84 except Exception as ex:
85 exception_log("Failed to open {}".format(uri), ex)
86 return False
87
[end of plugin/core/open.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugin/core/open.py b/plugin/core/open.py
--- a/plugin/core/open.py
+++ b/plugin/core/open.py
@@ -24,11 +24,15 @@
The provided uri MUST be a file URI
"""
file = parse_uri(uri)[1]
- # window.open_file brings the file to focus if it's already opened, which we don't want.
- # So we first check if there's already a view for that file.
+ # window.open_file brings the file to focus if it's already opened, which we don't want (unless it's supposed
+ # to open as a separate view).
view = window.find_open_file(file)
if view:
- return Promise.resolve(view)
+ opens_in_current_group = group == -1 or window.active_group() == group
+ opens_as_new_selection = (flags & (sublime.ADD_TO_SELECTION | sublime.REPLACE_MRU)) != 0
+ return_existing_view = opens_in_current_group and not opens_as_new_selection
+ if return_existing_view:
+ return Promise.resolve(view)
view = window.open_file(file, flags, group)
if not view.is_loading():
|
{"golden_diff": "diff --git a/plugin/core/open.py b/plugin/core/open.py\n--- a/plugin/core/open.py\n+++ b/plugin/core/open.py\n@@ -24,11 +24,15 @@\n The provided uri MUST be a file URI\n \"\"\"\n file = parse_uri(uri)[1]\n- # window.open_file brings the file to focus if it's already opened, which we don't want.\n- # So we first check if there's already a view for that file.\n+ # window.open_file brings the file to focus if it's already opened, which we don't want (unless it's supposed\n+ # to open as a separate view).\n view = window.find_open_file(file)\n if view:\n- return Promise.resolve(view)\n+ opens_in_current_group = group == -1 or window.active_group() == group\n+ opens_as_new_selection = (flags & (sublime.ADD_TO_SELECTION | sublime.REPLACE_MRU)) != 0\n+ return_existing_view = opens_in_current_group and not opens_as_new_selection\n+ if return_existing_view:\n+ return Promise.resolve(view)\n \n view = window.open_file(file, flags, group)\n if not view.is_loading():\n", "issue": "Side by side option for symbol action links in hover popup doesn't work if location is in same file\n**Describe the bug**\r\nThe side by side icon link for \"Definition\" / \"Type Definition\" / \"Declaration\" from the hover popup doesn't work if the location of the definition/declaration is in the same file.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Have `\"show_symbol_action_links\": true` in the settings (this is the default value)\r\n2. Hover over symbol (e.g. function call) which has a definition in the same file\r\n3. Click on \u25e8 next to \"Definition\", or use <kbd>Ctrl</kbd> + click on the text link\r\n4. See that the view scrolls to the location, instead of opening the location in a new tab to the right\r\n\r\n**Expected behavior**\r\nLSP should open the definition in a new new to the right, similar to how the built-in definitions popup from ST does\r\n\r\n**Environment (please complete the following information):**\r\n- OS: Win 10\r\n- LSP version: main\r\n\r\n**Additional context**\r\n\r\nSeems like the `flags` argument which includes the \"side_by_side\" information is lost/ignored here:\r\nhttps://github.com/sublimelsp/LSP/blob/1bcd518102c1516c9d808c974b7d2a5eba7d0b80/plugin/core/open.py#L30-L31\n", "before_files": [{"content": "from .logging import exception_log\nfrom .promise import Promise\nfrom .promise import ResolveFunc\nfrom .protocol import DocumentUri\nfrom .protocol import Range\nfrom .protocol import RangeLsp\nfrom .typing import Dict, Tuple, Optional\nfrom .url import parse_uri\nfrom .views import range_to_region\nimport os\nimport sublime\nimport subprocess\n\n\nopening_files = {} # type: Dict[str, Tuple[Promise[Optional[sublime.View]], ResolveFunc[Optional[sublime.View]]]]\n\n\ndef open_file(\n window: sublime.Window, uri: DocumentUri, flags: int = 0, group: int = -1\n) -> Promise[Optional[sublime.View]]:\n \"\"\"\n Open a file asynchronously.\n It is only safe to call this function from the UI thread.\n The provided uri MUST be a file URI\n \"\"\"\n file = parse_uri(uri)[1]\n # window.open_file brings the file to focus if it's already opened, which we don't want.\n # So we first check if there's already a view for that file.\n view = window.find_open_file(file)\n if view:\n return Promise.resolve(view)\n\n view = window.open_file(file, flags, group)\n if not view.is_loading():\n # It's already loaded. Possibly already open in a tab.\n return Promise.resolve(view)\n\n # Is the view opening right now? Then return the associated unresolved promise\n for fn, value in opening_files.items():\n if fn == file or os.path.samefile(fn, file):\n # Return the unresolved promise. A future on_load event will resolve the promise.\n return value[0]\n\n # Prepare a new promise to be resolved by a future on_load event (see the event listener in main.py)\n def fullfill(resolve: ResolveFunc[Optional[sublime.View]]) -> None:\n global opening_files\n # Save the promise in the first element of the tuple -- except we cannot yet do that here\n opening_files[file] = (None, resolve) # type: ignore\n\n promise = Promise(fullfill)\n tup = opening_files[file]\n # Save the promise in the first element of the tuple so that the for-loop above can return it\n opening_files[file] = (promise, tup[1])\n return promise\n\n\ndef center_selection(v: sublime.View, r: RangeLsp) -> sublime.View:\n selection = range_to_region(Range.from_lsp(r), v)\n v.run_command(\"lsp_selection_set\", {\"regions\": [(selection.a, selection.a)]})\n window = v.window()\n if window:\n window.focus_view(v)\n if int(sublime.version()) >= 4124:\n v.show_at_center(selection, animate=False)\n else:\n # TODO: remove later when a stable build lands\n v.show_at_center(selection) # type: ignore\n return v\n\n\ndef open_externally(uri: str, take_focus: bool) -> bool:\n \"\"\"\n A blocking function that invokes the OS's \"open with default extension\"\n \"\"\"\n try:\n # TODO: handle take_focus\n if sublime.platform() == \"windows\":\n os.startfile(uri) # type: ignore\n elif sublime.platform() == \"osx\":\n subprocess.check_call((\"/usr/bin/open\", uri))\n else: # linux\n subprocess.check_call((\"xdg-open\", uri))\n return True\n except Exception as ex:\n exception_log(\"Failed to open {}\".format(uri), ex)\n return False\n", "path": "plugin/core/open.py"}]}
| 1,765 | 258 |
gh_patches_debug_1713
|
rasdani/github-patches
|
git_diff
|
pallets__werkzeug-1032
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
HTML text can vanish in the Werkzeug interactive debugger
(I feel like I might have raised this bug before, but I can’t find it if I have.)
If you’re using the interactive debugger and you type a command includes something that looks like an HTML tag, it gets treated as literal HTML text. This causes it to disappear once you’ve finished the command, which makes for an inconsistent history.
Here’s a simple repro:

The HTML tag should continue to be visible after executing your command.
Python/Werkzeug versions, although I know I’ve seen this on older versions too:
```console
$ python --version
Python 3.5.0
$ pip freeze | grep Werkzeug
Werkzeug==0.11.10
```
</issue>
<code>
[start of werkzeug/debug/console.py]
1 # -*- coding: utf-8 -*-
2 """
3 werkzeug.debug.console
4 ~~~~~~~~~~~~~~~~~~~~~~
5
6 Interactive console support.
7
8 :copyright: (c) 2014 by the Werkzeug Team, see AUTHORS for more details.
9 :license: BSD.
10 """
11 import sys
12 import code
13 from types import CodeType
14
15 from werkzeug.utils import escape
16 from werkzeug.local import Local
17 from werkzeug.debug.repr import debug_repr, dump, helper
18
19
20 _local = Local()
21
22
23 class HTMLStringO(object):
24
25 """A StringO version that HTML escapes on write."""
26
27 def __init__(self):
28 self._buffer = []
29
30 def isatty(self):
31 return False
32
33 def close(self):
34 pass
35
36 def flush(self):
37 pass
38
39 def seek(self, n, mode=0):
40 pass
41
42 def readline(self):
43 if len(self._buffer) == 0:
44 return ''
45 ret = self._buffer[0]
46 del self._buffer[0]
47 return ret
48
49 def reset(self):
50 val = ''.join(self._buffer)
51 del self._buffer[:]
52 return val
53
54 def _write(self, x):
55 if isinstance(x, bytes):
56 x = x.decode('utf-8', 'replace')
57 self._buffer.append(x)
58
59 def write(self, x):
60 self._write(escape(x))
61
62 def writelines(self, x):
63 self._write(escape(''.join(x)))
64
65
66 class ThreadedStream(object):
67
68 """Thread-local wrapper for sys.stdout for the interactive console."""
69
70 def push():
71 if not isinstance(sys.stdout, ThreadedStream):
72 sys.stdout = ThreadedStream()
73 _local.stream = HTMLStringO()
74 push = staticmethod(push)
75
76 def fetch():
77 try:
78 stream = _local.stream
79 except AttributeError:
80 return ''
81 return stream.reset()
82 fetch = staticmethod(fetch)
83
84 def displayhook(obj):
85 try:
86 stream = _local.stream
87 except AttributeError:
88 return _displayhook(obj)
89 # stream._write bypasses escaping as debug_repr is
90 # already generating HTML for us.
91 if obj is not None:
92 _local._current_ipy.locals['_'] = obj
93 stream._write(debug_repr(obj))
94 displayhook = staticmethod(displayhook)
95
96 def __setattr__(self, name, value):
97 raise AttributeError('read only attribute %s' % name)
98
99 def __dir__(self):
100 return dir(sys.__stdout__)
101
102 def __getattribute__(self, name):
103 if name == '__members__':
104 return dir(sys.__stdout__)
105 try:
106 stream = _local.stream
107 except AttributeError:
108 stream = sys.__stdout__
109 return getattr(stream, name)
110
111 def __repr__(self):
112 return repr(sys.__stdout__)
113
114
115 # add the threaded stream as display hook
116 _displayhook = sys.displayhook
117 sys.displayhook = ThreadedStream.displayhook
118
119
120 class _ConsoleLoader(object):
121
122 def __init__(self):
123 self._storage = {}
124
125 def register(self, code, source):
126 self._storage[id(code)] = source
127 # register code objects of wrapped functions too.
128 for var in code.co_consts:
129 if isinstance(var, CodeType):
130 self._storage[id(var)] = source
131
132 def get_source_by_code(self, code):
133 try:
134 return self._storage[id(code)]
135 except KeyError:
136 pass
137
138
139 def _wrap_compiler(console):
140 compile = console.compile
141
142 def func(source, filename, symbol):
143 code = compile(source, filename, symbol)
144 console.loader.register(code, source)
145 return code
146 console.compile = func
147
148
149 class _InteractiveConsole(code.InteractiveInterpreter):
150
151 def __init__(self, globals, locals):
152 code.InteractiveInterpreter.__init__(self, locals)
153 self.globals = dict(globals)
154 self.globals['dump'] = dump
155 self.globals['help'] = helper
156 self.globals['__loader__'] = self.loader = _ConsoleLoader()
157 self.more = False
158 self.buffer = []
159 _wrap_compiler(self)
160
161 def runsource(self, source):
162 source = source.rstrip() + '\n'
163 ThreadedStream.push()
164 prompt = self.more and '... ' or '>>> '
165 try:
166 source_to_eval = ''.join(self.buffer + [source])
167 if code.InteractiveInterpreter.runsource(self,
168 source_to_eval, '<debugger>', 'single'):
169 self.more = True
170 self.buffer.append(source)
171 else:
172 self.more = False
173 del self.buffer[:]
174 finally:
175 output = ThreadedStream.fetch()
176 return prompt + source + output
177
178 def runcode(self, code):
179 try:
180 eval(code, self.globals, self.locals)
181 except Exception:
182 self.showtraceback()
183
184 def showtraceback(self):
185 from werkzeug.debug.tbtools import get_current_traceback
186 tb = get_current_traceback(skip=1)
187 sys.stdout._write(tb.render_summary())
188
189 def showsyntaxerror(self, filename=None):
190 from werkzeug.debug.tbtools import get_current_traceback
191 tb = get_current_traceback(skip=4)
192 sys.stdout._write(tb.render_summary())
193
194 def write(self, data):
195 sys.stdout.write(data)
196
197
198 class Console(object):
199
200 """An interactive console."""
201
202 def __init__(self, globals=None, locals=None):
203 if locals is None:
204 locals = {}
205 if globals is None:
206 globals = {}
207 self._ipy = _InteractiveConsole(globals, locals)
208
209 def eval(self, code):
210 _local._current_ipy = self._ipy
211 old_sys_stdout = sys.stdout
212 try:
213 return self._ipy.runsource(code)
214 finally:
215 sys.stdout = old_sys_stdout
216
[end of werkzeug/debug/console.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/werkzeug/debug/console.py b/werkzeug/debug/console.py
--- a/werkzeug/debug/console.py
+++ b/werkzeug/debug/console.py
@@ -173,7 +173,7 @@
del self.buffer[:]
finally:
output = ThreadedStream.fetch()
- return prompt + source + output
+ return prompt + escape(source) + output
def runcode(self, code):
try:
|
{"golden_diff": "diff --git a/werkzeug/debug/console.py b/werkzeug/debug/console.py\n--- a/werkzeug/debug/console.py\n+++ b/werkzeug/debug/console.py\n@@ -173,7 +173,7 @@\n del self.buffer[:]\n finally:\n output = ThreadedStream.fetch()\n- return prompt + source + output\n+ return prompt + escape(source) + output\n \n def runcode(self, code):\n try:\n", "issue": "HTML text can vanish in the Werkzeug interactive debugger\n(I feel like I might have raised this bug before, but I can\u2019t find it if I have.)\r\n\r\nIf you\u2019re using the interactive debugger and you type a command includes something that looks like an HTML tag, it gets treated as literal HTML text. This causes it to disappear once you\u2019ve finished the command, which makes for an inconsistent history.\r\n\r\nHere\u2019s a simple repro:\r\n\r\n\r\n\r\nThe HTML tag should continue to be visible after executing your command.\r\n\r\nPython/Werkzeug versions, although I know I\u2019ve seen this on older versions too:\r\n\r\n```console\r\n$ python --version\r\nPython 3.5.0\r\n\r\n$ pip freeze | grep Werkzeug\r\nWerkzeug==0.11.10\r\n```\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\n werkzeug.debug.console\n ~~~~~~~~~~~~~~~~~~~~~~\n\n Interactive console support.\n\n :copyright: (c) 2014 by the Werkzeug Team, see AUTHORS for more details.\n :license: BSD.\n\"\"\"\nimport sys\nimport code\nfrom types import CodeType\n\nfrom werkzeug.utils import escape\nfrom werkzeug.local import Local\nfrom werkzeug.debug.repr import debug_repr, dump, helper\n\n\n_local = Local()\n\n\nclass HTMLStringO(object):\n\n \"\"\"A StringO version that HTML escapes on write.\"\"\"\n\n def __init__(self):\n self._buffer = []\n\n def isatty(self):\n return False\n\n def close(self):\n pass\n\n def flush(self):\n pass\n\n def seek(self, n, mode=0):\n pass\n\n def readline(self):\n if len(self._buffer) == 0:\n return ''\n ret = self._buffer[0]\n del self._buffer[0]\n return ret\n\n def reset(self):\n val = ''.join(self._buffer)\n del self._buffer[:]\n return val\n\n def _write(self, x):\n if isinstance(x, bytes):\n x = x.decode('utf-8', 'replace')\n self._buffer.append(x)\n\n def write(self, x):\n self._write(escape(x))\n\n def writelines(self, x):\n self._write(escape(''.join(x)))\n\n\nclass ThreadedStream(object):\n\n \"\"\"Thread-local wrapper for sys.stdout for the interactive console.\"\"\"\n\n def push():\n if not isinstance(sys.stdout, ThreadedStream):\n sys.stdout = ThreadedStream()\n _local.stream = HTMLStringO()\n push = staticmethod(push)\n\n def fetch():\n try:\n stream = _local.stream\n except AttributeError:\n return ''\n return stream.reset()\n fetch = staticmethod(fetch)\n\n def displayhook(obj):\n try:\n stream = _local.stream\n except AttributeError:\n return _displayhook(obj)\n # stream._write bypasses escaping as debug_repr is\n # already generating HTML for us.\n if obj is not None:\n _local._current_ipy.locals['_'] = obj\n stream._write(debug_repr(obj))\n displayhook = staticmethod(displayhook)\n\n def __setattr__(self, name, value):\n raise AttributeError('read only attribute %s' % name)\n\n def __dir__(self):\n return dir(sys.__stdout__)\n\n def __getattribute__(self, name):\n if name == '__members__':\n return dir(sys.__stdout__)\n try:\n stream = _local.stream\n except AttributeError:\n stream = sys.__stdout__\n return getattr(stream, name)\n\n def __repr__(self):\n return repr(sys.__stdout__)\n\n\n# add the threaded stream as display hook\n_displayhook = sys.displayhook\nsys.displayhook = ThreadedStream.displayhook\n\n\nclass _ConsoleLoader(object):\n\n def __init__(self):\n self._storage = {}\n\n def register(self, code, source):\n self._storage[id(code)] = source\n # register code objects of wrapped functions too.\n for var in code.co_consts:\n if isinstance(var, CodeType):\n self._storage[id(var)] = source\n\n def get_source_by_code(self, code):\n try:\n return self._storage[id(code)]\n except KeyError:\n pass\n\n\ndef _wrap_compiler(console):\n compile = console.compile\n\n def func(source, filename, symbol):\n code = compile(source, filename, symbol)\n console.loader.register(code, source)\n return code\n console.compile = func\n\n\nclass _InteractiveConsole(code.InteractiveInterpreter):\n\n def __init__(self, globals, locals):\n code.InteractiveInterpreter.__init__(self, locals)\n self.globals = dict(globals)\n self.globals['dump'] = dump\n self.globals['help'] = helper\n self.globals['__loader__'] = self.loader = _ConsoleLoader()\n self.more = False\n self.buffer = []\n _wrap_compiler(self)\n\n def runsource(self, source):\n source = source.rstrip() + '\\n'\n ThreadedStream.push()\n prompt = self.more and '... ' or '>>> '\n try:\n source_to_eval = ''.join(self.buffer + [source])\n if code.InteractiveInterpreter.runsource(self,\n source_to_eval, '<debugger>', 'single'):\n self.more = True\n self.buffer.append(source)\n else:\n self.more = False\n del self.buffer[:]\n finally:\n output = ThreadedStream.fetch()\n return prompt + source + output\n\n def runcode(self, code):\n try:\n eval(code, self.globals, self.locals)\n except Exception:\n self.showtraceback()\n\n def showtraceback(self):\n from werkzeug.debug.tbtools import get_current_traceback\n tb = get_current_traceback(skip=1)\n sys.stdout._write(tb.render_summary())\n\n def showsyntaxerror(self, filename=None):\n from werkzeug.debug.tbtools import get_current_traceback\n tb = get_current_traceback(skip=4)\n sys.stdout._write(tb.render_summary())\n\n def write(self, data):\n sys.stdout.write(data)\n\n\nclass Console(object):\n\n \"\"\"An interactive console.\"\"\"\n\n def __init__(self, globals=None, locals=None):\n if locals is None:\n locals = {}\n if globals is None:\n globals = {}\n self._ipy = _InteractiveConsole(globals, locals)\n\n def eval(self, code):\n _local._current_ipy = self._ipy\n old_sys_stdout = sys.stdout\n try:\n return self._ipy.runsource(code)\n finally:\n sys.stdout = old_sys_stdout\n", "path": "werkzeug/debug/console.py"}]}
| 2,576 | 98 |
gh_patches_debug_19667
|
rasdani/github-patches
|
git_diff
|
hedyorg__hedy-1383
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[UI idea] Group customization pages within for-teachers url
**Idea incl level**
Currently the class customization page has a dedicated url at `/customize-class`. Due to the commit https://github.com/Felienne/hedy/commit/42ab2641d2c26a101a870371e7c16f0de8729439 we automatically extract the current page from the url and display this in the menu bar as active. As the `/customize-class` page has no own menu option no active page is shown. Because the page belongs conceptually to the `/for-teachers` section it would be nice to show this page as active. We can solve this issue by making it a sub url of `/for-teachers` such as `/for-teachers/customize-class`. A structure that can also be used for possible future page belonging to the teacher section such as `/customize-student`.
</issue>
<code>
[start of website/teacher.py]
1 from website.auth import requires_login, is_teacher, current_user
2 import utils
3 import uuid
4 from flask import g, request, jsonify, redirect
5 from flask_helpers import render_template
6 import os
7 import hedyweb
8 import hedy_content
9 TRANSLATIONS = hedyweb.Translations ()
10 from config import config
11 cookie_name = config ['session'] ['cookie_name']
12
13 def routes (app, database):
14 global DATABASE
15 DATABASE = database
16
17 @app.route('/classes', methods=['GET'])
18 @requires_login
19 def get_classes (user):
20 if not is_teacher(user):
21 return utils.page_403 (TRANSLATIONS, current_user()['username'], g.lang, TRANSLATIONS.get_translations (g.lang, 'ui').get ('retrieve_class'))
22 return jsonify (DATABASE.get_teacher_classes (user ['username'], True))
23
24 @app.route('/class/<class_id>', methods=['GET'])
25 @requires_login
26 def get_class (user, class_id):
27 app.logger.info('This is info output')
28 if not is_teacher(user):
29 return utils.page_403 (TRANSLATIONS, current_user()['username'], g.lang, TRANSLATIONS.get_translations (g.lang, 'ui').get ('retrieve_class'))
30 Class = DATABASE.get_class (class_id)
31 if not Class or Class ['teacher'] != user ['username']:
32 return utils.page_404 (TRANSLATIONS, current_user()['username'], g.lang, TRANSLATIONS.get_translations(g.lang, 'ui').get('no_such_class'))
33 students = []
34 for student_username in Class.get ('students', []):
35 student = DATABASE.user_by_username (student_username)
36 programs = DATABASE.programs_for_user(student_username)
37 highest_level = max(program['level'] for program in programs) if len(programs) else 0
38 sorted_public_programs = list(sorted([program for program in programs if program.get ('public')], key=lambda p: p['date']))
39 if sorted_public_programs:
40 latest_shared = sorted_public_programs[-1]
41 latest_shared['link'] = os.getenv ('BASE_URL') + f"/hedy/{latest_shared['id']}/view"
42 else:
43 latest_shared = None
44 students.append ({'username': student_username, 'last_login': utils.datetotimeordate (utils.mstoisostring (student ['last_login'])), 'programs': len (programs), 'highest_level': highest_level, 'latest_shared': latest_shared})
45
46 if utils.is_testing_request (request):
47 return jsonify ({'students': students, 'link': Class ['link'], 'name': Class ['name'], 'id': Class ['id']})
48 return render_template ('class-overview.html', auth=TRANSLATIONS.get_translations (g.lang, 'Auth'), current_page='for-teachers', class_info={'students': students, 'link': os.getenv ('BASE_URL') + '/hedy/l/' + Class ['link'], 'name': Class ['name'], 'id': Class ['id']})
49
50 @app.route('/class', methods=['POST'])
51 @requires_login
52 def create_class (user):
53 if not is_teacher(user):
54 return 'Only teachers can create classes', 403
55
56 body = request.json
57 # Validations
58 if not isinstance(body, dict):
59 return 'body must be an object', 400
60 if not isinstance(body.get('name'), str):
61 return 'name must be a string', 400
62
63 # We use this extra call to verify if the class name doesn't already exist, if so it's a duplicate
64 Classes = DATABASE.get_teacher_classes(user['username'], True)
65 for Class in Classes:
66 if Class['name'] == body['name']:
67 return "duplicate", 200
68
69 Class = {
70 'id': uuid.uuid4().hex,
71 'date': utils.timems (),
72 'teacher': user ['username'],
73 'link': utils.random_id_generator (7),
74 'name': body ['name']
75 }
76
77 DATABASE.store_class (Class)
78
79 return {'id': Class['id']}, 200
80
81 @app.route('/class/<class_id>', methods=['PUT'])
82 @requires_login
83 def update_class (user, class_id):
84 if not is_teacher(user):
85 return 'Only teachers can update classes', 403
86
87 body = request.json
88 # Validations
89 if not isinstance(body, dict):
90 return 'body must be an object', 400
91 if not isinstance(body.get('name'), str):
92 return 'name must be a string', 400
93
94 Class = DATABASE.get_class (class_id)
95 if not Class or Class ['teacher'] != user ['username']:
96 return 'No such class', 404
97
98 # We use this extra call to verify if the class name doesn't already exist, if so it's a duplicate
99 Classes = DATABASE.get_teacher_classes(user ['username'], True)
100 for Class in Classes:
101 if Class['name'] == body['name']:
102 return "duplicate", 200
103
104 Class = DATABASE.update_class (class_id, body ['name'])
105
106 return {}, 200
107
108 @app.route('/class/<class_id>', methods=['DELETE'])
109 @requires_login
110 def delete_class (user, class_id):
111 Class = DATABASE.get_class (class_id)
112 if not Class or Class ['teacher'] != user ['username']:
113 return 'No such class', 404
114
115 DATABASE.delete_class (Class)
116
117 return {}, 200
118
119 @app.route('/class/<class_id>/prejoin/<link>', methods=['GET'])
120 def prejoin_class (class_id, link):
121 Class = DATABASE.get_class (class_id)
122 if not Class or Class ['link'] != link:
123 return utils.page_404 (TRANSLATIONS, current_user()['username'], g.lang, TRANSLATIONS.get_translations(g.lang, 'ui').get('invalid_class_link'))
124 user = {}
125 if request.cookies.get (cookie_name):
126 token = DATABASE.get_token(request.cookies.get (cookie_name))
127 if token:
128 if token ['username'] in Class.get ('students', []):
129 return render_template ('class-already-joined.html', auth=TRANSLATIONS.get_translations (g.lang, 'Auth'), current_page='my-profile', class_info={'name': Class ['name']})
130 user = DATABASE.user_by_username(token ['username'])
131
132 return render_template ('class-prejoin.html',
133 auth=TRANSLATIONS.get_translations (g.lang, 'Auth'),
134 current_page='my-profile',
135 class_info={
136 'link': os.getenv ('BASE_URL') + '/class/' + Class ['id'] + '/join/' + Class ['link'] + '?lang=' + g.lang,
137 'name': Class ['name'],
138 })
139
140 @app.route('/class/<class_id>/join/<link>', methods=['GET'])
141 @requires_login
142 def join_class (user, class_id, link):
143 Class = DATABASE.get_class (class_id)
144 if not Class or Class ['link'] != link:
145 return utils.page_404 (TRANSLATIONS, current_user()['username'], g.lang, TRANSLATIONS.get_translations(g.lang, 'ui').get('invalid_class_link'))
146
147 DATABASE.add_student_to_class (Class ['id'], user ['username'])
148
149 return redirect(request.url.replace('/class/' + class_id + '/join/' + link, '/my-profile'), code=302)
150
151 @app.route('/class/<class_id>/student/<student_id>', methods=['DELETE'])
152 @requires_login
153 def leave_class (user, class_id, student_id):
154
155 Class = DATABASE.get_class (class_id)
156 if not Class or Class ['teacher'] != user ['username']:
157 return 'No such class', 404
158
159 DATABASE.remove_student_from_class (Class ['id'], student_id)
160
161 return {}, 200
162
163 @app.route('/customize-class/<class_id>', methods=['GET'])
164 @requires_login
165 def get_class_info(user, class_id):
166 if not is_teacher(user):
167 return utils.page_403 (TRANSLATIONS, current_user()['username'], g.lang, TRANSLATIONS.get_translations (g.lang, 'ui').get ('retrieve_class'))
168 Class = DATABASE.get_class(class_id)
169 if not Class or Class['teacher'] != user['username']:
170 return utils.page_404(TRANSLATIONS, current_user()['username'], g.lang,
171 TRANSLATIONS.get_translations(g.lang, 'ui').get('no_such_class'))
172
173 if hedy_content.Adventures(g.lang).has_adventures():
174 adventures = hedy_content.Adventures(g.lang).get_adventure_keyname_name_levels()
175 else:
176 adventures = hedy_content.Adventures("en").get_adventure_keyname_name_levels()
177 levels = hedy_content.LevelDefaults(g.lang).levels
178 preferences = DATABASE.get_customizations_class(class_id)
179
180 return render_template('customize-class.html', auth=TRANSLATIONS.get_translations(g.lang, 'Auth'),
181 ui=TRANSLATIONS.get_translations(g.lang, 'ui'),
182 class_info={'name': Class['name'], 'id': Class['id']}, levels=levels,
183 adventures=adventures, preferences=preferences, current_page='for-teachers')
184
185 @app.route('/customize-class/<class_id>', methods=['PUT'])
186 @requires_login
187 def update_level_preferences(user, class_id):
188 if not is_teacher(user):
189 return 'Only teachers can update class preferences', 403
190
191 body = request.json
192 print(body)
193 # Validations
194 if not isinstance(body, dict):
195 return 'body must be an object', 400
196 if not isinstance(body.get('example_programs'), bool):
197 return 'amount of example programs must be an integer', 400
198 if not isinstance(body.get('hide_level'), bool):
199 return 'level switch must be a boolean', 400
200 if not isinstance(body.get('hide_prev_level'), bool):
201 return 'level switch must be a boolean', 400
202 if not isinstance(body.get('hide_next_level'), bool):
203 return 'level switch must be a boolean', 400
204 if not isinstance(int(body.get('level')), int):
205 return 'level must ben an integer', 400
206
207 Class = DATABASE.get_class(class_id)
208 if not Class or Class['teacher'] != user['username']:
209 return 'No such class', 404
210
211 customizations = {}
212 customizations['id'] = class_id
213 customizations['level'] = int(body.get('level'))
214 customizations['adventures'] = body.get('adventures')
215 customizations['example_programs'] = body.get('example_programs')
216 customizations['hide'] = body.get('hide_level')
217 customizations['hide_prev_level'] = body.get('hide_prev_level')
218 customizations['hide_next_level'] = body.get('hide_next_level')
219
220
221 Class = DATABASE.update_customizations_class(customizations)
222
223 return {}, 200
224
225 @app.route('/hedy/l/<link_id>', methods=['GET'])
226 def resolve_class_link (link_id):
227 Class = DATABASE.resolve_class_link (link_id)
228 if not Class:
229 return utils.page_404 (TRANSLATIONS, current_user()['username'], g.lang, TRANSLATIONS.get_translations(g.lang, 'ui').get('invalid_class_link'))
230 return redirect(request.url.replace('/hedy/l/' + link_id, '/class/' + Class ['id'] + '/prejoin/' + link_id), code=302)
231
[end of website/teacher.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/website/teacher.py b/website/teacher.py
--- a/website/teacher.py
+++ b/website/teacher.py
@@ -21,7 +21,7 @@
return utils.page_403 (TRANSLATIONS, current_user()['username'], g.lang, TRANSLATIONS.get_translations (g.lang, 'ui').get ('retrieve_class'))
return jsonify (DATABASE.get_teacher_classes (user ['username'], True))
- @app.route('/class/<class_id>', methods=['GET'])
+ @app.route('/for-teachers/class/<class_id>', methods=['GET'])
@requires_login
def get_class (user, class_id):
app.logger.info('This is info output')
@@ -160,7 +160,7 @@
return {}, 200
- @app.route('/customize-class/<class_id>', methods=['GET'])
+ @app.route('/for-teachers/customize-class/<class_id>', methods=['GET'])
@requires_login
def get_class_info(user, class_id):
if not is_teacher(user):
|
{"golden_diff": "diff --git a/website/teacher.py b/website/teacher.py\n--- a/website/teacher.py\n+++ b/website/teacher.py\n@@ -21,7 +21,7 @@\n return utils.page_403 (TRANSLATIONS, current_user()['username'], g.lang, TRANSLATIONS.get_translations (g.lang, 'ui').get ('retrieve_class'))\n return jsonify (DATABASE.get_teacher_classes (user ['username'], True))\n \n- @app.route('/class/<class_id>', methods=['GET'])\n+ @app.route('/for-teachers/class/<class_id>', methods=['GET'])\n @requires_login\n def get_class (user, class_id):\n app.logger.info('This is info output')\n@@ -160,7 +160,7 @@\n \n return {}, 200\n \n- @app.route('/customize-class/<class_id>', methods=['GET'])\n+ @app.route('/for-teachers/customize-class/<class_id>', methods=['GET'])\n @requires_login\n def get_class_info(user, class_id):\n if not is_teacher(user):\n", "issue": "[UI idea] Group customization pages within for-teachers url\n**Idea incl level**\r\nCurrently the class customization page has a dedicated url at `/customize-class`. Due to the commit https://github.com/Felienne/hedy/commit/42ab2641d2c26a101a870371e7c16f0de8729439 we automatically extract the current page from the url and display this in the menu bar as active. As the `/customize-class` page has no own menu option no active page is shown. Because the page belongs conceptually to the `/for-teachers` section it would be nice to show this page as active. We can solve this issue by making it a sub url of `/for-teachers` such as `/for-teachers/customize-class`. A structure that can also be used for possible future page belonging to the teacher section such as `/customize-student`.\r\n\r\n\n", "before_files": [{"content": "from website.auth import requires_login, is_teacher, current_user\nimport utils\nimport uuid\nfrom flask import g, request, jsonify, redirect\nfrom flask_helpers import render_template\nimport os\nimport hedyweb\nimport hedy_content\nTRANSLATIONS = hedyweb.Translations ()\nfrom config import config\ncookie_name = config ['session'] ['cookie_name']\n\ndef routes (app, database):\n global DATABASE\n DATABASE = database\n\n @app.route('/classes', methods=['GET'])\n @requires_login\n def get_classes (user):\n if not is_teacher(user):\n return utils.page_403 (TRANSLATIONS, current_user()['username'], g.lang, TRANSLATIONS.get_translations (g.lang, 'ui').get ('retrieve_class'))\n return jsonify (DATABASE.get_teacher_classes (user ['username'], True))\n\n @app.route('/class/<class_id>', methods=['GET'])\n @requires_login\n def get_class (user, class_id):\n app.logger.info('This is info output')\n if not is_teacher(user):\n return utils.page_403 (TRANSLATIONS, current_user()['username'], g.lang, TRANSLATIONS.get_translations (g.lang, 'ui').get ('retrieve_class'))\n Class = DATABASE.get_class (class_id)\n if not Class or Class ['teacher'] != user ['username']:\n return utils.page_404 (TRANSLATIONS, current_user()['username'], g.lang, TRANSLATIONS.get_translations(g.lang, 'ui').get('no_such_class'))\n students = []\n for student_username in Class.get ('students', []):\n student = DATABASE.user_by_username (student_username)\n programs = DATABASE.programs_for_user(student_username)\n highest_level = max(program['level'] for program in programs) if len(programs) else 0\n sorted_public_programs = list(sorted([program for program in programs if program.get ('public')], key=lambda p: p['date']))\n if sorted_public_programs:\n latest_shared = sorted_public_programs[-1]\n latest_shared['link'] = os.getenv ('BASE_URL') + f\"/hedy/{latest_shared['id']}/view\"\n else:\n latest_shared = None\n students.append ({'username': student_username, 'last_login': utils.datetotimeordate (utils.mstoisostring (student ['last_login'])), 'programs': len (programs), 'highest_level': highest_level, 'latest_shared': latest_shared})\n\n if utils.is_testing_request (request):\n return jsonify ({'students': students, 'link': Class ['link'], 'name': Class ['name'], 'id': Class ['id']})\n return render_template ('class-overview.html', auth=TRANSLATIONS.get_translations (g.lang, 'Auth'), current_page='for-teachers', class_info={'students': students, 'link': os.getenv ('BASE_URL') + '/hedy/l/' + Class ['link'], 'name': Class ['name'], 'id': Class ['id']})\n\n @app.route('/class', methods=['POST'])\n @requires_login\n def create_class (user):\n if not is_teacher(user):\n return 'Only teachers can create classes', 403\n\n body = request.json\n # Validations\n if not isinstance(body, dict):\n return 'body must be an object', 400\n if not isinstance(body.get('name'), str):\n return 'name must be a string', 400\n\n # We use this extra call to verify if the class name doesn't already exist, if so it's a duplicate\n Classes = DATABASE.get_teacher_classes(user['username'], True)\n for Class in Classes:\n if Class['name'] == body['name']:\n return \"duplicate\", 200\n\n Class = {\n 'id': uuid.uuid4().hex,\n 'date': utils.timems (),\n 'teacher': user ['username'],\n 'link': utils.random_id_generator (7),\n 'name': body ['name']\n }\n\n DATABASE.store_class (Class)\n\n return {'id': Class['id']}, 200\n\n @app.route('/class/<class_id>', methods=['PUT'])\n @requires_login\n def update_class (user, class_id):\n if not is_teacher(user):\n return 'Only teachers can update classes', 403\n\n body = request.json\n # Validations\n if not isinstance(body, dict):\n return 'body must be an object', 400\n if not isinstance(body.get('name'), str):\n return 'name must be a string', 400\n\n Class = DATABASE.get_class (class_id)\n if not Class or Class ['teacher'] != user ['username']:\n return 'No such class', 404\n\n # We use this extra call to verify if the class name doesn't already exist, if so it's a duplicate\n Classes = DATABASE.get_teacher_classes(user ['username'], True)\n for Class in Classes:\n if Class['name'] == body['name']:\n return \"duplicate\", 200\n\n Class = DATABASE.update_class (class_id, body ['name'])\n\n return {}, 200\n\n @app.route('/class/<class_id>', methods=['DELETE'])\n @requires_login\n def delete_class (user, class_id):\n Class = DATABASE.get_class (class_id)\n if not Class or Class ['teacher'] != user ['username']:\n return 'No such class', 404\n\n DATABASE.delete_class (Class)\n\n return {}, 200\n\n @app.route('/class/<class_id>/prejoin/<link>', methods=['GET'])\n def prejoin_class (class_id, link):\n Class = DATABASE.get_class (class_id)\n if not Class or Class ['link'] != link:\n return utils.page_404 (TRANSLATIONS, current_user()['username'], g.lang, TRANSLATIONS.get_translations(g.lang, 'ui').get('invalid_class_link'))\n user = {}\n if request.cookies.get (cookie_name):\n token = DATABASE.get_token(request.cookies.get (cookie_name))\n if token:\n if token ['username'] in Class.get ('students', []):\n return render_template ('class-already-joined.html', auth=TRANSLATIONS.get_translations (g.lang, 'Auth'), current_page='my-profile', class_info={'name': Class ['name']})\n user = DATABASE.user_by_username(token ['username'])\n\n return render_template ('class-prejoin.html',\n auth=TRANSLATIONS.get_translations (g.lang, 'Auth'),\n current_page='my-profile',\n class_info={\n 'link': os.getenv ('BASE_URL') + '/class/' + Class ['id'] + '/join/' + Class ['link'] + '?lang=' + g.lang,\n 'name': Class ['name'],\n })\n\n @app.route('/class/<class_id>/join/<link>', methods=['GET'])\n @requires_login\n def join_class (user, class_id, link):\n Class = DATABASE.get_class (class_id)\n if not Class or Class ['link'] != link:\n return utils.page_404 (TRANSLATIONS, current_user()['username'], g.lang, TRANSLATIONS.get_translations(g.lang, 'ui').get('invalid_class_link'))\n\n DATABASE.add_student_to_class (Class ['id'], user ['username'])\n\n return redirect(request.url.replace('/class/' + class_id + '/join/' + link, '/my-profile'), code=302)\n\n @app.route('/class/<class_id>/student/<student_id>', methods=['DELETE'])\n @requires_login\n def leave_class (user, class_id, student_id):\n\n Class = DATABASE.get_class (class_id)\n if not Class or Class ['teacher'] != user ['username']:\n return 'No such class', 404\n\n DATABASE.remove_student_from_class (Class ['id'], student_id)\n\n return {}, 200\n\n @app.route('/customize-class/<class_id>', methods=['GET'])\n @requires_login\n def get_class_info(user, class_id):\n if not is_teacher(user):\n return utils.page_403 (TRANSLATIONS, current_user()['username'], g.lang, TRANSLATIONS.get_translations (g.lang, 'ui').get ('retrieve_class'))\n Class = DATABASE.get_class(class_id)\n if not Class or Class['teacher'] != user['username']:\n return utils.page_404(TRANSLATIONS, current_user()['username'], g.lang,\n TRANSLATIONS.get_translations(g.lang, 'ui').get('no_such_class'))\n\n if hedy_content.Adventures(g.lang).has_adventures():\n adventures = hedy_content.Adventures(g.lang).get_adventure_keyname_name_levels()\n else:\n adventures = hedy_content.Adventures(\"en\").get_adventure_keyname_name_levels()\n levels = hedy_content.LevelDefaults(g.lang).levels\n preferences = DATABASE.get_customizations_class(class_id)\n\n return render_template('customize-class.html', auth=TRANSLATIONS.get_translations(g.lang, 'Auth'),\n ui=TRANSLATIONS.get_translations(g.lang, 'ui'),\n class_info={'name': Class['name'], 'id': Class['id']}, levels=levels,\n adventures=adventures, preferences=preferences, current_page='for-teachers')\n\n @app.route('/customize-class/<class_id>', methods=['PUT'])\n @requires_login\n def update_level_preferences(user, class_id):\n if not is_teacher(user):\n return 'Only teachers can update class preferences', 403\n\n body = request.json\n print(body)\n # Validations\n if not isinstance(body, dict):\n return 'body must be an object', 400\n if not isinstance(body.get('example_programs'), bool):\n return 'amount of example programs must be an integer', 400\n if not isinstance(body.get('hide_level'), bool):\n return 'level switch must be a boolean', 400\n if not isinstance(body.get('hide_prev_level'), bool):\n return 'level switch must be a boolean', 400\n if not isinstance(body.get('hide_next_level'), bool):\n return 'level switch must be a boolean', 400\n if not isinstance(int(body.get('level')), int):\n return 'level must ben an integer', 400\n\n Class = DATABASE.get_class(class_id)\n if not Class or Class['teacher'] != user['username']:\n return 'No such class', 404\n\n customizations = {}\n customizations['id'] = class_id\n customizations['level'] = int(body.get('level'))\n customizations['adventures'] = body.get('adventures')\n customizations['example_programs'] = body.get('example_programs')\n customizations['hide'] = body.get('hide_level')\n customizations['hide_prev_level'] = body.get('hide_prev_level')\n customizations['hide_next_level'] = body.get('hide_next_level')\n\n\n Class = DATABASE.update_customizations_class(customizations)\n\n return {}, 200\n\n @app.route('/hedy/l/<link_id>', methods=['GET'])\n def resolve_class_link (link_id):\n Class = DATABASE.resolve_class_link (link_id)\n if not Class:\n return utils.page_404 (TRANSLATIONS, current_user()['username'], g.lang, TRANSLATIONS.get_translations(g.lang, 'ui').get('invalid_class_link'))\n return redirect(request.url.replace('/hedy/l/' + link_id, '/class/' + Class ['id'] + '/prejoin/' + link_id), code=302)\n", "path": "website/teacher.py"}]}
| 3,861 | 238 |
gh_patches_debug_3800
|
rasdani/github-patches
|
git_diff
|
kubeflow__pipelines-7364
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[sample] Error running xgboost_training_cm.py
### Environment
* How did you deploy Kubeflow Pipelines (KFP)? GCP marketplace
<!-- For more information, see an overview of KFP installation options: https://www.kubeflow.org/docs/pipelines/installation/overview/. -->
* KFP version: 1.7.1
<!-- Specify the version of Kubeflow Pipelines that you are using. The version number appears in the left side navigation of user interface.
To find the version number, See version number shows on bottom of KFP UI left sidenav. -->
* KFP SDK version:
<!-- Specify the output of the following shell command: $pip3 list | grep kfp -->
```
kfp 1.8.11
kfp-pipeline-spec 0.1.13
kfp-server-api 1.8.1
```
### Steps to reproduce
<!--
Specify how to reproduce the problem.
This may include information such as: a description of the process, code snippets, log output, or screenshots.
-->
Follow the steps given in the following link to deploy `xgboost_training_cm.py`
https://github.com/kubeflow/pipelines/tree/master/samples/core/xgboost_training_cm
### Expected result
<!-- What should the correct behavior be? -->
There shows an error with `dataproc-create-cluster` (the second block)
```
Traceback (most recent call last):
File "/usr/local/lib/python3.7/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/usr/local/lib/python3.7/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/ml/kfp_component/launcher/__main__.py", line 45, in <module>
main()
File "/ml/kfp_component/launcher/__main__.py", line 42, in main
launch(args.file_or_module, args.args)
File "/ml/kfp_component/launcher/launcher.py", line 45, in launch
return fire.Fire(module, command=args, name=module.__name__)
File "/usr/local/lib/python3.7/site-packages/fire/core.py", line 127, in Fire
component_trace = _Fire(component, args, context, name)
File "/usr/local/lib/python3.7/site-packages/fire/core.py", line 366, in _Fire
component, remaining_args)
File "/usr/local/lib/python3.7/site-packages/fire/core.py", line 542, in _CallCallable
result = fn(*varargs, **kwargs)
File "/ml/kfp_component/google/dataproc/_create_cluster.py", line 76, in create_cluster
client = DataprocClient()
File "/ml/kfp_component/google/common/_utils.py", line 170, in __init__
self._build_client()
TypeError: _build_client() takes 0 positional arguments but 1 was given
```
### Materials and Reference
<!-- Help us debug this issue by providing resources such as: sample code, background context, or links to references. -->
N/A
---
<!-- Don't delete message below to encourage users to support your issue! -->
Impacted by this bug? Give it a 👍. We prioritise the issues with the most 👍.
</issue>
<code>
[start of components/gcp/container/component_sdk/python/kfp_component/google/common/_utils.py]
1 # Copyright 2018 The Kubeflow Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import abc
16 import logging
17 import re
18 import os
19 import time
20 from functools import wraps
21 from typing import Any, Callable, Optional, Tuple
22
23 def normalize_name(name,
24 valid_first_char_pattern='a-zA-Z',
25 valid_char_pattern='0-9a-zA-Z_',
26 invalid_char_placeholder='_',
27 prefix_placeholder='x_'):
28 """Normalize a name to a valid resource name.
29
30 Uses ``valid_first_char_pattern`` and ``valid_char_pattern`` regex pattern
31 to find invalid characters from ``name`` and replaces them with
32 ``invalid_char_placeholder`` or prefix the name with ``prefix_placeholder``.
33
34 Args:
35 name: The name to be normalized.
36 valid_first_char_pattern: The regex pattern for the first character.
37 valid_char_pattern: The regex pattern for all the characters in the name.
38 invalid_char_placeholder: The placeholder to replace invalid characters.
39 prefix_placeholder: The placeholder to prefix the name if the first char
40 is invalid.
41
42 Returns:
43 The normalized name. Unchanged if all characters are valid.
44 """
45 if not name:
46 return name
47 normalized_name = re.sub('[^{}]+'.format(valid_char_pattern),
48 invalid_char_placeholder, name)
49 if not re.match('[{}]'.format(valid_first_char_pattern),
50 normalized_name[0]):
51 normalized_name = prefix_placeholder + normalized_name
52 if name != normalized_name:
53 logging.info('Normalize name from "{}" to "{}".'.format(
54 name, normalized_name))
55 return normalized_name
56
57 def dump_file(path, content):
58 """Dumps string into local file.
59
60 Args:
61 path: the local path to the file.
62 content: the string content to dump.
63 """
64 directory = os.path.dirname(path)
65 if not os.path.exists(directory):
66 os.makedirs(directory)
67 elif os.path.exists(path):
68 logging.warning('The file {} will be overwritten.'.format(path))
69 with open(path, 'w') as f:
70 f.write(content)
71
72 def check_resource_changed(requested_resource,
73 existing_resource, property_names):
74 """Check if a resource has been changed.
75
76 The function checks requested resource with existing resource
77 by comparing specified property names. Check fails if any property
78 name in the list is in ``requested_resource`` but its value is
79 different with the value in ``existing_resource``.
80
81 Args:
82 requested_resource: the user requested resource paylod.
83 existing_resource: the existing resource payload from data storage.
84 property_names: a list of property names.
85
86 Return:
87 True if ``requested_resource`` has been changed.
88 """
89 for property_name in property_names:
90 if not property_name in requested_resource:
91 continue
92 existing_value = existing_resource.get(property_name, None)
93 if requested_resource[property_name] != existing_value:
94 return True
95 return False
96
97 def wait_operation_done(get_operation, wait_interval):
98 """Waits for an operation to be done.
99
100 Args:
101 get_operation: the name of the operation.
102 wait_interval: the wait interview between pulling job
103 status.
104
105 Returns:
106 The completed operation.
107 """
108 while True:
109 operation = get_operation()
110 operation_name = operation.get('name')
111 done = operation.get('done', False)
112 if not done:
113 logging.info('Operation {} is not done. Wait for {}s.'.format(
114 operation_name, wait_interval))
115 time.sleep(wait_interval)
116 continue
117 error = operation.get('error', None)
118 if error:
119 raise RuntimeError('Failed to complete operation {}: {} {}'.format(
120 operation_name,
121 error.get('code', 'Unknown code'),
122 error.get('message', 'Unknown message'),
123 ))
124 return operation
125
126
127 def with_retries(
128 func: Callable,
129 on_error: Optional[Callable[[], Any]] = None,
130 errors: Tuple[Exception, ...] = Exception,
131 number_of_retries: int = 5,
132 delay: float = 1,
133 ):
134 """Retry decorator.
135
136 The decorator catches `errors`, calls `on_error` and retries after waiting `delay` seconds.
137
138 Args:
139 number_of_retries (int): Total number of retries if error is raised.
140 delay (float): Number of seconds to wait between consecutive retries.
141 """
142
143 @wraps(func)
144 def wrapper(self, *args, **kwargs):
145 remaining_retries = number_of_retries
146 while remaining_retries:
147 try:
148 return func(self, *args, **kwargs)
149 except errors as e:
150 remaining_retries -= 1
151 if not remaining_retries:
152 raise
153
154 logging.warning(
155 'Caught {}. Retrying in {} seconds...'.format(
156 e.__class__.__name__, delay
157 )
158 )
159
160 time.sleep(delay)
161 if on_error:
162 on_error()
163
164 return wrapper
165
166
167 class ClientWithRetries:
168
169 def __init__(self):
170 self._build_client()
171 for name, member in self.__dict__.items():
172 if callable(member) and not name.startswith("_"):
173 self.__dict__[name] = with_retries(func=member, errors=(BrokenPipeError, IOError), on_error=self._build_client)
174
175 @abc.abstractmethod
176 def _build_client():
177 raise NotImplementedError()
178
[end of components/gcp/container/component_sdk/python/kfp_component/google/common/_utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/components/gcp/container/component_sdk/python/kfp_component/google/common/_utils.py b/components/gcp/container/component_sdk/python/kfp_component/google/common/_utils.py
--- a/components/gcp/container/component_sdk/python/kfp_component/google/common/_utils.py
+++ b/components/gcp/container/component_sdk/python/kfp_component/google/common/_utils.py
@@ -173,5 +173,5 @@
self.__dict__[name] = with_retries(func=member, errors=(BrokenPipeError, IOError), on_error=self._build_client)
@abc.abstractmethod
- def _build_client():
+ def _build_client(self):
raise NotImplementedError()
|
{"golden_diff": "diff --git a/components/gcp/container/component_sdk/python/kfp_component/google/common/_utils.py b/components/gcp/container/component_sdk/python/kfp_component/google/common/_utils.py\n--- a/components/gcp/container/component_sdk/python/kfp_component/google/common/_utils.py\n+++ b/components/gcp/container/component_sdk/python/kfp_component/google/common/_utils.py\n@@ -173,5 +173,5 @@\n self.__dict__[name] = with_retries(func=member, errors=(BrokenPipeError, IOError), on_error=self._build_client)\n \n @abc.abstractmethod\n- def _build_client():\n+ def _build_client(self):\n raise NotImplementedError()\n", "issue": "[sample] Error running xgboost_training_cm.py\n### Environment\r\n\r\n* How did you deploy Kubeflow Pipelines (KFP)? GCP marketplace\r\n<!-- For more information, see an overview of KFP installation options: https://www.kubeflow.org/docs/pipelines/installation/overview/. -->\r\n* KFP version: 1.7.1\r\n<!-- Specify the version of Kubeflow Pipelines that you are using. The version number appears in the left side navigation of user interface.\r\nTo find the version number, See version number shows on bottom of KFP UI left sidenav. -->\r\n* KFP SDK version: \r\n<!-- Specify the output of the following shell command: $pip3 list | grep kfp -->\r\n```\r\nkfp 1.8.11\r\nkfp-pipeline-spec 0.1.13\r\nkfp-server-api 1.8.1\r\n```\r\n\r\n### Steps to reproduce\r\n\r\n<!--\r\nSpecify how to reproduce the problem. \r\nThis may include information such as: a description of the process, code snippets, log output, or screenshots.\r\n-->\r\nFollow the steps given in the following link to deploy `xgboost_training_cm.py` \r\nhttps://github.com/kubeflow/pipelines/tree/master/samples/core/xgboost_training_cm\r\n\r\n### Expected result\r\n\r\n<!-- What should the correct behavior be? -->\r\nThere shows an error with `dataproc-create-cluster` (the second block)\r\n```\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.7/runpy.py\", line 193, in _run_module_as_main\r\n \"__main__\", mod_spec)\r\n File \"/usr/local/lib/python3.7/runpy.py\", line 85, in _run_code\r\n exec(code, run_globals)\r\n File \"/ml/kfp_component/launcher/__main__.py\", line 45, in <module>\r\n main()\r\n File \"/ml/kfp_component/launcher/__main__.py\", line 42, in main\r\n launch(args.file_or_module, args.args)\r\n File \"/ml/kfp_component/launcher/launcher.py\", line 45, in launch\r\n return fire.Fire(module, command=args, name=module.__name__)\r\n File \"/usr/local/lib/python3.7/site-packages/fire/core.py\", line 127, in Fire\r\n component_trace = _Fire(component, args, context, name)\r\n File \"/usr/local/lib/python3.7/site-packages/fire/core.py\", line 366, in _Fire\r\n component, remaining_args)\r\n File \"/usr/local/lib/python3.7/site-packages/fire/core.py\", line 542, in _CallCallable\r\n result = fn(*varargs, **kwargs)\r\n File \"/ml/kfp_component/google/dataproc/_create_cluster.py\", line 76, in create_cluster\r\n client = DataprocClient()\r\n File \"/ml/kfp_component/google/common/_utils.py\", line 170, in __init__\r\n self._build_client()\r\nTypeError: _build_client() takes 0 positional arguments but 1 was given\r\n```\r\n\r\n### Materials and Reference\r\n\r\n<!-- Help us debug this issue by providing resources such as: sample code, background context, or links to references. -->\r\nN/A\r\n\r\n---\r\n\r\n<!-- Don't delete message below to encourage users to support your issue! -->\r\nImpacted by this bug? Give it a \ud83d\udc4d. We prioritise the issues with the most \ud83d\udc4d.\r\n\n", "before_files": [{"content": "# Copyright 2018 The Kubeflow Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport abc\nimport logging\nimport re\nimport os\nimport time\nfrom functools import wraps\nfrom typing import Any, Callable, Optional, Tuple\n\ndef normalize_name(name,\n valid_first_char_pattern='a-zA-Z',\n valid_char_pattern='0-9a-zA-Z_',\n invalid_char_placeholder='_',\n prefix_placeholder='x_'):\n \"\"\"Normalize a name to a valid resource name.\n\n Uses ``valid_first_char_pattern`` and ``valid_char_pattern`` regex pattern\n to find invalid characters from ``name`` and replaces them with \n ``invalid_char_placeholder`` or prefix the name with ``prefix_placeholder``.\n\n Args:\n name: The name to be normalized.\n valid_first_char_pattern: The regex pattern for the first character.\n valid_char_pattern: The regex pattern for all the characters in the name.\n invalid_char_placeholder: The placeholder to replace invalid characters.\n prefix_placeholder: The placeholder to prefix the name if the first char \n is invalid.\n \n Returns:\n The normalized name. Unchanged if all characters are valid.\n \"\"\"\n if not name:\n return name\n normalized_name = re.sub('[^{}]+'.format(valid_char_pattern), \n invalid_char_placeholder, name)\n if not re.match('[{}]'.format(valid_first_char_pattern), \n normalized_name[0]):\n normalized_name = prefix_placeholder + normalized_name\n if name != normalized_name:\n logging.info('Normalize name from \"{}\" to \"{}\".'.format(\n name, normalized_name))\n return normalized_name\n\ndef dump_file(path, content):\n \"\"\"Dumps string into local file.\n\n Args:\n path: the local path to the file.\n content: the string content to dump.\n \"\"\"\n directory = os.path.dirname(path)\n if not os.path.exists(directory):\n os.makedirs(directory)\n elif os.path.exists(path):\n logging.warning('The file {} will be overwritten.'.format(path))\n with open(path, 'w') as f:\n f.write(content)\n\ndef check_resource_changed(requested_resource, \n existing_resource, property_names):\n \"\"\"Check if a resource has been changed.\n\n The function checks requested resource with existing resource\n by comparing specified property names. Check fails if any property\n name in the list is in ``requested_resource`` but its value is\n different with the value in ``existing_resource``.\n\n Args:\n requested_resource: the user requested resource paylod.\n existing_resource: the existing resource payload from data storage.\n property_names: a list of property names.\n\n Return:\n True if ``requested_resource`` has been changed.\n \"\"\"\n for property_name in property_names:\n if not property_name in requested_resource:\n continue\n existing_value = existing_resource.get(property_name, None)\n if requested_resource[property_name] != existing_value:\n return True\n return False\n\ndef wait_operation_done(get_operation, wait_interval):\n \"\"\"Waits for an operation to be done.\n\n Args:\n get_operation: the name of the operation.\n wait_interval: the wait interview between pulling job\n status.\n\n Returns:\n The completed operation.\n \"\"\"\n while True:\n operation = get_operation()\n operation_name = operation.get('name')\n done = operation.get('done', False)\n if not done:\n logging.info('Operation {} is not done. Wait for {}s.'.format(\n operation_name, wait_interval))\n time.sleep(wait_interval)\n continue\n error = operation.get('error', None)\n if error:\n raise RuntimeError('Failed to complete operation {}: {} {}'.format(\n operation_name,\n error.get('code', 'Unknown code'),\n error.get('message', 'Unknown message'),\n ))\n return operation\n\n\ndef with_retries(\n func: Callable,\n on_error: Optional[Callable[[], Any]] = None,\n errors: Tuple[Exception, ...] = Exception,\n number_of_retries: int = 5,\n delay: float = 1,\n):\n \"\"\"Retry decorator.\n\n The decorator catches `errors`, calls `on_error` and retries after waiting `delay` seconds.\n\n Args:\n number_of_retries (int): Total number of retries if error is raised.\n delay (float): Number of seconds to wait between consecutive retries.\n \"\"\"\n\n @wraps(func)\n def wrapper(self, *args, **kwargs):\n remaining_retries = number_of_retries\n while remaining_retries:\n try:\n return func(self, *args, **kwargs)\n except errors as e:\n remaining_retries -= 1\n if not remaining_retries:\n raise\n\n logging.warning(\n 'Caught {}. Retrying in {} seconds...'.format(\n e.__class__.__name__, delay\n )\n )\n\n time.sleep(delay)\n if on_error:\n on_error()\n\n return wrapper\n\n\nclass ClientWithRetries:\n\n def __init__(self):\n self._build_client()\n for name, member in self.__dict__.items():\n if callable(member) and not name.startswith(\"_\"):\n self.__dict__[name] = with_retries(func=member, errors=(BrokenPipeError, IOError), on_error=self._build_client)\n\n @abc.abstractmethod\n def _build_client():\n raise NotImplementedError()\n", "path": "components/gcp/container/component_sdk/python/kfp_component/google/common/_utils.py"}]}
| 2,981 | 142 |
gh_patches_debug_32215
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-1633
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[RSA] Add functions to recover (p, q) given (n, e, d)
Right now we require (p, q, d, dmp1, dmq1, iqmp, e, n). We provide functions to generate the CRT coefficients, but they assume the user has p & q. To support other valid key material sources we need functions that recover p & q given (n, e, d).
The preferred algorithm to perform this task can be found in Appendix C of [SP-800-56B](http://csrc.nist.gov/publications/nistpubs/800-56B/sp800-56B.pdf).
[RSA] Add functions to recover (p, q) given (n, e, d)
Right now we require (p, q, d, dmp1, dmq1, iqmp, e, n). We provide functions to generate the CRT coefficients, but they assume the user has p & q. To support other valid key material sources we need functions that recover p & q given (n, e, d).
The preferred algorithm to perform this task can be found in Appendix C of [SP-800-56B](http://csrc.nist.gov/publications/nistpubs/800-56B/sp800-56B.pdf).
</issue>
<code>
[start of src/cryptography/hazmat/primitives/asymmetric/rsa.py]
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5 from __future__ import absolute_import, division, print_function
6
7 import six
8
9 from cryptography import utils
10 from cryptography.exceptions import UnsupportedAlgorithm, _Reasons
11 from cryptography.hazmat.backends.interfaces import RSABackend
12
13
14 def generate_private_key(public_exponent, key_size, backend):
15 if not isinstance(backend, RSABackend):
16 raise UnsupportedAlgorithm(
17 "Backend object does not implement RSABackend.",
18 _Reasons.BACKEND_MISSING_INTERFACE
19 )
20
21 _verify_rsa_parameters(public_exponent, key_size)
22 return backend.generate_rsa_private_key(public_exponent, key_size)
23
24
25 def _verify_rsa_parameters(public_exponent, key_size):
26 if public_exponent < 3:
27 raise ValueError("public_exponent must be >= 3.")
28
29 if public_exponent & 1 == 0:
30 raise ValueError("public_exponent must be odd.")
31
32 if key_size < 512:
33 raise ValueError("key_size must be at least 512-bits.")
34
35
36 def _check_private_key_components(p, q, private_exponent, dmp1, dmq1, iqmp,
37 public_exponent, modulus):
38 if modulus < 3:
39 raise ValueError("modulus must be >= 3.")
40
41 if p >= modulus:
42 raise ValueError("p must be < modulus.")
43
44 if q >= modulus:
45 raise ValueError("q must be < modulus.")
46
47 if dmp1 >= modulus:
48 raise ValueError("dmp1 must be < modulus.")
49
50 if dmq1 >= modulus:
51 raise ValueError("dmq1 must be < modulus.")
52
53 if iqmp >= modulus:
54 raise ValueError("iqmp must be < modulus.")
55
56 if private_exponent >= modulus:
57 raise ValueError("private_exponent must be < modulus.")
58
59 if public_exponent < 3 or public_exponent >= modulus:
60 raise ValueError("public_exponent must be >= 3 and < modulus.")
61
62 if public_exponent & 1 == 0:
63 raise ValueError("public_exponent must be odd.")
64
65 if dmp1 & 1 == 0:
66 raise ValueError("dmp1 must be odd.")
67
68 if dmq1 & 1 == 0:
69 raise ValueError("dmq1 must be odd.")
70
71 if p * q != modulus:
72 raise ValueError("p*q must equal modulus.")
73
74
75 def _check_public_key_components(e, n):
76 if n < 3:
77 raise ValueError("n must be >= 3.")
78
79 if e < 3 or e >= n:
80 raise ValueError("e must be >= 3 and < n.")
81
82 if e & 1 == 0:
83 raise ValueError("e must be odd.")
84
85
86 def _modinv(e, m):
87 """
88 Modular Multiplicative Inverse. Returns x such that: (x*e) mod m == 1
89 """
90 x1, y1, x2, y2 = 1, 0, 0, 1
91 a, b = e, m
92 while b > 0:
93 q, r = divmod(a, b)
94 xn, yn = x1 - q * x2, y1 - q * y2
95 a, b, x1, y1, x2, y2 = b, r, x2, y2, xn, yn
96 return x1 % m
97
98
99 def rsa_crt_iqmp(p, q):
100 """
101 Compute the CRT (q ** -1) % p value from RSA primes p and q.
102 """
103 return _modinv(q, p)
104
105
106 def rsa_crt_dmp1(private_exponent, p):
107 """
108 Compute the CRT private_exponent % (p - 1) value from the RSA
109 private_exponent and p.
110 """
111 return private_exponent % (p - 1)
112
113
114 def rsa_crt_dmq1(private_exponent, q):
115 """
116 Compute the CRT private_exponent % (q - 1) value from the RSA
117 private_exponent and q.
118 """
119 return private_exponent % (q - 1)
120
121
122 class RSAPrivateNumbers(object):
123 def __init__(self, p, q, d, dmp1, dmq1, iqmp,
124 public_numbers):
125 if (
126 not isinstance(p, six.integer_types) or
127 not isinstance(q, six.integer_types) or
128 not isinstance(d, six.integer_types) or
129 not isinstance(dmp1, six.integer_types) or
130 not isinstance(dmq1, six.integer_types) or
131 not isinstance(iqmp, six.integer_types)
132 ):
133 raise TypeError(
134 "RSAPrivateNumbers p, q, d, dmp1, dmq1, iqmp arguments must"
135 " all be an integers."
136 )
137
138 if not isinstance(public_numbers, RSAPublicNumbers):
139 raise TypeError(
140 "RSAPrivateNumbers public_numbers must be an RSAPublicNumbers"
141 " instance."
142 )
143
144 self._p = p
145 self._q = q
146 self._d = d
147 self._dmp1 = dmp1
148 self._dmq1 = dmq1
149 self._iqmp = iqmp
150 self._public_numbers = public_numbers
151
152 p = utils.read_only_property("_p")
153 q = utils.read_only_property("_q")
154 d = utils.read_only_property("_d")
155 dmp1 = utils.read_only_property("_dmp1")
156 dmq1 = utils.read_only_property("_dmq1")
157 iqmp = utils.read_only_property("_iqmp")
158 public_numbers = utils.read_only_property("_public_numbers")
159
160 def private_key(self, backend):
161 return backend.load_rsa_private_numbers(self)
162
163 def __eq__(self, other):
164 if not isinstance(other, RSAPrivateNumbers):
165 return NotImplemented
166
167 return (
168 self.p == other.p and
169 self.q == other.q and
170 self.d == other.d and
171 self.dmp1 == other.dmp1 and
172 self.dmq1 == other.dmq1 and
173 self.iqmp == other.iqmp and
174 self.public_numbers == other.public_numbers
175 )
176
177 def __ne__(self, other):
178 return not self == other
179
180
181 class RSAPublicNumbers(object):
182 def __init__(self, e, n):
183 if (
184 not isinstance(e, six.integer_types) or
185 not isinstance(n, six.integer_types)
186 ):
187 raise TypeError("RSAPublicNumbers arguments must be integers.")
188
189 self._e = e
190 self._n = n
191
192 e = utils.read_only_property("_e")
193 n = utils.read_only_property("_n")
194
195 def public_key(self, backend):
196 return backend.load_rsa_public_numbers(self)
197
198 def __repr__(self):
199 return "<RSAPublicNumbers(e={0}, n={1})>".format(self._e, self._n)
200
201 def __eq__(self, other):
202 if not isinstance(other, RSAPublicNumbers):
203 return NotImplemented
204
205 return self.e == other.e and self.n == other.n
206
207 def __ne__(self, other):
208 return not self == other
209
[end of src/cryptography/hazmat/primitives/asymmetric/rsa.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cryptography/hazmat/primitives/asymmetric/rsa.py b/src/cryptography/hazmat/primitives/asymmetric/rsa.py
--- a/src/cryptography/hazmat/primitives/asymmetric/rsa.py
+++ b/src/cryptography/hazmat/primitives/asymmetric/rsa.py
@@ -4,6 +4,8 @@
from __future__ import absolute_import, division, print_function
+from fractions import gcd
+
import six
from cryptography import utils
@@ -119,6 +121,55 @@
return private_exponent % (q - 1)
+# Controls the number of iterations rsa_recover_prime_factors will perform
+# to obtain the prime factors. Each iteration increments by 2 so the actual
+# maximum attempts is half this number.
+_MAX_RECOVERY_ATTEMPTS = 1000
+
+
+def rsa_recover_prime_factors(n, e, d):
+ """
+ Compute factors p and q from the private exponent d. We assume that n has
+ no more than two factors. This function is adapted from code in PyCrypto.
+ """
+ # See 8.2.2(i) in Handbook of Applied Cryptography.
+ ktot = d * e - 1
+ # The quantity d*e-1 is a multiple of phi(n), even,
+ # and can be represented as t*2^s.
+ t = ktot
+ while t % 2 == 0:
+ t = t // 2
+ # Cycle through all multiplicative inverses in Zn.
+ # The algorithm is non-deterministic, but there is a 50% chance
+ # any candidate a leads to successful factoring.
+ # See "Digitalized Signatures and Public Key Functions as Intractable
+ # as Factorization", M. Rabin, 1979
+ spotted = False
+ a = 2
+ while not spotted and a < _MAX_RECOVERY_ATTEMPTS:
+ k = t
+ # Cycle through all values a^{t*2^i}=a^k
+ while k < ktot:
+ cand = pow(a, k, n)
+ # Check if a^k is a non-trivial root of unity (mod n)
+ if cand != 1 and cand != (n - 1) and pow(cand, 2, n) == 1:
+ # We have found a number such that (cand-1)(cand+1)=0 (mod n).
+ # Either of the terms divides n.
+ p = gcd(cand + 1, n)
+ spotted = True
+ break
+ k *= 2
+ # This value was not any good... let's try another!
+ a += 2
+ if not spotted:
+ raise ValueError("Unable to compute factors p and q from exponent d.")
+ # Found !
+ q, r = divmod(n, p)
+ assert r == 0
+
+ return (p, q)
+
+
class RSAPrivateNumbers(object):
def __init__(self, p, q, d, dmp1, dmq1, iqmp,
public_numbers):
|
{"golden_diff": "diff --git a/src/cryptography/hazmat/primitives/asymmetric/rsa.py b/src/cryptography/hazmat/primitives/asymmetric/rsa.py\n--- a/src/cryptography/hazmat/primitives/asymmetric/rsa.py\n+++ b/src/cryptography/hazmat/primitives/asymmetric/rsa.py\n@@ -4,6 +4,8 @@\n \n from __future__ import absolute_import, division, print_function\n \n+from fractions import gcd\n+\n import six\n \n from cryptography import utils\n@@ -119,6 +121,55 @@\n return private_exponent % (q - 1)\n \n \n+# Controls the number of iterations rsa_recover_prime_factors will perform\n+# to obtain the prime factors. Each iteration increments by 2 so the actual\n+# maximum attempts is half this number.\n+_MAX_RECOVERY_ATTEMPTS = 1000\n+\n+\n+def rsa_recover_prime_factors(n, e, d):\n+ \"\"\"\n+ Compute factors p and q from the private exponent d. We assume that n has\n+ no more than two factors. This function is adapted from code in PyCrypto.\n+ \"\"\"\n+ # See 8.2.2(i) in Handbook of Applied Cryptography.\n+ ktot = d * e - 1\n+ # The quantity d*e-1 is a multiple of phi(n), even,\n+ # and can be represented as t*2^s.\n+ t = ktot\n+ while t % 2 == 0:\n+ t = t // 2\n+ # Cycle through all multiplicative inverses in Zn.\n+ # The algorithm is non-deterministic, but there is a 50% chance\n+ # any candidate a leads to successful factoring.\n+ # See \"Digitalized Signatures and Public Key Functions as Intractable\n+ # as Factorization\", M. Rabin, 1979\n+ spotted = False\n+ a = 2\n+ while not spotted and a < _MAX_RECOVERY_ATTEMPTS:\n+ k = t\n+ # Cycle through all values a^{t*2^i}=a^k\n+ while k < ktot:\n+ cand = pow(a, k, n)\n+ # Check if a^k is a non-trivial root of unity (mod n)\n+ if cand != 1 and cand != (n - 1) and pow(cand, 2, n) == 1:\n+ # We have found a number such that (cand-1)(cand+1)=0 (mod n).\n+ # Either of the terms divides n.\n+ p = gcd(cand + 1, n)\n+ spotted = True\n+ break\n+ k *= 2\n+ # This value was not any good... let's try another!\n+ a += 2\n+ if not spotted:\n+ raise ValueError(\"Unable to compute factors p and q from exponent d.\")\n+ # Found !\n+ q, r = divmod(n, p)\n+ assert r == 0\n+\n+ return (p, q)\n+\n+\n class RSAPrivateNumbers(object):\n def __init__(self, p, q, d, dmp1, dmq1, iqmp,\n public_numbers):\n", "issue": "[RSA] Add functions to recover (p, q) given (n, e, d)\nRight now we require (p, q, d, dmp1, dmq1, iqmp, e, n). We provide functions to generate the CRT coefficients, but they assume the user has p & q. To support other valid key material sources we need functions that recover p & q given (n, e, d).\n\nThe preferred algorithm to perform this task can be found in Appendix C of [SP-800-56B](http://csrc.nist.gov/publications/nistpubs/800-56B/sp800-56B.pdf).\n\n[RSA] Add functions to recover (p, q) given (n, e, d)\nRight now we require (p, q, d, dmp1, dmq1, iqmp, e, n). We provide functions to generate the CRT coefficients, but they assume the user has p & q. To support other valid key material sources we need functions that recover p & q given (n, e, d).\n\nThe preferred algorithm to perform this task can be found in Appendix C of [SP-800-56B](http://csrc.nist.gov/publications/nistpubs/800-56B/sp800-56B.pdf).\n\n", "before_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport six\n\nfrom cryptography import utils\nfrom cryptography.exceptions import UnsupportedAlgorithm, _Reasons\nfrom cryptography.hazmat.backends.interfaces import RSABackend\n\n\ndef generate_private_key(public_exponent, key_size, backend):\n if not isinstance(backend, RSABackend):\n raise UnsupportedAlgorithm(\n \"Backend object does not implement RSABackend.\",\n _Reasons.BACKEND_MISSING_INTERFACE\n )\n\n _verify_rsa_parameters(public_exponent, key_size)\n return backend.generate_rsa_private_key(public_exponent, key_size)\n\n\ndef _verify_rsa_parameters(public_exponent, key_size):\n if public_exponent < 3:\n raise ValueError(\"public_exponent must be >= 3.\")\n\n if public_exponent & 1 == 0:\n raise ValueError(\"public_exponent must be odd.\")\n\n if key_size < 512:\n raise ValueError(\"key_size must be at least 512-bits.\")\n\n\ndef _check_private_key_components(p, q, private_exponent, dmp1, dmq1, iqmp,\n public_exponent, modulus):\n if modulus < 3:\n raise ValueError(\"modulus must be >= 3.\")\n\n if p >= modulus:\n raise ValueError(\"p must be < modulus.\")\n\n if q >= modulus:\n raise ValueError(\"q must be < modulus.\")\n\n if dmp1 >= modulus:\n raise ValueError(\"dmp1 must be < modulus.\")\n\n if dmq1 >= modulus:\n raise ValueError(\"dmq1 must be < modulus.\")\n\n if iqmp >= modulus:\n raise ValueError(\"iqmp must be < modulus.\")\n\n if private_exponent >= modulus:\n raise ValueError(\"private_exponent must be < modulus.\")\n\n if public_exponent < 3 or public_exponent >= modulus:\n raise ValueError(\"public_exponent must be >= 3 and < modulus.\")\n\n if public_exponent & 1 == 0:\n raise ValueError(\"public_exponent must be odd.\")\n\n if dmp1 & 1 == 0:\n raise ValueError(\"dmp1 must be odd.\")\n\n if dmq1 & 1 == 0:\n raise ValueError(\"dmq1 must be odd.\")\n\n if p * q != modulus:\n raise ValueError(\"p*q must equal modulus.\")\n\n\ndef _check_public_key_components(e, n):\n if n < 3:\n raise ValueError(\"n must be >= 3.\")\n\n if e < 3 or e >= n:\n raise ValueError(\"e must be >= 3 and < n.\")\n\n if e & 1 == 0:\n raise ValueError(\"e must be odd.\")\n\n\ndef _modinv(e, m):\n \"\"\"\n Modular Multiplicative Inverse. Returns x such that: (x*e) mod m == 1\n \"\"\"\n x1, y1, x2, y2 = 1, 0, 0, 1\n a, b = e, m\n while b > 0:\n q, r = divmod(a, b)\n xn, yn = x1 - q * x2, y1 - q * y2\n a, b, x1, y1, x2, y2 = b, r, x2, y2, xn, yn\n return x1 % m\n\n\ndef rsa_crt_iqmp(p, q):\n \"\"\"\n Compute the CRT (q ** -1) % p value from RSA primes p and q.\n \"\"\"\n return _modinv(q, p)\n\n\ndef rsa_crt_dmp1(private_exponent, p):\n \"\"\"\n Compute the CRT private_exponent % (p - 1) value from the RSA\n private_exponent and p.\n \"\"\"\n return private_exponent % (p - 1)\n\n\ndef rsa_crt_dmq1(private_exponent, q):\n \"\"\"\n Compute the CRT private_exponent % (q - 1) value from the RSA\n private_exponent and q.\n \"\"\"\n return private_exponent % (q - 1)\n\n\nclass RSAPrivateNumbers(object):\n def __init__(self, p, q, d, dmp1, dmq1, iqmp,\n public_numbers):\n if (\n not isinstance(p, six.integer_types) or\n not isinstance(q, six.integer_types) or\n not isinstance(d, six.integer_types) or\n not isinstance(dmp1, six.integer_types) or\n not isinstance(dmq1, six.integer_types) or\n not isinstance(iqmp, six.integer_types)\n ):\n raise TypeError(\n \"RSAPrivateNumbers p, q, d, dmp1, dmq1, iqmp arguments must\"\n \" all be an integers.\"\n )\n\n if not isinstance(public_numbers, RSAPublicNumbers):\n raise TypeError(\n \"RSAPrivateNumbers public_numbers must be an RSAPublicNumbers\"\n \" instance.\"\n )\n\n self._p = p\n self._q = q\n self._d = d\n self._dmp1 = dmp1\n self._dmq1 = dmq1\n self._iqmp = iqmp\n self._public_numbers = public_numbers\n\n p = utils.read_only_property(\"_p\")\n q = utils.read_only_property(\"_q\")\n d = utils.read_only_property(\"_d\")\n dmp1 = utils.read_only_property(\"_dmp1\")\n dmq1 = utils.read_only_property(\"_dmq1\")\n iqmp = utils.read_only_property(\"_iqmp\")\n public_numbers = utils.read_only_property(\"_public_numbers\")\n\n def private_key(self, backend):\n return backend.load_rsa_private_numbers(self)\n\n def __eq__(self, other):\n if not isinstance(other, RSAPrivateNumbers):\n return NotImplemented\n\n return (\n self.p == other.p and\n self.q == other.q and\n self.d == other.d and\n self.dmp1 == other.dmp1 and\n self.dmq1 == other.dmq1 and\n self.iqmp == other.iqmp and\n self.public_numbers == other.public_numbers\n )\n\n def __ne__(self, other):\n return not self == other\n\n\nclass RSAPublicNumbers(object):\n def __init__(self, e, n):\n if (\n not isinstance(e, six.integer_types) or\n not isinstance(n, six.integer_types)\n ):\n raise TypeError(\"RSAPublicNumbers arguments must be integers.\")\n\n self._e = e\n self._n = n\n\n e = utils.read_only_property(\"_e\")\n n = utils.read_only_property(\"_n\")\n\n def public_key(self, backend):\n return backend.load_rsa_public_numbers(self)\n\n def __repr__(self):\n return \"<RSAPublicNumbers(e={0}, n={1})>\".format(self._e, self._n)\n\n def __eq__(self, other):\n if not isinstance(other, RSAPublicNumbers):\n return NotImplemented\n\n return self.e == other.e and self.n == other.n\n\n def __ne__(self, other):\n return not self == other\n", "path": "src/cryptography/hazmat/primitives/asymmetric/rsa.py"}]}
| 2,969 | 720 |
gh_patches_debug_4149
|
rasdani/github-patches
|
git_diff
|
netbox-community__netbox-14565
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Enable `ENFORCE_GLOBAL_UNIQUE` by default
### NetBox version
v3.6.6
### Feature type
Change to existing functionality
### Proposed functionality
Change the default value of the [`ENFORCE_GLOBAL_UNIQUE`](https://docs.netbox.dev/en/stable/configuration/miscellaneous/#enforce_global_unique) configuration parameter from false to true. This will enforce unique IP addressing within the global (non-VRF) table by default.
This change would affect only deployments without any configuration already defined.
Please use a :+1: or :-1: response below to indicate your support for/opposition to this proposed change.
### Use case
Enforcing unique IP space by default is more restrictive and thus safer than the current default. Obviously, the parameter can still be toggled as needed.
This change would also be consistent with the `enforce_unique` field on the VRF model, which defaults to True.
### Database changes
_No response_
### External dependencies
_No response_
</issue>
<code>
[start of netbox/netbox/config/parameters.py]
1 from django import forms
2 from django.contrib.postgres.forms import SimpleArrayField
3 from django.utils.translation import gettext_lazy as _
4
5
6 class ConfigParam:
7
8 def __init__(self, name, label, default, description='', field=None, field_kwargs=None):
9 self.name = name
10 self.label = label
11 self.default = default
12 self.field = field or forms.CharField
13 self.description = description
14 self.field_kwargs = field_kwargs or {}
15
16
17 PARAMS = (
18
19 # Banners
20 ConfigParam(
21 name='BANNER_LOGIN',
22 label=_('Login banner'),
23 default='',
24 description=_("Additional content to display on the login page"),
25 field_kwargs={
26 'widget': forms.Textarea(
27 attrs={'class': 'vLargeTextField'}
28 ),
29 },
30 ),
31 ConfigParam(
32 name='BANNER_MAINTENANCE',
33 label=_('Maintenance banner'),
34 default='NetBox is currently in maintenance mode. Functionality may be limited.',
35 description=_('Additional content to display when in maintenance mode'),
36 field_kwargs={
37 'widget': forms.Textarea(
38 attrs={'class': 'vLargeTextField'}
39 ),
40 },
41 ),
42 ConfigParam(
43 name='BANNER_TOP',
44 label=_('Top banner'),
45 default='',
46 description=_("Additional content to display at the top of every page"),
47 field_kwargs={
48 'widget': forms.Textarea(
49 attrs={'class': 'vLargeTextField'}
50 ),
51 },
52 ),
53 ConfigParam(
54 name='BANNER_BOTTOM',
55 label=_('Bottom banner'),
56 default='',
57 description=_("Additional content to display at the bottom of every page"),
58 field_kwargs={
59 'widget': forms.Textarea(
60 attrs={'class': 'vLargeTextField'}
61 ),
62 },
63 ),
64
65 # IPAM
66 ConfigParam(
67 name='ENFORCE_GLOBAL_UNIQUE',
68 label=_('Globally unique IP space'),
69 default=False,
70 description=_("Enforce unique IP addressing within the global table"),
71 field=forms.BooleanField
72 ),
73 ConfigParam(
74 name='PREFER_IPV4',
75 label=_('Prefer IPv4'),
76 default=False,
77 description=_("Prefer IPv4 addresses over IPv6"),
78 field=forms.BooleanField
79 ),
80
81 # Racks
82 ConfigParam(
83 name='RACK_ELEVATION_DEFAULT_UNIT_HEIGHT',
84 label=_('Rack unit height'),
85 default=22,
86 description=_("Default unit height for rendered rack elevations"),
87 field=forms.IntegerField
88 ),
89 ConfigParam(
90 name='RACK_ELEVATION_DEFAULT_UNIT_WIDTH',
91 label=_('Rack unit width'),
92 default=220,
93 description=_("Default unit width for rendered rack elevations"),
94 field=forms.IntegerField
95 ),
96
97 # Power
98 ConfigParam(
99 name='POWERFEED_DEFAULT_VOLTAGE',
100 label=_('Powerfeed voltage'),
101 default=120,
102 description=_("Default voltage for powerfeeds"),
103 field=forms.IntegerField
104 ),
105 ConfigParam(
106 name='POWERFEED_DEFAULT_AMPERAGE',
107 label=_('Powerfeed amperage'),
108 default=15,
109 description=_("Default amperage for powerfeeds"),
110 field=forms.IntegerField
111 ),
112 ConfigParam(
113 name='POWERFEED_DEFAULT_MAX_UTILIZATION',
114 label=_('Powerfeed max utilization'),
115 default=80,
116 description=_("Default max utilization for powerfeeds"),
117 field=forms.IntegerField
118 ),
119
120 # Security
121 ConfigParam(
122 name='ALLOWED_URL_SCHEMES',
123 label=_('Allowed URL schemes'),
124 default=(
125 'file', 'ftp', 'ftps', 'http', 'https', 'irc', 'mailto', 'sftp', 'ssh', 'tel', 'telnet', 'tftp', 'vnc',
126 'xmpp',
127 ),
128 description=_("Permitted schemes for URLs in user-provided content"),
129 field=SimpleArrayField,
130 field_kwargs={'base_field': forms.CharField()}
131 ),
132
133 # Pagination
134 ConfigParam(
135 name='PAGINATE_COUNT',
136 label=_('Default page size'),
137 default=50,
138 field=forms.IntegerField
139 ),
140 ConfigParam(
141 name='MAX_PAGE_SIZE',
142 label=_('Maximum page size'),
143 default=1000,
144 field=forms.IntegerField
145 ),
146
147 # Validation
148 ConfigParam(
149 name='CUSTOM_VALIDATORS',
150 label=_('Custom validators'),
151 default={},
152 description=_("Custom validation rules (JSON)"),
153 field=forms.JSONField,
154 field_kwargs={
155 'widget': forms.Textarea(),
156 },
157 ),
158 ConfigParam(
159 name='PROTECTION_RULES',
160 label=_('Protection rules'),
161 default={},
162 description=_("Deletion protection rules (JSON)"),
163 field=forms.JSONField,
164 field_kwargs={
165 'widget': forms.Textarea(),
166 },
167 ),
168
169 # User preferences
170 ConfigParam(
171 name='DEFAULT_USER_PREFERENCES',
172 label=_('Default preferences'),
173 default={},
174 description=_("Default preferences for new users"),
175 field=forms.JSONField
176 ),
177
178 # Miscellaneous
179 ConfigParam(
180 name='MAINTENANCE_MODE',
181 label=_('Maintenance mode'),
182 default=False,
183 description=_("Enable maintenance mode"),
184 field=forms.BooleanField
185 ),
186 ConfigParam(
187 name='GRAPHQL_ENABLED',
188 label=_('GraphQL enabled'),
189 default=True,
190 description=_("Enable the GraphQL API"),
191 field=forms.BooleanField
192 ),
193 ConfigParam(
194 name='CHANGELOG_RETENTION',
195 label=_('Changelog retention'),
196 default=90,
197 description=_("Days to retain changelog history (set to zero for unlimited)"),
198 field=forms.IntegerField
199 ),
200 ConfigParam(
201 name='JOB_RETENTION',
202 label=_('Job result retention'),
203 default=90,
204 description=_("Days to retain job result history (set to zero for unlimited)"),
205 field=forms.IntegerField
206 ),
207 ConfigParam(
208 name='MAPS_URL',
209 label=_('Maps URL'),
210 default='https://maps.google.com/?q=',
211 description=_("Base URL for mapping geographic locations")
212 ),
213
214 )
215
[end of netbox/netbox/config/parameters.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/netbox/netbox/config/parameters.py b/netbox/netbox/config/parameters.py
--- a/netbox/netbox/config/parameters.py
+++ b/netbox/netbox/config/parameters.py
@@ -66,7 +66,7 @@
ConfigParam(
name='ENFORCE_GLOBAL_UNIQUE',
label=_('Globally unique IP space'),
- default=False,
+ default=True,
description=_("Enforce unique IP addressing within the global table"),
field=forms.BooleanField
),
|
{"golden_diff": "diff --git a/netbox/netbox/config/parameters.py b/netbox/netbox/config/parameters.py\n--- a/netbox/netbox/config/parameters.py\n+++ b/netbox/netbox/config/parameters.py\n@@ -66,7 +66,7 @@\n ConfigParam(\n name='ENFORCE_GLOBAL_UNIQUE',\n label=_('Globally unique IP space'),\n- default=False,\n+ default=True,\n description=_(\"Enforce unique IP addressing within the global table\"),\n field=forms.BooleanField\n ),\n", "issue": "Enable `ENFORCE_GLOBAL_UNIQUE` by default\n### NetBox version\r\n\r\nv3.6.6\r\n\r\n### Feature type\r\n\r\nChange to existing functionality\r\n\r\n### Proposed functionality\r\n\r\nChange the default value of the [`ENFORCE_GLOBAL_UNIQUE`](https://docs.netbox.dev/en/stable/configuration/miscellaneous/#enforce_global_unique) configuration parameter from false to true. This will enforce unique IP addressing within the global (non-VRF) table by default.\r\n\r\nThis change would affect only deployments without any configuration already defined.\r\n\r\nPlease use a :+1: or :-1: response below to indicate your support for/opposition to this proposed change.\r\n\r\n### Use case\r\n\r\nEnforcing unique IP space by default is more restrictive and thus safer than the current default. Obviously, the parameter can still be toggled as needed.\r\n\r\nThis change would also be consistent with the `enforce_unique` field on the VRF model, which defaults to True.\r\n\r\n### Database changes\r\n\r\n_No response_\r\n\r\n### External dependencies\r\n\r\n_No response_\n", "before_files": [{"content": "from django import forms\nfrom django.contrib.postgres.forms import SimpleArrayField\nfrom django.utils.translation import gettext_lazy as _\n\n\nclass ConfigParam:\n\n def __init__(self, name, label, default, description='', field=None, field_kwargs=None):\n self.name = name\n self.label = label\n self.default = default\n self.field = field or forms.CharField\n self.description = description\n self.field_kwargs = field_kwargs or {}\n\n\nPARAMS = (\n\n # Banners\n ConfigParam(\n name='BANNER_LOGIN',\n label=_('Login banner'),\n default='',\n description=_(\"Additional content to display on the login page\"),\n field_kwargs={\n 'widget': forms.Textarea(\n attrs={'class': 'vLargeTextField'}\n ),\n },\n ),\n ConfigParam(\n name='BANNER_MAINTENANCE',\n label=_('Maintenance banner'),\n default='NetBox is currently in maintenance mode. Functionality may be limited.',\n description=_('Additional content to display when in maintenance mode'),\n field_kwargs={\n 'widget': forms.Textarea(\n attrs={'class': 'vLargeTextField'}\n ),\n },\n ),\n ConfigParam(\n name='BANNER_TOP',\n label=_('Top banner'),\n default='',\n description=_(\"Additional content to display at the top of every page\"),\n field_kwargs={\n 'widget': forms.Textarea(\n attrs={'class': 'vLargeTextField'}\n ),\n },\n ),\n ConfigParam(\n name='BANNER_BOTTOM',\n label=_('Bottom banner'),\n default='',\n description=_(\"Additional content to display at the bottom of every page\"),\n field_kwargs={\n 'widget': forms.Textarea(\n attrs={'class': 'vLargeTextField'}\n ),\n },\n ),\n\n # IPAM\n ConfigParam(\n name='ENFORCE_GLOBAL_UNIQUE',\n label=_('Globally unique IP space'),\n default=False,\n description=_(\"Enforce unique IP addressing within the global table\"),\n field=forms.BooleanField\n ),\n ConfigParam(\n name='PREFER_IPV4',\n label=_('Prefer IPv4'),\n default=False,\n description=_(\"Prefer IPv4 addresses over IPv6\"),\n field=forms.BooleanField\n ),\n\n # Racks\n ConfigParam(\n name='RACK_ELEVATION_DEFAULT_UNIT_HEIGHT',\n label=_('Rack unit height'),\n default=22,\n description=_(\"Default unit height for rendered rack elevations\"),\n field=forms.IntegerField\n ),\n ConfigParam(\n name='RACK_ELEVATION_DEFAULT_UNIT_WIDTH',\n label=_('Rack unit width'),\n default=220,\n description=_(\"Default unit width for rendered rack elevations\"),\n field=forms.IntegerField\n ),\n\n # Power\n ConfigParam(\n name='POWERFEED_DEFAULT_VOLTAGE',\n label=_('Powerfeed voltage'),\n default=120,\n description=_(\"Default voltage for powerfeeds\"),\n field=forms.IntegerField\n ),\n ConfigParam(\n name='POWERFEED_DEFAULT_AMPERAGE',\n label=_('Powerfeed amperage'),\n default=15,\n description=_(\"Default amperage for powerfeeds\"),\n field=forms.IntegerField\n ),\n ConfigParam(\n name='POWERFEED_DEFAULT_MAX_UTILIZATION',\n label=_('Powerfeed max utilization'),\n default=80,\n description=_(\"Default max utilization for powerfeeds\"),\n field=forms.IntegerField\n ),\n\n # Security\n ConfigParam(\n name='ALLOWED_URL_SCHEMES',\n label=_('Allowed URL schemes'),\n default=(\n 'file', 'ftp', 'ftps', 'http', 'https', 'irc', 'mailto', 'sftp', 'ssh', 'tel', 'telnet', 'tftp', 'vnc',\n 'xmpp',\n ),\n description=_(\"Permitted schemes for URLs in user-provided content\"),\n field=SimpleArrayField,\n field_kwargs={'base_field': forms.CharField()}\n ),\n\n # Pagination\n ConfigParam(\n name='PAGINATE_COUNT',\n label=_('Default page size'),\n default=50,\n field=forms.IntegerField\n ),\n ConfigParam(\n name='MAX_PAGE_SIZE',\n label=_('Maximum page size'),\n default=1000,\n field=forms.IntegerField\n ),\n\n # Validation\n ConfigParam(\n name='CUSTOM_VALIDATORS',\n label=_('Custom validators'),\n default={},\n description=_(\"Custom validation rules (JSON)\"),\n field=forms.JSONField,\n field_kwargs={\n 'widget': forms.Textarea(),\n },\n ),\n ConfigParam(\n name='PROTECTION_RULES',\n label=_('Protection rules'),\n default={},\n description=_(\"Deletion protection rules (JSON)\"),\n field=forms.JSONField,\n field_kwargs={\n 'widget': forms.Textarea(),\n },\n ),\n\n # User preferences\n ConfigParam(\n name='DEFAULT_USER_PREFERENCES',\n label=_('Default preferences'),\n default={},\n description=_(\"Default preferences for new users\"),\n field=forms.JSONField\n ),\n\n # Miscellaneous\n ConfigParam(\n name='MAINTENANCE_MODE',\n label=_('Maintenance mode'),\n default=False,\n description=_(\"Enable maintenance mode\"),\n field=forms.BooleanField\n ),\n ConfigParam(\n name='GRAPHQL_ENABLED',\n label=_('GraphQL enabled'),\n default=True,\n description=_(\"Enable the GraphQL API\"),\n field=forms.BooleanField\n ),\n ConfigParam(\n name='CHANGELOG_RETENTION',\n label=_('Changelog retention'),\n default=90,\n description=_(\"Days to retain changelog history (set to zero for unlimited)\"),\n field=forms.IntegerField\n ),\n ConfigParam(\n name='JOB_RETENTION',\n label=_('Job result retention'),\n default=90,\n description=_(\"Days to retain job result history (set to zero for unlimited)\"),\n field=forms.IntegerField\n ),\n ConfigParam(\n name='MAPS_URL',\n label=_('Maps URL'),\n default='https://maps.google.com/?q=',\n description=_(\"Base URL for mapping geographic locations\")\n ),\n\n)\n", "path": "netbox/netbox/config/parameters.py"}]}
| 2,551 | 108 |
gh_patches_debug_42600
|
rasdani/github-patches
|
git_diff
|
pyro-ppl__pyro-145
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Provide default implementation of batch_log_pdf
Could we provide a default implementation of `batch_log_pdf` as a simple for loop?
```py
class Distribution(object):
...
def batch_log_pdf(self, x, batch_size, *args, **kwargs):
result = torch.Tensor([batch_size])
for i in range(batch_size):
result[i] = self.log_pdf(x[i], *args, **kwargs)
return torch.autograd.Variable(result) # Caller decides whether to .sum().
```
Or do we want to instead implement correct handling of `NotImplementedError`s everywhere `batch_log_pdf` is used?
Disclaimer: I don't understand what `batch_log_pdf` does, and there is no docstring.
Edited to not sum the result.
</issue>
<code>
[start of pyro/distributions/distribution.py]
1 class Distribution(object):
2 """
3 Distribution abstract base class
4 """
5
6 def __init__(self, *args, **kwargs):
7 """
8 Constructor for base distribution class.
9
10 Currently takes no explicit arguments.
11 """
12 self.reparameterized = False
13
14 def __call__(self, *args, **kwargs):
15 """
16 Samples on call
17 """
18 return self.sample(*args, **kwargs)
19
20 def sample(self, *args, **kwargs):
21 """
22 Virtual sample method.
23 """
24 raise NotImplementedError()
25
26 def log_pdf(self, x):
27 raise NotImplementedError()
28
29 def batch_log_pdf(self, x, batch_size):
30 raise NotImplementedError()
31
32 def support(self):
33 raise NotImplementedError("Support not supported for {}".format(str(type(self))))
34
35 def analytic_mean(self, *args, **kwargs):
36 """
37 Analytic mean of the distribution, to be implemented by derived classes.
38 Note that this is optional, and currently only used for testing distributions.
39 :return: Analytic mean, assuming it can be computed analytically given the distribution parameters
40 :rtype: torch.autograd.Variable.
41 """
42 raise NotImplementedError("Method not implemented by the subclass {}".format(str(type(self))))
43
44 def analytic_var(self, *args, **kwargs):
45 """
46 Analytic variance of the distribution, to be implemented by derived classes.
47 Note that this is optional, and currently only used for testing distributions.
48 :return: Analytic variance, assuming it can be computed analytically given the distribution parameters
49 :rtype: torch.autograd.Variable.
50 """
51 raise NotImplementedError("Method not implemented by the subclass {}".format(str(type(self))))
52
[end of pyro/distributions/distribution.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pyro/distributions/distribution.py b/pyro/distributions/distribution.py
--- a/pyro/distributions/distribution.py
+++ b/pyro/distributions/distribution.py
@@ -1,6 +1,17 @@
+import torch
+
+
class Distribution(object):
"""
- Distribution abstract base class
+ Abstract base class for probability distributions.
+
+ Instances can either be constructed from a fixed parameter and called without paramters,
+ or constructed without a parameter and called with a paramter.
+ It is not allowed to specify a parameter both during construction and when calling.
+ When calling with a parameter, it is preferred to use one of the singleton instances
+ in pyro.distributions rather than constructing a new instance without a parameter.
+
+ Derived classes must implement the `sample`, and `batch_log_pdf` methods.
"""
def __init__(self, *args, **kwargs):
@@ -13,39 +24,69 @@
def __call__(self, *args, **kwargs):
"""
- Samples on call
+ Samples a random value.
+
+ :return: A random value.
+ :rtype: torch.autograd.Variable
"""
return self.sample(*args, **kwargs)
def sample(self, *args, **kwargs):
"""
- Virtual sample method.
+ Samples a random value.
+
+ :return: A random value.
+ :rtype: torch.autograd.Variable
"""
- raise NotImplementedError()
+ raise NotImplementedError
- def log_pdf(self, x):
- raise NotImplementedError()
+ def log_pdf(self, x, *args, **kwargs):
+ """
+ Evaluates total log probability density for one or a batch of samples and parameters.
- def batch_log_pdf(self, x, batch_size):
- raise NotImplementedError()
+ :param torch.autograd.Variable x: A value.
+ :return: total log probability density as a one-dimensional torch.autograd.Variable of size 1.
+ :rtype: torch.autograd.Variable
+ """
+ return torch.sum(self.batch_log_pdf(x, *args, **kwargs))
- def support(self):
- raise NotImplementedError("Support not supported for {}".format(str(type(self))))
+ def batch_log_pdf(self, x, *args, **kwargs):
+ """
+ Evaluates log probability densities for one or a batch of samples and parameters.
+
+ :param torch.autograd.Variable x: A single value or a batch of values batched along axis 0.
+ :return: log probability densities as a one-dimensional torch.autograd.Variable.
+ :rtype: torch.autograd.Variable
+ """
+ raise NotImplementedError
+
+ def support(self, *args, **kwargs):
+ """
+ Returns a representation of the distribution's support.
+
+ :return: A representation of the distribution's support.
+ :rtype: torch.Tensor
+ """
+ raise NotImplementedError("Support not implemented for {}".format(type(self)))
def analytic_mean(self, *args, **kwargs):
"""
Analytic mean of the distribution, to be implemented by derived classes.
+
Note that this is optional, and currently only used for testing distributions.
+
:return: Analytic mean, assuming it can be computed analytically given the distribution parameters
:rtype: torch.autograd.Variable.
"""
- raise NotImplementedError("Method not implemented by the subclass {}".format(str(type(self))))
+ raise NotImplementedError("Method not implemented by the subclass {}".format(type(self)))
def analytic_var(self, *args, **kwargs):
"""
Analytic variance of the distribution, to be implemented by derived classes.
+
Note that this is optional, and currently only used for testing distributions.
+
:return: Analytic variance, assuming it can be computed analytically given the distribution parameters
:rtype: torch.autograd.Variable.
"""
- raise NotImplementedError("Method not implemented by the subclass {}".format(str(type(self))))
+ raise NotImplementedError("Method not implemented by the subclass {}".format(type(self)))
|
{"golden_diff": "diff --git a/pyro/distributions/distribution.py b/pyro/distributions/distribution.py\n--- a/pyro/distributions/distribution.py\n+++ b/pyro/distributions/distribution.py\n@@ -1,6 +1,17 @@\n+import torch\n+\n+\n class Distribution(object):\n \"\"\"\n- Distribution abstract base class\n+ Abstract base class for probability distributions.\n+\n+ Instances can either be constructed from a fixed parameter and called without paramters,\n+ or constructed without a parameter and called with a paramter.\n+ It is not allowed to specify a parameter both during construction and when calling.\n+ When calling with a parameter, it is preferred to use one of the singleton instances\n+ in pyro.distributions rather than constructing a new instance without a parameter.\n+\n+ Derived classes must implement the `sample`, and `batch_log_pdf` methods.\n \"\"\"\n \n def __init__(self, *args, **kwargs):\n@@ -13,39 +24,69 @@\n \n def __call__(self, *args, **kwargs):\n \"\"\"\n- Samples on call\n+ Samples a random value.\n+\n+ :return: A random value.\n+ :rtype: torch.autograd.Variable\n \"\"\"\n return self.sample(*args, **kwargs)\n \n def sample(self, *args, **kwargs):\n \"\"\"\n- Virtual sample method.\n+ Samples a random value.\n+\n+ :return: A random value.\n+ :rtype: torch.autograd.Variable\n \"\"\"\n- raise NotImplementedError()\n+ raise NotImplementedError\n \n- def log_pdf(self, x):\n- raise NotImplementedError()\n+ def log_pdf(self, x, *args, **kwargs):\n+ \"\"\"\n+ Evaluates total log probability density for one or a batch of samples and parameters.\n \n- def batch_log_pdf(self, x, batch_size):\n- raise NotImplementedError()\n+ :param torch.autograd.Variable x: A value.\n+ :return: total log probability density as a one-dimensional torch.autograd.Variable of size 1.\n+ :rtype: torch.autograd.Variable\n+ \"\"\"\n+ return torch.sum(self.batch_log_pdf(x, *args, **kwargs))\n \n- def support(self):\n- raise NotImplementedError(\"Support not supported for {}\".format(str(type(self))))\n+ def batch_log_pdf(self, x, *args, **kwargs):\n+ \"\"\"\n+ Evaluates log probability densities for one or a batch of samples and parameters.\n+\n+ :param torch.autograd.Variable x: A single value or a batch of values batched along axis 0.\n+ :return: log probability densities as a one-dimensional torch.autograd.Variable.\n+ :rtype: torch.autograd.Variable\n+ \"\"\"\n+ raise NotImplementedError\n+\n+ def support(self, *args, **kwargs):\n+ \"\"\"\n+ Returns a representation of the distribution's support.\n+\n+ :return: A representation of the distribution's support.\n+ :rtype: torch.Tensor\n+ \"\"\"\n+ raise NotImplementedError(\"Support not implemented for {}\".format(type(self)))\n \n def analytic_mean(self, *args, **kwargs):\n \"\"\"\n Analytic mean of the distribution, to be implemented by derived classes.\n+\n Note that this is optional, and currently only used for testing distributions.\n+\n :return: Analytic mean, assuming it can be computed analytically given the distribution parameters\n :rtype: torch.autograd.Variable.\n \"\"\"\n- raise NotImplementedError(\"Method not implemented by the subclass {}\".format(str(type(self))))\n+ raise NotImplementedError(\"Method not implemented by the subclass {}\".format(type(self)))\n \n def analytic_var(self, *args, **kwargs):\n \"\"\"\n Analytic variance of the distribution, to be implemented by derived classes.\n+\n Note that this is optional, and currently only used for testing distributions.\n+\n :return: Analytic variance, assuming it can be computed analytically given the distribution parameters\n :rtype: torch.autograd.Variable.\n \"\"\"\n- raise NotImplementedError(\"Method not implemented by the subclass {}\".format(str(type(self))))\n+ raise NotImplementedError(\"Method not implemented by the subclass {}\".format(type(self)))\n", "issue": "Provide default implementation of batch_log_pdf\nCould we provide a default implementation of `batch_log_pdf` as a simple for loop?\r\n```py\r\nclass Distribution(object):\r\n ...\r\n def batch_log_pdf(self, x, batch_size, *args, **kwargs):\r\n result = torch.Tensor([batch_size])\r\n for i in range(batch_size):\r\n result[i] = self.log_pdf(x[i], *args, **kwargs)\r\n return torch.autograd.Variable(result) # Caller decides whether to .sum().\r\n```\r\nOr do we want to instead implement correct handling of `NotImplementedError`s everywhere `batch_log_pdf` is used?\r\n\r\nDisclaimer: I don't understand what `batch_log_pdf` does, and there is no docstring.\r\n\r\nEdited to not sum the result.\n", "before_files": [{"content": "class Distribution(object):\n \"\"\"\n Distribution abstract base class\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n \"\"\"\n Constructor for base distribution class.\n\n Currently takes no explicit arguments.\n \"\"\"\n self.reparameterized = False\n\n def __call__(self, *args, **kwargs):\n \"\"\"\n Samples on call\n \"\"\"\n return self.sample(*args, **kwargs)\n\n def sample(self, *args, **kwargs):\n \"\"\"\n Virtual sample method.\n \"\"\"\n raise NotImplementedError()\n\n def log_pdf(self, x):\n raise NotImplementedError()\n\n def batch_log_pdf(self, x, batch_size):\n raise NotImplementedError()\n\n def support(self):\n raise NotImplementedError(\"Support not supported for {}\".format(str(type(self))))\n\n def analytic_mean(self, *args, **kwargs):\n \"\"\"\n Analytic mean of the distribution, to be implemented by derived classes.\n Note that this is optional, and currently only used for testing distributions.\n :return: Analytic mean, assuming it can be computed analytically given the distribution parameters\n :rtype: torch.autograd.Variable.\n \"\"\"\n raise NotImplementedError(\"Method not implemented by the subclass {}\".format(str(type(self))))\n\n def analytic_var(self, *args, **kwargs):\n \"\"\"\n Analytic variance of the distribution, to be implemented by derived classes.\n Note that this is optional, and currently only used for testing distributions.\n :return: Analytic variance, assuming it can be computed analytically given the distribution parameters\n :rtype: torch.autograd.Variable.\n \"\"\"\n raise NotImplementedError(\"Method not implemented by the subclass {}\".format(str(type(self))))\n", "path": "pyro/distributions/distribution.py"}]}
| 1,143 | 876 |
gh_patches_debug_32842
|
rasdani/github-patches
|
git_diff
|
TheAlgorithms__Python-9069
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Delete base85 algorithm
### Describe your change:
Re #6216
Normally, I'm not in favour of just deleting algorithms, but I would make the argument that this is not an algorithm, rather just a snippet of code that utilises another library.
Per `CONTRIBTUING.md`
> Algorithms in this repo should not be how-to examples for existing Python packages. Instead, they should perform internal calculations or manipulations to convert input values into different output values
This `base85` algorithm has essentially got two lines of code that purely utilise a singular library. The doctests only test an external library
This repository should not contains examples on how to use a certain library, that would be the library documentation here
https://docs.python.org/3/library/base64.html
* [ ] Add an algorithm?
* [ ] Fix a bug or typo in an existing algorithm?
* [ ] Documentation change?
* [x] Delete an algorithm
### Checklist:
* [x] I have read [CONTRIBUTING.md](https://github.com/TheAlgorithms/Python/blob/master/CONTRIBUTING.md).
* [x] This pull request is all my own work -- I have not plagiarized.
* [x] I know that pull requests will not be merged if they fail the automated tests.
* [x] This PR only changes one algorithm file. To ease review, please open separate PRs for separate algorithms.
* [x] All new Python files are placed inside an existing directory.
* [x] All filenames are in all lowercase characters with no spaces or dashes.
* [x] All functions and variable names follow Python naming conventions.
* [x] All function parameters and return values are annotated with Python [type hints](https://docs.python.org/3/library/typing.html).
* [x] All functions have [doctests](https://docs.python.org/3/library/doctest.html) that pass the automated testing.
* [x] All new algorithms include at least one URL that points to Wikipedia or another similar explanation.
* [x] If this pull request resolves one or more open issues then the description above includes the issue number(s) with a [closing keyword](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue): "Fixes #ISSUE-NUMBER".
</issue>
<code>
[start of ciphers/base85.py]
1 import base64
2
3
4 def base85_encode(string: str) -> bytes:
5 """
6 >>> base85_encode("")
7 b''
8 >>> base85_encode("12345")
9 b'0etOA2#'
10 >>> base85_encode("base 85")
11 b'@UX=h+?24'
12 """
13 # encoded the input to a bytes-like object and then a85encode that
14 return base64.a85encode(string.encode("utf-8"))
15
16
17 def base85_decode(a85encoded: bytes) -> str:
18 """
19 >>> base85_decode(b"")
20 ''
21 >>> base85_decode(b"0etOA2#")
22 '12345'
23 >>> base85_decode(b"@UX=h+?24")
24 'base 85'
25 """
26 # a85decode the input into bytes and decode that into a human readable string
27 return base64.a85decode(a85encoded).decode("utf-8")
28
29
30 if __name__ == "__main__":
31 import doctest
32
33 doctest.testmod()
34
[end of ciphers/base85.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ciphers/base85.py b/ciphers/base85.py
--- a/ciphers/base85.py
+++ b/ciphers/base85.py
@@ -1,30 +1,55 @@
-import base64
+"""
+Base85 (Ascii85) encoding and decoding
+https://en.wikipedia.org/wiki/Ascii85
+"""
-def base85_encode(string: str) -> bytes:
+
+def _base10_to_85(d: int) -> str:
+ return "".join(chr(d % 85 + 33)) + _base10_to_85(d // 85) if d > 0 else ""
+
+
+def _base85_to_10(digits: list) -> int:
+ return sum(char * 85**i for i, char in enumerate(reversed(digits)))
+
+
+def ascii85_encode(data: bytes) -> bytes:
"""
- >>> base85_encode("")
+ >>> ascii85_encode(b"")
b''
- >>> base85_encode("12345")
+ >>> ascii85_encode(b"12345")
b'0etOA2#'
- >>> base85_encode("base 85")
+ >>> ascii85_encode(b"base 85")
b'@UX=h+?24'
"""
- # encoded the input to a bytes-like object and then a85encode that
- return base64.a85encode(string.encode("utf-8"))
+ binary_data = "".join(bin(ord(d))[2:].zfill(8) for d in data.decode("utf-8"))
+ null_values = (32 * ((len(binary_data) // 32) + 1) - len(binary_data)) // 8
+ binary_data = binary_data.ljust(32 * ((len(binary_data) // 32) + 1), "0")
+ b85_chunks = [int(_s, 2) for _s in map("".join, zip(*[iter(binary_data)] * 32))]
+ result = "".join(_base10_to_85(chunk)[::-1] for chunk in b85_chunks)
+ return bytes(result[:-null_values] if null_values % 4 != 0 else result, "utf-8")
-def base85_decode(a85encoded: bytes) -> str:
+def ascii85_decode(data: bytes) -> bytes:
"""
- >>> base85_decode(b"")
- ''
- >>> base85_decode(b"0etOA2#")
- '12345'
- >>> base85_decode(b"@UX=h+?24")
- 'base 85'
+ >>> ascii85_decode(b"")
+ b''
+ >>> ascii85_decode(b"0etOA2#")
+ b'12345'
+ >>> ascii85_decode(b"@UX=h+?24")
+ b'base 85'
"""
- # a85decode the input into bytes and decode that into a human readable string
- return base64.a85decode(a85encoded).decode("utf-8")
+ null_values = 5 * ((len(data) // 5) + 1) - len(data)
+ binary_data = data.decode("utf-8") + "u" * null_values
+ b85_chunks = map("".join, zip(*[iter(binary_data)] * 5))
+ b85_segments = [[ord(_s) - 33 for _s in chunk] for chunk in b85_chunks]
+ results = [bin(_base85_to_10(chunk))[2::].zfill(32) for chunk in b85_segments]
+ char_chunks = [
+ [chr(int(_s, 2)) for _s in map("".join, zip(*[iter(r)] * 8))] for r in results
+ ]
+ result = "".join("".join(char) for char in char_chunks)
+ offset = int(null_values % 5 == 0)
+ return bytes(result[: offset - null_values], "utf-8")
if __name__ == "__main__":
|
{"golden_diff": "diff --git a/ciphers/base85.py b/ciphers/base85.py\n--- a/ciphers/base85.py\n+++ b/ciphers/base85.py\n@@ -1,30 +1,55 @@\n-import base64\n+\"\"\"\n+Base85 (Ascii85) encoding and decoding\n \n+https://en.wikipedia.org/wiki/Ascii85\n+\"\"\"\n \n-def base85_encode(string: str) -> bytes:\n+\n+def _base10_to_85(d: int) -> str:\n+ return \"\".join(chr(d % 85 + 33)) + _base10_to_85(d // 85) if d > 0 else \"\"\n+\n+\n+def _base85_to_10(digits: list) -> int:\n+ return sum(char * 85**i for i, char in enumerate(reversed(digits)))\n+\n+\n+def ascii85_encode(data: bytes) -> bytes:\n \"\"\"\n- >>> base85_encode(\"\")\n+ >>> ascii85_encode(b\"\")\n b''\n- >>> base85_encode(\"12345\")\n+ >>> ascii85_encode(b\"12345\")\n b'0etOA2#'\n- >>> base85_encode(\"base 85\")\n+ >>> ascii85_encode(b\"base 85\")\n b'@UX=h+?24'\n \"\"\"\n- # encoded the input to a bytes-like object and then a85encode that\n- return base64.a85encode(string.encode(\"utf-8\"))\n+ binary_data = \"\".join(bin(ord(d))[2:].zfill(8) for d in data.decode(\"utf-8\"))\n+ null_values = (32 * ((len(binary_data) // 32) + 1) - len(binary_data)) // 8\n+ binary_data = binary_data.ljust(32 * ((len(binary_data) // 32) + 1), \"0\")\n+ b85_chunks = [int(_s, 2) for _s in map(\"\".join, zip(*[iter(binary_data)] * 32))]\n+ result = \"\".join(_base10_to_85(chunk)[::-1] for chunk in b85_chunks)\n+ return bytes(result[:-null_values] if null_values % 4 != 0 else result, \"utf-8\")\n \n \n-def base85_decode(a85encoded: bytes) -> str:\n+def ascii85_decode(data: bytes) -> bytes:\n \"\"\"\n- >>> base85_decode(b\"\")\n- ''\n- >>> base85_decode(b\"0etOA2#\")\n- '12345'\n- >>> base85_decode(b\"@UX=h+?24\")\n- 'base 85'\n+ >>> ascii85_decode(b\"\")\n+ b''\n+ >>> ascii85_decode(b\"0etOA2#\")\n+ b'12345'\n+ >>> ascii85_decode(b\"@UX=h+?24\")\n+ b'base 85'\n \"\"\"\n- # a85decode the input into bytes and decode that into a human readable string\n- return base64.a85decode(a85encoded).decode(\"utf-8\")\n+ null_values = 5 * ((len(data) // 5) + 1) - len(data)\n+ binary_data = data.decode(\"utf-8\") + \"u\" * null_values\n+ b85_chunks = map(\"\".join, zip(*[iter(binary_data)] * 5))\n+ b85_segments = [[ord(_s) - 33 for _s in chunk] for chunk in b85_chunks]\n+ results = [bin(_base85_to_10(chunk))[2::].zfill(32) for chunk in b85_segments]\n+ char_chunks = [\n+ [chr(int(_s, 2)) for _s in map(\"\".join, zip(*[iter(r)] * 8))] for r in results\n+ ]\n+ result = \"\".join(\"\".join(char) for char in char_chunks)\n+ offset = int(null_values % 5 == 0)\n+ return bytes(result[: offset - null_values], \"utf-8\")\n \n \n if __name__ == \"__main__\":\n", "issue": "Delete base85 algorithm\n### Describe your change:\r\nRe #6216\r\n\r\nNormally, I'm not in favour of just deleting algorithms, but I would make the argument that this is not an algorithm, rather just a snippet of code that utilises another library.\r\n\r\nPer `CONTRIBTUING.md`\r\n> Algorithms in this repo should not be how-to examples for existing Python packages. Instead, they should perform internal calculations or manipulations to convert input values into different output values\r\nThis `base85` algorithm has essentially got two lines of code that purely utilise a singular library. The doctests only test an external library\r\n\r\nThis repository should not contains examples on how to use a certain library, that would be the library documentation here\r\nhttps://docs.python.org/3/library/base64.html\r\n\r\n\r\n* [ ] Add an algorithm?\r\n* [ ] Fix a bug or typo in an existing algorithm?\r\n* [ ] Documentation change?\r\n* [x] Delete an algorithm\r\n\r\n### Checklist:\r\n* [x] I have read [CONTRIBUTING.md](https://github.com/TheAlgorithms/Python/blob/master/CONTRIBUTING.md).\r\n* [x] This pull request is all my own work -- I have not plagiarized.\r\n* [x] I know that pull requests will not be merged if they fail the automated tests.\r\n* [x] This PR only changes one algorithm file. To ease review, please open separate PRs for separate algorithms.\r\n* [x] All new Python files are placed inside an existing directory.\r\n* [x] All filenames are in all lowercase characters with no spaces or dashes.\r\n* [x] All functions and variable names follow Python naming conventions.\r\n* [x] All function parameters and return values are annotated with Python [type hints](https://docs.python.org/3/library/typing.html).\r\n* [x] All functions have [doctests](https://docs.python.org/3/library/doctest.html) that pass the automated testing.\r\n* [x] All new algorithms include at least one URL that points to Wikipedia or another similar explanation.\r\n* [x] If this pull request resolves one or more open issues then the description above includes the issue number(s) with a [closing keyword](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue): \"Fixes #ISSUE-NUMBER\".\r\n\n", "before_files": [{"content": "import base64\n\n\ndef base85_encode(string: str) -> bytes:\n \"\"\"\n >>> base85_encode(\"\")\n b''\n >>> base85_encode(\"12345\")\n b'0etOA2#'\n >>> base85_encode(\"base 85\")\n b'@UX=h+?24'\n \"\"\"\n # encoded the input to a bytes-like object and then a85encode that\n return base64.a85encode(string.encode(\"utf-8\"))\n\n\ndef base85_decode(a85encoded: bytes) -> str:\n \"\"\"\n >>> base85_decode(b\"\")\n ''\n >>> base85_decode(b\"0etOA2#\")\n '12345'\n >>> base85_decode(b\"@UX=h+?24\")\n 'base 85'\n \"\"\"\n # a85decode the input into bytes and decode that into a human readable string\n return base64.a85decode(a85encoded).decode(\"utf-8\")\n\n\nif __name__ == \"__main__\":\n import doctest\n\n doctest.testmod()\n", "path": "ciphers/base85.py"}]}
| 1,337 | 951 |
gh_patches_debug_28897
|
rasdani/github-patches
|
git_diff
|
privacyidea__privacyidea-2663
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Database migration fails if the URI contains '%' signs
If the `SQLALCHEMY_DATABASE_URI` contains query parameters like `ssl_ca=/path/to/cert` the path separators will be url-encoded with `%` signs.
This fails when passing the URI to the alembic configuration (https://alembic.sqlalchemy.org/en/latest/api/config.html#alembic.config.Config.set_main_option).
The `%` signs should be escaped in the URI string before passing it to alembic.
</issue>
<code>
[start of migrations/env.py]
1 from __future__ import with_statement
2 from alembic import context
3 from sqlalchemy import engine_from_config, pool
4 from sqlalchemy.engine.url import make_url
5 from logging.config import fileConfig
6
7 # this is the Alembic Config object, which provides
8 # access to the values within the .ini file in use.
9
10 config = context.config
11
12 # Interpret the config file for Python logging.
13 # This line sets up loggers basically.
14 fileConfig(config.config_file_name)
15
16 # add your model's MetaData object here
17 # for 'autogenerate' support
18 # from myapp import mymodel
19 # target_metadata = mymodel.Base.metadata
20 from flask import current_app
21
22
23 def set_database_url(config):
24 url = current_app.config.get('SQLALCHEMY_DATABASE_URI')
25 try:
26 # In case of MySQL, add ``charset=utf8`` to the parameters (if no charset is set),
27 # because this is what Flask-SQLAlchemy does
28 if url.startswith("mysql"):
29 parsed_url = make_url(url)
30 parsed_url.query.setdefault("charset", "utf8")
31 url = str(parsed_url)
32 except Exception as exx:
33 print(u"Attempted to set charset=utf8 on connection, but failed: {}".format(exx))
34 config.set_main_option('sqlalchemy.url', url)
35
36
37 set_database_url(config)
38 target_metadata = current_app.extensions['migrate'].db.metadata
39
40 # other values from the config, defined by the needs of env.py,
41 # can be acquired:
42 # my_important_option = config.get_main_option("my_important_option")
43 # ... etc.
44
45
46 def run_migrations_offline():
47 """Run migrations in 'offline' mode.
48
49 This configures the context with just a URL
50 and not an Engine, though an Engine is acceptable
51 here as well. By skipping the Engine creation
52 we don't even need a DBAPI to be available.
53
54 Calls to context.execute() here emit the given string to the
55 script output.
56
57 """
58 url = config.get_main_option("sqlalchemy.url")
59 context.configure(url=url)
60
61 with context.begin_transaction():
62 context.run_migrations()
63
64
65 def run_migrations_online():
66 """Run migrations in 'online' mode.
67
68 In this scenario we need to create an Engine
69 and associate a connection with the context.
70
71 """
72 # FIX for Postgres updates
73 url = config.get_section(config.config_ini_section).get("sqlalchemy.url")
74 driver = url.split(":")[0]
75
76 if driver == "postgresql+psycopg2":
77 engine = engine_from_config(
78 config.get_section(config.config_ini_section),
79 prefix='sqlalchemy.',
80 isolation_level="AUTOCOMMIT",
81 poolclass=pool.NullPool)
82 else:
83 engine = engine_from_config(
84 config.get_section(config.config_ini_section),
85 prefix='sqlalchemy.',
86 poolclass=pool.NullPool)
87
88 connection = engine.connect()
89 context.configure(
90 connection=connection,
91 target_metadata=target_metadata,
92 compare_type=True
93 )
94
95 try:
96 with context.begin_transaction():
97 context.run_migrations()
98 finally:
99 connection.close()
100
101 if context.is_offline_mode():
102 print("Running offline")
103 run_migrations_offline()
104 else:
105 print("Running online")
106 run_migrations_online()
107
108
[end of migrations/env.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/migrations/env.py b/migrations/env.py
--- a/migrations/env.py
+++ b/migrations/env.py
@@ -3,6 +3,7 @@
from sqlalchemy import engine_from_config, pool
from sqlalchemy.engine.url import make_url
from logging.config import fileConfig
+from six.moves.urllib.parse import quote
# this is the Alembic Config object, which provides
# access to the values within the .ini file in use.
@@ -28,10 +29,13 @@
if url.startswith("mysql"):
parsed_url = make_url(url)
parsed_url.query.setdefault("charset", "utf8")
+ # We need to quote the password in case it contains special chars
+ parsed_url.password = quote(parsed_url.password)
url = str(parsed_url)
except Exception as exx:
print(u"Attempted to set charset=utf8 on connection, but failed: {}".format(exx))
- config.set_main_option('sqlalchemy.url', url)
+ # set_main_option() requires escaped "%" signs in the string
+ config.set_main_option('sqlalchemy.url', url.replace('%', '%%'))
set_database_url(config)
@@ -98,10 +102,10 @@
finally:
connection.close()
+
if context.is_offline_mode():
print("Running offline")
run_migrations_offline()
else:
print("Running online")
run_migrations_online()
-
|
{"golden_diff": "diff --git a/migrations/env.py b/migrations/env.py\n--- a/migrations/env.py\n+++ b/migrations/env.py\n@@ -3,6 +3,7 @@\n from sqlalchemy import engine_from_config, pool\n from sqlalchemy.engine.url import make_url\n from logging.config import fileConfig\n+from six.moves.urllib.parse import quote\n \n # this is the Alembic Config object, which provides\n # access to the values within the .ini file in use.\n@@ -28,10 +29,13 @@\n if url.startswith(\"mysql\"):\n parsed_url = make_url(url)\n parsed_url.query.setdefault(\"charset\", \"utf8\")\n+ # We need to quote the password in case it contains special chars\n+ parsed_url.password = quote(parsed_url.password)\n url = str(parsed_url)\n except Exception as exx:\n print(u\"Attempted to set charset=utf8 on connection, but failed: {}\".format(exx))\n- config.set_main_option('sqlalchemy.url', url)\n+ # set_main_option() requires escaped \"%\" signs in the string\n+ config.set_main_option('sqlalchemy.url', url.replace('%', '%%'))\n \n \n set_database_url(config)\n@@ -98,10 +102,10 @@\n finally:\n connection.close()\n \n+\n if context.is_offline_mode():\n print(\"Running offline\")\n run_migrations_offline()\n else:\n print(\"Running online\")\n run_migrations_online()\n-\n", "issue": "Database migration fails if the URI contains '%' signs\nIf the `SQLALCHEMY_DATABASE_URI` contains query parameters like `ssl_ca=/path/to/cert` the path separators will be url-encoded with `%` signs.\r\nThis fails when passing the URI to the alembic configuration (https://alembic.sqlalchemy.org/en/latest/api/config.html#alembic.config.Config.set_main_option).\r\nThe `%` signs should be escaped in the URI string before passing it to alembic.\n", "before_files": [{"content": "from __future__ import with_statement\nfrom alembic import context\nfrom sqlalchemy import engine_from_config, pool\nfrom sqlalchemy.engine.url import make_url\nfrom logging.config import fileConfig\n\n# this is the Alembic Config object, which provides\n# access to the values within the .ini file in use.\n\nconfig = context.config\n\n# Interpret the config file for Python logging.\n# This line sets up loggers basically.\nfileConfig(config.config_file_name)\n\n# add your model's MetaData object here\n# for 'autogenerate' support\n# from myapp import mymodel\n# target_metadata = mymodel.Base.metadata\nfrom flask import current_app\n\n\ndef set_database_url(config):\n url = current_app.config.get('SQLALCHEMY_DATABASE_URI')\n try:\n # In case of MySQL, add ``charset=utf8`` to the parameters (if no charset is set),\n # because this is what Flask-SQLAlchemy does\n if url.startswith(\"mysql\"):\n parsed_url = make_url(url)\n parsed_url.query.setdefault(\"charset\", \"utf8\")\n url = str(parsed_url)\n except Exception as exx:\n print(u\"Attempted to set charset=utf8 on connection, but failed: {}\".format(exx))\n config.set_main_option('sqlalchemy.url', url)\n\n\nset_database_url(config)\ntarget_metadata = current_app.extensions['migrate'].db.metadata\n\n# other values from the config, defined by the needs of env.py,\n# can be acquired:\n# my_important_option = config.get_main_option(\"my_important_option\")\n# ... etc.\n\n\ndef run_migrations_offline():\n \"\"\"Run migrations in 'offline' mode.\n\n This configures the context with just a URL\n and not an Engine, though an Engine is acceptable\n here as well. By skipping the Engine creation\n we don't even need a DBAPI to be available.\n\n Calls to context.execute() here emit the given string to the\n script output.\n\n \"\"\"\n url = config.get_main_option(\"sqlalchemy.url\")\n context.configure(url=url)\n\n with context.begin_transaction():\n context.run_migrations()\n\n\ndef run_migrations_online():\n \"\"\"Run migrations in 'online' mode.\n\n In this scenario we need to create an Engine\n and associate a connection with the context.\n\n \"\"\"\n # FIX for Postgres updates\n url = config.get_section(config.config_ini_section).get(\"sqlalchemy.url\")\n driver = url.split(\":\")[0]\n\n if driver == \"postgresql+psycopg2\":\n engine = engine_from_config(\n config.get_section(config.config_ini_section),\n prefix='sqlalchemy.',\n isolation_level=\"AUTOCOMMIT\",\n poolclass=pool.NullPool)\n else:\n engine = engine_from_config(\n config.get_section(config.config_ini_section),\n prefix='sqlalchemy.',\n poolclass=pool.NullPool)\n\n connection = engine.connect()\n context.configure(\n connection=connection,\n target_metadata=target_metadata,\n compare_type=True\n )\n\n try:\n with context.begin_transaction():\n context.run_migrations()\n finally:\n connection.close()\n\nif context.is_offline_mode():\n print(\"Running offline\")\n run_migrations_offline()\nelse:\n print(\"Running online\")\n run_migrations_online()\n\n", "path": "migrations/env.py"}]}
| 1,550 | 313 |
gh_patches_debug_11387
|
rasdani/github-patches
|
git_diff
|
encode__uvicorn-592
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Uvicorn via gunicorn worker doesn't respect `--forwarded-allow-ips`
I use uvicorn in docker as uvicorn-worker for gunicorn for my fastapi app. My application needs to know the real client IP of each request, so I use proxy-server with the `X-Forwarded-For` header.
Gunicorn has a special option to change proxy-ip to real-ip, so I running gunicorn like this:
```
gunicorn \
ppm_telegram_bot.api:app \
--forwarded-allow-ips="*"
--worker-class=uvicorn.workers.UvicornWorker \
--bind=0.0.0.0:$PORT
```
Because I'm in a container, my WSGI/ASGI server receives requests not from the localhost, but from the docker network.
But uvicorn-worker doesn't respect gunicorn's `forwarded-allow-ips`, so in `ProxyHeadersMiddleware.trusted_hosts` I receive default `127.0.0.1` and proxy-ip instead of real-ip.
https://github.com/encode/uvicorn/blob/9d9f8820a8155e36dcb5e4d4023f470e51aa4e03/uvicorn/middleware/proxy_headers.py#L14-L17
It looks like uvicorn-worker can forward this information to config via `config_kwargs`: https://github.com/encode/uvicorn/blob/9d9f8820a8155e36dcb5e4d4023f470e51aa4e03/uvicorn/workers.py#L28-L35
I could do PR with this change, if required 🙌
</issue>
<code>
[start of uvicorn/workers.py]
1 import asyncio
2 import logging
3
4 from gunicorn.workers.base import Worker
5 from uvicorn.config import Config
6 from uvicorn.main import Server
7
8
9 class UvicornWorker(Worker):
10 """
11 A worker class for Gunicorn that interfaces with an ASGI consumer callable,
12 rather than a WSGI callable.
13 """
14
15 CONFIG_KWARGS = {"loop": "uvloop", "http": "httptools"}
16
17 def __init__(self, *args, **kwargs):
18 super(UvicornWorker, self).__init__(*args, **kwargs)
19
20 logger = logging.getLogger("uvicorn.error")
21 logger.handlers = self.log.error_log.handlers
22 logger.setLevel(self.log.error_log.level)
23
24 logger = logging.getLogger("uvicorn.access")
25 logger.handlers = self.log.access_log.handlers
26 logger.setLevel(self.log.access_log.level)
27
28 config_kwargs = {
29 "app": None,
30 "log_config": None,
31 "timeout_keep_alive": self.cfg.keepalive,
32 "timeout_notify": self.timeout,
33 "callback_notify": self.callback_notify,
34 "limit_max_requests": self.max_requests,
35 }
36
37 if self.cfg.is_ssl:
38 ssl_kwargs = {
39 "ssl_keyfile": self.cfg.ssl_options.get("keyfile"),
40 "ssl_certfile": self.cfg.ssl_options.get("certfile"),
41 "ssl_version": self.cfg.ssl_options.get("ssl_version"),
42 "ssl_cert_reqs": self.cfg.ssl_options.get("cert_reqs"),
43 "ssl_ca_certs": self.cfg.ssl_options.get("ca_certs"),
44 "ssl_ciphers": self.cfg.ssl_options.get("ciphers"),
45 }
46 config_kwargs.update(ssl_kwargs)
47
48 if self.cfg.settings["backlog"].value:
49 config_kwargs["backlog"] = self.cfg.settings["backlog"].value
50
51 config_kwargs.update(self.CONFIG_KWARGS)
52
53 self.config = Config(**config_kwargs)
54
55 def init_process(self):
56 self.config.setup_event_loop()
57 super(UvicornWorker, self).init_process()
58
59 def init_signals(self):
60 pass
61
62 def run(self):
63 self.config.app = self.wsgi
64 server = Server(config=self.config)
65 loop = asyncio.get_event_loop()
66 loop.run_until_complete(server.serve(sockets=self.sockets))
67
68 async def callback_notify(self):
69 self.notify()
70
71
72 class UvicornH11Worker(UvicornWorker):
73 CONFIG_KWARGS = {"loop": "asyncio", "http": "h11"}
74
[end of uvicorn/workers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/uvicorn/workers.py b/uvicorn/workers.py
--- a/uvicorn/workers.py
+++ b/uvicorn/workers.py
@@ -2,6 +2,7 @@
import logging
from gunicorn.workers.base import Worker
+
from uvicorn.config import Config
from uvicorn.main import Server
@@ -32,6 +33,7 @@
"timeout_notify": self.timeout,
"callback_notify": self.callback_notify,
"limit_max_requests": self.max_requests,
+ "forwarded_allow_ips": self.cfg.forwarded_allow_ips,
}
if self.cfg.is_ssl:
|
{"golden_diff": "diff --git a/uvicorn/workers.py b/uvicorn/workers.py\n--- a/uvicorn/workers.py\n+++ b/uvicorn/workers.py\n@@ -2,6 +2,7 @@\n import logging\n \n from gunicorn.workers.base import Worker\n+\n from uvicorn.config import Config\n from uvicorn.main import Server\n \n@@ -32,6 +33,7 @@\n \"timeout_notify\": self.timeout,\n \"callback_notify\": self.callback_notify,\n \"limit_max_requests\": self.max_requests,\n+ \"forwarded_allow_ips\": self.cfg.forwarded_allow_ips,\n }\n \n if self.cfg.is_ssl:\n", "issue": "Uvicorn via gunicorn worker doesn't respect `--forwarded-allow-ips`\nI use uvicorn in docker as uvicorn-worker for gunicorn for my fastapi app. My application needs to know the real client IP of each request, so I use proxy-server with the `X-Forwarded-For` header.\r\n\r\nGunicorn has a special option to change proxy-ip to real-ip, so I running gunicorn like this:\r\n```\r\ngunicorn \\\r\n ppm_telegram_bot.api:app \\\r\n --forwarded-allow-ips=\"*\" \r\n --worker-class=uvicorn.workers.UvicornWorker \\\r\n --bind=0.0.0.0:$PORT\r\n```\r\n\r\nBecause I'm in a container, my WSGI/ASGI server receives requests not from the localhost, but from the docker network.\r\n\r\nBut uvicorn-worker doesn't respect gunicorn's `forwarded-allow-ips`, so in `ProxyHeadersMiddleware.trusted_hosts` I receive default `127.0.0.1` and proxy-ip instead of real-ip.\r\nhttps://github.com/encode/uvicorn/blob/9d9f8820a8155e36dcb5e4d4023f470e51aa4e03/uvicorn/middleware/proxy_headers.py#L14-L17\r\n\r\nIt looks like uvicorn-worker can forward this information to config via `config_kwargs`: https://github.com/encode/uvicorn/blob/9d9f8820a8155e36dcb5e4d4023f470e51aa4e03/uvicorn/workers.py#L28-L35\r\n\r\nI could do PR with this change, if required \ud83d\ude4c \n", "before_files": [{"content": "import asyncio\nimport logging\n\nfrom gunicorn.workers.base import Worker\nfrom uvicorn.config import Config\nfrom uvicorn.main import Server\n\n\nclass UvicornWorker(Worker):\n \"\"\"\n A worker class for Gunicorn that interfaces with an ASGI consumer callable,\n rather than a WSGI callable.\n \"\"\"\n\n CONFIG_KWARGS = {\"loop\": \"uvloop\", \"http\": \"httptools\"}\n\n def __init__(self, *args, **kwargs):\n super(UvicornWorker, self).__init__(*args, **kwargs)\n\n logger = logging.getLogger(\"uvicorn.error\")\n logger.handlers = self.log.error_log.handlers\n logger.setLevel(self.log.error_log.level)\n\n logger = logging.getLogger(\"uvicorn.access\")\n logger.handlers = self.log.access_log.handlers\n logger.setLevel(self.log.access_log.level)\n\n config_kwargs = {\n \"app\": None,\n \"log_config\": None,\n \"timeout_keep_alive\": self.cfg.keepalive,\n \"timeout_notify\": self.timeout,\n \"callback_notify\": self.callback_notify,\n \"limit_max_requests\": self.max_requests,\n }\n\n if self.cfg.is_ssl:\n ssl_kwargs = {\n \"ssl_keyfile\": self.cfg.ssl_options.get(\"keyfile\"),\n \"ssl_certfile\": self.cfg.ssl_options.get(\"certfile\"),\n \"ssl_version\": self.cfg.ssl_options.get(\"ssl_version\"),\n \"ssl_cert_reqs\": self.cfg.ssl_options.get(\"cert_reqs\"),\n \"ssl_ca_certs\": self.cfg.ssl_options.get(\"ca_certs\"),\n \"ssl_ciphers\": self.cfg.ssl_options.get(\"ciphers\"),\n }\n config_kwargs.update(ssl_kwargs)\n\n if self.cfg.settings[\"backlog\"].value:\n config_kwargs[\"backlog\"] = self.cfg.settings[\"backlog\"].value\n\n config_kwargs.update(self.CONFIG_KWARGS)\n\n self.config = Config(**config_kwargs)\n\n def init_process(self):\n self.config.setup_event_loop()\n super(UvicornWorker, self).init_process()\n\n def init_signals(self):\n pass\n\n def run(self):\n self.config.app = self.wsgi\n server = Server(config=self.config)\n loop = asyncio.get_event_loop()\n loop.run_until_complete(server.serve(sockets=self.sockets))\n\n async def callback_notify(self):\n self.notify()\n\n\nclass UvicornH11Worker(UvicornWorker):\n CONFIG_KWARGS = {\"loop\": \"asyncio\", \"http\": \"h11\"}\n", "path": "uvicorn/workers.py"}]}
| 1,592 | 137 |
gh_patches_debug_1288
|
rasdani/github-patches
|
git_diff
|
archlinux__archinstall-555
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Version Bump in conf.py?
https://github.com/archlinux/archinstall/blob/a4033a7d3a94916f2b4972d212f9d0069fca39cd/docs/conf.py#L44
</issue>
<code>
[start of docs/conf.py]
1 import os
2 import re
3 import sys
4
5 sys.path.insert(0, os.path.abspath('..'))
6
7
8 def process_docstring(app, what, name, obj, options, lines):
9 spaces_pat = re.compile(r"( {8})")
10 ll = []
11 for line in lines:
12 ll.append(spaces_pat.sub(" ", line))
13 lines[:] = ll
14
15
16 def setup(app):
17 app.connect('autodoc-process-docstring', process_docstring)
18
19
20 # Configuration file for the Sphinx documentation builder.
21 #
22 # This file only contains a selection of the most common options. For a full
23 # list see the documentation:
24 # https://www.sphinx-doc.org/en/master/usage/configuration.html
25
26 # -- Path setup --------------------------------------------------------------
27
28 # If extensions (or modules to document with autodoc) are in another directory,
29 # add these directories to sys.path here. If the directory is relative to the
30 # documentation root, use os.path.abspath to make it absolute, like shown here.
31 #
32 # import os
33 # import sys
34 # sys.path.insert(0, os.path.abspath('.'))
35
36
37 # -- Project information -----------------------------------------------------
38
39 project = 'python-archinstall'
40 copyright = '2020, Anton Hvornum'
41 author = 'Anton Hvornum'
42
43 # The full version, including alpha/beta/rc tags
44 release = 'v2.1.0'
45
46 # -- General configuration ---------------------------------------------------
47
48 master_doc = 'index'
49 # Add any Sphinx extension module names here, as strings. They can be
50 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
51 # ones.
52 extensions = [
53 'sphinx.ext.autodoc',
54 'sphinx.ext.inheritance_diagram',
55 'sphinx.ext.todo'
56 ]
57
58 # Add any paths that contain templates here, relative to this directory.
59 templates_path = ['_templates']
60
61 # List of patterns, relative to source directory, that match files and
62 # directories to ignore when looking for source files.
63 # This pattern also affects html_static_path and html_extra_path.
64 exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
65
66 # -- Options for HTML output -------------------------------------------------
67
68 # The theme to use for HTML and HTML Help pages. See the documentation for
69 # a list of builtin themes.
70 #
71 # html_theme = 'alabaster'
72 html_theme = 'sphinx_rtd_theme'
73
74 html_logo = "_static/logo.png"
75
76 # Add any paths that contain custom static files (such as style sheets) here,
77 # relative to this directory. They are copied after the builtin static files,
78 # so a file named "default.css" will overwrite the builtin "default.css".
79 html_static_path = ['_static']
80
81 # If false, no module index is generated.
82 html_domain_indices = True
83
84 # If false, no index is generated.
85 html_use_index = True
86
87 # If true, the index is split into individual pages for each letter.
88 html_split_index = True
89
90 # If true, links to the reST sources are added to the pages.
91 html_show_sourcelink = False
92
93 # If true, "Created using Sphinx" is shown in the HTML footer. Default is True.
94 # html_show_sphinx = True
95
96 # If true, "(C) Copyright ..." is shown in the HTML footer. Default is True.
97 # html_show_copyright = True
98
99 # If true, an OpenSearch description file will be output, and all pages will
100 # contain a <link> tag referring to it. The value of this option must be the
101 # base URL from which the finished HTML is served.
102 # html_use_opensearch = ''
103
104 # This is the file name suffix for HTML files (e.g. ".xhtml").
105 # html_file_suffix = None
106
107 # Output file base name for HTML help builder.
108 htmlhelp_basename = 'archinstalldoc'
109
110 # -- Options for manual page output --------------------------------------------
111
112 # One entry per manual page. List of tuples
113 # (source start file, name, description, authors, manual section).
114 man_pages = [("index", "archinstall", u"archinstall Documentation", [u"Anton Hvornum"], 1)]
115
116 # If true, show URL addresses after external links.
117 # man_show_urls = False
118
119
120 # -- Options for Texinfo output ------------------------------------------------
121
122 # Grouping the document tree into Texinfo files. List of tuples
123 # (source start file, target name, title, author,
124 # dir menu entry, description, category)
125 texinfo_documents = [
126 ("index", "archinstall", u"archinstall Documentation", u"Anton Hvornum", "archinstall", "Simple and minimal HTTP server."),
127 ]
128
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -41,7 +41,7 @@
author = 'Anton Hvornum'
# The full version, including alpha/beta/rc tags
-release = 'v2.1.0'
+release = 'v2.3.0.dev0'
# -- General configuration ---------------------------------------------------
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -41,7 +41,7 @@\n author = 'Anton Hvornum'\n \n # The full version, including alpha/beta/rc tags\n-release = 'v2.1.0'\n+release = 'v2.3.0.dev0'\n \n # -- General configuration ---------------------------------------------------\n", "issue": "Version Bump in conf.py?\nhttps://github.com/archlinux/archinstall/blob/a4033a7d3a94916f2b4972d212f9d0069fca39cd/docs/conf.py#L44\n", "before_files": [{"content": "import os\nimport re\nimport sys\n\nsys.path.insert(0, os.path.abspath('..'))\n\n\ndef process_docstring(app, what, name, obj, options, lines):\n\tspaces_pat = re.compile(r\"( {8})\")\n\tll = []\n\tfor line in lines:\n\t\tll.append(spaces_pat.sub(\" \", line))\n\tlines[:] = ll\n\n\ndef setup(app):\n\tapp.connect('autodoc-process-docstring', process_docstring)\n\n\n# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common options. For a full\n# list see the documentation:\n# https://www.sphinx-doc.org/en/master/usage/configuration.html\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\n# import os\n# import sys\n# sys.path.insert(0, os.path.abspath('.'))\n\n\n# -- Project information -----------------------------------------------------\n\nproject = 'python-archinstall'\ncopyright = '2020, Anton Hvornum'\nauthor = 'Anton Hvornum'\n\n# The full version, including alpha/beta/rc tags\nrelease = 'v2.1.0'\n\n# -- General configuration ---------------------------------------------------\n\nmaster_doc = 'index'\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n\t'sphinx.ext.autodoc',\n\t'sphinx.ext.inheritance_diagram',\n\t'sphinx.ext.todo'\n]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\n# html_theme = 'alabaster'\nhtml_theme = 'sphinx_rtd_theme'\n\nhtml_logo = \"_static/logo.png\"\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# If false, no module index is generated.\nhtml_domain_indices = True\n\n# If false, no index is generated.\nhtml_use_index = True\n\n# If true, the index is split into individual pages for each letter.\nhtml_split_index = True\n\n# If true, links to the reST sources are added to the pages.\nhtml_show_sourcelink = False\n\n# If true, \"Created using Sphinx\" is shown in the HTML footer. Default is True.\n# html_show_sphinx = True\n\n# If true, \"(C) Copyright ...\" is shown in the HTML footer. Default is True.\n# html_show_copyright = True\n\n# If true, an OpenSearch description file will be output, and all pages will\n# contain a <link> tag referring to it. The value of this option must be the\n# base URL from which the finished HTML is served.\n# html_use_opensearch = ''\n\n# This is the file name suffix for HTML files (e.g. \".xhtml\").\n# html_file_suffix = None\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'archinstalldoc'\n\n# -- Options for manual page output --------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [(\"index\", \"archinstall\", u\"archinstall Documentation\", [u\"Anton Hvornum\"], 1)]\n\n# If true, show URL addresses after external links.\n# man_show_urls = False\n\n\n# -- Options for Texinfo output ------------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n\t(\"index\", \"archinstall\", u\"archinstall Documentation\", u\"Anton Hvornum\", \"archinstall\", \"Simple and minimal HTTP server.\"),\n]\n", "path": "docs/conf.py"}]}
| 1,863 | 88 |
gh_patches_debug_27326
|
rasdani/github-patches
|
git_diff
|
huggingface__dataset-viewer-207
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
regression: fallback if streaming fails is disabled
Causes https://github.com/huggingface/datasets/issues/3185 for example: the fallback should have loaded the dataset in normal mode.
</issue>
<code>
[start of src/datasets_preview_backend/config.py]
1 import os
2
3 from dotenv import load_dotenv
4
5 from datasets_preview_backend.constants import (
6 DEFAULT_APP_HOSTNAME,
7 DEFAULT_APP_PORT,
8 DEFAULT_ASSETS_DIRECTORY,
9 DEFAULT_DATASETS_ENABLE_PRIVATE,
10 DEFAULT_DATASETS_REVISION,
11 DEFAULT_HF_TOKEN,
12 DEFAULT_LOG_LEVEL,
13 DEFAULT_MAX_AGE_LONG_SECONDS,
14 DEFAULT_MAX_AGE_SHORT_SECONDS,
15 DEFAULT_MONGO_CACHE_DATABASE,
16 DEFAULT_MONGO_QUEUE_DATABASE,
17 DEFAULT_MONGO_URL,
18 DEFAULT_ROWS_MAX_BYTES,
19 DEFAULT_ROWS_MAX_NUMBER,
20 DEFAULT_ROWS_MIN_NUMBER,
21 DEFAULT_WEB_CONCURRENCY,
22 )
23 from datasets_preview_backend.utils import (
24 get_bool_value,
25 get_int_value,
26 get_str_or_none_value,
27 get_str_value,
28 )
29
30 # Load environment variables defined in .env, if any
31 load_dotenv()
32
33 APP_HOSTNAME = get_str_value(d=os.environ, key="APP_HOSTNAME", default=DEFAULT_APP_HOSTNAME)
34 APP_PORT = get_int_value(d=os.environ, key="APP_PORT", default=DEFAULT_APP_PORT)
35 ASSETS_DIRECTORY = get_str_or_none_value(d=os.environ, key="ASSETS_DIRECTORY", default=DEFAULT_ASSETS_DIRECTORY)
36 DATASETS_ENABLE_PRIVATE = get_bool_value(
37 d=os.environ, key="DATASETS_ENABLE_PRIVATE", default=DEFAULT_DATASETS_ENABLE_PRIVATE
38 )
39 DATASETS_REVISION = get_str_value(d=os.environ, key="DATASETS_REVISION", default=DEFAULT_DATASETS_REVISION)
40 HF_TOKEN = get_str_or_none_value(d=os.environ, key="HF_TOKEN", default=DEFAULT_HF_TOKEN)
41 LOG_LEVEL = get_str_value(d=os.environ, key="LOG_LEVEL", default=DEFAULT_LOG_LEVEL)
42 MAX_AGE_LONG_SECONDS = get_int_value(d=os.environ, key="MAX_AGE_LONG_SECONDS", default=DEFAULT_MAX_AGE_LONG_SECONDS)
43 MAX_AGE_SHORT_SECONDS = get_int_value(d=os.environ, key="MAX_AGE_SHORT_SECONDS", default=DEFAULT_MAX_AGE_SHORT_SECONDS)
44 MONGO_CACHE_DATABASE = get_str_value(d=os.environ, key="MONGO_CACHE_DATABASE", default=DEFAULT_MONGO_CACHE_DATABASE)
45 MONGO_QUEUE_DATABASE = get_str_value(d=os.environ, key="MONGO_QUEUE_DATABASE", default=DEFAULT_MONGO_QUEUE_DATABASE)
46 MONGO_URL = get_str_value(d=os.environ, key="MONGO_URL", default=DEFAULT_MONGO_URL)
47 WEB_CONCURRENCY = get_int_value(d=os.environ, key="WEB_CONCURRENCY", default=DEFAULT_WEB_CONCURRENCY)
48
49 # Ensure datasets library uses the expected revision for canonical datasets
50 os.environ["HF_SCRIPTS_VERSION"] = DATASETS_REVISION
51
52 # for tests - to be removed
53 ROWS_MAX_BYTES = get_int_value(d=os.environ, key="ROWS_MAX_BYTES", default=DEFAULT_ROWS_MAX_BYTES)
54 ROWS_MAX_NUMBER = get_int_value(d=os.environ, key="ROWS_MAX_NUMBER", default=DEFAULT_ROWS_MAX_NUMBER)
55 ROWS_MIN_NUMBER = get_int_value(d=os.environ, key="ROWS_MIN_NUMBER", default=DEFAULT_ROWS_MIN_NUMBER)
56
[end of src/datasets_preview_backend/config.py]
[start of src/datasets_preview_backend/models/row.py]
1 import itertools
2 import logging
3 from typing import Any, Dict, List, Optional
4
5 from datasets import Dataset, DownloadMode, IterableDataset, load_dataset
6
7 from datasets_preview_backend.constants import DEFAULT_ROWS_MAX_NUMBER
8 from datasets_preview_backend.utils import retry
9
10 logger = logging.getLogger(__name__)
11
12
13 Row = Dict[str, Any]
14
15
16 @retry(logger=logger)
17 def get_rows(
18 dataset_name: str,
19 config_name: str,
20 split_name: str,
21 hf_token: Optional[str] = None,
22 streaming: bool = True,
23 rows_max_number: Optional[int] = None,
24 ) -> List[Row]:
25 if rows_max_number is None:
26 rows_max_number = DEFAULT_ROWS_MAX_NUMBER
27 dataset = load_dataset(
28 dataset_name,
29 name=config_name,
30 split=split_name,
31 streaming=True,
32 download_mode=DownloadMode.FORCE_REDOWNLOAD,
33 use_auth_token=hf_token,
34 )
35 if streaming:
36 if not isinstance(dataset, IterableDataset):
37 raise TypeError("load_dataset should return an IterableDataset")
38 elif not isinstance(dataset, Dataset):
39 raise TypeError("load_dataset should return a Dataset")
40 rows_plus_one = list(itertools.islice(dataset, rows_max_number + 1))
41 # ^^ to be able to detect if a split has exactly ROWS_MAX_NUMBER rows
42 if len(rows_plus_one) <= rows_max_number:
43 logger.debug(f"all the rows in the split have been fetched ({len(rows_plus_one)})")
44 else:
45 logger.debug(f"the rows in the split have been truncated ({rows_max_number} rows)")
46 return rows_plus_one[:rows_max_number]
47
[end of src/datasets_preview_backend/models/row.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/datasets_preview_backend/config.py b/src/datasets_preview_backend/config.py
--- a/src/datasets_preview_backend/config.py
+++ b/src/datasets_preview_backend/config.py
@@ -12,6 +12,7 @@
DEFAULT_LOG_LEVEL,
DEFAULT_MAX_AGE_LONG_SECONDS,
DEFAULT_MAX_AGE_SHORT_SECONDS,
+ DEFAULT_MAX_SIZE_FALLBACK,
DEFAULT_MONGO_CACHE_DATABASE,
DEFAULT_MONGO_QUEUE_DATABASE,
DEFAULT_MONGO_URL,
@@ -50,6 +51,7 @@
os.environ["HF_SCRIPTS_VERSION"] = DATASETS_REVISION
# for tests - to be removed
+MAX_SIZE_FALLBACK = get_int_value(os.environ, "MAX_SIZE_FALLBACK", DEFAULT_MAX_SIZE_FALLBACK)
ROWS_MAX_BYTES = get_int_value(d=os.environ, key="ROWS_MAX_BYTES", default=DEFAULT_ROWS_MAX_BYTES)
ROWS_MAX_NUMBER = get_int_value(d=os.environ, key="ROWS_MAX_NUMBER", default=DEFAULT_ROWS_MAX_NUMBER)
ROWS_MIN_NUMBER = get_int_value(d=os.environ, key="ROWS_MIN_NUMBER", default=DEFAULT_ROWS_MIN_NUMBER)
diff --git a/src/datasets_preview_backend/models/row.py b/src/datasets_preview_backend/models/row.py
--- a/src/datasets_preview_backend/models/row.py
+++ b/src/datasets_preview_backend/models/row.py
@@ -28,7 +28,7 @@
dataset_name,
name=config_name,
split=split_name,
- streaming=True,
+ streaming=streaming,
download_mode=DownloadMode.FORCE_REDOWNLOAD,
use_auth_token=hf_token,
)
|
{"golden_diff": "diff --git a/src/datasets_preview_backend/config.py b/src/datasets_preview_backend/config.py\n--- a/src/datasets_preview_backend/config.py\n+++ b/src/datasets_preview_backend/config.py\n@@ -12,6 +12,7 @@\n DEFAULT_LOG_LEVEL,\n DEFAULT_MAX_AGE_LONG_SECONDS,\n DEFAULT_MAX_AGE_SHORT_SECONDS,\n+ DEFAULT_MAX_SIZE_FALLBACK,\n DEFAULT_MONGO_CACHE_DATABASE,\n DEFAULT_MONGO_QUEUE_DATABASE,\n DEFAULT_MONGO_URL,\n@@ -50,6 +51,7 @@\n os.environ[\"HF_SCRIPTS_VERSION\"] = DATASETS_REVISION\n \n # for tests - to be removed\n+MAX_SIZE_FALLBACK = get_int_value(os.environ, \"MAX_SIZE_FALLBACK\", DEFAULT_MAX_SIZE_FALLBACK)\n ROWS_MAX_BYTES = get_int_value(d=os.environ, key=\"ROWS_MAX_BYTES\", default=DEFAULT_ROWS_MAX_BYTES)\n ROWS_MAX_NUMBER = get_int_value(d=os.environ, key=\"ROWS_MAX_NUMBER\", default=DEFAULT_ROWS_MAX_NUMBER)\n ROWS_MIN_NUMBER = get_int_value(d=os.environ, key=\"ROWS_MIN_NUMBER\", default=DEFAULT_ROWS_MIN_NUMBER)\ndiff --git a/src/datasets_preview_backend/models/row.py b/src/datasets_preview_backend/models/row.py\n--- a/src/datasets_preview_backend/models/row.py\n+++ b/src/datasets_preview_backend/models/row.py\n@@ -28,7 +28,7 @@\n dataset_name,\n name=config_name,\n split=split_name,\n- streaming=True,\n+ streaming=streaming,\n download_mode=DownloadMode.FORCE_REDOWNLOAD,\n use_auth_token=hf_token,\n )\n", "issue": "regression: fallback if streaming fails is disabled\nCauses https://github.com/huggingface/datasets/issues/3185 for example: the fallback should have loaded the dataset in normal mode.\n", "before_files": [{"content": "import os\n\nfrom dotenv import load_dotenv\n\nfrom datasets_preview_backend.constants import (\n DEFAULT_APP_HOSTNAME,\n DEFAULT_APP_PORT,\n DEFAULT_ASSETS_DIRECTORY,\n DEFAULT_DATASETS_ENABLE_PRIVATE,\n DEFAULT_DATASETS_REVISION,\n DEFAULT_HF_TOKEN,\n DEFAULT_LOG_LEVEL,\n DEFAULT_MAX_AGE_LONG_SECONDS,\n DEFAULT_MAX_AGE_SHORT_SECONDS,\n DEFAULT_MONGO_CACHE_DATABASE,\n DEFAULT_MONGO_QUEUE_DATABASE,\n DEFAULT_MONGO_URL,\n DEFAULT_ROWS_MAX_BYTES,\n DEFAULT_ROWS_MAX_NUMBER,\n DEFAULT_ROWS_MIN_NUMBER,\n DEFAULT_WEB_CONCURRENCY,\n)\nfrom datasets_preview_backend.utils import (\n get_bool_value,\n get_int_value,\n get_str_or_none_value,\n get_str_value,\n)\n\n# Load environment variables defined in .env, if any\nload_dotenv()\n\nAPP_HOSTNAME = get_str_value(d=os.environ, key=\"APP_HOSTNAME\", default=DEFAULT_APP_HOSTNAME)\nAPP_PORT = get_int_value(d=os.environ, key=\"APP_PORT\", default=DEFAULT_APP_PORT)\nASSETS_DIRECTORY = get_str_or_none_value(d=os.environ, key=\"ASSETS_DIRECTORY\", default=DEFAULT_ASSETS_DIRECTORY)\nDATASETS_ENABLE_PRIVATE = get_bool_value(\n d=os.environ, key=\"DATASETS_ENABLE_PRIVATE\", default=DEFAULT_DATASETS_ENABLE_PRIVATE\n)\nDATASETS_REVISION = get_str_value(d=os.environ, key=\"DATASETS_REVISION\", default=DEFAULT_DATASETS_REVISION)\nHF_TOKEN = get_str_or_none_value(d=os.environ, key=\"HF_TOKEN\", default=DEFAULT_HF_TOKEN)\nLOG_LEVEL = get_str_value(d=os.environ, key=\"LOG_LEVEL\", default=DEFAULT_LOG_LEVEL)\nMAX_AGE_LONG_SECONDS = get_int_value(d=os.environ, key=\"MAX_AGE_LONG_SECONDS\", default=DEFAULT_MAX_AGE_LONG_SECONDS)\nMAX_AGE_SHORT_SECONDS = get_int_value(d=os.environ, key=\"MAX_AGE_SHORT_SECONDS\", default=DEFAULT_MAX_AGE_SHORT_SECONDS)\nMONGO_CACHE_DATABASE = get_str_value(d=os.environ, key=\"MONGO_CACHE_DATABASE\", default=DEFAULT_MONGO_CACHE_DATABASE)\nMONGO_QUEUE_DATABASE = get_str_value(d=os.environ, key=\"MONGO_QUEUE_DATABASE\", default=DEFAULT_MONGO_QUEUE_DATABASE)\nMONGO_URL = get_str_value(d=os.environ, key=\"MONGO_URL\", default=DEFAULT_MONGO_URL)\nWEB_CONCURRENCY = get_int_value(d=os.environ, key=\"WEB_CONCURRENCY\", default=DEFAULT_WEB_CONCURRENCY)\n\n# Ensure datasets library uses the expected revision for canonical datasets\nos.environ[\"HF_SCRIPTS_VERSION\"] = DATASETS_REVISION\n\n# for tests - to be removed\nROWS_MAX_BYTES = get_int_value(d=os.environ, key=\"ROWS_MAX_BYTES\", default=DEFAULT_ROWS_MAX_BYTES)\nROWS_MAX_NUMBER = get_int_value(d=os.environ, key=\"ROWS_MAX_NUMBER\", default=DEFAULT_ROWS_MAX_NUMBER)\nROWS_MIN_NUMBER = get_int_value(d=os.environ, key=\"ROWS_MIN_NUMBER\", default=DEFAULT_ROWS_MIN_NUMBER)\n", "path": "src/datasets_preview_backend/config.py"}, {"content": "import itertools\nimport logging\nfrom typing import Any, Dict, List, Optional\n\nfrom datasets import Dataset, DownloadMode, IterableDataset, load_dataset\n\nfrom datasets_preview_backend.constants import DEFAULT_ROWS_MAX_NUMBER\nfrom datasets_preview_backend.utils import retry\n\nlogger = logging.getLogger(__name__)\n\n\nRow = Dict[str, Any]\n\n\n@retry(logger=logger)\ndef get_rows(\n dataset_name: str,\n config_name: str,\n split_name: str,\n hf_token: Optional[str] = None,\n streaming: bool = True,\n rows_max_number: Optional[int] = None,\n) -> List[Row]:\n if rows_max_number is None:\n rows_max_number = DEFAULT_ROWS_MAX_NUMBER\n dataset = load_dataset(\n dataset_name,\n name=config_name,\n split=split_name,\n streaming=True,\n download_mode=DownloadMode.FORCE_REDOWNLOAD,\n use_auth_token=hf_token,\n )\n if streaming:\n if not isinstance(dataset, IterableDataset):\n raise TypeError(\"load_dataset should return an IterableDataset\")\n elif not isinstance(dataset, Dataset):\n raise TypeError(\"load_dataset should return a Dataset\")\n rows_plus_one = list(itertools.islice(dataset, rows_max_number + 1))\n # ^^ to be able to detect if a split has exactly ROWS_MAX_NUMBER rows\n if len(rows_plus_one) <= rows_max_number:\n logger.debug(f\"all the rows in the split have been fetched ({len(rows_plus_one)})\")\n else:\n logger.debug(f\"the rows in the split have been truncated ({rows_max_number} rows)\")\n return rows_plus_one[:rows_max_number]\n", "path": "src/datasets_preview_backend/models/row.py"}]}
| 1,768 | 344 |
gh_patches_debug_51276
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-3848
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
lint takes a long time
Fix that.
</issue>
<code>
[start of exporter/opentelemetry-exporter-opencensus/src/opentelemetry/exporter/opencensus/util.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from os import getpid
16 from socket import gethostname
17 from time import time
18
19 # pylint: disable=wrong-import-position
20 from google.protobuf.timestamp_pb2 import Timestamp
21 from opencensus.proto.agent.common.v1 import common_pb2
22 from opencensus.proto.trace.v1 import trace_pb2
23
24 from opentelemetry.exporter.opencensus.version import (
25 __version__ as opencensusexporter_exporter_version,
26 )
27 from opentelemetry.trace import SpanKind
28 from opentelemetry.util._importlib_metadata import version
29
30 OPENTELEMETRY_VERSION = version("opentelemetry-api")
31
32
33 def proto_timestamp_from_time_ns(time_ns):
34 """Converts datetime to protobuf timestamp.
35
36 Args:
37 time_ns: Time in nanoseconds
38
39 Returns:
40 Returns protobuf timestamp.
41 """
42 ts = Timestamp()
43 if time_ns is not None:
44 # pylint: disable=no-member
45 ts.FromNanoseconds(time_ns)
46 return ts
47
48
49 # pylint: disable=no-member
50 def get_collector_span_kind(kind: SpanKind):
51 if kind is SpanKind.SERVER:
52 return trace_pb2.Span.SpanKind.SERVER
53 if kind is SpanKind.CLIENT:
54 return trace_pb2.Span.SpanKind.CLIENT
55 return trace_pb2.Span.SpanKind.SPAN_KIND_UNSPECIFIED
56
57
58 def add_proto_attribute_value(pb_attributes, key, value):
59 """Sets string, int, boolean or float value on protobuf
60 span, link or annotation attributes.
61
62 Args:
63 pb_attributes: protobuf Span's attributes property.
64 key: attribute key to set.
65 value: attribute value
66 """
67
68 if isinstance(value, bool):
69 pb_attributes.attribute_map[key].bool_value = value
70 elif isinstance(value, int):
71 pb_attributes.attribute_map[key].int_value = value
72 elif isinstance(value, str):
73 pb_attributes.attribute_map[key].string_value.value = value
74 elif isinstance(value, float):
75 pb_attributes.attribute_map[key].double_value = value
76 else:
77 pb_attributes.attribute_map[key].string_value.value = str(value)
78
79
80 # pylint: disable=no-member
81 def get_node(service_name, host_name):
82 """Generates Node message from params and system information.
83
84 Args:
85 service_name: Name of Collector service.
86 host_name: Host name.
87 """
88 return common_pb2.Node(
89 identifier=common_pb2.ProcessIdentifier(
90 host_name=gethostname() if host_name is None else host_name,
91 pid=getpid(),
92 start_timestamp=proto_timestamp_from_time_ns(int(time() * 1e9)),
93 ),
94 library_info=common_pb2.LibraryInfo(
95 language=common_pb2.LibraryInfo.Language.Value("PYTHON"),
96 exporter_version=opencensusexporter_exporter_version,
97 core_library_version=OPENTELEMETRY_VERSION,
98 ),
99 service_info=common_pb2.ServiceInfo(name=service_name),
100 )
101
[end of exporter/opentelemetry-exporter-opencensus/src/opentelemetry/exporter/opencensus/util.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/exporter/opentelemetry-exporter-opencensus/src/opentelemetry/exporter/opencensus/util.py b/exporter/opentelemetry-exporter-opencensus/src/opentelemetry/exporter/opencensus/util.py
--- a/exporter/opentelemetry-exporter-opencensus/src/opentelemetry/exporter/opencensus/util.py
+++ b/exporter/opentelemetry-exporter-opencensus/src/opentelemetry/exporter/opencensus/util.py
@@ -17,7 +17,9 @@
from time import time
# pylint: disable=wrong-import-position
-from google.protobuf.timestamp_pb2 import Timestamp
+from google.protobuf.timestamp_pb2 import ( # pylint: disable=no-name-in-module
+ Timestamp,
+)
from opencensus.proto.agent.common.v1 import common_pb2
from opencensus.proto.trace.v1 import trace_pb2
|
{"golden_diff": "diff --git a/exporter/opentelemetry-exporter-opencensus/src/opentelemetry/exporter/opencensus/util.py b/exporter/opentelemetry-exporter-opencensus/src/opentelemetry/exporter/opencensus/util.py\n--- a/exporter/opentelemetry-exporter-opencensus/src/opentelemetry/exporter/opencensus/util.py\n+++ b/exporter/opentelemetry-exporter-opencensus/src/opentelemetry/exporter/opencensus/util.py\n@@ -17,7 +17,9 @@\n from time import time\n \n # pylint: disable=wrong-import-position\n-from google.protobuf.timestamp_pb2 import Timestamp\n+from google.protobuf.timestamp_pb2 import ( # pylint: disable=no-name-in-module\n+ Timestamp,\n+)\n from opencensus.proto.agent.common.v1 import common_pb2\n from opencensus.proto.trace.v1 import trace_pb2\n", "issue": "lint takes a long time\nFix that.\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom os import getpid\nfrom socket import gethostname\nfrom time import time\n\n# pylint: disable=wrong-import-position\nfrom google.protobuf.timestamp_pb2 import Timestamp\nfrom opencensus.proto.agent.common.v1 import common_pb2\nfrom opencensus.proto.trace.v1 import trace_pb2\n\nfrom opentelemetry.exporter.opencensus.version import (\n __version__ as opencensusexporter_exporter_version,\n)\nfrom opentelemetry.trace import SpanKind\nfrom opentelemetry.util._importlib_metadata import version\n\nOPENTELEMETRY_VERSION = version(\"opentelemetry-api\")\n\n\ndef proto_timestamp_from_time_ns(time_ns):\n \"\"\"Converts datetime to protobuf timestamp.\n\n Args:\n time_ns: Time in nanoseconds\n\n Returns:\n Returns protobuf timestamp.\n \"\"\"\n ts = Timestamp()\n if time_ns is not None:\n # pylint: disable=no-member\n ts.FromNanoseconds(time_ns)\n return ts\n\n\n# pylint: disable=no-member\ndef get_collector_span_kind(kind: SpanKind):\n if kind is SpanKind.SERVER:\n return trace_pb2.Span.SpanKind.SERVER\n if kind is SpanKind.CLIENT:\n return trace_pb2.Span.SpanKind.CLIENT\n return trace_pb2.Span.SpanKind.SPAN_KIND_UNSPECIFIED\n\n\ndef add_proto_attribute_value(pb_attributes, key, value):\n \"\"\"Sets string, int, boolean or float value on protobuf\n span, link or annotation attributes.\n\n Args:\n pb_attributes: protobuf Span's attributes property.\n key: attribute key to set.\n value: attribute value\n \"\"\"\n\n if isinstance(value, bool):\n pb_attributes.attribute_map[key].bool_value = value\n elif isinstance(value, int):\n pb_attributes.attribute_map[key].int_value = value\n elif isinstance(value, str):\n pb_attributes.attribute_map[key].string_value.value = value\n elif isinstance(value, float):\n pb_attributes.attribute_map[key].double_value = value\n else:\n pb_attributes.attribute_map[key].string_value.value = str(value)\n\n\n# pylint: disable=no-member\ndef get_node(service_name, host_name):\n \"\"\"Generates Node message from params and system information.\n\n Args:\n service_name: Name of Collector service.\n host_name: Host name.\n \"\"\"\n return common_pb2.Node(\n identifier=common_pb2.ProcessIdentifier(\n host_name=gethostname() if host_name is None else host_name,\n pid=getpid(),\n start_timestamp=proto_timestamp_from_time_ns(int(time() * 1e9)),\n ),\n library_info=common_pb2.LibraryInfo(\n language=common_pb2.LibraryInfo.Language.Value(\"PYTHON\"),\n exporter_version=opencensusexporter_exporter_version,\n core_library_version=OPENTELEMETRY_VERSION,\n ),\n service_info=common_pb2.ServiceInfo(name=service_name),\n )\n", "path": "exporter/opentelemetry-exporter-opencensus/src/opentelemetry/exporter/opencensus/util.py"}]}
| 1,510 | 183 |
gh_patches_debug_12574
|
rasdani/github-patches
|
git_diff
|
celery__celery-4399
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Build task documentation with sphinx fails (error while formatting arguments)
## Checklist
this has been tested with both version 4.0.2 and master (8c8354f)
## Steps to reproduce
```bash
$ git clone https://github.com/inveniosoftware/invenio-indexer.git
$ cd invenio-indexer/
$ pip install -e .[all]
$ sphinx-build -qnNW docs docs/_build/html
```
You can see that `invenio-indexer` correctly implements the requirements to document a celery task:
- https://github.com/inveniosoftware/invenio-indexer/blob/master/docs/conf.py#L52
- https://github.com/inveniosoftware/invenio-indexer/blob/master/docs/api.rst#celery-tasks
## Expected behavior
It should build the documentation of the tasks. This is **working** in Celery 3.1.25.
## Actual behavior
I get the following error:
```
invenio-indexer/docs/api.rst:54: WARNING: error while formatting arguments for invenio_indexer.tasks.index_record: 'NoneType' object is not callable
```
Am I missing something? Should it work differently than Celery 3?
Request on_timeout should ignore soft time limit exception
When Request.on_timeout receive a soft timeout from billiard, it does the same as if it was receiving a hard time limit exception. This is ran by the controller.
But the task may catch this exception and eg. return (this is what soft timeout are for).
This cause:
1. the result to be saved once as an exception by the controller (on_timeout) and another time with the result returned by the task
2. the task status to be passed to failure and to success on the same manner
3. if the task is participating to a chord, the chord result counter (at least with redis) is incremented twice (instead of once), making the chord to return prematurely and eventually loose tasks…
1, 2 and 3 can leads of course to strange race conditions…
## Steps to reproduce (Illustration)
with the program in test_timeout.py:
```python
import time
import celery
app = celery.Celery('test_timeout')
app.conf.update(
result_backend="redis://localhost/0",
broker_url="amqp://celery:celery@localhost:5672/host",
)
@app.task(soft_time_limit=1)
def test():
try:
time.sleep(2)
except Exception:
return 1
@app.task()
def add(args):
print("### adding", args)
return sum(args)
@app.task()
def on_error(context, exception, traceback, **kwargs):
print("### on_error: ", exception)
if __name__ == "__main__":
result = celery.chord([test.s().set(link_error=on_error.s()), test.s().set(link_error=on_error.s())])(add.s())
result.get()
```
start a worker and the program:
```
$ celery -A test_timeout worker -l WARNING
$ python3 test_timeout.py
```
## Expected behavior
add method is called with `[1, 1]` as argument and test_timeout.py return normally
## Actual behavior
The test_timeout.py fails, with
```
celery.backends.base.ChordError: Callback error: ChordError("Dependency 15109e05-da43-449f-9081-85d839ac0ef2 raised SoftTimeLimitExceeded('SoftTimeLimitExceeded(True,)',)",
```
On the worker side, the **on_error is called but the add method as well !**
```
[2017-11-29 23:07:25,538: WARNING/MainProcess] Soft time limit (1s) exceeded for test_timeout.test[15109e05-da43-449f-9081-85d839ac0ef2]
[2017-11-29 23:07:25,546: WARNING/MainProcess] ### on_error:
[2017-11-29 23:07:25,546: WARNING/MainProcess] SoftTimeLimitExceeded(True,)
[2017-11-29 23:07:25,547: WARNING/MainProcess] Soft time limit (1s) exceeded for test_timeout.test[38f3f7f2-4a89-4318-8ee9-36a987f73757]
[2017-11-29 23:07:25,553: ERROR/MainProcess] Chord callback for 'ef6d7a38-d1b4-40ad-b937-ffa84e40bb23' raised: ChordError("Dependency 15109e05-da43-449f-9081-85d839ac0ef2 raised SoftTimeLimitExceeded('SoftTimeLimitExceeded(True,)',)",)
Traceback (most recent call last):
File "/usr/local/lib/python3.4/dist-packages/celery/backends/redis.py", line 290, in on_chord_part_return
callback.delay([unpack(tup, decode) for tup in resl])
File "/usr/local/lib/python3.4/dist-packages/celery/backends/redis.py", line 290, in <listcomp>
callback.delay([unpack(tup, decode) for tup in resl])
File "/usr/local/lib/python3.4/dist-packages/celery/backends/redis.py", line 243, in _unpack_chord_result
raise ChordError('Dependency {0} raised {1!r}'.format(tid, retval))
celery.exceptions.ChordError: Dependency 15109e05-da43-449f-9081-85d839ac0ef2 raised SoftTimeLimitExceeded('SoftTimeLimitExceeded(True,)',)
[2017-11-29 23:07:25,565: WARNING/MainProcess] ### on_error:
[2017-11-29 23:07:25,565: WARNING/MainProcess] SoftTimeLimitExceeded(True,)
[2017-11-29 23:07:27,262: WARNING/PoolWorker-2] ### adding
[2017-11-29 23:07:27,264: WARNING/PoolWorker-2] [1, 1]
```
Of course, on purpose did I choose to call the test.s() twice, to show that the count in the chord continues. In fact:
- the chord result is incremented twice by the error of soft time limit
- the chord result is again incremented twice by the correct returning of `test` task
## Conclusion
Request.on_timeout should not process soft time limit exception.
here is a quick monkey patch (correction of celery is trivial)
```python
def patch_celery_request_on_timeout():
from celery.worker import request
orig = request.Request.on_timeout
def patched_on_timeout(self, soft, timeout):
if not soft:
orig(self, soft, timeout)
request.Request.on_timeout = patched_on_timeout
patch_celery_request_on_timeout()
```
## version info
software -> celery:4.1.0 (latentcall) kombu:4.0.2 py:3.4.3
billiard:3.5.0.2 py-amqp:2.1.4
platform -> system:Linux arch:64bit, ELF imp:CPython
loader -> celery.loaders.app.AppLoader
settings -> transport:amqp results:redis://10.0.3.253/0
</issue>
<code>
[start of celery/contrib/sphinx.py]
1 # -*- coding: utf-8 -*-
2 """Sphinx documentation plugin used to document tasks.
3
4 Introduction
5 ============
6
7 Usage
8 -----
9
10 Add the extension to your :file:`docs/conf.py` configuration module:
11
12 .. code-block:: python
13
14 extensions = (...,
15 'celery.contrib.sphinx')
16
17 If you'd like to change the prefix for tasks in reference documentation
18 then you can change the ``celery_task_prefix`` configuration value:
19
20 .. code-block:: python
21
22 celery_task_prefix = '(task)' # < default
23
24 With the extension installed `autodoc` will automatically find
25 task decorated objects and generate the correct (as well as
26 add a ``(task)`` prefix), and you can also refer to the tasks
27 using `:task:proj.tasks.add` syntax.
28
29 Use ``.. autotask::`` to manually document a task.
30 """
31 from __future__ import absolute_import, unicode_literals
32 from inspect import formatargspec
33 from sphinx.domains.python import PyModulelevel
34 from sphinx.ext.autodoc import FunctionDocumenter
35 from celery.app.task import BaseTask
36 from celery.five import getfullargspec
37
38
39 class TaskDocumenter(FunctionDocumenter):
40 """Document task definitions."""
41
42 objtype = 'task'
43 member_order = 11
44
45 @classmethod
46 def can_document_member(cls, member, membername, isattr, parent):
47 return isinstance(member, BaseTask) and getattr(member, '__wrapped__')
48
49 def format_args(self):
50 wrapped = getattr(self.object, '__wrapped__', None)
51 if wrapped is not None:
52 argspec = getfullargspec(wrapped)
53 fmt = formatargspec(*argspec)
54 fmt = fmt.replace('\\', '\\\\')
55 return fmt
56 return ''
57
58 def document_members(self, all_members=False):
59 pass
60
61
62 class TaskDirective(PyModulelevel):
63 """Sphinx task directive."""
64
65 def get_signature_prefix(self, sig):
66 return self.env.config.celery_task_prefix
67
68
69 def setup(app):
70 """Setup Sphinx extension."""
71 app.add_autodocumenter(TaskDocumenter)
72 app.add_directive_to_domain('py', 'task', TaskDirective)
73 app.add_config_value('celery_task_prefix', '(task)', True)
74
[end of celery/contrib/sphinx.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/celery/contrib/sphinx.py b/celery/contrib/sphinx.py
--- a/celery/contrib/sphinx.py
+++ b/celery/contrib/sphinx.py
@@ -29,11 +29,13 @@
Use ``.. autotask::`` to manually document a task.
"""
from __future__ import absolute_import, unicode_literals
-from inspect import formatargspec
from sphinx.domains.python import PyModulelevel
from sphinx.ext.autodoc import FunctionDocumenter
from celery.app.task import BaseTask
-from celery.five import getfullargspec
+try: # pragma: no cover
+ from inspect import formatargspec, getfullargspec
+except ImportError: # Py2
+ from inspect import formatargspec, getargspec as getfullargspec # noqa
class TaskDocumenter(FunctionDocumenter):
|
{"golden_diff": "diff --git a/celery/contrib/sphinx.py b/celery/contrib/sphinx.py\n--- a/celery/contrib/sphinx.py\n+++ b/celery/contrib/sphinx.py\n@@ -29,11 +29,13 @@\n Use ``.. autotask::`` to manually document a task.\n \"\"\"\n from __future__ import absolute_import, unicode_literals\n-from inspect import formatargspec\n from sphinx.domains.python import PyModulelevel\n from sphinx.ext.autodoc import FunctionDocumenter\n from celery.app.task import BaseTask\n-from celery.five import getfullargspec\n+try: # pragma: no cover\n+ from inspect import formatargspec, getfullargspec\n+except ImportError: # Py2\n+ from inspect import formatargspec, getargspec as getfullargspec # noqa\n \n \n class TaskDocumenter(FunctionDocumenter):\n", "issue": "Build task documentation with sphinx fails (error while formatting arguments)\n## Checklist\r\n\r\nthis has been tested with both version 4.0.2 and master (8c8354f)\r\n\r\n## Steps to reproduce\r\n\r\n```bash\r\n$ git clone https://github.com/inveniosoftware/invenio-indexer.git\r\n$ cd invenio-indexer/\r\n$ pip install -e .[all]\r\n$ sphinx-build -qnNW docs docs/_build/html\r\n```\r\n\r\nYou can see that `invenio-indexer` correctly implements the requirements to document a celery task:\r\n- https://github.com/inveniosoftware/invenio-indexer/blob/master/docs/conf.py#L52\r\n- https://github.com/inveniosoftware/invenio-indexer/blob/master/docs/api.rst#celery-tasks\r\n\r\n## Expected behavior\r\n\r\nIt should build the documentation of the tasks. This is **working** in Celery 3.1.25.\r\n\r\n## Actual behavior\r\n\r\nI get the following error:\r\n\r\n```\r\ninvenio-indexer/docs/api.rst:54: WARNING: error while formatting arguments for invenio_indexer.tasks.index_record: 'NoneType' object is not callable\r\n```\r\n\r\nAm I missing something? Should it work differently than Celery 3?\nRequest on_timeout should ignore soft time limit exception\nWhen Request.on_timeout receive a soft timeout from billiard, it does the same as if it was receiving a hard time limit exception. This is ran by the controller.\r\n\r\nBut the task may catch this exception and eg. return (this is what soft timeout are for).\r\n\r\nThis cause:\r\n1. the result to be saved once as an exception by the controller (on_timeout) and another time with the result returned by the task\r\n2. the task status to be passed to failure and to success on the same manner\r\n3. if the task is participating to a chord, the chord result counter (at least with redis) is incremented twice (instead of once), making the chord to return prematurely and eventually loose tasks\u2026\r\n\r\n1, 2 and 3 can leads of course to strange race conditions\u2026\r\n\r\n## Steps to reproduce (Illustration)\r\n\r\nwith the program in test_timeout.py:\r\n\r\n```python\r\nimport time\r\nimport celery\r\n\r\n\r\napp = celery.Celery('test_timeout')\r\napp.conf.update(\r\n result_backend=\"redis://localhost/0\",\r\n broker_url=\"amqp://celery:celery@localhost:5672/host\",\r\n)\r\n\r\[email protected](soft_time_limit=1)\r\ndef test():\r\n try:\r\n time.sleep(2)\r\n except Exception:\r\n return 1\r\n\r\[email protected]()\r\ndef add(args):\r\n print(\"### adding\", args)\r\n return sum(args)\r\n\r\[email protected]()\r\ndef on_error(context, exception, traceback, **kwargs):\r\n print(\"### on_error:\u00a0\", exception)\r\n\r\nif __name__ == \"__main__\":\r\n result = celery.chord([test.s().set(link_error=on_error.s()), test.s().set(link_error=on_error.s())])(add.s())\r\n result.get()\r\n```\r\n\r\nstart a worker and the program:\r\n\r\n```\r\n$ celery -A test_timeout worker -l WARNING\r\n$ python3 test_timeout.py\r\n```\r\n\r\n## Expected behavior\r\n\r\nadd method is called with `[1, 1]` as argument and test_timeout.py return normally\r\n\r\n## Actual behavior\r\n\r\nThe test_timeout.py fails, with\r\n```\r\ncelery.backends.base.ChordError: Callback error: ChordError(\"Dependency 15109e05-da43-449f-9081-85d839ac0ef2 raised SoftTimeLimitExceeded('SoftTimeLimitExceeded(True,)',)\",\r\n```\r\nOn the worker side, the **on_error is called but the add method as well !**\r\n\r\n```\r\n[2017-11-29 23:07:25,538: WARNING/MainProcess] Soft time limit (1s) exceeded for test_timeout.test[15109e05-da43-449f-9081-85d839ac0ef2]\r\n[2017-11-29 23:07:25,546: WARNING/MainProcess] ### on_error:\r\n[2017-11-29 23:07:25,546: WARNING/MainProcess] SoftTimeLimitExceeded(True,)\r\n[2017-11-29 23:07:25,547: WARNING/MainProcess] Soft time limit (1s) exceeded for test_timeout.test[38f3f7f2-4a89-4318-8ee9-36a987f73757]\r\n[2017-11-29 23:07:25,553: ERROR/MainProcess] Chord callback for 'ef6d7a38-d1b4-40ad-b937-ffa84e40bb23' raised: ChordError(\"Dependency 15109e05-da43-449f-9081-85d839ac0ef2 raised SoftTimeLimitExceeded('SoftTimeLimitExceeded(True,)',)\",)\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.4/dist-packages/celery/backends/redis.py\", line 290, in on_chord_part_return\r\n callback.delay([unpack(tup, decode) for tup in resl])\r\n File \"/usr/local/lib/python3.4/dist-packages/celery/backends/redis.py\", line 290, in <listcomp>\r\n callback.delay([unpack(tup, decode) for tup in resl])\r\n File \"/usr/local/lib/python3.4/dist-packages/celery/backends/redis.py\", line 243, in _unpack_chord_result\r\n raise ChordError('Dependency {0} raised {1!r}'.format(tid, retval))\r\ncelery.exceptions.ChordError: Dependency 15109e05-da43-449f-9081-85d839ac0ef2 raised SoftTimeLimitExceeded('SoftTimeLimitExceeded(True,)',)\r\n[2017-11-29 23:07:25,565: WARNING/MainProcess] ### on_error:\r\n[2017-11-29 23:07:25,565: WARNING/MainProcess] SoftTimeLimitExceeded(True,)\r\n[2017-11-29 23:07:27,262: WARNING/PoolWorker-2] ### adding\r\n[2017-11-29 23:07:27,264: WARNING/PoolWorker-2] [1, 1]\r\n```\r\n\r\nOf course, on purpose did I choose to call the test.s() twice, to show that the count in the chord continues. In fact:\r\n- the chord result is incremented twice by the error of soft time limit\r\n- the chord result is again incremented twice by the correct returning of `test` task\r\n\r\n## Conclusion\r\n\r\nRequest.on_timeout should not process soft time limit exception. \r\n\r\nhere is a quick monkey patch (correction of celery is trivial)\r\n\r\n```python\r\ndef patch_celery_request_on_timeout():\r\n from celery.worker import request\r\n orig = request.Request.on_timeout\r\n def patched_on_timeout(self, soft, timeout):\r\n if not soft:\r\n orig(self, soft, timeout)\r\n request.Request.on_timeout = patched_on_timeout\r\npatch_celery_request_on_timeout()\r\n```\r\n\r\n\r\n\r\n## version info\r\n\r\nsoftware -> celery:4.1.0 (latentcall) kombu:4.0.2 py:3.4.3\r\n billiard:3.5.0.2 py-amqp:2.1.4\r\nplatform -> system:Linux arch:64bit, ELF imp:CPython\r\nloader -> celery.loaders.app.AppLoader\r\nsettings -> transport:amqp results:redis://10.0.3.253/0\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"Sphinx documentation plugin used to document tasks.\n\nIntroduction\n============\n\nUsage\n-----\n\nAdd the extension to your :file:`docs/conf.py` configuration module:\n\n.. code-block:: python\n\n extensions = (...,\n 'celery.contrib.sphinx')\n\nIf you'd like to change the prefix for tasks in reference documentation\nthen you can change the ``celery_task_prefix`` configuration value:\n\n.. code-block:: python\n\n celery_task_prefix = '(task)' # < default\n\nWith the extension installed `autodoc` will automatically find\ntask decorated objects and generate the correct (as well as\nadd a ``(task)`` prefix), and you can also refer to the tasks\nusing `:task:proj.tasks.add` syntax.\n\nUse ``.. autotask::`` to manually document a task.\n\"\"\"\nfrom __future__ import absolute_import, unicode_literals\nfrom inspect import formatargspec\nfrom sphinx.domains.python import PyModulelevel\nfrom sphinx.ext.autodoc import FunctionDocumenter\nfrom celery.app.task import BaseTask\nfrom celery.five import getfullargspec\n\n\nclass TaskDocumenter(FunctionDocumenter):\n \"\"\"Document task definitions.\"\"\"\n\n objtype = 'task'\n member_order = 11\n\n @classmethod\n def can_document_member(cls, member, membername, isattr, parent):\n return isinstance(member, BaseTask) and getattr(member, '__wrapped__')\n\n def format_args(self):\n wrapped = getattr(self.object, '__wrapped__', None)\n if wrapped is not None:\n argspec = getfullargspec(wrapped)\n fmt = formatargspec(*argspec)\n fmt = fmt.replace('\\\\', '\\\\\\\\')\n return fmt\n return ''\n\n def document_members(self, all_members=False):\n pass\n\n\nclass TaskDirective(PyModulelevel):\n \"\"\"Sphinx task directive.\"\"\"\n\n def get_signature_prefix(self, sig):\n return self.env.config.celery_task_prefix\n\n\ndef setup(app):\n \"\"\"Setup Sphinx extension.\"\"\"\n app.add_autodocumenter(TaskDocumenter)\n app.add_directive_to_domain('py', 'task', TaskDirective)\n app.add_config_value('celery_task_prefix', '(task)', True)\n", "path": "celery/contrib/sphinx.py"}]}
| 2,924 | 195 |
gh_patches_debug_22398
|
rasdani/github-patches
|
git_diff
|
fonttools__fonttools-1605
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Float yMin value: required argument is not an integer
If a font file has a float value in `yMin`—and I assume equally in `xMin`, `xMax` or `yMax`—it will fail to save with the error `required argument is not an integer` ([`fontTools/misc/sstruct.py in pack at line 75`](https://github.com/fonttools/fonttools/blob/3.40.0/Lib/fontTools/misc/sstruct.py#L75), fonttools v3.40.0).
Trace:
```
fontTools/misc/sstruct.py in pack at line 75
fontTools/ttLib/tables/_h_e_a_d.py in compile at line 69
fontTools/ttLib/ttFont.py in getTableData at line 651
fontTools/ttLib/ttFont.py in _writeTable at line 633
fontTools/ttLib/ttFont.py in _save at line 212
fontTools/ttLib/ttFont.py in save at line 173
```
Variables at point of error:
```python
formatstring = ">llIIHHQQhhhhHHhhh"
elements = [
65536,
65601,
1208942685,
1594834165,
3,
1000,
3551183604,
3640213847,
-132,
-170.009,
788,
835,
0,
3,
2,
0,
0
]
```
As you can see the value `-170.009` would trigger the error. If integers are expected then rounding should probably be applied.
</issue>
<code>
[start of Lib/fontTools/ttLib/tables/_h_e_a_d.py]
1 from __future__ import print_function, division, absolute_import
2 from fontTools.misc.py23 import *
3 from fontTools.misc import sstruct
4 from fontTools.misc.textTools import safeEval, num2binary, binary2num
5 from fontTools.misc.timeTools import timestampFromString, timestampToString, timestampNow
6 from fontTools.misc.timeTools import epoch_diff as mac_epoch_diff # For backward compat
7 from . import DefaultTable
8 import logging
9
10
11 log = logging.getLogger(__name__)
12
13 headFormat = """
14 > # big endian
15 tableVersion: 16.16F
16 fontRevision: 16.16F
17 checkSumAdjustment: I
18 magicNumber: I
19 flags: H
20 unitsPerEm: H
21 created: Q
22 modified: Q
23 xMin: h
24 yMin: h
25 xMax: h
26 yMax: h
27 macStyle: H
28 lowestRecPPEM: H
29 fontDirectionHint: h
30 indexToLocFormat: h
31 glyphDataFormat: h
32 """
33
34 class table__h_e_a_d(DefaultTable.DefaultTable):
35
36 dependencies = ['maxp', 'loca', 'CFF ']
37
38 def decompile(self, data, ttFont):
39 dummy, rest = sstruct.unpack2(headFormat, data, self)
40 if rest:
41 # this is quite illegal, but there seem to be fonts out there that do this
42 log.warning("extra bytes at the end of 'head' table")
43 assert rest == "\0\0"
44
45 # For timestamp fields, ignore the top four bytes. Some fonts have
46 # bogus values there. Since till 2038 those bytes only can be zero,
47 # ignore them.
48 #
49 # https://github.com/fonttools/fonttools/issues/99#issuecomment-66776810
50 for stamp in 'created', 'modified':
51 value = getattr(self, stamp)
52 if value > 0xFFFFFFFF:
53 log.warning("'%s' timestamp out of range; ignoring top bytes", stamp)
54 value &= 0xFFFFFFFF
55 setattr(self, stamp, value)
56 if value < 0x7C259DC0: # January 1, 1970 00:00:00
57 log.warning("'%s' timestamp seems very low; regarding as unix timestamp", stamp)
58 value += 0x7C259DC0
59 setattr(self, stamp, value)
60
61 def compile(self, ttFont):
62 if ttFont.recalcBBoxes:
63 # For TT-flavored fonts, xMin, yMin, xMax and yMax are set in table__m_a_x_p.recalc().
64 if 'CFF ' in ttFont:
65 topDict = ttFont['CFF '].cff.topDictIndex[0]
66 self.xMin, self.yMin, self.xMax, self.yMax = topDict.FontBBox
67 if ttFont.recalcTimestamp:
68 self.modified = timestampNow()
69 data = sstruct.pack(headFormat, self)
70 return data
71
72 def toXML(self, writer, ttFont):
73 writer.comment("Most of this table will be recalculated by the compiler")
74 writer.newline()
75 formatstring, names, fixes = sstruct.getformat(headFormat)
76 for name in names:
77 value = getattr(self, name)
78 if name in ("created", "modified"):
79 value = timestampToString(value)
80 if name in ("magicNumber", "checkSumAdjustment"):
81 if value < 0:
82 value = value + 0x100000000
83 value = hex(value)
84 if value[-1:] == "L":
85 value = value[:-1]
86 elif name in ("macStyle", "flags"):
87 value = num2binary(value, 16)
88 writer.simpletag(name, value=value)
89 writer.newline()
90
91 def fromXML(self, name, attrs, content, ttFont):
92 value = attrs["value"]
93 if name in ("created", "modified"):
94 value = timestampFromString(value)
95 elif name in ("macStyle", "flags"):
96 value = binary2num(value)
97 else:
98 value = safeEval(value)
99 setattr(self, name, value)
100
[end of Lib/fontTools/ttLib/tables/_h_e_a_d.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/Lib/fontTools/ttLib/tables/_h_e_a_d.py b/Lib/fontTools/ttLib/tables/_h_e_a_d.py
--- a/Lib/fontTools/ttLib/tables/_h_e_a_d.py
+++ b/Lib/fontTools/ttLib/tables/_h_e_a_d.py
@@ -4,6 +4,7 @@
from fontTools.misc.textTools import safeEval, num2binary, binary2num
from fontTools.misc.timeTools import timestampFromString, timestampToString, timestampNow
from fontTools.misc.timeTools import epoch_diff as mac_epoch_diff # For backward compat
+from fontTools.misc.arrayTools import intRect
from . import DefaultTable
import logging
@@ -63,7 +64,7 @@
# For TT-flavored fonts, xMin, yMin, xMax and yMax are set in table__m_a_x_p.recalc().
if 'CFF ' in ttFont:
topDict = ttFont['CFF '].cff.topDictIndex[0]
- self.xMin, self.yMin, self.xMax, self.yMax = topDict.FontBBox
+ self.xMin, self.yMin, self.xMax, self.yMax = intRect(topDict.FontBBox)
if ttFont.recalcTimestamp:
self.modified = timestampNow()
data = sstruct.pack(headFormat, self)
|
{"golden_diff": "diff --git a/Lib/fontTools/ttLib/tables/_h_e_a_d.py b/Lib/fontTools/ttLib/tables/_h_e_a_d.py\n--- a/Lib/fontTools/ttLib/tables/_h_e_a_d.py\n+++ b/Lib/fontTools/ttLib/tables/_h_e_a_d.py\n@@ -4,6 +4,7 @@\n from fontTools.misc.textTools import safeEval, num2binary, binary2num\n from fontTools.misc.timeTools import timestampFromString, timestampToString, timestampNow\n from fontTools.misc.timeTools import epoch_diff as mac_epoch_diff # For backward compat\n+from fontTools.misc.arrayTools import intRect\n from . import DefaultTable\n import logging\n \n@@ -63,7 +64,7 @@\n \t\t\t# For TT-flavored fonts, xMin, yMin, xMax and yMax are set in table__m_a_x_p.recalc().\n \t\t\tif 'CFF ' in ttFont:\n \t\t\t\ttopDict = ttFont['CFF '].cff.topDictIndex[0]\n-\t\t\t\tself.xMin, self.yMin, self.xMax, self.yMax = topDict.FontBBox\n+\t\t\t\tself.xMin, self.yMin, self.xMax, self.yMax = intRect(topDict.FontBBox)\n \t\tif ttFont.recalcTimestamp:\n \t\t\tself.modified = timestampNow()\n \t\tdata = sstruct.pack(headFormat, self)\n", "issue": "Float yMin value: required argument is not an integer\nIf a font file has a float value in `yMin`\u2014and I assume equally in `xMin`, `xMax` or `yMax`\u2014it will fail to save with the error `required argument is not an integer` ([`fontTools/misc/sstruct.py in pack at line 75`](https://github.com/fonttools/fonttools/blob/3.40.0/Lib/fontTools/misc/sstruct.py#L75), fonttools v3.40.0).\r\n\r\nTrace:\r\n```\r\nfontTools/misc/sstruct.py in pack at line 75\r\nfontTools/ttLib/tables/_h_e_a_d.py in compile at line 69\r\nfontTools/ttLib/ttFont.py in getTableData at line 651\r\nfontTools/ttLib/ttFont.py in _writeTable at line 633\r\nfontTools/ttLib/ttFont.py in _save at line 212\r\nfontTools/ttLib/ttFont.py in save at line 173\r\n```\r\n\r\nVariables at point of error:\r\n```python\r\nformatstring = \">llIIHHQQhhhhHHhhh\"\r\nelements = [\r\n 65536, \r\n 65601, \r\n 1208942685, \r\n 1594834165, \r\n 3, \r\n 1000, \r\n 3551183604, \r\n 3640213847, \r\n -132, \r\n -170.009, \r\n 788, \r\n 835, \r\n 0, \r\n 3, \r\n 2, \r\n 0, \r\n 0\r\n]\r\n```\r\n\r\nAs you can see the value `-170.009` would trigger the error. If integers are expected then rounding should probably be applied.\n", "before_files": [{"content": "from __future__ import print_function, division, absolute_import\nfrom fontTools.misc.py23 import *\nfrom fontTools.misc import sstruct\nfrom fontTools.misc.textTools import safeEval, num2binary, binary2num\nfrom fontTools.misc.timeTools import timestampFromString, timestampToString, timestampNow\nfrom fontTools.misc.timeTools import epoch_diff as mac_epoch_diff # For backward compat\nfrom . import DefaultTable\nimport logging\n\n\nlog = logging.getLogger(__name__)\n\nheadFormat = \"\"\"\n\t\t>\t# big endian\n\t\ttableVersion: 16.16F\n\t\tfontRevision: 16.16F\n\t\tcheckSumAdjustment: I\n\t\tmagicNumber: I\n\t\tflags: H\n\t\tunitsPerEm: H\n\t\tcreated: Q\n\t\tmodified: Q\n\t\txMin: h\n\t\tyMin: h\n\t\txMax: h\n\t\tyMax: h\n\t\tmacStyle: H\n\t\tlowestRecPPEM: H\n\t\tfontDirectionHint: h\n\t\tindexToLocFormat: h\n\t\tglyphDataFormat: h\n\"\"\"\n\nclass table__h_e_a_d(DefaultTable.DefaultTable):\n\n\tdependencies = ['maxp', 'loca', 'CFF ']\n\n\tdef decompile(self, data, ttFont):\n\t\tdummy, rest = sstruct.unpack2(headFormat, data, self)\n\t\tif rest:\n\t\t\t# this is quite illegal, but there seem to be fonts out there that do this\n\t\t\tlog.warning(\"extra bytes at the end of 'head' table\")\n\t\t\tassert rest == \"\\0\\0\"\n\n\t\t# For timestamp fields, ignore the top four bytes. Some fonts have\n\t\t# bogus values there. Since till 2038 those bytes only can be zero,\n\t\t# ignore them.\n\t\t#\n\t\t# https://github.com/fonttools/fonttools/issues/99#issuecomment-66776810\n\t\tfor stamp in 'created', 'modified':\n\t\t\tvalue = getattr(self, stamp)\n\t\t\tif value > 0xFFFFFFFF:\n\t\t\t\tlog.warning(\"'%s' timestamp out of range; ignoring top bytes\", stamp)\n\t\t\t\tvalue &= 0xFFFFFFFF\n\t\t\t\tsetattr(self, stamp, value)\n\t\t\tif value < 0x7C259DC0: # January 1, 1970 00:00:00\n\t\t\t\tlog.warning(\"'%s' timestamp seems very low; regarding as unix timestamp\", stamp)\n\t\t\t\tvalue += 0x7C259DC0\n\t\t\t\tsetattr(self, stamp, value)\n\n\tdef compile(self, ttFont):\n\t\tif ttFont.recalcBBoxes:\n\t\t\t# For TT-flavored fonts, xMin, yMin, xMax and yMax are set in table__m_a_x_p.recalc().\n\t\t\tif 'CFF ' in ttFont:\n\t\t\t\ttopDict = ttFont['CFF '].cff.topDictIndex[0]\n\t\t\t\tself.xMin, self.yMin, self.xMax, self.yMax = topDict.FontBBox\n\t\tif ttFont.recalcTimestamp:\n\t\t\tself.modified = timestampNow()\n\t\tdata = sstruct.pack(headFormat, self)\n\t\treturn data\n\n\tdef toXML(self, writer, ttFont):\n\t\twriter.comment(\"Most of this table will be recalculated by the compiler\")\n\t\twriter.newline()\n\t\tformatstring, names, fixes = sstruct.getformat(headFormat)\n\t\tfor name in names:\n\t\t\tvalue = getattr(self, name)\n\t\t\tif name in (\"created\", \"modified\"):\n\t\t\t\tvalue = timestampToString(value)\n\t\t\tif name in (\"magicNumber\", \"checkSumAdjustment\"):\n\t\t\t\tif value < 0:\n\t\t\t\t\tvalue = value + 0x100000000\n\t\t\t\tvalue = hex(value)\n\t\t\t\tif value[-1:] == \"L\":\n\t\t\t\t\tvalue = value[:-1]\n\t\t\telif name in (\"macStyle\", \"flags\"):\n\t\t\t\tvalue = num2binary(value, 16)\n\t\t\twriter.simpletag(name, value=value)\n\t\t\twriter.newline()\n\n\tdef fromXML(self, name, attrs, content, ttFont):\n\t\tvalue = attrs[\"value\"]\n\t\tif name in (\"created\", \"modified\"):\n\t\t\tvalue = timestampFromString(value)\n\t\telif name in (\"macStyle\", \"flags\"):\n\t\t\tvalue = binary2num(value)\n\t\telse:\n\t\t\tvalue = safeEval(value)\n\t\tsetattr(self, name, value)\n", "path": "Lib/fontTools/ttLib/tables/_h_e_a_d.py"}]}
| 2,151 | 302 |
gh_patches_debug_58005
|
rasdani/github-patches
|
git_diff
|
CiviWiki__OpenCiviWiki-1042
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
{FEAT}: Automated testing with actions.
### Idea summary
Usage of GitHub actions.
### Further details
We can use GitHub Actions to check/test the code that is being pushed upstream via PRs and it can be tested before merging automatically (Technically it is Continuous Integration).
</issue>
<code>
[start of project/accounts/models.py]
1 from django.contrib.auth.models import AbstractUser
2 import os
3 import io
4 from django.core.files.storage import default_storage
5 from django.conf import settings
6 from django.db import models
7 from PIL import Image, ImageOps
8 from django.core.files.uploadedfile import InMemoryUploadedFile
9
10 from taggit.managers import TaggableManager
11
12 from api.models.category import Category
13 from common.utils import PathAndRename
14
15
16 class User(AbstractUser):
17 """
18 A new custom User model for any functionality needed in the future. Extending AbstractUser
19 allows for adding new fields to the user model as needed.
20 """
21
22 class Meta:
23 db_table = "users"
24
25
26 # Image manipulation constants
27 PROFILE_IMG_SIZE = (171, 171)
28 PROFILE_IMG_THUMB_SIZE = (40, 40)
29 WHITE_BG = (255, 255, 255)
30
31
32 class ProfileManager(models.Manager):
33 def summarize(self, profile):
34 from api.models.civi import Civi
35
36 data = {
37 "username": profile.user.username,
38 "first_name": profile.first_name,
39 "last_name": profile.last_name,
40 "about_me": profile.about_me,
41 "history": [
42 Civi.objects.serialize(c)
43 for c in Civi.objects.filter(author_id=profile.id).order_by("-created")
44 ],
45 "profile_image": profile.profile_image_url,
46 "followers": self.followers(profile),
47 "following": self.following(profile),
48 }
49 return data
50
51 def chip_summarize(self, profile):
52 data = {
53 "username": profile.user.username,
54 "first_name": profile.first_name,
55 "last_name": profile.last_name,
56 "profile_image": profile.profile_image_url,
57 }
58 return data
59
60 def card_summarize(self, profile, request_profile):
61 # Length at which to truncate 'about me' text
62 about_me_truncate_length = 150
63
64 # If 'about me' text is longer than 150 characters... add elipsis (truncate)
65 ellipsis_if_too_long = (
66 "" if len(profile.about_me) <= about_me_truncate_length else "..."
67 )
68
69 data = {
70 "id": profile.user.id,
71 "username": profile.user.username,
72 "first_name": profile.first_name,
73 "last_name": profile.last_name,
74 "about_me": profile.about_me[:about_me_truncate_length] + ellipsis_if_too_long,
75 "profile_image": profile.profile_image_url,
76 "follow_state": True
77 if profile in request_profile.following.all()
78 else False,
79 "request_profile": request_profile.first_name,
80 }
81 return data
82
83 def followers(self, profile):
84 return [self.chip_summarize(follower) for follower in profile.followers.all()]
85
86 def following(self, profile):
87 return [self.chip_summarize(following) for following in profile.following.all()]
88
89
90 profile_upload_path = PathAndRename("")
91
92
93 class Profile(models.Model):
94 user = models.ForeignKey(User, on_delete=models.CASCADE)
95 first_name = models.CharField(max_length=63, blank=False)
96 last_name = models.CharField(max_length=63, blank=False)
97 about_me = models.CharField(max_length=511, blank=True)
98
99 categories = models.ManyToManyField(
100 Category, related_name="user_categories", symmetrical=False
101 )
102 tags = TaggableManager()
103
104 followers = models.ManyToManyField(
105 "self", related_name="follower", symmetrical=False
106 )
107 following = models.ManyToManyField(
108 "self", related_name="followings", symmetrical=False
109 )
110
111 is_verified = models.BooleanField(default=False)
112 full_profile = models.BooleanField(default=False)
113
114 objects = ProfileManager()
115 profile_image = models.ImageField(
116 upload_to=profile_upload_path, blank=True, null=True
117 )
118 profile_image_thumb = models.ImageField(
119 upload_to=profile_upload_path, blank=True, null=True
120 )
121
122 @property
123 def full_name(self):
124 """Returns the person's full name."""
125
126 return f"{self.first_name} {self.last_name}"
127
128 @property
129 def profile_image_url(self):
130 """Return placeholder profile image if user didn't upload one"""
131
132 if self.profile_image:
133 file_exists = default_storage.exists(
134 os.path.join(settings.MEDIA_ROOT, self.profile_image.name)
135 )
136 if file_exists:
137 return self.profile_image.url
138
139 return "/static/img/no_image_md.png"
140
141 @property
142 def profile_image_thumb_url(self):
143 """Return placeholder profile image if user didn't upload one"""
144
145 if self.profile_image_thumb:
146 file_exists = default_storage.exists(
147 os.path.join(settings.MEDIA_ROOT, self.profile_image_thumb.name)
148 )
149 if file_exists:
150 return self.profile_image_thumb.url
151
152 return "/static/img/no_image_md.png"
153
154 def __init__(self, *args, **kwargs):
155 super(Profile, self).__init__(*args, **kwargs)
156
157 def save(self, *args, **kwargs):
158 """ Image crop/resize and thumbnail creation """
159
160 # New Profile image --
161 if self.profile_image:
162 self.resize_profile_image()
163
164 self.full_profile = self.is_full_profile()
165
166 super(Profile, self).save(*args, **kwargs)
167
168 def resize_profile_image(self):
169 """
170 Resizes and crops the user uploaded image and creates a thumbnail version of it
171 """
172 profile_image_field = self.profile_image
173 image_file = io.StringIO(profile_image_field.read())
174 profile_image = Image.open(image_file)
175 profile_image.load()
176
177 # Resize image
178 profile_image = ImageOps.fit(
179 profile_image, PROFILE_IMG_SIZE, Image.ANTIALIAS, centering=(0.5, 0.5)
180 )
181
182 # Convert to JPG image format with white background
183 if profile_image.mode not in ("L", "RGB"):
184 white_bg_img = Image.new("RGB", PROFILE_IMG_SIZE, WHITE_BG)
185 white_bg_img.paste(profile_image, mask=profile_image.split()[3])
186 profile_image = white_bg_img
187
188 # Save new cropped image
189 tmp_image_file = io.StringIO()
190 profile_image.save(tmp_image_file, "JPEG", quality=90)
191 tmp_image_file.seek(0)
192 self.profile_image = InMemoryUploadedFile(
193 tmp_image_file,
194 "ImageField",
195 self.profile_image.name,
196 "image/jpeg",
197 tmp_image_file.len,
198 None,
199 )
200 # Make a Thumbnail Image for the new resized image
201 thumb_image = profile_image.copy()
202 thumb_image.thumbnail(PROFILE_IMG_THUMB_SIZE, resample=Image.ANTIALIAS)
203 tmp_image_file = io.StringIO()
204 thumb_image.save(tmp_image_file, "JPEG", quality=90)
205 tmp_image_file.seek(0)
206 self.profile_image_thumb = InMemoryUploadedFile(
207 tmp_image_file,
208 "ImageField",
209 self.profile_image.name,
210 "image/jpeg",
211 tmp_image_file.len,
212 None,
213 )
214
215 def is_full_profile(self):
216 if self.first_name and self.last_name:
217 return True
218 else:
219 return False
220
[end of project/accounts/models.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/project/accounts/models.py b/project/accounts/models.py
--- a/project/accounts/models.py
+++ b/project/accounts/models.py
@@ -9,7 +9,7 @@
from taggit.managers import TaggableManager
-from api.models.category import Category
+from api.models import Category
from common.utils import PathAndRename
|
{"golden_diff": "diff --git a/project/accounts/models.py b/project/accounts/models.py\n--- a/project/accounts/models.py\n+++ b/project/accounts/models.py\n@@ -9,7 +9,7 @@\n \n from taggit.managers import TaggableManager\n \n-from api.models.category import Category\n+from api.models import Category\n from common.utils import PathAndRename\n", "issue": "{FEAT}: Automated testing with actions.\n### Idea summary\n\nUsage of GitHub actions.\n\n### Further details\n\nWe can use GitHub Actions to check/test the code that is being pushed upstream via PRs and it can be tested before merging automatically (Technically it is Continuous Integration).\n", "before_files": [{"content": "from django.contrib.auth.models import AbstractUser\nimport os\nimport io\nfrom django.core.files.storage import default_storage\nfrom django.conf import settings\nfrom django.db import models\nfrom PIL import Image, ImageOps\nfrom django.core.files.uploadedfile import InMemoryUploadedFile\n\nfrom taggit.managers import TaggableManager\n\nfrom api.models.category import Category\nfrom common.utils import PathAndRename\n\n\nclass User(AbstractUser):\n \"\"\"\n A new custom User model for any functionality needed in the future. Extending AbstractUser\n allows for adding new fields to the user model as needed.\n \"\"\"\n\n class Meta:\n db_table = \"users\"\n\n\n# Image manipulation constants\nPROFILE_IMG_SIZE = (171, 171)\nPROFILE_IMG_THUMB_SIZE = (40, 40)\nWHITE_BG = (255, 255, 255)\n\n\nclass ProfileManager(models.Manager):\n def summarize(self, profile):\n from api.models.civi import Civi\n\n data = {\n \"username\": profile.user.username,\n \"first_name\": profile.first_name,\n \"last_name\": profile.last_name,\n \"about_me\": profile.about_me,\n \"history\": [\n Civi.objects.serialize(c)\n for c in Civi.objects.filter(author_id=profile.id).order_by(\"-created\")\n ],\n \"profile_image\": profile.profile_image_url,\n \"followers\": self.followers(profile),\n \"following\": self.following(profile),\n }\n return data\n\n def chip_summarize(self, profile):\n data = {\n \"username\": profile.user.username,\n \"first_name\": profile.first_name,\n \"last_name\": profile.last_name,\n \"profile_image\": profile.profile_image_url,\n }\n return data\n\n def card_summarize(self, profile, request_profile):\n # Length at which to truncate 'about me' text\n about_me_truncate_length = 150\n\n # If 'about me' text is longer than 150 characters... add elipsis (truncate)\n ellipsis_if_too_long = (\n \"\" if len(profile.about_me) <= about_me_truncate_length else \"...\"\n )\n\n data = {\n \"id\": profile.user.id,\n \"username\": profile.user.username,\n \"first_name\": profile.first_name,\n \"last_name\": profile.last_name,\n \"about_me\": profile.about_me[:about_me_truncate_length] + ellipsis_if_too_long,\n \"profile_image\": profile.profile_image_url,\n \"follow_state\": True\n if profile in request_profile.following.all()\n else False,\n \"request_profile\": request_profile.first_name,\n }\n return data\n\n def followers(self, profile):\n return [self.chip_summarize(follower) for follower in profile.followers.all()]\n\n def following(self, profile):\n return [self.chip_summarize(following) for following in profile.following.all()]\n\n\nprofile_upload_path = PathAndRename(\"\")\n\n\nclass Profile(models.Model):\n user = models.ForeignKey(User, on_delete=models.CASCADE)\n first_name = models.CharField(max_length=63, blank=False)\n last_name = models.CharField(max_length=63, blank=False)\n about_me = models.CharField(max_length=511, blank=True)\n\n categories = models.ManyToManyField(\n Category, related_name=\"user_categories\", symmetrical=False\n )\n tags = TaggableManager()\n\n followers = models.ManyToManyField(\n \"self\", related_name=\"follower\", symmetrical=False\n )\n following = models.ManyToManyField(\n \"self\", related_name=\"followings\", symmetrical=False\n )\n\n is_verified = models.BooleanField(default=False)\n full_profile = models.BooleanField(default=False)\n\n objects = ProfileManager()\n profile_image = models.ImageField(\n upload_to=profile_upload_path, blank=True, null=True\n )\n profile_image_thumb = models.ImageField(\n upload_to=profile_upload_path, blank=True, null=True\n )\n\n @property\n def full_name(self):\n \"\"\"Returns the person's full name.\"\"\"\n\n return f\"{self.first_name} {self.last_name}\"\n\n @property\n def profile_image_url(self):\n \"\"\"Return placeholder profile image if user didn't upload one\"\"\"\n\n if self.profile_image:\n file_exists = default_storage.exists(\n os.path.join(settings.MEDIA_ROOT, self.profile_image.name)\n )\n if file_exists:\n return self.profile_image.url\n\n return \"/static/img/no_image_md.png\"\n\n @property\n def profile_image_thumb_url(self):\n \"\"\"Return placeholder profile image if user didn't upload one\"\"\"\n\n if self.profile_image_thumb:\n file_exists = default_storage.exists(\n os.path.join(settings.MEDIA_ROOT, self.profile_image_thumb.name)\n )\n if file_exists:\n return self.profile_image_thumb.url\n\n return \"/static/img/no_image_md.png\"\n\n def __init__(self, *args, **kwargs):\n super(Profile, self).__init__(*args, **kwargs)\n\n def save(self, *args, **kwargs):\n \"\"\" Image crop/resize and thumbnail creation \"\"\"\n\n # New Profile image --\n if self.profile_image:\n self.resize_profile_image()\n\n self.full_profile = self.is_full_profile()\n\n super(Profile, self).save(*args, **kwargs)\n\n def resize_profile_image(self):\n \"\"\"\n Resizes and crops the user uploaded image and creates a thumbnail version of it\n \"\"\"\n profile_image_field = self.profile_image\n image_file = io.StringIO(profile_image_field.read())\n profile_image = Image.open(image_file)\n profile_image.load()\n\n # Resize image\n profile_image = ImageOps.fit(\n profile_image, PROFILE_IMG_SIZE, Image.ANTIALIAS, centering=(0.5, 0.5)\n )\n\n # Convert to JPG image format with white background\n if profile_image.mode not in (\"L\", \"RGB\"):\n white_bg_img = Image.new(\"RGB\", PROFILE_IMG_SIZE, WHITE_BG)\n white_bg_img.paste(profile_image, mask=profile_image.split()[3])\n profile_image = white_bg_img\n\n # Save new cropped image\n tmp_image_file = io.StringIO()\n profile_image.save(tmp_image_file, \"JPEG\", quality=90)\n tmp_image_file.seek(0)\n self.profile_image = InMemoryUploadedFile(\n tmp_image_file,\n \"ImageField\",\n self.profile_image.name,\n \"image/jpeg\",\n tmp_image_file.len,\n None,\n )\n # Make a Thumbnail Image for the new resized image\n thumb_image = profile_image.copy()\n thumb_image.thumbnail(PROFILE_IMG_THUMB_SIZE, resample=Image.ANTIALIAS)\n tmp_image_file = io.StringIO()\n thumb_image.save(tmp_image_file, \"JPEG\", quality=90)\n tmp_image_file.seek(0)\n self.profile_image_thumb = InMemoryUploadedFile(\n tmp_image_file,\n \"ImageField\",\n self.profile_image.name,\n \"image/jpeg\",\n tmp_image_file.len,\n None,\n )\n\n def is_full_profile(self):\n if self.first_name and self.last_name:\n return True\n else:\n return False\n", "path": "project/accounts/models.py"}]}
| 2,688 | 71 |
gh_patches_debug_6860
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-5858
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
TLS logging broken with new cryptography
https://github.com/pyca/cryptography/pull/8391 dropped `SSL_get_server_tmp_key()` so we need to disable the code that uses it if it's not available.
</issue>
<code>
[start of scrapy/utils/ssl.py]
1 import OpenSSL._util as pyOpenSSLutil
2 import OpenSSL.SSL
3
4 from scrapy.utils.python import to_unicode
5
6
7 def ffi_buf_to_string(buf):
8 return to_unicode(pyOpenSSLutil.ffi.string(buf))
9
10
11 def x509name_to_string(x509name):
12 # from OpenSSL.crypto.X509Name.__repr__
13 result_buffer = pyOpenSSLutil.ffi.new("char[]", 512)
14 pyOpenSSLutil.lib.X509_NAME_oneline(
15 x509name._name, result_buffer, len(result_buffer)
16 )
17
18 return ffi_buf_to_string(result_buffer)
19
20
21 def get_temp_key_info(ssl_object):
22 # adapted from OpenSSL apps/s_cb.c::ssl_print_tmp_key()
23 temp_key_p = pyOpenSSLutil.ffi.new("EVP_PKEY **")
24 if not pyOpenSSLutil.lib.SSL_get_server_tmp_key(ssl_object, temp_key_p):
25 return None
26 temp_key = temp_key_p[0]
27 if temp_key == pyOpenSSLutil.ffi.NULL:
28 return None
29 temp_key = pyOpenSSLutil.ffi.gc(temp_key, pyOpenSSLutil.lib.EVP_PKEY_free)
30 key_info = []
31 key_type = pyOpenSSLutil.lib.EVP_PKEY_id(temp_key)
32 if key_type == pyOpenSSLutil.lib.EVP_PKEY_RSA:
33 key_info.append("RSA")
34 elif key_type == pyOpenSSLutil.lib.EVP_PKEY_DH:
35 key_info.append("DH")
36 elif key_type == pyOpenSSLutil.lib.EVP_PKEY_EC:
37 key_info.append("ECDH")
38 ec_key = pyOpenSSLutil.lib.EVP_PKEY_get1_EC_KEY(temp_key)
39 ec_key = pyOpenSSLutil.ffi.gc(ec_key, pyOpenSSLutil.lib.EC_KEY_free)
40 nid = pyOpenSSLutil.lib.EC_GROUP_get_curve_name(
41 pyOpenSSLutil.lib.EC_KEY_get0_group(ec_key)
42 )
43 cname = pyOpenSSLutil.lib.EC_curve_nid2nist(nid)
44 if cname == pyOpenSSLutil.ffi.NULL:
45 cname = pyOpenSSLutil.lib.OBJ_nid2sn(nid)
46 key_info.append(ffi_buf_to_string(cname))
47 else:
48 key_info.append(ffi_buf_to_string(pyOpenSSLutil.lib.OBJ_nid2sn(key_type)))
49 key_info.append(f"{pyOpenSSLutil.lib.EVP_PKEY_bits(temp_key)} bits")
50 return ", ".join(key_info)
51
52
53 def get_openssl_version():
54 system_openssl = OpenSSL.SSL.SSLeay_version(OpenSSL.SSL.SSLEAY_VERSION).decode(
55 "ascii", errors="replace"
56 )
57 return f"{OpenSSL.version.__version__} ({system_openssl})"
58
[end of scrapy/utils/ssl.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scrapy/utils/ssl.py b/scrapy/utils/ssl.py
--- a/scrapy/utils/ssl.py
+++ b/scrapy/utils/ssl.py
@@ -20,6 +20,9 @@
def get_temp_key_info(ssl_object):
# adapted from OpenSSL apps/s_cb.c::ssl_print_tmp_key()
+ if not hasattr(pyOpenSSLutil.lib, "SSL_get_server_tmp_key"):
+ # removed in cryptography 40.0.0
+ return None
temp_key_p = pyOpenSSLutil.ffi.new("EVP_PKEY **")
if not pyOpenSSLutil.lib.SSL_get_server_tmp_key(ssl_object, temp_key_p):
return None
|
{"golden_diff": "diff --git a/scrapy/utils/ssl.py b/scrapy/utils/ssl.py\n--- a/scrapy/utils/ssl.py\n+++ b/scrapy/utils/ssl.py\n@@ -20,6 +20,9 @@\n \n def get_temp_key_info(ssl_object):\n # adapted from OpenSSL apps/s_cb.c::ssl_print_tmp_key()\n+ if not hasattr(pyOpenSSLutil.lib, \"SSL_get_server_tmp_key\"):\n+ # removed in cryptography 40.0.0\n+ return None\n temp_key_p = pyOpenSSLutil.ffi.new(\"EVP_PKEY **\")\n if not pyOpenSSLutil.lib.SSL_get_server_tmp_key(ssl_object, temp_key_p):\n return None\n", "issue": "TLS logging broken with new cryptography\nhttps://github.com/pyca/cryptography/pull/8391 dropped `SSL_get_server_tmp_key()` so we need to disable the code that uses it if it's not available.\n", "before_files": [{"content": "import OpenSSL._util as pyOpenSSLutil\nimport OpenSSL.SSL\n\nfrom scrapy.utils.python import to_unicode\n\n\ndef ffi_buf_to_string(buf):\n return to_unicode(pyOpenSSLutil.ffi.string(buf))\n\n\ndef x509name_to_string(x509name):\n # from OpenSSL.crypto.X509Name.__repr__\n result_buffer = pyOpenSSLutil.ffi.new(\"char[]\", 512)\n pyOpenSSLutil.lib.X509_NAME_oneline(\n x509name._name, result_buffer, len(result_buffer)\n )\n\n return ffi_buf_to_string(result_buffer)\n\n\ndef get_temp_key_info(ssl_object):\n # adapted from OpenSSL apps/s_cb.c::ssl_print_tmp_key()\n temp_key_p = pyOpenSSLutil.ffi.new(\"EVP_PKEY **\")\n if not pyOpenSSLutil.lib.SSL_get_server_tmp_key(ssl_object, temp_key_p):\n return None\n temp_key = temp_key_p[0]\n if temp_key == pyOpenSSLutil.ffi.NULL:\n return None\n temp_key = pyOpenSSLutil.ffi.gc(temp_key, pyOpenSSLutil.lib.EVP_PKEY_free)\n key_info = []\n key_type = pyOpenSSLutil.lib.EVP_PKEY_id(temp_key)\n if key_type == pyOpenSSLutil.lib.EVP_PKEY_RSA:\n key_info.append(\"RSA\")\n elif key_type == pyOpenSSLutil.lib.EVP_PKEY_DH:\n key_info.append(\"DH\")\n elif key_type == pyOpenSSLutil.lib.EVP_PKEY_EC:\n key_info.append(\"ECDH\")\n ec_key = pyOpenSSLutil.lib.EVP_PKEY_get1_EC_KEY(temp_key)\n ec_key = pyOpenSSLutil.ffi.gc(ec_key, pyOpenSSLutil.lib.EC_KEY_free)\n nid = pyOpenSSLutil.lib.EC_GROUP_get_curve_name(\n pyOpenSSLutil.lib.EC_KEY_get0_group(ec_key)\n )\n cname = pyOpenSSLutil.lib.EC_curve_nid2nist(nid)\n if cname == pyOpenSSLutil.ffi.NULL:\n cname = pyOpenSSLutil.lib.OBJ_nid2sn(nid)\n key_info.append(ffi_buf_to_string(cname))\n else:\n key_info.append(ffi_buf_to_string(pyOpenSSLutil.lib.OBJ_nid2sn(key_type)))\n key_info.append(f\"{pyOpenSSLutil.lib.EVP_PKEY_bits(temp_key)} bits\")\n return \", \".join(key_info)\n\n\ndef get_openssl_version():\n system_openssl = OpenSSL.SSL.SSLeay_version(OpenSSL.SSL.SSLEAY_VERSION).decode(\n \"ascii\", errors=\"replace\"\n )\n return f\"{OpenSSL.version.__version__} ({system_openssl})\"\n", "path": "scrapy/utils/ssl.py"}]}
| 1,294 | 155 |
gh_patches_debug_50223
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-916
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Release 2.1.6
On the docket:
+ [x] Don't delete the root `__init__.py` when devendoring. #915
</issue>
<code>
[start of pex/version.py]
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = '2.1.5'
5
[end of pex/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = '2.1.5'
+__version__ = '2.1.6'
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = '2.1.5'\n+__version__ = '2.1.6'\n", "issue": "Release 2.1.6\nOn the docket:\r\n+ [x] Don't delete the root `__init__.py` when devendoring. #915\r\n\n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = '2.1.5'\n", "path": "pex/version.py"}]}
| 620 | 94 |
gh_patches_debug_14868
|
rasdani/github-patches
|
git_diff
|
ray-project__ray-6571
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[tune] Ray Tune fails to parse typing hints of the function for experiment
### What is the problem?
If the function for experiment has a [typing hint](https://docs.python.org/3/library/typing.html) for its argument `config`, then Ray Tune fails to parse the argument and assumes that there is a reporter signature. The cause of this problem is in this source code:
https://github.com/ray-project/ray/blob/1eaa57c98f8870a43e1ea14ec011b6bd4be97c8d/python/ray/tune/function_runner.py#L250-L257
Changing
`func_args = inspect.getargspec(train_func).args`
to
`func_args = inspect.getfullargspec(train_func).args`
might solve the problem.
*Ray version and other system information (Python version, TensorFlow version, OS):*
Ray: 0.8.0
Python: 3.7.5
OS: Ubuntu 18.04
*Does the problem occur on the [latest wheels](https://ray.readthedocs.io/en/latest/installation.html)?*
I couldn't install the latest wheel. So I can't confirm it.
### Reproduction
The following is a modification of the first examples in the [Ray Tune Documentation](https://ray.readthedocs.io/en/latest/tune.html#quick-start), where I added a typing hint `config: Dict[str, Any]` for the argument of function `train_mnist`.
```
from typing import Dict, Any
import torch.optim as optim
from ray import tune
from ray.tune.examples.mnist_pytorch import get_data_loaders, ConvNet, train, test
def train_mnist(config: Dict[str, Any]):
train_loader, test_loader = get_data_loaders()
model = ConvNet()
optimizer = optim.SGD(model.parameters(), lr=config["lr"])
for i in range(10):
train(model, optimizer, train_loader)
acc = test(model, test_loader)
tune.track.log(mean_accuracy=acc)
analysis = tune.run(train_mnist, config={"lr": tune.grid_search([0.001, 0.01, 0.1])})
print("Best config: ", analysis.get_best_config(metric="mean_accuracy"))
# Get a dataframe for analyzing trial results.
df = analysis.dataframe()
```
When running the code you get this error message:
**TypeError: train_mnist() takes 1 positional argument but 2 were given**
</issue>
<code>
[start of python/ray/tune/function_runner.py]
1 from __future__ import absolute_import
2 from __future__ import division
3 from __future__ import print_function
4
5 import logging
6 import time
7 import inspect
8 import threading
9 import traceback
10 from six.moves import queue
11
12 from ray.tune import track
13 from ray.tune import TuneError
14 from ray.tune.trainable import Trainable
15 from ray.tune.result import TIME_THIS_ITER_S, RESULT_DUPLICATE
16
17 logger = logging.getLogger(__name__)
18
19 # Time between FunctionRunner checks when fetching
20 # new results after signaling the reporter to continue
21 RESULT_FETCH_TIMEOUT = 0.2
22
23 ERROR_REPORT_TIMEOUT = 10
24 ERROR_FETCH_TIMEOUT = 1
25
26
27 class StatusReporter(object):
28 """Object passed into your function that you can report status through.
29
30 Example:
31 >>> def trainable_function(config, reporter):
32 >>> assert isinstance(reporter, StatusReporter)
33 >>> reporter(timesteps_this_iter=1)
34 """
35
36 def __init__(self, result_queue, continue_semaphore, logdir=None):
37 self._queue = result_queue
38 self._last_report_time = None
39 self._continue_semaphore = continue_semaphore
40 self._logdir = logdir
41
42 def __call__(self, **kwargs):
43 """Report updated training status.
44
45 Pass in `done=True` when the training job is completed.
46
47 Args:
48 kwargs: Latest training result status.
49
50 Example:
51 >>> reporter(mean_accuracy=1, training_iteration=4)
52 >>> reporter(mean_accuracy=1, training_iteration=4, done=True)
53
54 Raises:
55 StopIteration: A StopIteration exception is raised if the trial has
56 been signaled to stop.
57 """
58
59 assert self._last_report_time is not None, (
60 "StatusReporter._start() must be called before the first "
61 "report __call__ is made to ensure correct runtime metrics.")
62
63 # time per iteration is recorded directly in the reporter to ensure
64 # any delays in logging results aren't counted
65 report_time = time.time()
66 if TIME_THIS_ITER_S not in kwargs:
67 kwargs[TIME_THIS_ITER_S] = report_time - self._last_report_time
68 self._last_report_time = report_time
69
70 # add results to a thread-safe queue
71 self._queue.put(kwargs.copy(), block=True)
72
73 # This blocks until notification from the FunctionRunner that the last
74 # result has been returned to Tune and that the function is safe to
75 # resume training.
76 self._continue_semaphore.acquire()
77
78 def _start(self):
79 self._last_report_time = time.time()
80
81 @property
82 def logdir(self):
83 return self._logdir
84
85
86 class _RunnerThread(threading.Thread):
87 """Supervisor thread that runs your script."""
88
89 def __init__(self, entrypoint, error_queue):
90 threading.Thread.__init__(self)
91 self._entrypoint = entrypoint
92 self._error_queue = error_queue
93 self.daemon = True
94
95 def run(self):
96 try:
97 self._entrypoint()
98 except StopIteration:
99 logger.debug(
100 ("Thread runner raised StopIteration. Interperting it as a "
101 "signal to terminate the thread without error."))
102 except Exception as e:
103 logger.exception("Runner Thread raised error.")
104 try:
105 # report the error but avoid indefinite blocking which would
106 # prevent the exception from being propagated in the unlikely
107 # case that something went terribly wrong
108 err_tb_str = traceback.format_exc()
109 self._error_queue.put(
110 err_tb_str, block=True, timeout=ERROR_REPORT_TIMEOUT)
111 except queue.Full:
112 logger.critical(
113 ("Runner Thread was unable to report error to main "
114 "function runner thread. This means a previous error "
115 "was not processed. This should never happen."))
116 raise e
117
118
119 class FunctionRunner(Trainable):
120 """Trainable that runs a user function reporting results.
121
122 This mode of execution does not support checkpoint/restore."""
123
124 _name = "func"
125
126 def _setup(self, config):
127 # Semaphore for notifying the reporter to continue with the computation
128 # and to generate the next result.
129 self._continue_semaphore = threading.Semaphore(0)
130
131 # Queue for passing results between threads
132 self._results_queue = queue.Queue(1)
133
134 # Queue for passing errors back from the thread runner. The error queue
135 # has a max size of one to prevent stacking error and force error
136 # reporting to block until finished.
137 self._error_queue = queue.Queue(1)
138
139 self._status_reporter = StatusReporter(
140 self._results_queue, self._continue_semaphore, self.logdir)
141 self._last_result = {}
142 config = config.copy()
143
144 def entrypoint():
145 return self._trainable_func(config, self._status_reporter)
146
147 # the runner thread is not started until the first call to _train
148 self._runner = _RunnerThread(entrypoint, self._error_queue)
149
150 def _trainable_func(self):
151 """Subclasses can override this to set the trainable func."""
152
153 raise NotImplementedError
154
155 def _train(self):
156 """Implements train() for a Function API.
157
158 If the RunnerThread finishes without reporting "done",
159 Tune will automatically provide a magic keyword __duplicate__
160 along with a result with "done=True". The TrialRunner will handle the
161 result accordingly (see tune/trial_runner.py).
162 """
163 if self._runner.is_alive():
164 # if started and alive, inform the reporter to continue and
165 # generate the next result
166 self._continue_semaphore.release()
167 else:
168 # if not alive, try to start
169 self._status_reporter._start()
170 try:
171 self._runner.start()
172 except RuntimeError:
173 # If this is reached, it means the thread was started and is
174 # now done or has raised an exception.
175 pass
176
177 result = None
178 while result is None and self._runner.is_alive():
179 # fetch the next produced result
180 try:
181 result = self._results_queue.get(
182 block=True, timeout=RESULT_FETCH_TIMEOUT)
183 except queue.Empty:
184 pass
185
186 # if no result were found, then the runner must no longer be alive
187 if result is None:
188 # Try one last time to fetch results in case results were reported
189 # in between the time of the last check and the termination of the
190 # thread runner.
191 try:
192 result = self._results_queue.get(block=False)
193 except queue.Empty:
194 pass
195
196 # check if error occured inside the thread runner
197 if result is None:
198 # only raise an error from the runner if all results are consumed
199 self._report_thread_runner_error(block=True)
200
201 # Under normal conditions, this code should never be reached since
202 # this branch should only be visited if the runner thread raised
203 # an exception. If no exception were raised, it means that the
204 # runner thread never reported any results which should not be
205 # possible when wrapping functions with `wrap_function`.
206 raise TuneError(
207 ("Wrapped function ran until completion without reporting "
208 "results or raising an exception."))
209
210 else:
211 if not self._error_queue.empty():
212 logger.warning(
213 ("Runner error waiting to be raised in main thread. "
214 "Logging all available results first."))
215
216 # This keyword appears if the train_func using the Function API
217 # finishes without "done=True". This duplicates the last result, but
218 # the TrialRunner will not log this result again.
219 if "__duplicate__" in result:
220 new_result = self._last_result.copy()
221 new_result.update(result)
222 result = new_result
223
224 self._last_result = result
225 return result
226
227 def _stop(self):
228 # If everything stayed in synch properly, this should never happen.
229 if not self._results_queue.empty():
230 logger.warning(
231 ("Some results were added after the trial stop condition. "
232 "These results won't be logged."))
233
234 # Check for any errors that might have been missed.
235 self._report_thread_runner_error()
236
237 def _report_thread_runner_error(self, block=False):
238 try:
239 err_tb_str = self._error_queue.get(
240 block=block, timeout=ERROR_FETCH_TIMEOUT)
241 raise TuneError(("Trial raised an exception. Traceback:\n{}"
242 .format(err_tb_str)))
243 except queue.Empty:
244 pass
245
246
247 def wrap_function(train_func):
248
249 use_track = False
250 try:
251 func_args = inspect.getargspec(train_func).args
252 use_track = ("reporter" not in func_args and len(func_args) == 1)
253 if use_track:
254 logger.info("tune.track signature detected.")
255 except Exception:
256 logger.info(
257 "Function inspection failed - assuming reporter signature.")
258
259 class WrappedFunc(FunctionRunner):
260 def _trainable_func(self, config, reporter):
261 output = train_func(config, reporter)
262 # If train_func returns, we need to notify the main event loop
263 # of the last result while avoiding double logging. This is done
264 # with the keyword RESULT_DUPLICATE -- see tune/trial_runner.py.
265 reporter(**{RESULT_DUPLICATE: True})
266 return output
267
268 class WrappedTrackFunc(FunctionRunner):
269 def _trainable_func(self, config, reporter):
270 track.init(_tune_reporter=reporter)
271 output = train_func(config)
272 reporter(**{RESULT_DUPLICATE: True})
273 track.shutdown()
274 return output
275
276 return WrappedTrackFunc if use_track else WrappedFunc
277
[end of python/ray/tune/function_runner.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/python/ray/tune/function_runner.py b/python/ray/tune/function_runner.py
--- a/python/ray/tune/function_runner.py
+++ b/python/ray/tune/function_runner.py
@@ -7,6 +7,7 @@
import inspect
import threading
import traceback
+import sys
from six.moves import queue
from ray.tune import track
@@ -248,7 +249,10 @@
use_track = False
try:
- func_args = inspect.getargspec(train_func).args
+ if sys.version_info >= (3, 3):
+ func_args = inspect.getfullargspec(train_func).args
+ else:
+ func_args = inspect.getargspec(train_func).args
use_track = ("reporter" not in func_args and len(func_args) == 1)
if use_track:
logger.info("tune.track signature detected.")
|
{"golden_diff": "diff --git a/python/ray/tune/function_runner.py b/python/ray/tune/function_runner.py\n--- a/python/ray/tune/function_runner.py\n+++ b/python/ray/tune/function_runner.py\n@@ -7,6 +7,7 @@\n import inspect\n import threading\n import traceback\n+import sys\n from six.moves import queue\n \n from ray.tune import track\n@@ -248,7 +249,10 @@\n \n use_track = False\n try:\n- func_args = inspect.getargspec(train_func).args\n+ if sys.version_info >= (3, 3):\n+ func_args = inspect.getfullargspec(train_func).args\n+ else:\n+ func_args = inspect.getargspec(train_func).args\n use_track = (\"reporter\" not in func_args and len(func_args) == 1)\n if use_track:\n logger.info(\"tune.track signature detected.\")\n", "issue": "[tune] Ray Tune fails to parse typing hints of the function for experiment\n### What is the problem?\r\nIf the function for experiment has a [typing hint](https://docs.python.org/3/library/typing.html) for its argument `config`, then Ray Tune fails to parse the argument and assumes that there is a reporter signature. The cause of this problem is in this source code:\r\nhttps://github.com/ray-project/ray/blob/1eaa57c98f8870a43e1ea14ec011b6bd4be97c8d/python/ray/tune/function_runner.py#L250-L257\r\nChanging \r\n`func_args = inspect.getargspec(train_func).args` \r\nto\r\n`func_args = inspect.getfullargspec(train_func).args` \r\nmight solve the problem.\r\n\r\n*Ray version and other system information (Python version, TensorFlow version, OS):*\r\nRay: 0.8.0\r\nPython: 3.7.5\r\nOS: Ubuntu 18.04\r\n\r\n*Does the problem occur on the [latest wheels](https://ray.readthedocs.io/en/latest/installation.html)?*\r\nI couldn't install the latest wheel. So I can't confirm it.\r\n\r\n### Reproduction\r\nThe following is a modification of the first examples in the [Ray Tune Documentation](https://ray.readthedocs.io/en/latest/tune.html#quick-start), where I added a typing hint `config: Dict[str, Any]` for the argument of function `train_mnist`.\r\n\r\n```\r\nfrom typing import Dict, Any\r\n\r\nimport torch.optim as optim\r\nfrom ray import tune\r\nfrom ray.tune.examples.mnist_pytorch import get_data_loaders, ConvNet, train, test\r\n\r\n\r\ndef train_mnist(config: Dict[str, Any]):\r\n train_loader, test_loader = get_data_loaders()\r\n model = ConvNet()\r\n optimizer = optim.SGD(model.parameters(), lr=config[\"lr\"])\r\n for i in range(10):\r\n train(model, optimizer, train_loader)\r\n acc = test(model, test_loader)\r\n tune.track.log(mean_accuracy=acc)\r\n\r\n\r\nanalysis = tune.run(train_mnist, config={\"lr\": tune.grid_search([0.001, 0.01, 0.1])})\r\n\r\nprint(\"Best config: \", analysis.get_best_config(metric=\"mean_accuracy\"))\r\n\r\n# Get a dataframe for analyzing trial results.\r\ndf = analysis.dataframe()\r\n```\r\nWhen running the code you get this error message:\r\n**TypeError: train_mnist() takes 1 positional argument but 2 were given**\r\n\n", "before_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport logging\nimport time\nimport inspect\nimport threading\nimport traceback\nfrom six.moves import queue\n\nfrom ray.tune import track\nfrom ray.tune import TuneError\nfrom ray.tune.trainable import Trainable\nfrom ray.tune.result import TIME_THIS_ITER_S, RESULT_DUPLICATE\n\nlogger = logging.getLogger(__name__)\n\n# Time between FunctionRunner checks when fetching\n# new results after signaling the reporter to continue\nRESULT_FETCH_TIMEOUT = 0.2\n\nERROR_REPORT_TIMEOUT = 10\nERROR_FETCH_TIMEOUT = 1\n\n\nclass StatusReporter(object):\n \"\"\"Object passed into your function that you can report status through.\n\n Example:\n >>> def trainable_function(config, reporter):\n >>> assert isinstance(reporter, StatusReporter)\n >>> reporter(timesteps_this_iter=1)\n \"\"\"\n\n def __init__(self, result_queue, continue_semaphore, logdir=None):\n self._queue = result_queue\n self._last_report_time = None\n self._continue_semaphore = continue_semaphore\n self._logdir = logdir\n\n def __call__(self, **kwargs):\n \"\"\"Report updated training status.\n\n Pass in `done=True` when the training job is completed.\n\n Args:\n kwargs: Latest training result status.\n\n Example:\n >>> reporter(mean_accuracy=1, training_iteration=4)\n >>> reporter(mean_accuracy=1, training_iteration=4, done=True)\n\n Raises:\n StopIteration: A StopIteration exception is raised if the trial has\n been signaled to stop.\n \"\"\"\n\n assert self._last_report_time is not None, (\n \"StatusReporter._start() must be called before the first \"\n \"report __call__ is made to ensure correct runtime metrics.\")\n\n # time per iteration is recorded directly in the reporter to ensure\n # any delays in logging results aren't counted\n report_time = time.time()\n if TIME_THIS_ITER_S not in kwargs:\n kwargs[TIME_THIS_ITER_S] = report_time - self._last_report_time\n self._last_report_time = report_time\n\n # add results to a thread-safe queue\n self._queue.put(kwargs.copy(), block=True)\n\n # This blocks until notification from the FunctionRunner that the last\n # result has been returned to Tune and that the function is safe to\n # resume training.\n self._continue_semaphore.acquire()\n\n def _start(self):\n self._last_report_time = time.time()\n\n @property\n def logdir(self):\n return self._logdir\n\n\nclass _RunnerThread(threading.Thread):\n \"\"\"Supervisor thread that runs your script.\"\"\"\n\n def __init__(self, entrypoint, error_queue):\n threading.Thread.__init__(self)\n self._entrypoint = entrypoint\n self._error_queue = error_queue\n self.daemon = True\n\n def run(self):\n try:\n self._entrypoint()\n except StopIteration:\n logger.debug(\n (\"Thread runner raised StopIteration. Interperting it as a \"\n \"signal to terminate the thread without error.\"))\n except Exception as e:\n logger.exception(\"Runner Thread raised error.\")\n try:\n # report the error but avoid indefinite blocking which would\n # prevent the exception from being propagated in the unlikely\n # case that something went terribly wrong\n err_tb_str = traceback.format_exc()\n self._error_queue.put(\n err_tb_str, block=True, timeout=ERROR_REPORT_TIMEOUT)\n except queue.Full:\n logger.critical(\n (\"Runner Thread was unable to report error to main \"\n \"function runner thread. This means a previous error \"\n \"was not processed. This should never happen.\"))\n raise e\n\n\nclass FunctionRunner(Trainable):\n \"\"\"Trainable that runs a user function reporting results.\n\n This mode of execution does not support checkpoint/restore.\"\"\"\n\n _name = \"func\"\n\n def _setup(self, config):\n # Semaphore for notifying the reporter to continue with the computation\n # and to generate the next result.\n self._continue_semaphore = threading.Semaphore(0)\n\n # Queue for passing results between threads\n self._results_queue = queue.Queue(1)\n\n # Queue for passing errors back from the thread runner. The error queue\n # has a max size of one to prevent stacking error and force error\n # reporting to block until finished.\n self._error_queue = queue.Queue(1)\n\n self._status_reporter = StatusReporter(\n self._results_queue, self._continue_semaphore, self.logdir)\n self._last_result = {}\n config = config.copy()\n\n def entrypoint():\n return self._trainable_func(config, self._status_reporter)\n\n # the runner thread is not started until the first call to _train\n self._runner = _RunnerThread(entrypoint, self._error_queue)\n\n def _trainable_func(self):\n \"\"\"Subclasses can override this to set the trainable func.\"\"\"\n\n raise NotImplementedError\n\n def _train(self):\n \"\"\"Implements train() for a Function API.\n\n If the RunnerThread finishes without reporting \"done\",\n Tune will automatically provide a magic keyword __duplicate__\n along with a result with \"done=True\". The TrialRunner will handle the\n result accordingly (see tune/trial_runner.py).\n \"\"\"\n if self._runner.is_alive():\n # if started and alive, inform the reporter to continue and\n # generate the next result\n self._continue_semaphore.release()\n else:\n # if not alive, try to start\n self._status_reporter._start()\n try:\n self._runner.start()\n except RuntimeError:\n # If this is reached, it means the thread was started and is\n # now done or has raised an exception.\n pass\n\n result = None\n while result is None and self._runner.is_alive():\n # fetch the next produced result\n try:\n result = self._results_queue.get(\n block=True, timeout=RESULT_FETCH_TIMEOUT)\n except queue.Empty:\n pass\n\n # if no result were found, then the runner must no longer be alive\n if result is None:\n # Try one last time to fetch results in case results were reported\n # in between the time of the last check and the termination of the\n # thread runner.\n try:\n result = self._results_queue.get(block=False)\n except queue.Empty:\n pass\n\n # check if error occured inside the thread runner\n if result is None:\n # only raise an error from the runner if all results are consumed\n self._report_thread_runner_error(block=True)\n\n # Under normal conditions, this code should never be reached since\n # this branch should only be visited if the runner thread raised\n # an exception. If no exception were raised, it means that the\n # runner thread never reported any results which should not be\n # possible when wrapping functions with `wrap_function`.\n raise TuneError(\n (\"Wrapped function ran until completion without reporting \"\n \"results or raising an exception.\"))\n\n else:\n if not self._error_queue.empty():\n logger.warning(\n (\"Runner error waiting to be raised in main thread. \"\n \"Logging all available results first.\"))\n\n # This keyword appears if the train_func using the Function API\n # finishes without \"done=True\". This duplicates the last result, but\n # the TrialRunner will not log this result again.\n if \"__duplicate__\" in result:\n new_result = self._last_result.copy()\n new_result.update(result)\n result = new_result\n\n self._last_result = result\n return result\n\n def _stop(self):\n # If everything stayed in synch properly, this should never happen.\n if not self._results_queue.empty():\n logger.warning(\n (\"Some results were added after the trial stop condition. \"\n \"These results won't be logged.\"))\n\n # Check for any errors that might have been missed.\n self._report_thread_runner_error()\n\n def _report_thread_runner_error(self, block=False):\n try:\n err_tb_str = self._error_queue.get(\n block=block, timeout=ERROR_FETCH_TIMEOUT)\n raise TuneError((\"Trial raised an exception. Traceback:\\n{}\"\n .format(err_tb_str)))\n except queue.Empty:\n pass\n\n\ndef wrap_function(train_func):\n\n use_track = False\n try:\n func_args = inspect.getargspec(train_func).args\n use_track = (\"reporter\" not in func_args and len(func_args) == 1)\n if use_track:\n logger.info(\"tune.track signature detected.\")\n except Exception:\n logger.info(\n \"Function inspection failed - assuming reporter signature.\")\n\n class WrappedFunc(FunctionRunner):\n def _trainable_func(self, config, reporter):\n output = train_func(config, reporter)\n # If train_func returns, we need to notify the main event loop\n # of the last result while avoiding double logging. This is done\n # with the keyword RESULT_DUPLICATE -- see tune/trial_runner.py.\n reporter(**{RESULT_DUPLICATE: True})\n return output\n\n class WrappedTrackFunc(FunctionRunner):\n def _trainable_func(self, config, reporter):\n track.init(_tune_reporter=reporter)\n output = train_func(config)\n reporter(**{RESULT_DUPLICATE: True})\n track.shutdown()\n return output\n\n return WrappedTrackFunc if use_track else WrappedFunc\n", "path": "python/ray/tune/function_runner.py"}]}
| 3,870 | 201 |
gh_patches_debug_236
|
rasdani/github-patches
|
git_diff
|
jazzband__pip-tools-2042
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Broken build due to failed `linkcheck` job
I've noticed that matrix badges are frequently inaccessible, see README:
<img width="893" alt="image" src="https://github.com/jazzband/pip-tools/assets/7377671/94c2d45a-12ef-4237-8a85-434ee1bd7c05">
Sometimes, a certain issue even results in CI builds [breaking](https://github.com/jazzband/pip-tools/actions/runs/5920050370/job/16051009863#step:10:446) (caught in #1973):
```
broken https://img.shields.io/matrix/pip-tools:matrix.org?label=Discuss%20on%20Matrix%20at%20%23pip-tools%3Amatrix.org&logo=matrix&server_fqdn=matrix.org&style=flat - 408 Client Error: Request Timeout for url: https://img.shields.io/matrix/pip-tools:matrix.org?label=Discuss%20on%20Matrix%20at%20%23pip-tools%3Amatrix.org&logo=matrix&server_fqdn=matrix.org&style=flat
```
Perhaps we should consider [ignoring](https://github.com/jazzband/pip-tools/blob/04d2235716bc43cad3c10288081a4d2b7ee56944/docs/conf.py#L55-L57) `https://img.shields.io/matrix` as well?
/cc @webknjaz
</issue>
<code>
[start of docs/conf.py]
1 # https://www.sphinx-doc.org/en/master/usage/configuration.html
2 """Configuration file for the Sphinx documentation builder."""
3
4 from __future__ import annotations
5
6 from importlib.metadata import version as get_version
7 from pathlib import Path
8
9 from sphinx.util import logging
10 from sphinx.util.console import bold
11
12 logger = logging.getLogger(__name__)
13
14 # -- Path setup --------------------------------------------------------------
15
16 PROJECT_ROOT_DIR = Path(__file__).parents[1].resolve()
17
18
19 # -- Project information -----------------------------------------------------
20
21 project = "pip-tools"
22 author = f"{project} Contributors"
23 copyright = f"The {author}"
24
25 # The full version, including alpha/beta/rc tags
26 release = get_version(project)
27
28 # The short X.Y version
29 version = ".".join(release.split(".")[:3])
30
31 logger.info(bold("%s version: %s"), project, version)
32 logger.info(bold("%s release: %s"), project, release)
33
34 # -- General configuration ---------------------------------------------------
35
36 # Add any Sphinx extension module names here, as strings. They can be
37 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
38 # ones.
39 extensions = ["myst_parser", "sphinxcontrib.programoutput"]
40
41
42 # -- Options for HTML output -------------------------------------------------
43
44 # The theme to use for HTML and HTML Help pages. See the documentation for
45 # a list of builtin themes.
46 #
47 html_theme = "furo"
48 html_title = f"<nobr>{project}</nobr> documentation v{release}"
49
50
51 # -------------------------------------------------------------------------
52 default_role = "any"
53 nitpicky = True
54
55 linkcheck_ignore = [
56 r"^https://matrix\.to/#",
57 ]
58
59 suppress_warnings = ["myst.xref_missing"]
60
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -54,6 +54,7 @@
linkcheck_ignore = [
r"^https://matrix\.to/#",
+ r"^https://img.shields.io/matrix",
]
suppress_warnings = ["myst.xref_missing"]
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -54,6 +54,7 @@\n \n linkcheck_ignore = [\n r\"^https://matrix\\.to/#\",\n+ r\"^https://img.shields.io/matrix\",\n ]\n \n suppress_warnings = [\"myst.xref_missing\"]\n", "issue": "Broken build due to failed `linkcheck` job\nI've noticed that matrix badges are frequently inaccessible, see README:\r\n<img width=\"893\" alt=\"image\" src=\"https://github.com/jazzband/pip-tools/assets/7377671/94c2d45a-12ef-4237-8a85-434ee1bd7c05\">\r\n\r\nSometimes, a certain issue even results in CI builds [breaking](https://github.com/jazzband/pip-tools/actions/runs/5920050370/job/16051009863#step:10:446) (caught in #1973):\r\n\r\n```\r\nbroken https://img.shields.io/matrix/pip-tools:matrix.org?label=Discuss%20on%20Matrix%20at%20%23pip-tools%3Amatrix.org&logo=matrix&server_fqdn=matrix.org&style=flat - 408 Client Error: Request Timeout for url: https://img.shields.io/matrix/pip-tools:matrix.org?label=Discuss%20on%20Matrix%20at%20%23pip-tools%3Amatrix.org&logo=matrix&server_fqdn=matrix.org&style=flat\r\n```\r\n\r\nPerhaps we should consider [ignoring](https://github.com/jazzband/pip-tools/blob/04d2235716bc43cad3c10288081a4d2b7ee56944/docs/conf.py#L55-L57) `https://img.shields.io/matrix` as well?\r\n\r\n/cc @webknjaz \r\n\n", "before_files": [{"content": "# https://www.sphinx-doc.org/en/master/usage/configuration.html\n\"\"\"Configuration file for the Sphinx documentation builder.\"\"\"\n\nfrom __future__ import annotations\n\nfrom importlib.metadata import version as get_version\nfrom pathlib import Path\n\nfrom sphinx.util import logging\nfrom sphinx.util.console import bold\n\nlogger = logging.getLogger(__name__)\n\n# -- Path setup --------------------------------------------------------------\n\nPROJECT_ROOT_DIR = Path(__file__).parents[1].resolve()\n\n\n# -- Project information -----------------------------------------------------\n\nproject = \"pip-tools\"\nauthor = f\"{project} Contributors\"\ncopyright = f\"The {author}\"\n\n# The full version, including alpha/beta/rc tags\nrelease = get_version(project)\n\n# The short X.Y version\nversion = \".\".join(release.split(\".\")[:3])\n\nlogger.info(bold(\"%s version: %s\"), project, version)\nlogger.info(bold(\"%s release: %s\"), project, release)\n\n# -- General configuration ---------------------------------------------------\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\"myst_parser\", \"sphinxcontrib.programoutput\"]\n\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = \"furo\"\nhtml_title = f\"<nobr>{project}</nobr> documentation v{release}\"\n\n\n# -------------------------------------------------------------------------\ndefault_role = \"any\"\nnitpicky = True\n\nlinkcheck_ignore = [\n r\"^https://matrix\\.to/#\",\n]\n\nsuppress_warnings = [\"myst.xref_missing\"]\n", "path": "docs/conf.py"}]}
| 1,388 | 77 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.