
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
18.9k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 465
23.6k
| num_tokens_prompt
int64 556
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_38039 | rasdani/github-patches | git_diff | ansible__ansible-43947 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Serverless Module - Support Verbose Mode
<!---
Verify first that your issue/request is not already reported on GitHub.
Also test if the latest release, and master branch are affected too.
-->
##### ISSUE TYPE
<!--- Pick one below and delete the rest: -->
- Feature Idea
##### COMPONENT NAME
<!--- Name of the module/plugin/task/feature -->
<!--- Please do not include extra details here, e.g. "vyos_command" not "the network module vyos_command" -->
- serverless.py
##### ANSIBLE VERSION
<!--- Paste verbatim output from "ansible --version" between quotes below -->
```
ansible 2.4.0.0
```
##### CONFIGURATION
<!---
If using Ansible 2.4 or above, paste the results of "ansible-config dump --only-changed"
Otherwise, mention any settings you have changed/added/removed in ansible.cfg
(or using the ANSIBLE_* environment variables).
-->
```
DEFAULT_HOST_LIST(env: ANSIBLE_INVENTORY) = [u'/.../inventory/dev']
```
##### OS / ENVIRONMENT
<!---
Mention the OS you are running Ansible from, and the OS you are
managing, or say "N/A" for anything that is not platform-specific.
Also mention the specific version of what you are trying to control,
e.g. if this is a network bug the version of firmware on the network device.
-->
- N/A
##### SUMMARY
<!--- Explain the problem briefly -->
When using Ansible to deploy Serverless projects it would be very helpful to be able to turn on verbose mode (`-v`)
**Reference:** https://serverless.com/framework/docs/providers/aws/cli-reference/deploy/
##### STEPS TO REPRODUCE
<!---
For bugs, show exactly how to reproduce the problem, using a minimal test-case.
For new features, show how the feature would be used.
-->
<!--- Paste example playbooks or commands between quotes below -->
Add `verbose="true"` to `serverless` command and/or piggyback on Ansible verbose mode
```yaml
- name: configure | Run Serverless
serverless: stage="{{ env }}" region="{{ ec2_region }}" service_path="{{ serverless_service_path }}" verbose="true"
```
<!--- You can also paste gist.github.com links for larger files -->
##### EXPECTED RESULTS
<!--- What did you expect to happen when running the steps above? -->
You would see Serverless verbose logging in the Ansible log
```
Serverless: Packaging service...
Serverless: Creating Stack...
Serverless: Checking Stack create progress...
CloudFormation - CREATE_IN_PROGRESS - AWS::CloudFormation::Stack - ***
CloudFormation - CREATE_IN_PROGRESS - AWS::S3::Bucket - ServerlessDeploymentBucket
(removed additional printout)
Serverless: Operation failed!
```
##### ACTUAL RESULTS
<!--- What actually happened? If possible run with extra verbosity (-vvvv) -->
<!--- Paste verbatim command output between quotes below -->
```
Serverless: Packaging service...
Serverless: Creating Stack...
Serverless: Checking Stack create progress...
....
Serverless: Operation failed!
```
**Note:** The `....` seen above is Serverless not listing all AWS commands because it's not in verbose mode
</issue>
<code>
[start of lib/ansible/modules/cloud/misc/serverless.py]
1 #!/usr/bin/python
2 # -*- coding: utf-8 -*-
3
4 # (c) 2016, Ryan Scott Brown <[email protected]>
5 # GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)
6
7 from __future__ import absolute_import, division, print_function
8 __metaclass__ = type
9
10
11 ANSIBLE_METADATA = {'metadata_version': '1.1',
12 'status': ['preview'],
13 'supported_by': 'community'}
14
15
16 DOCUMENTATION = '''
17 ---
18 module: serverless
19 short_description: Manages a Serverless Framework project
20 description:
21 - Provides support for managing Serverless Framework (https://serverless.com/) project deployments and stacks.
22 version_added: "2.3"
23 options:
24 state:
25 choices: ['present', 'absent']
26 description:
27 - Goal state of given stage/project
28 required: false
29 default: present
30 serverless_bin_path:
31 description:
32 - The path of a serverless framework binary relative to the 'service_path' eg. node_module/.bin/serverless
33 required: false
34 version_added: "2.4"
35 service_path:
36 description:
37 - The path to the root of the Serverless Service to be operated on.
38 required: true
39 stage:
40 description:
41 - The name of the serverless framework project stage to deploy to. This uses the serverless framework default "dev".
42 required: false
43 functions:
44 description:
45 - A list of specific functions to deploy. If this is not provided, all functions in the service will be deployed.
46 required: false
47 default: []
48 region:
49 description:
50 - AWS region to deploy the service to
51 required: false
52 default: us-east-1
53 deploy:
54 description:
55 - Whether or not to deploy artifacts after building them. When this option is `false` all the functions will be built, but no stack update will be
56 run to send them out. This is mostly useful for generating artifacts to be stored/deployed elsewhere.
57 required: false
58 default: true
59 notes:
60 - Currently, the `serverless` command must be in the path of the node executing the task. In the future this may be a flag.
61 requirements: [ "serverless", "yaml" ]
62 author: "Ryan Scott Brown @ryansb"
63 '''
64
65 EXAMPLES = """
66 # Basic deploy of a service
67 - serverless:
68 service_path: '{{ project_dir }}'
69 state: present
70
71 # Deploy specific functions
72 - serverless:
73 service_path: '{{ project_dir }}'
74 functions:
75 - my_func_one
76 - my_func_two
77
78 # deploy a project, then pull its resource list back into Ansible
79 - serverless:
80 stage: dev
81 region: us-east-1
82 service_path: '{{ project_dir }}'
83 register: sls
84 # The cloudformation stack is always named the same as the full service, so the
85 # cloudformation_facts module can get a full list of the stack resources, as
86 # well as stack events and outputs
87 - cloudformation_facts:
88 region: us-east-1
89 stack_name: '{{ sls.service_name }}'
90 stack_resources: true
91
92 # Deploy a project but use a locally installed serverless binary instead of the global serverless binary
93 - serverless:
94 stage: dev
95 region: us-east-1
96 service_path: '{{ project_dir }}'
97 serverless_bin_path: node_modules/.bin/serverless
98 """
99
100 RETURN = """
101 service_name:
102 type: string
103 description: The service name specified in the serverless.yml that was just deployed.
104 returned: always
105 sample: my-fancy-service-dev
106 state:
107 type: string
108 description: Whether the stack for the serverless project is present/absent.
109 returned: always
110 command:
111 type: string
112 description: Full `serverless` command run by this module, in case you want to re-run the command outside the module.
113 returned: always
114 sample: serverless deploy --stage production
115 """
116
117 import os
118 import traceback
119
120 try:
121 import yaml
122 HAS_YAML = True
123 except ImportError:
124 HAS_YAML = False
125
126 from ansible.module_utils.basic import AnsibleModule
127
128
129 def read_serverless_config(module):
130 path = module.params.get('service_path')
131
132 try:
133 with open(os.path.join(path, 'serverless.yml')) as sls_config:
134 config = yaml.safe_load(sls_config.read())
135 return config
136 except IOError as e:
137 module.fail_json(msg="Could not open serverless.yml in {}. err: {}".format(path, str(e)), exception=traceback.format_exc())
138
139 module.fail_json(msg="Failed to open serverless config at {}".format(
140 os.path.join(path, 'serverless.yml')))
141
142
143 def get_service_name(module, stage):
144 config = read_serverless_config(module)
145 if config.get('service') is None:
146 module.fail_json(msg="Could not read `service` key from serverless.yml file")
147
148 if stage:
149 return "{}-{}".format(config['service'], stage)
150
151 return "{}-{}".format(config['service'], config.get('stage', 'dev'))
152
153
154 def main():
155 module = AnsibleModule(
156 argument_spec=dict(
157 service_path=dict(required=True, type='path'),
158 state=dict(default='present', choices=['present', 'absent'], required=False),
159 functions=dict(type='list', required=False),
160 region=dict(default='', required=False),
161 stage=dict(default='', required=False),
162 deploy=dict(default=True, type='bool', required=False),
163 serverless_bin_path=dict(required=False, type='path')
164 ),
165 )
166
167 if not HAS_YAML:
168 module.fail_json(msg='yaml is required for this module')
169
170 service_path = module.params.get('service_path')
171 state = module.params.get('state')
172 functions = module.params.get('functions')
173 region = module.params.get('region')
174 stage = module.params.get('stage')
175 deploy = module.params.get('deploy', True)
176 serverless_bin_path = module.params.get('serverless_bin_path')
177
178 if serverless_bin_path is not None:
179 command = serverless_bin_path + " "
180 else:
181 command = "serverless "
182
183 if state == 'present':
184 command += 'deploy '
185 elif state == 'absent':
186 command += 'remove '
187 else:
188 module.fail_json(msg="State must either be 'present' or 'absent'. Received: {}".format(state))
189
190 if not deploy and state == 'present':
191 command += '--noDeploy '
192 if region:
193 command += '--region {} '.format(region)
194 if stage:
195 command += '--stage {} '.format(stage)
196
197 rc, out, err = module.run_command(command, cwd=service_path)
198 if rc != 0:
199 if state == 'absent' and "-{}' does not exist".format(stage) in out:
200 module.exit_json(changed=False, state='absent', command=command,
201 out=out, service_name=get_service_name(module, stage))
202
203 module.fail_json(msg="Failure when executing Serverless command. Exited {}.\nstdout: {}\nstderr: {}".format(rc, out, err))
204
205 # gather some facts about the deployment
206 module.exit_json(changed=True, state='present', out=out, command=command,
207 service_name=get_service_name(module, stage))
208
209
210 if __name__ == '__main__':
211 main()
212
[end of lib/ansible/modules/cloud/misc/serverless.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/lib/ansible/modules/cloud/misc/serverless.py b/lib/ansible/modules/cloud/misc/serverless.py
--- a/lib/ansible/modules/cloud/misc/serverless.py
+++ b/lib/ansible/modules/cloud/misc/serverless.py
@@ -56,6 +56,18 @@
run to send them out. This is mostly useful for generating artifacts to be stored/deployed elsewhere.
required: false
default: true
+ force:
+ description:
+ - Whether or not to force full deployment, equivalent to serverless `--force` option.
+ required: false
+ default: false
+ version_added: "2.7"
+ verbose:
+ description:
+ - Shows all stack events during deployment, and display any Stack Output.
+ required: false
+ default: false
+ version_added: "2.7"
notes:
- Currently, the `serverless` command must be in the path of the node executing the task. In the future this may be a flag.
requirements: [ "serverless", "yaml" ]
@@ -160,7 +172,9 @@
region=dict(default='', required=False),
stage=dict(default='', required=False),
deploy=dict(default=True, type='bool', required=False),
- serverless_bin_path=dict(required=False, type='path')
+ serverless_bin_path=dict(required=False, type='path'),
+ force=dict(default=False, required=False),
+ verbose=dict(default=False, required=False)
),
)
@@ -173,6 +187,8 @@
region = module.params.get('region')
stage = module.params.get('stage')
deploy = module.params.get('deploy', True)
+ force = module.params.get('force', False)
+ verbose = module.params.get('verbose', False)
serverless_bin_path = module.params.get('serverless_bin_path')
if serverless_bin_path is not None:
@@ -187,12 +203,18 @@
else:
module.fail_json(msg="State must either be 'present' or 'absent'. Received: {}".format(state))
- if not deploy and state == 'present':
- command += '--noDeploy '
+ if state == 'present':
+ if not deploy:
+ command += '--noDeploy '
+ elif force:
+ command += '--force '
+
if region:
command += '--region {} '.format(region)
if stage:
command += '--stage {} '.format(stage)
+ if verbose:
+ command += '--verbose '
rc, out, err = module.run_command(command, cwd=service_path)
if rc != 0:
| {"golden_diff": "diff --git a/lib/ansible/modules/cloud/misc/serverless.py b/lib/ansible/modules/cloud/misc/serverless.py\n--- a/lib/ansible/modules/cloud/misc/serverless.py\n+++ b/lib/ansible/modules/cloud/misc/serverless.py\n@@ -56,6 +56,18 @@\n run to send them out. This is mostly useful for generating artifacts to be stored/deployed elsewhere.\n required: false\n default: true\n+ force:\n+ description:\n+ - Whether or not to force full deployment, equivalent to serverless `--force` option.\n+ required: false\n+ default: false\n+ version_added: \"2.7\"\n+ verbose:\n+ description:\n+ - Shows all stack events during deployment, and display any Stack Output.\n+ required: false\n+ default: false\n+ version_added: \"2.7\"\n notes:\n - Currently, the `serverless` command must be in the path of the node executing the task. In the future this may be a flag.\n requirements: [ \"serverless\", \"yaml\" ]\n@@ -160,7 +172,9 @@\n region=dict(default='', required=False),\n stage=dict(default='', required=False),\n deploy=dict(default=True, type='bool', required=False),\n- serverless_bin_path=dict(required=False, type='path')\n+ serverless_bin_path=dict(required=False, type='path'),\n+ force=dict(default=False, required=False),\n+ verbose=dict(default=False, required=False)\n ),\n )\n \n@@ -173,6 +187,8 @@\n region = module.params.get('region')\n stage = module.params.get('stage')\n deploy = module.params.get('deploy', True)\n+ force = module.params.get('force', False)\n+ verbose = module.params.get('verbose', False)\n serverless_bin_path = module.params.get('serverless_bin_path')\n \n if serverless_bin_path is not None:\n@@ -187,12 +203,18 @@\n else:\n module.fail_json(msg=\"State must either be 'present' or 'absent'. Received: {}\".format(state))\n \n- if not deploy and state == 'present':\n- command += '--noDeploy '\n+ if state == 'present':\n+ if not deploy:\n+ command += '--noDeploy '\n+ elif force:\n+ command += '--force '\n+\n if region:\n command += '--region {} '.format(region)\n if stage:\n command += '--stage {} '.format(stage)\n+ if verbose:\n+ command += '--verbose '\n \n rc, out, err = module.run_command(command, cwd=service_path)\n if rc != 0:\n", "issue": "Serverless Module - Support Verbose Mode\n<!---\r\nVerify first that your issue/request is not already reported on GitHub.\r\nAlso test if the latest release, and master branch are affected too.\r\n-->\r\n\r\n##### ISSUE TYPE\r\n<!--- Pick one below and delete the rest: -->\r\n - Feature Idea\r\n\r\n##### COMPONENT NAME\r\n<!--- Name of the module/plugin/task/feature -->\r\n<!--- Please do not include extra details here, e.g. \"vyos_command\" not \"the network module vyos_command\" -->\r\n- serverless.py\r\n\r\n##### ANSIBLE VERSION\r\n<!--- Paste verbatim output from \"ansible --version\" between quotes below -->\r\n```\r\nansible 2.4.0.0\r\n```\r\n\r\n##### CONFIGURATION\r\n<!---\r\nIf using Ansible 2.4 or above, paste the results of \"ansible-config dump --only-changed\"\r\n\r\nOtherwise, mention any settings you have changed/added/removed in ansible.cfg\r\n(or using the ANSIBLE_* environment variables).\r\n-->\r\n```\r\nDEFAULT_HOST_LIST(env: ANSIBLE_INVENTORY) = [u'/.../inventory/dev']\r\n```\r\n\r\n##### OS / ENVIRONMENT\r\n<!---\r\nMention the OS you are running Ansible from, and the OS you are\r\nmanaging, or say \"N/A\" for anything that is not platform-specific.\r\nAlso mention the specific version of what you are trying to control,\r\ne.g. if this is a network bug the version of firmware on the network device.\r\n-->\r\n- N/A\r\n\r\n##### SUMMARY\r\n<!--- Explain the problem briefly -->\r\n\r\nWhen using Ansible to deploy Serverless projects it would be very helpful to be able to turn on verbose mode (`-v`)\r\n\r\n**Reference:** https://serverless.com/framework/docs/providers/aws/cli-reference/deploy/\r\n\r\n##### STEPS TO REPRODUCE\r\n<!---\r\nFor bugs, show exactly how to reproduce the problem, using a minimal test-case.\r\nFor new features, show how the feature would be used.\r\n-->\r\n\r\n<!--- Paste example playbooks or commands between quotes below -->\r\nAdd `verbose=\"true\"` to `serverless` command and/or piggyback on Ansible verbose mode\r\n```yaml\r\n- name: configure | Run Serverless\r\n serverless: stage=\"{{ env }}\" region=\"{{ ec2_region }}\" service_path=\"{{ serverless_service_path }}\" verbose=\"true\"\r\n```\r\n\r\n<!--- You can also paste gist.github.com links for larger files -->\r\n\r\n##### EXPECTED RESULTS\r\n<!--- What did you expect to happen when running the steps above? -->\r\nYou would see Serverless verbose logging in the Ansible log\r\n```\r\nServerless: Packaging service...\r\nServerless: Creating Stack...\r\nServerless: Checking Stack create progress...\r\nCloudFormation - CREATE_IN_PROGRESS - AWS::CloudFormation::Stack - ***\r\nCloudFormation - CREATE_IN_PROGRESS - AWS::S3::Bucket - ServerlessDeploymentBucket\r\n(removed additional printout)\r\nServerless: Operation failed!\r\n```\r\n##### ACTUAL RESULTS\r\n<!--- What actually happened? If possible run with extra verbosity (-vvvv) -->\r\n\r\n<!--- Paste verbatim command output between quotes below -->\r\n```\r\nServerless: Packaging service...\r\nServerless: Creating Stack...\r\nServerless: Checking Stack create progress...\r\n....\r\nServerless: Operation failed!\r\n```\r\n**Note:** The `....` seen above is Serverless not listing all AWS commands because it's not in verbose mode\n", "before_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# (c) 2016, Ryan Scott Brown <[email protected]>\n# GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)\n\nfrom __future__ import absolute_import, division, print_function\n__metaclass__ = type\n\n\nANSIBLE_METADATA = {'metadata_version': '1.1',\n 'status': ['preview'],\n 'supported_by': 'community'}\n\n\nDOCUMENTATION = '''\n---\nmodule: serverless\nshort_description: Manages a Serverless Framework project\ndescription:\n - Provides support for managing Serverless Framework (https://serverless.com/) project deployments and stacks.\nversion_added: \"2.3\"\noptions:\n state:\n choices: ['present', 'absent']\n description:\n - Goal state of given stage/project\n required: false\n default: present\n serverless_bin_path:\n description:\n - The path of a serverless framework binary relative to the 'service_path' eg. node_module/.bin/serverless\n required: false\n version_added: \"2.4\"\n service_path:\n description:\n - The path to the root of the Serverless Service to be operated on.\n required: true\n stage:\n description:\n - The name of the serverless framework project stage to deploy to. This uses the serverless framework default \"dev\".\n required: false\n functions:\n description:\n - A list of specific functions to deploy. If this is not provided, all functions in the service will be deployed.\n required: false\n default: []\n region:\n description:\n - AWS region to deploy the service to\n required: false\n default: us-east-1\n deploy:\n description:\n - Whether or not to deploy artifacts after building them. When this option is `false` all the functions will be built, but no stack update will be\n run to send them out. This is mostly useful for generating artifacts to be stored/deployed elsewhere.\n required: false\n default: true\nnotes:\n - Currently, the `serverless` command must be in the path of the node executing the task. In the future this may be a flag.\nrequirements: [ \"serverless\", \"yaml\" ]\nauthor: \"Ryan Scott Brown @ryansb\"\n'''\n\nEXAMPLES = \"\"\"\n# Basic deploy of a service\n- serverless:\n service_path: '{{ project_dir }}'\n state: present\n\n# Deploy specific functions\n- serverless:\n service_path: '{{ project_dir }}'\n functions:\n - my_func_one\n - my_func_two\n\n# deploy a project, then pull its resource list back into Ansible\n- serverless:\n stage: dev\n region: us-east-1\n service_path: '{{ project_dir }}'\n register: sls\n# The cloudformation stack is always named the same as the full service, so the\n# cloudformation_facts module can get a full list of the stack resources, as\n# well as stack events and outputs\n- cloudformation_facts:\n region: us-east-1\n stack_name: '{{ sls.service_name }}'\n stack_resources: true\n\n# Deploy a project but use a locally installed serverless binary instead of the global serverless binary\n- serverless:\n stage: dev\n region: us-east-1\n service_path: '{{ project_dir }}'\n serverless_bin_path: node_modules/.bin/serverless\n\"\"\"\n\nRETURN = \"\"\"\nservice_name:\n type: string\n description: The service name specified in the serverless.yml that was just deployed.\n returned: always\n sample: my-fancy-service-dev\nstate:\n type: string\n description: Whether the stack for the serverless project is present/absent.\n returned: always\ncommand:\n type: string\n description: Full `serverless` command run by this module, in case you want to re-run the command outside the module.\n returned: always\n sample: serverless deploy --stage production\n\"\"\"\n\nimport os\nimport traceback\n\ntry:\n import yaml\n HAS_YAML = True\nexcept ImportError:\n HAS_YAML = False\n\nfrom ansible.module_utils.basic import AnsibleModule\n\n\ndef read_serverless_config(module):\n path = module.params.get('service_path')\n\n try:\n with open(os.path.join(path, 'serverless.yml')) as sls_config:\n config = yaml.safe_load(sls_config.read())\n return config\n except IOError as e:\n module.fail_json(msg=\"Could not open serverless.yml in {}. err: {}\".format(path, str(e)), exception=traceback.format_exc())\n\n module.fail_json(msg=\"Failed to open serverless config at {}\".format(\n os.path.join(path, 'serverless.yml')))\n\n\ndef get_service_name(module, stage):\n config = read_serverless_config(module)\n if config.get('service') is None:\n module.fail_json(msg=\"Could not read `service` key from serverless.yml file\")\n\n if stage:\n return \"{}-{}\".format(config['service'], stage)\n\n return \"{}-{}\".format(config['service'], config.get('stage', 'dev'))\n\n\ndef main():\n module = AnsibleModule(\n argument_spec=dict(\n service_path=dict(required=True, type='path'),\n state=dict(default='present', choices=['present', 'absent'], required=False),\n functions=dict(type='list', required=False),\n region=dict(default='', required=False),\n stage=dict(default='', required=False),\n deploy=dict(default=True, type='bool', required=False),\n serverless_bin_path=dict(required=False, type='path')\n ),\n )\n\n if not HAS_YAML:\n module.fail_json(msg='yaml is required for this module')\n\n service_path = module.params.get('service_path')\n state = module.params.get('state')\n functions = module.params.get('functions')\n region = module.params.get('region')\n stage = module.params.get('stage')\n deploy = module.params.get('deploy', True)\n serverless_bin_path = module.params.get('serverless_bin_path')\n\n if serverless_bin_path is not None:\n command = serverless_bin_path + \" \"\n else:\n command = \"serverless \"\n\n if state == 'present':\n command += 'deploy '\n elif state == 'absent':\n command += 'remove '\n else:\n module.fail_json(msg=\"State must either be 'present' or 'absent'. Received: {}\".format(state))\n\n if not deploy and state == 'present':\n command += '--noDeploy '\n if region:\n command += '--region {} '.format(region)\n if stage:\n command += '--stage {} '.format(stage)\n\n rc, out, err = module.run_command(command, cwd=service_path)\n if rc != 0:\n if state == 'absent' and \"-{}' does not exist\".format(stage) in out:\n module.exit_json(changed=False, state='absent', command=command,\n out=out, service_name=get_service_name(module, stage))\n\n module.fail_json(msg=\"Failure when executing Serverless command. Exited {}.\\nstdout: {}\\nstderr: {}\".format(rc, out, err))\n\n # gather some facts about the deployment\n module.exit_json(changed=True, state='present', out=out, command=command,\n service_name=get_service_name(module, stage))\n\n\nif __name__ == '__main__':\n main()\n", "path": "lib/ansible/modules/cloud/misc/serverless.py"}]} | 3,376 | 586 |
gh_patches_debug_31936 | rasdani/github-patches | git_diff | WordPress__openverse-api-210 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Feature] Add new Authority Type
## Problem
<!-- Describe a problem solved by this feature; or delete the section entirely. -->
We currently lack an authority type for curated image galleries: places like https://stocksnap.io where content is manually curated by the platform, but it isn't a site with social, user-uploaded content, or isn't a formal GLAM institution.
## Description
<!-- Describe the feature and how it solves the problem. -->
Our current authorities:
https://github.com/WordPress/openverse-api/blob/9d0d724651f18cc9f96931e01bea92b8032bd6a0/ingestion_server/ingestion_server/authority.py#L32-L36
Should be modified to:
```diff
boost = {
- AuthorityTypes.CURATED: 90,
+ AuthorityTypes.CURATED: 87.5,
+ AuthorityTypes.CULTURAL_INSTITUTIONS: 90,
AuthorityTypes.SOCIAL_MEDIA: 80,
AuthorityTypes.DEFAULT: 85
}
```
We'll also need to re-classify the existing providers classified as `CURATED` to `CULTURAL_INSTITUTIONS` and add a line for StockSnap here (we might also want to sort these alphabetically):
https://github.com/WordPress/openverse-api/blob/9d0d724651f18cc9f96931e01bea92b8032bd6a0/ingestion_server/ingestion_server/authority.py#L37-L53
## Alternatives
<!-- Describe any alternative solutions or features you have considered. How is this feature better? -->
## Additional context
<!-- Add any other context about the feature here; or delete the section entirely. -->
## Implementation
<!-- Replace the [ ] with [x] to check the box. -->
- [ ] 🙋 I would be interested in implementing this feature.
</issue>
<code>
[start of ingestion_server/ingestion_server/authority.py]
1 from enum import Enum, auto
2
3
4 """
5 Authority is a ranking from 0 to 100 (with 0 being least authoritative)
6 indicating the pedigree of an image. Some examples of things that could impact
7 authority:
8 - The reputation of the website that posted an image
9 - The popularity of the uploader on a social media site in terms of number of
10 followers
11 - Whether the uploader has uploaded images that have previously been flagged for
12 copyright infringement.
13 - etc
14
15 The authority can be set from the catalog layer through the meta_data field
16 or through the ingestion layer. As of now, we are only factoring in the
17 reputation of the website as a static hand-picked list based on experience
18 and search result quality, with the intention to add more sophisticated and
19 tailored measures of authority later on.
20
21 Also note that this is just one factor in rankings, and the magnitude of the
22 boost can be adjusted at search-time.
23 """
24
25
26 class AuthorityTypes(Enum):
27 CURATED = auto()
28 SOCIAL_MEDIA = auto()
29 DEFAULT = auto()
30
31
32 # We want to boost curated collections where each image has been vetted for
33 # cultural significance.
34 boost = {
35 AuthorityTypes.CURATED: 90,
36 AuthorityTypes.SOCIAL_MEDIA: 80,
37 AuthorityTypes.DEFAULT: 85,
38 }
39 authority_types = {
40 "flickr": AuthorityTypes.SOCIAL_MEDIA,
41 "behance": AuthorityTypes.SOCIAL_MEDIA,
42 "thingiverse": AuthorityTypes.SOCIAL_MEDIA,
43 "sketchfab": AuthorityTypes.SOCIAL_MEDIA,
44 "deviantart": AuthorityTypes.SOCIAL_MEDIA,
45 "thorvaldsensmuseum": AuthorityTypes.CURATED,
46 "svgsilh": AuthorityTypes.CURATED,
47 "smithsonian": AuthorityTypes.CURATED,
48 "rijksmuseum": AuthorityTypes.CURATED,
49 "museumsvictoria": AuthorityTypes.CURATED,
50 "met": AuthorityTypes.CURATED,
51 "mccordsmuseum": AuthorityTypes.CURATED,
52 "digitaltmuseum": AuthorityTypes.CURATED,
53 "clevelandmuseum": AuthorityTypes.CURATED,
54 "brooklynmuseum": AuthorityTypes.CURATED,
55 }
56
57
58 def get_authority_boost(source):
59 authority_boost = None
60 if source in authority_types:
61 authority_type = authority_types[source]
62 if authority_type in boost:
63 authority_boost = boost[authority_type]
64 else:
65 authority_boost = boost[AuthorityTypes.DEFAULT]
66 return authority_boost
67
[end of ingestion_server/ingestion_server/authority.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/ingestion_server/ingestion_server/authority.py b/ingestion_server/ingestion_server/authority.py
--- a/ingestion_server/ingestion_server/authority.py
+++ b/ingestion_server/ingestion_server/authority.py
@@ -25,6 +25,7 @@
class AuthorityTypes(Enum):
CURATED = auto()
+ CULTURAL_INSTITUTION = auto()
SOCIAL_MEDIA = auto()
DEFAULT = auto()
@@ -32,26 +33,29 @@
# We want to boost curated collections where each image has been vetted for
# cultural significance.
boost = {
- AuthorityTypes.CURATED: 90,
- AuthorityTypes.SOCIAL_MEDIA: 80,
- AuthorityTypes.DEFAULT: 85,
+ AuthorityTypes.CURATED: 85,
+ AuthorityTypes.CULTURAL_INSTITUTION: 90,
+ AuthorityTypes.SOCIAL_MEDIA: 75,
+ AuthorityTypes.DEFAULT: 80,
}
+
authority_types = {
"flickr": AuthorityTypes.SOCIAL_MEDIA,
"behance": AuthorityTypes.SOCIAL_MEDIA,
"thingiverse": AuthorityTypes.SOCIAL_MEDIA,
"sketchfab": AuthorityTypes.SOCIAL_MEDIA,
"deviantart": AuthorityTypes.SOCIAL_MEDIA,
- "thorvaldsensmuseum": AuthorityTypes.CURATED,
- "svgsilh": AuthorityTypes.CURATED,
- "smithsonian": AuthorityTypes.CURATED,
- "rijksmuseum": AuthorityTypes.CURATED,
- "museumsvictoria": AuthorityTypes.CURATED,
- "met": AuthorityTypes.CURATED,
- "mccordsmuseum": AuthorityTypes.CURATED,
- "digitaltmuseum": AuthorityTypes.CURATED,
- "clevelandmuseum": AuthorityTypes.CURATED,
- "brooklynmuseum": AuthorityTypes.CURATED,
+ "thorvaldsensmuseum": AuthorityTypes.CULTURAL_INSTITUTION,
+ "svgsilh": AuthorityTypes.CULTURAL_INSTITUTION,
+ "smithsonian": AuthorityTypes.CULTURAL_INSTITUTION,
+ "rijksmuseum": AuthorityTypes.CULTURAL_INSTITUTION,
+ "museumsvictoria": AuthorityTypes.CULTURAL_INSTITUTION,
+ "met": AuthorityTypes.CULTURAL_INSTITUTION,
+ "mccordsmuseum": AuthorityTypes.CULTURAL_INSTITUTION,
+ "digitaltmuseum": AuthorityTypes.CULTURAL_INSTITUTION,
+ "clevelandmuseum": AuthorityTypes.CULTURAL_INSTITUTION,
+ "brooklynmuseum": AuthorityTypes.CULTURAL_INSTITUTION,
+ "stocksnap": AuthorityTypes.CURATED,
}
| {"golden_diff": "diff --git a/ingestion_server/ingestion_server/authority.py b/ingestion_server/ingestion_server/authority.py\n--- a/ingestion_server/ingestion_server/authority.py\n+++ b/ingestion_server/ingestion_server/authority.py\n@@ -25,6 +25,7 @@\n \n class AuthorityTypes(Enum):\n CURATED = auto()\n+ CULTURAL_INSTITUTION = auto()\n SOCIAL_MEDIA = auto()\n DEFAULT = auto()\n \n@@ -32,26 +33,29 @@\n # We want to boost curated collections where each image has been vetted for\n # cultural significance.\n boost = {\n- AuthorityTypes.CURATED: 90,\n- AuthorityTypes.SOCIAL_MEDIA: 80,\n- AuthorityTypes.DEFAULT: 85,\n+ AuthorityTypes.CURATED: 85,\n+ AuthorityTypes.CULTURAL_INSTITUTION: 90,\n+ AuthorityTypes.SOCIAL_MEDIA: 75,\n+ AuthorityTypes.DEFAULT: 80,\n }\n+\n authority_types = {\n \"flickr\": AuthorityTypes.SOCIAL_MEDIA,\n \"behance\": AuthorityTypes.SOCIAL_MEDIA,\n \"thingiverse\": AuthorityTypes.SOCIAL_MEDIA,\n \"sketchfab\": AuthorityTypes.SOCIAL_MEDIA,\n \"deviantart\": AuthorityTypes.SOCIAL_MEDIA,\n- \"thorvaldsensmuseum\": AuthorityTypes.CURATED,\n- \"svgsilh\": AuthorityTypes.CURATED,\n- \"smithsonian\": AuthorityTypes.CURATED,\n- \"rijksmuseum\": AuthorityTypes.CURATED,\n- \"museumsvictoria\": AuthorityTypes.CURATED,\n- \"met\": AuthorityTypes.CURATED,\n- \"mccordsmuseum\": AuthorityTypes.CURATED,\n- \"digitaltmuseum\": AuthorityTypes.CURATED,\n- \"clevelandmuseum\": AuthorityTypes.CURATED,\n- \"brooklynmuseum\": AuthorityTypes.CURATED,\n+ \"thorvaldsensmuseum\": AuthorityTypes.CULTURAL_INSTITUTION,\n+ \"svgsilh\": AuthorityTypes.CULTURAL_INSTITUTION,\n+ \"smithsonian\": AuthorityTypes.CULTURAL_INSTITUTION,\n+ \"rijksmuseum\": AuthorityTypes.CULTURAL_INSTITUTION,\n+ \"museumsvictoria\": AuthorityTypes.CULTURAL_INSTITUTION,\n+ \"met\": AuthorityTypes.CULTURAL_INSTITUTION,\n+ \"mccordsmuseum\": AuthorityTypes.CULTURAL_INSTITUTION,\n+ \"digitaltmuseum\": AuthorityTypes.CULTURAL_INSTITUTION,\n+ \"clevelandmuseum\": AuthorityTypes.CULTURAL_INSTITUTION,\n+ \"brooklynmuseum\": AuthorityTypes.CULTURAL_INSTITUTION,\n+ \"stocksnap\": AuthorityTypes.CURATED,\n }\n", "issue": "[Feature] Add new Authority Type\n## Problem\r\n<!-- Describe a problem solved by this feature; or delete the section entirely. -->\r\n\r\nWe currently lack an authority type for curated image galleries: places like https://stocksnap.io where content is manually curated by the platform, but it isn't a site with social, user-uploaded content, or isn't a formal GLAM institution.\r\n\r\n## Description\r\n<!-- Describe the feature and how it solves the problem. -->\r\n\r\nOur current authorities:\r\n\r\nhttps://github.com/WordPress/openverse-api/blob/9d0d724651f18cc9f96931e01bea92b8032bd6a0/ingestion_server/ingestion_server/authority.py#L32-L36\r\n\r\nShould be modified to:\r\n\r\n\r\n```diff\r\nboost = {\r\n- AuthorityTypes.CURATED: 90,\r\n+ AuthorityTypes.CURATED: 87.5,\r\n+ AuthorityTypes.CULTURAL_INSTITUTIONS: 90,\r\n AuthorityTypes.SOCIAL_MEDIA: 80,\r\n AuthorityTypes.DEFAULT: 85\r\n}\r\n```\r\n\r\nWe'll also need to re-classify the existing providers classified as `CURATED` to `CULTURAL_INSTITUTIONS` and add a line for StockSnap here (we might also want to sort these alphabetically):\r\n\r\nhttps://github.com/WordPress/openverse-api/blob/9d0d724651f18cc9f96931e01bea92b8032bd6a0/ingestion_server/ingestion_server/authority.py#L37-L53\r\n\r\n\r\n\r\n## Alternatives\r\n<!-- Describe any alternative solutions or features you have considered. How is this feature better? -->\r\n\r\n## Additional context\r\n<!-- Add any other context about the feature here; or delete the section entirely. -->\r\n\r\n## Implementation\r\n<!-- Replace the [ ] with [x] to check the box. -->\r\n- [ ] \ud83d\ude4b I would be interested in implementing this feature.\r\n\n", "before_files": [{"content": "from enum import Enum, auto\n\n\n\"\"\"\nAuthority is a ranking from 0 to 100 (with 0 being least authoritative)\nindicating the pedigree of an image. Some examples of things that could impact\nauthority:\n- The reputation of the website that posted an image\n- The popularity of the uploader on a social media site in terms of number of\nfollowers\n- Whether the uploader has uploaded images that have previously been flagged for\ncopyright infringement.\n- etc\n\nThe authority can be set from the catalog layer through the meta_data field\nor through the ingestion layer. As of now, we are only factoring in the\nreputation of the website as a static hand-picked list based on experience\nand search result quality, with the intention to add more sophisticated and\ntailored measures of authority later on.\n\nAlso note that this is just one factor in rankings, and the magnitude of the\nboost can be adjusted at search-time.\n\"\"\"\n\n\nclass AuthorityTypes(Enum):\n CURATED = auto()\n SOCIAL_MEDIA = auto()\n DEFAULT = auto()\n\n\n# We want to boost curated collections where each image has been vetted for\n# cultural significance.\nboost = {\n AuthorityTypes.CURATED: 90,\n AuthorityTypes.SOCIAL_MEDIA: 80,\n AuthorityTypes.DEFAULT: 85,\n}\nauthority_types = {\n \"flickr\": AuthorityTypes.SOCIAL_MEDIA,\n \"behance\": AuthorityTypes.SOCIAL_MEDIA,\n \"thingiverse\": AuthorityTypes.SOCIAL_MEDIA,\n \"sketchfab\": AuthorityTypes.SOCIAL_MEDIA,\n \"deviantart\": AuthorityTypes.SOCIAL_MEDIA,\n \"thorvaldsensmuseum\": AuthorityTypes.CURATED,\n \"svgsilh\": AuthorityTypes.CURATED,\n \"smithsonian\": AuthorityTypes.CURATED,\n \"rijksmuseum\": AuthorityTypes.CURATED,\n \"museumsvictoria\": AuthorityTypes.CURATED,\n \"met\": AuthorityTypes.CURATED,\n \"mccordsmuseum\": AuthorityTypes.CURATED,\n \"digitaltmuseum\": AuthorityTypes.CURATED,\n \"clevelandmuseum\": AuthorityTypes.CURATED,\n \"brooklynmuseum\": AuthorityTypes.CURATED,\n}\n\n\ndef get_authority_boost(source):\n authority_boost = None\n if source in authority_types:\n authority_type = authority_types[source]\n if authority_type in boost:\n authority_boost = boost[authority_type]\n else:\n authority_boost = boost[AuthorityTypes.DEFAULT]\n return authority_boost\n", "path": "ingestion_server/ingestion_server/authority.py"}]} | 1,636 | 614 |
gh_patches_debug_1353 | rasdani/github-patches | git_diff | microsoft__Qcodes-87 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
PR #70 breaks parameter .get and .set functionality
I cannot debug the issue properly because all the objects are `multiprocessing` objects. A minimal example showing the issue:
``` python
%matplotlib nbagg
import matplotlib.pyplot as plt
import time
import numpy as np
import qcodes as qc
from toymodel import AModel, MockGates, MockSource, MockMeter, AverageGetter, AverageAndRaw
# now create this "experiment"
model = AModel()
gates = MockGates('gates', model=model)
c0, c1, c2 = gates.chan0, gates.chan1, gates.chan2
print('fine so far...')
print('error...')
c2.get()
print('no effect?')
c2.set(0.5)
```
</issue>
<code>
[start of docs/examples/toymodel.py]
1 # code for example notebook
2
3 import math
4
5 from qcodes import MockInstrument, MockModel, Parameter, Loop, DataArray
6 from qcodes.utils.validators import Numbers
7
8
9 class AModel(MockModel):
10 def __init__(self):
11 self._gates = [0.0, 0.0, 0.0]
12 self._excitation = 0.1
13 super().__init__()
14
15 def _output(self):
16 # my super exciting model!
17 # make a nice pattern that looks sort of double-dotty
18 # with the first two gates controlling the two dots,
19 # and the third looking like Vsd
20 delta_i = 10
21 delta_j = 10
22 di = (self._gates[0] + delta_i / 2) % delta_i - delta_i / 2
23 dj = (self._gates[1] + delta_j / 2) % delta_j - delta_j / 2
24 vsd = math.sqrt(self._gates[2]**2 + self._excitation**2)
25 dij = math.sqrt(di**2 + dj**2) - vsd
26 g = (vsd**2 + 1) * (1 / (dij**2 + 1) +
27 0.1 * (math.atan(-dij) + math.pi / 2))
28 return g
29
30 def fmt(self, value):
31 return '{:.3f}'.format(value)
32
33 def gates_set(self, parameter, value):
34 if parameter[0] == 'c':
35 self._gates[int(parameter[1:])] = float(value)
36 elif parameter == 'rst' and value is None:
37 self._gates = [0.0, 0.0, 0.0]
38 else:
39 raise ValueError
40
41 def gates_get(self, parameter):
42 if parameter[0] == 'c':
43 return self.fmt(self.gates[int(parameter[1:])])
44 else:
45 raise ValueError
46
47 def source_set(self, parameter, value):
48 if parameter == 'ampl':
49 self._excitation = float(value)
50 else:
51 raise ValueError
52
53 def source_get(self, parameter):
54 if parameter == 'ampl':
55 return self.fmt(self._excitation)
56 else:
57 raise ValueError
58
59 def meter_get(self, parameter):
60 if parameter == 'ampl':
61 return self.fmt(self._output() * self._excitation)
62 else:
63 raise ValueError
64
65
66 # make our mock instruments
67 # real instruments would subclass IPInstrument or VisaInstrument
68 # or just the base Instrument instead of MockInstrument,
69 # and be instantiated with an address rather than a model
70 class MockGates(MockInstrument):
71 def __init__(self, name, model=None, **kwargs):
72 super().__init__(name, model=model, **kwargs)
73
74 for i in range(3):
75 cmdbase = 'c{}'.format(i)
76 self.add_parameter('chan{}'.format(i),
77 label='Gate Channel {} (mV)'.format(i),
78 get_cmd=cmdbase + '?',
79 set_cmd=cmdbase + ':{:.4f}',
80 get_parser=float,
81 vals=Numbers(-100, 100))
82
83 self.add_function('reset', call_cmd='rst')
84
85
86 class MockSource(MockInstrument):
87 def __init__(self, name, model=None, **kwargs):
88 super().__init__(name, model=model, **kwargs)
89
90 # this parameter uses built-in sweeping to change slowly
91 self.add_parameter('amplitude',
92 label='Source Amplitude (\u03bcV)',
93 get_cmd='ampl?',
94 set_cmd='ampl:{:.4f}',
95 get_parser=float,
96 vals=Numbers(0, 10),
97 sweep_step=0.1,
98 sweep_delay=0.05)
99
100
101 class MockMeter(MockInstrument):
102 def __init__(self, name, model=None, **kwargs):
103 super().__init__(name, model=model, **kwargs)
104
105 self.add_parameter('amplitude',
106 label='Current (nA)',
107 get_cmd='ampl?',
108 get_parser=float)
109
110
111 class AverageGetter(Parameter):
112 def __init__(self, measured_param, sweep_values, delay):
113 super().__init__(name='avg_' + measured_param.name)
114 self.measured_param = measured_param
115 self.sweep_values = sweep_values
116 self.delay = delay
117 if hasattr(measured_param, 'label'):
118 self.label = 'Average: ' + measured_param.label
119
120 def get(self):
121 loop = Loop(self.sweep_values, self.delay).each(self.measured_param)
122 data = loop.run_temp()
123 return data.arrays[self.measured_param.name].mean()
124
125
126 class AverageAndRaw(Parameter):
127 def __init__(self, measured_param, sweep_values, delay):
128 name = measured_param.name
129 super().__init__(names=(name, 'avg_' + name))
130 self.measured_param = measured_param
131 self.sweep_values = sweep_values
132 self.delay = delay
133 self.sizes = (len(sweep_values), None)
134 set_array = DataArray(parameter=sweep_values.parameter,
135 preset_data=sweep_values)
136 self.setpoints = (set_array, None)
137 if hasattr(measured_param, 'label'):
138 self.labels = (measured_param.label,
139 'Average: ' + measured_param.label)
140
141 def get(self):
142 loop = Loop(self.sweep_values, self.delay).each(self.measured_param)
143 data = loop.run_temp()
144 array = data.arrays[self.measured_param.name]
145 return (array, array.mean())
146
[end of docs/examples/toymodel.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/docs/examples/toymodel.py b/docs/examples/toymodel.py
--- a/docs/examples/toymodel.py
+++ b/docs/examples/toymodel.py
@@ -40,7 +40,7 @@
def gates_get(self, parameter):
if parameter[0] == 'c':
- return self.fmt(self.gates[int(parameter[1:])])
+ return self.fmt(self._gates[int(parameter[1:])])
else:
raise ValueError
| {"golden_diff": "diff --git a/docs/examples/toymodel.py b/docs/examples/toymodel.py\n--- a/docs/examples/toymodel.py\n+++ b/docs/examples/toymodel.py\n@@ -40,7 +40,7 @@\n \n def gates_get(self, parameter):\n if parameter[0] == 'c':\n- return self.fmt(self.gates[int(parameter[1:])])\n+ return self.fmt(self._gates[int(parameter[1:])])\n else:\n raise ValueError\n", "issue": "PR #70 breaks parameter .get and .set functionality\nI cannot debug the issue properly because all the objects are `multiprocessing` objects. A minimal example showing the issue:\n\n``` python\n%matplotlib nbagg\nimport matplotlib.pyplot as plt\nimport time\nimport numpy as np\nimport qcodes as qc\n\nfrom toymodel import AModel, MockGates, MockSource, MockMeter, AverageGetter, AverageAndRaw\n\n# now create this \"experiment\"\nmodel = AModel()\ngates = MockGates('gates', model=model)\n\nc0, c1, c2 = gates.chan0, gates.chan1, gates.chan2\nprint('fine so far...')\n\nprint('error...')\nc2.get()\nprint('no effect?')\nc2.set(0.5)\n\n```\n\n", "before_files": [{"content": "# code for example notebook\n\nimport math\n\nfrom qcodes import MockInstrument, MockModel, Parameter, Loop, DataArray\nfrom qcodes.utils.validators import Numbers\n\n\nclass AModel(MockModel):\n def __init__(self):\n self._gates = [0.0, 0.0, 0.0]\n self._excitation = 0.1\n super().__init__()\n\n def _output(self):\n # my super exciting model!\n # make a nice pattern that looks sort of double-dotty\n # with the first two gates controlling the two dots,\n # and the third looking like Vsd\n delta_i = 10\n delta_j = 10\n di = (self._gates[0] + delta_i / 2) % delta_i - delta_i / 2\n dj = (self._gates[1] + delta_j / 2) % delta_j - delta_j / 2\n vsd = math.sqrt(self._gates[2]**2 + self._excitation**2)\n dij = math.sqrt(di**2 + dj**2) - vsd\n g = (vsd**2 + 1) * (1 / (dij**2 + 1) +\n 0.1 * (math.atan(-dij) + math.pi / 2))\n return g\n\n def fmt(self, value):\n return '{:.3f}'.format(value)\n\n def gates_set(self, parameter, value):\n if parameter[0] == 'c':\n self._gates[int(parameter[1:])] = float(value)\n elif parameter == 'rst' and value is None:\n self._gates = [0.0, 0.0, 0.0]\n else:\n raise ValueError\n\n def gates_get(self, parameter):\n if parameter[0] == 'c':\n return self.fmt(self.gates[int(parameter[1:])])\n else:\n raise ValueError\n\n def source_set(self, parameter, value):\n if parameter == 'ampl':\n self._excitation = float(value)\n else:\n raise ValueError\n\n def source_get(self, parameter):\n if parameter == 'ampl':\n return self.fmt(self._excitation)\n else:\n raise ValueError\n\n def meter_get(self, parameter):\n if parameter == 'ampl':\n return self.fmt(self._output() * self._excitation)\n else:\n raise ValueError\n\n\n# make our mock instruments\n# real instruments would subclass IPInstrument or VisaInstrument\n# or just the base Instrument instead of MockInstrument,\n# and be instantiated with an address rather than a model\nclass MockGates(MockInstrument):\n def __init__(self, name, model=None, **kwargs):\n super().__init__(name, model=model, **kwargs)\n\n for i in range(3):\n cmdbase = 'c{}'.format(i)\n self.add_parameter('chan{}'.format(i),\n label='Gate Channel {} (mV)'.format(i),\n get_cmd=cmdbase + '?',\n set_cmd=cmdbase + ':{:.4f}',\n get_parser=float,\n vals=Numbers(-100, 100))\n\n self.add_function('reset', call_cmd='rst')\n\n\nclass MockSource(MockInstrument):\n def __init__(self, name, model=None, **kwargs):\n super().__init__(name, model=model, **kwargs)\n\n # this parameter uses built-in sweeping to change slowly\n self.add_parameter('amplitude',\n label='Source Amplitude (\\u03bcV)',\n get_cmd='ampl?',\n set_cmd='ampl:{:.4f}',\n get_parser=float,\n vals=Numbers(0, 10),\n sweep_step=0.1,\n sweep_delay=0.05)\n\n\nclass MockMeter(MockInstrument):\n def __init__(self, name, model=None, **kwargs):\n super().__init__(name, model=model, **kwargs)\n\n self.add_parameter('amplitude',\n label='Current (nA)',\n get_cmd='ampl?',\n get_parser=float)\n\n\nclass AverageGetter(Parameter):\n def __init__(self, measured_param, sweep_values, delay):\n super().__init__(name='avg_' + measured_param.name)\n self.measured_param = measured_param\n self.sweep_values = sweep_values\n self.delay = delay\n if hasattr(measured_param, 'label'):\n self.label = 'Average: ' + measured_param.label\n\n def get(self):\n loop = Loop(self.sweep_values, self.delay).each(self.measured_param)\n data = loop.run_temp()\n return data.arrays[self.measured_param.name].mean()\n\n\nclass AverageAndRaw(Parameter):\n def __init__(self, measured_param, sweep_values, delay):\n name = measured_param.name\n super().__init__(names=(name, 'avg_' + name))\n self.measured_param = measured_param\n self.sweep_values = sweep_values\n self.delay = delay\n self.sizes = (len(sweep_values), None)\n set_array = DataArray(parameter=sweep_values.parameter,\n preset_data=sweep_values)\n self.setpoints = (set_array, None)\n if hasattr(measured_param, 'label'):\n self.labels = (measured_param.label,\n 'Average: ' + measured_param.label)\n\n def get(self):\n loop = Loop(self.sweep_values, self.delay).each(self.measured_param)\n data = loop.run_temp()\n array = data.arrays[self.measured_param.name]\n return (array, array.mean())\n", "path": "docs/examples/toymodel.py"}]} | 2,262 | 105 |
gh_patches_debug_38636 | rasdani/github-patches | git_diff | e-valuation__EvaP-1105 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Release Sisyphus data only after successful post
When a user enters answers on the student vote page and then logs out in another window before submitting the form, Sisyphus releases the form data on the form submit, because a 302 redirect to the login page is not an error case.
The data should be kept in browser storage until the vote was successfully counted.
Release Sisyphus data only after successful post
When a user enters answers on the student vote page and then logs out in another window before submitting the form, Sisyphus releases the form data on the form submit, because a 302 redirect to the login page is not an error case.
The data should be kept in browser storage until the vote was successfully counted.
</issue>
<code>
[start of evap/student/views.py]
1 from collections import OrderedDict
2
3 from django.contrib import messages
4 from django.core.exceptions import PermissionDenied, SuspiciousOperation
5 from django.db import transaction
6 from django.shortcuts import get_object_or_404, redirect, render
7 from django.utils.translation import ugettext as _
8
9 from evap.evaluation.auth import participant_required
10 from evap.evaluation.models import Course, Semester
11 from evap.evaluation.tools import STUDENT_STATES_ORDERED
12
13 from evap.student.forms import QuestionsForm
14 from evap.student.tools import question_id
15
16
17 @participant_required
18 def index(request):
19 # retrieve all courses, where the user is a participant and that are not new
20 courses = list(set(Course.objects.filter(participants=request.user).exclude(state="new")))
21 voted_courses = list(set(Course.objects.filter(voters=request.user)))
22 due_courses = list(set(Course.objects.filter(participants=request.user, state='in_evaluation').exclude(voters=request.user)))
23
24 sorter = lambda course: (list(STUDENT_STATES_ORDERED.keys()).index(course.student_state), course.vote_end_date, course.name)
25 courses.sort(key=sorter)
26
27 semesters = Semester.objects.all()
28 semester_list = [dict(semester_name=semester.name, id=semester.id, is_active_semester=semester.is_active_semester,
29 courses=[course for course in courses if course.semester_id == semester.id]) for semester in semesters]
30
31 template_data = dict(
32 semester_list=semester_list,
33 voted_courses=voted_courses,
34 due_courses=due_courses,
35 can_download_grades=request.user.can_download_grades,
36 )
37 return render(request, "student_index.html", template_data)
38
39
40 def vote_preview(request, course, for_rendering_in_modal=False):
41 """
42 Renders a preview of the voting page for the given course.
43 Not used by the student app itself, but by staff and contributor.
44 """
45 form_groups = helper_create_voting_form_groups(request, course.contributions.all())
46 course_form_group = form_groups.pop(course.general_contribution)
47 contributor_form_groups = list((contribution.contributor, contribution.label, form_group, False) for contribution, form_group in form_groups.items())
48
49 template_data = dict(
50 errors_exist=False,
51 course_form_group=course_form_group,
52 contributor_form_groups=contributor_form_groups,
53 course=course,
54 preview=True,
55 for_rendering_in_modal=for_rendering_in_modal)
56 return render(request, "student_vote.html", template_data)
57
58
59 @participant_required
60 def vote(request, course_id):
61 # retrieve course and make sure that the user is allowed to vote
62 course = get_object_or_404(Course, id=course_id)
63 if not course.can_user_vote(request.user):
64 raise PermissionDenied
65
66
67 # prevent a user from voting on themselves.
68 contributions_to_vote_on = course.contributions.exclude(contributor=request.user).all()
69 form_groups = helper_create_voting_form_groups(request, contributions_to_vote_on)
70
71 if not all(all(form.is_valid() for form in form_group) for form_group in form_groups.values()):
72 errors_exist = any(helper_has_errors(form_group) for form_group in form_groups.values())
73
74 course_form_group = form_groups.pop(course.general_contribution)
75
76 contributor_form_groups = list((contribution.contributor, contribution.label, form_group, helper_has_errors(form_group)) for contribution, form_group in form_groups.items())
77
78 template_data = dict(
79 errors_exist=errors_exist,
80 course_form_group=course_form_group,
81 contributor_form_groups=contributor_form_groups,
82 course=course,
83 participants_warning=course.num_participants <= 5,
84 preview=False,
85 vote_end_datetime=course.vote_end_datetime,
86 hours_left_for_evaluation=course.time_left_for_evaluation.seconds//3600,
87 minutes_left_for_evaluation=(course.time_left_for_evaluation.seconds//60)%60,
88 evaluation_ends_soon=course.evaluation_ends_soon())
89 return render(request, "student_vote.html", template_data)
90
91 # all forms are valid, begin vote operation
92 with transaction.atomic():
93 # add user to course.voters
94 # not using course.voters.add(request.user) since it fails silently when done twice.
95 # manually inserting like this gives us the 'created' return value and ensures at the database level that nobody votes twice.
96 __, created = course.voters.through.objects.get_or_create(userprofile_id=request.user.pk, course_id=course.pk)
97 if not created: # vote already got recorded, bail out
98 raise SuspiciousOperation("A second vote has been received shortly after the first one.")
99
100 for contribution, form_group in form_groups.items():
101 for questionnaire_form in form_group:
102 questionnaire = questionnaire_form.questionnaire
103 for question in questionnaire.question_set.all():
104 identifier = question_id(contribution, questionnaire, question)
105 value = questionnaire_form.cleaned_data.get(identifier)
106
107 if question.is_text_question:
108 if value:
109 question.answer_class.objects.create(
110 contribution=contribution,
111 question=question,
112 answer=value)
113 elif question.is_heading_question:
114 pass # ignore these
115 else:
116 if value != 6:
117 answer_counter, __ = question.answer_class.objects.get_or_create(contribution=contribution, question=question, answer=value)
118 answer_counter.add_vote()
119 answer_counter.save()
120
121 course.course_evaluated.send(sender=Course, request=request, semester=course.semester)
122
123 messages.success(request, _("Your vote was recorded."))
124 return redirect('student:index')
125
126
127 def helper_create_voting_form_groups(request, contributions):
128 form_groups = OrderedDict()
129 for contribution in contributions:
130 questionnaires = contribution.questionnaires.all()
131 if not questionnaires.exists():
132 continue
133 form_groups[contribution] = [QuestionsForm(request.POST or None, contribution=contribution, questionnaire=questionnaire) for questionnaire in questionnaires]
134 return form_groups
135
136
137 def helper_has_errors(form_group):
138 return any(form.errors for form in form_group)
139
[end of evap/student/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/evap/student/views.py b/evap/student/views.py
--- a/evap/student/views.py
+++ b/evap/student/views.py
@@ -3,7 +3,9 @@
from django.contrib import messages
from django.core.exceptions import PermissionDenied, SuspiciousOperation
from django.db import transaction
+from django.http import HttpResponse
from django.shortcuts import get_object_or_404, redirect, render
+from django.urls import reverse
from django.utils.translation import ugettext as _
from evap.evaluation.auth import participant_required
@@ -13,6 +15,7 @@
from evap.student.forms import QuestionsForm
from evap.student.tools import question_id
+SUCCESS_MAGIC_STRING = 'vote submitted successfully'
@participant_required
def index(request):
@@ -58,12 +61,11 @@
@participant_required
def vote(request, course_id):
- # retrieve course and make sure that the user is allowed to vote
+
course = get_object_or_404(Course, id=course_id)
if not course.can_user_vote(request.user):
raise PermissionDenied
-
# prevent a user from voting on themselves.
contributions_to_vote_on = course.contributions.exclude(contributor=request.user).all()
form_groups = helper_create_voting_form_groups(request, contributions_to_vote_on)
@@ -85,6 +87,8 @@
vote_end_datetime=course.vote_end_datetime,
hours_left_for_evaluation=course.time_left_for_evaluation.seconds//3600,
minutes_left_for_evaluation=(course.time_left_for_evaluation.seconds//60)%60,
+ success_magic_string=SUCCESS_MAGIC_STRING,
+ success_redirect_url=reverse('student:index'),
evaluation_ends_soon=course.evaluation_ends_soon())
return render(request, "student_vote.html", template_data)
@@ -121,7 +125,7 @@
course.course_evaluated.send(sender=Course, request=request, semester=course.semester)
messages.success(request, _("Your vote was recorded."))
- return redirect('student:index')
+ return HttpResponse(SUCCESS_MAGIC_STRING)
def helper_create_voting_form_groups(request, contributions):
| {"golden_diff": "diff --git a/evap/student/views.py b/evap/student/views.py\n--- a/evap/student/views.py\n+++ b/evap/student/views.py\n@@ -3,7 +3,9 @@\n from django.contrib import messages\n from django.core.exceptions import PermissionDenied, SuspiciousOperation\n from django.db import transaction\n+from django.http import HttpResponse\n from django.shortcuts import get_object_or_404, redirect, render\n+from django.urls import reverse\n from django.utils.translation import ugettext as _\n \n from evap.evaluation.auth import participant_required\n@@ -13,6 +15,7 @@\n from evap.student.forms import QuestionsForm\n from evap.student.tools import question_id\n \n+SUCCESS_MAGIC_STRING = 'vote submitted successfully'\n \n @participant_required\n def index(request):\n@@ -58,12 +61,11 @@\n \n @participant_required\n def vote(request, course_id):\n- # retrieve course and make sure that the user is allowed to vote\n+\n course = get_object_or_404(Course, id=course_id)\n if not course.can_user_vote(request.user):\n raise PermissionDenied\n \n- \n # prevent a user from voting on themselves.\n contributions_to_vote_on = course.contributions.exclude(contributor=request.user).all()\n form_groups = helper_create_voting_form_groups(request, contributions_to_vote_on)\n@@ -85,6 +87,8 @@\n vote_end_datetime=course.vote_end_datetime,\n hours_left_for_evaluation=course.time_left_for_evaluation.seconds//3600,\n minutes_left_for_evaluation=(course.time_left_for_evaluation.seconds//60)%60,\n+ success_magic_string=SUCCESS_MAGIC_STRING,\n+ success_redirect_url=reverse('student:index'),\n evaluation_ends_soon=course.evaluation_ends_soon())\n return render(request, \"student_vote.html\", template_data)\n \n@@ -121,7 +125,7 @@\n course.course_evaluated.send(sender=Course, request=request, semester=course.semester)\n \n messages.success(request, _(\"Your vote was recorded.\"))\n- return redirect('student:index')\n+ return HttpResponse(SUCCESS_MAGIC_STRING)\n \n \n def helper_create_voting_form_groups(request, contributions):\n", "issue": "Release Sisyphus data only after successful post\nWhen a user enters answers on the student vote page and then logs out in another window before submitting the form, Sisyphus releases the form data on the form submit, because a 302 redirect to the login page is not an error case.\r\nThe data should be kept in browser storage until the vote was successfully counted.\nRelease Sisyphus data only after successful post\nWhen a user enters answers on the student vote page and then logs out in another window before submitting the form, Sisyphus releases the form data on the form submit, because a 302 redirect to the login page is not an error case.\r\nThe data should be kept in browser storage until the vote was successfully counted.\n", "before_files": [{"content": "from collections import OrderedDict\n\nfrom django.contrib import messages\nfrom django.core.exceptions import PermissionDenied, SuspiciousOperation\nfrom django.db import transaction\nfrom django.shortcuts import get_object_or_404, redirect, render\nfrom django.utils.translation import ugettext as _\n\nfrom evap.evaluation.auth import participant_required\nfrom evap.evaluation.models import Course, Semester\nfrom evap.evaluation.tools import STUDENT_STATES_ORDERED\n\nfrom evap.student.forms import QuestionsForm\nfrom evap.student.tools import question_id\n\n\n@participant_required\ndef index(request):\n # retrieve all courses, where the user is a participant and that are not new\n courses = list(set(Course.objects.filter(participants=request.user).exclude(state=\"new\")))\n voted_courses = list(set(Course.objects.filter(voters=request.user)))\n due_courses = list(set(Course.objects.filter(participants=request.user, state='in_evaluation').exclude(voters=request.user)))\n\n sorter = lambda course: (list(STUDENT_STATES_ORDERED.keys()).index(course.student_state), course.vote_end_date, course.name)\n courses.sort(key=sorter)\n\n semesters = Semester.objects.all()\n semester_list = [dict(semester_name=semester.name, id=semester.id, is_active_semester=semester.is_active_semester,\n courses=[course for course in courses if course.semester_id == semester.id]) for semester in semesters]\n\n template_data = dict(\n semester_list=semester_list,\n voted_courses=voted_courses,\n due_courses=due_courses,\n can_download_grades=request.user.can_download_grades,\n )\n return render(request, \"student_index.html\", template_data)\n\n\ndef vote_preview(request, course, for_rendering_in_modal=False):\n \"\"\"\n Renders a preview of the voting page for the given course.\n Not used by the student app itself, but by staff and contributor.\n \"\"\"\n form_groups = helper_create_voting_form_groups(request, course.contributions.all())\n course_form_group = form_groups.pop(course.general_contribution)\n contributor_form_groups = list((contribution.contributor, contribution.label, form_group, False) for contribution, form_group in form_groups.items())\n\n template_data = dict(\n errors_exist=False,\n course_form_group=course_form_group,\n contributor_form_groups=contributor_form_groups,\n course=course,\n preview=True,\n for_rendering_in_modal=for_rendering_in_modal)\n return render(request, \"student_vote.html\", template_data)\n\n\n@participant_required\ndef vote(request, course_id):\n # retrieve course and make sure that the user is allowed to vote\n course = get_object_or_404(Course, id=course_id)\n if not course.can_user_vote(request.user):\n raise PermissionDenied\n\n \n # prevent a user from voting on themselves.\n contributions_to_vote_on = course.contributions.exclude(contributor=request.user).all()\n form_groups = helper_create_voting_form_groups(request, contributions_to_vote_on)\n\n if not all(all(form.is_valid() for form in form_group) for form_group in form_groups.values()):\n errors_exist = any(helper_has_errors(form_group) for form_group in form_groups.values())\n\n course_form_group = form_groups.pop(course.general_contribution)\n\n contributor_form_groups = list((contribution.contributor, contribution.label, form_group, helper_has_errors(form_group)) for contribution, form_group in form_groups.items())\n\n template_data = dict(\n errors_exist=errors_exist,\n course_form_group=course_form_group,\n contributor_form_groups=contributor_form_groups,\n course=course,\n participants_warning=course.num_participants <= 5,\n preview=False,\n vote_end_datetime=course.vote_end_datetime,\n hours_left_for_evaluation=course.time_left_for_evaluation.seconds//3600,\n minutes_left_for_evaluation=(course.time_left_for_evaluation.seconds//60)%60,\n evaluation_ends_soon=course.evaluation_ends_soon())\n return render(request, \"student_vote.html\", template_data)\n\n # all forms are valid, begin vote operation\n with transaction.atomic():\n # add user to course.voters\n # not using course.voters.add(request.user) since it fails silently when done twice.\n # manually inserting like this gives us the 'created' return value and ensures at the database level that nobody votes twice.\n __, created = course.voters.through.objects.get_or_create(userprofile_id=request.user.pk, course_id=course.pk)\n if not created: # vote already got recorded, bail out\n raise SuspiciousOperation(\"A second vote has been received shortly after the first one.\")\n\n for contribution, form_group in form_groups.items():\n for questionnaire_form in form_group:\n questionnaire = questionnaire_form.questionnaire\n for question in questionnaire.question_set.all():\n identifier = question_id(contribution, questionnaire, question)\n value = questionnaire_form.cleaned_data.get(identifier)\n\n if question.is_text_question:\n if value:\n question.answer_class.objects.create(\n contribution=contribution,\n question=question,\n answer=value)\n elif question.is_heading_question:\n pass # ignore these\n else:\n if value != 6:\n answer_counter, __ = question.answer_class.objects.get_or_create(contribution=contribution, question=question, answer=value)\n answer_counter.add_vote()\n answer_counter.save()\n\n course.course_evaluated.send(sender=Course, request=request, semester=course.semester)\n\n messages.success(request, _(\"Your vote was recorded.\"))\n return redirect('student:index')\n\n\ndef helper_create_voting_form_groups(request, contributions):\n form_groups = OrderedDict()\n for contribution in contributions:\n questionnaires = contribution.questionnaires.all()\n if not questionnaires.exists():\n continue\n form_groups[contribution] = [QuestionsForm(request.POST or None, contribution=contribution, questionnaire=questionnaire) for questionnaire in questionnaires]\n return form_groups\n\n\ndef helper_has_errors(form_group):\n return any(form.errors for form in form_group)\n", "path": "evap/student/views.py"}]} | 2,276 | 474 |
gh_patches_debug_38096 | rasdani/github-patches | git_diff | Qiskit__qiskit-7447 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
dag_drawer should check the existence of filename extension
### Information
- **Qiskit Terra version**: 0.10.0.dev0+831d942
- **Python version**: 3.7
- **Operating system**: Mac
### What is the current behavior?
If a filename without extension is passed to the function `dag_drawer`, this [line](https://github.com/Qiskit/qiskit-terra/blob/d090eca91dc1afdb68f563885c4ccf13b31de20e/qiskit/visualization/dag_visualization.py#L91) reports two errors:
```
nxpd.pydot.InvocationException: Program terminated with status: 1. stderr follows: Format: "XXXXX" not recognized. Use one of: ......
During handling of the above exception, another exception occurred:
qiskit.visualization.exceptions.VisualizationError: 'dag_drawer requires GraphViz installed in the system. Check https://www.graphviz.org/download/ for details on how to install GraphViz in your system.'
```
This is confusing because the second error thrown by Qiskit is not the cause of the problem.
### Steps to reproduce the problem
Try `dag_drawer(dag, filename='abc')`
### What is the expected behavior?
Make the error catching better.
### Suggested solutions
We could either catch this error by reading and filtering the error message, or we could check the existence of the filename's extension, and provide a default one.
</issue>
<code>
[start of qiskit/exceptions.py]
1 # This code is part of Qiskit.
2 #
3 # (C) Copyright IBM 2017, 2020.
4 #
5 # This code is licensed under the Apache License, Version 2.0. You may
6 # obtain a copy of this license in the LICENSE.txt file in the root directory
7 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
8 #
9 # Any modifications or derivative works of this code must retain this
10 # copyright notice, and modified files need to carry a notice indicating
11 # that they have been altered from the originals.
12
13 """Exceptions for errors raised by Qiskit."""
14
15 from typing import Optional
16 import warnings
17
18
19 class QiskitError(Exception):
20 """Base class for errors raised by Qiskit."""
21
22 def __init__(self, *message):
23 """Set the error message."""
24 super().__init__(" ".join(message))
25 self.message = " ".join(message)
26
27 def __str__(self):
28 """Return the message."""
29 return repr(self.message)
30
31
32 class QiskitIndexError(QiskitError, IndexError):
33 """Raised when a sequence subscript is out of range."""
34
35 def __init__(self, *args):
36 """Set the error message."""
37 warnings.warn(
38 "QiskitIndexError class is being deprecated and it is going to be remove in the future",
39 DeprecationWarning,
40 stacklevel=2,
41 )
42 super().__init__(*args)
43
44
45 class QiskitUserConfigError(QiskitError):
46 """Raised when an error is encountered reading a user config file."""
47
48 message = "User config invalid"
49
50
51 class MissingOptionalLibraryError(QiskitError, ImportError):
52 """Raised when an optional library is missing."""
53
54 def __init__(
55 self, libname: str, name: str, pip_install: Optional[str] = None, msg: Optional[str] = None
56 ) -> None:
57 """Set the error message.
58 Args:
59 libname: Name of missing library
60 name: Name of class, function, module that uses this library
61 pip_install: pip install command, if any
62 msg: Descriptive message, if any
63 """
64 message = [f"The '{libname}' library is required to use '{name}'."]
65 if pip_install:
66 message.append(f"You can install it with '{pip_install}'.")
67 if msg:
68 message.append(f" {msg}.")
69
70 super().__init__(" ".join(message))
71 self.message = " ".join(message)
72
73 def __str__(self) -> str:
74 """Return the message."""
75 return repr(self.message)
76
[end of qiskit/exceptions.py]
[start of qiskit/visualization/dag_visualization.py]
1 # This code is part of Qiskit.
2 #
3 # (C) Copyright IBM 2017, 2018, 2020.
4 #
5 # This code is licensed under the Apache License, Version 2.0. You may
6 # obtain a copy of this license in the LICENSE.txt file in the root directory
7 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
8 #
9 # Any modifications or derivative works of this code must retain this
10 # copyright notice, and modified files need to carry a notice indicating
11 # that they have been altered from the originals.
12
13 # pylint: disable=invalid-name
14
15 """
16 Visualization function for DAG circuit representation.
17 """
18
19 import os
20 import sys
21 import tempfile
22
23 from qiskit.dagcircuit.dagnode import DAGOpNode, DAGInNode, DAGOutNode
24 from qiskit.exceptions import MissingOptionalLibraryError
25 from .exceptions import VisualizationError
26
27 try:
28 from PIL import Image
29
30 HAS_PIL = True
31 except ImportError:
32 HAS_PIL = False
33
34
35 def dag_drawer(dag, scale=0.7, filename=None, style="color"):
36 """Plot the directed acyclic graph (dag) to represent operation dependencies
37 in a quantum circuit.
38
39 Note this function leverages
40 `pydot <https://github.com/erocarrera/pydot>`_ to generate the graph, which
41 means that having `Graphviz <https://www.graphviz.org/>`_ installed on your
42 system is required for this to work.
43
44 The current release of Graphviz can be downloaded here: <https://graphviz.gitlab.io/download/>.
45 Download the version of the software that matches your environment and follow the instructions
46 to install Graph Visualization Software (Graphviz) on your operating system.
47
48 Args:
49 dag (DAGCircuit): The dag to draw.
50 scale (float): scaling factor
51 filename (str): file path to save image to (format inferred from name)
52 style (str): 'plain': B&W graph
53 'color' (default): color input/output/op nodes
54
55 Returns:
56 PIL.Image: if in Jupyter notebook and not saving to file,
57 otherwise None.
58
59 Raises:
60 VisualizationError: when style is not recognized.
61 MissingOptionalLibraryError: when pydot or pillow are not installed.
62
63 Example:
64 .. jupyter-execute::
65
66 %matplotlib inline
67 from qiskit import QuantumRegister, ClassicalRegister, QuantumCircuit
68 from qiskit.dagcircuit import DAGCircuit
69 from qiskit.converters import circuit_to_dag
70 from qiskit.visualization import dag_drawer
71
72 q = QuantumRegister(3, 'q')
73 c = ClassicalRegister(3, 'c')
74 circ = QuantumCircuit(q, c)
75 circ.h(q[0])
76 circ.cx(q[0], q[1])
77 circ.measure(q[0], c[0])
78 circ.rz(0.5, q[1]).c_if(c, 2)
79
80 dag = circuit_to_dag(circ)
81 dag_drawer(dag)
82 """
83 try:
84 import pydot
85 except ImportError as ex:
86 raise MissingOptionalLibraryError(
87 libname="PyDot",
88 name="dag_drawer",
89 pip_install="pip install pydot",
90 ) from ex
91 # NOTE: use type str checking to avoid potential cyclical import
92 # the two tradeoffs ere that it will not handle subclasses and it is
93 # slower (which doesn't matter for a visualization function)
94 type_str = str(type(dag))
95 if "DAGDependency" in type_str:
96 graph_attrs = {"dpi": str(100 * scale)}
97
98 def node_attr_func(node):
99 if style == "plain":
100 return {}
101 if style == "color":
102 n = {}
103 n["label"] = str(node.node_id) + ": " + str(node.name)
104 if node.name == "measure":
105 n["color"] = "blue"
106 n["style"] = "filled"
107 n["fillcolor"] = "lightblue"
108 if node.name == "barrier":
109 n["color"] = "black"
110 n["style"] = "filled"
111 n["fillcolor"] = "green"
112 if node.op._directive:
113 n["color"] = "black"
114 n["style"] = "filled"
115 n["fillcolor"] = "red"
116 if node.op.condition:
117 n["label"] = str(node.node_id) + ": " + str(node.name) + " (conditional)"
118 n["color"] = "black"
119 n["style"] = "filled"
120 n["fillcolor"] = "lightgreen"
121 return n
122 else:
123 raise VisualizationError("Unrecognized style %s for the dag_drawer." % style)
124
125 edge_attr_func = None
126
127 else:
128 bit_labels = {
129 bit: f"{reg.name}[{idx}]"
130 for reg in list(dag.qregs.values()) + list(dag.cregs.values())
131 for (idx, bit) in enumerate(reg)
132 }
133
134 graph_attrs = {"dpi": str(100 * scale)}
135
136 def node_attr_func(node):
137 if style == "plain":
138 return {}
139 if style == "color":
140 n = {}
141 if isinstance(node, DAGOpNode):
142 n["label"] = node.name
143 n["color"] = "blue"
144 n["style"] = "filled"
145 n["fillcolor"] = "lightblue"
146 if isinstance(node, DAGInNode):
147 n["label"] = bit_labels[node.wire]
148 n["color"] = "black"
149 n["style"] = "filled"
150 n["fillcolor"] = "green"
151 if isinstance(node, DAGOutNode):
152 n["label"] = bit_labels[node.wire]
153 n["color"] = "black"
154 n["style"] = "filled"
155 n["fillcolor"] = "red"
156 return n
157 else:
158 raise VisualizationError("Invalid style %s" % style)
159
160 def edge_attr_func(edge):
161 e = {}
162 e["label"] = bit_labels[edge]
163 return e
164
165 dot_str = dag._multi_graph.to_dot(node_attr_func, edge_attr_func, graph_attrs)
166 dot = pydot.graph_from_dot_data(dot_str)[0]
167
168 if filename:
169 extension = filename.split(".")[-1]
170 dot.write(filename, format=extension)
171 return None
172 elif ("ipykernel" in sys.modules) and ("spyder" not in sys.modules):
173 if not HAS_PIL:
174 raise MissingOptionalLibraryError(
175 libname="pillow",
176 name="dag_drawer",
177 pip_install="pip install pillow",
178 )
179
180 with tempfile.TemporaryDirectory() as tmpdirname:
181 tmp_path = os.path.join(tmpdirname, "dag.png")
182 dot.write_png(tmp_path)
183 with Image.open(tmp_path) as test_image:
184 image = test_image.copy()
185 os.remove(tmp_path)
186 return image
187 else:
188 if not HAS_PIL:
189 raise MissingOptionalLibraryError(
190 libname="pillow",
191 name="dag_drawer",
192 pip_install="pip install pillow",
193 )
194 with tempfile.TemporaryDirectory() as tmpdirname:
195 tmp_path = os.path.join(tmpdirname, "dag.png")
196 dot.write_png(tmp_path)
197 image = Image.open(tmp_path)
198 image.show()
199 os.remove(tmp_path)
200 return None
201
[end of qiskit/visualization/dag_visualization.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/qiskit/exceptions.py b/qiskit/exceptions.py
--- a/qiskit/exceptions.py
+++ b/qiskit/exceptions.py
@@ -73,3 +73,7 @@
def __str__(self) -> str:
"""Return the message."""
return repr(self.message)
+
+
+class InvalidFileError(QiskitError):
+ """Raised when the file provided is not valid for the specific task."""
diff --git a/qiskit/visualization/dag_visualization.py b/qiskit/visualization/dag_visualization.py
--- a/qiskit/visualization/dag_visualization.py
+++ b/qiskit/visualization/dag_visualization.py
@@ -21,7 +21,7 @@
import tempfile
from qiskit.dagcircuit.dagnode import DAGOpNode, DAGInNode, DAGOutNode
-from qiskit.exceptions import MissingOptionalLibraryError
+from qiskit.exceptions import MissingOptionalLibraryError, InvalidFileError
from .exceptions import VisualizationError
try:
@@ -31,6 +31,64 @@
except ImportError:
HAS_PIL = False
+FILENAME_EXTENSIONS = {
+ "bmp",
+ "canon",
+ "cgimage",
+ "cmap",
+ "cmapx",
+ "cmapx_np",
+ "dot",
+ "dot_json",
+ "eps",
+ "exr",
+ "fig",
+ "gd",
+ "gd2",
+ "gif",
+ "gv",
+ "icns",
+ "ico",
+ "imap",
+ "imap_np",
+ "ismap",
+ "jp2",
+ "jpe",
+ "jpeg",
+ "jpg",
+ "json",
+ "json0",
+ "mp",
+ "pct",
+ "pdf",
+ "pic",
+ "pict",
+ "plain",
+ "plain-ext",
+ "png",
+ "pov",
+ "ps",
+ "ps2",
+ "psd",
+ "sgi",
+ "svg",
+ "svgz",
+ "tga",
+ "tif",
+ "tiff",
+ "tk",
+ "vdx",
+ "vml",
+ "vmlz",
+ "vrml",
+ "wbmp",
+ "webp",
+ "xdot",
+ "xdot1.2",
+ "xdot1.4",
+ "xdot_json",
+}
+
def dag_drawer(dag, scale=0.7, filename=None, style="color"):
"""Plot the directed acyclic graph (dag) to represent operation dependencies
@@ -59,6 +117,7 @@
Raises:
VisualizationError: when style is not recognized.
MissingOptionalLibraryError: when pydot or pillow are not installed.
+ InvalidFileError: when filename provided is not valid
Example:
.. jupyter-execute::
@@ -166,7 +225,13 @@
dot = pydot.graph_from_dot_data(dot_str)[0]
if filename:
+ if "." not in filename:
+ raise InvalidFileError("Parameter 'filename' must be in format 'name.extension'")
extension = filename.split(".")[-1]
+ if extension not in FILENAME_EXTENSIONS:
+ raise InvalidFileError(
+ "Filename extension must be one of: " + " ".join(FILENAME_EXTENSIONS)
+ )
dot.write(filename, format=extension)
return None
elif ("ipykernel" in sys.modules) and ("spyder" not in sys.modules):
| {"golden_diff": "diff --git a/qiskit/exceptions.py b/qiskit/exceptions.py\n--- a/qiskit/exceptions.py\n+++ b/qiskit/exceptions.py\n@@ -73,3 +73,7 @@\n def __str__(self) -> str:\n \"\"\"Return the message.\"\"\"\n return repr(self.message)\n+\n+\n+class InvalidFileError(QiskitError):\n+ \"\"\"Raised when the file provided is not valid for the specific task.\"\"\"\ndiff --git a/qiskit/visualization/dag_visualization.py b/qiskit/visualization/dag_visualization.py\n--- a/qiskit/visualization/dag_visualization.py\n+++ b/qiskit/visualization/dag_visualization.py\n@@ -21,7 +21,7 @@\n import tempfile\n \n from qiskit.dagcircuit.dagnode import DAGOpNode, DAGInNode, DAGOutNode\n-from qiskit.exceptions import MissingOptionalLibraryError\n+from qiskit.exceptions import MissingOptionalLibraryError, InvalidFileError\n from .exceptions import VisualizationError\n \n try:\n@@ -31,6 +31,64 @@\n except ImportError:\n HAS_PIL = False\n \n+FILENAME_EXTENSIONS = {\n+ \"bmp\",\n+ \"canon\",\n+ \"cgimage\",\n+ \"cmap\",\n+ \"cmapx\",\n+ \"cmapx_np\",\n+ \"dot\",\n+ \"dot_json\",\n+ \"eps\",\n+ \"exr\",\n+ \"fig\",\n+ \"gd\",\n+ \"gd2\",\n+ \"gif\",\n+ \"gv\",\n+ \"icns\",\n+ \"ico\",\n+ \"imap\",\n+ \"imap_np\",\n+ \"ismap\",\n+ \"jp2\",\n+ \"jpe\",\n+ \"jpeg\",\n+ \"jpg\",\n+ \"json\",\n+ \"json0\",\n+ \"mp\",\n+ \"pct\",\n+ \"pdf\",\n+ \"pic\",\n+ \"pict\",\n+ \"plain\",\n+ \"plain-ext\",\n+ \"png\",\n+ \"pov\",\n+ \"ps\",\n+ \"ps2\",\n+ \"psd\",\n+ \"sgi\",\n+ \"svg\",\n+ \"svgz\",\n+ \"tga\",\n+ \"tif\",\n+ \"tiff\",\n+ \"tk\",\n+ \"vdx\",\n+ \"vml\",\n+ \"vmlz\",\n+ \"vrml\",\n+ \"wbmp\",\n+ \"webp\",\n+ \"xdot\",\n+ \"xdot1.2\",\n+ \"xdot1.4\",\n+ \"xdot_json\",\n+}\n+\n \n def dag_drawer(dag, scale=0.7, filename=None, style=\"color\"):\n \"\"\"Plot the directed acyclic graph (dag) to represent operation dependencies\n@@ -59,6 +117,7 @@\n Raises:\n VisualizationError: when style is not recognized.\n MissingOptionalLibraryError: when pydot or pillow are not installed.\n+ InvalidFileError: when filename provided is not valid\n \n Example:\n .. jupyter-execute::\n@@ -166,7 +225,13 @@\n dot = pydot.graph_from_dot_data(dot_str)[0]\n \n if filename:\n+ if \".\" not in filename:\n+ raise InvalidFileError(\"Parameter 'filename' must be in format 'name.extension'\")\n extension = filename.split(\".\")[-1]\n+ if extension not in FILENAME_EXTENSIONS:\n+ raise InvalidFileError(\n+ \"Filename extension must be one of: \" + \" \".join(FILENAME_EXTENSIONS)\n+ )\n dot.write(filename, format=extension)\n return None\n elif (\"ipykernel\" in sys.modules) and (\"spyder\" not in sys.modules):\n", "issue": "dag_drawer should check the existence of filename extension\n### Information\r\n\r\n- **Qiskit Terra version**: 0.10.0.dev0+831d942\r\n- **Python version**: 3.7\r\n- **Operating system**: Mac\r\n\r\n### What is the current behavior?\r\n\r\nIf a filename without extension is passed to the function `dag_drawer`, this [line](https://github.com/Qiskit/qiskit-terra/blob/d090eca91dc1afdb68f563885c4ccf13b31de20e/qiskit/visualization/dag_visualization.py#L91) reports two errors:\r\n```\r\nnxpd.pydot.InvocationException: Program terminated with status: 1. stderr follows: Format: \"XXXXX\" not recognized. Use one of: ......\r\nDuring handling of the above exception, another exception occurred:\r\nqiskit.visualization.exceptions.VisualizationError: 'dag_drawer requires GraphViz installed in the system. Check https://www.graphviz.org/download/ for details on how to install GraphViz in your system.'\r\n```\r\n\r\nThis is confusing because the second error thrown by Qiskit is not the cause of the problem.\r\n\r\n### Steps to reproduce the problem\r\n\r\nTry `dag_drawer(dag, filename='abc')`\r\n\r\n### What is the expected behavior? \r\n\r\nMake the error catching better.\r\n\r\n### Suggested solutions\r\n\r\nWe could either catch this error by reading and filtering the error message, or we could check the existence of the filename's extension, and provide a default one.\r\n\n", "before_files": [{"content": "# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2020.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n\"\"\"Exceptions for errors raised by Qiskit.\"\"\"\n\nfrom typing import Optional\nimport warnings\n\n\nclass QiskitError(Exception):\n \"\"\"Base class for errors raised by Qiskit.\"\"\"\n\n def __init__(self, *message):\n \"\"\"Set the error message.\"\"\"\n super().__init__(\" \".join(message))\n self.message = \" \".join(message)\n\n def __str__(self):\n \"\"\"Return the message.\"\"\"\n return repr(self.message)\n\n\nclass QiskitIndexError(QiskitError, IndexError):\n \"\"\"Raised when a sequence subscript is out of range.\"\"\"\n\n def __init__(self, *args):\n \"\"\"Set the error message.\"\"\"\n warnings.warn(\n \"QiskitIndexError class is being deprecated and it is going to be remove in the future\",\n DeprecationWarning,\n stacklevel=2,\n )\n super().__init__(*args)\n\n\nclass QiskitUserConfigError(QiskitError):\n \"\"\"Raised when an error is encountered reading a user config file.\"\"\"\n\n message = \"User config invalid\"\n\n\nclass MissingOptionalLibraryError(QiskitError, ImportError):\n \"\"\"Raised when an optional library is missing.\"\"\"\n\n def __init__(\n self, libname: str, name: str, pip_install: Optional[str] = None, msg: Optional[str] = None\n ) -> None:\n \"\"\"Set the error message.\n Args:\n libname: Name of missing library\n name: Name of class, function, module that uses this library\n pip_install: pip install command, if any\n msg: Descriptive message, if any\n \"\"\"\n message = [f\"The '{libname}' library is required to use '{name}'.\"]\n if pip_install:\n message.append(f\"You can install it with '{pip_install}'.\")\n if msg:\n message.append(f\" {msg}.\")\n\n super().__init__(\" \".join(message))\n self.message = \" \".join(message)\n\n def __str__(self) -> str:\n \"\"\"Return the message.\"\"\"\n return repr(self.message)\n", "path": "qiskit/exceptions.py"}, {"content": "# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2018, 2020.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n# pylint: disable=invalid-name\n\n\"\"\"\nVisualization function for DAG circuit representation.\n\"\"\"\n\nimport os\nimport sys\nimport tempfile\n\nfrom qiskit.dagcircuit.dagnode import DAGOpNode, DAGInNode, DAGOutNode\nfrom qiskit.exceptions import MissingOptionalLibraryError\nfrom .exceptions import VisualizationError\n\ntry:\n from PIL import Image\n\n HAS_PIL = True\nexcept ImportError:\n HAS_PIL = False\n\n\ndef dag_drawer(dag, scale=0.7, filename=None, style=\"color\"):\n \"\"\"Plot the directed acyclic graph (dag) to represent operation dependencies\n in a quantum circuit.\n\n Note this function leverages\n `pydot <https://github.com/erocarrera/pydot>`_ to generate the graph, which\n means that having `Graphviz <https://www.graphviz.org/>`_ installed on your\n system is required for this to work.\n\n The current release of Graphviz can be downloaded here: <https://graphviz.gitlab.io/download/>.\n Download the version of the software that matches your environment and follow the instructions\n to install Graph Visualization Software (Graphviz) on your operating system.\n\n Args:\n dag (DAGCircuit): The dag to draw.\n scale (float): scaling factor\n filename (str): file path to save image to (format inferred from name)\n style (str): 'plain': B&W graph\n 'color' (default): color input/output/op nodes\n\n Returns:\n PIL.Image: if in Jupyter notebook and not saving to file,\n otherwise None.\n\n Raises:\n VisualizationError: when style is not recognized.\n MissingOptionalLibraryError: when pydot or pillow are not installed.\n\n Example:\n .. jupyter-execute::\n\n %matplotlib inline\n from qiskit import QuantumRegister, ClassicalRegister, QuantumCircuit\n from qiskit.dagcircuit import DAGCircuit\n from qiskit.converters import circuit_to_dag\n from qiskit.visualization import dag_drawer\n\n q = QuantumRegister(3, 'q')\n c = ClassicalRegister(3, 'c')\n circ = QuantumCircuit(q, c)\n circ.h(q[0])\n circ.cx(q[0], q[1])\n circ.measure(q[0], c[0])\n circ.rz(0.5, q[1]).c_if(c, 2)\n\n dag = circuit_to_dag(circ)\n dag_drawer(dag)\n \"\"\"\n try:\n import pydot\n except ImportError as ex:\n raise MissingOptionalLibraryError(\n libname=\"PyDot\",\n name=\"dag_drawer\",\n pip_install=\"pip install pydot\",\n ) from ex\n # NOTE: use type str checking to avoid potential cyclical import\n # the two tradeoffs ere that it will not handle subclasses and it is\n # slower (which doesn't matter for a visualization function)\n type_str = str(type(dag))\n if \"DAGDependency\" in type_str:\n graph_attrs = {\"dpi\": str(100 * scale)}\n\n def node_attr_func(node):\n if style == \"plain\":\n return {}\n if style == \"color\":\n n = {}\n n[\"label\"] = str(node.node_id) + \": \" + str(node.name)\n if node.name == \"measure\":\n n[\"color\"] = \"blue\"\n n[\"style\"] = \"filled\"\n n[\"fillcolor\"] = \"lightblue\"\n if node.name == \"barrier\":\n n[\"color\"] = \"black\"\n n[\"style\"] = \"filled\"\n n[\"fillcolor\"] = \"green\"\n if node.op._directive:\n n[\"color\"] = \"black\"\n n[\"style\"] = \"filled\"\n n[\"fillcolor\"] = \"red\"\n if node.op.condition:\n n[\"label\"] = str(node.node_id) + \": \" + str(node.name) + \" (conditional)\"\n n[\"color\"] = \"black\"\n n[\"style\"] = \"filled\"\n n[\"fillcolor\"] = \"lightgreen\"\n return n\n else:\n raise VisualizationError(\"Unrecognized style %s for the dag_drawer.\" % style)\n\n edge_attr_func = None\n\n else:\n bit_labels = {\n bit: f\"{reg.name}[{idx}]\"\n for reg in list(dag.qregs.values()) + list(dag.cregs.values())\n for (idx, bit) in enumerate(reg)\n }\n\n graph_attrs = {\"dpi\": str(100 * scale)}\n\n def node_attr_func(node):\n if style == \"plain\":\n return {}\n if style == \"color\":\n n = {}\n if isinstance(node, DAGOpNode):\n n[\"label\"] = node.name\n n[\"color\"] = \"blue\"\n n[\"style\"] = \"filled\"\n n[\"fillcolor\"] = \"lightblue\"\n if isinstance(node, DAGInNode):\n n[\"label\"] = bit_labels[node.wire]\n n[\"color\"] = \"black\"\n n[\"style\"] = \"filled\"\n n[\"fillcolor\"] = \"green\"\n if isinstance(node, DAGOutNode):\n n[\"label\"] = bit_labels[node.wire]\n n[\"color\"] = \"black\"\n n[\"style\"] = \"filled\"\n n[\"fillcolor\"] = \"red\"\n return n\n else:\n raise VisualizationError(\"Invalid style %s\" % style)\n\n def edge_attr_func(edge):\n e = {}\n e[\"label\"] = bit_labels[edge]\n return e\n\n dot_str = dag._multi_graph.to_dot(node_attr_func, edge_attr_func, graph_attrs)\n dot = pydot.graph_from_dot_data(dot_str)[0]\n\n if filename:\n extension = filename.split(\".\")[-1]\n dot.write(filename, format=extension)\n return None\n elif (\"ipykernel\" in sys.modules) and (\"spyder\" not in sys.modules):\n if not HAS_PIL:\n raise MissingOptionalLibraryError(\n libname=\"pillow\",\n name=\"dag_drawer\",\n pip_install=\"pip install pillow\",\n )\n\n with tempfile.TemporaryDirectory() as tmpdirname:\n tmp_path = os.path.join(tmpdirname, \"dag.png\")\n dot.write_png(tmp_path)\n with Image.open(tmp_path) as test_image:\n image = test_image.copy()\n os.remove(tmp_path)\n return image\n else:\n if not HAS_PIL:\n raise MissingOptionalLibraryError(\n libname=\"pillow\",\n name=\"dag_drawer\",\n pip_install=\"pip install pillow\",\n )\n with tempfile.TemporaryDirectory() as tmpdirname:\n tmp_path = os.path.join(tmpdirname, \"dag.png\")\n dot.write_png(tmp_path)\n image = Image.open(tmp_path)\n image.show()\n os.remove(tmp_path)\n return None\n", "path": "qiskit/visualization/dag_visualization.py"}]} | 3,716 | 817 |
gh_patches_debug_1170 | rasdani/github-patches | git_diff | bokeh__bokeh-4542 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
clustering app example needs updates for recent changes
Fails because `theme.yaml` tries to set `title_text_font_size` on `Plot` This bypasses the (python) property that deprecates this former `Plot` property, and tries to set a (Bokeh) property with that name directly on the plot. This fails, because of the work to make `Title` its own model.
Will fix up the `theme.yaml` and note this problem in migration guide. Since we barely demonstrated and not discussed the theming, hopefully this will not bite many people at all.
</issue>
<code>
[start of examples/app/clustering/main.py]
1 import numpy as np
2 np.random.seed(0)
3
4 from bokeh.io import curdoc
5 from bokeh.models import ColumnDataSource, VBox, HBox, Select, Slider
6 from bokeh.plotting import Figure
7 from bokeh.palettes import Spectral6
8
9 from sklearn import cluster, datasets
10 from sklearn.neighbors import kneighbors_graph
11 from sklearn.preprocessing import StandardScaler
12
13 # define some helper functions
14 def clustering(X, algorithm, n_clusters):
15 # normalize dataset for easier parameter selection
16 X = StandardScaler().fit_transform(X)
17
18 # estimate bandwidth for mean shift
19 bandwidth = cluster.estimate_bandwidth(X, quantile=0.3)
20
21 # connectivity matrix for structured Ward
22 connectivity = kneighbors_graph(X, n_neighbors=10, include_self=False)
23
24 # make connectivity symmetric
25 connectivity = 0.5 * (connectivity + connectivity.T)
26
27 # Generate the new colors:
28 if algorithm=='MiniBatchKMeans':
29 model = cluster.MiniBatchKMeans(n_clusters=n_clusters)
30
31 elif algorithm=='Birch':
32 model = cluster.Birch(n_clusters=n_clusters)
33
34 elif algorithm=='DBSCAN':
35 model = cluster.DBSCAN(eps=.2)
36
37 elif algorithm=='AffinityPropagation':
38 model = cluster.AffinityPropagation(damping=.9,
39 preference=-200)
40
41 elif algorithm=='MeanShift':
42 model = cluster.MeanShift(bandwidth=bandwidth,
43 bin_seeding=True)
44
45 elif algorithm=='SpectralClustering':
46 model = cluster.SpectralClustering(n_clusters=n_clusters,
47 eigen_solver='arpack',
48 affinity="nearest_neighbors")
49
50 elif algorithm=='Ward':
51 model = cluster.AgglomerativeClustering(n_clusters=n_clusters,
52 linkage='ward',
53 connectivity=connectivity)
54
55 elif algorithm=='AgglomerativeClustering':
56 model = cluster.AgglomerativeClustering(linkage="average",
57 affinity="cityblock",
58 n_clusters=n_clusters,
59 connectivity=connectivity)
60
61 model.fit(X)
62
63 if hasattr(model, 'labels_'):
64 y_pred = model.labels_.astype(np.int)
65 else:
66 y_pred = model.predict(X)
67
68 return X, y_pred
69
70 def get_dataset(dataset, n_samples):
71 if dataset == 'Noisy Circles':
72 return datasets.make_circles(n_samples=n_samples,
73 factor=0.5,
74 noise=0.05)
75
76 elif dataset == 'Noisy Moons':
77 return datasets.make_moons(n_samples=n_samples,
78 noise=0.05)
79
80 elif dataset == 'Blobs':
81 return datasets.make_blobs(n_samples=n_samples,
82 random_state=8)
83
84 elif dataset == "No Structure":
85 return np.random.rand(n_samples, 2), None
86
87 # set up initial data
88 n_samples = 1500
89 n_clusters = 2
90 algorithm = 'MiniBatchKMeans'
91 dataset = 'Noisy Circles'
92
93 X, y = get_dataset(dataset, n_samples)
94 X, y_pred = clustering(X, algorithm, n_clusters)
95 spectral = np.hstack([Spectral6] * 20)
96 colors = [spectral[i] for i in y]
97
98 # set up plot (styling in theme.yaml)
99 plot = Figure(toolbar_location=None, title=algorithm)
100 source = ColumnDataSource(data=dict(x=X[:, 0], y=X[:, 1], colors=colors))
101 plot.circle('x', 'y', fill_color='colors', line_color=None, source=source)
102
103 # set up widgets
104 clustering_algorithms= [
105 'MiniBatchKMeans',
106 'AffinityPropagation',
107 'MeanShift',
108 'SpectralClustering',
109 'Ward',
110 'AgglomerativeClustering',
111 'DBSCAN',
112 'Birch'
113 ]
114
115 datasets_names = [
116 'Noisy Circles',
117 'Noisy Moons',
118 'Blobs',
119 'No Structure'
120 ]
121
122 algorithm_select = Select(value='MiniBatchKMeans',
123 title='Select algorithm:',
124 options=clustering_algorithms)
125
126 dataset_select = Select(value='Noisy Circles',
127 title='Select dataset:',
128 options=datasets_names)
129
130 samples_slider = Slider(title="Number of samples",
131 value=1500.0,
132 start=1000.0,
133 end=3000.0,
134 step=100)
135
136 clusters_slider = Slider(title="Number of clusters",
137 value=2.0,
138 start=2.0,
139 end=10.0,
140 step=1)
141
142 # set up callbacks
143 def update_algorithm_or_clusters(attrname, old, new):
144 global X
145
146 algorithm = algorithm_select.value
147 n_clusters = int(clusters_slider.value)
148
149 X, y_pred = clustering(X, algorithm, n_clusters)
150 colors = [spectral[i] for i in y_pred]
151
152 source.data['colors'] = colors
153 source.data['x'] = X[:, 0]
154 source.data['y'] = X[:, 1]
155
156 plot.title = algorithm
157
158 def update_samples_or_dataset(attrname, old, new):
159 global X, y
160
161 dataset = dataset_select.value
162 algorithm = algorithm_select.value
163 n_clusters = int(clusters_slider.value)
164 n_samples = int(samples_slider.value)
165
166 X, y = get_dataset(dataset, n_samples)
167 X, y_pred = clustering(X, algorithm, n_clusters)
168 colors = [spectral[i] for i in y_pred]
169
170 source.data['x'] = X[:, 0]
171 source.data['y'] = X[:, 1]
172 source.data['colors'] = colors
173
174 algorithm_select.on_change('value', update_algorithm_or_clusters)
175 clusters_slider.on_change('value', update_algorithm_or_clusters)
176
177 dataset_select.on_change('value', update_samples_or_dataset)
178 samples_slider.on_change('value', update_samples_or_dataset)
179
180 # set up layout
181 selects = HBox(dataset_select, algorithm_select)
182 inputs = VBox(samples_slider, clusters_slider, selects)
183
184 # add to document
185 curdoc().add_root(HBox(inputs, plot, width=800))
186
[end of examples/app/clustering/main.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/examples/app/clustering/main.py b/examples/app/clustering/main.py
--- a/examples/app/clustering/main.py
+++ b/examples/app/clustering/main.py
@@ -153,7 +153,7 @@
source.data['x'] = X[:, 0]
source.data['y'] = X[:, 1]
- plot.title = algorithm
+ plot.title.text = algorithm
def update_samples_or_dataset(attrname, old, new):
global X, y
| {"golden_diff": "diff --git a/examples/app/clustering/main.py b/examples/app/clustering/main.py\n--- a/examples/app/clustering/main.py\n+++ b/examples/app/clustering/main.py\n@@ -153,7 +153,7 @@\n source.data['x'] = X[:, 0]\n source.data['y'] = X[:, 1]\n \n- plot.title = algorithm\n+ plot.title.text = algorithm\n \n def update_samples_or_dataset(attrname, old, new):\n global X, y\n", "issue": "clustering app example needs updates for recent changes\nFails because `theme.yaml` tries to set `title_text_font_size` on `Plot` This bypasses the (python) property that deprecates this former `Plot` property, and tries to set a (Bokeh) property with that name directly on the plot. This fails, because of the work to make `Title` its own model.\n\nWill fix up the `theme.yaml` and note this problem in migration guide. Since we barely demonstrated and not discussed the theming, hopefully this will not bite many people at all. \n\n", "before_files": [{"content": "import numpy as np\nnp.random.seed(0)\n\nfrom bokeh.io import curdoc\nfrom bokeh.models import ColumnDataSource, VBox, HBox, Select, Slider\nfrom bokeh.plotting import Figure\nfrom bokeh.palettes import Spectral6\n\nfrom sklearn import cluster, datasets\nfrom sklearn.neighbors import kneighbors_graph\nfrom sklearn.preprocessing import StandardScaler\n\n# define some helper functions\ndef clustering(X, algorithm, n_clusters):\n # normalize dataset for easier parameter selection\n X = StandardScaler().fit_transform(X)\n\n # estimate bandwidth for mean shift\n bandwidth = cluster.estimate_bandwidth(X, quantile=0.3)\n\n # connectivity matrix for structured Ward\n connectivity = kneighbors_graph(X, n_neighbors=10, include_self=False)\n\n # make connectivity symmetric\n connectivity = 0.5 * (connectivity + connectivity.T)\n\n # Generate the new colors:\n if algorithm=='MiniBatchKMeans':\n model = cluster.MiniBatchKMeans(n_clusters=n_clusters)\n\n elif algorithm=='Birch':\n model = cluster.Birch(n_clusters=n_clusters)\n\n elif algorithm=='DBSCAN':\n model = cluster.DBSCAN(eps=.2)\n\n elif algorithm=='AffinityPropagation':\n model = cluster.AffinityPropagation(damping=.9,\n preference=-200)\n\n elif algorithm=='MeanShift':\n model = cluster.MeanShift(bandwidth=bandwidth,\n bin_seeding=True)\n\n elif algorithm=='SpectralClustering':\n model = cluster.SpectralClustering(n_clusters=n_clusters,\n eigen_solver='arpack',\n affinity=\"nearest_neighbors\")\n\n elif algorithm=='Ward':\n model = cluster.AgglomerativeClustering(n_clusters=n_clusters,\n linkage='ward',\n connectivity=connectivity)\n\n elif algorithm=='AgglomerativeClustering':\n model = cluster.AgglomerativeClustering(linkage=\"average\",\n affinity=\"cityblock\",\n n_clusters=n_clusters,\n connectivity=connectivity)\n\n model.fit(X)\n\n if hasattr(model, 'labels_'):\n y_pred = model.labels_.astype(np.int)\n else:\n y_pred = model.predict(X)\n\n return X, y_pred\n\ndef get_dataset(dataset, n_samples):\n if dataset == 'Noisy Circles':\n return datasets.make_circles(n_samples=n_samples,\n factor=0.5,\n noise=0.05)\n\n elif dataset == 'Noisy Moons':\n return datasets.make_moons(n_samples=n_samples,\n noise=0.05)\n\n elif dataset == 'Blobs':\n return datasets.make_blobs(n_samples=n_samples,\n random_state=8)\n\n elif dataset == \"No Structure\":\n return np.random.rand(n_samples, 2), None\n\n# set up initial data\nn_samples = 1500\nn_clusters = 2\nalgorithm = 'MiniBatchKMeans'\ndataset = 'Noisy Circles'\n\nX, y = get_dataset(dataset, n_samples)\nX, y_pred = clustering(X, algorithm, n_clusters)\nspectral = np.hstack([Spectral6] * 20)\ncolors = [spectral[i] for i in y]\n\n# set up plot (styling in theme.yaml)\nplot = Figure(toolbar_location=None, title=algorithm)\nsource = ColumnDataSource(data=dict(x=X[:, 0], y=X[:, 1], colors=colors))\nplot.circle('x', 'y', fill_color='colors', line_color=None, source=source)\n\n# set up widgets\nclustering_algorithms= [\n 'MiniBatchKMeans',\n 'AffinityPropagation',\n 'MeanShift',\n 'SpectralClustering',\n 'Ward',\n 'AgglomerativeClustering',\n 'DBSCAN',\n 'Birch'\n]\n\ndatasets_names = [\n 'Noisy Circles',\n 'Noisy Moons',\n 'Blobs',\n 'No Structure'\n]\n\nalgorithm_select = Select(value='MiniBatchKMeans',\n title='Select algorithm:',\n options=clustering_algorithms)\n\ndataset_select = Select(value='Noisy Circles',\n title='Select dataset:',\n options=datasets_names)\n\nsamples_slider = Slider(title=\"Number of samples\",\n value=1500.0,\n start=1000.0,\n end=3000.0,\n step=100)\n\nclusters_slider = Slider(title=\"Number of clusters\",\n value=2.0,\n start=2.0,\n end=10.0,\n step=1)\n\n# set up callbacks\ndef update_algorithm_or_clusters(attrname, old, new):\n global X\n\n algorithm = algorithm_select.value\n n_clusters = int(clusters_slider.value)\n\n X, y_pred = clustering(X, algorithm, n_clusters)\n colors = [spectral[i] for i in y_pred]\n\n source.data['colors'] = colors\n source.data['x'] = X[:, 0]\n source.data['y'] = X[:, 1]\n\n plot.title = algorithm\n\ndef update_samples_or_dataset(attrname, old, new):\n global X, y\n\n dataset = dataset_select.value\n algorithm = algorithm_select.value\n n_clusters = int(clusters_slider.value)\n n_samples = int(samples_slider.value)\n\n X, y = get_dataset(dataset, n_samples)\n X, y_pred = clustering(X, algorithm, n_clusters)\n colors = [spectral[i] for i in y_pred]\n\n source.data['x'] = X[:, 0]\n source.data['y'] = X[:, 1]\n source.data['colors'] = colors\n\nalgorithm_select.on_change('value', update_algorithm_or_clusters)\nclusters_slider.on_change('value', update_algorithm_or_clusters)\n\ndataset_select.on_change('value', update_samples_or_dataset)\nsamples_slider.on_change('value', update_samples_or_dataset)\n\n# set up layout\nselects = HBox(dataset_select, algorithm_select)\ninputs = VBox(samples_slider, clusters_slider, selects)\n\n# add to document\ncurdoc().add_root(HBox(inputs, plot, width=800))\n", "path": "examples/app/clustering/main.py"}]} | 2,425 | 108 |
gh_patches_debug_21392 | rasdani/github-patches | git_diff | Flexget__Flexget-2511 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Notify (Pushbullet) Plugin Error.
Hi, since last week i have this error in my log. Up to this point everything worked without problems.
```
2019-11-13 10:30 ERROR notify_entry NexBox 'x-ratelimit-reset'
Traceback (most recent call last):
File "/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notify.py", line 104, in send_notification
send_notification(*args, **kwargs)
File "/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notification_framework.py", line 124, in send_notification
title, message, rendered_config
File "/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notifiers/pushbullet.py", line 89, in notify
self.send_push(key, title, message, config.get('url'), d, 'device_iden')
File "/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notifiers/pushbullet.py", line 130, in send_push
int(response.headers['X-Ratelimit-Reset'])
File "/usr/local/lib/python3.5/dist-packages/requests/structures.py", line 52, in __getitem__
return self._store[key.lower()][1]
KeyError: 'x-ratelimit-reset'
```
Flexget: 2.21.32
API: 1.5.0
Same with Flexget 3.0.8 and Python 3.8
Notify (Pushbullet) Plugin Error.
Hi, since last week i have this error in my log. Up to this point everything worked without problems.
```
2019-11-13 10:30 ERROR notify_entry NexBox 'x-ratelimit-reset'
Traceback (most recent call last):
File "/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notify.py", line 104, in send_notification
send_notification(*args, **kwargs)
File "/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notification_framework.py", line 124, in send_notification
title, message, rendered_config
File "/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notifiers/pushbullet.py", line 89, in notify
self.send_push(key, title, message, config.get('url'), d, 'device_iden')
File "/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notifiers/pushbullet.py", line 130, in send_push
int(response.headers['X-Ratelimit-Reset'])
File "/usr/local/lib/python3.5/dist-packages/requests/structures.py", line 52, in __getitem__
return self._store[key.lower()][1]
KeyError: 'x-ratelimit-reset'
```
Flexget: 2.21.32
API: 1.5.0
Same with Flexget 3.0.8 and Python 3.8
</issue>
<code>
[start of flexget/components/notify/notifiers/pushover.py]
1 import datetime
2 import logging
3
4 from requests.exceptions import RequestException
5
6 from flexget import plugin
7 from flexget.config_schema import one_or_more
8 from flexget.event import event
9 from flexget.plugin import PluginWarning
10 from flexget.utils.requests import Session as RequestSession
11 from flexget.utils.requests import TimedLimiter
12
13 plugin_name = 'pushover'
14 log = logging.getLogger(plugin_name)
15
16 PUSHOVER_URL = 'https://api.pushover.net/1/messages.json'
17
18 requests = RequestSession(max_retries=3)
19 requests.add_domain_limiter(TimedLimiter('pushover.net', '5 seconds'))
20
21
22 class PushoverNotifier:
23 """
24 Example::
25
26 notify:
27 entries:
28 via:
29 - pushover:
30 user_key: <USER_KEY> (can also be a list of userkeys)
31 token: <TOKEN>
32 [device: <DEVICE_STRING>]
33 [priority: <PRIORITY>]
34 [url: <URL>]
35 [url_title: <URL_TITLE>]
36 [sound: <SOUND>]
37 [retry]: <RETRY>]
38 [expire]: <EXPIRE>]
39 [callback]: <CALLBACK>]
40 [html]: <HTML>]
41 """
42
43 schema = {
44 'type': 'object',
45 'properties': {
46 'user_key': one_or_more({'type': 'string'}),
47 'api_key': {'type': 'string', 'default': 'aPwSHwkLcNaavShxktBpgJH4bRWc3m'},
48 'device': one_or_more({'type': 'string'}),
49 'priority': {
50 'oneOf': [{'type': 'number', 'minimum': -2, 'maximum': 2}, {'type': 'string'}]
51 },
52 'url': {'type': 'string'},
53 'url_title': {'type': 'string'},
54 'sound': {'type': 'string'},
55 'retry': {'type': 'integer', 'minimum': 30},
56 'expire': {'type': 'integer', 'maximum': 86400},
57 'callback': {'type': 'string'},
58 'html': {'type': 'boolean'},
59 },
60 'required': ['user_key'],
61 'additionalProperties': False,
62 }
63
64 def notify(self, title, message, config):
65 """
66 Sends a Pushover notification
67
68 :param str title: the message's title
69 :param str message: the message to send
70 :param dict config: The pushover config
71 """
72 notification = {
73 'token': config.get('api_key'),
74 'message': message,
75 'title': title,
76 'device': config.get('device'),
77 'priority': config.get('priority'),
78 'url': config.get('url'),
79 'url_title': config.get('url_title'),
80 'sound': config.get('sound'),
81 'retry': config.get('retry'),
82 'expire': config.get('expire'),
83 'callback': config.get('callback'),
84 }
85
86 # HTML parsing mode
87 if config.get('html'):
88 notification['html'] = 1
89
90 # Support multiple devices
91 if isinstance(notification['device'], list):
92 notification['device'] = ','.join(notification['device'])
93
94 # Special case, verify certain fields exists if priority is 2
95 priority = config.get('priority')
96 expire = config.get('expire')
97 retry = config.get('retry')
98 if priority == 2 and not all([expire, retry]):
99 log.warning(
100 'Priority set to 2 but fields "expire" and "retry" are not both present.Lowering priority to 1'
101 )
102 notification['priority'] = 1
103
104 if not isinstance(config['user_key'], list):
105 config['user_key'] = [config['user_key']]
106
107 for user in config['user_key']:
108 notification['user'] = user
109 try:
110 response = requests.post(PUSHOVER_URL, data=notification)
111 except RequestException as e:
112 if e.response is not None:
113 if e.response.status_code == 429:
114 reset_time = datetime.datetime.fromtimestamp(
115 int(e.response.headers['X-Limit-App-Reset'])
116 ).strftime('%Y-%m-%d %H:%M:%S')
117 error_message = (
118 'Monthly pushover message limit reached. Next reset: %s' % reset_time
119 )
120 else:
121 error_message = e.response.json()['errors'][0]
122 else:
123 error_message = str(e)
124 raise PluginWarning(error_message)
125
126 reset_time = datetime.datetime.fromtimestamp(
127 int(response.headers['X-Limit-App-Reset'])
128 ).strftime('%Y-%m-%d %H:%M:%S')
129 remaining = response.headers['X-Limit-App-Remaining']
130 log.debug(
131 'Pushover notification sent. Notifications remaining until next reset: %s. '
132 'Next reset at: %s',
133 remaining,
134 reset_time,
135 )
136
137
138 @event('plugin.register')
139 def register_plugin():
140 plugin.register(PushoverNotifier, plugin_name, api_ver=2, interfaces=['notifiers'])
141
[end of flexget/components/notify/notifiers/pushover.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/flexget/components/notify/notifiers/pushover.py b/flexget/components/notify/notifiers/pushover.py
--- a/flexget/components/notify/notifiers/pushover.py
+++ b/flexget/components/notify/notifiers/pushover.py
@@ -111,12 +111,15 @@
except RequestException as e:
if e.response is not None:
if e.response.status_code == 429:
- reset_time = datetime.datetime.fromtimestamp(
- int(e.response.headers['X-Limit-App-Reset'])
- ).strftime('%Y-%m-%d %H:%M:%S')
- error_message = (
- 'Monthly pushover message limit reached. Next reset: %s' % reset_time
- )
+ app_reset = e.response.headers.get('X-Limit-App-Reset')
+ if app_reset:
+ reset_time = datetime.datetime.fromtimestamp(int(app_reset)).strftime(
+ '%Y-%m-%d %H:%M:%S'
+ )
+ error_message = (
+ f'Monthly pushover message limit reached. Next reset: {reset_time}'
+ )
+
else:
error_message = e.response.json()['errors'][0]
else:
| {"golden_diff": "diff --git a/flexget/components/notify/notifiers/pushover.py b/flexget/components/notify/notifiers/pushover.py\n--- a/flexget/components/notify/notifiers/pushover.py\n+++ b/flexget/components/notify/notifiers/pushover.py\n@@ -111,12 +111,15 @@\n except RequestException as e:\n if e.response is not None:\n if e.response.status_code == 429:\n- reset_time = datetime.datetime.fromtimestamp(\n- int(e.response.headers['X-Limit-App-Reset'])\n- ).strftime('%Y-%m-%d %H:%M:%S')\n- error_message = (\n- 'Monthly pushover message limit reached. Next reset: %s' % reset_time\n- )\n+ app_reset = e.response.headers.get('X-Limit-App-Reset')\n+ if app_reset:\n+ reset_time = datetime.datetime.fromtimestamp(int(app_reset)).strftime(\n+ '%Y-%m-%d %H:%M:%S'\n+ )\n+ error_message = (\n+ f'Monthly pushover message limit reached. Next reset: {reset_time}'\n+ )\n+\n else:\n error_message = e.response.json()['errors'][0]\n else:\n", "issue": "Notify (Pushbullet) Plugin Error.\nHi, since last week i have this error in my log. Up to this point everything worked without problems.\r\n```\r\n2019-11-13 10:30 ERROR notify_entry NexBox 'x-ratelimit-reset'\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notify.py\", line 104, in send_notification\r\n send_notification(*args, **kwargs)\r\n File \"/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notification_framework.py\", line 124, in send_notification\r\n title, message, rendered_config\r\n File \"/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notifiers/pushbullet.py\", line 89, in notify\r\n self.send_push(key, title, message, config.get('url'), d, 'device_iden')\r\n File \"/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notifiers/pushbullet.py\", line 130, in send_push\r\n int(response.headers['X-Ratelimit-Reset'])\r\n File \"/usr/local/lib/python3.5/dist-packages/requests/structures.py\", line 52, in __getitem__\r\n return self._store[key.lower()][1]\r\nKeyError: 'x-ratelimit-reset'\r\n```\r\nFlexget: 2.21.32\r\nAPI: 1.5.0\r\n\r\nSame with Flexget 3.0.8 and Python 3.8\nNotify (Pushbullet) Plugin Error.\nHi, since last week i have this error in my log. Up to this point everything worked without problems.\r\n```\r\n2019-11-13 10:30 ERROR notify_entry NexBox 'x-ratelimit-reset'\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notify.py\", line 104, in send_notification\r\n send_notification(*args, **kwargs)\r\n File \"/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notification_framework.py\", line 124, in send_notification\r\n title, message, rendered_config\r\n File \"/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notifiers/pushbullet.py\", line 89, in notify\r\n self.send_push(key, title, message, config.get('url'), d, 'device_iden')\r\n File \"/usr/local/lib/python3.5/dist-packages/flexget/components/notify/notifiers/pushbullet.py\", line 130, in send_push\r\n int(response.headers['X-Ratelimit-Reset'])\r\n File \"/usr/local/lib/python3.5/dist-packages/requests/structures.py\", line 52, in __getitem__\r\n return self._store[key.lower()][1]\r\nKeyError: 'x-ratelimit-reset'\r\n```\r\nFlexget: 2.21.32\r\nAPI: 1.5.0\r\n\r\nSame with Flexget 3.0.8 and Python 3.8\n", "before_files": [{"content": "import datetime\nimport logging\n\nfrom requests.exceptions import RequestException\n\nfrom flexget import plugin\nfrom flexget.config_schema import one_or_more\nfrom flexget.event import event\nfrom flexget.plugin import PluginWarning\nfrom flexget.utils.requests import Session as RequestSession\nfrom flexget.utils.requests import TimedLimiter\n\nplugin_name = 'pushover'\nlog = logging.getLogger(plugin_name)\n\nPUSHOVER_URL = 'https://api.pushover.net/1/messages.json'\n\nrequests = RequestSession(max_retries=3)\nrequests.add_domain_limiter(TimedLimiter('pushover.net', '5 seconds'))\n\n\nclass PushoverNotifier:\n \"\"\"\n Example::\n\n notify:\n entries:\n via:\n - pushover:\n user_key: <USER_KEY> (can also be a list of userkeys)\n token: <TOKEN>\n [device: <DEVICE_STRING>]\n [priority: <PRIORITY>]\n [url: <URL>]\n [url_title: <URL_TITLE>]\n [sound: <SOUND>]\n [retry]: <RETRY>]\n [expire]: <EXPIRE>]\n [callback]: <CALLBACK>]\n [html]: <HTML>]\n \"\"\"\n\n schema = {\n 'type': 'object',\n 'properties': {\n 'user_key': one_or_more({'type': 'string'}),\n 'api_key': {'type': 'string', 'default': 'aPwSHwkLcNaavShxktBpgJH4bRWc3m'},\n 'device': one_or_more({'type': 'string'}),\n 'priority': {\n 'oneOf': [{'type': 'number', 'minimum': -2, 'maximum': 2}, {'type': 'string'}]\n },\n 'url': {'type': 'string'},\n 'url_title': {'type': 'string'},\n 'sound': {'type': 'string'},\n 'retry': {'type': 'integer', 'minimum': 30},\n 'expire': {'type': 'integer', 'maximum': 86400},\n 'callback': {'type': 'string'},\n 'html': {'type': 'boolean'},\n },\n 'required': ['user_key'],\n 'additionalProperties': False,\n }\n\n def notify(self, title, message, config):\n \"\"\"\n Sends a Pushover notification\n\n :param str title: the message's title\n :param str message: the message to send\n :param dict config: The pushover config\n \"\"\"\n notification = {\n 'token': config.get('api_key'),\n 'message': message,\n 'title': title,\n 'device': config.get('device'),\n 'priority': config.get('priority'),\n 'url': config.get('url'),\n 'url_title': config.get('url_title'),\n 'sound': config.get('sound'),\n 'retry': config.get('retry'),\n 'expire': config.get('expire'),\n 'callback': config.get('callback'),\n }\n\n # HTML parsing mode\n if config.get('html'):\n notification['html'] = 1\n\n # Support multiple devices\n if isinstance(notification['device'], list):\n notification['device'] = ','.join(notification['device'])\n\n # Special case, verify certain fields exists if priority is 2\n priority = config.get('priority')\n expire = config.get('expire')\n retry = config.get('retry')\n if priority == 2 and not all([expire, retry]):\n log.warning(\n 'Priority set to 2 but fields \"expire\" and \"retry\" are not both present.Lowering priority to 1'\n )\n notification['priority'] = 1\n\n if not isinstance(config['user_key'], list):\n config['user_key'] = [config['user_key']]\n\n for user in config['user_key']:\n notification['user'] = user\n try:\n response = requests.post(PUSHOVER_URL, data=notification)\n except RequestException as e:\n if e.response is not None:\n if e.response.status_code == 429:\n reset_time = datetime.datetime.fromtimestamp(\n int(e.response.headers['X-Limit-App-Reset'])\n ).strftime('%Y-%m-%d %H:%M:%S')\n error_message = (\n 'Monthly pushover message limit reached. Next reset: %s' % reset_time\n )\n else:\n error_message = e.response.json()['errors'][0]\n else:\n error_message = str(e)\n raise PluginWarning(error_message)\n\n reset_time = datetime.datetime.fromtimestamp(\n int(response.headers['X-Limit-App-Reset'])\n ).strftime('%Y-%m-%d %H:%M:%S')\n remaining = response.headers['X-Limit-App-Remaining']\n log.debug(\n 'Pushover notification sent. Notifications remaining until next reset: %s. '\n 'Next reset at: %s',\n remaining,\n reset_time,\n )\n\n\n@event('plugin.register')\ndef register_plugin():\n plugin.register(PushoverNotifier, plugin_name, api_ver=2, interfaces=['notifiers'])\n", "path": "flexget/components/notify/notifiers/pushover.py"}]} | 2,648 | 278 |
gh_patches_debug_4331 | rasdani/github-patches | git_diff | AUTOMATIC1111__stable-diffusion-webui-4919 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug]: Torch deepdanbooru refuses to run on CPU
### Is there an existing issue for this?
- [X] I have searched the existing issues and checked the recent builds/commits
### What happened?
When trying to launch deepdanbooru with `--use-cpu all` it fails with `RuntimeError: No CUDA GPUs are available`.
### Steps to reproduce the problem
1. Launch webui in CPU only mode.
2. Press "Interrogate Deepdanbooru"
3. Exception occurs
### What should have happened?
Should work in CPU like the older implementation.
### Commit where the problem happens
c81d440d876dfd2ab3560410f37442ef56fc6632
### What platforms do you use to access UI ?
Linux
### What browsers do you use to access the UI ?
Mozilla Firefox
### Command Line Arguments
```Shell
ACCELERATE="True" CUDA_VISIBLE_DEVICES="-1" bash webui.sh --use-cpu all --precision=full --no-half --no-half-vae --skip-torch-cuda-test --deepdanbooru --opt-channelslast --always-batch-cond-uncond
```
### Additional information, context and logs
_No response_
[Bug]: DeepDanBooru Interrogate fails if using --device-id 1 on startup
### Is there an existing issue for this?
- [X] I have searched the existing issues and checked the recent builds/commits
### What happened?
I use 2 GPUs in my system. device 0 is for training and 1 is what I use for the webui.
Using the webui on default or device-id 0, works as I expect. However if I use 1, I can not interrogate anymore.
### Steps to reproduce the problem
Add --device-id 1 to your startup commands.
add or send an image to img2img
press Interrogate DeepBooru
### What should have happened?
The prompt should have been populated, instead this error is generated:
Traceback (most recent call last):
File "C:\sd\forks\auto1111\venv\lib\site-packages\gradio\routes.py", line 284, in run_predict
output = await app.blocks.process_api(
File "C:\sd\forks\auto1111\venv\lib\site-packages\gradio\blocks.py", line 982, in process_api
result = await self.call_function(fn_index, inputs, iterator)
File "C:\sd\forks\auto1111\venv\lib\site-packages\gradio\blocks.py", line 824, in call_function
prediction = await anyio.to_thread.run_sync(
File "C:\sd\forks\auto1111\venv\lib\site-packages\anyio\to_thread.py", line 31, in run_sync
return await get_asynclib().run_sync_in_worker_thread(
File "C:\sd\forks\auto1111\venv\lib\site-packages\anyio\_backends\_asyncio.py", line 937, in run_sync_in_worker_thread
return await future
File "C:\sd\forks\auto1111\venv\lib\site-packages\anyio\_backends\_asyncio.py", line 867, in run
result = context.run(func, *args)
File "C:\sd\forks\auto1111\modules\ui.py", line 352, in interrogate_deepbooru
prompt = deepbooru.model.tag(image)
File "C:\sd\forks\auto1111\modules\deepbooru.py", line 45, in tag
res = self.tag_multi(pil_image)
File "C:\sd\forks\auto1111\modules\deepbooru.py", line 62, in tag_multi
y = self.model(x)[0].detach().cpu().numpy()
File "C:\sd\forks\auto1111\venv\lib\site-packages\torch\nn\modules\module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "C:\sd\forks\auto1111\modules\deepbooru_model.py", line 199, in forward
t_360 = self.n_Conv_0(t_359_padded)
File "C:\sd\forks\auto1111\venv\lib\site-packages\torch\nn\modules\module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "C:\sd\forks\auto1111\venv\lib\site-packages\torch\nn\modules\conv.py", line 457, in forward
return self._conv_forward(input, self.weight, self.bias)
File "C:\sd\forks\auto1111\venv\lib\site-packages\torch\nn\modules\conv.py", line 453, in _conv_forward
return F.conv2d(input, weight, bias, self.stride,
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1! (when checking argument for argument weight in method wrapper__cudnn_convolution)
### Commit where the problem happens
Commit hash: 828438b4a190759807f9054932cae3a8b880ddf1
### What platforms do you use to access UI ?
Windows
### What browsers do you use to access the UI ?
Google Chrome, Microsoft Edge
### Command Line Arguments
```Shell
--api --force-enable-xformers --ckpt-dir "C:\sd\models" --embeddings-dir "C:\sd\embeddings" --hypernetwork-dir "C:\sd\hypernetworks" --vae-path "C:\sd\models\VAE" --device-id 1
```
### Additional information, context and logs
_No response_
</issue>
<code>
[start of modules/deepbooru.py]
1 import os
2 import re
3
4 import torch
5 from PIL import Image
6 import numpy as np
7
8 from modules import modelloader, paths, deepbooru_model, devices, images, shared
9
10 re_special = re.compile(r'([\\()])')
11
12
13 class DeepDanbooru:
14 def __init__(self):
15 self.model = None
16
17 def load(self):
18 if self.model is not None:
19 return
20
21 files = modelloader.load_models(
22 model_path=os.path.join(paths.models_path, "torch_deepdanbooru"),
23 model_url='https://github.com/AUTOMATIC1111/TorchDeepDanbooru/releases/download/v1/model-resnet_custom_v3.pt',
24 ext_filter=".pt",
25 download_name='model-resnet_custom_v3.pt',
26 )
27
28 self.model = deepbooru_model.DeepDanbooruModel()
29 self.model.load_state_dict(torch.load(files[0], map_location="cpu"))
30
31 self.model.eval()
32 self.model.to(devices.cpu, devices.dtype)
33
34 def start(self):
35 self.load()
36 self.model.to(devices.device)
37
38 def stop(self):
39 if not shared.opts.interrogate_keep_models_in_memory:
40 self.model.to(devices.cpu)
41 devices.torch_gc()
42
43 def tag(self, pil_image):
44 self.start()
45 res = self.tag_multi(pil_image)
46 self.stop()
47
48 return res
49
50 def tag_multi(self, pil_image, force_disable_ranks=False):
51 threshold = shared.opts.interrogate_deepbooru_score_threshold
52 use_spaces = shared.opts.deepbooru_use_spaces
53 use_escape = shared.opts.deepbooru_escape
54 alpha_sort = shared.opts.deepbooru_sort_alpha
55 include_ranks = shared.opts.interrogate_return_ranks and not force_disable_ranks
56
57 pic = images.resize_image(2, pil_image.convert("RGB"), 512, 512)
58 a = np.expand_dims(np.array(pic, dtype=np.float32), 0) / 255
59
60 with torch.no_grad(), devices.autocast():
61 x = torch.from_numpy(a).cuda()
62 y = self.model(x)[0].detach().cpu().numpy()
63
64 probability_dict = {}
65
66 for tag, probability in zip(self.model.tags, y):
67 if probability < threshold:
68 continue
69
70 if tag.startswith("rating:"):
71 continue
72
73 probability_dict[tag] = probability
74
75 if alpha_sort:
76 tags = sorted(probability_dict)
77 else:
78 tags = [tag for tag, _ in sorted(probability_dict.items(), key=lambda x: -x[1])]
79
80 res = []
81
82 for tag in tags:
83 probability = probability_dict[tag]
84 tag_outformat = tag
85 if use_spaces:
86 tag_outformat = tag_outformat.replace('_', ' ')
87 if use_escape:
88 tag_outformat = re.sub(re_special, r'\\\1', tag_outformat)
89 if include_ranks:
90 tag_outformat = f"({tag_outformat}:{probability:.3f})"
91
92 res.append(tag_outformat)
93
94 return ", ".join(res)
95
96
97 model = DeepDanbooru()
98
[end of modules/deepbooru.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/modules/deepbooru.py b/modules/deepbooru.py
--- a/modules/deepbooru.py
+++ b/modules/deepbooru.py
@@ -58,7 +58,7 @@
a = np.expand_dims(np.array(pic, dtype=np.float32), 0) / 255
with torch.no_grad(), devices.autocast():
- x = torch.from_numpy(a).cuda()
+ x = torch.from_numpy(a).to(devices.device)
y = self.model(x)[0].detach().cpu().numpy()
probability_dict = {}
| {"golden_diff": "diff --git a/modules/deepbooru.py b/modules/deepbooru.py\n--- a/modules/deepbooru.py\n+++ b/modules/deepbooru.py\n@@ -58,7 +58,7 @@\n a = np.expand_dims(np.array(pic, dtype=np.float32), 0) / 255\n \n with torch.no_grad(), devices.autocast():\n- x = torch.from_numpy(a).cuda()\n+ x = torch.from_numpy(a).to(devices.device)\n y = self.model(x)[0].detach().cpu().numpy()\n \n probability_dict = {}\n", "issue": "[Bug]: Torch deepdanbooru refuses to run on CPU\n### Is there an existing issue for this?\n\n- [X] I have searched the existing issues and checked the recent builds/commits\n\n### What happened?\n\nWhen trying to launch deepdanbooru with `--use-cpu all` it fails with `RuntimeError: No CUDA GPUs are available`.\n\n### Steps to reproduce the problem\n\n1. Launch webui in CPU only mode.\r\n2. Press \"Interrogate Deepdanbooru\"\r\n3. Exception occurs\r\n\n\n### What should have happened?\n\nShould work in CPU like the older implementation.\n\n### Commit where the problem happens\n\nc81d440d876dfd2ab3560410f37442ef56fc6632\n\n### What platforms do you use to access UI ?\n\nLinux\n\n### What browsers do you use to access the UI ?\n\nMozilla Firefox\n\n### Command Line Arguments\n\n```Shell\nACCELERATE=\"True\" CUDA_VISIBLE_DEVICES=\"-1\" bash webui.sh --use-cpu all --precision=full --no-half --no-half-vae --skip-torch-cuda-test --deepdanbooru --opt-channelslast --always-batch-cond-uncond\n```\n\n\n### Additional information, context and logs\n\n_No response_\n[Bug]: DeepDanBooru Interrogate fails if using --device-id 1 on startup\n### Is there an existing issue for this?\n\n- [X] I have searched the existing issues and checked the recent builds/commits\n\n### What happened?\n\nI use 2 GPUs in my system. device 0 is for training and 1 is what I use for the webui.\r\n\r\nUsing the webui on default or device-id 0, works as I expect. However if I use 1, I can not interrogate anymore.\n\n### Steps to reproduce the problem\n\nAdd --device-id 1 to your startup commands.\r\n\r\nadd or send an image to img2img\r\n\r\npress Interrogate DeepBooru\n\n### What should have happened?\n\nThe prompt should have been populated, instead this error is generated:\r\n\r\nTraceback (most recent call last):\r\n File \"C:\\sd\\forks\\auto1111\\venv\\lib\\site-packages\\gradio\\routes.py\", line 284, in run_predict\r\n output = await app.blocks.process_api(\r\n File \"C:\\sd\\forks\\auto1111\\venv\\lib\\site-packages\\gradio\\blocks.py\", line 982, in process_api\r\n result = await self.call_function(fn_index, inputs, iterator)\r\n File \"C:\\sd\\forks\\auto1111\\venv\\lib\\site-packages\\gradio\\blocks.py\", line 824, in call_function\r\n prediction = await anyio.to_thread.run_sync(\r\n File \"C:\\sd\\forks\\auto1111\\venv\\lib\\site-packages\\anyio\\to_thread.py\", line 31, in run_sync\r\n return await get_asynclib().run_sync_in_worker_thread(\r\n File \"C:\\sd\\forks\\auto1111\\venv\\lib\\site-packages\\anyio\\_backends\\_asyncio.py\", line 937, in run_sync_in_worker_thread\r\n return await future\r\n File \"C:\\sd\\forks\\auto1111\\venv\\lib\\site-packages\\anyio\\_backends\\_asyncio.py\", line 867, in run\r\n result = context.run(func, *args)\r\n File \"C:\\sd\\forks\\auto1111\\modules\\ui.py\", line 352, in interrogate_deepbooru\r\n prompt = deepbooru.model.tag(image)\r\n File \"C:\\sd\\forks\\auto1111\\modules\\deepbooru.py\", line 45, in tag\r\n res = self.tag_multi(pil_image)\r\n File \"C:\\sd\\forks\\auto1111\\modules\\deepbooru.py\", line 62, in tag_multi\r\n y = self.model(x)[0].detach().cpu().numpy()\r\n File \"C:\\sd\\forks\\auto1111\\venv\\lib\\site-packages\\torch\\nn\\modules\\module.py\", line 1130, in _call_impl\r\n return forward_call(*input, **kwargs)\r\n File \"C:\\sd\\forks\\auto1111\\modules\\deepbooru_model.py\", line 199, in forward\r\n t_360 = self.n_Conv_0(t_359_padded)\r\n File \"C:\\sd\\forks\\auto1111\\venv\\lib\\site-packages\\torch\\nn\\modules\\module.py\", line 1130, in _call_impl\r\n return forward_call(*input, **kwargs)\r\n File \"C:\\sd\\forks\\auto1111\\venv\\lib\\site-packages\\torch\\nn\\modules\\conv.py\", line 457, in forward\r\n return self._conv_forward(input, self.weight, self.bias)\r\n File \"C:\\sd\\forks\\auto1111\\venv\\lib\\site-packages\\torch\\nn\\modules\\conv.py\", line 453, in _conv_forward\r\n return F.conv2d(input, weight, bias, self.stride,\r\nRuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1! (when checking argument for argument weight in method wrapper__cudnn_convolution)\n\n### Commit where the problem happens\n\nCommit hash: 828438b4a190759807f9054932cae3a8b880ddf1\n\n### What platforms do you use to access UI ?\n\nWindows\n\n### What browsers do you use to access the UI ?\n\nGoogle Chrome, Microsoft Edge\n\n### Command Line Arguments\n\n```Shell\n--api --force-enable-xformers --ckpt-dir \"C:\\sd\\models\" --embeddings-dir \"C:\\sd\\embeddings\" --hypernetwork-dir \"C:\\sd\\hypernetworks\" --vae-path \"C:\\sd\\models\\VAE\" --device-id 1\n```\n\n\n### Additional information, context and logs\n\n_No response_\n", "before_files": [{"content": "import os\nimport re\n\nimport torch\nfrom PIL import Image\nimport numpy as np\n\nfrom modules import modelloader, paths, deepbooru_model, devices, images, shared\n\nre_special = re.compile(r'([\\\\()])')\n\n\nclass DeepDanbooru:\n def __init__(self):\n self.model = None\n\n def load(self):\n if self.model is not None:\n return\n\n files = modelloader.load_models(\n model_path=os.path.join(paths.models_path, \"torch_deepdanbooru\"),\n model_url='https://github.com/AUTOMATIC1111/TorchDeepDanbooru/releases/download/v1/model-resnet_custom_v3.pt',\n ext_filter=\".pt\",\n download_name='model-resnet_custom_v3.pt',\n )\n\n self.model = deepbooru_model.DeepDanbooruModel()\n self.model.load_state_dict(torch.load(files[0], map_location=\"cpu\"))\n\n self.model.eval()\n self.model.to(devices.cpu, devices.dtype)\n\n def start(self):\n self.load()\n self.model.to(devices.device)\n\n def stop(self):\n if not shared.opts.interrogate_keep_models_in_memory:\n self.model.to(devices.cpu)\n devices.torch_gc()\n\n def tag(self, pil_image):\n self.start()\n res = self.tag_multi(pil_image)\n self.stop()\n\n return res\n\n def tag_multi(self, pil_image, force_disable_ranks=False):\n threshold = shared.opts.interrogate_deepbooru_score_threshold\n use_spaces = shared.opts.deepbooru_use_spaces\n use_escape = shared.opts.deepbooru_escape\n alpha_sort = shared.opts.deepbooru_sort_alpha\n include_ranks = shared.opts.interrogate_return_ranks and not force_disable_ranks\n\n pic = images.resize_image(2, pil_image.convert(\"RGB\"), 512, 512)\n a = np.expand_dims(np.array(pic, dtype=np.float32), 0) / 255\n\n with torch.no_grad(), devices.autocast():\n x = torch.from_numpy(a).cuda()\n y = self.model(x)[0].detach().cpu().numpy()\n\n probability_dict = {}\n\n for tag, probability in zip(self.model.tags, y):\n if probability < threshold:\n continue\n\n if tag.startswith(\"rating:\"):\n continue\n\n probability_dict[tag] = probability\n\n if alpha_sort:\n tags = sorted(probability_dict)\n else:\n tags = [tag for tag, _ in sorted(probability_dict.items(), key=lambda x: -x[1])]\n\n res = []\n\n for tag in tags:\n probability = probability_dict[tag]\n tag_outformat = tag\n if use_spaces:\n tag_outformat = tag_outformat.replace('_', ' ')\n if use_escape:\n tag_outformat = re.sub(re_special, r'\\\\\\1', tag_outformat)\n if include_ranks:\n tag_outformat = f\"({tag_outformat}:{probability:.3f})\"\n\n res.append(tag_outformat)\n\n return \", \".join(res)\n\n\nmodel = DeepDanbooru()\n", "path": "modules/deepbooru.py"}]} | 2,767 | 130 |
gh_patches_debug_4380 | rasdani/github-patches | git_diff | ivy-llc__ivy-20893 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
qr
Adding the qr function to paddle.tensor.linalg as per the todo issue
</issue>
<code>
[start of ivy/functional/frontends/paddle/tensor/linalg.py]
1 # global
2 import ivy
3 from ivy.func_wrapper import with_unsupported_dtypes, with_supported_dtypes
4 from ivy.functional.frontends.paddle import promote_types_of_paddle_inputs
5 from ivy.functional.frontends.paddle.func_wrapper import (
6 to_ivy_arrays_and_back,
7 )
8
9
10 @with_supported_dtypes({"2.4.1 and above": ("int64",)}, "paddle")
11 @to_ivy_arrays_and_back
12 def bincount(x, weights=None, minlength=0, name=None):
13 return ivy.bincount(x, weights=weights, minlength=minlength)
14
15
16 # bmm
17 @with_unsupported_dtypes({"2.5.1 and below": ("float16", "bfloat16")}, "paddle")
18 @to_ivy_arrays_and_back
19 def bmm(x, y, transpose_x=False, transpose_y=False, name=None):
20 if len(ivy.shape(x)) != 3 or len(ivy.shape(y)) != 3:
21 raise RuntimeError("input must be 3D matrices")
22 x, y = promote_types_of_paddle_inputs(x, y)
23 return ivy.matmul(x, y, transpose_a=transpose_x, transpose_b=transpose_y)
24
25
26 # cholesky
27 @with_supported_dtypes({"2.5.1 and below": ("float32", "float64")}, "paddle")
28 @to_ivy_arrays_and_back
29 def cholesky(x, /, *, upper=False, name=None):
30 return ivy.cholesky(x, upper=upper)
31
32
33 # cholesky_solve
34 @with_supported_dtypes({"2.5.1 and below": ("float32", "float64")}, "paddle")
35 @to_ivy_arrays_and_back
36 def cholesky_solve(x, y, /, *, upper=False, name=None):
37 if upper:
38 y = ivy.matrix_transpose(y)
39 Y = ivy.solve(y, x)
40 return ivy.solve(ivy.matrix_transpose(y), Y)
41
42
43 # cond
44 @with_supported_dtypes({"2.5.1 and below": ("float32", "float64")}, "paddle")
45 @to_ivy_arrays_and_back
46 def cond(x, p=None, name=None):
47 ret = ivy.cond(x, p=p, out=name)
48 if ret.shape == ():
49 ret = ret.reshape((1,))
50 return ret
51
52
53 @with_supported_dtypes(
54 {"2.5.1 and below": ("float32", "float64", "int32", "int64")}, "paddle"
55 )
56 @to_ivy_arrays_and_back
57 def cross(x, y, /, *, axis=9, name=None):
58 x, y = promote_types_of_paddle_inputs(x, y)
59 return ivy.cross(x, y, axis=axis)
60
61
62 @with_supported_dtypes({"2.4.1 and above": ("float64", "float32")}, "paddle")
63 @to_ivy_arrays_and_back
64 def dist(x, y, p=2):
65 ret = ivy.vector_norm(ivy.subtract(x, y), ord=p)
66 return ivy.reshape(ret, (1,))
67
68
69 # dot
70 @with_supported_dtypes({"2.5.1 and below": ("float32", "float64")}, "paddle")
71 @to_ivy_arrays_and_back
72 def dot(x, y, name=None):
73 x, y = promote_types_of_paddle_inputs(x, y)
74 out = ivy.multiply(x, y)
75 return ivy.sum(out, axis=ivy.get_num_dims(x) - 1, keepdims=False)
76
77
78 # eig
79 @to_ivy_arrays_and_back
80 def eig(x, name=None):
81 return ivy.eig(x)
82
83
84 # eigh
85 @to_ivy_arrays_and_back
86 def eigh(x, UPLO="L", name=None):
87 return ivy.eigh(x, UPLO=UPLO)
88
89
90 # eigvals
91 @to_ivy_arrays_and_back
92 def eigvals(x, name=None):
93 return ivy.eigvals(x)
94
95
96 # eigvalsh
97 @to_ivy_arrays_and_back
98 def eigvalsh(x, UPLO="L", name=None):
99 return ivy.eigvalsh(x, UPLO=UPLO)
100
101
102 # matmul
103 @with_unsupported_dtypes({"2.5.1 and below": ("float16", "bfloat16")}, "paddle")
104 @to_ivy_arrays_and_back
105 def matmul(x, y, transpose_x=False, transpose_y=False, name=None):
106 x, y = promote_types_of_paddle_inputs(x, y)
107 return ivy.matmul(x, y, transpose_a=transpose_x, transpose_b=transpose_y)
108
109
110 # matrix_power
111 @with_unsupported_dtypes({"2.5.1 and below": ("float16", "bfloat16")}, "paddle")
112 @to_ivy_arrays_and_back
113 def matrix_power(x, n, name=None):
114 return ivy.matrix_power(x, n)
115
116
117 # norm
118 @with_supported_dtypes({"2.5.1 and below": ("float32", "float64")}, "paddle")
119 @to_ivy_arrays_and_back
120 def norm(x, p="fro", axis=None, keepdim=False, name=None):
121 if axis is None and p is not None:
122 if p == "fro":
123 p = 2
124 ret = ivy.vector_norm(x.flatten(), ord=p, axis=-1)
125 if keepdim:
126 ret = ret.reshape([1] * len(x.shape))
127 if len(ret.shape) == 0:
128 return ivy.array([ret])
129 return ret
130
131 if isinstance(axis, tuple):
132 axis = list(axis)
133 if isinstance(axis, list) and len(axis) == 1:
134 axis = axis[0]
135
136 if isinstance(axis, int):
137 if p == "fro":
138 p = 2
139 if p in [0, 1, 2, ivy.inf, -ivy.inf]:
140 ret = ivy.vector_norm(x, ord=p, axis=axis, keepdims=keepdim)
141 elif isinstance(p, (int, float)):
142 ret = ivy.pow(
143 ivy.sum(ivy.pow(ivy.abs(x), p), axis=axis, keepdims=keepdim),
144 float(1.0 / p),
145 )
146
147 elif isinstance(axis, list) and len(axis) == 2:
148 if p == 0:
149 raise ValueError
150 elif p == 1:
151 ret = ivy.sum(ivy.abs(x), axis=axis, keepdims=keepdim)
152 elif p == 2 or p == "fro":
153 ret = ivy.matrix_norm(x, ord="fro", axis=axis, keepdims=keepdim)
154 elif p == ivy.inf:
155 ret = ivy.max(ivy.abs(x), axis=axis, keepdims=keepdim)
156 elif p == -ivy.inf:
157 ret = ivy.min(ivy.abs(x), axis=axis, keepdims=keepdim)
158 elif isinstance(p, (int, float)) and p > 0:
159 ret = ivy.pow(
160 ivy.sum(ivy.pow(ivy.abs(x), p), axis=axis, keepdims=keepdim),
161 float(1.0 / p),
162 )
163 else:
164 raise ValueError
165
166 else:
167 raise ValueError
168
169 if len(ret.shape) == 0:
170 ret = ivy.array(
171 [ret]
172 ) # this is done so as to match shape of output from paddle
173 return ret
174
175
176 # pinv
177 @with_unsupported_dtypes({"2.5.1 and below": ("float16", "bfloat16")}, "paddle")
178 @to_ivy_arrays_and_back
179 def pinv(x, rcond=1e-15, hermitian=False, name=None):
180 # TODO: Add hermitian functionality
181 return ivy.pinv(x, rtol=rcond)
182
183
184 # solve
185 @with_unsupported_dtypes({"2.5.1 and below": ("float16", "bfloat16")}, "paddle")
186 @to_ivy_arrays_and_back
187 def solve(x1, x2, name=None):
188 return ivy.solve(x1, x2)
189
190
191 # transpose
192 @with_unsupported_dtypes({"2.5.1 and below": ("uint8", "int8", "int16")}, "paddle")
193 @to_ivy_arrays_and_back
194 def transpose(x, perm, name=None):
195 return ivy.permute_dims(x, axes=perm)
196
[end of ivy/functional/frontends/paddle/tensor/linalg.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/ivy/functional/frontends/paddle/tensor/linalg.py b/ivy/functional/frontends/paddle/tensor/linalg.py
--- a/ivy/functional/frontends/paddle/tensor/linalg.py
+++ b/ivy/functional/frontends/paddle/tensor/linalg.py
@@ -181,6 +181,13 @@
return ivy.pinv(x, rtol=rcond)
+# qr
+@with_supported_dtypes({"2.5.1 and below": ("float32", "float64")}, "paddle")
+@to_ivy_arrays_and_back
+def qr(x, mode="reduced", name=None):
+ return ivy.qr(x, mode=mode)
+
+
# solve
@with_unsupported_dtypes({"2.5.1 and below": ("float16", "bfloat16")}, "paddle")
@to_ivy_arrays_and_back
| {"golden_diff": "diff --git a/ivy/functional/frontends/paddle/tensor/linalg.py b/ivy/functional/frontends/paddle/tensor/linalg.py\n--- a/ivy/functional/frontends/paddle/tensor/linalg.py\n+++ b/ivy/functional/frontends/paddle/tensor/linalg.py\n@@ -181,6 +181,13 @@\n return ivy.pinv(x, rtol=rcond)\n \n \n+# qr\n+@with_supported_dtypes({\"2.5.1 and below\": (\"float32\", \"float64\")}, \"paddle\")\n+@to_ivy_arrays_and_back\n+def qr(x, mode=\"reduced\", name=None):\n+ return ivy.qr(x, mode=mode)\n+\n+\n # solve\n @with_unsupported_dtypes({\"2.5.1 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n @to_ivy_arrays_and_back\n", "issue": "qr\nAdding the qr function to paddle.tensor.linalg as per the todo issue\n", "before_files": [{"content": "# global\nimport ivy\nfrom ivy.func_wrapper import with_unsupported_dtypes, with_supported_dtypes\nfrom ivy.functional.frontends.paddle import promote_types_of_paddle_inputs\nfrom ivy.functional.frontends.paddle.func_wrapper import (\n to_ivy_arrays_and_back,\n)\n\n\n@with_supported_dtypes({\"2.4.1 and above\": (\"int64\",)}, \"paddle\")\n@to_ivy_arrays_and_back\ndef bincount(x, weights=None, minlength=0, name=None):\n return ivy.bincount(x, weights=weights, minlength=minlength)\n\n\n# bmm\n@with_unsupported_dtypes({\"2.5.1 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef bmm(x, y, transpose_x=False, transpose_y=False, name=None):\n if len(ivy.shape(x)) != 3 or len(ivy.shape(y)) != 3:\n raise RuntimeError(\"input must be 3D matrices\")\n x, y = promote_types_of_paddle_inputs(x, y)\n return ivy.matmul(x, y, transpose_a=transpose_x, transpose_b=transpose_y)\n\n\n# cholesky\n@with_supported_dtypes({\"2.5.1 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef cholesky(x, /, *, upper=False, name=None):\n return ivy.cholesky(x, upper=upper)\n\n\n# cholesky_solve\n@with_supported_dtypes({\"2.5.1 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef cholesky_solve(x, y, /, *, upper=False, name=None):\n if upper:\n y = ivy.matrix_transpose(y)\n Y = ivy.solve(y, x)\n return ivy.solve(ivy.matrix_transpose(y), Y)\n\n\n# cond\n@with_supported_dtypes({\"2.5.1 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef cond(x, p=None, name=None):\n ret = ivy.cond(x, p=p, out=name)\n if ret.shape == ():\n ret = ret.reshape((1,))\n return ret\n\n\n@with_supported_dtypes(\n {\"2.5.1 and below\": (\"float32\", \"float64\", \"int32\", \"int64\")}, \"paddle\"\n)\n@to_ivy_arrays_and_back\ndef cross(x, y, /, *, axis=9, name=None):\n x, y = promote_types_of_paddle_inputs(x, y)\n return ivy.cross(x, y, axis=axis)\n\n\n@with_supported_dtypes({\"2.4.1 and above\": (\"float64\", \"float32\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef dist(x, y, p=2):\n ret = ivy.vector_norm(ivy.subtract(x, y), ord=p)\n return ivy.reshape(ret, (1,))\n\n\n# dot\n@with_supported_dtypes({\"2.5.1 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef dot(x, y, name=None):\n x, y = promote_types_of_paddle_inputs(x, y)\n out = ivy.multiply(x, y)\n return ivy.sum(out, axis=ivy.get_num_dims(x) - 1, keepdims=False)\n\n\n# eig\n@to_ivy_arrays_and_back\ndef eig(x, name=None):\n return ivy.eig(x)\n\n\n# eigh\n@to_ivy_arrays_and_back\ndef eigh(x, UPLO=\"L\", name=None):\n return ivy.eigh(x, UPLO=UPLO)\n\n\n# eigvals\n@to_ivy_arrays_and_back\ndef eigvals(x, name=None):\n return ivy.eigvals(x)\n\n\n# eigvalsh\n@to_ivy_arrays_and_back\ndef eigvalsh(x, UPLO=\"L\", name=None):\n return ivy.eigvalsh(x, UPLO=UPLO)\n\n\n# matmul\n@with_unsupported_dtypes({\"2.5.1 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef matmul(x, y, transpose_x=False, transpose_y=False, name=None):\n x, y = promote_types_of_paddle_inputs(x, y)\n return ivy.matmul(x, y, transpose_a=transpose_x, transpose_b=transpose_y)\n\n\n# matrix_power\n@with_unsupported_dtypes({\"2.5.1 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef matrix_power(x, n, name=None):\n return ivy.matrix_power(x, n)\n\n\n# norm\n@with_supported_dtypes({\"2.5.1 and below\": (\"float32\", \"float64\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef norm(x, p=\"fro\", axis=None, keepdim=False, name=None):\n if axis is None and p is not None:\n if p == \"fro\":\n p = 2\n ret = ivy.vector_norm(x.flatten(), ord=p, axis=-1)\n if keepdim:\n ret = ret.reshape([1] * len(x.shape))\n if len(ret.shape) == 0:\n return ivy.array([ret])\n return ret\n\n if isinstance(axis, tuple):\n axis = list(axis)\n if isinstance(axis, list) and len(axis) == 1:\n axis = axis[0]\n\n if isinstance(axis, int):\n if p == \"fro\":\n p = 2\n if p in [0, 1, 2, ivy.inf, -ivy.inf]:\n ret = ivy.vector_norm(x, ord=p, axis=axis, keepdims=keepdim)\n elif isinstance(p, (int, float)):\n ret = ivy.pow(\n ivy.sum(ivy.pow(ivy.abs(x), p), axis=axis, keepdims=keepdim),\n float(1.0 / p),\n )\n\n elif isinstance(axis, list) and len(axis) == 2:\n if p == 0:\n raise ValueError\n elif p == 1:\n ret = ivy.sum(ivy.abs(x), axis=axis, keepdims=keepdim)\n elif p == 2 or p == \"fro\":\n ret = ivy.matrix_norm(x, ord=\"fro\", axis=axis, keepdims=keepdim)\n elif p == ivy.inf:\n ret = ivy.max(ivy.abs(x), axis=axis, keepdims=keepdim)\n elif p == -ivy.inf:\n ret = ivy.min(ivy.abs(x), axis=axis, keepdims=keepdim)\n elif isinstance(p, (int, float)) and p > 0:\n ret = ivy.pow(\n ivy.sum(ivy.pow(ivy.abs(x), p), axis=axis, keepdims=keepdim),\n float(1.0 / p),\n )\n else:\n raise ValueError\n\n else:\n raise ValueError\n\n if len(ret.shape) == 0:\n ret = ivy.array(\n [ret]\n ) # this is done so as to match shape of output from paddle\n return ret\n\n\n# pinv\n@with_unsupported_dtypes({\"2.5.1 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef pinv(x, rcond=1e-15, hermitian=False, name=None):\n # TODO: Add hermitian functionality\n return ivy.pinv(x, rtol=rcond)\n\n\n# solve\n@with_unsupported_dtypes({\"2.5.1 and below\": (\"float16\", \"bfloat16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef solve(x1, x2, name=None):\n return ivy.solve(x1, x2)\n\n\n# transpose\n@with_unsupported_dtypes({\"2.5.1 and below\": (\"uint8\", \"int8\", \"int16\")}, \"paddle\")\n@to_ivy_arrays_and_back\ndef transpose(x, perm, name=None):\n return ivy.permute_dims(x, axes=perm)\n", "path": "ivy/functional/frontends/paddle/tensor/linalg.py"}]} | 2,931 | 205 |
gh_patches_debug_14673 | rasdani/github-patches | git_diff | xonsh__xonsh-427 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Tab completing on empty line with prompt_toolkit kills terminal
Arch Linux with xonsh 0.2.2 and using prompt toolkit. Hitting TAB on an empty line crashes the terminal (rxvt-unicode). I can see the traceback for a split second but then the terminal is gone.
This doesn't happen using readline.
</issue>
<code>
[start of xonsh/prompt_toolkit_key_bindings.py]
1 """Key bindings for prompt_toolkit xonsh shell."""
2 import builtins
3
4 from prompt_toolkit.filters import Filter
5 from prompt_toolkit.keys import Keys
6
7
8 class TabShouldInsertIndentFilter(Filter):
9 """
10 Filter that is intended to check if <Tab> should insert indent instead of
11 starting autocompletion.
12 It basically just checks if there are only whitespaces before the cursor -
13 if so indent should be inserted, otherwise autocompletion.
14 """
15 def __call__(self, cli):
16 before_cursor = cli.current_buffer.document.current_line_before_cursor
17
18 return bool(not before_cursor or before_cursor.isspace())
19
20
21 def load_xonsh_bindings(key_bindings_manager):
22 """
23 Load custom key bindings.
24 """
25 handle = key_bindings_manager.registry.add_binding
26 env = builtins.__xonsh_env__
27
28 @handle(Keys.Tab, filter=TabShouldInsertIndentFilter())
29 def _(event):
30 """
31 If there are only whitespaces before current cursor position insert
32 indent instead of autocompleting.
33 """
34 event.cli.current_buffer.insert_text(env['INDENT'])
35
36
37
[end of xonsh/prompt_toolkit_key_bindings.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/xonsh/prompt_toolkit_key_bindings.py b/xonsh/prompt_toolkit_key_bindings.py
--- a/xonsh/prompt_toolkit_key_bindings.py
+++ b/xonsh/prompt_toolkit_key_bindings.py
@@ -15,7 +15,7 @@
def __call__(self, cli):
before_cursor = cli.current_buffer.document.current_line_before_cursor
- return bool(not before_cursor or before_cursor.isspace())
+ return bool(before_cursor.isspace())
def load_xonsh_bindings(key_bindings_manager):
@@ -31,6 +31,6 @@
If there are only whitespaces before current cursor position insert
indent instead of autocompleting.
"""
- event.cli.current_buffer.insert_text(env['INDENT'])
+ event.cli.current_buffer.insert_text(env.get('INDENT'))
| {"golden_diff": "diff --git a/xonsh/prompt_toolkit_key_bindings.py b/xonsh/prompt_toolkit_key_bindings.py\n--- a/xonsh/prompt_toolkit_key_bindings.py\n+++ b/xonsh/prompt_toolkit_key_bindings.py\n@@ -15,7 +15,7 @@\n def __call__(self, cli):\n before_cursor = cli.current_buffer.document.current_line_before_cursor\n \n- return bool(not before_cursor or before_cursor.isspace())\n+ return bool(before_cursor.isspace())\n \n \n def load_xonsh_bindings(key_bindings_manager):\n@@ -31,6 +31,6 @@\n If there are only whitespaces before current cursor position insert\n indent instead of autocompleting.\n \"\"\"\n- event.cli.current_buffer.insert_text(env['INDENT'])\n+ event.cli.current_buffer.insert_text(env.get('INDENT'))\n", "issue": "Tab completing on empty line with prompt_toolkit kills terminal\nArch Linux with xonsh 0.2.2 and using prompt toolkit. Hitting TAB on an empty line crashes the terminal (rxvt-unicode). I can see the traceback for a split second but then the terminal is gone. \n\nThis doesn't happen using readline.\n\n", "before_files": [{"content": "\"\"\"Key bindings for prompt_toolkit xonsh shell.\"\"\"\nimport builtins\n\nfrom prompt_toolkit.filters import Filter\nfrom prompt_toolkit.keys import Keys\n\n\nclass TabShouldInsertIndentFilter(Filter):\n \"\"\"\n Filter that is intended to check if <Tab> should insert indent instead of\n starting autocompletion.\n It basically just checks if there are only whitespaces before the cursor -\n if so indent should be inserted, otherwise autocompletion.\n \"\"\"\n def __call__(self, cli):\n before_cursor = cli.current_buffer.document.current_line_before_cursor\n\n return bool(not before_cursor or before_cursor.isspace())\n\n\ndef load_xonsh_bindings(key_bindings_manager):\n \"\"\"\n Load custom key bindings.\n \"\"\"\n handle = key_bindings_manager.registry.add_binding\n env = builtins.__xonsh_env__\n\n @handle(Keys.Tab, filter=TabShouldInsertIndentFilter())\n def _(event):\n \"\"\"\n If there are only whitespaces before current cursor position insert\n indent instead of autocompleting.\n \"\"\"\n event.cli.current_buffer.insert_text(env['INDENT'])\n\n\n", "path": "xonsh/prompt_toolkit_key_bindings.py"}]} | 916 | 182 |
gh_patches_debug_7426 | rasdani/github-patches | git_diff | cltk__cltk-938 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add "Gorman Trees" corpus for Greek
https://github.com/perseids-publications/gorman-trees = https://perseids-publications.github.io/gorman-trees/
~500,000 tokens of parsed Ancient Greek.
</issue>
<code>
[start of cltk/corpus/greek/corpora.py]
1 """Greek language corpora available for download or loading locally.
2 All remote corpora hosted by github on the cltk organization account, eg:
3 'http://github.com/cltk' + name
4 """
5
6 GREEK_CORPORA = [
7 {'name': 'greek_software_tlgu',
8 'origin': 'https://github.com/cltk/greek_software_tlgu.git',
9 'location': 'remote',
10 'type': 'software'},
11 {'encoding': 'utf-8',
12 'markup': 'tei_xml',
13 'origin': 'https://github.com/cltk/greek_text_perseus.git',
14 'name': 'greek_text_perseus',
15 'location': 'remote',
16 'type': 'text'},
17 {'encoding': 'latin-1',
18 'markup': 'beta_code',
19 'origin': None,
20 'name': 'phi7',
21 'location': 'local',
22 'type': 'text'},
23 {'encoding': 'latin-1',
24 'markup': 'beta_code',
25 'name': 'tlg',
26 'origin': None,
27 'location': 'local',
28 'type': 'text'},
29 {'encoding': 'utf-8',
30 'markup': 'plaintext',
31 'name': 'greek_proper_names_cltk',
32 'origin': 'https://github.com/cltk/greek_proper_names_cltk.git',
33 'location': 'remote',
34 'type': 'lexicon'},
35 {'name': 'greek_models_cltk',
36 'origin': 'https://github.com/cltk/greek_models_cltk.git',
37 'location': 'remote',
38 'type': 'model'},
39 {'encoding': 'utf-8',
40 'markup': 'xml',
41 'origin': 'https://github.com/cltk/greek_treebank_perseus.git',
42 'name': 'greek_treebank_perseus',
43 'location': 'remote',
44 'type': 'treebank'},
45 {'encoding': 'xml',
46 'markup': 'plaintext',
47 'origin': 'https://github.com/cltk/greek_lexica_perseus.git',
48 'name': 'greek_lexica_perseus',
49 'location': 'remote',
50 'type': 'lexicon'},
51 {'encoding': 'utf-8',
52 'markup': 'plaintext',
53 'origin': 'https://github.com/cltk/greek_training_set_sentence_cltk.git',
54 'name': 'greek_training_set_sentence_cltk',
55 'location': 'remote',
56 'type': 'training_set'},
57 {'name': 'greek_word2vec_cltk',
58 'origin': 'https://github.com/cltk/greek_word2vec_cltk.git',
59 'location': 'remote',
60 'type': 'model'},
61 {'name': 'greek_text_lacus_curtius',
62 'origin': 'https://github.com/cltk/greek_text_lacus_curtius.git',
63 'location': 'remote',
64 'type': 'text'},
65 {'name': 'greek_text_first1kgreek',
66 'origin': 'https://github.com/cltk/First1KGreek',
67 'location': 'remote',
68 'type': 'text'},
69 {'name': 'greek_text_tesserae',
70 'encoding': 'utf-8',
71 'markup': 'plaintext', #modified plaintext with Tesserae-style citations
72 'origin': 'https://github.com/cltk/greek_text_tesserae.git',
73 'location': 'remote',
74 'type': 'text'},
75 ]
76
[end of cltk/corpus/greek/corpora.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/cltk/corpus/greek/corpora.py b/cltk/corpus/greek/corpora.py
--- a/cltk/corpus/greek/corpora.py
+++ b/cltk/corpus/greek/corpora.py
@@ -42,6 +42,12 @@
'name': 'greek_treebank_perseus',
'location': 'remote',
'type': 'treebank'},
+ {'encoding': 'utf-8',
+ 'markup': 'xml',
+ 'origin': 'https://github.com/vgorman1/Greek-Dependency-Trees.git',
+ 'name': 'greek_treebank_gorman',
+ 'location': 'remote',
+ 'type': 'treebank'},
{'encoding': 'xml',
'markup': 'plaintext',
'origin': 'https://github.com/cltk/greek_lexica_perseus.git',
| {"golden_diff": "diff --git a/cltk/corpus/greek/corpora.py b/cltk/corpus/greek/corpora.py\n--- a/cltk/corpus/greek/corpora.py\n+++ b/cltk/corpus/greek/corpora.py\n@@ -42,6 +42,12 @@\n 'name': 'greek_treebank_perseus',\n 'location': 'remote',\n 'type': 'treebank'},\n+ {'encoding': 'utf-8',\n+ 'markup': 'xml',\n+ 'origin': 'https://github.com/vgorman1/Greek-Dependency-Trees.git',\n+ 'name': 'greek_treebank_gorman',\n+ 'location': 'remote',\n+ 'type': 'treebank'},\n {'encoding': 'xml',\n 'markup': 'plaintext',\n 'origin': 'https://github.com/cltk/greek_lexica_perseus.git',\n", "issue": "Add \"Gorman Trees\" corpus for Greek\nhttps://github.com/perseids-publications/gorman-trees = https://perseids-publications.github.io/gorman-trees/\r\n\r\n~500,000 tokens of parsed Ancient Greek.\n", "before_files": [{"content": "\"\"\"Greek language corpora available for download or loading locally.\nAll remote corpora hosted by github on the cltk organization account, eg:\n'http://github.com/cltk' + name\n\"\"\"\n\nGREEK_CORPORA = [\n {'name': 'greek_software_tlgu',\n 'origin': 'https://github.com/cltk/greek_software_tlgu.git',\n 'location': 'remote',\n 'type': 'software'},\n {'encoding': 'utf-8',\n 'markup': 'tei_xml',\n 'origin': 'https://github.com/cltk/greek_text_perseus.git',\n 'name': 'greek_text_perseus',\n 'location': 'remote',\n 'type': 'text'},\n {'encoding': 'latin-1',\n 'markup': 'beta_code',\n 'origin': None,\n 'name': 'phi7',\n 'location': 'local',\n 'type': 'text'},\n {'encoding': 'latin-1',\n 'markup': 'beta_code',\n 'name': 'tlg',\n 'origin': None,\n 'location': 'local',\n 'type': 'text'},\n {'encoding': 'utf-8',\n 'markup': 'plaintext',\n 'name': 'greek_proper_names_cltk',\n 'origin': 'https://github.com/cltk/greek_proper_names_cltk.git',\n 'location': 'remote',\n 'type': 'lexicon'},\n {'name': 'greek_models_cltk',\n 'origin': 'https://github.com/cltk/greek_models_cltk.git',\n 'location': 'remote',\n 'type': 'model'},\n {'encoding': 'utf-8',\n 'markup': 'xml',\n 'origin': 'https://github.com/cltk/greek_treebank_perseus.git',\n 'name': 'greek_treebank_perseus',\n 'location': 'remote',\n 'type': 'treebank'},\n {'encoding': 'xml',\n 'markup': 'plaintext',\n 'origin': 'https://github.com/cltk/greek_lexica_perseus.git',\n 'name': 'greek_lexica_perseus',\n 'location': 'remote',\n 'type': 'lexicon'},\n {'encoding': 'utf-8',\n 'markup': 'plaintext',\n 'origin': 'https://github.com/cltk/greek_training_set_sentence_cltk.git',\n 'name': 'greek_training_set_sentence_cltk',\n 'location': 'remote',\n 'type': 'training_set'},\n {'name': 'greek_word2vec_cltk',\n 'origin': 'https://github.com/cltk/greek_word2vec_cltk.git',\n 'location': 'remote',\n 'type': 'model'},\n {'name': 'greek_text_lacus_curtius',\n 'origin': 'https://github.com/cltk/greek_text_lacus_curtius.git',\n 'location': 'remote',\n 'type': 'text'},\n {'name': 'greek_text_first1kgreek',\n 'origin': 'https://github.com/cltk/First1KGreek',\n 'location': 'remote',\n 'type': 'text'},\n {'name': 'greek_text_tesserae',\n 'encoding': 'utf-8',\n 'markup': 'plaintext', #modified plaintext with Tesserae-style citations\n 'origin': 'https://github.com/cltk/greek_text_tesserae.git',\n 'location': 'remote',\n 'type': 'text'},\n]\n", "path": "cltk/corpus/greek/corpora.py"}]} | 1,499 | 201 |
gh_patches_debug_1199 | rasdani/github-patches | git_diff | OpenNMT__OpenNMT-tf-6 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Poor translation results with the Transformer
The Transformer model produces very bad translation results. Its implementation should be revised and fixed.
See also the reference implementation at https://github.com/tensorflow/tensor2tensor.
</issue>
<code>
[start of opennmt/utils/transformer.py]
1 """Define functions related to the Google's Transformer model."""
2
3 import tensorflow as tf
4
5
6 def scaled_dot_attention(queries,
7 keys,
8 values,
9 mode,
10 values_length=None,
11 mask_future=False,
12 dropout=0.0):
13 """Computes the scaled dot-product attention as described
14 in https://arxiv.org/abs/1706.03762.
15
16 Args:
17 queries: The sequence of queries. A tensor of shape :math:`[B, T_1, ...]`.
18 keys: The sequence use to calculate attention scores. A tensor of shape
19 :math:`[B, T_2, ...]`.
20 values: The sequence to attend. A tensor of shape :math:`[B, T_2, ...]`.
21 mode: A ``tf.estimator.ModeKeys`` mode.
22 values_length: The length of the values to attend.
23 mask_future: Mask attention to future positions.
24 dropout: The probability to drop units from the inputs.
25
26 Returns:
27 A tuple ``(context vector, attention vector)``.
28 """
29 # Scaled dot-product between queries and keys.
30 dot = tf.matmul(queries, keys, transpose_b=True)
31 dot = tf.div(dot, tf.sqrt(tf.cast(tf.shape(keys)[-1], tf.float32)))
32
33 if values_length is not None:
34 # Give no weight to illegal connections.
35 if mask_future:
36 # When masking the future, a position can only attend to previous timesteps.
37 mask = tf.map_fn(
38 lambda x: tf.sequence_mask(
39 tf.minimum(tf.range(tf.shape(values)[1]) + 1, x),
40 maxlen=tf.shape(values)[1],
41 dtype=tf.float32),
42 values_length,
43 dtype=tf.float32)
44 else:
45 # Otherwise, simply prevent attention on out-of-range positions.
46 mask = tf.sequence_mask(
47 values_length,
48 maxlen=tf.shape(values)[1],
49 dtype=tf.float32)
50 mask = tf.expand_dims(mask, axis=1)
51
52 dot = dot * mask + ((1.0 - mask) * tf.float32.min)
53
54 # Compute attention weights.
55 attn = tf.nn.softmax(dot)
56 attn = tf.layers.dropout(
57 attn,
58 rate=dropout,
59 training=mode == tf.estimator.ModeKeys.TRAIN)
60
61 # Compute attention context.
62 context = tf.matmul(attn, values)
63
64 return context, attn
65
66
67 def multi_head_attention(num_heads,
68 queries,
69 keys,
70 values,
71 mode,
72 values_length=None,
73 mask_future=False,
74 dropout=0.0):
75 """Computes the multi-head attention as described in
76 https://arxiv.org/abs/1706.03762.
77
78 Args:
79 num_heads: The number of attention heads.
80 queries: The sequence of queries. A tensor of shape :math:`[B, T_1, ...]`.
81 keys: The sequence use to calculate attention scores. A tensor of shape
82 :math:`[B, T_2, ...]`.
83 values: The sequence to attend. A tensor of shape :math:`[B, T_2, ...]`.
84 mode: A ``tf.estimator.ModeKeys`` mode.
85 values_length: The length of the values to attend.
86 mask_future: Mask attention to future positions.
87 dropout: The probability to drop units from the inputs.
88
89 Returns:
90 The concatenated attention context of each head.
91 """
92 input_dim = keys.get_shape().as_list()[-1]
93
94 if input_dim % num_heads != 0:
95 raise ValueError("Multi head attention requires the input dimension to be a"
96 " multiple of {}".format(num_heads))
97
98 head_dim = input_dim / num_heads
99 heads = []
100
101 for i in range(num_heads):
102 with tf.variable_scope("head_{}".format(i)):
103 # Project queries, keys and values to different and smaller subspaces.
104 queries_proj = tf.layers.conv1d(queries, head_dim, 1)
105 keys_proj = tf.layers.conv1d(keys, head_dim, 1)
106 values_proj = tf.layers.conv1d(values, head_dim, 1)
107
108 head_i, _ = scaled_dot_attention(
109 queries_proj,
110 keys_proj,
111 values_proj,
112 mode,
113 values_length=values_length,
114 mask_future=mask_future,
115 dropout=dropout)
116
117 heads.append(head_i)
118
119 # Concatenate all heads output.
120 combined = tf.concat(heads, axis=2)
121 outputs = tf.layers.conv1d(combined, input_dim, 1)
122
123 return outputs
124
125 def feed_forward(x, inner_dim):
126 """Implements the Transformer's "Feed Forward" layer.
127
128 .. math::
129
130 ffn(x) = max(0, x*W_1 + b_1)*W_2 + b_2
131
132 Args:
133 x: The input.
134 inner_dim: The number of units of the inner linear transformation.
135
136 Returns:
137 The transformed input.
138 """
139 input_dim = x.get_shape().as_list()[-1]
140
141 inner = tf.layers.conv1d(x, inner_dim, 1, activation=tf.nn.relu)
142 outer = tf.layers.conv1d(inner, input_dim, 1)
143
144 return outer
145
146 def add_and_norm(inputs,
147 outputs,
148 mode,
149 dropout=0.1):
150 """Implements the Transformer's "Add & Norm" layer.
151
152 Args:
153 inputs: The input of the previous layer.
154 outputs: The output of the previous layer.
155 mode: A ``tf.estimator.ModeKeys`` mode.
156 dropout: The probability to drop units in :obj:`outputs`.
157
158 Returns:
159 The residual and normalized output.
160 """
161 outputs = tf.layers.dropout(
162 outputs,
163 rate=dropout,
164 training=mode == tf.estimator.ModeKeys.TRAIN)
165 outputs += inputs
166 outputs = tf.contrib.layers.layer_norm(outputs)
167 return outputs
168
[end of opennmt/utils/transformer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/opennmt/utils/transformer.py b/opennmt/utils/transformer.py
--- a/opennmt/utils/transformer.py
+++ b/opennmt/utils/transformer.py
@@ -163,5 +163,5 @@
rate=dropout,
training=mode == tf.estimator.ModeKeys.TRAIN)
outputs += inputs
- outputs = tf.contrib.layers.layer_norm(outputs)
+ outputs = tf.contrib.layers.layer_norm(outputs, begin_norm_axis=-1)
return outputs
| {"golden_diff": "diff --git a/opennmt/utils/transformer.py b/opennmt/utils/transformer.py\n--- a/opennmt/utils/transformer.py\n+++ b/opennmt/utils/transformer.py\n@@ -163,5 +163,5 @@\n rate=dropout,\n training=mode == tf.estimator.ModeKeys.TRAIN)\n outputs += inputs\n- outputs = tf.contrib.layers.layer_norm(outputs)\n+ outputs = tf.contrib.layers.layer_norm(outputs, begin_norm_axis=-1)\n return outputs\n", "issue": "Poor translation results with the Transformer\nThe Transformer model produces very bad translation results. Its implementation should be revised and fixed.\r\n\r\nSee also the reference implementation at https://github.com/tensorflow/tensor2tensor.\n", "before_files": [{"content": "\"\"\"Define functions related to the Google's Transformer model.\"\"\"\n\nimport tensorflow as tf\n\n\ndef scaled_dot_attention(queries,\n keys,\n values,\n mode,\n values_length=None,\n mask_future=False,\n dropout=0.0):\n \"\"\"Computes the scaled dot-product attention as described\n in https://arxiv.org/abs/1706.03762.\n\n Args:\n queries: The sequence of queries. A tensor of shape :math:`[B, T_1, ...]`.\n keys: The sequence use to calculate attention scores. A tensor of shape\n :math:`[B, T_2, ...]`.\n values: The sequence to attend. A tensor of shape :math:`[B, T_2, ...]`.\n mode: A ``tf.estimator.ModeKeys`` mode.\n values_length: The length of the values to attend.\n mask_future: Mask attention to future positions.\n dropout: The probability to drop units from the inputs.\n\n Returns:\n A tuple ``(context vector, attention vector)``.\n \"\"\"\n # Scaled dot-product between queries and keys.\n dot = tf.matmul(queries, keys, transpose_b=True)\n dot = tf.div(dot, tf.sqrt(tf.cast(tf.shape(keys)[-1], tf.float32)))\n\n if values_length is not None:\n # Give no weight to illegal connections.\n if mask_future:\n # When masking the future, a position can only attend to previous timesteps.\n mask = tf.map_fn(\n lambda x: tf.sequence_mask(\n tf.minimum(tf.range(tf.shape(values)[1]) + 1, x),\n maxlen=tf.shape(values)[1],\n dtype=tf.float32),\n values_length,\n dtype=tf.float32)\n else:\n # Otherwise, simply prevent attention on out-of-range positions.\n mask = tf.sequence_mask(\n values_length,\n maxlen=tf.shape(values)[1],\n dtype=tf.float32)\n mask = tf.expand_dims(mask, axis=1)\n\n dot = dot * mask + ((1.0 - mask) * tf.float32.min)\n\n # Compute attention weights.\n attn = tf.nn.softmax(dot)\n attn = tf.layers.dropout(\n attn,\n rate=dropout,\n training=mode == tf.estimator.ModeKeys.TRAIN)\n\n # Compute attention context.\n context = tf.matmul(attn, values)\n\n return context, attn\n\n\ndef multi_head_attention(num_heads,\n queries,\n keys,\n values,\n mode,\n values_length=None,\n mask_future=False,\n dropout=0.0):\n \"\"\"Computes the multi-head attention as described in\n https://arxiv.org/abs/1706.03762.\n\n Args:\n num_heads: The number of attention heads.\n queries: The sequence of queries. A tensor of shape :math:`[B, T_1, ...]`.\n keys: The sequence use to calculate attention scores. A tensor of shape\n :math:`[B, T_2, ...]`.\n values: The sequence to attend. A tensor of shape :math:`[B, T_2, ...]`.\n mode: A ``tf.estimator.ModeKeys`` mode.\n values_length: The length of the values to attend.\n mask_future: Mask attention to future positions.\n dropout: The probability to drop units from the inputs.\n\n Returns:\n The concatenated attention context of each head.\n \"\"\"\n input_dim = keys.get_shape().as_list()[-1]\n\n if input_dim % num_heads != 0:\n raise ValueError(\"Multi head attention requires the input dimension to be a\"\n \" multiple of {}\".format(num_heads))\n\n head_dim = input_dim / num_heads\n heads = []\n\n for i in range(num_heads):\n with tf.variable_scope(\"head_{}\".format(i)):\n # Project queries, keys and values to different and smaller subspaces.\n queries_proj = tf.layers.conv1d(queries, head_dim, 1)\n keys_proj = tf.layers.conv1d(keys, head_dim, 1)\n values_proj = tf.layers.conv1d(values, head_dim, 1)\n\n head_i, _ = scaled_dot_attention(\n queries_proj,\n keys_proj,\n values_proj,\n mode,\n values_length=values_length,\n mask_future=mask_future,\n dropout=dropout)\n\n heads.append(head_i)\n\n # Concatenate all heads output.\n combined = tf.concat(heads, axis=2)\n outputs = tf.layers.conv1d(combined, input_dim, 1)\n\n return outputs\n\ndef feed_forward(x, inner_dim):\n \"\"\"Implements the Transformer's \"Feed Forward\" layer.\n\n .. math::\n\n ffn(x) = max(0, x*W_1 + b_1)*W_2 + b_2\n\n Args:\n x: The input.\n inner_dim: The number of units of the inner linear transformation.\n\n Returns:\n The transformed input.\n \"\"\"\n input_dim = x.get_shape().as_list()[-1]\n\n inner = tf.layers.conv1d(x, inner_dim, 1, activation=tf.nn.relu)\n outer = tf.layers.conv1d(inner, input_dim, 1)\n\n return outer\n\ndef add_and_norm(inputs,\n outputs,\n mode,\n dropout=0.1):\n \"\"\"Implements the Transformer's \"Add & Norm\" layer.\n\n Args:\n inputs: The input of the previous layer.\n outputs: The output of the previous layer.\n mode: A ``tf.estimator.ModeKeys`` mode.\n dropout: The probability to drop units in :obj:`outputs`.\n\n Returns:\n The residual and normalized output.\n \"\"\"\n outputs = tf.layers.dropout(\n outputs,\n rate=dropout,\n training=mode == tf.estimator.ModeKeys.TRAIN)\n outputs += inputs\n outputs = tf.contrib.layers.layer_norm(outputs)\n return outputs\n", "path": "opennmt/utils/transformer.py"}]} | 2,268 | 113 |
gh_patches_debug_11190 | rasdani/github-patches | git_diff | freedomofpress__securedrop-4467 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add list of supported languages to the metadata API
Whether or not a SecureDrop is available in one of the [supported languages](https://docs.securedrop.org/en/latest/admin.html#configuring-localization-for-the-source-interface-and-the-journalist-interface) is public information enumerated at the bottom of the source interface, but it's not currently exposed in the metadata API.
Returning the list of supported languages along with the other instance metadata would be useful, including for the envisioned source interface scanner integrated with securedrop.org.
# User Stories
As a translator, I want to know which languages are currently used by SecureDrop users, so I know if and where my translations have real world impact.
As a SecureDrop support team member, I want to know at a glance whether news organizations have configured supported languages, so I can point out to them if/when translations relevant to them are available.
As a SecureDrop.org visitor, I'd like to know if a SecureDrop instance is available in the language I speak, so that I know if I can navigate it with confidence, and that it is likely to accept submissions in my language.
</issue>
<code>
[start of securedrop/source_app/api.py]
1 import json
2 import platform
3
4 from flask import Blueprint, make_response
5
6 import version
7
8
9 def make_blueprint(config):
10 view = Blueprint('api', __name__)
11
12 @view.route('/metadata')
13 def metadata():
14 meta = {'gpg_fpr': config.JOURNALIST_KEY,
15 'sd_version': version.__version__,
16 'server_os': platform.linux_distribution()[1],
17 }
18 resp = make_response(json.dumps(meta))
19 resp.headers['Content-Type'] = 'application/json'
20 return resp
21
22 return view
23
[end of securedrop/source_app/api.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/securedrop/source_app/api.py b/securedrop/source_app/api.py
--- a/securedrop/source_app/api.py
+++ b/securedrop/source_app/api.py
@@ -11,10 +11,12 @@
@view.route('/metadata')
def metadata():
- meta = {'gpg_fpr': config.JOURNALIST_KEY,
- 'sd_version': version.__version__,
- 'server_os': platform.linux_distribution()[1],
- }
+ meta = {
+ 'gpg_fpr': config.JOURNALIST_KEY,
+ 'sd_version': version.__version__,
+ 'server_os': platform.linux_distribution()[1],
+ 'supported_languages': config.SUPPORTED_LOCALES
+ }
resp = make_response(json.dumps(meta))
resp.headers['Content-Type'] = 'application/json'
return resp
| {"golden_diff": "diff --git a/securedrop/source_app/api.py b/securedrop/source_app/api.py\n--- a/securedrop/source_app/api.py\n+++ b/securedrop/source_app/api.py\n@@ -11,10 +11,12 @@\n \n @view.route('/metadata')\n def metadata():\n- meta = {'gpg_fpr': config.JOURNALIST_KEY,\n- 'sd_version': version.__version__,\n- 'server_os': platform.linux_distribution()[1],\n- }\n+ meta = {\n+ 'gpg_fpr': config.JOURNALIST_KEY,\n+ 'sd_version': version.__version__,\n+ 'server_os': platform.linux_distribution()[1],\n+ 'supported_languages': config.SUPPORTED_LOCALES\n+ }\n resp = make_response(json.dumps(meta))\n resp.headers['Content-Type'] = 'application/json'\n return resp\n", "issue": "Add list of supported languages to the metadata API\nWhether or not a SecureDrop is available in one of the [supported languages](https://docs.securedrop.org/en/latest/admin.html#configuring-localization-for-the-source-interface-and-the-journalist-interface) is public information enumerated at the bottom of the source interface, but it's not currently exposed in the metadata API.\r\n\r\nReturning the list of supported languages along with the other instance metadata would be useful, including for the envisioned source interface scanner integrated with securedrop.org. \r\n\r\n# User Stories\r\n\r\nAs a translator, I want to know which languages are currently used by SecureDrop users, so I know if and where my translations have real world impact.\r\n\r\nAs a SecureDrop support team member, I want to know at a glance whether news organizations have configured supported languages, so I can point out to them if/when translations relevant to them are available.\r\n\r\nAs a SecureDrop.org visitor, I'd like to know if a SecureDrop instance is available in the language I speak, so that I know if I can navigate it with confidence, and that it is likely to accept submissions in my language.\n", "before_files": [{"content": "import json\nimport platform\n\nfrom flask import Blueprint, make_response\n\nimport version\n\n\ndef make_blueprint(config):\n view = Blueprint('api', __name__)\n\n @view.route('/metadata')\n def metadata():\n meta = {'gpg_fpr': config.JOURNALIST_KEY,\n 'sd_version': version.__version__,\n 'server_os': platform.linux_distribution()[1],\n }\n resp = make_response(json.dumps(meta))\n resp.headers['Content-Type'] = 'application/json'\n return resp\n\n return view\n", "path": "securedrop/source_app/api.py"}]} | 920 | 191 |
gh_patches_debug_23850 | rasdani/github-patches | git_diff | Pyomo__pyomo-322 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Let's drop support for Python 2.6
I don't see any meaningful reason to continue support for Python2.6, but let's start a conversation here about this possible change.
I've seen evidence that we're spending time supporting this version of Python without deriving any meaningful utility.
</issue>
<code>
[start of setup.py]
1 # ___________________________________________________________________________
2 #
3 # Pyomo: Python Optimization Modeling Objects
4 # Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC
5 # Under the terms of Contract DE-NA0003525 with National Technology and
6 # Engineering Solutions of Sandia, LLC, the U.S. Government retains certain
7 # rights in this software.
8 # This software is distributed under the 3-clause BSD License.
9 # ___________________________________________________________________________
10
11 """
12 Script to generate the installer for pyomo.
13 """
14
15 import sys
16 import os
17
18
19 def _find_packages(path):
20 """
21 Generate a list of nested packages
22 """
23 pkg_list = []
24 if not os.path.exists(path):
25 return []
26 if not os.path.exists(path+os.sep+"__init__.py"):
27 return []
28 else:
29 pkg_list.append(path)
30 for root, dirs, files in os.walk(path, topdown=True):
31 if root in pkg_list and "__init__.py" in files:
32 for name in dirs:
33 if os.path.exists(root+os.sep+name+os.sep+"__init__.py"):
34 pkg_list.append(root+os.sep+name)
35 return [pkg for pkg in map(lambda x:x.replace(os.sep, "."), pkg_list)]
36
37
38 def read(*rnames):
39 return open(os.path.join(os.path.dirname(__file__), *rnames)).read()
40
41 requires = [
42 'PyUtilib>=5.6.3',
43 'appdirs',
44 'ply',
45 'six>=1.4',
46 ]
47 if sys.version_info < (2, 7):
48 requires.append('argparse')
49 requires.append('unittest2')
50 requires.append('ordereddict')
51
52 from setuptools import setup
53 packages = _find_packages('pyomo')
54
55 setup(name='Pyomo',
56 #
57 # Note: trunk should have *next* major.minor
58 # VOTD and Final releases will have major.minor.revnum
59 #
60 # When cutting a release, ALSO update _major/_minor/_revnum in
61 #
62 # pyomo/pyomo/version/__init__.py
63 # pyomo/RELEASE.txt
64 #
65 version='5.5.1',
66 maintainer='William E. Hart',
67 maintainer_email='[email protected]',
68 url='http://pyomo.org',
69 license='BSD',
70 platforms=["any"],
71 description='Pyomo: Python Optimization Modeling Objects',
72 long_description=read('README.txt'),
73 classifiers=[
74 'Development Status :: 5 - Production/Stable',
75 'Intended Audience :: End Users/Desktop',
76 'Intended Audience :: Science/Research',
77 'License :: OSI Approved :: BSD License',
78 'Natural Language :: English',
79 'Operating System :: MacOS',
80 'Operating System :: Microsoft :: Windows',
81 'Operating System :: Unix',
82 'Programming Language :: Python',
83 'Programming Language :: Python :: 2',
84 'Programming Language :: Python :: 2.6',
85 'Programming Language :: Python :: 2.7',
86 'Programming Language :: Python :: 3',
87 'Programming Language :: Python :: 3.4',
88 'Programming Language :: Python :: 3.5',
89 'Programming Language :: Python :: 3.6',
90 'Programming Language :: Python :: Implementation :: CPython',
91 'Programming Language :: Python :: Implementation :: Jython',
92 'Programming Language :: Python :: Implementation :: PyPy',
93 'Topic :: Scientific/Engineering :: Mathematics',
94 'Topic :: Software Development :: Libraries :: Python Modules' ],
95 packages=packages,
96 keywords=['optimization'],
97 install_requires=requires,
98 entry_points="""
99 [console_scripts]
100 runbenders=pyomo.pysp.benders:Benders_main
101 evaluate_xhat=pyomo.pysp.evaluate_xhat:EvaluateXhat_main
102 runph=pyomo.pysp.phinit:PH_main
103 runef=pyomo.pysp.ef_writer_script:main
104 phsolverserver=pyomo.pysp.phsolverserver:main
105 scenariotreeserver=pyomo.pysp.scenariotree.server_pyro:main
106 computeconf=pyomo.pysp.computeconf:main
107
108 results_schema=pyomo.scripting.commands:results_schema
109 pyro_mip_server = pyomo.scripting.pyro_mip_server:main
110 test.pyomo = pyomo.scripting.runtests:runPyomoTests
111 pyomo = pyomo.scripting.pyomo_main:main
112 pyomo_ns = pyomo.scripting.commands:pyomo_ns
113 pyomo_nsc = pyomo.scripting.commands:pyomo_nsc
114 kill_pyro_mip_servers = pyomo.scripting.commands:kill_pyro_mip_servers
115 launch_pyro_mip_servers = pyomo.scripting.commands:launch_pyro_mip_servers
116 readsol = pyomo.scripting.commands:readsol
117 OSSolverService = pyomo.scripting.commands:OSSolverService
118 pyomo_python = pyomo.scripting.commands:pyomo_python
119 pyomo_old=pyomo.scripting.pyomo_command:main
120 get_pyomo_extras = scripts.get_pyomo_extras:main
121
122 [pyomo.command]
123 pyomo.runbenders=pyomo.pysp.benders
124 pyomo.evaluate_xhat=pyomo.pysp.evaluate_xhat
125 pyomo.runph=pyomo.pysp.phinit
126 pyomo.runef=pyomo.pysp.ef_writer_script
127 pyomo.phsolverserver=pyomo.pysp.phsolverserver
128 pyomo.scenariotreeserver=pyomo.pysp.scenariotree.server_pyro
129 pyomo.computeconf=pyomo.pysp.computeconf
130
131 pyomo.help = pyomo.scripting.driver_help
132 pyomo.test.pyomo = pyomo.scripting.runtests
133 pyomo.pyro_mip_server = pyomo.scripting.pyro_mip_server
134 pyomo.results_schema=pyomo.scripting.commands
135 """
136 )
137
[end of setup.py]
[start of admin/jenkins.py]
1 # ___________________________________________________________________________
2 #
3 # Pyomo: Python Optimization Modeling Objects
4 # Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC
5 # Under the terms of Contract DE-NA0003525 with National Technology and
6 # Engineering Solutions of Sandia, LLC, the U.S. Government retains certain
7 # rights in this software.
8 # This software is distributed under the 3-clause BSD License.
9 # ___________________________________________________________________________
10
11 import glob
12 import sys
13 import os
14 import subprocess
15 try:
16 from subprocess import check_output as _run_cmd
17 except:
18 # python 2.6
19 from subprocess import check_call as _run_cmd
20 import driver
21
22 config = sys.argv[1]
23 hname = os.uname()[1]
24 hname = hname.split('.')[0]
25
26 print("\nStarting jenkins.py")
27 print("Configuration=%s" % config)
28
29 os.environ['CONFIGFILE'] = os.environ['WORKSPACE']+'/src/pyomo/admin/config.ini'
30 #
31 # Is the following even needed?
32 #
33 if 'PYTHONPATH' in os.environ:
34 os.environ['PYTHONPATH'] += os.environ['WORKSPACE'] + os.pathsep + os.environ['PYTHONPATH']
35 else:
36 os.environ['PYTHONPATH'] = os.environ['WORKSPACE']
37 sys.path.append(os.environ['WORKSPACE'])
38
39 sys.argv = ['dummy', '--trunk', '--source', 'src', '-a', 'pyyaml']
40
41 #
42 # Machine-specific configurations
43 #
44 #if hname == "snotra":
45 # ### snotra configuration is now handled through local module files
46 #
47
48
49 if 'LD_LIBRARY_PATH' not in os.environ:
50 os.environ['LD_LIBRARY_PATH'] = ""
51
52 print("\nPython version: %s" % sys.version)
53 print("\nSystem PATH:\n\t%s" % os.environ['PATH'])
54 print("\nPython path:\n\t%s" % sys.path)
55
56 coverage_omit=','.join([
57 os.sep.join([os.environ['WORKSPACE'], 'src', 'pyomo', 'pyomo', '*', 'tests']),
58 'pyomo.*.tests',
59 os.sep.join([os.environ['WORKSPACE'], 'src', 'pyutilib.*']),
60 'pyutilib.*',
61 ])
62
63 pyomo_packages = [
64 'pyomo.%s' % os.path.basename(x) for x in
65 glob.glob(os.path.join(
66 os.environ['WORKSPACE'], 'src', 'pyomo', 'pyomo', '*' ))
67 if os.path.isdir(x) ]
68
69 if config == "notests":
70 driver.perform_install('pyomo', config='pyomo_all.ini')
71
72 elif config == "default":
73 driver.perform_build('pyomo', coverage=True, omit=coverage_omit, config='pyomo_all.ini')
74
75 elif config == "core":
76 # Install
77 print("-" * 60)
78 print("Installing Pyomo")
79 print("-" * 60)
80 driver.perform_install('pyomo', config='pyomo_all.ini')
81 print("-" * 60)
82 print("Running 'pyomo install-extras' ...")
83 print("-" * 60)
84 if _run_cmd is subprocess.check_call:
85 _run_cmd("python/bin/pyomo install-extras", shell=True)
86 elif _run_cmd is subprocess.check_output:
87 output = _run_cmd("python/bin/pyomo install-extras", shell=True)
88 print(output.decode('ascii'))
89 else:
90 assert False
91 # Test
92 os.environ['TEST_PACKAGES'] = ' '.join([
93 'pyomo.checker','pyomo.core','pyomo.environ','pyomo.opt',
94 'pyomo.repn','pyomo.scripting','pyomo.solvers','pyomo.util',
95 'pyomo.version'])
96 print("-" * 60)
97 print("Performing tests")
98 print("-" * 60)
99 driver.perform_tests('pyomo', coverage=True, omit=coverage_omit)
100
101 elif config == "nonpysp":
102 os.environ['TEST_PACKAGES'] = ' '.join(
103 x for x in pyomo_packages if x != 'pyomo.pysp' )
104 driver.perform_build('pyomo', coverage=True, omit=coverage_omit, config='pyomo_all.ini')
105
106 elif config == "parallel":
107 os.environ['NOSE_PROCESS_TIMEOUT'] = '1800' # 30 minutes
108 driver.perform_build('pyomo', cat='parallel', coverage=True, omit=coverage_omit, config='pyomo_all.ini')
109
110 elif config == "expensive":
111 driver.perform_build('pyomo',
112 cat='expensive', coverage=True, omit=coverage_omit,
113 virtualenv_args=sys.argv[1:])
114
115 elif config == "booktests" or config == "book":
116 # Install
117 driver.perform_install('pyomo', config='pyomo_all.ini')
118 print("Running 'pyomo install-extras' ...")
119 if _run_cmd is subprocess.check_call:
120 output = _run_cmd("python/bin/python src/pyomo/scripts/get_pyomo_extras.py -v", shell=True)
121 elif _run_cmd is subprocess.check_output:
122 output = _run_cmd("python/bin/python src/pyomo/scripts/get_pyomo_extras.py -v", shell=True)
123 print(output.decode('ascii'))
124 else:
125 assert False
126 # Test
127 os.environ['NOSE_PROCESS_TIMEOUT'] = '1800'
128 driver.perform_tests('pyomo', cat='book')
129
130 elif config == "perf":
131 os.environ['NOSE_PROCESS_TIMEOUT'] = '1800'
132 driver.perform_build('pyomo', cat='performance')
133
134
[end of admin/jenkins.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/admin/jenkins.py b/admin/jenkins.py
--- a/admin/jenkins.py
+++ b/admin/jenkins.py
@@ -12,11 +12,7 @@
import sys
import os
import subprocess
-try:
- from subprocess import check_output as _run_cmd
-except:
- # python 2.6
- from subprocess import check_call as _run_cmd
+from subprocess import check_output as _run_cmd
import driver
config = sys.argv[1]
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -81,7 +81,6 @@
'Operating System :: Unix',
'Programming Language :: Python',
'Programming Language :: Python :: 2',
- 'Programming Language :: Python :: 2.6',
'Programming Language :: Python :: 2.7',
'Programming Language :: Python :: 3',
'Programming Language :: Python :: 3.4',
@@ -95,6 +94,7 @@
packages=packages,
keywords=['optimization'],
install_requires=requires,
+ python_requires='>=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*',
entry_points="""
[console_scripts]
runbenders=pyomo.pysp.benders:Benders_main
| {"golden_diff": "diff --git a/admin/jenkins.py b/admin/jenkins.py\n--- a/admin/jenkins.py\n+++ b/admin/jenkins.py\n@@ -12,11 +12,7 @@\n import sys\n import os\n import subprocess\n-try:\n- from subprocess import check_output as _run_cmd\n-except:\n- # python 2.6\n- from subprocess import check_call as _run_cmd\n+from subprocess import check_output as _run_cmd\n import driver\n \n config = sys.argv[1]\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -81,7 +81,6 @@\n 'Operating System :: Unix',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n- 'Programming Language :: Python :: 2.6',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n@@ -95,6 +94,7 @@\n packages=packages,\n keywords=['optimization'],\n install_requires=requires,\n+ python_requires='>=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*',\n entry_points=\"\"\"\n [console_scripts]\n runbenders=pyomo.pysp.benders:Benders_main\n", "issue": "Let's drop support for Python 2.6\nI don't see any meaningful reason to continue support for Python2.6, but let's start a conversation here about this possible change.\r\n\r\nI've seen evidence that we're spending time supporting this version of Python without deriving any meaningful utility.\n", "before_files": [{"content": "# ___________________________________________________________________________\n#\n# Pyomo: Python Optimization Modeling Objects\n# Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC\n# Under the terms of Contract DE-NA0003525 with National Technology and\n# Engineering Solutions of Sandia, LLC, the U.S. Government retains certain\n# rights in this software.\n# This software is distributed under the 3-clause BSD License.\n# ___________________________________________________________________________\n\n\"\"\"\nScript to generate the installer for pyomo.\n\"\"\"\n\nimport sys\nimport os\n\n\ndef _find_packages(path):\n \"\"\"\n Generate a list of nested packages\n \"\"\"\n pkg_list = []\n if not os.path.exists(path):\n return []\n if not os.path.exists(path+os.sep+\"__init__.py\"):\n return []\n else:\n pkg_list.append(path)\n for root, dirs, files in os.walk(path, topdown=True):\n if root in pkg_list and \"__init__.py\" in files:\n for name in dirs:\n if os.path.exists(root+os.sep+name+os.sep+\"__init__.py\"):\n pkg_list.append(root+os.sep+name)\n return [pkg for pkg in map(lambda x:x.replace(os.sep, \".\"), pkg_list)]\n\n\ndef read(*rnames):\n return open(os.path.join(os.path.dirname(__file__), *rnames)).read()\n\nrequires = [\n 'PyUtilib>=5.6.3',\n 'appdirs',\n 'ply',\n 'six>=1.4',\n ]\nif sys.version_info < (2, 7):\n requires.append('argparse')\n requires.append('unittest2')\n requires.append('ordereddict')\n\nfrom setuptools import setup\npackages = _find_packages('pyomo')\n\nsetup(name='Pyomo',\n #\n # Note: trunk should have *next* major.minor\n # VOTD and Final releases will have major.minor.revnum\n #\n # When cutting a release, ALSO update _major/_minor/_revnum in\n #\n # pyomo/pyomo/version/__init__.py\n # pyomo/RELEASE.txt\n #\n version='5.5.1',\n maintainer='William E. Hart',\n maintainer_email='[email protected]',\n url='http://pyomo.org',\n license='BSD',\n platforms=[\"any\"],\n description='Pyomo: Python Optimization Modeling Objects',\n long_description=read('README.txt'),\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: End Users/Desktop',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: BSD License',\n 'Natural Language :: English',\n 'Operating System :: MacOS',\n 'Operating System :: Microsoft :: Windows',\n 'Operating System :: Unix',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.6',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: Implementation :: CPython',\n 'Programming Language :: Python :: Implementation :: Jython',\n 'Programming Language :: Python :: Implementation :: PyPy',\n 'Topic :: Scientific/Engineering :: Mathematics',\n 'Topic :: Software Development :: Libraries :: Python Modules' ],\n packages=packages,\n keywords=['optimization'],\n install_requires=requires,\n entry_points=\"\"\"\n [console_scripts]\n runbenders=pyomo.pysp.benders:Benders_main\n evaluate_xhat=pyomo.pysp.evaluate_xhat:EvaluateXhat_main\n runph=pyomo.pysp.phinit:PH_main\n runef=pyomo.pysp.ef_writer_script:main\n phsolverserver=pyomo.pysp.phsolverserver:main\n scenariotreeserver=pyomo.pysp.scenariotree.server_pyro:main\n computeconf=pyomo.pysp.computeconf:main\n\n results_schema=pyomo.scripting.commands:results_schema\n pyro_mip_server = pyomo.scripting.pyro_mip_server:main\n test.pyomo = pyomo.scripting.runtests:runPyomoTests\n pyomo = pyomo.scripting.pyomo_main:main\n pyomo_ns = pyomo.scripting.commands:pyomo_ns\n pyomo_nsc = pyomo.scripting.commands:pyomo_nsc\n kill_pyro_mip_servers = pyomo.scripting.commands:kill_pyro_mip_servers\n launch_pyro_mip_servers = pyomo.scripting.commands:launch_pyro_mip_servers\n readsol = pyomo.scripting.commands:readsol\n OSSolverService = pyomo.scripting.commands:OSSolverService\n pyomo_python = pyomo.scripting.commands:pyomo_python\n pyomo_old=pyomo.scripting.pyomo_command:main\n get_pyomo_extras = scripts.get_pyomo_extras:main\n\n [pyomo.command]\n pyomo.runbenders=pyomo.pysp.benders\n pyomo.evaluate_xhat=pyomo.pysp.evaluate_xhat\n pyomo.runph=pyomo.pysp.phinit\n pyomo.runef=pyomo.pysp.ef_writer_script\n pyomo.phsolverserver=pyomo.pysp.phsolverserver\n pyomo.scenariotreeserver=pyomo.pysp.scenariotree.server_pyro\n pyomo.computeconf=pyomo.pysp.computeconf\n\n pyomo.help = pyomo.scripting.driver_help\n pyomo.test.pyomo = pyomo.scripting.runtests\n pyomo.pyro_mip_server = pyomo.scripting.pyro_mip_server\n pyomo.results_schema=pyomo.scripting.commands\n \"\"\"\n )\n", "path": "setup.py"}, {"content": "# ___________________________________________________________________________\n#\n# Pyomo: Python Optimization Modeling Objects\n# Copyright 2017 National Technology and Engineering Solutions of Sandia, LLC\n# Under the terms of Contract DE-NA0003525 with National Technology and \n# Engineering Solutions of Sandia, LLC, the U.S. Government retains certain \n# rights in this software.\n# This software is distributed under the 3-clause BSD License.\n# ___________________________________________________________________________\n\nimport glob\nimport sys\nimport os\nimport subprocess\ntry:\n from subprocess import check_output as _run_cmd\nexcept:\n # python 2.6\n from subprocess import check_call as _run_cmd\nimport driver\n\nconfig = sys.argv[1]\nhname = os.uname()[1]\nhname = hname.split('.')[0]\n\nprint(\"\\nStarting jenkins.py\")\nprint(\"Configuration=%s\" % config)\n\nos.environ['CONFIGFILE'] = os.environ['WORKSPACE']+'/src/pyomo/admin/config.ini'\n#\n# Is the following even needed?\n#\nif 'PYTHONPATH' in os.environ:\n os.environ['PYTHONPATH'] += os.environ['WORKSPACE'] + os.pathsep + os.environ['PYTHONPATH']\nelse:\n os.environ['PYTHONPATH'] = os.environ['WORKSPACE']\nsys.path.append(os.environ['WORKSPACE'])\n\nsys.argv = ['dummy', '--trunk', '--source', 'src', '-a', 'pyyaml']\n\n#\n# Machine-specific configurations\n#\n#if hname == \"snotra\":\n# ### snotra configuration is now handled through local module files\n#\n\n\nif 'LD_LIBRARY_PATH' not in os.environ:\n os.environ['LD_LIBRARY_PATH'] = \"\"\n\nprint(\"\\nPython version: %s\" % sys.version)\nprint(\"\\nSystem PATH:\\n\\t%s\" % os.environ['PATH'])\nprint(\"\\nPython path:\\n\\t%s\" % sys.path)\n\ncoverage_omit=','.join([\n os.sep.join([os.environ['WORKSPACE'], 'src', 'pyomo', 'pyomo', '*', 'tests']),\n 'pyomo.*.tests',\n os.sep.join([os.environ['WORKSPACE'], 'src', 'pyutilib.*']),\n 'pyutilib.*',\n])\n\npyomo_packages = [\n 'pyomo.%s' % os.path.basename(x) for x in\n glob.glob(os.path.join(\n os.environ['WORKSPACE'], 'src', 'pyomo', 'pyomo', '*' ))\n if os.path.isdir(x) ]\n\nif config == \"notests\":\n driver.perform_install('pyomo', config='pyomo_all.ini')\n\nelif config == \"default\":\n driver.perform_build('pyomo', coverage=True, omit=coverage_omit, config='pyomo_all.ini')\n\nelif config == \"core\":\n # Install\n print(\"-\" * 60)\n print(\"Installing Pyomo\")\n print(\"-\" * 60)\n driver.perform_install('pyomo', config='pyomo_all.ini')\n print(\"-\" * 60)\n print(\"Running 'pyomo install-extras' ...\")\n print(\"-\" * 60)\n if _run_cmd is subprocess.check_call:\n _run_cmd(\"python/bin/pyomo install-extras\", shell=True)\n elif _run_cmd is subprocess.check_output:\n output = _run_cmd(\"python/bin/pyomo install-extras\", shell=True)\n print(output.decode('ascii'))\n else:\n assert False\n # Test\n os.environ['TEST_PACKAGES'] = ' '.join([\n 'pyomo.checker','pyomo.core','pyomo.environ','pyomo.opt',\n 'pyomo.repn','pyomo.scripting','pyomo.solvers','pyomo.util',\n 'pyomo.version'])\n print(\"-\" * 60)\n print(\"Performing tests\")\n print(\"-\" * 60)\n driver.perform_tests('pyomo', coverage=True, omit=coverage_omit)\n\nelif config == \"nonpysp\":\n os.environ['TEST_PACKAGES'] = ' '.join(\n x for x in pyomo_packages if x != 'pyomo.pysp' )\n driver.perform_build('pyomo', coverage=True, omit=coverage_omit, config='pyomo_all.ini')\n\nelif config == \"parallel\":\n os.environ['NOSE_PROCESS_TIMEOUT'] = '1800' # 30 minutes\n driver.perform_build('pyomo', cat='parallel', coverage=True, omit=coverage_omit, config='pyomo_all.ini')\n\nelif config == \"expensive\":\n driver.perform_build('pyomo',\n cat='expensive', coverage=True, omit=coverage_omit,\n virtualenv_args=sys.argv[1:])\n\nelif config == \"booktests\" or config == \"book\":\n # Install\n driver.perform_install('pyomo', config='pyomo_all.ini')\n print(\"Running 'pyomo install-extras' ...\")\n if _run_cmd is subprocess.check_call:\n output = _run_cmd(\"python/bin/python src/pyomo/scripts/get_pyomo_extras.py -v\", shell=True)\n elif _run_cmd is subprocess.check_output:\n output = _run_cmd(\"python/bin/python src/pyomo/scripts/get_pyomo_extras.py -v\", shell=True)\n print(output.decode('ascii'))\n else:\n assert False\n # Test\n os.environ['NOSE_PROCESS_TIMEOUT'] = '1800'\n driver.perform_tests('pyomo', cat='book')\n\nelif config == \"perf\":\n os.environ['NOSE_PROCESS_TIMEOUT'] = '1800'\n driver.perform_build('pyomo', cat='performance')\n\n", "path": "admin/jenkins.py"}]} | 3,716 | 299 |
gh_patches_debug_64229 | rasdani/github-patches | git_diff | optuna__optuna-3237 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Drop version constraint of Sphinx
<!-- Please write a clear and concise description of the feature proposal. -->
## Motivation
Since sphinx v4.0.0, CIs failed to build the document. #2657 tries to resolve the failures by adding the version constraint. But, it would be great to remove the constraint by fixing the root problem.
## Possible solutions
- Remove the constraint by finding the root problem.
- Wait for forthcoming sphinx: other sphinx users reported the bug of sphinx 4.0.0 (see [milestones of sphinx 4.0.1](https://github.com/sphinx-doc/sphinx/milestone/106)).
</issue>
<code>
[start of setup.py]
1 import os
2 from typing import Dict
3 from typing import List
4 from typing import Optional
5
6 import pkg_resources
7 from setuptools import find_packages
8 from setuptools import setup
9
10
11 def get_version() -> str:
12
13 version_filepath = os.path.join(os.path.dirname(__file__), "optuna", "version.py")
14 with open(version_filepath) as f:
15 for line in f:
16 if line.startswith("__version__"):
17 return line.strip().split()[-1][1:-1]
18 assert False
19
20
21 def get_long_description() -> str:
22
23 readme_filepath = os.path.join(os.path.dirname(__file__), "README.md")
24 with open(readme_filepath) as f:
25 return f.read()
26
27
28 def get_install_requires() -> List[str]:
29
30 requirements = [
31 "alembic",
32 "cliff",
33 "cmaes>=0.8.2",
34 "colorlog",
35 "numpy",
36 "packaging>=20.0",
37 "scipy!=1.4.0",
38 "sqlalchemy>=1.1.0",
39 "tqdm",
40 "PyYAML", # Only used in `optuna/cli.py`.
41 ]
42 return requirements
43
44
45 def get_tests_require() -> List[str]:
46
47 return get_extras_require()["testing"]
48
49
50 def get_extras_require() -> Dict[str, List[str]]:
51
52 requirements = {
53 "checking": [
54 "black",
55 "hacking",
56 "isort",
57 "blackdoc",
58 "mypy",
59 "types-setuptools",
60 "types-redis",
61 "types-PyYAML",
62 ],
63 "codecov": ["codecov", "pytest-cov"],
64 "doctest": [
65 "cma",
66 "matplotlib>=3.0.0",
67 "pandas",
68 "plotly>=4.0.0",
69 "scikit-learn>=0.24.2",
70 "scikit-optimize",
71 "mlflow",
72 ],
73 "document": [
74 # TODO(nzw): Remove the version constraint after resolving the issue
75 # https://github.com/optuna/optuna/issues/2658.
76 "sphinx<4.0.0",
77 "sphinx_rtd_theme",
78 "sphinx-copybutton",
79 "sphinx-gallery",
80 "sphinx-plotly-directive",
81 "pillow",
82 "matplotlib",
83 "scikit-learn",
84 "plotly>=4.0.0", # optuna/visualization.
85 "pandas",
86 "lightgbm",
87 "torch==1.10.0",
88 "torchvision==0.11.1",
89 "torchaudio==0.10.0",
90 "thop",
91 ],
92 "experimental": ["redis"],
93 "testing": [
94 "chainer>=5.0.0",
95 "cma",
96 "fakeredis",
97 "lightgbm",
98 "matplotlib>=3.0.0",
99 "mlflow",
100 "mpi4py",
101 "mxnet",
102 "pandas",
103 "plotly>=4.0.0",
104 "pytest",
105 "scikit-learn>=0.24.2",
106 "scikit-optimize",
107 "xgboost",
108 "tensorflow",
109 "tensorflow-datasets",
110 "pytorch-ignite",
111 "pytorch-lightning>=1.5.0",
112 "skorch",
113 "catalyst>=21.3",
114 "torch==1.10.0 ; sys_platform=='darwin'",
115 "torch==1.10.0+cpu ; sys_platform!='darwin'",
116 "torchvision==0.11.1 ; sys_platform=='darwin'",
117 "torchvision==0.11.1+cpu ; sys_platform!='darwin'",
118 "torchaudio==0.10.0",
119 # TODO(himkt): Remove `nltk` after solving
120 # https://github.com/allenai/allennlp/issues/5521
121 "nltk<3.6.6",
122 "allennlp>=2.2.0 ; python_version>'3.6'",
123 "botorch>=0.4.0 ; python_version>'3.6'",
124 "fastai",
125 ],
126 "tests": [
127 "fakeredis",
128 "pytest",
129 ],
130 "optional": [
131 "matplotlib>=3.0.0", # optuna/visualization/matplotlib
132 "pandas", # optuna/study.py
133 "plotly>=4.0.0", # optuna/visualization.
134 "redis", # optuna/storages/redis.py.
135 "scikit-learn>=0.24.2",
136 # optuna/visualization/param_importances.py.
137 ],
138 "integration": [
139 "chainer>=5.0.0",
140 "cma",
141 "lightgbm",
142 "mlflow",
143 "wandb",
144 "mpi4py",
145 "mxnet",
146 "pandas",
147 "scikit-learn>=0.24.2",
148 "scikit-optimize",
149 "xgboost",
150 "tensorflow",
151 "tensorflow-datasets",
152 "pytorch-ignite",
153 "pytorch-lightning>=1.5.0",
154 "skorch",
155 "catalyst>=21.3",
156 "torch==1.10.0 ; sys_platform=='darwin'",
157 "torch==1.10.0+cpu ; sys_platform!='darwin'",
158 "torchvision==0.11.1 ; sys_platform=='darwin'",
159 "torchvision==0.11.1+cpu ; sys_platform!='darwin'",
160 "torchaudio==0.10.0",
161 # TODO(himkt): Remove `nltk` after solving
162 # https://github.com/allenai/allennlp/issues/5521
163 "nltk<3.6.6",
164 "allennlp>=2.2.0 ; python_version>'3.6'",
165 "botorch>=0.4.0 ; python_version>'3.6'",
166 "fastai",
167 ],
168 "benchmark": [
169 "asv",
170 "virtualenv",
171 ],
172 }
173
174 return requirements
175
176
177 def find_any_distribution(pkgs: List[str]) -> Optional[pkg_resources.Distribution]:
178
179 for pkg in pkgs:
180 try:
181 return pkg_resources.get_distribution(pkg)
182 except pkg_resources.DistributionNotFound:
183 pass
184 return None
185
186
187 setup(
188 name="optuna",
189 version=get_version(),
190 description="A hyperparameter optimization framework",
191 long_description=get_long_description(),
192 long_description_content_type="text/markdown",
193 author="Takuya Akiba",
194 author_email="[email protected]",
195 url="https://optuna.org/",
196 packages=find_packages(exclude=("tests", "tests.*", "benchmarks")),
197 package_data={
198 "optuna": [
199 "storages/_rdb/alembic.ini",
200 "storages/_rdb/alembic/*.*",
201 "storages/_rdb/alembic/versions/*.*",
202 "py.typed",
203 ]
204 },
205 python_requires=">=3.6",
206 install_requires=get_install_requires(),
207 tests_require=get_tests_require(),
208 extras_require=get_extras_require(),
209 entry_points={
210 "console_scripts": ["optuna = optuna.cli:main"],
211 "optuna.command": [
212 "create-study = optuna.cli:_CreateStudy",
213 "delete-study = optuna.cli:_DeleteStudy",
214 "study set-user-attr = optuna.cli:_StudySetUserAttribute",
215 "studies = optuna.cli:_Studies",
216 "trials = optuna.cli:_Trials",
217 "best-trial = optuna.cli:_BestTrial",
218 "best-trials = optuna.cli:_BestTrials",
219 "study optimize = optuna.cli:_StudyOptimize",
220 "storage upgrade = optuna.cli:_StorageUpgrade",
221 "ask = optuna.cli:_Ask",
222 "tell = optuna.cli:_Tell",
223 ],
224 },
225 classifiers=[
226 "Development Status :: 5 - Production/Stable",
227 "Intended Audience :: Science/Research",
228 "Intended Audience :: Developers",
229 "License :: OSI Approved :: MIT License",
230 "Programming Language :: Python :: 3",
231 "Programming Language :: Python :: 3.6",
232 "Programming Language :: Python :: 3.7",
233 "Programming Language :: Python :: 3.8",
234 "Programming Language :: Python :: 3.9",
235 "Programming Language :: Python :: 3 :: Only",
236 "Topic :: Scientific/Engineering",
237 "Topic :: Scientific/Engineering :: Mathematics",
238 "Topic :: Scientific/Engineering :: Artificial Intelligence",
239 "Topic :: Software Development",
240 "Topic :: Software Development :: Libraries",
241 "Topic :: Software Development :: Libraries :: Python Modules",
242 ],
243 )
244
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -71,9 +71,7 @@
"mlflow",
],
"document": [
- # TODO(nzw): Remove the version constraint after resolving the issue
- # https://github.com/optuna/optuna/issues/2658.
- "sphinx<4.0.0",
+ "sphinx",
"sphinx_rtd_theme",
"sphinx-copybutton",
"sphinx-gallery",
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -71,9 +71,7 @@\n \"mlflow\",\n ],\n \"document\": [\n- # TODO(nzw): Remove the version constraint after resolving the issue\n- # https://github.com/optuna/optuna/issues/2658.\n- \"sphinx<4.0.0\",\n+ \"sphinx\",\n \"sphinx_rtd_theme\",\n \"sphinx-copybutton\",\n \"sphinx-gallery\",\n", "issue": "Drop version constraint of Sphinx\n<!-- Please write a clear and concise description of the feature proposal. -->\r\n\r\n## Motivation\r\n\r\nSince sphinx v4.0.0, CIs failed to build the document. #2657 tries to resolve the failures by adding the version constraint. But, it would be great to remove the constraint by fixing the root problem.\r\n\r\n## Possible solutions\r\n\r\n- Remove the constraint by finding the root problem.\r\n- Wait for forthcoming sphinx: other sphinx users reported the bug of sphinx 4.0.0 (see [milestones of sphinx 4.0.1](https://github.com/sphinx-doc/sphinx/milestone/106)). \r\n\r\n\n", "before_files": [{"content": "import os\nfrom typing import Dict\nfrom typing import List\nfrom typing import Optional\n\nimport pkg_resources\nfrom setuptools import find_packages\nfrom setuptools import setup\n\n\ndef get_version() -> str:\n\n version_filepath = os.path.join(os.path.dirname(__file__), \"optuna\", \"version.py\")\n with open(version_filepath) as f:\n for line in f:\n if line.startswith(\"__version__\"):\n return line.strip().split()[-1][1:-1]\n assert False\n\n\ndef get_long_description() -> str:\n\n readme_filepath = os.path.join(os.path.dirname(__file__), \"README.md\")\n with open(readme_filepath) as f:\n return f.read()\n\n\ndef get_install_requires() -> List[str]:\n\n requirements = [\n \"alembic\",\n \"cliff\",\n \"cmaes>=0.8.2\",\n \"colorlog\",\n \"numpy\",\n \"packaging>=20.0\",\n \"scipy!=1.4.0\",\n \"sqlalchemy>=1.1.0\",\n \"tqdm\",\n \"PyYAML\", # Only used in `optuna/cli.py`.\n ]\n return requirements\n\n\ndef get_tests_require() -> List[str]:\n\n return get_extras_require()[\"testing\"]\n\n\ndef get_extras_require() -> Dict[str, List[str]]:\n\n requirements = {\n \"checking\": [\n \"black\",\n \"hacking\",\n \"isort\",\n \"blackdoc\",\n \"mypy\",\n \"types-setuptools\",\n \"types-redis\",\n \"types-PyYAML\",\n ],\n \"codecov\": [\"codecov\", \"pytest-cov\"],\n \"doctest\": [\n \"cma\",\n \"matplotlib>=3.0.0\",\n \"pandas\",\n \"plotly>=4.0.0\",\n \"scikit-learn>=0.24.2\",\n \"scikit-optimize\",\n \"mlflow\",\n ],\n \"document\": [\n # TODO(nzw): Remove the version constraint after resolving the issue\n # https://github.com/optuna/optuna/issues/2658.\n \"sphinx<4.0.0\",\n \"sphinx_rtd_theme\",\n \"sphinx-copybutton\",\n \"sphinx-gallery\",\n \"sphinx-plotly-directive\",\n \"pillow\",\n \"matplotlib\",\n \"scikit-learn\",\n \"plotly>=4.0.0\", # optuna/visualization.\n \"pandas\",\n \"lightgbm\",\n \"torch==1.10.0\",\n \"torchvision==0.11.1\",\n \"torchaudio==0.10.0\",\n \"thop\",\n ],\n \"experimental\": [\"redis\"],\n \"testing\": [\n \"chainer>=5.0.0\",\n \"cma\",\n \"fakeredis\",\n \"lightgbm\",\n \"matplotlib>=3.0.0\",\n \"mlflow\",\n \"mpi4py\",\n \"mxnet\",\n \"pandas\",\n \"plotly>=4.0.0\",\n \"pytest\",\n \"scikit-learn>=0.24.2\",\n \"scikit-optimize\",\n \"xgboost\",\n \"tensorflow\",\n \"tensorflow-datasets\",\n \"pytorch-ignite\",\n \"pytorch-lightning>=1.5.0\",\n \"skorch\",\n \"catalyst>=21.3\",\n \"torch==1.10.0 ; sys_platform=='darwin'\",\n \"torch==1.10.0+cpu ; sys_platform!='darwin'\",\n \"torchvision==0.11.1 ; sys_platform=='darwin'\",\n \"torchvision==0.11.1+cpu ; sys_platform!='darwin'\",\n \"torchaudio==0.10.0\",\n # TODO(himkt): Remove `nltk` after solving\n # https://github.com/allenai/allennlp/issues/5521\n \"nltk<3.6.6\",\n \"allennlp>=2.2.0 ; python_version>'3.6'\",\n \"botorch>=0.4.0 ; python_version>'3.6'\",\n \"fastai\",\n ],\n \"tests\": [\n \"fakeredis\",\n \"pytest\",\n ],\n \"optional\": [\n \"matplotlib>=3.0.0\", # optuna/visualization/matplotlib\n \"pandas\", # optuna/study.py\n \"plotly>=4.0.0\", # optuna/visualization.\n \"redis\", # optuna/storages/redis.py.\n \"scikit-learn>=0.24.2\",\n # optuna/visualization/param_importances.py.\n ],\n \"integration\": [\n \"chainer>=5.0.0\",\n \"cma\",\n \"lightgbm\",\n \"mlflow\",\n \"wandb\",\n \"mpi4py\",\n \"mxnet\",\n \"pandas\",\n \"scikit-learn>=0.24.2\",\n \"scikit-optimize\",\n \"xgboost\",\n \"tensorflow\",\n \"tensorflow-datasets\",\n \"pytorch-ignite\",\n \"pytorch-lightning>=1.5.0\",\n \"skorch\",\n \"catalyst>=21.3\",\n \"torch==1.10.0 ; sys_platform=='darwin'\",\n \"torch==1.10.0+cpu ; sys_platform!='darwin'\",\n \"torchvision==0.11.1 ; sys_platform=='darwin'\",\n \"torchvision==0.11.1+cpu ; sys_platform!='darwin'\",\n \"torchaudio==0.10.0\",\n # TODO(himkt): Remove `nltk` after solving\n # https://github.com/allenai/allennlp/issues/5521\n \"nltk<3.6.6\",\n \"allennlp>=2.2.0 ; python_version>'3.6'\",\n \"botorch>=0.4.0 ; python_version>'3.6'\",\n \"fastai\",\n ],\n \"benchmark\": [\n \"asv\",\n \"virtualenv\",\n ],\n }\n\n return requirements\n\n\ndef find_any_distribution(pkgs: List[str]) -> Optional[pkg_resources.Distribution]:\n\n for pkg in pkgs:\n try:\n return pkg_resources.get_distribution(pkg)\n except pkg_resources.DistributionNotFound:\n pass\n return None\n\n\nsetup(\n name=\"optuna\",\n version=get_version(),\n description=\"A hyperparameter optimization framework\",\n long_description=get_long_description(),\n long_description_content_type=\"text/markdown\",\n author=\"Takuya Akiba\",\n author_email=\"[email protected]\",\n url=\"https://optuna.org/\",\n packages=find_packages(exclude=(\"tests\", \"tests.*\", \"benchmarks\")),\n package_data={\n \"optuna\": [\n \"storages/_rdb/alembic.ini\",\n \"storages/_rdb/alembic/*.*\",\n \"storages/_rdb/alembic/versions/*.*\",\n \"py.typed\",\n ]\n },\n python_requires=\">=3.6\",\n install_requires=get_install_requires(),\n tests_require=get_tests_require(),\n extras_require=get_extras_require(),\n entry_points={\n \"console_scripts\": [\"optuna = optuna.cli:main\"],\n \"optuna.command\": [\n \"create-study = optuna.cli:_CreateStudy\",\n \"delete-study = optuna.cli:_DeleteStudy\",\n \"study set-user-attr = optuna.cli:_StudySetUserAttribute\",\n \"studies = optuna.cli:_Studies\",\n \"trials = optuna.cli:_Trials\",\n \"best-trial = optuna.cli:_BestTrial\",\n \"best-trials = optuna.cli:_BestTrials\",\n \"study optimize = optuna.cli:_StudyOptimize\",\n \"storage upgrade = optuna.cli:_StorageUpgrade\",\n \"ask = optuna.cli:_Ask\",\n \"tell = optuna.cli:_Tell\",\n ],\n },\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"Intended Audience :: Science/Research\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: MIT License\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3 :: Only\",\n \"Topic :: Scientific/Engineering\",\n \"Topic :: Scientific/Engineering :: Mathematics\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n \"Topic :: Software Development\",\n \"Topic :: Software Development :: Libraries\",\n \"Topic :: Software Development :: Libraries :: Python Modules\",\n ],\n)\n", "path": "setup.py"}]} | 3,235 | 117 |
gh_patches_debug_11233 | rasdani/github-patches | git_diff | Lightning-Universe__lightning-flash-493 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Serve sanity check never called with PL master
## 🐛 Bug
`LightningModule.run_sanity_check` has been renamed to `_run_sanity_check`
</issue>
<code>
[start of flash/core/trainer.py]
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 import inspect
15 import warnings
16 from argparse import ArgumentParser, Namespace
17 from functools import wraps
18 from typing import Callable, List, Optional, Union
19
20 import torch
21 from pytorch_lightning import LightningDataModule, LightningModule
22 from pytorch_lightning import Trainer as PlTrainer
23 from pytorch_lightning.callbacks import BaseFinetuning
24 from pytorch_lightning.utilities import rank_zero_warn
25 from pytorch_lightning.utilities.argparse import add_argparse_args, get_init_arguments_and_types, parse_env_variables
26 from pytorch_lightning.utilities.exceptions import MisconfigurationException
27 from torch.utils.data import DataLoader
28
29 import flash
30 from flash.core.finetuning import _DEFAULTS_FINETUNE_STRATEGIES, instantiate_default_finetuning_callbacks
31 from flash.core.utilities.imports import _SERVE_AVAILABLE
32
33
34 def from_argparse_args(cls, args: Union[Namespace, ArgumentParser], **kwargs):
35 """Modified version of ``pytorch_lightning.utilities.argparse.from_argparse_args`` which populates ``valid_kwargs``
36 from ``pytorch_lightning.Trainer``."""
37 if isinstance(args, ArgumentParser):
38 args = cls.parse_argparser(args)
39
40 params = vars(args)
41
42 # we only want to pass in valid PLTrainer args, the rest may be user specific
43 valid_kwargs = inspect.signature(PlTrainer.__init__).parameters
44 trainer_kwargs = {name: params[name] for name in valid_kwargs if name in params}
45 trainer_kwargs.update(**kwargs)
46
47 return cls(**trainer_kwargs)
48
49
50 def _defaults_from_env_vars(fn: Callable) -> Callable:
51 """Copy of ``pytorch_lightning.trainer.connectors.env_vars_connector._defaults_from_env_vars``. Required to fix
52 build error in readthedocs."""
53
54 @wraps(fn)
55 def insert_env_defaults(self, *args, **kwargs):
56 cls = self.__class__ # get the class
57 if args: # inace any args passed move them to kwargs
58 # parse only the argument names
59 cls_arg_names = [arg[0] for arg in get_init_arguments_and_types(cls)]
60 # convert args to kwargs
61 kwargs.update(dict(zip(cls_arg_names, args)))
62 env_variables = vars(parse_env_variables(cls))
63 # update the kwargs by env variables
64 kwargs = dict(list(env_variables.items()) + list(kwargs.items()))
65
66 # all args were already moved to kwargs
67 return fn(self, **kwargs)
68
69 return insert_env_defaults
70
71
72 class Trainer(PlTrainer):
73
74 @_defaults_from_env_vars
75 def __init__(self, *args, serve_sanity_check: bool = False, **kwargs):
76 if flash._IS_TESTING:
77 if torch.cuda.is_available():
78 kwargs["gpus"] = 1
79 kwargs["max_epochs"] = 3
80 kwargs["limit_train_batches"] = 1.0
81 kwargs["limit_val_batches"] = 1.0
82 kwargs["limit_test_batches"] = 1.0
83 kwargs["fast_dev_run"] = False
84 else:
85 kwargs["fast_dev_run"] = True
86 super().__init__(*args, **kwargs)
87
88 self.serve_sanity_check = serve_sanity_check
89
90 def run_sanity_check(self, ref_model):
91 super().run_sanity_check(ref_model)
92
93 if self.serve_sanity_check and ref_model.is_servable and _SERVE_AVAILABLE:
94 ref_model.run_serve_sanity_check()
95
96 def fit(
97 self,
98 model: LightningModule,
99 train_dataloader: Optional[DataLoader] = None,
100 val_dataloaders: Optional[Union[DataLoader, List[DataLoader]]] = None,
101 datamodule: Optional[LightningDataModule] = None,
102 ):
103 r"""
104 Runs the full optimization routine. Same as :meth:`pytorch_lightning.Trainer.fit`
105
106 Args:
107 datamodule: A instance of :class:`LightningDataModule`.
108
109 model: Model to fit.
110
111 train_dataloader: A Pytorch DataLoader with training samples. If the model has
112 a predefined train_dataloader method this will be skipped.
113
114 val_dataloaders: Either a single Pytorch Dataloader or a list of them, specifying validation samples.
115 If the model has a predefined val_dataloaders method this will be skipped
116 """
117 if any(isinstance(c, BaseFinetuning) for c in self.callbacks):
118 # TODO: if we find a finetuning callback in the trainer should we remove it? or just warn the user?
119 warnings.warn("Warning: You are calling fit(), but your trainer is using a fine-tuning callback")
120 return super().fit(model, train_dataloader, val_dataloaders, datamodule)
121
122 def finetune(
123 self,
124 model: LightningModule,
125 train_dataloader: Optional[DataLoader] = None,
126 val_dataloaders: Optional[Union[DataLoader, List[DataLoader]]] = None,
127 datamodule: Optional[LightningDataModule] = None,
128 strategy: Optional[Union[str, BaseFinetuning]] = None,
129 ):
130 r"""
131
132 Runs the full optimization routine. Same as :meth:`pytorch_lightning.Trainer.fit`, but unfreezes layers
133 of the backbone throughout training layers of the backbone throughout training.
134
135 Args:
136 datamodule: A instance of :class:`LightningDataModule`.
137
138 model: Model to fit.
139
140 train_dataloader: A PyTorch DataLoader with training samples. If the model has
141 a predefined train_dataloader method this will be skipped.
142
143 val_dataloaders: Either a single PyTorch Dataloader or a list of them, specifying validation samples.
144 If the model has a predefined val_dataloaders method this will be skipped
145
146 strategy: Should either be a string or a finetuning callback subclassing
147 :class:`pytorch_lightning.callbacks.BaseFinetuning`.
148
149 Default strategies can be enabled with these strings:
150
151 - ``"no_freeze"``,
152 - ``"freeze"``,
153 - ``"freeze_unfreeze"``,
154 - ``"unfreeze_milestones"``.
155 """
156 self._resolve_callbacks(model, strategy)
157 return super().fit(model, train_dataloader, val_dataloaders, datamodule)
158
159 def _resolve_callbacks(self, model, strategy):
160 """
161 This function is used to select the `BaseFinetuning` to be used for finetuning.
162 """
163 if strategy is not None and not isinstance(strategy, (str, BaseFinetuning)):
164 raise MisconfigurationException(
165 "strategy should be a ``pytorch_lightning.callbacks.BaseFinetuning``"
166 f"callback or a str within {list(_DEFAULTS_FINETUNE_STRATEGIES.keys())}"
167 )
168
169 if isinstance(strategy, BaseFinetuning):
170 callback = [strategy]
171 else:
172 # todo: change to ``configure_callbacks`` when merged to Lightning.
173 model_callback = model.configure_finetune_callback()
174 if len(model_callback) > 1:
175 raise MisconfigurationException(
176 f"{model} configure_finetune_callback should create a list with only 1 callback"
177 )
178 if len(model_callback) == 1:
179 if strategy is not None:
180 rank_zero_warn(
181 "The model contains a default finetune callback. The provided {strategy} will be overriden.\n"
182 " HINT: Provide a `BaseFinetuning` callback as strategy to make it prioritized. ", UserWarning
183 )
184 callback = model_callback
185 else:
186 callback = instantiate_default_finetuning_callbacks(strategy)
187
188 self.callbacks = self._merge_callbacks(self.callbacks, callback)
189
190 @staticmethod
191 def _merge_callbacks(old_callbacks: List, new_callbacks: List) -> List:
192 """
193 This function keeps only 1 instance of each callback type,
194 extending new_callbacks with old_callbacks
195 """
196 if len(new_callbacks) == 0:
197 return old_callbacks
198 new_callbacks_types = {type(c) for c in new_callbacks}
199 old_callbacks_types = {type(c) for c in old_callbacks}
200 override_types = new_callbacks_types.intersection(old_callbacks_types)
201 new_callbacks.extend(c for c in old_callbacks if type(c) not in override_types)
202 return new_callbacks
203
204 @classmethod
205 def add_argparse_args(cls, *args, **kwargs) -> ArgumentParser:
206 # the lightning trainer implementation does not support subclasses.
207 # context: https://github.com/PyTorchLightning/lightning-flash/issues/342#issuecomment-848892447
208 return add_argparse_args(PlTrainer, *args, **kwargs)
209
210 @classmethod
211 def from_argparse_args(cls, args: Union[Namespace, ArgumentParser], **kwargs) -> 'Trainer':
212 # the lightning trainer implementation does not support subclasses.
213 # context: https://github.com/PyTorchLightning/lightning-flash/issues/342#issuecomment-848892447
214 return from_argparse_args(Trainer, args, **kwargs)
215
[end of flash/core/trainer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/flash/core/trainer.py b/flash/core/trainer.py
--- a/flash/core/trainer.py
+++ b/flash/core/trainer.py
@@ -87,8 +87,15 @@
self.serve_sanity_check = serve_sanity_check
+ def _run_sanity_check(self, ref_model):
+ if hasattr(super(), "_run_sanity_check"):
+ super()._run_sanity_check(ref_model)
+
+ self.run_sanity_check(ref_model)
+
def run_sanity_check(self, ref_model):
- super().run_sanity_check(ref_model)
+ if hasattr(super(), "run_sanity_check"):
+ super().run_sanity_check(ref_model)
if self.serve_sanity_check and ref_model.is_servable and _SERVE_AVAILABLE:
ref_model.run_serve_sanity_check()
| {"golden_diff": "diff --git a/flash/core/trainer.py b/flash/core/trainer.py\n--- a/flash/core/trainer.py\n+++ b/flash/core/trainer.py\n@@ -87,8 +87,15 @@\n \n self.serve_sanity_check = serve_sanity_check\n \n+ def _run_sanity_check(self, ref_model):\n+ if hasattr(super(), \"_run_sanity_check\"):\n+ super()._run_sanity_check(ref_model)\n+\n+ self.run_sanity_check(ref_model)\n+\n def run_sanity_check(self, ref_model):\n- super().run_sanity_check(ref_model)\n+ if hasattr(super(), \"run_sanity_check\"):\n+ super().run_sanity_check(ref_model)\n \n if self.serve_sanity_check and ref_model.is_servable and _SERVE_AVAILABLE:\n ref_model.run_serve_sanity_check()\n", "issue": "Serve sanity check never called with PL master\n## \ud83d\udc1b Bug\r\n\r\n`LightningModule.run_sanity_check` has been renamed to `_run_sanity_check`\n", "before_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport inspect\nimport warnings\nfrom argparse import ArgumentParser, Namespace\nfrom functools import wraps\nfrom typing import Callable, List, Optional, Union\n\nimport torch\nfrom pytorch_lightning import LightningDataModule, LightningModule\nfrom pytorch_lightning import Trainer as PlTrainer\nfrom pytorch_lightning.callbacks import BaseFinetuning\nfrom pytorch_lightning.utilities import rank_zero_warn\nfrom pytorch_lightning.utilities.argparse import add_argparse_args, get_init_arguments_and_types, parse_env_variables\nfrom pytorch_lightning.utilities.exceptions import MisconfigurationException\nfrom torch.utils.data import DataLoader\n\nimport flash\nfrom flash.core.finetuning import _DEFAULTS_FINETUNE_STRATEGIES, instantiate_default_finetuning_callbacks\nfrom flash.core.utilities.imports import _SERVE_AVAILABLE\n\n\ndef from_argparse_args(cls, args: Union[Namespace, ArgumentParser], **kwargs):\n \"\"\"Modified version of ``pytorch_lightning.utilities.argparse.from_argparse_args`` which populates ``valid_kwargs``\n from ``pytorch_lightning.Trainer``.\"\"\"\n if isinstance(args, ArgumentParser):\n args = cls.parse_argparser(args)\n\n params = vars(args)\n\n # we only want to pass in valid PLTrainer args, the rest may be user specific\n valid_kwargs = inspect.signature(PlTrainer.__init__).parameters\n trainer_kwargs = {name: params[name] for name in valid_kwargs if name in params}\n trainer_kwargs.update(**kwargs)\n\n return cls(**trainer_kwargs)\n\n\ndef _defaults_from_env_vars(fn: Callable) -> Callable:\n \"\"\"Copy of ``pytorch_lightning.trainer.connectors.env_vars_connector._defaults_from_env_vars``. Required to fix\n build error in readthedocs.\"\"\"\n\n @wraps(fn)\n def insert_env_defaults(self, *args, **kwargs):\n cls = self.__class__ # get the class\n if args: # inace any args passed move them to kwargs\n # parse only the argument names\n cls_arg_names = [arg[0] for arg in get_init_arguments_and_types(cls)]\n # convert args to kwargs\n kwargs.update(dict(zip(cls_arg_names, args)))\n env_variables = vars(parse_env_variables(cls))\n # update the kwargs by env variables\n kwargs = dict(list(env_variables.items()) + list(kwargs.items()))\n\n # all args were already moved to kwargs\n return fn(self, **kwargs)\n\n return insert_env_defaults\n\n\nclass Trainer(PlTrainer):\n\n @_defaults_from_env_vars\n def __init__(self, *args, serve_sanity_check: bool = False, **kwargs):\n if flash._IS_TESTING:\n if torch.cuda.is_available():\n kwargs[\"gpus\"] = 1\n kwargs[\"max_epochs\"] = 3\n kwargs[\"limit_train_batches\"] = 1.0\n kwargs[\"limit_val_batches\"] = 1.0\n kwargs[\"limit_test_batches\"] = 1.0\n kwargs[\"fast_dev_run\"] = False\n else:\n kwargs[\"fast_dev_run\"] = True\n super().__init__(*args, **kwargs)\n\n self.serve_sanity_check = serve_sanity_check\n\n def run_sanity_check(self, ref_model):\n super().run_sanity_check(ref_model)\n\n if self.serve_sanity_check and ref_model.is_servable and _SERVE_AVAILABLE:\n ref_model.run_serve_sanity_check()\n\n def fit(\n self,\n model: LightningModule,\n train_dataloader: Optional[DataLoader] = None,\n val_dataloaders: Optional[Union[DataLoader, List[DataLoader]]] = None,\n datamodule: Optional[LightningDataModule] = None,\n ):\n r\"\"\"\n Runs the full optimization routine. Same as :meth:`pytorch_lightning.Trainer.fit`\n\n Args:\n datamodule: A instance of :class:`LightningDataModule`.\n\n model: Model to fit.\n\n train_dataloader: A Pytorch DataLoader with training samples. If the model has\n a predefined train_dataloader method this will be skipped.\n\n val_dataloaders: Either a single Pytorch Dataloader or a list of them, specifying validation samples.\n If the model has a predefined val_dataloaders method this will be skipped\n \"\"\"\n if any(isinstance(c, BaseFinetuning) for c in self.callbacks):\n # TODO: if we find a finetuning callback in the trainer should we remove it? or just warn the user?\n warnings.warn(\"Warning: You are calling fit(), but your trainer is using a fine-tuning callback\")\n return super().fit(model, train_dataloader, val_dataloaders, datamodule)\n\n def finetune(\n self,\n model: LightningModule,\n train_dataloader: Optional[DataLoader] = None,\n val_dataloaders: Optional[Union[DataLoader, List[DataLoader]]] = None,\n datamodule: Optional[LightningDataModule] = None,\n strategy: Optional[Union[str, BaseFinetuning]] = None,\n ):\n r\"\"\"\n\n Runs the full optimization routine. Same as :meth:`pytorch_lightning.Trainer.fit`, but unfreezes layers\n of the backbone throughout training layers of the backbone throughout training.\n\n Args:\n datamodule: A instance of :class:`LightningDataModule`.\n\n model: Model to fit.\n\n train_dataloader: A PyTorch DataLoader with training samples. If the model has\n a predefined train_dataloader method this will be skipped.\n\n val_dataloaders: Either a single PyTorch Dataloader or a list of them, specifying validation samples.\n If the model has a predefined val_dataloaders method this will be skipped\n\n strategy: Should either be a string or a finetuning callback subclassing\n :class:`pytorch_lightning.callbacks.BaseFinetuning`.\n\n Default strategies can be enabled with these strings:\n\n - ``\"no_freeze\"``,\n - ``\"freeze\"``,\n - ``\"freeze_unfreeze\"``,\n - ``\"unfreeze_milestones\"``.\n \"\"\"\n self._resolve_callbacks(model, strategy)\n return super().fit(model, train_dataloader, val_dataloaders, datamodule)\n\n def _resolve_callbacks(self, model, strategy):\n \"\"\"\n This function is used to select the `BaseFinetuning` to be used for finetuning.\n \"\"\"\n if strategy is not None and not isinstance(strategy, (str, BaseFinetuning)):\n raise MisconfigurationException(\n \"strategy should be a ``pytorch_lightning.callbacks.BaseFinetuning``\"\n f\"callback or a str within {list(_DEFAULTS_FINETUNE_STRATEGIES.keys())}\"\n )\n\n if isinstance(strategy, BaseFinetuning):\n callback = [strategy]\n else:\n # todo: change to ``configure_callbacks`` when merged to Lightning.\n model_callback = model.configure_finetune_callback()\n if len(model_callback) > 1:\n raise MisconfigurationException(\n f\"{model} configure_finetune_callback should create a list with only 1 callback\"\n )\n if len(model_callback) == 1:\n if strategy is not None:\n rank_zero_warn(\n \"The model contains a default finetune callback. The provided {strategy} will be overriden.\\n\"\n \" HINT: Provide a `BaseFinetuning` callback as strategy to make it prioritized. \", UserWarning\n )\n callback = model_callback\n else:\n callback = instantiate_default_finetuning_callbacks(strategy)\n\n self.callbacks = self._merge_callbacks(self.callbacks, callback)\n\n @staticmethod\n def _merge_callbacks(old_callbacks: List, new_callbacks: List) -> List:\n \"\"\"\n This function keeps only 1 instance of each callback type,\n extending new_callbacks with old_callbacks\n \"\"\"\n if len(new_callbacks) == 0:\n return old_callbacks\n new_callbacks_types = {type(c) for c in new_callbacks}\n old_callbacks_types = {type(c) for c in old_callbacks}\n override_types = new_callbacks_types.intersection(old_callbacks_types)\n new_callbacks.extend(c for c in old_callbacks if type(c) not in override_types)\n return new_callbacks\n\n @classmethod\n def add_argparse_args(cls, *args, **kwargs) -> ArgumentParser:\n # the lightning trainer implementation does not support subclasses.\n # context: https://github.com/PyTorchLightning/lightning-flash/issues/342#issuecomment-848892447\n return add_argparse_args(PlTrainer, *args, **kwargs)\n\n @classmethod\n def from_argparse_args(cls, args: Union[Namespace, ArgumentParser], **kwargs) -> 'Trainer':\n # the lightning trainer implementation does not support subclasses.\n # context: https://github.com/PyTorchLightning/lightning-flash/issues/342#issuecomment-848892447\n return from_argparse_args(Trainer, args, **kwargs)\n", "path": "flash/core/trainer.py"}]} | 3,201 | 187 |
gh_patches_debug_21810 | rasdani/github-patches | git_diff | getsentry__sentry-7880 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Slack Integration:
Hi, I'm having trouble setting up the new Slack integration to work with private channels.
- With the legacy integration we had Sentry sending messages into private channels.
- When authorizing the Slack app I selected "Specific channels" and entered the names of the private channels, as well as "slackbot, which is private to you"..
- The authorization appeared to succeed. After authorizing I saw a message `Sentry APP [2:39 PM]
was added to this conversation by Luke Moore.` in those channels.
- When editing the alert rule I've set the "take these actions" to send a notification to the private workspace but I see the error: 'The slack resource "website-private" does not exist or has not been granted access in the SideFX Slack workspace.' I've tried with and without a leading "#".
Am I doing something wrong?


</issue>
<code>
[start of src/sentry/integrations/slack/integration.py]
1 from __future__ import absolute_import
2
3 from sentry import http
4 from sentry.integrations import Integration, IntegrationMetadata
5 from sentry.utils.pipeline import NestedPipelineView
6 from sentry.identity.pipeline import IdentityProviderPipeline
7 from sentry.utils.http import absolute_uri
8
9 DESCRIPTION = """
10 Define a relationship between Sentry and your Slack workspace(s).
11
12 * Unfurls Sentry URLs in slack, providing context and actionability on issues
13 directly within your Slack workspace.
14 * Resolve, ignore, and assign issues with minimal context switching.
15 * Configure rule based Slack notifications to automatically be posted into the
16 specified channel.
17 """
18
19 alert_link = {
20 'text': 'Looking to send Sentry alerts to Slack? Add an **Alert Rule** for this project.',
21 'link': '/settings/{orgId}/{projectId}/alerts/rules/'
22 }
23
24 metadata = IntegrationMetadata(
25 description=DESCRIPTION.strip(),
26 author='The Sentry Team',
27 issue_url='https://github.com/getsentry/sentry/issues/new?title=Slack%20Integration:%20&labels=Component%3A%20Integrations',
28 source_url='https://github.com/getsentry/sentry/tree/master/src/sentry/integrations/slack',
29 aspects={
30 'alert_link': alert_link,
31 }
32 )
33
34
35 class SlackIntegration(Integration):
36 key = 'slack'
37 name = 'Slack'
38 metadata = metadata
39
40 identity_oauth_scopes = frozenset([
41 'channels:read',
42 'users:read'
43 'chat:write',
44 'links:read',
45 'links:write',
46 'team:read',
47 ])
48
49 setup_dialog_config = {
50 'width': 600,
51 'height': 900,
52 }
53
54 def get_pipeline_views(self):
55 identity_pipeline_config = {
56 'oauth_scopes': self.identity_oauth_scopes,
57 'redirect_url': absolute_uri('/extensions/slack/setup/'),
58 }
59
60 identity_pipeline_view = NestedPipelineView(
61 bind_key='identity',
62 provider_key='slack',
63 pipeline_cls=IdentityProviderPipeline,
64 config=identity_pipeline_config,
65 )
66
67 return [identity_pipeline_view]
68
69 def get_team_info(self, access_token):
70 payload = {
71 'token': access_token,
72 }
73
74 session = http.build_session()
75 resp = session.get('https://slack.com/api/team.info', params=payload)
76 resp.raise_for_status()
77 resp = resp.json()
78
79 return resp['team']
80
81 def build_integration(self, state):
82 data = state['identity']['data']
83 assert data['ok']
84
85 scopes = sorted(self.identity_oauth_scopes)
86 team_data = self.get_team_info(data['access_token'])
87
88 return {
89 'name': data['team_name'],
90 'external_id': data['team_id'],
91 'metadata': {
92 'access_token': data['access_token'],
93 'scopes': scopes,
94 'icon': team_data['icon']['image_132'],
95 'domain_name': team_data['domain'] + '.slack.com',
96 },
97 'user_identity': {
98 'type': 'slack',
99 'external_id': data['installer_user_id'],
100 'scopes': [],
101 'data': {},
102 },
103 }
104
[end of src/sentry/integrations/slack/integration.py]
[start of src/sentry/integrations/slack/notify_action.py]
1 from __future__ import absolute_import
2
3 from django import forms
4 from django.utils.translation import ugettext_lazy as _
5
6 from sentry import http
7 from sentry.rules.actions.base import EventAction
8 from sentry.utils import metrics, json
9 from sentry.models import Integration
10
11 from .utils import build_attachment
12
13 MEMBER_PREFIX = '@'
14 CHANNEL_PREFIX = '#'
15 strip_channel_chars = ''.join([MEMBER_PREFIX, CHANNEL_PREFIX])
16
17
18 class SlackNotifyServiceForm(forms.Form):
19 workspace = forms.ChoiceField(choices=(), widget=forms.Select(
20 ))
21 channel = forms.CharField(widget=forms.TextInput())
22 channel_id = forms.HiddenInput()
23 tags = forms.CharField(required=False, widget=forms.TextInput())
24
25 def __init__(self, *args, **kwargs):
26 # NOTE: Workspace maps directly to the integration ID
27 workspace_list = [(i.id, i.name) for i in kwargs.pop('integrations')]
28 self.channel_transformer = kwargs.pop('channel_transformer')
29
30 super(SlackNotifyServiceForm, self).__init__(*args, **kwargs)
31
32 if workspace_list:
33 self.fields['workspace'].initial = workspace_list[0][0]
34
35 self.fields['workspace'].choices = workspace_list
36 self.fields['workspace'].widget.choices = self.fields['workspace'].choices
37
38 def clean(self):
39 cleaned_data = super(SlackNotifyServiceForm, self).clean()
40
41 workspace = cleaned_data.get('workspace')
42 channel = cleaned_data.get('channel', '').lstrip(strip_channel_chars)
43
44 channel_id = self.channel_transformer(workspace, channel)
45
46 if channel_id is None and workspace is not None:
47 params = {
48 'channel': channel,
49 'workspace': dict(self.fields['workspace'].choices).get(int(workspace)),
50 }
51
52 raise forms.ValidationError(
53 _('The slack resource "%(channel)s" does not exist or has not been granted access in the %(workspace)s Slack workspace.'),
54 code='invalid',
55 params=params,
56 )
57
58 channel_prefix, channel_id = channel_id
59 cleaned_data['channel'] = channel_prefix + channel
60 cleaned_data['channel_id'] = channel_id
61
62 return cleaned_data
63
64
65 class SlackNotifyServiceAction(EventAction):
66 form_cls = SlackNotifyServiceForm
67 label = u'Send a notification to the {workspace} Slack workspace to {channel} and include tags {tags}'
68
69 def __init__(self, *args, **kwargs):
70 super(SlackNotifyServiceAction, self).__init__(*args, **kwargs)
71 self.form_fields = {
72 'workspace': {
73 'type': 'choice',
74 'choices': [(i.id, i.name) for i in self.get_integrations()]
75 },
76 'channel': {
77 'type': 'string',
78 'placeholder': 'i.e #critical'
79 },
80 'tags': {
81 'type': 'string',
82 'placeholder': 'i.e environment,user,my_tag'
83 }
84 }
85
86 def is_enabled(self):
87 return self.get_integrations().exists()
88
89 def after(self, event, state):
90 if event.group.is_ignored():
91 return
92
93 integration_id = self.get_option('workspace')
94 channel = self.get_option('channel_id')
95 tags = set(self.get_tags_list())
96
97 try:
98 integration = Integration.objects.get(
99 provider='slack',
100 organizations=self.project.organization,
101 id=integration_id
102 )
103 except Integration.DoesNotExist:
104 # Integration removed, rule still active.
105 return
106
107 def send_notification(event, futures):
108 rules = [f.rule for f in futures]
109 attachment = build_attachment(event.group, event=event, tags=tags, rules=rules)
110
111 payload = {
112 'token': integration.metadata['access_token'],
113 'channel': channel,
114 'attachments': json.dumps([attachment]),
115 }
116
117 session = http.build_session()
118 resp = session.post('https://slack.com/api/chat.postMessage', data=payload)
119 resp.raise_for_status()
120 resp = resp.json()
121 if not resp.get('ok'):
122 self.logger.info('rule.fail.slack_post', extra={'error': resp.get('error')})
123
124 key = u'slack:{}:{}'.format(integration_id, channel)
125
126 metrics.incr('notifications.sent', instance='slack.notification')
127 yield self.future(send_notification, key=key)
128
129 def render_label(self):
130 try:
131 integration_name = Integration.objects.get(
132 provider='slack',
133 organizations=self.project.organization,
134 id=self.get_option('workspace')
135 ).name
136 except Integration.DoesNotExist:
137 integration_name = '[removed]'
138
139 tags = self.get_tags_list()
140
141 return self.label.format(
142 workspace=integration_name,
143 channel=self.get_option('channel'),
144 tags=u'[{}]'.format(', '.join(tags)),
145 )
146
147 def get_tags_list(self):
148 return [s.strip() for s in self.get_option('tags', '').split(',')]
149
150 def get_integrations(self):
151 return Integration.objects.filter(
152 provider='slack',
153 organizations=self.project.organization,
154 )
155
156 def get_form_instance(self):
157 return self.form_cls(
158 self.data,
159 integrations=self.get_integrations(),
160 channel_transformer=self.get_channel_id,
161 )
162
163 def get_channel_id(self, integration_id, name):
164 try:
165 integration = Integration.objects.get(
166 provider='slack',
167 organizations=self.project.organization,
168 id=integration_id,
169 )
170 except Integration.DoesNotExist:
171 return None
172
173 session = http.build_session()
174
175 token_payload = {
176 'token': integration.metadata['access_token'],
177 }
178
179 # Get slack app resource permissions
180 resp = session.get('https://slack.com/api/apps.permissions.info', params=token_payload)
181 resp = resp.json()
182 if not resp.get('ok'):
183 extra = {'error': resp.get('error')}
184 self.logger.info('rule.slack.permission_check_failed', extra=extra)
185 return None
186
187 channel_perms = resp['info']['channel']['resources']
188 dm_perms = resp['info']['im']['resources']
189
190 # Look for channel ID
191 channels_payload = dict(token_payload, **{
192 'exclude_archived': False,
193 'exclude_members': True,
194 })
195
196 resp = session.get('https://slack.com/api/channels.list', params=channels_payload)
197 resp = resp.json()
198 if not resp.get('ok'):
199 self.logger.info('rule.slack.channel_list_failed', extra={'error': resp.get('error')})
200 return None
201
202 channel_id = {c['name']: c['id'] for c in resp['channels']}.get(name)
203
204 if channel_id:
205 if channel_id in channel_perms['excluded_ids']:
206 return None
207
208 if not channel_perms['wildcard'] and channel_id not in channel_perms['ids']:
209 return None
210
211 return (CHANNEL_PREFIX, channel_id)
212
213 # Look for user ID
214 resp = session.get('https://slack.com/api/users.list', params=token_payload)
215 resp = resp.json()
216 if not resp.get('ok'):
217 self.logger.info('rule.slack.user_list_failed', extra={'error': resp.get('error')})
218 return None
219
220 member_id = {c['name']: c['id'] for c in resp['members']}.get(name)
221
222 if member_id and member_id in dm_perms['ids']:
223 return (MEMBER_PREFIX, member_id)
224
225 return None
226
[end of src/sentry/integrations/slack/notify_action.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/sentry/integrations/slack/integration.py b/src/sentry/integrations/slack/integration.py
--- a/src/sentry/integrations/slack/integration.py
+++ b/src/sentry/integrations/slack/integration.py
@@ -39,7 +39,8 @@
identity_oauth_scopes = frozenset([
'channels:read',
- 'users:read'
+ 'groups:read',
+ 'users:read',
'chat:write',
'links:read',
'links:write',
diff --git a/src/sentry/integrations/slack/notify_action.py b/src/sentry/integrations/slack/notify_action.py
--- a/src/sentry/integrations/slack/notify_action.py
+++ b/src/sentry/integrations/slack/notify_action.py
@@ -201,6 +201,17 @@
channel_id = {c['name']: c['id'] for c in resp['channels']}.get(name)
+ # Channel may be private, use the groups.list endpoint to find them
+ if not channel_id:
+ resp = session.get('https://slack.com/api/groups.list', params=channels_payload)
+ resp = resp.json()
+ if not resp.get('ok'):
+ self.logger.info('rule.slack.group_list_failed', extra={'error': resp.get('error')})
+ return None
+
+ channel_id = {c['name']: c['id'] for c in resp['groups']}.get(name)
+
+ # We should sufficiently have been able to find the channel by now
if channel_id:
if channel_id in channel_perms['excluded_ids']:
return None
| {"golden_diff": "diff --git a/src/sentry/integrations/slack/integration.py b/src/sentry/integrations/slack/integration.py\n--- a/src/sentry/integrations/slack/integration.py\n+++ b/src/sentry/integrations/slack/integration.py\n@@ -39,7 +39,8 @@\n \n identity_oauth_scopes = frozenset([\n 'channels:read',\n- 'users:read'\n+ 'groups:read',\n+ 'users:read',\n 'chat:write',\n 'links:read',\n 'links:write',\ndiff --git a/src/sentry/integrations/slack/notify_action.py b/src/sentry/integrations/slack/notify_action.py\n--- a/src/sentry/integrations/slack/notify_action.py\n+++ b/src/sentry/integrations/slack/notify_action.py\n@@ -201,6 +201,17 @@\n \n channel_id = {c['name']: c['id'] for c in resp['channels']}.get(name)\n \n+ # Channel may be private, use the groups.list endpoint to find them\n+ if not channel_id:\n+ resp = session.get('https://slack.com/api/groups.list', params=channels_payload)\n+ resp = resp.json()\n+ if not resp.get('ok'):\n+ self.logger.info('rule.slack.group_list_failed', extra={'error': resp.get('error')})\n+ return None\n+\n+ channel_id = {c['name']: c['id'] for c in resp['groups']}.get(name)\n+\n+ # We should sufficiently have been able to find the channel by now\n if channel_id:\n if channel_id in channel_perms['excluded_ids']:\n return None\n", "issue": "Slack Integration: \nHi, I'm having trouble setting up the new Slack integration to work with private channels.\r\n- With the legacy integration we had Sentry sending messages into private channels.\r\n- When authorizing the Slack app I selected \"Specific channels\" and entered the names of the private channels, as well as \"slackbot, which is private to you\"..\r\n- The authorization appeared to succeed. After authorizing I saw a message `Sentry APP [2:39 PM]\r\nwas added to this conversation by Luke Moore.` in those channels.\r\n- When editing the alert rule I've set the \"take these actions\" to send a notification to the private workspace but I see the error: 'The slack resource \"website-private\" does not exist or has not been granted access in the SideFX Slack workspace.' I've tried with and without a leading \"#\".\r\n\r\nAm I doing something wrong?\r\n\r\n\n", "before_files": [{"content": "from __future__ import absolute_import\n\nfrom sentry import http\nfrom sentry.integrations import Integration, IntegrationMetadata\nfrom sentry.utils.pipeline import NestedPipelineView\nfrom sentry.identity.pipeline import IdentityProviderPipeline\nfrom sentry.utils.http import absolute_uri\n\nDESCRIPTION = \"\"\"\nDefine a relationship between Sentry and your Slack workspace(s).\n\n * Unfurls Sentry URLs in slack, providing context and actionability on issues\n directly within your Slack workspace.\n * Resolve, ignore, and assign issues with minimal context switching.\n * Configure rule based Slack notifications to automatically be posted into the\n specified channel.\n\"\"\"\n\nalert_link = {\n 'text': 'Looking to send Sentry alerts to Slack? Add an **Alert Rule** for this project.',\n 'link': '/settings/{orgId}/{projectId}/alerts/rules/'\n}\n\nmetadata = IntegrationMetadata(\n description=DESCRIPTION.strip(),\n author='The Sentry Team',\n issue_url='https://github.com/getsentry/sentry/issues/new?title=Slack%20Integration:%20&labels=Component%3A%20Integrations',\n source_url='https://github.com/getsentry/sentry/tree/master/src/sentry/integrations/slack',\n aspects={\n 'alert_link': alert_link,\n }\n)\n\n\nclass SlackIntegration(Integration):\n key = 'slack'\n name = 'Slack'\n metadata = metadata\n\n identity_oauth_scopes = frozenset([\n 'channels:read',\n 'users:read'\n 'chat:write',\n 'links:read',\n 'links:write',\n 'team:read',\n ])\n\n setup_dialog_config = {\n 'width': 600,\n 'height': 900,\n }\n\n def get_pipeline_views(self):\n identity_pipeline_config = {\n 'oauth_scopes': self.identity_oauth_scopes,\n 'redirect_url': absolute_uri('/extensions/slack/setup/'),\n }\n\n identity_pipeline_view = NestedPipelineView(\n bind_key='identity',\n provider_key='slack',\n pipeline_cls=IdentityProviderPipeline,\n config=identity_pipeline_config,\n )\n\n return [identity_pipeline_view]\n\n def get_team_info(self, access_token):\n payload = {\n 'token': access_token,\n }\n\n session = http.build_session()\n resp = session.get('https://slack.com/api/team.info', params=payload)\n resp.raise_for_status()\n resp = resp.json()\n\n return resp['team']\n\n def build_integration(self, state):\n data = state['identity']['data']\n assert data['ok']\n\n scopes = sorted(self.identity_oauth_scopes)\n team_data = self.get_team_info(data['access_token'])\n\n return {\n 'name': data['team_name'],\n 'external_id': data['team_id'],\n 'metadata': {\n 'access_token': data['access_token'],\n 'scopes': scopes,\n 'icon': team_data['icon']['image_132'],\n 'domain_name': team_data['domain'] + '.slack.com',\n },\n 'user_identity': {\n 'type': 'slack',\n 'external_id': data['installer_user_id'],\n 'scopes': [],\n 'data': {},\n },\n }\n", "path": "src/sentry/integrations/slack/integration.py"}, {"content": "from __future__ import absolute_import\n\nfrom django import forms\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom sentry import http\nfrom sentry.rules.actions.base import EventAction\nfrom sentry.utils import metrics, json\nfrom sentry.models import Integration\n\nfrom .utils import build_attachment\n\nMEMBER_PREFIX = '@'\nCHANNEL_PREFIX = '#'\nstrip_channel_chars = ''.join([MEMBER_PREFIX, CHANNEL_PREFIX])\n\n\nclass SlackNotifyServiceForm(forms.Form):\n workspace = forms.ChoiceField(choices=(), widget=forms.Select(\n ))\n channel = forms.CharField(widget=forms.TextInput())\n channel_id = forms.HiddenInput()\n tags = forms.CharField(required=False, widget=forms.TextInput())\n\n def __init__(self, *args, **kwargs):\n # NOTE: Workspace maps directly to the integration ID\n workspace_list = [(i.id, i.name) for i in kwargs.pop('integrations')]\n self.channel_transformer = kwargs.pop('channel_transformer')\n\n super(SlackNotifyServiceForm, self).__init__(*args, **kwargs)\n\n if workspace_list:\n self.fields['workspace'].initial = workspace_list[0][0]\n\n self.fields['workspace'].choices = workspace_list\n self.fields['workspace'].widget.choices = self.fields['workspace'].choices\n\n def clean(self):\n cleaned_data = super(SlackNotifyServiceForm, self).clean()\n\n workspace = cleaned_data.get('workspace')\n channel = cleaned_data.get('channel', '').lstrip(strip_channel_chars)\n\n channel_id = self.channel_transformer(workspace, channel)\n\n if channel_id is None and workspace is not None:\n params = {\n 'channel': channel,\n 'workspace': dict(self.fields['workspace'].choices).get(int(workspace)),\n }\n\n raise forms.ValidationError(\n _('The slack resource \"%(channel)s\" does not exist or has not been granted access in the %(workspace)s Slack workspace.'),\n code='invalid',\n params=params,\n )\n\n channel_prefix, channel_id = channel_id\n cleaned_data['channel'] = channel_prefix + channel\n cleaned_data['channel_id'] = channel_id\n\n return cleaned_data\n\n\nclass SlackNotifyServiceAction(EventAction):\n form_cls = SlackNotifyServiceForm\n label = u'Send a notification to the {workspace} Slack workspace to {channel} and include tags {tags}'\n\n def __init__(self, *args, **kwargs):\n super(SlackNotifyServiceAction, self).__init__(*args, **kwargs)\n self.form_fields = {\n 'workspace': {\n 'type': 'choice',\n 'choices': [(i.id, i.name) for i in self.get_integrations()]\n },\n 'channel': {\n 'type': 'string',\n 'placeholder': 'i.e #critical'\n },\n 'tags': {\n 'type': 'string',\n 'placeholder': 'i.e environment,user,my_tag'\n }\n }\n\n def is_enabled(self):\n return self.get_integrations().exists()\n\n def after(self, event, state):\n if event.group.is_ignored():\n return\n\n integration_id = self.get_option('workspace')\n channel = self.get_option('channel_id')\n tags = set(self.get_tags_list())\n\n try:\n integration = Integration.objects.get(\n provider='slack',\n organizations=self.project.organization,\n id=integration_id\n )\n except Integration.DoesNotExist:\n # Integration removed, rule still active.\n return\n\n def send_notification(event, futures):\n rules = [f.rule for f in futures]\n attachment = build_attachment(event.group, event=event, tags=tags, rules=rules)\n\n payload = {\n 'token': integration.metadata['access_token'],\n 'channel': channel,\n 'attachments': json.dumps([attachment]),\n }\n\n session = http.build_session()\n resp = session.post('https://slack.com/api/chat.postMessage', data=payload)\n resp.raise_for_status()\n resp = resp.json()\n if not resp.get('ok'):\n self.logger.info('rule.fail.slack_post', extra={'error': resp.get('error')})\n\n key = u'slack:{}:{}'.format(integration_id, channel)\n\n metrics.incr('notifications.sent', instance='slack.notification')\n yield self.future(send_notification, key=key)\n\n def render_label(self):\n try:\n integration_name = Integration.objects.get(\n provider='slack',\n organizations=self.project.organization,\n id=self.get_option('workspace')\n ).name\n except Integration.DoesNotExist:\n integration_name = '[removed]'\n\n tags = self.get_tags_list()\n\n return self.label.format(\n workspace=integration_name,\n channel=self.get_option('channel'),\n tags=u'[{}]'.format(', '.join(tags)),\n )\n\n def get_tags_list(self):\n return [s.strip() for s in self.get_option('tags', '').split(',')]\n\n def get_integrations(self):\n return Integration.objects.filter(\n provider='slack',\n organizations=self.project.organization,\n )\n\n def get_form_instance(self):\n return self.form_cls(\n self.data,\n integrations=self.get_integrations(),\n channel_transformer=self.get_channel_id,\n )\n\n def get_channel_id(self, integration_id, name):\n try:\n integration = Integration.objects.get(\n provider='slack',\n organizations=self.project.organization,\n id=integration_id,\n )\n except Integration.DoesNotExist:\n return None\n\n session = http.build_session()\n\n token_payload = {\n 'token': integration.metadata['access_token'],\n }\n\n # Get slack app resource permissions\n resp = session.get('https://slack.com/api/apps.permissions.info', params=token_payload)\n resp = resp.json()\n if not resp.get('ok'):\n extra = {'error': resp.get('error')}\n self.logger.info('rule.slack.permission_check_failed', extra=extra)\n return None\n\n channel_perms = resp['info']['channel']['resources']\n dm_perms = resp['info']['im']['resources']\n\n # Look for channel ID\n channels_payload = dict(token_payload, **{\n 'exclude_archived': False,\n 'exclude_members': True,\n })\n\n resp = session.get('https://slack.com/api/channels.list', params=channels_payload)\n resp = resp.json()\n if not resp.get('ok'):\n self.logger.info('rule.slack.channel_list_failed', extra={'error': resp.get('error')})\n return None\n\n channel_id = {c['name']: c['id'] for c in resp['channels']}.get(name)\n\n if channel_id:\n if channel_id in channel_perms['excluded_ids']:\n return None\n\n if not channel_perms['wildcard'] and channel_id not in channel_perms['ids']:\n return None\n\n return (CHANNEL_PREFIX, channel_id)\n\n # Look for user ID\n resp = session.get('https://slack.com/api/users.list', params=token_payload)\n resp = resp.json()\n if not resp.get('ok'):\n self.logger.info('rule.slack.user_list_failed', extra={'error': resp.get('error')})\n return None\n\n member_id = {c['name']: c['id'] for c in resp['members']}.get(name)\n\n if member_id and member_id in dm_perms['ids']:\n return (MEMBER_PREFIX, member_id)\n\n return None\n", "path": "src/sentry/integrations/slack/notify_action.py"}]} | 3,939 | 377 |
gh_patches_debug_17916 | rasdani/github-patches | git_diff | pex-tool__pex-556 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Release 1.4.7
docket of user-facing issues fixed:
+ #550: Pex 1.4.6 builds a failing pex
</issue>
<code>
[start of pex/version.py]
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = '1.4.6'
5
6 # Versions 34.0.0 through 35.0.2 (last pre-36.0.0) de-vendored dependencies which causes problems
7 # for pex code so we exclude that range.
8 SETUPTOOLS_REQUIREMENT = 'setuptools>=20.3,<41,!=34.*,!=35.*'
9
10 WHEEL_REQUIREMENT = 'wheel>=0.26.0,<0.32'
11
[end of pex/version.py]
[start of setup.py]
1 # Copyright 2014 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 import os
5
6 from setuptools import setup
7
8 with open(os.path.join(os.path.dirname(__file__), 'README.rst')) as fp:
9 LONG_DESCRIPTION = fp.read() + '\n'
10
11 with open(os.path.join(os.path.dirname(__file__), 'CHANGES.rst')) as fp:
12 LONG_DESCRIPTION += fp.read()
13
14
15 # This seems to be a fairly standard version file pattern.
16 #
17 # Populates the following variables:
18 # __version__
19 # __setuptools_requirement
20 # __wheel_requirement
21 __version__ = ''
22 version_py_file = os.path.join(os.path.dirname(__file__), 'pex', 'version.py')
23 with open(version_py_file) as version_py:
24 exec(compile(version_py.read(), version_py_file, 'exec'))
25
26
27 setup(
28 name = 'pex',
29 version = __version__,
30 description = "The PEX packaging toolchain.",
31 long_description = LONG_DESCRIPTION,
32 url = 'https://github.com/pantsbuild/pex',
33 license = 'Apache License, Version 2.0',
34 zip_safe = True,
35 classifiers = [
36 'Intended Audience :: Developers',
37 'License :: OSI Approved :: Apache Software License',
38 'Operating System :: Unix',
39 'Operating System :: POSIX :: Linux',
40 'Operating System :: MacOS :: MacOS X',
41 'Programming Language :: Python',
42 'Programming Language :: Python :: 2',
43 'Programming Language :: Python :: 2.7',
44 'Programming Language :: Python :: 3',
45 'Programming Language :: Python :: 3.3',
46 'Programming Language :: Python :: 3.4',
47 'Programming Language :: Python :: 3.5',
48 'Programming Language :: Python :: 3.6',
49 ],
50 packages = [
51 'pex',
52 'pex.bin',
53 'pex.commands',
54 ],
55 install_requires = [
56 SETUPTOOLS_REQUIREMENT,
57 WHEEL_REQUIREMENT,
58 ],
59 extras_require={
60 # For improved subprocess robustness under python2.7.
61 'subprocess': ['subprocess32>=3.2.7'],
62 # For improved requirement resolution and fetching robustness.
63 'requests': ['requests>=2.8.14'],
64 # For improved requirement resolution and fetching performance.
65 'cachecontrol': ['CacheControl>=0.12.3'],
66 },
67 tests_require = [
68 'mock',
69 'twitter.common.contextutil>=0.3.1,<0.4.0',
70 'twitter.common.lang>=0.3.1,<0.4.0',
71 'twitter.common.testing>=0.3.1,<0.4.0',
72 'twitter.common.dirutil>=0.3.1,<0.4.0',
73 'pytest',
74 ],
75 entry_points = {
76 'distutils.commands': [
77 'bdist_pex = pex.commands.bdist_pex:bdist_pex',
78 ],
79 'console_scripts': [
80 'pex = pex.bin.pex:main',
81 ],
82 },
83 )
84
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,7 +1,7 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = '1.4.6'
+__version__ = '1.4.7'
# Versions 34.0.0 through 35.0.2 (last pre-36.0.0) de-vendored dependencies which causes problems
# for pex code so we exclude that range.
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -29,6 +29,7 @@
version = __version__,
description = "The PEX packaging toolchain.",
long_description = LONG_DESCRIPTION,
+ long_description_content_type="text/x-rst",
url = 'https://github.com/pantsbuild/pex',
license = 'Apache License, Version 2.0',
zip_safe = True,
| {"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,7 +1,7 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = '1.4.6'\n+__version__ = '1.4.7'\n \n # Versions 34.0.0 through 35.0.2 (last pre-36.0.0) de-vendored dependencies which causes problems\n # for pex code so we exclude that range.\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -29,6 +29,7 @@\n version = __version__,\n description = \"The PEX packaging toolchain.\",\n long_description = LONG_DESCRIPTION,\n+ long_description_content_type=\"text/x-rst\",\n url = 'https://github.com/pantsbuild/pex',\n license = 'Apache License, Version 2.0',\n zip_safe = True,\n", "issue": "Release 1.4.7\ndocket of user-facing issues fixed:\r\n+ #550: Pex 1.4.6 builds a failing pex\n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = '1.4.6'\n\n# Versions 34.0.0 through 35.0.2 (last pre-36.0.0) de-vendored dependencies which causes problems\n# for pex code so we exclude that range.\nSETUPTOOLS_REQUIREMENT = 'setuptools>=20.3,<41,!=34.*,!=35.*'\n\nWHEEL_REQUIREMENT = 'wheel>=0.26.0,<0.32'\n", "path": "pex/version.py"}, {"content": "# Copyright 2014 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nimport os\n\nfrom setuptools import setup\n\nwith open(os.path.join(os.path.dirname(__file__), 'README.rst')) as fp:\n LONG_DESCRIPTION = fp.read() + '\\n'\n\nwith open(os.path.join(os.path.dirname(__file__), 'CHANGES.rst')) as fp:\n LONG_DESCRIPTION += fp.read()\n\n\n# This seems to be a fairly standard version file pattern.\n#\n# Populates the following variables:\n# __version__\n# __setuptools_requirement\n# __wheel_requirement\n__version__ = ''\nversion_py_file = os.path.join(os.path.dirname(__file__), 'pex', 'version.py')\nwith open(version_py_file) as version_py:\n exec(compile(version_py.read(), version_py_file, 'exec'))\n\n\nsetup(\n name = 'pex',\n version = __version__,\n description = \"The PEX packaging toolchain.\",\n long_description = LONG_DESCRIPTION,\n url = 'https://github.com/pantsbuild/pex',\n license = 'Apache License, Version 2.0',\n zip_safe = True,\n classifiers = [\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: Apache Software License',\n 'Operating System :: Unix',\n 'Operating System :: POSIX :: Linux',\n 'Operating System :: MacOS :: MacOS X',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n ],\n packages = [\n 'pex',\n 'pex.bin',\n 'pex.commands',\n ],\n install_requires = [\n SETUPTOOLS_REQUIREMENT,\n WHEEL_REQUIREMENT,\n ],\n extras_require={\n # For improved subprocess robustness under python2.7.\n 'subprocess': ['subprocess32>=3.2.7'],\n # For improved requirement resolution and fetching robustness.\n 'requests': ['requests>=2.8.14'],\n # For improved requirement resolution and fetching performance.\n 'cachecontrol': ['CacheControl>=0.12.3'],\n },\n tests_require = [\n 'mock',\n 'twitter.common.contextutil>=0.3.1,<0.4.0',\n 'twitter.common.lang>=0.3.1,<0.4.0',\n 'twitter.common.testing>=0.3.1,<0.4.0',\n 'twitter.common.dirutil>=0.3.1,<0.4.0',\n 'pytest',\n ],\n entry_points = {\n 'distutils.commands': [\n 'bdist_pex = pex.commands.bdist_pex:bdist_pex',\n ],\n 'console_scripts': [\n 'pex = pex.bin.pex:main',\n ],\n },\n)\n", "path": "setup.py"}]} | 1,572 | 244 |
gh_patches_debug_2 | rasdani/github-patches | git_diff | CTFd__CTFd-598 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Docker startup getting stuck on mysqladmin ping
**Environment**:
- CTFd Version/Commit: ctfd/ctfd:latest from Docker hub (17 days old)
- Operating System: Amazon Linux AMI 2017.09.j x86_64 ECS HVM GP2
- Web Browser and Version: N/A
**What happened?**
Trying to setup CTFd with AWS ECS and RDS Aurora.
If I don't set the DATABASE_URL env variable, it works fine and starts.
If I do set the DATABASE_URL to mysql+pymysql://ctfd:<MYPASSWORD>@ctfd.<resource-id>i.eu-west-1.rds.amazonaws.com/ctfd I get stuck on docker-entrypoint.sh:7 `while ! mysqladmin ping -h db --silent; do`
**What did you expect to happen?**
That the ping should succeed and startup continue
**How to reproduce your issue**
Create an ECS task with ctfd/ctfd as image source, set env variable SECRET_KEY and DATABASE_URL. Start container.
I have made sure the container can access the database by running `docker exec container-id mysql -h ctfd.<resource-id>.eu-west-1.rds.amazonaws.com -p<SECRET PASSWORD>` which works.
**Any associated stack traces or error logs**
Just stuck on "Waiting on MySQL"
My question is basically: am I doing something wrong and should somehow make that "db" resolve to the database or is the script incorrect and should take the value of DATABASE_URL into account?
</issue>
<code>
[start of wsgi.py]
1 from CTFd import create_app
2
3 app = create_app()
4
[end of wsgi.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/wsgi.py b/wsgi.py
deleted file mode 100644
--- a/wsgi.py
+++ /dev/null
@@ -1,3 +0,0 @@
-from CTFd import create_app
-
-app = create_app()
| {"golden_diff": "diff --git a/wsgi.py b/wsgi.py\ndeleted file mode 100644\n--- a/wsgi.py\n+++ /dev/null\n@@ -1,3 +0,0 @@\n-from CTFd import create_app\n-\n-app = create_app()\n", "issue": "Docker startup getting stuck on mysqladmin ping\n**Environment**:\r\n\r\n - CTFd Version/Commit: ctfd/ctfd:latest from Docker hub (17 days old)\r\n - Operating System: Amazon Linux AMI 2017.09.j x86_64 ECS HVM GP2\r\n - Web Browser and Version: N/A\r\n\r\n**What happened?**\r\n\r\nTrying to setup CTFd with AWS ECS and RDS Aurora.\r\nIf I don't set the DATABASE_URL env variable, it works fine and starts.\r\nIf I do set the DATABASE_URL to mysql+pymysql://ctfd:<MYPASSWORD>@ctfd.<resource-id>i.eu-west-1.rds.amazonaws.com/ctfd I get stuck on docker-entrypoint.sh:7 `while ! mysqladmin ping -h db --silent; do`\r\n\r\n**What did you expect to happen?**\r\n\r\nThat the ping should succeed and startup continue\r\n\r\n**How to reproduce your issue**\r\n\r\nCreate an ECS task with ctfd/ctfd as image source, set env variable SECRET_KEY and DATABASE_URL. Start container.\r\n\r\nI have made sure the container can access the database by running `docker exec container-id mysql -h ctfd.<resource-id>.eu-west-1.rds.amazonaws.com -p<SECRET PASSWORD>` which works.\r\n\r\n**Any associated stack traces or error logs**\r\n\r\nJust stuck on \"Waiting on MySQL\"\r\n\r\n\r\nMy question is basically: am I doing something wrong and should somehow make that \"db\" resolve to the database or is the script incorrect and should take the value of DATABASE_URL into account?\n", "before_files": [{"content": "from CTFd import create_app\n\napp = create_app()\n", "path": "wsgi.py"}]} | 879 | 58 |
gh_patches_debug_48613 | rasdani/github-patches | git_diff | OpenEnergyPlatform__oeplatform-1475 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Scenario bundles: Output datasets render weirdly
## Description of the issue
I added an output dataset for the WAM scenario for this factsheet: https://openenergy-platform.org/scenario-bundles/id/95a65aca-6915-b64a-cac7-3831c12885b4

It reads wrongly and shows more than only the title of the dataset, i.e. it should only be rendered as: Rahmendaten für den Projektionsbericht 2023 (Datentabelle) - as it does for the WEM scenario (this was already existing before the new release).
## Steps to Reproduce
1. Add a dataset to a scenario
2.
3.
## Ideas of solution
Describe possible ideas for solution and evaluate advantages and disadvantages.
## Context and Environment
* Version used:
* Operating system:
* Environment setup and (python) version:
## Workflow checklist
- [ ] I am aware of the workflow in [CONTRIBUTING.md](https://github.com/OpenEnergyPlatform/oeplatform/blob/develop/CONTRIBUTING.md)
</issue>
<code>
[start of oeplatform/__init__.py]
1 __version__ = "0.16.1"
2
[end of oeplatform/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/oeplatform/__init__.py b/oeplatform/__init__.py
--- a/oeplatform/__init__.py
+++ b/oeplatform/__init__.py
@@ -1 +1 @@
-__version__ = "0.16.1"
+__version__ = "0.16.2"
| {"golden_diff": "diff --git a/oeplatform/__init__.py b/oeplatform/__init__.py\n--- a/oeplatform/__init__.py\n+++ b/oeplatform/__init__.py\n@@ -1 +1 @@\n-__version__ = \"0.16.1\"\n+__version__ = \"0.16.2\"\n", "issue": "Scenario bundles: Output datasets render weirdly\n## Description of the issue\r\n\r\nI added an output dataset for the WAM scenario for this factsheet: https://openenergy-platform.org/scenario-bundles/id/95a65aca-6915-b64a-cac7-3831c12885b4\r\n\r\n\r\n\r\nIt reads wrongly and shows more than only the title of the dataset, i.e. it should only be rendered as: Rahmendaten f\u00fcr den Projektionsbericht 2023 (Datentabelle) - as it does for the WEM scenario (this was already existing before the new release). \r\n\r\n\r\n## Steps to Reproduce\r\n1. Add a dataset to a scenario\r\n2.\r\n3.\r\n\r\n## Ideas of solution\r\n\r\nDescribe possible ideas for solution and evaluate advantages and disadvantages.\r\n\r\n## Context and Environment\r\n* Version used: \r\n* Operating system: \r\n* Environment setup and (python) version: \r\n\r\n## Workflow checklist\r\n- [ ] I am aware of the workflow in [CONTRIBUTING.md](https://github.com/OpenEnergyPlatform/oeplatform/blob/develop/CONTRIBUTING.md)\r\n\n", "before_files": [{"content": "__version__ = \"0.16.1\"\n", "path": "oeplatform/__init__.py"}]} | 851 | 72 |
gh_patches_debug_15419 | rasdani/github-patches | git_diff | pyodide__pyodide-337 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
buildpkg doesn't clean up after failed or interrupted downloads

when I run `make` command in docker environment, it shows this bug. I think it's the network that cause this error.
We can use `rm -rf /src/packages/numpy/build` to solve this problem
</issue>
<code>
[start of pyodide_build/buildpkg.py]
1 #!/usr/bin/env python3
2
3 """
4 Builds a Pyodide package.
5 """
6
7 import argparse
8 import hashlib
9 import os
10 from pathlib import Path
11 import shutil
12 import subprocess
13
14
15 from . import common
16
17
18 def check_checksum(path, pkg):
19 """
20 Checks that a tarball matches the checksum in the package metadata.
21 """
22 checksum_keys = {'md5', 'sha256'}.intersection(pkg['source'])
23 if not checksum_keys:
24 return
25 elif len(checksum_keys) != 1:
26 raise ValueError('Only one checksum should be included in a package '
27 'setup; found {}.'.format(checksum_keys))
28 checksum_algorithm = checksum_keys.pop()
29 checksum = pkg['source'][checksum_algorithm]
30 CHUNK_SIZE = 1 << 16
31 h = getattr(hashlib, checksum_algorithm)()
32 with open(path, 'rb') as fd:
33 while True:
34 chunk = fd.read(CHUNK_SIZE)
35 h.update(chunk)
36 if len(chunk) < CHUNK_SIZE:
37 break
38 if h.hexdigest() != checksum:
39 raise ValueError("Invalid {} checksum".format(checksum_algorithm))
40
41
42 def download_and_extract(buildpath, packagedir, pkg, args):
43 tarballpath = buildpath / Path(pkg['source']['url']).name
44 if not tarballpath.is_file():
45 subprocess.run([
46 'wget', '-q', '-O', str(tarballpath), pkg['source']['url']
47 ], check=True)
48 check_checksum(tarballpath, pkg)
49 srcpath = buildpath / packagedir
50 if not srcpath.is_dir():
51 shutil.unpack_archive(str(tarballpath), str(buildpath))
52 return srcpath
53
54
55 def patch(path, srcpath, pkg, args):
56 if (srcpath / '.patched').is_file():
57 return
58
59 # Apply all of the patches
60 orig_dir = Path.cwd()
61 pkgdir = path.parent.resolve()
62 os.chdir(srcpath)
63 try:
64 for patch in pkg['source'].get('patches', []):
65 subprocess.run([
66 'patch', '-p1', '--binary', '-i', pkgdir / patch
67 ], check=True)
68 finally:
69 os.chdir(orig_dir)
70
71 # Add any extra files
72 for src, dst in pkg['source'].get('extras', []):
73 shutil.copyfile(pkgdir / src, srcpath / dst)
74
75 with open(srcpath / '.patched', 'wb') as fd:
76 fd.write(b'\n')
77
78
79 def compile(path, srcpath, pkg, args):
80 if (srcpath / '.built').is_file():
81 return
82
83 orig_dir = Path.cwd()
84 os.chdir(srcpath)
85 env = dict(os.environ)
86 if pkg.get('build', {}).get('skip_host', True):
87 env['SKIP_HOST'] = ''
88
89 try:
90 subprocess.run([
91 str(Path(args.host) / 'bin' / 'python3'),
92 '-m', 'pyodide_build', 'pywasmcross',
93 '--cflags',
94 args.cflags + ' ' +
95 pkg.get('build', {}).get('cflags', ''),
96 '--ldflags',
97 args.ldflags + ' ' +
98 pkg.get('build', {}).get('ldflags', ''),
99 '--host', args.host,
100 '--target', args.target], env=env, check=True)
101 finally:
102 os.chdir(orig_dir)
103
104 post = pkg.get('build', {}).get('post')
105 if post is not None:
106 site_packages_dir = (
107 srcpath / 'install' / 'lib' / 'python3.7' / 'site-packages')
108 pkgdir = path.parent.resolve()
109 env = {
110 'SITEPACKAGES': site_packages_dir,
111 'PKGDIR': pkgdir
112 }
113 subprocess.run([
114 'bash', '-c', post], env=env, check=True)
115
116 with open(srcpath / '.built', 'wb') as fd:
117 fd.write(b'\n')
118
119
120 def package_files(buildpath, srcpath, pkg, args):
121 if (buildpath / '.packaged').is_file():
122 return
123
124 name = pkg['package']['name']
125 install_prefix = (srcpath / 'install').resolve()
126 subprocess.run([
127 'python',
128 common.ROOTDIR / 'file_packager.py',
129 name + '.data',
130 '--abi={0}'.format(args.package_abi),
131 '--lz4',
132 '--preload',
133 '{}@/'.format(install_prefix),
134 '--js-output={}'.format(name + '.js'),
135 '--export-name=pyodide._module',
136 '--exclude', '*.wasm.pre',
137 '--exclude', '*__pycache__*',
138 '--use-preload-plugins'],
139 cwd=buildpath, check=True)
140 subprocess.run([
141 'uglifyjs',
142 buildpath / (name + '.js'),
143 '-o',
144 buildpath / (name + '.js')], check=True)
145
146 with open(buildpath / '.packaged', 'wb') as fd:
147 fd.write(b'\n')
148
149
150 def build_package(path, args):
151 pkg = common.parse_package(path)
152 packagedir = pkg['package']['name'] + '-' + pkg['package']['version']
153 dirpath = path.parent
154 orig_path = Path.cwd()
155 os.chdir(dirpath)
156 try:
157 buildpath = dirpath / 'build'
158 if not buildpath.resolve().is_dir():
159 os.makedirs(buildpath)
160 srcpath = download_and_extract(buildpath, packagedir, pkg, args)
161 patch(path, srcpath, pkg, args)
162 compile(path, srcpath, pkg, args)
163 package_files(buildpath, srcpath, pkg, args)
164 finally:
165 os.chdir(orig_path)
166
167
168 def make_parser(parser):
169 parser.description = 'Build a pyodide package.'
170 parser.add_argument(
171 'package', type=str, nargs=1,
172 help="Path to meta.yaml package description")
173 parser.add_argument(
174 '--package_abi', type=int, required=True,
175 help='The ABI number for the package to be built')
176 parser.add_argument(
177 '--cflags', type=str, nargs='?', default=common.DEFAULTCFLAGS,
178 help='Extra compiling flags')
179 parser.add_argument(
180 '--ldflags', type=str, nargs='?', default=common.DEFAULTLDFLAGS,
181 help='Extra linking flags')
182 parser.add_argument(
183 '--host', type=str, nargs='?', default=common.HOSTPYTHON,
184 help='The path to the host Python installation')
185 parser.add_argument(
186 '--target', type=str, nargs='?', default=common.TARGETPYTHON,
187 help='The path to the target Python installation')
188 return parser
189
190
191 def main(args):
192 path = Path(args.package[0]).resolve()
193 build_package(path, args)
194
195
196 if __name__ == '__main__':
197 parser = make_parser(argparse.ArgumentParser())
198 args = parser.parse_args()
199 main(args)
200
[end of pyodide_build/buildpkg.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/pyodide_build/buildpkg.py b/pyodide_build/buildpkg.py
--- a/pyodide_build/buildpkg.py
+++ b/pyodide_build/buildpkg.py
@@ -42,10 +42,14 @@
def download_and_extract(buildpath, packagedir, pkg, args):
tarballpath = buildpath / Path(pkg['source']['url']).name
if not tarballpath.is_file():
- subprocess.run([
- 'wget', '-q', '-O', str(tarballpath), pkg['source']['url']
- ], check=True)
- check_checksum(tarballpath, pkg)
+ try:
+ subprocess.run([
+ 'wget', '-q', '-O', str(tarballpath), pkg['source']['url']
+ ], check=True)
+ check_checksum(tarballpath, pkg)
+ except Exception:
+ tarballpath.unlink()
+ raise
srcpath = buildpath / packagedir
if not srcpath.is_dir():
shutil.unpack_archive(str(tarballpath), str(buildpath))
| {"golden_diff": "diff --git a/pyodide_build/buildpkg.py b/pyodide_build/buildpkg.py\n--- a/pyodide_build/buildpkg.py\n+++ b/pyodide_build/buildpkg.py\n@@ -42,10 +42,14 @@\n def download_and_extract(buildpath, packagedir, pkg, args):\n tarballpath = buildpath / Path(pkg['source']['url']).name\n if not tarballpath.is_file():\n- subprocess.run([\n- 'wget', '-q', '-O', str(tarballpath), pkg['source']['url']\n- ], check=True)\n- check_checksum(tarballpath, pkg)\n+ try:\n+ subprocess.run([\n+ 'wget', '-q', '-O', str(tarballpath), pkg['source']['url']\n+ ], check=True)\n+ check_checksum(tarballpath, pkg)\n+ except Exception:\n+ tarballpath.unlink()\n+ raise\n srcpath = buildpath / packagedir\n if not srcpath.is_dir():\n shutil.unpack_archive(str(tarballpath), str(buildpath))\n", "issue": "buildpkg doesn't clean up after failed or interrupted downloads\n\r\n\r\nwhen I run `make` command in docker environment, it shows this bug. I think it's the network that cause this error. \r\n\r\nWe can use `rm -rf /src/packages/numpy/build` to solve this problem \n", "before_files": [{"content": "#!/usr/bin/env python3\n\n\"\"\"\nBuilds a Pyodide package.\n\"\"\"\n\nimport argparse\nimport hashlib\nimport os\nfrom pathlib import Path\nimport shutil\nimport subprocess\n\n\nfrom . import common\n\n\ndef check_checksum(path, pkg):\n \"\"\"\n Checks that a tarball matches the checksum in the package metadata.\n \"\"\"\n checksum_keys = {'md5', 'sha256'}.intersection(pkg['source'])\n if not checksum_keys:\n return\n elif len(checksum_keys) != 1:\n raise ValueError('Only one checksum should be included in a package '\n 'setup; found {}.'.format(checksum_keys))\n checksum_algorithm = checksum_keys.pop()\n checksum = pkg['source'][checksum_algorithm]\n CHUNK_SIZE = 1 << 16\n h = getattr(hashlib, checksum_algorithm)()\n with open(path, 'rb') as fd:\n while True:\n chunk = fd.read(CHUNK_SIZE)\n h.update(chunk)\n if len(chunk) < CHUNK_SIZE:\n break\n if h.hexdigest() != checksum:\n raise ValueError(\"Invalid {} checksum\".format(checksum_algorithm))\n\n\ndef download_and_extract(buildpath, packagedir, pkg, args):\n tarballpath = buildpath / Path(pkg['source']['url']).name\n if not tarballpath.is_file():\n subprocess.run([\n 'wget', '-q', '-O', str(tarballpath), pkg['source']['url']\n ], check=True)\n check_checksum(tarballpath, pkg)\n srcpath = buildpath / packagedir\n if not srcpath.is_dir():\n shutil.unpack_archive(str(tarballpath), str(buildpath))\n return srcpath\n\n\ndef patch(path, srcpath, pkg, args):\n if (srcpath / '.patched').is_file():\n return\n\n # Apply all of the patches\n orig_dir = Path.cwd()\n pkgdir = path.parent.resolve()\n os.chdir(srcpath)\n try:\n for patch in pkg['source'].get('patches', []):\n subprocess.run([\n 'patch', '-p1', '--binary', '-i', pkgdir / patch\n ], check=True)\n finally:\n os.chdir(orig_dir)\n\n # Add any extra files\n for src, dst in pkg['source'].get('extras', []):\n shutil.copyfile(pkgdir / src, srcpath / dst)\n\n with open(srcpath / '.patched', 'wb') as fd:\n fd.write(b'\\n')\n\n\ndef compile(path, srcpath, pkg, args):\n if (srcpath / '.built').is_file():\n return\n\n orig_dir = Path.cwd()\n os.chdir(srcpath)\n env = dict(os.environ)\n if pkg.get('build', {}).get('skip_host', True):\n env['SKIP_HOST'] = ''\n\n try:\n subprocess.run([\n str(Path(args.host) / 'bin' / 'python3'),\n '-m', 'pyodide_build', 'pywasmcross',\n '--cflags',\n args.cflags + ' ' +\n pkg.get('build', {}).get('cflags', ''),\n '--ldflags',\n args.ldflags + ' ' +\n pkg.get('build', {}).get('ldflags', ''),\n '--host', args.host,\n '--target', args.target], env=env, check=True)\n finally:\n os.chdir(orig_dir)\n\n post = pkg.get('build', {}).get('post')\n if post is not None:\n site_packages_dir = (\n srcpath / 'install' / 'lib' / 'python3.7' / 'site-packages')\n pkgdir = path.parent.resolve()\n env = {\n 'SITEPACKAGES': site_packages_dir,\n 'PKGDIR': pkgdir\n }\n subprocess.run([\n 'bash', '-c', post], env=env, check=True)\n\n with open(srcpath / '.built', 'wb') as fd:\n fd.write(b'\\n')\n\n\ndef package_files(buildpath, srcpath, pkg, args):\n if (buildpath / '.packaged').is_file():\n return\n\n name = pkg['package']['name']\n install_prefix = (srcpath / 'install').resolve()\n subprocess.run([\n 'python',\n common.ROOTDIR / 'file_packager.py',\n name + '.data',\n '--abi={0}'.format(args.package_abi),\n '--lz4',\n '--preload',\n '{}@/'.format(install_prefix),\n '--js-output={}'.format(name + '.js'),\n '--export-name=pyodide._module',\n '--exclude', '*.wasm.pre',\n '--exclude', '*__pycache__*',\n '--use-preload-plugins'],\n cwd=buildpath, check=True)\n subprocess.run([\n 'uglifyjs',\n buildpath / (name + '.js'),\n '-o',\n buildpath / (name + '.js')], check=True)\n\n with open(buildpath / '.packaged', 'wb') as fd:\n fd.write(b'\\n')\n\n\ndef build_package(path, args):\n pkg = common.parse_package(path)\n packagedir = pkg['package']['name'] + '-' + pkg['package']['version']\n dirpath = path.parent\n orig_path = Path.cwd()\n os.chdir(dirpath)\n try:\n buildpath = dirpath / 'build'\n if not buildpath.resolve().is_dir():\n os.makedirs(buildpath)\n srcpath = download_and_extract(buildpath, packagedir, pkg, args)\n patch(path, srcpath, pkg, args)\n compile(path, srcpath, pkg, args)\n package_files(buildpath, srcpath, pkg, args)\n finally:\n os.chdir(orig_path)\n\n\ndef make_parser(parser):\n parser.description = 'Build a pyodide package.'\n parser.add_argument(\n 'package', type=str, nargs=1,\n help=\"Path to meta.yaml package description\")\n parser.add_argument(\n '--package_abi', type=int, required=True,\n help='The ABI number for the package to be built')\n parser.add_argument(\n '--cflags', type=str, nargs='?', default=common.DEFAULTCFLAGS,\n help='Extra compiling flags')\n parser.add_argument(\n '--ldflags', type=str, nargs='?', default=common.DEFAULTLDFLAGS,\n help='Extra linking flags')\n parser.add_argument(\n '--host', type=str, nargs='?', default=common.HOSTPYTHON,\n help='The path to the host Python installation')\n parser.add_argument(\n '--target', type=str, nargs='?', default=common.TARGETPYTHON,\n help='The path to the target Python installation')\n return parser\n\n\ndef main(args):\n path = Path(args.package[0]).resolve()\n build_package(path, args)\n\n\nif __name__ == '__main__':\n parser = make_parser(argparse.ArgumentParser())\n args = parser.parse_args()\n main(args)\n", "path": "pyodide_build/buildpkg.py"}]} | 2,645 | 236 |
gh_patches_debug_22159 | rasdani/github-patches | git_diff | pymedusa__Medusa-3046 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Error: SSLError(SSLError("bad handshake: SysCallError(-1, 'Unexpected EOF')",),)
```
2017-08-22 17:13:36 ERROR SHOWQUEUE-ADD :: [49e9fc3] 289590 Error while loading information from indexer TVDBv2. Error: SSLError(SSLError("bad handshake: SysCallError(-1, 'Unexpected EOF')",),)
Traceback (most recent call last):
File "/app/medusa/medusa/show_queue.py", line 419, in run
check_existing_shows(s, self.indexer)
File "/app/medusa/medusa/helpers/externals.py", line 131, in check_existing_shows
new_show_externals = get_externals(indexer=indexer, indexed_show=indexed_show)
File "/app/medusa/medusa/helpers/externals.py", line 105, in get_externals
new_show_externals.update(t.get_id_by_external(**new_show_externals))
File "/app/medusa/medusa/indexers/tmdb/tmdb.py", line 593, in get_id_by_external
result = self.tmdb.Find(kwargs.get(external_id)).info(**{'external_source': external_id})
File "/app/medusa/lib/tmdbsimple/find.py", line 50, in info
response = self._GET(path, kwargs)
File "/app/medusa/lib/tmdbsimple/base.py", line 87, in _GET
return self._request('GET', path, params=params)
File "/app/medusa/lib/tmdbsimple/base.py", line 80, in _request
headers=self.headers)
File "/app/medusa/lib/requests/sessions.py", line 475, in request
resp = self.send(prep, **send_kwargs)
File "/app/medusa/lib/requests/sessions.py", line 585, in send
r = adapter.send(request, **kwargs)
File "/app/medusa/lib/cachecontrol/adapter.py", line 46, in send
resp = super(CacheControlAdapter, self).send(request, **kw)
File "/app/medusa/lib/requests/adapters.py", line 477, in send
raise SSLError(e, request=request)
SSLError: ("bad handshake: SysCallError(-1, 'Unexpected EOF')",)
```
</issue>
<code>
[start of medusa/helpers/externals.py]
1 # coding=utf-8
2
3 """Externals helper functions."""
4
5 import logging
6
7 from medusa import app, db
8 from medusa.indexers.indexer_api import indexerApi
9 from medusa.indexers.indexer_config import indexerConfig, mappings
10 from medusa.indexers.indexer_exceptions import IndexerException, IndexerShowAllreadyInLibrary, IndexerUnavailable
11 from medusa.logger.adapters.style import BraceAdapter
12
13 from traktor import AuthException, TokenExpiredException, TraktApi, TraktException
14
15 log = BraceAdapter(logging.getLogger(__name__))
16 log.logger.addHandler(logging.NullHandler())
17
18
19 def get_trakt_externals(externals):
20 """Small trakt api wrapper, to request trakt externals using multiple external id's.
21
22 :param externals: Dictionary of key/value pairs with external id's.
23 """
24 def trakt_request(api, trakt_url):
25 """Perform the request and handle possible token refresh."""
26 try:
27 trakt_result = api.request(trakt_url) or []
28 if api.access_token_refreshed:
29 app.TRAKT_ACCESS_TOKEN = api.access_token
30 app.TRAKT_REFRESH_TOKEN = api.refresh_token
31 app.instance.save_config()
32 except (AuthException, TraktException, TokenExpiredException) as e:
33 log.info(u'Could not use Trakt to enrich with externals: {0}',
34 e.message or e)
35 return []
36 else:
37 return trakt_result
38
39 trakt_settings = {'trakt_api_key': app.TRAKT_API_KEY,
40 'trakt_api_secret': app.TRAKT_API_SECRET,
41 'trakt_access_token': app.TRAKT_ACCESS_TOKEN,
42 'trakt_refresh_token': app.TRAKT_REFRESH_TOKEN}
43 trakt_api = TraktApi(app.SSL_VERIFY, app.TRAKT_TIMEOUT, **trakt_settings)
44
45 id_lookup = '/search/{external_key}/{external_value}?type=show'
46 trakt_mapping = {'tvdb_id': 'tvdb', 'imdb_id': 'imdb', 'tmdb_id': 'tmdb', 'trakt_id': 'trakt'}
47 trakt_mapping_rev = {v: k for k, v in trakt_mapping.items()}
48
49 for external_key in externals:
50 if not trakt_mapping.get(external_key) or not externals[external_key]:
51 continue
52
53 url = id_lookup.format(external_key=trakt_mapping[external_key], external_value=externals[external_key])
54 log.debug(
55 u'Looking for externals using Trakt and {indexer} id {number}', {
56 'indexer': trakt_mapping[external_key],
57 'number': externals[external_key],
58 }
59 )
60 result = trakt_request(trakt_api, url)
61 if result and len(result) and result[0].get('show') and result[0]['show'].get('ids'):
62 ids = {trakt_mapping_rev[k]: v for k, v in result[0]['show'].get('ids').items()
63 if v and trakt_mapping_rev.get(k)}
64 return ids
65 return {}
66
67
68 def get_externals(show=None, indexer=None, indexed_show=None):
69 """Use as much as possible sources to map known id's.
70
71 Provide the external id's you have in a dictionary, and use as much available resources as possible to retrieve
72 external id's.
73 :param show: Series object.
74 :param indexer: Indexer id. For example 1 for tvdb or 4 for tmdb.
75 :param indexed_show: The result of a fully indexed shows. For example after an t['12345']
76 """
77 if show:
78 indexer = show.indexer
79 new_show_externals = show.externals
80 else:
81 if not indexer or not indexed_show:
82 raise Exception('Need a minimum of a show object or an indexer + indexer_api '
83 '(Show searched through indexerApi.')
84 new_show_externals = getattr(indexed_show, 'externals', {})
85
86 # For this show let's get all externals, and use them.
87 mappings = {indexer: indexerConfig[indexer]['mapped_to'] for indexer in indexerConfig}
88 other_indexers = [mapped_indexer for mapped_indexer in mappings if mapped_indexer != indexer]
89
90 # We for example want to add through tmdb, but the show is already added through tvdb.
91 # If tmdb doesn't have a mapping to imdb, but tvmaze does, there is a small chance we can use that.
92
93 for other_indexer in other_indexers:
94 lindexer_api_pararms = indexerApi(other_indexer).api_params.copy()
95 try:
96 t = indexerApi(other_indexer).indexer(**lindexer_api_pararms)
97 except IndexerUnavailable:
98 continue
99 if hasattr(t, 'get_id_by_external'):
100 log.debug(u"Trying other indexer: {indexer} get_id_by_external",
101 {'indexer': indexerApi(other_indexer).name})
102 # Call the get_id_by_external and pass all the externals we have,
103 # except for the indexers own.
104 try:
105 new_show_externals.update(t.get_id_by_external(**new_show_externals))
106 except IndexerException as error:
107 log.warning(
108 u'Error getting external ids for other'
109 u' indexer {name}: {reason}',
110 {'name': indexerApi(show.indexer).name, 'reason': error.message})
111
112 # Try to update with the Trakt externals.
113 if app.USE_TRAKT:
114 new_show_externals.update(get_trakt_externals(new_show_externals))
115
116 return new_show_externals
117
118
119 def check_existing_shows(indexed_show, indexer):
120 """Check if the searched show already exists in the current library.
121
122 :param indexed_show: (Indexer Show object) The indexed show from -for example- tvdb. It might already have some
123 externals like imdb_id which can be used to search at tmdb, tvmaze or trakt.
124 :param indexer: (int) The indexer id, which has been used to search the indexed_show with.
125 :return: Raises the exception IndexerShowAllreadyInLibrary() when the show is already in your library.
126 """
127 # For this show let's get all externals, and use them.
128 mappings = {indexer: indexerConfig[indexer]['mapped_to'] for indexer in indexerConfig}
129 other_indexers = [mapped_indexer for mapped_indexer in mappings if mapped_indexer != indexer]
130
131 new_show_externals = get_externals(indexer=indexer, indexed_show=indexed_show)
132
133 # Iterate through all shows in library, and see if one of our externals matches it's indexer_id
134 # Or one of it's externals.
135 for show in app.showList:
136
137 # Check if the new shows indexer id matches the external for the show
138 # in library
139 if show.externals.get(mappings[indexer]) and indexed_show['id'] == show.externals.get(mappings[indexer]):
140 log.debug(u'Show already in database. [{id}] {name}',
141 {'name': show.name, 'id': indexed_show['id']})
142 raise IndexerShowAllreadyInLibrary('The show {0} has already been added by the indexer {1}. '
143 'Please remove the show, before you can add it through {2}.'
144 .format(show.name, indexerApi(show.indexer).name,
145 indexerApi(indexer).name))
146
147 for new_show_external_key in new_show_externals.keys():
148 if show.indexer not in other_indexers:
149 continue
150
151 # Check if one of the new shows externals matches one of the
152 # externals for the show in library.
153 if not new_show_externals.get(new_show_external_key) or not show.externals.get(new_show_external_key):
154 continue
155
156 if new_show_externals.get(new_show_external_key) == show.externals.get(new_show_external_key):
157 log.debug(
158 u'Show already in database under external ID ({existing})'
159 u' for ({id}) {name}', {
160 'name': show.name,
161 'id': show.externals.get(new_show_external_key),
162 'existing': new_show_external_key,
163 }
164 )
165 raise IndexerShowAllreadyInLibrary('The show {0} has already been added by the indexer {1}. '
166 'Please remove the show, before you can add it through {2}.'
167 .format(show.name, indexerApi(show.indexer).name,
168 indexerApi(indexer).name))
169
170
171 def load_externals_from_db(indexer=None, indexer_id=None):
172 """Load and recreate the indexers external id's.
173
174 :param indexer: Optional pass indexer id, else use the current shows indexer.
175 :type indexer: int
176 :param indexer_id: Optional pass indexer id, else use the current shows indexer.
177 :type indexer_id: int
178 """
179 externals = {}
180
181 main_db_con = db.DBConnection()
182 sql = (b'SELECT indexer, indexer_id, mindexer, mindexer_id '
183 b'FROM indexer_mapping '
184 b'WHERE (indexer = ? AND indexer_id = ?) '
185 b'OR (mindexer = ? AND mindexer_id = ?)')
186
187 results = main_db_con.select(sql, [indexer, indexer_id, indexer, indexer_id])
188
189 for result in results:
190 try:
191 if result[b'indexer'] == indexer:
192 externals[mappings[result[b'mindexer']]] = result[b'mindexer_id']
193 else:
194 externals[mappings[result[b'indexer']]] = result[b'indexer_id']
195 except KeyError as e:
196 log.error(u'Indexer not supported in current mappings: {id}', {'id': e.message})
197
198 return externals
199
[end of medusa/helpers/externals.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/medusa/helpers/externals.py b/medusa/helpers/externals.py
--- a/medusa/helpers/externals.py
+++ b/medusa/helpers/externals.py
@@ -10,6 +10,7 @@
from medusa.indexers.indexer_exceptions import IndexerException, IndexerShowAllreadyInLibrary, IndexerUnavailable
from medusa.logger.adapters.style import BraceAdapter
+from requests.exceptions import RequestException
from traktor import AuthException, TokenExpiredException, TraktApi, TraktException
log = BraceAdapter(logging.getLogger(__name__))
@@ -103,7 +104,7 @@
# except for the indexers own.
try:
new_show_externals.update(t.get_id_by_external(**new_show_externals))
- except IndexerException as error:
+ except (IndexerException, RequestException) as error:
log.warning(
u'Error getting external ids for other'
u' indexer {name}: {reason}',
| {"golden_diff": "diff --git a/medusa/helpers/externals.py b/medusa/helpers/externals.py\n--- a/medusa/helpers/externals.py\n+++ b/medusa/helpers/externals.py\n@@ -10,6 +10,7 @@\n from medusa.indexers.indexer_exceptions import IndexerException, IndexerShowAllreadyInLibrary, IndexerUnavailable\n from medusa.logger.adapters.style import BraceAdapter\n \n+from requests.exceptions import RequestException\n from traktor import AuthException, TokenExpiredException, TraktApi, TraktException\n \n log = BraceAdapter(logging.getLogger(__name__))\n@@ -103,7 +104,7 @@\n # except for the indexers own.\n try:\n new_show_externals.update(t.get_id_by_external(**new_show_externals))\n- except IndexerException as error:\n+ except (IndexerException, RequestException) as error:\n log.warning(\n u'Error getting external ids for other'\n u' indexer {name}: {reason}',\n", "issue": "Error: SSLError(SSLError(\"bad handshake: SysCallError(-1, 'Unexpected EOF')\",),)\n```\r\n2017-08-22 17:13:36 ERROR SHOWQUEUE-ADD :: [49e9fc3] 289590 Error while loading information from indexer TVDBv2. Error: SSLError(SSLError(\"bad handshake: SysCallError(-1, 'Unexpected EOF')\",),)\r\nTraceback (most recent call last):\r\n File \"/app/medusa/medusa/show_queue.py\", line 419, in run\r\n check_existing_shows(s, self.indexer)\r\n File \"/app/medusa/medusa/helpers/externals.py\", line 131, in check_existing_shows\r\n new_show_externals = get_externals(indexer=indexer, indexed_show=indexed_show)\r\n File \"/app/medusa/medusa/helpers/externals.py\", line 105, in get_externals\r\n new_show_externals.update(t.get_id_by_external(**new_show_externals))\r\n File \"/app/medusa/medusa/indexers/tmdb/tmdb.py\", line 593, in get_id_by_external\r\n result = self.tmdb.Find(kwargs.get(external_id)).info(**{'external_source': external_id})\r\n File \"/app/medusa/lib/tmdbsimple/find.py\", line 50, in info\r\n response = self._GET(path, kwargs)\r\n File \"/app/medusa/lib/tmdbsimple/base.py\", line 87, in _GET\r\n return self._request('GET', path, params=params)\r\n File \"/app/medusa/lib/tmdbsimple/base.py\", line 80, in _request\r\n headers=self.headers)\r\n File \"/app/medusa/lib/requests/sessions.py\", line 475, in request\r\n resp = self.send(prep, **send_kwargs)\r\n File \"/app/medusa/lib/requests/sessions.py\", line 585, in send\r\n r = adapter.send(request, **kwargs)\r\n File \"/app/medusa/lib/cachecontrol/adapter.py\", line 46, in send\r\n resp = super(CacheControlAdapter, self).send(request, **kw)\r\n File \"/app/medusa/lib/requests/adapters.py\", line 477, in send\r\n raise SSLError(e, request=request)\r\nSSLError: (\"bad handshake: SysCallError(-1, 'Unexpected EOF')\",)\r\n```\n", "before_files": [{"content": "# coding=utf-8\n\n\"\"\"Externals helper functions.\"\"\"\n\nimport logging\n\nfrom medusa import app, db\nfrom medusa.indexers.indexer_api import indexerApi\nfrom medusa.indexers.indexer_config import indexerConfig, mappings\nfrom medusa.indexers.indexer_exceptions import IndexerException, IndexerShowAllreadyInLibrary, IndexerUnavailable\nfrom medusa.logger.adapters.style import BraceAdapter\n\nfrom traktor import AuthException, TokenExpiredException, TraktApi, TraktException\n\nlog = BraceAdapter(logging.getLogger(__name__))\nlog.logger.addHandler(logging.NullHandler())\n\n\ndef get_trakt_externals(externals):\n \"\"\"Small trakt api wrapper, to request trakt externals using multiple external id's.\n\n :param externals: Dictionary of key/value pairs with external id's.\n \"\"\"\n def trakt_request(api, trakt_url):\n \"\"\"Perform the request and handle possible token refresh.\"\"\"\n try:\n trakt_result = api.request(trakt_url) or []\n if api.access_token_refreshed:\n app.TRAKT_ACCESS_TOKEN = api.access_token\n app.TRAKT_REFRESH_TOKEN = api.refresh_token\n app.instance.save_config()\n except (AuthException, TraktException, TokenExpiredException) as e:\n log.info(u'Could not use Trakt to enrich with externals: {0}',\n e.message or e)\n return []\n else:\n return trakt_result\n\n trakt_settings = {'trakt_api_key': app.TRAKT_API_KEY,\n 'trakt_api_secret': app.TRAKT_API_SECRET,\n 'trakt_access_token': app.TRAKT_ACCESS_TOKEN,\n 'trakt_refresh_token': app.TRAKT_REFRESH_TOKEN}\n trakt_api = TraktApi(app.SSL_VERIFY, app.TRAKT_TIMEOUT, **trakt_settings)\n\n id_lookup = '/search/{external_key}/{external_value}?type=show'\n trakt_mapping = {'tvdb_id': 'tvdb', 'imdb_id': 'imdb', 'tmdb_id': 'tmdb', 'trakt_id': 'trakt'}\n trakt_mapping_rev = {v: k for k, v in trakt_mapping.items()}\n\n for external_key in externals:\n if not trakt_mapping.get(external_key) or not externals[external_key]:\n continue\n\n url = id_lookup.format(external_key=trakt_mapping[external_key], external_value=externals[external_key])\n log.debug(\n u'Looking for externals using Trakt and {indexer} id {number}', {\n 'indexer': trakt_mapping[external_key],\n 'number': externals[external_key],\n }\n )\n result = trakt_request(trakt_api, url)\n if result and len(result) and result[0].get('show') and result[0]['show'].get('ids'):\n ids = {trakt_mapping_rev[k]: v for k, v in result[0]['show'].get('ids').items()\n if v and trakt_mapping_rev.get(k)}\n return ids\n return {}\n\n\ndef get_externals(show=None, indexer=None, indexed_show=None):\n \"\"\"Use as much as possible sources to map known id's.\n\n Provide the external id's you have in a dictionary, and use as much available resources as possible to retrieve\n external id's.\n :param show: Series object.\n :param indexer: Indexer id. For example 1 for tvdb or 4 for tmdb.\n :param indexed_show: The result of a fully indexed shows. For example after an t['12345']\n \"\"\"\n if show:\n indexer = show.indexer\n new_show_externals = show.externals\n else:\n if not indexer or not indexed_show:\n raise Exception('Need a minimum of a show object or an indexer + indexer_api '\n '(Show searched through indexerApi.')\n new_show_externals = getattr(indexed_show, 'externals', {})\n\n # For this show let's get all externals, and use them.\n mappings = {indexer: indexerConfig[indexer]['mapped_to'] for indexer in indexerConfig}\n other_indexers = [mapped_indexer for mapped_indexer in mappings if mapped_indexer != indexer]\n\n # We for example want to add through tmdb, but the show is already added through tvdb.\n # If tmdb doesn't have a mapping to imdb, but tvmaze does, there is a small chance we can use that.\n\n for other_indexer in other_indexers:\n lindexer_api_pararms = indexerApi(other_indexer).api_params.copy()\n try:\n t = indexerApi(other_indexer).indexer(**lindexer_api_pararms)\n except IndexerUnavailable:\n continue\n if hasattr(t, 'get_id_by_external'):\n log.debug(u\"Trying other indexer: {indexer} get_id_by_external\",\n {'indexer': indexerApi(other_indexer).name})\n # Call the get_id_by_external and pass all the externals we have,\n # except for the indexers own.\n try:\n new_show_externals.update(t.get_id_by_external(**new_show_externals))\n except IndexerException as error:\n log.warning(\n u'Error getting external ids for other'\n u' indexer {name}: {reason}',\n {'name': indexerApi(show.indexer).name, 'reason': error.message})\n\n # Try to update with the Trakt externals.\n if app.USE_TRAKT:\n new_show_externals.update(get_trakt_externals(new_show_externals))\n\n return new_show_externals\n\n\ndef check_existing_shows(indexed_show, indexer):\n \"\"\"Check if the searched show already exists in the current library.\n\n :param indexed_show: (Indexer Show object) The indexed show from -for example- tvdb. It might already have some\n externals like imdb_id which can be used to search at tmdb, tvmaze or trakt.\n :param indexer: (int) The indexer id, which has been used to search the indexed_show with.\n :return: Raises the exception IndexerShowAllreadyInLibrary() when the show is already in your library.\n \"\"\"\n # For this show let's get all externals, and use them.\n mappings = {indexer: indexerConfig[indexer]['mapped_to'] for indexer in indexerConfig}\n other_indexers = [mapped_indexer for mapped_indexer in mappings if mapped_indexer != indexer]\n\n new_show_externals = get_externals(indexer=indexer, indexed_show=indexed_show)\n\n # Iterate through all shows in library, and see if one of our externals matches it's indexer_id\n # Or one of it's externals.\n for show in app.showList:\n\n # Check if the new shows indexer id matches the external for the show\n # in library\n if show.externals.get(mappings[indexer]) and indexed_show['id'] == show.externals.get(mappings[indexer]):\n log.debug(u'Show already in database. [{id}] {name}',\n {'name': show.name, 'id': indexed_show['id']})\n raise IndexerShowAllreadyInLibrary('The show {0} has already been added by the indexer {1}. '\n 'Please remove the show, before you can add it through {2}.'\n .format(show.name, indexerApi(show.indexer).name,\n indexerApi(indexer).name))\n\n for new_show_external_key in new_show_externals.keys():\n if show.indexer not in other_indexers:\n continue\n\n # Check if one of the new shows externals matches one of the\n # externals for the show in library.\n if not new_show_externals.get(new_show_external_key) or not show.externals.get(new_show_external_key):\n continue\n\n if new_show_externals.get(new_show_external_key) == show.externals.get(new_show_external_key):\n log.debug(\n u'Show already in database under external ID ({existing})'\n u' for ({id}) {name}', {\n 'name': show.name,\n 'id': show.externals.get(new_show_external_key),\n 'existing': new_show_external_key,\n }\n )\n raise IndexerShowAllreadyInLibrary('The show {0} has already been added by the indexer {1}. '\n 'Please remove the show, before you can add it through {2}.'\n .format(show.name, indexerApi(show.indexer).name,\n indexerApi(indexer).name))\n\n\ndef load_externals_from_db(indexer=None, indexer_id=None):\n \"\"\"Load and recreate the indexers external id's.\n\n :param indexer: Optional pass indexer id, else use the current shows indexer.\n :type indexer: int\n :param indexer_id: Optional pass indexer id, else use the current shows indexer.\n :type indexer_id: int\n \"\"\"\n externals = {}\n\n main_db_con = db.DBConnection()\n sql = (b'SELECT indexer, indexer_id, mindexer, mindexer_id '\n b'FROM indexer_mapping '\n b'WHERE (indexer = ? AND indexer_id = ?) '\n b'OR (mindexer = ? AND mindexer_id = ?)')\n\n results = main_db_con.select(sql, [indexer, indexer_id, indexer, indexer_id])\n\n for result in results:\n try:\n if result[b'indexer'] == indexer:\n externals[mappings[result[b'mindexer']]] = result[b'mindexer_id']\n else:\n externals[mappings[result[b'indexer']]] = result[b'indexer_id']\n except KeyError as e:\n log.error(u'Indexer not supported in current mappings: {id}', {'id': e.message})\n\n return externals\n", "path": "medusa/helpers/externals.py"}]} | 3,706 | 220 |
gh_patches_debug_5934 | rasdani/github-patches | git_diff | microsoft__knossos-ksc-465 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Zero vectors check is slow
The `vec` class used in ksc-generated code contains an `is_zero_` flag which optimizes the case of all-zero vectors. But this adds overhead in cases where all-zero never happens, e.g. GMM objective function is approximately 50% slower when compared to not having the flag (tested with GCC 7). Is there some way to get the best of both worlds here?
</issue>
<code>
[start of src/python/ksc/utils.py]
1 from collections import namedtuple
2 import importlib.util
3 import os
4 import numpy as np
5 import subprocess
6 import sys
7 from tempfile import NamedTemporaryFile
8
9 from ksc.type import Type
10
11 def ensure_list_of_lists(l):
12 """return input, wrapped in a singleton list if its first element is not a list
13
14 ensure_list_of_lists([]) = []
15 ensure_list_of_lists([1]) = [[1]]
16 ensure_list_of_lists([[1]]) = [[1]]
17 ensure_list_of_lists([[1,2]]) = [[1, 2]]
18 ensure_list_of_lists([[1,2], [3,4]]) = [[1, 2], [3, 4]]
19 """
20
21 if not isinstance(l, list):
22 raise ValueError("Expect a list")
23 if len(l) < 1: # Empty list is empty list
24 return l
25 if not isinstance(l[0], list):
26 return [l]
27 else:
28 return l
29
30 def paren(s):
31 return "(" + s + ")"
32
33 ShapeType = namedtuple("ShapeType", ["shape", "type"])
34
35 PYTHON_MODULE_NAME = "ks_mod"
36
37 def import_module_from_path(module_name, path):
38 # These three lines are for loading a module from a file in Python 3.5+
39 # https://bugs.python.org/issue21436
40 spec = importlib.util.spec_from_file_location(module_name, path)
41 py_out = importlib.util.module_from_spec(spec)
42 spec.loader.exec_module(py_out)
43 return py_out
44
45 def translate_and_import(*args):
46 from ksc.translate import translate
47 py_out = translate(*args, with_main=False)
48 with NamedTemporaryFile(mode="w", suffix=".py", delete=False) as f:
49 f.write(py_out)
50 print(f.name)
51 return import_module_from_path(PYTHON_MODULE_NAME, f.name)
52
53 def subprocess_run(cmd, env=None):
54 return subprocess.run(cmd, stdout=subprocess.PIPE, env=env).stdout.decode().strip("\n")
55
56 def generate_cpp_from_ks(ks_str):
57 if "KSC_PATH" in os.environ:
58 ksc_path = os.environ["KSC_PATH"]
59 else:
60 ksc_path = "./ksc"
61 with NamedTemporaryFile(mode="w", suffix=".ks", delete=False) as fks:
62 fks.write(ks_str)
63 with NamedTemporaryFile(mode="w", suffix=".kso", delete=False) as fkso:
64 pass
65 with NamedTemporaryFile(mode="w", suffix=".cpp", delete=False) as fcpp:
66 pass
67 try:
68 subprocess.check_call([
69 ksc_path,
70 "--generate-cpp-without-diffs",
71 "--ks-source-file", fks.name,
72 "--ks-output-file", fkso.name,
73 "--cpp-output-file", fcpp.name
74 ])
75 except subprocess.CalledProcessError:
76 print(f"ks_str={ks_str}")
77 raise
78 finally:
79 os.unlink(fks.name)
80 with open(fcpp.name) as f:
81 out = f.read()
82 # only delete these file if no error
83 os.unlink(fcpp.name)
84 os.unlink(fkso.name)
85 return out
86
87 def build_py_module_from_cpp(cpp_str, pybind11_path):
88 if "KSC_RUNTIME_DIR" in os.environ:
89 ksc_runtime_dir = os.environ["KSC_RUNTIME_DIR"]
90 else:
91 ksc_runtime_dir = "./src/runtime"
92
93 with NamedTemporaryFile(mode="w", suffix=".cpp", delete=False) as fcpp:
94 fcpp.write(cpp_str)
95
96 extension_suffix = subprocess_run(['python3-config', '--extension-suffix'])
97
98 with NamedTemporaryFile(mode="w", suffix=extension_suffix, delete=False) as fpymod:
99 pass
100 module_path = fpymod.name
101 module_name = os.path.basename(module_path).split(".")[0]
102 python_includes = subprocess_run(
103 [sys.executable, "-m", "pybind11", "--includes"],
104 env={"PYTHONPATH": "pybind11"}
105 )
106 try:
107 cmd = (f"g++-7 -I{ksc_runtime_dir} -I{pybind11_path}/include "
108 + python_includes
109 + " -Wall"
110 " -std=c++17"
111 " -O3"
112 " -fPIC"
113 " -shared"
114 f" -DPYTHON_MODULE_NAME={module_name}"
115 f" -o {module_path} "
116 + fcpp.name)
117 print(cmd)
118 subprocess.check_call(cmd, shell=True)
119 except subprocess.CalledProcessError:
120 print(f"cpp_str={cpp_str}")
121 raise
122 finally:
123 os.unlink(fcpp.name)
124 return module_name, module_path
125
126 def arg_type_strings(types):
127 return "".join(t.shortstr() for t in types)
128
129 def generate_and_compile_cpp_from_ks(ks_str, name_to_call, arg_types, pybind11_path="pybind11"):
130
131 cpp_str = """
132 #include <pybind11/pybind11.h>
133 #include <pybind11/stl.h>
134 #include <pybind11/operators.h>
135
136 namespace py = pybind11;
137
138 {generated_cpp_source}
139
140 int ks::main(ks::allocator *) {{ return 0; }};
141
142 ks::allocator g_alloc{{ 1'000'000'000 }};
143
144 /* template<typename T>
145 void declare_vec(py::module &m, std::string typestr) {{
146 using Class = ks::vec<T>;
147 std::string pyclass_name = std::string("vec_") + typestr;
148 py::class_<Class>(m, pyclass_name.c_str(), py::module_local())
149 .def(py::init<>())
150 .def(py::init([](std::vector<T> const& v) {{ return ks::vec<T>(&g_alloc, v); }}))
151 .def("is_zero", &Class::is_zero)
152 .def("__getitem__", [](const ks::vec<T> &a, const int &b) {{
153 return a[b];
154 }})
155 .def("__len__", [](const ks::vec<T> &a) {{ return a.size(); }});
156 }} */
157
158 template<typename RetType, typename... ParamTypes>
159 auto withGlobalAllocator(RetType(*f)(ks::allocator*, ParamTypes...)) {{
160 return [f](ParamTypes... params) {{ return f(&g_alloc, params...); }};
161 }}
162
163 PYBIND11_MODULE(PYTHON_MODULE_NAME, m) {{
164 m.def("main", withGlobalAllocator(&ks::{name_to_call}));
165 }}
166 """.format(
167 generated_cpp_source=generate_cpp_from_ks(ks_str),
168 name_to_call=(name_to_call + "@" + arg_type_strings(arg_types)).replace("@", "$a")
169 )
170 module_name, module_path = build_py_module_from_cpp(cpp_str, pybind11_path)
171 return import_module_from_path(module_name, module_path)
172
173 def shape_type_from_object(o):
174 # import here to avoid circular dependencies
175 from ksc.abstract_value import AbstractValue
176 if hasattr(o, "shape") and hasattr(o, "dtype"):
177 # numpy array-like object
178 if np.issubdtype(o.dtype, np.floating):
179 el_type = Type.Float
180 elif np.issubdtype(o.dtype, np.integer):
181 el_type = Type.Integer
182 elif np.issubdtype(o.dtype, np.bool_):
183 el_type = Type.Bool
184 else:
185 raise ValueError(f"Cannot handle element type {o.dtype}")
186 vec_type = el_type
187 for _ in range(o.ndim):
188 vec_type = Type.Vec(vec_type)
189 return ShapeType(o.shape, vec_type)
190 elif isinstance(o, AbstractValue):
191 return o.shape_type
192 elif hasattr(o, "data") and o.data is not None:
193 # value node
194 return shape_type_from_object(o.data)
195 elif isinstance(o, list):
196 s0, t0 = shape_type_from_object(o[0])
197 assert all(shape_type_from_object(e) == (s0, t0) for e in o)
198 return ShapeType((len(o),) + s0, Type.Vec(t0))
199 elif isinstance(o, tuple):
200 ss, ts = zip(*[shape_type_from_object(e) for e in o])
201 return ShapeType(tuple(ss), Type.Tuple(*ts))
202 elif isinstance(o, bool):
203 return ShapeType((), Type.Bool)
204 elif isinstance(o, int):
205 return ShapeType((), Type.Integer)
206 elif isinstance(o, float):
207 return ShapeType((), Type.Float)
208 else:
209 raise ValueError(f"Cannot handle object {o}")
210
[end of src/python/ksc/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/python/ksc/utils.py b/src/python/ksc/utils.py
--- a/src/python/ksc/utils.py
+++ b/src/python/ksc/utils.py
@@ -148,7 +148,6 @@
py::class_<Class>(m, pyclass_name.c_str(), py::module_local())
.def(py::init<>())
.def(py::init([](std::vector<T> const& v) {{ return ks::vec<T>(&g_alloc, v); }}))
- .def("is_zero", &Class::is_zero)
.def("__getitem__", [](const ks::vec<T> &a, const int &b) {{
return a[b];
}})
| {"golden_diff": "diff --git a/src/python/ksc/utils.py b/src/python/ksc/utils.py\n--- a/src/python/ksc/utils.py\n+++ b/src/python/ksc/utils.py\n@@ -148,7 +148,6 @@\n py::class_<Class>(m, pyclass_name.c_str(), py::module_local())\n .def(py::init<>())\n .def(py::init([](std::vector<T> const& v) {{ return ks::vec<T>(&g_alloc, v); }}))\n- .def(\"is_zero\", &Class::is_zero)\n .def(\"__getitem__\", [](const ks::vec<T> &a, const int &b) {{\n \treturn a[b];\n }})\n", "issue": "Zero vectors check is slow\nThe `vec` class used in ksc-generated code contains an `is_zero_` flag which optimizes the case of all-zero vectors. But this adds overhead in cases where all-zero never happens, e.g. GMM objective function is approximately 50% slower when compared to not having the flag (tested with GCC 7). Is there some way to get the best of both worlds here?\n", "before_files": [{"content": "from collections import namedtuple\nimport importlib.util\nimport os\nimport numpy as np\nimport subprocess\nimport sys\nfrom tempfile import NamedTemporaryFile\n\nfrom ksc.type import Type\n\ndef ensure_list_of_lists(l):\n \"\"\"return input, wrapped in a singleton list if its first element is not a list\n\n ensure_list_of_lists([]) = []\n ensure_list_of_lists([1]) = [[1]]\n ensure_list_of_lists([[1]]) = [[1]]\n ensure_list_of_lists([[1,2]]) = [[1, 2]]\n ensure_list_of_lists([[1,2], [3,4]]) = [[1, 2], [3, 4]]\n \"\"\"\n\n if not isinstance(l, list):\n raise ValueError(\"Expect a list\")\n if len(l) < 1: # Empty list is empty list\n return l\n if not isinstance(l[0], list):\n return [l]\n else:\n return l\n\ndef paren(s):\n return \"(\" + s + \")\"\n\nShapeType = namedtuple(\"ShapeType\", [\"shape\", \"type\"])\n\nPYTHON_MODULE_NAME = \"ks_mod\"\n\ndef import_module_from_path(module_name, path):\n # These three lines are for loading a module from a file in Python 3.5+\n # https://bugs.python.org/issue21436\n spec = importlib.util.spec_from_file_location(module_name, path)\n py_out = importlib.util.module_from_spec(spec)\n spec.loader.exec_module(py_out)\n return py_out\n\ndef translate_and_import(*args):\n from ksc.translate import translate\n py_out = translate(*args, with_main=False)\n with NamedTemporaryFile(mode=\"w\", suffix=\".py\", delete=False) as f:\n f.write(py_out)\n print(f.name)\n return import_module_from_path(PYTHON_MODULE_NAME, f.name)\n\ndef subprocess_run(cmd, env=None):\n return subprocess.run(cmd, stdout=subprocess.PIPE, env=env).stdout.decode().strip(\"\\n\")\n\ndef generate_cpp_from_ks(ks_str):\n if \"KSC_PATH\" in os.environ:\n ksc_path = os.environ[\"KSC_PATH\"]\n else:\n ksc_path = \"./ksc\"\n with NamedTemporaryFile(mode=\"w\", suffix=\".ks\", delete=False) as fks:\n fks.write(ks_str)\n with NamedTemporaryFile(mode=\"w\", suffix=\".kso\", delete=False) as fkso:\n pass\n with NamedTemporaryFile(mode=\"w\", suffix=\".cpp\", delete=False) as fcpp:\n pass\n try:\n subprocess.check_call([\n ksc_path,\n \"--generate-cpp-without-diffs\",\n \"--ks-source-file\", fks.name,\n \"--ks-output-file\", fkso.name,\n \"--cpp-output-file\", fcpp.name\n ])\n except subprocess.CalledProcessError:\n print(f\"ks_str={ks_str}\")\n raise\n finally:\n os.unlink(fks.name)\n with open(fcpp.name) as f:\n out = f.read()\n # only delete these file if no error\n os.unlink(fcpp.name)\n os.unlink(fkso.name)\n return out\n\ndef build_py_module_from_cpp(cpp_str, pybind11_path):\n if \"KSC_RUNTIME_DIR\" in os.environ:\n ksc_runtime_dir = os.environ[\"KSC_RUNTIME_DIR\"]\n else:\n ksc_runtime_dir = \"./src/runtime\"\n\n with NamedTemporaryFile(mode=\"w\", suffix=\".cpp\", delete=False) as fcpp:\n fcpp.write(cpp_str)\n\n extension_suffix = subprocess_run(['python3-config', '--extension-suffix'])\n\n with NamedTemporaryFile(mode=\"w\", suffix=extension_suffix, delete=False) as fpymod:\n pass\n module_path = fpymod.name\n module_name = os.path.basename(module_path).split(\".\")[0]\n python_includes = subprocess_run(\n [sys.executable, \"-m\", \"pybind11\", \"--includes\"],\n env={\"PYTHONPATH\": \"pybind11\"}\n )\n try:\n cmd = (f\"g++-7 -I{ksc_runtime_dir} -I{pybind11_path}/include \"\n + python_includes\n + \" -Wall\"\n \" -std=c++17\"\n \" -O3\"\n \" -fPIC\"\n \" -shared\"\n f\" -DPYTHON_MODULE_NAME={module_name}\"\n f\" -o {module_path} \"\n + fcpp.name)\n print(cmd)\n subprocess.check_call(cmd, shell=True)\n except subprocess.CalledProcessError:\n print(f\"cpp_str={cpp_str}\")\n raise\n finally:\n os.unlink(fcpp.name)\n return module_name, module_path\n\ndef arg_type_strings(types):\n return \"\".join(t.shortstr() for t in types)\n\ndef generate_and_compile_cpp_from_ks(ks_str, name_to_call, arg_types, pybind11_path=\"pybind11\"):\n\n cpp_str = \"\"\"\n#include <pybind11/pybind11.h>\n#include <pybind11/stl.h>\n#include <pybind11/operators.h>\n\nnamespace py = pybind11;\n\n{generated_cpp_source}\n\nint ks::main(ks::allocator *) {{ return 0; }};\n\nks::allocator g_alloc{{ 1'000'000'000 }};\n\n/* template<typename T>\nvoid declare_vec(py::module &m, std::string typestr) {{\n using Class = ks::vec<T>;\n std::string pyclass_name = std::string(\"vec_\") + typestr;\n py::class_<Class>(m, pyclass_name.c_str(), py::module_local())\n .def(py::init<>())\n .def(py::init([](std::vector<T> const& v) {{ return ks::vec<T>(&g_alloc, v); }}))\n .def(\"is_zero\", &Class::is_zero)\n .def(\"__getitem__\", [](const ks::vec<T> &a, const int &b) {{\n\treturn a[b];\n }})\n .def(\"__len__\", [](const ks::vec<T> &a) {{ return a.size(); }});\n}} */\n\ntemplate<typename RetType, typename... ParamTypes>\nauto withGlobalAllocator(RetType(*f)(ks::allocator*, ParamTypes...)) {{\n return [f](ParamTypes... params) {{ return f(&g_alloc, params...); }};\n}}\n\nPYBIND11_MODULE(PYTHON_MODULE_NAME, m) {{\n m.def(\"main\", withGlobalAllocator(&ks::{name_to_call}));\n}}\n\"\"\".format(\n generated_cpp_source=generate_cpp_from_ks(ks_str),\n name_to_call=(name_to_call + \"@\" + arg_type_strings(arg_types)).replace(\"@\", \"$a\")\n )\n module_name, module_path = build_py_module_from_cpp(cpp_str, pybind11_path)\n return import_module_from_path(module_name, module_path)\n\ndef shape_type_from_object(o):\n # import here to avoid circular dependencies\n from ksc.abstract_value import AbstractValue\n if hasattr(o, \"shape\") and hasattr(o, \"dtype\"):\n # numpy array-like object\n if np.issubdtype(o.dtype, np.floating):\n el_type = Type.Float\n elif np.issubdtype(o.dtype, np.integer):\n el_type = Type.Integer\n elif np.issubdtype(o.dtype, np.bool_):\n el_type = Type.Bool\n else:\n raise ValueError(f\"Cannot handle element type {o.dtype}\")\n vec_type = el_type\n for _ in range(o.ndim):\n vec_type = Type.Vec(vec_type)\n return ShapeType(o.shape, vec_type)\n elif isinstance(o, AbstractValue):\n return o.shape_type\n elif hasattr(o, \"data\") and o.data is not None:\n # value node\n return shape_type_from_object(o.data)\n elif isinstance(o, list):\n s0, t0 = shape_type_from_object(o[0])\n assert all(shape_type_from_object(e) == (s0, t0) for e in o)\n return ShapeType((len(o),) + s0, Type.Vec(t0))\n elif isinstance(o, tuple):\n ss, ts = zip(*[shape_type_from_object(e) for e in o])\n return ShapeType(tuple(ss), Type.Tuple(*ts))\n elif isinstance(o, bool):\n return ShapeType((), Type.Bool)\n elif isinstance(o, int):\n return ShapeType((), Type.Integer)\n elif isinstance(o, float):\n return ShapeType((), Type.Float)\n else:\n raise ValueError(f\"Cannot handle object {o}\")\n", "path": "src/python/ksc/utils.py"}]} | 3,028 | 155 |
gh_patches_debug_34416 | rasdani/github-patches | git_diff | ethereum__web3.py-447 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Suspicion that `@reject_recursive_repeats` is not thread-safe
* Version: 3.16.2
* Python: 3.6
* OS: osx
### What was wrong?
When executing a few contract calls concurrently, I kept getting errors like:
```
File "/usr/local/lib/python3.6/site-packages/web3/contract.py", line 870, in call_contract_function
normalized_data = map_abi_data(normalizers, output_types, output_data)
File "/usr/local/lib/python3.6/site-packages/eth_utils/string.py", line 85, in inner
return force_obj_to_text(fn(*args, **kwargs))
File "/usr/local/lib/python3.6/site-packages/web3/utils/abi.py", line 437, in map_abi_data
return pipe(data, *pipeline)
File "cytoolz/functoolz.pyx", line 586, in cytoolz.functoolz.pipe (cytoolz/functoolz.c:10663)
File "cytoolz/functoolz.pyx", line 562, in cytoolz.functoolz.c_pipe (cytoolz/functoolz.c:10494)
File "/usr/local/lib/python3.6/site-packages/web3/utils/decorators.py", line 31, in wrapped
wrapped_val = to_wrap(*args)
File "/usr/local/lib/python3.6/site-packages/web3/utils/formatters.py", line 117, in recursive_map
items_mapped = map_collection(recurse, data)
File "/usr/local/lib/python3.6/site-packages/web3/utils/formatters.py", line 104, in map_collection
return datatype(map(func, collection))
File "/usr/local/lib/python3.6/site-packages/web3/utils/formatters.py", line 116, in recurse
return recursive_map(func, item)
File "/usr/local/lib/python3.6/site-packages/web3/utils/decorators.py", line 29, in wrapped
raise ValueError('Recursively called %s with %r' % (to_wrap, args))
ValueError: Recursively called <function recursive_map at 0x7f012ea030d0> with (<function strip_abi_type at 0x7f012ea06ae8>, ABITypedData(abi_type='address', data='0x168910909606A2Fca90D4C28Fa39b50407b9C526'))
```
and
```
File "/usr/local/lib/python3.6/site-packages/web3/contract.py", line 870, in call_contract_function
normalized_data = map_abi_data(normalizers, output_types, output_data)
File "/usr/local/lib/python3.6/site-packages/eth_utils/string.py", line 85, in inner
return force_obj_to_text(fn(*args, **kwargs))
File "/usr/local/lib/python3.6/site-packages/web3/utils/abi.py", line 437, in map_abi_data
return pipe(data, *pipeline)
File "cytoolz/functoolz.pyx", line 586, in cytoolz.functoolz.pipe (cytoolz/functoolz.c:10663)
File "cytoolz/functoolz.pyx", line 562, in cytoolz.functoolz.c_pipe (cytoolz/functoolz.c:10494)
File "/usr/local/lib/python3.6/site-packages/web3/utils/decorators.py", line 29, in wrapped
raise ValueError('Recursively called %s with %r' % (to_wrap, args))
ValueError: Recursively called <function recursive_map at 0x7f012ea030d0> with (<function strip_abi_type at 0x7f012ea06ae8>, [ABITypedData(abi_type='uint256', data=1000000000000000000), ABITypedData(abi_type='address', data='0xC66eA802717bFb9833400264Dd12c2bCeAa34a6d'), ABITypedData(abi_type='uint256', data=100000000000000000000), ABITypedData(abi_type='address', data='0xECF8F87f810EcF450940c9f60066b4a7a501d6A7'), ABITypedData(abi_type='address', data='0xbe69Be9133DAA77AeAFcA0d6330c7Ba44f597b15'), ABITypedData(abi_type='bool', data=True), ABITypedData(abi_type='uint64', data=1505245070)])
```
We are connecting to a Parity node.
### How can it be fixed?
My suspicion is that because `@reject_recursive_repeats` keeps state in `to_wrap.__already_called`, this is not thread-safe and will fail if two threads want to parse the same data at the same time.
</issue>
<code>
[start of web3/utils/compat/compat_gevent.py]
1 import collections
2
3 import gevent
4 from gevent.pywsgi import ( # noqa: F401
5 WSGIServer,
6 )
7 from gevent import ( # noqa: F401
8 subprocess,
9 socket,
10 threading,
11 )
12
13 import pylru
14
15 from geventhttpclient import HTTPClient
16
17 from web3.utils.six import urlparse
18
19
20 _client_cache = pylru.lrucache(8)
21
22
23 sleep = gevent.sleep
24 spawn = gevent.spawn
25 GreenletThread = gevent.Greenlet
26
27
28 class Timeout(gevent.Timeout):
29 def check(self):
30 pass
31
32 def sleep(self, seconds):
33 gevent.sleep(seconds)
34
35
36 def make_server(host, port, application, *args, **kwargs):
37 server = WSGIServer((host, port), application, *args, **kwargs)
38 return server
39
40
41 def _get_client(host, port, **kwargs):
42 ordered_kwargs = collections.OrderedDict(sorted(kwargs.items()))
43 cache_key = '{0}:{1}:{2}'.format(
44 host,
45 port,
46 ':'.join((
47 "{0}={1}".format(str(key), str(value))
48 for key, value in ordered_kwargs.items()
49 ))
50 )
51 if cache_key not in _client_cache:
52 _client_cache[cache_key] = HTTPClient(host, port, **kwargs)
53 return _client_cache[cache_key]
54
55
56 def make_post_request(endpoint_uri, data, **kwargs):
57 url_parts = urlparse(endpoint_uri)
58
59 host, _, port = url_parts.netloc.partition(':')
60
61 if not port:
62 if url_parts.scheme == 'http':
63 port = 80
64 elif url_parts.scheme == 'https':
65 port = 443
66 else:
67 raise ValueError("Unsupported scheme: '{0}'".format(url_parts.scheme))
68
69 kwargs.setdefault('ssl', url_parts.scheme == 'https')
70 kwargs.setdefault('connection_timeout', 10)
71 kwargs.setdefault('network_timeout', 10)
72 kwargs.setdefault('concurrency', 10)
73
74 client = _get_client(host, port, **kwargs)
75 response = client.post(url_parts.path, body=data)
76 response_body = response.read()
77
78 return response_body
79
[end of web3/utils/compat/compat_gevent.py]
[start of web3/utils/decorators.py]
1 import functools
2 import warnings
3
4
5 class combomethod(object):
6 def __init__(self, method):
7 self.method = method
8
9 def __get__(self, obj=None, objtype=None):
10 @functools.wraps(self.method)
11 def _wrapper(*args, **kwargs):
12 if obj is not None:
13 return self.method(obj, *args, **kwargs)
14 else:
15 return self.method(objtype, *args, **kwargs)
16 return _wrapper
17
18
19 def reject_recursive_repeats(to_wrap):
20 '''
21 Prevent simple cycles by returning None when called recursively with same instance
22 '''
23 to_wrap.__already_called = {}
24
25 @functools.wraps(to_wrap)
26 def wrapped(*args):
27 instances = tuple(map(id, args))
28 if instances in to_wrap.__already_called:
29 raise ValueError('Recursively called %s with %r' % (to_wrap, args))
30 to_wrap.__already_called[instances] = True
31 wrapped_val = to_wrap(*args)
32 del to_wrap.__already_called[instances]
33 return wrapped_val
34 return wrapped
35
36
37 def deprecated_for(replace_message):
38 '''
39 Decorate a deprecated function, with info about what to use instead, like:
40
41 @deprecated_for("toBytes()")
42 def toAscii(arg):
43 ...
44 '''
45 def decorator(to_wrap):
46 @functools.wraps(to_wrap)
47 def wrapper(*args, **kwargs):
48 warnings.simplefilter('always', DeprecationWarning)
49 warnings.warn(
50 "%s is deprecated in favor of %s" % (to_wrap.__name__, replace_message),
51 category=DeprecationWarning,
52 stacklevel=2)
53 warnings.simplefilter('default', DeprecationWarning)
54 return to_wrap(*args, **kwargs)
55 return wrapper
56 return decorator
57
[end of web3/utils/decorators.py]
[start of web3/utils/compat/compat_stdlib.py]
1 """
2 A minimal implementation of the various gevent APIs used within this codebase.
3 """
4 import time
5 import threading
6 import subprocess # noqa: F401
7 import socket # noqa: F401
8 from wsgiref.simple_server import make_server # noqa: F401
9
10
11 sleep = time.sleep
12
13
14 class Timeout(Exception):
15 """
16 A limited subset of the `gevent.Timeout` context manager.
17 """
18 seconds = None
19 exception = None
20 begun_at = None
21 is_running = None
22
23 def __init__(self, seconds=None, exception=None, *args, **kwargs):
24 self.seconds = seconds
25 self.exception = exception
26
27 def __enter__(self):
28 self.start()
29 return self
30
31 def __exit__(self, exc_type, exc_val, exc_tb):
32 return False
33
34 def __str__(self):
35 if self.seconds is None:
36 return ''
37 return "{0} seconds".format(self.seconds)
38
39 @property
40 def expire_at(self):
41 if self.seconds is None:
42 raise ValueError("Timeouts with `seconds == None` do not have an expiration time")
43 elif self.begun_at is None:
44 raise ValueError("Timeout has not been started")
45 return self.begun_at + self.seconds
46
47 def start(self):
48 if self.is_running is not None:
49 raise ValueError("Timeout has already been started")
50 self.begun_at = time.time()
51 self.is_running = True
52
53 def check(self):
54 if self.is_running is None:
55 raise ValueError("Timeout has not been started")
56 elif self.is_running is False:
57 raise ValueError("Timeout has already been cancelled")
58 elif self.seconds is None:
59 return
60 elif time.time() > self.expire_at:
61 self.is_running = False
62 if isinstance(self.exception, type):
63 raise self.exception(str(self))
64 elif isinstance(self.exception, Exception):
65 raise self.exception
66 else:
67 raise self
68
69 def cancel(self):
70 self.is_running = False
71
72 def sleep(self, seconds):
73 time.sleep(seconds)
74 self.check()
75
76
77 class empty(object):
78 pass
79
80
81 class ThreadWithReturn(threading.Thread):
82 def __init__(self, target=None, args=None, kwargs=None):
83 super(ThreadWithReturn, self).__init__(
84 target=target,
85 args=args or tuple(),
86 kwargs=kwargs or {},
87 )
88 self.target = target
89 self.args = args
90 self.kwargs = kwargs
91
92 def run(self):
93 self._return = self.target(*self.args, **self.kwargs)
94
95 def get(self, timeout=None):
96 self.join(timeout)
97 try:
98 return self._return
99 except AttributeError:
100 raise RuntimeError("Something went wrong. No `_return` property was set")
101
102
103 def spawn(target, thread_class=ThreadWithReturn, *args, **kwargs):
104 thread = thread_class(
105 target=target,
106 args=args,
107 kwargs=kwargs,
108 )
109 thread.daemon = True
110 thread.start()
111 return thread
112
113
114 class GreenletThread(threading.Thread):
115 def __init__(self, target=None, args=None, kwargs=None):
116 if target is None:
117 target = self._run
118 super(GreenletThread, self).__init__(
119 target=target,
120 args=args or tuple(),
121 kwargs=kwargs or {},
122 )
123 self.daemon = True
124
125 def _run(self):
126 pass
127
[end of web3/utils/compat/compat_stdlib.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/web3/utils/compat/compat_gevent.py b/web3/utils/compat/compat_gevent.py
--- a/web3/utils/compat/compat_gevent.py
+++ b/web3/utils/compat/compat_gevent.py
@@ -5,6 +5,7 @@
WSGIServer,
)
from gevent import ( # noqa: F401
+ getcurrent,
subprocess,
socket,
threading,
@@ -25,6 +26,19 @@
GreenletThread = gevent.Greenlet
+class ClassicThread(object):
+ def __init__(self, threadid):
+ self.ident = threadid
+
+
+def get_current_thread():
+ threadid = id(getcurrent())
+ return ClassicThread(threadid)
+
+
+threading.current_thread = get_current_thread
+
+
class Timeout(gevent.Timeout):
def check(self):
pass
diff --git a/web3/utils/compat/compat_stdlib.py b/web3/utils/compat/compat_stdlib.py
--- a/web3/utils/compat/compat_stdlib.py
+++ b/web3/utils/compat/compat_stdlib.py
@@ -100,8 +100,8 @@
raise RuntimeError("Something went wrong. No `_return` property was set")
-def spawn(target, thread_class=ThreadWithReturn, *args, **kwargs):
- thread = thread_class(
+def spawn(target, *args, **kwargs):
+ thread = ThreadWithReturn(
target=target,
args=args,
kwargs=kwargs,
diff --git a/web3/utils/decorators.py b/web3/utils/decorators.py
--- a/web3/utils/decorators.py
+++ b/web3/utils/decorators.py
@@ -1,6 +1,10 @@
import functools
import warnings
+from web3.utils.compat import (
+ threading,
+)
+
class combomethod(object):
def __init__(self, method):
@@ -24,12 +28,14 @@
@functools.wraps(to_wrap)
def wrapped(*args):
- instances = tuple(map(id, args))
- if instances in to_wrap.__already_called:
+ arg_instances = tuple(map(id, args))
+ thread_id = threading.current_thread().ident
+ thread_local_args = (thread_id,) + arg_instances
+ if thread_local_args in to_wrap.__already_called:
raise ValueError('Recursively called %s with %r' % (to_wrap, args))
- to_wrap.__already_called[instances] = True
+ to_wrap.__already_called[thread_local_args] = True
wrapped_val = to_wrap(*args)
- del to_wrap.__already_called[instances]
+ del to_wrap.__already_called[thread_local_args]
return wrapped_val
return wrapped
| {"golden_diff": "diff --git a/web3/utils/compat/compat_gevent.py b/web3/utils/compat/compat_gevent.py\n--- a/web3/utils/compat/compat_gevent.py\n+++ b/web3/utils/compat/compat_gevent.py\n@@ -5,6 +5,7 @@\n WSGIServer,\n )\n from gevent import ( # noqa: F401\n+ getcurrent,\n subprocess,\n socket,\n threading,\n@@ -25,6 +26,19 @@\n GreenletThread = gevent.Greenlet\n \n \n+class ClassicThread(object):\n+ def __init__(self, threadid):\n+ self.ident = threadid\n+\n+\n+def get_current_thread():\n+ threadid = id(getcurrent())\n+ return ClassicThread(threadid)\n+\n+\n+threading.current_thread = get_current_thread\n+\n+\n class Timeout(gevent.Timeout):\n def check(self):\n pass\ndiff --git a/web3/utils/compat/compat_stdlib.py b/web3/utils/compat/compat_stdlib.py\n--- a/web3/utils/compat/compat_stdlib.py\n+++ b/web3/utils/compat/compat_stdlib.py\n@@ -100,8 +100,8 @@\n raise RuntimeError(\"Something went wrong. No `_return` property was set\")\n \n \n-def spawn(target, thread_class=ThreadWithReturn, *args, **kwargs):\n- thread = thread_class(\n+def spawn(target, *args, **kwargs):\n+ thread = ThreadWithReturn(\n target=target,\n args=args,\n kwargs=kwargs,\ndiff --git a/web3/utils/decorators.py b/web3/utils/decorators.py\n--- a/web3/utils/decorators.py\n+++ b/web3/utils/decorators.py\n@@ -1,6 +1,10 @@\n import functools\n import warnings\n \n+from web3.utils.compat import (\n+ threading,\n+)\n+\n \n class combomethod(object):\n def __init__(self, method):\n@@ -24,12 +28,14 @@\n \n @functools.wraps(to_wrap)\n def wrapped(*args):\n- instances = tuple(map(id, args))\n- if instances in to_wrap.__already_called:\n+ arg_instances = tuple(map(id, args))\n+ thread_id = threading.current_thread().ident\n+ thread_local_args = (thread_id,) + arg_instances\n+ if thread_local_args in to_wrap.__already_called:\n raise ValueError('Recursively called %s with %r' % (to_wrap, args))\n- to_wrap.__already_called[instances] = True\n+ to_wrap.__already_called[thread_local_args] = True\n wrapped_val = to_wrap(*args)\n- del to_wrap.__already_called[instances]\n+ del to_wrap.__already_called[thread_local_args]\n return wrapped_val\n return wrapped\n", "issue": "Suspicion that `@reject_recursive_repeats` is not thread-safe\n* Version: 3.16.2\r\n* Python: 3.6\r\n* OS: osx\r\n\r\n\r\n### What was wrong?\r\n\r\nWhen executing a few contract calls concurrently, I kept getting errors like:\r\n\r\n```\r\nFile \"/usr/local/lib/python3.6/site-packages/web3/contract.py\", line 870, in call_contract_function\r\n normalized_data = map_abi_data(normalizers, output_types, output_data)\r\n File \"/usr/local/lib/python3.6/site-packages/eth_utils/string.py\", line 85, in inner\r\n return force_obj_to_text(fn(*args, **kwargs))\r\n File \"/usr/local/lib/python3.6/site-packages/web3/utils/abi.py\", line 437, in map_abi_data\r\n return pipe(data, *pipeline)\r\n File \"cytoolz/functoolz.pyx\", line 586, in cytoolz.functoolz.pipe (cytoolz/functoolz.c:10663)\r\n File \"cytoolz/functoolz.pyx\", line 562, in cytoolz.functoolz.c_pipe (cytoolz/functoolz.c:10494)\r\n File \"/usr/local/lib/python3.6/site-packages/web3/utils/decorators.py\", line 31, in wrapped\r\n wrapped_val = to_wrap(*args)\r\n File \"/usr/local/lib/python3.6/site-packages/web3/utils/formatters.py\", line 117, in recursive_map\r\n items_mapped = map_collection(recurse, data)\r\n File \"/usr/local/lib/python3.6/site-packages/web3/utils/formatters.py\", line 104, in map_collection\r\n return datatype(map(func, collection))\r\n File \"/usr/local/lib/python3.6/site-packages/web3/utils/formatters.py\", line 116, in recurse\r\n return recursive_map(func, item)\r\n File \"/usr/local/lib/python3.6/site-packages/web3/utils/decorators.py\", line 29, in wrapped\r\n raise ValueError('Recursively called %s with %r' % (to_wrap, args))\r\nValueError: Recursively called <function recursive_map at 0x7f012ea030d0> with (<function strip_abi_type at 0x7f012ea06ae8>, ABITypedData(abi_type='address', data='0x168910909606A2Fca90D4C28Fa39b50407b9C526'))\r\n```\r\n\r\nand\r\n\r\n```\r\n File \"/usr/local/lib/python3.6/site-packages/web3/contract.py\", line 870, in call_contract_function\r\n normalized_data = map_abi_data(normalizers, output_types, output_data)\r\n File \"/usr/local/lib/python3.6/site-packages/eth_utils/string.py\", line 85, in inner\r\n return force_obj_to_text(fn(*args, **kwargs))\r\n File \"/usr/local/lib/python3.6/site-packages/web3/utils/abi.py\", line 437, in map_abi_data\r\n return pipe(data, *pipeline)\r\n File \"cytoolz/functoolz.pyx\", line 586, in cytoolz.functoolz.pipe (cytoolz/functoolz.c:10663)\r\n File \"cytoolz/functoolz.pyx\", line 562, in cytoolz.functoolz.c_pipe (cytoolz/functoolz.c:10494)\r\n File \"/usr/local/lib/python3.6/site-packages/web3/utils/decorators.py\", line 29, in wrapped\r\n raise ValueError('Recursively called %s with %r' % (to_wrap, args))\r\nValueError: Recursively called <function recursive_map at 0x7f012ea030d0> with (<function strip_abi_type at 0x7f012ea06ae8>, [ABITypedData(abi_type='uint256', data=1000000000000000000), ABITypedData(abi_type='address', data='0xC66eA802717bFb9833400264Dd12c2bCeAa34a6d'), ABITypedData(abi_type='uint256', data=100000000000000000000), ABITypedData(abi_type='address', data='0xECF8F87f810EcF450940c9f60066b4a7a501d6A7'), ABITypedData(abi_type='address', data='0xbe69Be9133DAA77AeAFcA0d6330c7Ba44f597b15'), ABITypedData(abi_type='bool', data=True), ABITypedData(abi_type='uint64', data=1505245070)])\r\n```\r\n\r\nWe are connecting to a Parity node.\r\n\r\n### How can it be fixed?\r\n\r\nMy suspicion is that because `@reject_recursive_repeats` keeps state in `to_wrap.__already_called`, this is not thread-safe and will fail if two threads want to parse the same data at the same time.\r\n\n", "before_files": [{"content": "import collections\n\nimport gevent\nfrom gevent.pywsgi import ( # noqa: F401\n WSGIServer,\n)\nfrom gevent import ( # noqa: F401\n subprocess,\n socket,\n threading,\n)\n\nimport pylru\n\nfrom geventhttpclient import HTTPClient\n\nfrom web3.utils.six import urlparse\n\n\n_client_cache = pylru.lrucache(8)\n\n\nsleep = gevent.sleep\nspawn = gevent.spawn\nGreenletThread = gevent.Greenlet\n\n\nclass Timeout(gevent.Timeout):\n def check(self):\n pass\n\n def sleep(self, seconds):\n gevent.sleep(seconds)\n\n\ndef make_server(host, port, application, *args, **kwargs):\n server = WSGIServer((host, port), application, *args, **kwargs)\n return server\n\n\ndef _get_client(host, port, **kwargs):\n ordered_kwargs = collections.OrderedDict(sorted(kwargs.items()))\n cache_key = '{0}:{1}:{2}'.format(\n host,\n port,\n ':'.join((\n \"{0}={1}\".format(str(key), str(value))\n for key, value in ordered_kwargs.items()\n ))\n )\n if cache_key not in _client_cache:\n _client_cache[cache_key] = HTTPClient(host, port, **kwargs)\n return _client_cache[cache_key]\n\n\ndef make_post_request(endpoint_uri, data, **kwargs):\n url_parts = urlparse(endpoint_uri)\n\n host, _, port = url_parts.netloc.partition(':')\n\n if not port:\n if url_parts.scheme == 'http':\n port = 80\n elif url_parts.scheme == 'https':\n port = 443\n else:\n raise ValueError(\"Unsupported scheme: '{0}'\".format(url_parts.scheme))\n\n kwargs.setdefault('ssl', url_parts.scheme == 'https')\n kwargs.setdefault('connection_timeout', 10)\n kwargs.setdefault('network_timeout', 10)\n kwargs.setdefault('concurrency', 10)\n\n client = _get_client(host, port, **kwargs)\n response = client.post(url_parts.path, body=data)\n response_body = response.read()\n\n return response_body\n", "path": "web3/utils/compat/compat_gevent.py"}, {"content": "import functools\nimport warnings\n\n\nclass combomethod(object):\n def __init__(self, method):\n self.method = method\n\n def __get__(self, obj=None, objtype=None):\n @functools.wraps(self.method)\n def _wrapper(*args, **kwargs):\n if obj is not None:\n return self.method(obj, *args, **kwargs)\n else:\n return self.method(objtype, *args, **kwargs)\n return _wrapper\n\n\ndef reject_recursive_repeats(to_wrap):\n '''\n Prevent simple cycles by returning None when called recursively with same instance\n '''\n to_wrap.__already_called = {}\n\n @functools.wraps(to_wrap)\n def wrapped(*args):\n instances = tuple(map(id, args))\n if instances in to_wrap.__already_called:\n raise ValueError('Recursively called %s with %r' % (to_wrap, args))\n to_wrap.__already_called[instances] = True\n wrapped_val = to_wrap(*args)\n del to_wrap.__already_called[instances]\n return wrapped_val\n return wrapped\n\n\ndef deprecated_for(replace_message):\n '''\n Decorate a deprecated function, with info about what to use instead, like:\n\n @deprecated_for(\"toBytes()\")\n def toAscii(arg):\n ...\n '''\n def decorator(to_wrap):\n @functools.wraps(to_wrap)\n def wrapper(*args, **kwargs):\n warnings.simplefilter('always', DeprecationWarning)\n warnings.warn(\n \"%s is deprecated in favor of %s\" % (to_wrap.__name__, replace_message),\n category=DeprecationWarning,\n stacklevel=2)\n warnings.simplefilter('default', DeprecationWarning)\n return to_wrap(*args, **kwargs)\n return wrapper\n return decorator\n", "path": "web3/utils/decorators.py"}, {"content": "\"\"\"\nA minimal implementation of the various gevent APIs used within this codebase.\n\"\"\"\nimport time\nimport threading\nimport subprocess # noqa: F401\nimport socket # noqa: F401\nfrom wsgiref.simple_server import make_server # noqa: F401\n\n\nsleep = time.sleep\n\n\nclass Timeout(Exception):\n \"\"\"\n A limited subset of the `gevent.Timeout` context manager.\n \"\"\"\n seconds = None\n exception = None\n begun_at = None\n is_running = None\n\n def __init__(self, seconds=None, exception=None, *args, **kwargs):\n self.seconds = seconds\n self.exception = exception\n\n def __enter__(self):\n self.start()\n return self\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n return False\n\n def __str__(self):\n if self.seconds is None:\n return ''\n return \"{0} seconds\".format(self.seconds)\n\n @property\n def expire_at(self):\n if self.seconds is None:\n raise ValueError(\"Timeouts with `seconds == None` do not have an expiration time\")\n elif self.begun_at is None:\n raise ValueError(\"Timeout has not been started\")\n return self.begun_at + self.seconds\n\n def start(self):\n if self.is_running is not None:\n raise ValueError(\"Timeout has already been started\")\n self.begun_at = time.time()\n self.is_running = True\n\n def check(self):\n if self.is_running is None:\n raise ValueError(\"Timeout has not been started\")\n elif self.is_running is False:\n raise ValueError(\"Timeout has already been cancelled\")\n elif self.seconds is None:\n return\n elif time.time() > self.expire_at:\n self.is_running = False\n if isinstance(self.exception, type):\n raise self.exception(str(self))\n elif isinstance(self.exception, Exception):\n raise self.exception\n else:\n raise self\n\n def cancel(self):\n self.is_running = False\n\n def sleep(self, seconds):\n time.sleep(seconds)\n self.check()\n\n\nclass empty(object):\n pass\n\n\nclass ThreadWithReturn(threading.Thread):\n def __init__(self, target=None, args=None, kwargs=None):\n super(ThreadWithReturn, self).__init__(\n target=target,\n args=args or tuple(),\n kwargs=kwargs or {},\n )\n self.target = target\n self.args = args\n self.kwargs = kwargs\n\n def run(self):\n self._return = self.target(*self.args, **self.kwargs)\n\n def get(self, timeout=None):\n self.join(timeout)\n try:\n return self._return\n except AttributeError:\n raise RuntimeError(\"Something went wrong. No `_return` property was set\")\n\n\ndef spawn(target, thread_class=ThreadWithReturn, *args, **kwargs):\n thread = thread_class(\n target=target,\n args=args,\n kwargs=kwargs,\n )\n thread.daemon = True\n thread.start()\n return thread\n\n\nclass GreenletThread(threading.Thread):\n def __init__(self, target=None, args=None, kwargs=None):\n if target is None:\n target = self._run\n super(GreenletThread, self).__init__(\n target=target,\n args=args or tuple(),\n kwargs=kwargs or {},\n )\n self.daemon = True\n\n def _run(self):\n pass\n", "path": "web3/utils/compat/compat_stdlib.py"}]} | 3,959 | 616 |
gh_patches_debug_9646 | rasdani/github-patches | git_diff | Lightning-AI__torchmetrics-1303 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
SpearmanCorrCoef has unnecessary explicit dtype check
## 🐛 Bug
If you're running a model with `torch.cuda.amp.autocast` to `bf16`, you may have model outputs in `bf16` and labels in `fp32`, and then run `metric.compute()` outside of the autocast. Everything works completely fine for most (perhaps all other?) metrics, but `SpearmanCorrCoef` has an explicit check that the `dtype` of the `preds` and `target` are the same (https://github.com/Lightning-AI/metrics/blob/70a844f5aa598035eae50f3268563cfab103c62d/src/torchmetrics/functional/regression/spearman.py#L65). I do not think this check is necessary, because torch will automatically promote one of them when they are multiplied together, which is the only operation between the two tensors that happens while computing spearman. I may be missing something, but it would be great to remove this explicit check so that code using this metric does not need to explicitly cast the inputs, or to just handle the casting inside the metric if it is necessary for some reason.
### To Reproduce
```
In [1]: import torch
...: from torchmetrics import MeanSquaredError, SpearmanCorrCoef
...:
...: preds = torch.rand((100,), dtype=torch.bfloat16)
...: target = torch.rand((100,), dtype=torch.float)
...: fp32preds = preds.detach().clone().float()
...:
...: sp1 = SpearmanCorrCoef()
...: sp2 = SpearmanCorrCoef()
...:
...: # Spearman update errors
...: sp1.update(preds, target)
/workdisk/danielking/composer_venv/lib/python3.9/site-packages/torchmetrics/utilities/prints.py:36: UserWarning: Metric `SpearmanCorrcoef` will save all targets and predictions in the buffer. For large datasets, this may lead to large memory footprint.
warnings.warn(*args, **kwargs)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-1-162d7ed78d22> in <cell line: 12>()
10
11 # Spearman update errors
---> 12 sp1.update(preds, target)
13 sp2.update(fp32preds, target)
14 print(sp1.compute())
/workdisk/danielking/composer_venv/lib/python3.9/site-packages/torchmetrics/metric.py in wrapped_func(*args, **kwargs)
265 self._update_called = True
266 with torch.set_grad_enabled(self._enable_grad):
--> 267 return update(*args, **kwargs)
268
269 return wrapped_func
/workdisk/danielking/composer_venv/lib/python3.9/site-packages/torchmetrics/regression/spearman.py in update(self, preds, target)
88 target: Ground truth values
89 """
---> 90 preds, target = _spearman_corrcoef_update(preds, target)
91 self.preds.append(preds)
92 self.target.append(target)
/workdisk/danielking/composer_venv/lib/python3.9/site-packages/torchmetrics/functional/regression/spearman.py in _spearman_corrcoef_update(preds, target)
62
63 if preds.dtype != target.dtype:
---> 64 raise TypeError(
65 "Expected `preds` and `target` to have the same data type."
66 f" Got preds: {preds.dtype} and target: {target.dtype}."
TypeError: Expected `preds` and `target` to have the same data type. Got preds: torch.bfloat16 and target: torch.float32.
```
and if you comment out the dtype check
```
In [1]: import torch
...: from torchmetrics import MeanSquaredError, SpearmanCorrCoef
...:
...: preds = torch.rand((100,), dtype=torch.bfloat16)
...: target = torch.rand((100,), dtype=torch.float)
...: fp32preds = preds.detach().clone().float()
...:
...: sp1 = SpearmanCorrCoef()
...: sp2 = SpearmanCorrCoef()
...:
...: # Spearman update errors
...: sp1.update(preds, target)
...: sp2.update(fp32preds, target)
...:
...:
...: print(sp1.compute())
...: print(sp2.compute())
/workdisk/danielking/composer_venv/lib/python3.9/site-packages/torchmetrics/utilities/prints.py:36: UserWarning: Metric `SpearmanCorrcoef` will save all targets and predictions in the buffer. For large datasets, this may lead to large memory footprint.
warnings.warn(*args, **kwargs)
tensor(-0.0699)
tensor(-0.0699)
```
#### Code sample
See above
### Expected behavior
Spearman computation works with `preds` and `target` having different `dtype`.
### Environment
Checked that it is an issue on `0.10.1`, and the check still exists on master (linked above)
</issue>
<code>
[start of src/torchmetrics/functional/regression/spearman.py]
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from typing import Tuple
15
16 import torch
17 from torch import Tensor
18
19 from torchmetrics.utilities.checks import _check_same_shape
20
21
22 def _find_repeats(data: Tensor) -> Tensor:
23 """find and return values which have repeats i.e. the same value are more than once in the tensor."""
24 temp = data.detach().clone()
25 temp = temp.sort()[0]
26
27 change = torch.cat([torch.tensor([True], device=temp.device), temp[1:] != temp[:-1]])
28 unique = temp[change]
29 change_idx = torch.cat([torch.nonzero(change), torch.tensor([[temp.numel()]], device=temp.device)]).flatten()
30 freq = change_idx[1:] - change_idx[:-1]
31 atleast2 = freq > 1
32 return unique[atleast2]
33
34
35 def _rank_data(data: Tensor) -> Tensor:
36 """Calculate the rank for each element of a tensor.
37
38 The rank refers to the indices of an element in the corresponding sorted tensor (starting from 1).
39 Duplicates of the same value will be assigned the mean of their rank.
40
41 Adopted from `Rank of element tensor`_
42 """
43 n = data.numel()
44 rank = torch.empty_like(data)
45 idx = data.argsort()
46 rank[idx[:n]] = torch.arange(1, n + 1, dtype=data.dtype, device=data.device)
47
48 repeats = _find_repeats(data)
49 for r in repeats:
50 condition = data == r
51 rank[condition] = rank[condition].mean()
52 return rank
53
54
55 def _spearman_corrcoef_update(preds: Tensor, target: Tensor, num_outputs: int) -> Tuple[Tensor, Tensor]:
56 """Updates and returns variables required to compute Spearman Correlation Coefficient.
57
58 Checks for same shape and type of input tensors.
59
60 Args:
61 preds: Predicted tensor
62 target: Ground truth tensor
63 """
64
65 if preds.dtype != target.dtype:
66 raise TypeError(
67 "Expected `preds` and `target` to have the same data type."
68 f" Got preds: {preds.dtype} and target: {target.dtype}."
69 )
70 _check_same_shape(preds, target)
71 if preds.ndim > 2 or target.ndim > 2:
72 raise ValueError(
73 f"Expected both predictions and target to be either 1- or 2-dimensional tensors,"
74 f" but got {target.ndim} and {preds.ndim}."
75 )
76 if (num_outputs == 1 and preds.ndim != 1) or (num_outputs > 1 and num_outputs != preds.shape[-1]):
77 raise ValueError(
78 f"Expected argument `num_outputs` to match the second dimension of input, but got {num_outputs}"
79 f" and {preds.ndim}."
80 )
81
82 return preds, target
83
84
85 def _spearman_corrcoef_compute(preds: Tensor, target: Tensor, eps: float = 1e-6) -> Tensor:
86 """Computes Spearman Correlation Coefficient.
87
88 Args:
89 preds: Predicted tensor
90 target: Ground truth tensor
91 eps: Avoids ``ZeroDivisionError``.
92
93 Example:
94 >>> target = torch.tensor([3, -0.5, 2, 7])
95 >>> preds = torch.tensor([2.5, 0.0, 2, 8])
96 >>> preds, target = _spearman_corrcoef_update(preds, target, num_outputs=1)
97 >>> _spearman_corrcoef_compute(preds, target)
98 tensor(1.0000)
99 """
100 if preds.ndim == 1:
101 preds = _rank_data(preds)
102 target = _rank_data(target)
103 else:
104 preds = torch.stack([_rank_data(p) for p in preds.T]).T
105 target = torch.stack([_rank_data(t) for t in target.T]).T
106
107 preds_diff = preds - preds.mean(0)
108 target_diff = target - target.mean(0)
109
110 cov = (preds_diff * target_diff).mean(0)
111 preds_std = torch.sqrt((preds_diff * preds_diff).mean(0))
112 target_std = torch.sqrt((target_diff * target_diff).mean(0))
113
114 corrcoef = cov / (preds_std * target_std + eps)
115 return torch.clamp(corrcoef, -1.0, 1.0)
116
117
118 def spearman_corrcoef(preds: Tensor, target: Tensor) -> Tensor:
119 r"""Computes `spearmans rank correlation coefficient`_:
120
121 .. math:
122 r_s = = \frac{cov(rg_x, rg_y)}{\sigma_{rg_x} * \sigma_{rg_y}}
123
124 where :math:`rg_x` and :math:`rg_y` are the rank associated to the variables x and y. Spearmans correlations
125 coefficient corresponds to the standard pearsons correlation coefficient calculated on the rank variables.
126
127 Args:
128 preds: estimated scores
129 target: ground truth scores
130
131 Example (single output regression):
132 >>> from torchmetrics.functional import spearman_corrcoef
133 >>> target = torch.tensor([3, -0.5, 2, 7])
134 >>> preds = torch.tensor([2.5, 0.0, 2, 8])
135 >>> spearman_corrcoef(preds, target)
136 tensor(1.0000)
137
138 Example (multi output regression):
139 >>> from torchmetrics.functional import spearman_corrcoef
140 >>> target = torch.tensor([[3, -0.5], [2, 7]])
141 >>> preds = torch.tensor([[2.5, 0.0], [2, 8]])
142 >>> spearman_corrcoef(preds, target)
143 tensor([1.0000, 1.0000])
144 """
145 preds, target = _spearman_corrcoef_update(preds, target, num_outputs=1 if preds.ndim == 1 else preds.shape[-1])
146 return _spearman_corrcoef_compute(preds, target)
147
[end of src/torchmetrics/functional/regression/spearman.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/torchmetrics/functional/regression/spearman.py b/src/torchmetrics/functional/regression/spearman.py
--- a/src/torchmetrics/functional/regression/spearman.py
+++ b/src/torchmetrics/functional/regression/spearman.py
@@ -62,10 +62,9 @@
target: Ground truth tensor
"""
- if preds.dtype != target.dtype:
+ if not (preds.is_floating_point() and target.is_floating_point()):
raise TypeError(
- "Expected `preds` and `target` to have the same data type."
- f" Got preds: {preds.dtype} and target: {target.dtype}."
+ "Expected `preds` and `target` both to be floating point tensors, but got {pred.dtype} and {target.dtype}"
)
_check_same_shape(preds, target)
if preds.ndim > 2 or target.ndim > 2:
| {"golden_diff": "diff --git a/src/torchmetrics/functional/regression/spearman.py b/src/torchmetrics/functional/regression/spearman.py\n--- a/src/torchmetrics/functional/regression/spearman.py\n+++ b/src/torchmetrics/functional/regression/spearman.py\n@@ -62,10 +62,9 @@\n target: Ground truth tensor\n \"\"\"\n \n- if preds.dtype != target.dtype:\n+ if not (preds.is_floating_point() and target.is_floating_point()):\n raise TypeError(\n- \"Expected `preds` and `target` to have the same data type.\"\n- f\" Got preds: {preds.dtype} and target: {target.dtype}.\"\n+ \"Expected `preds` and `target` both to be floating point tensors, but got {pred.dtype} and {target.dtype}\"\n )\n _check_same_shape(preds, target)\n if preds.ndim > 2 or target.ndim > 2:\n", "issue": "SpearmanCorrCoef has unnecessary explicit dtype check\n## \ud83d\udc1b Bug\r\nIf you're running a model with `torch.cuda.amp.autocast` to `bf16`, you may have model outputs in `bf16` and labels in `fp32`, and then run `metric.compute()` outside of the autocast. Everything works completely fine for most (perhaps all other?) metrics, but `SpearmanCorrCoef` has an explicit check that the `dtype` of the `preds` and `target` are the same (https://github.com/Lightning-AI/metrics/blob/70a844f5aa598035eae50f3268563cfab103c62d/src/torchmetrics/functional/regression/spearman.py#L65). I do not think this check is necessary, because torch will automatically promote one of them when they are multiplied together, which is the only operation between the two tensors that happens while computing spearman. I may be missing something, but it would be great to remove this explicit check so that code using this metric does not need to explicitly cast the inputs, or to just handle the casting inside the metric if it is necessary for some reason.\r\n\r\n### To Reproduce\r\n```\r\nIn [1]: import torch\r\n ...: from torchmetrics import MeanSquaredError, SpearmanCorrCoef\r\n ...: \r\n ...: preds = torch.rand((100,), dtype=torch.bfloat16)\r\n ...: target = torch.rand((100,), dtype=torch.float)\r\n ...: fp32preds = preds.detach().clone().float()\r\n ...: \r\n ...: sp1 = SpearmanCorrCoef()\r\n ...: sp2 = SpearmanCorrCoef()\r\n ...: \r\n ...: # Spearman update errors\r\n ...: sp1.update(preds, target)\r\n/workdisk/danielking/composer_venv/lib/python3.9/site-packages/torchmetrics/utilities/prints.py:36: UserWarning: Metric `SpearmanCorrcoef` will save all targets and predictions in the buffer. For large datasets, this may lead to large memory footprint.\r\n warnings.warn(*args, **kwargs)\r\n---------------------------------------------------------------------------\r\nTypeError Traceback (most recent call last)\r\n<ipython-input-1-162d7ed78d22> in <cell line: 12>()\r\n 10 \r\n 11 # Spearman update errors\r\n---> 12 sp1.update(preds, target)\r\n 13 sp2.update(fp32preds, target)\r\n 14 print(sp1.compute())\r\n\r\n/workdisk/danielking/composer_venv/lib/python3.9/site-packages/torchmetrics/metric.py in wrapped_func(*args, **kwargs)\r\n 265 self._update_called = True\r\n 266 with torch.set_grad_enabled(self._enable_grad):\r\n--> 267 return update(*args, **kwargs)\r\n 268 \r\n 269 return wrapped_func\r\n\r\n/workdisk/danielking/composer_venv/lib/python3.9/site-packages/torchmetrics/regression/spearman.py in update(self, preds, target)\r\n 88 target: Ground truth values\r\n 89 \"\"\"\r\n---> 90 preds, target = _spearman_corrcoef_update(preds, target)\r\n 91 self.preds.append(preds)\r\n 92 self.target.append(target)\r\n\r\n/workdisk/danielking/composer_venv/lib/python3.9/site-packages/torchmetrics/functional/regression/spearman.py in _spearman_corrcoef_update(preds, target)\r\n 62 \r\n 63 if preds.dtype != target.dtype:\r\n---> 64 raise TypeError(\r\n 65 \"Expected `preds` and `target` to have the same data type.\"\r\n 66 f\" Got preds: {preds.dtype} and target: {target.dtype}.\"\r\n\r\nTypeError: Expected `preds` and `target` to have the same data type. Got preds: torch.bfloat16 and target: torch.float32.\r\n```\r\n\r\nand if you comment out the dtype check\r\n```\r\nIn [1]: import torch\r\n ...: from torchmetrics import MeanSquaredError, SpearmanCorrCoef\r\n ...: \r\n ...: preds = torch.rand((100,), dtype=torch.bfloat16)\r\n ...: target = torch.rand((100,), dtype=torch.float)\r\n ...: fp32preds = preds.detach().clone().float()\r\n ...: \r\n ...: sp1 = SpearmanCorrCoef()\r\n ...: sp2 = SpearmanCorrCoef()\r\n ...: \r\n ...: # Spearman update errors\r\n ...: sp1.update(preds, target)\r\n ...: sp2.update(fp32preds, target)\r\n ...: \r\n ...: \r\n ...: print(sp1.compute())\r\n ...: print(sp2.compute())\r\n/workdisk/danielking/composer_venv/lib/python3.9/site-packages/torchmetrics/utilities/prints.py:36: UserWarning: Metric `SpearmanCorrcoef` will save all targets and predictions in the buffer. For large datasets, this may lead to large memory footprint.\r\n warnings.warn(*args, **kwargs)\r\ntensor(-0.0699)\r\ntensor(-0.0699)\r\n```\r\n\r\n#### Code sample\r\nSee above\r\n\r\n### Expected behavior\r\nSpearman computation works with `preds` and `target` having different `dtype`.\r\n\r\n### Environment\r\nChecked that it is an issue on `0.10.1`, and the check still exists on master (linked above)\r\n\r\n\n", "before_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom typing import Tuple\n\nimport torch\nfrom torch import Tensor\n\nfrom torchmetrics.utilities.checks import _check_same_shape\n\n\ndef _find_repeats(data: Tensor) -> Tensor:\n \"\"\"find and return values which have repeats i.e. the same value are more than once in the tensor.\"\"\"\n temp = data.detach().clone()\n temp = temp.sort()[0]\n\n change = torch.cat([torch.tensor([True], device=temp.device), temp[1:] != temp[:-1]])\n unique = temp[change]\n change_idx = torch.cat([torch.nonzero(change), torch.tensor([[temp.numel()]], device=temp.device)]).flatten()\n freq = change_idx[1:] - change_idx[:-1]\n atleast2 = freq > 1\n return unique[atleast2]\n\n\ndef _rank_data(data: Tensor) -> Tensor:\n \"\"\"Calculate the rank for each element of a tensor.\n\n The rank refers to the indices of an element in the corresponding sorted tensor (starting from 1).\n Duplicates of the same value will be assigned the mean of their rank.\n\n Adopted from `Rank of element tensor`_\n \"\"\"\n n = data.numel()\n rank = torch.empty_like(data)\n idx = data.argsort()\n rank[idx[:n]] = torch.arange(1, n + 1, dtype=data.dtype, device=data.device)\n\n repeats = _find_repeats(data)\n for r in repeats:\n condition = data == r\n rank[condition] = rank[condition].mean()\n return rank\n\n\ndef _spearman_corrcoef_update(preds: Tensor, target: Tensor, num_outputs: int) -> Tuple[Tensor, Tensor]:\n \"\"\"Updates and returns variables required to compute Spearman Correlation Coefficient.\n\n Checks for same shape and type of input tensors.\n\n Args:\n preds: Predicted tensor\n target: Ground truth tensor\n \"\"\"\n\n if preds.dtype != target.dtype:\n raise TypeError(\n \"Expected `preds` and `target` to have the same data type.\"\n f\" Got preds: {preds.dtype} and target: {target.dtype}.\"\n )\n _check_same_shape(preds, target)\n if preds.ndim > 2 or target.ndim > 2:\n raise ValueError(\n f\"Expected both predictions and target to be either 1- or 2-dimensional tensors,\"\n f\" but got {target.ndim} and {preds.ndim}.\"\n )\n if (num_outputs == 1 and preds.ndim != 1) or (num_outputs > 1 and num_outputs != preds.shape[-1]):\n raise ValueError(\n f\"Expected argument `num_outputs` to match the second dimension of input, but got {num_outputs}\"\n f\" and {preds.ndim}.\"\n )\n\n return preds, target\n\n\ndef _spearman_corrcoef_compute(preds: Tensor, target: Tensor, eps: float = 1e-6) -> Tensor:\n \"\"\"Computes Spearman Correlation Coefficient.\n\n Args:\n preds: Predicted tensor\n target: Ground truth tensor\n eps: Avoids ``ZeroDivisionError``.\n\n Example:\n >>> target = torch.tensor([3, -0.5, 2, 7])\n >>> preds = torch.tensor([2.5, 0.0, 2, 8])\n >>> preds, target = _spearman_corrcoef_update(preds, target, num_outputs=1)\n >>> _spearman_corrcoef_compute(preds, target)\n tensor(1.0000)\n \"\"\"\n if preds.ndim == 1:\n preds = _rank_data(preds)\n target = _rank_data(target)\n else:\n preds = torch.stack([_rank_data(p) for p in preds.T]).T\n target = torch.stack([_rank_data(t) for t in target.T]).T\n\n preds_diff = preds - preds.mean(0)\n target_diff = target - target.mean(0)\n\n cov = (preds_diff * target_diff).mean(0)\n preds_std = torch.sqrt((preds_diff * preds_diff).mean(0))\n target_std = torch.sqrt((target_diff * target_diff).mean(0))\n\n corrcoef = cov / (preds_std * target_std + eps)\n return torch.clamp(corrcoef, -1.0, 1.0)\n\n\ndef spearman_corrcoef(preds: Tensor, target: Tensor) -> Tensor:\n r\"\"\"Computes `spearmans rank correlation coefficient`_:\n\n .. math:\n r_s = = \\frac{cov(rg_x, rg_y)}{\\sigma_{rg_x} * \\sigma_{rg_y}}\n\n where :math:`rg_x` and :math:`rg_y` are the rank associated to the variables x and y. Spearmans correlations\n coefficient corresponds to the standard pearsons correlation coefficient calculated on the rank variables.\n\n Args:\n preds: estimated scores\n target: ground truth scores\n\n Example (single output regression):\n >>> from torchmetrics.functional import spearman_corrcoef\n >>> target = torch.tensor([3, -0.5, 2, 7])\n >>> preds = torch.tensor([2.5, 0.0, 2, 8])\n >>> spearman_corrcoef(preds, target)\n tensor(1.0000)\n\n Example (multi output regression):\n >>> from torchmetrics.functional import spearman_corrcoef\n >>> target = torch.tensor([[3, -0.5], [2, 7]])\n >>> preds = torch.tensor([[2.5, 0.0], [2, 8]])\n >>> spearman_corrcoef(preds, target)\n tensor([1.0000, 1.0000])\n \"\"\"\n preds, target = _spearman_corrcoef_update(preds, target, num_outputs=1 if preds.ndim == 1 else preds.shape[-1])\n return _spearman_corrcoef_compute(preds, target)\n", "path": "src/torchmetrics/functional/regression/spearman.py"}]} | 3,565 | 210 |
gh_patches_debug_2066 | rasdani/github-patches | git_diff | scikit-image__scikit-image-3152 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
skimage.test does not execute the unit test
## Description
`skimage.test` does not run the unit tests.
```
~$ python -c "import skimage; print(skimage.__version__); skimage.test()"
0.14.0
====================================================================== test session starts ======================================================================
platform linux -- Python 3.6.5, pytest-3.6.1, py-1.5.3, pluggy-0.6.0
rootdir: /home/jhelmus, inifile:
================================================================= no tests ran in 0.00 seconds ==================================================================
ERROR: file not found: skimage
```
<details><summary>Environment Details</summary>
```
$ conda info
active environment : sktest
active env location : /home/jhelmus/anaconda3/envs/sktest
shell level : 1
user config file : /home/jhelmus/.condarc
populated config files : /home/jhelmus/.condarc
conda version : 4.5.4
conda-build version : 3.9.1
python version : 3.6.4.final.0
base environment : /home/jhelmus/anaconda3 (writable)
channel URLs : https://repo.anaconda.com/pkgs/main/linux-64
https://repo.anaconda.com/pkgs/main/noarch
https://repo.anaconda.com/pkgs/free/linux-64
https://repo.anaconda.com/pkgs/free/noarch
https://repo.anaconda.com/pkgs/r/linux-64
https://repo.anaconda.com/pkgs/r/noarch
https://repo.anaconda.com/pkgs/pro/linux-64
https://repo.anaconda.com/pkgs/pro/noarch
package cache : /home/jhelmus/anaconda3/pkgs
/home/jhelmus/.conda/pkgs
envs directories : /home/jhelmus/anaconda3/envs
/home/jhelmus/.conda/envs
platform : linux-64
user-agent : conda/4.5.4 requests/2.18.4 CPython/3.6.4 Linux/4.13.0-41-generic ubuntu/16.04 glibc/2.23
UID:GID : 1000:1000
netrc file : None
offline mode : False
$ conda create -n sktest python=3.6 pip
Solving environment: done
## Package Plan ##
environment location: /home/jhelmus/anaconda3/envs/sktest
added / updated specs:
- pip
- python=3.6
The following NEW packages will be INSTALLED:
ca-certificates: 2018.03.07-0 defaults
certifi: 2018.4.16-py36_0 defaults
libedit: 3.1.20170329-h6b74fdf_2 defaults
libffi: 3.2.1-hd88cf55_4 defaults
libgcc-ng: 7.2.0-hdf63c60_3 defaults
libstdcxx-ng: 7.2.0-hdf63c60_3 defaults
ncurses: 6.1-hf484d3e_0 defaults
openssl: 1.0.2o-h20670df_0 defaults
pip: 10.0.1-py36_0 defaults
python: 3.6.5-hc3d631a_2 defaults
readline: 7.0-ha6073c6_4 defaults
setuptools: 39.2.0-py36_0 defaults
sqlite: 3.23.1-he433501_0 defaults
tk: 8.6.7-hc745277_3 defaults
wheel: 0.31.1-py36_0 defaults
xz: 5.2.4-h14c3975_4 defaults
zlib: 1.2.11-ha838bed_2 defaults
Proceed ([y]/n)? y
...
$ pip install scikit-image
Collecting scikit-image
Using cached https://files.pythonhosted.org/packages/34/79/cefff573a53ca3fb4c390739d19541b95f371e24d2990aed4cd8837971f0/scikit_image-0.14.0-cp36-cp36m-manylinux1_x86_64.whl
...
Successfully installed PyWavelets-0.5.2 cloudpickle-0.5.3 cycler-0.10.0 dask-0.17.5 decorator-4.3.0 kiwisolver-1.0.1 matplotlib-2.2.2 networkx-2.1 numpy-1.14.3 pillow-5.1.0 pyparsing-2.2.0 python-dateutil-2.7.3 pytz-2018.4 scikit-image-0.14.0 scipy-1.1.0 six-1.11.0 toolz-0.9.0
$ pip install pytest
Collecting pytest
Using cached https://files.pythonhosted.org/packages/d3/75/e79b66c9fe6166a90004bb8fb02bab06213c3348e93f3be41d7eaf625554/pytest-3.6.1-py2.py3-none-any.whl
Collecting pluggy<0.7,>=0.5 (from pytest)
...
Successfully installed atomicwrites-1.1.5 attrs-18.1.0 more-itertools-4.2.0 pluggy-0.6.0 py-1.5.3 pytest-3.6.1
```
</details>
## Way to reproduce
- [x] Code example
- [ ] Relevant images (if any)
- [x] Operating system and version
- [x] Python version
- [x] scikit-image version (run `skimage.__version__`)
This has been observed on conda-forge, see conda-forge/scikit-image-feedstock#23
</issue>
<code>
[start of skimage/__init__.py]
1 """Image Processing SciKit (Toolbox for SciPy)
2
3 ``scikit-image`` (a.k.a. ``skimage``) is a collection of algorithms for image
4 processing and computer vision.
5
6 The main package of ``skimage`` only provides a few utilities for converting
7 between image data types; for most features, you need to import one of the
8 following subpackages:
9
10 Subpackages
11 -----------
12 color
13 Color space conversion.
14 data
15 Test images and example data.
16 draw
17 Drawing primitives (lines, text, etc.) that operate on NumPy arrays.
18 exposure
19 Image intensity adjustment, e.g., histogram equalization, etc.
20 feature
21 Feature detection and extraction, e.g., texture analysis corners, etc.
22 filters
23 Sharpening, edge finding, rank filters, thresholding, etc.
24 graph
25 Graph-theoretic operations, e.g., shortest paths.
26 io
27 Reading, saving, and displaying images and video.
28 measure
29 Measurement of image properties, e.g., similarity and contours.
30 morphology
31 Morphological operations, e.g., opening or skeletonization.
32 novice
33 Simplified interface for teaching purposes.
34 restoration
35 Restoration algorithms, e.g., deconvolution algorithms, denoising, etc.
36 segmentation
37 Partitioning an image into multiple regions.
38 transform
39 Geometric and other transforms, e.g., rotation or the Radon transform.
40 util
41 Generic utilities.
42 viewer
43 A simple graphical user interface for visualizing results and exploring
44 parameters.
45
46 Utility Functions
47 -----------------
48 img_as_float
49 Convert an image to floating point format, with values in [0, 1].
50 img_as_uint
51 Convert an image to unsigned integer format, with values in [0, 65535].
52 img_as_int
53 Convert an image to signed integer format, with values in [-32768, 32767].
54 img_as_ubyte
55 Convert an image to unsigned byte format, with values in [0, 255].
56
57 """
58
59 import os.path as osp
60 import imp
61 import functools
62 import warnings
63 import sys
64
65 pkg_dir = osp.abspath(osp.dirname(__file__))
66 data_dir = osp.join(pkg_dir, 'data')
67
68 __version__ = '0.15dev'
69
70
71 if sys.version_info < (3,):
72 raise ImportError("""
73
74 You are running scikit-image on Python 2.
75
76 Unfortunately, scikit-image 0.15 and above no longer work on this
77 version of Python. You therefore have two options: either upgrade to
78 Python 3, or install an older version of scikit-image using
79
80 $ pip install 'scikit-image<0.15'
81
82 Please also consider updating `pip` and `setuptools`:
83
84 $ pip install pip setuptools --upgrade
85
86 Newer versions of these tools avoid installing packages incompatible
87 with your version of Python.
88 """)
89
90
91 try:
92 imp.find_module('pytest')
93 except ImportError:
94 def _test(doctest=False, verbose=False):
95 """This would run all unit tests, but pytest couldn't be
96 imported so the test suite can not run.
97 """
98 raise ImportError("Could not load pytest. Unit tests not available.")
99
100 else:
101 def _test(doctest=False, verbose=False):
102 """Run all unit tests."""
103 import pytest
104 import warnings
105 args = ['skimage']
106 if verbose:
107 args.extend(['-v', '-s'])
108 if doctest:
109 args.extend(['--doctest-modules'])
110 # Make sure warnings do not break the doc tests
111 with warnings.catch_warnings():
112 warnings.simplefilter("ignore")
113 success = pytest.main(args)
114 else:
115 success = pytest.main(args)
116 # Return sys.exit code
117 if success:
118 return 0
119 else:
120 return 1
121
122
123 # do not use `test` as function name as this leads to a recursion problem with
124 # the nose test suite
125 test = _test
126 test_verbose = functools.partial(test, verbose=True)
127 test_verbose.__doc__ = test.__doc__
128 doctest = functools.partial(test, doctest=True)
129 doctest.__doc__ = doctest.__doc__
130 doctest_verbose = functools.partial(test, doctest=True, verbose=True)
131 doctest_verbose.__doc__ = doctest.__doc__
132
133
134 # Logic for checking for improper install and importing while in the source
135 # tree when package has not been installed inplace.
136 # Code adapted from scikit-learn's __check_build module.
137 _INPLACE_MSG = """
138 It appears that you are importing a local scikit-image source tree. For
139 this, you need to have an inplace install. Maybe you are in the source
140 directory and you need to try from another location."""
141
142 _STANDARD_MSG = """
143 Your install of scikit-image appears to be broken.
144 Try re-installing the package following the instructions at:
145 http://scikit-image.org/docs/stable/install.html """
146
147
148 def _raise_build_error(e):
149 # Raise a comprehensible error
150 local_dir = osp.split(__file__)[0]
151 msg = _STANDARD_MSG
152 if local_dir == "skimage":
153 # Picking up the local install: this will work only if the
154 # install is an 'inplace build'
155 msg = _INPLACE_MSG
156 raise ImportError("""%s
157 It seems that scikit-image has not been built correctly.
158 %s""" % (e, msg))
159
160 try:
161 # This variable is injected in the __builtins__ by the build
162 # process. It used to enable importing subpackages of skimage when
163 # the binaries are not built
164 __SKIMAGE_SETUP__
165 except NameError:
166 __SKIMAGE_SETUP__ = False
167
168 if __SKIMAGE_SETUP__:
169 sys.stderr.write('Partial import of skimage during the build process.\n')
170 # We are not importing the rest of the scikit during the build
171 # process, as it may not be compiled yet
172 else:
173 try:
174 from ._shared import geometry
175 del geometry
176 except ImportError as e:
177 _raise_build_error(e)
178 from .util.dtype import *
179
180
181 def lookfor(what):
182 """Do a keyword search on scikit-image docstrings.
183
184 Parameters
185 ----------
186 what : str
187 Words to look for.
188
189 """
190 import numpy as np
191 import sys
192 return np.lookfor(what, sys.modules[__name__])
193
194
195 del warnings, functools, osp, imp, sys
196
[end of skimage/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/skimage/__init__.py b/skimage/__init__.py
--- a/skimage/__init__.py
+++ b/skimage/__init__.py
@@ -102,7 +102,7 @@
"""Run all unit tests."""
import pytest
import warnings
- args = ['skimage']
+ args = ['--pyargs', 'skimage']
if verbose:
args.extend(['-v', '-s'])
if doctest:
| {"golden_diff": "diff --git a/skimage/__init__.py b/skimage/__init__.py\n--- a/skimage/__init__.py\n+++ b/skimage/__init__.py\n@@ -102,7 +102,7 @@\n \"\"\"Run all unit tests.\"\"\"\n import pytest\n import warnings\n- args = ['skimage']\n+ args = ['--pyargs', 'skimage']\n if verbose:\n args.extend(['-v', '-s'])\n if doctest:\n", "issue": "skimage.test does not execute the unit test\n## Description\r\n\r\n`skimage.test` does not run the unit tests. \r\n\r\n```\r\n~$ python -c \"import skimage; print(skimage.__version__); skimage.test()\"\r\n0.14.0\r\n====================================================================== test session starts ======================================================================\r\nplatform linux -- Python 3.6.5, pytest-3.6.1, py-1.5.3, pluggy-0.6.0\r\nrootdir: /home/jhelmus, inifile:\r\n\r\n================================================================= no tests ran in 0.00 seconds ==================================================================\r\nERROR: file not found: skimage\r\n```\r\n\r\n<details><summary>Environment Details</summary>\r\n\r\n```\r\n$ conda info\r\n\r\n active environment : sktest\r\n active env location : /home/jhelmus/anaconda3/envs/sktest\r\n shell level : 1\r\n user config file : /home/jhelmus/.condarc\r\n populated config files : /home/jhelmus/.condarc\r\n conda version : 4.5.4\r\n conda-build version : 3.9.1\r\n python version : 3.6.4.final.0\r\n base environment : /home/jhelmus/anaconda3 (writable)\r\n channel URLs : https://repo.anaconda.com/pkgs/main/linux-64\r\n https://repo.anaconda.com/pkgs/main/noarch\r\n https://repo.anaconda.com/pkgs/free/linux-64\r\n https://repo.anaconda.com/pkgs/free/noarch\r\n https://repo.anaconda.com/pkgs/r/linux-64\r\n https://repo.anaconda.com/pkgs/r/noarch\r\n https://repo.anaconda.com/pkgs/pro/linux-64\r\n https://repo.anaconda.com/pkgs/pro/noarch\r\n package cache : /home/jhelmus/anaconda3/pkgs\r\n /home/jhelmus/.conda/pkgs\r\n envs directories : /home/jhelmus/anaconda3/envs\r\n /home/jhelmus/.conda/envs\r\n platform : linux-64\r\n user-agent : conda/4.5.4 requests/2.18.4 CPython/3.6.4 Linux/4.13.0-41-generic ubuntu/16.04 glibc/2.23\r\n UID:GID : 1000:1000\r\n netrc file : None\r\n offline mode : False\r\n$ conda create -n sktest python=3.6 pip\r\nSolving environment: done\r\n\r\n## Package Plan ##\r\n\r\n environment location: /home/jhelmus/anaconda3/envs/sktest\r\n\r\n added / updated specs: \r\n - pip\r\n - python=3.6\r\n\r\n\r\nThe following NEW packages will be INSTALLED:\r\n\r\n ca-certificates: 2018.03.07-0 defaults\r\n certifi: 2018.4.16-py36_0 defaults\r\n libedit: 3.1.20170329-h6b74fdf_2 defaults\r\n libffi: 3.2.1-hd88cf55_4 defaults\r\n libgcc-ng: 7.2.0-hdf63c60_3 defaults\r\n libstdcxx-ng: 7.2.0-hdf63c60_3 defaults\r\n ncurses: 6.1-hf484d3e_0 defaults\r\n openssl: 1.0.2o-h20670df_0 defaults\r\n pip: 10.0.1-py36_0 defaults\r\n python: 3.6.5-hc3d631a_2 defaults\r\n readline: 7.0-ha6073c6_4 defaults\r\n setuptools: 39.2.0-py36_0 defaults\r\n sqlite: 3.23.1-he433501_0 defaults\r\n tk: 8.6.7-hc745277_3 defaults\r\n wheel: 0.31.1-py36_0 defaults\r\n xz: 5.2.4-h14c3975_4 defaults\r\n zlib: 1.2.11-ha838bed_2 defaults\r\n\r\nProceed ([y]/n)? y\r\n...\r\n$ pip install scikit-image\r\nCollecting scikit-image\r\n Using cached https://files.pythonhosted.org/packages/34/79/cefff573a53ca3fb4c390739d19541b95f371e24d2990aed4cd8837971f0/scikit_image-0.14.0-cp36-cp36m-manylinux1_x86_64.whl\r\n...\r\nSuccessfully installed PyWavelets-0.5.2 cloudpickle-0.5.3 cycler-0.10.0 dask-0.17.5 decorator-4.3.0 kiwisolver-1.0.1 matplotlib-2.2.2 networkx-2.1 numpy-1.14.3 pillow-5.1.0 pyparsing-2.2.0 python-dateutil-2.7.3 pytz-2018.4 scikit-image-0.14.0 scipy-1.1.0 six-1.11.0 toolz-0.9.0\r\n$ pip install pytest\r\nCollecting pytest\r\n Using cached https://files.pythonhosted.org/packages/d3/75/e79b66c9fe6166a90004bb8fb02bab06213c3348e93f3be41d7eaf625554/pytest-3.6.1-py2.py3-none-any.whl\r\nCollecting pluggy<0.7,>=0.5 (from pytest)\r\n...\r\nSuccessfully installed atomicwrites-1.1.5 attrs-18.1.0 more-itertools-4.2.0 pluggy-0.6.0 py-1.5.3 pytest-3.6.1\r\n```\r\n\r\n</details>\r\n\r\n\r\n## Way to reproduce\r\n\r\n- [x] Code example\r\n- [ ] Relevant images (if any)\r\n- [x] Operating system and version\r\n- [x] Python version\r\n- [x] scikit-image version (run `skimage.__version__`)\r\n\r\nThis has been observed on conda-forge, see conda-forge/scikit-image-feedstock#23\r\n\n", "before_files": [{"content": "\"\"\"Image Processing SciKit (Toolbox for SciPy)\n\n``scikit-image`` (a.k.a. ``skimage``) is a collection of algorithms for image\nprocessing and computer vision.\n\nThe main package of ``skimage`` only provides a few utilities for converting\nbetween image data types; for most features, you need to import one of the\nfollowing subpackages:\n\nSubpackages\n-----------\ncolor\n Color space conversion.\ndata\n Test images and example data.\ndraw\n Drawing primitives (lines, text, etc.) that operate on NumPy arrays.\nexposure\n Image intensity adjustment, e.g., histogram equalization, etc.\nfeature\n Feature detection and extraction, e.g., texture analysis corners, etc.\nfilters\n Sharpening, edge finding, rank filters, thresholding, etc.\ngraph\n Graph-theoretic operations, e.g., shortest paths.\nio\n Reading, saving, and displaying images and video.\nmeasure\n Measurement of image properties, e.g., similarity and contours.\nmorphology\n Morphological operations, e.g., opening or skeletonization.\nnovice\n Simplified interface for teaching purposes.\nrestoration\n Restoration algorithms, e.g., deconvolution algorithms, denoising, etc.\nsegmentation\n Partitioning an image into multiple regions.\ntransform\n Geometric and other transforms, e.g., rotation or the Radon transform.\nutil\n Generic utilities.\nviewer\n A simple graphical user interface for visualizing results and exploring\n parameters.\n\nUtility Functions\n-----------------\nimg_as_float\n Convert an image to floating point format, with values in [0, 1].\nimg_as_uint\n Convert an image to unsigned integer format, with values in [0, 65535].\nimg_as_int\n Convert an image to signed integer format, with values in [-32768, 32767].\nimg_as_ubyte\n Convert an image to unsigned byte format, with values in [0, 255].\n\n\"\"\"\n\nimport os.path as osp\nimport imp\nimport functools\nimport warnings\nimport sys\n\npkg_dir = osp.abspath(osp.dirname(__file__))\ndata_dir = osp.join(pkg_dir, 'data')\n\n__version__ = '0.15dev'\n\n\nif sys.version_info < (3,):\n raise ImportError(\"\"\"\n\nYou are running scikit-image on Python 2.\n\nUnfortunately, scikit-image 0.15 and above no longer work on this\nversion of Python. You therefore have two options: either upgrade to\nPython 3, or install an older version of scikit-image using\n\n $ pip install 'scikit-image<0.15'\n\nPlease also consider updating `pip` and `setuptools`:\n\n $ pip install pip setuptools --upgrade\n\nNewer versions of these tools avoid installing packages incompatible\nwith your version of Python.\n\"\"\")\n\n\ntry:\n imp.find_module('pytest')\nexcept ImportError:\n def _test(doctest=False, verbose=False):\n \"\"\"This would run all unit tests, but pytest couldn't be\n imported so the test suite can not run.\n \"\"\"\n raise ImportError(\"Could not load pytest. Unit tests not available.\")\n\nelse:\n def _test(doctest=False, verbose=False):\n \"\"\"Run all unit tests.\"\"\"\n import pytest\n import warnings\n args = ['skimage']\n if verbose:\n args.extend(['-v', '-s'])\n if doctest:\n args.extend(['--doctest-modules'])\n # Make sure warnings do not break the doc tests\n with warnings.catch_warnings():\n warnings.simplefilter(\"ignore\")\n success = pytest.main(args)\n else:\n success = pytest.main(args)\n # Return sys.exit code\n if success:\n return 0\n else:\n return 1\n\n\n# do not use `test` as function name as this leads to a recursion problem with\n# the nose test suite\ntest = _test\ntest_verbose = functools.partial(test, verbose=True)\ntest_verbose.__doc__ = test.__doc__\ndoctest = functools.partial(test, doctest=True)\ndoctest.__doc__ = doctest.__doc__\ndoctest_verbose = functools.partial(test, doctest=True, verbose=True)\ndoctest_verbose.__doc__ = doctest.__doc__\n\n\n# Logic for checking for improper install and importing while in the source\n# tree when package has not been installed inplace.\n# Code adapted from scikit-learn's __check_build module.\n_INPLACE_MSG = \"\"\"\nIt appears that you are importing a local scikit-image source tree. For\nthis, you need to have an inplace install. Maybe you are in the source\ndirectory and you need to try from another location.\"\"\"\n\n_STANDARD_MSG = \"\"\"\nYour install of scikit-image appears to be broken.\nTry re-installing the package following the instructions at:\nhttp://scikit-image.org/docs/stable/install.html \"\"\"\n\n\ndef _raise_build_error(e):\n # Raise a comprehensible error\n local_dir = osp.split(__file__)[0]\n msg = _STANDARD_MSG\n if local_dir == \"skimage\":\n # Picking up the local install: this will work only if the\n # install is an 'inplace build'\n msg = _INPLACE_MSG\n raise ImportError(\"\"\"%s\nIt seems that scikit-image has not been built correctly.\n%s\"\"\" % (e, msg))\n\ntry:\n # This variable is injected in the __builtins__ by the build\n # process. It used to enable importing subpackages of skimage when\n # the binaries are not built\n __SKIMAGE_SETUP__\nexcept NameError:\n __SKIMAGE_SETUP__ = False\n\nif __SKIMAGE_SETUP__:\n sys.stderr.write('Partial import of skimage during the build process.\\n')\n # We are not importing the rest of the scikit during the build\n # process, as it may not be compiled yet\nelse:\n try:\n from ._shared import geometry\n del geometry\n except ImportError as e:\n _raise_build_error(e)\n from .util.dtype import *\n\n\ndef lookfor(what):\n \"\"\"Do a keyword search on scikit-image docstrings.\n\n Parameters\n ----------\n what : str\n Words to look for.\n\n \"\"\"\n import numpy as np\n import sys\n return np.lookfor(what, sys.modules[__name__])\n\n\ndel warnings, functools, osp, imp, sys\n", "path": "skimage/__init__.py"}]} | 3,918 | 109 |
gh_patches_debug_30986 | rasdani/github-patches | git_diff | googleapis__google-cloud-python-3756 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
datastore: No way to exclude_from_indexes new properties on updated entities
When loading an `Entity` from the datastore and updating it, there is no way to exclude new attributes from being indexed, since the only public API for setting `exclude_from_indexes` is on the `Entity` constructor. To work around this, I am currently setting `entity._exclude_from_indexes = (...)` in my code, which is not a "public" API.
Example:
```python
client = google.cloud.datastore.Client()
key = client.key('SomeEntityKey')
entity = google.cloud.datastore.Entity(key, exclude_from_indexes=('foo', 'bar'))
entity['foo'] = 'foo'
print 'entity.exclude_from_indexes:', entity.exclude_from_indexes
client.put(entity)
entity2 = client.get(entity.key)
print 'entity2.exclude_from_indexes:', entity2.exclude_from_indexes
entity2['bar'] = 'bar'
client.put(entity2)
```
Output:
```
entity.exclude_from_indexes: frozenset(['foo', 'bar'])
entity2.exclude_from_indexes: frozenset([u'foo'])
```
This is actually "expected" based on how the Datastore works, however, in the code sample above, there should be some way for me to put the entity back, without copying it into a brand new `Entity`.
Tested using:
* Mac OS X 10.11.6
* Python 2.7.10
* The following Google packages:
```
gapic-google-cloud-datastore-v1==0.15.3
google-auth==1.0.1
google-auth-httplib2==0.0.2
google-cloud-core==0.24.1
google-cloud-datastore==1.0.0
google-cloud-storage==1.1.1
google-gax==0.15.13
google-resumable-media==0.0.2
googleapis-common-protos==1.5.2
proto-google-cloud-datastore-v1==0.90.4
```
</issue>
<code>
[start of datastore/google/cloud/datastore/entity.py]
1 # Copyright 2014 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Class for representing a single entity in the Cloud Datastore."""
16
17
18 from google.cloud._helpers import _ensure_tuple_or_list
19
20
21 class Entity(dict):
22 """Entities are akin to rows in a relational database
23
24 An entity storing the actual instance of data.
25
26 Each entity is officially represented with a
27 :class:`~google.cloud.datastore.key.Key`, however it is possible that
28 you might create an entity with only a partial key (that is, a key
29 with a kind, and possibly a parent, but without an ID). In such a
30 case, the datastore service will automatically assign an ID to the
31 partial key.
32
33 Entities in this API act like dictionaries with extras built in that
34 allow you to delete or persist the data stored on the entity.
35
36 Entities are mutable and act like a subclass of a dictionary.
37 This means you could take an existing entity and change the key
38 to duplicate the object.
39
40 Use :meth:`~google.cloud.datastore.client.Client.get` to retrieve an
41 existing entity:
42
43 .. testsetup:: entity-ctor
44
45 from google.cloud import datastore
46 from tests.system.test_system import Config # system tests
47
48 client = datastore.Client()
49 key = client.key('EntityKind', 1234, namespace='_Doctest')
50 entity = datastore.Entity(key=key)
51 entity['property'] = 'value'
52 Config.TO_DELETE.append(entity)
53
54 client.put(entity)
55
56 .. doctest:: entity-ctor
57
58 >>> client.get(key)
59 <Entity('EntityKind', 1234) {'property': 'value'}>
60
61 You can the set values on the entity just like you would on any
62 other dictionary.
63
64 .. doctest:: entity-ctor
65
66 >>> entity['age'] = 20
67 >>> entity['name'] = 'JJ'
68
69 However, not all types are allowed as a value for a Google Cloud Datastore
70 entity. The following basic types are supported by the API:
71
72 * :class:`datetime.datetime`
73 * :class:`~google.cloud.datastore.key.Key`
74 * :class:`bool`
75 * :class:`float`
76 * :class:`int` (as well as :class:`long` in Python 2)
77 * ``unicode`` (called ``str`` in Python 3)
78 * ``bytes`` (called ``str`` in Python 2)
79 * :class:`~google.cloud.datastore.helpers.GeoPoint`
80 * :data:`None`
81
82 In addition, two container types are supported:
83
84 * :class:`list`
85 * :class:`~google.cloud.datastore.entity.Entity`
86
87 Each entry in a list must be one of the value types (basic or
88 container) and each value in an
89 :class:`~google.cloud.datastore.entity.Entity` must as well. In
90 this case an :class:`~google.cloud.datastore.entity.Entity` **as a
91 container** acts as a :class:`dict`, but also has the special annotations
92 of ``key`` and ``exclude_from_indexes``.
93
94 And you can treat an entity like a regular Python dictionary:
95
96 .. testsetup:: entity-dict
97
98 from google.cloud import datastore
99
100 entity = datastore.Entity()
101 entity['age'] = 20
102 entity['name'] = 'JJ'
103
104 .. doctest:: entity-dict
105
106 >>> sorted(entity.keys())
107 ['age', 'name']
108 >>> sorted(entity.items())
109 [('age', 20), ('name', 'JJ')]
110
111 .. note::
112
113 When saving an entity to the backend, values which are "text"
114 (``unicode`` in Python2, ``str`` in Python3) will be saved using
115 the 'text_value' field, after being encoded to UTF-8. When
116 retrieved from the back-end, such values will be decoded to "text"
117 again. Values which are "bytes" (``str`` in Python2, ``bytes`` in
118 Python3), will be saved using the 'blob_value' field, without
119 any decoding / encoding step.
120
121 :type key: :class:`google.cloud.datastore.key.Key`
122 :param key: Optional key to be set on entity.
123
124 :type exclude_from_indexes: tuple of string
125 :param exclude_from_indexes: Names of fields whose values are not to be
126 indexed for this entity.
127 """
128
129 def __init__(self, key=None, exclude_from_indexes=()):
130 super(Entity, self).__init__()
131 self.key = key
132 self._exclude_from_indexes = set(_ensure_tuple_or_list(
133 'exclude_from_indexes', exclude_from_indexes))
134 # NOTE: This will be populated when parsing a protobuf in
135 # google.cloud.datastore.helpers.entity_from_protobuf.
136 self._meanings = {}
137
138 def __eq__(self, other):
139 """Compare two entities for equality.
140
141 Entities compare equal if their keys compare equal and their
142 properties compare equal.
143
144 :rtype: bool
145 :returns: True if the entities compare equal, else False.
146 """
147 if not isinstance(other, Entity):
148 return False
149
150 return (self.key == other.key and
151 self._exclude_from_indexes == other._exclude_from_indexes and
152 self._meanings == other._meanings and
153 super(Entity, self).__eq__(other))
154
155 def __ne__(self, other):
156 """Compare two entities for inequality.
157
158 Entities compare equal if their keys compare equal and their
159 properties compare equal.
160
161 :rtype: bool
162 :returns: False if the entities compare equal, else True.
163 """
164 return not self.__eq__(other)
165
166 @property
167 def kind(self):
168 """Get the kind of the current entity.
169
170 .. note::
171 This relies entirely on the :class:`google.cloud.datastore.key.Key`
172 set on the entity. That means that we're not storing the kind
173 of the entity at all, just the properties and a pointer to a
174 Key which knows its Kind.
175 """
176 if self.key:
177 return self.key.kind
178
179 @property
180 def exclude_from_indexes(self):
181 """Names of fields which are *not* to be indexed for this entity.
182
183 :rtype: sequence of field names
184 :returns: The set of fields excluded from indexes.
185 """
186 return frozenset(self._exclude_from_indexes)
187
188 def __repr__(self):
189 if self.key:
190 return '<Entity%s %s>' % (self.key._flat_path,
191 super(Entity, self).__repr__())
192 else:
193 return '<Entity %s>' % (super(Entity, self).__repr__(),)
194
[end of datastore/google/cloud/datastore/entity.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/datastore/google/cloud/datastore/entity.py b/datastore/google/cloud/datastore/entity.py
--- a/datastore/google/cloud/datastore/entity.py
+++ b/datastore/google/cloud/datastore/entity.py
@@ -129,8 +129,9 @@
def __init__(self, key=None, exclude_from_indexes=()):
super(Entity, self).__init__()
self.key = key
- self._exclude_from_indexes = set(_ensure_tuple_or_list(
+ self.exclude_from_indexes = set(_ensure_tuple_or_list(
'exclude_from_indexes', exclude_from_indexes))
+ """Names of fields which are *not* to be indexed for this entity."""
# NOTE: This will be populated when parsing a protobuf in
# google.cloud.datastore.helpers.entity_from_protobuf.
self._meanings = {}
@@ -148,7 +149,7 @@
return False
return (self.key == other.key and
- self._exclude_from_indexes == other._exclude_from_indexes and
+ self.exclude_from_indexes == other.exclude_from_indexes and
self._meanings == other._meanings and
super(Entity, self).__eq__(other))
@@ -176,15 +177,6 @@
if self.key:
return self.key.kind
- @property
- def exclude_from_indexes(self):
- """Names of fields which are *not* to be indexed for this entity.
-
- :rtype: sequence of field names
- :returns: The set of fields excluded from indexes.
- """
- return frozenset(self._exclude_from_indexes)
-
def __repr__(self):
if self.key:
return '<Entity%s %s>' % (self.key._flat_path,
| {"golden_diff": "diff --git a/datastore/google/cloud/datastore/entity.py b/datastore/google/cloud/datastore/entity.py\n--- a/datastore/google/cloud/datastore/entity.py\n+++ b/datastore/google/cloud/datastore/entity.py\n@@ -129,8 +129,9 @@\n def __init__(self, key=None, exclude_from_indexes=()):\n super(Entity, self).__init__()\n self.key = key\n- self._exclude_from_indexes = set(_ensure_tuple_or_list(\n+ self.exclude_from_indexes = set(_ensure_tuple_or_list(\n 'exclude_from_indexes', exclude_from_indexes))\n+ \"\"\"Names of fields which are *not* to be indexed for this entity.\"\"\"\n # NOTE: This will be populated when parsing a protobuf in\n # google.cloud.datastore.helpers.entity_from_protobuf.\n self._meanings = {}\n@@ -148,7 +149,7 @@\n return False\n \n return (self.key == other.key and\n- self._exclude_from_indexes == other._exclude_from_indexes and\n+ self.exclude_from_indexes == other.exclude_from_indexes and\n self._meanings == other._meanings and\n super(Entity, self).__eq__(other))\n \n@@ -176,15 +177,6 @@\n if self.key:\n return self.key.kind\n \n- @property\n- def exclude_from_indexes(self):\n- \"\"\"Names of fields which are *not* to be indexed for this entity.\n-\n- :rtype: sequence of field names\n- :returns: The set of fields excluded from indexes.\n- \"\"\"\n- return frozenset(self._exclude_from_indexes)\n-\n def __repr__(self):\n if self.key:\n return '<Entity%s %s>' % (self.key._flat_path,\n", "issue": "datastore: No way to exclude_from_indexes new properties on updated entities\nWhen loading an `Entity` from the datastore and updating it, there is no way to exclude new attributes from being indexed, since the only public API for setting `exclude_from_indexes` is on the `Entity` constructor. To work around this, I am currently setting `entity._exclude_from_indexes = (...)` in my code, which is not a \"public\" API.\r\n\r\nExample:\r\n\r\n```python\r\nclient = google.cloud.datastore.Client()\r\nkey = client.key('SomeEntityKey')\r\nentity = google.cloud.datastore.Entity(key, exclude_from_indexes=('foo', 'bar'))\r\nentity['foo'] = 'foo'\r\nprint 'entity.exclude_from_indexes:', entity.exclude_from_indexes\r\nclient.put(entity)\r\n\r\nentity2 = client.get(entity.key)\r\nprint 'entity2.exclude_from_indexes:', entity2.exclude_from_indexes\r\nentity2['bar'] = 'bar'\r\nclient.put(entity2)\r\n```\r\n\r\nOutput:\r\n\r\n```\r\nentity.exclude_from_indexes: frozenset(['foo', 'bar'])\r\nentity2.exclude_from_indexes: frozenset([u'foo'])\r\n```\r\n\r\nThis is actually \"expected\" based on how the Datastore works, however, in the code sample above, there should be some way for me to put the entity back, without copying it into a brand new `Entity`.\r\n\r\n\r\nTested using:\r\n\r\n* Mac OS X 10.11.6\r\n* Python 2.7.10\r\n* The following Google packages:\r\n```\r\ngapic-google-cloud-datastore-v1==0.15.3\r\ngoogle-auth==1.0.1\r\ngoogle-auth-httplib2==0.0.2\r\ngoogle-cloud-core==0.24.1\r\ngoogle-cloud-datastore==1.0.0\r\ngoogle-cloud-storage==1.1.1\r\ngoogle-gax==0.15.13\r\ngoogle-resumable-media==0.0.2\r\ngoogleapis-common-protos==1.5.2\r\nproto-google-cloud-datastore-v1==0.90.4\r\n```\r\n\n", "before_files": [{"content": "# Copyright 2014 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Class for representing a single entity in the Cloud Datastore.\"\"\"\n\n\nfrom google.cloud._helpers import _ensure_tuple_or_list\n\n\nclass Entity(dict):\n \"\"\"Entities are akin to rows in a relational database\n\n An entity storing the actual instance of data.\n\n Each entity is officially represented with a\n :class:`~google.cloud.datastore.key.Key`, however it is possible that\n you might create an entity with only a partial key (that is, a key\n with a kind, and possibly a parent, but without an ID). In such a\n case, the datastore service will automatically assign an ID to the\n partial key.\n\n Entities in this API act like dictionaries with extras built in that\n allow you to delete or persist the data stored on the entity.\n\n Entities are mutable and act like a subclass of a dictionary.\n This means you could take an existing entity and change the key\n to duplicate the object.\n\n Use :meth:`~google.cloud.datastore.client.Client.get` to retrieve an\n existing entity:\n\n .. testsetup:: entity-ctor\n\n from google.cloud import datastore\n from tests.system.test_system import Config # system tests\n\n client = datastore.Client()\n key = client.key('EntityKind', 1234, namespace='_Doctest')\n entity = datastore.Entity(key=key)\n entity['property'] = 'value'\n Config.TO_DELETE.append(entity)\n\n client.put(entity)\n\n .. doctest:: entity-ctor\n\n >>> client.get(key)\n <Entity('EntityKind', 1234) {'property': 'value'}>\n\n You can the set values on the entity just like you would on any\n other dictionary.\n\n .. doctest:: entity-ctor\n\n >>> entity['age'] = 20\n >>> entity['name'] = 'JJ'\n\n However, not all types are allowed as a value for a Google Cloud Datastore\n entity. The following basic types are supported by the API:\n\n * :class:`datetime.datetime`\n * :class:`~google.cloud.datastore.key.Key`\n * :class:`bool`\n * :class:`float`\n * :class:`int` (as well as :class:`long` in Python 2)\n * ``unicode`` (called ``str`` in Python 3)\n * ``bytes`` (called ``str`` in Python 2)\n * :class:`~google.cloud.datastore.helpers.GeoPoint`\n * :data:`None`\n\n In addition, two container types are supported:\n\n * :class:`list`\n * :class:`~google.cloud.datastore.entity.Entity`\n\n Each entry in a list must be one of the value types (basic or\n container) and each value in an\n :class:`~google.cloud.datastore.entity.Entity` must as well. In\n this case an :class:`~google.cloud.datastore.entity.Entity` **as a\n container** acts as a :class:`dict`, but also has the special annotations\n of ``key`` and ``exclude_from_indexes``.\n\n And you can treat an entity like a regular Python dictionary:\n\n .. testsetup:: entity-dict\n\n from google.cloud import datastore\n\n entity = datastore.Entity()\n entity['age'] = 20\n entity['name'] = 'JJ'\n\n .. doctest:: entity-dict\n\n >>> sorted(entity.keys())\n ['age', 'name']\n >>> sorted(entity.items())\n [('age', 20), ('name', 'JJ')]\n\n .. note::\n\n When saving an entity to the backend, values which are \"text\"\n (``unicode`` in Python2, ``str`` in Python3) will be saved using\n the 'text_value' field, after being encoded to UTF-8. When\n retrieved from the back-end, such values will be decoded to \"text\"\n again. Values which are \"bytes\" (``str`` in Python2, ``bytes`` in\n Python3), will be saved using the 'blob_value' field, without\n any decoding / encoding step.\n\n :type key: :class:`google.cloud.datastore.key.Key`\n :param key: Optional key to be set on entity.\n\n :type exclude_from_indexes: tuple of string\n :param exclude_from_indexes: Names of fields whose values are not to be\n indexed for this entity.\n \"\"\"\n\n def __init__(self, key=None, exclude_from_indexes=()):\n super(Entity, self).__init__()\n self.key = key\n self._exclude_from_indexes = set(_ensure_tuple_or_list(\n 'exclude_from_indexes', exclude_from_indexes))\n # NOTE: This will be populated when parsing a protobuf in\n # google.cloud.datastore.helpers.entity_from_protobuf.\n self._meanings = {}\n\n def __eq__(self, other):\n \"\"\"Compare two entities for equality.\n\n Entities compare equal if their keys compare equal and their\n properties compare equal.\n\n :rtype: bool\n :returns: True if the entities compare equal, else False.\n \"\"\"\n if not isinstance(other, Entity):\n return False\n\n return (self.key == other.key and\n self._exclude_from_indexes == other._exclude_from_indexes and\n self._meanings == other._meanings and\n super(Entity, self).__eq__(other))\n\n def __ne__(self, other):\n \"\"\"Compare two entities for inequality.\n\n Entities compare equal if their keys compare equal and their\n properties compare equal.\n\n :rtype: bool\n :returns: False if the entities compare equal, else True.\n \"\"\"\n return not self.__eq__(other)\n\n @property\n def kind(self):\n \"\"\"Get the kind of the current entity.\n\n .. note::\n This relies entirely on the :class:`google.cloud.datastore.key.Key`\n set on the entity. That means that we're not storing the kind\n of the entity at all, just the properties and a pointer to a\n Key which knows its Kind.\n \"\"\"\n if self.key:\n return self.key.kind\n\n @property\n def exclude_from_indexes(self):\n \"\"\"Names of fields which are *not* to be indexed for this entity.\n\n :rtype: sequence of field names\n :returns: The set of fields excluded from indexes.\n \"\"\"\n return frozenset(self._exclude_from_indexes)\n\n def __repr__(self):\n if self.key:\n return '<Entity%s %s>' % (self.key._flat_path,\n super(Entity, self).__repr__())\n else:\n return '<Entity %s>' % (super(Entity, self).__repr__(),)\n", "path": "datastore/google/cloud/datastore/entity.py"}]} | 3,023 | 382 |
gh_patches_debug_38270 | rasdani/github-patches | git_diff | pre-commit__pre-commit-958 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Investigate / implement shallow cloning
Now that github supports it, might be worth the speed improvements
It would have to be smart enough to fall back to slow clone when the option isn't available (either the client is too old or the server is too old)
</issue>
<code>
[start of pre_commit/languages/node.py]
1 from __future__ import unicode_literals
2
3 import contextlib
4 import os
5 import sys
6
7 import pre_commit.constants as C
8 from pre_commit.envcontext import envcontext
9 from pre_commit.envcontext import Var
10 from pre_commit.languages import helpers
11 from pre_commit.languages.python import bin_dir
12 from pre_commit.util import clean_path_on_failure
13 from pre_commit.util import cmd_output
14
15
16 ENVIRONMENT_DIR = 'node_env'
17 get_default_version = helpers.basic_get_default_version
18 healthy = helpers.basic_healthy
19
20
21 def _envdir(prefix, version):
22 directory = helpers.environment_dir(ENVIRONMENT_DIR, version)
23 return prefix.path(directory)
24
25
26 def get_env_patch(venv):
27 if sys.platform == 'cygwin': # pragma: no cover
28 _, win_venv, _ = cmd_output('cygpath', '-w', venv)
29 install_prefix = r'{}\bin'.format(win_venv.strip())
30 elif sys.platform == 'win32': # pragma: no cover
31 install_prefix = bin_dir(venv)
32 else: # pragma: windows no cover
33 install_prefix = venv
34 return (
35 ('NODE_VIRTUAL_ENV', venv),
36 ('NPM_CONFIG_PREFIX', install_prefix),
37 ('npm_config_prefix', install_prefix),
38 ('NODE_PATH', os.path.join(venv, 'lib', 'node_modules')),
39 ('PATH', (bin_dir(venv), os.pathsep, Var('PATH'))),
40 )
41
42
43 @contextlib.contextmanager
44 def in_env(prefix, language_version):
45 with envcontext(get_env_patch(_envdir(prefix, language_version))):
46 yield
47
48
49 def install_environment(prefix, version, additional_dependencies):
50 additional_dependencies = tuple(additional_dependencies)
51 assert prefix.exists('package.json')
52 envdir = _envdir(prefix, version)
53
54 # https://msdn.microsoft.com/en-us/library/windows/desktop/aa365247(v=vs.85).aspx?f=255&MSPPError=-2147217396#maxpath
55 if sys.platform == 'win32': # pragma: no cover
56 envdir = '\\\\?\\' + os.path.normpath(envdir)
57 with clean_path_on_failure(envdir):
58 cmd = [
59 sys.executable, '-mnodeenv', '--prebuilt', '--clean-src', envdir,
60 ]
61 if version != C.DEFAULT:
62 cmd.extend(['-n', version])
63 cmd_output(*cmd)
64
65 dep = 'git+file:///{}'.format(prefix.prefix_dir)
66 with in_env(prefix, version):
67 helpers.run_setup_cmd(
68 prefix,
69 ('npm', 'install', '-g', dep) + additional_dependencies,
70 )
71
72
73 def run_hook(hook, file_args):
74 with in_env(hook.prefix, hook.language_version):
75 return helpers.run_xargs(hook, helpers.to_cmd(hook), file_args)
76
[end of pre_commit/languages/node.py]
[start of pre_commit/store.py]
1 from __future__ import unicode_literals
2
3 import contextlib
4 import io
5 import logging
6 import os.path
7 import sqlite3
8 import tempfile
9
10 import pre_commit.constants as C
11 from pre_commit import file_lock
12 from pre_commit import git
13 from pre_commit.util import clean_path_on_failure
14 from pre_commit.util import cmd_output
15 from pre_commit.util import resource_text
16 from pre_commit.util import rmtree
17
18
19 logger = logging.getLogger('pre_commit')
20
21
22 def _get_default_directory():
23 """Returns the default directory for the Store. This is intentionally
24 underscored to indicate that `Store.get_default_directory` is the intended
25 way to get this information. This is also done so
26 `Store.get_default_directory` can be mocked in tests and
27 `_get_default_directory` can be tested.
28 """
29 return os.environ.get('PRE_COMMIT_HOME') or os.path.join(
30 os.environ.get('XDG_CACHE_HOME') or os.path.expanduser('~/.cache'),
31 'pre-commit',
32 )
33
34
35 class Store(object):
36 get_default_directory = staticmethod(_get_default_directory)
37
38 def __init__(self, directory=None):
39 self.directory = directory or Store.get_default_directory()
40 self.db_path = os.path.join(self.directory, 'db.db')
41
42 if not os.path.exists(self.directory):
43 os.makedirs(self.directory)
44 with io.open(os.path.join(self.directory, 'README'), 'w') as f:
45 f.write(
46 'This directory is maintained by the pre-commit project.\n'
47 'Learn more: https://github.com/pre-commit/pre-commit\n',
48 )
49
50 if os.path.exists(self.db_path):
51 return
52 with self.exclusive_lock():
53 # Another process may have already completed this work
54 if os.path.exists(self.db_path): # pragma: no cover (race)
55 return
56 # To avoid a race where someone ^Cs between db creation and
57 # execution of the CREATE TABLE statement
58 fd, tmpfile = tempfile.mkstemp(dir=self.directory)
59 # We'll be managing this file ourselves
60 os.close(fd)
61 with self.connect(db_path=tmpfile) as db:
62 db.executescript(
63 'CREATE TABLE repos ('
64 ' repo TEXT NOT NULL,'
65 ' ref TEXT NOT NULL,'
66 ' path TEXT NOT NULL,'
67 ' PRIMARY KEY (repo, ref)'
68 ');',
69 )
70 self._create_config_table_if_not_exists(db)
71
72 # Atomic file move
73 os.rename(tmpfile, self.db_path)
74
75 @contextlib.contextmanager
76 def exclusive_lock(self):
77 def blocked_cb(): # pragma: no cover (tests are single-process)
78 logger.info('Locking pre-commit directory')
79
80 with file_lock.lock(os.path.join(self.directory, '.lock'), blocked_cb):
81 yield
82
83 @contextlib.contextmanager
84 def connect(self, db_path=None):
85 db_path = db_path or self.db_path
86 # sqlite doesn't close its fd with its contextmanager >.<
87 # contextlib.closing fixes this.
88 # See: https://stackoverflow.com/a/28032829/812183
89 with contextlib.closing(sqlite3.connect(db_path)) as db:
90 # this creates a transaction
91 with db:
92 yield db
93
94 @classmethod
95 def db_repo_name(cls, repo, deps):
96 if deps:
97 return '{}:{}'.format(repo, ','.join(sorted(deps)))
98 else:
99 return repo
100
101 def _new_repo(self, repo, ref, deps, make_strategy):
102 repo = self.db_repo_name(repo, deps)
103
104 def _get_result():
105 # Check if we already exist
106 with self.connect() as db:
107 result = db.execute(
108 'SELECT path FROM repos WHERE repo = ? AND ref = ?',
109 (repo, ref),
110 ).fetchone()
111 if result:
112 return result[0]
113
114 result = _get_result()
115 if result:
116 return result
117 with self.exclusive_lock():
118 # Another process may have already completed this work
119 result = _get_result()
120 if result: # pragma: no cover (race)
121 return result
122
123 logger.info('Initializing environment for {}.'.format(repo))
124
125 directory = tempfile.mkdtemp(prefix='repo', dir=self.directory)
126 with clean_path_on_failure(directory):
127 make_strategy(directory)
128
129 # Update our db with the created repo
130 with self.connect() as db:
131 db.execute(
132 'INSERT INTO repos (repo, ref, path) VALUES (?, ?, ?)',
133 [repo, ref, directory],
134 )
135 return directory
136
137 def clone(self, repo, ref, deps=()):
138 """Clone the given url and checkout the specific ref."""
139 def clone_strategy(directory):
140 env = git.no_git_env()
141
142 cmd = ('git', 'clone', '--no-checkout', repo, directory)
143 cmd_output(*cmd, env=env)
144
145 def _git_cmd(*args):
146 return cmd_output('git', *args, cwd=directory, env=env)
147
148 _git_cmd('reset', ref, '--hard')
149 _git_cmd('submodule', 'update', '--init', '--recursive')
150
151 return self._new_repo(repo, ref, deps, clone_strategy)
152
153 LOCAL_RESOURCES = (
154 'Cargo.toml', 'main.go', 'main.rs', '.npmignore', 'package.json',
155 'pre_commit_dummy_package.gemspec', 'setup.py',
156 )
157
158 def make_local(self, deps):
159 def make_local_strategy(directory):
160 for resource in self.LOCAL_RESOURCES:
161 contents = resource_text('empty_template_{}'.format(resource))
162 with io.open(os.path.join(directory, resource), 'w') as f:
163 f.write(contents)
164
165 env = git.no_git_env()
166
167 # initialize the git repository so it looks more like cloned repos
168 def _git_cmd(*args):
169 cmd_output('git', *args, cwd=directory, env=env)
170
171 _git_cmd('init', '.')
172 _git_cmd('config', 'remote.origin.url', '<<unknown>>')
173 _git_cmd('add', '.')
174 git.commit(repo=directory)
175
176 return self._new_repo(
177 'local', C.LOCAL_REPO_VERSION, deps, make_local_strategy,
178 )
179
180 def _create_config_table_if_not_exists(self, db):
181 db.executescript(
182 'CREATE TABLE IF NOT EXISTS configs ('
183 ' path TEXT NOT NULL,'
184 ' PRIMARY KEY (path)'
185 ');',
186 )
187
188 def mark_config_used(self, path):
189 path = os.path.realpath(path)
190 # don't insert config files that do not exist
191 if not os.path.exists(path):
192 return
193 with self.connect() as db:
194 # TODO: eventually remove this and only create in _create
195 self._create_config_table_if_not_exists(db)
196 db.execute('INSERT OR IGNORE INTO configs VALUES (?)', (path,))
197
198 def select_all_configs(self):
199 with self.connect() as db:
200 self._create_config_table_if_not_exists(db)
201 rows = db.execute('SELECT path FROM configs').fetchall()
202 return [path for path, in rows]
203
204 def delete_configs(self, configs):
205 with self.connect() as db:
206 rows = [(path,) for path in configs]
207 db.executemany('DELETE FROM configs WHERE path = ?', rows)
208
209 def select_all_repos(self):
210 with self.connect() as db:
211 return db.execute('SELECT repo, ref, path from repos').fetchall()
212
213 def delete_repo(self, db_repo_name, ref, path):
214 with self.connect() as db:
215 db.execute(
216 'DELETE FROM repos WHERE repo = ? and ref = ?',
217 (db_repo_name, ref),
218 )
219 rmtree(path)
220
[end of pre_commit/store.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/pre_commit/languages/node.py b/pre_commit/languages/node.py
--- a/pre_commit/languages/node.py
+++ b/pre_commit/languages/node.py
@@ -62,11 +62,13 @@
cmd.extend(['-n', version])
cmd_output(*cmd)
- dep = 'git+file:///{}'.format(prefix.prefix_dir)
with in_env(prefix, version):
+ # https://npm.community/t/npm-install-g-git-vs-git-clone-cd-npm-install-g/5449
+ # install as if we installed from git
+ helpers.run_setup_cmd(prefix, ('npm', 'install'))
helpers.run_setup_cmd(
prefix,
- ('npm', 'install', '-g', dep) + additional_dependencies,
+ ('npm', 'install', '-g', '.') + additional_dependencies,
)
diff --git a/pre_commit/store.py b/pre_commit/store.py
--- a/pre_commit/store.py
+++ b/pre_commit/store.py
@@ -10,6 +10,7 @@
import pre_commit.constants as C
from pre_commit import file_lock
from pre_commit import git
+from pre_commit.util import CalledProcessError
from pre_commit.util import clean_path_on_failure
from pre_commit.util import cmd_output
from pre_commit.util import resource_text
@@ -134,19 +135,43 @@
)
return directory
+ def _complete_clone(self, ref, git_cmd):
+ """Perform a complete clone of a repository and its submodules """
+
+ git_cmd('fetch', 'origin')
+ git_cmd('checkout', ref)
+ git_cmd('submodule', 'update', '--init', '--recursive')
+
+ def _shallow_clone(self, ref, git_cmd): # pragma: windows no cover
+ """Perform a shallow clone of a repository and its submodules """
+
+ git_config = 'protocol.version=2'
+ git_cmd('-c', git_config, 'fetch', 'origin', ref, '--depth=1')
+ git_cmd('checkout', ref)
+ git_cmd(
+ '-c', git_config, 'submodule', 'update', '--init',
+ '--recursive', '--depth=1',
+ )
+
def clone(self, repo, ref, deps=()):
"""Clone the given url and checkout the specific ref."""
+
+ if os.path.isdir(repo):
+ repo = os.path.abspath(repo)
+
def clone_strategy(directory):
env = git.no_git_env()
- cmd = ('git', 'clone', '--no-checkout', repo, directory)
- cmd_output(*cmd, env=env)
-
def _git_cmd(*args):
- return cmd_output('git', *args, cwd=directory, env=env)
+ cmd_output('git', *args, cwd=directory, env=env)
+
+ _git_cmd('init', '.')
+ _git_cmd('remote', 'add', 'origin', repo)
- _git_cmd('reset', ref, '--hard')
- _git_cmd('submodule', 'update', '--init', '--recursive')
+ try:
+ self._shallow_clone(ref, _git_cmd)
+ except CalledProcessError:
+ self._complete_clone(ref, _git_cmd)
return self._new_repo(repo, ref, deps, clone_strategy)
| {"golden_diff": "diff --git a/pre_commit/languages/node.py b/pre_commit/languages/node.py\n--- a/pre_commit/languages/node.py\n+++ b/pre_commit/languages/node.py\n@@ -62,11 +62,13 @@\n cmd.extend(['-n', version])\n cmd_output(*cmd)\n \n- dep = 'git+file:///{}'.format(prefix.prefix_dir)\n with in_env(prefix, version):\n+ # https://npm.community/t/npm-install-g-git-vs-git-clone-cd-npm-install-g/5449\n+ # install as if we installed from git\n+ helpers.run_setup_cmd(prefix, ('npm', 'install'))\n helpers.run_setup_cmd(\n prefix,\n- ('npm', 'install', '-g', dep) + additional_dependencies,\n+ ('npm', 'install', '-g', '.') + additional_dependencies,\n )\n \n \ndiff --git a/pre_commit/store.py b/pre_commit/store.py\n--- a/pre_commit/store.py\n+++ b/pre_commit/store.py\n@@ -10,6 +10,7 @@\n import pre_commit.constants as C\n from pre_commit import file_lock\n from pre_commit import git\n+from pre_commit.util import CalledProcessError\n from pre_commit.util import clean_path_on_failure\n from pre_commit.util import cmd_output\n from pre_commit.util import resource_text\n@@ -134,19 +135,43 @@\n )\n return directory\n \n+ def _complete_clone(self, ref, git_cmd):\n+ \"\"\"Perform a complete clone of a repository and its submodules \"\"\"\n+\n+ git_cmd('fetch', 'origin')\n+ git_cmd('checkout', ref)\n+ git_cmd('submodule', 'update', '--init', '--recursive')\n+\n+ def _shallow_clone(self, ref, git_cmd): # pragma: windows no cover\n+ \"\"\"Perform a shallow clone of a repository and its submodules \"\"\"\n+\n+ git_config = 'protocol.version=2'\n+ git_cmd('-c', git_config, 'fetch', 'origin', ref, '--depth=1')\n+ git_cmd('checkout', ref)\n+ git_cmd(\n+ '-c', git_config, 'submodule', 'update', '--init',\n+ '--recursive', '--depth=1',\n+ )\n+\n def clone(self, repo, ref, deps=()):\n \"\"\"Clone the given url and checkout the specific ref.\"\"\"\n+\n+ if os.path.isdir(repo):\n+ repo = os.path.abspath(repo)\n+\n def clone_strategy(directory):\n env = git.no_git_env()\n \n- cmd = ('git', 'clone', '--no-checkout', repo, directory)\n- cmd_output(*cmd, env=env)\n-\n def _git_cmd(*args):\n- return cmd_output('git', *args, cwd=directory, env=env)\n+ cmd_output('git', *args, cwd=directory, env=env)\n+\n+ _git_cmd('init', '.')\n+ _git_cmd('remote', 'add', 'origin', repo)\n \n- _git_cmd('reset', ref, '--hard')\n- _git_cmd('submodule', 'update', '--init', '--recursive')\n+ try:\n+ self._shallow_clone(ref, _git_cmd)\n+ except CalledProcessError:\n+ self._complete_clone(ref, _git_cmd)\n \n return self._new_repo(repo, ref, deps, clone_strategy)\n", "issue": "Investigate / implement shallow cloning\nNow that github supports it, might be worth the speed improvements\r\n\r\nIt would have to be smart enough to fall back to slow clone when the option isn't available (either the client is too old or the server is too old)\n", "before_files": [{"content": "from __future__ import unicode_literals\n\nimport contextlib\nimport os\nimport sys\n\nimport pre_commit.constants as C\nfrom pre_commit.envcontext import envcontext\nfrom pre_commit.envcontext import Var\nfrom pre_commit.languages import helpers\nfrom pre_commit.languages.python import bin_dir\nfrom pre_commit.util import clean_path_on_failure\nfrom pre_commit.util import cmd_output\n\n\nENVIRONMENT_DIR = 'node_env'\nget_default_version = helpers.basic_get_default_version\nhealthy = helpers.basic_healthy\n\n\ndef _envdir(prefix, version):\n directory = helpers.environment_dir(ENVIRONMENT_DIR, version)\n return prefix.path(directory)\n\n\ndef get_env_patch(venv):\n if sys.platform == 'cygwin': # pragma: no cover\n _, win_venv, _ = cmd_output('cygpath', '-w', venv)\n install_prefix = r'{}\\bin'.format(win_venv.strip())\n elif sys.platform == 'win32': # pragma: no cover\n install_prefix = bin_dir(venv)\n else: # pragma: windows no cover\n install_prefix = venv\n return (\n ('NODE_VIRTUAL_ENV', venv),\n ('NPM_CONFIG_PREFIX', install_prefix),\n ('npm_config_prefix', install_prefix),\n ('NODE_PATH', os.path.join(venv, 'lib', 'node_modules')),\n ('PATH', (bin_dir(venv), os.pathsep, Var('PATH'))),\n )\n\n\[email protected]\ndef in_env(prefix, language_version):\n with envcontext(get_env_patch(_envdir(prefix, language_version))):\n yield\n\n\ndef install_environment(prefix, version, additional_dependencies):\n additional_dependencies = tuple(additional_dependencies)\n assert prefix.exists('package.json')\n envdir = _envdir(prefix, version)\n\n # https://msdn.microsoft.com/en-us/library/windows/desktop/aa365247(v=vs.85).aspx?f=255&MSPPError=-2147217396#maxpath\n if sys.platform == 'win32': # pragma: no cover\n envdir = '\\\\\\\\?\\\\' + os.path.normpath(envdir)\n with clean_path_on_failure(envdir):\n cmd = [\n sys.executable, '-mnodeenv', '--prebuilt', '--clean-src', envdir,\n ]\n if version != C.DEFAULT:\n cmd.extend(['-n', version])\n cmd_output(*cmd)\n\n dep = 'git+file:///{}'.format(prefix.prefix_dir)\n with in_env(prefix, version):\n helpers.run_setup_cmd(\n prefix,\n ('npm', 'install', '-g', dep) + additional_dependencies,\n )\n\n\ndef run_hook(hook, file_args):\n with in_env(hook.prefix, hook.language_version):\n return helpers.run_xargs(hook, helpers.to_cmd(hook), file_args)\n", "path": "pre_commit/languages/node.py"}, {"content": "from __future__ import unicode_literals\n\nimport contextlib\nimport io\nimport logging\nimport os.path\nimport sqlite3\nimport tempfile\n\nimport pre_commit.constants as C\nfrom pre_commit import file_lock\nfrom pre_commit import git\nfrom pre_commit.util import clean_path_on_failure\nfrom pre_commit.util import cmd_output\nfrom pre_commit.util import resource_text\nfrom pre_commit.util import rmtree\n\n\nlogger = logging.getLogger('pre_commit')\n\n\ndef _get_default_directory():\n \"\"\"Returns the default directory for the Store. This is intentionally\n underscored to indicate that `Store.get_default_directory` is the intended\n way to get this information. This is also done so\n `Store.get_default_directory` can be mocked in tests and\n `_get_default_directory` can be tested.\n \"\"\"\n return os.environ.get('PRE_COMMIT_HOME') or os.path.join(\n os.environ.get('XDG_CACHE_HOME') or os.path.expanduser('~/.cache'),\n 'pre-commit',\n )\n\n\nclass Store(object):\n get_default_directory = staticmethod(_get_default_directory)\n\n def __init__(self, directory=None):\n self.directory = directory or Store.get_default_directory()\n self.db_path = os.path.join(self.directory, 'db.db')\n\n if not os.path.exists(self.directory):\n os.makedirs(self.directory)\n with io.open(os.path.join(self.directory, 'README'), 'w') as f:\n f.write(\n 'This directory is maintained by the pre-commit project.\\n'\n 'Learn more: https://github.com/pre-commit/pre-commit\\n',\n )\n\n if os.path.exists(self.db_path):\n return\n with self.exclusive_lock():\n # Another process may have already completed this work\n if os.path.exists(self.db_path): # pragma: no cover (race)\n return\n # To avoid a race where someone ^Cs between db creation and\n # execution of the CREATE TABLE statement\n fd, tmpfile = tempfile.mkstemp(dir=self.directory)\n # We'll be managing this file ourselves\n os.close(fd)\n with self.connect(db_path=tmpfile) as db:\n db.executescript(\n 'CREATE TABLE repos ('\n ' repo TEXT NOT NULL,'\n ' ref TEXT NOT NULL,'\n ' path TEXT NOT NULL,'\n ' PRIMARY KEY (repo, ref)'\n ');',\n )\n self._create_config_table_if_not_exists(db)\n\n # Atomic file move\n os.rename(tmpfile, self.db_path)\n\n @contextlib.contextmanager\n def exclusive_lock(self):\n def blocked_cb(): # pragma: no cover (tests are single-process)\n logger.info('Locking pre-commit directory')\n\n with file_lock.lock(os.path.join(self.directory, '.lock'), blocked_cb):\n yield\n\n @contextlib.contextmanager\n def connect(self, db_path=None):\n db_path = db_path or self.db_path\n # sqlite doesn't close its fd with its contextmanager >.<\n # contextlib.closing fixes this.\n # See: https://stackoverflow.com/a/28032829/812183\n with contextlib.closing(sqlite3.connect(db_path)) as db:\n # this creates a transaction\n with db:\n yield db\n\n @classmethod\n def db_repo_name(cls, repo, deps):\n if deps:\n return '{}:{}'.format(repo, ','.join(sorted(deps)))\n else:\n return repo\n\n def _new_repo(self, repo, ref, deps, make_strategy):\n repo = self.db_repo_name(repo, deps)\n\n def _get_result():\n # Check if we already exist\n with self.connect() as db:\n result = db.execute(\n 'SELECT path FROM repos WHERE repo = ? AND ref = ?',\n (repo, ref),\n ).fetchone()\n if result:\n return result[0]\n\n result = _get_result()\n if result:\n return result\n with self.exclusive_lock():\n # Another process may have already completed this work\n result = _get_result()\n if result: # pragma: no cover (race)\n return result\n\n logger.info('Initializing environment for {}.'.format(repo))\n\n directory = tempfile.mkdtemp(prefix='repo', dir=self.directory)\n with clean_path_on_failure(directory):\n make_strategy(directory)\n\n # Update our db with the created repo\n with self.connect() as db:\n db.execute(\n 'INSERT INTO repos (repo, ref, path) VALUES (?, ?, ?)',\n [repo, ref, directory],\n )\n return directory\n\n def clone(self, repo, ref, deps=()):\n \"\"\"Clone the given url and checkout the specific ref.\"\"\"\n def clone_strategy(directory):\n env = git.no_git_env()\n\n cmd = ('git', 'clone', '--no-checkout', repo, directory)\n cmd_output(*cmd, env=env)\n\n def _git_cmd(*args):\n return cmd_output('git', *args, cwd=directory, env=env)\n\n _git_cmd('reset', ref, '--hard')\n _git_cmd('submodule', 'update', '--init', '--recursive')\n\n return self._new_repo(repo, ref, deps, clone_strategy)\n\n LOCAL_RESOURCES = (\n 'Cargo.toml', 'main.go', 'main.rs', '.npmignore', 'package.json',\n 'pre_commit_dummy_package.gemspec', 'setup.py',\n )\n\n def make_local(self, deps):\n def make_local_strategy(directory):\n for resource in self.LOCAL_RESOURCES:\n contents = resource_text('empty_template_{}'.format(resource))\n with io.open(os.path.join(directory, resource), 'w') as f:\n f.write(contents)\n\n env = git.no_git_env()\n\n # initialize the git repository so it looks more like cloned repos\n def _git_cmd(*args):\n cmd_output('git', *args, cwd=directory, env=env)\n\n _git_cmd('init', '.')\n _git_cmd('config', 'remote.origin.url', '<<unknown>>')\n _git_cmd('add', '.')\n git.commit(repo=directory)\n\n return self._new_repo(\n 'local', C.LOCAL_REPO_VERSION, deps, make_local_strategy,\n )\n\n def _create_config_table_if_not_exists(self, db):\n db.executescript(\n 'CREATE TABLE IF NOT EXISTS configs ('\n ' path TEXT NOT NULL,'\n ' PRIMARY KEY (path)'\n ');',\n )\n\n def mark_config_used(self, path):\n path = os.path.realpath(path)\n # don't insert config files that do not exist\n if not os.path.exists(path):\n return\n with self.connect() as db:\n # TODO: eventually remove this and only create in _create\n self._create_config_table_if_not_exists(db)\n db.execute('INSERT OR IGNORE INTO configs VALUES (?)', (path,))\n\n def select_all_configs(self):\n with self.connect() as db:\n self._create_config_table_if_not_exists(db)\n rows = db.execute('SELECT path FROM configs').fetchall()\n return [path for path, in rows]\n\n def delete_configs(self, configs):\n with self.connect() as db:\n rows = [(path,) for path in configs]\n db.executemany('DELETE FROM configs WHERE path = ?', rows)\n\n def select_all_repos(self):\n with self.connect() as db:\n return db.execute('SELECT repo, ref, path from repos').fetchall()\n\n def delete_repo(self, db_repo_name, ref, path):\n with self.connect() as db:\n db.execute(\n 'DELETE FROM repos WHERE repo = ? and ref = ?',\n (db_repo_name, ref),\n )\n rmtree(path)\n", "path": "pre_commit/store.py"}]} | 3,616 | 734 |
gh_patches_debug_14211 | rasdani/github-patches | git_diff | cupy__cupy-1573 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Support SciPy 1.0
SciPy 1.0 released. It has some compatibility breaks in `scipy.sparse`. We need to fix implementations or tests.
</issue>
<code>
[start of cupyx/scipy/sparse/compressed.py]
1 import numpy
2 try:
3 import scipy.sparse
4 scipy_available = True
5 except ImportError:
6 scipy_available = False
7
8 import cupy
9 from cupy import core
10 from cupy.creation import basic
11 from cupy import cusparse
12 from cupyx.scipy.sparse import base
13 from cupyx.scipy.sparse import data as sparse_data
14 from cupyx.scipy.sparse import util
15
16
17 class _compressed_sparse_matrix(sparse_data._data_matrix):
18
19 _compress_getitem_kern = core.ElementwiseKernel(
20 'T d, S ind, int32 minor', 'raw T answer',
21 'if (ind == minor) atomicAdd(&answer[0], d);',
22 'compress_getitem')
23
24 _compress_getitem_complex_kern = core.ElementwiseKernel(
25 'T real, T imag, S ind, int32 minor',
26 'raw T answer_real, raw T answer_imag',
27 '''
28 if (ind == minor) {
29 atomicAdd(&answer_real[0], real);
30 atomicAdd(&answer_imag[0], imag);
31 }
32 ''',
33 'compress_getitem_complex')
34
35 def __init__(self, arg1, shape=None, dtype=None, copy=False):
36 if shape is not None and len(shape) != 2:
37 raise ValueError(
38 'Only two-dimensional sparse arrays are supported.')
39
40 if base.issparse(arg1):
41 x = arg1.asformat(self.format)
42 data = x.data
43 indices = x.indices
44 indptr = x.indptr
45
46 if arg1.format != self.format:
47 # When formats are differnent, all arrays are already copied
48 copy = False
49
50 if shape is None:
51 shape = arg1.shape
52
53 has_canonical_format = x.has_canonical_format
54 elif util.isshape(arg1):
55 m, n = arg1
56 m, n = int(m), int(n)
57 data = basic.zeros(0, dtype if dtype else 'd')
58 indices = basic.zeros(0, 'i')
59 indptr = basic.zeros(self._swap(m, n)[0] + 1, dtype='i')
60 # shape and copy argument is ignored
61 shape = (m, n)
62 copy = False
63 has_canonical_format = True
64
65 elif scipy_available and scipy.sparse.issparse(arg1):
66 # Convert scipy.sparse to cupyx.scipy.sparse
67 x = arg1.asformat(self.format)
68 data = cupy.array(x.data)
69 indices = cupy.array(x.indices, dtype='i')
70 indptr = cupy.array(x.indptr, dtype='i')
71 copy = False
72
73 if shape is None:
74 shape = arg1.shape
75 has_canonical_format = x.has_canonical_format
76
77 elif isinstance(arg1, tuple) and len(arg1) == 3:
78 data, indices, indptr = arg1
79 if not (base.isdense(data) and data.ndim == 1 and
80 base.isdense(indices) and indices.ndim == 1 and
81 base.isdense(indptr) and indptr.ndim == 1):
82 raise ValueError(
83 'data, indices, and indptr should be 1-D')
84
85 if len(data) != len(indices):
86 raise ValueError('indices and data should have the same size')
87
88 has_canonical_format = False
89
90 elif base.isdense(arg1):
91 if arg1.ndim > 2:
92 raise TypeError('expected dimension <= 2 array or matrix')
93 elif arg1.ndim == 1:
94 arg1 = arg1[None]
95 elif arg1.ndim == 0:
96 arg1 = arg1[None, None]
97 data, indices, indptr = self._convert_dense(arg1)
98 copy = False
99 if shape is None:
100 shape = arg1.shape
101
102 has_canonical_format = True
103
104 else:
105 raise ValueError(
106 'Unsupported initializer format')
107
108 if dtype is None:
109 dtype = data.dtype
110 else:
111 dtype = numpy.dtype(dtype)
112
113 if dtype != 'f' and dtype != 'd' and dtype != 'F' and dtype != 'D':
114 raise ValueError(
115 'Only float32, float64, complex64 and complex128 '
116 'are supported')
117
118 data = data.astype(dtype, copy=copy)
119 sparse_data._data_matrix.__init__(self, data)
120
121 self.indices = indices.astype('i', copy=copy)
122 self.indptr = indptr.astype('i', copy=copy)
123
124 if shape is None:
125 shape = self._swap(len(indptr) - 1, int(indices.max()) + 1)
126
127 major, minor = self._swap(*shape)
128 if len(indptr) != major + 1:
129 raise ValueError('index pointer size (%d) should be (%d)'
130 % (len(indptr), major + 1))
131
132 self._descr = cusparse.MatDescriptor.create()
133 self._shape = shape
134 self._has_canonical_format = has_canonical_format
135
136 def _with_data(self, data):
137 return self.__class__(
138 (data, self.indices.copy(), self.indptr.copy()), shape=self.shape)
139
140 def _convert_dense(self, x):
141 raise NotImplementedError
142
143 def _swap(self, x, y):
144 raise NotImplementedError
145
146 def _add_sparse(self, other, alpha, beta):
147 raise NotImplementedError
148
149 def _add(self, other, lhs_negative, rhs_negative):
150 if cupy.isscalar(other):
151 if other == 0:
152 if lhs_negative:
153 return -self
154 else:
155 return self.copy()
156 else:
157 raise NotImplementedError(
158 'adding a nonzero scalar to a sparse matrix is not '
159 'supported')
160 elif base.isspmatrix(other):
161 alpha = -1 if lhs_negative else 1
162 beta = -1 if rhs_negative else 1
163 return self._add_sparse(other, alpha, beta)
164 elif base.isdense(other):
165 if lhs_negative:
166 if rhs_negative:
167 return -self.todense() - other
168 else:
169 return other - self.todense()
170 else:
171 if rhs_negative:
172 return self.todense() - other
173 else:
174 return self.todense() + other
175 else:
176 return NotImplemented
177
178 def __add__(self, other):
179 return self._add(other, False, False)
180
181 def __radd__(self, other):
182 return self._add(other, False, False)
183
184 def __sub__(self, other):
185 return self._add(other, False, True)
186
187 def __rsub__(self, other):
188 return self._add(other, True, False)
189
190 def __getitem__(self, slices):
191 if isinstance(slices, tuple):
192 slices = list(slices)
193 elif isinstance(slices, list):
194 slices = list(slices)
195 if all([isinstance(s, int) for s in slices]):
196 slices = [slices]
197 else:
198 slices = [slices]
199
200 ellipsis = -1
201 n_ellipsis = 0
202 for i, s in enumerate(slices):
203 if s is None:
204 raise IndexError('newaxis is not supported')
205 elif s is Ellipsis:
206 ellipsis = i
207 n_ellipsis += 1
208 if n_ellipsis > 0:
209 ellipsis_size = self.ndim - (len(slices) - 1)
210 slices[ellipsis:ellipsis + 1] = [slice(None)] * ellipsis_size
211
212 if len(slices) == 2:
213 row, col = slices
214 elif len(slices) == 1:
215 row, col = slices[0], slice(None)
216 else:
217 raise IndexError('invalid number of indices')
218
219 major, minor = self._swap(row, col)
220 major_size, minor_size = self._swap(*self._shape)
221 if numpy.isscalar(major):
222 i = int(major)
223 if i < 0:
224 i += major_size
225 if not (0 <= i < major_size):
226 raise IndexError('index out of bounds')
227 if numpy.isscalar(minor):
228 j = int(minor)
229 if j < 0:
230 j += minor_size
231 if not (0 <= j < minor_size):
232 raise IndexError('index out of bounds')
233 return self._get_single(i, j)
234 elif minor == slice(None):
235 return self._get_major_slice(slice(i, i + 1))
236 elif isinstance(major, slice):
237 if minor == slice(None):
238 return self._get_major_slice(major)
239
240 raise ValueError('unsupported indexing')
241
242 def _get_single(self, major, minor):
243 start = self.indptr[major]
244 end = self.indptr[major + 1]
245 answer = cupy.zeros((), self.dtype)
246 data = self.data[start:end]
247 indices = self.indices[start:end]
248 if self.dtype.kind == 'c':
249 self._compress_getitem_complex_kern(
250 data.real, data.imag, indices, minor, answer.real, answer.imag)
251 else:
252 self._compress_getitem_kern(
253 data, indices, minor, answer)
254 return answer[()]
255
256 def _get_major_slice(self, major):
257 major_size, minor_size = self._swap(*self._shape)
258 # major.indices cannot be used because scipy.sparse behaves differently
259 major_start = major.start
260 major_stop = major.stop
261 major_step = major.step
262 if major_start is None:
263 major_start = 0
264 if major_stop is None:
265 major_stop = major_size
266 if major_step is None:
267 major_step = 1
268 if major_start < 0:
269 major_start += major_size
270 if major_stop < 0:
271 major_stop += major_size
272
273 if major_step != 1:
274 raise ValueError('slicing with step != 1 not supported')
275
276 if not (0 <= major_start <= major_size and
277 0 <= major_stop <= major_size and
278 major_start <= major_stop):
279 raise IndexError('index out of bounds')
280
281 start = self.indptr[major_start]
282 stop = self.indptr[major_stop]
283 data = self.data[start:stop]
284 indptr = self.indptr[major_start:major_stop + 1] - start
285 indices = self.indices[start:stop]
286
287 shape = self._swap(len(indptr) - 1, minor_size)
288 return self.__class__(
289 (data, indices, indptr), shape=shape, dtype=self.dtype, copy=False)
290
291 @property
292 def has_canonical_format(self):
293 return self._has_canonical_format
294
295 def get_shape(self):
296 """Returns the shape of the matrix.
297
298 Returns:
299 tuple: Shape of the matrix.
300 """
301 return self._shape
302
303 def getnnz(self, axis=None):
304 """Returns the number of stored values, including explicit zeros.
305
306 Args:
307 axis: Not supported yet.
308
309 Returns:
310 int: The number of stored values.
311
312 """
313 if axis is None:
314 return self.data.size
315 else:
316 raise ValueError
317
318 # TODO(unno): Implement sorted_indices
319
320 def sum_duplicates(self):
321 if self._has_canonical_format:
322 return
323 if self.data.size == 0:
324 self._has_canonical_format = True
325 return
326 coo = self.tocoo()
327 coo.sum_duplicates()
328 self.__init__(coo.asformat(self.format))
329 self._has_canonical_format = True
330
[end of cupyx/scipy/sparse/compressed.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/cupyx/scipy/sparse/compressed.py b/cupyx/scipy/sparse/compressed.py
--- a/cupyx/scipy/sparse/compressed.py
+++ b/cupyx/scipy/sparse/compressed.py
@@ -269,13 +269,13 @@
major_start += major_size
if major_stop < 0:
major_stop += major_size
+ major_start = max(min(major_start, major_size), 0)
+ major_stop = max(min(major_stop, major_size), 0)
if major_step != 1:
raise ValueError('slicing with step != 1 not supported')
- if not (0 <= major_start <= major_size and
- 0 <= major_stop <= major_size and
- major_start <= major_stop):
+ if not (major_start <= major_stop):
raise IndexError('index out of bounds')
start = self.indptr[major_start]
| {"golden_diff": "diff --git a/cupyx/scipy/sparse/compressed.py b/cupyx/scipy/sparse/compressed.py\n--- a/cupyx/scipy/sparse/compressed.py\n+++ b/cupyx/scipy/sparse/compressed.py\n@@ -269,13 +269,13 @@\n major_start += major_size\n if major_stop < 0:\n major_stop += major_size\n+ major_start = max(min(major_start, major_size), 0)\n+ major_stop = max(min(major_stop, major_size), 0)\n \n if major_step != 1:\n raise ValueError('slicing with step != 1 not supported')\n \n- if not (0 <= major_start <= major_size and\n- 0 <= major_stop <= major_size and\n- major_start <= major_stop):\n+ if not (major_start <= major_stop):\n raise IndexError('index out of bounds')\n \n start = self.indptr[major_start]\n", "issue": "Support SciPy 1.0\nSciPy 1.0 released. It has some compatibility breaks in `scipy.sparse`. We need to fix implementations or tests.\n", "before_files": [{"content": "import numpy\ntry:\n import scipy.sparse\n scipy_available = True\nexcept ImportError:\n scipy_available = False\n\nimport cupy\nfrom cupy import core\nfrom cupy.creation import basic\nfrom cupy import cusparse\nfrom cupyx.scipy.sparse import base\nfrom cupyx.scipy.sparse import data as sparse_data\nfrom cupyx.scipy.sparse import util\n\n\nclass _compressed_sparse_matrix(sparse_data._data_matrix):\n\n _compress_getitem_kern = core.ElementwiseKernel(\n 'T d, S ind, int32 minor', 'raw T answer',\n 'if (ind == minor) atomicAdd(&answer[0], d);',\n 'compress_getitem')\n\n _compress_getitem_complex_kern = core.ElementwiseKernel(\n 'T real, T imag, S ind, int32 minor',\n 'raw T answer_real, raw T answer_imag',\n '''\n if (ind == minor) {\n atomicAdd(&answer_real[0], real);\n atomicAdd(&answer_imag[0], imag);\n }\n ''',\n 'compress_getitem_complex')\n\n def __init__(self, arg1, shape=None, dtype=None, copy=False):\n if shape is not None and len(shape) != 2:\n raise ValueError(\n 'Only two-dimensional sparse arrays are supported.')\n\n if base.issparse(arg1):\n x = arg1.asformat(self.format)\n data = x.data\n indices = x.indices\n indptr = x.indptr\n\n if arg1.format != self.format:\n # When formats are differnent, all arrays are already copied\n copy = False\n\n if shape is None:\n shape = arg1.shape\n\n has_canonical_format = x.has_canonical_format\n elif util.isshape(arg1):\n m, n = arg1\n m, n = int(m), int(n)\n data = basic.zeros(0, dtype if dtype else 'd')\n indices = basic.zeros(0, 'i')\n indptr = basic.zeros(self._swap(m, n)[0] + 1, dtype='i')\n # shape and copy argument is ignored\n shape = (m, n)\n copy = False\n has_canonical_format = True\n\n elif scipy_available and scipy.sparse.issparse(arg1):\n # Convert scipy.sparse to cupyx.scipy.sparse\n x = arg1.asformat(self.format)\n data = cupy.array(x.data)\n indices = cupy.array(x.indices, dtype='i')\n indptr = cupy.array(x.indptr, dtype='i')\n copy = False\n\n if shape is None:\n shape = arg1.shape\n has_canonical_format = x.has_canonical_format\n\n elif isinstance(arg1, tuple) and len(arg1) == 3:\n data, indices, indptr = arg1\n if not (base.isdense(data) and data.ndim == 1 and\n base.isdense(indices) and indices.ndim == 1 and\n base.isdense(indptr) and indptr.ndim == 1):\n raise ValueError(\n 'data, indices, and indptr should be 1-D')\n\n if len(data) != len(indices):\n raise ValueError('indices and data should have the same size')\n\n has_canonical_format = False\n\n elif base.isdense(arg1):\n if arg1.ndim > 2:\n raise TypeError('expected dimension <= 2 array or matrix')\n elif arg1.ndim == 1:\n arg1 = arg1[None]\n elif arg1.ndim == 0:\n arg1 = arg1[None, None]\n data, indices, indptr = self._convert_dense(arg1)\n copy = False\n if shape is None:\n shape = arg1.shape\n\n has_canonical_format = True\n\n else:\n raise ValueError(\n 'Unsupported initializer format')\n\n if dtype is None:\n dtype = data.dtype\n else:\n dtype = numpy.dtype(dtype)\n\n if dtype != 'f' and dtype != 'd' and dtype != 'F' and dtype != 'D':\n raise ValueError(\n 'Only float32, float64, complex64 and complex128 '\n 'are supported')\n\n data = data.astype(dtype, copy=copy)\n sparse_data._data_matrix.__init__(self, data)\n\n self.indices = indices.astype('i', copy=copy)\n self.indptr = indptr.astype('i', copy=copy)\n\n if shape is None:\n shape = self._swap(len(indptr) - 1, int(indices.max()) + 1)\n\n major, minor = self._swap(*shape)\n if len(indptr) != major + 1:\n raise ValueError('index pointer size (%d) should be (%d)'\n % (len(indptr), major + 1))\n\n self._descr = cusparse.MatDescriptor.create()\n self._shape = shape\n self._has_canonical_format = has_canonical_format\n\n def _with_data(self, data):\n return self.__class__(\n (data, self.indices.copy(), self.indptr.copy()), shape=self.shape)\n\n def _convert_dense(self, x):\n raise NotImplementedError\n\n def _swap(self, x, y):\n raise NotImplementedError\n\n def _add_sparse(self, other, alpha, beta):\n raise NotImplementedError\n\n def _add(self, other, lhs_negative, rhs_negative):\n if cupy.isscalar(other):\n if other == 0:\n if lhs_negative:\n return -self\n else:\n return self.copy()\n else:\n raise NotImplementedError(\n 'adding a nonzero scalar to a sparse matrix is not '\n 'supported')\n elif base.isspmatrix(other):\n alpha = -1 if lhs_negative else 1\n beta = -1 if rhs_negative else 1\n return self._add_sparse(other, alpha, beta)\n elif base.isdense(other):\n if lhs_negative:\n if rhs_negative:\n return -self.todense() - other\n else:\n return other - self.todense()\n else:\n if rhs_negative:\n return self.todense() - other\n else:\n return self.todense() + other\n else:\n return NotImplemented\n\n def __add__(self, other):\n return self._add(other, False, False)\n\n def __radd__(self, other):\n return self._add(other, False, False)\n\n def __sub__(self, other):\n return self._add(other, False, True)\n\n def __rsub__(self, other):\n return self._add(other, True, False)\n\n def __getitem__(self, slices):\n if isinstance(slices, tuple):\n slices = list(slices)\n elif isinstance(slices, list):\n slices = list(slices)\n if all([isinstance(s, int) for s in slices]):\n slices = [slices]\n else:\n slices = [slices]\n\n ellipsis = -1\n n_ellipsis = 0\n for i, s in enumerate(slices):\n if s is None:\n raise IndexError('newaxis is not supported')\n elif s is Ellipsis:\n ellipsis = i\n n_ellipsis += 1\n if n_ellipsis > 0:\n ellipsis_size = self.ndim - (len(slices) - 1)\n slices[ellipsis:ellipsis + 1] = [slice(None)] * ellipsis_size\n\n if len(slices) == 2:\n row, col = slices\n elif len(slices) == 1:\n row, col = slices[0], slice(None)\n else:\n raise IndexError('invalid number of indices')\n\n major, minor = self._swap(row, col)\n major_size, minor_size = self._swap(*self._shape)\n if numpy.isscalar(major):\n i = int(major)\n if i < 0:\n i += major_size\n if not (0 <= i < major_size):\n raise IndexError('index out of bounds')\n if numpy.isscalar(minor):\n j = int(minor)\n if j < 0:\n j += minor_size\n if not (0 <= j < minor_size):\n raise IndexError('index out of bounds')\n return self._get_single(i, j)\n elif minor == slice(None):\n return self._get_major_slice(slice(i, i + 1))\n elif isinstance(major, slice):\n if minor == slice(None):\n return self._get_major_slice(major)\n\n raise ValueError('unsupported indexing')\n\n def _get_single(self, major, minor):\n start = self.indptr[major]\n end = self.indptr[major + 1]\n answer = cupy.zeros((), self.dtype)\n data = self.data[start:end]\n indices = self.indices[start:end]\n if self.dtype.kind == 'c':\n self._compress_getitem_complex_kern(\n data.real, data.imag, indices, minor, answer.real, answer.imag)\n else:\n self._compress_getitem_kern(\n data, indices, minor, answer)\n return answer[()]\n\n def _get_major_slice(self, major):\n major_size, minor_size = self._swap(*self._shape)\n # major.indices cannot be used because scipy.sparse behaves differently\n major_start = major.start\n major_stop = major.stop\n major_step = major.step\n if major_start is None:\n major_start = 0\n if major_stop is None:\n major_stop = major_size\n if major_step is None:\n major_step = 1\n if major_start < 0:\n major_start += major_size\n if major_stop < 0:\n major_stop += major_size\n\n if major_step != 1:\n raise ValueError('slicing with step != 1 not supported')\n\n if not (0 <= major_start <= major_size and\n 0 <= major_stop <= major_size and\n major_start <= major_stop):\n raise IndexError('index out of bounds')\n\n start = self.indptr[major_start]\n stop = self.indptr[major_stop]\n data = self.data[start:stop]\n indptr = self.indptr[major_start:major_stop + 1] - start\n indices = self.indices[start:stop]\n\n shape = self._swap(len(indptr) - 1, minor_size)\n return self.__class__(\n (data, indices, indptr), shape=shape, dtype=self.dtype, copy=False)\n\n @property\n def has_canonical_format(self):\n return self._has_canonical_format\n\n def get_shape(self):\n \"\"\"Returns the shape of the matrix.\n\n Returns:\n tuple: Shape of the matrix.\n \"\"\"\n return self._shape\n\n def getnnz(self, axis=None):\n \"\"\"Returns the number of stored values, including explicit zeros.\n\n Args:\n axis: Not supported yet.\n\n Returns:\n int: The number of stored values.\n\n \"\"\"\n if axis is None:\n return self.data.size\n else:\n raise ValueError\n\n # TODO(unno): Implement sorted_indices\n\n def sum_duplicates(self):\n if self._has_canonical_format:\n return\n if self.data.size == 0:\n self._has_canonical_format = True\n return\n coo = self.tocoo()\n coo.sum_duplicates()\n self.__init__(coo.asformat(self.format))\n self._has_canonical_format = True\n", "path": "cupyx/scipy/sparse/compressed.py"}]} | 3,972 | 213 |
gh_patches_debug_15901 | rasdani/github-patches | git_diff | sql-machine-learning__elasticdl-322 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
build local docker image using docker python api
for the edl client to build docker image locally, we need a wrapper for docker python sdk: https://pypi.org/project/docker firstly.
</issue>
<code>
[start of elasticdl/client/client.py]
1 import os
2 import inspect
3 import shutil
4 import time
5 import getpass
6 from string import Template
7
8 def run(model_class, train_data_dir=None,
9 num_epoch=1, minibatch_size=10,
10 record_per_task=100, num_worker=1, grads_to_wait=2):
11 m_path, m_file = _getModelFile()
12 m_file_in_docker = "/model/" + m_file
13 timestamp = int(round(time.time() * 1000))
14 _build_docker_image(m_path, m_file, m_file_in_docker, timestamp)
15 yaml_file = _generate_yaml(m_file_in_docker, model_class.__name__, train_data_dir=train_data_dir,
16 num_epoch=num_epoch, minibatch_size=minibatch_size,
17 record_per_task=record_per_task, num_worker=num_worker,
18 grads_to_wait=grads_to_wait, timestamp=timestamp)
19 _submit(yaml_file)
20
21 def _getModelFile():
22 m_file = inspect.currentframe().f_back.f_back.f_code.co_filename
23 m_path = os.path.abspath(os.path.dirname(m_file))
24 return m_path, m_file
25
26 def _build_docker_image(m_path, m_file, m_file_in_docker, timestamp):
27 d_path = os.path.abspath(os.path.dirname(
28 inspect.currentframe().f_back.f_code.co_filename))
29 new_dfile = m_path + "/Dockerfile"
30 shutil.copyfile(d_path + "/../Dockerfile.dev", new_dfile)
31
32 with open(new_dfile, 'a') as df:
33 df.write("COPY " + m_file + " " + m_file_in_docker)
34 val = os.system('docker build -t elasticdl:dev_' + str(timestamp) + ' -f Dockerfile .')
35
36 # TODO: upload docker image to docker hub.
37
38 def _generate_yaml(m_file, m_class,
39 train_data_dir=None, num_epoch=1,
40 minibatch_size=10, record_per_task=100,
41 num_worker=1, grads_to_wait=2, timestamp=1):
42 YAML_TEMPLATE = """
43 apiVersion: v1
44 kind: Pod
45 metadata:
46 name: elasticdl-master-$timestamp
47 labels:
48 purpose: test-command
49 spec:
50 containers:
51 - name: elasticdl-master-$timestamp
52 image: elasticdl:dev_$timestamp
53 command: ["python"]
54 args: ["-m", "elasticdl.master.main",
55 "--model-file", "$m_file",
56 "--num_worker", "$num_worker",
57 "--worker_image", "elasticdl:dev_$timestamp",
58 "--job_name", "elasticdl-$timestamp",
59 "--model-class", "$m_class",
60 "--train_data_dir", "$train_data_dir",
61 "--num_epoch", "$num_epoch",
62 "--grads_to_wait", "$grads_to_wait",
63 "--minibatch_size", "$minibatch_size",
64 "--record_per_task", "$record_per_task"]
65 imagePullPolicy: Never
66 env:
67 - name: MY_POD_IP
68 valueFrom:
69 fieldRef:
70 fieldPath: status.podIP
71 restartPolicy: Never
72 """
73 t = Template(YAML_TEMPLATE)
74 yaml_file = 'job_desc.yaml'
75 with open(yaml_file, "w") as yaml:
76 yaml.write(t.substitute(m_file=m_file, m_class=m_class,
77 train_data_dir=train_data_dir,
78 timestamp=timestamp, num_worker=num_worker, num_epoch=num_epoch,
79 minibatch_size=minibatch_size, record_per_task=record_per_task,
80 user=getpass.getuser(), grads_to_wait=grads_to_wait))
81 return yaml_file
82
83 def _submit(yaml_file):
84 os.system('kubectl create -f ' + yaml_file)
85
[end of elasticdl/client/client.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/elasticdl/client/client.py b/elasticdl/client/client.py
--- a/elasticdl/client/client.py
+++ b/elasticdl/client/client.py
@@ -4,6 +4,8 @@
import time
import getpass
from string import Template
+import docker
+
def run(model_class, train_data_dir=None,
num_epoch=1, minibatch_size=10,
@@ -31,7 +33,9 @@
with open(new_dfile, 'a') as df:
df.write("COPY " + m_file + " " + m_file_in_docker)
- val = os.system('docker build -t elasticdl:dev_' + str(timestamp) + ' -f Dockerfile .')
+ client = docker.APIClient(base_url='unix://var/run/docker.sock')
+ for line in client.build(dockerfile='Dockerfile', path='.', tag='elasticdl:dev_' + str(timestamp)):
+ print(str(line, encoding = "utf-8"))
# TODO: upload docker image to docker hub.
| {"golden_diff": "diff --git a/elasticdl/client/client.py b/elasticdl/client/client.py\n--- a/elasticdl/client/client.py\n+++ b/elasticdl/client/client.py\n@@ -4,6 +4,8 @@\n import time\n import getpass\n from string import Template\n+import docker\n+\n \n def run(model_class, train_data_dir=None, \n num_epoch=1, minibatch_size=10, \n@@ -31,7 +33,9 @@\n \n with open(new_dfile, 'a') as df:\n df.write(\"COPY \" + m_file + \" \" + m_file_in_docker)\n- val = os.system('docker build -t elasticdl:dev_' + str(timestamp) + ' -f Dockerfile .')\n+ client = docker.APIClient(base_url='unix://var/run/docker.sock') \n+ for line in client.build(dockerfile='Dockerfile', path='.', tag='elasticdl:dev_' + str(timestamp)):\n+ print(str(line, encoding = \"utf-8\"))\n \n # TODO: upload docker image to docker hub.\n", "issue": "build local docker image using docker python api\nfor the edl client to build docker image locally, we need a wrapper for docker python sdk: https://pypi.org/project/docker firstly.\n", "before_files": [{"content": "import os\nimport inspect\nimport shutil\nimport time\nimport getpass\nfrom string import Template\n\ndef run(model_class, train_data_dir=None, \n num_epoch=1, minibatch_size=10, \n record_per_task=100, num_worker=1, grads_to_wait=2):\n m_path, m_file = _getModelFile()\n m_file_in_docker = \"/model/\" + m_file \n timestamp = int(round(time.time() * 1000))\n _build_docker_image(m_path, m_file, m_file_in_docker, timestamp)\n yaml_file = _generate_yaml(m_file_in_docker, model_class.__name__, train_data_dir=train_data_dir, \n num_epoch=num_epoch, minibatch_size=minibatch_size, \n record_per_task=record_per_task, num_worker=num_worker, \n grads_to_wait=grads_to_wait, timestamp=timestamp)\n _submit(yaml_file)\n\ndef _getModelFile():\n m_file = inspect.currentframe().f_back.f_back.f_code.co_filename\n m_path = os.path.abspath(os.path.dirname(m_file))\n return m_path, m_file\n\ndef _build_docker_image(m_path, m_file, m_file_in_docker, timestamp):\n d_path = os.path.abspath(os.path.dirname(\n inspect.currentframe().f_back.f_code.co_filename))\n new_dfile = m_path + \"/Dockerfile\"\n shutil.copyfile(d_path + \"/../Dockerfile.dev\", new_dfile)\n\n with open(new_dfile, 'a') as df:\n df.write(\"COPY \" + m_file + \" \" + m_file_in_docker)\n val = os.system('docker build -t elasticdl:dev_' + str(timestamp) + ' -f Dockerfile .')\n\n # TODO: upload docker image to docker hub.\n\ndef _generate_yaml(m_file, m_class,\n train_data_dir=None, num_epoch=1,\n minibatch_size=10, record_per_task=100, \n num_worker=1, grads_to_wait=2, timestamp=1):\n YAML_TEMPLATE = \"\"\"\n apiVersion: v1\n kind: Pod\n metadata:\n name: elasticdl-master-$timestamp\n labels:\n purpose: test-command\n spec:\n containers:\n - name: elasticdl-master-$timestamp\n image: elasticdl:dev_$timestamp\n command: [\"python\"]\n args: [\"-m\", \"elasticdl.master.main\",\n \"--model-file\", \"$m_file\",\n \"--num_worker\", \"$num_worker\",\n \"--worker_image\", \"elasticdl:dev_$timestamp\",\n \"--job_name\", \"elasticdl-$timestamp\",\n \"--model-class\", \"$m_class\",\n \"--train_data_dir\", \"$train_data_dir\",\n \"--num_epoch\", \"$num_epoch\",\n \"--grads_to_wait\", \"$grads_to_wait\",\n \"--minibatch_size\", \"$minibatch_size\",\n \"--record_per_task\", \"$record_per_task\"]\n imagePullPolicy: Never\n env:\n - name: MY_POD_IP\n valueFrom:\n fieldRef:\n fieldPath: status.podIP\n restartPolicy: Never\n \"\"\"\n t = Template(YAML_TEMPLATE)\n yaml_file = 'job_desc.yaml'\n with open(yaml_file, \"w\") as yaml:\n yaml.write(t.substitute(m_file=m_file, m_class=m_class, \n train_data_dir=train_data_dir, \n timestamp=timestamp, num_worker=num_worker, num_epoch=num_epoch,\n minibatch_size=minibatch_size, record_per_task=record_per_task,\n user=getpass.getuser(), grads_to_wait=grads_to_wait))\n return yaml_file\n\ndef _submit(yaml_file):\n os.system('kubectl create -f ' + yaml_file)\n", "path": "elasticdl/client/client.py"}]} | 1,550 | 234 |
gh_patches_debug_34012 | rasdani/github-patches | git_diff | deeppavlov__DeepPavlov-545 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Why Levenshtein Corrector make strange inserts inplace of punctuation marks?
```
from deeppavlov.deep import find_config, deep_download
from deeppavlov.core.commands.infer import build_model_from_config
config = find_config('levenshtein_corrector_ru')
deep_download(config)
model = build_model_from_config(config)
print(model(['Сегодня.']))
print(model(['в 3 . Сегодня.']))
```
Gives me
> ['сегодня в']
> ['в 3 и сегодня и']
There are strange "." --> "в" and "." --> "и" inserts.
</issue>
<code>
[start of deeppavlov/models/spelling_correction/levenshtein/searcher_component.py]
1 # Copyright 2017 Neural Networks and Deep Learning lab, MIPT
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from math import log10
16 from typing import Iterable, List, Tuple
17
18 from deeppavlov.core.common.registry import register
19 from deeppavlov.core.models.component import Component
20 from deeppavlov.core.common.log import get_logger
21
22 from .levenshtein_searcher import LevenshteinSearcher
23
24
25 logger = get_logger(__name__)
26
27
28 @register('spelling_levenshtein')
29 class LevenshteinSearcherComponent(Component):
30 """Component that finds replacement candidates for tokens at a set Damerau-Levenshtein distance
31
32 Args:
33 words: list of every correct word
34 max_distance: maximum allowed Damerau-Levenshtein distance between source words and candidates
35 error_probability: assigned probability for every edit
36
37 Attributes:
38 max_distance: maximum allowed Damerau-Levenshtein distance between source words and candidates
39 error_probability: assigned logarithmic probability for every edit
40 vocab_penalty: assigned logarithmic probability of an out of vocabulary token being the correct one without
41 changes
42 """
43
44 def __init__(self, words: Iterable[str], max_distance: int=1, error_probability: float=1e-4, *args, **kwargs):
45 words = list({word.strip().lower().replace('ё', 'е') for word in words})
46 alphabet = sorted({letter for word in words for letter in word})
47 self.max_distance = max_distance
48 self.error_probability = log10(error_probability)
49 self.vocab_penalty = self.error_probability * 2
50 self.searcher = LevenshteinSearcher(alphabet, words, allow_spaces=True, euristics=2)
51
52 def _infer_instance(self, tokens: Iterable[str]) -> List[List[Tuple[float, str]]]:
53 candidates = []
54 for word in tokens:
55 c = {candidate: self.error_probability * distance
56 for candidate, distance in self.searcher.search(word, d=self.max_distance)}
57 c[word] = c.get(word, self.vocab_penalty)
58 candidates.append([(score, candidate) for candidate, score in c.items()])
59 return candidates
60
61 def __call__(self, batch: Iterable[Iterable[str]], *args, **kwargs) -> List[List[List[Tuple[float, str]]]]:
62 """Propose candidates for tokens in sentences
63
64 Args:
65 batch: batch of tokenized sentences
66
67 Returns:
68 batch of lists of probabilities and candidates for every token
69 """
70 return [self._infer_instance(tokens) for tokens in batch]
71
[end of deeppavlov/models/spelling_correction/levenshtein/searcher_component.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/deeppavlov/models/spelling_correction/levenshtein/searcher_component.py b/deeppavlov/models/spelling_correction/levenshtein/searcher_component.py
--- a/deeppavlov/models/spelling_correction/levenshtein/searcher_component.py
+++ b/deeppavlov/models/spelling_correction/levenshtein/searcher_component.py
@@ -11,7 +11,7 @@
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
-
+import string
from math import log10
from typing import Iterable, List, Tuple
@@ -41,6 +41,8 @@
changes
"""
+ _punctuation = frozenset(string.punctuation)
+
def __init__(self, words: Iterable[str], max_distance: int=1, error_probability: float=1e-4, *args, **kwargs):
words = list({word.strip().lower().replace('ё', 'е') for word in words})
alphabet = sorted({letter for word in words for letter in word})
@@ -52,10 +54,13 @@
def _infer_instance(self, tokens: Iterable[str]) -> List[List[Tuple[float, str]]]:
candidates = []
for word in tokens:
- c = {candidate: self.error_probability * distance
- for candidate, distance in self.searcher.search(word, d=self.max_distance)}
- c[word] = c.get(word, self.vocab_penalty)
- candidates.append([(score, candidate) for candidate, score in c.items()])
+ if word in self._punctuation:
+ candidates.append([(0, word)])
+ else:
+ c = {candidate: self.error_probability * distance
+ for candidate, distance in self.searcher.search(word, d=self.max_distance)}
+ c[word] = c.get(word, self.vocab_penalty)
+ candidates.append([(score, candidate) for candidate, score in c.items()])
return candidates
def __call__(self, batch: Iterable[Iterable[str]], *args, **kwargs) -> List[List[List[Tuple[float, str]]]]:
| {"golden_diff": "diff --git a/deeppavlov/models/spelling_correction/levenshtein/searcher_component.py b/deeppavlov/models/spelling_correction/levenshtein/searcher_component.py\n--- a/deeppavlov/models/spelling_correction/levenshtein/searcher_component.py\n+++ b/deeppavlov/models/spelling_correction/levenshtein/searcher_component.py\n@@ -11,7 +11,7 @@\n # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n # See the License for the specific language governing permissions and\n # limitations under the License.\n-\n+import string\n from math import log10\n from typing import Iterable, List, Tuple\n \n@@ -41,6 +41,8 @@\n changes\n \"\"\"\n \n+ _punctuation = frozenset(string.punctuation)\n+\n def __init__(self, words: Iterable[str], max_distance: int=1, error_probability: float=1e-4, *args, **kwargs):\n words = list({word.strip().lower().replace('\u0451', '\u0435') for word in words})\n alphabet = sorted({letter for word in words for letter in word})\n@@ -52,10 +54,13 @@\n def _infer_instance(self, tokens: Iterable[str]) -> List[List[Tuple[float, str]]]:\n candidates = []\n for word in tokens:\n- c = {candidate: self.error_probability * distance\n- for candidate, distance in self.searcher.search(word, d=self.max_distance)}\n- c[word] = c.get(word, self.vocab_penalty)\n- candidates.append([(score, candidate) for candidate, score in c.items()])\n+ if word in self._punctuation:\n+ candidates.append([(0, word)])\n+ else:\n+ c = {candidate: self.error_probability * distance\n+ for candidate, distance in self.searcher.search(word, d=self.max_distance)}\n+ c[word] = c.get(word, self.vocab_penalty)\n+ candidates.append([(score, candidate) for candidate, score in c.items()])\n return candidates\n \n def __call__(self, batch: Iterable[Iterable[str]], *args, **kwargs) -> List[List[List[Tuple[float, str]]]]:\n", "issue": "Why Levenshtein Corrector make strange inserts inplace of punctuation marks?\n```\r\nfrom deeppavlov.deep import find_config, deep_download\r\nfrom deeppavlov.core.commands.infer import build_model_from_config\r\nconfig = find_config('levenshtein_corrector_ru')\r\ndeep_download(config)\r\nmodel = build_model_from_config(config)\r\nprint(model(['\u0421\u0435\u0433\u043e\u0434\u043d\u044f.']))\r\nprint(model(['\u0432 3 . \u0421\u0435\u0433\u043e\u0434\u043d\u044f.']))\r\n```\r\nGives me\r\n> ['\u0441\u0435\u0433\u043e\u0434\u043d\u044f \u0432']\r\n> ['\u0432 3 \u0438 \u0441\u0435\u0433\u043e\u0434\u043d\u044f \u0438']\r\n\r\nThere are strange \".\" --> \"\u0432\" and \".\" --> \"\u0438\" inserts.\n", "before_files": [{"content": "# Copyright 2017 Neural Networks and Deep Learning lab, MIPT\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom math import log10\nfrom typing import Iterable, List, Tuple\n\nfrom deeppavlov.core.common.registry import register\nfrom deeppavlov.core.models.component import Component\nfrom deeppavlov.core.common.log import get_logger\n\nfrom .levenshtein_searcher import LevenshteinSearcher\n\n\nlogger = get_logger(__name__)\n\n\n@register('spelling_levenshtein')\nclass LevenshteinSearcherComponent(Component):\n \"\"\"Component that finds replacement candidates for tokens at a set Damerau-Levenshtein distance\n\n Args:\n words: list of every correct word\n max_distance: maximum allowed Damerau-Levenshtein distance between source words and candidates\n error_probability: assigned probability for every edit\n\n Attributes:\n max_distance: maximum allowed Damerau-Levenshtein distance between source words and candidates\n error_probability: assigned logarithmic probability for every edit\n vocab_penalty: assigned logarithmic probability of an out of vocabulary token being the correct one without\n changes\n \"\"\"\n\n def __init__(self, words: Iterable[str], max_distance: int=1, error_probability: float=1e-4, *args, **kwargs):\n words = list({word.strip().lower().replace('\u0451', '\u0435') for word in words})\n alphabet = sorted({letter for word in words for letter in word})\n self.max_distance = max_distance\n self.error_probability = log10(error_probability)\n self.vocab_penalty = self.error_probability * 2\n self.searcher = LevenshteinSearcher(alphabet, words, allow_spaces=True, euristics=2)\n\n def _infer_instance(self, tokens: Iterable[str]) -> List[List[Tuple[float, str]]]:\n candidates = []\n for word in tokens:\n c = {candidate: self.error_probability * distance\n for candidate, distance in self.searcher.search(word, d=self.max_distance)}\n c[word] = c.get(word, self.vocab_penalty)\n candidates.append([(score, candidate) for candidate, score in c.items()])\n return candidates\n\n def __call__(self, batch: Iterable[Iterable[str]], *args, **kwargs) -> List[List[List[Tuple[float, str]]]]:\n \"\"\"Propose candidates for tokens in sentences\n\n Args:\n batch: batch of tokenized sentences\n\n Returns:\n batch of lists of probabilities and candidates for every token\n \"\"\"\n return [self._infer_instance(tokens) for tokens in batch]\n", "path": "deeppavlov/models/spelling_correction/levenshtein/searcher_component.py"}]} | 1,491 | 481 |
gh_patches_debug_33190 | rasdani/github-patches | git_diff | linz__geostore-121 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Use Python 3.8 across the board
We've already encountered some issues with Python 3.6 (cattrs no longer supporting it and less support for type annotations), and we have no reason to support multiple Python versions in production.
To do:
- [x] Set Python version in `.python-version`.
- [ ] Use a single version in CI, removing the need for the strategy matrix.
- [ ] Use the `PYTHON_3_8` runtime for AWS Lambda jobs.
- [ ] Change the version in `pyproject.toml` to `^3.8,<3.9`.
</issue>
<code>
[start of infra/datalake/api_stack.py]
1 """
2 Data Lake AWS resources definitions.
3 """
4 from aws_cdk import aws_lambda, core
5 from aws_cdk.core import Tags
6
7
8 class APIStack(core.Stack):
9 """Data Lake stack definition."""
10
11 def __init__(self, scope: core.Construct, stack_id: str, datasets_table, **kwargs) -> None:
12 super().__init__(scope, stack_id, **kwargs)
13
14 ############################################################################################
15 # ### API ENDPOINTS ########################################################################
16 ############################################################################################
17
18 endpoints = ("datasets",)
19
20 for endpoint in endpoints:
21 endpoint_function = aws_lambda.Function(
22 self,
23 f"{endpoint}-endpoint-function",
24 function_name=f"{endpoint}-endpoint",
25 handler=f"endpoints.{endpoint}.entrypoint.lambda_handler",
26 runtime=aws_lambda.Runtime.PYTHON_3_6,
27 code=aws_lambda.Code.from_asset(
28 path="..",
29 bundling=core.BundlingOptions(
30 # pylint:disable=no-member
31 image=aws_lambda.Runtime.PYTHON_3_6.bundling_docker_image,
32 command=["backend/bundle.bash", f"endpoints/{endpoint}"],
33 ),
34 ),
35 )
36
37 datasets_table.grant_read_write_data(endpoint_function)
38 datasets_table.grant(
39 endpoint_function, "dynamodb:DescribeTable"
40 ) # required by pynamodb
41
42 Tags.of(endpoint_function).add("ApplicationLayer", "api")
43
[end of infra/datalake/api_stack.py]
[start of infra/datalake/processing_stack.py]
1 """
2 Data Lake processing stack.
3 """
4 import textwrap
5
6 from aws_cdk import (
7 aws_batch,
8 aws_ec2,
9 aws_ecs,
10 aws_iam,
11 aws_lambda,
12 aws_stepfunctions,
13 aws_stepfunctions_tasks,
14 core,
15 )
16 from aws_cdk.core import Tags
17
18
19 class ProcessingStack(core.Stack):
20 """Data Lake processing stack definition."""
21
22 # pylint: disable=too-many-locals
23 def __init__(self, scope: core.Construct, stack_id: str, deploy_env, vpc, **kwargs) -> None:
24 super().__init__(scope, stack_id, **kwargs)
25
26 ############################################################################################
27 # ### DATASET VERSION CREATE ###############################################################
28 ############################################################################################
29
30 # STATE MACHINE TASKS CONFIGURATION
31 # * type: lambda|batch
32 # * parallel: True|False
33 # * input_path: "$"
34 # * output_path: "$"
35 # * result_path: "$"
36 # * items_path: "$"
37 creation_tasks = {}
38
39 creation_tasks["content_iterator"] = {"type": "lambda", "result_path": "$.content"}
40
41 creation_tasks["validation_summary"] = {"type": "lambda", "result_path": "$.validation"}
42
43 creation_tasks["validation_failure"] = {
44 "type": "lambda",
45 "result_path": aws_stepfunctions.JsonPath.DISCARD,
46 }
47
48 creation_tasks["check_flat_directory_structure"] = {
49 "type": "batch",
50 "parallel": False,
51 "result_path": aws_stepfunctions.JsonPath.DISCARD,
52 }
53
54 creation_tasks["check_files_checksums"] = {
55 "type": "batch",
56 "parallel": True,
57 "result_path": aws_stepfunctions.JsonPath.DISCARD,
58 }
59
60 # AWS BATCH COMPUTE ENVIRONMENT
61 batch_service_role = aws_iam.Role(
62 self,
63 "batch-service-role",
64 assumed_by=aws_iam.ServicePrincipal("batch.amazonaws.com"),
65 managed_policies=[
66 aws_iam.ManagedPolicy.from_aws_managed_policy_name(
67 "service-role/AWSBatchServiceRole"
68 ),
69 ],
70 )
71
72 batch_instance_role = aws_iam.Role(
73 self,
74 "batch-instance-role",
75 assumed_by=aws_iam.ServicePrincipal("ec2.amazonaws.com"),
76 managed_policies=[
77 aws_iam.ManagedPolicy.from_aws_managed_policy_name(
78 "service-role/AmazonEC2ContainerServiceforEC2Role"
79 ),
80 ],
81 )
82
83 batch_instance_profile = aws_iam.CfnInstanceProfile(
84 self,
85 "batch-instance-profile",
86 roles=[
87 batch_instance_role.role_name,
88 ],
89 )
90
91 batch_launch_template_data = textwrap.dedent(
92 """
93 MIME-Version: 1.0
94 Content-Type: multipart/mixed; boundary="==MYBOUNDARY=="
95
96 --==MYBOUNDARY==
97 Content-Type: text/x-shellscript; charset="us-ascii"
98
99 #!/bin/bash
100 echo ECS_IMAGE_PULL_BEHAVIOR=prefer-cached >> /etc/ecs/ecs.config
101
102 --==MYBOUNDARY==--
103 """
104 )
105
106 batch_launch_template = aws_ec2.CfnLaunchTemplate(
107 self,
108 "batch-launch-template",
109 launch_template_name="datalake-batch-launch-template",
110 launch_template_data={
111 "userData": core.Fn.base64(batch_launch_template_data.strip()),
112 },
113 )
114
115 if deploy_env == "prod":
116 instance_types = [
117 aws_ec2.InstanceType("c5.xlarge"),
118 aws_ec2.InstanceType("c5.2xlarge"),
119 aws_ec2.InstanceType("c5.4xlarge"),
120 aws_ec2.InstanceType("c5.9xlarge"),
121 ]
122 else:
123 instance_types = [
124 aws_ec2.InstanceType("m5.large"),
125 aws_ec2.InstanceType("m5.xlarge"),
126 ]
127
128 batch_compute_environment = aws_batch.ComputeEnvironment(
129 self,
130 "compute-environment",
131 compute_resources=aws_batch.ComputeResources(
132 vpc=vpc,
133 # vpc_subnets=vpc.select_subnets(subnet_group_name="ecs-cluster"), # TODO
134 minv_cpus=0,
135 desiredv_cpus=0,
136 maxv_cpus=1000,
137 instance_types=instance_types,
138 instance_role=batch_instance_profile.instance_profile_name,
139 allocation_strategy=aws_batch.AllocationStrategy("BEST_FIT_PROGRESSIVE"),
140 launch_template=aws_batch.LaunchTemplateSpecification(
141 launch_template_name=batch_launch_template.launch_template_name
142 ),
143 ),
144 service_role=batch_service_role,
145 )
146
147 batch_job_queue = aws_batch.JobQueue(
148 self,
149 "dataset-version-creation-queue",
150 compute_environments=[
151 aws_batch.JobQueueComputeEnvironment(
152 compute_environment=batch_compute_environment, order=10
153 ),
154 ],
155 priority=10,
156 )
157
158 # LAMBDA AND AWS BATCH BUNDLING AND STATE MACHINE TASKS CREATION
159 step_tasks = {}
160 for task_name in creation_tasks:
161
162 task = creation_tasks[task_name]
163
164 # lambda functions
165 if task["type"] == "lambda":
166
167 lambda_function = aws_lambda.Function(
168 self,
169 f"{task_name}-function",
170 handler=f"processing.{task_name}.task.lambda_handler",
171 runtime=aws_lambda.Runtime.PYTHON_3_6,
172 code=aws_lambda.Code.from_asset(
173 path="..",
174 bundling=core.BundlingOptions(
175 # pylint:disable=no-member
176 image=aws_lambda.Runtime.PYTHON_3_6.bundling_docker_image,
177 command=["backend/bundle.bash", f"processing/{task_name}"],
178 ),
179 ),
180 )
181
182 step_tasks[task_name] = aws_stepfunctions_tasks.LambdaInvoke(
183 self,
184 task_name,
185 lambda_function=lambda_function,
186 input_path=task.get("input_path", "$"),
187 output_path=task.get("output_path", "$"),
188 result_path=task.get("result_path", "$"),
189 payload_response_only=True,
190 )
191
192 Tags.of(lambda_function).add("ApplicationLayer", "data-processing")
193
194 # aws batch jobs
195 if task["type"] == "batch":
196
197 job_definition = aws_batch.JobDefinition(
198 self,
199 f"{task_name}-job",
200 container=aws_batch.JobDefinitionContainer(
201 image=aws_ecs.ContainerImage.from_asset(
202 directory=f"../backend/processing/{task_name}",
203 ),
204 memory_limit_mib=3900 if deploy_env == "prod" else 500,
205 vcpus=1,
206 ),
207 retry_attempts=4,
208 )
209
210 job_command = [
211 "--dataset-id",
212 "Ref::dataset_id",
213 "--version-id",
214 "Ref::version_id",
215 "--type",
216 "Ref::type",
217 "--metadata-url",
218 "Ref::metadata_url",
219 "--dataset-id",
220 ]
221 job_environment = {"BATCH_JOB_FIRST_ITEM_INDEX": "Ref::first_item"}
222
223 job_payload_data = {
224 "dataset_id.$": "$.dataset_id",
225 "version_id.$": "$.version_id",
226 "type.$": "$.type",
227 "metadata_url.$": "$.metadata_url",
228 }
229 job_payload_data_parallel = {"first_item.$": "$.content.first_item"}
230 job_payload_single = aws_stepfunctions.TaskInput.from_object(job_payload_data)
231 job_payload_parallel = aws_stepfunctions.TaskInput.from_object(
232 {**job_payload_data, **job_payload_data_parallel}
233 )
234
235 if task["parallel"]:
236 step_tasks[task_name] = aws_stepfunctions_tasks.BatchSubmitJob(
237 self,
238 task_name,
239 job_name=f"{task_name}-job",
240 job_definition=job_definition,
241 job_queue=batch_job_queue,
242 array_size=aws_stepfunctions.JsonPath.number_at("$.content.iteration_size"),
243 input_path=task.get("input_path", "$"),
244 output_path=task.get("output_path", "$"),
245 result_path=task.get("result_path", "$"),
246 container_overrides=aws_stepfunctions_tasks.BatchContainerOverrides(
247 command=job_command,
248 environment=job_environment,
249 ),
250 payload=job_payload_parallel,
251 )
252
253 else:
254 step_tasks[task_name] = aws_stepfunctions_tasks.BatchSubmitJob(
255 self,
256 task_name,
257 job_name=f"{task_name}-job",
258 job_definition=job_definition,
259 job_queue=batch_job_queue,
260 input_path=task.get("input_path", "$"),
261 output_path=task.get("output_path", "$"),
262 result_path=task.get("result_path", "$"),
263 container_overrides=aws_stepfunctions_tasks.BatchContainerOverrides(
264 command=job_command,
265 ),
266 payload=job_payload_single,
267 )
268
269 # success task
270 step_tasks["success"] = aws_stepfunctions.Succeed(
271 self,
272 "success",
273 )
274
275 # STATE MACHINE
276 # state machine definition
277 dataset_version_creation_definition = (
278 step_tasks["check_flat_directory_structure"]
279 .next(step_tasks["content_iterator"])
280 .next(step_tasks["check_files_checksums"])
281 .next(
282 aws_stepfunctions.Choice(self, "content_iteration_finished")
283 .when(
284 aws_stepfunctions.Condition.not_(
285 aws_stepfunctions.Condition.number_equals("$.content.next_item", -1)
286 ),
287 step_tasks["content_iterator"],
288 )
289 .otherwise(
290 step_tasks["validation_summary"].next(
291 aws_stepfunctions.Choice(self, "validation_successful")
292 .when(
293 aws_stepfunctions.Condition.boolean_equals(
294 "$.validation.success", True
295 ),
296 step_tasks["success"],
297 )
298 .otherwise(step_tasks["validation_failure"])
299 ),
300 )
301 )
302 )
303
304 # state machine
305 creation_process = aws_stepfunctions.StateMachine( # pylint:disable=unused-variable
306 self,
307 "dataset-version-creation",
308 definition=dataset_version_creation_definition,
309 )
310
[end of infra/datalake/processing_stack.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/infra/datalake/api_stack.py b/infra/datalake/api_stack.py
--- a/infra/datalake/api_stack.py
+++ b/infra/datalake/api_stack.py
@@ -23,12 +23,12 @@
f"{endpoint}-endpoint-function",
function_name=f"{endpoint}-endpoint",
handler=f"endpoints.{endpoint}.entrypoint.lambda_handler",
- runtime=aws_lambda.Runtime.PYTHON_3_6,
+ runtime=aws_lambda.Runtime.PYTHON_3_8,
code=aws_lambda.Code.from_asset(
path="..",
bundling=core.BundlingOptions(
# pylint:disable=no-member
- image=aws_lambda.Runtime.PYTHON_3_6.bundling_docker_image,
+ image=aws_lambda.Runtime.PYTHON_3_8.bundling_docker_image,
command=["backend/bundle.bash", f"endpoints/{endpoint}"],
),
),
diff --git a/infra/datalake/processing_stack.py b/infra/datalake/processing_stack.py
--- a/infra/datalake/processing_stack.py
+++ b/infra/datalake/processing_stack.py
@@ -168,12 +168,12 @@
self,
f"{task_name}-function",
handler=f"processing.{task_name}.task.lambda_handler",
- runtime=aws_lambda.Runtime.PYTHON_3_6,
+ runtime=aws_lambda.Runtime.PYTHON_3_8,
code=aws_lambda.Code.from_asset(
path="..",
bundling=core.BundlingOptions(
# pylint:disable=no-member
- image=aws_lambda.Runtime.PYTHON_3_6.bundling_docker_image,
+ image=aws_lambda.Runtime.PYTHON_3_8.bundling_docker_image,
command=["backend/bundle.bash", f"processing/{task_name}"],
),
),
| {"golden_diff": "diff --git a/infra/datalake/api_stack.py b/infra/datalake/api_stack.py\n--- a/infra/datalake/api_stack.py\n+++ b/infra/datalake/api_stack.py\n@@ -23,12 +23,12 @@\n f\"{endpoint}-endpoint-function\",\n function_name=f\"{endpoint}-endpoint\",\n handler=f\"endpoints.{endpoint}.entrypoint.lambda_handler\",\n- runtime=aws_lambda.Runtime.PYTHON_3_6,\n+ runtime=aws_lambda.Runtime.PYTHON_3_8,\n code=aws_lambda.Code.from_asset(\n path=\"..\",\n bundling=core.BundlingOptions(\n # pylint:disable=no-member\n- image=aws_lambda.Runtime.PYTHON_3_6.bundling_docker_image,\n+ image=aws_lambda.Runtime.PYTHON_3_8.bundling_docker_image,\n command=[\"backend/bundle.bash\", f\"endpoints/{endpoint}\"],\n ),\n ),\ndiff --git a/infra/datalake/processing_stack.py b/infra/datalake/processing_stack.py\n--- a/infra/datalake/processing_stack.py\n+++ b/infra/datalake/processing_stack.py\n@@ -168,12 +168,12 @@\n self,\n f\"{task_name}-function\",\n handler=f\"processing.{task_name}.task.lambda_handler\",\n- runtime=aws_lambda.Runtime.PYTHON_3_6,\n+ runtime=aws_lambda.Runtime.PYTHON_3_8,\n code=aws_lambda.Code.from_asset(\n path=\"..\",\n bundling=core.BundlingOptions(\n # pylint:disable=no-member\n- image=aws_lambda.Runtime.PYTHON_3_6.bundling_docker_image,\n+ image=aws_lambda.Runtime.PYTHON_3_8.bundling_docker_image,\n command=[\"backend/bundle.bash\", f\"processing/{task_name}\"],\n ),\n ),\n", "issue": "Use Python 3.8 across the board\nWe've already encountered some issues with Python 3.6 (cattrs no longer supporting it and less support for type annotations), and we have no reason to support multiple Python versions in production.\r\n\r\nTo do:\r\n\r\n- [x] Set Python version in `.python-version`.\r\n- [ ] Use a single version in CI, removing the need for the strategy matrix.\r\n- [ ] Use the `PYTHON_3_8` runtime for AWS Lambda jobs.\r\n- [ ] Change the version in `pyproject.toml` to `^3.8,<3.9`.\n", "before_files": [{"content": "\"\"\"\nData Lake AWS resources definitions.\n\"\"\"\nfrom aws_cdk import aws_lambda, core\nfrom aws_cdk.core import Tags\n\n\nclass APIStack(core.Stack):\n \"\"\"Data Lake stack definition.\"\"\"\n\n def __init__(self, scope: core.Construct, stack_id: str, datasets_table, **kwargs) -> None:\n super().__init__(scope, stack_id, **kwargs)\n\n ############################################################################################\n # ### API ENDPOINTS ########################################################################\n ############################################################################################\n\n endpoints = (\"datasets\",)\n\n for endpoint in endpoints:\n endpoint_function = aws_lambda.Function(\n self,\n f\"{endpoint}-endpoint-function\",\n function_name=f\"{endpoint}-endpoint\",\n handler=f\"endpoints.{endpoint}.entrypoint.lambda_handler\",\n runtime=aws_lambda.Runtime.PYTHON_3_6,\n code=aws_lambda.Code.from_asset(\n path=\"..\",\n bundling=core.BundlingOptions(\n # pylint:disable=no-member\n image=aws_lambda.Runtime.PYTHON_3_6.bundling_docker_image,\n command=[\"backend/bundle.bash\", f\"endpoints/{endpoint}\"],\n ),\n ),\n )\n\n datasets_table.grant_read_write_data(endpoint_function)\n datasets_table.grant(\n endpoint_function, \"dynamodb:DescribeTable\"\n ) # required by pynamodb\n\n Tags.of(endpoint_function).add(\"ApplicationLayer\", \"api\")\n", "path": "infra/datalake/api_stack.py"}, {"content": "\"\"\"\nData Lake processing stack.\n\"\"\"\nimport textwrap\n\nfrom aws_cdk import (\n aws_batch,\n aws_ec2,\n aws_ecs,\n aws_iam,\n aws_lambda,\n aws_stepfunctions,\n aws_stepfunctions_tasks,\n core,\n)\nfrom aws_cdk.core import Tags\n\n\nclass ProcessingStack(core.Stack):\n \"\"\"Data Lake processing stack definition.\"\"\"\n\n # pylint: disable=too-many-locals\n def __init__(self, scope: core.Construct, stack_id: str, deploy_env, vpc, **kwargs) -> None:\n super().__init__(scope, stack_id, **kwargs)\n\n ############################################################################################\n # ### DATASET VERSION CREATE ###############################################################\n ############################################################################################\n\n # STATE MACHINE TASKS CONFIGURATION\n # * type: lambda|batch\n # * parallel: True|False\n # * input_path: \"$\"\n # * output_path: \"$\"\n # * result_path: \"$\"\n # * items_path: \"$\"\n creation_tasks = {}\n\n creation_tasks[\"content_iterator\"] = {\"type\": \"lambda\", \"result_path\": \"$.content\"}\n\n creation_tasks[\"validation_summary\"] = {\"type\": \"lambda\", \"result_path\": \"$.validation\"}\n\n creation_tasks[\"validation_failure\"] = {\n \"type\": \"lambda\",\n \"result_path\": aws_stepfunctions.JsonPath.DISCARD,\n }\n\n creation_tasks[\"check_flat_directory_structure\"] = {\n \"type\": \"batch\",\n \"parallel\": False,\n \"result_path\": aws_stepfunctions.JsonPath.DISCARD,\n }\n\n creation_tasks[\"check_files_checksums\"] = {\n \"type\": \"batch\",\n \"parallel\": True,\n \"result_path\": aws_stepfunctions.JsonPath.DISCARD,\n }\n\n # AWS BATCH COMPUTE ENVIRONMENT\n batch_service_role = aws_iam.Role(\n self,\n \"batch-service-role\",\n assumed_by=aws_iam.ServicePrincipal(\"batch.amazonaws.com\"),\n managed_policies=[\n aws_iam.ManagedPolicy.from_aws_managed_policy_name(\n \"service-role/AWSBatchServiceRole\"\n ),\n ],\n )\n\n batch_instance_role = aws_iam.Role(\n self,\n \"batch-instance-role\",\n assumed_by=aws_iam.ServicePrincipal(\"ec2.amazonaws.com\"),\n managed_policies=[\n aws_iam.ManagedPolicy.from_aws_managed_policy_name(\n \"service-role/AmazonEC2ContainerServiceforEC2Role\"\n ),\n ],\n )\n\n batch_instance_profile = aws_iam.CfnInstanceProfile(\n self,\n \"batch-instance-profile\",\n roles=[\n batch_instance_role.role_name,\n ],\n )\n\n batch_launch_template_data = textwrap.dedent(\n \"\"\"\n MIME-Version: 1.0\n Content-Type: multipart/mixed; boundary=\"==MYBOUNDARY==\"\n\n --==MYBOUNDARY==\n Content-Type: text/x-shellscript; charset=\"us-ascii\"\n\n #!/bin/bash\n echo ECS_IMAGE_PULL_BEHAVIOR=prefer-cached >> /etc/ecs/ecs.config\n\n --==MYBOUNDARY==--\n \"\"\"\n )\n\n batch_launch_template = aws_ec2.CfnLaunchTemplate(\n self,\n \"batch-launch-template\",\n launch_template_name=\"datalake-batch-launch-template\",\n launch_template_data={\n \"userData\": core.Fn.base64(batch_launch_template_data.strip()),\n },\n )\n\n if deploy_env == \"prod\":\n instance_types = [\n aws_ec2.InstanceType(\"c5.xlarge\"),\n aws_ec2.InstanceType(\"c5.2xlarge\"),\n aws_ec2.InstanceType(\"c5.4xlarge\"),\n aws_ec2.InstanceType(\"c5.9xlarge\"),\n ]\n else:\n instance_types = [\n aws_ec2.InstanceType(\"m5.large\"),\n aws_ec2.InstanceType(\"m5.xlarge\"),\n ]\n\n batch_compute_environment = aws_batch.ComputeEnvironment(\n self,\n \"compute-environment\",\n compute_resources=aws_batch.ComputeResources(\n vpc=vpc,\n # vpc_subnets=vpc.select_subnets(subnet_group_name=\"ecs-cluster\"), # TODO\n minv_cpus=0,\n desiredv_cpus=0,\n maxv_cpus=1000,\n instance_types=instance_types,\n instance_role=batch_instance_profile.instance_profile_name,\n allocation_strategy=aws_batch.AllocationStrategy(\"BEST_FIT_PROGRESSIVE\"),\n launch_template=aws_batch.LaunchTemplateSpecification(\n launch_template_name=batch_launch_template.launch_template_name\n ),\n ),\n service_role=batch_service_role,\n )\n\n batch_job_queue = aws_batch.JobQueue(\n self,\n \"dataset-version-creation-queue\",\n compute_environments=[\n aws_batch.JobQueueComputeEnvironment(\n compute_environment=batch_compute_environment, order=10\n ),\n ],\n priority=10,\n )\n\n # LAMBDA AND AWS BATCH BUNDLING AND STATE MACHINE TASKS CREATION\n step_tasks = {}\n for task_name in creation_tasks:\n\n task = creation_tasks[task_name]\n\n # lambda functions\n if task[\"type\"] == \"lambda\":\n\n lambda_function = aws_lambda.Function(\n self,\n f\"{task_name}-function\",\n handler=f\"processing.{task_name}.task.lambda_handler\",\n runtime=aws_lambda.Runtime.PYTHON_3_6,\n code=aws_lambda.Code.from_asset(\n path=\"..\",\n bundling=core.BundlingOptions(\n # pylint:disable=no-member\n image=aws_lambda.Runtime.PYTHON_3_6.bundling_docker_image,\n command=[\"backend/bundle.bash\", f\"processing/{task_name}\"],\n ),\n ),\n )\n\n step_tasks[task_name] = aws_stepfunctions_tasks.LambdaInvoke(\n self,\n task_name,\n lambda_function=lambda_function,\n input_path=task.get(\"input_path\", \"$\"),\n output_path=task.get(\"output_path\", \"$\"),\n result_path=task.get(\"result_path\", \"$\"),\n payload_response_only=True,\n )\n\n Tags.of(lambda_function).add(\"ApplicationLayer\", \"data-processing\")\n\n # aws batch jobs\n if task[\"type\"] == \"batch\":\n\n job_definition = aws_batch.JobDefinition(\n self,\n f\"{task_name}-job\",\n container=aws_batch.JobDefinitionContainer(\n image=aws_ecs.ContainerImage.from_asset(\n directory=f\"../backend/processing/{task_name}\",\n ),\n memory_limit_mib=3900 if deploy_env == \"prod\" else 500,\n vcpus=1,\n ),\n retry_attempts=4,\n )\n\n job_command = [\n \"--dataset-id\",\n \"Ref::dataset_id\",\n \"--version-id\",\n \"Ref::version_id\",\n \"--type\",\n \"Ref::type\",\n \"--metadata-url\",\n \"Ref::metadata_url\",\n \"--dataset-id\",\n ]\n job_environment = {\"BATCH_JOB_FIRST_ITEM_INDEX\": \"Ref::first_item\"}\n\n job_payload_data = {\n \"dataset_id.$\": \"$.dataset_id\",\n \"version_id.$\": \"$.version_id\",\n \"type.$\": \"$.type\",\n \"metadata_url.$\": \"$.metadata_url\",\n }\n job_payload_data_parallel = {\"first_item.$\": \"$.content.first_item\"}\n job_payload_single = aws_stepfunctions.TaskInput.from_object(job_payload_data)\n job_payload_parallel = aws_stepfunctions.TaskInput.from_object(\n {**job_payload_data, **job_payload_data_parallel}\n )\n\n if task[\"parallel\"]:\n step_tasks[task_name] = aws_stepfunctions_tasks.BatchSubmitJob(\n self,\n task_name,\n job_name=f\"{task_name}-job\",\n job_definition=job_definition,\n job_queue=batch_job_queue,\n array_size=aws_stepfunctions.JsonPath.number_at(\"$.content.iteration_size\"),\n input_path=task.get(\"input_path\", \"$\"),\n output_path=task.get(\"output_path\", \"$\"),\n result_path=task.get(\"result_path\", \"$\"),\n container_overrides=aws_stepfunctions_tasks.BatchContainerOverrides(\n command=job_command,\n environment=job_environment,\n ),\n payload=job_payload_parallel,\n )\n\n else:\n step_tasks[task_name] = aws_stepfunctions_tasks.BatchSubmitJob(\n self,\n task_name,\n job_name=f\"{task_name}-job\",\n job_definition=job_definition,\n job_queue=batch_job_queue,\n input_path=task.get(\"input_path\", \"$\"),\n output_path=task.get(\"output_path\", \"$\"),\n result_path=task.get(\"result_path\", \"$\"),\n container_overrides=aws_stepfunctions_tasks.BatchContainerOverrides(\n command=job_command,\n ),\n payload=job_payload_single,\n )\n\n # success task\n step_tasks[\"success\"] = aws_stepfunctions.Succeed(\n self,\n \"success\",\n )\n\n # STATE MACHINE\n # state machine definition\n dataset_version_creation_definition = (\n step_tasks[\"check_flat_directory_structure\"]\n .next(step_tasks[\"content_iterator\"])\n .next(step_tasks[\"check_files_checksums\"])\n .next(\n aws_stepfunctions.Choice(self, \"content_iteration_finished\")\n .when(\n aws_stepfunctions.Condition.not_(\n aws_stepfunctions.Condition.number_equals(\"$.content.next_item\", -1)\n ),\n step_tasks[\"content_iterator\"],\n )\n .otherwise(\n step_tasks[\"validation_summary\"].next(\n aws_stepfunctions.Choice(self, \"validation_successful\")\n .when(\n aws_stepfunctions.Condition.boolean_equals(\n \"$.validation.success\", True\n ),\n step_tasks[\"success\"],\n )\n .otherwise(step_tasks[\"validation_failure\"])\n ),\n )\n )\n )\n\n # state machine\n creation_process = aws_stepfunctions.StateMachine( # pylint:disable=unused-variable\n self,\n \"dataset-version-creation\",\n definition=dataset_version_creation_definition,\n )\n", "path": "infra/datalake/processing_stack.py"}]} | 4,012 | 425 |
gh_patches_debug_42258 | rasdani/github-patches | git_diff | getsentry__sentry-61362 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Streamline issue platfrom message processing for non-Kafka envs
From https://github.com/getsentry/sentry/pull/59330#pullrequestreview-1713484895,
We can simplify the logic and make our tests more meaningful by not duplicating the message processing logic in dev environments. Instead, we can massage the message format to match a Kafka payloads and directly call `process_message`.
</issue>
<code>
[start of src/sentry/issues/producer.py]
1 from __future__ import annotations
2
3 import logging
4 from typing import Any, Dict, MutableMapping, Optional, cast
5
6 from arroyo import Topic
7 from arroyo.backends.kafka import KafkaPayload, KafkaProducer, build_kafka_configuration
8 from django.conf import settings
9
10 from sentry import features
11 from sentry.issues.issue_occurrence import IssueOccurrence
12 from sentry.issues.status_change_consumer import bulk_get_groups_from_fingerprints, update_status
13 from sentry.issues.status_change_message import StatusChangeMessage
14 from sentry.models.project import Project
15 from sentry.services.hybrid_cloud import ValueEqualityEnum
16 from sentry.utils import json
17 from sentry.utils.arroyo_producer import SingletonProducer
18 from sentry.utils.kafka_config import get_kafka_producer_cluster_options, get_topic_definition
19
20 logger = logging.getLogger(__name__)
21
22
23 class PayloadType(ValueEqualityEnum):
24 OCCURRENCE = "occurrence"
25 STATUS_CHANGE = "status_change"
26
27
28 def _get_occurrence_producer() -> KafkaProducer:
29 cluster_name = get_topic_definition(settings.KAFKA_INGEST_OCCURRENCES)["cluster"]
30 producer_config = get_kafka_producer_cluster_options(cluster_name)
31 producer_config.pop("compression.type", None)
32 producer_config.pop("message.max.bytes", None)
33 return KafkaProducer(build_kafka_configuration(default_config=producer_config))
34
35
36 _occurrence_producer = SingletonProducer(
37 _get_occurrence_producer, max_futures=settings.SENTRY_ISSUE_PLATFORM_FUTURES_MAX_LIMIT
38 )
39
40
41 def produce_occurrence_to_kafka(
42 payload_type: PayloadType | None = PayloadType.OCCURRENCE,
43 occurrence: IssueOccurrence | None = None,
44 status_change: StatusChangeMessage | None = None,
45 event_data: Optional[Dict[str, Any]] = None,
46 ) -> None:
47 payload_data = None
48 if payload_type == PayloadType.OCCURRENCE:
49 payload_data = _prepare_occurrence_message(occurrence, event_data)
50 elif payload_type == PayloadType.STATUS_CHANGE:
51 payload_data = _prepare_status_change_message(status_change)
52 else:
53 raise NotImplementedError(f"Unknown payload type: {payload_type}")
54
55 if payload_data is None:
56 return
57
58 payload = KafkaPayload(None, json.dumps(payload_data).encode("utf-8"), [])
59 _occurrence_producer.produce(Topic(settings.KAFKA_INGEST_OCCURRENCES), payload)
60
61
62 def _prepare_occurrence_message(
63 occurrence: IssueOccurrence | None, event_data: Optional[Dict[str, Any]]
64 ) -> MutableMapping[str, Any] | None:
65 if not occurrence:
66 raise ValueError("occurrence must be provided")
67 if event_data and occurrence.event_id != event_data["event_id"]:
68 raise ValueError("Event id on occurrence and event_data must be the same")
69 if settings.SENTRY_EVENTSTREAM != "sentry.eventstream.kafka.KafkaEventStream":
70 # If we're not running Kafka then we're just in dev. Skip producing to Kafka and just
71 # write to the issue platform directly
72 from sentry.issues.ingest import process_occurrence_data
73 from sentry.issues.occurrence_consumer import (
74 lookup_event_and_process_issue_occurrence,
75 process_event_and_issue_occurrence,
76 )
77
78 occurrence_dict = occurrence.to_dict()
79 process_occurrence_data(occurrence_dict)
80 if event_data:
81 process_event_and_issue_occurrence(occurrence_dict, event_data)
82 else:
83 lookup_event_and_process_issue_occurrence(occurrence_dict)
84 return None
85
86 payload_data = cast(MutableMapping[str, Any], occurrence.to_dict())
87 payload_data["payload_type"] = PayloadType.OCCURRENCE.value
88 if event_data:
89 payload_data["event"] = event_data
90
91 return payload_data
92
93
94 def _prepare_status_change_message(
95 status_change: StatusChangeMessage | None,
96 ) -> MutableMapping[str, Any] | None:
97 if not status_change:
98 raise ValueError("status_change must be provided")
99
100 organization = Project.objects.get(id=status_change.project_id).organization
101 if not features.has("organizations:issue-platform-api-crons-sd", organization):
102 return None
103
104 if settings.SENTRY_EVENTSTREAM != "sentry.eventstream.kafka.KafkaEventStream":
105 # Do the change
106 # If we're not running Kafka then we're just in dev. Skip producing to Kafka and just
107 # write to the issue platform directly
108 from sentry.issues.ingest import process_occurrence_data
109
110 process_occurrence_data(status_change.to_dict())
111 fingerprint = status_change.fingerprint
112 groups_by_fingerprints = bulk_get_groups_from_fingerprints(
113 [(status_change.project_id, fingerprint)]
114 )
115
116 key = (status_change.project_id, fingerprint[0])
117 group = groups_by_fingerprints.get(key, None)
118 if not group:
119 return None
120 update_status(group, status_change.to_dict())
121 return None
122
123 payload_data = cast(MutableMapping[str, Any], status_change.to_dict())
124 payload_data["payload_type"] = PayloadType.STATUS_CHANGE.value
125 return payload_data
126
[end of src/sentry/issues/producer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/sentry/issues/producer.py b/src/sentry/issues/producer.py
--- a/src/sentry/issues/producer.py
+++ b/src/sentry/issues/producer.py
@@ -5,11 +5,12 @@
from arroyo import Topic
from arroyo.backends.kafka import KafkaPayload, KafkaProducer, build_kafka_configuration
+from arroyo.types import Message, Value
from django.conf import settings
from sentry import features
from sentry.issues.issue_occurrence import IssueOccurrence
-from sentry.issues.status_change_consumer import bulk_get_groups_from_fingerprints, update_status
+from sentry.issues.run import process_message
from sentry.issues.status_change_message import StatusChangeMessage
from sentry.models.project import Project
from sentry.services.hybrid_cloud import ValueEqualityEnum
@@ -56,6 +57,12 @@
return
payload = KafkaPayload(None, json.dumps(payload_data).encode("utf-8"), [])
+ if settings.SENTRY_EVENTSTREAM != "sentry.eventstream.kafka.KafkaEventStream":
+ # If we're not running Kafka then we're just in dev.
+ # Skip producing to Kafka and just process the message directly
+ process_message(Message(Value(payload=payload, committable={})))
+ return
+
_occurrence_producer.produce(Topic(settings.KAFKA_INGEST_OCCURRENCES), payload)
@@ -66,22 +73,6 @@
raise ValueError("occurrence must be provided")
if event_data and occurrence.event_id != event_data["event_id"]:
raise ValueError("Event id on occurrence and event_data must be the same")
- if settings.SENTRY_EVENTSTREAM != "sentry.eventstream.kafka.KafkaEventStream":
- # If we're not running Kafka then we're just in dev. Skip producing to Kafka and just
- # write to the issue platform directly
- from sentry.issues.ingest import process_occurrence_data
- from sentry.issues.occurrence_consumer import (
- lookup_event_and_process_issue_occurrence,
- process_event_and_issue_occurrence,
- )
-
- occurrence_dict = occurrence.to_dict()
- process_occurrence_data(occurrence_dict)
- if event_data:
- process_event_and_issue_occurrence(occurrence_dict, event_data)
- else:
- lookup_event_and_process_issue_occurrence(occurrence_dict)
- return None
payload_data = cast(MutableMapping[str, Any], occurrence.to_dict())
payload_data["payload_type"] = PayloadType.OCCURRENCE.value
@@ -101,25 +92,6 @@
if not features.has("organizations:issue-platform-api-crons-sd", organization):
return None
- if settings.SENTRY_EVENTSTREAM != "sentry.eventstream.kafka.KafkaEventStream":
- # Do the change
- # If we're not running Kafka then we're just in dev. Skip producing to Kafka and just
- # write to the issue platform directly
- from sentry.issues.ingest import process_occurrence_data
-
- process_occurrence_data(status_change.to_dict())
- fingerprint = status_change.fingerprint
- groups_by_fingerprints = bulk_get_groups_from_fingerprints(
- [(status_change.project_id, fingerprint)]
- )
-
- key = (status_change.project_id, fingerprint[0])
- group = groups_by_fingerprints.get(key, None)
- if not group:
- return None
- update_status(group, status_change.to_dict())
- return None
-
payload_data = cast(MutableMapping[str, Any], status_change.to_dict())
payload_data["payload_type"] = PayloadType.STATUS_CHANGE.value
return payload_data
| {"golden_diff": "diff --git a/src/sentry/issues/producer.py b/src/sentry/issues/producer.py\n--- a/src/sentry/issues/producer.py\n+++ b/src/sentry/issues/producer.py\n@@ -5,11 +5,12 @@\n \n from arroyo import Topic\n from arroyo.backends.kafka import KafkaPayload, KafkaProducer, build_kafka_configuration\n+from arroyo.types import Message, Value\n from django.conf import settings\n \n from sentry import features\n from sentry.issues.issue_occurrence import IssueOccurrence\n-from sentry.issues.status_change_consumer import bulk_get_groups_from_fingerprints, update_status\n+from sentry.issues.run import process_message\n from sentry.issues.status_change_message import StatusChangeMessage\n from sentry.models.project import Project\n from sentry.services.hybrid_cloud import ValueEqualityEnum\n@@ -56,6 +57,12 @@\n return\n \n payload = KafkaPayload(None, json.dumps(payload_data).encode(\"utf-8\"), [])\n+ if settings.SENTRY_EVENTSTREAM != \"sentry.eventstream.kafka.KafkaEventStream\":\n+ # If we're not running Kafka then we're just in dev.\n+ # Skip producing to Kafka and just process the message directly\n+ process_message(Message(Value(payload=payload, committable={})))\n+ return\n+\n _occurrence_producer.produce(Topic(settings.KAFKA_INGEST_OCCURRENCES), payload)\n \n \n@@ -66,22 +73,6 @@\n raise ValueError(\"occurrence must be provided\")\n if event_data and occurrence.event_id != event_data[\"event_id\"]:\n raise ValueError(\"Event id on occurrence and event_data must be the same\")\n- if settings.SENTRY_EVENTSTREAM != \"sentry.eventstream.kafka.KafkaEventStream\":\n- # If we're not running Kafka then we're just in dev. Skip producing to Kafka and just\n- # write to the issue platform directly\n- from sentry.issues.ingest import process_occurrence_data\n- from sentry.issues.occurrence_consumer import (\n- lookup_event_and_process_issue_occurrence,\n- process_event_and_issue_occurrence,\n- )\n-\n- occurrence_dict = occurrence.to_dict()\n- process_occurrence_data(occurrence_dict)\n- if event_data:\n- process_event_and_issue_occurrence(occurrence_dict, event_data)\n- else:\n- lookup_event_and_process_issue_occurrence(occurrence_dict)\n- return None\n \n payload_data = cast(MutableMapping[str, Any], occurrence.to_dict())\n payload_data[\"payload_type\"] = PayloadType.OCCURRENCE.value\n@@ -101,25 +92,6 @@\n if not features.has(\"organizations:issue-platform-api-crons-sd\", organization):\n return None\n \n- if settings.SENTRY_EVENTSTREAM != \"sentry.eventstream.kafka.KafkaEventStream\":\n- # Do the change\n- # If we're not running Kafka then we're just in dev. Skip producing to Kafka and just\n- # write to the issue platform directly\n- from sentry.issues.ingest import process_occurrence_data\n-\n- process_occurrence_data(status_change.to_dict())\n- fingerprint = status_change.fingerprint\n- groups_by_fingerprints = bulk_get_groups_from_fingerprints(\n- [(status_change.project_id, fingerprint)]\n- )\n-\n- key = (status_change.project_id, fingerprint[0])\n- group = groups_by_fingerprints.get(key, None)\n- if not group:\n- return None\n- update_status(group, status_change.to_dict())\n- return None\n-\n payload_data = cast(MutableMapping[str, Any], status_change.to_dict())\n payload_data[\"payload_type\"] = PayloadType.STATUS_CHANGE.value\n return payload_data\n", "issue": "Streamline issue platfrom message processing for non-Kafka envs\nFrom https://github.com/getsentry/sentry/pull/59330#pullrequestreview-1713484895, \n\nWe can simplify the logic and make our tests more meaningful by not duplicating the message processing logic in dev environments. Instead, we can massage the message format to match a Kafka payloads and directly call `process_message`. \n", "before_files": [{"content": "from __future__ import annotations\n\nimport logging\nfrom typing import Any, Dict, MutableMapping, Optional, cast\n\nfrom arroyo import Topic\nfrom arroyo.backends.kafka import KafkaPayload, KafkaProducer, build_kafka_configuration\nfrom django.conf import settings\n\nfrom sentry import features\nfrom sentry.issues.issue_occurrence import IssueOccurrence\nfrom sentry.issues.status_change_consumer import bulk_get_groups_from_fingerprints, update_status\nfrom sentry.issues.status_change_message import StatusChangeMessage\nfrom sentry.models.project import Project\nfrom sentry.services.hybrid_cloud import ValueEqualityEnum\nfrom sentry.utils import json\nfrom sentry.utils.arroyo_producer import SingletonProducer\nfrom sentry.utils.kafka_config import get_kafka_producer_cluster_options, get_topic_definition\n\nlogger = logging.getLogger(__name__)\n\n\nclass PayloadType(ValueEqualityEnum):\n OCCURRENCE = \"occurrence\"\n STATUS_CHANGE = \"status_change\"\n\n\ndef _get_occurrence_producer() -> KafkaProducer:\n cluster_name = get_topic_definition(settings.KAFKA_INGEST_OCCURRENCES)[\"cluster\"]\n producer_config = get_kafka_producer_cluster_options(cluster_name)\n producer_config.pop(\"compression.type\", None)\n producer_config.pop(\"message.max.bytes\", None)\n return KafkaProducer(build_kafka_configuration(default_config=producer_config))\n\n\n_occurrence_producer = SingletonProducer(\n _get_occurrence_producer, max_futures=settings.SENTRY_ISSUE_PLATFORM_FUTURES_MAX_LIMIT\n)\n\n\ndef produce_occurrence_to_kafka(\n payload_type: PayloadType | None = PayloadType.OCCURRENCE,\n occurrence: IssueOccurrence | None = None,\n status_change: StatusChangeMessage | None = None,\n event_data: Optional[Dict[str, Any]] = None,\n) -> None:\n payload_data = None\n if payload_type == PayloadType.OCCURRENCE:\n payload_data = _prepare_occurrence_message(occurrence, event_data)\n elif payload_type == PayloadType.STATUS_CHANGE:\n payload_data = _prepare_status_change_message(status_change)\n else:\n raise NotImplementedError(f\"Unknown payload type: {payload_type}\")\n\n if payload_data is None:\n return\n\n payload = KafkaPayload(None, json.dumps(payload_data).encode(\"utf-8\"), [])\n _occurrence_producer.produce(Topic(settings.KAFKA_INGEST_OCCURRENCES), payload)\n\n\ndef _prepare_occurrence_message(\n occurrence: IssueOccurrence | None, event_data: Optional[Dict[str, Any]]\n) -> MutableMapping[str, Any] | None:\n if not occurrence:\n raise ValueError(\"occurrence must be provided\")\n if event_data and occurrence.event_id != event_data[\"event_id\"]:\n raise ValueError(\"Event id on occurrence and event_data must be the same\")\n if settings.SENTRY_EVENTSTREAM != \"sentry.eventstream.kafka.KafkaEventStream\":\n # If we're not running Kafka then we're just in dev. Skip producing to Kafka and just\n # write to the issue platform directly\n from sentry.issues.ingest import process_occurrence_data\n from sentry.issues.occurrence_consumer import (\n lookup_event_and_process_issue_occurrence,\n process_event_and_issue_occurrence,\n )\n\n occurrence_dict = occurrence.to_dict()\n process_occurrence_data(occurrence_dict)\n if event_data:\n process_event_and_issue_occurrence(occurrence_dict, event_data)\n else:\n lookup_event_and_process_issue_occurrence(occurrence_dict)\n return None\n\n payload_data = cast(MutableMapping[str, Any], occurrence.to_dict())\n payload_data[\"payload_type\"] = PayloadType.OCCURRENCE.value\n if event_data:\n payload_data[\"event\"] = event_data\n\n return payload_data\n\n\ndef _prepare_status_change_message(\n status_change: StatusChangeMessage | None,\n) -> MutableMapping[str, Any] | None:\n if not status_change:\n raise ValueError(\"status_change must be provided\")\n\n organization = Project.objects.get(id=status_change.project_id).organization\n if not features.has(\"organizations:issue-platform-api-crons-sd\", organization):\n return None\n\n if settings.SENTRY_EVENTSTREAM != \"sentry.eventstream.kafka.KafkaEventStream\":\n # Do the change\n # If we're not running Kafka then we're just in dev. Skip producing to Kafka and just\n # write to the issue platform directly\n from sentry.issues.ingest import process_occurrence_data\n\n process_occurrence_data(status_change.to_dict())\n fingerprint = status_change.fingerprint\n groups_by_fingerprints = bulk_get_groups_from_fingerprints(\n [(status_change.project_id, fingerprint)]\n )\n\n key = (status_change.project_id, fingerprint[0])\n group = groups_by_fingerprints.get(key, None)\n if not group:\n return None\n update_status(group, status_change.to_dict())\n return None\n\n payload_data = cast(MutableMapping[str, Any], status_change.to_dict())\n payload_data[\"payload_type\"] = PayloadType.STATUS_CHANGE.value\n return payload_data\n", "path": "src/sentry/issues/producer.py"}]} | 2,001 | 819 |
gh_patches_debug_2711 | rasdani/github-patches | git_diff | getmoto__moto-1462 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add opsworks app mocks
Add the mocks of OpsWork create_app and describe_apps calls. This is part of #1477
</issue>
<code>
[start of moto/__init__.py]
1 from __future__ import unicode_literals
2 import logging
3 # logging.getLogger('boto').setLevel(logging.CRITICAL)
4
5 __title__ = 'moto'
6 __version__ = '1.2.0',
7
8 from .acm import mock_acm # flake8: noqa
9 from .apigateway import mock_apigateway, mock_apigateway_deprecated # flake8: noqa
10 from .autoscaling import mock_autoscaling, mock_autoscaling_deprecated # flake8: noqa
11 from .awslambda import mock_lambda, mock_lambda_deprecated # flake8: noqa
12 from .cloudformation import mock_cloudformation, mock_cloudformation_deprecated # flake8: noqa
13 from .cloudwatch import mock_cloudwatch, mock_cloudwatch_deprecated # flake8: noqa
14 from .datapipeline import mock_datapipeline, mock_datapipeline_deprecated # flake8: noqa
15 from .dynamodb import mock_dynamodb, mock_dynamodb_deprecated # flake8: noqa
16 from .dynamodb2 import mock_dynamodb2, mock_dynamodb2_deprecated # flake8: noqa
17 from .ec2 import mock_ec2, mock_ec2_deprecated # flake8: noqa
18 from .ecr import mock_ecr, mock_ecr_deprecated # flake8: noqa
19 from .ecs import mock_ecs, mock_ecs_deprecated # flake8: noqa
20 from .elb import mock_elb, mock_elb_deprecated # flake8: noqa
21 from .elbv2 import mock_elbv2 # flake8: noqa
22 from .emr import mock_emr, mock_emr_deprecated # flake8: noqa
23 from .events import mock_events # flake8: noqa
24 from .glacier import mock_glacier, mock_glacier_deprecated # flake8: noqa
25 from .iam import mock_iam, mock_iam_deprecated # flake8: noqa
26 from .kinesis import mock_kinesis, mock_kinesis_deprecated # flake8: noqa
27 from .kms import mock_kms, mock_kms_deprecated # flake8: noqa
28 from .opsworks import mock_opsworks, mock_opsworks_deprecated # flake8: noqa
29 from .polly import mock_polly # flake8: noqa
30 from .rds import mock_rds, mock_rds_deprecated # flake8: noqa
31 from .rds2 import mock_rds2, mock_rds2_deprecated # flake8: noqa
32 from .redshift import mock_redshift, mock_redshift_deprecated # flake8: noqa
33 from .s3 import mock_s3, mock_s3_deprecated # flake8: noqa
34 from .ses import mock_ses, mock_ses_deprecated # flake8: noqa
35 from .sns import mock_sns, mock_sns_deprecated # flake8: noqa
36 from .sqs import mock_sqs, mock_sqs_deprecated # flake8: noqa
37 from .sts import mock_sts, mock_sts_deprecated # flake8: noqa
38 from .ssm import mock_ssm # flake8: noqa
39 from .route53 import mock_route53, mock_route53_deprecated # flake8: noqa
40 from .swf import mock_swf, mock_swf_deprecated # flake8: noqa
41 from .xray import mock_xray, mock_xray_client, XRaySegment # flake8: noqa
42 from .logs import mock_logs, mock_logs_deprecated # flake8: noqa
43 from .batch import mock_batch # flake8: noqa
44 from .resourcegroupstaggingapi import mock_resourcegroupstaggingapi # flake8: noqa
45 from .iot import mock_iot # flake8: noqa
46 from .iotdata import mock_iotdata # flake8: noqa
47
48
49 try:
50 # Need to monkey-patch botocore requests back to underlying urllib3 classes
51 from botocore.awsrequest import HTTPSConnectionPool, HTTPConnectionPool, HTTPConnection, VerifiedHTTPSConnection
52 except ImportError:
53 pass
54 else:
55 HTTPSConnectionPool.ConnectionCls = VerifiedHTTPSConnection
56 HTTPConnectionPool.ConnectionCls = HTTPConnection
57
[end of moto/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/moto/__init__.py b/moto/__init__.py
--- a/moto/__init__.py
+++ b/moto/__init__.py
@@ -3,7 +3,7 @@
# logging.getLogger('boto').setLevel(logging.CRITICAL)
__title__ = 'moto'
-__version__ = '1.2.0',
+__version__ = '1.2.0'
from .acm import mock_acm # flake8: noqa
from .apigateway import mock_apigateway, mock_apigateway_deprecated # flake8: noqa
| {"golden_diff": "diff --git a/moto/__init__.py b/moto/__init__.py\n--- a/moto/__init__.py\n+++ b/moto/__init__.py\n@@ -3,7 +3,7 @@\n # logging.getLogger('boto').setLevel(logging.CRITICAL)\n \n __title__ = 'moto'\n-__version__ = '1.2.0',\n+__version__ = '1.2.0'\n \n from .acm import mock_acm # flake8: noqa\n from .apigateway import mock_apigateway, mock_apigateway_deprecated # flake8: noqa\n", "issue": "Add opsworks app mocks\nAdd the mocks of OpsWork create_app and describe_apps calls. This is part of #1477 \n", "before_files": [{"content": "from __future__ import unicode_literals\nimport logging\n# logging.getLogger('boto').setLevel(logging.CRITICAL)\n\n__title__ = 'moto'\n__version__ = '1.2.0',\n\nfrom .acm import mock_acm # flake8: noqa\nfrom .apigateway import mock_apigateway, mock_apigateway_deprecated # flake8: noqa\nfrom .autoscaling import mock_autoscaling, mock_autoscaling_deprecated # flake8: noqa\nfrom .awslambda import mock_lambda, mock_lambda_deprecated # flake8: noqa\nfrom .cloudformation import mock_cloudformation, mock_cloudformation_deprecated # flake8: noqa\nfrom .cloudwatch import mock_cloudwatch, mock_cloudwatch_deprecated # flake8: noqa\nfrom .datapipeline import mock_datapipeline, mock_datapipeline_deprecated # flake8: noqa\nfrom .dynamodb import mock_dynamodb, mock_dynamodb_deprecated # flake8: noqa\nfrom .dynamodb2 import mock_dynamodb2, mock_dynamodb2_deprecated # flake8: noqa\nfrom .ec2 import mock_ec2, mock_ec2_deprecated # flake8: noqa\nfrom .ecr import mock_ecr, mock_ecr_deprecated # flake8: noqa\nfrom .ecs import mock_ecs, mock_ecs_deprecated # flake8: noqa\nfrom .elb import mock_elb, mock_elb_deprecated # flake8: noqa\nfrom .elbv2 import mock_elbv2 # flake8: noqa\nfrom .emr import mock_emr, mock_emr_deprecated # flake8: noqa\nfrom .events import mock_events # flake8: noqa\nfrom .glacier import mock_glacier, mock_glacier_deprecated # flake8: noqa\nfrom .iam import mock_iam, mock_iam_deprecated # flake8: noqa\nfrom .kinesis import mock_kinesis, mock_kinesis_deprecated # flake8: noqa\nfrom .kms import mock_kms, mock_kms_deprecated # flake8: noqa\nfrom .opsworks import mock_opsworks, mock_opsworks_deprecated # flake8: noqa\nfrom .polly import mock_polly # flake8: noqa\nfrom .rds import mock_rds, mock_rds_deprecated # flake8: noqa\nfrom .rds2 import mock_rds2, mock_rds2_deprecated # flake8: noqa\nfrom .redshift import mock_redshift, mock_redshift_deprecated # flake8: noqa\nfrom .s3 import mock_s3, mock_s3_deprecated # flake8: noqa\nfrom .ses import mock_ses, mock_ses_deprecated # flake8: noqa\nfrom .sns import mock_sns, mock_sns_deprecated # flake8: noqa\nfrom .sqs import mock_sqs, mock_sqs_deprecated # flake8: noqa\nfrom .sts import mock_sts, mock_sts_deprecated # flake8: noqa\nfrom .ssm import mock_ssm # flake8: noqa\nfrom .route53 import mock_route53, mock_route53_deprecated # flake8: noqa\nfrom .swf import mock_swf, mock_swf_deprecated # flake8: noqa\nfrom .xray import mock_xray, mock_xray_client, XRaySegment # flake8: noqa\nfrom .logs import mock_logs, mock_logs_deprecated # flake8: noqa\nfrom .batch import mock_batch # flake8: noqa\nfrom .resourcegroupstaggingapi import mock_resourcegroupstaggingapi # flake8: noqa\nfrom .iot import mock_iot # flake8: noqa\nfrom .iotdata import mock_iotdata # flake8: noqa\n\n\ntry:\n # Need to monkey-patch botocore requests back to underlying urllib3 classes\n from botocore.awsrequest import HTTPSConnectionPool, HTTPConnectionPool, HTTPConnection, VerifiedHTTPSConnection\nexcept ImportError:\n pass\nelse:\n HTTPSConnectionPool.ConnectionCls = VerifiedHTTPSConnection\n HTTPConnectionPool.ConnectionCls = HTTPConnection\n", "path": "moto/__init__.py"}]} | 1,605 | 134 |
gh_patches_debug_3787 | rasdani/github-patches | git_diff | zigpy__zha-device-handlers-506 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] Osram switch mini
**Describe the bug**
Adding a OSRAM Lightify Switch Mini to my network is not working out after quirk was added some time ago.
Before quirk: I picked up zha_events.
After quirk: The remote switches everything(switched bulbs cover) in my network on and off.
**To Reproduce**
Steps to reproduce the behavior:
Removed remote, deletes entries from zha.storage and other HA files I could find the remote.
Device signature:
{
"node_descriptor": "NodeDescriptor(byte1=2, byte2=64, mac_capability_flags=128, manufacturer_code=4364, maximum_buffer_size=82, maximum_incoming_transfer_size=82, server_mask=0, maximum_outgoing_transfer_size=82, descriptor_capability_field=0)",
"endpoints": {},
"manufacturer": "OSRAM",
"model": "Lightify Switch Mini",
"class": "zhaquirks.osram.switchmini.OsramSwitchMini"
}
Manage cluster is empty.

**Expected behavior**
A remote that switches the stuff I want, not everything(via zha_event for my usage)
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Additional context**
[osramminiadd.txt](https://github.com/zigpy/zha-device-handlers/files/5267371/osramminiadd.txt)
</issue>
<code>
[start of zhaquirks/osram/switchmini.py]
1 """Osram Smart+ Switch Mini device."""
2 from zigpy.profiles import zha
3 from zigpy.quirks import CustomDevice
4 from zigpy.zcl.clusters.general import (
5 Basic,
6 Groups,
7 Identify,
8 LevelControl,
9 OnOff,
10 Ota,
11 PowerConfiguration,
12 Scenes,
13 PollControl,
14 )
15 from zigpy.zcl.clusters.lighting import Color
16 from zigpy.zcl.clusters.lightlink import LightLink
17
18 from . import OSRAM
19 from ..const import (
20 DEVICE_TYPE,
21 ENDPOINTS,
22 INPUT_CLUSTERS,
23 OUTPUT_CLUSTERS,
24 PROFILE_ID,
25 SHORT_PRESS,
26 COMMAND,
27 COMMAND_ON,
28 MODELS_INFO,
29 BUTTON_1,
30 ENDPOINT_ID,
31 COMMAND_STEP_ON_OFF,
32 COMMAND_STOP,
33 BUTTON_2,
34 BUTTON_3,
35 LONG_RELEASE,
36 LONG_PRESS,
37 COMMAND_MOVE_TO_LEVEL_ON_OFF,
38 COMMAND_OFF,
39 COMMAND_MOVE,
40 )
41
42 OSRAM_CLUSTER = 0xFD00
43
44
45 class OsramSwitchMini(CustomDevice):
46 """Osram Smart+ Switch Mini device."""
47
48 signature = {
49 MODELS_INFO: [(OSRAM, "Lightify Switch Mini")],
50 ENDPOINTS: {
51 # <SimpleDescriptor endpoint=1 profile=260 device_type=2064
52 # device_version=1
53 # input_clusters=[0, 1, 20, 4096, 64758]
54 # output_clusters=[3, 4, 5, 6, 8, 25, 768, 4096]>
55 1: {
56 PROFILE_ID: zha.PROFILE_ID,
57 DEVICE_TYPE: zha.DeviceType.COLOR_SCENE_CONTROLLER,
58 INPUT_CLUSTERS: [
59 Basic.cluster_id,
60 PowerConfiguration.cluster_id,
61 PollControl.cluster_id,
62 LightLink.cluster_id,
63 OSRAM_CLUSTER,
64 ],
65 OUTPUT_CLUSTERS: [
66 Identify.cluster_id,
67 Groups.cluster_id,
68 Scenes.cluster_id,
69 OnOff.cluster_id,
70 LevelControl.cluster_id,
71 Ota.cluster_id,
72 Color.cluster_id,
73 LightLink.cluster_id,
74 ],
75 },
76 # <SimpleDescriptor endpoint=2 profile=260 device_type=2064
77 # device_version=1
78 # input_clusters=[0, 4096, 64768]
79 # output_clusters=[3, 4, 5, 6, 8, 768, 4096]>
80 2: {
81 PROFILE_ID: zha.PROFILE_ID,
82 DEVICE_TYPE: zha.DeviceType.COLOR_SCENE_CONTROLLER,
83 INPUT_CLUSTERS: [Basic.cluster_id, LightLink.cluster_id, OSRAM_CLUSTER],
84 OUTPUT_CLUSTERS: [
85 Identify.cluster_id,
86 Groups.cluster_id,
87 Scenes.cluster_id,
88 OnOff.cluster_id,
89 LevelControl.cluster_id,
90 Color.cluster_id,
91 LightLink.cluster_id,
92 ],
93 },
94 # <SimpleDescriptor endpoint=2 profile=260 device_type=2064
95 # device_version=1
96 # input_clusters=[0, 4096, 64768]
97 # output_clusters=[3, 4, 5, 6, 8, 768, 4096]>
98 3: {
99 PROFILE_ID: zha.PROFILE_ID,
100 DEVICE_TYPE: zha.DeviceType.COLOR_SCENE_CONTROLLER,
101 INPUT_CLUSTERS: [Basic.cluster_id, LightLink.cluster_id, OSRAM_CLUSTER],
102 OUTPUT_CLUSTERS: [
103 Identify.cluster_id,
104 Groups.cluster_id,
105 Scenes.cluster_id,
106 OnOff.cluster_id,
107 LevelControl.cluster_id,
108 Color.cluster_id,
109 LightLink.cluster_id,
110 ],
111 },
112 },
113 }
114
115 device_automation_triggers = {
116 (SHORT_PRESS, BUTTON_1): {COMMAND: COMMAND_ON, ENDPOINT_ID: 1},
117 (LONG_PRESS, BUTTON_1): {COMMAND: COMMAND_STEP_ON_OFF, ENDPOINT_ID: 1},
118 (LONG_RELEASE, BUTTON_1): {COMMAND: COMMAND_STOP, ENDPOINT_ID: 1},
119 (SHORT_PRESS, BUTTON_2): {
120 COMMAND: COMMAND_MOVE_TO_LEVEL_ON_OFF,
121 ENDPOINT_ID: 3,
122 },
123 (LONG_PRESS, BUTTON_2): {COMMAND: "move_to_saturation", ENDPOINT_ID: 3},
124 (LONG_RELEASE, BUTTON_2): {COMMAND: "move_hue", ENDPOINT_ID: 3},
125 (SHORT_PRESS, BUTTON_3): {COMMAND: COMMAND_OFF, ENDPOINT_ID: 2},
126 (LONG_PRESS, BUTTON_3): {COMMAND: COMMAND_MOVE, ENDPOINT_ID: 2},
127 (LONG_RELEASE, BUTTON_3): {COMMAND: COMMAND_STOP, ENDPOINT_ID: 2},
128 }
129
[end of zhaquirks/osram/switchmini.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/zhaquirks/osram/switchmini.py b/zhaquirks/osram/switchmini.py
--- a/zhaquirks/osram/switchmini.py
+++ b/zhaquirks/osram/switchmini.py
@@ -112,6 +112,9 @@
},
}
+ replacement = {**signature}
+ replacement.pop(MODELS_INFO)
+
device_automation_triggers = {
(SHORT_PRESS, BUTTON_1): {COMMAND: COMMAND_ON, ENDPOINT_ID: 1},
(LONG_PRESS, BUTTON_1): {COMMAND: COMMAND_STEP_ON_OFF, ENDPOINT_ID: 1},
| {"golden_diff": "diff --git a/zhaquirks/osram/switchmini.py b/zhaquirks/osram/switchmini.py\n--- a/zhaquirks/osram/switchmini.py\n+++ b/zhaquirks/osram/switchmini.py\n@@ -112,6 +112,9 @@\n },\n }\n \n+ replacement = {**signature}\n+ replacement.pop(MODELS_INFO)\n+\n device_automation_triggers = {\n (SHORT_PRESS, BUTTON_1): {COMMAND: COMMAND_ON, ENDPOINT_ID: 1},\n (LONG_PRESS, BUTTON_1): {COMMAND: COMMAND_STEP_ON_OFF, ENDPOINT_ID: 1},\n", "issue": "[BUG] Osram switch mini\n**Describe the bug**\r\nAdding a OSRAM Lightify Switch Mini to my network is not working out after quirk was added some time ago.\r\n\r\nBefore quirk: I picked up zha_events.\r\n\r\nAfter quirk: The remote switches everything(switched bulbs cover) in my network on and off.\r\n\r\n\r\n \r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\nRemoved remote, deletes entries from zha.storage and other HA files I could find the remote.\r\n\r\nDevice signature:\r\n{\r\n \"node_descriptor\": \"NodeDescriptor(byte1=2, byte2=64, mac_capability_flags=128, manufacturer_code=4364, maximum_buffer_size=82, maximum_incoming_transfer_size=82, server_mask=0, maximum_outgoing_transfer_size=82, descriptor_capability_field=0)\",\r\n \"endpoints\": {},\r\n \"manufacturer\": \"OSRAM\",\r\n \"model\": \"Lightify Switch Mini\",\r\n \"class\": \"zhaquirks.osram.switchmini.OsramSwitchMini\"\r\n}\r\n\r\nManage cluster is empty.\r\n\r\n\r\n**Expected behavior**\r\nA remote that switches the stuff I want, not everything(via zha_event for my usage)\r\n\r\n**Screenshots**\r\nIf applicable, add screenshots to help explain your problem.\r\n\r\n**Additional context**\r\n[osramminiadd.txt](https://github.com/zigpy/zha-device-handlers/files/5267371/osramminiadd.txt)\r\n\n", "before_files": [{"content": "\"\"\"Osram Smart+ Switch Mini device.\"\"\"\nfrom zigpy.profiles import zha\nfrom zigpy.quirks import CustomDevice\nfrom zigpy.zcl.clusters.general import (\n Basic,\n Groups,\n Identify,\n LevelControl,\n OnOff,\n Ota,\n PowerConfiguration,\n Scenes,\n PollControl,\n)\nfrom zigpy.zcl.clusters.lighting import Color\nfrom zigpy.zcl.clusters.lightlink import LightLink\n\nfrom . import OSRAM\nfrom ..const import (\n DEVICE_TYPE,\n ENDPOINTS,\n INPUT_CLUSTERS,\n OUTPUT_CLUSTERS,\n PROFILE_ID,\n SHORT_PRESS,\n COMMAND,\n COMMAND_ON,\n MODELS_INFO,\n BUTTON_1,\n ENDPOINT_ID,\n COMMAND_STEP_ON_OFF,\n COMMAND_STOP,\n BUTTON_2,\n BUTTON_3,\n LONG_RELEASE,\n LONG_PRESS,\n COMMAND_MOVE_TO_LEVEL_ON_OFF,\n COMMAND_OFF,\n COMMAND_MOVE,\n)\n\nOSRAM_CLUSTER = 0xFD00\n\n\nclass OsramSwitchMini(CustomDevice):\n \"\"\"Osram Smart+ Switch Mini device.\"\"\"\n\n signature = {\n MODELS_INFO: [(OSRAM, \"Lightify Switch Mini\")],\n ENDPOINTS: {\n # <SimpleDescriptor endpoint=1 profile=260 device_type=2064\n # device_version=1\n # input_clusters=[0, 1, 20, 4096, 64758]\n # output_clusters=[3, 4, 5, 6, 8, 25, 768, 4096]>\n 1: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.COLOR_SCENE_CONTROLLER,\n INPUT_CLUSTERS: [\n Basic.cluster_id,\n PowerConfiguration.cluster_id,\n PollControl.cluster_id,\n LightLink.cluster_id,\n OSRAM_CLUSTER,\n ],\n OUTPUT_CLUSTERS: [\n Identify.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n Ota.cluster_id,\n Color.cluster_id,\n LightLink.cluster_id,\n ],\n },\n # <SimpleDescriptor endpoint=2 profile=260 device_type=2064\n # device_version=1\n # input_clusters=[0, 4096, 64768]\n # output_clusters=[3, 4, 5, 6, 8, 768, 4096]>\n 2: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.COLOR_SCENE_CONTROLLER,\n INPUT_CLUSTERS: [Basic.cluster_id, LightLink.cluster_id, OSRAM_CLUSTER],\n OUTPUT_CLUSTERS: [\n Identify.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n Color.cluster_id,\n LightLink.cluster_id,\n ],\n },\n # <SimpleDescriptor endpoint=2 profile=260 device_type=2064\n # device_version=1\n # input_clusters=[0, 4096, 64768]\n # output_clusters=[3, 4, 5, 6, 8, 768, 4096]>\n 3: {\n PROFILE_ID: zha.PROFILE_ID,\n DEVICE_TYPE: zha.DeviceType.COLOR_SCENE_CONTROLLER,\n INPUT_CLUSTERS: [Basic.cluster_id, LightLink.cluster_id, OSRAM_CLUSTER],\n OUTPUT_CLUSTERS: [\n Identify.cluster_id,\n Groups.cluster_id,\n Scenes.cluster_id,\n OnOff.cluster_id,\n LevelControl.cluster_id,\n Color.cluster_id,\n LightLink.cluster_id,\n ],\n },\n },\n }\n\n device_automation_triggers = {\n (SHORT_PRESS, BUTTON_1): {COMMAND: COMMAND_ON, ENDPOINT_ID: 1},\n (LONG_PRESS, BUTTON_1): {COMMAND: COMMAND_STEP_ON_OFF, ENDPOINT_ID: 1},\n (LONG_RELEASE, BUTTON_1): {COMMAND: COMMAND_STOP, ENDPOINT_ID: 1},\n (SHORT_PRESS, BUTTON_2): {\n COMMAND: COMMAND_MOVE_TO_LEVEL_ON_OFF,\n ENDPOINT_ID: 3,\n },\n (LONG_PRESS, BUTTON_2): {COMMAND: \"move_to_saturation\", ENDPOINT_ID: 3},\n (LONG_RELEASE, BUTTON_2): {COMMAND: \"move_hue\", ENDPOINT_ID: 3},\n (SHORT_PRESS, BUTTON_3): {COMMAND: COMMAND_OFF, ENDPOINT_ID: 2},\n (LONG_PRESS, BUTTON_3): {COMMAND: COMMAND_MOVE, ENDPOINT_ID: 2},\n (LONG_RELEASE, BUTTON_3): {COMMAND: COMMAND_STOP, ENDPOINT_ID: 2},\n }\n", "path": "zhaquirks/osram/switchmini.py"}]} | 2,237 | 143 |
gh_patches_debug_37979 | rasdani/github-patches | git_diff | weni-ai__bothub-engine-167 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix health checker /ping/ - infinite looping
Improve check_database_connection function
We can improve this code like that:
```python
def check_database_connection(**kwargs):
for conn in connections.all():
try:
conn.cursor()
return True
except OperationalError:
return False
return False
```
reported by @eltonplima in #158
Improve check_database_connection function
We can improve this code like that:
```python
def check_database_connection(**kwargs):
for conn in connections.all():
try:
conn.cursor()
return True
except OperationalError:
return False
return False
```
reported by @eltonplima in #158
</issue>
<code>
[start of bothub/health/checks.py]
1 def check_database_connection(**kwargs):
2 from django.db import connections
3 from django.db.utils import OperationalError
4 db_conn = connections['default']
5 if not db_conn:
6 return False
7 try:
8 db_conn.cursor()
9 return True
10 except OperationalError as e:
11 return False
12
13
14 def check_accessible_api(request, **kwargs):
15 import requests
16 HTTP_HOST = request.META.get('HTTP_HOST')
17 repositories_url = 'http://{}/api/repositories/'.format(HTTP_HOST)
18 request = requests.get(repositories_url)
19 try:
20 request.raise_for_status()
21 return True
22 except requests.HTTPError as e:
23 return False
24
[end of bothub/health/checks.py]
[start of setup.py]
1 from setuptools import setup, find_packages
2
3
4 setup(
5 name='bothub',
6 version='1.13.3',
7 description='bothub',
8 packages=find_packages(),
9 install_requires=[
10 'python-decouple',
11 'requests',
12 'django==2.0.6',
13 'djangorestframework==3.7.7',
14 'whitenoise',
15 'dj-database-url',
16 'django-cors-headers',
17 'django-filter',
18 'coreapi',
19 ],
20 python_requires='>=3.6',
21 )
22
[end of setup.py]
[start of bothub/settings.py]
1 import os
2 import dj_database_url
3
4 from decouple import config
5
6
7 # Build paths inside the project like this: os.path.join(BASE_DIR, ...)
8 BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
9
10
11 # SECURITY WARNING: keep the secret key used in production secret!
12 SECRET_KEY = config('SECRET_KEY')
13
14 # SECURITY WARNING: don't run with debug turned on in production!
15 DEBUG = config('DEBUG', default=False, cast=bool)
16
17 ALLOWED_HOSTS = config(
18 'ALLOWED_HOSTS',
19 default='*',
20 cast=lambda v: [s.strip() for s in v.split(',')])
21
22
23 # Application definition
24
25 INSTALLED_APPS = [
26 'django.contrib.admin',
27 'django.contrib.auth',
28 'django.contrib.contenttypes',
29 'django.contrib.sessions',
30 'django.contrib.messages',
31 'django.contrib.staticfiles',
32 'rest_framework',
33 'rest_framework.authtoken',
34 'django_filters',
35 'corsheaders',
36 'bothub.authentication',
37 'bothub.common',
38 'bothub.api',
39 ]
40
41 MIDDLEWARE = [
42 'django.middleware.security.SecurityMiddleware',
43 'whitenoise.middleware.WhiteNoiseMiddleware',
44 'django.contrib.sessions.middleware.SessionMiddleware',
45 'corsheaders.middleware.CorsMiddleware',
46 'django.middleware.common.CommonMiddleware',
47 'django.middleware.csrf.CsrfViewMiddleware',
48 'django.contrib.auth.middleware.AuthenticationMiddleware',
49 'django.contrib.messages.middleware.MessageMiddleware',
50 'django.middleware.clickjacking.XFrameOptionsMiddleware',
51 ]
52
53 ROOT_URLCONF = 'bothub.urls'
54
55 TEMPLATES = [
56 {
57 'BACKEND': 'django.template.backends.django.DjangoTemplates',
58 'DIRS': [],
59 'APP_DIRS': True,
60 'OPTIONS': {
61 'context_processors': [
62 'django.template.context_processors.debug',
63 'django.template.context_processors.request',
64 'django.contrib.auth.context_processors.auth',
65 'django.contrib.messages.context_processors.messages',
66 ],
67 },
68 },
69 ]
70
71 WSGI_APPLICATION = 'bothub.wsgi.application'
72
73
74 # Database
75
76 DATABASES = {}
77 DATABASES['default'] = dj_database_url.parse(
78 config(
79 'DEFAULT_DATABASE',
80 default='sqlite:///db.sqlite3'))
81
82
83 # Auth
84
85 AUTH_USER_MODEL = 'authentication.User'
86
87
88 # Password validation
89
90 AUTH_PASSWORD_VALIDATORS = [
91 {
92 'NAME': 'django.contrib.auth.password_validation.' +
93 'UserAttributeSimilarityValidator',
94 },
95 {
96 'NAME': 'django.contrib.auth.password_validation.' +
97 'MinimumLengthValidator',
98 },
99 {
100 'NAME': 'django.contrib.auth.password_validation.' +
101 'CommonPasswordValidator',
102 },
103 {
104 'NAME': 'django.contrib.auth.password_validation.' +
105 'NumericPasswordValidator',
106 },
107 ]
108
109
110 # Internationalization
111
112 LANGUAGE_CODE = config('LANGUAGE_CODE', default='en-us')
113
114 TIME_ZONE = config('TIME_ZONE', default='UTC')
115
116 USE_I18N = True
117
118 USE_L10N = True
119
120 USE_TZ = True
121
122
123 # Static files (CSS, JavaScript, Images)
124
125 STATIC_URL = config('STATIC_URL', default='/static/')
126
127 STATIC_ROOT = os.path.join(BASE_DIR, 'staticfiles')
128
129 STATICFILES_STORAGE = 'whitenoise.storage.CompressedManifestStaticFilesStorage'
130
131
132 # rest framework
133
134 REST_FRAMEWORK = {
135 'DEFAULT_AUTHENTICATION_CLASSES': [
136 'rest_framework.authentication.TokenAuthentication',
137 ],
138 'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.' +
139 'LimitOffsetPagination',
140 'PAGE_SIZE': 20,
141 'DEFAULT_FILTER_BACKENDS': [
142 'django_filters.rest_framework.DjangoFilterBackend',
143 ],
144 'DEFAULT_METADATA_CLASS': 'bothub.api.metadata.Metadata',
145 }
146
147
148 # cors headers
149
150 CORS_ORIGIN_ALLOW_ALL = True
151 CORS_URLS_REGEX = r'^/api/.*$'
152
153
154 # mail
155
156 envvar_EMAIL_HOST = config('EMAIL_HOST', default=None)
157
158 ADMINS = config(
159 'ADMINS',
160 default='',
161 cast=lambda v: [
162 (
163 s.strip().split('|')[0],
164 s.strip().split('|')[1],
165 ) for s in v.split(',')] if v else [])
166 EMAIL_SUBJECT_PREFIX = '[bothub] '
167 DEFAULT_FROM_EMAIL = config(
168 'DEFAULT_FROM_EMAIL',
169 default='webmaster@localhost')
170 SERVER_EMAIL = config('SERVER_EMAIL', default='root@localhost')
171
172 if envvar_EMAIL_HOST:
173 EMAIL_HOST = envvar_EMAIL_HOST
174 EMAIL_PORT = config('EMAIL_PORT', default=25, cast=int)
175 EMAIL_HOST_USER = config('EMAIL_HOST_USER', default='')
176 EMAIL_HOST_PASSWORD = config('EMAIL_HOST_PASSWORD', default='')
177 EMAIL_USE_SSL = config('EMAIL_USE_SSL', default=False, cast=bool)
178 EMAIL_USE_TLS = config('EMAIL_USE_TLS', default=False, cast=bool)
179 else:
180 EMAIL_BACKEND = 'django.core.mail.backends.console.EmailBackend'
181
182
183 # webapp
184
185 BOTHUB_WEBAPP_BASE_URL = config(
186 'BOTHUB_WEBAPP_BASE_URL',
187 default='http://localhost:8080/')
188
189
190 # NLP
191
192 BOTHUB_NLP_BASE_URL = config(
193 'BOTHUB_NLP_BASE_URL',
194 default='http://localhost:8001/')
195
196
197 # CSRF
198
199 CSRF_COOKIE_DOMAIN = config(
200 'CSRF_COOKIE_DOMAIN',
201 default=None)
202
203 CSRF_COOKIE_SECURE = config(
204 'CSRF_COOKIE_SECURE',
205 default=False,
206 cast=bool)
207
[end of bothub/settings.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/bothub/health/checks.py b/bothub/health/checks.py
--- a/bothub/health/checks.py
+++ b/bothub/health/checks.py
@@ -1,23 +1,37 @@
+import logging
+
+from rest_framework import status
+
+
+logger = logging.getLogger('bothub.health.checks')
+
+CHECK_ACCESSIBLE_API_URL = '/api/repositories/'
+
+
def check_database_connection(**kwargs):
from django.db import connections
from django.db.utils import OperationalError
- db_conn = connections['default']
- if not db_conn:
- return False
- try:
- db_conn.cursor()
- return True
- except OperationalError as e:
+ if len(connections.all()) is 0:
return False
+ logger.info('found {} database connection'.format(len(connections.all())))
+ for i, conn in enumerate(connections.all(), 1):
+ try:
+ conn.cursor()
+ logger.info('#{} db connection OKAY'.format(i))
+ except OperationalError as e:
+ logger.warning('#{} db connection ERROR'.format(i))
+ return False
+ return True
def check_accessible_api(request, **kwargs):
- import requests
- HTTP_HOST = request.META.get('HTTP_HOST')
- repositories_url = 'http://{}/api/repositories/'.format(HTTP_HOST)
- request = requests.get(repositories_url)
- try:
- request.raise_for_status()
+ from django.test import Client
+ logger.info('making request to {}'.format(CHECK_ACCESSIBLE_API_URL))
+ client = Client()
+ response = client.get(CHECK_ACCESSIBLE_API_URL)
+ logger.info('{} status code: {}'.format(
+ CHECK_ACCESSIBLE_API_URL,
+ response.status_code))
+ if response.status_code is status.HTTP_200_OK:
return True
- except requests.HTTPError as e:
- return False
+ return False
diff --git a/bothub/settings.py b/bothub/settings.py
--- a/bothub/settings.py
+++ b/bothub/settings.py
@@ -2,6 +2,7 @@
import dj_database_url
from decouple import config
+from django.utils.log import DEFAULT_LOGGING
# Build paths inside the project like this: os.path.join(BASE_DIR, ...)
@@ -191,7 +192,7 @@
BOTHUB_NLP_BASE_URL = config(
'BOTHUB_NLP_BASE_URL',
- default='http://localhost:8001/')
+ default='http://localhost:2657/')
# CSRF
@@ -204,3 +205,21 @@
'CSRF_COOKIE_SECURE',
default=False,
cast=bool)
+
+
+# Logging
+
+LOGGING = DEFAULT_LOGGING
+LOGGING['formatters']['bothub.health'] = {
+ 'format': '[bothub.health] {message}',
+ 'style': '{',
+}
+LOGGING['handlers']['bothub.health'] = {
+ 'level': 'DEBUG',
+ 'class': 'logging.StreamHandler',
+ 'formatter': 'bothub.health',
+}
+LOGGING['loggers']['bothub.health.checks'] = {
+ 'handlers': ['bothub.health'],
+ 'level': 'DEBUG',
+}
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -3,7 +3,7 @@
setup(
name='bothub',
- version='1.13.3',
+ version='1.13.4',
description='bothub',
packages=find_packages(),
install_requires=[
| {"golden_diff": "diff --git a/bothub/health/checks.py b/bothub/health/checks.py\n--- a/bothub/health/checks.py\n+++ b/bothub/health/checks.py\n@@ -1,23 +1,37 @@\n+import logging\n+\n+from rest_framework import status\n+\n+\n+logger = logging.getLogger('bothub.health.checks')\n+\n+CHECK_ACCESSIBLE_API_URL = '/api/repositories/'\n+\n+\n def check_database_connection(**kwargs):\n from django.db import connections\n from django.db.utils import OperationalError\n- db_conn = connections['default']\n- if not db_conn:\n- return False\n- try:\n- db_conn.cursor()\n- return True\n- except OperationalError as e:\n+ if len(connections.all()) is 0:\n return False\n+ logger.info('found {} database connection'.format(len(connections.all())))\n+ for i, conn in enumerate(connections.all(), 1):\n+ try:\n+ conn.cursor()\n+ logger.info('#{} db connection OKAY'.format(i))\n+ except OperationalError as e:\n+ logger.warning('#{} db connection ERROR'.format(i))\n+ return False\n+ return True\n \n \n def check_accessible_api(request, **kwargs):\n- import requests\n- HTTP_HOST = request.META.get('HTTP_HOST')\n- repositories_url = 'http://{}/api/repositories/'.format(HTTP_HOST)\n- request = requests.get(repositories_url)\n- try:\n- request.raise_for_status()\n+ from django.test import Client\n+ logger.info('making request to {}'.format(CHECK_ACCESSIBLE_API_URL))\n+ client = Client()\n+ response = client.get(CHECK_ACCESSIBLE_API_URL)\n+ logger.info('{} status code: {}'.format(\n+ CHECK_ACCESSIBLE_API_URL,\n+ response.status_code))\n+ if response.status_code is status.HTTP_200_OK:\n return True\n- except requests.HTTPError as e:\n- return False\n+ return False\ndiff --git a/bothub/settings.py b/bothub/settings.py\n--- a/bothub/settings.py\n+++ b/bothub/settings.py\n@@ -2,6 +2,7 @@\n import dj_database_url\n \n from decouple import config\n+from django.utils.log import DEFAULT_LOGGING\n \n \n # Build paths inside the project like this: os.path.join(BASE_DIR, ...)\n@@ -191,7 +192,7 @@\n \n BOTHUB_NLP_BASE_URL = config(\n 'BOTHUB_NLP_BASE_URL',\n- default='http://localhost:8001/')\n+ default='http://localhost:2657/')\n \n \n # CSRF\n@@ -204,3 +205,21 @@\n 'CSRF_COOKIE_SECURE',\n default=False,\n cast=bool)\n+\n+\n+# Logging\n+\n+LOGGING = DEFAULT_LOGGING\n+LOGGING['formatters']['bothub.health'] = {\n+ 'format': '[bothub.health] {message}',\n+ 'style': '{',\n+}\n+LOGGING['handlers']['bothub.health'] = {\n+ 'level': 'DEBUG',\n+ 'class': 'logging.StreamHandler',\n+ 'formatter': 'bothub.health',\n+}\n+LOGGING['loggers']['bothub.health.checks'] = {\n+ 'handlers': ['bothub.health'],\n+ 'level': 'DEBUG',\n+}\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -3,7 +3,7 @@\n \n setup(\n name='bothub',\n- version='1.13.3',\n+ version='1.13.4',\n description='bothub',\n packages=find_packages(),\n install_requires=[\n", "issue": "Fix health checker /ping/ - infinite looping\n\nImprove check_database_connection function\nWe can improve this code like that:\r\n\r\n```python\r\ndef check_database_connection(**kwargs):\r\n for conn in connections.all():\r\n try:\r\n conn.cursor()\r\n return True\r\n except OperationalError:\r\n return False\r\n return False\r\n```\r\n\r\nreported by @eltonplima in #158 \nImprove check_database_connection function\nWe can improve this code like that:\r\n\r\n```python\r\ndef check_database_connection(**kwargs):\r\n for conn in connections.all():\r\n try:\r\n conn.cursor()\r\n return True\r\n except OperationalError:\r\n return False\r\n return False\r\n```\r\n\r\nreported by @eltonplima in #158 \n", "before_files": [{"content": "def check_database_connection(**kwargs):\n from django.db import connections\n from django.db.utils import OperationalError\n db_conn = connections['default']\n if not db_conn:\n return False\n try:\n db_conn.cursor()\n return True\n except OperationalError as e:\n return False\n\n\ndef check_accessible_api(request, **kwargs):\n import requests\n HTTP_HOST = request.META.get('HTTP_HOST')\n repositories_url = 'http://{}/api/repositories/'.format(HTTP_HOST)\n request = requests.get(repositories_url)\n try:\n request.raise_for_status()\n return True\n except requests.HTTPError as e:\n return False\n", "path": "bothub/health/checks.py"}, {"content": "from setuptools import setup, find_packages\n\n\nsetup(\n name='bothub',\n version='1.13.3',\n description='bothub',\n packages=find_packages(),\n install_requires=[\n 'python-decouple',\n 'requests',\n 'django==2.0.6',\n 'djangorestframework==3.7.7',\n 'whitenoise',\n 'dj-database-url',\n 'django-cors-headers',\n 'django-filter',\n 'coreapi',\n ],\n python_requires='>=3.6',\n)\n", "path": "setup.py"}, {"content": "import os\nimport dj_database_url\n\nfrom decouple import config\n\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = config('SECRET_KEY')\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = config('DEBUG', default=False, cast=bool)\n\nALLOWED_HOSTS = config(\n 'ALLOWED_HOSTS',\n default='*',\n cast=lambda v: [s.strip() for s in v.split(',')])\n\n\n# Application definition\n\nINSTALLED_APPS = [\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'rest_framework',\n 'rest_framework.authtoken',\n 'django_filters',\n 'corsheaders',\n 'bothub.authentication',\n 'bothub.common',\n 'bothub.api',\n]\n\nMIDDLEWARE = [\n 'django.middleware.security.SecurityMiddleware',\n 'whitenoise.middleware.WhiteNoiseMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'corsheaders.middleware.CorsMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n]\n\nROOT_URLCONF = 'bothub.urls'\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': [],\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n 'django.contrib.messages.context_processors.messages',\n ],\n },\n },\n]\n\nWSGI_APPLICATION = 'bothub.wsgi.application'\n\n\n# Database\n\nDATABASES = {}\nDATABASES['default'] = dj_database_url.parse(\n config(\n 'DEFAULT_DATABASE',\n default='sqlite:///db.sqlite3'))\n\n\n# Auth\n\nAUTH_USER_MODEL = 'authentication.User'\n\n\n# Password validation\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n 'NAME': 'django.contrib.auth.password_validation.' +\n 'UserAttributeSimilarityValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.' +\n 'MinimumLengthValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.' +\n 'CommonPasswordValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.' +\n 'NumericPasswordValidator',\n },\n]\n\n\n# Internationalization\n\nLANGUAGE_CODE = config('LANGUAGE_CODE', default='en-us')\n\nTIME_ZONE = config('TIME_ZONE', default='UTC')\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n\n# Static files (CSS, JavaScript, Images)\n\nSTATIC_URL = config('STATIC_URL', default='/static/')\n\nSTATIC_ROOT = os.path.join(BASE_DIR, 'staticfiles')\n\nSTATICFILES_STORAGE = 'whitenoise.storage.CompressedManifestStaticFilesStorage'\n\n\n# rest framework\n\nREST_FRAMEWORK = {\n 'DEFAULT_AUTHENTICATION_CLASSES': [\n 'rest_framework.authentication.TokenAuthentication',\n ],\n 'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.' +\n 'LimitOffsetPagination',\n 'PAGE_SIZE': 20,\n 'DEFAULT_FILTER_BACKENDS': [\n 'django_filters.rest_framework.DjangoFilterBackend',\n ],\n 'DEFAULT_METADATA_CLASS': 'bothub.api.metadata.Metadata',\n}\n\n\n# cors headers\n\nCORS_ORIGIN_ALLOW_ALL = True\nCORS_URLS_REGEX = r'^/api/.*$'\n\n\n# mail\n\nenvvar_EMAIL_HOST = config('EMAIL_HOST', default=None)\n\nADMINS = config(\n 'ADMINS',\n default='',\n cast=lambda v: [\n (\n s.strip().split('|')[0],\n s.strip().split('|')[1],\n ) for s in v.split(',')] if v else [])\nEMAIL_SUBJECT_PREFIX = '[bothub] '\nDEFAULT_FROM_EMAIL = config(\n 'DEFAULT_FROM_EMAIL',\n default='webmaster@localhost')\nSERVER_EMAIL = config('SERVER_EMAIL', default='root@localhost')\n\nif envvar_EMAIL_HOST:\n EMAIL_HOST = envvar_EMAIL_HOST\n EMAIL_PORT = config('EMAIL_PORT', default=25, cast=int)\n EMAIL_HOST_USER = config('EMAIL_HOST_USER', default='')\n EMAIL_HOST_PASSWORD = config('EMAIL_HOST_PASSWORD', default='')\n EMAIL_USE_SSL = config('EMAIL_USE_SSL', default=False, cast=bool)\n EMAIL_USE_TLS = config('EMAIL_USE_TLS', default=False, cast=bool)\nelse:\n EMAIL_BACKEND = 'django.core.mail.backends.console.EmailBackend'\n\n\n# webapp\n\nBOTHUB_WEBAPP_BASE_URL = config(\n 'BOTHUB_WEBAPP_BASE_URL',\n default='http://localhost:8080/')\n\n\n# NLP\n\nBOTHUB_NLP_BASE_URL = config(\n 'BOTHUB_NLP_BASE_URL',\n default='http://localhost:8001/')\n\n\n# CSRF\n\nCSRF_COOKIE_DOMAIN = config(\n 'CSRF_COOKIE_DOMAIN',\n default=None)\n\nCSRF_COOKIE_SECURE = config(\n 'CSRF_COOKIE_SECURE',\n default=False,\n cast=bool)\n", "path": "bothub/settings.py"}]} | 2,733 | 814 |
gh_patches_debug_3354 | rasdani/github-patches | git_diff | openstates__openstates-scrapers-2985 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
AL failing since at least 2019-06-01
AL has been failing since 2019-06-01
Based on automated runs it appears that AL has not run successfully in 2 days (2019-06-01).
```
loaded Open States pupa settings...
al (scrape, import)
bills: {}
05:01:33 CRITICAL pupa: Session(s) Regular Session 2019 were reported by Alabama.get_session_list() but were not found in Alabama.legislative_sessions or Alabama.ignored_scraped_sessions.
```
Visit http://bobsled.openstates.org for more info.
</issue>
<code>
[start of openstates/al/__init__.py]
1 from pupa.scrape import Jurisdiction, Organization
2
3 from .bills import ALBillScraper
4 from .events import ALEventScraper
5 from .people import ALPersonScraper
6
7
8 class Alabama(Jurisdiction):
9 division_id = "ocd-division/country:us/state:al"
10 classification = "government"
11 name = "Alabama"
12 url = "http://www.legislature.state.al.us/"
13 scrapers = {
14 'bills': ALBillScraper,
15 'events': ALEventScraper,
16 'people': ALPersonScraper,
17 }
18 legislative_sessions = [
19 {
20 "_scraped_name": "Regular Session 2011",
21 "classification": "primary",
22 "identifier": "2011rs",
23 "name": "2011 Regular Session"
24 },
25 {
26 "_scraped_name": "First Special Session 2012",
27 "classification": "special",
28 "identifier": "2012fs",
29 "name": "First Special Session 2012"
30 },
31 {
32 "_scraped_name": "Regular Session 2012",
33 "classification": "primary",
34 "identifier": "2012rs",
35 "name": "2012 Regular Session"
36 },
37 {
38 "_scraped_name": "Regular Session 2013",
39 "classification": "primary",
40 "identifier": "2013rs",
41 "name": "2013 Regular Session"
42 },
43 {
44 "_scraped_name": "Regular Session 2014",
45 "classification": "primary",
46 "identifier": "2014rs",
47 "name": "2014 Regular Session"
48 },
49 {
50 "_scraped_name": "First Special Session 2015",
51 "classification": "special",
52 "identifier": "2015fs",
53 "name": "First Special Session 2015"
54 },
55 {
56 "_scraped_name": "Organizational Session 2015",
57 "classification": "primary",
58 "identifier": "2015os",
59 "name": "2015 Organizational Session"
60 },
61 {
62 "_scraped_name": "Regular Session 2015",
63 "classification": "primary",
64 "identifier": "2015rs",
65 "name": "2015 Regular Session"
66 },
67 {
68 "_scraped_name": "Second Special Session 2015",
69 "classification": "special",
70 "identifier": "2015ss",
71 "name": "Second Special Session 2015"
72 },
73 {
74 "_scraped_name": "First Special Session 2016",
75 "classification": "special",
76 "identifier": "2016fs",
77 "name": "First Special Session 2016"
78 },
79 {
80 "_scraped_name": "Regular Session 2016",
81 "classification": "primary",
82 "identifier": "2016rs",
83 "name": "2016 Regular Session"
84 },
85 {
86 "_scraped_name": "Regular Session 2017",
87 "classification": "primary",
88 "end_date": "2017-05-31",
89 "identifier": "2017rs",
90 "name": "2017 Regular Session",
91 "start_date": "2017-02-07"
92 },
93 {
94 "_scraped_name": "Regular Session 2018",
95 "classification": "primary",
96 "end_date": "2018-03-29",
97 "identifier": "2018rs",
98 "name": "2018 Regular Session",
99 "start_date": "2018-01-09",
100 },
101 {
102 "_scraped_name": "First Special Session 2019",
103 "classification": "special",
104 "identifier": "2019fs",
105 "name": "First Special Session 2019",
106 "start_date": "2019-03-08"
107 },
108 {
109 "_scraped_name": " Regular Session 2019",
110 "classification": "primary",
111 "end_date": "2019-06-17",
112 "identifier": "2019rs",
113 "name": "2019 Regular Session",
114 "start_date": "2019-03-05"
115 },
116 ]
117 ignored_scraped_sessions = [
118 "Regular Session 1998",
119 "Organizational Session 1999",
120 "Regular Session 1999",
121 "First Special Session 1999",
122 "Organizational Session 2011",
123 "Second Special Session 1999",
124 "Regular Session 2000",
125 "Regular Session 2001",
126 "First Special Session 2001",
127 "Second Special Session 2001",
128 "Third Special Session 2001",
129 "Fourth Special Session 2001",
130 "Regular Session 2002",
131 "Organizational Session 2003",
132 "Regular Session 2003",
133 "First Special Session 2003",
134 "Second Special Session 2003",
135 "Regular Session 2004",
136 "First Special Session 2004",
137 "Regular Session 2005",
138 "First Special Session 2005",
139 "Regular Session 2006",
140 "Organizational Session 2007",
141 "Regular Session 2007",
142 "First Special Session 2007",
143 "Regular Session 2008",
144 "First Special Session 2008",
145 "Regular Session 2009",
146 "Regular Session 2010",
147 "First Special Session 2009",
148 "First Special Session 2010",
149 "Regular Session 2016",
150 "Organizational Session 2019",
151 ]
152
153 def get_organizations(self):
154 legislature_name = "Alabama Legislature"
155
156 legislature = Organization(name=legislature_name,
157 classification="legislature")
158 upper = Organization('Senate', classification='upper',
159 parent_id=legislature._id)
160 lower = Organization('House', classification='lower',
161 parent_id=legislature._id)
162
163 yield legislature
164 yield upper
165 yield lower
166
167 def get_session_list(self):
168 import lxml.html
169 import requests
170
171 s = requests.Session()
172 r = s.get('http://alisondb.legislature.state.al.us/alison/SelectSession.aspx')
173 doc = lxml.html.fromstring(r.text)
174 return doc.xpath('//*[@id="ContentPlaceHolder1_gvSessions"]/tr/td/font/a/font/text()')
175
[end of openstates/al/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/openstates/al/__init__.py b/openstates/al/__init__.py
--- a/openstates/al/__init__.py
+++ b/openstates/al/__init__.py
@@ -106,7 +106,7 @@
"start_date": "2019-03-08"
},
{
- "_scraped_name": " Regular Session 2019",
+ "_scraped_name": "Regular Session 2019",
"classification": "primary",
"end_date": "2019-06-17",
"identifier": "2019rs",
| {"golden_diff": "diff --git a/openstates/al/__init__.py b/openstates/al/__init__.py\n--- a/openstates/al/__init__.py\n+++ b/openstates/al/__init__.py\n@@ -106,7 +106,7 @@\n \"start_date\": \"2019-03-08\"\n },\n {\n- \"_scraped_name\": \" Regular Session 2019\",\n+ \"_scraped_name\": \"Regular Session 2019\",\n \"classification\": \"primary\",\n \"end_date\": \"2019-06-17\",\n \"identifier\": \"2019rs\",\n", "issue": "AL failing since at least 2019-06-01\nAL has been failing since 2019-06-01\n\nBased on automated runs it appears that AL has not run successfully in 2 days (2019-06-01).\n\n\n```\n loaded Open States pupa settings...\nal (scrape, import)\n bills: {}\n05:01:33 CRITICAL pupa: Session(s) Regular Session 2019 were reported by Alabama.get_session_list() but were not found in Alabama.legislative_sessions or Alabama.ignored_scraped_sessions.\n```\n\nVisit http://bobsled.openstates.org for more info.\n\n", "before_files": [{"content": "from pupa.scrape import Jurisdiction, Organization\n\nfrom .bills import ALBillScraper\nfrom .events import ALEventScraper\nfrom .people import ALPersonScraper\n\n\nclass Alabama(Jurisdiction):\n division_id = \"ocd-division/country:us/state:al\"\n classification = \"government\"\n name = \"Alabama\"\n url = \"http://www.legislature.state.al.us/\"\n scrapers = {\n 'bills': ALBillScraper,\n 'events': ALEventScraper,\n 'people': ALPersonScraper,\n }\n legislative_sessions = [\n {\n \"_scraped_name\": \"Regular Session 2011\",\n \"classification\": \"primary\",\n \"identifier\": \"2011rs\",\n \"name\": \"2011 Regular Session\"\n },\n {\n \"_scraped_name\": \"First Special Session 2012\",\n \"classification\": \"special\",\n \"identifier\": \"2012fs\",\n \"name\": \"First Special Session 2012\"\n },\n {\n \"_scraped_name\": \"Regular Session 2012\",\n \"classification\": \"primary\",\n \"identifier\": \"2012rs\",\n \"name\": \"2012 Regular Session\"\n },\n {\n \"_scraped_name\": \"Regular Session 2013\",\n \"classification\": \"primary\",\n \"identifier\": \"2013rs\",\n \"name\": \"2013 Regular Session\"\n },\n {\n \"_scraped_name\": \"Regular Session 2014\",\n \"classification\": \"primary\",\n \"identifier\": \"2014rs\",\n \"name\": \"2014 Regular Session\"\n },\n {\n \"_scraped_name\": \"First Special Session 2015\",\n \"classification\": \"special\",\n \"identifier\": \"2015fs\",\n \"name\": \"First Special Session 2015\"\n },\n {\n \"_scraped_name\": \"Organizational Session 2015\",\n \"classification\": \"primary\",\n \"identifier\": \"2015os\",\n \"name\": \"2015 Organizational Session\"\n },\n {\n \"_scraped_name\": \"Regular Session 2015\",\n \"classification\": \"primary\",\n \"identifier\": \"2015rs\",\n \"name\": \"2015 Regular Session\"\n },\n {\n \"_scraped_name\": \"Second Special Session 2015\",\n \"classification\": \"special\",\n \"identifier\": \"2015ss\",\n \"name\": \"Second Special Session 2015\"\n },\n {\n \"_scraped_name\": \"First Special Session 2016\",\n \"classification\": \"special\",\n \"identifier\": \"2016fs\",\n \"name\": \"First Special Session 2016\"\n },\n {\n \"_scraped_name\": \"Regular Session 2016\",\n \"classification\": \"primary\",\n \"identifier\": \"2016rs\",\n \"name\": \"2016 Regular Session\"\n },\n {\n \"_scraped_name\": \"Regular Session 2017\",\n \"classification\": \"primary\",\n \"end_date\": \"2017-05-31\",\n \"identifier\": \"2017rs\",\n \"name\": \"2017 Regular Session\",\n \"start_date\": \"2017-02-07\"\n },\n {\n \"_scraped_name\": \"Regular Session 2018\",\n \"classification\": \"primary\",\n \"end_date\": \"2018-03-29\",\n \"identifier\": \"2018rs\",\n \"name\": \"2018 Regular Session\",\n \"start_date\": \"2018-01-09\",\n },\n {\n \"_scraped_name\": \"First Special Session 2019\",\n \"classification\": \"special\",\n \"identifier\": \"2019fs\",\n \"name\": \"First Special Session 2019\",\n \"start_date\": \"2019-03-08\"\n },\n {\n \"_scraped_name\": \" Regular Session 2019\",\n \"classification\": \"primary\",\n \"end_date\": \"2019-06-17\",\n \"identifier\": \"2019rs\",\n \"name\": \"2019 Regular Session\",\n \"start_date\": \"2019-03-05\"\n },\n ]\n ignored_scraped_sessions = [\n \"Regular Session 1998\",\n \"Organizational Session 1999\",\n \"Regular Session 1999\",\n \"First Special Session 1999\",\n \"Organizational Session 2011\",\n \"Second Special Session 1999\",\n \"Regular Session 2000\",\n \"Regular Session 2001\",\n \"First Special Session 2001\",\n \"Second Special Session 2001\",\n \"Third Special Session 2001\",\n \"Fourth Special Session 2001\",\n \"Regular Session 2002\",\n \"Organizational Session 2003\",\n \"Regular Session 2003\",\n \"First Special Session 2003\",\n \"Second Special Session 2003\",\n \"Regular Session 2004\",\n \"First Special Session 2004\",\n \"Regular Session 2005\",\n \"First Special Session 2005\",\n \"Regular Session 2006\",\n \"Organizational Session 2007\",\n \"Regular Session 2007\",\n \"First Special Session 2007\",\n \"Regular Session 2008\",\n \"First Special Session 2008\",\n \"Regular Session 2009\",\n \"Regular Session 2010\",\n \"First Special Session 2009\",\n \"First Special Session 2010\",\n \"Regular Session 2016\",\n \"Organizational Session 2019\",\n ]\n\n def get_organizations(self):\n legislature_name = \"Alabama Legislature\"\n\n legislature = Organization(name=legislature_name,\n classification=\"legislature\")\n upper = Organization('Senate', classification='upper',\n parent_id=legislature._id)\n lower = Organization('House', classification='lower',\n parent_id=legislature._id)\n\n yield legislature\n yield upper\n yield lower\n\n def get_session_list(self):\n import lxml.html\n import requests\n\n s = requests.Session()\n r = s.get('http://alisondb.legislature.state.al.us/alison/SelectSession.aspx')\n doc = lxml.html.fromstring(r.text)\n return doc.xpath('//*[@id=\"ContentPlaceHolder1_gvSessions\"]/tr/td/font/a/font/text()')\n", "path": "openstates/al/__init__.py"}]} | 2,659 | 144 |
gh_patches_debug_4470 | rasdani/github-patches | git_diff | pytorch__pytorch-2084 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Negative dimension behaviour in torch.stack
Support for using a negative dimension in `torch.stack` currently works as follows:
```python
if dim < 0:
dim += sequence[0].dim()
```
This is not consistent with the behaviour of `torch.unsqueeze`, which uses `dim += input.dim() + 1`. The unsqueeze behaviour is better since it is possible to use negative indexing to insert a new dimension as the last dimension.
## Example
`torch.stack` with `dim=-1` adds a new dimension in the second-to-last position. This is confusing. It is not possible to use negative indexing to add a dimension in the last position (ie can't achieve a 3x2 result).
```python
>>> a = torch.Tensor([1, 2, 3])
>>> b = torch.Tensor([4, 5, 6])
>>> torch.stack([a, b], -1)
1 2 3
4 5 6
[torch.FloatTensor of size 2x3]
```
Contrast this to using `torch.unsqueeze` and `torch.cat` with `dim=-1`, which adds a new dimension in the last position:
```python
>>> a = torch.Tensor([1, 2, 3])
>>> b = torch.Tensor([4, 5, 6])
>>> torch.cat([a.unsqueeze(-1), b.unsqueeze(-1)], -1)
1 4
2 5
3 6
[torch.FloatTensor of size 3x2]
```
</issue>
<code>
[start of torch/functional.py]
1 import torch
2 from ._utils import _range
3 from operator import mul
4 from functools import reduce
5
6 __all__ = [
7 'split', 'chunk', 'stack', 'unbind', 'btriunpack', 'matmul',
8 ]
9
10
11 def split(tensor, split_size, dim=0):
12 """Splits the tensor into equally sized chunks (if possible).
13
14 Last chunk will be smaller if the tensor size along a given dimension
15 is not divisible by ``split_size``.
16
17 Arguments:
18 tensor (Tensor): tensor to split.
19 split_size (int): size of a single chunk.
20 dim (int): dimension along which to split the tensor.
21 """
22 if dim < 0:
23 dim += tensor.dim()
24 dim_size = tensor.size(dim)
25 num_splits = (dim_size + split_size - 1) // split_size
26 last_split_size = split_size - (split_size * num_splits - dim_size)
27
28 def get_split_size(i):
29 return split_size if i < num_splits - 1 else last_split_size
30 return tuple(tensor.narrow(int(dim), int(i * split_size), int(get_split_size(i))) for i
31 in _range(0, num_splits))
32
33
34 def chunk(tensor, chunks, dim=0):
35 """Splits a tensor into a number of chunks along a given dimension.
36
37 Arguments:
38 tensor (Tensor): tensor to split.
39 chunks (int): number of chunks to return.
40 dim (int): dimension along which to split the tensor.
41 """
42 if dim < 0:
43 dim += tensor.dim()
44 split_size = (tensor.size(dim) + chunks - 1) // chunks
45 return split(tensor, split_size, dim)
46
47
48 def stack(sequence, dim=0, out=None):
49 """Concatenates sequence of tensors along a new dimension.
50
51 All tensors need to be of the same size.
52
53 Arguments:
54 sequence (Sequence): sequence of tensors to concatenate.
55 dim (int): dimension to insert. Has to be between 0 and the number
56 of dimensions of concatenated tensors (inclusive).
57 """
58 if len(sequence) == 0:
59 raise ValueError("stack expects a non-empty sequence of tensors")
60 if dim < 0:
61 dim += sequence[0].dim()
62 inputs = [t.unsqueeze(dim) for t in sequence]
63 if out is None:
64 return torch.cat(inputs, dim)
65 else:
66 return torch.cat(inputs, dim, out=out)
67
68
69 def unbind(tensor, dim=0):
70 """Removes a tensor dimension.
71
72 Returns a tuple of all slices along a given dimension, already without it.
73
74 Arguments:
75 tensor (Tensor): tensor to unbind.
76 dim (int): dimension to remove.
77 """
78 return tuple(tensor.select(dim, i) for i in _range(tensor.size(dim)))
79
80
81 def btriunpack(LU_data, LU_pivots, unpack_data=True, unpack_pivots=True):
82 """Unpacks the data and pivots from a batched LU factorization (btrifact) of a tensor.
83
84 Returns a tuple indexed by:
85 0: The pivots.
86 1: The L tensor.
87 2: The U tensor.
88
89 Arguments:
90 LU_data (Tensor): The packed LU factorization data.
91 LU_pivots (Tensor): The packed LU factorization pivots.
92 unpack_data (bool): Flag indicating if the data should be unpacked.
93 unpack_pivots (bool): Flag indicating if the pivots should be unpacked.
94 """
95
96 nBatch, sz, _ = LU_data.size()
97
98 if unpack_data:
99 I_U = torch.triu(torch.ones(sz, sz)).type_as(LU_data).byte().unsqueeze(0).expand(nBatch, sz, sz)
100 I_L = 1 - I_U
101 L = LU_data.new(LU_data.size()).zero_()
102 U = LU_data.new(LU_data.size()).zero_()
103 I_diag = torch.eye(sz).type_as(LU_data).byte().unsqueeze(0).expand(nBatch, sz, sz)
104 L[I_diag] = 1.0
105 L[I_L] = LU_data[I_L]
106 U[I_U] = LU_data[I_U]
107 else:
108 L = U = None
109
110 if unpack_pivots:
111 P = torch.eye(sz).type_as(LU_data).unsqueeze(0).repeat(nBatch, 1, 1)
112 for i in range(nBatch):
113 for j in range(sz):
114 k = LU_pivots[i, j] - 1
115 t = P[i, :, j].clone()
116 P[i, :, j] = P[i, :, k]
117 P[i, :, k] = t
118 else:
119 P = None
120
121 return P, L, U
122
123
124 def matmul(tensor1, tensor2, out=None):
125 """Matrix product of two tensors.
126
127 The behavior depends on the dimensionality of the tensors as follows:
128
129 - If both tensors are 1-dimensional, the dot product (scalar) is returned.
130 - If both arguments are 2-dimensional, the matrix-matrix product is returned.
131 - If the first argument is 1-dimensional and the second argument is 2-dimensional,
132 a 1 is prepended to its dimension for the purpose of the matrix multiply.
133 After the matrix multiply, the prepended dimension is removed.
134 - If the first argument is 2-dimensional and the second argument is 1-dimensional,
135 the matrix-vector product is returned.
136 - If both arguments are at least 1-dimensional and at least one argument is
137 N-dimensional (where N > 2), then a batched matrix multiply is returned. If the first
138 argument is 1-dimensional, a 1 is prepended to its dimension for the purpose of the
139 batched matrix multiply and removed after. If the second argument is 1-dimensional, a
140 1 is appended to its dimension for the purpose of the batched matrix multiple and removed after.
141 The non-matrix (i.e. batch) dimensions are :ref:`broadcasted <broadcasting-semantics>` (and thus
142 must be broadcastable). For example, if :attr:`tensor1` is a `j x 1 x n x m` Tensor
143 and :attr:`tensor2` is a `k x m x p` Tensor, :attr:`out` will be an `j x k x n x p` Tensor.
144
145 .. note::
146
147 The 1-dimensional dot product version of this function does not support an :attr:`out` parameter.
148
149 Arguments:
150 tensor1 (Tensor): First tensor to be multiplied
151 tensor2 (Tensor): Second tensor to be multiplied
152 out (Tensor, optional): Output tensor
153 """
154 dim_tensor1 = tensor1.dim()
155 dim_tensor2 = tensor2.dim()
156 if dim_tensor1 == 1 and dim_tensor2 == 1:
157 if out is None:
158 return torch.dot(tensor1, tensor2)
159 else:
160 raise ValueError("out must be None for 1-d tensor matmul, returns a scalar")
161 if dim_tensor1 == 2 and dim_tensor2 == 1:
162 if out is None:
163 return torch.mv(tensor1, tensor2)
164 else:
165 return torch.mv(tensor1, tensor2, out=out)
166 elif dim_tensor1 == 1 and dim_tensor2 == 2:
167 if out is None:
168 return torch.mm(tensor1.unsqueeze(0), tensor2).squeeze_(0)
169 else:
170 return torch.mm(tensor1.unsqueeze(0), tensor2, out=out).squeeze_(0)
171 elif dim_tensor1 == 2 and dim_tensor2 == 2:
172 if out is None:
173 return torch.mm(tensor1, tensor2)
174 else:
175 return torch.mm(tensor1, tensor2, out=out)
176 elif dim_tensor1 >= 3 and (dim_tensor2 == 1 or dim_tensor2 == 2):
177 # optimization: use mm instead of bmm by folding tensor1's batch into
178 # its leading matrix dimension.
179
180 if dim_tensor2 == 1:
181 tensor2 = tensor2.unsqueeze(-1)
182
183 size1 = tensor1.size()
184 size2 = tensor2.size()
185 output_size = size1[:-1] + size2[-1:]
186
187 # fold the batch into the first dimension
188 tensor1 = tensor1.contiguous().view(-1, size1[-1])
189
190 if out is None or not out.is_contiguous():
191 output = torch.mm(tensor1, tensor2)
192 else:
193 output = torch.mm(tensor1, tensor2, out=out)
194
195 output = output.view(output_size)
196
197 if dim_tensor2 == 1:
198 output = output.squeeze(-1)
199
200 if out is not None:
201 out.set_(output)
202 return out
203
204 return output
205 elif (dim_tensor1 >= 1 and dim_tensor2 >= 1) and (dim_tensor1 >= 3 or dim_tensor2 >= 3):
206 # ensure each tensor size is at least 3-dimensional
207 tensor1_exp_size = torch.Size((1,) * max(3 - tensor1.dim(), 0) + tensor1.size())
208 # rhs needs to be a separate case since we can't freely expand 1s on the rhs, but can on lhs
209 if dim_tensor2 == 1:
210 tensor2 = tensor2.unsqueeze(1)
211 tensor2_exp_size = torch.Size((1,) * max(3 - tensor2.dim(), 0) + tensor2.size())
212
213 # expand the batch portion (i.e. cut off matrix dimensions and expand rest)
214 expand_batch_portion = torch._C._infer_size(tensor1_exp_size[:-2], tensor2_exp_size[:-2])
215
216 # flatten expanded batches
217 tensor1_expanded = tensor1.expand(*(expand_batch_portion + tensor1_exp_size[-2:])) \
218 .contiguous().view(reduce(mul, expand_batch_portion), *tensor1_exp_size[-2:])
219 tensor2_expanded = tensor2.expand(*(expand_batch_portion + tensor2_exp_size[-2:])) \
220 .contiguous().view(reduce(mul, expand_batch_portion), *tensor2_exp_size[-2:])
221
222 # reshape batches back into result
223 total_expansion = expand_batch_portion + (tensor1_exp_size[-2], tensor2_exp_size[-1])
224
225 def maybeSqueeze(tensor):
226 if dim_tensor1 == 1:
227 return tensor.squeeze(-2)
228 elif dim_tensor2 == 1:
229 return tensor.squeeze(-1)
230 else:
231 return tensor
232
233 if out is None or not out.is_contiguous():
234 output = torch.bmm(tensor1_expanded, tensor2_expanded)
235 else:
236 output = torch.bmm(tensor1_expanded, tensor2_expanded, out=out)
237
238 output = maybeSqueeze(output.view(total_expansion))
239
240 if out is not None:
241 out.set_(output)
242 return out
243
244 return output
245
246 raise ValueError("both arguments to __matmul__ need to be at least 1D, "
247 "but they are {}D and {}D".format(dim_tensor1, dim_tensor2))
248
[end of torch/functional.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/torch/functional.py b/torch/functional.py
--- a/torch/functional.py
+++ b/torch/functional.py
@@ -58,7 +58,7 @@
if len(sequence) == 0:
raise ValueError("stack expects a non-empty sequence of tensors")
if dim < 0:
- dim += sequence[0].dim()
+ dim += sequence[0].dim() + 1
inputs = [t.unsqueeze(dim) for t in sequence]
if out is None:
return torch.cat(inputs, dim)
| {"golden_diff": "diff --git a/torch/functional.py b/torch/functional.py\n--- a/torch/functional.py\n+++ b/torch/functional.py\n@@ -58,7 +58,7 @@\n if len(sequence) == 0:\n raise ValueError(\"stack expects a non-empty sequence of tensors\")\n if dim < 0:\n- dim += sequence[0].dim()\n+ dim += sequence[0].dim() + 1\n inputs = [t.unsqueeze(dim) for t in sequence]\n if out is None:\n return torch.cat(inputs, dim)\n", "issue": "Negative dimension behaviour in torch.stack\nSupport for using a negative dimension in `torch.stack` currently works as follows:\r\n\r\n```python\r\nif dim < 0:\r\n dim += sequence[0].dim()\r\n```\r\n\r\nThis is not consistent with the behaviour of `torch.unsqueeze`, which uses `dim += input.dim() + 1`. The unsqueeze behaviour is better since it is possible to use negative indexing to insert a new dimension as the last dimension.\r\n\r\n## Example\r\n\r\n`torch.stack` with `dim=-1` adds a new dimension in the second-to-last position. This is confusing. It is not possible to use negative indexing to add a dimension in the last position (ie can't achieve a 3x2 result).\r\n\r\n```python\r\n>>> a = torch.Tensor([1, 2, 3])\r\n>>> b = torch.Tensor([4, 5, 6])\r\n>>> torch.stack([a, b], -1)\r\n\r\n 1 2 3\r\n 4 5 6\r\n[torch.FloatTensor of size 2x3]\r\n```\r\n\r\nContrast this to using `torch.unsqueeze` and `torch.cat` with `dim=-1`, which adds a new dimension in the last position:\r\n\r\n```python\r\n>>> a = torch.Tensor([1, 2, 3])\r\n>>> b = torch.Tensor([4, 5, 6])\r\n>>> torch.cat([a.unsqueeze(-1), b.unsqueeze(-1)], -1)\r\n\r\n 1 4\r\n 2 5\r\n 3 6\r\n[torch.FloatTensor of size 3x2]\r\n```\n", "before_files": [{"content": "import torch\nfrom ._utils import _range\nfrom operator import mul\nfrom functools import reduce\n\n__all__ = [\n 'split', 'chunk', 'stack', 'unbind', 'btriunpack', 'matmul',\n]\n\n\ndef split(tensor, split_size, dim=0):\n \"\"\"Splits the tensor into equally sized chunks (if possible).\n\n Last chunk will be smaller if the tensor size along a given dimension\n is not divisible by ``split_size``.\n\n Arguments:\n tensor (Tensor): tensor to split.\n split_size (int): size of a single chunk.\n dim (int): dimension along which to split the tensor.\n \"\"\"\n if dim < 0:\n dim += tensor.dim()\n dim_size = tensor.size(dim)\n num_splits = (dim_size + split_size - 1) // split_size\n last_split_size = split_size - (split_size * num_splits - dim_size)\n\n def get_split_size(i):\n return split_size if i < num_splits - 1 else last_split_size\n return tuple(tensor.narrow(int(dim), int(i * split_size), int(get_split_size(i))) for i\n in _range(0, num_splits))\n\n\ndef chunk(tensor, chunks, dim=0):\n \"\"\"Splits a tensor into a number of chunks along a given dimension.\n\n Arguments:\n tensor (Tensor): tensor to split.\n chunks (int): number of chunks to return.\n dim (int): dimension along which to split the tensor.\n \"\"\"\n if dim < 0:\n dim += tensor.dim()\n split_size = (tensor.size(dim) + chunks - 1) // chunks\n return split(tensor, split_size, dim)\n\n\ndef stack(sequence, dim=0, out=None):\n \"\"\"Concatenates sequence of tensors along a new dimension.\n\n All tensors need to be of the same size.\n\n Arguments:\n sequence (Sequence): sequence of tensors to concatenate.\n dim (int): dimension to insert. Has to be between 0 and the number\n of dimensions of concatenated tensors (inclusive).\n \"\"\"\n if len(sequence) == 0:\n raise ValueError(\"stack expects a non-empty sequence of tensors\")\n if dim < 0:\n dim += sequence[0].dim()\n inputs = [t.unsqueeze(dim) for t in sequence]\n if out is None:\n return torch.cat(inputs, dim)\n else:\n return torch.cat(inputs, dim, out=out)\n\n\ndef unbind(tensor, dim=0):\n \"\"\"Removes a tensor dimension.\n\n Returns a tuple of all slices along a given dimension, already without it.\n\n Arguments:\n tensor (Tensor): tensor to unbind.\n dim (int): dimension to remove.\n \"\"\"\n return tuple(tensor.select(dim, i) for i in _range(tensor.size(dim)))\n\n\ndef btriunpack(LU_data, LU_pivots, unpack_data=True, unpack_pivots=True):\n \"\"\"Unpacks the data and pivots from a batched LU factorization (btrifact) of a tensor.\n\n Returns a tuple indexed by:\n 0: The pivots.\n 1: The L tensor.\n 2: The U tensor.\n\n Arguments:\n LU_data (Tensor): The packed LU factorization data.\n LU_pivots (Tensor): The packed LU factorization pivots.\n unpack_data (bool): Flag indicating if the data should be unpacked.\n unpack_pivots (bool): Flag indicating if the pivots should be unpacked.\n \"\"\"\n\n nBatch, sz, _ = LU_data.size()\n\n if unpack_data:\n I_U = torch.triu(torch.ones(sz, sz)).type_as(LU_data).byte().unsqueeze(0).expand(nBatch, sz, sz)\n I_L = 1 - I_U\n L = LU_data.new(LU_data.size()).zero_()\n U = LU_data.new(LU_data.size()).zero_()\n I_diag = torch.eye(sz).type_as(LU_data).byte().unsqueeze(0).expand(nBatch, sz, sz)\n L[I_diag] = 1.0\n L[I_L] = LU_data[I_L]\n U[I_U] = LU_data[I_U]\n else:\n L = U = None\n\n if unpack_pivots:\n P = torch.eye(sz).type_as(LU_data).unsqueeze(0).repeat(nBatch, 1, 1)\n for i in range(nBatch):\n for j in range(sz):\n k = LU_pivots[i, j] - 1\n t = P[i, :, j].clone()\n P[i, :, j] = P[i, :, k]\n P[i, :, k] = t\n else:\n P = None\n\n return P, L, U\n\n\ndef matmul(tensor1, tensor2, out=None):\n \"\"\"Matrix product of two tensors.\n\n The behavior depends on the dimensionality of the tensors as follows:\n\n - If both tensors are 1-dimensional, the dot product (scalar) is returned.\n - If both arguments are 2-dimensional, the matrix-matrix product is returned.\n - If the first argument is 1-dimensional and the second argument is 2-dimensional,\n a 1 is prepended to its dimension for the purpose of the matrix multiply.\n After the matrix multiply, the prepended dimension is removed.\n - If the first argument is 2-dimensional and the second argument is 1-dimensional,\n the matrix-vector product is returned.\n - If both arguments are at least 1-dimensional and at least one argument is\n N-dimensional (where N > 2), then a batched matrix multiply is returned. If the first\n argument is 1-dimensional, a 1 is prepended to its dimension for the purpose of the\n batched matrix multiply and removed after. If the second argument is 1-dimensional, a\n 1 is appended to its dimension for the purpose of the batched matrix multiple and removed after.\n The non-matrix (i.e. batch) dimensions are :ref:`broadcasted <broadcasting-semantics>` (and thus\n must be broadcastable). For example, if :attr:`tensor1` is a `j x 1 x n x m` Tensor\n and :attr:`tensor2` is a `k x m x p` Tensor, :attr:`out` will be an `j x k x n x p` Tensor.\n\n .. note::\n\n The 1-dimensional dot product version of this function does not support an :attr:`out` parameter.\n\n Arguments:\n tensor1 (Tensor): First tensor to be multiplied\n tensor2 (Tensor): Second tensor to be multiplied\n out (Tensor, optional): Output tensor\n \"\"\"\n dim_tensor1 = tensor1.dim()\n dim_tensor2 = tensor2.dim()\n if dim_tensor1 == 1 and dim_tensor2 == 1:\n if out is None:\n return torch.dot(tensor1, tensor2)\n else:\n raise ValueError(\"out must be None for 1-d tensor matmul, returns a scalar\")\n if dim_tensor1 == 2 and dim_tensor2 == 1:\n if out is None:\n return torch.mv(tensor1, tensor2)\n else:\n return torch.mv(tensor1, tensor2, out=out)\n elif dim_tensor1 == 1 and dim_tensor2 == 2:\n if out is None:\n return torch.mm(tensor1.unsqueeze(0), tensor2).squeeze_(0)\n else:\n return torch.mm(tensor1.unsqueeze(0), tensor2, out=out).squeeze_(0)\n elif dim_tensor1 == 2 and dim_tensor2 == 2:\n if out is None:\n return torch.mm(tensor1, tensor2)\n else:\n return torch.mm(tensor1, tensor2, out=out)\n elif dim_tensor1 >= 3 and (dim_tensor2 == 1 or dim_tensor2 == 2):\n # optimization: use mm instead of bmm by folding tensor1's batch into\n # its leading matrix dimension.\n\n if dim_tensor2 == 1:\n tensor2 = tensor2.unsqueeze(-1)\n\n size1 = tensor1.size()\n size2 = tensor2.size()\n output_size = size1[:-1] + size2[-1:]\n\n # fold the batch into the first dimension\n tensor1 = tensor1.contiguous().view(-1, size1[-1])\n\n if out is None or not out.is_contiguous():\n output = torch.mm(tensor1, tensor2)\n else:\n output = torch.mm(tensor1, tensor2, out=out)\n\n output = output.view(output_size)\n\n if dim_tensor2 == 1:\n output = output.squeeze(-1)\n\n if out is not None:\n out.set_(output)\n return out\n\n return output\n elif (dim_tensor1 >= 1 and dim_tensor2 >= 1) and (dim_tensor1 >= 3 or dim_tensor2 >= 3):\n # ensure each tensor size is at least 3-dimensional\n tensor1_exp_size = torch.Size((1,) * max(3 - tensor1.dim(), 0) + tensor1.size())\n # rhs needs to be a separate case since we can't freely expand 1s on the rhs, but can on lhs\n if dim_tensor2 == 1:\n tensor2 = tensor2.unsqueeze(1)\n tensor2_exp_size = torch.Size((1,) * max(3 - tensor2.dim(), 0) + tensor2.size())\n\n # expand the batch portion (i.e. cut off matrix dimensions and expand rest)\n expand_batch_portion = torch._C._infer_size(tensor1_exp_size[:-2], tensor2_exp_size[:-2])\n\n # flatten expanded batches\n tensor1_expanded = tensor1.expand(*(expand_batch_portion + tensor1_exp_size[-2:])) \\\n .contiguous().view(reduce(mul, expand_batch_portion), *tensor1_exp_size[-2:])\n tensor2_expanded = tensor2.expand(*(expand_batch_portion + tensor2_exp_size[-2:])) \\\n .contiguous().view(reduce(mul, expand_batch_portion), *tensor2_exp_size[-2:])\n\n # reshape batches back into result\n total_expansion = expand_batch_portion + (tensor1_exp_size[-2], tensor2_exp_size[-1])\n\n def maybeSqueeze(tensor):\n if dim_tensor1 == 1:\n return tensor.squeeze(-2)\n elif dim_tensor2 == 1:\n return tensor.squeeze(-1)\n else:\n return tensor\n\n if out is None or not out.is_contiguous():\n output = torch.bmm(tensor1_expanded, tensor2_expanded)\n else:\n output = torch.bmm(tensor1_expanded, tensor2_expanded, out=out)\n\n output = maybeSqueeze(output.view(total_expansion))\n\n if out is not None:\n out.set_(output)\n return out\n\n return output\n\n raise ValueError(\"both arguments to __matmul__ need to be at least 1D, \"\n \"but they are {}D and {}D\".format(dim_tensor1, dim_tensor2))\n", "path": "torch/functional.py"}]} | 3,916 | 124 |
gh_patches_debug_37625 | rasdani/github-patches | git_diff | google__mobly-23 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove code paths related to mobly.test_runner.TestRunner.import_test_modules
In the new invocation model, the import_test_modules function and its associated code paths are not needed any more and should be removed.
</issue>
<code>
[start of mobly/keys.py]
1 #!/usr/bin/env python3.4
2 #
3 # Copyright 2016 Google Inc.
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16
17 import enum
18 """This module has the global key values that are used across framework
19 modules.
20 """
21
22
23 class Config(enum.Enum):
24 """Enum values for test config related lookups.
25 """
26 # Keys used to look up values from test config files.
27 # These keys define the wording of test configs and their internal
28 # references.
29 key_log_path = "logpath"
30 key_testbed = "testbed"
31 key_testbed_name = "name"
32 key_config_path = "configpath"
33 key_test_paths = "testpaths"
34 key_port = "Port"
35 key_address = "Address"
36 # Internal keys, used internally, not exposed to user's config files.
37 ikey_user_param = "user_params"
38 ikey_testbed_name = "testbed_name"
39 ikey_logger = "log"
40 ikey_logpath = "log_path"
41 ikey_cli_args = "cli_args"
42
43 # A list of keys whose values in configs should not be passed to test
44 # classes without unpacking first.
45 reserved_keys = (key_testbed, key_log_path, key_test_paths)
46
47
48 def get_name_by_value(value):
49 for name, member in Config.__members__.items():
50 if member.value == value:
51 return name
52 return None
53
54
55 def get_internal_value(external_value):
56 """Translates the value of an external key to the value of its
57 corresponding internal key.
58 """
59 return value_to_value(external_value, "i%s")
60
61
62 def get_module_name(name_in_config):
63 """Translates the name of a controller in config file to its module name.
64 """
65 return value_to_value(name_in_config, "m_%s")
66
67
68 def value_to_value(ref_value, pattern):
69 """Translates the value of a key to the value of its corresponding key. The
70 corresponding key is chosen based on the variable name pattern.
71 """
72 ref_key_name = get_name_by_value(ref_value)
73 if not ref_key_name:
74 return None
75 target_key_name = pattern % ref_key_name
76 try:
77 return getattr(Config, target_key_name).value
78 except AttributeError:
79 return None
80
[end of mobly/keys.py]
[start of mobly/config_parser.py]
1 #!/usr/bin/env python3.4
2 #
3 # Copyright 2016 Google Inc.
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16
17 from builtins import str
18
19 import os
20 import sys
21
22 from mobly import keys
23 from mobly import utils
24
25 # An environment variable defining the base location for Mobly logs.
26 _ENV_MOBLY_LOGPATH = 'MOBLY_LOGPATH'
27
28 # An environment variable defining the test search paths for Mobly.
29 _ENV_MOBLY_TESTPATHS = 'MOBLY_TESTPATHS'
30 _PATH_SEPARATOR = ':'
31
32
33 class MoblyConfigError(Exception):
34 """Raised when there is a problem in test configuration file."""
35
36
37 def _validate_test_config(test_config):
38 """Validates the raw configuration loaded from the config file.
39
40 Making sure all the required fields exist.
41 """
42 for k in keys.Config.reserved_keys.value:
43 if k not in test_config:
44 raise MoblyConfigError("Required key %s missing in test config." % k)
45
46
47 def _validate_testbed_name(name):
48 """Validates the name of a test bed.
49
50 Since test bed names are used as part of the test run id, it needs to meet
51 certain requirements.
52
53 Args:
54 name: The test bed's name specified in config file.
55
56 Raises:
57 If the name does not meet any criteria, MoblyConfigError is raised.
58 """
59 if not name:
60 raise MoblyConfigError("Test bed names can't be empty.")
61 if not isinstance(name, str):
62 raise MoblyConfigError("Test bed names have to be string.")
63 for l in name:
64 if l not in utils.valid_filename_chars:
65 raise MoblyConfigError(
66 "Char '%s' is not allowed in test bed names." % l)
67
68
69 def _validate_testbed_configs(testbed_configs):
70 """Validates the testbed configurations.
71
72 Args:
73 testbed_configs: A list of testbed configuration json objects.
74
75 Raises:
76 If any part of the configuration is invalid, MoblyConfigError is raised.
77 """
78 seen_names = set()
79 # Cross checks testbed configs for resource conflicts.
80 for config in testbed_configs:
81 # Check for conflicts between multiple concurrent testbed configs.
82 # No need to call it if there's only one testbed config.
83 name = config[keys.Config.key_testbed_name.value]
84 _validate_testbed_name(name)
85 # Test bed names should be unique.
86 if name in seen_names:
87 raise MoblyConfigError("Duplicate testbed name %s found." % name)
88 seen_names.add(name)
89
90
91 def _verify_test_class_name(test_cls_name):
92 if not test_cls_name.endswith("Test"):
93 raise MoblyConfigError(
94 ("Requested test class '%s' does not follow the test class naming "
95 "convention *Test.") % test_cls_name)
96
97
98 def gen_term_signal_handler(test_runners):
99 def termination_sig_handler(signal_num, frame):
100 for t in test_runners:
101 t.stop()
102 sys.exit(1)
103 return termination_sig_handler
104
105
106 def _parse_one_test_specifier(item):
107 """Parse one test specifier from command line input.
108
109 This also verifies that the test class name and test case names follow
110 Mobly's naming conventions. A test class name has to end with "Test"; a test
111 case name has to start with "test".
112
113 Args:
114 item: A string that specifies a test class or test cases in one test
115 class to run.
116
117 Returns:
118 A tuple of a string and a list of strings. The string is the test class
119 name, the list of strings is a list of test case names. The list can be
120 None.
121 """
122 tokens = item.split(':')
123 if len(tokens) > 2:
124 raise MoblyConfigError("Syntax error in test specifier %s" % item)
125 if len(tokens) == 1:
126 # This should be considered a test class name
127 test_cls_name = tokens[0]
128 _verify_test_class_name(test_cls_name)
129 return (test_cls_name, None)
130 elif len(tokens) == 2:
131 # This should be considered a test class name followed by
132 # a list of test case names.
133 test_cls_name, test_case_names = tokens
134 clean_names = []
135 _verify_test_class_name(test_cls_name)
136 for elem in test_case_names.split(','):
137 test_case_name = elem.strip()
138 if not test_case_name.startswith("test_"):
139 raise MoblyConfigError(("Requested test case '%s' in test class "
140 "'%s' does not follow the test case "
141 "naming convention test_*.") %
142 (test_case_name, test_cls_name))
143 clean_names.append(test_case_name)
144 return (test_cls_name, clean_names)
145
146
147 def parse_test_list(test_list):
148 """Parse user provided test list into internal format for test_runner.
149
150 Args:
151 test_list: A list of test classes/cases.
152 """
153 result = []
154 for elem in test_list:
155 result.append(_parse_one_test_specifier(elem))
156 return result
157
158
159 def load_test_config_file(test_config_path, tb_filters=None):
160 """Processes the test configuration file provied by user.
161
162 Loads the configuration file into a json object, unpacks each testbed
163 config into its own json object, and validate the configuration in the
164 process.
165
166 Args:
167 test_config_path: Path to the test configuration file.
168 tb_filters: A subset of test bed names to be pulled from the config
169 file. If None, then all test beds will be selected.
170
171 Returns:
172 A list of test configuration json objects to be passed to
173 test_runner.TestRunner.
174 """
175 configs = utils.load_config(test_config_path)
176 if tb_filters:
177 tbs = []
178 for tb in configs[keys.Config.key_testbed.value]:
179 if tb[keys.Config.key_testbed_name.value] in tb_filters:
180 tbs.append(tb)
181 if len(tbs) != len(tb_filters):
182 raise MoblyConfigError(
183 ("Expect to find %d test bed configs, found %d. Check if"
184 " you have the correct test bed names.") %
185 (len(tb_filters), len(tbs)))
186 configs[keys.Config.key_testbed.value] = tbs
187
188 if (not keys.Config.key_log_path.value in configs and
189 _ENV_MOBLY_LOGPATH in os.environ):
190 print('Using environment log path: %s' %
191 (os.environ[_ENV_MOBLY_LOGPATH]))
192 configs[keys.Config.key_log_path.value] = os.environ[_ENV_MOBLY_LOGPATH]
193 if (not keys.Config.key_test_paths.value in configs and
194 _ENV_MOBLY_TESTPATHS in os.environ):
195 print('Using environment test paths: %s' %
196 (os.environ[_ENV_MOBLY_TESTPATHS]))
197 configs[keys.Config.key_test_paths.value] = os.environ[
198 _ENV_MOBLY_TESTPATHS].split(_PATH_SEPARATOR)
199
200 _validate_test_config(configs)
201 _validate_testbed_configs(configs[keys.Config.key_testbed.value])
202 k_log_path = keys.Config.key_log_path.value
203 configs[k_log_path] = utils.abs_path(configs[k_log_path])
204 config_path, _ = os.path.split(utils.abs_path(test_config_path))
205 configs[keys.Config.key_config_path] = config_path
206 tps = configs[keys.Config.key_test_paths.value]
207 # Unpack testbeds into separate json objects.
208 beds = configs.pop(keys.Config.key_testbed.value)
209 config_jsons = []
210 # TODO: See if there is a better way to do this: b/29836695
211 config_path, _ = os.path.split(utils.abs_path(test_config_path))
212 configs[keys.Config.key_config_path] = config_path
213 for original_bed_config in beds:
214 new_test_config = dict(configs)
215 new_test_config[keys.Config.key_testbed.value] = original_bed_config
216 # Keys in each test bed config will be copied to a level up to be
217 # picked up for user_params. If the key already exists in the upper
218 # level, the local one defined in test bed config overwrites the
219 # general one.
220 new_test_config.update(original_bed_config)
221 config_jsons.append(new_test_config)
222 return config_jsons
223
224
225 def parse_test_file(fpath):
226 """Parses a test file that contains test specifiers.
227
228 Args:
229 fpath: A string that is the path to the test file to parse.
230
231 Returns:
232 A list of strings, each is a test specifier.
233 """
234 with open(fpath, 'r') as f:
235 tf = []
236 for line in f:
237 line = line.strip()
238 if not line:
239 continue
240 if len(tf) and (tf[-1].endswith(':') or tf[-1].endswith(',')):
241 tf[-1] += line
242 else:
243 tf.append(line)
244 return tf
245
[end of mobly/config_parser.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/mobly/config_parser.py b/mobly/config_parser.py
--- a/mobly/config_parser.py
+++ b/mobly/config_parser.py
@@ -25,10 +25,6 @@
# An environment variable defining the base location for Mobly logs.
_ENV_MOBLY_LOGPATH = 'MOBLY_LOGPATH'
-# An environment variable defining the test search paths for Mobly.
-_ENV_MOBLY_TESTPATHS = 'MOBLY_TESTPATHS'
-_PATH_SEPARATOR = ':'
-
class MoblyConfigError(Exception):
"""Raised when there is a problem in test configuration file."""
@@ -190,12 +186,6 @@
print('Using environment log path: %s' %
(os.environ[_ENV_MOBLY_LOGPATH]))
configs[keys.Config.key_log_path.value] = os.environ[_ENV_MOBLY_LOGPATH]
- if (not keys.Config.key_test_paths.value in configs and
- _ENV_MOBLY_TESTPATHS in os.environ):
- print('Using environment test paths: %s' %
- (os.environ[_ENV_MOBLY_TESTPATHS]))
- configs[keys.Config.key_test_paths.value] = os.environ[
- _ENV_MOBLY_TESTPATHS].split(_PATH_SEPARATOR)
_validate_test_config(configs)
_validate_testbed_configs(configs[keys.Config.key_testbed.value])
@@ -203,7 +193,6 @@
configs[k_log_path] = utils.abs_path(configs[k_log_path])
config_path, _ = os.path.split(utils.abs_path(test_config_path))
configs[keys.Config.key_config_path] = config_path
- tps = configs[keys.Config.key_test_paths.value]
# Unpack testbeds into separate json objects.
beds = configs.pop(keys.Config.key_testbed.value)
config_jsons = []
diff --git a/mobly/keys.py b/mobly/keys.py
--- a/mobly/keys.py
+++ b/mobly/keys.py
@@ -30,7 +30,6 @@
key_testbed = "testbed"
key_testbed_name = "name"
key_config_path = "configpath"
- key_test_paths = "testpaths"
key_port = "Port"
key_address = "Address"
# Internal keys, used internally, not exposed to user's config files.
@@ -42,7 +41,7 @@
# A list of keys whose values in configs should not be passed to test
# classes without unpacking first.
- reserved_keys = (key_testbed, key_log_path, key_test_paths)
+ reserved_keys = (key_testbed, key_log_path)
def get_name_by_value(value):
| {"golden_diff": "diff --git a/mobly/config_parser.py b/mobly/config_parser.py\n--- a/mobly/config_parser.py\n+++ b/mobly/config_parser.py\n@@ -25,10 +25,6 @@\n # An environment variable defining the base location for Mobly logs.\n _ENV_MOBLY_LOGPATH = 'MOBLY_LOGPATH'\n \n-# An environment variable defining the test search paths for Mobly.\n-_ENV_MOBLY_TESTPATHS = 'MOBLY_TESTPATHS'\n-_PATH_SEPARATOR = ':'\n-\n \n class MoblyConfigError(Exception):\n \"\"\"Raised when there is a problem in test configuration file.\"\"\"\n@@ -190,12 +186,6 @@\n print('Using environment log path: %s' %\n (os.environ[_ENV_MOBLY_LOGPATH]))\n configs[keys.Config.key_log_path.value] = os.environ[_ENV_MOBLY_LOGPATH]\n- if (not keys.Config.key_test_paths.value in configs and\n- _ENV_MOBLY_TESTPATHS in os.environ):\n- print('Using environment test paths: %s' %\n- (os.environ[_ENV_MOBLY_TESTPATHS]))\n- configs[keys.Config.key_test_paths.value] = os.environ[\n- _ENV_MOBLY_TESTPATHS].split(_PATH_SEPARATOR)\n \n _validate_test_config(configs)\n _validate_testbed_configs(configs[keys.Config.key_testbed.value])\n@@ -203,7 +193,6 @@\n configs[k_log_path] = utils.abs_path(configs[k_log_path])\n config_path, _ = os.path.split(utils.abs_path(test_config_path))\n configs[keys.Config.key_config_path] = config_path\n- tps = configs[keys.Config.key_test_paths.value]\n # Unpack testbeds into separate json objects.\n beds = configs.pop(keys.Config.key_testbed.value)\n config_jsons = []\ndiff --git a/mobly/keys.py b/mobly/keys.py\n--- a/mobly/keys.py\n+++ b/mobly/keys.py\n@@ -30,7 +30,6 @@\n key_testbed = \"testbed\"\n key_testbed_name = \"name\"\n key_config_path = \"configpath\"\n- key_test_paths = \"testpaths\"\n key_port = \"Port\"\n key_address = \"Address\"\n # Internal keys, used internally, not exposed to user's config files.\n@@ -42,7 +41,7 @@\n \n # A list of keys whose values in configs should not be passed to test\n # classes without unpacking first.\n- reserved_keys = (key_testbed, key_log_path, key_test_paths)\n+ reserved_keys = (key_testbed, key_log_path)\n \n \n def get_name_by_value(value):\n", "issue": "Remove code paths related to mobly.test_runner.TestRunner.import_test_modules\nIn the new invocation model, the import_test_modules function and its associated code paths are not needed any more and should be removed.\n", "before_files": [{"content": "#!/usr/bin/env python3.4\n#\n# Copyright 2016 Google Inc.\n# \n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n# \n# http://www.apache.org/licenses/LICENSE-2.0\n# \n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport enum\n\"\"\"This module has the global key values that are used across framework\nmodules.\n\"\"\"\n\n\nclass Config(enum.Enum):\n \"\"\"Enum values for test config related lookups.\n \"\"\"\n # Keys used to look up values from test config files.\n # These keys define the wording of test configs and their internal\n # references.\n key_log_path = \"logpath\"\n key_testbed = \"testbed\"\n key_testbed_name = \"name\"\n key_config_path = \"configpath\"\n key_test_paths = \"testpaths\"\n key_port = \"Port\"\n key_address = \"Address\"\n # Internal keys, used internally, not exposed to user's config files.\n ikey_user_param = \"user_params\"\n ikey_testbed_name = \"testbed_name\"\n ikey_logger = \"log\"\n ikey_logpath = \"log_path\"\n ikey_cli_args = \"cli_args\"\n\n # A list of keys whose values in configs should not be passed to test\n # classes without unpacking first.\n reserved_keys = (key_testbed, key_log_path, key_test_paths)\n\n\ndef get_name_by_value(value):\n for name, member in Config.__members__.items():\n if member.value == value:\n return name\n return None\n\n\ndef get_internal_value(external_value):\n \"\"\"Translates the value of an external key to the value of its\n corresponding internal key.\n \"\"\"\n return value_to_value(external_value, \"i%s\")\n\n\ndef get_module_name(name_in_config):\n \"\"\"Translates the name of a controller in config file to its module name.\n \"\"\"\n return value_to_value(name_in_config, \"m_%s\")\n\n\ndef value_to_value(ref_value, pattern):\n \"\"\"Translates the value of a key to the value of its corresponding key. The\n corresponding key is chosen based on the variable name pattern.\n \"\"\"\n ref_key_name = get_name_by_value(ref_value)\n if not ref_key_name:\n return None\n target_key_name = pattern % ref_key_name\n try:\n return getattr(Config, target_key_name).value\n except AttributeError:\n return None\n", "path": "mobly/keys.py"}, {"content": "#!/usr/bin/env python3.4\n#\n# Copyright 2016 Google Inc.\n# \n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n# \n# http://www.apache.org/licenses/LICENSE-2.0\n# \n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom builtins import str\n\nimport os\nimport sys\n\nfrom mobly import keys\nfrom mobly import utils\n\n# An environment variable defining the base location for Mobly logs.\n_ENV_MOBLY_LOGPATH = 'MOBLY_LOGPATH'\n\n# An environment variable defining the test search paths for Mobly.\n_ENV_MOBLY_TESTPATHS = 'MOBLY_TESTPATHS'\n_PATH_SEPARATOR = ':'\n\n\nclass MoblyConfigError(Exception):\n \"\"\"Raised when there is a problem in test configuration file.\"\"\"\n\n\ndef _validate_test_config(test_config):\n \"\"\"Validates the raw configuration loaded from the config file.\n\n Making sure all the required fields exist.\n \"\"\"\n for k in keys.Config.reserved_keys.value:\n if k not in test_config:\n raise MoblyConfigError(\"Required key %s missing in test config.\" % k)\n\n\ndef _validate_testbed_name(name):\n \"\"\"Validates the name of a test bed.\n\n Since test bed names are used as part of the test run id, it needs to meet\n certain requirements.\n\n Args:\n name: The test bed's name specified in config file.\n\n Raises:\n If the name does not meet any criteria, MoblyConfigError is raised.\n \"\"\"\n if not name:\n raise MoblyConfigError(\"Test bed names can't be empty.\")\n if not isinstance(name, str):\n raise MoblyConfigError(\"Test bed names have to be string.\")\n for l in name:\n if l not in utils.valid_filename_chars:\n raise MoblyConfigError(\n \"Char '%s' is not allowed in test bed names.\" % l)\n\n\ndef _validate_testbed_configs(testbed_configs):\n \"\"\"Validates the testbed configurations.\n\n Args:\n testbed_configs: A list of testbed configuration json objects.\n\n Raises:\n If any part of the configuration is invalid, MoblyConfigError is raised.\n \"\"\"\n seen_names = set()\n # Cross checks testbed configs for resource conflicts.\n for config in testbed_configs:\n # Check for conflicts between multiple concurrent testbed configs.\n # No need to call it if there's only one testbed config.\n name = config[keys.Config.key_testbed_name.value]\n _validate_testbed_name(name)\n # Test bed names should be unique.\n if name in seen_names:\n raise MoblyConfigError(\"Duplicate testbed name %s found.\" % name)\n seen_names.add(name)\n\n\ndef _verify_test_class_name(test_cls_name):\n if not test_cls_name.endswith(\"Test\"):\n raise MoblyConfigError(\n (\"Requested test class '%s' does not follow the test class naming \"\n \"convention *Test.\") % test_cls_name)\n\n\ndef gen_term_signal_handler(test_runners):\n def termination_sig_handler(signal_num, frame):\n for t in test_runners:\n t.stop()\n sys.exit(1)\n return termination_sig_handler\n\n\ndef _parse_one_test_specifier(item):\n \"\"\"Parse one test specifier from command line input.\n\n This also verifies that the test class name and test case names follow\n Mobly's naming conventions. A test class name has to end with \"Test\"; a test\n case name has to start with \"test\".\n\n Args:\n item: A string that specifies a test class or test cases in one test\n class to run.\n\n Returns:\n A tuple of a string and a list of strings. The string is the test class\n name, the list of strings is a list of test case names. The list can be\n None.\n \"\"\"\n tokens = item.split(':')\n if len(tokens) > 2:\n raise MoblyConfigError(\"Syntax error in test specifier %s\" % item)\n if len(tokens) == 1:\n # This should be considered a test class name\n test_cls_name = tokens[0]\n _verify_test_class_name(test_cls_name)\n return (test_cls_name, None)\n elif len(tokens) == 2:\n # This should be considered a test class name followed by\n # a list of test case names.\n test_cls_name, test_case_names = tokens\n clean_names = []\n _verify_test_class_name(test_cls_name)\n for elem in test_case_names.split(','):\n test_case_name = elem.strip()\n if not test_case_name.startswith(\"test_\"):\n raise MoblyConfigError((\"Requested test case '%s' in test class \"\n \"'%s' does not follow the test case \"\n \"naming convention test_*.\") %\n (test_case_name, test_cls_name))\n clean_names.append(test_case_name)\n return (test_cls_name, clean_names)\n\n\ndef parse_test_list(test_list):\n \"\"\"Parse user provided test list into internal format for test_runner.\n\n Args:\n test_list: A list of test classes/cases.\n \"\"\"\n result = []\n for elem in test_list:\n result.append(_parse_one_test_specifier(elem))\n return result\n\n\ndef load_test_config_file(test_config_path, tb_filters=None):\n \"\"\"Processes the test configuration file provied by user.\n\n Loads the configuration file into a json object, unpacks each testbed\n config into its own json object, and validate the configuration in the\n process.\n\n Args:\n test_config_path: Path to the test configuration file.\n tb_filters: A subset of test bed names to be pulled from the config\n file. If None, then all test beds will be selected.\n\n Returns:\n A list of test configuration json objects to be passed to\n test_runner.TestRunner.\n \"\"\"\n configs = utils.load_config(test_config_path)\n if tb_filters:\n tbs = []\n for tb in configs[keys.Config.key_testbed.value]:\n if tb[keys.Config.key_testbed_name.value] in tb_filters:\n tbs.append(tb)\n if len(tbs) != len(tb_filters):\n raise MoblyConfigError(\n (\"Expect to find %d test bed configs, found %d. Check if\"\n \" you have the correct test bed names.\") %\n (len(tb_filters), len(tbs)))\n configs[keys.Config.key_testbed.value] = tbs\n\n if (not keys.Config.key_log_path.value in configs and\n _ENV_MOBLY_LOGPATH in os.environ):\n print('Using environment log path: %s' %\n (os.environ[_ENV_MOBLY_LOGPATH]))\n configs[keys.Config.key_log_path.value] = os.environ[_ENV_MOBLY_LOGPATH]\n if (not keys.Config.key_test_paths.value in configs and\n _ENV_MOBLY_TESTPATHS in os.environ):\n print('Using environment test paths: %s' %\n (os.environ[_ENV_MOBLY_TESTPATHS]))\n configs[keys.Config.key_test_paths.value] = os.environ[\n _ENV_MOBLY_TESTPATHS].split(_PATH_SEPARATOR)\n\n _validate_test_config(configs)\n _validate_testbed_configs(configs[keys.Config.key_testbed.value])\n k_log_path = keys.Config.key_log_path.value\n configs[k_log_path] = utils.abs_path(configs[k_log_path])\n config_path, _ = os.path.split(utils.abs_path(test_config_path))\n configs[keys.Config.key_config_path] = config_path\n tps = configs[keys.Config.key_test_paths.value]\n # Unpack testbeds into separate json objects.\n beds = configs.pop(keys.Config.key_testbed.value)\n config_jsons = []\n # TODO: See if there is a better way to do this: b/29836695\n config_path, _ = os.path.split(utils.abs_path(test_config_path))\n configs[keys.Config.key_config_path] = config_path\n for original_bed_config in beds:\n new_test_config = dict(configs)\n new_test_config[keys.Config.key_testbed.value] = original_bed_config\n # Keys in each test bed config will be copied to a level up to be\n # picked up for user_params. If the key already exists in the upper\n # level, the local one defined in test bed config overwrites the\n # general one.\n new_test_config.update(original_bed_config)\n config_jsons.append(new_test_config)\n return config_jsons\n\n\ndef parse_test_file(fpath):\n \"\"\"Parses a test file that contains test specifiers.\n\n Args:\n fpath: A string that is the path to the test file to parse.\n\n Returns:\n A list of strings, each is a test specifier.\n \"\"\"\n with open(fpath, 'r') as f:\n tf = []\n for line in f:\n line = line.strip()\n if not line:\n continue\n if len(tf) and (tf[-1].endswith(':') or tf[-1].endswith(',')):\n tf[-1] += line\n else:\n tf.append(line)\n return tf\n", "path": "mobly/config_parser.py"}]} | 4,042 | 600 |
gh_patches_debug_22507 | rasdani/github-patches | git_diff | pyg-team__pytorch_geometric-7819 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Batch.from_data_list seems to give different batch results depending on attribute name
### 🐛 Describe the bug
Hi, when using the `torch_geometric.data.Batch` and `torch_geometric.data.Data` class to organize my graph information, I realized the following feature:
```python
import torch
import torch_geometric
from torch_geometric.data import Data, Batch
data_list = []
for i in range(3):
data = Data(x=torch.randn(5, 3))
data.image_index = torch.ones(5)
data_list.append(data)
batch = Batch.from_data_list(data_list)
print(batch.image_index)
# Gives tensor([ 1., 1., 1., 1., 1., 6., 6., 6., 6., 6., 11., 11., 11., 11., 11.])
data_list = []
for i in range(3):
data = Data(x=torch.randn(5, 3))
data.foo = torch.ones(5)
data_list.append(data)
batch = Batch.from_data_list(data_list)
print(batch.foo)
# Gives tensor([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
```
So it seems that one can get different "batched" results depending on the name of the attribute to which one stores the information. In fact, it seems one gets the former behavior when the string `index` is contained in the attribute name. Was this feature put in place by intention? FYI, I'm using verion `2.2.0`
### Environment
* PyG version: `2.2.0`
* PyTorch version: `1.13.1+cu116`
* OS: Linux
* Python version: `3.8.10`
* CUDA/cuDNN version: `cu116`
* How you installed PyTorch and PyG (`conda`, `pip`, source): `pip`
* Any other relevant information (*e.g.*, version of `torch-scatter`):
</issue>
<code>
[start of torch_geometric/data/batch.py]
1 import inspect
2 from collections.abc import Sequence
3 from typing import Any, List, Optional, Union
4
5 import numpy as np
6 import torch
7 from torch import Tensor
8
9 from torch_geometric.data.collate import collate
10 from torch_geometric.data.data import BaseData, Data
11 from torch_geometric.data.dataset import IndexType
12 from torch_geometric.data.separate import separate
13
14
15 class DynamicInheritance(type):
16 # A meta class that sets the base class of a `Batch` object, e.g.:
17 # * `Batch(Data)` in case `Data` objects are batched together
18 # * `Batch(HeteroData)` in case `HeteroData` objects are batched together
19 def __call__(cls, *args, **kwargs):
20 base_cls = kwargs.pop('_base_cls', Data)
21
22 if issubclass(base_cls, Batch):
23 new_cls = base_cls
24 else:
25 name = f'{base_cls.__name__}{cls.__name__}'
26
27 # NOTE `MetaResolver` is necessary to resolve metaclass conflict
28 # problems between `DynamicInheritance` and the metaclass of
29 # `base_cls`. In particular, it creates a new common metaclass
30 # from the defined metaclasses.
31 class MetaResolver(type(cls), type(base_cls)):
32 pass
33
34 if name not in globals():
35 globals()[name] = MetaResolver(name, (cls, base_cls), {})
36 new_cls = globals()[name]
37
38 params = list(inspect.signature(base_cls.__init__).parameters.items())
39 for i, (k, v) in enumerate(params[1:]):
40 if k == 'args' or k == 'kwargs':
41 continue
42 if i < len(args) or k in kwargs:
43 continue
44 if v.default is not inspect.Parameter.empty:
45 continue
46 kwargs[k] = None
47
48 return super(DynamicInheritance, new_cls).__call__(*args, **kwargs)
49
50
51 class DynamicInheritanceGetter:
52 def __call__(self, cls, base_cls):
53 return cls(_base_cls=base_cls)
54
55
56 class Batch(metaclass=DynamicInheritance):
57 r"""A data object describing a batch of graphs as one big (disconnected)
58 graph.
59 Inherits from :class:`torch_geometric.data.Data` or
60 :class:`torch_geometric.data.HeteroData`.
61 In addition, single graphs can be identified via the assignment vector
62 :obj:`batch`, which maps each node to its respective graph identifier.
63 """
64 @classmethod
65 def from_data_list(cls, data_list: List[BaseData],
66 follow_batch: Optional[List[str]] = None,
67 exclude_keys: Optional[List[str]] = None):
68 r"""Constructs a :class:`~torch_geometric.data.Batch` object from a
69 Python list of :class:`~torch_geometric.data.Data` or
70 :class:`~torch_geometric.data.HeteroData` objects.
71 The assignment vector :obj:`batch` is created on the fly.
72 In addition, creates assignment vectors for each key in
73 :obj:`follow_batch`.
74 Will exclude any keys given in :obj:`exclude_keys`."""
75
76 batch, slice_dict, inc_dict = collate(
77 cls,
78 data_list=data_list,
79 increment=True,
80 add_batch=not isinstance(data_list[0], Batch),
81 follow_batch=follow_batch,
82 exclude_keys=exclude_keys,
83 )
84
85 batch._num_graphs = len(data_list)
86 batch._slice_dict = slice_dict
87 batch._inc_dict = inc_dict
88
89 return batch
90
91 def get_example(self, idx: int) -> BaseData:
92 r"""Gets the :class:`~torch_geometric.data.Data` or
93 :class:`~torch_geometric.data.HeteroData` object at index :obj:`idx`.
94 The :class:`~torch_geometric.data.Batch` object must have been created
95 via :meth:`from_data_list` in order to be able to reconstruct the
96 initial object."""
97
98 if not hasattr(self, '_slice_dict'):
99 raise RuntimeError(
100 ("Cannot reconstruct 'Data' object from 'Batch' because "
101 "'Batch' was not created via 'Batch.from_data_list()'"))
102
103 data = separate(
104 cls=self.__class__.__bases__[-1],
105 batch=self,
106 idx=idx,
107 slice_dict=self._slice_dict,
108 inc_dict=self._inc_dict,
109 decrement=True,
110 )
111
112 return data
113
114 def index_select(self, idx: IndexType) -> List[BaseData]:
115 r"""Creates a subset of :class:`~torch_geometric.data.Data` or
116 :class:`~torch_geometric.data.HeteroData` objects from specified
117 indices :obj:`idx`.
118 Indices :obj:`idx` can be a slicing object, *e.g.*, :obj:`[2:5]`, a
119 list, a tuple, or a :obj:`torch.Tensor` or :obj:`np.ndarray` of type
120 long or bool.
121 The :class:`~torch_geometric.data.Batch` object must have been created
122 via :meth:`from_data_list` in order to be able to reconstruct the
123 initial objects."""
124 if isinstance(idx, slice):
125 idx = list(range(self.num_graphs)[idx])
126
127 elif isinstance(idx, Tensor) and idx.dtype == torch.long:
128 idx = idx.flatten().tolist()
129
130 elif isinstance(idx, Tensor) and idx.dtype == torch.bool:
131 idx = idx.flatten().nonzero(as_tuple=False).flatten().tolist()
132
133 elif isinstance(idx, np.ndarray) and idx.dtype == np.int64:
134 idx = idx.flatten().tolist()
135
136 elif isinstance(idx, np.ndarray) and idx.dtype == bool:
137 idx = idx.flatten().nonzero()[0].flatten().tolist()
138
139 elif isinstance(idx, Sequence) and not isinstance(idx, str):
140 pass
141
142 else:
143 raise IndexError(
144 f"Only slices (':'), list, tuples, torch.tensor and "
145 f"np.ndarray of dtype long or bool are valid indices (got "
146 f"'{type(idx).__name__}')")
147
148 return [self.get_example(i) for i in idx]
149
150 def __getitem__(self, idx: Union[int, np.integer, str, IndexType]) -> Any:
151 if (isinstance(idx, (int, np.integer))
152 or (isinstance(idx, Tensor) and idx.dim() == 0)
153 or (isinstance(idx, np.ndarray) and np.isscalar(idx))):
154 return self.get_example(idx)
155 elif isinstance(idx, str) or (isinstance(idx, tuple)
156 and isinstance(idx[0], str)):
157 # Accessing attributes or node/edge types:
158 return super().__getitem__(idx)
159 else:
160 return self.index_select(idx)
161
162 def to_data_list(self) -> List[BaseData]:
163 r"""Reconstructs the list of :class:`~torch_geometric.data.Data` or
164 :class:`~torch_geometric.data.HeteroData` objects from the
165 :class:`~torch_geometric.data.Batch` object.
166 The :class:`~torch_geometric.data.Batch` object must have been created
167 via :meth:`from_data_list` in order to be able to reconstruct the
168 initial objects."""
169 return [self.get_example(i) for i in range(self.num_graphs)]
170
171 @property
172 def num_graphs(self) -> int:
173 """Returns the number of graphs in the batch."""
174 if hasattr(self, '_num_graphs'):
175 return self._num_graphs
176 elif hasattr(self, 'ptr'):
177 return self.ptr.numel() - 1
178 elif hasattr(self, 'batch'):
179 return int(self.batch.max()) + 1
180 else:
181 raise ValueError("Can not infer the number of graphs")
182
183 def __len__(self) -> int:
184 return self.num_graphs
185
186 def __reduce__(self):
187 state = self.__dict__.copy()
188 return DynamicInheritanceGetter(), self.__class__.__bases__, state
189
[end of torch_geometric/data/batch.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/torch_geometric/data/batch.py b/torch_geometric/data/batch.py
--- a/torch_geometric/data/batch.py
+++ b/torch_geometric/data/batch.py
@@ -60,6 +60,23 @@
:class:`torch_geometric.data.HeteroData`.
In addition, single graphs can be identified via the assignment vector
:obj:`batch`, which maps each node to its respective graph identifier.
+
+ :pyg:`PyG` allows modification to the underlying batching procedure by
+ overwriting the :meth:`~Data.__inc__` and :meth:`~Data.__cat_dim__`
+ functionalities.
+ The :meth:`~Data.__inc__` method defines the incremental count between two
+ consecutive graph attributes.
+ By default, :pyg:`PyG` increments attributes by the number of nodes
+ whenever their attribute names contain the substring :obj:`index`
+ (for historical reasons), which comes in handy for attributes such as
+ :obj:`edge_index` or :obj:`node_index`.
+ However, note that this may lead to unexpected behavior for attributes
+ whose names contain the substring :obj:`index` but should not be
+ incremented.
+ To make sure, it is best practice to always double-check the output of
+ batching.
+ Furthermore, :meth:`~Data.__cat_dim__` defines in which dimension graph
+ tensors of the same attribute should be concatenated together.
"""
@classmethod
def from_data_list(cls, data_list: List[BaseData],
| {"golden_diff": "diff --git a/torch_geometric/data/batch.py b/torch_geometric/data/batch.py\n--- a/torch_geometric/data/batch.py\n+++ b/torch_geometric/data/batch.py\n@@ -60,6 +60,23 @@\n :class:`torch_geometric.data.HeteroData`.\n In addition, single graphs can be identified via the assignment vector\n :obj:`batch`, which maps each node to its respective graph identifier.\n+\n+ :pyg:`PyG` allows modification to the underlying batching procedure by\n+ overwriting the :meth:`~Data.__inc__` and :meth:`~Data.__cat_dim__`\n+ functionalities.\n+ The :meth:`~Data.__inc__` method defines the incremental count between two\n+ consecutive graph attributes.\n+ By default, :pyg:`PyG` increments attributes by the number of nodes\n+ whenever their attribute names contain the substring :obj:`index`\n+ (for historical reasons), which comes in handy for attributes such as\n+ :obj:`edge_index` or :obj:`node_index`.\n+ However, note that this may lead to unexpected behavior for attributes\n+ whose names contain the substring :obj:`index` but should not be\n+ incremented.\n+ To make sure, it is best practice to always double-check the output of\n+ batching.\n+ Furthermore, :meth:`~Data.__cat_dim__` defines in which dimension graph\n+ tensors of the same attribute should be concatenated together.\n \"\"\"\n @classmethod\n def from_data_list(cls, data_list: List[BaseData],\n", "issue": "Batch.from_data_list seems to give different batch results depending on attribute name\n### \ud83d\udc1b Describe the bug\r\n\r\nHi, when using the `torch_geometric.data.Batch` and `torch_geometric.data.Data` class to organize my graph information, I realized the following feature:\r\n```python\r\nimport torch\r\nimport torch_geometric\r\nfrom torch_geometric.data import Data, Batch\r\n\r\ndata_list = []\r\nfor i in range(3):\r\n data = Data(x=torch.randn(5, 3))\r\n data.image_index = torch.ones(5)\r\n data_list.append(data)\r\n \r\nbatch = Batch.from_data_list(data_list)\r\nprint(batch.image_index)\r\n# Gives tensor([ 1., 1., 1., 1., 1., 6., 6., 6., 6., 6., 11., 11., 11., 11., 11.])\r\n\r\ndata_list = []\r\nfor i in range(3):\r\n data = Data(x=torch.randn(5, 3))\r\n data.foo = torch.ones(5)\r\n data_list.append(data)\r\n \r\nbatch = Batch.from_data_list(data_list)\r\nprint(batch.foo)\r\n# Gives tensor([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])\r\n``` \r\n\r\nSo it seems that one can get different \"batched\" results depending on the name of the attribute to which one stores the information. In fact, it seems one gets the former behavior when the string `index` is contained in the attribute name. Was this feature put in place by intention? FYI, I'm using verion `2.2.0`\r\n\r\n### Environment\r\n\r\n* PyG version: `2.2.0`\r\n* PyTorch version: `1.13.1+cu116`\r\n* OS: Linux\r\n* Python version: `3.8.10`\r\n* CUDA/cuDNN version: `cu116`\r\n* How you installed PyTorch and PyG (`conda`, `pip`, source): `pip`\r\n* Any other relevant information (*e.g.*, version of `torch-scatter`):\r\n\n", "before_files": [{"content": "import inspect\nfrom collections.abc import Sequence\nfrom typing import Any, List, Optional, Union\n\nimport numpy as np\nimport torch\nfrom torch import Tensor\n\nfrom torch_geometric.data.collate import collate\nfrom torch_geometric.data.data import BaseData, Data\nfrom torch_geometric.data.dataset import IndexType\nfrom torch_geometric.data.separate import separate\n\n\nclass DynamicInheritance(type):\n # A meta class that sets the base class of a `Batch` object, e.g.:\n # * `Batch(Data)` in case `Data` objects are batched together\n # * `Batch(HeteroData)` in case `HeteroData` objects are batched together\n def __call__(cls, *args, **kwargs):\n base_cls = kwargs.pop('_base_cls', Data)\n\n if issubclass(base_cls, Batch):\n new_cls = base_cls\n else:\n name = f'{base_cls.__name__}{cls.__name__}'\n\n # NOTE `MetaResolver` is necessary to resolve metaclass conflict\n # problems between `DynamicInheritance` and the metaclass of\n # `base_cls`. In particular, it creates a new common metaclass\n # from the defined metaclasses.\n class MetaResolver(type(cls), type(base_cls)):\n pass\n\n if name not in globals():\n globals()[name] = MetaResolver(name, (cls, base_cls), {})\n new_cls = globals()[name]\n\n params = list(inspect.signature(base_cls.__init__).parameters.items())\n for i, (k, v) in enumerate(params[1:]):\n if k == 'args' or k == 'kwargs':\n continue\n if i < len(args) or k in kwargs:\n continue\n if v.default is not inspect.Parameter.empty:\n continue\n kwargs[k] = None\n\n return super(DynamicInheritance, new_cls).__call__(*args, **kwargs)\n\n\nclass DynamicInheritanceGetter:\n def __call__(self, cls, base_cls):\n return cls(_base_cls=base_cls)\n\n\nclass Batch(metaclass=DynamicInheritance):\n r\"\"\"A data object describing a batch of graphs as one big (disconnected)\n graph.\n Inherits from :class:`torch_geometric.data.Data` or\n :class:`torch_geometric.data.HeteroData`.\n In addition, single graphs can be identified via the assignment vector\n :obj:`batch`, which maps each node to its respective graph identifier.\n \"\"\"\n @classmethod\n def from_data_list(cls, data_list: List[BaseData],\n follow_batch: Optional[List[str]] = None,\n exclude_keys: Optional[List[str]] = None):\n r\"\"\"Constructs a :class:`~torch_geometric.data.Batch` object from a\n Python list of :class:`~torch_geometric.data.Data` or\n :class:`~torch_geometric.data.HeteroData` objects.\n The assignment vector :obj:`batch` is created on the fly.\n In addition, creates assignment vectors for each key in\n :obj:`follow_batch`.\n Will exclude any keys given in :obj:`exclude_keys`.\"\"\"\n\n batch, slice_dict, inc_dict = collate(\n cls,\n data_list=data_list,\n increment=True,\n add_batch=not isinstance(data_list[0], Batch),\n follow_batch=follow_batch,\n exclude_keys=exclude_keys,\n )\n\n batch._num_graphs = len(data_list)\n batch._slice_dict = slice_dict\n batch._inc_dict = inc_dict\n\n return batch\n\n def get_example(self, idx: int) -> BaseData:\n r\"\"\"Gets the :class:`~torch_geometric.data.Data` or\n :class:`~torch_geometric.data.HeteroData` object at index :obj:`idx`.\n The :class:`~torch_geometric.data.Batch` object must have been created\n via :meth:`from_data_list` in order to be able to reconstruct the\n initial object.\"\"\"\n\n if not hasattr(self, '_slice_dict'):\n raise RuntimeError(\n (\"Cannot reconstruct 'Data' object from 'Batch' because \"\n \"'Batch' was not created via 'Batch.from_data_list()'\"))\n\n data = separate(\n cls=self.__class__.__bases__[-1],\n batch=self,\n idx=idx,\n slice_dict=self._slice_dict,\n inc_dict=self._inc_dict,\n decrement=True,\n )\n\n return data\n\n def index_select(self, idx: IndexType) -> List[BaseData]:\n r\"\"\"Creates a subset of :class:`~torch_geometric.data.Data` or\n :class:`~torch_geometric.data.HeteroData` objects from specified\n indices :obj:`idx`.\n Indices :obj:`idx` can be a slicing object, *e.g.*, :obj:`[2:5]`, a\n list, a tuple, or a :obj:`torch.Tensor` or :obj:`np.ndarray` of type\n long or bool.\n The :class:`~torch_geometric.data.Batch` object must have been created\n via :meth:`from_data_list` in order to be able to reconstruct the\n initial objects.\"\"\"\n if isinstance(idx, slice):\n idx = list(range(self.num_graphs)[idx])\n\n elif isinstance(idx, Tensor) and idx.dtype == torch.long:\n idx = idx.flatten().tolist()\n\n elif isinstance(idx, Tensor) and idx.dtype == torch.bool:\n idx = idx.flatten().nonzero(as_tuple=False).flatten().tolist()\n\n elif isinstance(idx, np.ndarray) and idx.dtype == np.int64:\n idx = idx.flatten().tolist()\n\n elif isinstance(idx, np.ndarray) and idx.dtype == bool:\n idx = idx.flatten().nonzero()[0].flatten().tolist()\n\n elif isinstance(idx, Sequence) and not isinstance(idx, str):\n pass\n\n else:\n raise IndexError(\n f\"Only slices (':'), list, tuples, torch.tensor and \"\n f\"np.ndarray of dtype long or bool are valid indices (got \"\n f\"'{type(idx).__name__}')\")\n\n return [self.get_example(i) for i in idx]\n\n def __getitem__(self, idx: Union[int, np.integer, str, IndexType]) -> Any:\n if (isinstance(idx, (int, np.integer))\n or (isinstance(idx, Tensor) and idx.dim() == 0)\n or (isinstance(idx, np.ndarray) and np.isscalar(idx))):\n return self.get_example(idx)\n elif isinstance(idx, str) or (isinstance(idx, tuple)\n and isinstance(idx[0], str)):\n # Accessing attributes or node/edge types:\n return super().__getitem__(idx)\n else:\n return self.index_select(idx)\n\n def to_data_list(self) -> List[BaseData]:\n r\"\"\"Reconstructs the list of :class:`~torch_geometric.data.Data` or\n :class:`~torch_geometric.data.HeteroData` objects from the\n :class:`~torch_geometric.data.Batch` object.\n The :class:`~torch_geometric.data.Batch` object must have been created\n via :meth:`from_data_list` in order to be able to reconstruct the\n initial objects.\"\"\"\n return [self.get_example(i) for i in range(self.num_graphs)]\n\n @property\n def num_graphs(self) -> int:\n \"\"\"Returns the number of graphs in the batch.\"\"\"\n if hasattr(self, '_num_graphs'):\n return self._num_graphs\n elif hasattr(self, 'ptr'):\n return self.ptr.numel() - 1\n elif hasattr(self, 'batch'):\n return int(self.batch.max()) + 1\n else:\n raise ValueError(\"Can not infer the number of graphs\")\n\n def __len__(self) -> int:\n return self.num_graphs\n\n def __reduce__(self):\n state = self.__dict__.copy()\n return DynamicInheritanceGetter(), self.__class__.__bases__, state\n", "path": "torch_geometric/data/batch.py"}]} | 3,197 | 346 |
gh_patches_debug_27558 | rasdani/github-patches | git_diff | fossasia__open-event-server-5311 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Wrong Mail Statistics which troubles it to work completely
**Describe the bug**
<!-- A clear and concise description of what the bug is. -->
Wrong Mail Statistics which troubles it to work completely
**To Reproduce**
Steps to reproduce the behavior:
1. Go to '...'
2. Click on '....'
3. Scroll down to '....'
4. See error
**Expected behavior**
<!-- A clear and concise description of what you expected to happen. -->
**Stacktrace**
<!-- If applicable, add stacktrace to help explain your problem. -->
**Additional details (please complete the following information):**
- OS: [e.g. MacOS, Ubuntu, CentOS]
- Python Version [e.g. `3.5`, `3.6`]
- `HEAD` Commit hash [e.g. `4629c62`]
**Additional context**
<!-- Add any other context about the problem here. -->
**Wanna work on this issue**
</issue>
<code>
[start of app/api/admin_statistics_api/mails.py]
1 from flask_rest_jsonapi import ResourceDetail
2 from marshmallow_jsonapi.flask import Schema
3 from marshmallow_jsonapi import fields
4 from datetime import datetime, timedelta
5 import pytz
6
7 from app.api.helpers.utilities import dasherize
8 from app.api.bootstrap import api
9 from app.models import db
10 from app.models.mail import Mail
11 from app.api.data_layers.NoModelLayer import NoModelLayer
12 from app.api.helpers.db import get_count
13
14
15 class AdminStatisticsMailSchema(Schema):
16 """
17 Api schema
18 """
19 class Meta:
20 """
21 Meta class
22 """
23 type_ = 'admin-statistics-mail'
24 self_view = 'v1.admin_statistics_mail_detail'
25 inflect = dasherize
26
27 id = fields.String()
28 one_day = fields.Method("mail_last_1_day")
29 three_days = fields.Method("mail_last_3_days")
30 seven_days = fields.Method("mail_last_7_days")
31 thirty_days = fields.Method("mail_last_30_days")
32
33 def mail_last_1_day(self, obj):
34 return get_count(Mail.query.filter(datetime.now(pytz.utc) - Mail.time <= timedelta(days=1)))
35
36 def mail_last_3_days(self, obj):
37 return get_count(Mail.query.filter(datetime.now(pytz.utc) - Mail.time <= timedelta(days=3)))
38
39 def mail_last_7_days(self, obj):
40 return get_count(Mail.query.filter(datetime.now(pytz.utc) - Mail.time <= timedelta(days=7)))
41
42 def mail_last_30_days(self, obj):
43 return get_count(Mail.query.filter(datetime.now(pytz.utc) - Mail.time <= timedelta(days=30)))
44
45
46 class AdminStatisticsMailDetail(ResourceDetail):
47 """
48 Detail by id
49 """
50 methods = ['GET']
51 decorators = (api.has_permission('is_admin'),)
52 schema = AdminStatisticsMailSchema
53 data_layer = {
54 'class': NoModelLayer,
55 'session': db.session
56 }
57
[end of app/api/admin_statistics_api/mails.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/app/api/admin_statistics_api/mails.py b/app/api/admin_statistics_api/mails.py
--- a/app/api/admin_statistics_api/mails.py
+++ b/app/api/admin_statistics_api/mails.py
@@ -31,16 +31,24 @@
thirty_days = fields.Method("mail_last_30_days")
def mail_last_1_day(self, obj):
- return get_count(Mail.query.filter(datetime.now(pytz.utc) - Mail.time <= timedelta(days=1)))
+ all_mails = get_count(Mail.query.filter_by(time=datetime.now(pytz.utc)))
+ mails_till_last_1_day = get_count(Mail.query.filter(Mail.time <= datetime.now(pytz.utc) - timedelta(days=1)))
+ return all_mails - mails_till_last_1_day
def mail_last_3_days(self, obj):
- return get_count(Mail.query.filter(datetime.now(pytz.utc) - Mail.time <= timedelta(days=3)))
+ all_mails = get_count(Mail.query.filter_by(time=datetime.now(pytz.utc)))
+ mails_till_last_3_day = get_count(Mail.query.filter(Mail.time <= datetime.now(pytz.utc) - timedelta(days=3)))
+ return all_mails - mails_till_last_3_day
def mail_last_7_days(self, obj):
- return get_count(Mail.query.filter(datetime.now(pytz.utc) - Mail.time <= timedelta(days=7)))
+ all_mails = get_count(Mail.query.filter_by(time=datetime.now(pytz.utc)))
+ mails_till_last_7_day = get_count(Mail.query.filter(Mail.time <= datetime.now(pytz.utc) - timedelta(days=7)))
+ return all_mails - mails_till_last_7_day
def mail_last_30_days(self, obj):
- return get_count(Mail.query.filter(datetime.now(pytz.utc) - Mail.time <= timedelta(days=30)))
+ all_mails = get_count(Mail.query.filter_by(time=datetime.now(pytz.utc)))
+ mails_till_last_30_day = get_count(Mail.query.filter(Mail.time <= datetime.now(pytz.utc) - timedelta(days=30)))
+ return all_mails - mails_till_last_30_day
class AdminStatisticsMailDetail(ResourceDetail):
| {"golden_diff": "diff --git a/app/api/admin_statistics_api/mails.py b/app/api/admin_statistics_api/mails.py\n--- a/app/api/admin_statistics_api/mails.py\n+++ b/app/api/admin_statistics_api/mails.py\n@@ -31,16 +31,24 @@\n thirty_days = fields.Method(\"mail_last_30_days\")\n \n def mail_last_1_day(self, obj):\n- return get_count(Mail.query.filter(datetime.now(pytz.utc) - Mail.time <= timedelta(days=1)))\n+ all_mails = get_count(Mail.query.filter_by(time=datetime.now(pytz.utc)))\n+ mails_till_last_1_day = get_count(Mail.query.filter(Mail.time <= datetime.now(pytz.utc) - timedelta(days=1)))\n+ return all_mails - mails_till_last_1_day\n \n def mail_last_3_days(self, obj):\n- return get_count(Mail.query.filter(datetime.now(pytz.utc) - Mail.time <= timedelta(days=3)))\n+ all_mails = get_count(Mail.query.filter_by(time=datetime.now(pytz.utc)))\n+ mails_till_last_3_day = get_count(Mail.query.filter(Mail.time <= datetime.now(pytz.utc) - timedelta(days=3)))\n+ return all_mails - mails_till_last_3_day\n \n def mail_last_7_days(self, obj):\n- return get_count(Mail.query.filter(datetime.now(pytz.utc) - Mail.time <= timedelta(days=7)))\n+ all_mails = get_count(Mail.query.filter_by(time=datetime.now(pytz.utc)))\n+ mails_till_last_7_day = get_count(Mail.query.filter(Mail.time <= datetime.now(pytz.utc) - timedelta(days=7)))\n+ return all_mails - mails_till_last_7_day\n \n def mail_last_30_days(self, obj):\n- return get_count(Mail.query.filter(datetime.now(pytz.utc) - Mail.time <= timedelta(days=30)))\n+ all_mails = get_count(Mail.query.filter_by(time=datetime.now(pytz.utc)))\n+ mails_till_last_30_day = get_count(Mail.query.filter(Mail.time <= datetime.now(pytz.utc) - timedelta(days=30)))\n+ return all_mails - mails_till_last_30_day\n \n \n class AdminStatisticsMailDetail(ResourceDetail):\n", "issue": "Wrong Mail Statistics which troubles it to work completely\n**Describe the bug**\r\n<!-- A clear and concise description of what the bug is. -->\r\nWrong Mail Statistics which troubles it to work completely\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Go to '...'\r\n2. Click on '....'\r\n3. Scroll down to '....'\r\n4. See error\r\n\r\n**Expected behavior**\r\n<!-- A clear and concise description of what you expected to happen. -->\r\n\r\n**Stacktrace**\r\n<!-- If applicable, add stacktrace to help explain your problem. -->\r\n\r\n**Additional details (please complete the following information):**\r\n - OS: [e.g. MacOS, Ubuntu, CentOS]\r\n - Python Version [e.g. `3.5`, `3.6`]\r\n - `HEAD` Commit hash [e.g. `4629c62`]\r\n\r\n**Additional context**\r\n<!-- Add any other context about the problem here. -->\r\n**Wanna work on this issue**\n", "before_files": [{"content": "from flask_rest_jsonapi import ResourceDetail\nfrom marshmallow_jsonapi.flask import Schema\nfrom marshmallow_jsonapi import fields\nfrom datetime import datetime, timedelta\nimport pytz\n\nfrom app.api.helpers.utilities import dasherize\nfrom app.api.bootstrap import api\nfrom app.models import db\nfrom app.models.mail import Mail\nfrom app.api.data_layers.NoModelLayer import NoModelLayer\nfrom app.api.helpers.db import get_count\n\n\nclass AdminStatisticsMailSchema(Schema):\n \"\"\"\n Api schema\n \"\"\"\n class Meta:\n \"\"\"\n Meta class\n \"\"\"\n type_ = 'admin-statistics-mail'\n self_view = 'v1.admin_statistics_mail_detail'\n inflect = dasherize\n\n id = fields.String()\n one_day = fields.Method(\"mail_last_1_day\")\n three_days = fields.Method(\"mail_last_3_days\")\n seven_days = fields.Method(\"mail_last_7_days\")\n thirty_days = fields.Method(\"mail_last_30_days\")\n\n def mail_last_1_day(self, obj):\n return get_count(Mail.query.filter(datetime.now(pytz.utc) - Mail.time <= timedelta(days=1)))\n\n def mail_last_3_days(self, obj):\n return get_count(Mail.query.filter(datetime.now(pytz.utc) - Mail.time <= timedelta(days=3)))\n\n def mail_last_7_days(self, obj):\n return get_count(Mail.query.filter(datetime.now(pytz.utc) - Mail.time <= timedelta(days=7)))\n\n def mail_last_30_days(self, obj):\n return get_count(Mail.query.filter(datetime.now(pytz.utc) - Mail.time <= timedelta(days=30)))\n\n\nclass AdminStatisticsMailDetail(ResourceDetail):\n \"\"\"\n Detail by id\n \"\"\"\n methods = ['GET']\n decorators = (api.has_permission('is_admin'),)\n schema = AdminStatisticsMailSchema\n data_layer = {\n 'class': NoModelLayer,\n 'session': db.session\n }\n", "path": "app/api/admin_statistics_api/mails.py"}]} | 1,267 | 507 |
gh_patches_debug_8500 | rasdani/github-patches | git_diff | onnx__onnx-6117 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
MacOS release action is failing.
### Description
(https://github.com/actions/setup-python/issues/855)
### Motivation and Context
<!-- - Why is this change required? What problem does it solve? -->
<!-- - If it fixes an open issue, please link to the issue here. -->
</issue>
<code>
[start of setup.py]
1 # Copyright (c) ONNX Project Contributors
2 #
3 # SPDX-License-Identifier: Apache-2.0
4
5 # NOTE: Put all metadata in pyproject.toml.
6 # Set the environment variable `ONNX_PREVIEW_BUILD=1` to build the dev preview release.
7 from __future__ import annotations
8
9 import contextlib
10 import datetime
11 import glob
12 import logging
13 import multiprocessing
14 import os
15 import platform
16 import shlex
17 import shutil
18 import subprocess
19 import sys
20 import sysconfig
21 import textwrap
22 from typing import ClassVar
23
24 import setuptools
25 import setuptools.command.build_ext
26 import setuptools.command.build_py
27 import setuptools.command.develop
28
29 TOP_DIR = os.path.realpath(os.path.dirname(__file__))
30 CMAKE_BUILD_DIR = os.path.join(TOP_DIR, ".setuptools-cmake-build")
31
32 WINDOWS = os.name == "nt"
33
34 CMAKE = shutil.which("cmake3") or shutil.which("cmake")
35
36 ################################################################################
37 # Global variables for controlling the build variant
38 ################################################################################
39
40 # Default value is set to TRUE\1 to keep the settings same as the current ones.
41 # However going forward the recommended way to is to set this to False\0
42 ONNX_ML = os.getenv("ONNX_ML") != "0"
43 ONNX_VERIFY_PROTO3 = os.getenv("ONNX_VERIFY_PROTO3") == "1"
44 ONNX_NAMESPACE = os.getenv("ONNX_NAMESPACE", "onnx")
45 ONNX_BUILD_TESTS = os.getenv("ONNX_BUILD_TESTS") == "1"
46 ONNX_DISABLE_EXCEPTIONS = os.getenv("ONNX_DISABLE_EXCEPTIONS") == "1"
47 ONNX_DISABLE_STATIC_REGISTRATION = os.getenv("ONNX_DISABLE_STATIC_REGISTRATION") == "1"
48 ONNX_PREVIEW_BUILD = os.getenv("ONNX_PREVIEW_BUILD") == "1"
49
50 USE_MSVC_STATIC_RUNTIME = os.getenv("USE_MSVC_STATIC_RUNTIME", "0") == "1"
51 DEBUG = os.getenv("DEBUG", "0") == "1"
52 COVERAGE = os.getenv("COVERAGE", "0") == "1"
53
54 # Customize the wheel plat-name, usually needed for MacOS builds.
55 # See usage in .github/workflows/release_mac.yml
56 ONNX_WHEEL_PLATFORM_NAME = os.getenv("ONNX_WHEEL_PLATFORM_NAME")
57
58 ################################################################################
59 # Pre Check
60 ################################################################################
61
62 assert CMAKE, "Could not find cmake in PATH"
63
64 ################################################################################
65 # Version
66 ################################################################################
67
68 try:
69 _git_version = (
70 subprocess.check_output(["git", "rev-parse", "HEAD"], cwd=TOP_DIR)
71 .decode("ascii")
72 .strip()
73 )
74 except (OSError, subprocess.CalledProcessError):
75 _git_version = ""
76
77 with open(os.path.join(TOP_DIR, "VERSION_NUMBER"), encoding="utf-8") as version_file:
78 _version = version_file.read().strip()
79 if ONNX_PREVIEW_BUILD:
80 # Create the dev build for weekly releases
81 todays_date = datetime.date.today().strftime("%Y%m%d")
82 _version += ".dev" + todays_date
83 VERSION_INFO = {"version": _version, "git_version": _git_version}
84
85 ################################################################################
86 # Utilities
87 ################################################################################
88
89
90 @contextlib.contextmanager
91 def cd(path):
92 if not os.path.isabs(path):
93 raise RuntimeError(f"Can only cd to absolute path, got: {path}")
94 orig_path = os.getcwd()
95 os.chdir(path)
96 try:
97 yield
98 finally:
99 os.chdir(orig_path)
100
101
102 def get_ext_suffix():
103 return sysconfig.get_config_var("EXT_SUFFIX")
104
105
106 ################################################################################
107 # Customized commands
108 ################################################################################
109
110
111 def create_version(directory: str):
112 """Create version.py based on VERSION_INFO."""
113 version_file_path = os.path.join(directory, "onnx", "version.py")
114 os.makedirs(os.path.dirname(version_file_path), exist_ok=True)
115
116 with open(version_file_path, "w", encoding="utf-8") as f:
117 f.write(
118 textwrap.dedent(
119 f"""\
120 # This file is generated by setup.py. DO NOT EDIT!
121
122
123 version = "{VERSION_INFO['version']}"
124 git_version = "{VERSION_INFO['git_version']}"
125 """
126 )
127 )
128
129
130 class CmakeBuild(setuptools.Command):
131 """Compiles everything when `python setup.py build` is run using cmake.
132
133 Custom args can be passed to cmake by specifying the `CMAKE_ARGS`
134 environment variable.
135
136 The number of CPUs used by `make` can be specified by passing `-j<ncpus>`
137 to `setup.py build`. By default all CPUs are used.
138 """
139
140 user_options: ClassVar[list] = [
141 ("jobs=", "j", "Specifies the number of jobs to use with make")
142 ]
143
144 def initialize_options(self):
145 self.jobs = None
146
147 def finalize_options(self):
148 self.set_undefined_options("build", ("parallel", "jobs"))
149 if self.jobs is None and os.getenv("MAX_JOBS") is not None:
150 self.jobs = os.getenv("MAX_JOBS")
151 self.jobs = multiprocessing.cpu_count() if self.jobs is None else int(self.jobs)
152
153 def run(self):
154 os.makedirs(CMAKE_BUILD_DIR, exist_ok=True)
155
156 with cd(CMAKE_BUILD_DIR):
157 build_type = "Release"
158 # configure
159 cmake_args = [
160 CMAKE,
161 f"-DPYTHON_INCLUDE_DIR={sysconfig.get_path('include')}",
162 f"-DPYTHON_EXECUTABLE={sys.executable}",
163 "-DBUILD_ONNX_PYTHON=ON",
164 "-DCMAKE_EXPORT_COMPILE_COMMANDS=ON",
165 f"-DONNX_NAMESPACE={ONNX_NAMESPACE}",
166 f"-DPY_EXT_SUFFIX={get_ext_suffix() or ''}",
167 ]
168 if COVERAGE:
169 cmake_args.append("-DONNX_COVERAGE=ON")
170 if COVERAGE or DEBUG:
171 # in order to get accurate coverage information, the
172 # build needs to turn off optimizations
173 build_type = "Debug"
174 cmake_args.append(f"-DCMAKE_BUILD_TYPE={build_type}")
175 if WINDOWS:
176 cmake_args.extend(
177 [
178 # we need to link with libpython on windows, so
179 # passing python version to window in order to
180 # find python in cmake
181 f"-DPY_VERSION={'{}.{}'.format(*sys.version_info[:2])}",
182 ]
183 )
184 if USE_MSVC_STATIC_RUNTIME:
185 cmake_args.append("-DONNX_USE_MSVC_STATIC_RUNTIME=ON")
186 if platform.architecture()[0] == "64bit":
187 if "arm" in platform.machine().lower():
188 cmake_args.extend(["-A", "ARM64"])
189 else:
190 cmake_args.extend(["-A", "x64", "-T", "host=x64"])
191 else: # noqa: PLR5501
192 if "arm" in platform.machine().lower():
193 cmake_args.extend(["-A", "ARM"])
194 else:
195 cmake_args.extend(["-A", "Win32", "-T", "host=x86"])
196 if ONNX_ML:
197 cmake_args.append("-DONNX_ML=1")
198 if ONNX_VERIFY_PROTO3:
199 cmake_args.append("-DONNX_VERIFY_PROTO3=1")
200 if ONNX_BUILD_TESTS:
201 cmake_args.append("-DONNX_BUILD_TESTS=ON")
202 if ONNX_DISABLE_EXCEPTIONS:
203 cmake_args.append("-DONNX_DISABLE_EXCEPTIONS=ON")
204 if ONNX_DISABLE_STATIC_REGISTRATION:
205 cmake_args.append("-DONNX_DISABLE_STATIC_REGISTRATION=ON")
206 if "CMAKE_ARGS" in os.environ:
207 extra_cmake_args = shlex.split(os.environ["CMAKE_ARGS"])
208 # prevent crossfire with downstream scripts
209 del os.environ["CMAKE_ARGS"]
210 logging.info("Extra cmake args: %s", extra_cmake_args)
211 cmake_args.extend(extra_cmake_args)
212 cmake_args.append(TOP_DIR)
213 logging.info("Using cmake args: %s", cmake_args)
214 if "-DONNX_DISABLE_EXCEPTIONS=ON" in cmake_args:
215 raise RuntimeError(
216 "-DONNX_DISABLE_EXCEPTIONS=ON option is only available for c++ builds. Python binding require exceptions to be enabled."
217 )
218 subprocess.check_call(cmake_args)
219
220 build_args = [CMAKE, "--build", os.curdir]
221 if WINDOWS:
222 build_args.extend(["--config", build_type])
223 build_args.extend(["--", f"/maxcpucount:{self.jobs}"])
224 else:
225 build_args.extend(["--", "-j", str(self.jobs)])
226 subprocess.check_call(build_args)
227
228
229 class BuildPy(setuptools.command.build_py.build_py):
230 def run(self):
231 if self.editable_mode:
232 dst_dir = TOP_DIR
233 else:
234 dst_dir = self.build_lib
235 create_version(dst_dir)
236 return super().run()
237
238
239 class Develop(setuptools.command.develop.develop):
240 def run(self):
241 create_version(TOP_DIR)
242 return super().run()
243
244
245 class BuildExt(setuptools.command.build_ext.build_ext):
246 def run(self):
247 self.run_command("cmake_build")
248 return super().run()
249
250 def build_extensions(self):
251 # We override this method entirely because the actual building is done
252 # by cmake_build. Here we just copy the built extensions to the final
253 # destination.
254 build_lib = self.build_lib
255 extension_dst_dir = os.path.join(build_lib, "onnx")
256 os.makedirs(extension_dst_dir, exist_ok=True)
257
258 for ext in self.extensions:
259 fullname = self.get_ext_fullname(ext.name)
260 filename = os.path.basename(self.get_ext_filename(fullname))
261
262 if not WINDOWS:
263 lib_dir = CMAKE_BUILD_DIR
264 else:
265 # Windows compiled extensions are stored in Release/Debug subfolders
266 debug_lib_dir = os.path.join(CMAKE_BUILD_DIR, "Debug")
267 release_lib_dir = os.path.join(CMAKE_BUILD_DIR, "Release")
268 if os.path.exists(debug_lib_dir):
269 lib_dir = debug_lib_dir
270 elif os.path.exists(release_lib_dir):
271 lib_dir = release_lib_dir
272 src = os.path.join(lib_dir, filename)
273 dst = os.path.join(extension_dst_dir, filename)
274 self.copy_file(src, dst)
275
276 # Copy over the generated python files to build/source dir depending on editable mode
277 if self.editable_mode:
278 dst_dir = TOP_DIR
279 else:
280 dst_dir = build_lib
281
282 generated_py_files = glob.glob(os.path.join(CMAKE_BUILD_DIR, "onnx", "*.py"))
283 generated_pyi_files = glob.glob(os.path.join(CMAKE_BUILD_DIR, "onnx", "*.pyi"))
284 assert generated_py_files, "Bug: No generated python files found"
285 assert generated_pyi_files, "Bug: No generated python stubs found"
286 for src in (*generated_py_files, *generated_pyi_files):
287 dst = os.path.join(dst_dir, os.path.relpath(src, CMAKE_BUILD_DIR))
288 os.makedirs(os.path.dirname(dst), exist_ok=True)
289 self.copy_file(src, dst)
290
291
292 CMD_CLASS = {
293 "cmake_build": CmakeBuild,
294 "build_py": BuildPy,
295 "build_ext": BuildExt,
296 "develop": Develop,
297 }
298
299 ################################################################################
300 # Extensions
301 ################################################################################
302
303 EXT_MODULES = [setuptools.Extension(name="onnx.onnx_cpp2py_export", sources=[])]
304
305
306 ################################################################################
307 # Final
308 ################################################################################
309
310 setuptools.setup(
311 ext_modules=EXT_MODULES,
312 cmdclass=CMD_CLASS,
313 version=VERSION_INFO["version"],
314 options=(
315 {"bdist_wheel": {"plat_name": ONNX_WHEEL_PLATFORM_NAME}}
316 if ONNX_WHEEL_PLATFORM_NAME is not None
317 else {}
318 ),
319 )
320
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -51,8 +51,8 @@
DEBUG = os.getenv("DEBUG", "0") == "1"
COVERAGE = os.getenv("COVERAGE", "0") == "1"
-# Customize the wheel plat-name, usually needed for MacOS builds.
-# See usage in .github/workflows/release_mac.yml
+# Customize the wheel plat-name; sometimes useful for MacOS builds.
+# See https://github.com/onnx/onnx/pull/6117
ONNX_WHEEL_PLATFORM_NAME = os.getenv("ONNX_WHEEL_PLATFORM_NAME")
################################################################################
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -51,8 +51,8 @@\n DEBUG = os.getenv(\"DEBUG\", \"0\") == \"1\"\n COVERAGE = os.getenv(\"COVERAGE\", \"0\") == \"1\"\n \n-# Customize the wheel plat-name, usually needed for MacOS builds.\n-# See usage in .github/workflows/release_mac.yml\n+# Customize the wheel plat-name; sometimes useful for MacOS builds.\n+# See https://github.com/onnx/onnx/pull/6117\n ONNX_WHEEL_PLATFORM_NAME = os.getenv(\"ONNX_WHEEL_PLATFORM_NAME\")\n \n ################################################################################\n", "issue": "MacOS release action is failing.\n### Description\r\n\r\n(https://github.com/actions/setup-python/issues/855)\r\n\r\n### Motivation and Context\r\n<!-- - Why is this change required? What problem does it solve? -->\r\n<!-- - If it fixes an open issue, please link to the issue here. -->\r\n\n", "before_files": [{"content": "# Copyright (c) ONNX Project Contributors\n#\n# SPDX-License-Identifier: Apache-2.0\n\n# NOTE: Put all metadata in pyproject.toml.\n# Set the environment variable `ONNX_PREVIEW_BUILD=1` to build the dev preview release.\nfrom __future__ import annotations\n\nimport contextlib\nimport datetime\nimport glob\nimport logging\nimport multiprocessing\nimport os\nimport platform\nimport shlex\nimport shutil\nimport subprocess\nimport sys\nimport sysconfig\nimport textwrap\nfrom typing import ClassVar\n\nimport setuptools\nimport setuptools.command.build_ext\nimport setuptools.command.build_py\nimport setuptools.command.develop\n\nTOP_DIR = os.path.realpath(os.path.dirname(__file__))\nCMAKE_BUILD_DIR = os.path.join(TOP_DIR, \".setuptools-cmake-build\")\n\nWINDOWS = os.name == \"nt\"\n\nCMAKE = shutil.which(\"cmake3\") or shutil.which(\"cmake\")\n\n################################################################################\n# Global variables for controlling the build variant\n################################################################################\n\n# Default value is set to TRUE\\1 to keep the settings same as the current ones.\n# However going forward the recommended way to is to set this to False\\0\nONNX_ML = os.getenv(\"ONNX_ML\") != \"0\"\nONNX_VERIFY_PROTO3 = os.getenv(\"ONNX_VERIFY_PROTO3\") == \"1\"\nONNX_NAMESPACE = os.getenv(\"ONNX_NAMESPACE\", \"onnx\")\nONNX_BUILD_TESTS = os.getenv(\"ONNX_BUILD_TESTS\") == \"1\"\nONNX_DISABLE_EXCEPTIONS = os.getenv(\"ONNX_DISABLE_EXCEPTIONS\") == \"1\"\nONNX_DISABLE_STATIC_REGISTRATION = os.getenv(\"ONNX_DISABLE_STATIC_REGISTRATION\") == \"1\"\nONNX_PREVIEW_BUILD = os.getenv(\"ONNX_PREVIEW_BUILD\") == \"1\"\n\nUSE_MSVC_STATIC_RUNTIME = os.getenv(\"USE_MSVC_STATIC_RUNTIME\", \"0\") == \"1\"\nDEBUG = os.getenv(\"DEBUG\", \"0\") == \"1\"\nCOVERAGE = os.getenv(\"COVERAGE\", \"0\") == \"1\"\n\n# Customize the wheel plat-name, usually needed for MacOS builds.\n# See usage in .github/workflows/release_mac.yml\nONNX_WHEEL_PLATFORM_NAME = os.getenv(\"ONNX_WHEEL_PLATFORM_NAME\")\n\n################################################################################\n# Pre Check\n################################################################################\n\nassert CMAKE, \"Could not find cmake in PATH\"\n\n################################################################################\n# Version\n################################################################################\n\ntry:\n _git_version = (\n subprocess.check_output([\"git\", \"rev-parse\", \"HEAD\"], cwd=TOP_DIR)\n .decode(\"ascii\")\n .strip()\n )\nexcept (OSError, subprocess.CalledProcessError):\n _git_version = \"\"\n\nwith open(os.path.join(TOP_DIR, \"VERSION_NUMBER\"), encoding=\"utf-8\") as version_file:\n _version = version_file.read().strip()\n if ONNX_PREVIEW_BUILD:\n # Create the dev build for weekly releases\n todays_date = datetime.date.today().strftime(\"%Y%m%d\")\n _version += \".dev\" + todays_date\n VERSION_INFO = {\"version\": _version, \"git_version\": _git_version}\n\n################################################################################\n# Utilities\n################################################################################\n\n\[email protected]\ndef cd(path):\n if not os.path.isabs(path):\n raise RuntimeError(f\"Can only cd to absolute path, got: {path}\")\n orig_path = os.getcwd()\n os.chdir(path)\n try:\n yield\n finally:\n os.chdir(orig_path)\n\n\ndef get_ext_suffix():\n return sysconfig.get_config_var(\"EXT_SUFFIX\")\n\n\n################################################################################\n# Customized commands\n################################################################################\n\n\ndef create_version(directory: str):\n \"\"\"Create version.py based on VERSION_INFO.\"\"\"\n version_file_path = os.path.join(directory, \"onnx\", \"version.py\")\n os.makedirs(os.path.dirname(version_file_path), exist_ok=True)\n\n with open(version_file_path, \"w\", encoding=\"utf-8\") as f:\n f.write(\n textwrap.dedent(\n f\"\"\"\\\n # This file is generated by setup.py. DO NOT EDIT!\n\n\n version = \"{VERSION_INFO['version']}\"\n git_version = \"{VERSION_INFO['git_version']}\"\n \"\"\"\n )\n )\n\n\nclass CmakeBuild(setuptools.Command):\n \"\"\"Compiles everything when `python setup.py build` is run using cmake.\n\n Custom args can be passed to cmake by specifying the `CMAKE_ARGS`\n environment variable.\n\n The number of CPUs used by `make` can be specified by passing `-j<ncpus>`\n to `setup.py build`. By default all CPUs are used.\n \"\"\"\n\n user_options: ClassVar[list] = [\n (\"jobs=\", \"j\", \"Specifies the number of jobs to use with make\")\n ]\n\n def initialize_options(self):\n self.jobs = None\n\n def finalize_options(self):\n self.set_undefined_options(\"build\", (\"parallel\", \"jobs\"))\n if self.jobs is None and os.getenv(\"MAX_JOBS\") is not None:\n self.jobs = os.getenv(\"MAX_JOBS\")\n self.jobs = multiprocessing.cpu_count() if self.jobs is None else int(self.jobs)\n\n def run(self):\n os.makedirs(CMAKE_BUILD_DIR, exist_ok=True)\n\n with cd(CMAKE_BUILD_DIR):\n build_type = \"Release\"\n # configure\n cmake_args = [\n CMAKE,\n f\"-DPYTHON_INCLUDE_DIR={sysconfig.get_path('include')}\",\n f\"-DPYTHON_EXECUTABLE={sys.executable}\",\n \"-DBUILD_ONNX_PYTHON=ON\",\n \"-DCMAKE_EXPORT_COMPILE_COMMANDS=ON\",\n f\"-DONNX_NAMESPACE={ONNX_NAMESPACE}\",\n f\"-DPY_EXT_SUFFIX={get_ext_suffix() or ''}\",\n ]\n if COVERAGE:\n cmake_args.append(\"-DONNX_COVERAGE=ON\")\n if COVERAGE or DEBUG:\n # in order to get accurate coverage information, the\n # build needs to turn off optimizations\n build_type = \"Debug\"\n cmake_args.append(f\"-DCMAKE_BUILD_TYPE={build_type}\")\n if WINDOWS:\n cmake_args.extend(\n [\n # we need to link with libpython on windows, so\n # passing python version to window in order to\n # find python in cmake\n f\"-DPY_VERSION={'{}.{}'.format(*sys.version_info[:2])}\",\n ]\n )\n if USE_MSVC_STATIC_RUNTIME:\n cmake_args.append(\"-DONNX_USE_MSVC_STATIC_RUNTIME=ON\")\n if platform.architecture()[0] == \"64bit\":\n if \"arm\" in platform.machine().lower():\n cmake_args.extend([\"-A\", \"ARM64\"])\n else:\n cmake_args.extend([\"-A\", \"x64\", \"-T\", \"host=x64\"])\n else: # noqa: PLR5501\n if \"arm\" in platform.machine().lower():\n cmake_args.extend([\"-A\", \"ARM\"])\n else:\n cmake_args.extend([\"-A\", \"Win32\", \"-T\", \"host=x86\"])\n if ONNX_ML:\n cmake_args.append(\"-DONNX_ML=1\")\n if ONNX_VERIFY_PROTO3:\n cmake_args.append(\"-DONNX_VERIFY_PROTO3=1\")\n if ONNX_BUILD_TESTS:\n cmake_args.append(\"-DONNX_BUILD_TESTS=ON\")\n if ONNX_DISABLE_EXCEPTIONS:\n cmake_args.append(\"-DONNX_DISABLE_EXCEPTIONS=ON\")\n if ONNX_DISABLE_STATIC_REGISTRATION:\n cmake_args.append(\"-DONNX_DISABLE_STATIC_REGISTRATION=ON\")\n if \"CMAKE_ARGS\" in os.environ:\n extra_cmake_args = shlex.split(os.environ[\"CMAKE_ARGS\"])\n # prevent crossfire with downstream scripts\n del os.environ[\"CMAKE_ARGS\"]\n logging.info(\"Extra cmake args: %s\", extra_cmake_args)\n cmake_args.extend(extra_cmake_args)\n cmake_args.append(TOP_DIR)\n logging.info(\"Using cmake args: %s\", cmake_args)\n if \"-DONNX_DISABLE_EXCEPTIONS=ON\" in cmake_args:\n raise RuntimeError(\n \"-DONNX_DISABLE_EXCEPTIONS=ON option is only available for c++ builds. Python binding require exceptions to be enabled.\"\n )\n subprocess.check_call(cmake_args)\n\n build_args = [CMAKE, \"--build\", os.curdir]\n if WINDOWS:\n build_args.extend([\"--config\", build_type])\n build_args.extend([\"--\", f\"/maxcpucount:{self.jobs}\"])\n else:\n build_args.extend([\"--\", \"-j\", str(self.jobs)])\n subprocess.check_call(build_args)\n\n\nclass BuildPy(setuptools.command.build_py.build_py):\n def run(self):\n if self.editable_mode:\n dst_dir = TOP_DIR\n else:\n dst_dir = self.build_lib\n create_version(dst_dir)\n return super().run()\n\n\nclass Develop(setuptools.command.develop.develop):\n def run(self):\n create_version(TOP_DIR)\n return super().run()\n\n\nclass BuildExt(setuptools.command.build_ext.build_ext):\n def run(self):\n self.run_command(\"cmake_build\")\n return super().run()\n\n def build_extensions(self):\n # We override this method entirely because the actual building is done\n # by cmake_build. Here we just copy the built extensions to the final\n # destination.\n build_lib = self.build_lib\n extension_dst_dir = os.path.join(build_lib, \"onnx\")\n os.makedirs(extension_dst_dir, exist_ok=True)\n\n for ext in self.extensions:\n fullname = self.get_ext_fullname(ext.name)\n filename = os.path.basename(self.get_ext_filename(fullname))\n\n if not WINDOWS:\n lib_dir = CMAKE_BUILD_DIR\n else:\n # Windows compiled extensions are stored in Release/Debug subfolders\n debug_lib_dir = os.path.join(CMAKE_BUILD_DIR, \"Debug\")\n release_lib_dir = os.path.join(CMAKE_BUILD_DIR, \"Release\")\n if os.path.exists(debug_lib_dir):\n lib_dir = debug_lib_dir\n elif os.path.exists(release_lib_dir):\n lib_dir = release_lib_dir\n src = os.path.join(lib_dir, filename)\n dst = os.path.join(extension_dst_dir, filename)\n self.copy_file(src, dst)\n\n # Copy over the generated python files to build/source dir depending on editable mode\n if self.editable_mode:\n dst_dir = TOP_DIR\n else:\n dst_dir = build_lib\n\n generated_py_files = glob.glob(os.path.join(CMAKE_BUILD_DIR, \"onnx\", \"*.py\"))\n generated_pyi_files = glob.glob(os.path.join(CMAKE_BUILD_DIR, \"onnx\", \"*.pyi\"))\n assert generated_py_files, \"Bug: No generated python files found\"\n assert generated_pyi_files, \"Bug: No generated python stubs found\"\n for src in (*generated_py_files, *generated_pyi_files):\n dst = os.path.join(dst_dir, os.path.relpath(src, CMAKE_BUILD_DIR))\n os.makedirs(os.path.dirname(dst), exist_ok=True)\n self.copy_file(src, dst)\n\n\nCMD_CLASS = {\n \"cmake_build\": CmakeBuild,\n \"build_py\": BuildPy,\n \"build_ext\": BuildExt,\n \"develop\": Develop,\n}\n\n################################################################################\n# Extensions\n################################################################################\n\nEXT_MODULES = [setuptools.Extension(name=\"onnx.onnx_cpp2py_export\", sources=[])]\n\n\n################################################################################\n# Final\n################################################################################\n\nsetuptools.setup(\n ext_modules=EXT_MODULES,\n cmdclass=CMD_CLASS,\n version=VERSION_INFO[\"version\"],\n options=(\n {\"bdist_wheel\": {\"plat_name\": ONNX_WHEEL_PLATFORM_NAME}}\n if ONNX_WHEEL_PLATFORM_NAME is not None\n else {}\n ),\n)\n", "path": "setup.py"}]} | 3,928 | 141 |
gh_patches_debug_18016 | rasdani/github-patches | git_diff | cisagov__manage.get.gov-1097 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug] Invitation to co-manage domain did not work
### Current Behavior
Added Gaby as co-manager of my domain (career-least-left.gov) in staging using the email she has linked to her Login.gov account. She was **not** instantly added as co-manager. Instead, she's pending in the "Invitations" queue. Even after she logged into the staging registrar, it never triggered to add her as a co-manager.
The functionality worked correctly for the other users I've tried (who also have Login.gov accounts). This is the only instance where it hasn't worked.
### Expected Behavior
Upon adding user with Login.gov account, they should immediately appear in the "Active users" table and have access to the domain.
### Steps to Reproduce
1. Add Gaby to an approved domain _(I'm not posting her email in this ticket for privacy reasons; reach out to her directly for email address)_
2. Note whether she is immediately added to the "Active users"table
3. Ask her to verify whether she has access to the domain in her account.
### Environment
_No response_
### Additional Context
_No response_
### Issue Links
_No response_
</issue>
<code>
[start of src/registrar/fixtures_users.py]
1 import logging
2 from faker import Faker
3
4 from registrar.models import (
5 User,
6 UserGroup,
7 )
8
9 fake = Faker()
10 logger = logging.getLogger(__name__)
11
12
13 class UserFixture:
14 """
15 Load users into the database.
16
17 Make sure this class' `load` method is called from `handle`
18 in management/commands/load.py, then use `./manage.py load`
19 to run this code.
20 """
21
22 ADMINS = [
23 {
24 "username": "5f283494-31bd-49b5-b024-a7e7cae00848",
25 "first_name": "Rachid",
26 "last_name": "Mrad",
27 },
28 {
29 "username": "eb2214cd-fc0c-48c0-9dbd-bc4cd6820c74",
30 "first_name": "Alysia",
31 "last_name": "Broddrick",
32 },
33 {
34 "username": "8f8e7293-17f7-4716-889b-1990241cbd39",
35 "first_name": "Katherine",
36 "last_name": "Osos",
37 },
38 {
39 "username": "70488e0a-e937-4894-a28c-16f5949effd4",
40 "first_name": "Gaby",
41 "last_name": "DiSarli",
42 },
43 {
44 "username": "83c2b6dd-20a2-4cac-bb40-e22a72d2955c",
45 "first_name": "Cameron",
46 "last_name": "Dixon",
47 },
48 {
49 "username": "0353607a-cbba-47d2-98d7-e83dcd5b90ea",
50 "first_name": "Ryan",
51 "last_name": "Brooks",
52 },
53 {
54 "username": "30001ee7-0467-4df2-8db2-786e79606060",
55 "first_name": "Zander",
56 "last_name": "Adkinson",
57 },
58 {
59 "username": "2bf518c2-485a-4c42-ab1a-f5a8b0a08484",
60 "first_name": "Paul",
61 "last_name": "Kuykendall",
62 },
63 {
64 "username": "2a88a97b-be96-4aad-b99e-0b605b492c78",
65 "first_name": "Rebecca",
66 "last_name": "Hsieh",
67 },
68 {
69 "username": "fa69c8e8-da83-4798-a4f2-263c9ce93f52",
70 "first_name": "David",
71 "last_name": "Kennedy",
72 },
73 {
74 "username": "f14433d8-f0e9-41bf-9c72-b99b110e665d",
75 "first_name": "Nicolle",
76 "last_name": "LeClair",
77 },
78 {
79 "username": "24840450-bf47-4d89-8aa9-c612fe68f9da",
80 "first_name": "Erin",
81 "last_name": "Song",
82 },
83 {
84 "username": "e0ea8b94-6e53-4430-814a-849a7ca45f21",
85 "first_name": "Kristina",
86 "last_name": "Yin",
87 },
88 ]
89
90 STAFF = [
91 {
92 "username": "319c490d-453b-43d9-bc4d-7d6cd8ff6844",
93 "first_name": "Rachid-Analyst",
94 "last_name": "Mrad-Analyst",
95 "email": "[email protected]",
96 },
97 {
98 "username": "b6a15987-5c88-4e26-8de2-ca71a0bdb2cd",
99 "first_name": "Alysia-Analyst",
100 "last_name": "Alysia-Analyst",
101 },
102 {
103 "username": "91a9b97c-bd0a-458d-9823-babfde7ebf44",
104 "first_name": "Katherine-Analyst",
105 "last_name": "Osos-Analyst",
106 "email": "[email protected]",
107 },
108 {
109 "username": "2cc0cde8-8313-4a50-99d8-5882e71443e8",
110 "first_name": "Zander-Analyst",
111 "last_name": "Adkinson-Analyst",
112 },
113 {
114 "username": "57ab5847-7789-49fe-a2f9-21d38076d699",
115 "first_name": "Paul-Analyst",
116 "last_name": "Kuykendall-Analyst",
117 },
118 {
119 "username": "e474e7a9-71ca-449d-833c-8a6e094dd117",
120 "first_name": "Rebecca-Analyst",
121 "last_name": "Hsieh-Analyst",
122 },
123 {
124 "username": "5dc6c9a6-61d9-42b4-ba54-4beff28bac3c",
125 "first_name": "David-Analyst",
126 "last_name": "Kennedy-Analyst",
127 },
128 {
129 "username": "0eb6f326-a3d4-410f-a521-aa4c1fad4e47",
130 "first_name": "Gaby-Analyst",
131 "last_name": "DiSarli-Analyst",
132 "email": "[email protected]",
133 },
134 {
135 "username": "cfe7c2fc-e24a-480e-8b78-28645a1459b3",
136 "first_name": "Nicolle-Analyst",
137 "last_name": "LeClair-Analyst",
138 "email": "[email protected]",
139 },
140 {
141 "username": "378d0bc4-d5a7-461b-bd84-3ae6f6864af9",
142 "first_name": "Erin-Analyst",
143 "last_name": "Song-Analyst",
144 "email": "[email protected]",
145 },
146 {
147 "username": "9a98e4c9-9409-479d-964e-4aec7799107f",
148 "first_name": "Kristina-Analyst",
149 "last_name": "Yin-Analyst",
150 "email": "[email protected]",
151 },
152 ]
153
154 def load_users(cls, users, group_name):
155 logger.info(f"Going to load {len(users)} users in group {group_name}")
156 for user_data in users:
157 try:
158 user, _ = User.objects.get_or_create(username=user_data["username"])
159 user.is_superuser = False
160 user.first_name = user_data["first_name"]
161 user.last_name = user_data["last_name"]
162 if "email" in user_data:
163 user.email = user_data["email"]
164 user.is_staff = True
165 user.is_active = True
166 group = UserGroup.objects.get(name=group_name)
167 user.groups.add(group)
168 user.save()
169 logger.debug(f"User object created for {user_data['first_name']}")
170 except Exception as e:
171 logger.warning(e)
172 logger.info(f"All users in group {group_name} loaded.")
173
174 @classmethod
175 def load(cls):
176 cls.load_users(cls, cls.ADMINS, "full_access_group")
177 cls.load_users(cls, cls.STAFF, "cisa_analysts_group")
178
[end of src/registrar/fixtures_users.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/registrar/fixtures_users.py b/src/registrar/fixtures_users.py
--- a/src/registrar/fixtures_users.py
+++ b/src/registrar/fixtures_users.py
@@ -39,6 +39,7 @@
"username": "70488e0a-e937-4894-a28c-16f5949effd4",
"first_name": "Gaby",
"last_name": "DiSarli",
+ "email": "[email protected]",
},
{
"username": "83c2b6dd-20a2-4cac-bb40-e22a72d2955c",
@@ -129,7 +130,7 @@
"username": "0eb6f326-a3d4-410f-a521-aa4c1fad4e47",
"first_name": "Gaby-Analyst",
"last_name": "DiSarli-Analyst",
- "email": "[email protected]",
+ "email": "[email protected]",
},
{
"username": "cfe7c2fc-e24a-480e-8b78-28645a1459b3",
| {"golden_diff": "diff --git a/src/registrar/fixtures_users.py b/src/registrar/fixtures_users.py\n--- a/src/registrar/fixtures_users.py\n+++ b/src/registrar/fixtures_users.py\n@@ -39,6 +39,7 @@\n \"username\": \"70488e0a-e937-4894-a28c-16f5949effd4\",\n \"first_name\": \"Gaby\",\n \"last_name\": \"DiSarli\",\n+ \"email\": \"[email protected]\",\n },\n {\n \"username\": \"83c2b6dd-20a2-4cac-bb40-e22a72d2955c\",\n@@ -129,7 +130,7 @@\n \"username\": \"0eb6f326-a3d4-410f-a521-aa4c1fad4e47\",\n \"first_name\": \"Gaby-Analyst\",\n \"last_name\": \"DiSarli-Analyst\",\n- \"email\": \"[email protected]\",\n+ \"email\": \"[email protected]\",\n },\n {\n \"username\": \"cfe7c2fc-e24a-480e-8b78-28645a1459b3\",\n", "issue": "[Bug] Invitation to co-manage domain did not work\n### Current Behavior\n\nAdded Gaby as co-manager of my domain (career-least-left.gov) in staging using the email she has linked to her Login.gov account. She was **not** instantly added as co-manager. Instead, she's pending in the \"Invitations\" queue. Even after she logged into the staging registrar, it never triggered to add her as a co-manager.\n\nThe functionality worked correctly for the other users I've tried (who also have Login.gov accounts). This is the only instance where it hasn't worked.\n\n### Expected Behavior\n\nUpon adding user with Login.gov account, they should immediately appear in the \"Active users\" table and have access to the domain.\n\n### Steps to Reproduce\n\n1. Add Gaby to an approved domain _(I'm not posting her email in this ticket for privacy reasons; reach out to her directly for email address)_\n2. Note whether she is immediately added to the \"Active users\"table\n3. Ask her to verify whether she has access to the domain in her account.\n\n\n### Environment\n\n_No response_\n\n### Additional Context\n\n_No response_\n\n### Issue Links\n\n_No response_\n", "before_files": [{"content": "import logging\nfrom faker import Faker\n\nfrom registrar.models import (\n User,\n UserGroup,\n)\n\nfake = Faker()\nlogger = logging.getLogger(__name__)\n\n\nclass UserFixture:\n \"\"\"\n Load users into the database.\n\n Make sure this class' `load` method is called from `handle`\n in management/commands/load.py, then use `./manage.py load`\n to run this code.\n \"\"\"\n\n ADMINS = [\n {\n \"username\": \"5f283494-31bd-49b5-b024-a7e7cae00848\",\n \"first_name\": \"Rachid\",\n \"last_name\": \"Mrad\",\n },\n {\n \"username\": \"eb2214cd-fc0c-48c0-9dbd-bc4cd6820c74\",\n \"first_name\": \"Alysia\",\n \"last_name\": \"Broddrick\",\n },\n {\n \"username\": \"8f8e7293-17f7-4716-889b-1990241cbd39\",\n \"first_name\": \"Katherine\",\n \"last_name\": \"Osos\",\n },\n {\n \"username\": \"70488e0a-e937-4894-a28c-16f5949effd4\",\n \"first_name\": \"Gaby\",\n \"last_name\": \"DiSarli\",\n },\n {\n \"username\": \"83c2b6dd-20a2-4cac-bb40-e22a72d2955c\",\n \"first_name\": \"Cameron\",\n \"last_name\": \"Dixon\",\n },\n {\n \"username\": \"0353607a-cbba-47d2-98d7-e83dcd5b90ea\",\n \"first_name\": \"Ryan\",\n \"last_name\": \"Brooks\",\n },\n {\n \"username\": \"30001ee7-0467-4df2-8db2-786e79606060\",\n \"first_name\": \"Zander\",\n \"last_name\": \"Adkinson\",\n },\n {\n \"username\": \"2bf518c2-485a-4c42-ab1a-f5a8b0a08484\",\n \"first_name\": \"Paul\",\n \"last_name\": \"Kuykendall\",\n },\n {\n \"username\": \"2a88a97b-be96-4aad-b99e-0b605b492c78\",\n \"first_name\": \"Rebecca\",\n \"last_name\": \"Hsieh\",\n },\n {\n \"username\": \"fa69c8e8-da83-4798-a4f2-263c9ce93f52\",\n \"first_name\": \"David\",\n \"last_name\": \"Kennedy\",\n },\n {\n \"username\": \"f14433d8-f0e9-41bf-9c72-b99b110e665d\",\n \"first_name\": \"Nicolle\",\n \"last_name\": \"LeClair\",\n },\n {\n \"username\": \"24840450-bf47-4d89-8aa9-c612fe68f9da\",\n \"first_name\": \"Erin\",\n \"last_name\": \"Song\",\n },\n {\n \"username\": \"e0ea8b94-6e53-4430-814a-849a7ca45f21\",\n \"first_name\": \"Kristina\",\n \"last_name\": \"Yin\",\n },\n ]\n\n STAFF = [\n {\n \"username\": \"319c490d-453b-43d9-bc4d-7d6cd8ff6844\",\n \"first_name\": \"Rachid-Analyst\",\n \"last_name\": \"Mrad-Analyst\",\n \"email\": \"[email protected]\",\n },\n {\n \"username\": \"b6a15987-5c88-4e26-8de2-ca71a0bdb2cd\",\n \"first_name\": \"Alysia-Analyst\",\n \"last_name\": \"Alysia-Analyst\",\n },\n {\n \"username\": \"91a9b97c-bd0a-458d-9823-babfde7ebf44\",\n \"first_name\": \"Katherine-Analyst\",\n \"last_name\": \"Osos-Analyst\",\n \"email\": \"[email protected]\",\n },\n {\n \"username\": \"2cc0cde8-8313-4a50-99d8-5882e71443e8\",\n \"first_name\": \"Zander-Analyst\",\n \"last_name\": \"Adkinson-Analyst\",\n },\n {\n \"username\": \"57ab5847-7789-49fe-a2f9-21d38076d699\",\n \"first_name\": \"Paul-Analyst\",\n \"last_name\": \"Kuykendall-Analyst\",\n },\n {\n \"username\": \"e474e7a9-71ca-449d-833c-8a6e094dd117\",\n \"first_name\": \"Rebecca-Analyst\",\n \"last_name\": \"Hsieh-Analyst\",\n },\n {\n \"username\": \"5dc6c9a6-61d9-42b4-ba54-4beff28bac3c\",\n \"first_name\": \"David-Analyst\",\n \"last_name\": \"Kennedy-Analyst\",\n },\n {\n \"username\": \"0eb6f326-a3d4-410f-a521-aa4c1fad4e47\",\n \"first_name\": \"Gaby-Analyst\",\n \"last_name\": \"DiSarli-Analyst\",\n \"email\": \"[email protected]\",\n },\n {\n \"username\": \"cfe7c2fc-e24a-480e-8b78-28645a1459b3\",\n \"first_name\": \"Nicolle-Analyst\",\n \"last_name\": \"LeClair-Analyst\",\n \"email\": \"[email protected]\",\n },\n {\n \"username\": \"378d0bc4-d5a7-461b-bd84-3ae6f6864af9\",\n \"first_name\": \"Erin-Analyst\",\n \"last_name\": \"Song-Analyst\",\n \"email\": \"[email protected]\",\n },\n {\n \"username\": \"9a98e4c9-9409-479d-964e-4aec7799107f\",\n \"first_name\": \"Kristina-Analyst\",\n \"last_name\": \"Yin-Analyst\",\n \"email\": \"[email protected]\",\n },\n ]\n\n def load_users(cls, users, group_name):\n logger.info(f\"Going to load {len(users)} users in group {group_name}\")\n for user_data in users:\n try:\n user, _ = User.objects.get_or_create(username=user_data[\"username\"])\n user.is_superuser = False\n user.first_name = user_data[\"first_name\"]\n user.last_name = user_data[\"last_name\"]\n if \"email\" in user_data:\n user.email = user_data[\"email\"]\n user.is_staff = True\n user.is_active = True\n group = UserGroup.objects.get(name=group_name)\n user.groups.add(group)\n user.save()\n logger.debug(f\"User object created for {user_data['first_name']}\")\n except Exception as e:\n logger.warning(e)\n logger.info(f\"All users in group {group_name} loaded.\")\n\n @classmethod\n def load(cls):\n cls.load_users(cls, cls.ADMINS, \"full_access_group\")\n cls.load_users(cls, cls.STAFF, \"cisa_analysts_group\")\n", "path": "src/registrar/fixtures_users.py"}]} | 3,143 | 310 |
gh_patches_debug_14292 | rasdani/github-patches | git_diff | secdev__scapy-855 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
test_pyx problem
I have a unit test that uses scapy library like this:
```
$ cat ut.py
from scapy.all import *
def test_foo():
pass
```
The problem is that testing framework (pytest) detects internal scapy function test_pyx as a test:
```
ut.py::test_foo PASSED
ut.py::test_pyx <- venv/src/scapy/scapy/consts.py PASSED
```
This is because test_pyx function from scapy/consts.py is unnecessarily imported from scapy.all
and pytest treats all test_* functions as tests.
Scapy from current master branch.
</issue>
<code>
[start of scapy/consts.py]
1 ## This file is part of Scapy
2 ## See http://www.secdev.org/projects/scapy for more informations
3 ## Copyright (C) Philippe Biondi <[email protected]>
4 ## This program is published under a GPLv2 license
5
6 import os, inspect
7 from sys import platform, maxsize
8 import platform as platform_lib
9 from scapy.error import *
10
11 import subprocess
12
13 try:
14 from matplotlib import get_backend as matplotlib_get_backend
15 import matplotlib.pyplot as plt
16 MATPLOTLIB = 1
17 if "inline" in matplotlib_get_backend():
18 MATPLOTLIB_INLINED = 1
19 else:
20 MATPLOTLIB_INLINED = 0
21 MATPLOTLIB_DEFAULT_PLOT_KARGS = {"marker": "+"}
22 # RuntimeError to catch gtk "Cannot open display" error
23 except (ImportError, RuntimeError):
24 plt = None
25 MATPLOTLIB = 0
26 MATPLOTLIB_INLINED = 0
27 MATPLOTLIB_DEFAULT_PLOT_KARGS = dict()
28 log_loading.info("Can't import matplotlib. Won't be able to plot.")
29
30 def test_pyx():
31 """Returns if PyX is correctly installed or not"""
32 try:
33 with open(os.devnull, 'wb') as devnull:
34 r = subprocess.check_call(["pdflatex", "--version"], stdout=devnull, stderr=subprocess.STDOUT)
35 except:
36 return False
37 else:
38 return r == 0
39
40 try:
41 import pyx
42 if test_pyx():
43 PYX = 1
44 else:
45 log_loading.warning("PyX dependencies are not installed ! Please install TexLive or MikTeX.")
46 PYX = 0
47 except ImportError:
48 log_loading.info("Can't import PyX. Won't be able to use psdump() or pdfdump().")
49 PYX = 0
50
51
52 LINUX = platform.startswith("linux")
53 OPENBSD = platform.startswith("openbsd")
54 FREEBSD = "freebsd" in platform
55 NETBSD = platform.startswith("netbsd")
56 DARWIN = platform.startswith("darwin")
57 SOLARIS = platform.startswith("sunos")
58 WINDOWS = platform.startswith("win32")
59 BSD = DARWIN or FREEBSD or OPENBSD or NETBSD
60 # See https://docs.python.org/3/library/platform.html#cross-platform
61 IS_64BITS = maxsize > 2**32
62
63 if WINDOWS:
64 try:
65 if float(platform_lib.release()) >= 8.1:
66 LOOPBACK_NAME = "Microsoft KM-TEST Loopback Adapter"
67 else:
68 LOOPBACK_NAME = "Microsoft Loopback Adapter"
69 except ValueError:
70 LOOPBACK_NAME = "Microsoft Loopback Adapter"
71 # Will be different on Windows
72 LOOPBACK_INTERFACE = None
73 else:
74 uname = os.uname()
75 LOOPBACK_NAME = "lo" if LINUX else "lo0"
76 LOOPBACK_INTERFACE = LOOPBACK_NAME
77
78 def parent_function():
79 return inspect.getouterframes(inspect.currentframe())
80
[end of scapy/consts.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/scapy/consts.py b/scapy/consts.py
--- a/scapy/consts.py
+++ b/scapy/consts.py
@@ -27,7 +27,7 @@
MATPLOTLIB_DEFAULT_PLOT_KARGS = dict()
log_loading.info("Can't import matplotlib. Won't be able to plot.")
-def test_pyx():
+def _test_pyx():
"""Returns if PyX is correctly installed or not"""
try:
with open(os.devnull, 'wb') as devnull:
@@ -39,7 +39,7 @@
try:
import pyx
- if test_pyx():
+ if _test_pyx():
PYX = 1
else:
log_loading.warning("PyX dependencies are not installed ! Please install TexLive or MikTeX.")
| {"golden_diff": "diff --git a/scapy/consts.py b/scapy/consts.py\n--- a/scapy/consts.py\n+++ b/scapy/consts.py\n@@ -27,7 +27,7 @@\n MATPLOTLIB_DEFAULT_PLOT_KARGS = dict()\n log_loading.info(\"Can't import matplotlib. Won't be able to plot.\")\n \n-def test_pyx():\n+def _test_pyx():\n \"\"\"Returns if PyX is correctly installed or not\"\"\"\n try:\n with open(os.devnull, 'wb') as devnull:\n@@ -39,7 +39,7 @@\n \n try:\n import pyx\n- if test_pyx():\n+ if _test_pyx():\n PYX = 1\n else:\n log_loading.warning(\"PyX dependencies are not installed ! Please install TexLive or MikTeX.\")\n", "issue": "test_pyx problem\nI have a unit test that uses scapy library like this:\r\n```\r\n$ cat ut.py \r\nfrom scapy.all import *\r\n\r\ndef test_foo():\r\n pass\r\n```\r\nThe problem is that testing framework (pytest) detects internal scapy function test_pyx as a test:\r\n```\r\nut.py::test_foo PASSED\r\nut.py::test_pyx <- venv/src/scapy/scapy/consts.py PASSED\r\n```\r\nThis is because test_pyx function from scapy/consts.py is unnecessarily imported from scapy.all\r\nand pytest treats all test_* functions as tests.\r\n\r\nScapy from current master branch.\r\n\r\n\n", "before_files": [{"content": "## This file is part of Scapy\n## See http://www.secdev.org/projects/scapy for more informations\n## Copyright (C) Philippe Biondi <[email protected]>\n## This program is published under a GPLv2 license\n\nimport os, inspect\nfrom sys import platform, maxsize\nimport platform as platform_lib\nfrom scapy.error import *\n\nimport subprocess\n\ntry:\n from matplotlib import get_backend as matplotlib_get_backend\n import matplotlib.pyplot as plt\n MATPLOTLIB = 1\n if \"inline\" in matplotlib_get_backend():\n MATPLOTLIB_INLINED = 1\n else:\n MATPLOTLIB_INLINED = 0\n MATPLOTLIB_DEFAULT_PLOT_KARGS = {\"marker\": \"+\"}\n# RuntimeError to catch gtk \"Cannot open display\" error\nexcept (ImportError, RuntimeError):\n plt = None\n MATPLOTLIB = 0\n MATPLOTLIB_INLINED = 0\n MATPLOTLIB_DEFAULT_PLOT_KARGS = dict()\n log_loading.info(\"Can't import matplotlib. Won't be able to plot.\")\n\ndef test_pyx():\n \"\"\"Returns if PyX is correctly installed or not\"\"\"\n try:\n with open(os.devnull, 'wb') as devnull:\n r = subprocess.check_call([\"pdflatex\", \"--version\"], stdout=devnull, stderr=subprocess.STDOUT)\n except:\n return False\n else:\n return r == 0\n\ntry:\n import pyx\n if test_pyx():\n PYX = 1\n else:\n log_loading.warning(\"PyX dependencies are not installed ! Please install TexLive or MikTeX.\")\n PYX = 0\nexcept ImportError:\n log_loading.info(\"Can't import PyX. Won't be able to use psdump() or pdfdump().\")\n PYX = 0\n\n\nLINUX = platform.startswith(\"linux\")\nOPENBSD = platform.startswith(\"openbsd\")\nFREEBSD = \"freebsd\" in platform\nNETBSD = platform.startswith(\"netbsd\")\nDARWIN = platform.startswith(\"darwin\")\nSOLARIS = platform.startswith(\"sunos\")\nWINDOWS = platform.startswith(\"win32\")\nBSD = DARWIN or FREEBSD or OPENBSD or NETBSD\n# See https://docs.python.org/3/library/platform.html#cross-platform\nIS_64BITS = maxsize > 2**32\n\nif WINDOWS:\n try:\n if float(platform_lib.release()) >= 8.1:\n LOOPBACK_NAME = \"Microsoft KM-TEST Loopback Adapter\"\n else:\n LOOPBACK_NAME = \"Microsoft Loopback Adapter\"\n except ValueError:\n LOOPBACK_NAME = \"Microsoft Loopback Adapter\"\n # Will be different on Windows\n LOOPBACK_INTERFACE = None\nelse:\n uname = os.uname()\n LOOPBACK_NAME = \"lo\" if LINUX else \"lo0\"\n LOOPBACK_INTERFACE = LOOPBACK_NAME\n\ndef parent_function():\n return inspect.getouterframes(inspect.currentframe())\n", "path": "scapy/consts.py"}]} | 1,467 | 182 |
gh_patches_debug_18508 | rasdani/github-patches | git_diff | qutebrowser__qutebrowser-4382 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Shift-home doesn't mark anything in commandline
Shift-end works fine, but shift-home doesn't - probably due to qutebrowser changing the cursor position to after the `:`.
</issue>
<code>
[start of qutebrowser/misc/miscwidgets.py]
1 # vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:
2
3 # Copyright 2014-2018 Florian Bruhin (The Compiler) <[email protected]>
4 #
5 # This file is part of qutebrowser.
6 #
7 # qutebrowser is free software: you can redistribute it and/or modify
8 # it under the terms of the GNU General Public License as published by
9 # the Free Software Foundation, either version 3 of the License, or
10 # (at your option) any later version.
11 #
12 # qutebrowser is distributed in the hope that it will be useful,
13 # but WITHOUT ANY WARRANTY; without even the implied warranty of
14 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
15 # GNU General Public License for more details.
16 #
17 # You should have received a copy of the GNU General Public License
18 # along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.
19
20 """Misc. widgets used at different places."""
21
22 from PyQt5.QtCore import pyqtSlot, pyqtSignal, Qt, QSize, QTimer
23 from PyQt5.QtWidgets import (QLineEdit, QWidget, QHBoxLayout, QLabel,
24 QStyleOption, QStyle, QLayout, QApplication)
25 from PyQt5.QtGui import QValidator, QPainter
26
27 from qutebrowser.config import config
28 from qutebrowser.utils import utils
29 from qutebrowser.misc import cmdhistory
30
31
32 class MinimalLineEditMixin:
33
34 """A mixin to give a QLineEdit a minimal look and nicer repr()."""
35
36 def __init__(self):
37 self.setStyleSheet("""
38 QLineEdit {
39 border: 0px;
40 padding-left: 1px;
41 background-color: transparent;
42 }
43 """)
44 self.setAttribute(Qt.WA_MacShowFocusRect, False)
45
46 def keyPressEvent(self, e):
47 """Override keyPressEvent to paste primary selection on Shift + Ins."""
48 if e.key() == Qt.Key_Insert and e.modifiers() == Qt.ShiftModifier:
49 try:
50 text = utils.get_clipboard(selection=True, fallback=True)
51 except utils.ClipboardError:
52 e.ignore()
53 else:
54 e.accept()
55 self.insert(text)
56 return
57 super().keyPressEvent(e)
58
59 def __repr__(self):
60 return utils.get_repr(self)
61
62
63 class CommandLineEdit(QLineEdit):
64
65 """A QLineEdit with a history and prompt chars.
66
67 Attributes:
68 history: The command history object.
69 _validator: The current command validator.
70 _promptlen: The length of the current prompt.
71 """
72
73 def __init__(self, *, parent=None):
74 super().__init__(parent)
75 self.history = cmdhistory.History(parent=self)
76 self._validator = _CommandValidator(self)
77 self.setValidator(self._validator)
78 self.textEdited.connect(self.on_text_edited)
79 self.cursorPositionChanged.connect(self.__on_cursor_position_changed)
80 self._promptlen = 0
81
82 def __repr__(self):
83 return utils.get_repr(self, text=self.text())
84
85 @pyqtSlot(str)
86 def on_text_edited(self, _text):
87 """Slot for textEdited. Stop history browsing."""
88 self.history.stop()
89
90 @pyqtSlot(int, int)
91 def __on_cursor_position_changed(self, _old, new):
92 """Prevent the cursor moving to the prompt.
93
94 We use __ here to avoid accidentally overriding it in subclasses.
95 """
96 if new < self._promptlen:
97 self.setCursorPosition(self._promptlen)
98
99 def set_prompt(self, text):
100 """Set the current prompt to text.
101
102 This updates the validator, and makes sure the user can't move the
103 cursor behind the prompt.
104 """
105 self._validator.prompt = text
106 self._promptlen = len(text)
107
108 def home(self, mark):
109 """Override home so it works properly with our cursor restriction."""
110 oldpos = self.cursorPosition()
111 self.setCursorPosition(self._promptlen)
112 if mark:
113 self.setSelection(self._promptlen, oldpos - self._promptlen)
114
115
116 class _CommandValidator(QValidator):
117
118 """Validator to prevent the : from getting deleted.
119
120 Attributes:
121 prompt: The current prompt.
122 """
123
124 def __init__(self, parent=None):
125 super().__init__(parent)
126 self.prompt = None
127
128 def validate(self, string, pos):
129 """Override QValidator::validate.
130
131 Args:
132 string: The string to validate.
133 pos: The current cursor position.
134
135 Return:
136 A tuple (status, string, pos) as a QValidator should.
137 """
138 if self.prompt is None or string.startswith(self.prompt):
139 return (QValidator.Acceptable, string, pos)
140 else:
141 return (QValidator.Invalid, string, pos)
142
143
144 class DetailFold(QWidget):
145
146 """A "fold" widget with an arrow to show/hide details.
147
148 Attributes:
149 _folded: Whether the widget is currently folded or not.
150 _hbox: The HBoxLayout the arrow/label are in.
151 _arrow: The FoldArrow widget.
152
153 Signals:
154 toggled: Emitted when the widget was folded/unfolded.
155 arg 0: bool, if the contents are currently visible.
156 """
157
158 toggled = pyqtSignal(bool)
159
160 def __init__(self, text, parent=None):
161 super().__init__(parent)
162 self._folded = True
163 self._hbox = QHBoxLayout(self)
164 self._hbox.setContentsMargins(0, 0, 0, 0)
165 self._arrow = _FoldArrow()
166 self._hbox.addWidget(self._arrow)
167 label = QLabel(text)
168 self._hbox.addWidget(label)
169 self._hbox.addStretch()
170
171 def toggle(self):
172 """Toggle the fold of the widget."""
173 self._folded = not self._folded
174 self._arrow.fold(self._folded)
175 self.toggled.emit(not self._folded)
176
177 def mousePressEvent(self, e):
178 """Toggle the fold if the widget was pressed.
179
180 Args:
181 e: The QMouseEvent.
182 """
183 if e.button() == Qt.LeftButton:
184 e.accept()
185 self.toggle()
186 else:
187 super().mousePressEvent(e)
188
189
190 class _FoldArrow(QWidget):
191
192 """The arrow shown for the DetailFold widget.
193
194 Attributes:
195 _folded: Whether the widget is currently folded or not.
196 """
197
198 def __init__(self, parent=None):
199 super().__init__(parent)
200 self._folded = True
201
202 def fold(self, folded):
203 """Fold/unfold the widget.
204
205 Args:
206 folded: The new desired state.
207 """
208 self._folded = folded
209 self.update()
210
211 def paintEvent(self, _event):
212 """Paint the arrow.
213
214 Args:
215 _paint: The QPaintEvent (unused).
216 """
217 opt = QStyleOption()
218 opt.initFrom(self)
219 painter = QPainter(self)
220 if self._folded:
221 elem = QStyle.PE_IndicatorArrowRight
222 else:
223 elem = QStyle.PE_IndicatorArrowDown
224 self.style().drawPrimitive(elem, opt, painter, self)
225
226 def minimumSizeHint(self):
227 """Return a sensible size."""
228 return QSize(8, 8)
229
230
231 class WrapperLayout(QLayout):
232
233 """A Qt layout which simply wraps a single widget.
234
235 This is used so the widget is hidden behind a defined API and can't
236 easily be accidentally accessed.
237 """
238
239 def __init__(self, parent=None):
240 super().__init__(parent)
241 self._widget = None
242
243 def addItem(self, _widget):
244 raise utils.Unreachable
245
246 def sizeHint(self):
247 return self._widget.sizeHint()
248
249 def itemAt(self, _index):
250 return None
251
252 def takeAt(self, _index):
253 raise utils.Unreachable
254
255 def setGeometry(self, rect):
256 self._widget.setGeometry(rect)
257
258 def wrap(self, container, widget):
259 """Wrap the given widget in the given container."""
260 self._widget = widget
261 container.setFocusProxy(widget)
262 widget.setParent(container)
263
264 def unwrap(self):
265 self._widget.setParent(None)
266 self._widget.deleteLater()
267
268
269 class PseudoLayout(QLayout):
270
271 """A layout which isn't actually a real layout.
272
273 This is used to replace QWebEngineView's internal layout, as a WORKAROUND
274 for https://bugreports.qt.io/browse/QTBUG-68224 and other related issues.
275
276 This is partly inspired by https://codereview.qt-project.org/#/c/230894/
277 which does something similar as part of Qt.
278 """
279
280 def addItem(self, item):
281 assert self.parent() is not None
282 item.widget().setParent(self.parent())
283
284 def removeItem(self, item):
285 item.widget().setParent(None)
286
287 def count(self):
288 return 0
289
290 def itemAt(self, _pos):
291 return None
292
293 def widget(self):
294 return self.parent().render_widget()
295
296 def setGeometry(self, rect):
297 """Resize the render widget when the view is resized."""
298 widget = self.widget()
299 if widget is not None:
300 widget.setGeometry(rect)
301
302 def sizeHint(self):
303 """Make sure the view has the sizeHint of the render widget."""
304 widget = self.widget()
305 if widget is not None:
306 return widget.sizeHint()
307 return QSize()
308
309
310 class FullscreenNotification(QLabel):
311
312 """A label telling the user this page is now fullscreen."""
313
314 def __init__(self, parent=None):
315 super().__init__(parent)
316 self.setStyleSheet("""
317 background-color: rgba(50, 50, 50, 80%);
318 color: white;
319 border-radius: 20px;
320 padding: 30px;
321 """)
322
323 all_bindings = config.key_instance.get_reverse_bindings_for('normal')
324 bindings = all_bindings.get('fullscreen --leave')
325 if bindings:
326 key = bindings[0]
327 self.setText("Press {} to exit fullscreen.".format(key))
328 else:
329 self.setText("Page is now fullscreen.")
330
331 self.resize(self.sizeHint())
332 if config.val.content.windowed_fullscreen:
333 geom = self.parentWidget().geometry()
334 else:
335 geom = QApplication.desktop().screenGeometry(self)
336 self.move((geom.width() - self.sizeHint().width()) / 2, 30)
337
338 def set_timeout(self, timeout):
339 """Hide the widget after the given timeout."""
340 QTimer.singleShot(timeout, self._on_timeout)
341
342 @pyqtSlot()
343 def _on_timeout(self):
344 """Hide and delete the widget."""
345 self.hide()
346 self.deleteLater()
347
[end of qutebrowser/misc/miscwidgets.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/qutebrowser/misc/miscwidgets.py b/qutebrowser/misc/miscwidgets.py
--- a/qutebrowser/misc/miscwidgets.py
+++ b/qutebrowser/misc/miscwidgets.py
@@ -94,7 +94,7 @@
We use __ here to avoid accidentally overriding it in subclasses.
"""
if new < self._promptlen:
- self.setCursorPosition(self._promptlen)
+ self.cursorForward(self.hasSelectedText(), self._promptlen - new)
def set_prompt(self, text):
"""Set the current prompt to text.
@@ -105,13 +105,6 @@
self._validator.prompt = text
self._promptlen = len(text)
- def home(self, mark):
- """Override home so it works properly with our cursor restriction."""
- oldpos = self.cursorPosition()
- self.setCursorPosition(self._promptlen)
- if mark:
- self.setSelection(self._promptlen, oldpos - self._promptlen)
-
class _CommandValidator(QValidator):
| {"golden_diff": "diff --git a/qutebrowser/misc/miscwidgets.py b/qutebrowser/misc/miscwidgets.py\n--- a/qutebrowser/misc/miscwidgets.py\n+++ b/qutebrowser/misc/miscwidgets.py\n@@ -94,7 +94,7 @@\n We use __ here to avoid accidentally overriding it in subclasses.\n \"\"\"\n if new < self._promptlen:\n- self.setCursorPosition(self._promptlen)\n+ self.cursorForward(self.hasSelectedText(), self._promptlen - new)\n \n def set_prompt(self, text):\n \"\"\"Set the current prompt to text.\n@@ -105,13 +105,6 @@\n self._validator.prompt = text\n self._promptlen = len(text)\n \n- def home(self, mark):\n- \"\"\"Override home so it works properly with our cursor restriction.\"\"\"\n- oldpos = self.cursorPosition()\n- self.setCursorPosition(self._promptlen)\n- if mark:\n- self.setSelection(self._promptlen, oldpos - self._promptlen)\n-\n \n class _CommandValidator(QValidator):\n", "issue": "Shift-home doesn't mark anything in commandline\nShift-end works fine, but shift-home doesn't - probably due to qutebrowser changing the cursor position to after the `:`.\n", "before_files": [{"content": "# vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:\n\n# Copyright 2014-2018 Florian Bruhin (The Compiler) <[email protected]>\n#\n# This file is part of qutebrowser.\n#\n# qutebrowser is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# qutebrowser is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.\n\n\"\"\"Misc. widgets used at different places.\"\"\"\n\nfrom PyQt5.QtCore import pyqtSlot, pyqtSignal, Qt, QSize, QTimer\nfrom PyQt5.QtWidgets import (QLineEdit, QWidget, QHBoxLayout, QLabel,\n QStyleOption, QStyle, QLayout, QApplication)\nfrom PyQt5.QtGui import QValidator, QPainter\n\nfrom qutebrowser.config import config\nfrom qutebrowser.utils import utils\nfrom qutebrowser.misc import cmdhistory\n\n\nclass MinimalLineEditMixin:\n\n \"\"\"A mixin to give a QLineEdit a minimal look and nicer repr().\"\"\"\n\n def __init__(self):\n self.setStyleSheet(\"\"\"\n QLineEdit {\n border: 0px;\n padding-left: 1px;\n background-color: transparent;\n }\n \"\"\")\n self.setAttribute(Qt.WA_MacShowFocusRect, False)\n\n def keyPressEvent(self, e):\n \"\"\"Override keyPressEvent to paste primary selection on Shift + Ins.\"\"\"\n if e.key() == Qt.Key_Insert and e.modifiers() == Qt.ShiftModifier:\n try:\n text = utils.get_clipboard(selection=True, fallback=True)\n except utils.ClipboardError:\n e.ignore()\n else:\n e.accept()\n self.insert(text)\n return\n super().keyPressEvent(e)\n\n def __repr__(self):\n return utils.get_repr(self)\n\n\nclass CommandLineEdit(QLineEdit):\n\n \"\"\"A QLineEdit with a history and prompt chars.\n\n Attributes:\n history: The command history object.\n _validator: The current command validator.\n _promptlen: The length of the current prompt.\n \"\"\"\n\n def __init__(self, *, parent=None):\n super().__init__(parent)\n self.history = cmdhistory.History(parent=self)\n self._validator = _CommandValidator(self)\n self.setValidator(self._validator)\n self.textEdited.connect(self.on_text_edited)\n self.cursorPositionChanged.connect(self.__on_cursor_position_changed)\n self._promptlen = 0\n\n def __repr__(self):\n return utils.get_repr(self, text=self.text())\n\n @pyqtSlot(str)\n def on_text_edited(self, _text):\n \"\"\"Slot for textEdited. Stop history browsing.\"\"\"\n self.history.stop()\n\n @pyqtSlot(int, int)\n def __on_cursor_position_changed(self, _old, new):\n \"\"\"Prevent the cursor moving to the prompt.\n\n We use __ here to avoid accidentally overriding it in subclasses.\n \"\"\"\n if new < self._promptlen:\n self.setCursorPosition(self._promptlen)\n\n def set_prompt(self, text):\n \"\"\"Set the current prompt to text.\n\n This updates the validator, and makes sure the user can't move the\n cursor behind the prompt.\n \"\"\"\n self._validator.prompt = text\n self._promptlen = len(text)\n\n def home(self, mark):\n \"\"\"Override home so it works properly with our cursor restriction.\"\"\"\n oldpos = self.cursorPosition()\n self.setCursorPosition(self._promptlen)\n if mark:\n self.setSelection(self._promptlen, oldpos - self._promptlen)\n\n\nclass _CommandValidator(QValidator):\n\n \"\"\"Validator to prevent the : from getting deleted.\n\n Attributes:\n prompt: The current prompt.\n \"\"\"\n\n def __init__(self, parent=None):\n super().__init__(parent)\n self.prompt = None\n\n def validate(self, string, pos):\n \"\"\"Override QValidator::validate.\n\n Args:\n string: The string to validate.\n pos: The current cursor position.\n\n Return:\n A tuple (status, string, pos) as a QValidator should.\n \"\"\"\n if self.prompt is None or string.startswith(self.prompt):\n return (QValidator.Acceptable, string, pos)\n else:\n return (QValidator.Invalid, string, pos)\n\n\nclass DetailFold(QWidget):\n\n \"\"\"A \"fold\" widget with an arrow to show/hide details.\n\n Attributes:\n _folded: Whether the widget is currently folded or not.\n _hbox: The HBoxLayout the arrow/label are in.\n _arrow: The FoldArrow widget.\n\n Signals:\n toggled: Emitted when the widget was folded/unfolded.\n arg 0: bool, if the contents are currently visible.\n \"\"\"\n\n toggled = pyqtSignal(bool)\n\n def __init__(self, text, parent=None):\n super().__init__(parent)\n self._folded = True\n self._hbox = QHBoxLayout(self)\n self._hbox.setContentsMargins(0, 0, 0, 0)\n self._arrow = _FoldArrow()\n self._hbox.addWidget(self._arrow)\n label = QLabel(text)\n self._hbox.addWidget(label)\n self._hbox.addStretch()\n\n def toggle(self):\n \"\"\"Toggle the fold of the widget.\"\"\"\n self._folded = not self._folded\n self._arrow.fold(self._folded)\n self.toggled.emit(not self._folded)\n\n def mousePressEvent(self, e):\n \"\"\"Toggle the fold if the widget was pressed.\n\n Args:\n e: The QMouseEvent.\n \"\"\"\n if e.button() == Qt.LeftButton:\n e.accept()\n self.toggle()\n else:\n super().mousePressEvent(e)\n\n\nclass _FoldArrow(QWidget):\n\n \"\"\"The arrow shown for the DetailFold widget.\n\n Attributes:\n _folded: Whether the widget is currently folded or not.\n \"\"\"\n\n def __init__(self, parent=None):\n super().__init__(parent)\n self._folded = True\n\n def fold(self, folded):\n \"\"\"Fold/unfold the widget.\n\n Args:\n folded: The new desired state.\n \"\"\"\n self._folded = folded\n self.update()\n\n def paintEvent(self, _event):\n \"\"\"Paint the arrow.\n\n Args:\n _paint: The QPaintEvent (unused).\n \"\"\"\n opt = QStyleOption()\n opt.initFrom(self)\n painter = QPainter(self)\n if self._folded:\n elem = QStyle.PE_IndicatorArrowRight\n else:\n elem = QStyle.PE_IndicatorArrowDown\n self.style().drawPrimitive(elem, opt, painter, self)\n\n def minimumSizeHint(self):\n \"\"\"Return a sensible size.\"\"\"\n return QSize(8, 8)\n\n\nclass WrapperLayout(QLayout):\n\n \"\"\"A Qt layout which simply wraps a single widget.\n\n This is used so the widget is hidden behind a defined API and can't\n easily be accidentally accessed.\n \"\"\"\n\n def __init__(self, parent=None):\n super().__init__(parent)\n self._widget = None\n\n def addItem(self, _widget):\n raise utils.Unreachable\n\n def sizeHint(self):\n return self._widget.sizeHint()\n\n def itemAt(self, _index):\n return None\n\n def takeAt(self, _index):\n raise utils.Unreachable\n\n def setGeometry(self, rect):\n self._widget.setGeometry(rect)\n\n def wrap(self, container, widget):\n \"\"\"Wrap the given widget in the given container.\"\"\"\n self._widget = widget\n container.setFocusProxy(widget)\n widget.setParent(container)\n\n def unwrap(self):\n self._widget.setParent(None)\n self._widget.deleteLater()\n\n\nclass PseudoLayout(QLayout):\n\n \"\"\"A layout which isn't actually a real layout.\n\n This is used to replace QWebEngineView's internal layout, as a WORKAROUND\n for https://bugreports.qt.io/browse/QTBUG-68224 and other related issues.\n\n This is partly inspired by https://codereview.qt-project.org/#/c/230894/\n which does something similar as part of Qt.\n \"\"\"\n\n def addItem(self, item):\n assert self.parent() is not None\n item.widget().setParent(self.parent())\n\n def removeItem(self, item):\n item.widget().setParent(None)\n\n def count(self):\n return 0\n\n def itemAt(self, _pos):\n return None\n\n def widget(self):\n return self.parent().render_widget()\n\n def setGeometry(self, rect):\n \"\"\"Resize the render widget when the view is resized.\"\"\"\n widget = self.widget()\n if widget is not None:\n widget.setGeometry(rect)\n\n def sizeHint(self):\n \"\"\"Make sure the view has the sizeHint of the render widget.\"\"\"\n widget = self.widget()\n if widget is not None:\n return widget.sizeHint()\n return QSize()\n\n\nclass FullscreenNotification(QLabel):\n\n \"\"\"A label telling the user this page is now fullscreen.\"\"\"\n\n def __init__(self, parent=None):\n super().__init__(parent)\n self.setStyleSheet(\"\"\"\n background-color: rgba(50, 50, 50, 80%);\n color: white;\n border-radius: 20px;\n padding: 30px;\n \"\"\")\n\n all_bindings = config.key_instance.get_reverse_bindings_for('normal')\n bindings = all_bindings.get('fullscreen --leave')\n if bindings:\n key = bindings[0]\n self.setText(\"Press {} to exit fullscreen.\".format(key))\n else:\n self.setText(\"Page is now fullscreen.\")\n\n self.resize(self.sizeHint())\n if config.val.content.windowed_fullscreen:\n geom = self.parentWidget().geometry()\n else:\n geom = QApplication.desktop().screenGeometry(self)\n self.move((geom.width() - self.sizeHint().width()) / 2, 30)\n\n def set_timeout(self, timeout):\n \"\"\"Hide the widget after the given timeout.\"\"\"\n QTimer.singleShot(timeout, self._on_timeout)\n\n @pyqtSlot()\n def _on_timeout(self):\n \"\"\"Hide and delete the widget.\"\"\"\n self.hide()\n self.deleteLater()\n", "path": "qutebrowser/misc/miscwidgets.py"}]} | 3,831 | 226 |
gh_patches_debug_19624 | rasdani/github-patches | git_diff | Cloud-CV__EvalAI-1979 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Search submissions by challenge name in submissions table
Currently, we support searching the submissions by the `participant team name, challenge phase name, created by name and submission status`. We would like to add searching the submissions by `challenge name` and also add the same to default list filtering options.
Search submissions by challenge name in submissions table
Currently, we support searching the submissions by the `participant team name, challenge phase name, created by name and submission status`. We would like to add searching the submissions by `challenge name` and also add the same to default list filtering options.
</issue>
<code>
[start of apps/jobs/admin.py]
1 import logging
2
3 from django.contrib import admin
4
5 from base.admin import ImportExportTimeStampedAdmin
6
7 from .models import Submission
8 from .sender import publish_submission_message
9
10
11 logger = logging.getLogger(__name__)
12
13
14 @admin.register(Submission)
15 class SubmissionAdmin(ImportExportTimeStampedAdmin):
16 actions = ['submit_job_to_worker']
17 list_display = ('participant_team', 'get_challenge_name_and_id', 'challenge_phase',
18 'created_by', 'status', 'is_public', 'submission_number', 'submitted_at',
19 'execution_time', 'input_file', 'stdout_file', 'stderr_file',
20 'submission_result_file', 'submission_metadata_file',)
21 list_filter = ('participant_team', 'challenge_phase',
22 'status', 'is_public',)
23 search_fields = ('participant_team__team_name', 'challenge_phase__name',
24 'created_by__username', 'status',)
25
26 def get_challenge_name_and_id(self, obj):
27 """Return challenge name corresponding to phase"""
28 return "%s - %s" % (obj.challenge_phase.challenge.title, obj.challenge_phase.challenge.id)
29 get_challenge_name_and_id.short_description = 'Challenge'
30 get_challenge_name_and_id.admin_order_field = 'challenge_phase__challenge'
31
32 def submit_job_to_worker(self, request, queryset):
33 for submission in queryset:
34 challenge_id = submission.challenge_phase.challenge.id
35 challenge_phase_id = submission.challenge_phase.id
36 submission_id = submission.id
37 logger.info("[x] Received submission message with challenge id {}, challenge phase id {}, submission id {}"
38 .format(challenge_id, challenge_phase_id, submission_id))
39 publish_submission_message(challenge_id, challenge_phase_id, submission.id)
40 queryset.update(status=Submission.SUBMITTED)
41
42 submit_job_to_worker.short_description = "Run selected submissions"
43
[end of apps/jobs/admin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/apps/jobs/admin.py b/apps/jobs/admin.py
--- a/apps/jobs/admin.py
+++ b/apps/jobs/admin.py
@@ -18,10 +18,9 @@
'created_by', 'status', 'is_public', 'submission_number', 'submitted_at',
'execution_time', 'input_file', 'stdout_file', 'stderr_file',
'submission_result_file', 'submission_metadata_file',)
- list_filter = ('participant_team', 'challenge_phase',
- 'status', 'is_public',)
+ list_filter = ('challenge_phase__challenge', 'challenge_phase', 'status', 'is_public',)
search_fields = ('participant_team__team_name', 'challenge_phase__name',
- 'created_by__username', 'status',)
+ 'challenge_phase__challenge__title', 'created_by__username', 'status',)
def get_challenge_name_and_id(self, obj):
"""Return challenge name corresponding to phase"""
| {"golden_diff": "diff --git a/apps/jobs/admin.py b/apps/jobs/admin.py\n--- a/apps/jobs/admin.py\n+++ b/apps/jobs/admin.py\n@@ -18,10 +18,9 @@\n 'created_by', 'status', 'is_public', 'submission_number', 'submitted_at',\n 'execution_time', 'input_file', 'stdout_file', 'stderr_file',\n 'submission_result_file', 'submission_metadata_file',)\n- list_filter = ('participant_team', 'challenge_phase',\n- 'status', 'is_public',)\n+ list_filter = ('challenge_phase__challenge', 'challenge_phase', 'status', 'is_public',)\n search_fields = ('participant_team__team_name', 'challenge_phase__name',\n- 'created_by__username', 'status',)\n+ 'challenge_phase__challenge__title', 'created_by__username', 'status',)\n \n def get_challenge_name_and_id(self, obj):\n \"\"\"Return challenge name corresponding to phase\"\"\"\n", "issue": "Search submissions by challenge name in submissions table\nCurrently, we support searching the submissions by the `participant team name, challenge phase name, created by name and submission status`. We would like to add searching the submissions by `challenge name` and also add the same to default list filtering options.\nSearch submissions by challenge name in submissions table\nCurrently, we support searching the submissions by the `participant team name, challenge phase name, created by name and submission status`. We would like to add searching the submissions by `challenge name` and also add the same to default list filtering options.\n", "before_files": [{"content": "import logging\n\nfrom django.contrib import admin\n\nfrom base.admin import ImportExportTimeStampedAdmin\n\nfrom .models import Submission\nfrom .sender import publish_submission_message\n\n\nlogger = logging.getLogger(__name__)\n\n\[email protected](Submission)\nclass SubmissionAdmin(ImportExportTimeStampedAdmin):\n actions = ['submit_job_to_worker']\n list_display = ('participant_team', 'get_challenge_name_and_id', 'challenge_phase',\n 'created_by', 'status', 'is_public', 'submission_number', 'submitted_at',\n 'execution_time', 'input_file', 'stdout_file', 'stderr_file',\n 'submission_result_file', 'submission_metadata_file',)\n list_filter = ('participant_team', 'challenge_phase',\n 'status', 'is_public',)\n search_fields = ('participant_team__team_name', 'challenge_phase__name',\n 'created_by__username', 'status',)\n\n def get_challenge_name_and_id(self, obj):\n \"\"\"Return challenge name corresponding to phase\"\"\"\n return \"%s - %s\" % (obj.challenge_phase.challenge.title, obj.challenge_phase.challenge.id)\n get_challenge_name_and_id.short_description = 'Challenge'\n get_challenge_name_and_id.admin_order_field = 'challenge_phase__challenge'\n\n def submit_job_to_worker(self, request, queryset):\n for submission in queryset:\n challenge_id = submission.challenge_phase.challenge.id\n challenge_phase_id = submission.challenge_phase.id\n submission_id = submission.id\n logger.info(\"[x] Received submission message with challenge id {}, challenge phase id {}, submission id {}\"\n .format(challenge_id, challenge_phase_id, submission_id))\n publish_submission_message(challenge_id, challenge_phase_id, submission.id)\n queryset.update(status=Submission.SUBMITTED)\n\n submit_job_to_worker.short_description = \"Run selected submissions\"\n", "path": "apps/jobs/admin.py"}]} | 1,111 | 205 |
gh_patches_debug_25771 | rasdani/github-patches | git_diff | mne-tools__mne-python-5796 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ENH: Allow retrieval of GFP
#2538 added the ability to plot GFPs. Currently, the GFP is [only temporarily calculated for plotting](https://github.com/Eric89GXL/mne-python/blob/7f8c69bae49041bb4f0507539ccda1bda7f0b394/mne/viz/evoked.py#L397), and the user has no easy way to access the data.
In our EEG workflow, we typically calculate GFPs for every single participant and condition, and average conditions across participants for plotting; or we compute statistics based on the GFP differences. It is therefore highly important for us to have easy access to the GFPs. We resorted to doing the calculations manually based on `Evoked.data`, but this is cumbersome as one has to "leave" the MNE sphere and implement the operations by hand via NumPy and/or Pandas -- which is not easy for beginners and error-prone, as Pandas by default [uses the unbiased estimator](http://stackoverflow.com/questions/24984178/different-std-in-pandas-vs-numpy) for standard deviation and NumPy doesn't.
I can try to implement a GFP function, but I would need assistance in doing so. I don't really know where to start or where to put that code: should it be a method of the `Evoked` class? Potentially exposed as a property, so it could be accessed via `Evoked.gfp`? Or should it be an entirely new class? Would it have to have its own plotting method? etc. pp. Any help and suggestions would be greatly appreciated.
</issue>
<code>
[start of tutorials/plot_object_evoked.py]
1 """
2 .. _tut_evoked_objects:
3
4 The :class:`Evoked <mne.Evoked>` data structure: evoked/averaged data
5 =====================================================================
6
7 The :class:`Evoked <mne.Evoked>` data structure is mainly used for storing
8 averaged data over trials. In MNE the evoked objects are usually created by
9 averaging epochs data with :func:`mne.Epochs.average`.
10 """
11
12 import os.path as op
13
14 import mne
15
16 ###############################################################################
17 # Here for convenience we read the evoked dataset from a file.
18 data_path = mne.datasets.sample.data_path()
19 fname = op.join(data_path, 'MEG', 'sample', 'sample_audvis-ave.fif')
20 evokeds = mne.read_evokeds(fname, baseline=(None, 0), proj=True)
21 print(evokeds)
22
23 ###############################################################################
24 # Notice that the reader function returned a list of evoked instances. This is
25 # because you can store multiple categories into a single file. Here we have
26 # categories of
27 # ``['Left Auditory', 'Right Auditory', 'Left Visual', 'Right Visual']``.
28 # We can also use ``condition`` parameter to read in only one category.
29 evoked = mne.read_evokeds(fname, condition='Left Auditory')
30 evoked.apply_baseline((None, 0)).apply_proj()
31 print(evoked)
32
33 ###############################################################################
34 # If you're gone through the tutorials of raw and epochs datasets, you're
35 # probably already familiar with the :class:`Info <mne.Info>` attribute.
36 # There is nothing new or special with the ``evoked.info``. All the relevant
37 # info is still there.
38 print(evoked.info)
39 print(evoked.times)
40
41 ###############################################################################
42 # The evoked data structure also contains some new attributes easily
43 # accessible:
44 print(evoked.nave) # Number of averaged epochs.
45 print(evoked.first) # First time sample.
46 print(evoked.last) # Last time sample.
47 print(evoked.comment) # Comment on dataset. Usually the condition.
48 print(evoked.kind) # Type of data, either average or standard_error.
49
50 ###############################################################################
51 # The data is also easily accessible. Since the evoked data arrays are usually
52 # much smaller than raw or epochs datasets, they are preloaded into the memory
53 # when the evoked object is constructed. You can access the data as a numpy
54 # array.
55 data = evoked.data
56 print(data.shape)
57
58 ###############################################################################
59 # The data is arranged in an array of shape `(n_channels, n_times)`. Notice
60 # that unlike epochs, evoked object does not support indexing. This means that
61 # to access the data of a specific channel you must use the data array
62 # directly.
63 print('Data from channel {0}:'.format(evoked.ch_names[10]))
64 print(data[10])
65
66 ###############################################################################
67 # If you want to import evoked data from some other system and you have it in a
68 # numpy array you can use :class:`mne.EvokedArray` for that. All you need is
69 # the data and some info about the evoked data. For more information, see
70 # :ref:`tut_creating_data_structures`.
71 evoked = mne.EvokedArray(data, evoked.info, tmin=evoked.times[0])
72 evoked.plot(time_unit='s')
73
74 ###############################################################################
75 # To write an evoked dataset to a file, use the :meth:`mne.Evoked.save` method.
76 # To save multiple categories to a single file, see :func:`mne.write_evokeds`.
77
[end of tutorials/plot_object_evoked.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/tutorials/plot_object_evoked.py b/tutorials/plot_object_evoked.py
--- a/tutorials/plot_object_evoked.py
+++ b/tutorials/plot_object_evoked.py
@@ -8,9 +8,11 @@
averaged data over trials. In MNE the evoked objects are usually created by
averaging epochs data with :func:`mne.Epochs.average`.
"""
+# sphinx_gallery_thumbnail_number = 2
import os.path as op
+import matplotlib.pyplot as plt
import mne
###############################################################################
@@ -63,6 +65,16 @@
print('Data from channel {0}:'.format(evoked.ch_names[10]))
print(data[10])
+###############################################################################
+# In the same vein, we can quickly extract (and, e.g., plot) the GFP as the
+# standard deviation across channels, here shown just for EEG.
+
+gfp = evoked.copy().pick_types(eeg=True, meg=False).data.std(axis=0)
+fig, ax = plt.subplots(1)
+ax.plot(evoked.times, gfp / 1e6) # scale to uV
+ax.set(xlabel='Time (sec)', ylabel='GFP (uV)')
+fig.tight_layout()
+
###############################################################################
# If you want to import evoked data from some other system and you have it in a
# numpy array you can use :class:`mne.EvokedArray` for that. All you need is
| {"golden_diff": "diff --git a/tutorials/plot_object_evoked.py b/tutorials/plot_object_evoked.py\n--- a/tutorials/plot_object_evoked.py\n+++ b/tutorials/plot_object_evoked.py\n@@ -8,9 +8,11 @@\n averaged data over trials. In MNE the evoked objects are usually created by\n averaging epochs data with :func:`mne.Epochs.average`.\n \"\"\"\n+# sphinx_gallery_thumbnail_number = 2\n \n import os.path as op\n \n+import matplotlib.pyplot as plt\n import mne\n \n ###############################################################################\n@@ -63,6 +65,16 @@\n print('Data from channel {0}:'.format(evoked.ch_names[10]))\n print(data[10])\n \n+###############################################################################\n+# In the same vein, we can quickly extract (and, e.g., plot) the GFP as the\n+# standard deviation across channels, here shown just for EEG.\n+\n+gfp = evoked.copy().pick_types(eeg=True, meg=False).data.std(axis=0)\n+fig, ax = plt.subplots(1)\n+ax.plot(evoked.times, gfp / 1e6) # scale to uV\n+ax.set(xlabel='Time (sec)', ylabel='GFP (uV)')\n+fig.tight_layout()\n+\n ###############################################################################\n # If you want to import evoked data from some other system and you have it in a\n # numpy array you can use :class:`mne.EvokedArray` for that. All you need is\n", "issue": "ENH: Allow retrieval of GFP\n#2538 added the ability to plot GFPs. Currently, the GFP is [only temporarily calculated for plotting](https://github.com/Eric89GXL/mne-python/blob/7f8c69bae49041bb4f0507539ccda1bda7f0b394/mne/viz/evoked.py#L397), and the user has no easy way to access the data. \r\n\r\n In our EEG workflow, we typically calculate GFPs for every single participant and condition, and average conditions across participants for plotting; or we compute statistics based on the GFP differences. It is therefore highly important for us to have easy access to the GFPs. We resorted to doing the calculations manually based on `Evoked.data`, but this is cumbersome as one has to \"leave\" the MNE sphere and implement the operations by hand via NumPy and/or Pandas -- which is not easy for beginners and error-prone, as Pandas by default [uses the unbiased estimator](http://stackoverflow.com/questions/24984178/different-std-in-pandas-vs-numpy) for standard deviation and NumPy doesn't.\r\n\r\nI can try to implement a GFP function, but I would need assistance in doing so. I don't really know where to start or where to put that code: should it be a method of the `Evoked` class? Potentially exposed as a property, so it could be accessed via `Evoked.gfp`? Or should it be an entirely new class? Would it have to have its own plotting method? etc. pp. Any help and suggestions would be greatly appreciated.\n", "before_files": [{"content": "\"\"\"\n.. _tut_evoked_objects:\n\nThe :class:`Evoked <mne.Evoked>` data structure: evoked/averaged data\n=====================================================================\n\nThe :class:`Evoked <mne.Evoked>` data structure is mainly used for storing\naveraged data over trials. In MNE the evoked objects are usually created by\naveraging epochs data with :func:`mne.Epochs.average`.\n\"\"\"\n\nimport os.path as op\n\nimport mne\n\n###############################################################################\n# Here for convenience we read the evoked dataset from a file.\ndata_path = mne.datasets.sample.data_path()\nfname = op.join(data_path, 'MEG', 'sample', 'sample_audvis-ave.fif')\nevokeds = mne.read_evokeds(fname, baseline=(None, 0), proj=True)\nprint(evokeds)\n\n###############################################################################\n# Notice that the reader function returned a list of evoked instances. This is\n# because you can store multiple categories into a single file. Here we have\n# categories of\n# ``['Left Auditory', 'Right Auditory', 'Left Visual', 'Right Visual']``.\n# We can also use ``condition`` parameter to read in only one category.\nevoked = mne.read_evokeds(fname, condition='Left Auditory')\nevoked.apply_baseline((None, 0)).apply_proj()\nprint(evoked)\n\n###############################################################################\n# If you're gone through the tutorials of raw and epochs datasets, you're\n# probably already familiar with the :class:`Info <mne.Info>` attribute.\n# There is nothing new or special with the ``evoked.info``. All the relevant\n# info is still there.\nprint(evoked.info)\nprint(evoked.times)\n\n###############################################################################\n# The evoked data structure also contains some new attributes easily\n# accessible:\nprint(evoked.nave) # Number of averaged epochs.\nprint(evoked.first) # First time sample.\nprint(evoked.last) # Last time sample.\nprint(evoked.comment) # Comment on dataset. Usually the condition.\nprint(evoked.kind) # Type of data, either average or standard_error.\n\n###############################################################################\n# The data is also easily accessible. Since the evoked data arrays are usually\n# much smaller than raw or epochs datasets, they are preloaded into the memory\n# when the evoked object is constructed. You can access the data as a numpy\n# array.\ndata = evoked.data\nprint(data.shape)\n\n###############################################################################\n# The data is arranged in an array of shape `(n_channels, n_times)`. Notice\n# that unlike epochs, evoked object does not support indexing. This means that\n# to access the data of a specific channel you must use the data array\n# directly.\nprint('Data from channel {0}:'.format(evoked.ch_names[10]))\nprint(data[10])\n\n###############################################################################\n# If you want to import evoked data from some other system and you have it in a\n# numpy array you can use :class:`mne.EvokedArray` for that. All you need is\n# the data and some info about the evoked data. For more information, see\n# :ref:`tut_creating_data_structures`.\nevoked = mne.EvokedArray(data, evoked.info, tmin=evoked.times[0])\nevoked.plot(time_unit='s')\n\n###############################################################################\n# To write an evoked dataset to a file, use the :meth:`mne.Evoked.save` method.\n# To save multiple categories to a single file, see :func:`mne.write_evokeds`.\n", "path": "tutorials/plot_object_evoked.py"}]} | 1,802 | 318 |
gh_patches_debug_20791 | rasdani/github-patches | git_diff | CTFd__CTFd-1657 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add email sender address override
Right now the email sender is set to the From address which isn't right in all situations. We need a way to override the email sender if it's not supposed to be the same as the From address.
https://help.mailgun.com/hc/en-us/articles/202236494-What-is-the-difference-between-the-From-and-Sender-
https://stackoverflow.com/questions/4367358/whats-the-difference-between-sender-from-and-return-path
</issue>
<code>
[start of CTFd/utils/email/smtp.py]
1 import smtplib
2 from email.message import EmailMessage
3 from email.utils import formataddr
4 from socket import timeout
5
6 from CTFd.utils import get_app_config, get_config
7
8
9 def get_smtp(host, port, username=None, password=None, TLS=None, SSL=None, auth=None):
10 if SSL is None:
11 smtp = smtplib.SMTP(host, port, timeout=3)
12 else:
13 smtp = smtplib.SMTP_SSL(host, port, timeout=3)
14
15 if TLS:
16 smtp.starttls()
17
18 if auth:
19 smtp.login(username, password)
20 return smtp
21
22
23 def sendmail(addr, text, subject):
24 ctf_name = get_config("ctf_name")
25 mailfrom_addr = get_config("mailfrom_addr") or get_app_config("MAILFROM_ADDR")
26 mailfrom_addr = formataddr((ctf_name, mailfrom_addr))
27
28 data = {
29 "host": get_config("mail_server") or get_app_config("MAIL_SERVER"),
30 "port": int(get_config("mail_port") or get_app_config("MAIL_PORT")),
31 }
32 username = get_config("mail_username") or get_app_config("MAIL_USERNAME")
33 password = get_config("mail_password") or get_app_config("MAIL_PASSWORD")
34 TLS = get_config("mail_tls") or get_app_config("MAIL_TLS")
35 SSL = get_config("mail_ssl") or get_app_config("MAIL_SSL")
36 auth = get_config("mail_useauth") or get_app_config("MAIL_USEAUTH")
37
38 if username:
39 data["username"] = username
40 if password:
41 data["password"] = password
42 if TLS:
43 data["TLS"] = TLS
44 if SSL:
45 data["SSL"] = SSL
46 if auth:
47 data["auth"] = auth
48
49 try:
50 smtp = get_smtp(**data)
51
52 msg = EmailMessage()
53 msg.set_content(text)
54
55 msg["Subject"] = subject
56 msg["From"] = mailfrom_addr
57 msg["To"] = addr
58
59 smtp.send_message(msg)
60
61 smtp.quit()
62 return True, "Email sent"
63 except smtplib.SMTPException as e:
64 return False, str(e)
65 except timeout:
66 return False, "SMTP server connection timed out"
67 except Exception as e:
68 return False, str(e)
69
[end of CTFd/utils/email/smtp.py]
[start of CTFd/config.py]
1 import configparser
2 import os
3 from distutils.util import strtobool
4
5
6 class EnvInterpolation(configparser.BasicInterpolation):
7 """Interpolation which expands environment variables in values."""
8
9 def before_get(self, parser, section, option, value, defaults):
10 value = super().before_get(parser, section, option, value, defaults)
11 envvar = os.getenv(option)
12 if value == "" and envvar:
13 return process_string_var(envvar)
14 else:
15 return value
16
17
18 def process_string_var(value):
19 if value == "":
20 return None
21
22 if value.isdigit():
23 return int(value)
24 elif value.replace(".", "", 1).isdigit():
25 return float(value)
26
27 try:
28 return bool(strtobool(value))
29 except ValueError:
30 return value
31
32
33 def process_boolean_str(value):
34 if type(value) is bool:
35 return value
36
37 if value is None:
38 return False
39
40 if value == "":
41 return None
42
43 return bool(strtobool(value))
44
45
46 def empty_str_cast(value, default=None):
47 if value == "":
48 return default
49 return value
50
51
52 def gen_secret_key():
53 # Attempt to read the secret from the secret file
54 # This will fail if the secret has not been written
55 try:
56 with open(".ctfd_secret_key", "rb") as secret:
57 key = secret.read()
58 except (OSError, IOError):
59 key = None
60
61 if not key:
62 key = os.urandom(64)
63 # Attempt to write the secret file
64 # This will fail if the filesystem is read-only
65 try:
66 with open(".ctfd_secret_key", "wb") as secret:
67 secret.write(key)
68 secret.flush()
69 except (OSError, IOError):
70 pass
71 return key
72
73
74 config_ini = configparser.ConfigParser(interpolation=EnvInterpolation())
75 config_ini.optionxform = str # Makes the key value case-insensitive
76 path = os.path.join(os.path.dirname(os.path.abspath(__file__)), "config.ini")
77 config_ini.read(path)
78
79
80 # fmt: off
81 class ServerConfig(object):
82 SECRET_KEY: str = empty_str_cast(config_ini["server"]["SECRET_KEY"]) \
83 or gen_secret_key()
84
85 DATABASE_URL: str = empty_str_cast(config_ini["server"]["DATABASE_URL"]) \
86 or f"sqlite:///{os.path.dirname(os.path.abspath(__file__))}/ctfd.db"
87
88 REDIS_URL: str = empty_str_cast(config_ini["server"]["REDIS_URL"])
89
90 SQLALCHEMY_DATABASE_URI = DATABASE_URL
91 CACHE_REDIS_URL = REDIS_URL
92 if CACHE_REDIS_URL:
93 CACHE_TYPE: str = "redis"
94 else:
95 CACHE_TYPE: str = "filesystem"
96 CACHE_DIR: str = os.path.join(
97 os.path.dirname(__file__), os.pardir, ".data", "filesystem_cache"
98 )
99 # Override the threshold of cached values on the filesystem. The default is 500. Don't change unless you know what you're doing.
100 CACHE_THRESHOLD: int = 0
101
102 # === SECURITY ===
103 SESSION_COOKIE_HTTPONLY: bool = config_ini["security"].getboolean("SESSION_COOKIE_HTTPONLY", fallback=True)
104
105 SESSION_COOKIE_SAMESITE: str = empty_str_cast(config_ini["security"]["SESSION_COOKIE_SAMESITE"]) \
106 or "Lax"
107
108 PERMANENT_SESSION_LIFETIME: int = config_ini["security"].getint("PERMANENT_SESSION_LIFETIME") \
109 or 604800
110
111 """
112 TRUSTED_PROXIES:
113 Defines a set of regular expressions used for finding a user's IP address if the CTFd instance
114 is behind a proxy. If you are running a CTF and users are on the same network as you, you may choose to remove
115 some proxies from the list.
116
117 CTFd only uses IP addresses for cursory tracking purposes. It is ill-advised to do anything complicated based
118 solely on IP addresses unless you know what you are doing.
119 """
120 TRUSTED_PROXIES = [
121 r"^127\.0\.0\.1$",
122 # Remove the following proxies if you do not trust the local network
123 # For example if you are running a CTF on your laptop and the teams are
124 # all on the same network
125 r"^::1$",
126 r"^fc00:",
127 r"^10\.",
128 r"^172\.(1[6-9]|2[0-9]|3[0-1])\.",
129 r"^192\.168\.",
130 ]
131
132 # === EMAIL ===
133 MAILFROM_ADDR: str = config_ini["email"]["MAILFROM_ADDR"] \
134 or "[email protected]"
135
136 MAIL_SERVER: str = empty_str_cast(config_ini["email"]["MAIL_SERVER"])
137
138 MAIL_PORT: int = empty_str_cast(config_ini["email"]["MAIL_PORT"])
139
140 MAIL_USEAUTH: bool = process_boolean_str(config_ini["email"]["MAIL_USEAUTH"])
141
142 MAIL_USERNAME: str = empty_str_cast(config_ini["email"]["MAIL_USERNAME"])
143
144 MAIL_PASSWORD: str = empty_str_cast(config_ini["email"]["MAIL_PASSWORD"])
145
146 MAIL_TLS: bool = process_boolean_str(config_ini["email"]["MAIL_TLS"])
147
148 MAIL_SSL: bool = process_boolean_str(config_ini["email"]["MAIL_SSL"])
149
150 MAILGUN_API_KEY: str = empty_str_cast(config_ini["email"]["MAILGUN_API_KEY"])
151
152 MAILGUN_BASE_URL: str = empty_str_cast(config_ini["email"]["MAILGUN_API_KEY"])
153
154 # === LOGS ===
155 LOG_FOLDER: str = empty_str_cast(config_ini["logs"]["LOG_FOLDER"]) \
156 or os.path.join(os.path.dirname(os.path.abspath(__file__)), "logs")
157
158 # === UPLOADS ===
159 UPLOAD_PROVIDER: str = empty_str_cast(config_ini["uploads"]["UPLOAD_PROVIDER"]) \
160 or "filesystem"
161
162 UPLOAD_FOLDER: str = empty_str_cast(config_ini["uploads"]["UPLOAD_FOLDER"]) \
163 or os.path.join(os.path.dirname(os.path.abspath(__file__)), "uploads")
164
165 if UPLOAD_PROVIDER == "s3":
166 AWS_ACCESS_KEY_ID: str = empty_str_cast(config_ini["uploads"]["AWS_ACCESS_KEY_ID"])
167
168 AWS_SECRET_ACCESS_KEY: str = empty_str_cast(config_ini["uploads"]["AWS_SECRET_ACCESS_KEY"])
169
170 AWS_S3_BUCKET: str = empty_str_cast(config_ini["uploads"]["AWS_S3_BUCKET"])
171
172 AWS_S3_ENDPOINT_URL: str = empty_str_cast(config_ini["uploads"]["AWS_S3_ENDPOINT_URL"])
173
174 # === OPTIONAL ===
175 REVERSE_PROXY: bool = empty_str_cast(config_ini["optional"]["REVERSE_PROXY"], default=False)
176
177 TEMPLATES_AUTO_RELOAD: bool = empty_str_cast(config_ini["optional"]["TEMPLATES_AUTO_RELOAD"], default=True)
178
179 SQLALCHEMY_TRACK_MODIFICATIONS: bool = empty_str_cast(config_ini["optional"]["SQLALCHEMY_TRACK_MODIFICATIONS"], default=False)
180
181 SWAGGER_UI: bool = empty_str_cast(config_ini["optional"]["SWAGGER_UI"], default=False)
182
183 SWAGGER_UI_ENDPOINT: str = "/" if SWAGGER_UI else None
184
185 UPDATE_CHECK: bool = empty_str_cast(config_ini["optional"]["UPDATE_CHECK"], default=True)
186
187 APPLICATION_ROOT: str = empty_str_cast(config_ini["optional"]["APPLICATION_ROOT"], default="/")
188
189 SERVER_SENT_EVENTS: bool = empty_str_cast(config_ini["optional"]["SERVER_SENT_EVENTS"], default=True)
190
191 HTML_SANITIZATION: bool = empty_str_cast(config_ini["optional"]["HTML_SANITIZATION"], default=False)
192
193 if DATABASE_URL.startswith("sqlite") is False:
194 SQLALCHEMY_ENGINE_OPTIONS = {
195 "max_overflow": int(empty_str_cast(config_ini["optional"]["SQLALCHEMY_MAX_OVERFLOW"], default=20)), # noqa: E131
196 "pool_pre_ping": empty_str_cast(config_ini["optional"]["SQLALCHEMY_POOL_PRE_PING"], default=True), # noqa: E131
197 }
198
199 # === OAUTH ===
200 OAUTH_CLIENT_ID: str = empty_str_cast(config_ini["oauth"]["OAUTH_CLIENT_ID"])
201 OAUTH_CLIENT_SECRET: str = empty_str_cast(config_ini["oauth"]["OAUTH_CLIENT_SECRET"])
202 # fmt: on
203
204
205 class TestingConfig(ServerConfig):
206 SECRET_KEY = "AAAAAAAAAAAAAAAAAAAA"
207 PRESERVE_CONTEXT_ON_EXCEPTION = False
208 TESTING = True
209 DEBUG = True
210 SQLALCHEMY_DATABASE_URI = os.getenv("TESTING_DATABASE_URL") or "sqlite://"
211 SERVER_NAME = "localhost"
212 UPDATE_CHECK = False
213 REDIS_URL = None
214 CACHE_TYPE = "simple"
215 CACHE_THRESHOLD = 500
216 SAFE_MODE = True
217
218
219 # Actually initialize ServerConfig to allow us to add more attributes on
220 Config = ServerConfig()
221 for k, v in config_ini.items("extra"):
222 setattr(Config, k, process_string_var(v))
223
[end of CTFd/config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/CTFd/config.py b/CTFd/config.py
--- a/CTFd/config.py
+++ b/CTFd/config.py
@@ -147,6 +147,8 @@
MAIL_SSL: bool = process_boolean_str(config_ini["email"]["MAIL_SSL"])
+ MAILSENDER_ADDR: str = empty_str_cast(config_ini["email"]["MAILSENDER_ADDR"])
+
MAILGUN_API_KEY: str = empty_str_cast(config_ini["email"]["MAILGUN_API_KEY"])
MAILGUN_BASE_URL: str = empty_str_cast(config_ini["email"]["MAILGUN_API_KEY"])
diff --git a/CTFd/utils/email/smtp.py b/CTFd/utils/email/smtp.py
--- a/CTFd/utils/email/smtp.py
+++ b/CTFd/utils/email/smtp.py
@@ -56,7 +56,15 @@
msg["From"] = mailfrom_addr
msg["To"] = addr
- smtp.send_message(msg)
+ # Check whether we are using an admin-defined SMTP server
+ custom_smtp = bool(get_config("mail_server"))
+
+ # We should only consider the MAILSENDER_ADDR value on servers defined in config
+ if custom_smtp:
+ smtp.send_message(msg)
+ else:
+ mailsender_addr = get_app_config("MAILSENDER_ADDR")
+ smtp.send_message(msg, from_addr=mailsender_addr)
smtp.quit()
return True, "Email sent"
| {"golden_diff": "diff --git a/CTFd/config.py b/CTFd/config.py\n--- a/CTFd/config.py\n+++ b/CTFd/config.py\n@@ -147,6 +147,8 @@\n \n MAIL_SSL: bool = process_boolean_str(config_ini[\"email\"][\"MAIL_SSL\"])\n \n+ MAILSENDER_ADDR: str = empty_str_cast(config_ini[\"email\"][\"MAILSENDER_ADDR\"])\n+\n MAILGUN_API_KEY: str = empty_str_cast(config_ini[\"email\"][\"MAILGUN_API_KEY\"])\n \n MAILGUN_BASE_URL: str = empty_str_cast(config_ini[\"email\"][\"MAILGUN_API_KEY\"])\ndiff --git a/CTFd/utils/email/smtp.py b/CTFd/utils/email/smtp.py\n--- a/CTFd/utils/email/smtp.py\n+++ b/CTFd/utils/email/smtp.py\n@@ -56,7 +56,15 @@\n msg[\"From\"] = mailfrom_addr\n msg[\"To\"] = addr\n \n- smtp.send_message(msg)\n+ # Check whether we are using an admin-defined SMTP server\n+ custom_smtp = bool(get_config(\"mail_server\"))\n+\n+ # We should only consider the MAILSENDER_ADDR value on servers defined in config\n+ if custom_smtp:\n+ smtp.send_message(msg)\n+ else:\n+ mailsender_addr = get_app_config(\"MAILSENDER_ADDR\")\n+ smtp.send_message(msg, from_addr=mailsender_addr)\n \n smtp.quit()\n return True, \"Email sent\"\n", "issue": "Add email sender address override\nRight now the email sender is set to the From address which isn't right in all situations. We need a way to override the email sender if it's not supposed to be the same as the From address. \r\n\r\nhttps://help.mailgun.com/hc/en-us/articles/202236494-What-is-the-difference-between-the-From-and-Sender-\r\nhttps://stackoverflow.com/questions/4367358/whats-the-difference-between-sender-from-and-return-path\n", "before_files": [{"content": "import smtplib\nfrom email.message import EmailMessage\nfrom email.utils import formataddr\nfrom socket import timeout\n\nfrom CTFd.utils import get_app_config, get_config\n\n\ndef get_smtp(host, port, username=None, password=None, TLS=None, SSL=None, auth=None):\n if SSL is None:\n smtp = smtplib.SMTP(host, port, timeout=3)\n else:\n smtp = smtplib.SMTP_SSL(host, port, timeout=3)\n\n if TLS:\n smtp.starttls()\n\n if auth:\n smtp.login(username, password)\n return smtp\n\n\ndef sendmail(addr, text, subject):\n ctf_name = get_config(\"ctf_name\")\n mailfrom_addr = get_config(\"mailfrom_addr\") or get_app_config(\"MAILFROM_ADDR\")\n mailfrom_addr = formataddr((ctf_name, mailfrom_addr))\n\n data = {\n \"host\": get_config(\"mail_server\") or get_app_config(\"MAIL_SERVER\"),\n \"port\": int(get_config(\"mail_port\") or get_app_config(\"MAIL_PORT\")),\n }\n username = get_config(\"mail_username\") or get_app_config(\"MAIL_USERNAME\")\n password = get_config(\"mail_password\") or get_app_config(\"MAIL_PASSWORD\")\n TLS = get_config(\"mail_tls\") or get_app_config(\"MAIL_TLS\")\n SSL = get_config(\"mail_ssl\") or get_app_config(\"MAIL_SSL\")\n auth = get_config(\"mail_useauth\") or get_app_config(\"MAIL_USEAUTH\")\n\n if username:\n data[\"username\"] = username\n if password:\n data[\"password\"] = password\n if TLS:\n data[\"TLS\"] = TLS\n if SSL:\n data[\"SSL\"] = SSL\n if auth:\n data[\"auth\"] = auth\n\n try:\n smtp = get_smtp(**data)\n\n msg = EmailMessage()\n msg.set_content(text)\n\n msg[\"Subject\"] = subject\n msg[\"From\"] = mailfrom_addr\n msg[\"To\"] = addr\n\n smtp.send_message(msg)\n\n smtp.quit()\n return True, \"Email sent\"\n except smtplib.SMTPException as e:\n return False, str(e)\n except timeout:\n return False, \"SMTP server connection timed out\"\n except Exception as e:\n return False, str(e)\n", "path": "CTFd/utils/email/smtp.py"}, {"content": "import configparser\nimport os\nfrom distutils.util import strtobool\n\n\nclass EnvInterpolation(configparser.BasicInterpolation):\n \"\"\"Interpolation which expands environment variables in values.\"\"\"\n\n def before_get(self, parser, section, option, value, defaults):\n value = super().before_get(parser, section, option, value, defaults)\n envvar = os.getenv(option)\n if value == \"\" and envvar:\n return process_string_var(envvar)\n else:\n return value\n\n\ndef process_string_var(value):\n if value == \"\":\n return None\n\n if value.isdigit():\n return int(value)\n elif value.replace(\".\", \"\", 1).isdigit():\n return float(value)\n\n try:\n return bool(strtobool(value))\n except ValueError:\n return value\n\n\ndef process_boolean_str(value):\n if type(value) is bool:\n return value\n\n if value is None:\n return False\n\n if value == \"\":\n return None\n\n return bool(strtobool(value))\n\n\ndef empty_str_cast(value, default=None):\n if value == \"\":\n return default\n return value\n\n\ndef gen_secret_key():\n # Attempt to read the secret from the secret file\n # This will fail if the secret has not been written\n try:\n with open(\".ctfd_secret_key\", \"rb\") as secret:\n key = secret.read()\n except (OSError, IOError):\n key = None\n\n if not key:\n key = os.urandom(64)\n # Attempt to write the secret file\n # This will fail if the filesystem is read-only\n try:\n with open(\".ctfd_secret_key\", \"wb\") as secret:\n secret.write(key)\n secret.flush()\n except (OSError, IOError):\n pass\n return key\n\n\nconfig_ini = configparser.ConfigParser(interpolation=EnvInterpolation())\nconfig_ini.optionxform = str # Makes the key value case-insensitive\npath = os.path.join(os.path.dirname(os.path.abspath(__file__)), \"config.ini\")\nconfig_ini.read(path)\n\n\n# fmt: off\nclass ServerConfig(object):\n SECRET_KEY: str = empty_str_cast(config_ini[\"server\"][\"SECRET_KEY\"]) \\\n or gen_secret_key()\n\n DATABASE_URL: str = empty_str_cast(config_ini[\"server\"][\"DATABASE_URL\"]) \\\n or f\"sqlite:///{os.path.dirname(os.path.abspath(__file__))}/ctfd.db\"\n\n REDIS_URL: str = empty_str_cast(config_ini[\"server\"][\"REDIS_URL\"])\n\n SQLALCHEMY_DATABASE_URI = DATABASE_URL\n CACHE_REDIS_URL = REDIS_URL\n if CACHE_REDIS_URL:\n CACHE_TYPE: str = \"redis\"\n else:\n CACHE_TYPE: str = \"filesystem\"\n CACHE_DIR: str = os.path.join(\n os.path.dirname(__file__), os.pardir, \".data\", \"filesystem_cache\"\n )\n # Override the threshold of cached values on the filesystem. The default is 500. Don't change unless you know what you're doing.\n CACHE_THRESHOLD: int = 0\n\n # === SECURITY ===\n SESSION_COOKIE_HTTPONLY: bool = config_ini[\"security\"].getboolean(\"SESSION_COOKIE_HTTPONLY\", fallback=True)\n\n SESSION_COOKIE_SAMESITE: str = empty_str_cast(config_ini[\"security\"][\"SESSION_COOKIE_SAMESITE\"]) \\\n or \"Lax\"\n\n PERMANENT_SESSION_LIFETIME: int = config_ini[\"security\"].getint(\"PERMANENT_SESSION_LIFETIME\") \\\n or 604800\n\n \"\"\"\n TRUSTED_PROXIES:\n Defines a set of regular expressions used for finding a user's IP address if the CTFd instance\n is behind a proxy. If you are running a CTF and users are on the same network as you, you may choose to remove\n some proxies from the list.\n\n CTFd only uses IP addresses for cursory tracking purposes. It is ill-advised to do anything complicated based\n solely on IP addresses unless you know what you are doing.\n \"\"\"\n TRUSTED_PROXIES = [\n r\"^127\\.0\\.0\\.1$\",\n # Remove the following proxies if you do not trust the local network\n # For example if you are running a CTF on your laptop and the teams are\n # all on the same network\n r\"^::1$\",\n r\"^fc00:\",\n r\"^10\\.\",\n r\"^172\\.(1[6-9]|2[0-9]|3[0-1])\\.\",\n r\"^192\\.168\\.\",\n ]\n\n # === EMAIL ===\n MAILFROM_ADDR: str = config_ini[\"email\"][\"MAILFROM_ADDR\"] \\\n or \"[email protected]\"\n\n MAIL_SERVER: str = empty_str_cast(config_ini[\"email\"][\"MAIL_SERVER\"])\n\n MAIL_PORT: int = empty_str_cast(config_ini[\"email\"][\"MAIL_PORT\"])\n\n MAIL_USEAUTH: bool = process_boolean_str(config_ini[\"email\"][\"MAIL_USEAUTH\"])\n\n MAIL_USERNAME: str = empty_str_cast(config_ini[\"email\"][\"MAIL_USERNAME\"])\n\n MAIL_PASSWORD: str = empty_str_cast(config_ini[\"email\"][\"MAIL_PASSWORD\"])\n\n MAIL_TLS: bool = process_boolean_str(config_ini[\"email\"][\"MAIL_TLS\"])\n\n MAIL_SSL: bool = process_boolean_str(config_ini[\"email\"][\"MAIL_SSL\"])\n\n MAILGUN_API_KEY: str = empty_str_cast(config_ini[\"email\"][\"MAILGUN_API_KEY\"])\n\n MAILGUN_BASE_URL: str = empty_str_cast(config_ini[\"email\"][\"MAILGUN_API_KEY\"])\n\n # === LOGS ===\n LOG_FOLDER: str = empty_str_cast(config_ini[\"logs\"][\"LOG_FOLDER\"]) \\\n or os.path.join(os.path.dirname(os.path.abspath(__file__)), \"logs\")\n\n # === UPLOADS ===\n UPLOAD_PROVIDER: str = empty_str_cast(config_ini[\"uploads\"][\"UPLOAD_PROVIDER\"]) \\\n or \"filesystem\"\n\n UPLOAD_FOLDER: str = empty_str_cast(config_ini[\"uploads\"][\"UPLOAD_FOLDER\"]) \\\n or os.path.join(os.path.dirname(os.path.abspath(__file__)), \"uploads\")\n\n if UPLOAD_PROVIDER == \"s3\":\n AWS_ACCESS_KEY_ID: str = empty_str_cast(config_ini[\"uploads\"][\"AWS_ACCESS_KEY_ID\"])\n\n AWS_SECRET_ACCESS_KEY: str = empty_str_cast(config_ini[\"uploads\"][\"AWS_SECRET_ACCESS_KEY\"])\n\n AWS_S3_BUCKET: str = empty_str_cast(config_ini[\"uploads\"][\"AWS_S3_BUCKET\"])\n\n AWS_S3_ENDPOINT_URL: str = empty_str_cast(config_ini[\"uploads\"][\"AWS_S3_ENDPOINT_URL\"])\n\n # === OPTIONAL ===\n REVERSE_PROXY: bool = empty_str_cast(config_ini[\"optional\"][\"REVERSE_PROXY\"], default=False)\n\n TEMPLATES_AUTO_RELOAD: bool = empty_str_cast(config_ini[\"optional\"][\"TEMPLATES_AUTO_RELOAD\"], default=True)\n\n SQLALCHEMY_TRACK_MODIFICATIONS: bool = empty_str_cast(config_ini[\"optional\"][\"SQLALCHEMY_TRACK_MODIFICATIONS\"], default=False)\n\n SWAGGER_UI: bool = empty_str_cast(config_ini[\"optional\"][\"SWAGGER_UI\"], default=False)\n\n SWAGGER_UI_ENDPOINT: str = \"/\" if SWAGGER_UI else None\n\n UPDATE_CHECK: bool = empty_str_cast(config_ini[\"optional\"][\"UPDATE_CHECK\"], default=True)\n\n APPLICATION_ROOT: str = empty_str_cast(config_ini[\"optional\"][\"APPLICATION_ROOT\"], default=\"/\")\n\n SERVER_SENT_EVENTS: bool = empty_str_cast(config_ini[\"optional\"][\"SERVER_SENT_EVENTS\"], default=True)\n\n HTML_SANITIZATION: bool = empty_str_cast(config_ini[\"optional\"][\"HTML_SANITIZATION\"], default=False)\n\n if DATABASE_URL.startswith(\"sqlite\") is False:\n SQLALCHEMY_ENGINE_OPTIONS = {\n \"max_overflow\": int(empty_str_cast(config_ini[\"optional\"][\"SQLALCHEMY_MAX_OVERFLOW\"], default=20)), # noqa: E131\n \"pool_pre_ping\": empty_str_cast(config_ini[\"optional\"][\"SQLALCHEMY_POOL_PRE_PING\"], default=True), # noqa: E131\n }\n\n # === OAUTH ===\n OAUTH_CLIENT_ID: str = empty_str_cast(config_ini[\"oauth\"][\"OAUTH_CLIENT_ID\"])\n OAUTH_CLIENT_SECRET: str = empty_str_cast(config_ini[\"oauth\"][\"OAUTH_CLIENT_SECRET\"])\n# fmt: on\n\n\nclass TestingConfig(ServerConfig):\n SECRET_KEY = \"AAAAAAAAAAAAAAAAAAAA\"\n PRESERVE_CONTEXT_ON_EXCEPTION = False\n TESTING = True\n DEBUG = True\n SQLALCHEMY_DATABASE_URI = os.getenv(\"TESTING_DATABASE_URL\") or \"sqlite://\"\n SERVER_NAME = \"localhost\"\n UPDATE_CHECK = False\n REDIS_URL = None\n CACHE_TYPE = \"simple\"\n CACHE_THRESHOLD = 500\n SAFE_MODE = True\n\n\n# Actually initialize ServerConfig to allow us to add more attributes on\nConfig = ServerConfig()\nfor k, v in config_ini.items(\"extra\"):\n setattr(Config, k, process_string_var(v))\n", "path": "CTFd/config.py"}]} | 3,779 | 324 |
gh_patches_debug_1665 | rasdani/github-patches | git_diff | python-pillow__Pillow-1686 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Repeated looping over image stack shows last frame in place of first frame
When looping through the frames in an animation or TIFF stack with `ImageSequence.Iterator`, the frame pointer is not reset for the first frame. Consequently, if the loop is run through a second time the final frame is shown again instead of the first frame.
### Demo
Code
``` python
from PIL import Image, ImageSequence
import os
# Make a test image
os.system((
"convert -depth 8 -size 1x1 xc:'rgb(100,100,100)' xc:'rgb(121,121,121)'"
" xc:'rgb(142,142,142)' xc:'rgb(163,163,163)' image.tif"
))
# Open the image
im = Image.open('image.tif')
# Run through the image
print('First run')
for frame in ImageSequence.Iterator(im):
print(list(frame.getdata()))
# Run through the image again
print('Second run')
for frame in ImageSequence.Iterator(im):
print(list(frame.getdata()))
```
Output
```
First run
[100]
[121]
[142]
[163]
Second run
[163]
[121]
[142]
[163]
```
</issue>
<code>
[start of PIL/ImageSequence.py]
1 #
2 # The Python Imaging Library.
3 # $Id$
4 #
5 # sequence support classes
6 #
7 # history:
8 # 1997-02-20 fl Created
9 #
10 # Copyright (c) 1997 by Secret Labs AB.
11 # Copyright (c) 1997 by Fredrik Lundh.
12 #
13 # See the README file for information on usage and redistribution.
14 #
15
16 ##
17
18
19 class Iterator(object):
20 """
21 This class implements an iterator object that can be used to loop
22 over an image sequence.
23
24 You can use the ``[]`` operator to access elements by index. This operator
25 will raise an :py:exc:`IndexError` if you try to access a nonexistent
26 frame.
27
28 :param im: An image object.
29 """
30
31 def __init__(self, im):
32 if not hasattr(im, "seek"):
33 raise AttributeError("im must have seek method")
34 self.im = im
35
36 def __getitem__(self, ix):
37 try:
38 if ix:
39 self.im.seek(ix)
40 return self.im
41 except EOFError:
42 raise IndexError # end of sequence
43
[end of PIL/ImageSequence.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/PIL/ImageSequence.py b/PIL/ImageSequence.py
--- a/PIL/ImageSequence.py
+++ b/PIL/ImageSequence.py
@@ -35,8 +35,7 @@
def __getitem__(self, ix):
try:
- if ix:
- self.im.seek(ix)
+ self.im.seek(ix)
return self.im
except EOFError:
raise IndexError # end of sequence
| {"golden_diff": "diff --git a/PIL/ImageSequence.py b/PIL/ImageSequence.py\n--- a/PIL/ImageSequence.py\n+++ b/PIL/ImageSequence.py\n@@ -35,8 +35,7 @@\n \n def __getitem__(self, ix):\n try:\n- if ix:\n- self.im.seek(ix)\n+ self.im.seek(ix)\n return self.im\n except EOFError:\n raise IndexError # end of sequence\n", "issue": "Repeated looping over image stack shows last frame in place of first frame\nWhen looping through the frames in an animation or TIFF stack with `ImageSequence.Iterator`, the frame pointer is not reset for the first frame. Consequently, if the loop is run through a second time the final frame is shown again instead of the first frame.\n### Demo\n\nCode\n\n``` python\nfrom PIL import Image, ImageSequence\nimport os\n# Make a test image\nos.system((\n \"convert -depth 8 -size 1x1 xc:'rgb(100,100,100)' xc:'rgb(121,121,121)'\"\n \" xc:'rgb(142,142,142)' xc:'rgb(163,163,163)' image.tif\"\n))\n# Open the image\nim = Image.open('image.tif')\n# Run through the image\nprint('First run')\nfor frame in ImageSequence.Iterator(im):\n print(list(frame.getdata()))\n# Run through the image again\nprint('Second run')\nfor frame in ImageSequence.Iterator(im):\n print(list(frame.getdata()))\n```\n\nOutput\n\n```\nFirst run\n[100]\n[121]\n[142]\n[163]\nSecond run\n[163]\n[121]\n[142]\n[163]\n```\n\n", "before_files": [{"content": "#\n# The Python Imaging Library.\n# $Id$\n#\n# sequence support classes\n#\n# history:\n# 1997-02-20 fl Created\n#\n# Copyright (c) 1997 by Secret Labs AB.\n# Copyright (c) 1997 by Fredrik Lundh.\n#\n# See the README file for information on usage and redistribution.\n#\n\n##\n\n\nclass Iterator(object):\n \"\"\"\n This class implements an iterator object that can be used to loop\n over an image sequence.\n\n You can use the ``[]`` operator to access elements by index. This operator\n will raise an :py:exc:`IndexError` if you try to access a nonexistent\n frame.\n\n :param im: An image object.\n \"\"\"\n\n def __init__(self, im):\n if not hasattr(im, \"seek\"):\n raise AttributeError(\"im must have seek method\")\n self.im = im\n\n def __getitem__(self, ix):\n try:\n if ix:\n self.im.seek(ix)\n return self.im\n except EOFError:\n raise IndexError # end of sequence\n", "path": "PIL/ImageSequence.py"}]} | 1,151 | 95 |
gh_patches_debug_6731 | rasdani/github-patches | git_diff | Bitmessage__PyBitmessage-1334 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Crashing on Boot
$ python src/bitmessagemain.py
Loading existing config files from /home/.config/PyBitmessage/
2018-08-05 13:19:02,170 - WARNING - Using default logger configuration
2018-08-05 13:19:02,592 - CRITICAL - Unhandled exception
Traceback (most recent call last):
File "src/bitmessagemain.py", line 507, in <module>
File "src/bitmessagemain.py", line 503, in main
File "src/bitmessagemain.py", line 276, in start
File "PyBitmessage/src/knownnodes.py", line 100, in readKnownNodes
pickle_deserialize_old_knownnodes(source)
File "PyBitmessage/src/knownnodes.py", line 63, in pickle_deserialize_old_knownnodes
knownNodes = pickle.load(source)
File "/usr/lib/python2.7/pickle.py", line 1384, in load
return Unpickler(file).load()
File "/usr/lib/python2.7/pickle.py", line 864, in load
dispatch[key](self)
File "/usr/lib/python2.7/pickle.py", line 886, in load_eof
raise EOFError
EOFError
Cleaning up lockfile
</issue>
<code>
[start of src/knownnodes.py]
1 import json
2 import os
3 import pickle
4 # import sys
5 import threading
6 import time
7
8 import state
9 from bmconfigparser import BMConfigParser
10 from debug import logger
11
12 knownNodesLock = threading.Lock()
13 knownNodes = {stream: {} for stream in range(1, 4)}
14
15 knownNodesTrimAmount = 2000
16
17 # forget a node after rating is this low
18 knownNodesForgetRating = -0.5
19
20 DEFAULT_NODES = (
21 state.Peer('5.45.99.75', 8444),
22 state.Peer('75.167.159.54', 8444),
23 state.Peer('95.165.168.168', 8444),
24 state.Peer('85.180.139.241', 8444),
25 state.Peer('158.222.217.190', 8080),
26 state.Peer('178.62.12.187', 8448),
27 state.Peer('24.188.198.204', 8111),
28 state.Peer('109.147.204.113', 1195),
29 state.Peer('178.11.46.221', 8444)
30 )
31
32
33 def json_serialize_knownnodes(output):
34 """
35 Reorganize knownnodes dict and write it as JSON to output
36 """
37 _serialized = []
38 for stream, peers in knownNodes.iteritems():
39 for peer, info in peers.iteritems():
40 info.update(rating=round(info.get('rating', 0), 2))
41 _serialized.append({
42 'stream': stream, 'peer': peer._asdict(), 'info': info
43 })
44 json.dump(_serialized, output, indent=4)
45
46
47 def json_deserialize_knownnodes(source):
48 """
49 Read JSON from source and make knownnodes dict
50 """
51 for node in json.load(source):
52 peer = node['peer']
53 peer['host'] = str(peer['host'])
54 knownNodes[node['stream']][state.Peer(**peer)] = node['info']
55
56
57 def pickle_deserialize_old_knownnodes(source):
58 """
59 Unpickle source and reorganize knownnodes dict if it's in old format
60 the old format was {Peer:lastseen, ...}
61 the new format is {Peer:{"lastseen":i, "rating":f}}
62 """
63 knownNodes = pickle.load(source)
64 for stream in knownNodes.keys():
65 for node, params in knownNodes[stream].items():
66 if isinstance(params, (float, int)):
67 addKnownNode(stream, node, params)
68
69
70 def saveKnownNodes(dirName=None):
71 if dirName is None:
72 dirName = state.appdata
73 with knownNodesLock:
74 with open(os.path.join(dirName, 'knownnodes.dat'), 'wb') as output:
75 json_serialize_knownnodes(output)
76
77
78 def addKnownNode(stream, peer, lastseen=None, is_self=False):
79 knownNodes[stream][peer] = {
80 "lastseen": lastseen or time.time(),
81 "rating": 0,
82 "self": is_self,
83 }
84
85
86 def createDefaultKnownNodes():
87 for peer in DEFAULT_NODES:
88 addKnownNode(1, peer)
89 saveKnownNodes()
90
91
92 def readKnownNodes():
93 try:
94 with open(state.appdata + 'knownnodes.dat', 'rb') as source:
95 with knownNodesLock:
96 try:
97 json_deserialize_knownnodes(source)
98 except ValueError:
99 source.seek(0)
100 pickle_deserialize_old_knownnodes(source)
101 except (IOError, OSError, KeyError):
102 logger.debug(
103 'Failed to read nodes from knownnodes.dat', exc_info=True)
104 createDefaultKnownNodes()
105
106 config = BMConfigParser()
107 # if config.safeGetInt('bitmessagesettings', 'settingsversion') > 10:
108 # sys.exit(
109 # 'Bitmessage cannot read future versions of the keys file'
110 # ' (keys.dat). Run the newer version of Bitmessage.')
111
112 # your own onion address, if setup
113 onionhostname = config.safeGet('bitmessagesettings', 'onionhostname')
114 if onionhostname and ".onion" in onionhostname:
115 onionport = config.safeGetInt('bitmessagesettings', 'onionport')
116 if onionport:
117 addKnownNode(1, state.Peer(onionhostname, onionport), is_self=True)
118
119
120 def increaseRating(peer):
121 increaseAmount = 0.1
122 maxRating = 1
123 with knownNodesLock:
124 for stream in knownNodes.keys():
125 try:
126 knownNodes[stream][peer]["rating"] = min(
127 knownNodes[stream][peer]["rating"] + increaseAmount,
128 maxRating
129 )
130 except KeyError:
131 pass
132
133
134 def decreaseRating(peer):
135 decreaseAmount = 0.1
136 minRating = -1
137 with knownNodesLock:
138 for stream in knownNodes.keys():
139 try:
140 knownNodes[stream][peer]["rating"] = max(
141 knownNodes[stream][peer]["rating"] - decreaseAmount,
142 minRating
143 )
144 except KeyError:
145 pass
146
147
148 def trimKnownNodes(recAddrStream=1):
149 if len(knownNodes[recAddrStream]) < \
150 BMConfigParser().safeGetInt("knownnodes", "maxnodes"):
151 return
152 with knownNodesLock:
153 oldestList = sorted(
154 knownNodes[recAddrStream],
155 key=lambda x: x['lastseen']
156 )[:knownNodesTrimAmount]
157 for oldest in oldestList:
158 del knownNodes[recAddrStream][oldest]
159
[end of src/knownnodes.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/knownnodes.py b/src/knownnodes.py
--- a/src/knownnodes.py
+++ b/src/knownnodes.py
@@ -98,7 +98,7 @@
except ValueError:
source.seek(0)
pickle_deserialize_old_knownnodes(source)
- except (IOError, OSError, KeyError):
+ except (IOError, OSError, KeyError, EOFError):
logger.debug(
'Failed to read nodes from knownnodes.dat', exc_info=True)
createDefaultKnownNodes()
| {"golden_diff": "diff --git a/src/knownnodes.py b/src/knownnodes.py\n--- a/src/knownnodes.py\n+++ b/src/knownnodes.py\n@@ -98,7 +98,7 @@\n except ValueError:\n source.seek(0)\n pickle_deserialize_old_knownnodes(source)\n- except (IOError, OSError, KeyError):\n+ except (IOError, OSError, KeyError, EOFError):\n logger.debug(\n 'Failed to read nodes from knownnodes.dat', exc_info=True)\n createDefaultKnownNodes()\n", "issue": "Crashing on Boot\n$ python src/bitmessagemain.py \r\nLoading existing config files from /home/.config/PyBitmessage/\r\n2018-08-05 13:19:02,170 - WARNING - Using default logger configuration\r\n2018-08-05 13:19:02,592 - CRITICAL - Unhandled exception\r\nTraceback (most recent call last):\r\n File \"src/bitmessagemain.py\", line 507, in <module>\r\n File \"src/bitmessagemain.py\", line 503, in main\r\n File \"src/bitmessagemain.py\", line 276, in start\r\n File \"PyBitmessage/src/knownnodes.py\", line 100, in readKnownNodes\r\n pickle_deserialize_old_knownnodes(source)\r\n File \"PyBitmessage/src/knownnodes.py\", line 63, in pickle_deserialize_old_knownnodes\r\n knownNodes = pickle.load(source)\r\n File \"/usr/lib/python2.7/pickle.py\", line 1384, in load\r\n return Unpickler(file).load()\r\n File \"/usr/lib/python2.7/pickle.py\", line 864, in load\r\n dispatch[key](self)\r\n File \"/usr/lib/python2.7/pickle.py\", line 886, in load_eof\r\n raise EOFError\r\nEOFError\r\nCleaning up lockfile\r\n\n", "before_files": [{"content": "import json\nimport os\nimport pickle\n# import sys\nimport threading\nimport time\n\nimport state\nfrom bmconfigparser import BMConfigParser\nfrom debug import logger\n\nknownNodesLock = threading.Lock()\nknownNodes = {stream: {} for stream in range(1, 4)}\n\nknownNodesTrimAmount = 2000\n\n# forget a node after rating is this low\nknownNodesForgetRating = -0.5\n\nDEFAULT_NODES = (\n state.Peer('5.45.99.75', 8444),\n state.Peer('75.167.159.54', 8444),\n state.Peer('95.165.168.168', 8444),\n state.Peer('85.180.139.241', 8444),\n state.Peer('158.222.217.190', 8080),\n state.Peer('178.62.12.187', 8448),\n state.Peer('24.188.198.204', 8111),\n state.Peer('109.147.204.113', 1195),\n state.Peer('178.11.46.221', 8444)\n)\n\n\ndef json_serialize_knownnodes(output):\n \"\"\"\n Reorganize knownnodes dict and write it as JSON to output\n \"\"\"\n _serialized = []\n for stream, peers in knownNodes.iteritems():\n for peer, info in peers.iteritems():\n info.update(rating=round(info.get('rating', 0), 2))\n _serialized.append({\n 'stream': stream, 'peer': peer._asdict(), 'info': info\n })\n json.dump(_serialized, output, indent=4)\n\n\ndef json_deserialize_knownnodes(source):\n \"\"\"\n Read JSON from source and make knownnodes dict\n \"\"\"\n for node in json.load(source):\n peer = node['peer']\n peer['host'] = str(peer['host'])\n knownNodes[node['stream']][state.Peer(**peer)] = node['info']\n\n\ndef pickle_deserialize_old_knownnodes(source):\n \"\"\"\n Unpickle source and reorganize knownnodes dict if it's in old format\n the old format was {Peer:lastseen, ...}\n the new format is {Peer:{\"lastseen\":i, \"rating\":f}}\n \"\"\"\n knownNodes = pickle.load(source)\n for stream in knownNodes.keys():\n for node, params in knownNodes[stream].items():\n if isinstance(params, (float, int)):\n addKnownNode(stream, node, params)\n\n\ndef saveKnownNodes(dirName=None):\n if dirName is None:\n dirName = state.appdata\n with knownNodesLock:\n with open(os.path.join(dirName, 'knownnodes.dat'), 'wb') as output:\n json_serialize_knownnodes(output)\n\n\ndef addKnownNode(stream, peer, lastseen=None, is_self=False):\n knownNodes[stream][peer] = {\n \"lastseen\": lastseen or time.time(),\n \"rating\": 0,\n \"self\": is_self,\n }\n\n\ndef createDefaultKnownNodes():\n for peer in DEFAULT_NODES:\n addKnownNode(1, peer)\n saveKnownNodes()\n\n\ndef readKnownNodes():\n try:\n with open(state.appdata + 'knownnodes.dat', 'rb') as source:\n with knownNodesLock:\n try:\n json_deserialize_knownnodes(source)\n except ValueError:\n source.seek(0)\n pickle_deserialize_old_knownnodes(source)\n except (IOError, OSError, KeyError):\n logger.debug(\n 'Failed to read nodes from knownnodes.dat', exc_info=True)\n createDefaultKnownNodes()\n\n config = BMConfigParser()\n # if config.safeGetInt('bitmessagesettings', 'settingsversion') > 10:\n # sys.exit(\n # 'Bitmessage cannot read future versions of the keys file'\n # ' (keys.dat). Run the newer version of Bitmessage.')\n\n # your own onion address, if setup\n onionhostname = config.safeGet('bitmessagesettings', 'onionhostname')\n if onionhostname and \".onion\" in onionhostname:\n onionport = config.safeGetInt('bitmessagesettings', 'onionport')\n if onionport:\n addKnownNode(1, state.Peer(onionhostname, onionport), is_self=True)\n\n\ndef increaseRating(peer):\n increaseAmount = 0.1\n maxRating = 1\n with knownNodesLock:\n for stream in knownNodes.keys():\n try:\n knownNodes[stream][peer][\"rating\"] = min(\n knownNodes[stream][peer][\"rating\"] + increaseAmount,\n maxRating\n )\n except KeyError:\n pass\n\n\ndef decreaseRating(peer):\n decreaseAmount = 0.1\n minRating = -1\n with knownNodesLock:\n for stream in knownNodes.keys():\n try:\n knownNodes[stream][peer][\"rating\"] = max(\n knownNodes[stream][peer][\"rating\"] - decreaseAmount,\n minRating\n )\n except KeyError:\n pass\n\n\ndef trimKnownNodes(recAddrStream=1):\n if len(knownNodes[recAddrStream]) < \\\n BMConfigParser().safeGetInt(\"knownnodes\", \"maxnodes\"):\n return\n with knownNodesLock:\n oldestList = sorted(\n knownNodes[recAddrStream],\n key=lambda x: x['lastseen']\n )[:knownNodesTrimAmount]\n for oldest in oldestList:\n del knownNodes[recAddrStream][oldest]\n", "path": "src/knownnodes.py"}]} | 2,493 | 113 |
gh_patches_debug_31249 | rasdani/github-patches | git_diff | scikit-hep__pyhf-2278 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Documentation of default Minuit strategy choice
### Summary
The documentation of `minuit_optimizer` lists `strategy` as a possible kwarg with default value of `None`, but it does not explain what that choice leads to. `pyhf` uses `0`/`1` depending on whether user-provided gradients are used (#1172 / #1183), and I believe it would be good to have that documented on the optimizer page. I'd be happy to submit a PR.
### Documentation Page Link
https://pyhf.readthedocs.io/en/v0.6.3/_generated/pyhf.optimize.opt_minuit.minuit_optimizer.html#pyhf.optimize.opt_minuit.minuit_optimizer
### Code of Conduct
- [X] I agree to follow the Code of Conduct
</issue>
<code>
[start of src/pyhf/optimize/opt_minuit.py]
1 """Minuit Optimizer Class."""
2 from pyhf import exceptions
3 from pyhf.optimize.mixins import OptimizerMixin
4 import scipy
5 import iminuit
6
7
8 class minuit_optimizer(OptimizerMixin):
9 """
10 Optimizer that minimizes via :meth:`iminuit.Minuit.migrad`.
11 """
12
13 __slots__ = ['name', 'errordef', 'steps', 'strategy', 'tolerance']
14
15 def __init__(self, *args, **kwargs):
16 """
17 Create :class:`iminuit.Minuit` optimizer.
18
19 .. note::
20
21 ``errordef`` should be 1.0 for a least-squares cost function and 0.50
22 for negative log-likelihood function --- see `MINUIT: Function Minimization
23 and Error Analysis Reference Manual <https://cdsweb.cern.ch/record/2296388/>`_
24 Section 7.1: Function normalization and ERROR DEF.
25 This parameter is sometimes called ``UP`` in the ``MINUIT`` docs.
26
27
28 Args:
29 errordef (:obj:`float`): See minuit docs. Default is ``1.0``.
30 steps (:obj:`int`): Number of steps for the bounds. Default is ``1000``.
31 strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`. Default is ``None``.
32 tolerance (:obj:`float`): Tolerance for termination.
33 See specific optimizer for detailed meaning.
34 Default is ``0.1``.
35 """
36 self.name = 'minuit'
37 self.errordef = kwargs.pop('errordef', 1)
38 self.steps = kwargs.pop('steps', 1000)
39 self.strategy = kwargs.pop('strategy', None)
40 self.tolerance = kwargs.pop('tolerance', 0.1)
41 super().__init__(*args, **kwargs)
42
43 def _get_minimizer(
44 self,
45 objective_and_grad,
46 init_pars,
47 init_bounds,
48 fixed_vals=None,
49 do_grad=False,
50 par_names=None,
51 ):
52 fixed_vals = fixed_vals or []
53 # Minuit wants True/False for each parameter
54 fixed_bools = [False] * len(init_pars)
55 for index, val in fixed_vals:
56 fixed_bools[index] = True
57 init_pars[index] = val
58
59 # Minuit requires jac=callable
60 if do_grad:
61 wrapped_objective = lambda pars: objective_and_grad(pars)[0] # noqa: E731
62 jac = lambda pars: objective_and_grad(pars)[1] # noqa: E731
63 else:
64 wrapped_objective = objective_and_grad
65 jac = None
66
67 minuit = iminuit.Minuit(wrapped_objective, init_pars, grad=jac, name=par_names)
68 minuit.limits = init_bounds
69 minuit.fixed = fixed_bools
70 minuit.print_level = self.verbose
71 minuit.errordef = self.errordef
72 return minuit
73
74 def _minimize(
75 self,
76 minimizer,
77 func,
78 x0,
79 do_grad=False,
80 bounds=None,
81 fixed_vals=None,
82 options={},
83 ):
84 """
85 Same signature as :func:`scipy.optimize.minimize`.
86
87 Note: an additional `minuit` is injected into the fitresult to get the
88 underlying minimizer.
89
90 Minimizer Options:
91 * maxiter (:obj:`int`): Maximum number of iterations. Default is ``100000``.
92 * strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`.
93 Default is to configure in response to ``do_grad``.
94 * tolerance (:obj:`float`): Tolerance for termination.
95 See specific optimizer for detailed meaning.
96 Default is ``0.1``.
97
98 Returns:
99 fitresult (scipy.optimize.OptimizeResult): the fit result
100 """
101 maxiter = options.pop('maxiter', self.maxiter)
102 # 0: Fast, user-provided gradient
103 # 1: Default, no user-provided gradient
104 strategy = options.pop(
105 'strategy', self.strategy if self.strategy is not None else not do_grad
106 )
107 tolerance = options.pop('tolerance', self.tolerance)
108 if options:
109 raise exceptions.Unsupported(
110 f"Unsupported options were passed in: {list(options)}."
111 )
112
113 minimizer.strategy = strategy
114 minimizer.tol = tolerance
115 minimizer.migrad(ncall=maxiter)
116 # Following lines below come from:
117 # https://github.com/scikit-hep/iminuit/blob/23bad7697e39d363f259ca8349684df939b1b2e6/src/iminuit/_minimize.py#L111-L130
118 message = "Optimization terminated successfully."
119 if not minimizer.valid:
120 message = "Optimization failed."
121 fmin = minimizer.fmin
122 if fmin.has_reached_call_limit:
123 message += " Call limit was reached."
124 if fmin.is_above_max_edm:
125 message += " Estimated distance to minimum too large."
126
127 hess_inv = None
128 corr = None
129 unc = None
130 if minimizer.valid:
131 # Extra call to hesse() after migrad() is always needed for good error estimates. If you pass a user-provided gradient to MINUIT, convergence is faster.
132 minimizer.hesse()
133 hess_inv = minimizer.covariance
134 corr = hess_inv.correlation()
135 unc = minimizer.errors
136
137 return scipy.optimize.OptimizeResult(
138 x=minimizer.values,
139 unc=unc,
140 corr=corr,
141 success=minimizer.valid,
142 fun=minimizer.fval,
143 hess_inv=hess_inv,
144 message=message,
145 nfev=minimizer.nfcn,
146 njev=minimizer.ngrad,
147 minuit=minimizer,
148 )
149
[end of src/pyhf/optimize/opt_minuit.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/pyhf/optimize/opt_minuit.py b/src/pyhf/optimize/opt_minuit.py
--- a/src/pyhf/optimize/opt_minuit.py
+++ b/src/pyhf/optimize/opt_minuit.py
@@ -28,7 +28,10 @@
Args:
errordef (:obj:`float`): See minuit docs. Default is ``1.0``.
steps (:obj:`int`): Number of steps for the bounds. Default is ``1000``.
- strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`. Default is ``None``.
+ strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`.
+ Default is ``None``, which results in either
+ :attr:`iminuit.Minuit.strategy` ``0`` or ``1`` from the evaluation of
+ ``int(not pyhf.tensorlib.default_do_grad)``.
tolerance (:obj:`float`): Tolerance for termination.
See specific optimizer for detailed meaning.
Default is ``0.1``.
@@ -99,11 +102,14 @@
fitresult (scipy.optimize.OptimizeResult): the fit result
"""
maxiter = options.pop('maxiter', self.maxiter)
- # 0: Fast, user-provided gradient
- # 1: Default, no user-provided gradient
- strategy = options.pop(
- 'strategy', self.strategy if self.strategy is not None else not do_grad
- )
+ # do_grad value results in iminuit.Minuit.strategy of either:
+ # 0: Fast. Does not check a user-provided gradient.
+ # 1: Default. Checks user-provided gradient against numerical gradient.
+ strategy = options.pop("strategy", self.strategy)
+ # Guard against None from either self.strategy defaulting to None or
+ # passing strategy=None as options kwarg
+ if strategy is None:
+ strategy = 0 if do_grad else 1
tolerance = options.pop('tolerance', self.tolerance)
if options:
raise exceptions.Unsupported(
| {"golden_diff": "diff --git a/src/pyhf/optimize/opt_minuit.py b/src/pyhf/optimize/opt_minuit.py\n--- a/src/pyhf/optimize/opt_minuit.py\n+++ b/src/pyhf/optimize/opt_minuit.py\n@@ -28,7 +28,10 @@\n Args:\n errordef (:obj:`float`): See minuit docs. Default is ``1.0``.\n steps (:obj:`int`): Number of steps for the bounds. Default is ``1000``.\n- strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`. Default is ``None``.\n+ strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`.\n+ Default is ``None``, which results in either\n+ :attr:`iminuit.Minuit.strategy` ``0`` or ``1`` from the evaluation of\n+ ``int(not pyhf.tensorlib.default_do_grad)``.\n tolerance (:obj:`float`): Tolerance for termination.\n See specific optimizer for detailed meaning.\n Default is ``0.1``.\n@@ -99,11 +102,14 @@\n fitresult (scipy.optimize.OptimizeResult): the fit result\n \"\"\"\n maxiter = options.pop('maxiter', self.maxiter)\n- # 0: Fast, user-provided gradient\n- # 1: Default, no user-provided gradient\n- strategy = options.pop(\n- 'strategy', self.strategy if self.strategy is not None else not do_grad\n- )\n+ # do_grad value results in iminuit.Minuit.strategy of either:\n+ # 0: Fast. Does not check a user-provided gradient.\n+ # 1: Default. Checks user-provided gradient against numerical gradient.\n+ strategy = options.pop(\"strategy\", self.strategy)\n+ # Guard against None from either self.strategy defaulting to None or\n+ # passing strategy=None as options kwarg\n+ if strategy is None:\n+ strategy = 0 if do_grad else 1\n tolerance = options.pop('tolerance', self.tolerance)\n if options:\n raise exceptions.Unsupported(\n", "issue": "Documentation of default Minuit strategy choice\n### Summary\n\nThe documentation of `minuit_optimizer` lists `strategy` as a possible kwarg with default value of `None`, but it does not explain what that choice leads to. `pyhf` uses `0`/`1` depending on whether user-provided gradients are used (#1172 / #1183), and I believe it would be good to have that documented on the optimizer page. I'd be happy to submit a PR.\n\n### Documentation Page Link\n\nhttps://pyhf.readthedocs.io/en/v0.6.3/_generated/pyhf.optimize.opt_minuit.minuit_optimizer.html#pyhf.optimize.opt_minuit.minuit_optimizer\n\n### Code of Conduct\n\n- [X] I agree to follow the Code of Conduct\n", "before_files": [{"content": "\"\"\"Minuit Optimizer Class.\"\"\"\nfrom pyhf import exceptions\nfrom pyhf.optimize.mixins import OptimizerMixin\nimport scipy\nimport iminuit\n\n\nclass minuit_optimizer(OptimizerMixin):\n \"\"\"\n Optimizer that minimizes via :meth:`iminuit.Minuit.migrad`.\n \"\"\"\n\n __slots__ = ['name', 'errordef', 'steps', 'strategy', 'tolerance']\n\n def __init__(self, *args, **kwargs):\n \"\"\"\n Create :class:`iminuit.Minuit` optimizer.\n\n .. note::\n\n ``errordef`` should be 1.0 for a least-squares cost function and 0.50\n for negative log-likelihood function --- see `MINUIT: Function Minimization\n and Error Analysis Reference Manual <https://cdsweb.cern.ch/record/2296388/>`_\n Section 7.1: Function normalization and ERROR DEF.\n This parameter is sometimes called ``UP`` in the ``MINUIT`` docs.\n\n\n Args:\n errordef (:obj:`float`): See minuit docs. Default is ``1.0``.\n steps (:obj:`int`): Number of steps for the bounds. Default is ``1000``.\n strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`. Default is ``None``.\n tolerance (:obj:`float`): Tolerance for termination.\n See specific optimizer for detailed meaning.\n Default is ``0.1``.\n \"\"\"\n self.name = 'minuit'\n self.errordef = kwargs.pop('errordef', 1)\n self.steps = kwargs.pop('steps', 1000)\n self.strategy = kwargs.pop('strategy', None)\n self.tolerance = kwargs.pop('tolerance', 0.1)\n super().__init__(*args, **kwargs)\n\n def _get_minimizer(\n self,\n objective_and_grad,\n init_pars,\n init_bounds,\n fixed_vals=None,\n do_grad=False,\n par_names=None,\n ):\n fixed_vals = fixed_vals or []\n # Minuit wants True/False for each parameter\n fixed_bools = [False] * len(init_pars)\n for index, val in fixed_vals:\n fixed_bools[index] = True\n init_pars[index] = val\n\n # Minuit requires jac=callable\n if do_grad:\n wrapped_objective = lambda pars: objective_and_grad(pars)[0] # noqa: E731\n jac = lambda pars: objective_and_grad(pars)[1] # noqa: E731\n else:\n wrapped_objective = objective_and_grad\n jac = None\n\n minuit = iminuit.Minuit(wrapped_objective, init_pars, grad=jac, name=par_names)\n minuit.limits = init_bounds\n minuit.fixed = fixed_bools\n minuit.print_level = self.verbose\n minuit.errordef = self.errordef\n return minuit\n\n def _minimize(\n self,\n minimizer,\n func,\n x0,\n do_grad=False,\n bounds=None,\n fixed_vals=None,\n options={},\n ):\n \"\"\"\n Same signature as :func:`scipy.optimize.minimize`.\n\n Note: an additional `minuit` is injected into the fitresult to get the\n underlying minimizer.\n\n Minimizer Options:\n * maxiter (:obj:`int`): Maximum number of iterations. Default is ``100000``.\n * strategy (:obj:`int`): See :attr:`iminuit.Minuit.strategy`.\n Default is to configure in response to ``do_grad``.\n * tolerance (:obj:`float`): Tolerance for termination.\n See specific optimizer for detailed meaning.\n Default is ``0.1``.\n\n Returns:\n fitresult (scipy.optimize.OptimizeResult): the fit result\n \"\"\"\n maxiter = options.pop('maxiter', self.maxiter)\n # 0: Fast, user-provided gradient\n # 1: Default, no user-provided gradient\n strategy = options.pop(\n 'strategy', self.strategy if self.strategy is not None else not do_grad\n )\n tolerance = options.pop('tolerance', self.tolerance)\n if options:\n raise exceptions.Unsupported(\n f\"Unsupported options were passed in: {list(options)}.\"\n )\n\n minimizer.strategy = strategy\n minimizer.tol = tolerance\n minimizer.migrad(ncall=maxiter)\n # Following lines below come from:\n # https://github.com/scikit-hep/iminuit/blob/23bad7697e39d363f259ca8349684df939b1b2e6/src/iminuit/_minimize.py#L111-L130\n message = \"Optimization terminated successfully.\"\n if not minimizer.valid:\n message = \"Optimization failed.\"\n fmin = minimizer.fmin\n if fmin.has_reached_call_limit:\n message += \" Call limit was reached.\"\n if fmin.is_above_max_edm:\n message += \" Estimated distance to minimum too large.\"\n\n hess_inv = None\n corr = None\n unc = None\n if minimizer.valid:\n # Extra call to hesse() after migrad() is always needed for good error estimates. If you pass a user-provided gradient to MINUIT, convergence is faster.\n minimizer.hesse()\n hess_inv = minimizer.covariance\n corr = hess_inv.correlation()\n unc = minimizer.errors\n\n return scipy.optimize.OptimizeResult(\n x=minimizer.values,\n unc=unc,\n corr=corr,\n success=minimizer.valid,\n fun=minimizer.fval,\n hess_inv=hess_inv,\n message=message,\n nfev=minimizer.nfcn,\n njev=minimizer.ngrad,\n minuit=minimizer,\n )\n", "path": "src/pyhf/optimize/opt_minuit.py"}]} | 2,349 | 471 |
gh_patches_debug_15378 | rasdani/github-patches | git_diff | mkdocs__mkdocs-244 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Default theme files are added when a custom theme is used and no "parent" theme is specified
I'm using `theme_dir` to specify a custom theme directory with the latest versions of Bootstrap and Font Awesome, and I'm not specifying `theme` because I don't want to inherit files from a parent theme. However, since `theme` defaults to 'mkdocs', my site directory ends up with two different versions of these libraries in addition to other files I'm not using like prettify.
I tried explicitly setting `theme` to null, but that didn't work. As a hack, setting `theme` to a custom name works for `mkdocs build`, but not `mkdocs serve`.
This wasn't an issue with v0.9, but I've noticed it since upgrading to v0.11.1.
</issue>
<code>
[start of mkdocs/config.py]
1 # coding: utf-8
2
3 from mkdocs import utils
4 from mkdocs.compat import urlparse
5 from mkdocs.exceptions import ConfigurationError
6
7 import os
8 import yaml
9
10 DEFAULT_CONFIG = {
11 'site_name': None,
12 'pages': None,
13
14 'site_url': None,
15 'site_description': None,
16 'site_author': None,
17 'site_favicon': None,
18
19 'theme': 'mkdocs',
20 'docs_dir': 'docs',
21 'site_dir': 'site',
22 'theme_dir': None,
23
24 'copyright': None,
25 'google_analytics': None,
26
27 # The address on which to serve the livereloading docs server.
28 'dev_addr': '127.0.0.1:8000',
29
30 # If `True`, use `<page_name>/index.hmtl` style files with hyperlinks to the directory.
31 # If `False`, use `<page_name>.html style file with hyperlinks to the file.
32 # True generates nicer URLs, but False is useful if browsing the output on a filesystem.
33 'use_directory_urls': True,
34
35 # Specify a link to the project source repo to be included
36 # in the documentation pages.
37 'repo_url': None,
38
39 # A name to use for the link to the project source repo.
40 # Default: If repo_url is unset then None, otherwise
41 # "GitHub" or "Bitbucket" for known url or Hostname for unknown urls.
42 'repo_name': None,
43
44 # Specify which css or javascript files from the docs
45 # directionary should be additionally included in the site.
46 # Default: List of all .css and .js files in the docs dir.
47 'extra_css': None,
48 'extra_javascript': None,
49
50 # Determine if the site should include the nav and next/prev elements.
51 # Default: True if the site has more than one page, False otherwise.
52 'include_nav': None,
53 'include_next_prev': None,
54
55 # PyMarkdown extension names.
56 'markdown_extensions': (),
57
58 # Determine if the site should generate a json search index and include
59 # search elements in the theme. - TODO
60 'include_search': False,
61
62 # Determine if the site should include a 404.html page.
63 # TODO: Implment this. Make this None, have it True if a 404.html
64 # template exists in the theme or docs dir.
65 'include_404': False,
66
67 # Determine if the site should include a sitemap.xml page.
68 # TODO: Implement this. Make this None, have it True if a sitemap.xml
69 # template exists in the theme or docs dir.
70 'include_sitemap': False,
71 }
72
73
74 def load_config(filename='mkdocs.yml', options=None):
75 options = options or {}
76 if 'config' in options:
77 filename = options['config']
78 if not os.path.exists(filename):
79 raise ConfigurationError("Config file '%s' does not exist." % filename)
80 with open(filename, 'r') as fp:
81 user_config = yaml.load(fp)
82 user_config.update(options)
83 return validate_config(user_config)
84
85
86 def validate_config(user_config):
87 config = DEFAULT_CONFIG.copy()
88 config.update(user_config)
89
90 if not config['site_name']:
91 raise ConfigurationError("Config must contain 'site_name' setting.")
92
93 # If not specified, then the 'pages' config simply includes all
94 # markdown files in the docs dir, without generating any header items
95 # for them.
96 pages = []
97 extra_css = []
98 extra_javascript = []
99 for (dirpath, dirnames, filenames) in os.walk(config['docs_dir']):
100 for filename in sorted(filenames):
101 fullpath = os.path.join(dirpath, filename)
102 relpath = os.path.relpath(fullpath, config['docs_dir'])
103
104 if utils.is_markdown_file(filename):
105 # index pages should always be the first listed page.
106 if os.path.splitext(relpath)[0] == 'index':
107 pages.insert(0, relpath)
108 else:
109 pages.append(relpath)
110 elif utils.is_css_file(filename):
111 extra_css.append(relpath)
112 elif utils.is_javascript_file(filename):
113 extra_javascript.append(relpath)
114
115 if config['pages'] is None:
116 config['pages'] = pages
117
118 if config['extra_css'] is None:
119 config['extra_css'] = extra_css
120
121 if config['extra_javascript'] is None:
122 config['extra_javascript'] = extra_javascript
123
124 package_dir = os.path.dirname(__file__)
125 theme_dir = [os.path.join(package_dir, 'themes', config['theme'])]
126
127 if config['theme_dir'] is not None:
128 theme_dir.insert(0, config['theme_dir'])
129
130 config['theme_dir'] = theme_dir
131
132 if config['repo_url'] is not None and config['repo_name'] is None:
133 repo_host = urlparse(config['repo_url']).netloc.lower()
134 if repo_host == 'github.com':
135 config['repo_name'] = 'GitHub'
136 elif repo_host == 'bitbucket.com':
137 config['repo_name'] = 'Bitbucket'
138 else:
139 config['repo_name'] = repo_host.split('.')[0].title()
140
141 if config['include_next_prev'] is None:
142 config['include_next_prev'] = len(config['pages']) > 1
143
144 if config['include_nav'] is None:
145 config['include_nav'] = len(config['pages']) > 1
146
147 # To Do:
148
149 # The docs dir must exist.
150 # The theme dir must exist.
151 # Ensure 'theme' is one of 'mkdocs', 'readthedocs', 'custom'
152 # A homepage 'index' must exist.
153 # The theme 'base.html' file must exist.
154 # Cannot set repo_name without setting repo_url.
155 # Cannot set 'include_next_prev: true' when only one page exists.
156 # Cannot set 'include_nav: true' when only one page exists.
157 # Error if any config keys provided that are not in the DEFAULT_CONFIG.
158
159 return config
160
[end of mkdocs/config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/mkdocs/config.py b/mkdocs/config.py
--- a/mkdocs/config.py
+++ b/mkdocs/config.py
@@ -85,6 +85,9 @@
def validate_config(user_config):
config = DEFAULT_CONFIG.copy()
+
+ theme_in_config = 'theme' in user_config
+
config.update(user_config)
if not config['site_name']:
@@ -125,6 +128,10 @@
theme_dir = [os.path.join(package_dir, 'themes', config['theme'])]
if config['theme_dir'] is not None:
+ # If the user has given us a custom theme but not a
+ # builtin theme name then we don't want to merge them.
+ if not theme_in_config:
+ theme_dir = []
theme_dir.insert(0, config['theme_dir'])
config['theme_dir'] = theme_dir
| {"golden_diff": "diff --git a/mkdocs/config.py b/mkdocs/config.py\n--- a/mkdocs/config.py\n+++ b/mkdocs/config.py\n@@ -85,6 +85,9 @@\n \n def validate_config(user_config):\n config = DEFAULT_CONFIG.copy()\n+\n+ theme_in_config = 'theme' in user_config\n+\n config.update(user_config)\n \n if not config['site_name']:\n@@ -125,6 +128,10 @@\n theme_dir = [os.path.join(package_dir, 'themes', config['theme'])]\n \n if config['theme_dir'] is not None:\n+ # If the user has given us a custom theme but not a\n+ # builtin theme name then we don't want to merge them.\n+ if not theme_in_config:\n+ theme_dir = []\n theme_dir.insert(0, config['theme_dir'])\n \n config['theme_dir'] = theme_dir\n", "issue": "Default theme files are added when a custom theme is used and no \"parent\" theme is specified\nI'm using `theme_dir` to specify a custom theme directory with the latest versions of Bootstrap and Font Awesome, and I'm not specifying `theme` because I don't want to inherit files from a parent theme. However, since `theme` defaults to 'mkdocs', my site directory ends up with two different versions of these libraries in addition to other files I'm not using like prettify.\n\nI tried explicitly setting `theme` to null, but that didn't work. As a hack, setting `theme` to a custom name works for `mkdocs build`, but not `mkdocs serve`.\n\nThis wasn't an issue with v0.9, but I've noticed it since upgrading to v0.11.1.\n\n", "before_files": [{"content": "# coding: utf-8\n\nfrom mkdocs import utils\nfrom mkdocs.compat import urlparse\nfrom mkdocs.exceptions import ConfigurationError\n\nimport os\nimport yaml\n\nDEFAULT_CONFIG = {\n 'site_name': None,\n 'pages': None,\n\n 'site_url': None,\n 'site_description': None,\n 'site_author': None,\n 'site_favicon': None,\n\n 'theme': 'mkdocs',\n 'docs_dir': 'docs',\n 'site_dir': 'site',\n 'theme_dir': None,\n\n 'copyright': None,\n 'google_analytics': None,\n\n # The address on which to serve the livereloading docs server.\n 'dev_addr': '127.0.0.1:8000',\n\n # If `True`, use `<page_name>/index.hmtl` style files with hyperlinks to the directory.\n # If `False`, use `<page_name>.html style file with hyperlinks to the file.\n # True generates nicer URLs, but False is useful if browsing the output on a filesystem.\n 'use_directory_urls': True,\n\n # Specify a link to the project source repo to be included\n # in the documentation pages.\n 'repo_url': None,\n\n # A name to use for the link to the project source repo.\n # Default: If repo_url is unset then None, otherwise\n # \"GitHub\" or \"Bitbucket\" for known url or Hostname for unknown urls.\n 'repo_name': None,\n\n # Specify which css or javascript files from the docs\n # directionary should be additionally included in the site.\n # Default: List of all .css and .js files in the docs dir.\n 'extra_css': None,\n 'extra_javascript': None,\n\n # Determine if the site should include the nav and next/prev elements.\n # Default: True if the site has more than one page, False otherwise.\n 'include_nav': None,\n 'include_next_prev': None,\n\n # PyMarkdown extension names.\n 'markdown_extensions': (),\n\n # Determine if the site should generate a json search index and include\n # search elements in the theme. - TODO\n 'include_search': False,\n\n # Determine if the site should include a 404.html page.\n # TODO: Implment this. Make this None, have it True if a 404.html\n # template exists in the theme or docs dir.\n 'include_404': False,\n\n # Determine if the site should include a sitemap.xml page.\n # TODO: Implement this. Make this None, have it True if a sitemap.xml\n # template exists in the theme or docs dir.\n 'include_sitemap': False,\n}\n\n\ndef load_config(filename='mkdocs.yml', options=None):\n options = options or {}\n if 'config' in options:\n filename = options['config']\n if not os.path.exists(filename):\n raise ConfigurationError(\"Config file '%s' does not exist.\" % filename)\n with open(filename, 'r') as fp:\n user_config = yaml.load(fp)\n user_config.update(options)\n return validate_config(user_config)\n\n\ndef validate_config(user_config):\n config = DEFAULT_CONFIG.copy()\n config.update(user_config)\n\n if not config['site_name']:\n raise ConfigurationError(\"Config must contain 'site_name' setting.\")\n\n # If not specified, then the 'pages' config simply includes all\n # markdown files in the docs dir, without generating any header items\n # for them.\n pages = []\n extra_css = []\n extra_javascript = []\n for (dirpath, dirnames, filenames) in os.walk(config['docs_dir']):\n for filename in sorted(filenames):\n fullpath = os.path.join(dirpath, filename)\n relpath = os.path.relpath(fullpath, config['docs_dir'])\n\n if utils.is_markdown_file(filename):\n # index pages should always be the first listed page.\n if os.path.splitext(relpath)[0] == 'index':\n pages.insert(0, relpath)\n else:\n pages.append(relpath)\n elif utils.is_css_file(filename):\n extra_css.append(relpath)\n elif utils.is_javascript_file(filename):\n extra_javascript.append(relpath)\n\n if config['pages'] is None:\n config['pages'] = pages\n\n if config['extra_css'] is None:\n config['extra_css'] = extra_css\n\n if config['extra_javascript'] is None:\n config['extra_javascript'] = extra_javascript\n\n package_dir = os.path.dirname(__file__)\n theme_dir = [os.path.join(package_dir, 'themes', config['theme'])]\n\n if config['theme_dir'] is not None:\n theme_dir.insert(0, config['theme_dir'])\n\n config['theme_dir'] = theme_dir\n\n if config['repo_url'] is not None and config['repo_name'] is None:\n repo_host = urlparse(config['repo_url']).netloc.lower()\n if repo_host == 'github.com':\n config['repo_name'] = 'GitHub'\n elif repo_host == 'bitbucket.com':\n config['repo_name'] = 'Bitbucket'\n else:\n config['repo_name'] = repo_host.split('.')[0].title()\n\n if config['include_next_prev'] is None:\n config['include_next_prev'] = len(config['pages']) > 1\n\n if config['include_nav'] is None:\n config['include_nav'] = len(config['pages']) > 1\n\n # To Do:\n\n # The docs dir must exist.\n # The theme dir must exist.\n # Ensure 'theme' is one of 'mkdocs', 'readthedocs', 'custom'\n # A homepage 'index' must exist.\n # The theme 'base.html' file must exist.\n # Cannot set repo_name without setting repo_url.\n # Cannot set 'include_next_prev: true' when only one page exists.\n # Cannot set 'include_nav: true' when only one page exists.\n # Error if any config keys provided that are not in the DEFAULT_CONFIG.\n\n return config\n", "path": "mkdocs/config.py"}]} | 2,413 | 202 |
gh_patches_debug_16844 | rasdani/github-patches | git_diff | aws-cloudformation__cfn-lint-1227 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Warning Check on Unused Parameter hides Error Check about Missing Parameter Type
*cfn-lint version: cfn-lint 0.25.3*
Parameters defined in a template, but not directly used, are not validated for missing attributes like `Type`.
For various reasons, we want to include parameters in our templates that are not used by resources in the templates and therefore disable `W2001` When this happens, the following template will not fail cfn-lint. If I uncomment the `Metadata` section, I will finally see the `E1012` failure. I should not have to resolve a Warning in order to unmask an Error.
```yaml
Parameters:
Foo:
Description: "Foo?"
Conditions:
AlwaysFalse: !Equals [ true, false ]
Resources:
# Metadata:
# Foo: !Ref Foo
NullResource:
Type: Custom::NullResource
Condition: AlwaysFalse
```
</issue>
<code>
[start of src/cfnlint/rules/parameters/Configuration.py]
1 """
2 Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.
3 SPDX-License-Identifier: MIT-0
4 """
5 from cfnlint.rules import CloudFormationLintRule
6 from cfnlint.rules import RuleMatch
7
8
9 class Configuration(CloudFormationLintRule):
10 """Check if Parameters are configured correctly"""
11 id = 'E2001'
12 shortdesc = 'Parameters have appropriate properties'
13 description = 'Making sure the parameters are properly configured'
14 source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/parameters-section-structure.html'
15 tags = ['parameters']
16
17 valid_keys = [
18 'AllowedPattern',
19 'AllowedValues',
20 'ConstraintDescription',
21 'Default',
22 'Description',
23 'MaxLength',
24 'MaxValue',
25 'MinLength',
26 'MinValue',
27 'NoEcho',
28 'Type',
29 ]
30
31 def match(self, cfn):
32 """Check CloudFormation Parameters"""
33
34 matches = []
35
36 for paramname, paramvalue in cfn.get_parameters().items():
37 for propname, _ in paramvalue.items():
38 if propname not in self.valid_keys:
39 message = 'Parameter {0} has invalid property {1}'
40 matches.append(RuleMatch(
41 ['Parameters', paramname, propname],
42 message.format(paramname, propname)
43 ))
44
45 return matches
46
[end of src/cfnlint/rules/parameters/Configuration.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/cfnlint/rules/parameters/Configuration.py b/src/cfnlint/rules/parameters/Configuration.py
--- a/src/cfnlint/rules/parameters/Configuration.py
+++ b/src/cfnlint/rules/parameters/Configuration.py
@@ -28,6 +28,10 @@
'Type',
]
+ required_keys = [
+ 'Type'
+ ]
+
def match(self, cfn):
"""Check CloudFormation Parameters"""
@@ -41,5 +45,12 @@
['Parameters', paramname, propname],
message.format(paramname, propname)
))
+ for reqname in self.required_keys:
+ if reqname not in paramvalue.keys():
+ message = 'Parameter {0} is missing required property {1}'
+ matches.append(RuleMatch(
+ ['Parameters', paramname],
+ message.format(paramname, reqname)
+ ))
return matches
| {"golden_diff": "diff --git a/src/cfnlint/rules/parameters/Configuration.py b/src/cfnlint/rules/parameters/Configuration.py\n--- a/src/cfnlint/rules/parameters/Configuration.py\n+++ b/src/cfnlint/rules/parameters/Configuration.py\n@@ -28,6 +28,10 @@\n 'Type',\n ]\n \n+ required_keys = [\n+ 'Type'\n+ ]\n+\n def match(self, cfn):\n \"\"\"Check CloudFormation Parameters\"\"\"\n \n@@ -41,5 +45,12 @@\n ['Parameters', paramname, propname],\n message.format(paramname, propname)\n ))\n+ for reqname in self.required_keys:\n+ if reqname not in paramvalue.keys():\n+ message = 'Parameter {0} is missing required property {1}'\n+ matches.append(RuleMatch(\n+ ['Parameters', paramname],\n+ message.format(paramname, reqname)\n+ ))\n \n return matches\n", "issue": "Warning Check on Unused Parameter hides Error Check about Missing Parameter Type\n*cfn-lint version: cfn-lint 0.25.3*\r\n\r\nParameters defined in a template, but not directly used, are not validated for missing attributes like `Type`.\r\n\r\nFor various reasons, we want to include parameters in our templates that are not used by resources in the templates and therefore disable `W2001` When this happens, the following template will not fail cfn-lint. If I uncomment the `Metadata` section, I will finally see the `E1012` failure. I should not have to resolve a Warning in order to unmask an Error.\r\n\r\n```yaml\r\nParameters:\r\n Foo:\r\n Description: \"Foo?\"\r\nConditions:\r\n AlwaysFalse: !Equals [ true, false ]\r\nResources:\r\n # Metadata:\r\n # Foo: !Ref Foo\r\n NullResource:\r\n Type: Custom::NullResource\r\n Condition: AlwaysFalse\r\n```\r\n\n", "before_files": [{"content": "\"\"\"\nCopyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nfrom cfnlint.rules import CloudFormationLintRule\nfrom cfnlint.rules import RuleMatch\n\n\nclass Configuration(CloudFormationLintRule):\n \"\"\"Check if Parameters are configured correctly\"\"\"\n id = 'E2001'\n shortdesc = 'Parameters have appropriate properties'\n description = 'Making sure the parameters are properly configured'\n source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/parameters-section-structure.html'\n tags = ['parameters']\n\n valid_keys = [\n 'AllowedPattern',\n 'AllowedValues',\n 'ConstraintDescription',\n 'Default',\n 'Description',\n 'MaxLength',\n 'MaxValue',\n 'MinLength',\n 'MinValue',\n 'NoEcho',\n 'Type',\n ]\n\n def match(self, cfn):\n \"\"\"Check CloudFormation Parameters\"\"\"\n\n matches = []\n\n for paramname, paramvalue in cfn.get_parameters().items():\n for propname, _ in paramvalue.items():\n if propname not in self.valid_keys:\n message = 'Parameter {0} has invalid property {1}'\n matches.append(RuleMatch(\n ['Parameters', paramname, propname],\n message.format(paramname, propname)\n ))\n\n return matches\n", "path": "src/cfnlint/rules/parameters/Configuration.py"}]} | 1,126 | 208 |
gh_patches_debug_2759 | rasdani/github-patches | git_diff | getnikola__nikola-3437 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
The post_list plugin prevents 'else' functionality in templates
<!--
Before creating an issue:
* make sure you are using an up-to-date version of Nikola
* search for existing issues that might be related
Make sure to:
* provide information about your environment (below)
* include all the output you get, and any other information related to your problem
Nikola v7.6.4, as provided by Ubuntu, is NOT SUPPORTED.
If you are using this version, you should upgrade: https://getnikola.com/getting-started.html
-->
### Environment
**Python Version:**
3.7.8
**Nikola Version:**
8.1.1
**Operating System:**
Mac OS Catalina (10.15.5) / Ubuntu 19.10
### Description:
In the default template for the `post-list` plugin, namely `post_list_directive.tmpl`
```python
{% if posts %}
<ul class="post-list">
...
```
Which suggests that there is some possibility that the template will be called with no posts.
While in `list_post.tmpl`, which you can also use with `post-list`, we have this:
```python
{% if posts %}
<ul class="postlist">
{% for post in posts %}
<li><time class="listdate" datetime="{{ post.formatted_date('webiso') }}" title="{{ post.formatted_date(date_format)|e }}">{{ post.formatted_date(date_format)|e }}</time> <a href="{{ post.permalink() }}" class="listtitle">{{ post.title()|e }}</a></li>
{% endfor %}
</ul>
{% else %}
<p>{{ messages("No posts found.") }}</p>
{% endif %}
```
Which is obviously expected to be able to handle the situation when there are no posts.
However, when the plugin returns no posts, the `else` block is not executed. In fact, it appears that the template is not called at all when no posts are returned.
This is because of these lines in `post_list.py`, at around lines 221-222:
```python
if not posts:
return '', []
```
It seems that because the empty values are returned, processing is not passed to the template. Removing those lines fixes the problem and allows the template's `else` clause to work.
I can't see that this change breaks anything else, so I'll submit a pull request for it, unless someone has an objection.
</issue>
<code>
[start of nikola/plugins/shortcode/post_list.py]
1 # -*- coding: utf-8 -*-
2
3 # Copyright © 2013-2020 Udo Spallek, Roberto Alsina and others.
4
5 # Permission is hereby granted, free of charge, to any
6 # person obtaining a copy of this software and associated
7 # documentation files (the "Software"), to deal in the
8 # Software without restriction, including without limitation
9 # the rights to use, copy, modify, merge, publish,
10 # distribute, sublicense, and/or sell copies of the
11 # Software, and to permit persons to whom the Software is
12 # furnished to do so, subject to the following conditions:
13 #
14 # The above copyright notice and this permission notice
15 # shall be included in all copies or substantial portions of
16 # the Software.
17 #
18 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY
19 # KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
20 # WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
21 # PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS
22 # OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR
23 # OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
24 # OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
25 # SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
26
27 """Post list shortcode."""
28
29
30 import operator
31 import os
32 import uuid
33
34 import natsort
35
36 from nikola import utils
37 from nikola.packages.datecond import date_in_range
38 from nikola.plugin_categories import ShortcodePlugin
39
40
41 class PostListShortcode(ShortcodePlugin):
42 """Provide a shortcode to create a list of posts.
43
44 Post List
45 =========
46 :Directive Arguments: None.
47 :Directive Options: lang, start, stop, reverse, sort, date, tags, categories, sections, slugs, post_type, template, id
48 :Directive Content: None.
49
50 The posts appearing in the list can be filtered by options.
51 *List slicing* is provided with the *start*, *stop* and *reverse* options.
52
53 The following not required options are recognized:
54
55 ``start`` : integer
56 The index of the first post to show.
57 A negative value like ``-3`` will show the *last* three posts in the
58 post-list.
59 Defaults to None.
60
61 ``stop`` : integer
62 The index of the last post to show.
63 A value negative value like ``-1`` will show every post, but not the
64 *last* in the post-list.
65 Defaults to None.
66
67 ``reverse`` : flag
68 Reverse the order of the post-list.
69 Defaults is to not reverse the order of posts.
70
71 ``sort`` : string
72 Sort post list by one of each post's attributes, usually ``title`` or a
73 custom ``priority``. Defaults to None (chronological sorting).
74
75 ``date`` : string
76 Show posts that match date range specified by this option. Format:
77
78 * comma-separated clauses (AND)
79 * clause: attribute comparison_operator value (spaces optional)
80 * attribute: year, month, day, hour, month, second, weekday, isoweekday; or empty for full datetime
81 * comparison_operator: == != <= >= < >
82 * value: integer, 'now', 'today', or dateutil-compatible date input
83
84 ``tags`` : string [, string...]
85 Filter posts to show only posts having at least one of the ``tags``.
86 Defaults to None.
87
88 ``require_all_tags`` : flag
89 Change tag filter behaviour to show only posts that have all specified ``tags``.
90 Defaults to False.
91
92 ``categories`` : string [, string...]
93 Filter posts to show only posts having one of the ``categories``.
94 Defaults to None.
95
96 ``sections`` : string [, string...]
97 Filter posts to show only posts having one of the ``sections``.
98 Defaults to None.
99
100 ``slugs`` : string [, string...]
101 Filter posts to show only posts having at least one of the ``slugs``.
102 Defaults to None.
103
104 ``post_type`` (or ``type``) : string
105 Show only ``posts``, ``pages`` or ``all``.
106 Replaces ``all``. Defaults to ``posts``.
107
108 ``lang`` : string
109 The language of post *titles* and *links*.
110 Defaults to default language.
111
112 ``template`` : string
113 The name of an alternative template to render the post-list.
114 Defaults to ``post_list_directive.tmpl``
115
116 ``id`` : string
117 A manual id for the post list.
118 Defaults to a random name composed by 'post_list_' + uuid.uuid4().hex.
119 """
120
121 name = "post_list"
122
123 def set_site(self, site):
124 """Set the site."""
125 super().set_site(site)
126 site.register_shortcode('post-list', self.handler)
127
128 def handler(self, start=None, stop=None, reverse=False, tags=None, require_all_tags=False, categories=None,
129 sections=None, slugs=None, post_type='post', type=False,
130 lang=None, template='post_list_directive.tmpl', sort=None,
131 id=None, data=None, state=None, site=None, date=None, filename=None, post=None):
132 """Generate HTML for post-list."""
133 if lang is None:
134 lang = utils.LocaleBorg().current_lang
135 if site.invariant: # for testing purposes
136 post_list_id = id or 'post_list_' + 'fixedvaluethatisnotauuid'
137 else:
138 post_list_id = id or 'post_list_' + uuid.uuid4().hex
139
140 # Get post from filename if available
141 if filename:
142 self_post = site.post_per_input_file.get(filename)
143 else:
144 self_post = None
145
146 if self_post:
147 self_post.register_depfile("####MAGIC####TIMELINE", lang=lang)
148
149 # If we get strings for start/stop, make them integers
150 if start is not None:
151 start = int(start)
152 if stop is not None:
153 stop = int(stop)
154
155 # Parse tags/categories/sections/slugs (input is strings)
156 categories = [c.strip().lower() for c in categories.split(',')] if categories else []
157 sections = [s.strip().lower() for s in sections.split(',')] if sections else []
158 slugs = [s.strip() for s in slugs.split(',')] if slugs else []
159
160 filtered_timeline = []
161 posts = []
162 step = None if reverse is False else -1
163
164 if type is not False:
165 post_type = type
166
167 if post_type == 'page' or post_type == 'pages':
168 timeline = [p for p in site.timeline if not p.use_in_feeds]
169 elif post_type == 'all':
170 timeline = [p for p in site.timeline]
171 else: # post
172 timeline = [p for p in site.timeline if p.use_in_feeds]
173
174 # self_post should be removed from timeline because this is redundant
175 timeline = [p for p in timeline if p.source_path != filename]
176
177 if categories:
178 timeline = [p for p in timeline if p.meta('category', lang=lang).lower() in categories]
179
180 if sections:
181 timeline = [p for p in timeline if p.section_name(lang).lower() in sections]
182
183 if tags:
184 tags = {t.strip().lower() for t in tags.split(',')}
185 if require_all_tags:
186 compare = set.issubset
187 else:
188 compare = operator.and_
189 for post in timeline:
190 post_tags = {t.lower() for t in post.tags}
191 if compare(tags, post_tags):
192 filtered_timeline.append(post)
193 else:
194 filtered_timeline = timeline
195
196 if sort:
197 filtered_timeline = natsort.natsorted(filtered_timeline, key=lambda post: post.meta[lang][sort], alg=natsort.ns.F | natsort.ns.IC)
198
199 if date:
200 _now = utils.current_time()
201 filtered_timeline = [p for p in filtered_timeline if date_in_range(utils.html_unescape(date), p.date, now=_now)]
202
203 for post in filtered_timeline[start:stop:step]:
204 if slugs:
205 cont = True
206 for slug in slugs:
207 if slug == post.meta('slug'):
208 cont = False
209
210 if cont:
211 continue
212
213 bp = post.translated_base_path(lang)
214 if os.path.exists(bp) and state:
215 state.document.settings.record_dependencies.add(bp)
216 elif os.path.exists(bp) and self_post:
217 self_post.register_depfile(bp, lang=lang)
218
219 posts += [post]
220
221 if not posts:
222 return '', []
223
224 template_deps = site.template_system.template_deps(template)
225 if state:
226 # Register template as a dependency (Issue #2391)
227 for d in template_deps:
228 state.document.settings.record_dependencies.add(d)
229 elif self_post:
230 for d in template_deps:
231 self_post.register_depfile(d, lang=lang)
232
233 template_data = {
234 'lang': lang,
235 'posts': posts,
236 # Need to provide str, not TranslatableSetting (Issue #2104)
237 'date_format': site.GLOBAL_CONTEXT.get('date_format')[lang],
238 'post_list_id': post_list_id,
239 'messages': site.MESSAGES,
240 '_link': site.link,
241 }
242 output = site.template_system.render_template(
243 template, None, template_data)
244 return output, template_deps
245
246
247 # Request file name from shortcode (Issue #2412)
248 PostListShortcode.handler.nikola_shortcode_pass_filename = True
249
[end of nikola/plugins/shortcode/post_list.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/nikola/plugins/shortcode/post_list.py b/nikola/plugins/shortcode/post_list.py
--- a/nikola/plugins/shortcode/post_list.py
+++ b/nikola/plugins/shortcode/post_list.py
@@ -218,9 +218,6 @@
posts += [post]
- if not posts:
- return '', []
-
template_deps = site.template_system.template_deps(template)
if state:
# Register template as a dependency (Issue #2391)
| {"golden_diff": "diff --git a/nikola/plugins/shortcode/post_list.py b/nikola/plugins/shortcode/post_list.py\n--- a/nikola/plugins/shortcode/post_list.py\n+++ b/nikola/plugins/shortcode/post_list.py\n@@ -218,9 +218,6 @@\n \n posts += [post]\n \n- if not posts:\n- return '', []\n-\n template_deps = site.template_system.template_deps(template)\n if state:\n # Register template as a dependency (Issue #2391)\n", "issue": "The post_list plugin prevents 'else' functionality in templates\n<!--\r\nBefore creating an issue:\r\n* make sure you are using an up-to-date version of Nikola\r\n* search for existing issues that might be related\r\n\r\nMake sure to:\r\n* provide information about your environment (below)\r\n* include all the output you get, and any other information related to your problem\r\n\r\nNikola v7.6.4, as provided by Ubuntu, is NOT SUPPORTED.\r\nIf you are using this version, you should upgrade: https://getnikola.com/getting-started.html\r\n-->\r\n\r\n### Environment\r\n\r\n**Python Version:**\r\n\r\n3.7.8\r\n\r\n**Nikola Version:**\r\n\r\n8.1.1\r\n\r\n**Operating System:**\r\n\r\nMac OS Catalina (10.15.5) / Ubuntu 19.10 \r\n\r\n### Description:\r\n\r\nIn the default template for the `post-list` plugin, namely `post_list_directive.tmpl`\r\n\r\n```python\r\n{% if posts %}\r\n <ul class=\"post-list\">\r\n ...\r\n```\r\nWhich suggests that there is some possibility that the template will be called with no posts.\r\n\r\nWhile in `list_post.tmpl`, which you can also use with `post-list`, we have this:\r\n\r\n```python\r\n {% if posts %}\r\n <ul class=\"postlist\">\r\n {% for post in posts %}\r\n <li><time class=\"listdate\" datetime=\"{{ post.formatted_date('webiso') }}\" title=\"{{ post.formatted_date(date_format)|e }}\">{{ post.formatted_date(date_format)|e }}</time> <a href=\"{{ post.permalink() }}\" class=\"listtitle\">{{ post.title()|e }}</a></li>\r\n {% endfor %}\r\n </ul>\r\n {% else %}\r\n <p>{{ messages(\"No posts found.\") }}</p>\r\n {% endif %}\r\n```\r\n\r\nWhich is obviously expected to be able to handle the situation when there are no posts.\r\n\r\nHowever, when the plugin returns no posts, the `else` block is not executed. In fact, it appears that the template is not called at all when no posts are returned. \r\n\r\nThis is because of these lines in `post_list.py`, at around lines 221-222:\r\n\r\n```python\r\n if not posts:\r\n return '', []\r\n```\r\n\r\nIt seems that because the empty values are returned, processing is not passed to the template. Removing those lines fixes the problem and allows the template's `else` clause to work.\r\n\r\nI can't see that this change breaks anything else, so I'll submit a pull request for it, unless someone has an objection.\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2013-2020 Udo Spallek, Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\n\"\"\"Post list shortcode.\"\"\"\n\n\nimport operator\nimport os\nimport uuid\n\nimport natsort\n\nfrom nikola import utils\nfrom nikola.packages.datecond import date_in_range\nfrom nikola.plugin_categories import ShortcodePlugin\n\n\nclass PostListShortcode(ShortcodePlugin):\n \"\"\"Provide a shortcode to create a list of posts.\n\n Post List\n =========\n :Directive Arguments: None.\n :Directive Options: lang, start, stop, reverse, sort, date, tags, categories, sections, slugs, post_type, template, id\n :Directive Content: None.\n\n The posts appearing in the list can be filtered by options.\n *List slicing* is provided with the *start*, *stop* and *reverse* options.\n\n The following not required options are recognized:\n\n ``start`` : integer\n The index of the first post to show.\n A negative value like ``-3`` will show the *last* three posts in the\n post-list.\n Defaults to None.\n\n ``stop`` : integer\n The index of the last post to show.\n A value negative value like ``-1`` will show every post, but not the\n *last* in the post-list.\n Defaults to None.\n\n ``reverse`` : flag\n Reverse the order of the post-list.\n Defaults is to not reverse the order of posts.\n\n ``sort`` : string\n Sort post list by one of each post's attributes, usually ``title`` or a\n custom ``priority``. Defaults to None (chronological sorting).\n\n ``date`` : string\n Show posts that match date range specified by this option. Format:\n\n * comma-separated clauses (AND)\n * clause: attribute comparison_operator value (spaces optional)\n * attribute: year, month, day, hour, month, second, weekday, isoweekday; or empty for full datetime\n * comparison_operator: == != <= >= < >\n * value: integer, 'now', 'today', or dateutil-compatible date input\n\n ``tags`` : string [, string...]\n Filter posts to show only posts having at least one of the ``tags``.\n Defaults to None.\n\n ``require_all_tags`` : flag\n Change tag filter behaviour to show only posts that have all specified ``tags``.\n Defaults to False.\n\n ``categories`` : string [, string...]\n Filter posts to show only posts having one of the ``categories``.\n Defaults to None.\n\n ``sections`` : string [, string...]\n Filter posts to show only posts having one of the ``sections``.\n Defaults to None.\n\n ``slugs`` : string [, string...]\n Filter posts to show only posts having at least one of the ``slugs``.\n Defaults to None.\n\n ``post_type`` (or ``type``) : string\n Show only ``posts``, ``pages`` or ``all``.\n Replaces ``all``. Defaults to ``posts``.\n\n ``lang`` : string\n The language of post *titles* and *links*.\n Defaults to default language.\n\n ``template`` : string\n The name of an alternative template to render the post-list.\n Defaults to ``post_list_directive.tmpl``\n\n ``id`` : string\n A manual id for the post list.\n Defaults to a random name composed by 'post_list_' + uuid.uuid4().hex.\n \"\"\"\n\n name = \"post_list\"\n\n def set_site(self, site):\n \"\"\"Set the site.\"\"\"\n super().set_site(site)\n site.register_shortcode('post-list', self.handler)\n\n def handler(self, start=None, stop=None, reverse=False, tags=None, require_all_tags=False, categories=None,\n sections=None, slugs=None, post_type='post', type=False,\n lang=None, template='post_list_directive.tmpl', sort=None,\n id=None, data=None, state=None, site=None, date=None, filename=None, post=None):\n \"\"\"Generate HTML for post-list.\"\"\"\n if lang is None:\n lang = utils.LocaleBorg().current_lang\n if site.invariant: # for testing purposes\n post_list_id = id or 'post_list_' + 'fixedvaluethatisnotauuid'\n else:\n post_list_id = id or 'post_list_' + uuid.uuid4().hex\n\n # Get post from filename if available\n if filename:\n self_post = site.post_per_input_file.get(filename)\n else:\n self_post = None\n\n if self_post:\n self_post.register_depfile(\"####MAGIC####TIMELINE\", lang=lang)\n\n # If we get strings for start/stop, make them integers\n if start is not None:\n start = int(start)\n if stop is not None:\n stop = int(stop)\n\n # Parse tags/categories/sections/slugs (input is strings)\n categories = [c.strip().lower() for c in categories.split(',')] if categories else []\n sections = [s.strip().lower() for s in sections.split(',')] if sections else []\n slugs = [s.strip() for s in slugs.split(',')] if slugs else []\n\n filtered_timeline = []\n posts = []\n step = None if reverse is False else -1\n\n if type is not False:\n post_type = type\n\n if post_type == 'page' or post_type == 'pages':\n timeline = [p for p in site.timeline if not p.use_in_feeds]\n elif post_type == 'all':\n timeline = [p for p in site.timeline]\n else: # post\n timeline = [p for p in site.timeline if p.use_in_feeds]\n\n # self_post should be removed from timeline because this is redundant\n timeline = [p for p in timeline if p.source_path != filename]\n\n if categories:\n timeline = [p for p in timeline if p.meta('category', lang=lang).lower() in categories]\n\n if sections:\n timeline = [p for p in timeline if p.section_name(lang).lower() in sections]\n\n if tags:\n tags = {t.strip().lower() for t in tags.split(',')}\n if require_all_tags:\n compare = set.issubset\n else:\n compare = operator.and_\n for post in timeline:\n post_tags = {t.lower() for t in post.tags}\n if compare(tags, post_tags):\n filtered_timeline.append(post)\n else:\n filtered_timeline = timeline\n\n if sort:\n filtered_timeline = natsort.natsorted(filtered_timeline, key=lambda post: post.meta[lang][sort], alg=natsort.ns.F | natsort.ns.IC)\n\n if date:\n _now = utils.current_time()\n filtered_timeline = [p for p in filtered_timeline if date_in_range(utils.html_unescape(date), p.date, now=_now)]\n\n for post in filtered_timeline[start:stop:step]:\n if slugs:\n cont = True\n for slug in slugs:\n if slug == post.meta('slug'):\n cont = False\n\n if cont:\n continue\n\n bp = post.translated_base_path(lang)\n if os.path.exists(bp) and state:\n state.document.settings.record_dependencies.add(bp)\n elif os.path.exists(bp) and self_post:\n self_post.register_depfile(bp, lang=lang)\n\n posts += [post]\n\n if not posts:\n return '', []\n\n template_deps = site.template_system.template_deps(template)\n if state:\n # Register template as a dependency (Issue #2391)\n for d in template_deps:\n state.document.settings.record_dependencies.add(d)\n elif self_post:\n for d in template_deps:\n self_post.register_depfile(d, lang=lang)\n\n template_data = {\n 'lang': lang,\n 'posts': posts,\n # Need to provide str, not TranslatableSetting (Issue #2104)\n 'date_format': site.GLOBAL_CONTEXT.get('date_format')[lang],\n 'post_list_id': post_list_id,\n 'messages': site.MESSAGES,\n '_link': site.link,\n }\n output = site.template_system.render_template(\n template, None, template_data)\n return output, template_deps\n\n\n# Request file name from shortcode (Issue #2412)\nPostListShortcode.handler.nikola_shortcode_pass_filename = True\n", "path": "nikola/plugins/shortcode/post_list.py"}]} | 3,806 | 112 |
gh_patches_debug_24993 | rasdani/github-patches | git_diff | keras-team__keras-nlp-425 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Naming inconsistency between Gpt2 and XLMRoberta
We handle case differently in our current naming for `Gpt2` and `XLMRoberta`. We should align on either:
- `XLMRoberta` and `GPT2`
- `XlmRoberta` and `Gpt2`
Once we decided on the naming we want, this can just be a simple rename. We should probably do this before the next major release.
</issue>
<code>
[start of keras_nlp/models/__init__.py]
1 # Copyright 2022 The KerasNLP Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from keras_nlp.models.bert.bert_models import Bert
16 from keras_nlp.models.bert.bert_preprocessing import BertPreprocessor
17 from keras_nlp.models.bert.bert_tasks import BertClassifier
18 from keras_nlp.models.distilbert.distilbert_models import DistilBert
19 from keras_nlp.models.distilbert.distilbert_preprocessing import (
20 DistilBertPreprocessor,
21 )
22 from keras_nlp.models.gpt2.gpt2_models import Gpt2
23 from keras_nlp.models.roberta.roberta_models import Roberta
24 from keras_nlp.models.roberta.roberta_tasks import RobertaClassifier
25 from keras_nlp.models.xlm_roberta.xlm_roberta_models import XLMRoberta
26 from keras_nlp.models.xlm_roberta.xlm_roberta_preprocessing import (
27 XLMRobertaPreprocessor,
28 )
29
[end of keras_nlp/models/__init__.py]
[start of keras_nlp/models/gpt2/gpt2_models.py]
1 # Copyright 2022 The KerasNLP Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """GPT-2 backbone models."""
16
17 import tensorflow as tf
18 from tensorflow import keras
19
20 from keras_nlp.layers import PositionEmbedding
21 from keras_nlp.layers import TransformerDecoder
22
23
24 def _gpt_2_kernel_initializer(stddev=0.02):
25 return keras.initializers.RandomNormal(stddev=stddev)
26
27
28 @keras.utils.register_keras_serializable(package="keras_nlp")
29 class Gpt2(keras.Model):
30 """GPT-2 core network with hyperparameters.
31
32 This network implements a Transformer-based decoder network,
33 Generative Pretrained Transformer-2 (GPT-2), as described in
34 ["Language Models are Unsupervised Multitask Learners"](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf).
35 It includes the embedding lookups and transformer layers.
36
37 The default constructor gives a fully customizable, randomly initalized
38 GPT-2 model with any number of layers, heads, and embedding
39 dimensions. To load preset architectures and weights, use the `from_presets`
40 constructor.
41
42 Args:
43 vocabulary_size: int. The size of the token vocabulary.
44 num_layers: int. The number of transformer layers.
45 num_heads: int. The number of attention heads for each transformer.
46 The hidden size must be divisible by the number of attention heads.
47 hidden_dim: int. The size of the transformer encoding and pooler layers.
48 intermediate_dim: int. The output dimension of the first Dense layer in
49 a two-layer feedforward network for each transformer.
50 dropout: float. Dropout probability for the Transformer encoder.
51 max_sequence_length: int. The maximum sequence length that this encoder
52 can consume. If None, `max_sequence_length` uses the value from
53 sequence length. This determines the variable shape for positional
54 embeddings.
55
56 Example usage:
57 ```python
58 input_data = {
59 "token_ids": tf.random.uniform(
60 shape=(1, 12), dtype=tf.int64, maxval=model.vocabulary_size
61 ),
62 "padding_mask": tf.constant(
63 [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0], shape=(1, 12)
64 ),
65 }
66
67 # Randomly initialized GPT-2 decoder
68 model = keras_nlp.models.Gpt2(
69 vocabulary_size=50257,
70 num_layers=12,
71 num_heads=12,
72 hidden_dim=768,
73 intermediate_dim=3072,
74 max_sequence_length=1024,
75 )
76
77 # Call the model on the input data.
78 output = model(input_data)
79 ```
80 """
81
82 def __init__(
83 self,
84 vocabulary_size,
85 num_layers,
86 num_heads,
87 hidden_dim,
88 intermediate_dim,
89 dropout=0.1,
90 max_sequence_length=1024,
91 **kwargs,
92 ):
93
94 # Inputs
95 token_ids = keras.Input(shape=(None,), dtype="int32", name="token_ids")
96 padding_mask = keras.Input(
97 shape=(None,), dtype="int32", name="padding_mask"
98 )
99
100 # Embed tokens, positions.
101 token_embedding = keras.layers.Embedding(
102 input_dim=vocabulary_size,
103 output_dim=hidden_dim,
104 embeddings_initializer=_gpt_2_kernel_initializer(stddev=0.01),
105 name="token_embedding",
106 )(token_ids)
107
108 # Can't use `TokenAndPositionEmbedding` layer here because of different
109 # initializers.
110 position_embedding = PositionEmbedding(
111 initializer=_gpt_2_kernel_initializer(stddev=0.02),
112 sequence_length=max_sequence_length,
113 name="position_embedding",
114 )(token_embedding)
115
116 # Sum and apply dropout to embeddings.
117 x = keras.layers.Add()((token_embedding, position_embedding))
118 x = keras.layers.Dropout(
119 dropout,
120 name="embeddings_dropout",
121 )(x)
122
123 # Apply successive transformer decoder blocks.
124 for i in range(num_layers):
125 x = TransformerDecoder(
126 intermediate_dim=intermediate_dim,
127 num_heads=num_heads,
128 dropout=dropout,
129 activation=lambda x: keras.activations.gelu(
130 x, approximate=True
131 ),
132 layer_norm_epsilon=1e-05,
133 kernel_initializer=_gpt_2_kernel_initializer(stddev=0.02),
134 normalize_first=True,
135 name=f"transformer_layer_{i}",
136 )(x, decoder_padding_mask=padding_mask)
137
138 sequence_output = keras.layers.LayerNormalization(
139 name="layer_norm",
140 axis=-1,
141 epsilon=1e-05,
142 dtype=tf.float32,
143 )(x)
144
145 # Set default for `name` if none given
146 if "name" not in kwargs:
147 kwargs["name"] = "backbone"
148
149 # Instantiate using Functional API Model constructor
150 super().__init__(
151 inputs={
152 "token_ids": token_ids,
153 "padding_mask": padding_mask,
154 },
155 outputs=sequence_output,
156 **kwargs,
157 )
158 # All references to `self` below this line
159 self.vocabulary_size = vocabulary_size
160 self.num_layers = num_layers
161 self.num_heads = num_heads
162 self.hidden_dim = hidden_dim
163 self.intermediate_dim = intermediate_dim
164 self.dropout = dropout
165 self.max_sequence_length = max_sequence_length
166
167 def get_config(self):
168 return {
169 "vocabulary_size": self.vocabulary_size,
170 "num_layers": self.num_layers,
171 "num_heads": self.num_heads,
172 "hidden_dim": self.hidden_dim,
173 "intermediate_dim": self.intermediate_dim,
174 "dropout": self.dropout,
175 "max_sequence_length": self.max_sequence_length,
176 "name": self.name,
177 "trainable": self.trainable,
178 }
179
180 @classmethod
181 def from_config(cls, config):
182 return cls(**config)
183
184 @classmethod
185 def from_preset(
186 cls,
187 preset,
188 load_weights=True,
189 **kwargs,
190 ):
191 raise NotImplementedError
192
[end of keras_nlp/models/gpt2/gpt2_models.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/keras_nlp/models/__init__.py b/keras_nlp/models/__init__.py
--- a/keras_nlp/models/__init__.py
+++ b/keras_nlp/models/__init__.py
@@ -19,7 +19,7 @@
from keras_nlp.models.distilbert.distilbert_preprocessing import (
DistilBertPreprocessor,
)
-from keras_nlp.models.gpt2.gpt2_models import Gpt2
+from keras_nlp.models.gpt2.gpt2_models import GPT2
from keras_nlp.models.roberta.roberta_models import Roberta
from keras_nlp.models.roberta.roberta_tasks import RobertaClassifier
from keras_nlp.models.xlm_roberta.xlm_roberta_models import XLMRoberta
diff --git a/keras_nlp/models/gpt2/gpt2_models.py b/keras_nlp/models/gpt2/gpt2_models.py
--- a/keras_nlp/models/gpt2/gpt2_models.py
+++ b/keras_nlp/models/gpt2/gpt2_models.py
@@ -26,7 +26,7 @@
@keras.utils.register_keras_serializable(package="keras_nlp")
-class Gpt2(keras.Model):
+class GPT2(keras.Model):
"""GPT-2 core network with hyperparameters.
This network implements a Transformer-based decoder network,
@@ -65,7 +65,7 @@
}
# Randomly initialized GPT-2 decoder
- model = keras_nlp.models.Gpt2(
+ model = keras_nlp.models.GPT2(
vocabulary_size=50257,
num_layers=12,
num_heads=12,
| {"golden_diff": "diff --git a/keras_nlp/models/__init__.py b/keras_nlp/models/__init__.py\n--- a/keras_nlp/models/__init__.py\n+++ b/keras_nlp/models/__init__.py\n@@ -19,7 +19,7 @@\n from keras_nlp.models.distilbert.distilbert_preprocessing import (\n DistilBertPreprocessor,\n )\n-from keras_nlp.models.gpt2.gpt2_models import Gpt2\n+from keras_nlp.models.gpt2.gpt2_models import GPT2\n from keras_nlp.models.roberta.roberta_models import Roberta\n from keras_nlp.models.roberta.roberta_tasks import RobertaClassifier\n from keras_nlp.models.xlm_roberta.xlm_roberta_models import XLMRoberta\ndiff --git a/keras_nlp/models/gpt2/gpt2_models.py b/keras_nlp/models/gpt2/gpt2_models.py\n--- a/keras_nlp/models/gpt2/gpt2_models.py\n+++ b/keras_nlp/models/gpt2/gpt2_models.py\n@@ -26,7 +26,7 @@\n \n \n @keras.utils.register_keras_serializable(package=\"keras_nlp\")\n-class Gpt2(keras.Model):\n+class GPT2(keras.Model):\n \"\"\"GPT-2 core network with hyperparameters.\n \n This network implements a Transformer-based decoder network,\n@@ -65,7 +65,7 @@\n }\n \n # Randomly initialized GPT-2 decoder\n- model = keras_nlp.models.Gpt2(\n+ model = keras_nlp.models.GPT2(\n vocabulary_size=50257,\n num_layers=12,\n num_heads=12,\n", "issue": "Naming inconsistency between Gpt2 and XLMRoberta\nWe handle case differently in our current naming for `Gpt2` and `XLMRoberta`. We should align on either:\r\n - `XLMRoberta` and `GPT2`\r\n - `XlmRoberta` and `Gpt2`\r\n\r\nOnce we decided on the naming we want, this can just be a simple rename. We should probably do this before the next major release.\n", "before_files": [{"content": "# Copyright 2022 The KerasNLP Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom keras_nlp.models.bert.bert_models import Bert\nfrom keras_nlp.models.bert.bert_preprocessing import BertPreprocessor\nfrom keras_nlp.models.bert.bert_tasks import BertClassifier\nfrom keras_nlp.models.distilbert.distilbert_models import DistilBert\nfrom keras_nlp.models.distilbert.distilbert_preprocessing import (\n DistilBertPreprocessor,\n)\nfrom keras_nlp.models.gpt2.gpt2_models import Gpt2\nfrom keras_nlp.models.roberta.roberta_models import Roberta\nfrom keras_nlp.models.roberta.roberta_tasks import RobertaClassifier\nfrom keras_nlp.models.xlm_roberta.xlm_roberta_models import XLMRoberta\nfrom keras_nlp.models.xlm_roberta.xlm_roberta_preprocessing import (\n XLMRobertaPreprocessor,\n)\n", "path": "keras_nlp/models/__init__.py"}, {"content": "# Copyright 2022 The KerasNLP Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"GPT-2 backbone models.\"\"\"\n\nimport tensorflow as tf\nfrom tensorflow import keras\n\nfrom keras_nlp.layers import PositionEmbedding\nfrom keras_nlp.layers import TransformerDecoder\n\n\ndef _gpt_2_kernel_initializer(stddev=0.02):\n return keras.initializers.RandomNormal(stddev=stddev)\n\n\[email protected]_keras_serializable(package=\"keras_nlp\")\nclass Gpt2(keras.Model):\n \"\"\"GPT-2 core network with hyperparameters.\n\n This network implements a Transformer-based decoder network,\n Generative Pretrained Transformer-2 (GPT-2), as described in\n [\"Language Models are Unsupervised Multitask Learners\"](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf).\n It includes the embedding lookups and transformer layers.\n\n The default constructor gives a fully customizable, randomly initalized\n GPT-2 model with any number of layers, heads, and embedding\n dimensions. To load preset architectures and weights, use the `from_presets`\n constructor.\n\n Args:\n vocabulary_size: int. The size of the token vocabulary.\n num_layers: int. The number of transformer layers.\n num_heads: int. The number of attention heads for each transformer.\n The hidden size must be divisible by the number of attention heads.\n hidden_dim: int. The size of the transformer encoding and pooler layers.\n intermediate_dim: int. The output dimension of the first Dense layer in\n a two-layer feedforward network for each transformer.\n dropout: float. Dropout probability for the Transformer encoder.\n max_sequence_length: int. The maximum sequence length that this encoder\n can consume. If None, `max_sequence_length` uses the value from\n sequence length. This determines the variable shape for positional\n embeddings.\n\n Example usage:\n ```python\n input_data = {\n \"token_ids\": tf.random.uniform(\n shape=(1, 12), dtype=tf.int64, maxval=model.vocabulary_size\n ),\n \"padding_mask\": tf.constant(\n [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0], shape=(1, 12)\n ),\n }\n\n # Randomly initialized GPT-2 decoder\n model = keras_nlp.models.Gpt2(\n vocabulary_size=50257,\n num_layers=12,\n num_heads=12,\n hidden_dim=768,\n intermediate_dim=3072,\n max_sequence_length=1024,\n )\n\n # Call the model on the input data.\n output = model(input_data)\n ```\n \"\"\"\n\n def __init__(\n self,\n vocabulary_size,\n num_layers,\n num_heads,\n hidden_dim,\n intermediate_dim,\n dropout=0.1,\n max_sequence_length=1024,\n **kwargs,\n ):\n\n # Inputs\n token_ids = keras.Input(shape=(None,), dtype=\"int32\", name=\"token_ids\")\n padding_mask = keras.Input(\n shape=(None,), dtype=\"int32\", name=\"padding_mask\"\n )\n\n # Embed tokens, positions.\n token_embedding = keras.layers.Embedding(\n input_dim=vocabulary_size,\n output_dim=hidden_dim,\n embeddings_initializer=_gpt_2_kernel_initializer(stddev=0.01),\n name=\"token_embedding\",\n )(token_ids)\n\n # Can't use `TokenAndPositionEmbedding` layer here because of different\n # initializers.\n position_embedding = PositionEmbedding(\n initializer=_gpt_2_kernel_initializer(stddev=0.02),\n sequence_length=max_sequence_length,\n name=\"position_embedding\",\n )(token_embedding)\n\n # Sum and apply dropout to embeddings.\n x = keras.layers.Add()((token_embedding, position_embedding))\n x = keras.layers.Dropout(\n dropout,\n name=\"embeddings_dropout\",\n )(x)\n\n # Apply successive transformer decoder blocks.\n for i in range(num_layers):\n x = TransformerDecoder(\n intermediate_dim=intermediate_dim,\n num_heads=num_heads,\n dropout=dropout,\n activation=lambda x: keras.activations.gelu(\n x, approximate=True\n ),\n layer_norm_epsilon=1e-05,\n kernel_initializer=_gpt_2_kernel_initializer(stddev=0.02),\n normalize_first=True,\n name=f\"transformer_layer_{i}\",\n )(x, decoder_padding_mask=padding_mask)\n\n sequence_output = keras.layers.LayerNormalization(\n name=\"layer_norm\",\n axis=-1,\n epsilon=1e-05,\n dtype=tf.float32,\n )(x)\n\n # Set default for `name` if none given\n if \"name\" not in kwargs:\n kwargs[\"name\"] = \"backbone\"\n\n # Instantiate using Functional API Model constructor\n super().__init__(\n inputs={\n \"token_ids\": token_ids,\n \"padding_mask\": padding_mask,\n },\n outputs=sequence_output,\n **kwargs,\n )\n # All references to `self` below this line\n self.vocabulary_size = vocabulary_size\n self.num_layers = num_layers\n self.num_heads = num_heads\n self.hidden_dim = hidden_dim\n self.intermediate_dim = intermediate_dim\n self.dropout = dropout\n self.max_sequence_length = max_sequence_length\n\n def get_config(self):\n return {\n \"vocabulary_size\": self.vocabulary_size,\n \"num_layers\": self.num_layers,\n \"num_heads\": self.num_heads,\n \"hidden_dim\": self.hidden_dim,\n \"intermediate_dim\": self.intermediate_dim,\n \"dropout\": self.dropout,\n \"max_sequence_length\": self.max_sequence_length,\n \"name\": self.name,\n \"trainable\": self.trainable,\n }\n\n @classmethod\n def from_config(cls, config):\n return cls(**config)\n\n @classmethod\n def from_preset(\n cls,\n preset,\n load_weights=True,\n **kwargs,\n ):\n raise NotImplementedError\n", "path": "keras_nlp/models/gpt2/gpt2_models.py"}]} | 2,968 | 389 |
gh_patches_debug_2783 | rasdani/github-patches | git_diff | chainer__chainer-524 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Error type mismatch when broadcast fails
When broadcast fails, numpy causes `ValueError`, but cupy causes `RuntimeError`.
</issue>
<code>
[start of cupy/manipulation/dims.py]
1 import six
2
3 import cupy
4 from cupy import internal
5
6
7 zip_longest = six.moves.zip_longest
8 six_zip = six.moves.zip
9
10
11 def atleast_1d(*arys):
12 """Converts arrays to arrays with dimensions >= 1.
13
14 Args:
15 arys (tuple of arrays): Arrays to be converted. All arguments must be
16 cupy.ndarray objects. Only zero-dimensional array is affected.
17
18 Returns:
19 If there are only one input, then it returns its converted version.
20 Otherwise, it returns a list of converted arrays.
21
22 .. seealso:: :func:`numpy.atleast_1d`
23
24 """
25 res = []
26 for a in arys:
27 if not isinstance(a, cupy.ndarray):
28 raise TypeError('Only cupy arrays can be atleast_1d')
29 if a.ndim == 0:
30 a = a.reshape(1)
31 res.append(a)
32 if len(res) == 1:
33 res = res[0]
34 return res
35
36
37 def atleast_2d(*arys):
38 """Converts arrays to arrays with dimensions >= 2.
39
40 If an input array has dimensions less than two, then this function inserts
41 new axes at the head of dimensions to make it have two dimensions.
42
43 Args:
44 arys (tuple of arrays): Arrays to be converted. All arguments must be
45 cupy.ndarray objects.
46
47 Returns:
48 If there are only one input, then it returns its converted version.
49 Otherwise, it returns a list of converted arrays.
50
51 .. seealso:: :func:`numpy.atleast_2d`
52
53 """
54 res = []
55 for a in arys:
56 if not isinstance(a, cupy.ndarray):
57 raise TypeError('Only cupy arrays can be atleast_2d')
58 if a.ndim == 0:
59 a = a.reshape(1, 1)
60 elif a.ndim == 1:
61 a = a[cupy.newaxis, :]
62 res.append(a)
63 if len(res) == 1:
64 res = res[0]
65 return res
66
67
68 def atleast_3d(*arys):
69 """Converts arrays to arrays with dimensions >= 3.
70
71 If an input array has dimensions less than three, then this function
72 inserts new axes to make it have three dimensions. The place of the new
73 axes are following:
74
75 - If its shape is ``()``, then the shape of output is ``(1, 1, 1)``.
76 - If its shape is ``(N,)``, then the shape of output is ``(1, N, 1)``.
77 - If its shape is ``(M, N)``, then the shape of output is ``(M, N, 1)``.
78 - Otherwise, the output is the input array itself.
79
80 Args:
81 arys (tuple of arrays): Arrays to be converted. All arguments must be
82 cupy.ndarray objects.
83
84 Returns:
85 If there are only one input, then it returns its converted version.
86 Otherwise, it returns a list of converted arrays.
87
88 .. seealso:: :func:`numpy.atleast_3d`
89
90 """
91 res = []
92 for a in arys:
93 if not isinstance(a, cupy.ndarray):
94 raise TypeError('Only cupy arrays can be atleast_3d')
95 if a.ndim == 0:
96 a = a.reshape(1, 1, 1)
97 elif a.ndim == 1:
98 a = a[cupy.newaxis, :, cupy.newaxis]
99 elif a.ndim == 2:
100 a = a[:, :, cupy.newaxis]
101 res.append(a)
102 if len(res) == 1:
103 res = res[0]
104 return res
105
106
107 class broadcast(object):
108 """Object that performs broadcasting.
109
110 CuPy actually uses this class to support broadcasting in various
111 operations. Note that this class does not provide an iterator.
112
113 Args:
114 arrays (tuple of arrays): Arrays to be broadcasted.
115
116 Attributes:
117 shape (tuple of ints): The broadcasted shape.
118 nd (int): Number of dimensions of the broadcasted shape.
119 size (int): Total size of the broadcasted shape.
120 values (list of arrays): The broadcasted arrays.
121
122 .. seealso:: :class:`numpy.broadcast`
123
124 """
125
126 def __init__(self, *arrays):
127 ndarray = cupy.ndarray
128 rev = slice(None, None, -1)
129 shape_arr = [a._shape[rev] for a in arrays
130 if isinstance(a, ndarray)]
131 r_shape = [max(ss) for ss in zip_longest(*shape_arr, fillvalue=0)]
132
133 self.shape = shape = tuple(r_shape[rev])
134 self.size = size = internal.prod(shape)
135 self.nd = ndim = len(shape)
136
137 broadcasted = list(arrays)
138 for i, a in enumerate(broadcasted):
139 if not isinstance(a, ndarray):
140 continue
141
142 a_shape = a.shape
143 if a_shape == shape:
144 continue
145
146 r_strides = [
147 a_st if sh == a_sh else (0 if a_sh == 1 else None)
148 for sh, a_sh, a_st
149 in six_zip(r_shape, a._shape[rev], a._strides[rev])]
150
151 if None in r_strides:
152 raise RuntimeError('Broadcasting failed')
153
154 offset = (0,) * (ndim - len(r_strides))
155
156 broadcasted[i] = view = a.view()
157 view._shape = shape
158 view._strides = offset + tuple(r_strides[rev])
159 view._size = size
160 view._c_contiguous = -1
161 view._f_contiguous = -1
162
163 self.values = tuple(broadcasted)
164
165
166 def broadcast_arrays(*args):
167 """Broadcasts given arrays.
168
169 Args:
170 args (tuple of arrays): Arrays to broadcast for each other.
171
172 Returns:
173 list: A list of broadcasted arrays.
174
175 .. seealso:: :func:`numpy.broadcast_arrays`
176
177 """
178 return broadcast(*args).values
179
180
181 def expand_dims(a, axis):
182 """Expands given arrays.
183
184 Args:
185 a (cupy.ndarray): Array to be expanded.
186 axis (int): Position where new axis is to be inserted.
187
188 Returns:
189 cupy.ndarray: The number of dimensions is one greater than that of
190 the input array.
191
192 .. seealso:: :func:`numpy.expand_dims`
193
194 """
195 shape = a.shape
196 if axis < 0:
197 axis = axis + len(shape) + 1
198 return a.reshape(shape[:axis] + (1,) + shape[axis:])
199
200
201 def squeeze(a, axis=None):
202 """Removes size-one axes from the shape of an array.
203
204 Args:
205 a (cupy.ndarray): Array to be reshaped.
206 axis (int or tuple of ints): Axes to be removed. This function removes
207 all size-one axes by default. If one of the specified axes is not
208 of size one, an exception is raised.
209
210 Returns:
211 cupy.ndarray: An array without (specified) size-one axes.
212
213 .. seealso:: :func:`numpy.squeeze`
214
215 """
216 if axis is None:
217 axis = tuple(i for i, n in enumerate(a._shape) if n == 1)
218 elif isinstance(axis, int):
219 axis = axis,
220
221 new_shape = []
222 new_strides = []
223 j = 0
224 for i, n in enumerate(a._shape):
225 if j < len(axis) and i == axis[j]:
226 if n != 1:
227 raise RuntimeError('Cannot squeeze dimension of size > 1')
228 j += 1
229 else:
230 new_shape.append(n)
231 new_strides.append(a._strides[i])
232
233 v = a.view()
234 v._shape = tuple(new_shape)
235 v._strides = tuple(new_strides)
236 v._c_contiguous = -1
237 v._f_contiguous = -1
238 return v
239
[end of cupy/manipulation/dims.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/cupy/manipulation/dims.py b/cupy/manipulation/dims.py
--- a/cupy/manipulation/dims.py
+++ b/cupy/manipulation/dims.py
@@ -149,7 +149,7 @@
in six_zip(r_shape, a._shape[rev], a._strides[rev])]
if None in r_strides:
- raise RuntimeError('Broadcasting failed')
+ raise ValueError('Broadcasting failed')
offset = (0,) * (ndim - len(r_strides))
| {"golden_diff": "diff --git a/cupy/manipulation/dims.py b/cupy/manipulation/dims.py\n--- a/cupy/manipulation/dims.py\n+++ b/cupy/manipulation/dims.py\n@@ -149,7 +149,7 @@\n in six_zip(r_shape, a._shape[rev], a._strides[rev])]\n \n if None in r_strides:\n- raise RuntimeError('Broadcasting failed')\n+ raise ValueError('Broadcasting failed')\n \n offset = (0,) * (ndim - len(r_strides))\n", "issue": "Error type mismatch when broadcast fails\nWhen broadcast fails, numpy causes `ValueError`, but cupy causes `RuntimeError`.\n\n", "before_files": [{"content": "import six\n\nimport cupy\nfrom cupy import internal\n\n\nzip_longest = six.moves.zip_longest\nsix_zip = six.moves.zip\n\n\ndef atleast_1d(*arys):\n \"\"\"Converts arrays to arrays with dimensions >= 1.\n\n Args:\n arys (tuple of arrays): Arrays to be converted. All arguments must be\n cupy.ndarray objects. Only zero-dimensional array is affected.\n\n Returns:\n If there are only one input, then it returns its converted version.\n Otherwise, it returns a list of converted arrays.\n\n .. seealso:: :func:`numpy.atleast_1d`\n\n \"\"\"\n res = []\n for a in arys:\n if not isinstance(a, cupy.ndarray):\n raise TypeError('Only cupy arrays can be atleast_1d')\n if a.ndim == 0:\n a = a.reshape(1)\n res.append(a)\n if len(res) == 1:\n res = res[0]\n return res\n\n\ndef atleast_2d(*arys):\n \"\"\"Converts arrays to arrays with dimensions >= 2.\n\n If an input array has dimensions less than two, then this function inserts\n new axes at the head of dimensions to make it have two dimensions.\n\n Args:\n arys (tuple of arrays): Arrays to be converted. All arguments must be\n cupy.ndarray objects.\n\n Returns:\n If there are only one input, then it returns its converted version.\n Otherwise, it returns a list of converted arrays.\n\n .. seealso:: :func:`numpy.atleast_2d`\n\n \"\"\"\n res = []\n for a in arys:\n if not isinstance(a, cupy.ndarray):\n raise TypeError('Only cupy arrays can be atleast_2d')\n if a.ndim == 0:\n a = a.reshape(1, 1)\n elif a.ndim == 1:\n a = a[cupy.newaxis, :]\n res.append(a)\n if len(res) == 1:\n res = res[0]\n return res\n\n\ndef atleast_3d(*arys):\n \"\"\"Converts arrays to arrays with dimensions >= 3.\n\n If an input array has dimensions less than three, then this function\n inserts new axes to make it have three dimensions. The place of the new\n axes are following:\n\n - If its shape is ``()``, then the shape of output is ``(1, 1, 1)``.\n - If its shape is ``(N,)``, then the shape of output is ``(1, N, 1)``.\n - If its shape is ``(M, N)``, then the shape of output is ``(M, N, 1)``.\n - Otherwise, the output is the input array itself.\n\n Args:\n arys (tuple of arrays): Arrays to be converted. All arguments must be\n cupy.ndarray objects.\n\n Returns:\n If there are only one input, then it returns its converted version.\n Otherwise, it returns a list of converted arrays.\n\n .. seealso:: :func:`numpy.atleast_3d`\n\n \"\"\"\n res = []\n for a in arys:\n if not isinstance(a, cupy.ndarray):\n raise TypeError('Only cupy arrays can be atleast_3d')\n if a.ndim == 0:\n a = a.reshape(1, 1, 1)\n elif a.ndim == 1:\n a = a[cupy.newaxis, :, cupy.newaxis]\n elif a.ndim == 2:\n a = a[:, :, cupy.newaxis]\n res.append(a)\n if len(res) == 1:\n res = res[0]\n return res\n\n\nclass broadcast(object):\n \"\"\"Object that performs broadcasting.\n\n CuPy actually uses this class to support broadcasting in various\n operations. Note that this class does not provide an iterator.\n\n Args:\n arrays (tuple of arrays): Arrays to be broadcasted.\n\n Attributes:\n shape (tuple of ints): The broadcasted shape.\n nd (int): Number of dimensions of the broadcasted shape.\n size (int): Total size of the broadcasted shape.\n values (list of arrays): The broadcasted arrays.\n\n .. seealso:: :class:`numpy.broadcast`\n\n \"\"\"\n\n def __init__(self, *arrays):\n ndarray = cupy.ndarray\n rev = slice(None, None, -1)\n shape_arr = [a._shape[rev] for a in arrays\n if isinstance(a, ndarray)]\n r_shape = [max(ss) for ss in zip_longest(*shape_arr, fillvalue=0)]\n\n self.shape = shape = tuple(r_shape[rev])\n self.size = size = internal.prod(shape)\n self.nd = ndim = len(shape)\n\n broadcasted = list(arrays)\n for i, a in enumerate(broadcasted):\n if not isinstance(a, ndarray):\n continue\n\n a_shape = a.shape\n if a_shape == shape:\n continue\n\n r_strides = [\n a_st if sh == a_sh else (0 if a_sh == 1 else None)\n for sh, a_sh, a_st\n in six_zip(r_shape, a._shape[rev], a._strides[rev])]\n\n if None in r_strides:\n raise RuntimeError('Broadcasting failed')\n\n offset = (0,) * (ndim - len(r_strides))\n\n broadcasted[i] = view = a.view()\n view._shape = shape\n view._strides = offset + tuple(r_strides[rev])\n view._size = size\n view._c_contiguous = -1\n view._f_contiguous = -1\n\n self.values = tuple(broadcasted)\n\n\ndef broadcast_arrays(*args):\n \"\"\"Broadcasts given arrays.\n\n Args:\n args (tuple of arrays): Arrays to broadcast for each other.\n\n Returns:\n list: A list of broadcasted arrays.\n\n .. seealso:: :func:`numpy.broadcast_arrays`\n\n \"\"\"\n return broadcast(*args).values\n\n\ndef expand_dims(a, axis):\n \"\"\"Expands given arrays.\n\n Args:\n a (cupy.ndarray): Array to be expanded.\n axis (int): Position where new axis is to be inserted.\n\n Returns:\n cupy.ndarray: The number of dimensions is one greater than that of\n the input array.\n\n .. seealso:: :func:`numpy.expand_dims`\n\n \"\"\"\n shape = a.shape\n if axis < 0:\n axis = axis + len(shape) + 1\n return a.reshape(shape[:axis] + (1,) + shape[axis:])\n\n\ndef squeeze(a, axis=None):\n \"\"\"Removes size-one axes from the shape of an array.\n\n Args:\n a (cupy.ndarray): Array to be reshaped.\n axis (int or tuple of ints): Axes to be removed. This function removes\n all size-one axes by default. If one of the specified axes is not\n of size one, an exception is raised.\n\n Returns:\n cupy.ndarray: An array without (specified) size-one axes.\n\n .. seealso:: :func:`numpy.squeeze`\n\n \"\"\"\n if axis is None:\n axis = tuple(i for i, n in enumerate(a._shape) if n == 1)\n elif isinstance(axis, int):\n axis = axis,\n\n new_shape = []\n new_strides = []\n j = 0\n for i, n in enumerate(a._shape):\n if j < len(axis) and i == axis[j]:\n if n != 1:\n raise RuntimeError('Cannot squeeze dimension of size > 1')\n j += 1\n else:\n new_shape.append(n)\n new_strides.append(a._strides[i])\n\n v = a.view()\n v._shape = tuple(new_shape)\n v._strides = tuple(new_strides)\n v._c_contiguous = -1\n v._f_contiguous = -1\n return v\n", "path": "cupy/manipulation/dims.py"}]} | 2,920 | 122 |
gh_patches_debug_31157 | rasdani/github-patches | git_diff | alltheplaces__alltheplaces-3349 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Spider signet_jewelers is broken
During the global build at 2021-07-14-14-42-22, spider **signet_jewelers** failed with **2353 features** and **6 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-07-14-14-42-22/logs/signet_jewelers.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-07-14-14-42-22/output/signet_jewelers.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-07-14-14-42-22/output/signet_jewelers.geojson))
</issue>
<code>
[start of locations/spiders/signet_jewelers.py]
1 # -*- coding: utf-8 -*-
2 import json
3 import re
4
5 import scrapy
6
7 from locations.items import GeojsonPointItem
8 from locations.hours import OpeningHours
9
10
11 class SignetJewelersSpider(scrapy.Spider):
12 name = "signet_jewelers"
13 allowed_domains = ['www.jared.com', 'www.kay.com', 'www.zales.com', 'www.pagoda.com', 'www.peoplesjewellers.com',
14 'www.ernestjones.co.uk', 'www.hsamuel.co.uk']
15 download_delay = 0.5 # limit the delay to avoid 403 errors
16
17 ca_prov = ['Alberta', 'British Columbia', 'Manitoba', 'New Brunswick', 'Newfoundland and Labrador',
18 'Nova Scotia', 'Ontario', 'Saskatchewan']
19
20 states = ["Alabama", "Alaska", "Arizona", "Arkansas", "California", "Colorado",
21 "Connecticut", "Delaware", "Florida", "Georgia", "Hawaii", "Idaho", "Illinois",
22 "Indiana", "Iowa", "Kansas", "Kentucky", "Louisiana", "Maine", "Maryland",
23 "Massachusetts", "Michigan", "Minnesota", "Mississippi", "Missouri", "Montana",
24 "Nebraska", "Nevada", "New Hampshire", "New Jersey", "New Mexico", "New York",
25 "North Carolina", "North Dakota", "Ohio", "Oklahoma", "Oregon", "Pennsylvania",
26 "Rhode Island", "South Carolina", "South Dakota", "Tennessee", "Texas", "Utah",
27 "Vermont", "Virginia", "Washington", "West Virginia", "Wisconsin", "Wyoming"
28 ]
29
30 def start_requests(self):
31 north_america_brands = ["jared", "kay", "zales", "pagoda", "peoplesjewellers"]
32
33 uk_urls = [
34 'https://www.hsamuel.co.uk/scripts/dist/store-locator/functionality/store-details.min.js?sprint-17_20190911.3',
35 'https://www.ernestjones.co.uk/scripts/store-locator/storeLocationDetails.js']
36
37 for url in uk_urls:
38 yield scrapy.Request(url=url, callback=self.parse_uk)
39
40 template = 'https://www.{brand}.com/store-finder/view-stores/{region}'
41
42 for brand in north_america_brands:
43 if brand == "peoplesjewellers":
44 for prov in SignetJewelersSpider.ca_prov:
45 url = template.format(brand=brand, region=prov)
46 yield scrapy.Request(url, callback=self.parse_cities)
47 else:
48 for state in SignetJewelersSpider.states:
49 url = template.format(brand=brand, region=state)
50 yield scrapy.Request(url, callback=self.parse_cities)
51
52 def parse_cities(self, response):
53 cities = response.xpath('//*[@class="viewstoreslist"]/a/@href').extract()
54 for i in cities:
55 yield scrapy.Request(response.urljoin(i), callback=self.parse)
56
57 def parse(self, response):
58 script = " ".join(response.xpath('//*[@id="js-store-details"]/div/script/text()').extract())
59 data = re.search(r'storeInformation\s=\s((?s).*)', script).groups()[0]
60 data = data.replace(";", '')
61 data = eval(data)
62
63 if data["region"] in SignetJewelersSpider.ca_prov:
64 country = 'CA'
65 else:
66 country = 'US'
67
68 properties = {
69 'ref': data["name"],
70 'name': data["displayName"],
71 'addr_full': data["line1"],
72 'city': data["town"],
73 'state': data["region"],
74 'postcode': data["postalCode"],
75 'country': country,
76 'lat': data["latitude"],
77 'lon': data["longitude"],
78 'phone': data["phone"],
79 'website': response.url,
80 'brand': re.search(r'www.(\w+)', response.url)[1],
81 }
82
83 yield GeojsonPointItem(**properties)
84
85 def parse_uk(self, response):
86 data = re.search(r'Signet.allStoreDetails=((?s).*)', response.text)[1]
87 data = data.replace(';', '')
88 data = json.loads(data)
89
90 for store in data:
91 properties = {
92 'ref': store["number"],
93 'name': store["name"],
94 'addr_full': store["addressLine1"],
95 'city': store["town"],
96 'postcode': store["postcode"],
97 'country': 'GB',
98 'lat': store["latitude"],
99 'lon': store["longitude"],
100 'brand': re.search(r'www.(\w+)', response.url)[1],
101 }
102
103 yield GeojsonPointItem(**properties)
104
[end of locations/spiders/signet_jewelers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/locations/spiders/signet_jewelers.py b/locations/spiders/signet_jewelers.py
--- a/locations/spiders/signet_jewelers.py
+++ b/locations/spiders/signet_jewelers.py
@@ -56,29 +56,38 @@
def parse(self, response):
script = " ".join(response.xpath('//*[@id="js-store-details"]/div/script/text()').extract())
- data = re.search(r'storeInformation\s=\s((?s).*)', script).groups()[0]
- data = data.replace(";", '')
- data = eval(data)
-
- if data["region"] in SignetJewelersSpider.ca_prov:
- country = 'CA'
- else:
- country = 'US'
-
- properties = {
- 'ref': data["name"],
- 'name': data["displayName"],
- 'addr_full': data["line1"],
- 'city': data["town"],
- 'state': data["region"],
- 'postcode': data["postalCode"],
- 'country': country,
- 'lat': data["latitude"],
- 'lon': data["longitude"],
- 'phone': data["phone"],
- 'website': response.url,
- 'brand': re.search(r'www.(\w+)', response.url)[1],
- }
+ data = None
+
+ if re.search(r'storeInformation\s=\s((?s).*)', script) is not None:
+ data = re.search(r'storeInformation\s=\s((?s).*)', script).groups()
+
+ properties = {}
+
+ if data is not None:
+ if len(data) > 0:
+ data = data[0]
+ data = data.replace(";", '')
+ data = eval(data)
+
+ if data["region"] in SignetJewelersSpider.ca_prov:
+ country = 'CA'
+ else:
+ country = 'US'
+
+ properties = {
+ 'ref': data["name"],
+ 'name': data["displayName"],
+ 'addr_full': data["line1"],
+ 'city': data["town"],
+ 'state': data["region"],
+ 'postcode': data["postalCode"],
+ 'country': country,
+ 'lat': data["latitude"],
+ 'lon': data["longitude"],
+ 'phone': data["phone"],
+ 'website': response.url,
+ 'brand': re.search(r'www.(\w+)', response.url)[1],
+ }
yield GeojsonPointItem(**properties)
| {"golden_diff": "diff --git a/locations/spiders/signet_jewelers.py b/locations/spiders/signet_jewelers.py\n--- a/locations/spiders/signet_jewelers.py\n+++ b/locations/spiders/signet_jewelers.py\n@@ -56,29 +56,38 @@\n \n def parse(self, response):\n script = \" \".join(response.xpath('//*[@id=\"js-store-details\"]/div/script/text()').extract())\n- data = re.search(r'storeInformation\\s=\\s((?s).*)', script).groups()[0]\n- data = data.replace(\";\", '')\n- data = eval(data)\n-\n- if data[\"region\"] in SignetJewelersSpider.ca_prov:\n- country = 'CA'\n- else:\n- country = 'US'\n-\n- properties = {\n- 'ref': data[\"name\"],\n- 'name': data[\"displayName\"],\n- 'addr_full': data[\"line1\"],\n- 'city': data[\"town\"],\n- 'state': data[\"region\"],\n- 'postcode': data[\"postalCode\"],\n- 'country': country,\n- 'lat': data[\"latitude\"],\n- 'lon': data[\"longitude\"],\n- 'phone': data[\"phone\"],\n- 'website': response.url,\n- 'brand': re.search(r'www.(\\w+)', response.url)[1],\n- }\n+ data = None\n+\n+ if re.search(r'storeInformation\\s=\\s((?s).*)', script) is not None:\n+ data = re.search(r'storeInformation\\s=\\s((?s).*)', script).groups()\n+\n+ properties = {}\n+\n+ if data is not None:\n+ if len(data) > 0:\n+ data = data[0]\n+ data = data.replace(\";\", '')\n+ data = eval(data)\n+\n+ if data[\"region\"] in SignetJewelersSpider.ca_prov:\n+ country = 'CA'\n+ else:\n+ country = 'US'\n+\n+ properties = {\n+ 'ref': data[\"name\"],\n+ 'name': data[\"displayName\"],\n+ 'addr_full': data[\"line1\"],\n+ 'city': data[\"town\"],\n+ 'state': data[\"region\"],\n+ 'postcode': data[\"postalCode\"],\n+ 'country': country,\n+ 'lat': data[\"latitude\"],\n+ 'lon': data[\"longitude\"],\n+ 'phone': data[\"phone\"],\n+ 'website': response.url,\n+ 'brand': re.search(r'www.(\\w+)', response.url)[1],\n+ }\n \n yield GeojsonPointItem(**properties)\n", "issue": "Spider signet_jewelers is broken\nDuring the global build at 2021-07-14-14-42-22, spider **signet_jewelers** failed with **2353 features** and **6 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-07-14-14-42-22/logs/signet_jewelers.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-07-14-14-42-22/output/signet_jewelers.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-07-14-14-42-22/output/signet_jewelers.geojson))\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport json\nimport re\n\nimport scrapy\n\nfrom locations.items import GeojsonPointItem\nfrom locations.hours import OpeningHours\n\n\nclass SignetJewelersSpider(scrapy.Spider):\n name = \"signet_jewelers\"\n allowed_domains = ['www.jared.com', 'www.kay.com', 'www.zales.com', 'www.pagoda.com', 'www.peoplesjewellers.com',\n 'www.ernestjones.co.uk', 'www.hsamuel.co.uk']\n download_delay = 0.5 # limit the delay to avoid 403 errors\n\n ca_prov = ['Alberta', 'British Columbia', 'Manitoba', 'New Brunswick', 'Newfoundland and Labrador',\n 'Nova Scotia', 'Ontario', 'Saskatchewan']\n\n states = [\"Alabama\", \"Alaska\", \"Arizona\", \"Arkansas\", \"California\", \"Colorado\",\n \"Connecticut\", \"Delaware\", \"Florida\", \"Georgia\", \"Hawaii\", \"Idaho\", \"Illinois\",\n \"Indiana\", \"Iowa\", \"Kansas\", \"Kentucky\", \"Louisiana\", \"Maine\", \"Maryland\",\n \"Massachusetts\", \"Michigan\", \"Minnesota\", \"Mississippi\", \"Missouri\", \"Montana\",\n \"Nebraska\", \"Nevada\", \"New Hampshire\", \"New Jersey\", \"New Mexico\", \"New York\",\n \"North Carolina\", \"North Dakota\", \"Ohio\", \"Oklahoma\", \"Oregon\", \"Pennsylvania\",\n \"Rhode Island\", \"South Carolina\", \"South Dakota\", \"Tennessee\", \"Texas\", \"Utah\",\n \"Vermont\", \"Virginia\", \"Washington\", \"West Virginia\", \"Wisconsin\", \"Wyoming\"\n ]\n\n def start_requests(self):\n north_america_brands = [\"jared\", \"kay\", \"zales\", \"pagoda\", \"peoplesjewellers\"]\n\n uk_urls = [\n 'https://www.hsamuel.co.uk/scripts/dist/store-locator/functionality/store-details.min.js?sprint-17_20190911.3',\n 'https://www.ernestjones.co.uk/scripts/store-locator/storeLocationDetails.js']\n\n for url in uk_urls:\n yield scrapy.Request(url=url, callback=self.parse_uk)\n\n template = 'https://www.{brand}.com/store-finder/view-stores/{region}'\n\n for brand in north_america_brands:\n if brand == \"peoplesjewellers\":\n for prov in SignetJewelersSpider.ca_prov:\n url = template.format(brand=brand, region=prov)\n yield scrapy.Request(url, callback=self.parse_cities)\n else:\n for state in SignetJewelersSpider.states:\n url = template.format(brand=brand, region=state)\n yield scrapy.Request(url, callback=self.parse_cities)\n\n def parse_cities(self, response):\n cities = response.xpath('//*[@class=\"viewstoreslist\"]/a/@href').extract()\n for i in cities:\n yield scrapy.Request(response.urljoin(i), callback=self.parse)\n\n def parse(self, response):\n script = \" \".join(response.xpath('//*[@id=\"js-store-details\"]/div/script/text()').extract())\n data = re.search(r'storeInformation\\s=\\s((?s).*)', script).groups()[0]\n data = data.replace(\";\", '')\n data = eval(data)\n\n if data[\"region\"] in SignetJewelersSpider.ca_prov:\n country = 'CA'\n else:\n country = 'US'\n\n properties = {\n 'ref': data[\"name\"],\n 'name': data[\"displayName\"],\n 'addr_full': data[\"line1\"],\n 'city': data[\"town\"],\n 'state': data[\"region\"],\n 'postcode': data[\"postalCode\"],\n 'country': country,\n 'lat': data[\"latitude\"],\n 'lon': data[\"longitude\"],\n 'phone': data[\"phone\"],\n 'website': response.url,\n 'brand': re.search(r'www.(\\w+)', response.url)[1],\n }\n\n yield GeojsonPointItem(**properties)\n\n def parse_uk(self, response):\n data = re.search(r'Signet.allStoreDetails=((?s).*)', response.text)[1]\n data = data.replace(';', '')\n data = json.loads(data)\n\n for store in data:\n properties = {\n 'ref': store[\"number\"],\n 'name': store[\"name\"],\n 'addr_full': store[\"addressLine1\"],\n 'city': store[\"town\"],\n 'postcode': store[\"postcode\"],\n 'country': 'GB',\n 'lat': store[\"latitude\"],\n 'lon': store[\"longitude\"],\n 'brand': re.search(r'www.(\\w+)', response.url)[1],\n }\n\n yield GeojsonPointItem(**properties)\n", "path": "locations/spiders/signet_jewelers.py"}]} | 2,012 | 587 |
gh_patches_debug_37852 | rasdani/github-patches | git_diff | akvo__akvo-rsr-5268 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Feature Request: Document the results framework
### What are you trying to do?
Understand how the results framework functions
### Describe the solution you'd like
A technical documentation of how it works.
### Have you consider alternatives?
_No response_
### Additional context
_No response_
</issue>
<code>
[start of akvo/rsr/models/project_hierarchy.py]
1 # -*- coding: utf-8 -*-
2
3 # Akvo RSR is covered by the GNU Affero General Public License.
4 # See more details in the license.txt file located at the root folder of the Akvo RSR module.
5 # For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
6
7 from django.db import models
8 from django.utils.translation import ugettext_lazy as _
9
10
11 class ProjectHierarchy(models.Model):
12 project_relation = 'projecthierarchy__in'
13 root_project = models.OneToOneField('Project', on_delete=models.CASCADE, db_index=True)
14 max_depth = models.PositiveSmallIntegerField()
15 is_master = models.BooleanField(_('is master program'), default=False)
16
17 class Meta:
18 app_label = 'rsr'
19 verbose_name = _('program')
20 verbose_name_plural = _('programs')
21 ordering = ['-id']
22
23 @property
24 def descendants(self):
25 return self.root_project.descendants(max_depth=self.max_depth)
26
27 @property
28 def project_count(self):
29 return self.descendants.count() - 1 # remove root_project from count
30
31 @property
32 def project_ids(self):
33 return self.descendants.values_list('id', flat=True)
34
35 @property
36 def organisation(self):
37 return self.root_project.reporting_org
38
39 def __str__(self):
40 return self.root_project.title
41
[end of akvo/rsr/models/project_hierarchy.py]
[start of doc/conf.py]
1 # Configuration file for the Sphinx documentation builder.
2 #
3 # For the full list of built-in configuration values, see the documentation:
4 # https://www.sphinx-doc.org/en/master/usage/configuration.html
5
6 # -- Project information -----------------------------------------------------
7 # https://www.sphinx-doc.org/en/master/usage/configuration.html#project-information
8
9 import os
10 import sys
11 import django
12 sys.path.insert(0, os.path.abspath('..'))
13 os.environ['DJANGO_SETTINGS_MODULE'] = 'akvo.settings'
14 django.setup()
15
16 project = 'Akvo RSR'
17 copyright = '2023, Akvo Foundation'
18 author = 'Akvo Foundation'
19
20 # -- General configuration ---------------------------------------------------
21 # https://www.sphinx-doc.org/en/master/usage/configuration.html#general-configuration
22
23 extensions = [
24 'sphinx.ext.autodoc',
25 'sphinx.ext.autosummary',
26 'sphinx.ext.viewcode',
27 'myst_parser',
28 ]
29
30 templates_path = ['_templates']
31 exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
32
33
34
35 # -- Options for HTML output -------------------------------------------------
36 # https://www.sphinx-doc.org/en/master/usage/configuration.html#options-for-html-output
37
38 html_theme = 'cloud'
39 html_static_path = ['_static']
40
[end of doc/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/akvo/rsr/models/project_hierarchy.py b/akvo/rsr/models/project_hierarchy.py
--- a/akvo/rsr/models/project_hierarchy.py
+++ b/akvo/rsr/models/project_hierarchy.py
@@ -9,10 +9,22 @@
class ProjectHierarchy(models.Model):
+ """
+ The actual "Program" with a project hierarchy.
+ """
project_relation = 'projecthierarchy__in'
+
root_project = models.OneToOneField('Project', on_delete=models.CASCADE, db_index=True)
+ """
+ The root of the program
+ It can be used to create subprograms / a program tree
+ """
+
max_depth = models.PositiveSmallIntegerField()
+ """TODO: It is unclear why this field currently exists"""
+
is_master = models.BooleanField(_('is master program'), default=False)
+ """Used when an organisation has one program under which they would like to create subprograms"""
class Meta:
app_label = 'rsr'
@@ -22,10 +34,15 @@
@property
def descendants(self):
+ """
+ The entire tree in a list.
+ No order is guaranteed
+ """
return self.root_project.descendants(max_depth=self.max_depth)
@property
def project_count(self):
+ """The number of children without counting the root project"""
return self.descendants.count() - 1 # remove root_project from count
@property
@@ -34,6 +51,7 @@
@property
def organisation(self):
+ """The reporting organisation of the tree"""
return self.root_project.reporting_org
def __str__(self):
diff --git a/doc/conf.py b/doc/conf.py
--- a/doc/conf.py
+++ b/doc/conf.py
@@ -21,6 +21,7 @@
# https://www.sphinx-doc.org/en/master/usage/configuration.html#general-configuration
extensions = [
+ 'sphinxcontrib.plantuml',
'sphinx.ext.autodoc',
'sphinx.ext.autosummary',
'sphinx.ext.viewcode',
@@ -30,7 +31,9 @@
templates_path = ['_templates']
exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
-
+myst_enable_extensions = [
+ "colon_fence", # https://myst-parser.readthedocs.io/en/latest/syntax/optional.html#syntax-colon-fence
+]
# -- Options for HTML output -------------------------------------------------
# https://www.sphinx-doc.org/en/master/usage/configuration.html#options-for-html-output
| {"golden_diff": "diff --git a/akvo/rsr/models/project_hierarchy.py b/akvo/rsr/models/project_hierarchy.py\n--- a/akvo/rsr/models/project_hierarchy.py\n+++ b/akvo/rsr/models/project_hierarchy.py\n@@ -9,10 +9,22 @@\n \n \n class ProjectHierarchy(models.Model):\n+ \"\"\"\n+ The actual \"Program\" with a project hierarchy.\n+ \"\"\"\n project_relation = 'projecthierarchy__in'\n+\n root_project = models.OneToOneField('Project', on_delete=models.CASCADE, db_index=True)\n+ \"\"\"\n+ The root of the program\n+ It can be used to create subprograms / a program tree\n+ \"\"\"\n+\n max_depth = models.PositiveSmallIntegerField()\n+ \"\"\"TODO: It is unclear why this field currently exists\"\"\"\n+\n is_master = models.BooleanField(_('is master program'), default=False)\n+ \"\"\"Used when an organisation has one program under which they would like to create subprograms\"\"\"\n \n class Meta:\n app_label = 'rsr'\n@@ -22,10 +34,15 @@\n \n @property\n def descendants(self):\n+ \"\"\"\n+ The entire tree in a list.\n+ No order is guaranteed\n+ \"\"\"\n return self.root_project.descendants(max_depth=self.max_depth)\n \n @property\n def project_count(self):\n+ \"\"\"The number of children without counting the root project\"\"\"\n return self.descendants.count() - 1 # remove root_project from count\n \n @property\n@@ -34,6 +51,7 @@\n \n @property\n def organisation(self):\n+ \"\"\"The reporting organisation of the tree\"\"\"\n return self.root_project.reporting_org\n \n def __str__(self):\ndiff --git a/doc/conf.py b/doc/conf.py\n--- a/doc/conf.py\n+++ b/doc/conf.py\n@@ -21,6 +21,7 @@\n # https://www.sphinx-doc.org/en/master/usage/configuration.html#general-configuration\n \n extensions = [\n+ 'sphinxcontrib.plantuml',\n 'sphinx.ext.autodoc',\n 'sphinx.ext.autosummary',\n 'sphinx.ext.viewcode',\n@@ -30,7 +31,9 @@\n templates_path = ['_templates']\n exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']\n \n-\n+myst_enable_extensions = [\n+ \"colon_fence\", # https://myst-parser.readthedocs.io/en/latest/syntax/optional.html#syntax-colon-fence\n+]\n \n # -- Options for HTML output -------------------------------------------------\n # https://www.sphinx-doc.org/en/master/usage/configuration.html#options-for-html-output\n", "issue": "Feature Request: Document the results framework\n### What are you trying to do?\n\nUnderstand how the results framework functions\n\n### Describe the solution you'd like\n\nA technical documentation of how it works.\n\n### Have you consider alternatives?\n\n_No response_\n\n### Additional context\n\n_No response_\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\nfrom django.db import models\nfrom django.utils.translation import ugettext_lazy as _\n\n\nclass ProjectHierarchy(models.Model):\n project_relation = 'projecthierarchy__in'\n root_project = models.OneToOneField('Project', on_delete=models.CASCADE, db_index=True)\n max_depth = models.PositiveSmallIntegerField()\n is_master = models.BooleanField(_('is master program'), default=False)\n\n class Meta:\n app_label = 'rsr'\n verbose_name = _('program')\n verbose_name_plural = _('programs')\n ordering = ['-id']\n\n @property\n def descendants(self):\n return self.root_project.descendants(max_depth=self.max_depth)\n\n @property\n def project_count(self):\n return self.descendants.count() - 1 # remove root_project from count\n\n @property\n def project_ids(self):\n return self.descendants.values_list('id', flat=True)\n\n @property\n def organisation(self):\n return self.root_project.reporting_org\n\n def __str__(self):\n return self.root_project.title\n", "path": "akvo/rsr/models/project_hierarchy.py"}, {"content": "# Configuration file for the Sphinx documentation builder.\n#\n# For the full list of built-in configuration values, see the documentation:\n# https://www.sphinx-doc.org/en/master/usage/configuration.html\n\n# -- Project information -----------------------------------------------------\n# https://www.sphinx-doc.org/en/master/usage/configuration.html#project-information\n\nimport os\nimport sys\nimport django\nsys.path.insert(0, os.path.abspath('..'))\nos.environ['DJANGO_SETTINGS_MODULE'] = 'akvo.settings'\ndjango.setup()\n\nproject = 'Akvo RSR'\ncopyright = '2023, Akvo Foundation'\nauthor = 'Akvo Foundation'\n\n# -- General configuration ---------------------------------------------------\n# https://www.sphinx-doc.org/en/master/usage/configuration.html#general-configuration\n\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.autosummary',\n 'sphinx.ext.viewcode',\n 'myst_parser',\n]\n\ntemplates_path = ['_templates']\nexclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']\n\n\n\n# -- Options for HTML output -------------------------------------------------\n# https://www.sphinx-doc.org/en/master/usage/configuration.html#options-for-html-output\n\nhtml_theme = 'cloud'\nhtml_static_path = ['_static']\n", "path": "doc/conf.py"}]} | 1,309 | 569 |
gh_patches_debug_32277 | rasdani/github-patches | git_diff | weni-ai__bothub-engine-78 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Is possible translate example to same language
</issue>
<code>
[start of bothub/api/serializers/translate.py]
1 from rest_framework import serializers
2
3 from django.utils.translation import gettext as _
4
5 from bothub.common.models import RepositoryTranslatedExampleEntity
6 from bothub.common.models import RepositoryTranslatedExample
7 from bothub.common.models import RepositoryExample
8
9 from ..validators import CanContributeInRepositoryTranslatedExampleValidator
10 from ..validators import CanContributeInRepositoryExampleValidator
11 from ..validators import TranslatedExampleEntitiesValidator
12
13
14 class RepositoryTranslatedExampleEntitySeralizer(serializers.ModelSerializer):
15 class Meta:
16 model = RepositoryTranslatedExampleEntity
17 fields = [
18 'id',
19 'repository_translated_example',
20 'start',
21 'end',
22 'entity',
23 'created_at',
24 'value',
25 ]
26
27 repository_translated_example = serializers.PrimaryKeyRelatedField(
28 queryset=RepositoryTranslatedExample.objects,
29 validators=[
30 CanContributeInRepositoryTranslatedExampleValidator(),
31 ],
32 help_text='Example translation ID')
33 value = serializers.SerializerMethodField()
34
35 def get_value(self, obj):
36 return obj.value
37
38
39 class RepositoryTranslatedExampleSerializer(serializers.ModelSerializer):
40 class Meta:
41 model = RepositoryTranslatedExample
42 fields = [
43 'id',
44 'original_example',
45 'from_language',
46 'language',
47 'text',
48 'has_valid_entities',
49 'entities',
50 'created_at',
51 ]
52
53 original_example = serializers.PrimaryKeyRelatedField(
54 queryset=RepositoryExample.objects,
55 validators=[
56 CanContributeInRepositoryExampleValidator(),
57 ],
58 help_text=_('Example\'s ID'))
59 from_language = serializers.SerializerMethodField()
60 has_valid_entities = serializers.SerializerMethodField()
61 entities = RepositoryTranslatedExampleEntitySeralizer(
62 many=True,
63 read_only=True)
64
65 def get_from_language(self, obj):
66 return obj.original_example.repository_update.language
67
68 def get_has_valid_entities(self, obj):
69 return obj.has_valid_entities
70
71
72 class NewRepositoryTranslatedExampleEntitySeralizer(
73 serializers.ModelSerializer):
74 class Meta:
75 model = RepositoryTranslatedExampleEntity
76 fields = [
77 'start',
78 'end',
79 'entity',
80 ]
81
82
83 class NewRepositoryTranslatedExampleSerializer(serializers.ModelSerializer):
84 class Meta:
85 model = RepositoryTranslatedExample
86 fields = [
87 'id',
88 'original_example',
89 'language',
90 'text',
91 'has_valid_entities',
92 'entities',
93 ]
94
95 def __init__(self, *args, **kwargs):
96 super().__init__(*args, **kwargs)
97 self.validators.append(TranslatedExampleEntitiesValidator())
98
99 original_example = serializers.PrimaryKeyRelatedField(
100 queryset=RepositoryExample.objects,
101 validators=[
102 CanContributeInRepositoryExampleValidator(),
103 ],
104 help_text=_('Example\'s ID'))
105 has_valid_entities = serializers.SerializerMethodField()
106 entities = NewRepositoryTranslatedExampleEntitySeralizer(
107 many=True,
108 style={'text_field': 'text'})
109
110 def get_has_valid_entities(self, obj):
111 return obj.has_valid_entities
112
113 def create(self, validated_data):
114 entities_data = validated_data.pop('entities')
115
116 translated = self.Meta.model.objects.create(**validated_data)
117 for entity_data in entities_data:
118 RepositoryTranslatedExampleEntity.objects.create(
119 repository_translated_example=translated,
120 **entity_data)
121 return translated
122
[end of bothub/api/serializers/translate.py]
[start of bothub/api/validators.py]
1 from django.utils.translation import gettext as _
2 from rest_framework.exceptions import PermissionDenied
3 from rest_framework.exceptions import ValidationError
4
5 from bothub.common.models import RepositoryTranslatedExample
6
7
8 class CanContributeInRepositoryValidator(object):
9 def __call__(self, value):
10 user_authorization = value.get_user_authorization(
11 self.request.user)
12 if not user_authorization.can_contribute:
13 raise PermissionDenied(
14 _('You can\'t contribute in this repository'))
15
16 def set_context(self, serializer):
17 self.request = serializer.context.get('request')
18
19
20 class CanContributeInRepositoryExampleValidator(object):
21 def __call__(self, value):
22 repository = value.repository_update.repository
23 user_authorization = repository.get_user_authorization(
24 self.request.user)
25 if not user_authorization.can_contribute:
26 raise PermissionDenied(
27 _('You can\'t contribute in this repository'))
28
29 def set_context(self, serializer):
30 self.request = serializer.context.get('request')
31
32
33 class CanContributeInRepositoryTranslatedExampleValidator(object):
34 def __call__(self, value):
35 repository = value.original_example.repository_update.repository
36 user_authorization = repository.get_user_authorization(
37 self.request.user)
38 if not user_authorization.can_contribute:
39 raise PermissionDenied(
40 _('You can\'t contribute in this repository'))
41
42 def set_context(self, serializer):
43 self.request = serializer.context.get('request')
44
45
46 class TranslatedExampleEntitiesValidator(object):
47 def __call__(self, attrs):
48 original_example = attrs.get('original_example')
49 entities_valid = RepositoryTranslatedExample.same_entities_validator(
50 list(map(lambda x: dict(x), attrs.get('entities'))),
51 list(map(lambda x: x.to_dict, original_example.entities.all())))
52 if not entities_valid:
53 raise ValidationError({'entities': _('Invalid entities')})
54
[end of bothub/api/validators.py]
[start of setup.py]
1 from setuptools import setup, find_packages
2
3 with open('requirements.txt') as fp:
4 install_requires = fp.read()
5 install_requires = list(
6 filter(lambda x: len(x) > 0, install_requires.split('\n')))
7
8 setup(
9 name='bothub',
10 version='1.7.2',
11 description='bothub',
12 packages=find_packages(),
13 install_requires=install_requires,
14 python_requires='>=3.6',
15 )
16
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/bothub/api/serializers/translate.py b/bothub/api/serializers/translate.py
--- a/bothub/api/serializers/translate.py
+++ b/bothub/api/serializers/translate.py
@@ -9,6 +9,7 @@
from ..validators import CanContributeInRepositoryTranslatedExampleValidator
from ..validators import CanContributeInRepositoryExampleValidator
from ..validators import TranslatedExampleEntitiesValidator
+from ..validators import TranslatedExampleLanguageValidator
class RepositoryTranslatedExampleEntitySeralizer(serializers.ModelSerializer):
@@ -95,6 +96,7 @@
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.validators.append(TranslatedExampleEntitiesValidator())
+ self.validators.append(TranslatedExampleLanguageValidator())
original_example = serializers.PrimaryKeyRelatedField(
queryset=RepositoryExample.objects,
diff --git a/bothub/api/validators.py b/bothub/api/validators.py
--- a/bothub/api/validators.py
+++ b/bothub/api/validators.py
@@ -51,3 +51,11 @@
list(map(lambda x: x.to_dict, original_example.entities.all())))
if not entities_valid:
raise ValidationError({'entities': _('Invalid entities')})
+
+
+class TranslatedExampleLanguageValidator(object):
+ def __call__(self, attrs):
+ original_example = attrs.get('original_example')
+ language = attrs.get('language')
+ if original_example.repository_update.language == language:
+ raise ValidationError({'language': _('Can\'t translate to same language')})
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -7,7 +7,7 @@
setup(
name='bothub',
- version='1.7.2',
+ version='1.7.3',
description='bothub',
packages=find_packages(),
install_requires=install_requires,
| {"golden_diff": "diff --git a/bothub/api/serializers/translate.py b/bothub/api/serializers/translate.py\n--- a/bothub/api/serializers/translate.py\n+++ b/bothub/api/serializers/translate.py\n@@ -9,6 +9,7 @@\n from ..validators import CanContributeInRepositoryTranslatedExampleValidator\n from ..validators import CanContributeInRepositoryExampleValidator\n from ..validators import TranslatedExampleEntitiesValidator\n+from ..validators import TranslatedExampleLanguageValidator\n \n \n class RepositoryTranslatedExampleEntitySeralizer(serializers.ModelSerializer):\n@@ -95,6 +96,7 @@\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.validators.append(TranslatedExampleEntitiesValidator())\n+ self.validators.append(TranslatedExampleLanguageValidator())\n \n original_example = serializers.PrimaryKeyRelatedField(\n queryset=RepositoryExample.objects,\ndiff --git a/bothub/api/validators.py b/bothub/api/validators.py\n--- a/bothub/api/validators.py\n+++ b/bothub/api/validators.py\n@@ -51,3 +51,11 @@\n list(map(lambda x: x.to_dict, original_example.entities.all())))\n if not entities_valid:\n raise ValidationError({'entities': _('Invalid entities')})\n+\n+\n+class TranslatedExampleLanguageValidator(object):\n+ def __call__(self, attrs):\n+ original_example = attrs.get('original_example')\n+ language = attrs.get('language')\n+ if original_example.repository_update.language == language:\n+ raise ValidationError({'language': _('Can\\'t translate to same language')})\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -7,7 +7,7 @@\n \n setup(\n name='bothub',\n- version='1.7.2',\n+ version='1.7.3',\n description='bothub',\n packages=find_packages(),\n install_requires=install_requires,\n", "issue": "Is possible translate example to same language\n\n", "before_files": [{"content": "from rest_framework import serializers\n\nfrom django.utils.translation import gettext as _\n\nfrom bothub.common.models import RepositoryTranslatedExampleEntity\nfrom bothub.common.models import RepositoryTranslatedExample\nfrom bothub.common.models import RepositoryExample\n\nfrom ..validators import CanContributeInRepositoryTranslatedExampleValidator\nfrom ..validators import CanContributeInRepositoryExampleValidator\nfrom ..validators import TranslatedExampleEntitiesValidator\n\n\nclass RepositoryTranslatedExampleEntitySeralizer(serializers.ModelSerializer):\n class Meta:\n model = RepositoryTranslatedExampleEntity\n fields = [\n 'id',\n 'repository_translated_example',\n 'start',\n 'end',\n 'entity',\n 'created_at',\n 'value',\n ]\n\n repository_translated_example = serializers.PrimaryKeyRelatedField(\n queryset=RepositoryTranslatedExample.objects,\n validators=[\n CanContributeInRepositoryTranslatedExampleValidator(),\n ],\n help_text='Example translation ID')\n value = serializers.SerializerMethodField()\n\n def get_value(self, obj):\n return obj.value\n\n\nclass RepositoryTranslatedExampleSerializer(serializers.ModelSerializer):\n class Meta:\n model = RepositoryTranslatedExample\n fields = [\n 'id',\n 'original_example',\n 'from_language',\n 'language',\n 'text',\n 'has_valid_entities',\n 'entities',\n 'created_at',\n ]\n\n original_example = serializers.PrimaryKeyRelatedField(\n queryset=RepositoryExample.objects,\n validators=[\n CanContributeInRepositoryExampleValidator(),\n ],\n help_text=_('Example\\'s ID'))\n from_language = serializers.SerializerMethodField()\n has_valid_entities = serializers.SerializerMethodField()\n entities = RepositoryTranslatedExampleEntitySeralizer(\n many=True,\n read_only=True)\n\n def get_from_language(self, obj):\n return obj.original_example.repository_update.language\n\n def get_has_valid_entities(self, obj):\n return obj.has_valid_entities\n\n\nclass NewRepositoryTranslatedExampleEntitySeralizer(\n serializers.ModelSerializer):\n class Meta:\n model = RepositoryTranslatedExampleEntity\n fields = [\n 'start',\n 'end',\n 'entity',\n ]\n\n\nclass NewRepositoryTranslatedExampleSerializer(serializers.ModelSerializer):\n class Meta:\n model = RepositoryTranslatedExample\n fields = [\n 'id',\n 'original_example',\n 'language',\n 'text',\n 'has_valid_entities',\n 'entities',\n ]\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.validators.append(TranslatedExampleEntitiesValidator())\n\n original_example = serializers.PrimaryKeyRelatedField(\n queryset=RepositoryExample.objects,\n validators=[\n CanContributeInRepositoryExampleValidator(),\n ],\n help_text=_('Example\\'s ID'))\n has_valid_entities = serializers.SerializerMethodField()\n entities = NewRepositoryTranslatedExampleEntitySeralizer(\n many=True,\n style={'text_field': 'text'})\n\n def get_has_valid_entities(self, obj):\n return obj.has_valid_entities\n\n def create(self, validated_data):\n entities_data = validated_data.pop('entities')\n\n translated = self.Meta.model.objects.create(**validated_data)\n for entity_data in entities_data:\n RepositoryTranslatedExampleEntity.objects.create(\n repository_translated_example=translated,\n **entity_data)\n return translated\n", "path": "bothub/api/serializers/translate.py"}, {"content": "from django.utils.translation import gettext as _\nfrom rest_framework.exceptions import PermissionDenied\nfrom rest_framework.exceptions import ValidationError\n\nfrom bothub.common.models import RepositoryTranslatedExample\n\n\nclass CanContributeInRepositoryValidator(object):\n def __call__(self, value):\n user_authorization = value.get_user_authorization(\n self.request.user)\n if not user_authorization.can_contribute:\n raise PermissionDenied(\n _('You can\\'t contribute in this repository'))\n\n def set_context(self, serializer):\n self.request = serializer.context.get('request')\n\n\nclass CanContributeInRepositoryExampleValidator(object):\n def __call__(self, value):\n repository = value.repository_update.repository\n user_authorization = repository.get_user_authorization(\n self.request.user)\n if not user_authorization.can_contribute:\n raise PermissionDenied(\n _('You can\\'t contribute in this repository'))\n\n def set_context(self, serializer):\n self.request = serializer.context.get('request')\n\n\nclass CanContributeInRepositoryTranslatedExampleValidator(object):\n def __call__(self, value):\n repository = value.original_example.repository_update.repository\n user_authorization = repository.get_user_authorization(\n self.request.user)\n if not user_authorization.can_contribute:\n raise PermissionDenied(\n _('You can\\'t contribute in this repository'))\n\n def set_context(self, serializer):\n self.request = serializer.context.get('request')\n\n\nclass TranslatedExampleEntitiesValidator(object):\n def __call__(self, attrs):\n original_example = attrs.get('original_example')\n entities_valid = RepositoryTranslatedExample.same_entities_validator(\n list(map(lambda x: dict(x), attrs.get('entities'))),\n list(map(lambda x: x.to_dict, original_example.entities.all())))\n if not entities_valid:\n raise ValidationError({'entities': _('Invalid entities')})\n", "path": "bothub/api/validators.py"}, {"content": "from setuptools import setup, find_packages\n\nwith open('requirements.txt') as fp:\n install_requires = fp.read()\ninstall_requires = list(\n filter(lambda x: len(x) > 0, install_requires.split('\\n')))\n\nsetup(\n name='bothub',\n version='1.7.2',\n description='bothub',\n packages=find_packages(),\n install_requires=install_requires,\n python_requires='>=3.6',\n)\n", "path": "setup.py"}]} | 2,123 | 424 |
gh_patches_debug_36681 | rasdani/github-patches | git_diff | meltano__meltano-6069 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix `KeyError: venv_name` and similar errors in lockfiles
</issue>
<code>
[start of src/meltano/core/plugin_lock_service.py]
1 """Plugin Lockfile Service."""
2
3 from __future__ import annotations
4
5 import json
6 from pathlib import Path
7
8 from structlog.stdlib import get_logger
9
10 from meltano.core.plugin.base import BasePlugin, PluginRef, StandalonePlugin, Variant
11 from meltano.core.project import Project
12
13 logger = get_logger(__name__)
14
15
16 class LockfileAlreadyExistsError(Exception):
17 """Raised when a plugin lockfile already exists."""
18
19 def __init__(self, message: str, path: Path, plugin: PluginRef):
20 """Create a new LockfileAlreadyExistsError.
21
22 Args:
23 message: The error message.
24 path: The path to the existing lockfile.
25 plugin: The plugin that was locked.
26 """
27 self.path = path
28 self.plugin = plugin
29 super().__init__(message)
30
31
32 class PluginLockService:
33 """Plugin Lockfile Service."""
34
35 def __init__(self, project: Project):
36 """Create a new Plugin Lockfile Service.
37
38 Args:
39 project: The Meltano project.
40 """
41 self.project = project
42
43 def save(
44 self,
45 plugin: BasePlugin,
46 *,
47 overwrite: bool = False,
48 exists_ok: bool = False,
49 ):
50 """Save the plugin lockfile.
51
52 Args:
53 plugin: The plugin definition to save.
54 overwrite: Whether to overwrite the lockfile if it already exists.
55 exists_ok: Whether raise an exception if the lockfile already exists.
56
57 Raises:
58 LockfileAlreadyExistsError: If the lockfile already exists and is not
59 flagged for overwriting.
60 """
61 variant = None if plugin.variant == Variant.DEFAULT_NAME else plugin.variant
62
63 logger.info(f"Locking a {type(plugin)}")
64
65 plugin_def = plugin.definition
66 path = self.project.plugin_lock_path(
67 plugin_def.type,
68 plugin_def.name,
69 variant_name=variant,
70 )
71
72 if path.exists() and not overwrite and not exists_ok:
73 raise LockfileAlreadyExistsError(
74 f"Lockfile already exists: {path}",
75 path,
76 plugin,
77 )
78
79 variant = plugin_def.find_variant(plugin.variant)
80 locked_def = StandalonePlugin.from_variant(
81 variant,
82 plugin.name,
83 plugin.namespace,
84 plugin.type,
85 label=plugin.label,
86 )
87
88 with path.open("w") as lockfile:
89 json.dump(locked_def.canonical(), lockfile, indent=2)
90
91 logger.debug("Locked plugin definition", path=path)
92
[end of src/meltano/core/plugin_lock_service.py]
[start of src/meltano/core/project_add_service.py]
1 """Add plugins to the project."""
2
3 from __future__ import annotations
4
5 import enum
6
7 from .plugin import BasePlugin, PluginType, Variant
8 from .plugin.project_plugin import ProjectPlugin
9 from .project import Project
10 from .project_plugins_service import PluginAlreadyAddedException, ProjectPluginsService
11
12
13 class PluginAddedReason(str, enum.Enum):
14 """The reason why a plugin was added to the project."""
15
16 #: The plugin was added by the user.
17 USER_REQUEST = "user_request"
18
19 #: The plugin was added because it is related to another plugin.
20 RELATED = "related"
21
22 #: The plugin was added because it is required by another plugin.
23 REQUIRED = "required"
24
25
26 class MissingPluginException(Exception):
27 """Raised when a plugin is not found."""
28
29
30 class ProjectAddService:
31 """Project Add Service."""
32
33 def __init__(
34 self,
35 project: Project,
36 plugins_service: ProjectPluginsService = None,
37 ):
38 """Create a new Project Add Service.
39
40 Args:
41 project: The project to add plugins to.
42 plugins_service: The project plugins service.
43 """
44 self.project = project
45 self.plugins_service = plugins_service or ProjectPluginsService(project)
46
47 def add(
48 self,
49 plugin_type: PluginType,
50 plugin_name: str,
51 lock: bool = True,
52 **attrs,
53 ) -> ProjectPlugin:
54 """Add a new plugin to the project.
55
56 Args:
57 plugin_type: The type of the plugin to add.
58 plugin_name (str): The name of the plugin to add.
59 lock: Whether to generate a lockfile for the plugin.
60 attrs: Additional attributes to add to the plugin.
61
62 Returns:
63 The added plugin.
64 """
65 plugin = ProjectPlugin(
66 plugin_type, plugin_name, **attrs, default_variant=Variant.DEFAULT_NAME
67 )
68
69 with self.plugins_service.disallow_discovery_yaml():
70 self.plugins_service.ensure_parent(plugin)
71
72 # If we are inheriting from a base plugin definition,
73 # repeat the variant and pip_url in meltano.yml
74 parent = plugin.parent
75 if isinstance(parent, BasePlugin):
76 plugin.variant = parent.variant
77 plugin.pip_url = parent.pip_url
78
79 added = self.add_plugin(plugin)
80
81 if lock and not added.is_custom():
82 self.plugins_service.lock_service.save(
83 added.parent,
84 exists_ok=plugin.inherit_from is not None,
85 )
86
87 return added
88
89 def add_plugin(self, plugin: ProjectPlugin):
90 """Add a plugin to the project.
91
92 Args:
93 plugin: The plugin to add.
94
95 Returns:
96 The added plugin.
97 """
98 return self.plugins_service.add_to_file(plugin)
99
100 def add_required(
101 self,
102 plugin: ProjectPlugin,
103 lock: bool = True,
104 ):
105 """Add all required plugins to the project.
106
107 Args:
108 plugin: The plugin to get requirements from.
109 lock: Whether to generate a lockfile for the plugin.
110
111 Returns:
112 The added plugins.
113 """
114 added_plugins = []
115 for plugin_type, plugins in plugin.all_requires.items():
116 for plugin_req in plugins:
117 try:
118 plugin = self.add(
119 plugin_type,
120 plugin_req.name,
121 variant=plugin_req.variant,
122 lock=lock,
123 )
124 except PluginAlreadyAddedException:
125 continue
126
127 added_plugins.append(plugin)
128
129 added_plugins_with_required = []
130 for added in added_plugins:
131 added_plugins_with_required.extend([added, *self.add_required(added)])
132
133 return added_plugins_with_required
134
[end of src/meltano/core/project_add_service.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/meltano/core/plugin_lock_service.py b/src/meltano/core/plugin_lock_service.py
--- a/src/meltano/core/plugin_lock_service.py
+++ b/src/meltano/core/plugin_lock_service.py
@@ -7,7 +7,8 @@
from structlog.stdlib import get_logger
-from meltano.core.plugin.base import BasePlugin, PluginRef, StandalonePlugin, Variant
+from meltano.core.plugin.base import PluginRef, StandalonePlugin, Variant
+from meltano.core.plugin.project_plugin import ProjectPlugin
from meltano.core.project import Project
logger = get_logger(__name__)
@@ -42,7 +43,7 @@
def save(
self,
- plugin: BasePlugin,
+ plugin: ProjectPlugin,
*,
overwrite: bool = False,
exists_ok: bool = False,
@@ -58,11 +59,12 @@
LockfileAlreadyExistsError: If the lockfile already exists and is not
flagged for overwriting.
"""
- variant = None if plugin.variant == Variant.DEFAULT_NAME else plugin.variant
-
- logger.info(f"Locking a {type(plugin)}")
+ base_plugin = plugin.parent
+ variant = (
+ None if base_plugin.variant == Variant.DEFAULT_NAME else base_plugin.variant
+ )
- plugin_def = plugin.definition
+ plugin_def = base_plugin.definition
path = self.project.plugin_lock_path(
plugin_def.type,
plugin_def.name,
@@ -76,13 +78,13 @@
plugin,
)
- variant = plugin_def.find_variant(plugin.variant)
+ variant = plugin_def.find_variant(base_plugin.variant)
locked_def = StandalonePlugin.from_variant(
variant,
- plugin.name,
- plugin.namespace,
- plugin.type,
- label=plugin.label,
+ base_plugin.name,
+ base_plugin.namespace,
+ base_plugin.type,
+ label=base_plugin.label,
)
with path.open("w") as lockfile:
diff --git a/src/meltano/core/project_add_service.py b/src/meltano/core/project_add_service.py
--- a/src/meltano/core/project_add_service.py
+++ b/src/meltano/core/project_add_service.py
@@ -80,7 +80,7 @@
if lock and not added.is_custom():
self.plugins_service.lock_service.save(
- added.parent,
+ added,
exists_ok=plugin.inherit_from is not None,
)
| {"golden_diff": "diff --git a/src/meltano/core/plugin_lock_service.py b/src/meltano/core/plugin_lock_service.py\n--- a/src/meltano/core/plugin_lock_service.py\n+++ b/src/meltano/core/plugin_lock_service.py\n@@ -7,7 +7,8 @@\n \n from structlog.stdlib import get_logger\n \n-from meltano.core.plugin.base import BasePlugin, PluginRef, StandalonePlugin, Variant\n+from meltano.core.plugin.base import PluginRef, StandalonePlugin, Variant\n+from meltano.core.plugin.project_plugin import ProjectPlugin\n from meltano.core.project import Project\n \n logger = get_logger(__name__)\n@@ -42,7 +43,7 @@\n \n def save(\n self,\n- plugin: BasePlugin,\n+ plugin: ProjectPlugin,\n *,\n overwrite: bool = False,\n exists_ok: bool = False,\n@@ -58,11 +59,12 @@\n LockfileAlreadyExistsError: If the lockfile already exists and is not\n flagged for overwriting.\n \"\"\"\n- variant = None if plugin.variant == Variant.DEFAULT_NAME else plugin.variant\n-\n- logger.info(f\"Locking a {type(plugin)}\")\n+ base_plugin = plugin.parent\n+ variant = (\n+ None if base_plugin.variant == Variant.DEFAULT_NAME else base_plugin.variant\n+ )\n \n- plugin_def = plugin.definition\n+ plugin_def = base_plugin.definition\n path = self.project.plugin_lock_path(\n plugin_def.type,\n plugin_def.name,\n@@ -76,13 +78,13 @@\n plugin,\n )\n \n- variant = plugin_def.find_variant(plugin.variant)\n+ variant = plugin_def.find_variant(base_plugin.variant)\n locked_def = StandalonePlugin.from_variant(\n variant,\n- plugin.name,\n- plugin.namespace,\n- plugin.type,\n- label=plugin.label,\n+ base_plugin.name,\n+ base_plugin.namespace,\n+ base_plugin.type,\n+ label=base_plugin.label,\n )\n \n with path.open(\"w\") as lockfile:\ndiff --git a/src/meltano/core/project_add_service.py b/src/meltano/core/project_add_service.py\n--- a/src/meltano/core/project_add_service.py\n+++ b/src/meltano/core/project_add_service.py\n@@ -80,7 +80,7 @@\n \n if lock and not added.is_custom():\n self.plugins_service.lock_service.save(\n- added.parent,\n+ added,\n exists_ok=plugin.inherit_from is not None,\n )\n", "issue": "Fix `KeyError: venv_name` and similar errors in lockfiles\n\n", "before_files": [{"content": "\"\"\"Plugin Lockfile Service.\"\"\"\n\nfrom __future__ import annotations\n\nimport json\nfrom pathlib import Path\n\nfrom structlog.stdlib import get_logger\n\nfrom meltano.core.plugin.base import BasePlugin, PluginRef, StandalonePlugin, Variant\nfrom meltano.core.project import Project\n\nlogger = get_logger(__name__)\n\n\nclass LockfileAlreadyExistsError(Exception):\n \"\"\"Raised when a plugin lockfile already exists.\"\"\"\n\n def __init__(self, message: str, path: Path, plugin: PluginRef):\n \"\"\"Create a new LockfileAlreadyExistsError.\n\n Args:\n message: The error message.\n path: The path to the existing lockfile.\n plugin: The plugin that was locked.\n \"\"\"\n self.path = path\n self.plugin = plugin\n super().__init__(message)\n\n\nclass PluginLockService:\n \"\"\"Plugin Lockfile Service.\"\"\"\n\n def __init__(self, project: Project):\n \"\"\"Create a new Plugin Lockfile Service.\n\n Args:\n project: The Meltano project.\n \"\"\"\n self.project = project\n\n def save(\n self,\n plugin: BasePlugin,\n *,\n overwrite: bool = False,\n exists_ok: bool = False,\n ):\n \"\"\"Save the plugin lockfile.\n\n Args:\n plugin: The plugin definition to save.\n overwrite: Whether to overwrite the lockfile if it already exists.\n exists_ok: Whether raise an exception if the lockfile already exists.\n\n Raises:\n LockfileAlreadyExistsError: If the lockfile already exists and is not\n flagged for overwriting.\n \"\"\"\n variant = None if plugin.variant == Variant.DEFAULT_NAME else plugin.variant\n\n logger.info(f\"Locking a {type(plugin)}\")\n\n plugin_def = plugin.definition\n path = self.project.plugin_lock_path(\n plugin_def.type,\n plugin_def.name,\n variant_name=variant,\n )\n\n if path.exists() and not overwrite and not exists_ok:\n raise LockfileAlreadyExistsError(\n f\"Lockfile already exists: {path}\",\n path,\n plugin,\n )\n\n variant = plugin_def.find_variant(plugin.variant)\n locked_def = StandalonePlugin.from_variant(\n variant,\n plugin.name,\n plugin.namespace,\n plugin.type,\n label=plugin.label,\n )\n\n with path.open(\"w\") as lockfile:\n json.dump(locked_def.canonical(), lockfile, indent=2)\n\n logger.debug(\"Locked plugin definition\", path=path)\n", "path": "src/meltano/core/plugin_lock_service.py"}, {"content": "\"\"\"Add plugins to the project.\"\"\"\n\nfrom __future__ import annotations\n\nimport enum\n\nfrom .plugin import BasePlugin, PluginType, Variant\nfrom .plugin.project_plugin import ProjectPlugin\nfrom .project import Project\nfrom .project_plugins_service import PluginAlreadyAddedException, ProjectPluginsService\n\n\nclass PluginAddedReason(str, enum.Enum):\n \"\"\"The reason why a plugin was added to the project.\"\"\"\n\n #: The plugin was added by the user.\n USER_REQUEST = \"user_request\"\n\n #: The plugin was added because it is related to another plugin.\n RELATED = \"related\"\n\n #: The plugin was added because it is required by another plugin.\n REQUIRED = \"required\"\n\n\nclass MissingPluginException(Exception):\n \"\"\"Raised when a plugin is not found.\"\"\"\n\n\nclass ProjectAddService:\n \"\"\"Project Add Service.\"\"\"\n\n def __init__(\n self,\n project: Project,\n plugins_service: ProjectPluginsService = None,\n ):\n \"\"\"Create a new Project Add Service.\n\n Args:\n project: The project to add plugins to.\n plugins_service: The project plugins service.\n \"\"\"\n self.project = project\n self.plugins_service = plugins_service or ProjectPluginsService(project)\n\n def add(\n self,\n plugin_type: PluginType,\n plugin_name: str,\n lock: bool = True,\n **attrs,\n ) -> ProjectPlugin:\n \"\"\"Add a new plugin to the project.\n\n Args:\n plugin_type: The type of the plugin to add.\n plugin_name (str): The name of the plugin to add.\n lock: Whether to generate a lockfile for the plugin.\n attrs: Additional attributes to add to the plugin.\n\n Returns:\n The added plugin.\n \"\"\"\n plugin = ProjectPlugin(\n plugin_type, plugin_name, **attrs, default_variant=Variant.DEFAULT_NAME\n )\n\n with self.plugins_service.disallow_discovery_yaml():\n self.plugins_service.ensure_parent(plugin)\n\n # If we are inheriting from a base plugin definition,\n # repeat the variant and pip_url in meltano.yml\n parent = plugin.parent\n if isinstance(parent, BasePlugin):\n plugin.variant = parent.variant\n plugin.pip_url = parent.pip_url\n\n added = self.add_plugin(plugin)\n\n if lock and not added.is_custom():\n self.plugins_service.lock_service.save(\n added.parent,\n exists_ok=plugin.inherit_from is not None,\n )\n\n return added\n\n def add_plugin(self, plugin: ProjectPlugin):\n \"\"\"Add a plugin to the project.\n\n Args:\n plugin: The plugin to add.\n\n Returns:\n The added plugin.\n \"\"\"\n return self.plugins_service.add_to_file(plugin)\n\n def add_required(\n self,\n plugin: ProjectPlugin,\n lock: bool = True,\n ):\n \"\"\"Add all required plugins to the project.\n\n Args:\n plugin: The plugin to get requirements from.\n lock: Whether to generate a lockfile for the plugin.\n\n Returns:\n The added plugins.\n \"\"\"\n added_plugins = []\n for plugin_type, plugins in plugin.all_requires.items():\n for plugin_req in plugins:\n try:\n plugin = self.add(\n plugin_type,\n plugin_req.name,\n variant=plugin_req.variant,\n lock=lock,\n )\n except PluginAlreadyAddedException:\n continue\n\n added_plugins.append(plugin)\n\n added_plugins_with_required = []\n for added in added_plugins:\n added_plugins_with_required.extend([added, *self.add_required(added)])\n\n return added_plugins_with_required\n", "path": "src/meltano/core/project_add_service.py"}]} | 2,347 | 540 |
gh_patches_debug_6562 | rasdani/github-patches | git_diff | activeloopai__deeplake-1350 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] dataset_meta.json isn't updated after create_tensor
## 🐛🐛 Bug Report
After loading an existing dataset with hub.dataset, create_tensor doesn't update the "tensors" attribute in dataset_meta.json.
### ⚗️ Current Behavior
For example, a dataset called "hub_dataset" with tensor "images" already exists. Loading it with hub.dataset then appending a new tensor, "test":
```python
ds = hub.dataset("hub_dataset")
ds.create_tensor('test')
```
The "tensors" attribute in dataset_meta.json won't contain the "test" tensor.
```json
{"version": "2.0.8", "tensors": ["images"]}
```
### ⚙️ Environment
- `Python` version(s): [3.7.11]
- `OS`: Ubuntu 18.04
</issue>
<code>
[start of hub/core/storage/local.py]
1 import os
2 import shutil
3 from typing import Optional, Set
4
5 from hub.core.storage.provider import StorageProvider
6 from hub.util.exceptions import DirectoryAtPathException, FileAtPathException
7
8
9 class LocalProvider(StorageProvider):
10 """Provider class for using the local filesystem."""
11
12 def __init__(self, root: str):
13 """Initializes the LocalProvider.
14
15 Example:
16 local_provider = LocalProvider("/home/ubuntu/Documents/")
17
18 Args:
19 root (str): The root of the provider. All read/write request keys will be appended to root."
20
21 Raises:
22 FileAtPathException: If the root is a file instead of a directory.
23 """
24 if os.path.isfile(root):
25 raise FileAtPathException(root)
26 self.root = root
27 self.files: Optional[Set[str]] = None
28
29 def subdir(self, path: str):
30 return self.__class__(os.path.join(self.root, path))
31
32 def __getitem__(self, path: str):
33 """Gets the object present at the path within the given byte range.
34
35 Example:
36 local_provider = LocalProvider("/home/ubuntu/Documents/")
37 my_data = local_provider["abc.txt"]
38
39 Args:
40 path (str): The path relative to the root of the provider.
41
42 Returns:
43 bytes: The bytes of the object present at the path.
44
45 Raises:
46 KeyError: If an object is not found at the path.
47 DirectoryAtPathException: If a directory is found at the path.
48 Exception: Any other exception encountered while trying to fetch the object.
49 """
50 try:
51 full_path = self._check_is_file(path)
52 with open(full_path, "rb") as file:
53 return file.read()
54 except DirectoryAtPathException:
55 raise
56 except FileNotFoundError:
57 raise KeyError(path)
58
59 def __setitem__(self, path: str, value: bytes):
60 """Sets the object present at the path with the value
61
62 Example:
63 local_provider = LocalProvider("/home/ubuntu/Documents/")
64 local_provider["abc.txt"] = b"abcd"
65
66 Args:
67 path (str): the path relative to the root of the provider.
68 value (bytes): the value to be assigned at the path.
69
70 Raises:
71 Exception: If unable to set item due to directory at path or permission or space issues.
72 FileAtPathException: If the directory to the path is a file instead of a directory.
73 ReadOnlyError: If the provider is in read-only mode.
74 """
75 self.check_readonly()
76 full_path = self._check_is_file(path)
77 directory = os.path.dirname(full_path)
78 if os.path.isfile(directory):
79 raise FileAtPathException(directory)
80 if not os.path.exists(directory):
81 os.makedirs(directory, exist_ok=True)
82 with open(full_path, "wb") as file:
83 file.write(value)
84 if self.files is not None:
85 self.files.add(path)
86
87 def __delitem__(self, path: str):
88 """Delete the object present at the path.
89
90 Example:
91 local_provider = LocalProvider("/home/ubuntu/Documents/")
92 del local_provider["abc.txt"]
93
94 Args:
95 path (str): the path to the object relative to the root of the provider.
96
97 Raises:
98 KeyError: If an object is not found at the path.
99 DirectoryAtPathException: If a directory is found at the path.
100 Exception: Any other exception encountered while trying to fetch the object.
101 ReadOnlyError: If the provider is in read-only mode.
102 """
103 self.check_readonly()
104 try:
105 full_path = self._check_is_file(path)
106 os.remove(full_path)
107 if self.files is not None:
108 self.files.discard(path)
109 except DirectoryAtPathException:
110 raise
111 except FileNotFoundError:
112 raise KeyError
113
114 def __iter__(self):
115 """Generator function that iterates over the keys of the provider.
116
117 Example:
118 local_provider = LocalProvider("/home/ubuntu/Documents/")
119 for my_data in local_provider:
120 pass
121
122 Yields:
123 str: the path of the object that it is iterating over, relative to the root of the provider.
124 """
125 yield from self._all_keys()
126
127 def __len__(self):
128 """Returns the number of files present inside the root of the provider.
129
130 Example:
131 local_provider = LocalProvider("/home/ubuntu/Documents/")
132 len(local_provider)
133
134 Returns:
135 int: the number of files present inside the root.
136 """
137 return len(self._all_keys())
138
139 def _all_keys(self, refresh: bool = False) -> Set[str]:
140 """Lists all the objects present at the root of the Provider.
141
142 Args:
143 refresh (bool): refresh keys
144
145 Returns:
146 set: set of all the objects found at the root of the Provider.
147 """
148 if self.files is None or refresh:
149 full_path = os.path.expanduser(self.root)
150 key_set = set()
151 for root, dirs, files in os.walk(full_path):
152 for file in files:
153 key_set.add(
154 os.path.relpath(os.path.join(full_path, file), full_path)
155 )
156 self.files = key_set
157 return self.files
158
159 def _check_is_file(self, path: str):
160 """Checks if the path is a file. Returns the full_path to file if True.
161
162 Args:
163 path (str): the path to the object relative to the root of the provider.
164
165 Returns:
166 str: the full path to the requested file.
167
168 Raises:
169 DirectoryAtPathException: If a directory is found at the path.
170 """
171 full_path = os.path.join(self.root, path)
172 full_path = os.path.expanduser(full_path)
173 if os.path.isdir(full_path):
174 raise DirectoryAtPathException
175 return full_path
176
177 def clear(self):
178 """Deletes ALL data on the local machine (under self.root). Exercise caution!"""
179 self.check_readonly()
180 self.files = set()
181 full_path = os.path.expanduser(self.root)
182 if os.path.exists(full_path):
183 shutil.rmtree(full_path)
184
185 def __contains__(self, key) -> bool:
186 full_path = self._check_is_file(key)
187 return os.path.exists(full_path)
188
[end of hub/core/storage/local.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/hub/core/storage/local.py b/hub/core/storage/local.py
--- a/hub/core/storage/local.py
+++ b/hub/core/storage/local.py
@@ -150,9 +150,7 @@
key_set = set()
for root, dirs, files in os.walk(full_path):
for file in files:
- key_set.add(
- os.path.relpath(os.path.join(full_path, file), full_path)
- )
+ key_set.add(os.path.relpath(os.path.join(root, file), full_path))
self.files = key_set
return self.files
| {"golden_diff": "diff --git a/hub/core/storage/local.py b/hub/core/storage/local.py\n--- a/hub/core/storage/local.py\n+++ b/hub/core/storage/local.py\n@@ -150,9 +150,7 @@\n key_set = set()\n for root, dirs, files in os.walk(full_path):\n for file in files:\n- key_set.add(\n- os.path.relpath(os.path.join(full_path, file), full_path)\n- )\n+ key_set.add(os.path.relpath(os.path.join(root, file), full_path))\n self.files = key_set\n return self.files\n", "issue": "[BUG] dataset_meta.json isn't updated after create_tensor\n## \ud83d\udc1b\ud83d\udc1b Bug Report\r\n\r\nAfter loading an existing dataset with hub.dataset, create_tensor doesn't update the \"tensors\" attribute in dataset_meta.json.\r\n\r\n### \u2697\ufe0f Current Behavior\r\n\r\nFor example, a dataset called \"hub_dataset\" with tensor \"images\" already exists. Loading it with hub.dataset then appending a new tensor, \"test\":\r\n\r\n```python\r\nds = hub.dataset(\"hub_dataset\")\r\nds.create_tensor('test')\r\n```\r\nThe \"tensors\" attribute in dataset_meta.json won't contain the \"test\" tensor.\r\n\r\n```json\r\n{\"version\": \"2.0.8\", \"tensors\": [\"images\"]}\r\n```\r\n\r\n### \u2699\ufe0f Environment\r\n- `Python` version(s): [3.7.11]\r\n- `OS`: Ubuntu 18.04\n", "before_files": [{"content": "import os\nimport shutil\nfrom typing import Optional, Set\n\nfrom hub.core.storage.provider import StorageProvider\nfrom hub.util.exceptions import DirectoryAtPathException, FileAtPathException\n\n\nclass LocalProvider(StorageProvider):\n \"\"\"Provider class for using the local filesystem.\"\"\"\n\n def __init__(self, root: str):\n \"\"\"Initializes the LocalProvider.\n\n Example:\n local_provider = LocalProvider(\"/home/ubuntu/Documents/\")\n\n Args:\n root (str): The root of the provider. All read/write request keys will be appended to root.\"\n\n Raises:\n FileAtPathException: If the root is a file instead of a directory.\n \"\"\"\n if os.path.isfile(root):\n raise FileAtPathException(root)\n self.root = root\n self.files: Optional[Set[str]] = None\n\n def subdir(self, path: str):\n return self.__class__(os.path.join(self.root, path))\n\n def __getitem__(self, path: str):\n \"\"\"Gets the object present at the path within the given byte range.\n\n Example:\n local_provider = LocalProvider(\"/home/ubuntu/Documents/\")\n my_data = local_provider[\"abc.txt\"]\n\n Args:\n path (str): The path relative to the root of the provider.\n\n Returns:\n bytes: The bytes of the object present at the path.\n\n Raises:\n KeyError: If an object is not found at the path.\n DirectoryAtPathException: If a directory is found at the path.\n Exception: Any other exception encountered while trying to fetch the object.\n \"\"\"\n try:\n full_path = self._check_is_file(path)\n with open(full_path, \"rb\") as file:\n return file.read()\n except DirectoryAtPathException:\n raise\n except FileNotFoundError:\n raise KeyError(path)\n\n def __setitem__(self, path: str, value: bytes):\n \"\"\"Sets the object present at the path with the value\n\n Example:\n local_provider = LocalProvider(\"/home/ubuntu/Documents/\")\n local_provider[\"abc.txt\"] = b\"abcd\"\n\n Args:\n path (str): the path relative to the root of the provider.\n value (bytes): the value to be assigned at the path.\n\n Raises:\n Exception: If unable to set item due to directory at path or permission or space issues.\n FileAtPathException: If the directory to the path is a file instead of a directory.\n ReadOnlyError: If the provider is in read-only mode.\n \"\"\"\n self.check_readonly()\n full_path = self._check_is_file(path)\n directory = os.path.dirname(full_path)\n if os.path.isfile(directory):\n raise FileAtPathException(directory)\n if not os.path.exists(directory):\n os.makedirs(directory, exist_ok=True)\n with open(full_path, \"wb\") as file:\n file.write(value)\n if self.files is not None:\n self.files.add(path)\n\n def __delitem__(self, path: str):\n \"\"\"Delete the object present at the path.\n\n Example:\n local_provider = LocalProvider(\"/home/ubuntu/Documents/\")\n del local_provider[\"abc.txt\"]\n\n Args:\n path (str): the path to the object relative to the root of the provider.\n\n Raises:\n KeyError: If an object is not found at the path.\n DirectoryAtPathException: If a directory is found at the path.\n Exception: Any other exception encountered while trying to fetch the object.\n ReadOnlyError: If the provider is in read-only mode.\n \"\"\"\n self.check_readonly()\n try:\n full_path = self._check_is_file(path)\n os.remove(full_path)\n if self.files is not None:\n self.files.discard(path)\n except DirectoryAtPathException:\n raise\n except FileNotFoundError:\n raise KeyError\n\n def __iter__(self):\n \"\"\"Generator function that iterates over the keys of the provider.\n\n Example:\n local_provider = LocalProvider(\"/home/ubuntu/Documents/\")\n for my_data in local_provider:\n pass\n\n Yields:\n str: the path of the object that it is iterating over, relative to the root of the provider.\n \"\"\"\n yield from self._all_keys()\n\n def __len__(self):\n \"\"\"Returns the number of files present inside the root of the provider.\n\n Example:\n local_provider = LocalProvider(\"/home/ubuntu/Documents/\")\n len(local_provider)\n\n Returns:\n int: the number of files present inside the root.\n \"\"\"\n return len(self._all_keys())\n\n def _all_keys(self, refresh: bool = False) -> Set[str]:\n \"\"\"Lists all the objects present at the root of the Provider.\n\n Args:\n refresh (bool): refresh keys\n\n Returns:\n set: set of all the objects found at the root of the Provider.\n \"\"\"\n if self.files is None or refresh:\n full_path = os.path.expanduser(self.root)\n key_set = set()\n for root, dirs, files in os.walk(full_path):\n for file in files:\n key_set.add(\n os.path.relpath(os.path.join(full_path, file), full_path)\n )\n self.files = key_set\n return self.files\n\n def _check_is_file(self, path: str):\n \"\"\"Checks if the path is a file. Returns the full_path to file if True.\n\n Args:\n path (str): the path to the object relative to the root of the provider.\n\n Returns:\n str: the full path to the requested file.\n\n Raises:\n DirectoryAtPathException: If a directory is found at the path.\n \"\"\"\n full_path = os.path.join(self.root, path)\n full_path = os.path.expanduser(full_path)\n if os.path.isdir(full_path):\n raise DirectoryAtPathException\n return full_path\n\n def clear(self):\n \"\"\"Deletes ALL data on the local machine (under self.root). Exercise caution!\"\"\"\n self.check_readonly()\n self.files = set()\n full_path = os.path.expanduser(self.root)\n if os.path.exists(full_path):\n shutil.rmtree(full_path)\n\n def __contains__(self, key) -> bool:\n full_path = self._check_is_file(key)\n return os.path.exists(full_path)\n", "path": "hub/core/storage/local.py"}]} | 2,496 | 132 |
gh_patches_debug_23135 | rasdani/github-patches | git_diff | kornia__kornia-1543 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`RandomMotionBlur` fails when `kernel_size` is a `Tuple[int, int]`
### Describe the bug
Using the `RandomMotionBlur` augmentation with a tuple for `kernel_size` throws a `TypeError`. This appears to happen because internally `apply_transform` is trying to convert `kernel_size` to an `int` while receiving a collection of numbers
### Reproduction steps
```python
import kornia as K
import torch
x = torch.rand(3,3,224,224)
tfm = K.augmentation.RandomMotionBlur((7,21), (15.,15.), (-1.,1.), p=1)
tfm(x)
```
### Expected behavior
Successfully perform the transform with a different kernel size every batch
### Environment
```shell
wget https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py
# For security purposes, please check the contents of collect_env.py before running it.
python collect_env.py
```
- PyTorch Version (e.g., 1.0): 1.10.1
- OS (e.g., Linux): macOS 12.0.1 (x86_64)
- How you installed PyTorch (`conda`, `pip`, source): pip
- Python version: 3.7.10
- CUDA/cuDNN version: NA
- GPU models and configuration: NA
- Any other relevant information: NA
### Additional context
Full stack trace:
```python
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-4-a535d4587048> in <module>
----> 1 tfm(x)
~/miniconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1100 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1101 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1102 return forward_call(*input, **kwargs)
1103 # Do not call functions when jit is used
1104 full_backward_hooks, non_full_backward_hooks = [], []
~/miniconda3/lib/python3.7/site-packages/kornia/augmentation/base.py in forward(self, input, params, return_transform)
268
269 self._params = params
--> 270 output = self.apply_func(in_tensor, in_transform, self._params, return_transform)
271 return _transform_output_shape(output, ori_shape) if self.keepdim else output
272
~/miniconda3/lib/python3.7/site-packages/kornia/augmentation/base.py in apply_func(self, in_tensor, in_transform, params, return_transform)
227 elif torch.sum(to_apply) == len(to_apply):
228 trans_matrix = self.compute_transformation(in_tensor, params)
--> 229 output = self.apply_transform(in_tensor, params, trans_matrix)
230 else:
231 output = in_tensor.clone()
~/miniconda3/lib/python3.7/site-packages/kornia/augmentation/augmentation.py in apply_transform(self, input, params, transform)
1400 self, input: torch.Tensor, params: Dict[str, torch.Tensor], transform: Optional[torch.Tensor] = None
1401 ) -> torch.Tensor:
-> 1402 kernel_size: int = cast(int, params["ksize_factor"].unique().item())
1403 angle = params["angle_factor"]
1404 direction = params["direction_factor"]
ValueError: only one element tensors can be converted to Python scalars
```
</issue>
<code>
[start of kornia/augmentation/_2d/intensity/motion_blur.py]
1 from typing import Dict, Optional, Tuple, Union, cast
2
3 import torch
4
5 from kornia.augmentation import random_generator as rg
6 from kornia.augmentation._2d.intensity.base import IntensityAugmentationBase2D
7 from kornia.constants import BorderType, Resample
8 from kornia.filters import motion_blur
9
10
11 class RandomMotionBlur(IntensityAugmentationBase2D):
12 r"""Perform motion blur on 2D images (4D tensor).
13
14 .. image:: _static/img/RandomMotionBlur.png
15
16 Args:
17 p: probability of applying the transformation.
18 kernel_size: motion kernel size (odd and positive).
19 If int, the kernel will have a fixed size.
20 If Tuple[int, int], it will randomly generate the value from the range batch-wisely.
21 angle: angle of the motion blur in degrees (anti-clockwise rotation).
22 If float, it will generate the value from (-angle, angle).
23 direction: forward/backward direction of the motion blur.
24 Lower values towards -1.0 will point the motion blur towards the back (with angle provided via angle),
25 while higher values towards 1.0 will point the motion blur forward. A value of 0.0 leads to a
26 uniformly (but still angled) motion blur.
27 If float, it will generate the value from (-direction, direction).
28 If Tuple[int, int], it will randomly generate the value from the range.
29 border_type: the padding mode to be applied before convolving.
30 CONSTANT = 0, REFLECT = 1, REPLICATE = 2, CIRCULAR = 3.
31 resample: the interpolation mode.
32 keepdim: whether to keep the output shape the same as input (True) or broadcast it
33 to the batch form (False).
34
35 Shape:
36 - Input: :math:`(C, H, W)` or :math:`(B, C, H, W)`, Optional: :math:`(B, 3, 3)`
37 - Output: :math:`(B, C, H, W)`
38
39 Note:
40 Input tensor must be float and normalized into [0, 1] for the best differentiability support.
41 Additionally, this function accepts another transformation tensor (:math:`(B, 3, 3)`), then the
42 applied transformation will be merged int to the input transformation tensor and returned.
43
44 Please set ``resample`` to ``'bilinear'`` if more meaningful gradients wanted.
45
46 .. note::
47 This function internally uses :func:`kornia.filters.motion_blur`.
48
49 Examples:
50 >>> rng = torch.manual_seed(0)
51 >>> input = torch.ones(1, 1, 5, 5)
52 >>> motion_blur = RandomMotionBlur(3, 35., 0.5, p=1.)
53 >>> motion_blur(input)
54 tensor([[[[0.5773, 1.0000, 1.0000, 1.0000, 0.7561],
55 [0.5773, 1.0000, 1.0000, 1.0000, 0.7561],
56 [0.5773, 1.0000, 1.0000, 1.0000, 0.7561],
57 [0.5773, 1.0000, 1.0000, 1.0000, 0.7561],
58 [0.5773, 1.0000, 1.0000, 1.0000, 0.7561]]]])
59
60 To apply the exact augmenation again, you may take the advantage of the previous parameter state:
61 >>> input = torch.randn(1, 3, 32, 32)
62 >>> aug = RandomMotionBlur(3, 35., 0.5, p=1.)
63 >>> (aug(input) == aug(input, params=aug._params)).all()
64 tensor(True)
65 """
66
67 def __init__(
68 self,
69 kernel_size: Union[int, Tuple[int, int]],
70 angle: Union[torch.Tensor, float, Tuple[float, float]],
71 direction: Union[torch.Tensor, float, Tuple[float, float]],
72 border_type: Union[int, str, BorderType] = BorderType.CONSTANT.name,
73 resample: Union[str, int, Resample] = Resample.NEAREST.name,
74 return_transform: bool = False,
75 same_on_batch: bool = False,
76 p: float = 0.5,
77 keepdim: bool = False,
78 ) -> None:
79 super().__init__(p=p, return_transform=return_transform, same_on_batch=same_on_batch, keepdim=keepdim)
80 self._param_generator = rg.MotionBlurGenerator(kernel_size, angle, direction)
81 self.flags = dict(border_type=BorderType.get(border_type), resample=Resample.get(resample))
82
83 def apply_transform(
84 self, input: torch.Tensor, params: Dict[str, torch.Tensor], transform: Optional[torch.Tensor] = None
85 ) -> torch.Tensor:
86 kernel_size: int = cast(int, params["ksize_factor"].unique().item())
87 angle = params["angle_factor"]
88 direction = params["direction_factor"]
89 return motion_blur(
90 input,
91 kernel_size,
92 angle,
93 direction,
94 border_type=self.flags["border_type"].name.lower(),
95 mode=self.flags["resample"].name.lower(),
96 )
97
[end of kornia/augmentation/_2d/intensity/motion_blur.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/kornia/augmentation/_2d/intensity/motion_blur.py b/kornia/augmentation/_2d/intensity/motion_blur.py
--- a/kornia/augmentation/_2d/intensity/motion_blur.py
+++ b/kornia/augmentation/_2d/intensity/motion_blur.py
@@ -1,4 +1,4 @@
-from typing import Dict, Optional, Tuple, Union, cast
+from typing import Dict, List, Optional, Tuple, Union, cast
import torch
@@ -83,14 +83,14 @@
def apply_transform(
self, input: torch.Tensor, params: Dict[str, torch.Tensor], transform: Optional[torch.Tensor] = None
) -> torch.Tensor:
- kernel_size: int = cast(int, params["ksize_factor"].unique().item())
- angle = params["angle_factor"]
- direction = params["direction_factor"]
+ # sample a kernel size
+ kernel_size_list: List[int] = params["ksize_factor"].tolist()
+ idx: int = cast(int, torch.randint(len(kernel_size_list), (1,)).item())
return motion_blur(
input,
- kernel_size,
- angle,
- direction,
+ kernel_size=kernel_size_list[idx],
+ angle=params["angle_factor"],
+ direction=params["direction_factor"],
border_type=self.flags["border_type"].name.lower(),
mode=self.flags["resample"].name.lower(),
)
| {"golden_diff": "diff --git a/kornia/augmentation/_2d/intensity/motion_blur.py b/kornia/augmentation/_2d/intensity/motion_blur.py\n--- a/kornia/augmentation/_2d/intensity/motion_blur.py\n+++ b/kornia/augmentation/_2d/intensity/motion_blur.py\n@@ -1,4 +1,4 @@\n-from typing import Dict, Optional, Tuple, Union, cast\n+from typing import Dict, List, Optional, Tuple, Union, cast\n \n import torch\n \n@@ -83,14 +83,14 @@\n def apply_transform(\n self, input: torch.Tensor, params: Dict[str, torch.Tensor], transform: Optional[torch.Tensor] = None\n ) -> torch.Tensor:\n- kernel_size: int = cast(int, params[\"ksize_factor\"].unique().item())\n- angle = params[\"angle_factor\"]\n- direction = params[\"direction_factor\"]\n+ # sample a kernel size\n+ kernel_size_list: List[int] = params[\"ksize_factor\"].tolist()\n+ idx: int = cast(int, torch.randint(len(kernel_size_list), (1,)).item())\n return motion_blur(\n input,\n- kernel_size,\n- angle,\n- direction,\n+ kernel_size=kernel_size_list[idx],\n+ angle=params[\"angle_factor\"],\n+ direction=params[\"direction_factor\"],\n border_type=self.flags[\"border_type\"].name.lower(),\n mode=self.flags[\"resample\"].name.lower(),\n )\n", "issue": "`RandomMotionBlur` fails when `kernel_size` is a `Tuple[int, int]`\n### Describe the bug\r\n\r\nUsing the `RandomMotionBlur` augmentation with a tuple for `kernel_size` throws a `TypeError`. This appears to happen because internally `apply_transform` is trying to convert `kernel_size` to an `int` while receiving a collection of numbers\r\n\r\n### Reproduction steps\r\n\r\n```python\r\nimport kornia as K\r\nimport torch\r\n\r\nx = torch.rand(3,3,224,224)\r\ntfm = K.augmentation.RandomMotionBlur((7,21), (15.,15.), (-1.,1.), p=1)\r\n\r\ntfm(x)\r\n```\r\n\r\n\r\n### Expected behavior\r\n\r\nSuccessfully perform the transform with a different kernel size every batch\r\n\r\n### Environment\r\n\r\n```shell\r\nwget https://raw.githubusercontent.com/pytorch/pytorch/master/torch/utils/collect_env.py\r\n# For security purposes, please check the contents of collect_env.py before running it.\r\npython collect_env.py\r\n```\r\n- PyTorch Version (e.g., 1.0): 1.10.1\r\n- OS (e.g., Linux): macOS 12.0.1 (x86_64)\r\n- How you installed PyTorch (`conda`, `pip`, source): pip\r\n- Python version: 3.7.10\r\n- CUDA/cuDNN version: NA\r\n- GPU models and configuration: NA\r\n- Any other relevant information: NA\r\n\r\n\r\n\r\n\r\n### Additional context\r\n\r\nFull stack trace:\r\n\r\n```python\r\n---------------------------------------------------------------------------\r\nValueError Traceback (most recent call last)\r\n<ipython-input-4-a535d4587048> in <module>\r\n----> 1 tfm(x)\r\n\r\n~/miniconda3/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)\r\n 1100 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks\r\n 1101 or _global_forward_hooks or _global_forward_pre_hooks):\r\n-> 1102 return forward_call(*input, **kwargs)\r\n 1103 # Do not call functions when jit is used\r\n 1104 full_backward_hooks, non_full_backward_hooks = [], []\r\n\r\n~/miniconda3/lib/python3.7/site-packages/kornia/augmentation/base.py in forward(self, input, params, return_transform)\r\n 268 \r\n 269 self._params = params\r\n--> 270 output = self.apply_func(in_tensor, in_transform, self._params, return_transform)\r\n 271 return _transform_output_shape(output, ori_shape) if self.keepdim else output\r\n 272 \r\n\r\n~/miniconda3/lib/python3.7/site-packages/kornia/augmentation/base.py in apply_func(self, in_tensor, in_transform, params, return_transform)\r\n 227 elif torch.sum(to_apply) == len(to_apply):\r\n 228 trans_matrix = self.compute_transformation(in_tensor, params)\r\n--> 229 output = self.apply_transform(in_tensor, params, trans_matrix)\r\n 230 else:\r\n 231 output = in_tensor.clone()\r\n\r\n~/miniconda3/lib/python3.7/site-packages/kornia/augmentation/augmentation.py in apply_transform(self, input, params, transform)\r\n 1400 self, input: torch.Tensor, params: Dict[str, torch.Tensor], transform: Optional[torch.Tensor] = None\r\n 1401 ) -> torch.Tensor:\r\n-> 1402 kernel_size: int = cast(int, params[\"ksize_factor\"].unique().item())\r\n 1403 angle = params[\"angle_factor\"]\r\n 1404 direction = params[\"direction_factor\"]\r\n\r\nValueError: only one element tensors can be converted to Python scalars\r\n```\n", "before_files": [{"content": "from typing import Dict, Optional, Tuple, Union, cast\n\nimport torch\n\nfrom kornia.augmentation import random_generator as rg\nfrom kornia.augmentation._2d.intensity.base import IntensityAugmentationBase2D\nfrom kornia.constants import BorderType, Resample\nfrom kornia.filters import motion_blur\n\n\nclass RandomMotionBlur(IntensityAugmentationBase2D):\n r\"\"\"Perform motion blur on 2D images (4D tensor).\n\n .. image:: _static/img/RandomMotionBlur.png\n\n Args:\n p: probability of applying the transformation.\n kernel_size: motion kernel size (odd and positive).\n If int, the kernel will have a fixed size.\n If Tuple[int, int], it will randomly generate the value from the range batch-wisely.\n angle: angle of the motion blur in degrees (anti-clockwise rotation).\n If float, it will generate the value from (-angle, angle).\n direction: forward/backward direction of the motion blur.\n Lower values towards -1.0 will point the motion blur towards the back (with angle provided via angle),\n while higher values towards 1.0 will point the motion blur forward. A value of 0.0 leads to a\n uniformly (but still angled) motion blur.\n If float, it will generate the value from (-direction, direction).\n If Tuple[int, int], it will randomly generate the value from the range.\n border_type: the padding mode to be applied before convolving.\n CONSTANT = 0, REFLECT = 1, REPLICATE = 2, CIRCULAR = 3.\n resample: the interpolation mode.\n keepdim: whether to keep the output shape the same as input (True) or broadcast it\n to the batch form (False).\n\n Shape:\n - Input: :math:`(C, H, W)` or :math:`(B, C, H, W)`, Optional: :math:`(B, 3, 3)`\n - Output: :math:`(B, C, H, W)`\n\n Note:\n Input tensor must be float and normalized into [0, 1] for the best differentiability support.\n Additionally, this function accepts another transformation tensor (:math:`(B, 3, 3)`), then the\n applied transformation will be merged int to the input transformation tensor and returned.\n\n Please set ``resample`` to ``'bilinear'`` if more meaningful gradients wanted.\n\n .. note::\n This function internally uses :func:`kornia.filters.motion_blur`.\n\n Examples:\n >>> rng = torch.manual_seed(0)\n >>> input = torch.ones(1, 1, 5, 5)\n >>> motion_blur = RandomMotionBlur(3, 35., 0.5, p=1.)\n >>> motion_blur(input)\n tensor([[[[0.5773, 1.0000, 1.0000, 1.0000, 0.7561],\n [0.5773, 1.0000, 1.0000, 1.0000, 0.7561],\n [0.5773, 1.0000, 1.0000, 1.0000, 0.7561],\n [0.5773, 1.0000, 1.0000, 1.0000, 0.7561],\n [0.5773, 1.0000, 1.0000, 1.0000, 0.7561]]]])\n\n To apply the exact augmenation again, you may take the advantage of the previous parameter state:\n >>> input = torch.randn(1, 3, 32, 32)\n >>> aug = RandomMotionBlur(3, 35., 0.5, p=1.)\n >>> (aug(input) == aug(input, params=aug._params)).all()\n tensor(True)\n \"\"\"\n\n def __init__(\n self,\n kernel_size: Union[int, Tuple[int, int]],\n angle: Union[torch.Tensor, float, Tuple[float, float]],\n direction: Union[torch.Tensor, float, Tuple[float, float]],\n border_type: Union[int, str, BorderType] = BorderType.CONSTANT.name,\n resample: Union[str, int, Resample] = Resample.NEAREST.name,\n return_transform: bool = False,\n same_on_batch: bool = False,\n p: float = 0.5,\n keepdim: bool = False,\n ) -> None:\n super().__init__(p=p, return_transform=return_transform, same_on_batch=same_on_batch, keepdim=keepdim)\n self._param_generator = rg.MotionBlurGenerator(kernel_size, angle, direction)\n self.flags = dict(border_type=BorderType.get(border_type), resample=Resample.get(resample))\n\n def apply_transform(\n self, input: torch.Tensor, params: Dict[str, torch.Tensor], transform: Optional[torch.Tensor] = None\n ) -> torch.Tensor:\n kernel_size: int = cast(int, params[\"ksize_factor\"].unique().item())\n angle = params[\"angle_factor\"]\n direction = params[\"direction_factor\"]\n return motion_blur(\n input,\n kernel_size,\n angle,\n direction,\n border_type=self.flags[\"border_type\"].name.lower(),\n mode=self.flags[\"resample\"].name.lower(),\n )\n", "path": "kornia/augmentation/_2d/intensity/motion_blur.py"}]} | 2,841 | 328 |
gh_patches_debug_16402 | rasdani/github-patches | git_diff | fonttools__fonttools-717 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
hmtx code should round values
Currently, float values result in exception:
```
self._writeTable(masterTable, writer, done)
File "/usr/local/lib/python2.7/dist-packages/fonttools-3.0-py2.7.egg/fontTools/ttLib/__init__.py", line 648, in _writeTable
tabledata = self.getTableData(tag)
File "/usr/local/lib/python2.7/dist-packages/fonttools-3.0-py2.7.egg/fontTools/ttLib/__init__.py", line 659, in getTableData
return self.tables[tag].compile(self)
File "/usr/local/lib/python2.7/dist-packages/fonttools-3.0-py2.7.egg/fontTools/ttLib/tables/_h_m_t_x.py", line 68, in compile
allMetrics = array.array("h", allMetrics)
TypeError: integer argument expected, got float
```
Possibly warn? Though it will become annoying if we do.
</issue>
<code>
[start of Lib/fontTools/ttLib/tables/_h_m_t_x.py]
1 from __future__ import print_function, division, absolute_import
2 from fontTools.misc.py23 import *
3 from fontTools import ttLib
4 from fontTools.misc.textTools import safeEval
5 from . import DefaultTable
6 import sys
7 import struct
8 import array
9 import logging
10
11
12 log = logging.getLogger(__name__)
13
14
15 class table__h_m_t_x(DefaultTable.DefaultTable):
16
17 headerTag = 'hhea'
18 advanceName = 'width'
19 sideBearingName = 'lsb'
20 numberOfMetricsName = 'numberOfHMetrics'
21 longMetricFormat = 'Hh'
22
23 def decompile(self, data, ttFont):
24 numGlyphs = ttFont['maxp'].numGlyphs
25 numberOfMetrics = int(getattr(ttFont[self.headerTag], self.numberOfMetricsName))
26 if numberOfMetrics > numGlyphs:
27 log.warning("The %s.%s exceeds the maxp.numGlyphs" % (
28 self.headerTag, self.numberOfMetricsName))
29 numberOfMetrics = numGlyphs
30 if len(data) < 4 * numberOfMetrics:
31 raise ttLib.TTLibError("not enough '%s' table data" % self.tableTag)
32 # Note: advanceWidth is unsigned, but some font editors might
33 # read/write as signed. We can't be sure whether it was a mistake
34 # or not, so we read as unsigned but also issue a warning...
35 metricsFmt = ">" + self.longMetricFormat * numberOfMetrics
36 metrics = struct.unpack(metricsFmt, data[:4 * numberOfMetrics])
37 data = data[4 * numberOfMetrics:]
38 numberOfSideBearings = numGlyphs - numberOfMetrics
39 sideBearings = array.array("h", data[:2 * numberOfSideBearings])
40 data = data[2 * numberOfSideBearings:]
41
42 if sys.byteorder != "big":
43 sideBearings.byteswap()
44 if data:
45 log.warning("too much '%s' table data" % self.tableTag)
46 self.metrics = {}
47 glyphOrder = ttFont.getGlyphOrder()
48 for i in range(numberOfMetrics):
49 glyphName = glyphOrder[i]
50 advanceWidth, lsb = metrics[i*2:i*2+2]
51 if advanceWidth > 32767:
52 log.warning(
53 "Glyph %r has a huge advance %s (%d); is it intentional or "
54 "an (invalid) negative value?", glyphName, self.advanceName,
55 advanceWidth)
56 self.metrics[glyphName] = (advanceWidth, lsb)
57 lastAdvance = metrics[-2]
58 for i in range(numberOfSideBearings):
59 glyphName = glyphOrder[i + numberOfMetrics]
60 self.metrics[glyphName] = (lastAdvance, sideBearings[i])
61
62 def compile(self, ttFont):
63 metrics = []
64 hasNegativeAdvances = False
65 for glyphName in ttFont.getGlyphOrder():
66 advanceWidth, sideBearing = self.metrics[glyphName]
67 if advanceWidth < 0:
68 log.error("Glyph %r has negative advance %s" % (
69 glyphName, self.advanceName))
70 hasNegativeAdvances = True
71 metrics.append([advanceWidth, sideBearing])
72 lastAdvance = metrics[-1][0]
73 lastIndex = len(metrics)
74 while metrics[lastIndex-2][0] == lastAdvance:
75 lastIndex -= 1
76 if lastIndex <= 1:
77 # all advances are equal
78 lastIndex = 1
79 break
80 additionalMetrics = metrics[lastIndex:]
81 additionalMetrics = [sb for advance, sb in additionalMetrics]
82 metrics = metrics[:lastIndex]
83 numberOfMetrics = len(metrics)
84 setattr(ttFont[self.headerTag], self.numberOfMetricsName, numberOfMetrics)
85
86 allMetrics = []
87 for item in metrics:
88 allMetrics.extend(item)
89 metricsFmt = ">" + self.longMetricFormat * numberOfMetrics
90 try:
91 data = struct.pack(metricsFmt, *allMetrics)
92 except struct.error as e:
93 if "out of range" in str(e) and hasNegativeAdvances:
94 raise ttLib.TTLibError(
95 "'%s' table can't contain negative advance %ss"
96 % (self.tableTag, self.advanceName))
97 else:
98 raise
99 additionalMetrics = array.array("h", additionalMetrics)
100 if sys.byteorder != "big":
101 additionalMetrics.byteswap()
102 data = data + additionalMetrics.tostring()
103 return data
104
105 def toXML(self, writer, ttFont):
106 names = sorted(self.metrics.keys())
107 for glyphName in names:
108 advance, sb = self.metrics[glyphName]
109 writer.simpletag("mtx", [
110 ("name", glyphName),
111 (self.advanceName, advance),
112 (self.sideBearingName, sb),
113 ])
114 writer.newline()
115
116 def fromXML(self, name, attrs, content, ttFont):
117 if not hasattr(self, "metrics"):
118 self.metrics = {}
119 if name == "mtx":
120 self.metrics[attrs["name"]] = (safeEval(attrs[self.advanceName]),
121 safeEval(attrs[self.sideBearingName]))
122
123 def __delitem__(self, glyphName):
124 del self.metrics[glyphName]
125
126 def __getitem__(self, glyphName):
127 return self.metrics[glyphName]
128
129 def __setitem__(self, glyphName, advance_sb_pair):
130 self.metrics[glyphName] = tuple(advance_sb_pair)
131
[end of Lib/fontTools/ttLib/tables/_h_m_t_x.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/Lib/fontTools/ttLib/tables/_h_m_t_x.py b/Lib/fontTools/ttLib/tables/_h_m_t_x.py
--- a/Lib/fontTools/ttLib/tables/_h_m_t_x.py
+++ b/Lib/fontTools/ttLib/tables/_h_m_t_x.py
@@ -78,14 +78,14 @@
lastIndex = 1
break
additionalMetrics = metrics[lastIndex:]
- additionalMetrics = [sb for advance, sb in additionalMetrics]
+ additionalMetrics = [int(round(sb)) for _, sb in additionalMetrics]
metrics = metrics[:lastIndex]
numberOfMetrics = len(metrics)
setattr(ttFont[self.headerTag], self.numberOfMetricsName, numberOfMetrics)
allMetrics = []
- for item in metrics:
- allMetrics.extend(item)
+ for advance, sb in metrics:
+ allMetrics.extend([int(round(advance)), int(round(sb))])
metricsFmt = ">" + self.longMetricFormat * numberOfMetrics
try:
data = struct.pack(metricsFmt, *allMetrics)
| {"golden_diff": "diff --git a/Lib/fontTools/ttLib/tables/_h_m_t_x.py b/Lib/fontTools/ttLib/tables/_h_m_t_x.py\n--- a/Lib/fontTools/ttLib/tables/_h_m_t_x.py\n+++ b/Lib/fontTools/ttLib/tables/_h_m_t_x.py\n@@ -78,14 +78,14 @@\n \t\t\t\tlastIndex = 1\n \t\t\t\tbreak\n \t\tadditionalMetrics = metrics[lastIndex:]\n-\t\tadditionalMetrics = [sb for advance, sb in additionalMetrics]\n+\t\tadditionalMetrics = [int(round(sb)) for _, sb in additionalMetrics]\n \t\tmetrics = metrics[:lastIndex]\n \t\tnumberOfMetrics = len(metrics)\n \t\tsetattr(ttFont[self.headerTag], self.numberOfMetricsName, numberOfMetrics)\n \n \t\tallMetrics = []\n-\t\tfor item in metrics:\n-\t\t\tallMetrics.extend(item)\n+\t\tfor advance, sb in metrics:\n+\t\t\tallMetrics.extend([int(round(advance)), int(round(sb))])\n \t\tmetricsFmt = \">\" + self.longMetricFormat * numberOfMetrics\n \t\ttry:\n \t\t\tdata = struct.pack(metricsFmt, *allMetrics)\n", "issue": "hmtx code should round values\nCurrently, float values result in exception:\n\n```\n self._writeTable(masterTable, writer, done)\n File \"/usr/local/lib/python2.7/dist-packages/fonttools-3.0-py2.7.egg/fontTools/ttLib/__init__.py\", line 648, in _writeTable\n tabledata = self.getTableData(tag)\n File \"/usr/local/lib/python2.7/dist-packages/fonttools-3.0-py2.7.egg/fontTools/ttLib/__init__.py\", line 659, in getTableData\n return self.tables[tag].compile(self)\n File \"/usr/local/lib/python2.7/dist-packages/fonttools-3.0-py2.7.egg/fontTools/ttLib/tables/_h_m_t_x.py\", line 68, in compile\n allMetrics = array.array(\"h\", allMetrics)\nTypeError: integer argument expected, got float\n```\n\nPossibly warn? Though it will become annoying if we do.\n\n", "before_files": [{"content": "from __future__ import print_function, division, absolute_import\nfrom fontTools.misc.py23 import *\nfrom fontTools import ttLib\nfrom fontTools.misc.textTools import safeEval\nfrom . import DefaultTable\nimport sys\nimport struct\nimport array\nimport logging\n\n\nlog = logging.getLogger(__name__)\n\n\nclass table__h_m_t_x(DefaultTable.DefaultTable):\n\n\theaderTag = 'hhea'\n\tadvanceName = 'width'\n\tsideBearingName = 'lsb'\n\tnumberOfMetricsName = 'numberOfHMetrics'\n\tlongMetricFormat = 'Hh'\n\n\tdef decompile(self, data, ttFont):\n\t\tnumGlyphs = ttFont['maxp'].numGlyphs\n\t\tnumberOfMetrics = int(getattr(ttFont[self.headerTag], self.numberOfMetricsName))\n\t\tif numberOfMetrics > numGlyphs:\n\t\t\tlog.warning(\"The %s.%s exceeds the maxp.numGlyphs\" % (\n\t\t\t\tself.headerTag, self.numberOfMetricsName))\n\t\t\tnumberOfMetrics = numGlyphs\n\t\tif len(data) < 4 * numberOfMetrics:\n\t\t\traise ttLib.TTLibError(\"not enough '%s' table data\" % self.tableTag)\n\t\t# Note: advanceWidth is unsigned, but some font editors might\n\t\t# read/write as signed. We can't be sure whether it was a mistake\n\t\t# or not, so we read as unsigned but also issue a warning...\n\t\tmetricsFmt = \">\" + self.longMetricFormat * numberOfMetrics\n\t\tmetrics = struct.unpack(metricsFmt, data[:4 * numberOfMetrics])\n\t\tdata = data[4 * numberOfMetrics:]\n\t\tnumberOfSideBearings = numGlyphs - numberOfMetrics\n\t\tsideBearings = array.array(\"h\", data[:2 * numberOfSideBearings])\n\t\tdata = data[2 * numberOfSideBearings:]\n\n\t\tif sys.byteorder != \"big\":\n\t\t\tsideBearings.byteswap()\n\t\tif data:\n\t\t\tlog.warning(\"too much '%s' table data\" % self.tableTag)\n\t\tself.metrics = {}\n\t\tglyphOrder = ttFont.getGlyphOrder()\n\t\tfor i in range(numberOfMetrics):\n\t\t\tglyphName = glyphOrder[i]\n\t\t\tadvanceWidth, lsb = metrics[i*2:i*2+2]\n\t\t\tif advanceWidth > 32767:\n\t\t\t\tlog.warning(\n\t\t\t\t\t\"Glyph %r has a huge advance %s (%d); is it intentional or \"\n\t\t\t\t\t\"an (invalid) negative value?\", glyphName, self.advanceName,\n\t\t\t\t\tadvanceWidth)\n\t\t\tself.metrics[glyphName] = (advanceWidth, lsb)\n\t\tlastAdvance = metrics[-2]\n\t\tfor i in range(numberOfSideBearings):\n\t\t\tglyphName = glyphOrder[i + numberOfMetrics]\n\t\t\tself.metrics[glyphName] = (lastAdvance, sideBearings[i])\n\n\tdef compile(self, ttFont):\n\t\tmetrics = []\n\t\thasNegativeAdvances = False\n\t\tfor glyphName in ttFont.getGlyphOrder():\n\t\t\tadvanceWidth, sideBearing = self.metrics[glyphName]\n\t\t\tif advanceWidth < 0:\n\t\t\t\tlog.error(\"Glyph %r has negative advance %s\" % (\n\t\t\t\t\tglyphName, self.advanceName))\n\t\t\t\thasNegativeAdvances = True\n\t\t\tmetrics.append([advanceWidth, sideBearing])\n\t\tlastAdvance = metrics[-1][0]\n\t\tlastIndex = len(metrics)\n\t\twhile metrics[lastIndex-2][0] == lastAdvance:\n\t\t\tlastIndex -= 1\n\t\t\tif lastIndex <= 1:\n\t\t\t\t# all advances are equal\n\t\t\t\tlastIndex = 1\n\t\t\t\tbreak\n\t\tadditionalMetrics = metrics[lastIndex:]\n\t\tadditionalMetrics = [sb for advance, sb in additionalMetrics]\n\t\tmetrics = metrics[:lastIndex]\n\t\tnumberOfMetrics = len(metrics)\n\t\tsetattr(ttFont[self.headerTag], self.numberOfMetricsName, numberOfMetrics)\n\n\t\tallMetrics = []\n\t\tfor item in metrics:\n\t\t\tallMetrics.extend(item)\n\t\tmetricsFmt = \">\" + self.longMetricFormat * numberOfMetrics\n\t\ttry:\n\t\t\tdata = struct.pack(metricsFmt, *allMetrics)\n\t\texcept struct.error as e:\n\t\t\tif \"out of range\" in str(e) and hasNegativeAdvances:\n\t\t\t\traise ttLib.TTLibError(\n\t\t\t\t\t\"'%s' table can't contain negative advance %ss\"\n\t\t\t\t\t% (self.tableTag, self.advanceName))\n\t\t\telse:\n\t\t\t\traise\n\t\tadditionalMetrics = array.array(\"h\", additionalMetrics)\n\t\tif sys.byteorder != \"big\":\n\t\t\tadditionalMetrics.byteswap()\n\t\tdata = data + additionalMetrics.tostring()\n\t\treturn data\n\n\tdef toXML(self, writer, ttFont):\n\t\tnames = sorted(self.metrics.keys())\n\t\tfor glyphName in names:\n\t\t\tadvance, sb = self.metrics[glyphName]\n\t\t\twriter.simpletag(\"mtx\", [\n\t\t\t\t\t(\"name\", glyphName),\n\t\t\t\t\t(self.advanceName, advance),\n\t\t\t\t\t(self.sideBearingName, sb),\n\t\t\t\t\t])\n\t\t\twriter.newline()\n\n\tdef fromXML(self, name, attrs, content, ttFont):\n\t\tif not hasattr(self, \"metrics\"):\n\t\t\tself.metrics = {}\n\t\tif name == \"mtx\":\n\t\t\tself.metrics[attrs[\"name\"]] = (safeEval(attrs[self.advanceName]),\n\t\t\t\t\tsafeEval(attrs[self.sideBearingName]))\n\n\tdef __delitem__(self, glyphName):\n\t\tdel self.metrics[glyphName]\n\n\tdef __getitem__(self, glyphName):\n\t\treturn self.metrics[glyphName]\n\n\tdef __setitem__(self, glyphName, advance_sb_pair):\n\t\tself.metrics[glyphName] = tuple(advance_sb_pair)\n", "path": "Lib/fontTools/ttLib/tables/_h_m_t_x.py"}]} | 2,257 | 248 |
gh_patches_debug_5813 | rasdani/github-patches | git_diff | saleor__saleor-2087 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Missing variable in "fulfillment" email
Two small issues in the "fulfillment" email:
- logo is missing
- in footer there is missing template variable
I've just tested it and this is how the email looks like:

</issue>
<code>
[start of saleor/order/emails.py]
1 from celery import shared_task
2 from django.conf import settings
3 from django.contrib.sites.models import Site
4 from django.urls import reverse
5 from templated_email import send_templated_mail
6
7 from ..core.utils import build_absolute_uri
8 from ..seo.schema.email import get_order_confirmation_markup
9 from .models import Fulfillment, Order
10
11 CONFIRM_ORDER_TEMPLATE = 'source/order/confirm_order'
12 CONFIRM_FULFILLMENT_TEMPLATE = 'source/order/confirm_fulfillment'
13 UPDATE_FULFILLMENT_TEMPLATE = 'source/order/update_fulfillment'
14 CONFIRM_PAYMENT_TEMPLATE = 'source/order/payment/confirm_payment'
15 CONFIRM_NOTE_TEMPLATE = 'source/order/note/confirm_note'
16
17
18 def get_email_context(order_token):
19 """Prepares context required for email template rendering."""
20 site = Site.objects.get_current()
21 order_url = build_absolute_uri(
22 reverse('order:details', kwargs={'token': order_token}))
23 ctx = {
24 'protocol': 'https' if settings.ENABLE_SSL else 'http',
25 'site_name': site.name,
26 'domain': site.domain,
27 'url': order_url}
28 return ctx
29
30
31 def collect_data_for_email(order_pk, template):
32 """Collects data required for email sending.
33
34 Args:
35 order_pk (int): order primary key
36 template (str): email template path
37 """
38 order = Order.objects.get(pk=order_pk)
39 recipient_email = order.get_user_current_email()
40 email_context = get_email_context(order.token)
41
42 # Order confirmation template requires additional information
43 if template == CONFIRM_ORDER_TEMPLATE:
44 email_markup = get_order_confirmation_markup(order)
45 email_context.update(
46 {'order': order, 'schema_markup': email_markup})
47
48 return {
49 'recipient_list': [recipient_email], 'template_name': template,
50 'context': email_context, 'from_email': settings.ORDER_FROM_EMAIL}
51
52
53 def collect_data_for_fullfillment_email(order_pk, template, fulfillment_pk):
54 fulfillment = Fulfillment.objects.get(pk=fulfillment_pk)
55 email_data = collect_data_for_email(order_pk, template)
56 email_data.update({'context': {'fulfillment': fulfillment}})
57 return email_data
58
59
60 @shared_task
61 def send_order_confirmation(order_pk):
62 """Sends order confirmation email."""
63 email_data = collect_data_for_email(order_pk, CONFIRM_ORDER_TEMPLATE)
64 send_templated_mail(**email_data)
65
66
67 @shared_task
68 def send_fulfillment_confirmation(order_pk, fulfillment_pk):
69 email_data = collect_data_for_fullfillment_email(
70 order_pk, CONFIRM_FULFILLMENT_TEMPLATE, fulfillment_pk)
71 send_templated_mail(**email_data)
72
73
74 @shared_task
75 def send_fulfillment_update(order_pk, fulfillment_pk):
76 email_data = collect_data_for_fullfillment_email(
77 order_pk, UPDATE_FULFILLMENT_TEMPLATE, fulfillment_pk)
78 send_templated_mail(**email_data)
79
80
81 @shared_task
82 def send_payment_confirmation(order_pk):
83 """Sends payment confirmation email."""
84 email_data = collect_data_for_email(order_pk, CONFIRM_PAYMENT_TEMPLATE)
85 send_templated_mail(**email_data)
86
87
88 @shared_task
89 def send_note_confirmation(order_pk):
90 """Notifies customer, when new note was added to an order."""
91 email_data = collect_data_for_email(order_pk, CONFIRM_NOTE_TEMPLATE)
92 send_templated_mail(**email_data)
93
[end of saleor/order/emails.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/saleor/order/emails.py b/saleor/order/emails.py
--- a/saleor/order/emails.py
+++ b/saleor/order/emails.py
@@ -53,7 +53,7 @@
def collect_data_for_fullfillment_email(order_pk, template, fulfillment_pk):
fulfillment = Fulfillment.objects.get(pk=fulfillment_pk)
email_data = collect_data_for_email(order_pk, template)
- email_data.update({'context': {'fulfillment': fulfillment}})
+ email_data['context'].update({'fulfillment': fulfillment})
return email_data
| {"golden_diff": "diff --git a/saleor/order/emails.py b/saleor/order/emails.py\n--- a/saleor/order/emails.py\n+++ b/saleor/order/emails.py\n@@ -53,7 +53,7 @@\n def collect_data_for_fullfillment_email(order_pk, template, fulfillment_pk):\n fulfillment = Fulfillment.objects.get(pk=fulfillment_pk)\n email_data = collect_data_for_email(order_pk, template)\n- email_data.update({'context': {'fulfillment': fulfillment}})\n+ email_data['context'].update({'fulfillment': fulfillment})\n return email_data\n", "issue": "Missing variable in \"fulfillment\" email\nTwo small issues in the \"fulfillment\" email:\r\n- logo is missing\r\n- in footer there is missing template variable\r\n\r\nI've just tested it and this is how the email looks like:\r\n\r\n\r\n\n", "before_files": [{"content": "from celery import shared_task\nfrom django.conf import settings\nfrom django.contrib.sites.models import Site\nfrom django.urls import reverse\nfrom templated_email import send_templated_mail\n\nfrom ..core.utils import build_absolute_uri\nfrom ..seo.schema.email import get_order_confirmation_markup\nfrom .models import Fulfillment, Order\n\nCONFIRM_ORDER_TEMPLATE = 'source/order/confirm_order'\nCONFIRM_FULFILLMENT_TEMPLATE = 'source/order/confirm_fulfillment'\nUPDATE_FULFILLMENT_TEMPLATE = 'source/order/update_fulfillment'\nCONFIRM_PAYMENT_TEMPLATE = 'source/order/payment/confirm_payment'\nCONFIRM_NOTE_TEMPLATE = 'source/order/note/confirm_note'\n\n\ndef get_email_context(order_token):\n \"\"\"Prepares context required for email template rendering.\"\"\"\n site = Site.objects.get_current()\n order_url = build_absolute_uri(\n reverse('order:details', kwargs={'token': order_token}))\n ctx = {\n 'protocol': 'https' if settings.ENABLE_SSL else 'http',\n 'site_name': site.name,\n 'domain': site.domain,\n 'url': order_url}\n return ctx\n\n\ndef collect_data_for_email(order_pk, template):\n \"\"\"Collects data required for email sending.\n\n Args:\n order_pk (int): order primary key\n template (str): email template path\n \"\"\"\n order = Order.objects.get(pk=order_pk)\n recipient_email = order.get_user_current_email()\n email_context = get_email_context(order.token)\n\n # Order confirmation template requires additional information\n if template == CONFIRM_ORDER_TEMPLATE:\n email_markup = get_order_confirmation_markup(order)\n email_context.update(\n {'order': order, 'schema_markup': email_markup})\n\n return {\n 'recipient_list': [recipient_email], 'template_name': template,\n 'context': email_context, 'from_email': settings.ORDER_FROM_EMAIL}\n\n\ndef collect_data_for_fullfillment_email(order_pk, template, fulfillment_pk):\n fulfillment = Fulfillment.objects.get(pk=fulfillment_pk)\n email_data = collect_data_for_email(order_pk, template)\n email_data.update({'context': {'fulfillment': fulfillment}})\n return email_data\n\n\n@shared_task\ndef send_order_confirmation(order_pk):\n \"\"\"Sends order confirmation email.\"\"\"\n email_data = collect_data_for_email(order_pk, CONFIRM_ORDER_TEMPLATE)\n send_templated_mail(**email_data)\n\n\n@shared_task\ndef send_fulfillment_confirmation(order_pk, fulfillment_pk):\n email_data = collect_data_for_fullfillment_email(\n order_pk, CONFIRM_FULFILLMENT_TEMPLATE, fulfillment_pk)\n send_templated_mail(**email_data)\n\n\n@shared_task\ndef send_fulfillment_update(order_pk, fulfillment_pk):\n email_data = collect_data_for_fullfillment_email(\n order_pk, UPDATE_FULFILLMENT_TEMPLATE, fulfillment_pk)\n send_templated_mail(**email_data)\n\n\n@shared_task\ndef send_payment_confirmation(order_pk):\n \"\"\"Sends payment confirmation email.\"\"\"\n email_data = collect_data_for_email(order_pk, CONFIRM_PAYMENT_TEMPLATE)\n send_templated_mail(**email_data)\n\n\n@shared_task\ndef send_note_confirmation(order_pk):\n \"\"\"Notifies customer, when new note was added to an order.\"\"\"\n email_data = collect_data_for_email(order_pk, CONFIRM_NOTE_TEMPLATE)\n send_templated_mail(**email_data)\n", "path": "saleor/order/emails.py"}]} | 1,554 | 131 |
gh_patches_debug_728 | rasdani/github-patches | git_diff | speechbrain__speechbrain-1504 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Torch 1.12 not compatible?
working to install speechbrain 0.5.12, and getting the error that "speechbrain 0.5.12 requires torch<=1.11,>=1.7, but you have torch 1.12.0 which is incompatible." read elsewhere that it should work with >=1.7.
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python3
2 import os
3 import sys
4 import site
5 import setuptools
6 from distutils.core import setup
7
8
9 # Editable install in user site directory can be allowed with this hack:
10 # https://github.com/pypa/pip/issues/7953.
11 site.ENABLE_USER_SITE = "--user" in sys.argv[1:]
12
13 with open("README.md") as f:
14 long_description = f.read()
15
16 with open(os.path.join("speechbrain", "version.txt")) as f:
17 version = f.read().strip()
18
19 setup(
20 name="speechbrain",
21 version=version,
22 description="All-in-one speech toolkit in pure Python and Pytorch",
23 long_description=long_description,
24 long_description_content_type="text/markdown",
25 author="Mirco Ravanelli & Others",
26 author_email="[email protected]",
27 classifiers=[
28 "Programming Language :: Python :: 3",
29 "License :: OSI Approved :: Apache Software License",
30 ],
31 packages=setuptools.find_packages(),
32 package_data={"speechbrain": ["version.txt", "log-config.yaml"]},
33 install_requires=[
34 "hyperpyyaml",
35 "joblib",
36 "numpy",
37 "packaging",
38 "scipy",
39 "sentencepiece",
40 "torch>=1.7,<=1.11",
41 "torchaudio",
42 "tqdm",
43 "huggingface_hub",
44 ],
45 python_requires=">=3.7",
46 url="https://speechbrain.github.io/",
47 )
48
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -37,7 +37,7 @@
"packaging",
"scipy",
"sentencepiece",
- "torch>=1.7,<=1.11",
+ "torch>=1.9",
"torchaudio",
"tqdm",
"huggingface_hub",
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -37,7 +37,7 @@\n \"packaging\",\n \"scipy\",\n \"sentencepiece\",\n- \"torch>=1.7,<=1.11\",\n+ \"torch>=1.9\",\n \"torchaudio\",\n \"tqdm\",\n \"huggingface_hub\",\n", "issue": "Torch 1.12 not compatible?\nworking to install speechbrain 0.5.12, and getting the error that \"speechbrain 0.5.12 requires torch<=1.11,>=1.7, but you have torch 1.12.0 which is incompatible.\" read elsewhere that it should work with >=1.7. \n", "before_files": [{"content": "#!/usr/bin/env python3\nimport os\nimport sys\nimport site\nimport setuptools\nfrom distutils.core import setup\n\n\n# Editable install in user site directory can be allowed with this hack:\n# https://github.com/pypa/pip/issues/7953.\nsite.ENABLE_USER_SITE = \"--user\" in sys.argv[1:]\n\nwith open(\"README.md\") as f:\n long_description = f.read()\n\nwith open(os.path.join(\"speechbrain\", \"version.txt\")) as f:\n version = f.read().strip()\n\nsetup(\n name=\"speechbrain\",\n version=version,\n description=\"All-in-one speech toolkit in pure Python and Pytorch\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n author=\"Mirco Ravanelli & Others\",\n author_email=\"[email protected]\",\n classifiers=[\n \"Programming Language :: Python :: 3\",\n \"License :: OSI Approved :: Apache Software License\",\n ],\n packages=setuptools.find_packages(),\n package_data={\"speechbrain\": [\"version.txt\", \"log-config.yaml\"]},\n install_requires=[\n \"hyperpyyaml\",\n \"joblib\",\n \"numpy\",\n \"packaging\",\n \"scipy\",\n \"sentencepiece\",\n \"torch>=1.7,<=1.11\",\n \"torchaudio\",\n \"tqdm\",\n \"huggingface_hub\",\n ],\n python_requires=\">=3.7\",\n url=\"https://speechbrain.github.io/\",\n)\n", "path": "setup.py"}]} | 1,018 | 90 |
gh_patches_debug_41349 | rasdani/github-patches | git_diff | privacyidea__privacyidea-2589 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Migration fails when skipping the 3.3 version
In v3.3 the dedicated admin user was added to the policy table and the corresponding data was migrated (https://github.com/privacyidea/privacyidea/blob/master/migrations/versions/a7e91b18a460_.py).
But if the migration skips the 3.3 version, the data migration fails because the [`models.py`](https://github.com/privacyidea/privacyidea/blob/master/privacyidea/models.py) describes a different version of the database than the physical version.
By using a temporary policy table description in the migration script we can mitigate this failure.
This applies to privacyIDEA version 3.4 and up.
</issue>
<code>
[start of migrations/versions/a7e91b18a460_.py]
1 """add dedicated adminuser to policies
2
3 Revision ID: a7e91b18a460
4 Revises: 0c7123345224
5 Create Date: 2020-01-29 13:42:15.390923
6
7 """
8
9 # revision identifiers, used by Alembic.
10 revision = 'a7e91b18a460'
11 down_revision = '0c7123345224'
12
13 from alembic import op
14 import sqlalchemy as sa
15 from privacyidea.models import Policy
16 from sqlalchemy import orm
17
18
19 def upgrade():
20 try:
21 op.add_column('policy', sa.Column('adminuser', sa.Unicode(length=256), nullable=True))
22 except Exception as exx:
23 print('Adding of column "adminuser" in table policy failed: {!r}'.format(exx))
24 print('This is expected behavior if this column already exists.')
25
26 # Now that we added the column in the table, we can move the "user" from admin-policies to
27 # the "adminuser" column
28
29 try:
30 bind = op.get_bind()
31 session = orm.Session(bind=bind)
32 pol_name = None
33 for policy in session.query(Policy).filter(Policy.user != "", Policy.scope == "admin"):
34 pol_name = policy.name
35 # move the "user" to the "adminuser"
36 policy.adminuser = policy.user
37 policy.user = u""
38 session.commit()
39 except Exception as exx:
40 session.rollback()
41 print("Failed to migrate column adminuser in policies due to error in policy '{0!s}'.".format(pol_name))
42 print(exx)
43
44
45 def downgrade():
46 op.drop_column('policy', 'adminuser')
47
[end of migrations/versions/a7e91b18a460_.py]
[start of privacyidea/lib/auditmodules/containeraudit.py]
1 # -*- coding: utf-8 -*-
2 #
3 # 2019-11-07 Cornelius Kölbel <[email protected]>
4 # initial code for writing audit information to a file
5 #
6 # This code is free software; you can redistribute it and/or
7 # modify it under the terms of the GNU AFFERO GENERAL PUBLIC LICENSE
8 # License as published by the Free Software Foundation; either
9 # version 3 of the License, or any later version.
10 #
11 # This code is distributed in the hope that it will be useful,
12 # but WITHOUT ANY WARRANTY; without even the implied warranty of
13 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 # GNU AFFERO GENERAL PUBLIC LICENSE for more details.
15 #
16 # You should have received a copy of the GNU Affero General Public
17 # License along with this program. If not, see <http://www.gnu.org/licenses/>.
18 #
19 #
20 __doc__ = """The Container Audit Module allows to write audit information to several different
21 audit modules at the same time. E.g. it can write audit information to the SQL Audit Module and to the
22 Logger Audit Module. This way audit information can be saved in the SQL database and at the same time
23 be passed to a file or external services via the Python logging facility.
24
25 The Container Audit Module is configured like this:
26
27 PI_AUDIT_MODULE = 'privacyidea.lib.auditmodules.containeraudit'
28 PI_AUDIT_CONTAINER_WRITE = ['privacyidea.lib.auditmodules.sqlaudit','privacyidea.lib.auditmodules.loggeraudit']
29 PI_AUDIT_CONTAINER_READ = 'privacyidea.lib.auditmodules.sqlaudit'
30
31 You also have to provide the configuration parameters for the referenced audit modules.
32
33 """
34
35 import logging
36 from privacyidea.lib.auditmodules.base import (Audit as AuditBase)
37 from privacyidea.lib.utils import get_module_class
38
39
40 log = logging.getLogger(__name__)
41
42
43 class Audit(AuditBase):
44 """
45 This is the ContainerAudit module, which writes the audit entries
46 to a list of audit modules.
47 """
48
49 def __init__(self, config=None):
50 super(Audit, self).__init__(config)
51 self.name = "containeraudit"
52 write_conf = self.config.get('PI_AUDIT_CONTAINER_WRITE')
53 read_conf = self.config.get('PI_AUDIT_CONTAINER_READ')
54 # Initialize all modules
55 self.write_modules = [get_module_class(audit_module, "Audit", "log")(config) for audit_module in write_conf]
56 self.read_module = get_module_class(read_conf, "Audit", "log")(config)
57 if not self.read_module.is_readable:
58 log.warning(u"The specified PI_AUDIT_CONTAINER_READ {0!s} is not readable.".format(self.read_module))
59
60 @property
61 def has_data(self):
62 return any([x.has_data for x in self.write_modules])
63
64 def log(self, param):
65 """
66 Call the log method for all writeable modules
67 """
68 for module in self.write_modules:
69 module.log(param)
70
71 def add_to_log(self, param, add_with_comma=False):
72 """
73 Call the add_to_log method for all writeable modules
74 """
75 for module in self.write_modules:
76 module.add_to_log(param, add_with_comma)
77
78 def add_policy(self, policyname):
79 """
80 Call the add_policy method for all writeable modules
81 """
82 for module in self.write_modules:
83 module.add_policy(policyname)
84
85 def search(self, search_dict, page_size=15, page=1, sortorder="asc",
86 timelimit=None):
87 """
88 Call the search method for the one readable module
89 """
90 return self.read_module.search(search_dict, page_size=page_size, page=page,
91 sortorder=sortorder, timelimit=timelimit)
92
93 def get_count(self, search_dict, timedelta=None, success=None):
94 """
95 Call the count method for the one readable module
96 """
97 return self.read_module.get_count(search_dict, timedelta=timedelta, success=success)
98
99 def csv_generator(self, param=None, user=None, timelimit=None):
100 """
101 Call the csv_generator method for the one readable module
102 """
103 return self.read_module.csv_generator(param=param, user=user,
104 timelimit=timelimit)
105
106 def get_total(self, param, AND=True, display_error=True, timelimit=None):
107 """
108 Call the total method for the one readable module
109 """
110 return self.read_module.get_total(param, AND=AND, display_error=display_error, timelimit=timelimit)
111
112 def finalize_log(self):
113 """
114 Call the finalize method of all writeable audit modules
115 """
116 for module in self.write_modules:
117 module.finalize_log()
118
[end of privacyidea/lib/auditmodules/containeraudit.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/migrations/versions/a7e91b18a460_.py b/migrations/versions/a7e91b18a460_.py
--- a/migrations/versions/a7e91b18a460_.py
+++ b/migrations/versions/a7e91b18a460_.py
@@ -12,8 +12,31 @@
from alembic import op
import sqlalchemy as sa
-from privacyidea.models import Policy
from sqlalchemy import orm
+from sqlalchemy.ext.declarative import declarative_base
+
+Base = declarative_base()
+
+
+# Use table definition from the point where the changes took place. If we use
+# the table definition from models.py we might run into problems
+class Policy(Base):
+ __tablename__ = "policy"
+ __table_args__ = {'mysql_row_format': 'DYNAMIC'}
+ id = sa.Column(sa.Integer, sa.Sequence("policy_seq"), primary_key=True)
+ active = sa.Column(sa.Boolean, default=True)
+ check_all_resolvers = sa.Column(sa.Boolean, default=False)
+ name = sa.Column(sa.Unicode(64), unique=True, nullable=False)
+ scope = sa.Column(sa.Unicode(32), nullable=False)
+ action = sa.Column(sa.Unicode(2000), default=u"")
+ realm = sa.Column(sa.Unicode(256), default=u"")
+ adminrealm = sa.Column(sa.Unicode(256), default=u"")
+ adminuser = sa.Column(sa.Unicode(256), default=u"")
+ resolver = sa.Column(sa.Unicode(256), default=u"")
+ user = sa.Column(sa.Unicode(256), default=u"")
+ client = sa.Column(sa.Unicode(256), default=u"")
+ time = sa.Column(sa.Unicode(64), default=u"")
+ priority = sa.Column(sa.Integer, default=1, nullable=False)
def upgrade():
@@ -25,12 +48,11 @@
# Now that we added the column in the table, we can move the "user" from admin-policies to
# the "adminuser" column
-
+ bind = op.get_bind()
+ session = orm.Session(bind=bind)
+ pol_name = None
try:
- bind = op.get_bind()
- session = orm.Session(bind=bind)
- pol_name = None
- for policy in session.query(Policy).filter(Policy.user != "", Policy.scope == "admin"):
+ for policy in session.query(Policy).filter(Policy.user != u"", Policy.scope == u"admin"):
pol_name = policy.name
# move the "user" to the "adminuser"
policy.adminuser = policy.user
@@ -38,7 +60,8 @@
session.commit()
except Exception as exx:
session.rollback()
- print("Failed to migrate column adminuser in policies due to error in policy '{0!s}'.".format(pol_name))
+ print("Failed to migrate column adminuser in policies due to error in "
+ "policy '{0!s}'.".format(pol_name))
print(exx)
diff --git a/privacyidea/lib/auditmodules/containeraudit.py b/privacyidea/lib/auditmodules/containeraudit.py
--- a/privacyidea/lib/auditmodules/containeraudit.py
+++ b/privacyidea/lib/auditmodules/containeraudit.py
@@ -46,14 +46,15 @@
to a list of audit modules.
"""
- def __init__(self, config=None):
- super(Audit, self).__init__(config)
+ def __init__(self, config=None, startdate=None):
+ super(Audit, self).__init__(config, startdate)
self.name = "containeraudit"
write_conf = self.config.get('PI_AUDIT_CONTAINER_WRITE')
read_conf = self.config.get('PI_AUDIT_CONTAINER_READ')
# Initialize all modules
- self.write_modules = [get_module_class(audit_module, "Audit", "log")(config) for audit_module in write_conf]
- self.read_module = get_module_class(read_conf, "Audit", "log")(config)
+ self.write_modules = [get_module_class(audit_module, "Audit", "log")(config, startdate)
+ for audit_module in write_conf]
+ self.read_module = get_module_class(read_conf, "Audit", "log")(config, startdate)
if not self.read_module.is_readable:
log.warning(u"The specified PI_AUDIT_CONTAINER_READ {0!s} is not readable.".format(self.read_module))
| {"golden_diff": "diff --git a/migrations/versions/a7e91b18a460_.py b/migrations/versions/a7e91b18a460_.py\n--- a/migrations/versions/a7e91b18a460_.py\n+++ b/migrations/versions/a7e91b18a460_.py\n@@ -12,8 +12,31 @@\n \n from alembic import op\n import sqlalchemy as sa\n-from privacyidea.models import Policy\n from sqlalchemy import orm\n+from sqlalchemy.ext.declarative import declarative_base\n+\n+Base = declarative_base()\n+\n+\n+# Use table definition from the point where the changes took place. If we use\n+# the table definition from models.py we might run into problems\n+class Policy(Base):\n+ __tablename__ = \"policy\"\n+ __table_args__ = {'mysql_row_format': 'DYNAMIC'}\n+ id = sa.Column(sa.Integer, sa.Sequence(\"policy_seq\"), primary_key=True)\n+ active = sa.Column(sa.Boolean, default=True)\n+ check_all_resolvers = sa.Column(sa.Boolean, default=False)\n+ name = sa.Column(sa.Unicode(64), unique=True, nullable=False)\n+ scope = sa.Column(sa.Unicode(32), nullable=False)\n+ action = sa.Column(sa.Unicode(2000), default=u\"\")\n+ realm = sa.Column(sa.Unicode(256), default=u\"\")\n+ adminrealm = sa.Column(sa.Unicode(256), default=u\"\")\n+ adminuser = sa.Column(sa.Unicode(256), default=u\"\")\n+ resolver = sa.Column(sa.Unicode(256), default=u\"\")\n+ user = sa.Column(sa.Unicode(256), default=u\"\")\n+ client = sa.Column(sa.Unicode(256), default=u\"\")\n+ time = sa.Column(sa.Unicode(64), default=u\"\")\n+ priority = sa.Column(sa.Integer, default=1, nullable=False)\n \n \n def upgrade():\n@@ -25,12 +48,11 @@\n \n # Now that we added the column in the table, we can move the \"user\" from admin-policies to\n # the \"adminuser\" column\n-\n+ bind = op.get_bind()\n+ session = orm.Session(bind=bind)\n+ pol_name = None\n try:\n- bind = op.get_bind()\n- session = orm.Session(bind=bind)\n- pol_name = None\n- for policy in session.query(Policy).filter(Policy.user != \"\", Policy.scope == \"admin\"):\n+ for policy in session.query(Policy).filter(Policy.user != u\"\", Policy.scope == u\"admin\"):\n pol_name = policy.name\n # move the \"user\" to the \"adminuser\"\n policy.adminuser = policy.user\n@@ -38,7 +60,8 @@\n session.commit()\n except Exception as exx:\n session.rollback()\n- print(\"Failed to migrate column adminuser in policies due to error in policy '{0!s}'.\".format(pol_name))\n+ print(\"Failed to migrate column adminuser in policies due to error in \"\n+ \"policy '{0!s}'.\".format(pol_name))\n print(exx)\n \n \ndiff --git a/privacyidea/lib/auditmodules/containeraudit.py b/privacyidea/lib/auditmodules/containeraudit.py\n--- a/privacyidea/lib/auditmodules/containeraudit.py\n+++ b/privacyidea/lib/auditmodules/containeraudit.py\n@@ -46,14 +46,15 @@\n to a list of audit modules.\n \"\"\"\n \n- def __init__(self, config=None):\n- super(Audit, self).__init__(config)\n+ def __init__(self, config=None, startdate=None):\n+ super(Audit, self).__init__(config, startdate)\n self.name = \"containeraudit\"\n write_conf = self.config.get('PI_AUDIT_CONTAINER_WRITE')\n read_conf = self.config.get('PI_AUDIT_CONTAINER_READ')\n # Initialize all modules\n- self.write_modules = [get_module_class(audit_module, \"Audit\", \"log\")(config) for audit_module in write_conf]\n- self.read_module = get_module_class(read_conf, \"Audit\", \"log\")(config)\n+ self.write_modules = [get_module_class(audit_module, \"Audit\", \"log\")(config, startdate)\n+ for audit_module in write_conf]\n+ self.read_module = get_module_class(read_conf, \"Audit\", \"log\")(config, startdate)\n if not self.read_module.is_readable:\n log.warning(u\"The specified PI_AUDIT_CONTAINER_READ {0!s} is not readable.\".format(self.read_module))\n", "issue": "Migration fails when skipping the 3.3 version\nIn v3.3 the dedicated admin user was added to the policy table and the corresponding data was migrated (https://github.com/privacyidea/privacyidea/blob/master/migrations/versions/a7e91b18a460_.py).\r\nBut if the migration skips the 3.3 version, the data migration fails because the [`models.py`](https://github.com/privacyidea/privacyidea/blob/master/privacyidea/models.py) describes a different version of the database than the physical version.\r\nBy using a temporary policy table description in the migration script we can mitigate this failure.\r\nThis applies to privacyIDEA version 3.4 and up.\n", "before_files": [{"content": "\"\"\"add dedicated adminuser to policies\n\nRevision ID: a7e91b18a460\nRevises: 0c7123345224\nCreate Date: 2020-01-29 13:42:15.390923\n\n\"\"\"\n\n# revision identifiers, used by Alembic.\nrevision = 'a7e91b18a460'\ndown_revision = '0c7123345224'\n\nfrom alembic import op\nimport sqlalchemy as sa\nfrom privacyidea.models import Policy\nfrom sqlalchemy import orm\n\n\ndef upgrade():\n try:\n op.add_column('policy', sa.Column('adminuser', sa.Unicode(length=256), nullable=True))\n except Exception as exx:\n print('Adding of column \"adminuser\" in table policy failed: {!r}'.format(exx))\n print('This is expected behavior if this column already exists.')\n\n # Now that we added the column in the table, we can move the \"user\" from admin-policies to\n # the \"adminuser\" column\n\n try:\n bind = op.get_bind()\n session = orm.Session(bind=bind)\n pol_name = None\n for policy in session.query(Policy).filter(Policy.user != \"\", Policy.scope == \"admin\"):\n pol_name = policy.name\n # move the \"user\" to the \"adminuser\"\n policy.adminuser = policy.user\n policy.user = u\"\"\n session.commit()\n except Exception as exx:\n session.rollback()\n print(\"Failed to migrate column adminuser in policies due to error in policy '{0!s}'.\".format(pol_name))\n print(exx)\n\n\ndef downgrade():\n op.drop_column('policy', 'adminuser')\n", "path": "migrations/versions/a7e91b18a460_.py"}, {"content": "# -*- coding: utf-8 -*-\n#\n# 2019-11-07 Cornelius K\u00f6lbel <[email protected]>\n# initial code for writing audit information to a file\n#\n# This code is free software; you can redistribute it and/or\n# modify it under the terms of the GNU AFFERO GENERAL PUBLIC LICENSE\n# License as published by the Free Software Foundation; either\n# version 3 of the License, or any later version.\n#\n# This code is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU AFFERO GENERAL PUBLIC LICENSE for more details.\n#\n# You should have received a copy of the GNU Affero General Public\n# License along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\n#\n__doc__ = \"\"\"The Container Audit Module allows to write audit information to several different\naudit modules at the same time. E.g. it can write audit information to the SQL Audit Module and to the \nLogger Audit Module. This way audit information can be saved in the SQL database and at the same time\nbe passed to a file or external services via the Python logging facility. \n\nThe Container Audit Module is configured like this:\n\n PI_AUDIT_MODULE = 'privacyidea.lib.auditmodules.containeraudit'\n PI_AUDIT_CONTAINER_WRITE = ['privacyidea.lib.auditmodules.sqlaudit','privacyidea.lib.auditmodules.loggeraudit']\n PI_AUDIT_CONTAINER_READ = 'privacyidea.lib.auditmodules.sqlaudit'\n\nYou also have to provide the configuration parameters for the referenced audit modules.\n\n\"\"\"\n\nimport logging\nfrom privacyidea.lib.auditmodules.base import (Audit as AuditBase)\nfrom privacyidea.lib.utils import get_module_class\n\n\nlog = logging.getLogger(__name__)\n\n\nclass Audit(AuditBase):\n \"\"\"\n This is the ContainerAudit module, which writes the audit entries\n to a list of audit modules.\n \"\"\"\n\n def __init__(self, config=None):\n super(Audit, self).__init__(config)\n self.name = \"containeraudit\"\n write_conf = self.config.get('PI_AUDIT_CONTAINER_WRITE')\n read_conf = self.config.get('PI_AUDIT_CONTAINER_READ')\n # Initialize all modules\n self.write_modules = [get_module_class(audit_module, \"Audit\", \"log\")(config) for audit_module in write_conf]\n self.read_module = get_module_class(read_conf, \"Audit\", \"log\")(config)\n if not self.read_module.is_readable:\n log.warning(u\"The specified PI_AUDIT_CONTAINER_READ {0!s} is not readable.\".format(self.read_module))\n\n @property\n def has_data(self):\n return any([x.has_data for x in self.write_modules])\n\n def log(self, param):\n \"\"\"\n Call the log method for all writeable modules\n \"\"\"\n for module in self.write_modules:\n module.log(param)\n\n def add_to_log(self, param, add_with_comma=False):\n \"\"\"\n Call the add_to_log method for all writeable modules\n \"\"\"\n for module in self.write_modules:\n module.add_to_log(param, add_with_comma)\n\n def add_policy(self, policyname):\n \"\"\"\n Call the add_policy method for all writeable modules\n \"\"\"\n for module in self.write_modules:\n module.add_policy(policyname)\n\n def search(self, search_dict, page_size=15, page=1, sortorder=\"asc\",\n timelimit=None):\n \"\"\"\n Call the search method for the one readable module\n \"\"\"\n return self.read_module.search(search_dict, page_size=page_size, page=page,\n sortorder=sortorder, timelimit=timelimit)\n\n def get_count(self, search_dict, timedelta=None, success=None):\n \"\"\"\n Call the count method for the one readable module\n \"\"\"\n return self.read_module.get_count(search_dict, timedelta=timedelta, success=success)\n\n def csv_generator(self, param=None, user=None, timelimit=None):\n \"\"\"\n Call the csv_generator method for the one readable module\n \"\"\"\n return self.read_module.csv_generator(param=param, user=user,\n timelimit=timelimit)\n\n def get_total(self, param, AND=True, display_error=True, timelimit=None):\n \"\"\"\n Call the total method for the one readable module\n \"\"\"\n return self.read_module.get_total(param, AND=AND, display_error=display_error, timelimit=timelimit)\n\n def finalize_log(self):\n \"\"\"\n Call the finalize method of all writeable audit modules\n \"\"\"\n for module in self.write_modules:\n module.finalize_log()\n", "path": "privacyidea/lib/auditmodules/containeraudit.py"}]} | 2,479 | 1,021 |
gh_patches_debug_11334 | rasdani/github-patches | git_diff | chainer__chainer-737 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Use `numpy.uintp` for `size_t`
`numpy.intp` is `ssize_t`, and is not `size_t`. When value of `ptr` allocated by `malloc` method is larger than the maximum value of `ssize_t`, `numpy.intp(ptr)` causes an error, because it checks actual value of `ptr`.
We need to use `numpy.uintp` in this case.
Note that `numpy.uintp` is not documented in the reference manual http://docs.scipy.org/doc/numpy-1.10.1/user/basics.types.html
</issue>
<code>
[start of chainer/functions/math/matmul.py]
1 import numpy
2 import six
3
4 from chainer import cuda
5 from chainer import function
6 from chainer.utils import type_check
7
8
9 def _mat_ptrs(a):
10 """Creates an array of pointers to matrices
11
12 Args:
13 a: A batch of matrices on GPU
14 Returns:
15 GPU array of pointers to matrices
16 """
17 if a.shape[0] == 1:
18 return cuda.cupy.full((1,), a[0].data.ptr, dtype=numpy.intp)
19 else:
20 stride = a[1].data.ptr - a[0].data.ptr
21 return cuda.cupy.arange(
22 a[0].data.ptr,
23 a[0].data.ptr + stride * a.shape[0],
24 stride,
25 dtype=numpy.intp)
26
27
28 def _as_mat(x):
29 return x.reshape((len(x), 1)) if len(x.shape) == 1 else x
30
31
32 def _as_batch_mat(x):
33 return x.reshape((x.shape[0], x.shape[1], 1)) if len(x.shape) == 2 else x
34
35
36 def _matmul(a, b, transa=False, transb=False, transout=False):
37 a = _as_mat(a)
38 b = _as_mat(b)
39 if transa:
40 a = a.T
41 if transb:
42 b = b.T
43 if transout:
44 # (A B)^T = B^T A^T
45 a, b = b.T, a.T
46 return a.dot(b)
47
48
49 def _get_ld(a):
50 shape = a.shape[-2:]
51 strides = a.strides[-2:]
52 trans = numpy.argmin(strides)
53 return trans, int(max(shape[trans], max(strides) // a.itemsize))
54
55
56 def _batch_matmul_gpu(a, b, out, transa=False, transb=False, transout=False):
57 a = _as_batch_mat(a)
58 b = _as_batch_mat(b)
59 trans_axis = (0, 2, 1)
60 if transout:
61 out = out.transpose(trans_axis)
62 needtrans, _ = _get_ld(out)
63 if needtrans == 1:
64 # (A B)^T = B^T A^T
65 a, b = b, a
66 transa, transb = not transb, not transa
67 out = out.transpose(trans_axis)
68 if transa:
69 a = a.transpose(trans_axis)
70 if transb:
71 b = b.transpose(trans_axis)
72
73 transa, lda = _get_ld(a)
74 transb, ldb = _get_ld(b)
75 transout, ldout = _get_ld(out)
76 la, n, ka = a.shape
77 lb, kb, m = b.shape
78
79 assert ka == kb
80 assert transout == 0 or ldout == 1
81 assert out.shape == (la, n, m)
82
83 ap = _mat_ptrs(a)
84 bp = _mat_ptrs(b)
85 outp = _mat_ptrs(out)
86 cuda.cublas.sgemmBatched(
87 cuda.Device().cublas_handle,
88 transa,
89 transb,
90 n, m, ka, 1.0,
91 ap.data.ptr, lda,
92 bp.data.ptr, ldb,
93 0.0, outp.data.ptr, ldout, la)
94
95
96 def _check_ndim(in_type, lower=1, upper=2):
97 type_check.expect(
98 in_type.ndim >= lower,
99 in_type.ndim <= upper
100 )
101
102
103 def _convert_type(in_type, vector_ndim=1):
104 if in_type.ndim.eval() == vector_ndim:
105 in_type = type_check.Variable(
106 type_check.TypeInfo(in_type.shape.eval() + (1,),
107 in_type.dtype),
108 '%s(1-D array)' % in_type.name)
109 else:
110 in_type.name = '%s(2-D array)' % in_type.name
111 return in_type
112
113
114 def _get_check_index(trans, right, row_idx=0, col_idx=1):
115 if trans ^ right:
116 return row_idx
117 else:
118 return col_idx
119
120
121 class MatMul(function.Function):
122 def __init__(self, transa=False, transb=False):
123 self.transa = transa
124 self.transb = transb
125
126 def check_type_forward(self, in_types):
127 type_check.expect(in_types.size() == 2)
128 a_type, b_type = in_types
129
130 type_check.expect(
131 a_type.dtype == numpy.float32,
132 b_type.dtype == numpy.float32
133 )
134
135 _check_ndim(a_type)
136 _check_ndim(b_type)
137
138 a_type = _convert_type(a_type)
139 b_type = _convert_type(b_type)
140 a_idx = _get_check_index(self.transa, False)
141 b_idx = _get_check_index(self.transb, True)
142 type_check.expect(
143 a_type.shape[a_idx] == b_type.shape[b_idx]
144 )
145
146 def forward(self, x):
147 return _matmul(x[0], x[1], transa=self.transa, transb=self.transb),
148
149 def backward(self, x, gy):
150 gx0 = _matmul(
151 gy[0], x[1], transb=not self.transb, transout=self.transa
152 ).reshape(x[0].shape)
153 gx1 = _matmul(
154 x[0], gy[0], transa=not self.transa, transout=self.transb
155 ).reshape(x[1].shape)
156 return gx0, gx1
157
158
159 def matmul(a, b, transa=False, transb=False):
160 """Computes the matrix multiplication of two arrays.
161
162 Args:
163 a (Variable): The left operand of the matrix multiplication.
164 A 1-D array of shape (N,) is considered as an Nx1 matrix.
165 A 2-D array of shape (M, N) is considered as an MxN matrix.
166 b (Variable): The right operand of the matrix multiplication.
167 Its array is treated as a matrix in the same way as ``a``'s array.
168 transa (bool): If true, transpose a.
169 transb (bool): If true, transpose b.
170
171 Returns:
172 ~chainer.Variable: The result of the matrix multiplication as a 2-D
173 array.
174 """
175 return MatMul(transa=transa, transb=transb)(a, b)
176
177
178 class BatchMatMul(function.Function):
179 def __init__(self, transa=False, transb=False):
180 self.transa = transa
181 self.transb = transb
182
183 def _output_shape(self, a, b):
184 batch_size = a.shape[0]
185 a_mat_shape = _as_mat(a[0]).shape
186 b_mat_shape = _as_mat(b[0]).shape
187 m = a_mat_shape[1 if self.transa else 0]
188 n = b_mat_shape[0 if self.transb else 1]
189 return (batch_size, m, n)
190
191 def check_type_forward(self, in_types):
192 type_check.expect(in_types.size() == 2)
193 a_type, b_type = in_types
194
195 type_check.expect(
196 a_type.dtype == numpy.float32,
197 b_type.dtype == numpy.float32
198 )
199
200 _check_ndim(a_type, lower=2, upper=3)
201 _check_ndim(b_type, lower=2, upper=3)
202
203 a_type = _convert_type(a_type, vector_ndim=2)
204 b_type = _convert_type(b_type, vector_ndim=2)
205 a_idx = _get_check_index(self.transa, False, row_idx=1, col_idx=2)
206 b_idx = _get_check_index(self.transb, True, row_idx=1, col_idx=2)
207 type_check.expect(
208 a_type.shape[a_idx] == b_type.shape[b_idx]
209 )
210
211 def forward_cpu(self, x):
212 a, b = x
213 batch_size = a.shape[0]
214 shape = self._output_shape(a, b)
215 ret_dtype = numpy.find_common_type([a.dtype, b.dtype], [])
216 ret = numpy.empty(shape, dtype=ret_dtype)
217 for i in six.moves.range(batch_size):
218 ret[i] = _matmul(
219 a[i], b[i], transa=self.transa, transb=self.transb)
220 return ret,
221
222 def backward_cpu(self, x, gy):
223 a, b = x
224 batch_size = a.shape[0]
225 ga = numpy.empty_like(a)
226 gb = numpy.empty_like(b)
227 for i in six.moves.range(batch_size):
228 ga[i] = _matmul(
229 gy[0][i], b[i], transb=not self.transb,
230 transout=self.transa).reshape(a[0].shape)
231 gb[i] = _matmul(
232 a[i], gy[0][i], transa=not self.transa,
233 transout=self.transb).reshape(b[0].shape)
234 return ga, gb
235
236 def forward_gpu(self, x):
237 a, b = x
238 shape = self._output_shape(a, b)
239 ret = cuda.zeros(shape)
240 _batch_matmul_gpu(
241 a, b, transa=self.transa, transb=self.transb, out=ret)
242 return ret,
243
244 def backward_gpu(self, x, gy):
245 a, b = x
246 batch_size = a.shape[0]
247 ga = cuda.empty((batch_size,) + _as_mat(a[0]).shape)
248 gb = cuda.empty((batch_size,) + _as_mat(b[0]).shape)
249 _batch_matmul_gpu(
250 gy[0], b, transb=not self.transb, transout=self.transa, out=ga)
251 _batch_matmul_gpu(
252 a, gy[0], transa=not self.transa, transout=self.transb, out=gb)
253 ga = ga.reshape(a.shape)
254 gb = gb.reshape(b.shape)
255 return ga, gb
256
257
258 def batch_matmul(a, b, transa=False, transb=False):
259 """Computes the batch matrix multiplications of two sets of arrays.
260
261 Args:
262 a (Variable): The left operand of the batch matrix multiplications.
263 A 2-D array of shape (B, N,) is considered as B Nx1 matrices.
264 A 3-D array of shape (B, M, N) is considered as B MxN matrices.
265 b (Variable): The right operand of the batch matrix multiplications.
266 Its array is treated as matrices in the same way as ``a``'s array.
267 transa (bool): If true, transpose each matrix in a.
268 transb (bool): If true, transpose each matrix in b.
269
270 Returns:
271 ~chainer.Variable: The result of the batch matrix multiplications as a
272 3-D array.
273 """
274 return BatchMatMul(transa=transa, transb=transb)(a, b)
275
[end of chainer/functions/math/matmul.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/chainer/functions/math/matmul.py b/chainer/functions/math/matmul.py
--- a/chainer/functions/math/matmul.py
+++ b/chainer/functions/math/matmul.py
@@ -15,14 +15,14 @@
GPU array of pointers to matrices
"""
if a.shape[0] == 1:
- return cuda.cupy.full((1,), a[0].data.ptr, dtype=numpy.intp)
+ return cuda.cupy.full((1,), a[0].data.ptr, dtype=numpy.uintp)
else:
stride = a[1].data.ptr - a[0].data.ptr
return cuda.cupy.arange(
a[0].data.ptr,
a[0].data.ptr + stride * a.shape[0],
stride,
- dtype=numpy.intp)
+ dtype=numpy.uintp)
def _as_mat(x):
| {"golden_diff": "diff --git a/chainer/functions/math/matmul.py b/chainer/functions/math/matmul.py\n--- a/chainer/functions/math/matmul.py\n+++ b/chainer/functions/math/matmul.py\n@@ -15,14 +15,14 @@\n GPU array of pointers to matrices\n \"\"\"\n if a.shape[0] == 1:\n- return cuda.cupy.full((1,), a[0].data.ptr, dtype=numpy.intp)\n+ return cuda.cupy.full((1,), a[0].data.ptr, dtype=numpy.uintp)\n else:\n stride = a[1].data.ptr - a[0].data.ptr\n return cuda.cupy.arange(\n a[0].data.ptr,\n a[0].data.ptr + stride * a.shape[0],\n stride,\n- dtype=numpy.intp)\n+ dtype=numpy.uintp)\n \n \n def _as_mat(x):\n", "issue": "Use `numpy.uintp` for `size_t`\n`numpy.intp` is `ssize_t`, and is not `size_t`. When value of `ptr` allocated by `malloc` method is larger than the maximum value of `ssize_t`, `numpy.intp(ptr)` causes an error, because it checks actual value of `ptr`.\nWe need to use `numpy.uintp` in this case.\n\nNote that `numpy.uintp` is not documented in the reference manual http://docs.scipy.org/doc/numpy-1.10.1/user/basics.types.html\n\n", "before_files": [{"content": "import numpy\nimport six\n\nfrom chainer import cuda\nfrom chainer import function\nfrom chainer.utils import type_check\n\n\ndef _mat_ptrs(a):\n \"\"\"Creates an array of pointers to matrices\n\n Args:\n a: A batch of matrices on GPU\n Returns:\n GPU array of pointers to matrices\n \"\"\"\n if a.shape[0] == 1:\n return cuda.cupy.full((1,), a[0].data.ptr, dtype=numpy.intp)\n else:\n stride = a[1].data.ptr - a[0].data.ptr\n return cuda.cupy.arange(\n a[0].data.ptr,\n a[0].data.ptr + stride * a.shape[0],\n stride,\n dtype=numpy.intp)\n\n\ndef _as_mat(x):\n return x.reshape((len(x), 1)) if len(x.shape) == 1 else x\n\n\ndef _as_batch_mat(x):\n return x.reshape((x.shape[0], x.shape[1], 1)) if len(x.shape) == 2 else x\n\n\ndef _matmul(a, b, transa=False, transb=False, transout=False):\n a = _as_mat(a)\n b = _as_mat(b)\n if transa:\n a = a.T\n if transb:\n b = b.T\n if transout:\n # (A B)^T = B^T A^T\n a, b = b.T, a.T\n return a.dot(b)\n\n\ndef _get_ld(a):\n shape = a.shape[-2:]\n strides = a.strides[-2:]\n trans = numpy.argmin(strides)\n return trans, int(max(shape[trans], max(strides) // a.itemsize))\n\n\ndef _batch_matmul_gpu(a, b, out, transa=False, transb=False, transout=False):\n a = _as_batch_mat(a)\n b = _as_batch_mat(b)\n trans_axis = (0, 2, 1)\n if transout:\n out = out.transpose(trans_axis)\n needtrans, _ = _get_ld(out)\n if needtrans == 1:\n # (A B)^T = B^T A^T\n a, b = b, a\n transa, transb = not transb, not transa\n out = out.transpose(trans_axis)\n if transa:\n a = a.transpose(trans_axis)\n if transb:\n b = b.transpose(trans_axis)\n\n transa, lda = _get_ld(a)\n transb, ldb = _get_ld(b)\n transout, ldout = _get_ld(out)\n la, n, ka = a.shape\n lb, kb, m = b.shape\n\n assert ka == kb\n assert transout == 0 or ldout == 1\n assert out.shape == (la, n, m)\n\n ap = _mat_ptrs(a)\n bp = _mat_ptrs(b)\n outp = _mat_ptrs(out)\n cuda.cublas.sgemmBatched(\n cuda.Device().cublas_handle,\n transa,\n transb,\n n, m, ka, 1.0,\n ap.data.ptr, lda,\n bp.data.ptr, ldb,\n 0.0, outp.data.ptr, ldout, la)\n\n\ndef _check_ndim(in_type, lower=1, upper=2):\n type_check.expect(\n in_type.ndim >= lower,\n in_type.ndim <= upper\n )\n\n\ndef _convert_type(in_type, vector_ndim=1):\n if in_type.ndim.eval() == vector_ndim:\n in_type = type_check.Variable(\n type_check.TypeInfo(in_type.shape.eval() + (1,),\n in_type.dtype),\n '%s(1-D array)' % in_type.name)\n else:\n in_type.name = '%s(2-D array)' % in_type.name\n return in_type\n\n\ndef _get_check_index(trans, right, row_idx=0, col_idx=1):\n if trans ^ right:\n return row_idx\n else:\n return col_idx\n\n\nclass MatMul(function.Function):\n def __init__(self, transa=False, transb=False):\n self.transa = transa\n self.transb = transb\n\n def check_type_forward(self, in_types):\n type_check.expect(in_types.size() == 2)\n a_type, b_type = in_types\n\n type_check.expect(\n a_type.dtype == numpy.float32,\n b_type.dtype == numpy.float32\n )\n\n _check_ndim(a_type)\n _check_ndim(b_type)\n\n a_type = _convert_type(a_type)\n b_type = _convert_type(b_type)\n a_idx = _get_check_index(self.transa, False)\n b_idx = _get_check_index(self.transb, True)\n type_check.expect(\n a_type.shape[a_idx] == b_type.shape[b_idx]\n )\n\n def forward(self, x):\n return _matmul(x[0], x[1], transa=self.transa, transb=self.transb),\n\n def backward(self, x, gy):\n gx0 = _matmul(\n gy[0], x[1], transb=not self.transb, transout=self.transa\n ).reshape(x[0].shape)\n gx1 = _matmul(\n x[0], gy[0], transa=not self.transa, transout=self.transb\n ).reshape(x[1].shape)\n return gx0, gx1\n\n\ndef matmul(a, b, transa=False, transb=False):\n \"\"\"Computes the matrix multiplication of two arrays.\n\n Args:\n a (Variable): The left operand of the matrix multiplication.\n A 1-D array of shape (N,) is considered as an Nx1 matrix.\n A 2-D array of shape (M, N) is considered as an MxN matrix.\n b (Variable): The right operand of the matrix multiplication.\n Its array is treated as a matrix in the same way as ``a``'s array.\n transa (bool): If true, transpose a.\n transb (bool): If true, transpose b.\n\n Returns:\n ~chainer.Variable: The result of the matrix multiplication as a 2-D\n array.\n \"\"\"\n return MatMul(transa=transa, transb=transb)(a, b)\n\n\nclass BatchMatMul(function.Function):\n def __init__(self, transa=False, transb=False):\n self.transa = transa\n self.transb = transb\n\n def _output_shape(self, a, b):\n batch_size = a.shape[0]\n a_mat_shape = _as_mat(a[0]).shape\n b_mat_shape = _as_mat(b[0]).shape\n m = a_mat_shape[1 if self.transa else 0]\n n = b_mat_shape[0 if self.transb else 1]\n return (batch_size, m, n)\n\n def check_type_forward(self, in_types):\n type_check.expect(in_types.size() == 2)\n a_type, b_type = in_types\n\n type_check.expect(\n a_type.dtype == numpy.float32,\n b_type.dtype == numpy.float32\n )\n\n _check_ndim(a_type, lower=2, upper=3)\n _check_ndim(b_type, lower=2, upper=3)\n\n a_type = _convert_type(a_type, vector_ndim=2)\n b_type = _convert_type(b_type, vector_ndim=2)\n a_idx = _get_check_index(self.transa, False, row_idx=1, col_idx=2)\n b_idx = _get_check_index(self.transb, True, row_idx=1, col_idx=2)\n type_check.expect(\n a_type.shape[a_idx] == b_type.shape[b_idx]\n )\n\n def forward_cpu(self, x):\n a, b = x\n batch_size = a.shape[0]\n shape = self._output_shape(a, b)\n ret_dtype = numpy.find_common_type([a.dtype, b.dtype], [])\n ret = numpy.empty(shape, dtype=ret_dtype)\n for i in six.moves.range(batch_size):\n ret[i] = _matmul(\n a[i], b[i], transa=self.transa, transb=self.transb)\n return ret,\n\n def backward_cpu(self, x, gy):\n a, b = x\n batch_size = a.shape[0]\n ga = numpy.empty_like(a)\n gb = numpy.empty_like(b)\n for i in six.moves.range(batch_size):\n ga[i] = _matmul(\n gy[0][i], b[i], transb=not self.transb,\n transout=self.transa).reshape(a[0].shape)\n gb[i] = _matmul(\n a[i], gy[0][i], transa=not self.transa,\n transout=self.transb).reshape(b[0].shape)\n return ga, gb\n\n def forward_gpu(self, x):\n a, b = x\n shape = self._output_shape(a, b)\n ret = cuda.zeros(shape)\n _batch_matmul_gpu(\n a, b, transa=self.transa, transb=self.transb, out=ret)\n return ret,\n\n def backward_gpu(self, x, gy):\n a, b = x\n batch_size = a.shape[0]\n ga = cuda.empty((batch_size,) + _as_mat(a[0]).shape)\n gb = cuda.empty((batch_size,) + _as_mat(b[0]).shape)\n _batch_matmul_gpu(\n gy[0], b, transb=not self.transb, transout=self.transa, out=ga)\n _batch_matmul_gpu(\n a, gy[0], transa=not self.transa, transout=self.transb, out=gb)\n ga = ga.reshape(a.shape)\n gb = gb.reshape(b.shape)\n return ga, gb\n\n\ndef batch_matmul(a, b, transa=False, transb=False):\n \"\"\"Computes the batch matrix multiplications of two sets of arrays.\n\n Args:\n a (Variable): The left operand of the batch matrix multiplications.\n A 2-D array of shape (B, N,) is considered as B Nx1 matrices.\n A 3-D array of shape (B, M, N) is considered as B MxN matrices.\n b (Variable): The right operand of the batch matrix multiplications.\n Its array is treated as matrices in the same way as ``a``'s array.\n transa (bool): If true, transpose each matrix in a.\n transb (bool): If true, transpose each matrix in b.\n\n Returns:\n ~chainer.Variable: The result of the batch matrix multiplications as a\n 3-D array.\n \"\"\"\n return BatchMatMul(transa=transa, transb=transb)(a, b)\n", "path": "chainer/functions/math/matmul.py"}]} | 3,785 | 197 |
gh_patches_debug_3634 | rasdani/github-patches | git_diff | getsentry__sentry-53802 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Recently Active Members should be first on the dropdown
When selecting an action for an issue alert, Recently Active Members should be the first option and pre-selected.
</issue>
<code>
[start of src/sentry/notifications/types.py]
1 from __future__ import annotations
2
3 from enum import Enum
4 from typing import Optional
5
6 from sentry.services.hybrid_cloud import ValueEqualityEnum
7
8 """
9 TODO(postgres): We've encoded these enums as integers to facilitate
10 communication with the DB. We'd prefer to encode them as strings to facilitate
11 communication with the API and plan to do so as soon as we use native enums in
12 Postgres. In the meantime each enum has an adjacent object that maps the
13 integers to their string values.
14 """
15
16
17 def get_notification_setting_type_name(value: int | NotificationSettingTypes) -> Optional[str]:
18 return NOTIFICATION_SETTING_TYPES.get(NotificationSettingTypes(value))
19
20
21 def get_notification_setting_value_name(value: int) -> Optional[str]:
22 return NOTIFICATION_SETTING_OPTION_VALUES.get(NotificationSettingOptionValues(value))
23
24
25 def get_notification_scope_name(value: int) -> Optional[str]:
26 return NOTIFICATION_SCOPE_TYPE.get(NotificationScopeType(value))
27
28
29 class NotificationSettingTypes(ValueEqualityEnum):
30 """
31 Each of these categories of Notification settings has at least an option for
32 "on" or "off". Workflow also includes SUBSCRIBE_ONLY and Deploy also
33 includes COMMITTED_ONLY and both of these values are described below.
34 """
35
36 # Control all notification types. Currently unused.
37 DEFAULT = 0
38
39 # When Sentry sees there is a new code deploy.
40 DEPLOY = 10
41
42 # When Sentry sees and issue that triggers an Alert Rule.
43 ISSUE_ALERTS = 20
44
45 # Notifications for changes in assignment, resolution, comments, etc.
46 WORKFLOW = 30
47
48 # Notification when an issue happens shortly after your release. This notification type is no longer supported.
49 ACTIVE_RELEASE = 31
50
51 # Notifications that require approval like a request to invite a member
52 APPROVAL = 40
53
54 # Notifications about quotas
55 QUOTA = 50
56
57 # Sub category of quotas for each event category
58 QUOTA_ERRORS = 51
59 QUOTA_TRANSACTIONS = 52
60 QUOTA_ATTACHMENTS = 53
61 QUOTA_REPLAYS = 56
62
63 # Sub category of quotas for warnings before hitting the actual limit
64 QUOTA_WARNINGS = 54
65
66 # Sub category of quotas for spend allocation notifications
67 QUOTA_SPEND_ALLOCATIONS = 55
68
69 # Notifications about spikes
70 SPIKE_PROTECTION = 60
71
72
73 NOTIFICATION_SETTING_TYPES = {
74 NotificationSettingTypes.DEFAULT: "default",
75 NotificationSettingTypes.DEPLOY: "deploy",
76 NotificationSettingTypes.ISSUE_ALERTS: "alerts",
77 NotificationSettingTypes.WORKFLOW: "workflow",
78 NotificationSettingTypes.ACTIVE_RELEASE: "activeRelease",
79 NotificationSettingTypes.APPROVAL: "approval",
80 NotificationSettingTypes.QUOTA: "quota",
81 NotificationSettingTypes.QUOTA_ERRORS: "quotaErrors",
82 NotificationSettingTypes.QUOTA_TRANSACTIONS: "quotaTransactions",
83 NotificationSettingTypes.QUOTA_ATTACHMENTS: "quotaAttachments",
84 NotificationSettingTypes.QUOTA_REPLAYS: "quotaReplays",
85 NotificationSettingTypes.QUOTA_WARNINGS: "quotaWarnings",
86 NotificationSettingTypes.QUOTA_SPEND_ALLOCATIONS: "quotaSpendAllocations",
87 NotificationSettingTypes.SPIKE_PROTECTION: "spikeProtection",
88 }
89
90
91 class NotificationSettingOptionValues(ValueEqualityEnum):
92 """
93 An empty row in the DB should be represented as
94 NotificationSettingOptionValues.DEFAULT.
95 """
96
97 # Defer to a setting one level up.
98 DEFAULT = 0
99
100 # Mute this kind of notification.
101 NEVER = 10
102
103 # Un-mute this kind of notification.
104 ALWAYS = 20
105
106 # Workflow only. Only send notifications about Issues that the target has
107 # explicitly or implicitly opted-into.
108 SUBSCRIBE_ONLY = 30
109
110 # Deploy only. Only send notifications when the set of changes in the deploy
111 # included a commit authored by the target.
112 COMMITTED_ONLY = 40
113
114
115 NOTIFICATION_SETTING_OPTION_VALUES = {
116 NotificationSettingOptionValues.DEFAULT: "default",
117 NotificationSettingOptionValues.NEVER: "never",
118 NotificationSettingOptionValues.ALWAYS: "always",
119 NotificationSettingOptionValues.SUBSCRIBE_ONLY: "subscribe_only",
120 NotificationSettingOptionValues.COMMITTED_ONLY: "committed_only",
121 }
122
123
124 class NotificationScopeType(ValueEqualityEnum):
125 USER = 0
126 ORGANIZATION = 10
127 PROJECT = 20
128 TEAM = 30
129
130
131 NOTIFICATION_SCOPE_TYPE = {
132 NotificationScopeType.USER: "user",
133 NotificationScopeType.ORGANIZATION: "organization",
134 NotificationScopeType.PROJECT: "project",
135 NotificationScopeType.TEAM: "team",
136 }
137
138
139 class FineTuningAPIKey(Enum):
140 ALERTS = "alerts"
141 APPROVAL = "approval"
142 DEPLOY = "deploy"
143 EMAIL = "email"
144 QUOTA = "quota"
145 REPORTS = "reports"
146 WORKFLOW = "workflow"
147 SPIKE_PROTECTION = "spikeProtection"
148
149
150 class UserOptionsSettingsKey(Enum):
151 DEPLOY = "deployNotifications"
152 SELF_ACTIVITY = "personalActivityNotifications"
153 SELF_ASSIGN = "selfAssignOnResolve"
154 SUBSCRIBE_BY_DEFAULT = "subscribeByDefault"
155 WORKFLOW = "workflowNotifications"
156 ACTIVE_RELEASE = "activeReleaseNotifications"
157 APPROVAL = "approvalNotifications"
158 QUOTA = "quotaNotifications"
159 SPIKE_PROTECTION = "spikeProtectionNotifications"
160
161
162 VALID_VALUES_FOR_KEY = {
163 NotificationSettingTypes.APPROVAL: {
164 NotificationSettingOptionValues.ALWAYS,
165 NotificationSettingOptionValues.NEVER,
166 },
167 NotificationSettingTypes.DEPLOY: {
168 NotificationSettingOptionValues.ALWAYS,
169 NotificationSettingOptionValues.COMMITTED_ONLY,
170 NotificationSettingOptionValues.NEVER,
171 },
172 NotificationSettingTypes.ISSUE_ALERTS: {
173 NotificationSettingOptionValues.ALWAYS,
174 NotificationSettingOptionValues.NEVER,
175 },
176 NotificationSettingTypes.QUOTA: {
177 NotificationSettingOptionValues.ALWAYS,
178 NotificationSettingOptionValues.NEVER,
179 },
180 NotificationSettingTypes.QUOTA_ERRORS: {
181 NotificationSettingOptionValues.ALWAYS,
182 NotificationSettingOptionValues.NEVER,
183 },
184 NotificationSettingTypes.QUOTA_TRANSACTIONS: {
185 NotificationSettingOptionValues.ALWAYS,
186 NotificationSettingOptionValues.NEVER,
187 },
188 NotificationSettingTypes.QUOTA_ATTACHMENTS: {
189 NotificationSettingOptionValues.ALWAYS,
190 NotificationSettingOptionValues.NEVER,
191 },
192 NotificationSettingTypes.QUOTA_REPLAYS: {
193 NotificationSettingOptionValues.ALWAYS,
194 NotificationSettingOptionValues.NEVER,
195 },
196 NotificationSettingTypes.QUOTA_WARNINGS: {
197 NotificationSettingOptionValues.ALWAYS,
198 NotificationSettingOptionValues.NEVER,
199 },
200 NotificationSettingTypes.QUOTA_SPEND_ALLOCATIONS: {
201 NotificationSettingOptionValues.ALWAYS,
202 NotificationSettingOptionValues.NEVER,
203 },
204 NotificationSettingTypes.WORKFLOW: {
205 NotificationSettingOptionValues.ALWAYS,
206 NotificationSettingOptionValues.SUBSCRIBE_ONLY,
207 NotificationSettingOptionValues.NEVER,
208 },
209 NotificationSettingTypes.SPIKE_PROTECTION: {
210 NotificationSettingOptionValues.ALWAYS,
211 NotificationSettingOptionValues.NEVER,
212 },
213 }
214
215
216 class GroupSubscriptionReason:
217 implicit = -1 # not for use as a persisted field value
218 committed = -2 # not for use as a persisted field value
219 processing_issue = -3 # not for use as a persisted field value
220
221 unknown = 0
222 comment = 1
223 assigned = 2
224 bookmark = 3
225 status_change = 4
226 deploy_setting = 5
227 mentioned = 6
228 team_mentioned = 7
229
230 descriptions = {
231 implicit: "have opted to receive updates for all issues within "
232 "projects that you are a member of",
233 committed: "were involved in a commit that is part of this release",
234 processing_issue: "are subscribed to alerts for this project",
235 comment: "have commented on this issue",
236 assigned: "have been assigned to this issue",
237 bookmark: "have bookmarked this issue",
238 status_change: "have changed the resolution status of this issue",
239 deploy_setting: "opted to receive all deploy notifications for this organization",
240 mentioned: "have been mentioned in this issue",
241 team_mentioned: "are a member of a team mentioned in this issue",
242 }
243
244
245 SUBSCRIPTION_REASON_MAP = {
246 GroupSubscriptionReason.comment: "commented",
247 GroupSubscriptionReason.assigned: "assigned",
248 GroupSubscriptionReason.bookmark: "bookmarked",
249 GroupSubscriptionReason.status_change: "changed_status",
250 GroupSubscriptionReason.mentioned: "mentioned",
251 }
252
253
254 class ActionTargetType(Enum):
255 ISSUE_OWNERS = "IssueOwners"
256 TEAM = "Team"
257 MEMBER = "Member"
258
259
260 ACTION_CHOICES = [
261 (ActionTargetType.ISSUE_OWNERS.value, "Issue Owners"),
262 (ActionTargetType.TEAM.value, "Team"),
263 (ActionTargetType.MEMBER.value, "Member"),
264 ]
265
266
267 class FallthroughChoiceType(Enum):
268 ALL_MEMBERS = "AllMembers"
269 ACTIVE_MEMBERS = "ActiveMembers"
270 NO_ONE = "NoOne"
271
272
273 FALLTHROUGH_CHOICES = [
274 (FallthroughChoiceType.ALL_MEMBERS.value, "All Project Members"),
275 (FallthroughChoiceType.ACTIVE_MEMBERS.value, "Recently Active Members"),
276 (FallthroughChoiceType.NO_ONE.value, "No One"),
277 ]
278
279
280 class AssigneeTargetType(Enum):
281 UNASSIGNED = "Unassigned"
282 TEAM = "Team"
283 MEMBER = "Member"
284
285
286 ASSIGNEE_CHOICES = [
287 (AssigneeTargetType.UNASSIGNED.value, "Unassigned"),
288 (AssigneeTargetType.TEAM.value, "Team"),
289 (AssigneeTargetType.MEMBER.value, "Member"),
290 ]
291
[end of src/sentry/notifications/types.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/sentry/notifications/types.py b/src/sentry/notifications/types.py
--- a/src/sentry/notifications/types.py
+++ b/src/sentry/notifications/types.py
@@ -271,8 +271,8 @@
FALLTHROUGH_CHOICES = [
- (FallthroughChoiceType.ALL_MEMBERS.value, "All Project Members"),
(FallthroughChoiceType.ACTIVE_MEMBERS.value, "Recently Active Members"),
+ (FallthroughChoiceType.ALL_MEMBERS.value, "All Project Members"),
(FallthroughChoiceType.NO_ONE.value, "No One"),
]
| {"golden_diff": "diff --git a/src/sentry/notifications/types.py b/src/sentry/notifications/types.py\n--- a/src/sentry/notifications/types.py\n+++ b/src/sentry/notifications/types.py\n@@ -271,8 +271,8 @@\n \n \n FALLTHROUGH_CHOICES = [\n- (FallthroughChoiceType.ALL_MEMBERS.value, \"All Project Members\"),\n (FallthroughChoiceType.ACTIVE_MEMBERS.value, \"Recently Active Members\"),\n+ (FallthroughChoiceType.ALL_MEMBERS.value, \"All Project Members\"),\n (FallthroughChoiceType.NO_ONE.value, \"No One\"),\n ]\n", "issue": "Recently Active Members should be first on the dropdown\nWhen selecting an action for an issue alert, Recently Active Members should be the first option and pre-selected.\n\n\n\n\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom enum import Enum\nfrom typing import Optional\n\nfrom sentry.services.hybrid_cloud import ValueEqualityEnum\n\n\"\"\"\nTODO(postgres): We've encoded these enums as integers to facilitate\ncommunication with the DB. We'd prefer to encode them as strings to facilitate\ncommunication with the API and plan to do so as soon as we use native enums in\nPostgres. In the meantime each enum has an adjacent object that maps the\nintegers to their string values.\n\"\"\"\n\n\ndef get_notification_setting_type_name(value: int | NotificationSettingTypes) -> Optional[str]:\n return NOTIFICATION_SETTING_TYPES.get(NotificationSettingTypes(value))\n\n\ndef get_notification_setting_value_name(value: int) -> Optional[str]:\n return NOTIFICATION_SETTING_OPTION_VALUES.get(NotificationSettingOptionValues(value))\n\n\ndef get_notification_scope_name(value: int) -> Optional[str]:\n return NOTIFICATION_SCOPE_TYPE.get(NotificationScopeType(value))\n\n\nclass NotificationSettingTypes(ValueEqualityEnum):\n \"\"\"\n Each of these categories of Notification settings has at least an option for\n \"on\" or \"off\". Workflow also includes SUBSCRIBE_ONLY and Deploy also\n includes COMMITTED_ONLY and both of these values are described below.\n \"\"\"\n\n # Control all notification types. Currently unused.\n DEFAULT = 0\n\n # When Sentry sees there is a new code deploy.\n DEPLOY = 10\n\n # When Sentry sees and issue that triggers an Alert Rule.\n ISSUE_ALERTS = 20\n\n # Notifications for changes in assignment, resolution, comments, etc.\n WORKFLOW = 30\n\n # Notification when an issue happens shortly after your release. This notification type is no longer supported.\n ACTIVE_RELEASE = 31\n\n # Notifications that require approval like a request to invite a member\n APPROVAL = 40\n\n # Notifications about quotas\n QUOTA = 50\n\n # Sub category of quotas for each event category\n QUOTA_ERRORS = 51\n QUOTA_TRANSACTIONS = 52\n QUOTA_ATTACHMENTS = 53\n QUOTA_REPLAYS = 56\n\n # Sub category of quotas for warnings before hitting the actual limit\n QUOTA_WARNINGS = 54\n\n # Sub category of quotas for spend allocation notifications\n QUOTA_SPEND_ALLOCATIONS = 55\n\n # Notifications about spikes\n SPIKE_PROTECTION = 60\n\n\nNOTIFICATION_SETTING_TYPES = {\n NotificationSettingTypes.DEFAULT: \"default\",\n NotificationSettingTypes.DEPLOY: \"deploy\",\n NotificationSettingTypes.ISSUE_ALERTS: \"alerts\",\n NotificationSettingTypes.WORKFLOW: \"workflow\",\n NotificationSettingTypes.ACTIVE_RELEASE: \"activeRelease\",\n NotificationSettingTypes.APPROVAL: \"approval\",\n NotificationSettingTypes.QUOTA: \"quota\",\n NotificationSettingTypes.QUOTA_ERRORS: \"quotaErrors\",\n NotificationSettingTypes.QUOTA_TRANSACTIONS: \"quotaTransactions\",\n NotificationSettingTypes.QUOTA_ATTACHMENTS: \"quotaAttachments\",\n NotificationSettingTypes.QUOTA_REPLAYS: \"quotaReplays\",\n NotificationSettingTypes.QUOTA_WARNINGS: \"quotaWarnings\",\n NotificationSettingTypes.QUOTA_SPEND_ALLOCATIONS: \"quotaSpendAllocations\",\n NotificationSettingTypes.SPIKE_PROTECTION: \"spikeProtection\",\n}\n\n\nclass NotificationSettingOptionValues(ValueEqualityEnum):\n \"\"\"\n An empty row in the DB should be represented as\n NotificationSettingOptionValues.DEFAULT.\n \"\"\"\n\n # Defer to a setting one level up.\n DEFAULT = 0\n\n # Mute this kind of notification.\n NEVER = 10\n\n # Un-mute this kind of notification.\n ALWAYS = 20\n\n # Workflow only. Only send notifications about Issues that the target has\n # explicitly or implicitly opted-into.\n SUBSCRIBE_ONLY = 30\n\n # Deploy only. Only send notifications when the set of changes in the deploy\n # included a commit authored by the target.\n COMMITTED_ONLY = 40\n\n\nNOTIFICATION_SETTING_OPTION_VALUES = {\n NotificationSettingOptionValues.DEFAULT: \"default\",\n NotificationSettingOptionValues.NEVER: \"never\",\n NotificationSettingOptionValues.ALWAYS: \"always\",\n NotificationSettingOptionValues.SUBSCRIBE_ONLY: \"subscribe_only\",\n NotificationSettingOptionValues.COMMITTED_ONLY: \"committed_only\",\n}\n\n\nclass NotificationScopeType(ValueEqualityEnum):\n USER = 0\n ORGANIZATION = 10\n PROJECT = 20\n TEAM = 30\n\n\nNOTIFICATION_SCOPE_TYPE = {\n NotificationScopeType.USER: \"user\",\n NotificationScopeType.ORGANIZATION: \"organization\",\n NotificationScopeType.PROJECT: \"project\",\n NotificationScopeType.TEAM: \"team\",\n}\n\n\nclass FineTuningAPIKey(Enum):\n ALERTS = \"alerts\"\n APPROVAL = \"approval\"\n DEPLOY = \"deploy\"\n EMAIL = \"email\"\n QUOTA = \"quota\"\n REPORTS = \"reports\"\n WORKFLOW = \"workflow\"\n SPIKE_PROTECTION = \"spikeProtection\"\n\n\nclass UserOptionsSettingsKey(Enum):\n DEPLOY = \"deployNotifications\"\n SELF_ACTIVITY = \"personalActivityNotifications\"\n SELF_ASSIGN = \"selfAssignOnResolve\"\n SUBSCRIBE_BY_DEFAULT = \"subscribeByDefault\"\n WORKFLOW = \"workflowNotifications\"\n ACTIVE_RELEASE = \"activeReleaseNotifications\"\n APPROVAL = \"approvalNotifications\"\n QUOTA = \"quotaNotifications\"\n SPIKE_PROTECTION = \"spikeProtectionNotifications\"\n\n\nVALID_VALUES_FOR_KEY = {\n NotificationSettingTypes.APPROVAL: {\n NotificationSettingOptionValues.ALWAYS,\n NotificationSettingOptionValues.NEVER,\n },\n NotificationSettingTypes.DEPLOY: {\n NotificationSettingOptionValues.ALWAYS,\n NotificationSettingOptionValues.COMMITTED_ONLY,\n NotificationSettingOptionValues.NEVER,\n },\n NotificationSettingTypes.ISSUE_ALERTS: {\n NotificationSettingOptionValues.ALWAYS,\n NotificationSettingOptionValues.NEVER,\n },\n NotificationSettingTypes.QUOTA: {\n NotificationSettingOptionValues.ALWAYS,\n NotificationSettingOptionValues.NEVER,\n },\n NotificationSettingTypes.QUOTA_ERRORS: {\n NotificationSettingOptionValues.ALWAYS,\n NotificationSettingOptionValues.NEVER,\n },\n NotificationSettingTypes.QUOTA_TRANSACTIONS: {\n NotificationSettingOptionValues.ALWAYS,\n NotificationSettingOptionValues.NEVER,\n },\n NotificationSettingTypes.QUOTA_ATTACHMENTS: {\n NotificationSettingOptionValues.ALWAYS,\n NotificationSettingOptionValues.NEVER,\n },\n NotificationSettingTypes.QUOTA_REPLAYS: {\n NotificationSettingOptionValues.ALWAYS,\n NotificationSettingOptionValues.NEVER,\n },\n NotificationSettingTypes.QUOTA_WARNINGS: {\n NotificationSettingOptionValues.ALWAYS,\n NotificationSettingOptionValues.NEVER,\n },\n NotificationSettingTypes.QUOTA_SPEND_ALLOCATIONS: {\n NotificationSettingOptionValues.ALWAYS,\n NotificationSettingOptionValues.NEVER,\n },\n NotificationSettingTypes.WORKFLOW: {\n NotificationSettingOptionValues.ALWAYS,\n NotificationSettingOptionValues.SUBSCRIBE_ONLY,\n NotificationSettingOptionValues.NEVER,\n },\n NotificationSettingTypes.SPIKE_PROTECTION: {\n NotificationSettingOptionValues.ALWAYS,\n NotificationSettingOptionValues.NEVER,\n },\n}\n\n\nclass GroupSubscriptionReason:\n implicit = -1 # not for use as a persisted field value\n committed = -2 # not for use as a persisted field value\n processing_issue = -3 # not for use as a persisted field value\n\n unknown = 0\n comment = 1\n assigned = 2\n bookmark = 3\n status_change = 4\n deploy_setting = 5\n mentioned = 6\n team_mentioned = 7\n\n descriptions = {\n implicit: \"have opted to receive updates for all issues within \"\n \"projects that you are a member of\",\n committed: \"were involved in a commit that is part of this release\",\n processing_issue: \"are subscribed to alerts for this project\",\n comment: \"have commented on this issue\",\n assigned: \"have been assigned to this issue\",\n bookmark: \"have bookmarked this issue\",\n status_change: \"have changed the resolution status of this issue\",\n deploy_setting: \"opted to receive all deploy notifications for this organization\",\n mentioned: \"have been mentioned in this issue\",\n team_mentioned: \"are a member of a team mentioned in this issue\",\n }\n\n\nSUBSCRIPTION_REASON_MAP = {\n GroupSubscriptionReason.comment: \"commented\",\n GroupSubscriptionReason.assigned: \"assigned\",\n GroupSubscriptionReason.bookmark: \"bookmarked\",\n GroupSubscriptionReason.status_change: \"changed_status\",\n GroupSubscriptionReason.mentioned: \"mentioned\",\n}\n\n\nclass ActionTargetType(Enum):\n ISSUE_OWNERS = \"IssueOwners\"\n TEAM = \"Team\"\n MEMBER = \"Member\"\n\n\nACTION_CHOICES = [\n (ActionTargetType.ISSUE_OWNERS.value, \"Issue Owners\"),\n (ActionTargetType.TEAM.value, \"Team\"),\n (ActionTargetType.MEMBER.value, \"Member\"),\n]\n\n\nclass FallthroughChoiceType(Enum):\n ALL_MEMBERS = \"AllMembers\"\n ACTIVE_MEMBERS = \"ActiveMembers\"\n NO_ONE = \"NoOne\"\n\n\nFALLTHROUGH_CHOICES = [\n (FallthroughChoiceType.ALL_MEMBERS.value, \"All Project Members\"),\n (FallthroughChoiceType.ACTIVE_MEMBERS.value, \"Recently Active Members\"),\n (FallthroughChoiceType.NO_ONE.value, \"No One\"),\n]\n\n\nclass AssigneeTargetType(Enum):\n UNASSIGNED = \"Unassigned\"\n TEAM = \"Team\"\n MEMBER = \"Member\"\n\n\nASSIGNEE_CHOICES = [\n (AssigneeTargetType.UNASSIGNED.value, \"Unassigned\"),\n (AssigneeTargetType.TEAM.value, \"Team\"),\n (AssigneeTargetType.MEMBER.value, \"Member\"),\n]\n", "path": "src/sentry/notifications/types.py"}]} | 3,524 | 124 |
gh_patches_debug_28749 | rasdani/github-patches | git_diff | cloud-custodian__cloud-custodian-4040 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
cloudtrail filter `is-shadow` always matches all resources
</issue>
<code>
[start of c7n/resources/cloudtrail.py]
1 # Copyright 2017-2019 Capital One Services, LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from __future__ import absolute_import, division, print_function, unicode_literals
15
16 import logging
17 import operator
18
19 from c7n.actions import Action
20 from c7n.exceptions import PolicyValidationError
21 from c7n.filters import ValueFilter, Filter
22 from c7n.manager import resources
23 from c7n.query import QueryResourceManager
24 from c7n.utils import local_session, type_schema
25
26 from .aws import shape_validate, Arn
27
28 log = logging.getLogger('c7n.resources.cloudtrail')
29
30
31 @resources.register('cloudtrail')
32 class CloudTrail(QueryResourceManager):
33
34 class resource_type(object):
35 service = 'cloudtrail'
36 enum_spec = ('describe_trails', 'trailList', None)
37 filter_name = 'trailNameList'
38 filter_type = 'list'
39 arn = id = 'TrailARN'
40 name = 'Name'
41 dimension = None
42 config_type = "AWS::CloudTrail::Trail"
43
44
45 @CloudTrail.filter_registry.register('is-shadow')
46 class IsShadow(Filter):
47 """Identify shadow trails (secondary copies), shadow trails
48 can't be modified directly, the origin trail needs to be modified.
49
50 Shadow trails are created for multi-region trails as well for
51 organizational trails.
52 """
53 schema = type_schema('is-shadow', state={'type': 'boolean'})
54 permissions = ('cloudtrail:DescribeTrails',)
55 embedded = False
56
57 def process(self, resources, event=None):
58 anded = lambda x: True # NOQA
59 op = self.data.get('state', True) and anded or operator.__not__
60 rcount = len(resources)
61 trails = [t for t in resources if op(self.is_shadow(t))]
62 if len(trails) != rcount and self.embedded:
63 self.log.info("implicitly filtering shadow trails %d -> %d",
64 rcount, len(trails))
65 return trails
66
67 def is_shadow(self, t):
68 if t.get('IsOrganizationTrail') and self.manager.config.account_id not in t['TrailARN']:
69 return True
70 if t.get('IsMultiRegionTrail') and t['HomeRegion'] not in t['TrailARN']:
71 return True
72
73
74 @CloudTrail.filter_registry.register('status')
75 class Status(ValueFilter):
76 """Filter a cloudtrail by its status.
77
78 :Example:
79
80 .. code-block:: yaml
81
82 policies:
83 - name: cloudtrail-not-active
84 resource: aws.cloudtrail
85 filters:
86 - type: status
87 key: IsLogging
88 value: False
89 """
90
91 schema = type_schema('status', rinherit=ValueFilter.schema)
92 permissions = ('cloudtrail:GetTrailStatus',)
93 annotation_key = 'c7n:TrailStatus'
94
95 def process(self, resources, event=None):
96 for r in resources:
97 region = self.manager.config.region
98 trail_arn = Arn.parse(r['TrailARN'])
99
100 if (r.get('IsOrganizationTrail') and
101 self.manager.config.account_id != trail_arn.account_id):
102 continue
103 if r.get('HomeRegion') and r['HomeRegion'] != region:
104 region = trail_arn.region
105 if self.annotation_key in r:
106 continue
107 client = local_session(self.manager.session_factory).client(
108 'cloudtrail', region_name=region)
109 status = client.get_trail_status(Name=r['Name'])
110 status.pop('ResponseMetadata')
111 r[self.annotation_key] = status
112
113 return super(Status, self).process(resources)
114
115 def __call__(self, r):
116 return self.match(r['c7n:TrailStatus'])
117
118
119 @CloudTrail.action_registry.register('update-trail')
120 class UpdateTrail(Action):
121 """Update trail attributes.
122
123 :Example:
124
125 .. code-block:: yaml
126
127 policies:
128 - name: cloudtrail-set-log
129 resource: aws.cloudtrail
130 filters:
131 - or:
132 - KmsKeyId: empty
133 - LogFileValidationEnabled: false
134 actions:
135 - type: update-trail
136 attributes:
137 KmsKeyId: arn:aws:kms:us-west-2:111122223333:key/1234abcd-12ab-34cd-56ef
138 EnableLogFileValidation: true
139 """
140 schema = type_schema(
141 'update-trail',
142 attributes={'type': 'object'},
143 required=('attributes',))
144 shape = 'UpdateTrailRequest'
145 permissions = ('cloudtrail:UpdateTrail',)
146
147 def validate(self):
148 attrs = dict(self.data['attributes'])
149 if 'Name' in attrs:
150 raise PolicyValidationError(
151 "Can't include Name in update-trail action")
152 attrs['Name'] = 'PolicyValidation'
153 return shape_validate(
154 attrs,
155 self.shape,
156 self.manager.resource_type.service)
157
158 def process(self, resources):
159 client = local_session(self.manager.session_factory).client('cloudtrail')
160 shadow_check = IsShadow({'state': False}, self.manager)
161 shadow_check.embedded = True
162 resources = shadow_check.process(resources)
163
164 for r in resources:
165 client.update_trail(
166 Name=r['Name'],
167 **self.data['attributes'])
168
169
170 @CloudTrail.action_registry.register('set-logging')
171 class SetLogging(Action):
172 """Set the logging state of a trail
173
174 :Example:
175
176 .. code-block:: yaml
177
178 policies:
179 - name: cloudtrail-not-active
180 resource: aws.cloudtrail
181 filters:
182 - type: status
183 key: IsLogging
184 value: False
185 actions:
186 - type: set-logging
187 enabled: True
188 """
189 schema = type_schema(
190 'set-logging', enabled={'type': 'boolean'})
191
192 def get_permissions(self):
193 enable = self.data.get('enabled', True)
194 if enable is True:
195 return ('cloudtrail:StartLogging',)
196 else:
197 return ('cloudtrail:StopLogging',)
198
199 def process(self, resources):
200 client = local_session(self.manager.session_factory).client('cloudtrail')
201 shadow_check = IsShadow({'state': False}, self.manager)
202 shadow_check.embedded = True
203 resources = shadow_check.process(resources)
204 enable = self.data.get('enabled', True)
205
206 for r in resources:
207 if enable:
208 client.start_logging(Name=r['Name'])
209 else:
210 client.stop_logging(Name=r['Name'])
211
[end of c7n/resources/cloudtrail.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/c7n/resources/cloudtrail.py b/c7n/resources/cloudtrail.py
--- a/c7n/resources/cloudtrail.py
+++ b/c7n/resources/cloudtrail.py
@@ -14,7 +14,6 @@
from __future__ import absolute_import, division, print_function, unicode_literals
import logging
-import operator
from c7n.actions import Action
from c7n.exceptions import PolicyValidationError
@@ -55,10 +54,8 @@
embedded = False
def process(self, resources, event=None):
- anded = lambda x: True # NOQA
- op = self.data.get('state', True) and anded or operator.__not__
rcount = len(resources)
- trails = [t for t in resources if op(self.is_shadow(t))]
+ trails = [t for t in resources if (self.is_shadow(t) == self.data.get('state', True))]
if len(trails) != rcount and self.embedded:
self.log.info("implicitly filtering shadow trails %d -> %d",
rcount, len(trails))
@@ -67,8 +64,9 @@
def is_shadow(self, t):
if t.get('IsOrganizationTrail') and self.manager.config.account_id not in t['TrailARN']:
return True
- if t.get('IsMultiRegionTrail') and t['HomeRegion'] not in t['TrailARN']:
+ if t.get('IsMultiRegionTrail') and t['HomeRegion'] != self.manager.config.region:
return True
+ return False
@CloudTrail.filter_registry.register('status')
| {"golden_diff": "diff --git a/c7n/resources/cloudtrail.py b/c7n/resources/cloudtrail.py\n--- a/c7n/resources/cloudtrail.py\n+++ b/c7n/resources/cloudtrail.py\n@@ -14,7 +14,6 @@\n from __future__ import absolute_import, division, print_function, unicode_literals\n \n import logging\n-import operator\n \n from c7n.actions import Action\n from c7n.exceptions import PolicyValidationError\n@@ -55,10 +54,8 @@\n embedded = False\n \n def process(self, resources, event=None):\n- anded = lambda x: True # NOQA\n- op = self.data.get('state', True) and anded or operator.__not__\n rcount = len(resources)\n- trails = [t for t in resources if op(self.is_shadow(t))]\n+ trails = [t for t in resources if (self.is_shadow(t) == self.data.get('state', True))]\n if len(trails) != rcount and self.embedded:\n self.log.info(\"implicitly filtering shadow trails %d -> %d\",\n rcount, len(trails))\n@@ -67,8 +64,9 @@\n def is_shadow(self, t):\n if t.get('IsOrganizationTrail') and self.manager.config.account_id not in t['TrailARN']:\n return True\n- if t.get('IsMultiRegionTrail') and t['HomeRegion'] not in t['TrailARN']:\n+ if t.get('IsMultiRegionTrail') and t['HomeRegion'] != self.manager.config.region:\n return True\n+ return False\n \n \n @CloudTrail.filter_registry.register('status')\n", "issue": "cloudtrail filter `is-shadow` always matches all resources\n\n", "before_files": [{"content": "# Copyright 2017-2019 Capital One Services, LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport logging\nimport operator\n\nfrom c7n.actions import Action\nfrom c7n.exceptions import PolicyValidationError\nfrom c7n.filters import ValueFilter, Filter\nfrom c7n.manager import resources\nfrom c7n.query import QueryResourceManager\nfrom c7n.utils import local_session, type_schema\n\nfrom .aws import shape_validate, Arn\n\nlog = logging.getLogger('c7n.resources.cloudtrail')\n\n\[email protected]('cloudtrail')\nclass CloudTrail(QueryResourceManager):\n\n class resource_type(object):\n service = 'cloudtrail'\n enum_spec = ('describe_trails', 'trailList', None)\n filter_name = 'trailNameList'\n filter_type = 'list'\n arn = id = 'TrailARN'\n name = 'Name'\n dimension = None\n config_type = \"AWS::CloudTrail::Trail\"\n\n\[email protected]_registry.register('is-shadow')\nclass IsShadow(Filter):\n \"\"\"Identify shadow trails (secondary copies), shadow trails\n can't be modified directly, the origin trail needs to be modified.\n\n Shadow trails are created for multi-region trails as well for\n organizational trails.\n \"\"\"\n schema = type_schema('is-shadow', state={'type': 'boolean'})\n permissions = ('cloudtrail:DescribeTrails',)\n embedded = False\n\n def process(self, resources, event=None):\n anded = lambda x: True # NOQA\n op = self.data.get('state', True) and anded or operator.__not__\n rcount = len(resources)\n trails = [t for t in resources if op(self.is_shadow(t))]\n if len(trails) != rcount and self.embedded:\n self.log.info(\"implicitly filtering shadow trails %d -> %d\",\n rcount, len(trails))\n return trails\n\n def is_shadow(self, t):\n if t.get('IsOrganizationTrail') and self.manager.config.account_id not in t['TrailARN']:\n return True\n if t.get('IsMultiRegionTrail') and t['HomeRegion'] not in t['TrailARN']:\n return True\n\n\[email protected]_registry.register('status')\nclass Status(ValueFilter):\n \"\"\"Filter a cloudtrail by its status.\n\n :Example:\n\n .. code-block:: yaml\n\n policies:\n - name: cloudtrail-not-active\n resource: aws.cloudtrail\n filters:\n - type: status\n key: IsLogging\n value: False\n \"\"\"\n\n schema = type_schema('status', rinherit=ValueFilter.schema)\n permissions = ('cloudtrail:GetTrailStatus',)\n annotation_key = 'c7n:TrailStatus'\n\n def process(self, resources, event=None):\n for r in resources:\n region = self.manager.config.region\n trail_arn = Arn.parse(r['TrailARN'])\n\n if (r.get('IsOrganizationTrail') and\n self.manager.config.account_id != trail_arn.account_id):\n continue\n if r.get('HomeRegion') and r['HomeRegion'] != region:\n region = trail_arn.region\n if self.annotation_key in r:\n continue\n client = local_session(self.manager.session_factory).client(\n 'cloudtrail', region_name=region)\n status = client.get_trail_status(Name=r['Name'])\n status.pop('ResponseMetadata')\n r[self.annotation_key] = status\n\n return super(Status, self).process(resources)\n\n def __call__(self, r):\n return self.match(r['c7n:TrailStatus'])\n\n\[email protected]_registry.register('update-trail')\nclass UpdateTrail(Action):\n \"\"\"Update trail attributes.\n\n :Example:\n\n .. code-block:: yaml\n\n policies:\n - name: cloudtrail-set-log\n resource: aws.cloudtrail\n filters:\n - or:\n - KmsKeyId: empty\n - LogFileValidationEnabled: false\n actions:\n - type: update-trail\n attributes:\n KmsKeyId: arn:aws:kms:us-west-2:111122223333:key/1234abcd-12ab-34cd-56ef\n EnableLogFileValidation: true\n \"\"\"\n schema = type_schema(\n 'update-trail',\n attributes={'type': 'object'},\n required=('attributes',))\n shape = 'UpdateTrailRequest'\n permissions = ('cloudtrail:UpdateTrail',)\n\n def validate(self):\n attrs = dict(self.data['attributes'])\n if 'Name' in attrs:\n raise PolicyValidationError(\n \"Can't include Name in update-trail action\")\n attrs['Name'] = 'PolicyValidation'\n return shape_validate(\n attrs,\n self.shape,\n self.manager.resource_type.service)\n\n def process(self, resources):\n client = local_session(self.manager.session_factory).client('cloudtrail')\n shadow_check = IsShadow({'state': False}, self.manager)\n shadow_check.embedded = True\n resources = shadow_check.process(resources)\n\n for r in resources:\n client.update_trail(\n Name=r['Name'],\n **self.data['attributes'])\n\n\[email protected]_registry.register('set-logging')\nclass SetLogging(Action):\n \"\"\"Set the logging state of a trail\n\n :Example:\n\n .. code-block:: yaml\n\n policies:\n - name: cloudtrail-not-active\n resource: aws.cloudtrail\n filters:\n - type: status\n key: IsLogging\n value: False\n actions:\n - type: set-logging\n enabled: True\n \"\"\"\n schema = type_schema(\n 'set-logging', enabled={'type': 'boolean'})\n\n def get_permissions(self):\n enable = self.data.get('enabled', True)\n if enable is True:\n return ('cloudtrail:StartLogging',)\n else:\n return ('cloudtrail:StopLogging',)\n\n def process(self, resources):\n client = local_session(self.manager.session_factory).client('cloudtrail')\n shadow_check = IsShadow({'state': False}, self.manager)\n shadow_check.embedded = True\n resources = shadow_check.process(resources)\n enable = self.data.get('enabled', True)\n\n for r in resources:\n if enable:\n client.start_logging(Name=r['Name'])\n else:\n client.stop_logging(Name=r['Name'])\n", "path": "c7n/resources/cloudtrail.py"}]} | 2,584 | 351 |
gh_patches_debug_20804 | rasdani/github-patches | git_diff | opsdroid__opsdroid-844 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Handle slacker connector invalid token exception
<!-- Before you post an issue or if you are unsure about something join our gitter channel https://gitter.im/opsdroid/ and ask away! We are more than happy to help you. -->
# Description
This issue was found by @petri with #763
When we use an invalid token with the slacker connector opsdroid crashes badly. This is probably due to the fact that we changed dependencies and the code doesn't handle the exception raised by the aioslacker library.
We should probably refactor the connect method to check if the exception `slacker.Error: invalid_auth` was raised, if so an error message should be logged and opsdroid should still be able to run.
## Steps to Reproduce
- Set a slack connector with a bad token on config.yaml
- run opsdroid
## Expected Functionality
Opsdroid should still run but a message should be logged that the connector won't be active due to bad token.
## Experienced Functionality
Opsdroid crashes with a traceback
```python
Traceback (most recent call last):
File "/usr/local/Cellar/python3/3.6.1/Frameworks/Python.framework/Versions/3.6/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/usr/local/Cellar/python3/3.6.1/Frameworks/Python.framework/Versions/3.6/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/Users/fabiorosado/Documents/GitHub/opsdroid/opsdroid/__main__.py", line 206, in <module>
init()
File "/Users/fabiorosado/Documents/GitHub/opsdroid/opsdroid/__main__.py", line 203, in init
main()
File "/Users/fabiorosado/.local/share/virtualenvs/opsdroid-13bLHlYD/lib/python3.6/site-packages/click/core.py", line 764, in __call__
return self.main(*args, **kwargs)
File "/Users/fabiorosado/.local/share/virtualenvs/opsdroid-13bLHlYD/lib/python3.6/site-packages/click/core.py", line 717, in main
rv = self.invoke(ctx)
File "/Users/fabiorosado/.local/share/virtualenvs/opsdroid-13bLHlYD/lib/python3.6/site-packages/click/core.py", line 956, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/Users/fabiorosado/.local/share/virtualenvs/opsdroid-13bLHlYD/lib/python3.6/site-packages/click/core.py", line 555, in invoke
return callback(*args, **kwargs)
File "/Users/fabiorosado/Documents/GitHub/opsdroid/opsdroid/__main__.py", line 196, in main
opsdroid.load()
File "/Users/fabiorosado/Documents/GitHub/opsdroid/opsdroid/core.py", line 153, in load
self.start_connectors(self.modules["connectors"])
File "/Users/fabiorosado/Documents/GitHub/opsdroid/opsdroid/core.py", line 248, in start_connectors
self.eventloop.run_until_complete(connector.connect(self))
File "/usr/local/Cellar/python3/3.6.1/Frameworks/Python.framework/Versions/3.6/lib/python3.6/asyncio/base_events.py", line 466, in run_until_complete
return future.result()
File "/Users/fabiorosado/Documents/GitHub/opsdroid/opsdroid/connector/slack/__init__.py", line 50, in connect
connection = await self.slacker.rtm.start()
File "/Users/fabiorosado/.local/share/virtualenvs/opsdroid-13bLHlYD/lib/python3.6/site-packages/aioslacker/__init__.py", line 97, in __request
raise Error(response.error)
slacker.Error: invalid_auth
Exception ignored in: <bound method BaseEventLoop.__del__ of <_UnixSelectorEventLoop running=False closed=True debug=False>>
Traceback (most recent call last):
File "/usr/local/Cellar/python3/3.6.1/Frameworks/Python.framework/Versions/3.6/lib/python3.6/asyncio/base_events.py", line 511, in __del__
File "/usr/local/Cellar/python3/3.6.1/Frameworks/Python.framework/Versions/3.6/lib/python3.6/asyncio/unix_events.py", line 65, in close
File "/usr/local/Cellar/python3/3.6.1/Frameworks/Python.framework/Versions/3.6/lib/python3.6/asyncio/unix_events.py", line 146, in remove_signal_handler
File "/usr/local/Cellar/python3/3.6.1/Frameworks/Python.framework/Versions/3.6/lib/python3.6/signal.py", line 47, in signal
TypeError: signal handler must be signal.SIG_IGN, signal.SIG_DFL, or a callable object
```
## Versions
- **Opsdroid version:** latest
- **Python version:** 3.6
- **OS/Docker version:** MacOs Mojave
## Configuration File
Please include your version of the configuration file bellow.
```yaml
connectors:
- name: slack
api-token: "jdit-ksd12okr"
```
## Additional Details
Any other details you wish to include such as screenshots, console messages, etc.
<!-- Love opsdroid? Please consider supporting our collective:
+👉 https://opencollective.com/opsdroid/donate -->
</issue>
<code>
[start of opsdroid/connector/slack/__init__.py]
1 """A connector for Slack."""
2 import logging
3 import asyncio
4 import json
5 import re
6
7 import aiohttp
8 import websockets
9 import slacker
10 from aioslacker import Slacker
11 from emoji import demojize
12
13 from opsdroid.connector import Connector
14 from opsdroid.events import Message
15
16
17 _LOGGER = logging.getLogger(__name__)
18
19
20 class ConnectorSlack(Connector):
21 """A connector for Slack."""
22
23 def __init__(self, config, opsdroid=None):
24 """Create the connector."""
25 super().__init__(config, opsdroid=opsdroid)
26 _LOGGER.debug("Starting Slack connector")
27 self.name = "slack"
28 self.config = config
29 self.default_room = config.get("default-room", "#general")
30 self.icon_emoji = config.get("icon-emoji", ':robot_face:')
31 self.token = config["api-token"]
32 self.slacker = Slacker(self.token)
33 self.websocket = None
34 self.bot_name = config.get("bot-name", 'opsdroid')
35 self.known_users = {}
36 self.keepalive = None
37 self.reconnecting = False
38 self.listening = True
39 self._message_id = 0
40
41 async def connect(self):
42 """Connect to the chat service."""
43 _LOGGER.info("Connecting to Slack")
44
45 try:
46 connection = await self.slacker.rtm.start()
47 self.websocket = await websockets.connect(connection.body['url'])
48
49 _LOGGER.debug("Connected as %s", self.bot_name)
50 _LOGGER.debug("Using icon %s", self.icon_emoji)
51 _LOGGER.debug("Default room is %s", self.default_room)
52 _LOGGER.info("Connected successfully")
53
54 if self.keepalive is None or self.keepalive.done():
55 self.keepalive = self.opsdroid.eventloop.create_task(
56 self.keepalive_websocket())
57 except aiohttp.ClientOSError as error:
58 _LOGGER.error(error)
59 _LOGGER.error("Failed to connect to Slack, retrying in 10")
60 await self.reconnect(10)
61 except Exception:
62 await self.disconnect()
63 raise
64
65 async def reconnect(self, delay=None):
66 """Reconnect to the websocket."""
67 try:
68 self.reconnecting = True
69 if delay is not None:
70 await asyncio.sleep(delay)
71 await self.connect()
72 finally:
73 self.reconnecting = False
74
75 async def disconnect(self):
76 """Disconnect from Slack."""
77 await self.slacker.close()
78
79 async def listen(self):
80 """Listen for and parse new messages."""
81 while self.listening:
82 await self.receive_from_websocket()
83
84 async def receive_from_websocket(self):
85 """Get the next message from the websocket."""
86 try:
87 content = await self.websocket.recv()
88 await self.process_message(json.loads(content))
89 except websockets.exceptions.ConnectionClosed:
90 _LOGGER.info("Slack websocket closed, reconnecting...")
91 await self.reconnect(5)
92
93 async def process_message(self, message):
94 """Process a raw message and pass it to the parser."""
95 if "type" in message and message["type"] == "message" and \
96 "user" in message:
97
98 # Ignore bot messages
99 if "subtype" in message and \
100 message["subtype"] == "bot_message":
101 return
102
103 # Lookup username
104 _LOGGER.debug("Looking up sender username")
105 try:
106 user_info = await self.lookup_username(message["user"])
107 except ValueError:
108 return
109
110 # Replace usernames in the message
111 _LOGGER.debug("Replacing userids in message with usernames")
112 message["text"] = await self.replace_usernames(
113 message["text"])
114
115 await self.opsdroid.parse(Message(user_info["name"],
116 message["channel"],
117 self,
118 message["text"],
119 raw_event=message))
120
121 async def respond(self, message, room=None):
122 """Respond with a message."""
123 _LOGGER.debug("Responding with: '%s' in room %s",
124 message.text, message.room)
125 await self.slacker.chat.post_message(message.room,
126 message.text,
127 as_user=False,
128 username=self.bot_name,
129 icon_emoji=self.icon_emoji)
130
131 async def react(self, message, emoji):
132 """React to a message."""
133 emoji = demojize(emoji)
134 _LOGGER.debug("Reacting with: %s", emoji)
135 try:
136 await self.slacker.reactions.post('reactions.add', data={
137 'name': emoji,
138 'channel': message.room,
139 'timestamp': message.raw_event['ts']
140 })
141 except slacker.Error as error:
142 if str(error) == 'invalid_name':
143 _LOGGER.warning('Slack does not support the emoji %s', emoji)
144 else:
145 raise
146
147 async def keepalive_websocket(self):
148 """Keep pinging the websocket to keep it alive."""
149 while self.listening:
150 await self.ping_websocket()
151
152 async def ping_websocket(self):
153 """Ping the websocket."""
154 await asyncio.sleep(60)
155 self._message_id += 1
156 try:
157 await self.websocket.send(
158 json.dumps({'id': self._message_id, 'type': 'ping'}))
159 except (websockets.exceptions.InvalidState,
160 websockets.exceptions.ConnectionClosed,
161 aiohttp.ClientOSError,
162 TimeoutError):
163 _LOGGER.info("Slack websocket closed, reconnecting...")
164 if not self.reconnecting:
165 await self.reconnect()
166
167 async def lookup_username(self, userid):
168 """Lookup a username and cache it."""
169 if userid in self.known_users:
170 user_info = self.known_users[userid]
171 else:
172 response = await self.slacker.users.info(userid)
173 user_info = response.body["user"]
174 if isinstance(user_info, dict):
175 self.known_users[userid] = user_info
176 else:
177 raise ValueError("Returned user is not a dict.")
178 return user_info
179
180 async def replace_usernames(self, message):
181 """Replace User ID with username in message text."""
182 userids = re.findall(r"\<\@([A-Z0-9]+)(?:\|.+)?\>", message)
183 for userid in userids:
184 user_info = await self.lookup_username(userid)
185 message = message.replace("<@{userid}>".format(userid=userid),
186 user_info["name"])
187 return message
188
[end of opsdroid/connector/slack/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/opsdroid/connector/slack/__init__.py b/opsdroid/connector/slack/__init__.py
--- a/opsdroid/connector/slack/__init__.py
+++ b/opsdroid/connector/slack/__init__.py
@@ -58,6 +58,9 @@
_LOGGER.error(error)
_LOGGER.error("Failed to connect to Slack, retrying in 10")
await self.reconnect(10)
+ except slacker.Error as error:
+ _LOGGER.error("Unable to connect to Slack due to %s - "
+ "The Slack Connector will not be available.", error)
except Exception:
await self.disconnect()
raise
@@ -79,7 +82,10 @@
async def listen(self):
"""Listen for and parse new messages."""
while self.listening:
- await self.receive_from_websocket()
+ try:
+ await self.receive_from_websocket()
+ except AttributeError:
+ break
async def receive_from_websocket(self):
"""Get the next message from the websocket."""
| {"golden_diff": "diff --git a/opsdroid/connector/slack/__init__.py b/opsdroid/connector/slack/__init__.py\n--- a/opsdroid/connector/slack/__init__.py\n+++ b/opsdroid/connector/slack/__init__.py\n@@ -58,6 +58,9 @@\n _LOGGER.error(error)\n _LOGGER.error(\"Failed to connect to Slack, retrying in 10\")\n await self.reconnect(10)\n+ except slacker.Error as error:\n+ _LOGGER.error(\"Unable to connect to Slack due to %s - \"\n+ \"The Slack Connector will not be available.\", error)\n except Exception:\n await self.disconnect()\n raise\n@@ -79,7 +82,10 @@\n async def listen(self):\n \"\"\"Listen for and parse new messages.\"\"\"\n while self.listening:\n- await self.receive_from_websocket()\n+ try:\n+ await self.receive_from_websocket()\n+ except AttributeError:\n+ break\n \n async def receive_from_websocket(self):\n \"\"\"Get the next message from the websocket.\"\"\"\n", "issue": "Handle slacker connector invalid token exception\n<!-- Before you post an issue or if you are unsure about something join our gitter channel https://gitter.im/opsdroid/ and ask away! We are more than happy to help you. -->\r\n# Description\r\nThis issue was found by @petri with #763\r\n\r\nWhen we use an invalid token with the slacker connector opsdroid crashes badly. This is probably due to the fact that we changed dependencies and the code doesn't handle the exception raised by the aioslacker library.\r\n\r\nWe should probably refactor the connect method to check if the exception `slacker.Error: invalid_auth` was raised, if so an error message should be logged and opsdroid should still be able to run.\r\n\r\n\r\n## Steps to Reproduce\r\n- Set a slack connector with a bad token on config.yaml\r\n- run opsdroid\r\n\r\n\r\n## Expected Functionality\r\nOpsdroid should still run but a message should be logged that the connector won't be active due to bad token.\r\n\r\n\r\n## Experienced Functionality\r\nOpsdroid crashes with a traceback\r\n\r\n```python\r\nTraceback (most recent call last):\r\n File \"/usr/local/Cellar/python3/3.6.1/Frameworks/Python.framework/Versions/3.6/lib/python3.6/runpy.py\", line 193, in _run_module_as_main\r\n \"__main__\", mod_spec)\r\n File \"/usr/local/Cellar/python3/3.6.1/Frameworks/Python.framework/Versions/3.6/lib/python3.6/runpy.py\", line 85, in _run_code\r\n exec(code, run_globals)\r\n File \"/Users/fabiorosado/Documents/GitHub/opsdroid/opsdroid/__main__.py\", line 206, in <module>\r\n init()\r\n File \"/Users/fabiorosado/Documents/GitHub/opsdroid/opsdroid/__main__.py\", line 203, in init\r\n main()\r\n File \"/Users/fabiorosado/.local/share/virtualenvs/opsdroid-13bLHlYD/lib/python3.6/site-packages/click/core.py\", line 764, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/Users/fabiorosado/.local/share/virtualenvs/opsdroid-13bLHlYD/lib/python3.6/site-packages/click/core.py\", line 717, in main\r\n rv = self.invoke(ctx)\r\n File \"/Users/fabiorosado/.local/share/virtualenvs/opsdroid-13bLHlYD/lib/python3.6/site-packages/click/core.py\", line 956, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/Users/fabiorosado/.local/share/virtualenvs/opsdroid-13bLHlYD/lib/python3.6/site-packages/click/core.py\", line 555, in invoke\r\n return callback(*args, **kwargs)\r\n File \"/Users/fabiorosado/Documents/GitHub/opsdroid/opsdroid/__main__.py\", line 196, in main\r\n opsdroid.load()\r\n File \"/Users/fabiorosado/Documents/GitHub/opsdroid/opsdroid/core.py\", line 153, in load\r\n self.start_connectors(self.modules[\"connectors\"])\r\n File \"/Users/fabiorosado/Documents/GitHub/opsdroid/opsdroid/core.py\", line 248, in start_connectors\r\n self.eventloop.run_until_complete(connector.connect(self))\r\n File \"/usr/local/Cellar/python3/3.6.1/Frameworks/Python.framework/Versions/3.6/lib/python3.6/asyncio/base_events.py\", line 466, in run_until_complete\r\n return future.result()\r\n File \"/Users/fabiorosado/Documents/GitHub/opsdroid/opsdroid/connector/slack/__init__.py\", line 50, in connect\r\n connection = await self.slacker.rtm.start()\r\n File \"/Users/fabiorosado/.local/share/virtualenvs/opsdroid-13bLHlYD/lib/python3.6/site-packages/aioslacker/__init__.py\", line 97, in __request\r\n raise Error(response.error)\r\nslacker.Error: invalid_auth\r\nException ignored in: <bound method BaseEventLoop.__del__ of <_UnixSelectorEventLoop running=False closed=True debug=False>>\r\nTraceback (most recent call last):\r\n File \"/usr/local/Cellar/python3/3.6.1/Frameworks/Python.framework/Versions/3.6/lib/python3.6/asyncio/base_events.py\", line 511, in __del__\r\n File \"/usr/local/Cellar/python3/3.6.1/Frameworks/Python.framework/Versions/3.6/lib/python3.6/asyncio/unix_events.py\", line 65, in close\r\n File \"/usr/local/Cellar/python3/3.6.1/Frameworks/Python.framework/Versions/3.6/lib/python3.6/asyncio/unix_events.py\", line 146, in remove_signal_handler\r\n File \"/usr/local/Cellar/python3/3.6.1/Frameworks/Python.framework/Versions/3.6/lib/python3.6/signal.py\", line 47, in signal\r\nTypeError: signal handler must be signal.SIG_IGN, signal.SIG_DFL, or a callable object\r\n```\r\n\r\n## Versions\r\n- **Opsdroid version:** latest\r\n- **Python version:** 3.6\r\n- **OS/Docker version:** MacOs Mojave\r\n\r\n## Configuration File\r\nPlease include your version of the configuration file bellow.\r\n\r\n```yaml\r\nconnectors:\r\n - name: slack\r\n api-token: \"jdit-ksd12okr\"\r\n```\r\n\r\n## Additional Details\r\nAny other details you wish to include such as screenshots, console messages, etc.\r\n\r\n\r\n<!-- Love opsdroid? Please consider supporting our collective:\r\n +\ud83d\udc49 https://opencollective.com/opsdroid/donate -->\n", "before_files": [{"content": "\"\"\"A connector for Slack.\"\"\"\nimport logging\nimport asyncio\nimport json\nimport re\n\nimport aiohttp\nimport websockets\nimport slacker\nfrom aioslacker import Slacker\nfrom emoji import demojize\n\nfrom opsdroid.connector import Connector\nfrom opsdroid.events import Message\n\n\n_LOGGER = logging.getLogger(__name__)\n\n\nclass ConnectorSlack(Connector):\n \"\"\"A connector for Slack.\"\"\"\n\n def __init__(self, config, opsdroid=None):\n \"\"\"Create the connector.\"\"\"\n super().__init__(config, opsdroid=opsdroid)\n _LOGGER.debug(\"Starting Slack connector\")\n self.name = \"slack\"\n self.config = config\n self.default_room = config.get(\"default-room\", \"#general\")\n self.icon_emoji = config.get(\"icon-emoji\", ':robot_face:')\n self.token = config[\"api-token\"]\n self.slacker = Slacker(self.token)\n self.websocket = None\n self.bot_name = config.get(\"bot-name\", 'opsdroid')\n self.known_users = {}\n self.keepalive = None\n self.reconnecting = False\n self.listening = True\n self._message_id = 0\n\n async def connect(self):\n \"\"\"Connect to the chat service.\"\"\"\n _LOGGER.info(\"Connecting to Slack\")\n\n try:\n connection = await self.slacker.rtm.start()\n self.websocket = await websockets.connect(connection.body['url'])\n\n _LOGGER.debug(\"Connected as %s\", self.bot_name)\n _LOGGER.debug(\"Using icon %s\", self.icon_emoji)\n _LOGGER.debug(\"Default room is %s\", self.default_room)\n _LOGGER.info(\"Connected successfully\")\n\n if self.keepalive is None or self.keepalive.done():\n self.keepalive = self.opsdroid.eventloop.create_task(\n self.keepalive_websocket())\n except aiohttp.ClientOSError as error:\n _LOGGER.error(error)\n _LOGGER.error(\"Failed to connect to Slack, retrying in 10\")\n await self.reconnect(10)\n except Exception:\n await self.disconnect()\n raise\n\n async def reconnect(self, delay=None):\n \"\"\"Reconnect to the websocket.\"\"\"\n try:\n self.reconnecting = True\n if delay is not None:\n await asyncio.sleep(delay)\n await self.connect()\n finally:\n self.reconnecting = False\n\n async def disconnect(self):\n \"\"\"Disconnect from Slack.\"\"\"\n await self.slacker.close()\n\n async def listen(self):\n \"\"\"Listen for and parse new messages.\"\"\"\n while self.listening:\n await self.receive_from_websocket()\n\n async def receive_from_websocket(self):\n \"\"\"Get the next message from the websocket.\"\"\"\n try:\n content = await self.websocket.recv()\n await self.process_message(json.loads(content))\n except websockets.exceptions.ConnectionClosed:\n _LOGGER.info(\"Slack websocket closed, reconnecting...\")\n await self.reconnect(5)\n\n async def process_message(self, message):\n \"\"\"Process a raw message and pass it to the parser.\"\"\"\n if \"type\" in message and message[\"type\"] == \"message\" and \\\n \"user\" in message:\n\n # Ignore bot messages\n if \"subtype\" in message and \\\n message[\"subtype\"] == \"bot_message\":\n return\n\n # Lookup username\n _LOGGER.debug(\"Looking up sender username\")\n try:\n user_info = await self.lookup_username(message[\"user\"])\n except ValueError:\n return\n\n # Replace usernames in the message\n _LOGGER.debug(\"Replacing userids in message with usernames\")\n message[\"text\"] = await self.replace_usernames(\n message[\"text\"])\n\n await self.opsdroid.parse(Message(user_info[\"name\"],\n message[\"channel\"],\n self,\n message[\"text\"],\n raw_event=message))\n\n async def respond(self, message, room=None):\n \"\"\"Respond with a message.\"\"\"\n _LOGGER.debug(\"Responding with: '%s' in room %s\",\n message.text, message.room)\n await self.slacker.chat.post_message(message.room,\n message.text,\n as_user=False,\n username=self.bot_name,\n icon_emoji=self.icon_emoji)\n\n async def react(self, message, emoji):\n \"\"\"React to a message.\"\"\"\n emoji = demojize(emoji)\n _LOGGER.debug(\"Reacting with: %s\", emoji)\n try:\n await self.slacker.reactions.post('reactions.add', data={\n 'name': emoji,\n 'channel': message.room,\n 'timestamp': message.raw_event['ts']\n })\n except slacker.Error as error:\n if str(error) == 'invalid_name':\n _LOGGER.warning('Slack does not support the emoji %s', emoji)\n else:\n raise\n\n async def keepalive_websocket(self):\n \"\"\"Keep pinging the websocket to keep it alive.\"\"\"\n while self.listening:\n await self.ping_websocket()\n\n async def ping_websocket(self):\n \"\"\"Ping the websocket.\"\"\"\n await asyncio.sleep(60)\n self._message_id += 1\n try:\n await self.websocket.send(\n json.dumps({'id': self._message_id, 'type': 'ping'}))\n except (websockets.exceptions.InvalidState,\n websockets.exceptions.ConnectionClosed,\n aiohttp.ClientOSError,\n TimeoutError):\n _LOGGER.info(\"Slack websocket closed, reconnecting...\")\n if not self.reconnecting:\n await self.reconnect()\n\n async def lookup_username(self, userid):\n \"\"\"Lookup a username and cache it.\"\"\"\n if userid in self.known_users:\n user_info = self.known_users[userid]\n else:\n response = await self.slacker.users.info(userid)\n user_info = response.body[\"user\"]\n if isinstance(user_info, dict):\n self.known_users[userid] = user_info\n else:\n raise ValueError(\"Returned user is not a dict.\")\n return user_info\n\n async def replace_usernames(self, message):\n \"\"\"Replace User ID with username in message text.\"\"\"\n userids = re.findall(r\"\\<\\@([A-Z0-9]+)(?:\\|.+)?\\>\", message)\n for userid in userids:\n user_info = await self.lookup_username(userid)\n message = message.replace(\"<@{userid}>\".format(userid=userid),\n user_info[\"name\"])\n return message\n", "path": "opsdroid/connector/slack/__init__.py"}]} | 3,703 | 240 |
gh_patches_debug_17137 | rasdani/github-patches | git_diff | falconry__falcon-2104 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Clarify that `TestClient` does not use the app's JSON handlers
As I'm writing pytest tests for my ASGI app, I'm using the TestClient as a fixture as described in the docs:
```python
@pytest.fixture
def falcon_test_client():
return TestClient(get_app())
```
`get_app()` is a function that creates and configures my app including some custom Json handlers (which as you can see below I also use for `application/x-www-form-urlencoded`):
```python
def get_app():
app = App()
json_handler = JSONHandler(
dumps=partial(json.dumps, cls=CustomJsonEncoder),
loads=partial(json.loads, cls=CustomJsonEncoder),
)
extra_handlers = {
falcon.MEDIA_JSON: json_handler,
falcon.MEDIA_URLENCODED: json_handler,
}
app.req_options.media_handlers.update(extra_handlers)
app.resp_options.media_handlers.update(extra_handlers)
# ... routes ...
return app
```
`CustomJsonEncoder` is an encoder that can handle `UUID` and `datetime` objects; testing it with `json.dumps()` works so I know the problem is not there.
The problem is that when I try to give some data that includes a `UUID` to `simulate_post()`, it fails with `TypeError: Object of type UUID is not JSON serializable`, and I can see from pytest's traceback that at the moment of the exception, `self` is `json.encoder.JSONEncoder`, namely not the custom encoder I defined.
This is the simple test I'm trying this with:
```python
def test_(falcon_test_client):
response = falcon_test_client.simulate_post(
"/my/endpoint",
json={
"data": {}, # Just a dict with str keys and a UUID as value
},
)
```
I'm either forgetting something or I got something wrong, but I'm not sure what and how.
Also, I was rather confused when I was looking for ways to simulate and receive `x-www-form-urlencoded` data: if I set the `content_type` accordingly in something like `simulate_post()` and put the data in `body` as a dict¹, `req.get_media()` in the route handler seems to receive it as plain text.
If I put the data in the `json` parameter, as stated in the docs, the `content_type` is forced to `application/json`, making my test subtly different from reality, and since there doesn't seem to be a way to avoid this behaviour, I'd rather use an alternative that keeps the content type intact. How should I handle this?
¹ I know that that is basically JSON, but my app needs to receive webhooks from an app which sends JSON-like data as `x-www-form-urlencoded`.
</issue>
<code>
[start of falcon/media/json.py]
1 from functools import partial
2 import json
3
4 from falcon import errors
5 from falcon import http_error
6 from falcon.media.base import BaseHandler
7 from falcon.media.base import TextBaseHandlerWS
8
9
10 class JSONHandler(BaseHandler):
11 """JSON media handler.
12
13 This handler uses Python's standard :py:mod:`json` library by default, but
14 can be easily configured to use any of a number of third-party JSON
15 libraries, depending on your needs. For example, you can often
16 realize a significant performance boost under CPython by using an
17 alternative library. Good options in this respect include `orjson`,
18 `python-rapidjson`, and `mujson`.
19
20 This handler will raise a :class:`falcon.MediaNotFoundError` when attempting
21 to parse an empty body, or a :class:`falcon.MediaMalformedError`
22 if an error happens while parsing the body.
23
24 Note:
25 If you are deploying to PyPy, we recommend sticking with the standard
26 library's JSON implementation, since it will be faster in most cases
27 as compared to a third-party library.
28
29 .. rubric:: Custom JSON library
30
31 You can replace the default JSON handler by using a custom JSON library
32 (see also: :ref:`custom_media_handlers`). Overriding the default JSON
33 implementation is simply a matter of specifying the desired ``dumps`` and
34 ``loads`` functions::
35
36 import falcon
37 from falcon import media
38
39 import rapidjson
40
41 json_handler = media.JSONHandler(
42 dumps=rapidjson.dumps,
43 loads=rapidjson.loads,
44 )
45 extra_handlers = {
46 'application/json': json_handler,
47 }
48
49 app = falcon.App()
50 app.req_options.media_handlers.update(extra_handlers)
51 app.resp_options.media_handlers.update(extra_handlers)
52
53 .. rubric:: Custom serialization parameters
54
55 Even if you decide to stick with the stdlib's :any:`json.dumps` and
56 :any:`json.loads`, you can wrap them using :any:`functools.partial` to
57 provide custom serialization or deserialization parameters supported by the
58 ``dumps`` and ``loads`` functions, respectively
59 (see also: :ref:`prettifying-json-responses`)::
60
61 import falcon
62 from falcon import media
63
64 from functools import partial
65
66 json_handler = media.JSONHandler(
67 dumps=partial(
68 json.dumps,
69 default=str,
70 sort_keys=True,
71 ),
72 )
73 extra_handlers = {
74 'application/json': json_handler,
75 }
76
77 app = falcon.App()
78 app.req_options.media_handlers.update(extra_handlers)
79 app.resp_options.media_handlers.update(extra_handlers)
80
81 By default, ``ensure_ascii`` is passed to the ``json.dumps`` function.
82 If you override the ``dumps`` function, you will need to explicitly set
83 ``ensure_ascii`` to ``False`` in order to enable the serialization of
84 Unicode characters to UTF-8. This is easily done by using
85 :any:`functools.partial` to apply the desired keyword argument. As also
86 demonstrated in the previous paragraph, you can use this same technique to
87 customize any option supported by the ``dumps`` and ``loads`` functions::
88
89 from functools import partial
90
91 from falcon import media
92 import rapidjson
93
94 json_handler = media.JSONHandler(
95 dumps=partial(
96 rapidjson.dumps,
97 ensure_ascii=False, sort_keys=True
98 ),
99 )
100
101 .. _custom-media-json-encoder:
102
103 .. rubric:: Custom JSON encoder
104
105 You can also override the default :class:`~json.JSONEncoder` by using a
106 custom Encoder and updating the media handlers for ``application/json``
107 type to use that::
108
109 import json
110 from datetime import datetime
111 from functools import partial
112
113 import falcon
114 from falcon import media
115
116 class DatetimeEncoder(json.JSONEncoder):
117 \"\"\"Json Encoder that supports datetime objects.\"\"\"
118
119 def default(self, obj):
120 if isinstance(obj, datetime):
121 return obj.isoformat()
122 return super().default(obj)
123
124 app = falcon.App()
125
126 json_handler = media.JSONHandler(
127 dumps=partial(json.dumps, cls=DatetimeEncoder),
128 )
129 extra_handlers = {
130 'application/json': json_handler,
131 }
132
133 app.req_options.media_handlers.update(extra_handlers)
134 app.resp_options.media_handlers.update(extra_handlers)
135
136
137 Keyword Arguments:
138 dumps (func): Function to use when serializing JSON responses.
139 loads (func): Function to use when deserializing JSON requests.
140 """
141
142 def __init__(self, dumps=None, loads=None):
143 self._dumps = dumps or partial(json.dumps, ensure_ascii=False)
144 self._loads = loads or json.loads
145
146 # PERF(kgriffs): Test dumps once up front so we can set the
147 # proper serialize implementation.
148 result = self._dumps({'message': 'Hello World'})
149 if isinstance(result, str):
150 self.serialize = self._serialize_s
151 self.serialize_async = self._serialize_async_s
152 else:
153 self.serialize = self._serialize_b
154 self.serialize_async = self._serialize_async_b
155
156 # NOTE(kgriffs): To be safe, only enable the optimized protocol when
157 # not subclassed.
158 if type(self) is JSONHandler:
159 self._serialize_sync = self.serialize
160 self._deserialize_sync = self._deserialize
161
162 def _deserialize(self, data):
163 if not data:
164 raise errors.MediaNotFoundError('JSON')
165 try:
166 return self._loads(data.decode())
167 except ValueError as err:
168 raise errors.MediaMalformedError('JSON') from err
169
170 def deserialize(self, stream, content_type, content_length):
171 return self._deserialize(stream.read())
172
173 async def deserialize_async(self, stream, content_type, content_length):
174 return self._deserialize(await stream.read())
175
176 # NOTE(kgriffs): Make content_type a kwarg to support the
177 # Request.render_body() shortcut optimization.
178 def _serialize_s(self, media, content_type=None) -> bytes:
179 return self._dumps(media).encode()
180
181 async def _serialize_async_s(self, media, content_type) -> bytes:
182 return self._dumps(media).encode()
183
184 def _serialize_b(self, media, content_type) -> bytes:
185 return self._dumps(media)
186
187 async def _serialize_async_b(self, media, content_type) -> bytes:
188 return self._dumps(media)
189
190
191 class JSONHandlerWS(TextBaseHandlerWS):
192 """WebSocket media handler for de(serializing) JSON to/from TEXT payloads.
193
194 This handler uses Python's standard :py:mod:`json` library by default, but
195 can be easily configured to use any of a number of third-party JSON
196 libraries, depending on your needs. For example, you can often
197 realize a significant performance boost under CPython by using an
198 alternative library. Good options in this respect include `orjson`,
199 `python-rapidjson`, and `mujson`.
200
201 Note:
202 If you are deploying to PyPy, we recommend sticking with the standard
203 library's JSON implementation, since it will be faster in most cases
204 as compared to a third-party library.
205
206 Overriding the default JSON implementation is simply a matter of specifying
207 the desired ``dumps`` and ``loads`` functions::
208
209 import falcon
210 from falcon import media
211
212 import rapidjson
213
214 json_handler = media.JSONHandlerWS(
215 dumps=rapidjson.dumps,
216 loads=rapidjson.loads,
217 )
218
219 app = falcon.asgi.App()
220 app.ws_options.media_handlers[falcon.WebSocketPayloadType.TEXT] = json_handler
221
222 By default, ``ensure_ascii`` is passed to the ``json.dumps`` function.
223 If you override the ``dumps`` function, you will need to explicitly set
224 ``ensure_ascii`` to ``False`` in order to enable the serialization of
225 Unicode characters to UTF-8. This is easily done by using
226 :any:`functools.partial` to apply the desired keyword argument. In fact, you
227 can use this same technique to customize any option supported by the
228 ``dumps`` and ``loads`` functions::
229
230 from functools import partial
231
232 from falcon import media
233 import rapidjson
234
235 json_handler = media.JSONHandlerWS(
236 dumps=partial(
237 rapidjson.dumps,
238 ensure_ascii=False, sort_keys=True
239 ),
240 )
241
242 Keyword Arguments:
243 dumps (func): Function to use when serializing JSON.
244 loads (func): Function to use when deserializing JSON.
245 """
246
247 __slots__ = ['dumps', 'loads']
248
249 def __init__(self, dumps=None, loads=None):
250 self._dumps = dumps or partial(json.dumps, ensure_ascii=False)
251 self._loads = loads or json.loads
252
253 def serialize(self, media: object) -> str:
254 return self._dumps(media)
255
256 def deserialize(self, payload: str) -> object:
257 return self._loads(payload)
258
259
260 http_error._DEFAULT_JSON_HANDLER = _DEFAULT_JSON_HANDLER = JSONHandler() # type: ignore
261
[end of falcon/media/json.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/falcon/media/json.py b/falcon/media/json.py
--- a/falcon/media/json.py
+++ b/falcon/media/json.py
@@ -133,6 +133,15 @@
app.req_options.media_handlers.update(extra_handlers)
app.resp_options.media_handlers.update(extra_handlers)
+ .. note:: When testing an application employing a custom JSON encoder, bear
+ in mind that :class:`~.testing.TestClient` is decoupled from the app,
+ and it simulates requests as if they were performed by a third-party
+ client (just sans network). Therefore, passing the **json** parameter
+ to :ref:`simulate_* <testing_standalone_methods>` methods will
+ effectively use the stdlib's :func:`json.dumps`. If you want to
+ serialize custom objects for testing, you will need to dump them into a
+ string yourself, and pass it using the **body** parameter instead
+ (accompanied by the ``application/json`` content type header).
Keyword Arguments:
dumps (func): Function to use when serializing JSON responses.
| {"golden_diff": "diff --git a/falcon/media/json.py b/falcon/media/json.py\n--- a/falcon/media/json.py\n+++ b/falcon/media/json.py\n@@ -133,6 +133,15 @@\n app.req_options.media_handlers.update(extra_handlers)\n app.resp_options.media_handlers.update(extra_handlers)\n \n+ .. note:: When testing an application employing a custom JSON encoder, bear\n+ in mind that :class:`~.testing.TestClient` is decoupled from the app,\n+ and it simulates requests as if they were performed by a third-party\n+ client (just sans network). Therefore, passing the **json** parameter\n+ to :ref:`simulate_* <testing_standalone_methods>` methods will\n+ effectively use the stdlib's :func:`json.dumps`. If you want to\n+ serialize custom objects for testing, you will need to dump them into a\n+ string yourself, and pass it using the **body** parameter instead\n+ (accompanied by the ``application/json`` content type header).\n \n Keyword Arguments:\n dumps (func): Function to use when serializing JSON responses.\n", "issue": "Clarify that `TestClient` does not use the app's JSON handlers\nAs I'm writing pytest tests for my ASGI app, I'm using the TestClient as a fixture as described in the docs:\r\n\r\n```python\r\[email protected]\r\ndef falcon_test_client():\r\n return TestClient(get_app())\r\n```\r\n\r\n`get_app()` is a function that creates and configures my app including some custom Json handlers (which as you can see below I also use for `application/x-www-form-urlencoded`):\r\n```python\r\ndef get_app():\r\n app = App()\r\n\r\n json_handler = JSONHandler(\r\n dumps=partial(json.dumps, cls=CustomJsonEncoder),\r\n loads=partial(json.loads, cls=CustomJsonEncoder),\r\n )\r\n\r\n extra_handlers = {\r\n falcon.MEDIA_JSON: json_handler,\r\n falcon.MEDIA_URLENCODED: json_handler,\r\n }\r\n\r\n app.req_options.media_handlers.update(extra_handlers)\r\n app.resp_options.media_handlers.update(extra_handlers)\r\n\r\n # ... routes ...\r\n\r\n return app\r\n```\r\n\r\n`CustomJsonEncoder` is an encoder that can handle `UUID` and `datetime` objects; testing it with `json.dumps()` works so I know the problem is not there.\r\n\r\nThe problem is that when I try to give some data that includes a `UUID` to `simulate_post()`, it fails with `TypeError: Object of type UUID is not JSON serializable`, and I can see from pytest's traceback that at the moment of the exception, `self` is `json.encoder.JSONEncoder`, namely not the custom encoder I defined.\r\n\r\nThis is the simple test I'm trying this with:\r\n\r\n```python\r\ndef test_(falcon_test_client):\r\n response = falcon_test_client.simulate_post(\r\n \"/my/endpoint\",\r\n json={\r\n \"data\": {}, # Just a dict with str keys and a UUID as value\r\n },\r\n )\r\n```\r\n\r\nI'm either forgetting something or I got something wrong, but I'm not sure what and how.\r\n\r\nAlso, I was rather confused when I was looking for ways to simulate and receive `x-www-form-urlencoded` data: if I set the `content_type` accordingly in something like `simulate_post()` and put the data in `body` as a dict\u00b9, `req.get_media()` in the route handler seems to receive it as plain text. \r\nIf I put the data in the `json` parameter, as stated in the docs, the `content_type` is forced to `application/json`, making my test subtly different from reality, and since there doesn't seem to be a way to avoid this behaviour, I'd rather use an alternative that keeps the content type intact. How should I handle this?\r\n\r\n\u00b9 I know that that is basically JSON, but my app needs to receive webhooks from an app which sends JSON-like data as `x-www-form-urlencoded`.\n", "before_files": [{"content": "from functools import partial\nimport json\n\nfrom falcon import errors\nfrom falcon import http_error\nfrom falcon.media.base import BaseHandler\nfrom falcon.media.base import TextBaseHandlerWS\n\n\nclass JSONHandler(BaseHandler):\n \"\"\"JSON media handler.\n\n This handler uses Python's standard :py:mod:`json` library by default, but\n can be easily configured to use any of a number of third-party JSON\n libraries, depending on your needs. For example, you can often\n realize a significant performance boost under CPython by using an\n alternative library. Good options in this respect include `orjson`,\n `python-rapidjson`, and `mujson`.\n\n This handler will raise a :class:`falcon.MediaNotFoundError` when attempting\n to parse an empty body, or a :class:`falcon.MediaMalformedError`\n if an error happens while parsing the body.\n\n Note:\n If you are deploying to PyPy, we recommend sticking with the standard\n library's JSON implementation, since it will be faster in most cases\n as compared to a third-party library.\n\n .. rubric:: Custom JSON library\n\n You can replace the default JSON handler by using a custom JSON library\n (see also: :ref:`custom_media_handlers`). Overriding the default JSON\n implementation is simply a matter of specifying the desired ``dumps`` and\n ``loads`` functions::\n\n import falcon\n from falcon import media\n\n import rapidjson\n\n json_handler = media.JSONHandler(\n dumps=rapidjson.dumps,\n loads=rapidjson.loads,\n )\n extra_handlers = {\n 'application/json': json_handler,\n }\n\n app = falcon.App()\n app.req_options.media_handlers.update(extra_handlers)\n app.resp_options.media_handlers.update(extra_handlers)\n\n .. rubric:: Custom serialization parameters\n\n Even if you decide to stick with the stdlib's :any:`json.dumps` and\n :any:`json.loads`, you can wrap them using :any:`functools.partial` to\n provide custom serialization or deserialization parameters supported by the\n ``dumps`` and ``loads`` functions, respectively\n (see also: :ref:`prettifying-json-responses`)::\n\n import falcon\n from falcon import media\n\n from functools import partial\n\n json_handler = media.JSONHandler(\n dumps=partial(\n json.dumps,\n default=str,\n sort_keys=True,\n ),\n )\n extra_handlers = {\n 'application/json': json_handler,\n }\n\n app = falcon.App()\n app.req_options.media_handlers.update(extra_handlers)\n app.resp_options.media_handlers.update(extra_handlers)\n\n By default, ``ensure_ascii`` is passed to the ``json.dumps`` function.\n If you override the ``dumps`` function, you will need to explicitly set\n ``ensure_ascii`` to ``False`` in order to enable the serialization of\n Unicode characters to UTF-8. This is easily done by using\n :any:`functools.partial` to apply the desired keyword argument. As also\n demonstrated in the previous paragraph, you can use this same technique to\n customize any option supported by the ``dumps`` and ``loads`` functions::\n\n from functools import partial\n\n from falcon import media\n import rapidjson\n\n json_handler = media.JSONHandler(\n dumps=partial(\n rapidjson.dumps,\n ensure_ascii=False, sort_keys=True\n ),\n )\n\n .. _custom-media-json-encoder:\n\n .. rubric:: Custom JSON encoder\n\n You can also override the default :class:`~json.JSONEncoder` by using a\n custom Encoder and updating the media handlers for ``application/json``\n type to use that::\n\n import json\n from datetime import datetime\n from functools import partial\n\n import falcon\n from falcon import media\n\n class DatetimeEncoder(json.JSONEncoder):\n \\\"\\\"\\\"Json Encoder that supports datetime objects.\\\"\\\"\\\"\n\n def default(self, obj):\n if isinstance(obj, datetime):\n return obj.isoformat()\n return super().default(obj)\n\n app = falcon.App()\n\n json_handler = media.JSONHandler(\n dumps=partial(json.dumps, cls=DatetimeEncoder),\n )\n extra_handlers = {\n 'application/json': json_handler,\n }\n\n app.req_options.media_handlers.update(extra_handlers)\n app.resp_options.media_handlers.update(extra_handlers)\n\n\n Keyword Arguments:\n dumps (func): Function to use when serializing JSON responses.\n loads (func): Function to use when deserializing JSON requests.\n \"\"\"\n\n def __init__(self, dumps=None, loads=None):\n self._dumps = dumps or partial(json.dumps, ensure_ascii=False)\n self._loads = loads or json.loads\n\n # PERF(kgriffs): Test dumps once up front so we can set the\n # proper serialize implementation.\n result = self._dumps({'message': 'Hello World'})\n if isinstance(result, str):\n self.serialize = self._serialize_s\n self.serialize_async = self._serialize_async_s\n else:\n self.serialize = self._serialize_b\n self.serialize_async = self._serialize_async_b\n\n # NOTE(kgriffs): To be safe, only enable the optimized protocol when\n # not subclassed.\n if type(self) is JSONHandler:\n self._serialize_sync = self.serialize\n self._deserialize_sync = self._deserialize\n\n def _deserialize(self, data):\n if not data:\n raise errors.MediaNotFoundError('JSON')\n try:\n return self._loads(data.decode())\n except ValueError as err:\n raise errors.MediaMalformedError('JSON') from err\n\n def deserialize(self, stream, content_type, content_length):\n return self._deserialize(stream.read())\n\n async def deserialize_async(self, stream, content_type, content_length):\n return self._deserialize(await stream.read())\n\n # NOTE(kgriffs): Make content_type a kwarg to support the\n # Request.render_body() shortcut optimization.\n def _serialize_s(self, media, content_type=None) -> bytes:\n return self._dumps(media).encode()\n\n async def _serialize_async_s(self, media, content_type) -> bytes:\n return self._dumps(media).encode()\n\n def _serialize_b(self, media, content_type) -> bytes:\n return self._dumps(media)\n\n async def _serialize_async_b(self, media, content_type) -> bytes:\n return self._dumps(media)\n\n\nclass JSONHandlerWS(TextBaseHandlerWS):\n \"\"\"WebSocket media handler for de(serializing) JSON to/from TEXT payloads.\n\n This handler uses Python's standard :py:mod:`json` library by default, but\n can be easily configured to use any of a number of third-party JSON\n libraries, depending on your needs. For example, you can often\n realize a significant performance boost under CPython by using an\n alternative library. Good options in this respect include `orjson`,\n `python-rapidjson`, and `mujson`.\n\n Note:\n If you are deploying to PyPy, we recommend sticking with the standard\n library's JSON implementation, since it will be faster in most cases\n as compared to a third-party library.\n\n Overriding the default JSON implementation is simply a matter of specifying\n the desired ``dumps`` and ``loads`` functions::\n\n import falcon\n from falcon import media\n\n import rapidjson\n\n json_handler = media.JSONHandlerWS(\n dumps=rapidjson.dumps,\n loads=rapidjson.loads,\n )\n\n app = falcon.asgi.App()\n app.ws_options.media_handlers[falcon.WebSocketPayloadType.TEXT] = json_handler\n\n By default, ``ensure_ascii`` is passed to the ``json.dumps`` function.\n If you override the ``dumps`` function, you will need to explicitly set\n ``ensure_ascii`` to ``False`` in order to enable the serialization of\n Unicode characters to UTF-8. This is easily done by using\n :any:`functools.partial` to apply the desired keyword argument. In fact, you\n can use this same technique to customize any option supported by the\n ``dumps`` and ``loads`` functions::\n\n from functools import partial\n\n from falcon import media\n import rapidjson\n\n json_handler = media.JSONHandlerWS(\n dumps=partial(\n rapidjson.dumps,\n ensure_ascii=False, sort_keys=True\n ),\n )\n\n Keyword Arguments:\n dumps (func): Function to use when serializing JSON.\n loads (func): Function to use when deserializing JSON.\n \"\"\"\n\n __slots__ = ['dumps', 'loads']\n\n def __init__(self, dumps=None, loads=None):\n self._dumps = dumps or partial(json.dumps, ensure_ascii=False)\n self._loads = loads or json.loads\n\n def serialize(self, media: object) -> str:\n return self._dumps(media)\n\n def deserialize(self, payload: str) -> object:\n return self._loads(payload)\n\n\nhttp_error._DEFAULT_JSON_HANDLER = _DEFAULT_JSON_HANDLER = JSONHandler() # type: ignore\n", "path": "falcon/media/json.py"}]} | 3,786 | 243 |
gh_patches_debug_450 | rasdani/github-patches | git_diff | spyder-ide__spyder-6089 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Spyder not starting in macOS because pyopengl is present
I updated python and spyder using "conda update spyder" and "conda update python" respectively on MacOSX. Is this a python error or a spyder error?
Please find attached the conda list output listing the versions.
Thanks for your support.
--------
Traceback (most recent call last):
File "/Users/Nagraj/anaconda3/bin/spyder", line 7, in
[conda_list.txt](https://github.com/spyder-ide/spyder/files/1590875/conda_list.txt)
from spyder.app.start import main
File "/Users/Nagraj/anaconda3/lib/python3.6/site-packages/spyder/app/start.py", line 19, in
from OpenGL import GL
File "/Users/Nagraj/anaconda3/lib/python3.6/site-packages/OpenGL/GL/__init__.py", line 3, in
from OpenGL import error as _error
File "/Users/Nagraj/anaconda3/lib/python3.6/site-packages/OpenGL/error.py", line 12, in
from OpenGL import platform, _configflags
File "/Users/Nagraj/anaconda3/lib/python3.6/site-packages/OpenGL/platform/__init__.py", line 35, in
_load()
File "/Users/Nagraj/anaconda3/lib/python3.6/site-packages/OpenGL/platform/__init__.py", line 29, in _load
plugin = plugin_class()
TypeError: 'NoneType' object is not callable
</issue>
<code>
[start of spyder/app/start.py]
1 # -*- coding: utf-8 -*-
2
3 # Std imports
4 import os
5 import os.path as osp
6 import random
7 import socket
8 import sys
9 import time
10
11 # To prevent a race condition with ZMQ
12 # See issue 5324
13 import zmq
14
15 # This import is needed to fix errors with OpenGL when installed using pip
16 # See issue 3332
17 try:
18 from OpenGL import GL
19 except ImportError:
20 # pyopengl is not present when installed using conda
21 pass
22
23 # Local imports
24 from spyder.app.cli_options import get_options
25 from spyder.config.base import get_conf_path, running_in_mac_app
26 from spyder.config.main import CONF
27 from spyder.utils.external import lockfile
28 from spyder.py3compat import is_unicode
29
30
31 def send_args_to_spyder(args):
32 """
33 Simple socket client used to send the args passed to the Spyder
34 executable to an already running instance.
35
36 Args can be Python scripts or files with these extensions: .spydata, .mat,
37 .npy, or .h5, which can be imported by the Variable Explorer.
38 """
39 port = CONF.get('main', 'open_files_port')
40
41 # Wait ~50 secs for the server to be up
42 # Taken from http://stackoverflow.com/a/4766598/438386
43 for _x in range(200):
44 try:
45 for arg in args:
46 client = socket.socket(socket.AF_INET, socket.SOCK_STREAM,
47 socket.IPPROTO_TCP)
48 client.connect(("127.0.0.1", port))
49 if is_unicode(arg):
50 arg = arg.encode('utf-8')
51 client.send(osp.abspath(arg))
52 client.close()
53 except socket.error:
54 time.sleep(0.25)
55 continue
56 break
57
58
59 def main():
60 """
61 Start Spyder application.
62
63 If single instance mode is turned on (default behavior) and an instance of
64 Spyder is already running, this will just parse and send command line
65 options to the application.
66 """
67 # Parse command line options
68 options, args = get_options()
69
70 # Store variable to be used in self.restart (restart spyder instance)
71 os.environ['SPYDER_ARGS'] = str(sys.argv[1:])
72
73 #==========================================================================
74 # Proper high DPI scaling is available in Qt >= 5.6.0. This attibute must
75 # be set before creating the application.
76 #==========================================================================
77 if CONF.get('main', 'high_dpi_custom_scale_factor'):
78 factors = str(CONF.get('main', 'high_dpi_custom_scale_factors'))
79 f = list(filter(None, factors.split(';')))
80 if len(f) == 1:
81 os.environ['QT_SCALE_FACTOR'] = f[0]
82 else:
83 os.environ['QT_SCREEN_SCALE_FACTORS'] = factors
84 else:
85 os.environ['QT_SCALE_FACTOR'] = ''
86 os.environ['QT_SCREEN_SCALE_FACTORS'] = ''
87
88 # Prevent Spyder from crashing in macOS if locale is not defined
89 if sys.platform == 'darwin':
90 LANG = os.environ.get('LANG')
91 LC_ALL = os.environ.get('LC_ALL')
92 if bool(LANG) and not bool(LC_ALL):
93 LC_ALL = LANG
94 elif not bool(LANG) and bool(LC_ALL):
95 LANG = LC_ALL
96 else:
97 LANG = LC_ALL = 'en_US.UTF-8'
98
99 os.environ['LANG'] = LANG
100 os.environ['LC_ALL'] = LC_ALL
101
102 if CONF.get('main', 'single_instance') and not options.new_instance \
103 and not options.reset_config_files and not running_in_mac_app():
104 # Minimal delay (0.1-0.2 secs) to avoid that several
105 # instances started at the same time step in their
106 # own foots while trying to create the lock file
107 time.sleep(random.randrange(1000, 2000, 90)/10000.)
108
109 # Lock file creation
110 lock_file = get_conf_path('spyder.lock')
111 lock = lockfile.FilesystemLock(lock_file)
112
113 # Try to lock spyder.lock. If it's *possible* to do it, then
114 # there is no previous instance running and we can start a
115 # new one. If *not*, then there is an instance already
116 # running, which is locking that file
117 try:
118 lock_created = lock.lock()
119 except:
120 # If locking fails because of errors in the lockfile
121 # module, try to remove a possibly stale spyder.lock.
122 # This is reported to solve all problems with
123 # lockfile (See issue 2363)
124 try:
125 if os.name == 'nt':
126 if osp.isdir(lock_file):
127 import shutil
128 shutil.rmtree(lock_file, ignore_errors=True)
129 else:
130 if osp.islink(lock_file):
131 os.unlink(lock_file)
132 except:
133 pass
134
135 # Then start Spyder as usual and *don't* continue
136 # executing this script because it doesn't make
137 # sense
138 from spyder.app import mainwindow
139 mainwindow.main()
140 return
141
142 if lock_created:
143 # Start a new instance
144 from spyder.app import mainwindow
145 mainwindow.main()
146 else:
147 # Pass args to Spyder or print an informative
148 # message
149 if args:
150 send_args_to_spyder(args)
151 else:
152 print("Spyder is already running. If you want to open a new \n"
153 "instance, please pass to it the --new-instance option")
154 else:
155 from spyder.app import mainwindow
156 mainwindow.main()
157
158
159 if __name__ == "__main__":
160 main()
161
[end of spyder/app/start.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/spyder/app/start.py b/spyder/app/start.py
--- a/spyder/app/start.py
+++ b/spyder/app/start.py
@@ -16,8 +16,7 @@
# See issue 3332
try:
from OpenGL import GL
-except ImportError:
- # pyopengl is not present when installed using conda
+except:
pass
# Local imports
| {"golden_diff": "diff --git a/spyder/app/start.py b/spyder/app/start.py\n--- a/spyder/app/start.py\n+++ b/spyder/app/start.py\n@@ -16,8 +16,7 @@\n # See issue 3332\r\n try:\r\n from OpenGL import GL\r\n-except ImportError:\r\n- # pyopengl is not present when installed using conda\r\n+except:\r\n pass\r\n \r\n # Local imports\n", "issue": "Spyder not starting in macOS because pyopengl is present\n\r\n\r\nI updated python and spyder using \"conda update spyder\" and \"conda update python\" respectively on MacOSX. Is this a python error or a spyder error? \r\n\r\nPlease find attached the conda list output listing the versions.\r\n\r\nThanks for your support. \r\n--------\r\nTraceback (most recent call last):\r\nFile \"/Users/Nagraj/anaconda3/bin/spyder\", line 7, in \r\n[conda_list.txt](https://github.com/spyder-ide/spyder/files/1590875/conda_list.txt)\r\n\r\nfrom spyder.app.start import main\r\nFile \"/Users/Nagraj/anaconda3/lib/python3.6/site-packages/spyder/app/start.py\", line 19, in \r\nfrom OpenGL import GL\r\nFile \"/Users/Nagraj/anaconda3/lib/python3.6/site-packages/OpenGL/GL/__init__.py\", line 3, in \r\nfrom OpenGL import error as _error\r\nFile \"/Users/Nagraj/anaconda3/lib/python3.6/site-packages/OpenGL/error.py\", line 12, in \r\nfrom OpenGL import platform, _configflags\r\nFile \"/Users/Nagraj/anaconda3/lib/python3.6/site-packages/OpenGL/platform/__init__.py\", line 35, in \r\n_load()\r\nFile \"/Users/Nagraj/anaconda3/lib/python3.6/site-packages/OpenGL/platform/__init__.py\", line 29, in _load\r\nplugin = plugin_class()\r\nTypeError: 'NoneType' object is not callable\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\r\n\r\n# Std imports\r\nimport os\r\nimport os.path as osp\r\nimport random\r\nimport socket\r\nimport sys\r\nimport time\r\n\r\n# To prevent a race condition with ZMQ\r\n# See issue 5324\r\nimport zmq\r\n\r\n# This import is needed to fix errors with OpenGL when installed using pip\r\n# See issue 3332\r\ntry:\r\n from OpenGL import GL\r\nexcept ImportError:\r\n # pyopengl is not present when installed using conda\r\n pass\r\n\r\n# Local imports\r\nfrom spyder.app.cli_options import get_options\r\nfrom spyder.config.base import get_conf_path, running_in_mac_app\r\nfrom spyder.config.main import CONF\r\nfrom spyder.utils.external import lockfile\r\nfrom spyder.py3compat import is_unicode\r\n\r\n\r\ndef send_args_to_spyder(args):\r\n \"\"\"\r\n Simple socket client used to send the args passed to the Spyder \r\n executable to an already running instance.\r\n\r\n Args can be Python scripts or files with these extensions: .spydata, .mat,\r\n .npy, or .h5, which can be imported by the Variable Explorer.\r\n \"\"\"\r\n port = CONF.get('main', 'open_files_port')\r\n\r\n # Wait ~50 secs for the server to be up\r\n # Taken from http://stackoverflow.com/a/4766598/438386\r\n for _x in range(200):\r\n try:\r\n for arg in args:\r\n client = socket.socket(socket.AF_INET, socket.SOCK_STREAM,\r\n socket.IPPROTO_TCP)\r\n client.connect((\"127.0.0.1\", port))\r\n if is_unicode(arg):\r\n arg = arg.encode('utf-8')\r\n client.send(osp.abspath(arg))\r\n client.close()\r\n except socket.error:\r\n time.sleep(0.25)\r\n continue\r\n break\r\n\r\n\r\ndef main():\r\n \"\"\"\r\n Start Spyder application.\r\n\r\n If single instance mode is turned on (default behavior) and an instance of\r\n Spyder is already running, this will just parse and send command line\r\n options to the application.\r\n \"\"\"\r\n # Parse command line options\r\n options, args = get_options()\r\n\r\n # Store variable to be used in self.restart (restart spyder instance)\r\n os.environ['SPYDER_ARGS'] = str(sys.argv[1:])\r\n\r\n #==========================================================================\r\n # Proper high DPI scaling is available in Qt >= 5.6.0. This attibute must\r\n # be set before creating the application.\r\n #==========================================================================\r\n if CONF.get('main', 'high_dpi_custom_scale_factor'):\r\n factors = str(CONF.get('main', 'high_dpi_custom_scale_factors'))\r\n f = list(filter(None, factors.split(';')))\r\n if len(f) == 1:\r\n os.environ['QT_SCALE_FACTOR'] = f[0]\r\n else:\r\n os.environ['QT_SCREEN_SCALE_FACTORS'] = factors\r\n else:\r\n os.environ['QT_SCALE_FACTOR'] = ''\r\n os.environ['QT_SCREEN_SCALE_FACTORS'] = ''\r\n\r\n # Prevent Spyder from crashing in macOS if locale is not defined\r\n if sys.platform == 'darwin':\r\n LANG = os.environ.get('LANG')\r\n LC_ALL = os.environ.get('LC_ALL')\r\n if bool(LANG) and not bool(LC_ALL):\r\n LC_ALL = LANG\r\n elif not bool(LANG) and bool(LC_ALL):\r\n LANG = LC_ALL\r\n else:\r\n LANG = LC_ALL = 'en_US.UTF-8'\r\n\r\n os.environ['LANG'] = LANG\r\n os.environ['LC_ALL'] = LC_ALL\r\n\r\n if CONF.get('main', 'single_instance') and not options.new_instance \\\r\n and not options.reset_config_files and not running_in_mac_app():\r\n # Minimal delay (0.1-0.2 secs) to avoid that several\r\n # instances started at the same time step in their\r\n # own foots while trying to create the lock file\r\n time.sleep(random.randrange(1000, 2000, 90)/10000.)\r\n\r\n # Lock file creation\r\n lock_file = get_conf_path('spyder.lock')\r\n lock = lockfile.FilesystemLock(lock_file)\r\n\r\n # Try to lock spyder.lock. If it's *possible* to do it, then\r\n # there is no previous instance running and we can start a\r\n # new one. If *not*, then there is an instance already\r\n # running, which is locking that file\r\n try:\r\n lock_created = lock.lock()\r\n except:\r\n # If locking fails because of errors in the lockfile\r\n # module, try to remove a possibly stale spyder.lock.\r\n # This is reported to solve all problems with\r\n # lockfile (See issue 2363)\r\n try:\r\n if os.name == 'nt':\r\n if osp.isdir(lock_file):\r\n import shutil\r\n shutil.rmtree(lock_file, ignore_errors=True)\r\n else:\r\n if osp.islink(lock_file):\r\n os.unlink(lock_file)\r\n except:\r\n pass\r\n\r\n # Then start Spyder as usual and *don't* continue\r\n # executing this script because it doesn't make\r\n # sense\r\n from spyder.app import mainwindow\r\n mainwindow.main()\r\n return\r\n\r\n if lock_created:\r\n # Start a new instance\r\n from spyder.app import mainwindow\r\n mainwindow.main()\r\n else:\r\n # Pass args to Spyder or print an informative\r\n # message\r\n if args:\r\n send_args_to_spyder(args)\r\n else:\r\n print(\"Spyder is already running. If you want to open a new \\n\"\r\n \"instance, please pass to it the --new-instance option\")\r\n else:\r\n from spyder.app import mainwindow\r\n mainwindow.main()\r\n\r\n\r\nif __name__ == \"__main__\":\r\n main()\r\n", "path": "spyder/app/start.py"}]} | 2,511 | 95 |
gh_patches_debug_18013 | rasdani/github-patches | git_diff | lk-geimfari__mimesis-446 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
romanized decorator mutates ROMANIZATION_DICT
After `@romanized` is used, ROMANIZATION_DICT gets updated and every module importing it will get this mutated ROMANIZATION_DICT.
Snippet below should reproduce problem.
```
from mimesis import decorators, data
if __name__ == '__main__':
print('ROMANIZATION_DICT: before')
print(data.ROMANIZATION_DICT)
@decorators.romanized('ru')
def russian_name(): return 'Петр Петрович'
# next line is where ROMANIZATION_DICT mutates
russian_name()
print('ROMANIZATION_DICT: after')
print(data.ROMANIZATION_DICT)
```
Problem is here:
https://github.com/lk-geimfari/mimesis/blob/master/mimesis/decorators.py#L29
</issue>
<code>
[start of mimesis/decorators.py]
1 """Decorators for the public API and for internal purpose."""
2
3 import functools
4 from string import ascii_letters as letters
5 from string import digits, punctuation
6 from typing import Callable
7
8 from mimesis import data
9 from mimesis.exceptions import UnsupportedLocale
10
11
12 def romanized(locale: str = '') -> Callable:
13 """Romanize the Cyrillic text.
14
15 Transliterate the Cyrillic language from the Cyrillic
16 script into the Latin alphabet.
17
18 .. note:: At this moment it works only for `ru`, `uk`, `kk`.
19
20 :param locale: Locale code.
21 :return: Latinized text.
22 """
23 def romanized_deco(func):
24 @functools.wraps(func)
25 def wrapper(*args, **kwargs):
26 try:
27 alphabet = data.ROMANIZATION_DICT[locale]
28 # Add common cyrillic common letters
29 alphabet.update(data.COMMON_LETTERS)
30 # String can contain ascii symbols, digits and
31 # punctuation symbols.
32 alphabet.update({s: s for s in
33 letters + digits + punctuation})
34 except KeyError:
35 raise UnsupportedLocale(locale)
36 result = func(*args, **kwargs)
37 txt = ''.join([alphabet[i] for i in result if i in alphabet])
38 return txt
39
40 return wrapper
41
42 return romanized_deco
43
[end of mimesis/decorators.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/mimesis/decorators.py b/mimesis/decorators.py
--- a/mimesis/decorators.py
+++ b/mimesis/decorators.py
@@ -24,13 +24,13 @@
@functools.wraps(func)
def wrapper(*args, **kwargs):
try:
- alphabet = data.ROMANIZATION_DICT[locale]
- # Add common cyrillic common letters
- alphabet.update(data.COMMON_LETTERS)
# String can contain ascii symbols, digits and
# punctuation symbols.
- alphabet.update({s: s for s in
- letters + digits + punctuation})
+ alphabet = {s: s for s in
+ letters + digits + punctuation}
+ alphabet.update(data.ROMANIZATION_DICT[locale])
+ # Add common cyrillic letters
+ alphabet.update(data.COMMON_LETTERS)
except KeyError:
raise UnsupportedLocale(locale)
result = func(*args, **kwargs)
| {"golden_diff": "diff --git a/mimesis/decorators.py b/mimesis/decorators.py\n--- a/mimesis/decorators.py\n+++ b/mimesis/decorators.py\n@@ -24,13 +24,13 @@\n @functools.wraps(func)\n def wrapper(*args, **kwargs):\n try:\n- alphabet = data.ROMANIZATION_DICT[locale]\n- # Add common cyrillic common letters\n- alphabet.update(data.COMMON_LETTERS)\n # String can contain ascii symbols, digits and\n # punctuation symbols.\n- alphabet.update({s: s for s in\n- letters + digits + punctuation})\n+ alphabet = {s: s for s in\n+ letters + digits + punctuation}\n+ alphabet.update(data.ROMANIZATION_DICT[locale])\n+ # Add common cyrillic letters\n+ alphabet.update(data.COMMON_LETTERS)\n except KeyError:\n raise UnsupportedLocale(locale)\n result = func(*args, **kwargs)\n", "issue": "romanized decorator mutates ROMANIZATION_DICT\nAfter `@romanized` is used, ROMANIZATION_DICT gets updated and every module importing it will get this mutated ROMANIZATION_DICT.\r\nSnippet below should reproduce problem.\r\n```\r\nfrom mimesis import decorators, data\r\n\r\n\r\nif __name__ == '__main__':\r\n print('ROMANIZATION_DICT: before')\r\n print(data.ROMANIZATION_DICT)\r\n\r\n @decorators.romanized('ru')\r\n def russian_name(): return '\u041f\u0435\u0442\u0440 \u041f\u0435\u0442\u0440\u043e\u0432\u0438\u0447'\r\n # next line is where ROMANIZATION_DICT mutates\r\n russian_name()\r\n\r\n print('ROMANIZATION_DICT: after')\r\n print(data.ROMANIZATION_DICT)\r\n```\r\nProblem is here:\r\nhttps://github.com/lk-geimfari/mimesis/blob/master/mimesis/decorators.py#L29\r\n\n", "before_files": [{"content": "\"\"\"Decorators for the public API and for internal purpose.\"\"\"\n\nimport functools\nfrom string import ascii_letters as letters\nfrom string import digits, punctuation\nfrom typing import Callable\n\nfrom mimesis import data\nfrom mimesis.exceptions import UnsupportedLocale\n\n\ndef romanized(locale: str = '') -> Callable:\n \"\"\"Romanize the Cyrillic text.\n\n Transliterate the Cyrillic language from the Cyrillic\n script into the Latin alphabet.\n\n .. note:: At this moment it works only for `ru`, `uk`, `kk`.\n\n :param locale: Locale code.\n :return: Latinized text.\n \"\"\"\n def romanized_deco(func):\n @functools.wraps(func)\n def wrapper(*args, **kwargs):\n try:\n alphabet = data.ROMANIZATION_DICT[locale]\n # Add common cyrillic common letters\n alphabet.update(data.COMMON_LETTERS)\n # String can contain ascii symbols, digits and\n # punctuation symbols.\n alphabet.update({s: s for s in\n letters + digits + punctuation})\n except KeyError:\n raise UnsupportedLocale(locale)\n result = func(*args, **kwargs)\n txt = ''.join([alphabet[i] for i in result if i in alphabet])\n return txt\n\n return wrapper\n\n return romanized_deco\n", "path": "mimesis/decorators.py"}]} | 1,078 | 220 |
gh_patches_debug_26944 | rasdani/github-patches | git_diff | Qiskit__qiskit-12321 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add insert_barrier argument to UnitaryOverlap
### What should we add?
This argument would insert a barrier between the two unitaries. This is useful if you want to prevent circuit optimization between the two parts.
</issue>
<code>
[start of qiskit/circuit/library/overlap.py]
1 # This code is part of Qiskit.
2 #
3 # (C) Copyright IBM 2023.
4 #
5 # This code is licensed under the Apache License, Version 2.0. You may
6 # obtain a copy of this license in the LICENSE.txt file in the root directory
7 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
8 #
9 # Any modifications or derivative works of this code must retain this
10 # copyright notice, and modified files need to carry a notice indicating
11 # that they have been altered from the originals.
12
13 """Unitary overlap circuit."""
14
15 from qiskit.circuit import QuantumCircuit, Gate
16 from qiskit.circuit.parametervector import ParameterVector
17 from qiskit.circuit.exceptions import CircuitError
18 from qiskit.circuit import Barrier
19
20
21 class UnitaryOverlap(QuantumCircuit):
22 r"""Circuit that returns the overlap between two unitaries :math:`U_2^{\dag} U_1`.
23
24 The input quantum circuits must represent unitary operations, since they must be invertible.
25 If the inputs will have parameters, they are replaced by :class:`.ParameterVector`\s with
26 names `"p1"` (for circuit ``unitary1``) and `"p2"` (for circuit ``unitary_2``) in the output
27 circuit.
28
29 This circuit is usually employed in computing the fidelity:
30
31 .. math::
32
33 \left|\langle 0| U_2^{\dag} U_1|0\rangle\right|^{2}
34
35 by computing the probability of being in the all-zeros bit-string, or equivalently,
36 the expectation value of projector :math:`|0\rangle\langle 0|`.
37
38 Example::
39
40 import numpy as np
41 from qiskit.circuit.library import EfficientSU2, UnitaryOverlap
42 from qiskit.primitives import Sampler
43
44 # get two circuit to prepare states of which we comput the overlap
45 circuit = EfficientSU2(2, reps=1)
46 unitary1 = circuit.assign_parameters(np.random.random(circuit.num_parameters))
47 unitary2 = circuit.assign_parameters(np.random.random(circuit.num_parameters))
48
49 # create the overlap circuit
50 overlap = UnitaryOverap(unitary1, unitary2)
51
52 # sample from the overlap
53 sampler = Sampler(options={"shots": 100})
54 result = sampler.run(overlap).result()
55
56 # the fidelity is the probability to measure 0
57 fidelity = result.quasi_dists[0].get(0, 0)
58
59 """
60
61 def __init__(
62 self, unitary1: QuantumCircuit, unitary2: QuantumCircuit, prefix1="p1", prefix2="p2"
63 ):
64 """
65 Args:
66 unitary1: Unitary acting on the ket vector.
67 unitary2: Unitary whose inverse operates on the bra vector.
68 prefix1: The name of the parameter vector associated to ``unitary1``,
69 if it is parameterized. Defaults to ``"p1"``.
70 prefix2: The name of the parameter vector associated to ``unitary2``,
71 if it is parameterized. Defaults to ``"p2"``.
72
73 Raises:
74 CircuitError: Number of qubits in ``unitary1`` and ``unitary2`` does not match.
75 CircuitError: Inputs contain measurements and/or resets.
76 """
77 # check inputs are valid
78 if unitary1.num_qubits != unitary2.num_qubits:
79 raise CircuitError(
80 f"Number of qubits in unitaries does "
81 f"not match: {unitary1.num_qubits} != {unitary2.num_qubits}."
82 )
83
84 unitaries = [unitary1, unitary2]
85 for unitary in unitaries:
86 _check_unitary(unitary)
87
88 # Vectors of new parameters, if any. Need the unitaries in a list here to ensure
89 # we can overwrite them.
90 for i, prefix in enumerate([prefix1, prefix2]):
91 if unitaries[i].num_parameters > 0:
92 new_params = ParameterVector(prefix, unitaries[i].num_parameters)
93 unitaries[i] = unitaries[i].assign_parameters(new_params)
94
95 # Generate the actual overlap circuit
96 super().__init__(unitaries[0].num_qubits, name="UnitaryOverlap")
97 self.compose(unitaries[0], inplace=True)
98 self.compose(unitaries[1].inverse(), inplace=True)
99
100
101 def _check_unitary(circuit):
102 """Check a circuit is unitary by checking if all operations are of type ``Gate``."""
103
104 for instruction in circuit.data:
105 if not isinstance(instruction.operation, (Gate, Barrier)):
106 raise CircuitError(
107 (
108 "One or more instructions cannot be converted to"
109 ' a gate. "{}" is not a gate instruction'
110 ).format(instruction.operation.name)
111 )
112
[end of qiskit/circuit/library/overlap.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/qiskit/circuit/library/overlap.py b/qiskit/circuit/library/overlap.py
--- a/qiskit/circuit/library/overlap.py
+++ b/qiskit/circuit/library/overlap.py
@@ -59,7 +59,12 @@
"""
def __init__(
- self, unitary1: QuantumCircuit, unitary2: QuantumCircuit, prefix1="p1", prefix2="p2"
+ self,
+ unitary1: QuantumCircuit,
+ unitary2: QuantumCircuit,
+ prefix1: str = "p1",
+ prefix2: str = "p2",
+ insert_barrier: bool = False,
):
"""
Args:
@@ -69,6 +74,7 @@
if it is parameterized. Defaults to ``"p1"``.
prefix2: The name of the parameter vector associated to ``unitary2``,
if it is parameterized. Defaults to ``"p2"``.
+ insert_barrier: Whether to insert a barrier between the two unitaries.
Raises:
CircuitError: Number of qubits in ``unitary1`` and ``unitary2`` does not match.
@@ -95,6 +101,8 @@
# Generate the actual overlap circuit
super().__init__(unitaries[0].num_qubits, name="UnitaryOverlap")
self.compose(unitaries[0], inplace=True)
+ if insert_barrier:
+ self.barrier()
self.compose(unitaries[1].inverse(), inplace=True)
| {"golden_diff": "diff --git a/qiskit/circuit/library/overlap.py b/qiskit/circuit/library/overlap.py\n--- a/qiskit/circuit/library/overlap.py\n+++ b/qiskit/circuit/library/overlap.py\n@@ -59,7 +59,12 @@\n \"\"\"\n \n def __init__(\n- self, unitary1: QuantumCircuit, unitary2: QuantumCircuit, prefix1=\"p1\", prefix2=\"p2\"\n+ self,\n+ unitary1: QuantumCircuit,\n+ unitary2: QuantumCircuit,\n+ prefix1: str = \"p1\",\n+ prefix2: str = \"p2\",\n+ insert_barrier: bool = False,\n ):\n \"\"\"\n Args:\n@@ -69,6 +74,7 @@\n if it is parameterized. Defaults to ``\"p1\"``.\n prefix2: The name of the parameter vector associated to ``unitary2``,\n if it is parameterized. Defaults to ``\"p2\"``.\n+ insert_barrier: Whether to insert a barrier between the two unitaries.\n \n Raises:\n CircuitError: Number of qubits in ``unitary1`` and ``unitary2`` does not match.\n@@ -95,6 +101,8 @@\n # Generate the actual overlap circuit\n super().__init__(unitaries[0].num_qubits, name=\"UnitaryOverlap\")\n self.compose(unitaries[0], inplace=True)\n+ if insert_barrier:\n+ self.barrier()\n self.compose(unitaries[1].inverse(), inplace=True)\n", "issue": "Add insert_barrier argument to UnitaryOverlap\n### What should we add?\n\nThis argument would insert a barrier between the two unitaries. This is useful if you want to prevent circuit optimization between the two parts.\n", "before_files": [{"content": "# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2023.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\n\"\"\"Unitary overlap circuit.\"\"\"\n\nfrom qiskit.circuit import QuantumCircuit, Gate\nfrom qiskit.circuit.parametervector import ParameterVector\nfrom qiskit.circuit.exceptions import CircuitError\nfrom qiskit.circuit import Barrier\n\n\nclass UnitaryOverlap(QuantumCircuit):\n r\"\"\"Circuit that returns the overlap between two unitaries :math:`U_2^{\\dag} U_1`.\n\n The input quantum circuits must represent unitary operations, since they must be invertible.\n If the inputs will have parameters, they are replaced by :class:`.ParameterVector`\\s with\n names `\"p1\"` (for circuit ``unitary1``) and `\"p2\"` (for circuit ``unitary_2``) in the output\n circuit.\n\n This circuit is usually employed in computing the fidelity:\n\n .. math::\n\n \\left|\\langle 0| U_2^{\\dag} U_1|0\\rangle\\right|^{2}\n\n by computing the probability of being in the all-zeros bit-string, or equivalently,\n the expectation value of projector :math:`|0\\rangle\\langle 0|`.\n\n Example::\n\n import numpy as np\n from qiskit.circuit.library import EfficientSU2, UnitaryOverlap\n from qiskit.primitives import Sampler\n\n # get two circuit to prepare states of which we comput the overlap\n circuit = EfficientSU2(2, reps=1)\n unitary1 = circuit.assign_parameters(np.random.random(circuit.num_parameters))\n unitary2 = circuit.assign_parameters(np.random.random(circuit.num_parameters))\n\n # create the overlap circuit\n overlap = UnitaryOverap(unitary1, unitary2)\n\n # sample from the overlap\n sampler = Sampler(options={\"shots\": 100})\n result = sampler.run(overlap).result()\n\n # the fidelity is the probability to measure 0\n fidelity = result.quasi_dists[0].get(0, 0)\n\n \"\"\"\n\n def __init__(\n self, unitary1: QuantumCircuit, unitary2: QuantumCircuit, prefix1=\"p1\", prefix2=\"p2\"\n ):\n \"\"\"\n Args:\n unitary1: Unitary acting on the ket vector.\n unitary2: Unitary whose inverse operates on the bra vector.\n prefix1: The name of the parameter vector associated to ``unitary1``,\n if it is parameterized. Defaults to ``\"p1\"``.\n prefix2: The name of the parameter vector associated to ``unitary2``,\n if it is parameterized. Defaults to ``\"p2\"``.\n\n Raises:\n CircuitError: Number of qubits in ``unitary1`` and ``unitary2`` does not match.\n CircuitError: Inputs contain measurements and/or resets.\n \"\"\"\n # check inputs are valid\n if unitary1.num_qubits != unitary2.num_qubits:\n raise CircuitError(\n f\"Number of qubits in unitaries does \"\n f\"not match: {unitary1.num_qubits} != {unitary2.num_qubits}.\"\n )\n\n unitaries = [unitary1, unitary2]\n for unitary in unitaries:\n _check_unitary(unitary)\n\n # Vectors of new parameters, if any. Need the unitaries in a list here to ensure\n # we can overwrite them.\n for i, prefix in enumerate([prefix1, prefix2]):\n if unitaries[i].num_parameters > 0:\n new_params = ParameterVector(prefix, unitaries[i].num_parameters)\n unitaries[i] = unitaries[i].assign_parameters(new_params)\n\n # Generate the actual overlap circuit\n super().__init__(unitaries[0].num_qubits, name=\"UnitaryOverlap\")\n self.compose(unitaries[0], inplace=True)\n self.compose(unitaries[1].inverse(), inplace=True)\n\n\ndef _check_unitary(circuit):\n \"\"\"Check a circuit is unitary by checking if all operations are of type ``Gate``.\"\"\"\n\n for instruction in circuit.data:\n if not isinstance(instruction.operation, (Gate, Barrier)):\n raise CircuitError(\n (\n \"One or more instructions cannot be converted to\"\n ' a gate. \"{}\" is not a gate instruction'\n ).format(instruction.operation.name)\n )\n", "path": "qiskit/circuit/library/overlap.py"}]} | 1,880 | 346 |
gh_patches_debug_60680 | rasdani/github-patches | git_diff | OCHA-DAP__hdx-ckan-1798 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Ebola page: loading second page of datasets reloads to top of page
Would it be easy to have it load the page at the `Datasets [41]` line?
</issue>
<code>
[start of ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py]
1 '''
2 Created on Nov 3, 2014
3
4 @author: alexandru-m-g
5 '''
6
7 import logging
8 import datetime as dt
9 import decimal
10
11 import pylons.config as config
12
13 import ckan.lib.base as base
14 import ckan.logic as logic
15 import ckan.model as model
16 import ckan.common as common
17 import ckan.lib.helpers as h
18
19 render = base.render
20 get_action = logic.get_action
21 c = common.c
22 request = common.request
23 _ = common._
24
25 Decimal = decimal.Decimal
26
27 log = logging.getLogger(__name__)
28
29
30 class CrisisController(base.BaseController):
31
32 def show(self):
33
34 context = {'model': model, 'session': model.Session,
35 'user': c.user or c.author, 'for_view': True,
36 'auth_user_obj': c.userobj}
37
38 datastore_resource_id = self._get_datastore_resource_id(
39 context, config.get('hdx.crisis.ebola_dataset', None), config.get('hdx.crisis.ebola_resource_title', None))
40 if datastore_resource_id:
41 c.top_line_items = self._get_top_line_items(
42 context, datastore_resource_id)
43
44 limit = 25
45 c.q = u'ebola'
46
47 page = int(request.params.get('page', 1))
48 data_dict = {'sort': u'metadata_modified desc',
49 'fq': '+dataset_type:dataset',
50 'rows': limit,
51 'q': c.q,
52 'start': (page - 1) * limit
53 }
54 query = get_action("package_search")(context, data_dict)
55
56 def pager_url(q=None, page=None):
57 return h.url_for('show_crisis', page=page)
58
59 c.page = h.Page(
60 collection=query['results'],
61 page=page,
62 url=pager_url,
63 item_count=query['count'],
64 items_per_page=limit
65 )
66 c.items = query['results']
67 c.item_count = query['count']
68
69 c.other_links = {}
70 c.other_links['show_more'] = h.url_for(
71 "search", **{'q': u'ebola', 'sort': u'metadata_modified desc',
72 'ext_indicator': '0'})
73
74 return render('crisis/crisis.html')
75
76 def _get_decimal_value(self, value):
77 decimal_value = Decimal(str(value)).quantize(
78 Decimal('.1'), rounding=decimal.ROUND_HALF_UP)
79 return decimal_value
80
81 def _format_results(self, result):
82 for r in result['records']:
83 d = dt.datetime.strptime(r[u'latest_date'], '%Y-%m-%dT%H:%M:%S')
84 r[u'latest_date'] = dt.datetime.strftime(d, '%b %d, %Y')
85
86 modified_value = r[u'value']
87 if r[u'units'] == 'ratio':
88 modified_value *= 100.0
89 elif r[u'units'] == 'million':
90 modified_value /= 1000000.0
91
92 int_value = int(modified_value)
93 if int_value == modified_value:
94 r[u'formatted_value'] = '{:,}'.format(int_value)
95 else:
96 if r[u'units'] == 'ratio':
97 r[u'formatted_value'] = '{:,.1f}'.format(
98 self._get_decimal_value(modified_value))
99 elif r[u'units'] == 'million':
100 r[u'formatted_value'] = '{:,.1f}'.format(
101 self._get_decimal_value(modified_value))
102 #r[u'formatted_value'] += ' ' + _('million')
103
104 def _get_top_line_items(self, context, datastore_resource_id):
105 modified_context = dict(context)
106 modified_context['ignore_auth'] = True
107 result = get_action('datastore_search')(
108 modified_context, {'resource_id': datastore_resource_id})
109 if 'records' in result:
110 self._format_results(result)
111 return result['records']
112 return []
113
114 def _get_datastore_resource_id(self, context, dataset_id, resource_name):
115 try:
116 modified_context = dict(context)
117 modified_context['ignore_auth'] = True
118 dataset = get_action('package_show')(
119 modified_context, {'id': dataset_id})
120
121 if 'resources' in dataset:
122 for r in dataset['resources']:
123 if 'datastore_active' in r and r['datastore_active'] \
124 and r['name'] == resource_name:
125 return r['id']
126 return None
127 except:
128 log.warning('No dataset with id ' + dataset_id)
129 return None
130
[end of ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py b/ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py
--- a/ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py
+++ b/ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py
@@ -54,7 +54,8 @@
query = get_action("package_search")(context, data_dict)
def pager_url(q=None, page=None):
- return h.url_for('show_crisis', page=page)
+ url = h.url_for('show_crisis', page=page) + '#datasets-section'
+ return url
c.page = h.Page(
collection=query['results'],
| {"golden_diff": "diff --git a/ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py b/ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py\n--- a/ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py\n+++ b/ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py\n@@ -54,7 +54,8 @@\n query = get_action(\"package_search\")(context, data_dict)\n \n def pager_url(q=None, page=None):\n- return h.url_for('show_crisis', page=page)\n+ url = h.url_for('show_crisis', page=page) + '#datasets-section'\n+ return url\n \n c.page = h.Page(\n collection=query['results'],\n", "issue": "Ebola page: loading second page of datasets reloads to top of page\nWould it be easy to have it load the page at the `Datasets [41]` line?\n\n", "before_files": [{"content": "'''\nCreated on Nov 3, 2014\n\n@author: alexandru-m-g\n'''\n\nimport logging\nimport datetime as dt\nimport decimal\n\nimport pylons.config as config\n\nimport ckan.lib.base as base\nimport ckan.logic as logic\nimport ckan.model as model\nimport ckan.common as common\nimport ckan.lib.helpers as h\n\nrender = base.render\nget_action = logic.get_action\nc = common.c\nrequest = common.request\n_ = common._\n\nDecimal = decimal.Decimal\n\nlog = logging.getLogger(__name__)\n\n\nclass CrisisController(base.BaseController):\n\n def show(self):\n\n context = {'model': model, 'session': model.Session,\n 'user': c.user or c.author, 'for_view': True,\n 'auth_user_obj': c.userobj}\n\n datastore_resource_id = self._get_datastore_resource_id(\n context, config.get('hdx.crisis.ebola_dataset', None), config.get('hdx.crisis.ebola_resource_title', None))\n if datastore_resource_id:\n c.top_line_items = self._get_top_line_items(\n context, datastore_resource_id)\n\n limit = 25\n c.q = u'ebola'\n\n page = int(request.params.get('page', 1))\n data_dict = {'sort': u'metadata_modified desc',\n 'fq': '+dataset_type:dataset',\n 'rows': limit,\n 'q': c.q,\n 'start': (page - 1) * limit\n }\n query = get_action(\"package_search\")(context, data_dict)\n\n def pager_url(q=None, page=None):\n return h.url_for('show_crisis', page=page)\n\n c.page = h.Page(\n collection=query['results'],\n page=page,\n url=pager_url,\n item_count=query['count'],\n items_per_page=limit\n )\n c.items = query['results']\n c.item_count = query['count']\n\n c.other_links = {}\n c.other_links['show_more'] = h.url_for(\n \"search\", **{'q': u'ebola', 'sort': u'metadata_modified desc',\n 'ext_indicator': '0'})\n\n return render('crisis/crisis.html')\n\n def _get_decimal_value(self, value):\n decimal_value = Decimal(str(value)).quantize(\n Decimal('.1'), rounding=decimal.ROUND_HALF_UP)\n return decimal_value\n\n def _format_results(self, result):\n for r in result['records']:\n d = dt.datetime.strptime(r[u'latest_date'], '%Y-%m-%dT%H:%M:%S')\n r[u'latest_date'] = dt.datetime.strftime(d, '%b %d, %Y')\n\n modified_value = r[u'value']\n if r[u'units'] == 'ratio':\n modified_value *= 100.0\n elif r[u'units'] == 'million':\n modified_value /= 1000000.0\n\n int_value = int(modified_value)\n if int_value == modified_value:\n r[u'formatted_value'] = '{:,}'.format(int_value)\n else:\n if r[u'units'] == 'ratio':\n r[u'formatted_value'] = '{:,.1f}'.format(\n self._get_decimal_value(modified_value))\n elif r[u'units'] == 'million':\n r[u'formatted_value'] = '{:,.1f}'.format(\n self._get_decimal_value(modified_value))\n #r[u'formatted_value'] += ' ' + _('million')\n\n def _get_top_line_items(self, context, datastore_resource_id):\n modified_context = dict(context)\n modified_context['ignore_auth'] = True\n result = get_action('datastore_search')(\n modified_context, {'resource_id': datastore_resource_id})\n if 'records' in result:\n self._format_results(result)\n return result['records']\n return []\n\n def _get_datastore_resource_id(self, context, dataset_id, resource_name):\n try:\n modified_context = dict(context)\n modified_context['ignore_auth'] = True\n dataset = get_action('package_show')(\n modified_context, {'id': dataset_id})\n\n if 'resources' in dataset:\n for r in dataset['resources']:\n if 'datastore_active' in r and r['datastore_active'] \\\n and r['name'] == resource_name:\n return r['id']\n return None\n except:\n log.warning('No dataset with id ' + dataset_id)\n return None\n", "path": "ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py"}]} | 1,884 | 201 |
gh_patches_debug_7958 | rasdani/github-patches | git_diff | apache__tvm-13442 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug][ci] Deploy docs is busted
See for example https://ci.tlcpack.ai/blue/organizations/jenkins/tvm/detail/main/4756/pipeline
```
Traceback (most recent call last):
File "./ci/scripts/jenkins/s3.py", line 134, in <module>
chmod(files)
File "./ci/scripts/jenkins/s3.py", line 70, in chmod
SH.run(f"chmod +x {' '.join(to_chmod)}")
File "/tmp/jenkins-ba6c252c/workspace/exec_0/tvm/deploy-docs/ci/scripts/jenkins/cmd_utils.py", line 78, in run
return subprocess.run(cmd, **defaults)
File "/usr/lib/python3.8/subprocess.py", line 493, in run
with Popen(*popenargs, **kwargs) as process:
File "/usr/lib/python3.8/subprocess.py", line 858, in __init__
self._execute_child(args, executable, preexec_fn, close_fds,
File "/usr/lib/python3.8/subprocess.py", line 1704, in _execute_child
raise child_exception_type(errno_num, err_msg, err_filename)
OSError: [Errno 7] Argument list too long: '/bin/sh'
```
cc @Mousius @driazati @gigiblender
</issue>
<code>
[start of ci/scripts/jenkins/s3.py]
1 #!/usr/bin/env python3
2 # Licensed to the Apache Software Foundation (ASF) under one
3 # or more contributor license agreements. See the NOTICE file
4 # distributed with this work for additional information
5 # regarding copyright ownership. The ASF licenses this file
6 # to you under the Apache License, Version 2.0 (the
7 # "License"); you may not use this file except in compliance
8 # with the License. You may obtain a copy of the License at
9 #
10 # http://www.apache.org/licenses/LICENSE-2.0
11 #
12 # Unless required by applicable law or agreed to in writing,
13 # software distributed under the License is distributed on an
14 # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
15 # KIND, either express or implied. See the License for the
16 # specific language governing permissions and limitations
17 # under the License.
18
19 import argparse
20 import logging
21 import re
22 from pathlib import Path
23 from typing import List
24 from enum import Enum
25
26 from cmd_utils import Sh, REPO_ROOT, init_log
27
28 RETRY_SCRIPT = REPO_ROOT / "ci" / "scripts" / "jenkins" / "retry.sh"
29 S3_DOWNLOAD_REGEX = re.compile(r"download: s3://.* to (.*)")
30 SH = Sh()
31
32
33 class Action(Enum):
34 UPLOAD = 1
35 DOWNLOAD = 2
36
37
38 def show_md5(item: str) -> None:
39 if not Path(item).is_dir():
40 sh.run(f"md5sum {item}")
41
42
43 def parse_output_files(stdout: str) -> List[str]:
44 """
45 Grab the list of downloaded files from the output of 'aws s3 cp'. Lines look
46 like:
47
48 download: s3://some/prefix/a_file.txt to a_file.txt
49 """
50 files = []
51 for line in stdout.split("\n"):
52 line = line.strip()
53 if line == "":
54 continue
55 m = S3_DOWNLOAD_REGEX.match(line)
56 if m:
57 files.append(m.groups()[0])
58
59 return files
60
61
62 def chmod(files: List[str]) -> None:
63 """
64 S3 has no concept of file permissions so add them back in here to every file
65 """
66 # Add execute bit for downloads
67 to_chmod = [str(f) for f in files]
68 logging.info(f"Adding execute bit for files: {to_chmod}")
69 if len(to_chmod) > 0:
70 SH.run(f"chmod +x {' '.join(to_chmod)}")
71
72
73 def s3(source: str, destination: str, recursive: bool) -> List[str]:
74 """
75 Send or download the source to the destination in S3
76 """
77 cmd = f". {RETRY_SCRIPT.relative_to(REPO_ROOT)} && retry 3 aws s3 cp --no-progress"
78
79 if recursive:
80 cmd += " --recursive"
81
82 cmd += f" {source} {destination}"
83 _, stdout = SH.tee(cmd)
84 return stdout
85
86
87 if __name__ == "__main__":
88 init_log()
89 help = "Uploads or downloads files from S3"
90 parser = argparse.ArgumentParser(description=help)
91 parser.add_argument("--action", help="either 'upload' or 'download'", required=True)
92 parser.add_argument("--bucket", help="s3 bucket", required=True)
93 parser.add_argument(
94 "--prefix", help="s3 bucket + tag (e.g. s3://tvm-ci-prod/PR-1234/cpu", required=True
95 )
96 parser.add_argument("--items", help="files and folders to upload", nargs="+")
97
98 args = parser.parse_args()
99 logging.info(args)
100
101 sh = Sh()
102
103 if Path.cwd() != REPO_ROOT:
104 logging.error(f"s3.py can only be executed from the repo root, instead was in {Path.cwd()}")
105 exit(1)
106
107 prefix = args.prefix.strip("/")
108 s3_path = f"s3://{args.bucket}/{prefix}"
109 logging.info(f"Using s3 path: {s3_path}")
110
111 if args.action == "upload":
112 action = Action.UPLOAD
113 elif args.action == "download":
114 action = Action.DOWNLOAD
115 else:
116 logging.error(f"Unsupported action: {args.action}")
117 exit(1)
118
119 if args.items is None:
120 if args.action == "upload":
121 logging.error(f"Cannot upload without --items")
122 exit(1)
123 else:
124 # Download the whole prefix
125 items = ["."]
126
127 else:
128 items = args.items
129
130 for item in items:
131 if action == Action.DOWNLOAD:
132 stdout = s3(source=s3_path, destination=item, recursive=True)
133 files = parse_output_files(stdout)
134 chmod(files)
135 for file in files:
136 # Show md5 after downloading
137 show_md5(file)
138 elif action == Action.UPLOAD:
139 show_md5(item)
140 s3(item, s3_path + "/" + item, recursive=Path(item).is_dir())
141
[end of ci/scripts/jenkins/s3.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/ci/scripts/jenkins/s3.py b/ci/scripts/jenkins/s3.py
--- a/ci/scripts/jenkins/s3.py
+++ b/ci/scripts/jenkins/s3.py
@@ -129,7 +129,12 @@
for item in items:
if action == Action.DOWNLOAD:
- stdout = s3(source=s3_path, destination=item, recursive=True)
+ source = s3_path
+ recursive = True
+ if item != ".":
+ source = s3_path + "/" + item
+ recursive = False
+ stdout = s3(source=source, destination=item, recursive=recursive)
files = parse_output_files(stdout)
chmod(files)
for file in files:
| {"golden_diff": "diff --git a/ci/scripts/jenkins/s3.py b/ci/scripts/jenkins/s3.py\n--- a/ci/scripts/jenkins/s3.py\n+++ b/ci/scripts/jenkins/s3.py\n@@ -129,7 +129,12 @@\n \n for item in items:\n if action == Action.DOWNLOAD:\n- stdout = s3(source=s3_path, destination=item, recursive=True)\n+ source = s3_path\n+ recursive = True\n+ if item != \".\":\n+ source = s3_path + \"/\" + item\n+ recursive = False\n+ stdout = s3(source=source, destination=item, recursive=recursive)\n files = parse_output_files(stdout)\n chmod(files)\n for file in files:\n", "issue": "[Bug][ci] Deploy docs is busted\nSee for example https://ci.tlcpack.ai/blue/organizations/jenkins/tvm/detail/main/4756/pipeline\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"./ci/scripts/jenkins/s3.py\", line 134, in <module>\r\n chmod(files)\r\n File \"./ci/scripts/jenkins/s3.py\", line 70, in chmod\r\n SH.run(f\"chmod +x {' '.join(to_chmod)}\")\r\n File \"/tmp/jenkins-ba6c252c/workspace/exec_0/tvm/deploy-docs/ci/scripts/jenkins/cmd_utils.py\", line 78, in run\r\n return subprocess.run(cmd, **defaults)\r\n File \"/usr/lib/python3.8/subprocess.py\", line 493, in run\r\n with Popen(*popenargs, **kwargs) as process:\r\n File \"/usr/lib/python3.8/subprocess.py\", line 858, in __init__\r\n self._execute_child(args, executable, preexec_fn, close_fds,\r\n File \"/usr/lib/python3.8/subprocess.py\", line 1704, in _execute_child\r\n raise child_exception_type(errno_num, err_msg, err_filename)\r\nOSError: [Errno 7] Argument list too long: '/bin/sh'\r\n```\n\ncc @Mousius @driazati @gigiblender\n", "before_files": [{"content": "#!/usr/bin/env python3\n# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n\nimport argparse\nimport logging\nimport re\nfrom pathlib import Path\nfrom typing import List\nfrom enum import Enum\n\nfrom cmd_utils import Sh, REPO_ROOT, init_log\n\nRETRY_SCRIPT = REPO_ROOT / \"ci\" / \"scripts\" / \"jenkins\" / \"retry.sh\"\nS3_DOWNLOAD_REGEX = re.compile(r\"download: s3://.* to (.*)\")\nSH = Sh()\n\n\nclass Action(Enum):\n UPLOAD = 1\n DOWNLOAD = 2\n\n\ndef show_md5(item: str) -> None:\n if not Path(item).is_dir():\n sh.run(f\"md5sum {item}\")\n\n\ndef parse_output_files(stdout: str) -> List[str]:\n \"\"\"\n Grab the list of downloaded files from the output of 'aws s3 cp'. Lines look\n like:\n\n download: s3://some/prefix/a_file.txt to a_file.txt\n \"\"\"\n files = []\n for line in stdout.split(\"\\n\"):\n line = line.strip()\n if line == \"\":\n continue\n m = S3_DOWNLOAD_REGEX.match(line)\n if m:\n files.append(m.groups()[0])\n\n return files\n\n\ndef chmod(files: List[str]) -> None:\n \"\"\"\n S3 has no concept of file permissions so add them back in here to every file\n \"\"\"\n # Add execute bit for downloads\n to_chmod = [str(f) for f in files]\n logging.info(f\"Adding execute bit for files: {to_chmod}\")\n if len(to_chmod) > 0:\n SH.run(f\"chmod +x {' '.join(to_chmod)}\")\n\n\ndef s3(source: str, destination: str, recursive: bool) -> List[str]:\n \"\"\"\n Send or download the source to the destination in S3\n \"\"\"\n cmd = f\". {RETRY_SCRIPT.relative_to(REPO_ROOT)} && retry 3 aws s3 cp --no-progress\"\n\n if recursive:\n cmd += \" --recursive\"\n\n cmd += f\" {source} {destination}\"\n _, stdout = SH.tee(cmd)\n return stdout\n\n\nif __name__ == \"__main__\":\n init_log()\n help = \"Uploads or downloads files from S3\"\n parser = argparse.ArgumentParser(description=help)\n parser.add_argument(\"--action\", help=\"either 'upload' or 'download'\", required=True)\n parser.add_argument(\"--bucket\", help=\"s3 bucket\", required=True)\n parser.add_argument(\n \"--prefix\", help=\"s3 bucket + tag (e.g. s3://tvm-ci-prod/PR-1234/cpu\", required=True\n )\n parser.add_argument(\"--items\", help=\"files and folders to upload\", nargs=\"+\")\n\n args = parser.parse_args()\n logging.info(args)\n\n sh = Sh()\n\n if Path.cwd() != REPO_ROOT:\n logging.error(f\"s3.py can only be executed from the repo root, instead was in {Path.cwd()}\")\n exit(1)\n\n prefix = args.prefix.strip(\"/\")\n s3_path = f\"s3://{args.bucket}/{prefix}\"\n logging.info(f\"Using s3 path: {s3_path}\")\n\n if args.action == \"upload\":\n action = Action.UPLOAD\n elif args.action == \"download\":\n action = Action.DOWNLOAD\n else:\n logging.error(f\"Unsupported action: {args.action}\")\n exit(1)\n\n if args.items is None:\n if args.action == \"upload\":\n logging.error(f\"Cannot upload without --items\")\n exit(1)\n else:\n # Download the whole prefix\n items = [\".\"]\n\n else:\n items = args.items\n\n for item in items:\n if action == Action.DOWNLOAD:\n stdout = s3(source=s3_path, destination=item, recursive=True)\n files = parse_output_files(stdout)\n chmod(files)\n for file in files:\n # Show md5 after downloading\n show_md5(file)\n elif action == Action.UPLOAD:\n show_md5(item)\n s3(item, s3_path + \"/\" + item, recursive=Path(item).is_dir())\n", "path": "ci/scripts/jenkins/s3.py"}]} | 2,234 | 165 |
gh_patches_debug_37188 | rasdani/github-patches | git_diff | pfnet__pytorch-pfn-extras-159 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Make TensorBoardWriter no-op if tensorboard is not available
</issue>
<code>
[start of example/mnist.py]
1 import argparse
2 import torch
3 import torch.nn as nn
4 import torch.nn.functional as F
5 import torch.optim as optim
6 from torchvision import datasets, transforms
7
8 import pytorch_pfn_extras as ppe
9 import pytorch_pfn_extras.training.extensions as extensions
10
11
12 class Net(nn.Module):
13 def __init__(self):
14 super().__init__()
15 self.conv1 = nn.Conv2d(1, 20, 5, 1)
16 self.conv2 = nn.Conv2d(20, 50, 5, 1)
17 self.fc1 = nn.Linear(4 * 4 * 50, 500)
18 self.fc2 = nn.Linear(500, 10)
19
20 def forward(self, x):
21 x = F.relu(self.conv1(x))
22 x = F.max_pool2d(x, 2, 2)
23 x = F.relu(self.conv2(x))
24 x = F.max_pool2d(x, 2, 2)
25 x = x.flatten(start_dim=1)
26 x = F.relu(self.fc1(x))
27 x = self.fc2(x)
28 ppe.nn.ensure(x, shape=(None, 10))
29 return F.log_softmax(x, dim=1)
30
31
32 def train(manager, args, model, device, train_loader):
33 while not manager.stop_trigger:
34 model.train()
35 for _, (data, target) in enumerate(train_loader):
36 with manager.run_iteration(step_optimizers=['main']):
37 data, target = data.to(device), target.to(device)
38 output = model(data)
39 loss = F.nll_loss(output, target)
40 ppe.reporting.report({'train/loss': loss.item()})
41 loss.backward()
42
43
44 def test(args, model, device, data, target):
45 """ The extension loops over the iterator in order to
46 drive the evaluator progress bar and reporting
47 averages
48 """
49 model.eval()
50 data, target = data.to(device), target.to(device)
51 output = model(data)
52 # Final result will be average of averages of the same size
53 test_loss = F.nll_loss(output, target, reduction='mean').item()
54 ppe.reporting.report({'val/loss': test_loss})
55 pred = output.argmax(dim=1, keepdim=True)
56
57 correct = pred.eq(target.view_as(pred)).sum().item()
58 ppe.reporting.report({'val/acc': correct / len(data)})
59
60
61 def main():
62 # Training settings
63 parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
64 parser.add_argument('--batch-size', type=int, default=64, metavar='N',
65 help='input batch size for training (default: 64)')
66 parser.add_argument('--test-batch-size', type=int, default=1000,
67 metavar='N',
68 help='input batch size for testing (default: 1000)')
69 parser.add_argument('--epochs', type=int, default=10, metavar='N',
70 help='number of epochs to train (default: 10)')
71 parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
72 help='learning rate (default: 0.01)')
73 parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
74 help='SGD momentum (default: 0.5)')
75 parser.add_argument('--no-cuda', dest='cuda',
76 action='store_false', default=True,
77 help='disables CUDA training')
78 parser.add_argument('--seed', type=int, default=1, metavar='S',
79 help='random seed (default: 1)')
80 parser.add_argument('--save-model', action='store_true', default=False,
81 help='For Saving the current Model')
82 parser.add_argument('--snapshot', type=str, default=None,
83 help='path to snapshot file')
84 args = parser.parse_args()
85 use_cuda = args.cuda and torch.cuda.is_available()
86
87 torch.manual_seed(args.seed)
88
89 device = torch.device("cuda" if use_cuda else "cpu")
90
91 kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}
92 train_loader = torch.utils.data.DataLoader(
93 datasets.MNIST('../data', train=True, download=True,
94 transform=transforms.Compose([
95 transforms.ToTensor(),
96 transforms.Normalize((0.1307,), (0.3081,))
97 ])),
98 batch_size=args.batch_size, shuffle=True,
99 **kwargs) # type: ignore[arg-type]
100 test_loader = torch.utils.data.DataLoader(
101 datasets.MNIST('../data', train=False, transform=transforms.Compose([
102 transforms.ToTensor(),
103 transforms.Normalize((0.1307,), (0.3081,))
104 ])),
105 batch_size=args.test_batch_size, shuffle=True,
106 **kwargs) # type: ignore[arg-type]
107
108 model = Net()
109 model.to(device)
110
111 optimizer = optim.SGD(
112 model.parameters(), lr=args.lr, momentum=args.momentum)
113
114 # manager.extend(...) also works
115 my_extensions = [
116 extensions.LogReport(),
117 extensions.ProgressBar(),
118 extensions.observe_lr(optimizer=optimizer),
119 extensions.ParameterStatistics(model, prefix='model'),
120 extensions.VariableStatisticsPlot(model),
121 extensions.Evaluator(
122 test_loader, model,
123 eval_func=lambda data, target:
124 test(args, model, device, data, target),
125 progress_bar=True),
126 extensions.PlotReport(
127 ['train/loss', 'val/loss'], 'epoch', filename='loss.png'),
128 extensions.PrintReport(['epoch', 'iteration',
129 'train/loss', 'lr', 'model/fc2.bias/grad/min',
130 'val/loss', 'val/acc']),
131 extensions.snapshot(),
132 ]
133 # Custom stop triggers can be added to the manager and
134 # their status accessed through `manager.stop_trigger`
135 trigger = None
136 # trigger = ppe.training.triggers.EarlyStoppingTrigger(
137 # check_trigger=(1, 'epoch'), monitor='val/loss')
138 manager = ppe.training.ExtensionsManager(
139 model, optimizer, args.epochs,
140 extensions=my_extensions,
141 iters_per_epoch=len(train_loader),
142 stop_trigger=trigger)
143 # Lets load the snapshot
144 if args.snapshot is not None:
145 state = torch.load(args.snapshot)
146 manager.load_state_dict(state)
147 train(manager, args, model, device, train_loader)
148 # Test function is called from the evaluator extension
149 # to get access to the reporter and other facilities
150 # test(args, model, device, test_loader)
151
152 if (args.save_model):
153 torch.save(model.state_dict(), "mnist_cnn.pt")
154
155
156 if __name__ == '__main__':
157 main()
158
[end of example/mnist.py]
[start of pytorch_pfn_extras/writing/_tensorboard_writer.py]
1 from typing import Any, KeysView, Optional
2
3 from pytorch_pfn_extras.writing._writer_base import (
4 _TargetType, _SaveFun, _FileSystem
5 )
6
7
8 class TensorBoardWriter(object):
9 """ Writer that sends statistics to TensorBoard.
10
11 This class contains a `torch.utils.tensorboard.SummaryWriter`
12 object that is used to send the collected statistics to TensorBoard.
13 A list of stats can be specified to report only the desired ones.
14
15 Args:
16 savefun: Ignored.
17 fs: Ignored.
18 out_dir: Passed as ``log_dir`` argument to SummaryWriter.
19 stats (list): List of statistic keys.
20 kwds: Passed as an additional arguments to SummaryWriter.
21 """
22 def __init__(
23 self,
24 savefun: Optional[_SaveFun] = None,
25 fs: _FileSystem = None,
26 out_dir: Optional[str] = None,
27 stats: Optional[KeysView[str]] = None,
28 **kwds: Any
29 ) -> None:
30 from torch.utils.tensorboard import SummaryWriter
31 self._stats = stats
32 self._writer: Optional[SummaryWriter] = (
33 SummaryWriter( # type: ignore[no-untyped-call]
34 log_dir=out_dir, **kwds))
35
36 def __del__(self) -> None:
37 self.finalize()
38
39 def __call__(
40 self,
41 filename: str,
42 out_dir: str,
43 target: _TargetType,
44 *,
45 savefun: Optional[_SaveFun] = None,
46 append: bool = False,
47 ) -> None:
48 """Sends the statistics to the TensorBoard.
49
50 Args:
51 filename: Ignored.
52 out_dir: Ignored.
53 target (dict or list): The statistics of the iteration. If given as
54 a list, only the last element (assumed to be a dict containing
55 the latest iteration statistics) is reported.
56 savefun: Ignored.
57 append: Ignored.
58 """
59 if self._writer is None:
60 raise RuntimeError('TensorBoardWriter already finalized')
61
62 stats_cpu = target
63 if isinstance(target, list):
64 stats_cpu = target[-1]
65
66 if not isinstance(stats_cpu, dict):
67 raise TypeError('target must be dict or list of dicts')
68 keys = stats_cpu.keys()
69 if self._stats is not None:
70 keys = self._stats
71 for key in keys:
72 value = stats_cpu[key]
73 self._writer.add_scalar( # type: ignore[no-untyped-call]
74 key, value, stats_cpu['iteration'])
75
76 def finalize(self) -> None:
77 writer = self._writer
78 if writer is not None:
79 writer.close() # type: ignore[no-untyped-call]
80 self._writer = None
81
[end of pytorch_pfn_extras/writing/_tensorboard_writer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/example/mnist.py b/example/mnist.py
--- a/example/mnist.py
+++ b/example/mnist.py
@@ -114,6 +114,12 @@
# manager.extend(...) also works
my_extensions = [
extensions.LogReport(),
+
+ # Enables TensorBoard support.
+ # Run `tensorboard --logdir runs` to launch the TensorBoard.
+ extensions.LogReport(
+ writer=ppe.writing.TensorBoardWriter(out_dir='runs'),
+ trigger=(1, 'iteration')),
extensions.ProgressBar(),
extensions.observe_lr(optimizer=optimizer),
extensions.ParameterStatistics(model, prefix='model'),
diff --git a/pytorch_pfn_extras/writing/_tensorboard_writer.py b/pytorch_pfn_extras/writing/_tensorboard_writer.py
--- a/pytorch_pfn_extras/writing/_tensorboard_writer.py
+++ b/pytorch_pfn_extras/writing/_tensorboard_writer.py
@@ -1,4 +1,5 @@
from typing import Any, KeysView, Optional
+import warnings
from pytorch_pfn_extras.writing._writer_base import (
_TargetType, _SaveFun, _FileSystem
@@ -27,10 +28,17 @@
stats: Optional[KeysView[str]] = None,
**kwds: Any
) -> None:
- from torch.utils.tensorboard import SummaryWriter
+ self._writer = None
+ try:
+ import torch.utils.tensorboard
+ except ImportError:
+ warnings.warn(
+ 'tensorboard is unavailable. '
+ 'TensorBoardWriter will do nothing.')
+ return
self._stats = stats
- self._writer: Optional[SummaryWriter] = (
- SummaryWriter( # type: ignore[no-untyped-call]
+ self._writer = (
+ torch.utils.tensorboard.SummaryWriter( # type: ignore[no-untyped-call]
log_dir=out_dir, **kwds))
def __del__(self) -> None:
@@ -57,8 +65,7 @@
append: Ignored.
"""
if self._writer is None:
- raise RuntimeError('TensorBoardWriter already finalized')
-
+ return
stats_cpu = target
if isinstance(target, list):
stats_cpu = target[-1]
@@ -74,7 +81,6 @@
key, value, stats_cpu['iteration'])
def finalize(self) -> None:
- writer = self._writer
- if writer is not None:
- writer.close() # type: ignore[no-untyped-call]
- self._writer = None
+ if self._writer is not None:
+ self._writer.close() # type: ignore[no-untyped-call]
+ self._writer = None
| {"golden_diff": "diff --git a/example/mnist.py b/example/mnist.py\n--- a/example/mnist.py\n+++ b/example/mnist.py\n@@ -114,6 +114,12 @@\n # manager.extend(...) also works\n my_extensions = [\n extensions.LogReport(),\n+\n+ # Enables TensorBoard support.\n+ # Run `tensorboard --logdir runs` to launch the TensorBoard.\n+ extensions.LogReport(\n+ writer=ppe.writing.TensorBoardWriter(out_dir='runs'),\n+ trigger=(1, 'iteration')),\n extensions.ProgressBar(),\n extensions.observe_lr(optimizer=optimizer),\n extensions.ParameterStatistics(model, prefix='model'),\ndiff --git a/pytorch_pfn_extras/writing/_tensorboard_writer.py b/pytorch_pfn_extras/writing/_tensorboard_writer.py\n--- a/pytorch_pfn_extras/writing/_tensorboard_writer.py\n+++ b/pytorch_pfn_extras/writing/_tensorboard_writer.py\n@@ -1,4 +1,5 @@\n from typing import Any, KeysView, Optional\n+import warnings\n \n from pytorch_pfn_extras.writing._writer_base import (\n _TargetType, _SaveFun, _FileSystem\n@@ -27,10 +28,17 @@\n stats: Optional[KeysView[str]] = None,\n **kwds: Any\n ) -> None:\n- from torch.utils.tensorboard import SummaryWriter\n+ self._writer = None\n+ try:\n+ import torch.utils.tensorboard\n+ except ImportError:\n+ warnings.warn(\n+ 'tensorboard is unavailable. '\n+ 'TensorBoardWriter will do nothing.')\n+ return\n self._stats = stats\n- self._writer: Optional[SummaryWriter] = (\n- SummaryWriter( # type: ignore[no-untyped-call]\n+ self._writer = (\n+ torch.utils.tensorboard.SummaryWriter( # type: ignore[no-untyped-call]\n log_dir=out_dir, **kwds))\n \n def __del__(self) -> None:\n@@ -57,8 +65,7 @@\n append: Ignored.\n \"\"\"\n if self._writer is None:\n- raise RuntimeError('TensorBoardWriter already finalized')\n-\n+ return\n stats_cpu = target\n if isinstance(target, list):\n stats_cpu = target[-1]\n@@ -74,7 +81,6 @@\n key, value, stats_cpu['iteration'])\n \n def finalize(self) -> None:\n- writer = self._writer\n- if writer is not None:\n- writer.close() # type: ignore[no-untyped-call]\n- self._writer = None\n+ if self._writer is not None:\n+ self._writer.close() # type: ignore[no-untyped-call]\n+ self._writer = None\n", "issue": "Make TensorBoardWriter no-op if tensorboard is not available\n\n", "before_files": [{"content": "import argparse\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torch.optim as optim\nfrom torchvision import datasets, transforms\n\nimport pytorch_pfn_extras as ppe\nimport pytorch_pfn_extras.training.extensions as extensions\n\n\nclass Net(nn.Module):\n def __init__(self):\n super().__init__()\n self.conv1 = nn.Conv2d(1, 20, 5, 1)\n self.conv2 = nn.Conv2d(20, 50, 5, 1)\n self.fc1 = nn.Linear(4 * 4 * 50, 500)\n self.fc2 = nn.Linear(500, 10)\n\n def forward(self, x):\n x = F.relu(self.conv1(x))\n x = F.max_pool2d(x, 2, 2)\n x = F.relu(self.conv2(x))\n x = F.max_pool2d(x, 2, 2)\n x = x.flatten(start_dim=1)\n x = F.relu(self.fc1(x))\n x = self.fc2(x)\n ppe.nn.ensure(x, shape=(None, 10))\n return F.log_softmax(x, dim=1)\n\n\ndef train(manager, args, model, device, train_loader):\n while not manager.stop_trigger:\n model.train()\n for _, (data, target) in enumerate(train_loader):\n with manager.run_iteration(step_optimizers=['main']):\n data, target = data.to(device), target.to(device)\n output = model(data)\n loss = F.nll_loss(output, target)\n ppe.reporting.report({'train/loss': loss.item()})\n loss.backward()\n\n\ndef test(args, model, device, data, target):\n \"\"\" The extension loops over the iterator in order to\n drive the evaluator progress bar and reporting\n averages\n \"\"\"\n model.eval()\n data, target = data.to(device), target.to(device)\n output = model(data)\n # Final result will be average of averages of the same size\n test_loss = F.nll_loss(output, target, reduction='mean').item()\n ppe.reporting.report({'val/loss': test_loss})\n pred = output.argmax(dim=1, keepdim=True)\n\n correct = pred.eq(target.view_as(pred)).sum().item()\n ppe.reporting.report({'val/acc': correct / len(data)})\n\n\ndef main():\n # Training settings\n parser = argparse.ArgumentParser(description='PyTorch MNIST Example')\n parser.add_argument('--batch-size', type=int, default=64, metavar='N',\n help='input batch size for training (default: 64)')\n parser.add_argument('--test-batch-size', type=int, default=1000,\n metavar='N',\n help='input batch size for testing (default: 1000)')\n parser.add_argument('--epochs', type=int, default=10, metavar='N',\n help='number of epochs to train (default: 10)')\n parser.add_argument('--lr', type=float, default=0.01, metavar='LR',\n help='learning rate (default: 0.01)')\n parser.add_argument('--momentum', type=float, default=0.5, metavar='M',\n help='SGD momentum (default: 0.5)')\n parser.add_argument('--no-cuda', dest='cuda',\n action='store_false', default=True,\n help='disables CUDA training')\n parser.add_argument('--seed', type=int, default=1, metavar='S',\n help='random seed (default: 1)')\n parser.add_argument('--save-model', action='store_true', default=False,\n help='For Saving the current Model')\n parser.add_argument('--snapshot', type=str, default=None,\n help='path to snapshot file')\n args = parser.parse_args()\n use_cuda = args.cuda and torch.cuda.is_available()\n\n torch.manual_seed(args.seed)\n\n device = torch.device(\"cuda\" if use_cuda else \"cpu\")\n\n kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}\n train_loader = torch.utils.data.DataLoader(\n datasets.MNIST('../data', train=True, download=True,\n transform=transforms.Compose([\n transforms.ToTensor(),\n transforms.Normalize((0.1307,), (0.3081,))\n ])),\n batch_size=args.batch_size, shuffle=True,\n **kwargs) # type: ignore[arg-type]\n test_loader = torch.utils.data.DataLoader(\n datasets.MNIST('../data', train=False, transform=transforms.Compose([\n transforms.ToTensor(),\n transforms.Normalize((0.1307,), (0.3081,))\n ])),\n batch_size=args.test_batch_size, shuffle=True,\n **kwargs) # type: ignore[arg-type]\n\n model = Net()\n model.to(device)\n\n optimizer = optim.SGD(\n model.parameters(), lr=args.lr, momentum=args.momentum)\n\n # manager.extend(...) also works\n my_extensions = [\n extensions.LogReport(),\n extensions.ProgressBar(),\n extensions.observe_lr(optimizer=optimizer),\n extensions.ParameterStatistics(model, prefix='model'),\n extensions.VariableStatisticsPlot(model),\n extensions.Evaluator(\n test_loader, model,\n eval_func=lambda data, target:\n test(args, model, device, data, target),\n progress_bar=True),\n extensions.PlotReport(\n ['train/loss', 'val/loss'], 'epoch', filename='loss.png'),\n extensions.PrintReport(['epoch', 'iteration',\n 'train/loss', 'lr', 'model/fc2.bias/grad/min',\n 'val/loss', 'val/acc']),\n extensions.snapshot(),\n ]\n # Custom stop triggers can be added to the manager and\n # their status accessed through `manager.stop_trigger`\n trigger = None\n # trigger = ppe.training.triggers.EarlyStoppingTrigger(\n # check_trigger=(1, 'epoch'), monitor='val/loss')\n manager = ppe.training.ExtensionsManager(\n model, optimizer, args.epochs,\n extensions=my_extensions,\n iters_per_epoch=len(train_loader),\n stop_trigger=trigger)\n # Lets load the snapshot\n if args.snapshot is not None:\n state = torch.load(args.snapshot)\n manager.load_state_dict(state)\n train(manager, args, model, device, train_loader)\n # Test function is called from the evaluator extension\n # to get access to the reporter and other facilities\n # test(args, model, device, test_loader)\n\n if (args.save_model):\n torch.save(model.state_dict(), \"mnist_cnn.pt\")\n\n\nif __name__ == '__main__':\n main()\n", "path": "example/mnist.py"}, {"content": "from typing import Any, KeysView, Optional\n\nfrom pytorch_pfn_extras.writing._writer_base import (\n _TargetType, _SaveFun, _FileSystem\n)\n\n\nclass TensorBoardWriter(object):\n \"\"\" Writer that sends statistics to TensorBoard.\n\n This class contains a `torch.utils.tensorboard.SummaryWriter`\n object that is used to send the collected statistics to TensorBoard.\n A list of stats can be specified to report only the desired ones.\n\n Args:\n savefun: Ignored.\n fs: Ignored.\n out_dir: Passed as ``log_dir`` argument to SummaryWriter.\n stats (list): List of statistic keys.\n kwds: Passed as an additional arguments to SummaryWriter.\n \"\"\"\n def __init__(\n self,\n savefun: Optional[_SaveFun] = None,\n fs: _FileSystem = None,\n out_dir: Optional[str] = None,\n stats: Optional[KeysView[str]] = None,\n **kwds: Any\n ) -> None:\n from torch.utils.tensorboard import SummaryWriter\n self._stats = stats\n self._writer: Optional[SummaryWriter] = (\n SummaryWriter( # type: ignore[no-untyped-call]\n log_dir=out_dir, **kwds))\n\n def __del__(self) -> None:\n self.finalize()\n\n def __call__(\n self,\n filename: str,\n out_dir: str,\n target: _TargetType,\n *,\n savefun: Optional[_SaveFun] = None,\n append: bool = False,\n ) -> None:\n \"\"\"Sends the statistics to the TensorBoard.\n\n Args:\n filename: Ignored.\n out_dir: Ignored.\n target (dict or list): The statistics of the iteration. If given as\n a list, only the last element (assumed to be a dict containing\n the latest iteration statistics) is reported.\n savefun: Ignored.\n append: Ignored.\n \"\"\"\n if self._writer is None:\n raise RuntimeError('TensorBoardWriter already finalized')\n\n stats_cpu = target\n if isinstance(target, list):\n stats_cpu = target[-1]\n\n if not isinstance(stats_cpu, dict):\n raise TypeError('target must be dict or list of dicts')\n keys = stats_cpu.keys()\n if self._stats is not None:\n keys = self._stats\n for key in keys:\n value = stats_cpu[key]\n self._writer.add_scalar( # type: ignore[no-untyped-call]\n key, value, stats_cpu['iteration'])\n\n def finalize(self) -> None:\n writer = self._writer\n if writer is not None:\n writer.close() # type: ignore[no-untyped-call]\n self._writer = None\n", "path": "pytorch_pfn_extras/writing/_tensorboard_writer.py"}]} | 3,147 | 612 |
gh_patches_debug_2938 | rasdani/github-patches | git_diff | Parsl__parsl-613 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
TorqueProvider fails on NSCC
The following patch is required in order to run the `TorqueProvider` on NSCC:
```
[nscc04] ~/libsubmit >git diff
diff --git a/libsubmit/providers/torque/template.py b/libsubmit/providers/torque/template.py
index a00ce7c..056c648 100644
--- a/libsubmit/providers/torque/template.py
+++ b/libsubmit/providers/torque/template.py
@@ -8,7 +8,6 @@ template_string = '''#!/bin/bash
#PBS -l nodes=${nodes_per_block}:ppn=${tasks_per_node}
#PBS -o ${submit_script_dir}/${jobname}.submit.stdout
#PBS -e ${submit_script_dir}/${jobname}.submit.stderr
-#PBS -v WORKER_LOGGING_LEVEL
${overrides}
export JOBNAME="${jobname}"
```
Otherwise, the job fails with `qsub: cannot send environment with the job`. Could we just merge the patch, or should we make this configurable somehow?
</issue>
<code>
[start of parsl/providers/torque/template.py]
1 template_string = '''#!/bin/bash
2
3 #PBS -S /bin/bash
4 #PBS -N ${jobname}
5 #PBS -m n
6 #PBS -k eo
7 #PBS -l walltime=$walltime
8 #PBS -l nodes=${nodes_per_block}:ppn=${tasks_per_node}
9 #PBS -o ${submit_script_dir}/${jobname}.submit.stdout
10 #PBS -e ${submit_script_dir}/${jobname}.submit.stderr
11 #PBS -v WORKER_LOGGING_LEVEL
12 ${overrides}
13
14 export JOBNAME="${jobname}"
15
16 ${user_script}
17
18 '''
19
[end of parsl/providers/torque/template.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/parsl/providers/torque/template.py b/parsl/providers/torque/template.py
--- a/parsl/providers/torque/template.py
+++ b/parsl/providers/torque/template.py
@@ -8,7 +8,6 @@
#PBS -l nodes=${nodes_per_block}:ppn=${tasks_per_node}
#PBS -o ${submit_script_dir}/${jobname}.submit.stdout
#PBS -e ${submit_script_dir}/${jobname}.submit.stderr
-#PBS -v WORKER_LOGGING_LEVEL
${overrides}
export JOBNAME="${jobname}"
| {"golden_diff": "diff --git a/parsl/providers/torque/template.py b/parsl/providers/torque/template.py\n--- a/parsl/providers/torque/template.py\n+++ b/parsl/providers/torque/template.py\n@@ -8,7 +8,6 @@\n #PBS -l nodes=${nodes_per_block}:ppn=${tasks_per_node}\n #PBS -o ${submit_script_dir}/${jobname}.submit.stdout\n #PBS -e ${submit_script_dir}/${jobname}.submit.stderr\n-#PBS -v WORKER_LOGGING_LEVEL\n ${overrides}\n \n export JOBNAME=\"${jobname}\"\n", "issue": "TorqueProvider fails on NSCC \nThe following patch is required in order to run the `TorqueProvider` on NSCC:\r\n```\r\n[nscc04] ~/libsubmit >git diff\r\ndiff --git a/libsubmit/providers/torque/template.py b/libsubmit/providers/torque/template.py\r\nindex a00ce7c..056c648 100644\r\n--- a/libsubmit/providers/torque/template.py\r\n+++ b/libsubmit/providers/torque/template.py\r\n@@ -8,7 +8,6 @@ template_string = '''#!/bin/bash\r\n #PBS -l nodes=${nodes_per_block}:ppn=${tasks_per_node}\r\n #PBS -o ${submit_script_dir}/${jobname}.submit.stdout\r\n #PBS -e ${submit_script_dir}/${jobname}.submit.stderr\r\n-#PBS -v WORKER_LOGGING_LEVEL\r\n ${overrides}\r\n\r\n export JOBNAME=\"${jobname}\"\r\n```\r\n\r\nOtherwise, the job fails with `qsub: cannot send environment with the job`. Could we just merge the patch, or should we make this configurable somehow?\n", "before_files": [{"content": "template_string = '''#!/bin/bash\n\n#PBS -S /bin/bash\n#PBS -N ${jobname}\n#PBS -m n\n#PBS -k eo\n#PBS -l walltime=$walltime\n#PBS -l nodes=${nodes_per_block}:ppn=${tasks_per_node}\n#PBS -o ${submit_script_dir}/${jobname}.submit.stdout\n#PBS -e ${submit_script_dir}/${jobname}.submit.stderr\n#PBS -v WORKER_LOGGING_LEVEL\n${overrides}\n\nexport JOBNAME=\"${jobname}\"\n\n${user_script}\n\n'''\n", "path": "parsl/providers/torque/template.py"}]} | 916 | 123 |
gh_patches_debug_584 | rasdani/github-patches | git_diff | pex-tool__pex-1709 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Release 2.1.77
On the docket:
+ [x] Fix pathologic lock creation slowness. #1707
+ [x] Support uncompressed PEXes. (#1705)
</issue>
<code>
[start of pex/version.py]
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = "2.1.76"
5
[end of pex/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = "2.1.76"
+__version__ = "2.1.77"
| {"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = \"2.1.76\"\n+__version__ = \"2.1.77\"\n", "issue": "Release 2.1.77\nOn the docket:\r\n+ [x] Fix pathologic lock creation slowness. #1707 \r\n+ [x] Support uncompressed PEXes. (#1705)\n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.76\"\n", "path": "pex/version.py"}]} | 631 | 96 |
gh_patches_debug_38123 | rasdani/github-patches | git_diff | kubeflow__pipelines-5750 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[v2compat] configurable default pipeline root
Quoted from https://github.com/kubeflow/pipelines/issues/4649#issuecomment-844035914
Blocks https://github.com/kubeflow/pipelines/issues/5680
> FYI, KFP v2 compatible mode has been released, see documentation: https://www.kubeflow.org/docs/components/pipelines/sdk/v2/.
>
> It doesn't support artifact repository configuration, this is one of the things we want to support too. So I'm posting early thoughts on this related issue.
>
> Let me first try to summarize requirements for configuring artifact repositories for both KFP v2 compatible and v2.
>
> ## Object store specific credentials requirements
> For GCS, AWS S3, we suggest setting up credentials, so that they represent identity of the pipeline step, so that not only artifact upload/download, calls to other Cloud services should also use the same credentials. For this reason, we don't recommend setting credentials in artifact repository config. The suggestion is to configure the identity transparently if possible using GCP workload identity or AWS IRSA. If credentials are really necessary, they can be configured using pipeline DSL via [kfp.gcp.use_gcp_secret](https://kubeflow-pipelines.readthedocs.io/en/latest/source/kfp.extensions.html#kfp.gcp.use_gcp_secret) or [kfp.aws.use_aws_secret](https://kubeflow-pipelines.readthedocs.io/en/latest/source/kfp.extensions.html#kfp.aws.use_aws_secret) etc. These principles should apply to other Cloud Providers that has credentials that can be used with all its services.
>
> For on-prem object store like MinIO, the credentials do not represent an identity, they are only used to access a specified object store instance. Therefore, it's reasonable to include them in artifact repository config.
>
> ## In summary
> * For GCS, only pipeline root needs to be configurable.
> * For AWS S3, besides pipeline root, we also need region, endpoint etc to be configurable.
> * For MinIO or similar on-prem object stores, besides pipeline root, we also need endpoint, credentials to be configurable.
>
> We cannot implement a spec for every possible object stores, so likely we should use the same spec as what [Go CDK](https://gocloud.dev/) supports or depend on cloud provider contributions.
>
> Go CDK supports provider specific query params to configure some things other than object key, so we might consider adopting these query params, so that pipeline root can be more expressive, so we might not need other configurations.
> e.g. for S3, it's possible to configure region via a query param: https://gocloud.dev/howto/blob/#s3
>
> ```
> s3://my-bucket?region=us-west-1
> ```
>
> ## How we configure pipeline root, other configs and credentials?
> Ideally, pipeline root can include all other configs, so that we can uniquely identify an artifact.
> Ideally, credentials should be configurable transparently.
>
> When both ideal requirements are met, we only need to support namespace level default pipeline root. All other configurations can be done by specifying different pipeline roots.
>
> However, now MinIO violates the requirement that credentials can be configured transparently. Therefore, we need a mechanism to either
>
> * configure which credentials should be used with which pipeline root (probably, write rules like which pipeline_root prefix/query param should use which credentials)
> * or configure credentials with pipeline root together as artifact repository (but then we should specify artifact repos, not pipeline roots)
> * or ask users to configure credentials separately from pipeline_root
>
> We probably need more thoughts on the exact config format, this seems like a complex problem.
</issue>
<code>
[start of manifests/kustomize/base/installs/multi-user/pipelines-profile-controller/sync.py]
1 # Copyright 2020-2021 The Kubeflow Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from http.server import BaseHTTPRequestHandler, HTTPServer
16 import json
17 import os
18 import base64
19
20 kfp_version = os.environ["KFP_VERSION"]
21 disable_istio_sidecar = os.environ.get("DISABLE_ISTIO_SIDECAR") == "true"
22 mlpipeline_minio_access_key = base64.b64encode(
23 bytes(os.environ.get("MINIO_ACCESS_KEY"), 'utf-8')).decode('utf-8')
24 mlpipeline_minio_secret_key = base64.b64encode(
25 bytes(os.environ.get("MINIO_SECRET_KEY"), 'utf-8')).decode('utf-8')
26
27
28 class Controller(BaseHTTPRequestHandler):
29 def sync(self, parent, children):
30 pipeline_enabled = parent.get("metadata", {}).get(
31 "labels", {}).get("pipelines.kubeflow.org/enabled")
32
33 if pipeline_enabled != "true":
34 return {"status": {}, "children": []}
35
36 # Compute status based on observed state.
37 desired_status = {
38 "kubeflow-pipelines-ready": \
39 len(children["Secret.v1"]) == 1 and \
40 len(children["ConfigMap.v1"]) == 1 and \
41 len(children["Deployment.apps/v1"]) == 2 and \
42 len(children["Service.v1"]) == 2 and \
43 len(children["DestinationRule.networking.istio.io/v1alpha3"]) == 1 and \
44 len(children["AuthorizationPolicy.security.istio.io/v1beta1"]) == 1 and \
45 "True" or "False"
46 }
47
48 # Generate the desired child object(s).
49 # parent is a namespace
50 namespace = parent.get("metadata", {}).get("name")
51 desired_resources = [
52 {
53 "apiVersion": "v1",
54 "kind": "ConfigMap",
55 "metadata": {
56 "name": "metadata-grpc-configmap",
57 "namespace": namespace,
58 },
59 "data": {
60 "METADATA_GRPC_SERVICE_HOST":
61 "metadata-grpc-service.kubeflow",
62 "METADATA_GRPC_SERVICE_PORT": "8080",
63 },
64 },
65 # Visualization server related manifests below
66 {
67 "apiVersion": "apps/v1",
68 "kind": "Deployment",
69 "metadata": {
70 "labels": {
71 "app": "ml-pipeline-visualizationserver"
72 },
73 "name": "ml-pipeline-visualizationserver",
74 "namespace": namespace,
75 },
76 "spec": {
77 "selector": {
78 "matchLabels": {
79 "app": "ml-pipeline-visualizationserver"
80 },
81 },
82 "template": {
83 "metadata": {
84 "labels": {
85 "app": "ml-pipeline-visualizationserver"
86 },
87 "annotations": disable_istio_sidecar and {
88 "sidecar.istio.io/inject": "false"
89 } or {},
90 },
91 "spec": {
92 "containers": [{
93 "image":
94 "gcr.io/ml-pipeline/visualization-server:" +
95 kfp_version,
96 "imagePullPolicy":
97 "IfNotPresent",
98 "name":
99 "ml-pipeline-visualizationserver",
100 "ports": [{
101 "containerPort": 8888
102 }],
103 "resources": {
104 "requests": {
105 "cpu": "50m",
106 "memory": "200Mi"
107 },
108 "limits": {
109 "cpu": "500m",
110 "memory": "1Gi"
111 },
112 }
113 }],
114 "serviceAccountName":
115 "default-editor",
116 },
117 },
118 },
119 },
120 {
121 "apiVersion": "networking.istio.io/v1alpha3",
122 "kind": "DestinationRule",
123 "metadata": {
124 "name": "ml-pipeline-visualizationserver",
125 "namespace": namespace,
126 },
127 "spec": {
128 "host": "ml-pipeline-visualizationserver",
129 "trafficPolicy": {
130 "tls": {
131 "mode": "ISTIO_MUTUAL"
132 }
133 }
134 }
135 },
136 {
137 "apiVersion": "security.istio.io/v1beta1",
138 "kind": "AuthorizationPolicy",
139 "metadata": {
140 "name": "ml-pipeline-visualizationserver",
141 "namespace": namespace,
142 },
143 "spec": {
144 "selector": {
145 "matchLabels": {
146 "app": "ml-pipeline-visualizationserver"
147 }
148 },
149 "rules": [{
150 "from": [{
151 "source": {
152 "principals": ["cluster.local/ns/kubeflow/sa/ml-pipeline"]
153 }
154 }]
155 }]
156 }
157 },
158 {
159 "apiVersion": "v1",
160 "kind": "Service",
161 "metadata": {
162 "name": "ml-pipeline-visualizationserver",
163 "namespace": namespace,
164 },
165 "spec": {
166 "ports": [{
167 "name": "http",
168 "port": 8888,
169 "protocol": "TCP",
170 "targetPort": 8888,
171 }],
172 "selector": {
173 "app": "ml-pipeline-visualizationserver",
174 },
175 },
176 },
177 # Artifact fetcher related resources below.
178 {
179 "apiVersion": "apps/v1",
180 "kind": "Deployment",
181 "metadata": {
182 "labels": {
183 "app": "ml-pipeline-ui-artifact"
184 },
185 "name": "ml-pipeline-ui-artifact",
186 "namespace": namespace,
187 },
188 "spec": {
189 "selector": {
190 "matchLabels": {
191 "app": "ml-pipeline-ui-artifact"
192 }
193 },
194 "template": {
195 "metadata": {
196 "labels": {
197 "app": "ml-pipeline-ui-artifact"
198 },
199 "annotations": disable_istio_sidecar and {
200 "sidecar.istio.io/inject": "false"
201 } or {},
202 },
203 "spec": {
204 "containers": [{
205 "name":
206 "ml-pipeline-ui-artifact",
207 "image":
208 "gcr.io/ml-pipeline/frontend:" + kfp_version,
209 "imagePullPolicy":
210 "IfNotPresent",
211 "ports": [{
212 "containerPort": 3000
213 }],
214 "resources": {
215 "requests": {
216 "cpu": "10m",
217 "memory": "70Mi"
218 },
219 "limits": {
220 "cpu": "100m",
221 "memory": "500Mi"
222 },
223 }
224 }],
225 "serviceAccountName":
226 "default-editor"
227 }
228 }
229 }
230 },
231 {
232 "apiVersion": "v1",
233 "kind": "Service",
234 "metadata": {
235 "name": "ml-pipeline-ui-artifact",
236 "namespace": namespace,
237 "labels": {
238 "app": "ml-pipeline-ui-artifact"
239 }
240 },
241 "spec": {
242 "ports": [{
243 "name":
244 "http", # name is required to let istio understand request protocol
245 "port": 80,
246 "protocol": "TCP",
247 "targetPort": 3000
248 }],
249 "selector": {
250 "app": "ml-pipeline-ui-artifact"
251 }
252 }
253 },
254 ]
255 print('Received request:', parent)
256 print('Desired resources except secrets:', desired_resources)
257 # Moved after the print argument because this is sensitive data.
258 desired_resources.append({
259 "apiVersion": "v1",
260 "kind": "Secret",
261 "metadata": {
262 "name": "mlpipeline-minio-artifact",
263 "namespace": namespace,
264 },
265 "data": {
266 "accesskey": mlpipeline_minio_access_key,
267 "secretkey": mlpipeline_minio_secret_key,
268 },
269 })
270
271 return {"status": desired_status, "children": desired_resources}
272
273 def do_POST(self):
274 # Serve the sync() function as a JSON webhook.
275 observed = json.loads(
276 self.rfile.read(int(self.headers.get("content-length"))))
277 desired = self.sync(observed["parent"], observed["children"])
278
279 self.send_response(200)
280 self.send_header("Content-type", "application/json")
281 self.end_headers()
282 self.wfile.write(bytes(json.dumps(desired), 'utf-8'))
283
284
285 HTTPServer(("", 8080), Controller).serve_forever()
286
[end of manifests/kustomize/base/installs/multi-user/pipelines-profile-controller/sync.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/manifests/kustomize/base/installs/multi-user/pipelines-profile-controller/sync.py b/manifests/kustomize/base/installs/multi-user/pipelines-profile-controller/sync.py
--- a/manifests/kustomize/base/installs/multi-user/pipelines-profile-controller/sync.py
+++ b/manifests/kustomize/base/installs/multi-user/pipelines-profile-controller/sync.py
@@ -18,6 +18,8 @@
import base64
kfp_version = os.environ["KFP_VERSION"]
+# KFP_DEFAULT_PIPELINE_ROOT is optional
+kfp_default_pipeline_root = os.environ.get("KFP_DEFAULT_PIPELINE_ROOT")
disable_istio_sidecar = os.environ.get("DISABLE_ISTIO_SIDECAR") == "true"
mlpipeline_minio_access_key = base64.b64encode(
bytes(os.environ.get("MINIO_ACCESS_KEY"), 'utf-8')).decode('utf-8')
@@ -27,17 +29,35 @@
class Controller(BaseHTTPRequestHandler):
def sync(self, parent, children):
+ # parent is a namespace
+ namespace = parent.get("metadata", {}).get("name")
pipeline_enabled = parent.get("metadata", {}).get(
"labels", {}).get("pipelines.kubeflow.org/enabled")
if pipeline_enabled != "true":
return {"status": {}, "children": []}
+ desired_configmap_count = 1
+ desired_resources = []
+ if kfp_default_pipeline_root:
+ desired_configmap_count = 2
+ desired_resources += [{
+ "apiVersion": "v1",
+ "kind": "ConfigMap",
+ "metadata": {
+ "name": "kfp-launcher",
+ "namespace": namespace,
+ },
+ "data": {
+ "defaultPipelineRoot": kfp_default_pipeline_root,
+ },
+ }]
+
# Compute status based on observed state.
desired_status = {
"kubeflow-pipelines-ready": \
len(children["Secret.v1"]) == 1 and \
- len(children["ConfigMap.v1"]) == 1 and \
+ len(children["ConfigMap.v1"]) == desired_configmap_count and \
len(children["Deployment.apps/v1"]) == 2 and \
len(children["Service.v1"]) == 2 and \
len(children["DestinationRule.networking.istio.io/v1alpha3"]) == 1 and \
@@ -46,9 +66,7 @@
}
# Generate the desired child object(s).
- # parent is a namespace
- namespace = parent.get("metadata", {}).get("name")
- desired_resources = [
+ desired_resources += [
{
"apiVersion": "v1",
"kind": "ConfigMap",
| {"golden_diff": "diff --git a/manifests/kustomize/base/installs/multi-user/pipelines-profile-controller/sync.py b/manifests/kustomize/base/installs/multi-user/pipelines-profile-controller/sync.py\n--- a/manifests/kustomize/base/installs/multi-user/pipelines-profile-controller/sync.py\n+++ b/manifests/kustomize/base/installs/multi-user/pipelines-profile-controller/sync.py\n@@ -18,6 +18,8 @@\n import base64\n \n kfp_version = os.environ[\"KFP_VERSION\"]\n+# KFP_DEFAULT_PIPELINE_ROOT is optional\n+kfp_default_pipeline_root = os.environ.get(\"KFP_DEFAULT_PIPELINE_ROOT\")\n disable_istio_sidecar = os.environ.get(\"DISABLE_ISTIO_SIDECAR\") == \"true\"\n mlpipeline_minio_access_key = base64.b64encode(\n bytes(os.environ.get(\"MINIO_ACCESS_KEY\"), 'utf-8')).decode('utf-8')\n@@ -27,17 +29,35 @@\n \n class Controller(BaseHTTPRequestHandler):\n def sync(self, parent, children):\n+ # parent is a namespace\n+ namespace = parent.get(\"metadata\", {}).get(\"name\")\n pipeline_enabled = parent.get(\"metadata\", {}).get(\n \"labels\", {}).get(\"pipelines.kubeflow.org/enabled\")\n \n if pipeline_enabled != \"true\":\n return {\"status\": {}, \"children\": []}\n \n+ desired_configmap_count = 1\n+ desired_resources = []\n+ if kfp_default_pipeline_root:\n+ desired_configmap_count = 2\n+ desired_resources += [{\n+ \"apiVersion\": \"v1\",\n+ \"kind\": \"ConfigMap\",\n+ \"metadata\": {\n+ \"name\": \"kfp-launcher\",\n+ \"namespace\": namespace,\n+ },\n+ \"data\": {\n+ \"defaultPipelineRoot\": kfp_default_pipeline_root,\n+ },\n+ }]\n+\n # Compute status based on observed state.\n desired_status = {\n \"kubeflow-pipelines-ready\": \\\n len(children[\"Secret.v1\"]) == 1 and \\\n- len(children[\"ConfigMap.v1\"]) == 1 and \\\n+ len(children[\"ConfigMap.v1\"]) == desired_configmap_count and \\\n len(children[\"Deployment.apps/v1\"]) == 2 and \\\n len(children[\"Service.v1\"]) == 2 and \\\n len(children[\"DestinationRule.networking.istio.io/v1alpha3\"]) == 1 and \\\n@@ -46,9 +66,7 @@\n }\n \n # Generate the desired child object(s).\n- # parent is a namespace\n- namespace = parent.get(\"metadata\", {}).get(\"name\")\n- desired_resources = [\n+ desired_resources += [\n {\n \"apiVersion\": \"v1\",\n \"kind\": \"ConfigMap\",\n", "issue": "[v2compat] configurable default pipeline root\nQuoted from https://github.com/kubeflow/pipelines/issues/4649#issuecomment-844035914\r\nBlocks https://github.com/kubeflow/pipelines/issues/5680\r\n\r\n> FYI, KFP v2 compatible mode has been released, see documentation: https://www.kubeflow.org/docs/components/pipelines/sdk/v2/.\r\n> \r\n> It doesn't support artifact repository configuration, this is one of the things we want to support too. So I'm posting early thoughts on this related issue.\r\n> \r\n> Let me first try to summarize requirements for configuring artifact repositories for both KFP v2 compatible and v2.\r\n> \r\n> ## Object store specific credentials requirements\r\n> For GCS, AWS S3, we suggest setting up credentials, so that they represent identity of the pipeline step, so that not only artifact upload/download, calls to other Cloud services should also use the same credentials. For this reason, we don't recommend setting credentials in artifact repository config. The suggestion is to configure the identity transparently if possible using GCP workload identity or AWS IRSA. If credentials are really necessary, they can be configured using pipeline DSL via [kfp.gcp.use_gcp_secret](https://kubeflow-pipelines.readthedocs.io/en/latest/source/kfp.extensions.html#kfp.gcp.use_gcp_secret) or [kfp.aws.use_aws_secret](https://kubeflow-pipelines.readthedocs.io/en/latest/source/kfp.extensions.html#kfp.aws.use_aws_secret) etc. These principles should apply to other Cloud Providers that has credentials that can be used with all its services.\r\n> \r\n> For on-prem object store like MinIO, the credentials do not represent an identity, they are only used to access a specified object store instance. Therefore, it's reasonable to include them in artifact repository config.\r\n> \r\n> ## In summary\r\n> * For GCS, only pipeline root needs to be configurable.\r\n> * For AWS S3, besides pipeline root, we also need region, endpoint etc to be configurable.\r\n> * For MinIO or similar on-prem object stores, besides pipeline root, we also need endpoint, credentials to be configurable.\r\n> \r\n> We cannot implement a spec for every possible object stores, so likely we should use the same spec as what [Go CDK](https://gocloud.dev/) supports or depend on cloud provider contributions.\r\n> \r\n> Go CDK supports provider specific query params to configure some things other than object key, so we might consider adopting these query params, so that pipeline root can be more expressive, so we might not need other configurations.\r\n> e.g. for S3, it's possible to configure region via a query param: https://gocloud.dev/howto/blob/#s3\r\n> \r\n> ```\r\n> s3://my-bucket?region=us-west-1\r\n> ```\r\n> \r\n> ## How we configure pipeline root, other configs and credentials?\r\n> Ideally, pipeline root can include all other configs, so that we can uniquely identify an artifact.\r\n> Ideally, credentials should be configurable transparently.\r\n> \r\n> When both ideal requirements are met, we only need to support namespace level default pipeline root. All other configurations can be done by specifying different pipeline roots.\r\n> \r\n> However, now MinIO violates the requirement that credentials can be configured transparently. Therefore, we need a mechanism to either\r\n> \r\n> * configure which credentials should be used with which pipeline root (probably, write rules like which pipeline_root prefix/query param should use which credentials)\r\n> * or configure credentials with pipeline root together as artifact repository (but then we should specify artifact repos, not pipeline roots)\r\n> * or ask users to configure credentials separately from pipeline_root\r\n> \r\n> We probably need more thoughts on the exact config format, this seems like a complex problem.\r\n\r\n\n", "before_files": [{"content": "# Copyright 2020-2021 The Kubeflow Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom http.server import BaseHTTPRequestHandler, HTTPServer\nimport json\nimport os\nimport base64\n\nkfp_version = os.environ[\"KFP_VERSION\"]\ndisable_istio_sidecar = os.environ.get(\"DISABLE_ISTIO_SIDECAR\") == \"true\"\nmlpipeline_minio_access_key = base64.b64encode(\n bytes(os.environ.get(\"MINIO_ACCESS_KEY\"), 'utf-8')).decode('utf-8')\nmlpipeline_minio_secret_key = base64.b64encode(\n bytes(os.environ.get(\"MINIO_SECRET_KEY\"), 'utf-8')).decode('utf-8')\n\n\nclass Controller(BaseHTTPRequestHandler):\n def sync(self, parent, children):\n pipeline_enabled = parent.get(\"metadata\", {}).get(\n \"labels\", {}).get(\"pipelines.kubeflow.org/enabled\")\n\n if pipeline_enabled != \"true\":\n return {\"status\": {}, \"children\": []}\n\n # Compute status based on observed state.\n desired_status = {\n \"kubeflow-pipelines-ready\": \\\n len(children[\"Secret.v1\"]) == 1 and \\\n len(children[\"ConfigMap.v1\"]) == 1 and \\\n len(children[\"Deployment.apps/v1\"]) == 2 and \\\n len(children[\"Service.v1\"]) == 2 and \\\n len(children[\"DestinationRule.networking.istio.io/v1alpha3\"]) == 1 and \\\n len(children[\"AuthorizationPolicy.security.istio.io/v1beta1\"]) == 1 and \\\n \"True\" or \"False\"\n }\n\n # Generate the desired child object(s).\n # parent is a namespace\n namespace = parent.get(\"metadata\", {}).get(\"name\")\n desired_resources = [\n {\n \"apiVersion\": \"v1\",\n \"kind\": \"ConfigMap\",\n \"metadata\": {\n \"name\": \"metadata-grpc-configmap\",\n \"namespace\": namespace,\n },\n \"data\": {\n \"METADATA_GRPC_SERVICE_HOST\":\n \"metadata-grpc-service.kubeflow\",\n \"METADATA_GRPC_SERVICE_PORT\": \"8080\",\n },\n },\n # Visualization server related manifests below\n {\n \"apiVersion\": \"apps/v1\",\n \"kind\": \"Deployment\",\n \"metadata\": {\n \"labels\": {\n \"app\": \"ml-pipeline-visualizationserver\"\n },\n \"name\": \"ml-pipeline-visualizationserver\",\n \"namespace\": namespace,\n },\n \"spec\": {\n \"selector\": {\n \"matchLabels\": {\n \"app\": \"ml-pipeline-visualizationserver\"\n },\n },\n \"template\": {\n \"metadata\": {\n \"labels\": {\n \"app\": \"ml-pipeline-visualizationserver\"\n },\n \"annotations\": disable_istio_sidecar and {\n \"sidecar.istio.io/inject\": \"false\"\n } or {},\n },\n \"spec\": {\n \"containers\": [{\n \"image\":\n \"gcr.io/ml-pipeline/visualization-server:\" +\n kfp_version,\n \"imagePullPolicy\":\n \"IfNotPresent\",\n \"name\":\n \"ml-pipeline-visualizationserver\",\n \"ports\": [{\n \"containerPort\": 8888\n }],\n \"resources\": {\n \"requests\": {\n \"cpu\": \"50m\",\n \"memory\": \"200Mi\"\n },\n \"limits\": {\n \"cpu\": \"500m\",\n \"memory\": \"1Gi\"\n },\n }\n }],\n \"serviceAccountName\":\n \"default-editor\",\n },\n },\n },\n },\n {\n \"apiVersion\": \"networking.istio.io/v1alpha3\",\n \"kind\": \"DestinationRule\",\n \"metadata\": {\n \"name\": \"ml-pipeline-visualizationserver\",\n \"namespace\": namespace,\n },\n \"spec\": {\n \"host\": \"ml-pipeline-visualizationserver\",\n \"trafficPolicy\": {\n \"tls\": {\n \"mode\": \"ISTIO_MUTUAL\"\n }\n }\n }\n },\n {\n \"apiVersion\": \"security.istio.io/v1beta1\",\n \"kind\": \"AuthorizationPolicy\",\n \"metadata\": {\n \"name\": \"ml-pipeline-visualizationserver\",\n \"namespace\": namespace,\n },\n \"spec\": {\n \"selector\": {\n \"matchLabels\": {\n \"app\": \"ml-pipeline-visualizationserver\"\n }\n },\n \"rules\": [{\n \"from\": [{\n \"source\": {\n \"principals\": [\"cluster.local/ns/kubeflow/sa/ml-pipeline\"]\n }\n }]\n }]\n }\n },\n {\n \"apiVersion\": \"v1\",\n \"kind\": \"Service\",\n \"metadata\": {\n \"name\": \"ml-pipeline-visualizationserver\",\n \"namespace\": namespace,\n },\n \"spec\": {\n \"ports\": [{\n \"name\": \"http\",\n \"port\": 8888,\n \"protocol\": \"TCP\",\n \"targetPort\": 8888,\n }],\n \"selector\": {\n \"app\": \"ml-pipeline-visualizationserver\",\n },\n },\n },\n # Artifact fetcher related resources below.\n {\n \"apiVersion\": \"apps/v1\",\n \"kind\": \"Deployment\",\n \"metadata\": {\n \"labels\": {\n \"app\": \"ml-pipeline-ui-artifact\"\n },\n \"name\": \"ml-pipeline-ui-artifact\",\n \"namespace\": namespace,\n },\n \"spec\": {\n \"selector\": {\n \"matchLabels\": {\n \"app\": \"ml-pipeline-ui-artifact\"\n }\n },\n \"template\": {\n \"metadata\": {\n \"labels\": {\n \"app\": \"ml-pipeline-ui-artifact\"\n },\n \"annotations\": disable_istio_sidecar and {\n \"sidecar.istio.io/inject\": \"false\"\n } or {},\n },\n \"spec\": {\n \"containers\": [{\n \"name\":\n \"ml-pipeline-ui-artifact\",\n \"image\":\n \"gcr.io/ml-pipeline/frontend:\" + kfp_version,\n \"imagePullPolicy\":\n \"IfNotPresent\",\n \"ports\": [{\n \"containerPort\": 3000\n }],\n \"resources\": {\n \"requests\": {\n \"cpu\": \"10m\",\n \"memory\": \"70Mi\"\n },\n \"limits\": {\n \"cpu\": \"100m\",\n \"memory\": \"500Mi\"\n },\n }\n }],\n \"serviceAccountName\":\n \"default-editor\"\n }\n }\n }\n },\n {\n \"apiVersion\": \"v1\",\n \"kind\": \"Service\",\n \"metadata\": {\n \"name\": \"ml-pipeline-ui-artifact\",\n \"namespace\": namespace,\n \"labels\": {\n \"app\": \"ml-pipeline-ui-artifact\"\n }\n },\n \"spec\": {\n \"ports\": [{\n \"name\":\n \"http\", # name is required to let istio understand request protocol\n \"port\": 80,\n \"protocol\": \"TCP\",\n \"targetPort\": 3000\n }],\n \"selector\": {\n \"app\": \"ml-pipeline-ui-artifact\"\n }\n }\n },\n ]\n print('Received request:', parent)\n print('Desired resources except secrets:', desired_resources)\n # Moved after the print argument because this is sensitive data.\n desired_resources.append({\n \"apiVersion\": \"v1\",\n \"kind\": \"Secret\",\n \"metadata\": {\n \"name\": \"mlpipeline-minio-artifact\",\n \"namespace\": namespace,\n },\n \"data\": {\n \"accesskey\": mlpipeline_minio_access_key,\n \"secretkey\": mlpipeline_minio_secret_key,\n },\n })\n\n return {\"status\": desired_status, \"children\": desired_resources}\n\n def do_POST(self):\n # Serve the sync() function as a JSON webhook.\n observed = json.loads(\n self.rfile.read(int(self.headers.get(\"content-length\"))))\n desired = self.sync(observed[\"parent\"], observed[\"children\"])\n\n self.send_response(200)\n self.send_header(\"Content-type\", \"application/json\")\n self.end_headers()\n self.wfile.write(bytes(json.dumps(desired), 'utf-8'))\n\n\nHTTPServer((\"\", 8080), Controller).serve_forever()\n", "path": "manifests/kustomize/base/installs/multi-user/pipelines-profile-controller/sync.py"}]} | 4,082 | 617 |
gh_patches_debug_27762 | rasdani/github-patches | git_diff | pypi__warehouse-6297 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Database is out of sync with models
Autogenerating a migration from 0abc1b27707bdf9a1ca94ba8392f0086b1eeb492 produces some differences that Alembic is attempting to rectify:
Running:
```
$ docker-compose run web python -m warehouse db revision --autogenerate --message "Sync"
```
Produces:
```python
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Sync
Revision ID: 71ccb4f929b0
Revises: 5ea52744d154
Create Date: 2019-07-26 17:00:45.297526
"""
from alembic import op
import sqlalchemy as sa
revision = '71ccb4f929b0'
down_revision = '5ea52744d154'
# Note: It is VERY important to ensure that a migration does not lock for a
# long period of time and to ensure that each individual migration does
# not break compatibility with the *previous* version of the code base.
# This is because the migrations will be ran automatically as part of the
# deployment process, but while the previous version of the code is still
# up and running. Thus backwards incompatible changes must be broken up
# over multiple migrations inside of multiple pull requests in order to
# phase them in over multiple deploys.
def upgrade():
# ### commands auto generated by Alembic - please adjust! ###
op.create_unique_constraint('_user_macaroons_description_uc', 'macaroons', ['description', 'user_id'])
op.drop_index('user_security_keys_label_key', table_name='user_security_keys')
op.create_unique_constraint('user_security_keys_label_key', 'user_security_keys', ['label'])
# ### end Alembic commands ###
def downgrade():
# ### commands auto generated by Alembic - please adjust! ###
op.drop_constraint('user_security_keys_label_key', 'user_security_keys', type_='unique')
op.create_index('user_security_keys_label_key', 'user_security_keys', ['user_id'], unique=False)
op.drop_constraint('_user_macaroons_description_uc', 'macaroons', type_='unique')
# ### end Alembic commands ###
```
Ideally both `upgrade` and `downgrade` would be no-ops here.
</issue>
<code>
[start of warehouse/migrations/versions/48def930fcfd_webauthn_and_macaroon_constraints.py]
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12 """
13 WebAuthn and Macaroon constraints
14
15 Revision ID: 48def930fcfd
16 Revises: 5ea52744d154
17 Create Date: 2019-07-26 17:55:41.802528
18 """
19
20 from alembic import op
21
22 revision = "48def930fcfd"
23 down_revision = "5ea52744d154"
24
25
26 def upgrade():
27 op.create_unique_constraint(
28 "_user_macaroons_description_uc", "macaroons", ["description", "user_id"]
29 )
30 op.drop_index("user_security_keys_label_key", table_name="user_security_keys")
31 op.create_unique_constraint(
32 "user_security_keys_label_key", "user_security_keys", ["label"]
33 )
34
35
36 def downgrade():
37 op.drop_constraint(
38 "user_security_keys_label_key", "user_security_keys", type_="unique"
39 )
40 op.create_index(
41 "user_security_keys_label_key", "user_security_keys", ["user_id"], unique=False
42 )
43 op.drop_constraint("_user_macaroons_description_uc", "macaroons", type_="unique")
44
[end of warehouse/migrations/versions/48def930fcfd_webauthn_and_macaroon_constraints.py]
[start of warehouse/accounts/models.py]
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 import enum
14
15 from citext import CIText
16 from sqlalchemy import (
17 Binary,
18 Boolean,
19 CheckConstraint,
20 Column,
21 DateTime,
22 Enum,
23 ForeignKey,
24 Index,
25 Integer,
26 String,
27 UniqueConstraint,
28 orm,
29 select,
30 sql,
31 )
32 from sqlalchemy.dialects.postgresql import UUID
33 from sqlalchemy.ext.hybrid import hybrid_property
34 from sqlalchemy.orm.exc import NoResultFound
35
36 from warehouse import db
37 from warehouse.sitemap.models import SitemapMixin
38 from warehouse.utils.attrs import make_repr
39
40
41 class UserFactory:
42 def __init__(self, request):
43 self.request = request
44
45 def __getitem__(self, username):
46 try:
47 return self.request.db.query(User).filter(User.username == username).one()
48 except NoResultFound:
49 raise KeyError from None
50
51
52 class DisableReason(enum.Enum):
53
54 CompromisedPassword = "password compromised"
55
56
57 class User(SitemapMixin, db.Model):
58
59 __tablename__ = "users"
60 __table_args__ = (
61 CheckConstraint("length(username) <= 50", name="users_valid_username_length"),
62 CheckConstraint(
63 "username ~* '^([A-Z0-9]|[A-Z0-9][A-Z0-9._-]*[A-Z0-9])$'",
64 name="users_valid_username",
65 ),
66 )
67
68 __repr__ = make_repr("username")
69
70 username = Column(CIText, nullable=False, unique=True)
71 name = Column(String(length=100), nullable=False)
72 password = Column(String(length=128), nullable=False)
73 password_date = Column(DateTime, nullable=True, server_default=sql.func.now())
74 is_active = Column(Boolean, nullable=False, server_default=sql.false())
75 is_superuser = Column(Boolean, nullable=False, server_default=sql.false())
76 is_moderator = Column(Boolean, nullable=False, server_default=sql.false())
77 date_joined = Column(DateTime, server_default=sql.func.now())
78 last_login = Column(DateTime, nullable=False, server_default=sql.func.now())
79 disabled_for = Column(
80 Enum(DisableReason, values_callable=lambda x: [e.value for e in x]),
81 nullable=True,
82 )
83
84 totp_secret = Column(Binary(length=20), nullable=True)
85
86 webauthn = orm.relationship(
87 "WebAuthn", backref="user", cascade="all, delete-orphan", lazy=False
88 )
89
90 emails = orm.relationship(
91 "Email", backref="user", cascade="all, delete-orphan", lazy=False
92 )
93
94 macaroons = orm.relationship(
95 "Macaroon", backref="user", cascade="all, delete-orphan", lazy=False
96 )
97
98 @property
99 def primary_email(self):
100 primaries = [x for x in self.emails if x.primary]
101 if primaries:
102 return primaries[0]
103
104 @hybrid_property
105 def email(self):
106 primary_email = self.primary_email
107 return primary_email.email if primary_email else None
108
109 @email.expression
110 def email(self):
111 return (
112 select([Email.email])
113 .where((Email.user_id == self.id) & (Email.primary.is_(True)))
114 .as_scalar()
115 )
116
117 @property
118 def has_two_factor(self):
119 return self.totp_secret is not None or len(self.webauthn) > 0
120
121 @property
122 def has_primary_verified_email(self):
123 return self.primary_email is not None and self.primary_email.verified
124
125
126 class WebAuthn(db.Model):
127 __tablename__ = "user_security_keys"
128 __table_args__ = (
129 UniqueConstraint("label", name="user_security_keys_label_key"),
130 Index("user_security_keys_label_key", "user_id"),
131 )
132
133 user_id = Column(
134 UUID(as_uuid=True),
135 ForeignKey("users.id", deferrable=True, initially="DEFERRED"),
136 nullable=False,
137 )
138 label = Column(String, nullable=False)
139 credential_id = Column(String, unique=True, nullable=False)
140 public_key = Column(String, unique=True, nullable=True)
141 sign_count = Column(Integer, default=0)
142
143
144 class UnverifyReasons(enum.Enum):
145
146 SpamComplaint = "spam complaint"
147 HardBounce = "hard bounce"
148 SoftBounce = "soft bounce"
149
150
151 class Email(db.ModelBase):
152
153 __tablename__ = "user_emails"
154 __table_args__ = (
155 UniqueConstraint("email", name="user_emails_email_key"),
156 Index("user_emails_user_id", "user_id"),
157 )
158
159 id = Column(Integer, primary_key=True, nullable=False)
160 user_id = Column(
161 UUID(as_uuid=True),
162 ForeignKey("users.id", deferrable=True, initially="DEFERRED"),
163 nullable=False,
164 )
165 email = Column(String(length=254), nullable=False)
166 primary = Column(Boolean, nullable=False)
167 verified = Column(Boolean, nullable=False)
168
169 # Deliverability information
170 unverify_reason = Column(
171 Enum(UnverifyReasons, values_callable=lambda x: [e.value for e in x]),
172 nullable=True,
173 )
174 transient_bounces = Column(Integer, nullable=False, server_default=sql.text("0"))
175
[end of warehouse/accounts/models.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/warehouse/accounts/models.py b/warehouse/accounts/models.py
--- a/warehouse/accounts/models.py
+++ b/warehouse/accounts/models.py
@@ -126,8 +126,7 @@
class WebAuthn(db.Model):
__tablename__ = "user_security_keys"
__table_args__ = (
- UniqueConstraint("label", name="user_security_keys_label_key"),
- Index("user_security_keys_label_key", "user_id"),
+ UniqueConstraint("label", "user_id", name="_user_security_keys_label_uc"),
)
user_id = Column(
diff --git a/warehouse/migrations/versions/48def930fcfd_webauthn_and_macaroon_constraints.py b/warehouse/migrations/versions/48def930fcfd_webauthn_and_macaroon_constraints.py
--- a/warehouse/migrations/versions/48def930fcfd_webauthn_and_macaroon_constraints.py
+++ b/warehouse/migrations/versions/48def930fcfd_webauthn_and_macaroon_constraints.py
@@ -27,17 +27,17 @@
op.create_unique_constraint(
"_user_macaroons_description_uc", "macaroons", ["description", "user_id"]
)
- op.drop_index("user_security_keys_label_key", table_name="user_security_keys")
op.create_unique_constraint(
- "user_security_keys_label_key", "user_security_keys", ["label"]
+ "_user_security_keys_label_uc", "user_security_keys", ["label", "user_id"]
)
+ op.drop_index("user_security_keys_label_key", table_name="user_security_keys")
def downgrade():
- op.drop_constraint(
- "user_security_keys_label_key", "user_security_keys", type_="unique"
- )
op.create_index(
"user_security_keys_label_key", "user_security_keys", ["user_id"], unique=False
)
+ op.drop_constraint(
+ "_user_security_keys_label_uc", "user_security_keys", type_="unique"
+ )
op.drop_constraint("_user_macaroons_description_uc", "macaroons", type_="unique")
| {"golden_diff": "diff --git a/warehouse/accounts/models.py b/warehouse/accounts/models.py\n--- a/warehouse/accounts/models.py\n+++ b/warehouse/accounts/models.py\n@@ -126,8 +126,7 @@\n class WebAuthn(db.Model):\n __tablename__ = \"user_security_keys\"\n __table_args__ = (\n- UniqueConstraint(\"label\", name=\"user_security_keys_label_key\"),\n- Index(\"user_security_keys_label_key\", \"user_id\"),\n+ UniqueConstraint(\"label\", \"user_id\", name=\"_user_security_keys_label_uc\"),\n )\n \n user_id = Column(\ndiff --git a/warehouse/migrations/versions/48def930fcfd_webauthn_and_macaroon_constraints.py b/warehouse/migrations/versions/48def930fcfd_webauthn_and_macaroon_constraints.py\n--- a/warehouse/migrations/versions/48def930fcfd_webauthn_and_macaroon_constraints.py\n+++ b/warehouse/migrations/versions/48def930fcfd_webauthn_and_macaroon_constraints.py\n@@ -27,17 +27,17 @@\n op.create_unique_constraint(\n \"_user_macaroons_description_uc\", \"macaroons\", [\"description\", \"user_id\"]\n )\n- op.drop_index(\"user_security_keys_label_key\", table_name=\"user_security_keys\")\n op.create_unique_constraint(\n- \"user_security_keys_label_key\", \"user_security_keys\", [\"label\"]\n+ \"_user_security_keys_label_uc\", \"user_security_keys\", [\"label\", \"user_id\"]\n )\n+ op.drop_index(\"user_security_keys_label_key\", table_name=\"user_security_keys\")\n \n \n def downgrade():\n- op.drop_constraint(\n- \"user_security_keys_label_key\", \"user_security_keys\", type_=\"unique\"\n- )\n op.create_index(\n \"user_security_keys_label_key\", \"user_security_keys\", [\"user_id\"], unique=False\n )\n+ op.drop_constraint(\n+ \"_user_security_keys_label_uc\", \"user_security_keys\", type_=\"unique\"\n+ )\n op.drop_constraint(\"_user_macaroons_description_uc\", \"macaroons\", type_=\"unique\")\n", "issue": "Database is out of sync with models\nAutogenerating a migration from 0abc1b27707bdf9a1ca94ba8392f0086b1eeb492 produces some differences that Alembic is attempting to rectify:\r\n\r\nRunning:\r\n```\r\n$ docker-compose run web python -m warehouse db revision --autogenerate --message \"Sync\"\r\n```\r\n\r\nProduces:\r\n```python\r\n# Licensed under the Apache License, Version 2.0 (the \"License\");\r\n# you may not use this file except in compliance with the License.\r\n# You may obtain a copy of the License at\r\n#\r\n# http://www.apache.org/licenses/LICENSE-2.0\r\n#\r\n# Unless required by applicable law or agreed to in writing, software\r\n# distributed under the License is distributed on an \"AS IS\" BASIS,\r\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\r\n# See the License for the specific language governing permissions and\r\n# limitations under the License.\r\n\"\"\"\r\nSync\r\n\r\nRevision ID: 71ccb4f929b0\r\nRevises: 5ea52744d154\r\nCreate Date: 2019-07-26 17:00:45.297526\r\n\"\"\"\r\n\r\nfrom alembic import op\r\nimport sqlalchemy as sa\r\n\r\n\r\nrevision = '71ccb4f929b0'\r\ndown_revision = '5ea52744d154'\r\n\r\n# Note: It is VERY important to ensure that a migration does not lock for a\r\n# long period of time and to ensure that each individual migration does\r\n# not break compatibility with the *previous* version of the code base.\r\n# This is because the migrations will be ran automatically as part of the\r\n# deployment process, but while the previous version of the code is still\r\n# up and running. Thus backwards incompatible changes must be broken up\r\n# over multiple migrations inside of multiple pull requests in order to\r\n# phase them in over multiple deploys.\r\n\r\ndef upgrade():\r\n # ### commands auto generated by Alembic - please adjust! ###\r\n op.create_unique_constraint('_user_macaroons_description_uc', 'macaroons', ['description', 'user_id'])\r\n op.drop_index('user_security_keys_label_key', table_name='user_security_keys')\r\n op.create_unique_constraint('user_security_keys_label_key', 'user_security_keys', ['label'])\r\n # ### end Alembic commands ###\r\n\r\n\r\ndef downgrade():\r\n # ### commands auto generated by Alembic - please adjust! ###\r\n op.drop_constraint('user_security_keys_label_key', 'user_security_keys', type_='unique')\r\n op.create_index('user_security_keys_label_key', 'user_security_keys', ['user_id'], unique=False)\r\n op.drop_constraint('_user_macaroons_description_uc', 'macaroons', type_='unique')\r\n # ### end Alembic commands ### \r\n```\r\n\r\nIdeally both `upgrade` and `downgrade` would be no-ops here.\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"\nWebAuthn and Macaroon constraints\n\nRevision ID: 48def930fcfd\nRevises: 5ea52744d154\nCreate Date: 2019-07-26 17:55:41.802528\n\"\"\"\n\nfrom alembic import op\n\nrevision = \"48def930fcfd\"\ndown_revision = \"5ea52744d154\"\n\n\ndef upgrade():\n op.create_unique_constraint(\n \"_user_macaroons_description_uc\", \"macaroons\", [\"description\", \"user_id\"]\n )\n op.drop_index(\"user_security_keys_label_key\", table_name=\"user_security_keys\")\n op.create_unique_constraint(\n \"user_security_keys_label_key\", \"user_security_keys\", [\"label\"]\n )\n\n\ndef downgrade():\n op.drop_constraint(\n \"user_security_keys_label_key\", \"user_security_keys\", type_=\"unique\"\n )\n op.create_index(\n \"user_security_keys_label_key\", \"user_security_keys\", [\"user_id\"], unique=False\n )\n op.drop_constraint(\"_user_macaroons_description_uc\", \"macaroons\", type_=\"unique\")\n", "path": "warehouse/migrations/versions/48def930fcfd_webauthn_and_macaroon_constraints.py"}, {"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport enum\n\nfrom citext import CIText\nfrom sqlalchemy import (\n Binary,\n Boolean,\n CheckConstraint,\n Column,\n DateTime,\n Enum,\n ForeignKey,\n Index,\n Integer,\n String,\n UniqueConstraint,\n orm,\n select,\n sql,\n)\nfrom sqlalchemy.dialects.postgresql import UUID\nfrom sqlalchemy.ext.hybrid import hybrid_property\nfrom sqlalchemy.orm.exc import NoResultFound\n\nfrom warehouse import db\nfrom warehouse.sitemap.models import SitemapMixin\nfrom warehouse.utils.attrs import make_repr\n\n\nclass UserFactory:\n def __init__(self, request):\n self.request = request\n\n def __getitem__(self, username):\n try:\n return self.request.db.query(User).filter(User.username == username).one()\n except NoResultFound:\n raise KeyError from None\n\n\nclass DisableReason(enum.Enum):\n\n CompromisedPassword = \"password compromised\"\n\n\nclass User(SitemapMixin, db.Model):\n\n __tablename__ = \"users\"\n __table_args__ = (\n CheckConstraint(\"length(username) <= 50\", name=\"users_valid_username_length\"),\n CheckConstraint(\n \"username ~* '^([A-Z0-9]|[A-Z0-9][A-Z0-9._-]*[A-Z0-9])$'\",\n name=\"users_valid_username\",\n ),\n )\n\n __repr__ = make_repr(\"username\")\n\n username = Column(CIText, nullable=False, unique=True)\n name = Column(String(length=100), nullable=False)\n password = Column(String(length=128), nullable=False)\n password_date = Column(DateTime, nullable=True, server_default=sql.func.now())\n is_active = Column(Boolean, nullable=False, server_default=sql.false())\n is_superuser = Column(Boolean, nullable=False, server_default=sql.false())\n is_moderator = Column(Boolean, nullable=False, server_default=sql.false())\n date_joined = Column(DateTime, server_default=sql.func.now())\n last_login = Column(DateTime, nullable=False, server_default=sql.func.now())\n disabled_for = Column(\n Enum(DisableReason, values_callable=lambda x: [e.value for e in x]),\n nullable=True,\n )\n\n totp_secret = Column(Binary(length=20), nullable=True)\n\n webauthn = orm.relationship(\n \"WebAuthn\", backref=\"user\", cascade=\"all, delete-orphan\", lazy=False\n )\n\n emails = orm.relationship(\n \"Email\", backref=\"user\", cascade=\"all, delete-orphan\", lazy=False\n )\n\n macaroons = orm.relationship(\n \"Macaroon\", backref=\"user\", cascade=\"all, delete-orphan\", lazy=False\n )\n\n @property\n def primary_email(self):\n primaries = [x for x in self.emails if x.primary]\n if primaries:\n return primaries[0]\n\n @hybrid_property\n def email(self):\n primary_email = self.primary_email\n return primary_email.email if primary_email else None\n\n @email.expression\n def email(self):\n return (\n select([Email.email])\n .where((Email.user_id == self.id) & (Email.primary.is_(True)))\n .as_scalar()\n )\n\n @property\n def has_two_factor(self):\n return self.totp_secret is not None or len(self.webauthn) > 0\n\n @property\n def has_primary_verified_email(self):\n return self.primary_email is not None and self.primary_email.verified\n\n\nclass WebAuthn(db.Model):\n __tablename__ = \"user_security_keys\"\n __table_args__ = (\n UniqueConstraint(\"label\", name=\"user_security_keys_label_key\"),\n Index(\"user_security_keys_label_key\", \"user_id\"),\n )\n\n user_id = Column(\n UUID(as_uuid=True),\n ForeignKey(\"users.id\", deferrable=True, initially=\"DEFERRED\"),\n nullable=False,\n )\n label = Column(String, nullable=False)\n credential_id = Column(String, unique=True, nullable=False)\n public_key = Column(String, unique=True, nullable=True)\n sign_count = Column(Integer, default=0)\n\n\nclass UnverifyReasons(enum.Enum):\n\n SpamComplaint = \"spam complaint\"\n HardBounce = \"hard bounce\"\n SoftBounce = \"soft bounce\"\n\n\nclass Email(db.ModelBase):\n\n __tablename__ = \"user_emails\"\n __table_args__ = (\n UniqueConstraint(\"email\", name=\"user_emails_email_key\"),\n Index(\"user_emails_user_id\", \"user_id\"),\n )\n\n id = Column(Integer, primary_key=True, nullable=False)\n user_id = Column(\n UUID(as_uuid=True),\n ForeignKey(\"users.id\", deferrable=True, initially=\"DEFERRED\"),\n nullable=False,\n )\n email = Column(String(length=254), nullable=False)\n primary = Column(Boolean, nullable=False)\n verified = Column(Boolean, nullable=False)\n\n # Deliverability information\n unverify_reason = Column(\n Enum(UnverifyReasons, values_callable=lambda x: [e.value for e in x]),\n nullable=True,\n )\n transient_bounces = Column(Integer, nullable=False, server_default=sql.text(\"0\"))\n", "path": "warehouse/accounts/models.py"}]} | 3,354 | 471 |
gh_patches_debug_60843 | rasdani/github-patches | git_diff | doccano__doccano-1670 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Database table for SpanType has invalid name
How to reproduce the behaviour
---------
- Pull latest changes from master
- ./manage.py migrate
- ./api/migrations/0033_auto_20220127_0654.py will migrate the database table for `SpanType` to `label_types_spanType`
- Delete a project `Project.objects.first().delete()``
Exception:
<img width="511" alt="image" src="https://user-images.githubusercontent.com/6747788/152384221-a6a549b8-1cca-49c0-86e4-6a20f7d0a266.png">
The issue can be resolved by either renaming db table `label_types_spanType` to `label_types_spantype` or by explicitly setting `tb_table` for SpanType model like this: `db_table = "label_types_spanType"`
Your Environment
---------
* Operating System: macOS Monterey, doccano is locally executed
* Python Version Used: 3.9
</issue>
<code>
[start of backend/api/migrations/0033_auto_20220127_0654.py]
1 # Generated by Django 3.2.11 on 2022-01-27 06:54
2
3 from django.db import migrations
4
5
6 class Migration(migrations.Migration):
7
8 dependencies = [
9 ('labels', '0003_auto_20220127_0654'),
10 ('api', '0032_auto_20220127_0654'),
11 ]
12
13 operations = [
14 migrations.SeparateDatabaseAndState(
15 state_operations=[
16 migrations.DeleteModel(
17 name='CategoryType',
18 ),
19 migrations.DeleteModel(
20 name='RelationTypes',
21 ),
22 migrations.DeleteModel(
23 name='SpanType',
24 ),
25 ],
26 database_operations=[
27 migrations.AlterModelTable(
28 name='CategoryType',
29 table='label_types_categorytype'
30 ),
31 migrations.AlterModelTable(
32 name='RelationTypes',
33 table='label_types_relationtypes'
34 ),
35 migrations.AlterModelTable(
36 name='SpanType',
37 table='label_types_spanType'
38 )
39 ]
40 )
41 ]
42
[end of backend/api/migrations/0033_auto_20220127_0654.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/backend/api/migrations/0033_auto_20220127_0654.py b/backend/api/migrations/0033_auto_20220127_0654.py
--- a/backend/api/migrations/0033_auto_20220127_0654.py
+++ b/backend/api/migrations/0033_auto_20220127_0654.py
@@ -34,7 +34,7 @@
),
migrations.AlterModelTable(
name='SpanType',
- table='label_types_spanType'
+ table='label_types_spantype'
)
]
)
| {"golden_diff": "diff --git a/backend/api/migrations/0033_auto_20220127_0654.py b/backend/api/migrations/0033_auto_20220127_0654.py\n--- a/backend/api/migrations/0033_auto_20220127_0654.py\n+++ b/backend/api/migrations/0033_auto_20220127_0654.py\n@@ -34,7 +34,7 @@\n ),\n migrations.AlterModelTable(\n name='SpanType',\n- table='label_types_spanType'\n+ table='label_types_spantype'\n )\n ]\n )\n", "issue": "Database table for SpanType has invalid name \nHow to reproduce the behaviour\r\n---------\r\n- Pull latest changes from master\r\n- ./manage.py migrate\r\n- ./api/migrations/0033_auto_20220127_0654.py will migrate the database table for `SpanType` to `label_types_spanType`\r\n- Delete a project `Project.objects.first().delete()``\r\n\r\nException:\r\n\r\n<img width=\"511\" alt=\"image\" src=\"https://user-images.githubusercontent.com/6747788/152384221-a6a549b8-1cca-49c0-86e4-6a20f7d0a266.png\">\r\n \r\nThe issue can be resolved by either renaming db table `label_types_spanType` to `label_types_spantype` or by explicitly setting `tb_table` for SpanType model like this: `db_table = \"label_types_spanType\"`\r\n\r\nYour Environment\r\n---------\r\n* Operating System: macOS Monterey, doccano is locally executed\r\n* Python Version Used: 3.9\r\n\n", "before_files": [{"content": "# Generated by Django 3.2.11 on 2022-01-27 06:54\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('labels', '0003_auto_20220127_0654'),\n ('api', '0032_auto_20220127_0654'),\n ]\n\n operations = [\n migrations.SeparateDatabaseAndState(\n state_operations=[\n migrations.DeleteModel(\n name='CategoryType',\n ),\n migrations.DeleteModel(\n name='RelationTypes',\n ),\n migrations.DeleteModel(\n name='SpanType',\n ),\n ],\n database_operations=[\n migrations.AlterModelTable(\n name='CategoryType',\n table='label_types_categorytype'\n ),\n migrations.AlterModelTable(\n name='RelationTypes',\n table='label_types_relationtypes'\n ),\n migrations.AlterModelTable(\n name='SpanType',\n table='label_types_spanType'\n )\n ]\n )\n ]\n", "path": "backend/api/migrations/0033_auto_20220127_0654.py"}]} | 1,131 | 163 |
gh_patches_debug_29475 | rasdani/github-patches | git_diff | litestar-org__litestar-2259 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
StaticFilesConfig and virtual directories
I'm trying to write a ``FileSystemProtocol`` to load files from the package data using [importlib_resources](https://importlib-resources.readthedocs.io/en/latest/using.html#). But because ``directories`` is defined as ``DirectoryPath``, pydantic checks if the given directories exist in the local filesystem.
This is not generally true, especially in any kind of virtual filesystem (e.g. a zipped package). I think this condition should be relaxed to support virtual filesystems.
https://github.com/starlite-api/starlite/blob/9bb6dcd57c10a591377cf8e3a537e9292566d5b9/starlite/config/static_files.py#L32
</issue>
<code>
[start of docs/examples/contrib/sqlalchemy/sqlalchemy_repository_bulk_operations.py]
1 import json
2 from pathlib import Path
3 from typing import Any
4
5 from rich import get_console
6 from sqlalchemy import create_engine
7 from sqlalchemy.orm import Mapped, Session, sessionmaker
8
9 from litestar.contrib.sqlalchemy.base import UUIDBase
10 from litestar.contrib.sqlalchemy.repository import SQLAlchemySyncRepository
11 from litestar.repository.filters import LimitOffset
12
13 here = Path(__file__).parent
14 console = get_console()
15
16
17 class USState(UUIDBase):
18 # you can optionally override the generated table name by manually setting it.
19 __tablename__ = "us_state_lookup" # type: ignore[assignment]
20 abbreviation: Mapped[str]
21 name: Mapped[str]
22
23
24 class USStateRepository(SQLAlchemySyncRepository[USState]):
25 """US State repository."""
26
27 model_type = USState
28
29
30 engine = create_engine(
31 "duckdb:///:memory:",
32 future=True,
33 )
34 session_factory: sessionmaker[Session] = sessionmaker(engine, expire_on_commit=False)
35
36
37 def open_fixture(fixtures_path: Path, fixture_name: str) -> Any:
38 """Loads JSON file with the specified fixture name
39
40 Args:
41 fixtures_path (Path): The path to look for fixtures
42 fixture_name (str): The fixture name to load.
43
44 Raises:
45 FileNotFoundError: Fixtures not found.
46
47 Returns:
48 Any: The parsed JSON data
49 """
50 fixture = Path(fixtures_path / f"{fixture_name}.json")
51 if fixture.exists():
52 with fixture.open(mode="r", encoding="utf-8") as f:
53 f_data = f.read()
54 return json.loads(f_data)
55 raise FileNotFoundError(f"Could not find the {fixture_name} fixture")
56
57
58 def run_script() -> None:
59 """Load data from a fixture."""
60
61 # Initializes the database.
62 with engine.begin() as conn:
63 USState.metadata.create_all(conn)
64
65 with session_factory() as db_session:
66 # 1) load the JSON data into the US States table
67 repo = USStateRepository(session=db_session)
68 fixture = open_fixture(here, USStateRepository.model_type.__tablename__) # type: ignore
69 objs = repo.add_many([USStateRepository.model_type(**raw_obj) for raw_obj in fixture])
70 db_session.commit()
71 console.print(f"Created {len(objs)} new objects.")
72
73 # 2) Select paginated data and total row count.
74 created_objs, total_objs = repo.list_and_count(LimitOffset(limit=10, offset=0))
75 console.print(f"Selected {len(created_objs)} records out of a total of {total_objs}.")
76
77 # 2) Let's remove the batch of records selected.
78 deleted_objs = repo.delete_many([new_obj.id for new_obj in created_objs])
79 console.print(f"Removed {len(deleted_objs)} records out of a total of {total_objs}.")
80
81 # 3) Le'ts count the remaining rows
82 remaining_count = repo.count()
83 console.print(f"Found {remaining_count} remaining records after delete.")
84
85
86 if __name__ == "__main__":
87 run_script()
88
[end of docs/examples/contrib/sqlalchemy/sqlalchemy_repository_bulk_operations.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/docs/examples/contrib/sqlalchemy/sqlalchemy_repository_bulk_operations.py b/docs/examples/contrib/sqlalchemy/sqlalchemy_repository_bulk_operations.py
--- a/docs/examples/contrib/sqlalchemy/sqlalchemy_repository_bulk_operations.py
+++ b/docs/examples/contrib/sqlalchemy/sqlalchemy_repository_bulk_operations.py
@@ -63,7 +63,7 @@
USState.metadata.create_all(conn)
with session_factory() as db_session:
- # 1) load the JSON data into the US States table
+ # 1) Load the JSON data into the US States table.
repo = USStateRepository(session=db_session)
fixture = open_fixture(here, USStateRepository.model_type.__tablename__) # type: ignore
objs = repo.add_many([USStateRepository.model_type(**raw_obj) for raw_obj in fixture])
@@ -74,11 +74,11 @@
created_objs, total_objs = repo.list_and_count(LimitOffset(limit=10, offset=0))
console.print(f"Selected {len(created_objs)} records out of a total of {total_objs}.")
- # 2) Let's remove the batch of records selected.
+ # 3) Let's remove the batch of records selected.
deleted_objs = repo.delete_many([new_obj.id for new_obj in created_objs])
console.print(f"Removed {len(deleted_objs)} records out of a total of {total_objs}.")
- # 3) Le'ts count the remaining rows
+ # 4) Let's count the remaining rows
remaining_count = repo.count()
console.print(f"Found {remaining_count} remaining records after delete.")
| {"golden_diff": "diff --git a/docs/examples/contrib/sqlalchemy/sqlalchemy_repository_bulk_operations.py b/docs/examples/contrib/sqlalchemy/sqlalchemy_repository_bulk_operations.py\n--- a/docs/examples/contrib/sqlalchemy/sqlalchemy_repository_bulk_operations.py\n+++ b/docs/examples/contrib/sqlalchemy/sqlalchemy_repository_bulk_operations.py\n@@ -63,7 +63,7 @@\n USState.metadata.create_all(conn)\n \n with session_factory() as db_session:\n- # 1) load the JSON data into the US States table\n+ # 1) Load the JSON data into the US States table.\n repo = USStateRepository(session=db_session)\n fixture = open_fixture(here, USStateRepository.model_type.__tablename__) # type: ignore\n objs = repo.add_many([USStateRepository.model_type(**raw_obj) for raw_obj in fixture])\n@@ -74,11 +74,11 @@\n created_objs, total_objs = repo.list_and_count(LimitOffset(limit=10, offset=0))\n console.print(f\"Selected {len(created_objs)} records out of a total of {total_objs}.\")\n \n- # 2) Let's remove the batch of records selected.\n+ # 3) Let's remove the batch of records selected.\n deleted_objs = repo.delete_many([new_obj.id for new_obj in created_objs])\n console.print(f\"Removed {len(deleted_objs)} records out of a total of {total_objs}.\")\n \n- # 3) Le'ts count the remaining rows\n+ # 4) Let's count the remaining rows\n remaining_count = repo.count()\n console.print(f\"Found {remaining_count} remaining records after delete.\")\n", "issue": "StaticFilesConfig and virtual directories\nI'm trying to write a ``FileSystemProtocol`` to load files from the package data using [importlib_resources](https://importlib-resources.readthedocs.io/en/latest/using.html#). But because ``directories`` is defined as ``DirectoryPath``, pydantic checks if the given directories exist in the local filesystem. \r\n\r\nThis is not generally true, especially in any kind of virtual filesystem (e.g. a zipped package). I think this condition should be relaxed to support virtual filesystems.\r\n\r\nhttps://github.com/starlite-api/starlite/blob/9bb6dcd57c10a591377cf8e3a537e9292566d5b9/starlite/config/static_files.py#L32\n", "before_files": [{"content": "import json\nfrom pathlib import Path\nfrom typing import Any\n\nfrom rich import get_console\nfrom sqlalchemy import create_engine\nfrom sqlalchemy.orm import Mapped, Session, sessionmaker\n\nfrom litestar.contrib.sqlalchemy.base import UUIDBase\nfrom litestar.contrib.sqlalchemy.repository import SQLAlchemySyncRepository\nfrom litestar.repository.filters import LimitOffset\n\nhere = Path(__file__).parent\nconsole = get_console()\n\n\nclass USState(UUIDBase):\n # you can optionally override the generated table name by manually setting it.\n __tablename__ = \"us_state_lookup\" # type: ignore[assignment]\n abbreviation: Mapped[str]\n name: Mapped[str]\n\n\nclass USStateRepository(SQLAlchemySyncRepository[USState]):\n \"\"\"US State repository.\"\"\"\n\n model_type = USState\n\n\nengine = create_engine(\n \"duckdb:///:memory:\",\n future=True,\n)\nsession_factory: sessionmaker[Session] = sessionmaker(engine, expire_on_commit=False)\n\n\ndef open_fixture(fixtures_path: Path, fixture_name: str) -> Any:\n \"\"\"Loads JSON file with the specified fixture name\n\n Args:\n fixtures_path (Path): The path to look for fixtures\n fixture_name (str): The fixture name to load.\n\n Raises:\n FileNotFoundError: Fixtures not found.\n\n Returns:\n Any: The parsed JSON data\n \"\"\"\n fixture = Path(fixtures_path / f\"{fixture_name}.json\")\n if fixture.exists():\n with fixture.open(mode=\"r\", encoding=\"utf-8\") as f:\n f_data = f.read()\n return json.loads(f_data)\n raise FileNotFoundError(f\"Could not find the {fixture_name} fixture\")\n\n\ndef run_script() -> None:\n \"\"\"Load data from a fixture.\"\"\"\n\n # Initializes the database.\n with engine.begin() as conn:\n USState.metadata.create_all(conn)\n\n with session_factory() as db_session:\n # 1) load the JSON data into the US States table\n repo = USStateRepository(session=db_session)\n fixture = open_fixture(here, USStateRepository.model_type.__tablename__) # type: ignore\n objs = repo.add_many([USStateRepository.model_type(**raw_obj) for raw_obj in fixture])\n db_session.commit()\n console.print(f\"Created {len(objs)} new objects.\")\n\n # 2) Select paginated data and total row count.\n created_objs, total_objs = repo.list_and_count(LimitOffset(limit=10, offset=0))\n console.print(f\"Selected {len(created_objs)} records out of a total of {total_objs}.\")\n\n # 2) Let's remove the batch of records selected.\n deleted_objs = repo.delete_many([new_obj.id for new_obj in created_objs])\n console.print(f\"Removed {len(deleted_objs)} records out of a total of {total_objs}.\")\n\n # 3) Le'ts count the remaining rows\n remaining_count = repo.count()\n console.print(f\"Found {remaining_count} remaining records after delete.\")\n\n\nif __name__ == \"__main__\":\n run_script()\n", "path": "docs/examples/contrib/sqlalchemy/sqlalchemy_repository_bulk_operations.py"}]} | 1,546 | 357 |
gh_patches_debug_25431 | rasdani/github-patches | git_diff | lutris__lutris-994 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Auto update latest DXVK versions
https://github.com/lutris/lutris/blob/525c84d9da173e84fd5585eed6b9d2fef5bef2b2/lutris/util/dxvk.py#L11-L12
Instead of writing static versions, use GitHub API to get the latest versions of DXVK:
```bash
curl -s https://api.github.com/repos/doitsujin/dxvk/tags | jq '[.[] | .name] | join(", ")'
"v0.62, v0.61, v0.60, v0.54, v0.53, v0.52, v0.51, v0.50, v0.42, v0.41, v0.40, v0.31, v0.30, v0.21, v0.20"
```
</issue>
<code>
[start of lutris/util/dxvk.py]
1 """DXVK helper module"""
2 import os
3 import time
4 import shutil
5
6 from lutris.settings import RUNTIME_DIR
7 from lutris.util.log import logger
8 from lutris.util.extract import extract_archive
9 from lutris.util.downloader import Downloader
10
11 DXVK_LATEST = "0.52"
12 DXVK_PAST_RELEASES = ["0.51", "0.50", "0.42", "0.31", "0.21"]
13
14
15 class DXVKManager:
16 """Utility class to install DXVK dlls to a Wine prefix"""
17 base_url = "https://github.com/doitsujin/dxvk/releases/download/v{}/dxvk-{}.tar.gz"
18 base_dir = os.path.join(RUNTIME_DIR, 'dxvk')
19 dxvk_dlls = ('dxgi', 'd3d11')
20 latest_version = DXVK_LATEST
21
22 def __init__(self, prefix, arch='win64', version=None):
23 self.prefix = prefix
24 if not os.path.isdir(self.base_dir):
25 os.makedirs(self.base_dir)
26 self._version = version
27 self.wine_arch = arch
28
29 @property
30 def version(self):
31 """Return version of DXVK (latest known version if not provided)"""
32 if self._version:
33 return self._version
34 return self.latest_version
35
36 @property
37 def dxvk_path(self):
38 """Return path to DXVK local cache"""
39 return os.path.join(self.base_dir, self.version)
40
41 @staticmethod
42 def is_dxvk_dll(dll_path):
43 """Check if a given DLL path is provided by DXVK
44
45 Very basic check to see if a dll exists and is over 1MB. If this is the
46 case, then consider the DLL to be from DXVK
47 """
48 if os.path.exists(dll_path):
49 dll_stats = os.stat(dll_path)
50 dll_size = dll_stats.st_size
51 else:
52 dll_size = 0
53 return dll_size > 1024 * 1024
54
55 def is_available(self):
56 """Return whether DXVK is cached locally"""
57 return os.path.exists(self.dxvk_path)
58
59 def download(self):
60 """Download DXVK to the local cache"""
61 # There's a glitch in one of the archive's names
62 fixed_version = 'v0.40' if self.version == '0.40' else self.version
63 dxvk_url = self.base_url.format(self.version, fixed_version)
64 if self.is_available():
65 logger.warning("DXVK already available at %s", self.dxvk_path)
66
67 dxvk_archive_path = os.path.join(self.base_dir, os.path.basename(dxvk_url))
68 downloader = Downloader(dxvk_url, dxvk_archive_path)
69 downloader.start()
70 while downloader.check_progress() < 1:
71 time.sleep(1)
72 if not os.path.exists(dxvk_archive_path):
73 logger.error("DXVK %s not downloaded")
74 return
75 if os.stat(dxvk_archive_path).st_size:
76 extract_archive(dxvk_archive_path, self.dxvk_path, merge_single=True)
77 else:
78 logger.error("%s is an empty file", self.dxvk_path)
79 os.remove(dxvk_archive_path)
80
81 def enable_dxvk_dll(self, system_dir, dxvk_arch, dll):
82 """Copies DXVK dlls to the appropriate destination"""
83 wine_dll_path = os.path.join(system_dir, '%s.dll' % dll)
84 logger.info("Replacing %s/%s with DXVK version", system_dir, dll)
85 if not self.is_dxvk_dll(wine_dll_path):
86 # Backing up original version (may not be needed)
87 if os.path.exists(wine_dll_path):
88 shutil.move(wine_dll_path, wine_dll_path + ".orig")
89 # Copying DXVK's version
90 dxvk_dll_path = os.path.join(self.dxvk_path, dxvk_arch, "%s.dll" % dll)
91 shutil.copy(dxvk_dll_path, wine_dll_path)
92
93 def disable_dxvk_dll(self, system_dir, dxvk_arch, dll):
94 """Remove DXVK DLL from Wine prefix"""
95 wine_dll_path = os.path.join(system_dir, '%s.dll' % dll)
96 if self.is_dxvk_dll(wine_dll_path):
97 logger.info("Removing DXVK dll %s/%s", system_dir, dll)
98 os.remove(wine_dll_path)
99 # Restoring original version (may not be needed)
100 if os.path.exists(wine_dll_path + '.orig'):
101 shutil.move(wine_dll_path + '.orig', wine_dll_path)
102
103 def _iter_dxvk_dlls(self):
104 windows_path = os.path.join(self.prefix, 'drive_c/windows')
105 if self.wine_arch == 'win64':
106 system_dirs = {
107 'x64': os.path.join(windows_path, 'system32'),
108 'x32': os.path.join(windows_path, 'syswow64')
109 }
110 elif self.wine_arch == 'win32':
111 system_dirs = {
112 'x32': os.path.join(windows_path, 'system32'),
113 }
114
115 for dxvk_arch, system_dir in system_dirs.items():
116 for dll in self.dxvk_dlls:
117 yield system_dir, dxvk_arch, dll
118
119 def enable(self):
120 """Enable DXVK for the current prefix"""
121 if not os.path.exists(self.dxvk_path):
122 logger.error("DXVK %s is not availble locally" % self.version)
123 return
124 for system_dir, dxvk_arch, dll in self._iter_dxvk_dlls():
125 self.enable_dxvk_dll(system_dir, dxvk_arch, dll)
126
127 def disable(self):
128 """Disable DXVK for the current prefix"""
129 for system_dir, dxvk_arch, dll in self._iter_dxvk_dlls():
130 self.disable_dxvk_dll(system_dir, dxvk_arch, dll)
131
[end of lutris/util/dxvk.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/lutris/util/dxvk.py b/lutris/util/dxvk.py
--- a/lutris/util/dxvk.py
+++ b/lutris/util/dxvk.py
@@ -1,16 +1,41 @@
"""DXVK helper module"""
import os
+import json
import time
import shutil
+import urllib.request
from lutris.settings import RUNTIME_DIR
from lutris.util.log import logger
from lutris.util.extract import extract_archive
from lutris.util.downloader import Downloader
-DXVK_LATEST = "0.52"
-DXVK_PAST_RELEASES = ["0.51", "0.50", "0.42", "0.31", "0.21"]
+def get_latest_dxvk_versions():
+ """Get latest DXVK versions from GitHub"""
+ dxvk_url = "https://api.github.com/repos/doitsujin/dxvk/tags"
+ cache = os.path.join(RUNTIME_DIR, 'dxvk', 'dxvk_versions.json')
+
+ # If the DXVK cache does not exist then download it
+ if not os.path.exists(cache):
+ urllib.request.urlretrieve(dxvk_url, cache)
+
+ # Re-download DXVK versions cache if more than a day old
+ if os.path.getmtime(cache)+86400 < time.time():
+ urllib.request.urlretrieve(dxvk_url, cache)
+
+ with open(cache, "r") as f:
+ dxvk_json = json.load(f)
+ DXVK_LATEST = dxvk_json[0]['name'].replace('v','')
+ DXVK_PAST_RELEASES = [x['name'].replace('v', '') for x in dxvk_json][1:]
+
+ return DXVK_LATEST, DXVK_PAST_RELEASES
+
+try:
+ DXVK_LATEST, DXVK_PAST_RELEASES = get_latest_dxvk_versions()
+except:
+ DXVK_LATEST = "0.52"
+ DXVK_PAST_RELEASES = ["0.51", "0.50", "0.42", "0.31", "0.21"]
class DXVKManager:
"""Utility class to install DXVK dlls to a Wine prefix"""
| {"golden_diff": "diff --git a/lutris/util/dxvk.py b/lutris/util/dxvk.py\n--- a/lutris/util/dxvk.py\n+++ b/lutris/util/dxvk.py\n@@ -1,16 +1,41 @@\n \"\"\"DXVK helper module\"\"\"\n import os\n+import json\n import time\n import shutil\n+import urllib.request\n \n from lutris.settings import RUNTIME_DIR\n from lutris.util.log import logger\n from lutris.util.extract import extract_archive\n from lutris.util.downloader import Downloader\n \n-DXVK_LATEST = \"0.52\"\n-DXVK_PAST_RELEASES = [\"0.51\", \"0.50\", \"0.42\", \"0.31\", \"0.21\"]\n \n+def get_latest_dxvk_versions():\n+ \"\"\"Get latest DXVK versions from GitHub\"\"\"\n+ dxvk_url = \"https://api.github.com/repos/doitsujin/dxvk/tags\"\n+ cache = os.path.join(RUNTIME_DIR, 'dxvk', 'dxvk_versions.json')\n+\n+ # If the DXVK cache does not exist then download it\n+ if not os.path.exists(cache):\n+ urllib.request.urlretrieve(dxvk_url, cache)\n+\n+ # Re-download DXVK versions cache if more than a day old\n+ if os.path.getmtime(cache)+86400 < time.time():\n+ urllib.request.urlretrieve(dxvk_url, cache)\n+\n+ with open(cache, \"r\") as f:\n+ dxvk_json = json.load(f)\n+ DXVK_LATEST = dxvk_json[0]['name'].replace('v','')\n+ DXVK_PAST_RELEASES = [x['name'].replace('v', '') for x in dxvk_json][1:]\n+\n+ return DXVK_LATEST, DXVK_PAST_RELEASES\n+\n+try:\n+ DXVK_LATEST, DXVK_PAST_RELEASES = get_latest_dxvk_versions()\n+except:\n+ DXVK_LATEST = \"0.52\"\n+ DXVK_PAST_RELEASES = [\"0.51\", \"0.50\", \"0.42\", \"0.31\", \"0.21\"]\n \n class DXVKManager:\n \"\"\"Utility class to install DXVK dlls to a Wine prefix\"\"\"\n", "issue": "Auto update latest DXVK versions\nhttps://github.com/lutris/lutris/blob/525c84d9da173e84fd5585eed6b9d2fef5bef2b2/lutris/util/dxvk.py#L11-L12\r\n\r\nInstead of writing static versions, use GitHub API to get the latest versions of DXVK:\r\n```bash\r\ncurl -s https://api.github.com/repos/doitsujin/dxvk/tags | jq '[.[] | .name] | join(\", \")'\r\n\"v0.62, v0.61, v0.60, v0.54, v0.53, v0.52, v0.51, v0.50, v0.42, v0.41, v0.40, v0.31, v0.30, v0.21, v0.20\"\r\n```\n", "before_files": [{"content": "\"\"\"DXVK helper module\"\"\"\nimport os\nimport time\nimport shutil\n\nfrom lutris.settings import RUNTIME_DIR\nfrom lutris.util.log import logger\nfrom lutris.util.extract import extract_archive\nfrom lutris.util.downloader import Downloader\n\nDXVK_LATEST = \"0.52\"\nDXVK_PAST_RELEASES = [\"0.51\", \"0.50\", \"0.42\", \"0.31\", \"0.21\"]\n\n\nclass DXVKManager:\n \"\"\"Utility class to install DXVK dlls to a Wine prefix\"\"\"\n base_url = \"https://github.com/doitsujin/dxvk/releases/download/v{}/dxvk-{}.tar.gz\"\n base_dir = os.path.join(RUNTIME_DIR, 'dxvk')\n dxvk_dlls = ('dxgi', 'd3d11')\n latest_version = DXVK_LATEST\n\n def __init__(self, prefix, arch='win64', version=None):\n self.prefix = prefix\n if not os.path.isdir(self.base_dir):\n os.makedirs(self.base_dir)\n self._version = version\n self.wine_arch = arch\n\n @property\n def version(self):\n \"\"\"Return version of DXVK (latest known version if not provided)\"\"\"\n if self._version:\n return self._version\n return self.latest_version\n\n @property\n def dxvk_path(self):\n \"\"\"Return path to DXVK local cache\"\"\"\n return os.path.join(self.base_dir, self.version)\n\n @staticmethod\n def is_dxvk_dll(dll_path):\n \"\"\"Check if a given DLL path is provided by DXVK\n\n Very basic check to see if a dll exists and is over 1MB. If this is the\n case, then consider the DLL to be from DXVK\n \"\"\"\n if os.path.exists(dll_path):\n dll_stats = os.stat(dll_path)\n dll_size = dll_stats.st_size\n else:\n dll_size = 0\n return dll_size > 1024 * 1024\n\n def is_available(self):\n \"\"\"Return whether DXVK is cached locally\"\"\"\n return os.path.exists(self.dxvk_path)\n\n def download(self):\n \"\"\"Download DXVK to the local cache\"\"\"\n # There's a glitch in one of the archive's names\n fixed_version = 'v0.40' if self.version == '0.40' else self.version\n dxvk_url = self.base_url.format(self.version, fixed_version)\n if self.is_available():\n logger.warning(\"DXVK already available at %s\", self.dxvk_path)\n\n dxvk_archive_path = os.path.join(self.base_dir, os.path.basename(dxvk_url))\n downloader = Downloader(dxvk_url, dxvk_archive_path)\n downloader.start()\n while downloader.check_progress() < 1:\n time.sleep(1)\n if not os.path.exists(dxvk_archive_path):\n logger.error(\"DXVK %s not downloaded\")\n return\n if os.stat(dxvk_archive_path).st_size:\n extract_archive(dxvk_archive_path, self.dxvk_path, merge_single=True)\n else:\n logger.error(\"%s is an empty file\", self.dxvk_path)\n os.remove(dxvk_archive_path)\n\n def enable_dxvk_dll(self, system_dir, dxvk_arch, dll):\n \"\"\"Copies DXVK dlls to the appropriate destination\"\"\"\n wine_dll_path = os.path.join(system_dir, '%s.dll' % dll)\n logger.info(\"Replacing %s/%s with DXVK version\", system_dir, dll)\n if not self.is_dxvk_dll(wine_dll_path):\n # Backing up original version (may not be needed)\n if os.path.exists(wine_dll_path):\n shutil.move(wine_dll_path, wine_dll_path + \".orig\")\n # Copying DXVK's version\n dxvk_dll_path = os.path.join(self.dxvk_path, dxvk_arch, \"%s.dll\" % dll)\n shutil.copy(dxvk_dll_path, wine_dll_path)\n\n def disable_dxvk_dll(self, system_dir, dxvk_arch, dll):\n \"\"\"Remove DXVK DLL from Wine prefix\"\"\"\n wine_dll_path = os.path.join(system_dir, '%s.dll' % dll)\n if self.is_dxvk_dll(wine_dll_path):\n logger.info(\"Removing DXVK dll %s/%s\", system_dir, dll)\n os.remove(wine_dll_path)\n # Restoring original version (may not be needed)\n if os.path.exists(wine_dll_path + '.orig'):\n shutil.move(wine_dll_path + '.orig', wine_dll_path)\n\n def _iter_dxvk_dlls(self):\n windows_path = os.path.join(self.prefix, 'drive_c/windows')\n if self.wine_arch == 'win64':\n system_dirs = {\n 'x64': os.path.join(windows_path, 'system32'),\n 'x32': os.path.join(windows_path, 'syswow64')\n }\n elif self.wine_arch == 'win32':\n system_dirs = {\n 'x32': os.path.join(windows_path, 'system32'),\n }\n\n for dxvk_arch, system_dir in system_dirs.items():\n for dll in self.dxvk_dlls:\n yield system_dir, dxvk_arch, dll\n\n def enable(self):\n \"\"\"Enable DXVK for the current prefix\"\"\"\n if not os.path.exists(self.dxvk_path):\n logger.error(\"DXVK %s is not availble locally\" % self.version)\n return\n for system_dir, dxvk_arch, dll in self._iter_dxvk_dlls():\n self.enable_dxvk_dll(system_dir, dxvk_arch, dll)\n\n def disable(self):\n \"\"\"Disable DXVK for the current prefix\"\"\"\n for system_dir, dxvk_arch, dll in self._iter_dxvk_dlls():\n self.disable_dxvk_dll(system_dir, dxvk_arch, dll)\n", "path": "lutris/util/dxvk.py"}]} | 2,317 | 501 |
gh_patches_debug_5624 | rasdani/github-patches | git_diff | Textualize__textual-2981 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`Switch` should stop the `Click` event from bubbling
At the moment `Switch` handles `Click` but then lets it bubble; there's no good reason to do that and it also stops the ability to write something like this:
```python
from textual.app import App, ComposeResult
from textual.containers import Horizontal
from textual.widgets import Header, Footer, Label, Switch
class LabeledSwitch( Horizontal ):
def on_click( self ) -> None:
self.query_one(Switch).toggle()
class ClickableLabelApp( App[ None ] ):
def compose( self ) -> ComposeResult:
yield Header()
with LabeledSwitch():
yield Label( "Click me!" )
yield Switch()
yield Footer()
if __name__ == "__main__":
ClickableLabelApp().run()
```
where the idea is to make a compound widget that lets you click on the `Label` or the `Switch` and the `Switch` will toggle -- only it doesn't work if you click on the `Switch` because it ends up double-toggling.
</issue>
<code>
[start of src/textual/widgets/_switch.py]
1 from __future__ import annotations
2
3 from typing import TYPE_CHECKING, ClassVar
4
5 from rich.console import RenderableType
6
7 from ..binding import Binding, BindingType
8 from ..events import Click
9 from ..geometry import Size
10 from ..message import Message
11 from ..reactive import reactive
12 from ..scrollbar import ScrollBarRender
13 from ..widget import Widget
14
15 if TYPE_CHECKING:
16 from typing_extensions import Self
17
18
19 class Switch(Widget, can_focus=True):
20 """A switch widget that represents a boolean value.
21
22 Can be toggled by clicking on it or through its [bindings][textual.widgets.Switch.BINDINGS].
23
24 The switch widget also contains [component classes][textual.widgets.Switch.COMPONENT_CLASSES]
25 that enable more customization.
26 """
27
28 BINDINGS: ClassVar[list[BindingType]] = [
29 Binding("enter,space", "toggle", "Toggle", show=False),
30 ]
31 """
32 | Key(s) | Description |
33 | :- | :- |
34 | enter,space | Toggle the switch state. |
35 """
36
37 COMPONENT_CLASSES: ClassVar[set[str]] = {
38 "switch--slider",
39 }
40 """
41 | Class | Description |
42 | :- | :- |
43 | `switch--slider` | Targets the slider of the switch. |
44 """
45
46 DEFAULT_CSS = """
47 Switch {
48 border: tall transparent;
49 background: $boost;
50 height: auto;
51 width: auto;
52 padding: 0 2;
53 }
54
55 Switch > .switch--slider {
56 background: $panel-darken-2;
57 color: $panel-lighten-2;
58 }
59
60 Switch:hover {
61 border: tall $background;
62 }
63
64 Switch:focus {
65 border: tall $accent;
66 }
67
68 Switch.-on {
69
70 }
71
72 Switch.-on > .switch--slider {
73 color: $success;
74 }
75 """
76
77 value = reactive(False, init=False)
78 """The value of the switch; `True` for on and `False` for off."""
79
80 slider_pos = reactive(0.0)
81 """The position of the slider."""
82
83 class Changed(Message, bubble=True):
84 """Posted when the status of the switch changes.
85
86 Can be handled using `on_switch_changed` in a subclass of `Switch`
87 or in a parent widget in the DOM.
88
89 Attributes:
90 value: The value that the switch was changed to.
91 switch: The `Switch` widget that was changed.
92 """
93
94 def __init__(self, switch: Switch, value: bool) -> None:
95 super().__init__()
96 self.value: bool = value
97 self.switch: Switch = switch
98
99 @property
100 def control(self) -> Switch:
101 """Alias for self.switch."""
102 return self.switch
103
104 def __init__(
105 self,
106 value: bool = False,
107 *,
108 animate: bool = True,
109 name: str | None = None,
110 id: str | None = None,
111 classes: str | None = None,
112 disabled: bool = False,
113 ):
114 """Initialise the switch.
115
116 Args:
117 value: The initial value of the switch.
118 animate: True if the switch should animate when toggled.
119 name: The name of the switch.
120 id: The ID of the switch in the DOM.
121 classes: The CSS classes of the switch.
122 disabled: Whether the switch is disabled or not.
123 """
124 super().__init__(name=name, id=id, classes=classes, disabled=disabled)
125 if value:
126 self.slider_pos = 1.0
127 self._reactive_value = value
128 self._should_animate = animate
129
130 def watch_value(self, value: bool) -> None:
131 target_slider_pos = 1.0 if value else 0.0
132 if self._should_animate:
133 self.animate("slider_pos", target_slider_pos, duration=0.3)
134 else:
135 self.slider_pos = target_slider_pos
136 self.post_message(self.Changed(self, self.value))
137
138 def watch_slider_pos(self, slider_pos: float) -> None:
139 self.set_class(slider_pos == 1, "-on")
140
141 def render(self) -> RenderableType:
142 style = self.get_component_rich_style("switch--slider")
143 return ScrollBarRender(
144 virtual_size=100,
145 window_size=50,
146 position=self.slider_pos * 50,
147 style=style,
148 vertical=False,
149 )
150
151 def get_content_width(self, container: Size, viewport: Size) -> int:
152 return 4
153
154 def get_content_height(self, container: Size, viewport: Size, width: int) -> int:
155 return 1
156
157 async def _on_click(self, _: Click) -> None:
158 """Toggle the state of the switch."""
159 self.toggle()
160
161 def action_toggle(self) -> None:
162 """Toggle the state of the switch."""
163 self.toggle()
164
165 def toggle(self) -> Self:
166 """Toggle the switch value.
167
168 As a result of the value changing, a `Switch.Changed` message will
169 be posted.
170
171 Returns:
172 The `Switch` instance.
173 """
174 self.value = not self.value
175 return self
176
[end of src/textual/widgets/_switch.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/textual/widgets/_switch.py b/src/textual/widgets/_switch.py
--- a/src/textual/widgets/_switch.py
+++ b/src/textual/widgets/_switch.py
@@ -154,8 +154,9 @@
def get_content_height(self, container: Size, viewport: Size, width: int) -> int:
return 1
- async def _on_click(self, _: Click) -> None:
+ async def _on_click(self, event: Click) -> None:
"""Toggle the state of the switch."""
+ event.stop()
self.toggle()
def action_toggle(self) -> None:
| {"golden_diff": "diff --git a/src/textual/widgets/_switch.py b/src/textual/widgets/_switch.py\n--- a/src/textual/widgets/_switch.py\n+++ b/src/textual/widgets/_switch.py\n@@ -154,8 +154,9 @@\n def get_content_height(self, container: Size, viewport: Size, width: int) -> int:\n return 1\n \n- async def _on_click(self, _: Click) -> None:\n+ async def _on_click(self, event: Click) -> None:\n \"\"\"Toggle the state of the switch.\"\"\"\n+ event.stop()\n self.toggle()\n \n def action_toggle(self) -> None:\n", "issue": "`Switch` should stop the `Click` event from bubbling\nAt the moment `Switch` handles `Click` but then lets it bubble; there's no good reason to do that and it also stops the ability to write something like this:\r\n\r\n```python\r\nfrom textual.app import App, ComposeResult\r\nfrom textual.containers import Horizontal\r\nfrom textual.widgets import Header, Footer, Label, Switch\r\n\r\nclass LabeledSwitch( Horizontal ):\r\n\r\n def on_click( self ) -> None:\r\n self.query_one(Switch).toggle()\r\n\r\nclass ClickableLabelApp( App[ None ] ):\r\n\r\n def compose( self ) -> ComposeResult:\r\n yield Header()\r\n with LabeledSwitch():\r\n yield Label( \"Click me!\" )\r\n yield Switch()\r\n yield Footer()\r\n\r\nif __name__ == \"__main__\":\r\n ClickableLabelApp().run()\r\n```\r\n\r\nwhere the idea is to make a compound widget that lets you click on the `Label` or the `Switch` and the `Switch` will toggle -- only it doesn't work if you click on the `Switch` because it ends up double-toggling.\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING, ClassVar\n\nfrom rich.console import RenderableType\n\nfrom ..binding import Binding, BindingType\nfrom ..events import Click\nfrom ..geometry import Size\nfrom ..message import Message\nfrom ..reactive import reactive\nfrom ..scrollbar import ScrollBarRender\nfrom ..widget import Widget\n\nif TYPE_CHECKING:\n from typing_extensions import Self\n\n\nclass Switch(Widget, can_focus=True):\n \"\"\"A switch widget that represents a boolean value.\n\n Can be toggled by clicking on it or through its [bindings][textual.widgets.Switch.BINDINGS].\n\n The switch widget also contains [component classes][textual.widgets.Switch.COMPONENT_CLASSES]\n that enable more customization.\n \"\"\"\n\n BINDINGS: ClassVar[list[BindingType]] = [\n Binding(\"enter,space\", \"toggle\", \"Toggle\", show=False),\n ]\n \"\"\"\n | Key(s) | Description |\n | :- | :- |\n | enter,space | Toggle the switch state. |\n \"\"\"\n\n COMPONENT_CLASSES: ClassVar[set[str]] = {\n \"switch--slider\",\n }\n \"\"\"\n | Class | Description |\n | :- | :- |\n | `switch--slider` | Targets the slider of the switch. |\n \"\"\"\n\n DEFAULT_CSS = \"\"\"\n Switch {\n border: tall transparent;\n background: $boost;\n height: auto;\n width: auto;\n padding: 0 2;\n }\n\n Switch > .switch--slider {\n background: $panel-darken-2;\n color: $panel-lighten-2;\n }\n\n Switch:hover {\n border: tall $background;\n }\n\n Switch:focus {\n border: tall $accent;\n }\n\n Switch.-on {\n\n }\n\n Switch.-on > .switch--slider {\n color: $success;\n }\n \"\"\"\n\n value = reactive(False, init=False)\n \"\"\"The value of the switch; `True` for on and `False` for off.\"\"\"\n\n slider_pos = reactive(0.0)\n \"\"\"The position of the slider.\"\"\"\n\n class Changed(Message, bubble=True):\n \"\"\"Posted when the status of the switch changes.\n\n Can be handled using `on_switch_changed` in a subclass of `Switch`\n or in a parent widget in the DOM.\n\n Attributes:\n value: The value that the switch was changed to.\n switch: The `Switch` widget that was changed.\n \"\"\"\n\n def __init__(self, switch: Switch, value: bool) -> None:\n super().__init__()\n self.value: bool = value\n self.switch: Switch = switch\n\n @property\n def control(self) -> Switch:\n \"\"\"Alias for self.switch.\"\"\"\n return self.switch\n\n def __init__(\n self,\n value: bool = False,\n *,\n animate: bool = True,\n name: str | None = None,\n id: str | None = None,\n classes: str | None = None,\n disabled: bool = False,\n ):\n \"\"\"Initialise the switch.\n\n Args:\n value: The initial value of the switch.\n animate: True if the switch should animate when toggled.\n name: The name of the switch.\n id: The ID of the switch in the DOM.\n classes: The CSS classes of the switch.\n disabled: Whether the switch is disabled or not.\n \"\"\"\n super().__init__(name=name, id=id, classes=classes, disabled=disabled)\n if value:\n self.slider_pos = 1.0\n self._reactive_value = value\n self._should_animate = animate\n\n def watch_value(self, value: bool) -> None:\n target_slider_pos = 1.0 if value else 0.0\n if self._should_animate:\n self.animate(\"slider_pos\", target_slider_pos, duration=0.3)\n else:\n self.slider_pos = target_slider_pos\n self.post_message(self.Changed(self, self.value))\n\n def watch_slider_pos(self, slider_pos: float) -> None:\n self.set_class(slider_pos == 1, \"-on\")\n\n def render(self) -> RenderableType:\n style = self.get_component_rich_style(\"switch--slider\")\n return ScrollBarRender(\n virtual_size=100,\n window_size=50,\n position=self.slider_pos * 50,\n style=style,\n vertical=False,\n )\n\n def get_content_width(self, container: Size, viewport: Size) -> int:\n return 4\n\n def get_content_height(self, container: Size, viewport: Size, width: int) -> int:\n return 1\n\n async def _on_click(self, _: Click) -> None:\n \"\"\"Toggle the state of the switch.\"\"\"\n self.toggle()\n\n def action_toggle(self) -> None:\n \"\"\"Toggle the state of the switch.\"\"\"\n self.toggle()\n\n def toggle(self) -> Self:\n \"\"\"Toggle the switch value.\n\n As a result of the value changing, a `Switch.Changed` message will\n be posted.\n\n Returns:\n The `Switch` instance.\n \"\"\"\n self.value = not self.value\n return self\n", "path": "src/textual/widgets/_switch.py"}]} | 2,328 | 140 |
gh_patches_debug_4016 | rasdani/github-patches | git_diff | ansible__awx-14626 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Issue on awx.awx.export/import awx cli/collection
### Please confirm the following
- [X] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).
- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.
- [X] I understand that AWX is open source software provided for free and that I might not receive a timely response.
- [X] I am **NOT** reporting a (potential) security vulnerability. (These should be emailed to `[email protected]` instead.)
### Bug Summary
Hi team,
I founded tow bugs related awx cli and collection import / export.
The first issue is related export module, that not work if user is a system_auditor (or not have certain admin role in object like schedule.
I already found why this bug is present and proposed a PR: #14626 .
Second "bug" is related import module (I don't know and don't find if someone decide it) and is related how import will be processed.
Actually import perform a `POST`, if object not exists, or a `PUT`, if object exists. In case of we `PUT` an object that already exist api will replace it in all fields, including encrypted key, that in export are removed (correctly).
So, i don't know if it's better approach with `PATCH` instead a `PUT`, but I think that here the issue is in the export itself, that will replace value of encrypted key `$encrypted$` with `''` .
The side effect of "restore" `$encrypted$ ` on the export is that we remove it for the POST, due to the fact that is a reseved keyword.
I will propose a PR also to fix the second bugs
### AWX version
23.3.1
### Select the relevant components
- [ ] UI
- [ ] UI (tech preview)
- [X] API
- [ ] Docs
- [X] Collection
- [X] CLI
- [ ] Other
### Installation method
kubernetes
### Modifications
no
### Ansible version
_No response_
### Operating system
_No response_
### Web browser
_No response_
### Steps to reproduce
bug 1: execute an export of schedule with a system_auditor
bug 2: import a credential already present in AWX
### Expected results
bug 1: export will go fine
bug 2: credential will be updated with only fields present in export
### Actual results
bug 1: export will fail
bug 2: credential will be replaced with exported data. But due to the fact that encrypted key are not exported and replaced the value `$encrypted$` with `''` we replace current secrets with `''`
### Additional information
_No response_
</issue>
<code>
[start of awxkit/awxkit/api/utils.py]
1 import logging
2 import re
3
4
5 log = logging.getLogger(__name__)
6
7 descRE = re.compile(r'^[*] `(\w+)`: [^(]*\((\w+), ([^)]+)\)')
8
9
10 def freeze(key):
11 if key is None:
12 return None
13 return frozenset((k, freeze(v) if isinstance(v, dict) else v) for k, v in key.items())
14
15
16 def parse_description(desc):
17 options = {}
18 for line in desc[desc.index('POST') :].splitlines():
19 match = descRE.match(line)
20 if not match:
21 continue
22 options[match.group(1)] = {'type': match.group(2), 'required': match.group(3) == 'required'}
23 return options
24
25
26 def remove_encrypted(value):
27 if value == '$encrypted$':
28 return ''
29 if isinstance(value, list):
30 return [remove_encrypted(item) for item in value]
31 if isinstance(value, dict):
32 return {k: remove_encrypted(v) for k, v in value.items()}
33 return value
34
35
36 def get_post_fields(page, cache):
37 options_page = cache.get_options(page)
38 if options_page is None:
39 return None
40
41 if 'POST' not in options_page.r.headers.get('Allow', ''):
42 return None
43
44 if 'POST' in options_page.json['actions']:
45 return options_page.json['actions']['POST']
46 else:
47 log.warning("Insufficient privileges on %s, inferring POST fields from description.", options_page.endpoint)
48 return parse_description(options_page.json['description'])
49
[end of awxkit/awxkit/api/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/awxkit/awxkit/api/utils.py b/awxkit/awxkit/api/utils.py
--- a/awxkit/awxkit/api/utils.py
+++ b/awxkit/awxkit/api/utils.py
@@ -15,7 +15,12 @@
def parse_description(desc):
options = {}
- for line in desc[desc.index('POST') :].splitlines():
+ desc_lines = []
+ if 'POST' in desc:
+ desc_lines = desc[desc.index('POST') :].splitlines()
+ else:
+ desc_lines = desc.splitlines()
+ for line in desc_lines:
match = descRE.match(line)
if not match:
continue
| {"golden_diff": "diff --git a/awxkit/awxkit/api/utils.py b/awxkit/awxkit/api/utils.py\n--- a/awxkit/awxkit/api/utils.py\n+++ b/awxkit/awxkit/api/utils.py\n@@ -15,7 +15,12 @@\n \n def parse_description(desc):\n options = {}\n- for line in desc[desc.index('POST') :].splitlines():\n+ desc_lines = []\n+ if 'POST' in desc:\n+ desc_lines = desc[desc.index('POST') :].splitlines()\n+ else:\n+ desc_lines = desc.splitlines()\n+ for line in desc_lines:\n match = descRE.match(line)\n if not match:\n continue\n", "issue": "Issue on awx.awx.export/import awx cli/collection\n### Please confirm the following\r\n\r\n- [X] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).\r\n- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.\r\n- [X] I understand that AWX is open source software provided for free and that I might not receive a timely response.\r\n- [X] I am **NOT** reporting a (potential) security vulnerability. (These should be emailed to `[email protected]` instead.)\r\n\r\n### Bug Summary\r\n\r\nHi team,\r\nI founded tow bugs related awx cli and collection import / export.\r\n\r\nThe first issue is related export module, that not work if user is a system_auditor (or not have certain admin role in object like schedule.\r\nI already found why this bug is present and proposed a PR: #14626 .\r\n\r\nSecond \"bug\" is related import module (I don't know and don't find if someone decide it) and is related how import will be processed.\r\nActually import perform a `POST`, if object not exists, or a `PUT`, if object exists. In case of we `PUT` an object that already exist api will replace it in all fields, including encrypted key, that in export are removed (correctly).\r\n\r\nSo, i don't know if it's better approach with `PATCH` instead a `PUT`, but I think that here the issue is in the export itself, that will replace value of encrypted key `$encrypted$` with `''` .\r\nThe side effect of \"restore\" `$encrypted$ ` on the export is that we remove it for the POST, due to the fact that is a reseved keyword.\r\n \r\n I will propose a PR also to fix the second bugs\r\n\r\n### AWX version\r\n\r\n23.3.1\r\n\r\n### Select the relevant components\r\n\r\n- [ ] UI\r\n- [ ] UI (tech preview)\r\n- [X] API\r\n- [ ] Docs\r\n- [X] Collection\r\n- [X] CLI\r\n- [ ] Other\r\n\r\n### Installation method\r\n\r\nkubernetes\r\n\r\n### Modifications\r\n\r\nno\r\n\r\n### Ansible version\r\n\r\n_No response_\r\n\r\n### Operating system\r\n\r\n_No response_\r\n\r\n### Web browser\r\n\r\n_No response_\r\n\r\n### Steps to reproduce\r\n\r\nbug 1: execute an export of schedule with a system_auditor\r\n\r\nbug 2: import a credential already present in AWX\r\n\r\n### Expected results\r\n\r\nbug 1: export will go fine\r\n\r\nbug 2: credential will be updated with only fields present in export\r\n\r\n### Actual results\r\n\r\nbug 1: export will fail\r\n\r\nbug 2: credential will be replaced with exported data. But due to the fact that encrypted key are not exported and replaced the value `$encrypted$` with `''` we replace current secrets with `''`\r\n\r\n### Additional information\r\n\r\n_No response_\n", "before_files": [{"content": "import logging\nimport re\n\n\nlog = logging.getLogger(__name__)\n\ndescRE = re.compile(r'^[*] `(\\w+)`: [^(]*\\((\\w+), ([^)]+)\\)')\n\n\ndef freeze(key):\n if key is None:\n return None\n return frozenset((k, freeze(v) if isinstance(v, dict) else v) for k, v in key.items())\n\n\ndef parse_description(desc):\n options = {}\n for line in desc[desc.index('POST') :].splitlines():\n match = descRE.match(line)\n if not match:\n continue\n options[match.group(1)] = {'type': match.group(2), 'required': match.group(3) == 'required'}\n return options\n\n\ndef remove_encrypted(value):\n if value == '$encrypted$':\n return ''\n if isinstance(value, list):\n return [remove_encrypted(item) for item in value]\n if isinstance(value, dict):\n return {k: remove_encrypted(v) for k, v in value.items()}\n return value\n\n\ndef get_post_fields(page, cache):\n options_page = cache.get_options(page)\n if options_page is None:\n return None\n\n if 'POST' not in options_page.r.headers.get('Allow', ''):\n return None\n\n if 'POST' in options_page.json['actions']:\n return options_page.json['actions']['POST']\n else:\n log.warning(\"Insufficient privileges on %s, inferring POST fields from description.\", options_page.endpoint)\n return parse_description(options_page.json['description'])\n", "path": "awxkit/awxkit/api/utils.py"}]} | 1,589 | 165 |
gh_patches_debug_59177 | rasdani/github-patches | git_diff | fossasia__open-event-server-4147 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
IntegrityError: (psycopg2.IntegrityError) column "field_identifier" contains null values
https://sentry.eventyay.com/eventyay/api/issues/25/
```
IntegrityError: (psycopg2.IntegrityError) column "field_identifier" contains null values
[SQL: 'ALTER TABLE custom_forms ADD COLUMN field_identifier VARCHAR NOT NULL']
(25 additional frame(s) were not displayed)
...
File "sqlalchemy/engine/base.py", line 1189, in _execute_context
context)
File "sqlalchemy/engine/base.py", line 1402, in _handle_dbapi_exception
exc_info
File "sqlalchemy/util/compat.py", line 203, in raise_from_cause
reraise(type(exception), exception, tb=exc_tb, cause=cause)
File "sqlalchemy/engine/base.py", line 1182, in _execute_context
context)
File "sqlalchemy/engine/default.py", line 470, in do_execute
cursor.execute(statement, parameters)
IntegrityError: (psycopg2.IntegrityError) column "field_identifier" contains null values
[SQL: 'ALTER TABLE custom_forms ADD COLUMN field_identifier VARCHAR NOT NULL']
```
</issue>
<code>
[start of migrations/versions/aefa134809bf_.py]
1 """empty message
2
3 Revision ID: aefa134809bf
4 Revises: 2b39d8c05788
5 Create Date: 2017-07-21 20:37:50.193436
6
7 """
8
9 from alembic import op
10 import sqlalchemy as sa
11 import sqlalchemy_utils
12
13
14 # revision identifiers, used by Alembic.
15 revision = 'aefa134809bf'
16 down_revision = '2b39d8c05788'
17
18
19 def upgrade():
20 # ### commands auto generated by Alembic - please adjust! ###
21 op.add_column('custom_forms', sa.Column('field_identifier', sa.String(), nullable=False))
22 op.add_column('custom_forms', sa.Column('form', sa.String(), nullable=False))
23 op.add_column('custom_forms', sa.Column('is_fixed', sa.Boolean(), nullable=True))
24 op.add_column('custom_forms', sa.Column('is_included', sa.Boolean(), nullable=True))
25 op.add_column('custom_forms', sa.Column('is_required', sa.Boolean(), nullable=True))
26 op.add_column('custom_forms', sa.Column('type', sa.String(), nullable=False))
27 op.create_unique_constraint('custom_form_identifier', 'custom_forms', ['event_id', 'field_identifier', 'form'])
28 op.drop_column('custom_forms', 'speaker_form')
29 op.drop_column('custom_forms', 'session_form')
30 # ### end Alembic commands ###
31
32
33 def downgrade():
34 # ### commands auto generated by Alembic - please adjust! ###
35 op.add_column('custom_forms', sa.Column('session_form', sa.VARCHAR(), autoincrement=False, nullable=False))
36 op.add_column('custom_forms', sa.Column('speaker_form', sa.VARCHAR(), autoincrement=False, nullable=False))
37 op.drop_constraint('custom_form_identifier', 'custom_forms', type_='unique')
38 op.drop_column('custom_forms', 'type')
39 op.drop_column('custom_forms', 'is_required')
40 op.drop_column('custom_forms', 'is_included')
41 op.drop_column('custom_forms', 'is_fixed')
42 op.drop_column('custom_forms', 'form')
43 op.drop_column('custom_forms', 'field_identifier')
44 # ### end Alembic commands ###
45
[end of migrations/versions/aefa134809bf_.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/migrations/versions/aefa134809bf_.py b/migrations/versions/aefa134809bf_.py
--- a/migrations/versions/aefa134809bf_.py
+++ b/migrations/versions/aefa134809bf_.py
@@ -18,6 +18,7 @@
def upgrade():
# ### commands auto generated by Alembic - please adjust! ###
+ op.execute("DELETE FROM custom_forms")
op.add_column('custom_forms', sa.Column('field_identifier', sa.String(), nullable=False))
op.add_column('custom_forms', sa.Column('form', sa.String(), nullable=False))
op.add_column('custom_forms', sa.Column('is_fixed', sa.Boolean(), nullable=True))
| {"golden_diff": "diff --git a/migrations/versions/aefa134809bf_.py b/migrations/versions/aefa134809bf_.py\n--- a/migrations/versions/aefa134809bf_.py\n+++ b/migrations/versions/aefa134809bf_.py\n@@ -18,6 +18,7 @@\n \n def upgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n+ op.execute(\"DELETE FROM custom_forms\")\n op.add_column('custom_forms', sa.Column('field_identifier', sa.String(), nullable=False))\n op.add_column('custom_forms', sa.Column('form', sa.String(), nullable=False))\n op.add_column('custom_forms', sa.Column('is_fixed', sa.Boolean(), nullable=True))\n", "issue": "IntegrityError: (psycopg2.IntegrityError) column \"field_identifier\" contains null values\nhttps://sentry.eventyay.com/eventyay/api/issues/25/\r\n\r\n```\r\nIntegrityError: (psycopg2.IntegrityError) column \"field_identifier\" contains null values\r\n [SQL: 'ALTER TABLE custom_forms ADD COLUMN field_identifier VARCHAR NOT NULL']\r\n(25 additional frame(s) were not displayed)\r\n...\r\n File \"sqlalchemy/engine/base.py\", line 1189, in _execute_context\r\n context)\r\n File \"sqlalchemy/engine/base.py\", line 1402, in _handle_dbapi_exception\r\n exc_info\r\n File \"sqlalchemy/util/compat.py\", line 203, in raise_from_cause\r\n reraise(type(exception), exception, tb=exc_tb, cause=cause)\r\n File \"sqlalchemy/engine/base.py\", line 1182, in _execute_context\r\n context)\r\n File \"sqlalchemy/engine/default.py\", line 470, in do_execute\r\n cursor.execute(statement, parameters)\r\n\r\nIntegrityError: (psycopg2.IntegrityError) column \"field_identifier\" contains null values\r\n [SQL: 'ALTER TABLE custom_forms ADD COLUMN field_identifier VARCHAR NOT NULL']\r\n```\n", "before_files": [{"content": "\"\"\"empty message\n\nRevision ID: aefa134809bf\nRevises: 2b39d8c05788\nCreate Date: 2017-07-21 20:37:50.193436\n\n\"\"\"\n\nfrom alembic import op\nimport sqlalchemy as sa\nimport sqlalchemy_utils\n\n\n# revision identifiers, used by Alembic.\nrevision = 'aefa134809bf'\ndown_revision = '2b39d8c05788'\n\n\ndef upgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.add_column('custom_forms', sa.Column('field_identifier', sa.String(), nullable=False))\n op.add_column('custom_forms', sa.Column('form', sa.String(), nullable=False))\n op.add_column('custom_forms', sa.Column('is_fixed', sa.Boolean(), nullable=True))\n op.add_column('custom_forms', sa.Column('is_included', sa.Boolean(), nullable=True))\n op.add_column('custom_forms', sa.Column('is_required', sa.Boolean(), nullable=True))\n op.add_column('custom_forms', sa.Column('type', sa.String(), nullable=False))\n op.create_unique_constraint('custom_form_identifier', 'custom_forms', ['event_id', 'field_identifier', 'form'])\n op.drop_column('custom_forms', 'speaker_form')\n op.drop_column('custom_forms', 'session_form')\n # ### end Alembic commands ###\n\n\ndef downgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.add_column('custom_forms', sa.Column('session_form', sa.VARCHAR(), autoincrement=False, nullable=False))\n op.add_column('custom_forms', sa.Column('speaker_form', sa.VARCHAR(), autoincrement=False, nullable=False))\n op.drop_constraint('custom_form_identifier', 'custom_forms', type_='unique')\n op.drop_column('custom_forms', 'type')\n op.drop_column('custom_forms', 'is_required')\n op.drop_column('custom_forms', 'is_included')\n op.drop_column('custom_forms', 'is_fixed')\n op.drop_column('custom_forms', 'form')\n op.drop_column('custom_forms', 'field_identifier')\n # ### end Alembic commands ###\n", "path": "migrations/versions/aefa134809bf_.py"}]} | 1,395 | 172 |
gh_patches_debug_18270 | rasdani/github-patches | git_diff | dask__distributed-6904 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Importing from distributed shows pyright error
**What happened**:
When type-checking a program that imports from distributed with pyright, an error is accused:
```python
# foo.py
from distributed import Client
print(Client)
```
```
pyright foo.py
...
/tmp/test-area/foo.py:1:25 - error: "Client" is not exported from module "distributed"
Import from "distributed.client" instead (reportPrivateImportUsage)
1 error, 0 warnings, 0 informations
```
**What you expected to happen**:
I expect the package to be correctly typed, following PEP 484
**Anything else we need to know?**:
PEP 484 states that
> Modules and variables imported into the stub are not considered exported from the stub unless the import uses the `import ... as ... form` or the equivalent `from ... import ... as ... form`
and Pyright follows this guideline, although mypy doesn't.
**Environment**:
- Dask version: 2022.8.0
- Python version: 3.10.5
- Operating System: Arch linux
- Install method (conda, pip, source): pip inside an environment
</issue>
<code>
[start of distributed/__init__.py]
1 from __future__ import annotations
2
3 # isort: off
4 from distributed import config # load distributed configuration first
5 from distributed import widgets # load distributed widgets second
6
7 # isort: on
8
9 import atexit
10
11 import dask
12 from dask.config import config # type: ignore
13
14 from distributed._version import get_versions
15 from distributed.actor import Actor, ActorFuture, BaseActorFuture
16 from distributed.client import (
17 Client,
18 CompatibleExecutor,
19 Future,
20 as_completed,
21 default_client,
22 fire_and_forget,
23 futures_of,
24 get_task_metadata,
25 get_task_stream,
26 performance_report,
27 wait,
28 )
29 from distributed.core import Status, connect, rpc
30 from distributed.deploy import Adaptive, LocalCluster, SpecCluster, SSHCluster
31 from distributed.diagnostics.plugin import (
32 Environ,
33 NannyPlugin,
34 PipInstall,
35 SchedulerPlugin,
36 UploadDirectory,
37 UploadFile,
38 WorkerPlugin,
39 )
40 from distributed.diagnostics.progressbar import progress
41 from distributed.event import Event
42 from distributed.lock import Lock
43 from distributed.multi_lock import MultiLock
44 from distributed.nanny import Nanny
45 from distributed.pubsub import Pub, Sub
46 from distributed.queues import Queue
47 from distributed.scheduler import KilledWorker, Scheduler
48 from distributed.security import Security
49 from distributed.semaphore import Semaphore
50 from distributed.threadpoolexecutor import rejoin
51 from distributed.utils import CancelledError, TimeoutError, sync
52 from distributed.variable import Variable
53 from distributed.worker import (
54 Reschedule,
55 Worker,
56 get_client,
57 get_worker,
58 print,
59 secede,
60 warn,
61 )
62 from distributed.worker_client import local_client, worker_client
63
64
65 def __getattr__(name):
66 global __version__, __git_revision__
67
68 if name == "__version__":
69 from importlib.metadata import version
70
71 __version__ = version("distributed")
72 return __version__
73
74 if name == "__git_revision__":
75 from distributed._version import get_versions
76
77 __git_revision__ = get_versions()["full-revisionid"]
78 return __git_revision__
79
80 raise AttributeError(f"module {__name__!r} has no attribute {name!r}")
81
82
83 _python_shutting_down = False
84
85
86 @atexit.register
87 def _():
88 """Set a global when Python shuts down.
89
90 Note
91 ----
92 This function must be registered with atexit *after* any class that invokes
93 ``dstributed.utils.is_python_shutting_down`` has been defined. This way it
94 will be called before the ``__del__`` method of those classes.
95
96 See Also
97 --------
98 distributed.utils.is_python_shutting_down
99 """
100 global _python_shutting_down
101 _python_shutting_down = True
102
[end of distributed/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/distributed/__init__.py b/distributed/__init__.py
--- a/distributed/__init__.py
+++ b/distributed/__init__.py
@@ -99,3 +99,65 @@
"""
global _python_shutting_down
_python_shutting_down = True
+
+
+__all__ = [
+ "Actor",
+ "ActorFuture",
+ "Adaptive",
+ "BaseActorFuture",
+ "CancelledError",
+ "Client",
+ "CompatibleExecutor",
+ "Environ",
+ "Event",
+ "Future",
+ "KilledWorker",
+ "LocalCluster",
+ "Lock",
+ "MultiLock",
+ "Nanny",
+ "NannyPlugin",
+ "PipInstall",
+ "Pub",
+ "Queue",
+ "Reschedule",
+ "SSHCluster",
+ "Scheduler",
+ "SchedulerPlugin",
+ "Security",
+ "Semaphore",
+ "SpecCluster",
+ "Status",
+ "Sub",
+ "TimeoutError",
+ "UploadDirectory",
+ "UploadFile",
+ "Variable",
+ "Worker",
+ "WorkerPlugin",
+ "as_completed",
+ "config",
+ "connect",
+ "dask",
+ "default_client",
+ "fire_and_forget",
+ "futures_of",
+ "get_client",
+ "get_task_metadata",
+ "get_task_stream",
+ "get_versions",
+ "get_worker",
+ "local_client",
+ "performance_report",
+ "print",
+ "progress",
+ "rejoin",
+ "rpc",
+ "secede",
+ "sync",
+ "wait",
+ "warn",
+ "widgets",
+ "worker_client",
+]
| {"golden_diff": "diff --git a/distributed/__init__.py b/distributed/__init__.py\n--- a/distributed/__init__.py\n+++ b/distributed/__init__.py\n@@ -99,3 +99,65 @@\n \"\"\"\n global _python_shutting_down\n _python_shutting_down = True\n+\n+\n+__all__ = [\n+ \"Actor\",\n+ \"ActorFuture\",\n+ \"Adaptive\",\n+ \"BaseActorFuture\",\n+ \"CancelledError\",\n+ \"Client\",\n+ \"CompatibleExecutor\",\n+ \"Environ\",\n+ \"Event\",\n+ \"Future\",\n+ \"KilledWorker\",\n+ \"LocalCluster\",\n+ \"Lock\",\n+ \"MultiLock\",\n+ \"Nanny\",\n+ \"NannyPlugin\",\n+ \"PipInstall\",\n+ \"Pub\",\n+ \"Queue\",\n+ \"Reschedule\",\n+ \"SSHCluster\",\n+ \"Scheduler\",\n+ \"SchedulerPlugin\",\n+ \"Security\",\n+ \"Semaphore\",\n+ \"SpecCluster\",\n+ \"Status\",\n+ \"Sub\",\n+ \"TimeoutError\",\n+ \"UploadDirectory\",\n+ \"UploadFile\",\n+ \"Variable\",\n+ \"Worker\",\n+ \"WorkerPlugin\",\n+ \"as_completed\",\n+ \"config\",\n+ \"connect\",\n+ \"dask\",\n+ \"default_client\",\n+ \"fire_and_forget\",\n+ \"futures_of\",\n+ \"get_client\",\n+ \"get_task_metadata\",\n+ \"get_task_stream\",\n+ \"get_versions\",\n+ \"get_worker\",\n+ \"local_client\",\n+ \"performance_report\",\n+ \"print\",\n+ \"progress\",\n+ \"rejoin\",\n+ \"rpc\",\n+ \"secede\",\n+ \"sync\",\n+ \"wait\",\n+ \"warn\",\n+ \"widgets\",\n+ \"worker_client\",\n+]\n", "issue": "Importing from distributed shows pyright error\n**What happened**:\r\nWhen type-checking a program that imports from distributed with pyright, an error is accused:\r\n\r\n```python\r\n# foo.py\r\nfrom distributed import Client\r\nprint(Client)\r\n```\r\n\r\n```\r\npyright foo.py\r\n...\r\n /tmp/test-area/foo.py:1:25 - error: \"Client\" is not exported from module \"distributed\"\r\n \u00a0\u00a0Import from \"distributed.client\" instead (reportPrivateImportUsage)\r\n1 error, 0 warnings, 0 informations\r\n```\r\n\r\n**What you expected to happen**:\r\nI expect the package to be correctly typed, following PEP 484\r\n\r\n\r\n**Anything else we need to know?**:\r\n\r\nPEP 484 states that\r\n\r\n> Modules and variables imported into the stub are not considered exported from the stub unless the import uses the `import ... as ... form` or the equivalent `from ... import ... as ... form`\r\n\r\nand Pyright follows this guideline, although mypy doesn't.\r\n\r\n**Environment**:\r\n\r\n- Dask version: 2022.8.0\r\n- Python version: 3.10.5\r\n- Operating System: Arch linux\r\n- Install method (conda, pip, source): pip inside an environment\n", "before_files": [{"content": "from __future__ import annotations\n\n# isort: off\nfrom distributed import config # load distributed configuration first\nfrom distributed import widgets # load distributed widgets second\n\n# isort: on\n\nimport atexit\n\nimport dask\nfrom dask.config import config # type: ignore\n\nfrom distributed._version import get_versions\nfrom distributed.actor import Actor, ActorFuture, BaseActorFuture\nfrom distributed.client import (\n Client,\n CompatibleExecutor,\n Future,\n as_completed,\n default_client,\n fire_and_forget,\n futures_of,\n get_task_metadata,\n get_task_stream,\n performance_report,\n wait,\n)\nfrom distributed.core import Status, connect, rpc\nfrom distributed.deploy import Adaptive, LocalCluster, SpecCluster, SSHCluster\nfrom distributed.diagnostics.plugin import (\n Environ,\n NannyPlugin,\n PipInstall,\n SchedulerPlugin,\n UploadDirectory,\n UploadFile,\n WorkerPlugin,\n)\nfrom distributed.diagnostics.progressbar import progress\nfrom distributed.event import Event\nfrom distributed.lock import Lock\nfrom distributed.multi_lock import MultiLock\nfrom distributed.nanny import Nanny\nfrom distributed.pubsub import Pub, Sub\nfrom distributed.queues import Queue\nfrom distributed.scheduler import KilledWorker, Scheduler\nfrom distributed.security import Security\nfrom distributed.semaphore import Semaphore\nfrom distributed.threadpoolexecutor import rejoin\nfrom distributed.utils import CancelledError, TimeoutError, sync\nfrom distributed.variable import Variable\nfrom distributed.worker import (\n Reschedule,\n Worker,\n get_client,\n get_worker,\n print,\n secede,\n warn,\n)\nfrom distributed.worker_client import local_client, worker_client\n\n\ndef __getattr__(name):\n global __version__, __git_revision__\n\n if name == \"__version__\":\n from importlib.metadata import version\n\n __version__ = version(\"distributed\")\n return __version__\n\n if name == \"__git_revision__\":\n from distributed._version import get_versions\n\n __git_revision__ = get_versions()[\"full-revisionid\"]\n return __git_revision__\n\n raise AttributeError(f\"module {__name__!r} has no attribute {name!r}\")\n\n\n_python_shutting_down = False\n\n\[email protected]\ndef _():\n \"\"\"Set a global when Python shuts down.\n\n Note\n ----\n This function must be registered with atexit *after* any class that invokes\n ``dstributed.utils.is_python_shutting_down`` has been defined. This way it\n will be called before the ``__del__`` method of those classes.\n\n See Also\n --------\n distributed.utils.is_python_shutting_down\n \"\"\"\n global _python_shutting_down\n _python_shutting_down = True\n", "path": "distributed/__init__.py"}]} | 1,577 | 412 |
gh_patches_debug_7595 | rasdani/github-patches | git_diff | pypa__setuptools-1530 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Officially support Python 3.7
- [x] Test against 3.7 (#1514)
- [ ] Add Python 3.7 classifier
@jaraco @pganssle @benoit-pierre: Didn't see another issue to track this. Not sure what else is necessary here to consider this "supported", feel free to edit as necessary.
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 """
3 Distutils setup file, used to install or test 'setuptools'
4 """
5
6 import io
7 import os
8 import sys
9 import textwrap
10
11 import setuptools
12
13 here = os.path.dirname(__file__)
14
15
16 def require_metadata():
17 "Prevent improper installs without necessary metadata. See #659"
18 egg_info_dir = os.path.join(here, 'setuptools.egg-info')
19 if not os.path.exists(egg_info_dir):
20 msg = (
21 "Cannot build setuptools without metadata. "
22 "Run `bootstrap.py`."
23 )
24 raise RuntimeError(msg)
25
26
27 def read_commands():
28 command_ns = {}
29 cmd_module_path = 'setuptools/command/__init__.py'
30 init_path = os.path.join(here, cmd_module_path)
31 with open(init_path) as init_file:
32 exec(init_file.read(), command_ns)
33 return command_ns['__all__']
34
35
36 def _gen_console_scripts():
37 yield "easy_install = setuptools.command.easy_install:main"
38
39 # Gentoo distributions manage the python-version-specific scripts
40 # themselves, so those platforms define an environment variable to
41 # suppress the creation of the version-specific scripts.
42 var_names = (
43 'SETUPTOOLS_DISABLE_VERSIONED_EASY_INSTALL_SCRIPT',
44 'DISTRIBUTE_DISABLE_VERSIONED_EASY_INSTALL_SCRIPT',
45 )
46 if any(os.environ.get(var) not in (None, "", "0") for var in var_names):
47 return
48 tmpl = "easy_install-{shortver} = setuptools.command.easy_install:main"
49 yield tmpl.format(shortver=sys.version[:3])
50
51
52 readme_path = os.path.join(here, 'README.rst')
53 with io.open(readme_path, encoding='utf-8') as readme_file:
54 long_description = readme_file.read()
55
56 package_data = dict(
57 setuptools=['script (dev).tmpl', 'script.tmpl', 'site-patch.py'],
58 )
59
60 force_windows_specific_files = (
61 os.environ.get("SETUPTOOLS_INSTALL_WINDOWS_SPECIFIC_FILES", "1").lower()
62 not in ("", "0", "false", "no")
63 )
64
65 include_windows_files = (
66 sys.platform == 'win32' or
67 os.name == 'java' and os._name == 'nt' or
68 force_windows_specific_files
69 )
70
71 if include_windows_files:
72 package_data.setdefault('setuptools', []).extend(['*.exe'])
73 package_data.setdefault('setuptools.command', []).extend(['*.xml'])
74
75 needs_wheel = set(['release', 'bdist_wheel']).intersection(sys.argv)
76 wheel = ['wheel'] if needs_wheel else []
77
78
79 def pypi_link(pkg_filename):
80 """
81 Given the filename, including md5 fragment, construct the
82 dependency link for PyPI.
83 """
84 root = 'https://files.pythonhosted.org/packages/source'
85 name, sep, rest = pkg_filename.partition('-')
86 parts = root, name[0], name, pkg_filename
87 return '/'.join(parts)
88
89
90 setup_params = dict(
91 name="setuptools",
92 version="40.5.0",
93 description=(
94 "Easily download, build, install, upgrade, and uninstall "
95 "Python packages"
96 ),
97 author="Python Packaging Authority",
98 author_email="[email protected]",
99 long_description=long_description,
100 long_description_content_type='text/x-rst; charset=UTF-8',
101 keywords="CPAN PyPI distutils eggs package management",
102 url="https://github.com/pypa/setuptools",
103 project_urls={
104 "Documentation": "https://setuptools.readthedocs.io/",
105 },
106 src_root=None,
107 packages=setuptools.find_packages(exclude=['*.tests']),
108 package_data=package_data,
109 py_modules=['easy_install'],
110 zip_safe=True,
111 entry_points={
112 "distutils.commands": [
113 "%(cmd)s = setuptools.command.%(cmd)s:%(cmd)s" % locals()
114 for cmd in read_commands()
115 ],
116 "distutils.setup_keywords": [
117 "eager_resources = setuptools.dist:assert_string_list",
118 "namespace_packages = setuptools.dist:check_nsp",
119 "extras_require = setuptools.dist:check_extras",
120 "install_requires = setuptools.dist:check_requirements",
121 "tests_require = setuptools.dist:check_requirements",
122 "setup_requires = setuptools.dist:check_requirements",
123 "python_requires = setuptools.dist:check_specifier",
124 "entry_points = setuptools.dist:check_entry_points",
125 "test_suite = setuptools.dist:check_test_suite",
126 "zip_safe = setuptools.dist:assert_bool",
127 "package_data = setuptools.dist:check_package_data",
128 "exclude_package_data = setuptools.dist:check_package_data",
129 "include_package_data = setuptools.dist:assert_bool",
130 "packages = setuptools.dist:check_packages",
131 "dependency_links = setuptools.dist:assert_string_list",
132 "test_loader = setuptools.dist:check_importable",
133 "test_runner = setuptools.dist:check_importable",
134 "use_2to3 = setuptools.dist:assert_bool",
135 "convert_2to3_doctests = setuptools.dist:assert_string_list",
136 "use_2to3_fixers = setuptools.dist:assert_string_list",
137 "use_2to3_exclude_fixers = setuptools.dist:assert_string_list",
138 ],
139 "egg_info.writers": [
140 "PKG-INFO = setuptools.command.egg_info:write_pkg_info",
141 "requires.txt = setuptools.command.egg_info:write_requirements",
142 "entry_points.txt = setuptools.command.egg_info:write_entries",
143 "eager_resources.txt = setuptools.command.egg_info:overwrite_arg",
144 (
145 "namespace_packages.txt = "
146 "setuptools.command.egg_info:overwrite_arg"
147 ),
148 "top_level.txt = setuptools.command.egg_info:write_toplevel_names",
149 "depends.txt = setuptools.command.egg_info:warn_depends_obsolete",
150 "dependency_links.txt = setuptools.command.egg_info:overwrite_arg",
151 ],
152 "console_scripts": list(_gen_console_scripts()),
153 "setuptools.installation":
154 ['eggsecutable = setuptools.command.easy_install:bootstrap'],
155 },
156 classifiers=textwrap.dedent("""
157 Development Status :: 5 - Production/Stable
158 Intended Audience :: Developers
159 License :: OSI Approved :: MIT License
160 Operating System :: OS Independent
161 Programming Language :: Python :: 2
162 Programming Language :: Python :: 2.7
163 Programming Language :: Python :: 3
164 Programming Language :: Python :: 3.4
165 Programming Language :: Python :: 3.5
166 Programming Language :: Python :: 3.6
167 Topic :: Software Development :: Libraries :: Python Modules
168 Topic :: System :: Archiving :: Packaging
169 Topic :: System :: Systems Administration
170 Topic :: Utilities
171 """).strip().splitlines(),
172 python_requires='>=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*',
173 extras_require={
174 "ssl:sys_platform=='win32'": "wincertstore==0.2",
175 "certs": "certifi==2016.9.26",
176 },
177 dependency_links=[
178 pypi_link(
179 'certifi-2016.9.26.tar.gz#md5=baa81e951a29958563689d868ef1064d',
180 ),
181 pypi_link(
182 'wincertstore-0.2.zip#md5=ae728f2f007185648d0c7a8679b361e2',
183 ),
184 ],
185 scripts=[],
186 setup_requires=[
187 ] + wheel,
188 )
189
190 if __name__ == '__main__':
191 # allow setup.py to run from another directory
192 here and os.chdir(here)
193 require_metadata()
194 dist = setuptools.setup(**setup_params)
195
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -164,6 +164,7 @@
Programming Language :: Python :: 3.4
Programming Language :: Python :: 3.5
Programming Language :: Python :: 3.6
+ Programming Language :: Python :: 3.7
Topic :: Software Development :: Libraries :: Python Modules
Topic :: System :: Archiving :: Packaging
Topic :: System :: Systems Administration
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -164,6 +164,7 @@\n Programming Language :: Python :: 3.4\n Programming Language :: Python :: 3.5\n Programming Language :: Python :: 3.6\n+ Programming Language :: Python :: 3.7\n Topic :: Software Development :: Libraries :: Python Modules\n Topic :: System :: Archiving :: Packaging\n Topic :: System :: Systems Administration\n", "issue": "Officially support Python 3.7\n- [x] Test against 3.7 (#1514)\r\n- [ ] Add Python 3.7 classifier\r\n\r\n@jaraco @pganssle @benoit-pierre: Didn't see another issue to track this. Not sure what else is necessary here to consider this \"supported\", feel free to edit as necessary.\n", "before_files": [{"content": "#!/usr/bin/env python\n\"\"\"\nDistutils setup file, used to install or test 'setuptools'\n\"\"\"\n\nimport io\nimport os\nimport sys\nimport textwrap\n\nimport setuptools\n\nhere = os.path.dirname(__file__)\n\n\ndef require_metadata():\n \"Prevent improper installs without necessary metadata. See #659\"\n egg_info_dir = os.path.join(here, 'setuptools.egg-info')\n if not os.path.exists(egg_info_dir):\n msg = (\n \"Cannot build setuptools without metadata. \"\n \"Run `bootstrap.py`.\"\n )\n raise RuntimeError(msg)\n\n\ndef read_commands():\n command_ns = {}\n cmd_module_path = 'setuptools/command/__init__.py'\n init_path = os.path.join(here, cmd_module_path)\n with open(init_path) as init_file:\n exec(init_file.read(), command_ns)\n return command_ns['__all__']\n\n\ndef _gen_console_scripts():\n yield \"easy_install = setuptools.command.easy_install:main\"\n\n # Gentoo distributions manage the python-version-specific scripts\n # themselves, so those platforms define an environment variable to\n # suppress the creation of the version-specific scripts.\n var_names = (\n 'SETUPTOOLS_DISABLE_VERSIONED_EASY_INSTALL_SCRIPT',\n 'DISTRIBUTE_DISABLE_VERSIONED_EASY_INSTALL_SCRIPT',\n )\n if any(os.environ.get(var) not in (None, \"\", \"0\") for var in var_names):\n return\n tmpl = \"easy_install-{shortver} = setuptools.command.easy_install:main\"\n yield tmpl.format(shortver=sys.version[:3])\n\n\nreadme_path = os.path.join(here, 'README.rst')\nwith io.open(readme_path, encoding='utf-8') as readme_file:\n long_description = readme_file.read()\n\npackage_data = dict(\n setuptools=['script (dev).tmpl', 'script.tmpl', 'site-patch.py'],\n)\n\nforce_windows_specific_files = (\n os.environ.get(\"SETUPTOOLS_INSTALL_WINDOWS_SPECIFIC_FILES\", \"1\").lower()\n not in (\"\", \"0\", \"false\", \"no\")\n)\n\ninclude_windows_files = (\n sys.platform == 'win32' or\n os.name == 'java' and os._name == 'nt' or\n force_windows_specific_files\n)\n\nif include_windows_files:\n package_data.setdefault('setuptools', []).extend(['*.exe'])\n package_data.setdefault('setuptools.command', []).extend(['*.xml'])\n\nneeds_wheel = set(['release', 'bdist_wheel']).intersection(sys.argv)\nwheel = ['wheel'] if needs_wheel else []\n\n\ndef pypi_link(pkg_filename):\n \"\"\"\n Given the filename, including md5 fragment, construct the\n dependency link for PyPI.\n \"\"\"\n root = 'https://files.pythonhosted.org/packages/source'\n name, sep, rest = pkg_filename.partition('-')\n parts = root, name[0], name, pkg_filename\n return '/'.join(parts)\n\n\nsetup_params = dict(\n name=\"setuptools\",\n version=\"40.5.0\",\n description=(\n \"Easily download, build, install, upgrade, and uninstall \"\n \"Python packages\"\n ),\n author=\"Python Packaging Authority\",\n author_email=\"[email protected]\",\n long_description=long_description,\n long_description_content_type='text/x-rst; charset=UTF-8',\n keywords=\"CPAN PyPI distutils eggs package management\",\n url=\"https://github.com/pypa/setuptools\",\n project_urls={\n \"Documentation\": \"https://setuptools.readthedocs.io/\",\n },\n src_root=None,\n packages=setuptools.find_packages(exclude=['*.tests']),\n package_data=package_data,\n py_modules=['easy_install'],\n zip_safe=True,\n entry_points={\n \"distutils.commands\": [\n \"%(cmd)s = setuptools.command.%(cmd)s:%(cmd)s\" % locals()\n for cmd in read_commands()\n ],\n \"distutils.setup_keywords\": [\n \"eager_resources = setuptools.dist:assert_string_list\",\n \"namespace_packages = setuptools.dist:check_nsp\",\n \"extras_require = setuptools.dist:check_extras\",\n \"install_requires = setuptools.dist:check_requirements\",\n \"tests_require = setuptools.dist:check_requirements\",\n \"setup_requires = setuptools.dist:check_requirements\",\n \"python_requires = setuptools.dist:check_specifier\",\n \"entry_points = setuptools.dist:check_entry_points\",\n \"test_suite = setuptools.dist:check_test_suite\",\n \"zip_safe = setuptools.dist:assert_bool\",\n \"package_data = setuptools.dist:check_package_data\",\n \"exclude_package_data = setuptools.dist:check_package_data\",\n \"include_package_data = setuptools.dist:assert_bool\",\n \"packages = setuptools.dist:check_packages\",\n \"dependency_links = setuptools.dist:assert_string_list\",\n \"test_loader = setuptools.dist:check_importable\",\n \"test_runner = setuptools.dist:check_importable\",\n \"use_2to3 = setuptools.dist:assert_bool\",\n \"convert_2to3_doctests = setuptools.dist:assert_string_list\",\n \"use_2to3_fixers = setuptools.dist:assert_string_list\",\n \"use_2to3_exclude_fixers = setuptools.dist:assert_string_list\",\n ],\n \"egg_info.writers\": [\n \"PKG-INFO = setuptools.command.egg_info:write_pkg_info\",\n \"requires.txt = setuptools.command.egg_info:write_requirements\",\n \"entry_points.txt = setuptools.command.egg_info:write_entries\",\n \"eager_resources.txt = setuptools.command.egg_info:overwrite_arg\",\n (\n \"namespace_packages.txt = \"\n \"setuptools.command.egg_info:overwrite_arg\"\n ),\n \"top_level.txt = setuptools.command.egg_info:write_toplevel_names\",\n \"depends.txt = setuptools.command.egg_info:warn_depends_obsolete\",\n \"dependency_links.txt = setuptools.command.egg_info:overwrite_arg\",\n ],\n \"console_scripts\": list(_gen_console_scripts()),\n \"setuptools.installation\":\n ['eggsecutable = setuptools.command.easy_install:bootstrap'],\n },\n classifiers=textwrap.dedent(\"\"\"\n Development Status :: 5 - Production/Stable\n Intended Audience :: Developers\n License :: OSI Approved :: MIT License\n Operating System :: OS Independent\n Programming Language :: Python :: 2\n Programming Language :: Python :: 2.7\n Programming Language :: Python :: 3\n Programming Language :: Python :: 3.4\n Programming Language :: Python :: 3.5\n Programming Language :: Python :: 3.6\n Topic :: Software Development :: Libraries :: Python Modules\n Topic :: System :: Archiving :: Packaging\n Topic :: System :: Systems Administration\n Topic :: Utilities\n \"\"\").strip().splitlines(),\n python_requires='>=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*',\n extras_require={\n \"ssl:sys_platform=='win32'\": \"wincertstore==0.2\",\n \"certs\": \"certifi==2016.9.26\",\n },\n dependency_links=[\n pypi_link(\n 'certifi-2016.9.26.tar.gz#md5=baa81e951a29958563689d868ef1064d',\n ),\n pypi_link(\n 'wincertstore-0.2.zip#md5=ae728f2f007185648d0c7a8679b361e2',\n ),\n ],\n scripts=[],\n setup_requires=[\n ] + wheel,\n)\n\nif __name__ == '__main__':\n # allow setup.py to run from another directory\n here and os.chdir(here)\n require_metadata()\n dist = setuptools.setup(**setup_params)\n", "path": "setup.py"}]} | 2,803 | 108 |
gh_patches_debug_8505 | rasdani/github-patches | git_diff | Textualize__textual-1552 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Change Clock color
Following on from #1411, perhaps the clock colour needs a wee revisit too?

</issue>
<code>
[start of src/textual/widgets/_header.py]
1 from __future__ import annotations
2
3 from datetime import datetime
4
5 from rich.text import Text
6
7 from ..widget import Widget
8 from ..reactive import Reactive, watch
9
10
11 class HeaderIcon(Widget):
12 """Display an 'icon' on the left of the header."""
13
14 DEFAULT_CSS = """
15 HeaderIcon {
16 dock: left;
17 padding: 0 1;
18 width: 8;
19 content-align: left middle;
20 }
21 """
22 icon = Reactive("⭘")
23
24 def render(self):
25 return self.icon
26
27
28 class HeaderClockSpace(Widget):
29 """The space taken up by the clock on the right of the header."""
30
31 DEFAULT_CSS = """
32 HeaderClockSpace {
33 dock: right;
34 width: 10;
35 padding: 0 1;
36 }
37 """
38
39 def render(self) -> str:
40 return ""
41
42
43 class HeaderClock(HeaderClockSpace):
44 """Display a clock on the right of the header."""
45
46 DEFAULT_CSS = """
47 HeaderClock {
48 background: $secondary-background-lighten-1;
49 color: $text;
50 text-opacity: 85%;
51 content-align: center middle;
52 }
53 """
54
55 def on_mount(self) -> None:
56 self.set_interval(1, callback=self.refresh, name=f"update header clock")
57
58 def render(self):
59 return Text(datetime.now().time().strftime("%X"))
60
61
62 class HeaderTitle(Widget):
63 """Display the title / subtitle in the header."""
64
65 DEFAULT_CSS = """
66 HeaderTitle {
67 content-align: center middle;
68 width: 100%;
69 }
70 """
71
72 text: Reactive[str] = Reactive("")
73 sub_text = Reactive("")
74
75 def render(self) -> Text:
76 text = Text(self.text, no_wrap=True, overflow="ellipsis")
77 if self.sub_text:
78 text.append(" — ")
79 text.append(self.sub_text, "dim")
80 return text
81
82
83 class Header(Widget):
84 """A header widget with icon and clock.
85
86 Args:
87 show_clock (bool, optional): True if the clock should be shown on the right of the header.
88 """
89
90 DEFAULT_CSS = """
91 Header {
92 dock: top;
93 width: 100%;
94 background: $foreground 5%;
95 color: $text;
96 height: 1;
97 }
98 Header.-tall {
99 height: 3;
100 }
101 """
102
103 tall = Reactive(False)
104
105 DEFAULT_CLASSES = ""
106
107 def __init__(
108 self,
109 show_clock: bool = False,
110 *,
111 name: str | None = None,
112 id: str | None = None,
113 classes: str | None = None,
114 ):
115 super().__init__(name=name, id=id, classes=classes)
116 self.show_clock = show_clock
117
118 def compose(self):
119 yield HeaderIcon()
120 yield HeaderTitle()
121 yield HeaderClock() if self.show_clock else HeaderClockSpace()
122
123 def watch_tall(self, tall: bool) -> None:
124 self.set_class(tall, "-tall")
125
126 def on_click(self):
127 self.toggle_class("-tall")
128
129 def on_mount(self) -> None:
130 def set_title(title: str) -> None:
131 self.query_one(HeaderTitle).text = title
132
133 def set_sub_title(sub_title: str) -> None:
134 self.query_one(HeaderTitle).sub_text = sub_title
135
136 watch(self.app, "title", set_title)
137 watch(self.app, "sub_title", set_sub_title)
138
[end of src/textual/widgets/_header.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/textual/widgets/_header.py b/src/textual/widgets/_header.py
--- a/src/textual/widgets/_header.py
+++ b/src/textual/widgets/_header.py
@@ -45,7 +45,7 @@
DEFAULT_CSS = """
HeaderClock {
- background: $secondary-background-lighten-1;
+ background: $foreground-darken-1 5%;
color: $text;
text-opacity: 85%;
content-align: center middle;
@@ -97,7 +97,7 @@
}
Header.-tall {
height: 3;
- }
+ }
"""
tall = Reactive(False)
| {"golden_diff": "diff --git a/src/textual/widgets/_header.py b/src/textual/widgets/_header.py\n--- a/src/textual/widgets/_header.py\n+++ b/src/textual/widgets/_header.py\n@@ -45,7 +45,7 @@\n \n DEFAULT_CSS = \"\"\"\n HeaderClock {\n- background: $secondary-background-lighten-1;\n+ background: $foreground-darken-1 5%;\n color: $text;\n text-opacity: 85%;\n content-align: center middle;\n@@ -97,7 +97,7 @@\n }\n Header.-tall {\n height: 3;\n- } \n+ }\n \"\"\"\n \n tall = Reactive(False)\n", "issue": "Change Clock color\nFollowing on from #1411, perhaps the clock colour needs a wee revisit too?\r\n\r\n\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom datetime import datetime\n\nfrom rich.text import Text\n\nfrom ..widget import Widget\nfrom ..reactive import Reactive, watch\n\n\nclass HeaderIcon(Widget):\n \"\"\"Display an 'icon' on the left of the header.\"\"\"\n\n DEFAULT_CSS = \"\"\"\n HeaderIcon {\n dock: left;\n padding: 0 1;\n width: 8;\n content-align: left middle;\n }\n \"\"\"\n icon = Reactive(\"\u2b58\")\n\n def render(self):\n return self.icon\n\n\nclass HeaderClockSpace(Widget):\n \"\"\"The space taken up by the clock on the right of the header.\"\"\"\n\n DEFAULT_CSS = \"\"\"\n HeaderClockSpace {\n dock: right;\n width: 10;\n padding: 0 1;\n }\n \"\"\"\n\n def render(self) -> str:\n return \"\"\n\n\nclass HeaderClock(HeaderClockSpace):\n \"\"\"Display a clock on the right of the header.\"\"\"\n\n DEFAULT_CSS = \"\"\"\n HeaderClock {\n background: $secondary-background-lighten-1;\n color: $text;\n text-opacity: 85%;\n content-align: center middle;\n }\n \"\"\"\n\n def on_mount(self) -> None:\n self.set_interval(1, callback=self.refresh, name=f\"update header clock\")\n\n def render(self):\n return Text(datetime.now().time().strftime(\"%X\"))\n\n\nclass HeaderTitle(Widget):\n \"\"\"Display the title / subtitle in the header.\"\"\"\n\n DEFAULT_CSS = \"\"\"\n HeaderTitle {\n content-align: center middle;\n width: 100%;\n }\n \"\"\"\n\n text: Reactive[str] = Reactive(\"\")\n sub_text = Reactive(\"\")\n\n def render(self) -> Text:\n text = Text(self.text, no_wrap=True, overflow=\"ellipsis\")\n if self.sub_text:\n text.append(\" \u2014 \")\n text.append(self.sub_text, \"dim\")\n return text\n\n\nclass Header(Widget):\n \"\"\"A header widget with icon and clock.\n\n Args:\n show_clock (bool, optional): True if the clock should be shown on the right of the header.\n \"\"\"\n\n DEFAULT_CSS = \"\"\"\n Header {\n dock: top;\n width: 100%;\n background: $foreground 5%;\n color: $text;\n height: 1;\n }\n Header.-tall {\n height: 3;\n } \n \"\"\"\n\n tall = Reactive(False)\n\n DEFAULT_CLASSES = \"\"\n\n def __init__(\n self,\n show_clock: bool = False,\n *,\n name: str | None = None,\n id: str | None = None,\n classes: str | None = None,\n ):\n super().__init__(name=name, id=id, classes=classes)\n self.show_clock = show_clock\n\n def compose(self):\n yield HeaderIcon()\n yield HeaderTitle()\n yield HeaderClock() if self.show_clock else HeaderClockSpace()\n\n def watch_tall(self, tall: bool) -> None:\n self.set_class(tall, \"-tall\")\n\n def on_click(self):\n self.toggle_class(\"-tall\")\n\n def on_mount(self) -> None:\n def set_title(title: str) -> None:\n self.query_one(HeaderTitle).text = title\n\n def set_sub_title(sub_title: str) -> None:\n self.query_one(HeaderTitle).sub_text = sub_title\n\n watch(self.app, \"title\", set_title)\n watch(self.app, \"sub_title\", set_sub_title)\n", "path": "src/textual/widgets/_header.py"}]} | 1,716 | 150 |
gh_patches_debug_642 | rasdani/github-patches | git_diff | pex-tool__pex-2062 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Release 2.1.123
On the docket:
+ [x] Create lockfile for xmlsec fails #2063
+ [x] Internal not enough values to unpack error for pex3 lock create 'pip @ https://github.com/pypa/pip/archive/22.0.2.zip' ... #2057
+ [x] Pex lock creation does not handle wheels with non {cp,pp,py} pyver tag. #2059
</issue>
<code>
[start of pex/version.py]
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = "2.1.122"
5
[end of pex/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = "2.1.122"
+__version__ = "2.1.123"
| {"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = \"2.1.122\"\n+__version__ = \"2.1.123\"\n", "issue": "Release 2.1.123\nOn the docket:\r\n+ [x] Create lockfile for xmlsec fails #2063\r\n+ [x] Internal not enough values to unpack error for pex3 lock create 'pip @ https://github.com/pypa/pip/archive/22.0.2.zip' ... #2057\r\n+ [x] Pex lock creation does not handle wheels with non {cp,pp,py} pyver tag. #2059\n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.122\"\n", "path": "pex/version.py"}]} | 692 | 98 |
gh_patches_debug_39170 | rasdani/github-patches | git_diff | open-telemetry__opentelemetry-python-contrib-1134 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Instrument SQLAlchemy engine connection phase
** Is your feature request related to a problem? **
The SQLAlchemy instrumentation does not trace the actual connection to the database
**Describe the solution you'd like**
I want that `connect` function will also be traced
**Describe alternatives you've considered**
Which alternative solutions or features have you considered?
**Additional context**
We are working with SQLAlchemy (snowflake db) and we implemented a solution where we can see the `connect` span also as attached in the screenshot (the span is `database-connect`)

</issue>
<code>
[start of instrumentation/opentelemetry-instrumentation-sqlalchemy/src/opentelemetry/instrumentation/sqlalchemy/__init__.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """
16 Instrument `sqlalchemy`_ to report SQL queries.
17
18 There are two options for instrumenting code. The first option is to use
19 the ``opentelemetry-instrument`` executable which will automatically
20 instrument your SQLAlchemy engine. The second is to programmatically enable
21 instrumentation via the following code:
22
23 .. _sqlalchemy: https://pypi.org/project/sqlalchemy/
24
25 Usage
26 -----
27 .. code:: python
28
29 from sqlalchemy import create_engine
30
31 from opentelemetry.instrumentation.sqlalchemy import SQLAlchemyInstrumentor
32 import sqlalchemy
33
34 engine = create_engine("sqlite:///:memory:")
35 SQLAlchemyInstrumentor().instrument(
36 engine=engine,
37 )
38
39 # of the async variant of SQLAlchemy
40
41 from sqlalchemy.ext.asyncio import create_async_engine
42
43 from opentelemetry.instrumentation.sqlalchemy import SQLAlchemyInstrumentor
44 import sqlalchemy
45
46 engine = create_async_engine("sqlite:///:memory:")
47 SQLAlchemyInstrumentor().instrument(
48 engine=engine.sync_engine
49 )
50
51 API
52 ---
53 """
54 from collections.abc import Sequence
55 from typing import Collection
56
57 import sqlalchemy
58 from packaging.version import parse as parse_version
59 from wrapt import wrap_function_wrapper as _w
60
61 from opentelemetry.instrumentation.instrumentor import BaseInstrumentor
62 from opentelemetry.instrumentation.sqlalchemy.engine import (
63 EngineTracer,
64 _get_tracer,
65 _wrap_create_async_engine,
66 _wrap_create_engine,
67 )
68 from opentelemetry.instrumentation.sqlalchemy.package import _instruments
69 from opentelemetry.instrumentation.utils import unwrap
70
71
72 class SQLAlchemyInstrumentor(BaseInstrumentor):
73 """An instrumentor for SQLAlchemy
74 See `BaseInstrumentor`
75 """
76
77 def instrumentation_dependencies(self) -> Collection[str]:
78 return _instruments
79
80 def _instrument(self, **kwargs):
81 """Instruments SQLAlchemy engine creation methods and the engine
82 if passed as an argument.
83
84 Args:
85 **kwargs: Optional arguments
86 ``engine``: a SQLAlchemy engine instance
87 ``engines``: a list of SQLAlchemy engine instances
88 ``tracer_provider``: a TracerProvider, defaults to global
89
90 Returns:
91 An instrumented engine if passed in as an argument or list of instrumented engines, None otherwise.
92 """
93 tracer_provider = kwargs.get("tracer_provider")
94 _w("sqlalchemy", "create_engine", _wrap_create_engine(tracer_provider))
95 _w(
96 "sqlalchemy.engine",
97 "create_engine",
98 _wrap_create_engine(tracer_provider),
99 )
100 if parse_version(sqlalchemy.__version__).release >= (1, 4):
101 _w(
102 "sqlalchemy.ext.asyncio",
103 "create_async_engine",
104 _wrap_create_async_engine(tracer_provider),
105 )
106
107 if kwargs.get("engine") is not None:
108 return EngineTracer(
109 _get_tracer(tracer_provider),
110 kwargs.get("engine"),
111 kwargs.get("enable_commenter", False),
112 )
113 if kwargs.get("engines") is not None and isinstance(
114 kwargs.get("engines"), Sequence
115 ):
116 return [
117 EngineTracer(
118 _get_tracer(tracer_provider),
119 engine,
120 kwargs.get("enable_commenter", False),
121 )
122 for engine in kwargs.get("engines")
123 ]
124
125 return None
126
127 def _uninstrument(self, **kwargs):
128 unwrap(sqlalchemy, "create_engine")
129 unwrap(sqlalchemy.engine, "create_engine")
130 if parse_version(sqlalchemy.__version__).release >= (1, 4):
131 unwrap(sqlalchemy.ext.asyncio, "create_async_engine")
132
[end of instrumentation/opentelemetry-instrumentation-sqlalchemy/src/opentelemetry/instrumentation/sqlalchemy/__init__.py]
[start of instrumentation/opentelemetry-instrumentation-sqlalchemy/src/opentelemetry/instrumentation/sqlalchemy/engine.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 import os
15
16 from sqlalchemy.event import listen # pylint: disable=no-name-in-module
17
18 from opentelemetry import trace
19 from opentelemetry.instrumentation.sqlalchemy.package import (
20 _instrumenting_module_name,
21 )
22 from opentelemetry.instrumentation.sqlalchemy.version import __version__
23 from opentelemetry.instrumentation.utils import (
24 _generate_opentelemetry_traceparent,
25 _generate_sql_comment,
26 )
27 from opentelemetry.semconv.trace import NetTransportValues, SpanAttributes
28 from opentelemetry.trace import Span
29 from opentelemetry.trace.status import Status, StatusCode
30
31
32 def _normalize_vendor(vendor):
33 """Return a canonical name for a type of database."""
34 if not vendor:
35 return "db" # should this ever happen?
36
37 if "sqlite" in vendor:
38 return "sqlite"
39
40 if "postgres" in vendor or vendor == "psycopg2":
41 return "postgresql"
42
43 return vendor
44
45
46 def _get_tracer(tracer_provider=None):
47 return trace.get_tracer(
48 _instrumenting_module_name,
49 __version__,
50 tracer_provider=tracer_provider,
51 )
52
53
54 def _wrap_create_async_engine(tracer_provider=None):
55 # pylint: disable=unused-argument
56 def _wrap_create_async_engine_internal(func, module, args, kwargs):
57 """Trace the SQLAlchemy engine, creating an `EngineTracer`
58 object that will listen to SQLAlchemy events.
59 """
60 engine = func(*args, **kwargs)
61 EngineTracer(_get_tracer(tracer_provider), engine.sync_engine)
62 return engine
63
64 return _wrap_create_async_engine_internal
65
66
67 def _wrap_create_engine(tracer_provider=None):
68 # pylint: disable=unused-argument
69 def _wrap_create_engine_internal(func, module, args, kwargs):
70 """Trace the SQLAlchemy engine, creating an `EngineTracer`
71 object that will listen to SQLAlchemy events.
72 """
73 engine = func(*args, **kwargs)
74 EngineTracer(_get_tracer(tracer_provider), engine)
75 return engine
76
77 return _wrap_create_engine_internal
78
79
80 class EngineTracer:
81 def __init__(self, tracer, engine, enable_commenter=False):
82 self.tracer = tracer
83 self.engine = engine
84 self.vendor = _normalize_vendor(engine.name)
85 self.enable_commenter = enable_commenter
86
87 listen(
88 engine, "before_cursor_execute", self._before_cur_exec, retval=True
89 )
90 listen(engine, "after_cursor_execute", _after_cur_exec)
91 listen(engine, "handle_error", _handle_error)
92
93 def _operation_name(self, db_name, statement):
94 parts = []
95 if isinstance(statement, str):
96 # otel spec recommends against parsing SQL queries. We are not trying to parse SQL
97 # but simply truncating the statement to the first word. This covers probably >95%
98 # use cases and uses the SQL statement in span name correctly as per the spec.
99 # For some very special cases it might not record the correct statement if the SQL
100 # dialect is too weird but in any case it shouldn't break anything.
101 parts.append(statement.split()[0])
102 if db_name:
103 parts.append(db_name)
104 if not parts:
105 return self.vendor
106 return " ".join(parts)
107
108 # pylint: disable=unused-argument
109 def _before_cur_exec(
110 self, conn, cursor, statement, params, context, executemany
111 ):
112 attrs, found = _get_attributes_from_url(conn.engine.url)
113 if not found:
114 attrs = _get_attributes_from_cursor(self.vendor, cursor, attrs)
115
116 db_name = attrs.get(SpanAttributes.DB_NAME, "")
117 span = self.tracer.start_span(
118 self._operation_name(db_name, statement),
119 kind=trace.SpanKind.CLIENT,
120 )
121 with trace.use_span(span, end_on_exit=False):
122 if span.is_recording():
123 span.set_attribute(SpanAttributes.DB_STATEMENT, statement)
124 span.set_attribute(SpanAttributes.DB_SYSTEM, self.vendor)
125 for key, value in attrs.items():
126 span.set_attribute(key, value)
127
128 context._otel_span = span
129 if self.enable_commenter:
130 statement = statement + EngineTracer._generate_comment(span=span)
131
132 return statement, params
133
134 @staticmethod
135 def _generate_comment(span: Span) -> str:
136 span_context = span.get_span_context()
137 meta = {}
138 if span_context.is_valid:
139 meta.update(_generate_opentelemetry_traceparent(span))
140 return _generate_sql_comment(**meta)
141
142
143 # pylint: disable=unused-argument
144 def _after_cur_exec(conn, cursor, statement, params, context, executemany):
145 span = getattr(context, "_otel_span", None)
146 if span is None:
147 return
148
149 span.end()
150
151
152 def _handle_error(context):
153 span = getattr(context.execution_context, "_otel_span", None)
154 if span is None:
155 return
156
157 if span.is_recording():
158 span.set_status(
159 Status(
160 StatusCode.ERROR,
161 str(context.original_exception),
162 )
163 )
164 span.end()
165
166
167 def _get_attributes_from_url(url):
168 """Set connection tags from the url. return true if successful."""
169 attrs = {}
170 if url.host:
171 attrs[SpanAttributes.NET_PEER_NAME] = url.host
172 if url.port:
173 attrs[SpanAttributes.NET_PEER_PORT] = url.port
174 if url.database:
175 attrs[SpanAttributes.DB_NAME] = url.database
176 if url.username:
177 attrs[SpanAttributes.DB_USER] = url.username
178 return attrs, bool(url.host)
179
180
181 def _get_attributes_from_cursor(vendor, cursor, attrs):
182 """Attempt to set db connection attributes by introspecting the cursor."""
183 if vendor == "postgresql":
184 info = getattr(getattr(cursor, "connection", None), "info", None)
185 if not info:
186 return attrs
187
188 attrs[SpanAttributes.DB_NAME] = info.dbname
189 is_unix_socket = info.host and info.host.startswith("/")
190
191 if is_unix_socket:
192 attrs[SpanAttributes.NET_TRANSPORT] = NetTransportValues.UNIX.value
193 if info.port:
194 # postgresql enforces this pattern on all socket names
195 attrs[SpanAttributes.NET_PEER_NAME] = os.path.join(
196 info.host, f".s.PGSQL.{info.port}"
197 )
198 else:
199 attrs[
200 SpanAttributes.NET_TRANSPORT
201 ] = NetTransportValues.IP_TCP.value
202 attrs[SpanAttributes.NET_PEER_NAME] = info.host
203 if info.port:
204 attrs[SpanAttributes.NET_PEER_PORT] = int(info.port)
205 return attrs
206
[end of instrumentation/opentelemetry-instrumentation-sqlalchemy/src/opentelemetry/instrumentation/sqlalchemy/engine.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/instrumentation/opentelemetry-instrumentation-sqlalchemy/src/opentelemetry/instrumentation/sqlalchemy/__init__.py b/instrumentation/opentelemetry-instrumentation-sqlalchemy/src/opentelemetry/instrumentation/sqlalchemy/__init__.py
--- a/instrumentation/opentelemetry-instrumentation-sqlalchemy/src/opentelemetry/instrumentation/sqlalchemy/__init__.py
+++ b/instrumentation/opentelemetry-instrumentation-sqlalchemy/src/opentelemetry/instrumentation/sqlalchemy/__init__.py
@@ -56,12 +56,14 @@
import sqlalchemy
from packaging.version import parse as parse_version
+from sqlalchemy.engine.base import Engine
from wrapt import wrap_function_wrapper as _w
from opentelemetry.instrumentation.instrumentor import BaseInstrumentor
from opentelemetry.instrumentation.sqlalchemy.engine import (
EngineTracer,
_get_tracer,
+ _wrap_connect,
_wrap_create_async_engine,
_wrap_create_engine,
)
@@ -97,13 +99,17 @@
"create_engine",
_wrap_create_engine(tracer_provider),
)
+ _w(
+ "sqlalchemy.engine.base",
+ "Engine.connect",
+ _wrap_connect(tracer_provider),
+ )
if parse_version(sqlalchemy.__version__).release >= (1, 4):
_w(
"sqlalchemy.ext.asyncio",
"create_async_engine",
_wrap_create_async_engine(tracer_provider),
)
-
if kwargs.get("engine") is not None:
return EngineTracer(
_get_tracer(tracer_provider),
@@ -127,5 +133,6 @@
def _uninstrument(self, **kwargs):
unwrap(sqlalchemy, "create_engine")
unwrap(sqlalchemy.engine, "create_engine")
+ unwrap(Engine, "connect")
if parse_version(sqlalchemy.__version__).release >= (1, 4):
unwrap(sqlalchemy.ext.asyncio, "create_async_engine")
diff --git a/instrumentation/opentelemetry-instrumentation-sqlalchemy/src/opentelemetry/instrumentation/sqlalchemy/engine.py b/instrumentation/opentelemetry-instrumentation-sqlalchemy/src/opentelemetry/instrumentation/sqlalchemy/engine.py
--- a/instrumentation/opentelemetry-instrumentation-sqlalchemy/src/opentelemetry/instrumentation/sqlalchemy/engine.py
+++ b/instrumentation/opentelemetry-instrumentation-sqlalchemy/src/opentelemetry/instrumentation/sqlalchemy/engine.py
@@ -77,6 +77,23 @@
return _wrap_create_engine_internal
+def _wrap_connect(tracer_provider=None):
+ tracer = trace.get_tracer(
+ _instrumenting_module_name,
+ __version__,
+ tracer_provider=tracer_provider,
+ )
+
+ # pylint: disable=unused-argument
+ def _wrap_connect_internal(func, module, args, kwargs):
+ with tracer.start_as_current_span(
+ "connect", kind=trace.SpanKind.CLIENT
+ ):
+ return func(*args, **kwargs)
+
+ return _wrap_connect_internal
+
+
class EngineTracer:
def __init__(self, tracer, engine, enable_commenter=False):
self.tracer = tracer
| {"golden_diff": "diff --git a/instrumentation/opentelemetry-instrumentation-sqlalchemy/src/opentelemetry/instrumentation/sqlalchemy/__init__.py b/instrumentation/opentelemetry-instrumentation-sqlalchemy/src/opentelemetry/instrumentation/sqlalchemy/__init__.py\n--- a/instrumentation/opentelemetry-instrumentation-sqlalchemy/src/opentelemetry/instrumentation/sqlalchemy/__init__.py\n+++ b/instrumentation/opentelemetry-instrumentation-sqlalchemy/src/opentelemetry/instrumentation/sqlalchemy/__init__.py\n@@ -56,12 +56,14 @@\n \n import sqlalchemy\n from packaging.version import parse as parse_version\n+from sqlalchemy.engine.base import Engine\n from wrapt import wrap_function_wrapper as _w\n \n from opentelemetry.instrumentation.instrumentor import BaseInstrumentor\n from opentelemetry.instrumentation.sqlalchemy.engine import (\n EngineTracer,\n _get_tracer,\n+ _wrap_connect,\n _wrap_create_async_engine,\n _wrap_create_engine,\n )\n@@ -97,13 +99,17 @@\n \"create_engine\",\n _wrap_create_engine(tracer_provider),\n )\n+ _w(\n+ \"sqlalchemy.engine.base\",\n+ \"Engine.connect\",\n+ _wrap_connect(tracer_provider),\n+ )\n if parse_version(sqlalchemy.__version__).release >= (1, 4):\n _w(\n \"sqlalchemy.ext.asyncio\",\n \"create_async_engine\",\n _wrap_create_async_engine(tracer_provider),\n )\n-\n if kwargs.get(\"engine\") is not None:\n return EngineTracer(\n _get_tracer(tracer_provider),\n@@ -127,5 +133,6 @@\n def _uninstrument(self, **kwargs):\n unwrap(sqlalchemy, \"create_engine\")\n unwrap(sqlalchemy.engine, \"create_engine\")\n+ unwrap(Engine, \"connect\")\n if parse_version(sqlalchemy.__version__).release >= (1, 4):\n unwrap(sqlalchemy.ext.asyncio, \"create_async_engine\")\ndiff --git a/instrumentation/opentelemetry-instrumentation-sqlalchemy/src/opentelemetry/instrumentation/sqlalchemy/engine.py b/instrumentation/opentelemetry-instrumentation-sqlalchemy/src/opentelemetry/instrumentation/sqlalchemy/engine.py\n--- a/instrumentation/opentelemetry-instrumentation-sqlalchemy/src/opentelemetry/instrumentation/sqlalchemy/engine.py\n+++ b/instrumentation/opentelemetry-instrumentation-sqlalchemy/src/opentelemetry/instrumentation/sqlalchemy/engine.py\n@@ -77,6 +77,23 @@\n return _wrap_create_engine_internal\n \n \n+def _wrap_connect(tracer_provider=None):\n+ tracer = trace.get_tracer(\n+ _instrumenting_module_name,\n+ __version__,\n+ tracer_provider=tracer_provider,\n+ )\n+\n+ # pylint: disable=unused-argument\n+ def _wrap_connect_internal(func, module, args, kwargs):\n+ with tracer.start_as_current_span(\n+ \"connect\", kind=trace.SpanKind.CLIENT\n+ ):\n+ return func(*args, **kwargs)\n+\n+ return _wrap_connect_internal\n+\n+\n class EngineTracer:\n def __init__(self, tracer, engine, enable_commenter=False):\n self.tracer = tracer\n", "issue": "Instrument SQLAlchemy engine connection phase\n** Is your feature request related to a problem? **\r\nThe SQLAlchemy instrumentation does not trace the actual connection to the database\r\n\r\n**Describe the solution you'd like**\r\nI want that `connect` function will also be traced\r\n\r\n**Describe alternatives you've considered**\r\nWhich alternative solutions or features have you considered?\r\n\r\n**Additional context**\r\nWe are working with SQLAlchemy (snowflake db) and we implemented a solution where we can see the `connect` span also as attached in the screenshot (the span is `database-connect`)\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nInstrument `sqlalchemy`_ to report SQL queries.\n\nThere are two options for instrumenting code. The first option is to use\nthe ``opentelemetry-instrument`` executable which will automatically\ninstrument your SQLAlchemy engine. The second is to programmatically enable\ninstrumentation via the following code:\n\n.. _sqlalchemy: https://pypi.org/project/sqlalchemy/\n\nUsage\n-----\n.. code:: python\n\n from sqlalchemy import create_engine\n\n from opentelemetry.instrumentation.sqlalchemy import SQLAlchemyInstrumentor\n import sqlalchemy\n\n engine = create_engine(\"sqlite:///:memory:\")\n SQLAlchemyInstrumentor().instrument(\n engine=engine,\n )\n\n # of the async variant of SQLAlchemy\n\n from sqlalchemy.ext.asyncio import create_async_engine\n\n from opentelemetry.instrumentation.sqlalchemy import SQLAlchemyInstrumentor\n import sqlalchemy\n\n engine = create_async_engine(\"sqlite:///:memory:\")\n SQLAlchemyInstrumentor().instrument(\n engine=engine.sync_engine\n )\n\nAPI\n---\n\"\"\"\nfrom collections.abc import Sequence\nfrom typing import Collection\n\nimport sqlalchemy\nfrom packaging.version import parse as parse_version\nfrom wrapt import wrap_function_wrapper as _w\n\nfrom opentelemetry.instrumentation.instrumentor import BaseInstrumentor\nfrom opentelemetry.instrumentation.sqlalchemy.engine import (\n EngineTracer,\n _get_tracer,\n _wrap_create_async_engine,\n _wrap_create_engine,\n)\nfrom opentelemetry.instrumentation.sqlalchemy.package import _instruments\nfrom opentelemetry.instrumentation.utils import unwrap\n\n\nclass SQLAlchemyInstrumentor(BaseInstrumentor):\n \"\"\"An instrumentor for SQLAlchemy\n See `BaseInstrumentor`\n \"\"\"\n\n def instrumentation_dependencies(self) -> Collection[str]:\n return _instruments\n\n def _instrument(self, **kwargs):\n \"\"\"Instruments SQLAlchemy engine creation methods and the engine\n if passed as an argument.\n\n Args:\n **kwargs: Optional arguments\n ``engine``: a SQLAlchemy engine instance\n ``engines``: a list of SQLAlchemy engine instances\n ``tracer_provider``: a TracerProvider, defaults to global\n\n Returns:\n An instrumented engine if passed in as an argument or list of instrumented engines, None otherwise.\n \"\"\"\n tracer_provider = kwargs.get(\"tracer_provider\")\n _w(\"sqlalchemy\", \"create_engine\", _wrap_create_engine(tracer_provider))\n _w(\n \"sqlalchemy.engine\",\n \"create_engine\",\n _wrap_create_engine(tracer_provider),\n )\n if parse_version(sqlalchemy.__version__).release >= (1, 4):\n _w(\n \"sqlalchemy.ext.asyncio\",\n \"create_async_engine\",\n _wrap_create_async_engine(tracer_provider),\n )\n\n if kwargs.get(\"engine\") is not None:\n return EngineTracer(\n _get_tracer(tracer_provider),\n kwargs.get(\"engine\"),\n kwargs.get(\"enable_commenter\", False),\n )\n if kwargs.get(\"engines\") is not None and isinstance(\n kwargs.get(\"engines\"), Sequence\n ):\n return [\n EngineTracer(\n _get_tracer(tracer_provider),\n engine,\n kwargs.get(\"enable_commenter\", False),\n )\n for engine in kwargs.get(\"engines\")\n ]\n\n return None\n\n def _uninstrument(self, **kwargs):\n unwrap(sqlalchemy, \"create_engine\")\n unwrap(sqlalchemy.engine, \"create_engine\")\n if parse_version(sqlalchemy.__version__).release >= (1, 4):\n unwrap(sqlalchemy.ext.asyncio, \"create_async_engine\")\n", "path": "instrumentation/opentelemetry-instrumentation-sqlalchemy/src/opentelemetry/instrumentation/sqlalchemy/__init__.py"}, {"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport os\n\nfrom sqlalchemy.event import listen # pylint: disable=no-name-in-module\n\nfrom opentelemetry import trace\nfrom opentelemetry.instrumentation.sqlalchemy.package import (\n _instrumenting_module_name,\n)\nfrom opentelemetry.instrumentation.sqlalchemy.version import __version__\nfrom opentelemetry.instrumentation.utils import (\n _generate_opentelemetry_traceparent,\n _generate_sql_comment,\n)\nfrom opentelemetry.semconv.trace import NetTransportValues, SpanAttributes\nfrom opentelemetry.trace import Span\nfrom opentelemetry.trace.status import Status, StatusCode\n\n\ndef _normalize_vendor(vendor):\n \"\"\"Return a canonical name for a type of database.\"\"\"\n if not vendor:\n return \"db\" # should this ever happen?\n\n if \"sqlite\" in vendor:\n return \"sqlite\"\n\n if \"postgres\" in vendor or vendor == \"psycopg2\":\n return \"postgresql\"\n\n return vendor\n\n\ndef _get_tracer(tracer_provider=None):\n return trace.get_tracer(\n _instrumenting_module_name,\n __version__,\n tracer_provider=tracer_provider,\n )\n\n\ndef _wrap_create_async_engine(tracer_provider=None):\n # pylint: disable=unused-argument\n def _wrap_create_async_engine_internal(func, module, args, kwargs):\n \"\"\"Trace the SQLAlchemy engine, creating an `EngineTracer`\n object that will listen to SQLAlchemy events.\n \"\"\"\n engine = func(*args, **kwargs)\n EngineTracer(_get_tracer(tracer_provider), engine.sync_engine)\n return engine\n\n return _wrap_create_async_engine_internal\n\n\ndef _wrap_create_engine(tracer_provider=None):\n # pylint: disable=unused-argument\n def _wrap_create_engine_internal(func, module, args, kwargs):\n \"\"\"Trace the SQLAlchemy engine, creating an `EngineTracer`\n object that will listen to SQLAlchemy events.\n \"\"\"\n engine = func(*args, **kwargs)\n EngineTracer(_get_tracer(tracer_provider), engine)\n return engine\n\n return _wrap_create_engine_internal\n\n\nclass EngineTracer:\n def __init__(self, tracer, engine, enable_commenter=False):\n self.tracer = tracer\n self.engine = engine\n self.vendor = _normalize_vendor(engine.name)\n self.enable_commenter = enable_commenter\n\n listen(\n engine, \"before_cursor_execute\", self._before_cur_exec, retval=True\n )\n listen(engine, \"after_cursor_execute\", _after_cur_exec)\n listen(engine, \"handle_error\", _handle_error)\n\n def _operation_name(self, db_name, statement):\n parts = []\n if isinstance(statement, str):\n # otel spec recommends against parsing SQL queries. We are not trying to parse SQL\n # but simply truncating the statement to the first word. This covers probably >95%\n # use cases and uses the SQL statement in span name correctly as per the spec.\n # For some very special cases it might not record the correct statement if the SQL\n # dialect is too weird but in any case it shouldn't break anything.\n parts.append(statement.split()[0])\n if db_name:\n parts.append(db_name)\n if not parts:\n return self.vendor\n return \" \".join(parts)\n\n # pylint: disable=unused-argument\n def _before_cur_exec(\n self, conn, cursor, statement, params, context, executemany\n ):\n attrs, found = _get_attributes_from_url(conn.engine.url)\n if not found:\n attrs = _get_attributes_from_cursor(self.vendor, cursor, attrs)\n\n db_name = attrs.get(SpanAttributes.DB_NAME, \"\")\n span = self.tracer.start_span(\n self._operation_name(db_name, statement),\n kind=trace.SpanKind.CLIENT,\n )\n with trace.use_span(span, end_on_exit=False):\n if span.is_recording():\n span.set_attribute(SpanAttributes.DB_STATEMENT, statement)\n span.set_attribute(SpanAttributes.DB_SYSTEM, self.vendor)\n for key, value in attrs.items():\n span.set_attribute(key, value)\n\n context._otel_span = span\n if self.enable_commenter:\n statement = statement + EngineTracer._generate_comment(span=span)\n\n return statement, params\n\n @staticmethod\n def _generate_comment(span: Span) -> str:\n span_context = span.get_span_context()\n meta = {}\n if span_context.is_valid:\n meta.update(_generate_opentelemetry_traceparent(span))\n return _generate_sql_comment(**meta)\n\n\n# pylint: disable=unused-argument\ndef _after_cur_exec(conn, cursor, statement, params, context, executemany):\n span = getattr(context, \"_otel_span\", None)\n if span is None:\n return\n\n span.end()\n\n\ndef _handle_error(context):\n span = getattr(context.execution_context, \"_otel_span\", None)\n if span is None:\n return\n\n if span.is_recording():\n span.set_status(\n Status(\n StatusCode.ERROR,\n str(context.original_exception),\n )\n )\n span.end()\n\n\ndef _get_attributes_from_url(url):\n \"\"\"Set connection tags from the url. return true if successful.\"\"\"\n attrs = {}\n if url.host:\n attrs[SpanAttributes.NET_PEER_NAME] = url.host\n if url.port:\n attrs[SpanAttributes.NET_PEER_PORT] = url.port\n if url.database:\n attrs[SpanAttributes.DB_NAME] = url.database\n if url.username:\n attrs[SpanAttributes.DB_USER] = url.username\n return attrs, bool(url.host)\n\n\ndef _get_attributes_from_cursor(vendor, cursor, attrs):\n \"\"\"Attempt to set db connection attributes by introspecting the cursor.\"\"\"\n if vendor == \"postgresql\":\n info = getattr(getattr(cursor, \"connection\", None), \"info\", None)\n if not info:\n return attrs\n\n attrs[SpanAttributes.DB_NAME] = info.dbname\n is_unix_socket = info.host and info.host.startswith(\"/\")\n\n if is_unix_socket:\n attrs[SpanAttributes.NET_TRANSPORT] = NetTransportValues.UNIX.value\n if info.port:\n # postgresql enforces this pattern on all socket names\n attrs[SpanAttributes.NET_PEER_NAME] = os.path.join(\n info.host, f\".s.PGSQL.{info.port}\"\n )\n else:\n attrs[\n SpanAttributes.NET_TRANSPORT\n ] = NetTransportValues.IP_TCP.value\n attrs[SpanAttributes.NET_PEER_NAME] = info.host\n if info.port:\n attrs[SpanAttributes.NET_PEER_PORT] = int(info.port)\n return attrs\n", "path": "instrumentation/opentelemetry-instrumentation-sqlalchemy/src/opentelemetry/instrumentation/sqlalchemy/engine.py"}]} | 4,016 | 699 |
gh_patches_debug_19154 | rasdani/github-patches | git_diff | bokeh__bokeh-6656 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
TypeError: 'unicode' does not have the buffer interface
#### ALL software version info (bokeh, python, notebook, OS, browser, any other relevant packages)
bokeh 0.12.6
python 2.7.12
64 bit Ubuntu 16.04
Chrome browser
#### Description of expected behavior and the observed behavior
I get `500: Internal Server Error` when I try to use signed sessions with bokeh.
#### Complete, minimal, self-contained example code that reproduces the issue
I use `sliders.py` example from Bokeh Gallery. I use the following to run the app and generate the session id:
Run the app:
```bash
export BOKEH_SECRET_KEY=KKXYhtUJmQ5f8LiQJdeUGOF4HIeTzf5zOBZmlxrXtF6D
export BOKEH_SIGN_SESSIONS=True
bokeh serve sliders.py --session-ids external-signed
```
Generate session id:
```bash
export BOKEH_SECRET_KEY=KKXYhtUJmQ5f8LiQJdeUGOF4HIeTzf5zOBZmlxrXtF6D
export BOKEH_SIGN_SESSIONS=True
python -c "from bokeh.util.session_id import generate_session_id; print(generate_session_id())"
```
Example url to access app:
http://localhost:5006/sliders?bokeh-session-id=4RJKVrnFVe60gB5urh9sE3jUnSGDkJAfCwvoaDsoMB8f-W6QAfyDoxORtN7mb6DHAzftAhpfnxVdzC-6gIT13uV0
#### Stack traceback and/or browser JavaScript console output
JavaScript console output:
```
Failed to load resource: the server responded with a status of 500 (Internal Server Error)
```
Bokeh traceback:
```
2017-07-21 00:23:58,161 Uncaught exception GET /sliders?bokeh-session-id=4RJKVrnFVe60gB5urh9sE3jUnSGDkJAfCwvoaDsoMB8f-W6QAfyDoxORtN7mb6DHAzftAhpfnxVdzC-6gIT13uV0 (::1)
HTTPServerRequest(protocol='http', host='localhost:5006', method='GET', uri='/sliders?bokeh-session-id=4RJKVrnFVe60gB5urh9sE3jUnSGDkJAfCwvoaDsoMB8f-W6QAfyDoxORtN7mb6DHAzftAhpfnxVdzC-6gIT13uV0', version='HTTP/1.1', remote_ip='::1', headers={'Accept-Language': 'en-US,en;q=0.8,ru;q=0.6,de;q=0.4', 'Accept-Encoding': 'gzip, deflate, br', 'Host': 'localhost:5006', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/59.0.3071.109 Chrome/59.0.3071.109 Safari/537.36', 'Connection': 'keep-alive', 'Cookie': '_xsrf=2|4ab25a11|f7d3fbdf1fab4d2b01135d63518a4f9a|1498856594; username-localhost-8888="2|1:0|10:1499014969|23:username-localhost-8888|44:ODVmNmU2NjIwYjUwNDlhYzk2MzY4OWQ5NDU2ZTExYjU=|3a908d5ba83bca558deae2665732f340eeef5ce69a2763c6cef367fd892e22b7"', 'Upgrade-Insecure-Requests': '1'})
Traceback (most recent call last):
File "/usr/local/lib/python2.7/dist-packages/tornado/web.py", line 1469, in _execute
result = yield result
File "/usr/local/lib/python2.7/dist-packages/tornado/gen.py", line 1015, in run
value = future.result()
File "/usr/local/lib/python2.7/dist-packages/tornado/concurrent.py", line 237, in result
raise_exc_info(self._exc_info)
File "/usr/local/lib/python2.7/dist-packages/tornado/gen.py", line 1021, in run
yielded = self.gen.throw(*exc_info)
File "/usr/local/lib/python2.7/dist-packages/bokeh/server/views/doc_handler.py", line 27, in get
session = yield self.get_session()
File "/usr/local/lib/python2.7/dist-packages/tornado/gen.py", line 1015, in run
value = future.result()
File "/usr/local/lib/python2.7/dist-packages/tornado/concurrent.py", line 237, in result
raise_exc_info(self._exc_info)
File "/usr/local/lib/python2.7/dist-packages/tornado/gen.py", line 285, in wrapper
yielded = next(result)
File "/usr/local/lib/python2.7/dist-packages/bokeh/server/views/session_handler.py", line 36, in get_session
signed=self.application.sign_sessions):
File "/usr/local/lib/python2.7/dist-packages/bokeh/util/session_id.py", line 156, in check_session_id_signature
return hmac.compare_digest(expected_signature, provided_signature)
TypeError: 'unicode' does not have the buffer interface
```
#### Screenshots or screencasts of the bug in action

</issue>
<code>
[start of bokeh/util/session_id.py]
1 ''' Utilities for generating and manipulating session IDs.
2
3 A session ID would typically be associated with each browser tab viewing
4 an application or plot. Each session has its own state separate from any
5 other sessions hosted by the server.
6
7 '''
8 from __future__ import absolute_import, print_function
9
10 import base64
11 import codecs
12 import hashlib
13 import hmac
14 import random
15 import time
16
17 from six import binary_type
18
19 from bokeh.settings import settings
20
21 # Use the system PRNG for session id generation (if possible)
22 # NOTE: secure random string generation implementation is adapted
23 # from the Django project. Reference:
24 # https://github.com/django/django/blob/0ed7d155635da9f79d4dd67e4889087d3673c6da/django/utils/crypto.py
25 try:
26 random = random.SystemRandom()
27 using_sysrandom = True
28 except NotImplementedError:
29 import warnings
30 warnings.warn('A secure pseudo-random number generator is not available '
31 'on your system. Falling back to Mersenne Twister.')
32 if settings.secret_key() is None:
33 warnings.warn('A secure pseudo-random number generator is not available '
34 'and no BOKEH_SECRET_KEY has been set. '
35 'Setting a secret key will mitigate the lack of a secure '
36 'generator.')
37 using_sysrandom = False
38
39 def _ensure_bytes(secret_key):
40 if secret_key is None:
41 return None
42 elif isinstance(secret_key, binary_type):
43 return secret_key
44 else:
45 return codecs.encode(secret_key, 'utf-8')
46
47 # this is broken out for unit testability
48 def _reseed_if_needed(using_sysrandom, secret_key):
49 secret_key = _ensure_bytes(secret_key)
50 if not using_sysrandom:
51 # This is ugly, and a hack, but it makes things better than
52 # the alternative of predictability. This re-seeds the PRNG
53 # using a value that is hard for an attacker to predict, every
54 # time a random string is required. This may change the
55 # properties of the chosen random sequence slightly, but this
56 # is better than absolute predictability.
57 random.seed(
58 hashlib.sha256(
59 ("%s%s%s" % (
60 random.getstate(),
61 time.time(),
62 secret_key)).encode('utf-8')
63 ).digest())
64
65 def _base64_encode(decoded):
66 # base64 encode both takes and returns bytes, we want to work with strings.
67 # If 'decoded' isn't bytes already, assume it's utf-8
68 decoded_as_bytes = _ensure_bytes(decoded)
69 encoded = codecs.decode(base64.urlsafe_b64encode(decoded_as_bytes), 'ascii')
70 # remove padding '=' chars that cause trouble
71 return str(encoded.rstrip('='))
72
73 def _signature(base_id, secret_key):
74 secret_key = _ensure_bytes(secret_key)
75 base_id = codecs.encode(base_id, "utf-8")
76 signer = hmac.new(secret_key, base_id, hashlib.sha256)
77 return _base64_encode(signer.digest())
78
79 def _get_random_string(length=44,
80 allowed_chars='abcdefghijklmnopqrstuvwxyz'
81 'ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789',
82 secret_key=settings.secret_key_bytes()):
83 """
84 Return a securely generated random string.
85 With the a-z, A-Z, 0-9 character set:
86 Length 12 is a 71-bit value. log_2((26+26+10)^12) =~ 71
87 Length 44 is a 261-bit value. log_2((26+26+10)^44) = 261
88 """
89 secret_key = _ensure_bytes(secret_key)
90 _reseed_if_needed(using_sysrandom, secret_key)
91 return ''.join(random.choice(allowed_chars) for i in range(length))
92
93 def generate_secret_key():
94 """
95 Generate a new securely-generated secret key appropriate
96 for SHA-256 HMAC signatures. This key could be used to
97 sign Bokeh server session IDs for example.
98 """
99 return _get_random_string()
100
101 def generate_session_id(secret_key=settings.secret_key_bytes(), signed=settings.sign_sessions()):
102 """Generate a random session ID.
103
104 Typically, each browser tab connected to a Bokeh application
105 has its own session ID. In production deployments of a Bokeh
106 app, session IDs should be random and unguessable - otherwise
107 users of the app could interfere with one another.
108
109 If session IDs are signed with a secret key, the server can
110 verify that the generator of the session ID was "authorized"
111 (the generator had to know the secret key). This can be used
112 to have a separate process, such as another web application,
113 which generates new sessions on a Bokeh server. This other
114 process may require users to log in before redirecting them to
115 the Bokeh server with a valid session ID, for example.
116
117 Args:
118 secret_key (str, optional) : Secret key (default: value of 'BOKEH_SECRET_KEY' env var)
119 signed (bool, optional) : Whether to sign the session ID (default: value of
120 'BOKEH_SIGN_SESSIONS' env var)
121
122 """
123 secret_key = _ensure_bytes(secret_key)
124 if signed:
125 # note: '-' can also be in the base64 encoded signature
126 base_id = _get_random_string(secret_key=secret_key)
127 return base_id + '-' + _signature(base_id, secret_key)
128 else:
129 return _get_random_string(secret_key=secret_key)
130
131 def check_session_id_signature(session_id, secret_key=settings.secret_key_bytes(),
132 signed=settings.sign_sessions()):
133 """Check the signature of a session ID, returning True if it's valid.
134
135 The server uses this function to check whether a session ID
136 was generated with the correct secret key. If signed sessions are disabled,
137 this function always returns True.
138
139 Args:
140 session_id (str) : The session ID to check
141 secret_key (str, optional) : Secret key (default: value of 'BOKEH_SECRET_KEY' env var)
142 signed (bool, optional) : Whether to check anything (default: value of
143 'BOKEH_SIGN_SESSIONS' env var)
144
145 """
146 secret_key = _ensure_bytes(secret_key)
147 if signed:
148 pieces = session_id.split('-', 1)
149 if len(pieces) != 2:
150 return False
151 base_id = pieces[0]
152 provided_signature = pieces[1]
153 expected_signature = _signature(base_id, secret_key)
154 # hmac.compare_digest() uses a string compare algorithm that doesn't
155 # short-circuit so we don't allow timing analysis
156 return hmac.compare_digest(expected_signature, provided_signature)
157 else:
158 return True
159
[end of bokeh/util/session_id.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/bokeh/util/session_id.py b/bokeh/util/session_id.py
--- a/bokeh/util/session_id.py
+++ b/bokeh/util/session_id.py
@@ -17,6 +17,7 @@
from six import binary_type
from bokeh.settings import settings
+from bokeh.util.string import encode_utf8
# Use the system PRNG for session id generation (if possible)
# NOTE: secure random string generation implementation is adapted
@@ -153,6 +154,7 @@
expected_signature = _signature(base_id, secret_key)
# hmac.compare_digest() uses a string compare algorithm that doesn't
# short-circuit so we don't allow timing analysis
- return hmac.compare_digest(expected_signature, provided_signature)
+ # encode_utf8 is used to ensure that strings have same encoding
+ return hmac.compare_digest(encode_utf8(expected_signature), encode_utf8(provided_signature))
else:
return True
| {"golden_diff": "diff --git a/bokeh/util/session_id.py b/bokeh/util/session_id.py\n--- a/bokeh/util/session_id.py\n+++ b/bokeh/util/session_id.py\n@@ -17,6 +17,7 @@\n from six import binary_type\n \n from bokeh.settings import settings\n+from bokeh.util.string import encode_utf8\n \n # Use the system PRNG for session id generation (if possible)\n # NOTE: secure random string generation implementation is adapted\n@@ -153,6 +154,7 @@\n expected_signature = _signature(base_id, secret_key)\n # hmac.compare_digest() uses a string compare algorithm that doesn't\n # short-circuit so we don't allow timing analysis\n- return hmac.compare_digest(expected_signature, provided_signature)\n+ # encode_utf8 is used to ensure that strings have same encoding\n+ return hmac.compare_digest(encode_utf8(expected_signature), encode_utf8(provided_signature))\n else:\n return True\n", "issue": "TypeError: 'unicode' does not have the buffer interface\n#### ALL software version info (bokeh, python, notebook, OS, browser, any other relevant packages)\r\n\r\nbokeh 0.12.6\r\npython 2.7.12\r\n64 bit Ubuntu 16.04\r\nChrome browser\r\n\r\n#### Description of expected behavior and the observed behavior\r\n\r\nI get `500: Internal Server Error` when I try to use signed sessions with bokeh. \r\n\r\n#### Complete, minimal, self-contained example code that reproduces the issue\r\n\r\nI use `sliders.py` example from Bokeh Gallery. I use the following to run the app and generate the session id:\r\n\r\nRun the app:\r\n```bash\r\nexport BOKEH_SECRET_KEY=KKXYhtUJmQ5f8LiQJdeUGOF4HIeTzf5zOBZmlxrXtF6D\r\nexport BOKEH_SIGN_SESSIONS=True\r\nbokeh serve sliders.py --session-ids external-signed\r\n```\r\n\r\nGenerate session id:\r\n```bash \r\nexport BOKEH_SECRET_KEY=KKXYhtUJmQ5f8LiQJdeUGOF4HIeTzf5zOBZmlxrXtF6D\r\nexport BOKEH_SIGN_SESSIONS=True\r\npython -c \"from bokeh.util.session_id import generate_session_id; print(generate_session_id())\"\r\n```\r\n\r\nExample url to access app:\r\nhttp://localhost:5006/sliders?bokeh-session-id=4RJKVrnFVe60gB5urh9sE3jUnSGDkJAfCwvoaDsoMB8f-W6QAfyDoxORtN7mb6DHAzftAhpfnxVdzC-6gIT13uV0\r\n\r\n#### Stack traceback and/or browser JavaScript console output\r\n\r\nJavaScript console output:\r\n```\r\nFailed to load resource: the server responded with a status of 500 (Internal Server Error)\r\n```\r\n\r\nBokeh traceback:\r\n```\r\n2017-07-21 00:23:58,161 Uncaught exception GET /sliders?bokeh-session-id=4RJKVrnFVe60gB5urh9sE3jUnSGDkJAfCwvoaDsoMB8f-W6QAfyDoxORtN7mb6DHAzftAhpfnxVdzC-6gIT13uV0 (::1)\r\nHTTPServerRequest(protocol='http', host='localhost:5006', method='GET', uri='/sliders?bokeh-session-id=4RJKVrnFVe60gB5urh9sE3jUnSGDkJAfCwvoaDsoMB8f-W6QAfyDoxORtN7mb6DHAzftAhpfnxVdzC-6gIT13uV0', version='HTTP/1.1', remote_ip='::1', headers={'Accept-Language': 'en-US,en;q=0.8,ru;q=0.6,de;q=0.4', 'Accept-Encoding': 'gzip, deflate, br', 'Host': 'localhost:5006', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/59.0.3071.109 Chrome/59.0.3071.109 Safari/537.36', 'Connection': 'keep-alive', 'Cookie': '_xsrf=2|4ab25a11|f7d3fbdf1fab4d2b01135d63518a4f9a|1498856594; username-localhost-8888=\"2|1:0|10:1499014969|23:username-localhost-8888|44:ODVmNmU2NjIwYjUwNDlhYzk2MzY4OWQ5NDU2ZTExYjU=|3a908d5ba83bca558deae2665732f340eeef5ce69a2763c6cef367fd892e22b7\"', 'Upgrade-Insecure-Requests': '1'})\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python2.7/dist-packages/tornado/web.py\", line 1469, in _execute\r\n result = yield result\r\n File \"/usr/local/lib/python2.7/dist-packages/tornado/gen.py\", line 1015, in run\r\n value = future.result()\r\n File \"/usr/local/lib/python2.7/dist-packages/tornado/concurrent.py\", line 237, in result\r\n raise_exc_info(self._exc_info)\r\n File \"/usr/local/lib/python2.7/dist-packages/tornado/gen.py\", line 1021, in run\r\n yielded = self.gen.throw(*exc_info)\r\n File \"/usr/local/lib/python2.7/dist-packages/bokeh/server/views/doc_handler.py\", line 27, in get\r\n session = yield self.get_session()\r\n File \"/usr/local/lib/python2.7/dist-packages/tornado/gen.py\", line 1015, in run\r\n value = future.result()\r\n File \"/usr/local/lib/python2.7/dist-packages/tornado/concurrent.py\", line 237, in result\r\n raise_exc_info(self._exc_info)\r\n File \"/usr/local/lib/python2.7/dist-packages/tornado/gen.py\", line 285, in wrapper\r\n yielded = next(result)\r\n File \"/usr/local/lib/python2.7/dist-packages/bokeh/server/views/session_handler.py\", line 36, in get_session\r\n signed=self.application.sign_sessions):\r\n File \"/usr/local/lib/python2.7/dist-packages/bokeh/util/session_id.py\", line 156, in check_session_id_signature\r\n return hmac.compare_digest(expected_signature, provided_signature)\r\nTypeError: 'unicode' does not have the buffer interface\r\n```\r\n\r\n#### Screenshots or screencasts of the bug in action\r\n\r\n\r\n\n", "before_files": [{"content": "''' Utilities for generating and manipulating session IDs.\n\nA session ID would typically be associated with each browser tab viewing\nan application or plot. Each session has its own state separate from any\nother sessions hosted by the server.\n\n'''\nfrom __future__ import absolute_import, print_function\n\nimport base64\nimport codecs\nimport hashlib\nimport hmac\nimport random\nimport time\n\nfrom six import binary_type\n\nfrom bokeh.settings import settings\n\n# Use the system PRNG for session id generation (if possible)\n# NOTE: secure random string generation implementation is adapted\n# from the Django project. Reference:\n# https://github.com/django/django/blob/0ed7d155635da9f79d4dd67e4889087d3673c6da/django/utils/crypto.py\ntry:\n random = random.SystemRandom()\n using_sysrandom = True\nexcept NotImplementedError:\n import warnings\n warnings.warn('A secure pseudo-random number generator is not available '\n 'on your system. Falling back to Mersenne Twister.')\n if settings.secret_key() is None:\n warnings.warn('A secure pseudo-random number generator is not available '\n 'and no BOKEH_SECRET_KEY has been set. '\n 'Setting a secret key will mitigate the lack of a secure '\n 'generator.')\n using_sysrandom = False\n\ndef _ensure_bytes(secret_key):\n if secret_key is None:\n return None\n elif isinstance(secret_key, binary_type):\n return secret_key\n else:\n return codecs.encode(secret_key, 'utf-8')\n\n# this is broken out for unit testability\ndef _reseed_if_needed(using_sysrandom, secret_key):\n secret_key = _ensure_bytes(secret_key)\n if not using_sysrandom:\n # This is ugly, and a hack, but it makes things better than\n # the alternative of predictability. This re-seeds the PRNG\n # using a value that is hard for an attacker to predict, every\n # time a random string is required. This may change the\n # properties of the chosen random sequence slightly, but this\n # is better than absolute predictability.\n random.seed(\n hashlib.sha256(\n (\"%s%s%s\" % (\n random.getstate(),\n time.time(),\n secret_key)).encode('utf-8')\n ).digest())\n\ndef _base64_encode(decoded):\n # base64 encode both takes and returns bytes, we want to work with strings.\n # If 'decoded' isn't bytes already, assume it's utf-8\n decoded_as_bytes = _ensure_bytes(decoded)\n encoded = codecs.decode(base64.urlsafe_b64encode(decoded_as_bytes), 'ascii')\n # remove padding '=' chars that cause trouble\n return str(encoded.rstrip('='))\n\ndef _signature(base_id, secret_key):\n secret_key = _ensure_bytes(secret_key)\n base_id = codecs.encode(base_id, \"utf-8\")\n signer = hmac.new(secret_key, base_id, hashlib.sha256)\n return _base64_encode(signer.digest())\n\ndef _get_random_string(length=44,\n allowed_chars='abcdefghijklmnopqrstuvwxyz'\n 'ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789',\n secret_key=settings.secret_key_bytes()):\n \"\"\"\n Return a securely generated random string.\n With the a-z, A-Z, 0-9 character set:\n Length 12 is a 71-bit value. log_2((26+26+10)^12) =~ 71\n Length 44 is a 261-bit value. log_2((26+26+10)^44) = 261\n \"\"\"\n secret_key = _ensure_bytes(secret_key)\n _reseed_if_needed(using_sysrandom, secret_key)\n return ''.join(random.choice(allowed_chars) for i in range(length))\n\ndef generate_secret_key():\n \"\"\"\n Generate a new securely-generated secret key appropriate\n for SHA-256 HMAC signatures. This key could be used to\n sign Bokeh server session IDs for example.\n \"\"\"\n return _get_random_string()\n\ndef generate_session_id(secret_key=settings.secret_key_bytes(), signed=settings.sign_sessions()):\n \"\"\"Generate a random session ID.\n\n Typically, each browser tab connected to a Bokeh application\n has its own session ID. In production deployments of a Bokeh\n app, session IDs should be random and unguessable - otherwise\n users of the app could interfere with one another.\n\n If session IDs are signed with a secret key, the server can\n verify that the generator of the session ID was \"authorized\"\n (the generator had to know the secret key). This can be used\n to have a separate process, such as another web application,\n which generates new sessions on a Bokeh server. This other\n process may require users to log in before redirecting them to\n the Bokeh server with a valid session ID, for example.\n\n Args:\n secret_key (str, optional) : Secret key (default: value of 'BOKEH_SECRET_KEY' env var)\n signed (bool, optional) : Whether to sign the session ID (default: value of\n 'BOKEH_SIGN_SESSIONS' env var)\n\n \"\"\"\n secret_key = _ensure_bytes(secret_key)\n if signed:\n # note: '-' can also be in the base64 encoded signature\n base_id = _get_random_string(secret_key=secret_key)\n return base_id + '-' + _signature(base_id, secret_key)\n else:\n return _get_random_string(secret_key=secret_key)\n\ndef check_session_id_signature(session_id, secret_key=settings.secret_key_bytes(),\n signed=settings.sign_sessions()):\n \"\"\"Check the signature of a session ID, returning True if it's valid.\n\n The server uses this function to check whether a session ID\n was generated with the correct secret key. If signed sessions are disabled,\n this function always returns True.\n\n Args:\n session_id (str) : The session ID to check\n secret_key (str, optional) : Secret key (default: value of 'BOKEH_SECRET_KEY' env var)\n signed (bool, optional) : Whether to check anything (default: value of\n 'BOKEH_SIGN_SESSIONS' env var)\n\n \"\"\"\n secret_key = _ensure_bytes(secret_key)\n if signed:\n pieces = session_id.split('-', 1)\n if len(pieces) != 2:\n return False\n base_id = pieces[0]\n provided_signature = pieces[1]\n expected_signature = _signature(base_id, secret_key)\n # hmac.compare_digest() uses a string compare algorithm that doesn't\n # short-circuit so we don't allow timing analysis\n return hmac.compare_digest(expected_signature, provided_signature)\n else:\n return True\n", "path": "bokeh/util/session_id.py"}]} | 3,852 | 210 |
gh_patches_debug_25736 | rasdani/github-patches | git_diff | iterative__dvc-6240 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
import: error message when imported file does not exist
## Description
When you import a file from a exernal Git repository but you specify a wrong path you receive a confusing error message.
### Reproduce
```
dvc import [email protected]:iterative/example-get-started data/fake.xml
```
### Expected
A concise error that informs that data/fake.xml does not exist.
### Environment information
```
DVC version: 2.3.0 (pip)
---------------------------------
Platform: Python 3.7.9 on Linux-4.15.0-96-generic-x86_64-with-debian-buster-sid
Supports: http, https
Cache types: symlink
Cache directory: nfs on 10.10.30.245:/NAS/VA
Caches: local
Remotes: None
Workspace directory: ext4 on /dev/sdb1
Repo: dvc, git
```
I would like to help fix this problem, I thought about adding some regression test for https://github.com/iterative/dvc/blob/master/dvc/repo/imp_url.py similar to https://github.com/iterative/dvc/blob/master/tests/func/test_import_url.py#L107 and catch the exception later to return a proper message
</issue>
<code>
[start of dvc/dependency/repo.py]
1 import os
2 from collections import defaultdict
3 from typing import TYPE_CHECKING, Dict, Optional, Set
4
5 from voluptuous import Required
6
7 from dvc.path_info import PathInfo
8
9 from .base import Dependency
10
11 if TYPE_CHECKING:
12 from dvc.objects.db.base import ObjectDB
13 from dvc.objects.file import HashFile
14
15
16 class RepoDependency(Dependency):
17 PARAM_REPO = "repo"
18 PARAM_URL = "url"
19 PARAM_REV = "rev"
20 PARAM_REV_LOCK = "rev_lock"
21
22 REPO_SCHEMA = {
23 PARAM_REPO: {
24 Required(PARAM_URL): str,
25 PARAM_REV: str,
26 PARAM_REV_LOCK: str,
27 }
28 }
29
30 def __init__(self, def_repo, stage, *args, **kwargs):
31 self.def_repo = def_repo
32 self._staged_objs: Dict[str, "HashFile"] = {}
33 super().__init__(stage, *args, **kwargs)
34
35 def _parse_path(self, fs, path_info):
36 return None
37
38 @property
39 def is_in_repo(self):
40 return False
41
42 def __str__(self):
43 return "{} ({})".format(self.def_path, self.def_repo[self.PARAM_URL])
44
45 def workspace_status(self):
46 current = self.get_obj(locked=True).hash_info
47 updated = self.get_obj(locked=False).hash_info
48
49 if current != updated:
50 return {str(self): "update available"}
51
52 return {}
53
54 def status(self):
55 return self.workspace_status()
56
57 def save(self):
58 pass
59
60 def dumpd(self):
61 return {self.PARAM_PATH: self.def_path, self.PARAM_REPO: self.def_repo}
62
63 def download(self, to, jobs=None):
64 from dvc.checkout import checkout
65 from dvc.objects import save
66 from dvc.objects.db.git import GitObjectDB
67 from dvc.repo.fetch import fetch_from_odb
68
69 for odb, objs in self.get_used_objs().items():
70 if not isinstance(odb, GitObjectDB):
71 fetch_from_odb(self.repo, odb, objs, jobs=jobs)
72
73 obj = self.get_obj()
74 save(self.repo.odb.local, obj, jobs=jobs)
75 checkout(
76 to.path_info,
77 to.fs,
78 obj,
79 self.repo.odb.local,
80 dvcignore=None,
81 state=self.repo.state,
82 )
83
84 def update(self, rev=None):
85 if rev:
86 self.def_repo[self.PARAM_REV] = rev
87 with self._make_repo(locked=False) as repo:
88 self.def_repo[self.PARAM_REV_LOCK] = repo.get_rev()
89
90 def changed_checksum(self):
91 # From current repo point of view what describes RepoDependency is its
92 # origin project url and rev_lock, and it makes RepoDependency
93 # immutable, hence its impossible for checksum to change.
94 return False
95
96 def get_used_objs(
97 self, **kwargs
98 ) -> Dict[Optional["ObjectDB"], Set["HashFile"]]:
99 from dvc.config import NoRemoteError
100 from dvc.exceptions import NoOutputOrStageError
101 from dvc.objects.db.git import GitObjectDB
102 from dvc.objects.stage import stage
103
104 local_odb = self.repo.odb.local
105 locked = kwargs.pop("locked", True)
106 with self._make_repo(
107 locked=locked, cache_dir=local_odb.cache_dir
108 ) as repo:
109 used_objs = defaultdict(set)
110 rev = repo.get_rev()
111 if locked and self.def_repo.get(self.PARAM_REV_LOCK) is None:
112 self.def_repo[self.PARAM_REV_LOCK] = rev
113
114 path_info = PathInfo(repo.root_dir) / str(self.def_path)
115 try:
116 for odb, objs in repo.used_objs(
117 [os.fspath(path_info)],
118 force=True,
119 jobs=kwargs.get("jobs"),
120 recursive=True,
121 ).items():
122 if odb is None:
123 odb = repo.cloud.get_remote().odb
124 self._check_circular_import(odb)
125 used_objs[odb].update(objs)
126 except (NoRemoteError, NoOutputOrStageError):
127 pass
128
129 staged_obj = stage(
130 local_odb,
131 path_info,
132 repo.repo_fs,
133 local_odb.fs.PARAM_CHECKSUM,
134 )
135 self._staged_objs[rev] = staged_obj
136 git_odb = GitObjectDB(repo.repo_fs, repo.root_dir)
137 used_objs[git_odb].add(staged_obj)
138 return used_objs
139
140 def _check_circular_import(self, odb):
141 from dvc.exceptions import CircularImportError
142 from dvc.fs.repo import RepoFileSystem
143
144 if not odb or not isinstance(odb.fs, RepoFileSystem):
145 return
146
147 self_url = self.repo.url or self.repo.root_dir
148 if odb.fs.repo_url is not None and odb.fs.repo_url == self_url:
149 raise CircularImportError(self, odb.fs.repo_url, self_url)
150
151 def get_obj(self, filter_info=None, **kwargs):
152 from dvc.objects.stage import stage
153
154 odb = self.repo.odb.local
155 locked = kwargs.pop("locked", True)
156 with self._make_repo(locked=locked, cache_dir=odb.cache_dir) as repo:
157 rev = repo.get_rev()
158 if locked and self.def_repo.get(self.PARAM_REV_LOCK) is None:
159 self.def_repo[self.PARAM_REV_LOCK] = rev
160 obj = self._staged_objs.get(rev)
161 if obj is not None:
162 return obj
163
164 path_info = PathInfo(repo.root_dir) / str(self.def_path)
165 obj = stage(
166 odb,
167 path_info,
168 repo.repo_fs,
169 odb.fs.PARAM_CHECKSUM,
170 )
171 self._staged_objs[rev] = obj
172 return obj
173
174 def _make_repo(self, locked=True, **kwargs):
175 from dvc.external_repo import external_repo
176
177 d = self.def_repo
178 rev = self._get_rev(locked=locked)
179 return external_repo(d[self.PARAM_URL], rev=rev, **kwargs)
180
181 def _get_rev(self, locked=True):
182 d = self.def_repo
183 return (d.get(self.PARAM_REV_LOCK) if locked else None) or d.get(
184 self.PARAM_REV
185 )
186
[end of dvc/dependency/repo.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/dvc/dependency/repo.py b/dvc/dependency/repo.py
--- a/dvc/dependency/repo.py
+++ b/dvc/dependency/repo.py
@@ -97,7 +97,7 @@
self, **kwargs
) -> Dict[Optional["ObjectDB"], Set["HashFile"]]:
from dvc.config import NoRemoteError
- from dvc.exceptions import NoOutputOrStageError
+ from dvc.exceptions import NoOutputOrStageError, PathMissingError
from dvc.objects.db.git import GitObjectDB
from dvc.objects.stage import stage
@@ -126,12 +126,18 @@
except (NoRemoteError, NoOutputOrStageError):
pass
- staged_obj = stage(
- local_odb,
- path_info,
- repo.repo_fs,
- local_odb.fs.PARAM_CHECKSUM,
- )
+ try:
+ staged_obj = stage(
+ local_odb,
+ path_info,
+ repo.repo_fs,
+ local_odb.fs.PARAM_CHECKSUM,
+ )
+ except FileNotFoundError as exc:
+ raise PathMissingError(
+ self.def_path, self.def_repo[self.PARAM_URL]
+ ) from exc
+
self._staged_objs[rev] = staged_obj
git_odb = GitObjectDB(repo.repo_fs, repo.root_dir)
used_objs[git_odb].add(staged_obj)
| {"golden_diff": "diff --git a/dvc/dependency/repo.py b/dvc/dependency/repo.py\n--- a/dvc/dependency/repo.py\n+++ b/dvc/dependency/repo.py\n@@ -97,7 +97,7 @@\n self, **kwargs\n ) -> Dict[Optional[\"ObjectDB\"], Set[\"HashFile\"]]:\n from dvc.config import NoRemoteError\n- from dvc.exceptions import NoOutputOrStageError\n+ from dvc.exceptions import NoOutputOrStageError, PathMissingError\n from dvc.objects.db.git import GitObjectDB\n from dvc.objects.stage import stage\n \n@@ -126,12 +126,18 @@\n except (NoRemoteError, NoOutputOrStageError):\n pass\n \n- staged_obj = stage(\n- local_odb,\n- path_info,\n- repo.repo_fs,\n- local_odb.fs.PARAM_CHECKSUM,\n- )\n+ try:\n+ staged_obj = stage(\n+ local_odb,\n+ path_info,\n+ repo.repo_fs,\n+ local_odb.fs.PARAM_CHECKSUM,\n+ )\n+ except FileNotFoundError as exc:\n+ raise PathMissingError(\n+ self.def_path, self.def_repo[self.PARAM_URL]\n+ ) from exc\n+\n self._staged_objs[rev] = staged_obj\n git_odb = GitObjectDB(repo.repo_fs, repo.root_dir)\n used_objs[git_odb].add(staged_obj)\n", "issue": "import: error message when imported file does not exist\n## Description\r\n\r\nWhen you import a file from a exernal Git repository but you specify a wrong path you receive a confusing error message.\r\n\r\n### Reproduce\r\n```\r\ndvc import [email protected]:iterative/example-get-started data/fake.xml\r\n```\r\n\r\n### Expected\r\n\r\nA concise error that informs that data/fake.xml does not exist.\r\n\r\n### Environment information\r\n\r\n```\r\nDVC version: 2.3.0 (pip)\r\n---------------------------------\r\nPlatform: Python 3.7.9 on Linux-4.15.0-96-generic-x86_64-with-debian-buster-sid\r\nSupports: http, https\r\nCache types: symlink\r\nCache directory: nfs on 10.10.30.245:/NAS/VA\r\nCaches: local\r\nRemotes: None\r\nWorkspace directory: ext4 on /dev/sdb1\r\nRepo: dvc, git\r\n```\r\n\r\nI would like to help fix this problem, I thought about adding some regression test for https://github.com/iterative/dvc/blob/master/dvc/repo/imp_url.py similar to https://github.com/iterative/dvc/blob/master/tests/func/test_import_url.py#L107 and catch the exception later to return a proper message\n", "before_files": [{"content": "import os\nfrom collections import defaultdict\nfrom typing import TYPE_CHECKING, Dict, Optional, Set\n\nfrom voluptuous import Required\n\nfrom dvc.path_info import PathInfo\n\nfrom .base import Dependency\n\nif TYPE_CHECKING:\n from dvc.objects.db.base import ObjectDB\n from dvc.objects.file import HashFile\n\n\nclass RepoDependency(Dependency):\n PARAM_REPO = \"repo\"\n PARAM_URL = \"url\"\n PARAM_REV = \"rev\"\n PARAM_REV_LOCK = \"rev_lock\"\n\n REPO_SCHEMA = {\n PARAM_REPO: {\n Required(PARAM_URL): str,\n PARAM_REV: str,\n PARAM_REV_LOCK: str,\n }\n }\n\n def __init__(self, def_repo, stage, *args, **kwargs):\n self.def_repo = def_repo\n self._staged_objs: Dict[str, \"HashFile\"] = {}\n super().__init__(stage, *args, **kwargs)\n\n def _parse_path(self, fs, path_info):\n return None\n\n @property\n def is_in_repo(self):\n return False\n\n def __str__(self):\n return \"{} ({})\".format(self.def_path, self.def_repo[self.PARAM_URL])\n\n def workspace_status(self):\n current = self.get_obj(locked=True).hash_info\n updated = self.get_obj(locked=False).hash_info\n\n if current != updated:\n return {str(self): \"update available\"}\n\n return {}\n\n def status(self):\n return self.workspace_status()\n\n def save(self):\n pass\n\n def dumpd(self):\n return {self.PARAM_PATH: self.def_path, self.PARAM_REPO: self.def_repo}\n\n def download(self, to, jobs=None):\n from dvc.checkout import checkout\n from dvc.objects import save\n from dvc.objects.db.git import GitObjectDB\n from dvc.repo.fetch import fetch_from_odb\n\n for odb, objs in self.get_used_objs().items():\n if not isinstance(odb, GitObjectDB):\n fetch_from_odb(self.repo, odb, objs, jobs=jobs)\n\n obj = self.get_obj()\n save(self.repo.odb.local, obj, jobs=jobs)\n checkout(\n to.path_info,\n to.fs,\n obj,\n self.repo.odb.local,\n dvcignore=None,\n state=self.repo.state,\n )\n\n def update(self, rev=None):\n if rev:\n self.def_repo[self.PARAM_REV] = rev\n with self._make_repo(locked=False) as repo:\n self.def_repo[self.PARAM_REV_LOCK] = repo.get_rev()\n\n def changed_checksum(self):\n # From current repo point of view what describes RepoDependency is its\n # origin project url and rev_lock, and it makes RepoDependency\n # immutable, hence its impossible for checksum to change.\n return False\n\n def get_used_objs(\n self, **kwargs\n ) -> Dict[Optional[\"ObjectDB\"], Set[\"HashFile\"]]:\n from dvc.config import NoRemoteError\n from dvc.exceptions import NoOutputOrStageError\n from dvc.objects.db.git import GitObjectDB\n from dvc.objects.stage import stage\n\n local_odb = self.repo.odb.local\n locked = kwargs.pop(\"locked\", True)\n with self._make_repo(\n locked=locked, cache_dir=local_odb.cache_dir\n ) as repo:\n used_objs = defaultdict(set)\n rev = repo.get_rev()\n if locked and self.def_repo.get(self.PARAM_REV_LOCK) is None:\n self.def_repo[self.PARAM_REV_LOCK] = rev\n\n path_info = PathInfo(repo.root_dir) / str(self.def_path)\n try:\n for odb, objs in repo.used_objs(\n [os.fspath(path_info)],\n force=True,\n jobs=kwargs.get(\"jobs\"),\n recursive=True,\n ).items():\n if odb is None:\n odb = repo.cloud.get_remote().odb\n self._check_circular_import(odb)\n used_objs[odb].update(objs)\n except (NoRemoteError, NoOutputOrStageError):\n pass\n\n staged_obj = stage(\n local_odb,\n path_info,\n repo.repo_fs,\n local_odb.fs.PARAM_CHECKSUM,\n )\n self._staged_objs[rev] = staged_obj\n git_odb = GitObjectDB(repo.repo_fs, repo.root_dir)\n used_objs[git_odb].add(staged_obj)\n return used_objs\n\n def _check_circular_import(self, odb):\n from dvc.exceptions import CircularImportError\n from dvc.fs.repo import RepoFileSystem\n\n if not odb or not isinstance(odb.fs, RepoFileSystem):\n return\n\n self_url = self.repo.url or self.repo.root_dir\n if odb.fs.repo_url is not None and odb.fs.repo_url == self_url:\n raise CircularImportError(self, odb.fs.repo_url, self_url)\n\n def get_obj(self, filter_info=None, **kwargs):\n from dvc.objects.stage import stage\n\n odb = self.repo.odb.local\n locked = kwargs.pop(\"locked\", True)\n with self._make_repo(locked=locked, cache_dir=odb.cache_dir) as repo:\n rev = repo.get_rev()\n if locked and self.def_repo.get(self.PARAM_REV_LOCK) is None:\n self.def_repo[self.PARAM_REV_LOCK] = rev\n obj = self._staged_objs.get(rev)\n if obj is not None:\n return obj\n\n path_info = PathInfo(repo.root_dir) / str(self.def_path)\n obj = stage(\n odb,\n path_info,\n repo.repo_fs,\n odb.fs.PARAM_CHECKSUM,\n )\n self._staged_objs[rev] = obj\n return obj\n\n def _make_repo(self, locked=True, **kwargs):\n from dvc.external_repo import external_repo\n\n d = self.def_repo\n rev = self._get_rev(locked=locked)\n return external_repo(d[self.PARAM_URL], rev=rev, **kwargs)\n\n def _get_rev(self, locked=True):\n d = self.def_repo\n return (d.get(self.PARAM_REV_LOCK) if locked else None) or d.get(\n self.PARAM_REV\n )\n", "path": "dvc/dependency/repo.py"}]} | 2,629 | 321 |
gh_patches_debug_4100 | rasdani/github-patches | git_diff | Parsl__parsl-2115 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
grid engine provider hangs when qstat output is large
**Describe the bug**
From Quentin Le Boulc'h;
```
I still have the issue with the qstat command from Parsl which is hitting the 60s timeout. When I have 1000 jobs running every qstat fails, I can see many processes accumulating and Parsl get completely stucked.
I checked I can reproduce the issue by myself running the subprocess command you are using. With several hundreds of jobs running the proc.wait() is waiting forever. However a manual qstat returns the output in less than a second. And after killing the proc.wait() I can check that the stdout is actually here so the command has succeeded.
I can also reproduce the issue with a different command than `qstat`, like a simple script returning several hundreds of lines.
Could you check if there is some issue with your subprocess command?
See https://docs.python.org/3/library/subprocess.html#popen-objects for instance: “This will deadlock when using stdout=PIPE or stderr=PIPE and the child process generates enough output to a pipe such that it blocks waiting for the OS pipe buffer to accept more data. Use Popen.communicate() when using pipes to avoid that.”
```
**Expected behavior**
This should not hang
**Environment**
in2p3, parsl desc branch
</issue>
<code>
[start of parsl/channels/local/local.py]
1 import copy
2 import logging
3 import os
4 import shutil
5 import subprocess
6
7 from parsl.channels.base import Channel
8 from parsl.channels.errors import FileCopyException
9 from parsl.utils import RepresentationMixin
10
11 logger = logging.getLogger(__name__)
12
13
14 class LocalChannel(Channel, RepresentationMixin):
15 ''' This is not even really a channel, since opening a local shell is not heavy
16 and done so infrequently that they do not need a persistent channel
17 '''
18
19 def __init__(self, userhome=".", envs={}, script_dir=None):
20 ''' Initialize the local channel. script_dir is required by set to a default.
21
22 KwArgs:
23 - userhome (string): (default='.') This is provided as a way to override and set a specific userhome
24 - envs (dict) : A dictionary of env variables to be set when launching the shell
25 - script_dir (string): Directory to place scripts
26 '''
27 self.userhome = os.path.abspath(userhome)
28 self.hostname = "localhost"
29 self.envs = envs
30 local_env = os.environ.copy()
31 self._envs = copy.deepcopy(local_env)
32 self._envs.update(envs)
33 self.script_dir = script_dir
34
35 def execute_wait(self, cmd, walltime=None, envs={}):
36 ''' Synchronously execute a commandline string on the shell.
37
38 Args:
39 - cmd (string) : Commandline string to execute
40 - walltime (int) : walltime in seconds, this is not really used now.
41
42 Kwargs:
43 - envs (dict) : Dictionary of env variables. This will be used
44 to override the envs set at channel initialization.
45
46 Returns:
47 - retcode : Return code from the execution, -1 on fail
48 - stdout : stdout string
49 - stderr : stderr string
50
51 Raises:
52 None.
53 '''
54 retcode = -1
55 stdout = None
56 stderr = None
57
58 current_env = copy.deepcopy(self._envs)
59 current_env.update(envs)
60
61 try:
62 proc = subprocess.Popen(
63 cmd,
64 stdout=subprocess.PIPE,
65 stderr=subprocess.PIPE,
66 cwd=self.userhome,
67 env=current_env,
68 shell=True,
69 preexec_fn=os.setpgrp
70 )
71 proc.wait(timeout=walltime)
72 stdout = proc.stdout.read()
73 stderr = proc.stderr.read()
74 retcode = proc.returncode
75
76 except Exception as e:
77 logger.warning("Execution of command '{}' failed due to \n{}".format(cmd, e))
78 raise
79
80 return (retcode, stdout.decode("utf-8"), stderr.decode("utf-8"))
81
82 def push_file(self, source, dest_dir):
83 ''' If the source files dirpath is the same as dest_dir, a copy
84 is not necessary, and nothing is done. Else a copy is made.
85
86 Args:
87 - source (string) : Path to the source file
88 - dest_dir (string) : Path to the directory to which the files is to be copied
89
90 Returns:
91 - destination_path (String) : Absolute path of the destination file
92
93 Raises:
94 - FileCopyException : If file copy failed.
95 '''
96
97 local_dest = os.path.join(dest_dir, os.path.basename(source))
98
99 # Only attempt to copy if the target dir and source dir are different
100 if os.path.dirname(source) != dest_dir:
101 try:
102 shutil.copyfile(source, local_dest)
103 os.chmod(local_dest, 0o777)
104
105 except OSError as e:
106 raise FileCopyException(e, self.hostname)
107
108 else:
109 os.chmod(local_dest, 0o777)
110
111 return local_dest
112
113 def pull_file(self, remote_source, local_dir):
114 return self.push_file(remote_source, local_dir)
115
116 def close(self):
117 ''' There's nothing to close here, and this really doesn't do anything
118
119 Returns:
120 - False, because it really did not "close" this channel.
121 '''
122 return False
123
124 def isdir(self, path):
125 """Return true if the path refers to an existing directory.
126
127 Parameters
128 ----------
129 path : str
130 Path of directory to check.
131 """
132
133 return os.path.isdir(path)
134
135 def makedirs(self, path, mode=511, exist_ok=False):
136 """Create a directory.
137
138 If intermediate directories do not exist, they will be created.
139
140 Parameters
141 ----------
142 path : str
143 Path of directory to create.
144 mode : int
145 Permissions (posix-style) for the newly-created directory.
146 exist_ok : bool
147 If False, raise an OSError if the target directory already exists.
148 """
149
150 return os.makedirs(path, mode, exist_ok)
151
152 def abspath(self, path):
153 """Return the absolute path.
154
155 Parameters
156 ----------
157 path : str
158 Path for which the absolute path will be returned.
159 """
160 return os.path.abspath(path)
161
162 @property
163 def script_dir(self):
164 return self._script_dir
165
166 @script_dir.setter
167 def script_dir(self, value):
168 if value is not None:
169 value = self.abspath(value)
170 self._script_dir = value
171
[end of parsl/channels/local/local.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/parsl/channels/local/local.py b/parsl/channels/local/local.py
--- a/parsl/channels/local/local.py
+++ b/parsl/channels/local/local.py
@@ -68,9 +68,7 @@
shell=True,
preexec_fn=os.setpgrp
)
- proc.wait(timeout=walltime)
- stdout = proc.stdout.read()
- stderr = proc.stderr.read()
+ (stdout, stderr) = proc.communicate(timeout=walltime)
retcode = proc.returncode
except Exception as e:
| {"golden_diff": "diff --git a/parsl/channels/local/local.py b/parsl/channels/local/local.py\n--- a/parsl/channels/local/local.py\n+++ b/parsl/channels/local/local.py\n@@ -68,9 +68,7 @@\n shell=True,\n preexec_fn=os.setpgrp\n )\n- proc.wait(timeout=walltime)\n- stdout = proc.stdout.read()\n- stderr = proc.stderr.read()\n+ (stdout, stderr) = proc.communicate(timeout=walltime)\n retcode = proc.returncode\n \n except Exception as e:\n", "issue": "grid engine provider hangs when qstat output is large\n**Describe the bug**\r\n\r\nFrom Quentin Le Boulc'h;\r\n\r\n```\r\nI still have the issue with the qstat command from Parsl which is hitting the 60s timeout. When I have 1000 jobs running every qstat fails, I can see many processes accumulating and Parsl get completely stucked.\r\nI checked I can reproduce the issue by myself running the subprocess command you are using. With several hundreds of jobs running the proc.wait() is waiting forever. However a manual qstat returns the output in less than a second. And after killing the proc.wait() I can check that the stdout is actually here so the command has succeeded.\r\nI can also reproduce the issue with a different command than `qstat`, like a simple script returning several hundreds of lines.\r\nCould you check if there is some issue with your subprocess command?\r\nSee https://docs.python.org/3/library/subprocess.html#popen-objects for instance: \u201cThis will deadlock when using stdout=PIPE or stderr=PIPE and the child process generates enough output to a pipe such that it blocks waiting for the OS pipe buffer to accept more data. Use Popen.communicate() when using pipes to avoid that.\u201d\r\n```\r\n\r\n\r\n**Expected behavior**\r\nThis should not hang\r\n\r\n**Environment**\r\nin2p3, parsl desc branch\n", "before_files": [{"content": "import copy\nimport logging\nimport os\nimport shutil\nimport subprocess\n\nfrom parsl.channels.base import Channel\nfrom parsl.channels.errors import FileCopyException\nfrom parsl.utils import RepresentationMixin\n\nlogger = logging.getLogger(__name__)\n\n\nclass LocalChannel(Channel, RepresentationMixin):\n ''' This is not even really a channel, since opening a local shell is not heavy\n and done so infrequently that they do not need a persistent channel\n '''\n\n def __init__(self, userhome=\".\", envs={}, script_dir=None):\n ''' Initialize the local channel. script_dir is required by set to a default.\n\n KwArgs:\n - userhome (string): (default='.') This is provided as a way to override and set a specific userhome\n - envs (dict) : A dictionary of env variables to be set when launching the shell\n - script_dir (string): Directory to place scripts\n '''\n self.userhome = os.path.abspath(userhome)\n self.hostname = \"localhost\"\n self.envs = envs\n local_env = os.environ.copy()\n self._envs = copy.deepcopy(local_env)\n self._envs.update(envs)\n self.script_dir = script_dir\n\n def execute_wait(self, cmd, walltime=None, envs={}):\n ''' Synchronously execute a commandline string on the shell.\n\n Args:\n - cmd (string) : Commandline string to execute\n - walltime (int) : walltime in seconds, this is not really used now.\n\n Kwargs:\n - envs (dict) : Dictionary of env variables. This will be used\n to override the envs set at channel initialization.\n\n Returns:\n - retcode : Return code from the execution, -1 on fail\n - stdout : stdout string\n - stderr : stderr string\n\n Raises:\n None.\n '''\n retcode = -1\n stdout = None\n stderr = None\n\n current_env = copy.deepcopy(self._envs)\n current_env.update(envs)\n\n try:\n proc = subprocess.Popen(\n cmd,\n stdout=subprocess.PIPE,\n stderr=subprocess.PIPE,\n cwd=self.userhome,\n env=current_env,\n shell=True,\n preexec_fn=os.setpgrp\n )\n proc.wait(timeout=walltime)\n stdout = proc.stdout.read()\n stderr = proc.stderr.read()\n retcode = proc.returncode\n\n except Exception as e:\n logger.warning(\"Execution of command '{}' failed due to \\n{}\".format(cmd, e))\n raise\n\n return (retcode, stdout.decode(\"utf-8\"), stderr.decode(\"utf-8\"))\n\n def push_file(self, source, dest_dir):\n ''' If the source files dirpath is the same as dest_dir, a copy\n is not necessary, and nothing is done. Else a copy is made.\n\n Args:\n - source (string) : Path to the source file\n - dest_dir (string) : Path to the directory to which the files is to be copied\n\n Returns:\n - destination_path (String) : Absolute path of the destination file\n\n Raises:\n - FileCopyException : If file copy failed.\n '''\n\n local_dest = os.path.join(dest_dir, os.path.basename(source))\n\n # Only attempt to copy if the target dir and source dir are different\n if os.path.dirname(source) != dest_dir:\n try:\n shutil.copyfile(source, local_dest)\n os.chmod(local_dest, 0o777)\n\n except OSError as e:\n raise FileCopyException(e, self.hostname)\n\n else:\n os.chmod(local_dest, 0o777)\n\n return local_dest\n\n def pull_file(self, remote_source, local_dir):\n return self.push_file(remote_source, local_dir)\n\n def close(self):\n ''' There's nothing to close here, and this really doesn't do anything\n\n Returns:\n - False, because it really did not \"close\" this channel.\n '''\n return False\n\n def isdir(self, path):\n \"\"\"Return true if the path refers to an existing directory.\n\n Parameters\n ----------\n path : str\n Path of directory to check.\n \"\"\"\n\n return os.path.isdir(path)\n\n def makedirs(self, path, mode=511, exist_ok=False):\n \"\"\"Create a directory.\n\n If intermediate directories do not exist, they will be created.\n\n Parameters\n ----------\n path : str\n Path of directory to create.\n mode : int\n Permissions (posix-style) for the newly-created directory.\n exist_ok : bool\n If False, raise an OSError if the target directory already exists.\n \"\"\"\n\n return os.makedirs(path, mode, exist_ok)\n\n def abspath(self, path):\n \"\"\"Return the absolute path.\n\n Parameters\n ----------\n path : str\n Path for which the absolute path will be returned.\n \"\"\"\n return os.path.abspath(path)\n\n @property\n def script_dir(self):\n return self._script_dir\n\n @script_dir.setter\n def script_dir(self, value):\n if value is not None:\n value = self.abspath(value)\n self._script_dir = value\n", "path": "parsl/channels/local/local.py"}]} | 2,359 | 126 |
gh_patches_debug_14865 | rasdani/github-patches | git_diff | spacetelescope__jwql-419 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Make JWQL pip installable
Currently our `jwql` package is only installable by cloning the repository and running `setup.py`. It would be easier for users (and perhaps easier for us when distributing our code (#294)) if it were also uploaded to PyPI and `pip` installable.
</issue>
<code>
[start of setup.py]
1 import numpy as np
2 from setuptools import setup
3 from setuptools import find_packages
4
5 VERSION = '0.20.0'
6
7 AUTHORS = 'Matthew Bourque, Sara Ogaz, Joe Filippazzo, Bryan Hilbert, Misty Cracraft, '
8 AUTHORS += 'Graham Kanarek, Johannes Sahlmann, Lauren Chambers, Catherine Martlin'
9
10 REQUIRES = [
11 'astropy',
12 'astroquery>=0.3.9',
13 'authlib',
14 'bokeh>=1.0',
15 'django>=2.0',
16 'jinja2',
17 'jwedb',
18 'jwst',
19 'matplotlib',
20 'numpy',
21 'numpydoc',
22 'pandas',
23 'psycopg2',
24 'pysiaf',
25 'pytest',
26 'sphinx',
27 'sqlalchemy',
28 'stsci_rtd_theme'
29 ]
30
31 setup(
32 name='jwql',
33 version=VERSION,
34 description='The JWST Quicklook Project',
35 url='https://github.com/spacetelescope/jwql.git',
36 author=AUTHORS,
37 author_email='[email protected]',
38 license='BSD',
39 keywords=['astronomy', 'python'],
40 classifiers=['Programming Language :: Python'],
41 packages=find_packages(),
42 install_requires=REQUIRES,
43 include_package_data=True,
44 include_dirs=[np.get_include()],
45 )
46
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -4,8 +4,10 @@
VERSION = '0.20.0'
-AUTHORS = 'Matthew Bourque, Sara Ogaz, Joe Filippazzo, Bryan Hilbert, Misty Cracraft, '
-AUTHORS += 'Graham Kanarek, Johannes Sahlmann, Lauren Chambers, Catherine Martlin'
+AUTHORS = 'Matthew Bourque, Lauren Chambers, Misty Cracraft, Joe Filippazzo, Bryan Hilbert, '
+AUTHORS += 'Graham Kanarek, Catherine Martlin, Johannes Sahlmann'
+
+DESCRIPTION = 'The James Webb Space Telescope Quicklook Project'
REQUIRES = [
'astropy',
@@ -31,7 +33,7 @@
setup(
name='jwql',
version=VERSION,
- description='The JWST Quicklook Project',
+ description=DESCRIPTION,
url='https://github.com/spacetelescope/jwql.git',
author=AUTHORS,
author_email='[email protected]',
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -4,8 +4,10 @@\n \n VERSION = '0.20.0'\n \n-AUTHORS = 'Matthew Bourque, Sara Ogaz, Joe Filippazzo, Bryan Hilbert, Misty Cracraft, '\n-AUTHORS += 'Graham Kanarek, Johannes Sahlmann, Lauren Chambers, Catherine Martlin'\n+AUTHORS = 'Matthew Bourque, Lauren Chambers, Misty Cracraft, Joe Filippazzo, Bryan Hilbert, '\n+AUTHORS += 'Graham Kanarek, Catherine Martlin, Johannes Sahlmann'\n+\n+DESCRIPTION = 'The James Webb Space Telescope Quicklook Project'\n \n REQUIRES = [\n 'astropy',\n@@ -31,7 +33,7 @@\n setup(\n name='jwql',\n version=VERSION,\n- description='The JWST Quicklook Project',\n+ description=DESCRIPTION,\n url='https://github.com/spacetelescope/jwql.git',\n author=AUTHORS,\n author_email='[email protected]',\n", "issue": "Make JWQL pip installable\nCurrently our `jwql` package is only installable by cloning the repository and running `setup.py`. It would be easier for users (and perhaps easier for us when distributing our code (#294)) if it were also uploaded to PyPI and `pip` installable. \n", "before_files": [{"content": "import numpy as np\nfrom setuptools import setup\nfrom setuptools import find_packages\n\nVERSION = '0.20.0'\n\nAUTHORS = 'Matthew Bourque, Sara Ogaz, Joe Filippazzo, Bryan Hilbert, Misty Cracraft, '\nAUTHORS += 'Graham Kanarek, Johannes Sahlmann, Lauren Chambers, Catherine Martlin'\n\nREQUIRES = [\n 'astropy',\n 'astroquery>=0.3.9',\n 'authlib',\n 'bokeh>=1.0',\n 'django>=2.0',\n 'jinja2',\n 'jwedb',\n 'jwst',\n 'matplotlib',\n 'numpy',\n 'numpydoc',\n 'pandas',\n 'psycopg2',\n 'pysiaf',\n 'pytest',\n 'sphinx',\n 'sqlalchemy',\n 'stsci_rtd_theme'\n]\n\nsetup(\n name='jwql',\n version=VERSION,\n description='The JWST Quicklook Project',\n url='https://github.com/spacetelescope/jwql.git',\n author=AUTHORS,\n author_email='[email protected]',\n license='BSD',\n keywords=['astronomy', 'python'],\n classifiers=['Programming Language :: Python'],\n packages=find_packages(),\n install_requires=REQUIRES,\n include_package_data=True,\n include_dirs=[np.get_include()],\n)\n", "path": "setup.py"}]} | 978 | 244 |
gh_patches_debug_1991 | rasdani/github-patches | git_diff | pypi__warehouse-3056 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Disable 'delete confirm' button until confirmation word is correct
We currently have a modal on `warehouse/templates/manage/settings.html`, that allows the user to confirm that they want to delete their project:
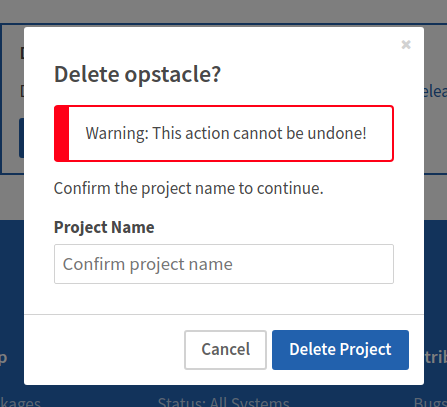
The user is required to enter the project name as an extra security measure. If they get it wrong, we show them this error:

## Proposal
It would be really nice if we could `disable` the delete button until the correct project name is given, e.g.
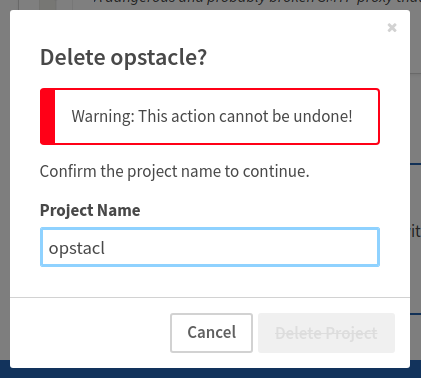
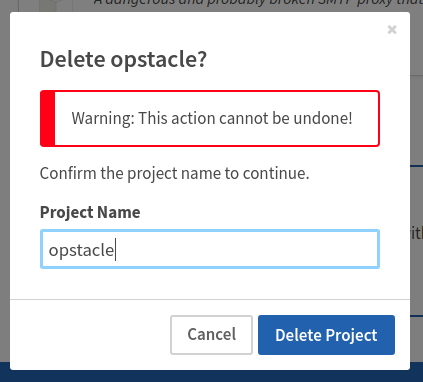
## Notes
We will have several other delete confirmation modals on other pages, sometimes with multiple modals on a single page (e.g. delete release, delete file) - so the code will need to be written to take this into account.
</issue>
<code>
[start of warehouse/utils/project.py]
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 from packaging.utils import canonicalize_name
14 from pyramid.httpexceptions import HTTPSeeOther
15
16 from warehouse.packaging.models import (
17 Release, Dependency, File, Role, JournalEntry, release_classifiers
18 )
19
20
21 def confirm_project(project, request, fail_route):
22 confirm = request.POST.get("confirm")
23 project_name = project.normalized_name
24 if not confirm:
25 request.session.flash(
26 "Must confirm the request.",
27 queue="error",
28 )
29 raise HTTPSeeOther(
30 request.route_path(fail_route, project_name=project_name)
31 )
32 if canonicalize_name(confirm) != project.normalized_name:
33 request.session.flash(
34 "Could not delete project - " +
35 f"{confirm!r} is not the same as {project.normalized_name!r}",
36 queue="error",
37 )
38 raise HTTPSeeOther(
39 request.route_path(fail_route, project_name=project_name)
40 )
41
42
43 def remove_project(project, request, flash=True):
44 # TODO: We don't actually delete files from the data store. We should add
45 # some kind of garbage collection at some point.
46
47 request.db.add(
48 JournalEntry(
49 name=project.name,
50 action="remove",
51 submitted_by=request.user,
52 submitted_from=request.remote_addr,
53 )
54 )
55 request.db.query(Role).filter(Role.project == project).delete()
56 request.db.query(File).filter(File.name == project.name).delete()
57 (request.db.query(Dependency).filter(Dependency.name == project.name)
58 .delete())
59 (request.db.execute(release_classifiers.delete()
60 .where(release_classifiers.c.name ==
61 project.name)))
62
63 # Load the following objects into the session and individually delete them
64 # so they are included in `session.deleted` and their cache keys are purged
65
66 # Delete releases first, otherwise they will get cascade-deleted by the
67 # project deletion and won't be purged
68 for release in (
69 request.db.query(Release)
70 .filter(Release.project == project)
71 .all()):
72 request.db.delete(release)
73
74 # Finally, delete the project
75 request.db.delete(project)
76
77 # Flush so we can repeat this multiple times if necessary
78 request.db.flush()
79
80 if flash:
81 request.session.flash(
82 f"Successfully deleted the project {project.name!r}.",
83 queue="success",
84 )
85
[end of warehouse/utils/project.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/warehouse/utils/project.py b/warehouse/utils/project.py
--- a/warehouse/utils/project.py
+++ b/warehouse/utils/project.py
@@ -19,7 +19,7 @@
def confirm_project(project, request, fail_route):
- confirm = request.POST.get("confirm")
+ confirm = request.POST.get("confirm_project_name")
project_name = project.normalized_name
if not confirm:
request.session.flash(
| {"golden_diff": "diff --git a/warehouse/utils/project.py b/warehouse/utils/project.py\n--- a/warehouse/utils/project.py\n+++ b/warehouse/utils/project.py\n@@ -19,7 +19,7 @@\n \n \n def confirm_project(project, request, fail_route):\n- confirm = request.POST.get(\"confirm\")\n+ confirm = request.POST.get(\"confirm_project_name\")\n project_name = project.normalized_name\n if not confirm:\n request.session.flash(\n", "issue": "Disable 'delete confirm' button until confirmation word is correct\nWe currently have a modal on `warehouse/templates/manage/settings.html`, that allows the user to confirm that they want to delete their project:\r\n\r\n\r\n\r\nThe user is required to enter the project name as an extra security measure. If they get it wrong, we show them this error:\r\n\r\n\r\n\r\n## Proposal\r\n\r\nIt would be really nice if we could `disable` the delete button until the correct project name is given, e.g.\r\n\r\n\r\n\r\n\r\n\r\n## Notes\r\n\r\nWe will have several other delete confirmation modals on other pages, sometimes with multiple modals on a single page (e.g. delete release, delete file) - so the code will need to be written to take this into account.\r\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom packaging.utils import canonicalize_name\nfrom pyramid.httpexceptions import HTTPSeeOther\n\nfrom warehouse.packaging.models import (\n Release, Dependency, File, Role, JournalEntry, release_classifiers\n)\n\n\ndef confirm_project(project, request, fail_route):\n confirm = request.POST.get(\"confirm\")\n project_name = project.normalized_name\n if not confirm:\n request.session.flash(\n \"Must confirm the request.\",\n queue=\"error\",\n )\n raise HTTPSeeOther(\n request.route_path(fail_route, project_name=project_name)\n )\n if canonicalize_name(confirm) != project.normalized_name:\n request.session.flash(\n \"Could not delete project - \" +\n f\"{confirm!r} is not the same as {project.normalized_name!r}\",\n queue=\"error\",\n )\n raise HTTPSeeOther(\n request.route_path(fail_route, project_name=project_name)\n )\n\n\ndef remove_project(project, request, flash=True):\n # TODO: We don't actually delete files from the data store. We should add\n # some kind of garbage collection at some point.\n\n request.db.add(\n JournalEntry(\n name=project.name,\n action=\"remove\",\n submitted_by=request.user,\n submitted_from=request.remote_addr,\n )\n )\n request.db.query(Role).filter(Role.project == project).delete()\n request.db.query(File).filter(File.name == project.name).delete()\n (request.db.query(Dependency).filter(Dependency.name == project.name)\n .delete())\n (request.db.execute(release_classifiers.delete()\n .where(release_classifiers.c.name ==\n project.name)))\n\n # Load the following objects into the session and individually delete them\n # so they are included in `session.deleted` and their cache keys are purged\n\n # Delete releases first, otherwise they will get cascade-deleted by the\n # project deletion and won't be purged\n for release in (\n request.db.query(Release)\n .filter(Release.project == project)\n .all()):\n request.db.delete(release)\n\n # Finally, delete the project\n request.db.delete(project)\n\n # Flush so we can repeat this multiple times if necessary\n request.db.flush()\n\n if flash:\n request.session.flash(\n f\"Successfully deleted the project {project.name!r}.\",\n queue=\"success\",\n )\n", "path": "warehouse/utils/project.py"}]} | 1,795 | 95 |
gh_patches_debug_5915 | rasdani/github-patches | git_diff | tobymao__sqlglot-1540 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
dblink domain throw ParseError for Oracle dialect
If you try to parse the statement below it returns an Invalid expression / unexpected token error
`sql_query = """ SELECT * FROM table_name@dblink_name.database_link_domain;"""
parsed = parse_one(sql_query , read='oracle')`
**Retrieved Error**

Adding DB domain link is optional but some times is needed to specify the complete service name. The syntax is as above
More info here: [Oracle Docs](https://docs.oracle.com/en/database/oracle/oracle-database/19/sqlrf/CREATE-DATABASE-LINK.html#GUID-D966642A-B19E-449D-9968-1121AF06D793)
</issue>
<code>
[start of sqlglot/dialects/oracle.py]
1 from __future__ import annotations
2
3 import typing as t
4
5 from sqlglot import exp, generator, parser, tokens, transforms
6 from sqlglot.dialects.dialect import Dialect, no_ilike_sql, rename_func, trim_sql
7 from sqlglot.helper import seq_get
8 from sqlglot.tokens import TokenType
9
10
11 def _parse_xml_table(self) -> exp.XMLTable:
12 this = self._parse_string()
13
14 passing = None
15 columns = None
16
17 if self._match_text_seq("PASSING"):
18 # The BY VALUE keywords are optional and are provided for semantic clarity
19 self._match_text_seq("BY", "VALUE")
20 passing = self._parse_csv(self._parse_column)
21
22 by_ref = self._match_text_seq("RETURNING", "SEQUENCE", "BY", "REF")
23
24 if self._match_text_seq("COLUMNS"):
25 columns = self._parse_csv(lambda: self._parse_column_def(self._parse_field(any_token=True)))
26
27 return self.expression(
28 exp.XMLTable,
29 this=this,
30 passing=passing,
31 columns=columns,
32 by_ref=by_ref,
33 )
34
35
36 class Oracle(Dialect):
37 # https://docs.oracle.com/database/121/SQLRF/sql_elements004.htm#SQLRF00212
38 # https://docs.python.org/3/library/datetime.html#strftime-and-strptime-format-codes
39 time_mapping = {
40 "AM": "%p", # Meridian indicator with or without periods
41 "A.M.": "%p", # Meridian indicator with or without periods
42 "PM": "%p", # Meridian indicator with or without periods
43 "P.M.": "%p", # Meridian indicator with or without periods
44 "D": "%u", # Day of week (1-7)
45 "DAY": "%A", # name of day
46 "DD": "%d", # day of month (1-31)
47 "DDD": "%j", # day of year (1-366)
48 "DY": "%a", # abbreviated name of day
49 "HH": "%I", # Hour of day (1-12)
50 "HH12": "%I", # alias for HH
51 "HH24": "%H", # Hour of day (0-23)
52 "IW": "%V", # Calendar week of year (1-52 or 1-53), as defined by the ISO 8601 standard
53 "MI": "%M", # Minute (0-59)
54 "MM": "%m", # Month (01-12; January = 01)
55 "MON": "%b", # Abbreviated name of month
56 "MONTH": "%B", # Name of month
57 "SS": "%S", # Second (0-59)
58 "WW": "%W", # Week of year (1-53)
59 "YY": "%y", # 15
60 "YYYY": "%Y", # 2015
61 }
62
63 class Parser(parser.Parser):
64 WINDOW_BEFORE_PAREN_TOKENS = {TokenType.OVER, TokenType.KEEP}
65
66 FUNCTIONS = {
67 **parser.Parser.FUNCTIONS, # type: ignore
68 "SQUARE": lambda args: exp.Pow(this=seq_get(args, 0), expression=exp.Literal.number(2)),
69 }
70
71 FUNCTION_PARSERS: t.Dict[str, t.Callable] = {
72 **parser.Parser.FUNCTION_PARSERS,
73 "XMLTABLE": _parse_xml_table,
74 }
75
76 TYPE_LITERAL_PARSERS = {
77 exp.DataType.Type.DATE: lambda self, this, _: self.expression(
78 exp.DateStrToDate, this=this
79 )
80 }
81
82 def _parse_column(self) -> t.Optional[exp.Expression]:
83 column = super()._parse_column()
84 if column:
85 column.set("join_mark", self._match(TokenType.JOIN_MARKER))
86 return column
87
88 def _parse_hint(self) -> t.Optional[exp.Expression]:
89 if self._match(TokenType.HINT):
90 start = self._curr
91 while self._curr and not self._match_pair(TokenType.STAR, TokenType.SLASH):
92 self._advance()
93
94 if not self._curr:
95 self.raise_error("Expected */ after HINT")
96
97 end = self._tokens[self._index - 3]
98 return exp.Hint(expressions=[self._find_sql(start, end)])
99
100 return None
101
102 class Generator(generator.Generator):
103 LOCKING_READS_SUPPORTED = True
104 JOIN_HINTS = False
105 TABLE_HINTS = False
106
107 TYPE_MAPPING = {
108 **generator.Generator.TYPE_MAPPING, # type: ignore
109 exp.DataType.Type.TINYINT: "NUMBER",
110 exp.DataType.Type.SMALLINT: "NUMBER",
111 exp.DataType.Type.INT: "NUMBER",
112 exp.DataType.Type.BIGINT: "NUMBER",
113 exp.DataType.Type.DECIMAL: "NUMBER",
114 exp.DataType.Type.DOUBLE: "DOUBLE PRECISION",
115 exp.DataType.Type.VARCHAR: "VARCHAR2",
116 exp.DataType.Type.NVARCHAR: "NVARCHAR2",
117 exp.DataType.Type.TEXT: "CLOB",
118 exp.DataType.Type.BINARY: "BLOB",
119 exp.DataType.Type.VARBINARY: "BLOB",
120 }
121
122 TRANSFORMS = {
123 **generator.Generator.TRANSFORMS, # type: ignore
124 exp.DateStrToDate: lambda self, e: self.func(
125 "TO_DATE", e.this, exp.Literal.string("YYYY-MM-DD")
126 ),
127 exp.Group: transforms.preprocess([transforms.unalias_group]),
128 exp.Hint: lambda self, e: f" /*+ {self.expressions(e).strip()} */",
129 exp.ILike: no_ilike_sql,
130 exp.IfNull: rename_func("NVL"),
131 exp.Select: transforms.preprocess([transforms.eliminate_distinct_on]),
132 exp.StrToTime: lambda self, e: f"TO_TIMESTAMP({self.sql(e, 'this')}, {self.format_time(e)})",
133 exp.Subquery: lambda self, e: self.subquery_sql(e, sep=" "),
134 exp.Substring: rename_func("SUBSTR"),
135 exp.Table: lambda self, e: self.table_sql(e, sep=" "),
136 exp.TimeToStr: lambda self, e: f"TO_CHAR({self.sql(e, 'this')}, {self.format_time(e)})",
137 exp.ToChar: lambda self, e: self.function_fallback_sql(e),
138 exp.Trim: trim_sql,
139 exp.UnixToTime: lambda self, e: f"TO_DATE('1970-01-01','YYYY-MM-DD') + ({self.sql(e, 'this')} / 86400)",
140 }
141
142 PROPERTIES_LOCATION = {
143 **generator.Generator.PROPERTIES_LOCATION, # type: ignore
144 exp.VolatileProperty: exp.Properties.Location.UNSUPPORTED,
145 }
146
147 LIMIT_FETCH = "FETCH"
148
149 def offset_sql(self, expression: exp.Offset) -> str:
150 return f"{super().offset_sql(expression)} ROWS"
151
152 def column_sql(self, expression: exp.Column) -> str:
153 column = super().column_sql(expression)
154 return f"{column} (+)" if expression.args.get("join_mark") else column
155
156 def xmltable_sql(self, expression: exp.XMLTable) -> str:
157 this = self.sql(expression, "this")
158 passing = self.expressions(expression, key="passing")
159 passing = f"{self.sep()}PASSING{self.seg(passing)}" if passing else ""
160 columns = self.expressions(expression, key="columns")
161 columns = f"{self.sep()}COLUMNS{self.seg(columns)}" if columns else ""
162 by_ref = (
163 f"{self.sep()}RETURNING SEQUENCE BY REF" if expression.args.get("by_ref") else ""
164 )
165 return f"XMLTABLE({self.sep('')}{self.indent(this + passing + by_ref + columns)}{self.seg(')', sep='')}"
166
167 class Tokenizer(tokens.Tokenizer):
168 KEYWORDS = {
169 **tokens.Tokenizer.KEYWORDS,
170 "(+)": TokenType.JOIN_MARKER,
171 "COLUMNS": TokenType.COLUMN,
172 "MATCH_RECOGNIZE": TokenType.MATCH_RECOGNIZE,
173 "MINUS": TokenType.EXCEPT,
174 "NVARCHAR2": TokenType.NVARCHAR,
175 "RETURNING": TokenType.RETURNING,
176 "START": TokenType.BEGIN,
177 "TOP": TokenType.TOP,
178 "VARCHAR2": TokenType.VARCHAR,
179 }
180
[end of sqlglot/dialects/oracle.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/sqlglot/dialects/oracle.py b/sqlglot/dialects/oracle.py
--- a/sqlglot/dialects/oracle.py
+++ b/sqlglot/dialects/oracle.py
@@ -165,6 +165,8 @@
return f"XMLTABLE({self.sep('')}{self.indent(this + passing + by_ref + columns)}{self.seg(')', sep='')}"
class Tokenizer(tokens.Tokenizer):
+ VAR_SINGLE_TOKENS = {"@"}
+
KEYWORDS = {
**tokens.Tokenizer.KEYWORDS,
"(+)": TokenType.JOIN_MARKER,
| {"golden_diff": "diff --git a/sqlglot/dialects/oracle.py b/sqlglot/dialects/oracle.py\n--- a/sqlglot/dialects/oracle.py\n+++ b/sqlglot/dialects/oracle.py\n@@ -165,6 +165,8 @@\n return f\"XMLTABLE({self.sep('')}{self.indent(this + passing + by_ref + columns)}{self.seg(')', sep='')}\"\n \n class Tokenizer(tokens.Tokenizer):\n+ VAR_SINGLE_TOKENS = {\"@\"}\n+\n KEYWORDS = {\n **tokens.Tokenizer.KEYWORDS,\n \"(+)\": TokenType.JOIN_MARKER,\n", "issue": "dblink domain throw ParseError for Oracle dialect\nIf you try to parse the statement below it returns an Invalid expression / unexpected token error\r\n`sql_query = \"\"\" SELECT * FROM table_name@dblink_name.database_link_domain;\"\"\" \r\nparsed = parse_one(sql_query , read='oracle')`\r\n\r\n**Retrieved Error**\r\n\r\n\r\nAdding DB domain link is optional but some times is needed to specify the complete service name. The syntax is as above\r\nMore info here: [Oracle Docs](https://docs.oracle.com/en/database/oracle/oracle-database/19/sqlrf/CREATE-DATABASE-LINK.html#GUID-D966642A-B19E-449D-9968-1121AF06D793)\n", "before_files": [{"content": "from __future__ import annotations\n\nimport typing as t\n\nfrom sqlglot import exp, generator, parser, tokens, transforms\nfrom sqlglot.dialects.dialect import Dialect, no_ilike_sql, rename_func, trim_sql\nfrom sqlglot.helper import seq_get\nfrom sqlglot.tokens import TokenType\n\n\ndef _parse_xml_table(self) -> exp.XMLTable:\n this = self._parse_string()\n\n passing = None\n columns = None\n\n if self._match_text_seq(\"PASSING\"):\n # The BY VALUE keywords are optional and are provided for semantic clarity\n self._match_text_seq(\"BY\", \"VALUE\")\n passing = self._parse_csv(self._parse_column)\n\n by_ref = self._match_text_seq(\"RETURNING\", \"SEQUENCE\", \"BY\", \"REF\")\n\n if self._match_text_seq(\"COLUMNS\"):\n columns = self._parse_csv(lambda: self._parse_column_def(self._parse_field(any_token=True)))\n\n return self.expression(\n exp.XMLTable,\n this=this,\n passing=passing,\n columns=columns,\n by_ref=by_ref,\n )\n\n\nclass Oracle(Dialect):\n # https://docs.oracle.com/database/121/SQLRF/sql_elements004.htm#SQLRF00212\n # https://docs.python.org/3/library/datetime.html#strftime-and-strptime-format-codes\n time_mapping = {\n \"AM\": \"%p\", # Meridian indicator with or without periods\n \"A.M.\": \"%p\", # Meridian indicator with or without periods\n \"PM\": \"%p\", # Meridian indicator with or without periods\n \"P.M.\": \"%p\", # Meridian indicator with or without periods\n \"D\": \"%u\", # Day of week (1-7)\n \"DAY\": \"%A\", # name of day\n \"DD\": \"%d\", # day of month (1-31)\n \"DDD\": \"%j\", # day of year (1-366)\n \"DY\": \"%a\", # abbreviated name of day\n \"HH\": \"%I\", # Hour of day (1-12)\n \"HH12\": \"%I\", # alias for HH\n \"HH24\": \"%H\", # Hour of day (0-23)\n \"IW\": \"%V\", # Calendar week of year (1-52 or 1-53), as defined by the ISO 8601 standard\n \"MI\": \"%M\", # Minute (0-59)\n \"MM\": \"%m\", # Month (01-12; January = 01)\n \"MON\": \"%b\", # Abbreviated name of month\n \"MONTH\": \"%B\", # Name of month\n \"SS\": \"%S\", # Second (0-59)\n \"WW\": \"%W\", # Week of year (1-53)\n \"YY\": \"%y\", # 15\n \"YYYY\": \"%Y\", # 2015\n }\n\n class Parser(parser.Parser):\n WINDOW_BEFORE_PAREN_TOKENS = {TokenType.OVER, TokenType.KEEP}\n\n FUNCTIONS = {\n **parser.Parser.FUNCTIONS, # type: ignore\n \"SQUARE\": lambda args: exp.Pow(this=seq_get(args, 0), expression=exp.Literal.number(2)),\n }\n\n FUNCTION_PARSERS: t.Dict[str, t.Callable] = {\n **parser.Parser.FUNCTION_PARSERS,\n \"XMLTABLE\": _parse_xml_table,\n }\n\n TYPE_LITERAL_PARSERS = {\n exp.DataType.Type.DATE: lambda self, this, _: self.expression(\n exp.DateStrToDate, this=this\n )\n }\n\n def _parse_column(self) -> t.Optional[exp.Expression]:\n column = super()._parse_column()\n if column:\n column.set(\"join_mark\", self._match(TokenType.JOIN_MARKER))\n return column\n\n def _parse_hint(self) -> t.Optional[exp.Expression]:\n if self._match(TokenType.HINT):\n start = self._curr\n while self._curr and not self._match_pair(TokenType.STAR, TokenType.SLASH):\n self._advance()\n\n if not self._curr:\n self.raise_error(\"Expected */ after HINT\")\n\n end = self._tokens[self._index - 3]\n return exp.Hint(expressions=[self._find_sql(start, end)])\n\n return None\n\n class Generator(generator.Generator):\n LOCKING_READS_SUPPORTED = True\n JOIN_HINTS = False\n TABLE_HINTS = False\n\n TYPE_MAPPING = {\n **generator.Generator.TYPE_MAPPING, # type: ignore\n exp.DataType.Type.TINYINT: \"NUMBER\",\n exp.DataType.Type.SMALLINT: \"NUMBER\",\n exp.DataType.Type.INT: \"NUMBER\",\n exp.DataType.Type.BIGINT: \"NUMBER\",\n exp.DataType.Type.DECIMAL: \"NUMBER\",\n exp.DataType.Type.DOUBLE: \"DOUBLE PRECISION\",\n exp.DataType.Type.VARCHAR: \"VARCHAR2\",\n exp.DataType.Type.NVARCHAR: \"NVARCHAR2\",\n exp.DataType.Type.TEXT: \"CLOB\",\n exp.DataType.Type.BINARY: \"BLOB\",\n exp.DataType.Type.VARBINARY: \"BLOB\",\n }\n\n TRANSFORMS = {\n **generator.Generator.TRANSFORMS, # type: ignore\n exp.DateStrToDate: lambda self, e: self.func(\n \"TO_DATE\", e.this, exp.Literal.string(\"YYYY-MM-DD\")\n ),\n exp.Group: transforms.preprocess([transforms.unalias_group]),\n exp.Hint: lambda self, e: f\" /*+ {self.expressions(e).strip()} */\",\n exp.ILike: no_ilike_sql,\n exp.IfNull: rename_func(\"NVL\"),\n exp.Select: transforms.preprocess([transforms.eliminate_distinct_on]),\n exp.StrToTime: lambda self, e: f\"TO_TIMESTAMP({self.sql(e, 'this')}, {self.format_time(e)})\",\n exp.Subquery: lambda self, e: self.subquery_sql(e, sep=\" \"),\n exp.Substring: rename_func(\"SUBSTR\"),\n exp.Table: lambda self, e: self.table_sql(e, sep=\" \"),\n exp.TimeToStr: lambda self, e: f\"TO_CHAR({self.sql(e, 'this')}, {self.format_time(e)})\",\n exp.ToChar: lambda self, e: self.function_fallback_sql(e),\n exp.Trim: trim_sql,\n exp.UnixToTime: lambda self, e: f\"TO_DATE('1970-01-01','YYYY-MM-DD') + ({self.sql(e, 'this')} / 86400)\",\n }\n\n PROPERTIES_LOCATION = {\n **generator.Generator.PROPERTIES_LOCATION, # type: ignore\n exp.VolatileProperty: exp.Properties.Location.UNSUPPORTED,\n }\n\n LIMIT_FETCH = \"FETCH\"\n\n def offset_sql(self, expression: exp.Offset) -> str:\n return f\"{super().offset_sql(expression)} ROWS\"\n\n def column_sql(self, expression: exp.Column) -> str:\n column = super().column_sql(expression)\n return f\"{column} (+)\" if expression.args.get(\"join_mark\") else column\n\n def xmltable_sql(self, expression: exp.XMLTable) -> str:\n this = self.sql(expression, \"this\")\n passing = self.expressions(expression, key=\"passing\")\n passing = f\"{self.sep()}PASSING{self.seg(passing)}\" if passing else \"\"\n columns = self.expressions(expression, key=\"columns\")\n columns = f\"{self.sep()}COLUMNS{self.seg(columns)}\" if columns else \"\"\n by_ref = (\n f\"{self.sep()}RETURNING SEQUENCE BY REF\" if expression.args.get(\"by_ref\") else \"\"\n )\n return f\"XMLTABLE({self.sep('')}{self.indent(this + passing + by_ref + columns)}{self.seg(')', sep='')}\"\n\n class Tokenizer(tokens.Tokenizer):\n KEYWORDS = {\n **tokens.Tokenizer.KEYWORDS,\n \"(+)\": TokenType.JOIN_MARKER,\n \"COLUMNS\": TokenType.COLUMN,\n \"MATCH_RECOGNIZE\": TokenType.MATCH_RECOGNIZE,\n \"MINUS\": TokenType.EXCEPT,\n \"NVARCHAR2\": TokenType.NVARCHAR,\n \"RETURNING\": TokenType.RETURNING,\n \"START\": TokenType.BEGIN,\n \"TOP\": TokenType.TOP,\n \"VARCHAR2\": TokenType.VARCHAR,\n }\n", "path": "sqlglot/dialects/oracle.py"}]} | 3,064 | 137 |
gh_patches_debug_12284 | rasdani/github-patches | git_diff | aws-cloudformation__cfn-lint-1185 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cors in serverless transform trips error
*cfn-lint version: 0.24.8
*Description of issue.*
Attempting to use CORS in API resource causes error.
E0001 Error transforming template: Resource with id [myserviceAwsUserApi] is invalid. Cors works only with inline Swagger specified in 'DefinitionBody' property
template_clean.yaml:1:1
Commenting out the Cors on lines 141-143 removes the problem:
[myservice_clean.yaml.txt](https://github.com/aws-cloudformation/cfn-python-lint/files/3816455/myservice_clean.yaml.txt)
</issue>
<code>
[start of src/cfnlint/transform.py]
1 """
2 Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.
3
4 Permission is hereby granted, free of charge, to any person obtaining a copy of this
5 software and associated documentation files (the "Software"), to deal in the Software
6 without restriction, including without limitation the rights to use, copy, modify,
7 merge, publish, distribute, sublicense, and/or sell copies of the Software, and to
8 permit persons to whom the Software is furnished to do so.
9
10 THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
11 INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
12 PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
13 HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
14 OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
15 SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
16 """
17 import os
18 import logging
19 import six
20 import samtranslator
21 from samtranslator.parser import parser
22 from samtranslator.translator.translator import Translator
23 from samtranslator.public.exceptions import InvalidDocumentException
24
25 from cfnlint.helpers import load_resources, convert_dict, format_json_string
26 from cfnlint.rules import Match, TransformError
27 LOGGER = logging.getLogger('cfnlint')
28
29
30 class Transform(object):
31 """
32 Application Serverless Module tranform Wrappor.
33 Based on code from AWS SAM CLI:
34 https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/commands/validate/lib/sam_template_validator.py
35 """
36
37 def __init__(self, filename, template, region):
38 """
39 Initialize Transform class
40 """
41 self._filename = filename
42 self._template = template
43 self._region = region
44 self._parameters = {}
45
46 self._managed_policy_map = self.load_managed_policies()
47 self._sam_parser = parser.Parser()
48
49 def template(self):
50 """Get the template"""
51 return self._template
52
53 def load_managed_policies(self):
54 """
55 Load the ManagedPolicies locally, based on the AWS-CLI:
56 https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/lib/samlib/default_managed_policies.json
57 """
58 return load_resources('data/Serverless/ManagedPolicies.json')
59
60 def _replace_local_codeuri(self):
61 """
62 Replaces the CodeUri in AWS::Serverless::Function and DefinitionUri in
63 AWS::Serverless::Api to a fake S3 Uri. This is to support running the
64 SAM Translator with valid values for these fields. If this in not done,
65 the template is invalid in the eyes of SAM Translator (the translator
66 does not support local paths)
67 """
68
69 all_resources = self._template.get('Resources', {})
70
71 for _, resource in all_resources.items():
72
73 resource_type = resource.get('Type')
74 resource_dict = resource.get('Properties')
75
76 if resource_type == 'AWS::Serverless::Function':
77
78 Transform._update_to_s3_uri('CodeUri', resource_dict)
79 auto_publish_alias = resource_dict.get('AutoPublishAlias')
80 if isinstance(auto_publish_alias, dict):
81 if len(auto_publish_alias) == 1:
82 for k, v in auto_publish_alias.items():
83 if k == 'Ref':
84 if v in self._template.get('Parameters'):
85 self._parameters[v] = 'Alias'
86 if resource_type in ['AWS::Serverless::LayerVersion']:
87 if resource_dict.get('ContentUri'):
88 Transform._update_to_s3_uri('ContentUri', resource_dict)
89 if resource_type == 'AWS::Serverless::Application':
90 if resource_dict.get('Location'):
91 resource_dict['Location'] = ''
92 Transform._update_to_s3_uri('Location', resource_dict)
93 if resource_type == 'AWS::Serverless::Api':
94 if ('DefinitionBody' not in resource_dict and
95 'Auth' not in resource_dict):
96 Transform._update_to_s3_uri('DefinitionUri', resource_dict)
97 else:
98 resource_dict['DefinitionBody'] = ''
99
100 def transform_template(self):
101 """
102 Transform the Template using the Serverless Application Model.
103 """
104 matches = []
105
106 try:
107 # Output the SAM Translator version in debug mode
108 LOGGER.info('SAM Translator: %s', samtranslator.__version__)
109
110 sam_translator = Translator(
111 managed_policy_map=self._managed_policy_map,
112 sam_parser=self._sam_parser)
113
114 self._replace_local_codeuri()
115
116 # Tell SAM to use the region we're linting in, this has to be
117 # controlled using the default AWS mechanisms, see also:
118 # https://github.com/awslabs/serverless-application-model/blob/master/samtranslator/translator/arn_generator.py
119 LOGGER.info('Setting AWS_DEFAULT_REGION to %s', self._region)
120 os.environ['AWS_DEFAULT_REGION'] = self._region
121
122 self._template = convert_dict(
123 sam_translator.translate(sam_template=self._template,
124 parameter_values=self._parameters))
125
126 LOGGER.info('Transformed template: \n%s',
127 format_json_string(self._template))
128 except InvalidDocumentException as e:
129 message = 'Error transforming template: {0}'
130 for cause in e.causes:
131 matches.append(Match(
132 1, 1,
133 1, 1,
134 self._filename,
135 TransformError(), message.format(cause.message)))
136 except Exception as e: # pylint: disable=W0703
137 LOGGER.debug('Error transforming template: %s', str(e))
138 LOGGER.debug('Stack trace: %s', e, exc_info=True)
139 message = 'Error transforming template: {0}'
140 matches.append(Match(
141 1, 1,
142 1, 1,
143 self._filename,
144 TransformError(), message.format(str(e))))
145
146 return matches
147
148 @staticmethod
149 def is_s3_uri(uri):
150 """
151 Checks the uri and determines if it is a valid S3 Uri
152 Parameters
153 ----------
154 uri str, required
155 Uri to check
156 Returns
157 -------
158 bool
159 Returns True if the uri given is an S3 uri, otherwise False
160 """
161 return isinstance(uri, six.string_types) and uri.startswith('s3://')
162
163 @staticmethod
164 def _update_to_s3_uri(
165 property_key, resource_property_dict,
166 s3_uri_value='s3://bucket/value'):
167 """
168 Updates the 'property_key' in the 'resource_property_dict' to the
169 value of 's3_uri_value'
170 Note: The function will mutate the resource_property_dict that is pass
171 in Parameters
172 ----------
173 property_key str, required
174 Key in the resource_property_dict
175 resource_property_dict dict, required
176 Property dictionary of a Resource in the template to replace
177 s3_uri_value str, optional
178 Value to update the value of the property_key to
179 """
180 uri_property = resource_property_dict.get(property_key, '.')
181
182 # ignore if dict or already an S3 Uri
183 if isinstance(uri_property, dict) or Transform.is_s3_uri(uri_property):
184 return
185
186 resource_property_dict[property_key] = s3_uri_value
187
[end of src/cfnlint/transform.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/src/cfnlint/transform.py b/src/cfnlint/transform.py
--- a/src/cfnlint/transform.py
+++ b/src/cfnlint/transform.py
@@ -92,7 +92,7 @@
Transform._update_to_s3_uri('Location', resource_dict)
if resource_type == 'AWS::Serverless::Api':
if ('DefinitionBody' not in resource_dict and
- 'Auth' not in resource_dict):
+ 'Auth' not in resource_dict and 'Cors' not in resource_dict):
Transform._update_to_s3_uri('DefinitionUri', resource_dict)
else:
resource_dict['DefinitionBody'] = ''
| {"golden_diff": "diff --git a/src/cfnlint/transform.py b/src/cfnlint/transform.py\n--- a/src/cfnlint/transform.py\n+++ b/src/cfnlint/transform.py\n@@ -92,7 +92,7 @@\n Transform._update_to_s3_uri('Location', resource_dict)\n if resource_type == 'AWS::Serverless::Api':\n if ('DefinitionBody' not in resource_dict and\n- 'Auth' not in resource_dict):\n+ 'Auth' not in resource_dict and 'Cors' not in resource_dict):\n Transform._update_to_s3_uri('DefinitionUri', resource_dict)\n else:\n resource_dict['DefinitionBody'] = ''\n", "issue": "Cors in serverless transform trips error \n*cfn-lint version: 0.24.8\r\n\r\n*Description of issue.*\r\nAttempting to use CORS in API resource causes error.\r\n\r\nE0001 Error transforming template: Resource with id [myserviceAwsUserApi] is invalid. Cors works only with inline Swagger specified in 'DefinitionBody' property\r\ntemplate_clean.yaml:1:1\r\n\r\nCommenting out the Cors on lines 141-143 removes the problem:\r\n\r\n\r\n\r\n[myservice_clean.yaml.txt](https://github.com/aws-cloudformation/cfn-python-lint/files/3816455/myservice_clean.yaml.txt)\r\n\n", "before_files": [{"content": "\"\"\"\n Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n\n Permission is hereby granted, free of charge, to any person obtaining a copy of this\n software and associated documentation files (the \"Software\"), to deal in the Software\n without restriction, including without limitation the rights to use, copy, modify,\n merge, publish, distribute, sublicense, and/or sell copies of the Software, and to\n permit persons to whom the Software is furnished to do so.\n\n THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,\n INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A\n PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\n HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION\n OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\"\"\"\nimport os\nimport logging\nimport six\nimport samtranslator\nfrom samtranslator.parser import parser\nfrom samtranslator.translator.translator import Translator\nfrom samtranslator.public.exceptions import InvalidDocumentException\n\nfrom cfnlint.helpers import load_resources, convert_dict, format_json_string\nfrom cfnlint.rules import Match, TransformError\nLOGGER = logging.getLogger('cfnlint')\n\n\nclass Transform(object):\n \"\"\"\n Application Serverless Module tranform Wrappor.\n Based on code from AWS SAM CLI:\n https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/commands/validate/lib/sam_template_validator.py\n \"\"\"\n\n def __init__(self, filename, template, region):\n \"\"\"\n Initialize Transform class\n \"\"\"\n self._filename = filename\n self._template = template\n self._region = region\n self._parameters = {}\n\n self._managed_policy_map = self.load_managed_policies()\n self._sam_parser = parser.Parser()\n\n def template(self):\n \"\"\"Get the template\"\"\"\n return self._template\n\n def load_managed_policies(self):\n \"\"\"\n Load the ManagedPolicies locally, based on the AWS-CLI:\n https://github.com/awslabs/aws-sam-cli/blob/develop/samcli/lib/samlib/default_managed_policies.json\n \"\"\"\n return load_resources('data/Serverless/ManagedPolicies.json')\n\n def _replace_local_codeuri(self):\n \"\"\"\n Replaces the CodeUri in AWS::Serverless::Function and DefinitionUri in\n AWS::Serverless::Api to a fake S3 Uri. This is to support running the\n SAM Translator with valid values for these fields. If this in not done,\n the template is invalid in the eyes of SAM Translator (the translator\n does not support local paths)\n \"\"\"\n\n all_resources = self._template.get('Resources', {})\n\n for _, resource in all_resources.items():\n\n resource_type = resource.get('Type')\n resource_dict = resource.get('Properties')\n\n if resource_type == 'AWS::Serverless::Function':\n\n Transform._update_to_s3_uri('CodeUri', resource_dict)\n auto_publish_alias = resource_dict.get('AutoPublishAlias')\n if isinstance(auto_publish_alias, dict):\n if len(auto_publish_alias) == 1:\n for k, v in auto_publish_alias.items():\n if k == 'Ref':\n if v in self._template.get('Parameters'):\n self._parameters[v] = 'Alias'\n if resource_type in ['AWS::Serverless::LayerVersion']:\n if resource_dict.get('ContentUri'):\n Transform._update_to_s3_uri('ContentUri', resource_dict)\n if resource_type == 'AWS::Serverless::Application':\n if resource_dict.get('Location'):\n resource_dict['Location'] = ''\n Transform._update_to_s3_uri('Location', resource_dict)\n if resource_type == 'AWS::Serverless::Api':\n if ('DefinitionBody' not in resource_dict and\n 'Auth' not in resource_dict):\n Transform._update_to_s3_uri('DefinitionUri', resource_dict)\n else:\n resource_dict['DefinitionBody'] = ''\n\n def transform_template(self):\n \"\"\"\n Transform the Template using the Serverless Application Model.\n \"\"\"\n matches = []\n\n try:\n # Output the SAM Translator version in debug mode\n LOGGER.info('SAM Translator: %s', samtranslator.__version__)\n\n sam_translator = Translator(\n managed_policy_map=self._managed_policy_map,\n sam_parser=self._sam_parser)\n\n self._replace_local_codeuri()\n\n # Tell SAM to use the region we're linting in, this has to be\n # controlled using the default AWS mechanisms, see also:\n # https://github.com/awslabs/serverless-application-model/blob/master/samtranslator/translator/arn_generator.py\n LOGGER.info('Setting AWS_DEFAULT_REGION to %s', self._region)\n os.environ['AWS_DEFAULT_REGION'] = self._region\n\n self._template = convert_dict(\n sam_translator.translate(sam_template=self._template,\n parameter_values=self._parameters))\n\n LOGGER.info('Transformed template: \\n%s',\n format_json_string(self._template))\n except InvalidDocumentException as e:\n message = 'Error transforming template: {0}'\n for cause in e.causes:\n matches.append(Match(\n 1, 1,\n 1, 1,\n self._filename,\n TransformError(), message.format(cause.message)))\n except Exception as e: # pylint: disable=W0703\n LOGGER.debug('Error transforming template: %s', str(e))\n LOGGER.debug('Stack trace: %s', e, exc_info=True)\n message = 'Error transforming template: {0}'\n matches.append(Match(\n 1, 1,\n 1, 1,\n self._filename,\n TransformError(), message.format(str(e))))\n\n return matches\n\n @staticmethod\n def is_s3_uri(uri):\n \"\"\"\n Checks the uri and determines if it is a valid S3 Uri\n Parameters\n ----------\n uri str, required\n Uri to check\n Returns\n -------\n bool\n Returns True if the uri given is an S3 uri, otherwise False\n \"\"\"\n return isinstance(uri, six.string_types) and uri.startswith('s3://')\n\n @staticmethod\n def _update_to_s3_uri(\n property_key, resource_property_dict,\n s3_uri_value='s3://bucket/value'):\n \"\"\"\n Updates the 'property_key' in the 'resource_property_dict' to the\n value of 's3_uri_value'\n Note: The function will mutate the resource_property_dict that is pass\n in Parameters\n ----------\n property_key str, required\n Key in the resource_property_dict\n resource_property_dict dict, required\n Property dictionary of a Resource in the template to replace\n s3_uri_value str, optional\n Value to update the value of the property_key to\n \"\"\"\n uri_property = resource_property_dict.get(property_key, '.')\n\n # ignore if dict or already an S3 Uri\n if isinstance(uri_property, dict) or Transform.is_s3_uri(uri_property):\n return\n\n resource_property_dict[property_key] = s3_uri_value\n", "path": "src/cfnlint/transform.py"}]} | 2,691 | 146 |
gh_patches_debug_26857 | rasdani/github-patches | git_diff | team-ocean__veros-272 | You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Compute initial streamfunction from initial velocity
Not knowing the numerics, and possibly not reading the docs carefully enough, it is unclear to me how to initialize the velocities in the model.
For a channel run, re-entrant in x, with intial velocity 0.1 m/s everywhere, no forcing, I tried do in `set_initial_conditions`: `s.u = update(vs.u, at[...], 0.1 * vs.maskU[..., None])`.
The velocity signal only lasts for one time step, and then it is gone. It _does_ create a small pressure perturbations that drive internal waves, but the mean flow of 0.1 m/s is immediately gone. Conversely, the initial conditions have psi=0 everywhere, and then immediately on the next time step there is a stream function, but if the units are really m^3/s it is far too small.
Was I to initialize psi at the beginning instead of u, or in addition to u?
</issue>
<code>
[start of veros/core/external/streamfunction_init.py]
1 from veros import logger, veros_kernel, veros_routine, KernelOutput
2 from veros.variables import allocate
3 from veros.distributed import global_max
4 from veros.core import utilities as mainutils
5 from veros.core.operators import numpy as npx, update, at
6 from veros.core.external import island, line_integrals
7 from veros.core.external.solvers import get_linear_solver
8
9
10 @veros_routine
11 def get_isleperim(state):
12 """
13 preprocess land map using MOMs algorithm for B-grid to determine number of islands
14 """
15 from veros.state import resize_dimension
16
17 vs = state.variables
18
19 island.isleperim(state)
20
21 # now that we know the number of islands we can resize
22 # all arrays depending on that
23 nisle = int(global_max(npx.max(vs.land_map)))
24 resize_dimension(state, "isle", nisle)
25 vs.isle = npx.arange(nisle)
26
27
28 @veros_routine
29 def streamfunction_init(state):
30 """
31 prepare for island integrals
32 """
33 vs = state.variables
34 settings = state.settings
35
36 logger.info("Initializing streamfunction method")
37
38 get_isleperim(state)
39
40 vs.update(boundary_masks(state))
41
42 # populate linear solver cache
43 linear_solver = get_linear_solver(state)
44
45 """
46 precalculate time independent boundary components of streamfunction
47 """
48 forc = allocate(state.dimensions, ("xt", "yt"))
49
50 vs.psin = update(vs.psin, at[...], vs.maskZ[..., -1, npx.newaxis])
51
52 for isle in range(state.dimensions["isle"]):
53 logger.info(f" Solving for boundary contribution by island {isle:d}")
54 isle_boundary = (
55 vs.line_dir_east_mask[..., isle]
56 | vs.line_dir_west_mask[..., isle]
57 | vs.line_dir_north_mask[..., isle]
58 | vs.line_dir_south_mask[..., isle]
59 )
60 isle_sol = linear_solver.solve(state, forc, vs.psin[:, :, isle], boundary_val=isle_boundary)
61 vs.psin = update(vs.psin, at[:, :, isle], isle_sol)
62
63 vs.psin = mainutils.enforce_boundaries(vs.psin, settings.enable_cyclic_x)
64
65 line_psin_out = island_integrals(state)
66 vs.update(line_psin_out)
67
68
69 @veros_kernel
70 def island_integrals(state):
71 """
72 precalculate time independent island integrals
73 """
74 vs = state.variables
75
76 uloc = allocate(state.dimensions, ("xt", "yt", "isle"))
77 vloc = allocate(state.dimensions, ("xt", "yt", "isle"))
78
79 uloc = update(
80 uloc,
81 at[1:, 1:, :],
82 -(vs.psin[1:, 1:, :] - vs.psin[1:, :-1, :])
83 * vs.maskU[1:, 1:, -1, npx.newaxis]
84 / vs.dyt[npx.newaxis, 1:, npx.newaxis]
85 * vs.hur[1:, 1:, npx.newaxis],
86 )
87
88 vloc = update(
89 vloc,
90 at[1:, 1:, ...],
91 (vs.psin[1:, 1:, :] - vs.psin[:-1, 1:, :])
92 * vs.maskV[1:, 1:, -1, npx.newaxis]
93 / (vs.cosu[npx.newaxis, 1:, npx.newaxis] * vs.dxt[1:, npx.newaxis, npx.newaxis])
94 * vs.hvr[1:, 1:, npx.newaxis],
95 )
96
97 vs.line_psin = line_integrals.line_integrals(state, uloc=uloc, vloc=vloc, kind="full")
98 return KernelOutput(line_psin=vs.line_psin)
99
100
101 @veros_kernel
102 def boundary_masks(state):
103 """
104 now that the number of islands is known we can allocate the rest of the variables
105 """
106 vs = state.variables
107 settings = state.settings
108
109 boundary_map = vs.land_map[..., npx.newaxis] == npx.arange(1, state.dimensions["isle"] + 1)
110
111 if settings.enable_cyclic_x:
112 vs.line_dir_east_mask = update(
113 vs.line_dir_east_mask, at[2:-2, 1:-1], boundary_map[3:-1, 1:-1] & ~boundary_map[3:-1, 2:]
114 )
115 vs.line_dir_west_mask = update(
116 vs.line_dir_west_mask, at[2:-2, 1:-1], boundary_map[2:-2, 2:] & ~boundary_map[2:-2, 1:-1]
117 )
118 vs.line_dir_south_mask = update(
119 vs.line_dir_south_mask, at[2:-2, 1:-1], boundary_map[2:-2, 1:-1] & ~boundary_map[3:-1, 1:-1]
120 )
121 vs.line_dir_north_mask = update(
122 vs.line_dir_north_mask, at[2:-2, 1:-1], boundary_map[3:-1, 2:] & ~boundary_map[2:-2, 2:]
123 )
124 else:
125 vs.line_dir_east_mask = update(
126 vs.line_dir_east_mask, at[1:-1, 1:-1], boundary_map[2:, 1:-1] & ~boundary_map[2:, 2:]
127 )
128 vs.line_dir_west_mask = update(
129 vs.line_dir_west_mask, at[1:-1, 1:-1], boundary_map[1:-1, 2:] & ~boundary_map[1:-1, 1:-1]
130 )
131 vs.line_dir_south_mask = update(
132 vs.line_dir_south_mask, at[1:-1, 1:-1], boundary_map[1:-1, 1:-1] & ~boundary_map[2:, 1:-1]
133 )
134 vs.line_dir_north_mask = update(
135 vs.line_dir_north_mask, at[1:-1, 1:-1], boundary_map[2:, 2:] & ~boundary_map[1:-1, 2:]
136 )
137
138 vs.isle_boundary_mask = ~npx.any(
139 vs.line_dir_east_mask | vs.line_dir_west_mask | vs.line_dir_south_mask | vs.line_dir_north_mask, axis=2
140 )
141
142 return KernelOutput(
143 isle_boundary_mask=vs.isle_boundary_mask,
144 line_dir_east_mask=vs.line_dir_east_mask,
145 line_dir_west_mask=vs.line_dir_west_mask,
146 line_dir_south_mask=vs.line_dir_south_mask,
147 line_dir_north_mask=vs.line_dir_north_mask,
148 )
149
[end of veros/core/external/streamfunction_init.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch> | diff --git a/veros/core/external/streamfunction_init.py b/veros/core/external/streamfunction_init.py
--- a/veros/core/external/streamfunction_init.py
+++ b/veros/core/external/streamfunction_init.py
@@ -3,7 +3,7 @@
from veros.distributed import global_max
from veros.core import utilities as mainutils
from veros.core.operators import numpy as npx, update, at
-from veros.core.external import island, line_integrals
+from veros.core.external import island, line_integrals, solve_stream
from veros.core.external.solvers import get_linear_solver
@@ -65,6 +65,29 @@
line_psin_out = island_integrals(state)
vs.update(line_psin_out)
+ """
+ take care of initial velocity
+ """
+
+ # transfer initial velocity to tendency
+ vs.du = update(vs.du, at[..., vs.tau], vs.u[..., vs.tau] / settings.dt_mom / (1.5 + settings.AB_eps))
+ vs.dv = update(vs.dv, at[..., vs.tau], vs.v[..., vs.tau] / settings.dt_mom / (1.5 + settings.AB_eps))
+ vs.u = update(vs.u, at[...], 0)
+ vs.v = update(vs.v, at[...], 0)
+
+ # run streamfunction solver to determine initial barotropic and baroclinic modes
+ solve_stream.solve_streamfunction(state)
+
+ vs.psi = update(vs.psi, at[...], vs.psi[..., vs.taup1, npx.newaxis])
+ vs.u = update(
+ vs.u, at[...], mainutils.enforce_boundaries(vs.u[..., vs.taup1, npx.newaxis], settings.enable_cyclic_x)
+ )
+ vs.v = update(
+ vs.v, at[...], mainutils.enforce_boundaries(vs.v[..., vs.taup1, npx.newaxis], settings.enable_cyclic_x)
+ )
+ vs.du = update(vs.du, at[..., vs.tau], 0)
+ vs.dv = update(vs.dv, at[..., vs.tau], 0)
+
@veros_kernel
def island_integrals(state):
| {"golden_diff": "diff --git a/veros/core/external/streamfunction_init.py b/veros/core/external/streamfunction_init.py\n--- a/veros/core/external/streamfunction_init.py\n+++ b/veros/core/external/streamfunction_init.py\n@@ -3,7 +3,7 @@\n from veros.distributed import global_max\n from veros.core import utilities as mainutils\n from veros.core.operators import numpy as npx, update, at\n-from veros.core.external import island, line_integrals\n+from veros.core.external import island, line_integrals, solve_stream\n from veros.core.external.solvers import get_linear_solver\n \n \n@@ -65,6 +65,29 @@\n line_psin_out = island_integrals(state)\n vs.update(line_psin_out)\n \n+ \"\"\"\n+ take care of initial velocity\n+ \"\"\"\n+\n+ # transfer initial velocity to tendency\n+ vs.du = update(vs.du, at[..., vs.tau], vs.u[..., vs.tau] / settings.dt_mom / (1.5 + settings.AB_eps))\n+ vs.dv = update(vs.dv, at[..., vs.tau], vs.v[..., vs.tau] / settings.dt_mom / (1.5 + settings.AB_eps))\n+ vs.u = update(vs.u, at[...], 0)\n+ vs.v = update(vs.v, at[...], 0)\n+\n+ # run streamfunction solver to determine initial barotropic and baroclinic modes\n+ solve_stream.solve_streamfunction(state)\n+\n+ vs.psi = update(vs.psi, at[...], vs.psi[..., vs.taup1, npx.newaxis])\n+ vs.u = update(\n+ vs.u, at[...], mainutils.enforce_boundaries(vs.u[..., vs.taup1, npx.newaxis], settings.enable_cyclic_x)\n+ )\n+ vs.v = update(\n+ vs.v, at[...], mainutils.enforce_boundaries(vs.v[..., vs.taup1, npx.newaxis], settings.enable_cyclic_x)\n+ )\n+ vs.du = update(vs.du, at[..., vs.tau], 0)\n+ vs.dv = update(vs.dv, at[..., vs.tau], 0)\n+\n \n @veros_kernel\n def island_integrals(state):\n", "issue": "Compute initial streamfunction from initial velocity\nNot knowing the numerics, and possibly not reading the docs carefully enough, it is unclear to me how to initialize the velocities in the model. \r\n\r\nFor a channel run, re-entrant in x, with intial velocity 0.1 m/s everywhere, no forcing, I tried do in `set_initial_conditions`: `s.u = update(vs.u, at[...], 0.1 * vs.maskU[..., None])`. \r\n\r\nThe velocity signal only lasts for one time step, and then it is gone. It _does_ create a small pressure perturbations that drive internal waves, but the mean flow of 0.1 m/s is immediately gone. Conversely, the initial conditions have psi=0 everywhere, and then immediately on the next time step there is a stream function, but if the units are really m^3/s it is far too small. \r\n\r\nWas I to initialize psi at the beginning instead of u, or in addition to u? \n", "before_files": [{"content": "from veros import logger, veros_kernel, veros_routine, KernelOutput\nfrom veros.variables import allocate\nfrom veros.distributed import global_max\nfrom veros.core import utilities as mainutils\nfrom veros.core.operators import numpy as npx, update, at\nfrom veros.core.external import island, line_integrals\nfrom veros.core.external.solvers import get_linear_solver\n\n\n@veros_routine\ndef get_isleperim(state):\n \"\"\"\n preprocess land map using MOMs algorithm for B-grid to determine number of islands\n \"\"\"\n from veros.state import resize_dimension\n\n vs = state.variables\n\n island.isleperim(state)\n\n # now that we know the number of islands we can resize\n # all arrays depending on that\n nisle = int(global_max(npx.max(vs.land_map)))\n resize_dimension(state, \"isle\", nisle)\n vs.isle = npx.arange(nisle)\n\n\n@veros_routine\ndef streamfunction_init(state):\n \"\"\"\n prepare for island integrals\n \"\"\"\n vs = state.variables\n settings = state.settings\n\n logger.info(\"Initializing streamfunction method\")\n\n get_isleperim(state)\n\n vs.update(boundary_masks(state))\n\n # populate linear solver cache\n linear_solver = get_linear_solver(state)\n\n \"\"\"\n precalculate time independent boundary components of streamfunction\n \"\"\"\n forc = allocate(state.dimensions, (\"xt\", \"yt\"))\n\n vs.psin = update(vs.psin, at[...], vs.maskZ[..., -1, npx.newaxis])\n\n for isle in range(state.dimensions[\"isle\"]):\n logger.info(f\" Solving for boundary contribution by island {isle:d}\")\n isle_boundary = (\n vs.line_dir_east_mask[..., isle]\n | vs.line_dir_west_mask[..., isle]\n | vs.line_dir_north_mask[..., isle]\n | vs.line_dir_south_mask[..., isle]\n )\n isle_sol = linear_solver.solve(state, forc, vs.psin[:, :, isle], boundary_val=isle_boundary)\n vs.psin = update(vs.psin, at[:, :, isle], isle_sol)\n\n vs.psin = mainutils.enforce_boundaries(vs.psin, settings.enable_cyclic_x)\n\n line_psin_out = island_integrals(state)\n vs.update(line_psin_out)\n\n\n@veros_kernel\ndef island_integrals(state):\n \"\"\"\n precalculate time independent island integrals\n \"\"\"\n vs = state.variables\n\n uloc = allocate(state.dimensions, (\"xt\", \"yt\", \"isle\"))\n vloc = allocate(state.dimensions, (\"xt\", \"yt\", \"isle\"))\n\n uloc = update(\n uloc,\n at[1:, 1:, :],\n -(vs.psin[1:, 1:, :] - vs.psin[1:, :-1, :])\n * vs.maskU[1:, 1:, -1, npx.newaxis]\n / vs.dyt[npx.newaxis, 1:, npx.newaxis]\n * vs.hur[1:, 1:, npx.newaxis],\n )\n\n vloc = update(\n vloc,\n at[1:, 1:, ...],\n (vs.psin[1:, 1:, :] - vs.psin[:-1, 1:, :])\n * vs.maskV[1:, 1:, -1, npx.newaxis]\n / (vs.cosu[npx.newaxis, 1:, npx.newaxis] * vs.dxt[1:, npx.newaxis, npx.newaxis])\n * vs.hvr[1:, 1:, npx.newaxis],\n )\n\n vs.line_psin = line_integrals.line_integrals(state, uloc=uloc, vloc=vloc, kind=\"full\")\n return KernelOutput(line_psin=vs.line_psin)\n\n\n@veros_kernel\ndef boundary_masks(state):\n \"\"\"\n now that the number of islands is known we can allocate the rest of the variables\n \"\"\"\n vs = state.variables\n settings = state.settings\n\n boundary_map = vs.land_map[..., npx.newaxis] == npx.arange(1, state.dimensions[\"isle\"] + 1)\n\n if settings.enable_cyclic_x:\n vs.line_dir_east_mask = update(\n vs.line_dir_east_mask, at[2:-2, 1:-1], boundary_map[3:-1, 1:-1] & ~boundary_map[3:-1, 2:]\n )\n vs.line_dir_west_mask = update(\n vs.line_dir_west_mask, at[2:-2, 1:-1], boundary_map[2:-2, 2:] & ~boundary_map[2:-2, 1:-1]\n )\n vs.line_dir_south_mask = update(\n vs.line_dir_south_mask, at[2:-2, 1:-1], boundary_map[2:-2, 1:-1] & ~boundary_map[3:-1, 1:-1]\n )\n vs.line_dir_north_mask = update(\n vs.line_dir_north_mask, at[2:-2, 1:-1], boundary_map[3:-1, 2:] & ~boundary_map[2:-2, 2:]\n )\n else:\n vs.line_dir_east_mask = update(\n vs.line_dir_east_mask, at[1:-1, 1:-1], boundary_map[2:, 1:-1] & ~boundary_map[2:, 2:]\n )\n vs.line_dir_west_mask = update(\n vs.line_dir_west_mask, at[1:-1, 1:-1], boundary_map[1:-1, 2:] & ~boundary_map[1:-1, 1:-1]\n )\n vs.line_dir_south_mask = update(\n vs.line_dir_south_mask, at[1:-1, 1:-1], boundary_map[1:-1, 1:-1] & ~boundary_map[2:, 1:-1]\n )\n vs.line_dir_north_mask = update(\n vs.line_dir_north_mask, at[1:-1, 1:-1], boundary_map[2:, 2:] & ~boundary_map[1:-1, 2:]\n )\n\n vs.isle_boundary_mask = ~npx.any(\n vs.line_dir_east_mask | vs.line_dir_west_mask | vs.line_dir_south_mask | vs.line_dir_north_mask, axis=2\n )\n\n return KernelOutput(\n isle_boundary_mask=vs.isle_boundary_mask,\n line_dir_east_mask=vs.line_dir_east_mask,\n line_dir_west_mask=vs.line_dir_west_mask,\n line_dir_south_mask=vs.line_dir_south_mask,\n line_dir_north_mask=vs.line_dir_north_mask,\n )\n", "path": "veros/core/external/streamfunction_init.py"}]} | 2,570 | 505 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.