
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
18.9k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 465
23.6k
| num_tokens_prompt
int64 556
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_9941
|
rasdani/github-patches
|
git_diff
|
conda__conda-6746
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug: Authenticated channels broken when using conda_env create.
<!--
Hi!
This is an issue tracker for conda -- the package manager. File feature requests
for conda here, as well as bug reports about something conda has messed up.
If your issue is a bug report or feature request for:
* a specific conda package from Anaconda ('defaults' channel):
==> file at https://github.com/ContinuumIO/anaconda-issues
* a specific conda package from conda-forge:
==> file at the corresponding feedstock under https://github.com/conda-forge
* repo.continuum.io access and service:
==> file at https://github.com/ContinuumIO/anaconda-issues
* anaconda.org access and service:
==> file at https://anaconda.org/contact/report
* commands under 'conda build':
==> file at https://github.com/conda/conda-build
* commands under 'conda env':
==> please file it here!
* all other conda commands that start with 'conda':
==> please file it here!
-->
**I'm submitting a...**
- [x] bug report
- [ ] feature request
### Current Behavior
Found two issues in Conda 4.4.x, which I believe are related so I've included them in the same ticket:
* `conda env create` ignores the authentication component of channels (as well as other components).
* When `conda env create` is run, the authentication component is skipped, causing `PackageNotFound` errors to be generated for private packages.
* `conda env create` does not respect the channel priority flag available in the context (based off of expected behavior defined here: https://conda.io/docs/user-guide/tasks/manage-channels.html#after-conda-4-1-0)
* When `conda env create` is run, channels with the same name are truncated before they reach the `Solver`; the `Solver` only receives the highest priority channel. This is not consistent with the channel priority behavior outlined above.
The problem appears to be happening with these 3 lines of code in the `conda` installer in the `conda_env`package: https://github.com/conda/conda/blob/master/conda_env/installers/conda.py#L31-L33
In that code, all of the channels retrieved from the `_channel_priority_map` are instantiated to `Channel` classes and then immediately truncated based on canonical name (for authed channels, this is only the channel name, with the token excluded).
### Steps to Reproduce
For the first issue, using this environment file (`authed.yaml`, NOTE: that you will need to replace the channel with a private channel you control):
```yaml
name: authed_env
channels:
- https://conda.anaconda.org/t/<TOKEN>/<CHANNEL>
dependencies:
- private_package
```
Run the following command and get:
```bash
$ conda env create -n authed_env -f authed.yaml
Solving environment: failed
ResolvePackageNotFound:
- private_package
```
For the second issue, using this environment file (`priority.yaml`)
```yaml
name: priority_env
channels:
- nextdoor
- https://conda.anaconda.org/t/<TOKEN>/<CHANNEL>
dependencies:
- private_package
```
And this `.condarc`
```yaml
channel_priority: false
```
Run this command and get.
```bash
$ conda env create -n priority_env -f priority.yaml
Solving environment: failed
ResolvePackageNotFound:
- private_package
```
This second is a little hidden because of the authenticated channel issue, but it's again caused by the `canonical_name` truncation.
### Expected Behavior
<!-- What do you think should happen? -->
* `conda env create` should allow environment files and `condarc` files to use authenticated channels (by respecting the full URL).
* The command should also not truncate channels that it passes to the `Solver`. This is not behavior that is exhibited in other areas where `Solver` is instantiated.
As a note, the expected behavior did successfully occur in the latest 4.3.x release.
##### `conda info`
<!-- between the ticks below, paste the output of 'conda info' -->
```
active environment : nextdoor
active env location : /var/lib/conda/envs/nextdoor
shell level : 1
user config file : /home/vagrant/.condarc
populated config files : /home/vagrant/.condarc
conda version : 4.4.7
conda-build version : not installed
python version : 3.6.3.final.0
base environment : /var/lib/conda (writable)
channel URLs : https://repo.continuum.io/pkgs/main/linux-64
https://repo.continuum.io/pkgs/main/noarch
https://repo.continuum.io/pkgs/free/linux-64
https://repo.continuum.io/pkgs/free/noarch
https://repo.continuum.io/pkgs/r/linux-64
https://repo.continuum.io/pkgs/r/noarch
https://repo.continuum.io/pkgs/pro/linux-64
https://repo.continuum.io/pkgs/pro/noarch
package cache : /var/lib/conda/pkgs
/home/vagrant/.conda/pkgs
envs directories : /var/lib/conda/envs
/home/vagrant/.conda/envs
platform : linux-64
user-agent : conda/4.4.7 requests/2.18.4 CPython/3.6.3 Linux/3.8.0-44-generic ubuntu/12.04 glibc/2.19
UID:GID : 1000:1000
netrc file : None
offline mode : False
```
##### `conda config --show-sources`
<!-- between the ticks below, paste the output of 'conda config --show-sources' -->
```
==> /home/vagrant/.condarc <==
channel_priority: False
channels:
- defaults
```
##### `conda list --show-channel-urls`
<!-- between the ticks below, paste the output of 'conda list --show-channel-urls' -->
```
# packages in environment at /var/lib/conda:
#
asn1crypto 0.23.0 py36h4639342_0 defaults
ca-certificates 2017.08.26 h1d4fec5_0 defaults
certifi 2017.11.5 py36hf29ccca_0 defaults
cffi 1.11.2 py36h2825082_0 defaults
chardet 3.0.4 py36h0f667ec_1 defaults
conda 4.4.7 py36_0 defaults
conda-env 2.6.0 h36134e3_1 defaults
cryptography 2.1.4 py36hd09be54_0 defaults
idna 2.6 py36h82fb2a8_1 defaults
libedit 3.1 heed3624_0 defaults
libffi 3.2.1 hd88cf55_4 defaults
libgcc-ng 7.2.0 h7cc24e2_2 defaults
libstdcxx-ng 7.2.0 h7a57d05_2 defaults
ncurses 6.0 h9df7e31_2 defaults
openssl 1.0.2n hb7f436b_0 defaults
pip 9.0.1 py36h6c6f9ce_4 defaults
pycosat 0.6.3 py36h0a5515d_0 defaults
pycparser 2.18 py36hf9f622e_1 defaults
pyopenssl 17.5.0 py36h20ba746_0 defaults
pysocks 1.6.7 py36hd97a5b1_1 defaults
python 3.6.3 h6c0c0dc_5 defaults
readline 7.0 ha6073c6_4 defaults
requests 2.18.4 py36he2e5f8d_1 defaults
ruamel_yaml 0.11.14 py36ha2fb22d_2 defaults
setuptools 36.5.0 py36he42e2e1_0 defaults
six 1.11.0 py36h372c433_1 defaults
sqlite 3.20.1 hb898158_2 defaults
tk 8.6.7 hc745277_3 defaults
urllib3 1.22 py36hbe7ace6_0 defaults
wheel 0.30.0 py36hfd4bba0_1 defaults
xz 5.2.3 h55aa19d_2 defaults
yaml 0.1.7 had09818_2 defaults
zlib 1.2.11 ha838bed_2 defaults
```
</issue>
<code>
[start of conda_env/installers/conda.py]
1 from __future__ import absolute_import
2
3 from os.path import basename
4
5 from conda._vendor.boltons.setutils import IndexedSet
6 from conda.base.context import context
7 from conda.core.solve import Solver
8 from conda.models.channel import Channel, prioritize_channels
9
10
11 def install(prefix, specs, args, env, *_, **kwargs):
12 # TODO: support all various ways this happens
13 # Including 'nodefaults' in the channels list disables the defaults
14 new_specs = []
15 channel_urls = set()
16 for elem in specs:
17 if "::" in elem:
18 channel_urls.add(elem.split("::")[0])
19 new_specs.append(elem.split("::")[-1])
20 else:
21 new_specs.append(elem)
22 specs = new_specs
23 channel_urls = list(channel_urls)
24 # TODO: support all various ways this happens
25 # Including 'nodefaults' in the channels list disables the defaults
26 channel_urls = channel_urls + [chan for chan in env.channels if chan != 'nodefaults']
27 if 'nodefaults' not in env.channels:
28 channel_urls.extend(context.channels)
29 _channel_priority_map = prioritize_channels(channel_urls)
30
31 channel_names = IndexedSet(Channel(url).canonical_name for url in _channel_priority_map)
32 channels = IndexedSet(Channel(cn) for cn in channel_names)
33 subdirs = IndexedSet(basename(url) for url in _channel_priority_map)
34
35 solver = Solver(prefix, channels, subdirs, specs_to_add=specs)
36 unlink_link_transaction = solver.solve_for_transaction(prune=getattr(args, 'prune', False))
37
38 pfe = unlink_link_transaction.get_pfe()
39 pfe.execute()
40 unlink_link_transaction.execute()
41
[end of conda_env/installers/conda.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/conda_env/installers/conda.py b/conda_env/installers/conda.py
--- a/conda_env/installers/conda.py
+++ b/conda_env/installers/conda.py
@@ -28,8 +28,7 @@
channel_urls.extend(context.channels)
_channel_priority_map = prioritize_channels(channel_urls)
- channel_names = IndexedSet(Channel(url).canonical_name for url in _channel_priority_map)
- channels = IndexedSet(Channel(cn) for cn in channel_names)
+ channels = IndexedSet(Channel(url) for url in _channel_priority_map)
subdirs = IndexedSet(basename(url) for url in _channel_priority_map)
solver = Solver(prefix, channels, subdirs, specs_to_add=specs)
|
{"golden_diff": "diff --git a/conda_env/installers/conda.py b/conda_env/installers/conda.py\n--- a/conda_env/installers/conda.py\n+++ b/conda_env/installers/conda.py\n@@ -28,8 +28,7 @@\n channel_urls.extend(context.channels)\n _channel_priority_map = prioritize_channels(channel_urls)\n \n- channel_names = IndexedSet(Channel(url).canonical_name for url in _channel_priority_map)\n- channels = IndexedSet(Channel(cn) for cn in channel_names)\n+ channels = IndexedSet(Channel(url) for url in _channel_priority_map)\n subdirs = IndexedSet(basename(url) for url in _channel_priority_map)\n \n solver = Solver(prefix, channels, subdirs, specs_to_add=specs)\n", "issue": "Bug: Authenticated channels broken when using conda_env create.\n<!--\r\nHi!\r\n\r\nThis is an issue tracker for conda -- the package manager. File feature requests\r\nfor conda here, as well as bug reports about something conda has messed up.\r\n\r\nIf your issue is a bug report or feature request for:\r\n * a specific conda package from Anaconda ('defaults' channel):\r\n ==> file at https://github.com/ContinuumIO/anaconda-issues\r\n * a specific conda package from conda-forge:\r\n ==> file at the corresponding feedstock under https://github.com/conda-forge\r\n * repo.continuum.io access and service:\r\n ==> file at https://github.com/ContinuumIO/anaconda-issues\r\n * anaconda.org access and service:\r\n ==> file at https://anaconda.org/contact/report\r\n * commands under 'conda build':\r\n ==> file at https://github.com/conda/conda-build\r\n * commands under 'conda env':\r\n ==> please file it here!\r\n * all other conda commands that start with 'conda':\r\n ==> please file it here!\r\n\r\n-->\r\n\r\n**I'm submitting a...**\r\n - [x] bug report\r\n - [ ] feature request\r\n\r\n\r\n### Current Behavior\r\nFound two issues in Conda 4.4.x, which I believe are related so I've included them in the same ticket:\r\n* `conda env create` ignores the authentication component of channels (as well as other components).\r\n * When `conda env create` is run, the authentication component is skipped, causing `PackageNotFound` errors to be generated for private packages.\r\n* `conda env create` does not respect the channel priority flag available in the context (based off of expected behavior defined here: https://conda.io/docs/user-guide/tasks/manage-channels.html#after-conda-4-1-0)\r\n * When `conda env create` is run, channels with the same name are truncated before they reach the `Solver`; the `Solver` only receives the highest priority channel. This is not consistent with the channel priority behavior outlined above.\r\n\r\nThe problem appears to be happening with these 3 lines of code in the `conda` installer in the `conda_env`package: https://github.com/conda/conda/blob/master/conda_env/installers/conda.py#L31-L33\r\n\r\nIn that code, all of the channels retrieved from the `_channel_priority_map` are instantiated to `Channel` classes and then immediately truncated based on canonical name (for authed channels, this is only the channel name, with the token excluded). \r\n\r\n### Steps to Reproduce\r\nFor the first issue, using this environment file (`authed.yaml`, NOTE: that you will need to replace the channel with a private channel you control):\r\n```yaml\r\nname: authed_env\r\nchannels:\r\n - https://conda.anaconda.org/t/<TOKEN>/<CHANNEL>\r\ndependencies:\r\n - private_package\r\n```\r\nRun the following command and get:\r\n```bash\r\n$ conda env create -n authed_env -f authed.yaml\r\nSolving environment: failed\r\n\r\nResolvePackageNotFound:\r\n - private_package\r\n```\r\n\r\nFor the second issue, using this environment file (`priority.yaml`)\r\n```yaml\r\nname: priority_env\r\nchannels:\r\n - nextdoor\r\n - https://conda.anaconda.org/t/<TOKEN>/<CHANNEL>\r\ndependencies:\r\n - private_package\r\n```\r\nAnd this `.condarc`\r\n```yaml\r\nchannel_priority: false\r\n```\r\nRun this command and get.\r\n```bash\r\n$ conda env create -n priority_env -f priority.yaml\r\nSolving environment: failed\r\n\r\nResolvePackageNotFound:\r\n - private_package\r\n```\r\nThis second is a little hidden because of the authenticated channel issue, but it's again caused by the `canonical_name` truncation.\r\n\r\n\r\n### Expected Behavior\r\n<!-- What do you think should happen? -->\r\n* `conda env create` should allow environment files and `condarc` files to use authenticated channels (by respecting the full URL). \r\n* The command should also not truncate channels that it passes to the `Solver`. This is not behavior that is exhibited in other areas where `Solver` is instantiated.\r\n\r\nAs a note, the expected behavior did successfully occur in the latest 4.3.x release.\r\n\r\n##### `conda info`\r\n<!-- between the ticks below, paste the output of 'conda info' -->\r\n```\r\n active environment : nextdoor\r\n active env location : /var/lib/conda/envs/nextdoor\r\n shell level : 1\r\n user config file : /home/vagrant/.condarc\r\n populated config files : /home/vagrant/.condarc\r\n conda version : 4.4.7\r\n conda-build version : not installed\r\n python version : 3.6.3.final.0\r\n base environment : /var/lib/conda (writable)\r\n channel URLs : https://repo.continuum.io/pkgs/main/linux-64\r\n https://repo.continuum.io/pkgs/main/noarch\r\n https://repo.continuum.io/pkgs/free/linux-64\r\n https://repo.continuum.io/pkgs/free/noarch\r\n https://repo.continuum.io/pkgs/r/linux-64\r\n https://repo.continuum.io/pkgs/r/noarch\r\n https://repo.continuum.io/pkgs/pro/linux-64\r\n https://repo.continuum.io/pkgs/pro/noarch\r\n package cache : /var/lib/conda/pkgs\r\n /home/vagrant/.conda/pkgs\r\n envs directories : /var/lib/conda/envs\r\n /home/vagrant/.conda/envs\r\n platform : linux-64\r\n user-agent : conda/4.4.7 requests/2.18.4 CPython/3.6.3 Linux/3.8.0-44-generic ubuntu/12.04 glibc/2.19\r\n UID:GID : 1000:1000\r\n netrc file : None\r\n offline mode : False\r\n```\r\n\r\n\r\n##### `conda config --show-sources`\r\n<!-- between the ticks below, paste the output of 'conda config --show-sources' -->\r\n```\r\n==> /home/vagrant/.condarc <==\r\nchannel_priority: False\r\nchannels:\r\n - defaults\r\n```\r\n\r\n\r\n##### `conda list --show-channel-urls`\r\n<!-- between the ticks below, paste the output of 'conda list --show-channel-urls' -->\r\n```\r\n# packages in environment at /var/lib/conda:\r\n#\r\nasn1crypto 0.23.0 py36h4639342_0 defaults\r\nca-certificates 2017.08.26 h1d4fec5_0 defaults\r\ncertifi 2017.11.5 py36hf29ccca_0 defaults\r\ncffi 1.11.2 py36h2825082_0 defaults\r\nchardet 3.0.4 py36h0f667ec_1 defaults\r\nconda 4.4.7 py36_0 defaults\r\nconda-env 2.6.0 h36134e3_1 defaults\r\ncryptography 2.1.4 py36hd09be54_0 defaults\r\nidna 2.6 py36h82fb2a8_1 defaults\r\nlibedit 3.1 heed3624_0 defaults\r\nlibffi 3.2.1 hd88cf55_4 defaults\r\nlibgcc-ng 7.2.0 h7cc24e2_2 defaults\r\nlibstdcxx-ng 7.2.0 h7a57d05_2 defaults\r\nncurses 6.0 h9df7e31_2 defaults\r\nopenssl 1.0.2n hb7f436b_0 defaults\r\npip 9.0.1 py36h6c6f9ce_4 defaults\r\npycosat 0.6.3 py36h0a5515d_0 defaults\r\npycparser 2.18 py36hf9f622e_1 defaults\r\npyopenssl 17.5.0 py36h20ba746_0 defaults\r\npysocks 1.6.7 py36hd97a5b1_1 defaults\r\npython 3.6.3 h6c0c0dc_5 defaults\r\nreadline 7.0 ha6073c6_4 defaults\r\nrequests 2.18.4 py36he2e5f8d_1 defaults\r\nruamel_yaml 0.11.14 py36ha2fb22d_2 defaults\r\nsetuptools 36.5.0 py36he42e2e1_0 defaults\r\nsix 1.11.0 py36h372c433_1 defaults\r\nsqlite 3.20.1 hb898158_2 defaults\r\ntk 8.6.7 hc745277_3 defaults\r\nurllib3 1.22 py36hbe7ace6_0 defaults\r\nwheel 0.30.0 py36hfd4bba0_1 defaults\r\nxz 5.2.3 h55aa19d_2 defaults\r\nyaml 0.1.7 had09818_2 defaults\r\nzlib 1.2.11 ha838bed_2 defaults\r\n```\r\n\n", "before_files": [{"content": "from __future__ import absolute_import\n\nfrom os.path import basename\n\nfrom conda._vendor.boltons.setutils import IndexedSet\nfrom conda.base.context import context\nfrom conda.core.solve import Solver\nfrom conda.models.channel import Channel, prioritize_channels\n\n\ndef install(prefix, specs, args, env, *_, **kwargs):\n # TODO: support all various ways this happens\n # Including 'nodefaults' in the channels list disables the defaults\n new_specs = []\n channel_urls = set()\n for elem in specs:\n if \"::\" in elem:\n channel_urls.add(elem.split(\"::\")[0])\n new_specs.append(elem.split(\"::\")[-1])\n else:\n new_specs.append(elem)\n specs = new_specs\n channel_urls = list(channel_urls)\n # TODO: support all various ways this happens\n # Including 'nodefaults' in the channels list disables the defaults\n channel_urls = channel_urls + [chan for chan in env.channels if chan != 'nodefaults']\n if 'nodefaults' not in env.channels:\n channel_urls.extend(context.channels)\n _channel_priority_map = prioritize_channels(channel_urls)\n\n channel_names = IndexedSet(Channel(url).canonical_name for url in _channel_priority_map)\n channels = IndexedSet(Channel(cn) for cn in channel_names)\n subdirs = IndexedSet(basename(url) for url in _channel_priority_map)\n\n solver = Solver(prefix, channels, subdirs, specs_to_add=specs)\n unlink_link_transaction = solver.solve_for_transaction(prune=getattr(args, 'prune', False))\n\n pfe = unlink_link_transaction.get_pfe()\n pfe.execute()\n unlink_link_transaction.execute()\n", "path": "conda_env/installers/conda.py"}]}
| 3,141 | 163 |
gh_patches_debug_306
|
rasdani/github-patches
|
git_diff
|
zulip__zulip-18598
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Pivotal integration exception
Hi,
I've added Pivotal integration and from time to time I receive those two e-mails when working in Pivotal:
I'm running ubuntu 20.04
If you need more information, I'd be happy to help.
```
Logger django.request, from module django.utils.log line 224:
Error generated by PivotalMessenger <pivotal-bot@***> (Member) on *** deployment
No stack trace available
Deployed code:
- git: None
- ZULIP_VERSION: 4.2
Request info:
- path: /api/v1/external/pivotal
- POST: {}
- REMOTE_ADDR: "35.184.18.147"
- QUERY_STRING: "api_key=******&stream=******&topic=******"
- SERVER_NAME: ""
```
```
Logger zerver.middleware.json_error_handler, from module zerver.middleware line 450:
Error generated by PivotalMessenger <pivotal-bot@***> (Member) on *** deployment
Traceback (most recent call last):
File "/usr/lib/python3.8/xml/etree/ElementTree.py", line 1693, in feed
self.parser.Parse(data, 0)
xml.parsers.expat.ExpatError: not well-formed (invalid token): line 1, column 0
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "./zerver/webhooks/pivotal/view.py", line 172, in api_pivotal_webhook
subject, content = api_pivotal_webhook_v3(request, user_profile)
File "./zerver/webhooks/pivotal/view.py", line 19, in api_pivotal_webhook_v3
payload = xml_fromstring(request.body)
File "/srv/zulip-venv-cache/9d0f5ac272f4e644b222ed65b0b5a996616a215f/zulip-py3-venv/lib/python3.8/site-packages/defusedxml/common.py", line 131, in fromstring
parser.feed(text)
File "/usr/lib/python3.8/xml/etree/ElementTree.py", line 1695, in feed
self._raiseerror(v)
File "/usr/lib/python3.8/xml/etree/ElementTree.py", line 1602, in _raiseerror
raise err
File "<string>", line None
xml.etree.ElementTree.ParseError: not well-formed (invalid token): line 1, column 0
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/srv/zulip-venv-cache/9d0f5ac272f4e644b222ed65b0b5a996616a215f/zulip-py3-venv/lib/python3.8/site-packages/django/core/handlers/base.py", line 181, in _get_response
response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "/srv/zulip-venv-cache/9d0f5ac272f4e644b222ed65b0b5a996616a215f/zulip-py3-venv/lib/python3.8/site-packages/django/views/decorators/csrf.py", line 54, in wrapped_view
return view_func(*args, **kwargs)
File "./zerver/lib/request.py", line 390, in _wrapped_view_func
return view_func(request, *args, **kwargs)
File "./zerver/decorator.py", line 354, in _wrapped_func_arguments
raise err
File "./zerver/decorator.py", line 334, in _wrapped_func_arguments
return view_func(request, user_profile, *args, **kwargs)
File "./zerver/lib/request.py", line 390, in _wrapped_view_func
return view_func(request, *args, **kwargs)
File "./zerver/webhooks/pivotal/view.py", line 175, in api_pivotal_webhook
subject, content = api_pivotal_webhook_v5(request, user_profile)
File "./zerver/webhooks/pivotal/view.py", line 87, in api_pivotal_webhook_v5
story_url = primary_resources["url"]
KeyError: 'url'
Deployed code:
- git: None
- ZULIP_VERSION: 4.2
Request info:
- path: /api/v1/external/pivotal
- POST: {}
- REMOTE_ADDR: "35.184.18.147"
- QUERY_STRING: "api_key=******&stream=******&topic=******"
- SERVER_NAME: ""
```
</issue>
<code>
[start of zerver/webhooks/pivotal/view.py]
1 """Webhooks for external integrations."""
2 import re
3 from typing import Any, Dict, List, Optional, Tuple
4
5 import orjson
6 from defusedxml.ElementTree import fromstring as xml_fromstring
7 from django.http import HttpRequest, HttpResponse
8 from django.utils.translation import gettext as _
9
10 from zerver.decorator import webhook_view
11 from zerver.lib.exceptions import UnsupportedWebhookEventType
12 from zerver.lib.request import has_request_variables
13 from zerver.lib.response import json_error, json_success
14 from zerver.lib.webhooks.common import check_send_webhook_message
15 from zerver.models import UserProfile
16
17
18 def api_pivotal_webhook_v3(request: HttpRequest, user_profile: UserProfile) -> Tuple[str, str]:
19 payload = xml_fromstring(request.body)
20
21 def get_text(attrs: List[str]) -> str:
22 start = payload
23 try:
24 for attr in attrs:
25 start = start.find(attr)
26 return start.text
27 except AttributeError:
28 return ""
29
30 event_type = payload.find("event_type").text
31 description = payload.find("description").text
32 project_id = payload.find("project_id").text
33 story_id = get_text(["stories", "story", "id"])
34 # Ugh, the URL in the XML data is not a clickable URL that works for the user
35 # so we try to build one that the user can actually click on
36 url = f"https://www.pivotaltracker.com/s/projects/{project_id}/stories/{story_id}"
37
38 # Pivotal doesn't tell us the name of the story, but it's usually in the
39 # description in quotes as the first quoted string
40 name_re = re.compile(r'[^"]+"([^"]+)".*')
41 match = name_re.match(description)
42 if match and len(match.groups()):
43 name = match.group(1)
44 else:
45 name = "Story changed" # Failed for an unknown reason, show something
46 more_info = f" [(view)]({url})."
47
48 if event_type == "story_update":
49 subject = name
50 content = description + more_info
51 elif event_type == "note_create":
52 subject = "Comment added"
53 content = description + more_info
54 elif event_type == "story_create":
55 issue_desc = get_text(["stories", "story", "description"])
56 issue_type = get_text(["stories", "story", "story_type"])
57 issue_status = get_text(["stories", "story", "current_state"])
58 estimate = get_text(["stories", "story", "estimate"])
59 if estimate != "":
60 estimate = f" worth {estimate} story points"
61 subject = name
62 content = f"{description} ({issue_status} {issue_type}{estimate}):\n\n~~~ quote\n{issue_desc}\n~~~\n\n{more_info}"
63 return subject, content
64
65
66 UNSUPPORTED_EVENT_TYPES = [
67 "task_create_activity",
68 "comment_delete_activity",
69 "task_delete_activity",
70 "task_update_activity",
71 "story_move_from_project_activity",
72 "story_delete_activity",
73 "story_move_into_project_activity",
74 "epic_update_activity",
75 ]
76
77
78 def api_pivotal_webhook_v5(request: HttpRequest, user_profile: UserProfile) -> Tuple[str, str]:
79 payload = orjson.loads(request.body)
80
81 event_type = payload["kind"]
82
83 project_name = payload["project"]["name"]
84 project_id = payload["project"]["id"]
85
86 primary_resources = payload["primary_resources"][0]
87 story_url = primary_resources["url"]
88 story_type = primary_resources.get("story_type")
89 story_id = primary_resources["id"]
90 story_name = primary_resources["name"]
91
92 performed_by = payload.get("performed_by", {}).get("name", "")
93
94 story_info = f"[{project_name}](https://www.pivotaltracker.com/s/projects/{project_id}): [{story_name}]({story_url})"
95
96 changes = payload.get("changes", [])
97
98 content = ""
99 subject = f"#{story_id}: {story_name}"
100
101 def extract_comment(change: Dict[str, Any]) -> Optional[str]:
102 if change.get("kind") == "comment":
103 return change.get("new_values", {}).get("text", None)
104 return None
105
106 if event_type == "story_update_activity":
107 # Find the changed valued and build a message
108 content += f"{performed_by} updated {story_info}:\n"
109 for change in changes:
110 old_values = change.get("original_values", {})
111 new_values = change["new_values"]
112
113 if "current_state" in old_values and "current_state" in new_values:
114 content += "* state changed from **{}** to **{}**\n".format(
115 old_values["current_state"], new_values["current_state"]
116 )
117 if "estimate" in old_values and "estimate" in new_values:
118 old_estimate = old_values.get("estimate", None)
119 if old_estimate is None:
120 estimate = "is now"
121 else:
122 estimate = f"changed from {old_estimate} to"
123 new_estimate = new_values["estimate"] if new_values["estimate"] is not None else "0"
124 content += f"* estimate {estimate} **{new_estimate} points**\n"
125 if "story_type" in old_values and "story_type" in new_values:
126 content += "* type changed from **{}** to **{}**\n".format(
127 old_values["story_type"], new_values["story_type"]
128 )
129
130 comment = extract_comment(change)
131 if comment is not None:
132 content += f"* Comment added:\n~~~quote\n{comment}\n~~~\n"
133
134 elif event_type == "comment_create_activity":
135 for change in changes:
136 comment = extract_comment(change)
137 if comment is not None:
138 content += (
139 f"{performed_by} added a comment to {story_info}:\n~~~quote\n{comment}\n~~~"
140 )
141 elif event_type == "story_create_activity":
142 content += f"{performed_by} created {story_type}: {story_info}\n"
143 for change in changes:
144 new_values = change.get("new_values", {})
145 if "current_state" in new_values:
146 content += "* State is **{}**\n".format(new_values["current_state"])
147 if "description" in new_values:
148 content += "* Description is\n\n> {}".format(new_values["description"])
149 elif event_type == "story_move_activity":
150 content = f"{performed_by} moved {story_info}"
151 for change in changes:
152 old_values = change.get("original_values", {})
153 new_values = change["new_values"]
154 if "current_state" in old_values and "current_state" in new_values:
155 content += " from **{}** to **{}**.".format(
156 old_values["current_state"], new_values["current_state"]
157 )
158 elif event_type in UNSUPPORTED_EVENT_TYPES:
159 # Known but unsupported Pivotal event types
160 pass
161 else:
162 raise UnsupportedWebhookEventType(event_type)
163
164 return subject, content
165
166
167 @webhook_view("Pivotal")
168 @has_request_variables
169 def api_pivotal_webhook(request: HttpRequest, user_profile: UserProfile) -> HttpResponse:
170 subject = content = None
171 try:
172 subject, content = api_pivotal_webhook_v3(request, user_profile)
173 except Exception:
174 # Attempt to parse v5 JSON payload
175 subject, content = api_pivotal_webhook_v5(request, user_profile)
176
177 if not content:
178 return json_error(_("Unable to handle Pivotal payload"))
179
180 check_send_webhook_message(request, user_profile, subject, content)
181 return json_success()
182
[end of zerver/webhooks/pivotal/view.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/zerver/webhooks/pivotal/view.py b/zerver/webhooks/pivotal/view.py
--- a/zerver/webhooks/pivotal/view.py
+++ b/zerver/webhooks/pivotal/view.py
@@ -72,6 +72,7 @@
"story_delete_activity",
"story_move_into_project_activity",
"epic_update_activity",
+ "label_create_activity",
]
|
{"golden_diff": "diff --git a/zerver/webhooks/pivotal/view.py b/zerver/webhooks/pivotal/view.py\n--- a/zerver/webhooks/pivotal/view.py\n+++ b/zerver/webhooks/pivotal/view.py\n@@ -72,6 +72,7 @@\n \"story_delete_activity\",\n \"story_move_into_project_activity\",\n \"epic_update_activity\",\n+ \"label_create_activity\",\n ]\n", "issue": "Pivotal integration exception\nHi, \r\nI've added Pivotal integration and from time to time I receive those two e-mails when working in Pivotal:\r\nI'm running ubuntu 20.04\r\n\r\nIf you need more information, I'd be happy to help.\r\n\r\n```\r\nLogger django.request, from module django.utils.log line 224:\r\nError generated by PivotalMessenger <pivotal-bot@***> (Member) on *** deployment\r\n\r\nNo stack trace available\r\n\r\nDeployed code:\r\n- git: None\r\n- ZULIP_VERSION: 4.2\r\n\r\n\r\nRequest info:\r\n- path: /api/v1/external/pivotal\r\n- POST: {}\r\n- REMOTE_ADDR: \"35.184.18.147\"\r\n- QUERY_STRING: \"api_key=******&stream=******&topic=******\"\r\n- SERVER_NAME: \"\"\r\n```\r\n\r\n```\r\nLogger zerver.middleware.json_error_handler, from module zerver.middleware line 450:\r\nError generated by PivotalMessenger <pivotal-bot@***> (Member) on *** deployment\r\n\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python3.8/xml/etree/ElementTree.py\", line 1693, in feed\r\n self.parser.Parse(data, 0)\r\nxml.parsers.expat.ExpatError: not well-formed (invalid token): line 1, column 0\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"./zerver/webhooks/pivotal/view.py\", line 172, in api_pivotal_webhook\r\n subject, content = api_pivotal_webhook_v3(request, user_profile)\r\n File \"./zerver/webhooks/pivotal/view.py\", line 19, in api_pivotal_webhook_v3\r\n payload = xml_fromstring(request.body)\r\n File \"/srv/zulip-venv-cache/9d0f5ac272f4e644b222ed65b0b5a996616a215f/zulip-py3-venv/lib/python3.8/site-packages/defusedxml/common.py\", line 131, in fromstring\r\n parser.feed(text)\r\n File \"/usr/lib/python3.8/xml/etree/ElementTree.py\", line 1695, in feed\r\n self._raiseerror(v)\r\n File \"/usr/lib/python3.8/xml/etree/ElementTree.py\", line 1602, in _raiseerror\r\n raise err\r\n File \"<string>\", line None\r\nxml.etree.ElementTree.ParseError: not well-formed (invalid token): line 1, column 0\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/srv/zulip-venv-cache/9d0f5ac272f4e644b222ed65b0b5a996616a215f/zulip-py3-venv/lib/python3.8/site-packages/django/core/handlers/base.py\", line 181, in _get_response\r\n response = wrapped_callback(request, *callback_args, **callback_kwargs)\r\n File \"/srv/zulip-venv-cache/9d0f5ac272f4e644b222ed65b0b5a996616a215f/zulip-py3-venv/lib/python3.8/site-packages/django/views/decorators/csrf.py\", line 54, in wrapped_view\r\n return view_func(*args, **kwargs)\r\n File \"./zerver/lib/request.py\", line 390, in _wrapped_view_func\r\n return view_func(request, *args, **kwargs)\r\n File \"./zerver/decorator.py\", line 354, in _wrapped_func_arguments\r\n raise err\r\n File \"./zerver/decorator.py\", line 334, in _wrapped_func_arguments\r\n return view_func(request, user_profile, *args, **kwargs)\r\n File \"./zerver/lib/request.py\", line 390, in _wrapped_view_func\r\n return view_func(request, *args, **kwargs)\r\n File \"./zerver/webhooks/pivotal/view.py\", line 175, in api_pivotal_webhook\r\n subject, content = api_pivotal_webhook_v5(request, user_profile)\r\n File \"./zerver/webhooks/pivotal/view.py\", line 87, in api_pivotal_webhook_v5\r\n story_url = primary_resources[\"url\"]\r\nKeyError: 'url'\r\n\r\n\r\nDeployed code:\r\n- git: None\r\n- ZULIP_VERSION: 4.2\r\n\r\n\r\nRequest info:\r\n- path: /api/v1/external/pivotal\r\n- POST: {}\r\n- REMOTE_ADDR: \"35.184.18.147\"\r\n- QUERY_STRING: \"api_key=******&stream=******&topic=******\"\r\n- SERVER_NAME: \"\"\r\n\r\n\r\n```\n", "before_files": [{"content": "\"\"\"Webhooks for external integrations.\"\"\"\nimport re\nfrom typing import Any, Dict, List, Optional, Tuple\n\nimport orjson\nfrom defusedxml.ElementTree import fromstring as xml_fromstring\nfrom django.http import HttpRequest, HttpResponse\nfrom django.utils.translation import gettext as _\n\nfrom zerver.decorator import webhook_view\nfrom zerver.lib.exceptions import UnsupportedWebhookEventType\nfrom zerver.lib.request import has_request_variables\nfrom zerver.lib.response import json_error, json_success\nfrom zerver.lib.webhooks.common import check_send_webhook_message\nfrom zerver.models import UserProfile\n\n\ndef api_pivotal_webhook_v3(request: HttpRequest, user_profile: UserProfile) -> Tuple[str, str]:\n payload = xml_fromstring(request.body)\n\n def get_text(attrs: List[str]) -> str:\n start = payload\n try:\n for attr in attrs:\n start = start.find(attr)\n return start.text\n except AttributeError:\n return \"\"\n\n event_type = payload.find(\"event_type\").text\n description = payload.find(\"description\").text\n project_id = payload.find(\"project_id\").text\n story_id = get_text([\"stories\", \"story\", \"id\"])\n # Ugh, the URL in the XML data is not a clickable URL that works for the user\n # so we try to build one that the user can actually click on\n url = f\"https://www.pivotaltracker.com/s/projects/{project_id}/stories/{story_id}\"\n\n # Pivotal doesn't tell us the name of the story, but it's usually in the\n # description in quotes as the first quoted string\n name_re = re.compile(r'[^\"]+\"([^\"]+)\".*')\n match = name_re.match(description)\n if match and len(match.groups()):\n name = match.group(1)\n else:\n name = \"Story changed\" # Failed for an unknown reason, show something\n more_info = f\" [(view)]({url}).\"\n\n if event_type == \"story_update\":\n subject = name\n content = description + more_info\n elif event_type == \"note_create\":\n subject = \"Comment added\"\n content = description + more_info\n elif event_type == \"story_create\":\n issue_desc = get_text([\"stories\", \"story\", \"description\"])\n issue_type = get_text([\"stories\", \"story\", \"story_type\"])\n issue_status = get_text([\"stories\", \"story\", \"current_state\"])\n estimate = get_text([\"stories\", \"story\", \"estimate\"])\n if estimate != \"\":\n estimate = f\" worth {estimate} story points\"\n subject = name\n content = f\"{description} ({issue_status} {issue_type}{estimate}):\\n\\n~~~ quote\\n{issue_desc}\\n~~~\\n\\n{more_info}\"\n return subject, content\n\n\nUNSUPPORTED_EVENT_TYPES = [\n \"task_create_activity\",\n \"comment_delete_activity\",\n \"task_delete_activity\",\n \"task_update_activity\",\n \"story_move_from_project_activity\",\n \"story_delete_activity\",\n \"story_move_into_project_activity\",\n \"epic_update_activity\",\n]\n\n\ndef api_pivotal_webhook_v5(request: HttpRequest, user_profile: UserProfile) -> Tuple[str, str]:\n payload = orjson.loads(request.body)\n\n event_type = payload[\"kind\"]\n\n project_name = payload[\"project\"][\"name\"]\n project_id = payload[\"project\"][\"id\"]\n\n primary_resources = payload[\"primary_resources\"][0]\n story_url = primary_resources[\"url\"]\n story_type = primary_resources.get(\"story_type\")\n story_id = primary_resources[\"id\"]\n story_name = primary_resources[\"name\"]\n\n performed_by = payload.get(\"performed_by\", {}).get(\"name\", \"\")\n\n story_info = f\"[{project_name}](https://www.pivotaltracker.com/s/projects/{project_id}): [{story_name}]({story_url})\"\n\n changes = payload.get(\"changes\", [])\n\n content = \"\"\n subject = f\"#{story_id}: {story_name}\"\n\n def extract_comment(change: Dict[str, Any]) -> Optional[str]:\n if change.get(\"kind\") == \"comment\":\n return change.get(\"new_values\", {}).get(\"text\", None)\n return None\n\n if event_type == \"story_update_activity\":\n # Find the changed valued and build a message\n content += f\"{performed_by} updated {story_info}:\\n\"\n for change in changes:\n old_values = change.get(\"original_values\", {})\n new_values = change[\"new_values\"]\n\n if \"current_state\" in old_values and \"current_state\" in new_values:\n content += \"* state changed from **{}** to **{}**\\n\".format(\n old_values[\"current_state\"], new_values[\"current_state\"]\n )\n if \"estimate\" in old_values and \"estimate\" in new_values:\n old_estimate = old_values.get(\"estimate\", None)\n if old_estimate is None:\n estimate = \"is now\"\n else:\n estimate = f\"changed from {old_estimate} to\"\n new_estimate = new_values[\"estimate\"] if new_values[\"estimate\"] is not None else \"0\"\n content += f\"* estimate {estimate} **{new_estimate} points**\\n\"\n if \"story_type\" in old_values and \"story_type\" in new_values:\n content += \"* type changed from **{}** to **{}**\\n\".format(\n old_values[\"story_type\"], new_values[\"story_type\"]\n )\n\n comment = extract_comment(change)\n if comment is not None:\n content += f\"* Comment added:\\n~~~quote\\n{comment}\\n~~~\\n\"\n\n elif event_type == \"comment_create_activity\":\n for change in changes:\n comment = extract_comment(change)\n if comment is not None:\n content += (\n f\"{performed_by} added a comment to {story_info}:\\n~~~quote\\n{comment}\\n~~~\"\n )\n elif event_type == \"story_create_activity\":\n content += f\"{performed_by} created {story_type}: {story_info}\\n\"\n for change in changes:\n new_values = change.get(\"new_values\", {})\n if \"current_state\" in new_values:\n content += \"* State is **{}**\\n\".format(new_values[\"current_state\"])\n if \"description\" in new_values:\n content += \"* Description is\\n\\n> {}\".format(new_values[\"description\"])\n elif event_type == \"story_move_activity\":\n content = f\"{performed_by} moved {story_info}\"\n for change in changes:\n old_values = change.get(\"original_values\", {})\n new_values = change[\"new_values\"]\n if \"current_state\" in old_values and \"current_state\" in new_values:\n content += \" from **{}** to **{}**.\".format(\n old_values[\"current_state\"], new_values[\"current_state\"]\n )\n elif event_type in UNSUPPORTED_EVENT_TYPES:\n # Known but unsupported Pivotal event types\n pass\n else:\n raise UnsupportedWebhookEventType(event_type)\n\n return subject, content\n\n\n@webhook_view(\"Pivotal\")\n@has_request_variables\ndef api_pivotal_webhook(request: HttpRequest, user_profile: UserProfile) -> HttpResponse:\n subject = content = None\n try:\n subject, content = api_pivotal_webhook_v3(request, user_profile)\n except Exception:\n # Attempt to parse v5 JSON payload\n subject, content = api_pivotal_webhook_v5(request, user_profile)\n\n if not content:\n return json_error(_(\"Unable to handle Pivotal payload\"))\n\n check_send_webhook_message(request, user_profile, subject, content)\n return json_success()\n", "path": "zerver/webhooks/pivotal/view.py"}]}
| 3,745 | 89 |
gh_patches_debug_20906
|
rasdani/github-patches
|
git_diff
|
mampfes__hacs_waste_collection_schedule-346
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Not using HA supported python version
HA supports the last two minor versions of Python, that is currently 3.10 and 3.9.
[calendar.py](https://github.com/mampfes/hacs_waste_collection_schedule/blob/master/custom_components/waste_collection_schedule/calendar.py#L118) makes use of Python 3.10 only type hinting features for optional arguments via unions:
`def calc_unique_calendar_id(scraper: Scraper, type: str | None = None):`
The union str | None is not supported as type hint by Python 3.9, hence the waste collection schedule fails to load albeit HA runs on a supported installation.
</issue>
<code>
[start of custom_components/waste_collection_schedule/calendar.py]
1 """Calendar platform support for Waste Collection Schedule."""
2
3 import logging
4 from datetime import timedelta, timezone, datetime
5
6 from homeassistant.components.calendar import CalendarEntity, CalendarEvent
7 from homeassistant.core import HomeAssistant
8 from homeassistant.util.dt import DEFAULT_TIME_ZONE
9
10 from custom_components.waste_collection_schedule.waste_collection_schedule.scraper import (
11 Scraper,
12 )
13
14 _LOGGER = logging.getLogger(__name__)
15
16
17 async def async_setup_platform(hass, config, async_add_entities, discovery_info=None):
18 """Set up calendar platform."""
19 # We only want this platform to be set up via discovery.
20 if discovery_info is None:
21 return
22
23 entities = []
24
25 api = discovery_info["api"]
26
27 for scraper in api.scrapers:
28 dedicated_calendar_types = scraper.get_dedicated_calendar_types()
29 global_calendar_types = scraper.get_global_calendar_types()
30
31 if dedicated_calendar_types is not None:
32 for type in dedicated_calendar_types:
33 unique_id = calc_unique_calendar_id(scraper, type)
34
35 entities.append(
36 WasteCollectionCalendar(
37 api,
38 scraper,
39 scraper.get_calendar_title_for_type(type),
40 [scraper.get_collection_type(type)],
41 unique_id,
42 )
43 )
44
45 if global_calendar_types is not None or dedicated_calendar_types is None:
46 unique_id = calc_unique_calendar_id(scraper)
47 entities.append(
48 WasteCollectionCalendar(
49 api,
50 scraper,
51 scraper.calendar_title,
52 [
53 scraper.get_collection_type(type)
54 for type in global_calendar_types
55 ]
56 if global_calendar_types is not None
57 else None,
58 unique_id,
59 )
60 )
61
62 async_add_entities(entities)
63
64
65 class WasteCollectionCalendar(CalendarEntity):
66 """Calendar entity class."""
67
68 def __init__(self, api, scraper, name, types, unique_id: str):
69 self._api = api
70 self._scraper = scraper
71 self._name = name
72 self._types = types
73 self._unique_id = unique_id
74 self._attr_unique_id = unique_id
75
76 @property
77 def name(self):
78 """Return entity name."""
79 return self._name
80
81 @property
82 def event(self):
83 """Return next collection event."""
84 collections = self._scraper.get_upcoming(
85 count=1, include_today=True, types=self._types
86 )
87
88 if len(collections) == 0:
89 return None
90 else:
91 return self._convert(collections[0])
92
93 async def async_get_events(
94 self, hass: HomeAssistant, start_date: datetime, end_date: datetime
95 ):
96 """Return all events within specified time span."""
97 events = []
98
99 for collection in self._scraper.get_upcoming(
100 include_today=True, types=self._types
101 ):
102 event = self._convert(collection)
103
104 if start_date <= event.start_datetime_local <= end_date:
105 events.append(event)
106
107 return events
108
109 def _convert(self, collection) -> CalendarEvent:
110 """Convert an collection into a Home Assistant calendar event."""
111 return CalendarEvent(
112 summary=collection.type,
113 start=collection.date,
114 end=collection.date + timedelta(days=1),
115 )
116
117
118 def calc_unique_calendar_id(scraper: Scraper, type: str | None = None):
119 return scraper.unique_id + ("_" + type if type is not None else "") + "_calendar"
120
[end of custom_components/waste_collection_schedule/calendar.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/custom_components/waste_collection_schedule/calendar.py b/custom_components/waste_collection_schedule/calendar.py
--- a/custom_components/waste_collection_schedule/calendar.py
+++ b/custom_components/waste_collection_schedule/calendar.py
@@ -1,15 +1,12 @@
"""Calendar platform support for Waste Collection Schedule."""
import logging
-from datetime import timedelta, timezone, datetime
+from datetime import datetime, timedelta
from homeassistant.components.calendar import CalendarEntity, CalendarEvent
from homeassistant.core import HomeAssistant
-from homeassistant.util.dt import DEFAULT_TIME_ZONE
-from custom_components.waste_collection_schedule.waste_collection_schedule.scraper import (
- Scraper,
-)
+from custom_components.waste_collection_schedule.waste_collection_schedule.scraper import Scraper
_LOGGER = logging.getLogger(__name__)
@@ -115,5 +112,5 @@
)
-def calc_unique_calendar_id(scraper: Scraper, type: str | None = None):
+def calc_unique_calendar_id(scraper: Scraper, type: str = None):
return scraper.unique_id + ("_" + type if type is not None else "") + "_calendar"
|
{"golden_diff": "diff --git a/custom_components/waste_collection_schedule/calendar.py b/custom_components/waste_collection_schedule/calendar.py\n--- a/custom_components/waste_collection_schedule/calendar.py\n+++ b/custom_components/waste_collection_schedule/calendar.py\n@@ -1,15 +1,12 @@\n \"\"\"Calendar platform support for Waste Collection Schedule.\"\"\"\n \n import logging\n-from datetime import timedelta, timezone, datetime\n+from datetime import datetime, timedelta\n \n from homeassistant.components.calendar import CalendarEntity, CalendarEvent\n from homeassistant.core import HomeAssistant\n-from homeassistant.util.dt import DEFAULT_TIME_ZONE\n \n-from custom_components.waste_collection_schedule.waste_collection_schedule.scraper import (\n- Scraper,\n-)\n+from custom_components.waste_collection_schedule.waste_collection_schedule.scraper import Scraper\n \n _LOGGER = logging.getLogger(__name__)\n \n@@ -115,5 +112,5 @@\n )\n \n \n-def calc_unique_calendar_id(scraper: Scraper, type: str | None = None):\n+def calc_unique_calendar_id(scraper: Scraper, type: str = None):\n return scraper.unique_id + (\"_\" + type if type is not None else \"\") + \"_calendar\"\n", "issue": "Not using HA supported python version\nHA supports the last two minor versions of Python, that is currently 3.10 and 3.9.\r\n[calendar.py](https://github.com/mampfes/hacs_waste_collection_schedule/blob/master/custom_components/waste_collection_schedule/calendar.py#L118) makes use of Python 3.10 only type hinting features for optional arguments via unions:\r\n`def calc_unique_calendar_id(scraper: Scraper, type: str | None = None):`\r\nThe union str | None is not supported as type hint by Python 3.9, hence the waste collection schedule fails to load albeit HA runs on a supported installation.\n", "before_files": [{"content": "\"\"\"Calendar platform support for Waste Collection Schedule.\"\"\"\n\nimport logging\nfrom datetime import timedelta, timezone, datetime\n\nfrom homeassistant.components.calendar import CalendarEntity, CalendarEvent\nfrom homeassistant.core import HomeAssistant\nfrom homeassistant.util.dt import DEFAULT_TIME_ZONE\n\nfrom custom_components.waste_collection_schedule.waste_collection_schedule.scraper import (\n Scraper,\n)\n\n_LOGGER = logging.getLogger(__name__)\n\n\nasync def async_setup_platform(hass, config, async_add_entities, discovery_info=None):\n \"\"\"Set up calendar platform.\"\"\"\n # We only want this platform to be set up via discovery.\n if discovery_info is None:\n return\n\n entities = []\n\n api = discovery_info[\"api\"]\n\n for scraper in api.scrapers:\n dedicated_calendar_types = scraper.get_dedicated_calendar_types()\n global_calendar_types = scraper.get_global_calendar_types()\n\n if dedicated_calendar_types is not None:\n for type in dedicated_calendar_types:\n unique_id = calc_unique_calendar_id(scraper, type)\n\n entities.append(\n WasteCollectionCalendar(\n api,\n scraper,\n scraper.get_calendar_title_for_type(type),\n [scraper.get_collection_type(type)],\n unique_id,\n )\n )\n\n if global_calendar_types is not None or dedicated_calendar_types is None:\n unique_id = calc_unique_calendar_id(scraper)\n entities.append(\n WasteCollectionCalendar(\n api,\n scraper,\n scraper.calendar_title,\n [\n scraper.get_collection_type(type)\n for type in global_calendar_types\n ]\n if global_calendar_types is not None\n else None,\n unique_id,\n )\n )\n\n async_add_entities(entities)\n\n\nclass WasteCollectionCalendar(CalendarEntity):\n \"\"\"Calendar entity class.\"\"\"\n\n def __init__(self, api, scraper, name, types, unique_id: str):\n self._api = api\n self._scraper = scraper\n self._name = name\n self._types = types\n self._unique_id = unique_id\n self._attr_unique_id = unique_id\n\n @property\n def name(self):\n \"\"\"Return entity name.\"\"\"\n return self._name\n\n @property\n def event(self):\n \"\"\"Return next collection event.\"\"\"\n collections = self._scraper.get_upcoming(\n count=1, include_today=True, types=self._types\n )\n\n if len(collections) == 0:\n return None\n else:\n return self._convert(collections[0])\n\n async def async_get_events(\n self, hass: HomeAssistant, start_date: datetime, end_date: datetime\n ):\n \"\"\"Return all events within specified time span.\"\"\"\n events = []\n\n for collection in self._scraper.get_upcoming(\n include_today=True, types=self._types\n ):\n event = self._convert(collection)\n\n if start_date <= event.start_datetime_local <= end_date:\n events.append(event)\n\n return events\n\n def _convert(self, collection) -> CalendarEvent:\n \"\"\"Convert an collection into a Home Assistant calendar event.\"\"\"\n return CalendarEvent(\n summary=collection.type,\n start=collection.date,\n end=collection.date + timedelta(days=1),\n )\n\n\ndef calc_unique_calendar_id(scraper: Scraper, type: str | None = None):\n return scraper.unique_id + (\"_\" + type if type is not None else \"\") + \"_calendar\"\n", "path": "custom_components/waste_collection_schedule/calendar.py"}]}
| 1,656 | 240 |
gh_patches_debug_2209
|
rasdani/github-patches
|
git_diff
|
OCHA-DAP__hdx-ckan-1887
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Please allow markdown to the organization description field
Right now markdown is not allowed in that field. I believe that this is preventing me from adding paragraphs and other particular styles to the text in question.

</issue>
<code>
[start of ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py]
1 '''
2 Created on Nov 3, 2014
3
4 @author: alexandru-m-g
5 '''
6
7 import logging
8
9 import ckan.lib.base as base
10 import ckan.logic as logic
11 import ckan.model as model
12 import ckan.common as common
13 import ckan.lib.helpers as h
14
15 import ckanext.hdx_crisis.dao.data_access as data_access
16 import ckanext.hdx_crisis.formatters.top_line_items_formatter as formatters
17
18 render = base.render
19 get_action = logic.get_action
20 c = common.c
21 request = common.request
22 _ = common._
23
24
25 log = logging.getLogger(__name__)
26
27
28 class CrisisController(base.BaseController):
29
30 def show(self):
31
32 context = {'model': model, 'session': model.Session,
33 'user': c.user or c.author, 'for_view': True,
34 'auth_user_obj': c.userobj}
35
36 crisis_data_access = data_access.EbolaCrisisDataAccess()
37 crisis_data_access.fetch_data(context)
38 c.top_line_items = crisis_data_access.get_top_line_items()
39
40 formatter = formatters.TopLineItemsFormatter(c.top_line_items)
41 formatter.format_results()
42
43 search_term = u'ebola'
44
45 self._generate_dataset_results(context, search_term)
46
47 self._generate_other_links(search_term)
48
49 return render('crisis/crisis.html')
50
51 def _generate_dataset_results(self, context, search_term):
52 limit = 25
53 c.q = search_term
54
55 page = int(request.params.get('page', 1))
56 data_dict = {'sort': u'metadata_modified desc',
57 'fq': '+dataset_type:dataset',
58 'rows': limit,
59 'q': c.q,
60 'start': (page - 1) * limit
61 }
62 query = get_action("package_search")(context, data_dict)
63
64 def pager_url(q=None, page=None):
65 url = h.url_for('show_crisis', page=page) + '#datasets-section'
66 return url
67
68 c.page = h.Page(
69 collection=query['results'],
70 page=page,
71 url=pager_url,
72 item_count=query['count'],
73 items_per_page=limit
74 )
75 c.items = query['results']
76 c.item_count = query['count']
77
78 def _generate_other_links(self, search_term):
79 c.other_links = {}
80 c.other_links['show_more'] = h.url_for(
81 "search", **{'q': search_term, 'sort': u'metadata_modified desc',
82 'ext_indicator': '0'})
83
[end of ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py b/ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py
--- a/ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py
+++ b/ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py
@@ -46,7 +46,7 @@
self._generate_other_links(search_term)
- return render('crisis/crisis.html')
+ return render('crisis/crisis-ebola.html')
def _generate_dataset_results(self, context, search_term):
limit = 25
|
{"golden_diff": "diff --git a/ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py b/ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py\n--- a/ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py\n+++ b/ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py\n@@ -46,7 +46,7 @@\n \n self._generate_other_links(search_term)\n \n- return render('crisis/crisis.html')\n+ return render('crisis/crisis-ebola.html')\n \n def _generate_dataset_results(self, context, search_term):\n limit = 25\n", "issue": "Please allow markdown to the organization description field\nRight now markdown is not allowed in that field. I believe that this is preventing me from adding paragraphs and other particular styles to the text in question. \n\n\n\n", "before_files": [{"content": "'''\nCreated on Nov 3, 2014\n\n@author: alexandru-m-g\n'''\n\nimport logging\n\nimport ckan.lib.base as base\nimport ckan.logic as logic\nimport ckan.model as model\nimport ckan.common as common\nimport ckan.lib.helpers as h\n\nimport ckanext.hdx_crisis.dao.data_access as data_access\nimport ckanext.hdx_crisis.formatters.top_line_items_formatter as formatters\n\nrender = base.render\nget_action = logic.get_action\nc = common.c\nrequest = common.request\n_ = common._\n\n\nlog = logging.getLogger(__name__)\n\n\nclass CrisisController(base.BaseController):\n\n def show(self):\n\n context = {'model': model, 'session': model.Session,\n 'user': c.user or c.author, 'for_view': True,\n 'auth_user_obj': c.userobj}\n\n crisis_data_access = data_access.EbolaCrisisDataAccess()\n crisis_data_access.fetch_data(context)\n c.top_line_items = crisis_data_access.get_top_line_items()\n\n formatter = formatters.TopLineItemsFormatter(c.top_line_items)\n formatter.format_results()\n\n search_term = u'ebola'\n\n self._generate_dataset_results(context, search_term)\n\n self._generate_other_links(search_term)\n\n return render('crisis/crisis.html')\n\n def _generate_dataset_results(self, context, search_term):\n limit = 25\n c.q = search_term\n\n page = int(request.params.get('page', 1))\n data_dict = {'sort': u'metadata_modified desc',\n 'fq': '+dataset_type:dataset',\n 'rows': limit,\n 'q': c.q,\n 'start': (page - 1) * limit\n }\n query = get_action(\"package_search\")(context, data_dict)\n\n def pager_url(q=None, page=None):\n url = h.url_for('show_crisis', page=page) + '#datasets-section'\n return url\n\n c.page = h.Page(\n collection=query['results'],\n page=page,\n url=pager_url,\n item_count=query['count'],\n items_per_page=limit\n )\n c.items = query['results']\n c.item_count = query['count']\n\n def _generate_other_links(self, search_term):\n c.other_links = {}\n c.other_links['show_more'] = h.url_for(\n \"search\", **{'q': search_term, 'sort': u'metadata_modified desc',\n 'ext_indicator': '0'})\n", "path": "ckanext-hdx_crisis/ckanext/hdx_crisis/controllers/crisis_controller.py"}]}
| 1,407 | 179 |
gh_patches_debug_39448
|
rasdani/github-patches
|
git_diff
|
scoutapp__scout_apm_python-355
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Instrument Starlette background tasks
Starlette supports [background tasks](https://www.starlette.io/background/). We should instrument these as background transactions.
</issue>
<code>
[start of src/scout_apm/async_/starlette.py]
1 # coding=utf-8
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 from starlette.requests import Request
5
6 import scout_apm.core
7 from scout_apm.core.tracked_request import TrackedRequest
8 from scout_apm.core.web_requests import (
9 create_filtered_path,
10 ignore_path,
11 track_amazon_request_queue_time,
12 track_request_queue_time,
13 )
14
15
16 class ScoutMiddleware:
17 def __init__(self, app):
18 self.app = app
19 installed = scout_apm.core.install()
20 self._do_nothing = not installed
21
22 async def __call__(self, scope, receive, send):
23 if self._do_nothing or scope["type"] != "http":
24 await self.app(scope, receive, send)
25 return
26
27 request = Request(scope)
28 tracked_request = TrackedRequest.instance()
29 # Can't name controller until post-routing - see final clause
30 controller_span = tracked_request.start_span(operation="Controller/Unknown")
31
32 tracked_request.tag(
33 "path",
34 create_filtered_path(request.url.path, request.query_params.multi_items()),
35 )
36 if ignore_path(request.url.path):
37 tracked_request.tag("ignore_transaction", True)
38
39 user_ip = (
40 request.headers.get("x-forwarded-for", default="").split(",")[0]
41 or request.headers.get("client-ip", default="").split(",")[0]
42 or request.client.host
43 )
44 tracked_request.tag("user_ip", user_ip)
45
46 queue_time = request.headers.get(
47 "x-queue-start", default=""
48 ) or request.headers.get("x-request-start", default="")
49 tracked_queue_time = track_request_queue_time(queue_time, tracked_request)
50 if not tracked_queue_time:
51 amazon_queue_time = request.headers.get("x-amzn-trace-id", default="")
52 track_amazon_request_queue_time(amazon_queue_time, tracked_request)
53
54 try:
55 await self.app(scope, receive, send)
56 except Exception as exc:
57 tracked_request.tag("error", "true")
58 raise exc
59 finally:
60 if "endpoint" in scope:
61 endpoint = scope["endpoint"]
62 controller_span.operation = "Controller/{}.{}".format(
63 endpoint.__module__, endpoint.__qualname__
64 )
65 tracked_request.is_real_request = True
66 tracked_request.stop_span()
67
[end of src/scout_apm/async_/starlette.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/scout_apm/async_/starlette.py b/src/scout_apm/async_/starlette.py
--- a/src/scout_apm/async_/starlette.py
+++ b/src/scout_apm/async_/starlette.py
@@ -1,6 +1,8 @@
# coding=utf-8
from __future__ import absolute_import, division, print_function, unicode_literals
+import wrapt
+from starlette.background import BackgroundTask
from starlette.requests import Request
import scout_apm.core
@@ -18,6 +20,8 @@
self.app = app
installed = scout_apm.core.install()
self._do_nothing = not installed
+ if installed:
+ install_background_instrumentation()
async def __call__(self, scope, receive, send):
if self._do_nothing or scope["type"] != "http":
@@ -51,16 +55,57 @@
amazon_queue_time = request.headers.get("x-amzn-trace-id", default="")
track_amazon_request_queue_time(amazon_queue_time, tracked_request)
- try:
- await self.app(scope, receive, send)
- except Exception as exc:
- tracked_request.tag("error", "true")
- raise exc
- finally:
+ def rename_controller_span_from_endpoint():
if "endpoint" in scope:
+ # Rename top span
endpoint = scope["endpoint"]
controller_span.operation = "Controller/{}.{}".format(
endpoint.__module__, endpoint.__qualname__
)
tracked_request.is_real_request = True
+
+ async def wrapped_send(data):
+ # Finish HTTP span when body finishes sending, not later (e.g.
+ # after background tasks)
+ if data.get("type", None) == "http.response.body" and not data.get(
+ "more_body", False
+ ):
+ rename_controller_span_from_endpoint()
+ tracked_request.stop_span()
+ return await send(data)
+
+ try:
+ await self.app(scope, receive, wrapped_send)
+ except Exception as exc:
+ tracked_request.tag("error", "true")
+ raise exc
+ finally:
+ if tracked_request.end_time is None:
+ rename_controller_span_from_endpoint()
+ tracked_request.stop_span()
+
+
+background_instrumentation_installed = False
+
+
+def install_background_instrumentation():
+ global background_instrumentation_installed
+ if background_instrumentation_installed:
+ return
+ background_instrumentation_installed = True
+
+ @wrapt.decorator
+ async def wrapped_background_call(wrapped, instance, args, kwargs):
+ tracked_request = TrackedRequest.instance()
+ tracked_request.is_real_request = True
+ tracked_request.start_span(
+ operation="Job/{}.{}".format(
+ instance.func.__module__, instance.func.__qualname__
+ )
+ )
+ try:
+ return await wrapped(*args, **kwargs)
+ finally:
tracked_request.stop_span()
+
+ BackgroundTask.__call__ = wrapped_background_call(BackgroundTask.__call__)
|
{"golden_diff": "diff --git a/src/scout_apm/async_/starlette.py b/src/scout_apm/async_/starlette.py\n--- a/src/scout_apm/async_/starlette.py\n+++ b/src/scout_apm/async_/starlette.py\n@@ -1,6 +1,8 @@\n # coding=utf-8\n from __future__ import absolute_import, division, print_function, unicode_literals\n \n+import wrapt\n+from starlette.background import BackgroundTask\n from starlette.requests import Request\n \n import scout_apm.core\n@@ -18,6 +20,8 @@\n self.app = app\n installed = scout_apm.core.install()\n self._do_nothing = not installed\n+ if installed:\n+ install_background_instrumentation()\n \n async def __call__(self, scope, receive, send):\n if self._do_nothing or scope[\"type\"] != \"http\":\n@@ -51,16 +55,57 @@\n amazon_queue_time = request.headers.get(\"x-amzn-trace-id\", default=\"\")\n track_amazon_request_queue_time(amazon_queue_time, tracked_request)\n \n- try:\n- await self.app(scope, receive, send)\n- except Exception as exc:\n- tracked_request.tag(\"error\", \"true\")\n- raise exc\n- finally:\n+ def rename_controller_span_from_endpoint():\n if \"endpoint\" in scope:\n+ # Rename top span\n endpoint = scope[\"endpoint\"]\n controller_span.operation = \"Controller/{}.{}\".format(\n endpoint.__module__, endpoint.__qualname__\n )\n tracked_request.is_real_request = True\n+\n+ async def wrapped_send(data):\n+ # Finish HTTP span when body finishes sending, not later (e.g.\n+ # after background tasks)\n+ if data.get(\"type\", None) == \"http.response.body\" and not data.get(\n+ \"more_body\", False\n+ ):\n+ rename_controller_span_from_endpoint()\n+ tracked_request.stop_span()\n+ return await send(data)\n+\n+ try:\n+ await self.app(scope, receive, wrapped_send)\n+ except Exception as exc:\n+ tracked_request.tag(\"error\", \"true\")\n+ raise exc\n+ finally:\n+ if tracked_request.end_time is None:\n+ rename_controller_span_from_endpoint()\n+ tracked_request.stop_span()\n+\n+\n+background_instrumentation_installed = False\n+\n+\n+def install_background_instrumentation():\n+ global background_instrumentation_installed\n+ if background_instrumentation_installed:\n+ return\n+ background_instrumentation_installed = True\n+\n+ @wrapt.decorator\n+ async def wrapped_background_call(wrapped, instance, args, kwargs):\n+ tracked_request = TrackedRequest.instance()\n+ tracked_request.is_real_request = True\n+ tracked_request.start_span(\n+ operation=\"Job/{}.{}\".format(\n+ instance.func.__module__, instance.func.__qualname__\n+ )\n+ )\n+ try:\n+ return await wrapped(*args, **kwargs)\n+ finally:\n tracked_request.stop_span()\n+\n+ BackgroundTask.__call__ = wrapped_background_call(BackgroundTask.__call__)\n", "issue": "Instrument Starlette background tasks\nStarlette supports [background tasks](https://www.starlette.io/background/). We should instrument these as background transactions.\n", "before_files": [{"content": "# coding=utf-8\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom starlette.requests import Request\n\nimport scout_apm.core\nfrom scout_apm.core.tracked_request import TrackedRequest\nfrom scout_apm.core.web_requests import (\n create_filtered_path,\n ignore_path,\n track_amazon_request_queue_time,\n track_request_queue_time,\n)\n\n\nclass ScoutMiddleware:\n def __init__(self, app):\n self.app = app\n installed = scout_apm.core.install()\n self._do_nothing = not installed\n\n async def __call__(self, scope, receive, send):\n if self._do_nothing or scope[\"type\"] != \"http\":\n await self.app(scope, receive, send)\n return\n\n request = Request(scope)\n tracked_request = TrackedRequest.instance()\n # Can't name controller until post-routing - see final clause\n controller_span = tracked_request.start_span(operation=\"Controller/Unknown\")\n\n tracked_request.tag(\n \"path\",\n create_filtered_path(request.url.path, request.query_params.multi_items()),\n )\n if ignore_path(request.url.path):\n tracked_request.tag(\"ignore_transaction\", True)\n\n user_ip = (\n request.headers.get(\"x-forwarded-for\", default=\"\").split(\",\")[0]\n or request.headers.get(\"client-ip\", default=\"\").split(\",\")[0]\n or request.client.host\n )\n tracked_request.tag(\"user_ip\", user_ip)\n\n queue_time = request.headers.get(\n \"x-queue-start\", default=\"\"\n ) or request.headers.get(\"x-request-start\", default=\"\")\n tracked_queue_time = track_request_queue_time(queue_time, tracked_request)\n if not tracked_queue_time:\n amazon_queue_time = request.headers.get(\"x-amzn-trace-id\", default=\"\")\n track_amazon_request_queue_time(amazon_queue_time, tracked_request)\n\n try:\n await self.app(scope, receive, send)\n except Exception as exc:\n tracked_request.tag(\"error\", \"true\")\n raise exc\n finally:\n if \"endpoint\" in scope:\n endpoint = scope[\"endpoint\"]\n controller_span.operation = \"Controller/{}.{}\".format(\n endpoint.__module__, endpoint.__qualname__\n )\n tracked_request.is_real_request = True\n tracked_request.stop_span()\n", "path": "src/scout_apm/async_/starlette.py"}]}
| 1,194 | 683 |
gh_patches_debug_39209
|
rasdani/github-patches
|
git_diff
|
nipy__nipype-2780
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Meshfix interface inverting command parameters
### Summary
Hi,
While using the MeshFix interface, I received this error:
```shell
RuntimeError: Command:
meshfix /path/to/file.off -a 2.000000 0.200000 --fineTuneIn 4 --shells 2 -o file_fixed.off -q
Standard output:
Fixing asin tolerance to 3.491368e-02
Standard error:
ERROR- number of substeps must be > 0.
Return code: 255
```
### Actual behavior
As shown previously, the interface generated command leading to this error is:
```shell
meshfix /path/to/file.off -a 2.000000 0.200000 --fineTuneIn 4 --shells 2 -o file_fixed.off -q
```
And the error is pretty clear, the `--fineTuneIn` argument requires a distance **and** a substeps number. Those two parameters are actualy given in the code:
```python
finetune_wm = pe.Node(interface=mf.MeshFix(), name='finetune_wm')
finetune_wm.inputs.quiet_mode = True
finetune_wm.inputs.epsilon_angle = 2
finetune_wm.inputs.number_of_biggest_shells = 2
finetune_wm.inputs.finetuning_substeps = 4 # Set the substeps number
finetune_wm.inputs.finetuning_distance = 0.2 # Set the distance
finetune_wm.inputs.finetuning_inwards = True # Set --fineTuneIn
```
And these parameters are also in the command but in a wrong order:
```shell
0.200000 --fineTuneIn 4
```
### Expected behavior
The correct order should be:
```shell
--fineTuneIn 0.200000 4
```
As writen in the doc:
> --fineTuneIn \<d\> \<n\> Used to fine-tune the minimal distance between surfaces
> A minimal distance d is ensured, and reached in n substeps
And then the command should be:
```shell
meshfix /path/to/file.off -a 2.000000 --fineTuneIn 0.200000 4 --shells 2 -o file_fixed.off -q
```
</issue>
<code>
[start of nipype/interfaces/meshfix.py]
1 # -*- coding: utf-8 -*-
2 # emacs: -*- mode: python; py-indent-offset: 4; indent-tabs-mode: nil -*-
3 # vi: set ft=python sts=4 ts=4 sw=4 et:
4 """ Fixes meshes:
5 """
6 from __future__ import (print_function, division, unicode_literals,
7 absolute_import)
8
9 import os.path as op
10 from ..utils.filemanip import split_filename
11 from .base import (CommandLine, CommandLineInputSpec, traits, TraitedSpec,
12 isdefined, File)
13
14
15 class MeshFixInputSpec(CommandLineInputSpec):
16 number_of_biggest_shells = traits.Int(
17 argstr='--shells %d', desc="Only the N biggest shells are kept")
18
19 epsilon_angle = traits.Range(
20 argstr='-a %f',
21 low=0.0,
22 high=2.0,
23 desc="Epsilon angle in degrees (must be between 0 and 2)")
24
25 join_overlapping_largest_components = traits.Bool(
26 argstr='-j',
27 xor=['join_closest_components'],
28 desc='Join 2 biggest components if they overlap, remove the rest.')
29
30 join_closest_components = traits.Bool(
31 argstr='-jc',
32 xor=['join_closest_components'],
33 desc='Join the closest pair of components.')
34
35 quiet_mode = traits.Bool(
36 argstr='-q', desc="Quiet mode, don't write much to stdout.")
37
38 dont_clean = traits.Bool(argstr='--no-clean', desc="Don't Clean")
39
40 save_as_stl = traits.Bool(
41 xor=['save_as_vrml', 'save_as_freesurfer_mesh'],
42 argstr='--stl',
43 desc="Result is saved in stereolithographic format (.stl)")
44 save_as_vrml = traits.Bool(
45 argstr='--wrl',
46 xor=['save_as_stl', 'save_as_freesurfer_mesh'],
47 desc="Result is saved in VRML1.0 format (.wrl)")
48 save_as_freesurfer_mesh = traits.Bool(
49 argstr='--fsmesh',
50 xor=['save_as_vrml', 'save_as_stl'],
51 desc="Result is saved in freesurfer mesh format")
52
53 remove_handles = traits.Bool(
54 argstr='--remove-handles', desc="Remove handles")
55
56 uniform_remeshing_steps = traits.Int(
57 argstr='-u %d',
58 requires=['uniform_remeshing_vertices'],
59 desc="Number of steps for uniform remeshing of the whole mesh")
60
61 uniform_remeshing_vertices = traits.Int(
62 argstr='--vertices %d',
63 requires=['uniform_remeshing_steps'],
64 desc="Constrains the number of vertices."
65 "Must be used with uniform_remeshing_steps")
66
67 laplacian_smoothing_steps = traits.Int(
68 argstr='--smooth %d',
69 desc="The number of laplacian smoothing steps to apply")
70
71 x_shift = traits.Int(
72 argstr='--smooth %d',
73 desc=
74 "Shifts the coordinates of the vertices when saving. Output must be in FreeSurfer format"
75 )
76
77 # Cutting, decoupling, dilation
78 cut_outer = traits.Int(
79 argstr='--cut-outer %d',
80 desc="Remove triangles of 1st that are outside of the 2nd shell.")
81 cut_inner = traits.Int(
82 argstr='--cut-inner %d',
83 desc=
84 "Remove triangles of 1st that are inside of the 2nd shell. Dilate 2nd by N; Fill holes and keep only 1st afterwards."
85 )
86 decouple_inin = traits.Int(
87 argstr='--decouple-inin %d',
88 desc="Treat 1st file as inner, 2nd file as outer component."
89 "Resolve overlaps by moving inners triangles inwards. Constrain the min distance between the components > d."
90 )
91 decouple_outin = traits.Int(
92 argstr='--decouple-outin %d',
93 desc="Treat 1st file as outer, 2nd file as inner component."
94 "Resolve overlaps by moving outers triangles inwards. Constrain the min distance between the components > d."
95 )
96 decouple_outout = traits.Int(
97 argstr='--decouple-outout %d',
98 desc="Treat 1st file as outer, 2nd file as inner component."
99 "Resolve overlaps by moving outers triangles outwards. Constrain the min distance between the components > d."
100 )
101
102 finetuning_inwards = traits.Bool(
103 argstr='--fineTuneIn ',
104 requires=['finetuning_distance', 'finetuning_substeps'])
105 finetuning_outwards = traits.Bool(
106 argstr='--fineTuneIn ',
107 requires=['finetuning_distance', 'finetuning_substeps'],
108 xor=['finetuning_inwards'],
109 desc=
110 'Similar to finetuning_inwards, but ensures minimal distance in the other direction'
111 )
112 finetuning_distance = traits.Float(
113 argstr='%f',
114 requires=['finetuning_substeps'],
115 desc="Used to fine-tune the minimal distance between surfaces."
116 "A minimal distance d is ensured, and reached in n substeps. When using the surfaces for subsequent volume meshing by gmsh, this step prevent too flat tetrahedra2)"
117 )
118 finetuning_substeps = traits.Int(
119 argstr='%d',
120 requires=['finetuning_distance'],
121 desc="Used to fine-tune the minimal distance between surfaces."
122 "A minimal distance d is ensured, and reached in n substeps. When using the surfaces for subsequent volume meshing by gmsh, this step prevent too flat tetrahedra2)"
123 )
124
125 dilation = traits.Int(
126 argstr='--dilate %d',
127 desc="Dilate the surface by d. d < 0 means shrinking.")
128 set_intersections_to_one = traits.Bool(
129 argstr='--intersect',
130 desc="If the mesh contains intersections, return value = 1."
131 "If saved in gmsh format, intersections will be highlighted.")
132
133 in_file1 = File(exists=True, argstr="%s", position=1, mandatory=True)
134 in_file2 = File(exists=True, argstr="%s", position=2)
135 output_type = traits.Enum(
136 'off', ['stl', 'msh', 'wrl', 'vrml', 'fs', 'off'],
137 usedefault=True,
138 desc='The output type to save the file as.')
139 out_filename = File(
140 genfile=True,
141 argstr="-o %s",
142 desc='The output filename for the fixed mesh file')
143
144
145 class MeshFixOutputSpec(TraitedSpec):
146 mesh_file = File(exists=True, desc='The output mesh file')
147
148
149 class MeshFix(CommandLine):
150 """
151 MeshFix v1.2-alpha - by Marco Attene, Mirko Windhoff, Axel Thielscher.
152
153 .. seealso::
154
155 http://jmeshlib.sourceforge.net
156 Sourceforge page
157
158 http://simnibs.de/installation/meshfixandgetfem
159 Ubuntu installation instructions
160
161 If MeshFix is used for research purposes, please cite the following paper:
162 M. Attene - A lightweight approach to repairing digitized polygon meshes.
163 The Visual Computer, 2010. (c) Springer.
164
165 Accepted input formats are OFF, PLY and STL.
166 Other formats (like .msh for gmsh) are supported only partially.
167
168 Example
169 -------
170
171 >>> import nipype.interfaces.meshfix as mf
172 >>> fix = mf.MeshFix()
173 >>> fix.inputs.in_file1 = 'lh-pial.stl'
174 >>> fix.inputs.in_file2 = 'rh-pial.stl'
175 >>> fix.run() # doctest: +SKIP
176 >>> fix.cmdline
177 'meshfix lh-pial.stl rh-pial.stl -o lh-pial_fixed.off'
178 """
179 _cmd = 'meshfix'
180 input_spec = MeshFixInputSpec
181 output_spec = MeshFixOutputSpec
182
183 def _list_outputs(self):
184 outputs = self.output_spec().get()
185 if isdefined(self.inputs.out_filename):
186 path, name, ext = split_filename(self.inputs.out_filename)
187 ext = ext.replace('.', '')
188 out_types = ['stl', 'msh', 'wrl', 'vrml', 'fs', 'off']
189 # Make sure that the output filename uses one of the possible file types
190 if any(ext == out_type.lower() for out_type in out_types):
191 outputs['mesh_file'] = op.abspath(self.inputs.out_filename)
192 else:
193 outputs['mesh_file'] = op.abspath(
194 name + '.' + self.inputs.output_type)
195 else:
196 outputs['mesh_file'] = op.abspath(self._gen_outfilename())
197 return outputs
198
199 def _gen_filename(self, name):
200 if name == 'out_filename':
201 return self._gen_outfilename()
202 else:
203 return None
204
205 def _gen_outfilename(self):
206 _, name, _ = split_filename(self.inputs.in_file1)
207 if self.inputs.save_as_freesurfer_mesh or self.inputs.output_type == 'fs':
208 self.inputs.output_type = 'fs'
209 self.inputs.save_as_freesurfer_mesh = True
210 if self.inputs.save_as_stl or self.inputs.output_type == 'stl':
211 self.inputs.output_type = 'stl'
212 self.inputs.save_as_stl = True
213 if self.inputs.save_as_vrml or self.inputs.output_type == 'vrml':
214 self.inputs.output_type = 'vrml'
215 self.inputs.save_as_vrml = True
216 return name + '_fixed.' + self.inputs.output_type
217
[end of nipype/interfaces/meshfix.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nipype/interfaces/meshfix.py b/nipype/interfaces/meshfix.py
--- a/nipype/interfaces/meshfix.py
+++ b/nipype/interfaces/meshfix.py
@@ -70,8 +70,7 @@
x_shift = traits.Int(
argstr='--smooth %d',
- desc=
- "Shifts the coordinates of the vertices when saving. Output must be in FreeSurfer format"
+ desc="Shifts the coordinates of the vertices when saving. Output must be in FreeSurfer format"
)
# Cutting, decoupling, dilation
@@ -80,8 +79,7 @@
desc="Remove triangles of 1st that are outside of the 2nd shell.")
cut_inner = traits.Int(
argstr='--cut-inner %d',
- desc=
- "Remove triangles of 1st that are inside of the 2nd shell. Dilate 2nd by N; Fill holes and keep only 1st afterwards."
+ desc="Remove triangles of 1st that are inside of the 2nd shell. Dilate 2nd by N; Fill holes and keep only 1st afterwards."
)
decouple_inin = traits.Int(
argstr='--decouple-inin %d',
@@ -101,23 +99,28 @@
finetuning_inwards = traits.Bool(
argstr='--fineTuneIn ',
- requires=['finetuning_distance', 'finetuning_substeps'])
+ requires=['finetuning_distance', 'finetuning_substeps'],
+ position=-3,
+ desc="Used to fine-tune the minimal distance between surfaces."
+ )
finetuning_outwards = traits.Bool(
- argstr='--fineTuneIn ',
+ argstr='--fineTuneOut ',
requires=['finetuning_distance', 'finetuning_substeps'],
+ position=-3,
xor=['finetuning_inwards'],
- desc=
- 'Similar to finetuning_inwards, but ensures minimal distance in the other direction'
+ desc='Similar to finetuning_inwards, but ensures minimal distance in the other direction'
)
finetuning_distance = traits.Float(
argstr='%f',
requires=['finetuning_substeps'],
+ position=-2,
desc="Used to fine-tune the minimal distance between surfaces."
"A minimal distance d is ensured, and reached in n substeps. When using the surfaces for subsequent volume meshing by gmsh, this step prevent too flat tetrahedra2)"
)
finetuning_substeps = traits.Int(
argstr='%d',
requires=['finetuning_distance'],
+ position=-1,
desc="Used to fine-tune the minimal distance between surfaces."
"A minimal distance d is ensured, and reached in n substeps. When using the surfaces for subsequent volume meshing by gmsh, this step prevent too flat tetrahedra2)"
)
|
{"golden_diff": "diff --git a/nipype/interfaces/meshfix.py b/nipype/interfaces/meshfix.py\n--- a/nipype/interfaces/meshfix.py\n+++ b/nipype/interfaces/meshfix.py\n@@ -70,8 +70,7 @@\n \n x_shift = traits.Int(\n argstr='--smooth %d',\n- desc=\n- \"Shifts the coordinates of the vertices when saving. Output must be in FreeSurfer format\"\n+ desc=\"Shifts the coordinates of the vertices when saving. Output must be in FreeSurfer format\"\n )\n \n # Cutting, decoupling, dilation\n@@ -80,8 +79,7 @@\n desc=\"Remove triangles of 1st that are outside of the 2nd shell.\")\n cut_inner = traits.Int(\n argstr='--cut-inner %d',\n- desc=\n- \"Remove triangles of 1st that are inside of the 2nd shell. Dilate 2nd by N; Fill holes and keep only 1st afterwards.\"\n+ desc=\"Remove triangles of 1st that are inside of the 2nd shell. Dilate 2nd by N; Fill holes and keep only 1st afterwards.\"\n )\n decouple_inin = traits.Int(\n argstr='--decouple-inin %d',\n@@ -101,23 +99,28 @@\n \n finetuning_inwards = traits.Bool(\n argstr='--fineTuneIn ',\n- requires=['finetuning_distance', 'finetuning_substeps'])\n+ requires=['finetuning_distance', 'finetuning_substeps'],\n+ position=-3,\n+ desc=\"Used to fine-tune the minimal distance between surfaces.\"\n+ )\n finetuning_outwards = traits.Bool(\n- argstr='--fineTuneIn ',\n+ argstr='--fineTuneOut ',\n requires=['finetuning_distance', 'finetuning_substeps'],\n+ position=-3,\n xor=['finetuning_inwards'],\n- desc=\n- 'Similar to finetuning_inwards, but ensures minimal distance in the other direction'\n+ desc='Similar to finetuning_inwards, but ensures minimal distance in the other direction'\n )\n finetuning_distance = traits.Float(\n argstr='%f',\n requires=['finetuning_substeps'],\n+ position=-2,\n desc=\"Used to fine-tune the minimal distance between surfaces.\"\n \"A minimal distance d is ensured, and reached in n substeps. When using the surfaces for subsequent volume meshing by gmsh, this step prevent too flat tetrahedra2)\"\n )\n finetuning_substeps = traits.Int(\n argstr='%d',\n requires=['finetuning_distance'],\n+ position=-1,\n desc=\"Used to fine-tune the minimal distance between surfaces.\"\n \"A minimal distance d is ensured, and reached in n substeps. When using the surfaces for subsequent volume meshing by gmsh, this step prevent too flat tetrahedra2)\"\n )\n", "issue": "Meshfix interface inverting command parameters\n### Summary\r\nHi,\r\nWhile using the MeshFix interface, I received this error:\r\n```shell\r\nRuntimeError: Command:\r\nmeshfix /path/to/file.off -a 2.000000 0.200000 --fineTuneIn 4 --shells 2 -o file_fixed.off -q\r\nStandard output:\r\nFixing asin tolerance to 3.491368e-02\r\nStandard error:\r\n\r\nERROR- number of substeps must be > 0.\r\nReturn code: 255\r\n```\r\n\r\n### Actual behavior\r\nAs shown previously, the interface generated command leading to this error is:\r\n```shell\r\nmeshfix /path/to/file.off -a 2.000000 0.200000 --fineTuneIn 4 --shells 2 -o file_fixed.off -q\r\n```\r\nAnd the error is pretty clear, the `--fineTuneIn` argument requires a distance **and** a substeps number. Those two parameters are actualy given in the code:\r\n```python\r\nfinetune_wm = pe.Node(interface=mf.MeshFix(), name='finetune_wm')\r\nfinetune_wm.inputs.quiet_mode = True\r\nfinetune_wm.inputs.epsilon_angle = 2\r\nfinetune_wm.inputs.number_of_biggest_shells = 2\r\nfinetune_wm.inputs.finetuning_substeps = 4 # Set the substeps number\r\nfinetune_wm.inputs.finetuning_distance = 0.2 # Set the distance\r\nfinetune_wm.inputs.finetuning_inwards = True # Set --fineTuneIn\r\n```\r\nAnd these parameters are also in the command but in a wrong order:\r\n```shell\r\n0.200000 --fineTuneIn 4\r\n```\r\n\r\n### Expected behavior\r\nThe correct order should be:\r\n```shell\r\n--fineTuneIn 0.200000 4\r\n```\r\nAs writen in the doc:\r\n> --fineTuneIn \\<d\\> \\<n\\> Used to fine-tune the minimal distance between surfaces \r\n> A minimal distance d is ensured, and reached in n substeps\r\n\r\nAnd then the command should be:\r\n```shell\r\nmeshfix /path/to/file.off -a 2.000000 --fineTuneIn 0.200000 4 --shells 2 -o file_fixed.off -q\r\n```\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# emacs: -*- mode: python; py-indent-offset: 4; indent-tabs-mode: nil -*-\n# vi: set ft=python sts=4 ts=4 sw=4 et:\n\"\"\" Fixes meshes:\n\"\"\"\nfrom __future__ import (print_function, division, unicode_literals,\n absolute_import)\n\nimport os.path as op\nfrom ..utils.filemanip import split_filename\nfrom .base import (CommandLine, CommandLineInputSpec, traits, TraitedSpec,\n isdefined, File)\n\n\nclass MeshFixInputSpec(CommandLineInputSpec):\n number_of_biggest_shells = traits.Int(\n argstr='--shells %d', desc=\"Only the N biggest shells are kept\")\n\n epsilon_angle = traits.Range(\n argstr='-a %f',\n low=0.0,\n high=2.0,\n desc=\"Epsilon angle in degrees (must be between 0 and 2)\")\n\n join_overlapping_largest_components = traits.Bool(\n argstr='-j',\n xor=['join_closest_components'],\n desc='Join 2 biggest components if they overlap, remove the rest.')\n\n join_closest_components = traits.Bool(\n argstr='-jc',\n xor=['join_closest_components'],\n desc='Join the closest pair of components.')\n\n quiet_mode = traits.Bool(\n argstr='-q', desc=\"Quiet mode, don't write much to stdout.\")\n\n dont_clean = traits.Bool(argstr='--no-clean', desc=\"Don't Clean\")\n\n save_as_stl = traits.Bool(\n xor=['save_as_vrml', 'save_as_freesurfer_mesh'],\n argstr='--stl',\n desc=\"Result is saved in stereolithographic format (.stl)\")\n save_as_vrml = traits.Bool(\n argstr='--wrl',\n xor=['save_as_stl', 'save_as_freesurfer_mesh'],\n desc=\"Result is saved in VRML1.0 format (.wrl)\")\n save_as_freesurfer_mesh = traits.Bool(\n argstr='--fsmesh',\n xor=['save_as_vrml', 'save_as_stl'],\n desc=\"Result is saved in freesurfer mesh format\")\n\n remove_handles = traits.Bool(\n argstr='--remove-handles', desc=\"Remove handles\")\n\n uniform_remeshing_steps = traits.Int(\n argstr='-u %d',\n requires=['uniform_remeshing_vertices'],\n desc=\"Number of steps for uniform remeshing of the whole mesh\")\n\n uniform_remeshing_vertices = traits.Int(\n argstr='--vertices %d',\n requires=['uniform_remeshing_steps'],\n desc=\"Constrains the number of vertices.\"\n \"Must be used with uniform_remeshing_steps\")\n\n laplacian_smoothing_steps = traits.Int(\n argstr='--smooth %d',\n desc=\"The number of laplacian smoothing steps to apply\")\n\n x_shift = traits.Int(\n argstr='--smooth %d',\n desc=\n \"Shifts the coordinates of the vertices when saving. Output must be in FreeSurfer format\"\n )\n\n # Cutting, decoupling, dilation\n cut_outer = traits.Int(\n argstr='--cut-outer %d',\n desc=\"Remove triangles of 1st that are outside of the 2nd shell.\")\n cut_inner = traits.Int(\n argstr='--cut-inner %d',\n desc=\n \"Remove triangles of 1st that are inside of the 2nd shell. Dilate 2nd by N; Fill holes and keep only 1st afterwards.\"\n )\n decouple_inin = traits.Int(\n argstr='--decouple-inin %d',\n desc=\"Treat 1st file as inner, 2nd file as outer component.\"\n \"Resolve overlaps by moving inners triangles inwards. Constrain the min distance between the components > d.\"\n )\n decouple_outin = traits.Int(\n argstr='--decouple-outin %d',\n desc=\"Treat 1st file as outer, 2nd file as inner component.\"\n \"Resolve overlaps by moving outers triangles inwards. Constrain the min distance between the components > d.\"\n )\n decouple_outout = traits.Int(\n argstr='--decouple-outout %d',\n desc=\"Treat 1st file as outer, 2nd file as inner component.\"\n \"Resolve overlaps by moving outers triangles outwards. Constrain the min distance between the components > d.\"\n )\n\n finetuning_inwards = traits.Bool(\n argstr='--fineTuneIn ',\n requires=['finetuning_distance', 'finetuning_substeps'])\n finetuning_outwards = traits.Bool(\n argstr='--fineTuneIn ',\n requires=['finetuning_distance', 'finetuning_substeps'],\n xor=['finetuning_inwards'],\n desc=\n 'Similar to finetuning_inwards, but ensures minimal distance in the other direction'\n )\n finetuning_distance = traits.Float(\n argstr='%f',\n requires=['finetuning_substeps'],\n desc=\"Used to fine-tune the minimal distance between surfaces.\"\n \"A minimal distance d is ensured, and reached in n substeps. When using the surfaces for subsequent volume meshing by gmsh, this step prevent too flat tetrahedra2)\"\n )\n finetuning_substeps = traits.Int(\n argstr='%d',\n requires=['finetuning_distance'],\n desc=\"Used to fine-tune the minimal distance between surfaces.\"\n \"A minimal distance d is ensured, and reached in n substeps. When using the surfaces for subsequent volume meshing by gmsh, this step prevent too flat tetrahedra2)\"\n )\n\n dilation = traits.Int(\n argstr='--dilate %d',\n desc=\"Dilate the surface by d. d < 0 means shrinking.\")\n set_intersections_to_one = traits.Bool(\n argstr='--intersect',\n desc=\"If the mesh contains intersections, return value = 1.\"\n \"If saved in gmsh format, intersections will be highlighted.\")\n\n in_file1 = File(exists=True, argstr=\"%s\", position=1, mandatory=True)\n in_file2 = File(exists=True, argstr=\"%s\", position=2)\n output_type = traits.Enum(\n 'off', ['stl', 'msh', 'wrl', 'vrml', 'fs', 'off'],\n usedefault=True,\n desc='The output type to save the file as.')\n out_filename = File(\n genfile=True,\n argstr=\"-o %s\",\n desc='The output filename for the fixed mesh file')\n\n\nclass MeshFixOutputSpec(TraitedSpec):\n mesh_file = File(exists=True, desc='The output mesh file')\n\n\nclass MeshFix(CommandLine):\n \"\"\"\n MeshFix v1.2-alpha - by Marco Attene, Mirko Windhoff, Axel Thielscher.\n\n .. seealso::\n\n http://jmeshlib.sourceforge.net\n Sourceforge page\n\n http://simnibs.de/installation/meshfixandgetfem\n Ubuntu installation instructions\n\n If MeshFix is used for research purposes, please cite the following paper:\n M. Attene - A lightweight approach to repairing digitized polygon meshes.\n The Visual Computer, 2010. (c) Springer.\n\n Accepted input formats are OFF, PLY and STL.\n Other formats (like .msh for gmsh) are supported only partially.\n\n Example\n -------\n\n >>> import nipype.interfaces.meshfix as mf\n >>> fix = mf.MeshFix()\n >>> fix.inputs.in_file1 = 'lh-pial.stl'\n >>> fix.inputs.in_file2 = 'rh-pial.stl'\n >>> fix.run() # doctest: +SKIP\n >>> fix.cmdline\n 'meshfix lh-pial.stl rh-pial.stl -o lh-pial_fixed.off'\n \"\"\"\n _cmd = 'meshfix'\n input_spec = MeshFixInputSpec\n output_spec = MeshFixOutputSpec\n\n def _list_outputs(self):\n outputs = self.output_spec().get()\n if isdefined(self.inputs.out_filename):\n path, name, ext = split_filename(self.inputs.out_filename)\n ext = ext.replace('.', '')\n out_types = ['stl', 'msh', 'wrl', 'vrml', 'fs', 'off']\n # Make sure that the output filename uses one of the possible file types\n if any(ext == out_type.lower() for out_type in out_types):\n outputs['mesh_file'] = op.abspath(self.inputs.out_filename)\n else:\n outputs['mesh_file'] = op.abspath(\n name + '.' + self.inputs.output_type)\n else:\n outputs['mesh_file'] = op.abspath(self._gen_outfilename())\n return outputs\n\n def _gen_filename(self, name):\n if name == 'out_filename':\n return self._gen_outfilename()\n else:\n return None\n\n def _gen_outfilename(self):\n _, name, _ = split_filename(self.inputs.in_file1)\n if self.inputs.save_as_freesurfer_mesh or self.inputs.output_type == 'fs':\n self.inputs.output_type = 'fs'\n self.inputs.save_as_freesurfer_mesh = True\n if self.inputs.save_as_stl or self.inputs.output_type == 'stl':\n self.inputs.output_type = 'stl'\n self.inputs.save_as_stl = True\n if self.inputs.save_as_vrml or self.inputs.output_type == 'vrml':\n self.inputs.output_type = 'vrml'\n self.inputs.save_as_vrml = True\n return name + '_fixed.' + self.inputs.output_type\n", "path": "nipype/interfaces/meshfix.py"}]}
| 3,734 | 658 |
gh_patches_debug_30534
|
rasdani/github-patches
|
git_diff
|
pantsbuild__pants-13941
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`log_level_by_target` doesn't seem to work well for Python targets
**Describe the bug**
Using the following:
```
level = "warn"
log_levels_by_target = {"pants.goal.stats_aggregator" = "info"}
```
when running `./pants --stats-log ...` I don't see the stats being logged.
**Pants version**
`main`
**OS**
Ubuntu
**Additional info**
I suspect this is because `log_levels_by_target` isn't used to configure the Python logger, and therefore the python logger for any Python module is configured to use the level set by `level`.
This can be seen by inspecting the logger in `src/python/pants/goal/stats_aggregator.py` which is set to the level `WARN`. Therefore I assume the log call never gets forwarded to the Rust-implemented handler, and therefore `log_levels_by_target` isn't considered.
</issue>
<code>
[start of src/python/pants/init/logging.py]
1 # Copyright 2018 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 from __future__ import annotations
5
6 import http.client
7 import locale
8 import logging
9 import sys
10 from contextlib import contextmanager
11 from io import BufferedReader, TextIOWrapper
12 from logging import Formatter, LogRecord, StreamHandler
13 from pathlib import PurePath
14 from typing import Iterator
15
16 import pants.util.logging as pants_logging
17 from pants.engine.internals import native_engine
18 from pants.option.option_value_container import OptionValueContainer
19 from pants.util.dirutil import safe_mkdir_for
20 from pants.util.docutil import doc_url
21 from pants.util.logging import LogLevel
22 from pants.util.strutil import strip_prefix
23
24 # Although logging supports the WARN level, its not documented and could conceivably be yanked.
25 # Since pants has supported 'warn' since inception, leave the 'warn' choice as-is but explicitly
26 # setup a 'WARN' logging level name that maps to 'WARNING'.
27 logging.addLevelName(logging.WARNING, "WARN")
28 logging.addLevelName(pants_logging.TRACE, "TRACE")
29
30
31 class _NativeHandler(StreamHandler):
32 """This class is installed as a Python logging module handler (using the logging.addHandler
33 method) and proxies logs to the Rust logging infrastructure."""
34
35 def emit(self, record: LogRecord) -> None:
36 native_engine.write_log(self.format(record), record.levelno, record.name)
37
38 def flush(self) -> None:
39 native_engine.flush_log()
40
41
42 class _ExceptionFormatter(Formatter):
43 """Possibly render the stacktrace and possibly give debug hints, based on global options."""
44
45 def __init__(self, level: LogLevel, *, print_stacktrace: bool) -> None:
46 super().__init__(None)
47 self.level = level
48 self.print_stacktrace = print_stacktrace
49
50 def formatException(self, exc_info):
51 stacktrace = super().formatException(exc_info) if self.print_stacktrace else ""
52
53 debug_instructions = []
54 if not self.print_stacktrace:
55 debug_instructions.append("--print-stacktrace for more error details")
56 if self.level not in {LogLevel.DEBUG, LogLevel.TRACE}:
57 debug_instructions.append("-ldebug for more logs")
58 debug_instructions = (
59 f"Use {' and/or '.join(debug_instructions)}. " if debug_instructions else ""
60 )
61
62 return (
63 f"{stacktrace}\n\n{debug_instructions}\nSee {doc_url('troubleshooting')} for common "
64 f"issues.\nConsider reaching out for help: {doc_url('getting-help')}\n"
65 )
66
67
68 @contextmanager
69 def stdio_destination(stdin_fileno: int, stdout_fileno: int, stderr_fileno: int) -> Iterator[None]:
70 """Sets a destination for both logging and stdio: must be called after `initialize_stdio`.
71
72 After `initialize_stdio` and outside of this contextmanager, the default stdio destination is
73 the pants.log. But inside of this block, all engine "tasks"/@rules that are spawned will have
74 thread/task-local state that directs their IO to the given destination. When the contextmanager
75 exits all tasks will be restored to the default destination (regardless of whether they have
76 completed).
77 """
78 if not logging.getLogger(None).handlers:
79 raise AssertionError("stdio_destination should only be called after initialize_stdio.")
80
81 native_engine.stdio_thread_console_set(stdin_fileno, stdout_fileno, stderr_fileno)
82 try:
83 yield
84 finally:
85 native_engine.stdio_thread_console_clear()
86
87
88 def stdio_destination_use_color(use_color: bool) -> None:
89 """Sets a color mode for the current thread's destination.
90
91 True or false force color to be used or not used: None causes TTY detection to decide whether
92 color will be used.
93
94 NB: This method is independent from either `stdio_destination` or `initialize_stdio` because
95 we cannot decide whether to use color for a particular destination until it is open AND we have
96 parsed options for the relevant connection.
97 """
98 native_engine.stdio_thread_console_color_mode_set(use_color)
99
100
101 @contextmanager
102 def _python_logging_setup(level: LogLevel, *, print_stacktrace: bool) -> Iterator[None]:
103 """Installs a root Python logger that routes all logging through a Rust logger."""
104
105 def trace_fn(self, message, *args, **kwargs):
106 if self.isEnabledFor(LogLevel.TRACE.level):
107 self._log(LogLevel.TRACE.level, message, *args, **kwargs)
108
109 logging.Logger.trace = trace_fn # type: ignore[attr-defined]
110 logger = logging.getLogger(None)
111
112 def clear_logging_handlers():
113 handlers = tuple(logger.handlers)
114 for handler in handlers:
115 logger.removeHandler(handler)
116 return handlers
117
118 def set_logging_handlers(handlers):
119 for handler in handlers:
120 logger.addHandler(handler)
121
122 # Remove existing handlers, and restore them afterward.
123 handlers = clear_logging_handlers()
124 try:
125 # This routes warnings through our loggers instead of straight to raw stderr.
126 logging.captureWarnings(True)
127 handler = _NativeHandler()
128 exc_formatter = _ExceptionFormatter(level, print_stacktrace=print_stacktrace)
129 handler.setFormatter(exc_formatter)
130 logger.addHandler(handler)
131 level.set_level_for(logger)
132
133 if logger.isEnabledFor(LogLevel.TRACE.level):
134 http.client.HTTPConnection.debuglevel = 1 # type: ignore[attr-defined]
135 requests_logger = logging.getLogger("requests.packages.urllib3")
136 LogLevel.TRACE.set_level_for(requests_logger)
137 requests_logger.propagate = True
138
139 yield
140 finally:
141 clear_logging_handlers()
142 set_logging_handlers(handlers)
143
144
145 @contextmanager
146 def initialize_stdio(global_bootstrap_options: OptionValueContainer) -> Iterator[None]:
147 """Mutates sys.std* and logging to route stdio for a Pants process to thread local destinations.
148
149 In this context, `sys.std*` and logging handlers will route through Rust code that uses
150 thread-local information to decide whether to write to a file, or to stdio file handles.
151
152 To control the stdio destination set by this method, use the `stdio_destination` context manager.
153
154 This is called in two different processes:
155 * PantsRunner, after it has determined that LocalPantsRunner will be running in process, and
156 immediately before setting a `stdio_destination` for the remainder of the run.
157 * PantsDaemon, immediately on startup. The process will then default to sending stdio to the log
158 until client connections arrive, at which point `stdio_destination` is used per-connection.
159 """
160 with initialize_stdio_raw(
161 global_bootstrap_options.level,
162 global_bootstrap_options.log_show_rust_3rdparty,
163 global_bootstrap_options.show_log_target,
164 _get_log_levels_by_target(global_bootstrap_options),
165 global_bootstrap_options.print_stacktrace,
166 global_bootstrap_options.ignore_warnings,
167 global_bootstrap_options.pants_workdir,
168 ):
169 yield
170
171
172 @contextmanager
173 def initialize_stdio_raw(
174 global_level: LogLevel,
175 log_show_rust_3rdparty: bool,
176 show_target: bool,
177 log_levels_by_target: dict[str, LogLevel],
178 print_stacktrace: bool,
179 ignore_warnings: list[str],
180 pants_workdir: str,
181 ) -> Iterator[None]:
182 literal_filters = []
183 regex_filters = []
184 for filt in ignore_warnings:
185 if filt.startswith("$regex$"):
186 regex_filters.append(strip_prefix(filt, "$regex$"))
187 else:
188 literal_filters.append(filt)
189
190 # Set the pants log destination.
191 log_path = str(pants_log_path(PurePath(pants_workdir)))
192 safe_mkdir_for(log_path)
193
194 # Initialize thread-local stdio, and replace sys.std* with proxies.
195 original_stdin, original_stdout, original_stderr = sys.stdin, sys.stdout, sys.stderr
196 try:
197 raw_stdin, sys.stdout, sys.stderr = native_engine.stdio_initialize(
198 global_level.level,
199 log_show_rust_3rdparty,
200 show_target,
201 {k: v.level for k, v in log_levels_by_target.items()},
202 tuple(literal_filters),
203 tuple(regex_filters),
204 log_path,
205 )
206 sys.stdin = TextIOWrapper(
207 BufferedReader(raw_stdin),
208 # NB: We set the default encoding explicitly to bypass logic in the TextIOWrapper
209 # constructor that would poke the underlying file (which is not valid until a
210 # `stdio_destination` is set).
211 encoding=locale.getpreferredencoding(False),
212 )
213
214 sys.__stdin__, sys.__stdout__, sys.__stderr__ = sys.stdin, sys.stdout, sys.stderr
215 # Install a Python logger that will route through the Rust logger.
216 with _python_logging_setup(global_level, print_stacktrace=print_stacktrace):
217 yield
218 finally:
219 sys.stdin, sys.stdout, sys.stderr = original_stdin, original_stdout, original_stderr
220 sys.__stdin__, sys.__stdout__, sys.__stderr__ = sys.stdin, sys.stdout, sys.stderr
221
222
223 def pants_log_path(workdir: PurePath) -> PurePath:
224 """Given the path of the workdir, returns the `pants.log` path."""
225 return workdir / "pants.log"
226
227
228 def _get_log_levels_by_target(
229 global_bootstrap_options: OptionValueContainer,
230 ) -> dict[str, LogLevel]:
231 raw_levels = global_bootstrap_options.log_levels_by_target
232 levels: dict[str, LogLevel] = {}
233 for key, value in raw_levels.items():
234 if not isinstance(key, str):
235 raise ValueError(
236 "Keys for log_domain_levels must be strings, but was given the key: {key} with type {type(key)}."
237 )
238 if not isinstance(value, str):
239 raise ValueError(
240 "Values for log_domain_levels must be strings, but was given the value: {value} with type {type(value)}."
241 )
242 log_level = LogLevel[value.upper()]
243 levels[key] = log_level
244 return levels
245
[end of src/python/pants/init/logging.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/python/pants/init/logging.py b/src/python/pants/init/logging.py
--- a/src/python/pants/init/logging.py
+++ b/src/python/pants/init/logging.py
@@ -99,7 +99,9 @@
@contextmanager
-def _python_logging_setup(level: LogLevel, *, print_stacktrace: bool) -> Iterator[None]:
+def _python_logging_setup(
+ level: LogLevel, log_levels_by_target: dict[str, LogLevel], *, print_stacktrace: bool
+) -> Iterator[None]:
"""Installs a root Python logger that routes all logging through a Rust logger."""
def trace_fn(self, message, *args, **kwargs):
@@ -130,6 +132,9 @@
logger.addHandler(handler)
level.set_level_for(logger)
+ for key, level in log_levels_by_target.items():
+ level.set_level_for(logging.getLogger(key))
+
if logger.isEnabledFor(LogLevel.TRACE.level):
http.client.HTTPConnection.debuglevel = 1 # type: ignore[attr-defined]
requests_logger = logging.getLogger("requests.packages.urllib3")
@@ -213,7 +218,9 @@
sys.__stdin__, sys.__stdout__, sys.__stderr__ = sys.stdin, sys.stdout, sys.stderr
# Install a Python logger that will route through the Rust logger.
- with _python_logging_setup(global_level, print_stacktrace=print_stacktrace):
+ with _python_logging_setup(
+ global_level, log_levels_by_target, print_stacktrace=print_stacktrace
+ ):
yield
finally:
sys.stdin, sys.stdout, sys.stderr = original_stdin, original_stdout, original_stderr
|
{"golden_diff": "diff --git a/src/python/pants/init/logging.py b/src/python/pants/init/logging.py\n--- a/src/python/pants/init/logging.py\n+++ b/src/python/pants/init/logging.py\n@@ -99,7 +99,9 @@\n \n \n @contextmanager\n-def _python_logging_setup(level: LogLevel, *, print_stacktrace: bool) -> Iterator[None]:\n+def _python_logging_setup(\n+ level: LogLevel, log_levels_by_target: dict[str, LogLevel], *, print_stacktrace: bool\n+) -> Iterator[None]:\n \"\"\"Installs a root Python logger that routes all logging through a Rust logger.\"\"\"\n \n def trace_fn(self, message, *args, **kwargs):\n@@ -130,6 +132,9 @@\n logger.addHandler(handler)\n level.set_level_for(logger)\n \n+ for key, level in log_levels_by_target.items():\n+ level.set_level_for(logging.getLogger(key))\n+\n if logger.isEnabledFor(LogLevel.TRACE.level):\n http.client.HTTPConnection.debuglevel = 1 # type: ignore[attr-defined]\n requests_logger = logging.getLogger(\"requests.packages.urllib3\")\n@@ -213,7 +218,9 @@\n \n sys.__stdin__, sys.__stdout__, sys.__stderr__ = sys.stdin, sys.stdout, sys.stderr\n # Install a Python logger that will route through the Rust logger.\n- with _python_logging_setup(global_level, print_stacktrace=print_stacktrace):\n+ with _python_logging_setup(\n+ global_level, log_levels_by_target, print_stacktrace=print_stacktrace\n+ ):\n yield\n finally:\n sys.stdin, sys.stdout, sys.stderr = original_stdin, original_stdout, original_stderr\n", "issue": "`log_level_by_target` doesn't seem to work well for Python targets\n**Describe the bug**\r\nUsing the following:\r\n```\r\nlevel = \"warn\"\r\nlog_levels_by_target = {\"pants.goal.stats_aggregator\" = \"info\"}\r\n```\r\nwhen running `./pants --stats-log ...` I don't see the stats being logged.\r\n\r\n**Pants version**\r\n`main`\r\n\r\n**OS**\r\nUbuntu\r\n\r\n**Additional info**\r\nI suspect this is because `log_levels_by_target` isn't used to configure the Python logger, and therefore the python logger for any Python module is configured to use the level set by `level`.\r\n\r\nThis can be seen by inspecting the logger in `src/python/pants/goal/stats_aggregator.py` which is set to the level `WARN`. Therefore I assume the log call never gets forwarded to the Rust-implemented handler, and therefore `log_levels_by_target` isn't considered.\r\n\n", "before_files": [{"content": "# Copyright 2018 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom __future__ import annotations\n\nimport http.client\nimport locale\nimport logging\nimport sys\nfrom contextlib import contextmanager\nfrom io import BufferedReader, TextIOWrapper\nfrom logging import Formatter, LogRecord, StreamHandler\nfrom pathlib import PurePath\nfrom typing import Iterator\n\nimport pants.util.logging as pants_logging\nfrom pants.engine.internals import native_engine\nfrom pants.option.option_value_container import OptionValueContainer\nfrom pants.util.dirutil import safe_mkdir_for\nfrom pants.util.docutil import doc_url\nfrom pants.util.logging import LogLevel\nfrom pants.util.strutil import strip_prefix\n\n# Although logging supports the WARN level, its not documented and could conceivably be yanked.\n# Since pants has supported 'warn' since inception, leave the 'warn' choice as-is but explicitly\n# setup a 'WARN' logging level name that maps to 'WARNING'.\nlogging.addLevelName(logging.WARNING, \"WARN\")\nlogging.addLevelName(pants_logging.TRACE, \"TRACE\")\n\n\nclass _NativeHandler(StreamHandler):\n \"\"\"This class is installed as a Python logging module handler (using the logging.addHandler\n method) and proxies logs to the Rust logging infrastructure.\"\"\"\n\n def emit(self, record: LogRecord) -> None:\n native_engine.write_log(self.format(record), record.levelno, record.name)\n\n def flush(self) -> None:\n native_engine.flush_log()\n\n\nclass _ExceptionFormatter(Formatter):\n \"\"\"Possibly render the stacktrace and possibly give debug hints, based on global options.\"\"\"\n\n def __init__(self, level: LogLevel, *, print_stacktrace: bool) -> None:\n super().__init__(None)\n self.level = level\n self.print_stacktrace = print_stacktrace\n\n def formatException(self, exc_info):\n stacktrace = super().formatException(exc_info) if self.print_stacktrace else \"\"\n\n debug_instructions = []\n if not self.print_stacktrace:\n debug_instructions.append(\"--print-stacktrace for more error details\")\n if self.level not in {LogLevel.DEBUG, LogLevel.TRACE}:\n debug_instructions.append(\"-ldebug for more logs\")\n debug_instructions = (\n f\"Use {' and/or '.join(debug_instructions)}. \" if debug_instructions else \"\"\n )\n\n return (\n f\"{stacktrace}\\n\\n{debug_instructions}\\nSee {doc_url('troubleshooting')} for common \"\n f\"issues.\\nConsider reaching out for help: {doc_url('getting-help')}\\n\"\n )\n\n\n@contextmanager\ndef stdio_destination(stdin_fileno: int, stdout_fileno: int, stderr_fileno: int) -> Iterator[None]:\n \"\"\"Sets a destination for both logging and stdio: must be called after `initialize_stdio`.\n\n After `initialize_stdio` and outside of this contextmanager, the default stdio destination is\n the pants.log. But inside of this block, all engine \"tasks\"/@rules that are spawned will have\n thread/task-local state that directs their IO to the given destination. When the contextmanager\n exits all tasks will be restored to the default destination (regardless of whether they have\n completed).\n \"\"\"\n if not logging.getLogger(None).handlers:\n raise AssertionError(\"stdio_destination should only be called after initialize_stdio.\")\n\n native_engine.stdio_thread_console_set(stdin_fileno, stdout_fileno, stderr_fileno)\n try:\n yield\n finally:\n native_engine.stdio_thread_console_clear()\n\n\ndef stdio_destination_use_color(use_color: bool) -> None:\n \"\"\"Sets a color mode for the current thread's destination.\n\n True or false force color to be used or not used: None causes TTY detection to decide whether\n color will be used.\n\n NB: This method is independent from either `stdio_destination` or `initialize_stdio` because\n we cannot decide whether to use color for a particular destination until it is open AND we have\n parsed options for the relevant connection.\n \"\"\"\n native_engine.stdio_thread_console_color_mode_set(use_color)\n\n\n@contextmanager\ndef _python_logging_setup(level: LogLevel, *, print_stacktrace: bool) -> Iterator[None]:\n \"\"\"Installs a root Python logger that routes all logging through a Rust logger.\"\"\"\n\n def trace_fn(self, message, *args, **kwargs):\n if self.isEnabledFor(LogLevel.TRACE.level):\n self._log(LogLevel.TRACE.level, message, *args, **kwargs)\n\n logging.Logger.trace = trace_fn # type: ignore[attr-defined]\n logger = logging.getLogger(None)\n\n def clear_logging_handlers():\n handlers = tuple(logger.handlers)\n for handler in handlers:\n logger.removeHandler(handler)\n return handlers\n\n def set_logging_handlers(handlers):\n for handler in handlers:\n logger.addHandler(handler)\n\n # Remove existing handlers, and restore them afterward.\n handlers = clear_logging_handlers()\n try:\n # This routes warnings through our loggers instead of straight to raw stderr.\n logging.captureWarnings(True)\n handler = _NativeHandler()\n exc_formatter = _ExceptionFormatter(level, print_stacktrace=print_stacktrace)\n handler.setFormatter(exc_formatter)\n logger.addHandler(handler)\n level.set_level_for(logger)\n\n if logger.isEnabledFor(LogLevel.TRACE.level):\n http.client.HTTPConnection.debuglevel = 1 # type: ignore[attr-defined]\n requests_logger = logging.getLogger(\"requests.packages.urllib3\")\n LogLevel.TRACE.set_level_for(requests_logger)\n requests_logger.propagate = True\n\n yield\n finally:\n clear_logging_handlers()\n set_logging_handlers(handlers)\n\n\n@contextmanager\ndef initialize_stdio(global_bootstrap_options: OptionValueContainer) -> Iterator[None]:\n \"\"\"Mutates sys.std* and logging to route stdio for a Pants process to thread local destinations.\n\n In this context, `sys.std*` and logging handlers will route through Rust code that uses\n thread-local information to decide whether to write to a file, or to stdio file handles.\n\n To control the stdio destination set by this method, use the `stdio_destination` context manager.\n\n This is called in two different processes:\n * PantsRunner, after it has determined that LocalPantsRunner will be running in process, and\n immediately before setting a `stdio_destination` for the remainder of the run.\n * PantsDaemon, immediately on startup. The process will then default to sending stdio to the log\n until client connections arrive, at which point `stdio_destination` is used per-connection.\n \"\"\"\n with initialize_stdio_raw(\n global_bootstrap_options.level,\n global_bootstrap_options.log_show_rust_3rdparty,\n global_bootstrap_options.show_log_target,\n _get_log_levels_by_target(global_bootstrap_options),\n global_bootstrap_options.print_stacktrace,\n global_bootstrap_options.ignore_warnings,\n global_bootstrap_options.pants_workdir,\n ):\n yield\n\n\n@contextmanager\ndef initialize_stdio_raw(\n global_level: LogLevel,\n log_show_rust_3rdparty: bool,\n show_target: bool,\n log_levels_by_target: dict[str, LogLevel],\n print_stacktrace: bool,\n ignore_warnings: list[str],\n pants_workdir: str,\n) -> Iterator[None]:\n literal_filters = []\n regex_filters = []\n for filt in ignore_warnings:\n if filt.startswith(\"$regex$\"):\n regex_filters.append(strip_prefix(filt, \"$regex$\"))\n else:\n literal_filters.append(filt)\n\n # Set the pants log destination.\n log_path = str(pants_log_path(PurePath(pants_workdir)))\n safe_mkdir_for(log_path)\n\n # Initialize thread-local stdio, and replace sys.std* with proxies.\n original_stdin, original_stdout, original_stderr = sys.stdin, sys.stdout, sys.stderr\n try:\n raw_stdin, sys.stdout, sys.stderr = native_engine.stdio_initialize(\n global_level.level,\n log_show_rust_3rdparty,\n show_target,\n {k: v.level for k, v in log_levels_by_target.items()},\n tuple(literal_filters),\n tuple(regex_filters),\n log_path,\n )\n sys.stdin = TextIOWrapper(\n BufferedReader(raw_stdin),\n # NB: We set the default encoding explicitly to bypass logic in the TextIOWrapper\n # constructor that would poke the underlying file (which is not valid until a\n # `stdio_destination` is set).\n encoding=locale.getpreferredencoding(False),\n )\n\n sys.__stdin__, sys.__stdout__, sys.__stderr__ = sys.stdin, sys.stdout, sys.stderr\n # Install a Python logger that will route through the Rust logger.\n with _python_logging_setup(global_level, print_stacktrace=print_stacktrace):\n yield\n finally:\n sys.stdin, sys.stdout, sys.stderr = original_stdin, original_stdout, original_stderr\n sys.__stdin__, sys.__stdout__, sys.__stderr__ = sys.stdin, sys.stdout, sys.stderr\n\n\ndef pants_log_path(workdir: PurePath) -> PurePath:\n \"\"\"Given the path of the workdir, returns the `pants.log` path.\"\"\"\n return workdir / \"pants.log\"\n\n\ndef _get_log_levels_by_target(\n global_bootstrap_options: OptionValueContainer,\n) -> dict[str, LogLevel]:\n raw_levels = global_bootstrap_options.log_levels_by_target\n levels: dict[str, LogLevel] = {}\n for key, value in raw_levels.items():\n if not isinstance(key, str):\n raise ValueError(\n \"Keys for log_domain_levels must be strings, but was given the key: {key} with type {type(key)}.\"\n )\n if not isinstance(value, str):\n raise ValueError(\n \"Values for log_domain_levels must be strings, but was given the value: {value} with type {type(value)}.\"\n )\n log_level = LogLevel[value.upper()]\n levels[key] = log_level\n return levels\n", "path": "src/python/pants/init/logging.py"}]}
| 3,478 | 364 |
gh_patches_debug_30422
|
rasdani/github-patches
|
git_diff
|
scikit-image__scikit-image-7310
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pixel_graph causes TypeError in map_array if mask is not given but edge_dunction is given
### Description:
If you give `edge_function` to `pixel_graph` but don't give `mask,` `mask` stays to be the default `None,` which would cause `TypeError 'The type of an array to be remapped should be an integer.'` in `map_array` even if we make sure the input image is integer.
I believe this is caused by the if statement at the beginning of the function. The if statement at the beginning does not cover the specific case I mentioned above, and the mask would not be changed from None.
The following is the lines I mentioned:
```python
if image.dtype == bool and mask is None:
mask = image
if mask is None and edge_function is None:
mask = np.ones_like(image, dtype=bool)
edge_function = _weighted_abs_diff
```
As the solution, I think separating if statement for `mask` and the one for `edge_function` works:
```python
if image.dtype == bool and mask is None:
mask = image
if mask is None:
mask = np.ones_like(image, dtype=bool)
if edge_function is None:
edge_function = _weighted_abs_diff
```
### Way to reproduce:
```python
import numpy as np
import skimage
image = np.array(
[[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
)
func = lambda x, y, z: np.abs(x-y)
adj1 = skimage.graph.pixel_graph(image) # No error
adj2 = skimage.graph.pixel_graph(image, edge_function = func) # TypeError
```
### Version information:
```Shell
3.10.12 (main, Jun 11 2023, 05:26:28) [GCC 11.4.0]
Linux-5.15.120+-x86_64-with-glibc2.35
scikit-image version: 0.19.3
numpy version: 1.23.5
```
</issue>
<code>
[start of skimage/graph/_graph.py]
1 import numpy as np
2 from scipy import sparse
3 from scipy.sparse import csgraph
4 from ..morphology._util import _raveled_offsets_and_distances
5 from ..util._map_array import map_array
6
7
8 def _weighted_abs_diff(values0, values1, distances):
9 """A default edge function for complete image graphs.
10
11 A pixel graph on an image with no edge values and no mask is a very
12 boring regular lattice, so we define a default edge weight to be the
13 absolute difference between values *weighted* by the distance
14 between them.
15
16 Parameters
17 ----------
18 values0 : array
19 The pixel values for each node.
20 values1 : array
21 The pixel values for each neighbor.
22 distances : array
23 The distance between each node and its neighbor.
24
25 Returns
26 -------
27 edge_values : array of float
28 The computed values: abs(values0 - values1) * distances.
29 """
30 return np.abs(values0 - values1) * distances
31
32
33 def pixel_graph(image, *, mask=None, edge_function=None, connectivity=1, spacing=None):
34 """Create an adjacency graph of pixels in an image.
35
36 Pixels where the mask is True are nodes in the returned graph, and they are
37 connected by edges to their neighbors according to the connectivity
38 parameter. By default, the *value* of an edge when a mask is given, or when
39 the image is itself the mask, is the Euclidean distance between the pixels.
40
41 However, if an int- or float-valued image is given with no mask, the value
42 of the edges is the absolute difference in intensity between adjacent
43 pixels, weighted by the Euclidean distance.
44
45 Parameters
46 ----------
47 image : array
48 The input image. If the image is of type bool, it will be used as the
49 mask as well.
50 mask : array of bool
51 Which pixels to use. If None, the graph for the whole image is used.
52 edge_function : callable
53 A function taking an array of pixel values, and an array of neighbor
54 pixel values, and an array of distances, and returning a value for the
55 edge. If no function is given, the value of an edge is just the
56 distance.
57 connectivity : int
58 The square connectivity of the pixel neighborhood: the number of
59 orthogonal steps allowed to consider a pixel a neighbor. See
60 `scipy.ndimage.generate_binary_structure` for details.
61 spacing : tuple of float
62 The spacing between pixels along each axis.
63
64 Returns
65 -------
66 graph : scipy.sparse.csr_matrix
67 A sparse adjacency matrix in which entry (i, j) is 1 if nodes i and j
68 are neighbors, 0 otherwise.
69 nodes : array of int
70 The nodes of the graph. These correspond to the raveled indices of the
71 nonzero pixels in the mask.
72 """
73 if image.dtype == bool and mask is None:
74 mask = image
75 if mask is None and edge_function is None:
76 mask = np.ones_like(image, dtype=bool)
77 edge_function = _weighted_abs_diff
78
79 # Strategy: we are going to build the (i, j, data) arrays of a scipy
80 # sparse COO matrix, then convert to CSR (which is fast).
81 # - grab the raveled IDs of the foreground (mask == True) parts of the
82 # image **in the padded space**.
83 # - broadcast them together with the raveled offsets to their neighbors.
84 # This gives us for each foreground pixel a list of neighbors (that
85 # may or may not be selected by the mask). (We also track the *distance*
86 # to each neighbor.)
87 # - select "valid" entries in the neighbors and distance arrays by indexing
88 # into the mask, which we can do since these are raveled indices.
89 # - use np.repeat() to repeat each source index according to the number
90 # of neighbors selected by the mask it has. Each of these repeated
91 # indices will be lined up with its neighbor, i.e. **this is the i
92 # array** of the COO format matrix.
93 # - use the mask as a boolean index to get a 1D view of the selected
94 # neighbors. **This is the j array.**
95 # - by default, the same boolean indexing can be applied to the distances
96 # to each neighbor, to give the **data array.** Optionally, a
97 # provided edge function can be computed on the pixel values and the
98 # distances to give a different value for the edges.
99 # Note, we use map_array to map the raveled coordinates in the padded
100 # image to the ones in the original image, and those are the returned
101 # nodes.
102 padded = np.pad(mask, 1, mode='constant', constant_values=False)
103 nodes_padded = np.flatnonzero(padded)
104 neighbor_offsets_padded, distances_padded = _raveled_offsets_and_distances(
105 padded.shape, connectivity=connectivity, spacing=spacing
106 )
107 neighbors_padded = nodes_padded[:, np.newaxis] + neighbor_offsets_padded
108 neighbor_distances_full = np.broadcast_to(distances_padded, neighbors_padded.shape)
109 nodes = np.flatnonzero(mask)
110 nodes_sequential = np.arange(nodes.size)
111 # neighbors outside the mask get mapped to 0, which is a valid index,
112 # BUT, they will be masked out in the next step.
113 neighbors = map_array(neighbors_padded, nodes_padded, nodes)
114 neighbors_mask = padded.reshape(-1)[neighbors_padded]
115 num_neighbors = np.sum(neighbors_mask, axis=1)
116 indices = np.repeat(nodes, num_neighbors)
117 indices_sequential = np.repeat(nodes_sequential, num_neighbors)
118 neighbor_indices = neighbors[neighbors_mask]
119 neighbor_distances = neighbor_distances_full[neighbors_mask]
120 neighbor_indices_sequential = map_array(neighbor_indices, nodes, nodes_sequential)
121 if edge_function is None:
122 data = neighbor_distances
123 else:
124 image_r = image.reshape(-1)
125 data = edge_function(
126 image_r[indices], image_r[neighbor_indices], neighbor_distances
127 )
128 m = nodes_sequential.size
129 mat = sparse.coo_matrix(
130 (data, (indices_sequential, neighbor_indices_sequential)), shape=(m, m)
131 )
132 graph = mat.tocsr()
133 return graph, nodes
134
135
136 def central_pixel(graph, nodes=None, shape=None, partition_size=100):
137 """Find the pixel with the highest closeness centrality.
138
139 Closeness centrality is the inverse of the total sum of shortest distances
140 from a node to every other node.
141
142 Parameters
143 ----------
144 graph : scipy.sparse.csr_matrix
145 The sparse matrix representation of the graph.
146 nodes : array of int
147 The raveled index of each node in graph in the image. If not provided,
148 the returned value will be the index in the input graph.
149 shape : tuple of int
150 The shape of the image in which the nodes are embedded. If provided,
151 the returned coordinates are a NumPy multi-index of the same
152 dimensionality as the input shape. Otherwise, the returned coordinate
153 is the raveled index provided in `nodes`.
154 partition_size : int
155 This function computes the shortest path distance between every pair
156 of nodes in the graph. This can result in a very large (N*N) matrix.
157 As a simple performance tweak, the distance values are computed in
158 lots of `partition_size`, resulting in a memory requirement of only
159 partition_size*N.
160
161 Returns
162 -------
163 position : int or tuple of int
164 If shape is given, the coordinate of the central pixel in the image.
165 Otherwise, the raveled index of that pixel.
166 distances : array of float
167 The total sum of distances from each node to each other reachable
168 node.
169 """
170 if nodes is None:
171 nodes = np.arange(graph.shape[0])
172 if partition_size is None:
173 num_splits = 1
174 else:
175 num_splits = max(2, graph.shape[0] // partition_size)
176 idxs = np.arange(graph.shape[0])
177 total_shortest_path_len_list = []
178 for partition in np.array_split(idxs, num_splits):
179 shortest_paths = csgraph.shortest_path(graph, directed=False, indices=partition)
180 shortest_paths_no_inf = np.nan_to_num(shortest_paths)
181 total_shortest_path_len_list.append(np.sum(shortest_paths_no_inf, axis=1))
182 total_shortest_path_len = np.concatenate(total_shortest_path_len_list)
183 nonzero = np.flatnonzero(total_shortest_path_len)
184 min_sp = np.argmin(total_shortest_path_len[nonzero])
185 raveled_index = nodes[nonzero[min_sp]]
186 if shape is not None:
187 central = np.unravel_index(raveled_index, shape)
188 else:
189 central = raveled_index
190 return central, total_shortest_path_len
191
[end of skimage/graph/_graph.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/skimage/graph/_graph.py b/skimage/graph/_graph.py
--- a/skimage/graph/_graph.py
+++ b/skimage/graph/_graph.py
@@ -70,11 +70,20 @@
The nodes of the graph. These correspond to the raveled indices of the
nonzero pixels in the mask.
"""
- if image.dtype == bool and mask is None:
- mask = image
- if mask is None and edge_function is None:
- mask = np.ones_like(image, dtype=bool)
- edge_function = _weighted_abs_diff
+ if mask is None:
+ if image.dtype == bool:
+ mask = image
+ else:
+ mask = np.ones_like(image, dtype=bool)
+
+ if edge_function is None:
+ if image.dtype == bool:
+
+ def edge_function(x, y, distances):
+ return distances
+
+ else:
+ edge_function = _weighted_abs_diff
# Strategy: we are going to build the (i, j, data) arrays of a scipy
# sparse COO matrix, then convert to CSR (which is fast).
@@ -118,13 +127,12 @@
neighbor_indices = neighbors[neighbors_mask]
neighbor_distances = neighbor_distances_full[neighbors_mask]
neighbor_indices_sequential = map_array(neighbor_indices, nodes, nodes_sequential)
- if edge_function is None:
- data = neighbor_distances
- else:
- image_r = image.reshape(-1)
- data = edge_function(
- image_r[indices], image_r[neighbor_indices], neighbor_distances
- )
+
+ image_r = image.reshape(-1)
+ data = edge_function(
+ image_r[indices], image_r[neighbor_indices], neighbor_distances
+ )
+
m = nodes_sequential.size
mat = sparse.coo_matrix(
(data, (indices_sequential, neighbor_indices_sequential)), shape=(m, m)
|
{"golden_diff": "diff --git a/skimage/graph/_graph.py b/skimage/graph/_graph.py\n--- a/skimage/graph/_graph.py\n+++ b/skimage/graph/_graph.py\n@@ -70,11 +70,20 @@\n The nodes of the graph. These correspond to the raveled indices of the\n nonzero pixels in the mask.\n \"\"\"\n- if image.dtype == bool and mask is None:\n- mask = image\n- if mask is None and edge_function is None:\n- mask = np.ones_like(image, dtype=bool)\n- edge_function = _weighted_abs_diff\n+ if mask is None:\n+ if image.dtype == bool:\n+ mask = image\n+ else:\n+ mask = np.ones_like(image, dtype=bool)\n+\n+ if edge_function is None:\n+ if image.dtype == bool:\n+\n+ def edge_function(x, y, distances):\n+ return distances\n+\n+ else:\n+ edge_function = _weighted_abs_diff\n \n # Strategy: we are going to build the (i, j, data) arrays of a scipy\n # sparse COO matrix, then convert to CSR (which is fast).\n@@ -118,13 +127,12 @@\n neighbor_indices = neighbors[neighbors_mask]\n neighbor_distances = neighbor_distances_full[neighbors_mask]\n neighbor_indices_sequential = map_array(neighbor_indices, nodes, nodes_sequential)\n- if edge_function is None:\n- data = neighbor_distances\n- else:\n- image_r = image.reshape(-1)\n- data = edge_function(\n- image_r[indices], image_r[neighbor_indices], neighbor_distances\n- )\n+\n+ image_r = image.reshape(-1)\n+ data = edge_function(\n+ image_r[indices], image_r[neighbor_indices], neighbor_distances\n+ )\n+\n m = nodes_sequential.size\n mat = sparse.coo_matrix(\n (data, (indices_sequential, neighbor_indices_sequential)), shape=(m, m)\n", "issue": "pixel_graph causes TypeError in map_array if mask is not given but edge_dunction is given\n### Description:\n\nIf you give `edge_function` to `pixel_graph` but don't give `mask,` `mask` stays to be the default `None,` which would cause `TypeError 'The type of an array to be remapped should be an integer.'` in `map_array` even if we make sure the input image is integer.\r\n\r\nI believe this is caused by the if statement at the beginning of the function. The if statement at the beginning does not cover the specific case I mentioned above, and the mask would not be changed from None.\r\n\r\nThe following is the lines I mentioned:\r\n\r\n```python\r\nif image.dtype == bool and mask is None:\r\n mask = image\r\nif mask is None and edge_function is None:\r\n mask = np.ones_like(image, dtype=bool)\r\n edge_function = _weighted_abs_diff\r\n```\r\n\r\nAs the solution, I think separating if statement for `mask` and the one for `edge_function` works:\r\n\r\n```python\r\nif image.dtype == bool and mask is None:\r\n mask = image\r\nif mask is None:\r\n mask = np.ones_like(image, dtype=bool)\r\nif edge_function is None:\r\n edge_function = _weighted_abs_diff\r\n```\r\n\n\n### Way to reproduce:\n\n```python\r\nimport numpy as np\r\nimport skimage\r\n\r\nimage = np.array(\r\n [[1, 2, 3],\r\n [4, 5, 6],\r\n [7, 8, 9]]\r\n) \r\n\r\nfunc = lambda x, y, z: np.abs(x-y)\r\nadj1 = skimage.graph.pixel_graph(image) # No error\r\nadj2 = skimage.graph.pixel_graph(image, edge_function = func) # TypeError\r\n```\n\n### Version information:\n\n```Shell\n3.10.12 (main, Jun 11 2023, 05:26:28) [GCC 11.4.0]\r\nLinux-5.15.120+-x86_64-with-glibc2.35\r\nscikit-image version: 0.19.3\r\nnumpy version: 1.23.5\n```\n\n", "before_files": [{"content": "import numpy as np\nfrom scipy import sparse\nfrom scipy.sparse import csgraph\nfrom ..morphology._util import _raveled_offsets_and_distances\nfrom ..util._map_array import map_array\n\n\ndef _weighted_abs_diff(values0, values1, distances):\n \"\"\"A default edge function for complete image graphs.\n\n A pixel graph on an image with no edge values and no mask is a very\n boring regular lattice, so we define a default edge weight to be the\n absolute difference between values *weighted* by the distance\n between them.\n\n Parameters\n ----------\n values0 : array\n The pixel values for each node.\n values1 : array\n The pixel values for each neighbor.\n distances : array\n The distance between each node and its neighbor.\n\n Returns\n -------\n edge_values : array of float\n The computed values: abs(values0 - values1) * distances.\n \"\"\"\n return np.abs(values0 - values1) * distances\n\n\ndef pixel_graph(image, *, mask=None, edge_function=None, connectivity=1, spacing=None):\n \"\"\"Create an adjacency graph of pixels in an image.\n\n Pixels where the mask is True are nodes in the returned graph, and they are\n connected by edges to their neighbors according to the connectivity\n parameter. By default, the *value* of an edge when a mask is given, or when\n the image is itself the mask, is the Euclidean distance between the pixels.\n\n However, if an int- or float-valued image is given with no mask, the value\n of the edges is the absolute difference in intensity between adjacent\n pixels, weighted by the Euclidean distance.\n\n Parameters\n ----------\n image : array\n The input image. If the image is of type bool, it will be used as the\n mask as well.\n mask : array of bool\n Which pixels to use. If None, the graph for the whole image is used.\n edge_function : callable\n A function taking an array of pixel values, and an array of neighbor\n pixel values, and an array of distances, and returning a value for the\n edge. If no function is given, the value of an edge is just the\n distance.\n connectivity : int\n The square connectivity of the pixel neighborhood: the number of\n orthogonal steps allowed to consider a pixel a neighbor. See\n `scipy.ndimage.generate_binary_structure` for details.\n spacing : tuple of float\n The spacing between pixels along each axis.\n\n Returns\n -------\n graph : scipy.sparse.csr_matrix\n A sparse adjacency matrix in which entry (i, j) is 1 if nodes i and j\n are neighbors, 0 otherwise.\n nodes : array of int\n The nodes of the graph. These correspond to the raveled indices of the\n nonzero pixels in the mask.\n \"\"\"\n if image.dtype == bool and mask is None:\n mask = image\n if mask is None and edge_function is None:\n mask = np.ones_like(image, dtype=bool)\n edge_function = _weighted_abs_diff\n\n # Strategy: we are going to build the (i, j, data) arrays of a scipy\n # sparse COO matrix, then convert to CSR (which is fast).\n # - grab the raveled IDs of the foreground (mask == True) parts of the\n # image **in the padded space**.\n # - broadcast them together with the raveled offsets to their neighbors.\n # This gives us for each foreground pixel a list of neighbors (that\n # may or may not be selected by the mask). (We also track the *distance*\n # to each neighbor.)\n # - select \"valid\" entries in the neighbors and distance arrays by indexing\n # into the mask, which we can do since these are raveled indices.\n # - use np.repeat() to repeat each source index according to the number\n # of neighbors selected by the mask it has. Each of these repeated\n # indices will be lined up with its neighbor, i.e. **this is the i\n # array** of the COO format matrix.\n # - use the mask as a boolean index to get a 1D view of the selected\n # neighbors. **This is the j array.**\n # - by default, the same boolean indexing can be applied to the distances\n # to each neighbor, to give the **data array.** Optionally, a\n # provided edge function can be computed on the pixel values and the\n # distances to give a different value for the edges.\n # Note, we use map_array to map the raveled coordinates in the padded\n # image to the ones in the original image, and those are the returned\n # nodes.\n padded = np.pad(mask, 1, mode='constant', constant_values=False)\n nodes_padded = np.flatnonzero(padded)\n neighbor_offsets_padded, distances_padded = _raveled_offsets_and_distances(\n padded.shape, connectivity=connectivity, spacing=spacing\n )\n neighbors_padded = nodes_padded[:, np.newaxis] + neighbor_offsets_padded\n neighbor_distances_full = np.broadcast_to(distances_padded, neighbors_padded.shape)\n nodes = np.flatnonzero(mask)\n nodes_sequential = np.arange(nodes.size)\n # neighbors outside the mask get mapped to 0, which is a valid index,\n # BUT, they will be masked out in the next step.\n neighbors = map_array(neighbors_padded, nodes_padded, nodes)\n neighbors_mask = padded.reshape(-1)[neighbors_padded]\n num_neighbors = np.sum(neighbors_mask, axis=1)\n indices = np.repeat(nodes, num_neighbors)\n indices_sequential = np.repeat(nodes_sequential, num_neighbors)\n neighbor_indices = neighbors[neighbors_mask]\n neighbor_distances = neighbor_distances_full[neighbors_mask]\n neighbor_indices_sequential = map_array(neighbor_indices, nodes, nodes_sequential)\n if edge_function is None:\n data = neighbor_distances\n else:\n image_r = image.reshape(-1)\n data = edge_function(\n image_r[indices], image_r[neighbor_indices], neighbor_distances\n )\n m = nodes_sequential.size\n mat = sparse.coo_matrix(\n (data, (indices_sequential, neighbor_indices_sequential)), shape=(m, m)\n )\n graph = mat.tocsr()\n return graph, nodes\n\n\ndef central_pixel(graph, nodes=None, shape=None, partition_size=100):\n \"\"\"Find the pixel with the highest closeness centrality.\n\n Closeness centrality is the inverse of the total sum of shortest distances\n from a node to every other node.\n\n Parameters\n ----------\n graph : scipy.sparse.csr_matrix\n The sparse matrix representation of the graph.\n nodes : array of int\n The raveled index of each node in graph in the image. If not provided,\n the returned value will be the index in the input graph.\n shape : tuple of int\n The shape of the image in which the nodes are embedded. If provided,\n the returned coordinates are a NumPy multi-index of the same\n dimensionality as the input shape. Otherwise, the returned coordinate\n is the raveled index provided in `nodes`.\n partition_size : int\n This function computes the shortest path distance between every pair\n of nodes in the graph. This can result in a very large (N*N) matrix.\n As a simple performance tweak, the distance values are computed in\n lots of `partition_size`, resulting in a memory requirement of only\n partition_size*N.\n\n Returns\n -------\n position : int or tuple of int\n If shape is given, the coordinate of the central pixel in the image.\n Otherwise, the raveled index of that pixel.\n distances : array of float\n The total sum of distances from each node to each other reachable\n node.\n \"\"\"\n if nodes is None:\n nodes = np.arange(graph.shape[0])\n if partition_size is None:\n num_splits = 1\n else:\n num_splits = max(2, graph.shape[0] // partition_size)\n idxs = np.arange(graph.shape[0])\n total_shortest_path_len_list = []\n for partition in np.array_split(idxs, num_splits):\n shortest_paths = csgraph.shortest_path(graph, directed=False, indices=partition)\n shortest_paths_no_inf = np.nan_to_num(shortest_paths)\n total_shortest_path_len_list.append(np.sum(shortest_paths_no_inf, axis=1))\n total_shortest_path_len = np.concatenate(total_shortest_path_len_list)\n nonzero = np.flatnonzero(total_shortest_path_len)\n min_sp = np.argmin(total_shortest_path_len[nonzero])\n raveled_index = nodes[nonzero[min_sp]]\n if shape is not None:\n central = np.unravel_index(raveled_index, shape)\n else:\n central = raveled_index\n return central, total_shortest_path_len\n", "path": "skimage/graph/_graph.py"}]}
| 3,410 | 439 |
gh_patches_debug_27631
|
rasdani/github-patches
|
git_diff
|
OpenMined__PySyft-2308
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
TrainConfig parameter "epochs"
**TrainConfig parameter "epochs" doesn't have effect.**
After changing the number of epochs=1 to epochs=100. The worker still do only 1 epoch.
```
train_config = sy.TrainConfig(
model=traced_model,
loss_fn=loss_fn,
batch_size=batch_size,
shuffle=True,
#max_nr_batches=max_nr_batches,
epochs=100,
lr=lr,
)
```
</issue>
<code>
[start of syft/federated/federated_client.py]
1 import torch as th
2 from torch.utils.data import BatchSampler, RandomSampler, SequentialSampler
3
4 from syft.generic import ObjectStorage
5 from syft.federated.train_config import TrainConfig
6
7
8 class FederatedClient(ObjectStorage):
9 """A Client able to execute federated learning in local datasets."""
10
11 def __init__(self, datasets=None):
12 super().__init__()
13 self.datasets = datasets if datasets is not None else dict()
14 self.optimizer = None
15 self.train_config = None
16
17 def add_dataset(self, dataset, key: str):
18 self.datasets[key] = dataset
19
20 def remove_dataset(self, key: str):
21 if key in self.datasets:
22 del self.datasets[key]
23
24 def set_obj(self, obj: object):
25 """Registers objects checking if which objects it should cache.
26
27 Args:
28 obj: An object to be registered.
29 """
30 if isinstance(obj, TrainConfig):
31 self.train_config = obj
32 self.optimizer = None
33 else:
34 super().set_obj(obj)
35
36 def _build_optimizer(
37 self, optimizer_name: str, model, lr: float, weight_decay: float
38 ) -> th.optim.Optimizer:
39 """Build an optimizer if needed.
40
41 Args:
42 optimizer_name: A string indicating the optimizer name.
43 lr: A float indicating the learning rate.
44 weight_decay: Weight decay parameter of the optimizer
45 Returns:
46 A Torch Optimizer.
47 """
48 if self.optimizer is not None:
49 return self.optimizer
50
51 optimizer_name = optimizer_name.lower()
52 if optimizer_name == "sgd":
53 optim_args = dict()
54 optim_args["lr"] = lr
55 if weight_decay is not None:
56 optim_args["weight_decay"] = weight_decay
57 self.optimizer = th.optim.SGD(model.parameters(), **optim_args)
58 else:
59 raise ValueError("Unknown optimizer: {}".format(optimizer_name))
60 return self.optimizer
61
62 def fit(self, dataset_key: str, **kwargs):
63 """Fits a model on the local dataset as specified in the local TrainConfig object.
64
65 Args:
66 dataset_key: Identifier of the local dataset that shall be used for training.
67 **kwargs: Unused.
68
69 Returns:
70 loss: Training loss on the last batch of training data.
71 """
72 if self.train_config is None:
73 raise ValueError("TrainConfig not defined.")
74
75 model = self.get_obj(self.train_config._model_id).obj
76 loss_fn = self.get_obj(self.train_config._loss_fn_id).obj
77
78 self._build_optimizer(
79 self.train_config.optimizer,
80 model,
81 lr=self.train_config.lr,
82 weight_decay=self.train_config.weight_decay,
83 )
84
85 return self._fit(model=model, dataset_key=dataset_key, loss_fn=loss_fn)
86
87 def _create_data_loader(self, dataset_key: str, shuffle: bool = False):
88 data_range = range(len(self.datasets[dataset_key]))
89 if shuffle:
90 sampler = RandomSampler(data_range)
91 else:
92 sampler = SequentialSampler(data_range)
93 data_loader = th.utils.data.DataLoader(
94 self.datasets[dataset_key],
95 batch_size=self.train_config.batch_size,
96 sampler=sampler,
97 num_workers=0,
98 )
99 return data_loader
100
101 def _fit(self, model, dataset_key, loss_fn):
102 model.train()
103 data_loader = self._create_data_loader(
104 dataset_key=dataset_key, shuffle=self.train_config.shuffle
105 )
106
107 loss = None
108 iteration_count = 0
109 for (data, target) in data_loader:
110 # Set gradients to zero
111 self.optimizer.zero_grad()
112
113 # Update model
114 output = model(data)
115 loss = loss_fn(target=target, pred=output)
116 loss.backward()
117 self.optimizer.step()
118
119 # Update and check interation count
120 iteration_count += 1
121 if iteration_count >= self.train_config.max_nr_batches >= 0:
122 break
123
124 return loss
125
[end of syft/federated/federated_client.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/syft/federated/federated_client.py b/syft/federated/federated_client.py
--- a/syft/federated/federated_client.py
+++ b/syft/federated/federated_client.py
@@ -72,6 +72,9 @@
if self.train_config is None:
raise ValueError("TrainConfig not defined.")
+ if dataset_key not in self.datasets:
+ raise ValueError("Dataset {} unknown.".format(dataset_key))
+
model = self.get_obj(self.train_config._model_id).obj
loss_fn = self.get_obj(self.train_config._loss_fn_id).obj
@@ -106,19 +109,21 @@
loss = None
iteration_count = 0
- for (data, target) in data_loader:
- # Set gradients to zero
- self.optimizer.zero_grad()
-
- # Update model
- output = model(data)
- loss = loss_fn(target=target, pred=output)
- loss.backward()
- self.optimizer.step()
-
- # Update and check interation count
- iteration_count += 1
- if iteration_count >= self.train_config.max_nr_batches >= 0:
- break
+
+ for _ in range(self.train_config.epochs):
+ for (data, target) in data_loader:
+ # Set gradients to zero
+ self.optimizer.zero_grad()
+
+ # Update model
+ output = model(data)
+ loss = loss_fn(target=target, pred=output)
+ loss.backward()
+ self.optimizer.step()
+
+ # Update and check interation count
+ iteration_count += 1
+ if iteration_count >= self.train_config.max_nr_batches >= 0:
+ break
return loss
|
{"golden_diff": "diff --git a/syft/federated/federated_client.py b/syft/federated/federated_client.py\n--- a/syft/federated/federated_client.py\n+++ b/syft/federated/federated_client.py\n@@ -72,6 +72,9 @@\n if self.train_config is None:\n raise ValueError(\"TrainConfig not defined.\")\n \n+ if dataset_key not in self.datasets:\n+ raise ValueError(\"Dataset {} unknown.\".format(dataset_key))\n+\n model = self.get_obj(self.train_config._model_id).obj\n loss_fn = self.get_obj(self.train_config._loss_fn_id).obj\n \n@@ -106,19 +109,21 @@\n \n loss = None\n iteration_count = 0\n- for (data, target) in data_loader:\n- # Set gradients to zero\n- self.optimizer.zero_grad()\n-\n- # Update model\n- output = model(data)\n- loss = loss_fn(target=target, pred=output)\n- loss.backward()\n- self.optimizer.step()\n-\n- # Update and check interation count\n- iteration_count += 1\n- if iteration_count >= self.train_config.max_nr_batches >= 0:\n- break\n+\n+ for _ in range(self.train_config.epochs):\n+ for (data, target) in data_loader:\n+ # Set gradients to zero\n+ self.optimizer.zero_grad()\n+\n+ # Update model\n+ output = model(data)\n+ loss = loss_fn(target=target, pred=output)\n+ loss.backward()\n+ self.optimizer.step()\n+\n+ # Update and check interation count\n+ iteration_count += 1\n+ if iteration_count >= self.train_config.max_nr_batches >= 0:\n+ break\n \n return loss\n", "issue": "TrainConfig parameter \"epochs\"\n**TrainConfig parameter \"epochs\" doesn't have effect.**\r\nAfter changing the number of epochs=1 to epochs=100. The worker still do only 1 epoch.\r\n\r\n```\r\ntrain_config = sy.TrainConfig(\r\n model=traced_model,\r\n loss_fn=loss_fn,\r\n batch_size=batch_size,\r\n shuffle=True,\r\n #max_nr_batches=max_nr_batches,\r\n epochs=100,\r\n lr=lr,\r\n )\r\n```\n", "before_files": [{"content": "import torch as th\nfrom torch.utils.data import BatchSampler, RandomSampler, SequentialSampler\n\nfrom syft.generic import ObjectStorage\nfrom syft.federated.train_config import TrainConfig\n\n\nclass FederatedClient(ObjectStorage):\n \"\"\"A Client able to execute federated learning in local datasets.\"\"\"\n\n def __init__(self, datasets=None):\n super().__init__()\n self.datasets = datasets if datasets is not None else dict()\n self.optimizer = None\n self.train_config = None\n\n def add_dataset(self, dataset, key: str):\n self.datasets[key] = dataset\n\n def remove_dataset(self, key: str):\n if key in self.datasets:\n del self.datasets[key]\n\n def set_obj(self, obj: object):\n \"\"\"Registers objects checking if which objects it should cache.\n\n Args:\n obj: An object to be registered.\n \"\"\"\n if isinstance(obj, TrainConfig):\n self.train_config = obj\n self.optimizer = None\n else:\n super().set_obj(obj)\n\n def _build_optimizer(\n self, optimizer_name: str, model, lr: float, weight_decay: float\n ) -> th.optim.Optimizer:\n \"\"\"Build an optimizer if needed.\n\n Args:\n optimizer_name: A string indicating the optimizer name.\n lr: A float indicating the learning rate.\n weight_decay: Weight decay parameter of the optimizer\n Returns:\n A Torch Optimizer.\n \"\"\"\n if self.optimizer is not None:\n return self.optimizer\n\n optimizer_name = optimizer_name.lower()\n if optimizer_name == \"sgd\":\n optim_args = dict()\n optim_args[\"lr\"] = lr\n if weight_decay is not None:\n optim_args[\"weight_decay\"] = weight_decay\n self.optimizer = th.optim.SGD(model.parameters(), **optim_args)\n else:\n raise ValueError(\"Unknown optimizer: {}\".format(optimizer_name))\n return self.optimizer\n\n def fit(self, dataset_key: str, **kwargs):\n \"\"\"Fits a model on the local dataset as specified in the local TrainConfig object.\n\n Args:\n dataset_key: Identifier of the local dataset that shall be used for training.\n **kwargs: Unused.\n\n Returns:\n loss: Training loss on the last batch of training data.\n \"\"\"\n if self.train_config is None:\n raise ValueError(\"TrainConfig not defined.\")\n\n model = self.get_obj(self.train_config._model_id).obj\n loss_fn = self.get_obj(self.train_config._loss_fn_id).obj\n\n self._build_optimizer(\n self.train_config.optimizer,\n model,\n lr=self.train_config.lr,\n weight_decay=self.train_config.weight_decay,\n )\n\n return self._fit(model=model, dataset_key=dataset_key, loss_fn=loss_fn)\n\n def _create_data_loader(self, dataset_key: str, shuffle: bool = False):\n data_range = range(len(self.datasets[dataset_key]))\n if shuffle:\n sampler = RandomSampler(data_range)\n else:\n sampler = SequentialSampler(data_range)\n data_loader = th.utils.data.DataLoader(\n self.datasets[dataset_key],\n batch_size=self.train_config.batch_size,\n sampler=sampler,\n num_workers=0,\n )\n return data_loader\n\n def _fit(self, model, dataset_key, loss_fn):\n model.train()\n data_loader = self._create_data_loader(\n dataset_key=dataset_key, shuffle=self.train_config.shuffle\n )\n\n loss = None\n iteration_count = 0\n for (data, target) in data_loader:\n # Set gradients to zero\n self.optimizer.zero_grad()\n\n # Update model\n output = model(data)\n loss = loss_fn(target=target, pred=output)\n loss.backward()\n self.optimizer.step()\n\n # Update and check interation count\n iteration_count += 1\n if iteration_count >= self.train_config.max_nr_batches >= 0:\n break\n\n return loss\n", "path": "syft/federated/federated_client.py"}]}
| 1,758 | 394 |
gh_patches_debug_21268
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-3523
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Empty search in the API leading to TypeError
Steps to reproduce:
- use Wagtail 1.9 & elasticsearch 2
- install Wagtail’s API
- go to /api/v2/pages/?search=
You end up with:
```
File "…/wagtail/api/v2/pagination.py" in paginate_queryset
36. self.total_count = queryset.count()
TypeError: count() takes exactly one argument (0 given)
```
</issue>
<code>
[start of wagtail/wagtailsearch/backends/base.py]
1
2 from __future__ import absolute_import, unicode_literals
3
4 from django.db.models.lookups import Lookup
5 from django.db.models.query import QuerySet
6 from django.db.models.sql.where import SubqueryConstraint, WhereNode
7 from django.utils.six import text_type
8
9 from wagtail.wagtailsearch.index import class_is_indexed
10
11
12 class FilterError(Exception):
13 pass
14
15
16 class FieldError(Exception):
17 pass
18
19
20 class BaseSearchQuery(object):
21 DEFAULT_OPERATOR = 'or'
22
23 def __init__(self, queryset, query_string, fields=None, operator=None, order_by_relevance=True):
24 self.queryset = queryset
25 self.query_string = query_string
26 self.fields = fields
27 self.operator = operator or self.DEFAULT_OPERATOR
28 self.order_by_relevance = order_by_relevance
29
30 def _get_filterable_field(self, field_attname):
31 # Get field
32 field = dict(
33 (field.get_attname(self.queryset.model), field)
34 for field in self.queryset.model.get_filterable_search_fields()
35 ).get(field_attname, None)
36
37 return field
38
39 def _process_lookup(self, field, lookup, value):
40 raise NotImplementedError
41
42 def _connect_filters(self, filters, connector, negated):
43 raise NotImplementedError
44
45 def _process_filter(self, field_attname, lookup, value):
46 # Get the field
47 field = self._get_filterable_field(field_attname)
48
49 if field is None:
50 raise FieldError(
51 'Cannot filter search results with field "' + field_attname + '". Please add index.FilterField(\'' +
52 field_attname + '\') to ' + self.queryset.model.__name__ + '.search_fields.'
53 )
54
55 # Process the lookup
56 result = self._process_lookup(field, lookup, value)
57
58 if result is None:
59 raise FilterError(
60 'Could not apply filter on search results: "' + field_attname + '__' +
61 lookup + ' = ' + text_type(value) + '". Lookup "' + lookup + '"" not recognised.'
62 )
63
64 return result
65
66 def _get_filters_from_where_node(self, where_node):
67 # Check if this is a leaf node
68 if isinstance(where_node, Lookup):
69 field_attname = where_node.lhs.target.attname
70 lookup = where_node.lookup_name
71 value = where_node.rhs
72
73 # Ignore pointer fields that show up in specific page type queries
74 if field_attname.endswith('_ptr_id'):
75 return
76
77 # Process the filter
78 return self._process_filter(field_attname, lookup, value)
79
80 elif isinstance(where_node, SubqueryConstraint):
81 raise FilterError('Could not apply filter on search results: Subqueries are not allowed.')
82
83 elif isinstance(where_node, WhereNode):
84 # Get child filters
85 connector = where_node.connector
86 child_filters = [self._get_filters_from_where_node(child) for child in where_node.children]
87 child_filters = [child_filter for child_filter in child_filters if child_filter]
88
89 return self._connect_filters(child_filters, connector, where_node.negated)
90
91 else:
92 raise FilterError('Could not apply filter on search results: Unknown where node: ' + str(type(where_node)))
93
94 def _get_filters_from_queryset(self):
95 return self._get_filters_from_where_node(self.queryset.query.where)
96
97
98 class BaseSearchResults(object):
99 def __init__(self, backend, query, prefetch_related=None):
100 self.backend = backend
101 self.query = query
102 self.prefetch_related = prefetch_related
103 self.start = 0
104 self.stop = None
105 self._results_cache = None
106 self._count_cache = None
107 self._score_field = None
108
109 def _set_limits(self, start=None, stop=None):
110 if stop is not None:
111 if self.stop is not None:
112 self.stop = min(self.stop, self.start + stop)
113 else:
114 self.stop = self.start + stop
115
116 if start is not None:
117 if self.stop is not None:
118 self.start = min(self.stop, self.start + start)
119 else:
120 self.start = self.start + start
121
122 def _clone(self):
123 klass = self.__class__
124 new = klass(self.backend, self.query, prefetch_related=self.prefetch_related)
125 new.start = self.start
126 new.stop = self.stop
127 new._score_field = self._score_field
128 return new
129
130 def _do_search(self):
131 raise NotImplementedError
132
133 def _do_count(self):
134 raise NotImplementedError
135
136 def results(self):
137 if self._results_cache is None:
138 self._results_cache = self._do_search()
139 return self._results_cache
140
141 def count(self):
142 if self._count_cache is None:
143 if self._results_cache is not None:
144 self._count_cache = len(self._results_cache)
145 else:
146 self._count_cache = self._do_count()
147 return self._count_cache
148
149 def __getitem__(self, key):
150 new = self._clone()
151
152 if isinstance(key, slice):
153 # Set limits
154 start = int(key.start) if key.start else None
155 stop = int(key.stop) if key.stop else None
156 new._set_limits(start, stop)
157
158 # Copy results cache
159 if self._results_cache is not None:
160 new._results_cache = self._results_cache[key]
161
162 return new
163 else:
164 if self._results_cache is not None:
165 return self._results_cache[key]
166
167 new.start = self.start + key
168 new.stop = self.start + key + 1
169 return list(new)[0]
170
171 def __iter__(self):
172 return iter(self.results())
173
174 def __len__(self):
175 return len(self.results())
176
177 def __repr__(self):
178 data = list(self[:21])
179 if len(data) > 20:
180 data[-1] = "...(remaining elements truncated)..."
181 return '<SearchResults %r>' % data
182
183 def annotate_score(self, field_name):
184 clone = self._clone()
185 clone._score_field = field_name
186 return clone
187
188
189 class BaseSearchBackend(object):
190 query_class = None
191 results_class = None
192 rebuilder_class = None
193
194 def __init__(self, params):
195 pass
196
197 def get_index_for_model(self, model):
198 return None
199
200 def get_rebuilder(self):
201 return None
202
203 def reset_index(self):
204 raise NotImplementedError
205
206 def add_type(self, model):
207 raise NotImplementedError
208
209 def refresh_index(self):
210 raise NotImplementedError
211
212 def add(self, obj):
213 raise NotImplementedError
214
215 def add_bulk(self, model, obj_list):
216 raise NotImplementedError
217
218 def delete(self, obj):
219 raise NotImplementedError
220
221 def search(self, query_string, model_or_queryset, fields=None, filters=None,
222 prefetch_related=None, operator=None, order_by_relevance=True):
223 # Find model/queryset
224 if isinstance(model_or_queryset, QuerySet):
225 model = model_or_queryset.model
226 queryset = model_or_queryset
227 else:
228 model = model_or_queryset
229 queryset = model_or_queryset.objects.all()
230
231 # Model must be a class that is in the index
232 if not class_is_indexed(model):
233 return []
234
235 # Check that theres still a query string after the clean up
236 if query_string == "":
237 return []
238
239 # Only fields that are indexed as a SearchField can be passed in fields
240 if fields:
241 allowed_fields = {field.field_name for field in model.get_searchable_search_fields()}
242
243 for field_name in fields:
244 if field_name not in allowed_fields:
245 raise FieldError(
246 'Cannot search with field "' + field_name + '". Please add index.SearchField(\'' +
247 field_name + '\') to ' + model.__name__ + '.search_fields.'
248 )
249
250 # Apply filters to queryset
251 if filters:
252 queryset = queryset.filter(**filters)
253
254 # Prefetch related
255 if prefetch_related:
256 for prefetch in prefetch_related:
257 queryset = queryset.prefetch_related(prefetch)
258
259 # Check operator
260 if operator is not None:
261 operator = operator.lower()
262 if operator not in ['or', 'and']:
263 raise ValueError("operator must be either 'or' or 'and'")
264
265 # Search
266 search_query = self.query_class(
267 queryset, query_string, fields=fields, operator=operator, order_by_relevance=order_by_relevance
268 )
269 return self.results_class(self, search_query)
270
[end of wagtail/wagtailsearch/backends/base.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/wagtail/wagtailsearch/backends/base.py b/wagtail/wagtailsearch/backends/base.py
--- a/wagtail/wagtailsearch/backends/base.py
+++ b/wagtail/wagtailsearch/backends/base.py
@@ -186,6 +186,20 @@
return clone
+class EmptySearchResults(BaseSearchResults):
+ def __init__(self):
+ return super(EmptySearchResults, self).__init__(None, None)
+
+ def _clone(self):
+ return self.__class__()
+
+ def _do_search(self):
+ return []
+
+ def _do_count(self):
+ return 0
+
+
class BaseSearchBackend(object):
query_class = None
results_class = None
@@ -230,11 +244,11 @@
# Model must be a class that is in the index
if not class_is_indexed(model):
- return []
+ return EmptySearchResults()
# Check that theres still a query string after the clean up
if query_string == "":
- return []
+ return EmptySearchResults()
# Only fields that are indexed as a SearchField can be passed in fields
if fields:
|
{"golden_diff": "diff --git a/wagtail/wagtailsearch/backends/base.py b/wagtail/wagtailsearch/backends/base.py\n--- a/wagtail/wagtailsearch/backends/base.py\n+++ b/wagtail/wagtailsearch/backends/base.py\n@@ -186,6 +186,20 @@\n return clone\n \n \n+class EmptySearchResults(BaseSearchResults):\n+ def __init__(self):\n+ return super(EmptySearchResults, self).__init__(None, None)\n+\n+ def _clone(self):\n+ return self.__class__()\n+\n+ def _do_search(self):\n+ return []\n+\n+ def _do_count(self):\n+ return 0\n+\n+\n class BaseSearchBackend(object):\n query_class = None\n results_class = None\n@@ -230,11 +244,11 @@\n \n # Model must be a class that is in the index\n if not class_is_indexed(model):\n- return []\n+ return EmptySearchResults()\n \n # Check that theres still a query string after the clean up\n if query_string == \"\":\n- return []\n+ return EmptySearchResults()\n \n # Only fields that are indexed as a SearchField can be passed in fields\n if fields:\n", "issue": "Empty search in the API leading to TypeError\nSteps to reproduce:\r\n- use Wagtail 1.9 & elasticsearch 2\r\n- install Wagtail\u2019s API\r\n- go to /api/v2/pages/?search=\r\n\r\nYou end up with:\r\n```\r\nFile \"\u2026/wagtail/api/v2/pagination.py\" in paginate_queryset\r\n 36. self.total_count = queryset.count()\r\n\r\nTypeError: count() takes exactly one argument (0 given)\r\n```\n", "before_files": [{"content": "\nfrom __future__ import absolute_import, unicode_literals\n\nfrom django.db.models.lookups import Lookup\nfrom django.db.models.query import QuerySet\nfrom django.db.models.sql.where import SubqueryConstraint, WhereNode\nfrom django.utils.six import text_type\n\nfrom wagtail.wagtailsearch.index import class_is_indexed\n\n\nclass FilterError(Exception):\n pass\n\n\nclass FieldError(Exception):\n pass\n\n\nclass BaseSearchQuery(object):\n DEFAULT_OPERATOR = 'or'\n\n def __init__(self, queryset, query_string, fields=None, operator=None, order_by_relevance=True):\n self.queryset = queryset\n self.query_string = query_string\n self.fields = fields\n self.operator = operator or self.DEFAULT_OPERATOR\n self.order_by_relevance = order_by_relevance\n\n def _get_filterable_field(self, field_attname):\n # Get field\n field = dict(\n (field.get_attname(self.queryset.model), field)\n for field in self.queryset.model.get_filterable_search_fields()\n ).get(field_attname, None)\n\n return field\n\n def _process_lookup(self, field, lookup, value):\n raise NotImplementedError\n\n def _connect_filters(self, filters, connector, negated):\n raise NotImplementedError\n\n def _process_filter(self, field_attname, lookup, value):\n # Get the field\n field = self._get_filterable_field(field_attname)\n\n if field is None:\n raise FieldError(\n 'Cannot filter search results with field \"' + field_attname + '\". Please add index.FilterField(\\'' +\n field_attname + '\\') to ' + self.queryset.model.__name__ + '.search_fields.'\n )\n\n # Process the lookup\n result = self._process_lookup(field, lookup, value)\n\n if result is None:\n raise FilterError(\n 'Could not apply filter on search results: \"' + field_attname + '__' +\n lookup + ' = ' + text_type(value) + '\". Lookup \"' + lookup + '\"\" not recognised.'\n )\n\n return result\n\n def _get_filters_from_where_node(self, where_node):\n # Check if this is a leaf node\n if isinstance(where_node, Lookup):\n field_attname = where_node.lhs.target.attname\n lookup = where_node.lookup_name\n value = where_node.rhs\n\n # Ignore pointer fields that show up in specific page type queries\n if field_attname.endswith('_ptr_id'):\n return\n\n # Process the filter\n return self._process_filter(field_attname, lookup, value)\n\n elif isinstance(where_node, SubqueryConstraint):\n raise FilterError('Could not apply filter on search results: Subqueries are not allowed.')\n\n elif isinstance(where_node, WhereNode):\n # Get child filters\n connector = where_node.connector\n child_filters = [self._get_filters_from_where_node(child) for child in where_node.children]\n child_filters = [child_filter for child_filter in child_filters if child_filter]\n\n return self._connect_filters(child_filters, connector, where_node.negated)\n\n else:\n raise FilterError('Could not apply filter on search results: Unknown where node: ' + str(type(where_node)))\n\n def _get_filters_from_queryset(self):\n return self._get_filters_from_where_node(self.queryset.query.where)\n\n\nclass BaseSearchResults(object):\n def __init__(self, backend, query, prefetch_related=None):\n self.backend = backend\n self.query = query\n self.prefetch_related = prefetch_related\n self.start = 0\n self.stop = None\n self._results_cache = None\n self._count_cache = None\n self._score_field = None\n\n def _set_limits(self, start=None, stop=None):\n if stop is not None:\n if self.stop is not None:\n self.stop = min(self.stop, self.start + stop)\n else:\n self.stop = self.start + stop\n\n if start is not None:\n if self.stop is not None:\n self.start = min(self.stop, self.start + start)\n else:\n self.start = self.start + start\n\n def _clone(self):\n klass = self.__class__\n new = klass(self.backend, self.query, prefetch_related=self.prefetch_related)\n new.start = self.start\n new.stop = self.stop\n new._score_field = self._score_field\n return new\n\n def _do_search(self):\n raise NotImplementedError\n\n def _do_count(self):\n raise NotImplementedError\n\n def results(self):\n if self._results_cache is None:\n self._results_cache = self._do_search()\n return self._results_cache\n\n def count(self):\n if self._count_cache is None:\n if self._results_cache is not None:\n self._count_cache = len(self._results_cache)\n else:\n self._count_cache = self._do_count()\n return self._count_cache\n\n def __getitem__(self, key):\n new = self._clone()\n\n if isinstance(key, slice):\n # Set limits\n start = int(key.start) if key.start else None\n stop = int(key.stop) if key.stop else None\n new._set_limits(start, stop)\n\n # Copy results cache\n if self._results_cache is not None:\n new._results_cache = self._results_cache[key]\n\n return new\n else:\n if self._results_cache is not None:\n return self._results_cache[key]\n\n new.start = self.start + key\n new.stop = self.start + key + 1\n return list(new)[0]\n\n def __iter__(self):\n return iter(self.results())\n\n def __len__(self):\n return len(self.results())\n\n def __repr__(self):\n data = list(self[:21])\n if len(data) > 20:\n data[-1] = \"...(remaining elements truncated)...\"\n return '<SearchResults %r>' % data\n\n def annotate_score(self, field_name):\n clone = self._clone()\n clone._score_field = field_name\n return clone\n\n\nclass BaseSearchBackend(object):\n query_class = None\n results_class = None\n rebuilder_class = None\n\n def __init__(self, params):\n pass\n\n def get_index_for_model(self, model):\n return None\n\n def get_rebuilder(self):\n return None\n\n def reset_index(self):\n raise NotImplementedError\n\n def add_type(self, model):\n raise NotImplementedError\n\n def refresh_index(self):\n raise NotImplementedError\n\n def add(self, obj):\n raise NotImplementedError\n\n def add_bulk(self, model, obj_list):\n raise NotImplementedError\n\n def delete(self, obj):\n raise NotImplementedError\n\n def search(self, query_string, model_or_queryset, fields=None, filters=None,\n prefetch_related=None, operator=None, order_by_relevance=True):\n # Find model/queryset\n if isinstance(model_or_queryset, QuerySet):\n model = model_or_queryset.model\n queryset = model_or_queryset\n else:\n model = model_or_queryset\n queryset = model_or_queryset.objects.all()\n\n # Model must be a class that is in the index\n if not class_is_indexed(model):\n return []\n\n # Check that theres still a query string after the clean up\n if query_string == \"\":\n return []\n\n # Only fields that are indexed as a SearchField can be passed in fields\n if fields:\n allowed_fields = {field.field_name for field in model.get_searchable_search_fields()}\n\n for field_name in fields:\n if field_name not in allowed_fields:\n raise FieldError(\n 'Cannot search with field \"' + field_name + '\". Please add index.SearchField(\\'' +\n field_name + '\\') to ' + model.__name__ + '.search_fields.'\n )\n\n # Apply filters to queryset\n if filters:\n queryset = queryset.filter(**filters)\n\n # Prefetch related\n if prefetch_related:\n for prefetch in prefetch_related:\n queryset = queryset.prefetch_related(prefetch)\n\n # Check operator\n if operator is not None:\n operator = operator.lower()\n if operator not in ['or', 'and']:\n raise ValueError(\"operator must be either 'or' or 'and'\")\n\n # Search\n search_query = self.query_class(\n queryset, query_string, fields=fields, operator=operator, order_by_relevance=order_by_relevance\n )\n return self.results_class(self, search_query)\n", "path": "wagtail/wagtailsearch/backends/base.py"}]}
| 3,195 | 277 |
gh_patches_debug_3339
|
rasdani/github-patches
|
git_diff
|
modin-project__modin-3493
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
AttributeError: module 'modin.pandas' has no attribute 'api'
### System information
- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**: Linux Ubuntu 20.04
- **Modin version** (`modin.__version__`): 0.10.2
- **Python version**: 3.8.10
- **Code we can use to reproduce**:
import modin.pandas as pd
indexer = pd.api.indexers.FixedForwardWindowIndexer(window_size=d)
df['new'] = df['rough'].rolling(window=indexer).apply(np.prod, raw=True) - 1
### Describe the problem
modin should have defaulted to pandas in case this functionality is not implemented instead of throwing an error.
### Source code / logs
indexer = pd.api.indexers.FixedForwardWindowIndexer(window_size=d)
AttributeError: module 'modin.pandas' has no attribute 'api'
</issue>
<code>
[start of modin/pandas/__init__.py]
1 # Licensed to Modin Development Team under one or more contributor license agreements.
2 # See the NOTICE file distributed with this work for additional information regarding
3 # copyright ownership. The Modin Development Team licenses this file to you under the
4 # Apache License, Version 2.0 (the "License"); you may not use this file except in
5 # compliance with the License. You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software distributed under
10 # the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF
11 # ANY KIND, either express or implied. See the License for the specific language
12 # governing permissions and limitations under the License.
13
14 import pandas
15
16 __pandas_version__ = "1.3.3"
17
18 if pandas.__version__ != __pandas_version__:
19 import warnings
20
21 warnings.warn(
22 "The pandas version installed {} does not match the supported pandas version in"
23 " Modin {}. This may cause undesired side effects!".format(
24 pandas.__version__, __pandas_version__
25 )
26 )
27
28 from pandas import (
29 eval,
30 cut,
31 factorize,
32 test,
33 qcut,
34 date_range,
35 period_range,
36 Index,
37 MultiIndex,
38 CategoricalIndex,
39 bdate_range,
40 DatetimeIndex,
41 Timedelta,
42 Timestamp,
43 to_timedelta,
44 set_eng_float_format,
45 options,
46 Flags,
47 set_option,
48 NaT,
49 PeriodIndex,
50 Categorical,
51 Interval,
52 UInt8Dtype,
53 UInt16Dtype,
54 UInt32Dtype,
55 UInt64Dtype,
56 SparseDtype,
57 Int8Dtype,
58 Int16Dtype,
59 Int32Dtype,
60 Int64Dtype,
61 Float32Dtype,
62 Float64Dtype,
63 StringDtype,
64 BooleanDtype,
65 CategoricalDtype,
66 DatetimeTZDtype,
67 IntervalDtype,
68 PeriodDtype,
69 RangeIndex,
70 Int64Index,
71 UInt64Index,
72 Float64Index,
73 TimedeltaIndex,
74 IntervalIndex,
75 IndexSlice,
76 Grouper,
77 array,
78 Period,
79 show_versions,
80 DateOffset,
81 timedelta_range,
82 infer_freq,
83 interval_range,
84 ExcelWriter,
85 datetime,
86 NamedAgg,
87 NA,
88 )
89 import os
90 import multiprocessing
91
92 from modin.config import Engine, Parameter
93
94 # Set this so that Pandas doesn't try to multithread by itself
95 os.environ["OMP_NUM_THREADS"] = "1"
96
97 _is_first_update = {}
98 dask_client = None
99 _NOINIT_ENGINES = {
100 "Python",
101 } # engines that don't require initialization, useful for unit tests
102
103
104 def _update_engine(publisher: Parameter):
105 global dask_client
106 from modin.config import Backend, CpuCount
107
108 if publisher.get() == "Ray":
109 if _is_first_update.get("Ray", True):
110 from modin.engines.ray.utils import initialize_ray
111
112 initialize_ray()
113 elif publisher.get() == "Native":
114 # With OmniSci backend there is only a single worker per node
115 # and we allow it to work on all cores.
116 if Backend.get() == "Omnisci":
117 os.environ["OMP_NUM_THREADS"] = str(CpuCount.get())
118 else:
119 raise ValueError(
120 f"Backend should be 'Omnisci' with 'Native' engine, but provided {Backend.get()}."
121 )
122 elif publisher.get() == "Dask":
123 if _is_first_update.get("Dask", True):
124 from modin.engines.dask.utils import initialize_dask
125
126 initialize_dask()
127 elif publisher.get() == "Cloudray":
128 from modin.experimental.cloud import get_connection
129
130 conn = get_connection()
131 if _is_first_update.get("Cloudray", True):
132
133 @conn.teleport
134 def init_remote_ray(partition):
135 from ray import ray_constants
136 import modin
137 from modin.engines.ray.utils import initialize_ray
138
139 modin.set_backends("Ray", partition)
140 initialize_ray(
141 override_is_cluster=True,
142 override_redis_address=f"localhost:{ray_constants.DEFAULT_PORT}",
143 override_redis_password=ray_constants.REDIS_DEFAULT_PASSWORD,
144 )
145
146 init_remote_ray(Backend.get())
147 # import FactoryDispatcher here to initialize IO class
148 # so it doesn't skew read_csv() timings later on
149 import modin.data_management.factories.dispatcher # noqa: F401
150 else:
151 get_connection().modules["modin"].set_backends("Ray", Backend.get())
152 elif publisher.get() == "Cloudpython":
153 from modin.experimental.cloud import get_connection
154
155 get_connection().modules["modin"].set_backends("Python")
156 elif publisher.get() == "Cloudnative":
157 from modin.experimental.cloud import get_connection
158
159 assert (
160 Backend.get() == "Omnisci"
161 ), f"Backend should be 'Omnisci' with 'Cloudnative' engine, but provided {Backend.get()}."
162 get_connection().modules["modin"].set_backends("Native", "OmniSci")
163
164 elif publisher.get() not in _NOINIT_ENGINES:
165 raise ImportError("Unrecognized execution engine: {}.".format(publisher.get()))
166
167 _is_first_update[publisher.get()] = False
168
169
170 from .. import __version__
171 from .dataframe import DataFrame
172 from .io import (
173 read_csv,
174 read_parquet,
175 read_json,
176 read_html,
177 read_clipboard,
178 read_excel,
179 read_hdf,
180 read_feather,
181 read_stata,
182 read_sas,
183 read_pickle,
184 read_sql,
185 read_gbq,
186 read_table,
187 read_fwf,
188 read_sql_table,
189 read_sql_query,
190 read_spss,
191 ExcelFile,
192 to_pickle,
193 HDFStore,
194 json_normalize,
195 read_orc,
196 read_xml,
197 )
198 from .series import Series
199 from .general import (
200 concat,
201 isna,
202 isnull,
203 merge,
204 merge_asof,
205 merge_ordered,
206 pivot_table,
207 notnull,
208 notna,
209 pivot,
210 to_numeric,
211 to_datetime,
212 unique,
213 value_counts,
214 get_dummies,
215 melt,
216 crosstab,
217 lreshape,
218 wide_to_long,
219 )
220 from .plotting import Plotting as plotting
221
222 __all__ = [
223 "DataFrame",
224 "Series",
225 "read_csv",
226 "read_parquet",
227 "read_json",
228 "read_html",
229 "read_clipboard",
230 "read_excel",
231 "read_hdf",
232 "read_feather",
233 "read_stata",
234 "read_sas",
235 "read_pickle",
236 "read_sql",
237 "read_gbq",
238 "read_table",
239 "read_spss",
240 "read_orc",
241 "json_normalize",
242 "concat",
243 "eval",
244 "cut",
245 "factorize",
246 "test",
247 "qcut",
248 "to_datetime",
249 "get_dummies",
250 "isna",
251 "isnull",
252 "merge",
253 "pivot_table",
254 "date_range",
255 "Index",
256 "MultiIndex",
257 "Series",
258 "bdate_range",
259 "period_range",
260 "DatetimeIndex",
261 "to_timedelta",
262 "set_eng_float_format",
263 "options",
264 "set_option",
265 "CategoricalIndex",
266 "Timedelta",
267 "Timestamp",
268 "NaT",
269 "PeriodIndex",
270 "Categorical",
271 "__version__",
272 "melt",
273 "crosstab",
274 "plotting",
275 "Interval",
276 "UInt8Dtype",
277 "UInt16Dtype",
278 "UInt32Dtype",
279 "UInt64Dtype",
280 "SparseDtype",
281 "Int8Dtype",
282 "Int16Dtype",
283 "Int32Dtype",
284 "Int64Dtype",
285 "CategoricalDtype",
286 "DatetimeTZDtype",
287 "IntervalDtype",
288 "PeriodDtype",
289 "BooleanDtype",
290 "StringDtype",
291 "NA",
292 "RangeIndex",
293 "Int64Index",
294 "UInt64Index",
295 "Float64Index",
296 "TimedeltaIndex",
297 "IntervalIndex",
298 "IndexSlice",
299 "Grouper",
300 "array",
301 "Period",
302 "show_versions",
303 "DateOffset",
304 "timedelta_range",
305 "infer_freq",
306 "interval_range",
307 "ExcelWriter",
308 "read_fwf",
309 "read_sql_table",
310 "read_sql_query",
311 "ExcelFile",
312 "to_pickle",
313 "HDFStore",
314 "lreshape",
315 "wide_to_long",
316 "merge_asof",
317 "merge_ordered",
318 "notnull",
319 "notna",
320 "pivot",
321 "to_numeric",
322 "unique",
323 "value_counts",
324 "datetime",
325 "NamedAgg",
326 ]
327
328 del pandas, Engine, Parameter
329
[end of modin/pandas/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/modin/pandas/__init__.py b/modin/pandas/__init__.py
--- a/modin/pandas/__init__.py
+++ b/modin/pandas/__init__.py
@@ -85,6 +85,7 @@
datetime,
NamedAgg,
NA,
+ api,
)
import os
import multiprocessing
@@ -323,6 +324,7 @@
"value_counts",
"datetime",
"NamedAgg",
+ "api",
]
del pandas, Engine, Parameter
|
{"golden_diff": "diff --git a/modin/pandas/__init__.py b/modin/pandas/__init__.py\n--- a/modin/pandas/__init__.py\n+++ b/modin/pandas/__init__.py\n@@ -85,6 +85,7 @@\n datetime,\n NamedAgg,\n NA,\n+ api,\n )\n import os\n import multiprocessing\n@@ -323,6 +324,7 @@\n \"value_counts\",\n \"datetime\",\n \"NamedAgg\",\n+ \"api\",\n ]\n \n del pandas, Engine, Parameter\n", "issue": "AttributeError: module 'modin.pandas' has no attribute 'api'\n### System information\r\n- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**: Linux Ubuntu 20.04\r\n- **Modin version** (`modin.__version__`): 0.10.2\r\n- **Python version**: 3.8.10\r\n- **Code we can use to reproduce**: \r\n\r\nimport modin.pandas as pd\r\n\r\nindexer = pd.api.indexers.FixedForwardWindowIndexer(window_size=d)\r\ndf['new'] = df['rough'].rolling(window=indexer).apply(np.prod, raw=True) - 1\r\n\r\n\r\n### Describe the problem\r\nmodin should have defaulted to pandas in case this functionality is not implemented instead of throwing an error.\r\n\r\n### Source code / logs\r\n indexer = pd.api.indexers.FixedForwardWindowIndexer(window_size=d)\r\nAttributeError: module 'modin.pandas' has no attribute 'api'\n", "before_files": [{"content": "# Licensed to Modin Development Team under one or more contributor license agreements.\n# See the NOTICE file distributed with this work for additional information regarding\n# copyright ownership. The Modin Development Team licenses this file to you under the\n# Apache License, Version 2.0 (the \"License\"); you may not use this file except in\n# compliance with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software distributed under\n# the License is distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF\n# ANY KIND, either express or implied. See the License for the specific language\n# governing permissions and limitations under the License.\n\nimport pandas\n\n__pandas_version__ = \"1.3.3\"\n\nif pandas.__version__ != __pandas_version__:\n import warnings\n\n warnings.warn(\n \"The pandas version installed {} does not match the supported pandas version in\"\n \" Modin {}. This may cause undesired side effects!\".format(\n pandas.__version__, __pandas_version__\n )\n )\n\nfrom pandas import (\n eval,\n cut,\n factorize,\n test,\n qcut,\n date_range,\n period_range,\n Index,\n MultiIndex,\n CategoricalIndex,\n bdate_range,\n DatetimeIndex,\n Timedelta,\n Timestamp,\n to_timedelta,\n set_eng_float_format,\n options,\n Flags,\n set_option,\n NaT,\n PeriodIndex,\n Categorical,\n Interval,\n UInt8Dtype,\n UInt16Dtype,\n UInt32Dtype,\n UInt64Dtype,\n SparseDtype,\n Int8Dtype,\n Int16Dtype,\n Int32Dtype,\n Int64Dtype,\n Float32Dtype,\n Float64Dtype,\n StringDtype,\n BooleanDtype,\n CategoricalDtype,\n DatetimeTZDtype,\n IntervalDtype,\n PeriodDtype,\n RangeIndex,\n Int64Index,\n UInt64Index,\n Float64Index,\n TimedeltaIndex,\n IntervalIndex,\n IndexSlice,\n Grouper,\n array,\n Period,\n show_versions,\n DateOffset,\n timedelta_range,\n infer_freq,\n interval_range,\n ExcelWriter,\n datetime,\n NamedAgg,\n NA,\n)\nimport os\nimport multiprocessing\n\nfrom modin.config import Engine, Parameter\n\n# Set this so that Pandas doesn't try to multithread by itself\nos.environ[\"OMP_NUM_THREADS\"] = \"1\"\n\n_is_first_update = {}\ndask_client = None\n_NOINIT_ENGINES = {\n \"Python\",\n} # engines that don't require initialization, useful for unit tests\n\n\ndef _update_engine(publisher: Parameter):\n global dask_client\n from modin.config import Backend, CpuCount\n\n if publisher.get() == \"Ray\":\n if _is_first_update.get(\"Ray\", True):\n from modin.engines.ray.utils import initialize_ray\n\n initialize_ray()\n elif publisher.get() == \"Native\":\n # With OmniSci backend there is only a single worker per node\n # and we allow it to work on all cores.\n if Backend.get() == \"Omnisci\":\n os.environ[\"OMP_NUM_THREADS\"] = str(CpuCount.get())\n else:\n raise ValueError(\n f\"Backend should be 'Omnisci' with 'Native' engine, but provided {Backend.get()}.\"\n )\n elif publisher.get() == \"Dask\":\n if _is_first_update.get(\"Dask\", True):\n from modin.engines.dask.utils import initialize_dask\n\n initialize_dask()\n elif publisher.get() == \"Cloudray\":\n from modin.experimental.cloud import get_connection\n\n conn = get_connection()\n if _is_first_update.get(\"Cloudray\", True):\n\n @conn.teleport\n def init_remote_ray(partition):\n from ray import ray_constants\n import modin\n from modin.engines.ray.utils import initialize_ray\n\n modin.set_backends(\"Ray\", partition)\n initialize_ray(\n override_is_cluster=True,\n override_redis_address=f\"localhost:{ray_constants.DEFAULT_PORT}\",\n override_redis_password=ray_constants.REDIS_DEFAULT_PASSWORD,\n )\n\n init_remote_ray(Backend.get())\n # import FactoryDispatcher here to initialize IO class\n # so it doesn't skew read_csv() timings later on\n import modin.data_management.factories.dispatcher # noqa: F401\n else:\n get_connection().modules[\"modin\"].set_backends(\"Ray\", Backend.get())\n elif publisher.get() == \"Cloudpython\":\n from modin.experimental.cloud import get_connection\n\n get_connection().modules[\"modin\"].set_backends(\"Python\")\n elif publisher.get() == \"Cloudnative\":\n from modin.experimental.cloud import get_connection\n\n assert (\n Backend.get() == \"Omnisci\"\n ), f\"Backend should be 'Omnisci' with 'Cloudnative' engine, but provided {Backend.get()}.\"\n get_connection().modules[\"modin\"].set_backends(\"Native\", \"OmniSci\")\n\n elif publisher.get() not in _NOINIT_ENGINES:\n raise ImportError(\"Unrecognized execution engine: {}.\".format(publisher.get()))\n\n _is_first_update[publisher.get()] = False\n\n\nfrom .. import __version__\nfrom .dataframe import DataFrame\nfrom .io import (\n read_csv,\n read_parquet,\n read_json,\n read_html,\n read_clipboard,\n read_excel,\n read_hdf,\n read_feather,\n read_stata,\n read_sas,\n read_pickle,\n read_sql,\n read_gbq,\n read_table,\n read_fwf,\n read_sql_table,\n read_sql_query,\n read_spss,\n ExcelFile,\n to_pickle,\n HDFStore,\n json_normalize,\n read_orc,\n read_xml,\n)\nfrom .series import Series\nfrom .general import (\n concat,\n isna,\n isnull,\n merge,\n merge_asof,\n merge_ordered,\n pivot_table,\n notnull,\n notna,\n pivot,\n to_numeric,\n to_datetime,\n unique,\n value_counts,\n get_dummies,\n melt,\n crosstab,\n lreshape,\n wide_to_long,\n)\nfrom .plotting import Plotting as plotting\n\n__all__ = [\n \"DataFrame\",\n \"Series\",\n \"read_csv\",\n \"read_parquet\",\n \"read_json\",\n \"read_html\",\n \"read_clipboard\",\n \"read_excel\",\n \"read_hdf\",\n \"read_feather\",\n \"read_stata\",\n \"read_sas\",\n \"read_pickle\",\n \"read_sql\",\n \"read_gbq\",\n \"read_table\",\n \"read_spss\",\n \"read_orc\",\n \"json_normalize\",\n \"concat\",\n \"eval\",\n \"cut\",\n \"factorize\",\n \"test\",\n \"qcut\",\n \"to_datetime\",\n \"get_dummies\",\n \"isna\",\n \"isnull\",\n \"merge\",\n \"pivot_table\",\n \"date_range\",\n \"Index\",\n \"MultiIndex\",\n \"Series\",\n \"bdate_range\",\n \"period_range\",\n \"DatetimeIndex\",\n \"to_timedelta\",\n \"set_eng_float_format\",\n \"options\",\n \"set_option\",\n \"CategoricalIndex\",\n \"Timedelta\",\n \"Timestamp\",\n \"NaT\",\n \"PeriodIndex\",\n \"Categorical\",\n \"__version__\",\n \"melt\",\n \"crosstab\",\n \"plotting\",\n \"Interval\",\n \"UInt8Dtype\",\n \"UInt16Dtype\",\n \"UInt32Dtype\",\n \"UInt64Dtype\",\n \"SparseDtype\",\n \"Int8Dtype\",\n \"Int16Dtype\",\n \"Int32Dtype\",\n \"Int64Dtype\",\n \"CategoricalDtype\",\n \"DatetimeTZDtype\",\n \"IntervalDtype\",\n \"PeriodDtype\",\n \"BooleanDtype\",\n \"StringDtype\",\n \"NA\",\n \"RangeIndex\",\n \"Int64Index\",\n \"UInt64Index\",\n \"Float64Index\",\n \"TimedeltaIndex\",\n \"IntervalIndex\",\n \"IndexSlice\",\n \"Grouper\",\n \"array\",\n \"Period\",\n \"show_versions\",\n \"DateOffset\",\n \"timedelta_range\",\n \"infer_freq\",\n \"interval_range\",\n \"ExcelWriter\",\n \"read_fwf\",\n \"read_sql_table\",\n \"read_sql_query\",\n \"ExcelFile\",\n \"to_pickle\",\n \"HDFStore\",\n \"lreshape\",\n \"wide_to_long\",\n \"merge_asof\",\n \"merge_ordered\",\n \"notnull\",\n \"notna\",\n \"pivot\",\n \"to_numeric\",\n \"unique\",\n \"value_counts\",\n \"datetime\",\n \"NamedAgg\",\n]\n\ndel pandas, Engine, Parameter\n", "path": "modin/pandas/__init__.py"}]}
| 3,615 | 121 |
gh_patches_debug_15340
|
rasdani/github-patches
|
git_diff
|
pypa__setuptools-2134
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Removing compatibility for Python 2
In #1458 and the Setuptools 45 release, this project dropped declared support for Python 2, adding a warning when a late version was invoked on Python 2. This warning helped address many of the systemic uses of Setuptools 45+ on Python 2, but there continue to be users (presumably) reporting that they've [encountered the warning](https://github.com/pypa/setuptools/issues?q=is%3Aissue+in%3Atitle+%22incompatible+install%22+).
I say presumably because most of them have submitted a blank template without providing any information.
Since March, these users have been directed to the template via bit.ly, so I have metrics on the number of users encountering and following the link.

It seems there have been 50-100 clicks per day since Apr 11. I'm guessing bit.ly doesn't give me data older than 30 days.
To put that in perspective, Setuptools received over 45M downloads in the last month, so the number of people that followed that link (3.3k) is 0.007% of the downloads.
Still, that's upwards of 100 people per day whose workflow would be broken until they could fix their environment.
Let's also consider that each of these users encountering this issue are following discouraged if not deprecated workflows and are creating new or updated environments (new since setuptools 45 was released in January).
It seems to me we have two options - support Python 2 until the incidents of users encountering this error message reduces to a trickle (what is that threshold) or bite the bullet and drop support for Python 2.
I'd like to review the outstanding issues relating to this issue, but my inclination is to move forward with dropping support.
</issue>
<code>
[start of pkg_resources/py2_warn.py]
1 import sys
2 import warnings
3 import textwrap
4
5
6 msg = textwrap.dedent("""
7 You are running Setuptools on Python 2, which is no longer
8 supported and
9 >>> SETUPTOOLS WILL STOP WORKING <<<
10 in a subsequent release (no sooner than 2020-04-20).
11 Please ensure you are installing
12 Setuptools using pip 9.x or later or pin to `setuptools<45`
13 in your environment.
14 If you have done those things and are still encountering
15 this message, please follow up at
16 https://bit.ly/setuptools-py2-warning.
17 """)
18
19 pre = "Setuptools will stop working on Python 2\n"
20
21 sys.version_info < (3,) and warnings.warn(pre + "*" * 60 + msg + "*" * 60)
22
[end of pkg_resources/py2_warn.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pkg_resources/py2_warn.py b/pkg_resources/py2_warn.py
--- a/pkg_resources/py2_warn.py
+++ b/pkg_resources/py2_warn.py
@@ -4,18 +4,13 @@
msg = textwrap.dedent("""
- You are running Setuptools on Python 2, which is no longer
- supported and
- >>> SETUPTOOLS WILL STOP WORKING <<<
- in a subsequent release (no sooner than 2020-04-20).
- Please ensure you are installing
- Setuptools using pip 9.x or later or pin to `setuptools<45`
- in your environment.
- If you have done those things and are still encountering
- this message, please follow up at
- https://bit.ly/setuptools-py2-warning.
+ Encountered a version of Setuptools that no longer supports
+ this version of Python. Please head to
+ https://bit.ly/setuptools-py2-warning for support.
""")
-pre = "Setuptools will stop working on Python 2\n"
+pre = "Setuptools no longer works on Python 2\n"
-sys.version_info < (3,) and warnings.warn(pre + "*" * 60 + msg + "*" * 60)
+if sys.version_info < (3,):
+ warnings.warn(pre + "*" * 60 + msg + "*" * 60)
+ raise SystemExit(32)
|
{"golden_diff": "diff --git a/pkg_resources/py2_warn.py b/pkg_resources/py2_warn.py\n--- a/pkg_resources/py2_warn.py\n+++ b/pkg_resources/py2_warn.py\n@@ -4,18 +4,13 @@\n \n \n msg = textwrap.dedent(\"\"\"\n- You are running Setuptools on Python 2, which is no longer\n- supported and\n- >>> SETUPTOOLS WILL STOP WORKING <<<\n- in a subsequent release (no sooner than 2020-04-20).\n- Please ensure you are installing\n- Setuptools using pip 9.x or later or pin to `setuptools<45`\n- in your environment.\n- If you have done those things and are still encountering\n- this message, please follow up at\n- https://bit.ly/setuptools-py2-warning.\n+ Encountered a version of Setuptools that no longer supports\n+ this version of Python. Please head to\n+ https://bit.ly/setuptools-py2-warning for support.\n \"\"\")\n \n-pre = \"Setuptools will stop working on Python 2\\n\"\n+pre = \"Setuptools no longer works on Python 2\\n\"\n \n-sys.version_info < (3,) and warnings.warn(pre + \"*\" * 60 + msg + \"*\" * 60)\n+if sys.version_info < (3,):\n+ warnings.warn(pre + \"*\" * 60 + msg + \"*\" * 60)\n+ raise SystemExit(32)\n", "issue": "Removing compatibility for Python 2\nIn #1458 and the Setuptools 45 release, this project dropped declared support for Python 2, adding a warning when a late version was invoked on Python 2. This warning helped address many of the systemic uses of Setuptools 45+ on Python 2, but there continue to be users (presumably) reporting that they've [encountered the warning](https://github.com/pypa/setuptools/issues?q=is%3Aissue+in%3Atitle+%22incompatible+install%22+).\r\n\r\nI say presumably because most of them have submitted a blank template without providing any information.\r\n\r\nSince March, these users have been directed to the template via bit.ly, so I have metrics on the number of users encountering and following the link.\r\n\r\n\r\n\r\nIt seems there have been 50-100 clicks per day since Apr 11. I'm guessing bit.ly doesn't give me data older than 30 days.\r\n\r\nTo put that in perspective, Setuptools received over 45M downloads in the last month, so the number of people that followed that link (3.3k) is 0.007% of the downloads.\r\n\r\nStill, that's upwards of 100 people per day whose workflow would be broken until they could fix their environment.\r\n\r\nLet's also consider that each of these users encountering this issue are following discouraged if not deprecated workflows and are creating new or updated environments (new since setuptools 45 was released in January).\r\n\r\nIt seems to me we have two options - support Python 2 until the incidents of users encountering this error message reduces to a trickle (what is that threshold) or bite the bullet and drop support for Python 2.\r\n\r\nI'd like to review the outstanding issues relating to this issue, but my inclination is to move forward with dropping support.\n", "before_files": [{"content": "import sys\nimport warnings\nimport textwrap\n\n\nmsg = textwrap.dedent(\"\"\"\n You are running Setuptools on Python 2, which is no longer\n supported and\n >>> SETUPTOOLS WILL STOP WORKING <<<\n in a subsequent release (no sooner than 2020-04-20).\n Please ensure you are installing\n Setuptools using pip 9.x or later or pin to `setuptools<45`\n in your environment.\n If you have done those things and are still encountering\n this message, please follow up at\n https://bit.ly/setuptools-py2-warning.\n \"\"\")\n\npre = \"Setuptools will stop working on Python 2\\n\"\n\nsys.version_info < (3,) and warnings.warn(pre + \"*\" * 60 + msg + \"*\" * 60)\n", "path": "pkg_resources/py2_warn.py"}]}
| 1,206 | 327 |
gh_patches_debug_33249
|
rasdani/github-patches
|
git_diff
|
vispy__vispy-2226
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Incorrect behavior with multipe clipping planes
I was checking up on that nice trick where the clipping planes logic is done in the vertex shader and then interpolated to the fragment shader, with the intention of applying it in pygfx too. However, I found that this trick does not work in the case of multiple clipping planes.
This can be shown with the following example:
```py
import numpy as np
from vispy import app, scene, io
from vispy.visuals.filters.clipping_planes import PlanesClipper
canvas = scene.SceneCanvas(keys='interactive', size=(800, 600), show=True)
view = canvas.central_widget.add_view()
cube = scene.visuals.Box(100, 100, 100, color=(1, 0, 0, 1), parent=view.scene)
view.camera = scene.cameras.TurntableCamera(parent=view.scene, fov=60)
clip_center = (0, 20, 60)
clipping_planes = np.concatenate(
[ np.array([[clip_center, [1, 0, 0]]]), np.array([[clip_center, [0, 1, 0]]])]
)
clipper = PlanesClipper()
clipper.clipping_planes = clipping_planes
cube.attach(clipper)
if __name__ == '__main__':
app.run()
```
If you turn the camera to look from above, you'll see this:

I think this can be explained with the following figure:

The black lines indicate two clipping planes (the shaded side is where they clip). The two blue dots represent two vertices with a line or polygon interpolating between them. Both dots are of equal distance two a plane, one on the + side and one on the - side. Now if the `min_plane_distance` (or whatever we ended up calling it :D ) is interpolated, it will have its zero point (the point where it starts clipping) in the middle.
cc @brisvag
</issue>
<code>
[start of vispy/visuals/filters/clipping_planes.py]
1 # -*- coding: utf-8 -*-
2 # Copyright (c) Vispy Development Team. All Rights Reserved.
3 # Distributed under the (new) BSD License. See LICENSE.txt for more info.
4
5 from functools import lru_cache
6
7 import numpy as np
8
9 from ..shaders import Function, Varying
10 from .base_filter import Filter
11
12
13 class PlanesClipper(Filter):
14 """Clips visual output based on arbitrary clipping planes.
15
16 Parameters
17 ----------
18 cliping_planes : ArrayLike
19 Each plane is defined by a position and a normal vector (magnitude is irrelevant). Shape: (n_planes, 2, 3)
20 coord_system : str
21 Coordinate system used by the clipping planes (see visuals.transforms.transform_system.py)
22
23 """
24
25 VERT_CODE = """
26 void clip() {
27 // Transform back to visual coordinates and clip based on that
28 $v_distance_from_clip = $clip_with_planes($itransform(gl_Position).xyz);
29 }
30 """
31
32 FRAG_CODE = """
33 void clip() {
34 if ($v_distance_from_clip < 0.)
35 discard;
36 }
37 """
38
39 def __init__(self, clipping_planes=None, coord_system='scene'):
40 tr = ['visual', 'scene', 'document', 'canvas', 'framebuffer', 'render']
41 if coord_system not in tr:
42 raise ValueError(f'Invalid coordinate system {coord_system}. Must be one of {tr}.')
43 self._coord_system = coord_system
44
45 super().__init__(
46 vcode=Function(self.VERT_CODE), vhook='post', vpos=1,
47 fcode=Function(self.FRAG_CODE), fhook='pre', fpos=1,
48 )
49
50 v_distance_from_clip = Varying('v_distance_from_clip', 'float')
51 self.vshader['v_distance_from_clip'] = v_distance_from_clip
52 self.fshader['v_distance_from_clip'] = v_distance_from_clip
53
54 self.clipping_planes = clipping_planes
55
56 @property
57 def coord_system(self):
58 """
59 Coordinate system used by the clipping planes (see visuals.transforms.transform_system.py)
60 """
61 # unsettable cause we can't update the transform after being attached
62 return self._coord_system
63
64 def _attach(self, visual):
65 super()._attach(visual)
66 self.vshader['itransform'] = visual.get_transform('render', self._coord_system)
67
68 @staticmethod
69 @lru_cache(maxsize=10)
70 def _build_clipping_planes_func(n_planes):
71 """Build the code snippet used to clip the volume based on self.clipping_planes."""
72 func_template = '''
73 float clip_planes(vec3 loc) {{
74 float distance_from_clip = 3.4e38; // max float
75 {clips};
76 return distance_from_clip;
77 }}
78 '''
79 # the vertex is considered clipped if on the "negative" side of the plane
80 clip_template = '''
81 vec3 relative_vec{idx} = loc - $clipping_plane_pos{idx};
82 float distance_from_clip{idx} = dot(relative_vec{idx}, $clipping_plane_norm{idx});
83 distance_from_clip = min(distance_from_clip{idx}, distance_from_clip);
84 '''
85 all_clips = []
86 for idx in range(n_planes):
87 all_clips.append(clip_template.format(idx=idx))
88 formatted_code = func_template.format(clips=''.join(all_clips))
89 return Function(formatted_code)
90
91 @property
92 def clipping_planes(self):
93 """Get the set of planes used to clip the mesh.
94 Each plane is defined by a position and a normal vector (magnitude is irrelevant). Shape: (n_planes, 2, 3)
95 """
96 return self._clipping_planes
97
98 @clipping_planes.setter
99 def clipping_planes(self, value):
100 if value is None:
101 value = np.empty([0, 2, 3])
102 self._clipping_planes = value
103
104 clip_func = self._build_clipping_planes_func(len(value))
105 self.vshader['clip_with_planes'] = clip_func
106
107 for idx, plane in enumerate(value):
108 clip_func[f'clipping_plane_pos{idx}'] = tuple(plane[0])
109 clip_func[f'clipping_plane_norm{idx}'] = tuple(plane[1])
110
[end of vispy/visuals/filters/clipping_planes.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/vispy/visuals/filters/clipping_planes.py b/vispy/visuals/filters/clipping_planes.py
--- a/vispy/visuals/filters/clipping_planes.py
+++ b/vispy/visuals/filters/clipping_planes.py
@@ -24,14 +24,15 @@
VERT_CODE = """
void clip() {
- // Transform back to visual coordinates and clip based on that
- $v_distance_from_clip = $clip_with_planes($itransform(gl_Position).xyz);
+ // pass position as varying for interpolation
+ $v_position = gl_Position;
}
"""
FRAG_CODE = """
void clip() {
- if ($v_distance_from_clip < 0.)
+ float distance_from_clip = $clip_with_planes($itransform($v_position).xyz);
+ if (distance_from_clip < 0.)
discard;
}
"""
@@ -47,9 +48,9 @@
fcode=Function(self.FRAG_CODE), fhook='pre', fpos=1,
)
- v_distance_from_clip = Varying('v_distance_from_clip', 'float')
- self.vshader['v_distance_from_clip'] = v_distance_from_clip
- self.fshader['v_distance_from_clip'] = v_distance_from_clip
+ v_position = Varying('v_position', 'vec4')
+ self.vshader['v_position'] = v_position
+ self.fshader['v_position'] = v_position
self.clipping_planes = clipping_planes
@@ -63,7 +64,7 @@
def _attach(self, visual):
super()._attach(visual)
- self.vshader['itransform'] = visual.get_transform('render', self._coord_system)
+ self.fshader['itransform'] = visual.get_transform('render', self._coord_system)
@staticmethod
@lru_cache(maxsize=10)
@@ -102,7 +103,7 @@
self._clipping_planes = value
clip_func = self._build_clipping_planes_func(len(value))
- self.vshader['clip_with_planes'] = clip_func
+ self.fshader['clip_with_planes'] = clip_func
for idx, plane in enumerate(value):
clip_func[f'clipping_plane_pos{idx}'] = tuple(plane[0])
|
{"golden_diff": "diff --git a/vispy/visuals/filters/clipping_planes.py b/vispy/visuals/filters/clipping_planes.py\n--- a/vispy/visuals/filters/clipping_planes.py\n+++ b/vispy/visuals/filters/clipping_planes.py\n@@ -24,14 +24,15 @@\n \n VERT_CODE = \"\"\"\n void clip() {\n- // Transform back to visual coordinates and clip based on that\n- $v_distance_from_clip = $clip_with_planes($itransform(gl_Position).xyz);\n+ // pass position as varying for interpolation\n+ $v_position = gl_Position;\n }\n \"\"\"\n \n FRAG_CODE = \"\"\"\n void clip() {\n- if ($v_distance_from_clip < 0.)\n+ float distance_from_clip = $clip_with_planes($itransform($v_position).xyz);\n+ if (distance_from_clip < 0.)\n discard;\n }\n \"\"\"\n@@ -47,9 +48,9 @@\n fcode=Function(self.FRAG_CODE), fhook='pre', fpos=1,\n )\n \n- v_distance_from_clip = Varying('v_distance_from_clip', 'float')\n- self.vshader['v_distance_from_clip'] = v_distance_from_clip\n- self.fshader['v_distance_from_clip'] = v_distance_from_clip\n+ v_position = Varying('v_position', 'vec4')\n+ self.vshader['v_position'] = v_position\n+ self.fshader['v_position'] = v_position\n \n self.clipping_planes = clipping_planes\n \n@@ -63,7 +64,7 @@\n \n def _attach(self, visual):\n super()._attach(visual)\n- self.vshader['itransform'] = visual.get_transform('render', self._coord_system)\n+ self.fshader['itransform'] = visual.get_transform('render', self._coord_system)\n \n @staticmethod\n @lru_cache(maxsize=10)\n@@ -102,7 +103,7 @@\n self._clipping_planes = value\n \n clip_func = self._build_clipping_planes_func(len(value))\n- self.vshader['clip_with_planes'] = clip_func\n+ self.fshader['clip_with_planes'] = clip_func\n \n for idx, plane in enumerate(value):\n clip_func[f'clipping_plane_pos{idx}'] = tuple(plane[0])\n", "issue": "Incorrect behavior with multipe clipping planes \nI was checking up on that nice trick where the clipping planes logic is done in the vertex shader and then interpolated to the fragment shader, with the intention of applying it in pygfx too. However, I found that this trick does not work in the case of multiple clipping planes.\r\n\r\nThis can be shown with the following example:\r\n```py\r\nimport numpy as np\r\nfrom vispy import app, scene, io\r\nfrom vispy.visuals.filters.clipping_planes import PlanesClipper\r\n\r\ncanvas = scene.SceneCanvas(keys='interactive', size=(800, 600), show=True)\r\nview = canvas.central_widget.add_view()\r\n\r\ncube = scene.visuals.Box(100, 100, 100, color=(1, 0, 0, 1), parent=view.scene)\r\n\r\nview.camera = scene.cameras.TurntableCamera(parent=view.scene, fov=60)\r\n\r\nclip_center = (0, 20, 60)\r\nclipping_planes = np.concatenate(\r\n [ np.array([[clip_center, [1, 0, 0]]]), np.array([[clip_center, [0, 1, 0]]])]\r\n)\r\n\r\nclipper = PlanesClipper()\r\nclipper.clipping_planes = clipping_planes\r\ncube.attach(clipper)\r\n\r\nif __name__ == '__main__':\r\n app.run()\r\n```\r\n\r\nIf you turn the camera to look from above, you'll see this:\r\n\r\n\r\n\r\n\r\nI think this can be explained with the following figure:\r\n\r\n\r\n\r\nThe black lines indicate two clipping planes (the shaded side is where they clip). The two blue dots represent two vertices with a line or polygon interpolating between them. Both dots are of equal distance two a plane, one on the + side and one on the - side. Now if the `min_plane_distance` (or whatever we ended up calling it :D ) is interpolated, it will have its zero point (the point where it starts clipping) in the middle.\r\n\r\ncc @brisvag \n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright (c) Vispy Development Team. All Rights Reserved.\n# Distributed under the (new) BSD License. See LICENSE.txt for more info.\n\nfrom functools import lru_cache\n\nimport numpy as np\n\nfrom ..shaders import Function, Varying\nfrom .base_filter import Filter\n\n\nclass PlanesClipper(Filter):\n \"\"\"Clips visual output based on arbitrary clipping planes.\n\n Parameters\n ----------\n cliping_planes : ArrayLike\n Each plane is defined by a position and a normal vector (magnitude is irrelevant). Shape: (n_planes, 2, 3)\n coord_system : str\n Coordinate system used by the clipping planes (see visuals.transforms.transform_system.py)\n\n \"\"\"\n\n VERT_CODE = \"\"\"\n void clip() {\n // Transform back to visual coordinates and clip based on that\n $v_distance_from_clip = $clip_with_planes($itransform(gl_Position).xyz);\n }\n \"\"\"\n\n FRAG_CODE = \"\"\"\n void clip() {\n if ($v_distance_from_clip < 0.)\n discard;\n }\n \"\"\"\n\n def __init__(self, clipping_planes=None, coord_system='scene'):\n tr = ['visual', 'scene', 'document', 'canvas', 'framebuffer', 'render']\n if coord_system not in tr:\n raise ValueError(f'Invalid coordinate system {coord_system}. Must be one of {tr}.')\n self._coord_system = coord_system\n\n super().__init__(\n vcode=Function(self.VERT_CODE), vhook='post', vpos=1,\n fcode=Function(self.FRAG_CODE), fhook='pre', fpos=1,\n )\n\n v_distance_from_clip = Varying('v_distance_from_clip', 'float')\n self.vshader['v_distance_from_clip'] = v_distance_from_clip\n self.fshader['v_distance_from_clip'] = v_distance_from_clip\n\n self.clipping_planes = clipping_planes\n\n @property\n def coord_system(self):\n \"\"\"\n Coordinate system used by the clipping planes (see visuals.transforms.transform_system.py)\n \"\"\"\n # unsettable cause we can't update the transform after being attached\n return self._coord_system\n\n def _attach(self, visual):\n super()._attach(visual)\n self.vshader['itransform'] = visual.get_transform('render', self._coord_system)\n\n @staticmethod\n @lru_cache(maxsize=10)\n def _build_clipping_planes_func(n_planes):\n \"\"\"Build the code snippet used to clip the volume based on self.clipping_planes.\"\"\"\n func_template = '''\n float clip_planes(vec3 loc) {{\n float distance_from_clip = 3.4e38; // max float\n {clips};\n return distance_from_clip;\n }}\n '''\n # the vertex is considered clipped if on the \"negative\" side of the plane\n clip_template = '''\n vec3 relative_vec{idx} = loc - $clipping_plane_pos{idx};\n float distance_from_clip{idx} = dot(relative_vec{idx}, $clipping_plane_norm{idx});\n distance_from_clip = min(distance_from_clip{idx}, distance_from_clip);\n '''\n all_clips = []\n for idx in range(n_planes):\n all_clips.append(clip_template.format(idx=idx))\n formatted_code = func_template.format(clips=''.join(all_clips))\n return Function(formatted_code)\n\n @property\n def clipping_planes(self):\n \"\"\"Get the set of planes used to clip the mesh.\n Each plane is defined by a position and a normal vector (magnitude is irrelevant). Shape: (n_planes, 2, 3)\n \"\"\"\n return self._clipping_planes\n\n @clipping_planes.setter\n def clipping_planes(self, value):\n if value is None:\n value = np.empty([0, 2, 3])\n self._clipping_planes = value\n\n clip_func = self._build_clipping_planes_func(len(value))\n self.vshader['clip_with_planes'] = clip_func\n\n for idx, plane in enumerate(value):\n clip_func[f'clipping_plane_pos{idx}'] = tuple(plane[0])\n clip_func[f'clipping_plane_norm{idx}'] = tuple(plane[1])\n", "path": "vispy/visuals/filters/clipping_planes.py"}]}
| 2,235 | 527 |
gh_patches_debug_10597
|
rasdani/github-patches
|
git_diff
|
e2nIEE__pandapower-849
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Estimation results
Hello,
I think in python file pandapower -> estimation -> results.py there is a baseMVA missing in the calculation.
I think line 22 should be adjusted to this, or similar:
`Sbus = np.multiply(V, np.conj(Ybus * V)) * baseMVA`
Thanks
</issue>
<code>
[start of pandapower/estimation/results.py]
1 # -*- coding: utf-8 -*-
2
3 # Copyright (c) 2016-2020 by University of Kassel and Fraunhofer Institute for Energy Economics
4 # and Energy System Technology (IEE), Kassel. All rights reserved.
5
6 import numpy as np
7
8 from pandapower.pypower.idx_bus import PD, QD
9 from pandapower.pf.ppci_variables import _get_pf_variables_from_ppci
10 from pandapower.pf.pfsoln_numba import pfsoln
11 from pandapower.results import _copy_results_ppci_to_ppc, _extract_results_se, init_results
12 from pandapower.auxiliary import _add_pf_options, get_values, _clean_up
13
14 def _calc_power_flow(ppci, V):
15 # store results for all elements
16 # calculate branch results (in ppc_i)
17 baseMVA, bus, gen, branch, ref, pv, pq, _, _, _, ref_gens = _get_pf_variables_from_ppci(ppci)
18 Ybus, Yf, Yt = ppci['internal']['Ybus'], ppci['internal']['Yf'], ppci['internal']['Yt']
19 ppci['bus'], ppci['gen'], ppci['branch'] = pfsoln(baseMVA, bus, gen, branch, Ybus, Yf, Yt, V, ref, ref_gens)
20
21 # calculate bus power injections
22 Sbus = np.multiply(V, np.conj(Ybus * V))
23 ppci["bus"][:, PD] = -Sbus.real # saved in per unit, injection -> demand
24 ppci["bus"][:, QD] = -Sbus.imag # saved in per unit, injection -> demand
25 return ppci
26
27
28 def _extract_result_ppci_to_pp(net, ppc, ppci):
29 # convert to pandapower indices
30 ppc = _copy_results_ppci_to_ppc(ppci, ppc, mode="se")
31
32 # extract results from ppc
33 try:
34 _add_pf_options(net, tolerance_mva=1e-8, trafo_loading="current",
35 numba=True, ac=True, algorithm='nr', max_iteration="auto")
36 except:
37 pass
38 # writes res_bus.vm_pu / va_degree and res_line
39 _extract_results_se(net, ppc)
40
41 # restore backup of previous results
42 _rename_results(net)
43
44 # additionally, write bus power demand results (these are not written in _extract_results)
45 mapping_table = net["_pd2ppc_lookups"]["bus"]
46 net.res_bus_est.index = net.bus.index
47 net.res_bus_est.p_mw = get_values(ppc["bus"][:, 2], net.bus.index.values,
48 mapping_table)
49 net.res_bus_est.q_mvar = get_values(ppc["bus"][:, 3], net.bus.index.values,
50 mapping_table)
51
52 _clean_up(net)
53 # delete results which are not correctly calculated
54 for k in list(net.keys()):
55 if k.startswith("res_") and k.endswith("_est") and \
56 k not in ("res_bus_est", "res_line_est", "res_trafo_est", "res_trafo3w_est"):
57 del net[k]
58 return net
59
60
61 def _copy_power_flow_results(net):
62 """
63 copy old power flow results (if they exist) into res_*_power_flow tables for backup
64 :param net: pandapower grid
65 :return:
66 """
67 elements_to_init = ["bus", "ext_grid", "line", "load", "load_3ph" "sgen", "sgen_3ph", "trafo", "trafo3w",
68 "shunt", "impedance", "gen", "ward", "xward", "dcline"]
69 for element in elements_to_init:
70 res_name = "res_" + element
71 res_name_pf = res_name + "_power_flow"
72 if res_name in net:
73 net[res_name_pf] = (net[res_name]).copy()
74 init_results(net)
75
76
77 def _rename_results(net):
78 """
79 write result tables to result tables for estimation (e.g., res_bus -> res_bus_est)
80 reset backed up result tables (e.g., res_bus_power_flow -> res_bus)
81 :param net: pandapower grid
82 :return:
83 """
84 elements_to_init = ["bus", "ext_grid", "line", "load", "sgen", "trafo", "trafo3w",
85 "shunt", "impedance", "gen", "ward", "xward", "dcline"]
86 # rename res_* tables to res_*_est and then res_*_power_flow to res_*
87 for element in elements_to_init:
88 res_name = "res_" + element
89 res_name_pf = res_name + "_power_flow"
90 res_name_est = res_name + "_est"
91 net[res_name_est] = net[res_name]
92 if res_name_pf in net:
93 net[res_name] = net[res_name_pf]
94 else:
95 del net[res_name]
96
97 def eppci2pp(net, ppc, eppci):
98 # calculate the branch power flow and bus power injection based on the estimated voltage vector
99 eppci = _calc_power_flow(eppci, eppci.V)
100
101 # extract the result from ppci to ppc and pandpower network
102 net = _extract_result_ppci_to_pp(net, ppc, eppci)
103 return net
104
105
[end of pandapower/estimation/results.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pandapower/estimation/results.py b/pandapower/estimation/results.py
--- a/pandapower/estimation/results.py
+++ b/pandapower/estimation/results.py
@@ -19,7 +19,7 @@
ppci['bus'], ppci['gen'], ppci['branch'] = pfsoln(baseMVA, bus, gen, branch, Ybus, Yf, Yt, V, ref, ref_gens)
# calculate bus power injections
- Sbus = np.multiply(V, np.conj(Ybus * V))
+ Sbus = np.multiply(V, np.conj(Ybus * V)) * baseMVA
ppci["bus"][:, PD] = -Sbus.real # saved in per unit, injection -> demand
ppci["bus"][:, QD] = -Sbus.imag # saved in per unit, injection -> demand
return ppci
|
{"golden_diff": "diff --git a/pandapower/estimation/results.py b/pandapower/estimation/results.py\n--- a/pandapower/estimation/results.py\n+++ b/pandapower/estimation/results.py\n@@ -19,7 +19,7 @@\n ppci['bus'], ppci['gen'], ppci['branch'] = pfsoln(baseMVA, bus, gen, branch, Ybus, Yf, Yt, V, ref, ref_gens)\n \n # calculate bus power injections\n- Sbus = np.multiply(V, np.conj(Ybus * V))\n+ Sbus = np.multiply(V, np.conj(Ybus * V)) * baseMVA\n ppci[\"bus\"][:, PD] = -Sbus.real # saved in per unit, injection -> demand\n ppci[\"bus\"][:, QD] = -Sbus.imag # saved in per unit, injection -> demand\n return ppci\n", "issue": "Estimation results\nHello,\r\n\r\nI think in python file pandapower -> estimation -> results.py there is a baseMVA missing in the calculation.\r\n\r\nI think line 22 should be adjusted to this, or similar:\r\n\r\n`Sbus = np.multiply(V, np.conj(Ybus * V)) * baseMVA`\r\n\r\nThanks\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright (c) 2016-2020 by University of Kassel and Fraunhofer Institute for Energy Economics\n# and Energy System Technology (IEE), Kassel. All rights reserved.\n\nimport numpy as np\n\nfrom pandapower.pypower.idx_bus import PD, QD\nfrom pandapower.pf.ppci_variables import _get_pf_variables_from_ppci\nfrom pandapower.pf.pfsoln_numba import pfsoln\nfrom pandapower.results import _copy_results_ppci_to_ppc, _extract_results_se, init_results\nfrom pandapower.auxiliary import _add_pf_options, get_values, _clean_up\n\ndef _calc_power_flow(ppci, V):\n # store results for all elements\n # calculate branch results (in ppc_i)\n baseMVA, bus, gen, branch, ref, pv, pq, _, _, _, ref_gens = _get_pf_variables_from_ppci(ppci)\n Ybus, Yf, Yt = ppci['internal']['Ybus'], ppci['internal']['Yf'], ppci['internal']['Yt']\n ppci['bus'], ppci['gen'], ppci['branch'] = pfsoln(baseMVA, bus, gen, branch, Ybus, Yf, Yt, V, ref, ref_gens)\n\n # calculate bus power injections\n Sbus = np.multiply(V, np.conj(Ybus * V))\n ppci[\"bus\"][:, PD] = -Sbus.real # saved in per unit, injection -> demand\n ppci[\"bus\"][:, QD] = -Sbus.imag # saved in per unit, injection -> demand\n return ppci\n\n\ndef _extract_result_ppci_to_pp(net, ppc, ppci):\n # convert to pandapower indices\n ppc = _copy_results_ppci_to_ppc(ppci, ppc, mode=\"se\")\n\n # extract results from ppc\n try:\n _add_pf_options(net, tolerance_mva=1e-8, trafo_loading=\"current\",\n numba=True, ac=True, algorithm='nr', max_iteration=\"auto\")\n except:\n pass\n # writes res_bus.vm_pu / va_degree and res_line\n _extract_results_se(net, ppc)\n\n # restore backup of previous results\n _rename_results(net)\n\n # additionally, write bus power demand results (these are not written in _extract_results)\n mapping_table = net[\"_pd2ppc_lookups\"][\"bus\"]\n net.res_bus_est.index = net.bus.index\n net.res_bus_est.p_mw = get_values(ppc[\"bus\"][:, 2], net.bus.index.values,\n mapping_table)\n net.res_bus_est.q_mvar = get_values(ppc[\"bus\"][:, 3], net.bus.index.values,\n mapping_table)\n\n _clean_up(net)\n # delete results which are not correctly calculated\n for k in list(net.keys()):\n if k.startswith(\"res_\") and k.endswith(\"_est\") and \\\n k not in (\"res_bus_est\", \"res_line_est\", \"res_trafo_est\", \"res_trafo3w_est\"):\n del net[k]\n return net\n\n\ndef _copy_power_flow_results(net):\n \"\"\"\n copy old power flow results (if they exist) into res_*_power_flow tables for backup\n :param net: pandapower grid\n :return:\n \"\"\"\n elements_to_init = [\"bus\", \"ext_grid\", \"line\", \"load\", \"load_3ph\" \"sgen\", \"sgen_3ph\", \"trafo\", \"trafo3w\",\n \"shunt\", \"impedance\", \"gen\", \"ward\", \"xward\", \"dcline\"]\n for element in elements_to_init:\n res_name = \"res_\" + element\n res_name_pf = res_name + \"_power_flow\"\n if res_name in net:\n net[res_name_pf] = (net[res_name]).copy()\n init_results(net)\n\n\ndef _rename_results(net):\n \"\"\"\n write result tables to result tables for estimation (e.g., res_bus -> res_bus_est)\n reset backed up result tables (e.g., res_bus_power_flow -> res_bus)\n :param net: pandapower grid\n :return:\n \"\"\"\n elements_to_init = [\"bus\", \"ext_grid\", \"line\", \"load\", \"sgen\", \"trafo\", \"trafo3w\",\n \"shunt\", \"impedance\", \"gen\", \"ward\", \"xward\", \"dcline\"]\n # rename res_* tables to res_*_est and then res_*_power_flow to res_*\n for element in elements_to_init:\n res_name = \"res_\" + element\n res_name_pf = res_name + \"_power_flow\"\n res_name_est = res_name + \"_est\"\n net[res_name_est] = net[res_name]\n if res_name_pf in net:\n net[res_name] = net[res_name_pf]\n else:\n del net[res_name]\n\ndef eppci2pp(net, ppc, eppci):\n # calculate the branch power flow and bus power injection based on the estimated voltage vector\n eppci = _calc_power_flow(eppci, eppci.V)\n\n # extract the result from ppci to ppc and pandpower network\n net = _extract_result_ppci_to_pp(net, ppc, eppci)\n return net\n\n", "path": "pandapower/estimation/results.py"}]}
| 2,016 | 211 |
gh_patches_debug_13532
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-2424
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Support serverless v2 DBInstanceClass
*cfn-lint version: 0.59.0*
*Allowed list of DBInstanceClass does not include "db.serverless"*
Please provide as much information as possible:
* Template linting issues:
* Please provide a CloudFormation sample that generated the issue.
```
DbInstance0:
Type: AWS::RDS::DBInstance
Properties:
Engine: aurora-postgresql
DBClusterIdentifier: !Ref MyAuroraCluster
DBInstanceClass: db.serverless
```
* Feature request:
* List of allowed db instance class to include `db.serverless`. Documentation: https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Concepts.DBInstanceClass.html#Concepts.DBInstanceClass.Types
Cfn-lint uses the [CloudFormation Resource Specifications](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/cfn-resource-specification.html) as the base to do validation. These files are included as part of the application version. Please update to the latest version of `cfn-lint` or update the spec files manually (`cfn-lint -u`)
- Yes this fixes it for me locally, but I need a release with the change because I'm running it via [GitHub actions](https://github.com/ScottBrenner/cfn-lint-action).
</issue>
<code>
[start of scripts/update_specs_from_pricing.py]
1 #!/usr/bin/env python
2 """
3 Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
4 SPDX-License-Identifier: MIT-0
5 """
6
7 """
8 Updates our dynamic patches from the pricing API
9 This script requires Boto3 and Credentials to call the Pricing API
10 """
11
12
13 import boto3
14 import json
15 import logging
16 LOGGER = logging.getLogger('cfnlint')
17
18
19 region_map = {
20 'Any': 'all',
21 'AWS GovCloud (US-East)': 'us-gov-east-1',
22 'AWS GovCloud (US-West)': 'us-gov-west-1',
23 'Africa (Cape Town)': 'af-south-1',
24 'Asia Pacific (Hong Kong)': 'ap-east-1',
25 'Asia Pacific (Jakarta)': 'ap-southeast-3',
26 'Asia Pacific (Mumbai)': 'ap-south-1',
27 'Asia Pacific (Osaka)': 'ap-northeast-3',
28 'Asia Pacific (Seoul)': 'ap-northeast-2',
29 'Asia Pacific (Singapore)': 'ap-southeast-1',
30 'Asia Pacific (Sydney)': 'ap-southeast-2',
31 'Asia Pacific (Tokyo)': 'ap-northeast-1',
32 'Canada (Central)': 'ca-central-1',
33 'China (Beijing)': 'cn-north-1',
34 'China (Ningxia)': 'cn-northwest-1',
35 'EU (Frankfurt)': 'eu-central-1',
36 'EU (Ireland)': 'eu-west-1',
37 'EU (London)': 'eu-west-2',
38 'EU (Milan)': 'eu-south-1',
39 'EU (Paris)': 'eu-west-3',
40 'EU (Stockholm)': 'eu-north-1',
41 'Middle East (Bahrain)': 'me-south-1',
42 'Middle East (UAE)': 'me-central-1',
43 'South America (Sao Paulo)': 'sa-east-1',
44 'US East (N. Virginia)': 'us-east-1',
45 'US East (Ohio)': 'us-east-2',
46 'US West (N. California)': 'us-west-1',
47 'US West (Oregon)': 'us-west-2',
48 'US West (Los Angeles)': 'us-west-2',
49 }
50
51 session = boto3.session.Session()
52 client = session.client('pricing', region_name='us-east-1')
53
54
55 def configure_logging():
56 """Setup Logging"""
57 ch = logging.StreamHandler()
58 ch.setLevel(logging.INFO)
59
60 LOGGER.setLevel(logging.INFO)
61 log_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
62 ch.setFormatter(log_formatter)
63
64 # make sure all other log handlers are removed before adding it back
65 for handler in LOGGER.handlers:
66 LOGGER.removeHandler(handler)
67 LOGGER.addHandler(ch)
68
69
70 def update_outputs(key, values, outputs):
71 """ update outputs with appropriate results """
72 for region in values:
73 element = {
74 "op": "add",
75 "path": "/ValueTypes/%s/AllowedValues" % key,
76 "value": sorted(values[region])
77 }
78 outputs[region].append(element)
79
80 return outputs
81
82
83 def get_paginator(service):
84 LOGGER.info('Get ' + service + ' pricing')
85 return client.get_paginator('get_products').paginate(
86 ServiceCode=service,
87 FormatVersion='aws_v1',
88 )
89
90
91 def get_dax_pricing():
92 results = {}
93 for page in get_paginator('AmazonDAX'):
94 for price_item in page.get('PriceList', []):
95 products = json.loads(price_item)
96 product = products.get('product', {})
97 if product:
98 if product.get('productFamily') in ['DAX']:
99 if not results.get(region_map[product.get('attributes').get('location')]):
100 results[region_map[product.get('attributes').get('location')]] = set()
101 results[region_map[product.get('attributes').get('location')]].add(
102 product.get('attributes').get('usagetype').split(':')[1]
103 )
104 return results
105
106
107 def get_mq_pricing():
108 remap = {
109 'mq.m5.2xl': 'mq.m5.2xlarge',
110 'mq.m5.4xl': 'mq.m5.4xlarge'
111 }
112 results = {}
113 for page in get_paginator('AmazonMQ'):
114 for price_item in page.get('PriceList', []):
115 products = json.loads(price_item)
116 product = products.get('product', {})
117 if product:
118 if product.get('productFamily') in ['Broker Instances']:
119 if not results.get(region_map[product.get('attributes').get('location')]):
120 results[region_map[product.get('attributes').get('location')]] = set()
121 usage_type = product.get('attributes').get('usagetype').split(':')[1]
122 results[region_map[product.get('attributes').get('location')]].add(
123 remap.get(usage_type, usage_type)
124 )
125 return results
126
127
128 def get_rds_pricing():
129 product_map = {
130 '2': ['mysql'],
131 '3': ['oracle-se1'],
132 '4': ['oracle-se'],
133 '5': ['oracle-ee'],
134 '6': ['oracle-se1'],
135 '8': ['sqlserver-se'],
136 '9': ['sqlserver-ee'],
137 '10': ['sqlserver-ex'],
138 '11': ['sqlserver-web'],
139 '12': ['sqlserver-se'],
140 '14': ['postgres'],
141 '15': ['sqlserver-ee'],
142 '16': ['aurora-mysql', 'aurora'],
143 '18': ['mariadb'],
144 '19': ['oracle-se2'],
145 '20': ['oracle-se2'],
146 '21': ['aurora-postgresql'],
147 }
148
149 license_map = {
150 'License included': 'license-included',
151 'Bring your own license': 'bring-your-own-license',
152 'No license required': 'general-public-license'
153 }
154
155 rds_specs = {}
156
157 results = {}
158 for page in get_paginator('AmazonRDS'):
159 for price_item in page.get('PriceList', []):
160 products = json.loads(price_item)
161 product = products.get('product', {})
162 if product:
163 if product.get('productFamily') in ['Database Instance']:
164 # Get overall instance types
165 if not results.get(region_map[product.get('attributes').get('location')]):
166 results[region_map[product.get('attributes').get('location')]] = set()
167 results[region_map[product.get('attributes').get('location')]].add(
168 product.get('attributes').get('instanceType')
169 )
170 # Rds Instance Size spec
171 product_names = product_map.get(product.get('attributes').get('engineCode'), [])
172 product_region = region_map.get(product.get('attributes').get('location'))
173 license_name = license_map.get(product.get('attributes').get('licenseModel'))
174 instance_type = product.get('attributes').get('instanceType')
175 for product_name in product_names:
176 if not rds_specs.get(license_name):
177 rds_specs[license_name] = {}
178 if not rds_specs.get(license_name).get(product_name):
179 rds_specs[license_name][product_name] = {}
180 if not rds_specs.get(license_name).get(product_name).get(product_region):
181 rds_specs[license_name][product_name][product_region] = set()
182
183 rds_specs[license_name][product_name][product_region].add(instance_type)
184
185 for license_name, license_values in rds_specs.items():
186 for product_name, product_values in license_values.items():
187 for product_region, instance_types in product_values.items():
188 rds_specs[license_name][product_name][product_region] = list(sorted(instance_types))
189
190 LOGGER.info('Updating RDS Spec files')
191 filename = 'src/cfnlint/data/AdditionalSpecs/RdsProperties.json'
192 with open(filename, 'w+', encoding='utf-8') as f:
193 json.dump(rds_specs, f, indent=1, sort_keys=True, separators=(',', ': '))
194 return results
195
196
197 def get_results(service, product_families):
198 results = {}
199 for page in get_paginator(service):
200 for price_item in page.get('PriceList', []):
201 products = json.loads(price_item)
202 product = products.get('product', {})
203 if product:
204 if product.get('productFamily') in product_families and product.get('attributes').get('locationType') == "AWS Region":
205 if product.get('attributes').get('location') not in region_map:
206 LOGGER.warning('Region "%s" not found', product.get('attributes').get('location'))
207 continue
208 if not results.get(region_map[product.get('attributes').get('location')]):
209 results[region_map[product.get('attributes').get('location')]] = set()
210 results[region_map[product.get('attributes').get('location')]].add(
211 product.get('attributes').get('instanceType')
212 )
213 return results
214
215
216 def main():
217 """ main function """
218 configure_logging()
219
220 outputs = {}
221 for region in region_map.values():
222 outputs[region] = []
223
224 outputs = update_outputs('Ec2InstanceType', get_results('AmazonEC2', ['Compute Instance', 'Compute Instance (bare metal)']), outputs)
225 outputs = update_outputs('AWS::AmazonMQ::Broker.HostInstanceType', get_mq_pricing(), outputs)
226 outputs = update_outputs('AWS::RDS::DBInstance.DBInstanceClass', get_rds_pricing(), outputs)
227 outputs = update_outputs('RedshiftInstanceType', get_results('AmazonRedshift', ['Compute Instance']), outputs)
228 outputs = update_outputs('DAXInstanceType', get_dax_pricing(), outputs)
229 outputs = update_outputs('DocumentDBInstanceClass', get_results('AmazonDocDB', ['Database Instance']), outputs)
230 outputs = update_outputs('NeptuneInstanceClass', get_results('AmazonNeptune', ['Database Instance']), outputs)
231 outputs = update_outputs('ElastiCacheInstanceType', get_results('AmazonElastiCache', ['Cache Instance']), outputs)
232 outputs = update_outputs('ElasticsearchInstanceType', get_results('AmazonES', ['Elastic Search Instance']), outputs)
233 outputs = update_outputs('EMRInstanceType', get_results('ElasticMapReduce', ['Elastic Map Reduce Instance']), outputs)
234 outputs = update_outputs('BlockchainInstanceType', get_results('AmazonManagedBlockchain', ['Blockchain Instance']), outputs)
235 outputs = update_outputs('AWS::GameLift::Fleet.EC2InstanceType', get_results('AmazonGameLift', ['GameLift EC2 Instance']), outputs)
236 outputs = update_outputs('AppStreamInstanceType', get_results('AmazonAppStream', ['Streaming Instance']), outputs)
237
238 LOGGER.info('Updating spec files')
239 for region, patches in outputs.items():
240 filename = 'src/cfnlint/data/ExtendedSpecs/%s/05_pricing_property_values.json' % region
241 with open(filename, 'w+', encoding='utf-8') as f:
242 json.dump(patches, f, indent=1, sort_keys=True, separators=(',', ': '))
243
244
245 if __name__ == '__main__':
246 try:
247 main()
248 except (ValueError, TypeError):
249 LOGGER.error(ValueError)
250
[end of scripts/update_specs_from_pricing.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scripts/update_specs_from_pricing.py b/scripts/update_specs_from_pricing.py
--- a/scripts/update_specs_from_pricing.py
+++ b/scripts/update_specs_from_pricing.py
@@ -178,7 +178,7 @@
if not rds_specs.get(license_name).get(product_name):
rds_specs[license_name][product_name] = {}
if not rds_specs.get(license_name).get(product_name).get(product_region):
- rds_specs[license_name][product_name][product_region] = set()
+ rds_specs[license_name][product_name][product_region] = set(['db.serverless'])
rds_specs[license_name][product_name][product_region].add(instance_type)
|
{"golden_diff": "diff --git a/scripts/update_specs_from_pricing.py b/scripts/update_specs_from_pricing.py\n--- a/scripts/update_specs_from_pricing.py\n+++ b/scripts/update_specs_from_pricing.py\n@@ -178,7 +178,7 @@\n if not rds_specs.get(license_name).get(product_name):\n rds_specs[license_name][product_name] = {}\n if not rds_specs.get(license_name).get(product_name).get(product_region):\n- rds_specs[license_name][product_name][product_region] = set()\n+ rds_specs[license_name][product_name][product_region] = set(['db.serverless'])\n \n rds_specs[license_name][product_name][product_region].add(instance_type)\n", "issue": "Support serverless v2 DBInstanceClass\n*cfn-lint version: 0.59.0*\r\n\r\n*Allowed list of DBInstanceClass does not include \"db.serverless\"*\r\n\r\nPlease provide as much information as possible:\r\n* Template linting issues:\r\n * Please provide a CloudFormation sample that generated the issue.\r\n```\r\n DbInstance0:\r\n Type: AWS::RDS::DBInstance\r\n Properties:\r\n Engine: aurora-postgresql\r\n DBClusterIdentifier: !Ref MyAuroraCluster\r\n DBInstanceClass: db.serverless\r\n```\r\n* Feature request:\r\n * List of allowed db instance class to include `db.serverless`. Documentation: https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/Concepts.DBInstanceClass.html#Concepts.DBInstanceClass.Types\r\n\r\n\r\nCfn-lint uses the [CloudFormation Resource Specifications](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/cfn-resource-specification.html) as the base to do validation. These files are included as part of the application version. Please update to the latest version of `cfn-lint` or update the spec files manually (`cfn-lint -u`)\r\n- Yes this fixes it for me locally, but I need a release with the change because I'm running it via [GitHub actions](https://github.com/ScottBrenner/cfn-lint-action).\n", "before_files": [{"content": "#!/usr/bin/env python\n\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\n\n\"\"\"\n Updates our dynamic patches from the pricing API\n This script requires Boto3 and Credentials to call the Pricing API\n\"\"\"\n\n\nimport boto3\nimport json\nimport logging\nLOGGER = logging.getLogger('cfnlint')\n\n\nregion_map = {\n 'Any': 'all',\n 'AWS GovCloud (US-East)': 'us-gov-east-1',\n 'AWS GovCloud (US-West)': 'us-gov-west-1',\n 'Africa (Cape Town)': 'af-south-1',\n 'Asia Pacific (Hong Kong)': 'ap-east-1',\n 'Asia Pacific (Jakarta)': 'ap-southeast-3',\n 'Asia Pacific (Mumbai)': 'ap-south-1',\n 'Asia Pacific (Osaka)': 'ap-northeast-3',\n 'Asia Pacific (Seoul)': 'ap-northeast-2',\n 'Asia Pacific (Singapore)': 'ap-southeast-1',\n 'Asia Pacific (Sydney)': 'ap-southeast-2',\n 'Asia Pacific (Tokyo)': 'ap-northeast-1',\n 'Canada (Central)': 'ca-central-1',\n 'China (Beijing)': 'cn-north-1',\n 'China (Ningxia)': 'cn-northwest-1',\n 'EU (Frankfurt)': 'eu-central-1',\n 'EU (Ireland)': 'eu-west-1',\n 'EU (London)': 'eu-west-2',\n 'EU (Milan)': 'eu-south-1',\n 'EU (Paris)': 'eu-west-3',\n 'EU (Stockholm)': 'eu-north-1',\n 'Middle East (Bahrain)': 'me-south-1',\n 'Middle East (UAE)': 'me-central-1',\n 'South America (Sao Paulo)': 'sa-east-1',\n 'US East (N. Virginia)': 'us-east-1',\n 'US East (Ohio)': 'us-east-2',\n 'US West (N. California)': 'us-west-1',\n 'US West (Oregon)': 'us-west-2',\n 'US West (Los Angeles)': 'us-west-2',\n}\n\nsession = boto3.session.Session()\nclient = session.client('pricing', region_name='us-east-1')\n\n\ndef configure_logging():\n \"\"\"Setup Logging\"\"\"\n ch = logging.StreamHandler()\n ch.setLevel(logging.INFO)\n\n LOGGER.setLevel(logging.INFO)\n log_formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')\n ch.setFormatter(log_formatter)\n\n # make sure all other log handlers are removed before adding it back\n for handler in LOGGER.handlers:\n LOGGER.removeHandler(handler)\n LOGGER.addHandler(ch)\n\n\ndef update_outputs(key, values, outputs):\n \"\"\" update outputs with appropriate results \"\"\"\n for region in values:\n element = {\n \"op\": \"add\",\n \"path\": \"/ValueTypes/%s/AllowedValues\" % key,\n \"value\": sorted(values[region])\n }\n outputs[region].append(element)\n\n return outputs\n\n\ndef get_paginator(service):\n LOGGER.info('Get ' + service + ' pricing')\n return client.get_paginator('get_products').paginate(\n ServiceCode=service,\n FormatVersion='aws_v1',\n )\n\n\ndef get_dax_pricing():\n results = {}\n for page in get_paginator('AmazonDAX'):\n for price_item in page.get('PriceList', []):\n products = json.loads(price_item)\n product = products.get('product', {})\n if product:\n if product.get('productFamily') in ['DAX']:\n if not results.get(region_map[product.get('attributes').get('location')]):\n results[region_map[product.get('attributes').get('location')]] = set()\n results[region_map[product.get('attributes').get('location')]].add(\n product.get('attributes').get('usagetype').split(':')[1]\n )\n return results\n\n\ndef get_mq_pricing():\n remap = {\n 'mq.m5.2xl': 'mq.m5.2xlarge',\n 'mq.m5.4xl': 'mq.m5.4xlarge'\n }\n results = {}\n for page in get_paginator('AmazonMQ'):\n for price_item in page.get('PriceList', []):\n products = json.loads(price_item)\n product = products.get('product', {})\n if product:\n if product.get('productFamily') in ['Broker Instances']:\n if not results.get(region_map[product.get('attributes').get('location')]):\n results[region_map[product.get('attributes').get('location')]] = set()\n usage_type = product.get('attributes').get('usagetype').split(':')[1]\n results[region_map[product.get('attributes').get('location')]].add(\n remap.get(usage_type, usage_type)\n )\n return results\n\n\ndef get_rds_pricing():\n product_map = {\n '2': ['mysql'],\n '3': ['oracle-se1'],\n '4': ['oracle-se'],\n '5': ['oracle-ee'],\n '6': ['oracle-se1'],\n '8': ['sqlserver-se'],\n '9': ['sqlserver-ee'],\n '10': ['sqlserver-ex'],\n '11': ['sqlserver-web'],\n '12': ['sqlserver-se'],\n '14': ['postgres'],\n '15': ['sqlserver-ee'],\n '16': ['aurora-mysql', 'aurora'],\n '18': ['mariadb'],\n '19': ['oracle-se2'],\n '20': ['oracle-se2'],\n '21': ['aurora-postgresql'],\n }\n\n license_map = {\n 'License included': 'license-included',\n 'Bring your own license': 'bring-your-own-license',\n 'No license required': 'general-public-license'\n }\n\n rds_specs = {}\n\n results = {}\n for page in get_paginator('AmazonRDS'):\n for price_item in page.get('PriceList', []):\n products = json.loads(price_item)\n product = products.get('product', {})\n if product:\n if product.get('productFamily') in ['Database Instance']:\n # Get overall instance types\n if not results.get(region_map[product.get('attributes').get('location')]):\n results[region_map[product.get('attributes').get('location')]] = set()\n results[region_map[product.get('attributes').get('location')]].add(\n product.get('attributes').get('instanceType')\n )\n # Rds Instance Size spec\n product_names = product_map.get(product.get('attributes').get('engineCode'), [])\n product_region = region_map.get(product.get('attributes').get('location'))\n license_name = license_map.get(product.get('attributes').get('licenseModel'))\n instance_type = product.get('attributes').get('instanceType')\n for product_name in product_names:\n if not rds_specs.get(license_name):\n rds_specs[license_name] = {}\n if not rds_specs.get(license_name).get(product_name):\n rds_specs[license_name][product_name] = {}\n if not rds_specs.get(license_name).get(product_name).get(product_region):\n rds_specs[license_name][product_name][product_region] = set()\n\n rds_specs[license_name][product_name][product_region].add(instance_type)\n\n for license_name, license_values in rds_specs.items():\n for product_name, product_values in license_values.items():\n for product_region, instance_types in product_values.items():\n rds_specs[license_name][product_name][product_region] = list(sorted(instance_types))\n\n LOGGER.info('Updating RDS Spec files')\n filename = 'src/cfnlint/data/AdditionalSpecs/RdsProperties.json'\n with open(filename, 'w+', encoding='utf-8') as f:\n json.dump(rds_specs, f, indent=1, sort_keys=True, separators=(',', ': '))\n return results\n\n\ndef get_results(service, product_families):\n results = {}\n for page in get_paginator(service):\n for price_item in page.get('PriceList', []):\n products = json.loads(price_item)\n product = products.get('product', {})\n if product:\n if product.get('productFamily') in product_families and product.get('attributes').get('locationType') == \"AWS Region\":\n if product.get('attributes').get('location') not in region_map:\n LOGGER.warning('Region \"%s\" not found', product.get('attributes').get('location'))\n continue\n if not results.get(region_map[product.get('attributes').get('location')]):\n results[region_map[product.get('attributes').get('location')]] = set()\n results[region_map[product.get('attributes').get('location')]].add(\n product.get('attributes').get('instanceType')\n )\n return results\n\n\ndef main():\n \"\"\" main function \"\"\"\n configure_logging()\n\n outputs = {}\n for region in region_map.values():\n outputs[region] = []\n\n outputs = update_outputs('Ec2InstanceType', get_results('AmazonEC2', ['Compute Instance', 'Compute Instance (bare metal)']), outputs)\n outputs = update_outputs('AWS::AmazonMQ::Broker.HostInstanceType', get_mq_pricing(), outputs)\n outputs = update_outputs('AWS::RDS::DBInstance.DBInstanceClass', get_rds_pricing(), outputs)\n outputs = update_outputs('RedshiftInstanceType', get_results('AmazonRedshift', ['Compute Instance']), outputs)\n outputs = update_outputs('DAXInstanceType', get_dax_pricing(), outputs)\n outputs = update_outputs('DocumentDBInstanceClass', get_results('AmazonDocDB', ['Database Instance']), outputs)\n outputs = update_outputs('NeptuneInstanceClass', get_results('AmazonNeptune', ['Database Instance']), outputs)\n outputs = update_outputs('ElastiCacheInstanceType', get_results('AmazonElastiCache', ['Cache Instance']), outputs)\n outputs = update_outputs('ElasticsearchInstanceType', get_results('AmazonES', ['Elastic Search Instance']), outputs)\n outputs = update_outputs('EMRInstanceType', get_results('ElasticMapReduce', ['Elastic Map Reduce Instance']), outputs)\n outputs = update_outputs('BlockchainInstanceType', get_results('AmazonManagedBlockchain', ['Blockchain Instance']), outputs)\n outputs = update_outputs('AWS::GameLift::Fleet.EC2InstanceType', get_results('AmazonGameLift', ['GameLift EC2 Instance']), outputs)\n outputs = update_outputs('AppStreamInstanceType', get_results('AmazonAppStream', ['Streaming Instance']), outputs)\n\n LOGGER.info('Updating spec files')\n for region, patches in outputs.items():\n filename = 'src/cfnlint/data/ExtendedSpecs/%s/05_pricing_property_values.json' % region\n with open(filename, 'w+', encoding='utf-8') as f:\n json.dump(patches, f, indent=1, sort_keys=True, separators=(',', ': '))\n\n\nif __name__ == '__main__':\n try:\n main()\n except (ValueError, TypeError):\n LOGGER.error(ValueError)\n", "path": "scripts/update_specs_from_pricing.py"}]}
| 3,942 | 160 |
gh_patches_debug_39309
|
rasdani/github-patches
|
git_diff
|
meltano__meltano-6601
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
bug: `meltano install` exits success even if migrations fail
I would expect `meltano install` to fail and exit with a non-zero exit code if the migrations fail. Instead, it proceeds to install plugins.
To reproduce:
```
$ meltano --version && python --version
meltano, version 2.2.0
Python 3.9.13
$ meltano init example
$ cd example
# this is just an example of a way to make migrations fail
$ sqlite3 .meltano/meltano.db "UPDATE alembic_version SET version_num = 'garbage';"
$ meltano install
2022-07-12T16:35:37.771519Z [info ] Environment 'dev' is active
2022-07-12T16:35:38.860146Z [error ] No such revision or branch 'garbage'
Traceback (most recent call last):
File ".venv/lib/python3.9/site-packages/meltano/core/migration_service.py", line 89, in upgrade
self.ensure_migration_needed(script, context, head)
File ".venv/lib/python3.9/site-packages/meltano/core/migration_service.py", line 55, in ensure_migration_needed
for rev in script.iterate_revisions(current_head, "base"):
File ".venv/lib/python3.9/site-packages/alembic/script/revision.py", line 799, in iterate_revisions
revisions, heads = fn(
File ".venv/lib/python3.9/site-packages/alembic/script/revision.py", line 1426, in _collect_upgrade_revisions
for rev in self._parse_upgrade_target(
File ".venv/lib/python3.9/site-packages/alembic/script/revision.py", line 1218, in _parse_upgrade_target
return self.get_revisions(target)
File ".venv/lib/python3.9/site-packages/alembic/script/revision.py", line 552, in get_revisions
return tuple(
File ".venv/lib/python3.9/site-packages/alembic/script/revision.py", line 553, in <genexpr>
self._revision_for_ident(rev_id, branch_label)
File ".venv/lib/python3.9/site-packages/alembic/script/revision.py", line 624, in _revision_for_ident
raise ResolutionError(
alembic.script.revision.ResolutionError: No such revision or branch 'garbage'
Cannot upgrade the system database. It might be corrupted or was created before database migrations where introduced (v0.34.0)
Installing 0 plugins...
$ echo $?
0
</issue>
<code>
[start of src/meltano/core/migration_service.py]
1 """Migration and system db management."""
2 from __future__ import annotations
3
4 import logging
5
6 import click
7 import sqlalchemy
8 from alembic import command
9 from alembic.config import Config
10 from alembic.runtime.migration import MigrationContext
11 from alembic.script import ScriptDirectory
12 from sqlalchemy.engine import Engine
13 from sqlalchemy.orm import Session
14
15 from meltano.api.models.security import Role, RolePermissions
16 from meltano.core.db import project_engine
17 from meltano.core.project import Project
18 from meltano.migrations import LOCK_PATH, MIGRATION_DIR
19
20 SPLAT = "*"
21
22
23 class MigrationError(Exception):
24 """Generic class for migration errors."""
25
26
27 class MigrationUneededException(Exception):
28 """Occurs when no migrations are needed."""
29
30
31 class MigrationService:
32 """Migration service."""
33
34 def __init__(self, engine: Engine) -> None:
35 """Initialize the migration service.
36
37 Args:
38 engine: The sqlalchemy engine to use for the migration and checks.
39 """
40 self.engine = engine
41
42 def ensure_migration_needed(
43 self, script: ScriptDirectory, context: MigrationContext, target_revision: str
44 ) -> None:
45 """Ensure that a migration of the system database is actually needed.
46
47 Args:
48 script: The alembic script directory.
49 context: The migration context.
50 target_revision: The desired target revision.
51
52 Raises:
53 MigrationUneededException: If no migration is needed.
54 """
55 current_head = context.get_current_revision()
56
57 for rev in script.iterate_revisions(current_head, "base"):
58 if rev.revision == target_revision:
59 raise MigrationUneededException
60
61 def upgrade( # noqa: WPS213, WPS231 too many expression and too complex
62 self, silent: bool = False
63 ) -> None:
64 """Upgrade to the latest revision.
65
66 Args:
67 silent: If true, don't print anything.
68
69 Raises:
70 MigrationError: If the upgrade fails.
71 """
72 conn = self.engine.connect()
73 cfg = Config()
74
75 # this connection is used in `env.py` for the migrations
76 cfg.attributes["connection"] = conn
77 cfg.set_main_option("script_location", str(MIGRATION_DIR))
78 script = ScriptDirectory.from_config(cfg)
79 # let's make sure we actually need to migrate
80
81 migration_logger = logging.getLogger("alembic.runtime.migration")
82 original_log_level = migration_logger.getEffectiveLevel()
83 if silent:
84 migration_logger.setLevel(logging.ERROR)
85
86 context = MigrationContext.configure(conn)
87
88 try: # noqa: WPS229
89 # try to find the locked version
90 head = LOCK_PATH.open().read().strip()
91 self.ensure_migration_needed(script, context, head)
92
93 if not silent:
94 click.secho(f"Upgrading database to {head}")
95 command.upgrade(cfg, head)
96
97 if silent:
98 migration_logger.setLevel(original_log_level)
99 except FileNotFoundError:
100 raise MigrationError(
101 "Cannot upgrade the system database, revision lock not found."
102 )
103 except MigrationUneededException:
104 if not silent:
105 click.secho("System database up-to-date.")
106 except Exception as err:
107 logging.exception(str(err))
108 click.secho(
109 "Cannot upgrade the system database. It might be corrupted or was created before database migrations where introduced (v0.34.0)",
110 fg="yellow",
111 err=True,
112 )
113 finally:
114 conn.close()
115
116 def seed(self, project: Project) -> None:
117 """Seed the database with the default roles and permissions.
118
119 Args:
120 project: The project to seed the database for.
121 """
122 _, session_maker = project_engine(project)
123 session = session_maker()
124 try: # noqa: WPS501, WPS229 Found too long try body length and finally without except
125 self._create_user_role(session)
126 session.commit()
127 finally:
128 session.close()
129
130 def _create_user_role(self, session: Session) -> None:
131 """Actually perform the database seeding creating users/roles.
132
133 Args:
134 session: The session to use.
135 """
136 if not session.query(Role).filter_by(name="admin").first():
137
138 session.add(
139 Role(
140 name="admin",
141 description="Meltano Admin",
142 permissions=[
143 RolePermissions(type="view:design", context=SPLAT),
144 RolePermissions(type="view:reports", context=SPLAT),
145 RolePermissions(type="modify:acl", context=SPLAT),
146 ],
147 )
148 )
149
150 if not session.query(Role).filter_by(name="regular").first():
151 session.merge(Role(name="regular", description="Meltano User"))
152
153 # add the universal permissions to Admin
154 admin = session.query(Role).filter_by(name="admin").one()
155 try:
156 session.query(RolePermissions).filter_by(
157 role=admin, type=SPLAT, context=SPLAT
158 ).one()
159 except sqlalchemy.orm.exc.NoResultFound:
160 admin.permissions.append(RolePermissions(type=SPLAT, context=SPLAT))
161
[end of src/meltano/core/migration_service.py]
[start of src/meltano/cli/params.py]
1 from __future__ import annotations
2
3 import functools
4
5 import click
6 from click.globals import get_current_context as get_current_click_context
7
8 from meltano.core.db import project_engine
9 from meltano.core.project_settings_service import ProjectSettingsService
10
11 from .utils import CliError
12
13
14 def database_uri_option(func):
15 @click.option("--database-uri", help="System database URI.")
16 def decorate(*args, database_uri=None, **kwargs):
17 if database_uri:
18 ProjectSettingsService.config_override["database_uri"] = database_uri
19
20 return func(*args, **kwargs)
21
22 return functools.update_wrapper(decorate, func)
23
24
25 class pass_project: # noqa: N801
26 """Pass current project to decorated CLI command function."""
27
28 __name__ = "project"
29
30 def __init__(self, migrate=False):
31 self.migrate = migrate
32
33 def __call__(self, func):
34 @database_uri_option
35 def decorate(*args, **kwargs):
36 ctx = get_current_click_context()
37
38 project = ctx.obj["project"]
39 if not project:
40 raise CliError(
41 f"`{ctx.command_path}` must be run inside a Meltano project.\n"
42 + "Use `meltano init <project_name>` to create one."
43 )
44
45 # register the system database connection
46 engine, _ = project_engine(project, default=True)
47
48 if self.migrate:
49 from meltano.core.migration_service import MigrationService
50
51 migration_service = MigrationService(engine)
52 migration_service.upgrade(silent=True)
53 migration_service.seed(project)
54
55 func(project, *args, **kwargs)
56
57 return functools.update_wrapper(decorate, func)
58
[end of src/meltano/cli/params.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/meltano/cli/params.py b/src/meltano/cli/params.py
--- a/src/meltano/cli/params.py
+++ b/src/meltano/cli/params.py
@@ -1,3 +1,5 @@
+"""Click parameter helper decorators."""
+
from __future__ import annotations
import functools
@@ -6,12 +8,19 @@
from click.globals import get_current_context as get_current_click_context
from meltano.core.db import project_engine
+from meltano.core.migration_service import MigrationError
from meltano.core.project_settings_service import ProjectSettingsService
from .utils import CliError
def database_uri_option(func):
+ """Database URI Click option decorator.
+
+ args:
+ func: The function to decorate.
+ """
+
@click.option("--database-uri", help="System database URI.")
def decorate(*args, database_uri=None, **kwargs):
if database_uri:
@@ -28,9 +37,20 @@
__name__ = "project"
def __init__(self, migrate=False):
+ """Instantiate decorator.
+
+ args:
+ migrate: Flag to perform database migration before passing the project.
+ """
self.migrate = migrate
def __call__(self, func):
+ """Return decorated function.
+
+ args:
+ func: The function to decorate.
+ """
+
@database_uri_option
def decorate(*args, **kwargs):
ctx = get_current_click_context()
@@ -48,9 +68,12 @@
if self.migrate:
from meltano.core.migration_service import MigrationService
- migration_service = MigrationService(engine)
- migration_service.upgrade(silent=True)
- migration_service.seed(project)
+ try:
+ migration_service = MigrationService(engine)
+ migration_service.upgrade(silent=True)
+ migration_service.seed(project)
+ except MigrationError as err:
+ raise CliError(str(err))
func(project, *args, **kwargs)
diff --git a/src/meltano/core/migration_service.py b/src/meltano/core/migration_service.py
--- a/src/meltano/core/migration_service.py
+++ b/src/meltano/core/migration_service.py
@@ -105,10 +105,8 @@
click.secho("System database up-to-date.")
except Exception as err:
logging.exception(str(err))
- click.secho(
- "Cannot upgrade the system database. It might be corrupted or was created before database migrations where introduced (v0.34.0)",
- fg="yellow",
- err=True,
+ raise MigrationError(
+ "Cannot upgrade the system database. It might be corrupted or was created before database migrations where introduced (v0.34.0)"
)
finally:
conn.close()
|
{"golden_diff": "diff --git a/src/meltano/cli/params.py b/src/meltano/cli/params.py\n--- a/src/meltano/cli/params.py\n+++ b/src/meltano/cli/params.py\n@@ -1,3 +1,5 @@\n+\"\"\"Click parameter helper decorators.\"\"\"\n+\n from __future__ import annotations\n \n import functools\n@@ -6,12 +8,19 @@\n from click.globals import get_current_context as get_current_click_context\n \n from meltano.core.db import project_engine\n+from meltano.core.migration_service import MigrationError\n from meltano.core.project_settings_service import ProjectSettingsService\n \n from .utils import CliError\n \n \n def database_uri_option(func):\n+ \"\"\"Database URI Click option decorator.\n+\n+ args:\n+ func: The function to decorate.\n+ \"\"\"\n+\n @click.option(\"--database-uri\", help=\"System database URI.\")\n def decorate(*args, database_uri=None, **kwargs):\n if database_uri:\n@@ -28,9 +37,20 @@\n __name__ = \"project\"\n \n def __init__(self, migrate=False):\n+ \"\"\"Instantiate decorator.\n+\n+ args:\n+ migrate: Flag to perform database migration before passing the project.\n+ \"\"\"\n self.migrate = migrate\n \n def __call__(self, func):\n+ \"\"\"Return decorated function.\n+\n+ args:\n+ func: The function to decorate.\n+ \"\"\"\n+\n @database_uri_option\n def decorate(*args, **kwargs):\n ctx = get_current_click_context()\n@@ -48,9 +68,12 @@\n if self.migrate:\n from meltano.core.migration_service import MigrationService\n \n- migration_service = MigrationService(engine)\n- migration_service.upgrade(silent=True)\n- migration_service.seed(project)\n+ try:\n+ migration_service = MigrationService(engine)\n+ migration_service.upgrade(silent=True)\n+ migration_service.seed(project)\n+ except MigrationError as err:\n+ raise CliError(str(err))\n \n func(project, *args, **kwargs)\n \ndiff --git a/src/meltano/core/migration_service.py b/src/meltano/core/migration_service.py\n--- a/src/meltano/core/migration_service.py\n+++ b/src/meltano/core/migration_service.py\n@@ -105,10 +105,8 @@\n click.secho(\"System database up-to-date.\")\n except Exception as err:\n logging.exception(str(err))\n- click.secho(\n- \"Cannot upgrade the system database. It might be corrupted or was created before database migrations where introduced (v0.34.0)\",\n- fg=\"yellow\",\n- err=True,\n+ raise MigrationError(\n+ \"Cannot upgrade the system database. It might be corrupted or was created before database migrations where introduced (v0.34.0)\"\n )\n finally:\n conn.close()\n", "issue": "bug: `meltano install` exits success even if migrations fail\nI would expect `meltano install` to fail and exit with a non-zero exit code if the migrations fail. Instead, it proceeds to install plugins.\r\n\r\nTo reproduce:\r\n\r\n```\r\n$ meltano --version && python --version\r\nmeltano, version 2.2.0\r\nPython 3.9.13\r\n$ meltano init example\r\n$ cd example\r\n# this is just an example of a way to make migrations fail\r\n$ sqlite3 .meltano/meltano.db \"UPDATE alembic_version SET version_num = 'garbage';\"\r\n$ meltano install \r\n2022-07-12T16:35:37.771519Z [info ] Environment 'dev' is active\r\n2022-07-12T16:35:38.860146Z [error ] No such revision or branch 'garbage' \r\nTraceback (most recent call last):\r\n File \".venv/lib/python3.9/site-packages/meltano/core/migration_service.py\", line 89, in upgrade\r\n self.ensure_migration_needed(script, context, head)\r\n File \".venv/lib/python3.9/site-packages/meltano/core/migration_service.py\", line 55, in ensure_migration_needed\r\n for rev in script.iterate_revisions(current_head, \"base\"):\r\n File \".venv/lib/python3.9/site-packages/alembic/script/revision.py\", line 799, in iterate_revisions\r\n revisions, heads = fn(\r\n File \".venv/lib/python3.9/site-packages/alembic/script/revision.py\", line 1426, in _collect_upgrade_revisions\r\n for rev in self._parse_upgrade_target(\r\n File \".venv/lib/python3.9/site-packages/alembic/script/revision.py\", line 1218, in _parse_upgrade_target\r\n return self.get_revisions(target)\r\n File \".venv/lib/python3.9/site-packages/alembic/script/revision.py\", line 552, in get_revisions\r\n return tuple(\r\n File \".venv/lib/python3.9/site-packages/alembic/script/revision.py\", line 553, in <genexpr>\r\n self._revision_for_ident(rev_id, branch_label)\r\n File \".venv/lib/python3.9/site-packages/alembic/script/revision.py\", line 624, in _revision_for_ident\r\n raise ResolutionError(\r\nalembic.script.revision.ResolutionError: No such revision or branch 'garbage'\r\nCannot upgrade the system database. It might be corrupted or was created before database migrations where introduced (v0.34.0)\r\nInstalling 0 plugins...\r\n$ echo $? \r\n0\r\n\n", "before_files": [{"content": "\"\"\"Migration and system db management.\"\"\"\nfrom __future__ import annotations\n\nimport logging\n\nimport click\nimport sqlalchemy\nfrom alembic import command\nfrom alembic.config import Config\nfrom alembic.runtime.migration import MigrationContext\nfrom alembic.script import ScriptDirectory\nfrom sqlalchemy.engine import Engine\nfrom sqlalchemy.orm import Session\n\nfrom meltano.api.models.security import Role, RolePermissions\nfrom meltano.core.db import project_engine\nfrom meltano.core.project import Project\nfrom meltano.migrations import LOCK_PATH, MIGRATION_DIR\n\nSPLAT = \"*\"\n\n\nclass MigrationError(Exception):\n \"\"\"Generic class for migration errors.\"\"\"\n\n\nclass MigrationUneededException(Exception):\n \"\"\"Occurs when no migrations are needed.\"\"\"\n\n\nclass MigrationService:\n \"\"\"Migration service.\"\"\"\n\n def __init__(self, engine: Engine) -> None:\n \"\"\"Initialize the migration service.\n\n Args:\n engine: The sqlalchemy engine to use for the migration and checks.\n \"\"\"\n self.engine = engine\n\n def ensure_migration_needed(\n self, script: ScriptDirectory, context: MigrationContext, target_revision: str\n ) -> None:\n \"\"\"Ensure that a migration of the system database is actually needed.\n\n Args:\n script: The alembic script directory.\n context: The migration context.\n target_revision: The desired target revision.\n\n Raises:\n MigrationUneededException: If no migration is needed.\n \"\"\"\n current_head = context.get_current_revision()\n\n for rev in script.iterate_revisions(current_head, \"base\"):\n if rev.revision == target_revision:\n raise MigrationUneededException\n\n def upgrade( # noqa: WPS213, WPS231 too many expression and too complex\n self, silent: bool = False\n ) -> None:\n \"\"\"Upgrade to the latest revision.\n\n Args:\n silent: If true, don't print anything.\n\n Raises:\n MigrationError: If the upgrade fails.\n \"\"\"\n conn = self.engine.connect()\n cfg = Config()\n\n # this connection is used in `env.py` for the migrations\n cfg.attributes[\"connection\"] = conn\n cfg.set_main_option(\"script_location\", str(MIGRATION_DIR))\n script = ScriptDirectory.from_config(cfg)\n # let's make sure we actually need to migrate\n\n migration_logger = logging.getLogger(\"alembic.runtime.migration\")\n original_log_level = migration_logger.getEffectiveLevel()\n if silent:\n migration_logger.setLevel(logging.ERROR)\n\n context = MigrationContext.configure(conn)\n\n try: # noqa: WPS229\n # try to find the locked version\n head = LOCK_PATH.open().read().strip()\n self.ensure_migration_needed(script, context, head)\n\n if not silent:\n click.secho(f\"Upgrading database to {head}\")\n command.upgrade(cfg, head)\n\n if silent:\n migration_logger.setLevel(original_log_level)\n except FileNotFoundError:\n raise MigrationError(\n \"Cannot upgrade the system database, revision lock not found.\"\n )\n except MigrationUneededException:\n if not silent:\n click.secho(\"System database up-to-date.\")\n except Exception as err:\n logging.exception(str(err))\n click.secho(\n \"Cannot upgrade the system database. It might be corrupted or was created before database migrations where introduced (v0.34.0)\",\n fg=\"yellow\",\n err=True,\n )\n finally:\n conn.close()\n\n def seed(self, project: Project) -> None:\n \"\"\"Seed the database with the default roles and permissions.\n\n Args:\n project: The project to seed the database for.\n \"\"\"\n _, session_maker = project_engine(project)\n session = session_maker()\n try: # noqa: WPS501, WPS229 Found too long try body length and finally without except\n self._create_user_role(session)\n session.commit()\n finally:\n session.close()\n\n def _create_user_role(self, session: Session) -> None:\n \"\"\"Actually perform the database seeding creating users/roles.\n\n Args:\n session: The session to use.\n \"\"\"\n if not session.query(Role).filter_by(name=\"admin\").first():\n\n session.add(\n Role(\n name=\"admin\",\n description=\"Meltano Admin\",\n permissions=[\n RolePermissions(type=\"view:design\", context=SPLAT),\n RolePermissions(type=\"view:reports\", context=SPLAT),\n RolePermissions(type=\"modify:acl\", context=SPLAT),\n ],\n )\n )\n\n if not session.query(Role).filter_by(name=\"regular\").first():\n session.merge(Role(name=\"regular\", description=\"Meltano User\"))\n\n # add the universal permissions to Admin\n admin = session.query(Role).filter_by(name=\"admin\").one()\n try:\n session.query(RolePermissions).filter_by(\n role=admin, type=SPLAT, context=SPLAT\n ).one()\n except sqlalchemy.orm.exc.NoResultFound:\n admin.permissions.append(RolePermissions(type=SPLAT, context=SPLAT))\n", "path": "src/meltano/core/migration_service.py"}, {"content": "from __future__ import annotations\n\nimport functools\n\nimport click\nfrom click.globals import get_current_context as get_current_click_context\n\nfrom meltano.core.db import project_engine\nfrom meltano.core.project_settings_service import ProjectSettingsService\n\nfrom .utils import CliError\n\n\ndef database_uri_option(func):\n @click.option(\"--database-uri\", help=\"System database URI.\")\n def decorate(*args, database_uri=None, **kwargs):\n if database_uri:\n ProjectSettingsService.config_override[\"database_uri\"] = database_uri\n\n return func(*args, **kwargs)\n\n return functools.update_wrapper(decorate, func)\n\n\nclass pass_project: # noqa: N801\n \"\"\"Pass current project to decorated CLI command function.\"\"\"\n\n __name__ = \"project\"\n\n def __init__(self, migrate=False):\n self.migrate = migrate\n\n def __call__(self, func):\n @database_uri_option\n def decorate(*args, **kwargs):\n ctx = get_current_click_context()\n\n project = ctx.obj[\"project\"]\n if not project:\n raise CliError(\n f\"`{ctx.command_path}` must be run inside a Meltano project.\\n\"\n + \"Use `meltano init <project_name>` to create one.\"\n )\n\n # register the system database connection\n engine, _ = project_engine(project, default=True)\n\n if self.migrate:\n from meltano.core.migration_service import MigrationService\n\n migration_service = MigrationService(engine)\n migration_service.upgrade(silent=True)\n migration_service.seed(project)\n\n func(project, *args, **kwargs)\n\n return functools.update_wrapper(decorate, func)\n", "path": "src/meltano/cli/params.py"}]}
| 3,116 | 621 |
gh_patches_debug_2797
|
rasdani/github-patches
|
git_diff
|
ansible-collections__community.vmware-1706
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Invalid return type for vmware_vsan_health_info
<!--- Verify first that your improvement is not already reported on GitHub -->
<!--- Also test if the latest release and devel branch are affected too -->
<!--- Complete *all* sections as described, this form is processed automatically -->
##### SUMMARY
<!--- Explain the problem briefly below, add suggestions to wording or structure -->
The documentation for vmware_vsan_health_info states that the [return type is dict](https://github.com/ansible-collections/community.vmware/blob/fa19ae68c0a720ab2f12122c9edb2d90d73880e9/plugins/modules/vmware_vsan_health_info.py#L66) but the response is wrapped into a `json.dumps` [converting it to string](https://github.com/ansible-collections/community.vmware/blob/fa19ae68c0a720ab2f12122c9edb2d90d73880e9/plugins/modules/vmware_vsan_health_info.py#L168). I am uncertain whether the return type documentation or the returned object should be adapted, but the current inconsistency should be fixed.
<!--- HINT: Did you know the documentation has an "Edit on GitHub" link on every page ? -->
##### ISSUE TYPE
- Documentation Report
##### COMPONENT NAME
<!--- Write the short name of the rst file, module, plugin, task or feature below, use your best guess if unsure -->
vmware_vsan_health_info
##### ANSIBLE VERSION
<!--- Paste verbatim output from "ansible --version" between quotes -->
```paste below
ansible [core 2.14.2]
config file = None
configured module search path = ['/var/home/philipp/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
ansible python module location = /var/home/philipp/.local/pipx/venvs/ansible-core/lib64/python3.11/site-packages/ansible
ansible collection location = /var/home/philipp/.ansible/collections:/usr/share/ansible/collections
executable location = /var/home/philipp/.local/bin/ansible
python version = 3.11.1 (main, Jan 6 2023, 00:00:00) [GCC 12.2.1 20221121 (Red Hat 12.2.1-4)] (/var/home/philipp/.local/pipx/venvs/ansible-core/bin/python)
jinja version = 3.1.2
libyaml = True
```
</issue>
<code>
[start of plugins/modules/vmware_vsan_health_info.py]
1 #!/usr/bin/python
2
3 # Copyright: (c) 2019, OVH SAS
4 # GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)
5 # SPDX-License-Identifier: GPL-3.0-or-later
6
7 from __future__ import absolute_import, division, print_function
8 __metaclass__ = type
9
10
11 DOCUMENTATION = r'''
12 ---
13 module: vmware_vsan_health_info
14 short_description: Gather information about a VMware vSAN cluster's health
15 description:
16 - "Gather information about a VMware vSAN cluster's health."
17 options:
18 datacenter:
19 description:
20 - Name of the Datacenter.
21 required: false
22 type: str
23 aliases: [ 'datacenter_name' ]
24 cluster_name:
25 description:
26 - Name of the vSAN cluster.
27 required: true
28 type: str
29 fetch_from_cache:
30 description:
31 - C(true) to return the result from cache directly instead of running the full health check.
32 required: false
33 default: false
34 type: bool
35 requirements:
36 - VMware vSAN Python's SDK
37 extends_documentation_fragment:
38 - community.vmware.vmware.documentation
39 author:
40 - Erwan Quelin (@equelin)
41 '''
42
43 EXAMPLES = r'''
44 - name: Gather health info from a vSAN's cluster
45 community.vmware.vmware_vsan_health_info:
46 hostname: "{{ vcenter_hostname }}"
47 username: "{{ vcenter_username }}"
48 password: "{{ vcenter_password }}"
49 cluster_name: 'vSAN01'
50 fetch_from_cache: false
51
52 - name: Gather health info from a vSAN's cluster with datacenter
53 community.vmware.vmware_vsan_health_info:
54 hostname: "{{ vcenter_hostname }}"
55 username: "{{ vcenter_username }}"
56 password: "{{ vcenter_password }}"
57 cluster_name: 'vSAN01'
58 datacenter: 'Datacenter_01'
59 fetch_from_cache: true
60 '''
61
62 RETURN = r'''
63 vsan_health_info:
64 description: vSAN cluster health info
65 returned: on success
66 type: dict
67 sample: {
68 "_vimtype": "vim.cluster.VsanClusterHealthSummary",
69 "burnInTest": null,
70 "clusterStatus": {
71 "_vimtype": "vim.cluster.VsanClusterHealthSystemStatusResult",
72 "goalState": "installed",
73 "status": "green",
74 "trackedHostsStatus": [
75 {
76 "_vimtype": "vim.host.VsanHostHealthSystemStatusResult",
77 "hostname": "esxi01.example.com",
78 "issues": [],
79 "status": "green"
80 },
81 {
82 "_vimtype": "vim.host.VsanHostHealthSystemStatusResult",
83 "hostname": "esxi04.example.com",
84 "issues": [],
85 "status": "green"
86 },
87 {
88 "_vimtype": "vim.host.VsanHostHealthSystemStatusResult",
89 "hostname": "esxi02.example.com",
90 "issues": [],
91 "status": "green"
92 },
93 {
94 "_vimtype": "vim.host.VsanHostHealthSystemStatusResult",
95 "hostname": "esxi03.example.com",
96 "issues": [],
97 "status": "green"
98 }
99 ],
100 "untrackedHosts": []
101 }
102 }
103 '''
104
105 import json
106 import traceback
107
108 try:
109 from pyVmomi import vmodl, VmomiSupport
110 HAS_PYVMOMI = True
111 HAS_PYVMOMIJSON = hasattr(VmomiSupport, 'VmomiJSONEncoder')
112 except ImportError:
113 PYVMOMI_IMP_ERR = traceback.format_exc()
114 HAS_PYVMOMI = False
115 HAS_PYVMOMIJSON = False
116
117 VSANPYTHONSDK_IMP_ERR = None
118 try:
119 import vsanapiutils
120 HAS_VSANPYTHONSDK = True
121 except ImportError:
122 VSANPYTHONSDK_IMP_ERR = traceback.format_exc()
123 HAS_VSANPYTHONSDK = False
124
125 from ansible.module_utils.basic import AnsibleModule, missing_required_lib
126 from ansible_collections.community.vmware.plugins.module_utils.vmware import vmware_argument_spec, PyVmomi
127
128
129 class VSANInfoManager(PyVmomi):
130 def __init__(self, module):
131 super(VSANInfoManager, self).__init__(module)
132 self.datacenter = None
133 self.cluster = None
134
135 def gather_info(self):
136 datacenter_name = self.module.params.get('datacenter')
137 if datacenter_name:
138 self.datacenter = self.find_datacenter_by_name(datacenter_name)
139 if self.datacenter is None:
140 self.module.fail_json(msg="Datacenter %s does not exist." % datacenter_name)
141
142 cluster_name = self.module.params.get('cluster_name')
143 self.cluster = self.find_cluster_by_name(cluster_name=cluster_name, datacenter_name=self.datacenter)
144 if self.cluster is None:
145 self.module.fail_json(msg="Cluster %s does not exist." % cluster_name)
146
147 fetch_from_cache = self.module.params.get('fetch_from_cache')
148
149 client_stub = self.si._GetStub()
150 ssl_context = client_stub.schemeArgs.get('context')
151
152 api_version = vsanapiutils.GetLatestVmodlVersion(self.module.params['hostname'])
153 vc_mos = vsanapiutils.GetVsanVcMos(client_stub, context=ssl_context, version=api_version)
154
155 vsan_cluster_health_system = vc_mos['vsan-cluster-health-system']
156
157 cluster_health = {}
158 try:
159 cluster_health = vsan_cluster_health_system.VsanQueryVcClusterHealthSummary(
160 cluster=self.cluster,
161 fetchFromCache=fetch_from_cache,
162 )
163 except vmodl.fault.NotFound as not_found:
164 self.module.fail_json(msg=not_found.msg)
165 except vmodl.fault.RuntimeFault as runtime_fault:
166 self.module.fail_json(msg=runtime_fault.msg)
167
168 health = json.dumps(cluster_health, cls=VmomiSupport.VmomiJSONEncoder, sort_keys=True, strip_dynamic=True)
169
170 self.module.exit_json(changed=False, vsan_health_info=health)
171
172
173 def main():
174 argument_spec = vmware_argument_spec()
175 argument_spec.update(
176 datacenter=dict(required=False, type='str', aliases=['datacenter_name']),
177 cluster_name=dict(required=True, type='str'),
178 fetch_from_cache=dict(required=False, type='bool', default=False)
179 )
180
181 module = AnsibleModule(
182 argument_spec=argument_spec,
183 supports_check_mode=True
184 )
185
186 if not HAS_VSANPYTHONSDK:
187 module.fail_json(msg=missing_required_lib('vSAN Management SDK for Python'), exception=VSANPYTHONSDK_IMP_ERR)
188
189 if not HAS_PYVMOMIJSON:
190 module.fail_json(msg='The installed version of pyvmomi lacks JSON output support; need pyvmomi>6.7.1')
191
192 vsan_info_manager = VSANInfoManager(module)
193 vsan_info_manager.gather_info()
194
195
196 if __name__ == '__main__':
197 main()
198
[end of plugins/modules/vmware_vsan_health_info.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugins/modules/vmware_vsan_health_info.py b/plugins/modules/vmware_vsan_health_info.py
--- a/plugins/modules/vmware_vsan_health_info.py
+++ b/plugins/modules/vmware_vsan_health_info.py
@@ -167,7 +167,7 @@
health = json.dumps(cluster_health, cls=VmomiSupport.VmomiJSONEncoder, sort_keys=True, strip_dynamic=True)
- self.module.exit_json(changed=False, vsan_health_info=health)
+ self.module.exit_json(changed=False, vsan_health_info=json.loads(health))
def main():
|
{"golden_diff": "diff --git a/plugins/modules/vmware_vsan_health_info.py b/plugins/modules/vmware_vsan_health_info.py\n--- a/plugins/modules/vmware_vsan_health_info.py\n+++ b/plugins/modules/vmware_vsan_health_info.py\n@@ -167,7 +167,7 @@\n \n health = json.dumps(cluster_health, cls=VmomiSupport.VmomiJSONEncoder, sort_keys=True, strip_dynamic=True)\n \n- self.module.exit_json(changed=False, vsan_health_info=health)\n+ self.module.exit_json(changed=False, vsan_health_info=json.loads(health))\n \n \n def main():\n", "issue": "Invalid return type for vmware_vsan_health_info\n<!--- Verify first that your improvement is not already reported on GitHub -->\r\n<!--- Also test if the latest release and devel branch are affected too -->\r\n<!--- Complete *all* sections as described, this form is processed automatically -->\r\n\r\n##### SUMMARY\r\n<!--- Explain the problem briefly below, add suggestions to wording or structure -->\r\n\r\nThe documentation for vmware_vsan_health_info states that the [return type is dict](https://github.com/ansible-collections/community.vmware/blob/fa19ae68c0a720ab2f12122c9edb2d90d73880e9/plugins/modules/vmware_vsan_health_info.py#L66) but the response is wrapped into a `json.dumps` [converting it to string](https://github.com/ansible-collections/community.vmware/blob/fa19ae68c0a720ab2f12122c9edb2d90d73880e9/plugins/modules/vmware_vsan_health_info.py#L168). I am uncertain whether the return type documentation or the returned object should be adapted, but the current inconsistency should be fixed.\r\n\r\n<!--- HINT: Did you know the documentation has an \"Edit on GitHub\" link on every page ? -->\r\n\r\n##### ISSUE TYPE\r\n- Documentation Report\r\n\r\n##### COMPONENT NAME\r\n<!--- Write the short name of the rst file, module, plugin, task or feature below, use your best guess if unsure -->\r\nvmware_vsan_health_info\r\n\r\n##### ANSIBLE VERSION\r\n<!--- Paste verbatim output from \"ansible --version\" between quotes -->\r\n```paste below\r\nansible [core 2.14.2]\r\n config file = None\r\n configured module search path = ['/var/home/philipp/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']\r\n ansible python module location = /var/home/philipp/.local/pipx/venvs/ansible-core/lib64/python3.11/site-packages/ansible\r\n ansible collection location = /var/home/philipp/.ansible/collections:/usr/share/ansible/collections\r\n executable location = /var/home/philipp/.local/bin/ansible\r\n python version = 3.11.1 (main, Jan 6 2023, 00:00:00) [GCC 12.2.1 20221121 (Red Hat 12.2.1-4)] (/var/home/philipp/.local/pipx/venvs/ansible-core/bin/python)\r\n jinja version = 3.1.2\r\n libyaml = True\r\n```\r\n\n", "before_files": [{"content": "#!/usr/bin/python\n\n# Copyright: (c) 2019, OVH SAS\n# GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)\n# SPDX-License-Identifier: GPL-3.0-or-later\n\nfrom __future__ import absolute_import, division, print_function\n__metaclass__ = type\n\n\nDOCUMENTATION = r'''\n---\nmodule: vmware_vsan_health_info\nshort_description: Gather information about a VMware vSAN cluster's health\ndescription:\n - \"Gather information about a VMware vSAN cluster's health.\"\noptions:\n datacenter:\n description:\n - Name of the Datacenter.\n required: false\n type: str\n aliases: [ 'datacenter_name' ]\n cluster_name:\n description:\n - Name of the vSAN cluster.\n required: true\n type: str\n fetch_from_cache:\n description:\n - C(true) to return the result from cache directly instead of running the full health check.\n required: false\n default: false\n type: bool\nrequirements:\n - VMware vSAN Python's SDK\nextends_documentation_fragment:\n- community.vmware.vmware.documentation\nauthor:\n - Erwan Quelin (@equelin)\n'''\n\nEXAMPLES = r'''\n- name: Gather health info from a vSAN's cluster\n community.vmware.vmware_vsan_health_info:\n hostname: \"{{ vcenter_hostname }}\"\n username: \"{{ vcenter_username }}\"\n password: \"{{ vcenter_password }}\"\n cluster_name: 'vSAN01'\n fetch_from_cache: false\n\n- name: Gather health info from a vSAN's cluster with datacenter\n community.vmware.vmware_vsan_health_info:\n hostname: \"{{ vcenter_hostname }}\"\n username: \"{{ vcenter_username }}\"\n password: \"{{ vcenter_password }}\"\n cluster_name: 'vSAN01'\n datacenter: 'Datacenter_01'\n fetch_from_cache: true\n'''\n\nRETURN = r'''\nvsan_health_info:\n description: vSAN cluster health info\n returned: on success\n type: dict\n sample: {\n \"_vimtype\": \"vim.cluster.VsanClusterHealthSummary\",\n \"burnInTest\": null,\n \"clusterStatus\": {\n \"_vimtype\": \"vim.cluster.VsanClusterHealthSystemStatusResult\",\n \"goalState\": \"installed\",\n \"status\": \"green\",\n \"trackedHostsStatus\": [\n {\n \"_vimtype\": \"vim.host.VsanHostHealthSystemStatusResult\",\n \"hostname\": \"esxi01.example.com\",\n \"issues\": [],\n \"status\": \"green\"\n },\n {\n \"_vimtype\": \"vim.host.VsanHostHealthSystemStatusResult\",\n \"hostname\": \"esxi04.example.com\",\n \"issues\": [],\n \"status\": \"green\"\n },\n {\n \"_vimtype\": \"vim.host.VsanHostHealthSystemStatusResult\",\n \"hostname\": \"esxi02.example.com\",\n \"issues\": [],\n \"status\": \"green\"\n },\n {\n \"_vimtype\": \"vim.host.VsanHostHealthSystemStatusResult\",\n \"hostname\": \"esxi03.example.com\",\n \"issues\": [],\n \"status\": \"green\"\n }\n ],\n \"untrackedHosts\": []\n }\n }\n'''\n\nimport json\nimport traceback\n\ntry:\n from pyVmomi import vmodl, VmomiSupport\n HAS_PYVMOMI = True\n HAS_PYVMOMIJSON = hasattr(VmomiSupport, 'VmomiJSONEncoder')\nexcept ImportError:\n PYVMOMI_IMP_ERR = traceback.format_exc()\n HAS_PYVMOMI = False\n HAS_PYVMOMIJSON = False\n\nVSANPYTHONSDK_IMP_ERR = None\ntry:\n import vsanapiutils\n HAS_VSANPYTHONSDK = True\nexcept ImportError:\n VSANPYTHONSDK_IMP_ERR = traceback.format_exc()\n HAS_VSANPYTHONSDK = False\n\nfrom ansible.module_utils.basic import AnsibleModule, missing_required_lib\nfrom ansible_collections.community.vmware.plugins.module_utils.vmware import vmware_argument_spec, PyVmomi\n\n\nclass VSANInfoManager(PyVmomi):\n def __init__(self, module):\n super(VSANInfoManager, self).__init__(module)\n self.datacenter = None\n self.cluster = None\n\n def gather_info(self):\n datacenter_name = self.module.params.get('datacenter')\n if datacenter_name:\n self.datacenter = self.find_datacenter_by_name(datacenter_name)\n if self.datacenter is None:\n self.module.fail_json(msg=\"Datacenter %s does not exist.\" % datacenter_name)\n\n cluster_name = self.module.params.get('cluster_name')\n self.cluster = self.find_cluster_by_name(cluster_name=cluster_name, datacenter_name=self.datacenter)\n if self.cluster is None:\n self.module.fail_json(msg=\"Cluster %s does not exist.\" % cluster_name)\n\n fetch_from_cache = self.module.params.get('fetch_from_cache')\n\n client_stub = self.si._GetStub()\n ssl_context = client_stub.schemeArgs.get('context')\n\n api_version = vsanapiutils.GetLatestVmodlVersion(self.module.params['hostname'])\n vc_mos = vsanapiutils.GetVsanVcMos(client_stub, context=ssl_context, version=api_version)\n\n vsan_cluster_health_system = vc_mos['vsan-cluster-health-system']\n\n cluster_health = {}\n try:\n cluster_health = vsan_cluster_health_system.VsanQueryVcClusterHealthSummary(\n cluster=self.cluster,\n fetchFromCache=fetch_from_cache,\n )\n except vmodl.fault.NotFound as not_found:\n self.module.fail_json(msg=not_found.msg)\n except vmodl.fault.RuntimeFault as runtime_fault:\n self.module.fail_json(msg=runtime_fault.msg)\n\n health = json.dumps(cluster_health, cls=VmomiSupport.VmomiJSONEncoder, sort_keys=True, strip_dynamic=True)\n\n self.module.exit_json(changed=False, vsan_health_info=health)\n\n\ndef main():\n argument_spec = vmware_argument_spec()\n argument_spec.update(\n datacenter=dict(required=False, type='str', aliases=['datacenter_name']),\n cluster_name=dict(required=True, type='str'),\n fetch_from_cache=dict(required=False, type='bool', default=False)\n )\n\n module = AnsibleModule(\n argument_spec=argument_spec,\n supports_check_mode=True\n )\n\n if not HAS_VSANPYTHONSDK:\n module.fail_json(msg=missing_required_lib('vSAN Management SDK for Python'), exception=VSANPYTHONSDK_IMP_ERR)\n\n if not HAS_PYVMOMIJSON:\n module.fail_json(msg='The installed version of pyvmomi lacks JSON output support; need pyvmomi>6.7.1')\n\n vsan_info_manager = VSANInfoManager(module)\n vsan_info_manager.gather_info()\n\n\nif __name__ == '__main__':\n main()\n", "path": "plugins/modules/vmware_vsan_health_info.py"}]}
| 3,126 | 135 |
gh_patches_debug_3313
|
rasdani/github-patches
|
git_diff
|
ansible-collections__community.general-6941
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
machinectl become plugin does not specify it requires a tty
### Summary
see https://github.com/ansible/ansible/issues/81254
if the plugin sets the class attribute:
```
require_tty = True
```
It would automatically disable pipelining and avoid such errors
### Issue Type
Bug Report
### Component Name
become/machinectl
### Ansible Version
```console (paste below)
$ ansible --version
```
all
### Community.general Version
```console (paste below)
$ ansible-galaxy collection list community.general
```
all
### Configuration
```console (paste below)
$ ansible-config dump --only-changed
```
N/A
### OS / Environment
N/A
### Steps to Reproduce
<!--- Paste example playbooks or commands between quotes below -->
```yaml (paste below)
```
Use machinectl become plugin + pipelining
### Expected Results
it works TM
### Actual Results
```console (paste below)
"msg": "MODULE FAILURE\nSee stdout/stderr for the exact error",
```
### Code of Conduct
- [X] I agree to follow the Ansible Code of Conduct
</issue>
<code>
[start of plugins/become/machinectl.py]
1 # -*- coding: utf-8 -*-
2 # Copyright (c) 2018, Ansible Project
3 # GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)
4 # SPDX-License-Identifier: GPL-3.0-or-later
5 from __future__ import (absolute_import, division, print_function)
6 __metaclass__ = type
7
8 DOCUMENTATION = '''
9 name: machinectl
10 short_description: Systemd's machinectl privilege escalation
11 description:
12 - This become plugins allows your remote/login user to execute commands as another user via the machinectl utility.
13 author: Ansible Core Team
14 options:
15 become_user:
16 description: User you 'become' to execute the task
17 default: ''
18 ini:
19 - section: privilege_escalation
20 key: become_user
21 - section: machinectl_become_plugin
22 key: user
23 vars:
24 - name: ansible_become_user
25 - name: ansible_machinectl_user
26 env:
27 - name: ANSIBLE_BECOME_USER
28 - name: ANSIBLE_MACHINECTL_USER
29 become_exe:
30 description: Machinectl executable
31 default: machinectl
32 ini:
33 - section: privilege_escalation
34 key: become_exe
35 - section: machinectl_become_plugin
36 key: executable
37 vars:
38 - name: ansible_become_exe
39 - name: ansible_machinectl_exe
40 env:
41 - name: ANSIBLE_BECOME_EXE
42 - name: ANSIBLE_MACHINECTL_EXE
43 become_flags:
44 description: Options to pass to machinectl
45 default: ''
46 ini:
47 - section: privilege_escalation
48 key: become_flags
49 - section: machinectl_become_plugin
50 key: flags
51 vars:
52 - name: ansible_become_flags
53 - name: ansible_machinectl_flags
54 env:
55 - name: ANSIBLE_BECOME_FLAGS
56 - name: ANSIBLE_MACHINECTL_FLAGS
57 become_pass:
58 description: Password for machinectl
59 required: false
60 vars:
61 - name: ansible_become_password
62 - name: ansible_become_pass
63 - name: ansible_machinectl_pass
64 env:
65 - name: ANSIBLE_BECOME_PASS
66 - name: ANSIBLE_MACHINECTL_PASS
67 ini:
68 - section: machinectl_become_plugin
69 key: password
70 notes:
71 - When not using this plugin with user C(root), it only works correctly with a polkit rule which will alter
72 the behaviour of machinectl. This rule must alter the prompt behaviour to ask directly for the user credentials,
73 if the user is allowed to perform the action (take a look at the examples section).
74 If such a rule is not present the plugin only work if it is used in context with the root user,
75 because then no further prompt will be shown by machinectl.
76 '''
77
78 EXAMPLES = r'''
79 # A polkit rule needed to use the module with a non-root user.
80 # See the Notes section for details.
81 60-machinectl-fast-user-auth.rules: |
82 polkit.addRule(function(action, subject) {
83 if(action.id == "org.freedesktop.machine1.host-shell" && subject.isInGroup("wheel")) {
84 return polkit.Result.AUTH_SELF_KEEP;
85 }
86 });
87 '''
88
89 from re import compile as re_compile
90
91 from ansible.plugins.become import BecomeBase
92 from ansible.module_utils._text import to_bytes
93
94
95 ansi_color_codes = re_compile(to_bytes(r'\x1B\[[0-9;]+m'))
96
97
98 class BecomeModule(BecomeBase):
99
100 name = 'community.general.machinectl'
101
102 prompt = 'Password: '
103 fail = ('==== AUTHENTICATION FAILED ====',)
104 success = ('==== AUTHENTICATION COMPLETE ====',)
105
106 @staticmethod
107 def remove_ansi_codes(line):
108 return ansi_color_codes.sub(b"", line)
109
110 def build_become_command(self, cmd, shell):
111 super(BecomeModule, self).build_become_command(cmd, shell)
112
113 if not cmd:
114 return cmd
115
116 become = self.get_option('become_exe')
117
118 flags = self.get_option('become_flags')
119 user = self.get_option('become_user')
120 return '%s -q shell %s %s@ %s' % (become, flags, user, self._build_success_command(cmd, shell))
121
122 def check_success(self, b_output):
123 b_output = self.remove_ansi_codes(b_output)
124 return super().check_success(b_output)
125
126 def check_incorrect_password(self, b_output):
127 b_output = self.remove_ansi_codes(b_output)
128 return super().check_incorrect_password(b_output)
129
130 def check_missing_password(self, b_output):
131 b_output = self.remove_ansi_codes(b_output)
132 return super().check_missing_password(b_output)
133
[end of plugins/become/machinectl.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugins/become/machinectl.py b/plugins/become/machinectl.py
--- a/plugins/become/machinectl.py
+++ b/plugins/become/machinectl.py
@@ -102,6 +102,7 @@
prompt = 'Password: '
fail = ('==== AUTHENTICATION FAILED ====',)
success = ('==== AUTHENTICATION COMPLETE ====',)
+ require_tty = True # see https://github.com/ansible-collections/community.general/issues/6932
@staticmethod
def remove_ansi_codes(line):
|
{"golden_diff": "diff --git a/plugins/become/machinectl.py b/plugins/become/machinectl.py\n--- a/plugins/become/machinectl.py\n+++ b/plugins/become/machinectl.py\n@@ -102,6 +102,7 @@\n prompt = 'Password: '\n fail = ('==== AUTHENTICATION FAILED ====',)\n success = ('==== AUTHENTICATION COMPLETE ====',)\n+ require_tty = True # see https://github.com/ansible-collections/community.general/issues/6932\n \n @staticmethod\n def remove_ansi_codes(line):\n", "issue": "machinectl become plugin does not specify it requires a tty\n### Summary\n\nsee https://github.com/ansible/ansible/issues/81254\r\n\r\nif the plugin sets the class attribute:\r\n\r\n```\r\n require_tty = True\r\n```\r\n\r\nIt would automatically disable pipelining and avoid such errors\n\n### Issue Type\n\nBug Report\n\n### Component Name\n\nbecome/machinectl\n\n### Ansible Version\n\n```console (paste below)\r\n$ ansible --version\r\n\r\n```\r\nall\n\n### Community.general Version\n\n```console (paste below)\r\n$ ansible-galaxy collection list community.general\r\n\r\n```\r\nall\n\n### Configuration\n\n```console (paste below)\r\n$ ansible-config dump --only-changed\r\n\r\n```\r\nN/A\n\n### OS / Environment\n\nN/A\n\n### Steps to Reproduce\n\n<!--- Paste example playbooks or commands between quotes below -->\r\n```yaml (paste below)\r\n\r\n```\r\nUse machinectl become plugin + pipelining\n\n### Expected Results\n\nit works TM\n\n### Actual Results\n\n```console (paste below)\r\n \"msg\": \"MODULE FAILURE\\nSee stdout/stderr for the exact error\",\r\n```\r\n\n\n### Code of Conduct\n\n- [X] I agree to follow the Ansible Code of Conduct\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright (c) 2018, Ansible Project\n# GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)\n# SPDX-License-Identifier: GPL-3.0-or-later\nfrom __future__ import (absolute_import, division, print_function)\n__metaclass__ = type\n\nDOCUMENTATION = '''\n name: machinectl\n short_description: Systemd's machinectl privilege escalation\n description:\n - This become plugins allows your remote/login user to execute commands as another user via the machinectl utility.\n author: Ansible Core Team\n options:\n become_user:\n description: User you 'become' to execute the task\n default: ''\n ini:\n - section: privilege_escalation\n key: become_user\n - section: machinectl_become_plugin\n key: user\n vars:\n - name: ansible_become_user\n - name: ansible_machinectl_user\n env:\n - name: ANSIBLE_BECOME_USER\n - name: ANSIBLE_MACHINECTL_USER\n become_exe:\n description: Machinectl executable\n default: machinectl\n ini:\n - section: privilege_escalation\n key: become_exe\n - section: machinectl_become_plugin\n key: executable\n vars:\n - name: ansible_become_exe\n - name: ansible_machinectl_exe\n env:\n - name: ANSIBLE_BECOME_EXE\n - name: ANSIBLE_MACHINECTL_EXE\n become_flags:\n description: Options to pass to machinectl\n default: ''\n ini:\n - section: privilege_escalation\n key: become_flags\n - section: machinectl_become_plugin\n key: flags\n vars:\n - name: ansible_become_flags\n - name: ansible_machinectl_flags\n env:\n - name: ANSIBLE_BECOME_FLAGS\n - name: ANSIBLE_MACHINECTL_FLAGS\n become_pass:\n description: Password for machinectl\n required: false\n vars:\n - name: ansible_become_password\n - name: ansible_become_pass\n - name: ansible_machinectl_pass\n env:\n - name: ANSIBLE_BECOME_PASS\n - name: ANSIBLE_MACHINECTL_PASS\n ini:\n - section: machinectl_become_plugin\n key: password\n notes:\n - When not using this plugin with user C(root), it only works correctly with a polkit rule which will alter\n the behaviour of machinectl. This rule must alter the prompt behaviour to ask directly for the user credentials,\n if the user is allowed to perform the action (take a look at the examples section).\n If such a rule is not present the plugin only work if it is used in context with the root user,\n because then no further prompt will be shown by machinectl.\n'''\n\nEXAMPLES = r'''\n# A polkit rule needed to use the module with a non-root user.\n# See the Notes section for details.\n60-machinectl-fast-user-auth.rules: |\n polkit.addRule(function(action, subject) {\n if(action.id == \"org.freedesktop.machine1.host-shell\" && subject.isInGroup(\"wheel\")) {\n return polkit.Result.AUTH_SELF_KEEP;\n }\n });\n'''\n\nfrom re import compile as re_compile\n\nfrom ansible.plugins.become import BecomeBase\nfrom ansible.module_utils._text import to_bytes\n\n\nansi_color_codes = re_compile(to_bytes(r'\\x1B\\[[0-9;]+m'))\n\n\nclass BecomeModule(BecomeBase):\n\n name = 'community.general.machinectl'\n\n prompt = 'Password: '\n fail = ('==== AUTHENTICATION FAILED ====',)\n success = ('==== AUTHENTICATION COMPLETE ====',)\n\n @staticmethod\n def remove_ansi_codes(line):\n return ansi_color_codes.sub(b\"\", line)\n\n def build_become_command(self, cmd, shell):\n super(BecomeModule, self).build_become_command(cmd, shell)\n\n if not cmd:\n return cmd\n\n become = self.get_option('become_exe')\n\n flags = self.get_option('become_flags')\n user = self.get_option('become_user')\n return '%s -q shell %s %s@ %s' % (become, flags, user, self._build_success_command(cmd, shell))\n\n def check_success(self, b_output):\n b_output = self.remove_ansi_codes(b_output)\n return super().check_success(b_output)\n\n def check_incorrect_password(self, b_output):\n b_output = self.remove_ansi_codes(b_output)\n return super().check_incorrect_password(b_output)\n\n def check_missing_password(self, b_output):\n b_output = self.remove_ansi_codes(b_output)\n return super().check_missing_password(b_output)\n", "path": "plugins/become/machinectl.py"}]}
| 2,182 | 126 |
gh_patches_debug_2736
|
rasdani/github-patches
|
git_diff
|
holoviz__panel-1064
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
outdated param dependency
it seems panel 0.8 uses `CalendarDateRange` from param. This [was introduced in param 1.9.2](https://github.com/holoviz/param/releases/tag/v1.9.2), but the param dependency is still at >=1.9.0
https://github.com/holoviz/panel/blob/master/setup.py#L93
This can lead to errors like
```
param.CalendarDateRange: DateRangeSlider,
AttributeError: module 'param' has no attribute 'CalendarDateRange'
```
when upgrading to panel 0.8.0.
Will make a simple PR to fix this
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2
3 import os
4 import shutil
5 import sys
6 import json
7
8 from setuptools import setup, find_packages
9 from setuptools.command.develop import develop
10 from setuptools.command.install import install
11 from setuptools.command.sdist import sdist
12
13 import pyct.build
14
15
16 def get_setup_version(reponame):
17 """
18 Helper to get the current version from either git describe or the
19 .version file (if available).
20 """
21 basepath = os.path.split(__file__)[0]
22 version_file_path = os.path.join(basepath, reponame, '.version')
23 try:
24 from param import version
25 except Exception:
26 version = None
27 if version is not None:
28 return version.Version.setup_version(basepath, reponame, archive_commit="$Format:%h$")
29 else:
30 print("WARNING: param>=1.6.0 unavailable. If you are installing a package, "
31 "this warning can safely be ignored. If you are creating a package or "
32 "otherwise operating in a git repository, you should install param>=1.6.0.")
33 return json.load(open(version_file_path, 'r'))['version_string']
34
35
36 def _build_paneljs():
37 from bokeh.ext import build
38 print("Building custom models:")
39 panel_dir = os.path.join(os.path.dirname(__file__), "panel")
40 build(panel_dir)
41
42
43 class CustomDevelopCommand(develop):
44 """Custom installation for development mode."""
45
46 def run(self):
47 _build_paneljs()
48 develop.run(self)
49
50
51 class CustomInstallCommand(install):
52 """Custom installation for install mode."""
53
54 def run(self):
55 _build_paneljs()
56 install.run(self)
57
58
59 class CustomSdistCommand(sdist):
60 """Custom installation for sdist mode."""
61
62 def run(self):
63 _build_paneljs()
64 sdist.run(self)
65
66
67 _COMMANDS = {
68 'develop': CustomDevelopCommand,
69 'install': CustomInstallCommand,
70 'sdist': CustomSdistCommand,
71 }
72
73 try:
74 from wheel.bdist_wheel import bdist_wheel
75
76 class CustomBdistWheelCommand(bdist_wheel):
77 """Custom bdist_wheel command to force cancelling qiskit-terra wheel
78 creation."""
79
80 def run(self):
81 """Do nothing so the command intentionally fails."""
82 _build_paneljs()
83 bdist_wheel.run(self)
84
85 _COMMANDS['bdist_wheel'] = CustomBdistWheelCommand
86 except Exception:
87 pass
88
89 ########## dependencies ##########
90
91 install_requires = [
92 'bokeh >=1.4.0,<2.0',
93 'param >=1.9.0',
94 'pyviz_comms >=0.7.3',
95 'markdown',
96 'tqdm',
97 'pyct >=0.4.4'
98 ]
99
100 _recommended = [
101 'notebook >=5.4',
102 'holoviews >=1.12.0',
103 'matplotlib',
104 'pillow',
105 'plotly'
106 ]
107
108 extras_require = {
109 'tests': [
110 'flake8',
111 'parameterized',
112 'pytest',
113 'scipy',
114 'nbsmoke >=0.2.0',
115 'pytest-cov',
116 'codecov',
117 # For examples
118 'hvplot',
119 'plotly',
120 'altair',
121 'streamz',
122 'vega_datasets',
123 'vtk',
124 'scikit-learn',
125 'datashader',
126 'jupyter_bokeh',
127 'django',
128 'pyvista',
129 ],
130 'recommended': _recommended,
131 'doc': _recommended + [
132 'nbsite >=0.6.1',
133 'sphinx_holoviz_theme',
134 'selenium',
135 'phantomjs',
136 'lxml',
137 ]
138 }
139
140 extras_require['all'] = sorted(set(sum(extras_require.values(), [])))
141
142 # Superset of what's in pyproject.toml (includes non-python
143 # dependencies). Also, pyproject.toml isn't supported by all tools
144 # anyway (e.g. older versions of pip, or conda - which also supports
145 # non-python dependencies). Note that setup_requires isn't used
146 # because it doesn't work well with pip.
147 extras_require['build'] = [
148 'param >=1.9.0',
149 'pyct >=0.4.4',
150 'setuptools >=30.3.0',
151 'bokeh >=1.4.0',
152 'pyviz_comms >=0.6.0',
153 # non-python dependency
154 'nodejs >=9.11.1',
155 ]
156
157 setup_args = dict(
158 name='panel',
159 version=get_setup_version("panel"),
160 description='A high level app and dashboarding solution for Python.',
161 long_description=open('README.md').read() if os.path.isfile('README.md') else 'Consult README.md',
162 long_description_content_type="text/markdown",
163 author="HoloViz",
164 author_email="[email protected]",
165 maintainer="HoloViz",
166 maintainer_email="[email protected]",
167 platforms=['Windows', 'Mac OS X', 'Linux'],
168 license='BSD',
169 url='http://panel.holoviz.org',
170 cmdclass=_COMMANDS,
171 packages=find_packages(),
172 include_package_data=True,
173 classifiers=[
174 "License :: OSI Approved :: BSD License",
175 "Development Status :: 5 - Production/Stable",
176 "Programming Language :: Python :: 2.7",
177 "Programming Language :: Python :: 3",
178 "Programming Language :: Python :: 3.6",
179 "Programming Language :: Python :: 3.7",
180 "Operating System :: OS Independent",
181 "Intended Audience :: Developers",
182 "Intended Audience :: Science/Research",
183 "Intended Audience :: Financial and Insurance Industry",
184 "Intended Audience :: Healthcare Industry",
185 "Intended Audience :: Information Technology",
186 "Intended Audience :: Legal Industry",
187 "Intended Audience :: Other Audience",
188 "Intended Audience :: Science/Research",
189 "Natural Language :: English",
190 "Topic :: Scientific/Engineering",
191 "Topic :: Scientific/Engineering :: Visualization",
192 "Topic :: Scientific/Engineering :: Information Analysis",
193 "Topic :: Office/Business",
194 "Topic :: Office/Business :: Financial",
195 "Topic :: Software Development :: Libraries"],
196 python_requires=">=2.7",
197 entry_points={
198 'console_scripts': [
199 'panel = panel.cli:main'
200 ]},
201 install_requires=install_requires,
202 extras_require=extras_require,
203 tests_require=extras_require['tests']
204 )
205
206 if __name__ == "__main__":
207 example_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),
208 'panel', 'examples')
209
210 if 'develop' not in sys.argv and 'egg_info' not in sys.argv:
211 pyct.build.examples(example_path, __file__, force=True)
212
213 setup(**setup_args)
214
215 if os.path.isdir(example_path):
216 shutil.rmtree(example_path)
217
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -142,7 +142,7 @@
# non-python dependencies). Note that setup_requires isn't used
# because it doesn't work well with pip.
extras_require['build'] = [
- 'param >=1.9.0',
+ 'param >=1.9.2',
'pyct >=0.4.4',
'setuptools >=30.3.0',
'bokeh >=1.4.0',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -142,7 +142,7 @@\n # non-python dependencies). Note that setup_requires isn't used\n # because it doesn't work well with pip.\n extras_require['build'] = [\n- 'param >=1.9.0',\n+ 'param >=1.9.2',\n 'pyct >=0.4.4',\n 'setuptools >=30.3.0',\n 'bokeh >=1.4.0',\n", "issue": "outdated param dependency\nit seems panel 0.8 uses `CalendarDateRange` from param. This [was introduced in param 1.9.2](https://github.com/holoviz/param/releases/tag/v1.9.2), but the param dependency is still at >=1.9.0\r\nhttps://github.com/holoviz/panel/blob/master/setup.py#L93\r\n\r\nThis can lead to errors like \r\n```\r\n param.CalendarDateRange: DateRangeSlider,\r\nAttributeError: module 'param' has no attribute 'CalendarDateRange'\r\n```\r\nwhen upgrading to panel 0.8.0.\r\nWill make a simple PR to fix this\n", "before_files": [{"content": "#!/usr/bin/env python\n\nimport os\nimport shutil\nimport sys\nimport json\n\nfrom setuptools import setup, find_packages\nfrom setuptools.command.develop import develop\nfrom setuptools.command.install import install\nfrom setuptools.command.sdist import sdist\n\nimport pyct.build\n\n\ndef get_setup_version(reponame):\n \"\"\"\n Helper to get the current version from either git describe or the\n .version file (if available).\n \"\"\"\n basepath = os.path.split(__file__)[0]\n version_file_path = os.path.join(basepath, reponame, '.version')\n try:\n from param import version\n except Exception:\n version = None\n if version is not None:\n return version.Version.setup_version(basepath, reponame, archive_commit=\"$Format:%h$\")\n else:\n print(\"WARNING: param>=1.6.0 unavailable. If you are installing a package, \"\n \"this warning can safely be ignored. If you are creating a package or \"\n \"otherwise operating in a git repository, you should install param>=1.6.0.\")\n return json.load(open(version_file_path, 'r'))['version_string']\n\n\ndef _build_paneljs():\n from bokeh.ext import build\n print(\"Building custom models:\")\n panel_dir = os.path.join(os.path.dirname(__file__), \"panel\")\n build(panel_dir)\n\n\nclass CustomDevelopCommand(develop):\n \"\"\"Custom installation for development mode.\"\"\"\n\n def run(self):\n _build_paneljs()\n develop.run(self)\n\n\nclass CustomInstallCommand(install):\n \"\"\"Custom installation for install mode.\"\"\"\n\n def run(self):\n _build_paneljs()\n install.run(self)\n\n\nclass CustomSdistCommand(sdist):\n \"\"\"Custom installation for sdist mode.\"\"\"\n\n def run(self):\n _build_paneljs()\n sdist.run(self)\n\n\n_COMMANDS = {\n 'develop': CustomDevelopCommand,\n 'install': CustomInstallCommand,\n 'sdist': CustomSdistCommand,\n}\n\ntry:\n from wheel.bdist_wheel import bdist_wheel\n\n class CustomBdistWheelCommand(bdist_wheel):\n \"\"\"Custom bdist_wheel command to force cancelling qiskit-terra wheel\n creation.\"\"\"\n\n def run(self):\n \"\"\"Do nothing so the command intentionally fails.\"\"\"\n _build_paneljs()\n bdist_wheel.run(self)\n\n _COMMANDS['bdist_wheel'] = CustomBdistWheelCommand\nexcept Exception:\n pass\n\n########## dependencies ##########\n\ninstall_requires = [\n 'bokeh >=1.4.0,<2.0',\n 'param >=1.9.0',\n 'pyviz_comms >=0.7.3',\n 'markdown',\n 'tqdm',\n 'pyct >=0.4.4'\n]\n\n_recommended = [\n 'notebook >=5.4',\n 'holoviews >=1.12.0',\n 'matplotlib',\n 'pillow',\n 'plotly'\n]\n\nextras_require = {\n 'tests': [\n 'flake8',\n 'parameterized',\n 'pytest',\n 'scipy',\n 'nbsmoke >=0.2.0',\n 'pytest-cov',\n 'codecov',\n # For examples\n 'hvplot',\n 'plotly',\n 'altair',\n 'streamz',\n 'vega_datasets',\n 'vtk',\n 'scikit-learn',\n 'datashader',\n 'jupyter_bokeh',\n 'django',\n 'pyvista',\n ],\n 'recommended': _recommended,\n 'doc': _recommended + [\n 'nbsite >=0.6.1',\n 'sphinx_holoviz_theme',\n 'selenium',\n 'phantomjs',\n 'lxml',\n ]\n}\n\nextras_require['all'] = sorted(set(sum(extras_require.values(), [])))\n\n# Superset of what's in pyproject.toml (includes non-python\n# dependencies). Also, pyproject.toml isn't supported by all tools\n# anyway (e.g. older versions of pip, or conda - which also supports\n# non-python dependencies). Note that setup_requires isn't used\n# because it doesn't work well with pip.\nextras_require['build'] = [\n 'param >=1.9.0',\n 'pyct >=0.4.4',\n 'setuptools >=30.3.0',\n 'bokeh >=1.4.0',\n 'pyviz_comms >=0.6.0',\n # non-python dependency\n 'nodejs >=9.11.1',\n]\n\nsetup_args = dict(\n name='panel',\n version=get_setup_version(\"panel\"),\n description='A high level app and dashboarding solution for Python.',\n long_description=open('README.md').read() if os.path.isfile('README.md') else 'Consult README.md',\n long_description_content_type=\"text/markdown\",\n author=\"HoloViz\",\n author_email=\"[email protected]\",\n maintainer=\"HoloViz\",\n maintainer_email=\"[email protected]\",\n platforms=['Windows', 'Mac OS X', 'Linux'],\n license='BSD',\n url='http://panel.holoviz.org',\n cmdclass=_COMMANDS,\n packages=find_packages(),\n include_package_data=True,\n classifiers=[\n \"License :: OSI Approved :: BSD License\",\n \"Development Status :: 5 - Production/Stable\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Operating System :: OS Independent\",\n \"Intended Audience :: Developers\",\n \"Intended Audience :: Science/Research\",\n \"Intended Audience :: Financial and Insurance Industry\",\n \"Intended Audience :: Healthcare Industry\",\n \"Intended Audience :: Information Technology\",\n \"Intended Audience :: Legal Industry\",\n \"Intended Audience :: Other Audience\",\n \"Intended Audience :: Science/Research\",\n \"Natural Language :: English\",\n \"Topic :: Scientific/Engineering\",\n \"Topic :: Scientific/Engineering :: Visualization\",\n \"Topic :: Scientific/Engineering :: Information Analysis\",\n \"Topic :: Office/Business\",\n \"Topic :: Office/Business :: Financial\",\n \"Topic :: Software Development :: Libraries\"],\n python_requires=\">=2.7\",\n entry_points={\n 'console_scripts': [\n 'panel = panel.cli:main'\n ]},\n install_requires=install_requires,\n extras_require=extras_require,\n tests_require=extras_require['tests']\n)\n\nif __name__ == \"__main__\":\n example_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),\n 'panel', 'examples')\n\n if 'develop' not in sys.argv and 'egg_info' not in sys.argv:\n pyct.build.examples(example_path, __file__, force=True)\n\n setup(**setup_args)\n\n if os.path.isdir(example_path):\n shutil.rmtree(example_path)\n", "path": "setup.py"}]}
| 2,726 | 120 |
gh_patches_debug_31282
|
rasdani/github-patches
|
git_diff
|
speechbrain__speechbrain-350
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
minloglevel issue with SentencePiece
Hi @aheba,
It's not the first time that I face this problem, and it's a big one on Cedar (could be the case on other clusters). SentencePiece 0.1.92 cannot be installed (as it is yanked according to the official GitHub, the version has some big regression bugs). Problem: 0.1.91 doesn't accept minloglevel as an argument raising an error
**OSError: Not found: unknown field name "minloglevel" in TrainerSpec.**
I suppose that we have to remove this option so it always work, but the logs are terrible ... any ideas ?
</issue>
<code>
[start of speechbrain/tokenizers/SentencePiece.py]
1 """Library for Byte-pair-encoding (BPE) tokenization.
2
3 Authors
4 * Abdelwahab Heba 2020
5 """
6
7 import os.path
8 import torch
9 import logging
10 import csv
11 import sentencepiece as spm
12 from speechbrain.data_io.data_io import merge_char
13
14 logger = logging.getLogger(__name__)
15
16
17 class SentencePiece:
18 """
19 BPE class call the SentencePiece unsupervised text tokenizer from Google.
20 Ref: https://github.com/google/sentencepiece
21
22 SetencePiece lib is an unsupervised text tokenizer and detokenizer.
23 It implements subword units like Byte-pair-encoding (BPE),
24 Unigram language model and char/word tokenizer.
25
26 Arguments
27 ---------
28 model_dir: str
29 The directory where the model is saved.
30 vocab_size: int, None, optional
31 Vocab size for the choosen tokenizer type (BPE, Unigram).
32 The vocab_size is optional for char, and mandatory for BPE & unigram
33 tokenization.
34 csv_train: str
35 Path of the csv file which is used for learn of create the tokenizer.
36 csv_read: str
37 The data entry which contain the word sequence in the csv file.
38 model_type: str
39 (bpe, char, unigram).
40 If "bpe", train unsupervised tokenization of piece of words. see:
41 https://www.aclweb.org/anthology/P16-1162/
42 If "word" take the vocabulary from the input text.
43 If "unigram" do piece of word tokenization using unigram language
44 model, see: https://arxiv.org/abs/1804.10959
45 char_format_input : bool
46 Default : False
47 Whether the csv_read entry contains characters format input.
48 (ex. a p p l e _ i s _ g o o d)
49 character_coverage: int
50 Default: 1.0, Amount of characters covered by the model, good defaults
51 are: 0.9995 for languages with rich character set like Japanse or
52 Chinese and 1.0 for other languages with small character set.
53 max_sentencepiece_length: int
54 Deault: 10,
55 Maximum number of characters for the tokens.
56 bos_id: int
57 Default: -1, if -1 the bos_id = unk_id = 0. otherwise, bos_id = int.
58 eos_id: int
59 Default: -1, if -1 the bos_id = unk_id = 0. otherwise, bos_id = int.
60 minloglevel: int
61 Default: 1, if 1 then the log(INFO) for BPE training is skipped
62 if 0, the log is printed.
63
64 Example
65 -------
66 >>> import torch
67 >>> dict_int2lab = {1: "HELLO", 2: "MORNING"}
68 >>> model_dir = "tests/unittests/tokenizer_data/"
69 >>> csv_train = "tests/unittests/tokenizer_data/dev-clean.csv"
70 >>> csv_read = "wrd"
71 >>> model_type = "bpe"
72 >>> bpe = SentencePiece(model_dir,2000, csv_train, csv_read, model_type)
73 >>> batch_seq = torch.Tensor([[1, 2, 2, 1],[1, 2, 1, 0]])
74 >>> batch_lens = torch.Tensor([1.0, 0.75])
75 >>> encoded_seq_ids, encoded_seq_pieces = bpe(
76 ... batch_seq, batch_lens, dict_int2lab, task="encode"
77 ... )
78 """
79
80 def __init__(
81 self,
82 model_dir,
83 vocab_size,
84 csv_train=None,
85 csv_read=None,
86 model_type="unigram",
87 char_format_input=False,
88 character_coverage=1.0,
89 max_sentencepiece_length=10,
90 bos_id=-1,
91 eos_id=-1,
92 pad_id=-1,
93 unk_id=0,
94 minloglevel=1,
95 ):
96 if model_type not in ["unigram", "bpe", "char"]:
97 raise ValueError("model_type must be one of : [unigram, bpe, char]")
98 if not os.path.isdir(model_dir):
99 os.makedirs(model_dir)
100 if not isinstance(vocab_size, int):
101 raise ValueError("vocab_size must be integer.")
102
103 self.csv_train = csv_train
104 self.csv_read = csv_read
105 self.text_file = os.path.join(
106 os.path.dirname(csv_train),
107 os.path.splitext(os.path.basename(csv_train))[0] + ".txt",
108 )
109 self.prefix_model_file = os.path.join(
110 model_dir, str(vocab_size) + "_" + model_type
111 )
112 self.vocab_size = str(vocab_size)
113 self.model_type = model_type
114 self.char_format_input = char_format_input
115 self.character_coverage = str(character_coverage)
116 self.max_sentencepiece_length = str(max_sentencepiece_length)
117 self.bos_id = str(bos_id)
118 self.eos_id = str(eos_id)
119 self.pad_id = str(pad_id)
120 self.unk_id = str(unk_id)
121 self.minloglevel = str(minloglevel)
122
123 if not os.path.isfile(self.prefix_model_file + ".model"):
124 logger.info("Train tokenizer with type:" + self.model_type)
125 if not os.path.isfile(self.text_file):
126 self._csv2text()
127 self._train_BPE()
128 else:
129 logger.info("Tokenizer is already trained.")
130 logger.info("==== Loading Tokenizer ===")
131 logger.info("Tokenizer path: " + self.prefix_model_file + ".model")
132 logger.info("Tokenizer vocab_size: " + str(self.vocab_size))
133 logger.info("Tokenizer type: " + self.model_type)
134 self.sp = spm.SentencePieceProcessor()
135 self.sp.load(self.prefix_model_file + ".model")
136
137 def _csv2text(self):
138 """
139 Read CSV file and convert specific data entries into text file.
140 """
141 if not os.path.isfile(os.path.abspath(self.csv_train)):
142 raise ValueError(
143 self.csv_train
144 + " is not a file. please provide csv file for training."
145 )
146 logger.info(
147 "Extract " + self.csv_read + " sequences from:" + self.csv_train
148 )
149 csv_file = open(self.csv_train, "r")
150 reader = csv.reader(csv_file)
151 headers = next(reader, None)
152 if self.csv_read not in headers:
153 raise ValueError(self.csv_read + "must exist in:" + self.csv_train)
154 index_label = headers.index(self.csv_read)
155 text_file = open(self.text_file, "w+")
156 for row in reader:
157 sent = row[index_label]
158 if self.char_format_input:
159 (sent,) = merge_char([sent.split()])
160 sent = " ".join(sent)
161 text_file.write(sent + "\n")
162 text_file.close()
163 csv_file.close()
164 logger.info("Text file created at: " + self.text_file)
165
166 def _train_BPE(self):
167 """
168 Train tokenizer with unsupervised techniques (BPE, Unigram) using
169 SentencePiece Library. If you use "char" mode, the SentencePiece
170 creates a char dict so the vocab_size attribute is not needed.
171 """
172 query = (
173 "--input="
174 + self.text_file
175 + " --model_prefix="
176 + self.prefix_model_file
177 + " --model_type="
178 + self.model_type
179 + " --bos_id="
180 + self.bos_id
181 + " --eos_id="
182 + self.eos_id
183 + " --pad_id="
184 + self.pad_id
185 + " --unk_id="
186 + self.unk_id
187 + " --max_sentencepiece_length="
188 + self.max_sentencepiece_length
189 + " --character_coverage="
190 + self.character_coverage
191 + " --minloglevel="
192 + self.minloglevel
193 )
194 if self.model_type not in ["char"]:
195 # include vocab_size
196 query += " --vocab_size=" + str(self.vocab_size)
197 # Train tokenizer
198 spm.SentencePieceTrainer.train(query)
199
200 def __call__(
201 self, batch, batch_lens=None, ind2lab=None, task="encode",
202 ):
203 """
204 This __call__ function implements the tokenizer encoder and decoder
205 (restoring the string of word) for BPE, Regularized BPE (with unigram),
206 and char (speechbrain/nnet/RNN.py).
207
208 Arguments
209 ----------
210 batch : tensor.IntTensor or list
211 list if ( batch_lens = None and task = "decode_from_list")
212 Contains the original labels. Shape: [batch_size, max_length]
213 batch_lens : tensor.LongTensor
214 Default: None,
215 Cotaining the relative length of each label sequences. Must be 1D
216 tensor of shape: [batch_size].
217 ind2lab : dict
218 Dictionnary which map the index from label sequences
219 (batch tensor) to string label.
220 task: str
221 ("encode", "decode", "decode_from_list)
222 "encode": convert the batch tensor into sequence of tokens.
223 the output contain a list of (tokens_seq, tokens_lens)
224 "decode": convert a tensor of tokens to a list of word sequences.
225 "decode_from_list": convert a list of token sequences to a list
226 of word sequences.
227 """
228 if task == "encode" and ind2lab is None:
229 raise ValueError("Tokenizer encoder must have the ind2lab function")
230
231 if task == "encode":
232 # Convert list of words/chars to bpe ids
233 bpe = []
234 max_bpe_len = 0
235 batch_lens = (batch_lens * batch.shape[1]).int()
236 for i, utt_seq in enumerate(batch):
237 tokens = [
238 ind2lab[int(index)] for index in utt_seq[: batch_lens[i]]
239 ]
240 if self.char_format_input:
241 (words_list,) = merge_char([tokens])
242 sent = " ".join(words_list)
243 else:
244 sent = " ".join(tokens)
245 bpe_encode = self.sp.encode_as_ids(sent)
246 bpe.append(bpe_encode)
247 # save the longest bpe sequence
248 # it help to compute the relative length of each utterance
249 if len(bpe_encode) > max_bpe_len:
250 max_bpe_len = len(bpe_encode)
251 # Create bpe tensor
252 bpe_tensor = torch.zeros(
253 (batch.shape[0], max_bpe_len), device=batch.device
254 )
255 bpe_lens = torch.zeros((batch.shape[0]), device=batch.device)
256 for i, bpe_utt in enumerate(bpe):
257 bpe_tensor[i, : len(bpe_utt)] = torch.Tensor(bpe_utt)
258 bpe_lens[i] = len(bpe_utt) / max_bpe_len
259 return bpe_tensor, bpe_lens
260 elif task == "decode_from_list":
261 # From list of hyps (not padded outputs)
262 # do decoding
263 return [self.sp.decode_ids(utt_seq).split(" ") for utt_seq in batch]
264 elif task == "decode":
265 # From a batch tensor and a length tensor
266 # find the absolute batch lengths and do decoding
267 batch_lens = (batch_lens * batch.shape[1]).int()
268 return [
269 self.sp.decode_ids(
270 utt_seq[: batch_lens[i]].int().tolist()
271 ).split(" ")
272 for i, utt_seq in enumerate(batch)
273 ]
274
[end of speechbrain/tokenizers/SentencePiece.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/speechbrain/tokenizers/SentencePiece.py b/speechbrain/tokenizers/SentencePiece.py
--- a/speechbrain/tokenizers/SentencePiece.py
+++ b/speechbrain/tokenizers/SentencePiece.py
@@ -57,9 +57,6 @@
Default: -1, if -1 the bos_id = unk_id = 0. otherwise, bos_id = int.
eos_id: int
Default: -1, if -1 the bos_id = unk_id = 0. otherwise, bos_id = int.
- minloglevel: int
- Default: 1, if 1 then the log(INFO) for BPE training is skipped
- if 0, the log is printed.
Example
-------
@@ -91,7 +88,6 @@
eos_id=-1,
pad_id=-1,
unk_id=0,
- minloglevel=1,
):
if model_type not in ["unigram", "bpe", "char"]:
raise ValueError("model_type must be one of : [unigram, bpe, char]")
@@ -118,7 +114,6 @@
self.eos_id = str(eos_id)
self.pad_id = str(pad_id)
self.unk_id = str(unk_id)
- self.minloglevel = str(minloglevel)
if not os.path.isfile(self.prefix_model_file + ".model"):
logger.info("Train tokenizer with type:" + self.model_type)
@@ -188,8 +183,6 @@
+ self.max_sentencepiece_length
+ " --character_coverage="
+ self.character_coverage
- + " --minloglevel="
- + self.minloglevel
)
if self.model_type not in ["char"]:
# include vocab_size
|
{"golden_diff": "diff --git a/speechbrain/tokenizers/SentencePiece.py b/speechbrain/tokenizers/SentencePiece.py\n--- a/speechbrain/tokenizers/SentencePiece.py\n+++ b/speechbrain/tokenizers/SentencePiece.py\n@@ -57,9 +57,6 @@\n Default: -1, if -1 the bos_id = unk_id = 0. otherwise, bos_id = int.\n eos_id: int\n Default: -1, if -1 the bos_id = unk_id = 0. otherwise, bos_id = int.\n- minloglevel: int\n- Default: 1, if 1 then the log(INFO) for BPE training is skipped\n- if 0, the log is printed.\n \n Example\n -------\n@@ -91,7 +88,6 @@\n eos_id=-1,\n pad_id=-1,\n unk_id=0,\n- minloglevel=1,\n ):\n if model_type not in [\"unigram\", \"bpe\", \"char\"]:\n raise ValueError(\"model_type must be one of : [unigram, bpe, char]\")\n@@ -118,7 +114,6 @@\n self.eos_id = str(eos_id)\n self.pad_id = str(pad_id)\n self.unk_id = str(unk_id)\n- self.minloglevel = str(minloglevel)\n \n if not os.path.isfile(self.prefix_model_file + \".model\"):\n logger.info(\"Train tokenizer with type:\" + self.model_type)\n@@ -188,8 +183,6 @@\n + self.max_sentencepiece_length\n + \" --character_coverage=\"\n + self.character_coverage\n- + \" --minloglevel=\"\n- + self.minloglevel\n )\n if self.model_type not in [\"char\"]:\n # include vocab_size\n", "issue": "minloglevel issue with SentencePiece\nHi @aheba,\r\n\r\nIt's not the first time that I face this problem, and it's a big one on Cedar (could be the case on other clusters). SentencePiece 0.1.92 cannot be installed (as it is yanked according to the official GitHub, the version has some big regression bugs). Problem: 0.1.91 doesn't accept minloglevel as an argument raising an error \r\n\r\n**OSError: Not found: unknown field name \"minloglevel\" in TrainerSpec.**\r\nI suppose that we have to remove this option so it always work, but the logs are terrible ... any ideas ?\n", "before_files": [{"content": "\"\"\"Library for Byte-pair-encoding (BPE) tokenization.\n\nAuthors\n * Abdelwahab Heba 2020\n\"\"\"\n\nimport os.path\nimport torch\nimport logging\nimport csv\nimport sentencepiece as spm\nfrom speechbrain.data_io.data_io import merge_char\n\nlogger = logging.getLogger(__name__)\n\n\nclass SentencePiece:\n \"\"\"\n BPE class call the SentencePiece unsupervised text tokenizer from Google.\n Ref: https://github.com/google/sentencepiece\n\n SetencePiece lib is an unsupervised text tokenizer and detokenizer.\n It implements subword units like Byte-pair-encoding (BPE),\n Unigram language model and char/word tokenizer.\n\n Arguments\n ---------\n model_dir: str\n The directory where the model is saved.\n vocab_size: int, None, optional\n Vocab size for the choosen tokenizer type (BPE, Unigram).\n The vocab_size is optional for char, and mandatory for BPE & unigram\n tokenization.\n csv_train: str\n Path of the csv file which is used for learn of create the tokenizer.\n csv_read: str\n The data entry which contain the word sequence in the csv file.\n model_type: str\n (bpe, char, unigram).\n If \"bpe\", train unsupervised tokenization of piece of words. see:\n https://www.aclweb.org/anthology/P16-1162/\n If \"word\" take the vocabulary from the input text.\n If \"unigram\" do piece of word tokenization using unigram language\n model, see: https://arxiv.org/abs/1804.10959\n char_format_input : bool\n Default : False\n Whether the csv_read entry contains characters format input.\n (ex. a p p l e _ i s _ g o o d)\n character_coverage: int\n Default: 1.0, Amount of characters covered by the model, good defaults\n are: 0.9995 for languages with rich character set like Japanse or\n Chinese and 1.0 for other languages with small character set.\n max_sentencepiece_length: int\n Deault: 10,\n Maximum number of characters for the tokens.\n bos_id: int\n Default: -1, if -1 the bos_id = unk_id = 0. otherwise, bos_id = int.\n eos_id: int\n Default: -1, if -1 the bos_id = unk_id = 0. otherwise, bos_id = int.\n minloglevel: int\n Default: 1, if 1 then the log(INFO) for BPE training is skipped\n if 0, the log is printed.\n\n Example\n -------\n >>> import torch\n >>> dict_int2lab = {1: \"HELLO\", 2: \"MORNING\"}\n >>> model_dir = \"tests/unittests/tokenizer_data/\"\n >>> csv_train = \"tests/unittests/tokenizer_data/dev-clean.csv\"\n >>> csv_read = \"wrd\"\n >>> model_type = \"bpe\"\n >>> bpe = SentencePiece(model_dir,2000, csv_train, csv_read, model_type)\n >>> batch_seq = torch.Tensor([[1, 2, 2, 1],[1, 2, 1, 0]])\n >>> batch_lens = torch.Tensor([1.0, 0.75])\n >>> encoded_seq_ids, encoded_seq_pieces = bpe(\n ... batch_seq, batch_lens, dict_int2lab, task=\"encode\"\n ... )\n \"\"\"\n\n def __init__(\n self,\n model_dir,\n vocab_size,\n csv_train=None,\n csv_read=None,\n model_type=\"unigram\",\n char_format_input=False,\n character_coverage=1.0,\n max_sentencepiece_length=10,\n bos_id=-1,\n eos_id=-1,\n pad_id=-1,\n unk_id=0,\n minloglevel=1,\n ):\n if model_type not in [\"unigram\", \"bpe\", \"char\"]:\n raise ValueError(\"model_type must be one of : [unigram, bpe, char]\")\n if not os.path.isdir(model_dir):\n os.makedirs(model_dir)\n if not isinstance(vocab_size, int):\n raise ValueError(\"vocab_size must be integer.\")\n\n self.csv_train = csv_train\n self.csv_read = csv_read\n self.text_file = os.path.join(\n os.path.dirname(csv_train),\n os.path.splitext(os.path.basename(csv_train))[0] + \".txt\",\n )\n self.prefix_model_file = os.path.join(\n model_dir, str(vocab_size) + \"_\" + model_type\n )\n self.vocab_size = str(vocab_size)\n self.model_type = model_type\n self.char_format_input = char_format_input\n self.character_coverage = str(character_coverage)\n self.max_sentencepiece_length = str(max_sentencepiece_length)\n self.bos_id = str(bos_id)\n self.eos_id = str(eos_id)\n self.pad_id = str(pad_id)\n self.unk_id = str(unk_id)\n self.minloglevel = str(minloglevel)\n\n if not os.path.isfile(self.prefix_model_file + \".model\"):\n logger.info(\"Train tokenizer with type:\" + self.model_type)\n if not os.path.isfile(self.text_file):\n self._csv2text()\n self._train_BPE()\n else:\n logger.info(\"Tokenizer is already trained.\")\n logger.info(\"==== Loading Tokenizer ===\")\n logger.info(\"Tokenizer path: \" + self.prefix_model_file + \".model\")\n logger.info(\"Tokenizer vocab_size: \" + str(self.vocab_size))\n logger.info(\"Tokenizer type: \" + self.model_type)\n self.sp = spm.SentencePieceProcessor()\n self.sp.load(self.prefix_model_file + \".model\")\n\n def _csv2text(self):\n \"\"\"\n Read CSV file and convert specific data entries into text file.\n \"\"\"\n if not os.path.isfile(os.path.abspath(self.csv_train)):\n raise ValueError(\n self.csv_train\n + \" is not a file. please provide csv file for training.\"\n )\n logger.info(\n \"Extract \" + self.csv_read + \" sequences from:\" + self.csv_train\n )\n csv_file = open(self.csv_train, \"r\")\n reader = csv.reader(csv_file)\n headers = next(reader, None)\n if self.csv_read not in headers:\n raise ValueError(self.csv_read + \"must exist in:\" + self.csv_train)\n index_label = headers.index(self.csv_read)\n text_file = open(self.text_file, \"w+\")\n for row in reader:\n sent = row[index_label]\n if self.char_format_input:\n (sent,) = merge_char([sent.split()])\n sent = \" \".join(sent)\n text_file.write(sent + \"\\n\")\n text_file.close()\n csv_file.close()\n logger.info(\"Text file created at: \" + self.text_file)\n\n def _train_BPE(self):\n \"\"\"\n Train tokenizer with unsupervised techniques (BPE, Unigram) using\n SentencePiece Library. If you use \"char\" mode, the SentencePiece\n creates a char dict so the vocab_size attribute is not needed.\n \"\"\"\n query = (\n \"--input=\"\n + self.text_file\n + \" --model_prefix=\"\n + self.prefix_model_file\n + \" --model_type=\"\n + self.model_type\n + \" --bos_id=\"\n + self.bos_id\n + \" --eos_id=\"\n + self.eos_id\n + \" --pad_id=\"\n + self.pad_id\n + \" --unk_id=\"\n + self.unk_id\n + \" --max_sentencepiece_length=\"\n + self.max_sentencepiece_length\n + \" --character_coverage=\"\n + self.character_coverage\n + \" --minloglevel=\"\n + self.minloglevel\n )\n if self.model_type not in [\"char\"]:\n # include vocab_size\n query += \" --vocab_size=\" + str(self.vocab_size)\n # Train tokenizer\n spm.SentencePieceTrainer.train(query)\n\n def __call__(\n self, batch, batch_lens=None, ind2lab=None, task=\"encode\",\n ):\n \"\"\"\n This __call__ function implements the tokenizer encoder and decoder\n (restoring the string of word) for BPE, Regularized BPE (with unigram),\n and char (speechbrain/nnet/RNN.py).\n\n Arguments\n ----------\n batch : tensor.IntTensor or list\n list if ( batch_lens = None and task = \"decode_from_list\")\n Contains the original labels. Shape: [batch_size, max_length]\n batch_lens : tensor.LongTensor\n Default: None,\n Cotaining the relative length of each label sequences. Must be 1D\n tensor of shape: [batch_size].\n ind2lab : dict\n Dictionnary which map the index from label sequences\n (batch tensor) to string label.\n task: str\n (\"encode\", \"decode\", \"decode_from_list)\n \"encode\": convert the batch tensor into sequence of tokens.\n the output contain a list of (tokens_seq, tokens_lens)\n \"decode\": convert a tensor of tokens to a list of word sequences.\n \"decode_from_list\": convert a list of token sequences to a list\n of word sequences.\n \"\"\"\n if task == \"encode\" and ind2lab is None:\n raise ValueError(\"Tokenizer encoder must have the ind2lab function\")\n\n if task == \"encode\":\n # Convert list of words/chars to bpe ids\n bpe = []\n max_bpe_len = 0\n batch_lens = (batch_lens * batch.shape[1]).int()\n for i, utt_seq in enumerate(batch):\n tokens = [\n ind2lab[int(index)] for index in utt_seq[: batch_lens[i]]\n ]\n if self.char_format_input:\n (words_list,) = merge_char([tokens])\n sent = \" \".join(words_list)\n else:\n sent = \" \".join(tokens)\n bpe_encode = self.sp.encode_as_ids(sent)\n bpe.append(bpe_encode)\n # save the longest bpe sequence\n # it help to compute the relative length of each utterance\n if len(bpe_encode) > max_bpe_len:\n max_bpe_len = len(bpe_encode)\n # Create bpe tensor\n bpe_tensor = torch.zeros(\n (batch.shape[0], max_bpe_len), device=batch.device\n )\n bpe_lens = torch.zeros((batch.shape[0]), device=batch.device)\n for i, bpe_utt in enumerate(bpe):\n bpe_tensor[i, : len(bpe_utt)] = torch.Tensor(bpe_utt)\n bpe_lens[i] = len(bpe_utt) / max_bpe_len\n return bpe_tensor, bpe_lens\n elif task == \"decode_from_list\":\n # From list of hyps (not padded outputs)\n # do decoding\n return [self.sp.decode_ids(utt_seq).split(\" \") for utt_seq in batch]\n elif task == \"decode\":\n # From a batch tensor and a length tensor\n # find the absolute batch lengths and do decoding\n batch_lens = (batch_lens * batch.shape[1]).int()\n return [\n self.sp.decode_ids(\n utt_seq[: batch_lens[i]].int().tolist()\n ).split(\" \")\n for i, utt_seq in enumerate(batch)\n ]\n", "path": "speechbrain/tokenizers/SentencePiece.py"}]}
| 3,899 | 398 |
gh_patches_debug_25376
|
rasdani/github-patches
|
git_diff
|
team-ocean__veros-49
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Job resubmission with job scheduler doesn't work
I was not able to find out the reason behind resubmission issue with job scheduler, such as:
`veros-resubmit -i acc.lowres -n 50 -l 62208000 -c "python acc.py -b bohrium -v debug" --callback "/usr/bin/sbatch /groups/ocean/nutrik/veros_cases/paper/acc/veros_batch.sh"`
Although jobs with run length of up to 29 days are resubmitted fine, those with longer run length are not resubmitted and no errors or messages are reported.
In fact, jobs are successfully resubmitted without scheduler (`--callback "./veros_batch.sh"`) for any run length.
</issue>
<code>
[start of veros/cli/veros_resubmit.py]
1 #!/usr/bin/env python
2
3 import functools
4 import subprocess
5 import shlex
6 import sys
7 import os
8
9 import click
10
11 LAST_N_FILENAME = "{identifier}.current_run"
12
13
14 class ShellCommand(click.ParamType):
15 name = "command"
16
17 def convert(self, value, param, ctx):
18 return shlex.split(value)
19
20
21 def get_current_n(filename):
22 if not os.path.isfile(filename):
23 return 0
24
25 with open(filename, "r") as f:
26 return int(f.read())
27
28
29 def write_next_n(n, filename):
30 with open(filename, "w") as f:
31 f.write(str(n))
32
33
34 def call_veros(cmd, name, n, runlen):
35 identifier = "{name}.{n:0>4}".format(name=name, n=n)
36 prev_id = "{name}.{n:0>4}".format(name=name, n=n - 1)
37 args = ["-s", "identifier", identifier, "-s", "restart_output_filename",
38 "{identifier}.restart.h5", "-s", "runlen", "{}".format(runlen)]
39 if n:
40 args += ["-s", "restart_input_filename", "{prev_id}.restart.h5".format(prev_id=prev_id)]
41 sys.stdout.write("\n >>> {}\n\n".format(" ".join(cmd + args)))
42 sys.stdout.flush()
43 try:
44 subprocess.check_call(cmd + args)
45 except subprocess.CalledProcessError:
46 raise RuntimeError("Run {} failed, exiting".format(n))
47
48
49 def resubmit(identifier, num_runs, length_per_run, veros_cmd, callback):
50 """Performs several runs of Veros back to back, using the previous run as restart input.
51
52 Intended to be used with scheduling systems (e.g. SLURM or PBS).
53
54 """
55 last_n_filename = LAST_N_FILENAME.format(identifier=identifier)
56
57 current_n = get_current_n(last_n_filename)
58 if current_n >= num_runs:
59 return
60
61 call_veros(veros_cmd, identifier, current_n, length_per_run)
62 write_next_n(current_n + 1, last_n_filename)
63 subprocess.Popen(callback)
64
65
66 @click.command("veros-resubmit", short_help="Re-run a Veros setup several times")
67 @click.option("-i", "--identifier", required=True,
68 help="Base identifier of the simulation")
69 @click.option("-n", "--num-runs", type=click.INT, required=True,
70 help="Total number of runs to execute")
71 @click.option("-l", "--length-per-run", type=click.FLOAT, required=True,
72 help="Length (in seconds) of each run")
73 @click.option("-c", "--veros-cmd", type=ShellCommand(), required=True,
74 help="The command that is used to call veros (quoted)")
75 @click.option("--callback", metavar="CMD", type=ShellCommand(), default=None,
76 help="Command to call after each run has finished (quoted, default: call self)")
77 @functools.wraps(resubmit)
78 def cli(*args, **kwargs):
79 if kwargs["callback"] is None:
80 kwargs["callback"] = sys.argv
81 resubmit(*args, **kwargs)
82
83
84 if __name__ == "__main__":
85 cli()
86
[end of veros/cli/veros_resubmit.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/veros/cli/veros_resubmit.py b/veros/cli/veros_resubmit.py
--- a/veros/cli/veros_resubmit.py
+++ b/veros/cli/veros_resubmit.py
@@ -5,10 +5,13 @@
import shlex
import sys
import os
+import time
import click
LAST_N_FILENAME = "{identifier}.current_run"
+CHILD_TIMEOUT = 10
+POLL_DELAY = 0.1
class ShellCommand(click.ParamType):
@@ -60,7 +63,21 @@
call_veros(veros_cmd, identifier, current_n, length_per_run)
write_next_n(current_n + 1, last_n_filename)
- subprocess.Popen(callback)
+ next_proc = subprocess.Popen(callback)
+
+ # catch immediately crashing processes
+ timeout = CHILD_TIMEOUT
+
+ while timeout > 0:
+ retcode = next_proc.poll()
+ if retcode is not None:
+ if retcode > 0:
+ # process crashed
+ raise RuntimeError("Callback exited with {}".format(retcode))
+ else:
+ break
+ time.sleep(POLL_DELAY)
+ timeout -= POLL_DELAY
@click.command("veros-resubmit", short_help="Re-run a Veros setup several times")
@@ -78,6 +95,7 @@
def cli(*args, **kwargs):
if kwargs["callback"] is None:
kwargs["callback"] = sys.argv
+
resubmit(*args, **kwargs)
|
{"golden_diff": "diff --git a/veros/cli/veros_resubmit.py b/veros/cli/veros_resubmit.py\n--- a/veros/cli/veros_resubmit.py\n+++ b/veros/cli/veros_resubmit.py\n@@ -5,10 +5,13 @@\n import shlex\n import sys\n import os\n+import time\n \n import click\n \n LAST_N_FILENAME = \"{identifier}.current_run\"\n+CHILD_TIMEOUT = 10\n+POLL_DELAY = 0.1\n \n \n class ShellCommand(click.ParamType):\n@@ -60,7 +63,21 @@\n \n call_veros(veros_cmd, identifier, current_n, length_per_run)\n write_next_n(current_n + 1, last_n_filename)\n- subprocess.Popen(callback)\n+ next_proc = subprocess.Popen(callback)\n+\n+ # catch immediately crashing processes\n+ timeout = CHILD_TIMEOUT\n+\n+ while timeout > 0:\n+ retcode = next_proc.poll()\n+ if retcode is not None:\n+ if retcode > 0:\n+ # process crashed\n+ raise RuntimeError(\"Callback exited with {}\".format(retcode))\n+ else:\n+ break\n+ time.sleep(POLL_DELAY)\n+ timeout -= POLL_DELAY\n \n \n @click.command(\"veros-resubmit\", short_help=\"Re-run a Veros setup several times\")\n@@ -78,6 +95,7 @@\n def cli(*args, **kwargs):\n if kwargs[\"callback\"] is None:\n kwargs[\"callback\"] = sys.argv\n+\n resubmit(*args, **kwargs)\n", "issue": "Job resubmission with job scheduler doesn't work \nI was not able to find out the reason behind resubmission issue with job scheduler, such as:\r\n`veros-resubmit -i acc.lowres -n 50 -l 62208000 -c \"python acc.py -b bohrium -v debug\" --callback \"/usr/bin/sbatch /groups/ocean/nutrik/veros_cases/paper/acc/veros_batch.sh\"`\r\nAlthough jobs with run length of up to 29 days are resubmitted fine, those with longer run length are not resubmitted and no errors or messages are reported.\r\n\r\nIn fact, jobs are successfully resubmitted without scheduler (`--callback \"./veros_batch.sh\"`) for any run length.\n", "before_files": [{"content": "#!/usr/bin/env python\n\nimport functools\nimport subprocess\nimport shlex\nimport sys\nimport os\n\nimport click\n\nLAST_N_FILENAME = \"{identifier}.current_run\"\n\n\nclass ShellCommand(click.ParamType):\n name = \"command\"\n\n def convert(self, value, param, ctx):\n return shlex.split(value)\n\n\ndef get_current_n(filename):\n if not os.path.isfile(filename):\n return 0\n\n with open(filename, \"r\") as f:\n return int(f.read())\n\n\ndef write_next_n(n, filename):\n with open(filename, \"w\") as f:\n f.write(str(n))\n\n\ndef call_veros(cmd, name, n, runlen):\n identifier = \"{name}.{n:0>4}\".format(name=name, n=n)\n prev_id = \"{name}.{n:0>4}\".format(name=name, n=n - 1)\n args = [\"-s\", \"identifier\", identifier, \"-s\", \"restart_output_filename\",\n \"{identifier}.restart.h5\", \"-s\", \"runlen\", \"{}\".format(runlen)]\n if n:\n args += [\"-s\", \"restart_input_filename\", \"{prev_id}.restart.h5\".format(prev_id=prev_id)]\n sys.stdout.write(\"\\n >>> {}\\n\\n\".format(\" \".join(cmd + args)))\n sys.stdout.flush()\n try:\n subprocess.check_call(cmd + args)\n except subprocess.CalledProcessError:\n raise RuntimeError(\"Run {} failed, exiting\".format(n))\n\n\ndef resubmit(identifier, num_runs, length_per_run, veros_cmd, callback):\n \"\"\"Performs several runs of Veros back to back, using the previous run as restart input.\n\n Intended to be used with scheduling systems (e.g. SLURM or PBS).\n\n \"\"\"\n last_n_filename = LAST_N_FILENAME.format(identifier=identifier)\n\n current_n = get_current_n(last_n_filename)\n if current_n >= num_runs:\n return\n\n call_veros(veros_cmd, identifier, current_n, length_per_run)\n write_next_n(current_n + 1, last_n_filename)\n subprocess.Popen(callback)\n\n\[email protected](\"veros-resubmit\", short_help=\"Re-run a Veros setup several times\")\[email protected](\"-i\", \"--identifier\", required=True,\n help=\"Base identifier of the simulation\")\[email protected](\"-n\", \"--num-runs\", type=click.INT, required=True,\n help=\"Total number of runs to execute\")\[email protected](\"-l\", \"--length-per-run\", type=click.FLOAT, required=True,\n help=\"Length (in seconds) of each run\")\[email protected](\"-c\", \"--veros-cmd\", type=ShellCommand(), required=True,\n help=\"The command that is used to call veros (quoted)\")\[email protected](\"--callback\", metavar=\"CMD\", type=ShellCommand(), default=None,\n help=\"Command to call after each run has finished (quoted, default: call self)\")\[email protected](resubmit)\ndef cli(*args, **kwargs):\n if kwargs[\"callback\"] is None:\n kwargs[\"callback\"] = sys.argv\n resubmit(*args, **kwargs)\n\n\nif __name__ == \"__main__\":\n cli()\n", "path": "veros/cli/veros_resubmit.py"}]}
| 1,571 | 347 |
gh_patches_debug_20474
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-trace-py-2744
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Incorrect types for patch() and patch_all() keyword arguments
### Which version of dd-trace-py are you using?
0.51.1
### Which version of pip are you using?
20.2.3
### Which version of the libraries are you using?
fastapi==0.63.0
### How can we reproduce your problem?
I have this line of code: ` ddtrace.patch(fastapi=True)`
And then in the command line I run `mypy project_dir`
### What is the result that you get?
`error: Argument "fastapi" to "patch" has incompatible type "bool"; expected "Dict[str, bool]"`
### What is the result that you expected?
No type errors
I believe this is because the type of the patch_modules parameter should be just `bool` and not `Dict[str, bool]` because it is a keyword arguments parameter (declared with **) for these two functions. See: https://www.python.org/dev/peps/pep-0484/#arbitrary-argument-lists-and-default-argument-values
</issue>
<code>
[start of ddtrace/monkey.py]
1 """Patch libraries to be automatically instrumented.
2
3 It can monkey patch supported standard libraries and third party modules.
4 A patched module will automatically report spans with its default configuration.
5
6 A library instrumentation can be configured (for instance, to report as another service)
7 using Pin. For that, check its documentation.
8 """
9 import importlib
10 import os
11 import sys
12 import threading
13 from typing import Any
14 from typing import Callable
15 from typing import Dict
16 from typing import List
17
18 from ddtrace.vendor.wrapt.importer import when_imported
19
20 from .internal.logger import get_logger
21 from .settings import _config as config
22 from .utils import formats
23 from .utils.deprecation import deprecated
24
25
26 log = get_logger(__name__)
27
28 # Default set of modules to automatically patch or not
29 PATCH_MODULES = {
30 "asyncio": True,
31 "boto": True,
32 "botocore": True,
33 "bottle": False,
34 "cassandra": True,
35 "celery": True,
36 "consul": True,
37 "django": True,
38 "elasticsearch": True,
39 "algoliasearch": True,
40 "futures": True,
41 "grpc": True,
42 "httpx": True,
43 "mongoengine": True,
44 "mysql": True,
45 "mysqldb": True,
46 "pymysql": True,
47 "mariadb": True,
48 "psycopg": True,
49 "pylibmc": True,
50 "pymemcache": True,
51 "pymongo": True,
52 "redis": True,
53 "rediscluster": True,
54 "requests": True,
55 "sanic": True,
56 "sqlalchemy": False, # Prefer DB client instrumentation
57 "sqlite3": True,
58 "aiohttp": True, # requires asyncio (Python 3.4+)
59 "aiopg": True,
60 "aiobotocore": False,
61 "httplib": False,
62 "urllib3": False,
63 "vertica": True,
64 "molten": True,
65 "jinja2": True,
66 "mako": True,
67 "flask": True,
68 "kombu": False,
69 "starlette": True,
70 # Ignore some web framework integrations that might be configured explicitly in code
71 "falcon": False,
72 "pylons": False,
73 "pyramid": False,
74 # Auto-enable logging if the environment variable DD_LOGS_INJECTION is true
75 "logging": config.logs_injection,
76 "pynamodb": True,
77 "pyodbc": True,
78 "fastapi": True,
79 "dogpile_cache": True,
80 }
81
82 _LOCK = threading.Lock()
83 _PATCHED_MODULES = set()
84
85 # Modules which are patched on first use
86 # DEV: These modules are patched when the user first imports them, rather than
87 # explicitly importing and patching them on application startup `ddtrace.patch_all(module=True)`
88 # DEV: This ensures we do not patch a module until it is needed
89 # DEV: <contrib name> => <list of module names that trigger a patch>
90 _PATCH_ON_IMPORT = {
91 "aiohttp": ("aiohttp",),
92 "aiobotocore": ("aiobotocore",),
93 "celery": ("celery",),
94 "flask": ("flask",),
95 "gevent": ("gevent",),
96 "requests": ("requests",),
97 "botocore": ("botocore",),
98 "elasticsearch": (
99 "elasticsearch",
100 "elasticsearch2",
101 "elasticsearch5",
102 "elasticsearch6",
103 "elasticsearch7",
104 ),
105 "pynamodb": ("pynamodb",),
106 }
107
108
109 class PatchException(Exception):
110 """Wraps regular `Exception` class when patching modules"""
111
112 pass
113
114
115 class ModuleNotFoundException(PatchException):
116 pass
117
118
119 def _on_import_factory(module, raise_errors=True):
120 # type: (str, bool) -> Callable[[Any], None]
121 """Factory to create an import hook for the provided module name"""
122
123 def on_import(hook):
124 # Import and patch module
125 path = "ddtrace.contrib.%s" % module
126 try:
127 imported_module = importlib.import_module(path)
128 except ImportError:
129 if raise_errors:
130 raise
131 log.error("failed to import ddtrace module %r when patching on import", path, exc_info=True)
132 else:
133 imported_module.patch()
134
135 return on_import
136
137
138 def patch_all(**patch_modules):
139 # type: (Dict[str, bool]) -> None
140 """Automatically patches all available modules.
141
142 In addition to ``patch_modules``, an override can be specified via an
143 environment variable, ``DD_TRACE_<module>_ENABLED`` for each module.
144
145 ``patch_modules`` have the highest precedence for overriding.
146
147 :param dict patch_modules: Override whether particular modules are patched or not.
148
149 >>> patch_all(redis=False, cassandra=False)
150 """
151 modules = PATCH_MODULES.copy()
152
153 # The enabled setting can be overridden by environment variables
154 for module, enabled in modules.items():
155 env_var = "DD_TRACE_%s_ENABLED" % module.upper()
156 if env_var not in os.environ:
157 continue
158
159 override_enabled = formats.asbool(os.environ[env_var])
160 modules[module] = override_enabled
161
162 # Arguments take precedence over the environment and the defaults.
163 modules.update(patch_modules)
164
165 patch(raise_errors=False, **modules)
166
167
168 def patch(raise_errors=True, **patch_modules):
169 # type: (bool, Dict[str, bool]) -> None
170 """Patch only a set of given modules.
171
172 :param bool raise_errors: Raise error if one patch fail.
173 :param dict patch_modules: List of modules to patch.
174
175 >>> patch(psycopg=True, elasticsearch=True)
176 """
177 modules = [m for (m, should_patch) in patch_modules.items() if should_patch]
178 for module in modules:
179 if module in _PATCH_ON_IMPORT:
180 modules_to_poi = _PATCH_ON_IMPORT[module]
181 for m in modules_to_poi:
182 # If the module has already been imported then patch immediately
183 if m in sys.modules:
184 _patch_module(module, raise_errors=raise_errors)
185 break
186 # Otherwise, add a hook to patch when it is imported for the first time
187 else:
188 # Use factory to create handler to close over `module` and `raise_errors` values from this loop
189 when_imported(m)(_on_import_factory(module, raise_errors))
190
191 # manually add module to patched modules
192 with _LOCK:
193 _PATCHED_MODULES.add(module)
194 else:
195 _patch_module(module, raise_errors=raise_errors)
196
197 patched_modules = _get_patched_modules()
198 log.info(
199 "patched %s/%s modules (%s)",
200 len(patched_modules),
201 len(modules),
202 ",".join(patched_modules),
203 )
204
205
206 @deprecated(
207 message="This function will be removed.",
208 version="1.0.0",
209 )
210 def patch_module(module, raise_errors=True):
211 # type: (str, bool) -> bool
212 return _patch_module(module, raise_errors=raise_errors)
213
214
215 def _patch_module(module, raise_errors=True):
216 # type: (str, bool) -> bool
217 """Patch a single module
218
219 Returns if the module got properly patched.
220 """
221 try:
222 return _attempt_patch_module(module)
223 except ModuleNotFoundException:
224 if raise_errors:
225 raise
226 return False
227 except Exception:
228 if raise_errors:
229 raise
230 log.debug("failed to patch %s", module, exc_info=True)
231 return False
232
233
234 @deprecated(
235 message="This function will be removed.",
236 version="1.0.0",
237 )
238 def get_patched_modules():
239 # type: () -> List[str]
240 return _get_patched_modules()
241
242
243 def _get_patched_modules():
244 # type: () -> List[str]
245 """Get the list of patched modules"""
246 with _LOCK:
247 return sorted(_PATCHED_MODULES)
248
249
250 def _attempt_patch_module(module):
251 # type: (str) -> bool
252 """_patch_module will attempt to monkey patch the module.
253
254 Returns if the module got patched.
255 Can also raise errors if it fails.
256 """
257 path = "ddtrace.contrib.%s" % module
258 with _LOCK:
259 if module in _PATCHED_MODULES and module not in _PATCH_ON_IMPORT:
260 log.debug("already patched: %s", path)
261 return False
262
263 try:
264 imported_module = importlib.import_module(path)
265 except ImportError:
266 # if the import fails, the integration is not available
267 raise ModuleNotFoundException(
268 "integration module %s does not exist, module will not have tracing available" % path
269 )
270 else:
271 # if patch() is not available in the module, it means
272 # that the library is not installed in the environment
273 if not hasattr(imported_module, "patch"):
274 raise AttributeError(
275 "%s.patch is not found. '%s' is not configured for this environment" % (path, module)
276 )
277
278 imported_module.patch() # type: ignore
279 _PATCHED_MODULES.add(module)
280 return True
281
[end of ddtrace/monkey.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ddtrace/monkey.py b/ddtrace/monkey.py
--- a/ddtrace/monkey.py
+++ b/ddtrace/monkey.py
@@ -12,7 +12,6 @@
import threading
from typing import Any
from typing import Callable
-from typing import Dict
from typing import List
from ddtrace.vendor.wrapt.importer import when_imported
@@ -136,7 +135,7 @@
def patch_all(**patch_modules):
- # type: (Dict[str, bool]) -> None
+ # type: (bool) -> None
"""Automatically patches all available modules.
In addition to ``patch_modules``, an override can be specified via an
@@ -166,7 +165,7 @@
def patch(raise_errors=True, **patch_modules):
- # type: (bool, Dict[str, bool]) -> None
+ # type: (bool, bool) -> None
"""Patch only a set of given modules.
:param bool raise_errors: Raise error if one patch fail.
|
{"golden_diff": "diff --git a/ddtrace/monkey.py b/ddtrace/monkey.py\n--- a/ddtrace/monkey.py\n+++ b/ddtrace/monkey.py\n@@ -12,7 +12,6 @@\n import threading\n from typing import Any\n from typing import Callable\n-from typing import Dict\n from typing import List\n \n from ddtrace.vendor.wrapt.importer import when_imported\n@@ -136,7 +135,7 @@\n \n \n def patch_all(**patch_modules):\n- # type: (Dict[str, bool]) -> None\n+ # type: (bool) -> None\n \"\"\"Automatically patches all available modules.\n \n In addition to ``patch_modules``, an override can be specified via an\n@@ -166,7 +165,7 @@\n \n \n def patch(raise_errors=True, **patch_modules):\n- # type: (bool, Dict[str, bool]) -> None\n+ # type: (bool, bool) -> None\n \"\"\"Patch only a set of given modules.\n \n :param bool raise_errors: Raise error if one patch fail.\n", "issue": "Incorrect types for patch() and patch_all() keyword arguments\n### Which version of dd-trace-py are you using?\r\n0.51.1\r\n\r\n### Which version of pip are you using?\r\n\r\n20.2.3\r\n\r\n### Which version of the libraries are you using?\r\n\r\nfastapi==0.63.0\r\n\r\n### How can we reproduce your problem?\r\n\r\nI have this line of code: ` ddtrace.patch(fastapi=True)`\r\n\r\nAnd then in the command line I run `mypy project_dir`\r\n\r\n### What is the result that you get?\r\n\r\n`error: Argument \"fastapi\" to \"patch\" has incompatible type \"bool\"; expected \"Dict[str, bool]\"`\r\n\r\n### What is the result that you expected?\r\n\r\nNo type errors\r\n\r\n\r\nI believe this is because the type of the patch_modules parameter should be just `bool` and not `Dict[str, bool]` because it is a keyword arguments parameter (declared with **) for these two functions. See: https://www.python.org/dev/peps/pep-0484/#arbitrary-argument-lists-and-default-argument-values \n", "before_files": [{"content": "\"\"\"Patch libraries to be automatically instrumented.\n\nIt can monkey patch supported standard libraries and third party modules.\nA patched module will automatically report spans with its default configuration.\n\nA library instrumentation can be configured (for instance, to report as another service)\nusing Pin. For that, check its documentation.\n\"\"\"\nimport importlib\nimport os\nimport sys\nimport threading\nfrom typing import Any\nfrom typing import Callable\nfrom typing import Dict\nfrom typing import List\n\nfrom ddtrace.vendor.wrapt.importer import when_imported\n\nfrom .internal.logger import get_logger\nfrom .settings import _config as config\nfrom .utils import formats\nfrom .utils.deprecation import deprecated\n\n\nlog = get_logger(__name__)\n\n# Default set of modules to automatically patch or not\nPATCH_MODULES = {\n \"asyncio\": True,\n \"boto\": True,\n \"botocore\": True,\n \"bottle\": False,\n \"cassandra\": True,\n \"celery\": True,\n \"consul\": True,\n \"django\": True,\n \"elasticsearch\": True,\n \"algoliasearch\": True,\n \"futures\": True,\n \"grpc\": True,\n \"httpx\": True,\n \"mongoengine\": True,\n \"mysql\": True,\n \"mysqldb\": True,\n \"pymysql\": True,\n \"mariadb\": True,\n \"psycopg\": True,\n \"pylibmc\": True,\n \"pymemcache\": True,\n \"pymongo\": True,\n \"redis\": True,\n \"rediscluster\": True,\n \"requests\": True,\n \"sanic\": True,\n \"sqlalchemy\": False, # Prefer DB client instrumentation\n \"sqlite3\": True,\n \"aiohttp\": True, # requires asyncio (Python 3.4+)\n \"aiopg\": True,\n \"aiobotocore\": False,\n \"httplib\": False,\n \"urllib3\": False,\n \"vertica\": True,\n \"molten\": True,\n \"jinja2\": True,\n \"mako\": True,\n \"flask\": True,\n \"kombu\": False,\n \"starlette\": True,\n # Ignore some web framework integrations that might be configured explicitly in code\n \"falcon\": False,\n \"pylons\": False,\n \"pyramid\": False,\n # Auto-enable logging if the environment variable DD_LOGS_INJECTION is true\n \"logging\": config.logs_injection,\n \"pynamodb\": True,\n \"pyodbc\": True,\n \"fastapi\": True,\n \"dogpile_cache\": True,\n}\n\n_LOCK = threading.Lock()\n_PATCHED_MODULES = set()\n\n# Modules which are patched on first use\n# DEV: These modules are patched when the user first imports them, rather than\n# explicitly importing and patching them on application startup `ddtrace.patch_all(module=True)`\n# DEV: This ensures we do not patch a module until it is needed\n# DEV: <contrib name> => <list of module names that trigger a patch>\n_PATCH_ON_IMPORT = {\n \"aiohttp\": (\"aiohttp\",),\n \"aiobotocore\": (\"aiobotocore\",),\n \"celery\": (\"celery\",),\n \"flask\": (\"flask\",),\n \"gevent\": (\"gevent\",),\n \"requests\": (\"requests\",),\n \"botocore\": (\"botocore\",),\n \"elasticsearch\": (\n \"elasticsearch\",\n \"elasticsearch2\",\n \"elasticsearch5\",\n \"elasticsearch6\",\n \"elasticsearch7\",\n ),\n \"pynamodb\": (\"pynamodb\",),\n}\n\n\nclass PatchException(Exception):\n \"\"\"Wraps regular `Exception` class when patching modules\"\"\"\n\n pass\n\n\nclass ModuleNotFoundException(PatchException):\n pass\n\n\ndef _on_import_factory(module, raise_errors=True):\n # type: (str, bool) -> Callable[[Any], None]\n \"\"\"Factory to create an import hook for the provided module name\"\"\"\n\n def on_import(hook):\n # Import and patch module\n path = \"ddtrace.contrib.%s\" % module\n try:\n imported_module = importlib.import_module(path)\n except ImportError:\n if raise_errors:\n raise\n log.error(\"failed to import ddtrace module %r when patching on import\", path, exc_info=True)\n else:\n imported_module.patch()\n\n return on_import\n\n\ndef patch_all(**patch_modules):\n # type: (Dict[str, bool]) -> None\n \"\"\"Automatically patches all available modules.\n\n In addition to ``patch_modules``, an override can be specified via an\n environment variable, ``DD_TRACE_<module>_ENABLED`` for each module.\n\n ``patch_modules`` have the highest precedence for overriding.\n\n :param dict patch_modules: Override whether particular modules are patched or not.\n\n >>> patch_all(redis=False, cassandra=False)\n \"\"\"\n modules = PATCH_MODULES.copy()\n\n # The enabled setting can be overridden by environment variables\n for module, enabled in modules.items():\n env_var = \"DD_TRACE_%s_ENABLED\" % module.upper()\n if env_var not in os.environ:\n continue\n\n override_enabled = formats.asbool(os.environ[env_var])\n modules[module] = override_enabled\n\n # Arguments take precedence over the environment and the defaults.\n modules.update(patch_modules)\n\n patch(raise_errors=False, **modules)\n\n\ndef patch(raise_errors=True, **patch_modules):\n # type: (bool, Dict[str, bool]) -> None\n \"\"\"Patch only a set of given modules.\n\n :param bool raise_errors: Raise error if one patch fail.\n :param dict patch_modules: List of modules to patch.\n\n >>> patch(psycopg=True, elasticsearch=True)\n \"\"\"\n modules = [m for (m, should_patch) in patch_modules.items() if should_patch]\n for module in modules:\n if module in _PATCH_ON_IMPORT:\n modules_to_poi = _PATCH_ON_IMPORT[module]\n for m in modules_to_poi:\n # If the module has already been imported then patch immediately\n if m in sys.modules:\n _patch_module(module, raise_errors=raise_errors)\n break\n # Otherwise, add a hook to patch when it is imported for the first time\n else:\n # Use factory to create handler to close over `module` and `raise_errors` values from this loop\n when_imported(m)(_on_import_factory(module, raise_errors))\n\n # manually add module to patched modules\n with _LOCK:\n _PATCHED_MODULES.add(module)\n else:\n _patch_module(module, raise_errors=raise_errors)\n\n patched_modules = _get_patched_modules()\n log.info(\n \"patched %s/%s modules (%s)\",\n len(patched_modules),\n len(modules),\n \",\".join(patched_modules),\n )\n\n\n@deprecated(\n message=\"This function will be removed.\",\n version=\"1.0.0\",\n)\ndef patch_module(module, raise_errors=True):\n # type: (str, bool) -> bool\n return _patch_module(module, raise_errors=raise_errors)\n\n\ndef _patch_module(module, raise_errors=True):\n # type: (str, bool) -> bool\n \"\"\"Patch a single module\n\n Returns if the module got properly patched.\n \"\"\"\n try:\n return _attempt_patch_module(module)\n except ModuleNotFoundException:\n if raise_errors:\n raise\n return False\n except Exception:\n if raise_errors:\n raise\n log.debug(\"failed to patch %s\", module, exc_info=True)\n return False\n\n\n@deprecated(\n message=\"This function will be removed.\",\n version=\"1.0.0\",\n)\ndef get_patched_modules():\n # type: () -> List[str]\n return _get_patched_modules()\n\n\ndef _get_patched_modules():\n # type: () -> List[str]\n \"\"\"Get the list of patched modules\"\"\"\n with _LOCK:\n return sorted(_PATCHED_MODULES)\n\n\ndef _attempt_patch_module(module):\n # type: (str) -> bool\n \"\"\"_patch_module will attempt to monkey patch the module.\n\n Returns if the module got patched.\n Can also raise errors if it fails.\n \"\"\"\n path = \"ddtrace.contrib.%s\" % module\n with _LOCK:\n if module in _PATCHED_MODULES and module not in _PATCH_ON_IMPORT:\n log.debug(\"already patched: %s\", path)\n return False\n\n try:\n imported_module = importlib.import_module(path)\n except ImportError:\n # if the import fails, the integration is not available\n raise ModuleNotFoundException(\n \"integration module %s does not exist, module will not have tracing available\" % path\n )\n else:\n # if patch() is not available in the module, it means\n # that the library is not installed in the environment\n if not hasattr(imported_module, \"patch\"):\n raise AttributeError(\n \"%s.patch is not found. '%s' is not configured for this environment\" % (path, module)\n )\n\n imported_module.patch() # type: ignore\n _PATCHED_MODULES.add(module)\n return True\n", "path": "ddtrace/monkey.py"}]}
| 3,515 | 233 |
gh_patches_debug_30694
|
rasdani/github-patches
|
git_diff
|
mampfes__hacs_waste_collection_schedule-1599
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug]: was_wolfsburg_de stopped fetching data
### I Have A Problem With:
A specific source
### What's Your Problem
The Source was_wolfsburg_de stopped fetching data for 2024. I suspect because the request link is no longer accurate.
I have experimented a bit, and with the following address I receive current data:
https://was-wolfsburg.de/subabfuhrtermine/php/abfuhrtermine.php
It only concerns "Restmüll, Bioabfall und Papierabfall". "Gelber Sack" is still functioning.
### Source (if relevant)
was_wolfsburg_de
### Logs
_No response_
### Relevant Configuration
_No response_
### Checklist Source Error
- [ ] Use the example parameters for your source (often available in the documentation) (don't forget to restart Home Assistant after changing the configuration)
- [ ] Checked that the website of your service provider is still working
- [ ] Tested my attributes on the service provider website (if possible)
- [X] I have tested with the latest version of the integration (master) (for HACS in the 3 dot menu of the integration click on "Redownload" and choose master as version)
### Checklist Sensor Error
- [ ] Checked in the Home Assistant Calendar tab if the event names match the types names (if types argument is used)
### Required
- [X] I have searched past (closed AND opened) issues to see if this bug has already been reported, and it hasn't been.
- [X] I understand that people give their precious time for free, and thus I've done my very best to make this problem as easy as possible to investigate.
</issue>
<code>
[start of custom_components/waste_collection_schedule/waste_collection_schedule/source/was_wolfsburg_de.py]
1 import datetime
2 import re
3
4 import requests
5 from waste_collection_schedule import Collection # type: ignore[attr-defined]
6 from waste_collection_schedule.service.ICS import ICS
7
8 TITLE = "Wolfsburger Abfallwirtschaft und Straßenreinigung"
9 DESCRIPTION = "Source for waste collections for WAS-Wolfsburg, Germany."
10 URL = "https://was-wolfsburg.de"
11 TEST_CASES = {
12 "Barnstorf": {"city": "Barnstorf", "street": "Bahnhofspassage"},
13 "Sülfeld": {"city": "Sülfeld", "street": "Bärheide"},
14 }
15 CHARACTER_MAP = {
16 ord("ü"): "u",
17 ord("ö"): "o", # doesn't appear to be needed
18 ord("ä"): "a", # doesn't appear to be needed
19 }
20
21
22 class Source:
23 def __init__(self, city: str, street: str):
24 self._city = city.translate(CHARACTER_MAP)
25 self._street = street.translate(CHARACTER_MAP)
26 self._ics = ICS()
27
28 def fetch(self):
29 # fetch "Gelber Sack"
30 args = {"g": self._city}
31 r = requests.get(
32 "https://was-wolfsburg.de/subgelberweihgarten/php/abfuhrgelber.php",
33 params=args,
34 )
35
36 entries = []
37 match = re.findall(r"(\d{2})\.(\d{2})\.(\d{4})", r.text)
38 for m in match:
39 date = datetime.date(day=int(m[0]), month=int(m[1]), year=int(m[2]))
40 entries.append(Collection(date, "Gelber Sack"))
41
42 # fetch remaining collections
43 args = {"ortabf": self._street}
44 r = requests.post(
45 "https://was-wolfsburg.de/subabfuhrtermine/ics_abfuhrtermine3.php",
46 data=args,
47 )
48 dates = self._ics.convert(r.text)
49 for d in dates:
50 entries.append(Collection(d[0], d[1]))
51
52 return entries
53
[end of custom_components/waste_collection_schedule/waste_collection_schedule/source/was_wolfsburg_de.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/was_wolfsburg_de.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/was_wolfsburg_de.py
--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/was_wolfsburg_de.py
+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/was_wolfsburg_de.py
@@ -12,6 +12,14 @@
"Barnstorf": {"city": "Barnstorf", "street": "Bahnhofspassage"},
"Sülfeld": {"city": "Sülfeld", "street": "Bärheide"},
}
+
+ICON_MAP = {
+ "Gelber Sack": "mdi:recycle",
+ "Bioabfall": "mdi:leaf",
+ "Restabfall": "mdi:trash-can",
+ "Altpapier": "mdi:file-document-outline",
+}
+
CHARACTER_MAP = {
ord("ü"): "u",
ord("ö"): "o", # doesn't appear to be needed
@@ -37,16 +45,21 @@
match = re.findall(r"(\d{2})\.(\d{2})\.(\d{4})", r.text)
for m in match:
date = datetime.date(day=int(m[0]), month=int(m[1]), year=int(m[2]))
- entries.append(Collection(date, "Gelber Sack"))
+ entries.append(
+ Collection(date, "Gelber Sack", icon=ICON_MAP["Gelber Sack"])
+ )
# fetch remaining collections
- args = {"ortabf": self._street}
- r = requests.post(
- "https://was-wolfsburg.de/subabfuhrtermine/ics_abfuhrtermine3.php",
- data=args,
+ args = {"k": self._street}
+ r = requests.get(
+ "https://was-wolfsburg.de/subabfuhrtermine/php/abfuhrtermine.php",
+ params=args,
+ )
+ match = re.findall(
+ r"(\d{2})\.(\d{2})\.(\d{4}).*?<em>\s*([A-Za-z- ]+)\s*</em>", r.text
)
- dates = self._ics.convert(r.text)
- for d in dates:
- entries.append(Collection(d[0], d[1]))
+ for m in match:
+ date = datetime.date(day=int(m[0]), month=int(m[1]), year=int(m[2]))
+ entries.append(Collection(date, m[3], icon=ICON_MAP[m[3]]))
return entries
|
{"golden_diff": "diff --git a/custom_components/waste_collection_schedule/waste_collection_schedule/source/was_wolfsburg_de.py b/custom_components/waste_collection_schedule/waste_collection_schedule/source/was_wolfsburg_de.py\n--- a/custom_components/waste_collection_schedule/waste_collection_schedule/source/was_wolfsburg_de.py\n+++ b/custom_components/waste_collection_schedule/waste_collection_schedule/source/was_wolfsburg_de.py\n@@ -12,6 +12,14 @@\n \"Barnstorf\": {\"city\": \"Barnstorf\", \"street\": \"Bahnhofspassage\"},\n \"S\u00fclfeld\": {\"city\": \"S\u00fclfeld\", \"street\": \"B\u00e4rheide\"},\n }\n+\n+ICON_MAP = {\n+ \"Gelber Sack\": \"mdi:recycle\",\n+ \"Bioabfall\": \"mdi:leaf\",\n+ \"Restabfall\": \"mdi:trash-can\",\n+ \"Altpapier\": \"mdi:file-document-outline\",\n+}\n+\n CHARACTER_MAP = {\n ord(\"\u00fc\"): \"u\",\n ord(\"\u00f6\"): \"o\", # doesn't appear to be needed\n@@ -37,16 +45,21 @@\n match = re.findall(r\"(\\d{2})\\.(\\d{2})\\.(\\d{4})\", r.text)\n for m in match:\n date = datetime.date(day=int(m[0]), month=int(m[1]), year=int(m[2]))\n- entries.append(Collection(date, \"Gelber Sack\"))\n+ entries.append(\n+ Collection(date, \"Gelber Sack\", icon=ICON_MAP[\"Gelber Sack\"])\n+ )\n \n # fetch remaining collections\n- args = {\"ortabf\": self._street}\n- r = requests.post(\n- \"https://was-wolfsburg.de/subabfuhrtermine/ics_abfuhrtermine3.php\",\n- data=args,\n+ args = {\"k\": self._street}\n+ r = requests.get(\n+ \"https://was-wolfsburg.de/subabfuhrtermine/php/abfuhrtermine.php\",\n+ params=args,\n+ )\n+ match = re.findall(\n+ r\"(\\d{2})\\.(\\d{2})\\.(\\d{4}).*?<em>\\s*([A-Za-z- ]+)\\s*</em>\", r.text\n )\n- dates = self._ics.convert(r.text)\n- for d in dates:\n- entries.append(Collection(d[0], d[1]))\n+ for m in match:\n+ date = datetime.date(day=int(m[0]), month=int(m[1]), year=int(m[2]))\n+ entries.append(Collection(date, m[3], icon=ICON_MAP[m[3]]))\n \n return entries\n", "issue": "[Bug]: was_wolfsburg_de stopped fetching data\n### I Have A Problem With:\n\nA specific source\n\n### What's Your Problem\n\nThe Source was_wolfsburg_de stopped fetching data for 2024. I suspect because the request link is no longer accurate.\r\nI have experimented a bit, and with the following address I receive current data: \r\n\r\nhttps://was-wolfsburg.de/subabfuhrtermine/php/abfuhrtermine.php\r\n\r\nIt only concerns \"Restm\u00fcll, Bioabfall und Papierabfall\". \"Gelber Sack\" is still functioning.\n\n### Source (if relevant)\n\nwas_wolfsburg_de\n\n### Logs\n\n_No response_\n\n### Relevant Configuration\n\n_No response_\n\n### Checklist Source Error\n\n- [ ] Use the example parameters for your source (often available in the documentation) (don't forget to restart Home Assistant after changing the configuration)\n- [ ] Checked that the website of your service provider is still working\n- [ ] Tested my attributes on the service provider website (if possible)\n- [X] I have tested with the latest version of the integration (master) (for HACS in the 3 dot menu of the integration click on \"Redownload\" and choose master as version)\n\n### Checklist Sensor Error\n\n- [ ] Checked in the Home Assistant Calendar tab if the event names match the types names (if types argument is used)\n\n### Required\n\n- [X] I have searched past (closed AND opened) issues to see if this bug has already been reported, and it hasn't been.\n- [X] I understand that people give their precious time for free, and thus I've done my very best to make this problem as easy as possible to investigate.\n", "before_files": [{"content": "import datetime\nimport re\n\nimport requests\nfrom waste_collection_schedule import Collection # type: ignore[attr-defined]\nfrom waste_collection_schedule.service.ICS import ICS\n\nTITLE = \"Wolfsburger Abfallwirtschaft und Stra\u00dfenreinigung\"\nDESCRIPTION = \"Source for waste collections for WAS-Wolfsburg, Germany.\"\nURL = \"https://was-wolfsburg.de\"\nTEST_CASES = {\n \"Barnstorf\": {\"city\": \"Barnstorf\", \"street\": \"Bahnhofspassage\"},\n \"S\u00fclfeld\": {\"city\": \"S\u00fclfeld\", \"street\": \"B\u00e4rheide\"},\n}\nCHARACTER_MAP = {\n ord(\"\u00fc\"): \"u\",\n ord(\"\u00f6\"): \"o\", # doesn't appear to be needed\n ord(\"\u00e4\"): \"a\", # doesn't appear to be needed\n}\n\n\nclass Source:\n def __init__(self, city: str, street: str):\n self._city = city.translate(CHARACTER_MAP)\n self._street = street.translate(CHARACTER_MAP)\n self._ics = ICS()\n\n def fetch(self):\n # fetch \"Gelber Sack\"\n args = {\"g\": self._city}\n r = requests.get(\n \"https://was-wolfsburg.de/subgelberweihgarten/php/abfuhrgelber.php\",\n params=args,\n )\n\n entries = []\n match = re.findall(r\"(\\d{2})\\.(\\d{2})\\.(\\d{4})\", r.text)\n for m in match:\n date = datetime.date(day=int(m[0]), month=int(m[1]), year=int(m[2]))\n entries.append(Collection(date, \"Gelber Sack\"))\n\n # fetch remaining collections\n args = {\"ortabf\": self._street}\n r = requests.post(\n \"https://was-wolfsburg.de/subabfuhrtermine/ics_abfuhrtermine3.php\",\n data=args,\n )\n dates = self._ics.convert(r.text)\n for d in dates:\n entries.append(Collection(d[0], d[1]))\n\n return entries\n", "path": "custom_components/waste_collection_schedule/waste_collection_schedule/source/was_wolfsburg_de.py"}]}
| 1,483 | 609 |
gh_patches_debug_18547
|
rasdani/github-patches
|
git_diff
|
searx__searx-1501
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Asksteem is gone
The API has been discontinued so it should probably be removed as an option entirely.
</issue>
<code>
[start of searx/engines/asksteem.py]
1 """
2 Asksteem (general)
3
4 @website https://asksteem.com/
5 @provide-api yes
6
7 @using-api yes
8 @results JSON (https://github.com/Hoxly/asksteem-docs/wiki)
9 @stable yes
10 @parse url, title, content
11 """
12
13 from json import loads
14 from searx.url_utils import urlencode
15
16 # engine dependent config
17 categories = ['general']
18 paging = True
19 language_support = False
20 disabled = True
21
22 # search-url
23 search_url = 'https://api.asksteem.com/search?{params}'
24 result_url = 'https://steemit.com/@{author}/{title}'
25
26
27 # do search-request
28 def request(query, params):
29 url = search_url.format(params=urlencode({'q': query, 'pg': params['pageno']}))
30 params['url'] = url
31 return params
32
33
34 # get response from search-request
35 def response(resp):
36 json = loads(resp.text)
37
38 results = []
39
40 for result in json.get('results', []):
41 results.append({'url': result_url.format(author=result['author'], title=result['permlink']),
42 'title': result['title'],
43 'content': result['summary']})
44 return results
45
[end of searx/engines/asksteem.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/searx/engines/asksteem.py b/searx/engines/asksteem.py
deleted file mode 100644
--- a/searx/engines/asksteem.py
+++ /dev/null
@@ -1,44 +0,0 @@
-"""
- Asksteem (general)
-
- @website https://asksteem.com/
- @provide-api yes
-
- @using-api yes
- @results JSON (https://github.com/Hoxly/asksteem-docs/wiki)
- @stable yes
- @parse url, title, content
-"""
-
-from json import loads
-from searx.url_utils import urlencode
-
-# engine dependent config
-categories = ['general']
-paging = True
-language_support = False
-disabled = True
-
-# search-url
-search_url = 'https://api.asksteem.com/search?{params}'
-result_url = 'https://steemit.com/@{author}/{title}'
-
-
-# do search-request
-def request(query, params):
- url = search_url.format(params=urlencode({'q': query, 'pg': params['pageno']}))
- params['url'] = url
- return params
-
-
-# get response from search-request
-def response(resp):
- json = loads(resp.text)
-
- results = []
-
- for result in json.get('results', []):
- results.append({'url': result_url.format(author=result['author'], title=result['permlink']),
- 'title': result['title'],
- 'content': result['summary']})
- return results
|
{"golden_diff": "diff --git a/searx/engines/asksteem.py b/searx/engines/asksteem.py\ndeleted file mode 100644\n--- a/searx/engines/asksteem.py\n+++ /dev/null\n@@ -1,44 +0,0 @@\n-\"\"\"\n- Asksteem (general)\n-\n- @website https://asksteem.com/\n- @provide-api yes\n-\n- @using-api yes\n- @results JSON (https://github.com/Hoxly/asksteem-docs/wiki)\n- @stable yes\n- @parse url, title, content\n-\"\"\"\n-\n-from json import loads\n-from searx.url_utils import urlencode\n-\n-# engine dependent config\n-categories = ['general']\n-paging = True\n-language_support = False\n-disabled = True\n-\n-# search-url\n-search_url = 'https://api.asksteem.com/search?{params}'\n-result_url = 'https://steemit.com/@{author}/{title}'\n-\n-\n-# do search-request\n-def request(query, params):\n- url = search_url.format(params=urlencode({'q': query, 'pg': params['pageno']}))\n- params['url'] = url\n- return params\n-\n-\n-# get response from search-request\n-def response(resp):\n- json = loads(resp.text)\n-\n- results = []\n-\n- for result in json.get('results', []):\n- results.append({'url': result_url.format(author=result['author'], title=result['permlink']),\n- 'title': result['title'],\n- 'content': result['summary']})\n- return results\n", "issue": "Asksteem is gone\nThe API has been discontinued so it should probably be removed as an option entirely.\n", "before_files": [{"content": "\"\"\"\n Asksteem (general)\n\n @website https://asksteem.com/\n @provide-api yes\n\n @using-api yes\n @results JSON (https://github.com/Hoxly/asksteem-docs/wiki)\n @stable yes\n @parse url, title, content\n\"\"\"\n\nfrom json import loads\nfrom searx.url_utils import urlencode\n\n# engine dependent config\ncategories = ['general']\npaging = True\nlanguage_support = False\ndisabled = True\n\n# search-url\nsearch_url = 'https://api.asksteem.com/search?{params}'\nresult_url = 'https://steemit.com/@{author}/{title}'\n\n\n# do search-request\ndef request(query, params):\n url = search_url.format(params=urlencode({'q': query, 'pg': params['pageno']}))\n params['url'] = url\n return params\n\n\n# get response from search-request\ndef response(resp):\n json = loads(resp.text)\n\n results = []\n\n for result in json.get('results', []):\n results.append({'url': result_url.format(author=result['author'], title=result['permlink']),\n 'title': result['title'],\n 'content': result['summary']})\n return results\n", "path": "searx/engines/asksteem.py"}]}
| 923 | 359 |
gh_patches_debug_33471
|
rasdani/github-patches
|
git_diff
|
python-discord__bot-854
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add ability to remove bot tag responses.
With the new fuzzy tags, there's a chance an user may think something which is not a tag is one; resulting in a similar tag being fetched
(`!t def` as an example resulting in a tag through the whole page)
Adding the ability to remove them (perhaps when it was fuzzy matched) would solve this and perhaps some others when a tag's purpose is misremembered.
</issue>
<code>
[start of bot/cogs/tags.py]
1 import logging
2 import re
3 import time
4 from pathlib import Path
5 from typing import Callable, Dict, Iterable, List, Optional
6
7 from discord import Colour, Embed
8 from discord.ext.commands import Cog, Context, group
9
10 from bot import constants
11 from bot.bot import Bot
12 from bot.converters import TagNameConverter
13 from bot.pagination import LinePaginator
14
15 log = logging.getLogger(__name__)
16
17 TEST_CHANNELS = (
18 constants.Channels.bot_commands,
19 constants.Channels.helpers
20 )
21
22 REGEX_NON_ALPHABET = re.compile(r"[^a-z]", re.MULTILINE & re.IGNORECASE)
23 FOOTER_TEXT = f"To show a tag, type {constants.Bot.prefix}tags <tagname>."
24
25
26 class Tags(Cog):
27 """Save new tags and fetch existing tags."""
28
29 def __init__(self, bot: Bot):
30 self.bot = bot
31 self.tag_cooldowns = {}
32 self._cache = self.get_tags()
33
34 @staticmethod
35 def get_tags() -> dict:
36 """Get all tags."""
37 # Save all tags in memory.
38 cache = {}
39 tag_files = Path("bot", "resources", "tags").iterdir()
40 for file in tag_files:
41 tag_title = file.stem
42 tag = {
43 "title": tag_title,
44 "embed": {
45 "description": file.read_text()
46 }
47 }
48 cache[tag_title] = tag
49 return cache
50
51 @staticmethod
52 def _fuzzy_search(search: str, target: str) -> float:
53 """A simple scoring algorithm based on how many letters are found / total, with order in mind."""
54 current, index = 0, 0
55 _search = REGEX_NON_ALPHABET.sub('', search.lower())
56 _targets = iter(REGEX_NON_ALPHABET.split(target.lower()))
57 _target = next(_targets)
58 try:
59 while True:
60 while index < len(_target) and _search[current] == _target[index]:
61 current += 1
62 index += 1
63 index, _target = 0, next(_targets)
64 except (StopIteration, IndexError):
65 pass
66 return current / len(_search) * 100
67
68 def _get_suggestions(self, tag_name: str, thresholds: Optional[List[int]] = None) -> List[str]:
69 """Return a list of suggested tags."""
70 scores: Dict[str, int] = {
71 tag_title: Tags._fuzzy_search(tag_name, tag['title'])
72 for tag_title, tag in self._cache.items()
73 }
74
75 thresholds = thresholds or [100, 90, 80, 70, 60]
76
77 for threshold in thresholds:
78 suggestions = [
79 self._cache[tag_title]
80 for tag_title, matching_score in scores.items()
81 if matching_score >= threshold
82 ]
83 if suggestions:
84 return suggestions
85
86 return []
87
88 def _get_tag(self, tag_name: str) -> list:
89 """Get a specific tag."""
90 found = [self._cache.get(tag_name.lower(), None)]
91 if not found[0]:
92 return self._get_suggestions(tag_name)
93 return found
94
95 def _get_tags_via_content(self, check: Callable[[Iterable], bool], keywords: str) -> list:
96 """
97 Search for tags via contents.
98
99 `predicate` will be the built-in any, all, or a custom callable. Must return a bool.
100 """
101 keywords_processed: List[str] = []
102 for keyword in keywords.split(','):
103 keyword_sanitized = keyword.strip().casefold()
104 if not keyword_sanitized:
105 # this happens when there are leading / trailing / consecutive comma.
106 continue
107 keywords_processed.append(keyword_sanitized)
108
109 if not keywords_processed:
110 # after sanitizing, we can end up with an empty list, for example when keywords is ','
111 # in that case, we simply want to search for such keywords directly instead.
112 keywords_processed = [keywords]
113
114 matching_tags = []
115 for tag in self._cache.values():
116 if check(query in tag['embed']['description'].casefold() for query in keywords_processed):
117 matching_tags.append(tag)
118
119 return matching_tags
120
121 async def _send_matching_tags(self, ctx: Context, keywords: str, matching_tags: list) -> None:
122 """Send the result of matching tags to user."""
123 if not matching_tags:
124 pass
125 elif len(matching_tags) == 1:
126 await ctx.send(embed=Embed().from_dict(matching_tags[0]['embed']))
127 else:
128 is_plural = keywords.strip().count(' ') > 0 or keywords.strip().count(',') > 0
129 embed = Embed(
130 title=f"Here are the tags containing the given keyword{'s' * is_plural}:",
131 description='\n'.join(tag['title'] for tag in matching_tags[:10])
132 )
133 await LinePaginator.paginate(
134 sorted(f"**»** {tag['title']}" for tag in matching_tags),
135 ctx,
136 embed,
137 footer_text=FOOTER_TEXT,
138 empty=False,
139 max_lines=15
140 )
141
142 @group(name='tags', aliases=('tag', 't'), invoke_without_command=True)
143 async def tags_group(self, ctx: Context, *, tag_name: TagNameConverter = None) -> None:
144 """Show all known tags, a single tag, or run a subcommand."""
145 await ctx.invoke(self.get_command, tag_name=tag_name)
146
147 @tags_group.group(name='search', invoke_without_command=True)
148 async def search_tag_content(self, ctx: Context, *, keywords: str) -> None:
149 """
150 Search inside tags' contents for tags. Allow searching for multiple keywords separated by comma.
151
152 Only search for tags that has ALL the keywords.
153 """
154 matching_tags = self._get_tags_via_content(all, keywords)
155 await self._send_matching_tags(ctx, keywords, matching_tags)
156
157 @search_tag_content.command(name='any')
158 async def search_tag_content_any_keyword(self, ctx: Context, *, keywords: Optional[str] = 'any') -> None:
159 """
160 Search inside tags' contents for tags. Allow searching for multiple keywords separated by comma.
161
162 Search for tags that has ANY of the keywords.
163 """
164 matching_tags = self._get_tags_via_content(any, keywords or 'any')
165 await self._send_matching_tags(ctx, keywords, matching_tags)
166
167 @tags_group.command(name='get', aliases=('show', 'g'))
168 async def get_command(self, ctx: Context, *, tag_name: TagNameConverter = None) -> None:
169 """Get a specified tag, or a list of all tags if no tag is specified."""
170 def _command_on_cooldown(tag_name: str) -> bool:
171 """
172 Check if the command is currently on cooldown, on a per-tag, per-channel basis.
173
174 The cooldown duration is set in constants.py.
175 """
176 now = time.time()
177
178 cooldown_conditions = (
179 tag_name
180 and tag_name in self.tag_cooldowns
181 and (now - self.tag_cooldowns[tag_name]["time"]) < constants.Cooldowns.tags
182 and self.tag_cooldowns[tag_name]["channel"] == ctx.channel.id
183 )
184
185 if cooldown_conditions:
186 return True
187 return False
188
189 if _command_on_cooldown(tag_name):
190 time_elapsed = time.time() - self.tag_cooldowns[tag_name]["time"]
191 time_left = constants.Cooldowns.tags - time_elapsed
192 log.info(
193 f"{ctx.author} tried to get the '{tag_name}' tag, but the tag is on cooldown. "
194 f"Cooldown ends in {time_left:.1f} seconds."
195 )
196 return
197
198 if tag_name is not None:
199 founds = self._get_tag(tag_name)
200
201 if len(founds) == 1:
202 tag = founds[0]
203 if ctx.channel.id not in TEST_CHANNELS:
204 self.tag_cooldowns[tag_name] = {
205 "time": time.time(),
206 "channel": ctx.channel.id
207 }
208 await ctx.send(embed=Embed.from_dict(tag['embed']))
209 elif founds and len(tag_name) >= 3:
210 await ctx.send(embed=Embed(
211 title='Did you mean ...',
212 description='\n'.join(tag['title'] for tag in founds[:10])
213 ))
214
215 else:
216 tags = self._cache.values()
217 if not tags:
218 await ctx.send(embed=Embed(
219 description="**There are no tags in the database!**",
220 colour=Colour.red()
221 ))
222 else:
223 embed: Embed = Embed(title="**Current tags**")
224 await LinePaginator.paginate(
225 sorted(f"**»** {tag['title']}" for tag in tags),
226 ctx,
227 embed,
228 footer_text=FOOTER_TEXT,
229 empty=False,
230 max_lines=15
231 )
232
233
234 def setup(bot: Bot) -> None:
235 """Load the Tags cog."""
236 bot.add_cog(Tags(bot))
237
[end of bot/cogs/tags.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bot/cogs/tags.py b/bot/cogs/tags.py
--- a/bot/cogs/tags.py
+++ b/bot/cogs/tags.py
@@ -11,6 +11,7 @@
from bot.bot import Bot
from bot.converters import TagNameConverter
from bot.pagination import LinePaginator
+from bot.utils.messages import wait_for_deletion
log = logging.getLogger(__name__)
@@ -167,6 +168,7 @@
@tags_group.command(name='get', aliases=('show', 'g'))
async def get_command(self, ctx: Context, *, tag_name: TagNameConverter = None) -> None:
"""Get a specified tag, or a list of all tags if no tag is specified."""
+
def _command_on_cooldown(tag_name: str) -> bool:
"""
Check if the command is currently on cooldown, on a per-tag, per-channel basis.
@@ -205,12 +207,22 @@
"time": time.time(),
"channel": ctx.channel.id
}
- await ctx.send(embed=Embed.from_dict(tag['embed']))
+ await wait_for_deletion(
+ await ctx.send(embed=Embed.from_dict(tag['embed'])),
+ [ctx.author.id],
+ client=self.bot
+ )
elif founds and len(tag_name) >= 3:
- await ctx.send(embed=Embed(
- title='Did you mean ...',
- description='\n'.join(tag['title'] for tag in founds[:10])
- ))
+ await wait_for_deletion(
+ await ctx.send(
+ embed=Embed(
+ title='Did you mean ...',
+ description='\n'.join(tag['title'] for tag in founds[:10])
+ )
+ ),
+ [ctx.author.id],
+ client=self.bot
+ )
else:
tags = self._cache.values()
|
{"golden_diff": "diff --git a/bot/cogs/tags.py b/bot/cogs/tags.py\n--- a/bot/cogs/tags.py\n+++ b/bot/cogs/tags.py\n@@ -11,6 +11,7 @@\n from bot.bot import Bot\n from bot.converters import TagNameConverter\n from bot.pagination import LinePaginator\n+from bot.utils.messages import wait_for_deletion\n \n log = logging.getLogger(__name__)\n \n@@ -167,6 +168,7 @@\n @tags_group.command(name='get', aliases=('show', 'g'))\n async def get_command(self, ctx: Context, *, tag_name: TagNameConverter = None) -> None:\n \"\"\"Get a specified tag, or a list of all tags if no tag is specified.\"\"\"\n+\n def _command_on_cooldown(tag_name: str) -> bool:\n \"\"\"\n Check if the command is currently on cooldown, on a per-tag, per-channel basis.\n@@ -205,12 +207,22 @@\n \"time\": time.time(),\n \"channel\": ctx.channel.id\n }\n- await ctx.send(embed=Embed.from_dict(tag['embed']))\n+ await wait_for_deletion(\n+ await ctx.send(embed=Embed.from_dict(tag['embed'])),\n+ [ctx.author.id],\n+ client=self.bot\n+ )\n elif founds and len(tag_name) >= 3:\n- await ctx.send(embed=Embed(\n- title='Did you mean ...',\n- description='\\n'.join(tag['title'] for tag in founds[:10])\n- ))\n+ await wait_for_deletion(\n+ await ctx.send(\n+ embed=Embed(\n+ title='Did you mean ...',\n+ description='\\n'.join(tag['title'] for tag in founds[:10])\n+ )\n+ ),\n+ [ctx.author.id],\n+ client=self.bot\n+ )\n \n else:\n tags = self._cache.values()\n", "issue": "Add ability to remove bot tag responses.\nWith the new fuzzy tags, there's a chance an user may think something which is not a tag is one; resulting in a similar tag being fetched \r\n(`!t def` as an example resulting in a tag through the whole page)\r\n\r\nAdding the ability to remove them (perhaps when it was fuzzy matched) would solve this and perhaps some others when a tag's purpose is misremembered.\n", "before_files": [{"content": "import logging\nimport re\nimport time\nfrom pathlib import Path\nfrom typing import Callable, Dict, Iterable, List, Optional\n\nfrom discord import Colour, Embed\nfrom discord.ext.commands import Cog, Context, group\n\nfrom bot import constants\nfrom bot.bot import Bot\nfrom bot.converters import TagNameConverter\nfrom bot.pagination import LinePaginator\n\nlog = logging.getLogger(__name__)\n\nTEST_CHANNELS = (\n constants.Channels.bot_commands,\n constants.Channels.helpers\n)\n\nREGEX_NON_ALPHABET = re.compile(r\"[^a-z]\", re.MULTILINE & re.IGNORECASE)\nFOOTER_TEXT = f\"To show a tag, type {constants.Bot.prefix}tags <tagname>.\"\n\n\nclass Tags(Cog):\n \"\"\"Save new tags and fetch existing tags.\"\"\"\n\n def __init__(self, bot: Bot):\n self.bot = bot\n self.tag_cooldowns = {}\n self._cache = self.get_tags()\n\n @staticmethod\n def get_tags() -> dict:\n \"\"\"Get all tags.\"\"\"\n # Save all tags in memory.\n cache = {}\n tag_files = Path(\"bot\", \"resources\", \"tags\").iterdir()\n for file in tag_files:\n tag_title = file.stem\n tag = {\n \"title\": tag_title,\n \"embed\": {\n \"description\": file.read_text()\n }\n }\n cache[tag_title] = tag\n return cache\n\n @staticmethod\n def _fuzzy_search(search: str, target: str) -> float:\n \"\"\"A simple scoring algorithm based on how many letters are found / total, with order in mind.\"\"\"\n current, index = 0, 0\n _search = REGEX_NON_ALPHABET.sub('', search.lower())\n _targets = iter(REGEX_NON_ALPHABET.split(target.lower()))\n _target = next(_targets)\n try:\n while True:\n while index < len(_target) and _search[current] == _target[index]:\n current += 1\n index += 1\n index, _target = 0, next(_targets)\n except (StopIteration, IndexError):\n pass\n return current / len(_search) * 100\n\n def _get_suggestions(self, tag_name: str, thresholds: Optional[List[int]] = None) -> List[str]:\n \"\"\"Return a list of suggested tags.\"\"\"\n scores: Dict[str, int] = {\n tag_title: Tags._fuzzy_search(tag_name, tag['title'])\n for tag_title, tag in self._cache.items()\n }\n\n thresholds = thresholds or [100, 90, 80, 70, 60]\n\n for threshold in thresholds:\n suggestions = [\n self._cache[tag_title]\n for tag_title, matching_score in scores.items()\n if matching_score >= threshold\n ]\n if suggestions:\n return suggestions\n\n return []\n\n def _get_tag(self, tag_name: str) -> list:\n \"\"\"Get a specific tag.\"\"\"\n found = [self._cache.get(tag_name.lower(), None)]\n if not found[0]:\n return self._get_suggestions(tag_name)\n return found\n\n def _get_tags_via_content(self, check: Callable[[Iterable], bool], keywords: str) -> list:\n \"\"\"\n Search for tags via contents.\n\n `predicate` will be the built-in any, all, or a custom callable. Must return a bool.\n \"\"\"\n keywords_processed: List[str] = []\n for keyword in keywords.split(','):\n keyword_sanitized = keyword.strip().casefold()\n if not keyword_sanitized:\n # this happens when there are leading / trailing / consecutive comma.\n continue\n keywords_processed.append(keyword_sanitized)\n\n if not keywords_processed:\n # after sanitizing, we can end up with an empty list, for example when keywords is ','\n # in that case, we simply want to search for such keywords directly instead.\n keywords_processed = [keywords]\n\n matching_tags = []\n for tag in self._cache.values():\n if check(query in tag['embed']['description'].casefold() for query in keywords_processed):\n matching_tags.append(tag)\n\n return matching_tags\n\n async def _send_matching_tags(self, ctx: Context, keywords: str, matching_tags: list) -> None:\n \"\"\"Send the result of matching tags to user.\"\"\"\n if not matching_tags:\n pass\n elif len(matching_tags) == 1:\n await ctx.send(embed=Embed().from_dict(matching_tags[0]['embed']))\n else:\n is_plural = keywords.strip().count(' ') > 0 or keywords.strip().count(',') > 0\n embed = Embed(\n title=f\"Here are the tags containing the given keyword{'s' * is_plural}:\",\n description='\\n'.join(tag['title'] for tag in matching_tags[:10])\n )\n await LinePaginator.paginate(\n sorted(f\"**\u00bb** {tag['title']}\" for tag in matching_tags),\n ctx,\n embed,\n footer_text=FOOTER_TEXT,\n empty=False,\n max_lines=15\n )\n\n @group(name='tags', aliases=('tag', 't'), invoke_without_command=True)\n async def tags_group(self, ctx: Context, *, tag_name: TagNameConverter = None) -> None:\n \"\"\"Show all known tags, a single tag, or run a subcommand.\"\"\"\n await ctx.invoke(self.get_command, tag_name=tag_name)\n\n @tags_group.group(name='search', invoke_without_command=True)\n async def search_tag_content(self, ctx: Context, *, keywords: str) -> None:\n \"\"\"\n Search inside tags' contents for tags. Allow searching for multiple keywords separated by comma.\n\n Only search for tags that has ALL the keywords.\n \"\"\"\n matching_tags = self._get_tags_via_content(all, keywords)\n await self._send_matching_tags(ctx, keywords, matching_tags)\n\n @search_tag_content.command(name='any')\n async def search_tag_content_any_keyword(self, ctx: Context, *, keywords: Optional[str] = 'any') -> None:\n \"\"\"\n Search inside tags' contents for tags. Allow searching for multiple keywords separated by comma.\n\n Search for tags that has ANY of the keywords.\n \"\"\"\n matching_tags = self._get_tags_via_content(any, keywords or 'any')\n await self._send_matching_tags(ctx, keywords, matching_tags)\n\n @tags_group.command(name='get', aliases=('show', 'g'))\n async def get_command(self, ctx: Context, *, tag_name: TagNameConverter = None) -> None:\n \"\"\"Get a specified tag, or a list of all tags if no tag is specified.\"\"\"\n def _command_on_cooldown(tag_name: str) -> bool:\n \"\"\"\n Check if the command is currently on cooldown, on a per-tag, per-channel basis.\n\n The cooldown duration is set in constants.py.\n \"\"\"\n now = time.time()\n\n cooldown_conditions = (\n tag_name\n and tag_name in self.tag_cooldowns\n and (now - self.tag_cooldowns[tag_name][\"time\"]) < constants.Cooldowns.tags\n and self.tag_cooldowns[tag_name][\"channel\"] == ctx.channel.id\n )\n\n if cooldown_conditions:\n return True\n return False\n\n if _command_on_cooldown(tag_name):\n time_elapsed = time.time() - self.tag_cooldowns[tag_name][\"time\"]\n time_left = constants.Cooldowns.tags - time_elapsed\n log.info(\n f\"{ctx.author} tried to get the '{tag_name}' tag, but the tag is on cooldown. \"\n f\"Cooldown ends in {time_left:.1f} seconds.\"\n )\n return\n\n if tag_name is not None:\n founds = self._get_tag(tag_name)\n\n if len(founds) == 1:\n tag = founds[0]\n if ctx.channel.id not in TEST_CHANNELS:\n self.tag_cooldowns[tag_name] = {\n \"time\": time.time(),\n \"channel\": ctx.channel.id\n }\n await ctx.send(embed=Embed.from_dict(tag['embed']))\n elif founds and len(tag_name) >= 3:\n await ctx.send(embed=Embed(\n title='Did you mean ...',\n description='\\n'.join(tag['title'] for tag in founds[:10])\n ))\n\n else:\n tags = self._cache.values()\n if not tags:\n await ctx.send(embed=Embed(\n description=\"**There are no tags in the database!**\",\n colour=Colour.red()\n ))\n else:\n embed: Embed = Embed(title=\"**Current tags**\")\n await LinePaginator.paginate(\n sorted(f\"**\u00bb** {tag['title']}\" for tag in tags),\n ctx,\n embed,\n footer_text=FOOTER_TEXT,\n empty=False,\n max_lines=15\n )\n\n\ndef setup(bot: Bot) -> None:\n \"\"\"Load the Tags cog.\"\"\"\n bot.add_cog(Tags(bot))\n", "path": "bot/cogs/tags.py"}]}
| 3,170 | 422 |
gh_patches_debug_18029
|
rasdani/github-patches
|
git_diff
|
python-poetry__poetry-1796
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Installing directory poetry package with dependencies in secondary source fails
<!--
Hi there! Thank you for discovering and submitting an issue.
Before you submit this; let's make sure of a few things.
Please make sure the following boxes are ticked if they are correct.
If not, please try and fulfill these first.
-->
<!-- Checked checkbox should look like this: [x] -->
- [x] I am on the [latest](https://github.com/sdispater/poetry/releases/latest) Poetry version.
- [x] I have searched the [issues](https://github.com/sdispater/poetry/issues) of this repo and believe that this is not a duplicate.
- [x] If an exception occurs when executing a command, I executed it again in debug mode (`-vvv` option).
<!--
Once those are done, if you're able to fill in the following list with your information,
it'd be very helpful to whoever handles the issue.
-->
- **MacOS 10.14**: <!-- Replace with version + name -->
- **1.0.0b8**: <!-- Replace with version -->
## Issue
Due to https://github.com/pypa/pip/issues/7444 installing a directory which is managed by poetry or has a pyproject.toml file present will cause the `--no-deps` argument to be ignored.
This can go unnoticed as long as you are only working with pypi dependencies but when your package depends on a private pypi repository this causes installs to fail.
</issue>
<code>
[start of poetry/packages/file_dependency.py]
1 import hashlib
2 import io
3
4 from pkginfo.distribution import HEADER_ATTRS
5 from pkginfo.distribution import HEADER_ATTRS_2_0
6
7 from poetry.utils._compat import Path
8
9 from .dependency import Dependency
10
11
12 # Patching pkginfo to support Metadata version 2.1 (PEP 566)
13 HEADER_ATTRS.update(
14 {"2.1": HEADER_ATTRS_2_0 + (("Provides-Extra", "provides_extra", True),)}
15 )
16
17
18 class FileDependency(Dependency):
19 def __init__(
20 self,
21 name,
22 path, # type: Path
23 category="main", # type: str
24 optional=False, # type: bool
25 base=None, # type: Path
26 ):
27 self._path = path
28 self._base = base
29 self._full_path = path
30
31 if self._base and not self._path.is_absolute():
32 self._full_path = self._base / self._path
33
34 if not self._full_path.exists():
35 raise ValueError("File {} does not exist".format(self._path))
36
37 if self._full_path.is_dir():
38 raise ValueError("{} is a directory, expected a file".format(self._path))
39
40 super(FileDependency, self).__init__(
41 name, "*", category=category, optional=optional, allows_prereleases=True
42 )
43
44 @property
45 def path(self):
46 return self._path
47
48 @property
49 def full_path(self):
50 return self._full_path.resolve()
51
52 def is_file(self):
53 return True
54
55 def hash(self):
56 h = hashlib.sha256()
57 with self._full_path.open("rb") as fp:
58 for content in iter(lambda: fp.read(io.DEFAULT_BUFFER_SIZE), b""):
59 h.update(content)
60
61 return h.hexdigest()
62
[end of poetry/packages/file_dependency.py]
[start of poetry/packages/directory_dependency.py]
1 from pkginfo.distribution import HEADER_ATTRS
2 from pkginfo.distribution import HEADER_ATTRS_2_0
3
4 from poetry.utils._compat import Path
5 from poetry.utils.toml_file import TomlFile
6
7 from .dependency import Dependency
8
9
10 # Patching pkginfo to support Metadata version 2.1 (PEP 566)
11 HEADER_ATTRS.update(
12 {"2.1": HEADER_ATTRS_2_0 + (("Provides-Extra", "provides_extra", True),)}
13 )
14
15
16 class DirectoryDependency(Dependency):
17 def __init__(
18 self,
19 name,
20 path, # type: Path
21 category="main", # type: str
22 optional=False, # type: bool
23 base=None, # type: Path
24 develop=True, # type: bool
25 ):
26 self._path = path
27 self._base = base
28 self._full_path = path
29 self._develop = develop
30 self._supports_poetry = False
31
32 if self._base and not self._path.is_absolute():
33 self._full_path = self._base / self._path
34
35 if not self._full_path.exists():
36 raise ValueError("Directory {} does not exist".format(self._path))
37
38 if self._full_path.is_file():
39 raise ValueError("{} is a file, expected a directory".format(self._path))
40
41 # Checking content to determine actions
42 setup = self._full_path / "setup.py"
43 pyproject = TomlFile(self._full_path / "pyproject.toml")
44 if pyproject.exists():
45 pyproject_content = pyproject.read()
46 self._supports_poetry = (
47 "tool" in pyproject_content and "poetry" in pyproject_content["tool"]
48 )
49
50 if not setup.exists() and not self._supports_poetry:
51 raise ValueError(
52 "Directory {} does not seem to be a Python package".format(
53 self._full_path
54 )
55 )
56
57 super(DirectoryDependency, self).__init__(
58 name, "*", category=category, optional=optional, allows_prereleases=True
59 )
60
61 @property
62 def path(self):
63 return self._path
64
65 @property
66 def full_path(self):
67 return self._full_path.resolve()
68
69 @property
70 def base(self):
71 return self._base
72
73 @property
74 def develop(self):
75 return self._develop
76
77 def supports_poetry(self):
78 return self._supports_poetry
79
80 def is_directory(self):
81 return True
82
[end of poetry/packages/directory_dependency.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/poetry/packages/directory_dependency.py b/poetry/packages/directory_dependency.py
--- a/poetry/packages/directory_dependency.py
+++ b/poetry/packages/directory_dependency.py
@@ -74,6 +74,17 @@
def develop(self):
return self._develop
+ @property
+ def base_pep_508_name(self): # type: () -> str
+ requirement = self.pretty_name
+
+ if self.extras:
+ requirement += "[{}]".format(",".join(self.extras))
+
+ requirement += " @ {}".format(self._path)
+
+ return requirement
+
def supports_poetry(self):
return self._supports_poetry
diff --git a/poetry/packages/file_dependency.py b/poetry/packages/file_dependency.py
--- a/poetry/packages/file_dependency.py
+++ b/poetry/packages/file_dependency.py
@@ -49,6 +49,17 @@
def full_path(self):
return self._full_path.resolve()
+ @property
+ def base_pep_508_name(self): # type: () -> str
+ requirement = self.pretty_name
+
+ if self.extras:
+ requirement += "[{}]".format(",".join(self.extras))
+
+ requirement += " @ {}".format(self._path)
+
+ return requirement
+
def is_file(self):
return True
|
{"golden_diff": "diff --git a/poetry/packages/directory_dependency.py b/poetry/packages/directory_dependency.py\n--- a/poetry/packages/directory_dependency.py\n+++ b/poetry/packages/directory_dependency.py\n@@ -74,6 +74,17 @@\n def develop(self):\n return self._develop\n \n+ @property\n+ def base_pep_508_name(self): # type: () -> str\n+ requirement = self.pretty_name\n+\n+ if self.extras:\n+ requirement += \"[{}]\".format(\",\".join(self.extras))\n+\n+ requirement += \" @ {}\".format(self._path)\n+\n+ return requirement\n+\n def supports_poetry(self):\n return self._supports_poetry\n \ndiff --git a/poetry/packages/file_dependency.py b/poetry/packages/file_dependency.py\n--- a/poetry/packages/file_dependency.py\n+++ b/poetry/packages/file_dependency.py\n@@ -49,6 +49,17 @@\n def full_path(self):\n return self._full_path.resolve()\n \n+ @property\n+ def base_pep_508_name(self): # type: () -> str\n+ requirement = self.pretty_name\n+\n+ if self.extras:\n+ requirement += \"[{}]\".format(\",\".join(self.extras))\n+\n+ requirement += \" @ {}\".format(self._path)\n+\n+ return requirement\n+\n def is_file(self):\n return True\n", "issue": "Installing directory poetry package with dependencies in secondary source fails\n<!--\r\n Hi there! Thank you for discovering and submitting an issue.\r\n\r\n Before you submit this; let's make sure of a few things.\r\n Please make sure the following boxes are ticked if they are correct.\r\n If not, please try and fulfill these first.\r\n-->\r\n\r\n<!-- Checked checkbox should look like this: [x] -->\r\n- [x] I am on the [latest](https://github.com/sdispater/poetry/releases/latest) Poetry version.\r\n- [x] I have searched the [issues](https://github.com/sdispater/poetry/issues) of this repo and believe that this is not a duplicate.\r\n- [x] If an exception occurs when executing a command, I executed it again in debug mode (`-vvv` option).\r\n\r\n<!--\r\n Once those are done, if you're able to fill in the following list with your information,\r\n it'd be very helpful to whoever handles the issue.\r\n-->\r\n\r\n- **MacOS 10.14**: <!-- Replace with version + name -->\r\n- **1.0.0b8**: <!-- Replace with version -->\r\n\r\n## Issue\r\nDue to https://github.com/pypa/pip/issues/7444 installing a directory which is managed by poetry or has a pyproject.toml file present will cause the `--no-deps` argument to be ignored. \r\n\r\nThis can go unnoticed as long as you are only working with pypi dependencies but when your package depends on a private pypi repository this causes installs to fail. \r\n\n", "before_files": [{"content": "import hashlib\nimport io\n\nfrom pkginfo.distribution import HEADER_ATTRS\nfrom pkginfo.distribution import HEADER_ATTRS_2_0\n\nfrom poetry.utils._compat import Path\n\nfrom .dependency import Dependency\n\n\n# Patching pkginfo to support Metadata version 2.1 (PEP 566)\nHEADER_ATTRS.update(\n {\"2.1\": HEADER_ATTRS_2_0 + ((\"Provides-Extra\", \"provides_extra\", True),)}\n)\n\n\nclass FileDependency(Dependency):\n def __init__(\n self,\n name,\n path, # type: Path\n category=\"main\", # type: str\n optional=False, # type: bool\n base=None, # type: Path\n ):\n self._path = path\n self._base = base\n self._full_path = path\n\n if self._base and not self._path.is_absolute():\n self._full_path = self._base / self._path\n\n if not self._full_path.exists():\n raise ValueError(\"File {} does not exist\".format(self._path))\n\n if self._full_path.is_dir():\n raise ValueError(\"{} is a directory, expected a file\".format(self._path))\n\n super(FileDependency, self).__init__(\n name, \"*\", category=category, optional=optional, allows_prereleases=True\n )\n\n @property\n def path(self):\n return self._path\n\n @property\n def full_path(self):\n return self._full_path.resolve()\n\n def is_file(self):\n return True\n\n def hash(self):\n h = hashlib.sha256()\n with self._full_path.open(\"rb\") as fp:\n for content in iter(lambda: fp.read(io.DEFAULT_BUFFER_SIZE), b\"\"):\n h.update(content)\n\n return h.hexdigest()\n", "path": "poetry/packages/file_dependency.py"}, {"content": "from pkginfo.distribution import HEADER_ATTRS\nfrom pkginfo.distribution import HEADER_ATTRS_2_0\n\nfrom poetry.utils._compat import Path\nfrom poetry.utils.toml_file import TomlFile\n\nfrom .dependency import Dependency\n\n\n# Patching pkginfo to support Metadata version 2.1 (PEP 566)\nHEADER_ATTRS.update(\n {\"2.1\": HEADER_ATTRS_2_0 + ((\"Provides-Extra\", \"provides_extra\", True),)}\n)\n\n\nclass DirectoryDependency(Dependency):\n def __init__(\n self,\n name,\n path, # type: Path\n category=\"main\", # type: str\n optional=False, # type: bool\n base=None, # type: Path\n develop=True, # type: bool\n ):\n self._path = path\n self._base = base\n self._full_path = path\n self._develop = develop\n self._supports_poetry = False\n\n if self._base and not self._path.is_absolute():\n self._full_path = self._base / self._path\n\n if not self._full_path.exists():\n raise ValueError(\"Directory {} does not exist\".format(self._path))\n\n if self._full_path.is_file():\n raise ValueError(\"{} is a file, expected a directory\".format(self._path))\n\n # Checking content to determine actions\n setup = self._full_path / \"setup.py\"\n pyproject = TomlFile(self._full_path / \"pyproject.toml\")\n if pyproject.exists():\n pyproject_content = pyproject.read()\n self._supports_poetry = (\n \"tool\" in pyproject_content and \"poetry\" in pyproject_content[\"tool\"]\n )\n\n if not setup.exists() and not self._supports_poetry:\n raise ValueError(\n \"Directory {} does not seem to be a Python package\".format(\n self._full_path\n )\n )\n\n super(DirectoryDependency, self).__init__(\n name, \"*\", category=category, optional=optional, allows_prereleases=True\n )\n\n @property\n def path(self):\n return self._path\n\n @property\n def full_path(self):\n return self._full_path.resolve()\n\n @property\n def base(self):\n return self._base\n\n @property\n def develop(self):\n return self._develop\n\n def supports_poetry(self):\n return self._supports_poetry\n\n def is_directory(self):\n return True\n", "path": "poetry/packages/directory_dependency.py"}]}
| 2,099 | 315 |
gh_patches_debug_9
|
rasdani/github-patches
|
git_diff
|
OCHA-DAP__hdx-ckan-1038
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update the version number on the logo and footer.
For sprint 25, we will increment to 0.3.2
</issue>
<code>
[start of ckanext-hdx_theme/ckanext/hdx_theme/version.py]
1 hdx_version='v0.3.1'
[end of ckanext-hdx_theme/ckanext/hdx_theme/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ckanext-hdx_theme/ckanext/hdx_theme/version.py b/ckanext-hdx_theme/ckanext/hdx_theme/version.py
--- a/ckanext-hdx_theme/ckanext/hdx_theme/version.py
+++ b/ckanext-hdx_theme/ckanext/hdx_theme/version.py
@@ -1 +1 @@
-hdx_version='v0.3.1'
\ No newline at end of file
+hdx_version='v0.3.2'
\ No newline at end of file
|
{"golden_diff": "diff --git a/ckanext-hdx_theme/ckanext/hdx_theme/version.py b/ckanext-hdx_theme/ckanext/hdx_theme/version.py\n--- a/ckanext-hdx_theme/ckanext/hdx_theme/version.py\n+++ b/ckanext-hdx_theme/ckanext/hdx_theme/version.py\n@@ -1 +1 @@\n-hdx_version='v0.3.1'\n\\ No newline at end of file\n+hdx_version='v0.3.2'\n\\ No newline at end of file\n", "issue": "Update the version number on the logo and footer.\nFor sprint 25, we will increment to 0.3.2\n\n", "before_files": [{"content": "hdx_version='v0.3.1'", "path": "ckanext-hdx_theme/ckanext/hdx_theme/version.py"}]}
| 593 | 120 |
gh_patches_debug_693
|
rasdani/github-patches
|
git_diff
|
Azure__azure-cli-extensions-4911
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`az webpubsub client start` errors with `TypeError: As of 3.10, the *loop* parameter was removed from Lock() since it is no longer necessary`
- If the issue is to do with Azure CLI 2.0 in-particular, create an issue here at [Azure/azure-cli](https://github.com/Azure/azure-cli/issues)
### Related command
```console
$ az webpubsub client start --name twitch-pubsub --resource-group twitchRG --user user1 --hub-name hub1
The command failed with an unexpected error. Here is the traceback:
As of 3.10, the *loop* parameter was removed from Lock() since it is no longer necessary
Traceback (most recent call last):
File "/opt/az/lib/python3.10/site-packages/knack/cli.py", line 231, in invoke
cmd_result = self.invocation.execute(args)
File "/opt/az/lib/python3.10/site-packages/azure/cli/core/commands/__init__.py", line 663, in execute
raise ex
File "/opt/az/lib/python3.10/site-packages/azure/cli/core/commands/__init__.py", line 726, in _run_jobs_serially
results.append(self._run_job(expanded_arg, cmd_copy))
File "/opt/az/lib/python3.10/site-packages/azure/cli/core/commands/__init__.py", line 697, in _run_job
result = cmd_copy(params)
File "/opt/az/lib/python3.10/site-packages/azure/cli/core/commands/__init__.py", line 333, in __call__
return self.handler(*args, **kwargs)
File "/opt/az/lib/python3.10/site-packages/azure/cli/core/commands/command_operation.py", line 121, in handler
return op(**command_args)
File "/home/anthony/.azure/cliextensions/webpubsub/azext_webpubsub/client.py", line 58, in start_client
asyncio.get_event_loop().run_until_complete(connect(token['url']))
File "/opt/az/lib/python3.10/asyncio/base_events.py", line 646, in run_until_complete
return future.result()
File "/home/anthony/.azure/cliextensions/webpubsub/azext_webpubsub/client.py", line 43, in connect
async with websockets.connect(url, subprotocols=['json.webpubsub.azure.v1']) as ws:
File "/home/anthony/.azure/cliextensions/webpubsub/websockets/client.py", line 517, in __aenter__
return await self
File "/home/anthony/.azure/cliextensions/webpubsub/websockets/client.py", line 535, in __await_impl__
transport, protocol = await self._create_connection()
File "/opt/az/lib/python3.10/asyncio/base_events.py", line 1089, in create_connection
transport, protocol = await self._create_connection_transport(
File "/opt/az/lib/python3.10/asyncio/base_events.py", line 1107, in _create_connection_transport
protocol = protocol_factory()
File "/home/anthony/.azure/cliextensions/webpubsub/websockets/client.py", line 69, in __init__
super().__init__(**kwargs)
File "/home/anthony/.azure/cliextensions/webpubsub/websockets/protocol.py", line 235, in __init__
self._drain_lock = asyncio.Lock(
File "/opt/az/lib/python3.10/asyncio/locks.py", line 78, in __init__
super().__init__(loop=loop)
File "/opt/az/lib/python3.10/asyncio/mixins.py", line 17, in __init__
raise TypeError(
TypeError: As of 3.10, the *loop* parameter was removed from Lock() since it is no longer necessary
```
### Extension name (the extension in question)
webpubsub
### Description of issue (in as much detail as possible)
appears this just needs an upgrade
I was able to work around by running (I'm in azure cloud shell):
```bash
/opt/az/bin/python3.10 -m pip install websockets --upgrade --target ~/.azure/cliextensions/webpubsub/
```
</issue>
<code>
[start of src/webpubsub/setup.py]
1 #!/usr/bin/env python
2
3 # --------------------------------------------------------------------------------------------
4 # Copyright (c) Microsoft Corporation. All rights reserved.
5 # Licensed under the MIT License. See License.txt in the project root for license information.
6 # --------------------------------------------------------------------------------------------
7
8
9 from codecs import open
10 from setuptools import setup, find_packages
11 try:
12 from azure_bdist_wheel import cmdclass
13 except ImportError:
14 from distutils import log as logger
15 logger.warn("Wheel is not available, disabling bdist_wheel hook")
16
17 # TODO: Confirm this is the right version number you want and it matches your
18 # HISTORY.rst entry.
19 VERSION = '1.1.0'
20
21 # The full list of classifiers is available at
22 # https://pypi.python.org/pypi?%3Aaction=list_classifiers
23 CLASSIFIERS = [
24 'Development Status :: 4 - Beta',
25 'Intended Audience :: Developers',
26 'Intended Audience :: System Administrators',
27 'Programming Language :: Python',
28 'Programming Language :: Python :: 3',
29 'Programming Language :: Python :: 3.6',
30 'Programming Language :: Python :: 3.7',
31 'Programming Language :: Python :: 3.8',
32 'License :: OSI Approved :: MIT License',
33 ]
34
35 # TODO: Add any additional SDK dependencies here
36 DEPENDENCIES = [
37 'websockets~=8.1'
38 ]
39
40 with open('README.rst', 'r', encoding='utf-8') as f:
41 README = f.read()
42 with open('HISTORY.rst', 'r', encoding='utf-8') as f:
43 HISTORY = f.read()
44
45 setup(
46 name='webpubsub',
47 version=VERSION,
48 description='Microsoft Azure Command-Line Tools Webpubsub Extension',
49 # TODO: Update author and email, if applicable
50 author='Microsoft Corporation',
51 author_email='[email protected]',
52 # TODO: change to your extension source code repo if the code will not be put in azure-cli-extensions repo
53 url='https://github.com/Azure/azure-cli-extensions/tree/main/src/webpubsub',
54 long_description=README + '\n\n' + HISTORY,
55 license='MIT',
56 classifiers=CLASSIFIERS,
57 packages=find_packages(),
58 install_requires=DEPENDENCIES,
59 package_data={'azext_webpubsub': ['azext_metadata.json']},
60 )
61
[end of src/webpubsub/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/webpubsub/setup.py b/src/webpubsub/setup.py
--- a/src/webpubsub/setup.py
+++ b/src/webpubsub/setup.py
@@ -34,7 +34,7 @@
# TODO: Add any additional SDK dependencies here
DEPENDENCIES = [
- 'websockets~=8.1'
+ 'websockets>=8.1'
]
with open('README.rst', 'r', encoding='utf-8') as f:
|
{"golden_diff": "diff --git a/src/webpubsub/setup.py b/src/webpubsub/setup.py\n--- a/src/webpubsub/setup.py\n+++ b/src/webpubsub/setup.py\n@@ -34,7 +34,7 @@\n \n # TODO: Add any additional SDK dependencies here\n DEPENDENCIES = [\n- 'websockets~=8.1'\n+ 'websockets>=8.1'\n ]\n \n with open('README.rst', 'r', encoding='utf-8') as f:\n", "issue": "`az webpubsub client start` errors with `TypeError: As of 3.10, the *loop* parameter was removed from Lock() since it is no longer necessary`\n- If the issue is to do with Azure CLI 2.0 in-particular, create an issue here at [Azure/azure-cli](https://github.com/Azure/azure-cli/issues)\r\n\r\n### Related command\r\n\r\n```console\r\n$ az webpubsub client start --name twitch-pubsub --resource-group twitchRG --user user1 --hub-name hub1\r\nThe command failed with an unexpected error. Here is the traceback:\r\nAs of 3.10, the *loop* parameter was removed from Lock() since it is no longer necessary\r\nTraceback (most recent call last):\r\n File \"/opt/az/lib/python3.10/site-packages/knack/cli.py\", line 231, in invoke\r\n cmd_result = self.invocation.execute(args)\r\n File \"/opt/az/lib/python3.10/site-packages/azure/cli/core/commands/__init__.py\", line 663, in execute\r\n raise ex\r\n File \"/opt/az/lib/python3.10/site-packages/azure/cli/core/commands/__init__.py\", line 726, in _run_jobs_serially\r\n results.append(self._run_job(expanded_arg, cmd_copy))\r\n File \"/opt/az/lib/python3.10/site-packages/azure/cli/core/commands/__init__.py\", line 697, in _run_job\r\n result = cmd_copy(params)\r\n File \"/opt/az/lib/python3.10/site-packages/azure/cli/core/commands/__init__.py\", line 333, in __call__\r\n return self.handler(*args, **kwargs)\r\n File \"/opt/az/lib/python3.10/site-packages/azure/cli/core/commands/command_operation.py\", line 121, in handler\r\n return op(**command_args)\r\n File \"/home/anthony/.azure/cliextensions/webpubsub/azext_webpubsub/client.py\", line 58, in start_client\r\n asyncio.get_event_loop().run_until_complete(connect(token['url']))\r\n File \"/opt/az/lib/python3.10/asyncio/base_events.py\", line 646, in run_until_complete\r\n return future.result()\r\n File \"/home/anthony/.azure/cliextensions/webpubsub/azext_webpubsub/client.py\", line 43, in connect\r\n async with websockets.connect(url, subprotocols=['json.webpubsub.azure.v1']) as ws:\r\n File \"/home/anthony/.azure/cliextensions/webpubsub/websockets/client.py\", line 517, in __aenter__\r\n return await self\r\n File \"/home/anthony/.azure/cliextensions/webpubsub/websockets/client.py\", line 535, in __await_impl__\r\n transport, protocol = await self._create_connection()\r\n File \"/opt/az/lib/python3.10/asyncio/base_events.py\", line 1089, in create_connection\r\n transport, protocol = await self._create_connection_transport(\r\n File \"/opt/az/lib/python3.10/asyncio/base_events.py\", line 1107, in _create_connection_transport\r\n protocol = protocol_factory()\r\n File \"/home/anthony/.azure/cliextensions/webpubsub/websockets/client.py\", line 69, in __init__\r\n super().__init__(**kwargs)\r\n File \"/home/anthony/.azure/cliextensions/webpubsub/websockets/protocol.py\", line 235, in __init__\r\n self._drain_lock = asyncio.Lock(\r\n File \"/opt/az/lib/python3.10/asyncio/locks.py\", line 78, in __init__\r\n super().__init__(loop=loop)\r\n File \"/opt/az/lib/python3.10/asyncio/mixins.py\", line 17, in __init__\r\n raise TypeError(\r\nTypeError: As of 3.10, the *loop* parameter was removed from Lock() since it is no longer necessary\r\n```\r\n\r\n### Extension name (the extension in question)\r\n\r\nwebpubsub\r\n\r\n### Description of issue (in as much detail as possible)\r\n\r\nappears this just needs an upgrade\r\n\r\nI was able to work around by running (I'm in azure cloud shell):\r\n\r\n```bash\r\n/opt/az/bin/python3.10 -m pip install websockets --upgrade --target ~/.azure/cliextensions/webpubsub/\r\n```\n", "before_files": [{"content": "#!/usr/bin/env python\n\n# --------------------------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See License.txt in the project root for license information.\n# --------------------------------------------------------------------------------------------\n\n\nfrom codecs import open\nfrom setuptools import setup, find_packages\ntry:\n from azure_bdist_wheel import cmdclass\nexcept ImportError:\n from distutils import log as logger\n logger.warn(\"Wheel is not available, disabling bdist_wheel hook\")\n\n# TODO: Confirm this is the right version number you want and it matches your\n# HISTORY.rst entry.\nVERSION = '1.1.0'\n\n# The full list of classifiers is available at\n# https://pypi.python.org/pypi?%3Aaction=list_classifiers\nCLASSIFIERS = [\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'Intended Audience :: System Administrators',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'License :: OSI Approved :: MIT License',\n]\n\n# TODO: Add any additional SDK dependencies here\nDEPENDENCIES = [\n 'websockets~=8.1'\n]\n\nwith open('README.rst', 'r', encoding='utf-8') as f:\n README = f.read()\nwith open('HISTORY.rst', 'r', encoding='utf-8') as f:\n HISTORY = f.read()\n\nsetup(\n name='webpubsub',\n version=VERSION,\n description='Microsoft Azure Command-Line Tools Webpubsub Extension',\n # TODO: Update author and email, if applicable\n author='Microsoft Corporation',\n author_email='[email protected]',\n # TODO: change to your extension source code repo if the code will not be put in azure-cli-extensions repo\n url='https://github.com/Azure/azure-cli-extensions/tree/main/src/webpubsub',\n long_description=README + '\\n\\n' + HISTORY,\n license='MIT',\n classifiers=CLASSIFIERS,\n packages=find_packages(),\n install_requires=DEPENDENCIES,\n package_data={'azext_webpubsub': ['azext_metadata.json']},\n)\n", "path": "src/webpubsub/setup.py"}]}
| 2,106 | 105 |
gh_patches_debug_33178
|
rasdani/github-patches
|
git_diff
|
qutebrowser__qutebrowser-1494
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix replacing of {url} in set_cmd_text_command
```
# FIXME we currently replace the URL in any place in the arguments,
# rather than just replacing it if it is a dedicated argument. We could
# split the args, but then trailing spaces would be lost, so I'm not
# sure what's the best thing to do here
text = text.replace('{url}', url)
```
Fix replacing of {url} in set_cmd_text_command
```
# FIXME we currently replace the URL in any place in the arguments,
# rather than just replacing it if it is a dedicated argument. We could
# split the args, but then trailing spaces would be lost, so I'm not
# sure what's the best thing to do here
text = text.replace('{url}', url)
```
</issue>
<code>
[start of qutebrowser/mainwindow/statusbar/command.py]
1 # vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:
2
3 # Copyright 2014-2016 Florian Bruhin (The Compiler) <[email protected]>
4 #
5 # This file is part of qutebrowser.
6 #
7 # qutebrowser is free software: you can redistribute it and/or modify
8 # it under the terms of the GNU General Public License as published by
9 # the Free Software Foundation, either version 3 of the License, or
10 # (at your option) any later version.
11 #
12 # qutebrowser is distributed in the hope that it will be useful,
13 # but WITHOUT ANY WARRANTY; without even the implied warranty of
14 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
15 # GNU General Public License for more details.
16 #
17 # You should have received a copy of the GNU General Public License
18 # along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.
19
20 """The commandline in the statusbar."""
21
22 from PyQt5.QtCore import pyqtSignal, pyqtSlot, Qt, QUrl, QSize
23 from PyQt5.QtWidgets import QSizePolicy
24
25 from qutebrowser.keyinput import modeman, modeparsers
26 from qutebrowser.commands import cmdexc, cmdutils
27 from qutebrowser.misc import cmdhistory
28 from qutebrowser.misc import miscwidgets as misc
29 from qutebrowser.utils import usertypes, log, objreg, qtutils
30
31
32 class Command(misc.MinimalLineEditMixin, misc.CommandLineEdit):
33
34 """The commandline part of the statusbar.
35
36 Attributes:
37 _win_id: The window ID this widget is associated with.
38
39 Signals:
40 got_cmd: Emitted when a command is triggered by the user.
41 arg: The command string.
42 clear_completion_selection: Emitted before the completion widget is
43 hidden.
44 hide_completion: Emitted when the completion widget should be hidden.
45 update_completion: Emitted when the completion should be shown/updated.
46 show_cmd: Emitted when command input should be shown.
47 hide_cmd: Emitted when command input can be hidden.
48 """
49
50 got_cmd = pyqtSignal(str)
51 clear_completion_selection = pyqtSignal()
52 hide_completion = pyqtSignal()
53 update_completion = pyqtSignal()
54 show_cmd = pyqtSignal()
55 hide_cmd = pyqtSignal()
56
57 def __init__(self, win_id, parent=None):
58 misc.CommandLineEdit.__init__(self, parent)
59 misc.MinimalLineEditMixin.__init__(self)
60 self._win_id = win_id
61 command_history = objreg.get('command-history')
62 self.history.handle_private_mode = True
63 self.history.history = command_history.data
64 self.history.changed.connect(command_history.changed)
65 self.setSizePolicy(QSizePolicy.MinimumExpanding, QSizePolicy.Ignored)
66 self.cursorPositionChanged.connect(self.update_completion)
67 self.textChanged.connect(self.update_completion)
68 self.textChanged.connect(self.updateGeometry)
69
70 def prefix(self):
71 """Get the currently entered command prefix."""
72 text = self.text()
73 if not text:
74 return ''
75 elif text[0] in modeparsers.STARTCHARS:
76 return text[0]
77 else:
78 return ''
79
80 @pyqtSlot(str)
81 def set_cmd_text(self, text):
82 """Preset the statusbar to some text.
83
84 Args:
85 text: The text to set as string.
86 """
87 self.setText(text)
88 log.modes.debug("Setting command text, focusing {!r}".format(self))
89 modeman.enter(self._win_id, usertypes.KeyMode.command, 'cmd focus')
90 self.setFocus()
91 self.show_cmd.emit()
92
93 @cmdutils.register(instance='status-command', name='set-cmd-text',
94 scope='window', maxsplit=0)
95 def set_cmd_text_command(self, text, space=False, append=False):
96 """Preset the statusbar to some text.
97
98 //
99
100 Wrapper for set_cmd_text to check the arguments and allow multiple
101 strings which will get joined.
102
103 Args:
104 text: The commandline to set.
105 space: If given, a space is added to the end.
106 append: If given, the text is appended to the current text.
107 """
108 tabbed_browser = objreg.get('tabbed-browser', scope='window',
109 window=self._win_id)
110 if '{url}' in text:
111 try:
112 url = tabbed_browser.current_url().toString(
113 QUrl.FullyEncoded | QUrl.RemovePassword)
114 except qtutils.QtValueError as e:
115 msg = "Current URL is invalid"
116 if e.reason:
117 msg += " ({})".format(e.reason)
118 msg += "!"
119 raise cmdexc.CommandError(msg)
120 # FIXME we currently replace the URL in any place in the arguments,
121 # rather than just replacing it if it is a dedicated argument. We
122 # could split the args, but then trailing spaces would be lost, so
123 # I'm not sure what's the best thing to do here
124 # https://github.com/The-Compiler/qutebrowser/issues/123
125 text = text.replace('{url}', url)
126
127 if space:
128 text += ' '
129 if append:
130 if not self.text():
131 raise cmdexc.CommandError("No current text!")
132 text = self.text() + text
133
134 if not text or text[0] not in modeparsers.STARTCHARS:
135 raise cmdexc.CommandError(
136 "Invalid command text '{}'.".format(text))
137 self.set_cmd_text(text)
138
139 @cmdutils.register(instance='status-command', hide=True,
140 modes=[usertypes.KeyMode.command], scope='window')
141 def command_history_prev(self):
142 """Go back in the commandline history."""
143 try:
144 if not self.history.is_browsing():
145 item = self.history.start(self.text().strip())
146 else:
147 item = self.history.previtem()
148 except (cmdhistory.HistoryEmptyError,
149 cmdhistory.HistoryEndReachedError):
150 return
151 if item:
152 self.set_cmd_text(item)
153
154 @cmdutils.register(instance='status-command', hide=True,
155 modes=[usertypes.KeyMode.command], scope='window')
156 def command_history_next(self):
157 """Go forward in the commandline history."""
158 if not self.history.is_browsing():
159 return
160 try:
161 item = self.history.nextitem()
162 except cmdhistory.HistoryEndReachedError:
163 return
164 if item:
165 self.set_cmd_text(item)
166
167 @cmdutils.register(instance='status-command', hide=True,
168 modes=[usertypes.KeyMode.command], scope='window')
169 def command_accept(self):
170 """Execute the command currently in the commandline."""
171 prefixes = {
172 ':': '',
173 '/': 'search -- ',
174 '?': 'search -r -- ',
175 }
176 text = self.text()
177 self.history.append(text)
178 modeman.leave(self._win_id, usertypes.KeyMode.command, 'cmd accept')
179 self.got_cmd.emit(prefixes[text[0]] + text[1:])
180
181 @pyqtSlot(usertypes.KeyMode)
182 def on_mode_left(self, mode):
183 """Clear up when command mode was left.
184
185 - Clear the statusbar text if it's explicitly unfocused.
186 - Clear completion selection
187 - Hide completion
188
189 Args:
190 mode: The mode which was left.
191 """
192 if mode == usertypes.KeyMode.command:
193 self.setText('')
194 self.history.stop()
195 self.hide_cmd.emit()
196 self.clear_completion_selection.emit()
197 self.hide_completion.emit()
198
199 def setText(self, text):
200 """Extend setText to set prefix and make sure the prompt is ok."""
201 if not text:
202 pass
203 elif text[0] in modeparsers.STARTCHARS:
204 super().set_prompt(text[0])
205 else:
206 raise AssertionError("setText got called with invalid text "
207 "'{}'!".format(text))
208 super().setText(text)
209
210 def keyPressEvent(self, e):
211 """Override keyPressEvent to ignore Return key presses.
212
213 If this widget is focused, we are in passthrough key mode, and
214 Enter/Shift+Enter/etc. will cause QLineEdit to think it's finished
215 without command_accept to be called.
216 """
217 if e.key() == Qt.Key_Return:
218 e.ignore()
219 return
220 else:
221 super().keyPressEvent(e)
222
223 def sizeHint(self):
224 """Dynamically calculate the needed size."""
225 height = super().sizeHint().height()
226 text = self.text()
227 if not text:
228 text = 'x'
229 width = self.fontMetrics().width(text)
230 return QSize(width, height)
231
[end of qutebrowser/mainwindow/statusbar/command.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/qutebrowser/mainwindow/statusbar/command.py b/qutebrowser/mainwindow/statusbar/command.py
--- a/qutebrowser/mainwindow/statusbar/command.py
+++ b/qutebrowser/mainwindow/statusbar/command.py
@@ -19,14 +19,14 @@
"""The commandline in the statusbar."""
-from PyQt5.QtCore import pyqtSignal, pyqtSlot, Qt, QUrl, QSize
+from PyQt5.QtCore import pyqtSignal, pyqtSlot, Qt, QSize
from PyQt5.QtWidgets import QSizePolicy
from qutebrowser.keyinput import modeman, modeparsers
-from qutebrowser.commands import cmdexc, cmdutils
-from qutebrowser.misc import cmdhistory
+from qutebrowser.commands import cmdexc, cmdutils, runners
+from qutebrowser.misc import cmdhistory, split
from qutebrowser.misc import miscwidgets as misc
-from qutebrowser.utils import usertypes, log, objreg, qtutils
+from qutebrowser.utils import usertypes, log, objreg
class Command(misc.MinimalLineEditMixin, misc.CommandLineEdit):
@@ -105,24 +105,9 @@
space: If given, a space is added to the end.
append: If given, the text is appended to the current text.
"""
- tabbed_browser = objreg.get('tabbed-browser', scope='window',
- window=self._win_id)
- if '{url}' in text:
- try:
- url = tabbed_browser.current_url().toString(
- QUrl.FullyEncoded | QUrl.RemovePassword)
- except qtutils.QtValueError as e:
- msg = "Current URL is invalid"
- if e.reason:
- msg += " ({})".format(e.reason)
- msg += "!"
- raise cmdexc.CommandError(msg)
- # FIXME we currently replace the URL in any place in the arguments,
- # rather than just replacing it if it is a dedicated argument. We
- # could split the args, but then trailing spaces would be lost, so
- # I'm not sure what's the best thing to do here
- # https://github.com/The-Compiler/qutebrowser/issues/123
- text = text.replace('{url}', url)
+ args = split.simple_split(text)
+ args = runners.replace_variables(self._win_id, args)
+ text = ' '.join(args)
if space:
text += ' '
|
{"golden_diff": "diff --git a/qutebrowser/mainwindow/statusbar/command.py b/qutebrowser/mainwindow/statusbar/command.py\n--- a/qutebrowser/mainwindow/statusbar/command.py\n+++ b/qutebrowser/mainwindow/statusbar/command.py\n@@ -19,14 +19,14 @@\n \n \"\"\"The commandline in the statusbar.\"\"\"\n \n-from PyQt5.QtCore import pyqtSignal, pyqtSlot, Qt, QUrl, QSize\n+from PyQt5.QtCore import pyqtSignal, pyqtSlot, Qt, QSize\n from PyQt5.QtWidgets import QSizePolicy\n \n from qutebrowser.keyinput import modeman, modeparsers\n-from qutebrowser.commands import cmdexc, cmdutils\n-from qutebrowser.misc import cmdhistory\n+from qutebrowser.commands import cmdexc, cmdutils, runners\n+from qutebrowser.misc import cmdhistory, split\n from qutebrowser.misc import miscwidgets as misc\n-from qutebrowser.utils import usertypes, log, objreg, qtutils\n+from qutebrowser.utils import usertypes, log, objreg\n \n \n class Command(misc.MinimalLineEditMixin, misc.CommandLineEdit):\n@@ -105,24 +105,9 @@\n space: If given, a space is added to the end.\n append: If given, the text is appended to the current text.\n \"\"\"\n- tabbed_browser = objreg.get('tabbed-browser', scope='window',\n- window=self._win_id)\n- if '{url}' in text:\n- try:\n- url = tabbed_browser.current_url().toString(\n- QUrl.FullyEncoded | QUrl.RemovePassword)\n- except qtutils.QtValueError as e:\n- msg = \"Current URL is invalid\"\n- if e.reason:\n- msg += \" ({})\".format(e.reason)\n- msg += \"!\"\n- raise cmdexc.CommandError(msg)\n- # FIXME we currently replace the URL in any place in the arguments,\n- # rather than just replacing it if it is a dedicated argument. We\n- # could split the args, but then trailing spaces would be lost, so\n- # I'm not sure what's the best thing to do here\n- # https://github.com/The-Compiler/qutebrowser/issues/123\n- text = text.replace('{url}', url)\n+ args = split.simple_split(text)\n+ args = runners.replace_variables(self._win_id, args)\n+ text = ' '.join(args)\n \n if space:\n text += ' '\n", "issue": "Fix replacing of {url} in set_cmd_text_command\n```\n # FIXME we currently replace the URL in any place in the arguments,\n # rather than just replacing it if it is a dedicated argument. We could\n # split the args, but then trailing spaces would be lost, so I'm not\n # sure what's the best thing to do here\n text = text.replace('{url}', url)\n```\n\nFix replacing of {url} in set_cmd_text_command\n```\n # FIXME we currently replace the URL in any place in the arguments,\n # rather than just replacing it if it is a dedicated argument. We could\n # split the args, but then trailing spaces would be lost, so I'm not\n # sure what's the best thing to do here\n text = text.replace('{url}', url)\n```\n\n", "before_files": [{"content": "# vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:\n\n# Copyright 2014-2016 Florian Bruhin (The Compiler) <[email protected]>\n#\n# This file is part of qutebrowser.\n#\n# qutebrowser is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# qutebrowser is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.\n\n\"\"\"The commandline in the statusbar.\"\"\"\n\nfrom PyQt5.QtCore import pyqtSignal, pyqtSlot, Qt, QUrl, QSize\nfrom PyQt5.QtWidgets import QSizePolicy\n\nfrom qutebrowser.keyinput import modeman, modeparsers\nfrom qutebrowser.commands import cmdexc, cmdutils\nfrom qutebrowser.misc import cmdhistory\nfrom qutebrowser.misc import miscwidgets as misc\nfrom qutebrowser.utils import usertypes, log, objreg, qtutils\n\n\nclass Command(misc.MinimalLineEditMixin, misc.CommandLineEdit):\n\n \"\"\"The commandline part of the statusbar.\n\n Attributes:\n _win_id: The window ID this widget is associated with.\n\n Signals:\n got_cmd: Emitted when a command is triggered by the user.\n arg: The command string.\n clear_completion_selection: Emitted before the completion widget is\n hidden.\n hide_completion: Emitted when the completion widget should be hidden.\n update_completion: Emitted when the completion should be shown/updated.\n show_cmd: Emitted when command input should be shown.\n hide_cmd: Emitted when command input can be hidden.\n \"\"\"\n\n got_cmd = pyqtSignal(str)\n clear_completion_selection = pyqtSignal()\n hide_completion = pyqtSignal()\n update_completion = pyqtSignal()\n show_cmd = pyqtSignal()\n hide_cmd = pyqtSignal()\n\n def __init__(self, win_id, parent=None):\n misc.CommandLineEdit.__init__(self, parent)\n misc.MinimalLineEditMixin.__init__(self)\n self._win_id = win_id\n command_history = objreg.get('command-history')\n self.history.handle_private_mode = True\n self.history.history = command_history.data\n self.history.changed.connect(command_history.changed)\n self.setSizePolicy(QSizePolicy.MinimumExpanding, QSizePolicy.Ignored)\n self.cursorPositionChanged.connect(self.update_completion)\n self.textChanged.connect(self.update_completion)\n self.textChanged.connect(self.updateGeometry)\n\n def prefix(self):\n \"\"\"Get the currently entered command prefix.\"\"\"\n text = self.text()\n if not text:\n return ''\n elif text[0] in modeparsers.STARTCHARS:\n return text[0]\n else:\n return ''\n\n @pyqtSlot(str)\n def set_cmd_text(self, text):\n \"\"\"Preset the statusbar to some text.\n\n Args:\n text: The text to set as string.\n \"\"\"\n self.setText(text)\n log.modes.debug(\"Setting command text, focusing {!r}\".format(self))\n modeman.enter(self._win_id, usertypes.KeyMode.command, 'cmd focus')\n self.setFocus()\n self.show_cmd.emit()\n\n @cmdutils.register(instance='status-command', name='set-cmd-text',\n scope='window', maxsplit=0)\n def set_cmd_text_command(self, text, space=False, append=False):\n \"\"\"Preset the statusbar to some text.\n\n //\n\n Wrapper for set_cmd_text to check the arguments and allow multiple\n strings which will get joined.\n\n Args:\n text: The commandline to set.\n space: If given, a space is added to the end.\n append: If given, the text is appended to the current text.\n \"\"\"\n tabbed_browser = objreg.get('tabbed-browser', scope='window',\n window=self._win_id)\n if '{url}' in text:\n try:\n url = tabbed_browser.current_url().toString(\n QUrl.FullyEncoded | QUrl.RemovePassword)\n except qtutils.QtValueError as e:\n msg = \"Current URL is invalid\"\n if e.reason:\n msg += \" ({})\".format(e.reason)\n msg += \"!\"\n raise cmdexc.CommandError(msg)\n # FIXME we currently replace the URL in any place in the arguments,\n # rather than just replacing it if it is a dedicated argument. We\n # could split the args, but then trailing spaces would be lost, so\n # I'm not sure what's the best thing to do here\n # https://github.com/The-Compiler/qutebrowser/issues/123\n text = text.replace('{url}', url)\n\n if space:\n text += ' '\n if append:\n if not self.text():\n raise cmdexc.CommandError(\"No current text!\")\n text = self.text() + text\n\n if not text or text[0] not in modeparsers.STARTCHARS:\n raise cmdexc.CommandError(\n \"Invalid command text '{}'.\".format(text))\n self.set_cmd_text(text)\n\n @cmdutils.register(instance='status-command', hide=True,\n modes=[usertypes.KeyMode.command], scope='window')\n def command_history_prev(self):\n \"\"\"Go back in the commandline history.\"\"\"\n try:\n if not self.history.is_browsing():\n item = self.history.start(self.text().strip())\n else:\n item = self.history.previtem()\n except (cmdhistory.HistoryEmptyError,\n cmdhistory.HistoryEndReachedError):\n return\n if item:\n self.set_cmd_text(item)\n\n @cmdutils.register(instance='status-command', hide=True,\n modes=[usertypes.KeyMode.command], scope='window')\n def command_history_next(self):\n \"\"\"Go forward in the commandline history.\"\"\"\n if not self.history.is_browsing():\n return\n try:\n item = self.history.nextitem()\n except cmdhistory.HistoryEndReachedError:\n return\n if item:\n self.set_cmd_text(item)\n\n @cmdutils.register(instance='status-command', hide=True,\n modes=[usertypes.KeyMode.command], scope='window')\n def command_accept(self):\n \"\"\"Execute the command currently in the commandline.\"\"\"\n prefixes = {\n ':': '',\n '/': 'search -- ',\n '?': 'search -r -- ',\n }\n text = self.text()\n self.history.append(text)\n modeman.leave(self._win_id, usertypes.KeyMode.command, 'cmd accept')\n self.got_cmd.emit(prefixes[text[0]] + text[1:])\n\n @pyqtSlot(usertypes.KeyMode)\n def on_mode_left(self, mode):\n \"\"\"Clear up when command mode was left.\n\n - Clear the statusbar text if it's explicitly unfocused.\n - Clear completion selection\n - Hide completion\n\n Args:\n mode: The mode which was left.\n \"\"\"\n if mode == usertypes.KeyMode.command:\n self.setText('')\n self.history.stop()\n self.hide_cmd.emit()\n self.clear_completion_selection.emit()\n self.hide_completion.emit()\n\n def setText(self, text):\n \"\"\"Extend setText to set prefix and make sure the prompt is ok.\"\"\"\n if not text:\n pass\n elif text[0] in modeparsers.STARTCHARS:\n super().set_prompt(text[0])\n else:\n raise AssertionError(\"setText got called with invalid text \"\n \"'{}'!\".format(text))\n super().setText(text)\n\n def keyPressEvent(self, e):\n \"\"\"Override keyPressEvent to ignore Return key presses.\n\n If this widget is focused, we are in passthrough key mode, and\n Enter/Shift+Enter/etc. will cause QLineEdit to think it's finished\n without command_accept to be called.\n \"\"\"\n if e.key() == Qt.Key_Return:\n e.ignore()\n return\n else:\n super().keyPressEvent(e)\n\n def sizeHint(self):\n \"\"\"Dynamically calculate the needed size.\"\"\"\n height = super().sizeHint().height()\n text = self.text()\n if not text:\n text = 'x'\n width = self.fontMetrics().width(text)\n return QSize(width, height)\n", "path": "qutebrowser/mainwindow/statusbar/command.py"}]}
| 3,155 | 541 |
gh_patches_debug_42493
|
rasdani/github-patches
|
git_diff
|
PrefectHQ__prefect-3725
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Allow exporter arguments in Jupyter ExecuteNotebook task
## Current behavior
When running the `jupyter.jupyter.ExecuteNotebook` task with `output_format='html'` the default settings for the HTMLExporter are used. There is no way to pass arguments to this exporter.
## Proposed behavior
Allow passing arguments to the HTMLExporter.
## Implementation suggestion
Something like `html_exporter = nbconvert.HTMLExporter(**exporter_kwargs)` on the following line:
https://github.com/PrefectHQ/prefect/blob/master/src/prefect/tasks/jupyter/jupyter.py#L65
## Example usecase
This allows you to exclude code cells, only showing their output, in the exported html document by passing the `exclude_input=True` argument to the exporter.
</issue>
<code>
[start of src/prefect/tasks/jupyter/jupyter.py]
1 import nbconvert
2 import nbformat
3 import papermill as pm
4
5 from prefect import Task
6 from prefect.utilities.tasks import defaults_from_attrs
7
8
9 class ExecuteNotebook(Task):
10 """
11 Task for running Jupyter Notebooks.
12 In order to parametrize the notebook, you need to mark the parameters cell as described in
13 the papermill documentation: https://papermill.readthedocs.io/en/latest/usage-parameterize.html
14
15 Args:
16 - path (string, optional): path to fetch the notebook from.
17 Can be a cloud storage path.
18 Can also be provided post-initialization by calling this task instance
19 - parameters (dict, optional): dictionary of parameters to use for the notebook
20 Can also be provided at runtime
21 - output_format (str, optional): Notebook output format.
22 Currently supported: json, html (default: json)
23 - kernel_name (string, optional): kernel name to run the notebook with.
24 If not provided, the default kernel will be used.
25 - **kwargs: additional keyword arguments to pass to the Task constructor
26 """
27
28 def __init__(
29 self,
30 path: str = None,
31 parameters: dict = None,
32 output_format: str = "json",
33 kernel_name: str = None,
34 **kwargs
35 ):
36 self.path = path
37 self.parameters = parameters
38 self.output_format = output_format
39 self.kernel_name = kernel_name
40 super().__init__(**kwargs)
41
42 @defaults_from_attrs("path", "parameters", "output_format")
43 def run(
44 self,
45 path: str = None,
46 parameters: dict = None,
47 output_format: str = None,
48 ) -> str:
49 """
50 Run a Jupyter notebook and output as HTML or JSON
51
52 Args:
53 - path (string, optional): path to fetch the notebook from; can also be
54 a cloud storage path
55 - parameters (dict, optional): dictionary of parameters to use for the notebook
56 - output_format (str, optional): Notebook output format.
57 Currently supported: json, html (default: json)
58 """
59 nb: nbformat.NotebookNode = pm.execute_notebook(
60 path, "-", parameters=parameters, kernel_name=self.kernel_name
61 )
62 if output_format == "json":
63 return nbformat.writes(nb)
64 if output_format == "html":
65 html_exporter = nbconvert.HTMLExporter()
66 (body, resources) = html_exporter.from_notebook_node(nb)
67 return body
68
69 raise NotImplementedError("Notebook output %s not supported", output_format)
70
[end of src/prefect/tasks/jupyter/jupyter.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/prefect/tasks/jupyter/jupyter.py b/src/prefect/tasks/jupyter/jupyter.py
--- a/src/prefect/tasks/jupyter/jupyter.py
+++ b/src/prefect/tasks/jupyter/jupyter.py
@@ -18,8 +18,12 @@
Can also be provided post-initialization by calling this task instance
- parameters (dict, optional): dictionary of parameters to use for the notebook
Can also be provided at runtime
- - output_format (str, optional): Notebook output format.
- Currently supported: json, html (default: json)
+ - output_format (str, optional): Notebook output format, should be a valid
+ nbconvert Exporter name. 'json' is treated as 'notebook'.
+ Valid exporter names: asciidoc, custom, html, latex, markdown,
+ notebook, pdf, python, rst, script, slides, webpdf. (default: notebook)
+ - exporter_kwargs (dict, optional): The arguments used for initializing
+ the exporter.
- kernel_name (string, optional): kernel name to run the notebook with.
If not provided, the default kernel will be used.
- **kwargs: additional keyword arguments to pass to the Task constructor
@@ -29,7 +33,8 @@
self,
path: str = None,
parameters: dict = None,
- output_format: str = "json",
+ output_format: str = "notebook",
+ exporter_kwargs: dict = None,
kernel_name: str = None,
**kwargs
):
@@ -37,33 +42,40 @@
self.parameters = parameters
self.output_format = output_format
self.kernel_name = kernel_name
+ self.exporter_kwargs = exporter_kwargs
super().__init__(**kwargs)
- @defaults_from_attrs("path", "parameters", "output_format")
+ @defaults_from_attrs("path", "parameters", "output_format", "exporter_kwargs")
def run(
self,
path: str = None,
parameters: dict = None,
output_format: str = None,
+ exporter_kwargs: dict = None,
) -> str:
"""
- Run a Jupyter notebook and output as HTML or JSON
+ Run a Jupyter notebook and output as HTML, notebook, or other formats.
Args:
- path (string, optional): path to fetch the notebook from; can also be
a cloud storage path
- parameters (dict, optional): dictionary of parameters to use for the notebook
- - output_format (str, optional): Notebook output format.
- Currently supported: json, html (default: json)
+ - output_format (str, optional): Notebook output format, should be a valid
+ nbconvert Exporter name. 'json' is treated as 'notebook'.
+ Valid exporter names: asciidoc, custom, html, latex, markdown,
+ notebook, pdf, python, rst, script, slides, webpdf. (default: notebook)
+ - exporter_kwargs (dict, optional): The arguments used for initializing
+ the exporter.
"""
nb: nbformat.NotebookNode = pm.execute_notebook(
path, "-", parameters=parameters, kernel_name=self.kernel_name
)
if output_format == "json":
- return nbformat.writes(nb)
- if output_format == "html":
- html_exporter = nbconvert.HTMLExporter()
- (body, resources) = html_exporter.from_notebook_node(nb)
- return body
+ output_format = "notebook"
- raise NotImplementedError("Notebook output %s not supported", output_format)
+ if exporter_kwargs is None:
+ exporter_kwargs = {}
+
+ exporter = nbconvert.get_exporter(output_format)
+ body, resources = nbconvert.export(exporter, nb, **exporter_kwargs)
+ return body
|
{"golden_diff": "diff --git a/src/prefect/tasks/jupyter/jupyter.py b/src/prefect/tasks/jupyter/jupyter.py\n--- a/src/prefect/tasks/jupyter/jupyter.py\n+++ b/src/prefect/tasks/jupyter/jupyter.py\n@@ -18,8 +18,12 @@\n Can also be provided post-initialization by calling this task instance\n - parameters (dict, optional): dictionary of parameters to use for the notebook\n Can also be provided at runtime\n- - output_format (str, optional): Notebook output format.\n- Currently supported: json, html (default: json)\n+ - output_format (str, optional): Notebook output format, should be a valid\n+ nbconvert Exporter name. 'json' is treated as 'notebook'.\n+ Valid exporter names: asciidoc, custom, html, latex, markdown,\n+ notebook, pdf, python, rst, script, slides, webpdf. (default: notebook)\n+ - exporter_kwargs (dict, optional): The arguments used for initializing\n+ the exporter.\n - kernel_name (string, optional): kernel name to run the notebook with.\n If not provided, the default kernel will be used.\n - **kwargs: additional keyword arguments to pass to the Task constructor\n@@ -29,7 +33,8 @@\n self,\n path: str = None,\n parameters: dict = None,\n- output_format: str = \"json\",\n+ output_format: str = \"notebook\",\n+ exporter_kwargs: dict = None,\n kernel_name: str = None,\n **kwargs\n ):\n@@ -37,33 +42,40 @@\n self.parameters = parameters\n self.output_format = output_format\n self.kernel_name = kernel_name\n+ self.exporter_kwargs = exporter_kwargs\n super().__init__(**kwargs)\n \n- @defaults_from_attrs(\"path\", \"parameters\", \"output_format\")\n+ @defaults_from_attrs(\"path\", \"parameters\", \"output_format\", \"exporter_kwargs\")\n def run(\n self,\n path: str = None,\n parameters: dict = None,\n output_format: str = None,\n+ exporter_kwargs: dict = None,\n ) -> str:\n \"\"\"\n- Run a Jupyter notebook and output as HTML or JSON\n+ Run a Jupyter notebook and output as HTML, notebook, or other formats.\n \n Args:\n - path (string, optional): path to fetch the notebook from; can also be\n a cloud storage path\n - parameters (dict, optional): dictionary of parameters to use for the notebook\n- - output_format (str, optional): Notebook output format.\n- Currently supported: json, html (default: json)\n+ - output_format (str, optional): Notebook output format, should be a valid\n+ nbconvert Exporter name. 'json' is treated as 'notebook'.\n+ Valid exporter names: asciidoc, custom, html, latex, markdown,\n+ notebook, pdf, python, rst, script, slides, webpdf. (default: notebook)\n+ - exporter_kwargs (dict, optional): The arguments used for initializing\n+ the exporter.\n \"\"\"\n nb: nbformat.NotebookNode = pm.execute_notebook(\n path, \"-\", parameters=parameters, kernel_name=self.kernel_name\n )\n if output_format == \"json\":\n- return nbformat.writes(nb)\n- if output_format == \"html\":\n- html_exporter = nbconvert.HTMLExporter()\n- (body, resources) = html_exporter.from_notebook_node(nb)\n- return body\n+ output_format = \"notebook\"\n \n- raise NotImplementedError(\"Notebook output %s not supported\", output_format)\n+ if exporter_kwargs is None:\n+ exporter_kwargs = {}\n+\n+ exporter = nbconvert.get_exporter(output_format)\n+ body, resources = nbconvert.export(exporter, nb, **exporter_kwargs)\n+ return body\n", "issue": "Allow exporter arguments in Jupyter ExecuteNotebook task\n## Current behavior\r\n\r\nWhen running the `jupyter.jupyter.ExecuteNotebook` task with `output_format='html'` the default settings for the HTMLExporter are used. There is no way to pass arguments to this exporter.\r\n\r\n## Proposed behavior\r\n\r\nAllow passing arguments to the HTMLExporter.\r\n\r\n## Implementation suggestion\r\n\r\nSomething like `html_exporter = nbconvert.HTMLExporter(**exporter_kwargs)` on the following line:\r\nhttps://github.com/PrefectHQ/prefect/blob/master/src/prefect/tasks/jupyter/jupyter.py#L65\r\n\r\n## Example usecase\r\n\r\nThis allows you to exclude code cells, only showing their output, in the exported html document by passing the `exclude_input=True` argument to the exporter.\n", "before_files": [{"content": "import nbconvert\nimport nbformat\nimport papermill as pm\n\nfrom prefect import Task\nfrom prefect.utilities.tasks import defaults_from_attrs\n\n\nclass ExecuteNotebook(Task):\n \"\"\"\n Task for running Jupyter Notebooks.\n In order to parametrize the notebook, you need to mark the parameters cell as described in\n the papermill documentation: https://papermill.readthedocs.io/en/latest/usage-parameterize.html\n\n Args:\n - path (string, optional): path to fetch the notebook from.\n Can be a cloud storage path.\n Can also be provided post-initialization by calling this task instance\n - parameters (dict, optional): dictionary of parameters to use for the notebook\n Can also be provided at runtime\n - output_format (str, optional): Notebook output format.\n Currently supported: json, html (default: json)\n - kernel_name (string, optional): kernel name to run the notebook with.\n If not provided, the default kernel will be used.\n - **kwargs: additional keyword arguments to pass to the Task constructor\n \"\"\"\n\n def __init__(\n self,\n path: str = None,\n parameters: dict = None,\n output_format: str = \"json\",\n kernel_name: str = None,\n **kwargs\n ):\n self.path = path\n self.parameters = parameters\n self.output_format = output_format\n self.kernel_name = kernel_name\n super().__init__(**kwargs)\n\n @defaults_from_attrs(\"path\", \"parameters\", \"output_format\")\n def run(\n self,\n path: str = None,\n parameters: dict = None,\n output_format: str = None,\n ) -> str:\n \"\"\"\n Run a Jupyter notebook and output as HTML or JSON\n\n Args:\n - path (string, optional): path to fetch the notebook from; can also be\n a cloud storage path\n - parameters (dict, optional): dictionary of parameters to use for the notebook\n - output_format (str, optional): Notebook output format.\n Currently supported: json, html (default: json)\n \"\"\"\n nb: nbformat.NotebookNode = pm.execute_notebook(\n path, \"-\", parameters=parameters, kernel_name=self.kernel_name\n )\n if output_format == \"json\":\n return nbformat.writes(nb)\n if output_format == \"html\":\n html_exporter = nbconvert.HTMLExporter()\n (body, resources) = html_exporter.from_notebook_node(nb)\n return body\n\n raise NotImplementedError(\"Notebook output %s not supported\", output_format)\n", "path": "src/prefect/tasks/jupyter/jupyter.py"}]}
| 1,381 | 857 |
gh_patches_debug_32560
|
rasdani/github-patches
|
git_diff
|
pytorch__vision-7107
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Weights enums cannot be pickled
### 🐛 Describe the bug
Trying to unplickle pickled weights enum object yields an error inside enum implementation (it cannot match constructed object with existing enum values). Here is reproducible example.
```python
import pickle
from torchvision.models import ResNet50_Weights
def main():
w = ResNet50_Weights.DEFAULT
kek = pickle.dumps(w)
lol = pickle.loads(kek)
print(lol)
if __name__ == '__main__':
main()
```
This happens because internally enum tries to match newly constructed enum value with declared values. And this fails because `Weights` dataclass has `transforms` field which is a callable. And if that callable is a `functools.partial`, it is technically a different object, even though it was constructed from the same original function with the same partial arguments. This snippet fixes the error, so you should get the idea for probable fix
```python
import functools
from torchvision.models._api import Weights
def new_eq(self, other):
if not isinstance(other, type(self)):
return False
if self.meta != other.meta or self.url != other.url:
return False
if not isinstance(self.transforms, functools.partial) or not isinstance(other.transforms, functools.partial):
return self.transforms == other.transforms
return all(getattr(self.transforms, a) == getattr(other.transforms, a) for a in ["func", "args", "keywords", "__dict__"])
Weights.__eq__ = new_eq
```
### Versions
```
Collecting environment information...
PyTorch version: 1.12.1
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 13.0.1 (arm64)
GCC version: Could not collect
Clang version: 14.0.0 (clang-1400.0.29.202)
CMake version: version 3.25.0
Libc version: N/A
Python version: 3.9.13 | packaged by conda-forge | (main, May 27 2022, 17:00:33) [Clang 13.0.1 ] (64-bit runtime)
Python platform: macOS-13.0.1-arm64-arm-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.971
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.22.4
[pip3] torch==1.12.1
[pip3] torchvision==0.13.1
[conda] numpy 1.22.4 py39h7df2422_0 conda-forge
[conda] torch 1.12.1 pypi_0 pypi
[conda] torchvision 0.13.1 pypi_0 pypi
```
</issue>
<code>
[start of torchvision/models/_api.py]
1 import importlib
2 import inspect
3 import sys
4 from dataclasses import dataclass, fields
5 from inspect import signature
6 from types import ModuleType
7 from typing import Any, Callable, cast, Dict, List, Mapping, Optional, TypeVar, Union
8
9 from torch import nn
10
11 from torchvision._utils import StrEnum
12
13 from .._internally_replaced_utils import load_state_dict_from_url
14
15
16 __all__ = ["WeightsEnum", "Weights", "get_model", "get_model_builder", "get_model_weights", "get_weight", "list_models"]
17
18
19 @dataclass
20 class Weights:
21 """
22 This class is used to group important attributes associated with the pre-trained weights.
23
24 Args:
25 url (str): The location where we find the weights.
26 transforms (Callable): A callable that constructs the preprocessing method (or validation preset transforms)
27 needed to use the model. The reason we attach a constructor method rather than an already constructed
28 object is because the specific object might have memory and thus we want to delay initialization until
29 needed.
30 meta (Dict[str, Any]): Stores meta-data related to the weights of the model and its configuration. These can be
31 informative attributes (for example the number of parameters/flops, recipe link/methods used in training
32 etc), configuration parameters (for example the `num_classes`) needed to construct the model or important
33 meta-data (for example the `classes` of a classification model) needed to use the model.
34 """
35
36 url: str
37 transforms: Callable
38 meta: Dict[str, Any]
39
40
41 class WeightsEnum(StrEnum):
42 """
43 This class is the parent class of all model weights. Each model building method receives an optional `weights`
44 parameter with its associated pre-trained weights. It inherits from `Enum` and its values should be of type
45 `Weights`.
46
47 Args:
48 value (Weights): The data class entry with the weight information.
49 """
50
51 def __init__(self, value: Weights):
52 self._value_ = value
53
54 @classmethod
55 def verify(cls, obj: Any) -> Any:
56 if obj is not None:
57 if type(obj) is str:
58 obj = cls.from_str(obj.replace(cls.__name__ + ".", ""))
59 elif not isinstance(obj, cls):
60 raise TypeError(
61 f"Invalid Weight class provided; expected {cls.__name__} but received {obj.__class__.__name__}."
62 )
63 return obj
64
65 def get_state_dict(self, progress: bool) -> Mapping[str, Any]:
66 return load_state_dict_from_url(self.url, progress=progress)
67
68 def __repr__(self) -> str:
69 return f"{self.__class__.__name__}.{self._name_}"
70
71 def __getattr__(self, name):
72 # Be able to fetch Weights attributes directly
73 for f in fields(Weights):
74 if f.name == name:
75 return object.__getattribute__(self.value, name)
76 return super().__getattr__(name)
77
78 def __deepcopy__(self, memodict=None):
79 return self
80
81
82 def get_weight(name: str) -> WeightsEnum:
83 """
84 Gets the weights enum value by its full name. Example: "ResNet50_Weights.IMAGENET1K_V1"
85
86 .. betastatus:: function
87
88 Args:
89 name (str): The name of the weight enum entry.
90
91 Returns:
92 WeightsEnum: The requested weight enum.
93 """
94 try:
95 enum_name, value_name = name.split(".")
96 except ValueError:
97 raise ValueError(f"Invalid weight name provided: '{name}'.")
98
99 base_module_name = ".".join(sys.modules[__name__].__name__.split(".")[:-1])
100 base_module = importlib.import_module(base_module_name)
101 model_modules = [base_module] + [
102 x[1] for x in inspect.getmembers(base_module, inspect.ismodule) if x[1].__file__.endswith("__init__.py")
103 ]
104
105 weights_enum = None
106 for m in model_modules:
107 potential_class = m.__dict__.get(enum_name, None)
108 if potential_class is not None and issubclass(potential_class, WeightsEnum):
109 weights_enum = potential_class
110 break
111
112 if weights_enum is None:
113 raise ValueError(f"The weight enum '{enum_name}' for the specific method couldn't be retrieved.")
114
115 return weights_enum.from_str(value_name)
116
117
118 def get_model_weights(name: Union[Callable, str]) -> WeightsEnum:
119 """
120 Returns the weights enum class associated to the given model.
121
122 .. betastatus:: function
123
124 Args:
125 name (callable or str): The model builder function or the name under which it is registered.
126
127 Returns:
128 weights_enum (WeightsEnum): The weights enum class associated with the model.
129 """
130 model = get_model_builder(name) if isinstance(name, str) else name
131 return _get_enum_from_fn(model)
132
133
134 def _get_enum_from_fn(fn: Callable) -> WeightsEnum:
135 """
136 Internal method that gets the weight enum of a specific model builder method.
137
138 Args:
139 fn (Callable): The builder method used to create the model.
140 Returns:
141 WeightsEnum: The requested weight enum.
142 """
143 sig = signature(fn)
144 if "weights" not in sig.parameters:
145 raise ValueError("The method is missing the 'weights' argument.")
146
147 ann = signature(fn).parameters["weights"].annotation
148 weights_enum = None
149 if isinstance(ann, type) and issubclass(ann, WeightsEnum):
150 weights_enum = ann
151 else:
152 # handle cases like Union[Optional, T]
153 # TODO: Replace ann.__args__ with typing.get_args(ann) after python >= 3.8
154 for t in ann.__args__: # type: ignore[union-attr]
155 if isinstance(t, type) and issubclass(t, WeightsEnum):
156 weights_enum = t
157 break
158
159 if weights_enum is None:
160 raise ValueError(
161 "The WeightsEnum class for the specific method couldn't be retrieved. Make sure the typing info is correct."
162 )
163
164 return cast(WeightsEnum, weights_enum)
165
166
167 M = TypeVar("M", bound=nn.Module)
168
169 BUILTIN_MODELS = {}
170
171
172 def register_model(name: Optional[str] = None) -> Callable[[Callable[..., M]], Callable[..., M]]:
173 def wrapper(fn: Callable[..., M]) -> Callable[..., M]:
174 key = name if name is not None else fn.__name__
175 if key in BUILTIN_MODELS:
176 raise ValueError(f"An entry is already registered under the name '{key}'.")
177 BUILTIN_MODELS[key] = fn
178 return fn
179
180 return wrapper
181
182
183 def list_models(module: Optional[ModuleType] = None) -> List[str]:
184 """
185 Returns a list with the names of registered models.
186
187 .. betastatus:: function
188
189 Args:
190 module (ModuleType, optional): The module from which we want to extract the available models.
191
192 Returns:
193 models (list): A list with the names of available models.
194 """
195 models = [
196 k for k, v in BUILTIN_MODELS.items() if module is None or v.__module__.rsplit(".", 1)[0] == module.__name__
197 ]
198 return sorted(models)
199
200
201 def get_model_builder(name: str) -> Callable[..., nn.Module]:
202 """
203 Gets the model name and returns the model builder method.
204
205 .. betastatus:: function
206
207 Args:
208 name (str): The name under which the model is registered.
209
210 Returns:
211 fn (Callable): The model builder method.
212 """
213 name = name.lower()
214 try:
215 fn = BUILTIN_MODELS[name]
216 except KeyError:
217 raise ValueError(f"Unknown model {name}")
218 return fn
219
220
221 def get_model(name: str, **config: Any) -> nn.Module:
222 """
223 Gets the model name and configuration and returns an instantiated model.
224
225 .. betastatus:: function
226
227 Args:
228 name (str): The name under which the model is registered.
229 **config (Any): parameters passed to the model builder method.
230
231 Returns:
232 model (nn.Module): The initialized model.
233 """
234 fn = get_model_builder(name)
235 return fn(**config)
236
[end of torchvision/models/_api.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/torchvision/models/_api.py b/torchvision/models/_api.py
--- a/torchvision/models/_api.py
+++ b/torchvision/models/_api.py
@@ -2,6 +2,7 @@
import inspect
import sys
from dataclasses import dataclass, fields
+from functools import partial
from inspect import signature
from types import ModuleType
from typing import Any, Callable, cast, Dict, List, Mapping, Optional, TypeVar, Union
@@ -37,6 +38,32 @@
transforms: Callable
meta: Dict[str, Any]
+ def __eq__(self, other: Any) -> bool:
+ # We need this custom implementation for correct deep-copy and deserialization behavior.
+ # TL;DR: After the definition of an enum, creating a new instance, i.e. by deep-copying or deserializing it,
+ # involves an equality check against the defined members. Unfortunately, the `transforms` attribute is often
+ # defined with `functools.partial` and `fn = partial(...); assert deepcopy(fn) != fn`. Without custom handling
+ # for it, the check against the defined members would fail and effectively prevent the weights from being
+ # deep-copied or deserialized.
+ # See https://github.com/pytorch/vision/pull/7107 for details.
+ if not isinstance(other, Weights):
+ return NotImplemented
+
+ if self.url != other.url:
+ return False
+
+ if self.meta != other.meta:
+ return False
+
+ if isinstance(self.transforms, partial) and isinstance(other.transforms, partial):
+ return (
+ self.transforms.func == other.transforms.func
+ and self.transforms.args == other.transforms.args
+ and self.transforms.keywords == other.transforms.keywords
+ )
+ else:
+ return self.transforms == other.transforms
+
class WeightsEnum(StrEnum):
"""
@@ -75,9 +102,6 @@
return object.__getattribute__(self.value, name)
return super().__getattr__(name)
- def __deepcopy__(self, memodict=None):
- return self
-
def get_weight(name: str) -> WeightsEnum:
"""
|
{"golden_diff": "diff --git a/torchvision/models/_api.py b/torchvision/models/_api.py\n--- a/torchvision/models/_api.py\n+++ b/torchvision/models/_api.py\n@@ -2,6 +2,7 @@\n import inspect\n import sys\n from dataclasses import dataclass, fields\n+from functools import partial\n from inspect import signature\n from types import ModuleType\n from typing import Any, Callable, cast, Dict, List, Mapping, Optional, TypeVar, Union\n@@ -37,6 +38,32 @@\n transforms: Callable\n meta: Dict[str, Any]\n \n+ def __eq__(self, other: Any) -> bool:\n+ # We need this custom implementation for correct deep-copy and deserialization behavior.\n+ # TL;DR: After the definition of an enum, creating a new instance, i.e. by deep-copying or deserializing it,\n+ # involves an equality check against the defined members. Unfortunately, the `transforms` attribute is often\n+ # defined with `functools.partial` and `fn = partial(...); assert deepcopy(fn) != fn`. Without custom handling\n+ # for it, the check against the defined members would fail and effectively prevent the weights from being\n+ # deep-copied or deserialized.\n+ # See https://github.com/pytorch/vision/pull/7107 for details.\n+ if not isinstance(other, Weights):\n+ return NotImplemented\n+\n+ if self.url != other.url:\n+ return False\n+\n+ if self.meta != other.meta:\n+ return False\n+\n+ if isinstance(self.transforms, partial) and isinstance(other.transforms, partial):\n+ return (\n+ self.transforms.func == other.transforms.func\n+ and self.transforms.args == other.transforms.args\n+ and self.transforms.keywords == other.transforms.keywords\n+ )\n+ else:\n+ return self.transforms == other.transforms\n+\n \n class WeightsEnum(StrEnum):\n \"\"\"\n@@ -75,9 +102,6 @@\n return object.__getattribute__(self.value, name)\n return super().__getattr__(name)\n \n- def __deepcopy__(self, memodict=None):\n- return self\n-\n \n def get_weight(name: str) -> WeightsEnum:\n \"\"\"\n", "issue": "Weights enums cannot be pickled\n### \ud83d\udc1b Describe the bug\r\n\r\nTrying to unplickle pickled weights enum object yields an error inside enum implementation (it cannot match constructed object with existing enum values). Here is reproducible example.\r\n\r\n```python\r\nimport pickle\r\n\r\nfrom torchvision.models import ResNet50_Weights\r\n\r\n\r\ndef main():\r\n w = ResNet50_Weights.DEFAULT\r\n kek = pickle.dumps(w)\r\n lol = pickle.loads(kek)\r\n print(lol)\r\n\r\n\r\nif __name__ == '__main__':\r\n main()\r\n```\r\n\r\nThis happens because internally enum tries to match newly constructed enum value with declared values. And this fails because `Weights` dataclass has `transforms` field which is a callable. And if that callable is a `functools.partial`, it is technically a different object, even though it was constructed from the same original function with the same partial arguments. This snippet fixes the error, so you should get the idea for probable fix\r\n\r\n```python\r\nimport functools\r\nfrom torchvision.models._api import Weights\r\n\r\ndef new_eq(self, other):\r\n if not isinstance(other, type(self)):\r\n return False\r\n if self.meta != other.meta or self.url != other.url:\r\n return False\r\n if not isinstance(self.transforms, functools.partial) or not isinstance(other.transforms, functools.partial):\r\n return self.transforms == other.transforms\r\n return all(getattr(self.transforms, a) == getattr(other.transforms, a) for a in [\"func\", \"args\", \"keywords\", \"__dict__\"])\r\n\r\nWeights.__eq__ = new_eq\r\n```\r\n\r\n### Versions\r\n\r\n```\r\nCollecting environment information...\r\nPyTorch version: 1.12.1\r\nIs debug build: False\r\nCUDA used to build PyTorch: None\r\nROCM used to build PyTorch: N/A\r\n\r\nOS: macOS 13.0.1 (arm64)\r\nGCC version: Could not collect\r\nClang version: 14.0.0 (clang-1400.0.29.202)\r\nCMake version: version 3.25.0\r\nLibc version: N/A\r\n\r\nPython version: 3.9.13 | packaged by conda-forge | (main, May 27 2022, 17:00:33) [Clang 13.0.1 ] (64-bit runtime)\r\nPython platform: macOS-13.0.1-arm64-arm-64bit\r\nIs CUDA available: False\r\nCUDA runtime version: No CUDA\r\nCUDA_MODULE_LOADING set to: N/A\r\nGPU models and configuration: No CUDA\r\nNvidia driver version: No CUDA\r\ncuDNN version: No CUDA\r\nHIP runtime version: N/A\r\nMIOpen runtime version: N/A\r\nIs XNNPACK available: True\r\n\r\nVersions of relevant libraries:\r\n[pip3] mypy==0.971\r\n[pip3] mypy-extensions==0.4.3\r\n[pip3] numpy==1.22.4\r\n[pip3] torch==1.12.1\r\n[pip3] torchvision==0.13.1\r\n[conda] numpy 1.22.4 py39h7df2422_0 conda-forge\r\n[conda] torch 1.12.1 pypi_0 pypi\r\n[conda] torchvision 0.13.1 pypi_0 pypi\r\n```\n", "before_files": [{"content": "import importlib\nimport inspect\nimport sys\nfrom dataclasses import dataclass, fields\nfrom inspect import signature\nfrom types import ModuleType\nfrom typing import Any, Callable, cast, Dict, List, Mapping, Optional, TypeVar, Union\n\nfrom torch import nn\n\nfrom torchvision._utils import StrEnum\n\nfrom .._internally_replaced_utils import load_state_dict_from_url\n\n\n__all__ = [\"WeightsEnum\", \"Weights\", \"get_model\", \"get_model_builder\", \"get_model_weights\", \"get_weight\", \"list_models\"]\n\n\n@dataclass\nclass Weights:\n \"\"\"\n This class is used to group important attributes associated with the pre-trained weights.\n\n Args:\n url (str): The location where we find the weights.\n transforms (Callable): A callable that constructs the preprocessing method (or validation preset transforms)\n needed to use the model. The reason we attach a constructor method rather than an already constructed\n object is because the specific object might have memory and thus we want to delay initialization until\n needed.\n meta (Dict[str, Any]): Stores meta-data related to the weights of the model and its configuration. These can be\n informative attributes (for example the number of parameters/flops, recipe link/methods used in training\n etc), configuration parameters (for example the `num_classes`) needed to construct the model or important\n meta-data (for example the `classes` of a classification model) needed to use the model.\n \"\"\"\n\n url: str\n transforms: Callable\n meta: Dict[str, Any]\n\n\nclass WeightsEnum(StrEnum):\n \"\"\"\n This class is the parent class of all model weights. Each model building method receives an optional `weights`\n parameter with its associated pre-trained weights. It inherits from `Enum` and its values should be of type\n `Weights`.\n\n Args:\n value (Weights): The data class entry with the weight information.\n \"\"\"\n\n def __init__(self, value: Weights):\n self._value_ = value\n\n @classmethod\n def verify(cls, obj: Any) -> Any:\n if obj is not None:\n if type(obj) is str:\n obj = cls.from_str(obj.replace(cls.__name__ + \".\", \"\"))\n elif not isinstance(obj, cls):\n raise TypeError(\n f\"Invalid Weight class provided; expected {cls.__name__} but received {obj.__class__.__name__}.\"\n )\n return obj\n\n def get_state_dict(self, progress: bool) -> Mapping[str, Any]:\n return load_state_dict_from_url(self.url, progress=progress)\n\n def __repr__(self) -> str:\n return f\"{self.__class__.__name__}.{self._name_}\"\n\n def __getattr__(self, name):\n # Be able to fetch Weights attributes directly\n for f in fields(Weights):\n if f.name == name:\n return object.__getattribute__(self.value, name)\n return super().__getattr__(name)\n\n def __deepcopy__(self, memodict=None):\n return self\n\n\ndef get_weight(name: str) -> WeightsEnum:\n \"\"\"\n Gets the weights enum value by its full name. Example: \"ResNet50_Weights.IMAGENET1K_V1\"\n\n .. betastatus:: function\n\n Args:\n name (str): The name of the weight enum entry.\n\n Returns:\n WeightsEnum: The requested weight enum.\n \"\"\"\n try:\n enum_name, value_name = name.split(\".\")\n except ValueError:\n raise ValueError(f\"Invalid weight name provided: '{name}'.\")\n\n base_module_name = \".\".join(sys.modules[__name__].__name__.split(\".\")[:-1])\n base_module = importlib.import_module(base_module_name)\n model_modules = [base_module] + [\n x[1] for x in inspect.getmembers(base_module, inspect.ismodule) if x[1].__file__.endswith(\"__init__.py\")\n ]\n\n weights_enum = None\n for m in model_modules:\n potential_class = m.__dict__.get(enum_name, None)\n if potential_class is not None and issubclass(potential_class, WeightsEnum):\n weights_enum = potential_class\n break\n\n if weights_enum is None:\n raise ValueError(f\"The weight enum '{enum_name}' for the specific method couldn't be retrieved.\")\n\n return weights_enum.from_str(value_name)\n\n\ndef get_model_weights(name: Union[Callable, str]) -> WeightsEnum:\n \"\"\"\n Returns the weights enum class associated to the given model.\n\n .. betastatus:: function\n\n Args:\n name (callable or str): The model builder function or the name under which it is registered.\n\n Returns:\n weights_enum (WeightsEnum): The weights enum class associated with the model.\n \"\"\"\n model = get_model_builder(name) if isinstance(name, str) else name\n return _get_enum_from_fn(model)\n\n\ndef _get_enum_from_fn(fn: Callable) -> WeightsEnum:\n \"\"\"\n Internal method that gets the weight enum of a specific model builder method.\n\n Args:\n fn (Callable): The builder method used to create the model.\n Returns:\n WeightsEnum: The requested weight enum.\n \"\"\"\n sig = signature(fn)\n if \"weights\" not in sig.parameters:\n raise ValueError(\"The method is missing the 'weights' argument.\")\n\n ann = signature(fn).parameters[\"weights\"].annotation\n weights_enum = None\n if isinstance(ann, type) and issubclass(ann, WeightsEnum):\n weights_enum = ann\n else:\n # handle cases like Union[Optional, T]\n # TODO: Replace ann.__args__ with typing.get_args(ann) after python >= 3.8\n for t in ann.__args__: # type: ignore[union-attr]\n if isinstance(t, type) and issubclass(t, WeightsEnum):\n weights_enum = t\n break\n\n if weights_enum is None:\n raise ValueError(\n \"The WeightsEnum class for the specific method couldn't be retrieved. Make sure the typing info is correct.\"\n )\n\n return cast(WeightsEnum, weights_enum)\n\n\nM = TypeVar(\"M\", bound=nn.Module)\n\nBUILTIN_MODELS = {}\n\n\ndef register_model(name: Optional[str] = None) -> Callable[[Callable[..., M]], Callable[..., M]]:\n def wrapper(fn: Callable[..., M]) -> Callable[..., M]:\n key = name if name is not None else fn.__name__\n if key in BUILTIN_MODELS:\n raise ValueError(f\"An entry is already registered under the name '{key}'.\")\n BUILTIN_MODELS[key] = fn\n return fn\n\n return wrapper\n\n\ndef list_models(module: Optional[ModuleType] = None) -> List[str]:\n \"\"\"\n Returns a list with the names of registered models.\n\n .. betastatus:: function\n\n Args:\n module (ModuleType, optional): The module from which we want to extract the available models.\n\n Returns:\n models (list): A list with the names of available models.\n \"\"\"\n models = [\n k for k, v in BUILTIN_MODELS.items() if module is None or v.__module__.rsplit(\".\", 1)[0] == module.__name__\n ]\n return sorted(models)\n\n\ndef get_model_builder(name: str) -> Callable[..., nn.Module]:\n \"\"\"\n Gets the model name and returns the model builder method.\n\n .. betastatus:: function\n\n Args:\n name (str): The name under which the model is registered.\n\n Returns:\n fn (Callable): The model builder method.\n \"\"\"\n name = name.lower()\n try:\n fn = BUILTIN_MODELS[name]\n except KeyError:\n raise ValueError(f\"Unknown model {name}\")\n return fn\n\n\ndef get_model(name: str, **config: Any) -> nn.Module:\n \"\"\"\n Gets the model name and configuration and returns an instantiated model.\n\n .. betastatus:: function\n\n Args:\n name (str): The name under which the model is registered.\n **config (Any): parameters passed to the model builder method.\n\n Returns:\n model (nn.Module): The initialized model.\n \"\"\"\n fn = get_model_builder(name)\n return fn(**config)\n", "path": "torchvision/models/_api.py"}]}
| 3,673 | 495 |
gh_patches_debug_19122
|
rasdani/github-patches
|
git_diff
|
aimhubio__aim-1917
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Pytorch track_gradients_dists errors out if some parameters don't have gradients
## 🐛 Bug
When collecting gradients for each layer weight of a model, the function `get_model_layers` errors out if some model parameters don't have gradients.
### Expected behavior
Ignore weights if grad is None.
### Environment
- Aim Version (e.g., 3.11.1)
- Python version 3.10
- pip version 22.0
- Any OS
</issue>
<code>
[start of aim/sdk/adapters/pytorch.py]
1 def track_params_dists(model, run):
2 from aim import Distribution
3 data_hist = get_model_layers(model, 'data')
4
5 for name, params in data_hist.items():
6 if 'weight' in params:
7 run.track(
8 Distribution(params['weight']),
9 name=name,
10 context={
11 'type': 'data',
12 'params': 'weights',
13 }
14 )
15 if 'bias' in params:
16 run.track(
17 Distribution(params['bias']),
18 name=name,
19 context={
20 'type': 'data',
21 'params': 'biases',
22 }
23 )
24
25
26 def track_gradients_dists(model, run):
27 from aim import Distribution
28 grad_hist = get_model_layers(model, 'grad')
29
30 for name, params in grad_hist.items():
31 if 'weight' in params:
32 run.track(
33 Distribution(params['weight']),
34 name=name,
35 context={
36 'type': 'gradients',
37 'params': 'weights',
38 }
39 )
40 if 'bias' in params:
41 run.track(
42 Distribution(params['bias']),
43 name=name,
44 context={
45 'type': 'gradients',
46 'params': 'biases',
47 }
48 )
49
50
51 def get_model_layers(model, dt, parent_name=None):
52 layers = {}
53 for name, m in model.named_children():
54 layer_name = '{}__{}'.format(parent_name, name) \
55 if parent_name \
56 else name
57 layer_name += '.{}'.format(type(m).__name__)
58
59 if len(list(m.named_children())):
60 layers.update(get_model_layers(m, dt, layer_name))
61 else:
62 layers[layer_name] = {}
63 if hasattr(m, 'weight') \
64 and m.weight is not None \
65 and hasattr(m.weight, dt):
66 layers[layer_name]['weight'] = get_pt_tensor(getattr(m.weight, dt)).numpy()
67
68 if hasattr(m, 'bias') \
69 and m.bias is not None \
70 and hasattr(m.bias, dt):
71 layers[layer_name]['bias'] = get_pt_tensor(getattr(m.bias, dt)).numpy()
72
73 return layers
74
75
76 # Move tensor from GPU to CPU
77 def get_pt_tensor(t):
78 return t.cpu() if hasattr(t, 'is_cuda') and t.is_cuda else t
79
[end of aim/sdk/adapters/pytorch.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/aim/sdk/adapters/pytorch.py b/aim/sdk/adapters/pytorch.py
--- a/aim/sdk/adapters/pytorch.py
+++ b/aim/sdk/adapters/pytorch.py
@@ -60,15 +60,17 @@
layers.update(get_model_layers(m, dt, layer_name))
else:
layers[layer_name] = {}
- if hasattr(m, 'weight') \
- and m.weight is not None \
- and hasattr(m.weight, dt):
- layers[layer_name]['weight'] = get_pt_tensor(getattr(m.weight, dt)).numpy()
+ weight = None
+ if hasattr(m, 'weight') and m.weight is not None:
+ weight = getattr(m.weight, dt, None)
+ if weight is not None:
+ layers[layer_name]['weight'] = get_pt_tensor(weight).numpy()
- if hasattr(m, 'bias') \
- and m.bias is not None \
- and hasattr(m.bias, dt):
- layers[layer_name]['bias'] = get_pt_tensor(getattr(m.bias, dt)).numpy()
+ bias = None
+ if hasattr(m, 'bias') and m.bias is not None:
+ bias = getattr(m.bias, dt, None)
+ if bias is not None:
+ layers[layer_name]['bias'] = get_pt_tensor(bias).numpy()
return layers
|
{"golden_diff": "diff --git a/aim/sdk/adapters/pytorch.py b/aim/sdk/adapters/pytorch.py\n--- a/aim/sdk/adapters/pytorch.py\n+++ b/aim/sdk/adapters/pytorch.py\n@@ -60,15 +60,17 @@\n layers.update(get_model_layers(m, dt, layer_name))\n else:\n layers[layer_name] = {}\n- if hasattr(m, 'weight') \\\n- and m.weight is not None \\\n- and hasattr(m.weight, dt):\n- layers[layer_name]['weight'] = get_pt_tensor(getattr(m.weight, dt)).numpy()\n+ weight = None\n+ if hasattr(m, 'weight') and m.weight is not None:\n+ weight = getattr(m.weight, dt, None)\n+ if weight is not None:\n+ layers[layer_name]['weight'] = get_pt_tensor(weight).numpy()\n \n- if hasattr(m, 'bias') \\\n- and m.bias is not None \\\n- and hasattr(m.bias, dt):\n- layers[layer_name]['bias'] = get_pt_tensor(getattr(m.bias, dt)).numpy()\n+ bias = None\n+ if hasattr(m, 'bias') and m.bias is not None:\n+ bias = getattr(m.bias, dt, None)\n+ if bias is not None:\n+ layers[layer_name]['bias'] = get_pt_tensor(bias).numpy()\n \n return layers\n", "issue": "Pytorch track_gradients_dists errors out if some parameters don't have gradients\n## \ud83d\udc1b Bug\r\n\r\nWhen collecting gradients for each layer weight of a model, the function `get_model_layers` errors out if some model parameters don't have gradients.\r\n\r\n### Expected behavior\r\n\r\nIgnore weights if grad is None.\r\n\r\n### Environment\r\n\r\n- Aim Version (e.g., 3.11.1)\r\n- Python version 3.10\r\n- pip version 22.0\r\n- Any OS\r\n\r\n\n", "before_files": [{"content": "def track_params_dists(model, run):\n from aim import Distribution\n data_hist = get_model_layers(model, 'data')\n\n for name, params in data_hist.items():\n if 'weight' in params:\n run.track(\n Distribution(params['weight']),\n name=name,\n context={\n 'type': 'data',\n 'params': 'weights',\n }\n )\n if 'bias' in params:\n run.track(\n Distribution(params['bias']),\n name=name,\n context={\n 'type': 'data',\n 'params': 'biases',\n }\n )\n\n\ndef track_gradients_dists(model, run):\n from aim import Distribution\n grad_hist = get_model_layers(model, 'grad')\n\n for name, params in grad_hist.items():\n if 'weight' in params:\n run.track(\n Distribution(params['weight']),\n name=name,\n context={\n 'type': 'gradients',\n 'params': 'weights',\n }\n )\n if 'bias' in params:\n run.track(\n Distribution(params['bias']),\n name=name,\n context={\n 'type': 'gradients',\n 'params': 'biases',\n }\n )\n\n\ndef get_model_layers(model, dt, parent_name=None):\n layers = {}\n for name, m in model.named_children():\n layer_name = '{}__{}'.format(parent_name, name) \\\n if parent_name \\\n else name\n layer_name += '.{}'.format(type(m).__name__)\n\n if len(list(m.named_children())):\n layers.update(get_model_layers(m, dt, layer_name))\n else:\n layers[layer_name] = {}\n if hasattr(m, 'weight') \\\n and m.weight is not None \\\n and hasattr(m.weight, dt):\n layers[layer_name]['weight'] = get_pt_tensor(getattr(m.weight, dt)).numpy()\n\n if hasattr(m, 'bias') \\\n and m.bias is not None \\\n and hasattr(m.bias, dt):\n layers[layer_name]['bias'] = get_pt_tensor(getattr(m.bias, dt)).numpy()\n\n return layers\n\n\n# Move tensor from GPU to CPU\ndef get_pt_tensor(t):\n return t.cpu() if hasattr(t, 'is_cuda') and t.is_cuda else t\n", "path": "aim/sdk/adapters/pytorch.py"}]}
| 1,274 | 302 |
gh_patches_debug_25849
|
rasdani/github-patches
|
git_diff
|
sunpy__sunpy-1725
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Helioviewer is not working, homepage is downloaded instead of the requested image.
Few days ago, the helioviewer interface not download the image requested.
```
from sunpy.net.helioviewer import HelioviewerClient
hv = HelioviewerClient()
hv.download_png('2012/07/16 10:08:00', 4.8, "[SDO,AIA,AIA,171,1,100],[SOHO,LASCO,C2,white-light,1,100]", x1=-2800, x2=2800, y1=-2800, y2=2800, directory='~/Desktop') # doctest: +SKIP
```
The file downloaded is the homepage from helioviewer!
</issue>
<code>
[start of sunpy/net/helioviewer.py]
1 """
2 This module provides a wrapper around the Helioviewer API.
3 """
4 from __future__ import absolute_import
5
6 #pylint: disable=E1101,F0401,W0231
7
8 __author__ = ["Keith Hughitt"]
9 __email__ = "[email protected]"
10
11 import os
12 import json
13 import codecs
14 import sunpy
15 from sunpy.time import parse_time
16 from sunpy.util.net import download_fileobj
17
18 from sunpy.extern.six.moves import urllib
19
20 __all__ = ['HelioviewerClient']
21
22
23 class HelioviewerClient(object):
24 """Helioviewer.org Client"""
25 def __init__(self, url="http://helioviewer.org/api/"):
26 self._api = url
27
28 def get_data_sources(self, **kwargs):
29 """Returns a structured list of datasources available at Helioviewer.org"""
30 params = {"action": "getDataSources"}
31 params.update(kwargs)
32
33 return self._get_json(params)
34
35 def get_closest_image(self, date, **kwargs):
36 """Finds the closest image available for the specified source and date.
37
38 For more information on what types of requests are available and the
39 expected usage for the response, consult the Helioviewer
40 API documentation: http://helioviewer.org/api
41
42 Parameters
43 ----------
44 date : `datetime.datetime`, `str`
45 A string or datetime object for the desired date of the image
46 observatory : string
47 (Optional) Observatory name
48 instrument : string
49 (Optional) instrument name
50 detector : string
51 (Optional) detector name
52 measurement : string
53 (Optional) measurement name
54 sourceId : int
55 (Optional) data source id
56
57 Returns
58 -------
59 out : `dict`
60 A dictionary containing meta-information for the closest image matched
61
62 Examples
63 --------
64 >>> from sunpy.net import HelioviewerClient
65
66 >>> client = HelioviewerClient()
67 >>> metadata = client.get_closest_image('2012/01/01', sourceId=11)
68 >>> print(metadata['date'])
69 2012-01-01 00:00:07
70 """
71 params = {
72 "action": "getClosestImage",
73 "date": self._format_date(date)
74 }
75 params.update(kwargs)
76
77 response = self._get_json(params)
78
79 # Cast date string to DateTime
80 response['date'] = parse_time(response['date'])
81
82 return response
83
84 def download_jp2(self, date, directory=None, overwrite=False, **kwargs):
85 """
86 Downloads the JPEG 2000 that most closely matches the specified time and
87 data source.
88
89 The data source may be specified either using it's sourceId from the
90 get_data_sources query, or a combination of observatory, instrument,
91 detector and measurement.
92
93 Parameters
94 ----------
95 date : `datetime.datetime`, string
96 A string or datetime object for the desired date of the image
97 directory : string
98 (Optional) Directory to download JPEG 2000 image to.
99 observatory : string
100 (Optional) Observatory name
101 instrument : string
102 (Optional) instrument name
103 detector : string
104 (Optional) detector name
105 measurement : string
106 (Optional) measurement name
107 sourceId : int
108 (Optional) data source id
109 jpip : bool
110 (Optional) Returns a JPIP URI if set to True
111
112 Returns
113 -------
114 out : string
115 Returns a filepath to the downloaded JPEG 2000 image or a URL if
116 the "jpip" parameter is set to True.
117
118 Examples
119 --------
120 >>> import sunpy.map
121 >>> from sunpy.net import helioviewer
122 >>> hv = helioviewer.HelioviewerClient()
123 >>> filepath = hv.download_jp2('2012/07/03 14:30:00', observatory='SDO', instrument='AIA', detector='AIA', measurement='171') # doctest: +SKIP
124 >>> aia = sunpy.map.Map(filepath) # doctest: +SKIP
125 >>> aia.peek() # doctest: +SKIP
126
127 >>> data_sources = hv.get_data_sources()
128 >>> hv.download_jp2('2012/07/03 14:30:00', sourceId=data_sources['SOHO']['LASCO']['C2']['white-light']['sourceId']) # doctest: +SKIP
129 """
130 params = {
131 "action": "getJP2Image",
132 "date": self._format_date(date)
133 }
134 params.update(kwargs)
135
136 # JPIP URL response
137 if 'jpip' in kwargs:
138 return self._get_json(params)
139
140 return self._get_file(params, directory, overwrite=overwrite)
141
142 def download_png(self, date, image_scale, layers, directory=None,
143 overwrite=False, **kwargs):
144 """Downloads a PNG image using data from Helioviewer.org.
145
146 Returns a single image containing all layers/image types requested.
147 If an image is not available for the date requested the closest
148 available image is returned. The region to be included in the
149 image may be specified using either the top-left and bottom-right
150 coordinates in arc-seconds, or a center point in arc-seconds and a
151 width and height in pixels. See the Helioviewer.org API Coordinates
152 Appendix for more information about working with coordinates in
153 Helioviewer.org.
154
155 Parameters
156 ----------
157 date : `datetime.datetime`, string
158 A string or datetime object for the desired date of the image
159 image_scale : float
160 The zoom scale of the image. Default scales that can be used are
161 0.6, 1.2, 2.4, and so on, increasing or decreasing by a factor
162 of 2. The full-res scale of an AIA image is 0.6.
163 layers : string
164 Each layer string is comma-separated with these values, e.g.:
165 "[sourceId,visible,opacity]" or "[obs,inst,det,meas,visible,opacity]"
166 Multiple layer string are by commas: "[layer1],[layer2],[layer3]"
167 directory : string
168 (Optional) Directory to download JPEG 2000 image to.
169 x1 : float
170 (Optional) The offset of the image's left boundary from the center
171 of the sun, in arcseconds.
172 y1 : float
173 (Optional) The offset of the image's top boundary from the center
174 of the sun, in arcseconds.
175 x2 : float
176 (Optional) The offset of the image's right boundary from the
177 center of the sun, in arcseconds.
178 y2 : float
179 (Optional) The offset of the image's bottom boundary from the
180 center of the sun, in arcseconds.
181 x0 : float
182 (Optional) The horizontal offset from the center of the Sun.
183 y0 : float
184 (Optional) The vertical offset from the center of the Sun.
185 width : int
186 (Optional) Width of the image in pixels (Maximum: 1920).
187 height : int
188 (Optional) Height of the image in pixels (Maximum: 1200).
189 watermark
190 (Optional) Whether or not the include the timestamps and the
191 Helioviewer.org logo in the image (Default=True).
192
193 Returns
194 -------
195 out : string
196 filepath to the PNG image
197
198 Examples
199 --------
200 >>> from sunpy.net.helioviewer import HelioviewerClient
201 >>> hv = HelioviewerClient()
202 >>> hv.download_png('2012/07/16 10:08:00', 2.4, "[SDO,AIA,AIA,171,1,100]", x0=0, y0=0, width=1024, height=1024) # doctest: +SKIP
203 >>> hv.download_png('2012/07/16 10:08:00', 4.8, "[SDO,AIA,AIA,171,1,100],[SOHO,LASCO,C2,white-light,1,100]", x1=-2800, x2=2800, y1=-2800, y2=2800, directory='~/Desktop') # doctest: +SKIP
204 """
205 params = {
206 "action": "takeScreenshot",
207 "date": self._format_date(date),
208 "imageScale": image_scale,
209 "layers": layers,
210 "display": True
211 }
212 params.update(kwargs)
213
214 return self._get_file(params, directory, overwrite=overwrite)
215
216 def is_online(self):
217 """Returns True if Helioviewer is online and available."""
218 try:
219 self.get_data_sources()
220 except urllib.error.URLError:
221 return False
222
223 return True
224
225 def _get_json(self, params):
226 """Returns a JSON result as a string"""
227 reader = codecs.getreader("utf-8")
228 response = self._request(params)
229 return json.load(reader(response))
230
231 def _get_file(self, params, directory=None, overwrite=False):
232 """Downloads a file and return the filepath to that file"""
233 # Query Helioviewer.org
234 if directory is None:
235 directory = sunpy.config.get('downloads', 'download_dir')
236 else:
237 directory = os.path.abspath(os.path.expanduser(directory))
238
239 response = self._request(params)
240 try:
241 filepath = download_fileobj(response, directory, overwrite=overwrite)
242 finally:
243 response.close()
244
245 return filepath
246
247 def _request(self, params):
248 """Sends an API request and returns the result
249
250 Parameters
251 ----------
252 params : `dict`
253 Parameters to send
254
255 Returns
256 -------
257 out : result of request
258 """
259 response = urllib.request.urlopen(
260 self._api, urllib.parse.urlencode(params).encode('utf-8'))
261
262 return response
263
264 def _format_date(self, date):
265 """Formats a date for Helioviewer API requests"""
266 return parse_time(date).strftime('%Y-%m-%dT%H:%M:%S.%f')[:-3] + "Z"
267
[end of sunpy/net/helioviewer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sunpy/net/helioviewer.py b/sunpy/net/helioviewer.py
--- a/sunpy/net/helioviewer.py
+++ b/sunpy/net/helioviewer.py
@@ -22,11 +22,18 @@
class HelioviewerClient(object):
"""Helioviewer.org Client"""
- def __init__(self, url="http://helioviewer.org/api/"):
+ def __init__(self, url="http://legacy.helioviewer.org/api/"):
+ """
+ url : location of the Helioviewer API. The default location points to
+ version 1 of the API. Version 1 of the Helioviewer API is
+ currently planned to be supported until the end of April 2017.
+ """
self._api = url
def get_data_sources(self, **kwargs):
- """Returns a structured list of datasources available at Helioviewer.org"""
+ """
+ Returns a structured list of datasources available at helioviewer.org.
+ """
params = {"action": "getDataSources"}
params.update(kwargs)
@@ -36,8 +43,8 @@
"""Finds the closest image available for the specified source and date.
For more information on what types of requests are available and the
- expected usage for the response, consult the Helioviewer
- API documentation: http://helioviewer.org/api
+ expected usage for the response, consult the Helioviewer API
+ documentation: http://legacy.helioviewer.org/api/docs/v1/ .
Parameters
----------
|
{"golden_diff": "diff --git a/sunpy/net/helioviewer.py b/sunpy/net/helioviewer.py\n--- a/sunpy/net/helioviewer.py\n+++ b/sunpy/net/helioviewer.py\n@@ -22,11 +22,18 @@\n \n class HelioviewerClient(object):\n \"\"\"Helioviewer.org Client\"\"\"\n- def __init__(self, url=\"http://helioviewer.org/api/\"):\n+ def __init__(self, url=\"http://legacy.helioviewer.org/api/\"):\n+ \"\"\"\n+ url : location of the Helioviewer API. The default location points to\n+ version 1 of the API. Version 1 of the Helioviewer API is\n+ currently planned to be supported until the end of April 2017.\n+ \"\"\"\n self._api = url\n \n def get_data_sources(self, **kwargs):\n- \"\"\"Returns a structured list of datasources available at Helioviewer.org\"\"\"\n+ \"\"\"\n+ Returns a structured list of datasources available at helioviewer.org.\n+ \"\"\"\n params = {\"action\": \"getDataSources\"}\n params.update(kwargs)\n \n@@ -36,8 +43,8 @@\n \"\"\"Finds the closest image available for the specified source and date.\n \n For more information on what types of requests are available and the\n- expected usage for the response, consult the Helioviewer\n- API documentation: http://helioviewer.org/api\n+ expected usage for the response, consult the Helioviewer API\n+ documentation: http://legacy.helioviewer.org/api/docs/v1/ .\n \n Parameters\n ----------\n", "issue": "Helioviewer is not working, homepage is downloaded instead of the requested image.\nFew days ago, the helioviewer interface not download the image requested.\n\n```\nfrom sunpy.net.helioviewer import HelioviewerClient\nhv = HelioviewerClient()\nhv.download_png('2012/07/16 10:08:00', 4.8, \"[SDO,AIA,AIA,171,1,100],[SOHO,LASCO,C2,white-light,1,100]\", x1=-2800, x2=2800, y1=-2800, y2=2800, directory='~/Desktop') # doctest: +SKIP\n```\n\nThe file downloaded is the homepage from helioviewer!\n\n", "before_files": [{"content": "\"\"\"\nThis module provides a wrapper around the Helioviewer API.\n\"\"\"\nfrom __future__ import absolute_import\n\n#pylint: disable=E1101,F0401,W0231\n\n__author__ = [\"Keith Hughitt\"]\n__email__ = \"[email protected]\"\n\nimport os\nimport json\nimport codecs\nimport sunpy\nfrom sunpy.time import parse_time\nfrom sunpy.util.net import download_fileobj\n\nfrom sunpy.extern.six.moves import urllib\n\n__all__ = ['HelioviewerClient']\n\n\nclass HelioviewerClient(object):\n \"\"\"Helioviewer.org Client\"\"\"\n def __init__(self, url=\"http://helioviewer.org/api/\"):\n self._api = url\n\n def get_data_sources(self, **kwargs):\n \"\"\"Returns a structured list of datasources available at Helioviewer.org\"\"\"\n params = {\"action\": \"getDataSources\"}\n params.update(kwargs)\n\n return self._get_json(params)\n\n def get_closest_image(self, date, **kwargs):\n \"\"\"Finds the closest image available for the specified source and date.\n\n For more information on what types of requests are available and the\n expected usage for the response, consult the Helioviewer\n API documentation: http://helioviewer.org/api\n\n Parameters\n ----------\n date : `datetime.datetime`, `str`\n A string or datetime object for the desired date of the image\n observatory : string\n (Optional) Observatory name\n instrument : string\n (Optional) instrument name\n detector : string\n (Optional) detector name\n measurement : string\n (Optional) measurement name\n sourceId : int\n (Optional) data source id\n\n Returns\n -------\n out : `dict`\n A dictionary containing meta-information for the closest image matched\n\n Examples\n --------\n >>> from sunpy.net import HelioviewerClient\n\n >>> client = HelioviewerClient()\n >>> metadata = client.get_closest_image('2012/01/01', sourceId=11)\n >>> print(metadata['date'])\n 2012-01-01 00:00:07\n \"\"\"\n params = {\n \"action\": \"getClosestImage\",\n \"date\": self._format_date(date)\n }\n params.update(kwargs)\n\n response = self._get_json(params)\n\n # Cast date string to DateTime\n response['date'] = parse_time(response['date'])\n\n return response\n\n def download_jp2(self, date, directory=None, overwrite=False, **kwargs):\n \"\"\"\n Downloads the JPEG 2000 that most closely matches the specified time and\n data source.\n\n The data source may be specified either using it's sourceId from the\n get_data_sources query, or a combination of observatory, instrument,\n detector and measurement.\n\n Parameters\n ----------\n date : `datetime.datetime`, string\n A string or datetime object for the desired date of the image\n directory : string\n (Optional) Directory to download JPEG 2000 image to.\n observatory : string\n (Optional) Observatory name\n instrument : string\n (Optional) instrument name\n detector : string\n (Optional) detector name\n measurement : string\n (Optional) measurement name\n sourceId : int\n (Optional) data source id\n jpip : bool\n (Optional) Returns a JPIP URI if set to True\n\n Returns\n -------\n out : string\n Returns a filepath to the downloaded JPEG 2000 image or a URL if\n the \"jpip\" parameter is set to True.\n\n Examples\n --------\n >>> import sunpy.map\n >>> from sunpy.net import helioviewer\n >>> hv = helioviewer.HelioviewerClient()\n >>> filepath = hv.download_jp2('2012/07/03 14:30:00', observatory='SDO', instrument='AIA', detector='AIA', measurement='171') # doctest: +SKIP\n >>> aia = sunpy.map.Map(filepath) # doctest: +SKIP\n >>> aia.peek() # doctest: +SKIP\n\n >>> data_sources = hv.get_data_sources()\n >>> hv.download_jp2('2012/07/03 14:30:00', sourceId=data_sources['SOHO']['LASCO']['C2']['white-light']['sourceId']) # doctest: +SKIP\n \"\"\"\n params = {\n \"action\": \"getJP2Image\",\n \"date\": self._format_date(date)\n }\n params.update(kwargs)\n\n # JPIP URL response\n if 'jpip' in kwargs:\n return self._get_json(params)\n\n return self._get_file(params, directory, overwrite=overwrite)\n\n def download_png(self, date, image_scale, layers, directory=None,\n overwrite=False, **kwargs):\n \"\"\"Downloads a PNG image using data from Helioviewer.org.\n\n Returns a single image containing all layers/image types requested.\n If an image is not available for the date requested the closest\n available image is returned. The region to be included in the\n image may be specified using either the top-left and bottom-right\n coordinates in arc-seconds, or a center point in arc-seconds and a\n width and height in pixels. See the Helioviewer.org API Coordinates\n Appendix for more information about working with coordinates in\n Helioviewer.org.\n\n Parameters\n ----------\n date : `datetime.datetime`, string\n A string or datetime object for the desired date of the image\n image_scale : float\n The zoom scale of the image. Default scales that can be used are\n 0.6, 1.2, 2.4, and so on, increasing or decreasing by a factor\n of 2. The full-res scale of an AIA image is 0.6.\n layers : string\n Each layer string is comma-separated with these values, e.g.:\n \"[sourceId,visible,opacity]\" or \"[obs,inst,det,meas,visible,opacity]\"\n Multiple layer string are by commas: \"[layer1],[layer2],[layer3]\"\n directory : string\n (Optional) Directory to download JPEG 2000 image to.\n x1 : float\n (Optional) The offset of the image's left boundary from the center\n of the sun, in arcseconds.\n y1 : float\n (Optional) The offset of the image's top boundary from the center\n of the sun, in arcseconds.\n x2 : float\n (Optional) The offset of the image's right boundary from the\n center of the sun, in arcseconds.\n y2 : float\n (Optional) The offset of the image's bottom boundary from the\n center of the sun, in arcseconds.\n x0 : float\n (Optional) The horizontal offset from the center of the Sun.\n y0 : float\n (Optional) The vertical offset from the center of the Sun.\n width : int\n (Optional) Width of the image in pixels (Maximum: 1920).\n height : int\n (Optional) Height of the image in pixels (Maximum: 1200).\n watermark\n (Optional) Whether or not the include the timestamps and the\n Helioviewer.org logo in the image (Default=True).\n\n Returns\n -------\n out : string\n filepath to the PNG image\n\n Examples\n --------\n >>> from sunpy.net.helioviewer import HelioviewerClient\n >>> hv = HelioviewerClient()\n >>> hv.download_png('2012/07/16 10:08:00', 2.4, \"[SDO,AIA,AIA,171,1,100]\", x0=0, y0=0, width=1024, height=1024) # doctest: +SKIP\n >>> hv.download_png('2012/07/16 10:08:00', 4.8, \"[SDO,AIA,AIA,171,1,100],[SOHO,LASCO,C2,white-light,1,100]\", x1=-2800, x2=2800, y1=-2800, y2=2800, directory='~/Desktop') # doctest: +SKIP\n \"\"\"\n params = {\n \"action\": \"takeScreenshot\",\n \"date\": self._format_date(date),\n \"imageScale\": image_scale,\n \"layers\": layers,\n \"display\": True\n }\n params.update(kwargs)\n\n return self._get_file(params, directory, overwrite=overwrite)\n\n def is_online(self):\n \"\"\"Returns True if Helioviewer is online and available.\"\"\"\n try:\n self.get_data_sources()\n except urllib.error.URLError:\n return False\n\n return True\n\n def _get_json(self, params):\n \"\"\"Returns a JSON result as a string\"\"\"\n reader = codecs.getreader(\"utf-8\")\n response = self._request(params)\n return json.load(reader(response))\n\n def _get_file(self, params, directory=None, overwrite=False):\n \"\"\"Downloads a file and return the filepath to that file\"\"\"\n # Query Helioviewer.org\n if directory is None:\n directory = sunpy.config.get('downloads', 'download_dir')\n else:\n directory = os.path.abspath(os.path.expanduser(directory))\n\n response = self._request(params)\n try:\n filepath = download_fileobj(response, directory, overwrite=overwrite)\n finally:\n response.close()\n\n return filepath\n\n def _request(self, params):\n \"\"\"Sends an API request and returns the result\n\n Parameters\n ----------\n params : `dict`\n Parameters to send\n\n Returns\n -------\n out : result of request\n \"\"\"\n response = urllib.request.urlopen(\n self._api, urllib.parse.urlencode(params).encode('utf-8'))\n\n return response\n\n def _format_date(self, date):\n \"\"\"Formats a date for Helioviewer API requests\"\"\"\n return parse_time(date).strftime('%Y-%m-%dT%H:%M:%S.%f')[:-3] + \"Z\"\n", "path": "sunpy/net/helioviewer.py"}]}
| 3,699 | 362 |
gh_patches_debug_9161
|
rasdani/github-patches
|
git_diff
|
ciudadanointeligente__votainteligente-portal-electoral-765
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Ordernar Propuestas
Por:
- [x] últimas creadas
- [x] Creadas por organización
- [x] Con más orazones.
Y por *defecto* puede ser:
- Random
- Por corazones, encuentro local, es organización.
</issue>
<code>
[start of popular_proposal/filters.py]
1 # coding=utf-8
2 from django_filters import (FilterSet,
3 ChoiceFilter,
4 ModelChoiceFilter,
5 )
6 from popular_proposal.models import PopularProposal
7 from popular_proposal.forms.form_texts import TOPIC_CHOICES
8 from elections.models import Area
9 from django.conf import settings
10 from constance import config
11 from django.forms import CharField, Form, ChoiceField
12 from haystack.query import SearchQuerySet
13
14
15 def filterable_areas(request):
16 if settings.FILTERABLE_AREAS_TYPE:
17 return Area.public.filter(classification__in=settings.FILTERABLE_AREAS_TYPE)
18 return Area.public.all()
19
20
21 class TextSearchForm(Form):
22 text = CharField(label=u'Qué buscas?', required=False)
23 order_by = ChoiceField(required=False,
24 label=u"Ordenar por",
25 choices=[('', u'Por apoyos'),
26 ('-created', u'Últimas primero'),
27 ])
28
29 def full_clean(self):
30 super(TextSearchForm, self).full_clean()
31 cleaned_data = {}
32 for k in self.cleaned_data:
33 v = self.cleaned_data.get(k, '')
34
35 if (isinstance(v, unicode) or isinstance(v, str)) and not v.strip():
36 cleaned_data[k] = None
37 self.cleaned_data.update(cleaned_data)
38
39
40 class ProposalWithoutAreaFilter(FilterSet):
41 clasification = ChoiceFilter(choices=TOPIC_CHOICES,
42 empty_label=u"Selecciona",
43 label=u"Clasificación")
44
45 def __init__(self,
46 data=None,
47 queryset=None,
48 prefix=None,
49 strict=None,
50 **kwargs):
51 self.area = kwargs.pop('area', None)
52 if self.area is None and data is not None:
53 self.area = data.get('area', None)
54 if self.area:
55 self.area = Area.objects.get(id=self.area)
56 if queryset is None:
57 queryset = PopularProposal.ordered.all()
58 if self.area is not None:
59 queryset = queryset.filter(area=self.area)
60 super(ProposalWithoutAreaFilter, self).__init__(data=data,
61 queryset=queryset,
62 prefix=prefix,
63 strict=strict)
64
65 @property
66 def form(self):
67 super(ProposalWithoutAreaFilter, self).form
68 is_filled_search = False
69 for k in self.data:
70 i = self.data[k]
71 is_filled_search = True
72 self._form.fields[k].initial = i
73 self._form.is_filled_search = is_filled_search
74 return self._form
75
76 @property
77 def qs(self):
78
79 super(ProposalWithoutAreaFilter, self).qs
80 self._qs = self._qs.exclude(area__id=config.HIDDEN_AREAS)
81 if not self.form.is_valid():
82 return self._qs
83 order_by = self.form.cleaned_data.get('order_by', None)
84 if order_by:
85 self._qs = self._qs.order_by(order_by)
86 else:
87 self._qs = self._qs.by_likers()
88 text = self.form.cleaned_data.get('text', '')
89
90 if text:
91 pks = []
92 text_search = SearchQuerySet().models(self._meta.model).auto_query(text)
93 for r in text_search:
94 pks.append(r.pk)
95 return self._qs.filter(id__in=pks)
96 return self._qs
97
98 class Meta:
99 model = PopularProposal
100 fields = ['clasification', ]
101 form = TextSearchForm
102
103
104 def possible_areas(request):
105 as_ = Area.public.all()
106 return as_
107
108
109 class ProposalWithAreaFilter(ProposalWithoutAreaFilter):
110 area = ModelChoiceFilter(queryset=possible_areas, label="Comuna donde fue generada")
111
112
113 class ProposalGeneratedAtFilter(ProposalWithoutAreaFilter):
114 generated_at = ModelChoiceFilter(queryset=filterable_areas,
115 empty_label=u"Selecciona",
116 label="Comuna donde fue generada")
117
[end of popular_proposal/filters.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/popular_proposal/filters.py b/popular_proposal/filters.py
--- a/popular_proposal/filters.py
+++ b/popular_proposal/filters.py
@@ -24,6 +24,8 @@
label=u"Ordenar por",
choices=[('', u'Por apoyos'),
('-created', u'Últimas primero'),
+ ('-proposer__profile__is_organization', u'De organizaciones primero'),
+ ('-is_local_meeting', u'Encuentros locales primero'),
])
def full_clean(self):
|
{"golden_diff": "diff --git a/popular_proposal/filters.py b/popular_proposal/filters.py\n--- a/popular_proposal/filters.py\n+++ b/popular_proposal/filters.py\n@@ -24,6 +24,8 @@\n label=u\"Ordenar por\",\n choices=[('', u'Por apoyos'),\n ('-created', u'\u00daltimas primero'),\n+ ('-proposer__profile__is_organization', u'De organizaciones primero'),\n+ ('-is_local_meeting', u'Encuentros locales primero'),\n ])\n \n def full_clean(self):\n", "issue": "Ordernar Propuestas\nPor:\r\n- [x] \u00faltimas creadas\r\n- [x] Creadas por organizaci\u00f3n\r\n- [x] Con m\u00e1s orazones.\r\n\r\nY por *defecto* puede ser:\r\n- Random\r\n- Por corazones, encuentro local, es organizaci\u00f3n.\n", "before_files": [{"content": "# coding=utf-8\nfrom django_filters import (FilterSet,\n ChoiceFilter,\n ModelChoiceFilter,\n )\nfrom popular_proposal.models import PopularProposal\nfrom popular_proposal.forms.form_texts import TOPIC_CHOICES\nfrom elections.models import Area\nfrom django.conf import settings\nfrom constance import config\nfrom django.forms import CharField, Form, ChoiceField\nfrom haystack.query import SearchQuerySet\n\n\ndef filterable_areas(request):\n if settings.FILTERABLE_AREAS_TYPE:\n return Area.public.filter(classification__in=settings.FILTERABLE_AREAS_TYPE)\n return Area.public.all()\n\n\nclass TextSearchForm(Form):\n text = CharField(label=u'Qu\u00e9 buscas?', required=False)\n order_by = ChoiceField(required=False,\n label=u\"Ordenar por\",\n choices=[('', u'Por apoyos'),\n ('-created', u'\u00daltimas primero'),\n ])\n\n def full_clean(self):\n super(TextSearchForm, self).full_clean()\n cleaned_data = {}\n for k in self.cleaned_data:\n v = self.cleaned_data.get(k, '')\n\n if (isinstance(v, unicode) or isinstance(v, str)) and not v.strip():\n cleaned_data[k] = None\n self.cleaned_data.update(cleaned_data)\n\n\nclass ProposalWithoutAreaFilter(FilterSet):\n clasification = ChoiceFilter(choices=TOPIC_CHOICES,\n empty_label=u\"Selecciona\",\n label=u\"Clasificaci\u00f3n\")\n\n def __init__(self,\n data=None,\n queryset=None,\n prefix=None,\n strict=None,\n **kwargs):\n self.area = kwargs.pop('area', None)\n if self.area is None and data is not None:\n self.area = data.get('area', None)\n if self.area:\n self.area = Area.objects.get(id=self.area)\n if queryset is None:\n queryset = PopularProposal.ordered.all()\n if self.area is not None:\n queryset = queryset.filter(area=self.area)\n super(ProposalWithoutAreaFilter, self).__init__(data=data,\n queryset=queryset,\n prefix=prefix,\n strict=strict)\n\n @property\n def form(self):\n super(ProposalWithoutAreaFilter, self).form\n is_filled_search = False\n for k in self.data:\n i = self.data[k]\n is_filled_search = True\n self._form.fields[k].initial = i\n self._form.is_filled_search = is_filled_search\n return self._form\n\n @property\n def qs(self):\n\n super(ProposalWithoutAreaFilter, self).qs\n self._qs = self._qs.exclude(area__id=config.HIDDEN_AREAS)\n if not self.form.is_valid():\n return self._qs\n order_by = self.form.cleaned_data.get('order_by', None)\n if order_by:\n self._qs = self._qs.order_by(order_by)\n else:\n self._qs = self._qs.by_likers()\n text = self.form.cleaned_data.get('text', '')\n\n if text:\n pks = []\n text_search = SearchQuerySet().models(self._meta.model).auto_query(text)\n for r in text_search:\n pks.append(r.pk)\n return self._qs.filter(id__in=pks)\n return self._qs\n\n class Meta:\n model = PopularProposal\n fields = ['clasification', ]\n form = TextSearchForm\n\n\ndef possible_areas(request):\n as_ = Area.public.all()\n return as_\n\n\nclass ProposalWithAreaFilter(ProposalWithoutAreaFilter):\n area = ModelChoiceFilter(queryset=possible_areas, label=\"Comuna donde fue generada\")\n\n\nclass ProposalGeneratedAtFilter(ProposalWithoutAreaFilter):\n generated_at = ModelChoiceFilter(queryset=filterable_areas,\n empty_label=u\"Selecciona\",\n label=\"Comuna donde fue generada\")\n", "path": "popular_proposal/filters.py"}]}
| 1,670 | 128 |
gh_patches_debug_14109
|
rasdani/github-patches
|
git_diff
|
mindsdb__lightwood-434
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
LightGBM is not deterministic
* Lightwood version: 0.58.0
Currently, our LightGBM mixer is not deterministic, presenting slight performance differences when trained for the same dataset. We should fix the corresponding random seeds so that this is doesn't happen anymore.
</issue>
<code>
[start of lightwood/mixers/lightgbm.py]
1 import numpy as np
2 import optuna.integration.lightgbm as lgb
3 import lightgbm
4 import optuna
5 import torch
6 import logging
7 import time
8
9 from lightwood.constants.lightwood import COLUMN_DATA_TYPES
10 from lightwood.helpers.device import get_devices
11 from lightwood.mixers import BaseMixer
12 from sklearn.preprocessing import OrdinalEncoder
13
14
15 optuna.logging.set_verbosity(optuna.logging.CRITICAL)
16
17
18 def check_gpu_support():
19 try:
20 data = np.random.rand(50, 2)
21 label = np.random.randint(2, size=50)
22 train_data = lightgbm.Dataset(data, label=label)
23 params = {'num_iterations': 1, 'device': 'gpu'}
24 gbm = lightgbm.train(params, train_set=train_data)
25 return True
26 except Exception as e:
27 return False
28
29 class LightGBMMixer(BaseMixer):
30 def __init__(self, stop_training_after_seconds=None, grid_search=False):
31 super().__init__()
32 self.models = {}
33 self.ord_encs = {}
34 self.label_sets = {}
35 self.stop_training_after_seconds = stop_training_after_seconds
36 self.grid_search = grid_search # using Optuna
37
38 # GPU Only available via --install-option=--gpu with opencl-dev and libboost dev (a bunch of them) installed, so let's turn this off for now and we can put it behind some flag later
39 self.device, _ = get_devices()
40 self.device_str = 'cpu' if str(self.device) == 'cpu' else 'gpu'
41 if self.device_str == 'gpu':
42 gpu_works = check_gpu_support()
43 if not gpu_works:
44 self.device = torch.device('cpu')
45 self.device_str = 'cpu'
46
47 self.max_bin = 255 # Default value
48 if self.device_str == 'gpu':
49 self.max_bin = 63 # As recommended by https://lightgbm.readthedocs.io/en/latest/Parameters.html#device_type
50
51 def _fit(self, train_ds, test_ds=None):
52 """
53 :param train_ds: DataSource
54 :param test_ds: DataSource
55 """
56
57 data = {
58 'train': {'ds': train_ds, 'data': None, 'label_data': {}},
59 'test': {'ds': test_ds, 'data': None, 'label_data': {}}
60 }
61
62 # Order is important here
63 for subset_name in ['train','test']:
64 cols = data[subset_name]['ds'].input_feature_names
65 out_cols = data[subset_name]['ds'].output_feature_names
66 for col_name in cols:
67 if data[subset_name]['data'] is None:
68 data[subset_name]['data'] = data[subset_name]['ds'].get_encoded_column_data(col_name).to(self.device)
69 else:
70 enc_col = data[subset_name]['ds'].get_encoded_column_data(col_name)
71 data[subset_name]['data'] = torch.cat((data[subset_name]['data'], enc_col.to(self.device)), 1)
72 data[subset_name]['data'] = data[subset_name]['data'].tolist()
73 for col_name in out_cols:
74 label_data = data[subset_name]['ds'].get_column_original_data(col_name)
75 if next(item for item in train_ds.output_features if item["name"] == col_name)['type'] == COLUMN_DATA_TYPES.CATEGORICAL:
76 if subset_name == 'train':
77 self.ord_encs[col_name] = OrdinalEncoder()
78 self.label_sets[col_name] = set(label_data)
79 self.label_sets[col_name].add('__mdb_unknown_cat')
80 self.ord_encs[col_name].fit(np.array(list(self.label_sets[col_name])).reshape(-1, 1))
81
82 label_data = [x if x in self.label_sets[col_name] else '__mdb_unknown_cat' for x in label_data]
83 label_data = self.ord_encs[col_name].transform(np.array(label_data).reshape(-1, 1)).flatten()
84
85 data[subset_name]['label_data'][col_name] = label_data
86
87 for col_name in train_ds.output_feature_names:
88 dtype = next(item for item in train_ds.output_features if item["name"] == col_name)['type']
89 if dtype not in [COLUMN_DATA_TYPES.NUMERIC, COLUMN_DATA_TYPES.CATEGORICAL]:
90 logging.info('cannot support {dtype} in lightgbm'.format(dtype=dtype))
91 continue
92 else:
93 objective = 'regression' if dtype == COLUMN_DATA_TYPES.NUMERIC else 'multiclass'
94 metric = 'l2' if dtype == COLUMN_DATA_TYPES.NUMERIC else 'multi_logloss'
95
96 params = {'objective': objective,
97 'metric': metric,
98 'verbose': -1,
99 'lambda_l1': 0.1,
100 'lambda_l2': 0.1,
101 'force_row_wise': True,
102 'device_type': self.device_str
103 }
104 if objective == 'multiclass':
105 self.all_classes = self.ord_encs[col_name].categories_[0]
106 params['num_class'] = self.all_classes.size
107
108 num_iterations = 50
109 kwargs = {}
110
111 if self.stop_training_after_seconds is not None:
112 train_data = lightgbm.Dataset(data['train']['data'], label=data['train']['label_data'][col_name])
113 validate_data = lightgbm.Dataset(data['test']['data'], label=data['test']['label_data'][col_name])
114 start = time.time()
115 params['num_iterations'] = 1
116 bst = lightgbm.train(params, train_data, valid_sets=validate_data, verbose_eval=False)
117 end = time.time()
118 seconds_for_one_iteration = max(0.1, end - start)
119 logging.info(f'A single GBM itteration takes {seconds_for_one_iteration} seconds')
120 max_itt = int(self.stop_training_after_seconds / seconds_for_one_iteration)
121 num_iterations = max(1, min(num_iterations, max_itt))
122 # Turn on grid search if training doesn't take too long using it
123 if max_itt >= num_iterations and seconds_for_one_iteration < 10:
124 self.grid_search = True
125 kwargs['time_budget'] = self.stop_training_after_seconds
126
127 train_data = lightgbm.Dataset(data['train']['data'], label=data['train']['label_data'][col_name])
128 validate_data = lightgbm.Dataset(data['test']['data'], label=data['test']['label_data'][col_name])
129 model = lgb if self.grid_search else lightgbm
130 logging.info(f'Training GBM ({model}) with {num_iterations} iterations given {self.stop_training_after_seconds} seconds constraint')
131 params['num_iterations'] = num_iterations
132 bst = model.train(params, train_data, valid_sets=validate_data, verbose_eval=False, **kwargs)
133
134 self.models[col_name] = bst
135
136 def _predict(self, when_data_source, include_extra_data=False):
137 """
138 :param when_data_source: DataSource
139 :param include_extra_data: bool
140 """
141 data = None
142 for col_name in when_data_source.input_feature_names:
143 if data is None:
144 data = when_data_source.get_encoded_column_data(col_name).to(self.device)
145 else:
146 data = torch.cat((data, when_data_source.get_encoded_column_data(col_name).to(self.device)), 1)
147 data = data.tolist()
148
149 ypred = {}
150 for col_name in when_data_source.output_feature_names:
151 col_config = [conf for conf in when_data_source.config['output_features'] if conf['name'] == col_name][0]
152 col_preds = self.models[col_name].predict(data)
153 ypred[col_name] = {}
154 if col_name in self.ord_encs:
155 ypred[col_name]['class_distribution'] = list(col_preds)
156 ypred[col_name]['class_labels'] = {i: cls for i, cls in enumerate(self.all_classes)}
157 col_preds = self.ord_encs[col_name].inverse_transform(np.argmax(col_preds, axis=1).reshape(-1, 1)).flatten()
158 if col_config.get('encoder_attrs', False):
159 if col_config['encoder_attrs'].get('positive_domain', False):
160 col_preds = col_preds.clip(0)
161 ypred[col_name]['predictions'] = list(col_preds)
162
163 return ypred
164
[end of lightwood/mixers/lightgbm.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lightwood/mixers/lightgbm.py b/lightwood/mixers/lightgbm.py
--- a/lightwood/mixers/lightgbm.py
+++ b/lightwood/mixers/lightgbm.py
@@ -123,6 +123,7 @@
if max_itt >= num_iterations and seconds_for_one_iteration < 10:
self.grid_search = True
kwargs['time_budget'] = self.stop_training_after_seconds
+ kwargs['optuna_seed'] = 0 # for reproducible grid search results
train_data = lightgbm.Dataset(data['train']['data'], label=data['train']['label_data'][col_name])
validate_data = lightgbm.Dataset(data['test']['data'], label=data['test']['label_data'][col_name])
|
{"golden_diff": "diff --git a/lightwood/mixers/lightgbm.py b/lightwood/mixers/lightgbm.py\n--- a/lightwood/mixers/lightgbm.py\n+++ b/lightwood/mixers/lightgbm.py\n@@ -123,6 +123,7 @@\n if max_itt >= num_iterations and seconds_for_one_iteration < 10:\n self.grid_search = True\n kwargs['time_budget'] = self.stop_training_after_seconds\n+ kwargs['optuna_seed'] = 0 # for reproducible grid search results\n \n train_data = lightgbm.Dataset(data['train']['data'], label=data['train']['label_data'][col_name])\n validate_data = lightgbm.Dataset(data['test']['data'], label=data['test']['label_data'][col_name])\n", "issue": "LightGBM is not deterministic\n* Lightwood version: 0.58.0\r\n\r\nCurrently, our LightGBM mixer is not deterministic, presenting slight performance differences when trained for the same dataset. We should fix the corresponding random seeds so that this is doesn't happen anymore.\r\n\n", "before_files": [{"content": "import numpy as np\nimport optuna.integration.lightgbm as lgb\nimport lightgbm\nimport optuna\nimport torch\nimport logging\nimport time\n\nfrom lightwood.constants.lightwood import COLUMN_DATA_TYPES\nfrom lightwood.helpers.device import get_devices\nfrom lightwood.mixers import BaseMixer\nfrom sklearn.preprocessing import OrdinalEncoder\n\n\noptuna.logging.set_verbosity(optuna.logging.CRITICAL)\n\n\ndef check_gpu_support():\n try:\n data = np.random.rand(50, 2)\n label = np.random.randint(2, size=50)\n train_data = lightgbm.Dataset(data, label=label)\n params = {'num_iterations': 1, 'device': 'gpu'}\n gbm = lightgbm.train(params, train_set=train_data)\n return True\n except Exception as e:\n return False\n\nclass LightGBMMixer(BaseMixer):\n def __init__(self, stop_training_after_seconds=None, grid_search=False):\n super().__init__()\n self.models = {}\n self.ord_encs = {}\n self.label_sets = {}\n self.stop_training_after_seconds = stop_training_after_seconds\n self.grid_search = grid_search # using Optuna\n\n # GPU Only available via --install-option=--gpu with opencl-dev and libboost dev (a bunch of them) installed, so let's turn this off for now and we can put it behind some flag later\n self.device, _ = get_devices()\n self.device_str = 'cpu' if str(self.device) == 'cpu' else 'gpu'\n if self.device_str == 'gpu':\n gpu_works = check_gpu_support()\n if not gpu_works:\n self.device = torch.device('cpu')\n self.device_str = 'cpu'\n\n self.max_bin = 255 # Default value\n if self.device_str == 'gpu':\n self.max_bin = 63 # As recommended by https://lightgbm.readthedocs.io/en/latest/Parameters.html#device_type\n\n def _fit(self, train_ds, test_ds=None):\n \"\"\"\n :param train_ds: DataSource\n :param test_ds: DataSource\n \"\"\"\n\n data = {\n 'train': {'ds': train_ds, 'data': None, 'label_data': {}},\n 'test': {'ds': test_ds, 'data': None, 'label_data': {}}\n }\n\n # Order is important here\n for subset_name in ['train','test']:\n cols = data[subset_name]['ds'].input_feature_names\n out_cols = data[subset_name]['ds'].output_feature_names\n for col_name in cols:\n if data[subset_name]['data'] is None:\n data[subset_name]['data'] = data[subset_name]['ds'].get_encoded_column_data(col_name).to(self.device)\n else:\n enc_col = data[subset_name]['ds'].get_encoded_column_data(col_name)\n data[subset_name]['data'] = torch.cat((data[subset_name]['data'], enc_col.to(self.device)), 1)\n data[subset_name]['data'] = data[subset_name]['data'].tolist()\n for col_name in out_cols:\n label_data = data[subset_name]['ds'].get_column_original_data(col_name)\n if next(item for item in train_ds.output_features if item[\"name\"] == col_name)['type'] == COLUMN_DATA_TYPES.CATEGORICAL:\n if subset_name == 'train':\n self.ord_encs[col_name] = OrdinalEncoder()\n self.label_sets[col_name] = set(label_data)\n self.label_sets[col_name].add('__mdb_unknown_cat')\n self.ord_encs[col_name].fit(np.array(list(self.label_sets[col_name])).reshape(-1, 1))\n\n label_data = [x if x in self.label_sets[col_name] else '__mdb_unknown_cat' for x in label_data]\n label_data = self.ord_encs[col_name].transform(np.array(label_data).reshape(-1, 1)).flatten()\n\n data[subset_name]['label_data'][col_name] = label_data\n\n for col_name in train_ds.output_feature_names:\n dtype = next(item for item in train_ds.output_features if item[\"name\"] == col_name)['type']\n if dtype not in [COLUMN_DATA_TYPES.NUMERIC, COLUMN_DATA_TYPES.CATEGORICAL]:\n logging.info('cannot support {dtype} in lightgbm'.format(dtype=dtype))\n continue\n else:\n objective = 'regression' if dtype == COLUMN_DATA_TYPES.NUMERIC else 'multiclass'\n metric = 'l2' if dtype == COLUMN_DATA_TYPES.NUMERIC else 'multi_logloss'\n\n params = {'objective': objective,\n 'metric': metric,\n 'verbose': -1,\n 'lambda_l1': 0.1,\n 'lambda_l2': 0.1,\n 'force_row_wise': True,\n 'device_type': self.device_str\n }\n if objective == 'multiclass':\n self.all_classes = self.ord_encs[col_name].categories_[0]\n params['num_class'] = self.all_classes.size\n\n num_iterations = 50\n kwargs = {}\n\n if self.stop_training_after_seconds is not None:\n train_data = lightgbm.Dataset(data['train']['data'], label=data['train']['label_data'][col_name])\n validate_data = lightgbm.Dataset(data['test']['data'], label=data['test']['label_data'][col_name])\n start = time.time()\n params['num_iterations'] = 1\n bst = lightgbm.train(params, train_data, valid_sets=validate_data, verbose_eval=False)\n end = time.time()\n seconds_for_one_iteration = max(0.1, end - start)\n logging.info(f'A single GBM itteration takes {seconds_for_one_iteration} seconds')\n max_itt = int(self.stop_training_after_seconds / seconds_for_one_iteration)\n num_iterations = max(1, min(num_iterations, max_itt))\n # Turn on grid search if training doesn't take too long using it\n if max_itt >= num_iterations and seconds_for_one_iteration < 10:\n self.grid_search = True\n kwargs['time_budget'] = self.stop_training_after_seconds\n\n train_data = lightgbm.Dataset(data['train']['data'], label=data['train']['label_data'][col_name])\n validate_data = lightgbm.Dataset(data['test']['data'], label=data['test']['label_data'][col_name])\n model = lgb if self.grid_search else lightgbm\n logging.info(f'Training GBM ({model}) with {num_iterations} iterations given {self.stop_training_after_seconds} seconds constraint')\n params['num_iterations'] = num_iterations\n bst = model.train(params, train_data, valid_sets=validate_data, verbose_eval=False, **kwargs)\n\n self.models[col_name] = bst\n\n def _predict(self, when_data_source, include_extra_data=False):\n \"\"\"\n :param when_data_source: DataSource\n :param include_extra_data: bool\n \"\"\"\n data = None\n for col_name in when_data_source.input_feature_names:\n if data is None:\n data = when_data_source.get_encoded_column_data(col_name).to(self.device)\n else:\n data = torch.cat((data, when_data_source.get_encoded_column_data(col_name).to(self.device)), 1)\n data = data.tolist()\n\n ypred = {}\n for col_name in when_data_source.output_feature_names:\n col_config = [conf for conf in when_data_source.config['output_features'] if conf['name'] == col_name][0]\n col_preds = self.models[col_name].predict(data)\n ypred[col_name] = {}\n if col_name in self.ord_encs:\n ypred[col_name]['class_distribution'] = list(col_preds)\n ypred[col_name]['class_labels'] = {i: cls for i, cls in enumerate(self.all_classes)}\n col_preds = self.ord_encs[col_name].inverse_transform(np.argmax(col_preds, axis=1).reshape(-1, 1)).flatten()\n if col_config.get('encoder_attrs', False):\n if col_config['encoder_attrs'].get('positive_domain', False):\n col_preds = col_preds.clip(0)\n ypred[col_name]['predictions'] = list(col_preds)\n\n return ypred\n", "path": "lightwood/mixers/lightgbm.py"}]}
| 2,779 | 170 |
gh_patches_debug_5999
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-4515
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Homebase spider webpage regex is too restrictive
The homebase_gb_ie.py spider contains a regex in sitemap_rules to restrict things to store pages:
`sitemap_rules = [(r"https:\/\/store\.homebase\.co\.uk\/[-\w]+\/[-.\w]+$", "parse_sd")]`
This regex is slightly too strict, as there's a store with a "." in the place level: https://store.homebase.co.uk/st.-albans/the-courtyard-alban-park , which is currently not returned.
To include this store, the regex should presumably be changed to
`sitemap_rules = [(r"https:\/\/store\.homebase\.co\.uk\/[-.\w]+\/[-.\w]+$", "parse_sd")]`
</issue>
<code>
[start of locations/spiders/homebase_gb_ie.py]
1 from scrapy.spiders import SitemapSpider
2
3 from locations.structured_data_spider import StructuredDataSpider
4
5
6 class HomebaseGBIESpider(SitemapSpider, StructuredDataSpider):
7 name = "homebase_gb_ie"
8 item_attributes = {"brand": "Homebase", "brand_wikidata": "Q9293447"}
9 sitemap_urls = ["https://store.homebase.co.uk/robots.txt"]
10 sitemap_rules = [(r"https:\/\/store\.homebase\.co\.uk\/[-\w]+\/[-.\w]+$", "parse_sd")]
11 skip_auto_cc = True
12
[end of locations/spiders/homebase_gb_ie.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/locations/spiders/homebase_gb_ie.py b/locations/spiders/homebase_gb_ie.py
--- a/locations/spiders/homebase_gb_ie.py
+++ b/locations/spiders/homebase_gb_ie.py
@@ -7,5 +7,5 @@
name = "homebase_gb_ie"
item_attributes = {"brand": "Homebase", "brand_wikidata": "Q9293447"}
sitemap_urls = ["https://store.homebase.co.uk/robots.txt"]
- sitemap_rules = [(r"https:\/\/store\.homebase\.co\.uk\/[-\w]+\/[-.\w]+$", "parse_sd")]
+ sitemap_rules = [(r"https:\/\/store\.homebase\.co\.uk\/[-.\w]+\/[-.\w]+$", "parse_sd")]
skip_auto_cc = True
|
{"golden_diff": "diff --git a/locations/spiders/homebase_gb_ie.py b/locations/spiders/homebase_gb_ie.py\n--- a/locations/spiders/homebase_gb_ie.py\n+++ b/locations/spiders/homebase_gb_ie.py\n@@ -7,5 +7,5 @@\n name = \"homebase_gb_ie\"\n item_attributes = {\"brand\": \"Homebase\", \"brand_wikidata\": \"Q9293447\"}\n sitemap_urls = [\"https://store.homebase.co.uk/robots.txt\"]\n- sitemap_rules = [(r\"https:\\/\\/store\\.homebase\\.co\\.uk\\/[-\\w]+\\/[-.\\w]+$\", \"parse_sd\")]\n+ sitemap_rules = [(r\"https:\\/\\/store\\.homebase\\.co\\.uk\\/[-.\\w]+\\/[-.\\w]+$\", \"parse_sd\")]\n skip_auto_cc = True\n", "issue": "Homebase spider webpage regex is too restrictive\nThe homebase_gb_ie.py spider contains a regex in sitemap_rules to restrict things to store pages:\r\n`sitemap_rules = [(r\"https:\\/\\/store\\.homebase\\.co\\.uk\\/[-\\w]+\\/[-.\\w]+$\", \"parse_sd\")]`\r\n\r\nThis regex is slightly too strict, as there's a store with a \".\" in the place level: https://store.homebase.co.uk/st.-albans/the-courtyard-alban-park , which is currently not returned.\r\n\r\nTo include this store, the regex should presumably be changed to\r\n`sitemap_rules = [(r\"https:\\/\\/store\\.homebase\\.co\\.uk\\/[-.\\w]+\\/[-.\\w]+$\", \"parse_sd\")]`\n", "before_files": [{"content": "from scrapy.spiders import SitemapSpider\n\nfrom locations.structured_data_spider import StructuredDataSpider\n\n\nclass HomebaseGBIESpider(SitemapSpider, StructuredDataSpider):\n name = \"homebase_gb_ie\"\n item_attributes = {\"brand\": \"Homebase\", \"brand_wikidata\": \"Q9293447\"}\n sitemap_urls = [\"https://store.homebase.co.uk/robots.txt\"]\n sitemap_rules = [(r\"https:\\/\\/store\\.homebase\\.co\\.uk\\/[-\\w]+\\/[-.\\w]+$\", \"parse_sd\")]\n skip_auto_cc = True\n", "path": "locations/spiders/homebase_gb_ie.py"}]}
| 844 | 184 |
gh_patches_debug_25900
|
rasdani/github-patches
|
git_diff
|
ray-project__ray-5653
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[tune] AssertionError: Resource invalid
<!--
General questions should be asked on the mailing list [email protected].
Questions about how to use Ray should be asked on
[StackOverflow](https://stackoverflow.com/questions/tagged/ray).
Before submitting an issue, please fill out the following form.
-->
### System information
- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**:
Ubuntu 16.04
- **Ray installed from (source or binary)**:
pip install https://s3-us-west-2.amazonaws.com/ray-wheels/latest/ray-0.8.0.dev4-cp36-cp36m-manylinux1_x86_64.whl
- **Ray version**:
0.8.0.dev4
- **Python version**:
3.6.7
- **Exact command to reproduce**:
<!--
You can obtain the Ray version with
python -c "import ray; print(ray.__version__)"
-->
### Describe the problem
<!-- Describe the problem clearly here. -->
I run 5 trials with ray.tune. In one of the trials (each time), an error occurs at the end of training: `AssertionError: Resource invalid: Resources(cpu=3, gpu=0.33, memory=0, object_store_memory=0, extra_cpu=0, extra_gpu=0, extra_memory=0, extra_object_store_memory=0, custom_resources={}, extra_custom_resources={})`.
When I trace back the error, I end up in the following function (ray/tune/resources.py):
```
def is_nonnegative(self):
all_values = [self.cpu, self.gpu, self.extra_cpu, self.extra_gpu]
all_values += list(self.custom_resources.values())
all_values += list(self.extra_custom_resources.values())
return all(v >= 0 for v in all_values)
```
It seems `custom_resources` and `extra_custom_resources` are not defined. It is weird that the error only occurs in one run... Is this a bug, or any suggestions on how to fix?
### Source code / logs
<!-- Include any logs or source code that would be helpful to diagnose the problem. If including tracebacks, please include the full traceback. Large logs and files should be attached. Try to provide a reproducible test case that is the bare minimum necessary to generate the problem. -->
__This is how I call `tune.run`__
```
tune.run(
ModelTrainerMT,
resources_per_trial={
'cpu': config['ncpu'],
'gpu': config['ngpu'],
},
num_samples=1,
config=best_config,
local_dir=store,
raise_on_failed_trial=True,
verbose=1,
with_server=False,
ray_auto_init=False,
scheduler=early_stopping_scheduler,
loggers=[JsonLogger, CSVLogger],
checkpoint_at_end=True,
reuse_actors=True,
stop={'epoch': 2 if args.test else config['max_t']}
)
```
__Traceback__
```
2019-09-06 09:56:45,526 ERROR trial_runner.py:557 -- Error processing event.
Traceback (most recent call last):
File "/opt/conda/lib/python3.6/site-packages/ray/tune/trial_runner.py", line 552, in _process_trial
self.trial_executor.stop_trial(trial)
File "/opt/conda/lib/python3.6/site-packages/ray/tune/ray_trial_executor.py", line 246, in stop_trial
self._return_resources(trial.resources)
File "/opt/conda/lib/python3.6/site-packages/ray/tune/ray_trial_executor.py", line 388, in _return_resources
"Resource invalid: {}".format(resources))
AssertionError: Resource invalid: Resources(cpu=3, gpu=0.33, memory=0, object_store_memory=0, extra_cpu=0, extra_gpu=0, extra_memory=0, extra_object_store_memory=0, custom_resources={}, extra_custom_resources={})
```
</issue>
<code>
[start of python/ray/tune/resources.py]
1 from __future__ import absolute_import
2 from __future__ import division
3 from __future__ import print_function
4
5 from collections import namedtuple
6 import logging
7 import json
8 # For compatibility under py2 to consider unicode as str
9 from six import string_types
10
11 from numbers import Number
12
13 from ray.tune import TuneError
14
15 logger = logging.getLogger(__name__)
16
17
18 class Resources(
19 namedtuple("Resources", [
20 "cpu", "gpu", "memory", "object_store_memory", "extra_cpu",
21 "extra_gpu", "extra_memory", "extra_object_store_memory",
22 "custom_resources", "extra_custom_resources"
23 ])):
24 """Ray resources required to schedule a trial.
25
26 Attributes:
27 cpu (float): Number of CPUs to allocate to the trial.
28 gpu (float): Number of GPUs to allocate to the trial.
29 memory (float): Memory to reserve for the trial.
30 object_store_memory (float): Object store memory to reserve.
31 extra_cpu (float): Extra CPUs to reserve in case the trial needs to
32 launch additional Ray actors that use CPUs.
33 extra_gpu (float): Extra GPUs to reserve in case the trial needs to
34 launch additional Ray actors that use GPUs.
35 extra_memory (float): Memory to reserve for the trial launching
36 additional Ray actors that use memory.
37 extra_object_store_memory (float): Object store memory to reserve for
38 the trial launching additional Ray actors that use object store
39 memory.
40 custom_resources (dict): Mapping of resource to quantity to allocate
41 to the trial.
42 extra_custom_resources (dict): Extra custom resources to reserve in
43 case the trial needs to launch additional Ray actors that use
44 any of these custom resources.
45
46 """
47
48 __slots__ = ()
49
50 def __new__(cls,
51 cpu,
52 gpu,
53 memory=0,
54 object_store_memory=0,
55 extra_cpu=0,
56 extra_gpu=0,
57 extra_memory=0,
58 extra_object_store_memory=0,
59 custom_resources=None,
60 extra_custom_resources=None):
61 custom_resources = custom_resources or {}
62 extra_custom_resources = extra_custom_resources or {}
63 leftovers = set(custom_resources) ^ set(extra_custom_resources)
64
65 for value in leftovers:
66 custom_resources.setdefault(value, 0)
67 extra_custom_resources.setdefault(value, 0)
68
69 all_values = [
70 cpu, gpu, memory, object_store_memory, extra_cpu, extra_gpu,
71 extra_memory, extra_object_store_memory
72 ]
73 all_values += list(custom_resources.values())
74 all_values += list(extra_custom_resources.values())
75 assert len(custom_resources) == len(extra_custom_resources)
76 for entry in all_values:
77 assert isinstance(entry, Number), ("Improper resource value.",
78 entry)
79 return super(Resources, cls).__new__(
80 cls, cpu, gpu, memory, object_store_memory, extra_cpu, extra_gpu,
81 extra_memory, extra_object_store_memory, custom_resources,
82 extra_custom_resources)
83
84 def summary_string(self):
85 summary = "{} CPUs, {} GPUs".format(self.cpu + self.extra_cpu,
86 self.gpu + self.extra_gpu)
87 if self.memory or self.extra_memory:
88 summary += ", {} GiB heap".format(
89 round((self.memory + self.extra_memory) / (1024**3), 2))
90 if self.object_store_memory or self.extra_object_store_memory:
91 summary += ", {} GiB objects".format(
92 round(
93 (self.object_store_memory + self.extra_object_store_memory)
94 / (1024**3), 2))
95 custom_summary = ", ".join([
96 "{} {}".format(self.get_res_total(res), res)
97 for res in self.custom_resources
98 ])
99 if custom_summary:
100 summary += " ({})".format(custom_summary)
101 return summary
102
103 def cpu_total(self):
104 return self.cpu + self.extra_cpu
105
106 def gpu_total(self):
107 return self.gpu + self.extra_gpu
108
109 def memory_total(self):
110 return self.memory + self.extra_memory
111
112 def object_store_memory_total(self):
113 return self.object_store_memory + self.extra_object_store_memory
114
115 def get_res_total(self, key):
116 return self.custom_resources.get(
117 key, 0) + self.extra_custom_resources.get(key, 0)
118
119 def get(self, key):
120 return self.custom_resources.get(key, 0)
121
122 def is_nonnegative(self):
123 all_values = [self.cpu, self.gpu, self.extra_cpu, self.extra_gpu]
124 all_values += list(self.custom_resources.values())
125 all_values += list(self.extra_custom_resources.values())
126 return all(v >= 0 for v in all_values)
127
128 @classmethod
129 def subtract(cls, original, to_remove):
130 cpu = original.cpu - to_remove.cpu
131 gpu = original.gpu - to_remove.gpu
132 memory = original.memory - to_remove.memory
133 object_store_memory = (
134 original.object_store_memory - to_remove.object_store_memory)
135 extra_cpu = original.extra_cpu - to_remove.extra_cpu
136 extra_gpu = original.extra_gpu - to_remove.extra_gpu
137 extra_memory = original.extra_memory - to_remove.extra_memory
138 extra_object_store_memory = (original.extra_object_store_memory -
139 to_remove.extra_object_store_memory)
140 all_resources = set(original.custom_resources).union(
141 set(to_remove.custom_resources))
142 new_custom_res = {
143 k: original.custom_resources.get(k, 0) -
144 to_remove.custom_resources.get(k, 0)
145 for k in all_resources
146 }
147 extra_custom_res = {
148 k: original.extra_custom_resources.get(k, 0) -
149 to_remove.extra_custom_resources.get(k, 0)
150 for k in all_resources
151 }
152 return Resources(cpu, gpu, memory, object_store_memory, extra_cpu,
153 extra_gpu, extra_memory, extra_object_store_memory,
154 new_custom_res, extra_custom_res)
155
156 def to_json(self):
157 return resources_to_json(self)
158
159
160 def json_to_resources(data):
161 if data is None or data == "null":
162 return None
163 if isinstance(data, string_types):
164 data = json.loads(data)
165 for k in data:
166 if k in ["driver_cpu_limit", "driver_gpu_limit"]:
167 raise TuneError(
168 "The field `{}` is no longer supported. Use `extra_cpu` "
169 "or `extra_gpu` instead.".format(k))
170 if k not in Resources._fields:
171 raise ValueError(
172 "Unknown resource field {}, must be one of {}".format(
173 k, Resources._fields))
174 return Resources(
175 data.get("cpu", 1), data.get("gpu", 0), data.get("memory", 0),
176 data.get("object_store_memory", 0), data.get("extra_cpu", 0),
177 data.get("extra_gpu", 0), data.get("extra_memory", 0),
178 data.get("extra_object_store_memory", 0), data.get("custom_resources"),
179 data.get("extra_custom_resources"))
180
181
182 def resources_to_json(resources):
183 if resources is None:
184 return None
185 return {
186 "cpu": resources.cpu,
187 "gpu": resources.gpu,
188 "memory": resources.memory,
189 "object_store_memory": resources.object_store_memory,
190 "extra_cpu": resources.extra_cpu,
191 "extra_gpu": resources.extra_gpu,
192 "extra_memory": resources.extra_memory,
193 "extra_object_store_memory": resources.extra_object_store_memory,
194 "custom_resources": resources.custom_resources.copy(),
195 "extra_custom_resources": resources.extra_custom_resources.copy()
196 }
197
[end of python/ray/tune/resources.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/python/ray/tune/resources.py b/python/ray/tune/resources.py
--- a/python/ray/tune/resources.py
+++ b/python/ray/tune/resources.py
@@ -5,11 +5,10 @@
from collections import namedtuple
import logging
import json
+from numbers import Number
# For compatibility under py2 to consider unicode as str
from six import string_types
-from numbers import Number
-
from ray.tune import TuneError
logger = logging.getLogger(__name__)
@@ -66,6 +65,23 @@
custom_resources.setdefault(value, 0)
extra_custom_resources.setdefault(value, 0)
+ cpu = round(cpu, 2)
+ gpu = round(gpu, 2)
+ memory = round(memory, 2)
+ object_store_memory = round(object_store_memory, 2)
+ extra_cpu = round(extra_cpu, 2)
+ extra_gpu = round(extra_gpu, 2)
+ extra_memory = round(extra_memory, 2)
+ extra_object_store_memory = round(extra_object_store_memory, 2)
+ custom_resources = {
+ resource: round(value, 2)
+ for resource, value in custom_resources.items()
+ }
+ extra_custom_resources = {
+ resource: round(value, 2)
+ for resource, value in extra_custom_resources.items()
+ }
+
all_values = [
cpu, gpu, memory, object_store_memory, extra_cpu, extra_gpu,
extra_memory, extra_object_store_memory
|
{"golden_diff": "diff --git a/python/ray/tune/resources.py b/python/ray/tune/resources.py\n--- a/python/ray/tune/resources.py\n+++ b/python/ray/tune/resources.py\n@@ -5,11 +5,10 @@\n from collections import namedtuple\n import logging\n import json\n+from numbers import Number\n # For compatibility under py2 to consider unicode as str\n from six import string_types\n \n-from numbers import Number\n-\n from ray.tune import TuneError\n \n logger = logging.getLogger(__name__)\n@@ -66,6 +65,23 @@\n custom_resources.setdefault(value, 0)\n extra_custom_resources.setdefault(value, 0)\n \n+ cpu = round(cpu, 2)\n+ gpu = round(gpu, 2)\n+ memory = round(memory, 2)\n+ object_store_memory = round(object_store_memory, 2)\n+ extra_cpu = round(extra_cpu, 2)\n+ extra_gpu = round(extra_gpu, 2)\n+ extra_memory = round(extra_memory, 2)\n+ extra_object_store_memory = round(extra_object_store_memory, 2)\n+ custom_resources = {\n+ resource: round(value, 2)\n+ for resource, value in custom_resources.items()\n+ }\n+ extra_custom_resources = {\n+ resource: round(value, 2)\n+ for resource, value in extra_custom_resources.items()\n+ }\n+\n all_values = [\n cpu, gpu, memory, object_store_memory, extra_cpu, extra_gpu,\n extra_memory, extra_object_store_memory\n", "issue": "[tune] AssertionError: Resource invalid\n<!--\r\nGeneral questions should be asked on the mailing list [email protected].\r\nQuestions about how to use Ray should be asked on\r\n[StackOverflow](https://stackoverflow.com/questions/tagged/ray).\r\n\r\nBefore submitting an issue, please fill out the following form.\r\n-->\r\n\r\n### System information\r\n- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**:\r\nUbuntu 16.04\r\n- **Ray installed from (source or binary)**:\r\npip install https://s3-us-west-2.amazonaws.com/ray-wheels/latest/ray-0.8.0.dev4-cp36-cp36m-manylinux1_x86_64.whl\r\n- **Ray version**:\r\n0.8.0.dev4\r\n- **Python version**:\r\n3.6.7\r\n- **Exact command to reproduce**:\r\n\r\n<!--\r\nYou can obtain the Ray version with\r\n\r\npython -c \"import ray; print(ray.__version__)\"\r\n-->\r\n\r\n### Describe the problem\r\n<!-- Describe the problem clearly here. -->\r\n\r\nI run 5 trials with ray.tune. In one of the trials (each time), an error occurs at the end of training: `AssertionError: Resource invalid: Resources(cpu=3, gpu=0.33, memory=0, object_store_memory=0, extra_cpu=0, extra_gpu=0, extra_memory=0, extra_object_store_memory=0, custom_resources={}, extra_custom_resources={})`.\r\n\r\nWhen I trace back the error, I end up in the following function (ray/tune/resources.py):\r\n\r\n```\r\ndef is_nonnegative(self):\r\n all_values = [self.cpu, self.gpu, self.extra_cpu, self.extra_gpu]\r\n all_values += list(self.custom_resources.values())\r\n all_values += list(self.extra_custom_resources.values())\r\n return all(v >= 0 for v in all_values)\r\n```\r\n\r\nIt seems `custom_resources` and `extra_custom_resources` are not defined. It is weird that the error only occurs in one run... Is this a bug, or any suggestions on how to fix?\r\n\r\n\r\n### Source code / logs\r\n<!-- Include any logs or source code that would be helpful to diagnose the problem. If including tracebacks, please include the full traceback. Large logs and files should be attached. Try to provide a reproducible test case that is the bare minimum necessary to generate the problem. -->\r\n\r\n__This is how I call `tune.run`__\r\n\r\n```\r\ntune.run(\r\n ModelTrainerMT,\r\n resources_per_trial={\r\n 'cpu': config['ncpu'],\r\n 'gpu': config['ngpu'],\r\n },\r\n num_samples=1,\r\n config=best_config,\r\n local_dir=store,\r\n raise_on_failed_trial=True,\r\n verbose=1,\r\n with_server=False,\r\n ray_auto_init=False,\r\n scheduler=early_stopping_scheduler,\r\n loggers=[JsonLogger, CSVLogger],\r\n checkpoint_at_end=True,\r\n reuse_actors=True,\r\n stop={'epoch': 2 if args.test else config['max_t']}\r\n)\r\n```\r\n\r\n__Traceback__\r\n\r\n```\r\n2019-09-06 09:56:45,526 ERROR trial_runner.py:557 -- Error processing event.\r\nTraceback (most recent call last):\r\n File \"/opt/conda/lib/python3.6/site-packages/ray/tune/trial_runner.py\", line 552, in _process_trial\r\n self.trial_executor.stop_trial(trial)\r\n File \"/opt/conda/lib/python3.6/site-packages/ray/tune/ray_trial_executor.py\", line 246, in stop_trial\r\n self._return_resources(trial.resources)\r\n File \"/opt/conda/lib/python3.6/site-packages/ray/tune/ray_trial_executor.py\", line 388, in _return_resources\r\n \"Resource invalid: {}\".format(resources))\r\nAssertionError: Resource invalid: Resources(cpu=3, gpu=0.33, memory=0, object_store_memory=0, extra_cpu=0, extra_gpu=0, extra_memory=0, extra_object_store_memory=0, custom_resources={}, extra_custom_resources={})\r\n```\r\n\r\n\r\n\n", "before_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nfrom collections import namedtuple\nimport logging\nimport json\n# For compatibility under py2 to consider unicode as str\nfrom six import string_types\n\nfrom numbers import Number\n\nfrom ray.tune import TuneError\n\nlogger = logging.getLogger(__name__)\n\n\nclass Resources(\n namedtuple(\"Resources\", [\n \"cpu\", \"gpu\", \"memory\", \"object_store_memory\", \"extra_cpu\",\n \"extra_gpu\", \"extra_memory\", \"extra_object_store_memory\",\n \"custom_resources\", \"extra_custom_resources\"\n ])):\n \"\"\"Ray resources required to schedule a trial.\n\n Attributes:\n cpu (float): Number of CPUs to allocate to the trial.\n gpu (float): Number of GPUs to allocate to the trial.\n memory (float): Memory to reserve for the trial.\n object_store_memory (float): Object store memory to reserve.\n extra_cpu (float): Extra CPUs to reserve in case the trial needs to\n launch additional Ray actors that use CPUs.\n extra_gpu (float): Extra GPUs to reserve in case the trial needs to\n launch additional Ray actors that use GPUs.\n extra_memory (float): Memory to reserve for the trial launching\n additional Ray actors that use memory.\n extra_object_store_memory (float): Object store memory to reserve for\n the trial launching additional Ray actors that use object store\n memory.\n custom_resources (dict): Mapping of resource to quantity to allocate\n to the trial.\n extra_custom_resources (dict): Extra custom resources to reserve in\n case the trial needs to launch additional Ray actors that use\n any of these custom resources.\n\n \"\"\"\n\n __slots__ = ()\n\n def __new__(cls,\n cpu,\n gpu,\n memory=0,\n object_store_memory=0,\n extra_cpu=0,\n extra_gpu=0,\n extra_memory=0,\n extra_object_store_memory=0,\n custom_resources=None,\n extra_custom_resources=None):\n custom_resources = custom_resources or {}\n extra_custom_resources = extra_custom_resources or {}\n leftovers = set(custom_resources) ^ set(extra_custom_resources)\n\n for value in leftovers:\n custom_resources.setdefault(value, 0)\n extra_custom_resources.setdefault(value, 0)\n\n all_values = [\n cpu, gpu, memory, object_store_memory, extra_cpu, extra_gpu,\n extra_memory, extra_object_store_memory\n ]\n all_values += list(custom_resources.values())\n all_values += list(extra_custom_resources.values())\n assert len(custom_resources) == len(extra_custom_resources)\n for entry in all_values:\n assert isinstance(entry, Number), (\"Improper resource value.\",\n entry)\n return super(Resources, cls).__new__(\n cls, cpu, gpu, memory, object_store_memory, extra_cpu, extra_gpu,\n extra_memory, extra_object_store_memory, custom_resources,\n extra_custom_resources)\n\n def summary_string(self):\n summary = \"{} CPUs, {} GPUs\".format(self.cpu + self.extra_cpu,\n self.gpu + self.extra_gpu)\n if self.memory or self.extra_memory:\n summary += \", {} GiB heap\".format(\n round((self.memory + self.extra_memory) / (1024**3), 2))\n if self.object_store_memory or self.extra_object_store_memory:\n summary += \", {} GiB objects\".format(\n round(\n (self.object_store_memory + self.extra_object_store_memory)\n / (1024**3), 2))\n custom_summary = \", \".join([\n \"{} {}\".format(self.get_res_total(res), res)\n for res in self.custom_resources\n ])\n if custom_summary:\n summary += \" ({})\".format(custom_summary)\n return summary\n\n def cpu_total(self):\n return self.cpu + self.extra_cpu\n\n def gpu_total(self):\n return self.gpu + self.extra_gpu\n\n def memory_total(self):\n return self.memory + self.extra_memory\n\n def object_store_memory_total(self):\n return self.object_store_memory + self.extra_object_store_memory\n\n def get_res_total(self, key):\n return self.custom_resources.get(\n key, 0) + self.extra_custom_resources.get(key, 0)\n\n def get(self, key):\n return self.custom_resources.get(key, 0)\n\n def is_nonnegative(self):\n all_values = [self.cpu, self.gpu, self.extra_cpu, self.extra_gpu]\n all_values += list(self.custom_resources.values())\n all_values += list(self.extra_custom_resources.values())\n return all(v >= 0 for v in all_values)\n\n @classmethod\n def subtract(cls, original, to_remove):\n cpu = original.cpu - to_remove.cpu\n gpu = original.gpu - to_remove.gpu\n memory = original.memory - to_remove.memory\n object_store_memory = (\n original.object_store_memory - to_remove.object_store_memory)\n extra_cpu = original.extra_cpu - to_remove.extra_cpu\n extra_gpu = original.extra_gpu - to_remove.extra_gpu\n extra_memory = original.extra_memory - to_remove.extra_memory\n extra_object_store_memory = (original.extra_object_store_memory -\n to_remove.extra_object_store_memory)\n all_resources = set(original.custom_resources).union(\n set(to_remove.custom_resources))\n new_custom_res = {\n k: original.custom_resources.get(k, 0) -\n to_remove.custom_resources.get(k, 0)\n for k in all_resources\n }\n extra_custom_res = {\n k: original.extra_custom_resources.get(k, 0) -\n to_remove.extra_custom_resources.get(k, 0)\n for k in all_resources\n }\n return Resources(cpu, gpu, memory, object_store_memory, extra_cpu,\n extra_gpu, extra_memory, extra_object_store_memory,\n new_custom_res, extra_custom_res)\n\n def to_json(self):\n return resources_to_json(self)\n\n\ndef json_to_resources(data):\n if data is None or data == \"null\":\n return None\n if isinstance(data, string_types):\n data = json.loads(data)\n for k in data:\n if k in [\"driver_cpu_limit\", \"driver_gpu_limit\"]:\n raise TuneError(\n \"The field `{}` is no longer supported. Use `extra_cpu` \"\n \"or `extra_gpu` instead.\".format(k))\n if k not in Resources._fields:\n raise ValueError(\n \"Unknown resource field {}, must be one of {}\".format(\n k, Resources._fields))\n return Resources(\n data.get(\"cpu\", 1), data.get(\"gpu\", 0), data.get(\"memory\", 0),\n data.get(\"object_store_memory\", 0), data.get(\"extra_cpu\", 0),\n data.get(\"extra_gpu\", 0), data.get(\"extra_memory\", 0),\n data.get(\"extra_object_store_memory\", 0), data.get(\"custom_resources\"),\n data.get(\"extra_custom_resources\"))\n\n\ndef resources_to_json(resources):\n if resources is None:\n return None\n return {\n \"cpu\": resources.cpu,\n \"gpu\": resources.gpu,\n \"memory\": resources.memory,\n \"object_store_memory\": resources.object_store_memory,\n \"extra_cpu\": resources.extra_cpu,\n \"extra_gpu\": resources.extra_gpu,\n \"extra_memory\": resources.extra_memory,\n \"extra_object_store_memory\": resources.extra_object_store_memory,\n \"custom_resources\": resources.custom_resources.copy(),\n \"extra_custom_resources\": resources.extra_custom_resources.copy()\n }\n", "path": "python/ray/tune/resources.py"}]}
| 3,501 | 332 |
gh_patches_debug_1557
|
rasdani/github-patches
|
git_diff
|
WordPress__openverse-api-637
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Return secure URLs for the fields thumbnail, detail_url and related_url.
_(Framed the verbiage of the title as a feature request)_ 🙏
## Problem
The response for search and detail requests includes insecure URLs (`http` instead of `https`) in the fields `thumbnail`, `detail_url` and `related_url`.

e.g.:
**Search**
https://api.openverse.engineering/v1/images/?q=flower
**Detail:**
https://api.openverse.engineering/v1/images/6c1769b0-a3e5-4dae-8a36-8531a6e1430f/
## Description
When trying to integrate Openverse with some code on the browser I ended up having to replace the scheme part of the URL for avoiding notices like ```xxxx was loaded over HTTPS, but requested an insecure resource 'http://api.openverse.engineering/v1/images/6c1769b0-a3e5-4dae-8a36-8531a6e1430f/'. This request has been blocked; the content must be served over HTTPS.`
</issue>
<code>
[start of api/catalog/api/serializers/base.py]
1 import re
2
3 from django.conf import settings
4 from rest_framework import serializers
5
6
7 class SchemableHyperlinkedIdentityField(serializers.HyperlinkedIdentityField):
8 """
9 This field returns the link but allows the option to replace the URL scheme.
10 """
11
12 def __init__(self, scheme=settings.API_LINK_SCHEME, *args, **kwargs):
13 super().__init__(*args, **kwargs)
14
15 self.scheme = scheme
16
17 def get_url(self, *args, **kwargs):
18 url = super().get_url(*args, **kwargs)
19
20 # Only rewrite URLs if a fixed scheme is provided
21 if self.scheme is not None:
22 re.sub(r"^\w+://", f"{self.scheme}://", url, 1)
23
24 return url
25
[end of api/catalog/api/serializers/base.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/api/catalog/api/serializers/base.py b/api/catalog/api/serializers/base.py
--- a/api/catalog/api/serializers/base.py
+++ b/api/catalog/api/serializers/base.py
@@ -19,6 +19,6 @@
# Only rewrite URLs if a fixed scheme is provided
if self.scheme is not None:
- re.sub(r"^\w+://", f"{self.scheme}://", url, 1)
+ url = re.sub(r"^\w+://", f"{self.scheme}://", url, 1)
return url
|
{"golden_diff": "diff --git a/api/catalog/api/serializers/base.py b/api/catalog/api/serializers/base.py\n--- a/api/catalog/api/serializers/base.py\n+++ b/api/catalog/api/serializers/base.py\n@@ -19,6 +19,6 @@\n \n # Only rewrite URLs if a fixed scheme is provided\n if self.scheme is not None:\n- re.sub(r\"^\\w+://\", f\"{self.scheme}://\", url, 1)\n+ url = re.sub(r\"^\\w+://\", f\"{self.scheme}://\", url, 1)\n \n return url\n", "issue": "Return secure URLs for the fields thumbnail, detail_url and related_url.\n_(Framed the verbiage of the title as a feature request)_ \ud83d\ude4f \r\n\r\n## Problem\r\n\r\nThe response for search and detail requests includes insecure URLs (`http` instead of `https`) in the fields `thumbnail`, `detail_url` and `related_url`.\r\n\r\n\r\n\r\n\r\ne.g.:\r\n\r\n**Search**\r\n\r\nhttps://api.openverse.engineering/v1/images/?q=flower\r\n\r\n**Detail:**\r\n\r\nhttps://api.openverse.engineering/v1/images/6c1769b0-a3e5-4dae-8a36-8531a6e1430f/\r\n\r\n## Description\r\n\r\nWhen trying to integrate Openverse with some code on the browser I ended up having to replace the scheme part of the URL for avoiding notices like ```xxxx was loaded over HTTPS, but requested an insecure resource 'http://api.openverse.engineering/v1/images/6c1769b0-a3e5-4dae-8a36-8531a6e1430f/'. This request has been blocked; the content must be served over HTTPS.`\r\n \r\n\n", "before_files": [{"content": "import re\n\nfrom django.conf import settings\nfrom rest_framework import serializers\n\n\nclass SchemableHyperlinkedIdentityField(serializers.HyperlinkedIdentityField):\n \"\"\"\n This field returns the link but allows the option to replace the URL scheme.\n \"\"\"\n\n def __init__(self, scheme=settings.API_LINK_SCHEME, *args, **kwargs):\n super().__init__(*args, **kwargs)\n\n self.scheme = scheme\n\n def get_url(self, *args, **kwargs):\n url = super().get_url(*args, **kwargs)\n\n # Only rewrite URLs if a fixed scheme is provided\n if self.scheme is not None:\n re.sub(r\"^\\w+://\", f\"{self.scheme}://\", url, 1)\n\n return url\n", "path": "api/catalog/api/serializers/base.py"}]}
| 1,059 | 130 |
gh_patches_debug_57595
|
rasdani/github-patches
|
git_diff
|
joke2k__faker-704
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
AttributeError: module 'faker.providers' has no attribute '__file__'
I converted my python code to .exe using cx_Freeze. While opening my .exe file I am getting this error.
Traceback (most recent call last):
File "C:\Program Files\Python36\lib\site-packages\cx_Freeze\initscripts\__startup__.py", line 14, in run
module.run()
File "C:\Program Files\Python36\lib\site-packages\cx_Freeze\initscripts\Console.py", line 26, in run
exec(code, m.__dict__)
File "DataGenerator.py", line 7, in <module>
File "C:\Program Files\Python36\lib\site-packages\faker\__init__.py", line 4, in <module>
from faker.factory import Factory
File "C:\Program Files\Python36\lib\site-packages\faker\factory.py", line 10, in <module>
from faker.config import DEFAULT_LOCALE, PROVIDERS, AVAILABLE_LOCALES
File "C:\Program Files\Python36\lib\site-packages\faker\config.py", line 11, in <module>
PROVIDERS = find_available_providers([import_module(path) for path in META_PROVIDERS_MODULES])
File "C:\Program Files\Python36\lib\site-packages\faker\utils\loading.py", line 29, in find_available_providers
providers = ['.'.join([providers_mod.__package__, mod]) for mod in list_module(providers_mod)]
File "C:\Program Files\Python36\lib\site-packages\faker\utils\loading.py", line 7, in list_module
path = os.path.dirname(module.__file__)
AttributeError: module 'faker.providers' has no attribute '__file__'
</issue>
<code>
[start of faker/utils/loading.py]
1 import os
2 import sys
3 from importlib import import_module
4 import pkgutil
5
6
7 def get_path(module):
8 if getattr(sys, 'frozen', False):
9 # frozen
10 path = os.path.dirname(sys.executable)
11 else:
12 # unfrozen
13 path = os.path.dirname(os.path.realpath(module.__file__))
14 return path
15
16
17 def list_module(module):
18 path = get_path(module)
19 modules = [name for finder, name,
20 is_pkg in pkgutil.iter_modules([path]) if is_pkg]
21 return modules
22
23
24 def find_available_locales(providers):
25 available_locales = set()
26
27 for provider_path in providers:
28
29 provider_module = import_module(provider_path)
30 if getattr(provider_module, 'localized', False):
31 langs = list_module(provider_module)
32 available_locales.update(langs)
33 return available_locales
34
35
36 def find_available_providers(modules):
37 available_providers = set()
38 for providers_mod in modules:
39 providers = [
40 '.'.join([providers_mod.__package__, mod])
41 for mod in list_module(providers_mod) if mod != '__pycache__'
42 ]
43 available_providers.update(providers)
44 return sorted(available_providers)
45
[end of faker/utils/loading.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/faker/utils/loading.py b/faker/utils/loading.py
--- a/faker/utils/loading.py
+++ b/faker/utils/loading.py
@@ -7,7 +7,10 @@
def get_path(module):
if getattr(sys, 'frozen', False):
# frozen
- path = os.path.dirname(sys.executable)
+ base_dir = os.path.dirname(sys.executable)
+ lib_dir = os.path.join(base_dir, "lib")
+ module_to_rel_path = os.path.join(*module.__package__.split("."))
+ path = os.path.join(lib_dir, module_to_rel_path)
else:
# unfrozen
path = os.path.dirname(os.path.realpath(module.__file__))
|
{"golden_diff": "diff --git a/faker/utils/loading.py b/faker/utils/loading.py\n--- a/faker/utils/loading.py\n+++ b/faker/utils/loading.py\n@@ -7,7 +7,10 @@\n def get_path(module):\n if getattr(sys, 'frozen', False):\n # frozen\n- path = os.path.dirname(sys.executable)\n+ base_dir = os.path.dirname(sys.executable)\n+ lib_dir = os.path.join(base_dir, \"lib\")\n+ module_to_rel_path = os.path.join(*module.__package__.split(\".\"))\n+ path = os.path.join(lib_dir, module_to_rel_path)\n else:\n # unfrozen\n path = os.path.dirname(os.path.realpath(module.__file__))\n", "issue": "AttributeError: module 'faker.providers' has no attribute '__file__'\nI converted my python code to .exe using cx_Freeze. While opening my .exe file I am getting this error.\r\n\r\nTraceback (most recent call last):\r\n File \"C:\\Program Files\\Python36\\lib\\site-packages\\cx_Freeze\\initscripts\\__startup__.py\", line 14, in run\r\n module.run()\r\n File \"C:\\Program Files\\Python36\\lib\\site-packages\\cx_Freeze\\initscripts\\Console.py\", line 26, in run\r\n exec(code, m.__dict__)\r\n File \"DataGenerator.py\", line 7, in <module>\r\n File \"C:\\Program Files\\Python36\\lib\\site-packages\\faker\\__init__.py\", line 4, in <module>\r\n from faker.factory import Factory\r\n File \"C:\\Program Files\\Python36\\lib\\site-packages\\faker\\factory.py\", line 10, in <module>\r\n from faker.config import DEFAULT_LOCALE, PROVIDERS, AVAILABLE_LOCALES\r\n File \"C:\\Program Files\\Python36\\lib\\site-packages\\faker\\config.py\", line 11, in <module>\r\n PROVIDERS = find_available_providers([import_module(path) for path in META_PROVIDERS_MODULES])\r\n File \"C:\\Program Files\\Python36\\lib\\site-packages\\faker\\utils\\loading.py\", line 29, in find_available_providers\r\n providers = ['.'.join([providers_mod.__package__, mod]) for mod in list_module(providers_mod)]\r\n File \"C:\\Program Files\\Python36\\lib\\site-packages\\faker\\utils\\loading.py\", line 7, in list_module\r\n path = os.path.dirname(module.__file__)\r\nAttributeError: module 'faker.providers' has no attribute '__file__'\n", "before_files": [{"content": "import os\nimport sys\nfrom importlib import import_module\nimport pkgutil\n\n\ndef get_path(module):\n if getattr(sys, 'frozen', False):\n # frozen\n path = os.path.dirname(sys.executable)\n else:\n # unfrozen\n path = os.path.dirname(os.path.realpath(module.__file__))\n return path\n\n\ndef list_module(module):\n path = get_path(module)\n modules = [name for finder, name,\n is_pkg in pkgutil.iter_modules([path]) if is_pkg]\n return modules\n\n\ndef find_available_locales(providers):\n available_locales = set()\n\n for provider_path in providers:\n\n provider_module = import_module(provider_path)\n if getattr(provider_module, 'localized', False):\n langs = list_module(provider_module)\n available_locales.update(langs)\n return available_locales\n\n\ndef find_available_providers(modules):\n available_providers = set()\n for providers_mod in modules:\n providers = [\n '.'.join([providers_mod.__package__, mod])\n for mod in list_module(providers_mod) if mod != '__pycache__'\n ]\n available_providers.update(providers)\n return sorted(available_providers)\n", "path": "faker/utils/loading.py"}]}
| 1,279 | 154 |
gh_patches_debug_8619
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmdetection3d-647
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug in indoor_converter
If `pkl_prefix=='sunrgbd'` we go to this [else](https://github.com/open-mmlab/mmdetection3d/blob/master/tools/data_converter/indoor_converter.py#L89) for `s3dis` and get `FileNotFoundError`.
</issue>
<code>
[start of tools/data_converter/indoor_converter.py]
1 import mmcv
2 import numpy as np
3 import os
4
5 from tools.data_converter.s3dis_data_utils import S3DISData, S3DISSegData
6 from tools.data_converter.scannet_data_utils import ScanNetData, ScanNetSegData
7 from tools.data_converter.sunrgbd_data_utils import SUNRGBDData
8
9
10 def create_indoor_info_file(data_path,
11 pkl_prefix='sunrgbd',
12 save_path=None,
13 use_v1=False,
14 workers=4):
15 """Create indoor information file.
16
17 Get information of the raw data and save it to the pkl file.
18
19 Args:
20 data_path (str): Path of the data.
21 pkl_prefix (str): Prefix of the pkl to be saved. Default: 'sunrgbd'.
22 save_path (str): Path of the pkl to be saved. Default: None.
23 use_v1 (bool): Whether to use v1. Default: False.
24 workers (int): Number of threads to be used. Default: 4.
25 """
26 assert os.path.exists(data_path)
27 assert pkl_prefix in ['sunrgbd', 'scannet', 's3dis'], \
28 f'unsupported indoor dataset {pkl_prefix}'
29 save_path = data_path if save_path is None else save_path
30 assert os.path.exists(save_path)
31
32 # generate infos for both detection and segmentation task
33 if pkl_prefix in ['sunrgbd', 'scannet']:
34 train_filename = os.path.join(save_path,
35 f'{pkl_prefix}_infos_train.pkl')
36 val_filename = os.path.join(save_path, f'{pkl_prefix}_infos_val.pkl')
37 if pkl_prefix == 'sunrgbd':
38 # SUN RGB-D has a train-val split
39 train_dataset = SUNRGBDData(
40 root_path=data_path, split='train', use_v1=use_v1)
41 val_dataset = SUNRGBDData(
42 root_path=data_path, split='val', use_v1=use_v1)
43 else:
44 # ScanNet has a train-val-test split
45 train_dataset = ScanNetData(root_path=data_path, split='train')
46 val_dataset = ScanNetData(root_path=data_path, split='val')
47 test_dataset = ScanNetData(root_path=data_path, split='test')
48 test_filename = os.path.join(save_path,
49 f'{pkl_prefix}_infos_test.pkl')
50
51 infos_train = train_dataset.get_infos(
52 num_workers=workers, has_label=True)
53 mmcv.dump(infos_train, train_filename, 'pkl')
54 print(f'{pkl_prefix} info train file is saved to {train_filename}')
55
56 infos_val = val_dataset.get_infos(num_workers=workers, has_label=True)
57 mmcv.dump(infos_val, val_filename, 'pkl')
58 print(f'{pkl_prefix} info val file is saved to {val_filename}')
59
60 if pkl_prefix == 'scannet':
61 infos_test = test_dataset.get_infos(
62 num_workers=workers, has_label=False)
63 mmcv.dump(infos_test, test_filename, 'pkl')
64 print(f'{pkl_prefix} info test file is saved to {test_filename}')
65
66 # generate infos for the semantic segmentation task
67 # e.g. re-sampled scene indexes and label weights
68 # scene indexes are used to re-sample rooms with different number of points
69 # label weights are used to balance classes with different number of points
70 if pkl_prefix == 'scannet':
71 # label weight computation function is adopted from
72 # https://github.com/charlesq34/pointnet2/blob/master/scannet/scannet_dataset.py#L24
73 train_dataset = ScanNetSegData(
74 data_root=data_path,
75 ann_file=train_filename,
76 split='train',
77 num_points=8192,
78 label_weight_func=lambda x: 1.0 / np.log(1.2 + x))
79 # TODO: do we need to generate on val set?
80 val_dataset = ScanNetSegData(
81 data_root=data_path,
82 ann_file=val_filename,
83 split='val',
84 num_points=8192,
85 label_weight_func=lambda x: 1.0 / np.log(1.2 + x))
86 # no need to generate for test set
87 train_dataset.get_seg_infos()
88 val_dataset.get_seg_infos()
89 else:
90 # S3DIS doesn't have a fixed train-val split
91 # it has 6 areas instead, so we generate info file for each of them
92 # in training, we will use dataset to wrap different areas
93 splits = [f'Area_{i}' for i in [1, 2, 3, 4, 5, 6]]
94 for split in splits:
95 dataset = S3DISData(root_path=data_path, split=split)
96 info = dataset.get_infos(num_workers=workers, has_label=True)
97 filename = os.path.join(save_path,
98 f'{pkl_prefix}_infos_{split}.pkl')
99 mmcv.dump(info, filename, 'pkl')
100 print(f'{pkl_prefix} info {split} file is saved to {filename}')
101 seg_dataset = S3DISSegData(
102 data_root=data_path,
103 ann_file=filename,
104 split=split,
105 num_points=4096,
106 label_weight_func=lambda x: 1.0 / np.log(1.2 + x))
107 seg_dataset.get_seg_infos()
108
[end of tools/data_converter/indoor_converter.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/tools/data_converter/indoor_converter.py b/tools/data_converter/indoor_converter.py
--- a/tools/data_converter/indoor_converter.py
+++ b/tools/data_converter/indoor_converter.py
@@ -86,7 +86,7 @@
# no need to generate for test set
train_dataset.get_seg_infos()
val_dataset.get_seg_infos()
- else:
+ elif pkl_prefix == 's3dis':
# S3DIS doesn't have a fixed train-val split
# it has 6 areas instead, so we generate info file for each of them
# in training, we will use dataset to wrap different areas
|
{"golden_diff": "diff --git a/tools/data_converter/indoor_converter.py b/tools/data_converter/indoor_converter.py\n--- a/tools/data_converter/indoor_converter.py\n+++ b/tools/data_converter/indoor_converter.py\n@@ -86,7 +86,7 @@\n # no need to generate for test set\n train_dataset.get_seg_infos()\n val_dataset.get_seg_infos()\n- else:\n+ elif pkl_prefix == 's3dis':\n # S3DIS doesn't have a fixed train-val split\n # it has 6 areas instead, so we generate info file for each of them\n # in training, we will use dataset to wrap different areas\n", "issue": "Bug in indoor_converter\nIf `pkl_prefix=='sunrgbd'` we go to this [else](https://github.com/open-mmlab/mmdetection3d/blob/master/tools/data_converter/indoor_converter.py#L89) for `s3dis` and get `FileNotFoundError`.\n", "before_files": [{"content": "import mmcv\nimport numpy as np\nimport os\n\nfrom tools.data_converter.s3dis_data_utils import S3DISData, S3DISSegData\nfrom tools.data_converter.scannet_data_utils import ScanNetData, ScanNetSegData\nfrom tools.data_converter.sunrgbd_data_utils import SUNRGBDData\n\n\ndef create_indoor_info_file(data_path,\n pkl_prefix='sunrgbd',\n save_path=None,\n use_v1=False,\n workers=4):\n \"\"\"Create indoor information file.\n\n Get information of the raw data and save it to the pkl file.\n\n Args:\n data_path (str): Path of the data.\n pkl_prefix (str): Prefix of the pkl to be saved. Default: 'sunrgbd'.\n save_path (str): Path of the pkl to be saved. Default: None.\n use_v1 (bool): Whether to use v1. Default: False.\n workers (int): Number of threads to be used. Default: 4.\n \"\"\"\n assert os.path.exists(data_path)\n assert pkl_prefix in ['sunrgbd', 'scannet', 's3dis'], \\\n f'unsupported indoor dataset {pkl_prefix}'\n save_path = data_path if save_path is None else save_path\n assert os.path.exists(save_path)\n\n # generate infos for both detection and segmentation task\n if pkl_prefix in ['sunrgbd', 'scannet']:\n train_filename = os.path.join(save_path,\n f'{pkl_prefix}_infos_train.pkl')\n val_filename = os.path.join(save_path, f'{pkl_prefix}_infos_val.pkl')\n if pkl_prefix == 'sunrgbd':\n # SUN RGB-D has a train-val split\n train_dataset = SUNRGBDData(\n root_path=data_path, split='train', use_v1=use_v1)\n val_dataset = SUNRGBDData(\n root_path=data_path, split='val', use_v1=use_v1)\n else:\n # ScanNet has a train-val-test split\n train_dataset = ScanNetData(root_path=data_path, split='train')\n val_dataset = ScanNetData(root_path=data_path, split='val')\n test_dataset = ScanNetData(root_path=data_path, split='test')\n test_filename = os.path.join(save_path,\n f'{pkl_prefix}_infos_test.pkl')\n\n infos_train = train_dataset.get_infos(\n num_workers=workers, has_label=True)\n mmcv.dump(infos_train, train_filename, 'pkl')\n print(f'{pkl_prefix} info train file is saved to {train_filename}')\n\n infos_val = val_dataset.get_infos(num_workers=workers, has_label=True)\n mmcv.dump(infos_val, val_filename, 'pkl')\n print(f'{pkl_prefix} info val file is saved to {val_filename}')\n\n if pkl_prefix == 'scannet':\n infos_test = test_dataset.get_infos(\n num_workers=workers, has_label=False)\n mmcv.dump(infos_test, test_filename, 'pkl')\n print(f'{pkl_prefix} info test file is saved to {test_filename}')\n\n # generate infos for the semantic segmentation task\n # e.g. re-sampled scene indexes and label weights\n # scene indexes are used to re-sample rooms with different number of points\n # label weights are used to balance classes with different number of points\n if pkl_prefix == 'scannet':\n # label weight computation function is adopted from\n # https://github.com/charlesq34/pointnet2/blob/master/scannet/scannet_dataset.py#L24\n train_dataset = ScanNetSegData(\n data_root=data_path,\n ann_file=train_filename,\n split='train',\n num_points=8192,\n label_weight_func=lambda x: 1.0 / np.log(1.2 + x))\n # TODO: do we need to generate on val set?\n val_dataset = ScanNetSegData(\n data_root=data_path,\n ann_file=val_filename,\n split='val',\n num_points=8192,\n label_weight_func=lambda x: 1.0 / np.log(1.2 + x))\n # no need to generate for test set\n train_dataset.get_seg_infos()\n val_dataset.get_seg_infos()\n else:\n # S3DIS doesn't have a fixed train-val split\n # it has 6 areas instead, so we generate info file for each of them\n # in training, we will use dataset to wrap different areas\n splits = [f'Area_{i}' for i in [1, 2, 3, 4, 5, 6]]\n for split in splits:\n dataset = S3DISData(root_path=data_path, split=split)\n info = dataset.get_infos(num_workers=workers, has_label=True)\n filename = os.path.join(save_path,\n f'{pkl_prefix}_infos_{split}.pkl')\n mmcv.dump(info, filename, 'pkl')\n print(f'{pkl_prefix} info {split} file is saved to {filename}')\n seg_dataset = S3DISSegData(\n data_root=data_path,\n ann_file=filename,\n split=split,\n num_points=4096,\n label_weight_func=lambda x: 1.0 / np.log(1.2 + x))\n seg_dataset.get_seg_infos()\n", "path": "tools/data_converter/indoor_converter.py"}]}
| 1,996 | 143 |
gh_patches_debug_32030
|
rasdani/github-patches
|
git_diff
|
jupyterhub__jupyterhub-1980
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Polish docs for 0.9 release
Open issues that we would like docs included (@minrk Please add to this list)
- [x] Merge and polish PR #1967 (Configuring user environments)
Additional 'to do' items
- [x] Update changelog
- [x] Update contributors list
Not strictly documentation
- [x] Update metadata in setup.py for pypi.org's additional display of docs now
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python3
2 # coding: utf-8
3
4 # Copyright (c) Juptyer Development Team.
5 # Distributed under the terms of the Modified BSD License.
6
7 #-----------------------------------------------------------------------------
8 # Minimal Python version sanity check (from IPython)
9 #-----------------------------------------------------------------------------
10
11 from __future__ import print_function
12
13 import os
14 import shutil
15 import sys
16
17 v = sys.version_info
18 if v[:2] < (3, 5):
19 error = "ERROR: JupyterHub requires Python version 3.5 or above."
20 print(error, file=sys.stderr)
21 sys.exit(1)
22
23 shell = False
24 if os.name in ('nt', 'dos'):
25 shell = True
26 warning = "WARNING: Windows is not officially supported"
27 print(warning, file=sys.stderr)
28
29 # At least we're on the python version we need, move on.
30
31 import os
32 from glob import glob
33 from subprocess import check_call
34
35 from setuptools import setup
36 from setuptools.command.bdist_egg import bdist_egg
37
38 pjoin = os.path.join
39
40 here = os.path.abspath(os.path.dirname(__file__))
41 share_jupyterhub = pjoin(here, 'share', 'jupyterhub')
42 static = pjoin(share_jupyterhub, 'static')
43
44 is_repo = os.path.exists(pjoin(here, '.git'))
45
46 #---------------------------------------------------------------------------
47 # Build basic package data, etc.
48 #---------------------------------------------------------------------------
49
50 def get_data_files():
51 """Get data files in share/jupyter"""
52
53 data_files = []
54 ntrim = len(here + os.path.sep)
55
56 for (d, dirs, filenames) in os.walk(share_jupyterhub):
57 data_files.append((
58 d[ntrim:],
59 [ pjoin(d, f) for f in filenames ]
60 ))
61 return data_files
62
63 def get_package_data():
64 """Get package data
65
66 (mostly alembic config)
67 """
68 package_data = {}
69 package_data['jupyterhub'] = [
70 'alembic.ini',
71 'alembic/*',
72 'alembic/versions/*',
73 ]
74 return package_data
75
76 ns = {}
77 with open(pjoin(here, 'jupyterhub', '_version.py')) as f:
78 exec(f.read(), {}, ns)
79
80
81 packages = []
82 for d, _, _ in os.walk('jupyterhub'):
83 if os.path.exists(pjoin(d, '__init__.py')):
84 packages.append(d.replace(os.path.sep, '.'))
85
86 setup_args = dict(
87 name = 'jupyterhub',
88 scripts = glob(pjoin('scripts', '*')),
89 packages = packages,
90 # dummy, so that install_data doesn't get skipped
91 # this will be overridden when bower is run anyway
92 data_files = get_data_files() or ['dummy'],
93 package_data = get_package_data(),
94 version = ns['__version__'],
95 description = "JupyterHub: A multi-user server for Jupyter notebooks",
96 long_description = "See https://jupyterhub.readthedocs.io for more info.",
97 author = "Jupyter Development Team",
98 author_email = "[email protected]",
99 url = "http://jupyter.org",
100 license = "BSD",
101 platforms = "Linux, Mac OS X",
102 keywords = ['Interactive', 'Interpreter', 'Shell', 'Web'],
103 python_requires = ">=3.5",
104 classifiers = [
105 'Intended Audience :: Developers',
106 'Intended Audience :: System Administrators',
107 'Intended Audience :: Science/Research',
108 'License :: OSI Approved :: BSD License',
109 'Programming Language :: Python',
110 'Programming Language :: Python :: 3',
111 ],
112 )
113
114 #---------------------------------------------------------------------------
115 # custom distutils commands
116 #---------------------------------------------------------------------------
117
118 # imports here, so they are after setuptools import if there was one
119 from distutils.cmd import Command
120 from distutils.command.build_py import build_py
121 from distutils.command.sdist import sdist
122
123
124 def mtime(path):
125 """shorthand for mtime"""
126 return os.stat(path).st_mtime
127
128
129 class BaseCommand(Command):
130 """Dumb empty command because Command needs subclasses to override too much"""
131 user_options = []
132
133 def initialize_options(self):
134 pass
135
136 def finalize_options(self):
137 pass
138
139 def get_inputs(self):
140 return []
141
142 def get_outputs(self):
143 return []
144
145
146 class NPM(BaseCommand):
147 description = "fetch static client-side components with bower"
148
149 user_options = []
150 node_modules = pjoin(here, 'node_modules')
151 bower_dir = pjoin(static, 'components')
152
153 def should_run(self):
154 if not shutil.which('npm'):
155 print("npm unavailable", file=sys.stderr)
156 return False
157 if not os.path.exists(self.bower_dir):
158 return True
159 if not os.path.exists(self.node_modules):
160 return True
161 if mtime(self.bower_dir) < mtime(self.node_modules):
162 return True
163 return mtime(self.node_modules) < mtime(pjoin(here, 'package.json'))
164
165 def run(self):
166 if not self.should_run():
167 print("npm dependencies up to date")
168 return
169
170 print("installing js dependencies with npm")
171 check_call(['npm', 'install', '--progress=false', '--unsafe-perm'], cwd=here, shell=shell)
172 os.utime(self.node_modules)
173
174 os.utime(self.bower_dir)
175 # update data-files in case this created new files
176 self.distribution.data_files = get_data_files()
177
178
179 class CSS(BaseCommand):
180 description = "compile CSS from LESS"
181
182 def should_run(self):
183 """Does less need to run?"""
184 # from IPython.html.tasks.py
185
186 css_targets = [pjoin(static, 'css', 'style.min.css')]
187 css_maps = [t + '.map' for t in css_targets]
188 targets = css_targets + css_maps
189 if not all(os.path.exists(t) for t in targets):
190 # some generated files don't exist
191 return True
192 earliest_target = sorted(mtime(t) for t in targets)[0]
193
194 # check if any .less files are newer than the generated targets
195 for (dirpath, dirnames, filenames) in os.walk(static):
196 for f in filenames:
197 if f.endswith('.less'):
198 path = pjoin(static, dirpath, f)
199 timestamp = mtime(path)
200 if timestamp > earliest_target:
201 return True
202
203 return False
204
205 def run(self):
206 if not self.should_run():
207 print("CSS up-to-date")
208 return
209
210 self.run_command('js')
211 print("Building css with less")
212
213 style_less = pjoin(static, 'less', 'style.less')
214 style_css = pjoin(static, 'css', 'style.min.css')
215 sourcemap = style_css + '.map'
216
217 args = [
218 'npm', 'run', 'lessc', '--', '--clean-css',
219 '--source-map-basepath={}'.format(static),
220 '--source-map={}'.format(sourcemap),
221 '--source-map-rootpath=../',
222 style_less, style_css,
223 ]
224 try:
225 check_call(args, cwd=here, shell=shell)
226 except OSError as e:
227 print("Failed to run lessc: %s" % e, file=sys.stderr)
228 print("You can install js dependencies with `npm install`", file=sys.stderr)
229 raise
230 # update data-files in case this created new files
231 self.distribution.data_files = get_data_files()
232
233
234 def js_css_first(cls, strict=True):
235 class Command(cls):
236 def run(self):
237 try:
238 self.run_command('js')
239 self.run_command('css')
240 except Exception:
241 if strict:
242 raise
243 else:
244 pass
245 return super().run()
246 return Command
247
248
249 class bdist_egg_disabled(bdist_egg):
250 """Disabled version of bdist_egg
251
252 Prevents setup.py install from performing setuptools' default easy_install,
253 which it should never ever do.
254 """
255 def run(self):
256 sys.exit("Aborting implicit building of eggs. Use `pip install .` to install from source.")
257
258
259 setup_args['cmdclass'] = {
260 'js': NPM,
261 'css': CSS,
262 'build_py': js_css_first(build_py, strict=is_repo),
263 'sdist': js_css_first(sdist, strict=True),
264 'bdist_egg': bdist_egg if 'bdist_egg' in sys.argv else bdist_egg_disabled,
265 }
266
267
268 # setuptools requirements
269
270 setup_args['zip_safe'] = False
271 from setuptools.command.develop import develop
272 class develop_js_css(develop):
273 def run(self):
274 if not self.uninstall:
275 self.distribution.run_command('js')
276 self.distribution.run_command('css')
277 develop.run(self)
278 setup_args['cmdclass']['develop'] = develop_js_css
279 setup_args['install_requires'] = install_requires = []
280
281 with open('requirements.txt') as f:
282 for line in f.readlines():
283 req = line.strip()
284 if not req or req.startswith('#') or '://' in req:
285 continue
286 install_requires.append(req)
287
288 #---------------------------------------------------------------------------
289 # setup
290 #---------------------------------------------------------------------------
291
292 def main():
293 setup(**setup_args)
294
295 if __name__ == '__main__':
296 main()
297
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -83,6 +83,10 @@
if os.path.exists(pjoin(d, '__init__.py')):
packages.append(d.replace(os.path.sep, '.'))
+with open('README.md', encoding="utf8") as f:
+ readme = f.read()
+
+
setup_args = dict(
name = 'jupyterhub',
scripts = glob(pjoin('scripts', '*')),
@@ -93,10 +97,11 @@
package_data = get_package_data(),
version = ns['__version__'],
description = "JupyterHub: A multi-user server for Jupyter notebooks",
- long_description = "See https://jupyterhub.readthedocs.io for more info.",
+ long_description = readme,
+ long_description_content_type = 'text/markdown',
author = "Jupyter Development Team",
author_email = "[email protected]",
- url = "http://jupyter.org",
+ url = "https://jupyter.org",
license = "BSD",
platforms = "Linux, Mac OS X",
keywords = ['Interactive', 'Interpreter', 'Shell', 'Web'],
@@ -109,6 +114,12 @@
'Programming Language :: Python',
'Programming Language :: Python :: 3',
],
+ project_urls = {
+ 'Documentation': 'https://jupyterhub.readthedocs.io',
+ 'Funding': 'https://jupyter.org/about',
+ 'Source': 'https://github.com/jupyterhub/jupyterhub/',
+ 'Tracker': 'https://github.com/jupyterhub/jupyterhub/issues',
+ },
)
#---------------------------------------------------------------------------
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -83,6 +83,10 @@\n if os.path.exists(pjoin(d, '__init__.py')):\n packages.append(d.replace(os.path.sep, '.'))\n \n+with open('README.md', encoding=\"utf8\") as f:\n+ readme = f.read()\n+\n+\n setup_args = dict(\n name = 'jupyterhub',\n scripts = glob(pjoin('scripts', '*')),\n@@ -93,10 +97,11 @@\n package_data = get_package_data(),\n version = ns['__version__'],\n description = \"JupyterHub: A multi-user server for Jupyter notebooks\",\n- long_description = \"See https://jupyterhub.readthedocs.io for more info.\",\n+ long_description = readme,\n+ long_description_content_type = 'text/markdown',\n author = \"Jupyter Development Team\",\n author_email = \"[email protected]\",\n- url = \"http://jupyter.org\",\n+ url = \"https://jupyter.org\",\n license = \"BSD\",\n platforms = \"Linux, Mac OS X\",\n keywords = ['Interactive', 'Interpreter', 'Shell', 'Web'],\n@@ -109,6 +114,12 @@\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n ],\n+ project_urls = {\n+ 'Documentation': 'https://jupyterhub.readthedocs.io',\n+ 'Funding': 'https://jupyter.org/about',\n+ 'Source': 'https://github.com/jupyterhub/jupyterhub/',\n+ 'Tracker': 'https://github.com/jupyterhub/jupyterhub/issues',\n+ },\n )\n \n #---------------------------------------------------------------------------\n", "issue": "Polish docs for 0.9 release\nOpen issues that we would like docs included (@minrk Please add to this list)\r\n- [x] Merge and polish PR #1967 (Configuring user environments)\r\n\r\nAdditional 'to do' items\r\n- [x] Update changelog\r\n- [x] Update contributors list\r\n\r\nNot strictly documentation\r\n- [x] Update metadata in setup.py for pypi.org's additional display of docs now\r\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n# coding: utf-8\n\n# Copyright (c) Juptyer Development Team.\n# Distributed under the terms of the Modified BSD License.\n\n#-----------------------------------------------------------------------------\n# Minimal Python version sanity check (from IPython)\n#-----------------------------------------------------------------------------\n\nfrom __future__ import print_function\n\nimport os\nimport shutil\nimport sys\n\nv = sys.version_info\nif v[:2] < (3, 5):\n error = \"ERROR: JupyterHub requires Python version 3.5 or above.\"\n print(error, file=sys.stderr)\n sys.exit(1)\n\nshell = False\nif os.name in ('nt', 'dos'):\n shell = True\n warning = \"WARNING: Windows is not officially supported\"\n print(warning, file=sys.stderr)\n\n# At least we're on the python version we need, move on.\n\nimport os\nfrom glob import glob\nfrom subprocess import check_call\n\nfrom setuptools import setup\nfrom setuptools.command.bdist_egg import bdist_egg\n\npjoin = os.path.join\n\nhere = os.path.abspath(os.path.dirname(__file__))\nshare_jupyterhub = pjoin(here, 'share', 'jupyterhub')\nstatic = pjoin(share_jupyterhub, 'static')\n\nis_repo = os.path.exists(pjoin(here, '.git'))\n\n#---------------------------------------------------------------------------\n# Build basic package data, etc.\n#---------------------------------------------------------------------------\n\ndef get_data_files():\n \"\"\"Get data files in share/jupyter\"\"\"\n\n data_files = []\n ntrim = len(here + os.path.sep)\n\n for (d, dirs, filenames) in os.walk(share_jupyterhub):\n data_files.append((\n d[ntrim:],\n [ pjoin(d, f) for f in filenames ]\n ))\n return data_files\n\ndef get_package_data():\n \"\"\"Get package data\n\n (mostly alembic config)\n \"\"\"\n package_data = {}\n package_data['jupyterhub'] = [\n 'alembic.ini',\n 'alembic/*',\n 'alembic/versions/*',\n ]\n return package_data\n\nns = {}\nwith open(pjoin(here, 'jupyterhub', '_version.py')) as f:\n exec(f.read(), {}, ns)\n\n\npackages = []\nfor d, _, _ in os.walk('jupyterhub'):\n if os.path.exists(pjoin(d, '__init__.py')):\n packages.append(d.replace(os.path.sep, '.'))\n\nsetup_args = dict(\n name = 'jupyterhub',\n scripts = glob(pjoin('scripts', '*')),\n packages = packages,\n # dummy, so that install_data doesn't get skipped\n # this will be overridden when bower is run anyway\n data_files = get_data_files() or ['dummy'],\n package_data = get_package_data(),\n version = ns['__version__'],\n description = \"JupyterHub: A multi-user server for Jupyter notebooks\",\n long_description = \"See https://jupyterhub.readthedocs.io for more info.\",\n author = \"Jupyter Development Team\",\n author_email = \"[email protected]\",\n url = \"http://jupyter.org\",\n license = \"BSD\",\n platforms = \"Linux, Mac OS X\",\n keywords = ['Interactive', 'Interpreter', 'Shell', 'Web'],\n python_requires = \">=3.5\",\n classifiers = [\n 'Intended Audience :: Developers',\n 'Intended Audience :: System Administrators',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: BSD License',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n ],\n)\n\n#---------------------------------------------------------------------------\n# custom distutils commands\n#---------------------------------------------------------------------------\n\n# imports here, so they are after setuptools import if there was one\nfrom distutils.cmd import Command\nfrom distutils.command.build_py import build_py\nfrom distutils.command.sdist import sdist\n\n\ndef mtime(path):\n \"\"\"shorthand for mtime\"\"\"\n return os.stat(path).st_mtime\n\n\nclass BaseCommand(Command):\n \"\"\"Dumb empty command because Command needs subclasses to override too much\"\"\"\n user_options = []\n\n def initialize_options(self):\n pass\n\n def finalize_options(self):\n pass\n\n def get_inputs(self):\n return []\n\n def get_outputs(self):\n return []\n\n\nclass NPM(BaseCommand):\n description = \"fetch static client-side components with bower\"\n\n user_options = []\n node_modules = pjoin(here, 'node_modules')\n bower_dir = pjoin(static, 'components')\n\n def should_run(self):\n if not shutil.which('npm'):\n print(\"npm unavailable\", file=sys.stderr)\n return False\n if not os.path.exists(self.bower_dir):\n return True\n if not os.path.exists(self.node_modules):\n return True\n if mtime(self.bower_dir) < mtime(self.node_modules):\n return True\n return mtime(self.node_modules) < mtime(pjoin(here, 'package.json'))\n\n def run(self):\n if not self.should_run():\n print(\"npm dependencies up to date\")\n return\n\n print(\"installing js dependencies with npm\")\n check_call(['npm', 'install', '--progress=false', '--unsafe-perm'], cwd=here, shell=shell)\n os.utime(self.node_modules)\n\n os.utime(self.bower_dir)\n # update data-files in case this created new files\n self.distribution.data_files = get_data_files()\n\n\nclass CSS(BaseCommand):\n description = \"compile CSS from LESS\"\n\n def should_run(self):\n \"\"\"Does less need to run?\"\"\"\n # from IPython.html.tasks.py\n\n css_targets = [pjoin(static, 'css', 'style.min.css')]\n css_maps = [t + '.map' for t in css_targets]\n targets = css_targets + css_maps\n if not all(os.path.exists(t) for t in targets):\n # some generated files don't exist\n return True\n earliest_target = sorted(mtime(t) for t in targets)[0]\n\n # check if any .less files are newer than the generated targets\n for (dirpath, dirnames, filenames) in os.walk(static):\n for f in filenames:\n if f.endswith('.less'):\n path = pjoin(static, dirpath, f)\n timestamp = mtime(path)\n if timestamp > earliest_target:\n return True\n\n return False\n\n def run(self):\n if not self.should_run():\n print(\"CSS up-to-date\")\n return\n\n self.run_command('js')\n print(\"Building css with less\")\n\n style_less = pjoin(static, 'less', 'style.less')\n style_css = pjoin(static, 'css', 'style.min.css')\n sourcemap = style_css + '.map'\n\n args = [\n 'npm', 'run', 'lessc', '--', '--clean-css',\n '--source-map-basepath={}'.format(static),\n '--source-map={}'.format(sourcemap),\n '--source-map-rootpath=../',\n style_less, style_css,\n ]\n try:\n check_call(args, cwd=here, shell=shell)\n except OSError as e:\n print(\"Failed to run lessc: %s\" % e, file=sys.stderr)\n print(\"You can install js dependencies with `npm install`\", file=sys.stderr)\n raise\n # update data-files in case this created new files\n self.distribution.data_files = get_data_files()\n\n\ndef js_css_first(cls, strict=True):\n class Command(cls):\n def run(self):\n try:\n self.run_command('js')\n self.run_command('css')\n except Exception:\n if strict:\n raise\n else:\n pass\n return super().run()\n return Command\n\n\nclass bdist_egg_disabled(bdist_egg):\n \"\"\"Disabled version of bdist_egg\n\n Prevents setup.py install from performing setuptools' default easy_install,\n which it should never ever do.\n \"\"\"\n def run(self):\n sys.exit(\"Aborting implicit building of eggs. Use `pip install .` to install from source.\")\n\n\nsetup_args['cmdclass'] = {\n 'js': NPM,\n 'css': CSS,\n 'build_py': js_css_first(build_py, strict=is_repo),\n 'sdist': js_css_first(sdist, strict=True),\n 'bdist_egg': bdist_egg if 'bdist_egg' in sys.argv else bdist_egg_disabled,\n}\n\n\n# setuptools requirements\n\nsetup_args['zip_safe'] = False\nfrom setuptools.command.develop import develop\nclass develop_js_css(develop):\n def run(self):\n if not self.uninstall:\n self.distribution.run_command('js')\n self.distribution.run_command('css')\n develop.run(self)\nsetup_args['cmdclass']['develop'] = develop_js_css\nsetup_args['install_requires'] = install_requires = []\n\nwith open('requirements.txt') as f:\n for line in f.readlines():\n req = line.strip()\n if not req or req.startswith('#') or '://' in req:\n continue\n install_requires.append(req)\n\n#---------------------------------------------------------------------------\n# setup\n#---------------------------------------------------------------------------\n\ndef main():\n setup(**setup_args)\n\nif __name__ == '__main__':\n main()\n", "path": "setup.py"}]}
| 3,430 | 396 |
gh_patches_debug_35715
|
rasdani/github-patches
|
git_diff
|
wandb__wandb-447
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
fastai: wandb not logging fastai validation loss with default args
`wandb --version && python --version && uname`
* Weights and Biases version: 0.8.5
* Python version: 3.7.3
* Operating System: Linux
* fast.ai version: 1.0.55
### Description
When you use the `fastai` callback `WandbCallback` with the default arguments you get some errors and the validation loss is not logged.
### What I Did
1. Run the following code in a jupyter notebook
```
import wandb
import fastai
from wandb.fastai import WandbCallback
from fastai.vision import *
from functools import partial
print(f'wandb version: {wandb.__version__}, fastai version: {fastai.__version__}')
wandb.init(project="fastai-test")
path = untar_data(URLs.MNIST_SAMPLE)
data = ImageDataBunch.from_folder(path)
learn = cnn_learner(data, models.resnet18, metrics=accuracy, callback_fns=WandbCallback)
learn.fit_one_cycle(1, 1e-2)
```
2. You'll get the following error:
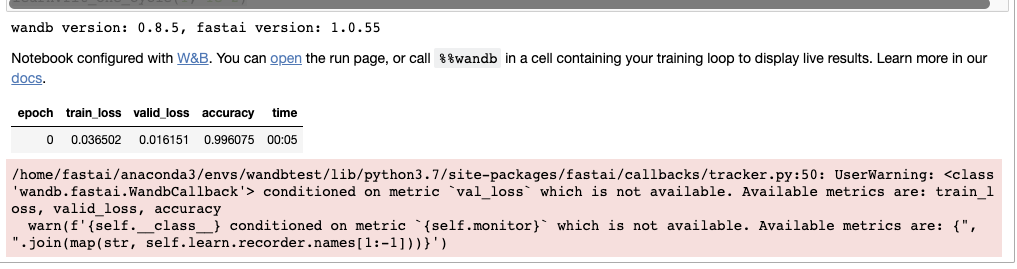
```
/home/fastai/anaconda3/envs/wandbtest/lib/python3.7/site-packages/fastai/callbacks/tracker.py:50: UserWarning: <class 'wandb.fastai.WandbCallback'> conditioned on metric `val_loss` which is not available. Available metrics are: train_loss, valid_loss, accuracy
warn(f'{self.__class__} conditioned on metric `{self.monitor}` which is not available. Available metrics are: {", ".join(map(str, self.learn.recorder.names[1:-1]))}')
```
3. To fix it you can tell it to monitor `valid_loss` by changing the callback to be:
``` python
learn = cnn_learner(data, models.resnet18, metrics=accuracy, callback_fns=partial(WandbCallback, monitor='valid_loss'))
```
I'm guessing that the name of the loss changed with fast.ai at some point.
</issue>
<code>
[start of wandb/fastai/__init__.py]
1 '''W&B Callback for fast.ai
2
3 This module hooks fast.ai Learners to Weights & Biases through a callback.
4 Requested logged data can be configured through the callback constructor.
5
6 Examples:
7 WandbCallback can be used when initializing the Learner::
8
9 from wandb.fastai import WandbCallback
10 [...]
11 learn = Learner(data, ..., callback_fns=WandbCallback)
12 learn.fit(epochs)
13
14 Custom parameters can be given using functools.partial::
15
16 from wandb.fastai import WandbCallback
17 from functools import partial
18 [...]
19 learn = Learner(data, ..., callback_fns=partial(WandbCallback, ...))
20 learn.fit(epochs)
21
22 Finally, it is possible to use WandbCallback only when starting
23 training. In this case it must be instantiated::
24
25 learn.fit(..., callbacks=WandbCallback())
26
27 or, with custom parameters::
28
29 learn.fit(..., callbacks=WandBCallback(learn, ...))
30 '''
31 import wandb
32 from fastai.callbacks import TrackerCallback
33 from pathlib import Path
34 import random
35 try:
36 import matplotlib
37 matplotlib.use('Agg') # non-interactive backend (avoid tkinter issues)
38 import matplotlib.pyplot as plt
39 except:
40 print('Warning: matplotlib required if logging sample image predictions')
41
42
43 class WandbCallback(TrackerCallback):
44
45 # Record if watch has been called previously (even in another instance)
46 watch_called = False
47
48 def __init__(self,
49 learn,
50 log="gradients",
51 save_model=True,
52 monitor='val_loss',
53 mode='auto',
54 input_type=None,
55 validation_data=None,
56 predictions=36):
57 """WandB fast.ai Callback
58
59 Automatically saves model topology, losses & metrics.
60 Optionally logs weights, gradients, sample predictions and best trained model.
61
62 Args:
63 learn (fastai.basic_train.Learner): the fast.ai learner to hook.
64 log (str): "gradients", "parameters", "all", or None. Losses & metrics are always logged.
65 save_model (bool): save model at the end of each epoch.
66 monitor (str): metric to monitor for saving best model.
67 mode (str): "auto", "min" or "max" to compare "monitor" values and define best model.
68 input_type (str): "images" or None. Used to display sample predictions.
69 validation_data (list): data used for sample predictions if input_type is set.
70 predictions (int): number of predictions to make if input_type is set and validation_data is None.
71 """
72
73 # Check if wandb.init has been called
74 if wandb.run is None:
75 raise ValueError(
76 'You must call wandb.init() before WandbCallback()')
77
78 # Adapted from fast.ai "SaveModelCallback"
79 super().__init__(learn, monitor=monitor, mode=mode)
80 self.save_model = save_model
81 self.model_path = Path(wandb.run.dir) / 'bestmodel.pth'
82
83 self.log = log
84 self.input_type = input_type
85 self.best = None
86
87 # Select items for sample predictions to see evolution along training
88 self.validation_data = validation_data
89 if input_type and not self.validation_data:
90 predictions = min(predictions, len(learn.data.valid_ds))
91 indices = random.sample(range(len(learn.data.valid_ds)),
92 predictions)
93 self.validation_data = [learn.data.valid_ds[i] for i in indices]
94
95 def on_train_begin(self, **kwargs):
96 "Call watch method to log model topology, gradients & weights"
97
98 # Set self.best, method inherited from "TrackerCallback" by "SaveModelCallback"
99 super().on_train_begin()
100
101 # Ensure we don't call "watch" multiple times
102 if not WandbCallback.watch_called:
103 WandbCallback.watch_called = True
104
105 # Logs model topology and optionally gradients and weights
106 wandb.watch(self.learn.model, log=self.log)
107
108 def on_epoch_end(self, epoch, smooth_loss, last_metrics, **kwargs):
109 "Logs training loss, validation loss and custom metrics & log prediction samples & save model"
110
111 if self.save_model:
112 # Adapted from fast.ai "SaveModelCallback"
113 current = self.get_monitor_value()
114 if current is not None and self.operator(current, self.best):
115 print(
116 'Better model found at epoch {} with {} value: {}.'.format(
117 epoch, self.monitor, current))
118 self.best = current
119
120 # Save within wandb folder
121 with self.model_path.open('wb') as model_file:
122 self.learn.save(model_file)
123
124 # Log sample predictions
125 if self.validation_data:
126 pred_log = []
127
128 for x, y in self.validation_data:
129 pred = self.learn.predict(x)
130
131 # scalar -> likely to be a category
132 if not pred[1].shape:
133 pred_log.append(
134 wandb.Image(
135 x.data,
136 caption='Ground Truth: {}\nPrediction: {}'.format(
137 y, pred[0])))
138
139 # most vision datasets have a "show" function we can use
140 elif hasattr(x, "show"):
141 # log input data
142 pred_log.append(
143 wandb.Image(x.data, caption='Input data', grouping=3))
144
145 # log label and prediction
146 for im, capt in (y, "Ground Truth"), (pred[0],
147 "Prediction"):
148 # Resize plot to image resolution
149 # from https://stackoverflow.com/a/13714915
150 my_dpi = 100
151 fig = plt.figure(frameon=False, dpi=my_dpi)
152 h, w = x.size
153 fig.set_size_inches(w / my_dpi, h / my_dpi)
154 ax = plt.Axes(fig, [0., 0., 1., 1.])
155 ax.set_axis_off()
156 fig.add_axes(ax)
157
158 # Superpose label or prediction to input image
159 x.show(ax=ax, y=im)
160 pred_log.append(wandb.Image(fig, caption=capt))
161 plt.close(fig)
162
163 # likely to be an image
164 elif hasattr(y, "shape") and (
165 (len(y.shape) == 2) or
166 (len(y.shape) == 3 and y.shape[0] in [1, 3, 4])):
167
168 pred_log.extend([
169 wandb.Image(x.data, caption='Input data', grouping=3),
170 wandb.Image(y.data, caption='Ground Truth'),
171 wandb.Image(pred[0].data, caption='Prediction')
172 ])
173
174 # we just log input data
175 else:
176 pred_log.append(wandb.Image(x.data, caption='Input data'))
177
178 wandb.log({"Prediction Samples": pred_log}, commit=False)
179
180 # Log losses & metrics
181 # Adapted from fast.ai "CSVLogger"
182 logs = {
183 name: stat
184 for name, stat in list(
185 zip(self.learn.recorder.names, [epoch, smooth_loss] +
186 last_metrics))[1:]
187 }
188 wandb.log(logs)
189
190 def on_train_end(self, **kwargs):
191 "Load the best model."
192
193 if self.save_model:
194 # Adapted from fast.ai "SaveModelCallback"
195 if self.model_path.is_file():
196 with self.model_path.open('rb') as model_file:
197 self.learn.load(model_file, purge=False)
198 print('Loaded best saved model from {}'.format(
199 self.model_path))
200
[end of wandb/fastai/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/wandb/fastai/__init__.py b/wandb/fastai/__init__.py
--- a/wandb/fastai/__init__.py
+++ b/wandb/fastai/__init__.py
@@ -29,6 +29,7 @@
learn.fit(..., callbacks=WandBCallback(learn, ...))
'''
import wandb
+import fastai
from fastai.callbacks import TrackerCallback
from pathlib import Path
import random
@@ -49,7 +50,7 @@
learn,
log="gradients",
save_model=True,
- monitor='val_loss',
+ monitor=None,
mode='auto',
input_type=None,
validation_data=None,
@@ -63,7 +64,7 @@
learn (fastai.basic_train.Learner): the fast.ai learner to hook.
log (str): "gradients", "parameters", "all", or None. Losses & metrics are always logged.
save_model (bool): save model at the end of each epoch.
- monitor (str): metric to monitor for saving best model.
+ monitor (str): metric to monitor for saving best model. None uses default TrackerCallback monitor value.
mode (str): "auto", "min" or "max" to compare "monitor" values and define best model.
input_type (str): "images" or None. Used to display sample predictions.
validation_data (list): data used for sample predictions if input_type is set.
@@ -76,7 +77,11 @@
'You must call wandb.init() before WandbCallback()')
# Adapted from fast.ai "SaveModelCallback"
- super().__init__(learn, monitor=monitor, mode=mode)
+ if monitor is None:
+ # use default TrackerCallback monitor value
+ super().__init__(learn, mode=mode)
+ else:
+ super().__init__(learn, monitor=monitor, mode=mode)
self.save_model = save_model
self.model_path = Path(wandb.run.dir) / 'bestmodel.pth'
|
{"golden_diff": "diff --git a/wandb/fastai/__init__.py b/wandb/fastai/__init__.py\n--- a/wandb/fastai/__init__.py\n+++ b/wandb/fastai/__init__.py\n@@ -29,6 +29,7 @@\n learn.fit(..., callbacks=WandBCallback(learn, ...))\n '''\n import wandb\n+import fastai\n from fastai.callbacks import TrackerCallback\n from pathlib import Path\n import random\n@@ -49,7 +50,7 @@\n learn,\n log=\"gradients\",\n save_model=True,\n- monitor='val_loss',\n+ monitor=None,\n mode='auto',\n input_type=None,\n validation_data=None,\n@@ -63,7 +64,7 @@\n learn (fastai.basic_train.Learner): the fast.ai learner to hook.\n log (str): \"gradients\", \"parameters\", \"all\", or None. Losses & metrics are always logged.\n save_model (bool): save model at the end of each epoch.\n- monitor (str): metric to monitor for saving best model.\n+ monitor (str): metric to monitor for saving best model. None uses default TrackerCallback monitor value.\n mode (str): \"auto\", \"min\" or \"max\" to compare \"monitor\" values and define best model.\n input_type (str): \"images\" or None. Used to display sample predictions.\n validation_data (list): data used for sample predictions if input_type is set.\n@@ -76,7 +77,11 @@\n 'You must call wandb.init() before WandbCallback()')\n \n # Adapted from fast.ai \"SaveModelCallback\"\n- super().__init__(learn, monitor=monitor, mode=mode)\n+ if monitor is None:\n+ # use default TrackerCallback monitor value\n+ super().__init__(learn, mode=mode)\n+ else:\n+ super().__init__(learn, monitor=monitor, mode=mode)\n self.save_model = save_model\n self.model_path = Path(wandb.run.dir) / 'bestmodel.pth'\n", "issue": "fastai: wandb not logging fastai validation loss with default args\n`wandb --version && python --version && uname`\r\n\r\n* Weights and Biases version: 0.8.5\r\n* Python version: 3.7.3\r\n* Operating System: Linux\r\n* fast.ai version: 1.0.55\r\n\r\n### Description\r\n\r\nWhen you use the `fastai` callback `WandbCallback` with the default arguments you get some errors and the validation loss is not logged.\r\n\r\n### What I Did\r\n\r\n1. Run the following code in a jupyter notebook\r\n```\r\nimport wandb\r\nimport fastai\r\nfrom wandb.fastai import WandbCallback\r\nfrom fastai.vision import *\r\nfrom functools import partial\r\nprint(f'wandb version: {wandb.__version__}, fastai version: {fastai.__version__}')\r\nwandb.init(project=\"fastai-test\")\r\npath = untar_data(URLs.MNIST_SAMPLE)\r\ndata = ImageDataBunch.from_folder(path)\r\nlearn = cnn_learner(data, models.resnet18, metrics=accuracy, callback_fns=WandbCallback)\r\nlearn.fit_one_cycle(1, 1e-2)\r\n```\r\n\r\n2. You'll get the following error:\r\n\r\n\r\n\r\n```\r\n/home/fastai/anaconda3/envs/wandbtest/lib/python3.7/site-packages/fastai/callbacks/tracker.py:50: UserWarning: <class 'wandb.fastai.WandbCallback'> conditioned on metric `val_loss` which is not available. Available metrics are: train_loss, valid_loss, accuracy\r\n warn(f'{self.__class__} conditioned on metric `{self.monitor}` which is not available. Available metrics are: {\", \".join(map(str, self.learn.recorder.names[1:-1]))}')\r\n```\r\n\r\n3. To fix it you can tell it to monitor `valid_loss` by changing the callback to be:\r\n\r\n``` python\r\nlearn = cnn_learner(data, models.resnet18, metrics=accuracy, callback_fns=partial(WandbCallback, monitor='valid_loss'))\r\n```\r\n\r\nI'm guessing that the name of the loss changed with fast.ai at some point.\r\n\n", "before_files": [{"content": "'''W&B Callback for fast.ai\n\nThis module hooks fast.ai Learners to Weights & Biases through a callback.\nRequested logged data can be configured through the callback constructor.\n\nExamples:\n WandbCallback can be used when initializing the Learner::\n\n from wandb.fastai import WandbCallback\n [...]\n learn = Learner(data, ..., callback_fns=WandbCallback)\n learn.fit(epochs)\n \n Custom parameters can be given using functools.partial::\n\n from wandb.fastai import WandbCallback\n from functools import partial\n [...]\n learn = Learner(data, ..., callback_fns=partial(WandbCallback, ...))\n learn.fit(epochs)\n\n Finally, it is possible to use WandbCallback only when starting\n training. In this case it must be instantiated::\n\n learn.fit(..., callbacks=WandbCallback())\n\n or, with custom parameters::\n\n learn.fit(..., callbacks=WandBCallback(learn, ...))\n'''\nimport wandb\nfrom fastai.callbacks import TrackerCallback\nfrom pathlib import Path\nimport random\ntry:\n import matplotlib\n matplotlib.use('Agg') # non-interactive backend (avoid tkinter issues)\n import matplotlib.pyplot as plt\nexcept:\n print('Warning: matplotlib required if logging sample image predictions')\n\n\nclass WandbCallback(TrackerCallback):\n\n # Record if watch has been called previously (even in another instance)\n watch_called = False\n\n def __init__(self,\n learn,\n log=\"gradients\",\n save_model=True,\n monitor='val_loss',\n mode='auto',\n input_type=None,\n validation_data=None,\n predictions=36):\n \"\"\"WandB fast.ai Callback\n\n Automatically saves model topology, losses & metrics.\n Optionally logs weights, gradients, sample predictions and best trained model.\n\n Args:\n learn (fastai.basic_train.Learner): the fast.ai learner to hook.\n log (str): \"gradients\", \"parameters\", \"all\", or None. Losses & metrics are always logged.\n save_model (bool): save model at the end of each epoch.\n monitor (str): metric to monitor for saving best model.\n mode (str): \"auto\", \"min\" or \"max\" to compare \"monitor\" values and define best model.\n input_type (str): \"images\" or None. Used to display sample predictions.\n validation_data (list): data used for sample predictions if input_type is set.\n predictions (int): number of predictions to make if input_type is set and validation_data is None.\n \"\"\"\n\n # Check if wandb.init has been called\n if wandb.run is None:\n raise ValueError(\n 'You must call wandb.init() before WandbCallback()')\n\n # Adapted from fast.ai \"SaveModelCallback\"\n super().__init__(learn, monitor=monitor, mode=mode)\n self.save_model = save_model\n self.model_path = Path(wandb.run.dir) / 'bestmodel.pth'\n\n self.log = log\n self.input_type = input_type\n self.best = None\n\n # Select items for sample predictions to see evolution along training\n self.validation_data = validation_data\n if input_type and not self.validation_data:\n predictions = min(predictions, len(learn.data.valid_ds))\n indices = random.sample(range(len(learn.data.valid_ds)),\n predictions)\n self.validation_data = [learn.data.valid_ds[i] for i in indices]\n\n def on_train_begin(self, **kwargs):\n \"Call watch method to log model topology, gradients & weights\"\n\n # Set self.best, method inherited from \"TrackerCallback\" by \"SaveModelCallback\"\n super().on_train_begin()\n\n # Ensure we don't call \"watch\" multiple times\n if not WandbCallback.watch_called:\n WandbCallback.watch_called = True\n\n # Logs model topology and optionally gradients and weights\n wandb.watch(self.learn.model, log=self.log)\n\n def on_epoch_end(self, epoch, smooth_loss, last_metrics, **kwargs):\n \"Logs training loss, validation loss and custom metrics & log prediction samples & save model\"\n\n if self.save_model:\n # Adapted from fast.ai \"SaveModelCallback\"\n current = self.get_monitor_value()\n if current is not None and self.operator(current, self.best):\n print(\n 'Better model found at epoch {} with {} value: {}.'.format(\n epoch, self.monitor, current))\n self.best = current\n\n # Save within wandb folder\n with self.model_path.open('wb') as model_file:\n self.learn.save(model_file)\n\n # Log sample predictions\n if self.validation_data:\n pred_log = []\n\n for x, y in self.validation_data:\n pred = self.learn.predict(x)\n\n # scalar -> likely to be a category\n if not pred[1].shape:\n pred_log.append(\n wandb.Image(\n x.data,\n caption='Ground Truth: {}\\nPrediction: {}'.format(\n y, pred[0])))\n\n # most vision datasets have a \"show\" function we can use\n elif hasattr(x, \"show\"):\n # log input data\n pred_log.append(\n wandb.Image(x.data, caption='Input data', grouping=3))\n\n # log label and prediction\n for im, capt in (y, \"Ground Truth\"), (pred[0],\n \"Prediction\"):\n # Resize plot to image resolution\n # from https://stackoverflow.com/a/13714915\n my_dpi = 100\n fig = plt.figure(frameon=False, dpi=my_dpi)\n h, w = x.size\n fig.set_size_inches(w / my_dpi, h / my_dpi)\n ax = plt.Axes(fig, [0., 0., 1., 1.])\n ax.set_axis_off()\n fig.add_axes(ax)\n\n # Superpose label or prediction to input image\n x.show(ax=ax, y=im)\n pred_log.append(wandb.Image(fig, caption=capt))\n plt.close(fig)\n\n # likely to be an image\n elif hasattr(y, \"shape\") and (\n (len(y.shape) == 2) or\n (len(y.shape) == 3 and y.shape[0] in [1, 3, 4])):\n\n pred_log.extend([\n wandb.Image(x.data, caption='Input data', grouping=3),\n wandb.Image(y.data, caption='Ground Truth'),\n wandb.Image(pred[0].data, caption='Prediction')\n ])\n\n # we just log input data\n else:\n pred_log.append(wandb.Image(x.data, caption='Input data'))\n\n wandb.log({\"Prediction Samples\": pred_log}, commit=False)\n\n # Log losses & metrics\n # Adapted from fast.ai \"CSVLogger\"\n logs = {\n name: stat\n for name, stat in list(\n zip(self.learn.recorder.names, [epoch, smooth_loss] +\n last_metrics))[1:]\n }\n wandb.log(logs)\n\n def on_train_end(self, **kwargs):\n \"Load the best model.\"\n\n if self.save_model:\n # Adapted from fast.ai \"SaveModelCallback\"\n if self.model_path.is_file():\n with self.model_path.open('rb') as model_file:\n self.learn.load(model_file, purge=False)\n print('Loaded best saved model from {}'.format(\n self.model_path))\n", "path": "wandb/fastai/__init__.py"}]}
| 3,160 | 454 |
gh_patches_debug_36598
|
rasdani/github-patches
|
git_diff
|
getredash__redash-1944
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Redash Permissions not working for some use cases
### Issue Summary
Currently, when query owner grants permission to another user for a query, the user is still unable to perform the following tasks:
* change data source
* schedule the query
* add and save new visualisation
I believe the user should have the ability to do all the things that the owner could do once permission has been granted.
### Technical details:
* Redash Version: 1.0.3
* Browser/OS: Chrome
* How did you install Redash: AWS using the AMI
</issue>
<code>
[start of redash/handlers/visualizations.py]
1 import json
2 from flask import request
3
4 from redash import models
5 from redash.permissions import require_permission, require_admin_or_owner
6 from redash.handlers.base import BaseResource, get_object_or_404
7
8
9 class VisualizationListResource(BaseResource):
10 @require_permission('edit_query')
11 def post(self):
12 kwargs = request.get_json(force=True)
13
14 query = get_object_or_404(models.Query.get_by_id_and_org, kwargs.pop('query_id'), self.current_org)
15 require_admin_or_owner(query.user_id)
16
17 kwargs['options'] = json.dumps(kwargs['options'])
18 kwargs['query_rel'] = query
19
20 vis = models.Visualization(**kwargs)
21 models.db.session.add(vis)
22 models.db.session.commit()
23 d = vis.to_dict(with_query=False)
24 return d
25
26
27 class VisualizationResource(BaseResource):
28 @require_permission('edit_query')
29 def post(self, visualization_id):
30 vis = get_object_or_404(models.Visualization.get_by_id_and_org, visualization_id, self.current_org)
31 require_admin_or_owner(vis.query_rel.user_id)
32
33 kwargs = request.get_json(force=True)
34 if 'options' in kwargs:
35 kwargs['options'] = json.dumps(kwargs['options'])
36
37 kwargs.pop('id', None)
38 kwargs.pop('query_id', None)
39
40 self.update_model(vis, kwargs)
41 d = vis.to_dict(with_query=False)
42 models.db.session.commit()
43 return d
44
45 @require_permission('edit_query')
46 def delete(self, visualization_id):
47 vis = get_object_or_404(models.Visualization.get_by_id_and_org, visualization_id, self.current_org)
48 require_admin_or_owner(vis.query_rel.user_id)
49 models.db.session.delete(vis)
50 models.db.session.commit()
51
[end of redash/handlers/visualizations.py]
[start of redash/permissions.py]
1 from flask_login import current_user
2 from flask_restful import abort
3 import functools
4 from funcy import flatten
5
6 view_only = True
7 not_view_only = False
8
9 ACCESS_TYPE_VIEW = 'view'
10 ACCESS_TYPE_MODIFY = 'modify'
11 ACCESS_TYPE_DELETE = 'delete'
12
13 ACCESS_TYPES = (ACCESS_TYPE_VIEW, ACCESS_TYPE_MODIFY, ACCESS_TYPE_DELETE)
14
15
16 def has_access(object_groups, user, need_view_only):
17 if 'admin' in user.permissions:
18 return True
19
20 matching_groups = set(object_groups.keys()).intersection(user.group_ids)
21
22 if not matching_groups:
23 return False
24
25 required_level = 1 if need_view_only else 2
26
27 group_level = 1 if all(flatten([object_groups[group] for group in matching_groups])) else 2
28
29 return required_level <= group_level
30
31
32 def require_access(object_groups, user, need_view_only):
33 if not has_access(object_groups, user, need_view_only):
34 abort(403)
35
36
37 class require_permissions(object):
38 def __init__(self, permissions):
39 self.permissions = permissions
40
41 def __call__(self, fn):
42 @functools.wraps(fn)
43 def decorated(*args, **kwargs):
44 has_permissions = current_user.has_permissions(self.permissions)
45
46 if has_permissions:
47 return fn(*args, **kwargs)
48 else:
49 abort(403)
50
51 return decorated
52
53
54 def require_permission(permission):
55 return require_permissions((permission,))
56
57
58 def require_admin(fn):
59 return require_permission('admin')(fn)
60
61
62 def require_super_admin(fn):
63 return require_permission('super_admin')(fn)
64
65
66 def has_permission_or_owner(permission, object_owner_id):
67 return int(object_owner_id) == current_user.id or current_user.has_permission(permission)
68
69
70 def is_admin_or_owner(object_owner_id):
71 return has_permission_or_owner('admin', object_owner_id)
72
73
74 def require_permission_or_owner(permission, object_owner_id):
75 if not has_permission_or_owner(permission, object_owner_id):
76 abort(403)
77
78
79 def require_admin_or_owner(object_owner_id):
80 if not is_admin_or_owner(object_owner_id):
81 abort(403, message="You don't have permission to edit this resource.")
82
83
84 def can_modify(obj, user):
85 return is_admin_or_owner(obj.user_id) or user.has_access(obj, ACCESS_TYPE_MODIFY)
86
87
88 def require_object_modify_permission(obj, user):
89 if not can_modify(obj, user):
90 abort(403)
91
[end of redash/permissions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/redash/handlers/visualizations.py b/redash/handlers/visualizations.py
--- a/redash/handlers/visualizations.py
+++ b/redash/handlers/visualizations.py
@@ -1,9 +1,12 @@
import json
+
from flask import request
from redash import models
-from redash.permissions import require_permission, require_admin_or_owner
from redash.handlers.base import BaseResource, get_object_or_404
+from redash.permissions import (require_admin_or_owner,
+ require_object_modify_permission,
+ require_permission)
class VisualizationListResource(BaseResource):
@@ -12,7 +15,7 @@
kwargs = request.get_json(force=True)
query = get_object_or_404(models.Query.get_by_id_and_org, kwargs.pop('query_id'), self.current_org)
- require_admin_or_owner(query.user_id)
+ require_object_modify_permission(query, self.current_user)
kwargs['options'] = json.dumps(kwargs['options'])
kwargs['query_rel'] = query
@@ -28,7 +31,7 @@
@require_permission('edit_query')
def post(self, visualization_id):
vis = get_object_or_404(models.Visualization.get_by_id_and_org, visualization_id, self.current_org)
- require_admin_or_owner(vis.query_rel.user_id)
+ require_object_modify_permission(vis.query_rel, self.current_user)
kwargs = request.get_json(force=True)
if 'options' in kwargs:
@@ -45,6 +48,6 @@
@require_permission('edit_query')
def delete(self, visualization_id):
vis = get_object_or_404(models.Visualization.get_by_id_and_org, visualization_id, self.current_org)
- require_admin_or_owner(vis.query_rel.user_id)
+ require_object_modify_permission(vis.query_rel, self.current_user)
models.db.session.delete(vis)
models.db.session.commit()
diff --git a/redash/permissions.py b/redash/permissions.py
--- a/redash/permissions.py
+++ b/redash/permissions.py
@@ -1,6 +1,7 @@
+import functools
+
from flask_login import current_user
from flask_restful import abort
-import functools
from funcy import flatten
view_only = True
|
{"golden_diff": "diff --git a/redash/handlers/visualizations.py b/redash/handlers/visualizations.py\n--- a/redash/handlers/visualizations.py\n+++ b/redash/handlers/visualizations.py\n@@ -1,9 +1,12 @@\n import json\n+\n from flask import request\n \n from redash import models\n-from redash.permissions import require_permission, require_admin_or_owner\n from redash.handlers.base import BaseResource, get_object_or_404\n+from redash.permissions import (require_admin_or_owner,\n+ require_object_modify_permission,\n+ require_permission)\n \n \n class VisualizationListResource(BaseResource):\n@@ -12,7 +15,7 @@\n kwargs = request.get_json(force=True)\n \n query = get_object_or_404(models.Query.get_by_id_and_org, kwargs.pop('query_id'), self.current_org)\n- require_admin_or_owner(query.user_id)\n+ require_object_modify_permission(query, self.current_user)\n \n kwargs['options'] = json.dumps(kwargs['options'])\n kwargs['query_rel'] = query\n@@ -28,7 +31,7 @@\n @require_permission('edit_query')\n def post(self, visualization_id):\n vis = get_object_or_404(models.Visualization.get_by_id_and_org, visualization_id, self.current_org)\n- require_admin_or_owner(vis.query_rel.user_id)\n+ require_object_modify_permission(vis.query_rel, self.current_user)\n \n kwargs = request.get_json(force=True)\n if 'options' in kwargs:\n@@ -45,6 +48,6 @@\n @require_permission('edit_query')\n def delete(self, visualization_id):\n vis = get_object_or_404(models.Visualization.get_by_id_and_org, visualization_id, self.current_org)\n- require_admin_or_owner(vis.query_rel.user_id)\n+ require_object_modify_permission(vis.query_rel, self.current_user)\n models.db.session.delete(vis)\n models.db.session.commit()\ndiff --git a/redash/permissions.py b/redash/permissions.py\n--- a/redash/permissions.py\n+++ b/redash/permissions.py\n@@ -1,6 +1,7 @@\n+import functools\n+\n from flask_login import current_user\n from flask_restful import abort\n-import functools\n from funcy import flatten\n \n view_only = True\n", "issue": "Redash Permissions not working for some use cases\n### Issue Summary\r\n\r\nCurrently, when query owner grants permission to another user for a query, the user is still unable to perform the following tasks:\r\n\r\n* change data source\r\n* schedule the query\r\n* add and save new visualisation\r\n\r\nI believe the user should have the ability to do all the things that the owner could do once permission has been granted.\r\n\r\n### Technical details:\r\n\r\n* Redash Version: 1.0.3\r\n* Browser/OS: Chrome\r\n* How did you install Redash: AWS using the AMI\r\n\n", "before_files": [{"content": "import json\nfrom flask import request\n\nfrom redash import models\nfrom redash.permissions import require_permission, require_admin_or_owner\nfrom redash.handlers.base import BaseResource, get_object_or_404\n\n\nclass VisualizationListResource(BaseResource):\n @require_permission('edit_query')\n def post(self):\n kwargs = request.get_json(force=True)\n\n query = get_object_or_404(models.Query.get_by_id_and_org, kwargs.pop('query_id'), self.current_org)\n require_admin_or_owner(query.user_id)\n\n kwargs['options'] = json.dumps(kwargs['options'])\n kwargs['query_rel'] = query\n\n vis = models.Visualization(**kwargs)\n models.db.session.add(vis)\n models.db.session.commit()\n d = vis.to_dict(with_query=False)\n return d\n\n\nclass VisualizationResource(BaseResource):\n @require_permission('edit_query')\n def post(self, visualization_id):\n vis = get_object_or_404(models.Visualization.get_by_id_and_org, visualization_id, self.current_org)\n require_admin_or_owner(vis.query_rel.user_id)\n\n kwargs = request.get_json(force=True)\n if 'options' in kwargs:\n kwargs['options'] = json.dumps(kwargs['options'])\n\n kwargs.pop('id', None)\n kwargs.pop('query_id', None)\n\n self.update_model(vis, kwargs)\n d = vis.to_dict(with_query=False)\n models.db.session.commit()\n return d\n\n @require_permission('edit_query')\n def delete(self, visualization_id):\n vis = get_object_or_404(models.Visualization.get_by_id_and_org, visualization_id, self.current_org)\n require_admin_or_owner(vis.query_rel.user_id)\n models.db.session.delete(vis)\n models.db.session.commit()\n", "path": "redash/handlers/visualizations.py"}, {"content": "from flask_login import current_user\nfrom flask_restful import abort\nimport functools\nfrom funcy import flatten\n\nview_only = True\nnot_view_only = False\n\nACCESS_TYPE_VIEW = 'view'\nACCESS_TYPE_MODIFY = 'modify'\nACCESS_TYPE_DELETE = 'delete'\n\nACCESS_TYPES = (ACCESS_TYPE_VIEW, ACCESS_TYPE_MODIFY, ACCESS_TYPE_DELETE)\n\n\ndef has_access(object_groups, user, need_view_only):\n if 'admin' in user.permissions:\n return True\n\n matching_groups = set(object_groups.keys()).intersection(user.group_ids)\n\n if not matching_groups:\n return False\n\n required_level = 1 if need_view_only else 2\n\n group_level = 1 if all(flatten([object_groups[group] for group in matching_groups])) else 2\n\n return required_level <= group_level\n\n\ndef require_access(object_groups, user, need_view_only):\n if not has_access(object_groups, user, need_view_only):\n abort(403)\n\n\nclass require_permissions(object):\n def __init__(self, permissions):\n self.permissions = permissions\n\n def __call__(self, fn):\n @functools.wraps(fn)\n def decorated(*args, **kwargs):\n has_permissions = current_user.has_permissions(self.permissions)\n\n if has_permissions:\n return fn(*args, **kwargs)\n else:\n abort(403)\n\n return decorated\n\n\ndef require_permission(permission):\n return require_permissions((permission,))\n\n\ndef require_admin(fn):\n return require_permission('admin')(fn)\n\n\ndef require_super_admin(fn):\n return require_permission('super_admin')(fn)\n\n\ndef has_permission_or_owner(permission, object_owner_id):\n return int(object_owner_id) == current_user.id or current_user.has_permission(permission)\n\n\ndef is_admin_or_owner(object_owner_id):\n return has_permission_or_owner('admin', object_owner_id)\n\n\ndef require_permission_or_owner(permission, object_owner_id):\n if not has_permission_or_owner(permission, object_owner_id):\n abort(403)\n\n\ndef require_admin_or_owner(object_owner_id):\n if not is_admin_or_owner(object_owner_id):\n abort(403, message=\"You don't have permission to edit this resource.\")\n\n\ndef can_modify(obj, user):\n return is_admin_or_owner(obj.user_id) or user.has_access(obj, ACCESS_TYPE_MODIFY)\n\n\ndef require_object_modify_permission(obj, user):\n if not can_modify(obj, user):\n abort(403)\n", "path": "redash/permissions.py"}]}
| 1,862 | 496 |
gh_patches_debug_16820
|
rasdani/github-patches
|
git_diff
|
PokemonGoF__PokemonGo-Bot-4568
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add option to separate usage of incubator unbreakable from breakable (2)
## Short Description:
- The 2, 5 and 10km eggs can be dispatched between either the infinite or the breakables incubators.
I wasn't able to test this option in real-game, since well... My bot is sleeping. From the tests I ran, the option should behave as excepted.
## Fixes/Resolves/Closes (please use correct syntax):
- Closes #3503
- Closes #3552
Not sure why it failed before (cf #4556)
</issue>
<code>
[start of pokemongo_bot/cell_workers/incubate_eggs.py]
1 from datetime import datetime, timedelta
2
3 from pokemongo_bot.human_behaviour import sleep
4 from pokemongo_bot.base_task import BaseTask
5
6
7 class IncubateEggs(BaseTask):
8 SUPPORTED_TASK_API_VERSION = 1
9
10 last_km_walked = 0
11
12 def initialize(self):
13 self.next_update = None
14 self.ready_incubators = []
15 self.used_incubators = []
16 self.eggs = []
17 self.km_walked = 0
18 self.hatching_animation_delay = 4.20
19 self.max_iv = 45.0
20
21 self._process_config()
22
23 def _process_config(self):
24 self.longer_eggs_first = self.config.get("longer_eggs_first", True)
25 self.min_interval = self.config.get('min_interval', 120)
26
27 self.breakable_incubator = self.config.get("breakable", [])
28 self.infinite_incubator = self.config.get("infinite", [])
29
30 def work(self):
31 try:
32 self._check_inventory()
33 except:
34 return
35
36 if self.used_incubators and IncubateEggs.last_km_walked != self.km_walked:
37 self.used_incubators.sort(key=lambda x: x.get("km"))
38 km_left = self.used_incubators[0]['km']-self.km_walked
39 if km_left <= 0:
40 self._hatch_eggs()
41 else:
42 self.bot.metrics.next_hatching_km(km_left)
43
44 if self._should_print():
45 self._print_eggs()
46 self._compute_next_update()
47
48 IncubateEggs.last_km_walked = self.km_walked
49
50 sorting = self.longer_eggs_first
51 self.eggs.sort(key=lambda x: x.get("km"), reverse=sorting)
52
53 if self.ready_incubators:
54 self._apply_incubators()
55
56 def _apply_incubators(self):
57 for incubator in self.ready_incubators:
58 if incubator.get('used', False):
59 continue
60 for egg in self.eggs:
61 if egg["used"] or egg["km"] == -1:
62 continue
63
64 if self.breakable_incubator:
65 # test if the incubator is of type breakable
66 if incubator.get('uses_remaining') is not None:
67 if egg["km"] not in self.breakable_incubator:
68 continue
69
70 if self.infinite_incubator:
71 # test if the incubator is of type infinite
72 if incubator.get('uses_remaining') is None:
73 if egg["km"] not in self.infinite_incubator:
74 continue
75
76 self.emit_event(
77 'incubate_try',
78 level='debug',
79 formatted="Attempting to apply incubator {incubator_id} to egg {egg_id}",
80 data={
81 'incubator_id': incubator['id'],
82 'egg_id': egg['id']
83 }
84 )
85 ret = self.bot.api.use_item_egg_incubator(
86 item_id=incubator["id"],
87 pokemon_id=egg["id"]
88 )
89 if ret:
90 code = ret.get("responses", {}).get("USE_ITEM_EGG_INCUBATOR", {}).get("result", 0)
91 if code == 1:
92 self.emit_event(
93 'incubate',
94 formatted='Incubating a {distance_in_km} egg.',
95 data={
96 'distance_in_km': str(egg['km'])
97 }
98 )
99 egg["used"] = True
100 incubator["used"] = True
101 break
102 elif code == 5 or code == 7:
103 self.emit_event(
104 'incubator_already_used',
105 level='debug',
106 formatted='Incubator in use.',
107 )
108 incubator["used"] = True
109 break
110 elif code == 6:
111 self.emit_event(
112 'egg_already_incubating',
113 level='debug',
114 formatted='Egg already incubating',
115 )
116 egg["used"] = True
117
118 def _check_inventory(self, lookup_ids=[]):
119 inv = {}
120 response_dict = self.bot.api.get_inventory()
121 matched_pokemon = []
122 temp_eggs = []
123 temp_used_incubators = []
124 temp_ready_incubators = []
125 inv = reduce(
126 dict.__getitem__,
127 ["responses", "GET_INVENTORY", "inventory_delta", "inventory_items"],
128 response_dict
129 )
130 for inv_data in inv:
131 inv_data = inv_data.get("inventory_item_data", {})
132 if "egg_incubators" in inv_data:
133 temp_used_incubators = []
134 temp_ready_incubators = []
135 incubators = inv_data.get("egg_incubators", {}).get("egg_incubator",[])
136 if isinstance(incubators, basestring): # checking for old response
137 incubators = [incubators]
138 for incubator in incubators:
139 if 'pokemon_id' in incubator:
140 start_km = incubator.get('start_km_walked', 9001)
141 km_walked = incubator.get('target_km_walked', 9001)
142 temp_used_incubators.append({
143 "id": incubator.get('id', -1),
144 "km": km_walked,
145 "km_needed": (km_walked - start_km)
146 })
147 else:
148 temp_ready_incubators.append({
149 "id": incubator.get('id', -1)
150 })
151 continue
152 if "pokemon_data" in inv_data:
153 pokemon = inv_data.get("pokemon_data", {})
154 if pokemon.get("is_egg", False) and "egg_incubator_id" not in pokemon:
155 temp_eggs.append({
156 "id": pokemon.get("id", -1),
157 "km": pokemon.get("egg_km_walked_target", -1),
158 "used": False
159 })
160 elif 'is_egg' not in pokemon and pokemon['id'] in lookup_ids:
161 pokemon.update({
162 "iv": [
163 pokemon.get('individual_attack', 0),
164 pokemon.get('individual_defense', 0),
165 pokemon.get('individual_stamina', 0)
166 ]})
167 matched_pokemon.append(pokemon)
168 continue
169 if "player_stats" in inv_data:
170 self.km_walked = inv_data.get("player_stats", {}).get("km_walked", 0)
171 if temp_used_incubators:
172 self.used_incubators = temp_used_incubators
173 if temp_ready_incubators:
174 self.ready_incubators = temp_ready_incubators
175 if temp_eggs:
176 self.eggs = temp_eggs
177 return matched_pokemon
178
179 def _hatch_eggs(self):
180 response_dict = self.bot.api.get_hatched_eggs()
181 log_color = 'green'
182 try:
183 result = reduce(dict.__getitem__, ["responses", "GET_HATCHED_EGGS"], response_dict)
184 except KeyError:
185 return
186 pokemon_ids = []
187 if 'pokemon_id' in result:
188 pokemon_ids = [id for id in result['pokemon_id']]
189 stardust = result.get('stardust_awarded', "error")
190 candy = result.get('candy_awarded', "error")
191 xp = result.get('experience_awarded', "error")
192 sleep(self.hatching_animation_delay)
193 self.bot.latest_inventory = None
194 try:
195 pokemon_data = self._check_inventory(pokemon_ids)
196 for pokemon in pokemon_data:
197 # pokemon ids seem to be offset by one
198 if pokemon['pokemon_id']!=-1:
199 pokemon['name'] = self.bot.pokemon_list[(pokemon.get('pokemon_id')-1)]['Name']
200 else:
201 pokemon['name'] = "error"
202 except:
203 pokemon_data = [{"name":"error","cp":"error","iv":"error"}]
204 if not pokemon_ids or pokemon_data[0]['name'] == "error":
205 self.emit_event(
206 'egg_hatched',
207 data={
208 'pokemon': 'error',
209 'cp': 'error',
210 'iv': 'error',
211 'exp': 'error',
212 'stardust': 'error',
213 'candy': 'error',
214 }
215 )
216 return
217 for i in range(len(pokemon_data)):
218 msg = "Egg hatched with a {pokemon} (CP {cp} - IV {iv}), {exp} exp, {stardust} stardust and {candy} candies."
219 self.bot.metrics.hatched_eggs(1)
220 self.emit_event(
221 'egg_hatched',
222 formatted=msg,
223 data={
224 'pokemon': pokemon_data[i]['name'],
225 'cp': pokemon_data[i]['cp'],
226 'iv': "{} {}".format(
227 "/".join(map(str, pokemon_data[i]['iv'])),
228 round(sum(pokemon_data[i]['iv'])/self.max_iv, 2)
229 ),
230 'exp': xp[i],
231 'stardust': stardust[i],
232 'candy': candy[i],
233 }
234 )
235
236 def _print_eggs(self):
237 if not self.used_incubators:
238 return
239
240 self.used_incubators.sort(key=lambda x: x.get("km"))
241
242 eggs = ['{:.2f}/{} km'.format(e['km_needed']-e['km']+self.km_walked, e['km_needed']) for e in self.used_incubators]
243
244 self.emit_event(
245 'next_egg_incubates',
246 formatted='Eggs incubating: [{eggs}] (Eggs left: {eggs_left}, Incubating: {eggs_inc})',
247 data={
248 'eggs_left': len(self.eggs),
249 'eggs_inc': len(self.used_incubators),
250 'eggs': ', '.join(eggs)
251 }
252 )
253
254 def _should_print(self):
255 """
256 Returns a value indicating whether the eggs should be displayed.
257 :return: True if the stats should be displayed; otherwise, False.
258 :rtype: bool
259 """
260 return self.next_update is None or datetime.now() >= self.next_update
261
262 def _compute_next_update(self):
263 """
264 Computes the next update datetime based on the minimum update interval.
265 :return: Nothing.
266 :rtype: None
267 """
268 self.next_update = datetime.now() + timedelta(seconds=self.min_interval)
[end of pokemongo_bot/cell_workers/incubate_eggs.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pokemongo_bot/cell_workers/incubate_eggs.py b/pokemongo_bot/cell_workers/incubate_eggs.py
--- a/pokemongo_bot/cell_workers/incubate_eggs.py
+++ b/pokemongo_bot/cell_workers/incubate_eggs.py
@@ -24,8 +24,8 @@
self.longer_eggs_first = self.config.get("longer_eggs_first", True)
self.min_interval = self.config.get('min_interval', 120)
- self.breakable_incubator = self.config.get("breakable", [])
- self.infinite_incubator = self.config.get("infinite", [])
+ self.breakable_incubator = self.config.get("breakable", [2,5,10])
+ self.infinite_incubator = self.config.get("infinite", [2,5,10])
def work(self):
try:
@@ -265,4 +265,4 @@
:return: Nothing.
:rtype: None
"""
- self.next_update = datetime.now() + timedelta(seconds=self.min_interval)
\ No newline at end of file
+ self.next_update = datetime.now() + timedelta(seconds=self.min_interval)
|
{"golden_diff": "diff --git a/pokemongo_bot/cell_workers/incubate_eggs.py b/pokemongo_bot/cell_workers/incubate_eggs.py\n--- a/pokemongo_bot/cell_workers/incubate_eggs.py\n+++ b/pokemongo_bot/cell_workers/incubate_eggs.py\n@@ -24,8 +24,8 @@\n self.longer_eggs_first = self.config.get(\"longer_eggs_first\", True)\n self.min_interval = self.config.get('min_interval', 120)\n \n- self.breakable_incubator = self.config.get(\"breakable\", [])\n- self.infinite_incubator = self.config.get(\"infinite\", [])\n+ self.breakable_incubator = self.config.get(\"breakable\", [2,5,10])\n+ self.infinite_incubator = self.config.get(\"infinite\", [2,5,10])\n \n def work(self):\n try:\n@@ -265,4 +265,4 @@\n :return: Nothing.\n :rtype: None\n \"\"\"\n- self.next_update = datetime.now() + timedelta(seconds=self.min_interval)\n\\ No newline at end of file\n+ self.next_update = datetime.now() + timedelta(seconds=self.min_interval)\n", "issue": "Add option to separate usage of incubator unbreakable from breakable (2)\n## Short Description:\n- The 2, 5 and 10km eggs can be dispatched between either the infinite or the breakables incubators.\n\nI wasn't able to test this option in real-game, since well... My bot is sleeping. From the tests I ran, the option should behave as excepted.\n## Fixes/Resolves/Closes (please use correct syntax):\n- Closes #3503\n- Closes #3552 \n\nNot sure why it failed before (cf #4556)\n\n", "before_files": [{"content": "from datetime import datetime, timedelta\n\nfrom pokemongo_bot.human_behaviour import sleep\nfrom pokemongo_bot.base_task import BaseTask\n\n\nclass IncubateEggs(BaseTask):\n SUPPORTED_TASK_API_VERSION = 1\n\n last_km_walked = 0\n\n def initialize(self):\n self.next_update = None\n self.ready_incubators = []\n self.used_incubators = []\n self.eggs = []\n self.km_walked = 0\n self.hatching_animation_delay = 4.20\n self.max_iv = 45.0\n\n self._process_config()\n\n def _process_config(self):\n self.longer_eggs_first = self.config.get(\"longer_eggs_first\", True)\n self.min_interval = self.config.get('min_interval', 120)\n \n self.breakable_incubator = self.config.get(\"breakable\", [])\n self.infinite_incubator = self.config.get(\"infinite\", [])\n \n def work(self):\n try:\n self._check_inventory()\n except:\n return\n\n if self.used_incubators and IncubateEggs.last_km_walked != self.km_walked:\n self.used_incubators.sort(key=lambda x: x.get(\"km\"))\n km_left = self.used_incubators[0]['km']-self.km_walked\n if km_left <= 0:\n self._hatch_eggs()\n else:\n self.bot.metrics.next_hatching_km(km_left)\n\n if self._should_print():\n self._print_eggs()\n self._compute_next_update()\n\n IncubateEggs.last_km_walked = self.km_walked\n\n sorting = self.longer_eggs_first\n self.eggs.sort(key=lambda x: x.get(\"km\"), reverse=sorting)\n\n if self.ready_incubators:\n self._apply_incubators()\n\n def _apply_incubators(self):\n for incubator in self.ready_incubators:\n if incubator.get('used', False):\n continue\n for egg in self.eggs:\n if egg[\"used\"] or egg[\"km\"] == -1:\n continue\n \n if self.breakable_incubator:\n # test if the incubator is of type breakable\n if incubator.get('uses_remaining') is not None:\n if egg[\"km\"] not in self.breakable_incubator:\n continue\n \n if self.infinite_incubator:\n # test if the incubator is of type infinite\n if incubator.get('uses_remaining') is None:\n if egg[\"km\"] not in self.infinite_incubator:\n continue\n \n self.emit_event(\n 'incubate_try',\n level='debug',\n formatted=\"Attempting to apply incubator {incubator_id} to egg {egg_id}\",\n data={\n 'incubator_id': incubator['id'],\n 'egg_id': egg['id']\n }\n )\n ret = self.bot.api.use_item_egg_incubator(\n item_id=incubator[\"id\"],\n pokemon_id=egg[\"id\"]\n )\n if ret:\n code = ret.get(\"responses\", {}).get(\"USE_ITEM_EGG_INCUBATOR\", {}).get(\"result\", 0)\n if code == 1:\n self.emit_event(\n 'incubate',\n formatted='Incubating a {distance_in_km} egg.',\n data={\n 'distance_in_km': str(egg['km'])\n }\n )\n egg[\"used\"] = True\n incubator[\"used\"] = True\n break\n elif code == 5 or code == 7:\n self.emit_event(\n 'incubator_already_used',\n level='debug',\n formatted='Incubator in use.',\n )\n incubator[\"used\"] = True\n break\n elif code == 6:\n self.emit_event(\n 'egg_already_incubating',\n level='debug',\n formatted='Egg already incubating',\n )\n egg[\"used\"] = True\n\n def _check_inventory(self, lookup_ids=[]):\n inv = {}\n response_dict = self.bot.api.get_inventory()\n matched_pokemon = []\n temp_eggs = []\n temp_used_incubators = []\n temp_ready_incubators = []\n inv = reduce(\n dict.__getitem__,\n [\"responses\", \"GET_INVENTORY\", \"inventory_delta\", \"inventory_items\"],\n response_dict\n )\n for inv_data in inv:\n inv_data = inv_data.get(\"inventory_item_data\", {})\n if \"egg_incubators\" in inv_data:\n temp_used_incubators = []\n temp_ready_incubators = []\n incubators = inv_data.get(\"egg_incubators\", {}).get(\"egg_incubator\",[])\n if isinstance(incubators, basestring): # checking for old response\n incubators = [incubators]\n for incubator in incubators: \n if 'pokemon_id' in incubator:\n start_km = incubator.get('start_km_walked', 9001)\n km_walked = incubator.get('target_km_walked', 9001)\n temp_used_incubators.append({\n \"id\": incubator.get('id', -1),\n \"km\": km_walked,\n \"km_needed\": (km_walked - start_km)\n })\n else:\n temp_ready_incubators.append({\n \"id\": incubator.get('id', -1)\n })\n continue\n if \"pokemon_data\" in inv_data:\n pokemon = inv_data.get(\"pokemon_data\", {})\n if pokemon.get(\"is_egg\", False) and \"egg_incubator_id\" not in pokemon:\n temp_eggs.append({\n \"id\": pokemon.get(\"id\", -1),\n \"km\": pokemon.get(\"egg_km_walked_target\", -1),\n \"used\": False\n })\n elif 'is_egg' not in pokemon and pokemon['id'] in lookup_ids:\n pokemon.update({\n \"iv\": [\n pokemon.get('individual_attack', 0),\n pokemon.get('individual_defense', 0),\n pokemon.get('individual_stamina', 0)\n ]})\n matched_pokemon.append(pokemon)\n continue\n if \"player_stats\" in inv_data:\n self.km_walked = inv_data.get(\"player_stats\", {}).get(\"km_walked\", 0)\n if temp_used_incubators:\n self.used_incubators = temp_used_incubators\n if temp_ready_incubators:\n self.ready_incubators = temp_ready_incubators\n if temp_eggs:\n self.eggs = temp_eggs\n return matched_pokemon\n\n def _hatch_eggs(self):\n response_dict = self.bot.api.get_hatched_eggs()\n log_color = 'green'\n try:\n result = reduce(dict.__getitem__, [\"responses\", \"GET_HATCHED_EGGS\"], response_dict)\n except KeyError:\n return\n pokemon_ids = []\n if 'pokemon_id' in result:\n pokemon_ids = [id for id in result['pokemon_id']]\n stardust = result.get('stardust_awarded', \"error\")\n candy = result.get('candy_awarded', \"error\")\n xp = result.get('experience_awarded', \"error\")\n sleep(self.hatching_animation_delay)\n self.bot.latest_inventory = None\n try:\n pokemon_data = self._check_inventory(pokemon_ids)\n for pokemon in pokemon_data:\n # pokemon ids seem to be offset by one\n if pokemon['pokemon_id']!=-1:\n pokemon['name'] = self.bot.pokemon_list[(pokemon.get('pokemon_id')-1)]['Name']\n else:\n pokemon['name'] = \"error\"\n except:\n pokemon_data = [{\"name\":\"error\",\"cp\":\"error\",\"iv\":\"error\"}]\n if not pokemon_ids or pokemon_data[0]['name'] == \"error\":\n self.emit_event(\n 'egg_hatched',\n data={\n 'pokemon': 'error',\n 'cp': 'error',\n 'iv': 'error',\n 'exp': 'error',\n 'stardust': 'error',\n 'candy': 'error',\n }\n )\n return\n for i in range(len(pokemon_data)):\n msg = \"Egg hatched with a {pokemon} (CP {cp} - IV {iv}), {exp} exp, {stardust} stardust and {candy} candies.\"\n self.bot.metrics.hatched_eggs(1)\n self.emit_event(\n 'egg_hatched',\n formatted=msg,\n data={\n 'pokemon': pokemon_data[i]['name'],\n 'cp': pokemon_data[i]['cp'],\n 'iv': \"{} {}\".format(\n \"/\".join(map(str, pokemon_data[i]['iv'])),\n round(sum(pokemon_data[i]['iv'])/self.max_iv, 2)\n ),\n 'exp': xp[i],\n 'stardust': stardust[i],\n 'candy': candy[i],\n }\n )\n\n def _print_eggs(self):\n if not self.used_incubators:\n return\n\n self.used_incubators.sort(key=lambda x: x.get(\"km\"))\n \n eggs = ['{:.2f}/{} km'.format(e['km_needed']-e['km']+self.km_walked, e['km_needed']) for e in self.used_incubators]\n\n self.emit_event(\n 'next_egg_incubates',\n formatted='Eggs incubating: [{eggs}] (Eggs left: {eggs_left}, Incubating: {eggs_inc})',\n data={\n 'eggs_left': len(self.eggs),\n 'eggs_inc': len(self.used_incubators),\n 'eggs': ', '.join(eggs)\n }\n )\n \n def _should_print(self):\n \"\"\"\n Returns a value indicating whether the eggs should be displayed.\n :return: True if the stats should be displayed; otherwise, False.\n :rtype: bool\n \"\"\"\n return self.next_update is None or datetime.now() >= self.next_update\n\n def _compute_next_update(self):\n \"\"\"\n Computes the next update datetime based on the minimum update interval.\n :return: Nothing.\n :rtype: None\n \"\"\"\n self.next_update = datetime.now() + timedelta(seconds=self.min_interval)", "path": "pokemongo_bot/cell_workers/incubate_eggs.py"}]}
| 3,632 | 277 |
gh_patches_debug_1800
|
rasdani/github-patches
|
git_diff
|
spack__spack-23014
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Installation issue with openjdk: "Error: NameError: name 'Prefix' is not defined"
### Steps to reproduce the issue
Latest spack develop on OS X gives:
```console
→ spack install -v hpcviewer
==> Warning: Missing a source id for [email protected]_9
[+] /usr (external openjdk-11.0.10_9-eoscwsxi5erdz5htmnixttlxjzhogare)
==> Installing hpcviewer-2021.03-a4q2ajczhy6u5dxcdszfx3lelqbf7tmd
==> No binary for hpcviewer-2021.03-a4q2ajczhy6u5dxcdszfx3lelqbf7tmd found: installing from source
==> Warning: Missing a source id for [email protected]_9
==> Warning: microarchitecture specific optimizations are not supported yet on mixed compiler toolchains [check [email protected] for further details]
==> Error: NameError: name 'Prefix' is not defined
```
### Information on your system
* Mac OS 10.15.5
* Spack cloned today
</issue>
<code>
[start of var/spack/repos/builtin/packages/openjdk/package.py]
1 # Copyright 2013-2021 Lawrence Livermore National Security, LLC and other
2 # Spack Project Developers. See the top-level COPYRIGHT file for details.
3 #
4 # SPDX-License-Identifier: (Apache-2.0 OR MIT)
5
6 import os
7 import platform
8 import re
9
10
11 # If you need to add a new version, please be aware that:
12 # - versions in the following dict are automatically added to the package
13 # - version tuple must be in the form (checksum, url)
14 # - checksum must be sha256
15 # - package key must be in the form '{os}-{arch}' where 'os' is in the
16 # format returned by platform.system() and 'arch' by platform.machine()
17
18 _versions = {
19 '11.0.9.1_1': {
20 'Linux-ppc64le': ('d94b6b46a14ab0974b1c1b89661741126d8cf8a0068b471b8f5fa286a71636b1', 'https://github.com/AdoptOpenJDK/openjdk11-binaries/releases/download/jdk-11.0.9.1%2B1/OpenJDK11U-jdk_ppc64le_linux_hotspot_11.0.9.1_1.tar.gz')},
21 '11.0.8_10': {
22 'Linux-x86_64': ('6e4cead158037cb7747ca47416474d4f408c9126be5b96f9befd532e0a762b47', 'https://github.com/AdoptOpenJDK/openjdk11-binaries/releases/download/jdk-11.0.8%2B10/OpenJDK11U-jdk_x64_linux_hotspot_11.0.8_10.tar.gz')},
23 '11.0.0-2020-01-01': {
24 'Linux-aarch64': ('05c7d9c90edacd853850fbb0f52f8aa482809d0452c599cb9fe0b28b3b4bf329', 'https://github.com/AdoptOpenJDK/openjdk11-binaries/releases/download/jdk11u-2020-01-01-06-13/OpenJDK11U-jdk_aarch64_linux_hotspot_2020-01-01-06-13.tar.gz')},
25 '11.0.2': {
26 'Linux-x86_64': ('99be79935354f5c0df1ad293620ea36d13f48ec3ea870c838f20c504c9668b57', 'https://download.java.net/java/GA/jdk11/9/GPL/openjdk-11.0.2_linux-x64_bin.tar.gz')},
27 '11.0.1': {
28 'Linux-x86_64': ('7a6bb980b9c91c478421f865087ad2d69086a0583aeeb9e69204785e8e97dcfd', 'https://download.java.net/java/GA/jdk11/13/GPL/openjdk-11.0.1_linux-x64_bin.tar.gz')},
29 '1.8.0_265-b01': {
30 'Linux-x86_64': ('1285da6278f2d38a790a21148d7e683f20de0799c44b937043830ef6b57f58c4', 'https://github.com/AdoptOpenJDK/openjdk8-binaries/releases/download/jdk8u265-b01/OpenJDK8U-jdk_x64_linux_hotspot_8u265b01.tar.gz')},
31 '1.8.0_191-b12': {
32 'Linux-aarch64': ('8eee0aede947b804f9a5f49c8a38b52aace8a30a9ebd9383b7d06042fb5a237c', 'https://github.com/AdoptOpenJDK/openjdk8-binaries/releases/download/jdk8u191-b12/OpenJDK8U-jdk_aarch64_linux_hotspot_8u191b12.tar.gz')},
33 '1.8.0_222-b10': {
34 'Linux-x86_64': ('20cff719c6de43f8bb58c7f59e251da7c1fa2207897c9a4768c8c669716dc819', 'https://github.com/AdoptOpenJDK/openjdk8-binaries/releases/download/jdk8u222-b10_openj9-0.15.1/OpenJDK8U-jdk_x64_linux_openj9_8u222b10_openj9-0.15.1.tar.gz')},
35 '1.8.0_202-b08': {
36 'Linux-x86_64': ('533dcd8d9ca15df231a1eb392fa713a66bca85a8e76d9b4ee30975f3823636b7', 'https://github.com/AdoptOpenJDK/openjdk8-binaries/releases/download/jdk8u202-b08/OpenJDK8U-jdk_x64_linux_openj9_8u202b08_openj9-0.12.0.tar.gz')},
37 '1.8.0_40-b25': {
38 'Linux-x86_64': ('79e96dce03a14271040023231a7d0ae374b755d48adf68bbdaec30294e4e2b88', 'https://download.java.net/openjdk/jdk8u40/ri/jdk_ri-8u40-b25-linux-x64-10_feb_2015.tar.gz')},
39 }
40
41
42 class Openjdk(Package):
43 """The free and opensource java implementation"""
44
45 homepage = "https://jdk.java.net"
46
47 for ver, packages in _versions.items():
48 key = "{0}-{1}".format(platform.system(), platform.machine())
49 pkg = packages.get(key)
50 if pkg:
51 version(ver, sha256=pkg[0], url=pkg[1])
52
53 provides('java@11', when='@11.0:11.99')
54 provides('java@10', when='@10.0:10.99')
55 provides('java@9', when='@9.0:9.99')
56 provides('java@8', when='@1.8.0:1.8.999')
57
58 conflicts('target=ppc64:', msg='openjdk is not available for ppc64 (big endian)')
59
60 # FIXME:
61 # 1. `extends('java')` doesn't work, you need to use `extends('openjdk')`
62 # 2. Packages cannot extend multiple packages, see #987
63 # 3. Update `YamlFilesystemView.merge` to allow a Package to completely
64 # override how it is symlinked into a view prefix. Then, spack activate
65 # can symlink all *.jar files to `prefix.lib.ext`
66 extendable = True
67
68 executables = ['^java$']
69
70 @classmethod
71 def determine_version(cls, exe):
72 output = Executable(exe)('-version', output=str, error=str)
73
74 # Make sure this is actually OpenJDK, not Oracle JDK
75 if 'openjdk' not in output:
76 return None
77
78 match = re.search(r'\(build (\S+)\)', output)
79 return match.group(1).replace('+', '_') if match else None
80
81 @property
82 def home(self):
83 """Most of the time, ``JAVA_HOME`` is simply ``spec['java'].prefix``.
84 However, if the user is using an externally installed JDK, it may be
85 symlinked. For example, on macOS, the ``java`` executable can be found
86 in ``/usr/bin``, but ``JAVA_HOME`` is actually
87 ``/Library/Java/JavaVirtualMachines/jdk-10.0.1.jdk/Contents/Home``.
88 Users may not know the actual installation directory and add ``/usr``
89 to their ``packages.yaml`` unknowingly. Run ``java_home`` if it exists
90 to determine exactly where it is installed. Specify which version we
91 are expecting in case multiple Java versions are installed.
92 See ``man java_home`` for more details."""
93
94 prefix = self.prefix
95 java_home = prefix.libexec.java_home
96 if os.path.exists(java_home):
97 java_home = Executable(java_home)
98 version = str(self.version.up_to(2))
99 prefix = java_home('--version', version, output=str).strip()
100 prefix = Prefix(prefix)
101
102 return prefix
103
104 @property
105 def libs(self):
106 """Depending on the version number and whether the full JDK or just
107 the JRE was installed, Java libraries can be in several locations:
108
109 * ``lib/libjvm.so``
110 * ``jre/lib/libjvm.dylib``
111
112 Search recursively to find the correct library location."""
113
114 return find_libraries(['libjvm'], root=self.home, recursive=True)
115
116 def install(self, spec, prefix):
117 install_tree('.', prefix)
118
119 def setup_run_environment(self, env):
120 """Set JAVA_HOME."""
121
122 env.set('JAVA_HOME', self.home)
123
124 def setup_dependent_build_environment(self, env, dependent_spec):
125 """Set JAVA_HOME and CLASSPATH.
126
127 CLASSPATH contains the installation prefix for the extension and any
128 other Java extensions it depends on."""
129
130 env.set('JAVA_HOME', self.home)
131
132 class_paths = []
133 for d in dependent_spec.traverse(deptype=('build', 'run', 'test')):
134 if d.package.extends(self.spec):
135 class_paths.extend(find(d.prefix, '*.jar'))
136
137 classpath = os.pathsep.join(class_paths)
138 env.set('CLASSPATH', classpath)
139
140 def setup_dependent_run_environment(self, env, dependent_spec):
141 """Set CLASSPATH.
142
143 CLASSPATH contains the installation prefix for the extension and any
144 other Java extensions it depends on."""
145 # For runtime environment set only the path for
146 # dependent_spec and prepend it to CLASSPATH
147 if dependent_spec.package.extends(self.spec):
148 class_paths = find(dependent_spec.prefix, '*.jar')
149 classpath = os.pathsep.join(class_paths)
150 env.prepend_path('CLASSPATH', classpath)
151
152 def setup_dependent_package(self, module, dependent_spec):
153 """Allows spec['java'].home to work."""
154
155 self.spec.home = self.home
156
[end of var/spack/repos/builtin/packages/openjdk/package.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/var/spack/repos/builtin/packages/openjdk/package.py b/var/spack/repos/builtin/packages/openjdk/package.py
--- a/var/spack/repos/builtin/packages/openjdk/package.py
+++ b/var/spack/repos/builtin/packages/openjdk/package.py
@@ -7,6 +7,7 @@
import platform
import re
+from spack.util.prefix import Prefix
# If you need to add a new version, please be aware that:
# - versions in the following dict are automatically added to the package
|
{"golden_diff": "diff --git a/var/spack/repos/builtin/packages/openjdk/package.py b/var/spack/repos/builtin/packages/openjdk/package.py\n--- a/var/spack/repos/builtin/packages/openjdk/package.py\n+++ b/var/spack/repos/builtin/packages/openjdk/package.py\n@@ -7,6 +7,7 @@\n import platform\n import re\n \n+from spack.util.prefix import Prefix\n \n # If you need to add a new version, please be aware that:\n # - versions in the following dict are automatically added to the package\n", "issue": "Installation issue with openjdk: \"Error: NameError: name 'Prefix' is not defined\"\n### Steps to reproduce the issue\r\n\r\nLatest spack develop on OS X gives:\r\n\r\n```console\r\n \u2192 spack install -v hpcviewer\r\n==> Warning: Missing a source id for [email protected]_9\r\n[+] /usr (external openjdk-11.0.10_9-eoscwsxi5erdz5htmnixttlxjzhogare)\r\n==> Installing hpcviewer-2021.03-a4q2ajczhy6u5dxcdszfx3lelqbf7tmd\r\n==> No binary for hpcviewer-2021.03-a4q2ajczhy6u5dxcdszfx3lelqbf7tmd found: installing from source\r\n==> Warning: Missing a source id for [email protected]_9\r\n==> Warning: microarchitecture specific optimizations are not supported yet on mixed compiler toolchains [check [email protected] for further details]\r\n==> Error: NameError: name 'Prefix' is not defined\r\n```\r\n\r\n### Information on your system\r\n\r\n* Mac OS 10.15.5\r\n* Spack cloned today\n", "before_files": [{"content": "# Copyright 2013-2021 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\n\nimport os\nimport platform\nimport re\n\n\n# If you need to add a new version, please be aware that:\n# - versions in the following dict are automatically added to the package\n# - version tuple must be in the form (checksum, url)\n# - checksum must be sha256\n# - package key must be in the form '{os}-{arch}' where 'os' is in the\n# format returned by platform.system() and 'arch' by platform.machine()\n\n_versions = {\n '11.0.9.1_1': {\n 'Linux-ppc64le': ('d94b6b46a14ab0974b1c1b89661741126d8cf8a0068b471b8f5fa286a71636b1', 'https://github.com/AdoptOpenJDK/openjdk11-binaries/releases/download/jdk-11.0.9.1%2B1/OpenJDK11U-jdk_ppc64le_linux_hotspot_11.0.9.1_1.tar.gz')},\n '11.0.8_10': {\n 'Linux-x86_64': ('6e4cead158037cb7747ca47416474d4f408c9126be5b96f9befd532e0a762b47', 'https://github.com/AdoptOpenJDK/openjdk11-binaries/releases/download/jdk-11.0.8%2B10/OpenJDK11U-jdk_x64_linux_hotspot_11.0.8_10.tar.gz')},\n '11.0.0-2020-01-01': {\n 'Linux-aarch64': ('05c7d9c90edacd853850fbb0f52f8aa482809d0452c599cb9fe0b28b3b4bf329', 'https://github.com/AdoptOpenJDK/openjdk11-binaries/releases/download/jdk11u-2020-01-01-06-13/OpenJDK11U-jdk_aarch64_linux_hotspot_2020-01-01-06-13.tar.gz')},\n '11.0.2': {\n 'Linux-x86_64': ('99be79935354f5c0df1ad293620ea36d13f48ec3ea870c838f20c504c9668b57', 'https://download.java.net/java/GA/jdk11/9/GPL/openjdk-11.0.2_linux-x64_bin.tar.gz')},\n '11.0.1': {\n 'Linux-x86_64': ('7a6bb980b9c91c478421f865087ad2d69086a0583aeeb9e69204785e8e97dcfd', 'https://download.java.net/java/GA/jdk11/13/GPL/openjdk-11.0.1_linux-x64_bin.tar.gz')},\n '1.8.0_265-b01': {\n 'Linux-x86_64': ('1285da6278f2d38a790a21148d7e683f20de0799c44b937043830ef6b57f58c4', 'https://github.com/AdoptOpenJDK/openjdk8-binaries/releases/download/jdk8u265-b01/OpenJDK8U-jdk_x64_linux_hotspot_8u265b01.tar.gz')},\n '1.8.0_191-b12': {\n 'Linux-aarch64': ('8eee0aede947b804f9a5f49c8a38b52aace8a30a9ebd9383b7d06042fb5a237c', 'https://github.com/AdoptOpenJDK/openjdk8-binaries/releases/download/jdk8u191-b12/OpenJDK8U-jdk_aarch64_linux_hotspot_8u191b12.tar.gz')},\n '1.8.0_222-b10': {\n 'Linux-x86_64': ('20cff719c6de43f8bb58c7f59e251da7c1fa2207897c9a4768c8c669716dc819', 'https://github.com/AdoptOpenJDK/openjdk8-binaries/releases/download/jdk8u222-b10_openj9-0.15.1/OpenJDK8U-jdk_x64_linux_openj9_8u222b10_openj9-0.15.1.tar.gz')},\n '1.8.0_202-b08': {\n 'Linux-x86_64': ('533dcd8d9ca15df231a1eb392fa713a66bca85a8e76d9b4ee30975f3823636b7', 'https://github.com/AdoptOpenJDK/openjdk8-binaries/releases/download/jdk8u202-b08/OpenJDK8U-jdk_x64_linux_openj9_8u202b08_openj9-0.12.0.tar.gz')},\n '1.8.0_40-b25': {\n 'Linux-x86_64': ('79e96dce03a14271040023231a7d0ae374b755d48adf68bbdaec30294e4e2b88', 'https://download.java.net/openjdk/jdk8u40/ri/jdk_ri-8u40-b25-linux-x64-10_feb_2015.tar.gz')},\n}\n\n\nclass Openjdk(Package):\n \"\"\"The free and opensource java implementation\"\"\"\n\n homepage = \"https://jdk.java.net\"\n\n for ver, packages in _versions.items():\n key = \"{0}-{1}\".format(platform.system(), platform.machine())\n pkg = packages.get(key)\n if pkg:\n version(ver, sha256=pkg[0], url=pkg[1])\n\n provides('java@11', when='@11.0:11.99')\n provides('java@10', when='@10.0:10.99')\n provides('java@9', when='@9.0:9.99')\n provides('java@8', when='@1.8.0:1.8.999')\n\n conflicts('target=ppc64:', msg='openjdk is not available for ppc64 (big endian)')\n\n # FIXME:\n # 1. `extends('java')` doesn't work, you need to use `extends('openjdk')`\n # 2. Packages cannot extend multiple packages, see #987\n # 3. Update `YamlFilesystemView.merge` to allow a Package to completely\n # override how it is symlinked into a view prefix. Then, spack activate\n # can symlink all *.jar files to `prefix.lib.ext`\n extendable = True\n\n executables = ['^java$']\n\n @classmethod\n def determine_version(cls, exe):\n output = Executable(exe)('-version', output=str, error=str)\n\n # Make sure this is actually OpenJDK, not Oracle JDK\n if 'openjdk' not in output:\n return None\n\n match = re.search(r'\\(build (\\S+)\\)', output)\n return match.group(1).replace('+', '_') if match else None\n\n @property\n def home(self):\n \"\"\"Most of the time, ``JAVA_HOME`` is simply ``spec['java'].prefix``.\n However, if the user is using an externally installed JDK, it may be\n symlinked. For example, on macOS, the ``java`` executable can be found\n in ``/usr/bin``, but ``JAVA_HOME`` is actually\n ``/Library/Java/JavaVirtualMachines/jdk-10.0.1.jdk/Contents/Home``.\n Users may not know the actual installation directory and add ``/usr``\n to their ``packages.yaml`` unknowingly. Run ``java_home`` if it exists\n to determine exactly where it is installed. Specify which version we\n are expecting in case multiple Java versions are installed.\n See ``man java_home`` for more details.\"\"\"\n\n prefix = self.prefix\n java_home = prefix.libexec.java_home\n if os.path.exists(java_home):\n java_home = Executable(java_home)\n version = str(self.version.up_to(2))\n prefix = java_home('--version', version, output=str).strip()\n prefix = Prefix(prefix)\n\n return prefix\n\n @property\n def libs(self):\n \"\"\"Depending on the version number and whether the full JDK or just\n the JRE was installed, Java libraries can be in several locations:\n\n * ``lib/libjvm.so``\n * ``jre/lib/libjvm.dylib``\n\n Search recursively to find the correct library location.\"\"\"\n\n return find_libraries(['libjvm'], root=self.home, recursive=True)\n\n def install(self, spec, prefix):\n install_tree('.', prefix)\n\n def setup_run_environment(self, env):\n \"\"\"Set JAVA_HOME.\"\"\"\n\n env.set('JAVA_HOME', self.home)\n\n def setup_dependent_build_environment(self, env, dependent_spec):\n \"\"\"Set JAVA_HOME and CLASSPATH.\n\n CLASSPATH contains the installation prefix for the extension and any\n other Java extensions it depends on.\"\"\"\n\n env.set('JAVA_HOME', self.home)\n\n class_paths = []\n for d in dependent_spec.traverse(deptype=('build', 'run', 'test')):\n if d.package.extends(self.spec):\n class_paths.extend(find(d.prefix, '*.jar'))\n\n classpath = os.pathsep.join(class_paths)\n env.set('CLASSPATH', classpath)\n\n def setup_dependent_run_environment(self, env, dependent_spec):\n \"\"\"Set CLASSPATH.\n\n CLASSPATH contains the installation prefix for the extension and any\n other Java extensions it depends on.\"\"\"\n # For runtime environment set only the path for\n # dependent_spec and prepend it to CLASSPATH\n if dependent_spec.package.extends(self.spec):\n class_paths = find(dependent_spec.prefix, '*.jar')\n classpath = os.pathsep.join(class_paths)\n env.prepend_path('CLASSPATH', classpath)\n\n def setup_dependent_package(self, module, dependent_spec):\n \"\"\"Allows spec['java'].home to work.\"\"\"\n\n self.spec.home = self.home\n", "path": "var/spack/repos/builtin/packages/openjdk/package.py"}]}
| 3,824 | 111 |
gh_patches_debug_3019
|
rasdani/github-patches
|
git_diff
|
rucio__rucio-4790
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix setup_webui script
Motivation
----------
Script has a wrong import, needs to be fixed.
</issue>
<code>
[start of setup_webui.py]
1 # -*- coding: utf-8 -*-
2 # Copyright 2015-2021 CERN
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 #
16 # Authors:
17 # - Vincent Garonne <[email protected]>, 2015-2017
18 # - Martin Barisits <[email protected]>, 2016-2021
19 # - Benedikt Ziemons <[email protected]>, 2021
20
21 import os
22 import sys
23
24 from setuptools import setup
25
26
27 if sys.version_info < (3, 6):
28 print('ERROR: Rucio WebUI requires at least Python 3.6 to run.')
29 sys.exit(1)
30
31 try:
32 from setuputil import get_rucio_version
33 except ImportError:
34 sys.path.append(os.path.abspath(os.path.dirname(__file__)))
35 from setuputil import get_rucio_version
36
37 name = 'rucio-webui'
38 packages = ['rucio', 'rucio.web', 'rucio.web.ui', 'rucio.web.ui.flask', 'rucio.web.flask.common']
39 data_files = []
40 description = "Rucio WebUI Package"
41
42 setup(
43 name=name,
44 version=get_rucio_version(),
45 packages=packages,
46 package_dir={'': 'lib'},
47 data_files=None,
48 include_package_data=True,
49 scripts=None,
50 author="Rucio",
51 author_email="[email protected]",
52 description=description,
53 license="Apache License, Version 2.0",
54 url="https://rucio.cern.ch/",
55 python_requires=">=3.6, <4",
56 classifiers=[
57 'Development Status :: 5 - Production/Stable',
58 'License :: OSI Approved :: Apache Software License',
59 'Intended Audience :: Information Technology',
60 'Intended Audience :: System Administrators',
61 'Operating System :: POSIX :: Linux',
62 'Natural Language :: English',
63 'Programming Language :: Python',
64 'Programming Language :: Python :: 3',
65 'Programming Language :: Python :: 3.6',
66 'Programming Language :: Python :: 3.7',
67 'Programming Language :: Python :: 3.8',
68 'Programming Language :: Python :: 3.9',
69 'Environment :: No Input/Output (Daemon)', ],
70 install_requires=['rucio>=1.2.5', ],
71 )
72
[end of setup_webui.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup_webui.py b/setup_webui.py
--- a/setup_webui.py
+++ b/setup_webui.py
@@ -35,7 +35,7 @@
from setuputil import get_rucio_version
name = 'rucio-webui'
-packages = ['rucio', 'rucio.web', 'rucio.web.ui', 'rucio.web.ui.flask', 'rucio.web.flask.common']
+packages = ['rucio', 'rucio.web', 'rucio.web.ui', 'rucio.web.ui.flask', 'rucio.web.ui.flask.common']
data_files = []
description = "Rucio WebUI Package"
|
{"golden_diff": "diff --git a/setup_webui.py b/setup_webui.py\n--- a/setup_webui.py\n+++ b/setup_webui.py\n@@ -35,7 +35,7 @@\n from setuputil import get_rucio_version\n \n name = 'rucio-webui'\n-packages = ['rucio', 'rucio.web', 'rucio.web.ui', 'rucio.web.ui.flask', 'rucio.web.flask.common']\n+packages = ['rucio', 'rucio.web', 'rucio.web.ui', 'rucio.web.ui.flask', 'rucio.web.ui.flask.common']\n data_files = []\n description = \"Rucio WebUI Package\"\n", "issue": "Fix setup_webui script\nMotivation\r\n----------\r\nScript has a wrong import, needs to be fixed.\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright 2015-2021 CERN\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n# Authors:\n# - Vincent Garonne <[email protected]>, 2015-2017\n# - Martin Barisits <[email protected]>, 2016-2021\n# - Benedikt Ziemons <[email protected]>, 2021\n\nimport os\nimport sys\n\nfrom setuptools import setup\n\n\nif sys.version_info < (3, 6):\n print('ERROR: Rucio WebUI requires at least Python 3.6 to run.')\n sys.exit(1)\n\ntry:\n from setuputil import get_rucio_version\nexcept ImportError:\n sys.path.append(os.path.abspath(os.path.dirname(__file__)))\n from setuputil import get_rucio_version\n\nname = 'rucio-webui'\npackages = ['rucio', 'rucio.web', 'rucio.web.ui', 'rucio.web.ui.flask', 'rucio.web.flask.common']\ndata_files = []\ndescription = \"Rucio WebUI Package\"\n\nsetup(\n name=name,\n version=get_rucio_version(),\n packages=packages,\n package_dir={'': 'lib'},\n data_files=None,\n include_package_data=True,\n scripts=None,\n author=\"Rucio\",\n author_email=\"[email protected]\",\n description=description,\n license=\"Apache License, Version 2.0\",\n url=\"https://rucio.cern.ch/\",\n python_requires=\">=3.6, <4\",\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'License :: OSI Approved :: Apache Software License',\n 'Intended Audience :: Information Technology',\n 'Intended Audience :: System Administrators',\n 'Operating System :: POSIX :: Linux',\n 'Natural Language :: English',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n 'Environment :: No Input/Output (Daemon)', ],\n install_requires=['rucio>=1.2.5', ],\n)\n", "path": "setup_webui.py"}]}
| 1,320 | 141 |
gh_patches_debug_26431
|
rasdani/github-patches
|
git_diff
|
tensorflow__tfx-91
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Import errors when trying to run Chicago Taxi on Dataflow
Similarly as in issue [#47](https://github.com/tensorflow/tfx/issues/47), I still have a problem with running CTE on Dataflow. When I use the code with no modifications, the error from previous issue persists - it seems that somehow the `try-except` around the imports doesn't do its job.
When I changed the code to include only the relative import in my fork [here](https://github.com/mwalenia/tfx/tree/import-fix), the problem disappeared, but another one manifested.
This time, there's a problem with importing `estimator` from tensorflow somewhere in the dependencies. Stacktrace:
```Traceback (most recent call last):
File "/usr/local/lib/python2.7/dist-packages/dataflow_worker/batchworker.py", line 773, in run
self._load_main_session(self.local_staging_directory)
File "/usr/local/lib/python2.7/dist-packages/dataflow_worker/batchworker.py", line 489, in _load_main_session
pickler.load_session(session_file)
File "/usr/local/lib/python2.7/dist-packages/apache_beam/internal/pickler.py", line 269, in load_session
return dill.load_session(file_path)
File "/usr/local/lib/python2.7/dist-packages/dill/_dill.py", line 410, in load_session
module = unpickler.load()
File "/usr/lib/python2.7/pickle.py", line 864, in load
dispatch[key](self)
File "/usr/lib/python2.7/pickle.py", line 1139, in load_reduce
value = func(*args)
File "/usr/local/lib/python2.7/dist-packages/dill/_dill.py", line 828, in _import_module
return getattr(__import__(module, None, None, [obj]), obj)
File "/usr/local/lib/python2.7/dist-packages/trainer/taxi.py", line 19, in <module>
from tensorflow_transform import coders as tft_coders
File "/usr/local/lib/python2.7/dist-packages/tensorflow_transform/__init__.py", line 19, in <module>
from tensorflow_transform.analyzers import *
File "/usr/local/lib/python2.7/dist-packages/tensorflow_transform/analyzers.py", line 39, in <module>
from tensorflow_transform import tf_utils
File "/usr/local/lib/python2.7/dist-packages/tensorflow_transform/tf_utils.py", line 24, in <module>
from tensorflow.contrib.proto.python.ops import encode_proto_op
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/__init__.py", line 48, in <module>
from tensorflow.contrib import distribute
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/distribute/__init__.py", line 34, in <module>
from tensorflow.contrib.distribute.python.tpu_strategy import TPUStrategy
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/distribute/python/tpu_strategy.py", line 27, in <module>
from tensorflow.contrib.tpu.python.ops import tpu_ops
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/tpu/__init__.py", line 73, in <module>
from tensorflow.contrib.tpu.python.tpu.keras_support import tpu_model as keras_to_tpu_model
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/tpu/python/tpu/keras_support.py", line 71, in <module>
from tensorflow.python.estimator import model_fn as model_fn_lib
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/estimator/__init__.py", line 25, in <module>
import tensorflow.python.estimator.estimator_lib
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/estimator/estimator_lib.py", line 22, in <module>
from tensorflow.python.estimator.canned.baseline import BaselineClassifier
File "/usr/local/lib/python2.7/dist-packages/tensorflow/python/estimator/canned/baseline.py", line 50, in <module>
from tensorflow.python.estimator import estimator
ImportError: cannot import name estimator
```
Is there anything I can do to fix this?
</issue>
<code>
[start of tfx/examples/chicago_taxi/setup.py]
1 # Copyright 2019 Google LLC. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """Setup dependencies for local and cloud deployment."""
15 import setuptools
16
17 # LINT.IfChange
18 TF_VERSION = '1.12.0'
19 # LINT.ThenChange(train_mlengine.sh, start_model_server_mlengine.sh)
20
21 # LINT.IfChange
22 BEAM_VERSION = '2.11.0'
23 # LINT.ThenChange(setup_beam_on_flink.sh)
24
25 if __name__ == '__main__':
26 setuptools.setup(
27 name='tfx_chicago_taxi',
28 version='0.12.0',
29 packages=setuptools.find_packages(),
30 install_requires=[
31 'apache-beam[gcp]==' + BEAM_VERSION,
32 'jupyter==1.0',
33 'numpy==1.14.5',
34 'protobuf==3.6.1',
35 'tensorflow==' + TF_VERSION,
36 'tensorflow-data-validation==0.12.0',
37 'tensorflow-metadata==0.12.1',
38 'tensorflow-model-analysis==0.12.1',
39 'tensorflow-serving-api==1.12.0',
40 'tensorflow-transform==0.12.0',
41 ],
42 python_requires='>=2.7,<3')
43
[end of tfx/examples/chicago_taxi/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/tfx/examples/chicago_taxi/setup.py b/tfx/examples/chicago_taxi/setup.py
--- a/tfx/examples/chicago_taxi/setup.py
+++ b/tfx/examples/chicago_taxi/setup.py
@@ -15,28 +15,29 @@
import setuptools
# LINT.IfChange
-TF_VERSION = '1.12.0'
+TF_VERSION = '1.13.1'
# LINT.ThenChange(train_mlengine.sh, start_model_server_mlengine.sh)
# LINT.IfChange
-BEAM_VERSION = '2.11.0'
+BEAM_VERSION = '2.12.0'
# LINT.ThenChange(setup_beam_on_flink.sh)
if __name__ == '__main__':
setuptools.setup(
name='tfx_chicago_taxi',
- version='0.12.0',
+ version='0.13.0',
packages=setuptools.find_packages(),
install_requires=[
- 'apache-beam[gcp]==' + BEAM_VERSION,
- 'jupyter==1.0',
- 'numpy==1.14.5',
- 'protobuf==3.6.1',
- 'tensorflow==' + TF_VERSION,
- 'tensorflow-data-validation==0.12.0',
- 'tensorflow-metadata==0.12.1',
- 'tensorflow-model-analysis==0.12.1',
- 'tensorflow-serving-api==1.12.0',
- 'tensorflow-transform==0.12.0',
+ 'apache-beam[gcp]>=' + BEAM_VERSION,
+ 'jupyter>=1.0,<2',
+ 'notebook>=5.7.8,<5.8',
+ 'numpy>=1.14.5,<2',
+ 'protobuf>=3.7.0,<3.8.0',
+ 'tensorflow>=' + TF_VERSION,
+ 'tensorflow-data-validation>=0.13.1,<0.14',
+ 'tensorflow-metadata>=0.13.1,<0.14',
+ 'tensorflow-model-analysis>=0.13.2,<0.14',
+ 'tensorflow-serving-api>=1.13.0,<1.14',
+ 'tensorflow-transform>=0.13.0,<0.14',
],
- python_requires='>=2.7,<3')
+ python_requires='>=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*,!=3.4.*,<4',)
|
{"golden_diff": "diff --git a/tfx/examples/chicago_taxi/setup.py b/tfx/examples/chicago_taxi/setup.py\n--- a/tfx/examples/chicago_taxi/setup.py\n+++ b/tfx/examples/chicago_taxi/setup.py\n@@ -15,28 +15,29 @@\n import setuptools\n \n # LINT.IfChange\n-TF_VERSION = '1.12.0'\n+TF_VERSION = '1.13.1'\n # LINT.ThenChange(train_mlengine.sh, start_model_server_mlengine.sh)\n \n # LINT.IfChange\n-BEAM_VERSION = '2.11.0'\n+BEAM_VERSION = '2.12.0'\n # LINT.ThenChange(setup_beam_on_flink.sh)\n \n if __name__ == '__main__':\n setuptools.setup(\n name='tfx_chicago_taxi',\n- version='0.12.0',\n+ version='0.13.0',\n packages=setuptools.find_packages(),\n install_requires=[\n- 'apache-beam[gcp]==' + BEAM_VERSION,\n- 'jupyter==1.0',\n- 'numpy==1.14.5',\n- 'protobuf==3.6.1',\n- 'tensorflow==' + TF_VERSION,\n- 'tensorflow-data-validation==0.12.0',\n- 'tensorflow-metadata==0.12.1',\n- 'tensorflow-model-analysis==0.12.1',\n- 'tensorflow-serving-api==1.12.0',\n- 'tensorflow-transform==0.12.0',\n+ 'apache-beam[gcp]>=' + BEAM_VERSION,\n+ 'jupyter>=1.0,<2',\n+ 'notebook>=5.7.8,<5.8',\n+ 'numpy>=1.14.5,<2',\n+ 'protobuf>=3.7.0,<3.8.0',\n+ 'tensorflow>=' + TF_VERSION,\n+ 'tensorflow-data-validation>=0.13.1,<0.14',\n+ 'tensorflow-metadata>=0.13.1,<0.14',\n+ 'tensorflow-model-analysis>=0.13.2,<0.14',\n+ 'tensorflow-serving-api>=1.13.0,<1.14',\n+ 'tensorflow-transform>=0.13.0,<0.14',\n ],\n- python_requires='>=2.7,<3')\n+ python_requires='>=2.7,!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*,!=3.4.*,<4',)\n", "issue": "Import errors when trying to run Chicago Taxi on Dataflow\nSimilarly as in issue [#47](https://github.com/tensorflow/tfx/issues/47), I still have a problem with running CTE on Dataflow. When I use the code with no modifications, the error from previous issue persists - it seems that somehow the `try-except` around the imports doesn't do its job.\r\n\r\nWhen I changed the code to include only the relative import in my fork [here](https://github.com/mwalenia/tfx/tree/import-fix), the problem disappeared, but another one manifested.\r\n\r\nThis time, there's a problem with importing `estimator` from tensorflow somewhere in the dependencies. Stacktrace:\r\n\r\n```Traceback (most recent call last):\r\n File \"/usr/local/lib/python2.7/dist-packages/dataflow_worker/batchworker.py\", line 773, in run\r\n self._load_main_session(self.local_staging_directory)\r\n File \"/usr/local/lib/python2.7/dist-packages/dataflow_worker/batchworker.py\", line 489, in _load_main_session\r\n pickler.load_session(session_file)\r\n File \"/usr/local/lib/python2.7/dist-packages/apache_beam/internal/pickler.py\", line 269, in load_session\r\n return dill.load_session(file_path)\r\n File \"/usr/local/lib/python2.7/dist-packages/dill/_dill.py\", line 410, in load_session\r\n module = unpickler.load()\r\n File \"/usr/lib/python2.7/pickle.py\", line 864, in load\r\n dispatch[key](self)\r\n File \"/usr/lib/python2.7/pickle.py\", line 1139, in load_reduce\r\n value = func(*args)\r\n File \"/usr/local/lib/python2.7/dist-packages/dill/_dill.py\", line 828, in _import_module\r\n return getattr(__import__(module, None, None, [obj]), obj)\r\n File \"/usr/local/lib/python2.7/dist-packages/trainer/taxi.py\", line 19, in <module>\r\n from tensorflow_transform import coders as tft_coders\r\n File \"/usr/local/lib/python2.7/dist-packages/tensorflow_transform/__init__.py\", line 19, in <module>\r\n from tensorflow_transform.analyzers import *\r\n File \"/usr/local/lib/python2.7/dist-packages/tensorflow_transform/analyzers.py\", line 39, in <module>\r\n from tensorflow_transform import tf_utils\r\n File \"/usr/local/lib/python2.7/dist-packages/tensorflow_transform/tf_utils.py\", line 24, in <module>\r\n from tensorflow.contrib.proto.python.ops import encode_proto_op\r\n File \"/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/__init__.py\", line 48, in <module>\r\n from tensorflow.contrib import distribute\r\n File \"/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/distribute/__init__.py\", line 34, in <module>\r\n from tensorflow.contrib.distribute.python.tpu_strategy import TPUStrategy\r\n File \"/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/distribute/python/tpu_strategy.py\", line 27, in <module>\r\n from tensorflow.contrib.tpu.python.ops import tpu_ops\r\n File \"/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/tpu/__init__.py\", line 73, in <module>\r\n from tensorflow.contrib.tpu.python.tpu.keras_support import tpu_model as keras_to_tpu_model\r\n File \"/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/tpu/python/tpu/keras_support.py\", line 71, in <module>\r\n from tensorflow.python.estimator import model_fn as model_fn_lib\r\n File \"/usr/local/lib/python2.7/dist-packages/tensorflow/python/estimator/__init__.py\", line 25, in <module>\r\n import tensorflow.python.estimator.estimator_lib\r\n File \"/usr/local/lib/python2.7/dist-packages/tensorflow/python/estimator/estimator_lib.py\", line 22, in <module>\r\n from tensorflow.python.estimator.canned.baseline import BaselineClassifier\r\n File \"/usr/local/lib/python2.7/dist-packages/tensorflow/python/estimator/canned/baseline.py\", line 50, in <module>\r\n from tensorflow.python.estimator import estimator\r\nImportError: cannot import name estimator\r\n```\r\n\r\nIs there anything I can do to fix this? \n", "before_files": [{"content": "# Copyright 2019 Google LLC. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Setup dependencies for local and cloud deployment.\"\"\"\nimport setuptools\n\n# LINT.IfChange\nTF_VERSION = '1.12.0'\n# LINT.ThenChange(train_mlengine.sh, start_model_server_mlengine.sh)\n\n# LINT.IfChange\nBEAM_VERSION = '2.11.0'\n# LINT.ThenChange(setup_beam_on_flink.sh)\n\nif __name__ == '__main__':\n setuptools.setup(\n name='tfx_chicago_taxi',\n version='0.12.0',\n packages=setuptools.find_packages(),\n install_requires=[\n 'apache-beam[gcp]==' + BEAM_VERSION,\n 'jupyter==1.0',\n 'numpy==1.14.5',\n 'protobuf==3.6.1',\n 'tensorflow==' + TF_VERSION,\n 'tensorflow-data-validation==0.12.0',\n 'tensorflow-metadata==0.12.1',\n 'tensorflow-model-analysis==0.12.1',\n 'tensorflow-serving-api==1.12.0',\n 'tensorflow-transform==0.12.0',\n ],\n python_requires='>=2.7,<3')\n", "path": "tfx/examples/chicago_taxi/setup.py"}]}
| 1,980 | 567 |
gh_patches_debug_10568
|
rasdani/github-patches
|
git_diff
|
buildbot__buildbot-3583
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Buildbot should check for duplicates in addURL
In a step if we call self.addURL() multiple times with same URL, buildbot doesn't check if URL is already added, and adds the duplicate URL. Buildbot should check if the URL is already added before adding the URL.
This happens when a script parses a lot of output and generate links for various things. We can manually maintain a list ourself and check for duplicates before calling addURL(), but it feels so basic that buildbot should be doing this check instead of callers of addURL() checking for duplicates.
</issue>
<code>
[start of master/buildbot/db/steps.py]
1 # This file is part of Buildbot. Buildbot is free software: you can
2 # redistribute it and/or modify it under the terms of the GNU General Public
3 # License as published by the Free Software Foundation, version 2.
4 #
5 # This program is distributed in the hope that it will be useful, but WITHOUT
6 # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
7 # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
8 # details.
9 #
10 # You should have received a copy of the GNU General Public License along with
11 # this program; if not, write to the Free Software Foundation, Inc., 51
12 # Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
13 #
14 # Copyright Buildbot Team Members
15
16 from __future__ import absolute_import
17 from __future__ import print_function
18
19 import json
20
21 import sqlalchemy as sa
22
23 from twisted.internet import defer
24 from twisted.internet import reactor
25
26 from buildbot.db import base
27 from buildbot.util import epoch2datetime
28
29
30 class StepsConnectorComponent(base.DBConnectorComponent):
31 # Documentation is in developer/db.rst
32 url_lock = None
33
34 def getStep(self, stepid=None, buildid=None, number=None, name=None):
35 tbl = self.db.model.steps
36 if stepid is not None:
37 wc = (tbl.c.id == stepid)
38 else:
39 if buildid is None:
40 return defer.fail(RuntimeError('must supply either stepid or buildid'))
41 if number is not None:
42 wc = (tbl.c.number == number)
43 elif name is not None:
44 wc = (tbl.c.name == name)
45 else:
46 return defer.fail(RuntimeError('must supply either number or name'))
47 wc = wc & (tbl.c.buildid == buildid)
48
49 def thd(conn):
50 q = self.db.model.steps.select(whereclause=wc)
51 res = conn.execute(q)
52 row = res.fetchone()
53
54 rv = None
55 if row:
56 rv = self._stepdictFromRow(row)
57 res.close()
58 return rv
59 return self.db.pool.do(thd)
60
61 def getSteps(self, buildid):
62 def thd(conn):
63 tbl = self.db.model.steps
64 q = tbl.select()
65 q = q.where(tbl.c.buildid == buildid)
66 q = q.order_by(tbl.c.number)
67 res = conn.execute(q)
68 return [self._stepdictFromRow(row) for row in res.fetchall()]
69 return self.db.pool.do(thd)
70
71 def addStep(self, buildid, name, state_string):
72 def thd(conn):
73 tbl = self.db.model.steps
74 # get the highest current number
75 r = conn.execute(sa.select([sa.func.max(tbl.c.number)],
76 whereclause=(tbl.c.buildid == buildid)))
77 number = r.scalar()
78 number = 0 if number is None else number + 1
79
80 # note that there is no chance for a race condition here,
81 # since only one master is inserting steps. If there is a
82 # conflict, then the name is likely already taken.
83 insert_row = dict(buildid=buildid, number=number,
84 started_at=None, complete_at=None,
85 state_string=state_string,
86 urls_json='[]', name=name)
87 try:
88 r = conn.execute(self.db.model.steps.insert(), insert_row)
89 got_id = r.inserted_primary_key[0]
90 except (sa.exc.IntegrityError, sa.exc.ProgrammingError):
91 got_id = None
92
93 if got_id:
94 return (got_id, number, name)
95
96 # we didn't get an id, so calculate a unique name and use that
97 # instead. Because names are truncated at the right to fit in a
98 # 50-character identifier, this isn't a simple query.
99 res = conn.execute(sa.select([tbl.c.name],
100 whereclause=((tbl.c.buildid == buildid))))
101 names = set([row[0] for row in res])
102 num = 1
103 while True:
104 numstr = '_%d' % num
105 newname = name[:50 - len(numstr)] + numstr
106 if newname not in names:
107 break
108 num += 1
109 insert_row['name'] = newname
110 r = conn.execute(self.db.model.steps.insert(), insert_row)
111 got_id = r.inserted_primary_key[0]
112 return (got_id, number, newname)
113 return self.db.pool.do(thd)
114
115 def startStep(self, stepid, _reactor=reactor):
116 started_at = _reactor.seconds()
117
118 def thd(conn):
119 tbl = self.db.model.steps
120 q = tbl.update(whereclause=(tbl.c.id == stepid))
121 conn.execute(q, started_at=started_at)
122 return self.db.pool.do(thd)
123
124 def setStepStateString(self, stepid, state_string):
125 def thd(conn):
126 tbl = self.db.model.steps
127 q = tbl.update(whereclause=(tbl.c.id == stepid))
128 conn.execute(q, state_string=state_string)
129 return self.db.pool.do(thd)
130
131 def addURL(self, stepid, name, url, _racehook=None):
132 # This methods adds an URL to the db
133 # This is a read modify write and thus there is a possibility
134 # that several urls are added at the same time (e.g with a deferredlist
135 # at the end of a step)
136 # this race condition is only inside the same master, as only one master
137 # is supposed to add urls to a buildstep.
138 # so threading.lock is used, as we are in the thread pool
139 if self.url_lock is None:
140 # this runs in reactor thread, so no race here..
141 self.url_lock = defer.DeferredLock()
142
143 def thd(conn):
144
145 tbl = self.db.model.steps
146 wc = (tbl.c.id == stepid)
147 q = sa.select([tbl.c.urls_json],
148 whereclause=wc)
149 res = conn.execute(q)
150 row = res.fetchone()
151 if _racehook is not None:
152 _racehook()
153 urls = json.loads(row.urls_json)
154 urls.append(dict(name=name, url=url))
155
156 q = tbl.update(whereclause=wc)
157 conn.execute(q, urls_json=json.dumps(urls))
158
159 return self.url_lock.run(lambda: self.db.pool.do(thd))
160
161 def finishStep(self, stepid, results, hidden, _reactor=reactor):
162 def thd(conn):
163 tbl = self.db.model.steps
164 q = tbl.update(whereclause=(tbl.c.id == stepid))
165 conn.execute(q,
166 complete_at=_reactor.seconds(),
167 results=results,
168 hidden=1 if hidden else 0)
169 return self.db.pool.do(thd)
170
171 def _stepdictFromRow(self, row):
172 def mkdt(epoch):
173 if epoch:
174 return epoch2datetime(epoch)
175
176 return dict(
177 id=row.id,
178 number=row.number,
179 name=row.name,
180 buildid=row.buildid,
181 started_at=mkdt(row.started_at),
182 complete_at=mkdt(row.complete_at),
183 state_string=row.state_string,
184 results=row.results,
185 urls=json.loads(row.urls_json),
186 hidden=bool(row.hidden))
187
[end of master/buildbot/db/steps.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/master/buildbot/db/steps.py b/master/buildbot/db/steps.py
--- a/master/buildbot/db/steps.py
+++ b/master/buildbot/db/steps.py
@@ -151,10 +151,13 @@
if _racehook is not None:
_racehook()
urls = json.loads(row.urls_json)
- urls.append(dict(name=name, url=url))
- q = tbl.update(whereclause=wc)
- conn.execute(q, urls_json=json.dumps(urls))
+ url_item = dict(name=name, url=url)
+
+ if url_item not in urls:
+ urls.append(url_item)
+ q = tbl.update(whereclause=wc)
+ conn.execute(q, urls_json=json.dumps(urls))
return self.url_lock.run(lambda: self.db.pool.do(thd))
|
{"golden_diff": "diff --git a/master/buildbot/db/steps.py b/master/buildbot/db/steps.py\n--- a/master/buildbot/db/steps.py\n+++ b/master/buildbot/db/steps.py\n@@ -151,10 +151,13 @@\n if _racehook is not None:\n _racehook()\n urls = json.loads(row.urls_json)\n- urls.append(dict(name=name, url=url))\n \n- q = tbl.update(whereclause=wc)\n- conn.execute(q, urls_json=json.dumps(urls))\n+ url_item = dict(name=name, url=url)\n+\n+ if url_item not in urls:\n+ urls.append(url_item)\n+ q = tbl.update(whereclause=wc)\n+ conn.execute(q, urls_json=json.dumps(urls))\n \n return self.url_lock.run(lambda: self.db.pool.do(thd))\n", "issue": "Buildbot should check for duplicates in addURL \nIn a step if we call self.addURL() multiple times with same URL, buildbot doesn't check if URL is already added, and adds the duplicate URL. Buildbot should check if the URL is already added before adding the URL.\r\n\r\nThis happens when a script parses a lot of output and generate links for various things. We can manually maintain a list ourself and check for duplicates before calling addURL(), but it feels so basic that buildbot should be doing this check instead of callers of addURL() checking for duplicates.\r\n\n", "before_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nfrom __future__ import absolute_import\nfrom __future__ import print_function\n\nimport json\n\nimport sqlalchemy as sa\n\nfrom twisted.internet import defer\nfrom twisted.internet import reactor\n\nfrom buildbot.db import base\nfrom buildbot.util import epoch2datetime\n\n\nclass StepsConnectorComponent(base.DBConnectorComponent):\n # Documentation is in developer/db.rst\n url_lock = None\n\n def getStep(self, stepid=None, buildid=None, number=None, name=None):\n tbl = self.db.model.steps\n if stepid is not None:\n wc = (tbl.c.id == stepid)\n else:\n if buildid is None:\n return defer.fail(RuntimeError('must supply either stepid or buildid'))\n if number is not None:\n wc = (tbl.c.number == number)\n elif name is not None:\n wc = (tbl.c.name == name)\n else:\n return defer.fail(RuntimeError('must supply either number or name'))\n wc = wc & (tbl.c.buildid == buildid)\n\n def thd(conn):\n q = self.db.model.steps.select(whereclause=wc)\n res = conn.execute(q)\n row = res.fetchone()\n\n rv = None\n if row:\n rv = self._stepdictFromRow(row)\n res.close()\n return rv\n return self.db.pool.do(thd)\n\n def getSteps(self, buildid):\n def thd(conn):\n tbl = self.db.model.steps\n q = tbl.select()\n q = q.where(tbl.c.buildid == buildid)\n q = q.order_by(tbl.c.number)\n res = conn.execute(q)\n return [self._stepdictFromRow(row) for row in res.fetchall()]\n return self.db.pool.do(thd)\n\n def addStep(self, buildid, name, state_string):\n def thd(conn):\n tbl = self.db.model.steps\n # get the highest current number\n r = conn.execute(sa.select([sa.func.max(tbl.c.number)],\n whereclause=(tbl.c.buildid == buildid)))\n number = r.scalar()\n number = 0 if number is None else number + 1\n\n # note that there is no chance for a race condition here,\n # since only one master is inserting steps. If there is a\n # conflict, then the name is likely already taken.\n insert_row = dict(buildid=buildid, number=number,\n started_at=None, complete_at=None,\n state_string=state_string,\n urls_json='[]', name=name)\n try:\n r = conn.execute(self.db.model.steps.insert(), insert_row)\n got_id = r.inserted_primary_key[0]\n except (sa.exc.IntegrityError, sa.exc.ProgrammingError):\n got_id = None\n\n if got_id:\n return (got_id, number, name)\n\n # we didn't get an id, so calculate a unique name and use that\n # instead. Because names are truncated at the right to fit in a\n # 50-character identifier, this isn't a simple query.\n res = conn.execute(sa.select([tbl.c.name],\n whereclause=((tbl.c.buildid == buildid))))\n names = set([row[0] for row in res])\n num = 1\n while True:\n numstr = '_%d' % num\n newname = name[:50 - len(numstr)] + numstr\n if newname not in names:\n break\n num += 1\n insert_row['name'] = newname\n r = conn.execute(self.db.model.steps.insert(), insert_row)\n got_id = r.inserted_primary_key[0]\n return (got_id, number, newname)\n return self.db.pool.do(thd)\n\n def startStep(self, stepid, _reactor=reactor):\n started_at = _reactor.seconds()\n\n def thd(conn):\n tbl = self.db.model.steps\n q = tbl.update(whereclause=(tbl.c.id == stepid))\n conn.execute(q, started_at=started_at)\n return self.db.pool.do(thd)\n\n def setStepStateString(self, stepid, state_string):\n def thd(conn):\n tbl = self.db.model.steps\n q = tbl.update(whereclause=(tbl.c.id == stepid))\n conn.execute(q, state_string=state_string)\n return self.db.pool.do(thd)\n\n def addURL(self, stepid, name, url, _racehook=None):\n # This methods adds an URL to the db\n # This is a read modify write and thus there is a possibility\n # that several urls are added at the same time (e.g with a deferredlist\n # at the end of a step)\n # this race condition is only inside the same master, as only one master\n # is supposed to add urls to a buildstep.\n # so threading.lock is used, as we are in the thread pool\n if self.url_lock is None:\n # this runs in reactor thread, so no race here..\n self.url_lock = defer.DeferredLock()\n\n def thd(conn):\n\n tbl = self.db.model.steps\n wc = (tbl.c.id == stepid)\n q = sa.select([tbl.c.urls_json],\n whereclause=wc)\n res = conn.execute(q)\n row = res.fetchone()\n if _racehook is not None:\n _racehook()\n urls = json.loads(row.urls_json)\n urls.append(dict(name=name, url=url))\n\n q = tbl.update(whereclause=wc)\n conn.execute(q, urls_json=json.dumps(urls))\n\n return self.url_lock.run(lambda: self.db.pool.do(thd))\n\n def finishStep(self, stepid, results, hidden, _reactor=reactor):\n def thd(conn):\n tbl = self.db.model.steps\n q = tbl.update(whereclause=(tbl.c.id == stepid))\n conn.execute(q,\n complete_at=_reactor.seconds(),\n results=results,\n hidden=1 if hidden else 0)\n return self.db.pool.do(thd)\n\n def _stepdictFromRow(self, row):\n def mkdt(epoch):\n if epoch:\n return epoch2datetime(epoch)\n\n return dict(\n id=row.id,\n number=row.number,\n name=row.name,\n buildid=row.buildid,\n started_at=mkdt(row.started_at),\n complete_at=mkdt(row.complete_at),\n state_string=row.state_string,\n results=row.results,\n urls=json.loads(row.urls_json),\n hidden=bool(row.hidden))\n", "path": "master/buildbot/db/steps.py"}]}
| 2,698 | 182 |
gh_patches_debug_30308
|
rasdani/github-patches
|
git_diff
|
microsoft__Qcodes-450
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unused class FileWrapper
In the io manager module there is a FileWrapper class that seems to be never used anywhere?
Aside from the dubious utility of such a class (maybe if documented one could figure out) , maybe we should just remove it ?
@QCoDeS/core ?
</issue>
<code>
[start of qcodes/data/io.py]
1 """
2 IO managers for QCodes.
3
4 IO managers wrap whatever physical storage layer the user wants to use
5 in an interface mimicking the built-in <open> context manager, with
6 some restrictions to minimize the overhead in creating new IO managers.
7
8 The main thing these managers need to implement is the open context manager:
9
10 - Only the context manager needs to be implemented, not separate
11 open function and close methods.
12
13 - open takes the standard parameters:
14
15 - filename: (string)
16 - mode: (string) only 'r' (read), 'w' (write), and 'a' (append) are
17 expected to be implemented. As with normal file objects, the only
18 difference between write and append is that write empties the file
19 before adding new data, and append leaves the existing contents in
20 place but starts writing at the end.
21 - encoding: If a special output encoding is desired. i.e. 'utf8
22
23 - the file-like object returned should implement a minimal set of operations.
24
25 In read mode:
26 - read([size]): read to the end or at most size bytes into a string
27 - readline([size]): read until a newline or up to size bytes, into a string
28 - iter(): usually return self, but can be any iterator over lines
29 - next(): assuming iter() returns self, this yields the next line.
30
31 (note: iter and next can be constructed automatically by FileWrapper
32 if you implement readline.)
33
34 In write or append mode:
35 - write(s): add string s to the end of the file.
36 - writelines(seq): add a sequence of strings (can be constructed
37 automatically if you use FileWrapper)
38
39 IO managers should also implement:
40
41 - a join method, ala os.path.join(\*args).
42 - a list method, that returns all objects matching location
43 - a remove method, ala os.remove(path) except that it will remove directories
44 as well as files, since we're allowing "locations" to be directories
45 or files.
46 """
47
48 from contextlib import contextmanager
49 import os
50 import re
51 import shutil
52 from fnmatch import fnmatch
53
54 ALLOWED_OPEN_MODES = ('r', 'w', 'a')
55
56
57 class DiskIO:
58
59 """
60 Simple IO object to wrap disk operations with a custom base location.
61
62 Also accepts both forward and backward slashes at any point, and
63 normalizes both to the OS we are currently on.
64
65 Args:
66 base_location (str): a path to the root data folder.
67 Converted to an absolute path immediately, so even if you supply a
68 relative path, later changes to the OS working directory will not
69 affect data paths.
70 """
71
72 def __init__(self, base_location):
73 if base_location is None:
74 self.base_location = None
75 else:
76 base_location = self._normalize_slashes(base_location)
77 self.base_location = os.path.abspath(base_location)
78
79 @contextmanager
80 def open(self, filename, mode, encoding=None):
81 """
82 Mimic the interface of the built in open context manager.
83
84 Args:
85 filename (str): path relative to base_location.
86
87 mode (str): 'r' (read), 'w' (write), or 'a' (append).
88 Other open modes are not supported because we don't want
89 to force all IO managers to support others.
90
91 Returns:
92 context manager yielding the open file
93 """
94 if mode not in ALLOWED_OPEN_MODES:
95 raise ValueError('mode {} not allowed in IO managers'.format(mode))
96
97 filepath = self.to_path(filename)
98
99 # make directories if needed
100 dirpath = os.path.dirname(filepath)
101 if not os.path.exists(dirpath):
102 os.makedirs(dirpath)
103
104 # normally we'd construct this context manager with try/finally, but
105 # here we already have a context manager for open so we just wrap it
106 with open(filepath, mode, encoding=encoding) as f:
107 yield f
108
109 def _normalize_slashes(self, location):
110 # note that this is NOT os.path.join - the difference is os.path.join
111 # discards empty strings, so if you use it on a re.split absolute
112 # path you will get a relative path!
113 return os.sep.join(re.split('[\\\\/]', location))
114
115 def to_path(self, location):
116 """
117 Convert a location string into a path on the local file system.
118
119 For DiskIO this just fixes slashes and prepends the base location,
120 doing nothing active with the file. But for other io managers that
121 refer to remote storage, this method may actually fetch the file and
122 put it at a temporary local path.
123
124 Args:
125 location (str): A location string for a complete dataset or
126 a file within it.
127
128 Returns:
129 path (str): The path on disk to which this location maps.
130 """
131 location = self._normalize_slashes(location)
132 if self.base_location:
133 return os.path.join(self.base_location, location)
134 else:
135 return location
136
137 def to_location(self, path):
138 """
139 Convert a local filesystem path into a location string.
140
141 Args:
142 path (str): a path on the local file system.
143
144 Returns:
145 location (str): the location string corresponding to this path.
146 """
147 if self.base_location:
148 return os.path.relpath(path, self.base_location)
149 else:
150 return path
151
152 def __repr__(self):
153 """Show the base location in the repr."""
154 return '<DiskIO, base_location={}>'.format(repr(self.base_location))
155
156 def join(self, *args):
157 """Context-dependent os.path.join for this io manager."""
158 return os.path.join(*list(map(self._normalize_slashes, args)))
159
160 def isfile(self, location):
161 """Check whether this location matches a file."""
162 path = self.to_path(location)
163 return os.path.isfile(path)
164
165 def list(self, location, maxdepth=1, include_dirs=False):
166 """
167 Return all files that match location.
168
169 This is either files whose names match up to an arbitrary extension,
170 or any files within an exactly matching directory name.
171
172 Args:
173 location (str): the location to match.
174 May contain the usual path wildcards * and ?
175
176 maxdepth (int, optional): maximum levels of directory nesting to
177 recurse into looking for files. Default 1.
178
179 include_dirs (bool, optional): whether to allow directories in
180 the results or just files. Default False.
181
182 Returns:
183 A list of matching files and/or directories, as locations
184 relative to our base_location.
185 """
186 location = self._normalize_slashes(location)
187 search_dir, pattern = os.path.split(location)
188 path = self.to_path(search_dir)
189
190 if not os.path.isdir(path):
191 return []
192
193 matches = [fn for fn in os.listdir(path) if fnmatch(fn, pattern + '*')]
194 out = []
195
196 for match in matches:
197 matchpath = self.join(path, match)
198 if os.path.isdir(matchpath) and fnmatch(match, pattern):
199 if maxdepth > 0:
200 # exact directory match - walk down to maxdepth
201 for root, dirs, files in os.walk(matchpath, topdown=True):
202 depth = root[len(path):].count(os.path.sep)
203 if depth == maxdepth:
204 dirs[:] = [] # don't recurse any further
205
206 for fn in files + (dirs if include_dirs else []):
207 out.append(self.to_location(self.join(root, fn)))
208
209 elif include_dirs:
210 out.append(self.join(search_dir, match))
211
212 elif (os.path.isfile(matchpath) and
213 (fnmatch(match, pattern) or
214 fnmatch(os.path.splitext(match)[0], pattern))):
215 # exact filename match, or match up to an extension
216 # note that we need fnmatch(match, pattern) in addition to the
217 # splitext test to cover the case of the base filename itself
218 # containing a dot.
219 out.append(self.join(search_dir, match))
220
221 return out
222
223 def remove(self, filename):
224 """Delete a file or folder and prune the directory tree."""
225 path = self.to_path(filename)
226 if(os.path.isdir(path)):
227 shutil.rmtree(path)
228 else:
229 os.remove(path)
230
231 filepath = os.path.split(path)[0]
232 try:
233 os.removedirs(filepath)
234 except OSError:
235 # directory was not empty - good that we're not removing it!
236 pass
237
238 def remove_all(self, location):
239 """
240 Delete all files/directories in the dataset at this location.
241
242 Afterward prunes the directory tree.
243 """
244 for fn in self.list(location):
245 self.remove(fn)
246
247
248 class FileWrapper:
249 def read(self, size=None):
250 raise NotImplementedError
251
252 def readline(self, size=None):
253 raise NotImplementedError
254
255 def __iter__(self):
256 return self
257
258 def __next__(self):
259 line = self.readline()
260 if line:
261 return line
262 else:
263 raise StopIteration
264
265 def write(self, s):
266 raise NotImplementedError
267
268 def writelines(self, seq):
269 for s in seq:
270 self.write(s)
271
[end of qcodes/data/io.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/qcodes/data/io.py b/qcodes/data/io.py
--- a/qcodes/data/io.py
+++ b/qcodes/data/io.py
@@ -28,13 +28,9 @@
- iter(): usually return self, but can be any iterator over lines
- next(): assuming iter() returns self, this yields the next line.
- (note: iter and next can be constructed automatically by FileWrapper
- if you implement readline.)
-
In write or append mode:
- write(s): add string s to the end of the file.
- - writelines(seq): add a sequence of strings (can be constructed
- automatically if you use FileWrapper)
+ - writelines(seq): add a sequence of strings
IO managers should also implement:
@@ -223,7 +219,7 @@
def remove(self, filename):
"""Delete a file or folder and prune the directory tree."""
path = self.to_path(filename)
- if(os.path.isdir(path)):
+ if os.path.isdir(path):
shutil.rmtree(path)
else:
os.remove(path)
@@ -243,28 +239,3 @@
"""
for fn in self.list(location):
self.remove(fn)
-
-
-class FileWrapper:
- def read(self, size=None):
- raise NotImplementedError
-
- def readline(self, size=None):
- raise NotImplementedError
-
- def __iter__(self):
- return self
-
- def __next__(self):
- line = self.readline()
- if line:
- return line
- else:
- raise StopIteration
-
- def write(self, s):
- raise NotImplementedError
-
- def writelines(self, seq):
- for s in seq:
- self.write(s)
|
{"golden_diff": "diff --git a/qcodes/data/io.py b/qcodes/data/io.py\n--- a/qcodes/data/io.py\n+++ b/qcodes/data/io.py\n@@ -28,13 +28,9 @@\n - iter(): usually return self, but can be any iterator over lines\n - next(): assuming iter() returns self, this yields the next line.\n \n- (note: iter and next can be constructed automatically by FileWrapper\n- if you implement readline.)\n-\n In write or append mode:\n - write(s): add string s to the end of the file.\n- - writelines(seq): add a sequence of strings (can be constructed\n- automatically if you use FileWrapper)\n+ - writelines(seq): add a sequence of strings\n \n IO managers should also implement:\n \n@@ -223,7 +219,7 @@\n def remove(self, filename):\n \"\"\"Delete a file or folder and prune the directory tree.\"\"\"\n path = self.to_path(filename)\n- if(os.path.isdir(path)):\n+ if os.path.isdir(path):\n shutil.rmtree(path)\n else:\n os.remove(path)\n@@ -243,28 +239,3 @@\n \"\"\"\n for fn in self.list(location):\n self.remove(fn)\n-\n-\n-class FileWrapper:\n- def read(self, size=None):\n- raise NotImplementedError\n-\n- def readline(self, size=None):\n- raise NotImplementedError\n-\n- def __iter__(self):\n- return self\n-\n- def __next__(self):\n- line = self.readline()\n- if line:\n- return line\n- else:\n- raise StopIteration\n-\n- def write(self, s):\n- raise NotImplementedError\n-\n- def writelines(self, seq):\n- for s in seq:\n- self.write(s)\n", "issue": "Unused class FileWrapper\nIn the io manager module there is a FileWrapper class that seems to be never used anywhere?\r\nAside from the dubious utility of such a class (maybe if documented one could figure out) , maybe we should just remove it ?\r\n\r\n@QCoDeS/core ? \r\n\n", "before_files": [{"content": "\"\"\"\nIO managers for QCodes.\n\nIO managers wrap whatever physical storage layer the user wants to use\nin an interface mimicking the built-in <open> context manager, with\nsome restrictions to minimize the overhead in creating new IO managers.\n\nThe main thing these managers need to implement is the open context manager:\n\n- Only the context manager needs to be implemented, not separate\n open function and close methods.\n\n- open takes the standard parameters:\n\n - filename: (string)\n - mode: (string) only 'r' (read), 'w' (write), and 'a' (append) are\n expected to be implemented. As with normal file objects, the only\n difference between write and append is that write empties the file\n before adding new data, and append leaves the existing contents in\n place but starts writing at the end.\n - encoding: If a special output encoding is desired. i.e. 'utf8\n\n- the file-like object returned should implement a minimal set of operations.\n\n In read mode:\n - read([size]): read to the end or at most size bytes into a string\n - readline([size]): read until a newline or up to size bytes, into a string\n - iter(): usually return self, but can be any iterator over lines\n - next(): assuming iter() returns self, this yields the next line.\n\n (note: iter and next can be constructed automatically by FileWrapper\n if you implement readline.)\n\n In write or append mode:\n - write(s): add string s to the end of the file.\n - writelines(seq): add a sequence of strings (can be constructed\n automatically if you use FileWrapper)\n\nIO managers should also implement:\n\n- a join method, ala os.path.join(\\*args).\n- a list method, that returns all objects matching location\n- a remove method, ala os.remove(path) except that it will remove directories\n as well as files, since we're allowing \"locations\" to be directories\n or files.\n\"\"\"\n\nfrom contextlib import contextmanager\nimport os\nimport re\nimport shutil\nfrom fnmatch import fnmatch\n\nALLOWED_OPEN_MODES = ('r', 'w', 'a')\n\n\nclass DiskIO:\n\n \"\"\"\n Simple IO object to wrap disk operations with a custom base location.\n\n Also accepts both forward and backward slashes at any point, and\n normalizes both to the OS we are currently on.\n\n Args:\n base_location (str): a path to the root data folder.\n Converted to an absolute path immediately, so even if you supply a\n relative path, later changes to the OS working directory will not\n affect data paths.\n \"\"\"\n\n def __init__(self, base_location):\n if base_location is None:\n self.base_location = None\n else:\n base_location = self._normalize_slashes(base_location)\n self.base_location = os.path.abspath(base_location)\n\n @contextmanager\n def open(self, filename, mode, encoding=None):\n \"\"\"\n Mimic the interface of the built in open context manager.\n\n Args:\n filename (str): path relative to base_location.\n\n mode (str): 'r' (read), 'w' (write), or 'a' (append).\n Other open modes are not supported because we don't want\n to force all IO managers to support others.\n\n Returns:\n context manager yielding the open file\n \"\"\"\n if mode not in ALLOWED_OPEN_MODES:\n raise ValueError('mode {} not allowed in IO managers'.format(mode))\n\n filepath = self.to_path(filename)\n\n # make directories if needed\n dirpath = os.path.dirname(filepath)\n if not os.path.exists(dirpath):\n os.makedirs(dirpath)\n\n # normally we'd construct this context manager with try/finally, but\n # here we already have a context manager for open so we just wrap it\n with open(filepath, mode, encoding=encoding) as f:\n yield f\n\n def _normalize_slashes(self, location):\n # note that this is NOT os.path.join - the difference is os.path.join\n # discards empty strings, so if you use it on a re.split absolute\n # path you will get a relative path!\n return os.sep.join(re.split('[\\\\\\\\/]', location))\n\n def to_path(self, location):\n \"\"\"\n Convert a location string into a path on the local file system.\n\n For DiskIO this just fixes slashes and prepends the base location,\n doing nothing active with the file. But for other io managers that\n refer to remote storage, this method may actually fetch the file and\n put it at a temporary local path.\n\n Args:\n location (str): A location string for a complete dataset or\n a file within it.\n\n Returns:\n path (str): The path on disk to which this location maps.\n \"\"\"\n location = self._normalize_slashes(location)\n if self.base_location:\n return os.path.join(self.base_location, location)\n else:\n return location\n\n def to_location(self, path):\n \"\"\"\n Convert a local filesystem path into a location string.\n\n Args:\n path (str): a path on the local file system.\n\n Returns:\n location (str): the location string corresponding to this path.\n \"\"\"\n if self.base_location:\n return os.path.relpath(path, self.base_location)\n else:\n return path\n\n def __repr__(self):\n \"\"\"Show the base location in the repr.\"\"\"\n return '<DiskIO, base_location={}>'.format(repr(self.base_location))\n\n def join(self, *args):\n \"\"\"Context-dependent os.path.join for this io manager.\"\"\"\n return os.path.join(*list(map(self._normalize_slashes, args)))\n\n def isfile(self, location):\n \"\"\"Check whether this location matches a file.\"\"\"\n path = self.to_path(location)\n return os.path.isfile(path)\n\n def list(self, location, maxdepth=1, include_dirs=False):\n \"\"\"\n Return all files that match location.\n\n This is either files whose names match up to an arbitrary extension,\n or any files within an exactly matching directory name.\n\n Args:\n location (str): the location to match.\n May contain the usual path wildcards * and ?\n\n maxdepth (int, optional): maximum levels of directory nesting to\n recurse into looking for files. Default 1.\n\n include_dirs (bool, optional): whether to allow directories in\n the results or just files. Default False.\n\n Returns:\n A list of matching files and/or directories, as locations\n relative to our base_location.\n \"\"\"\n location = self._normalize_slashes(location)\n search_dir, pattern = os.path.split(location)\n path = self.to_path(search_dir)\n\n if not os.path.isdir(path):\n return []\n\n matches = [fn for fn in os.listdir(path) if fnmatch(fn, pattern + '*')]\n out = []\n\n for match in matches:\n matchpath = self.join(path, match)\n if os.path.isdir(matchpath) and fnmatch(match, pattern):\n if maxdepth > 0:\n # exact directory match - walk down to maxdepth\n for root, dirs, files in os.walk(matchpath, topdown=True):\n depth = root[len(path):].count(os.path.sep)\n if depth == maxdepth:\n dirs[:] = [] # don't recurse any further\n\n for fn in files + (dirs if include_dirs else []):\n out.append(self.to_location(self.join(root, fn)))\n\n elif include_dirs:\n out.append(self.join(search_dir, match))\n\n elif (os.path.isfile(matchpath) and\n (fnmatch(match, pattern) or\n fnmatch(os.path.splitext(match)[0], pattern))):\n # exact filename match, or match up to an extension\n # note that we need fnmatch(match, pattern) in addition to the\n # splitext test to cover the case of the base filename itself\n # containing a dot.\n out.append(self.join(search_dir, match))\n\n return out\n\n def remove(self, filename):\n \"\"\"Delete a file or folder and prune the directory tree.\"\"\"\n path = self.to_path(filename)\n if(os.path.isdir(path)):\n shutil.rmtree(path)\n else:\n os.remove(path)\n\n filepath = os.path.split(path)[0]\n try:\n os.removedirs(filepath)\n except OSError:\n # directory was not empty - good that we're not removing it!\n pass\n\n def remove_all(self, location):\n \"\"\"\n Delete all files/directories in the dataset at this location.\n\n Afterward prunes the directory tree.\n \"\"\"\n for fn in self.list(location):\n self.remove(fn)\n\n\nclass FileWrapper:\n def read(self, size=None):\n raise NotImplementedError\n\n def readline(self, size=None):\n raise NotImplementedError\n\n def __iter__(self):\n return self\n\n def __next__(self):\n line = self.readline()\n if line:\n return line\n else:\n raise StopIteration\n\n def write(self, s):\n raise NotImplementedError\n\n def writelines(self, seq):\n for s in seq:\n self.write(s)\n", "path": "qcodes/data/io.py"}]}
| 3,297 | 393 |
gh_patches_debug_14922
|
rasdani/github-patches
|
git_diff
|
elastic__apm-agent-python-1765
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
botocore instrumentation creating empty services
When using `boto3` to call out to services outside of the specially handled services (S3, SQS, DynamoDB, SNS), the `botocore` instrumentation creates spans with an incorrect `service.name`. This results in extra, empty services in both the service list and the service map.
</issue>
<code>
[start of elasticapm/instrumentation/packages/botocore.py]
1 # BSD 3-Clause License
2 #
3 # Copyright (c) 2019, Elasticsearch BV
4 # All rights reserved.
5 #
6 # Redistribution and use in source and binary forms, with or without
7 # modification, are permitted provided that the following conditions are met:
8 #
9 # * Redistributions of source code must retain the above copyright notice, this
10 # list of conditions and the following disclaimer.
11 #
12 # * Redistributions in binary form must reproduce the above copyright notice,
13 # this list of conditions and the following disclaimer in the documentation
14 # and/or other materials provided with the distribution.
15 #
16 # * Neither the name of the copyright holder nor the names of its
17 # contributors may be used to endorse or promote products derived from
18 # this software without specific prior written permission.
19 #
20 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
21 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
22 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
23 # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
24 # FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
25 # DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
26 # SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
27 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
28 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
29 # OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
30
31 import urllib.parse
32 from collections import namedtuple
33
34 from elasticapm.conf import constants
35 from elasticapm.instrumentation.packages.base import AbstractInstrumentedModule
36 from elasticapm.traces import SpanType, capture_span, execution_context
37 from elasticapm.utils.disttracing import TraceParent
38 from elasticapm.utils.logging import get_logger
39
40 logger = get_logger("elasticapm.instrument")
41
42 SQS_MAX_ATTRIBUTES = 10
43
44
45 HandlerInfo = namedtuple("HandlerInfo", ("signature", "span_type", "span_subtype", "span_action", "context"))
46
47 # Used for boto3 < 1.7
48 endpoint_to_service_id = {"SNS": "SNS", "S3": "S3", "DYNAMODB": "DynamoDB", "SQS": "SQS"}
49
50
51 class BotocoreInstrumentation(AbstractInstrumentedModule):
52 name = "botocore"
53
54 instrument_list = [("botocore.client", "BaseClient._make_api_call")]
55
56 capture_span_ctx = capture_span
57
58 def _call(self, service, instance, args, kwargs):
59 """
60 This is split out from `call()` so that it can be re-used by the
61 aiobotocore instrumentation without duplicating all of this code.
62 """
63 operation_name = kwargs.get("operation_name", args[0])
64
65 parsed_url = urllib.parse.urlparse(instance.meta.endpoint_url)
66 context = {
67 "destination": {
68 "address": parsed_url.hostname,
69 "port": parsed_url.port,
70 "cloud": {"region": instance.meta.region_name},
71 }
72 }
73
74 handler_info = None
75 handler = handlers.get(service, False)
76 if handler:
77 handler_info = handler(operation_name, service, instance, args, kwargs, context)
78 if not handler_info:
79 handler_info = handle_default(operation_name, service, instance, args, kwargs, context)
80
81 return self.capture_span_ctx(
82 handler_info.signature,
83 span_type=handler_info.span_type,
84 leaf=True,
85 span_subtype=handler_info.span_subtype,
86 span_action=handler_info.span_action,
87 extra=handler_info.context,
88 )
89
90 def _get_service(self, instance):
91 service_model = instance.meta.service_model
92 if hasattr(service_model, "service_id"): # added in boto3 1.7
93 service = service_model.service_id
94 else:
95 service = service_model.service_name.upper()
96 service = endpoint_to_service_id.get(service, service)
97 return service
98
99 def call(self, module, method, wrapped, instance, args, kwargs):
100 service = self._get_service(instance)
101
102 ctx = self._call(service, instance, args, kwargs)
103 with ctx as span:
104 if service in pre_span_modifiers:
105 pre_span_modifiers[service](span, args, kwargs)
106 result = wrapped(*args, **kwargs)
107 if service in post_span_modifiers:
108 post_span_modifiers[service](span, args, kwargs, result)
109 request_id = result.get("ResponseMetadata", {}).get("RequestId")
110 if request_id:
111 span.update_context("http", {"request": {"id": request_id}})
112 return result
113
114
115 def handle_s3(operation_name, service, instance, args, kwargs, context):
116 span_type = "storage"
117 span_subtype = "s3"
118 span_action = operation_name
119 if len(args) > 1 and "Bucket" in args[1]:
120 bucket = args[1]["Bucket"]
121 else:
122 # TODO handle Access Points
123 bucket = ""
124 signature = f"S3 {operation_name} {bucket}"
125
126 context["destination"]["service"] = {"name": span_subtype, "resource": bucket, "type": span_type}
127
128 return HandlerInfo(signature, span_type, span_subtype, span_action, context)
129
130
131 def handle_dynamodb(operation_name, service, instance, args, kwargs, context):
132 span_type = "db"
133 span_subtype = "dynamodb"
134 span_action = "query"
135 if len(args) > 1 and "TableName" in args[1]:
136 table = args[1]["TableName"]
137 else:
138 table = ""
139 signature = f"DynamoDB {operation_name} {table}".rstrip()
140
141 context["db"] = {"type": "dynamodb", "instance": instance.meta.region_name}
142 if operation_name == "Query" and len(args) > 1 and "KeyConditionExpression" in args[1]:
143 context["db"]["statement"] = args[1]["KeyConditionExpression"]
144
145 context["destination"]["service"] = {"name": span_subtype, "resource": table, "type": span_type}
146 return HandlerInfo(signature, span_type, span_subtype, span_action, context)
147
148
149 def handle_sns(operation_name, service, instance, args, kwargs, context):
150 if operation_name != "Publish":
151 # only "publish" is handled specifically, other endpoints get the default treatment
152 return False
153 span_type = "messaging"
154 span_subtype = "sns"
155 span_action = "send"
156 topic_name = ""
157 if len(args) > 1:
158 if "Name" in args[1]:
159 topic_name = args[1]["Name"]
160 if "TopicArn" in args[1]:
161 topic_name = args[1]["TopicArn"].rsplit(":", maxsplit=1)[-1]
162 signature = f"SNS {operation_name} {topic_name}".rstrip()
163 context["destination"]["service"] = {
164 "name": span_subtype,
165 "resource": f"{span_subtype}/{topic_name}" if topic_name else span_subtype,
166 "type": span_type,
167 }
168 return HandlerInfo(signature, span_type, span_subtype, span_action, context)
169
170
171 SQS_OPERATIONS = {
172 "SendMessage": {"span_action": "send", "signature": "SEND to"},
173 "SendMessageBatch": {"span_action": "send_batch", "signature": "SEND_BATCH to"},
174 "ReceiveMessage": {"span_action": "receive", "signature": "RECEIVE from"},
175 "DeleteMessage": {"span_action": "delete", "signature": "DELETE from"},
176 "DeleteMessageBatch": {"span_action": "delete_batch", "signature": "DELETE_BATCH from"},
177 }
178
179
180 def handle_sqs(operation_name, service, instance, args, kwargs, context):
181 op = SQS_OPERATIONS.get(operation_name, None)
182 if not op:
183 # only "publish" is handled specifically, other endpoints get the default treatment
184 return False
185 span_type = "messaging"
186 span_subtype = "sqs"
187 topic_name = ""
188
189 if len(args) > 1:
190 topic_name = args[1]["QueueUrl"].rsplit("/", maxsplit=1)[-1]
191 signature = f"SQS {op['signature']} {topic_name}".rstrip() if topic_name else f"SQS {op['signature']}"
192 context["destination"]["service"] = {
193 "name": span_subtype,
194 "resource": f"{span_subtype}/{topic_name}" if topic_name else span_subtype,
195 "type": span_type,
196 }
197 return HandlerInfo(signature, span_type, span_subtype, op["span_action"], context)
198
199
200 def modify_span_sqs_pre(span, args, kwargs):
201 operation_name = kwargs.get("operation_name", args[0])
202 if span.id:
203 trace_parent = span.transaction.trace_parent.copy_from(span_id=span.id)
204 else:
205 # this is a dropped span, use transaction id instead
206 transaction = execution_context.get_transaction()
207 trace_parent = transaction.trace_parent.copy_from(span_id=transaction.id)
208 attributes = {constants.TRACEPARENT_HEADER_NAME: {"DataType": "String", "StringValue": trace_parent.to_string()}}
209 if trace_parent.tracestate:
210 attributes[constants.TRACESTATE_HEADER_NAME] = {"DataType": "String", "StringValue": trace_parent.tracestate}
211 if len(args) > 1:
212 if operation_name in ("SendMessage", "SendMessageBatch"):
213 attributes_count = len(attributes)
214 if operation_name == "SendMessage":
215 messages = [args[1]]
216 else:
217 messages = args[1]["Entries"]
218 for message in messages:
219 message["MessageAttributes"] = message.get("MessageAttributes") or {}
220 if len(message["MessageAttributes"]) + attributes_count <= SQS_MAX_ATTRIBUTES:
221 message["MessageAttributes"].update(attributes)
222 else:
223 logger.info("Not adding disttracing headers to message due to attribute limit reached")
224 elif operation_name == "ReceiveMessage":
225 message_attributes = args[1].setdefault("MessageAttributeNames", [])
226 if "All" not in message_attributes:
227 message_attributes.extend([constants.TRACEPARENT_HEADER_NAME, constants.TRACESTATE_HEADER_NAME])
228
229
230 def modify_span_sqs_post(span: SpanType, args, kwargs, result):
231 operation_name = kwargs.get("operation_name", args[0])
232 if operation_name == "ReceiveMessage" and "Messages" in result:
233 for message in result["Messages"][:1000]: # only up to 1000 span links are recorded
234 if "MessageAttributes" in message and constants.TRACEPARENT_HEADER_NAME in message["MessageAttributes"]:
235 tp = TraceParent.from_string(
236 message["MessageAttributes"][constants.TRACEPARENT_HEADER_NAME]["StringValue"]
237 )
238 span.add_link(tp)
239
240
241 def handle_default(operation_name, service, instance, args, kwargs, destination):
242 span_type = "aws"
243 span_subtype = service.lower()
244 span_action = operation_name
245
246 destination["service"] = {"name": span_subtype, "resource": span_subtype, "type": span_type}
247
248 signature = f"{service}:{operation_name}"
249 return HandlerInfo(signature, span_type, span_subtype, span_action, destination)
250
251
252 handlers = {
253 "S3": handle_s3,
254 "DynamoDB": handle_dynamodb,
255 "SNS": handle_sns,
256 "SQS": handle_sqs,
257 "default": handle_default,
258 }
259
260 pre_span_modifiers = {
261 "SQS": modify_span_sqs_pre,
262 }
263
264 post_span_modifiers = {
265 "SQS": modify_span_sqs_post,
266 }
267
[end of elasticapm/instrumentation/packages/botocore.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/elasticapm/instrumentation/packages/botocore.py b/elasticapm/instrumentation/packages/botocore.py
--- a/elasticapm/instrumentation/packages/botocore.py
+++ b/elasticapm/instrumentation/packages/botocore.py
@@ -238,15 +238,15 @@
span.add_link(tp)
-def handle_default(operation_name, service, instance, args, kwargs, destination):
+def handle_default(operation_name, service, instance, args, kwargs, context):
span_type = "aws"
span_subtype = service.lower()
span_action = operation_name
- destination["service"] = {"name": span_subtype, "resource": span_subtype, "type": span_type}
+ context["destination"]["service"] = {"name": span_subtype, "resource": span_subtype, "type": span_type}
signature = f"{service}:{operation_name}"
- return HandlerInfo(signature, span_type, span_subtype, span_action, destination)
+ return HandlerInfo(signature, span_type, span_subtype, span_action, context)
handlers = {
|
{"golden_diff": "diff --git a/elasticapm/instrumentation/packages/botocore.py b/elasticapm/instrumentation/packages/botocore.py\n--- a/elasticapm/instrumentation/packages/botocore.py\n+++ b/elasticapm/instrumentation/packages/botocore.py\n@@ -238,15 +238,15 @@\n span.add_link(tp)\n \n \n-def handle_default(operation_name, service, instance, args, kwargs, destination):\n+def handle_default(operation_name, service, instance, args, kwargs, context):\n span_type = \"aws\"\n span_subtype = service.lower()\n span_action = operation_name\n \n- destination[\"service\"] = {\"name\": span_subtype, \"resource\": span_subtype, \"type\": span_type}\n+ context[\"destination\"][\"service\"] = {\"name\": span_subtype, \"resource\": span_subtype, \"type\": span_type}\n \n signature = f\"{service}:{operation_name}\"\n- return HandlerInfo(signature, span_type, span_subtype, span_action, destination)\n+ return HandlerInfo(signature, span_type, span_subtype, span_action, context)\n \n \n handlers = {\n", "issue": "botocore instrumentation creating empty services\nWhen using `boto3` to call out to services outside of the specially handled services (S3, SQS, DynamoDB, SNS), the `botocore` instrumentation creates spans with an incorrect `service.name`. This results in extra, empty services in both the service list and the service map.\n", "before_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\nimport urllib.parse\nfrom collections import namedtuple\n\nfrom elasticapm.conf import constants\nfrom elasticapm.instrumentation.packages.base import AbstractInstrumentedModule\nfrom elasticapm.traces import SpanType, capture_span, execution_context\nfrom elasticapm.utils.disttracing import TraceParent\nfrom elasticapm.utils.logging import get_logger\n\nlogger = get_logger(\"elasticapm.instrument\")\n\nSQS_MAX_ATTRIBUTES = 10\n\n\nHandlerInfo = namedtuple(\"HandlerInfo\", (\"signature\", \"span_type\", \"span_subtype\", \"span_action\", \"context\"))\n\n# Used for boto3 < 1.7\nendpoint_to_service_id = {\"SNS\": \"SNS\", \"S3\": \"S3\", \"DYNAMODB\": \"DynamoDB\", \"SQS\": \"SQS\"}\n\n\nclass BotocoreInstrumentation(AbstractInstrumentedModule):\n name = \"botocore\"\n\n instrument_list = [(\"botocore.client\", \"BaseClient._make_api_call\")]\n\n capture_span_ctx = capture_span\n\n def _call(self, service, instance, args, kwargs):\n \"\"\"\n This is split out from `call()` so that it can be re-used by the\n aiobotocore instrumentation without duplicating all of this code.\n \"\"\"\n operation_name = kwargs.get(\"operation_name\", args[0])\n\n parsed_url = urllib.parse.urlparse(instance.meta.endpoint_url)\n context = {\n \"destination\": {\n \"address\": parsed_url.hostname,\n \"port\": parsed_url.port,\n \"cloud\": {\"region\": instance.meta.region_name},\n }\n }\n\n handler_info = None\n handler = handlers.get(service, False)\n if handler:\n handler_info = handler(operation_name, service, instance, args, kwargs, context)\n if not handler_info:\n handler_info = handle_default(operation_name, service, instance, args, kwargs, context)\n\n return self.capture_span_ctx(\n handler_info.signature,\n span_type=handler_info.span_type,\n leaf=True,\n span_subtype=handler_info.span_subtype,\n span_action=handler_info.span_action,\n extra=handler_info.context,\n )\n\n def _get_service(self, instance):\n service_model = instance.meta.service_model\n if hasattr(service_model, \"service_id\"): # added in boto3 1.7\n service = service_model.service_id\n else:\n service = service_model.service_name.upper()\n service = endpoint_to_service_id.get(service, service)\n return service\n\n def call(self, module, method, wrapped, instance, args, kwargs):\n service = self._get_service(instance)\n\n ctx = self._call(service, instance, args, kwargs)\n with ctx as span:\n if service in pre_span_modifiers:\n pre_span_modifiers[service](span, args, kwargs)\n result = wrapped(*args, **kwargs)\n if service in post_span_modifiers:\n post_span_modifiers[service](span, args, kwargs, result)\n request_id = result.get(\"ResponseMetadata\", {}).get(\"RequestId\")\n if request_id:\n span.update_context(\"http\", {\"request\": {\"id\": request_id}})\n return result\n\n\ndef handle_s3(operation_name, service, instance, args, kwargs, context):\n span_type = \"storage\"\n span_subtype = \"s3\"\n span_action = operation_name\n if len(args) > 1 and \"Bucket\" in args[1]:\n bucket = args[1][\"Bucket\"]\n else:\n # TODO handle Access Points\n bucket = \"\"\n signature = f\"S3 {operation_name} {bucket}\"\n\n context[\"destination\"][\"service\"] = {\"name\": span_subtype, \"resource\": bucket, \"type\": span_type}\n\n return HandlerInfo(signature, span_type, span_subtype, span_action, context)\n\n\ndef handle_dynamodb(operation_name, service, instance, args, kwargs, context):\n span_type = \"db\"\n span_subtype = \"dynamodb\"\n span_action = \"query\"\n if len(args) > 1 and \"TableName\" in args[1]:\n table = args[1][\"TableName\"]\n else:\n table = \"\"\n signature = f\"DynamoDB {operation_name} {table}\".rstrip()\n\n context[\"db\"] = {\"type\": \"dynamodb\", \"instance\": instance.meta.region_name}\n if operation_name == \"Query\" and len(args) > 1 and \"KeyConditionExpression\" in args[1]:\n context[\"db\"][\"statement\"] = args[1][\"KeyConditionExpression\"]\n\n context[\"destination\"][\"service\"] = {\"name\": span_subtype, \"resource\": table, \"type\": span_type}\n return HandlerInfo(signature, span_type, span_subtype, span_action, context)\n\n\ndef handle_sns(operation_name, service, instance, args, kwargs, context):\n if operation_name != \"Publish\":\n # only \"publish\" is handled specifically, other endpoints get the default treatment\n return False\n span_type = \"messaging\"\n span_subtype = \"sns\"\n span_action = \"send\"\n topic_name = \"\"\n if len(args) > 1:\n if \"Name\" in args[1]:\n topic_name = args[1][\"Name\"]\n if \"TopicArn\" in args[1]:\n topic_name = args[1][\"TopicArn\"].rsplit(\":\", maxsplit=1)[-1]\n signature = f\"SNS {operation_name} {topic_name}\".rstrip()\n context[\"destination\"][\"service\"] = {\n \"name\": span_subtype,\n \"resource\": f\"{span_subtype}/{topic_name}\" if topic_name else span_subtype,\n \"type\": span_type,\n }\n return HandlerInfo(signature, span_type, span_subtype, span_action, context)\n\n\nSQS_OPERATIONS = {\n \"SendMessage\": {\"span_action\": \"send\", \"signature\": \"SEND to\"},\n \"SendMessageBatch\": {\"span_action\": \"send_batch\", \"signature\": \"SEND_BATCH to\"},\n \"ReceiveMessage\": {\"span_action\": \"receive\", \"signature\": \"RECEIVE from\"},\n \"DeleteMessage\": {\"span_action\": \"delete\", \"signature\": \"DELETE from\"},\n \"DeleteMessageBatch\": {\"span_action\": \"delete_batch\", \"signature\": \"DELETE_BATCH from\"},\n}\n\n\ndef handle_sqs(operation_name, service, instance, args, kwargs, context):\n op = SQS_OPERATIONS.get(operation_name, None)\n if not op:\n # only \"publish\" is handled specifically, other endpoints get the default treatment\n return False\n span_type = \"messaging\"\n span_subtype = \"sqs\"\n topic_name = \"\"\n\n if len(args) > 1:\n topic_name = args[1][\"QueueUrl\"].rsplit(\"/\", maxsplit=1)[-1]\n signature = f\"SQS {op['signature']} {topic_name}\".rstrip() if topic_name else f\"SQS {op['signature']}\"\n context[\"destination\"][\"service\"] = {\n \"name\": span_subtype,\n \"resource\": f\"{span_subtype}/{topic_name}\" if topic_name else span_subtype,\n \"type\": span_type,\n }\n return HandlerInfo(signature, span_type, span_subtype, op[\"span_action\"], context)\n\n\ndef modify_span_sqs_pre(span, args, kwargs):\n operation_name = kwargs.get(\"operation_name\", args[0])\n if span.id:\n trace_parent = span.transaction.trace_parent.copy_from(span_id=span.id)\n else:\n # this is a dropped span, use transaction id instead\n transaction = execution_context.get_transaction()\n trace_parent = transaction.trace_parent.copy_from(span_id=transaction.id)\n attributes = {constants.TRACEPARENT_HEADER_NAME: {\"DataType\": \"String\", \"StringValue\": trace_parent.to_string()}}\n if trace_parent.tracestate:\n attributes[constants.TRACESTATE_HEADER_NAME] = {\"DataType\": \"String\", \"StringValue\": trace_parent.tracestate}\n if len(args) > 1:\n if operation_name in (\"SendMessage\", \"SendMessageBatch\"):\n attributes_count = len(attributes)\n if operation_name == \"SendMessage\":\n messages = [args[1]]\n else:\n messages = args[1][\"Entries\"]\n for message in messages:\n message[\"MessageAttributes\"] = message.get(\"MessageAttributes\") or {}\n if len(message[\"MessageAttributes\"]) + attributes_count <= SQS_MAX_ATTRIBUTES:\n message[\"MessageAttributes\"].update(attributes)\n else:\n logger.info(\"Not adding disttracing headers to message due to attribute limit reached\")\n elif operation_name == \"ReceiveMessage\":\n message_attributes = args[1].setdefault(\"MessageAttributeNames\", [])\n if \"All\" not in message_attributes:\n message_attributes.extend([constants.TRACEPARENT_HEADER_NAME, constants.TRACESTATE_HEADER_NAME])\n\n\ndef modify_span_sqs_post(span: SpanType, args, kwargs, result):\n operation_name = kwargs.get(\"operation_name\", args[0])\n if operation_name == \"ReceiveMessage\" and \"Messages\" in result:\n for message in result[\"Messages\"][:1000]: # only up to 1000 span links are recorded\n if \"MessageAttributes\" in message and constants.TRACEPARENT_HEADER_NAME in message[\"MessageAttributes\"]:\n tp = TraceParent.from_string(\n message[\"MessageAttributes\"][constants.TRACEPARENT_HEADER_NAME][\"StringValue\"]\n )\n span.add_link(tp)\n\n\ndef handle_default(operation_name, service, instance, args, kwargs, destination):\n span_type = \"aws\"\n span_subtype = service.lower()\n span_action = operation_name\n\n destination[\"service\"] = {\"name\": span_subtype, \"resource\": span_subtype, \"type\": span_type}\n\n signature = f\"{service}:{operation_name}\"\n return HandlerInfo(signature, span_type, span_subtype, span_action, destination)\n\n\nhandlers = {\n \"S3\": handle_s3,\n \"DynamoDB\": handle_dynamodb,\n \"SNS\": handle_sns,\n \"SQS\": handle_sqs,\n \"default\": handle_default,\n}\n\npre_span_modifiers = {\n \"SQS\": modify_span_sqs_pre,\n}\n\npost_span_modifiers = {\n \"SQS\": modify_span_sqs_post,\n}\n", "path": "elasticapm/instrumentation/packages/botocore.py"}]}
| 3,835 | 244 |
gh_patches_debug_20929
|
rasdani/github-patches
|
git_diff
|
python-discord__bot-373
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
make !otn accept uppercase and punctuation
There are weird unicode alternatives for stuff like capital letters and punctuation that will get through the discord "only lowercase and dashes" filters.
When someone uses `!otn a` and tries to add a name with an apostrophe, we currently are transforming those into something that the system will accept. Let's do the same for exclamation points, question marks, and uppercase letters!
* For exclamation points, use ǃ
* For questionmarks, use ?
* For uppercase, use 𝖠𝖡𝖢𝖣𝖤𝖥𝖦𝖧𝖨𝖩𝖪𝖫𝖬𝖭𝖮𝖯𝖰𝖱𝖲𝖳𝖴𝖵𝖶𝖷𝖸𝖹
</issue>
<code>
[start of bot/cogs/off_topic_names.py]
1 import asyncio
2 import logging
3 from datetime import datetime, timedelta
4
5 from discord import Colour, Embed
6 from discord.ext.commands import BadArgument, Bot, Context, Converter, group
7
8 from bot.constants import Channels, Keys, MODERATION_ROLES, URLs
9 from bot.decorators import with_role
10 from bot.pagination import LinePaginator
11
12
13 CHANNELS = (Channels.off_topic_0, Channels.off_topic_1, Channels.off_topic_2)
14 log = logging.getLogger(__name__)
15
16
17 class OffTopicName(Converter):
18 """A converter that ensures an added off-topic name is valid."""
19
20 @staticmethod
21 async def convert(ctx: Context, argument: str):
22 allowed_characters = ("-", "’", "'", "`")
23
24 if not (2 <= len(argument) <= 96):
25 raise BadArgument("Channel name must be between 2 and 96 chars long")
26
27 elif not all(c.isalnum() or c in allowed_characters for c in argument):
28 raise BadArgument(
29 "Channel name must only consist of "
30 "alphanumeric characters, minus signs or apostrophes."
31 )
32
33 elif not argument.islower():
34 raise BadArgument("Channel name must be lowercase")
35
36 # Replace some unusable apostrophe-like characters with "’".
37 return argument.replace("'", "’").replace("`", "’")
38
39
40 async def update_names(bot: Bot, headers: dict):
41 """
42 The background updater task that performs a channel name update daily.
43
44 Args:
45 bot (Bot):
46 The running bot instance, used for fetching data from the
47 website via the bot's `http_session`.
48 """
49
50 while True:
51 # Since we truncate the compute timedelta to seconds, we add one second to ensure
52 # we go past midnight in the `seconds_to_sleep` set below.
53 today_at_midnight = datetime.utcnow().replace(microsecond=0, second=0, minute=0, hour=0)
54 next_midnight = today_at_midnight + timedelta(days=1)
55 seconds_to_sleep = (next_midnight - datetime.utcnow()).seconds + 1
56 await asyncio.sleep(seconds_to_sleep)
57
58 response = await bot.http_session.get(
59 f'{URLs.site_off_topic_names_api}?random_items=3',
60 headers=headers
61 )
62 channel_0_name, channel_1_name, channel_2_name = await response.json()
63 channel_0, channel_1, channel_2 = (bot.get_channel(channel_id) for channel_id in CHANNELS)
64
65 await channel_0.edit(name=f'ot0-{channel_0_name}')
66 await channel_1.edit(name=f'ot1-{channel_1_name}')
67 await channel_2.edit(name=f'ot2-{channel_2_name}')
68 log.debug(
69 "Updated off-topic channel names to"
70 f" {channel_0_name}, {channel_1_name} and {channel_2_name}"
71 )
72
73
74 class OffTopicNames:
75 """Commands related to managing the off-topic category channel names."""
76
77 def __init__(self, bot: Bot):
78 self.bot = bot
79 self.headers = {"X-API-KEY": Keys.site_api}
80 self.updater_task = None
81
82 def __cleanup(self):
83 if self.updater_task is not None:
84 self.updater_task.cancel()
85
86 async def on_ready(self):
87 if self.updater_task is None:
88 coro = update_names(self.bot, self.headers)
89 self.updater_task = self.bot.loop.create_task(coro)
90
91 @group(name='otname', aliases=('otnames', 'otn'), invoke_without_command=True)
92 @with_role(*MODERATION_ROLES)
93 async def otname_group(self, ctx):
94 """Add or list items from the off-topic channel name rotation."""
95
96 await ctx.invoke(self.bot.get_command("help"), "otname")
97
98 @otname_group.command(name='add', aliases=('a',))
99 @with_role(*MODERATION_ROLES)
100 async def add_command(self, ctx, name: OffTopicName):
101 """Adds a new off-topic name to the rotation."""
102
103 result = await self.bot.http_session.post(
104 URLs.site_off_topic_names_api,
105 headers=self.headers,
106 params={'name': name}
107 )
108
109 response = await result.json()
110
111 if result.status == 200:
112 log.info(
113 f"{ctx.author.name}#{ctx.author.discriminator}"
114 f" added the off-topic channel name '{name}"
115 )
116 await ctx.send(":ok_hand:")
117 else:
118 error_reason = response.get('message', "No reason provided.")
119 await ctx.send(f":warning: got non-200 from the API: {error_reason}")
120
121 @otname_group.command(name='delete', aliases=('remove', 'rm', 'del', 'd'))
122 @with_role(*MODERATION_ROLES)
123 async def delete_command(self, ctx, name: OffTopicName):
124 """Removes a off-topic name from the rotation."""
125
126 result = await self.bot.http_session.delete(
127 URLs.site_off_topic_names_api,
128 headers=self.headers,
129 params={'name': name}
130 )
131
132 response = await result.json()
133
134 if result.status == 200:
135 if response['deleted'] == 0:
136 await ctx.send(f":warning: No name matching `{name}` was found in the database.")
137 else:
138 log.info(
139 f"{ctx.author.name}#{ctx.author.discriminator}"
140 f" deleted the off-topic channel name '{name}"
141 )
142 await ctx.send(":ok_hand:")
143 else:
144 error_reason = response.get('message', "No reason provided.")
145 await ctx.send(f":warning: got non-200 from the API: {error_reason}")
146
147 @otname_group.command(name='list', aliases=('l',))
148 @with_role(*MODERATION_ROLES)
149 async def list_command(self, ctx):
150 """
151 Lists all currently known off-topic channel names in a paginator.
152 Restricted to Moderator and above to not spoil the surprise.
153 """
154
155 result = await self.bot.http_session.get(
156 URLs.site_off_topic_names_api,
157 headers=self.headers
158 )
159 response = await result.json()
160 lines = sorted(f"• {name}" for name in response)
161
162 embed = Embed(
163 title=f"Known off-topic names (`{len(response)}` total)",
164 colour=Colour.blue()
165 )
166 await LinePaginator.paginate(lines, ctx, embed, max_size=400, empty=False)
167
168
169 def setup(bot: Bot):
170 bot.add_cog(OffTopicNames(bot))
171 log.info("Cog loaded: OffTopicNames")
172
[end of bot/cogs/off_topic_names.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bot/cogs/off_topic_names.py b/bot/cogs/off_topic_names.py
--- a/bot/cogs/off_topic_names.py
+++ b/bot/cogs/off_topic_names.py
@@ -19,7 +19,7 @@
@staticmethod
async def convert(ctx: Context, argument: str):
- allowed_characters = ("-", "’", "'", "`")
+ allowed_characters = "ABCDEFGHIJKLMNOPQRSTUVWXYZ!?'`"
if not (2 <= len(argument) <= 96):
raise BadArgument("Channel name must be between 2 and 96 chars long")
@@ -30,11 +30,11 @@
"alphanumeric characters, minus signs or apostrophes."
)
- elif not argument.islower():
- raise BadArgument("Channel name must be lowercase")
-
- # Replace some unusable apostrophe-like characters with "’".
- return argument.replace("'", "’").replace("`", "’")
+ # Replace invalid characters with unicode alternatives.
+ table = str.maketrans(
+ allowed_characters, '𝖠𝖡𝖢𝖣𝖤𝖥𝖦𝖧𝖨𝖩𝖪𝖫𝖬𝖭𝖮𝖯𝖰𝖱𝖲𝖳𝖴𝖵𝖶𝖷𝖸𝖹ǃ?’’'
+ )
+ return argument.translate(table)
async def update_names(bot: Bot, headers: dict):
|
{"golden_diff": "diff --git a/bot/cogs/off_topic_names.py b/bot/cogs/off_topic_names.py\n--- a/bot/cogs/off_topic_names.py\n+++ b/bot/cogs/off_topic_names.py\n@@ -19,7 +19,7 @@\n \n @staticmethod\n async def convert(ctx: Context, argument: str):\n- allowed_characters = (\"-\", \"\u2019\", \"'\", \"`\")\n+ allowed_characters = \"ABCDEFGHIJKLMNOPQRSTUVWXYZ!?'`\"\n \n if not (2 <= len(argument) <= 96):\n raise BadArgument(\"Channel name must be between 2 and 96 chars long\")\n@@ -30,11 +30,11 @@\n \"alphanumeric characters, minus signs or apostrophes.\"\n )\n \n- elif not argument.islower():\n- raise BadArgument(\"Channel name must be lowercase\")\n-\n- # Replace some unusable apostrophe-like characters with \"\u2019\".\n- return argument.replace(\"'\", \"\u2019\").replace(\"`\", \"\u2019\")\n+ # Replace invalid characters with unicode alternatives.\n+ table = str.maketrans(\n+ allowed_characters, '\ud835\udda0\ud835\udda1\ud835\udda2\ud835\udda3\ud835\udda4\ud835\udda5\ud835\udda6\ud835\udda7\ud835\udda8\ud835\udda9\ud835\uddaa\ud835\uddab\ud835\uddac\ud835\uddad\ud835\uddae\ud835\uddaf\ud835\uddb0\ud835\uddb1\ud835\uddb2\ud835\uddb3\ud835\uddb4\ud835\uddb5\ud835\uddb6\ud835\uddb7\ud835\uddb8\ud835\uddb9\u01c3\uff1f\u2019\u2019'\n+ )\n+ return argument.translate(table)\n \n \n async def update_names(bot: Bot, headers: dict):\n", "issue": "make !otn accept uppercase and punctuation\nThere are weird unicode alternatives for stuff like capital letters and punctuation that will get through the discord \"only lowercase and dashes\" filters.\r\n\r\nWhen someone uses `!otn a` and tries to add a name with an apostrophe, we currently are transforming those into something that the system will accept. Let's do the same for exclamation points, question marks, and uppercase letters!\r\n\r\n* For exclamation points, use \u01c3\r\n* For questionmarks, use \uff1f\r\n* For uppercase, use \ud835\udda0\ud835\udda1\ud835\udda2\ud835\udda3\ud835\udda4\ud835\udda5\ud835\udda6\ud835\udda7\ud835\udda8\ud835\udda9\ud835\uddaa\ud835\uddab\ud835\uddac\ud835\uddad\ud835\uddae\ud835\uddaf\ud835\uddb0\ud835\uddb1\ud835\uddb2\ud835\uddb3\ud835\uddb4\ud835\uddb5\ud835\uddb6\ud835\uddb7\ud835\uddb8\ud835\uddb9\n", "before_files": [{"content": "import asyncio\nimport logging\nfrom datetime import datetime, timedelta\n\nfrom discord import Colour, Embed\nfrom discord.ext.commands import BadArgument, Bot, Context, Converter, group\n\nfrom bot.constants import Channels, Keys, MODERATION_ROLES, URLs\nfrom bot.decorators import with_role\nfrom bot.pagination import LinePaginator\n\n\nCHANNELS = (Channels.off_topic_0, Channels.off_topic_1, Channels.off_topic_2)\nlog = logging.getLogger(__name__)\n\n\nclass OffTopicName(Converter):\n \"\"\"A converter that ensures an added off-topic name is valid.\"\"\"\n\n @staticmethod\n async def convert(ctx: Context, argument: str):\n allowed_characters = (\"-\", \"\u2019\", \"'\", \"`\")\n\n if not (2 <= len(argument) <= 96):\n raise BadArgument(\"Channel name must be between 2 and 96 chars long\")\n\n elif not all(c.isalnum() or c in allowed_characters for c in argument):\n raise BadArgument(\n \"Channel name must only consist of \"\n \"alphanumeric characters, minus signs or apostrophes.\"\n )\n\n elif not argument.islower():\n raise BadArgument(\"Channel name must be lowercase\")\n\n # Replace some unusable apostrophe-like characters with \"\u2019\".\n return argument.replace(\"'\", \"\u2019\").replace(\"`\", \"\u2019\")\n\n\nasync def update_names(bot: Bot, headers: dict):\n \"\"\"\n The background updater task that performs a channel name update daily.\n\n Args:\n bot (Bot):\n The running bot instance, used for fetching data from the\n website via the bot's `http_session`.\n \"\"\"\n\n while True:\n # Since we truncate the compute timedelta to seconds, we add one second to ensure\n # we go past midnight in the `seconds_to_sleep` set below.\n today_at_midnight = datetime.utcnow().replace(microsecond=0, second=0, minute=0, hour=0)\n next_midnight = today_at_midnight + timedelta(days=1)\n seconds_to_sleep = (next_midnight - datetime.utcnow()).seconds + 1\n await asyncio.sleep(seconds_to_sleep)\n\n response = await bot.http_session.get(\n f'{URLs.site_off_topic_names_api}?random_items=3',\n headers=headers\n )\n channel_0_name, channel_1_name, channel_2_name = await response.json()\n channel_0, channel_1, channel_2 = (bot.get_channel(channel_id) for channel_id in CHANNELS)\n\n await channel_0.edit(name=f'ot0-{channel_0_name}')\n await channel_1.edit(name=f'ot1-{channel_1_name}')\n await channel_2.edit(name=f'ot2-{channel_2_name}')\n log.debug(\n \"Updated off-topic channel names to\"\n f\" {channel_0_name}, {channel_1_name} and {channel_2_name}\"\n )\n\n\nclass OffTopicNames:\n \"\"\"Commands related to managing the off-topic category channel names.\"\"\"\n\n def __init__(self, bot: Bot):\n self.bot = bot\n self.headers = {\"X-API-KEY\": Keys.site_api}\n self.updater_task = None\n\n def __cleanup(self):\n if self.updater_task is not None:\n self.updater_task.cancel()\n\n async def on_ready(self):\n if self.updater_task is None:\n coro = update_names(self.bot, self.headers)\n self.updater_task = self.bot.loop.create_task(coro)\n\n @group(name='otname', aliases=('otnames', 'otn'), invoke_without_command=True)\n @with_role(*MODERATION_ROLES)\n async def otname_group(self, ctx):\n \"\"\"Add or list items from the off-topic channel name rotation.\"\"\"\n\n await ctx.invoke(self.bot.get_command(\"help\"), \"otname\")\n\n @otname_group.command(name='add', aliases=('a',))\n @with_role(*MODERATION_ROLES)\n async def add_command(self, ctx, name: OffTopicName):\n \"\"\"Adds a new off-topic name to the rotation.\"\"\"\n\n result = await self.bot.http_session.post(\n URLs.site_off_topic_names_api,\n headers=self.headers,\n params={'name': name}\n )\n\n response = await result.json()\n\n if result.status == 200:\n log.info(\n f\"{ctx.author.name}#{ctx.author.discriminator}\"\n f\" added the off-topic channel name '{name}\"\n )\n await ctx.send(\":ok_hand:\")\n else:\n error_reason = response.get('message', \"No reason provided.\")\n await ctx.send(f\":warning: got non-200 from the API: {error_reason}\")\n\n @otname_group.command(name='delete', aliases=('remove', 'rm', 'del', 'd'))\n @with_role(*MODERATION_ROLES)\n async def delete_command(self, ctx, name: OffTopicName):\n \"\"\"Removes a off-topic name from the rotation.\"\"\"\n\n result = await self.bot.http_session.delete(\n URLs.site_off_topic_names_api,\n headers=self.headers,\n params={'name': name}\n )\n\n response = await result.json()\n\n if result.status == 200:\n if response['deleted'] == 0:\n await ctx.send(f\":warning: No name matching `{name}` was found in the database.\")\n else:\n log.info(\n f\"{ctx.author.name}#{ctx.author.discriminator}\"\n f\" deleted the off-topic channel name '{name}\"\n )\n await ctx.send(\":ok_hand:\")\n else:\n error_reason = response.get('message', \"No reason provided.\")\n await ctx.send(f\":warning: got non-200 from the API: {error_reason}\")\n\n @otname_group.command(name='list', aliases=('l',))\n @with_role(*MODERATION_ROLES)\n async def list_command(self, ctx):\n \"\"\"\n Lists all currently known off-topic channel names in a paginator.\n Restricted to Moderator and above to not spoil the surprise.\n \"\"\"\n\n result = await self.bot.http_session.get(\n URLs.site_off_topic_names_api,\n headers=self.headers\n )\n response = await result.json()\n lines = sorted(f\"\u2022 {name}\" for name in response)\n\n embed = Embed(\n title=f\"Known off-topic names (`{len(response)}` total)\",\n colour=Colour.blue()\n )\n await LinePaginator.paginate(lines, ctx, embed, max_size=400, empty=False)\n\n\ndef setup(bot: Bot):\n bot.add_cog(OffTopicNames(bot))\n log.info(\"Cog loaded: OffTopicNames\")\n", "path": "bot/cogs/off_topic_names.py"}]}
| 2,538 | 318 |
gh_patches_debug_56601
|
rasdani/github-patches
|
git_diff
|
RedHatInsights__insights-core-2351
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Double Check satellite_version.CapsuleVersion Combiner
CapsuleVersion Combiner currently relies on satellite-capsule package.
satellite-capsule package can be installed on satellite server t0o and plugin rules may use the combiner to wrongly identify satellite server as capsule.
"foreman" package would not be there on Capsule server and hence can be added as a check.
</issue>
<code>
[start of insights/combiners/satellite_version.py]
1 """
2 Satellite Version
3 =================
4
5 The following modules are included:
6
7 SatelliteVersion - Version of Satellite Server
8 ----------------------------------------------
9 Combiner to get Satellite Server version information.
10
11 CapsuleVersion - Version of Satellite Capsule (>=6.2)
12 -----------------------------------------------------
13 Combiner to get Satellite Capsule version information. ONLY Satellite Capsule
14 6.2 and newer are supported.
15
16
17 """
18
19 from insights import combiner, SkipComponent
20 from insights.parsers.satellite_version import Satellite6Version as Sat6Ver
21 from insights.parsers.installed_rpms import InstalledRpms
22
23
24 # NOTE:
25 # The following table only tracks 6.0.x and 6.1.x.
26 # See https://access.redhat.com/articles/1343683
27 # But, there are some mistakes in the KCS, the versions in below map
28 # are corrected according to the corresponding ERRATA pages.
29 #
30 # Update: Thu Nov 14 10:51:19 CST 2019
31 #
32 sat6_ver_map = {
33 # Sat foreman candlepin katello
34 '6.0.8': ('1.6.0.53', '0.9.23', '1.5.0'),
35 '6.1.1': ('1.7.2.33', '0.9.49.3', '2.2.0.14'),
36 '6.1.2': ('1.7.2.36', '0.9.49.6', '2.2.0.16'),
37 '6.1.3': ('1.7.2.43', '0.9.49.8', '2.2.0.16'),
38 '6.1.4': ('1.7.2.46', '0.9.49.9', '2.2.0.16'),
39 '6.1.5': ('1.7.2.49', '0.9.49.9', '2.2.0.16'),
40 '6.1.6': ('1.7.2.50', '0.9.49.9', '2.2.0.17'),
41 '6.1.7': ('1.7.2.53', '0.9.49.11', '2.2.0.17'),
42 '6.1.8': ('1.7.2.55', '0.9.49.12', '2.2.0.19'),
43 '6.1.9': ('1.7.2.56', '0.9.49.12', '2.2.0.19'),
44 '6.1.10': ('1.7.2.61', '0.9.49.16', '2.2.0.19'),
45 '6.1.11': ('1.7.2.62', '0.9.49.19', '2.2.0.19'),
46 '6.1.12': ('1.7.2.63', '0.9.49.23', '2.2.0.19'),
47 }
48
49
50 def _parse_sat_version(version):
51 ver_sp = version.split(".") if version else []
52 major = int(ver_sp[0]) if ver_sp and ver_sp[0].isdigit() else None
53 minor = int(ver_sp[1]) if len(ver_sp) > 1 and ver_sp[1].isdigit() else None
54 return [major, minor]
55
56
57 @combiner(InstalledRpms, optional=[Sat6Ver])
58 class SatelliteVersion(object):
59 """
60 Check the parsers
61 :class:`insights.parsers.satellite_version.Satellite6Version` and
62 :class:`insights.parsers.installed_rpms.InstalledRpms` for satellite version
63 information.
64
65 Below is the logic to determine the satellite version::
66
67 1. For Satellite 6.1:
68
69 a. Check the version information in below files at first
70 - https://access.redhat.com/solutions/1392633
71 File: /usr/share/foreman/lib/satellite/version.rb
72
73 b. Check the version of package foreman, candlepin and katello, E.g.
74 - https://access.redhat.com/articles/1343683
75
76 Sat 6.0.8 Sat 6.1.10 Sat 6.1.11
77 foreman 1.6.0.53 1.7.2.61 1.7.2.62
78 candlepin 0.9.23 0.9.49.16 0.9.49.19
79 katello 1.5.0 2.2.0 2.2.0
80
81 2. For Satellite 6.2 and newer:
82
83 Check the version of satellite package directly:
84 - https://access.redhat.com/solutions/1392633
85
86 Sat 6.0.x Sat 6.1.x Sat 6.2.x
87 satellite - - 6.2.x
88
89 3. For Satellite 5.x
90 - https://access.redhat.com/solutions/1224043
91 NOTE: Because of satellite-branding is not deployed in Satellite
92 5.0~5.2, and satellite-schema can also be used for checking
93 the version, here checked satellite-schema instead of
94 satellite-branding.
95
96 Check the version of package satellite-schema directly:
97
98 Sat 5.0~5.2 Sat 5.3 ~
99 rhn-satellite-schema ok -
100 satellite-schema - ok
101
102 Attributes:
103 full(str): the full version format like `version-release`.
104 version(str): the satellite version do not includes `release`.
105 release(str): the `release` string in the version.
106 major(int): the major version.
107 minor(int): the minor version.
108
109 Raises:
110 SkipComponent: When it's not a Satellite machine or the Satellite
111 version cannot be determined according to current information.
112
113 Examples:
114 >>> sat_ver.full == 'satellite-6.2.0.11-1.el7sat'
115 True
116 >>> sat_ver.major
117 6
118 >>> sat_ver.minor
119 2
120 >>> sat_ver.version
121 '6.2.0.11'
122 >>> sat_ver.release
123 '1.el7sat'
124 """
125 def __init__(self, rpms, sat6_ver):
126 self.full = None
127 self.version = None
128 self.release = None
129 self.major = None
130 self.minor = None
131
132 # For Satellite 6.1, if satellite_version/version.rb is available:
133 if sat6_ver:
134 # no 'release' in this case, but more accurate
135 self.full = sat6_ver.full
136 self.version = sat6_ver.version
137 self.major = sat6_ver.major
138 self.minor = sat6_ver.minor
139 else:
140 # For Satellite 6.2 and newer, check the satellite package directly
141 sat62_pkg = rpms.get_max('satellite')
142 if sat62_pkg:
143 self.full = sat62_pkg.package
144 self.version = sat62_pkg.version
145 self.release = sat62_pkg.release
146 self.major, self.minor = _parse_sat_version(self.version)
147 else:
148 # For Satellite 6.0/6.1, check the version of:
149 # - foreman, candlepin and katello
150 fman = rpms.get_max('foreman')
151 cndp = rpms.get_max('candlepin')
152 ktlo = rpms.get_max('katello')
153 if fman and cndp and ktlo:
154 for sat_ver, map_ver in sat6_ver_map.items():
155 if all(pkg.version.startswith(mv) for pkg, mv in zip([fman, cndp, ktlo], map_ver)):
156 # no 'release' in this situation
157 self.major, self.minor = _parse_sat_version(sat_ver)
158 self.full = self.version = sat_ver
159 else:
160 # For Satellite 5.x
161 sat5_pkg = rpms.get_max('satellite-schema') or rpms.get_max('rhn-satellite-schema')
162 if sat5_pkg:
163 self.full = sat5_pkg.package
164 self.version = sat5_pkg.version
165 self.release = sat5_pkg.release
166 self.major, self.minor = _parse_sat_version(self.version)
167 if not self.full:
168 raise SkipComponent("Not a Satellite machine or unable to determine Satellite version")
169
170
171 @combiner(InstalledRpms)
172 class CapsuleVersion(object):
173 """
174 Check the parser
175 :class:`insights.parsers.installed_rpms.InstalledRpms` for satellite capsule
176 version information.
177
178 .. note::
179 ONLY Satellite Capsule 6.2 and newer are supported.
180
181 Below is the logic to determine the satellite version::
182
183 Check the version of satellite/satellite-capsule directly:
184 - https://access.redhat.com/solutions/1392633
185
186 Sat 6.0.x Sat 6.1.x Sat 6.2.x
187 satellite-capsule - - 6.2.x
188
189 Attributes:
190 full(str): the full version format like `version-release`.
191 version(str): the satellite version do not includes `release`.
192 release(str): the `release` string in the version.
193 major(int): the major version.
194 minor(int): the minor version.
195
196 Raises:
197 SkipComponent: When it's not a Satellite Capsule machine or the
198 Satellite Capsule version cannot be determined according to
199 current information.
200
201 Examples:
202 >>> cap_ver.full == 'satellite-capsule-6.2.0.11-1.el7sat'
203 True
204 >>> cap_ver.major
205 6
206 >>> cap_ver.minor
207 2
208 >>> cap_ver.version
209 '6.2.0.11'
210 >>> cap_ver.release
211 '1.el7sat'
212 """
213 def __init__(self, rpms):
214 self.full = None
215 self.version = None
216 self.release = None
217 self.major = None
218 self.minor = None
219
220 # For Capsule, ONLY 6.2 and newer are supported
221 sat62_pkg = rpms.get_max('satellite-capsule')
222 if sat62_pkg:
223 self.full = sat62_pkg.package
224 self.version = sat62_pkg.version
225 self.release = sat62_pkg.release
226 self.major, self.minor = _parse_sat_version(self.version)
227 else:
228 raise SkipComponent("Not a Satellite Capsule machine or unable to determine the version")
229
[end of insights/combiners/satellite_version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/insights/combiners/satellite_version.py b/insights/combiners/satellite_version.py
--- a/insights/combiners/satellite_version.py
+++ b/insights/combiners/satellite_version.py
@@ -219,7 +219,8 @@
# For Capsule, ONLY 6.2 and newer are supported
sat62_pkg = rpms.get_max('satellite-capsule')
- if sat62_pkg:
+ # foreman package should not be there on Capsule Server
+ if sat62_pkg and 'foreman' not in rpms:
self.full = sat62_pkg.package
self.version = sat62_pkg.version
self.release = sat62_pkg.release
|
{"golden_diff": "diff --git a/insights/combiners/satellite_version.py b/insights/combiners/satellite_version.py\n--- a/insights/combiners/satellite_version.py\n+++ b/insights/combiners/satellite_version.py\n@@ -219,7 +219,8 @@\n \n # For Capsule, ONLY 6.2 and newer are supported\n sat62_pkg = rpms.get_max('satellite-capsule')\n- if sat62_pkg:\n+ # foreman package should not be there on Capsule Server\n+ if sat62_pkg and 'foreman' not in rpms:\n self.full = sat62_pkg.package\n self.version = sat62_pkg.version\n self.release = sat62_pkg.release\n", "issue": "Double Check satellite_version.CapsuleVersion Combiner\nCapsuleVersion Combiner currently relies on satellite-capsule package.\r\n\r\nsatellite-capsule package can be installed on satellite server t0o and plugin rules may use the combiner to wrongly identify satellite server as capsule.\r\n\r\n\"foreman\" package would not be there on Capsule server and hence can be added as a check. \n", "before_files": [{"content": "\"\"\"\nSatellite Version\n=================\n\nThe following modules are included:\n\nSatelliteVersion - Version of Satellite Server\n----------------------------------------------\nCombiner to get Satellite Server version information.\n\nCapsuleVersion - Version of Satellite Capsule (>=6.2)\n-----------------------------------------------------\nCombiner to get Satellite Capsule version information. ONLY Satellite Capsule\n6.2 and newer are supported.\n\n\n\"\"\"\n\nfrom insights import combiner, SkipComponent\nfrom insights.parsers.satellite_version import Satellite6Version as Sat6Ver\nfrom insights.parsers.installed_rpms import InstalledRpms\n\n\n# NOTE:\n# The following table only tracks 6.0.x and 6.1.x.\n# See https://access.redhat.com/articles/1343683\n# But, there are some mistakes in the KCS, the versions in below map\n# are corrected according to the corresponding ERRATA pages.\n#\n# Update: Thu Nov 14 10:51:19 CST 2019\n#\nsat6_ver_map = {\n # Sat foreman candlepin katello\n '6.0.8': ('1.6.0.53', '0.9.23', '1.5.0'),\n '6.1.1': ('1.7.2.33', '0.9.49.3', '2.2.0.14'),\n '6.1.2': ('1.7.2.36', '0.9.49.6', '2.2.0.16'),\n '6.1.3': ('1.7.2.43', '0.9.49.8', '2.2.0.16'),\n '6.1.4': ('1.7.2.46', '0.9.49.9', '2.2.0.16'),\n '6.1.5': ('1.7.2.49', '0.9.49.9', '2.2.0.16'),\n '6.1.6': ('1.7.2.50', '0.9.49.9', '2.2.0.17'),\n '6.1.7': ('1.7.2.53', '0.9.49.11', '2.2.0.17'),\n '6.1.8': ('1.7.2.55', '0.9.49.12', '2.2.0.19'),\n '6.1.9': ('1.7.2.56', '0.9.49.12', '2.2.0.19'),\n '6.1.10': ('1.7.2.61', '0.9.49.16', '2.2.0.19'),\n '6.1.11': ('1.7.2.62', '0.9.49.19', '2.2.0.19'),\n '6.1.12': ('1.7.2.63', '0.9.49.23', '2.2.0.19'),\n}\n\n\ndef _parse_sat_version(version):\n ver_sp = version.split(\".\") if version else []\n major = int(ver_sp[0]) if ver_sp and ver_sp[0].isdigit() else None\n minor = int(ver_sp[1]) if len(ver_sp) > 1 and ver_sp[1].isdigit() else None\n return [major, minor]\n\n\n@combiner(InstalledRpms, optional=[Sat6Ver])\nclass SatelliteVersion(object):\n \"\"\"\n Check the parsers\n :class:`insights.parsers.satellite_version.Satellite6Version` and\n :class:`insights.parsers.installed_rpms.InstalledRpms` for satellite version\n information.\n\n Below is the logic to determine the satellite version::\n\n 1. For Satellite 6.1:\n\n a. Check the version information in below files at first\n - https://access.redhat.com/solutions/1392633\n File: /usr/share/foreman/lib/satellite/version.rb\n\n b. Check the version of package foreman, candlepin and katello, E.g.\n - https://access.redhat.com/articles/1343683\n\n Sat 6.0.8 Sat 6.1.10 Sat 6.1.11\n foreman 1.6.0.53 1.7.2.61 1.7.2.62\n candlepin 0.9.23 0.9.49.16 0.9.49.19\n katello 1.5.0 2.2.0 2.2.0\n\n 2. For Satellite 6.2 and newer:\n\n Check the version of satellite package directly:\n - https://access.redhat.com/solutions/1392633\n\n Sat 6.0.x Sat 6.1.x Sat 6.2.x\n satellite - - 6.2.x\n\n 3. For Satellite 5.x\n - https://access.redhat.com/solutions/1224043\n NOTE: Because of satellite-branding is not deployed in Satellite\n 5.0~5.2, and satellite-schema can also be used for checking\n the version, here checked satellite-schema instead of\n satellite-branding.\n\n Check the version of package satellite-schema directly:\n\n Sat 5.0~5.2 Sat 5.3 ~\n rhn-satellite-schema ok -\n satellite-schema - ok\n\n Attributes:\n full(str): the full version format like `version-release`.\n version(str): the satellite version do not includes `release`.\n release(str): the `release` string in the version.\n major(int): the major version.\n minor(int): the minor version.\n\n Raises:\n SkipComponent: When it's not a Satellite machine or the Satellite\n version cannot be determined according to current information.\n\n Examples:\n >>> sat_ver.full == 'satellite-6.2.0.11-1.el7sat'\n True\n >>> sat_ver.major\n 6\n >>> sat_ver.minor\n 2\n >>> sat_ver.version\n '6.2.0.11'\n >>> sat_ver.release\n '1.el7sat'\n \"\"\"\n def __init__(self, rpms, sat6_ver):\n self.full = None\n self.version = None\n self.release = None\n self.major = None\n self.minor = None\n\n # For Satellite 6.1, if satellite_version/version.rb is available:\n if sat6_ver:\n # no 'release' in this case, but more accurate\n self.full = sat6_ver.full\n self.version = sat6_ver.version\n self.major = sat6_ver.major\n self.minor = sat6_ver.minor\n else:\n # For Satellite 6.2 and newer, check the satellite package directly\n sat62_pkg = rpms.get_max('satellite')\n if sat62_pkg:\n self.full = sat62_pkg.package\n self.version = sat62_pkg.version\n self.release = sat62_pkg.release\n self.major, self.minor = _parse_sat_version(self.version)\n else:\n # For Satellite 6.0/6.1, check the version of:\n # - foreman, candlepin and katello\n fman = rpms.get_max('foreman')\n cndp = rpms.get_max('candlepin')\n ktlo = rpms.get_max('katello')\n if fman and cndp and ktlo:\n for sat_ver, map_ver in sat6_ver_map.items():\n if all(pkg.version.startswith(mv) for pkg, mv in zip([fman, cndp, ktlo], map_ver)):\n # no 'release' in this situation\n self.major, self.minor = _parse_sat_version(sat_ver)\n self.full = self.version = sat_ver\n else:\n # For Satellite 5.x\n sat5_pkg = rpms.get_max('satellite-schema') or rpms.get_max('rhn-satellite-schema')\n if sat5_pkg:\n self.full = sat5_pkg.package\n self.version = sat5_pkg.version\n self.release = sat5_pkg.release\n self.major, self.minor = _parse_sat_version(self.version)\n if not self.full:\n raise SkipComponent(\"Not a Satellite machine or unable to determine Satellite version\")\n\n\n@combiner(InstalledRpms)\nclass CapsuleVersion(object):\n \"\"\"\n Check the parser\n :class:`insights.parsers.installed_rpms.InstalledRpms` for satellite capsule\n version information.\n\n .. note::\n ONLY Satellite Capsule 6.2 and newer are supported.\n\n Below is the logic to determine the satellite version::\n\n Check the version of satellite/satellite-capsule directly:\n - https://access.redhat.com/solutions/1392633\n\n Sat 6.0.x Sat 6.1.x Sat 6.2.x\n satellite-capsule - - 6.2.x\n\n Attributes:\n full(str): the full version format like `version-release`.\n version(str): the satellite version do not includes `release`.\n release(str): the `release` string in the version.\n major(int): the major version.\n minor(int): the minor version.\n\n Raises:\n SkipComponent: When it's not a Satellite Capsule machine or the\n Satellite Capsule version cannot be determined according to\n current information.\n\n Examples:\n >>> cap_ver.full == 'satellite-capsule-6.2.0.11-1.el7sat'\n True\n >>> cap_ver.major\n 6\n >>> cap_ver.minor\n 2\n >>> cap_ver.version\n '6.2.0.11'\n >>> cap_ver.release\n '1.el7sat'\n \"\"\"\n def __init__(self, rpms):\n self.full = None\n self.version = None\n self.release = None\n self.major = None\n self.minor = None\n\n # For Capsule, ONLY 6.2 and newer are supported\n sat62_pkg = rpms.get_max('satellite-capsule')\n if sat62_pkg:\n self.full = sat62_pkg.package\n self.version = sat62_pkg.version\n self.release = sat62_pkg.release\n self.major, self.minor = _parse_sat_version(self.version)\n else:\n raise SkipComponent(\"Not a Satellite Capsule machine or unable to determine the version\")\n", "path": "insights/combiners/satellite_version.py"}]}
| 3,653 | 174 |
gh_patches_debug_34977
|
rasdani/github-patches
|
git_diff
|
avocado-framework__avocado-5196
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Allow the deployment and use of development versions of Avocado
**Is your feature request related to a problem? Please describe.**
Epic issue https://github.com/avocado-framework/avocado/issues/4934 covers aspects such as creating and publishing (AFAICT) packages for every Avocado release, for every Python version, and how they will be deployed and installed on `DeploymentSpawner`s.
But, this doesn't address the development time needs, where unreleased code may be needed in both the job side (say running out of a GIT checkout), and on the isolated spawner environment.
**Describe the solution you'd like**
There should be a way to signal a preference for given wheels to be used, instead of the latest release ones.
**Describe alternatives you've considered**
Building the wheels is probably going to be a separate step (such as the current `make whee`, and It will probably be necessary to refer to them by a local (non HTTP(s)) uri. Bonus point for an all-in-one `--mirror-this-repo-as-a-wheel-and-deploy-it` kind of feature, but I think this will be too complex.
</issue>
<code>
[start of avocado/plugins/spawners/podman.py]
1 import asyncio
2 import json
3 import logging
4 import os
5 import subprocess
6
7 from avocado.core.plugin_interfaces import CLI, DeploymentSpawner, Init
8 from avocado.core.settings import settings
9 from avocado.core.spawners.common import SpawnerMixin, SpawnMethod
10 from avocado.core.version import VERSION
11 from avocado.utils import distro
12 from avocado.utils.asset import Asset
13 from avocado.utils.podman import Podman, PodmanException
14
15 LOG = logging.getLogger(__name__)
16
17
18 ENTRY_POINT_CMD = "/tmp/avocado-runner"
19
20
21 class PodmanSpawnerInit(Init):
22
23 description = 'Podman (container) based spawner initialization'
24
25 def initialize(self):
26 section = 'spawner.podman'
27
28 help_msg = 'Path to the podman binary'
29 settings.register_option(
30 section=section,
31 key='bin',
32 help_msg=help_msg,
33 default='/usr/bin/podman')
34
35 this_distro = distro.detect()
36 if this_distro != distro.UNKNOWN_DISTRO:
37 default_distro = '{0}:{1}'.format(this_distro.name,
38 this_distro.version)
39 else:
40 default_distro = 'fedora:latest'
41 help_msg = ('Image name to use when creating the container. '
42 'The first default choice is a container image '
43 'matching the current OS. If unable to detect, '
44 'default becomes the latest Fedora release. Default '
45 'on this system: {0}'.format(default_distro))
46 settings.register_option(
47 section=section,
48 key='image',
49 help_msg=help_msg,
50 default=default_distro)
51
52
53 class PodmanCLI(CLI):
54
55 name = 'podman'
56 description = 'podman spawner command line options for "run"'
57
58 def configure(self, parser):
59 super().configure(parser)
60 parser = parser.subcommands.choices.get('run', None)
61 if parser is None:
62 return
63
64 parser = parser.add_argument_group('podman spawner specific options')
65 settings.add_argparser_to_option(namespace='spawner.podman.bin',
66 parser=parser,
67 long_arg='--spawner-podman-bin',
68 metavar='PODMAN_BIN')
69
70 settings.add_argparser_to_option(namespace='spawner.podman.image',
71 parser=parser,
72 long_arg='--spawner-podman-image',
73 metavar='CONTAINER_IMAGE')
74
75 def run(self, config):
76 pass
77
78
79 class PodmanSpawner(DeploymentSpawner, SpawnerMixin):
80
81 description = 'Podman (container) based spawner'
82 METHODS = [SpawnMethod.STANDALONE_EXECUTABLE]
83
84 _PYTHON_VERSIONS_CACHE = {}
85
86 def is_task_alive(self, runtime_task):
87 if runtime_task.spawner_handle is None:
88 return False
89 podman_bin = self.config.get('spawner.podman.bin')
90 cmd = [podman_bin, "ps", "--all", "--format={{.State}}",
91 "--filter=id=%s" % runtime_task.spawner_handle]
92 process = subprocess.Popen(cmd,
93 stdin=subprocess.DEVNULL,
94 stdout=subprocess.PIPE,
95 stderr=subprocess.DEVNULL)
96 out, _ = process.communicate()
97 # FIXME: check how podman 2.x is reporting valid "OK" states
98 return out.startswith(b'Up ')
99
100 def _fetch_asset(self, url):
101 cachedirs = self.config.get('datadir.paths.cache_dirs')
102 asset = Asset(url, cache_dirs=cachedirs)
103 return asset.fetch()
104
105 def get_eggs_paths(self, py_major, py_minor):
106 """Return the basic eggs needed to bootstrap Avocado.
107
108 This will return a tuple with the current location and where this
109 should be deployed.
110 """
111 result = []
112 # Setuptools
113 # For now let's pin to setuptools 59.2.
114 # TODO: Automatically get latest setuptools version.
115 eggs = [f"https://github.com/avocado-framework/setuptools/releases/download/v59.2.0/setuptools-59.2.0-py{py_major}.{py_minor}.egg",
116 f"https://github.com/avocado-framework/avocado/releases/download/{VERSION}/avocado_framework-{VERSION}-py{py_major}.{py_minor}.egg"]
117 for url in eggs:
118 path = self._fetch_asset(url)
119 to = os.path.join('/tmp/', os.path.basename(path))
120 result.append((path, to))
121 return result
122
123 @property
124 async def python_version(self):
125 image = self.config.get('spawner.podman.image')
126 if image not in self._PYTHON_VERSIONS_CACHE:
127 if not self.podman:
128 msg = "Cannot get Python version: self.podman not defined."
129 LOG.debug(msg)
130 return None, None, None
131 result = await self.podman.get_python_version(image)
132 self._PYTHON_VERSIONS_CACHE[image] = result
133 return self._PYTHON_VERSIONS_CACHE[image]
134
135 async def deploy_artifacts(self):
136 pass
137
138 async def deploy_avocado(self, where):
139 # Deploy all the eggs to container inside /tmp/
140 major, minor, _ = await self.python_version
141 eggs = self.get_eggs_paths(major, minor)
142
143 for egg, to in eggs:
144 await self.podman.copy_to_container(where, egg, to)
145
146 async def _create_container_for_task(self, runtime_task, env_args,
147 test_output=None):
148 mount_status_server_socket = False
149 mounted_status_server_socket = '/tmp/.status_server.sock'
150 status_server_uri = runtime_task.task.status_services[0].uri
151 if ':' not in status_server_uri:
152 # a unix domain socket is being used
153 mount_status_server_socket = True
154 runtime_task.task.status_services[0].uri = mounted_status_server_socket
155
156 _, _, python_binary = await self.python_version
157 entry_point_args = [python_binary,
158 '-m',
159 'avocado.core.nrunner',
160 'task-run']
161
162 task = runtime_task.task
163 entry_point_args.extend(task.get_command_args())
164 entry_point = json.dumps(entry_point_args)
165 entry_point_arg = "--entrypoint=" + entry_point
166
167 if mount_status_server_socket:
168 status_server_opts = (
169 "--privileged",
170 "-v", "%s:%s" % (status_server_uri,
171 mounted_status_server_socket)
172 )
173 else:
174 status_server_opts = ("--net=host", )
175
176 output_opts = ()
177 if test_output:
178 podman_output = runtime_task.task.runnable.output_dir
179 output_opts = ("-v", "%s:%s" % (test_output,
180 os.path.expanduser(podman_output)))
181
182 image = self.config.get('spawner.podman.image')
183
184 envs = [f"-e={k}={v}" for k, v in env_args.items()]
185 try:
186 # pylint: disable=W0201
187 _, stdout, _ = await self.podman.execute("create",
188 *status_server_opts,
189 *output_opts,
190 entry_point_arg,
191 *envs,
192 image)
193 except PodmanException as ex:
194 msg = f"Could not create podman container: {ex}"
195 runtime_task.status = msg
196 return False
197
198 return stdout.decode().strip()
199
200 async def spawn_task(self, runtime_task):
201 self.create_task_output_dir(runtime_task)
202 podman_bin = self.config.get('spawner.podman.bin')
203 try:
204 # pylint: disable=W0201
205 self.podman = Podman(podman_bin)
206 except PodmanException as ex:
207 runtime_task.status = str(ex)
208 return False
209
210 major, minor, _ = await self.python_version
211 # Return only the "to" location
212 eggs = self.get_eggs_paths(major, minor)
213 destination_eggs = ":".join(map(lambda egg: str(egg[1]), eggs))
214 env_args = {'PYTHONPATH': destination_eggs}
215 output_dir_path = self.task_output_dir(runtime_task)
216 container_id = await self._create_container_for_task(runtime_task,
217 env_args,
218 output_dir_path)
219
220 runtime_task.spawner_handle = container_id
221
222 await self.deploy_avocado(container_id)
223
224 try:
225 # pylint: disable=W0201
226 returncode, _, _ = await self.podman.start(container_id)
227 except PodmanException as ex:
228 msg = f"Could not start container: {ex}"
229 runtime_task.status = msg
230 LOG.error(msg)
231 return False
232
233 return returncode == 0
234
235 def create_task_output_dir(self, runtime_task):
236 output_dir_path = self.task_output_dir(runtime_task)
237 output_podman_path = '~/avocado/job-results/spawner/task'
238
239 os.makedirs(output_dir_path, exist_ok=True)
240 runtime_task.task.setup_output_dir(output_podman_path)
241
242 async def wait_task(self, runtime_task):
243 while True:
244 if not self.is_task_alive(runtime_task):
245 return
246 await asyncio.sleep(0.1)
247
248 @staticmethod
249 async def check_task_requirements(runtime_task):
250 """Check the runtime task requirements needed to be able to run"""
251 # right now, limit the check to the runner availability.
252 if runtime_task.task.runnable.pick_runner_command() is None:
253 return False
254 return True
255
[end of avocado/plugins/spawners/podman.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/avocado/plugins/spawners/podman.py b/avocado/plugins/spawners/podman.py
--- a/avocado/plugins/spawners/podman.py
+++ b/avocado/plugins/spawners/podman.py
@@ -49,6 +49,16 @@
help_msg=help_msg,
default=default_distro)
+ help_msg = ('Avocado egg path to be used during initial bootstrap '
+ 'of avocado inside the isolated environment. By default, '
+ 'Avocado will try to download (or get from cache) an '
+ 'egg from its repository.')
+
+ settings.register_option(section=section,
+ key='avocado_spawner_egg',
+ help_msg=help_msg,
+ default=None)
+
class PodmanCLI(CLI):
@@ -72,6 +82,13 @@
long_arg='--spawner-podman-image',
metavar='CONTAINER_IMAGE')
+ namespace = 'spawner.podman.avocado_spawner_egg'
+ long_arg = '--spawner-podman-avocado-egg'
+ settings.add_argparser_to_option(namespace=namespace,
+ parser=parser,
+ long_arg=long_arg,
+ metavar='AVOCADO_EGG')
+
def run(self, config):
pass
@@ -112,8 +129,14 @@
# Setuptools
# For now let's pin to setuptools 59.2.
# TODO: Automatically get latest setuptools version.
- eggs = [f"https://github.com/avocado-framework/setuptools/releases/download/v59.2.0/setuptools-59.2.0-py{py_major}.{py_minor}.egg",
- f"https://github.com/avocado-framework/avocado/releases/download/{VERSION}/avocado_framework-{VERSION}-py{py_major}.{py_minor}.egg"]
+ eggs = [f"https://github.com/avocado-framework/setuptools/releases/download/v59.2.0/setuptools-59.2.0-py{py_major}.{py_minor}.egg"]
+ local_egg = self.config.get('spawner.podman.avocado_spawner_egg')
+ if local_egg:
+ eggs.append(local_egg)
+ else:
+ remote_egg = f"https://github.com/avocado-framework/avocado/releases/download/{VERSION}/avocado_framework-{VERSION}-py{py_major}.{py_minor}.egg"
+ eggs.append(remote_egg)
+
for url in eggs:
path = self._fetch_asset(url)
to = os.path.join('/tmp/', os.path.basename(path))
|
{"golden_diff": "diff --git a/avocado/plugins/spawners/podman.py b/avocado/plugins/spawners/podman.py\n--- a/avocado/plugins/spawners/podman.py\n+++ b/avocado/plugins/spawners/podman.py\n@@ -49,6 +49,16 @@\n help_msg=help_msg,\n default=default_distro)\n \n+ help_msg = ('Avocado egg path to be used during initial bootstrap '\n+ 'of avocado inside the isolated environment. By default, '\n+ 'Avocado will try to download (or get from cache) an '\n+ 'egg from its repository.')\n+\n+ settings.register_option(section=section,\n+ key='avocado_spawner_egg',\n+ help_msg=help_msg,\n+ default=None)\n+\n \n class PodmanCLI(CLI):\n \n@@ -72,6 +82,13 @@\n long_arg='--spawner-podman-image',\n metavar='CONTAINER_IMAGE')\n \n+ namespace = 'spawner.podman.avocado_spawner_egg'\n+ long_arg = '--spawner-podman-avocado-egg'\n+ settings.add_argparser_to_option(namespace=namespace,\n+ parser=parser,\n+ long_arg=long_arg,\n+ metavar='AVOCADO_EGG')\n+\n def run(self, config):\n pass\n \n@@ -112,8 +129,14 @@\n # Setuptools\n # For now let's pin to setuptools 59.2.\n # TODO: Automatically get latest setuptools version.\n- eggs = [f\"https://github.com/avocado-framework/setuptools/releases/download/v59.2.0/setuptools-59.2.0-py{py_major}.{py_minor}.egg\",\n- f\"https://github.com/avocado-framework/avocado/releases/download/{VERSION}/avocado_framework-{VERSION}-py{py_major}.{py_minor}.egg\"]\n+ eggs = [f\"https://github.com/avocado-framework/setuptools/releases/download/v59.2.0/setuptools-59.2.0-py{py_major}.{py_minor}.egg\"]\n+ local_egg = self.config.get('spawner.podman.avocado_spawner_egg')\n+ if local_egg:\n+ eggs.append(local_egg)\n+ else:\n+ remote_egg = f\"https://github.com/avocado-framework/avocado/releases/download/{VERSION}/avocado_framework-{VERSION}-py{py_major}.{py_minor}.egg\"\n+ eggs.append(remote_egg)\n+\n for url in eggs:\n path = self._fetch_asset(url)\n to = os.path.join('/tmp/', os.path.basename(path))\n", "issue": "Allow the deployment and use of development versions of Avocado\n**Is your feature request related to a problem? Please describe.**\r\nEpic issue https://github.com/avocado-framework/avocado/issues/4934 covers aspects such as creating and publishing (AFAICT) packages for every Avocado release, for every Python version, and how they will be deployed and installed on `DeploymentSpawner`s.\r\n\r\nBut, this doesn't address the development time needs, where unreleased code may be needed in both the job side (say running out of a GIT checkout), and on the isolated spawner environment.\r\n\r\n**Describe the solution you'd like**\r\nThere should be a way to signal a preference for given wheels to be used, instead of the latest release ones. \r\n\r\n**Describe alternatives you've considered**\r\nBuilding the wheels is probably going to be a separate step (such as the current `make whee`, and It will probably be necessary to refer to them by a local (non HTTP(s)) uri. Bonus point for an all-in-one `--mirror-this-repo-as-a-wheel-and-deploy-it` kind of feature, but I think this will be too complex.\r\n\n", "before_files": [{"content": "import asyncio\nimport json\nimport logging\nimport os\nimport subprocess\n\nfrom avocado.core.plugin_interfaces import CLI, DeploymentSpawner, Init\nfrom avocado.core.settings import settings\nfrom avocado.core.spawners.common import SpawnerMixin, SpawnMethod\nfrom avocado.core.version import VERSION\nfrom avocado.utils import distro\nfrom avocado.utils.asset import Asset\nfrom avocado.utils.podman import Podman, PodmanException\n\nLOG = logging.getLogger(__name__)\n\n\nENTRY_POINT_CMD = \"/tmp/avocado-runner\"\n\n\nclass PodmanSpawnerInit(Init):\n\n description = 'Podman (container) based spawner initialization'\n\n def initialize(self):\n section = 'spawner.podman'\n\n help_msg = 'Path to the podman binary'\n settings.register_option(\n section=section,\n key='bin',\n help_msg=help_msg,\n default='/usr/bin/podman')\n\n this_distro = distro.detect()\n if this_distro != distro.UNKNOWN_DISTRO:\n default_distro = '{0}:{1}'.format(this_distro.name,\n this_distro.version)\n else:\n default_distro = 'fedora:latest'\n help_msg = ('Image name to use when creating the container. '\n 'The first default choice is a container image '\n 'matching the current OS. If unable to detect, '\n 'default becomes the latest Fedora release. Default '\n 'on this system: {0}'.format(default_distro))\n settings.register_option(\n section=section,\n key='image',\n help_msg=help_msg,\n default=default_distro)\n\n\nclass PodmanCLI(CLI):\n\n name = 'podman'\n description = 'podman spawner command line options for \"run\"'\n\n def configure(self, parser):\n super().configure(parser)\n parser = parser.subcommands.choices.get('run', None)\n if parser is None:\n return\n\n parser = parser.add_argument_group('podman spawner specific options')\n settings.add_argparser_to_option(namespace='spawner.podman.bin',\n parser=parser,\n long_arg='--spawner-podman-bin',\n metavar='PODMAN_BIN')\n\n settings.add_argparser_to_option(namespace='spawner.podman.image',\n parser=parser,\n long_arg='--spawner-podman-image',\n metavar='CONTAINER_IMAGE')\n\n def run(self, config):\n pass\n\n\nclass PodmanSpawner(DeploymentSpawner, SpawnerMixin):\n\n description = 'Podman (container) based spawner'\n METHODS = [SpawnMethod.STANDALONE_EXECUTABLE]\n\n _PYTHON_VERSIONS_CACHE = {}\n\n def is_task_alive(self, runtime_task):\n if runtime_task.spawner_handle is None:\n return False\n podman_bin = self.config.get('spawner.podman.bin')\n cmd = [podman_bin, \"ps\", \"--all\", \"--format={{.State}}\",\n \"--filter=id=%s\" % runtime_task.spawner_handle]\n process = subprocess.Popen(cmd,\n stdin=subprocess.DEVNULL,\n stdout=subprocess.PIPE,\n stderr=subprocess.DEVNULL)\n out, _ = process.communicate()\n # FIXME: check how podman 2.x is reporting valid \"OK\" states\n return out.startswith(b'Up ')\n\n def _fetch_asset(self, url):\n cachedirs = self.config.get('datadir.paths.cache_dirs')\n asset = Asset(url, cache_dirs=cachedirs)\n return asset.fetch()\n\n def get_eggs_paths(self, py_major, py_minor):\n \"\"\"Return the basic eggs needed to bootstrap Avocado.\n\n This will return a tuple with the current location and where this\n should be deployed.\n \"\"\"\n result = []\n # Setuptools\n # For now let's pin to setuptools 59.2.\n # TODO: Automatically get latest setuptools version.\n eggs = [f\"https://github.com/avocado-framework/setuptools/releases/download/v59.2.0/setuptools-59.2.0-py{py_major}.{py_minor}.egg\",\n f\"https://github.com/avocado-framework/avocado/releases/download/{VERSION}/avocado_framework-{VERSION}-py{py_major}.{py_minor}.egg\"]\n for url in eggs:\n path = self._fetch_asset(url)\n to = os.path.join('/tmp/', os.path.basename(path))\n result.append((path, to))\n return result\n\n @property\n async def python_version(self):\n image = self.config.get('spawner.podman.image')\n if image not in self._PYTHON_VERSIONS_CACHE:\n if not self.podman:\n msg = \"Cannot get Python version: self.podman not defined.\"\n LOG.debug(msg)\n return None, None, None\n result = await self.podman.get_python_version(image)\n self._PYTHON_VERSIONS_CACHE[image] = result\n return self._PYTHON_VERSIONS_CACHE[image]\n\n async def deploy_artifacts(self):\n pass\n\n async def deploy_avocado(self, where):\n # Deploy all the eggs to container inside /tmp/\n major, minor, _ = await self.python_version\n eggs = self.get_eggs_paths(major, minor)\n\n for egg, to in eggs:\n await self.podman.copy_to_container(where, egg, to)\n\n async def _create_container_for_task(self, runtime_task, env_args,\n test_output=None):\n mount_status_server_socket = False\n mounted_status_server_socket = '/tmp/.status_server.sock'\n status_server_uri = runtime_task.task.status_services[0].uri\n if ':' not in status_server_uri:\n # a unix domain socket is being used\n mount_status_server_socket = True\n runtime_task.task.status_services[0].uri = mounted_status_server_socket\n\n _, _, python_binary = await self.python_version\n entry_point_args = [python_binary,\n '-m',\n 'avocado.core.nrunner',\n 'task-run']\n\n task = runtime_task.task\n entry_point_args.extend(task.get_command_args())\n entry_point = json.dumps(entry_point_args)\n entry_point_arg = \"--entrypoint=\" + entry_point\n\n if mount_status_server_socket:\n status_server_opts = (\n \"--privileged\",\n \"-v\", \"%s:%s\" % (status_server_uri,\n mounted_status_server_socket)\n )\n else:\n status_server_opts = (\"--net=host\", )\n\n output_opts = ()\n if test_output:\n podman_output = runtime_task.task.runnable.output_dir\n output_opts = (\"-v\", \"%s:%s\" % (test_output,\n os.path.expanduser(podman_output)))\n\n image = self.config.get('spawner.podman.image')\n\n envs = [f\"-e={k}={v}\" for k, v in env_args.items()]\n try:\n # pylint: disable=W0201\n _, stdout, _ = await self.podman.execute(\"create\",\n *status_server_opts,\n *output_opts,\n entry_point_arg,\n *envs,\n image)\n except PodmanException as ex:\n msg = f\"Could not create podman container: {ex}\"\n runtime_task.status = msg\n return False\n\n return stdout.decode().strip()\n\n async def spawn_task(self, runtime_task):\n self.create_task_output_dir(runtime_task)\n podman_bin = self.config.get('spawner.podman.bin')\n try:\n # pylint: disable=W0201\n self.podman = Podman(podman_bin)\n except PodmanException as ex:\n runtime_task.status = str(ex)\n return False\n\n major, minor, _ = await self.python_version\n # Return only the \"to\" location\n eggs = self.get_eggs_paths(major, minor)\n destination_eggs = \":\".join(map(lambda egg: str(egg[1]), eggs))\n env_args = {'PYTHONPATH': destination_eggs}\n output_dir_path = self.task_output_dir(runtime_task)\n container_id = await self._create_container_for_task(runtime_task,\n env_args,\n output_dir_path)\n\n runtime_task.spawner_handle = container_id\n\n await self.deploy_avocado(container_id)\n\n try:\n # pylint: disable=W0201\n returncode, _, _ = await self.podman.start(container_id)\n except PodmanException as ex:\n msg = f\"Could not start container: {ex}\"\n runtime_task.status = msg\n LOG.error(msg)\n return False\n\n return returncode == 0\n\n def create_task_output_dir(self, runtime_task):\n output_dir_path = self.task_output_dir(runtime_task)\n output_podman_path = '~/avocado/job-results/spawner/task'\n\n os.makedirs(output_dir_path, exist_ok=True)\n runtime_task.task.setup_output_dir(output_podman_path)\n\n async def wait_task(self, runtime_task):\n while True:\n if not self.is_task_alive(runtime_task):\n return\n await asyncio.sleep(0.1)\n\n @staticmethod\n async def check_task_requirements(runtime_task):\n \"\"\"Check the runtime task requirements needed to be able to run\"\"\"\n # right now, limit the check to the runner availability.\n if runtime_task.task.runnable.pick_runner_command() is None:\n return False\n return True\n", "path": "avocado/plugins/spawners/podman.py"}]}
| 3,460 | 585 |
gh_patches_debug_19661
|
rasdani/github-patches
|
git_diff
|
gammapy__gammapy-5044
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
stat_null is not available on FluxPoints objects created with gammapy
**Gammapy version**
present dev, 1.1
**Bug description**
For `FluxPoints` created with gammapy estimators, the quantity `stat_null` is not available.
**To Reproduce**
1. Run the `spectral analysis notebook`. Then, accessing `flux_points.stat_null` gives an error
```
File ~/anaconda3/envs/gammapy-1.1/lib/python3.9/site-packages/gammapy/estimators/map/core.py:493, in FluxMaps.stat_null(self)
490 @property
491 def stat_null(self):
492 """Fit statistic value for the null hypothesis"""
--> 493 self._check_quantity("stat_null")
494 return self._data["stat_null"]
File ~/anaconda3/envs/gammapy-1.1/lib/python3.9/site-packages/gammapy/estimators/map/core.py:222, in FluxMaps._check_quantity(self, quantity)
220 def _check_quantity(self, quantity):
221 if quantity not in self.available_quantities:
--> 222 raise AttributeError(
223 f"Quantity '{quantity}' is not defined on current flux estimate."
224 )
AttributeError: Quantity 'stat_null' is not defined on current flux estimate.
```
Similarly for the PKS2155 lightcurve in gammapy-ata
**Other information**
This blocks the TS computation for #5007
</issue>
<code>
[start of gammapy/estimators/parameter.py]
1 # Licensed under a 3-clause BSD style license - see LICENSE.rst
2 import logging
3 import numpy as np
4 from gammapy.datasets import Datasets
5 from gammapy.datasets.actors import DatasetsActor
6 from gammapy.modeling import Fit
7 from .core import Estimator
8
9 log = logging.getLogger(__name__)
10
11
12 class ParameterEstimator(Estimator):
13 """Model parameter estimator.
14
15 Estimates a model parameter for a group of datasets. Compute best fit value,
16 symmetric and delta(TS) for a given null value. Additionally asymmetric errors
17 as well as parameter upper limit and fit statistic profile can be estimated.
18
19 Parameters
20 ----------
21 n_sigma : int
22 Sigma to use for asymmetric error computation. Default is 1.
23 n_sigma_ul : int
24 Sigma to use for upper limit computation. Default is 2.
25 null_value : float
26 Which null value to use for the parameter.
27 selection_optional : list of str, optional
28 Which additional quantities to estimate. Available options are:
29
30 * "all": all the optional steps are executed.
31 * "errn-errp": estimate asymmetric errors on parameter best fit value.
32 * "ul": estimate upper limits.
33 * "scan": estimate fit statistic profiles.
34
35 Default is None so the optional steps are not executed.
36 fit : `Fit`
37 Fit instance specifying the backend and fit options.
38 reoptimize : bool
39 Re-optimize other free model parameters. Default is True.
40 """
41
42 tag = "ParameterEstimator"
43 _available_selection_optional = ["errn-errp", "ul", "scan"]
44
45 def __init__(
46 self,
47 n_sigma=1,
48 n_sigma_ul=2,
49 null_value=1e-150,
50 selection_optional=None,
51 fit=None,
52 reoptimize=True,
53 ):
54 self.n_sigma = n_sigma
55 self.n_sigma_ul = n_sigma_ul
56 self.null_value = null_value
57 self.selection_optional = selection_optional
58
59 if fit is None:
60 fit = Fit()
61
62 self.fit = fit
63 self.reoptimize = reoptimize
64
65 def estimate_best_fit(self, datasets, parameter):
66 """Estimate parameter asymmetric errors.
67
68 Parameters
69 ----------
70 datasets : `~gammapy.datasets.Datasets`
71 Datasets.
72 parameter : `Parameter`
73 For which parameter to get the value.
74
75 Returns
76 -------
77 result : dict
78 Dictionary with the various parameter estimation values. Entries are:
79
80 * parameter.name: best fit parameter value.
81 * "stat": best fit total stat.
82 * "success": boolean flag for fit success.
83 * parameter.name_err: covariance-based error estimate on parameter value.
84 """
85 value, total_stat, success, error = np.nan, 0.0, False, np.nan
86
87 if np.any(datasets.contributes_to_stat):
88 result = self.fit.run(datasets=datasets)
89 value, error = parameter.value, parameter.error
90 total_stat = result.optimize_result.total_stat
91 success = result.success
92
93 return {
94 f"{parameter.name}": value,
95 "stat": total_stat,
96 "success": success,
97 f"{parameter.name}_err": error * self.n_sigma,
98 }
99
100 def estimate_ts(self, datasets, parameter):
101 """Estimate parameter ts.
102
103 Parameters
104 ----------
105 datasets : `~gammapy.datasets.Datasets`
106 Datasets.
107 parameter : `Parameter`
108 For which parameter to get the value.
109
110 Returns
111 -------
112 result : dict
113 Dictionary with the test statistic of the best fit value compared to the null hypothesis. Entries are:
114
115 * "ts" : fit statistic difference with null hypothesis.
116 * "npred" : predicted number of counts per dataset.
117 """
118 npred = self.estimate_npred(datasets=datasets)
119
120 if not np.any(datasets.contributes_to_stat):
121 stat = np.nan
122 npred["npred"][...] = np.nan
123 else:
124 stat = datasets.stat_sum()
125
126 with datasets.parameters.restore_status():
127 # compute ts value
128 parameter.value = self.null_value
129
130 if self.reoptimize:
131 parameter.frozen = True
132 _ = self.fit.optimize(datasets=datasets)
133
134 ts = datasets.stat_sum() - stat
135
136 return {
137 "ts": ts,
138 "npred": npred["npred"],
139 }
140
141 def estimate_errn_errp(self, datasets, parameter):
142 """Estimate parameter asymmetric errors.
143
144 Parameters
145 ----------
146 datasets : `~gammapy.datasets.Datasets`
147 Datasets.
148 parameter : `Parameter`
149 For which parameter to get the value.
150
151 Returns
152 -------
153 result : dict
154 Dictionary with the parameter asymmetric errors. Entries are:
155
156 * {parameter.name}_errp : positive error on parameter value.
157 * {parameter.name}_errn : negative error on parameter value.
158 """
159 if not np.any(datasets.contributes_to_stat):
160 return {
161 f"{parameter.name}_errp": np.nan,
162 f"{parameter.name}_errn": np.nan,
163 }
164
165 self.fit.optimize(datasets=datasets)
166
167 res = self.fit.confidence(
168 datasets=datasets,
169 parameter=parameter,
170 sigma=self.n_sigma,
171 reoptimize=self.reoptimize,
172 )
173
174 return {
175 f"{parameter.name}_errp": res["errp"],
176 f"{parameter.name}_errn": res["errn"],
177 }
178
179 def estimate_scan(self, datasets, parameter):
180 """Estimate parameter statistic scan.
181
182 Parameters
183 ----------
184 datasets : `~gammapy.datasets.Datasets`
185 The datasets used to estimate the model parameter.
186 parameter : `~gammapy.modeling.Parameter`
187 For which parameter to get the value.
188
189 Returns
190 -------
191 result : dict
192 Dictionary with the parameter fit scan values. Entries are:
193
194 * parameter.name_scan : parameter values scan.
195 * "stat_scan" : fit statistic values scan.
196 """
197 scan_values = parameter.scan_values
198
199 if not np.any(datasets.contributes_to_stat):
200 return {
201 f"{parameter.name}_scan": scan_values,
202 "stat_scan": scan_values * np.nan,
203 }
204
205 self.fit.optimize(datasets=datasets)
206
207 profile = self.fit.stat_profile(
208 datasets=datasets, parameter=parameter, reoptimize=self.reoptimize
209 )
210
211 return {
212 f"{parameter.name}_scan": scan_values,
213 "stat_scan": profile["stat_scan"],
214 }
215
216 def estimate_ul(self, datasets, parameter):
217 """Estimate parameter ul.
218
219 Parameters
220 ----------
221 datasets : `~gammapy.datasets.Datasets`
222 The datasets used to estimate the model parameter.
223 parameter : `~gammapy.modeling.Parameter`
224 For which parameter to get the value.
225
226 Returns
227 -------
228 result : dict
229 Dictionary with the parameter upper limits. Entries are:
230
231 * parameter.name_ul : upper limit on parameter value.
232 """
233 if not np.any(datasets.contributes_to_stat):
234 return {f"{parameter.name}_ul": np.nan}
235
236 self.fit.optimize(datasets=datasets)
237
238 res = self.fit.confidence(
239 datasets=datasets,
240 parameter=parameter,
241 sigma=self.n_sigma_ul,
242 reoptimize=self.reoptimize,
243 )
244 return {f"{parameter.name}_ul": res["errp"] + parameter.value}
245
246 @staticmethod
247 def estimate_counts(datasets):
248 """Estimate counts for the flux point.
249
250 Parameters
251 ----------
252 datasets : Datasets
253 Datasets.
254
255 Returns
256 -------
257 result : dict
258 Dictionary with an array with one entry per dataset with the sum of the
259 masked counts.
260 """
261 counts = []
262
263 for dataset in datasets:
264 mask = dataset.mask
265 counts.append(dataset.counts.data[mask].sum())
266
267 return {"counts": np.array(counts, dtype=int), "datasets": datasets.names}
268
269 @staticmethod
270 def estimate_npred(datasets):
271 """Estimate npred for the flux point.
272
273 Parameters
274 ----------
275 datasets : `~gammapy.datasets.Datasets`
276 Datasets.
277
278 Returns
279 -------
280 result : dict
281 Dictionary with an array with one entry per dataset with the sum of the
282 masked npred.
283 """
284 npred = []
285
286 for dataset in datasets:
287 mask = dataset.mask
288 npred.append(dataset.npred().data[mask].sum())
289
290 return {"npred": np.array(npred), "datasets": datasets.names}
291
292 def run(self, datasets, parameter):
293 """Run the parameter estimator.
294
295 Parameters
296 ----------
297 datasets : `~gammapy.datasets.Datasets`
298 The datasets used to estimate the model parameter.
299 parameter : `str` or `~gammapy.modeling.Parameter`
300 For which parameter to run the estimator.
301
302 Returns
303 -------
304 result : dict
305 Dictionary with the various parameter estimation values.
306 """
307 if not isinstance(datasets, DatasetsActor):
308 datasets = Datasets(datasets)
309 parameter = datasets.parameters[parameter]
310
311 with datasets.parameters.restore_status():
312
313 if not self.reoptimize:
314 datasets.parameters.freeze_all()
315 parameter.frozen = False
316
317 result = self.estimate_best_fit(datasets, parameter)
318 result.update(self.estimate_ts(datasets, parameter))
319
320 if "errn-errp" in self.selection_optional:
321 result.update(self.estimate_errn_errp(datasets, parameter))
322
323 if "ul" in self.selection_optional:
324 result.update(self.estimate_ul(datasets, parameter))
325
326 if "scan" in self.selection_optional:
327 result.update(self.estimate_scan(datasets, parameter))
328
329 result.update(self.estimate_counts(datasets))
330 return result
331
[end of gammapy/estimators/parameter.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/gammapy/estimators/parameter.py b/gammapy/estimators/parameter.py
--- a/gammapy/estimators/parameter.py
+++ b/gammapy/estimators/parameter.py
@@ -114,6 +114,7 @@
* "ts" : fit statistic difference with null hypothesis.
* "npred" : predicted number of counts per dataset.
+ * "stat_null" : total stat corresponding to the null hypothesis
"""
npred = self.estimate_npred(datasets=datasets)
@@ -132,11 +133,9 @@
_ = self.fit.optimize(datasets=datasets)
ts = datasets.stat_sum() - stat
+ stat_null = datasets.stat_sum()
- return {
- "ts": ts,
- "npred": npred["npred"],
- }
+ return {"ts": ts, "npred": npred["npred"], "stat_null": stat_null}
def estimate_errn_errp(self, datasets, parameter):
"""Estimate parameter asymmetric errors.
|
{"golden_diff": "diff --git a/gammapy/estimators/parameter.py b/gammapy/estimators/parameter.py\n--- a/gammapy/estimators/parameter.py\n+++ b/gammapy/estimators/parameter.py\n@@ -114,6 +114,7 @@\n \n * \"ts\" : fit statistic difference with null hypothesis.\n * \"npred\" : predicted number of counts per dataset.\n+ * \"stat_null\" : total stat corresponding to the null hypothesis\n \"\"\"\n npred = self.estimate_npred(datasets=datasets)\n \n@@ -132,11 +133,9 @@\n _ = self.fit.optimize(datasets=datasets)\n \n ts = datasets.stat_sum() - stat\n+ stat_null = datasets.stat_sum()\n \n- return {\n- \"ts\": ts,\n- \"npred\": npred[\"npred\"],\n- }\n+ return {\"ts\": ts, \"npred\": npred[\"npred\"], \"stat_null\": stat_null}\n \n def estimate_errn_errp(self, datasets, parameter):\n \"\"\"Estimate parameter asymmetric errors.\n", "issue": "stat_null is not available on FluxPoints objects created with gammapy\n**Gammapy version**\r\npresent dev, 1.1\r\n\r\n\r\n**Bug description**\r\nFor `FluxPoints` created with gammapy estimators, the quantity `stat_null` is not available.\r\n\r\n\r\n**To Reproduce**\r\n1. Run the `spectral analysis notebook`. Then, accessing `flux_points.stat_null` gives an error\r\n```\r\nFile ~/anaconda3/envs/gammapy-1.1/lib/python3.9/site-packages/gammapy/estimators/map/core.py:493, in FluxMaps.stat_null(self)\r\n 490 @property\r\n 491 def stat_null(self):\r\n 492 \"\"\"Fit statistic value for the null hypothesis\"\"\"\r\n--> 493 self._check_quantity(\"stat_null\")\r\n 494 return self._data[\"stat_null\"]\r\n\r\nFile ~/anaconda3/envs/gammapy-1.1/lib/python3.9/site-packages/gammapy/estimators/map/core.py:222, in FluxMaps._check_quantity(self, quantity)\r\n 220 def _check_quantity(self, quantity):\r\n 221 if quantity not in self.available_quantities:\r\n--> 222 raise AttributeError(\r\n 223 f\"Quantity '{quantity}' is not defined on current flux estimate.\"\r\n 224 )\r\n\r\nAttributeError: Quantity 'stat_null' is not defined on current flux estimate.\r\n```\r\n\r\nSimilarly for the PKS2155 lightcurve in gammapy-ata\r\n\r\n\r\n**Other information**\r\nThis blocks the TS computation for #5007\r\n\n", "before_files": [{"content": "# Licensed under a 3-clause BSD style license - see LICENSE.rst\nimport logging\nimport numpy as np\nfrom gammapy.datasets import Datasets\nfrom gammapy.datasets.actors import DatasetsActor\nfrom gammapy.modeling import Fit\nfrom .core import Estimator\n\nlog = logging.getLogger(__name__)\n\n\nclass ParameterEstimator(Estimator):\n \"\"\"Model parameter estimator.\n\n Estimates a model parameter for a group of datasets. Compute best fit value,\n symmetric and delta(TS) for a given null value. Additionally asymmetric errors\n as well as parameter upper limit and fit statistic profile can be estimated.\n\n Parameters\n ----------\n n_sigma : int\n Sigma to use for asymmetric error computation. Default is 1.\n n_sigma_ul : int\n Sigma to use for upper limit computation. Default is 2.\n null_value : float\n Which null value to use for the parameter.\n selection_optional : list of str, optional\n Which additional quantities to estimate. Available options are:\n\n * \"all\": all the optional steps are executed.\n * \"errn-errp\": estimate asymmetric errors on parameter best fit value.\n * \"ul\": estimate upper limits.\n * \"scan\": estimate fit statistic profiles.\n\n Default is None so the optional steps are not executed.\n fit : `Fit`\n Fit instance specifying the backend and fit options.\n reoptimize : bool\n Re-optimize other free model parameters. Default is True.\n \"\"\"\n\n tag = \"ParameterEstimator\"\n _available_selection_optional = [\"errn-errp\", \"ul\", \"scan\"]\n\n def __init__(\n self,\n n_sigma=1,\n n_sigma_ul=2,\n null_value=1e-150,\n selection_optional=None,\n fit=None,\n reoptimize=True,\n ):\n self.n_sigma = n_sigma\n self.n_sigma_ul = n_sigma_ul\n self.null_value = null_value\n self.selection_optional = selection_optional\n\n if fit is None:\n fit = Fit()\n\n self.fit = fit\n self.reoptimize = reoptimize\n\n def estimate_best_fit(self, datasets, parameter):\n \"\"\"Estimate parameter asymmetric errors.\n\n Parameters\n ----------\n datasets : `~gammapy.datasets.Datasets`\n Datasets.\n parameter : `Parameter`\n For which parameter to get the value.\n\n Returns\n -------\n result : dict\n Dictionary with the various parameter estimation values. Entries are:\n\n * parameter.name: best fit parameter value.\n * \"stat\": best fit total stat.\n * \"success\": boolean flag for fit success.\n * parameter.name_err: covariance-based error estimate on parameter value.\n \"\"\"\n value, total_stat, success, error = np.nan, 0.0, False, np.nan\n\n if np.any(datasets.contributes_to_stat):\n result = self.fit.run(datasets=datasets)\n value, error = parameter.value, parameter.error\n total_stat = result.optimize_result.total_stat\n success = result.success\n\n return {\n f\"{parameter.name}\": value,\n \"stat\": total_stat,\n \"success\": success,\n f\"{parameter.name}_err\": error * self.n_sigma,\n }\n\n def estimate_ts(self, datasets, parameter):\n \"\"\"Estimate parameter ts.\n\n Parameters\n ----------\n datasets : `~gammapy.datasets.Datasets`\n Datasets.\n parameter : `Parameter`\n For which parameter to get the value.\n\n Returns\n -------\n result : dict\n Dictionary with the test statistic of the best fit value compared to the null hypothesis. Entries are:\n\n * \"ts\" : fit statistic difference with null hypothesis.\n * \"npred\" : predicted number of counts per dataset.\n \"\"\"\n npred = self.estimate_npred(datasets=datasets)\n\n if not np.any(datasets.contributes_to_stat):\n stat = np.nan\n npred[\"npred\"][...] = np.nan\n else:\n stat = datasets.stat_sum()\n\n with datasets.parameters.restore_status():\n # compute ts value\n parameter.value = self.null_value\n\n if self.reoptimize:\n parameter.frozen = True\n _ = self.fit.optimize(datasets=datasets)\n\n ts = datasets.stat_sum() - stat\n\n return {\n \"ts\": ts,\n \"npred\": npred[\"npred\"],\n }\n\n def estimate_errn_errp(self, datasets, parameter):\n \"\"\"Estimate parameter asymmetric errors.\n\n Parameters\n ----------\n datasets : `~gammapy.datasets.Datasets`\n Datasets.\n parameter : `Parameter`\n For which parameter to get the value.\n\n Returns\n -------\n result : dict\n Dictionary with the parameter asymmetric errors. Entries are:\n\n * {parameter.name}_errp : positive error on parameter value.\n * {parameter.name}_errn : negative error on parameter value.\n \"\"\"\n if not np.any(datasets.contributes_to_stat):\n return {\n f\"{parameter.name}_errp\": np.nan,\n f\"{parameter.name}_errn\": np.nan,\n }\n\n self.fit.optimize(datasets=datasets)\n\n res = self.fit.confidence(\n datasets=datasets,\n parameter=parameter,\n sigma=self.n_sigma,\n reoptimize=self.reoptimize,\n )\n\n return {\n f\"{parameter.name}_errp\": res[\"errp\"],\n f\"{parameter.name}_errn\": res[\"errn\"],\n }\n\n def estimate_scan(self, datasets, parameter):\n \"\"\"Estimate parameter statistic scan.\n\n Parameters\n ----------\n datasets : `~gammapy.datasets.Datasets`\n The datasets used to estimate the model parameter.\n parameter : `~gammapy.modeling.Parameter`\n For which parameter to get the value.\n\n Returns\n -------\n result : dict\n Dictionary with the parameter fit scan values. Entries are:\n\n * parameter.name_scan : parameter values scan.\n * \"stat_scan\" : fit statistic values scan.\n \"\"\"\n scan_values = parameter.scan_values\n\n if not np.any(datasets.contributes_to_stat):\n return {\n f\"{parameter.name}_scan\": scan_values,\n \"stat_scan\": scan_values * np.nan,\n }\n\n self.fit.optimize(datasets=datasets)\n\n profile = self.fit.stat_profile(\n datasets=datasets, parameter=parameter, reoptimize=self.reoptimize\n )\n\n return {\n f\"{parameter.name}_scan\": scan_values,\n \"stat_scan\": profile[\"stat_scan\"],\n }\n\n def estimate_ul(self, datasets, parameter):\n \"\"\"Estimate parameter ul.\n\n Parameters\n ----------\n datasets : `~gammapy.datasets.Datasets`\n The datasets used to estimate the model parameter.\n parameter : `~gammapy.modeling.Parameter`\n For which parameter to get the value.\n\n Returns\n -------\n result : dict\n Dictionary with the parameter upper limits. Entries are:\n\n * parameter.name_ul : upper limit on parameter value.\n \"\"\"\n if not np.any(datasets.contributes_to_stat):\n return {f\"{parameter.name}_ul\": np.nan}\n\n self.fit.optimize(datasets=datasets)\n\n res = self.fit.confidence(\n datasets=datasets,\n parameter=parameter,\n sigma=self.n_sigma_ul,\n reoptimize=self.reoptimize,\n )\n return {f\"{parameter.name}_ul\": res[\"errp\"] + parameter.value}\n\n @staticmethod\n def estimate_counts(datasets):\n \"\"\"Estimate counts for the flux point.\n\n Parameters\n ----------\n datasets : Datasets\n Datasets.\n\n Returns\n -------\n result : dict\n Dictionary with an array with one entry per dataset with the sum of the\n masked counts.\n \"\"\"\n counts = []\n\n for dataset in datasets:\n mask = dataset.mask\n counts.append(dataset.counts.data[mask].sum())\n\n return {\"counts\": np.array(counts, dtype=int), \"datasets\": datasets.names}\n\n @staticmethod\n def estimate_npred(datasets):\n \"\"\"Estimate npred for the flux point.\n\n Parameters\n ----------\n datasets : `~gammapy.datasets.Datasets`\n Datasets.\n\n Returns\n -------\n result : dict\n Dictionary with an array with one entry per dataset with the sum of the\n masked npred.\n \"\"\"\n npred = []\n\n for dataset in datasets:\n mask = dataset.mask\n npred.append(dataset.npred().data[mask].sum())\n\n return {\"npred\": np.array(npred), \"datasets\": datasets.names}\n\n def run(self, datasets, parameter):\n \"\"\"Run the parameter estimator.\n\n Parameters\n ----------\n datasets : `~gammapy.datasets.Datasets`\n The datasets used to estimate the model parameter.\n parameter : `str` or `~gammapy.modeling.Parameter`\n For which parameter to run the estimator.\n\n Returns\n -------\n result : dict\n Dictionary with the various parameter estimation values.\n \"\"\"\n if not isinstance(datasets, DatasetsActor):\n datasets = Datasets(datasets)\n parameter = datasets.parameters[parameter]\n\n with datasets.parameters.restore_status():\n\n if not self.reoptimize:\n datasets.parameters.freeze_all()\n parameter.frozen = False\n\n result = self.estimate_best_fit(datasets, parameter)\n result.update(self.estimate_ts(datasets, parameter))\n\n if \"errn-errp\" in self.selection_optional:\n result.update(self.estimate_errn_errp(datasets, parameter))\n\n if \"ul\" in self.selection_optional:\n result.update(self.estimate_ul(datasets, parameter))\n\n if \"scan\" in self.selection_optional:\n result.update(self.estimate_scan(datasets, parameter))\n\n result.update(self.estimate_counts(datasets))\n return result\n", "path": "gammapy/estimators/parameter.py"}]}
| 3,904 | 247 |
gh_patches_debug_9250
|
rasdani/github-patches
|
git_diff
|
opensearch-project__opensearch-build-1852
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[RPM M1] Add a new block to call the generation code for RPM
Tasks | Estimate | Status | Notes | Dependencies
-- | -- | -- | -- | --
The generation code should pull the artifacts from the build workflow to a temporary location | 1 | Complete | | Build workflow must provide usable artifacts
The code will call existing install function to install plugins on min artifacts | 1 | Complete | |
After installation, the code will execute a tool or utility to wrap all the content into a RPM package | 5 | Complete | Require writing a script to utilize FPM to start with and later implement in pure python code. <br><br>20220204: We might change to rpmbuild directly without using FPM. See comments. | FPM usages
The code will also add dependencies to the RPM package so that things like JDK and additional libs for plugins can be installed and pulled separately | 5 | Complete | Need to study on RPM dependency setups | RPM Build Dependencies and the locations of each dependent artifact
The code will move the RPM package from the temp location to dist folder | 2 | Complete | |
</issue>
<code>
[start of src/assemble_workflow/bundle_rpm.py]
1 # SPDX-License-Identifier: Apache-2.0
2 #
3 # The OpenSearch Contributors require contributions made to
4 # this file be licensed under the Apache-2.0 license or a
5 # compatible open source license.
6
7 import logging
8 import os
9 import shutil
10 import subprocess
11
12 from manifests.build_manifest import BuildManifest
13 from system.os import rpm_architecture
14
15
16 class BundleRpm:
17
18 def __init__(self, filename: str, package_path: str, min_path: str) -> None:
19 self.filename = filename
20 self.package_path = package_path
21 self.min_path = min_path
22
23 def extract(self, dest: str) -> None:
24 cpio_basename = os.path.splitext(os.path.basename(self.package_path))[0]
25 cpio_path = os.path.join(dest, f"{cpio_basename}.cpio")
26 min_source_path = os.path.join(dest, 'usr', 'share', self.filename)
27 min_dest_path = os.path.join(dest, self.min_path)
28 min_config_path = os.path.join(dest, 'etc', self.filename)
29 min_bin_env_path = os.path.join(min_dest_path, 'bin', f"{self.filename}-env")
30
31 # Convert rpm to cpio so we can extract the content
32 logging.info(f"Convert rpm to cpio for extraction: {self.package_path} to {cpio_path}")
33 with open(cpio_path, 'wb') as fp:
34 subprocess.check_call(
35 [
36 'rpm2cpio',
37 self.package_path,
38 ],
39 stdout=fp,
40 cwd=dest,
41 )
42
43 # Extract cpio archive based on the rpm package
44 logging.info(f"Extract cpio {cpio_path} content to {dest}")
45 with open(cpio_path, 'rb') as fp:
46 subprocess.check_call(
47 [
48 'cpio',
49 '-imdv',
50 ],
51 stdin=fp,
52 stdout=subprocess.DEVNULL,
53 stderr=subprocess.STDOUT,
54 cwd=dest,
55 )
56
57 # Move core folder destination so plugin install can proceed
58 logging.info(f"Move {min_source_path} to {min_dest_path} for plugin installation")
59 shutil.move(min_source_path, min_dest_path)
60
61 # Multiple modifications and env vars setups before install plugins
62 # As bin/opensearch-env is different between archive and package
63 # https://github.com/opensearch-project/OpenSearch/issues/2092
64 os.environ[f"{self.filename.upper()}_PATH_CONF"] = min_config_path
65
66 if os.path.exists(min_bin_env_path):
67 # Backup original file
68 shutil.copy2(min_bin_env_path, f"{min_bin_env_path}.backup")
69 # Prevent sourcing as file is only in place after rpm installation
70 # So that min can install plugin zips
71 # Have to decode then encode back to ascii due to mypy complains TextIO not equals to BinaryIO
72 with open(min_bin_env_path, 'rb') as fp:
73 min_bin_env_lines = fp.read().decode('ascii')
74
75 with open(min_bin_env_path, 'wb') as fp:
76 fp.write(min_bin_env_lines.replace('source', '#source').encode('ascii'))
77
78 def build(self, name: str, dest: str, archive_path: str, build_cls: BuildManifest.Build) -> None:
79 # extract dest and build dest are not the same, this is restoring the extract dest
80 # mainly due to rpm requires several different setups compares to tarball and zip
81 ext_dest = os.path.dirname(archive_path)
82 min_source_path = os.path.join(ext_dest, 'usr', 'share', self.filename)
83 min_dest_path = os.path.join(ext_dest, self.min_path)
84 min_bin_env_path = os.path.join(min_dest_path, 'bin', f"{self.filename}-env")
85 bundle_artifact_path: str = None
86
87 # Remove env var
88 logging.info('Organize folder structure before generating rpm')
89 os.environ.pop('OPENSEARCH_PATH_CONF', None)
90
91 # Restore config file and core folder to original location
92 shutil.move(f"{min_bin_env_path}.backup", min_bin_env_path)
93 shutil.move(min_dest_path, min_source_path)
94
95 # Run bundle rpmbuild
96 bundle_cmd = " ".join(
97 [
98 'rpmbuild',
99 '-bb',
100 f"--define '_topdir {ext_dest}'",
101 f"--define '_version {build_cls.version}'",
102 f"--define '_architecture {rpm_architecture(build_cls.architecture)}'",
103 f"{self.filename}.rpm.spec",
104 ]
105 )
106
107 logging.info(f"Execute {bundle_cmd} in {ext_dest}")
108 subprocess.check_call(bundle_cmd, cwd=ext_dest, shell=True)
109
110 # Move artifact to repo root before being published to {dest}
111 for dirpath, dirnames, filenames in os.walk(os.path.join(ext_dest, 'RPMS')):
112 for filename in [file for file in filenames if file.endswith('.rpm')]:
113 bundle_artifact_path = os.path.join(dirpath, filename)
114 break
115
116 shutil.move(bundle_artifact_path, name)
117
[end of src/assemble_workflow/bundle_rpm.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/assemble_workflow/bundle_rpm.py b/src/assemble_workflow/bundle_rpm.py
--- a/src/assemble_workflow/bundle_rpm.py
+++ b/src/assemble_workflow/bundle_rpm.py
@@ -89,7 +89,10 @@
os.environ.pop('OPENSEARCH_PATH_CONF', None)
# Restore config file and core folder to original location
- shutil.move(f"{min_bin_env_path}.backup", min_bin_env_path)
+ if os.path.exists(f"{min_bin_env_path}.backup"):
+ logging.info(f"Restore {min_bin_env_path}.backup to {min_bin_env_path}")
+ shutil.move(f"{min_bin_env_path}.backup", min_bin_env_path)
+
shutil.move(min_dest_path, min_source_path)
# Run bundle rpmbuild
|
{"golden_diff": "diff --git a/src/assemble_workflow/bundle_rpm.py b/src/assemble_workflow/bundle_rpm.py\n--- a/src/assemble_workflow/bundle_rpm.py\n+++ b/src/assemble_workflow/bundle_rpm.py\n@@ -89,7 +89,10 @@\n os.environ.pop('OPENSEARCH_PATH_CONF', None)\n \n # Restore config file and core folder to original location\n- shutil.move(f\"{min_bin_env_path}.backup\", min_bin_env_path)\n+ if os.path.exists(f\"{min_bin_env_path}.backup\"):\n+ logging.info(f\"Restore {min_bin_env_path}.backup to {min_bin_env_path}\")\n+ shutil.move(f\"{min_bin_env_path}.backup\", min_bin_env_path)\n+\n shutil.move(min_dest_path, min_source_path)\n \n # Run bundle rpmbuild\n", "issue": "[RPM M1] Add a new block to call the generation code for RPM\nTasks | Estimate | Status | Notes | Dependencies\r\n-- | -- | -- | -- | --\r\nThe generation code should pull the artifacts from the build workflow to a temporary location | 1 | Complete | \u00a0 | Build workflow must provide usable artifacts\r\nThe code will call existing install function to install plugins on min artifacts | 1 | Complete | \u00a0 | \u00a0\r\nAfter installation, the code will execute a tool or utility to wrap all the content into a RPM package | 5 | Complete | Require writing a script to utilize FPM to start with and later implement in pure python code. <br><br>20220204: We might change to rpmbuild directly without using FPM. See comments. | FPM usages\r\nThe code will also add dependencies to the RPM package so that things like JDK and additional libs for plugins can be installed and pulled separately | 5 | Complete | Need to study on RPM dependency setups | RPM Build Dependencies and the locations of each dependent artifact\r\nThe code will move the RPM package from the temp location to dist folder | 2 | Complete | \u00a0 | \u00a0\r\n\r\n\n", "before_files": [{"content": "# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\nimport logging\nimport os\nimport shutil\nimport subprocess\n\nfrom manifests.build_manifest import BuildManifest\nfrom system.os import rpm_architecture\n\n\nclass BundleRpm:\n\n def __init__(self, filename: str, package_path: str, min_path: str) -> None:\n self.filename = filename\n self.package_path = package_path\n self.min_path = min_path\n\n def extract(self, dest: str) -> None:\n cpio_basename = os.path.splitext(os.path.basename(self.package_path))[0]\n cpio_path = os.path.join(dest, f\"{cpio_basename}.cpio\")\n min_source_path = os.path.join(dest, 'usr', 'share', self.filename)\n min_dest_path = os.path.join(dest, self.min_path)\n min_config_path = os.path.join(dest, 'etc', self.filename)\n min_bin_env_path = os.path.join(min_dest_path, 'bin', f\"{self.filename}-env\")\n\n # Convert rpm to cpio so we can extract the content\n logging.info(f\"Convert rpm to cpio for extraction: {self.package_path} to {cpio_path}\")\n with open(cpio_path, 'wb') as fp:\n subprocess.check_call(\n [\n 'rpm2cpio',\n self.package_path,\n ],\n stdout=fp,\n cwd=dest,\n )\n\n # Extract cpio archive based on the rpm package\n logging.info(f\"Extract cpio {cpio_path} content to {dest}\")\n with open(cpio_path, 'rb') as fp:\n subprocess.check_call(\n [\n 'cpio',\n '-imdv',\n ],\n stdin=fp,\n stdout=subprocess.DEVNULL,\n stderr=subprocess.STDOUT,\n cwd=dest,\n )\n\n # Move core folder destination so plugin install can proceed\n logging.info(f\"Move {min_source_path} to {min_dest_path} for plugin installation\")\n shutil.move(min_source_path, min_dest_path)\n\n # Multiple modifications and env vars setups before install plugins\n # As bin/opensearch-env is different between archive and package\n # https://github.com/opensearch-project/OpenSearch/issues/2092\n os.environ[f\"{self.filename.upper()}_PATH_CONF\"] = min_config_path\n\n if os.path.exists(min_bin_env_path):\n # Backup original file\n shutil.copy2(min_bin_env_path, f\"{min_bin_env_path}.backup\")\n # Prevent sourcing as file is only in place after rpm installation\n # So that min can install plugin zips\n # Have to decode then encode back to ascii due to mypy complains TextIO not equals to BinaryIO\n with open(min_bin_env_path, 'rb') as fp:\n min_bin_env_lines = fp.read().decode('ascii')\n\n with open(min_bin_env_path, 'wb') as fp:\n fp.write(min_bin_env_lines.replace('source', '#source').encode('ascii'))\n\n def build(self, name: str, dest: str, archive_path: str, build_cls: BuildManifest.Build) -> None:\n # extract dest and build dest are not the same, this is restoring the extract dest\n # mainly due to rpm requires several different setups compares to tarball and zip\n ext_dest = os.path.dirname(archive_path)\n min_source_path = os.path.join(ext_dest, 'usr', 'share', self.filename)\n min_dest_path = os.path.join(ext_dest, self.min_path)\n min_bin_env_path = os.path.join(min_dest_path, 'bin', f\"{self.filename}-env\")\n bundle_artifact_path: str = None\n\n # Remove env var\n logging.info('Organize folder structure before generating rpm')\n os.environ.pop('OPENSEARCH_PATH_CONF', None)\n\n # Restore config file and core folder to original location\n shutil.move(f\"{min_bin_env_path}.backup\", min_bin_env_path)\n shutil.move(min_dest_path, min_source_path)\n\n # Run bundle rpmbuild\n bundle_cmd = \" \".join(\n [\n 'rpmbuild',\n '-bb',\n f\"--define '_topdir {ext_dest}'\",\n f\"--define '_version {build_cls.version}'\",\n f\"--define '_architecture {rpm_architecture(build_cls.architecture)}'\",\n f\"{self.filename}.rpm.spec\",\n ]\n )\n\n logging.info(f\"Execute {bundle_cmd} in {ext_dest}\")\n subprocess.check_call(bundle_cmd, cwd=ext_dest, shell=True)\n\n # Move artifact to repo root before being published to {dest}\n for dirpath, dirnames, filenames in os.walk(os.path.join(ext_dest, 'RPMS')):\n for filename in [file for file in filenames if file.endswith('.rpm')]:\n bundle_artifact_path = os.path.join(dirpath, filename)\n break\n\n shutil.move(bundle_artifact_path, name)\n", "path": "src/assemble_workflow/bundle_rpm.py"}]}
| 2,122 | 180 |
gh_patches_debug_18748
|
rasdani/github-patches
|
git_diff
|
microsoft__PubSec-Info-Assistant-356
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Text Enrichment function not quoting blob paths correctly
We have some files with percentage (%) symbols in them, which appear to cause an issue when getting to the Text Enrichment stage of the Function App due to the way the `get_blob_and_sas` function works. Example file name: `Unemployment rate back up to 3.7% in October _ Australian Bureau of Statistics.pdf`
I would suggest replacing the code that manually substitutes spaces (below) with a proper URL quoting function like `blob_path = urllib.parse.quote(blob_path)`
https://github.com/microsoft/PubSec-Info-Assistant/blob/7fa4561652211b023965d4522b2bfd7168af4060/functions/shared_code/utilities_helper.py#L52
</issue>
<code>
[start of functions/shared_code/utilities_helper.py]
1 # Copyright (c) Microsoft Corporation.
2 # Licensed under the MIT license.
3
4 import os
5 import logging
6 from datetime import datetime, timedelta
7 from azure.storage.blob import generate_blob_sas, BlobSasPermissions
8
9 class UtilitiesHelper:
10 """ Helper class for utility functions"""
11 def __init__(self,
12 azure_blob_storage_account,
13 azure_blob_storage_endpoint,
14 azure_blob_storage_key
15 ):
16 self.azure_blob_storage_account = azure_blob_storage_account
17 self.azure_blob_storage_endpoint = azure_blob_storage_endpoint
18 self.azure_blob_storage_key = azure_blob_storage_key
19
20 def get_filename_and_extension(self, path):
21 """ Function to return the file name & type"""
22 # Split the path into base and extension
23 base_name = os.path.basename(path)
24 segments = path.split("/")
25 directory = "/".join(segments[1:-1]) + "/"
26 if directory == "/":
27 directory = ""
28 file_name, file_extension = os.path.splitext(base_name)
29 return file_name, file_extension, directory
30
31 def get_blob_and_sas(self, blob_path):
32 """ Function to retrieve the uri and sas token for a given blob in azure storage"""
33
34 # Get path and file name minus the root container
35 separator = "/"
36 file_path_w_name_no_cont = separator.join(
37 blob_path.split(separator)[1:])
38
39 container_name = separator.join(
40 blob_path.split(separator)[0:1])
41
42 # Gen SAS token
43 sas_token = generate_blob_sas(
44 account_name=self.azure_blob_storage_account,
45 container_name=container_name,
46 blob_name=file_path_w_name_no_cont,
47 account_key=self.azure_blob_storage_key,
48 permission=BlobSasPermissions(read=True),
49 expiry=datetime.utcnow() + timedelta(hours=1)
50 )
51 source_blob_path = f'{self.azure_blob_storage_endpoint}{blob_path}?{sas_token}'
52 source_blob_path = source_blob_path.replace(" ", "%20")
53 logging.info("Path and SAS token for file in azure storage are now generated \n")
54 return source_blob_path
[end of functions/shared_code/utilities_helper.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/functions/shared_code/utilities_helper.py b/functions/shared_code/utilities_helper.py
--- a/functions/shared_code/utilities_helper.py
+++ b/functions/shared_code/utilities_helper.py
@@ -3,6 +3,7 @@
import os
import logging
+import urllib.parse
from datetime import datetime, timedelta
from azure.storage.blob import generate_blob_sas, BlobSasPermissions
@@ -48,7 +49,7 @@
permission=BlobSasPermissions(read=True),
expiry=datetime.utcnow() + timedelta(hours=1)
)
+ blob_path = urllib.parse.quote(blob_path)
source_blob_path = f'{self.azure_blob_storage_endpoint}{blob_path}?{sas_token}'
- source_blob_path = source_blob_path.replace(" ", "%20")
logging.info("Path and SAS token for file in azure storage are now generated \n")
return source_blob_path
\ No newline at end of file
|
{"golden_diff": "diff --git a/functions/shared_code/utilities_helper.py b/functions/shared_code/utilities_helper.py\n--- a/functions/shared_code/utilities_helper.py\n+++ b/functions/shared_code/utilities_helper.py\n@@ -3,6 +3,7 @@\n \n import os\n import logging\n+import urllib.parse\n from datetime import datetime, timedelta\n from azure.storage.blob import generate_blob_sas, BlobSasPermissions\n \n@@ -48,7 +49,7 @@\n permission=BlobSasPermissions(read=True),\n expiry=datetime.utcnow() + timedelta(hours=1)\n )\n+ blob_path = urllib.parse.quote(blob_path)\n source_blob_path = f'{self.azure_blob_storage_endpoint}{blob_path}?{sas_token}'\n- source_blob_path = source_blob_path.replace(\" \", \"%20\")\n logging.info(\"Path and SAS token for file in azure storage are now generated \\n\")\n return source_blob_path\n\\ No newline at end of file\n", "issue": "Text Enrichment function not quoting blob paths correctly\nWe have some files with percentage (%) symbols in them, which appear to cause an issue when getting to the Text Enrichment stage of the Function App due to the way the `get_blob_and_sas` function works. Example file name: `Unemployment rate back up to 3.7% in October _ Australian Bureau of Statistics.pdf`\r\n\r\nI would suggest replacing the code that manually substitutes spaces (below) with a proper URL quoting function like `blob_path = urllib.parse.quote(blob_path)`\r\n\r\nhttps://github.com/microsoft/PubSec-Info-Assistant/blob/7fa4561652211b023965d4522b2bfd7168af4060/functions/shared_code/utilities_helper.py#L52\r\n\r\n\r\n\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation.\n# Licensed under the MIT license.\n\nimport os\nimport logging\nfrom datetime import datetime, timedelta\nfrom azure.storage.blob import generate_blob_sas, BlobSasPermissions\n\nclass UtilitiesHelper:\n \"\"\" Helper class for utility functions\"\"\"\n def __init__(self,\n azure_blob_storage_account,\n azure_blob_storage_endpoint,\n azure_blob_storage_key\n ):\n self.azure_blob_storage_account = azure_blob_storage_account\n self.azure_blob_storage_endpoint = azure_blob_storage_endpoint\n self.azure_blob_storage_key = azure_blob_storage_key\n \n def get_filename_and_extension(self, path):\n \"\"\" Function to return the file name & type\"\"\"\n # Split the path into base and extension\n base_name = os.path.basename(path)\n segments = path.split(\"/\")\n directory = \"/\".join(segments[1:-1]) + \"/\"\n if directory == \"/\":\n directory = \"\"\n file_name, file_extension = os.path.splitext(base_name)\n return file_name, file_extension, directory\n \n def get_blob_and_sas(self, blob_path):\n \"\"\" Function to retrieve the uri and sas token for a given blob in azure storage\"\"\"\n\n # Get path and file name minus the root container\n separator = \"/\"\n file_path_w_name_no_cont = separator.join(\n blob_path.split(separator)[1:])\n \n container_name = separator.join(\n blob_path.split(separator)[0:1])\n\n # Gen SAS token\n sas_token = generate_blob_sas(\n account_name=self.azure_blob_storage_account,\n container_name=container_name,\n blob_name=file_path_w_name_no_cont,\n account_key=self.azure_blob_storage_key,\n permission=BlobSasPermissions(read=True),\n expiry=datetime.utcnow() + timedelta(hours=1)\n )\n source_blob_path = f'{self.azure_blob_storage_endpoint}{blob_path}?{sas_token}'\n source_blob_path = source_blob_path.replace(\" \", \"%20\")\n logging.info(\"Path and SAS token for file in azure storage are now generated \\n\")\n return source_blob_path", "path": "functions/shared_code/utilities_helper.py"}]}
| 1,253 | 200 |
gh_patches_debug_27874
|
rasdani/github-patches
|
git_diff
|
cloud-custodian__cloud-custodian-7673
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Any way to filter on tags for Cognito identity-pool or user-pool?
### Discussed in https://github.com/orgs/cloud-custodian/discussions/7616
<div type='discussions-op-text'>
<sup>Originally posted by **stepkirk** August 5, 2022</sup>
We normally enforce tags on AWS resources by using Custodian to look for certain required tags on a resource and then, if the tags don't exist or aren't in the correct format, we mark the resource for deletion after a certain grace period. With the Cognito identity-pool and user-pool resources, it doesn't look like we can check for tags the normal way and it doesn't look like we can mark a resource for later deletion. Is that true or am I missing something?
Any plans to add tagging/marking support in the future for these Cognito resources?</div>
</issue>
<code>
[start of c7n/resources/cognito.py]
1 # Copyright The Cloud Custodian Authors.
2 # SPDX-License-Identifier: Apache-2.0
3 from botocore.exceptions import ClientError
4
5 from c7n.actions import BaseAction
6 from c7n.manager import resources
7 from c7n.query import QueryResourceManager, TypeInfo
8 from c7n.utils import local_session, type_schema
9
10
11 @resources.register('identity-pool')
12 class CognitoIdentityPool(QueryResourceManager):
13
14 class resource_type(TypeInfo):
15 service = 'cognito-identity'
16 enum_spec = ('list_identity_pools', 'IdentityPools', {'MaxResults': 60})
17 detail_spec = (
18 'describe_identity_pool', 'IdentityPoolId', 'IdentityPoolId', None)
19 id = 'IdentityPoolId'
20 name = 'IdentityPoolName'
21 arn_type = "identitypool"
22 cfn_type = 'AWS::Cognito::IdentityPool'
23
24
25 @CognitoIdentityPool.action_registry.register('delete')
26 class DeleteIdentityPool(BaseAction):
27 """Action to delete cognito identity pool
28
29 It is recommended to use a filter to avoid unwanted deletion of pools
30
31 :example:
32
33 .. code-block:: yaml
34
35 policies:
36 - name: identity-pool-delete
37 resource: identity-pool
38 actions:
39 - delete
40 """
41
42 schema = type_schema('delete')
43 permissions = ("cognito-identity:DeleteIdentityPool",)
44
45 def process(self, pools):
46 with self.executor_factory(max_workers=2) as w:
47 list(w.map(self.process_pool, pools))
48
49 def process_pool(self, pool):
50 client = local_session(
51 self.manager.session_factory).client('cognito-identity')
52 try:
53 client.delete_identity_pool(IdentityPoolId=pool['IdentityPoolId'])
54 except ClientError as e:
55 self.log.exception(
56 "Exception deleting identity pool:\n %s" % e)
57
58
59 @resources.register('user-pool')
60 class CognitoUserPool(QueryResourceManager):
61
62 class resource_type(TypeInfo):
63 service = "cognito-idp"
64 enum_spec = ('list_user_pools', 'UserPools', {'MaxResults': 60})
65 detail_spec = (
66 'describe_user_pool', 'UserPoolId', 'Id', 'UserPool')
67 id = 'Id'
68 name = 'Name'
69 arn_type = "userpool"
70 cfn_type = 'AWS::Cognito::UserPool'
71
72
73 @CognitoUserPool.action_registry.register('delete')
74 class DeleteUserPool(BaseAction):
75 """Action to delete cognito user pool
76
77 It is recommended to use a filter to avoid unwanted deletion of pools
78
79 :example:
80
81 .. code-block:: yaml
82
83 policies:
84 - name: user-pool-delete
85 resource: user-pool
86 actions:
87 - delete
88 """
89
90 schema = type_schema('delete')
91 permissions = ("cognito-idp:DeleteUserPool",)
92
93 def process(self, pools):
94 with self.executor_factory(max_workers=2) as w:
95 list(w.map(self.process_pool, pools))
96
97 def process_pool(self, pool):
98 client = local_session(
99 self.manager.session_factory).client('cognito-idp')
100 try:
101 client.delete_user_pool(UserPoolId=pool['Id'])
102 except ClientError as e:
103 self.log.exception(
104 "Exception deleting user pool:\n %s" % e)
105
[end of c7n/resources/cognito.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/c7n/resources/cognito.py b/c7n/resources/cognito.py
--- a/c7n/resources/cognito.py
+++ b/c7n/resources/cognito.py
@@ -4,10 +4,21 @@
from c7n.actions import BaseAction
from c7n.manager import resources
-from c7n.query import QueryResourceManager, TypeInfo
+from c7n.query import QueryResourceManager, TypeInfo, DescribeSource
+from c7n.tags import universal_augment
from c7n.utils import local_session, type_schema
+class DescribeIdentityPool(DescribeSource):
+ def augment(self, resources):
+ return universal_augment(self.manager, resources)
+
+
+class DescribeUserPool(DescribeSource):
+ def augment(self, resources):
+ return universal_augment(self.manager, resources)
+
+
@resources.register('identity-pool')
class CognitoIdentityPool(QueryResourceManager):
@@ -20,6 +31,11 @@
name = 'IdentityPoolName'
arn_type = "identitypool"
cfn_type = 'AWS::Cognito::IdentityPool'
+ universal_taggable = object()
+
+ source_mapping = {
+ 'describe': DescribeIdentityPool,
+ }
@CognitoIdentityPool.action_registry.register('delete')
@@ -69,6 +85,10 @@
arn_type = "userpool"
cfn_type = 'AWS::Cognito::UserPool'
+ source_mapping = {
+ 'describe': DescribeUserPool,
+ }
+
@CognitoUserPool.action_registry.register('delete')
class DeleteUserPool(BaseAction):
|
{"golden_diff": "diff --git a/c7n/resources/cognito.py b/c7n/resources/cognito.py\n--- a/c7n/resources/cognito.py\n+++ b/c7n/resources/cognito.py\n@@ -4,10 +4,21 @@\n \n from c7n.actions import BaseAction\n from c7n.manager import resources\n-from c7n.query import QueryResourceManager, TypeInfo\n+from c7n.query import QueryResourceManager, TypeInfo, DescribeSource\n+from c7n.tags import universal_augment\n from c7n.utils import local_session, type_schema\n \n \n+class DescribeIdentityPool(DescribeSource):\n+ def augment(self, resources):\n+ return universal_augment(self.manager, resources)\n+\n+\n+class DescribeUserPool(DescribeSource):\n+ def augment(self, resources):\n+ return universal_augment(self.manager, resources)\n+\n+\n @resources.register('identity-pool')\n class CognitoIdentityPool(QueryResourceManager):\n \n@@ -20,6 +31,11 @@\n name = 'IdentityPoolName'\n arn_type = \"identitypool\"\n cfn_type = 'AWS::Cognito::IdentityPool'\n+ universal_taggable = object()\n+\n+ source_mapping = {\n+ 'describe': DescribeIdentityPool,\n+ }\n \n \n @CognitoIdentityPool.action_registry.register('delete')\n@@ -69,6 +85,10 @@\n arn_type = \"userpool\"\n cfn_type = 'AWS::Cognito::UserPool'\n \n+ source_mapping = {\n+ 'describe': DescribeUserPool,\n+ }\n+\n \n @CognitoUserPool.action_registry.register('delete')\n class DeleteUserPool(BaseAction):\n", "issue": "Any way to filter on tags for Cognito identity-pool or user-pool?\n### Discussed in https://github.com/orgs/cloud-custodian/discussions/7616\r\n\r\n<div type='discussions-op-text'>\r\n\r\n<sup>Originally posted by **stepkirk** August 5, 2022</sup>\r\nWe normally enforce tags on AWS resources by using Custodian to look for certain required tags on a resource and then, if the tags don't exist or aren't in the correct format, we mark the resource for deletion after a certain grace period. With the Cognito identity-pool and user-pool resources, it doesn't look like we can check for tags the normal way and it doesn't look like we can mark a resource for later deletion. Is that true or am I missing something?\r\n\r\nAny plans to add tagging/marking support in the future for these Cognito resources?</div>\n", "before_files": [{"content": "# Copyright The Cloud Custodian Authors.\n# SPDX-License-Identifier: Apache-2.0\nfrom botocore.exceptions import ClientError\n\nfrom c7n.actions import BaseAction\nfrom c7n.manager import resources\nfrom c7n.query import QueryResourceManager, TypeInfo\nfrom c7n.utils import local_session, type_schema\n\n\[email protected]('identity-pool')\nclass CognitoIdentityPool(QueryResourceManager):\n\n class resource_type(TypeInfo):\n service = 'cognito-identity'\n enum_spec = ('list_identity_pools', 'IdentityPools', {'MaxResults': 60})\n detail_spec = (\n 'describe_identity_pool', 'IdentityPoolId', 'IdentityPoolId', None)\n id = 'IdentityPoolId'\n name = 'IdentityPoolName'\n arn_type = \"identitypool\"\n cfn_type = 'AWS::Cognito::IdentityPool'\n\n\[email protected]_registry.register('delete')\nclass DeleteIdentityPool(BaseAction):\n \"\"\"Action to delete cognito identity pool\n\n It is recommended to use a filter to avoid unwanted deletion of pools\n\n :example:\n\n .. code-block:: yaml\n\n policies:\n - name: identity-pool-delete\n resource: identity-pool\n actions:\n - delete\n \"\"\"\n\n schema = type_schema('delete')\n permissions = (\"cognito-identity:DeleteIdentityPool\",)\n\n def process(self, pools):\n with self.executor_factory(max_workers=2) as w:\n list(w.map(self.process_pool, pools))\n\n def process_pool(self, pool):\n client = local_session(\n self.manager.session_factory).client('cognito-identity')\n try:\n client.delete_identity_pool(IdentityPoolId=pool['IdentityPoolId'])\n except ClientError as e:\n self.log.exception(\n \"Exception deleting identity pool:\\n %s\" % e)\n\n\[email protected]('user-pool')\nclass CognitoUserPool(QueryResourceManager):\n\n class resource_type(TypeInfo):\n service = \"cognito-idp\"\n enum_spec = ('list_user_pools', 'UserPools', {'MaxResults': 60})\n detail_spec = (\n 'describe_user_pool', 'UserPoolId', 'Id', 'UserPool')\n id = 'Id'\n name = 'Name'\n arn_type = \"userpool\"\n cfn_type = 'AWS::Cognito::UserPool'\n\n\[email protected]_registry.register('delete')\nclass DeleteUserPool(BaseAction):\n \"\"\"Action to delete cognito user pool\n\n It is recommended to use a filter to avoid unwanted deletion of pools\n\n :example:\n\n .. code-block:: yaml\n\n policies:\n - name: user-pool-delete\n resource: user-pool\n actions:\n - delete\n \"\"\"\n\n schema = type_schema('delete')\n permissions = (\"cognito-idp:DeleteUserPool\",)\n\n def process(self, pools):\n with self.executor_factory(max_workers=2) as w:\n list(w.map(self.process_pool, pools))\n\n def process_pool(self, pool):\n client = local_session(\n self.manager.session_factory).client('cognito-idp')\n try:\n client.delete_user_pool(UserPoolId=pool['Id'])\n except ClientError as e:\n self.log.exception(\n \"Exception deleting user pool:\\n %s\" % e)\n", "path": "c7n/resources/cognito.py"}]}
| 1,669 | 355 |
gh_patches_debug_200
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-1566
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
signals docs are confusing
It seems it is not explained how to connect a callback to a singnal anywhere in Scrapy docs.
http://doc.scrapy.org/en/latest/topics/signals.html tells:
> You can connect to signals (or send your own) through the [Signals API](http://doc.scrapy.org/en/latest/topics/api.html#topics-api-signals).
But if you follow this link you get docs for scrapy.signalmanager.SignalManager - that's fine, but it is not explained where to get a SignalManager instance from.
There is an example in Extension docs (http://doc.scrapy.org/en/latest/topics/extensions.html#sample-extension), but
a) this is just an example;
b) it is not explained that crawler.signals is a SignalManager instance;
c) this example is neither in Signals docs nor in SignalManager docs.
There is also a bit of information here: http://doc.scrapy.org/en/latest/topics/api.html#scrapy.crawler.Crawler.signals, but
a) it is not linked to neither from Signal docs nor from SignalManager, so you can't find it if you don't know about it already;
b) it is not explained that crawler.signals is the only way to access signals.
So in the end users may get some luck connecting signals if they start from Crawler docs, but almost no luck if they start from Signals docs.
</issue>
<code>
[start of scrapy/utils/misc.py]
1 """Helper functions which doesn't fit anywhere else"""
2 import re
3 import hashlib
4 from importlib import import_module
5 from pkgutil import iter_modules
6
7 import six
8 from w3lib.html import replace_entities
9
10 from scrapy.utils.python import flatten, to_unicode
11 from scrapy.item import BaseItem
12
13
14 _ITERABLE_SINGLE_VALUES = dict, BaseItem, six.text_type, bytes
15
16
17 def arg_to_iter(arg):
18 """Convert an argument to an iterable. The argument can be a None, single
19 value, or an iterable.
20
21 Exception: if arg is a dict, [arg] will be returned
22 """
23 if arg is None:
24 return []
25 elif not isinstance(arg, _ITERABLE_SINGLE_VALUES) and hasattr(arg, '__iter__'):
26 return arg
27 else:
28 return [arg]
29
30
31 def load_object(path):
32 """Load an object given its absolute object path, and return it.
33
34 object can be a class, function, variable or an instance.
35 path ie: 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware'
36 """
37
38 try:
39 dot = path.rindex('.')
40 except ValueError:
41 raise ValueError("Error loading object '%s': not a full path" % path)
42
43 module, name = path[:dot], path[dot+1:]
44 mod = import_module(module)
45
46 try:
47 obj = getattr(mod, name)
48 except AttributeError:
49 raise NameError("Module '%s' doesn't define any object named '%s'" % (module, name))
50
51 return obj
52
53
54 def walk_modules(path):
55 """Loads a module and all its submodules from the given module path and
56 returns them. If *any* module throws an exception while importing, that
57 exception is thrown back.
58
59 For example: walk_modules('scrapy.utils')
60 """
61
62 mods = []
63 mod = import_module(path)
64 mods.append(mod)
65 if hasattr(mod, '__path__'):
66 for _, subpath, ispkg in iter_modules(mod.__path__):
67 fullpath = path + '.' + subpath
68 if ispkg:
69 mods += walk_modules(fullpath)
70 else:
71 submod = import_module(fullpath)
72 mods.append(submod)
73 return mods
74
75
76 def extract_regex(regex, text, encoding='utf-8'):
77 """Extract a list of unicode strings from the given text/encoding using the following policies:
78
79 * if the regex contains a named group called "extract" that will be returned
80 * if the regex contains multiple numbered groups, all those will be returned (flattened)
81 * if the regex doesn't contain any group the entire regex matching is returned
82 """
83
84 if isinstance(regex, six.string_types):
85 regex = re.compile(regex, re.UNICODE)
86
87 try:
88 strings = [regex.search(text).group('extract')] # named group
89 except:
90 strings = regex.findall(text) # full regex or numbered groups
91 strings = flatten(strings)
92
93 if isinstance(text, six.text_type):
94 return [replace_entities(s, keep=['lt', 'amp']) for s in strings]
95 else:
96 return [replace_entities(to_unicode(s, encoding), keep=['lt', 'amp'])
97 for s in strings]
98
99
100 def md5sum(file):
101 """Calculate the md5 checksum of a file-like object without reading its
102 whole content in memory.
103
104 >>> from io import BytesIO
105 >>> md5sum(BytesIO(b'file content to hash'))
106 '784406af91dd5a54fbb9c84c2236595a'
107 """
108 m = hashlib.md5()
109 while True:
110 d = file.read(8096)
111 if not d:
112 break
113 m.update(d)
114 return m.hexdigest()
115
116 def rel_has_nofollow(rel):
117 """Return True if link rel attribute has nofollow type"""
118 return True if rel is not None and 'nofollow' in rel.split() else False
119
120
[end of scrapy/utils/misc.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scrapy/utils/misc.py b/scrapy/utils/misc.py
--- a/scrapy/utils/misc.py
+++ b/scrapy/utils/misc.py
@@ -1,4 +1,4 @@
-"""Helper functions which doesn't fit anywhere else"""
+"""Helper functions which don't fit anywhere else"""
import re
import hashlib
from importlib import import_module
|
{"golden_diff": "diff --git a/scrapy/utils/misc.py b/scrapy/utils/misc.py\n--- a/scrapy/utils/misc.py\n+++ b/scrapy/utils/misc.py\n@@ -1,4 +1,4 @@\n-\"\"\"Helper functions which doesn't fit anywhere else\"\"\"\n+\"\"\"Helper functions which don't fit anywhere else\"\"\"\n import re\n import hashlib\n from importlib import import_module\n", "issue": "signals docs are confusing\nIt seems it is not explained how to connect a callback to a singnal anywhere in Scrapy docs.\n\nhttp://doc.scrapy.org/en/latest/topics/signals.html tells:\n\n> You can connect to signals (or send your own) through the [Signals API](http://doc.scrapy.org/en/latest/topics/api.html#topics-api-signals).\n\nBut if you follow this link you get docs for scrapy.signalmanager.SignalManager - that's fine, but it is not explained where to get a SignalManager instance from.\n\nThere is an example in Extension docs (http://doc.scrapy.org/en/latest/topics/extensions.html#sample-extension), but\n\na) this is just an example;\nb) it is not explained that crawler.signals is a SignalManager instance;\nc) this example is neither in Signals docs nor in SignalManager docs.\n\nThere is also a bit of information here: http://doc.scrapy.org/en/latest/topics/api.html#scrapy.crawler.Crawler.signals, but\n\na) it is not linked to neither from Signal docs nor from SignalManager, so you can't find it if you don't know about it already;\nb) it is not explained that crawler.signals is the only way to access signals.\n\nSo in the end users may get some luck connecting signals if they start from Crawler docs, but almost no luck if they start from Signals docs.\n\n", "before_files": [{"content": "\"\"\"Helper functions which doesn't fit anywhere else\"\"\"\nimport re\nimport hashlib\nfrom importlib import import_module\nfrom pkgutil import iter_modules\n\nimport six\nfrom w3lib.html import replace_entities\n\nfrom scrapy.utils.python import flatten, to_unicode\nfrom scrapy.item import BaseItem\n\n\n_ITERABLE_SINGLE_VALUES = dict, BaseItem, six.text_type, bytes\n\n\ndef arg_to_iter(arg):\n \"\"\"Convert an argument to an iterable. The argument can be a None, single\n value, or an iterable.\n\n Exception: if arg is a dict, [arg] will be returned\n \"\"\"\n if arg is None:\n return []\n elif not isinstance(arg, _ITERABLE_SINGLE_VALUES) and hasattr(arg, '__iter__'):\n return arg\n else:\n return [arg]\n\n\ndef load_object(path):\n \"\"\"Load an object given its absolute object path, and return it.\n\n object can be a class, function, variable or an instance.\n path ie: 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware'\n \"\"\"\n\n try:\n dot = path.rindex('.')\n except ValueError:\n raise ValueError(\"Error loading object '%s': not a full path\" % path)\n\n module, name = path[:dot], path[dot+1:]\n mod = import_module(module)\n\n try:\n obj = getattr(mod, name)\n except AttributeError:\n raise NameError(\"Module '%s' doesn't define any object named '%s'\" % (module, name))\n\n return obj\n\n\ndef walk_modules(path):\n \"\"\"Loads a module and all its submodules from the given module path and\n returns them. If *any* module throws an exception while importing, that\n exception is thrown back.\n\n For example: walk_modules('scrapy.utils')\n \"\"\"\n\n mods = []\n mod = import_module(path)\n mods.append(mod)\n if hasattr(mod, '__path__'):\n for _, subpath, ispkg in iter_modules(mod.__path__):\n fullpath = path + '.' + subpath\n if ispkg:\n mods += walk_modules(fullpath)\n else:\n submod = import_module(fullpath)\n mods.append(submod)\n return mods\n\n\ndef extract_regex(regex, text, encoding='utf-8'):\n \"\"\"Extract a list of unicode strings from the given text/encoding using the following policies:\n\n * if the regex contains a named group called \"extract\" that will be returned\n * if the regex contains multiple numbered groups, all those will be returned (flattened)\n * if the regex doesn't contain any group the entire regex matching is returned\n \"\"\"\n\n if isinstance(regex, six.string_types):\n regex = re.compile(regex, re.UNICODE)\n\n try:\n strings = [regex.search(text).group('extract')] # named group\n except:\n strings = regex.findall(text) # full regex or numbered groups\n strings = flatten(strings)\n\n if isinstance(text, six.text_type):\n return [replace_entities(s, keep=['lt', 'amp']) for s in strings]\n else:\n return [replace_entities(to_unicode(s, encoding), keep=['lt', 'amp'])\n for s in strings]\n\n\ndef md5sum(file):\n \"\"\"Calculate the md5 checksum of a file-like object without reading its\n whole content in memory.\n\n >>> from io import BytesIO\n >>> md5sum(BytesIO(b'file content to hash'))\n '784406af91dd5a54fbb9c84c2236595a'\n \"\"\"\n m = hashlib.md5()\n while True:\n d = file.read(8096)\n if not d:\n break\n m.update(d)\n return m.hexdigest()\n\ndef rel_has_nofollow(rel):\n \"\"\"Return True if link rel attribute has nofollow type\"\"\"\n return True if rel is not None and 'nofollow' in rel.split() else False\n \n", "path": "scrapy/utils/misc.py"}]}
| 1,926 | 77 |
gh_patches_debug_30112
|
rasdani/github-patches
|
git_diff
|
sonic-net__sonic-mgmt-4489
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Investigate backend T0 nighty failure during restart ptf
Latest run failed with the following error.
TASK [vm_set : Setup vlan port for vlan tunnel] ********************************
Wednesday 13 October 2021 12:17:07 +0000 (0:00:00.098) 0:00:22.391 *****
fatal: [STR2-ACS-SERV-18]: FAILED! => {"changed": false, "module_stderr": "Shared connection to 10.64.246.97 closed.\r\n", "module_stdout": "Traceback (most recent call last):\r\n File \"/home/azure/.ansible/tmp/ansible-tmp-1634127427.08-60041-68522534642110/AnsiballZ_vlan_port.py\", line 114, in <module>\r\n _ansiballz_main()\r\n File \"/home/azure/.ansible/tmp/ansible-tmp-1634127427.08-60041-68522534642110/AnsiballZ_vlan_port.py\", line 106, in _ansiballz_main\r\n invoke_module(zipped_mod, temp_path, ANSIBALLZ_PARAMS)\r\n File \"/home/azure/.ansible/tmp/ansible-tmp-1634127427.08-60041-68522534642110/AnsiballZ_vlan_port.py\", line 49, in invoke_module\r\n imp.load_module('__main__', mod, module, MOD_DESC)\r\n File \"/tmp/ansible_vlan_port_payload_apPh5r/__main__.py\", line 151, in <module>\r\n File \"/tmp/ansible_vlan_port_payload_apPh5r/__main__.py\", line 139, in main\r\n File \"/tmp/ansible_vlan_port_payload_apPh5r/__main__.py\", line 65, in create_vlan_ports\r\n File \"/tmp/ansible_vlan_port_payload_apPh5r/__main__.py\", line 50, in create_vlan_port\r\n File \"/tmp/ansible_vlan_port_payload_apPh5r/__main__.py\", line 113, in cmd\r\nException: ret_code=3, error message=ERROR: trying to add VLAN #2020 to IF -:enp59s0f1:- error: File exists\r\n. cmd=vconfig add enp59s0f1 2020\r\n", "msg": "MODULE FAILURE\nSee stdout/stderr for the exact error", "rc": 1}
</issue>
<code>
[start of ansible/roles/vm_set/library/vlan_port.py]
1 #!/usr/bin/python
2
3 import re
4 import sys
5 import time
6 import subprocess
7 from pprint import pprint
8 from ansible.module_utils.basic import *
9
10 DOCUMENTATION = '''
11 module: vlan_port
12 version_added: "0.1"
13 author: Guohan Lu ([email protected])
14 short_description: Get/Create/Remove vlan tunnel port in the test server for physical DUT
15 '''
16
17 EXAMPLES = '''
18 - name: Set front panel port for vlan tunnel
19 vlan_port:
20 external_port: "{{ external_port }}"
21 vlan_ids: "{{ device_vlan_list }}"
22 cmd: "list"
23 '''
24
25 DOCUMENTATION = '''
26 - external_port: external port
27 - vlan_ids: vlan list
28 '''
29
30 CMD_DEBUG_FNAME = '/tmp/vlan_port.cmds.txt'
31 EXCEPTION_DEBUG_FNAME = '/tmp/vlan_port.exception.txt'
32
33 class VlanPort(object):
34 def __init__(self, external_port, vlan_ids):
35 self.external_port = external_port
36 self.vlan_ids = vlan_ids
37 self.host_ifaces = VlanPort.ifconfig('ifconfig -a')
38
39 return
40
41 def up_external_port(self):
42 if self.external_port in self.host_ifaces:
43 VlanPort.iface_up(self.external_port)
44
45 return
46
47 def create_vlan_port(self, port, vlan_id):
48 vlan_port = "%s.%d" % (port, vlan_id)
49 if vlan_port not in self.host_ifaces:
50 VlanPort.cmd('vconfig add %s %d' % (port, vlan_id))
51
52 VlanPort.iface_up(vlan_port)
53
54 return
55
56 def destroy_vlan_port(self, vlan_port):
57 if vlan_port in self.host_ifaces:
58 VlanPort.iface_down(vlan_port)
59 VlanPort.cmd('vconfig rem %s' % vlan_port)
60
61 return
62
63 def create_vlan_ports(self):
64 for vlan_id in self.vlan_ids.values():
65 self.create_vlan_port(self.external_port, vlan_id)
66
67 def remove_vlan_ports(self):
68 for vlan_id in self.vlan_ids.values():
69 vlan_port = "%s.%d" % (self.external_port, vlan_id)
70 self.destroy_vlan_port(vlan_port)
71
72 @staticmethod
73 def ifconfig(cmdline):
74 out = VlanPort.cmd(cmdline)
75
76 ifaces = set()
77
78 rows = out.split('\n')
79 for row in rows:
80 if len(row) == 0:
81 continue
82 terms = row.split()
83 if not row[0].isspace():
84 ifaces.add(terms[0].rstrip(':'))
85
86 return ifaces
87
88 @staticmethod
89 def iface_up(iface_name, pid=None):
90 return VlanPort.iface_updown(iface_name, 'up', pid)
91
92 @staticmethod
93 def iface_down(iface_name, pid=None):
94 return VlanPort.iface_updown(iface_name, 'down', pid)
95
96 @staticmethod
97 def iface_updown(iface_name, state, pid):
98 if pid is None:
99 return VlanPort.cmd('ip link set %s %s' % (iface_name, state))
100 else:
101 return VlanPort.cmd('nsenter -t %s -n ip link set %s %s' % (pid, iface_name, state))
102
103 @staticmethod
104 def cmd(cmdline):
105 with open(CMD_DEBUG_FNAME, 'a') as fp:
106 pprint("CMD: %s" % cmdline, fp)
107 cmd = cmdline.split(' ')
108 process = subprocess.Popen(cmd, stdout=subprocess.PIPE, stdin=subprocess.PIPE, stderr=subprocess.PIPE)
109 stdout, stderr = process.communicate()
110 ret_code = process.returncode
111
112 if ret_code != 0:
113 raise Exception("ret_code=%d, error message=%s. cmd=%s" % (ret_code, stderr, cmdline))
114
115 with open(CMD_DEBUG_FNAME, 'a') as fp:
116 pprint("OUTPUT: %s" % stdout, fp)
117
118 return stdout.decode('utf-8')
119
120
121 def main():
122
123 module = AnsibleModule(argument_spec=dict(
124 cmd=dict(required=True, choices=['create', 'remove', 'list']),
125 external_port=dict(required=True, type='str'),
126 vlan_ids=dict(required=True, type='dict'),
127 ))
128
129 cmd = module.params['cmd']
130 external_port = module.params['external_port']
131 vlan_ids = module.params['vlan_ids']
132
133 fp_ports = {}
134
135 vp = VlanPort(external_port, vlan_ids)
136
137 vp.up_external_port()
138 if cmd == "create":
139 vp.create_vlan_ports()
140 elif cmd == "remove":
141 vp.remove_vlan_ports()
142
143 fp_port_templ = external_port + ".%s"
144 for a_port_index, vid in vlan_ids.items():
145 fp_ports[a_port_index] = fp_port_templ % vid
146
147 module.exit_json(changed=False, ansible_facts={'dut_fp_ports': fp_ports})
148
149
150 if __name__ == "__main__":
151 main()
152
[end of ansible/roles/vm_set/library/vlan_port.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ansible/roles/vm_set/library/vlan_port.py b/ansible/roles/vm_set/library/vlan_port.py
--- a/ansible/roles/vm_set/library/vlan_port.py
+++ b/ansible/roles/vm_set/library/vlan_port.py
@@ -47,6 +47,7 @@
def create_vlan_port(self, port, vlan_id):
vlan_port = "%s.%d" % (port, vlan_id)
if vlan_port not in self.host_ifaces:
+ VlanPort.cmd('vconfig rem %s' % vlan_port, True)
VlanPort.cmd('vconfig add %s %d' % (port, vlan_id))
VlanPort.iface_up(vlan_port)
@@ -101,7 +102,7 @@
return VlanPort.cmd('nsenter -t %s -n ip link set %s %s' % (pid, iface_name, state))
@staticmethod
- def cmd(cmdline):
+ def cmd(cmdline, ignore_error=False):
with open(CMD_DEBUG_FNAME, 'a') as fp:
pprint("CMD: %s" % cmdline, fp)
cmd = cmdline.split(' ')
@@ -109,11 +110,14 @@
stdout, stderr = process.communicate()
ret_code = process.returncode
- if ret_code != 0:
+ if ret_code != 0 and not ignore_error:
raise Exception("ret_code=%d, error message=%s. cmd=%s" % (ret_code, stderr, cmdline))
with open(CMD_DEBUG_FNAME, 'a') as fp:
- pprint("OUTPUT: %s" % stdout, fp)
+ if ret_code == 0:
+ pprint("OUTPUT: %s" % stdout, fp)
+ else:
+ pprint("ERR: %s" % stderr, fp)
return stdout.decode('utf-8')
|
{"golden_diff": "diff --git a/ansible/roles/vm_set/library/vlan_port.py b/ansible/roles/vm_set/library/vlan_port.py\n--- a/ansible/roles/vm_set/library/vlan_port.py\n+++ b/ansible/roles/vm_set/library/vlan_port.py\n@@ -47,6 +47,7 @@\n def create_vlan_port(self, port, vlan_id):\n vlan_port = \"%s.%d\" % (port, vlan_id)\n if vlan_port not in self.host_ifaces:\n+ VlanPort.cmd('vconfig rem %s' % vlan_port, True)\n VlanPort.cmd('vconfig add %s %d' % (port, vlan_id))\n \n VlanPort.iface_up(vlan_port)\n@@ -101,7 +102,7 @@\n return VlanPort.cmd('nsenter -t %s -n ip link set %s %s' % (pid, iface_name, state))\n \n @staticmethod\n- def cmd(cmdline):\n+ def cmd(cmdline, ignore_error=False):\n with open(CMD_DEBUG_FNAME, 'a') as fp:\n pprint(\"CMD: %s\" % cmdline, fp)\n cmd = cmdline.split(' ')\n@@ -109,11 +110,14 @@\n stdout, stderr = process.communicate()\n ret_code = process.returncode\n \n- if ret_code != 0:\n+ if ret_code != 0 and not ignore_error:\n raise Exception(\"ret_code=%d, error message=%s. cmd=%s\" % (ret_code, stderr, cmdline))\n \n with open(CMD_DEBUG_FNAME, 'a') as fp:\n- pprint(\"OUTPUT: %s\" % stdout, fp)\n+ if ret_code == 0:\n+ pprint(\"OUTPUT: %s\" % stdout, fp)\n+ else:\n+ pprint(\"ERR: %s\" % stderr, fp)\n \n return stdout.decode('utf-8')\n", "issue": "Investigate backend T0 nighty failure during restart ptf\nLatest run failed with the following error. \r\n\r\nTASK [vm_set : Setup vlan port for vlan tunnel] ********************************\r\nWednesday 13 October 2021 12:17:07 +0000 (0:00:00.098) 0:00:22.391 ***** \r\nfatal: [STR2-ACS-SERV-18]: FAILED! => {\"changed\": false, \"module_stderr\": \"Shared connection to 10.64.246.97 closed.\\r\\n\", \"module_stdout\": \"Traceback (most recent call last):\\r\\n File \\\"/home/azure/.ansible/tmp/ansible-tmp-1634127427.08-60041-68522534642110/AnsiballZ_vlan_port.py\\\", line 114, in <module>\\r\\n _ansiballz_main()\\r\\n File \\\"/home/azure/.ansible/tmp/ansible-tmp-1634127427.08-60041-68522534642110/AnsiballZ_vlan_port.py\\\", line 106, in _ansiballz_main\\r\\n invoke_module(zipped_mod, temp_path, ANSIBALLZ_PARAMS)\\r\\n File \\\"/home/azure/.ansible/tmp/ansible-tmp-1634127427.08-60041-68522534642110/AnsiballZ_vlan_port.py\\\", line 49, in invoke_module\\r\\n imp.load_module('__main__', mod, module, MOD_DESC)\\r\\n File \\\"/tmp/ansible_vlan_port_payload_apPh5r/__main__.py\\\", line 151, in <module>\\r\\n File \\\"/tmp/ansible_vlan_port_payload_apPh5r/__main__.py\\\", line 139, in main\\r\\n File \\\"/tmp/ansible_vlan_port_payload_apPh5r/__main__.py\\\", line 65, in create_vlan_ports\\r\\n File \\\"/tmp/ansible_vlan_port_payload_apPh5r/__main__.py\\\", line 50, in create_vlan_port\\r\\n File \\\"/tmp/ansible_vlan_port_payload_apPh5r/__main__.py\\\", line 113, in cmd\\r\\nException: ret_code=3, error message=ERROR: trying to add VLAN #2020 to IF -:enp59s0f1:- error: File exists\\r\\n. cmd=vconfig add enp59s0f1 2020\\r\\n\", \"msg\": \"MODULE FAILURE\\nSee stdout/stderr for the exact error\", \"rc\": 1}\r\n\n", "before_files": [{"content": "#!/usr/bin/python\n\nimport re\nimport sys\nimport time\nimport subprocess\nfrom pprint import pprint\nfrom ansible.module_utils.basic import *\n\nDOCUMENTATION = '''\nmodule: vlan_port\nversion_added: \"0.1\"\nauthor: Guohan Lu ([email protected])\nshort_description: Get/Create/Remove vlan tunnel port in the test server for physical DUT\n'''\n\nEXAMPLES = '''\n- name: Set front panel port for vlan tunnel\n vlan_port:\n external_port: \"{{ external_port }}\"\n vlan_ids: \"{{ device_vlan_list }}\"\n cmd: \"list\"\n'''\n\nDOCUMENTATION = '''\n - external_port: external port\n - vlan_ids: vlan list\n'''\n\nCMD_DEBUG_FNAME = '/tmp/vlan_port.cmds.txt'\nEXCEPTION_DEBUG_FNAME = '/tmp/vlan_port.exception.txt'\n\nclass VlanPort(object):\n def __init__(self, external_port, vlan_ids):\n self.external_port = external_port\n self.vlan_ids = vlan_ids\n self.host_ifaces = VlanPort.ifconfig('ifconfig -a')\n\n return\n\n def up_external_port(self):\n if self.external_port in self.host_ifaces:\n VlanPort.iface_up(self.external_port)\n\n return\n\n def create_vlan_port(self, port, vlan_id):\n vlan_port = \"%s.%d\" % (port, vlan_id)\n if vlan_port not in self.host_ifaces:\n VlanPort.cmd('vconfig add %s %d' % (port, vlan_id))\n\n VlanPort.iface_up(vlan_port)\n\n return\n\n def destroy_vlan_port(self, vlan_port):\n if vlan_port in self.host_ifaces:\n VlanPort.iface_down(vlan_port)\n VlanPort.cmd('vconfig rem %s' % vlan_port)\n\n return\n\n def create_vlan_ports(self):\n for vlan_id in self.vlan_ids.values():\n self.create_vlan_port(self.external_port, vlan_id)\n\n def remove_vlan_ports(self):\n for vlan_id in self.vlan_ids.values():\n vlan_port = \"%s.%d\" % (self.external_port, vlan_id)\n self.destroy_vlan_port(vlan_port)\n\n @staticmethod\n def ifconfig(cmdline):\n out = VlanPort.cmd(cmdline)\n\n ifaces = set()\n\n rows = out.split('\\n')\n for row in rows:\n if len(row) == 0:\n continue\n terms = row.split()\n if not row[0].isspace():\n ifaces.add(terms[0].rstrip(':'))\n\n return ifaces\n\n @staticmethod\n def iface_up(iface_name, pid=None):\n return VlanPort.iface_updown(iface_name, 'up', pid)\n\n @staticmethod\n def iface_down(iface_name, pid=None):\n return VlanPort.iface_updown(iface_name, 'down', pid)\n\n @staticmethod\n def iface_updown(iface_name, state, pid):\n if pid is None:\n return VlanPort.cmd('ip link set %s %s' % (iface_name, state))\n else:\n return VlanPort.cmd('nsenter -t %s -n ip link set %s %s' % (pid, iface_name, state))\n\n @staticmethod\n def cmd(cmdline):\n with open(CMD_DEBUG_FNAME, 'a') as fp:\n pprint(\"CMD: %s\" % cmdline, fp)\n cmd = cmdline.split(' ')\n process = subprocess.Popen(cmd, stdout=subprocess.PIPE, stdin=subprocess.PIPE, stderr=subprocess.PIPE)\n stdout, stderr = process.communicate()\n ret_code = process.returncode\n\n if ret_code != 0:\n raise Exception(\"ret_code=%d, error message=%s. cmd=%s\" % (ret_code, stderr, cmdline))\n\n with open(CMD_DEBUG_FNAME, 'a') as fp:\n pprint(\"OUTPUT: %s\" % stdout, fp)\n\n return stdout.decode('utf-8')\n\n\ndef main():\n\n module = AnsibleModule(argument_spec=dict(\n cmd=dict(required=True, choices=['create', 'remove', 'list']),\n external_port=dict(required=True, type='str'),\n vlan_ids=dict(required=True, type='dict'),\n ))\n\n cmd = module.params['cmd']\n external_port = module.params['external_port']\n vlan_ids = module.params['vlan_ids']\n\n fp_ports = {}\n\n vp = VlanPort(external_port, vlan_ids)\n\n vp.up_external_port()\n if cmd == \"create\":\n vp.create_vlan_ports()\n elif cmd == \"remove\":\n vp.remove_vlan_ports()\n\n fp_port_templ = external_port + \".%s\"\n for a_port_index, vid in vlan_ids.items():\n fp_ports[a_port_index] = fp_port_templ % vid\n\n module.exit_json(changed=False, ansible_facts={'dut_fp_ports': fp_ports})\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "ansible/roles/vm_set/library/vlan_port.py"}]}
| 2,619 | 430 |
gh_patches_debug_29045
|
rasdani/github-patches
|
git_diff
|
litestar-org__litestar-2864
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug: OpenAPI schema generation fails due to same operation IDs
### Description
If two routes with the same path, but different methods are defined then the OpenAPI generation fails due to both of them having the same value for operation ID. After running `git bisect`, #2805 seems to have introduced this.
### URL to code causing the issue
_No response_
### MCVE
```python
from litestar import get, post
from litestar.app import Litestar
from litestar.testing import create_test_client
@post("/")
async def post_handler() -> None:
...
@get("/")
async def get_handler() -> None:
...
with create_test_client([post_handler, get_handler]) as client:
response = client.get("/schema/openapi.json")
assert response.status_code == 200
```
### Steps to reproduce
_No response_
### Screenshots
_No response_
### Logs
_No response_
### Litestar Version
HEAD
### Platform
- [ ] Linux
- [ ] Mac
- [ ] Windows
- [ ] Other (Please specify in the description above)
<!-- POLAR PLEDGE BADGE START -->
---
> [!NOTE]
> While we are open for sponsoring on [GitHub Sponsors](https://github.com/sponsors/litestar-org/) and
> [OpenCollective](https://opencollective.com/litestar), we also utilize [Polar.sh](https://polar.sh/) to engage in pledge-based sponsorship.
>
> Check out all issues funded or available for funding [on our Polar.sh dashboard](https://polar.sh/litestar-org)
> * If you would like to see an issue prioritized, make a pledge towards it!
> * We receive the pledge once the issue is completed & verified
> * This, along with engagement in the community, helps us know which features are a priority to our users.
<a href="https://polar.sh/litestar-org/litestar/issues/2863">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://polar.sh/api/github/litestar-org/litestar/issues/2863/pledge.svg?darkmode=1">
<img alt="Fund with Polar" src="https://polar.sh/api/github/litestar-org/litestar/issues/2863/pledge.svg">
</picture>
</a>
<!-- POLAR PLEDGE BADGE END -->
</issue>
<code>
[start of litestar/_openapi/plugin.py]
1 from __future__ import annotations
2
3 from typing import TYPE_CHECKING
4
5 from litestar._openapi.datastructures import OpenAPIContext
6 from litestar._openapi.path_item import create_path_item_for_route
7 from litestar.exceptions import ImproperlyConfiguredException
8 from litestar.plugins import InitPluginProtocol
9 from litestar.plugins.base import ReceiveRoutePlugin
10 from litestar.routes import HTTPRoute
11
12 if TYPE_CHECKING:
13 from litestar.app import Litestar
14 from litestar.config.app import AppConfig
15 from litestar.openapi.config import OpenAPIConfig
16 from litestar.openapi.spec import OpenAPI
17 from litestar.routes import BaseRoute
18
19
20 class OpenAPIPlugin(InitPluginProtocol, ReceiveRoutePlugin):
21 __slots__ = (
22 "app",
23 "included_routes",
24 "_openapi_config",
25 "_openapi_schema",
26 )
27
28 def __init__(self, app: Litestar) -> None:
29 self.app = app
30 self.included_routes: list[HTTPRoute] = []
31 self._openapi_config: OpenAPIConfig | None = None
32 self._openapi_schema: OpenAPI | None = None
33
34 def _build_openapi_schema(self) -> OpenAPI:
35 openapi = self.openapi_config.to_openapi_schema()
36 context = OpenAPIContext(openapi_config=self.openapi_config, plugins=self.app.plugins.openapi)
37 openapi.paths = {
38 route.path_format or "/": create_path_item_for_route(context, route) for route in self.included_routes
39 }
40 openapi.components.schemas = context.schema_registry.generate_components_schemas()
41 return openapi
42
43 def provide_openapi(self) -> OpenAPI:
44 if not self._openapi_schema:
45 self._openapi_schema = self._build_openapi_schema()
46 return self._openapi_schema
47
48 def on_app_init(self, app_config: AppConfig) -> AppConfig:
49 if app_config.openapi_config:
50 self._openapi_config = app_config.openapi_config
51 app_config.route_handlers.append(self.openapi_config.openapi_controller)
52 return app_config
53
54 @property
55 def openapi_config(self) -> OpenAPIConfig:
56 if not self._openapi_config:
57 raise ImproperlyConfiguredException("OpenAPIConfig not initialized")
58 return self._openapi_config
59
60 def receive_route(self, route: BaseRoute) -> None:
61 if not isinstance(route, HTTPRoute):
62 return
63
64 if any(route_handler.resolve_include_in_schema() for route_handler, _ in route.route_handler_map.values()):
65 # Force recompute the schema if a new route is added
66 self._openapi_schema = None
67 self.included_routes.append(route)
68
[end of litestar/_openapi/plugin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/litestar/_openapi/plugin.py b/litestar/_openapi/plugin.py
--- a/litestar/_openapi/plugin.py
+++ b/litestar/_openapi/plugin.py
@@ -27,7 +27,7 @@
def __init__(self, app: Litestar) -> None:
self.app = app
- self.included_routes: list[HTTPRoute] = []
+ self.included_routes: dict[str, HTTPRoute] = {}
self._openapi_config: OpenAPIConfig | None = None
self._openapi_schema: OpenAPI | None = None
@@ -35,7 +35,8 @@
openapi = self.openapi_config.to_openapi_schema()
context = OpenAPIContext(openapi_config=self.openapi_config, plugins=self.app.plugins.openapi)
openapi.paths = {
- route.path_format or "/": create_path_item_for_route(context, route) for route in self.included_routes
+ route.path_format or "/": create_path_item_for_route(context, route)
+ for route in self.included_routes.values()
}
openapi.components.schemas = context.schema_registry.generate_components_schemas()
return openapi
@@ -64,4 +65,4 @@
if any(route_handler.resolve_include_in_schema() for route_handler, _ in route.route_handler_map.values()):
# Force recompute the schema if a new route is added
self._openapi_schema = None
- self.included_routes.append(route)
+ self.included_routes[route.path] = route
|
{"golden_diff": "diff --git a/litestar/_openapi/plugin.py b/litestar/_openapi/plugin.py\n--- a/litestar/_openapi/plugin.py\n+++ b/litestar/_openapi/plugin.py\n@@ -27,7 +27,7 @@\n \n def __init__(self, app: Litestar) -> None:\n self.app = app\n- self.included_routes: list[HTTPRoute] = []\n+ self.included_routes: dict[str, HTTPRoute] = {}\n self._openapi_config: OpenAPIConfig | None = None\n self._openapi_schema: OpenAPI | None = None\n \n@@ -35,7 +35,8 @@\n openapi = self.openapi_config.to_openapi_schema()\n context = OpenAPIContext(openapi_config=self.openapi_config, plugins=self.app.plugins.openapi)\n openapi.paths = {\n- route.path_format or \"/\": create_path_item_for_route(context, route) for route in self.included_routes\n+ route.path_format or \"/\": create_path_item_for_route(context, route)\n+ for route in self.included_routes.values()\n }\n openapi.components.schemas = context.schema_registry.generate_components_schemas()\n return openapi\n@@ -64,4 +65,4 @@\n if any(route_handler.resolve_include_in_schema() for route_handler, _ in route.route_handler_map.values()):\n # Force recompute the schema if a new route is added\n self._openapi_schema = None\n- self.included_routes.append(route)\n+ self.included_routes[route.path] = route\n", "issue": "Bug: OpenAPI schema generation fails due to same operation IDs\n### Description\n\nIf two routes with the same path, but different methods are defined then the OpenAPI generation fails due to both of them having the same value for operation ID. After running `git bisect`, #2805 seems to have introduced this.\n\n### URL to code causing the issue\n\n_No response_\n\n### MCVE\n\n```python\nfrom litestar import get, post\r\nfrom litestar.app import Litestar\r\nfrom litestar.testing import create_test_client\r\n\r\n\r\n@post(\"/\")\r\nasync def post_handler() -> None:\r\n ...\r\n\r\n\r\n@get(\"/\")\r\nasync def get_handler() -> None:\r\n ...\r\n\r\n\r\nwith create_test_client([post_handler, get_handler]) as client:\r\n response = client.get(\"/schema/openapi.json\")\r\n\r\n assert response.status_code == 200\n```\n\n\n### Steps to reproduce\n\n_No response_\n\n### Screenshots\n\n_No response_\n\n### Logs\n\n_No response_\n\n### Litestar Version\n\nHEAD\n\n### Platform\n\n- [ ] Linux\n- [ ] Mac\n- [ ] Windows\n- [ ] Other (Please specify in the description above)\n\n<!-- POLAR PLEDGE BADGE START -->\n---\n> [!NOTE] \n> While we are open for sponsoring on [GitHub Sponsors](https://github.com/sponsors/litestar-org/) and \n> [OpenCollective](https://opencollective.com/litestar), we also utilize [Polar.sh](https://polar.sh/) to engage in pledge-based sponsorship.\n>\n> Check out all issues funded or available for funding [on our Polar.sh dashboard](https://polar.sh/litestar-org)\n> * If you would like to see an issue prioritized, make a pledge towards it!\n> * We receive the pledge once the issue is completed & verified\n> * This, along with engagement in the community, helps us know which features are a priority to our users.\n\n<a href=\"https://polar.sh/litestar-org/litestar/issues/2863\">\n<picture>\n <source media=\"(prefers-color-scheme: dark)\" srcset=\"https://polar.sh/api/github/litestar-org/litestar/issues/2863/pledge.svg?darkmode=1\">\n <img alt=\"Fund with Polar\" src=\"https://polar.sh/api/github/litestar-org/litestar/issues/2863/pledge.svg\">\n</picture>\n</a>\n<!-- POLAR PLEDGE BADGE END -->\n\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING\n\nfrom litestar._openapi.datastructures import OpenAPIContext\nfrom litestar._openapi.path_item import create_path_item_for_route\nfrom litestar.exceptions import ImproperlyConfiguredException\nfrom litestar.plugins import InitPluginProtocol\nfrom litestar.plugins.base import ReceiveRoutePlugin\nfrom litestar.routes import HTTPRoute\n\nif TYPE_CHECKING:\n from litestar.app import Litestar\n from litestar.config.app import AppConfig\n from litestar.openapi.config import OpenAPIConfig\n from litestar.openapi.spec import OpenAPI\n from litestar.routes import BaseRoute\n\n\nclass OpenAPIPlugin(InitPluginProtocol, ReceiveRoutePlugin):\n __slots__ = (\n \"app\",\n \"included_routes\",\n \"_openapi_config\",\n \"_openapi_schema\",\n )\n\n def __init__(self, app: Litestar) -> None:\n self.app = app\n self.included_routes: list[HTTPRoute] = []\n self._openapi_config: OpenAPIConfig | None = None\n self._openapi_schema: OpenAPI | None = None\n\n def _build_openapi_schema(self) -> OpenAPI:\n openapi = self.openapi_config.to_openapi_schema()\n context = OpenAPIContext(openapi_config=self.openapi_config, plugins=self.app.plugins.openapi)\n openapi.paths = {\n route.path_format or \"/\": create_path_item_for_route(context, route) for route in self.included_routes\n }\n openapi.components.schemas = context.schema_registry.generate_components_schemas()\n return openapi\n\n def provide_openapi(self) -> OpenAPI:\n if not self._openapi_schema:\n self._openapi_schema = self._build_openapi_schema()\n return self._openapi_schema\n\n def on_app_init(self, app_config: AppConfig) -> AppConfig:\n if app_config.openapi_config:\n self._openapi_config = app_config.openapi_config\n app_config.route_handlers.append(self.openapi_config.openapi_controller)\n return app_config\n\n @property\n def openapi_config(self) -> OpenAPIConfig:\n if not self._openapi_config:\n raise ImproperlyConfiguredException(\"OpenAPIConfig not initialized\")\n return self._openapi_config\n\n def receive_route(self, route: BaseRoute) -> None:\n if not isinstance(route, HTTPRoute):\n return\n\n if any(route_handler.resolve_include_in_schema() for route_handler, _ in route.route_handler_map.values()):\n # Force recompute the schema if a new route is added\n self._openapi_schema = None\n self.included_routes.append(route)\n", "path": "litestar/_openapi/plugin.py"}]}
| 1,756 | 339 |
gh_patches_debug_31890
|
rasdani/github-patches
|
git_diff
|
lutris__lutris-1996
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Lutris fails to open .tar.gz with "not a gzip file" if file is a tar file
Lutris fails to open archive where 7z doesn't. If I rename the file to `TTRLinux-v1.2.3.tar` Lutris can open and extract it. `format: tar` doesn't work here.
```
files:
- client: https://download.toontownrewritten.com/launcher/linux/TTRLinux-v1.2.3.tar.gz
game:
exe: Launcher
installer:
- extract:
file: client
format: tar
```
```
2019-04-04 16:53:40,809: Downloading file 1 of 1
2019-04-04 16:53:40,811: Downloading [client]: https://download.toontownrewritten.com/launcher/linux/TTRLinux-v1.2.3.tar.gz to /home/cxf/.cache/lutris/installer/toontown-rewritten/client/TTRLinux-v1.2.3.tar.gz
2019-04-04 16:53:40,814: Downloading https://download.toontownrewritten.com/launcher/linux/TTRLinux-v1.2.3.tar.gz to /home/cxf/.cache/lutris/installer/toontown-rewritten/client/TTRLinux-v1.2.3.tar.gz
2019-04-04 16:53:40,816: Starting download of:
https://download.toontownrewritten.com/launcher/linux/TTRLinux-v1.2.3.tar.gz
2019-04-04 16:53:44,410: Finished downloading https://download.toontownrewritten.com/launcher/linux/TTRLinux-v1.2.3.tar.gz
2019-04-04 16:53:44,822: Installer command: {'extract': {'format': 'tar', 'file': 'client'}}
2019-04-04 16:53:44,823: Extracting TTRLinux-v1.2.3.tar.gz
2019-04-04 16:53:44,824: extracting file /home/cxf/.cache/lutris/installer/toontown-rewritten/client/TTRLinux-v1.2.3.tar.gz to /home/cxf/Games/toontown-rewritten
2019-04-04 16:53:44,831: Extracting /home/cxf/.cache/lutris/installer/toontown-rewritten/client/TTRLinux-v1.2.3.tar.gz to /home/cxf/Games/toontown-rewritten
2019-04-04 16:53:44,832: Extraction failed: not a gzip file
Traceback (most recent call last):
File "/usr/lib/python3.6/tarfile.py", line 1643, in gzopen
t = cls.taropen(name, mode, fileobj, **kwargs)
File "/usr/lib/python3.6/tarfile.py", line 1619, in taropen
return cls(name, mode, fileobj, **kwargs)
File "/usr/lib/python3.6/tarfile.py", line 1482, in __init__
self.firstmember = self.next()
File "/usr/lib/python3.6/tarfile.py", line 2297, in next
tarinfo = self.tarinfo.fromtarfile(self)
File "/usr/lib/python3.6/tarfile.py", line 1092, in fromtarfile
buf = tarfile.fileobj.read(BLOCKSIZE)
File "/usr/lib/python3.6/gzip.py", line 276, in read
return self._buffer.read(size)
File "/usr/lib/python3.6/_compression.py", line 68, in readinto
data = self.read(len(byte_view))
File "/usr/lib/python3.6/gzip.py", line 463, in read
if not self._read_gzip_header():
File "/usr/lib/python3.6/gzip.py", line 411, in _read_gzip_header
raise OSError('Not a gzipped file (%r)' % magic)
OSError: Not a gzipped file (b'To')
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/cxf/.lutris/lutris/util/extract.py", line 90, in extract_archive
_do_extract(path, temp_path, opener, mode, extractor)
File "/home/cxf/.lutris/lutris/util/extract.py", line 134, in _do_extract
handler = opener(archive, mode)
File "/usr/lib/python3.6/tarfile.py", line 1589, in open
return func(name, filemode, fileobj, **kwargs)
File "/usr/lib/python3.6/tarfile.py", line 1647, in gzopen
raise ReadError("not a gzip file")
tarfile.ReadError: not a gzip file
2019-04-04 16:53:44,835: Error while completing task <bound method CommandsMixin.extract of <lutris.installer.interpreter.ScriptInterpreter object at 0x7f0507748c88>>: not a gzip file
<class 'lutris.util.extract.ExtractFailure'> not a gzip file
File "/home/cxf/.lutris/lutris/util/jobs.py", line 30, in target
result = self.function(*args, **kwargs)
File "/home/cxf/.lutris/lutris/installer/commands.py", line 180, in extract
extract.extract_archive, filename, dest_path, merge_single, extractor
File "/home/cxf/.lutris/lutris/installer/commands.py", line 527, in _killable_process
result = result_obj.get() # Wait process end & reraise exceptions
File "/usr/lib/python3.6/multiprocessing/pool.py", line 670, in get
raise self._value
2019-04-04 16:53:49,289: Install cancelled
```
```
cxf@PC:~/Downloads$ 7z e TTRLinux-v1.2.3.tar.gz
7-Zip [64] 16.02 : Copyright (c) 1999-2016 Igor Pavlov : 2016-05-21
p7zip Version 16.02 (locale=en_US.UTF-8,Utf16=on,HugeFiles=on,64 bits,4 CPUs Intel(R) Core(TM) i5-4460 CPU @ 3.20GHz (306C3),ASM,AES-NI)
Scanning the drive for archives:
1 file, 37233152 bytes (36 MiB)
Extracting archive: TTRLinux-v1.2.3.tar.gz
WARNING:
TTRLinux-v1.2.3.tar.gz
Can not open the file as [gzip] archive
The file is open as [tar] archive
--
Path = TTRLinux-v1.2.3.tar.gz
Open WARNING: Can not open the file as [gzip] archive
Type = tar
Physical Size = 37233152
Headers Size = 2048
Code Page = UTF-8
Everything is Ok
Archives with Warnings: 1
Folders: 1
Files: 1
Size: 37231062
Compressed: 37233152
```
</issue>
<code>
[start of lutris/util/extract.py]
1 import os
2 import uuid
3 import shutil
4 import tarfile
5 import subprocess
6 import gzip
7 import zlib
8 from lutris.util import system
9 from lutris.util.log import logger
10 from lutris import settings
11
12
13 class ExtractFailure(Exception):
14 """Exception raised when and archive fails to extract"""
15
16
17 def is_7zip_supported(path, extractor):
18 supported_extractors = (
19 "7z",
20 "xz",
21 "bzip2",
22 "gzip",
23 "tar",
24 "zip",
25 "ar",
26 "arj",
27 "cab",
28 "chm",
29 "cpio",
30 "cramfs",
31 "dmg",
32 "ext",
33 "fat",
34 "gpt",
35 "hfs",
36 "ihex",
37 "iso",
38 "lzh",
39 "lzma",
40 "mbr",
41 "msi",
42 "nsis",
43 "ntfs",
44 "qcow2",
45 "rar",
46 "rpm",
47 "squashfs",
48 "udf",
49 "uefi",
50 "vdi",
51 "vhd",
52 "vmdk",
53 "wim",
54 "xar",
55 "z",
56 )
57 if extractor:
58 return extractor.lower() in supported_extractors
59 _base, ext = os.path.splitext(path)
60 if ext:
61 ext = ext.lstrip(".").lower()
62 return ext in supported_extractors
63
64
65 def extract_archive(path, to_directory=".", merge_single=True, extractor=None):
66 path = os.path.abspath(path)
67 mode = None
68 logger.debug("Extracting %s to %s", path, to_directory)
69
70 if path.endswith(".tar.gz") or path.endswith(".tgz") or extractor == "tgz":
71 opener, mode = tarfile.open, "r:gz"
72 elif path.endswith(".tar.xz") or path.endswith(".txz") or extractor == "txz":
73 opener, mode = tarfile.open, "r:xz"
74 elif path.endswith(".tar") or extractor == "tar":
75 opener, mode = tarfile.open, "r:"
76 elif path.endswith(".gz") or extractor == "gzip":
77 decompress_gz(path, to_directory)
78 return
79 elif path.endswith(".tar.bz2") or path.endswith(".tbz") or extractor == "bz2":
80 opener, mode = tarfile.open, "r:bz2"
81 elif is_7zip_supported(path, extractor):
82 opener = "7zip"
83 else:
84 raise RuntimeError(
85 "Could not extract `%s` as no appropriate extractor is found" % path
86 )
87 temp_name = ".extract-" + str(uuid.uuid4())[:8]
88 temp_path = temp_dir = os.path.join(to_directory, temp_name)
89 try:
90 _do_extract(path, temp_path, opener, mode, extractor)
91 except (OSError, zlib.error, tarfile.ReadError) as ex:
92 logger.exception("Extraction failed: %s", ex)
93 raise ExtractFailure(str(ex))
94 if merge_single:
95 extracted = os.listdir(temp_path)
96 if len(extracted) == 1:
97 temp_path = os.path.join(temp_path, extracted[0])
98
99 if os.path.isfile(temp_path):
100 destination_path = os.path.join(to_directory, extracted[0])
101 if os.path.isfile(destination_path):
102 logger.warning("Overwrite existing file %s", destination_path)
103 os.remove(destination_path)
104 shutil.move(temp_path, to_directory)
105 os.removedirs(temp_dir)
106 else:
107 for archive_file in os.listdir(temp_path):
108 source_path = os.path.join(temp_path, archive_file)
109 destination_path = os.path.join(to_directory, archive_file)
110 # logger.debug("Moving extracted files from %s to %s", source_path, destination_path)
111
112 if system.path_exists(destination_path):
113 logger.warning("Overwrite existing path %s", destination_path)
114 if os.path.isfile(destination_path):
115 os.remove(destination_path)
116 shutil.move(source_path, destination_path)
117 elif os.path.isdir(destination_path):
118 try:
119 system.merge_folders(source_path, destination_path)
120 except OSError as ex:
121 logger.error("Failed to merge to destination %s: %s", destination_path, ex)
122 raise ExtractFailure(str(ex))
123 else:
124 shutil.move(source_path, destination_path)
125 system.remove_folder(temp_dir)
126 logger.debug("Finished extracting %s to %s", path, to_directory)
127 return path, to_directory
128
129
130 def _do_extract(archive, dest, opener, mode=None, extractor=None):
131 if opener == "7zip":
132 extract_7zip(archive, dest, archive_type=extractor)
133 else:
134 handler = opener(archive, mode)
135 handler.extractall(dest)
136 handler.close()
137
138
139 def decompress_gz(file_path, dest_path=None):
140 """Decompress a gzip file."""
141 if dest_path:
142 dest_filename = os.path.join(dest_path, os.path.basename(file_path[:-3]))
143 else:
144 dest_filename = file_path[:-3]
145
146 gzipped_file = gzip.open(file_path, "rb")
147 file_content = gzipped_file.read()
148 gzipped_file.close()
149
150 dest_file = open(dest_filename, "wb")
151 dest_file.write(file_content)
152 dest_file.close()
153
154 return dest_path
155
156
157 def extract_7zip(path, dest, archive_type=None):
158 _7zip_path = os.path.join(settings.RUNTIME_DIR, "p7zip/7z")
159 if not system.path_exists(_7zip_path):
160 _7zip_path = system.find_executable("7z")
161 if not system.path_exists(_7zip_path):
162 raise OSError("7zip is not found in the lutris runtime or on the system")
163 command = [_7zip_path, "x", path, "-o{}".format(dest), "-aoa"]
164 if archive_type:
165 command.append("-t{}".format(archive_type))
166 subprocess.call(command)
167
[end of lutris/util/extract.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lutris/util/extract.py b/lutris/util/extract.py
--- a/lutris/util/extract.py
+++ b/lutris/util/extract.py
@@ -67,23 +67,42 @@
mode = None
logger.debug("Extracting %s to %s", path, to_directory)
- if path.endswith(".tar.gz") or path.endswith(".tgz") or extractor == "tgz":
+ if extractor is None:
+ if path.endswith(".tar.gz") or path.endswith(".tgz"):
+ extractor = "tgz"
+ elif path.endswith(".tar.xz") or path.endswith(".txz"):
+ extractor = "txz"
+ elif path.endswith(".tar"):
+ extractor = "tar"
+ elif path.endswith(".tar.bz2") or path.endswith(".tbz"):
+ extractor = "bz2"
+ elif path.endswith(".gz"):
+ extractor = "gzip"
+ elif is_7zip_supported(path, None):
+ extractor = None
+ else:
+ raise RuntimeError(
+ "Could not extract `%s` - no appropriate extractor found" % path
+ )
+
+ if extractor == "tgz":
opener, mode = tarfile.open, "r:gz"
- elif path.endswith(".tar.xz") or path.endswith(".txz") or extractor == "txz":
+ elif extractor == "txz":
opener, mode = tarfile.open, "r:xz"
- elif path.endswith(".tar") or extractor == "tar":
+ elif extractor == "tar":
opener, mode = tarfile.open, "r:"
- elif path.endswith(".gz") or extractor == "gzip":
+ elif extractor == "bz2":
+ opener, mode = tarfile.open, "r:bz2"
+ elif extractor == "gzip":
decompress_gz(path, to_directory)
return
- elif path.endswith(".tar.bz2") or path.endswith(".tbz") or extractor == "bz2":
- opener, mode = tarfile.open, "r:bz2"
- elif is_7zip_supported(path, extractor):
+ elif extractor is None or is_7zip_supported(path, extractor):
opener = "7zip"
else:
raise RuntimeError(
- "Could not extract `%s` as no appropriate extractor is found" % path
+ "Could not extract `%s` - unknown format specified" % path
)
+
temp_name = ".extract-" + str(uuid.uuid4())[:8]
temp_path = temp_dir = os.path.join(to_directory, temp_name)
try:
|
{"golden_diff": "diff --git a/lutris/util/extract.py b/lutris/util/extract.py\n--- a/lutris/util/extract.py\n+++ b/lutris/util/extract.py\n@@ -67,23 +67,42 @@\n mode = None\n logger.debug(\"Extracting %s to %s\", path, to_directory)\n \n- if path.endswith(\".tar.gz\") or path.endswith(\".tgz\") or extractor == \"tgz\":\n+ if extractor is None:\n+ if path.endswith(\".tar.gz\") or path.endswith(\".tgz\"):\n+ extractor = \"tgz\"\n+ elif path.endswith(\".tar.xz\") or path.endswith(\".txz\"):\n+ extractor = \"txz\"\n+ elif path.endswith(\".tar\"):\n+ extractor = \"tar\"\n+ elif path.endswith(\".tar.bz2\") or path.endswith(\".tbz\"):\n+ extractor = \"bz2\"\n+ elif path.endswith(\".gz\"):\n+ extractor = \"gzip\"\n+ elif is_7zip_supported(path, None):\n+ extractor = None\n+ else:\n+ raise RuntimeError(\n+ \"Could not extract `%s` - no appropriate extractor found\" % path\n+ )\n+\n+ if extractor == \"tgz\":\n opener, mode = tarfile.open, \"r:gz\"\n- elif path.endswith(\".tar.xz\") or path.endswith(\".txz\") or extractor == \"txz\":\n+ elif extractor == \"txz\":\n opener, mode = tarfile.open, \"r:xz\"\n- elif path.endswith(\".tar\") or extractor == \"tar\":\n+ elif extractor == \"tar\":\n opener, mode = tarfile.open, \"r:\"\n- elif path.endswith(\".gz\") or extractor == \"gzip\":\n+ elif extractor == \"bz2\":\n+ opener, mode = tarfile.open, \"r:bz2\"\n+ elif extractor == \"gzip\":\n decompress_gz(path, to_directory)\n return\n- elif path.endswith(\".tar.bz2\") or path.endswith(\".tbz\") or extractor == \"bz2\":\n- opener, mode = tarfile.open, \"r:bz2\"\n- elif is_7zip_supported(path, extractor):\n+ elif extractor is None or is_7zip_supported(path, extractor):\n opener = \"7zip\"\n else:\n raise RuntimeError(\n- \"Could not extract `%s` as no appropriate extractor is found\" % path\n+ \"Could not extract `%s` - unknown format specified\" % path\n )\n+\n temp_name = \".extract-\" + str(uuid.uuid4())[:8]\n temp_path = temp_dir = os.path.join(to_directory, temp_name)\n try:\n", "issue": "Lutris fails to open .tar.gz with \"not a gzip file\" if file is a tar file\nLutris fails to open archive where 7z doesn't. If I rename the file to `TTRLinux-v1.2.3.tar` Lutris can open and extract it. `format: tar` doesn't work here.\r\n\r\n```\r\nfiles:\r\n- client: https://download.toontownrewritten.com/launcher/linux/TTRLinux-v1.2.3.tar.gz\r\ngame:\r\n exe: Launcher\r\ninstaller:\r\n- extract:\r\n file: client\r\n format: tar\r\n```\r\n\r\n```\r\n2019-04-04 16:53:40,809: Downloading file 1 of 1\r\n2019-04-04 16:53:40,811: Downloading [client]: https://download.toontownrewritten.com/launcher/linux/TTRLinux-v1.2.3.tar.gz to /home/cxf/.cache/lutris/installer/toontown-rewritten/client/TTRLinux-v1.2.3.tar.gz\r\n2019-04-04 16:53:40,814: Downloading https://download.toontownrewritten.com/launcher/linux/TTRLinux-v1.2.3.tar.gz to /home/cxf/.cache/lutris/installer/toontown-rewritten/client/TTRLinux-v1.2.3.tar.gz\r\n2019-04-04 16:53:40,816: Starting download of:\r\n https://download.toontownrewritten.com/launcher/linux/TTRLinux-v1.2.3.tar.gz\r\n2019-04-04 16:53:44,410: Finished downloading https://download.toontownrewritten.com/launcher/linux/TTRLinux-v1.2.3.tar.gz\r\n2019-04-04 16:53:44,822: Installer command: {'extract': {'format': 'tar', 'file': 'client'}}\r\n2019-04-04 16:53:44,823: Extracting TTRLinux-v1.2.3.tar.gz\r\n2019-04-04 16:53:44,824: extracting file /home/cxf/.cache/lutris/installer/toontown-rewritten/client/TTRLinux-v1.2.3.tar.gz to /home/cxf/Games/toontown-rewritten\r\n2019-04-04 16:53:44,831: Extracting /home/cxf/.cache/lutris/installer/toontown-rewritten/client/TTRLinux-v1.2.3.tar.gz to /home/cxf/Games/toontown-rewritten\r\n2019-04-04 16:53:44,832: Extraction failed: not a gzip file\r\nTraceback (most recent call last):\r\n File \"/usr/lib/python3.6/tarfile.py\", line 1643, in gzopen\r\n t = cls.taropen(name, mode, fileobj, **kwargs)\r\n File \"/usr/lib/python3.6/tarfile.py\", line 1619, in taropen\r\n return cls(name, mode, fileobj, **kwargs)\r\n File \"/usr/lib/python3.6/tarfile.py\", line 1482, in __init__\r\n self.firstmember = self.next()\r\n File \"/usr/lib/python3.6/tarfile.py\", line 2297, in next\r\n tarinfo = self.tarinfo.fromtarfile(self)\r\n File \"/usr/lib/python3.6/tarfile.py\", line 1092, in fromtarfile\r\n buf = tarfile.fileobj.read(BLOCKSIZE)\r\n File \"/usr/lib/python3.6/gzip.py\", line 276, in read\r\n return self._buffer.read(size)\r\n File \"/usr/lib/python3.6/_compression.py\", line 68, in readinto\r\n data = self.read(len(byte_view))\r\n File \"/usr/lib/python3.6/gzip.py\", line 463, in read\r\n if not self._read_gzip_header():\r\n File \"/usr/lib/python3.6/gzip.py\", line 411, in _read_gzip_header\r\n raise OSError('Not a gzipped file (%r)' % magic)\r\nOSError: Not a gzipped file (b'To')\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/home/cxf/.lutris/lutris/util/extract.py\", line 90, in extract_archive\r\n _do_extract(path, temp_path, opener, mode, extractor)\r\n File \"/home/cxf/.lutris/lutris/util/extract.py\", line 134, in _do_extract\r\n handler = opener(archive, mode)\r\n File \"/usr/lib/python3.6/tarfile.py\", line 1589, in open\r\n return func(name, filemode, fileobj, **kwargs)\r\n File \"/usr/lib/python3.6/tarfile.py\", line 1647, in gzopen\r\n raise ReadError(\"not a gzip file\")\r\ntarfile.ReadError: not a gzip file\r\n2019-04-04 16:53:44,835: Error while completing task <bound method CommandsMixin.extract of <lutris.installer.interpreter.ScriptInterpreter object at 0x7f0507748c88>>: not a gzip file\r\n<class 'lutris.util.extract.ExtractFailure'> not a gzip file\r\n File \"/home/cxf/.lutris/lutris/util/jobs.py\", line 30, in target\r\n result = self.function(*args, **kwargs)\r\n File \"/home/cxf/.lutris/lutris/installer/commands.py\", line 180, in extract\r\n extract.extract_archive, filename, dest_path, merge_single, extractor\r\n File \"/home/cxf/.lutris/lutris/installer/commands.py\", line 527, in _killable_process\r\n result = result_obj.get() # Wait process end & reraise exceptions\r\n File \"/usr/lib/python3.6/multiprocessing/pool.py\", line 670, in get\r\n raise self._value\r\n2019-04-04 16:53:49,289: Install cancelled\r\n```\r\n\r\n```\r\ncxf@PC:~/Downloads$ 7z e TTRLinux-v1.2.3.tar.gz \r\n\r\n7-Zip [64] 16.02 : Copyright (c) 1999-2016 Igor Pavlov : 2016-05-21\r\np7zip Version 16.02 (locale=en_US.UTF-8,Utf16=on,HugeFiles=on,64 bits,4 CPUs Intel(R) Core(TM) i5-4460 CPU @ 3.20GHz (306C3),ASM,AES-NI)\r\n\r\nScanning the drive for archives:\r\n1 file, 37233152 bytes (36 MiB)\r\n\r\nExtracting archive: TTRLinux-v1.2.3.tar.gz\r\nWARNING:\r\nTTRLinux-v1.2.3.tar.gz\r\nCan not open the file as [gzip] archive\r\nThe file is open as [tar] archive\r\n\r\n--\r\nPath = TTRLinux-v1.2.3.tar.gz\r\nOpen WARNING: Can not open the file as [gzip] archive\r\nType = tar\r\nPhysical Size = 37233152\r\nHeaders Size = 2048\r\nCode Page = UTF-8\r\n\r\nEverything is Ok\r\n\r\nArchives with Warnings: 1\r\nFolders: 1\r\nFiles: 1\r\nSize: 37231062\r\nCompressed: 37233152\r\n```\r\n\n", "before_files": [{"content": "import os\nimport uuid\nimport shutil\nimport tarfile\nimport subprocess\nimport gzip\nimport zlib\nfrom lutris.util import system\nfrom lutris.util.log import logger\nfrom lutris import settings\n\n\nclass ExtractFailure(Exception):\n \"\"\"Exception raised when and archive fails to extract\"\"\"\n\n\ndef is_7zip_supported(path, extractor):\n supported_extractors = (\n \"7z\",\n \"xz\",\n \"bzip2\",\n \"gzip\",\n \"tar\",\n \"zip\",\n \"ar\",\n \"arj\",\n \"cab\",\n \"chm\",\n \"cpio\",\n \"cramfs\",\n \"dmg\",\n \"ext\",\n \"fat\",\n \"gpt\",\n \"hfs\",\n \"ihex\",\n \"iso\",\n \"lzh\",\n \"lzma\",\n \"mbr\",\n \"msi\",\n \"nsis\",\n \"ntfs\",\n \"qcow2\",\n \"rar\",\n \"rpm\",\n \"squashfs\",\n \"udf\",\n \"uefi\",\n \"vdi\",\n \"vhd\",\n \"vmdk\",\n \"wim\",\n \"xar\",\n \"z\",\n )\n if extractor:\n return extractor.lower() in supported_extractors\n _base, ext = os.path.splitext(path)\n if ext:\n ext = ext.lstrip(\".\").lower()\n return ext in supported_extractors\n\n\ndef extract_archive(path, to_directory=\".\", merge_single=True, extractor=None):\n path = os.path.abspath(path)\n mode = None\n logger.debug(\"Extracting %s to %s\", path, to_directory)\n\n if path.endswith(\".tar.gz\") or path.endswith(\".tgz\") or extractor == \"tgz\":\n opener, mode = tarfile.open, \"r:gz\"\n elif path.endswith(\".tar.xz\") or path.endswith(\".txz\") or extractor == \"txz\":\n opener, mode = tarfile.open, \"r:xz\"\n elif path.endswith(\".tar\") or extractor == \"tar\":\n opener, mode = tarfile.open, \"r:\"\n elif path.endswith(\".gz\") or extractor == \"gzip\":\n decompress_gz(path, to_directory)\n return\n elif path.endswith(\".tar.bz2\") or path.endswith(\".tbz\") or extractor == \"bz2\":\n opener, mode = tarfile.open, \"r:bz2\"\n elif is_7zip_supported(path, extractor):\n opener = \"7zip\"\n else:\n raise RuntimeError(\n \"Could not extract `%s` as no appropriate extractor is found\" % path\n )\n temp_name = \".extract-\" + str(uuid.uuid4())[:8]\n temp_path = temp_dir = os.path.join(to_directory, temp_name)\n try:\n _do_extract(path, temp_path, opener, mode, extractor)\n except (OSError, zlib.error, tarfile.ReadError) as ex:\n logger.exception(\"Extraction failed: %s\", ex)\n raise ExtractFailure(str(ex))\n if merge_single:\n extracted = os.listdir(temp_path)\n if len(extracted) == 1:\n temp_path = os.path.join(temp_path, extracted[0])\n\n if os.path.isfile(temp_path):\n destination_path = os.path.join(to_directory, extracted[0])\n if os.path.isfile(destination_path):\n logger.warning(\"Overwrite existing file %s\", destination_path)\n os.remove(destination_path)\n shutil.move(temp_path, to_directory)\n os.removedirs(temp_dir)\n else:\n for archive_file in os.listdir(temp_path):\n source_path = os.path.join(temp_path, archive_file)\n destination_path = os.path.join(to_directory, archive_file)\n # logger.debug(\"Moving extracted files from %s to %s\", source_path, destination_path)\n\n if system.path_exists(destination_path):\n logger.warning(\"Overwrite existing path %s\", destination_path)\n if os.path.isfile(destination_path):\n os.remove(destination_path)\n shutil.move(source_path, destination_path)\n elif os.path.isdir(destination_path):\n try:\n system.merge_folders(source_path, destination_path)\n except OSError as ex:\n logger.error(\"Failed to merge to destination %s: %s\", destination_path, ex)\n raise ExtractFailure(str(ex))\n else:\n shutil.move(source_path, destination_path)\n system.remove_folder(temp_dir)\n logger.debug(\"Finished extracting %s to %s\", path, to_directory)\n return path, to_directory\n\n\ndef _do_extract(archive, dest, opener, mode=None, extractor=None):\n if opener == \"7zip\":\n extract_7zip(archive, dest, archive_type=extractor)\n else:\n handler = opener(archive, mode)\n handler.extractall(dest)\n handler.close()\n\n\ndef decompress_gz(file_path, dest_path=None):\n \"\"\"Decompress a gzip file.\"\"\"\n if dest_path:\n dest_filename = os.path.join(dest_path, os.path.basename(file_path[:-3]))\n else:\n dest_filename = file_path[:-3]\n\n gzipped_file = gzip.open(file_path, \"rb\")\n file_content = gzipped_file.read()\n gzipped_file.close()\n\n dest_file = open(dest_filename, \"wb\")\n dest_file.write(file_content)\n dest_file.close()\n\n return dest_path\n\n\ndef extract_7zip(path, dest, archive_type=None):\n _7zip_path = os.path.join(settings.RUNTIME_DIR, \"p7zip/7z\")\n if not system.path_exists(_7zip_path):\n _7zip_path = system.find_executable(\"7z\")\n if not system.path_exists(_7zip_path):\n raise OSError(\"7zip is not found in the lutris runtime or on the system\")\n command = [_7zip_path, \"x\", path, \"-o{}\".format(dest), \"-aoa\"]\n if archive_type:\n command.append(\"-t{}\".format(archive_type))\n subprocess.call(command)\n", "path": "lutris/util/extract.py"}]}
| 4,006 | 580 |
gh_patches_debug_978
|
rasdani/github-patches
|
git_diff
|
pwr-Solaar__Solaar-2003
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Solaar exits with RC 1 when terminated
**Information**
<!-- Make sure that your issue is not one of the known issues in the Solaar documentation at https://pwr-solaar.github.io/Solaar/ -->
<!-- Do not bother opening an issue for a version older than 1.1.0. Upgrade to the latest version and see if your issue persists. -->
<!-- If you not running the current version of Solaar, strongly consider upgrading to the newest version. -->
- Solaar version (`solaar --version` or `git describe --tags` if cloned from this repository): solaar 1.1.8+dfsg-2
- Distribution: Debian testing
- Kernel version (ex. `uname -srmo`): `Linux 6.1.0-3-amd64 x86_64 GNU/Linux`
- Output of `solaar show`:
<details>
```
```
</details>
- Contents of `~/.config/solaar/config.yaml` (or `~/.config/solaar/config.json` if `~/.config/solaar/config.yaml` not present):
<details>
```
CONTENTS HERE
```
</details>
- Errors or warrnings from Solaar:
<!-- Under normal operation Solaar keeps a log of warning and error messages in ~/.tmp
while it is running as a file starting with 'Solaar'.
If this file is not available or does not have useful information you can
run Solaar as `solaar -dd`, after killing any running Solaar processes to
have Solaar log informational, warning, and error messages to stdout. -->
**Describe the bug**
When terminated, solaar exits with RC 1. This results in a failed unit if systemd is managing XDG autostart. No log warnings or stderr messages produced.
**To Reproduce**
Steps to reproduce the behavior:
1. run `solaar ; echo $?`
2. run `killall solaar`
3. see rc 1 printed
Workaround:
```
cat << EOF > ~/.config/systemd/user/[email protected]/exit-tweak.conf
[Service]
SuccessExitStatus=0 1
EOF
systemctl --user daemon-reload
```
</issue>
<code>
[start of lib/solaar/gtk.py]
1 #!/usr/bin/env python3
2 # -*- python-mode -*-
3 # -*- coding: UTF-8 -*-
4
5 ## Copyright (C) 2012-2013 Daniel Pavel
6 ##
7 ## This program is free software; you can redistribute it and/or modify
8 ## it under the terms of the GNU General Public License as published by
9 ## the Free Software Foundation; either version 2 of the License, or
10 ## (at your option) any later version.
11 ##
12 ## This program is distributed in the hope that it will be useful,
13 ## but WITHOUT ANY WARRANTY; without even the implied warranty of
14 ## MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
15 ## GNU General Public License for more details.
16 ##
17 ## You should have received a copy of the GNU General Public License along
18 ## with this program; if not, write to the Free Software Foundation, Inc.,
19 ## 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
20
21 import importlib
22 import logging
23 import os.path
24 import signal
25 import sys
26 import tempfile
27
28 from logging import INFO as _INFO
29 from logging import WARNING as _WARNING
30
31 import solaar.cli as _cli
32 import solaar.i18n as _i18n
33
34 from solaar import NAME, __version__
35
36 _log = logging.getLogger(__name__)
37
38 #
39 #
40 #
41
42
43 def _require(module, os_package, gi=None, gi_package=None, gi_version=None):
44 try:
45 if gi is not None:
46 gi.require_version(gi_package, gi_version)
47 return importlib.import_module(module)
48 except (ImportError, ValueError):
49 sys.exit('%s: missing required system package %s' % (NAME, os_package))
50
51
52 battery_icons_style = 'regular'
53 temp = tempfile.NamedTemporaryFile(prefix='Solaar_', mode='w', delete=True)
54
55
56 def _parse_arguments():
57 import argparse
58 arg_parser = argparse.ArgumentParser(
59 prog=NAME.lower(), epilog='For more information see https://pwr-solaar.github.io/Solaar'
60 )
61 arg_parser.add_argument(
62 '-d',
63 '--debug',
64 action='count',
65 default=0,
66 help='print logging messages, for debugging purposes (may be repeated for extra verbosity)'
67 )
68 arg_parser.add_argument(
69 '-D',
70 '--hidraw',
71 action='store',
72 dest='hidraw_path',
73 metavar='PATH',
74 help='unifying receiver to use; the first detected receiver if unspecified. Example: /dev/hidraw2'
75 )
76 arg_parser.add_argument('--restart-on-wake-up', action='store_true', help='restart Solaar on sleep wake-up (experimental)')
77 arg_parser.add_argument(
78 '-w', '--window', choices=('show', 'hide', 'only'), help='start with window showing / hidden / only (no tray icon)'
79 )
80 arg_parser.add_argument(
81 '-b',
82 '--battery-icons',
83 choices=('regular', 'symbolic', 'solaar'),
84 help='prefer regular battery / symbolic battery / solaar icons'
85 )
86 arg_parser.add_argument('--tray-icon-size', type=int, help='explicit size for tray icons')
87 arg_parser.add_argument('-V', '--version', action='version', version='%(prog)s ' + __version__)
88 arg_parser.add_argument('--help-actions', action='store_true', help='print help for the optional actions')
89 arg_parser.add_argument('action', nargs=argparse.REMAINDER, choices=_cli.actions, help='optional actions to perform')
90
91 args = arg_parser.parse_args()
92
93 if args.help_actions:
94 _cli.print_help()
95 return
96
97 if args.window is None:
98 args.window = 'show' # default behaviour is to show main window
99
100 global battery_icons_style
101 battery_icons_style = args.battery_icons if args.battery_icons is not None else 'regular'
102 global tray_icon_size
103 tray_icon_size = args.tray_icon_size
104
105 log_format = '%(asctime)s,%(msecs)03d %(levelname)8s [%(threadName)s] %(name)s: %(message)s'
106 log_level = logging.ERROR - 10 * args.debug
107 logging.getLogger('').setLevel(min(log_level, logging.WARNING))
108 file_handler = logging.StreamHandler(temp)
109 file_handler.setLevel(max(min(log_level, logging.WARNING), logging.INFO))
110 file_handler.setFormatter(logging.Formatter(log_format))
111 logging.getLogger('').addHandler(file_handler)
112 if args.debug > 0:
113 stream_handler = logging.StreamHandler()
114 stream_handler.setFormatter(logging.Formatter(log_format))
115 stream_handler.setLevel(log_level)
116 logging.getLogger('').addHandler(stream_handler)
117
118 if not args.action:
119 if _log.isEnabledFor(logging.INFO):
120 logging.info('language %s (%s), translations path %s', _i18n.language, _i18n.encoding, _i18n.path)
121
122 return args
123
124
125 # On first SIGINT, dump threads to stderr; on second, exit
126 def _handlesig(signl, stack):
127 import faulthandler
128 signal.signal(signal.SIGINT, signal.SIG_DFL)
129 signal.signal(signal.SIGTERM, signal.SIG_DFL)
130
131 if signl == int(signal.SIGINT):
132 if _log.isEnabledFor(_INFO):
133 faulthandler.dump_traceback()
134 sys.exit('%s: exit due to keyboard interrupt' % (NAME.lower()))
135 else:
136 sys.exit('')
137
138
139 def main():
140 _require('pyudev', 'python3-pyudev')
141
142 args = _parse_arguments()
143 if not args:
144 return
145 if args.action:
146 # if any argument, run comandline and exit
147 return _cli.run(args.action, args.hidraw_path)
148
149 gi = _require('gi', 'python3-gi (in Ubuntu) or python3-gobject (in Fedora)')
150 _require('gi.repository.Gtk', 'gir1.2-gtk-3.0', gi, 'Gtk', '3.0')
151
152 # handle ^C in console
153 signal.signal(signal.SIGINT, signal.SIG_DFL)
154 signal.signal(signal.SIGINT, _handlesig)
155 signal.signal(signal.SIGTERM, _handlesig)
156
157 udev_file = '42-logitech-unify-permissions.rules'
158 if _log.isEnabledFor(_WARNING) \
159 and not os.path.isfile('/etc/udev/rules.d/' + udev_file) \
160 and not os.path.isfile('/usr/lib/udev/rules.d/' + udev_file) \
161 and not os.path.isfile('/usr/local/lib/udev/rules.d/' + udev_file):
162 _log.warning('Solaar udev file not found in expected location')
163 _log.warning('See https://pwr-solaar.github.io/Solaar/installation for more information')
164 try:
165 import solaar.listener as listener
166 import solaar.ui as ui
167
168 listener.setup_scanner(ui.status_changed, ui.error_dialog)
169
170 import solaar.upower as _upower
171 if args.restart_on_wake_up:
172 _upower.watch(listener.start_all, listener.stop_all)
173 else:
174 _upower.watch(lambda: listener.ping_all(True))
175
176 import solaar.configuration as _configuration
177 _configuration.defer_saves = True # allow configuration saves to be deferred
178
179 # main UI event loop
180 ui.run_loop(listener.start_all, listener.stop_all, args.window != 'only', args.window != 'hide')
181 except Exception:
182 from traceback import format_exc
183 sys.exit('%s: error: %s' % (NAME.lower(), format_exc()))
184
185 temp.close()
186
187
188 if __name__ == '__main__':
189 main()
190
[end of lib/solaar/gtk.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lib/solaar/gtk.py b/lib/solaar/gtk.py
--- a/lib/solaar/gtk.py
+++ b/lib/solaar/gtk.py
@@ -133,7 +133,7 @@
faulthandler.dump_traceback()
sys.exit('%s: exit due to keyboard interrupt' % (NAME.lower()))
else:
- sys.exit('')
+ sys.exit(0)
def main():
|
{"golden_diff": "diff --git a/lib/solaar/gtk.py b/lib/solaar/gtk.py\n--- a/lib/solaar/gtk.py\n+++ b/lib/solaar/gtk.py\n@@ -133,7 +133,7 @@\n faulthandler.dump_traceback()\n sys.exit('%s: exit due to keyboard interrupt' % (NAME.lower()))\n else:\n- sys.exit('')\n+ sys.exit(0)\n \n \n def main():\n", "issue": "Solaar exits with RC 1 when terminated\n**Information**\r\n<!-- Make sure that your issue is not one of the known issues in the Solaar documentation at https://pwr-solaar.github.io/Solaar/ -->\r\n<!-- Do not bother opening an issue for a version older than 1.1.0. Upgrade to the latest version and see if your issue persists. -->\r\n<!-- If you not running the current version of Solaar, strongly consider upgrading to the newest version. -->\r\n- Solaar version (`solaar --version` or `git describe --tags` if cloned from this repository): solaar 1.1.8+dfsg-2\r\n- Distribution: Debian testing\r\n- Kernel version (ex. `uname -srmo`): `Linux 6.1.0-3-amd64 x86_64 GNU/Linux`\r\n- Output of `solaar show`: \r\n\r\n<details>\r\n\r\n```\r\n\r\n```\r\n</details>\r\n\r\n- Contents of `~/.config/solaar/config.yaml` (or `~/.config/solaar/config.json` if `~/.config/solaar/config.yaml` not present):\r\n\r\n<details>\r\n\r\n```\r\nCONTENTS HERE\r\n```\r\n</details>\r\n\r\n\r\n- Errors or warrnings from Solaar:\r\n<!-- Under normal operation Solaar keeps a log of warning and error messages in ~/.tmp\r\nwhile it is running as a file starting with 'Solaar'.\r\nIf this file is not available or does not have useful information you can\r\nrun Solaar as `solaar -dd`, after killing any running Solaar processes to\r\nhave Solaar log informational, warning, and error messages to stdout. -->\r\n\r\n\r\n**Describe the bug**\r\nWhen terminated, solaar exits with RC 1. This results in a failed unit if systemd is managing XDG autostart. No log warnings or stderr messages produced.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior: \r\n1. run `solaar ; echo $?`\r\n2. run `killall solaar`\r\n3. see rc 1 printed\r\n\r\nWorkaround:\r\n```\r\ncat << EOF > ~/.config/systemd/user/[email protected]/exit-tweak.conf \r\n[Service]\r\nSuccessExitStatus=0 1\r\nEOF\r\nsystemctl --user daemon-reload\r\n```\n", "before_files": [{"content": "#!/usr/bin/env python3\n# -*- python-mode -*-\n# -*- coding: UTF-8 -*-\n\n## Copyright (C) 2012-2013 Daniel Pavel\n##\n## This program is free software; you can redistribute it and/or modify\n## it under the terms of the GNU General Public License as published by\n## the Free Software Foundation; either version 2 of the License, or\n## (at your option) any later version.\n##\n## This program is distributed in the hope that it will be useful,\n## but WITHOUT ANY WARRANTY; without even the implied warranty of\n## MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n## GNU General Public License for more details.\n##\n## You should have received a copy of the GNU General Public License along\n## with this program; if not, write to the Free Software Foundation, Inc.,\n## 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n\nimport importlib\nimport logging\nimport os.path\nimport signal\nimport sys\nimport tempfile\n\nfrom logging import INFO as _INFO\nfrom logging import WARNING as _WARNING\n\nimport solaar.cli as _cli\nimport solaar.i18n as _i18n\n\nfrom solaar import NAME, __version__\n\n_log = logging.getLogger(__name__)\n\n#\n#\n#\n\n\ndef _require(module, os_package, gi=None, gi_package=None, gi_version=None):\n try:\n if gi is not None:\n gi.require_version(gi_package, gi_version)\n return importlib.import_module(module)\n except (ImportError, ValueError):\n sys.exit('%s: missing required system package %s' % (NAME, os_package))\n\n\nbattery_icons_style = 'regular'\ntemp = tempfile.NamedTemporaryFile(prefix='Solaar_', mode='w', delete=True)\n\n\ndef _parse_arguments():\n import argparse\n arg_parser = argparse.ArgumentParser(\n prog=NAME.lower(), epilog='For more information see https://pwr-solaar.github.io/Solaar'\n )\n arg_parser.add_argument(\n '-d',\n '--debug',\n action='count',\n default=0,\n help='print logging messages, for debugging purposes (may be repeated for extra verbosity)'\n )\n arg_parser.add_argument(\n '-D',\n '--hidraw',\n action='store',\n dest='hidraw_path',\n metavar='PATH',\n help='unifying receiver to use; the first detected receiver if unspecified. Example: /dev/hidraw2'\n )\n arg_parser.add_argument('--restart-on-wake-up', action='store_true', help='restart Solaar on sleep wake-up (experimental)')\n arg_parser.add_argument(\n '-w', '--window', choices=('show', 'hide', 'only'), help='start with window showing / hidden / only (no tray icon)'\n )\n arg_parser.add_argument(\n '-b',\n '--battery-icons',\n choices=('regular', 'symbolic', 'solaar'),\n help='prefer regular battery / symbolic battery / solaar icons'\n )\n arg_parser.add_argument('--tray-icon-size', type=int, help='explicit size for tray icons')\n arg_parser.add_argument('-V', '--version', action='version', version='%(prog)s ' + __version__)\n arg_parser.add_argument('--help-actions', action='store_true', help='print help for the optional actions')\n arg_parser.add_argument('action', nargs=argparse.REMAINDER, choices=_cli.actions, help='optional actions to perform')\n\n args = arg_parser.parse_args()\n\n if args.help_actions:\n _cli.print_help()\n return\n\n if args.window is None:\n args.window = 'show' # default behaviour is to show main window\n\n global battery_icons_style\n battery_icons_style = args.battery_icons if args.battery_icons is not None else 'regular'\n global tray_icon_size\n tray_icon_size = args.tray_icon_size\n\n log_format = '%(asctime)s,%(msecs)03d %(levelname)8s [%(threadName)s] %(name)s: %(message)s'\n log_level = logging.ERROR - 10 * args.debug\n logging.getLogger('').setLevel(min(log_level, logging.WARNING))\n file_handler = logging.StreamHandler(temp)\n file_handler.setLevel(max(min(log_level, logging.WARNING), logging.INFO))\n file_handler.setFormatter(logging.Formatter(log_format))\n logging.getLogger('').addHandler(file_handler)\n if args.debug > 0:\n stream_handler = logging.StreamHandler()\n stream_handler.setFormatter(logging.Formatter(log_format))\n stream_handler.setLevel(log_level)\n logging.getLogger('').addHandler(stream_handler)\n\n if not args.action:\n if _log.isEnabledFor(logging.INFO):\n logging.info('language %s (%s), translations path %s', _i18n.language, _i18n.encoding, _i18n.path)\n\n return args\n\n\n# On first SIGINT, dump threads to stderr; on second, exit\ndef _handlesig(signl, stack):\n import faulthandler\n signal.signal(signal.SIGINT, signal.SIG_DFL)\n signal.signal(signal.SIGTERM, signal.SIG_DFL)\n\n if signl == int(signal.SIGINT):\n if _log.isEnabledFor(_INFO):\n faulthandler.dump_traceback()\n sys.exit('%s: exit due to keyboard interrupt' % (NAME.lower()))\n else:\n sys.exit('')\n\n\ndef main():\n _require('pyudev', 'python3-pyudev')\n\n args = _parse_arguments()\n if not args:\n return\n if args.action:\n # if any argument, run comandline and exit\n return _cli.run(args.action, args.hidraw_path)\n\n gi = _require('gi', 'python3-gi (in Ubuntu) or python3-gobject (in Fedora)')\n _require('gi.repository.Gtk', 'gir1.2-gtk-3.0', gi, 'Gtk', '3.0')\n\n # handle ^C in console\n signal.signal(signal.SIGINT, signal.SIG_DFL)\n signal.signal(signal.SIGINT, _handlesig)\n signal.signal(signal.SIGTERM, _handlesig)\n\n udev_file = '42-logitech-unify-permissions.rules'\n if _log.isEnabledFor(_WARNING) \\\n and not os.path.isfile('/etc/udev/rules.d/' + udev_file) \\\n and not os.path.isfile('/usr/lib/udev/rules.d/' + udev_file) \\\n and not os.path.isfile('/usr/local/lib/udev/rules.d/' + udev_file):\n _log.warning('Solaar udev file not found in expected location')\n _log.warning('See https://pwr-solaar.github.io/Solaar/installation for more information')\n try:\n import solaar.listener as listener\n import solaar.ui as ui\n\n listener.setup_scanner(ui.status_changed, ui.error_dialog)\n\n import solaar.upower as _upower\n if args.restart_on_wake_up:\n _upower.watch(listener.start_all, listener.stop_all)\n else:\n _upower.watch(lambda: listener.ping_all(True))\n\n import solaar.configuration as _configuration\n _configuration.defer_saves = True # allow configuration saves to be deferred\n\n # main UI event loop\n ui.run_loop(listener.start_all, listener.stop_all, args.window != 'only', args.window != 'hide')\n except Exception:\n from traceback import format_exc\n sys.exit('%s: error: %s' % (NAME.lower(), format_exc()))\n\n temp.close()\n\n\nif __name__ == '__main__':\n main()\n", "path": "lib/solaar/gtk.py"}]}
| 3,145 | 99 |
gh_patches_debug_42690
|
rasdani/github-patches
|
git_diff
|
openai__gym-2070
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
flattened point dtype does not match flattened space dtype
Originally found this by using the FlattenObservationWrapper and seeing that my flattened space yielded different precision points than the original space. This is a bug that actually originates from the `spaces.utils.flatten_space` function and is caused by some missing dtype arguments.
Simplified examples of the bug:
```
from gym.spaces import utils
from gym.spaces import MultiDiscrete, MultiBinary
original_space = MultiDiscrete([2, 2, 100])
flattened_space = utils.flatten_space(original_space)
original_sample = original_space.sample()
flattened_sample = utils.flatten(original_space, original_sample)
assert flattened_space.dtype == flattened_sample.dtype
```
</issue>
<code>
[start of gym/spaces/utils.py]
1 from collections import OrderedDict
2 import numpy as np
3
4 from gym.spaces import Box
5 from gym.spaces import Discrete
6 from gym.spaces import MultiDiscrete
7 from gym.spaces import MultiBinary
8 from gym.spaces import Tuple
9 from gym.spaces import Dict
10
11
12 def flatdim(space):
13 """Return the number of dimensions a flattened equivalent of this space
14 would have.
15
16 Accepts a space and returns an integer. Raises ``NotImplementedError`` if
17 the space is not defined in ``gym.spaces``.
18 """
19 if isinstance(space, Box):
20 return int(np.prod(space.shape))
21 elif isinstance(space, Discrete):
22 return int(space.n)
23 elif isinstance(space, Tuple):
24 return int(sum([flatdim(s) for s in space.spaces]))
25 elif isinstance(space, Dict):
26 return int(sum([flatdim(s) for s in space.spaces.values()]))
27 elif isinstance(space, MultiBinary):
28 return int(space.n)
29 elif isinstance(space, MultiDiscrete):
30 return int(np.prod(space.shape))
31 else:
32 raise NotImplementedError
33
34
35 def flatten(space, x):
36 """Flatten a data point from a space.
37
38 This is useful when e.g. points from spaces must be passed to a neural
39 network, which only understands flat arrays of floats.
40
41 Accepts a space and a point from that space. Always returns a 1D array.
42 Raises ``NotImplementedError`` if the space is not defined in
43 ``gym.spaces``.
44 """
45 if isinstance(space, Box):
46 return np.asarray(x, dtype=np.float32).flatten()
47 elif isinstance(space, Discrete):
48 onehot = np.zeros(space.n, dtype=np.float32)
49 onehot[x] = 1.0
50 return onehot
51 elif isinstance(space, Tuple):
52 return np.concatenate(
53 [flatten(s, x_part) for x_part, s in zip(x, space.spaces)])
54 elif isinstance(space, Dict):
55 return np.concatenate(
56 [flatten(s, x[key]) for key, s in space.spaces.items()])
57 elif isinstance(space, MultiBinary):
58 return np.asarray(x).flatten()
59 elif isinstance(space, MultiDiscrete):
60 return np.asarray(x).flatten()
61 else:
62 raise NotImplementedError
63
64
65 def unflatten(space, x):
66 """Unflatten a data point from a space.
67
68 This reverses the transformation applied by ``flatten()``. You must ensure
69 that the ``space`` argument is the same as for the ``flatten()`` call.
70
71 Accepts a space and a flattened point. Returns a point with a structure
72 that matches the space. Raises ``NotImplementedError`` if the space is not
73 defined in ``gym.spaces``.
74 """
75 if isinstance(space, Box):
76 return np.asarray(x, dtype=np.float32).reshape(space.shape)
77 elif isinstance(space, Discrete):
78 return int(np.nonzero(x)[0][0])
79 elif isinstance(space, Tuple):
80 dims = [flatdim(s) for s in space.spaces]
81 list_flattened = np.split(x, np.cumsum(dims)[:-1])
82 list_unflattened = [
83 unflatten(s, flattened)
84 for flattened, s in zip(list_flattened, space.spaces)
85 ]
86 return tuple(list_unflattened)
87 elif isinstance(space, Dict):
88 dims = [flatdim(s) for s in space.spaces.values()]
89 list_flattened = np.split(x, np.cumsum(dims)[:-1])
90 list_unflattened = [
91 (key, unflatten(s, flattened))
92 for flattened, (key,
93 s) in zip(list_flattened, space.spaces.items())
94 ]
95 return OrderedDict(list_unflattened)
96 elif isinstance(space, MultiBinary):
97 return np.asarray(x).reshape(space.shape)
98 elif isinstance(space, MultiDiscrete):
99 return np.asarray(x).reshape(space.shape)
100 else:
101 raise NotImplementedError
102
103
104 def flatten_space(space):
105 """Flatten a space into a single ``Box``.
106
107 This is equivalent to ``flatten()``, but operates on the space itself. The
108 result always is a `Box` with flat boundaries. The box has exactly
109 ``flatdim(space)`` dimensions. Flattening a sample of the original space
110 has the same effect as taking a sample of the flattenend space.
111
112 Raises ``NotImplementedError`` if the space is not defined in
113 ``gym.spaces``.
114
115 Example::
116
117 >>> box = Box(0.0, 1.0, shape=(3, 4, 5))
118 >>> box
119 Box(3, 4, 5)
120 >>> flatten_space(box)
121 Box(60,)
122 >>> flatten(box, box.sample()) in flatten_space(box)
123 True
124
125 Example that flattens a discrete space::
126
127 >>> discrete = Discrete(5)
128 >>> flatten_space(discrete)
129 Box(5,)
130 >>> flatten(box, box.sample()) in flatten_space(box)
131 True
132
133 Example that recursively flattens a dict::
134
135 >>> space = Dict({"position": Discrete(2),
136 ... "velocity": Box(0, 1, shape=(2, 2))})
137 >>> flatten_space(space)
138 Box(6,)
139 >>> flatten(space, space.sample()) in flatten_space(space)
140 True
141 """
142 if isinstance(space, Box):
143 return Box(space.low.flatten(), space.high.flatten())
144 if isinstance(space, Discrete):
145 return Box(low=0, high=1, shape=(space.n, ))
146 if isinstance(space, Tuple):
147 space = [flatten_space(s) for s in space.spaces]
148 return Box(
149 low=np.concatenate([s.low for s in space]),
150 high=np.concatenate([s.high for s in space]),
151 )
152 if isinstance(space, Dict):
153 space = [flatten_space(s) for s in space.spaces.values()]
154 return Box(
155 low=np.concatenate([s.low for s in space]),
156 high=np.concatenate([s.high for s in space]),
157 )
158 if isinstance(space, MultiBinary):
159 return Box(low=0, high=1, shape=(space.n, ))
160 if isinstance(space, MultiDiscrete):
161 return Box(
162 low=np.zeros_like(space.nvec),
163 high=space.nvec,
164 )
165 raise NotImplementedError
166
[end of gym/spaces/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/gym/spaces/utils.py b/gym/spaces/utils.py
--- a/gym/spaces/utils.py
+++ b/gym/spaces/utils.py
@@ -43,10 +43,10 @@
``gym.spaces``.
"""
if isinstance(space, Box):
- return np.asarray(x, dtype=np.float32).flatten()
+ return np.asarray(x, dtype=space.dtype).flatten()
elif isinstance(space, Discrete):
- onehot = np.zeros(space.n, dtype=np.float32)
- onehot[x] = 1.0
+ onehot = np.zeros(space.n, dtype=space.dtype)
+ onehot[x] = 1
return onehot
elif isinstance(space, Tuple):
return np.concatenate(
@@ -55,9 +55,9 @@
return np.concatenate(
[flatten(s, x[key]) for key, s in space.spaces.items()])
elif isinstance(space, MultiBinary):
- return np.asarray(x).flatten()
+ return np.asarray(x, dtype=space.dtype).flatten()
elif isinstance(space, MultiDiscrete):
- return np.asarray(x).flatten()
+ return np.asarray(x, dtype=space.dtype).flatten()
else:
raise NotImplementedError
@@ -73,7 +73,7 @@
defined in ``gym.spaces``.
"""
if isinstance(space, Box):
- return np.asarray(x, dtype=np.float32).reshape(space.shape)
+ return np.asarray(x, dtype=space.dtype).reshape(space.shape)
elif isinstance(space, Discrete):
return int(np.nonzero(x)[0][0])
elif isinstance(space, Tuple):
@@ -94,9 +94,9 @@
]
return OrderedDict(list_unflattened)
elif isinstance(space, MultiBinary):
- return np.asarray(x).reshape(space.shape)
+ return np.asarray(x, dtype=space.dtype).reshape(space.shape)
elif isinstance(space, MultiDiscrete):
- return np.asarray(x).reshape(space.shape)
+ return np.asarray(x, dtype=space.dtype).reshape(space.shape)
else:
raise NotImplementedError
@@ -140,26 +140,33 @@
True
"""
if isinstance(space, Box):
- return Box(space.low.flatten(), space.high.flatten())
+ return Box(space.low.flatten(), space.high.flatten(), dtype=space.dtype)
if isinstance(space, Discrete):
- return Box(low=0, high=1, shape=(space.n, ))
+ return Box(low=0, high=1, shape=(space.n, ), dtype=space.dtype)
if isinstance(space, Tuple):
space = [flatten_space(s) for s in space.spaces]
return Box(
low=np.concatenate([s.low for s in space]),
high=np.concatenate([s.high for s in space]),
+ dtype=np.result_type(*[s.dtype for s in space])
)
if isinstance(space, Dict):
space = [flatten_space(s) for s in space.spaces.values()]
return Box(
low=np.concatenate([s.low for s in space]),
high=np.concatenate([s.high for s in space]),
+ dtype=np.result_type(*[s.dtype for s in space])
)
if isinstance(space, MultiBinary):
- return Box(low=0, high=1, shape=(space.n, ))
+ return Box(low=0,
+ high=1,
+ shape=(space.n, ),
+ dtype=space.dtype
+ )
if isinstance(space, MultiDiscrete):
return Box(
low=np.zeros_like(space.nvec),
high=space.nvec,
+ dtype=space.dtype
)
raise NotImplementedError
|
{"golden_diff": "diff --git a/gym/spaces/utils.py b/gym/spaces/utils.py\n--- a/gym/spaces/utils.py\n+++ b/gym/spaces/utils.py\n@@ -43,10 +43,10 @@\n ``gym.spaces``.\n \"\"\"\n if isinstance(space, Box):\n- return np.asarray(x, dtype=np.float32).flatten()\n+ return np.asarray(x, dtype=space.dtype).flatten()\n elif isinstance(space, Discrete):\n- onehot = np.zeros(space.n, dtype=np.float32)\n- onehot[x] = 1.0\n+ onehot = np.zeros(space.n, dtype=space.dtype)\n+ onehot[x] = 1\n return onehot\n elif isinstance(space, Tuple):\n return np.concatenate(\n@@ -55,9 +55,9 @@\n return np.concatenate(\n [flatten(s, x[key]) for key, s in space.spaces.items()])\n elif isinstance(space, MultiBinary):\n- return np.asarray(x).flatten()\n+ return np.asarray(x, dtype=space.dtype).flatten()\n elif isinstance(space, MultiDiscrete):\n- return np.asarray(x).flatten()\n+ return np.asarray(x, dtype=space.dtype).flatten()\n else:\n raise NotImplementedError\n \n@@ -73,7 +73,7 @@\n defined in ``gym.spaces``.\n \"\"\"\n if isinstance(space, Box):\n- return np.asarray(x, dtype=np.float32).reshape(space.shape)\n+ return np.asarray(x, dtype=space.dtype).reshape(space.shape)\n elif isinstance(space, Discrete):\n return int(np.nonzero(x)[0][0])\n elif isinstance(space, Tuple):\n@@ -94,9 +94,9 @@\n ]\n return OrderedDict(list_unflattened)\n elif isinstance(space, MultiBinary):\n- return np.asarray(x).reshape(space.shape)\n+ return np.asarray(x, dtype=space.dtype).reshape(space.shape)\n elif isinstance(space, MultiDiscrete):\n- return np.asarray(x).reshape(space.shape)\n+ return np.asarray(x, dtype=space.dtype).reshape(space.shape)\n else:\n raise NotImplementedError\n \n@@ -140,26 +140,33 @@\n True\n \"\"\"\n if isinstance(space, Box):\n- return Box(space.low.flatten(), space.high.flatten())\n+ return Box(space.low.flatten(), space.high.flatten(), dtype=space.dtype)\n if isinstance(space, Discrete):\n- return Box(low=0, high=1, shape=(space.n, ))\n+ return Box(low=0, high=1, shape=(space.n, ), dtype=space.dtype)\n if isinstance(space, Tuple):\n space = [flatten_space(s) for s in space.spaces]\n return Box(\n low=np.concatenate([s.low for s in space]),\n high=np.concatenate([s.high for s in space]),\n+ dtype=np.result_type(*[s.dtype for s in space])\n )\n if isinstance(space, Dict):\n space = [flatten_space(s) for s in space.spaces.values()]\n return Box(\n low=np.concatenate([s.low for s in space]),\n high=np.concatenate([s.high for s in space]),\n+ dtype=np.result_type(*[s.dtype for s in space])\n )\n if isinstance(space, MultiBinary):\n- return Box(low=0, high=1, shape=(space.n, ))\n+ return Box(low=0,\n+ high=1,\n+ shape=(space.n, ),\n+ dtype=space.dtype\n+ )\n if isinstance(space, MultiDiscrete):\n return Box(\n low=np.zeros_like(space.nvec),\n high=space.nvec,\n+ dtype=space.dtype\n )\n raise NotImplementedError\n", "issue": "flattened point dtype does not match flattened space dtype\nOriginally found this by using the FlattenObservationWrapper and seeing that my flattened space yielded different precision points than the original space. This is a bug that actually originates from the `spaces.utils.flatten_space` function and is caused by some missing dtype arguments. \r\n\r\nSimplified examples of the bug:\r\n```\r\nfrom gym.spaces import utils\r\nfrom gym.spaces import MultiDiscrete, MultiBinary\r\n\r\noriginal_space = MultiDiscrete([2, 2, 100])\r\nflattened_space = utils.flatten_space(original_space)\r\n\r\noriginal_sample = original_space.sample()\r\nflattened_sample = utils.flatten(original_space, original_sample)\r\n\r\nassert flattened_space.dtype == flattened_sample.dtype\r\n```\n", "before_files": [{"content": "from collections import OrderedDict\nimport numpy as np\n\nfrom gym.spaces import Box\nfrom gym.spaces import Discrete\nfrom gym.spaces import MultiDiscrete\nfrom gym.spaces import MultiBinary\nfrom gym.spaces import Tuple\nfrom gym.spaces import Dict\n\n\ndef flatdim(space):\n \"\"\"Return the number of dimensions a flattened equivalent of this space\n would have.\n\n Accepts a space and returns an integer. Raises ``NotImplementedError`` if\n the space is not defined in ``gym.spaces``.\n \"\"\"\n if isinstance(space, Box):\n return int(np.prod(space.shape))\n elif isinstance(space, Discrete):\n return int(space.n)\n elif isinstance(space, Tuple):\n return int(sum([flatdim(s) for s in space.spaces]))\n elif isinstance(space, Dict):\n return int(sum([flatdim(s) for s in space.spaces.values()]))\n elif isinstance(space, MultiBinary):\n return int(space.n)\n elif isinstance(space, MultiDiscrete):\n return int(np.prod(space.shape))\n else:\n raise NotImplementedError\n\n\ndef flatten(space, x):\n \"\"\"Flatten a data point from a space.\n\n This is useful when e.g. points from spaces must be passed to a neural\n network, which only understands flat arrays of floats.\n\n Accepts a space and a point from that space. Always returns a 1D array.\n Raises ``NotImplementedError`` if the space is not defined in\n ``gym.spaces``.\n \"\"\"\n if isinstance(space, Box):\n return np.asarray(x, dtype=np.float32).flatten()\n elif isinstance(space, Discrete):\n onehot = np.zeros(space.n, dtype=np.float32)\n onehot[x] = 1.0\n return onehot\n elif isinstance(space, Tuple):\n return np.concatenate(\n [flatten(s, x_part) for x_part, s in zip(x, space.spaces)])\n elif isinstance(space, Dict):\n return np.concatenate(\n [flatten(s, x[key]) for key, s in space.spaces.items()])\n elif isinstance(space, MultiBinary):\n return np.asarray(x).flatten()\n elif isinstance(space, MultiDiscrete):\n return np.asarray(x).flatten()\n else:\n raise NotImplementedError\n\n\ndef unflatten(space, x):\n \"\"\"Unflatten a data point from a space.\n\n This reverses the transformation applied by ``flatten()``. You must ensure\n that the ``space`` argument is the same as for the ``flatten()`` call.\n\n Accepts a space and a flattened point. Returns a point with a structure\n that matches the space. Raises ``NotImplementedError`` if the space is not\n defined in ``gym.spaces``.\n \"\"\"\n if isinstance(space, Box):\n return np.asarray(x, dtype=np.float32).reshape(space.shape)\n elif isinstance(space, Discrete):\n return int(np.nonzero(x)[0][0])\n elif isinstance(space, Tuple):\n dims = [flatdim(s) for s in space.spaces]\n list_flattened = np.split(x, np.cumsum(dims)[:-1])\n list_unflattened = [\n unflatten(s, flattened)\n for flattened, s in zip(list_flattened, space.spaces)\n ]\n return tuple(list_unflattened)\n elif isinstance(space, Dict):\n dims = [flatdim(s) for s in space.spaces.values()]\n list_flattened = np.split(x, np.cumsum(dims)[:-1])\n list_unflattened = [\n (key, unflatten(s, flattened))\n for flattened, (key,\n s) in zip(list_flattened, space.spaces.items())\n ]\n return OrderedDict(list_unflattened)\n elif isinstance(space, MultiBinary):\n return np.asarray(x).reshape(space.shape)\n elif isinstance(space, MultiDiscrete):\n return np.asarray(x).reshape(space.shape)\n else:\n raise NotImplementedError\n\n\ndef flatten_space(space):\n \"\"\"Flatten a space into a single ``Box``.\n\n This is equivalent to ``flatten()``, but operates on the space itself. The\n result always is a `Box` with flat boundaries. The box has exactly\n ``flatdim(space)`` dimensions. Flattening a sample of the original space\n has the same effect as taking a sample of the flattenend space.\n\n Raises ``NotImplementedError`` if the space is not defined in\n ``gym.spaces``.\n\n Example::\n\n >>> box = Box(0.0, 1.0, shape=(3, 4, 5))\n >>> box\n Box(3, 4, 5)\n >>> flatten_space(box)\n Box(60,)\n >>> flatten(box, box.sample()) in flatten_space(box)\n True\n\n Example that flattens a discrete space::\n\n >>> discrete = Discrete(5)\n >>> flatten_space(discrete)\n Box(5,)\n >>> flatten(box, box.sample()) in flatten_space(box)\n True\n\n Example that recursively flattens a dict::\n\n >>> space = Dict({\"position\": Discrete(2),\n ... \"velocity\": Box(0, 1, shape=(2, 2))})\n >>> flatten_space(space)\n Box(6,)\n >>> flatten(space, space.sample()) in flatten_space(space)\n True\n \"\"\"\n if isinstance(space, Box):\n return Box(space.low.flatten(), space.high.flatten())\n if isinstance(space, Discrete):\n return Box(low=0, high=1, shape=(space.n, ))\n if isinstance(space, Tuple):\n space = [flatten_space(s) for s in space.spaces]\n return Box(\n low=np.concatenate([s.low for s in space]),\n high=np.concatenate([s.high for s in space]),\n )\n if isinstance(space, Dict):\n space = [flatten_space(s) for s in space.spaces.values()]\n return Box(\n low=np.concatenate([s.low for s in space]),\n high=np.concatenate([s.high for s in space]),\n )\n if isinstance(space, MultiBinary):\n return Box(low=0, high=1, shape=(space.n, ))\n if isinstance(space, MultiDiscrete):\n return Box(\n low=np.zeros_like(space.nvec),\n high=space.nvec,\n )\n raise NotImplementedError\n", "path": "gym/spaces/utils.py"}]}
| 2,450 | 812 |
gh_patches_debug_19904
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-6771
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
New bandit failures
```
Test results:
>> Issue: [B113:request_without_timeout] Requests call without timeout
Severity: Medium Confidence: Low
CWE: CWE-400 (https://cwe.mitre.org/data/definitions/400.html)
More Info: https://bandit.readthedocs.io/en/1.7.5/plugins/b113_request_without_timeout.html
Location: ./admin/tests/test_integration.py:591:21
590 )
591 latest_release = requests.get(github_url).json()
592 latest_tag = str(latest_release["tag_name"])
--------------------------------------------------
>> Issue: [B113:request_without_timeout] Requests call without timeout
Severity: Medium Confidence: Low
CWE: CWE-400 (https://cwe.mitre.org/data/definitions/400.html)
More Info: https://bandit.readthedocs.io/en/1.7.5/plugins/b113_request_without_timeout.html
Location: ./admin/tests/test_integration.py:664:21
663 )
664 latest_release = requests.get(github_url).json()
665 latest_tag = str(latest_release["tag_name"])
--------------------------------------------------
>> Issue: [B608:hardcoded_sql_expressions] Possible SQL injection vector through string-based query construction.
Severity: Medium Confidence: Medium
CWE: CWE-89 (https://cwe.mitre.org/data/definitions/89.html)
More Info: https://bandit.readthedocs.io/en/1.7.5/plugins/b608_hardcoded_sql_expressions.html
Location: ./securedrop/alembic/versions/2e24fc7536e8_make_journalist_id_non_nullable.py:75:12
74 result = conn.execute( # nosec
75 f"SELECT 1 FROM {table} WHERE journalist_id IS NULL;"
76 ).first()
--------------------------------------------------
>> Issue: [B608:hardcoded_sql_expressions] Possible SQL injection vector through string-based query construction.
Severity: Medium Confidence: Low
CWE: CWE-89 (https://cwe.mitre.org/data/definitions/89.html)
More Info: https://bandit.readthedocs.io/en/1.7.5/plugins/b608_hardcoded_sql_expressions.html
Location: ./securedrop/alembic/versions/2e24fc7536e8_make_journalist_id_non_nullable.py:92:16
91 sa.text(
92 f"UPDATE OR IGNORE {table} SET journalist_id=:journalist_id "
93 "WHERE journalist_id IS NULL;"
94 ).bindparams(journalist_id=deleted_id)
--------------------------------------------------
```
</issue>
<code>
[start of securedrop/alembic/versions/2e24fc7536e8_make_journalist_id_non_nullable.py]
1 """make journalist_id non-nullable
2
3 Revision ID: 2e24fc7536e8
4 Revises: de00920916bf
5 Create Date: 2022-01-12 19:31:06.186285
6
7 """
8 import os
9 import uuid
10
11 import argon2
12 import sqlalchemy as sa
13 import two_factor
14 from alembic import op
15
16 # raise the errors if we're not in production
17 raise_errors = os.environ.get("SECUREDROP_ENV", "prod") != "prod"
18
19 try:
20 from models import ARGON2_PARAMS
21 from passphrases import PassphraseGenerator
22 except: # noqa
23 if raise_errors:
24 raise
25
26
27 # revision identifiers, used by Alembic.
28 revision = "2e24fc7536e8"
29 down_revision = "de00920916bf"
30 branch_labels = None
31 depends_on = None
32
33
34 def generate_passphrase_hash() -> str:
35 passphrase = PassphraseGenerator.get_default().generate_passphrase()
36 return argon2.PasswordHasher(**ARGON2_PARAMS).hash(passphrase)
37
38
39 def create_deleted() -> int:
40 """manually insert a "deleted" journalist user.
41
42 We need to do it this way since the model will reflect the current state of
43 the schema, not what it is at the current migration step
44
45 It should be basically identical to what Journalist.get_deleted() does
46 """
47 op.execute(
48 sa.text(
49 """\
50 INSERT INTO journalists (uuid, username, session_nonce, passphrase_hash, otp_secret)
51 VALUES (:uuid, "deleted", 0, :passphrase_hash, :otp_secret);
52 """
53 ).bindparams(
54 uuid=str(uuid.uuid4()),
55 passphrase_hash=generate_passphrase_hash(),
56 otp_secret=two_factor.random_base32(),
57 )
58 )
59 # Get the autoincrement ID back
60 conn = op.get_bind()
61 result = conn.execute('SELECT id FROM journalists WHERE username="deleted";').fetchall()
62 return result[0][0]
63
64
65 def migrate_nulls() -> None:
66 """migrate existing journalist_id=NULL over to deleted or delete them"""
67 op.execute("DELETE FROM journalist_login_attempt WHERE journalist_id IS NULL;")
68 op.execute("DELETE FROM revoked_tokens WHERE journalist_id IS NULL;")
69 # Look to see if we have data to migrate
70 tables = ("replies", "seen_files", "seen_messages", "seen_replies")
71 needs_migration = []
72 conn = op.get_bind()
73 for table in tables:
74 result = conn.execute( # nosec
75 f"SELECT 1 FROM {table} WHERE journalist_id IS NULL;"
76 ).first()
77 if result is not None:
78 needs_migration.append(table)
79
80 if not needs_migration:
81 return
82
83 deleted_id = create_deleted()
84 for table in needs_migration:
85 # The seen_ tables have UNIQUE(fk_id, journalist_id), so the deleted journalist can only
86 # have seen each item once. It is possible multiple NULL journalist have seen the same thing
87 # so we do this update in two passes.
88 # First we update as many rows to point to the deleted journalist as possible, ignoring any
89 # unique key violations.
90 op.execute(
91 sa.text(
92 f"UPDATE OR IGNORE {table} SET journalist_id=:journalist_id "
93 "WHERE journalist_id IS NULL;"
94 ).bindparams(journalist_id=deleted_id)
95 )
96 # Then we delete any leftovers which had been ignored earlier.
97 op.execute(f"DELETE FROM {table} WHERE journalist_id IS NULL") # nosec
98
99
100 def upgrade() -> None:
101 migrate_nulls()
102
103 with op.batch_alter_table("journalist_login_attempt", schema=None) as batch_op:
104 batch_op.alter_column("journalist_id", existing_type=sa.INTEGER(), nullable=False)
105
106 with op.batch_alter_table("replies", schema=None) as batch_op:
107 batch_op.alter_column("journalist_id", existing_type=sa.INTEGER(), nullable=False)
108
109 with op.batch_alter_table("revoked_tokens", schema=None) as batch_op:
110 batch_op.alter_column("journalist_id", existing_type=sa.INTEGER(), nullable=False)
111
112 with op.batch_alter_table("seen_files", schema=None) as batch_op:
113 batch_op.alter_column("journalist_id", existing_type=sa.INTEGER(), nullable=False)
114
115 with op.batch_alter_table("seen_messages", schema=None) as batch_op:
116 batch_op.alter_column("journalist_id", existing_type=sa.INTEGER(), nullable=False)
117
118 with op.batch_alter_table("seen_replies", schema=None) as batch_op:
119 batch_op.alter_column("journalist_id", existing_type=sa.INTEGER(), nullable=False)
120
121
122 def downgrade() -> None:
123 # We do not un-migrate the data back to journalist_id=NULL
124
125 with op.batch_alter_table("seen_replies", schema=None) as batch_op:
126 batch_op.alter_column("journalist_id", existing_type=sa.INTEGER(), nullable=True)
127
128 with op.batch_alter_table("seen_messages", schema=None) as batch_op:
129 batch_op.alter_column("journalist_id", existing_type=sa.INTEGER(), nullable=True)
130
131 with op.batch_alter_table("seen_files", schema=None) as batch_op:
132 batch_op.alter_column("journalist_id", existing_type=sa.INTEGER(), nullable=True)
133
134 with op.batch_alter_table("revoked_tokens", schema=None) as batch_op:
135 batch_op.alter_column("journalist_id", existing_type=sa.INTEGER(), nullable=True)
136
137 with op.batch_alter_table("replies", schema=None) as batch_op:
138 batch_op.alter_column("journalist_id", existing_type=sa.INTEGER(), nullable=True)
139
140 with op.batch_alter_table("journalist_login_attempt", schema=None) as batch_op:
141 batch_op.alter_column("journalist_id", existing_type=sa.INTEGER(), nullable=True)
142
[end of securedrop/alembic/versions/2e24fc7536e8_make_journalist_id_non_nullable.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/securedrop/alembic/versions/2e24fc7536e8_make_journalist_id_non_nullable.py b/securedrop/alembic/versions/2e24fc7536e8_make_journalist_id_non_nullable.py
--- a/securedrop/alembic/versions/2e24fc7536e8_make_journalist_id_non_nullable.py
+++ b/securedrop/alembic/versions/2e24fc7536e8_make_journalist_id_non_nullable.py
@@ -71,8 +71,8 @@
needs_migration = []
conn = op.get_bind()
for table in tables:
- result = conn.execute( # nosec
- f"SELECT 1 FROM {table} WHERE journalist_id IS NULL;"
+ result = conn.execute(
+ f"SELECT 1 FROM {table} WHERE journalist_id IS NULL;" # nosec
).first()
if result is not None:
needs_migration.append(table)
@@ -89,7 +89,7 @@
# unique key violations.
op.execute(
sa.text(
- f"UPDATE OR IGNORE {table} SET journalist_id=:journalist_id "
+ f"UPDATE OR IGNORE {table} SET journalist_id=:journalist_id " # nosec
"WHERE journalist_id IS NULL;"
).bindparams(journalist_id=deleted_id)
)
|
{"golden_diff": "diff --git a/securedrop/alembic/versions/2e24fc7536e8_make_journalist_id_non_nullable.py b/securedrop/alembic/versions/2e24fc7536e8_make_journalist_id_non_nullable.py\n--- a/securedrop/alembic/versions/2e24fc7536e8_make_journalist_id_non_nullable.py\n+++ b/securedrop/alembic/versions/2e24fc7536e8_make_journalist_id_non_nullable.py\n@@ -71,8 +71,8 @@\n needs_migration = []\n conn = op.get_bind()\n for table in tables:\n- result = conn.execute( # nosec\n- f\"SELECT 1 FROM {table} WHERE journalist_id IS NULL;\"\n+ result = conn.execute(\n+ f\"SELECT 1 FROM {table} WHERE journalist_id IS NULL;\" # nosec\n ).first()\n if result is not None:\n needs_migration.append(table)\n@@ -89,7 +89,7 @@\n # unique key violations.\n op.execute(\n sa.text(\n- f\"UPDATE OR IGNORE {table} SET journalist_id=:journalist_id \"\n+ f\"UPDATE OR IGNORE {table} SET journalist_id=:journalist_id \" # nosec\n \"WHERE journalist_id IS NULL;\"\n ).bindparams(journalist_id=deleted_id)\n )\n", "issue": "New bandit failures\n```\r\nTest results:\r\n>> Issue: [B113:request_without_timeout] Requests call without timeout\r\n Severity: Medium Confidence: Low\r\n CWE: CWE-400 (https://cwe.mitre.org/data/definitions/400.html)\r\n More Info: https://bandit.readthedocs.io/en/1.7.5/plugins/b113_request_without_timeout.html\r\n Location: ./admin/tests/test_integration.py:591:21\r\n590\t )\r\n591\t latest_release = requests.get(github_url).json()\r\n592\t latest_tag = str(latest_release[\"tag_name\"])\r\n\r\n--------------------------------------------------\r\n>> Issue: [B113:request_without_timeout] Requests call without timeout\r\n Severity: Medium Confidence: Low\r\n CWE: CWE-400 (https://cwe.mitre.org/data/definitions/400.html)\r\n More Info: https://bandit.readthedocs.io/en/1.7.5/plugins/b113_request_without_timeout.html\r\n Location: ./admin/tests/test_integration.py:664:21\r\n663\t )\r\n664\t latest_release = requests.get(github_url).json()\r\n665\t latest_tag = str(latest_release[\"tag_name\"])\r\n\r\n--------------------------------------------------\r\n>> Issue: [B608:hardcoded_sql_expressions] Possible SQL injection vector through string-based query construction.\r\n Severity: Medium Confidence: Medium\r\n CWE: CWE-89 (https://cwe.mitre.org/data/definitions/89.html)\r\n More Info: https://bandit.readthedocs.io/en/1.7.5/plugins/b608_hardcoded_sql_expressions.html\r\n Location: ./securedrop/alembic/versions/2e24fc7536e8_make_journalist_id_non_nullable.py:75:12\r\n74\t result = conn.execute( # nosec\r\n75\t f\"SELECT 1 FROM {table} WHERE journalist_id IS NULL;\"\r\n76\t ).first()\r\n\r\n--------------------------------------------------\r\n>> Issue: [B608:hardcoded_sql_expressions] Possible SQL injection vector through string-based query construction.\r\n Severity: Medium Confidence: Low\r\n CWE: CWE-89 (https://cwe.mitre.org/data/definitions/89.html)\r\n More Info: https://bandit.readthedocs.io/en/1.7.5/plugins/b608_hardcoded_sql_expressions.html\r\n Location: ./securedrop/alembic/versions/2e24fc7536e8_make_journalist_id_non_nullable.py:92:16\r\n91\t sa.text(\r\n92\t f\"UPDATE OR IGNORE {table} SET journalist_id=:journalist_id \"\r\n93\t \"WHERE journalist_id IS NULL;\"\r\n94\t ).bindparams(journalist_id=deleted_id)\r\n\r\n--------------------------------------------------\r\n```\n", "before_files": [{"content": "\"\"\"make journalist_id non-nullable\n\nRevision ID: 2e24fc7536e8\nRevises: de00920916bf\nCreate Date: 2022-01-12 19:31:06.186285\n\n\"\"\"\nimport os\nimport uuid\n\nimport argon2\nimport sqlalchemy as sa\nimport two_factor\nfrom alembic import op\n\n# raise the errors if we're not in production\nraise_errors = os.environ.get(\"SECUREDROP_ENV\", \"prod\") != \"prod\"\n\ntry:\n from models import ARGON2_PARAMS\n from passphrases import PassphraseGenerator\nexcept: # noqa\n if raise_errors:\n raise\n\n\n# revision identifiers, used by Alembic.\nrevision = \"2e24fc7536e8\"\ndown_revision = \"de00920916bf\"\nbranch_labels = None\ndepends_on = None\n\n\ndef generate_passphrase_hash() -> str:\n passphrase = PassphraseGenerator.get_default().generate_passphrase()\n return argon2.PasswordHasher(**ARGON2_PARAMS).hash(passphrase)\n\n\ndef create_deleted() -> int:\n \"\"\"manually insert a \"deleted\" journalist user.\n\n We need to do it this way since the model will reflect the current state of\n the schema, not what it is at the current migration step\n\n It should be basically identical to what Journalist.get_deleted() does\n \"\"\"\n op.execute(\n sa.text(\n \"\"\"\\\n INSERT INTO journalists (uuid, username, session_nonce, passphrase_hash, otp_secret)\n VALUES (:uuid, \"deleted\", 0, :passphrase_hash, :otp_secret);\n \"\"\"\n ).bindparams(\n uuid=str(uuid.uuid4()),\n passphrase_hash=generate_passphrase_hash(),\n otp_secret=two_factor.random_base32(),\n )\n )\n # Get the autoincrement ID back\n conn = op.get_bind()\n result = conn.execute('SELECT id FROM journalists WHERE username=\"deleted\";').fetchall()\n return result[0][0]\n\n\ndef migrate_nulls() -> None:\n \"\"\"migrate existing journalist_id=NULL over to deleted or delete them\"\"\"\n op.execute(\"DELETE FROM journalist_login_attempt WHERE journalist_id IS NULL;\")\n op.execute(\"DELETE FROM revoked_tokens WHERE journalist_id IS NULL;\")\n # Look to see if we have data to migrate\n tables = (\"replies\", \"seen_files\", \"seen_messages\", \"seen_replies\")\n needs_migration = []\n conn = op.get_bind()\n for table in tables:\n result = conn.execute( # nosec\n f\"SELECT 1 FROM {table} WHERE journalist_id IS NULL;\"\n ).first()\n if result is not None:\n needs_migration.append(table)\n\n if not needs_migration:\n return\n\n deleted_id = create_deleted()\n for table in needs_migration:\n # The seen_ tables have UNIQUE(fk_id, journalist_id), so the deleted journalist can only\n # have seen each item once. It is possible multiple NULL journalist have seen the same thing\n # so we do this update in two passes.\n # First we update as many rows to point to the deleted journalist as possible, ignoring any\n # unique key violations.\n op.execute(\n sa.text(\n f\"UPDATE OR IGNORE {table} SET journalist_id=:journalist_id \"\n \"WHERE journalist_id IS NULL;\"\n ).bindparams(journalist_id=deleted_id)\n )\n # Then we delete any leftovers which had been ignored earlier.\n op.execute(f\"DELETE FROM {table} WHERE journalist_id IS NULL\") # nosec\n\n\ndef upgrade() -> None:\n migrate_nulls()\n\n with op.batch_alter_table(\"journalist_login_attempt\", schema=None) as batch_op:\n batch_op.alter_column(\"journalist_id\", existing_type=sa.INTEGER(), nullable=False)\n\n with op.batch_alter_table(\"replies\", schema=None) as batch_op:\n batch_op.alter_column(\"journalist_id\", existing_type=sa.INTEGER(), nullable=False)\n\n with op.batch_alter_table(\"revoked_tokens\", schema=None) as batch_op:\n batch_op.alter_column(\"journalist_id\", existing_type=sa.INTEGER(), nullable=False)\n\n with op.batch_alter_table(\"seen_files\", schema=None) as batch_op:\n batch_op.alter_column(\"journalist_id\", existing_type=sa.INTEGER(), nullable=False)\n\n with op.batch_alter_table(\"seen_messages\", schema=None) as batch_op:\n batch_op.alter_column(\"journalist_id\", existing_type=sa.INTEGER(), nullable=False)\n\n with op.batch_alter_table(\"seen_replies\", schema=None) as batch_op:\n batch_op.alter_column(\"journalist_id\", existing_type=sa.INTEGER(), nullable=False)\n\n\ndef downgrade() -> None:\n # We do not un-migrate the data back to journalist_id=NULL\n\n with op.batch_alter_table(\"seen_replies\", schema=None) as batch_op:\n batch_op.alter_column(\"journalist_id\", existing_type=sa.INTEGER(), nullable=True)\n\n with op.batch_alter_table(\"seen_messages\", schema=None) as batch_op:\n batch_op.alter_column(\"journalist_id\", existing_type=sa.INTEGER(), nullable=True)\n\n with op.batch_alter_table(\"seen_files\", schema=None) as batch_op:\n batch_op.alter_column(\"journalist_id\", existing_type=sa.INTEGER(), nullable=True)\n\n with op.batch_alter_table(\"revoked_tokens\", schema=None) as batch_op:\n batch_op.alter_column(\"journalist_id\", existing_type=sa.INTEGER(), nullable=True)\n\n with op.batch_alter_table(\"replies\", schema=None) as batch_op:\n batch_op.alter_column(\"journalist_id\", existing_type=sa.INTEGER(), nullable=True)\n\n with op.batch_alter_table(\"journalist_login_attempt\", schema=None) as batch_op:\n batch_op.alter_column(\"journalist_id\", existing_type=sa.INTEGER(), nullable=True)\n", "path": "securedrop/alembic/versions/2e24fc7536e8_make_journalist_id_non_nullable.py"}]}
| 2,833 | 318 |
gh_patches_debug_3371
|
rasdani/github-patches
|
git_diff
|
e2nIEE__pandapower-1661
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pandapower.networks: nets have wrong order of columns
Example for net = nw.case24_ieee_rts():
```python
net.bus.head()
Out[43]:
in_service max_vm_pu min_vm_pu name type vn_kv zone
0 True 1.1 0.9 a b 138.0 1.0
1 True 1.1 0.9 b b 138.0 1.0
2 True 1.1 0.9 c b 138.0 1.0
3 True 1.1 0.9 d b 138.0 1.0
4 True 1.1 0.9 e b 138.0 1.0
```
</issue>
<code>
[start of setup.py]
1 # -*- coding: utf-8 -*-
2
3 # Copyright (c) 2016-2022 by University of Kassel and Fraunhofer Institute for Energy Economics
4 # and Energy System Technology (IEE), Kassel. All rights reserved.
5
6 from setuptools import setup, find_packages
7 import re
8
9 with open('README.rst', 'rb') as f:
10 install = f.read().decode('utf-8')
11
12 with open('CHANGELOG.rst', 'rb') as f:
13 changelog = f.read().decode('utf-8')
14
15 classifiers = [
16 'Development Status :: 5 - Production/Stable',
17 'Environment :: Console',
18 'Intended Audience :: Developers',
19 'Intended Audience :: Education',
20 'Intended Audience :: Science/Research',
21 'License :: OSI Approved :: BSD License',
22 'Natural Language :: English',
23 'Operating System :: OS Independent',
24 'Programming Language :: Python',
25 'Programming Language :: Python :: 3']
26
27 with open('.github/workflows/github_test_action.yml', 'rb') as f:
28 lines = f.read().decode('utf-8')
29 versions = set(re.findall('3.[7-9]', lines)) | set(re.findall('3.1[0-9]', lines))
30 for version in sorted(versions):
31 classifiers.append('Programming Language :: Python :: %s' % version)
32
33 long_description = '\n\n'.join((install, changelog))
34
35 setup(
36 name='pandapower',
37 version='2.10.1',
38 author='Leon Thurner, Alexander Scheidler',
39 author_email='[email protected], [email protected]',
40 description='An easy to use open source tool for power system modeling, analysis and optimization with a high degree of automation.',
41 long_description=long_description,
42 long_description_content_type='text/x-rst',
43 url='http://www.pandapower.org',
44 license='BSD',
45 install_requires=["pandas>=1.0",
46 "networkx>=2.5",
47 "scipy",
48 "numpy>=0.11",
49 "packaging",
50 "tqdm",
51 "deepdiff"],
52 extras_require={
53 "docs": ["numpydoc", "sphinx", "sphinx_rtd_theme"],
54 "plotting": ["plotly", "matplotlib", "python-igraph", "geopandas"],
55 # "shapely", "pyproj" are depedencies of geopandas and so already available;
56 # "base64", "hashlib", "zlib" produce installing problems, so they are not included
57 "test": ["pytest", "pytest-xdist"],
58 "performance": ["ortools"], # , "lightsim2grid"],
59 "fileio": ["xlsxwriter", "openpyxl", "cryptography", "geopandas"],
60 # "fiona" is a depedency of geopandas and so already available
61 "converter": ["matpowercaseframes"],
62 "all": ["numpydoc", "sphinx", "sphinx_rtd_theme",
63 "plotly", "matplotlib", "python-igraph", "geopandas",
64 "pytest", "pytest-xdist",
65 "ortools", # lightsim2grid,
66 "xlsxwriter", "openpyxl", "cryptography",
67 "matpowercaseframes"
68 ]}, # "shapely", "pyproj", "fiona" are depedencies of geopandas and so already available
69 # "hashlib", "zlib", "base64" produce installing problems, so it is not included
70 packages=find_packages(),
71 include_package_data=True,
72 classifiers=classifiers
73 )
74
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -45,7 +45,7 @@
install_requires=["pandas>=1.0",
"networkx>=2.5",
"scipy",
- "numpy>=0.11",
+ "numpy",
"packaging",
"tqdm",
"deepdiff"],
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -45,7 +45,7 @@\n install_requires=[\"pandas>=1.0\",\n \"networkx>=2.5\",\n \"scipy\",\n- \"numpy>=0.11\",\n+ \"numpy\",\n \"packaging\",\n \"tqdm\",\n \"deepdiff\"],\n", "issue": "pandapower.networks: nets have wrong order of columns\nExample for net = nw.case24_ieee_rts():\r\n\r\n```python\r\nnet.bus.head()\r\nOut[43]: \r\n in_service max_vm_pu min_vm_pu name type vn_kv zone\r\n0 True 1.1 0.9 a b 138.0 1.0\r\n1 True 1.1 0.9 b b 138.0 1.0\r\n2 True 1.1 0.9 c b 138.0 1.0\r\n3 True 1.1 0.9 d b 138.0 1.0\r\n4 True 1.1 0.9 e b 138.0 1.0\r\n```\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright (c) 2016-2022 by University of Kassel and Fraunhofer Institute for Energy Economics\n# and Energy System Technology (IEE), Kassel. All rights reserved.\n\nfrom setuptools import setup, find_packages\nimport re\n\nwith open('README.rst', 'rb') as f:\n install = f.read().decode('utf-8')\n\nwith open('CHANGELOG.rst', 'rb') as f:\n changelog = f.read().decode('utf-8')\n\nclassifiers = [\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: BSD License',\n 'Natural Language :: English',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3']\n\nwith open('.github/workflows/github_test_action.yml', 'rb') as f:\n lines = f.read().decode('utf-8')\n versions = set(re.findall('3.[7-9]', lines)) | set(re.findall('3.1[0-9]', lines))\n for version in sorted(versions):\n classifiers.append('Programming Language :: Python :: %s' % version)\n\nlong_description = '\\n\\n'.join((install, changelog))\n\nsetup(\n name='pandapower',\n version='2.10.1',\n author='Leon Thurner, Alexander Scheidler',\n author_email='[email protected], [email protected]',\n description='An easy to use open source tool for power system modeling, analysis and optimization with a high degree of automation.',\n long_description=long_description,\n long_description_content_type='text/x-rst',\n url='http://www.pandapower.org',\n license='BSD',\n install_requires=[\"pandas>=1.0\",\n \"networkx>=2.5\",\n \"scipy\",\n \"numpy>=0.11\",\n \"packaging\",\n \"tqdm\",\n \"deepdiff\"],\n extras_require={\n \"docs\": [\"numpydoc\", \"sphinx\", \"sphinx_rtd_theme\"],\n \"plotting\": [\"plotly\", \"matplotlib\", \"python-igraph\", \"geopandas\"],\n # \"shapely\", \"pyproj\" are depedencies of geopandas and so already available;\n # \"base64\", \"hashlib\", \"zlib\" produce installing problems, so they are not included\n \"test\": [\"pytest\", \"pytest-xdist\"],\n \"performance\": [\"ortools\"], # , \"lightsim2grid\"],\n \"fileio\": [\"xlsxwriter\", \"openpyxl\", \"cryptography\", \"geopandas\"],\n # \"fiona\" is a depedency of geopandas and so already available\n \"converter\": [\"matpowercaseframes\"],\n \"all\": [\"numpydoc\", \"sphinx\", \"sphinx_rtd_theme\",\n \"plotly\", \"matplotlib\", \"python-igraph\", \"geopandas\",\n \"pytest\", \"pytest-xdist\",\n \"ortools\", # lightsim2grid,\n \"xlsxwriter\", \"openpyxl\", \"cryptography\",\n \"matpowercaseframes\"\n ]}, # \"shapely\", \"pyproj\", \"fiona\" are depedencies of geopandas and so already available\n # \"hashlib\", \"zlib\", \"base64\" produce installing problems, so it is not included\n packages=find_packages(),\n include_package_data=True,\n classifiers=classifiers\n)\n", "path": "setup.py"}]}
| 1,696 | 88 |
gh_patches_debug_44158
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-contrib-1242
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Metrics instrumentation pyramid
HTTP metrics semconv: https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/metrics/semantic_conventions/http-metrics.md
</issue>
<code>
[start of instrumentation/opentelemetry-instrumentation-pyramid/src/opentelemetry/instrumentation/pyramid/callbacks.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from logging import getLogger
16 from time import time_ns
17
18 from pyramid.events import BeforeTraversal
19 from pyramid.httpexceptions import HTTPException, HTTPServerError
20 from pyramid.settings import asbool
21 from pyramid.tweens import EXCVIEW
22
23 import opentelemetry.instrumentation.wsgi as otel_wsgi
24 from opentelemetry import context, trace
25 from opentelemetry.instrumentation.propagators import (
26 get_global_response_propagator,
27 )
28 from opentelemetry.instrumentation.pyramid.version import __version__
29 from opentelemetry.instrumentation.utils import _start_internal_or_server_span
30 from opentelemetry.semconv.trace import SpanAttributes
31 from opentelemetry.util.http import get_excluded_urls
32
33 TWEEN_NAME = "opentelemetry.instrumentation.pyramid.trace_tween_factory"
34 SETTING_TRACE_ENABLED = "opentelemetry-pyramid.trace_enabled"
35
36 _ENVIRON_STARTTIME_KEY = "opentelemetry-pyramid.starttime_key"
37 _ENVIRON_SPAN_KEY = "opentelemetry-pyramid.span_key"
38 _ENVIRON_ACTIVATION_KEY = "opentelemetry-pyramid.activation_key"
39 _ENVIRON_ENABLED_KEY = "opentelemetry-pyramid.tracing_enabled_key"
40 _ENVIRON_TOKEN = "opentelemetry-pyramid.token"
41
42 _logger = getLogger(__name__)
43
44
45 _excluded_urls = get_excluded_urls("PYRAMID")
46
47
48 def includeme(config):
49 config.add_settings({SETTING_TRACE_ENABLED: True})
50
51 config.add_subscriber(_before_traversal, BeforeTraversal)
52 _insert_tween(config)
53
54
55 def _insert_tween(config):
56 settings = config.get_settings()
57 tweens = settings.get("pyramid.tweens")
58 # If the list is empty, pyramid does not consider the tweens have been
59 # set explicitly. And if our tween is already there, nothing to do
60 if not tweens or not tweens.strip():
61 # Add our tween just before the default exception handler
62 config.add_tween(TWEEN_NAME, over=EXCVIEW)
63
64
65 def _before_traversal(event):
66 request = event.request
67 request_environ = request.environ
68 span_name = otel_wsgi.get_default_span_name(request_environ)
69
70 enabled = request_environ.get(_ENVIRON_ENABLED_KEY)
71 if enabled is None:
72 _logger.warning(
73 "Opentelemetry pyramid tween 'opentelemetry.instrumentation.pyramid.trace_tween_factory'"
74 "was not called. Make sure that the tween is included in 'pyramid.tweens' if"
75 "the tween list was created manually"
76 )
77 return
78
79 if not enabled:
80 # Tracing not enabled, return
81 return
82
83 start_time = request_environ.get(_ENVIRON_STARTTIME_KEY)
84 tracer = trace.get_tracer(__name__, __version__)
85
86 if request.matched_route:
87 span_name = request.matched_route.pattern
88 else:
89 span_name = otel_wsgi.get_default_span_name(request_environ)
90
91 span, token = _start_internal_or_server_span(
92 tracer=tracer,
93 span_name=span_name,
94 start_time=start_time,
95 context_carrier=request_environ,
96 context_getter=otel_wsgi.wsgi_getter,
97 )
98
99 if span.is_recording():
100 attributes = otel_wsgi.collect_request_attributes(request_environ)
101 if request.matched_route:
102 attributes[
103 SpanAttributes.HTTP_ROUTE
104 ] = request.matched_route.pattern
105 for key, value in attributes.items():
106 span.set_attribute(key, value)
107 if span.kind == trace.SpanKind.SERVER:
108 custom_attributes = (
109 otel_wsgi.collect_custom_request_headers_attributes(
110 request_environ
111 )
112 )
113 if len(custom_attributes) > 0:
114 span.set_attributes(custom_attributes)
115
116 activation = trace.use_span(span, end_on_exit=True)
117 activation.__enter__() # pylint: disable=E1101
118 request_environ[_ENVIRON_ACTIVATION_KEY] = activation
119 request_environ[_ENVIRON_SPAN_KEY] = span
120 if token:
121 request_environ[_ENVIRON_TOKEN] = token
122
123
124 def trace_tween_factory(handler, registry):
125 settings = registry.settings
126 enabled = asbool(settings.get(SETTING_TRACE_ENABLED, True))
127
128 if not enabled:
129 # If disabled, make a tween that signals to the
130 # BeforeTraversal subscriber that tracing is disabled
131 def disabled_tween(request):
132 request.environ[_ENVIRON_ENABLED_KEY] = False
133 return handler(request)
134
135 return disabled_tween
136
137 # make a request tracing function
138 # pylint: disable=too-many-branches
139 def trace_tween(request):
140 # pylint: disable=E1101
141 if _excluded_urls.url_disabled(request.url):
142 request.environ[_ENVIRON_ENABLED_KEY] = False
143 # short-circuit when we don't want to trace anything
144 return handler(request)
145
146 request.environ[_ENVIRON_ENABLED_KEY] = True
147 request.environ[_ENVIRON_STARTTIME_KEY] = time_ns()
148
149 response = None
150 status = None
151
152 try:
153 response = handler(request)
154 except HTTPException as exc:
155 # If the exception is a pyramid HTTPException,
156 # that's still valuable information that isn't necessarily
157 # a 500. For instance, HTTPFound is a 302.
158 # As described in docs, Pyramid exceptions are all valid
159 # response types
160 response = exc
161 raise
162 except BaseException:
163 # In the case that a non-HTTPException is bubbled up we
164 # should infer a internal server error and raise
165 status = "500 InternalServerError"
166 raise
167 finally:
168 span = request.environ.get(_ENVIRON_SPAN_KEY)
169 enabled = request.environ.get(_ENVIRON_ENABLED_KEY)
170 if not span and enabled:
171 _logger.warning(
172 "Pyramid environ's OpenTelemetry span missing."
173 "If the OpenTelemetry tween was added manually, make sure"
174 "PyramidInstrumentor().instrument_config(config) is called"
175 )
176 elif enabled:
177 status = getattr(response, "status", status)
178
179 if status is not None:
180 otel_wsgi.add_response_attributes(
181 span,
182 status,
183 getattr(response, "headerlist", None),
184 )
185
186 if span.is_recording() and span.kind == trace.SpanKind.SERVER:
187 custom_attributes = (
188 otel_wsgi.collect_custom_response_headers_attributes(
189 getattr(response, "headerlist", None)
190 )
191 )
192 if len(custom_attributes) > 0:
193 span.set_attributes(custom_attributes)
194
195 propagator = get_global_response_propagator()
196 if propagator and hasattr(response, "headers"):
197 propagator.inject(response.headers)
198
199 activation = request.environ.get(_ENVIRON_ACTIVATION_KEY)
200
201 # Only considering HTTPServerError
202 # to make sure 200, 300 and 400 exceptions are not reported as error
203 if isinstance(response, HTTPServerError):
204 activation.__exit__(
205 type(response),
206 response,
207 getattr(response, "__traceback__", None),
208 )
209 else:
210 activation.__exit__(None, None, None)
211
212 env_token = request.environ.get(_ENVIRON_TOKEN, None)
213 if env_token is not None:
214 context.detach(env_token)
215
216 return response
217
218 return trace_tween
219
[end of instrumentation/opentelemetry-instrumentation-pyramid/src/opentelemetry/instrumentation/pyramid/callbacks.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/instrumentation/opentelemetry-instrumentation-pyramid/src/opentelemetry/instrumentation/pyramid/callbacks.py b/instrumentation/opentelemetry-instrumentation-pyramid/src/opentelemetry/instrumentation/pyramid/callbacks.py
--- a/instrumentation/opentelemetry-instrumentation-pyramid/src/opentelemetry/instrumentation/pyramid/callbacks.py
+++ b/instrumentation/opentelemetry-instrumentation-pyramid/src/opentelemetry/instrumentation/pyramid/callbacks.py
@@ -14,6 +14,7 @@
from logging import getLogger
from time import time_ns
+from timeit import default_timer
from pyramid.events import BeforeTraversal
from pyramid.httpexceptions import HTTPException, HTTPServerError
@@ -27,6 +28,7 @@
)
from opentelemetry.instrumentation.pyramid.version import __version__
from opentelemetry.instrumentation.utils import _start_internal_or_server_span
+from opentelemetry.metrics import get_meter
from opentelemetry.semconv.trace import SpanAttributes
from opentelemetry.util.http import get_excluded_urls
@@ -122,8 +124,20 @@
def trace_tween_factory(handler, registry):
+ # pylint: disable=too-many-statements
settings = registry.settings
enabled = asbool(settings.get(SETTING_TRACE_ENABLED, True))
+ meter = get_meter(__name__, __version__)
+ duration_histogram = meter.create_histogram(
+ name="http.server.duration",
+ unit="ms",
+ description="measures the duration of the inbound HTTP request",
+ )
+ active_requests_counter = meter.create_up_down_counter(
+ name="http.server.active_requests",
+ unit="requests",
+ description="measures the number of concurrent HTTP requests that are currently in-flight",
+ )
if not enabled:
# If disabled, make a tween that signals to the
@@ -137,14 +151,23 @@
# make a request tracing function
# pylint: disable=too-many-branches
def trace_tween(request):
- # pylint: disable=E1101
+ # pylint: disable=E1101, too-many-locals
if _excluded_urls.url_disabled(request.url):
request.environ[_ENVIRON_ENABLED_KEY] = False
# short-circuit when we don't want to trace anything
return handler(request)
+ attributes = otel_wsgi.collect_request_attributes(request.environ)
+
request.environ[_ENVIRON_ENABLED_KEY] = True
request.environ[_ENVIRON_STARTTIME_KEY] = time_ns()
+ active_requests_count_attrs = (
+ otel_wsgi._parse_active_request_count_attrs(attributes)
+ )
+ duration_attrs = otel_wsgi._parse_duration_attrs(attributes)
+
+ start = default_timer()
+ active_requests_counter.add(1, active_requests_count_attrs)
response = None
status = None
@@ -165,6 +188,15 @@
status = "500 InternalServerError"
raise
finally:
+ duration = max(round((default_timer() - start) * 1000), 0)
+ status = getattr(response, "status", status)
+ status_code = otel_wsgi._parse_status_code(status)
+ if status_code is not None:
+ duration_attrs[
+ SpanAttributes.HTTP_STATUS_CODE
+ ] = otel_wsgi._parse_status_code(status)
+ duration_histogram.record(duration, duration_attrs)
+ active_requests_counter.add(-1, active_requests_count_attrs)
span = request.environ.get(_ENVIRON_SPAN_KEY)
enabled = request.environ.get(_ENVIRON_ENABLED_KEY)
if not span and enabled:
@@ -174,7 +206,6 @@
"PyramidInstrumentor().instrument_config(config) is called"
)
elif enabled:
- status = getattr(response, "status", status)
if status is not None:
otel_wsgi.add_response_attributes(
|
{"golden_diff": "diff --git a/instrumentation/opentelemetry-instrumentation-pyramid/src/opentelemetry/instrumentation/pyramid/callbacks.py b/instrumentation/opentelemetry-instrumentation-pyramid/src/opentelemetry/instrumentation/pyramid/callbacks.py\n--- a/instrumentation/opentelemetry-instrumentation-pyramid/src/opentelemetry/instrumentation/pyramid/callbacks.py\n+++ b/instrumentation/opentelemetry-instrumentation-pyramid/src/opentelemetry/instrumentation/pyramid/callbacks.py\n@@ -14,6 +14,7 @@\n \n from logging import getLogger\n from time import time_ns\n+from timeit import default_timer\n \n from pyramid.events import BeforeTraversal\n from pyramid.httpexceptions import HTTPException, HTTPServerError\n@@ -27,6 +28,7 @@\n )\n from opentelemetry.instrumentation.pyramid.version import __version__\n from opentelemetry.instrumentation.utils import _start_internal_or_server_span\n+from opentelemetry.metrics import get_meter\n from opentelemetry.semconv.trace import SpanAttributes\n from opentelemetry.util.http import get_excluded_urls\n \n@@ -122,8 +124,20 @@\n \n \n def trace_tween_factory(handler, registry):\n+ # pylint: disable=too-many-statements\n settings = registry.settings\n enabled = asbool(settings.get(SETTING_TRACE_ENABLED, True))\n+ meter = get_meter(__name__, __version__)\n+ duration_histogram = meter.create_histogram(\n+ name=\"http.server.duration\",\n+ unit=\"ms\",\n+ description=\"measures the duration of the inbound HTTP request\",\n+ )\n+ active_requests_counter = meter.create_up_down_counter(\n+ name=\"http.server.active_requests\",\n+ unit=\"requests\",\n+ description=\"measures the number of concurrent HTTP requests that are currently in-flight\",\n+ )\n \n if not enabled:\n # If disabled, make a tween that signals to the\n@@ -137,14 +151,23 @@\n # make a request tracing function\n # pylint: disable=too-many-branches\n def trace_tween(request):\n- # pylint: disable=E1101\n+ # pylint: disable=E1101, too-many-locals\n if _excluded_urls.url_disabled(request.url):\n request.environ[_ENVIRON_ENABLED_KEY] = False\n # short-circuit when we don't want to trace anything\n return handler(request)\n \n+ attributes = otel_wsgi.collect_request_attributes(request.environ)\n+\n request.environ[_ENVIRON_ENABLED_KEY] = True\n request.environ[_ENVIRON_STARTTIME_KEY] = time_ns()\n+ active_requests_count_attrs = (\n+ otel_wsgi._parse_active_request_count_attrs(attributes)\n+ )\n+ duration_attrs = otel_wsgi._parse_duration_attrs(attributes)\n+\n+ start = default_timer()\n+ active_requests_counter.add(1, active_requests_count_attrs)\n \n response = None\n status = None\n@@ -165,6 +188,15 @@\n status = \"500 InternalServerError\"\n raise\n finally:\n+ duration = max(round((default_timer() - start) * 1000), 0)\n+ status = getattr(response, \"status\", status)\n+ status_code = otel_wsgi._parse_status_code(status)\n+ if status_code is not None:\n+ duration_attrs[\n+ SpanAttributes.HTTP_STATUS_CODE\n+ ] = otel_wsgi._parse_status_code(status)\n+ duration_histogram.record(duration, duration_attrs)\n+ active_requests_counter.add(-1, active_requests_count_attrs)\n span = request.environ.get(_ENVIRON_SPAN_KEY)\n enabled = request.environ.get(_ENVIRON_ENABLED_KEY)\n if not span and enabled:\n@@ -174,7 +206,6 @@\n \"PyramidInstrumentor().instrument_config(config) is called\"\n )\n elif enabled:\n- status = getattr(response, \"status\", status)\n \n if status is not None:\n otel_wsgi.add_response_attributes(\n", "issue": "Metrics instrumentation pyramid\nHTTP metrics semconv: https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/metrics/semantic_conventions/http-metrics.md\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom logging import getLogger\nfrom time import time_ns\n\nfrom pyramid.events import BeforeTraversal\nfrom pyramid.httpexceptions import HTTPException, HTTPServerError\nfrom pyramid.settings import asbool\nfrom pyramid.tweens import EXCVIEW\n\nimport opentelemetry.instrumentation.wsgi as otel_wsgi\nfrom opentelemetry import context, trace\nfrom opentelemetry.instrumentation.propagators import (\n get_global_response_propagator,\n)\nfrom opentelemetry.instrumentation.pyramid.version import __version__\nfrom opentelemetry.instrumentation.utils import _start_internal_or_server_span\nfrom opentelemetry.semconv.trace import SpanAttributes\nfrom opentelemetry.util.http import get_excluded_urls\n\nTWEEN_NAME = \"opentelemetry.instrumentation.pyramid.trace_tween_factory\"\nSETTING_TRACE_ENABLED = \"opentelemetry-pyramid.trace_enabled\"\n\n_ENVIRON_STARTTIME_KEY = \"opentelemetry-pyramid.starttime_key\"\n_ENVIRON_SPAN_KEY = \"opentelemetry-pyramid.span_key\"\n_ENVIRON_ACTIVATION_KEY = \"opentelemetry-pyramid.activation_key\"\n_ENVIRON_ENABLED_KEY = \"opentelemetry-pyramid.tracing_enabled_key\"\n_ENVIRON_TOKEN = \"opentelemetry-pyramid.token\"\n\n_logger = getLogger(__name__)\n\n\n_excluded_urls = get_excluded_urls(\"PYRAMID\")\n\n\ndef includeme(config):\n config.add_settings({SETTING_TRACE_ENABLED: True})\n\n config.add_subscriber(_before_traversal, BeforeTraversal)\n _insert_tween(config)\n\n\ndef _insert_tween(config):\n settings = config.get_settings()\n tweens = settings.get(\"pyramid.tweens\")\n # If the list is empty, pyramid does not consider the tweens have been\n # set explicitly. And if our tween is already there, nothing to do\n if not tweens or not tweens.strip():\n # Add our tween just before the default exception handler\n config.add_tween(TWEEN_NAME, over=EXCVIEW)\n\n\ndef _before_traversal(event):\n request = event.request\n request_environ = request.environ\n span_name = otel_wsgi.get_default_span_name(request_environ)\n\n enabled = request_environ.get(_ENVIRON_ENABLED_KEY)\n if enabled is None:\n _logger.warning(\n \"Opentelemetry pyramid tween 'opentelemetry.instrumentation.pyramid.trace_tween_factory'\"\n \"was not called. Make sure that the tween is included in 'pyramid.tweens' if\"\n \"the tween list was created manually\"\n )\n return\n\n if not enabled:\n # Tracing not enabled, return\n return\n\n start_time = request_environ.get(_ENVIRON_STARTTIME_KEY)\n tracer = trace.get_tracer(__name__, __version__)\n\n if request.matched_route:\n span_name = request.matched_route.pattern\n else:\n span_name = otel_wsgi.get_default_span_name(request_environ)\n\n span, token = _start_internal_or_server_span(\n tracer=tracer,\n span_name=span_name,\n start_time=start_time,\n context_carrier=request_environ,\n context_getter=otel_wsgi.wsgi_getter,\n )\n\n if span.is_recording():\n attributes = otel_wsgi.collect_request_attributes(request_environ)\n if request.matched_route:\n attributes[\n SpanAttributes.HTTP_ROUTE\n ] = request.matched_route.pattern\n for key, value in attributes.items():\n span.set_attribute(key, value)\n if span.kind == trace.SpanKind.SERVER:\n custom_attributes = (\n otel_wsgi.collect_custom_request_headers_attributes(\n request_environ\n )\n )\n if len(custom_attributes) > 0:\n span.set_attributes(custom_attributes)\n\n activation = trace.use_span(span, end_on_exit=True)\n activation.__enter__() # pylint: disable=E1101\n request_environ[_ENVIRON_ACTIVATION_KEY] = activation\n request_environ[_ENVIRON_SPAN_KEY] = span\n if token:\n request_environ[_ENVIRON_TOKEN] = token\n\n\ndef trace_tween_factory(handler, registry):\n settings = registry.settings\n enabled = asbool(settings.get(SETTING_TRACE_ENABLED, True))\n\n if not enabled:\n # If disabled, make a tween that signals to the\n # BeforeTraversal subscriber that tracing is disabled\n def disabled_tween(request):\n request.environ[_ENVIRON_ENABLED_KEY] = False\n return handler(request)\n\n return disabled_tween\n\n # make a request tracing function\n # pylint: disable=too-many-branches\n def trace_tween(request):\n # pylint: disable=E1101\n if _excluded_urls.url_disabled(request.url):\n request.environ[_ENVIRON_ENABLED_KEY] = False\n # short-circuit when we don't want to trace anything\n return handler(request)\n\n request.environ[_ENVIRON_ENABLED_KEY] = True\n request.environ[_ENVIRON_STARTTIME_KEY] = time_ns()\n\n response = None\n status = None\n\n try:\n response = handler(request)\n except HTTPException as exc:\n # If the exception is a pyramid HTTPException,\n # that's still valuable information that isn't necessarily\n # a 500. For instance, HTTPFound is a 302.\n # As described in docs, Pyramid exceptions are all valid\n # response types\n response = exc\n raise\n except BaseException:\n # In the case that a non-HTTPException is bubbled up we\n # should infer a internal server error and raise\n status = \"500 InternalServerError\"\n raise\n finally:\n span = request.environ.get(_ENVIRON_SPAN_KEY)\n enabled = request.environ.get(_ENVIRON_ENABLED_KEY)\n if not span and enabled:\n _logger.warning(\n \"Pyramid environ's OpenTelemetry span missing.\"\n \"If the OpenTelemetry tween was added manually, make sure\"\n \"PyramidInstrumentor().instrument_config(config) is called\"\n )\n elif enabled:\n status = getattr(response, \"status\", status)\n\n if status is not None:\n otel_wsgi.add_response_attributes(\n span,\n status,\n getattr(response, \"headerlist\", None),\n )\n\n if span.is_recording() and span.kind == trace.SpanKind.SERVER:\n custom_attributes = (\n otel_wsgi.collect_custom_response_headers_attributes(\n getattr(response, \"headerlist\", None)\n )\n )\n if len(custom_attributes) > 0:\n span.set_attributes(custom_attributes)\n\n propagator = get_global_response_propagator()\n if propagator and hasattr(response, \"headers\"):\n propagator.inject(response.headers)\n\n activation = request.environ.get(_ENVIRON_ACTIVATION_KEY)\n\n # Only considering HTTPServerError\n # to make sure 200, 300 and 400 exceptions are not reported as error\n if isinstance(response, HTTPServerError):\n activation.__exit__(\n type(response),\n response,\n getattr(response, \"__traceback__\", None),\n )\n else:\n activation.__exit__(None, None, None)\n\n env_token = request.environ.get(_ENVIRON_TOKEN, None)\n if env_token is not None:\n context.detach(env_token)\n\n return response\n\n return trace_tween\n", "path": "instrumentation/opentelemetry-instrumentation-pyramid/src/opentelemetry/instrumentation/pyramid/callbacks.py"}]}
| 2,861 | 872 |
gh_patches_debug_2737
|
rasdani/github-patches
|
git_diff
|
holoviz__panel-2616
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
--autoreload raises AttributeError: 'NoneType' object has no attribute 'stop'
I'm on the current Panel master. When I `panel serve 'script.py' --autoreload` this code
```python
import panel as pn
pn.extension()
import numpy as np
import holoviews as hv
from holoviews import opts, streams
from holoviews.plotting.links import DataLink
hv.extension('bokeh')
curve = hv.Curve(np.random.randn(10).cumsum()).opts(responsive=True, line_width=6)
table = hv.Table(curve).opts(editable=True)
component=pn.pane.HoloViews(table, height=500, sizing_mode="stretch_both")
pn.template.FastListTemplate(title="Table", main=[component]).servable()
```
and change the code I get the error
```bash
2021-08-04 06:40:44,760 Error thrown from periodic callback:
2021-08-04 06:40:44,763 Traceback (most recent call last):
File "c:\repos\private\panel_docker\panel\.venv\lib\site-packages\tornado\gen.py", line 526, in callback
result_list.append(f.result())
File "c:\repos\private\panel_docker\panel\.venv\lib\site-packages\bokeh\server\session.py", line 67, in _needs_document_lock_wrapper
result = func(self, *args, **kwargs)
File "c:\repos\private\panel_docker\panel\.venv\lib\site-packages\bokeh\server\session.py", line 195, in with_document_locked
return func(*args, **kwargs)
File "c:\repos\private\panel_docker\panel\.venv\lib\site-packages\bokeh\document\document.py", line 1212, in wrapper
return doc._with_self_as_curdoc(invoke)
File "c:\repos\private\panel_docker\panel\.venv\lib\site-packages\bokeh\document\document.py", line 1198, in _with_self_as_curdoc
return f()
File "c:\repos\private\panel_docker\panel\.venv\lib\site-packages\bokeh\document\document.py", line 1211, in invoke
return f(*args, **kwargs)
File "c:\repos\private\panel_docker\panel\panel\io\callbacks.py", line 72, in _periodic_callback
self.callback()
File "c:\repos\private\panel_docker\panel\panel\io\reload.py", line 155, in _reload_on_update
_check_file(modify_times, path)
File "c:\repos\private\panel_docker\panel\panel\io\reload.py", line 134, in _check_file
_reload(module)
File "c:\repos\private\panel_docker\panel\panel\io\reload.py", line 117, in _reload
cb.stop()
File "c:\repos\private\panel_docker\panel\panel\io\callbacks.py", line 134, in stop
self._cb.stop()
AttributeError: 'NoneType' object has no attribute 'stop'
```
I believe this is would be a major issue if 0.12.1 was released before fixing this @philippjfr
</issue>
<code>
[start of panel/io/callbacks.py]
1 """
2 Defines callbacks to be executed on a thread or by scheduling it
3 on a running bokeh server.
4 """
5 import time
6 import param
7
8 from bokeh.io import curdoc as _curdoc
9
10 from ..util import edit_readonly
11 from .state import state
12
13
14 class PeriodicCallback(param.Parameterized):
15 """
16 Periodic encapsulates a periodic callback which will run both
17 in tornado based notebook environments and on bokeh server. By
18 default the callback will run until the stop method is called,
19 but count and timeout values can be set to limit the number of
20 executions or the maximum length of time for which the callback
21 will run. The callback may also be started and stopped by setting
22 the running parameter to True or False respectively.
23 """
24
25 callback = param.Callable(doc="""
26 The callback to execute periodically.""")
27
28 count = param.Integer(default=None, doc="""
29 Number of times the callback will be executed, by default
30 this is unlimited.""")
31
32 period = param.Integer(default=500, doc="""
33 Period in milliseconds at which the callback is executed.""")
34
35 timeout = param.Integer(default=None, doc="""
36 Timeout in milliseconds from the start time at which the callback
37 expires.""")
38
39 running = param.Boolean(default=False, doc="""
40 Toggles whether the periodic callback is currently running.""")
41
42 def __init__(self, **params):
43 super().__init__(**params)
44 self._counter = 0
45 self._start_time = None
46 self._cb = None
47 self._updating = False
48 self._doc = None
49
50 @param.depends('running', watch=True)
51 def _start(self):
52 if not self.running or self._updating:
53 return
54 self.start()
55
56 @param.depends('running', watch=True)
57 def _stop(self):
58 if self.running or self._updating:
59 return
60 self.stop()
61
62 @param.depends('period', watch=True)
63 def _update_period(self):
64 if self._cb:
65 self.stop()
66 self.start()
67
68 def _periodic_callback(self):
69 with edit_readonly(state):
70 state.busy = True
71 try:
72 self.callback()
73 finally:
74 with edit_readonly(state):
75 state.busy = False
76 self._counter += 1
77 if self.timeout is not None:
78 dt = (time.time() - self._start_time) * 1000
79 if dt > self.timeout:
80 self.stop()
81 if self._counter == self.count:
82 self.stop()
83
84 @property
85 def counter(self):
86 """
87 Returns the execution count of the periodic callback.
88 """
89 return self._counter
90
91 def _cleanup(self, session_context):
92 self.stop()
93
94 def start(self):
95 """
96 Starts running the periodic callback.
97 """
98 if self._cb is not None:
99 raise RuntimeError('Periodic callback has already started.')
100 if not self.running:
101 try:
102 self._updating = True
103 self.running = True
104 finally:
105 self._updating = False
106 self._start_time = time.time()
107 if state.curdoc:
108 self._doc = state.curdoc
109 self._cb = self._doc.add_periodic_callback(self._periodic_callback, self.period)
110 else:
111 from tornado.ioloop import PeriodicCallback
112 self._cb = PeriodicCallback(self._periodic_callback, self.period)
113 self._cb.start()
114 try:
115 state.on_session_destroyed(self._cleanup)
116 except Exception:
117 pass
118
119 def stop(self):
120 """
121 Stops running the periodic callback.
122 """
123 if self.running:
124 try:
125 self._updating = True
126 self.running = False
127 finally:
128 self._updating = False
129 self._counter = 0
130 self._timeout = None
131 if self._doc:
132 self._doc.remove_periodic_callback(self._cb)
133 else:
134 self._cb.stop()
135 self._cb = None
136 doc = self._doc or _curdoc()
137 if doc:
138 doc.session_destroyed_callbacks = {
139 cb for cb in doc.session_destroyed_callbacks
140 if cb is not self._cleanup
141 }
142 self._doc = None
143
[end of panel/io/callbacks.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/panel/io/callbacks.py b/panel/io/callbacks.py
--- a/panel/io/callbacks.py
+++ b/panel/io/callbacks.py
@@ -130,7 +130,7 @@
self._timeout = None
if self._doc:
self._doc.remove_periodic_callback(self._cb)
- else:
+ elif self._cb:
self._cb.stop()
self._cb = None
doc = self._doc or _curdoc()
|
{"golden_diff": "diff --git a/panel/io/callbacks.py b/panel/io/callbacks.py\n--- a/panel/io/callbacks.py\n+++ b/panel/io/callbacks.py\n@@ -130,7 +130,7 @@\n self._timeout = None\n if self._doc:\n self._doc.remove_periodic_callback(self._cb)\n- else:\n+ elif self._cb:\n self._cb.stop()\n self._cb = None\n doc = self._doc or _curdoc()\n", "issue": "--autoreload raises AttributeError: 'NoneType' object has no attribute 'stop'\nI'm on the current Panel master. When I `panel serve 'script.py' --autoreload` this code\r\n\r\n```python\r\nimport panel as pn\r\npn.extension()\r\n\r\nimport numpy as np\r\nimport holoviews as hv\r\n\r\nfrom holoviews import opts, streams\r\nfrom holoviews.plotting.links import DataLink\r\n\r\nhv.extension('bokeh')\r\ncurve = hv.Curve(np.random.randn(10).cumsum()).opts(responsive=True, line_width=6)\r\ntable = hv.Table(curve).opts(editable=True)\r\ncomponent=pn.pane.HoloViews(table, height=500, sizing_mode=\"stretch_both\")\r\npn.template.FastListTemplate(title=\"Table\", main=[component]).servable()\r\n```\r\n\r\nand change the code I get the error\r\n\r\n```bash\r\n2021-08-04 06:40:44,760 Error thrown from periodic callback:\r\n2021-08-04 06:40:44,763 Traceback (most recent call last):\r\n File \"c:\\repos\\private\\panel_docker\\panel\\.venv\\lib\\site-packages\\tornado\\gen.py\", line 526, in callback\r\n result_list.append(f.result())\r\n File \"c:\\repos\\private\\panel_docker\\panel\\.venv\\lib\\site-packages\\bokeh\\server\\session.py\", line 67, in _needs_document_lock_wrapper\r\n result = func(self, *args, **kwargs)\r\n File \"c:\\repos\\private\\panel_docker\\panel\\.venv\\lib\\site-packages\\bokeh\\server\\session.py\", line 195, in with_document_locked\r\n return func(*args, **kwargs)\r\n File \"c:\\repos\\private\\panel_docker\\panel\\.venv\\lib\\site-packages\\bokeh\\document\\document.py\", line 1212, in wrapper\r\n return doc._with_self_as_curdoc(invoke)\r\n File \"c:\\repos\\private\\panel_docker\\panel\\.venv\\lib\\site-packages\\bokeh\\document\\document.py\", line 1198, in _with_self_as_curdoc\r\n return f()\r\n File \"c:\\repos\\private\\panel_docker\\panel\\.venv\\lib\\site-packages\\bokeh\\document\\document.py\", line 1211, in invoke\r\n return f(*args, **kwargs)\r\n File \"c:\\repos\\private\\panel_docker\\panel\\panel\\io\\callbacks.py\", line 72, in _periodic_callback\r\n self.callback()\r\n File \"c:\\repos\\private\\panel_docker\\panel\\panel\\io\\reload.py\", line 155, in _reload_on_update\r\n _check_file(modify_times, path)\r\n File \"c:\\repos\\private\\panel_docker\\panel\\panel\\io\\reload.py\", line 134, in _check_file\r\n _reload(module)\r\n File \"c:\\repos\\private\\panel_docker\\panel\\panel\\io\\reload.py\", line 117, in _reload\r\n cb.stop()\r\n File \"c:\\repos\\private\\panel_docker\\panel\\panel\\io\\callbacks.py\", line 134, in stop\r\n self._cb.stop()\r\nAttributeError: 'NoneType' object has no attribute 'stop'\r\n```\r\n\r\nI believe this is would be a major issue if 0.12.1 was released before fixing this @philippjfr \n", "before_files": [{"content": "\"\"\"\nDefines callbacks to be executed on a thread or by scheduling it\non a running bokeh server.\n\"\"\"\nimport time\nimport param\n\nfrom bokeh.io import curdoc as _curdoc\n\nfrom ..util import edit_readonly\nfrom .state import state\n\n\nclass PeriodicCallback(param.Parameterized):\n \"\"\"\n Periodic encapsulates a periodic callback which will run both\n in tornado based notebook environments and on bokeh server. By\n default the callback will run until the stop method is called,\n but count and timeout values can be set to limit the number of\n executions or the maximum length of time for which the callback\n will run. The callback may also be started and stopped by setting\n the running parameter to True or False respectively.\n \"\"\"\n\n callback = param.Callable(doc=\"\"\"\n The callback to execute periodically.\"\"\")\n\n count = param.Integer(default=None, doc=\"\"\"\n Number of times the callback will be executed, by default\n this is unlimited.\"\"\")\n\n period = param.Integer(default=500, doc=\"\"\"\n Period in milliseconds at which the callback is executed.\"\"\")\n\n timeout = param.Integer(default=None, doc=\"\"\"\n Timeout in milliseconds from the start time at which the callback\n expires.\"\"\")\n\n running = param.Boolean(default=False, doc=\"\"\"\n Toggles whether the periodic callback is currently running.\"\"\")\n\n def __init__(self, **params):\n super().__init__(**params)\n self._counter = 0\n self._start_time = None\n self._cb = None\n self._updating = False\n self._doc = None\n\n @param.depends('running', watch=True)\n def _start(self):\n if not self.running or self._updating:\n return\n self.start()\n\n @param.depends('running', watch=True)\n def _stop(self):\n if self.running or self._updating:\n return\n self.stop()\n\n @param.depends('period', watch=True)\n def _update_period(self):\n if self._cb:\n self.stop()\n self.start()\n\n def _periodic_callback(self):\n with edit_readonly(state):\n state.busy = True\n try:\n self.callback()\n finally:\n with edit_readonly(state):\n state.busy = False\n self._counter += 1\n if self.timeout is not None:\n dt = (time.time() - self._start_time) * 1000\n if dt > self.timeout:\n self.stop()\n if self._counter == self.count:\n self.stop()\n\n @property\n def counter(self):\n \"\"\"\n Returns the execution count of the periodic callback.\n \"\"\"\n return self._counter\n\n def _cleanup(self, session_context):\n self.stop()\n\n def start(self):\n \"\"\"\n Starts running the periodic callback.\n \"\"\"\n if self._cb is not None:\n raise RuntimeError('Periodic callback has already started.')\n if not self.running:\n try:\n self._updating = True\n self.running = True\n finally:\n self._updating = False\n self._start_time = time.time()\n if state.curdoc:\n self._doc = state.curdoc\n self._cb = self._doc.add_periodic_callback(self._periodic_callback, self.period)\n else:\n from tornado.ioloop import PeriodicCallback\n self._cb = PeriodicCallback(self._periodic_callback, self.period)\n self._cb.start()\n try:\n state.on_session_destroyed(self._cleanup)\n except Exception:\n pass\n\n def stop(self):\n \"\"\"\n Stops running the periodic callback.\n \"\"\"\n if self.running:\n try:\n self._updating = True\n self.running = False\n finally:\n self._updating = False\n self._counter = 0\n self._timeout = None\n if self._doc:\n self._doc.remove_periodic_callback(self._cb)\n else:\n self._cb.stop()\n self._cb = None\n doc = self._doc or _curdoc()\n if doc:\n doc.session_destroyed_callbacks = {\n cb for cb in doc.session_destroyed_callbacks\n if cb is not self._cleanup\n }\n self._doc = None\n", "path": "panel/io/callbacks.py"}]}
| 2,561 | 110 |
gh_patches_debug_18702
|
rasdani/github-patches
|
git_diff
|
CTFd__CTFd-1951
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add time to export filename
</issue>
<code>
[start of CTFd/admin/__init__.py]
1 import csv
2 import datetime
3 import os
4 from io import BytesIO, StringIO
5
6 from flask import Blueprint, abort
7 from flask import current_app as app
8 from flask import (
9 redirect,
10 render_template,
11 render_template_string,
12 request,
13 send_file,
14 url_for,
15 )
16
17 admin = Blueprint("admin", __name__)
18
19 # isort:imports-firstparty
20 from CTFd.admin import challenges # noqa: F401
21 from CTFd.admin import notifications # noqa: F401
22 from CTFd.admin import pages # noqa: F401
23 from CTFd.admin import scoreboard # noqa: F401
24 from CTFd.admin import statistics # noqa: F401
25 from CTFd.admin import submissions # noqa: F401
26 from CTFd.admin import teams # noqa: F401
27 from CTFd.admin import users # noqa: F401
28 from CTFd.cache import cache, clear_config, clear_pages, clear_standings
29 from CTFd.models import (
30 Awards,
31 Challenges,
32 Configs,
33 Notifications,
34 Pages,
35 Solves,
36 Submissions,
37 Teams,
38 Tracking,
39 Unlocks,
40 Users,
41 db,
42 get_class_by_tablename,
43 )
44 from CTFd.utils import config as ctf_config
45 from CTFd.utils import get_config, set_config
46 from CTFd.utils.csv import load_challenges_csv, load_teams_csv, load_users_csv
47 from CTFd.utils.decorators import admins_only
48 from CTFd.utils.exports import export_ctf as export_ctf_util
49 from CTFd.utils.exports import import_ctf as import_ctf_util
50 from CTFd.utils.helpers import get_errors
51 from CTFd.utils.security.auth import logout_user
52 from CTFd.utils.uploads import delete_file
53 from CTFd.utils.user import is_admin
54
55
56 @admin.route("/admin", methods=["GET"])
57 def view():
58 if is_admin():
59 return redirect(url_for("admin.statistics"))
60 return redirect(url_for("auth.login"))
61
62
63 @admin.route("/admin/plugins/<plugin>", methods=["GET", "POST"])
64 @admins_only
65 def plugin(plugin):
66 if request.method == "GET":
67 plugins_path = os.path.join(app.root_path, "plugins")
68
69 config_html_plugins = [
70 name
71 for name in os.listdir(plugins_path)
72 if os.path.isfile(os.path.join(plugins_path, name, "config.html"))
73 ]
74
75 if plugin in config_html_plugins:
76 config_html = open(
77 os.path.join(app.root_path, "plugins", plugin, "config.html")
78 ).read()
79 return render_template_string(config_html)
80 abort(404)
81 elif request.method == "POST":
82 for k, v in request.form.items():
83 if k == "nonce":
84 continue
85 set_config(k, v)
86 with app.app_context():
87 clear_config()
88 return "1"
89
90
91 @admin.route("/admin/import", methods=["POST"])
92 @admins_only
93 def import_ctf():
94 backup = request.files["backup"]
95 errors = get_errors()
96 try:
97 import_ctf_util(backup)
98 except Exception as e:
99 print(e)
100 errors.append(repr(e))
101
102 if errors:
103 return errors[0], 500
104 else:
105 return redirect(url_for("admin.config"))
106
107
108 @admin.route("/admin/export", methods=["GET", "POST"])
109 @admins_only
110 def export_ctf():
111 backup = export_ctf_util()
112 ctf_name = ctf_config.ctf_name()
113 day = datetime.datetime.now().strftime("%Y-%m-%d")
114 full_name = u"{}.{}.zip".format(ctf_name, day)
115 return send_file(
116 backup, cache_timeout=-1, as_attachment=True, attachment_filename=full_name
117 )
118
119
120 @admin.route("/admin/import/csv", methods=["POST"])
121 @admins_only
122 def import_csv():
123 csv_type = request.form["csv_type"]
124 # Try really hard to load data in properly no matter what nonsense Excel gave you
125 raw = request.files["csv_file"].stream.read()
126 try:
127 csvdata = raw.decode("utf-8-sig")
128 except UnicodeDecodeError:
129 try:
130 csvdata = raw.decode("cp1252")
131 except UnicodeDecodeError:
132 csvdata = raw.decode("latin-1")
133 csvfile = StringIO(csvdata)
134
135 loaders = {
136 "challenges": load_challenges_csv,
137 "users": load_users_csv,
138 "teams": load_teams_csv,
139 }
140
141 loader = loaders[csv_type]
142 reader = csv.DictReader(csvfile)
143 loader(reader)
144 return redirect(url_for("admin.config"))
145
146
147 @admin.route("/admin/export/csv")
148 @admins_only
149 def export_csv():
150 table = request.args.get("table")
151
152 # TODO: It might make sense to limit dumpable tables. Config could potentially leak sensitive information.
153 model = get_class_by_tablename(table)
154 if model is None:
155 abort(404)
156
157 temp = StringIO()
158 writer = csv.writer(temp)
159
160 header = [column.name for column in model.__mapper__.columns]
161 writer.writerow(header)
162
163 responses = model.query.all()
164
165 for curr in responses:
166 writer.writerow(
167 [getattr(curr, column.name) for column in model.__mapper__.columns]
168 )
169
170 temp.seek(0)
171
172 # In Python 3 send_file requires bytes
173 output = BytesIO()
174 output.write(temp.getvalue().encode("utf-8"))
175 output.seek(0)
176 temp.close()
177
178 return send_file(
179 output,
180 as_attachment=True,
181 cache_timeout=-1,
182 attachment_filename="{name}-{table}.csv".format(
183 name=ctf_config.ctf_name(), table=table
184 ),
185 )
186
187
188 @admin.route("/admin/config", methods=["GET", "POST"])
189 @admins_only
190 def config():
191 # Clear the config cache so that we don't get stale values
192 clear_config()
193
194 configs = Configs.query.all()
195 configs = {c.key: get_config(c.key) for c in configs}
196
197 themes = ctf_config.get_themes()
198 themes.remove(get_config("ctf_theme"))
199
200 return render_template("admin/config.html", themes=themes, **configs)
201
202
203 @admin.route("/admin/reset", methods=["GET", "POST"])
204 @admins_only
205 def reset():
206 if request.method == "POST":
207 require_setup = False
208 logout = False
209 next_url = url_for("admin.statistics")
210
211 data = request.form
212
213 if data.get("pages"):
214 _pages = Pages.query.all()
215 for p in _pages:
216 for f in p.files:
217 delete_file(file_id=f.id)
218
219 Pages.query.delete()
220
221 if data.get("notifications"):
222 Notifications.query.delete()
223
224 if data.get("challenges"):
225 _challenges = Challenges.query.all()
226 for c in _challenges:
227 for f in c.files:
228 delete_file(file_id=f.id)
229 Challenges.query.delete()
230
231 if data.get("accounts"):
232 Users.query.delete()
233 Teams.query.delete()
234 require_setup = True
235 logout = True
236
237 if data.get("submissions"):
238 Solves.query.delete()
239 Submissions.query.delete()
240 Awards.query.delete()
241 Unlocks.query.delete()
242 Tracking.query.delete()
243
244 if require_setup:
245 set_config("setup", False)
246 cache.clear()
247 logout_user()
248 next_url = url_for("views.setup")
249
250 db.session.commit()
251
252 clear_pages()
253 clear_standings()
254 clear_config()
255
256 if logout is True:
257 cache.clear()
258 logout_user()
259
260 db.session.close()
261 return redirect(next_url)
262
263 return render_template("admin/reset.html")
264
[end of CTFd/admin/__init__.py]
[start of manage.py]
1 import datetime
2 import shutil
3
4 from flask_migrate import MigrateCommand
5 from flask_script import Manager
6
7 from CTFd import create_app
8 from CTFd.utils import get_config as get_config_util
9 from CTFd.utils import set_config as set_config_util
10 from CTFd.utils.config import ctf_name
11 from CTFd.utils.exports import export_ctf as export_ctf_util
12 from CTFd.utils.exports import import_ctf as import_ctf_util
13
14 app = create_app()
15
16 manager = Manager(app)
17 manager.add_command("db", MigrateCommand)
18
19
20 def jsenums():
21 from CTFd.constants import JS_ENUMS
22 import json
23 import os
24
25 path = os.path.join(app.root_path, "themes/core/assets/js/constants.js")
26
27 with open(path, "w+") as f:
28 for k, v in JS_ENUMS.items():
29 f.write("const {} = Object.freeze({});".format(k, json.dumps(v)))
30
31
32 BUILD_COMMANDS = {"jsenums": jsenums}
33
34
35 @manager.command
36 def get_config(key):
37 with app.app_context():
38 print(get_config_util(key))
39
40
41 @manager.command
42 def set_config(key, value):
43 with app.app_context():
44 print(set_config_util(key, value).value)
45
46
47 @manager.command
48 def build(cmd):
49 with app.app_context():
50 cmd = BUILD_COMMANDS.get(cmd)
51 cmd()
52
53
54 @manager.command
55 def export_ctf(path=None):
56 with app.app_context():
57 backup = export_ctf_util()
58
59 if path:
60 with open(path, "wb") as target:
61 shutil.copyfileobj(backup, target)
62 else:
63 name = ctf_name()
64 day = datetime.datetime.now().strftime("%Y-%m-%d")
65 full_name = f"{name}.{day}.zip"
66
67 with open(full_name, "wb") as target:
68 shutil.copyfileobj(backup, target)
69
70 print(f"Exported {full_name}")
71
72
73 @manager.command
74 def import_ctf(path):
75 with app.app_context():
76 import_ctf_util(path)
77
78
79 if __name__ == "__main__":
80 manager.run()
81
[end of manage.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/CTFd/admin/__init__.py b/CTFd/admin/__init__.py
--- a/CTFd/admin/__init__.py
+++ b/CTFd/admin/__init__.py
@@ -110,7 +110,7 @@
def export_ctf():
backup = export_ctf_util()
ctf_name = ctf_config.ctf_name()
- day = datetime.datetime.now().strftime("%Y-%m-%d")
+ day = datetime.datetime.now().strftime("%Y-%m-%d_%T")
full_name = u"{}.{}.zip".format(ctf_name, day)
return send_file(
backup, cache_timeout=-1, as_attachment=True, attachment_filename=full_name
diff --git a/manage.py b/manage.py
--- a/manage.py
+++ b/manage.py
@@ -61,7 +61,7 @@
shutil.copyfileobj(backup, target)
else:
name = ctf_name()
- day = datetime.datetime.now().strftime("%Y-%m-%d")
+ day = datetime.datetime.now().strftime("%Y-%m-%d_%T")
full_name = f"{name}.{day}.zip"
with open(full_name, "wb") as target:
|
{"golden_diff": "diff --git a/CTFd/admin/__init__.py b/CTFd/admin/__init__.py\n--- a/CTFd/admin/__init__.py\n+++ b/CTFd/admin/__init__.py\n@@ -110,7 +110,7 @@\n def export_ctf():\n backup = export_ctf_util()\n ctf_name = ctf_config.ctf_name()\n- day = datetime.datetime.now().strftime(\"%Y-%m-%d\")\n+ day = datetime.datetime.now().strftime(\"%Y-%m-%d_%T\")\n full_name = u\"{}.{}.zip\".format(ctf_name, day)\n return send_file(\n backup, cache_timeout=-1, as_attachment=True, attachment_filename=full_name\ndiff --git a/manage.py b/manage.py\n--- a/manage.py\n+++ b/manage.py\n@@ -61,7 +61,7 @@\n shutil.copyfileobj(backup, target)\n else:\n name = ctf_name()\n- day = datetime.datetime.now().strftime(\"%Y-%m-%d\")\n+ day = datetime.datetime.now().strftime(\"%Y-%m-%d_%T\")\n full_name = f\"{name}.{day}.zip\"\n \n with open(full_name, \"wb\") as target:\n", "issue": "Add time to export filename\n\n", "before_files": [{"content": "import csv\nimport datetime\nimport os\nfrom io import BytesIO, StringIO\n\nfrom flask import Blueprint, abort\nfrom flask import current_app as app\nfrom flask import (\n redirect,\n render_template,\n render_template_string,\n request,\n send_file,\n url_for,\n)\n\nadmin = Blueprint(\"admin\", __name__)\n\n# isort:imports-firstparty\nfrom CTFd.admin import challenges # noqa: F401\nfrom CTFd.admin import notifications # noqa: F401\nfrom CTFd.admin import pages # noqa: F401\nfrom CTFd.admin import scoreboard # noqa: F401\nfrom CTFd.admin import statistics # noqa: F401\nfrom CTFd.admin import submissions # noqa: F401\nfrom CTFd.admin import teams # noqa: F401\nfrom CTFd.admin import users # noqa: F401\nfrom CTFd.cache import cache, clear_config, clear_pages, clear_standings\nfrom CTFd.models import (\n Awards,\n Challenges,\n Configs,\n Notifications,\n Pages,\n Solves,\n Submissions,\n Teams,\n Tracking,\n Unlocks,\n Users,\n db,\n get_class_by_tablename,\n)\nfrom CTFd.utils import config as ctf_config\nfrom CTFd.utils import get_config, set_config\nfrom CTFd.utils.csv import load_challenges_csv, load_teams_csv, load_users_csv\nfrom CTFd.utils.decorators import admins_only\nfrom CTFd.utils.exports import export_ctf as export_ctf_util\nfrom CTFd.utils.exports import import_ctf as import_ctf_util\nfrom CTFd.utils.helpers import get_errors\nfrom CTFd.utils.security.auth import logout_user\nfrom CTFd.utils.uploads import delete_file\nfrom CTFd.utils.user import is_admin\n\n\[email protected](\"/admin\", methods=[\"GET\"])\ndef view():\n if is_admin():\n return redirect(url_for(\"admin.statistics\"))\n return redirect(url_for(\"auth.login\"))\n\n\[email protected](\"/admin/plugins/<plugin>\", methods=[\"GET\", \"POST\"])\n@admins_only\ndef plugin(plugin):\n if request.method == \"GET\":\n plugins_path = os.path.join(app.root_path, \"plugins\")\n\n config_html_plugins = [\n name\n for name in os.listdir(plugins_path)\n if os.path.isfile(os.path.join(plugins_path, name, \"config.html\"))\n ]\n\n if plugin in config_html_plugins:\n config_html = open(\n os.path.join(app.root_path, \"plugins\", plugin, \"config.html\")\n ).read()\n return render_template_string(config_html)\n abort(404)\n elif request.method == \"POST\":\n for k, v in request.form.items():\n if k == \"nonce\":\n continue\n set_config(k, v)\n with app.app_context():\n clear_config()\n return \"1\"\n\n\[email protected](\"/admin/import\", methods=[\"POST\"])\n@admins_only\ndef import_ctf():\n backup = request.files[\"backup\"]\n errors = get_errors()\n try:\n import_ctf_util(backup)\n except Exception as e:\n print(e)\n errors.append(repr(e))\n\n if errors:\n return errors[0], 500\n else:\n return redirect(url_for(\"admin.config\"))\n\n\[email protected](\"/admin/export\", methods=[\"GET\", \"POST\"])\n@admins_only\ndef export_ctf():\n backup = export_ctf_util()\n ctf_name = ctf_config.ctf_name()\n day = datetime.datetime.now().strftime(\"%Y-%m-%d\")\n full_name = u\"{}.{}.zip\".format(ctf_name, day)\n return send_file(\n backup, cache_timeout=-1, as_attachment=True, attachment_filename=full_name\n )\n\n\[email protected](\"/admin/import/csv\", methods=[\"POST\"])\n@admins_only\ndef import_csv():\n csv_type = request.form[\"csv_type\"]\n # Try really hard to load data in properly no matter what nonsense Excel gave you\n raw = request.files[\"csv_file\"].stream.read()\n try:\n csvdata = raw.decode(\"utf-8-sig\")\n except UnicodeDecodeError:\n try:\n csvdata = raw.decode(\"cp1252\")\n except UnicodeDecodeError:\n csvdata = raw.decode(\"latin-1\")\n csvfile = StringIO(csvdata)\n\n loaders = {\n \"challenges\": load_challenges_csv,\n \"users\": load_users_csv,\n \"teams\": load_teams_csv,\n }\n\n loader = loaders[csv_type]\n reader = csv.DictReader(csvfile)\n loader(reader)\n return redirect(url_for(\"admin.config\"))\n\n\[email protected](\"/admin/export/csv\")\n@admins_only\ndef export_csv():\n table = request.args.get(\"table\")\n\n # TODO: It might make sense to limit dumpable tables. Config could potentially leak sensitive information.\n model = get_class_by_tablename(table)\n if model is None:\n abort(404)\n\n temp = StringIO()\n writer = csv.writer(temp)\n\n header = [column.name for column in model.__mapper__.columns]\n writer.writerow(header)\n\n responses = model.query.all()\n\n for curr in responses:\n writer.writerow(\n [getattr(curr, column.name) for column in model.__mapper__.columns]\n )\n\n temp.seek(0)\n\n # In Python 3 send_file requires bytes\n output = BytesIO()\n output.write(temp.getvalue().encode(\"utf-8\"))\n output.seek(0)\n temp.close()\n\n return send_file(\n output,\n as_attachment=True,\n cache_timeout=-1,\n attachment_filename=\"{name}-{table}.csv\".format(\n name=ctf_config.ctf_name(), table=table\n ),\n )\n\n\[email protected](\"/admin/config\", methods=[\"GET\", \"POST\"])\n@admins_only\ndef config():\n # Clear the config cache so that we don't get stale values\n clear_config()\n\n configs = Configs.query.all()\n configs = {c.key: get_config(c.key) for c in configs}\n\n themes = ctf_config.get_themes()\n themes.remove(get_config(\"ctf_theme\"))\n\n return render_template(\"admin/config.html\", themes=themes, **configs)\n\n\[email protected](\"/admin/reset\", methods=[\"GET\", \"POST\"])\n@admins_only\ndef reset():\n if request.method == \"POST\":\n require_setup = False\n logout = False\n next_url = url_for(\"admin.statistics\")\n\n data = request.form\n\n if data.get(\"pages\"):\n _pages = Pages.query.all()\n for p in _pages:\n for f in p.files:\n delete_file(file_id=f.id)\n\n Pages.query.delete()\n\n if data.get(\"notifications\"):\n Notifications.query.delete()\n\n if data.get(\"challenges\"):\n _challenges = Challenges.query.all()\n for c in _challenges:\n for f in c.files:\n delete_file(file_id=f.id)\n Challenges.query.delete()\n\n if data.get(\"accounts\"):\n Users.query.delete()\n Teams.query.delete()\n require_setup = True\n logout = True\n\n if data.get(\"submissions\"):\n Solves.query.delete()\n Submissions.query.delete()\n Awards.query.delete()\n Unlocks.query.delete()\n Tracking.query.delete()\n\n if require_setup:\n set_config(\"setup\", False)\n cache.clear()\n logout_user()\n next_url = url_for(\"views.setup\")\n\n db.session.commit()\n\n clear_pages()\n clear_standings()\n clear_config()\n\n if logout is True:\n cache.clear()\n logout_user()\n\n db.session.close()\n return redirect(next_url)\n\n return render_template(\"admin/reset.html\")\n", "path": "CTFd/admin/__init__.py"}, {"content": "import datetime\nimport shutil\n\nfrom flask_migrate import MigrateCommand\nfrom flask_script import Manager\n\nfrom CTFd import create_app\nfrom CTFd.utils import get_config as get_config_util\nfrom CTFd.utils import set_config as set_config_util\nfrom CTFd.utils.config import ctf_name\nfrom CTFd.utils.exports import export_ctf as export_ctf_util\nfrom CTFd.utils.exports import import_ctf as import_ctf_util\n\napp = create_app()\n\nmanager = Manager(app)\nmanager.add_command(\"db\", MigrateCommand)\n\n\ndef jsenums():\n from CTFd.constants import JS_ENUMS\n import json\n import os\n\n path = os.path.join(app.root_path, \"themes/core/assets/js/constants.js\")\n\n with open(path, \"w+\") as f:\n for k, v in JS_ENUMS.items():\n f.write(\"const {} = Object.freeze({});\".format(k, json.dumps(v)))\n\n\nBUILD_COMMANDS = {\"jsenums\": jsenums}\n\n\[email protected]\ndef get_config(key):\n with app.app_context():\n print(get_config_util(key))\n\n\[email protected]\ndef set_config(key, value):\n with app.app_context():\n print(set_config_util(key, value).value)\n\n\[email protected]\ndef build(cmd):\n with app.app_context():\n cmd = BUILD_COMMANDS.get(cmd)\n cmd()\n\n\[email protected]\ndef export_ctf(path=None):\n with app.app_context():\n backup = export_ctf_util()\n\n if path:\n with open(path, \"wb\") as target:\n shutil.copyfileobj(backup, target)\n else:\n name = ctf_name()\n day = datetime.datetime.now().strftime(\"%Y-%m-%d\")\n full_name = f\"{name}.{day}.zip\"\n\n with open(full_name, \"wb\") as target:\n shutil.copyfileobj(backup, target)\n\n print(f\"Exported {full_name}\")\n\n\[email protected]\ndef import_ctf(path):\n with app.app_context():\n import_ctf_util(path)\n\n\nif __name__ == \"__main__\":\n manager.run()\n", "path": "manage.py"}]}
| 3,543 | 268 |
gh_patches_debug_16150
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-1707
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add warning for `files` / `exclude` containing `/*`
it's a common mistake to believe that those fields are globs, they're not -- they're regular expressions. (and matching `/*` is nonsense, it matches `''`, `'/'` as well as `'//////////////////////////////////////////////////////'`
</issue>
<code>
[start of pre_commit/clientlib.py]
1 import argparse
2 import functools
3 import logging
4 import shlex
5 import sys
6 from typing import Any
7 from typing import Dict
8 from typing import Optional
9 from typing import Sequence
10
11 import cfgv
12 from identify.identify import ALL_TAGS
13
14 import pre_commit.constants as C
15 from pre_commit.color import add_color_option
16 from pre_commit.errors import FatalError
17 from pre_commit.languages.all import all_languages
18 from pre_commit.logging_handler import logging_handler
19 from pre_commit.util import parse_version
20 from pre_commit.util import yaml_load
21
22 logger = logging.getLogger('pre_commit')
23
24 check_string_regex = cfgv.check_and(cfgv.check_string, cfgv.check_regex)
25
26
27 def check_type_tag(tag: str) -> None:
28 if tag not in ALL_TAGS:
29 raise cfgv.ValidationError(
30 f'Type tag {tag!r} is not recognized. '
31 f'Try upgrading identify and pre-commit?',
32 )
33
34
35 def check_min_version(version: str) -> None:
36 if parse_version(version) > parse_version(C.VERSION):
37 raise cfgv.ValidationError(
38 f'pre-commit version {version} is required but version '
39 f'{C.VERSION} is installed. '
40 f'Perhaps run `pip install --upgrade pre-commit`.',
41 )
42
43
44 def _make_argparser(filenames_help: str) -> argparse.ArgumentParser:
45 parser = argparse.ArgumentParser()
46 parser.add_argument('filenames', nargs='*', help=filenames_help)
47 parser.add_argument('-V', '--version', action='version', version=C.VERSION)
48 add_color_option(parser)
49 return parser
50
51
52 MANIFEST_HOOK_DICT = cfgv.Map(
53 'Hook', 'id',
54
55 cfgv.Required('id', cfgv.check_string),
56 cfgv.Required('name', cfgv.check_string),
57 cfgv.Required('entry', cfgv.check_string),
58 cfgv.Required('language', cfgv.check_one_of(all_languages)),
59 cfgv.Optional('alias', cfgv.check_string, ''),
60
61 cfgv.Optional('files', check_string_regex, ''),
62 cfgv.Optional('exclude', check_string_regex, '^$'),
63 cfgv.Optional('types', cfgv.check_array(check_type_tag), ['file']),
64 cfgv.Optional('types_or', cfgv.check_array(check_type_tag), ['file']),
65 cfgv.Optional('exclude_types', cfgv.check_array(check_type_tag), []),
66
67 cfgv.Optional(
68 'additional_dependencies', cfgv.check_array(cfgv.check_string), [],
69 ),
70 cfgv.Optional('args', cfgv.check_array(cfgv.check_string), []),
71 cfgv.Optional('always_run', cfgv.check_bool, False),
72 cfgv.Optional('pass_filenames', cfgv.check_bool, True),
73 cfgv.Optional('description', cfgv.check_string, ''),
74 cfgv.Optional('language_version', cfgv.check_string, C.DEFAULT),
75 cfgv.Optional('log_file', cfgv.check_string, ''),
76 cfgv.Optional('minimum_pre_commit_version', cfgv.check_string, '0'),
77 cfgv.Optional('require_serial', cfgv.check_bool, False),
78 cfgv.Optional('stages', cfgv.check_array(cfgv.check_one_of(C.STAGES)), []),
79 cfgv.Optional('verbose', cfgv.check_bool, False),
80 )
81 MANIFEST_SCHEMA = cfgv.Array(MANIFEST_HOOK_DICT)
82
83
84 class InvalidManifestError(FatalError):
85 pass
86
87
88 load_manifest = functools.partial(
89 cfgv.load_from_filename,
90 schema=MANIFEST_SCHEMA,
91 load_strategy=yaml_load,
92 exc_tp=InvalidManifestError,
93 )
94
95
96 def validate_manifest_main(argv: Optional[Sequence[str]] = None) -> int:
97 parser = _make_argparser('Manifest filenames.')
98 args = parser.parse_args(argv)
99
100 with logging_handler(args.color):
101 ret = 0
102 for filename in args.filenames:
103 try:
104 load_manifest(filename)
105 except InvalidManifestError as e:
106 print(e)
107 ret = 1
108 return ret
109
110
111 LOCAL = 'local'
112 META = 'meta'
113
114
115 class MigrateShaToRev:
116 key = 'rev'
117
118 @staticmethod
119 def _cond(key: str) -> cfgv.Conditional:
120 return cfgv.Conditional(
121 key, cfgv.check_string,
122 condition_key='repo',
123 condition_value=cfgv.NotIn(LOCAL, META),
124 ensure_absent=True,
125 )
126
127 def check(self, dct: Dict[str, Any]) -> None:
128 if dct.get('repo') in {LOCAL, META}:
129 self._cond('rev').check(dct)
130 self._cond('sha').check(dct)
131 elif 'sha' in dct and 'rev' in dct:
132 raise cfgv.ValidationError('Cannot specify both sha and rev')
133 elif 'sha' in dct:
134 self._cond('sha').check(dct)
135 else:
136 self._cond('rev').check(dct)
137
138 def apply_default(self, dct: Dict[str, Any]) -> None:
139 if 'sha' in dct:
140 dct['rev'] = dct.pop('sha')
141
142 remove_default = cfgv.Required.remove_default
143
144
145 def _entry(modname: str) -> str:
146 """the hook `entry` is passed through `shlex.split()` by the command
147 runner, so to prevent issues with spaces and backslashes (on Windows)
148 it must be quoted here.
149 """
150 return f'{shlex.quote(sys.executable)} -m pre_commit.meta_hooks.{modname}'
151
152
153 def warn_unknown_keys_root(
154 extra: Sequence[str],
155 orig_keys: Sequence[str],
156 dct: Dict[str, str],
157 ) -> None:
158 logger.warning(f'Unexpected key(s) present at root: {", ".join(extra)}')
159
160
161 def warn_unknown_keys_repo(
162 extra: Sequence[str],
163 orig_keys: Sequence[str],
164 dct: Dict[str, str],
165 ) -> None:
166 logger.warning(
167 f'Unexpected key(s) present on {dct["repo"]}: {", ".join(extra)}',
168 )
169
170
171 _meta = (
172 (
173 'check-hooks-apply', (
174 ('name', 'Check hooks apply to the repository'),
175 ('files', C.CONFIG_FILE),
176 ('entry', _entry('check_hooks_apply')),
177 ),
178 ),
179 (
180 'check-useless-excludes', (
181 ('name', 'Check for useless excludes'),
182 ('files', C.CONFIG_FILE),
183 ('entry', _entry('check_useless_excludes')),
184 ),
185 ),
186 (
187 'identity', (
188 ('name', 'identity'),
189 ('verbose', True),
190 ('entry', _entry('identity')),
191 ),
192 ),
193 )
194
195 META_HOOK_DICT = cfgv.Map(
196 'Hook', 'id',
197 cfgv.Required('id', cfgv.check_string),
198 cfgv.Required('id', cfgv.check_one_of(tuple(k for k, _ in _meta))),
199 # language must be system
200 cfgv.Optional('language', cfgv.check_one_of({'system'}), 'system'),
201 *(
202 # default to the hook definition for the meta hooks
203 cfgv.ConditionalOptional(key, cfgv.check_any, value, 'id', hook_id)
204 for hook_id, values in _meta
205 for key, value in values
206 ),
207 *(
208 # default to the "manifest" parsing
209 cfgv.OptionalNoDefault(item.key, item.check_fn)
210 # these will always be defaulted above
211 if item.key in {'name', 'language', 'entry'} else
212 item
213 for item in MANIFEST_HOOK_DICT.items
214 ),
215 )
216 CONFIG_HOOK_DICT = cfgv.Map(
217 'Hook', 'id',
218
219 cfgv.Required('id', cfgv.check_string),
220
221 # All keys in manifest hook dict are valid in a config hook dict, but
222 # are optional.
223 # No defaults are provided here as the config is merged on top of the
224 # manifest.
225 *(
226 cfgv.OptionalNoDefault(item.key, item.check_fn)
227 for item in MANIFEST_HOOK_DICT.items
228 if item.key != 'id'
229 ),
230 )
231 CONFIG_REPO_DICT = cfgv.Map(
232 'Repository', 'repo',
233
234 cfgv.Required('repo', cfgv.check_string),
235
236 cfgv.ConditionalRecurse(
237 'hooks', cfgv.Array(CONFIG_HOOK_DICT),
238 'repo', cfgv.NotIn(LOCAL, META),
239 ),
240 cfgv.ConditionalRecurse(
241 'hooks', cfgv.Array(MANIFEST_HOOK_DICT),
242 'repo', LOCAL,
243 ),
244 cfgv.ConditionalRecurse(
245 'hooks', cfgv.Array(META_HOOK_DICT),
246 'repo', META,
247 ),
248
249 MigrateShaToRev(),
250 cfgv.WarnAdditionalKeys(('repo', 'rev', 'hooks'), warn_unknown_keys_repo),
251 )
252 DEFAULT_LANGUAGE_VERSION = cfgv.Map(
253 'DefaultLanguageVersion', None,
254 cfgv.NoAdditionalKeys(all_languages),
255 *(cfgv.Optional(x, cfgv.check_string, C.DEFAULT) for x in all_languages),
256 )
257 CONFIG_SCHEMA = cfgv.Map(
258 'Config', None,
259
260 cfgv.RequiredRecurse('repos', cfgv.Array(CONFIG_REPO_DICT)),
261 cfgv.OptionalRecurse(
262 'default_language_version', DEFAULT_LANGUAGE_VERSION, {},
263 ),
264 cfgv.Optional(
265 'default_stages',
266 cfgv.check_array(cfgv.check_one_of(C.STAGES)),
267 C.STAGES,
268 ),
269 cfgv.Optional('files', check_string_regex, ''),
270 cfgv.Optional('exclude', check_string_regex, '^$'),
271 cfgv.Optional('fail_fast', cfgv.check_bool, False),
272 cfgv.Optional(
273 'minimum_pre_commit_version',
274 cfgv.check_and(cfgv.check_string, check_min_version),
275 '0',
276 ),
277 cfgv.WarnAdditionalKeys(
278 (
279 'repos',
280 'default_language_version',
281 'default_stages',
282 'files',
283 'exclude',
284 'fail_fast',
285 'minimum_pre_commit_version',
286 ),
287 warn_unknown_keys_root,
288 ),
289 )
290
291
292 class InvalidConfigError(FatalError):
293 pass
294
295
296 def ordered_load_normalize_legacy_config(contents: str) -> Dict[str, Any]:
297 data = yaml_load(contents)
298 if isinstance(data, list):
299 logger.warning(
300 'normalizing pre-commit configuration to a top-level map. '
301 'support for top level list will be removed in a future version. '
302 'run: `pre-commit migrate-config` to automatically fix this.',
303 )
304 return {'repos': data}
305 else:
306 return data
307
308
309 load_config = functools.partial(
310 cfgv.load_from_filename,
311 schema=CONFIG_SCHEMA,
312 load_strategy=ordered_load_normalize_legacy_config,
313 exc_tp=InvalidConfigError,
314 )
315
316
317 def validate_config_main(argv: Optional[Sequence[str]] = None) -> int:
318 parser = _make_argparser('Config filenames.')
319 args = parser.parse_args(argv)
320
321 with logging_handler(args.color):
322 ret = 0
323 for filename in args.filenames:
324 try:
325 load_config(filename)
326 except InvalidConfigError as e:
327 print(e)
328 ret = 1
329 return ret
330
[end of pre_commit/clientlib.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pre_commit/clientlib.py b/pre_commit/clientlib.py
--- a/pre_commit/clientlib.py
+++ b/pre_commit/clientlib.py
@@ -112,6 +112,18 @@
META = 'meta'
+class OptionalSensibleRegex(cfgv.OptionalNoDefault):
+ def check(self, dct: Dict[str, Any]) -> None:
+ super().check(dct)
+
+ if '/*' in dct.get(self.key, ''):
+ logger.warning(
+ f'The {self.key!r} field in hook {dct.get("id")!r} is a '
+ f"regex, not a glob -- matching '/*' probably isn't what you "
+ f'want here',
+ )
+
+
class MigrateShaToRev:
key = 'rev'
@@ -227,6 +239,8 @@
for item in MANIFEST_HOOK_DICT.items
if item.key != 'id'
),
+ OptionalSensibleRegex('files', cfgv.check_string),
+ OptionalSensibleRegex('exclude', cfgv.check_string),
)
CONFIG_REPO_DICT = cfgv.Map(
'Repository', 'repo',
|
{"golden_diff": "diff --git a/pre_commit/clientlib.py b/pre_commit/clientlib.py\n--- a/pre_commit/clientlib.py\n+++ b/pre_commit/clientlib.py\n@@ -112,6 +112,18 @@\n META = 'meta'\n \n \n+class OptionalSensibleRegex(cfgv.OptionalNoDefault):\n+ def check(self, dct: Dict[str, Any]) -> None:\n+ super().check(dct)\n+\n+ if '/*' in dct.get(self.key, ''):\n+ logger.warning(\n+ f'The {self.key!r} field in hook {dct.get(\"id\")!r} is a '\n+ f\"regex, not a glob -- matching '/*' probably isn't what you \"\n+ f'want here',\n+ )\n+\n+\n class MigrateShaToRev:\n key = 'rev'\n \n@@ -227,6 +239,8 @@\n for item in MANIFEST_HOOK_DICT.items\n if item.key != 'id'\n ),\n+ OptionalSensibleRegex('files', cfgv.check_string),\n+ OptionalSensibleRegex('exclude', cfgv.check_string),\n )\n CONFIG_REPO_DICT = cfgv.Map(\n 'Repository', 'repo',\n", "issue": "Add warning for `files` / `exclude` containing `/*`\nit's a common mistake to believe that those fields are globs, they're not -- they're regular expressions. (and matching `/*` is nonsense, it matches `''`, `'/'` as well as `'//////////////////////////////////////////////////////'`\n", "before_files": [{"content": "import argparse\nimport functools\nimport logging\nimport shlex\nimport sys\nfrom typing import Any\nfrom typing import Dict\nfrom typing import Optional\nfrom typing import Sequence\n\nimport cfgv\nfrom identify.identify import ALL_TAGS\n\nimport pre_commit.constants as C\nfrom pre_commit.color import add_color_option\nfrom pre_commit.errors import FatalError\nfrom pre_commit.languages.all import all_languages\nfrom pre_commit.logging_handler import logging_handler\nfrom pre_commit.util import parse_version\nfrom pre_commit.util import yaml_load\n\nlogger = logging.getLogger('pre_commit')\n\ncheck_string_regex = cfgv.check_and(cfgv.check_string, cfgv.check_regex)\n\n\ndef check_type_tag(tag: str) -> None:\n if tag not in ALL_TAGS:\n raise cfgv.ValidationError(\n f'Type tag {tag!r} is not recognized. '\n f'Try upgrading identify and pre-commit?',\n )\n\n\ndef check_min_version(version: str) -> None:\n if parse_version(version) > parse_version(C.VERSION):\n raise cfgv.ValidationError(\n f'pre-commit version {version} is required but version '\n f'{C.VERSION} is installed. '\n f'Perhaps run `pip install --upgrade pre-commit`.',\n )\n\n\ndef _make_argparser(filenames_help: str) -> argparse.ArgumentParser:\n parser = argparse.ArgumentParser()\n parser.add_argument('filenames', nargs='*', help=filenames_help)\n parser.add_argument('-V', '--version', action='version', version=C.VERSION)\n add_color_option(parser)\n return parser\n\n\nMANIFEST_HOOK_DICT = cfgv.Map(\n 'Hook', 'id',\n\n cfgv.Required('id', cfgv.check_string),\n cfgv.Required('name', cfgv.check_string),\n cfgv.Required('entry', cfgv.check_string),\n cfgv.Required('language', cfgv.check_one_of(all_languages)),\n cfgv.Optional('alias', cfgv.check_string, ''),\n\n cfgv.Optional('files', check_string_regex, ''),\n cfgv.Optional('exclude', check_string_regex, '^$'),\n cfgv.Optional('types', cfgv.check_array(check_type_tag), ['file']),\n cfgv.Optional('types_or', cfgv.check_array(check_type_tag), ['file']),\n cfgv.Optional('exclude_types', cfgv.check_array(check_type_tag), []),\n\n cfgv.Optional(\n 'additional_dependencies', cfgv.check_array(cfgv.check_string), [],\n ),\n cfgv.Optional('args', cfgv.check_array(cfgv.check_string), []),\n cfgv.Optional('always_run', cfgv.check_bool, False),\n cfgv.Optional('pass_filenames', cfgv.check_bool, True),\n cfgv.Optional('description', cfgv.check_string, ''),\n cfgv.Optional('language_version', cfgv.check_string, C.DEFAULT),\n cfgv.Optional('log_file', cfgv.check_string, ''),\n cfgv.Optional('minimum_pre_commit_version', cfgv.check_string, '0'),\n cfgv.Optional('require_serial', cfgv.check_bool, False),\n cfgv.Optional('stages', cfgv.check_array(cfgv.check_one_of(C.STAGES)), []),\n cfgv.Optional('verbose', cfgv.check_bool, False),\n)\nMANIFEST_SCHEMA = cfgv.Array(MANIFEST_HOOK_DICT)\n\n\nclass InvalidManifestError(FatalError):\n pass\n\n\nload_manifest = functools.partial(\n cfgv.load_from_filename,\n schema=MANIFEST_SCHEMA,\n load_strategy=yaml_load,\n exc_tp=InvalidManifestError,\n)\n\n\ndef validate_manifest_main(argv: Optional[Sequence[str]] = None) -> int:\n parser = _make_argparser('Manifest filenames.')\n args = parser.parse_args(argv)\n\n with logging_handler(args.color):\n ret = 0\n for filename in args.filenames:\n try:\n load_manifest(filename)\n except InvalidManifestError as e:\n print(e)\n ret = 1\n return ret\n\n\nLOCAL = 'local'\nMETA = 'meta'\n\n\nclass MigrateShaToRev:\n key = 'rev'\n\n @staticmethod\n def _cond(key: str) -> cfgv.Conditional:\n return cfgv.Conditional(\n key, cfgv.check_string,\n condition_key='repo',\n condition_value=cfgv.NotIn(LOCAL, META),\n ensure_absent=True,\n )\n\n def check(self, dct: Dict[str, Any]) -> None:\n if dct.get('repo') in {LOCAL, META}:\n self._cond('rev').check(dct)\n self._cond('sha').check(dct)\n elif 'sha' in dct and 'rev' in dct:\n raise cfgv.ValidationError('Cannot specify both sha and rev')\n elif 'sha' in dct:\n self._cond('sha').check(dct)\n else:\n self._cond('rev').check(dct)\n\n def apply_default(self, dct: Dict[str, Any]) -> None:\n if 'sha' in dct:\n dct['rev'] = dct.pop('sha')\n\n remove_default = cfgv.Required.remove_default\n\n\ndef _entry(modname: str) -> str:\n \"\"\"the hook `entry` is passed through `shlex.split()` by the command\n runner, so to prevent issues with spaces and backslashes (on Windows)\n it must be quoted here.\n \"\"\"\n return f'{shlex.quote(sys.executable)} -m pre_commit.meta_hooks.{modname}'\n\n\ndef warn_unknown_keys_root(\n extra: Sequence[str],\n orig_keys: Sequence[str],\n dct: Dict[str, str],\n) -> None:\n logger.warning(f'Unexpected key(s) present at root: {\", \".join(extra)}')\n\n\ndef warn_unknown_keys_repo(\n extra: Sequence[str],\n orig_keys: Sequence[str],\n dct: Dict[str, str],\n) -> None:\n logger.warning(\n f'Unexpected key(s) present on {dct[\"repo\"]}: {\", \".join(extra)}',\n )\n\n\n_meta = (\n (\n 'check-hooks-apply', (\n ('name', 'Check hooks apply to the repository'),\n ('files', C.CONFIG_FILE),\n ('entry', _entry('check_hooks_apply')),\n ),\n ),\n (\n 'check-useless-excludes', (\n ('name', 'Check for useless excludes'),\n ('files', C.CONFIG_FILE),\n ('entry', _entry('check_useless_excludes')),\n ),\n ),\n (\n 'identity', (\n ('name', 'identity'),\n ('verbose', True),\n ('entry', _entry('identity')),\n ),\n ),\n)\n\nMETA_HOOK_DICT = cfgv.Map(\n 'Hook', 'id',\n cfgv.Required('id', cfgv.check_string),\n cfgv.Required('id', cfgv.check_one_of(tuple(k for k, _ in _meta))),\n # language must be system\n cfgv.Optional('language', cfgv.check_one_of({'system'}), 'system'),\n *(\n # default to the hook definition for the meta hooks\n cfgv.ConditionalOptional(key, cfgv.check_any, value, 'id', hook_id)\n for hook_id, values in _meta\n for key, value in values\n ),\n *(\n # default to the \"manifest\" parsing\n cfgv.OptionalNoDefault(item.key, item.check_fn)\n # these will always be defaulted above\n if item.key in {'name', 'language', 'entry'} else\n item\n for item in MANIFEST_HOOK_DICT.items\n ),\n)\nCONFIG_HOOK_DICT = cfgv.Map(\n 'Hook', 'id',\n\n cfgv.Required('id', cfgv.check_string),\n\n # All keys in manifest hook dict are valid in a config hook dict, but\n # are optional.\n # No defaults are provided here as the config is merged on top of the\n # manifest.\n *(\n cfgv.OptionalNoDefault(item.key, item.check_fn)\n for item in MANIFEST_HOOK_DICT.items\n if item.key != 'id'\n ),\n)\nCONFIG_REPO_DICT = cfgv.Map(\n 'Repository', 'repo',\n\n cfgv.Required('repo', cfgv.check_string),\n\n cfgv.ConditionalRecurse(\n 'hooks', cfgv.Array(CONFIG_HOOK_DICT),\n 'repo', cfgv.NotIn(LOCAL, META),\n ),\n cfgv.ConditionalRecurse(\n 'hooks', cfgv.Array(MANIFEST_HOOK_DICT),\n 'repo', LOCAL,\n ),\n cfgv.ConditionalRecurse(\n 'hooks', cfgv.Array(META_HOOK_DICT),\n 'repo', META,\n ),\n\n MigrateShaToRev(),\n cfgv.WarnAdditionalKeys(('repo', 'rev', 'hooks'), warn_unknown_keys_repo),\n)\nDEFAULT_LANGUAGE_VERSION = cfgv.Map(\n 'DefaultLanguageVersion', None,\n cfgv.NoAdditionalKeys(all_languages),\n *(cfgv.Optional(x, cfgv.check_string, C.DEFAULT) for x in all_languages),\n)\nCONFIG_SCHEMA = cfgv.Map(\n 'Config', None,\n\n cfgv.RequiredRecurse('repos', cfgv.Array(CONFIG_REPO_DICT)),\n cfgv.OptionalRecurse(\n 'default_language_version', DEFAULT_LANGUAGE_VERSION, {},\n ),\n cfgv.Optional(\n 'default_stages',\n cfgv.check_array(cfgv.check_one_of(C.STAGES)),\n C.STAGES,\n ),\n cfgv.Optional('files', check_string_regex, ''),\n cfgv.Optional('exclude', check_string_regex, '^$'),\n cfgv.Optional('fail_fast', cfgv.check_bool, False),\n cfgv.Optional(\n 'minimum_pre_commit_version',\n cfgv.check_and(cfgv.check_string, check_min_version),\n '0',\n ),\n cfgv.WarnAdditionalKeys(\n (\n 'repos',\n 'default_language_version',\n 'default_stages',\n 'files',\n 'exclude',\n 'fail_fast',\n 'minimum_pre_commit_version',\n ),\n warn_unknown_keys_root,\n ),\n)\n\n\nclass InvalidConfigError(FatalError):\n pass\n\n\ndef ordered_load_normalize_legacy_config(contents: str) -> Dict[str, Any]:\n data = yaml_load(contents)\n if isinstance(data, list):\n logger.warning(\n 'normalizing pre-commit configuration to a top-level map. '\n 'support for top level list will be removed in a future version. '\n 'run: `pre-commit migrate-config` to automatically fix this.',\n )\n return {'repos': data}\n else:\n return data\n\n\nload_config = functools.partial(\n cfgv.load_from_filename,\n schema=CONFIG_SCHEMA,\n load_strategy=ordered_load_normalize_legacy_config,\n exc_tp=InvalidConfigError,\n)\n\n\ndef validate_config_main(argv: Optional[Sequence[str]] = None) -> int:\n parser = _make_argparser('Config filenames.')\n args = parser.parse_args(argv)\n\n with logging_handler(args.color):\n ret = 0\n for filename in args.filenames:\n try:\n load_config(filename)\n except InvalidConfigError as e:\n print(e)\n ret = 1\n return ret\n", "path": "pre_commit/clientlib.py"}]}
| 3,844 | 260 |
gh_patches_debug_29268
|
rasdani/github-patches
|
git_diff
|
strawberry-graphql__strawberry-2141
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Deleting generator in subscription clean up will not call a 'finally' statement
<!-- Provide a general summary of the bug in the title above. -->
<!--- This template is entirely optional and can be removed, but is here to help both you and us. -->
<!--- Anything on lines wrapped in comments like these will not show up in the final text. -->
## Describe the Bug
I have found an issue with the way subscriptions are cleaned up when using the graphql-transport-ws protocol.
My subscription returns a AsyncIterator which look something like this:
```
async def get_value() -> AsyncIterator[int]:
try:
while True:
# Call some other code to
# get the value from another object
finally:
# Do some important cleanup here.
```
I have multiple subscriptions, which are being updated at 10Hz. When I cancel the subscriptions (for example, close the webpage calling subscribe), I get a `ConnectionResetError: "Cannot write to closing transport"` on the server side, presumably as the task has not yet been cancelled and is trying to send an updated value while the websocket is closing. Looking at the Strawberry code that handles this (subscriptions/protocols/graphql_transport_ws/handlers.py), I can see that this error is caught as a `BaseException` ([here](https://github.com/strawberry-graphql/strawberry/blob/fe9737b9d218f437500db215525a147de2ea1d64/strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py#L218)) and so this task and generator are deleted from the internal dictionaries.
What I have found however, is that when the generator is simply deleted in this clean up, the 'finally' statement in my try-finally implementation does not get executed and so I cannot perform any clean up. I have seen this lead to a memory leak, which is only stopped when the garbage collector comes round and runs the 'finally' statement.
To ensure the generator runs to completion and executes the 'finally' statement, I wonder whether the generator should be explicitly closed first, before deleting it from the internal subscriptions list, much like is done in the cleanup_operation() method ([here](https://github.com/strawberry-graphql/strawberry/blob/fe9737b9d218f437500db215525a147de2ea1d64/strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py#L282?)).
## System Information
- Operating system: Centos 7
- Strawberry version (if applicable): 0.121.1
- Python version: 3.8.12
## Additional Context
<!-- Add any other relevant information about the problem here. -->
</issue>
<code>
[start of strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py]
1 import asyncio
2 from abc import ABC, abstractmethod
3 from contextlib import suppress
4 from datetime import timedelta
5 from typing import Any, AsyncGenerator, Callable, Dict, List, Optional
6
7 from graphql import (
8 ExecutionResult as GraphQLExecutionResult,
9 GraphQLError,
10 GraphQLSyntaxError,
11 parse,
12 )
13 from graphql.error.graphql_error import format_error as format_graphql_error
14
15 from strawberry.schema import BaseSchema
16 from strawberry.subscriptions.protocols.graphql_transport_ws.types import (
17 CompleteMessage,
18 ConnectionAckMessage,
19 ConnectionInitMessage,
20 ErrorMessage,
21 GraphQLTransportMessage,
22 NextMessage,
23 PingMessage,
24 PongMessage,
25 SubscribeMessage,
26 SubscribeMessagePayload,
27 )
28 from strawberry.types.graphql import OperationType
29 from strawberry.utils.debug import pretty_print_graphql_operation
30 from strawberry.utils.operation import get_operation_type
31
32
33 class BaseGraphQLTransportWSHandler(ABC):
34 def __init__(
35 self,
36 schema: BaseSchema,
37 debug: bool,
38 connection_init_wait_timeout: timedelta,
39 ):
40 self.schema = schema
41 self.debug = debug
42 self.connection_init_wait_timeout = connection_init_wait_timeout
43 self.connection_init_timeout_task: Optional[asyncio.Task] = None
44 self.connection_init_received = False
45 self.connection_acknowledged = False
46 self.subscriptions: Dict[str, AsyncGenerator] = {}
47 self.tasks: Dict[str, asyncio.Task] = {}
48 self.completed_tasks: List[asyncio.Task] = []
49
50 @abstractmethod
51 async def get_context(self) -> Any:
52 """Return the operations context"""
53
54 @abstractmethod
55 async def get_root_value(self) -> Any:
56 """Return the schemas root value"""
57
58 @abstractmethod
59 async def send_json(self, data: dict) -> None:
60 """Send the data JSON encoded to the WebSocket client"""
61
62 @abstractmethod
63 async def close(self, code: int, reason: str) -> None:
64 """Close the WebSocket with the passed code and reason"""
65
66 @abstractmethod
67 async def handle_request(self) -> Any:
68 """Handle the request this instance was created for"""
69
70 async def handle(self) -> Any:
71 timeout_handler = self.handle_connection_init_timeout()
72 self.connection_init_timeout_task = asyncio.create_task(timeout_handler)
73 return await self.handle_request()
74
75 async def handle_connection_init_timeout(self):
76 delay = self.connection_init_wait_timeout.total_seconds()
77 await asyncio.sleep(delay=delay)
78
79 if self.connection_init_received:
80 return
81
82 reason = "Connection initialisation timeout"
83 await self.close(code=4408, reason=reason)
84
85 async def handle_message(self, message: dict):
86 handler: Callable
87 handler_arg: Any
88 try:
89 message_type = message.pop("type")
90
91 if message_type == ConnectionInitMessage.type:
92 handler = self.handle_connection_init
93 handler_arg = ConnectionInitMessage(**message)
94
95 elif message_type == PingMessage.type:
96 handler = self.handle_ping
97 handler_arg = PingMessage(**message)
98
99 elif message_type == PongMessage.type:
100 handler = self.handle_pong
101 handler_arg = PongMessage(**message)
102
103 elif message_type == SubscribeMessage.type:
104 handler = self.handle_subscribe
105 payload = SubscribeMessagePayload(**message.pop("payload"))
106 handler_arg = SubscribeMessage(payload=payload, **message)
107
108 elif message_type == CompleteMessage.type:
109 handler = self.handle_complete
110 handler_arg = CompleteMessage(**message)
111
112 else:
113 handler = self.handle_invalid_message
114 handler_arg = f"Unknown message type: {message_type}"
115
116 except (KeyError, TypeError):
117 handler = self.handle_invalid_message
118 handler_arg = "Failed to parse message"
119
120 await handler(handler_arg)
121 await self.reap_completed_tasks()
122
123 async def handle_connection_init(self, message: ConnectionInitMessage) -> None:
124 if self.connection_init_received:
125 reason = "Too many initialisation requests"
126 await self.close(code=4429, reason=reason)
127 return
128
129 self.connection_init_received = True
130 await self.send_message(ConnectionAckMessage())
131 self.connection_acknowledged = True
132
133 async def handle_ping(self, message: PingMessage) -> None:
134 await self.send_message(PongMessage())
135
136 async def handle_pong(self, message: PongMessage) -> None:
137 pass
138
139 async def handle_subscribe(self, message: SubscribeMessage) -> None:
140 if not self.connection_acknowledged:
141 await self.close(code=4401, reason="Unauthorized")
142 return
143
144 try:
145 graphql_document = parse(message.payload.query)
146 except GraphQLSyntaxError as exc:
147 await self.close(code=4400, reason=exc.message)
148 return
149
150 try:
151 operation_type = get_operation_type(
152 graphql_document, message.payload.operationName
153 )
154 except RuntimeError:
155 await self.close(code=4400, reason="Can't get GraphQL operation type")
156 return
157
158 if message.id in self.subscriptions:
159 reason = f"Subscriber for {message.id} already exists"
160 await self.close(code=4409, reason=reason)
161 return
162
163 if self.debug: # pragma: no cover
164 pretty_print_graphql_operation(
165 message.payload.operationName,
166 message.payload.query,
167 message.payload.variables,
168 )
169
170 context = await self.get_context()
171 root_value = await self.get_root_value()
172
173 # Get an AsyncGenerator yielding the results
174 if operation_type == OperationType.SUBSCRIPTION:
175 result_source = await self.schema.subscribe(
176 query=message.payload.query,
177 variable_values=message.payload.variables,
178 operation_name=message.payload.operationName,
179 context_value=context,
180 root_value=root_value,
181 )
182 else:
183 # create AsyncGenerator returning a single result
184 async def get_result_source():
185 yield await self.schema.execute(
186 query=message.payload.query,
187 variable_values=message.payload.variables,
188 context_value=context,
189 root_value=root_value,
190 operation_name=message.payload.operationName,
191 )
192
193 result_source = get_result_source()
194
195 # Handle initial validation errors
196 if isinstance(result_source, GraphQLExecutionResult):
197 assert result_source.errors
198 payload = [format_graphql_error(result_source.errors[0])]
199 await self.send_message(ErrorMessage(id=message.id, payload=payload))
200 self.schema.process_errors(result_source.errors)
201 return
202
203 # Create task to handle this subscription, reserve the operation ID
204 self.subscriptions[message.id] = result_source
205 self.tasks[message.id] = asyncio.create_task(
206 self.operation_task(result_source, message.id)
207 )
208
209 async def operation_task(
210 self, result_source: AsyncGenerator, operation_id: str
211 ) -> None:
212 """
213 Operation task top level method. Cleans up and de-registers the operation
214 once it is done.
215 """
216 try:
217 await self.handle_async_results(result_source, operation_id)
218 except BaseException: # pragma: no cover
219 # cleanup in case of something really unexpected
220 del self.subscriptions[operation_id]
221 del self.tasks[operation_id]
222 raise
223 else:
224 # de-register the operation _before_ sending the `Complete` message
225 # to make the `operation_id` immediately available for re-use
226 del self.subscriptions[operation_id]
227 del self.tasks[operation_id]
228 await self.send_message(CompleteMessage(id=operation_id))
229 finally:
230 # add this task to a list to be reaped later
231 task = asyncio.current_task()
232 assert task is not None
233 self.completed_tasks.append(task)
234
235 async def handle_async_results(
236 self,
237 result_source: AsyncGenerator,
238 operation_id: str,
239 ) -> None:
240 try:
241 async for result in result_source:
242 if result.errors:
243 error_payload = [format_graphql_error(err) for err in result.errors]
244 error_message = ErrorMessage(id=operation_id, payload=error_payload)
245 await self.send_message(error_message)
246 self.schema.process_errors(result.errors)
247 return
248 else:
249 next_payload = {"data": result.data}
250 next_message = NextMessage(id=operation_id, payload=next_payload)
251 await self.send_message(next_message)
252 except asyncio.CancelledError:
253 # CancelledErrors are expected during task cleanup.
254 return
255 except Exception as error:
256 # GraphQLErrors are handled by graphql-core and included in the
257 # ExecutionResult
258 error = GraphQLError(str(error), original_error=error)
259 error_payload = [format_graphql_error(error)]
260 error_message = ErrorMessage(id=operation_id, payload=error_payload)
261 await self.send_message(error_message)
262 self.schema.process_errors([error])
263 return
264
265 async def handle_complete(self, message: CompleteMessage) -> None:
266 await self.cleanup_operation(operation_id=message.id)
267
268 async def handle_invalid_message(self, error_message: str) -> None:
269 await self.close(code=4400, reason=error_message)
270
271 async def send_message(self, message: GraphQLTransportMessage) -> None:
272 data = message.as_dict()
273 await self.send_json(data)
274
275 async def cleanup_operation(self, operation_id: str) -> None:
276 if operation_id not in self.subscriptions:
277 return
278 generator = self.subscriptions.pop(operation_id)
279 task = self.tasks.pop(operation_id)
280 # since python 3.8, generators cannot be reliably closed
281 with suppress(RuntimeError):
282 await generator.aclose()
283 task.cancel()
284 with suppress(BaseException):
285 await task
286
287 async def reap_completed_tasks(self) -> None:
288 """
289 Await tasks that have completed
290 """
291 tasks, self.completed_tasks = self.completed_tasks, []
292 for task in tasks:
293 with suppress(BaseException):
294 await task
295
[end of strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py b/strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py
--- a/strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py
+++ b/strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py
@@ -217,6 +217,11 @@
await self.handle_async_results(result_source, operation_id)
except BaseException: # pragma: no cover
# cleanup in case of something really unexpected
+ # wait for generator to be closed to ensure that any existing
+ # 'finally' statement is called
+ result_source = self.subscriptions[operation_id]
+ with suppress(RuntimeError):
+ await result_source.aclose()
del self.subscriptions[operation_id]
del self.tasks[operation_id]
raise
@@ -275,14 +280,14 @@
async def cleanup_operation(self, operation_id: str) -> None:
if operation_id not in self.subscriptions:
return
- generator = self.subscriptions.pop(operation_id)
+ result_source = self.subscriptions.pop(operation_id)
task = self.tasks.pop(operation_id)
- # since python 3.8, generators cannot be reliably closed
- with suppress(RuntimeError):
- await generator.aclose()
task.cancel()
with suppress(BaseException):
await task
+ # since python 3.8, generators cannot be reliably closed
+ with suppress(RuntimeError):
+ await result_source.aclose()
async def reap_completed_tasks(self) -> None:
"""
|
{"golden_diff": "diff --git a/strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py b/strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py\n--- a/strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py\n+++ b/strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py\n@@ -217,6 +217,11 @@\n await self.handle_async_results(result_source, operation_id)\n except BaseException: # pragma: no cover\n # cleanup in case of something really unexpected\n+ # wait for generator to be closed to ensure that any existing\n+ # 'finally' statement is called\n+ result_source = self.subscriptions[operation_id]\n+ with suppress(RuntimeError):\n+ await result_source.aclose()\n del self.subscriptions[operation_id]\n del self.tasks[operation_id]\n raise\n@@ -275,14 +280,14 @@\n async def cleanup_operation(self, operation_id: str) -> None:\n if operation_id not in self.subscriptions:\n return\n- generator = self.subscriptions.pop(operation_id)\n+ result_source = self.subscriptions.pop(operation_id)\n task = self.tasks.pop(operation_id)\n- # since python 3.8, generators cannot be reliably closed\n- with suppress(RuntimeError):\n- await generator.aclose()\n task.cancel()\n with suppress(BaseException):\n await task\n+ # since python 3.8, generators cannot be reliably closed\n+ with suppress(RuntimeError):\n+ await result_source.aclose()\n \n async def reap_completed_tasks(self) -> None:\n \"\"\"\n", "issue": "Deleting generator in subscription clean up will not call a 'finally' statement\n<!-- Provide a general summary of the bug in the title above. -->\r\n\r\n<!--- This template is entirely optional and can be removed, but is here to help both you and us. -->\r\n<!--- Anything on lines wrapped in comments like these will not show up in the final text. -->\r\n\r\n## Describe the Bug\r\nI have found an issue with the way subscriptions are cleaned up when using the graphql-transport-ws protocol. \r\n\r\nMy subscription returns a AsyncIterator which look something like this:\r\n```\r\nasync def get_value() -> AsyncIterator[int]:\r\n try:\r\n while True:\r\n # Call some other code to \r\n # get the value from another object\r\n finally:\r\n # Do some important cleanup here.\r\n```\r\nI have multiple subscriptions, which are being updated at 10Hz. When I cancel the subscriptions (for example, close the webpage calling subscribe), I get a `ConnectionResetError: \"Cannot write to closing transport\"` on the server side, presumably as the task has not yet been cancelled and is trying to send an updated value while the websocket is closing. Looking at the Strawberry code that handles this (subscriptions/protocols/graphql_transport_ws/handlers.py), I can see that this error is caught as a `BaseException` ([here](https://github.com/strawberry-graphql/strawberry/blob/fe9737b9d218f437500db215525a147de2ea1d64/strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py#L218)) and so this task and generator are deleted from the internal dictionaries. \r\n\r\nWhat I have found however, is that when the generator is simply deleted in this clean up, the 'finally' statement in my try-finally implementation does not get executed and so I cannot perform any clean up. I have seen this lead to a memory leak, which is only stopped when the garbage collector comes round and runs the 'finally' statement. \r\n\r\nTo ensure the generator runs to completion and executes the 'finally' statement, I wonder whether the generator should be explicitly closed first, before deleting it from the internal subscriptions list, much like is done in the cleanup_operation() method ([here](https://github.com/strawberry-graphql/strawberry/blob/fe9737b9d218f437500db215525a147de2ea1d64/strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py#L282?)).\r\n\r\n## System Information\r\n\r\n - Operating system: Centos 7\r\n - Strawberry version (if applicable): 0.121.1\r\n - Python version: 3.8.12\r\n\r\n## Additional Context\r\n\r\n<!-- Add any other relevant information about the problem here. -->\r\n\n", "before_files": [{"content": "import asyncio\nfrom abc import ABC, abstractmethod\nfrom contextlib import suppress\nfrom datetime import timedelta\nfrom typing import Any, AsyncGenerator, Callable, Dict, List, Optional\n\nfrom graphql import (\n ExecutionResult as GraphQLExecutionResult,\n GraphQLError,\n GraphQLSyntaxError,\n parse,\n)\nfrom graphql.error.graphql_error import format_error as format_graphql_error\n\nfrom strawberry.schema import BaseSchema\nfrom strawberry.subscriptions.protocols.graphql_transport_ws.types import (\n CompleteMessage,\n ConnectionAckMessage,\n ConnectionInitMessage,\n ErrorMessage,\n GraphQLTransportMessage,\n NextMessage,\n PingMessage,\n PongMessage,\n SubscribeMessage,\n SubscribeMessagePayload,\n)\nfrom strawberry.types.graphql import OperationType\nfrom strawberry.utils.debug import pretty_print_graphql_operation\nfrom strawberry.utils.operation import get_operation_type\n\n\nclass BaseGraphQLTransportWSHandler(ABC):\n def __init__(\n self,\n schema: BaseSchema,\n debug: bool,\n connection_init_wait_timeout: timedelta,\n ):\n self.schema = schema\n self.debug = debug\n self.connection_init_wait_timeout = connection_init_wait_timeout\n self.connection_init_timeout_task: Optional[asyncio.Task] = None\n self.connection_init_received = False\n self.connection_acknowledged = False\n self.subscriptions: Dict[str, AsyncGenerator] = {}\n self.tasks: Dict[str, asyncio.Task] = {}\n self.completed_tasks: List[asyncio.Task] = []\n\n @abstractmethod\n async def get_context(self) -> Any:\n \"\"\"Return the operations context\"\"\"\n\n @abstractmethod\n async def get_root_value(self) -> Any:\n \"\"\"Return the schemas root value\"\"\"\n\n @abstractmethod\n async def send_json(self, data: dict) -> None:\n \"\"\"Send the data JSON encoded to the WebSocket client\"\"\"\n\n @abstractmethod\n async def close(self, code: int, reason: str) -> None:\n \"\"\"Close the WebSocket with the passed code and reason\"\"\"\n\n @abstractmethod\n async def handle_request(self) -> Any:\n \"\"\"Handle the request this instance was created for\"\"\"\n\n async def handle(self) -> Any:\n timeout_handler = self.handle_connection_init_timeout()\n self.connection_init_timeout_task = asyncio.create_task(timeout_handler)\n return await self.handle_request()\n\n async def handle_connection_init_timeout(self):\n delay = self.connection_init_wait_timeout.total_seconds()\n await asyncio.sleep(delay=delay)\n\n if self.connection_init_received:\n return\n\n reason = \"Connection initialisation timeout\"\n await self.close(code=4408, reason=reason)\n\n async def handle_message(self, message: dict):\n handler: Callable\n handler_arg: Any\n try:\n message_type = message.pop(\"type\")\n\n if message_type == ConnectionInitMessage.type:\n handler = self.handle_connection_init\n handler_arg = ConnectionInitMessage(**message)\n\n elif message_type == PingMessage.type:\n handler = self.handle_ping\n handler_arg = PingMessage(**message)\n\n elif message_type == PongMessage.type:\n handler = self.handle_pong\n handler_arg = PongMessage(**message)\n\n elif message_type == SubscribeMessage.type:\n handler = self.handle_subscribe\n payload = SubscribeMessagePayload(**message.pop(\"payload\"))\n handler_arg = SubscribeMessage(payload=payload, **message)\n\n elif message_type == CompleteMessage.type:\n handler = self.handle_complete\n handler_arg = CompleteMessage(**message)\n\n else:\n handler = self.handle_invalid_message\n handler_arg = f\"Unknown message type: {message_type}\"\n\n except (KeyError, TypeError):\n handler = self.handle_invalid_message\n handler_arg = \"Failed to parse message\"\n\n await handler(handler_arg)\n await self.reap_completed_tasks()\n\n async def handle_connection_init(self, message: ConnectionInitMessage) -> None:\n if self.connection_init_received:\n reason = \"Too many initialisation requests\"\n await self.close(code=4429, reason=reason)\n return\n\n self.connection_init_received = True\n await self.send_message(ConnectionAckMessage())\n self.connection_acknowledged = True\n\n async def handle_ping(self, message: PingMessage) -> None:\n await self.send_message(PongMessage())\n\n async def handle_pong(self, message: PongMessage) -> None:\n pass\n\n async def handle_subscribe(self, message: SubscribeMessage) -> None:\n if not self.connection_acknowledged:\n await self.close(code=4401, reason=\"Unauthorized\")\n return\n\n try:\n graphql_document = parse(message.payload.query)\n except GraphQLSyntaxError as exc:\n await self.close(code=4400, reason=exc.message)\n return\n\n try:\n operation_type = get_operation_type(\n graphql_document, message.payload.operationName\n )\n except RuntimeError:\n await self.close(code=4400, reason=\"Can't get GraphQL operation type\")\n return\n\n if message.id in self.subscriptions:\n reason = f\"Subscriber for {message.id} already exists\"\n await self.close(code=4409, reason=reason)\n return\n\n if self.debug: # pragma: no cover\n pretty_print_graphql_operation(\n message.payload.operationName,\n message.payload.query,\n message.payload.variables,\n )\n\n context = await self.get_context()\n root_value = await self.get_root_value()\n\n # Get an AsyncGenerator yielding the results\n if operation_type == OperationType.SUBSCRIPTION:\n result_source = await self.schema.subscribe(\n query=message.payload.query,\n variable_values=message.payload.variables,\n operation_name=message.payload.operationName,\n context_value=context,\n root_value=root_value,\n )\n else:\n # create AsyncGenerator returning a single result\n async def get_result_source():\n yield await self.schema.execute(\n query=message.payload.query,\n variable_values=message.payload.variables,\n context_value=context,\n root_value=root_value,\n operation_name=message.payload.operationName,\n )\n\n result_source = get_result_source()\n\n # Handle initial validation errors\n if isinstance(result_source, GraphQLExecutionResult):\n assert result_source.errors\n payload = [format_graphql_error(result_source.errors[0])]\n await self.send_message(ErrorMessage(id=message.id, payload=payload))\n self.schema.process_errors(result_source.errors)\n return\n\n # Create task to handle this subscription, reserve the operation ID\n self.subscriptions[message.id] = result_source\n self.tasks[message.id] = asyncio.create_task(\n self.operation_task(result_source, message.id)\n )\n\n async def operation_task(\n self, result_source: AsyncGenerator, operation_id: str\n ) -> None:\n \"\"\"\n Operation task top level method. Cleans up and de-registers the operation\n once it is done.\n \"\"\"\n try:\n await self.handle_async_results(result_source, operation_id)\n except BaseException: # pragma: no cover\n # cleanup in case of something really unexpected\n del self.subscriptions[operation_id]\n del self.tasks[operation_id]\n raise\n else:\n # de-register the operation _before_ sending the `Complete` message\n # to make the `operation_id` immediately available for re-use\n del self.subscriptions[operation_id]\n del self.tasks[operation_id]\n await self.send_message(CompleteMessage(id=operation_id))\n finally:\n # add this task to a list to be reaped later\n task = asyncio.current_task()\n assert task is not None\n self.completed_tasks.append(task)\n\n async def handle_async_results(\n self,\n result_source: AsyncGenerator,\n operation_id: str,\n ) -> None:\n try:\n async for result in result_source:\n if result.errors:\n error_payload = [format_graphql_error(err) for err in result.errors]\n error_message = ErrorMessage(id=operation_id, payload=error_payload)\n await self.send_message(error_message)\n self.schema.process_errors(result.errors)\n return\n else:\n next_payload = {\"data\": result.data}\n next_message = NextMessage(id=operation_id, payload=next_payload)\n await self.send_message(next_message)\n except asyncio.CancelledError:\n # CancelledErrors are expected during task cleanup.\n return\n except Exception as error:\n # GraphQLErrors are handled by graphql-core and included in the\n # ExecutionResult\n error = GraphQLError(str(error), original_error=error)\n error_payload = [format_graphql_error(error)]\n error_message = ErrorMessage(id=operation_id, payload=error_payload)\n await self.send_message(error_message)\n self.schema.process_errors([error])\n return\n\n async def handle_complete(self, message: CompleteMessage) -> None:\n await self.cleanup_operation(operation_id=message.id)\n\n async def handle_invalid_message(self, error_message: str) -> None:\n await self.close(code=4400, reason=error_message)\n\n async def send_message(self, message: GraphQLTransportMessage) -> None:\n data = message.as_dict()\n await self.send_json(data)\n\n async def cleanup_operation(self, operation_id: str) -> None:\n if operation_id not in self.subscriptions:\n return\n generator = self.subscriptions.pop(operation_id)\n task = self.tasks.pop(operation_id)\n # since python 3.8, generators cannot be reliably closed\n with suppress(RuntimeError):\n await generator.aclose()\n task.cancel()\n with suppress(BaseException):\n await task\n\n async def reap_completed_tasks(self) -> None:\n \"\"\"\n Await tasks that have completed\n \"\"\"\n tasks, self.completed_tasks = self.completed_tasks, []\n for task in tasks:\n with suppress(BaseException):\n await task\n", "path": "strawberry/subscriptions/protocols/graphql_transport_ws/handlers.py"}]}
| 4,027 | 353 |
gh_patches_debug_11326
|
rasdani/github-patches
|
git_diff
|
tobymao__sqlglot-2443
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Erroneous handling of redshift's JSON_PARSE
**sqlglot version: 18.16.1**
**Fully reproducible code snippet**
```python
import sqlglot
sql = "SELECT JSON_PARSE('[10001,10002,\"abc\"]');"
parsed = sqlglot.parse_one(sql,dialect="redshift")
parsed.sql(dialect="redshift")
#'SELECT PARSE_JSON(\'[10001,10002,"abc"]\')'
```
The generated sql triggers an error when executed in redshift
>Failed to execute query: ERROR: function parse_json("unknown") does not exist
Hint: No function matches the given name and argument types. You may need to add explicit type casts.
**Official Documentation**
https://docs.aws.amazon.com/redshift/latest/dg/JSON_PARSE.html
</issue>
<code>
[start of sqlglot/dialects/redshift.py]
1 from __future__ import annotations
2
3 import typing as t
4
5 from sqlglot import exp, transforms
6 from sqlglot.dialects.dialect import (
7 concat_to_dpipe_sql,
8 concat_ws_to_dpipe_sql,
9 generatedasidentitycolumnconstraint_sql,
10 rename_func,
11 ts_or_ds_to_date_sql,
12 )
13 from sqlglot.dialects.postgres import Postgres
14 from sqlglot.helper import seq_get
15 from sqlglot.tokens import TokenType
16
17
18 def _json_sql(self: Redshift.Generator, expression: exp.JSONExtract | exp.JSONExtractScalar) -> str:
19 return f'{self.sql(expression, "this")}."{expression.expression.name}"'
20
21
22 def _parse_date_add(args: t.List) -> exp.DateAdd:
23 return exp.DateAdd(
24 this=exp.TsOrDsToDate(this=seq_get(args, 2)),
25 expression=seq_get(args, 1),
26 unit=seq_get(args, 0),
27 )
28
29
30 class Redshift(Postgres):
31 # https://docs.aws.amazon.com/redshift/latest/dg/r_names.html
32 RESOLVES_IDENTIFIERS_AS_UPPERCASE = None
33
34 SUPPORTS_USER_DEFINED_TYPES = False
35 INDEX_OFFSET = 0
36
37 TIME_FORMAT = "'YYYY-MM-DD HH:MI:SS'"
38 TIME_MAPPING = {
39 **Postgres.TIME_MAPPING,
40 "MON": "%b",
41 "HH": "%H",
42 }
43
44 class Parser(Postgres.Parser):
45 FUNCTIONS = {
46 **Postgres.Parser.FUNCTIONS,
47 "ADD_MONTHS": lambda args: exp.DateAdd(
48 this=exp.TsOrDsToDate(this=seq_get(args, 0)),
49 expression=seq_get(args, 1),
50 unit=exp.var("month"),
51 ),
52 "DATEADD": _parse_date_add,
53 "DATE_ADD": _parse_date_add,
54 "DATEDIFF": lambda args: exp.DateDiff(
55 this=exp.TsOrDsToDate(this=seq_get(args, 2)),
56 expression=exp.TsOrDsToDate(this=seq_get(args, 1)),
57 unit=seq_get(args, 0),
58 ),
59 "STRTOL": exp.FromBase.from_arg_list,
60 }
61
62 NO_PAREN_FUNCTION_PARSERS = {
63 **Postgres.Parser.NO_PAREN_FUNCTION_PARSERS,
64 "APPROXIMATE": lambda self: self._parse_approximate_count(),
65 }
66
67 def _parse_table(
68 self,
69 schema: bool = False,
70 joins: bool = False,
71 alias_tokens: t.Optional[t.Collection[TokenType]] = None,
72 parse_bracket: bool = False,
73 ) -> t.Optional[exp.Expression]:
74 # Redshift supports UNPIVOTing SUPER objects, e.g. `UNPIVOT foo.obj[0] AS val AT attr`
75 unpivot = self._match(TokenType.UNPIVOT)
76 table = super()._parse_table(
77 schema=schema,
78 joins=joins,
79 alias_tokens=alias_tokens,
80 parse_bracket=parse_bracket,
81 )
82
83 return self.expression(exp.Pivot, this=table, unpivot=True) if unpivot else table
84
85 def _parse_types(
86 self, check_func: bool = False, schema: bool = False, allow_identifiers: bool = True
87 ) -> t.Optional[exp.Expression]:
88 this = super()._parse_types(
89 check_func=check_func, schema=schema, allow_identifiers=allow_identifiers
90 )
91
92 if (
93 isinstance(this, exp.DataType)
94 and this.is_type("varchar")
95 and this.expressions
96 and this.expressions[0].this == exp.column("MAX")
97 ):
98 this.set("expressions", [exp.var("MAX")])
99
100 return this
101
102 def _parse_convert(
103 self, strict: bool, safe: t.Optional[bool] = None
104 ) -> t.Optional[exp.Expression]:
105 to = self._parse_types()
106 self._match(TokenType.COMMA)
107 this = self._parse_bitwise()
108 return self.expression(exp.TryCast, this=this, to=to, safe=safe)
109
110 def _parse_approximate_count(self) -> t.Optional[exp.ApproxDistinct]:
111 index = self._index - 1
112 func = self._parse_function()
113
114 if isinstance(func, exp.Count) and isinstance(func.this, exp.Distinct):
115 return self.expression(exp.ApproxDistinct, this=seq_get(func.this.expressions, 0))
116 self._retreat(index)
117 return None
118
119 class Tokenizer(Postgres.Tokenizer):
120 BIT_STRINGS = []
121 HEX_STRINGS = []
122 STRING_ESCAPES = ["\\", "'"]
123
124 KEYWORDS = {
125 **Postgres.Tokenizer.KEYWORDS,
126 "HLLSKETCH": TokenType.HLLSKETCH,
127 "SUPER": TokenType.SUPER,
128 "SYSDATE": TokenType.CURRENT_TIMESTAMP,
129 "TOP": TokenType.TOP,
130 "UNLOAD": TokenType.COMMAND,
131 "VARBYTE": TokenType.VARBINARY,
132 }
133
134 # Redshift allows # to appear as a table identifier prefix
135 SINGLE_TOKENS = Postgres.Tokenizer.SINGLE_TOKENS.copy()
136 SINGLE_TOKENS.pop("#")
137
138 class Generator(Postgres.Generator):
139 LOCKING_READS_SUPPORTED = False
140 RENAME_TABLE_WITH_DB = False
141 QUERY_HINTS = False
142 VALUES_AS_TABLE = False
143 TZ_TO_WITH_TIME_ZONE = True
144 NVL2_SUPPORTED = True
145
146 TYPE_MAPPING = {
147 **Postgres.Generator.TYPE_MAPPING,
148 exp.DataType.Type.BINARY: "VARBYTE",
149 exp.DataType.Type.INT: "INTEGER",
150 exp.DataType.Type.TIMETZ: "TIME",
151 exp.DataType.Type.TIMESTAMPTZ: "TIMESTAMP",
152 exp.DataType.Type.VARBINARY: "VARBYTE",
153 }
154
155 PROPERTIES_LOCATION = {
156 **Postgres.Generator.PROPERTIES_LOCATION,
157 exp.LikeProperty: exp.Properties.Location.POST_WITH,
158 }
159
160 TRANSFORMS = {
161 **Postgres.Generator.TRANSFORMS,
162 exp.Concat: concat_to_dpipe_sql,
163 exp.ConcatWs: concat_ws_to_dpipe_sql,
164 exp.ApproxDistinct: lambda self, e: f"APPROXIMATE COUNT(DISTINCT {self.sql(e, 'this')})",
165 exp.CurrentTimestamp: lambda self, e: "SYSDATE",
166 exp.DateAdd: lambda self, e: self.func(
167 "DATEADD", exp.var(e.text("unit") or "day"), e.expression, e.this
168 ),
169 exp.DateDiff: lambda self, e: self.func(
170 "DATEDIFF", exp.var(e.text("unit") or "day"), e.expression, e.this
171 ),
172 exp.DistKeyProperty: lambda self, e: f"DISTKEY({e.name})",
173 exp.DistStyleProperty: lambda self, e: self.naked_property(e),
174 exp.FromBase: rename_func("STRTOL"),
175 exp.GeneratedAsIdentityColumnConstraint: generatedasidentitycolumnconstraint_sql,
176 exp.JSONExtract: _json_sql,
177 exp.JSONExtractScalar: _json_sql,
178 exp.SafeConcat: concat_to_dpipe_sql,
179 exp.Select: transforms.preprocess(
180 [transforms.eliminate_distinct_on, transforms.eliminate_semi_and_anti_joins]
181 ),
182 exp.SortKeyProperty: lambda self, e: f"{'COMPOUND ' if e.args['compound'] else ''}SORTKEY({self.format_args(*e.this)})",
183 exp.TsOrDsToDate: ts_or_ds_to_date_sql("redshift"),
184 }
185
186 # Postgres maps exp.Pivot to no_pivot_sql, but Redshift support pivots
187 TRANSFORMS.pop(exp.Pivot)
188
189 # Redshift uses the POW | POWER (expr1, expr2) syntax instead of expr1 ^ expr2 (postgres)
190 TRANSFORMS.pop(exp.Pow)
191
192 # Redshift supports ANY_VALUE(..)
193 TRANSFORMS.pop(exp.AnyValue)
194
195 RESERVED_KEYWORDS = {*Postgres.Generator.RESERVED_KEYWORDS, "snapshot", "type"}
196
197 def with_properties(self, properties: exp.Properties) -> str:
198 """Redshift doesn't have `WITH` as part of their with_properties so we remove it"""
199 return self.properties(properties, prefix=" ", suffix="")
200
201 def datatype_sql(self, expression: exp.DataType) -> str:
202 """
203 Redshift converts the `TEXT` data type to `VARCHAR(255)` by default when people more generally mean
204 VARCHAR of max length which is `VARCHAR(max)` in Redshift. Therefore if we get a `TEXT` data type
205 without precision we convert it to `VARCHAR(max)` and if it does have precision then we just convert
206 `TEXT` to `VARCHAR`.
207 """
208 if expression.is_type("text"):
209 expression = expression.copy()
210 expression.set("this", exp.DataType.Type.VARCHAR)
211 precision = expression.args.get("expressions")
212
213 if not precision:
214 expression.append("expressions", exp.var("MAX"))
215
216 return super().datatype_sql(expression)
217
[end of sqlglot/dialects/redshift.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sqlglot/dialects/redshift.py b/sqlglot/dialects/redshift.py
--- a/sqlglot/dialects/redshift.py
+++ b/sqlglot/dialects/redshift.py
@@ -175,6 +175,7 @@
exp.GeneratedAsIdentityColumnConstraint: generatedasidentitycolumnconstraint_sql,
exp.JSONExtract: _json_sql,
exp.JSONExtractScalar: _json_sql,
+ exp.ParseJSON: rename_func("JSON_PARSE"),
exp.SafeConcat: concat_to_dpipe_sql,
exp.Select: transforms.preprocess(
[transforms.eliminate_distinct_on, transforms.eliminate_semi_and_anti_joins]
|
{"golden_diff": "diff --git a/sqlglot/dialects/redshift.py b/sqlglot/dialects/redshift.py\n--- a/sqlglot/dialects/redshift.py\n+++ b/sqlglot/dialects/redshift.py\n@@ -175,6 +175,7 @@\n exp.GeneratedAsIdentityColumnConstraint: generatedasidentitycolumnconstraint_sql,\n exp.JSONExtract: _json_sql,\n exp.JSONExtractScalar: _json_sql,\n+ exp.ParseJSON: rename_func(\"JSON_PARSE\"),\n exp.SafeConcat: concat_to_dpipe_sql,\n exp.Select: transforms.preprocess(\n [transforms.eliminate_distinct_on, transforms.eliminate_semi_and_anti_joins]\n", "issue": "Erroneous handling of redshift's JSON_PARSE\n**sqlglot version: 18.16.1**\r\n\r\n**Fully reproducible code snippet**\r\n```python\r\nimport sqlglot\r\nsql = \"SELECT JSON_PARSE('[10001,10002,\\\"abc\\\"]');\"\r\nparsed = sqlglot.parse_one(sql,dialect=\"redshift\")\r\nparsed.sql(dialect=\"redshift\")\r\n#'SELECT PARSE_JSON(\\'[10001,10002,\"abc\"]\\')'\r\n```\r\nThe generated sql triggers an error when executed in redshift\r\n\r\n>Failed to execute query: ERROR: function parse_json(\"unknown\") does not exist\r\n Hint: No function matches the given name and argument types. You may need to add explicit type casts.\r\n\r\n**Official Documentation**\r\nhttps://docs.aws.amazon.com/redshift/latest/dg/JSON_PARSE.html\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport typing as t\n\nfrom sqlglot import exp, transforms\nfrom sqlglot.dialects.dialect import (\n concat_to_dpipe_sql,\n concat_ws_to_dpipe_sql,\n generatedasidentitycolumnconstraint_sql,\n rename_func,\n ts_or_ds_to_date_sql,\n)\nfrom sqlglot.dialects.postgres import Postgres\nfrom sqlglot.helper import seq_get\nfrom sqlglot.tokens import TokenType\n\n\ndef _json_sql(self: Redshift.Generator, expression: exp.JSONExtract | exp.JSONExtractScalar) -> str:\n return f'{self.sql(expression, \"this\")}.\"{expression.expression.name}\"'\n\n\ndef _parse_date_add(args: t.List) -> exp.DateAdd:\n return exp.DateAdd(\n this=exp.TsOrDsToDate(this=seq_get(args, 2)),\n expression=seq_get(args, 1),\n unit=seq_get(args, 0),\n )\n\n\nclass Redshift(Postgres):\n # https://docs.aws.amazon.com/redshift/latest/dg/r_names.html\n RESOLVES_IDENTIFIERS_AS_UPPERCASE = None\n\n SUPPORTS_USER_DEFINED_TYPES = False\n INDEX_OFFSET = 0\n\n TIME_FORMAT = \"'YYYY-MM-DD HH:MI:SS'\"\n TIME_MAPPING = {\n **Postgres.TIME_MAPPING,\n \"MON\": \"%b\",\n \"HH\": \"%H\",\n }\n\n class Parser(Postgres.Parser):\n FUNCTIONS = {\n **Postgres.Parser.FUNCTIONS,\n \"ADD_MONTHS\": lambda args: exp.DateAdd(\n this=exp.TsOrDsToDate(this=seq_get(args, 0)),\n expression=seq_get(args, 1),\n unit=exp.var(\"month\"),\n ),\n \"DATEADD\": _parse_date_add,\n \"DATE_ADD\": _parse_date_add,\n \"DATEDIFF\": lambda args: exp.DateDiff(\n this=exp.TsOrDsToDate(this=seq_get(args, 2)),\n expression=exp.TsOrDsToDate(this=seq_get(args, 1)),\n unit=seq_get(args, 0),\n ),\n \"STRTOL\": exp.FromBase.from_arg_list,\n }\n\n NO_PAREN_FUNCTION_PARSERS = {\n **Postgres.Parser.NO_PAREN_FUNCTION_PARSERS,\n \"APPROXIMATE\": lambda self: self._parse_approximate_count(),\n }\n\n def _parse_table(\n self,\n schema: bool = False,\n joins: bool = False,\n alias_tokens: t.Optional[t.Collection[TokenType]] = None,\n parse_bracket: bool = False,\n ) -> t.Optional[exp.Expression]:\n # Redshift supports UNPIVOTing SUPER objects, e.g. `UNPIVOT foo.obj[0] AS val AT attr`\n unpivot = self._match(TokenType.UNPIVOT)\n table = super()._parse_table(\n schema=schema,\n joins=joins,\n alias_tokens=alias_tokens,\n parse_bracket=parse_bracket,\n )\n\n return self.expression(exp.Pivot, this=table, unpivot=True) if unpivot else table\n\n def _parse_types(\n self, check_func: bool = False, schema: bool = False, allow_identifiers: bool = True\n ) -> t.Optional[exp.Expression]:\n this = super()._parse_types(\n check_func=check_func, schema=schema, allow_identifiers=allow_identifiers\n )\n\n if (\n isinstance(this, exp.DataType)\n and this.is_type(\"varchar\")\n and this.expressions\n and this.expressions[0].this == exp.column(\"MAX\")\n ):\n this.set(\"expressions\", [exp.var(\"MAX\")])\n\n return this\n\n def _parse_convert(\n self, strict: bool, safe: t.Optional[bool] = None\n ) -> t.Optional[exp.Expression]:\n to = self._parse_types()\n self._match(TokenType.COMMA)\n this = self._parse_bitwise()\n return self.expression(exp.TryCast, this=this, to=to, safe=safe)\n\n def _parse_approximate_count(self) -> t.Optional[exp.ApproxDistinct]:\n index = self._index - 1\n func = self._parse_function()\n\n if isinstance(func, exp.Count) and isinstance(func.this, exp.Distinct):\n return self.expression(exp.ApproxDistinct, this=seq_get(func.this.expressions, 0))\n self._retreat(index)\n return None\n\n class Tokenizer(Postgres.Tokenizer):\n BIT_STRINGS = []\n HEX_STRINGS = []\n STRING_ESCAPES = [\"\\\\\", \"'\"]\n\n KEYWORDS = {\n **Postgres.Tokenizer.KEYWORDS,\n \"HLLSKETCH\": TokenType.HLLSKETCH,\n \"SUPER\": TokenType.SUPER,\n \"SYSDATE\": TokenType.CURRENT_TIMESTAMP,\n \"TOP\": TokenType.TOP,\n \"UNLOAD\": TokenType.COMMAND,\n \"VARBYTE\": TokenType.VARBINARY,\n }\n\n # Redshift allows # to appear as a table identifier prefix\n SINGLE_TOKENS = Postgres.Tokenizer.SINGLE_TOKENS.copy()\n SINGLE_TOKENS.pop(\"#\")\n\n class Generator(Postgres.Generator):\n LOCKING_READS_SUPPORTED = False\n RENAME_TABLE_WITH_DB = False\n QUERY_HINTS = False\n VALUES_AS_TABLE = False\n TZ_TO_WITH_TIME_ZONE = True\n NVL2_SUPPORTED = True\n\n TYPE_MAPPING = {\n **Postgres.Generator.TYPE_MAPPING,\n exp.DataType.Type.BINARY: \"VARBYTE\",\n exp.DataType.Type.INT: \"INTEGER\",\n exp.DataType.Type.TIMETZ: \"TIME\",\n exp.DataType.Type.TIMESTAMPTZ: \"TIMESTAMP\",\n exp.DataType.Type.VARBINARY: \"VARBYTE\",\n }\n\n PROPERTIES_LOCATION = {\n **Postgres.Generator.PROPERTIES_LOCATION,\n exp.LikeProperty: exp.Properties.Location.POST_WITH,\n }\n\n TRANSFORMS = {\n **Postgres.Generator.TRANSFORMS,\n exp.Concat: concat_to_dpipe_sql,\n exp.ConcatWs: concat_ws_to_dpipe_sql,\n exp.ApproxDistinct: lambda self, e: f\"APPROXIMATE COUNT(DISTINCT {self.sql(e, 'this')})\",\n exp.CurrentTimestamp: lambda self, e: \"SYSDATE\",\n exp.DateAdd: lambda self, e: self.func(\n \"DATEADD\", exp.var(e.text(\"unit\") or \"day\"), e.expression, e.this\n ),\n exp.DateDiff: lambda self, e: self.func(\n \"DATEDIFF\", exp.var(e.text(\"unit\") or \"day\"), e.expression, e.this\n ),\n exp.DistKeyProperty: lambda self, e: f\"DISTKEY({e.name})\",\n exp.DistStyleProperty: lambda self, e: self.naked_property(e),\n exp.FromBase: rename_func(\"STRTOL\"),\n exp.GeneratedAsIdentityColumnConstraint: generatedasidentitycolumnconstraint_sql,\n exp.JSONExtract: _json_sql,\n exp.JSONExtractScalar: _json_sql,\n exp.SafeConcat: concat_to_dpipe_sql,\n exp.Select: transforms.preprocess(\n [transforms.eliminate_distinct_on, transforms.eliminate_semi_and_anti_joins]\n ),\n exp.SortKeyProperty: lambda self, e: f\"{'COMPOUND ' if e.args['compound'] else ''}SORTKEY({self.format_args(*e.this)})\",\n exp.TsOrDsToDate: ts_or_ds_to_date_sql(\"redshift\"),\n }\n\n # Postgres maps exp.Pivot to no_pivot_sql, but Redshift support pivots\n TRANSFORMS.pop(exp.Pivot)\n\n # Redshift uses the POW | POWER (expr1, expr2) syntax instead of expr1 ^ expr2 (postgres)\n TRANSFORMS.pop(exp.Pow)\n\n # Redshift supports ANY_VALUE(..)\n TRANSFORMS.pop(exp.AnyValue)\n\n RESERVED_KEYWORDS = {*Postgres.Generator.RESERVED_KEYWORDS, \"snapshot\", \"type\"}\n\n def with_properties(self, properties: exp.Properties) -> str:\n \"\"\"Redshift doesn't have `WITH` as part of their with_properties so we remove it\"\"\"\n return self.properties(properties, prefix=\" \", suffix=\"\")\n\n def datatype_sql(self, expression: exp.DataType) -> str:\n \"\"\"\n Redshift converts the `TEXT` data type to `VARCHAR(255)` by default when people more generally mean\n VARCHAR of max length which is `VARCHAR(max)` in Redshift. Therefore if we get a `TEXT` data type\n without precision we convert it to `VARCHAR(max)` and if it does have precision then we just convert\n `TEXT` to `VARCHAR`.\n \"\"\"\n if expression.is_type(\"text\"):\n expression = expression.copy()\n expression.set(\"this\", exp.DataType.Type.VARCHAR)\n precision = expression.args.get(\"expressions\")\n\n if not precision:\n expression.append(\"expressions\", exp.var(\"MAX\"))\n\n return super().datatype_sql(expression)\n", "path": "sqlglot/dialects/redshift.py"}]}
| 3,222 | 149 |
gh_patches_debug_20828
|
rasdani/github-patches
|
git_diff
|
bookwyrm-social__bookwyrm-619
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Reading goal status doesn't set plurals correctly
When someone is only planning to read 1 book, the status should say "1 book" not "1 books"
</issue>
<code>
[start of bookwyrm/views/goal.py]
1 ''' non-interactive pages '''
2 from django.contrib.auth.decorators import login_required
3 from django.http import HttpResponseNotFound
4 from django.shortcuts import redirect
5 from django.template.response import TemplateResponse
6 from django.utils.decorators import method_decorator
7 from django.views import View
8
9 from bookwyrm import forms, models
10 from bookwyrm.status import create_generated_note
11 from .helpers import get_user_from_username, object_visible_to_user
12
13
14 # pylint: disable= no-self-use
15 @method_decorator(login_required, name='dispatch')
16 class Goal(View):
17 ''' track books for the year '''
18 def get(self, request, username, year):
19 ''' reading goal page '''
20 user = get_user_from_username(username)
21 year = int(year)
22 goal = models.AnnualGoal.objects.filter(
23 year=year, user=user
24 ).first()
25 if not goal and user != request.user:
26 return HttpResponseNotFound()
27
28 if goal and not object_visible_to_user(request.user, goal):
29 return HttpResponseNotFound()
30
31 data = {
32 'title': '%s\'s %d Reading' % (user.display_name, year),
33 'goal_form': forms.GoalForm(instance=goal),
34 'goal': goal,
35 'user': user,
36 'year': year,
37 'is_self': request.user == user,
38 }
39 return TemplateResponse(request, 'goal.html', data)
40
41
42 def post(self, request, username, year):
43 ''' update or create an annual goal '''
44 user = get_user_from_username(username)
45 if user != request.user:
46 return HttpResponseNotFound()
47
48 year = int(year)
49 goal = models.AnnualGoal.objects.filter(
50 year=year, user=request.user
51 ).first()
52 form = forms.GoalForm(request.POST, instance=goal)
53 if not form.is_valid():
54 data = {
55 'title': '%s\'s %d Reading' % (request.user.display_name, year),
56 'goal_form': form,
57 'goal': goal,
58 'year': year,
59 }
60 return TemplateResponse(request, 'goal.html', data)
61 goal = form.save()
62
63 if request.POST.get('post-status'):
64 # create status, if appropraite
65 create_generated_note(
66 request.user,
67 'set a goal to read %d books in %d' % (goal.goal, goal.year),
68 privacy=goal.privacy
69 )
70
71 return redirect(request.headers.get('Referer', '/'))
72
[end of bookwyrm/views/goal.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bookwyrm/views/goal.py b/bookwyrm/views/goal.py
--- a/bookwyrm/views/goal.py
+++ b/bookwyrm/views/goal.py
@@ -2,6 +2,7 @@
from django.contrib.auth.decorators import login_required
from django.http import HttpResponseNotFound
from django.shortcuts import redirect
+from django.template.loader import get_template
from django.template.response import TemplateResponse
from django.utils.decorators import method_decorator
from django.views import View
@@ -62,9 +63,10 @@
if request.POST.get('post-status'):
# create status, if appropraite
+ template = get_template('snippets/generated_status/goal.html')
create_generated_note(
request.user,
- 'set a goal to read %d books in %d' % (goal.goal, goal.year),
+ template.render({'goal': goal, 'user': request.user}).strip(),
privacy=goal.privacy
)
|
{"golden_diff": "diff --git a/bookwyrm/views/goal.py b/bookwyrm/views/goal.py\n--- a/bookwyrm/views/goal.py\n+++ b/bookwyrm/views/goal.py\n@@ -2,6 +2,7 @@\n from django.contrib.auth.decorators import login_required\n from django.http import HttpResponseNotFound\n from django.shortcuts import redirect\n+from django.template.loader import get_template\n from django.template.response import TemplateResponse\n from django.utils.decorators import method_decorator\n from django.views import View\n@@ -62,9 +63,10 @@\n \n if request.POST.get('post-status'):\n # create status, if appropraite\n+ template = get_template('snippets/generated_status/goal.html')\n create_generated_note(\n request.user,\n- 'set a goal to read %d books in %d' % (goal.goal, goal.year),\n+ template.render({'goal': goal, 'user': request.user}).strip(),\n privacy=goal.privacy\n )\n", "issue": "Reading goal status doesn't set plurals correctly\nWhen someone is only planning to read 1 book, the status should say \"1 book\" not \"1 books\"\n", "before_files": [{"content": "''' non-interactive pages '''\nfrom django.contrib.auth.decorators import login_required\nfrom django.http import HttpResponseNotFound\nfrom django.shortcuts import redirect\nfrom django.template.response import TemplateResponse\nfrom django.utils.decorators import method_decorator\nfrom django.views import View\n\nfrom bookwyrm import forms, models\nfrom bookwyrm.status import create_generated_note\nfrom .helpers import get_user_from_username, object_visible_to_user\n\n\n# pylint: disable= no-self-use\n@method_decorator(login_required, name='dispatch')\nclass Goal(View):\n ''' track books for the year '''\n def get(self, request, username, year):\n ''' reading goal page '''\n user = get_user_from_username(username)\n year = int(year)\n goal = models.AnnualGoal.objects.filter(\n year=year, user=user\n ).first()\n if not goal and user != request.user:\n return HttpResponseNotFound()\n\n if goal and not object_visible_to_user(request.user, goal):\n return HttpResponseNotFound()\n\n data = {\n 'title': '%s\\'s %d Reading' % (user.display_name, year),\n 'goal_form': forms.GoalForm(instance=goal),\n 'goal': goal,\n 'user': user,\n 'year': year,\n 'is_self': request.user == user,\n }\n return TemplateResponse(request, 'goal.html', data)\n\n\n def post(self, request, username, year):\n ''' update or create an annual goal '''\n user = get_user_from_username(username)\n if user != request.user:\n return HttpResponseNotFound()\n\n year = int(year)\n goal = models.AnnualGoal.objects.filter(\n year=year, user=request.user\n ).first()\n form = forms.GoalForm(request.POST, instance=goal)\n if not form.is_valid():\n data = {\n 'title': '%s\\'s %d Reading' % (request.user.display_name, year),\n 'goal_form': form,\n 'goal': goal,\n 'year': year,\n }\n return TemplateResponse(request, 'goal.html', data)\n goal = form.save()\n\n if request.POST.get('post-status'):\n # create status, if appropraite\n create_generated_note(\n request.user,\n 'set a goal to read %d books in %d' % (goal.goal, goal.year),\n privacy=goal.privacy\n )\n\n return redirect(request.headers.get('Referer', '/'))\n", "path": "bookwyrm/views/goal.py"}]}
| 1,227 | 209 |
gh_patches_debug_32496
|
rasdani/github-patches
|
git_diff
|
beeware__toga-2348
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`toga.Image()` doesn't accept `None` as a value for `src`
### Describe the bug
`toga.Image()` doesn't accept `None` as a value for `src`, but according to the docs and code: https://github.com/beeware/toga/blob/61dff563d82da71bd2470cde27882731113eda2d/core/src/toga/images.py#L42C9-L42C41 it should accept `None` as a value.
### Steps to reproduce
1. Clone latest toga/main branch
2. `pip install -e ./core -e ./dummy -e ./gtk`
3. Create a new briefcase project
4. Use the following `app.py` script:
```
"""
My first application
"""
import toga
from toga.style import Pack
from toga.style.pack import COLUMN, ROW
class HelloWorld(toga.App):
def startup(self):
"""
Construct and show the Toga application.
Usually, you would add your application to a main content box.
We then create a main window (with a name matching the app), and
show the main window.
"""
main_box = toga.Box()
img = toga.Image(src=None)
self.main_window = toga.MainWindow(title=self.formal_name)
self.main_window.content = main_box
self.main_window.show()
def main():
return HelloWorld()
```
5. `briefcase dev`
6. Error encountered:
```
[helloworld] Starting in dev mode...
===========================================================================
Traceback (most recent call last):
File "/home/proneon267/Pictures/venv/lib/python3.11/site-packages/toga_gtk/app.py", line 87, in gtk_startup
self.interface._startup()
File "/home/proneon267/Pictures/venv/lib/python3.11/site-packages/toga/app.py", line 629, in _startup
self.startup()
File "/home/proneon267/Pictures/toga/helloworld/src/helloworld/app.py", line 20, in startup
img = toga.Image(src=None)
^^^^^^^^^^^^^^^^^^^^
File "/home/proneon267/Pictures/venv/lib/python3.11/site-packages/toga/images.py", line 63, in __init__
raise TypeError(
TypeError: Image.__init__() missing 1 required positional argument: 'src'
```
### Expected behavior
`toga.Image()` should accept `None` as a value for `src`
### Screenshots
_No response_
### Environment
- Operating System: Arch
- Python version: 3.11.6
- Software versions:
- Briefcase: 0.3.16
- Toga: latest
- ...
### Logs
```
No log files were generated.
```
### Additional context
_No response_
</issue>
<code>
[start of core/src/toga/images.py]
1 from __future__ import annotations
2
3 import sys
4 import warnings
5 from io import BytesIO
6 from pathlib import Path
7 from typing import TYPE_CHECKING, Any
8 from warnings import warn
9
10 try:
11 import PIL.Image
12
13 PIL_imported = True
14 except ImportError: # pragma: no cover
15 PIL_imported = False
16
17 import toga
18 from toga.platform import get_platform_factory
19
20 # Make sure deprecation warnings are shown by default
21 warnings.filterwarnings("default", category=DeprecationWarning)
22
23 if TYPE_CHECKING:
24 if sys.version_info < (3, 10):
25 from typing_extensions import TypeAlias, TypeVar
26 else:
27 from typing import TypeAlias, TypeVar
28
29 # Define a type variable for generics where an Image type is required.
30 ImageT = TypeVar("ImageT")
31
32 # Define the types that can be used as Image content
33 PathLike: TypeAlias = str | Path
34 BytesLike: TypeAlias = bytes | bytearray | memoryview
35 ImageLike: TypeAlias = Any
36 ImageContent: TypeAlias = PathLike | BytesLike | ImageLike
37
38
39 class Image:
40 def __init__(
41 self,
42 src: ImageContent | None = None,
43 *,
44 path=None, # DEPRECATED
45 data=None, # DEPRECATED
46 ):
47 """Create a new image.
48
49 :param src: The source from which to load the image. Can be any valid
50 :any:`image content <ImageContent>` type.
51 :param path: **DEPRECATED** - Use ``src``.
52 :param data: **DEPRECATED** - Use ``src``.
53 :raises FileNotFoundError: If a path is provided, but that path does not exist.
54 :raises ValueError: If the source cannot be loaded as an image.
55 """
56 ######################################################################
57 # 2023-11: Backwards compatibility
58 ######################################################################
59 num_provided = sum(arg is not None for arg in (src, path, data))
60 if num_provided > 1:
61 raise ValueError("Received multiple arguments to constructor.")
62 if num_provided == 0:
63 raise TypeError(
64 "Image.__init__() missing 1 required positional argument: 'src'"
65 )
66 if path is not None:
67 src = path
68 warn(
69 "Path argument is deprecated, use src instead.",
70 DeprecationWarning,
71 stacklevel=2,
72 )
73 elif data is not None:
74 src = data
75 warn(
76 "Data argument is deprecated, use src instead.",
77 DeprecationWarning,
78 stacklevel=2,
79 )
80 ######################################################################
81 # End backwards compatibility
82 ######################################################################
83
84 self.factory = get_platform_factory()
85 self._path = None
86
87 # Any "lump of bytes" should be valid here.
88 if isinstance(src, (bytes, bytearray, memoryview)):
89 self._impl = self.factory.Image(interface=self, data=src)
90
91 elif isinstance(src, (str, Path)):
92 self._path = toga.App.app.paths.app / src
93 if not self._path.is_file():
94 raise FileNotFoundError(f"Image file {self._path} does not exist")
95 self._impl = self.factory.Image(interface=self, path=self._path)
96
97 elif isinstance(src, Image):
98 self._impl = self.factory.Image(interface=self, data=src.data)
99
100 elif PIL_imported and isinstance(src, PIL.Image.Image):
101 buffer = BytesIO()
102 src.save(buffer, format="png", compress_level=0)
103 self._impl = self.factory.Image(interface=self, data=buffer.getvalue())
104
105 elif isinstance(src, self.factory.Image.RAW_TYPE):
106 self._impl = self.factory.Image(interface=self, raw=src)
107
108 else:
109 raise TypeError("Unsupported source type for Image")
110
111 @property
112 def size(self) -> (int, int):
113 """The size of the image, as a (width, height) tuple."""
114 return (self._impl.get_width(), self._impl.get_height())
115
116 @property
117 def width(self) -> int:
118 """The width of the image, in pixels."""
119 return self._impl.get_width()
120
121 @property
122 def height(self) -> int:
123 """The height of the image, in pixels."""
124 return self._impl.get_height()
125
126 @property
127 def data(self) -> bytes:
128 """The raw data for the image, in PNG format."""
129 return self._impl.get_data()
130
131 @property
132 def path(self) -> Path | None:
133 """The path from which the image was opened, if any (or None)."""
134 return self._path
135
136 def save(self, path: str | Path) -> None:
137 """Save image to given path.
138
139 The file format of the saved image will be determined by the extension of
140 the filename provided (e.g ``path/to/mypicture.png`` will save a PNG file).
141
142 :param path: Path to save the image to.
143 """
144 self._impl.save(path)
145
146 def as_format(self, format: type[ImageT]) -> ImageT:
147 """Return the image, converted to the image format specified.
148
149 :param format: The image class to return. Currently supports only :any:`Image`,
150 and :any:`PIL.Image.Image` if Pillow is installed.
151 :returns: The image in the requested format
152 :raises TypeError: If the format supplied is not recognized.
153 """
154 if isinstance(format, type) and issubclass(format, Image):
155 return format(self.data)
156
157 if PIL_imported and format is PIL.Image.Image:
158 buffer = BytesIO(self.data)
159 with PIL.Image.open(buffer) as pil_image:
160 pil_image.load()
161 return pil_image
162
163 raise TypeError(f"Unknown conversion format for Image: {format}")
164
[end of core/src/toga/images.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/core/src/toga/images.py b/core/src/toga/images.py
--- a/core/src/toga/images.py
+++ b/core/src/toga/images.py
@@ -36,13 +36,16 @@
ImageContent: TypeAlias = PathLike | BytesLike | ImageLike
+NOT_PROVIDED = object()
+
+
class Image:
def __init__(
self,
- src: ImageContent | None = None,
+ src: ImageContent = NOT_PROVIDED,
*,
- path=None, # DEPRECATED
- data=None, # DEPRECATED
+ path=NOT_PROVIDED, # DEPRECATED
+ data=NOT_PROVIDED, # DEPRECATED
):
"""Create a new image.
@@ -56,21 +59,21 @@
######################################################################
# 2023-11: Backwards compatibility
######################################################################
- num_provided = sum(arg is not None for arg in (src, path, data))
+ num_provided = sum(arg is not NOT_PROVIDED for arg in (src, path, data))
if num_provided > 1:
raise ValueError("Received multiple arguments to constructor.")
if num_provided == 0:
raise TypeError(
"Image.__init__() missing 1 required positional argument: 'src'"
)
- if path is not None:
+ if path is not NOT_PROVIDED:
src = path
warn(
"Path argument is deprecated, use src instead.",
DeprecationWarning,
stacklevel=2,
)
- elif data is not None:
+ elif data is not NOT_PROVIDED:
src = data
warn(
"Data argument is deprecated, use src instead.",
|
{"golden_diff": "diff --git a/core/src/toga/images.py b/core/src/toga/images.py\n--- a/core/src/toga/images.py\n+++ b/core/src/toga/images.py\n@@ -36,13 +36,16 @@\n ImageContent: TypeAlias = PathLike | BytesLike | ImageLike\n \n \n+NOT_PROVIDED = object()\n+\n+\n class Image:\n def __init__(\n self,\n- src: ImageContent | None = None,\n+ src: ImageContent = NOT_PROVIDED,\n *,\n- path=None, # DEPRECATED\n- data=None, # DEPRECATED\n+ path=NOT_PROVIDED, # DEPRECATED\n+ data=NOT_PROVIDED, # DEPRECATED\n ):\n \"\"\"Create a new image.\n \n@@ -56,21 +59,21 @@\n ######################################################################\n # 2023-11: Backwards compatibility\n ######################################################################\n- num_provided = sum(arg is not None for arg in (src, path, data))\n+ num_provided = sum(arg is not NOT_PROVIDED for arg in (src, path, data))\n if num_provided > 1:\n raise ValueError(\"Received multiple arguments to constructor.\")\n if num_provided == 0:\n raise TypeError(\n \"Image.__init__() missing 1 required positional argument: 'src'\"\n )\n- if path is not None:\n+ if path is not NOT_PROVIDED:\n src = path\n warn(\n \"Path argument is deprecated, use src instead.\",\n DeprecationWarning,\n stacklevel=2,\n )\n- elif data is not None:\n+ elif data is not NOT_PROVIDED:\n src = data\n warn(\n \"Data argument is deprecated, use src instead.\",\n", "issue": "`toga.Image()` doesn't accept `None` as a value for `src`\n### Describe the bug\n\n`toga.Image()` doesn't accept `None` as a value for `src`, but according to the docs and code: https://github.com/beeware/toga/blob/61dff563d82da71bd2470cde27882731113eda2d/core/src/toga/images.py#L42C9-L42C41 it should accept `None` as a value.\n\n### Steps to reproduce\n\n1. Clone latest toga/main branch\r\n2. `pip install -e ./core -e ./dummy -e ./gtk`\r\n3. Create a new briefcase project\r\n4. Use the following `app.py` script:\r\n```\r\n\"\"\"\r\nMy first application\r\n\"\"\"\r\nimport toga\r\nfrom toga.style import Pack\r\nfrom toga.style.pack import COLUMN, ROW\r\n\r\n\r\nclass HelloWorld(toga.App):\r\n\r\n def startup(self):\r\n \"\"\"\r\n Construct and show the Toga application.\r\n\r\n Usually, you would add your application to a main content box.\r\n We then create a main window (with a name matching the app), and\r\n show the main window.\r\n \"\"\"\r\n main_box = toga.Box()\r\n img = toga.Image(src=None)\r\n self.main_window = toga.MainWindow(title=self.formal_name)\r\n self.main_window.content = main_box\r\n self.main_window.show()\r\n\r\n\r\ndef main():\r\n return HelloWorld()\r\n```\r\n\r\n5. `briefcase dev`\r\n6. Error encountered:\r\n```\r\n\r\n[helloworld] Starting in dev mode...\r\n===========================================================================\r\nTraceback (most recent call last):\r\n File \"/home/proneon267/Pictures/venv/lib/python3.11/site-packages/toga_gtk/app.py\", line 87, in gtk_startup\r\n self.interface._startup()\r\n File \"/home/proneon267/Pictures/venv/lib/python3.11/site-packages/toga/app.py\", line 629, in _startup\r\n self.startup()\r\n File \"/home/proneon267/Pictures/toga/helloworld/src/helloworld/app.py\", line 20, in startup\r\n img = toga.Image(src=None)\r\n ^^^^^^^^^^^^^^^^^^^^\r\n File \"/home/proneon267/Pictures/venv/lib/python3.11/site-packages/toga/images.py\", line 63, in __init__\r\n raise TypeError(\r\nTypeError: Image.__init__() missing 1 required positional argument: 'src'\r\n```\r\n\n\n### Expected behavior\n\n`toga.Image()` should accept `None` as a value for `src`\n\n### Screenshots\n\n_No response_\n\n### Environment\n\n- Operating System: Arch\r\n- Python version: 3.11.6\r\n- Software versions:\r\n - Briefcase: 0.3.16\r\n - Toga: latest\r\n - ...\r\n\n\n### Logs\n\n```\r\nNo log files were generated.\r\n```\r\n\n\n### Additional context\n\n_No response_\n", "before_files": [{"content": "from __future__ import annotations\n\nimport sys\nimport warnings\nfrom io import BytesIO\nfrom pathlib import Path\nfrom typing import TYPE_CHECKING, Any\nfrom warnings import warn\n\ntry:\n import PIL.Image\n\n PIL_imported = True\nexcept ImportError: # pragma: no cover\n PIL_imported = False\n\nimport toga\nfrom toga.platform import get_platform_factory\n\n# Make sure deprecation warnings are shown by default\nwarnings.filterwarnings(\"default\", category=DeprecationWarning)\n\nif TYPE_CHECKING:\n if sys.version_info < (3, 10):\n from typing_extensions import TypeAlias, TypeVar\n else:\n from typing import TypeAlias, TypeVar\n\n # Define a type variable for generics where an Image type is required.\n ImageT = TypeVar(\"ImageT\")\n\n # Define the types that can be used as Image content\n PathLike: TypeAlias = str | Path\n BytesLike: TypeAlias = bytes | bytearray | memoryview\n ImageLike: TypeAlias = Any\n ImageContent: TypeAlias = PathLike | BytesLike | ImageLike\n\n\nclass Image:\n def __init__(\n self,\n src: ImageContent | None = None,\n *,\n path=None, # DEPRECATED\n data=None, # DEPRECATED\n ):\n \"\"\"Create a new image.\n\n :param src: The source from which to load the image. Can be any valid\n :any:`image content <ImageContent>` type.\n :param path: **DEPRECATED** - Use ``src``.\n :param data: **DEPRECATED** - Use ``src``.\n :raises FileNotFoundError: If a path is provided, but that path does not exist.\n :raises ValueError: If the source cannot be loaded as an image.\n \"\"\"\n ######################################################################\n # 2023-11: Backwards compatibility\n ######################################################################\n num_provided = sum(arg is not None for arg in (src, path, data))\n if num_provided > 1:\n raise ValueError(\"Received multiple arguments to constructor.\")\n if num_provided == 0:\n raise TypeError(\n \"Image.__init__() missing 1 required positional argument: 'src'\"\n )\n if path is not None:\n src = path\n warn(\n \"Path argument is deprecated, use src instead.\",\n DeprecationWarning,\n stacklevel=2,\n )\n elif data is not None:\n src = data\n warn(\n \"Data argument is deprecated, use src instead.\",\n DeprecationWarning,\n stacklevel=2,\n )\n ######################################################################\n # End backwards compatibility\n ######################################################################\n\n self.factory = get_platform_factory()\n self._path = None\n\n # Any \"lump of bytes\" should be valid here.\n if isinstance(src, (bytes, bytearray, memoryview)):\n self._impl = self.factory.Image(interface=self, data=src)\n\n elif isinstance(src, (str, Path)):\n self._path = toga.App.app.paths.app / src\n if not self._path.is_file():\n raise FileNotFoundError(f\"Image file {self._path} does not exist\")\n self._impl = self.factory.Image(interface=self, path=self._path)\n\n elif isinstance(src, Image):\n self._impl = self.factory.Image(interface=self, data=src.data)\n\n elif PIL_imported and isinstance(src, PIL.Image.Image):\n buffer = BytesIO()\n src.save(buffer, format=\"png\", compress_level=0)\n self._impl = self.factory.Image(interface=self, data=buffer.getvalue())\n\n elif isinstance(src, self.factory.Image.RAW_TYPE):\n self._impl = self.factory.Image(interface=self, raw=src)\n\n else:\n raise TypeError(\"Unsupported source type for Image\")\n\n @property\n def size(self) -> (int, int):\n \"\"\"The size of the image, as a (width, height) tuple.\"\"\"\n return (self._impl.get_width(), self._impl.get_height())\n\n @property\n def width(self) -> int:\n \"\"\"The width of the image, in pixels.\"\"\"\n return self._impl.get_width()\n\n @property\n def height(self) -> int:\n \"\"\"The height of the image, in pixels.\"\"\"\n return self._impl.get_height()\n\n @property\n def data(self) -> bytes:\n \"\"\"The raw data for the image, in PNG format.\"\"\"\n return self._impl.get_data()\n\n @property\n def path(self) -> Path | None:\n \"\"\"The path from which the image was opened, if any (or None).\"\"\"\n return self._path\n\n def save(self, path: str | Path) -> None:\n \"\"\"Save image to given path.\n\n The file format of the saved image will be determined by the extension of\n the filename provided (e.g ``path/to/mypicture.png`` will save a PNG file).\n\n :param path: Path to save the image to.\n \"\"\"\n self._impl.save(path)\n\n def as_format(self, format: type[ImageT]) -> ImageT:\n \"\"\"Return the image, converted to the image format specified.\n\n :param format: The image class to return. Currently supports only :any:`Image`,\n and :any:`PIL.Image.Image` if Pillow is installed.\n :returns: The image in the requested format\n :raises TypeError: If the format supplied is not recognized.\n \"\"\"\n if isinstance(format, type) and issubclass(format, Image):\n return format(self.data)\n\n if PIL_imported and format is PIL.Image.Image:\n buffer = BytesIO(self.data)\n with PIL.Image.open(buffer) as pil_image:\n pil_image.load()\n return pil_image\n\n raise TypeError(f\"Unknown conversion format for Image: {format}\")\n", "path": "core/src/toga/images.py"}]}
| 2,818 | 384 |
gh_patches_debug_33024
|
rasdani/github-patches
|
git_diff
|
svthalia__concrexit-1872
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
PaymentError: This payment has already been processed and hence cannot be deleted.
Sentry Issue: [CONCREXIT-8C](https://sentry.io/organizations/thalia/issues/2568657203/?referrer=github_integration)
```
PaymentError: This payment has already been processed and hence cannot be deleted.
(1 additional frame(s) were not displayed)
...
File "django/core/handlers/base.py", line 181, in _get_response
response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "django/views/decorators/http.py", line 40, in inner
return func(request, *args, **kwargs)
File "pizzas/views.py", line 38, in cancel_order
order.delete()
File "pizzas/models.py", line 256, in delete
delete_payment(self)
File "payments/services.py", line 98, in delete_payment
raise PaymentError(
```
</issue>
<code>
[start of website/pizzas/api/v2/views.py]
1 from oauth2_provider.contrib.rest_framework import IsAuthenticatedOrTokenHasScope
2 from rest_framework.generics import (
3 ListAPIView,
4 RetrieveAPIView,
5 get_object_or_404,
6 CreateAPIView,
7 DestroyAPIView,
8 UpdateAPIView,
9 )
10
11 from rest_framework import filters as framework_filters, status
12 from rest_framework.response import Response
13
14 from payments.exceptions import PaymentError
15 from payments.services import delete_payment
16 from pizzas.api.v2 import filters
17 from pizzas.api.v2.serializers import (
18 ProductSerializer,
19 FoodOrderSerializer,
20 FoodOrderUpdateSerializer,
21 FoodOrderCreateSerializer,
22 )
23 from pizzas.api.v2.serializers.food_event import FoodEventSerializer
24 from pizzas.models import FoodEvent, Product, FoodOrder
25 from thaliawebsite.api.v2.permissions import IsAuthenticatedOrTokenHasScopeForMethod
26
27
28 class FoodEventListView(ListAPIView):
29 """Returns an overview of all food events."""
30
31 serializer_class = FoodEventSerializer
32 queryset = FoodEvent.objects.all()
33 filter_backends = (
34 framework_filters.OrderingFilter,
35 filters.FoodEventDateFilterBackend,
36 )
37 ordering_fields = ("start", "end")
38 permission_classes = [
39 IsAuthenticatedOrTokenHasScope,
40 ]
41 required_scopes = ["food:read"]
42
43
44 class FoodEventDetailView(RetrieveAPIView):
45 """Returns one single food event."""
46
47 serializer_class = FoodEventSerializer
48 queryset = FoodEvent.objects.all()
49 permission_classes = [
50 IsAuthenticatedOrTokenHasScope,
51 ]
52 required_scopes = ["food:read"]
53
54
55 class FoodEventProductsListView(ListAPIView):
56 """Returns an overview of all products."""
57
58 serializer_class = ProductSerializer
59 queryset = Product.available_products.all()
60 filter_backends = (framework_filters.SearchFilter,)
61 search_fields = ("name",)
62 permission_classes = [
63 IsAuthenticatedOrTokenHasScope,
64 ]
65 required_scopes = ["food:read"]
66
67
68 class FoodEventOrderDetailView(
69 RetrieveAPIView, CreateAPIView, UpdateAPIView, DestroyAPIView
70 ):
71 """Returns details of a food order."""
72
73 permission_classes = [
74 IsAuthenticatedOrTokenHasScopeForMethod,
75 ]
76 required_scopes_per_method = {
77 "GET": ["food:read"],
78 "POST": ["food:order"],
79 "PUT": ["food:order"],
80 "PATCH": ["food:order"],
81 "DELETE": ["food:order"],
82 }
83
84 def get_serializer_class(self):
85 if self.request.method.lower() == "get":
86 return FoodOrderSerializer
87 if self.request.method.lower() == "post":
88 return FoodOrderCreateSerializer
89 return FoodOrderUpdateSerializer
90
91 def get_queryset(self):
92 return FoodOrder.objects.filter(food_event=self.food_event)
93
94 def get_object(self):
95 queryset = self.filter_queryset(self.get_queryset())
96 obj = get_object_or_404(queryset, member=self.request.member)
97
98 # May raise a permission denied
99 self.check_object_permissions(self.request, obj)
100
101 return obj
102
103 def dispatch(self, request, *args, **kwargs):
104 self.food_event = get_object_or_404(FoodEvent, pk=self.kwargs.get("pk"))
105 return super().dispatch(request, *args, **kwargs)
106
107 def update(self, request, *args, **kwargs):
108 super().update(request, *args, **kwargs)
109 instance = self.get_object()
110
111 if instance.payment:
112 try:
113 delete_payment(
114 instance, member=request.member, ignore_change_window=True
115 )
116 except PaymentError:
117 return Response(
118 "Your order could not be updated because it was already paid.",
119 status=status.HTTP_403_FORBIDDEN,
120 )
121
122 return Response(
123 FoodOrderSerializer(instance, context=self.get_serializer_context()).data
124 )
125
126 def create(self, request, *args, **kwargs):
127 serializer = self.get_serializer(data=request.data)
128 serializer.is_valid(raise_exception=True)
129 self.perform_create(serializer)
130 return Response(
131 FoodOrderSerializer(
132 serializer.instance, context=self.get_serializer_context()
133 ).data,
134 status=status.HTTP_201_CREATED,
135 )
136
[end of website/pizzas/api/v2/views.py]
[start of website/pizzas/views.py]
1 """Views provided by the pizzas package."""
2 from django.contrib import messages
3 from django.contrib.auth.decorators import login_required
4 from django.http import Http404
5 from django.shortcuts import get_object_or_404, render, redirect
6 from django.utils.translation import gettext_lazy as _
7 from django.views.decorators.http import require_http_methods
8
9 from payments.exceptions import PaymentError
10 from payments.services import delete_payment
11 from .models import FoodOrder, FoodEvent, Product
12
13
14 @login_required
15 def index(request):
16 """Overview of user order for a pizza event."""
17 products = Product.available_products.order_by("name")
18 if not request.user.has_perm("pizzas.order_restricted_products"):
19 products = products.exclude(restricted=True)
20 event = FoodEvent.current()
21 try:
22 obj = FoodOrder.objects.get(food_event=event, member=request.member)
23 except FoodOrder.DoesNotExist:
24 obj = None
25 context = {"event": event, "products": products, "order": obj}
26 return render(request, "pizzas/index.html", context)
27
28
29 @require_http_methods(["POST"])
30 def cancel_order(request):
31 """View that cancels a user's order."""
32 if "order" in request.POST:
33 try:
34 order = get_object_or_404(FoodOrder, pk=int(request.POST["order"]))
35 if not order.can_be_changed:
36 messages.error(request, _("You can no longer cancel."))
37 elif order.member == request.member:
38 order.delete()
39 messages.success(request, _("Your order has been cancelled."))
40 except Http404:
41 messages.error(request, _("Your order could not be found."))
42 return redirect("pizzas:index")
43
44
45 @login_required
46 def place_order(request):
47 """View that shows the detail of the current order."""
48 event = FoodEvent.current()
49 if not event:
50 return redirect("pizzas:index")
51
52 try:
53 obj = FoodOrder.objects.get(food_event=event, member=request.member)
54 current_order_locked = not obj.can_be_changed
55 except FoodOrder.DoesNotExist:
56 obj = None
57 current_order_locked = False
58
59 if "product" in request.POST and not current_order_locked:
60 productset = Product.available_products.all()
61 if not request.user.has_perm("pizzas.order_restricted_products"):
62 productset = productset.exclude(restricted=True)
63 try:
64 product = productset.get(pk=int(request.POST["product"]))
65 except Product.DoesNotExist as e:
66 raise Http404("Pizza does not exist") from e
67 if not obj:
68 obj = FoodOrder(food_event=event, member=request.member)
69 obj.product = product
70 if obj.payment:
71 try:
72 delete_payment(obj, member=request.member, ignore_change_window=True)
73 except PaymentError:
74 messages.error(
75 request,
76 _("Your order could not be updated because it was already paid."),
77 )
78 return redirect("pizzas:index")
79 obj.save()
80 return redirect("pizzas:index")
81
[end of website/pizzas/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/website/pizzas/api/v2/views.py b/website/pizzas/api/v2/views.py
--- a/website/pizzas/api/v2/views.py
+++ b/website/pizzas/api/v2/views.py
@@ -102,22 +102,17 @@
def dispatch(self, request, *args, **kwargs):
self.food_event = get_object_or_404(FoodEvent, pk=self.kwargs.get("pk"))
- return super().dispatch(request, *args, **kwargs)
+ try:
+ return super().dispatch(request, *args, **kwargs)
+ except PaymentError as e:
+ return Response(str(e), status=status.HTTP_403_FORBIDDEN,)
def update(self, request, *args, **kwargs):
super().update(request, *args, **kwargs)
instance = self.get_object()
if instance.payment:
- try:
- delete_payment(
- instance, member=request.member, ignore_change_window=True
- )
- except PaymentError:
- return Response(
- "Your order could not be updated because it was already paid.",
- status=status.HTTP_403_FORBIDDEN,
- )
+ delete_payment(instance, member=request.member, ignore_change_window=True)
return Response(
FoodOrderSerializer(instance, context=self.get_serializer_context()).data
diff --git a/website/pizzas/views.py b/website/pizzas/views.py
--- a/website/pizzas/views.py
+++ b/website/pizzas/views.py
@@ -35,8 +35,11 @@
if not order.can_be_changed:
messages.error(request, _("You can no longer cancel."))
elif order.member == request.member:
- order.delete()
- messages.success(request, _("Your order has been cancelled."))
+ try:
+ order.delete()
+ messages.success(request, _("Your order has been cancelled."))
+ except PaymentError as e:
+ messages.error(request, str(e))
except Http404:
messages.error(request, _("Your order could not be found."))
return redirect("pizzas:index")
|
{"golden_diff": "diff --git a/website/pizzas/api/v2/views.py b/website/pizzas/api/v2/views.py\n--- a/website/pizzas/api/v2/views.py\n+++ b/website/pizzas/api/v2/views.py\n@@ -102,22 +102,17 @@\n \n def dispatch(self, request, *args, **kwargs):\n self.food_event = get_object_or_404(FoodEvent, pk=self.kwargs.get(\"pk\"))\n- return super().dispatch(request, *args, **kwargs)\n+ try:\n+ return super().dispatch(request, *args, **kwargs)\n+ except PaymentError as e:\n+ return Response(str(e), status=status.HTTP_403_FORBIDDEN,)\n \n def update(self, request, *args, **kwargs):\n super().update(request, *args, **kwargs)\n instance = self.get_object()\n \n if instance.payment:\n- try:\n- delete_payment(\n- instance, member=request.member, ignore_change_window=True\n- )\n- except PaymentError:\n- return Response(\n- \"Your order could not be updated because it was already paid.\",\n- status=status.HTTP_403_FORBIDDEN,\n- )\n+ delete_payment(instance, member=request.member, ignore_change_window=True)\n \n return Response(\n FoodOrderSerializer(instance, context=self.get_serializer_context()).data\ndiff --git a/website/pizzas/views.py b/website/pizzas/views.py\n--- a/website/pizzas/views.py\n+++ b/website/pizzas/views.py\n@@ -35,8 +35,11 @@\n if not order.can_be_changed:\n messages.error(request, _(\"You can no longer cancel.\"))\n elif order.member == request.member:\n- order.delete()\n- messages.success(request, _(\"Your order has been cancelled.\"))\n+ try:\n+ order.delete()\n+ messages.success(request, _(\"Your order has been cancelled.\"))\n+ except PaymentError as e:\n+ messages.error(request, str(e))\n except Http404:\n messages.error(request, _(\"Your order could not be found.\"))\n return redirect(\"pizzas:index\")\n", "issue": "PaymentError: This payment has already been processed and hence cannot be deleted.\nSentry Issue: [CONCREXIT-8C](https://sentry.io/organizations/thalia/issues/2568657203/?referrer=github_integration)\n\n```\nPaymentError: This payment has already been processed and hence cannot be deleted.\n(1 additional frame(s) were not displayed)\n...\n File \"django/core/handlers/base.py\", line 181, in _get_response\n response = wrapped_callback(request, *callback_args, **callback_kwargs)\n File \"django/views/decorators/http.py\", line 40, in inner\n return func(request, *args, **kwargs)\n File \"pizzas/views.py\", line 38, in cancel_order\n order.delete()\n File \"pizzas/models.py\", line 256, in delete\n delete_payment(self)\n File \"payments/services.py\", line 98, in delete_payment\n raise PaymentError(\n```\n", "before_files": [{"content": "from oauth2_provider.contrib.rest_framework import IsAuthenticatedOrTokenHasScope\nfrom rest_framework.generics import (\n ListAPIView,\n RetrieveAPIView,\n get_object_or_404,\n CreateAPIView,\n DestroyAPIView,\n UpdateAPIView,\n)\n\nfrom rest_framework import filters as framework_filters, status\nfrom rest_framework.response import Response\n\nfrom payments.exceptions import PaymentError\nfrom payments.services import delete_payment\nfrom pizzas.api.v2 import filters\nfrom pizzas.api.v2.serializers import (\n ProductSerializer,\n FoodOrderSerializer,\n FoodOrderUpdateSerializer,\n FoodOrderCreateSerializer,\n)\nfrom pizzas.api.v2.serializers.food_event import FoodEventSerializer\nfrom pizzas.models import FoodEvent, Product, FoodOrder\nfrom thaliawebsite.api.v2.permissions import IsAuthenticatedOrTokenHasScopeForMethod\n\n\nclass FoodEventListView(ListAPIView):\n \"\"\"Returns an overview of all food events.\"\"\"\n\n serializer_class = FoodEventSerializer\n queryset = FoodEvent.objects.all()\n filter_backends = (\n framework_filters.OrderingFilter,\n filters.FoodEventDateFilterBackend,\n )\n ordering_fields = (\"start\", \"end\")\n permission_classes = [\n IsAuthenticatedOrTokenHasScope,\n ]\n required_scopes = [\"food:read\"]\n\n\nclass FoodEventDetailView(RetrieveAPIView):\n \"\"\"Returns one single food event.\"\"\"\n\n serializer_class = FoodEventSerializer\n queryset = FoodEvent.objects.all()\n permission_classes = [\n IsAuthenticatedOrTokenHasScope,\n ]\n required_scopes = [\"food:read\"]\n\n\nclass FoodEventProductsListView(ListAPIView):\n \"\"\"Returns an overview of all products.\"\"\"\n\n serializer_class = ProductSerializer\n queryset = Product.available_products.all()\n filter_backends = (framework_filters.SearchFilter,)\n search_fields = (\"name\",)\n permission_classes = [\n IsAuthenticatedOrTokenHasScope,\n ]\n required_scopes = [\"food:read\"]\n\n\nclass FoodEventOrderDetailView(\n RetrieveAPIView, CreateAPIView, UpdateAPIView, DestroyAPIView\n):\n \"\"\"Returns details of a food order.\"\"\"\n\n permission_classes = [\n IsAuthenticatedOrTokenHasScopeForMethod,\n ]\n required_scopes_per_method = {\n \"GET\": [\"food:read\"],\n \"POST\": [\"food:order\"],\n \"PUT\": [\"food:order\"],\n \"PATCH\": [\"food:order\"],\n \"DELETE\": [\"food:order\"],\n }\n\n def get_serializer_class(self):\n if self.request.method.lower() == \"get\":\n return FoodOrderSerializer\n if self.request.method.lower() == \"post\":\n return FoodOrderCreateSerializer\n return FoodOrderUpdateSerializer\n\n def get_queryset(self):\n return FoodOrder.objects.filter(food_event=self.food_event)\n\n def get_object(self):\n queryset = self.filter_queryset(self.get_queryset())\n obj = get_object_or_404(queryset, member=self.request.member)\n\n # May raise a permission denied\n self.check_object_permissions(self.request, obj)\n\n return obj\n\n def dispatch(self, request, *args, **kwargs):\n self.food_event = get_object_or_404(FoodEvent, pk=self.kwargs.get(\"pk\"))\n return super().dispatch(request, *args, **kwargs)\n\n def update(self, request, *args, **kwargs):\n super().update(request, *args, **kwargs)\n instance = self.get_object()\n\n if instance.payment:\n try:\n delete_payment(\n instance, member=request.member, ignore_change_window=True\n )\n except PaymentError:\n return Response(\n \"Your order could not be updated because it was already paid.\",\n status=status.HTTP_403_FORBIDDEN,\n )\n\n return Response(\n FoodOrderSerializer(instance, context=self.get_serializer_context()).data\n )\n\n def create(self, request, *args, **kwargs):\n serializer = self.get_serializer(data=request.data)\n serializer.is_valid(raise_exception=True)\n self.perform_create(serializer)\n return Response(\n FoodOrderSerializer(\n serializer.instance, context=self.get_serializer_context()\n ).data,\n status=status.HTTP_201_CREATED,\n )\n", "path": "website/pizzas/api/v2/views.py"}, {"content": "\"\"\"Views provided by the pizzas package.\"\"\"\nfrom django.contrib import messages\nfrom django.contrib.auth.decorators import login_required\nfrom django.http import Http404\nfrom django.shortcuts import get_object_or_404, render, redirect\nfrom django.utils.translation import gettext_lazy as _\nfrom django.views.decorators.http import require_http_methods\n\nfrom payments.exceptions import PaymentError\nfrom payments.services import delete_payment\nfrom .models import FoodOrder, FoodEvent, Product\n\n\n@login_required\ndef index(request):\n \"\"\"Overview of user order for a pizza event.\"\"\"\n products = Product.available_products.order_by(\"name\")\n if not request.user.has_perm(\"pizzas.order_restricted_products\"):\n products = products.exclude(restricted=True)\n event = FoodEvent.current()\n try:\n obj = FoodOrder.objects.get(food_event=event, member=request.member)\n except FoodOrder.DoesNotExist:\n obj = None\n context = {\"event\": event, \"products\": products, \"order\": obj}\n return render(request, \"pizzas/index.html\", context)\n\n\n@require_http_methods([\"POST\"])\ndef cancel_order(request):\n \"\"\"View that cancels a user's order.\"\"\"\n if \"order\" in request.POST:\n try:\n order = get_object_or_404(FoodOrder, pk=int(request.POST[\"order\"]))\n if not order.can_be_changed:\n messages.error(request, _(\"You can no longer cancel.\"))\n elif order.member == request.member:\n order.delete()\n messages.success(request, _(\"Your order has been cancelled.\"))\n except Http404:\n messages.error(request, _(\"Your order could not be found.\"))\n return redirect(\"pizzas:index\")\n\n\n@login_required\ndef place_order(request):\n \"\"\"View that shows the detail of the current order.\"\"\"\n event = FoodEvent.current()\n if not event:\n return redirect(\"pizzas:index\")\n\n try:\n obj = FoodOrder.objects.get(food_event=event, member=request.member)\n current_order_locked = not obj.can_be_changed\n except FoodOrder.DoesNotExist:\n obj = None\n current_order_locked = False\n\n if \"product\" in request.POST and not current_order_locked:\n productset = Product.available_products.all()\n if not request.user.has_perm(\"pizzas.order_restricted_products\"):\n productset = productset.exclude(restricted=True)\n try:\n product = productset.get(pk=int(request.POST[\"product\"]))\n except Product.DoesNotExist as e:\n raise Http404(\"Pizza does not exist\") from e\n if not obj:\n obj = FoodOrder(food_event=event, member=request.member)\n obj.product = product\n if obj.payment:\n try:\n delete_payment(obj, member=request.member, ignore_change_window=True)\n except PaymentError:\n messages.error(\n request,\n _(\"Your order could not be updated because it was already paid.\"),\n )\n return redirect(\"pizzas:index\")\n obj.save()\n return redirect(\"pizzas:index\")\n", "path": "website/pizzas/views.py"}]}
| 2,729 | 465 |
gh_patches_debug_39582
|
rasdani/github-patches
|
git_diff
|
microsoft__botbuilder-python-1523
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[PORT] Move TelemetryClient property to DialogContainer
> Port this change from botbuilder-dotnet/master branch:
https://github.com/microsoft/botbuilder-dotnet/pull/4178
Fixes #2638
Move TelemetryClient onto DialogContainer (implementation the same in AdaptiveDialog and ComponentDialog).
# Changed projects
* Microsoft.Bot.Builder.Dialogs.Adaptive
* Microsoft.Bot.Builder.Dialogs
</issue>
<code>
[start of libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_set.py]
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License.
3 import inspect
4 from hashlib import sha256
5 from typing import Dict
6
7 from botbuilder.core import TurnContext, BotAssert, StatePropertyAccessor
8 from .dialog import Dialog
9 from .dialog_state import DialogState
10
11
12 class DialogSet:
13 def __init__(self, dialog_state: StatePropertyAccessor = None):
14 # pylint: disable=import-outside-toplevel
15 if dialog_state is None:
16 frame = inspect.currentframe().f_back
17 try:
18 # try to access the caller's "self"
19 try:
20 self_obj = frame.f_locals["self"]
21 except KeyError:
22 raise TypeError("DialogSet(): dialog_state cannot be None.")
23 # Only ComponentDialog can initialize with None dialog_state
24 from .component_dialog import ComponentDialog
25 from .dialog_manager import DialogManager
26 from .dialog_container import DialogContainer
27
28 if not isinstance(
29 self_obj, (ComponentDialog, DialogContainer, DialogManager)
30 ):
31 raise TypeError("DialogSet(): dialog_state cannot be None.")
32 finally:
33 # make sure to clean up the frame at the end to avoid ref cycles
34 del frame
35
36 self._dialog_state = dialog_state
37 # self.__telemetry_client = NullBotTelemetryClient.Instance;
38
39 self._dialogs: Dict[str, Dialog] = {}
40 self._version: str = None
41
42 def get_version(self) -> str:
43 """
44 Gets a unique string which represents the combined versions of all dialogs in this this dialogset.
45 <returns>Version will change when any of the child dialogs version changes.</returns>
46 """
47 if not self._version:
48 version = ""
49 for _, dialog in self._dialogs.items():
50 aux_version = dialog.get_version()
51 if aux_version:
52 version += aux_version
53
54 self._version = sha256(version)
55
56 return self._version
57
58 def add(self, dialog: Dialog):
59 """
60 Adds a new dialog to the set and returns the added dialog.
61 :param dialog: The dialog to add.
62 """
63 if dialog is None or not isinstance(dialog, Dialog):
64 raise TypeError(
65 "DialogSet.add(): dialog cannot be None and must be a Dialog or derived class."
66 )
67
68 if dialog.id in self._dialogs:
69 raise TypeError(
70 "DialogSet.add(): A dialog with an id of '%s' already added."
71 % dialog.id
72 )
73
74 # dialog.telemetry_client = this._telemetry_client;
75 self._dialogs[dialog.id] = dialog
76
77 return self
78
79 async def create_context(self, turn_context: TurnContext) -> "DialogContext":
80 # This import prevents circular dependency issues
81 # pylint: disable=import-outside-toplevel
82 from .dialog_context import DialogContext
83
84 # pylint: disable=unnecessary-lambda
85 BotAssert.context_not_none(turn_context)
86
87 if not self._dialog_state:
88 raise RuntimeError(
89 "DialogSet.CreateContextAsync(): DialogSet created with a null IStatePropertyAccessor."
90 )
91
92 state: DialogState = await self._dialog_state.get(
93 turn_context, lambda: DialogState()
94 )
95
96 return DialogContext(self, turn_context, state)
97
98 async def find(self, dialog_id: str) -> Dialog:
99 """
100 Finds a dialog that was previously added to the set using add(dialog)
101 :param dialog_id: ID of the dialog/prompt to look up.
102 :return: The dialog if found, otherwise null.
103 """
104 if not dialog_id:
105 raise TypeError("DialogContext.find(): dialog_id cannot be None.")
106
107 if dialog_id in self._dialogs:
108 return self._dialogs[dialog_id]
109
110 return None
111
112 def find_dialog(self, dialog_id: str) -> Dialog:
113 """
114 Finds a dialog that was previously added to the set using add(dialog)
115 :param dialog_id: ID of the dialog/prompt to look up.
116 :return: The dialog if found, otherwise null.
117 """
118 if not dialog_id:
119 raise TypeError("DialogContext.find(): dialog_id cannot be None.")
120
121 if dialog_id in self._dialogs:
122 return self._dialogs[dialog_id]
123
124 return None
125
126 def __str__(self):
127 if self._dialogs:
128 return "dialog set empty!"
129 return " ".join(map(str, self._dialogs.keys()))
130
[end of libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_set.py]
[start of libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_container.py]
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License.
3
4 from abc import ABC, abstractmethod
5
6
7 from .dialog import Dialog
8 from .dialog_context import DialogContext
9 from .dialog_event import DialogEvent
10 from .dialog_events import DialogEvents
11 from .dialog_set import DialogSet
12
13
14 class DialogContainer(Dialog, ABC):
15 def __init__(self, dialog_id: str = None):
16 super().__init__(dialog_id)
17
18 self.dialogs = DialogSet()
19
20 @abstractmethod
21 def create_child_context(self, dialog_context: DialogContext) -> DialogContext:
22 raise NotImplementedError()
23
24 def find_dialog(self, dialog_id: str) -> Dialog:
25 # TODO: deprecate DialogSet.find
26 return self.dialogs.find_dialog(dialog_id)
27
28 async def on_dialog_event(
29 self, dialog_context: DialogContext, dialog_event: DialogEvent
30 ) -> bool:
31 """
32 Called when an event has been raised, using `DialogContext.emitEvent()`, by either the current dialog or a
33 dialog that the current dialog started.
34 :param dialog_context: The dialog context for the current turn of conversation.
35 :param dialog_event: The event being raised.
36 :return: True if the event is handled by the current dialog and bubbling should stop.
37 """
38 handled = await super().on_dialog_event(dialog_context, dialog_event)
39
40 # Trace unhandled "versionChanged" events.
41 if not handled and dialog_event.name == DialogEvents.version_changed:
42
43 trace_message = (
44 f"Unhandled dialog event: {dialog_event.name}. Active Dialog: "
45 f"{dialog_context.active_dialog.id}"
46 )
47
48 await dialog_context.context.send_trace_activity(trace_message)
49
50 return handled
51
52 def get_internal_version(self) -> str:
53 """
54 GetInternalVersion - Returns internal version identifier for this container.
55 DialogContainers detect changes of all sub-components in the container and map that to an DialogChanged event.
56 Because they do this, DialogContainers "hide" the internal changes and just have the .id. This isolates changes
57 to the container level unless a container doesn't handle it. To support this DialogContainers define a
58 protected virtual method GetInternalVersion() which computes if this dialog or child dialogs have changed
59 which is then examined via calls to check_for_version_change_async().
60 :return: version which represents the change of the internals of this container.
61 """
62 return self.dialogs.get_version()
63
64 async def check_for_version_change_async(self, dialog_context: DialogContext):
65 """
66 :param dialog_context: dialog context.
67 :return: task.
68 Checks to see if a containers child dialogs have changed since the current dialog instance
69 was started.
70
71 This should be called at the start of `beginDialog()`, `continueDialog()`, and `resumeDialog()`.
72 """
73 current = dialog_context.active_dialog.version
74 dialog_context.active_dialog.version = self.get_internal_version()
75
76 # Check for change of previously stored hash
77 if current and current != dialog_context.active_dialog.version:
78 # Give bot an opportunity to handle the change.
79 # - If bot handles it the changeHash will have been updated as to avoid triggering the
80 # change again.
81 await dialog_context.emit_event(
82 DialogEvents.version_changed, self.id, True, False
83 )
84
[end of libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_container.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_container.py b/libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_container.py
--- a/libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_container.py
+++ b/libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_container.py
@@ -4,6 +4,7 @@
from abc import ABC, abstractmethod
+from botbuilder.core import NullTelemetryClient, BotTelemetryClient
from .dialog import Dialog
from .dialog_context import DialogContext
from .dialog_event import DialogEvent
@@ -17,6 +18,31 @@
self.dialogs = DialogSet()
+ @property
+ def telemetry_client(self) -> BotTelemetryClient:
+ """
+ Gets the telemetry client for logging events.
+ """
+ return self._telemetry_client
+
+ @telemetry_client.setter
+ def telemetry_client(self, value: BotTelemetryClient) -> None:
+ """
+ Sets the telemetry client for all dialogs in this set.
+ """
+ if value is None:
+ self._telemetry_client = NullTelemetryClient()
+ else:
+ self._telemetry_client = value
+
+ # Care! Dialogs.TelemetryClient assignment internally assigns the
+ # TelemetryClient for each dialog which could lead to an eventual stack
+ # overflow in cyclical dialog structures.
+ # Don't set the telemetry client if the candidate instance is the same as
+ # the currently set one.
+ if self.dialogs.telemetry_client != value:
+ self.dialogs.telemetry_client = self._telemetry_client
+
@abstractmethod
def create_child_context(self, dialog_context: DialogContext) -> DialogContext:
raise NotImplementedError()
diff --git a/libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_set.py b/libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_set.py
--- a/libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_set.py
+++ b/libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_set.py
@@ -4,7 +4,13 @@
from hashlib import sha256
from typing import Dict
-from botbuilder.core import TurnContext, BotAssert, StatePropertyAccessor
+from botbuilder.core import (
+ NullTelemetryClient,
+ BotTelemetryClient,
+ TurnContext,
+ BotAssert,
+ StatePropertyAccessor,
+)
from .dialog import Dialog
from .dialog_state import DialogState
@@ -34,11 +40,31 @@
del frame
self._dialog_state = dialog_state
- # self.__telemetry_client = NullBotTelemetryClient.Instance;
+ self.__telemetry_client = NullTelemetryClient()
self._dialogs: Dict[str, Dialog] = {}
self._version: str = None
+ @property
+ def telemetry_client(self) -> BotTelemetryClient:
+ """
+ Gets the telemetry client for logging events.
+ """
+ return self.__telemetry_client
+
+ @telemetry_client.setter
+ def telemetry_client(self, value: BotTelemetryClient) -> None:
+ """
+ Sets the telemetry client for all dialogs in this set.
+ """
+ if value is None:
+ self.__telemetry_client = NullTelemetryClient()
+ else:
+ self.__telemetry_client = value
+
+ for dialog in self._dialogs.values():
+ dialog.telemetry_client = self.__telemetry_client
+
def get_version(self) -> str:
"""
Gets a unique string which represents the combined versions of all dialogs in this this dialogset.
|
{"golden_diff": "diff --git a/libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_container.py b/libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_container.py\n--- a/libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_container.py\n+++ b/libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_container.py\n@@ -4,6 +4,7 @@\n from abc import ABC, abstractmethod\n \n \n+from botbuilder.core import NullTelemetryClient, BotTelemetryClient\n from .dialog import Dialog\n from .dialog_context import DialogContext\n from .dialog_event import DialogEvent\n@@ -17,6 +18,31 @@\n \n self.dialogs = DialogSet()\n \n+ @property\n+ def telemetry_client(self) -> BotTelemetryClient:\n+ \"\"\"\n+ Gets the telemetry client for logging events.\n+ \"\"\"\n+ return self._telemetry_client\n+\n+ @telemetry_client.setter\n+ def telemetry_client(self, value: BotTelemetryClient) -> None:\n+ \"\"\"\n+ Sets the telemetry client for all dialogs in this set.\n+ \"\"\"\n+ if value is None:\n+ self._telemetry_client = NullTelemetryClient()\n+ else:\n+ self._telemetry_client = value\n+\n+ # Care! Dialogs.TelemetryClient assignment internally assigns the\n+ # TelemetryClient for each dialog which could lead to an eventual stack\n+ # overflow in cyclical dialog structures.\n+ # Don't set the telemetry client if the candidate instance is the same as\n+ # the currently set one.\n+ if self.dialogs.telemetry_client != value:\n+ self.dialogs.telemetry_client = self._telemetry_client\n+\n @abstractmethod\n def create_child_context(self, dialog_context: DialogContext) -> DialogContext:\n raise NotImplementedError()\ndiff --git a/libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_set.py b/libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_set.py\n--- a/libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_set.py\n+++ b/libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_set.py\n@@ -4,7 +4,13 @@\n from hashlib import sha256\n from typing import Dict\n \n-from botbuilder.core import TurnContext, BotAssert, StatePropertyAccessor\n+from botbuilder.core import (\n+ NullTelemetryClient,\n+ BotTelemetryClient,\n+ TurnContext,\n+ BotAssert,\n+ StatePropertyAccessor,\n+)\n from .dialog import Dialog\n from .dialog_state import DialogState\n \n@@ -34,11 +40,31 @@\n del frame\n \n self._dialog_state = dialog_state\n- # self.__telemetry_client = NullBotTelemetryClient.Instance;\n+ self.__telemetry_client = NullTelemetryClient()\n \n self._dialogs: Dict[str, Dialog] = {}\n self._version: str = None\n \n+ @property\n+ def telemetry_client(self) -> BotTelemetryClient:\n+ \"\"\"\n+ Gets the telemetry client for logging events.\n+ \"\"\"\n+ return self.__telemetry_client\n+\n+ @telemetry_client.setter\n+ def telemetry_client(self, value: BotTelemetryClient) -> None:\n+ \"\"\"\n+ Sets the telemetry client for all dialogs in this set.\n+ \"\"\"\n+ if value is None:\n+ self.__telemetry_client = NullTelemetryClient()\n+ else:\n+ self.__telemetry_client = value\n+\n+ for dialog in self._dialogs.values():\n+ dialog.telemetry_client = self.__telemetry_client\n+\n def get_version(self) -> str:\n \"\"\"\n Gets a unique string which represents the combined versions of all dialogs in this this dialogset.\n", "issue": "[PORT] Move TelemetryClient property to DialogContainer\n> Port this change from botbuilder-dotnet/master branch:\nhttps://github.com/microsoft/botbuilder-dotnet/pull/4178\n\nFixes #2638 \r\n\r\nMove TelemetryClient onto DialogContainer (implementation the same in AdaptiveDialog and ComponentDialog).\n\n\r\n# Changed projects\r\n* Microsoft.Bot.Builder.Dialogs.Adaptive\r\n* Microsoft.Bot.Builder.Dialogs\r\n\r\n\r\n\n\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\nimport inspect\nfrom hashlib import sha256\nfrom typing import Dict\n\nfrom botbuilder.core import TurnContext, BotAssert, StatePropertyAccessor\nfrom .dialog import Dialog\nfrom .dialog_state import DialogState\n\n\nclass DialogSet:\n def __init__(self, dialog_state: StatePropertyAccessor = None):\n # pylint: disable=import-outside-toplevel\n if dialog_state is None:\n frame = inspect.currentframe().f_back\n try:\n # try to access the caller's \"self\"\n try:\n self_obj = frame.f_locals[\"self\"]\n except KeyError:\n raise TypeError(\"DialogSet(): dialog_state cannot be None.\")\n # Only ComponentDialog can initialize with None dialog_state\n from .component_dialog import ComponentDialog\n from .dialog_manager import DialogManager\n from .dialog_container import DialogContainer\n\n if not isinstance(\n self_obj, (ComponentDialog, DialogContainer, DialogManager)\n ):\n raise TypeError(\"DialogSet(): dialog_state cannot be None.\")\n finally:\n # make sure to clean up the frame at the end to avoid ref cycles\n del frame\n\n self._dialog_state = dialog_state\n # self.__telemetry_client = NullBotTelemetryClient.Instance;\n\n self._dialogs: Dict[str, Dialog] = {}\n self._version: str = None\n\n def get_version(self) -> str:\n \"\"\"\n Gets a unique string which represents the combined versions of all dialogs in this this dialogset.\n <returns>Version will change when any of the child dialogs version changes.</returns>\n \"\"\"\n if not self._version:\n version = \"\"\n for _, dialog in self._dialogs.items():\n aux_version = dialog.get_version()\n if aux_version:\n version += aux_version\n\n self._version = sha256(version)\n\n return self._version\n\n def add(self, dialog: Dialog):\n \"\"\"\n Adds a new dialog to the set and returns the added dialog.\n :param dialog: The dialog to add.\n \"\"\"\n if dialog is None or not isinstance(dialog, Dialog):\n raise TypeError(\n \"DialogSet.add(): dialog cannot be None and must be a Dialog or derived class.\"\n )\n\n if dialog.id in self._dialogs:\n raise TypeError(\n \"DialogSet.add(): A dialog with an id of '%s' already added.\"\n % dialog.id\n )\n\n # dialog.telemetry_client = this._telemetry_client;\n self._dialogs[dialog.id] = dialog\n\n return self\n\n async def create_context(self, turn_context: TurnContext) -> \"DialogContext\":\n # This import prevents circular dependency issues\n # pylint: disable=import-outside-toplevel\n from .dialog_context import DialogContext\n\n # pylint: disable=unnecessary-lambda\n BotAssert.context_not_none(turn_context)\n\n if not self._dialog_state:\n raise RuntimeError(\n \"DialogSet.CreateContextAsync(): DialogSet created with a null IStatePropertyAccessor.\"\n )\n\n state: DialogState = await self._dialog_state.get(\n turn_context, lambda: DialogState()\n )\n\n return DialogContext(self, turn_context, state)\n\n async def find(self, dialog_id: str) -> Dialog:\n \"\"\"\n Finds a dialog that was previously added to the set using add(dialog)\n :param dialog_id: ID of the dialog/prompt to look up.\n :return: The dialog if found, otherwise null.\n \"\"\"\n if not dialog_id:\n raise TypeError(\"DialogContext.find(): dialog_id cannot be None.\")\n\n if dialog_id in self._dialogs:\n return self._dialogs[dialog_id]\n\n return None\n\n def find_dialog(self, dialog_id: str) -> Dialog:\n \"\"\"\n Finds a dialog that was previously added to the set using add(dialog)\n :param dialog_id: ID of the dialog/prompt to look up.\n :return: The dialog if found, otherwise null.\n \"\"\"\n if not dialog_id:\n raise TypeError(\"DialogContext.find(): dialog_id cannot be None.\")\n\n if dialog_id in self._dialogs:\n return self._dialogs[dialog_id]\n\n return None\n\n def __str__(self):\n if self._dialogs:\n return \"dialog set empty!\"\n return \" \".join(map(str, self._dialogs.keys()))\n", "path": "libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_set.py"}, {"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\n\nfrom abc import ABC, abstractmethod\n\n\nfrom .dialog import Dialog\nfrom .dialog_context import DialogContext\nfrom .dialog_event import DialogEvent\nfrom .dialog_events import DialogEvents\nfrom .dialog_set import DialogSet\n\n\nclass DialogContainer(Dialog, ABC):\n def __init__(self, dialog_id: str = None):\n super().__init__(dialog_id)\n\n self.dialogs = DialogSet()\n\n @abstractmethod\n def create_child_context(self, dialog_context: DialogContext) -> DialogContext:\n raise NotImplementedError()\n\n def find_dialog(self, dialog_id: str) -> Dialog:\n # TODO: deprecate DialogSet.find\n return self.dialogs.find_dialog(dialog_id)\n\n async def on_dialog_event(\n self, dialog_context: DialogContext, dialog_event: DialogEvent\n ) -> bool:\n \"\"\"\n Called when an event has been raised, using `DialogContext.emitEvent()`, by either the current dialog or a\n dialog that the current dialog started.\n :param dialog_context: The dialog context for the current turn of conversation.\n :param dialog_event: The event being raised.\n :return: True if the event is handled by the current dialog and bubbling should stop.\n \"\"\"\n handled = await super().on_dialog_event(dialog_context, dialog_event)\n\n # Trace unhandled \"versionChanged\" events.\n if not handled and dialog_event.name == DialogEvents.version_changed:\n\n trace_message = (\n f\"Unhandled dialog event: {dialog_event.name}. Active Dialog: \"\n f\"{dialog_context.active_dialog.id}\"\n )\n\n await dialog_context.context.send_trace_activity(trace_message)\n\n return handled\n\n def get_internal_version(self) -> str:\n \"\"\"\n GetInternalVersion - Returns internal version identifier for this container.\n DialogContainers detect changes of all sub-components in the container and map that to an DialogChanged event.\n Because they do this, DialogContainers \"hide\" the internal changes and just have the .id. This isolates changes\n to the container level unless a container doesn't handle it. To support this DialogContainers define a\n protected virtual method GetInternalVersion() which computes if this dialog or child dialogs have changed\n which is then examined via calls to check_for_version_change_async().\n :return: version which represents the change of the internals of this container.\n \"\"\"\n return self.dialogs.get_version()\n\n async def check_for_version_change_async(self, dialog_context: DialogContext):\n \"\"\"\n :param dialog_context: dialog context.\n :return: task.\n Checks to see if a containers child dialogs have changed since the current dialog instance\n was started.\n\n This should be called at the start of `beginDialog()`, `continueDialog()`, and `resumeDialog()`.\n \"\"\"\n current = dialog_context.active_dialog.version\n dialog_context.active_dialog.version = self.get_internal_version()\n\n # Check for change of previously stored hash\n if current and current != dialog_context.active_dialog.version:\n # Give bot an opportunity to handle the change.\n # - If bot handles it the changeHash will have been updated as to avoid triggering the\n # change again.\n await dialog_context.emit_event(\n DialogEvents.version_changed, self.id, True, False\n )\n", "path": "libraries/botbuilder-dialogs/botbuilder/dialogs/dialog_container.py"}]}
| 2,780 | 816 |
gh_patches_debug_1325
|
rasdani/github-patches
|
git_diff
|
pypa__setuptools-3307
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Docs] Clarify that "Keywords" page is an API reference for `setuptools.setup`
### Summary
https://setuptools.readthedocs.io/en/latest/references/keywords.html has no indicators what those keywords are for.
It also doesn't show up if you search for "setuptools.setup" in the sidebar search, and is generally innaccessible via search engines as well. It also has poor formatting, likely due to mismanaged indentation on the page.
### OS / Environment
_No response_
### Additional Information
It would be good to:
- have an introductory section in the page, describing what it is for -- explicitly mention "setuptools.setup" in this as well.
- provide anchors for each of the keyword arguments.
- fix the indentation for the list of various arguments.
### Code of Conduct
- [X] I agree to follow the PSF Code of Conduct
</issue>
<code>
[start of docs/conf.py]
1 extensions = ['sphinx.ext.autodoc', 'jaraco.packaging.sphinx', 'rst.linker']
2
3 master_doc = "index"
4
5 link_files = {
6 '../CHANGES.rst': dict(
7 using=dict(
8 BB='https://bitbucket.org',
9 GH='https://github.com',
10 ),
11 replace=[
12 dict(
13 pattern=r'(?<!\w)PR #(?P<pull>\d+)',
14 url='{package_url}/pull/{pull}',
15 ),
16 dict(
17 pattern=r'(?<!\w)(Issue )?#(?P<issue>\d+)',
18 url='{package_url}/issues/{issue}',
19 ),
20 dict(
21 pattern=r'BB Pull Request ?#(?P<bb_pull_request>\d+)',
22 url='{BB}/pypa/setuptools/pull-request/{bb_pull_request}',
23 ),
24 dict(
25 pattern=r'Distribute #(?P<distribute>\d+)',
26 url='{BB}/tarek/distribute/issue/{distribute}',
27 ),
28 dict(
29 pattern=r'Buildout #(?P<buildout>\d+)',
30 url='{GH}/buildout/buildout/issues/{buildout}',
31 ),
32 dict(
33 pattern=r'Old Setuptools #(?P<old_setuptools>\d+)',
34 url='http://bugs.python.org/setuptools/issue{old_setuptools}',
35 ),
36 dict(
37 pattern=r'Jython #(?P<jython>\d+)',
38 url='http://bugs.jython.org/issue{jython}',
39 ),
40 dict(
41 pattern=r'(Python #|bpo-)(?P<python>\d+)',
42 url='http://bugs.python.org/issue{python}',
43 ),
44 dict(
45 pattern=r'Interop #(?P<interop>\d+)',
46 url='{GH}/pypa/interoperability-peps/issues/{interop}',
47 ),
48 dict(
49 pattern=r'Pip #(?P<pip>\d+)',
50 url='{GH}/pypa/pip/issues/{pip}',
51 ),
52 dict(
53 pattern=r'Packaging #(?P<packaging>\d+)',
54 url='{GH}/pypa/packaging/issues/{packaging}',
55 ),
56 dict(
57 pattern=r'[Pp]ackaging (?P<packaging_ver>\d+(\.\d+)+)',
58 url='{GH}/pypa/packaging/blob/{packaging_ver}/CHANGELOG.rst',
59 ),
60 dict(
61 pattern=r'(?<![`/\w])PEP[- ](?P<pep_number>\d+)',
62 url='https://www.python.org/dev/peps/pep-{pep_number:0>4}/',
63 ),
64 dict(
65 pattern=r'setuptools_svn #(?P<setuptools_svn>\d+)',
66 url='{GH}/jaraco/setuptools_svn/issues/{setuptools_svn}',
67 ),
68 dict(
69 pattern=r'pypa/(?P<issue_repo>[\-\.\w]+)#(?P<issue_number>\d+)',
70 url='{GH}/pypa/{issue_repo}/issues/{issue_number}',
71 ),
72 dict(
73 pattern=r'pypa/(?P<commit_repo>[\-\.\w]+)@(?P<commit_number>[\da-f]+)',
74 url='{GH}/pypa/{commit_repo}/commit/{commit_number}',
75 ),
76 dict(
77 pattern=r'^(?m)((?P<scm_version>v?\d+(\.\d+){1,2}))\n[-=]+\n',
78 with_scm='{text}\n{rev[timestamp]:%d %b %Y}\n',
79 ),
80 ],
81 ),
82 }
83
84 # Be strict about any broken references:
85 nitpicky = True
86
87 # Include Python intersphinx mapping to prevent failures
88 # jaraco/skeleton#51
89 extensions += ['sphinx.ext.intersphinx']
90 intersphinx_mapping = {
91 'python': ('https://docs.python.org/3', None),
92 }
93
94 intersphinx_mapping.update({
95 'pypa-build': ('https://pypa-build.readthedocs.io/en/latest/', None)
96 })
97
98 # Add support for linking usernames
99 github_url = 'https://github.com'
100 github_repo_org = 'pypa'
101 github_repo_name = 'setuptools'
102 github_repo_slug = f'{github_repo_org}/{github_repo_name}'
103 github_repo_url = f'{github_url}/{github_repo_slug}'
104 github_sponsors_url = f'{github_url}/sponsors'
105 extlinks = {
106 'user': (f'{github_sponsors_url}/%s', '@'), # noqa: WPS323
107 'pypi': ('https://pypi.org/project/%s', '%s'), # noqa: WPS323
108 'wiki': ('https://wikipedia.org/wiki/%s', '%s'), # noqa: WPS323
109 }
110 extensions += ['sphinx.ext.extlinks']
111
112 # Ref: https://github.com/python-attrs/attrs/pull/571/files\
113 # #diff-85987f48f1258d9ee486e3191495582dR82
114 default_role = 'any'
115
116 # HTML theme
117 html_theme = 'furo'
118 html_logo = "images/logo.svg"
119
120 html_theme_options = {
121 "sidebar_hide_name": True,
122 "light_css_variables": {
123 "color-brand-primary": "#336790", # "blue"
124 "color-brand-content": "#336790",
125 },
126 "dark_css_variables": {
127 "color-brand-primary": "#E5B62F", # "yellow"
128 "color-brand-content": "#E5B62F",
129 },
130 }
131
132 # Add support for inline tabs
133 extensions += ['sphinx_inline_tabs']
134
135 # Support for distutils
136
137 # Ref: https://stackoverflow.com/a/30624034/595220
138 nitpick_ignore = [
139 ('c:func', 'SHGetSpecialFolderPath'), # ref to MS docs
140 ('envvar', 'DISTUTILS_DEBUG'), # undocumented
141 ('envvar', 'HOME'), # undocumented
142 ('envvar', 'PLAT'), # undocumented
143 ('py:attr', 'CCompiler.language_map'), # undocumented
144 ('py:attr', 'CCompiler.language_order'), # undocumented
145 ('py:class', 'distutils.dist.Distribution'), # undocumented
146 ('py:class', 'distutils.extension.Extension'), # undocumented
147 ('py:class', 'BorlandCCompiler'), # undocumented
148 ('py:class', 'CCompiler'), # undocumented
149 ('py:class', 'CygwinCCompiler'), # undocumented
150 ('py:class', 'distutils.dist.DistributionMetadata'), # undocumented
151 ('py:class', 'FileList'), # undocumented
152 ('py:class', 'IShellLink'), # ref to MS docs
153 ('py:class', 'MSVCCompiler'), # undocumented
154 ('py:class', 'OptionDummy'), # undocumented
155 ('py:class', 'UnixCCompiler'), # undocumented
156 ('py:exc', 'CompileError'), # undocumented
157 ('py:exc', 'DistutilsExecError'), # undocumented
158 ('py:exc', 'DistutilsFileError'), # undocumented
159 ('py:exc', 'LibError'), # undocumented
160 ('py:exc', 'LinkError'), # undocumented
161 ('py:exc', 'PreprocessError'), # undocumented
162 ('py:func', 'distutils.CCompiler.new_compiler'), # undocumented
163 # undocumented:
164 ('py:func', 'distutils.dist.DistributionMetadata.read_pkg_file'),
165 ('py:func', 'distutils.file_util._copy_file_contents'), # undocumented
166 ('py:func', 'distutils.log.debug'), # undocumented
167 ('py:func', 'distutils.spawn.find_executable'), # undocumented
168 ('py:func', 'distutils.spawn.spawn'), # undocumented
169 # TODO: check https://docutils.rtfd.io in the future
170 ('py:mod', 'docutils'), # there's no Sphinx site documenting this
171 ]
172
173 # Allow linking objects on other Sphinx sites seamlessly:
174 intersphinx_mapping.update(
175 python2=('https://docs.python.org/2', None),
176 python=('https://docs.python.org/3', None),
177 )
178
179 # Add support for the unreleased "next-version" change notes
180 extensions += ['sphinxcontrib.towncrier']
181 # Extension needs a path from here to the towncrier config.
182 towncrier_draft_working_directory = '..'
183 # Avoid an empty section for unpublished changes.
184 towncrier_draft_include_empty = False
185
186 extensions += ['jaraco.tidelift']
187
188 # Add icons (aka "favicons") to documentation
189 extensions += ['sphinx-favicon']
190 html_static_path = ['images'] # should contain the folder with icons
191
192 # List of dicts with <link> HTML attributes
193 # static-file points to files in the html_static_path (href is computed)
194 favicons = [
195 { # "Catch-all" goes first, otherwise some browsers will overwrite
196 "rel": "icon",
197 "type": "image/svg+xml",
198 "static-file": "logo-symbol-only.svg",
199 "sizes": "any"
200 },
201 { # Version with thicker strokes for better visibility at smaller sizes
202 "rel": "icon",
203 "type": "image/svg+xml",
204 "static-file": "favicon.svg",
205 "sizes": "16x16 24x24 32x32 48x48"
206 },
207 # rel="apple-touch-icon" does not support SVG yet
208 ]
209
210 intersphinx_mapping['pip'] = 'https://pip.pypa.io/en/latest', None
211 intersphinx_mapping['PyPUG'] = ('https://packaging.python.org/en/latest/', None)
212 intersphinx_mapping['packaging'] = ('https://packaging.pypa.io/en/latest/', None)
213 intersphinx_mapping['importlib-resources'] = (
214 'https://importlib-resources.readthedocs.io/en/latest', None
215 )
216
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -129,6 +129,12 @@
},
}
+# Redirect old docs so links and references in the ecosystem don't break
+extensions += ['sphinx_reredirects']
+redirects = {
+ "userguide/keywords": "/deprecated/changed_keywords.html",
+}
+
# Add support for inline tabs
extensions += ['sphinx_inline_tabs']
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -129,6 +129,12 @@\n },\n }\n \n+# Redirect old docs so links and references in the ecosystem don't break\n+extensions += ['sphinx_reredirects']\n+redirects = {\n+ \"userguide/keywords\": \"/deprecated/changed_keywords.html\",\n+}\n+\n # Add support for inline tabs\n extensions += ['sphinx_inline_tabs']\n", "issue": "[Docs] Clarify that \"Keywords\" page is an API reference for `setuptools.setup`\n### Summary\n\nhttps://setuptools.readthedocs.io/en/latest/references/keywords.html has no indicators what those keywords are for.\r\n\r\nIt also doesn't show up if you search for \"setuptools.setup\" in the sidebar search, and is generally innaccessible via search engines as well. It also has poor formatting, likely due to mismanaged indentation on the page.\n\n### OS / Environment\n\n_No response_\n\n### Additional Information\n\nIt would be good to:\r\n\r\n- have an introductory section in the page, describing what it is for -- explicitly mention \"setuptools.setup\" in this as well.\r\n- provide anchors for each of the keyword arguments.\r\n- fix the indentation for the list of various arguments.\r\n\n\n### Code of Conduct\n\n- [X] I agree to follow the PSF Code of Conduct\n", "before_files": [{"content": "extensions = ['sphinx.ext.autodoc', 'jaraco.packaging.sphinx', 'rst.linker']\n\nmaster_doc = \"index\"\n\nlink_files = {\n '../CHANGES.rst': dict(\n using=dict(\n BB='https://bitbucket.org',\n GH='https://github.com',\n ),\n replace=[\n dict(\n pattern=r'(?<!\\w)PR #(?P<pull>\\d+)',\n url='{package_url}/pull/{pull}',\n ),\n dict(\n pattern=r'(?<!\\w)(Issue )?#(?P<issue>\\d+)',\n url='{package_url}/issues/{issue}',\n ),\n dict(\n pattern=r'BB Pull Request ?#(?P<bb_pull_request>\\d+)',\n url='{BB}/pypa/setuptools/pull-request/{bb_pull_request}',\n ),\n dict(\n pattern=r'Distribute #(?P<distribute>\\d+)',\n url='{BB}/tarek/distribute/issue/{distribute}',\n ),\n dict(\n pattern=r'Buildout #(?P<buildout>\\d+)',\n url='{GH}/buildout/buildout/issues/{buildout}',\n ),\n dict(\n pattern=r'Old Setuptools #(?P<old_setuptools>\\d+)',\n url='http://bugs.python.org/setuptools/issue{old_setuptools}',\n ),\n dict(\n pattern=r'Jython #(?P<jython>\\d+)',\n url='http://bugs.jython.org/issue{jython}',\n ),\n dict(\n pattern=r'(Python #|bpo-)(?P<python>\\d+)',\n url='http://bugs.python.org/issue{python}',\n ),\n dict(\n pattern=r'Interop #(?P<interop>\\d+)',\n url='{GH}/pypa/interoperability-peps/issues/{interop}',\n ),\n dict(\n pattern=r'Pip #(?P<pip>\\d+)',\n url='{GH}/pypa/pip/issues/{pip}',\n ),\n dict(\n pattern=r'Packaging #(?P<packaging>\\d+)',\n url='{GH}/pypa/packaging/issues/{packaging}',\n ),\n dict(\n pattern=r'[Pp]ackaging (?P<packaging_ver>\\d+(\\.\\d+)+)',\n url='{GH}/pypa/packaging/blob/{packaging_ver}/CHANGELOG.rst',\n ),\n dict(\n pattern=r'(?<![`/\\w])PEP[- ](?P<pep_number>\\d+)',\n url='https://www.python.org/dev/peps/pep-{pep_number:0>4}/',\n ),\n dict(\n pattern=r'setuptools_svn #(?P<setuptools_svn>\\d+)',\n url='{GH}/jaraco/setuptools_svn/issues/{setuptools_svn}',\n ),\n dict(\n pattern=r'pypa/(?P<issue_repo>[\\-\\.\\w]+)#(?P<issue_number>\\d+)',\n url='{GH}/pypa/{issue_repo}/issues/{issue_number}',\n ),\n dict(\n pattern=r'pypa/(?P<commit_repo>[\\-\\.\\w]+)@(?P<commit_number>[\\da-f]+)',\n url='{GH}/pypa/{commit_repo}/commit/{commit_number}',\n ),\n dict(\n pattern=r'^(?m)((?P<scm_version>v?\\d+(\\.\\d+){1,2}))\\n[-=]+\\n',\n with_scm='{text}\\n{rev[timestamp]:%d %b %Y}\\n',\n ),\n ],\n ),\n}\n\n# Be strict about any broken references:\nnitpicky = True\n\n# Include Python intersphinx mapping to prevent failures\n# jaraco/skeleton#51\nextensions += ['sphinx.ext.intersphinx']\nintersphinx_mapping = {\n 'python': ('https://docs.python.org/3', None),\n}\n\nintersphinx_mapping.update({\n 'pypa-build': ('https://pypa-build.readthedocs.io/en/latest/', None)\n})\n\n# Add support for linking usernames\ngithub_url = 'https://github.com'\ngithub_repo_org = 'pypa'\ngithub_repo_name = 'setuptools'\ngithub_repo_slug = f'{github_repo_org}/{github_repo_name}'\ngithub_repo_url = f'{github_url}/{github_repo_slug}'\ngithub_sponsors_url = f'{github_url}/sponsors'\nextlinks = {\n 'user': (f'{github_sponsors_url}/%s', '@'), # noqa: WPS323\n 'pypi': ('https://pypi.org/project/%s', '%s'), # noqa: WPS323\n 'wiki': ('https://wikipedia.org/wiki/%s', '%s'), # noqa: WPS323\n}\nextensions += ['sphinx.ext.extlinks']\n\n# Ref: https://github.com/python-attrs/attrs/pull/571/files\\\n# #diff-85987f48f1258d9ee486e3191495582dR82\ndefault_role = 'any'\n\n# HTML theme\nhtml_theme = 'furo'\nhtml_logo = \"images/logo.svg\"\n\nhtml_theme_options = {\n \"sidebar_hide_name\": True,\n \"light_css_variables\": {\n \"color-brand-primary\": \"#336790\", # \"blue\"\n \"color-brand-content\": \"#336790\",\n },\n \"dark_css_variables\": {\n \"color-brand-primary\": \"#E5B62F\", # \"yellow\"\n \"color-brand-content\": \"#E5B62F\",\n },\n}\n\n# Add support for inline tabs\nextensions += ['sphinx_inline_tabs']\n\n# Support for distutils\n\n# Ref: https://stackoverflow.com/a/30624034/595220\nnitpick_ignore = [\n ('c:func', 'SHGetSpecialFolderPath'), # ref to MS docs\n ('envvar', 'DISTUTILS_DEBUG'), # undocumented\n ('envvar', 'HOME'), # undocumented\n ('envvar', 'PLAT'), # undocumented\n ('py:attr', 'CCompiler.language_map'), # undocumented\n ('py:attr', 'CCompiler.language_order'), # undocumented\n ('py:class', 'distutils.dist.Distribution'), # undocumented\n ('py:class', 'distutils.extension.Extension'), # undocumented\n ('py:class', 'BorlandCCompiler'), # undocumented\n ('py:class', 'CCompiler'), # undocumented\n ('py:class', 'CygwinCCompiler'), # undocumented\n ('py:class', 'distutils.dist.DistributionMetadata'), # undocumented\n ('py:class', 'FileList'), # undocumented\n ('py:class', 'IShellLink'), # ref to MS docs\n ('py:class', 'MSVCCompiler'), # undocumented\n ('py:class', 'OptionDummy'), # undocumented\n ('py:class', 'UnixCCompiler'), # undocumented\n ('py:exc', 'CompileError'), # undocumented\n ('py:exc', 'DistutilsExecError'), # undocumented\n ('py:exc', 'DistutilsFileError'), # undocumented\n ('py:exc', 'LibError'), # undocumented\n ('py:exc', 'LinkError'), # undocumented\n ('py:exc', 'PreprocessError'), # undocumented\n ('py:func', 'distutils.CCompiler.new_compiler'), # undocumented\n # undocumented:\n ('py:func', 'distutils.dist.DistributionMetadata.read_pkg_file'),\n ('py:func', 'distutils.file_util._copy_file_contents'), # undocumented\n ('py:func', 'distutils.log.debug'), # undocumented\n ('py:func', 'distutils.spawn.find_executable'), # undocumented\n ('py:func', 'distutils.spawn.spawn'), # undocumented\n # TODO: check https://docutils.rtfd.io in the future\n ('py:mod', 'docutils'), # there's no Sphinx site documenting this\n]\n\n# Allow linking objects on other Sphinx sites seamlessly:\nintersphinx_mapping.update(\n python2=('https://docs.python.org/2', None),\n python=('https://docs.python.org/3', None),\n)\n\n# Add support for the unreleased \"next-version\" change notes\nextensions += ['sphinxcontrib.towncrier']\n# Extension needs a path from here to the towncrier config.\ntowncrier_draft_working_directory = '..'\n# Avoid an empty section for unpublished changes.\ntowncrier_draft_include_empty = False\n\nextensions += ['jaraco.tidelift']\n\n# Add icons (aka \"favicons\") to documentation\nextensions += ['sphinx-favicon']\nhtml_static_path = ['images'] # should contain the folder with icons\n\n# List of dicts with <link> HTML attributes\n# static-file points to files in the html_static_path (href is computed)\nfavicons = [\n { # \"Catch-all\" goes first, otherwise some browsers will overwrite\n \"rel\": \"icon\",\n \"type\": \"image/svg+xml\",\n \"static-file\": \"logo-symbol-only.svg\",\n \"sizes\": \"any\"\n },\n { # Version with thicker strokes for better visibility at smaller sizes\n \"rel\": \"icon\",\n \"type\": \"image/svg+xml\",\n \"static-file\": \"favicon.svg\",\n \"sizes\": \"16x16 24x24 32x32 48x48\"\n },\n # rel=\"apple-touch-icon\" does not support SVG yet\n]\n\nintersphinx_mapping['pip'] = 'https://pip.pypa.io/en/latest', None\nintersphinx_mapping['PyPUG'] = ('https://packaging.python.org/en/latest/', None)\nintersphinx_mapping['packaging'] = ('https://packaging.pypa.io/en/latest/', None)\nintersphinx_mapping['importlib-resources'] = (\n 'https://importlib-resources.readthedocs.io/en/latest', None\n)\n", "path": "docs/conf.py"}]}
| 3,455 | 107 |
gh_patches_debug_12233
|
rasdani/github-patches
|
git_diff
|
googleapis__python-bigquery-833
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Expand pyarrow to support 5.x releases
Changelog: https://raw.githubusercontent.com/apache/arrow/4591d76fce2846a29dac33bf01e9ba0337b118e9/CHANGELOG.md
</issue>
<code>
[start of setup.py]
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import io
16 import os
17
18 import setuptools
19
20
21 # Package metadata.
22
23 name = "google-cloud-bigquery"
24 description = "Google BigQuery API client library"
25
26 # Should be one of:
27 # 'Development Status :: 3 - Alpha'
28 # 'Development Status :: 4 - Beta'
29 # 'Development Status :: 5 - Production/Stable'
30 release_status = "Development Status :: 5 - Production/Stable"
31 dependencies = [
32 "grpcio >= 1.38.1, < 2.0dev", # https://github.com/googleapis/python-bigquery/issues/695
33 # NOTE: Maintainers, please do not require google-api-core>=2.x.x
34 # Until this issue is closed
35 # https://github.com/googleapis/google-cloud-python/issues/10566
36 "google-api-core[grpc] >= 1.29.0, <3.0.0dev",
37 "proto-plus >= 1.10.0",
38 # NOTE: Maintainers, please do not require google-cloud-core>=2.x.x
39 # Until this issue is closed
40 # https://github.com/googleapis/google-cloud-python/issues/10566
41 "google-cloud-core >= 1.4.1, <3.0.0dev",
42 "google-resumable-media >= 0.6.0, < 3.0dev",
43 "packaging >= 14.3",
44 "protobuf >= 3.12.0",
45 "requests >= 2.18.0, < 3.0.0dev",
46 ]
47 extras = {
48 "bqstorage": [
49 "google-cloud-bigquery-storage >= 2.0.0, <3.0.0dev",
50 # Due to an issue in pip's dependency resolver, the `grpc` extra is not
51 # installed, even though `google-cloud-bigquery-storage` specifies it
52 # as `google-api-core[grpc]`. We thus need to explicitly specify it here.
53 # See: https://github.com/googleapis/python-bigquery/issues/83 The
54 # grpc.Channel.close() method isn't added until 1.32.0.
55 # https://github.com/grpc/grpc/pull/15254
56 "grpcio >= 1.38.1, < 2.0dev",
57 "pyarrow >= 1.0.0, < 5.0dev",
58 ],
59 "pandas": ["pandas>=0.23.0", "pyarrow >= 1.0.0, < 5.0dev"],
60 "bignumeric_type": ["pyarrow >= 3.0.0, < 5.0dev"],
61 "tqdm": ["tqdm >= 4.7.4, <5.0.0dev"],
62 "opentelemetry": [
63 "opentelemetry-api >= 0.11b0",
64 "opentelemetry-sdk >= 0.11b0",
65 "opentelemetry-instrumentation >= 0.11b0",
66 ],
67 }
68
69 all_extras = []
70
71 for extra in extras:
72 # Exclude this extra from all to avoid overly strict dependencies on core
73 # libraries such as pyarrow.
74 # https://github.com/googleapis/python-bigquery/issues/563
75 if extra in {"bignumeric_type"}:
76 continue
77 all_extras.extend(extras[extra])
78
79 extras["all"] = all_extras
80
81 # Setup boilerplate below this line.
82
83 package_root = os.path.abspath(os.path.dirname(__file__))
84
85 readme_filename = os.path.join(package_root, "README.rst")
86 with io.open(readme_filename, encoding="utf-8") as readme_file:
87 readme = readme_file.read()
88
89 version = {}
90 with open(os.path.join(package_root, "google/cloud/bigquery/version.py")) as fp:
91 exec(fp.read(), version)
92 version = version["__version__"]
93
94 # Only include packages under the 'google' namespace. Do not include tests,
95 # benchmarks, etc.
96 packages = [
97 package
98 for package in setuptools.PEP420PackageFinder.find()
99 if package.startswith("google")
100 ]
101
102 # Determine which namespaces are needed.
103 namespaces = ["google"]
104 if "google.cloud" in packages:
105 namespaces.append("google.cloud")
106
107
108 setuptools.setup(
109 name=name,
110 version=version,
111 description=description,
112 long_description=readme,
113 author="Google LLC",
114 author_email="[email protected]",
115 license="Apache 2.0",
116 url="https://github.com/googleapis/python-bigquery",
117 classifiers=[
118 release_status,
119 "Intended Audience :: Developers",
120 "License :: OSI Approved :: Apache Software License",
121 "Programming Language :: Python",
122 "Programming Language :: Python :: 3",
123 "Programming Language :: Python :: 3.6",
124 "Programming Language :: Python :: 3.7",
125 "Programming Language :: Python :: 3.8",
126 "Programming Language :: Python :: 3.9",
127 "Operating System :: OS Independent",
128 "Topic :: Internet",
129 ],
130 platforms="Posix; MacOS X; Windows",
131 packages=packages,
132 namespace_packages=namespaces,
133 install_requires=dependencies,
134 extras_require=extras,
135 python_requires=">=3.6, <3.10",
136 include_package_data=True,
137 zip_safe=False,
138 )
139
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -54,10 +54,10 @@
# grpc.Channel.close() method isn't added until 1.32.0.
# https://github.com/grpc/grpc/pull/15254
"grpcio >= 1.38.1, < 2.0dev",
- "pyarrow >= 1.0.0, < 5.0dev",
+ "pyarrow >= 1.0.0, < 6.0dev",
],
- "pandas": ["pandas>=0.23.0", "pyarrow >= 1.0.0, < 5.0dev"],
- "bignumeric_type": ["pyarrow >= 3.0.0, < 5.0dev"],
+ "pandas": ["pandas>=0.23.0", "pyarrow >= 1.0.0, < 6.0dev"],
+ "bignumeric_type": ["pyarrow >= 3.0.0, < 6.0dev"],
"tqdm": ["tqdm >= 4.7.4, <5.0.0dev"],
"opentelemetry": [
"opentelemetry-api >= 0.11b0",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -54,10 +54,10 @@\n # grpc.Channel.close() method isn't added until 1.32.0.\n # https://github.com/grpc/grpc/pull/15254\n \"grpcio >= 1.38.1, < 2.0dev\",\n- \"pyarrow >= 1.0.0, < 5.0dev\",\n+ \"pyarrow >= 1.0.0, < 6.0dev\",\n ],\n- \"pandas\": [\"pandas>=0.23.0\", \"pyarrow >= 1.0.0, < 5.0dev\"],\n- \"bignumeric_type\": [\"pyarrow >= 3.0.0, < 5.0dev\"],\n+ \"pandas\": [\"pandas>=0.23.0\", \"pyarrow >= 1.0.0, < 6.0dev\"],\n+ \"bignumeric_type\": [\"pyarrow >= 3.0.0, < 6.0dev\"],\n \"tqdm\": [\"tqdm >= 4.7.4, <5.0.0dev\"],\n \"opentelemetry\": [\n \"opentelemetry-api >= 0.11b0\",\n", "issue": "Expand pyarrow to support 5.x releases\nChangelog: https://raw.githubusercontent.com/apache/arrow/4591d76fce2846a29dac33bf01e9ba0337b118e9/CHANGELOG.md\n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\n\nimport setuptools\n\n\n# Package metadata.\n\nname = \"google-cloud-bigquery\"\ndescription = \"Google BigQuery API client library\"\n\n# Should be one of:\n# 'Development Status :: 3 - Alpha'\n# 'Development Status :: 4 - Beta'\n# 'Development Status :: 5 - Production/Stable'\nrelease_status = \"Development Status :: 5 - Production/Stable\"\ndependencies = [\n \"grpcio >= 1.38.1, < 2.0dev\", # https://github.com/googleapis/python-bigquery/issues/695\n # NOTE: Maintainers, please do not require google-api-core>=2.x.x\n # Until this issue is closed\n # https://github.com/googleapis/google-cloud-python/issues/10566\n \"google-api-core[grpc] >= 1.29.0, <3.0.0dev\",\n \"proto-plus >= 1.10.0\",\n # NOTE: Maintainers, please do not require google-cloud-core>=2.x.x\n # Until this issue is closed\n # https://github.com/googleapis/google-cloud-python/issues/10566\n \"google-cloud-core >= 1.4.1, <3.0.0dev\",\n \"google-resumable-media >= 0.6.0, < 3.0dev\",\n \"packaging >= 14.3\",\n \"protobuf >= 3.12.0\",\n \"requests >= 2.18.0, < 3.0.0dev\",\n]\nextras = {\n \"bqstorage\": [\n \"google-cloud-bigquery-storage >= 2.0.0, <3.0.0dev\",\n # Due to an issue in pip's dependency resolver, the `grpc` extra is not\n # installed, even though `google-cloud-bigquery-storage` specifies it\n # as `google-api-core[grpc]`. We thus need to explicitly specify it here.\n # See: https://github.com/googleapis/python-bigquery/issues/83 The\n # grpc.Channel.close() method isn't added until 1.32.0.\n # https://github.com/grpc/grpc/pull/15254\n \"grpcio >= 1.38.1, < 2.0dev\",\n \"pyarrow >= 1.0.0, < 5.0dev\",\n ],\n \"pandas\": [\"pandas>=0.23.0\", \"pyarrow >= 1.0.0, < 5.0dev\"],\n \"bignumeric_type\": [\"pyarrow >= 3.0.0, < 5.0dev\"],\n \"tqdm\": [\"tqdm >= 4.7.4, <5.0.0dev\"],\n \"opentelemetry\": [\n \"opentelemetry-api >= 0.11b0\",\n \"opentelemetry-sdk >= 0.11b0\",\n \"opentelemetry-instrumentation >= 0.11b0\",\n ],\n}\n\nall_extras = []\n\nfor extra in extras:\n # Exclude this extra from all to avoid overly strict dependencies on core\n # libraries such as pyarrow.\n # https://github.com/googleapis/python-bigquery/issues/563\n if extra in {\"bignumeric_type\"}:\n continue\n all_extras.extend(extras[extra])\n\nextras[\"all\"] = all_extras\n\n# Setup boilerplate below this line.\n\npackage_root = os.path.abspath(os.path.dirname(__file__))\n\nreadme_filename = os.path.join(package_root, \"README.rst\")\nwith io.open(readme_filename, encoding=\"utf-8\") as readme_file:\n readme = readme_file.read()\n\nversion = {}\nwith open(os.path.join(package_root, \"google/cloud/bigquery/version.py\")) as fp:\n exec(fp.read(), version)\nversion = version[\"__version__\"]\n\n# Only include packages under the 'google' namespace. Do not include tests,\n# benchmarks, etc.\npackages = [\n package\n for package in setuptools.PEP420PackageFinder.find()\n if package.startswith(\"google\")\n]\n\n# Determine which namespaces are needed.\nnamespaces = [\"google\"]\nif \"google.cloud\" in packages:\n namespaces.append(\"google.cloud\")\n\n\nsetuptools.setup(\n name=name,\n version=version,\n description=description,\n long_description=readme,\n author=\"Google LLC\",\n author_email=\"[email protected]\",\n license=\"Apache 2.0\",\n url=\"https://github.com/googleapis/python-bigquery\",\n classifiers=[\n release_status,\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Operating System :: OS Independent\",\n \"Topic :: Internet\",\n ],\n platforms=\"Posix; MacOS X; Windows\",\n packages=packages,\n namespace_packages=namespaces,\n install_requires=dependencies,\n extras_require=extras,\n python_requires=\">=3.6, <3.10\",\n include_package_data=True,\n zip_safe=False,\n)\n", "path": "setup.py"}]}
| 2,199 | 302 |
gh_patches_debug_6522
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-1256
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
False positive: Sub is required if a variable is used in a string in parameter descriptions
*cfn-lint version: 0.26.0*
*Description of issue.*
Parameter descriptions fail E1029 if they contain text which looks like variable substitution:
e.g.
```yaml
MyContentBucket:
Description: "Bucket name for content (usually ${VPCName}-my-content), use 'none' to disable creation"
Type: String
```
Gives an error:
[E1029: Sub is required if a variable is used in a string] (Found an embedded parameter outside of an "Fn::Sub" at Parameters/MyContentBucket/Description)
</issue>
<code>
[start of src/cfnlint/rules/functions/SubNeeded.py]
1 """
2 Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.
3 SPDX-License-Identifier: MIT-0
4 """
5 import re
6 from cfnlint.rules import CloudFormationLintRule
7 from cfnlint.rules import RuleMatch
8
9
10 class SubNeeded(CloudFormationLintRule):
11 """Check if a substitution string exists without a substitution function"""
12 id = 'E1029'
13 shortdesc = 'Sub is required if a variable is used in a string'
14 description = 'If a substitution variable exists in a string but isn\'t wrapped with the Fn::Sub function the deployment will fail.'
15 source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-sub.html'
16 tags = ['functions', 'sub']
17
18 # Free-form text properties to exclude from this rule
19 # content is part of AWS::CloudFormation::Init
20 excludes = ['UserData', 'ZipFile', 'Condition', 'AWS::CloudFormation::Init',
21 'CloudWatchAlarmDefinition', 'TopicRulePayload']
22 api_excludes = ['Uri', 'Body']
23
24 # IAM Policy has special variables that don't require !Sub, Check for these
25 # https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_variables.html
26 # https://docs.aws.amazon.com/iot/latest/developerguide/basic-policy-variables.html
27 # https://docs.aws.amazon.com/iot/latest/developerguide/thing-policy-variables.html
28 # https://docs.aws.amazon.com/transfer/latest/userguide/users.html#users-policies-scope-down
29 # https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_iam-condition-keys.html
30 resource_excludes = ['${aws:CurrentTime}', '${aws:EpochTime}',
31 '${aws:TokenIssueTime}', '${aws:principaltype}',
32 '${aws:SecureTransport}', '${aws:SourceIp}',
33 '${aws:UserAgent}', '${aws:userid}',
34 '${aws:username}', '${ec2:SourceInstanceARN}',
35 '${iot:Connection.Thing.ThingName}',
36 '${iot:Connection.Thing.ThingTypeName}',
37 '${iot:Connection.Thing.IsAttached}',
38 '${iot:ClientId}', '${transfer:HomeBucket}',
39 '${transfer:HomeDirectory}', '${transfer:HomeFolder}',
40 '${transfer:UserName}', '${redshift:DbUser}',
41 '${cognito-identity.amazonaws.com:aud}',
42 '${cognito-identity.amazonaws.com:sub}',
43 '${cognito-identity.amazonaws.com:amr}']
44
45 # https://docs.aws.amazon.com/redshift/latest/mgmt/redshift-iam-access-control-identity-based.html
46 condition_excludes = [
47 '${redshift:DbUser}',
48 ]
49
50 def _match_values(self, searchRegex, cfnelem, path):
51 """Recursively search for values matching the searchRegex"""
52 values = []
53 if isinstance(cfnelem, dict):
54 for key in cfnelem:
55 pathprop = path[:]
56 pathprop.append(key)
57 values.extend(self._match_values(searchRegex, cfnelem[key], pathprop))
58 elif isinstance(cfnelem, list):
59 for index, item in enumerate(cfnelem):
60 pathprop = path[:]
61 pathprop.append(index)
62 values.extend(self._match_values(searchRegex, item, pathprop))
63 else:
64 # Leaf node
65 if isinstance(cfnelem, str) and re.match(searchRegex, cfnelem):
66 # Get all variables as seperate paths
67 regex = re.compile(r'(\$\{.*?\.?.*?})')
68 for variable in re.findall(regex, cfnelem):
69 values.append(path + [variable])
70
71 return values
72
73 def match_values(self, searchRegex, cfn):
74 """
75 Search for values in all parts of the templates that match the searchRegex
76 """
77 results = []
78 results.extend(self._match_values(searchRegex, cfn.template, []))
79 # Globals are removed during a transform. They need to be checked manually
80 results.extend(self._match_values(searchRegex, cfn.template.get('Globals', {}), []))
81 return results
82
83 def _api_exceptions(self, value):
84 """ Key value exceptions """
85 parameter_search = re.compile(r'^\$\{stageVariables\..*\}$')
86 return re.match(parameter_search, value)
87
88 def match(self, cfn):
89 """Basic Rule Matching"""
90
91 matches = []
92
93 # Generic regex to match a string containing at least one ${parameter}
94 parameter_search = re.compile(r'^.*(\$\{.*\}.*(\$\{.*\}.*)*)$')
95
96 # Get a list of paths to every leaf node string containing at least one ${parameter}
97 parameter_string_paths = self.match_values(parameter_search, cfn)
98
99 # We want to search all of the paths to check if each one contains an 'Fn::Sub'
100 for parameter_string_path in parameter_string_paths:
101 # Exxclude the special IAM variables
102 variable = parameter_string_path[-1]
103
104 if 'Resource' in parameter_string_path:
105 if variable in self.resource_excludes:
106 continue
107 if 'Condition' in parameter_string_path:
108 if variable in self.condition_excludes:
109 continue
110
111 # Exclude literals (https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-sub.html)
112 if variable.startswith('${!'):
113 continue
114
115 found_sub = False
116 # Does the path contain an 'Fn::Sub'?
117 for step in parameter_string_path:
118 if step in self.api_excludes:
119 if self._api_exceptions(parameter_string_path[-1]):
120 found_sub = True
121 elif step == 'Fn::Sub' or step in self.excludes:
122 found_sub = True
123
124 # If we didn't find an 'Fn::Sub' it means a string containing a ${parameter} may not be evaluated correctly
125 if not found_sub:
126 # Remove the last item (the variable) to prevent multiple errors on 1 line errors
127 path = parameter_string_path[:-1]
128 message = 'Found an embedded parameter outside of an "Fn::Sub" at {}'.format(
129 '/'.join(map(str, path)))
130 matches.append(RuleMatch(path, message))
131
132 return matches
133
[end of src/cfnlint/rules/functions/SubNeeded.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cfnlint/rules/functions/SubNeeded.py b/src/cfnlint/rules/functions/SubNeeded.py
--- a/src/cfnlint/rules/functions/SubNeeded.py
+++ b/src/cfnlint/rules/functions/SubNeeded.py
@@ -98,6 +98,8 @@
# We want to search all of the paths to check if each one contains an 'Fn::Sub'
for parameter_string_path in parameter_string_paths:
+ if parameter_string_path[0] in ['Parameters']:
+ continue
# Exxclude the special IAM variables
variable = parameter_string_path[-1]
|
{"golden_diff": "diff --git a/src/cfnlint/rules/functions/SubNeeded.py b/src/cfnlint/rules/functions/SubNeeded.py\n--- a/src/cfnlint/rules/functions/SubNeeded.py\n+++ b/src/cfnlint/rules/functions/SubNeeded.py\n@@ -98,6 +98,8 @@\n \n # We want to search all of the paths to check if each one contains an 'Fn::Sub'\n for parameter_string_path in parameter_string_paths:\n+ if parameter_string_path[0] in ['Parameters']:\n+ continue\n # Exxclude the special IAM variables\n variable = parameter_string_path[-1]\n", "issue": "False positive: Sub is required if a variable is used in a string in parameter descriptions\n*cfn-lint version: 0.26.0*\r\n\r\n*Description of issue.*\r\nParameter descriptions fail E1029 if they contain text which looks like variable substitution:\r\n\r\ne.g.\r\n\r\n```yaml\r\n MyContentBucket:\r\n Description: \"Bucket name for content (usually ${VPCName}-my-content), use 'none' to disable creation\"\r\n Type: String\r\n```\r\n\r\nGives an error:\r\n\r\n [E1029: Sub is required if a variable is used in a string] (Found an embedded parameter outside of an \"Fn::Sub\" at Parameters/MyContentBucket/Description)\r\n\n", "before_files": [{"content": "\"\"\"\nCopyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nimport re\nfrom cfnlint.rules import CloudFormationLintRule\nfrom cfnlint.rules import RuleMatch\n\n\nclass SubNeeded(CloudFormationLintRule):\n \"\"\"Check if a substitution string exists without a substitution function\"\"\"\n id = 'E1029'\n shortdesc = 'Sub is required if a variable is used in a string'\n description = 'If a substitution variable exists in a string but isn\\'t wrapped with the Fn::Sub function the deployment will fail.'\n source_url = 'https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-sub.html'\n tags = ['functions', 'sub']\n\n # Free-form text properties to exclude from this rule\n # content is part of AWS::CloudFormation::Init\n excludes = ['UserData', 'ZipFile', 'Condition', 'AWS::CloudFormation::Init',\n 'CloudWatchAlarmDefinition', 'TopicRulePayload']\n api_excludes = ['Uri', 'Body']\n\n # IAM Policy has special variables that don't require !Sub, Check for these\n # https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_variables.html\n # https://docs.aws.amazon.com/iot/latest/developerguide/basic-policy-variables.html\n # https://docs.aws.amazon.com/iot/latest/developerguide/thing-policy-variables.html\n # https://docs.aws.amazon.com/transfer/latest/userguide/users.html#users-policies-scope-down\n # https://docs.aws.amazon.com/IAM/latest/UserGuide/reference_policies_iam-condition-keys.html\n resource_excludes = ['${aws:CurrentTime}', '${aws:EpochTime}',\n '${aws:TokenIssueTime}', '${aws:principaltype}',\n '${aws:SecureTransport}', '${aws:SourceIp}',\n '${aws:UserAgent}', '${aws:userid}',\n '${aws:username}', '${ec2:SourceInstanceARN}',\n '${iot:Connection.Thing.ThingName}',\n '${iot:Connection.Thing.ThingTypeName}',\n '${iot:Connection.Thing.IsAttached}',\n '${iot:ClientId}', '${transfer:HomeBucket}',\n '${transfer:HomeDirectory}', '${transfer:HomeFolder}',\n '${transfer:UserName}', '${redshift:DbUser}',\n '${cognito-identity.amazonaws.com:aud}',\n '${cognito-identity.amazonaws.com:sub}',\n '${cognito-identity.amazonaws.com:amr}']\n\n # https://docs.aws.amazon.com/redshift/latest/mgmt/redshift-iam-access-control-identity-based.html\n condition_excludes = [\n '${redshift:DbUser}',\n ]\n\n def _match_values(self, searchRegex, cfnelem, path):\n \"\"\"Recursively search for values matching the searchRegex\"\"\"\n values = []\n if isinstance(cfnelem, dict):\n for key in cfnelem:\n pathprop = path[:]\n pathprop.append(key)\n values.extend(self._match_values(searchRegex, cfnelem[key], pathprop))\n elif isinstance(cfnelem, list):\n for index, item in enumerate(cfnelem):\n pathprop = path[:]\n pathprop.append(index)\n values.extend(self._match_values(searchRegex, item, pathprop))\n else:\n # Leaf node\n if isinstance(cfnelem, str) and re.match(searchRegex, cfnelem):\n # Get all variables as seperate paths\n regex = re.compile(r'(\\$\\{.*?\\.?.*?})')\n for variable in re.findall(regex, cfnelem):\n values.append(path + [variable])\n\n return values\n\n def match_values(self, searchRegex, cfn):\n \"\"\"\n Search for values in all parts of the templates that match the searchRegex\n \"\"\"\n results = []\n results.extend(self._match_values(searchRegex, cfn.template, []))\n # Globals are removed during a transform. They need to be checked manually\n results.extend(self._match_values(searchRegex, cfn.template.get('Globals', {}), []))\n return results\n\n def _api_exceptions(self, value):\n \"\"\" Key value exceptions \"\"\"\n parameter_search = re.compile(r'^\\$\\{stageVariables\\..*\\}$')\n return re.match(parameter_search, value)\n\n def match(self, cfn):\n \"\"\"Basic Rule Matching\"\"\"\n\n matches = []\n\n # Generic regex to match a string containing at least one ${parameter}\n parameter_search = re.compile(r'^.*(\\$\\{.*\\}.*(\\$\\{.*\\}.*)*)$')\n\n # Get a list of paths to every leaf node string containing at least one ${parameter}\n parameter_string_paths = self.match_values(parameter_search, cfn)\n\n # We want to search all of the paths to check if each one contains an 'Fn::Sub'\n for parameter_string_path in parameter_string_paths:\n # Exxclude the special IAM variables\n variable = parameter_string_path[-1]\n\n if 'Resource' in parameter_string_path:\n if variable in self.resource_excludes:\n continue\n if 'Condition' in parameter_string_path:\n if variable in self.condition_excludes:\n continue\n\n # Exclude literals (https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-sub.html)\n if variable.startswith('${!'):\n continue\n\n found_sub = False\n # Does the path contain an 'Fn::Sub'?\n for step in parameter_string_path:\n if step in self.api_excludes:\n if self._api_exceptions(parameter_string_path[-1]):\n found_sub = True\n elif step == 'Fn::Sub' or step in self.excludes:\n found_sub = True\n\n # If we didn't find an 'Fn::Sub' it means a string containing a ${parameter} may not be evaluated correctly\n if not found_sub:\n # Remove the last item (the variable) to prevent multiple errors on 1 line errors\n path = parameter_string_path[:-1]\n message = 'Found an embedded parameter outside of an \"Fn::Sub\" at {}'.format(\n '/'.join(map(str, path)))\n matches.append(RuleMatch(path, message))\n\n return matches\n", "path": "src/cfnlint/rules/functions/SubNeeded.py"}]}
| 2,320 | 129 |
gh_patches_debug_17133
|
rasdani/github-patches
|
git_diff
|
python-poetry__poetry-7547
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
add -e/--executable to poetry env info to get the python executable path
- [x] I have searched the [issues](https://github.com/python-poetry/poetry/issues) of this repo and believe that this is not a duplicate.
- [x] I have searched the [FAQ](https://python-poetry.org/docs/faq/) and general [documentation](https://python-poetry.org/docs/) and believe that my question is not already covered.
## Feature Request
in addition to the already present `-p/--path` option, add a `-e/--execuatble` option to return the python executable path.
My use case: I'm starting to use Taskfile and poetry on some projects; these project are developed on both linux and windows;
I would like to avoid having to install tools such as mypy in the virtual environment, since they can be run from the outside (this also allows me to have faster CI, I have set up a custom docker image with all the tools needed).
mypy in particular wants to know the exact path of the python executable to work (passed as `--python-executable` option), so having a new `poetry env info --executable` option that outputs the python path would solve my issue in a cross-platform fashion.
</issue>
<code>
[start of src/poetry/console/commands/env/info.py]
1 from __future__ import annotations
2
3 from typing import TYPE_CHECKING
4
5 from cleo.helpers import option
6
7 from poetry.console.commands.command import Command
8
9
10 if TYPE_CHECKING:
11 from poetry.utils.env import Env
12
13
14 class EnvInfoCommand(Command):
15 name = "env info"
16 description = "Displays information about the current environment."
17
18 options = [option("path", "p", "Only display the environment's path.")]
19
20 def handle(self) -> int:
21 from poetry.utils.env import EnvManager
22
23 env = EnvManager(self.poetry).get()
24
25 if self.option("path"):
26 if not env.is_venv():
27 return 1
28
29 self.line(str(env.path))
30
31 return 0
32
33 self._display_complete_info(env)
34 return 0
35
36 def _display_complete_info(self, env: Env) -> None:
37 env_python_version = ".".join(str(s) for s in env.version_info[:3])
38 self.line("")
39 self.line("<b>Virtualenv</b>")
40 listing = [
41 f"<info>Python</info>: <comment>{env_python_version}</>",
42 f"<info>Implementation</info>: <comment>{env.python_implementation}</>",
43 (
44 "<info>Path</info>: "
45 f" <comment>{env.path if env.is_venv() else 'NA'}</>"
46 ),
47 (
48 "<info>Executable</info>: "
49 f" <comment>{env.python if env.is_venv() else 'NA'}</>"
50 ),
51 ]
52 if env.is_venv():
53 listing.append(
54 "<info>Valid</info>: "
55 f" <{'comment' if env.is_sane() else 'error'}>{env.is_sane()}</>"
56 )
57 self.line("\n".join(listing))
58
59 self.line("")
60
61 system_env = env.parent_env
62 python = ".".join(str(v) for v in system_env.version_info[:3])
63 self.line("<b>System</b>")
64 self.line(
65 "\n".join(
66 [
67 f"<info>Platform</info>: <comment>{env.platform}</>",
68 f"<info>OS</info>: <comment>{env.os}</>",
69 f"<info>Python</info>: <comment>{python}</>",
70 f"<info>Path</info>: <comment>{system_env.path}</>",
71 f"<info>Executable</info>: <comment>{system_env.python}</>",
72 ]
73 )
74 )
75
[end of src/poetry/console/commands/env/info.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/poetry/console/commands/env/info.py b/src/poetry/console/commands/env/info.py
--- a/src/poetry/console/commands/env/info.py
+++ b/src/poetry/console/commands/env/info.py
@@ -15,7 +15,12 @@
name = "env info"
description = "Displays information about the current environment."
- options = [option("path", "p", "Only display the environment's path.")]
+ options = [
+ option("path", "p", "Only display the environment's path."),
+ option(
+ "executable", "e", "Only display the environment's python executable path."
+ ),
+ ]
def handle(self) -> int:
from poetry.utils.env import EnvManager
@@ -30,6 +35,14 @@
return 0
+ if self.option("executable"):
+ if not env.is_venv():
+ return 1
+
+ self.line(str(env.python))
+
+ return 0
+
self._display_complete_info(env)
return 0
|
{"golden_diff": "diff --git a/src/poetry/console/commands/env/info.py b/src/poetry/console/commands/env/info.py\n--- a/src/poetry/console/commands/env/info.py\n+++ b/src/poetry/console/commands/env/info.py\n@@ -15,7 +15,12 @@\n name = \"env info\"\n description = \"Displays information about the current environment.\"\n \n- options = [option(\"path\", \"p\", \"Only display the environment's path.\")]\n+ options = [\n+ option(\"path\", \"p\", \"Only display the environment's path.\"),\n+ option(\n+ \"executable\", \"e\", \"Only display the environment's python executable path.\"\n+ ),\n+ ]\n \n def handle(self) -> int:\n from poetry.utils.env import EnvManager\n@@ -30,6 +35,14 @@\n \n return 0\n \n+ if self.option(\"executable\"):\n+ if not env.is_venv():\n+ return 1\n+\n+ self.line(str(env.python))\n+\n+ return 0\n+\n self._display_complete_info(env)\n return 0\n", "issue": "add -e/--executable to poetry env info to get the python executable path\n- [x] I have searched the [issues](https://github.com/python-poetry/poetry/issues) of this repo and believe that this is not a duplicate.\r\n- [x] I have searched the [FAQ](https://python-poetry.org/docs/faq/) and general [documentation](https://python-poetry.org/docs/) and believe that my question is not already covered.\r\n\r\n## Feature Request\r\n\r\nin addition to the already present `-p/--path` option, add a `-e/--execuatble` option to return the python executable path.\r\n\r\nMy use case: I'm starting to use Taskfile and poetry on some projects; these project are developed on both linux and windows;\r\n\r\nI would like to avoid having to install tools such as mypy in the virtual environment, since they can be run from the outside (this also allows me to have faster CI, I have set up a custom docker image with all the tools needed).\r\n\r\nmypy in particular wants to know the exact path of the python executable to work (passed as `--python-executable` option), so having a new `poetry env info --executable` option that outputs the python path would solve my issue in a cross-platform fashion.\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING\n\nfrom cleo.helpers import option\n\nfrom poetry.console.commands.command import Command\n\n\nif TYPE_CHECKING:\n from poetry.utils.env import Env\n\n\nclass EnvInfoCommand(Command):\n name = \"env info\"\n description = \"Displays information about the current environment.\"\n\n options = [option(\"path\", \"p\", \"Only display the environment's path.\")]\n\n def handle(self) -> int:\n from poetry.utils.env import EnvManager\n\n env = EnvManager(self.poetry).get()\n\n if self.option(\"path\"):\n if not env.is_venv():\n return 1\n\n self.line(str(env.path))\n\n return 0\n\n self._display_complete_info(env)\n return 0\n\n def _display_complete_info(self, env: Env) -> None:\n env_python_version = \".\".join(str(s) for s in env.version_info[:3])\n self.line(\"\")\n self.line(\"<b>Virtualenv</b>\")\n listing = [\n f\"<info>Python</info>: <comment>{env_python_version}</>\",\n f\"<info>Implementation</info>: <comment>{env.python_implementation}</>\",\n (\n \"<info>Path</info>: \"\n f\" <comment>{env.path if env.is_venv() else 'NA'}</>\"\n ),\n (\n \"<info>Executable</info>: \"\n f\" <comment>{env.python if env.is_venv() else 'NA'}</>\"\n ),\n ]\n if env.is_venv():\n listing.append(\n \"<info>Valid</info>: \"\n f\" <{'comment' if env.is_sane() else 'error'}>{env.is_sane()}</>\"\n )\n self.line(\"\\n\".join(listing))\n\n self.line(\"\")\n\n system_env = env.parent_env\n python = \".\".join(str(v) for v in system_env.version_info[:3])\n self.line(\"<b>System</b>\")\n self.line(\n \"\\n\".join(\n [\n f\"<info>Platform</info>: <comment>{env.platform}</>\",\n f\"<info>OS</info>: <comment>{env.os}</>\",\n f\"<info>Python</info>: <comment>{python}</>\",\n f\"<info>Path</info>: <comment>{system_env.path}</>\",\n f\"<info>Executable</info>: <comment>{system_env.python}</>\",\n ]\n )\n )\n", "path": "src/poetry/console/commands/env/info.py"}]}
| 1,491 | 245 |
gh_patches_debug_32591
|
rasdani/github-patches
|
git_diff
|
secdev__scapy-2537
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
IGMPv3 igmpize broken
#### Brief description
the `igmpize` method is broken when used on IGMPv3 message types that don't appear in IGMP.
#### Environment
- Scapy version: `scapy version and/or commit-hash`
aefcfd322999637abeed183447d60112070e7a35 (master)
- Python version: `e.g. 3.5`
Python 3.6.10
- Operating System: `e.g. Minix 3.4`
Nixos Unstable (nixos-20.09pre215947.82b54d49066)
#### How to reproduce
```
from scapy.contrib.igmpv3 import *
a = Ether()
b = IP()
c = IGMPv3()/IGMPv3mr(records = [IGMPv3gr(maddr = "232.1.1.10", srcaddrs = "10.0.0.10")])
x = a/b/c
x[IGMPv3].igmpize()
```
1. construct a simple IGMPv3 packet (but not a membership query, which is shared with IGMP)
2. try to `.igmpize()`
#### Actual result
```
>>> x[IGMPv3].igmpize()
WARNING: Invalid IGMP Type detected !
False
```
#### Expected result
It would return `True`, and then I would be able to send the packet with sendp() and it would be valid.
</issue>
<code>
[start of scapy/contrib/igmp.py]
1 # This file is part of Scapy
2 # Scapy is free software: you can redistribute it and/or modify
3 # it under the terms of the GNU General Public License as published by
4 # the Free Software Foundation, either version 2 of the License, or
5 # any later version.
6 #
7 # Scapy is distributed in the hope that it will be useful,
8 # but WITHOUT ANY WARRANTY; without even the implied warranty of
9 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
10 # GNU General Public License for more details.
11 #
12 # You should have received a copy of the GNU General Public License
13 # along with Scapy. If not, see <http://www.gnu.org/licenses/>.
14
15 # scapy.contrib.description = Internet Group Management Protocol v1/v2 (IGMP/IGMPv2)
16 # scapy.contrib.status = loads
17
18 from __future__ import print_function
19 from scapy.compat import chb, orb
20 from scapy.error import warning
21 from scapy.fields import ByteEnumField, ByteField, IPField, XShortField
22 from scapy.layers.inet import IP, IPOption_Router_Alert
23 from scapy.layers.l2 import Ether, getmacbyip
24 from scapy.packet import bind_layers, Packet
25 from scapy.utils import atol, checksum
26
27
28 def isValidMCAddr(ip):
29 """convert dotted quad string to long and check the first octet"""
30 FirstOct = atol(ip) >> 24 & 0xFF
31 return (FirstOct >= 224) and (FirstOct <= 239)
32
33
34 class IGMP(Packet):
35 """IGMP Message Class for v1 and v2.
36
37 This class is derived from class Packet. You need call "igmpize()"
38 so the packet is transformed according the RFC when sent.
39 a=Ether(src="00:01:02:03:04:05")
40 b=IP(src="1.2.3.4")
41 c=IGMP(type=0x12, gaddr="224.2.3.4")
42 x = a/b/c
43 x[IGMP].igmpize()
44 sendp(a/b/c, iface="en0")
45
46 Parameters:
47 type IGMP type field, 0x11, 0x12, 0x16 or 0x17
48 mrcode Maximum Response time (zero for v1)
49 gaddr Multicast Group Address 224.x.x.x/4
50
51 See RFC2236, Section 2. Introduction for definitions of proper
52 IGMPv2 message format http://www.faqs.org/rfcs/rfc2236.html
53 """
54 name = "IGMP"
55
56 igmptypes = {0x11: "Group Membership Query",
57 0x12: "Version 1 - Membership Report",
58 0x16: "Version 2 - Membership Report",
59 0x17: "Leave Group"}
60
61 fields_desc = [ByteEnumField("type", 0x11, igmptypes),
62 ByteField("mrcode", 20),
63 XShortField("chksum", None),
64 IPField("gaddr", "0.0.0.0")]
65
66 def post_build(self, p, pay):
67 """Called implicitly before a packet is sent to compute and place IGMP checksum.
68
69 Parameters:
70 self The instantiation of an IGMP class
71 p The IGMP message in hex in network byte order
72 pay Additional payload for the IGMP message
73 """
74 p += pay
75 if self.chksum is None:
76 ck = checksum(p)
77 p = p[:2] + chb(ck >> 8) + chb(ck & 0xff) + p[4:]
78 return p
79
80 @classmethod
81 def dispatch_hook(cls, _pkt=None, *args, **kargs):
82 if _pkt and len(_pkt) >= 4:
83 from scapy.contrib.igmpv3 import IGMPv3
84 if orb(_pkt[0]) in [0x22, 0x30, 0x31, 0x32]:
85 return IGMPv3
86 if orb(_pkt[0]) == 0x11 and len(_pkt) >= 12:
87 return IGMPv3
88 return IGMP
89
90 def igmpize(self):
91 """Called to explicitly fixup the packet according to the IGMP RFC
92
93 The rules are:
94 - General:
95 1. the Max Response time is meaningful only in Membership Queries and should be zero
96 - IP:
97 1. Send General Group Query to 224.0.0.1 (all systems)
98 2. Send Leave Group to 224.0.0.2 (all routers)
99 3a.Otherwise send the packet to the group address
100 3b.Send reports/joins to the group address
101 4. ttl = 1 (RFC 2236, section 2)
102 5. send the packet with the router alert IP option (RFC 2236, section 2)
103 - Ether:
104 1. Recalculate destination
105
106 Returns:
107 True The tuple ether/ip/self passed all check and represents
108 a proper IGMP packet.
109 False One of more validation checks failed and no fields
110 were adjusted.
111
112 The function will examine the IGMP message to assure proper format.
113 Corrections will be attempted if possible. The IP header is then properly
114 adjusted to ensure correct formatting and assignment. The Ethernet header
115 is then adjusted to the proper IGMP packet format.
116 """
117 gaddr = self.gaddr if hasattr(self, "gaddr") and self.gaddr else "0.0.0.0" # noqa: E501
118 underlayer = self.underlayer
119 if self.type not in [0x11, 0x30]: # General Rule 1 # noqa: E501
120 self.mrcode = 0
121 if isinstance(underlayer, IP):
122 if (self.type == 0x11):
123 if (gaddr == "0.0.0.0"):
124 underlayer.dst = "224.0.0.1" # IP rule 1 # noqa: E501
125 elif isValidMCAddr(gaddr):
126 underlayer.dst = gaddr # IP rule 3a # noqa: E501
127 else:
128 warning("Invalid IGMP Group Address detected !")
129 return False
130 elif ((self.type == 0x17) and isValidMCAddr(gaddr)):
131 underlayer.dst = "224.0.0.2" # IP rule 2 # noqa: E501
132 elif ((self.type == 0x12) or (self.type == 0x16)) and (isValidMCAddr(gaddr)): # noqa: E501
133 underlayer.dst = gaddr # IP rule 3b # noqa: E501
134 else:
135 warning("Invalid IGMP Type detected !")
136 return False
137 if not any(isinstance(x, IPOption_Router_Alert) for x in underlayer.options): # noqa: E501
138 underlayer.options.append(IPOption_Router_Alert())
139 underlayer.ttl = 1 # IP rule 4
140 _root = self.firstlayer()
141 if _root.haslayer(Ether):
142 # Force recalculate Ether dst
143 _root[Ether].dst = getmacbyip(underlayer.dst) # Ether rule 1 # noqa: E501
144 from scapy.contrib.igmpv3 import IGMPv3
145 if isinstance(self, IGMPv3):
146 self.encode_maxrespcode()
147 return True
148
149 def mysummary(self):
150 """Display a summary of the IGMP object."""
151 if isinstance(self.underlayer, IP):
152 return self.underlayer.sprintf("IGMP: %IP.src% > %IP.dst% %IGMP.type% %IGMP.gaddr%") # noqa: E501
153 else:
154 return self.sprintf("IGMP %IGMP.type% %IGMP.gaddr%")
155
156
157 bind_layers(IP, IGMP, frag=0,
158 proto=2,
159 ttl=1)
160
[end of scapy/contrib/igmp.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scapy/contrib/igmp.py b/scapy/contrib/igmp.py
--- a/scapy/contrib/igmp.py
+++ b/scapy/contrib/igmp.py
@@ -114,6 +114,7 @@
adjusted to ensure correct formatting and assignment. The Ethernet header
is then adjusted to the proper IGMP packet format.
"""
+ from scapy.contrib.igmpv3 import IGMPv3
gaddr = self.gaddr if hasattr(self, "gaddr") and self.gaddr else "0.0.0.0" # noqa: E501
underlayer = self.underlayer
if self.type not in [0x11, 0x30]: # General Rule 1 # noqa: E501
@@ -131,6 +132,8 @@
underlayer.dst = "224.0.0.2" # IP rule 2 # noqa: E501
elif ((self.type == 0x12) or (self.type == 0x16)) and (isValidMCAddr(gaddr)): # noqa: E501
underlayer.dst = gaddr # IP rule 3b # noqa: E501
+ elif (self.type in [0x11, 0x22, 0x30, 0x31, 0x32] and isinstance(self, IGMPv3)):
+ pass
else:
warning("Invalid IGMP Type detected !")
return False
@@ -141,7 +144,6 @@
if _root.haslayer(Ether):
# Force recalculate Ether dst
_root[Ether].dst = getmacbyip(underlayer.dst) # Ether rule 1 # noqa: E501
- from scapy.contrib.igmpv3 import IGMPv3
if isinstance(self, IGMPv3):
self.encode_maxrespcode()
return True
|
{"golden_diff": "diff --git a/scapy/contrib/igmp.py b/scapy/contrib/igmp.py\n--- a/scapy/contrib/igmp.py\n+++ b/scapy/contrib/igmp.py\n@@ -114,6 +114,7 @@\n adjusted to ensure correct formatting and assignment. The Ethernet header\n is then adjusted to the proper IGMP packet format.\n \"\"\"\n+ from scapy.contrib.igmpv3 import IGMPv3\n gaddr = self.gaddr if hasattr(self, \"gaddr\") and self.gaddr else \"0.0.0.0\" # noqa: E501\n underlayer = self.underlayer\n if self.type not in [0x11, 0x30]: # General Rule 1 # noqa: E501\n@@ -131,6 +132,8 @@\n underlayer.dst = \"224.0.0.2\" # IP rule 2 # noqa: E501\n elif ((self.type == 0x12) or (self.type == 0x16)) and (isValidMCAddr(gaddr)): # noqa: E501\n underlayer.dst = gaddr # IP rule 3b # noqa: E501\n+ elif (self.type in [0x11, 0x22, 0x30, 0x31, 0x32] and isinstance(self, IGMPv3)):\n+ pass\n else:\n warning(\"Invalid IGMP Type detected !\")\n return False\n@@ -141,7 +144,6 @@\n if _root.haslayer(Ether):\n # Force recalculate Ether dst\n _root[Ether].dst = getmacbyip(underlayer.dst) # Ether rule 1 # noqa: E501\n- from scapy.contrib.igmpv3 import IGMPv3\n if isinstance(self, IGMPv3):\n self.encode_maxrespcode()\n return True\n", "issue": "IGMPv3 igmpize broken\n#### Brief description\r\n\r\nthe `igmpize` method is broken when used on IGMPv3 message types that don't appear in IGMP.\r\n\r\n#### Environment\r\n\r\n- Scapy version: `scapy version and/or commit-hash`\r\n aefcfd322999637abeed183447d60112070e7a35 (master)\r\n- Python version: `e.g. 3.5`\r\n Python 3.6.10\r\n- Operating System: `e.g. Minix 3.4`\r\n Nixos Unstable (nixos-20.09pre215947.82b54d49066)\r\n\r\n#### How to reproduce\r\n\r\n```\r\nfrom scapy.contrib.igmpv3 import *\r\n\r\na = Ether()\r\nb = IP()\r\nc = IGMPv3()/IGMPv3mr(records = [IGMPv3gr(maddr = \"232.1.1.10\", srcaddrs = \"10.0.0.10\")])\r\nx = a/b/c\r\nx[IGMPv3].igmpize()\r\n```\r\n\r\n1. construct a simple IGMPv3 packet (but not a membership query, which is shared with IGMP)\r\n2. try to `.igmpize()`\r\n\r\n#### Actual result\r\n\r\n```\r\n>>> x[IGMPv3].igmpize()\r\nWARNING: Invalid IGMP Type detected !\r\nFalse\r\n```\r\n\r\n#### Expected result\r\n\r\nIt would return `True`, and then I would be able to send the packet with sendp() and it would be valid.\r\n\n", "before_files": [{"content": "# This file is part of Scapy\n# Scapy is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 2 of the License, or\n# any later version.\n#\n# Scapy is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Scapy. If not, see <http://www.gnu.org/licenses/>.\n\n# scapy.contrib.description = Internet Group Management Protocol v1/v2 (IGMP/IGMPv2)\n# scapy.contrib.status = loads\n\nfrom __future__ import print_function\nfrom scapy.compat import chb, orb\nfrom scapy.error import warning\nfrom scapy.fields import ByteEnumField, ByteField, IPField, XShortField\nfrom scapy.layers.inet import IP, IPOption_Router_Alert\nfrom scapy.layers.l2 import Ether, getmacbyip\nfrom scapy.packet import bind_layers, Packet\nfrom scapy.utils import atol, checksum\n\n\ndef isValidMCAddr(ip):\n \"\"\"convert dotted quad string to long and check the first octet\"\"\"\n FirstOct = atol(ip) >> 24 & 0xFF\n return (FirstOct >= 224) and (FirstOct <= 239)\n\n\nclass IGMP(Packet):\n \"\"\"IGMP Message Class for v1 and v2.\n\n This class is derived from class Packet. You need call \"igmpize()\"\n so the packet is transformed according the RFC when sent.\n a=Ether(src=\"00:01:02:03:04:05\")\n b=IP(src=\"1.2.3.4\")\n c=IGMP(type=0x12, gaddr=\"224.2.3.4\")\n x = a/b/c\n x[IGMP].igmpize()\n sendp(a/b/c, iface=\"en0\")\n\n Parameters:\n type IGMP type field, 0x11, 0x12, 0x16 or 0x17\n mrcode Maximum Response time (zero for v1)\n gaddr Multicast Group Address 224.x.x.x/4\n\n See RFC2236, Section 2. Introduction for definitions of proper\n IGMPv2 message format http://www.faqs.org/rfcs/rfc2236.html\n \"\"\"\n name = \"IGMP\"\n\n igmptypes = {0x11: \"Group Membership Query\",\n 0x12: \"Version 1 - Membership Report\",\n 0x16: \"Version 2 - Membership Report\",\n 0x17: \"Leave Group\"}\n\n fields_desc = [ByteEnumField(\"type\", 0x11, igmptypes),\n ByteField(\"mrcode\", 20),\n XShortField(\"chksum\", None),\n IPField(\"gaddr\", \"0.0.0.0\")]\n\n def post_build(self, p, pay):\n \"\"\"Called implicitly before a packet is sent to compute and place IGMP checksum.\n\n Parameters:\n self The instantiation of an IGMP class\n p The IGMP message in hex in network byte order\n pay Additional payload for the IGMP message\n \"\"\"\n p += pay\n if self.chksum is None:\n ck = checksum(p)\n p = p[:2] + chb(ck >> 8) + chb(ck & 0xff) + p[4:]\n return p\n\n @classmethod\n def dispatch_hook(cls, _pkt=None, *args, **kargs):\n if _pkt and len(_pkt) >= 4:\n from scapy.contrib.igmpv3 import IGMPv3\n if orb(_pkt[0]) in [0x22, 0x30, 0x31, 0x32]:\n return IGMPv3\n if orb(_pkt[0]) == 0x11 and len(_pkt) >= 12:\n return IGMPv3\n return IGMP\n\n def igmpize(self):\n \"\"\"Called to explicitly fixup the packet according to the IGMP RFC\n\n The rules are:\n - General:\n 1. the Max Response time is meaningful only in Membership Queries and should be zero\n - IP:\n 1. Send General Group Query to 224.0.0.1 (all systems)\n 2. Send Leave Group to 224.0.0.2 (all routers)\n 3a.Otherwise send the packet to the group address\n 3b.Send reports/joins to the group address\n 4. ttl = 1 (RFC 2236, section 2)\n 5. send the packet with the router alert IP option (RFC 2236, section 2)\n - Ether:\n 1. Recalculate destination\n\n Returns:\n True The tuple ether/ip/self passed all check and represents\n a proper IGMP packet.\n False One of more validation checks failed and no fields\n were adjusted.\n\n The function will examine the IGMP message to assure proper format.\n Corrections will be attempted if possible. The IP header is then properly\n adjusted to ensure correct formatting and assignment. The Ethernet header\n is then adjusted to the proper IGMP packet format.\n \"\"\"\n gaddr = self.gaddr if hasattr(self, \"gaddr\") and self.gaddr else \"0.0.0.0\" # noqa: E501\n underlayer = self.underlayer\n if self.type not in [0x11, 0x30]: # General Rule 1 # noqa: E501\n self.mrcode = 0\n if isinstance(underlayer, IP):\n if (self.type == 0x11):\n if (gaddr == \"0.0.0.0\"):\n underlayer.dst = \"224.0.0.1\" # IP rule 1 # noqa: E501\n elif isValidMCAddr(gaddr):\n underlayer.dst = gaddr # IP rule 3a # noqa: E501\n else:\n warning(\"Invalid IGMP Group Address detected !\")\n return False\n elif ((self.type == 0x17) and isValidMCAddr(gaddr)):\n underlayer.dst = \"224.0.0.2\" # IP rule 2 # noqa: E501\n elif ((self.type == 0x12) or (self.type == 0x16)) and (isValidMCAddr(gaddr)): # noqa: E501\n underlayer.dst = gaddr # IP rule 3b # noqa: E501\n else:\n warning(\"Invalid IGMP Type detected !\")\n return False\n if not any(isinstance(x, IPOption_Router_Alert) for x in underlayer.options): # noqa: E501\n underlayer.options.append(IPOption_Router_Alert())\n underlayer.ttl = 1 # IP rule 4\n _root = self.firstlayer()\n if _root.haslayer(Ether):\n # Force recalculate Ether dst\n _root[Ether].dst = getmacbyip(underlayer.dst) # Ether rule 1 # noqa: E501\n from scapy.contrib.igmpv3 import IGMPv3\n if isinstance(self, IGMPv3):\n self.encode_maxrespcode()\n return True\n\n def mysummary(self):\n \"\"\"Display a summary of the IGMP object.\"\"\"\n if isinstance(self.underlayer, IP):\n return self.underlayer.sprintf(\"IGMP: %IP.src% > %IP.dst% %IGMP.type% %IGMP.gaddr%\") # noqa: E501\n else:\n return self.sprintf(\"IGMP %IGMP.type% %IGMP.gaddr%\")\n\n\nbind_layers(IP, IGMP, frag=0,\n proto=2,\n ttl=1)\n", "path": "scapy/contrib/igmp.py"}]}
| 3,127 | 458 |
gh_patches_debug_35756
|
rasdani/github-patches
|
git_diff
|
Qiskit__qiskit-4787
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
mcry mode='basic' does not use ancillas
<!-- ⚠️ If you do not respect this template, your issue will be closed -->
<!-- ⚠️ Make sure to browse the opened and closed issues -->
### Information
- **0.14.2**:
- **3**:
- **Ubuntu**:
### What is the current behavior?
The mcry gate (implemented in https://github.com/Qiskit/qiskit-terra/blob/master/qiskit/circuit/library/standard_gates/multi_control_rotation_gates.py) has a 'basic' mode that expects ancillas, but calls mct in its default 'noancilla' mode. (so both mcry(mode = 'noancilla') and mcry(mode='basic') use no ancillas and a lot of gates).
### Steps to reproduce the problem
### What is the expected behavior?
mcry in mode='basic' should call mct with mode='basic'
### Suggested solutions
</issue>
<code>
[start of qiskit/circuit/library/standard_gates/multi_control_rotation_gates.py]
1 # This code is part of Qiskit.
2 #
3 # (C) Copyright IBM 2018, 2019.
4 #
5 # This code is licensed under the Apache License, Version 2.0. You may
6 # obtain a copy of this license in the LICENSE.txt file in the root directory
7 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
8 #
9 # Any modifications or derivative works of this code must retain this
10 # copyright notice, and modified files need to carry a notice indicating
11 # that they have been altered from the originals.
12 """
13 Multiple-Controlled U3 gate. Not using ancillary qubits.
14 """
15
16 import logging
17 from math import pi
18 from qiskit.circuit import QuantumCircuit, QuantumRegister, Qubit
19 from qiskit.circuit.library.standard_gates.u3 import _generate_gray_code
20 from qiskit.exceptions import QiskitError
21
22 logger = logging.getLogger(__name__)
23
24
25 def _apply_cu3(circuit, theta, phi, lam, control, target, use_basis_gates=True):
26 if use_basis_gates:
27 circuit.u1((lam + phi) / 2, control)
28 circuit.u1((lam - phi) / 2, target)
29 circuit.cx(control, target)
30 circuit.u3(-theta / 2, 0, -(phi + lam) / 2, target)
31 circuit.cx(control, target)
32 circuit.u3(theta / 2, phi, 0, target)
33 else:
34 circuit.cu3(theta, phi, lam, control, target)
35
36
37 def _apply_mcu3_graycode(circuit, theta, phi, lam, ctls, tgt, use_basis_gates):
38 """Apply multi-controlled u3 gate from ctls to tgt using graycode
39 pattern with single-step angles theta, phi, lam."""
40
41 n = len(ctls)
42
43 gray_code = _generate_gray_code(n)
44 last_pattern = None
45
46 for pattern in gray_code:
47 if '1' not in pattern:
48 continue
49 if last_pattern is None:
50 last_pattern = pattern
51 # find left most set bit
52 lm_pos = list(pattern).index('1')
53
54 # find changed bit
55 comp = [i != j for i, j in zip(pattern, last_pattern)]
56 if True in comp:
57 pos = comp.index(True)
58 else:
59 pos = None
60 if pos is not None:
61 if pos != lm_pos:
62 circuit.cx(ctls[pos], ctls[lm_pos])
63 else:
64 indices = [i for i, x in enumerate(pattern) if x == '1']
65 for idx in indices[1:]:
66 circuit.cx(ctls[idx], ctls[lm_pos])
67 # check parity and undo rotation
68 if pattern.count('1') % 2 == 0:
69 # inverse CU3: u3(theta, phi, lamb)^dagger = u3(-theta, -lam, -phi)
70 _apply_cu3(circuit, -theta, -lam, -phi, ctls[lm_pos], tgt,
71 use_basis_gates=use_basis_gates)
72 else:
73 _apply_cu3(circuit, theta, phi, lam, ctls[lm_pos], tgt,
74 use_basis_gates=use_basis_gates)
75 last_pattern = pattern
76
77
78 def mcrx(self, theta, q_controls, q_target, use_basis_gates=False):
79 """
80 Apply Multiple-Controlled X rotation gate
81
82 Args:
83 self (QuantumCircuit): The QuantumCircuit object to apply the mcrx gate on.
84 theta (float): angle theta
85 q_controls (list(Qubit)): The list of control qubits
86 q_target (Qubit): The target qubit
87 use_basis_gates (bool): use u1, u2, u3, cx, id
88
89 Raises:
90 QiskitError: parameter errors
91 """
92
93 # check controls
94 if isinstance(q_controls, QuantumRegister):
95 control_qubits = list(q_controls)
96 elif isinstance(q_controls, list):
97 control_qubits = q_controls
98 else:
99 raise QiskitError(
100 'The mcrx gate needs a list of qubits or a quantum register for controls.')
101
102 # check target
103 if isinstance(q_target, Qubit):
104 target_qubit = q_target
105 else:
106 raise QiskitError('The mcrx gate needs a single qubit as target.')
107
108 all_qubits = control_qubits + [target_qubit]
109
110 self._check_qargs(all_qubits)
111 self._check_dups(all_qubits)
112
113 n_c = len(control_qubits)
114 if n_c == 1: # cu3
115 _apply_cu3(self, theta, -pi/2, pi/2, control_qubits[0],
116 target_qubit, use_basis_gates=use_basis_gates)
117 else:
118 theta_step = theta * (1 / (2 ** (n_c - 1)))
119 _apply_mcu3_graycode(self, theta_step, -pi/2, pi/2, control_qubits,
120 target_qubit, use_basis_gates=use_basis_gates)
121
122
123 def mcry(self, theta, q_controls, q_target, q_ancillae, mode='basic',
124 use_basis_gates=False):
125 """
126 Apply Multiple-Controlled Y rotation gate
127
128 Args:
129 self (QuantumCircuit): The QuantumCircuit object to apply the mcry gate on.
130 theta (float): angle theta
131 q_controls (list(Qubit)): The list of control qubits
132 q_target (Qubit): The target qubit
133 q_ancillae (QuantumRegister or tuple(QuantumRegister, int)): The list of ancillary qubits.
134 mode (string): The implementation mode to use
135 use_basis_gates (bool): use u1, u2, u3, cx, id
136
137 Raises:
138 QiskitError: parameter errors
139 """
140
141 # check controls
142 if isinstance(q_controls, QuantumRegister):
143 control_qubits = list(q_controls)
144 elif isinstance(q_controls, list):
145 control_qubits = q_controls
146 else:
147 raise QiskitError('The mcry gate needs a list of qubits or a quantum '
148 'register for controls.')
149
150 # check target
151 if isinstance(q_target, Qubit):
152 target_qubit = q_target
153 else:
154 raise QiskitError('The mcry gate needs a single qubit as target.')
155
156 # check ancilla
157 if q_ancillae is None:
158 ancillary_qubits = []
159 elif isinstance(q_ancillae, QuantumRegister):
160 ancillary_qubits = list(q_ancillae)
161 elif isinstance(q_ancillae, list):
162 ancillary_qubits = q_ancillae
163 else:
164 raise QiskitError('The mcry gate needs None or a list of qubits or a '
165 'quantum register for ancilla.')
166
167 all_qubits = control_qubits + [target_qubit] + ancillary_qubits
168
169 self._check_qargs(all_qubits)
170 self._check_dups(all_qubits)
171
172 if mode == 'basic':
173 self.u3(theta / 2, 0, 0, q_target)
174 self.mct(q_controls, q_target, q_ancillae)
175 self.u3(-theta / 2, 0, 0, q_target)
176 self.mct(q_controls, q_target, q_ancillae)
177 elif mode == 'noancilla':
178 n_c = len(control_qubits)
179 if n_c == 1: # cu3
180 _apply_cu3(self, theta, 0, 0, control_qubits[0],
181 target_qubit, use_basis_gates=use_basis_gates)
182 else:
183 theta_step = theta * (1 / (2 ** (n_c - 1)))
184 _apply_mcu3_graycode(self, theta_step, 0, 0, control_qubits,
185 target_qubit, use_basis_gates=use_basis_gates)
186 else:
187 raise QiskitError('Unrecognized mode for building MCRY circuit: {}.'.format(mode))
188
189
190 def mcrz(self, lam, q_controls, q_target, use_basis_gates=False):
191 """
192 Apply Multiple-Controlled Z rotation gate
193
194 Args:
195 self (QuantumCircuit): The QuantumCircuit object to apply the mcrz gate on.
196 lam (float): angle lambda
197 q_controls (list(Qubit)): The list of control qubits
198 q_target (Qubit): The target qubit
199 use_basis_gates (bool): use u1, u2, u3, cx, id
200
201 Raises:
202 QiskitError: parameter errors
203 """
204
205 # check controls
206 if isinstance(q_controls, QuantumRegister):
207 control_qubits = list(q_controls)
208 elif isinstance(q_controls, list):
209 control_qubits = q_controls
210 else:
211 raise QiskitError(
212 'The mcrz gate needs a list of qubits or a quantum register for controls.')
213
214 # check target
215 if isinstance(q_target, Qubit):
216 target_qubit = q_target
217 else:
218 raise QiskitError('The mcrz gate needs a single qubit as target.')
219
220 all_qubits = control_qubits + [target_qubit]
221
222 self._check_qargs(all_qubits)
223 self._check_dups(all_qubits)
224
225 n_c = len(control_qubits)
226 if n_c == 1: # cu3
227 _apply_cu3(self, 0, 0, lam, control_qubits[0],
228 target_qubit, use_basis_gates=use_basis_gates)
229 else:
230 lam_step = lam * (1 / (2 ** (n_c - 1)))
231 _apply_mcu3_graycode(self, 0, 0, lam_step, control_qubits,
232 target_qubit, use_basis_gates=use_basis_gates)
233
234
235 QuantumCircuit.mcrx = mcrx
236 QuantumCircuit.mcry = mcry
237 QuantumCircuit.mcrz = mcrz
238
[end of qiskit/circuit/library/standard_gates/multi_control_rotation_gates.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/qiskit/circuit/library/standard_gates/multi_control_rotation_gates.py b/qiskit/circuit/library/standard_gates/multi_control_rotation_gates.py
--- a/qiskit/circuit/library/standard_gates/multi_control_rotation_gates.py
+++ b/qiskit/circuit/library/standard_gates/multi_control_rotation_gates.py
@@ -16,6 +16,7 @@
import logging
from math import pi
from qiskit.circuit import QuantumCircuit, QuantumRegister, Qubit
+from qiskit.circuit.library.standard_gates.x import MCXGate
from qiskit.circuit.library.standard_gates.u3 import _generate_gray_code
from qiskit.exceptions import QiskitError
@@ -31,7 +32,7 @@
circuit.cx(control, target)
circuit.u3(theta / 2, phi, 0, target)
else:
- circuit.cu3(theta, phi, lam, control, target)
+ circuit.cu(theta, phi, lam, 0, control, target)
def _apply_mcu3_graycode(circuit, theta, phi, lam, ctls, tgt, use_basis_gates):
@@ -120,7 +121,7 @@
target_qubit, use_basis_gates=use_basis_gates)
-def mcry(self, theta, q_controls, q_target, q_ancillae, mode='basic',
+def mcry(self, theta, q_controls, q_target, q_ancillae, mode=None,
use_basis_gates=False):
"""
Apply Multiple-Controlled Y rotation gate
@@ -169,11 +170,20 @@
self._check_qargs(all_qubits)
self._check_dups(all_qubits)
+ # auto-select the best mode
+ if mode is None:
+ # if enough ancillary qubits are provided, use the 'v-chain' method
+ additional_vchain = MCXGate.get_num_ancilla_qubits(len(control_qubits), 'v-chain')
+ if len(ancillary_qubits) >= additional_vchain:
+ mode = 'basic'
+ else:
+ mode = 'noancilla'
+
if mode == 'basic':
- self.u3(theta / 2, 0, 0, q_target)
- self.mct(q_controls, q_target, q_ancillae)
- self.u3(-theta / 2, 0, 0, q_target)
- self.mct(q_controls, q_target, q_ancillae)
+ self.ry(theta / 2, q_target)
+ self.mcx(q_controls, q_target, q_ancillae, mode='v-chain')
+ self.ry(-theta / 2, q_target)
+ self.mcx(q_controls, q_target, q_ancillae, mode='v-chain')
elif mode == 'noancilla':
n_c = len(control_qubits)
if n_c == 1: # cu3
|
{"golden_diff": "diff --git a/qiskit/circuit/library/standard_gates/multi_control_rotation_gates.py b/qiskit/circuit/library/standard_gates/multi_control_rotation_gates.py\n--- a/qiskit/circuit/library/standard_gates/multi_control_rotation_gates.py\n+++ b/qiskit/circuit/library/standard_gates/multi_control_rotation_gates.py\n@@ -16,6 +16,7 @@\n import logging\n from math import pi\n from qiskit.circuit import QuantumCircuit, QuantumRegister, Qubit\n+from qiskit.circuit.library.standard_gates.x import MCXGate\n from qiskit.circuit.library.standard_gates.u3 import _generate_gray_code\n from qiskit.exceptions import QiskitError\n \n@@ -31,7 +32,7 @@\n circuit.cx(control, target)\n circuit.u3(theta / 2, phi, 0, target)\n else:\n- circuit.cu3(theta, phi, lam, control, target)\n+ circuit.cu(theta, phi, lam, 0, control, target)\n \n \n def _apply_mcu3_graycode(circuit, theta, phi, lam, ctls, tgt, use_basis_gates):\n@@ -120,7 +121,7 @@\n target_qubit, use_basis_gates=use_basis_gates)\n \n \n-def mcry(self, theta, q_controls, q_target, q_ancillae, mode='basic',\n+def mcry(self, theta, q_controls, q_target, q_ancillae, mode=None,\n use_basis_gates=False):\n \"\"\"\n Apply Multiple-Controlled Y rotation gate\n@@ -169,11 +170,20 @@\n self._check_qargs(all_qubits)\n self._check_dups(all_qubits)\n \n+ # auto-select the best mode\n+ if mode is None:\n+ # if enough ancillary qubits are provided, use the 'v-chain' method\n+ additional_vchain = MCXGate.get_num_ancilla_qubits(len(control_qubits), 'v-chain')\n+ if len(ancillary_qubits) >= additional_vchain:\n+ mode = 'basic'\n+ else:\n+ mode = 'noancilla'\n+\n if mode == 'basic':\n- self.u3(theta / 2, 0, 0, q_target)\n- self.mct(q_controls, q_target, q_ancillae)\n- self.u3(-theta / 2, 0, 0, q_target)\n- self.mct(q_controls, q_target, q_ancillae)\n+ self.ry(theta / 2, q_target)\n+ self.mcx(q_controls, q_target, q_ancillae, mode='v-chain')\n+ self.ry(-theta / 2, q_target)\n+ self.mcx(q_controls, q_target, q_ancillae, mode='v-chain')\n elif mode == 'noancilla':\n n_c = len(control_qubits)\n if n_c == 1: # cu3\n", "issue": "mcry mode='basic' does not use ancillas\n<!-- \u26a0\ufe0f If you do not respect this template, your issue will be closed -->\r\n<!-- \u26a0\ufe0f Make sure to browse the opened and closed issues -->\r\n\r\n### Information\r\n\r\n- **0.14.2**:\r\n- **3**:\r\n- **Ubuntu**:\r\n\r\n### What is the current behavior?\r\nThe mcry gate (implemented in https://github.com/Qiskit/qiskit-terra/blob/master/qiskit/circuit/library/standard_gates/multi_control_rotation_gates.py) has a 'basic' mode that expects ancillas, but calls mct in its default 'noancilla' mode. (so both mcry(mode = 'noancilla') and mcry(mode='basic') use no ancillas and a lot of gates).\r\n\r\n\r\n### Steps to reproduce the problem\r\n\r\n\r\n\r\n### What is the expected behavior?\r\nmcry in mode='basic' should call mct with mode='basic'\r\n\r\n\r\n### Suggested solutions\r\n\r\n\r\n\n", "before_files": [{"content": "# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2018, 2019.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n\"\"\"\nMultiple-Controlled U3 gate. Not using ancillary qubits.\n\"\"\"\n\nimport logging\nfrom math import pi\nfrom qiskit.circuit import QuantumCircuit, QuantumRegister, Qubit\nfrom qiskit.circuit.library.standard_gates.u3 import _generate_gray_code\nfrom qiskit.exceptions import QiskitError\n\nlogger = logging.getLogger(__name__)\n\n\ndef _apply_cu3(circuit, theta, phi, lam, control, target, use_basis_gates=True):\n if use_basis_gates:\n circuit.u1((lam + phi) / 2, control)\n circuit.u1((lam - phi) / 2, target)\n circuit.cx(control, target)\n circuit.u3(-theta / 2, 0, -(phi + lam) / 2, target)\n circuit.cx(control, target)\n circuit.u3(theta / 2, phi, 0, target)\n else:\n circuit.cu3(theta, phi, lam, control, target)\n\n\ndef _apply_mcu3_graycode(circuit, theta, phi, lam, ctls, tgt, use_basis_gates):\n \"\"\"Apply multi-controlled u3 gate from ctls to tgt using graycode\n pattern with single-step angles theta, phi, lam.\"\"\"\n\n n = len(ctls)\n\n gray_code = _generate_gray_code(n)\n last_pattern = None\n\n for pattern in gray_code:\n if '1' not in pattern:\n continue\n if last_pattern is None:\n last_pattern = pattern\n # find left most set bit\n lm_pos = list(pattern).index('1')\n\n # find changed bit\n comp = [i != j for i, j in zip(pattern, last_pattern)]\n if True in comp:\n pos = comp.index(True)\n else:\n pos = None\n if pos is not None:\n if pos != lm_pos:\n circuit.cx(ctls[pos], ctls[lm_pos])\n else:\n indices = [i for i, x in enumerate(pattern) if x == '1']\n for idx in indices[1:]:\n circuit.cx(ctls[idx], ctls[lm_pos])\n # check parity and undo rotation\n if pattern.count('1') % 2 == 0:\n # inverse CU3: u3(theta, phi, lamb)^dagger = u3(-theta, -lam, -phi)\n _apply_cu3(circuit, -theta, -lam, -phi, ctls[lm_pos], tgt,\n use_basis_gates=use_basis_gates)\n else:\n _apply_cu3(circuit, theta, phi, lam, ctls[lm_pos], tgt,\n use_basis_gates=use_basis_gates)\n last_pattern = pattern\n\n\ndef mcrx(self, theta, q_controls, q_target, use_basis_gates=False):\n \"\"\"\n Apply Multiple-Controlled X rotation gate\n\n Args:\n self (QuantumCircuit): The QuantumCircuit object to apply the mcrx gate on.\n theta (float): angle theta\n q_controls (list(Qubit)): The list of control qubits\n q_target (Qubit): The target qubit\n use_basis_gates (bool): use u1, u2, u3, cx, id\n\n Raises:\n QiskitError: parameter errors\n \"\"\"\n\n # check controls\n if isinstance(q_controls, QuantumRegister):\n control_qubits = list(q_controls)\n elif isinstance(q_controls, list):\n control_qubits = q_controls\n else:\n raise QiskitError(\n 'The mcrx gate needs a list of qubits or a quantum register for controls.')\n\n # check target\n if isinstance(q_target, Qubit):\n target_qubit = q_target\n else:\n raise QiskitError('The mcrx gate needs a single qubit as target.')\n\n all_qubits = control_qubits + [target_qubit]\n\n self._check_qargs(all_qubits)\n self._check_dups(all_qubits)\n\n n_c = len(control_qubits)\n if n_c == 1: # cu3\n _apply_cu3(self, theta, -pi/2, pi/2, control_qubits[0],\n target_qubit, use_basis_gates=use_basis_gates)\n else:\n theta_step = theta * (1 / (2 ** (n_c - 1)))\n _apply_mcu3_graycode(self, theta_step, -pi/2, pi/2, control_qubits,\n target_qubit, use_basis_gates=use_basis_gates)\n\n\ndef mcry(self, theta, q_controls, q_target, q_ancillae, mode='basic',\n use_basis_gates=False):\n \"\"\"\n Apply Multiple-Controlled Y rotation gate\n\n Args:\n self (QuantumCircuit): The QuantumCircuit object to apply the mcry gate on.\n theta (float): angle theta\n q_controls (list(Qubit)): The list of control qubits\n q_target (Qubit): The target qubit\n q_ancillae (QuantumRegister or tuple(QuantumRegister, int)): The list of ancillary qubits.\n mode (string): The implementation mode to use\n use_basis_gates (bool): use u1, u2, u3, cx, id\n\n Raises:\n QiskitError: parameter errors\n \"\"\"\n\n # check controls\n if isinstance(q_controls, QuantumRegister):\n control_qubits = list(q_controls)\n elif isinstance(q_controls, list):\n control_qubits = q_controls\n else:\n raise QiskitError('The mcry gate needs a list of qubits or a quantum '\n 'register for controls.')\n\n # check target\n if isinstance(q_target, Qubit):\n target_qubit = q_target\n else:\n raise QiskitError('The mcry gate needs a single qubit as target.')\n\n # check ancilla\n if q_ancillae is None:\n ancillary_qubits = []\n elif isinstance(q_ancillae, QuantumRegister):\n ancillary_qubits = list(q_ancillae)\n elif isinstance(q_ancillae, list):\n ancillary_qubits = q_ancillae\n else:\n raise QiskitError('The mcry gate needs None or a list of qubits or a '\n 'quantum register for ancilla.')\n\n all_qubits = control_qubits + [target_qubit] + ancillary_qubits\n\n self._check_qargs(all_qubits)\n self._check_dups(all_qubits)\n\n if mode == 'basic':\n self.u3(theta / 2, 0, 0, q_target)\n self.mct(q_controls, q_target, q_ancillae)\n self.u3(-theta / 2, 0, 0, q_target)\n self.mct(q_controls, q_target, q_ancillae)\n elif mode == 'noancilla':\n n_c = len(control_qubits)\n if n_c == 1: # cu3\n _apply_cu3(self, theta, 0, 0, control_qubits[0],\n target_qubit, use_basis_gates=use_basis_gates)\n else:\n theta_step = theta * (1 / (2 ** (n_c - 1)))\n _apply_mcu3_graycode(self, theta_step, 0, 0, control_qubits,\n target_qubit, use_basis_gates=use_basis_gates)\n else:\n raise QiskitError('Unrecognized mode for building MCRY circuit: {}.'.format(mode))\n\n\ndef mcrz(self, lam, q_controls, q_target, use_basis_gates=False):\n \"\"\"\n Apply Multiple-Controlled Z rotation gate\n\n Args:\n self (QuantumCircuit): The QuantumCircuit object to apply the mcrz gate on.\n lam (float): angle lambda\n q_controls (list(Qubit)): The list of control qubits\n q_target (Qubit): The target qubit\n use_basis_gates (bool): use u1, u2, u3, cx, id\n\n Raises:\n QiskitError: parameter errors\n \"\"\"\n\n # check controls\n if isinstance(q_controls, QuantumRegister):\n control_qubits = list(q_controls)\n elif isinstance(q_controls, list):\n control_qubits = q_controls\n else:\n raise QiskitError(\n 'The mcrz gate needs a list of qubits or a quantum register for controls.')\n\n # check target\n if isinstance(q_target, Qubit):\n target_qubit = q_target\n else:\n raise QiskitError('The mcrz gate needs a single qubit as target.')\n\n all_qubits = control_qubits + [target_qubit]\n\n self._check_qargs(all_qubits)\n self._check_dups(all_qubits)\n\n n_c = len(control_qubits)\n if n_c == 1: # cu3\n _apply_cu3(self, 0, 0, lam, control_qubits[0],\n target_qubit, use_basis_gates=use_basis_gates)\n else:\n lam_step = lam * (1 / (2 ** (n_c - 1)))\n _apply_mcu3_graycode(self, 0, 0, lam_step, control_qubits,\n target_qubit, use_basis_gates=use_basis_gates)\n\n\nQuantumCircuit.mcrx = mcrx\nQuantumCircuit.mcry = mcry\nQuantumCircuit.mcrz = mcrz\n", "path": "qiskit/circuit/library/standard_gates/multi_control_rotation_gates.py"}]}
| 3,601 | 673 |
gh_patches_debug_38758
|
rasdani/github-patches
|
git_diff
|
python-discord__site-1104
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Consider dropping deploy preview support for redirects app
Do we need previews of the legacy redirects?
If not, we may be able to remove a lot of code from the redirects app.
</issue>
<code>
[start of pydis_site/apps/redirect/urls.py]
1 import dataclasses
2 import re
3
4 import yaml
5 from django import conf
6 from django.http import HttpResponse
7 from django.urls import URLPattern, path
8 from django_distill import distill_path
9
10 from pydis_site import settings
11 from pydis_site.apps.content import urls as pages_urls
12 from pydis_site.apps.redirect.views import CustomRedirectView
13 from pydis_site.apps.resources import urls as resources_urls
14
15 app_name = "redirect"
16
17
18 __PARAMETER_REGEX = re.compile(r"<\w+:\w+>")
19 REDIRECT_TEMPLATE = "<meta http-equiv=\"refresh\" content=\"0; URL={url}\"/>"
20
21
22 @dataclasses.dataclass(frozen=True)
23 class Redirect:
24 """Metadata about a redirect route."""
25
26 original_path: str
27 redirect_route: str
28 redirect_arguments: tuple[str] = tuple()
29
30 prefix_redirect: bool = False
31
32
33 def map_redirect(name: str, data: Redirect) -> list[URLPattern]:
34 """Return a pattern using the Redirects app, or a static HTML redirect for static builds."""
35 if not settings.STATIC_BUILD:
36 # Normal dynamic redirect
37 return [path(
38 data.original_path,
39 CustomRedirectView.as_view(
40 pattern_name=data.redirect_route,
41 static_args=tuple(data.redirect_arguments),
42 prefix_redirect=data.prefix_redirect
43 ),
44 name=name
45 )]
46
47 # Create static HTML redirects for static builds
48 new_app_name = data.redirect_route.split(":")[0]
49
50 if __PARAMETER_REGEX.search(data.original_path):
51 # Redirects for paths which accept parameters
52 # We generate an HTML redirect file for all possible entries
53 paths = []
54
55 class RedirectFunc:
56 def __init__(self, new_url: str, _name: str):
57 self.result = HttpResponse(REDIRECT_TEMPLATE.format(url=new_url))
58 self.__qualname__ = _name
59
60 def __call__(self, *args, **kwargs):
61 return self.result
62
63 if new_app_name == resources_urls.app_name:
64 items = resources_urls.get_all_resources()
65 elif new_app_name == pages_urls.app_name:
66 items = pages_urls.get_all_pages()
67 else:
68 raise ValueError(f"Unknown app in redirect: {new_app_name}")
69
70 for item in items:
71 entry = next(iter(item.values()))
72
73 # Replace dynamic redirect with concrete path
74 concrete_path = __PARAMETER_REGEX.sub(entry, data.original_path)
75 new_redirect = f"/{new_app_name}/{entry}"
76 pattern_name = f"{name}_{entry}"
77
78 paths.append(distill_path(
79 concrete_path,
80 RedirectFunc(new_redirect, pattern_name),
81 name=pattern_name
82 ))
83
84 return paths
85
86 redirect_path_name = "pages" if new_app_name == "content" else new_app_name
87 if len(data.redirect_arguments) > 0:
88 redirect_arg = data.redirect_arguments[0]
89 else:
90 redirect_arg = "resources/"
91 new_redirect = f"/{redirect_path_name}/{redirect_arg}"
92
93 if new_redirect == "/resources/resources/":
94 new_redirect = "/resources/"
95
96 return [distill_path(
97 data.original_path,
98 lambda *args: HttpResponse(REDIRECT_TEMPLATE.format(url=new_redirect)),
99 name=name,
100 )]
101
102
103 urlpatterns = []
104 for _name, _data in yaml.safe_load(conf.settings.REDIRECTIONS_PATH.read_text()).items():
105 urlpatterns.extend(map_redirect(_name, Redirect(**_data)))
106
[end of pydis_site/apps/redirect/urls.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pydis_site/apps/redirect/urls.py b/pydis_site/apps/redirect/urls.py
--- a/pydis_site/apps/redirect/urls.py
+++ b/pydis_site/apps/redirect/urls.py
@@ -3,14 +3,9 @@
import yaml
from django import conf
-from django.http import HttpResponse
from django.urls import URLPattern, path
-from django_distill import distill_path
-from pydis_site import settings
-from pydis_site.apps.content import urls as pages_urls
from pydis_site.apps.redirect.views import CustomRedirectView
-from pydis_site.apps.resources import urls as resources_urls
app_name = "redirect"
@@ -31,72 +26,15 @@
def map_redirect(name: str, data: Redirect) -> list[URLPattern]:
- """Return a pattern using the Redirects app, or a static HTML redirect for static builds."""
- if not settings.STATIC_BUILD:
- # Normal dynamic redirect
- return [path(
- data.original_path,
- CustomRedirectView.as_view(
- pattern_name=data.redirect_route,
- static_args=tuple(data.redirect_arguments),
- prefix_redirect=data.prefix_redirect
- ),
- name=name
- )]
-
- # Create static HTML redirects for static builds
- new_app_name = data.redirect_route.split(":")[0]
-
- if __PARAMETER_REGEX.search(data.original_path):
- # Redirects for paths which accept parameters
- # We generate an HTML redirect file for all possible entries
- paths = []
-
- class RedirectFunc:
- def __init__(self, new_url: str, _name: str):
- self.result = HttpResponse(REDIRECT_TEMPLATE.format(url=new_url))
- self.__qualname__ = _name
-
- def __call__(self, *args, **kwargs):
- return self.result
-
- if new_app_name == resources_urls.app_name:
- items = resources_urls.get_all_resources()
- elif new_app_name == pages_urls.app_name:
- items = pages_urls.get_all_pages()
- else:
- raise ValueError(f"Unknown app in redirect: {new_app_name}")
-
- for item in items:
- entry = next(iter(item.values()))
-
- # Replace dynamic redirect with concrete path
- concrete_path = __PARAMETER_REGEX.sub(entry, data.original_path)
- new_redirect = f"/{new_app_name}/{entry}"
- pattern_name = f"{name}_{entry}"
-
- paths.append(distill_path(
- concrete_path,
- RedirectFunc(new_redirect, pattern_name),
- name=pattern_name
- ))
-
- return paths
-
- redirect_path_name = "pages" if new_app_name == "content" else new_app_name
- if len(data.redirect_arguments) > 0:
- redirect_arg = data.redirect_arguments[0]
- else:
- redirect_arg = "resources/"
- new_redirect = f"/{redirect_path_name}/{redirect_arg}"
-
- if new_redirect == "/resources/resources/":
- new_redirect = "/resources/"
-
- return [distill_path(
+ """Return a pattern using the Redirects app."""
+ return [path(
data.original_path,
- lambda *args: HttpResponse(REDIRECT_TEMPLATE.format(url=new_redirect)),
- name=name,
+ CustomRedirectView.as_view(
+ pattern_name=data.redirect_route,
+ static_args=tuple(data.redirect_arguments),
+ prefix_redirect=data.prefix_redirect
+ ),
+ name=name
)]
|
{"golden_diff": "diff --git a/pydis_site/apps/redirect/urls.py b/pydis_site/apps/redirect/urls.py\n--- a/pydis_site/apps/redirect/urls.py\n+++ b/pydis_site/apps/redirect/urls.py\n@@ -3,14 +3,9 @@\n \n import yaml\n from django import conf\n-from django.http import HttpResponse\n from django.urls import URLPattern, path\n-from django_distill import distill_path\n \n-from pydis_site import settings\n-from pydis_site.apps.content import urls as pages_urls\n from pydis_site.apps.redirect.views import CustomRedirectView\n-from pydis_site.apps.resources import urls as resources_urls\n \n app_name = \"redirect\"\n \n@@ -31,72 +26,15 @@\n \n \n def map_redirect(name: str, data: Redirect) -> list[URLPattern]:\n- \"\"\"Return a pattern using the Redirects app, or a static HTML redirect for static builds.\"\"\"\n- if not settings.STATIC_BUILD:\n- # Normal dynamic redirect\n- return [path(\n- data.original_path,\n- CustomRedirectView.as_view(\n- pattern_name=data.redirect_route,\n- static_args=tuple(data.redirect_arguments),\n- prefix_redirect=data.prefix_redirect\n- ),\n- name=name\n- )]\n-\n- # Create static HTML redirects for static builds\n- new_app_name = data.redirect_route.split(\":\")[0]\n-\n- if __PARAMETER_REGEX.search(data.original_path):\n- # Redirects for paths which accept parameters\n- # We generate an HTML redirect file for all possible entries\n- paths = []\n-\n- class RedirectFunc:\n- def __init__(self, new_url: str, _name: str):\n- self.result = HttpResponse(REDIRECT_TEMPLATE.format(url=new_url))\n- self.__qualname__ = _name\n-\n- def __call__(self, *args, **kwargs):\n- return self.result\n-\n- if new_app_name == resources_urls.app_name:\n- items = resources_urls.get_all_resources()\n- elif new_app_name == pages_urls.app_name:\n- items = pages_urls.get_all_pages()\n- else:\n- raise ValueError(f\"Unknown app in redirect: {new_app_name}\")\n-\n- for item in items:\n- entry = next(iter(item.values()))\n-\n- # Replace dynamic redirect with concrete path\n- concrete_path = __PARAMETER_REGEX.sub(entry, data.original_path)\n- new_redirect = f\"/{new_app_name}/{entry}\"\n- pattern_name = f\"{name}_{entry}\"\n-\n- paths.append(distill_path(\n- concrete_path,\n- RedirectFunc(new_redirect, pattern_name),\n- name=pattern_name\n- ))\n-\n- return paths\n-\n- redirect_path_name = \"pages\" if new_app_name == \"content\" else new_app_name\n- if len(data.redirect_arguments) > 0:\n- redirect_arg = data.redirect_arguments[0]\n- else:\n- redirect_arg = \"resources/\"\n- new_redirect = f\"/{redirect_path_name}/{redirect_arg}\"\n-\n- if new_redirect == \"/resources/resources/\":\n- new_redirect = \"/resources/\"\n-\n- return [distill_path(\n+ \"\"\"Return a pattern using the Redirects app.\"\"\"\n+ return [path(\n data.original_path,\n- lambda *args: HttpResponse(REDIRECT_TEMPLATE.format(url=new_redirect)),\n- name=name,\n+ CustomRedirectView.as_view(\n+ pattern_name=data.redirect_route,\n+ static_args=tuple(data.redirect_arguments),\n+ prefix_redirect=data.prefix_redirect\n+ ),\n+ name=name\n )]\n", "issue": "Consider dropping deploy preview support for redirects app\nDo we need previews of the legacy redirects?\n\nIf not, we may be able to remove a lot of code from the redirects app.\n", "before_files": [{"content": "import dataclasses\nimport re\n\nimport yaml\nfrom django import conf\nfrom django.http import HttpResponse\nfrom django.urls import URLPattern, path\nfrom django_distill import distill_path\n\nfrom pydis_site import settings\nfrom pydis_site.apps.content import urls as pages_urls\nfrom pydis_site.apps.redirect.views import CustomRedirectView\nfrom pydis_site.apps.resources import urls as resources_urls\n\napp_name = \"redirect\"\n\n\n__PARAMETER_REGEX = re.compile(r\"<\\w+:\\w+>\")\nREDIRECT_TEMPLATE = \"<meta http-equiv=\\\"refresh\\\" content=\\\"0; URL={url}\\\"/>\"\n\n\[email protected](frozen=True)\nclass Redirect:\n \"\"\"Metadata about a redirect route.\"\"\"\n\n original_path: str\n redirect_route: str\n redirect_arguments: tuple[str] = tuple()\n\n prefix_redirect: bool = False\n\n\ndef map_redirect(name: str, data: Redirect) -> list[URLPattern]:\n \"\"\"Return a pattern using the Redirects app, or a static HTML redirect for static builds.\"\"\"\n if not settings.STATIC_BUILD:\n # Normal dynamic redirect\n return [path(\n data.original_path,\n CustomRedirectView.as_view(\n pattern_name=data.redirect_route,\n static_args=tuple(data.redirect_arguments),\n prefix_redirect=data.prefix_redirect\n ),\n name=name\n )]\n\n # Create static HTML redirects for static builds\n new_app_name = data.redirect_route.split(\":\")[0]\n\n if __PARAMETER_REGEX.search(data.original_path):\n # Redirects for paths which accept parameters\n # We generate an HTML redirect file for all possible entries\n paths = []\n\n class RedirectFunc:\n def __init__(self, new_url: str, _name: str):\n self.result = HttpResponse(REDIRECT_TEMPLATE.format(url=new_url))\n self.__qualname__ = _name\n\n def __call__(self, *args, **kwargs):\n return self.result\n\n if new_app_name == resources_urls.app_name:\n items = resources_urls.get_all_resources()\n elif new_app_name == pages_urls.app_name:\n items = pages_urls.get_all_pages()\n else:\n raise ValueError(f\"Unknown app in redirect: {new_app_name}\")\n\n for item in items:\n entry = next(iter(item.values()))\n\n # Replace dynamic redirect with concrete path\n concrete_path = __PARAMETER_REGEX.sub(entry, data.original_path)\n new_redirect = f\"/{new_app_name}/{entry}\"\n pattern_name = f\"{name}_{entry}\"\n\n paths.append(distill_path(\n concrete_path,\n RedirectFunc(new_redirect, pattern_name),\n name=pattern_name\n ))\n\n return paths\n\n redirect_path_name = \"pages\" if new_app_name == \"content\" else new_app_name\n if len(data.redirect_arguments) > 0:\n redirect_arg = data.redirect_arguments[0]\n else:\n redirect_arg = \"resources/\"\n new_redirect = f\"/{redirect_path_name}/{redirect_arg}\"\n\n if new_redirect == \"/resources/resources/\":\n new_redirect = \"/resources/\"\n\n return [distill_path(\n data.original_path,\n lambda *args: HttpResponse(REDIRECT_TEMPLATE.format(url=new_redirect)),\n name=name,\n )]\n\n\nurlpatterns = []\nfor _name, _data in yaml.safe_load(conf.settings.REDIRECTIONS_PATH.read_text()).items():\n urlpatterns.extend(map_redirect(_name, Redirect(**_data)))\n", "path": "pydis_site/apps/redirect/urls.py"}]}
| 1,517 | 773 |
gh_patches_debug_7175
|
rasdani/github-patches
|
git_diff
|
RedHatInsights__insights-core-2743
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove defunct entry_points
These scripts no longer exist. We should remove the entry_points.
* [insights.tools.generate_api_config](https://github.com/RedHatInsights/insights-core/blob/master/setup.py#L23)
* [insights.tools.perf](https://github.com/RedHatInsights/insights-core/blob/master/setup.py#L24)
</issue>
<code>
[start of setup.py]
1 import os
2 import sys
3 from setuptools import setup, find_packages
4
5 __here__ = os.path.dirname(os.path.abspath(__file__))
6
7 package_info = dict.fromkeys(["RELEASE", "COMMIT", "VERSION", "NAME"])
8
9 for name in package_info:
10 with open(os.path.join(__here__, "insights", name)) as f:
11 package_info[name] = f.read().strip()
12
13 entry_points = {
14 'console_scripts': [
15 'insights-collect = insights.collect:main',
16 'insights-run = insights:main',
17 'insights = insights.command_parser:main',
18 'insights-cat = insights.tools.cat:main',
19 'insights-dupkeycheck = insights.tools.dupkeycheck:main',
20 'insights-inspect = insights.tools.insights_inspect:main',
21 'insights-info = insights.tools.query:main',
22 'insights-ocpshell= insights.ocpshell:main',
23 'gen_api = insights.tools.generate_api_config:main',
24 'insights-perf = insights.tools.perf:main',
25 'client = insights.client:run',
26 'mangle = insights.util.mangle:main'
27 ]
28 }
29
30 runtime = set([
31 'six',
32 'requests',
33 'redis',
34 'cachecontrol',
35 'cachecontrol[redis]',
36 'cachecontrol[filecache]',
37 'defusedxml',
38 'lockfile',
39 'jinja2',
40 ])
41
42 if (sys.version_info < (2, 7)):
43 runtime.add('pyyaml>=3.10,<=3.13')
44 else:
45 runtime.add('pyyaml')
46
47
48 def maybe_require(pkg):
49 try:
50 __import__(pkg)
51 except ImportError:
52 runtime.add(pkg)
53
54
55 maybe_require("importlib")
56 maybe_require("argparse")
57
58
59 client = set([
60 'requests'
61 ])
62
63 develop = set([
64 'futures==3.0.5',
65 'wheel',
66 ])
67
68 docs = set([
69 'Sphinx<=3.0.2',
70 'nbsphinx',
71 'sphinx_rtd_theme',
72 'ipython',
73 'colorama',
74 'jinja2',
75 'Pygments'
76 ])
77
78 testing = set([
79 'coverage==4.3.4',
80 'pytest==3.0.6',
81 'pytest-cov==2.4.0',
82 'mock==2.0.0',
83 ])
84
85 cluster = set([
86 'ansible',
87 'pandas',
88 'colorama',
89 ])
90
91 openshift = set([
92 'openshift'
93 ])
94
95 linting = set([
96 'flake8==2.6.2',
97 ])
98
99 optional = set([
100 'python-cjson',
101 'python-logstash',
102 'python-statsd',
103 'watchdog',
104 ])
105
106 if __name__ == "__main__":
107 # allows for runtime modification of rpm name
108 name = os.environ.get("INSIGHTS_CORE_NAME", package_info["NAME"])
109
110 setup(
111 name=name,
112 version=package_info["VERSION"],
113 description="Insights Core is a data collection and analysis framework",
114 long_description=open("README.rst").read(),
115 url="https://github.com/redhatinsights/insights-core",
116 author="Red Hat, Inc.",
117 author_email="[email protected]",
118 packages=find_packages(),
119 install_requires=list(runtime),
120 package_data={'': ['LICENSE']},
121 license='Apache 2.0',
122 extras_require={
123 'develop': list(runtime | develop | client | docs | linting | testing | cluster),
124 'develop26': list(runtime | develop | client | linting | testing | cluster),
125 'client': list(runtime | client),
126 'client-develop': list(runtime | develop | client | linting | testing),
127 'cluster': list(runtime | cluster),
128 'openshift': list(runtime | openshift),
129 'optional': list(optional),
130 'docs': list(docs),
131 'linting': list(linting | client),
132 'testing': list(testing | client)
133 },
134 classifiers=[
135 'Development Status :: 5 - Production/Stable',
136 'Intended Audience :: Developers',
137 'Natural Language :: English',
138 'License :: OSI Approved :: Apache Software License',
139 'Programming Language :: Python',
140 'Programming Language :: Python :: 2.6',
141 'Programming Language :: Python :: 2.7',
142 'Programming Language :: Python :: 3.3',
143 'Programming Language :: Python :: 3.4',
144 'Programming Language :: Python :: 3.5',
145 'Programming Language :: Python :: 3.6'
146 ],
147 entry_points=entry_points,
148 include_package_data=True
149 )
150
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -20,8 +20,6 @@
'insights-inspect = insights.tools.insights_inspect:main',
'insights-info = insights.tools.query:main',
'insights-ocpshell= insights.ocpshell:main',
- 'gen_api = insights.tools.generate_api_config:main',
- 'insights-perf = insights.tools.perf:main',
'client = insights.client:run',
'mangle = insights.util.mangle:main'
]
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -20,8 +20,6 @@\n 'insights-inspect = insights.tools.insights_inspect:main',\n 'insights-info = insights.tools.query:main',\n 'insights-ocpshell= insights.ocpshell:main',\n- 'gen_api = insights.tools.generate_api_config:main',\n- 'insights-perf = insights.tools.perf:main',\n 'client = insights.client:run',\n 'mangle = insights.util.mangle:main'\n ]\n", "issue": "Remove defunct entry_points\nThese scripts no longer exist. We should remove the entry_points.\r\n\r\n* [insights.tools.generate_api_config](https://github.com/RedHatInsights/insights-core/blob/master/setup.py#L23)\r\n* [insights.tools.perf](https://github.com/RedHatInsights/insights-core/blob/master/setup.py#L24)\n", "before_files": [{"content": "import os\nimport sys\nfrom setuptools import setup, find_packages\n\n__here__ = os.path.dirname(os.path.abspath(__file__))\n\npackage_info = dict.fromkeys([\"RELEASE\", \"COMMIT\", \"VERSION\", \"NAME\"])\n\nfor name in package_info:\n with open(os.path.join(__here__, \"insights\", name)) as f:\n package_info[name] = f.read().strip()\n\nentry_points = {\n 'console_scripts': [\n 'insights-collect = insights.collect:main',\n 'insights-run = insights:main',\n 'insights = insights.command_parser:main',\n 'insights-cat = insights.tools.cat:main',\n 'insights-dupkeycheck = insights.tools.dupkeycheck:main',\n 'insights-inspect = insights.tools.insights_inspect:main',\n 'insights-info = insights.tools.query:main',\n 'insights-ocpshell= insights.ocpshell:main',\n 'gen_api = insights.tools.generate_api_config:main',\n 'insights-perf = insights.tools.perf:main',\n 'client = insights.client:run',\n 'mangle = insights.util.mangle:main'\n ]\n}\n\nruntime = set([\n 'six',\n 'requests',\n 'redis',\n 'cachecontrol',\n 'cachecontrol[redis]',\n 'cachecontrol[filecache]',\n 'defusedxml',\n 'lockfile',\n 'jinja2',\n])\n\nif (sys.version_info < (2, 7)):\n runtime.add('pyyaml>=3.10,<=3.13')\nelse:\n runtime.add('pyyaml')\n\n\ndef maybe_require(pkg):\n try:\n __import__(pkg)\n except ImportError:\n runtime.add(pkg)\n\n\nmaybe_require(\"importlib\")\nmaybe_require(\"argparse\")\n\n\nclient = set([\n 'requests'\n])\n\ndevelop = set([\n 'futures==3.0.5',\n 'wheel',\n])\n\ndocs = set([\n 'Sphinx<=3.0.2',\n 'nbsphinx',\n 'sphinx_rtd_theme',\n 'ipython',\n 'colorama',\n 'jinja2',\n 'Pygments'\n])\n\ntesting = set([\n 'coverage==4.3.4',\n 'pytest==3.0.6',\n 'pytest-cov==2.4.0',\n 'mock==2.0.0',\n])\n\ncluster = set([\n 'ansible',\n 'pandas',\n 'colorama',\n])\n\nopenshift = set([\n 'openshift'\n])\n\nlinting = set([\n 'flake8==2.6.2',\n])\n\noptional = set([\n 'python-cjson',\n 'python-logstash',\n 'python-statsd',\n 'watchdog',\n])\n\nif __name__ == \"__main__\":\n # allows for runtime modification of rpm name\n name = os.environ.get(\"INSIGHTS_CORE_NAME\", package_info[\"NAME\"])\n\n setup(\n name=name,\n version=package_info[\"VERSION\"],\n description=\"Insights Core is a data collection and analysis framework\",\n long_description=open(\"README.rst\").read(),\n url=\"https://github.com/redhatinsights/insights-core\",\n author=\"Red Hat, Inc.\",\n author_email=\"[email protected]\",\n packages=find_packages(),\n install_requires=list(runtime),\n package_data={'': ['LICENSE']},\n license='Apache 2.0',\n extras_require={\n 'develop': list(runtime | develop | client | docs | linting | testing | cluster),\n 'develop26': list(runtime | develop | client | linting | testing | cluster),\n 'client': list(runtime | client),\n 'client-develop': list(runtime | develop | client | linting | testing),\n 'cluster': list(runtime | cluster),\n 'openshift': list(runtime | openshift),\n 'optional': list(optional),\n 'docs': list(docs),\n 'linting': list(linting | client),\n 'testing': list(testing | client)\n },\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'Natural Language :: English',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2.6',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6'\n ],\n entry_points=entry_points,\n include_package_data=True\n )\n", "path": "setup.py"}]}
| 1,953 | 128 |
gh_patches_debug_26911
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-1424
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Need zope.interface.verify.verifyObject for ABCs.
Every object that claims to provide some interface should then use it in a unit test.
</issue>
<code>
[start of cryptography/utils.py]
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
10 # implied.
11 # See the License for the specific language governing permissions and
12 # limitations under the License.
13
14 from __future__ import absolute_import, division, print_function
15
16 import sys
17
18
19 DeprecatedIn06 = DeprecationWarning
20
21
22 def register_interface(iface):
23 def register_decorator(klass):
24 iface.register(klass)
25 return klass
26 return register_decorator
27
28
29 def read_only_property(name):
30 return property(lambda self: getattr(self, name))
31
32
33 def bit_length(x):
34 if sys.version_info >= (2, 7):
35 return x.bit_length()
36 else:
37 return len(bin(x)) - (2 + (x <= 0))
38
[end of cryptography/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/cryptography/utils.py b/cryptography/utils.py
--- a/cryptography/utils.py
+++ b/cryptography/utils.py
@@ -13,6 +13,8 @@
from __future__ import absolute_import, division, print_function
+import abc
+import inspect
import sys
@@ -21,6 +23,7 @@
def register_interface(iface):
def register_decorator(klass):
+ verify_interface(iface, klass)
iface.register(klass)
return klass
return register_decorator
@@ -30,6 +33,30 @@
return property(lambda self: getattr(self, name))
+class InterfaceNotImplemented(Exception):
+ pass
+
+
+def verify_interface(iface, klass):
+ for method in iface.__abstractmethods__:
+ if not hasattr(klass, method):
+ raise InterfaceNotImplemented(
+ "{0} is missing a {1!r} method".format(klass, method)
+ )
+ if isinstance(getattr(iface, method), abc.abstractproperty):
+ # Can't properly verify these yet.
+ continue
+ spec = inspect.getargspec(getattr(iface, method))
+ actual = inspect.getargspec(getattr(klass, method))
+ if spec != actual:
+ raise InterfaceNotImplemented(
+ "{0}.{1}'s signature differs from the expected. Expected: "
+ "{2!r}. Received: {3!r}".format(
+ klass, method, spec, actual
+ )
+ )
+
+
def bit_length(x):
if sys.version_info >= (2, 7):
return x.bit_length()
|
{"golden_diff": "diff --git a/cryptography/utils.py b/cryptography/utils.py\n--- a/cryptography/utils.py\n+++ b/cryptography/utils.py\n@@ -13,6 +13,8 @@\n \n from __future__ import absolute_import, division, print_function\n \n+import abc\n+import inspect\n import sys\n \n \n@@ -21,6 +23,7 @@\n \n def register_interface(iface):\n def register_decorator(klass):\n+ verify_interface(iface, klass)\n iface.register(klass)\n return klass\n return register_decorator\n@@ -30,6 +33,30 @@\n return property(lambda self: getattr(self, name))\n \n \n+class InterfaceNotImplemented(Exception):\n+ pass\n+\n+\n+def verify_interface(iface, klass):\n+ for method in iface.__abstractmethods__:\n+ if not hasattr(klass, method):\n+ raise InterfaceNotImplemented(\n+ \"{0} is missing a {1!r} method\".format(klass, method)\n+ )\n+ if isinstance(getattr(iface, method), abc.abstractproperty):\n+ # Can't properly verify these yet.\n+ continue\n+ spec = inspect.getargspec(getattr(iface, method))\n+ actual = inspect.getargspec(getattr(klass, method))\n+ if spec != actual:\n+ raise InterfaceNotImplemented(\n+ \"{0}.{1}'s signature differs from the expected. Expected: \"\n+ \"{2!r}. Received: {3!r}\".format(\n+ klass, method, spec, actual\n+ )\n+ )\n+\n+\n def bit_length(x):\n if sys.version_info >= (2, 7):\n return x.bit_length()\n", "issue": "Need zope.interface.verify.verifyObject for ABCs.\nEvery object that claims to provide some interface should then use it in a unit test.\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or\n# implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport sys\n\n\nDeprecatedIn06 = DeprecationWarning\n\n\ndef register_interface(iface):\n def register_decorator(klass):\n iface.register(klass)\n return klass\n return register_decorator\n\n\ndef read_only_property(name):\n return property(lambda self: getattr(self, name))\n\n\ndef bit_length(x):\n if sys.version_info >= (2, 7):\n return x.bit_length()\n else:\n return len(bin(x)) - (2 + (x <= 0))\n", "path": "cryptography/utils.py"}]}
| 868 | 357 |
gh_patches_debug_23901
|
rasdani/github-patches
|
git_diff
|
ultrabug__py3status-946
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
GitHub: Show correct count of unread notifications
If you have more than 50 unread notifications in total, and you want to see that total notification count, the GitHub module still only shows 50 due to pagination:
https://github.com/ultrabug/py3status/blob/master/py3status/modules/github.py#L155
</issue>
<code>
[start of py3status/modules/github.py]
1 # -*- coding: utf-8 -*-
2 """
3 Display Github notifications and issue/pull requests for a repo.
4
5 To check notifications a Github `username` and `personal access token` are
6 required. You can create a personal access token at
7 https://github.com/settings/tokens The only `scope` needed is `notifications`,
8 which provides readonly access to notifications.
9
10 The Github API is rate limited so setting `cache_timeout` too small may cause
11 issues see https://developer.github.com/v3/#rate-limiting for details
12
13 Configuration parameters:
14 auth_token: Github personal access token, needed to check notifications
15 see above.
16 (default None)
17 button_action: Button that when clicked opens the Github notification page
18 if notifications, else the project page for the repository if there is
19 one (otherwise the github home page). Setting to `None` disables.
20 (default 3)
21 button_refresh: Button that when clicked refreshes module.
22 Setting to `None` disables.
23 (default 2)
24 cache_timeout: How often we refresh this module in seconds
25 (default 60)
26 format: Format of output
27 *(default '{repo} {issues}/{pull_requests}{notifications}'
28 if username and auth_token provided else
29 '{repo} {issues}/{pull_requests}')*
30 format_notifications: Format of `{notification}` status placeholder.
31 (default ' N{notifications_count}')
32 notifications: Type of notifications can be `all` for all notifications or
33 `repo` to only get notifications for the repo specified. If repo is
34 not provided then all notifications will be checked.
35 (default 'all')
36 repo: Github repo to check
37 (default 'ultrabug/py3status')
38 username: Github username, needed to check notifications.
39 (default None)
40
41 Format placeholders:
42 {issues} Number of open issues.
43 {notifications} Notifications. If no notifications this will be empty.
44 {notifications_count} Number of notifications. This is also the __Only__
45 placeholder available to `format_notifications`.
46 {pull_requests} Number of open pull requests
47 {repo} short name of the repository being checked. eg py3status
48 {repo_full} full name of the repository being checked. eg ultrabug/py3status
49
50 Examples:
51 ```
52 # set github access credentials
53 github {
54 auth_token = '40_char_hex_access_token'
55 username = 'my_username'
56 }
57
58 # just check for any notifications
59 github {
60 auth_token = '40_char_hex_access_token'
61 username = 'my_username'
62 format = 'Github {notifications_count}'
63 }
64 ```
65
66 @author tobes
67
68 SAMPLE OUTPUT
69 {'full_text': 'py3status 34/24'}
70
71 notification
72 {'full_text': 'py3status 34/24 N3', 'urgent': True}
73 """
74
75 GITHUB_API_URL = 'https://api.github.com'
76 GITHUB_URL = 'https://github.com/'
77
78
79 class Py3status:
80 auth_token = None
81 button_action = 3
82 button_refresh = 2
83 cache_timeout = 60
84 format = None
85 format_notifications = ' N{notifications_count}'
86 notifications = 'all'
87 repo = 'ultrabug/py3status'
88 username = None
89
90 def post_config_hook(self):
91 self.first = True
92 self.notification_warning = False
93 self.repo_warning = False
94 self._issues = '?'
95 self._pulls = '?'
96 self._notify = '?'
97
98 def _init(self):
99 # Set format if user has not configured it.
100 if not self.format:
101 if self.username and self.auth_token:
102 # include notifications
103 self.format = '{repo} {issues}/{pull_requests}{notifications}'
104 else:
105 self.format = '{repo} {issues}/{pull_requests}'
106
107 def _github_count(self, url):
108 """
109 Get counts for requests that return 'total_count' in the json response.
110 """
111 if self.first:
112 return '?'
113 url = GITHUB_API_URL + url + '&per_page=1'
114 # if we have authentication details use them as we get better
115 # rate-limiting.
116 if self.username and self.auth_token:
117 auth = (self.username, self.auth_token)
118 else:
119 auth = None
120 try:
121 info = self.py3.request(url, timeout=10, auth=auth)
122 except (self.py3.RequestException):
123 return
124 if info and info.status_code == 200:
125 return(int(info.json()['total_count']))
126 if info.status_code == 422:
127 if not self.repo_warning:
128 self.py3.notify_user('Github repo cannot be found.')
129 self.repo_warning = True
130 return '?'
131
132 def _notifications(self):
133 """
134 Get the number of unread notifications.
135 """
136 if not self.username or not self.auth_token:
137 if not self.notification_warning:
138 self.py3.notify_user('Github module needs username and '
139 'auth_token to check notifications.')
140 self.notification_warning = True
141 return '?'
142 if self.first:
143 return '?'
144 if self.notifications == 'all' or not self.repo:
145 url = GITHUB_API_URL + '/notifications'
146 else:
147 url = GITHUB_API_URL + '/repos/' + self.repo + '/notifications'
148 url += '?per_page=100'
149 try:
150 info = self.py3.request(url, timeout=10,
151 auth=(self.username, self.auth_token))
152 except (self.py3.RequestException):
153 return
154 if info.status_code == 200:
155 return len(info.json())
156 if info.status_code == 404:
157 if not self.repo_warning:
158 self.py3.notify_user('Github repo cannot be found.')
159 self.repo_warning = True
160
161 def github(self):
162 if self.first:
163 self._init()
164 status = {}
165 urgent = False
166 # issues
167 if self.repo and self.py3.format_contains(self.format, 'issues'):
168 url = '/search/issues?q=state:open+type:issue+repo:' + self.repo
169 self._issues = self._github_count(url) or self._issues
170 status['issues'] = self._issues
171 # pull requests
172 if self.repo and self.py3.format_contains(self.format, 'pull_requests'):
173 url = '/search/issues?q=state:open+type:pr+repo:' + self.repo
174 self._pulls = self._github_count(url) or self._pulls
175 status['pull_requests'] = self._pulls
176 # notifications
177 if (self.py3.format_contains(self.format, 'notifications') or
178 self.py3.format_contains(self.format, 'notifications_count')):
179 count = self._notifications()
180 # if we don't have a notification count, then use the last value
181 # that we did have.
182 if count is None:
183 count = self._notify
184 self._notify = count
185 if count and count != '?':
186 notify = self.py3.safe_format(
187 self.format_notifications,
188 {'notifications_count': count})
189 urgent = True
190 else:
191 notify = ''
192 status['notifications'] = notify
193 status['notifications_count'] = count
194 # repo
195 try:
196 status['repo'] = self.repo.split('/')[1]
197 except IndexError:
198 status['repo'] = 'Error'
199 status['repo_full'] = self.repo
200
201 if self.first:
202 cached_until = 0
203 self.first = False
204 else:
205 cached_until = self.py3.time_in(self.cache_timeout)
206
207 return {
208 'full_text': self.py3.safe_format(self.format, status),
209 'cached_until': cached_until,
210 'urgent': urgent
211 }
212
213 def on_click(self, event):
214 button = event['button']
215 if button == self.button_action:
216 # open github in browser
217 if self._notify and self._notify != '?':
218 # open github notifications page
219 url = GITHUB_URL + 'notifications'
220 else:
221 if self.notifications == 'all' and not self.repo:
222 # open github.com if there are no unread notifications and no repo
223 url = GITHUB_URL
224 else:
225 # open repo page if there are no unread notifications
226 url = GITHUB_URL + self.repo
227 # open url in default browser
228 self.py3.command_run('xdg-open {}'.format(url))
229 self.py3.prevent_refresh()
230 elif button != self.button_refresh:
231 # only refresh the module if needed
232 self.py3.prevent_refresh()
233
234
235 if __name__ == "__main__":
236 """
237 Run module in test mode.
238 """
239 from py3status.module_test import module_test
240 module_test(Py3status)
241
[end of py3status/modules/github.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/py3status/modules/github.py b/py3status/modules/github.py
--- a/py3status/modules/github.py
+++ b/py3status/modules/github.py
@@ -152,7 +152,32 @@
except (self.py3.RequestException):
return
if info.status_code == 200:
- return len(info.json())
+ links = info._response.headers.get('Link', '').split(', ')
+ if not links:
+ return len(info.json())
+
+ last_page = 1
+ for link in links:
+ if 'rel="last"' in link:
+ import sys
+ if sys.version_info[0] == 2:
+ import urlparse
+ else:
+ import urllib.parse as urlparse
+ last_url = link[link.find('<') + 1:link.find('>')]
+ parsed = urlparse.urlparse(last_url)
+ last_page = int(urlparse.parse_qs(parsed.query)['page'][0])
+
+ if last_page == 1:
+ return len(info.json())
+ try:
+ last_page_info = self.py3.request(last_url, timeout=10,
+ auth=(self.username, self.auth_token))
+ except self.py3.RequestException:
+ return
+
+ return len(info.json()) * (last_page - 1) + len(last_page_info.json())
+
if info.status_code == 404:
if not self.repo_warning:
self.py3.notify_user('Github repo cannot be found.')
|
{"golden_diff": "diff --git a/py3status/modules/github.py b/py3status/modules/github.py\n--- a/py3status/modules/github.py\n+++ b/py3status/modules/github.py\n@@ -152,7 +152,32 @@\n except (self.py3.RequestException):\n return\n if info.status_code == 200:\n- return len(info.json())\n+ links = info._response.headers.get('Link', '').split(', ')\n+ if not links:\n+ return len(info.json())\n+\n+ last_page = 1\n+ for link in links:\n+ if 'rel=\"last\"' in link:\n+ import sys\n+ if sys.version_info[0] == 2:\n+ import urlparse\n+ else:\n+ import urllib.parse as urlparse\n+ last_url = link[link.find('<') + 1:link.find('>')]\n+ parsed = urlparse.urlparse(last_url)\n+ last_page = int(urlparse.parse_qs(parsed.query)['page'][0])\n+\n+ if last_page == 1:\n+ return len(info.json())\n+ try:\n+ last_page_info = self.py3.request(last_url, timeout=10,\n+ auth=(self.username, self.auth_token))\n+ except self.py3.RequestException:\n+ return\n+\n+ return len(info.json()) * (last_page - 1) + len(last_page_info.json())\n+\n if info.status_code == 404:\n if not self.repo_warning:\n self.py3.notify_user('Github repo cannot be found.')\n", "issue": "GitHub: Show correct count of unread notifications\nIf you have more than 50 unread notifications in total, and you want to see that total notification count, the GitHub module still only shows 50 due to pagination:\r\n\r\nhttps://github.com/ultrabug/py3status/blob/master/py3status/modules/github.py#L155\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nDisplay Github notifications and issue/pull requests for a repo.\n\nTo check notifications a Github `username` and `personal access token` are\nrequired. You can create a personal access token at\nhttps://github.com/settings/tokens The only `scope` needed is `notifications`,\nwhich provides readonly access to notifications.\n\nThe Github API is rate limited so setting `cache_timeout` too small may cause\nissues see https://developer.github.com/v3/#rate-limiting for details\n\nConfiguration parameters:\n auth_token: Github personal access token, needed to check notifications\n see above.\n (default None)\n button_action: Button that when clicked opens the Github notification page\n if notifications, else the project page for the repository if there is\n one (otherwise the github home page). Setting to `None` disables.\n (default 3)\n button_refresh: Button that when clicked refreshes module.\n Setting to `None` disables.\n (default 2)\n cache_timeout: How often we refresh this module in seconds\n (default 60)\n format: Format of output\n *(default '{repo} {issues}/{pull_requests}{notifications}'\n if username and auth_token provided else\n '{repo} {issues}/{pull_requests}')*\n format_notifications: Format of `{notification}` status placeholder.\n (default ' N{notifications_count}')\n notifications: Type of notifications can be `all` for all notifications or\n `repo` to only get notifications for the repo specified. If repo is\n not provided then all notifications will be checked.\n (default 'all')\n repo: Github repo to check\n (default 'ultrabug/py3status')\n username: Github username, needed to check notifications.\n (default None)\n\nFormat placeholders:\n {issues} Number of open issues.\n {notifications} Notifications. If no notifications this will be empty.\n {notifications_count} Number of notifications. This is also the __Only__\n placeholder available to `format_notifications`.\n {pull_requests} Number of open pull requests\n {repo} short name of the repository being checked. eg py3status\n {repo_full} full name of the repository being checked. eg ultrabug/py3status\n\nExamples:\n```\n# set github access credentials\ngithub {\n auth_token = '40_char_hex_access_token'\n username = 'my_username'\n}\n\n# just check for any notifications\ngithub {\n auth_token = '40_char_hex_access_token'\n username = 'my_username'\n format = 'Github {notifications_count}'\n}\n```\n\n@author tobes\n\nSAMPLE OUTPUT\n{'full_text': 'py3status 34/24'}\n\nnotification\n{'full_text': 'py3status 34/24 N3', 'urgent': True}\n\"\"\"\n\nGITHUB_API_URL = 'https://api.github.com'\nGITHUB_URL = 'https://github.com/'\n\n\nclass Py3status:\n auth_token = None\n button_action = 3\n button_refresh = 2\n cache_timeout = 60\n format = None\n format_notifications = ' N{notifications_count}'\n notifications = 'all'\n repo = 'ultrabug/py3status'\n username = None\n\n def post_config_hook(self):\n self.first = True\n self.notification_warning = False\n self.repo_warning = False\n self._issues = '?'\n self._pulls = '?'\n self._notify = '?'\n\n def _init(self):\n # Set format if user has not configured it.\n if not self.format:\n if self.username and self.auth_token:\n # include notifications\n self.format = '{repo} {issues}/{pull_requests}{notifications}'\n else:\n self.format = '{repo} {issues}/{pull_requests}'\n\n def _github_count(self, url):\n \"\"\"\n Get counts for requests that return 'total_count' in the json response.\n \"\"\"\n if self.first:\n return '?'\n url = GITHUB_API_URL + url + '&per_page=1'\n # if we have authentication details use them as we get better\n # rate-limiting.\n if self.username and self.auth_token:\n auth = (self.username, self.auth_token)\n else:\n auth = None\n try:\n info = self.py3.request(url, timeout=10, auth=auth)\n except (self.py3.RequestException):\n return\n if info and info.status_code == 200:\n return(int(info.json()['total_count']))\n if info.status_code == 422:\n if not self.repo_warning:\n self.py3.notify_user('Github repo cannot be found.')\n self.repo_warning = True\n return '?'\n\n def _notifications(self):\n \"\"\"\n Get the number of unread notifications.\n \"\"\"\n if not self.username or not self.auth_token:\n if not self.notification_warning:\n self.py3.notify_user('Github module needs username and '\n 'auth_token to check notifications.')\n self.notification_warning = True\n return '?'\n if self.first:\n return '?'\n if self.notifications == 'all' or not self.repo:\n url = GITHUB_API_URL + '/notifications'\n else:\n url = GITHUB_API_URL + '/repos/' + self.repo + '/notifications'\n url += '?per_page=100'\n try:\n info = self.py3.request(url, timeout=10,\n auth=(self.username, self.auth_token))\n except (self.py3.RequestException):\n return\n if info.status_code == 200:\n return len(info.json())\n if info.status_code == 404:\n if not self.repo_warning:\n self.py3.notify_user('Github repo cannot be found.')\n self.repo_warning = True\n\n def github(self):\n if self.first:\n self._init()\n status = {}\n urgent = False\n # issues\n if self.repo and self.py3.format_contains(self.format, 'issues'):\n url = '/search/issues?q=state:open+type:issue+repo:' + self.repo\n self._issues = self._github_count(url) or self._issues\n status['issues'] = self._issues\n # pull requests\n if self.repo and self.py3.format_contains(self.format, 'pull_requests'):\n url = '/search/issues?q=state:open+type:pr+repo:' + self.repo\n self._pulls = self._github_count(url) or self._pulls\n status['pull_requests'] = self._pulls\n # notifications\n if (self.py3.format_contains(self.format, 'notifications') or\n self.py3.format_contains(self.format, 'notifications_count')):\n count = self._notifications()\n # if we don't have a notification count, then use the last value\n # that we did have.\n if count is None:\n count = self._notify\n self._notify = count\n if count and count != '?':\n notify = self.py3.safe_format(\n self.format_notifications,\n {'notifications_count': count})\n urgent = True\n else:\n notify = ''\n status['notifications'] = notify\n status['notifications_count'] = count\n # repo\n try:\n status['repo'] = self.repo.split('/')[1]\n except IndexError:\n status['repo'] = 'Error'\n status['repo_full'] = self.repo\n\n if self.first:\n cached_until = 0\n self.first = False\n else:\n cached_until = self.py3.time_in(self.cache_timeout)\n\n return {\n 'full_text': self.py3.safe_format(self.format, status),\n 'cached_until': cached_until,\n 'urgent': urgent\n }\n\n def on_click(self, event):\n button = event['button']\n if button == self.button_action:\n # open github in browser\n if self._notify and self._notify != '?':\n # open github notifications page\n url = GITHUB_URL + 'notifications'\n else:\n if self.notifications == 'all' and not self.repo:\n # open github.com if there are no unread notifications and no repo\n url = GITHUB_URL\n else:\n # open repo page if there are no unread notifications\n url = GITHUB_URL + self.repo\n # open url in default browser\n self.py3.command_run('xdg-open {}'.format(url))\n self.py3.prevent_refresh()\n elif button != self.button_refresh:\n # only refresh the module if needed\n self.py3.prevent_refresh()\n\n\nif __name__ == \"__main__\":\n \"\"\"\n Run module in test mode.\n \"\"\"\n from py3status.module_test import module_test\n module_test(Py3status)\n", "path": "py3status/modules/github.py"}]}
| 3,107 | 336 |
gh_patches_debug_17382
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-5440
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`new-password` route is defined twice
It looks to me like this route in the admin UI is defined redundantly:
https://github.com/freedomofpress/securedrop/blob/develop/securedrop/journalist_app/admin.py#L219
https://github.com/freedomofpress/securedrop/blob/develop/securedrop/journalist_app/admin.py#L259
If there is no reason for this, we should remove one of the redundant definitions.
</issue>
<code>
[start of securedrop/journalist_app/admin.py]
1 # -*- coding: utf-8 -*-
2
3 import os
4
5 from flask import (Blueprint, render_template, request, url_for, redirect, g,
6 current_app, flash, abort)
7 from flask_babel import gettext
8 from sqlalchemy.exc import IntegrityError
9 from sqlalchemy.orm.exc import NoResultFound
10
11 from db import db
12 from models import (InstanceConfig, Journalist, InvalidUsernameException,
13 FirstOrLastNameError, PasswordError)
14 from journalist_app.decorators import admin_required
15 from journalist_app.utils import (make_password, commit_account_changes, set_diceware_password,
16 validate_hotp_secret, revoke_token)
17 from journalist_app.forms import LogoForm, NewUserForm, SubmissionPreferencesForm
18
19
20 def make_blueprint(config):
21 view = Blueprint('admin', __name__)
22
23 @view.route('/', methods=('GET', 'POST'))
24 @admin_required
25 def index():
26 users = Journalist.query.all()
27 return render_template("admin.html", users=users)
28
29 @view.route('/config', methods=('GET', 'POST'))
30 @admin_required
31 def manage_config():
32 # The UI prompt ("prevent") is the opposite of the setting ("allow"):
33 submission_preferences_form = SubmissionPreferencesForm(
34 prevent_document_uploads=not current_app.instance_config.allow_document_uploads)
35 logo_form = LogoForm()
36 if logo_form.validate_on_submit():
37 f = logo_form.logo.data
38 custom_logo_filepath = os.path.join(current_app.static_folder, 'i',
39 'custom_logo.png')
40 try:
41 f.save(custom_logo_filepath)
42 flash(gettext("Image updated."), "logo-success")
43 except Exception:
44 flash("Unable to process the image file."
45 " Try another one.", "logo-error")
46 finally:
47 return redirect(url_for("admin.manage_config"))
48 else:
49 for field, errors in list(logo_form.errors.items()):
50 for error in errors:
51 flash(error, "logo-error")
52 return render_template("config.html",
53 submission_preferences_form=submission_preferences_form,
54 logo_form=logo_form)
55
56 @view.route('/update-submission-preferences', methods=['POST'])
57 @admin_required
58 def update_submission_preferences():
59 form = SubmissionPreferencesForm()
60 if form.validate_on_submit():
61 # The UI prompt ("prevent") is the opposite of the setting ("allow"):
62 flash(gettext("Preferences saved."), "submission-preferences-success")
63 value = not bool(request.form.get('prevent_document_uploads'))
64 InstanceConfig.set('allow_document_uploads', value)
65 return redirect(url_for('admin.manage_config'))
66
67 @view.route('/add', methods=('GET', 'POST'))
68 @admin_required
69 def add_user():
70 form = NewUserForm()
71 if form.validate_on_submit():
72 form_valid = True
73 username = request.form['username']
74 first_name = request.form['first_name']
75 last_name = request.form['last_name']
76 password = request.form['password']
77 is_admin = bool(request.form.get('is_admin'))
78
79 try:
80 otp_secret = None
81 if request.form.get('is_hotp', False):
82 otp_secret = request.form.get('otp_secret', '')
83 new_user = Journalist(username=username,
84 password=password,
85 first_name=first_name,
86 last_name=last_name,
87 is_admin=is_admin,
88 otp_secret=otp_secret)
89 db.session.add(new_user)
90 db.session.commit()
91 except PasswordError:
92 flash(gettext(
93 'There was an error with the autogenerated password. '
94 'User not created. Please try again.'), 'error')
95 form_valid = False
96 except InvalidUsernameException as e:
97 form_valid = False
98 flash('Invalid username: ' + str(e), "error")
99 except IntegrityError as e:
100 db.session.rollback()
101 form_valid = False
102 if "UNIQUE constraint failed: journalists.username" in str(e):
103 flash(gettext('Username "{user}" already taken.'.format(
104 user=username)), "error")
105 else:
106 flash(gettext("An error occurred saving this user"
107 " to the database."
108 " Please inform your admin."),
109 "error")
110 current_app.logger.error("Adding user "
111 "'{}' failed: {}".format(
112 username, e))
113
114 if form_valid:
115 return redirect(url_for('admin.new_user_two_factor',
116 uid=new_user.id))
117
118 return render_template("admin_add_user.html",
119 password=make_password(config),
120 form=form)
121
122 @view.route('/2fa', methods=('GET', 'POST'))
123 @admin_required
124 def new_user_two_factor():
125 user = Journalist.query.get(request.args['uid'])
126
127 if request.method == 'POST':
128 token = request.form['token']
129 if user.verify_token(token):
130 flash(gettext(
131 "The two-factor code for user \"{user}\" was verified "
132 "successfully.").format(user=user.username),
133 "notification")
134 return redirect(url_for("admin.index"))
135 else:
136 flash(gettext(
137 "There was a problem verifying the two-factor code. Please try again."),
138 "error")
139
140 return render_template("admin_new_user_two_factor.html", user=user)
141
142 @view.route('/reset-2fa-totp', methods=['POST'])
143 @admin_required
144 def reset_two_factor_totp():
145 uid = request.form['uid']
146 user = Journalist.query.get(uid)
147 user.is_totp = True
148 user.regenerate_totp_shared_secret()
149 db.session.commit()
150 return redirect(url_for('admin.new_user_two_factor', uid=uid))
151
152 @view.route('/reset-2fa-hotp', methods=['POST'])
153 @admin_required
154 def reset_two_factor_hotp():
155 uid = request.form['uid']
156 otp_secret = request.form.get('otp_secret', None)
157 if otp_secret:
158 user = Journalist.query.get(uid)
159 if not validate_hotp_secret(user, otp_secret):
160 return render_template('admin_edit_hotp_secret.html', uid=uid)
161 db.session.commit()
162 return redirect(url_for('admin.new_user_two_factor', uid=uid))
163 else:
164 return render_template('admin_edit_hotp_secret.html', uid=uid)
165
166 @view.route('/edit/<int:user_id>', methods=('GET', 'POST'))
167 @admin_required
168 def edit_user(user_id):
169 user = Journalist.query.get(user_id)
170
171 if request.method == 'POST':
172 if request.form.get('username', None):
173 new_username = request.form['username']
174
175 try:
176 Journalist.check_username_acceptable(new_username)
177 except InvalidUsernameException as e:
178 flash('Invalid username: ' + str(e), 'error')
179 return redirect(url_for("admin.edit_user",
180 user_id=user_id))
181
182 if new_username == user.username:
183 pass
184 elif Journalist.query.filter_by(
185 username=new_username).one_or_none():
186 flash(gettext(
187 'Username "{user}" already taken.').format(
188 user=new_username),
189 "error")
190 return redirect(url_for("admin.edit_user",
191 user_id=user_id))
192 else:
193 user.username = new_username
194
195 try:
196 first_name = request.form['first_name']
197 Journalist.check_name_acceptable(first_name)
198 user.first_name = first_name
199 except FirstOrLastNameError as e:
200 flash(gettext('Name not updated: {}'.format(e)), "error")
201 return redirect(url_for("admin.edit_user", user_id=user_id))
202
203 try:
204 last_name = request.form['last_name']
205 Journalist.check_name_acceptable(last_name)
206 user.last_name = last_name
207 except FirstOrLastNameError as e:
208 flash(gettext('Name not updated: {}'.format(e)), "error")
209 return redirect(url_for("admin.edit_user", user_id=user_id))
210
211 user.is_admin = bool(request.form.get('is_admin'))
212
213 commit_account_changes(user)
214
215 password = make_password(config)
216 return render_template("edit_account.html", user=user,
217 password=password)
218
219 @view.route('/edit/<int:user_id>/new-password', methods=('POST',))
220 @admin_required
221 def set_password(user_id):
222 try:
223 user = Journalist.query.get(user_id)
224 except NoResultFound:
225 abort(404)
226
227 password = request.form.get('password')
228 if set_diceware_password(user, password) is not False:
229 if user.last_token is not None:
230 revoke_token(user, user.last_token)
231 user.session_nonce += 1
232 db.session.commit()
233
234 return redirect(url_for('admin.edit_user', user_id=user_id))
235
236 @view.route('/delete/<int:user_id>', methods=('POST',))
237 @admin_required
238 def delete_user(user_id):
239 user = Journalist.query.get(user_id)
240 if user_id == g.user.id:
241 # Do not flash because the interface already has safe guards.
242 # It can only happen by manually crafting a POST request
243 current_app.logger.error(
244 "Admin {} tried to delete itself".format(g.user.username))
245 abort(403)
246 elif user:
247 db.session.delete(user)
248 db.session.commit()
249 flash(gettext("Deleted user '{user}'.").format(
250 user=user.username), "notification")
251 else:
252 current_app.logger.error(
253 "Admin {} tried to delete nonexistent user with pk={}".format(
254 g.user.username, user_id))
255 abort(404)
256
257 return redirect(url_for('admin.index'))
258
259 @view.route('/edit/<int:user_id>/new-password', methods=('POST',))
260 @admin_required
261 def new_password(user_id):
262 try:
263 user = Journalist.query.get(user_id)
264 except NoResultFound:
265 abort(404)
266
267 password = request.form.get('password')
268 if set_diceware_password(user, password) is not False:
269 if user.last_token is not None:
270 revoke_token(user, user.last_token)
271 user.session_nonce += 1
272 db.session.commit()
273 return redirect(url_for('admin.edit_user', user_id=user_id))
274
275 @view.route('/ossec-test')
276 @admin_required
277 def ossec_test():
278 current_app.logger.error('This is a test OSSEC alert')
279 flash(gettext('Test alert sent. Please check your email.'),
280 'notification')
281 return redirect(url_for('admin.manage_config'))
282
283 return view
284
[end of securedrop/journalist_app/admin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/securedrop/journalist_app/admin.py b/securedrop/journalist_app/admin.py
--- a/securedrop/journalist_app/admin.py
+++ b/securedrop/journalist_app/admin.py
@@ -216,23 +216,6 @@
return render_template("edit_account.html", user=user,
password=password)
- @view.route('/edit/<int:user_id>/new-password', methods=('POST',))
- @admin_required
- def set_password(user_id):
- try:
- user = Journalist.query.get(user_id)
- except NoResultFound:
- abort(404)
-
- password = request.form.get('password')
- if set_diceware_password(user, password) is not False:
- if user.last_token is not None:
- revoke_token(user, user.last_token)
- user.session_nonce += 1
- db.session.commit()
-
- return redirect(url_for('admin.edit_user', user_id=user_id))
-
@view.route('/delete/<int:user_id>', methods=('POST',))
@admin_required
def delete_user(user_id):
|
{"golden_diff": "diff --git a/securedrop/journalist_app/admin.py b/securedrop/journalist_app/admin.py\n--- a/securedrop/journalist_app/admin.py\n+++ b/securedrop/journalist_app/admin.py\n@@ -216,23 +216,6 @@\n return render_template(\"edit_account.html\", user=user,\n password=password)\n \n- @view.route('/edit/<int:user_id>/new-password', methods=('POST',))\n- @admin_required\n- def set_password(user_id):\n- try:\n- user = Journalist.query.get(user_id)\n- except NoResultFound:\n- abort(404)\n-\n- password = request.form.get('password')\n- if set_diceware_password(user, password) is not False:\n- if user.last_token is not None:\n- revoke_token(user, user.last_token)\n- user.session_nonce += 1\n- db.session.commit()\n-\n- return redirect(url_for('admin.edit_user', user_id=user_id))\n-\n @view.route('/delete/<int:user_id>', methods=('POST',))\n @admin_required\n def delete_user(user_id):\n", "issue": "`new-password` route is defined twice\nIt looks to me like this route in the admin UI is defined redundantly:\r\nhttps://github.com/freedomofpress/securedrop/blob/develop/securedrop/journalist_app/admin.py#L219\r\nhttps://github.com/freedomofpress/securedrop/blob/develop/securedrop/journalist_app/admin.py#L259\r\n\r\nIf there is no reason for this, we should remove one of the redundant definitions.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nimport os\n\nfrom flask import (Blueprint, render_template, request, url_for, redirect, g,\n current_app, flash, abort)\nfrom flask_babel import gettext\nfrom sqlalchemy.exc import IntegrityError\nfrom sqlalchemy.orm.exc import NoResultFound\n\nfrom db import db\nfrom models import (InstanceConfig, Journalist, InvalidUsernameException,\n FirstOrLastNameError, PasswordError)\nfrom journalist_app.decorators import admin_required\nfrom journalist_app.utils import (make_password, commit_account_changes, set_diceware_password,\n validate_hotp_secret, revoke_token)\nfrom journalist_app.forms import LogoForm, NewUserForm, SubmissionPreferencesForm\n\n\ndef make_blueprint(config):\n view = Blueprint('admin', __name__)\n\n @view.route('/', methods=('GET', 'POST'))\n @admin_required\n def index():\n users = Journalist.query.all()\n return render_template(\"admin.html\", users=users)\n\n @view.route('/config', methods=('GET', 'POST'))\n @admin_required\n def manage_config():\n # The UI prompt (\"prevent\") is the opposite of the setting (\"allow\"):\n submission_preferences_form = SubmissionPreferencesForm(\n prevent_document_uploads=not current_app.instance_config.allow_document_uploads)\n logo_form = LogoForm()\n if logo_form.validate_on_submit():\n f = logo_form.logo.data\n custom_logo_filepath = os.path.join(current_app.static_folder, 'i',\n 'custom_logo.png')\n try:\n f.save(custom_logo_filepath)\n flash(gettext(\"Image updated.\"), \"logo-success\")\n except Exception:\n flash(\"Unable to process the image file.\"\n \" Try another one.\", \"logo-error\")\n finally:\n return redirect(url_for(\"admin.manage_config\"))\n else:\n for field, errors in list(logo_form.errors.items()):\n for error in errors:\n flash(error, \"logo-error\")\n return render_template(\"config.html\",\n submission_preferences_form=submission_preferences_form,\n logo_form=logo_form)\n\n @view.route('/update-submission-preferences', methods=['POST'])\n @admin_required\n def update_submission_preferences():\n form = SubmissionPreferencesForm()\n if form.validate_on_submit():\n # The UI prompt (\"prevent\") is the opposite of the setting (\"allow\"):\n flash(gettext(\"Preferences saved.\"), \"submission-preferences-success\")\n value = not bool(request.form.get('prevent_document_uploads'))\n InstanceConfig.set('allow_document_uploads', value)\n return redirect(url_for('admin.manage_config'))\n\n @view.route('/add', methods=('GET', 'POST'))\n @admin_required\n def add_user():\n form = NewUserForm()\n if form.validate_on_submit():\n form_valid = True\n username = request.form['username']\n first_name = request.form['first_name']\n last_name = request.form['last_name']\n password = request.form['password']\n is_admin = bool(request.form.get('is_admin'))\n\n try:\n otp_secret = None\n if request.form.get('is_hotp', False):\n otp_secret = request.form.get('otp_secret', '')\n new_user = Journalist(username=username,\n password=password,\n first_name=first_name,\n last_name=last_name,\n is_admin=is_admin,\n otp_secret=otp_secret)\n db.session.add(new_user)\n db.session.commit()\n except PasswordError:\n flash(gettext(\n 'There was an error with the autogenerated password. '\n 'User not created. Please try again.'), 'error')\n form_valid = False\n except InvalidUsernameException as e:\n form_valid = False\n flash('Invalid username: ' + str(e), \"error\")\n except IntegrityError as e:\n db.session.rollback()\n form_valid = False\n if \"UNIQUE constraint failed: journalists.username\" in str(e):\n flash(gettext('Username \"{user}\" already taken.'.format(\n user=username)), \"error\")\n else:\n flash(gettext(\"An error occurred saving this user\"\n \" to the database.\"\n \" Please inform your admin.\"),\n \"error\")\n current_app.logger.error(\"Adding user \"\n \"'{}' failed: {}\".format(\n username, e))\n\n if form_valid:\n return redirect(url_for('admin.new_user_two_factor',\n uid=new_user.id))\n\n return render_template(\"admin_add_user.html\",\n password=make_password(config),\n form=form)\n\n @view.route('/2fa', methods=('GET', 'POST'))\n @admin_required\n def new_user_two_factor():\n user = Journalist.query.get(request.args['uid'])\n\n if request.method == 'POST':\n token = request.form['token']\n if user.verify_token(token):\n flash(gettext(\n \"The two-factor code for user \\\"{user}\\\" was verified \"\n \"successfully.\").format(user=user.username),\n \"notification\")\n return redirect(url_for(\"admin.index\"))\n else:\n flash(gettext(\n \"There was a problem verifying the two-factor code. Please try again.\"),\n \"error\")\n\n return render_template(\"admin_new_user_two_factor.html\", user=user)\n\n @view.route('/reset-2fa-totp', methods=['POST'])\n @admin_required\n def reset_two_factor_totp():\n uid = request.form['uid']\n user = Journalist.query.get(uid)\n user.is_totp = True\n user.regenerate_totp_shared_secret()\n db.session.commit()\n return redirect(url_for('admin.new_user_two_factor', uid=uid))\n\n @view.route('/reset-2fa-hotp', methods=['POST'])\n @admin_required\n def reset_two_factor_hotp():\n uid = request.form['uid']\n otp_secret = request.form.get('otp_secret', None)\n if otp_secret:\n user = Journalist.query.get(uid)\n if not validate_hotp_secret(user, otp_secret):\n return render_template('admin_edit_hotp_secret.html', uid=uid)\n db.session.commit()\n return redirect(url_for('admin.new_user_two_factor', uid=uid))\n else:\n return render_template('admin_edit_hotp_secret.html', uid=uid)\n\n @view.route('/edit/<int:user_id>', methods=('GET', 'POST'))\n @admin_required\n def edit_user(user_id):\n user = Journalist.query.get(user_id)\n\n if request.method == 'POST':\n if request.form.get('username', None):\n new_username = request.form['username']\n\n try:\n Journalist.check_username_acceptable(new_username)\n except InvalidUsernameException as e:\n flash('Invalid username: ' + str(e), 'error')\n return redirect(url_for(\"admin.edit_user\",\n user_id=user_id))\n\n if new_username == user.username:\n pass\n elif Journalist.query.filter_by(\n username=new_username).one_or_none():\n flash(gettext(\n 'Username \"{user}\" already taken.').format(\n user=new_username),\n \"error\")\n return redirect(url_for(\"admin.edit_user\",\n user_id=user_id))\n else:\n user.username = new_username\n\n try:\n first_name = request.form['first_name']\n Journalist.check_name_acceptable(first_name)\n user.first_name = first_name\n except FirstOrLastNameError as e:\n flash(gettext('Name not updated: {}'.format(e)), \"error\")\n return redirect(url_for(\"admin.edit_user\", user_id=user_id))\n\n try:\n last_name = request.form['last_name']\n Journalist.check_name_acceptable(last_name)\n user.last_name = last_name\n except FirstOrLastNameError as e:\n flash(gettext('Name not updated: {}'.format(e)), \"error\")\n return redirect(url_for(\"admin.edit_user\", user_id=user_id))\n\n user.is_admin = bool(request.form.get('is_admin'))\n\n commit_account_changes(user)\n\n password = make_password(config)\n return render_template(\"edit_account.html\", user=user,\n password=password)\n\n @view.route('/edit/<int:user_id>/new-password', methods=('POST',))\n @admin_required\n def set_password(user_id):\n try:\n user = Journalist.query.get(user_id)\n except NoResultFound:\n abort(404)\n\n password = request.form.get('password')\n if set_diceware_password(user, password) is not False:\n if user.last_token is not None:\n revoke_token(user, user.last_token)\n user.session_nonce += 1\n db.session.commit()\n\n return redirect(url_for('admin.edit_user', user_id=user_id))\n\n @view.route('/delete/<int:user_id>', methods=('POST',))\n @admin_required\n def delete_user(user_id):\n user = Journalist.query.get(user_id)\n if user_id == g.user.id:\n # Do not flash because the interface already has safe guards.\n # It can only happen by manually crafting a POST request\n current_app.logger.error(\n \"Admin {} tried to delete itself\".format(g.user.username))\n abort(403)\n elif user:\n db.session.delete(user)\n db.session.commit()\n flash(gettext(\"Deleted user '{user}'.\").format(\n user=user.username), \"notification\")\n else:\n current_app.logger.error(\n \"Admin {} tried to delete nonexistent user with pk={}\".format(\n g.user.username, user_id))\n abort(404)\n\n return redirect(url_for('admin.index'))\n\n @view.route('/edit/<int:user_id>/new-password', methods=('POST',))\n @admin_required\n def new_password(user_id):\n try:\n user = Journalist.query.get(user_id)\n except NoResultFound:\n abort(404)\n\n password = request.form.get('password')\n if set_diceware_password(user, password) is not False:\n if user.last_token is not None:\n revoke_token(user, user.last_token)\n user.session_nonce += 1\n db.session.commit()\n return redirect(url_for('admin.edit_user', user_id=user_id))\n\n @view.route('/ossec-test')\n @admin_required\n def ossec_test():\n current_app.logger.error('This is a test OSSEC alert')\n flash(gettext('Test alert sent. Please check your email.'),\n 'notification')\n return redirect(url_for('admin.manage_config'))\n\n return view\n", "path": "securedrop/journalist_app/admin.py"}]}
| 3,594 | 251 |
gh_patches_debug_9935
|
rasdani/github-patches
|
git_diff
|
mosaicml__composer-850
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
tutorial url for CallbackHparams doesn't exist
The url pointed to in https://github.com/mosaicml/composer/blob/dev/composer/callbacks/callback_hparams.py#L35 doesn't exist: https://docs.mosaicml.com/en/latest/tutorials/adding_models_datasets.html#trainer-with-yahp
(I'd like to add a callback...)
</issue>
<code>
[start of composer/callbacks/callback_hparams.py]
1 # Copyright 2021 MosaicML. All Rights Reserved.
2
3 """Hyperparameters for callbacks."""
4 from __future__ import annotations
5
6 import abc
7 import textwrap
8 from dataclasses import dataclass
9 from typing import Optional
10
11 import yahp as hp
12
13 from composer.callbacks.checkpoint_saver import CheckpointSaver
14 from composer.callbacks.grad_monitor import GradMonitor
15 from composer.callbacks.lr_monitor import LRMonitor
16 from composer.callbacks.memory_monitor import MemoryMonitor
17 from composer.callbacks.speed_monitor import SpeedMonitor
18 from composer.core.callback import Callback
19 from composer.core.time import Time
20 from composer.utils import import_object
21
22 __all__ = [
23 "CallbackHparams",
24 "GradMonitorHparams",
25 "MemoryMonitorHparams",
26 "LRMonitorHparams",
27 "SpeedMonitorHparams",
28 "CheckpointSaverHparams",
29 ]
30
31
32 @dataclass
33 class CallbackHparams(hp.Hparams, abc.ABC):
34 """Base class for callback hyperparameters.
35
36 Callback parameters that are added to the callbacks argument of
37 :attr:`~composer.trainer.trainer_hparams.TrainerHparams` (e.g., via YAML or the CLI). See `Trainer with YAHP <https://docs.mosaicml.com/en/latest/tutorials/adding_models_datasets.html#trainer-with-yahp>`_ for more details.
38 These are initialized in the training loop.
39 """
40
41 @abc.abstractmethod
42 def initialize_object(self) -> Callback:
43 """Initialize the callback.
44
45 Returns:
46 Callback: An instance of the callback.
47 """
48 pass
49
50
51 @dataclass
52 class GradMonitorHparams(CallbackHparams):
53 """:class:`~.GradMonitor` hyperparamters.
54
55 Args:
56 log_layer_grad_norms (bool, optional):
57 See :class:`~.GradMonitor` for documentation.
58 """
59
60 log_layer_grad_norms: bool = hp.optional(
61 doc="Whether to log gradient norms for individual layers.",
62 default=False,
63 )
64
65 def initialize_object(self) -> GradMonitor:
66 """Initialize the GradMonitor callback.
67
68 Returns:
69 GradMonitor: An instance of :class:`~.GradMonitor`.
70 """
71 return GradMonitor(log_layer_grad_norms=self.log_layer_grad_norms)
72
73
74 @dataclass
75 class MemoryMonitorHparams(CallbackHparams):
76 """:class:`~.MemoryMonitor` hyperparameters.
77
78 There are no parameters as :class:`~.MemoryMonitor` does not take any parameters.
79 """
80
81 def initialize_object(self) -> MemoryMonitor:
82 """Initialize the MemoryMonitor callback.
83
84 Returns:
85 MemoryMonitor: An instance of :class:`~.MemoryMonitor`.
86 """
87 return MemoryMonitor()
88
89
90 @dataclass
91 class LRMonitorHparams(CallbackHparams):
92 """:class:`~.LRMonitor` hyperparameters.
93
94 There are no parameters as :class:`~.LRMonitor` does not take any parameters.
95 """
96
97 def initialize_object(self) -> LRMonitor:
98 """Initialize the LRMonitor callback.
99
100 Returns:
101 LRMonitor: An instance of :class:`~.LRMonitor`.
102 """
103 return LRMonitor()
104
105
106 @dataclass
107 class SpeedMonitorHparams(CallbackHparams):
108 """:class:`~.SpeedMonitor` hyperparameters.
109
110 Args:
111 window_size (int, optional): See :class:`~.SpeedMonitor` for documentation.
112 """
113 window_size: int = hp.optional(
114 doc="Number of batchs to use for a rolling average of throughput.",
115 default=100,
116 )
117
118 def initialize_object(self) -> SpeedMonitor:
119 """Initialize the SpeedMonitor callback.
120
121 Returns:
122 SpeedMonitor: An instance of :class:`~.SpeedMonitor`.
123 """
124 return SpeedMonitor(window_size=self.window_size)
125
126
127 @dataclass
128 class CheckpointSaverHparams(CallbackHparams):
129 """:class:`~.CheckpointSaver` hyperparameters.
130
131 Args:
132 save_folder (str, optional): See :class:`~.CheckpointSaver`.
133 filename (str, optional): See :class:`~.CheckpointSaver`.
134 artifact_name (str, optional): See :class:`~.CheckpointSaver`.
135 latest_filename (str, optional): See :class:`~.CheckpointSaver`.
136 overwrite (str, optional): See :class:`~.CheckpointSaver`.
137 weights_only (bool, optional): See :class:`~.CheckpointSaver`.
138 num_checkpoints_to_keep (int, optional): See :class:`~.CheckpointSaver`.
139
140 save_interval (str, optional): Either a :doc:`time-string </trainer/time>` or a path to a function.
141
142 If a :doc:`time-string </trainer/time>`, checkpoints will be saved according to this interval.
143
144 If a path to a function, it should be of the format ``'path.to.function:function_name'``. The function
145 should take (:class:`~.State`, :class:`~.Event`) and return a
146 boolean indicating whether a checkpoint should be saved given the current state and event. The event will
147 be either :attr:`~composer.core.event.Event.BATCH_CHECKPOINT` or
148 :attr:`~composer.core.event.Event.EPOCH_CHECKPOINT`.
149 """
150 save_folder: str = hp.optional(doc="Folder where checkpoints will be saved.", default="{run_name}/checkpoints")
151 filename: str = hp.optional("Checkpoint name format string.", default="ep{epoch}-ba{batch}-rank{rank}")
152 artifact_name: str = hp.optional("Checkpoint artifact name format string.",
153 default="{run_name}/checkpoints/ep{epoch}-ba{batch}-rank{rank}")
154 latest_filename: Optional[str] = hp.optional("Latest checkpoint symlink format string.",
155 default="latest-rank{rank}")
156 overwrite: bool = hp.optional("Whether to override existing checkpoints.", default=False)
157 weights_only: bool = hp.optional("Whether to save only checkpoint weights", default=False)
158 save_interval: str = hp.optional(textwrap.dedent("""\
159 Checkpoint interval or path to a `(State, Event) -> bool` function
160 returning whether a checkpoint should be saved."""),
161 default="1ep")
162 num_checkpoints_to_keep: int = hp.optional(
163 "Number of checkpoints to persist locally. Set to -1 to never delete checkpoints.",
164 default=-1,
165 )
166
167 def initialize_object(self) -> CheckpointSaver:
168 try:
169 save_interval = Time.from_timestring(self.save_interval)
170 except ValueError:
171 # assume it is a function path
172 save_interval = import_object(self.save_interval)
173 return CheckpointSaver(
174 folder=self.save_folder,
175 filename=self.filename,
176 artifact_name=self.artifact_name,
177 latest_filename=self.latest_filename,
178 overwrite=self.overwrite,
179 save_interval=save_interval,
180 weights_only=self.weights_only,
181 num_checkpoints_to_keep=self.num_checkpoints_to_keep,
182 )
183
[end of composer/callbacks/callback_hparams.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/composer/callbacks/callback_hparams.py b/composer/callbacks/callback_hparams.py
--- a/composer/callbacks/callback_hparams.py
+++ b/composer/callbacks/callback_hparams.py
@@ -31,12 +31,7 @@
@dataclass
class CallbackHparams(hp.Hparams, abc.ABC):
- """Base class for callback hyperparameters.
-
- Callback parameters that are added to the callbacks argument of
- :attr:`~composer.trainer.trainer_hparams.TrainerHparams` (e.g., via YAML or the CLI). See `Trainer with YAHP <https://docs.mosaicml.com/en/latest/tutorials/adding_models_datasets.html#trainer-with-yahp>`_ for more details.
- These are initialized in the training loop.
- """
+ """Base class for Callback hyperparameters."""
@abc.abstractmethod
def initialize_object(self) -> Callback:
|
{"golden_diff": "diff --git a/composer/callbacks/callback_hparams.py b/composer/callbacks/callback_hparams.py\n--- a/composer/callbacks/callback_hparams.py\n+++ b/composer/callbacks/callback_hparams.py\n@@ -31,12 +31,7 @@\n \n @dataclass\n class CallbackHparams(hp.Hparams, abc.ABC):\n- \"\"\"Base class for callback hyperparameters.\n-\n- Callback parameters that are added to the callbacks argument of\n- :attr:`~composer.trainer.trainer_hparams.TrainerHparams` (e.g., via YAML or the CLI). See `Trainer with YAHP <https://docs.mosaicml.com/en/latest/tutorials/adding_models_datasets.html#trainer-with-yahp>`_ for more details.\n- These are initialized in the training loop.\n- \"\"\"\n+ \"\"\"Base class for Callback hyperparameters.\"\"\"\n \n @abc.abstractmethod\n def initialize_object(self) -> Callback:\n", "issue": "tutorial url for CallbackHparams doesn't exist\nThe url pointed to in https://github.com/mosaicml/composer/blob/dev/composer/callbacks/callback_hparams.py#L35 doesn't exist: https://docs.mosaicml.com/en/latest/tutorials/adding_models_datasets.html#trainer-with-yahp\r\n\r\n(I'd like to add a callback...)\n", "before_files": [{"content": "# Copyright 2021 MosaicML. All Rights Reserved.\n\n\"\"\"Hyperparameters for callbacks.\"\"\"\nfrom __future__ import annotations\n\nimport abc\nimport textwrap\nfrom dataclasses import dataclass\nfrom typing import Optional\n\nimport yahp as hp\n\nfrom composer.callbacks.checkpoint_saver import CheckpointSaver\nfrom composer.callbacks.grad_monitor import GradMonitor\nfrom composer.callbacks.lr_monitor import LRMonitor\nfrom composer.callbacks.memory_monitor import MemoryMonitor\nfrom composer.callbacks.speed_monitor import SpeedMonitor\nfrom composer.core.callback import Callback\nfrom composer.core.time import Time\nfrom composer.utils import import_object\n\n__all__ = [\n \"CallbackHparams\",\n \"GradMonitorHparams\",\n \"MemoryMonitorHparams\",\n \"LRMonitorHparams\",\n \"SpeedMonitorHparams\",\n \"CheckpointSaverHparams\",\n]\n\n\n@dataclass\nclass CallbackHparams(hp.Hparams, abc.ABC):\n \"\"\"Base class for callback hyperparameters.\n\n Callback parameters that are added to the callbacks argument of\n :attr:`~composer.trainer.trainer_hparams.TrainerHparams` (e.g., via YAML or the CLI). See `Trainer with YAHP <https://docs.mosaicml.com/en/latest/tutorials/adding_models_datasets.html#trainer-with-yahp>`_ for more details.\n These are initialized in the training loop.\n \"\"\"\n\n @abc.abstractmethod\n def initialize_object(self) -> Callback:\n \"\"\"Initialize the callback.\n\n Returns:\n Callback: An instance of the callback.\n \"\"\"\n pass\n\n\n@dataclass\nclass GradMonitorHparams(CallbackHparams):\n \"\"\":class:`~.GradMonitor` hyperparamters.\n\n Args:\n log_layer_grad_norms (bool, optional): \n See :class:`~.GradMonitor` for documentation.\n \"\"\"\n\n log_layer_grad_norms: bool = hp.optional(\n doc=\"Whether to log gradient norms for individual layers.\",\n default=False,\n )\n\n def initialize_object(self) -> GradMonitor:\n \"\"\"Initialize the GradMonitor callback.\n\n Returns:\n GradMonitor: An instance of :class:`~.GradMonitor`.\n \"\"\"\n return GradMonitor(log_layer_grad_norms=self.log_layer_grad_norms)\n\n\n@dataclass\nclass MemoryMonitorHparams(CallbackHparams):\n \"\"\":class:`~.MemoryMonitor` hyperparameters.\n\n There are no parameters as :class:`~.MemoryMonitor` does not take any parameters.\n \"\"\"\n\n def initialize_object(self) -> MemoryMonitor:\n \"\"\"Initialize the MemoryMonitor callback.\n\n Returns:\n MemoryMonitor: An instance of :class:`~.MemoryMonitor`.\n \"\"\"\n return MemoryMonitor()\n\n\n@dataclass\nclass LRMonitorHparams(CallbackHparams):\n \"\"\":class:`~.LRMonitor` hyperparameters.\n\n There are no parameters as :class:`~.LRMonitor` does not take any parameters.\n \"\"\"\n\n def initialize_object(self) -> LRMonitor:\n \"\"\"Initialize the LRMonitor callback.\n\n Returns:\n LRMonitor: An instance of :class:`~.LRMonitor`.\n \"\"\"\n return LRMonitor()\n\n\n@dataclass\nclass SpeedMonitorHparams(CallbackHparams):\n \"\"\":class:`~.SpeedMonitor` hyperparameters.\n\n Args:\n window_size (int, optional): See :class:`~.SpeedMonitor` for documentation.\n \"\"\"\n window_size: int = hp.optional(\n doc=\"Number of batchs to use for a rolling average of throughput.\",\n default=100,\n )\n\n def initialize_object(self) -> SpeedMonitor:\n \"\"\"Initialize the SpeedMonitor callback.\n\n Returns:\n SpeedMonitor: An instance of :class:`~.SpeedMonitor`.\n \"\"\"\n return SpeedMonitor(window_size=self.window_size)\n\n\n@dataclass\nclass CheckpointSaverHparams(CallbackHparams):\n \"\"\":class:`~.CheckpointSaver` hyperparameters.\n \n Args:\n save_folder (str, optional): See :class:`~.CheckpointSaver`.\n filename (str, optional): See :class:`~.CheckpointSaver`.\n artifact_name (str, optional): See :class:`~.CheckpointSaver`.\n latest_filename (str, optional): See :class:`~.CheckpointSaver`.\n overwrite (str, optional): See :class:`~.CheckpointSaver`.\n weights_only (bool, optional): See :class:`~.CheckpointSaver`.\n num_checkpoints_to_keep (int, optional): See :class:`~.CheckpointSaver`.\n\n save_interval (str, optional): Either a :doc:`time-string </trainer/time>` or a path to a function.\n\n If a :doc:`time-string </trainer/time>`, checkpoints will be saved according to this interval.\n\n If a path to a function, it should be of the format ``'path.to.function:function_name'``. The function\n should take (:class:`~.State`, :class:`~.Event`) and return a\n boolean indicating whether a checkpoint should be saved given the current state and event. The event will\n be either :attr:`~composer.core.event.Event.BATCH_CHECKPOINT` or\n :attr:`~composer.core.event.Event.EPOCH_CHECKPOINT`.\n \"\"\"\n save_folder: str = hp.optional(doc=\"Folder where checkpoints will be saved.\", default=\"{run_name}/checkpoints\")\n filename: str = hp.optional(\"Checkpoint name format string.\", default=\"ep{epoch}-ba{batch}-rank{rank}\")\n artifact_name: str = hp.optional(\"Checkpoint artifact name format string.\",\n default=\"{run_name}/checkpoints/ep{epoch}-ba{batch}-rank{rank}\")\n latest_filename: Optional[str] = hp.optional(\"Latest checkpoint symlink format string.\",\n default=\"latest-rank{rank}\")\n overwrite: bool = hp.optional(\"Whether to override existing checkpoints.\", default=False)\n weights_only: bool = hp.optional(\"Whether to save only checkpoint weights\", default=False)\n save_interval: str = hp.optional(textwrap.dedent(\"\"\"\\\n Checkpoint interval or path to a `(State, Event) -> bool` function\n returning whether a checkpoint should be saved.\"\"\"),\n default=\"1ep\")\n num_checkpoints_to_keep: int = hp.optional(\n \"Number of checkpoints to persist locally. Set to -1 to never delete checkpoints.\",\n default=-1,\n )\n\n def initialize_object(self) -> CheckpointSaver:\n try:\n save_interval = Time.from_timestring(self.save_interval)\n except ValueError:\n # assume it is a function path\n save_interval = import_object(self.save_interval)\n return CheckpointSaver(\n folder=self.save_folder,\n filename=self.filename,\n artifact_name=self.artifact_name,\n latest_filename=self.latest_filename,\n overwrite=self.overwrite,\n save_interval=save_interval,\n weights_only=self.weights_only,\n num_checkpoints_to_keep=self.num_checkpoints_to_keep,\n )\n", "path": "composer/callbacks/callback_hparams.py"}]}
| 2,513 | 201 |
gh_patches_debug_3588
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-3753
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Show only relevant updates in typeahead on Akvo pages
Currently, all updates can be searched for on partner site updates typeahead.
</issue>
<code>
[start of akvo/rest/views/typeahead.py]
1 # -*- coding: utf-8 -*-
2
3 """Akvo RSR is covered by the GNU Affero General Public License.
4 See more details in the license.txt file located at the root folder of the
5 Akvo RSR module. For additional details on the GNU license please
6 see < http://www.gnu.org/licenses/agpl.html >.
7 """
8
9 from django.conf import settings
10 from rest_framework.decorators import api_view
11 from rest_framework.response import Response
12
13 from akvo.codelists.models import Country, Version
14 from akvo.rest.serializers import (TypeaheadCountrySerializer,
15 TypeaheadOrganisationSerializer,
16 TypeaheadProjectSerializer,
17 TypeaheadProjectUpdateSerializer,
18 TypeaheadKeywordSerializer,)
19 from akvo.rsr.models import Organisation, Project, ProjectUpdate
20 from akvo.rsr.views.project import _project_directory_coll
21
22
23 def rejig(queryset, serializer):
24 """Rearrange & add queryset count to the response data."""
25 return {
26 'count': queryset.count(),
27 'results': serializer.data
28 }
29
30
31 @api_view(['GET'])
32 def typeahead_country(request):
33 iati_version = Version.objects.get(code=settings.IATI_VERSION)
34 countries = Country.objects.filter(version=iati_version)
35 return Response(
36 rejig(countries, TypeaheadCountrySerializer(countries, many=True))
37 )
38
39
40 @api_view(['GET'])
41 def typeahead_organisation(request):
42 page = request.rsr_page
43 if request.GET.get('partners', '0') == '1' and page:
44 organisations = page.partners()
45 else:
46 # Project editor - all organizations
47 organisations = Organisation.objects.all()
48
49 organisations = organisations.values('id', 'name', 'long_name')
50
51 return Response(
52 rejig(organisations, TypeaheadOrganisationSerializer(organisations,
53 many=True))
54 )
55
56
57 @api_view(['GET'])
58 def typeahead_user_organisations(request):
59 user = request.user
60 is_admin = user.is_active and (user.is_superuser or user.is_admin)
61 organisations = user.approved_organisations() if not is_admin else Organisation.objects.all()
62 return Response(
63 rejig(organisations, TypeaheadOrganisationSerializer(organisations,
64 many=True))
65 )
66
67
68 @api_view(['GET'])
69 def typeahead_keyword(request):
70 page = request.rsr_page
71 keywords = page.keywords.all() if page else None
72 if keywords:
73 return Response(
74 rejig(keywords, TypeaheadKeywordSerializer(keywords, many=True))
75 )
76 # No keywords on rsr.akvo.org
77 return Response({})
78
79
80 @api_view(['GET'])
81 def typeahead_project(request):
82 """Return the typeaheads for projects.
83
84 Without any query parameters, it returns the info for all the projects in
85 the current context -- changes depending on whether we are on a partner
86 site, or the RSR site.
87
88 If a published query parameter is passed, only projects that have been
89 published are returned.
90
91 NOTE: The unauthenticated user gets information about all the projects when
92 using this API endpoint. More permission checking will need to be added,
93 if the amount of data being returned is changed.
94
95 """
96 if request.GET.get('published', '0') == '0':
97 # Project editor - organization projects, all
98 page = request.rsr_page
99 projects = page.all_projects() if page else Project.objects.all()
100 else:
101 # Search bar - organization projects, published
102 projects = _project_directory_coll(request)
103
104 projects = projects.exclude(title='')
105 return Response(
106 rejig(projects, TypeaheadProjectSerializer(projects, many=True))
107 )
108
109
110 @api_view(['GET'])
111 def typeahead_user_projects(request):
112 user = request.user
113 is_admin = user.is_active and (user.is_superuser or user.is_admin)
114 if is_admin:
115 projects = Project.objects.all()
116 else:
117 projects = user.approved_organisations().all_projects()
118 projects = projects.exclude(title='')
119 return Response(
120 rejig(projects, TypeaheadProjectSerializer(projects, many=True))
121 )
122
123
124 @api_view(['GET'])
125 def typeahead_impact_projects(request):
126 user = request.user
127 projects = Project.objects.all() if user.is_admin or user.is_superuser else user.my_projects()
128 projects = projects.published().filter(is_impact_project=True).order_by('title')
129
130 return Response(
131 rejig(projects, TypeaheadProjectSerializer(projects, many=True))
132 )
133
134
135 @api_view(['GET'])
136 def typeahead_projectupdate(request):
137 updates = ProjectUpdate.objects.all()
138 return Response(
139 rejig(updates, TypeaheadProjectUpdateSerializer(updates, many=True))
140 )
141
[end of akvo/rest/views/typeahead.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/akvo/rest/views/typeahead.py b/akvo/rest/views/typeahead.py
--- a/akvo/rest/views/typeahead.py
+++ b/akvo/rest/views/typeahead.py
@@ -134,7 +134,8 @@
@api_view(['GET'])
def typeahead_projectupdate(request):
- updates = ProjectUpdate.objects.all()
+ page = request.rsr_page
+ updates = page.updates() if page else ProjectUpdate.objects.all()
return Response(
rejig(updates, TypeaheadProjectUpdateSerializer(updates, many=True))
)
|
{"golden_diff": "diff --git a/akvo/rest/views/typeahead.py b/akvo/rest/views/typeahead.py\n--- a/akvo/rest/views/typeahead.py\n+++ b/akvo/rest/views/typeahead.py\n@@ -134,7 +134,8 @@\n \n @api_view(['GET'])\n def typeahead_projectupdate(request):\n- updates = ProjectUpdate.objects.all()\n+ page = request.rsr_page\n+ updates = page.updates() if page else ProjectUpdate.objects.all()\n return Response(\n rejig(updates, TypeaheadProjectUpdateSerializer(updates, many=True))\n )\n", "issue": "Show only relevant updates in typeahead on Akvo pages\nCurrently, all updates can be searched for on partner site updates typeahead. \n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Akvo RSR is covered by the GNU Affero General Public License.\nSee more details in the license.txt file located at the root folder of the\nAkvo RSR module. For additional details on the GNU license please\nsee < http://www.gnu.org/licenses/agpl.html >.\n\"\"\"\n\nfrom django.conf import settings\nfrom rest_framework.decorators import api_view\nfrom rest_framework.response import Response\n\nfrom akvo.codelists.models import Country, Version\nfrom akvo.rest.serializers import (TypeaheadCountrySerializer,\n TypeaheadOrganisationSerializer,\n TypeaheadProjectSerializer,\n TypeaheadProjectUpdateSerializer,\n TypeaheadKeywordSerializer,)\nfrom akvo.rsr.models import Organisation, Project, ProjectUpdate\nfrom akvo.rsr.views.project import _project_directory_coll\n\n\ndef rejig(queryset, serializer):\n \"\"\"Rearrange & add queryset count to the response data.\"\"\"\n return {\n 'count': queryset.count(),\n 'results': serializer.data\n }\n\n\n@api_view(['GET'])\ndef typeahead_country(request):\n iati_version = Version.objects.get(code=settings.IATI_VERSION)\n countries = Country.objects.filter(version=iati_version)\n return Response(\n rejig(countries, TypeaheadCountrySerializer(countries, many=True))\n )\n\n\n@api_view(['GET'])\ndef typeahead_organisation(request):\n page = request.rsr_page\n if request.GET.get('partners', '0') == '1' and page:\n organisations = page.partners()\n else:\n # Project editor - all organizations\n organisations = Organisation.objects.all()\n\n organisations = organisations.values('id', 'name', 'long_name')\n\n return Response(\n rejig(organisations, TypeaheadOrganisationSerializer(organisations,\n many=True))\n )\n\n\n@api_view(['GET'])\ndef typeahead_user_organisations(request):\n user = request.user\n is_admin = user.is_active and (user.is_superuser or user.is_admin)\n organisations = user.approved_organisations() if not is_admin else Organisation.objects.all()\n return Response(\n rejig(organisations, TypeaheadOrganisationSerializer(organisations,\n many=True))\n )\n\n\n@api_view(['GET'])\ndef typeahead_keyword(request):\n page = request.rsr_page\n keywords = page.keywords.all() if page else None\n if keywords:\n return Response(\n rejig(keywords, TypeaheadKeywordSerializer(keywords, many=True))\n )\n # No keywords on rsr.akvo.org\n return Response({})\n\n\n@api_view(['GET'])\ndef typeahead_project(request):\n \"\"\"Return the typeaheads for projects.\n\n Without any query parameters, it returns the info for all the projects in\n the current context -- changes depending on whether we are on a partner\n site, or the RSR site.\n\n If a published query parameter is passed, only projects that have been\n published are returned.\n\n NOTE: The unauthenticated user gets information about all the projects when\n using this API endpoint. More permission checking will need to be added,\n if the amount of data being returned is changed.\n\n \"\"\"\n if request.GET.get('published', '0') == '0':\n # Project editor - organization projects, all\n page = request.rsr_page\n projects = page.all_projects() if page else Project.objects.all()\n else:\n # Search bar - organization projects, published\n projects = _project_directory_coll(request)\n\n projects = projects.exclude(title='')\n return Response(\n rejig(projects, TypeaheadProjectSerializer(projects, many=True))\n )\n\n\n@api_view(['GET'])\ndef typeahead_user_projects(request):\n user = request.user\n is_admin = user.is_active and (user.is_superuser or user.is_admin)\n if is_admin:\n projects = Project.objects.all()\n else:\n projects = user.approved_organisations().all_projects()\n projects = projects.exclude(title='')\n return Response(\n rejig(projects, TypeaheadProjectSerializer(projects, many=True))\n )\n\n\n@api_view(['GET'])\ndef typeahead_impact_projects(request):\n user = request.user\n projects = Project.objects.all() if user.is_admin or user.is_superuser else user.my_projects()\n projects = projects.published().filter(is_impact_project=True).order_by('title')\n\n return Response(\n rejig(projects, TypeaheadProjectSerializer(projects, many=True))\n )\n\n\n@api_view(['GET'])\ndef typeahead_projectupdate(request):\n updates = ProjectUpdate.objects.all()\n return Response(\n rejig(updates, TypeaheadProjectUpdateSerializer(updates, many=True))\n )\n", "path": "akvo/rest/views/typeahead.py"}]}
| 1,883 | 129 |
gh_patches_debug_31114
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-2154
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CKV_AWS_174 incorrect reporting
CKV_AWS_174 is being triggered in our terraform code even though we have the viewer certificate set to use TLSv.1.2. Snippet of our code here:
viewer_certificate {
acm_certificate_arn = aws_acm_certificate.cert.arn
ssl_support_method = "sni-only"
minimum_protocol_version = "TLSv1.2_2019"
}
Steps to reproduce the behavior:
Running checkov on our terraform code
**Expected behavior**
This check should be passed
**Additional context**
It looks to me like the issue is in the code between lines 17 and 19. I dont think based on the terraform documentation and the if statements that it would ever pass if using an acm certificate
https://github.com/bridgecrewio/checkov/blob/master/checkov/terraform/checks/resource/aws/CloudfrontTLS12.py
</issue>
<code>
[start of checkov/terraform/checks/resource/aws/CloudfrontTLS12.py]
1 from checkov.common.models.enums import CheckCategories, CheckResult
2 from checkov.terraform.checks.resource.base_resource_value_check import BaseResourceValueCheck
3
4
5 class CloudFrontTLS12(BaseResourceValueCheck):
6 def __init__(self):
7 name = "Verify CloudFront Distribution Viewer Certificate is using TLS v1.2"
8 id = "CKV_AWS_174"
9 supported_resources = ["aws_cloudfront_distribution"]
10 categories = [CheckCategories.ENCRYPTION]
11 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
12
13 def scan_resource_conf(self, conf):
14 if "viewer_certificate" in conf.keys():
15 # check if cloudfront_default_certificate is true then this could use less than tls 1.2
16 viewer_certificate = conf["viewer_certificate"][0]
17 if 'cloudfront_default_certificate' in viewer_certificate:
18 #is not using the default certificate
19 if viewer_certificate["cloudfront_default_certificate"] is not True:
20 #these protocol versions
21 if "minimum_protocol_version" in viewer_certificate:
22 protocol=viewer_certificate["minimum_protocol_version"][0]
23 if protocol in ['TLSv1.2_2018', 'TLSv1.2_2019', 'TLSv1.2_2021']:
24 return CheckResult.PASSED
25
26 #No cert specified so using default which can be less that tls 1.2
27 return CheckResult.FAILED
28
29 def get_inspected_key(self):
30
31 return "viewer_certificate/[0]/minimum_protocol_version"
32
33 def get_expected_values(self):
34 return ['TLSv1.2_2018', 'TLSv1.2_2019', 'TLSv1.2_2021']
35
36
37 check = CloudFrontTLS12()
[end of checkov/terraform/checks/resource/aws/CloudfrontTLS12.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/checkov/terraform/checks/resource/aws/CloudfrontTLS12.py b/checkov/terraform/checks/resource/aws/CloudfrontTLS12.py
--- a/checkov/terraform/checks/resource/aws/CloudfrontTLS12.py
+++ b/checkov/terraform/checks/resource/aws/CloudfrontTLS12.py
@@ -12,18 +12,18 @@
def scan_resource_conf(self, conf):
if "viewer_certificate" in conf.keys():
- # check if cloudfront_default_certificate is true then this could use less than tls 1.2
viewer_certificate = conf["viewer_certificate"][0]
- if 'cloudfront_default_certificate' in viewer_certificate:
- #is not using the default certificate
- if viewer_certificate["cloudfront_default_certificate"] is not True:
- #these protocol versions
- if "minimum_protocol_version" in viewer_certificate:
- protocol=viewer_certificate["minimum_protocol_version"][0]
- if protocol in ['TLSv1.2_2018', 'TLSv1.2_2019', 'TLSv1.2_2021']:
- return CheckResult.PASSED
-
- #No cert specified so using default which can be less that tls 1.2
+ # check if cloudfront_default_certificate is true then this could use less than tls 1.2
+ if ("cloudfront_default_certificate" in viewer_certificate and viewer_certificate
+ ["cloudfront_default_certificate"][0] is not True) or (
+ 'minimum_protocol_version' in viewer_certificate):
+ # is not using the default certificate
+ if 'minimum_protocol_version' in viewer_certificate:
+ protocol = viewer_certificate["minimum_protocol_version"][0]
+ # these protocol versions
+ if protocol in ['TLSv1.2_2018', 'TLSv1.2_2019', 'TLSv1.2_2021']:
+ return CheckResult.PASSED
+ # No cert specified so using default which can be less that tls 1.2
return CheckResult.FAILED
def get_inspected_key(self):
@@ -34,4 +34,4 @@
return ['TLSv1.2_2018', 'TLSv1.2_2019', 'TLSv1.2_2021']
-check = CloudFrontTLS12()
\ No newline at end of file
+check = CloudFrontTLS12()
|
{"golden_diff": "diff --git a/checkov/terraform/checks/resource/aws/CloudfrontTLS12.py b/checkov/terraform/checks/resource/aws/CloudfrontTLS12.py\n--- a/checkov/terraform/checks/resource/aws/CloudfrontTLS12.py\n+++ b/checkov/terraform/checks/resource/aws/CloudfrontTLS12.py\n@@ -12,18 +12,18 @@\n \n def scan_resource_conf(self, conf):\n if \"viewer_certificate\" in conf.keys():\n- # check if cloudfront_default_certificate is true then this could use less than tls 1.2\n viewer_certificate = conf[\"viewer_certificate\"][0]\n- if 'cloudfront_default_certificate' in viewer_certificate:\n- #is not using the default certificate\n- if viewer_certificate[\"cloudfront_default_certificate\"] is not True:\n- #these protocol versions\n- if \"minimum_protocol_version\" in viewer_certificate:\n- protocol=viewer_certificate[\"minimum_protocol_version\"][0]\n- if protocol in ['TLSv1.2_2018', 'TLSv1.2_2019', 'TLSv1.2_2021']:\n- return CheckResult.PASSED\n-\n- #No cert specified so using default which can be less that tls 1.2\n+ # check if cloudfront_default_certificate is true then this could use less than tls 1.2\n+ if (\"cloudfront_default_certificate\" in viewer_certificate and viewer_certificate\n+ [\"cloudfront_default_certificate\"][0] is not True) or (\n+ 'minimum_protocol_version' in viewer_certificate):\n+ # is not using the default certificate\n+ if 'minimum_protocol_version' in viewer_certificate:\n+ protocol = viewer_certificate[\"minimum_protocol_version\"][0]\n+ # these protocol versions\n+ if protocol in ['TLSv1.2_2018', 'TLSv1.2_2019', 'TLSv1.2_2021']:\n+ return CheckResult.PASSED\n+ # No cert specified so using default which can be less that tls 1.2\n return CheckResult.FAILED\n \n def get_inspected_key(self):\n@@ -34,4 +34,4 @@\n return ['TLSv1.2_2018', 'TLSv1.2_2019', 'TLSv1.2_2021']\n \n \n-check = CloudFrontTLS12()\n\\ No newline at end of file\n+check = CloudFrontTLS12()\n", "issue": "CKV_AWS_174 incorrect reporting\nCKV_AWS_174 is being triggered in our terraform code even though we have the viewer certificate set to use TLSv.1.2. Snippet of our code here:\r\n\r\nviewer_certificate {\r\n acm_certificate_arn = aws_acm_certificate.cert.arn\r\n ssl_support_method = \"sni-only\"\r\n minimum_protocol_version = \"TLSv1.2_2019\" \r\n}\r\n\r\n\r\nSteps to reproduce the behavior:\r\nRunning checkov on our terraform code\r\n\r\n**Expected behavior**\r\nThis check should be passed\r\n\r\n\r\n\r\n**Additional context**\r\nIt looks to me like the issue is in the code between lines 17 and 19. I dont think based on the terraform documentation and the if statements that it would ever pass if using an acm certificate\r\n\r\nhttps://github.com/bridgecrewio/checkov/blob/master/checkov/terraform/checks/resource/aws/CloudfrontTLS12.py\r\n\n", "before_files": [{"content": "from checkov.common.models.enums import CheckCategories, CheckResult\nfrom checkov.terraform.checks.resource.base_resource_value_check import BaseResourceValueCheck\n\n\nclass CloudFrontTLS12(BaseResourceValueCheck):\n def __init__(self):\n name = \"Verify CloudFront Distribution Viewer Certificate is using TLS v1.2\"\n id = \"CKV_AWS_174\"\n supported_resources = [\"aws_cloudfront_distribution\"]\n categories = [CheckCategories.ENCRYPTION]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def scan_resource_conf(self, conf):\n if \"viewer_certificate\" in conf.keys():\n # check if cloudfront_default_certificate is true then this could use less than tls 1.2\n viewer_certificate = conf[\"viewer_certificate\"][0]\n if 'cloudfront_default_certificate' in viewer_certificate:\n #is not using the default certificate\n if viewer_certificate[\"cloudfront_default_certificate\"] is not True:\n #these protocol versions\n if \"minimum_protocol_version\" in viewer_certificate:\n protocol=viewer_certificate[\"minimum_protocol_version\"][0]\n if protocol in ['TLSv1.2_2018', 'TLSv1.2_2019', 'TLSv1.2_2021']:\n return CheckResult.PASSED\n\n #No cert specified so using default which can be less that tls 1.2\n return CheckResult.FAILED\n\n def get_inspected_key(self):\n\n return \"viewer_certificate/[0]/minimum_protocol_version\"\n\n def get_expected_values(self):\n return ['TLSv1.2_2018', 'TLSv1.2_2019', 'TLSv1.2_2021']\n\n\ncheck = CloudFrontTLS12()", "path": "checkov/terraform/checks/resource/aws/CloudfrontTLS12.py"}]}
| 1,216 | 551 |
gh_patches_debug_30894
|
rasdani/github-patches
|
git_diff
|
mars-project__mars-1712
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG][mars on ray] Failed to run in ray cluster mode.
**Describe the bug**
Ray cluster will load code from local (not deserialize from bytes), but mars `RemoteMetaStore` is nested in `RayStorage` class. Ray worker can't load the `RemoteMetaStore` from local code.
```
2020-11-17 16:48:29,349 WARNING worker.py:1157 -- Traceback (most recent call last):
File "/home/admin/.local/lib/python3.6/site-packages/ray/function_manager.py", line 445, in _load_actor_class_from_local
actor_class = getattr(module, class_name)
AttributeError: module 'mars.ray.core' has no attribute 'RemoteMetaStore'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "python/ray/_raylet.pyx", line 563, in ray._raylet.task_execution_handler
File "python/ray/_raylet.pyx", line 567, in ray._raylet.task_execution_handler
File "python/ray/_raylet.pyx", line 364, in ray._raylet.execute_task
File "/home/admin/.local/lib/python3.6/site-packages/ray/function_manager.py", line 394, in load_actor_class
job_id, actor_creation_function_descriptor)
File "/home/admin/.local/lib/python3.6/site-packages/ray/function_manager.py", line 454, in _load_actor_class_from_local
class_name))
RuntimeError: Actor RemoteMetaStore failed to be imported from local code.
An unexpected internal error occurred while the worker was executing a task.
```
**To Reproduce**
To help us reproducing this bug, please provide information below:
1. Python 3.6.5
2. pymars 0.6.0b2
3. ray 1.0.1
4. Minimal reproduce example.
``` python
from mars.session import new_session
ray_session = new_session(backend='ray', _load_code_from_local=True).as_default()
print(ray_session)
def main():
import mars.dataframe as md
import mars.tensor as mt
t = mt.random.rand(100, 4, chunk_size=30)
df = md.DataFrame(t, columns=list('abcd'))
print(df.describe().execute())
if __name__ == "__main__":
main()
```
**Expected behavior**
A clear and concise description of what you expected to happen.
**Additional context**
Add any other context about the problem here.
</issue>
<code>
[start of mars/ray/core.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 # Copyright 1999-2020 Alibaba Group Holding Ltd.
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16
17 import uuid
18 from collections import namedtuple
19 from functools import lru_cache
20 from typing import Dict
21
22 import ray
23
24 from ..graph import DAG
25 from ..operands import Fetch
26 from ..tiles import get_tiled
27 from ..utils import build_fetch_chunk
28 from ..executor import Executor, GraphExecution
29
30
31 class _OperandWrapper:
32 __slots__ = 'op', 'chunks'
33
34 def __init__(self, op, chunks):
35 """
36 As we only serde op for Ray executors, but op only weakly reference chunks,
37 So we create a wrapper here to keep the reference
38 """
39 self.op = op
40 self.chunks = chunks
41
42
43 def operand_serializer(op):
44 graph = DAG()
45 inputs = [build_fetch_chunk(inp) for inp in op.inputs or []]
46 new_op = op.copy()
47
48 kws = []
49 for c in op.outputs:
50 params = c.params.copy()
51 params['_key'] = c.key
52 params.update(c.extra_params)
53 kws.append(params)
54
55 chunks = new_op.new_chunks(inputs, kws=kws, output_limit=len(kws))
56 for obj in chunks + inputs:
57 graph.add_node(obj)
58
59 return graph.to_json()
60
61
62 def operand_deserializer(value):
63 graph = DAG.from_json(value)
64 if len(graph) == 1:
65 chunks = [list(graph)[0]]
66 else:
67 chunks = [c for c in graph if not isinstance(c.op, Fetch)]
68 op = chunks[0].op
69 return _OperandWrapper(op, chunks)
70
71
72 @lru_cache(500)
73 def _register_ray_serializer(op):
74 # register a custom serializer for Mars operand
75 try:
76 ray.register_custom_serializer(
77 type(op), serializer=operand_serializer,
78 deserializer=operand_deserializer)
79 except AttributeError: # ray >= 1.0
80 from ray.worker import global_worker
81
82 global_worker.check_connected()
83 context = global_worker.get_serialization_context()
84 context.register_custom_serializer(
85 type(op), serializer=operand_serializer,
86 deserializer=operand_deserializer)
87
88
89 class GraphExecutionForRay(GraphExecution):
90 def handle_op(self, *args, **kw):
91 return RayExecutor.handle(*args, **kw)
92
93
94 ChunkMeta = namedtuple('ChunkMeta', ['shape', 'object_id'])
95
96
97 class RayStorage:
98 """
99 `RayStorage` is a dict-like class. When executed in local, Mars executor will store chunk result in a
100 dict(chunk_key -> chunk_result), here uses Ray actor to store them as remote objects.
101 """
102
103 @ray.remote
104 class RemoteMetaStore:
105 def __init__(self):
106 self._store = dict()
107
108 def set_meta(self, chunk_key, meta):
109 self._store[chunk_key] = meta
110
111 def get_meta(self, chunk_key):
112 return self._store[chunk_key]
113
114 def get_shape(self, chunk_key):
115 return self._store[chunk_key].shape
116
117 def chunk_keys(self):
118 return list(self._store.keys())
119
120 def delete_keys(self, keys):
121 if not isinstance(keys, (list, tuple)):
122 keys = [keys]
123 for k in keys:
124 del self._store[k]
125
126 def __init__(self, meta_store=None):
127 self.meta_store = meta_store or RayStorage.RemoteMetaStore.remote()
128
129 def __getitem__(self, item):
130 meta: ChunkMeta = ray.get(self.meta_store.get_meta.remote(item))
131 return ray.get(meta.object_id)
132
133 def __setitem__(self, key, value):
134 object_id = ray.put(value)
135 shape = getattr(value, 'shape', None)
136 meta = ChunkMeta(shape=shape, object_id=object_id)
137 set_meta = self.meta_store.set_meta.remote(key, meta)
138 ray.wait([object_id, set_meta])
139
140 def copy(self):
141 return RayStorage(meta_store=self.meta_store)
142
143 def update(self, mapping: Dict):
144 tasks = []
145 for k, v in mapping.items():
146 object_id = ray.put(v)
147 tasks.append(object_id)
148 shape = getattr(v, 'shape', None)
149 meta = ChunkMeta(shape=shape, object_id=object_id)
150 set_meta = self.meta_store.set_meta.remote(k, meta)
151 tasks.append(set_meta)
152 ray.wait(tasks)
153
154 def __iter__(self):
155 return iter(ray.get(self.meta_store.chunk_keys.remote()))
156
157 def __delitem__(self, key):
158 ray.wait([self.meta_store.delete_keys.remote(key)])
159
160
161 @ray.remote
162 def execute_on_ray(func, results, op_wrapper: _OperandWrapper):
163 op = op_wrapper.op
164 func(results, op)
165
166
167 class RayExecutor(Executor):
168 """
169 Wraps the execute function as a Ray remote function, the type of `results` is `RayStorage`,
170 when operand is executed, it will fetch dependencies from a Ray actor.
171 """
172
173 _graph_execution_cls = GraphExecutionForRay
174
175 @classmethod
176 def handle(cls, op, results, mock=False):
177 method_name, mapper = ('execute', cls._op_runners) if not mock else \
178 ('estimate_size', cls._op_size_estimators)
179 try:
180 runner = mapper[type(op)]
181 except KeyError:
182 runner = getattr(op, method_name)
183
184 # register a custom serializer for Mars operand
185 _register_ray_serializer(op)
186
187 try:
188 ray.wait([execute_on_ray.remote(runner, results, op)])
189 except NotImplementedError:
190 for op_cls in mapper.keys():
191 if isinstance(op, op_cls):
192 mapper[type(op)] = mapper[op_cls]
193 runner = mapper[op_cls]
194
195 ray.wait(
196 [execute_on_ray.remote(runner, results, op)])
197 raise KeyError(f'No handler found for op: {op}')
198
199 @classmethod
200 def _get_chunk_shape(cls, chunk_key, chunk_result):
201 assert isinstance(chunk_result, RayStorage)
202 return ray.get(chunk_result.meta_store.get_shape.remote(chunk_key))
203
204
205 class RaySession:
206 """
207 Session to submit Mars job to Ray cluster.
208
209 If Ray is not initialized, kwargs will pass to initialize Ray.
210 """
211 def __init__(self, **kwargs):
212 # as we cannot serialize fuse chunk for now,
213 # we just disable numexpr for ray executor
214 engine = kwargs.pop('engine', ['numpy', 'dataframe'])
215 if not ray.is_initialized():
216 ray.init(**kwargs)
217 self._session_id = uuid.uuid4()
218 self._executor = RayExecutor(engine=engine,
219 storage=RayStorage())
220
221 @property
222 def session_id(self):
223 return self._session_id
224
225 @property
226 def executor(self):
227 return self._executor
228
229 def fetch(self, *tileables, **kw):
230 return self._executor.fetch_tileables(tileables, **kw)
231
232 def fetch_log(self, tileables, offsets=None, sizes=None): # pragma: no cover
233 raise NotImplementedError('`fetch_log` is not implemented for ray executor')
234
235 def run(self, *tileables, **kw):
236 """
237 Parallelism equals to Ray cluster CPUs.
238 """
239 if 'n_parallel' not in kw: # pragma: no cover
240 kw['n_parallel'] = ray.cluster_resources()['CPU']
241 return self._executor.execute_tileables(tileables, **kw)
242
243 def _update_tileable_shape(self, tileable):
244 from ..optimizes.tileable_graph import tileable_optimized
245
246 new_nsplits = self._executor.get_tileable_nsplits(tileable)
247 tiled = get_tiled(tileable, mapping=tileable_optimized)
248 for t in (tileable, tiled):
249 t._update_shape(tuple(sum(nsplit) for nsplit in new_nsplits))
250 tiled.nsplits = new_nsplits
251
252 def __enter__(self):
253 return self
254
255 def __exit__(self, *_):
256 self._executor = None
257
[end of mars/ray/core.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mars/ray/core.py b/mars/ray/core.py
--- a/mars/ray/core.py
+++ b/mars/ray/core.py
@@ -94,37 +94,37 @@
ChunkMeta = namedtuple('ChunkMeta', ['shape', 'object_id'])
-class RayStorage:
- """
- `RayStorage` is a dict-like class. When executed in local, Mars executor will store chunk result in a
- dict(chunk_key -> chunk_result), here uses Ray actor to store them as remote objects.
- """
[email protected]
+class RemoteMetaStore:
+ def __init__(self):
+ self._store = dict()
- @ray.remote
- class RemoteMetaStore:
- def __init__(self):
- self._store = dict()
+ def set_meta(self, chunk_key, meta):
+ self._store[chunk_key] = meta
- def set_meta(self, chunk_key, meta):
- self._store[chunk_key] = meta
+ def get_meta(self, chunk_key):
+ return self._store[chunk_key]
- def get_meta(self, chunk_key):
- return self._store[chunk_key]
+ def get_shape(self, chunk_key):
+ return self._store[chunk_key].shape
- def get_shape(self, chunk_key):
- return self._store[chunk_key].shape
+ def chunk_keys(self):
+ return list(self._store.keys())
- def chunk_keys(self):
- return list(self._store.keys())
+ def delete_keys(self, keys):
+ if not isinstance(keys, (list, tuple)):
+ keys = [keys]
+ for k in keys:
+ del self._store[k]
- def delete_keys(self, keys):
- if not isinstance(keys, (list, tuple)):
- keys = [keys]
- for k in keys:
- del self._store[k]
+class RayStorage:
+ """
+ `RayStorage` is a dict-like class. When executed in local, Mars executor will store chunk result in a
+ dict(chunk_key -> chunk_result), here uses Ray actor to store them as remote objects.
+ """
def __init__(self, meta_store=None):
- self.meta_store = meta_store or RayStorage.RemoteMetaStore.remote()
+ self.meta_store = meta_store or RemoteMetaStore.remote()
def __getitem__(self, item):
meta: ChunkMeta = ray.get(self.meta_store.get_meta.remote(item))
|
{"golden_diff": "diff --git a/mars/ray/core.py b/mars/ray/core.py\n--- a/mars/ray/core.py\n+++ b/mars/ray/core.py\n@@ -94,37 +94,37 @@\n ChunkMeta = namedtuple('ChunkMeta', ['shape', 'object_id'])\n \n \n-class RayStorage:\n- \"\"\"\n- `RayStorage` is a dict-like class. When executed in local, Mars executor will store chunk result in a\n- dict(chunk_key -> chunk_result), here uses Ray actor to store them as remote objects.\n- \"\"\"\[email protected]\n+class RemoteMetaStore:\n+ def __init__(self):\n+ self._store = dict()\n \n- @ray.remote\n- class RemoteMetaStore:\n- def __init__(self):\n- self._store = dict()\n+ def set_meta(self, chunk_key, meta):\n+ self._store[chunk_key] = meta\n \n- def set_meta(self, chunk_key, meta):\n- self._store[chunk_key] = meta\n+ def get_meta(self, chunk_key):\n+ return self._store[chunk_key]\n \n- def get_meta(self, chunk_key):\n- return self._store[chunk_key]\n+ def get_shape(self, chunk_key):\n+ return self._store[chunk_key].shape\n \n- def get_shape(self, chunk_key):\n- return self._store[chunk_key].shape\n+ def chunk_keys(self):\n+ return list(self._store.keys())\n \n- def chunk_keys(self):\n- return list(self._store.keys())\n+ def delete_keys(self, keys):\n+ if not isinstance(keys, (list, tuple)):\n+ keys = [keys]\n+ for k in keys:\n+ del self._store[k]\n \n- def delete_keys(self, keys):\n- if not isinstance(keys, (list, tuple)):\n- keys = [keys]\n- for k in keys:\n- del self._store[k]\n \n+class RayStorage:\n+ \"\"\"\n+ `RayStorage` is a dict-like class. When executed in local, Mars executor will store chunk result in a\n+ dict(chunk_key -> chunk_result), here uses Ray actor to store them as remote objects.\n+ \"\"\"\n def __init__(self, meta_store=None):\n- self.meta_store = meta_store or RayStorage.RemoteMetaStore.remote()\n+ self.meta_store = meta_store or RemoteMetaStore.remote()\n \n def __getitem__(self, item):\n meta: ChunkMeta = ray.get(self.meta_store.get_meta.remote(item))\n", "issue": "[BUG][mars on ray] Failed to run in ray cluster mode.\n**Describe the bug**\r\nRay cluster will load code from local (not deserialize from bytes), but mars `RemoteMetaStore` is nested in `RayStorage` class. Ray worker can't load the `RemoteMetaStore` from local code.\r\n\r\n```\r\n2020-11-17 16:48:29,349\tWARNING worker.py:1157 -- Traceback (most recent call last):\r\n File \"/home/admin/.local/lib/python3.6/site-packages/ray/function_manager.py\", line 445, in _load_actor_class_from_local\r\n actor_class = getattr(module, class_name)\r\nAttributeError: module 'mars.ray.core' has no attribute 'RemoteMetaStore'\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"python/ray/_raylet.pyx\", line 563, in ray._raylet.task_execution_handler\r\n File \"python/ray/_raylet.pyx\", line 567, in ray._raylet.task_execution_handler\r\n File \"python/ray/_raylet.pyx\", line 364, in ray._raylet.execute_task\r\n File \"/home/admin/.local/lib/python3.6/site-packages/ray/function_manager.py\", line 394, in load_actor_class\r\n job_id, actor_creation_function_descriptor)\r\n File \"/home/admin/.local/lib/python3.6/site-packages/ray/function_manager.py\", line 454, in _load_actor_class_from_local\r\n class_name))\r\nRuntimeError: Actor RemoteMetaStore failed to be imported from local code.\r\nAn unexpected internal error occurred while the worker was executing a task.\r\n```\r\n\r\n**To Reproduce**\r\nTo help us reproducing this bug, please provide information below:\r\n1. Python 3.6.5\r\n2. pymars 0.6.0b2\r\n3. ray 1.0.1\r\n4. Minimal reproduce example.\r\n``` python\r\nfrom mars.session import new_session\r\n\r\nray_session = new_session(backend='ray', _load_code_from_local=True).as_default()\r\nprint(ray_session)\r\n\r\n\r\ndef main():\r\n import mars.dataframe as md\r\n import mars.tensor as mt\r\n t = mt.random.rand(100, 4, chunk_size=30)\r\n df = md.DataFrame(t, columns=list('abcd'))\r\n print(df.describe().execute())\r\n\r\n\r\nif __name__ == \"__main__\":\r\n main()\r\n```\r\n\r\n**Expected behavior**\r\nA clear and concise description of what you expected to happen.\r\n\r\n**Additional context**\r\nAdd any other context about the problem here.\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n# Copyright 1999-2020 Alibaba Group Holding Ltd.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport uuid\nfrom collections import namedtuple\nfrom functools import lru_cache\nfrom typing import Dict\n\nimport ray\n\nfrom ..graph import DAG\nfrom ..operands import Fetch\nfrom ..tiles import get_tiled\nfrom ..utils import build_fetch_chunk\nfrom ..executor import Executor, GraphExecution\n\n\nclass _OperandWrapper:\n __slots__ = 'op', 'chunks'\n\n def __init__(self, op, chunks):\n \"\"\"\n As we only serde op for Ray executors, but op only weakly reference chunks,\n So we create a wrapper here to keep the reference\n \"\"\"\n self.op = op\n self.chunks = chunks\n\n\ndef operand_serializer(op):\n graph = DAG()\n inputs = [build_fetch_chunk(inp) for inp in op.inputs or []]\n new_op = op.copy()\n\n kws = []\n for c in op.outputs:\n params = c.params.copy()\n params['_key'] = c.key\n params.update(c.extra_params)\n kws.append(params)\n\n chunks = new_op.new_chunks(inputs, kws=kws, output_limit=len(kws))\n for obj in chunks + inputs:\n graph.add_node(obj)\n\n return graph.to_json()\n\n\ndef operand_deserializer(value):\n graph = DAG.from_json(value)\n if len(graph) == 1:\n chunks = [list(graph)[0]]\n else:\n chunks = [c for c in graph if not isinstance(c.op, Fetch)]\n op = chunks[0].op\n return _OperandWrapper(op, chunks)\n\n\n@lru_cache(500)\ndef _register_ray_serializer(op):\n # register a custom serializer for Mars operand\n try:\n ray.register_custom_serializer(\n type(op), serializer=operand_serializer,\n deserializer=operand_deserializer)\n except AttributeError: # ray >= 1.0\n from ray.worker import global_worker\n\n global_worker.check_connected()\n context = global_worker.get_serialization_context()\n context.register_custom_serializer(\n type(op), serializer=operand_serializer,\n deserializer=operand_deserializer)\n\n\nclass GraphExecutionForRay(GraphExecution):\n def handle_op(self, *args, **kw):\n return RayExecutor.handle(*args, **kw)\n\n\nChunkMeta = namedtuple('ChunkMeta', ['shape', 'object_id'])\n\n\nclass RayStorage:\n \"\"\"\n `RayStorage` is a dict-like class. When executed in local, Mars executor will store chunk result in a\n dict(chunk_key -> chunk_result), here uses Ray actor to store them as remote objects.\n \"\"\"\n\n @ray.remote\n class RemoteMetaStore:\n def __init__(self):\n self._store = dict()\n\n def set_meta(self, chunk_key, meta):\n self._store[chunk_key] = meta\n\n def get_meta(self, chunk_key):\n return self._store[chunk_key]\n\n def get_shape(self, chunk_key):\n return self._store[chunk_key].shape\n\n def chunk_keys(self):\n return list(self._store.keys())\n\n def delete_keys(self, keys):\n if not isinstance(keys, (list, tuple)):\n keys = [keys]\n for k in keys:\n del self._store[k]\n\n def __init__(self, meta_store=None):\n self.meta_store = meta_store or RayStorage.RemoteMetaStore.remote()\n\n def __getitem__(self, item):\n meta: ChunkMeta = ray.get(self.meta_store.get_meta.remote(item))\n return ray.get(meta.object_id)\n\n def __setitem__(self, key, value):\n object_id = ray.put(value)\n shape = getattr(value, 'shape', None)\n meta = ChunkMeta(shape=shape, object_id=object_id)\n set_meta = self.meta_store.set_meta.remote(key, meta)\n ray.wait([object_id, set_meta])\n\n def copy(self):\n return RayStorage(meta_store=self.meta_store)\n\n def update(self, mapping: Dict):\n tasks = []\n for k, v in mapping.items():\n object_id = ray.put(v)\n tasks.append(object_id)\n shape = getattr(v, 'shape', None)\n meta = ChunkMeta(shape=shape, object_id=object_id)\n set_meta = self.meta_store.set_meta.remote(k, meta)\n tasks.append(set_meta)\n ray.wait(tasks)\n\n def __iter__(self):\n return iter(ray.get(self.meta_store.chunk_keys.remote()))\n\n def __delitem__(self, key):\n ray.wait([self.meta_store.delete_keys.remote(key)])\n\n\[email protected]\ndef execute_on_ray(func, results, op_wrapper: _OperandWrapper):\n op = op_wrapper.op\n func(results, op)\n\n\nclass RayExecutor(Executor):\n \"\"\"\n Wraps the execute function as a Ray remote function, the type of `results` is `RayStorage`,\n when operand is executed, it will fetch dependencies from a Ray actor.\n \"\"\"\n\n _graph_execution_cls = GraphExecutionForRay\n\n @classmethod\n def handle(cls, op, results, mock=False):\n method_name, mapper = ('execute', cls._op_runners) if not mock else \\\n ('estimate_size', cls._op_size_estimators)\n try:\n runner = mapper[type(op)]\n except KeyError:\n runner = getattr(op, method_name)\n\n # register a custom serializer for Mars operand\n _register_ray_serializer(op)\n\n try:\n ray.wait([execute_on_ray.remote(runner, results, op)])\n except NotImplementedError:\n for op_cls in mapper.keys():\n if isinstance(op, op_cls):\n mapper[type(op)] = mapper[op_cls]\n runner = mapper[op_cls]\n\n ray.wait(\n [execute_on_ray.remote(runner, results, op)])\n raise KeyError(f'No handler found for op: {op}')\n\n @classmethod\n def _get_chunk_shape(cls, chunk_key, chunk_result):\n assert isinstance(chunk_result, RayStorage)\n return ray.get(chunk_result.meta_store.get_shape.remote(chunk_key))\n\n\nclass RaySession:\n \"\"\"\n Session to submit Mars job to Ray cluster.\n\n If Ray is not initialized, kwargs will pass to initialize Ray.\n \"\"\"\n def __init__(self, **kwargs):\n # as we cannot serialize fuse chunk for now,\n # we just disable numexpr for ray executor\n engine = kwargs.pop('engine', ['numpy', 'dataframe'])\n if not ray.is_initialized():\n ray.init(**kwargs)\n self._session_id = uuid.uuid4()\n self._executor = RayExecutor(engine=engine,\n storage=RayStorage())\n\n @property\n def session_id(self):\n return self._session_id\n\n @property\n def executor(self):\n return self._executor\n\n def fetch(self, *tileables, **kw):\n return self._executor.fetch_tileables(tileables, **kw)\n\n def fetch_log(self, tileables, offsets=None, sizes=None): # pragma: no cover\n raise NotImplementedError('`fetch_log` is not implemented for ray executor')\n\n def run(self, *tileables, **kw):\n \"\"\"\n Parallelism equals to Ray cluster CPUs.\n \"\"\"\n if 'n_parallel' not in kw: # pragma: no cover\n kw['n_parallel'] = ray.cluster_resources()['CPU']\n return self._executor.execute_tileables(tileables, **kw)\n\n def _update_tileable_shape(self, tileable):\n from ..optimizes.tileable_graph import tileable_optimized\n\n new_nsplits = self._executor.get_tileable_nsplits(tileable)\n tiled = get_tiled(tileable, mapping=tileable_optimized)\n for t in (tileable, tiled):\n t._update_shape(tuple(sum(nsplit) for nsplit in new_nsplits))\n tiled.nsplits = new_nsplits\n\n def __enter__(self):\n return self\n\n def __exit__(self, *_):\n self._executor = None\n", "path": "mars/ray/core.py"}]}
| 3,626 | 557 |
gh_patches_debug_30182
|
rasdani/github-patches
|
git_diff
|
pytorch__TensorRT-2519
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add support for `aten.slice_scatter`
</issue>
<code>
[start of py/torch_tensorrt/dynamo/lowering/_decompositions.py]
1 import logging
2 from typing import Any, Callable, Dict, List, Optional
3
4 import torch
5 from torch._decomp import register_decomposition
6 from torch._ops import OpOverload
7
8 from ._decomposition_groups import (
9 ENABLED_TORCH_DECOMPOSITIONS,
10 TORCH_TRT_DECOMPOSITIONS,
11 _core_aten_decompositions,
12 aten,
13 torch_disabled_decompositions,
14 torch_enabled_decompositions,
15 )
16
17 logger = logging.getLogger(__name__)
18
19
20 def register_torch_trt_decomposition(
21 aten_op: OpOverload, registry: Optional[Any] = None
22 ) -> Callable[[Any], Any]:
23 """Checks if the decomposition already exists in one of the sets
24 Registers the decomposition via the Torch utility
25
26 Alerts the user if the decomposition already exists, before registering
27 Throws an AssertionError if the user attempts to register a decomposition
28 which is present in the set of explicitly disabled decompositions
29 """
30 if aten_op in torch_enabled_decompositions:
31 logger.warning(
32 f"Detected custom decomposition for {aten_op}, which conflicts "
33 "with an existing Torch decomposition in torch_enabled_decompositions. "
34 "The custom implementation will take precedence."
35 )
36 elif aten_op in torch_disabled_decompositions:
37 logger.info(
38 f"Detected custom decomposition for {aten_op}, which is present "
39 "in torch_disabled_decompositions."
40 )
41
42 # Conflicts with _core_aten_decompositions will only occur if
43 # enable_experimental_decompositions is True in get_decompositions
44 if aten_op in _core_aten_decompositions:
45 logger.debug(
46 f"Detected custom decomposition for {aten_op}, which conflicts "
47 "with an existing Torch decomposition in core_aten_decompositions. "
48 "The custom implementation will take precedence."
49 )
50
51 def register(fn: Callable[[Any], Any]) -> Any:
52 return register_decomposition(aten_op=aten_op, registry=registry)(fn)
53
54 return register
55
56
57 def replace_inplace_op(aten_op: OpOverload, outplace_op: OpOverload) -> Any:
58 """Replace inplace operation with functional equivalent
59 Adapted from:
60 https://github.com/pytorch/pytorch/blob/3344d79e3f732dadd5c85b99a7aa1a022f187929/torch/_decomp/decompositions.py#L3355-L3361
61 """
62
63 @register_torch_trt_decomposition(aten_op, registry=TORCH_TRT_DECOMPOSITIONS)
64 def inplace_op(*args, **kwargs): # type: ignore
65 out = outplace_op(*args, **kwargs)
66 return args[0].copy_(out)
67
68 return inplace_op
69
70
71 replace_inplace_op(aten.add_, aten.add)
72 replace_inplace_op(aten.addbmm_, aten.addbmm)
73 replace_inplace_op(aten.addmm_, aten.addmm)
74 replace_inplace_op(aten.addmv_, aten.addmv)
75 replace_inplace_op(aten.baddbmm_, aten.baddbmm)
76 replace_inplace_op(aten.cumprod_, aten.cumprod)
77 replace_inplace_op(aten.index_put_, aten.index_put)
78 replace_inplace_op(aten.index_reduce_, aten.index_reduce)
79 replace_inplace_op(aten.relu_, aten.relu)
80 replace_inplace_op(aten.round_, aten.round)
81 replace_inplace_op(aten.scatter_, aten.scatter)
82 replace_inplace_op(aten.scatter_add_, aten.scatter_add)
83 replace_inplace_op(aten.scatter_reduce_, aten.scatter_reduce)
84
85
86 @register_torch_trt_decomposition(aten.rsqrt, registry=TORCH_TRT_DECOMPOSITIONS)
87 def rsqrt_replacement(*args, **kwargs) -> torch.Tensor: # type: ignore
88 return torch.reciprocal(torch.sqrt(*args, **kwargs))
89
90
91 @register_torch_trt_decomposition(aten._unsafe_view, registry=TORCH_TRT_DECOMPOSITIONS)
92 def unsafe_view_replacement(x: torch.Tensor, *args, **kwargs) -> torch.Tensor: # type: ignore
93 return torch.reshape(x, *args, **kwargs)
94
95
96 @register_torch_trt_decomposition(
97 torch.ops.aten.lift_fresh_copy, registry=TORCH_TRT_DECOMPOSITIONS
98 )
99 def lift_fresh_copy_replacement(x: torch.Tensor) -> torch.Tensor:
100 return x
101
102
103 @register_torch_trt_decomposition(aten.alias, registry=TORCH_TRT_DECOMPOSITIONS)
104 def alias_replacement(x: torch.Tensor) -> torch.Tensor:
105 return x
106
107
108 @register_torch_trt_decomposition(
109 torch.ops.aten.reciprocal.default, registry=TORCH_TRT_DECOMPOSITIONS
110 )
111 def reciprocal_replacement(
112 input_: torch.Tensor,
113 ) -> torch.Tensor:
114 return torch.div(1, input_)
115
116
117 @register_torch_trt_decomposition(
118 torch.ops.prims.var.default, registry=TORCH_TRT_DECOMPOSITIONS
119 )
120 def var_decomposition(
121 input_tensor: torch.Tensor,
122 dims: Optional[List[int]],
123 correction: int,
124 output_dtype: Optional[torch.dtype] = None,
125 ) -> torch.Tensor:
126 if dims is None:
127 dims = []
128
129 # If the dimensions are empty, variance is taken over all dimensions
130 if isinstance(dims, (tuple, list)) and len(dims) == 0:
131 N = input_tensor.numel()
132 # Otherwise, the number of samples is the product of the dimensions reduced over
133 else:
134 N = 1
135 for dim_i in dims:
136 N *= input_tensor.shape[dim_i]
137
138 # Compute the mean, difference, and correction term as per the formula:
139 # https://pytorch.org/docs/stable/generated/torch.var.html
140
141 # Additionally, prims does not support keepdim, and so we only keep dimensions
142 # on the first reduction, then remove it for the second
143 sample_mean = torch.mean(input_tensor, dims, keepdim=True)
144 diff = input_tensor - sample_mean
145 squared_diff = diff * diff
146 variance_unnormalized = torch.sum(squared_diff, dims, keepdim=False)
147
148 if correction is None:
149 correction_term = float(N - 1)
150 elif isinstance(correction, int):
151 correction_term = float(N - correction)
152 elif isinstance(correction, float):
153 correction_term = float(N) - correction
154 else:
155 raise RuntimeError("correction must be int or float")
156
157 if correction_term <= 0:
158 raise RuntimeError(f"correction term was non-positive, got: {correction_term}")
159
160 variance = variance_unnormalized / correction_term
161
162 return variance
163
164
165 @register_torch_trt_decomposition(
166 torch.ops.aten.empty_permuted.default, registry=TORCH_TRT_DECOMPOSITIONS
167 )
168 def empty_permuted_decomposition(*args, **kwargs) -> torch.Tensor:
169 empty_size = args[0]
170 empty_permute = args[1]
171 perm = [0] * len(empty_size)
172 for permute_index, permute_element in enumerate(empty_permute):
173 perm[permute_element] = permute_index
174 return torch.empty([empty_size[l] for l in empty_permute], **kwargs).permute(perm)
175
176
177 def get_decompositions(
178 enable_experimental_decompositions: bool = False,
179 ) -> Dict[OpOverload, Callable[[Any], Any]]:
180 if enable_experimental_decompositions:
181 CORE_ATEN_DECOMPOSITIONS_FILTERED: Dict[OpOverload, Callable[[Any], Any]] = {
182 decomp: _core_aten_decompositions[decomp]
183 for decomp in _core_aten_decompositions
184 if decomp not in torch_disabled_decompositions
185 }
186 return {**CORE_ATEN_DECOMPOSITIONS_FILTERED, **TORCH_TRT_DECOMPOSITIONS}
187 else:
188 return {**ENABLED_TORCH_DECOMPOSITIONS, **TORCH_TRT_DECOMPOSITIONS}
189
[end of py/torch_tensorrt/dynamo/lowering/_decompositions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/py/torch_tensorrt/dynamo/lowering/_decompositions.py b/py/torch_tensorrt/dynamo/lowering/_decompositions.py
--- a/py/torch_tensorrt/dynamo/lowering/_decompositions.py
+++ b/py/torch_tensorrt/dynamo/lowering/_decompositions.py
@@ -4,6 +4,7 @@
import torch
from torch._decomp import register_decomposition
from torch._ops import OpOverload
+from torch_tensorrt.dynamo.conversion.converter_utils import get_positive_dim
from ._decomposition_groups import (
ENABLED_TORCH_DECOMPOSITIONS,
@@ -174,6 +175,44 @@
return torch.empty([empty_size[l] for l in empty_permute], **kwargs).permute(perm)
+@register_torch_trt_decomposition(
+ torch.ops.aten.slice_scatter.default, registry=TORCH_TRT_DECOMPOSITIONS
+)
+def slice_scatter_decomposition(
+ input_tensor: torch.Tensor,
+ src_tensor: torch.Tensor,
+ dim: int,
+ start: Optional[int] = None,
+ end: Optional[int] = None,
+ step: Optional[int] = None,
+):
+ dim_size = input_tensor.shape[dim]
+ start = get_positive_dim(start, input_tensor.shape[dim])
+ if end is None:
+ end = dim_size
+ end = get_positive_dim(end, input_tensor.shape[dim])
+ if step is None:
+ step = 1
+
+ src_dim = src_tensor.shape
+ # step == 0 is not a valid torch case
+ # also src_dim should be equal to slice dimension
+
+ if start == 0 and end == dim_size and step == 1:
+ return src_tensor
+
+ cat_tensors = []
+ index_tensor_shape = []
+ for i, src_each_dim in enumerate(list(src_dim)):
+ if i != dim:
+ index_tensor_shape.append(src_each_dim)
+ for index in range(start, end, step):
+ cat_tensors.append(index * torch.ones(index_tensor_shape, dtype=torch.long))
+ index_tensor = torch.stack(cat_tensors, dim).cuda()
+ output_tensor = torch.scatter(input_tensor, dim, index_tensor, src_tensor)
+ return output_tensor
+
+
def get_decompositions(
enable_experimental_decompositions: bool = False,
) -> Dict[OpOverload, Callable[[Any], Any]]:
|
{"golden_diff": "diff --git a/py/torch_tensorrt/dynamo/lowering/_decompositions.py b/py/torch_tensorrt/dynamo/lowering/_decompositions.py\n--- a/py/torch_tensorrt/dynamo/lowering/_decompositions.py\n+++ b/py/torch_tensorrt/dynamo/lowering/_decompositions.py\n@@ -4,6 +4,7 @@\n import torch\n from torch._decomp import register_decomposition\n from torch._ops import OpOverload\n+from torch_tensorrt.dynamo.conversion.converter_utils import get_positive_dim\n \n from ._decomposition_groups import (\n ENABLED_TORCH_DECOMPOSITIONS,\n@@ -174,6 +175,44 @@\n return torch.empty([empty_size[l] for l in empty_permute], **kwargs).permute(perm)\n \n \n+@register_torch_trt_decomposition(\n+ torch.ops.aten.slice_scatter.default, registry=TORCH_TRT_DECOMPOSITIONS\n+)\n+def slice_scatter_decomposition(\n+ input_tensor: torch.Tensor,\n+ src_tensor: torch.Tensor,\n+ dim: int,\n+ start: Optional[int] = None,\n+ end: Optional[int] = None,\n+ step: Optional[int] = None,\n+):\n+ dim_size = input_tensor.shape[dim]\n+ start = get_positive_dim(start, input_tensor.shape[dim])\n+ if end is None:\n+ end = dim_size\n+ end = get_positive_dim(end, input_tensor.shape[dim])\n+ if step is None:\n+ step = 1\n+\n+ src_dim = src_tensor.shape\n+ # step == 0 is not a valid torch case\n+ # also src_dim should be equal to slice dimension\n+\n+ if start == 0 and end == dim_size and step == 1:\n+ return src_tensor\n+\n+ cat_tensors = []\n+ index_tensor_shape = []\n+ for i, src_each_dim in enumerate(list(src_dim)):\n+ if i != dim:\n+ index_tensor_shape.append(src_each_dim)\n+ for index in range(start, end, step):\n+ cat_tensors.append(index * torch.ones(index_tensor_shape, dtype=torch.long))\n+ index_tensor = torch.stack(cat_tensors, dim).cuda()\n+ output_tensor = torch.scatter(input_tensor, dim, index_tensor, src_tensor)\n+ return output_tensor\n+\n+\n def get_decompositions(\n enable_experimental_decompositions: bool = False,\n ) -> Dict[OpOverload, Callable[[Any], Any]]:\n", "issue": "Add support for `aten.slice_scatter`\n\n", "before_files": [{"content": "import logging\nfrom typing import Any, Callable, Dict, List, Optional\n\nimport torch\nfrom torch._decomp import register_decomposition\nfrom torch._ops import OpOverload\n\nfrom ._decomposition_groups import (\n ENABLED_TORCH_DECOMPOSITIONS,\n TORCH_TRT_DECOMPOSITIONS,\n _core_aten_decompositions,\n aten,\n torch_disabled_decompositions,\n torch_enabled_decompositions,\n)\n\nlogger = logging.getLogger(__name__)\n\n\ndef register_torch_trt_decomposition(\n aten_op: OpOverload, registry: Optional[Any] = None\n) -> Callable[[Any], Any]:\n \"\"\"Checks if the decomposition already exists in one of the sets\n Registers the decomposition via the Torch utility\n\n Alerts the user if the decomposition already exists, before registering\n Throws an AssertionError if the user attempts to register a decomposition\n which is present in the set of explicitly disabled decompositions\n \"\"\"\n if aten_op in torch_enabled_decompositions:\n logger.warning(\n f\"Detected custom decomposition for {aten_op}, which conflicts \"\n \"with an existing Torch decomposition in torch_enabled_decompositions. \"\n \"The custom implementation will take precedence.\"\n )\n elif aten_op in torch_disabled_decompositions:\n logger.info(\n f\"Detected custom decomposition for {aten_op}, which is present \"\n \"in torch_disabled_decompositions.\"\n )\n\n # Conflicts with _core_aten_decompositions will only occur if\n # enable_experimental_decompositions is True in get_decompositions\n if aten_op in _core_aten_decompositions:\n logger.debug(\n f\"Detected custom decomposition for {aten_op}, which conflicts \"\n \"with an existing Torch decomposition in core_aten_decompositions. \"\n \"The custom implementation will take precedence.\"\n )\n\n def register(fn: Callable[[Any], Any]) -> Any:\n return register_decomposition(aten_op=aten_op, registry=registry)(fn)\n\n return register\n\n\ndef replace_inplace_op(aten_op: OpOverload, outplace_op: OpOverload) -> Any:\n \"\"\"Replace inplace operation with functional equivalent\n Adapted from:\n https://github.com/pytorch/pytorch/blob/3344d79e3f732dadd5c85b99a7aa1a022f187929/torch/_decomp/decompositions.py#L3355-L3361\n \"\"\"\n\n @register_torch_trt_decomposition(aten_op, registry=TORCH_TRT_DECOMPOSITIONS)\n def inplace_op(*args, **kwargs): # type: ignore\n out = outplace_op(*args, **kwargs)\n return args[0].copy_(out)\n\n return inplace_op\n\n\nreplace_inplace_op(aten.add_, aten.add)\nreplace_inplace_op(aten.addbmm_, aten.addbmm)\nreplace_inplace_op(aten.addmm_, aten.addmm)\nreplace_inplace_op(aten.addmv_, aten.addmv)\nreplace_inplace_op(aten.baddbmm_, aten.baddbmm)\nreplace_inplace_op(aten.cumprod_, aten.cumprod)\nreplace_inplace_op(aten.index_put_, aten.index_put)\nreplace_inplace_op(aten.index_reduce_, aten.index_reduce)\nreplace_inplace_op(aten.relu_, aten.relu)\nreplace_inplace_op(aten.round_, aten.round)\nreplace_inplace_op(aten.scatter_, aten.scatter)\nreplace_inplace_op(aten.scatter_add_, aten.scatter_add)\nreplace_inplace_op(aten.scatter_reduce_, aten.scatter_reduce)\n\n\n@register_torch_trt_decomposition(aten.rsqrt, registry=TORCH_TRT_DECOMPOSITIONS)\ndef rsqrt_replacement(*args, **kwargs) -> torch.Tensor: # type: ignore\n return torch.reciprocal(torch.sqrt(*args, **kwargs))\n\n\n@register_torch_trt_decomposition(aten._unsafe_view, registry=TORCH_TRT_DECOMPOSITIONS)\ndef unsafe_view_replacement(x: torch.Tensor, *args, **kwargs) -> torch.Tensor: # type: ignore\n return torch.reshape(x, *args, **kwargs)\n\n\n@register_torch_trt_decomposition(\n torch.ops.aten.lift_fresh_copy, registry=TORCH_TRT_DECOMPOSITIONS\n)\ndef lift_fresh_copy_replacement(x: torch.Tensor) -> torch.Tensor:\n return x\n\n\n@register_torch_trt_decomposition(aten.alias, registry=TORCH_TRT_DECOMPOSITIONS)\ndef alias_replacement(x: torch.Tensor) -> torch.Tensor:\n return x\n\n\n@register_torch_trt_decomposition(\n torch.ops.aten.reciprocal.default, registry=TORCH_TRT_DECOMPOSITIONS\n)\ndef reciprocal_replacement(\n input_: torch.Tensor,\n) -> torch.Tensor:\n return torch.div(1, input_)\n\n\n@register_torch_trt_decomposition(\n torch.ops.prims.var.default, registry=TORCH_TRT_DECOMPOSITIONS\n)\ndef var_decomposition(\n input_tensor: torch.Tensor,\n dims: Optional[List[int]],\n correction: int,\n output_dtype: Optional[torch.dtype] = None,\n) -> torch.Tensor:\n if dims is None:\n dims = []\n\n # If the dimensions are empty, variance is taken over all dimensions\n if isinstance(dims, (tuple, list)) and len(dims) == 0:\n N = input_tensor.numel()\n # Otherwise, the number of samples is the product of the dimensions reduced over\n else:\n N = 1\n for dim_i in dims:\n N *= input_tensor.shape[dim_i]\n\n # Compute the mean, difference, and correction term as per the formula:\n # https://pytorch.org/docs/stable/generated/torch.var.html\n\n # Additionally, prims does not support keepdim, and so we only keep dimensions\n # on the first reduction, then remove it for the second\n sample_mean = torch.mean(input_tensor, dims, keepdim=True)\n diff = input_tensor - sample_mean\n squared_diff = diff * diff\n variance_unnormalized = torch.sum(squared_diff, dims, keepdim=False)\n\n if correction is None:\n correction_term = float(N - 1)\n elif isinstance(correction, int):\n correction_term = float(N - correction)\n elif isinstance(correction, float):\n correction_term = float(N) - correction\n else:\n raise RuntimeError(\"correction must be int or float\")\n\n if correction_term <= 0:\n raise RuntimeError(f\"correction term was non-positive, got: {correction_term}\")\n\n variance = variance_unnormalized / correction_term\n\n return variance\n\n\n@register_torch_trt_decomposition(\n torch.ops.aten.empty_permuted.default, registry=TORCH_TRT_DECOMPOSITIONS\n)\ndef empty_permuted_decomposition(*args, **kwargs) -> torch.Tensor:\n empty_size = args[0]\n empty_permute = args[1]\n perm = [0] * len(empty_size)\n for permute_index, permute_element in enumerate(empty_permute):\n perm[permute_element] = permute_index\n return torch.empty([empty_size[l] for l in empty_permute], **kwargs).permute(perm)\n\n\ndef get_decompositions(\n enable_experimental_decompositions: bool = False,\n) -> Dict[OpOverload, Callable[[Any], Any]]:\n if enable_experimental_decompositions:\n CORE_ATEN_DECOMPOSITIONS_FILTERED: Dict[OpOverload, Callable[[Any], Any]] = {\n decomp: _core_aten_decompositions[decomp]\n for decomp in _core_aten_decompositions\n if decomp not in torch_disabled_decompositions\n }\n return {**CORE_ATEN_DECOMPOSITIONS_FILTERED, **TORCH_TRT_DECOMPOSITIONS}\n else:\n return {**ENABLED_TORCH_DECOMPOSITIONS, **TORCH_TRT_DECOMPOSITIONS}\n", "path": "py/torch_tensorrt/dynamo/lowering/_decompositions.py"}]}
| 2,784 | 544 |
gh_patches_debug_5802
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-4094
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Investigate creation of duplicate user accounts with differently cased emails
- [ ] Verify that lookups using email are using `__iexact` or something like that.
- [ ] Figure out a plan for existing duplicates
</issue>
<code>
[start of akvo/rest/views/utils.py]
1 # -*- coding: utf-8 -*-
2
3 # Akvo RSR is covered by the GNU Affero General Public License.
4
5 # See more details in the license.txt file located at the root folder of the Akvo RSR module.
6 # For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
7
8 from django.conf import settings
9 from django.contrib.auth import get_user_model
10 from django.core.cache import cache
11 from django.utils.cache import get_cache_key, _generate_cache_header_key
12 from django.db import IntegrityError
13
14
15 def get_cached_data(request, key_prefix, data, serializer):
16 """Function to get serialized data from the cache based on the request."""
17 cache_header_key = _generate_cache_header_key(key_prefix, request)
18 if cache.get(cache_header_key) is None:
19 cache.set(cache_header_key, [], None)
20
21 cache_key = get_cache_key(request, key_prefix)
22 cached_data = cache.get(cache_key, None)
23 cache_used = True
24 if not cached_data and data is not None:
25 cache_used = False
26 cached_data = serializer(data, many=True).data
27 cache.set(cache_key, cached_data)
28
29 return cached_data, cache_used
30
31
32 def set_cached_data(request, key_prefix, data):
33 """Function to save data to the cache based on the request."""
34
35 cache_header_key = _generate_cache_header_key(key_prefix, request)
36 if cache.get(cache_header_key) is None:
37 cache.set(cache_header_key, [], None)
38
39 cache_key = get_cache_key(request, key_prefix)
40 cache.set(cache_key, data)
41
42
43 def get_qs_elements_for_page(qs, request, count):
44 """Return queryset elements to be shown on the current page"""
45 limit = int_or_none(request.GET.get('limit')) or settings.PROJECT_DIRECTORY_PAGE_SIZES[0]
46 limit = min(limit, settings.PROJECT_DIRECTORY_PAGE_SIZES[-1])
47 max_page_number = 1 + int(count / limit)
48 page_number = min(max_page_number, int_or_none(request.GET.get('page')) or 1)
49 start = (page_number - 1) * limit
50 end = page_number * limit
51 return qs[start:end]
52
53
54 def int_or_none(value):
55 """Return int or None given a value."""
56 try:
57 return int(value)
58 except Exception:
59 return None
60
61
62 def create_invited_user(email):
63 User = get_user_model()
64 # Check if the user already exists, based on the email address
65 try:
66 invited_user = User.objects.get(email=email)
67 except User.DoesNotExist:
68 try:
69 invited_user = User.objects.create_user(username=email, email=email)
70 except IntegrityError:
71 return None
72 return invited_user
73
[end of akvo/rest/views/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/akvo/rest/views/utils.py b/akvo/rest/views/utils.py
--- a/akvo/rest/views/utils.py
+++ b/akvo/rest/views/utils.py
@@ -63,7 +63,7 @@
User = get_user_model()
# Check if the user already exists, based on the email address
try:
- invited_user = User.objects.get(email=email)
+ invited_user = User.objects.get(email__iexact=email)
except User.DoesNotExist:
try:
invited_user = User.objects.create_user(username=email, email=email)
|
{"golden_diff": "diff --git a/akvo/rest/views/utils.py b/akvo/rest/views/utils.py\n--- a/akvo/rest/views/utils.py\n+++ b/akvo/rest/views/utils.py\n@@ -63,7 +63,7 @@\n User = get_user_model()\n # Check if the user already exists, based on the email address\n try:\n- invited_user = User.objects.get(email=email)\n+ invited_user = User.objects.get(email__iexact=email)\n except User.DoesNotExist:\n try:\n invited_user = User.objects.create_user(username=email, email=email)\n", "issue": "Investigate creation of duplicate user accounts with differently cased emails\n- [ ] Verify that lookups using email are using `__iexact` or something like that. \n- [ ] Figure out a plan for existing duplicates\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\nfrom django.conf import settings\nfrom django.contrib.auth import get_user_model\nfrom django.core.cache import cache\nfrom django.utils.cache import get_cache_key, _generate_cache_header_key\nfrom django.db import IntegrityError\n\n\ndef get_cached_data(request, key_prefix, data, serializer):\n \"\"\"Function to get serialized data from the cache based on the request.\"\"\"\n cache_header_key = _generate_cache_header_key(key_prefix, request)\n if cache.get(cache_header_key) is None:\n cache.set(cache_header_key, [], None)\n\n cache_key = get_cache_key(request, key_prefix)\n cached_data = cache.get(cache_key, None)\n cache_used = True\n if not cached_data and data is not None:\n cache_used = False\n cached_data = serializer(data, many=True).data\n cache.set(cache_key, cached_data)\n\n return cached_data, cache_used\n\n\ndef set_cached_data(request, key_prefix, data):\n \"\"\"Function to save data to the cache based on the request.\"\"\"\n\n cache_header_key = _generate_cache_header_key(key_prefix, request)\n if cache.get(cache_header_key) is None:\n cache.set(cache_header_key, [], None)\n\n cache_key = get_cache_key(request, key_prefix)\n cache.set(cache_key, data)\n\n\ndef get_qs_elements_for_page(qs, request, count):\n \"\"\"Return queryset elements to be shown on the current page\"\"\"\n limit = int_or_none(request.GET.get('limit')) or settings.PROJECT_DIRECTORY_PAGE_SIZES[0]\n limit = min(limit, settings.PROJECT_DIRECTORY_PAGE_SIZES[-1])\n max_page_number = 1 + int(count / limit)\n page_number = min(max_page_number, int_or_none(request.GET.get('page')) or 1)\n start = (page_number - 1) * limit\n end = page_number * limit\n return qs[start:end]\n\n\ndef int_or_none(value):\n \"\"\"Return int or None given a value.\"\"\"\n try:\n return int(value)\n except Exception:\n return None\n\n\ndef create_invited_user(email):\n User = get_user_model()\n # Check if the user already exists, based on the email address\n try:\n invited_user = User.objects.get(email=email)\n except User.DoesNotExist:\n try:\n invited_user = User.objects.create_user(username=email, email=email)\n except IntegrityError:\n return None\n return invited_user\n", "path": "akvo/rest/views/utils.py"}]}
| 1,305 | 124 |
gh_patches_debug_7429
|
rasdani/github-patches
|
git_diff
|
cloudtools__troposphere-457
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Elasticsearch Domain DomainName shouldn't be required
According to the CF documentation, `DomainName` isn't required: http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-elasticsearch-domain.html
</issue>
<code>
[start of troposphere/elasticsearch.py]
1 # Copyright (c) 2012-2015, Mark Peek <[email protected]>
2 # All rights reserved.
3 #
4 # See LICENSE file for full license.
5
6 from . import AWSProperty, AWSObject
7 from .validators import boolean, integer, integer_range, positive_integer
8
9 VALID_VOLUME_TYPES = ('standard', 'gp2', 'io1')
10
11 try:
12 from awacs.aws import Policy
13 policytypes = (dict, Policy)
14 except ImportError:
15 policytypes = dict,
16
17
18 def validate_volume_type(volume_type):
19 """Validate VolumeType for ElasticsearchDomain"""
20 if volume_type not in VALID_VOLUME_TYPES:
21 raise ValueError("Elasticsearch Domain VolumeType must be one of: %s" %
22 ", ".join(VALID_VOLUME_TYPES))
23 return volume_type
24
25
26 class EBSOptions(AWSProperty):
27 props = {
28 'EBSEnabled': (boolean, False),
29 'Iops': (positive_integer, False),
30 'VolumeSize': (integer, False),
31 'VolumeType': (validate_volume_type, False)
32 }
33
34 def validate(self):
35 volume_type = self.properties.get('VolumeType')
36 iops = self.properties.get('Iops')
37 if volume_type == 'io1' and not iops:
38 raise ValueError("Must specify Iops if VolumeType is 'io1'.")
39
40
41 class ElasticsearchClusterConfig(AWSProperty):
42 props = {
43 'DedicatedMasterCount': (integer, False),
44 'DedicatedMasterEnabled': (boolean, False),
45 'DedicatedMasterType': (basestring, False),
46 'InstanceCount': (integer, False),
47 'InstanceType': (basestring, False),
48 'ZoneAwarenessEnabled': (boolean, False)
49 }
50
51
52 class SnapshotOptions(AWSProperty):
53 props = {
54 'AutomatedSnapshotStartHour': (integer_range(0, 23), False)
55 }
56
57
58 class ElasticsearchDomain(AWSObject):
59 resource_type = "AWS::Elasticsearch::Domain"
60
61 props = {
62 'AccessPolicies': (policytypes, False),
63 'AdvancedOptions': (dict, False),
64 'DomainName': (basestring, True),
65 'EBSOptions': (EBSOptions, False),
66 'ElasticsearchClusterConfig': (ElasticsearchClusterConfig, False),
67 'SnapshotOptions': (SnapshotOptions, False),
68 'Tags': (list, False)
69 }
70
[end of troposphere/elasticsearch.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/troposphere/elasticsearch.py b/troposphere/elasticsearch.py
--- a/troposphere/elasticsearch.py
+++ b/troposphere/elasticsearch.py
@@ -61,7 +61,7 @@
props = {
'AccessPolicies': (policytypes, False),
'AdvancedOptions': (dict, False),
- 'DomainName': (basestring, True),
+ 'DomainName': (basestring, False),
'EBSOptions': (EBSOptions, False),
'ElasticsearchClusterConfig': (ElasticsearchClusterConfig, False),
'SnapshotOptions': (SnapshotOptions, False),
|
{"golden_diff": "diff --git a/troposphere/elasticsearch.py b/troposphere/elasticsearch.py\n--- a/troposphere/elasticsearch.py\n+++ b/troposphere/elasticsearch.py\n@@ -61,7 +61,7 @@\n props = {\n 'AccessPolicies': (policytypes, False),\n 'AdvancedOptions': (dict, False),\n- 'DomainName': (basestring, True),\n+ 'DomainName': (basestring, False),\n 'EBSOptions': (EBSOptions, False),\n 'ElasticsearchClusterConfig': (ElasticsearchClusterConfig, False),\n 'SnapshotOptions': (SnapshotOptions, False),\n", "issue": "Elasticsearch Domain DomainName shouldn't be required\nAccording to the CF documentation, `DomainName` isn't required: http://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-elasticsearch-domain.html\n\n", "before_files": [{"content": "# Copyright (c) 2012-2015, Mark Peek <[email protected]>\n# All rights reserved.\n#\n# See LICENSE file for full license.\n\nfrom . import AWSProperty, AWSObject\nfrom .validators import boolean, integer, integer_range, positive_integer\n\nVALID_VOLUME_TYPES = ('standard', 'gp2', 'io1')\n\ntry:\n from awacs.aws import Policy\n policytypes = (dict, Policy)\nexcept ImportError:\n policytypes = dict,\n\n\ndef validate_volume_type(volume_type):\n \"\"\"Validate VolumeType for ElasticsearchDomain\"\"\"\n if volume_type not in VALID_VOLUME_TYPES:\n raise ValueError(\"Elasticsearch Domain VolumeType must be one of: %s\" %\n \", \".join(VALID_VOLUME_TYPES))\n return volume_type\n\n\nclass EBSOptions(AWSProperty):\n props = {\n 'EBSEnabled': (boolean, False),\n 'Iops': (positive_integer, False),\n 'VolumeSize': (integer, False),\n 'VolumeType': (validate_volume_type, False)\n }\n\n def validate(self):\n volume_type = self.properties.get('VolumeType')\n iops = self.properties.get('Iops')\n if volume_type == 'io1' and not iops:\n raise ValueError(\"Must specify Iops if VolumeType is 'io1'.\")\n\n\nclass ElasticsearchClusterConfig(AWSProperty):\n props = {\n 'DedicatedMasterCount': (integer, False),\n 'DedicatedMasterEnabled': (boolean, False),\n 'DedicatedMasterType': (basestring, False),\n 'InstanceCount': (integer, False),\n 'InstanceType': (basestring, False),\n 'ZoneAwarenessEnabled': (boolean, False)\n }\n\n\nclass SnapshotOptions(AWSProperty):\n props = {\n 'AutomatedSnapshotStartHour': (integer_range(0, 23), False)\n }\n\n\nclass ElasticsearchDomain(AWSObject):\n resource_type = \"AWS::Elasticsearch::Domain\"\n\n props = {\n 'AccessPolicies': (policytypes, False),\n 'AdvancedOptions': (dict, False),\n 'DomainName': (basestring, True),\n 'EBSOptions': (EBSOptions, False),\n 'ElasticsearchClusterConfig': (ElasticsearchClusterConfig, False),\n 'SnapshotOptions': (SnapshotOptions, False),\n 'Tags': (list, False)\n }\n", "path": "troposphere/elasticsearch.py"}]}
| 1,235 | 139 |
gh_patches_debug_60691
|
rasdani/github-patches
|
git_diff
|
biolab__orange3-text-524
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
text processing module with slow internet conection
[textprocessingerr.txt](https://github.com/biolab/orange3-text/files/4551540/textprocessingerr.txt)
<!--
This is an issue template. Please fill in the relevant details in the
sections below.
-->
Hi! I have slow internet connection, less than 400Kbit/s. And when I use text preprocessing module I have an error.
If I disconnect my internet connection (disable wifi), the text processing module works fine.
If I have have internet connection more than 3Mbit/s, everything works fine.
##### Text version 0.9/0.8
##### Orange version 3.26/3.25
</issue>
<code>
[start of orangecontrib/text/preprocess/normalize.py]
1 import os
2 import json
3 import ufal.udpipe as udpipe
4 import serverfiles
5 from nltk import stem
6 from requests.exceptions import ConnectionError
7 from Orange.misc.environ import data_dir
8
9
10 from orangecontrib.text.misc import wait_nltk_data
11
12 __all__ = ['BaseNormalizer', 'WordNetLemmatizer', 'PorterStemmer',
13 'SnowballStemmer', 'DictionaryLookupNormalizer',
14 'UDPipeLemmatizer']
15
16
17 class BaseNormalizer:
18 """ A generic normalizer class.
19 You should either overwrite `normalize` method or provide a custom
20 normalizer.
21
22 Attributes:
23 name(str): A short name for normalization method (will be used in OWPreprocessor)
24 normalizer(Callable): An callabale object to be used for normalization.
25
26 """
27 name = NotImplemented
28 normalizer = NotImplemented
29 str_format = '{self.name}'
30
31 def __call__(self, tokens):
32 """ Normalizes tokens to canonical form. """
33 if isinstance(tokens, str):
34 return self.normalize(tokens)
35 return [self.normalize(token) for token in tokens]
36
37 def normalize(self, token):
38 return self.normalizer(token)
39
40 def __str__(self):
41 return self.str_format.format(self=self)
42
43
44 class WordNetLemmatizer(BaseNormalizer):
45 name = 'WordNet Lemmatizer'
46 normalizer = stem.WordNetLemmatizer().lemmatize
47
48 @wait_nltk_data
49 def __init__(self):
50 super().__init__()
51
52
53 class DictionaryLookupNormalizer(BaseNormalizer):
54 """ Normalizes token with a <token: canonical_form> dictionary. """
55 name = 'Dictionary Lookup'
56
57 def __init__(self, dictionary):
58 super().__init__()
59 self.dictionary = dictionary
60
61 def normalize(self, token):
62 return self.dictionary.get(token, token)
63
64
65 class PorterStemmer(BaseNormalizer):
66 name = 'Porter Stemmer'
67 normalizer = stem.PorterStemmer().stem
68
69
70 class SnowballStemmer(BaseNormalizer):
71 name = 'Snowball Stemmer'
72 str_format = '{self.name} ({self.language})'
73 supported_languages = [l.capitalize() for l in stem.SnowballStemmer.languages]
74
75 def __init__(self, language='English'):
76 self._language = language
77 self.normalizer = stem.SnowballStemmer(self.language.lower())
78
79 def normalize(self, token):
80 return self.normalizer.stem(token)
81
82 @property
83 def language(self):
84 return self._language
85
86 @language.setter
87 def language(self, value):
88 self._language = value
89 self.normalizer = stem.SnowballStemmer(self.language.lower())
90
91
92 def language_to_name(language):
93 return language.lower().replace(' ', '') + 'ud'
94
95
96 def file_to_name(file):
97 return file.replace('-', '').replace('_', '')
98
99
100 def file_to_language(file):
101 return file[:file.find('ud')-1]\
102 .replace('-', ' ').replace('_', ' ').capitalize()
103
104
105 class UDPipeModels:
106 server_url = "http://file.biolab.si/files/udpipe/"
107
108 def __init__(self):
109 self.local_data = os.path.join(data_dir(versioned=False), 'udpipe/')
110 self.serverfiles = serverfiles.ServerFiles(self.server_url)
111 self.localfiles = serverfiles.LocalFiles(self.local_data,
112 serverfiles=self.serverfiles)
113 self._supported_languages = []
114
115 def __getitem__(self, language):
116 file_name = self._find_file(language_to_name(language))
117 return self.localfiles.localpath_download(file_name)
118
119 @property
120 def model_files(self):
121 try:
122 return self.serverfiles.listfiles()
123 except ConnectionError:
124 return self.localfiles.listfiles()
125
126 def _find_file(self, language):
127 return next(filter(lambda f: file_to_name(f).startswith(language),
128 map(lambda f: f[0], self.model_files)))
129
130 @property
131 def supported_languages(self):
132 self._supported_languages = list(map(lambda f: file_to_language(f[0]),
133 self.model_files))
134 return self._supported_languages
135
136 @property
137 def online(self):
138 try:
139 self.serverfiles.listfiles()
140 return True
141 except ConnectionError:
142 return False
143
144
145 class UDPipeLemmatizer(BaseNormalizer):
146 name = 'UDPipe Lemmatizer'
147 str_format = '{self.name} ({self.language})'
148
149 def __init__(self, language='English'):
150 self._language = language
151 self.models = UDPipeModels()
152 self.model = None
153 self.output_format = udpipe.OutputFormat.newOutputFormat('epe')
154 self.use_tokenizer = False
155
156 def load_model(self):
157 if self.model is None:
158 self.model = udpipe.Model.load(self.models[self._language])
159
160 def normalize(self, token):
161 self.load_model()
162 sentence = udpipe.Sentence()
163 sentence.addWord(token)
164 self.model.tag(sentence, self.model.DEFAULT)
165 output = self.output_format.writeSentence(sentence)
166 return json.loads(output)['nodes'][0]['properties']['lemma']
167
168 def normalize_doc(self, document):
169 self.load_model()
170 tokens = []
171 tokenizer = self.model.newTokenizer(self.model.DEFAULT)
172 tokenizer.setText(document)
173 error = udpipe.ProcessingError()
174 sentence = udpipe.Sentence()
175 while tokenizer.nextSentence(sentence, error):
176 self.model.tag(sentence, self.model.DEFAULT)
177 output = self.output_format.writeSentence(sentence)
178 sentence = udpipe.Sentence()
179 tokens.extend([t['properties']['lemma']
180 for t in json.loads(output)['nodes']])
181 return tokens
182
183 @property
184 def language(self):
185 return self._language
186
187 @language.setter
188 def language(self, value):
189 self._language = value
190 self.model = None
191
192 def __getstate__(self):
193 return {'language': self.language}
194
195 def __setstate__(self, state):
196 self.__init__(state['language'])
197
198
[end of orangecontrib/text/preprocess/normalize.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/orangecontrib/text/preprocess/normalize.py b/orangecontrib/text/preprocess/normalize.py
--- a/orangecontrib/text/preprocess/normalize.py
+++ b/orangecontrib/text/preprocess/normalize.py
@@ -103,7 +103,7 @@
class UDPipeModels:
- server_url = "http://file.biolab.si/files/udpipe/"
+ server_url = "https://file.biolab.si/files/udpipe/"
def __init__(self):
self.local_data = os.path.join(data_dir(versioned=False), 'udpipe/')
|
{"golden_diff": "diff --git a/orangecontrib/text/preprocess/normalize.py b/orangecontrib/text/preprocess/normalize.py\n--- a/orangecontrib/text/preprocess/normalize.py\n+++ b/orangecontrib/text/preprocess/normalize.py\n@@ -103,7 +103,7 @@\n \n \n class UDPipeModels:\n- server_url = \"http://file.biolab.si/files/udpipe/\"\n+ server_url = \"https://file.biolab.si/files/udpipe/\"\n \n def __init__(self):\n self.local_data = os.path.join(data_dir(versioned=False), 'udpipe/')\n", "issue": "text processing module with slow internet conection\n[textprocessingerr.txt](https://github.com/biolab/orange3-text/files/4551540/textprocessingerr.txt)\r\n<!--\r\nThis is an issue template. Please fill in the relevant details in the\r\nsections below.\r\n-->\r\nHi! I have slow internet connection, less than 400Kbit/s. And when I use text preprocessing module I have an error.\r\nIf I disconnect my internet connection (disable wifi), the text processing module works fine.\r\nIf I have have internet connection more than 3Mbit/s, everything works fine.\r\n##### Text version 0.9/0.8\r\n##### Orange version 3.26/3.25\r\n\r\n\r\n\n", "before_files": [{"content": "import os\nimport json\nimport ufal.udpipe as udpipe\nimport serverfiles\nfrom nltk import stem\nfrom requests.exceptions import ConnectionError\nfrom Orange.misc.environ import data_dir\n\n\nfrom orangecontrib.text.misc import wait_nltk_data\n\n__all__ = ['BaseNormalizer', 'WordNetLemmatizer', 'PorterStemmer',\n 'SnowballStemmer', 'DictionaryLookupNormalizer',\n 'UDPipeLemmatizer']\n\n\nclass BaseNormalizer:\n \"\"\" A generic normalizer class.\n You should either overwrite `normalize` method or provide a custom\n normalizer.\n\n Attributes:\n name(str): A short name for normalization method (will be used in OWPreprocessor)\n normalizer(Callable): An callabale object to be used for normalization.\n\n \"\"\"\n name = NotImplemented\n normalizer = NotImplemented\n str_format = '{self.name}'\n\n def __call__(self, tokens):\n \"\"\" Normalizes tokens to canonical form. \"\"\"\n if isinstance(tokens, str):\n return self.normalize(tokens)\n return [self.normalize(token) for token in tokens]\n\n def normalize(self, token):\n return self.normalizer(token)\n\n def __str__(self):\n return self.str_format.format(self=self)\n\n\nclass WordNetLemmatizer(BaseNormalizer):\n name = 'WordNet Lemmatizer'\n normalizer = stem.WordNetLemmatizer().lemmatize\n\n @wait_nltk_data\n def __init__(self):\n super().__init__()\n\n\nclass DictionaryLookupNormalizer(BaseNormalizer):\n \"\"\" Normalizes token with a <token: canonical_form> dictionary. \"\"\"\n name = 'Dictionary Lookup'\n\n def __init__(self, dictionary):\n super().__init__()\n self.dictionary = dictionary\n\n def normalize(self, token):\n return self.dictionary.get(token, token)\n\n\nclass PorterStemmer(BaseNormalizer):\n name = 'Porter Stemmer'\n normalizer = stem.PorterStemmer().stem\n\n\nclass SnowballStemmer(BaseNormalizer):\n name = 'Snowball Stemmer'\n str_format = '{self.name} ({self.language})'\n supported_languages = [l.capitalize() for l in stem.SnowballStemmer.languages]\n\n def __init__(self, language='English'):\n self._language = language\n self.normalizer = stem.SnowballStemmer(self.language.lower())\n\n def normalize(self, token):\n return self.normalizer.stem(token)\n\n @property\n def language(self):\n return self._language\n\n @language.setter\n def language(self, value):\n self._language = value\n self.normalizer = stem.SnowballStemmer(self.language.lower())\n\n\ndef language_to_name(language):\n return language.lower().replace(' ', '') + 'ud'\n\n\ndef file_to_name(file):\n return file.replace('-', '').replace('_', '')\n\n\ndef file_to_language(file):\n return file[:file.find('ud')-1]\\\n .replace('-', ' ').replace('_', ' ').capitalize()\n\n\nclass UDPipeModels:\n server_url = \"http://file.biolab.si/files/udpipe/\"\n\n def __init__(self):\n self.local_data = os.path.join(data_dir(versioned=False), 'udpipe/')\n self.serverfiles = serverfiles.ServerFiles(self.server_url)\n self.localfiles = serverfiles.LocalFiles(self.local_data,\n serverfiles=self.serverfiles)\n self._supported_languages = []\n\n def __getitem__(self, language):\n file_name = self._find_file(language_to_name(language))\n return self.localfiles.localpath_download(file_name)\n\n @property\n def model_files(self):\n try:\n return self.serverfiles.listfiles()\n except ConnectionError:\n return self.localfiles.listfiles()\n\n def _find_file(self, language):\n return next(filter(lambda f: file_to_name(f).startswith(language),\n map(lambda f: f[0], self.model_files)))\n\n @property\n def supported_languages(self):\n self._supported_languages = list(map(lambda f: file_to_language(f[0]),\n self.model_files))\n return self._supported_languages\n\n @property\n def online(self):\n try:\n self.serverfiles.listfiles()\n return True\n except ConnectionError:\n return False\n\n\nclass UDPipeLemmatizer(BaseNormalizer):\n name = 'UDPipe Lemmatizer'\n str_format = '{self.name} ({self.language})'\n\n def __init__(self, language='English'):\n self._language = language\n self.models = UDPipeModels()\n self.model = None\n self.output_format = udpipe.OutputFormat.newOutputFormat('epe')\n self.use_tokenizer = False\n\n def load_model(self):\n if self.model is None:\n self.model = udpipe.Model.load(self.models[self._language])\n\n def normalize(self, token):\n self.load_model()\n sentence = udpipe.Sentence()\n sentence.addWord(token)\n self.model.tag(sentence, self.model.DEFAULT)\n output = self.output_format.writeSentence(sentence)\n return json.loads(output)['nodes'][0]['properties']['lemma']\n\n def normalize_doc(self, document):\n self.load_model()\n tokens = []\n tokenizer = self.model.newTokenizer(self.model.DEFAULT)\n tokenizer.setText(document)\n error = udpipe.ProcessingError()\n sentence = udpipe.Sentence()\n while tokenizer.nextSentence(sentence, error):\n self.model.tag(sentence, self.model.DEFAULT)\n output = self.output_format.writeSentence(sentence)\n sentence = udpipe.Sentence()\n tokens.extend([t['properties']['lemma']\n for t in json.loads(output)['nodes']])\n return tokens\n\n @property\n def language(self):\n return self._language\n\n @language.setter\n def language(self, value):\n self._language = value\n self.model = None\n\n def __getstate__(self):\n return {'language': self.language}\n\n def __setstate__(self, state):\n self.__init__(state['language'])\n\n", "path": "orangecontrib/text/preprocess/normalize.py"}]}
| 2,489 | 130 |
gh_patches_debug_6167
|
rasdani/github-patches
|
git_diff
|
mesonbuild__meson-2462
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
MSI installed meson fails to rerun in visual studio
Initially, I ran `meson build` from the source code directory `xxx` to create the build directory.
Later, if any `meson.build` files are modified, Visual studio fails to rerun Meson with the backtrace below. Meson is installed with MSI. It works with ninja as backend. It also works if meson isn't installed with MSI.
It seems like `mesonscript` in `regen_checker` is invalid when meson is installed with MSI.
```
>meson.exe : error : unrecognized arguments: --internal regenerate C:\Users\niklas\Documents\git\xxx C:\Users\niklas\Documents\git\xxx
1> Traceback (most recent call last):
1> File "C:\Users\niklas\AppData\Local\Programs\Python\Python36-32\lib\site-packages\cx_Freeze\initscripts\__startup__.py", line 14, in run
1> module.run()
1> File "C:\Users\niklas\AppData\Local\Programs\Python\Python36-32\lib\site-packages\cx_Freeze\initscripts\Console.py", line 26, in run
1> exec(code, m.__dict__)
1> File "meson.py", line 37, in <module>
1> File "meson.py", line 34, in main
1> File "mesonbuild\mesonmain.py", line 311, in run
1> File "mesonbuild\mesonmain.py", line 278, in run_script_command
1> File "mesonbuild\scripts\regen_checker.py", line 56, in run
1> File "mesonbuild\scripts\regen_checker.py", line 42, in regen
1> File "C:\Users\niklas\AppData\Local\Programs\Python\Python36-32\lib\subprocess.py", line 291, in check_call
1> raise CalledProcessError(retcode, cmd)
1> subprocess.CalledProcessError: Command '['C:\\Program Files\\Meson\\meson.exe', 'C:\\Users\\niklas\\Documents\\git\\xxx\\meson', '--internal', 'regenerate', 'C:\\Users\\niklas\\Documents\\git\\xxx\\build', 'C:\\Users\\niklas\\Documents\\git\\xxx', '--backend=vs2015']' returned non-zero exit status 2.
```
</issue>
<code>
[start of mesonbuild/scripts/regen_checker.py]
1 # Copyright 2015-2016 The Meson development team
2
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6
7 # http://www.apache.org/licenses/LICENSE-2.0
8
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import sys, os
16 import pickle, subprocess
17
18 # This could also be used for XCode.
19
20 def need_regen(regeninfo, regen_timestamp):
21 for i in regeninfo.depfiles:
22 curfile = os.path.join(regeninfo.build_dir, i)
23 curtime = os.stat(curfile).st_mtime
24 if curtime > regen_timestamp:
25 return True
26 # The timestamp file gets automatically deleted by MSBuild during a 'Clean' build.
27 # We must make sure to recreate it, even if we do not regenerate the solution.
28 # Otherwise, Visual Studio will always consider the REGEN project out of date.
29 print("Everything is up-to-date, regeneration of build files is not needed.")
30 from ..backend.vs2010backend import Vs2010Backend
31 Vs2010Backend.touch_regen_timestamp(regeninfo.build_dir)
32 return False
33
34 def regen(regeninfo, mesonscript, backend):
35 cmd = [sys.executable,
36 mesonscript,
37 '--internal',
38 'regenerate',
39 regeninfo.build_dir,
40 regeninfo.source_dir,
41 '--backend=' + backend]
42 subprocess.check_call(cmd)
43
44 def run(args):
45 private_dir = args[0]
46 dumpfile = os.path.join(private_dir, 'regeninfo.dump')
47 coredata = os.path.join(private_dir, 'coredata.dat')
48 with open(dumpfile, 'rb') as f:
49 regeninfo = pickle.load(f)
50 with open(coredata, 'rb') as f:
51 coredata = pickle.load(f)
52 mesonscript = coredata.meson_script_launcher
53 backend = coredata.get_builtin_option('backend')
54 regen_timestamp = os.stat(dumpfile).st_mtime
55 if need_regen(regeninfo, regen_timestamp):
56 regen(regeninfo, mesonscript, backend)
57 sys.exit(0)
58
59 if __name__ == '__main__':
60 run(sys.argv[1:])
61
[end of mesonbuild/scripts/regen_checker.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mesonbuild/scripts/regen_checker.py b/mesonbuild/scripts/regen_checker.py
--- a/mesonbuild/scripts/regen_checker.py
+++ b/mesonbuild/scripts/regen_checker.py
@@ -32,9 +32,11 @@
return False
def regen(regeninfo, mesonscript, backend):
- cmd = [sys.executable,
- mesonscript,
- '--internal',
+ if sys.executable.lower().endswith('meson.exe'):
+ cmd_exe = [sys.executable]
+ else:
+ cmd_exe = [sys.executable, mesonscript]
+ cmd = cmd_exe + ['--internal',
'regenerate',
regeninfo.build_dir,
regeninfo.source_dir,
|
{"golden_diff": "diff --git a/mesonbuild/scripts/regen_checker.py b/mesonbuild/scripts/regen_checker.py\n--- a/mesonbuild/scripts/regen_checker.py\n+++ b/mesonbuild/scripts/regen_checker.py\n@@ -32,9 +32,11 @@\n return False\n \n def regen(regeninfo, mesonscript, backend):\n- cmd = [sys.executable,\n- mesonscript,\n- '--internal',\n+ if sys.executable.lower().endswith('meson.exe'):\n+ cmd_exe = [sys.executable]\n+ else:\n+ cmd_exe = [sys.executable, mesonscript]\n+ cmd = cmd_exe + ['--internal',\n 'regenerate',\n regeninfo.build_dir,\n regeninfo.source_dir,\n", "issue": "MSI installed meson fails to rerun in visual studio\nInitially, I ran `meson build` from the source code directory `xxx` to create the build directory.\r\nLater, if any `meson.build` files are modified, Visual studio fails to rerun Meson with the backtrace below. Meson is installed with MSI. It works with ninja as backend. It also works if meson isn't installed with MSI.\r\n\r\nIt seems like `mesonscript` in `regen_checker` is invalid when meson is installed with MSI.\r\n\r\n```\r\n>meson.exe : error : unrecognized arguments: --internal regenerate C:\\Users\\niklas\\Documents\\git\\xxx C:\\Users\\niklas\\Documents\\git\\xxx\r\n1> Traceback (most recent call last):\r\n1> File \"C:\\Users\\niklas\\AppData\\Local\\Programs\\Python\\Python36-32\\lib\\site-packages\\cx_Freeze\\initscripts\\__startup__.py\", line 14, in run\r\n1> module.run()\r\n1> File \"C:\\Users\\niklas\\AppData\\Local\\Programs\\Python\\Python36-32\\lib\\site-packages\\cx_Freeze\\initscripts\\Console.py\", line 26, in run\r\n1> exec(code, m.__dict__)\r\n1> File \"meson.py\", line 37, in <module>\r\n1> File \"meson.py\", line 34, in main\r\n1> File \"mesonbuild\\mesonmain.py\", line 311, in run\r\n1> File \"mesonbuild\\mesonmain.py\", line 278, in run_script_command\r\n1> File \"mesonbuild\\scripts\\regen_checker.py\", line 56, in run\r\n1> File \"mesonbuild\\scripts\\regen_checker.py\", line 42, in regen\r\n1> File \"C:\\Users\\niklas\\AppData\\Local\\Programs\\Python\\Python36-32\\lib\\subprocess.py\", line 291, in check_call\r\n1> raise CalledProcessError(retcode, cmd)\r\n1> subprocess.CalledProcessError: Command '['C:\\\\Program Files\\\\Meson\\\\meson.exe', 'C:\\\\Users\\\\niklas\\\\Documents\\\\git\\\\xxx\\\\meson', '--internal', 'regenerate', 'C:\\\\Users\\\\niklas\\\\Documents\\\\git\\\\xxx\\\\build', 'C:\\\\Users\\\\niklas\\\\Documents\\\\git\\\\xxx', '--backend=vs2015']' returned non-zero exit status 2.\r\n```\n", "before_files": [{"content": "# Copyright 2015-2016 The Meson development team\n\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n\n# http://www.apache.org/licenses/LICENSE-2.0\n\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport sys, os\nimport pickle, subprocess\n\n# This could also be used for XCode.\n\ndef need_regen(regeninfo, regen_timestamp):\n for i in regeninfo.depfiles:\n curfile = os.path.join(regeninfo.build_dir, i)\n curtime = os.stat(curfile).st_mtime\n if curtime > regen_timestamp:\n return True\n # The timestamp file gets automatically deleted by MSBuild during a 'Clean' build.\n # We must make sure to recreate it, even if we do not regenerate the solution.\n # Otherwise, Visual Studio will always consider the REGEN project out of date.\n print(\"Everything is up-to-date, regeneration of build files is not needed.\")\n from ..backend.vs2010backend import Vs2010Backend\n Vs2010Backend.touch_regen_timestamp(regeninfo.build_dir)\n return False\n\ndef regen(regeninfo, mesonscript, backend):\n cmd = [sys.executable,\n mesonscript,\n '--internal',\n 'regenerate',\n regeninfo.build_dir,\n regeninfo.source_dir,\n '--backend=' + backend]\n subprocess.check_call(cmd)\n\ndef run(args):\n private_dir = args[0]\n dumpfile = os.path.join(private_dir, 'regeninfo.dump')\n coredata = os.path.join(private_dir, 'coredata.dat')\n with open(dumpfile, 'rb') as f:\n regeninfo = pickle.load(f)\n with open(coredata, 'rb') as f:\n coredata = pickle.load(f)\n mesonscript = coredata.meson_script_launcher\n backend = coredata.get_builtin_option('backend')\n regen_timestamp = os.stat(dumpfile).st_mtime\n if need_regen(regeninfo, regen_timestamp):\n regen(regeninfo, mesonscript, backend)\n sys.exit(0)\n\nif __name__ == '__main__':\n run(sys.argv[1:])\n", "path": "mesonbuild/scripts/regen_checker.py"}]}
| 1,789 | 167 |
gh_patches_debug_5400
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-2874
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Spider tgifridays is broken
During the global build at 2021-05-26-14-42-23, spider **tgifridays** failed with **0 features** and **0 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-05-26-14-42-23/logs/tgifridays.log) and [the output](https://data.alltheplaces.xyz/runs/2021-05-26-14-42-23/output/tgifridays.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-05-26-14-42-23/output/tgifridays.geojson))
</issue>
<code>
[start of locations/spiders/tgifridays.py]
1 # -*- coding: utf-8 -*-
2 import datetime
3 import re
4 import json
5
6 import scrapy
7 from locations.items import GeojsonPointItem
8 from locations.hours import OpeningHours
9
10
11 DAY_MAPPING = {
12 'Monday': 'Mo',
13 'Tuesday': 'Tu',
14 'Wednesday': 'We',
15 'Thursday': 'Th',
16 'Friday': 'Fr',
17 'Saturday': 'Sa',
18 'Sunday': 'Su'
19 }
20
21
22 class TGIFridaySpider(scrapy.Spider):
23 download_delay = 0.2
24 name = "tgifridays"
25 item_attributes = { 'brand': "TGI Friday's" }
26 allowed_domains = ["tgifridays.com"]
27 start_urls = (
28 'https://locations.tgifridays.com/sitemap.xml',
29 )
30
31 def parse_hours(self, hours):
32 opening_hours = OpeningHours()
33
34 for hour in hours:
35 if hour["opens"] == "Closed":
36 continue
37 elif hour["closes"] == "Closed":
38 continue
39 else:
40 opening_hours.add_range(
41 day=hour["dayOfWeek"].replace('http://schema.org/', '')[:2],
42 open_time=hour["opens"],
43 close_time=hour["closes"],
44 time_format='%I:%M%p',
45 )
46
47 return opening_hours.as_opening_hours()
48
49 def parse_store(self, response):
50 # The JSON blob has an extra "}\r\n" at the end
51 data = json.loads(response.xpath('//script[@type="application/ld+json"]/text()').extract_first()[:-3])
52
53 properties = {
54 'addr_full': data['address']['streetAddress'],
55 'phone': data['telephone'],
56 'city': data['address']['addressLocality'],
57 'state': data['address']['addressRegion'],
58 'postcode': data['address']['postalCode'],
59 'country': data['address']['addressCountry'],
60 'ref': data['@id'],
61 'website': data['url'],
62 'lat': data['geo']['latitude'],
63 'lon': data['geo']['longitude'],
64 'name': data['name'],
65 }
66
67 hours = self.parse_hours(data.get("openingHoursSpecification", []))
68 if hours:
69 properties["opening_hours"] = hours
70
71 yield GeojsonPointItem(**properties)
72
73 def parse(self, response):
74 response.selector.remove_namespaces()
75 city_urls = response.xpath('//url/loc/text()').extract()
76 for path in city_urls:
77 if path.count('/') == 5:
78 yield scrapy.Request(
79 path.strip(),
80 callback=self.parse_store,
81 )
82
[end of locations/spiders/tgifridays.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/locations/spiders/tgifridays.py b/locations/spiders/tgifridays.py
--- a/locations/spiders/tgifridays.py
+++ b/locations/spiders/tgifridays.py
@@ -32,9 +32,9 @@
opening_hours = OpeningHours()
for hour in hours:
- if hour["opens"] == "Closed":
+ if hour["opens"] in ("Closed", ""):
continue
- elif hour["closes"] == "Closed":
+ elif hour["closes"] in ("Closed", ""):
continue
else:
opening_hours.add_range(
|
{"golden_diff": "diff --git a/locations/spiders/tgifridays.py b/locations/spiders/tgifridays.py\n--- a/locations/spiders/tgifridays.py\n+++ b/locations/spiders/tgifridays.py\n@@ -32,9 +32,9 @@\n opening_hours = OpeningHours()\n \n for hour in hours:\n- if hour[\"opens\"] == \"Closed\":\n+ if hour[\"opens\"] in (\"Closed\", \"\"):\n continue\n- elif hour[\"closes\"] == \"Closed\":\n+ elif hour[\"closes\"] in (\"Closed\", \"\"):\n continue\n else:\n opening_hours.add_range(\n", "issue": "Spider tgifridays is broken\nDuring the global build at 2021-05-26-14-42-23, spider **tgifridays** failed with **0 features** and **0 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-05-26-14-42-23/logs/tgifridays.log) and [the output](https://data.alltheplaces.xyz/runs/2021-05-26-14-42-23/output/tgifridays.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-05-26-14-42-23/output/tgifridays.geojson))\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport datetime\nimport re\nimport json\n\nimport scrapy\nfrom locations.items import GeojsonPointItem\nfrom locations.hours import OpeningHours\n\n\nDAY_MAPPING = {\n 'Monday': 'Mo',\n 'Tuesday': 'Tu',\n 'Wednesday': 'We',\n 'Thursday': 'Th',\n 'Friday': 'Fr',\n 'Saturday': 'Sa',\n 'Sunday': 'Su'\n}\n\n\nclass TGIFridaySpider(scrapy.Spider):\n download_delay = 0.2\n name = \"tgifridays\"\n item_attributes = { 'brand': \"TGI Friday's\" }\n allowed_domains = [\"tgifridays.com\"]\n start_urls = (\n 'https://locations.tgifridays.com/sitemap.xml',\n )\n\n def parse_hours(self, hours):\n opening_hours = OpeningHours()\n\n for hour in hours:\n if hour[\"opens\"] == \"Closed\":\n continue\n elif hour[\"closes\"] == \"Closed\":\n continue\n else:\n opening_hours.add_range(\n day=hour[\"dayOfWeek\"].replace('http://schema.org/', '')[:2],\n open_time=hour[\"opens\"],\n close_time=hour[\"closes\"],\n time_format='%I:%M%p',\n )\n\n return opening_hours.as_opening_hours()\n\n def parse_store(self, response):\n # The JSON blob has an extra \"}\\r\\n\" at the end\n data = json.loads(response.xpath('//script[@type=\"application/ld+json\"]/text()').extract_first()[:-3])\n\n properties = {\n 'addr_full': data['address']['streetAddress'],\n 'phone': data['telephone'],\n 'city': data['address']['addressLocality'],\n 'state': data['address']['addressRegion'],\n 'postcode': data['address']['postalCode'],\n 'country': data['address']['addressCountry'],\n 'ref': data['@id'],\n 'website': data['url'],\n 'lat': data['geo']['latitude'],\n 'lon': data['geo']['longitude'],\n 'name': data['name'],\n }\n\n hours = self.parse_hours(data.get(\"openingHoursSpecification\", []))\n if hours:\n properties[\"opening_hours\"] = hours\n\n yield GeojsonPointItem(**properties)\n\n def parse(self, response):\n response.selector.remove_namespaces()\n city_urls = response.xpath('//url/loc/text()').extract()\n for path in city_urls:\n if path.count('/') == 5:\n yield scrapy.Request(\n path.strip(),\n callback=self.parse_store,\n )\n", "path": "locations/spiders/tgifridays.py"}]}
| 1,443 | 139 |
gh_patches_debug_30186
|
rasdani/github-patches
|
git_diff
|
sunpy__sunpy-5968
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
IRIS SJI maps call undefined header in self.wavelength
### Describe the bug
When creating SJI maps by feeding data and header separately into a Map() and then doing a plot, this causes an error because it calls an undefined header.
### To Reproduce
import glob
from [astropy.io](http://astropy.io/) import fits
from [sunpy.map](http://sunpy.map/) import Map
data_file = glob.glob('IRIS/*_SJI_2832_*fits')
data_file.sort()
hdul = [fits.open](http://fits.open/)(data_file[0])
header = hdul[0].header
data = hdul[0].data
Map(data[0], header).plot()
### What happened?
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
/tmp/ipykernel_73554/1651218312.py in <module>
7 data = hdul[0].data
8
----> 9 Map(data[0], header).plot()
~/SunEnvironment/lib64/python3.8/site-packages/astropy/units/decorators.py in wrapper(*func_args, **func_kwargs)
251 # Call the original function with any equivalencies in force.
252 with add_enabled_equivalencies(self.equivalencies):
--> 253 return_ = wrapped_function(*func_args, **func_kwargs)
254
255 valid_empty = (inspect.Signature.empty, None)
~/SunEnvironment/lib64/python3.8/site-packages/sunpy/map/mapbase.py in plot(self, annotate, axes, title, autoalign, clip_interval, **imshow_kwargs)
2406 plot_settings_title = plot_settings.pop('title')
2407 else:
-> 2408 plot_settings_title = self.latex_name
2409
2410 # Anything left in plot_settings is given to imshow
~/SunEnvironment/lib64/python3.8/site-packages/sunpy/map/mapbase.py in latex_name(self)
735 def latex_name(self):
736 """LaTeX formatted description of the Map."""
--> 737 if isinstance(self.measurement, u.Quantity):
738 return self._base_name().format(measurement=self.measurement._repr_latex_())
739 else:
~/SunEnvironment/lib64/python3.8/site-packages/sunpy/map/mapbase.py in measurement(self)
898 defaults to dimensionless units.
899 """
--> 900 return self.wavelength
901
902 @property
~/SunEnvironment/lib64/python3.8/site-packages/sunpy/map/sources/iris.py in wavelength(self)
61 Taken from WAVELNTH, or if not present TWAVE1.
62 """
---> 63 return header.get('wavelnth', header.get('twave1')) * self.waveunit
64
65 @classmethod
NameError: name 'header' is not defined
### Expected behavior
_No response_
### Screenshots

### System Details
sunpy.__version__ : 3.1.3
astropy.__version__: 4.3.1
### Installation method
pip
</issue>
<code>
[start of sunpy/map/sources/iris.py]
1
2 import astropy.units as u
3
4 from sunpy.map.mapbase import GenericMap, SpatialPair
5
6 __all__ = ['SJIMap']
7
8
9 class SJIMap(GenericMap):
10 """
11 A 2D IRIS Slit Jaw Imager Map.
12
13 The Interface Region Imaging Spectrograph (IRIS) small explorer spacecraft
14 provides simultaneous spectra and images of the photosphere, chromosphere,
15 transition region, and corona with 0.33 to 0.4 arcsec spatial resolution,
16 2-second temporal resolution and 1 km/s velocity resolution over a
17 field-of- view of up to 175 arcsec by 175 arcsec. IRIS consists of a 19-cm
18 UV telescope that feeds a slit-based dual-bandpass imaging spectrograph.
19
20 Slit-jaw images in four different passbands (C ii 1330, Si iv 1400,
21 Mg ii k 2796 and Mg ii wing 2830 A) can be taken simultaneously with
22 spectral rasters that sample regions up to 130 arcsec by 175 arcsec at a
23 variety of spatial samplings (from 0.33 arcsec and up).
24 IRIS is sensitive to emission from plasma at temperatures between
25 5000 K and 10 MK.
26
27 IRIS was launched into a Sun-synchronous orbit on 27 June 2013.
28
29 .. warning::
30
31 This object can only handle level 1 SJI files.
32
33 References
34 ----------
35 * `IRIS Mission Page <https://iris.lmsal.com>`_
36 * `IRIS Analysis Guide <https://iris.lmsal.com/itn26/itn26.pdf>`_
37 * `IRIS Instrument Paper <https://doi.org/10.1007/s11207-014-0485-y>`_
38 """
39 @property
40 def detector(self):
41 return "SJI"
42
43 @property
44 def spatial_units(self):
45 """
46 If not present in CUNIT{1,2} keywords, defaults to arcsec.
47 """
48 return SpatialPair(u.Unit(self.meta.get('cunit1', 'arcsec')),
49 u.Unit(self.meta.get('cunit2', 'arcsec')))
50
51 @property
52 def waveunit(self):
53 """
54 Taken from WAVEUNIT, or if not present defaults to Angstrom.
55 """
56 return u.Unit(header.get('waveunit', "Angstrom"))
57
58 @property
59 def wavelength(self):
60 """
61 Taken from WAVELNTH, or if not present TWAVE1.
62 """
63 return header.get('wavelnth', header.get('twave1')) * self.waveunit
64
65 @classmethod
66 def is_datasource_for(cls, data, header, **kwargs):
67 """Determines if header corresponds to an IRIS SJI image"""
68 tele = str(header.get('TELESCOP', '')).startswith('IRIS')
69 obs = str(header.get('INSTRUME', '')).startswith('SJI')
70 level = header.get('lvl_num') == 1
71 return tele and obs
72
[end of sunpy/map/sources/iris.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sunpy/map/sources/iris.py b/sunpy/map/sources/iris.py
--- a/sunpy/map/sources/iris.py
+++ b/sunpy/map/sources/iris.py
@@ -26,10 +26,6 @@
IRIS was launched into a Sun-synchronous orbit on 27 June 2013.
- .. warning::
-
- This object can only handle level 1 SJI files.
-
References
----------
* `IRIS Mission Page <https://iris.lmsal.com>`_
@@ -53,19 +49,27 @@
"""
Taken from WAVEUNIT, or if not present defaults to Angstrom.
"""
- return u.Unit(header.get('waveunit', "Angstrom"))
+ return u.Unit(self.meta.get('waveunit', "Angstrom"))
@property
def wavelength(self):
"""
Taken from WAVELNTH, or if not present TWAVE1.
"""
- return header.get('wavelnth', header.get('twave1')) * self.waveunit
+ return self.meta.get('wavelnth', self.meta.get('twave1')) * self.waveunit
+
+ @property
+ def unit(self):
+ unit_str = self.meta.get('bunit', None)
+ if unit_str is None:
+ return
+ # Remove "corrected" so that the unit can be parsed
+ unit_str = unit_str.lower().replace('corrected', '').strip()
+ return self._parse_fits_unit(unit_str)
@classmethod
def is_datasource_for(cls, data, header, **kwargs):
"""Determines if header corresponds to an IRIS SJI image"""
tele = str(header.get('TELESCOP', '')).startswith('IRIS')
obs = str(header.get('INSTRUME', '')).startswith('SJI')
- level = header.get('lvl_num') == 1
return tele and obs
|
{"golden_diff": "diff --git a/sunpy/map/sources/iris.py b/sunpy/map/sources/iris.py\n--- a/sunpy/map/sources/iris.py\n+++ b/sunpy/map/sources/iris.py\n@@ -26,10 +26,6 @@\n \n IRIS was launched into a Sun-synchronous orbit on 27 June 2013.\n \n- .. warning::\n-\n- This object can only handle level 1 SJI files.\n-\n References\n ----------\n * `IRIS Mission Page <https://iris.lmsal.com>`_\n@@ -53,19 +49,27 @@\n \"\"\"\n Taken from WAVEUNIT, or if not present defaults to Angstrom.\n \"\"\"\n- return u.Unit(header.get('waveunit', \"Angstrom\"))\n+ return u.Unit(self.meta.get('waveunit', \"Angstrom\"))\n \n @property\n def wavelength(self):\n \"\"\"\n Taken from WAVELNTH, or if not present TWAVE1.\n \"\"\"\n- return header.get('wavelnth', header.get('twave1')) * self.waveunit\n+ return self.meta.get('wavelnth', self.meta.get('twave1')) * self.waveunit\n+\n+ @property\n+ def unit(self):\n+ unit_str = self.meta.get('bunit', None)\n+ if unit_str is None:\n+ return\n+ # Remove \"corrected\" so that the unit can be parsed\n+ unit_str = unit_str.lower().replace('corrected', '').strip()\n+ return self._parse_fits_unit(unit_str)\n \n @classmethod\n def is_datasource_for(cls, data, header, **kwargs):\n \"\"\"Determines if header corresponds to an IRIS SJI image\"\"\"\n tele = str(header.get('TELESCOP', '')).startswith('IRIS')\n obs = str(header.get('INSTRUME', '')).startswith('SJI')\n- level = header.get('lvl_num') == 1\n return tele and obs\n", "issue": "IRIS SJI maps call undefined header in self.wavelength\n### Describe the bug\n\nWhen creating SJI maps by feeding data and header separately into a Map() and then doing a plot, this causes an error because it calls an undefined header.\n\n### To Reproduce\n\nimport glob\r\nfrom [astropy.io](http://astropy.io/) import fits\r\nfrom [sunpy.map](http://sunpy.map/) import Map\r\n\r\ndata_file = glob.glob('IRIS/*_SJI_2832_*fits')\r\ndata_file.sort()\r\n\r\nhdul = [fits.open](http://fits.open/)(data_file[0])\r\n \r\nheader = hdul[0].header\r\ndata = hdul[0].data\r\n\r\nMap(data[0], header).plot()\n\n### What happened?\n\n---------------------------------------------------------------------------\r\nNameError Traceback (most recent call last)\r\n/tmp/ipykernel_73554/1651218312.py in <module>\r\n 7 data = hdul[0].data\r\n 8 \r\n----> 9 Map(data[0], header).plot()\r\n\r\n~/SunEnvironment/lib64/python3.8/site-packages/astropy/units/decorators.py in wrapper(*func_args, **func_kwargs)\r\n 251 # Call the original function with any equivalencies in force.\r\n 252 with add_enabled_equivalencies(self.equivalencies):\r\n--> 253 return_ = wrapped_function(*func_args, **func_kwargs)\r\n 254 \r\n 255 valid_empty = (inspect.Signature.empty, None)\r\n\r\n~/SunEnvironment/lib64/python3.8/site-packages/sunpy/map/mapbase.py in plot(self, annotate, axes, title, autoalign, clip_interval, **imshow_kwargs)\r\n 2406 plot_settings_title = plot_settings.pop('title')\r\n 2407 else:\r\n-> 2408 plot_settings_title = self.latex_name\r\n 2409 \r\n 2410 # Anything left in plot_settings is given to imshow\r\n\r\n~/SunEnvironment/lib64/python3.8/site-packages/sunpy/map/mapbase.py in latex_name(self)\r\n 735 def latex_name(self):\r\n 736 \"\"\"LaTeX formatted description of the Map.\"\"\"\r\n--> 737 if isinstance(self.measurement, u.Quantity):\r\n 738 return self._base_name().format(measurement=self.measurement._repr_latex_())\r\n 739 else:\r\n\r\n~/SunEnvironment/lib64/python3.8/site-packages/sunpy/map/mapbase.py in measurement(self)\r\n 898 defaults to dimensionless units.\r\n 899 \"\"\"\r\n--> 900 return self.wavelength\r\n 901 \r\n 902 @property\r\n\r\n~/SunEnvironment/lib64/python3.8/site-packages/sunpy/map/sources/iris.py in wavelength(self)\r\n 61 Taken from WAVELNTH, or if not present TWAVE1.\r\n 62 \"\"\"\r\n---> 63 return header.get('wavelnth', header.get('twave1')) * self.waveunit\r\n 64 \r\n 65 @classmethod\r\n\r\nNameError: name 'header' is not defined\r\n\n\n### Expected behavior\n\n_No response_\n\n### Screenshots\n\n\r\n\n\n### System Details\n\nsunpy.__version__ : 3.1.3\r\nastropy.__version__: 4.3.1\n\n### Installation method\n\npip\n", "before_files": [{"content": "\nimport astropy.units as u\n\nfrom sunpy.map.mapbase import GenericMap, SpatialPair\n\n__all__ = ['SJIMap']\n\n\nclass SJIMap(GenericMap):\n \"\"\"\n A 2D IRIS Slit Jaw Imager Map.\n\n The Interface Region Imaging Spectrograph (IRIS) small explorer spacecraft\n provides simultaneous spectra and images of the photosphere, chromosphere,\n transition region, and corona with 0.33 to 0.4 arcsec spatial resolution,\n 2-second temporal resolution and 1 km/s velocity resolution over a\n field-of- view of up to 175 arcsec by 175 arcsec. IRIS consists of a 19-cm\n UV telescope that feeds a slit-based dual-bandpass imaging spectrograph.\n\n Slit-jaw images in four different passbands (C ii 1330, Si iv 1400,\n Mg ii k 2796 and Mg ii wing 2830 A) can be taken simultaneously with\n spectral rasters that sample regions up to 130 arcsec by 175 arcsec at a\n variety of spatial samplings (from 0.33 arcsec and up).\n IRIS is sensitive to emission from plasma at temperatures between\n 5000 K and 10 MK.\n\n IRIS was launched into a Sun-synchronous orbit on 27 June 2013.\n\n .. warning::\n\n This object can only handle level 1 SJI files.\n\n References\n ----------\n * `IRIS Mission Page <https://iris.lmsal.com>`_\n * `IRIS Analysis Guide <https://iris.lmsal.com/itn26/itn26.pdf>`_\n * `IRIS Instrument Paper <https://doi.org/10.1007/s11207-014-0485-y>`_\n \"\"\"\n @property\n def detector(self):\n return \"SJI\"\n\n @property\n def spatial_units(self):\n \"\"\"\n If not present in CUNIT{1,2} keywords, defaults to arcsec.\n \"\"\"\n return SpatialPair(u.Unit(self.meta.get('cunit1', 'arcsec')),\n u.Unit(self.meta.get('cunit2', 'arcsec')))\n\n @property\n def waveunit(self):\n \"\"\"\n Taken from WAVEUNIT, or if not present defaults to Angstrom.\n \"\"\"\n return u.Unit(header.get('waveunit', \"Angstrom\"))\n\n @property\n def wavelength(self):\n \"\"\"\n Taken from WAVELNTH, or if not present TWAVE1.\n \"\"\"\n return header.get('wavelnth', header.get('twave1')) * self.waveunit\n\n @classmethod\n def is_datasource_for(cls, data, header, **kwargs):\n \"\"\"Determines if header corresponds to an IRIS SJI image\"\"\"\n tele = str(header.get('TELESCOP', '')).startswith('IRIS')\n obs = str(header.get('INSTRUME', '')).startswith('SJI')\n level = header.get('lvl_num') == 1\n return tele and obs\n", "path": "sunpy/map/sources/iris.py"}]}
| 2,201 | 442 |
gh_patches_debug_20993
|
rasdani/github-patches
|
git_diff
|
dask__distributed-779
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
distributed-1.15.0rc1 seems wrongly requiring "futures" from a Python-3.6 installation
Collecting futures (from distributed>=1.14; extra == "complete"->dask[complete]->-r C:\Winpython\basedir36
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2
3 import os
4 from setuptools import setup
5 import sys
6 import versioneer
7
8 requires = open('requirements.txt').read().strip().split('\n')
9
10 setup(name='distributed',
11 version=versioneer.get_version(),
12 cmdclass=versioneer.get_cmdclass(),
13 description='Distributed computing',
14 url='https://distributed.readthedocs.io/en/latest/',
15 maintainer='Matthew Rocklin',
16 maintainer_email='[email protected]',
17 license='BSD',
18 package_data={ '': ['templates/index.html'], },
19 include_package_data=True,
20 install_requires=requires,
21 packages=['distributed',
22 'distributed.bokeh',
23 'distributed.bokeh.background',
24 'distributed.bokeh.status',
25 'distributed.bokeh.tasks',
26 'distributed.bokeh.workers',
27 'distributed.cli',
28 'distributed.deploy',
29 'distributed.diagnostics',
30 'distributed.protocol',
31 'distributed.http'],
32 long_description=(open('README.md').read() if os.path.exists('README.md')
33 else ''),
34 entry_points='''
35 [console_scripts]
36 dask-ssh=distributed.cli.dask_ssh:go
37 dask-submit=distributed.cli.dask_submit:go
38 dask-remote=distributed.cli.dask_remote:go
39 dask-scheduler=distributed.cli.dask_scheduler:go
40 dask-worker=distributed.cli.dask_worker:go
41 ''',
42 zip_safe=False)
43
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -6,6 +6,18 @@
import versioneer
requires = open('requirements.txt').read().strip().split('\n')
+install_requires = []
+extras_require = {}
+for r in requires:
+ if ';' in r:
+ # requirements.txt conditional dependencies need to be reformatted for wheels
+ # to the form: `'[extra_name]:condition' : ['requirements']`
+ req, cond = r.split(';', 1)
+ cond = ':' + cond
+ cond_reqs = extras_require.setdefault(cond, [])
+ cond_reqs.append(req)
+ else:
+ install_requires.append(r)
setup(name='distributed',
version=versioneer.get_version(),
@@ -17,7 +29,8 @@
license='BSD',
package_data={ '': ['templates/index.html'], },
include_package_data=True,
- install_requires=requires,
+ install_requires=install_requires,
+ extras_require=extras_require,
packages=['distributed',
'distributed.bokeh',
'distributed.bokeh.background',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -6,6 +6,18 @@\n import versioneer\n \n requires = open('requirements.txt').read().strip().split('\\n')\n+install_requires = []\n+extras_require = {}\n+for r in requires:\n+ if ';' in r:\n+ # requirements.txt conditional dependencies need to be reformatted for wheels\n+ # to the form: `'[extra_name]:condition' : ['requirements']`\n+ req, cond = r.split(';', 1)\n+ cond = ':' + cond\n+ cond_reqs = extras_require.setdefault(cond, [])\n+ cond_reqs.append(req)\n+ else:\n+ install_requires.append(r)\n \n setup(name='distributed',\n version=versioneer.get_version(),\n@@ -17,7 +29,8 @@\n license='BSD',\n package_data={ '': ['templates/index.html'], },\n include_package_data=True,\n- install_requires=requires,\n+ install_requires=install_requires,\n+ extras_require=extras_require,\n packages=['distributed',\n 'distributed.bokeh',\n 'distributed.bokeh.background',\n", "issue": "distributed-1.15.0rc1 seems wrongly requiring \"futures\" from a Python-3.6 installation\nCollecting futures (from distributed>=1.14; extra == \"complete\"->dask[complete]->-r C:\\Winpython\\basedir36\n", "before_files": [{"content": "#!/usr/bin/env python\n\nimport os\nfrom setuptools import setup\nimport sys\nimport versioneer\n\nrequires = open('requirements.txt').read().strip().split('\\n')\n\nsetup(name='distributed',\n version=versioneer.get_version(),\n cmdclass=versioneer.get_cmdclass(),\n description='Distributed computing',\n url='https://distributed.readthedocs.io/en/latest/',\n maintainer='Matthew Rocklin',\n maintainer_email='[email protected]',\n license='BSD',\n package_data={ '': ['templates/index.html'], },\n include_package_data=True,\n install_requires=requires,\n packages=['distributed',\n 'distributed.bokeh',\n 'distributed.bokeh.background',\n 'distributed.bokeh.status',\n 'distributed.bokeh.tasks',\n 'distributed.bokeh.workers',\n 'distributed.cli',\n 'distributed.deploy',\n 'distributed.diagnostics',\n 'distributed.protocol',\n 'distributed.http'],\n long_description=(open('README.md').read() if os.path.exists('README.md')\n else ''),\n entry_points='''\n [console_scripts]\n dask-ssh=distributed.cli.dask_ssh:go\n dask-submit=distributed.cli.dask_submit:go\n dask-remote=distributed.cli.dask_remote:go\n dask-scheduler=distributed.cli.dask_scheduler:go\n dask-worker=distributed.cli.dask_worker:go\n ''',\n zip_safe=False)\n", "path": "setup.py"}]}
| 972 | 249 |
gh_patches_debug_15546
|
rasdani/github-patches
|
git_diff
|
rlworkgroup__garage-605
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
variable initialization in local_tf_runner is slow and incorrect
The variable initialization code in function `initialize_tf_vars` of `garage/experiment/local_tf_runner.py` is written in a way that's both very inefficient and potentially incorrect. In particular, the list comprehension
````[
v for v in tf.global_variables()
if v.name.split(':')[0] in str(
self.sess.run(tf.report_uninitialized_variables()))
]
````
reruns the `tf.report_uninitialized_variables()` op every time the condition needs to be evaluated, which is very slow for larger graphs. It takes me several minutes to run for a convnet with 128x128x4 pixel inputs. Storing the result of this operation reduces runtime to mere seconds.
Further, the use of string operations can potentially lead to re-initializing some variables. If the name of some initialised variable A is a substring of an uninitialised variable B, the above list comprehension will include variable A in the result. A better alternative is to decode the bytestrings returned by `sess.run(tf.report_uninitialized_variables()` and construct a set.
The function code then becomes
````uninit_set = set(
e.decode() for e in self.sess.run(tf.report_uninitialized_variables())
)
self.sess.run(
tf.variables_initializer([
v for v in tf.global_variables()
if v.name.split(':')[0] in uninit_set
]))
````
If this idea seems reasonable, I am happy to make a pull request.
</issue>
<code>
[start of garage/experiment/local_tf_runner.py]
1 """
2 The local runner for tensorflow algorithms.
3
4 A runner setup context for algorithms during initialization and
5 pipelines data between sampler and algorithm during training.
6 """
7 import time
8
9 import tensorflow as tf
10
11 from garage.logger import logger
12 from garage.logger import snapshotter
13 from garage.logger import tabular
14
15 # Note: Optional module should be imported ad hoc to break circular dependency.
16
17
18 class LocalRunner:
19 """This class implements a local runner for tensorflow algorithms.
20
21 A local runner provides a default tensorflow session using python context.
22 This is useful for those experiment components (e.g. policy) that require a
23 tensorflow session during construction.
24
25 Use Runner.setup(algo, env) to setup algorithm and environement for runner
26 and Runner.train() to start training.
27
28 Examples:
29 with LocalRunner() as runner:
30 env = gym.make('CartPole-v1')
31 policy = CategoricalMLPPolicy(
32 env_spec=env.spec,
33 hidden_sizes=(32, 32))
34 algo = TRPO(
35 env=env,
36 policy=policy,
37 baseline=baseline,
38 max_path_length=100,
39 discount=0.99,
40 max_kl_step=0.01)
41 runner.setup(algo, env)
42 runner.train(n_epochs=100, batch_size=4000)
43
44 """
45
46 def __init__(self, sess=None, max_cpus=1):
47 """Create a new local runner.
48
49 Args:
50 max_cpus: The maximum number of parallel sampler workers.
51 sess: An optional tensorflow session.
52 A new session will be created immediately if not provided.
53
54 Note:
55 The local runner will set up a joblib task pool of size max_cpus
56 possibly later used by BatchSampler. If BatchSampler is not used,
57 the processes in the pool will remain dormant.
58
59 This setup is required to use tensorflow in a multiprocess
60 environment before a tensorflow session is created
61 because tensorflow is not fork-safe.
62
63 See https://github.com/tensorflow/tensorflow/issues/2448.
64
65 """
66 if max_cpus > 1:
67 from garage.sampler import singleton_pool
68 singleton_pool.initialize(max_cpus)
69 self.sess = sess or tf.Session()
70 self.has_setup = False
71 self.plot = False
72
73 def __enter__(self):
74 """Set self.sess as the default session.
75
76 Returns:
77 This local runner.
78
79 """
80 if tf.get_default_session() is not self.sess:
81 self.sess.__enter__()
82 return self
83
84 def __exit__(self, exc_type, exc_val, exc_tb):
85 """Leave session."""
86 if tf.get_default_session() is self.sess:
87 self.sess.__exit__(exc_type, exc_val, exc_tb)
88
89 def setup(self, algo, env, sampler_cls=None, sampler_args=None):
90 """Set up runner for algorithm and environment.
91
92 This method saves algo and env within runner and creates a sampler.
93
94 Note:
95 After setup() is called all variables in session should have been
96 initialized. setup() respects existing values in session so
97 policy weights can be loaded before setup().
98
99 Args:
100 algo: An algorithm instance.
101 env: An environement instance.
102 sampler_cls: A sampler class.
103 sampler_args: Arguments to be passed to sampler constructor.
104
105 """
106 self.algo = algo
107 self.env = env
108 self.policy = self.algo.policy
109
110 if sampler_args is None:
111 sampler_args = {}
112
113 if sampler_cls is None:
114 from garage.tf.algos.batch_polopt import BatchPolopt
115 if isinstance(algo, BatchPolopt):
116 if self.policy.vectorized:
117 from garage.tf.samplers import OnPolicyVectorizedSampler
118 sampler_cls = OnPolicyVectorizedSampler
119 else:
120 from garage.tf.samplers import BatchSampler
121 sampler_cls = BatchSampler
122 else:
123 from garage.tf.samplers import OffPolicyVectorizedSampler
124 sampler_cls = OffPolicyVectorizedSampler
125
126 self.sampler = sampler_cls(algo, env, **sampler_args)
127
128 self.initialize_tf_vars()
129 logger.log(self.sess.graph)
130 self.has_setup = True
131
132 def initialize_tf_vars(self):
133 """Initialize all uninitialized variables in session."""
134 with tf.name_scope("initialize_tf_vars"):
135 self.sess.run(
136 tf.variables_initializer([
137 v for v in tf.global_variables()
138 if v.name.split(':')[0] in str(
139 self.sess.run(tf.report_uninitialized_variables()))
140 ]))
141
142 def start_worker(self):
143 """Start Plotter and Sampler workers."""
144 self.sampler.start_worker()
145 if self.plot:
146 from garage.tf.plotter import Plotter
147 self.plotter = Plotter(self.env, self.policy)
148 self.plotter.start()
149
150 def shutdown_worker(self):
151 """Shutdown Plotter and Sampler workers."""
152 self.sampler.shutdown_worker()
153 if self.plot:
154 self.plotter.close()
155
156 def obtain_samples(self, itr, batch_size):
157 """Obtain one batch of samples.
158
159 Args:
160 itr: Index of iteration (epoch).
161 batch_size: Number of steps in batch.
162 This is a hint that the sampler may or may not respect.
163
164 Returns:
165 One batch of samples.
166
167 """
168 if self.n_epoch_cycles == 1:
169 logger.log('Obtaining samples...')
170 return self.sampler.obtain_samples(itr, batch_size)
171
172 def save_snapshot(self, itr, paths=None):
173 """Save snapshot of current batch.
174
175 Args:
176 itr: Index of iteration (epoch).
177 paths: Batch of samples after preprocessed.
178
179 """
180 assert self.has_setup
181
182 logger.log("Saving snapshot...")
183 params = self.algo.get_itr_snapshot(itr)
184 params['env'] = self.env
185 if paths:
186 params['paths'] = paths
187 snapshotter.save_itr_params(itr, params)
188 logger.log('Saved')
189
190 def log_diagnostics(self, pause_for_plot=False):
191 """Log diagnostics.
192
193 Args:
194 pause_for_plot: Pause for plot.
195
196 """
197 logger.log('Time %.2f s' % (time.time() - self.start_time))
198 logger.log('EpochTime %.2f s' % (time.time() - self.itr_start_time))
199 logger.log(tabular)
200 if self.plot:
201 self.plotter.update_plot(self.policy, self.algo.max_path_length)
202 if pause_for_plot:
203 input('Plotting evaluation run: Press Enter to " "continue...')
204
205 def train(self,
206 n_epochs,
207 n_epoch_cycles=1,
208 batch_size=None,
209 plot=False,
210 store_paths=False,
211 pause_for_plot=False):
212 """Start training.
213
214 Args:
215 n_epochs: Number of epochs.
216 n_epoch_cycles: Number of batches of samples in each epoch.
217 This is only useful for off-policy algorithm.
218 For on-policy algorithm this value should always be 1.
219 batch_size: Number of steps in batch.
220 plot: Visualize policy by doing rollout after each epoch.
221 store_paths: Save paths in snapshot.
222 pause_for_plot: Pause for plot.
223
224 Returns:
225 The average return in last epoch cycle.
226
227 """
228 assert self.has_setup, ('Use Runner.setup() to setup runner before '
229 'training.')
230 if batch_size is None:
231 from garage.tf.samplers import OffPolicyVectorizedSampler
232 if isinstance(self.sampler, OffPolicyVectorizedSampler):
233 batch_size = self.algo.max_path_length
234 else:
235 batch_size = 40 * self.algo.max_path_length
236
237 self.n_epoch_cycles = n_epoch_cycles
238
239 self.plot = plot
240 self.start_worker()
241 self.start_time = time.time()
242
243 itr = 0
244 last_return = None
245 for epoch in range(n_epochs):
246 self.itr_start_time = time.time()
247 paths = None
248 with logger.prefix('epoch #%d | ' % epoch):
249 for cycle in range(n_epoch_cycles):
250 paths = self.obtain_samples(itr, batch_size)
251 paths = self.sampler.process_samples(itr, paths)
252 last_return = self.algo.train_once(itr, paths)
253 itr += 1
254 self.save_snapshot(epoch, paths if store_paths else None)
255 self.log_diagnostics(pause_for_plot)
256 logger.dump_all(itr)
257 tabular.clear()
258
259 self.shutdown_worker()
260 return last_return
261
[end of garage/experiment/local_tf_runner.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/garage/experiment/local_tf_runner.py b/garage/experiment/local_tf_runner.py
--- a/garage/experiment/local_tf_runner.py
+++ b/garage/experiment/local_tf_runner.py
@@ -132,11 +132,14 @@
def initialize_tf_vars(self):
"""Initialize all uninitialized variables in session."""
with tf.name_scope("initialize_tf_vars"):
+ uninited_set = [
+ e.decode()
+ for e in self.sess.run(tf.report_uninitialized_variables())
+ ]
self.sess.run(
tf.variables_initializer([
v for v in tf.global_variables()
- if v.name.split(':')[0] in str(
- self.sess.run(tf.report_uninitialized_variables()))
+ if v.name.split(':')[0] in uninited_set
]))
def start_worker(self):
|
{"golden_diff": "diff --git a/garage/experiment/local_tf_runner.py b/garage/experiment/local_tf_runner.py\n--- a/garage/experiment/local_tf_runner.py\n+++ b/garage/experiment/local_tf_runner.py\n@@ -132,11 +132,14 @@\n def initialize_tf_vars(self):\n \"\"\"Initialize all uninitialized variables in session.\"\"\"\n with tf.name_scope(\"initialize_tf_vars\"):\n+ uninited_set = [\n+ e.decode()\n+ for e in self.sess.run(tf.report_uninitialized_variables())\n+ ]\n self.sess.run(\n tf.variables_initializer([\n v for v in tf.global_variables()\n- if v.name.split(':')[0] in str(\n- self.sess.run(tf.report_uninitialized_variables()))\n+ if v.name.split(':')[0] in uninited_set\n ]))\n \n def start_worker(self):\n", "issue": "variable initialization in local_tf_runner is slow and incorrect\nThe variable initialization code in function `initialize_tf_vars` of `garage/experiment/local_tf_runner.py` is written in a way that's both very inefficient and potentially incorrect. In particular, the list comprehension\r\n````[\r\n v for v in tf.global_variables()\r\n if v.name.split(':')[0] in str(\r\n self.sess.run(tf.report_uninitialized_variables()))\r\n]\r\n````\r\nreruns the `tf.report_uninitialized_variables()` op every time the condition needs to be evaluated, which is very slow for larger graphs. It takes me several minutes to run for a convnet with 128x128x4 pixel inputs. Storing the result of this operation reduces runtime to mere seconds.\r\n\r\nFurther, the use of string operations can potentially lead to re-initializing some variables. If the name of some initialised variable A is a substring of an uninitialised variable B, the above list comprehension will include variable A in the result. A better alternative is to decode the bytestrings returned by `sess.run(tf.report_uninitialized_variables()` and construct a set.\r\n\r\nThe function code then becomes\r\n\r\n````uninit_set = set(\r\n e.decode() for e in self.sess.run(tf.report_uninitialized_variables())\r\n )\r\n self.sess.run(\r\n tf.variables_initializer([\r\n v for v in tf.global_variables()\r\n if v.name.split(':')[0] in uninit_set\r\n ]))\r\n````\r\n\r\nIf this idea seems reasonable, I am happy to make a pull request.\n", "before_files": [{"content": "\"\"\"\nThe local runner for tensorflow algorithms.\n\nA runner setup context for algorithms during initialization and\npipelines data between sampler and algorithm during training.\n\"\"\"\nimport time\n\nimport tensorflow as tf\n\nfrom garage.logger import logger\nfrom garage.logger import snapshotter\nfrom garage.logger import tabular\n\n# Note: Optional module should be imported ad hoc to break circular dependency.\n\n\nclass LocalRunner:\n \"\"\"This class implements a local runner for tensorflow algorithms.\n\n A local runner provides a default tensorflow session using python context.\n This is useful for those experiment components (e.g. policy) that require a\n tensorflow session during construction.\n\n Use Runner.setup(algo, env) to setup algorithm and environement for runner\n and Runner.train() to start training.\n\n Examples:\n with LocalRunner() as runner:\n env = gym.make('CartPole-v1')\n policy = CategoricalMLPPolicy(\n env_spec=env.spec,\n hidden_sizes=(32, 32))\n algo = TRPO(\n env=env,\n policy=policy,\n baseline=baseline,\n max_path_length=100,\n discount=0.99,\n max_kl_step=0.01)\n runner.setup(algo, env)\n runner.train(n_epochs=100, batch_size=4000)\n\n \"\"\"\n\n def __init__(self, sess=None, max_cpus=1):\n \"\"\"Create a new local runner.\n\n Args:\n max_cpus: The maximum number of parallel sampler workers.\n sess: An optional tensorflow session.\n A new session will be created immediately if not provided.\n\n Note:\n The local runner will set up a joblib task pool of size max_cpus\n possibly later used by BatchSampler. If BatchSampler is not used,\n the processes in the pool will remain dormant.\n\n This setup is required to use tensorflow in a multiprocess\n environment before a tensorflow session is created\n because tensorflow is not fork-safe.\n\n See https://github.com/tensorflow/tensorflow/issues/2448.\n\n \"\"\"\n if max_cpus > 1:\n from garage.sampler import singleton_pool\n singleton_pool.initialize(max_cpus)\n self.sess = sess or tf.Session()\n self.has_setup = False\n self.plot = False\n\n def __enter__(self):\n \"\"\"Set self.sess as the default session.\n\n Returns:\n This local runner.\n\n \"\"\"\n if tf.get_default_session() is not self.sess:\n self.sess.__enter__()\n return self\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n \"\"\"Leave session.\"\"\"\n if tf.get_default_session() is self.sess:\n self.sess.__exit__(exc_type, exc_val, exc_tb)\n\n def setup(self, algo, env, sampler_cls=None, sampler_args=None):\n \"\"\"Set up runner for algorithm and environment.\n\n This method saves algo and env within runner and creates a sampler.\n\n Note:\n After setup() is called all variables in session should have been\n initialized. setup() respects existing values in session so\n policy weights can be loaded before setup().\n\n Args:\n algo: An algorithm instance.\n env: An environement instance.\n sampler_cls: A sampler class.\n sampler_args: Arguments to be passed to sampler constructor.\n\n \"\"\"\n self.algo = algo\n self.env = env\n self.policy = self.algo.policy\n\n if sampler_args is None:\n sampler_args = {}\n\n if sampler_cls is None:\n from garage.tf.algos.batch_polopt import BatchPolopt\n if isinstance(algo, BatchPolopt):\n if self.policy.vectorized:\n from garage.tf.samplers import OnPolicyVectorizedSampler\n sampler_cls = OnPolicyVectorizedSampler\n else:\n from garage.tf.samplers import BatchSampler\n sampler_cls = BatchSampler\n else:\n from garage.tf.samplers import OffPolicyVectorizedSampler\n sampler_cls = OffPolicyVectorizedSampler\n\n self.sampler = sampler_cls(algo, env, **sampler_args)\n\n self.initialize_tf_vars()\n logger.log(self.sess.graph)\n self.has_setup = True\n\n def initialize_tf_vars(self):\n \"\"\"Initialize all uninitialized variables in session.\"\"\"\n with tf.name_scope(\"initialize_tf_vars\"):\n self.sess.run(\n tf.variables_initializer([\n v for v in tf.global_variables()\n if v.name.split(':')[0] in str(\n self.sess.run(tf.report_uninitialized_variables()))\n ]))\n\n def start_worker(self):\n \"\"\"Start Plotter and Sampler workers.\"\"\"\n self.sampler.start_worker()\n if self.plot:\n from garage.tf.plotter import Plotter\n self.plotter = Plotter(self.env, self.policy)\n self.plotter.start()\n\n def shutdown_worker(self):\n \"\"\"Shutdown Plotter and Sampler workers.\"\"\"\n self.sampler.shutdown_worker()\n if self.plot:\n self.plotter.close()\n\n def obtain_samples(self, itr, batch_size):\n \"\"\"Obtain one batch of samples.\n\n Args:\n itr: Index of iteration (epoch).\n batch_size: Number of steps in batch.\n This is a hint that the sampler may or may not respect.\n\n Returns:\n One batch of samples.\n\n \"\"\"\n if self.n_epoch_cycles == 1:\n logger.log('Obtaining samples...')\n return self.sampler.obtain_samples(itr, batch_size)\n\n def save_snapshot(self, itr, paths=None):\n \"\"\"Save snapshot of current batch.\n\n Args:\n itr: Index of iteration (epoch).\n paths: Batch of samples after preprocessed.\n\n \"\"\"\n assert self.has_setup\n\n logger.log(\"Saving snapshot...\")\n params = self.algo.get_itr_snapshot(itr)\n params['env'] = self.env\n if paths:\n params['paths'] = paths\n snapshotter.save_itr_params(itr, params)\n logger.log('Saved')\n\n def log_diagnostics(self, pause_for_plot=False):\n \"\"\"Log diagnostics.\n\n Args:\n pause_for_plot: Pause for plot.\n\n \"\"\"\n logger.log('Time %.2f s' % (time.time() - self.start_time))\n logger.log('EpochTime %.2f s' % (time.time() - self.itr_start_time))\n logger.log(tabular)\n if self.plot:\n self.plotter.update_plot(self.policy, self.algo.max_path_length)\n if pause_for_plot:\n input('Plotting evaluation run: Press Enter to \" \"continue...')\n\n def train(self,\n n_epochs,\n n_epoch_cycles=1,\n batch_size=None,\n plot=False,\n store_paths=False,\n pause_for_plot=False):\n \"\"\"Start training.\n\n Args:\n n_epochs: Number of epochs.\n n_epoch_cycles: Number of batches of samples in each epoch.\n This is only useful for off-policy algorithm.\n For on-policy algorithm this value should always be 1.\n batch_size: Number of steps in batch.\n plot: Visualize policy by doing rollout after each epoch.\n store_paths: Save paths in snapshot.\n pause_for_plot: Pause for plot.\n\n Returns:\n The average return in last epoch cycle.\n\n \"\"\"\n assert self.has_setup, ('Use Runner.setup() to setup runner before '\n 'training.')\n if batch_size is None:\n from garage.tf.samplers import OffPolicyVectorizedSampler\n if isinstance(self.sampler, OffPolicyVectorizedSampler):\n batch_size = self.algo.max_path_length\n else:\n batch_size = 40 * self.algo.max_path_length\n\n self.n_epoch_cycles = n_epoch_cycles\n\n self.plot = plot\n self.start_worker()\n self.start_time = time.time()\n\n itr = 0\n last_return = None\n for epoch in range(n_epochs):\n self.itr_start_time = time.time()\n paths = None\n with logger.prefix('epoch #%d | ' % epoch):\n for cycle in range(n_epoch_cycles):\n paths = self.obtain_samples(itr, batch_size)\n paths = self.sampler.process_samples(itr, paths)\n last_return = self.algo.train_once(itr, paths)\n itr += 1\n self.save_snapshot(epoch, paths if store_paths else None)\n self.log_diagnostics(pause_for_plot)\n logger.dump_all(itr)\n tabular.clear()\n\n self.shutdown_worker()\n return last_return\n", "path": "garage/experiment/local_tf_runner.py"}]}
| 3,334 | 185 |
gh_patches_debug_13258
|
rasdani/github-patches
|
git_diff
|
lutris__lutris-2955
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
PCSX2 Runner: Add config path/file options (Feature request)
It would be nice to have a way to specify a config file as for example some games run better with a multi-threaded microVU than others. It would also enable to have different window sizes set for those seeking square pixels as some NTSC games run at 640x448 and others use 512x448. Same goes for PAL region games. :slightly_smiling_face:
The command line is: `PCSX2 --cfg=<str>`
I'm absolutely fine if you put it on low priority as probably only few people use PCSX2 anyways. :wink:
</issue>
<code>
[start of lutris/runners/pcsx2.py]
1 # Standard Library
2 from gettext import gettext as _
3
4 # Lutris Modules
5 from lutris.runners.runner import Runner
6 from lutris.util import system
7
8
9 class pcsx2(Runner):
10 human_name = _("PCSX2")
11 description = _("PlayStation 2 emulator")
12 platforms = [_("Sony PlayStation 2")]
13 runnable_alone = True
14 runner_executable = "pcsx2/PCSX2"
15 game_options = [{
16 "option": "main_file",
17 "type": "file",
18 "label": _("ISO file"),
19 "default_path": "game_path",
20 }]
21
22 runner_options = [
23 {
24 "option": "fullscreen",
25 "type": "bool",
26 "label": _("Fullscreen"),
27 "default": False,
28 },
29 {
30 "option": "full_boot",
31 "type": "bool",
32 "label": _("Fullboot"),
33 "default": False
34 },
35 {
36 "option": "nogui",
37 "type": "bool",
38 "label": _("No GUI"),
39 "default": False
40 },
41 {
42 "option": "config_file",
43 "type": "file",
44 "label": _("Custom config file"),
45 "advanced": True,
46 },
47 {
48 "option": "config_path",
49 "type": "directory_chooser",
50 "label": _("Custom config path"),
51 "advanced": True,
52 },
53 ]
54
55 def play(self):
56 arguments = [self.get_executable()]
57
58 if self.runner_config.get("fullscreen"):
59 arguments.append("--fullscreen")
60 if self.runner_config.get("full_boot"):
61 arguments.append("--fullboot")
62 if self.runner_config.get("nogui"):
63 arguments.append("--nogui")
64 if self.runner_config.get("config_file"):
65 arguments.append("--cfg=%s", self.runner_config["config_file"])
66 if self.runner_config.get("config_path"):
67 arguments.append("--cfgpath=%s", self.runner_config["config_path"])
68
69 iso = self.game_config.get("main_file") or ""
70 if not system.path_exists(iso):
71 return {"error": "FILE_NOT_FOUND", "file": iso}
72 arguments.append(iso)
73 return {"command": arguments}
74
[end of lutris/runners/pcsx2.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lutris/runners/pcsx2.py b/lutris/runners/pcsx2.py
--- a/lutris/runners/pcsx2.py
+++ b/lutris/runners/pcsx2.py
@@ -62,9 +62,9 @@
if self.runner_config.get("nogui"):
arguments.append("--nogui")
if self.runner_config.get("config_file"):
- arguments.append("--cfg=%s", self.runner_config["config_file"])
+ arguments.append("--cfg={}".format(self.runner_config["config_file"]))
if self.runner_config.get("config_path"):
- arguments.append("--cfgpath=%s", self.runner_config["config_path"])
+ arguments.append("--cfgpath={}".format(self.runner_config["config_path"]))
iso = self.game_config.get("main_file") or ""
if not system.path_exists(iso):
|
{"golden_diff": "diff --git a/lutris/runners/pcsx2.py b/lutris/runners/pcsx2.py\n--- a/lutris/runners/pcsx2.py\n+++ b/lutris/runners/pcsx2.py\n@@ -62,9 +62,9 @@\n if self.runner_config.get(\"nogui\"):\n arguments.append(\"--nogui\")\n if self.runner_config.get(\"config_file\"):\n- arguments.append(\"--cfg=%s\", self.runner_config[\"config_file\"])\n+ arguments.append(\"--cfg={}\".format(self.runner_config[\"config_file\"]))\n if self.runner_config.get(\"config_path\"):\n- arguments.append(\"--cfgpath=%s\", self.runner_config[\"config_path\"])\n+ arguments.append(\"--cfgpath={}\".format(self.runner_config[\"config_path\"]))\n \n iso = self.game_config.get(\"main_file\") or \"\"\n if not system.path_exists(iso):\n", "issue": "PCSX2 Runner: Add config path/file options (Feature request)\nIt would be nice to have a way to specify a config file as for example some games run better with a multi-threaded microVU than others. It would also enable to have different window sizes set for those seeking square pixels as some NTSC games run at 640x448 and others use 512x448. Same goes for PAL region games. :slightly_smiling_face: \r\n\r\nThe command line is: `PCSX2 --cfg=<str>`\r\n\r\nI'm absolutely fine if you put it on low priority as probably only few people use PCSX2 anyways. :wink: \n", "before_files": [{"content": "# Standard Library\nfrom gettext import gettext as _\n\n# Lutris Modules\nfrom lutris.runners.runner import Runner\nfrom lutris.util import system\n\n\nclass pcsx2(Runner):\n human_name = _(\"PCSX2\")\n description = _(\"PlayStation 2 emulator\")\n platforms = [_(\"Sony PlayStation 2\")]\n runnable_alone = True\n runner_executable = \"pcsx2/PCSX2\"\n game_options = [{\n \"option\": \"main_file\",\n \"type\": \"file\",\n \"label\": _(\"ISO file\"),\n \"default_path\": \"game_path\",\n }]\n\n runner_options = [\n {\n \"option\": \"fullscreen\",\n \"type\": \"bool\",\n \"label\": _(\"Fullscreen\"),\n \"default\": False,\n },\n {\n \"option\": \"full_boot\",\n \"type\": \"bool\",\n \"label\": _(\"Fullboot\"),\n \"default\": False\n },\n {\n \"option\": \"nogui\",\n \"type\": \"bool\",\n \"label\": _(\"No GUI\"),\n \"default\": False\n },\n {\n \"option\": \"config_file\",\n \"type\": \"file\",\n \"label\": _(\"Custom config file\"),\n \"advanced\": True,\n },\n {\n \"option\": \"config_path\",\n \"type\": \"directory_chooser\",\n \"label\": _(\"Custom config path\"),\n \"advanced\": True,\n },\n ]\n\n def play(self):\n arguments = [self.get_executable()]\n\n if self.runner_config.get(\"fullscreen\"):\n arguments.append(\"--fullscreen\")\n if self.runner_config.get(\"full_boot\"):\n arguments.append(\"--fullboot\")\n if self.runner_config.get(\"nogui\"):\n arguments.append(\"--nogui\")\n if self.runner_config.get(\"config_file\"):\n arguments.append(\"--cfg=%s\", self.runner_config[\"config_file\"])\n if self.runner_config.get(\"config_path\"):\n arguments.append(\"--cfgpath=%s\", self.runner_config[\"config_path\"])\n\n iso = self.game_config.get(\"main_file\") or \"\"\n if not system.path_exists(iso):\n return {\"error\": \"FILE_NOT_FOUND\", \"file\": iso}\n arguments.append(iso)\n return {\"command\": arguments}\n", "path": "lutris/runners/pcsx2.py"}]}
| 1,298 | 190 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.